
python抓取网页数据
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-02 19:23
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
python抓取网页数据(Python抓取框架Scrapy爬虫入门:页面提取的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-02 19:01
想了解Python爬虫框架Scrapy爬虫入门:页面提取的相关内容,本文将为大家仔细讲解Python框架Scrapy页面提取的相关知识和一些代码示例。欢迎阅读指正,先划重点:python爬虫框架Scrapy,scrapy爬取多个页面,python,scrapy框架,一起学习。
前言
Scrapy 是一个非常好的爬虫框架,它不仅提供了一些开箱即用的基础组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土宠网,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此作为爬虫入口,分析页面:
打开页面后会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多图集,没有翻页设置。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码。内容如下:
<p> 查看全部
python抓取网页数据(Python抓取框架Scrapy爬虫入门:页面提取的相关内容吗)
想了解Python爬虫框架Scrapy爬虫入门:页面提取的相关内容,本文将为大家仔细讲解Python框架Scrapy页面提取的相关知识和一些代码示例。欢迎阅读指正,先划重点:python爬虫框架Scrapy,scrapy爬取多个页面,python,scrapy框架,一起学习。
前言
Scrapy 是一个非常好的爬虫框架,它不仅提供了一些开箱即用的基础组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土宠网,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此作为爬虫入口,分析页面:
打开页面后会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多图集,没有翻页设置。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码。内容如下:
<p>
python抓取网页数据(我正在尝试抓取股票数据,但是即使我使用“按ID查找元素”,结果还是一个文本。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-29 19:23
我正在尝试获取股票数据,但即使我使用“按 ID 查找元素”,结果仍然是文本。我尝试了各种方法,例如通过 xpath 查找元素等。我尝试通过查找“属性‘目标’”来创建一个收录所有 ID 的数组,以便我可以遍历它,但我没有成功,所以我必须对每个 ID 进行编码。
import json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url = 'http://www.tsetmc.com/Loader.aspx?ParTree=15131F'
delay = 100
driver = webdriver.Chrome()
driver.get(url)
WebDriverWait(driver, delay)
zapna = driver.find_elements_by_id(id_='43479730079120887')
renik = driver.find_elements_by_id(id_='33854964748757477')
retko = driver.find_elements_by_id(id_='3823243780502959')
rampna = driver.find_elements_by_id(id_='67126881188552864')
mafakher = driver.find_elements_by_id(id_='4247709727327181')
for ii in retko:
print(ii.text , "\n")
driver.close()
结果是:
رتكوكنترلخوردگيتكينكو2,1512.531M63.044 B25,14523,88824,900-245-0.9724,907-238-0.9523,88825,699-749-33.2512,55324,90024,9035,4601
我期望的是:
رتكو
كنترلخوردگيتكينكو
2,151
2.531M
63.044 B
25,145
23,888
24,900
-245
-0.97
24,907
-238
-0.95
23,888
25,699
-749
-33.25
1
2,553
24,900
24,903
5,460
1
有什么想法吗? 查看全部
python抓取网页数据(我正在尝试抓取股票数据,但是即使我使用“按ID查找元素”,结果还是一个文本。)
我正在尝试获取股票数据,但即使我使用“按 ID 查找元素”,结果仍然是文本。我尝试了各种方法,例如通过 xpath 查找元素等。我尝试通过查找“属性‘目标’”来创建一个收录所有 ID 的数组,以便我可以遍历它,但我没有成功,所以我必须对每个 ID 进行编码。
import json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url = 'http://www.tsetmc.com/Loader.aspx?ParTree=15131F'
delay = 100
driver = webdriver.Chrome()
driver.get(url)
WebDriverWait(driver, delay)
zapna = driver.find_elements_by_id(id_='43479730079120887')
renik = driver.find_elements_by_id(id_='33854964748757477')
retko = driver.find_elements_by_id(id_='3823243780502959')
rampna = driver.find_elements_by_id(id_='67126881188552864')
mafakher = driver.find_elements_by_id(id_='4247709727327181')
for ii in retko:
print(ii.text , "\n")
driver.close()
结果是:
رتكوكنترلخوردگيتكينكو2,1512.531M63.044 B25,14523,88824,900-245-0.9724,907-238-0.9523,88825,699-749-33.2512,55324,90024,9035,4601
我期望的是:
رتكو
كنترلخوردگيتكينكو
2,151
2.531M
63.044 B
25,145
23,888
24,900
-245
-0.97
24,907
-238
-0.95
23,888
25,699
-749
-33.25
1
2,553
24,900
24,903
5,460
1
有什么想法吗?
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-29 09:14
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试找到的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试找到的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
python抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-29 08:09
Python3网络爬虫的基本操作(二):静态网络爬虫
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
看了上一篇博文,相信大家对爬虫有了一定的了解。在本文中,我们将解释如何抓取静态 Web 资源。(本人也是初学爬虫,简单总结一下所学分享给大家,如有错误请指出,谢谢!)
二.静态网页爬取1.安装Requests库
打开cmd,输入:(详细安装教程请参考之前的博客)
pip install requests
2.获取网页对应的内容
在Requests中,常见的功能就是获取某个网页的内容。现在我们还是以豆瓣()为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取我们想要的信息。上面代码的结果如下:
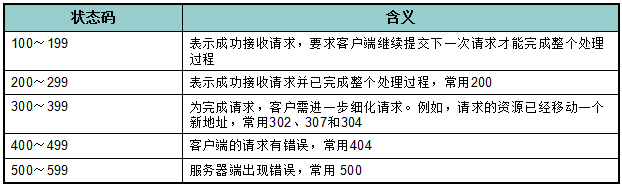
(1)req.status_code 用于检测响应状态码。
(所有状态码详情:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是服务器内容使用的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加特定的数据。例如,在构造URL时,我们通常将数据放在一个问号后面,并以key/value的形式放在URL中。(这里是把start=0传给)
在Requests中,可以直接将参数放入字典中,使用params构造URL。
例如:
import requests
key = {
'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
操作结果:
(2)自定义请求头
请求标头 Headers 提供有关其他实体的请求、响应或发送的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法获得正确的结果。我们如何获取网页的请求头?
我们以()为例,进入网页检查页面,下图中箭头所指的部分就是网页的请求头部分(Requests Headers)
提取重要部分,编写代码:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
(3)超时
有时候爬虫会遇到服务器长时间不返回,那么程序就会一直等待,导致程序执行不顺畅。因此,您可以在超时参数设置为等待秒数后,使用Requests 停止等待响应。(我们一般把这个值设置为20秒)
这里我们设置秒数为0.0001秒,看看会抛出什么异常:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers, timeout=0.0001)
print("响应状态码:", req.status_code)
操作结果:
三.项目实践
举个例子来练习,目的是获取起点中文网月票榜上一百本书的名字。
1.网站分析
打开起点中文网站月票列表的网页,使用“check”查看网页的请求头,写上我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一页只有 20 本书信息。如果要获取全部 100 本书的信息,总共需要获取 5 页。 查看全部
python抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
Python3网络爬虫的基本操作(二):静态网络爬虫
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
看了上一篇博文,相信大家对爬虫有了一定的了解。在本文中,我们将解释如何抓取静态 Web 资源。(本人也是初学爬虫,简单总结一下所学分享给大家,如有错误请指出,谢谢!)
二.静态网页爬取1.安装Requests库
打开cmd,输入:(详细安装教程请参考之前的博客)
pip install requests
2.获取网页对应的内容
在Requests中,常见的功能就是获取某个网页的内容。现在我们还是以豆瓣()为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取我们想要的信息。上面代码的结果如下:
(1)req.status_code 用于检测响应状态码。
(所有状态码详情:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是服务器内容使用的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加特定的数据。例如,在构造URL时,我们通常将数据放在一个问号后面,并以key/value的形式放在URL中。(这里是把start=0传给)
在Requests中,可以直接将参数放入字典中,使用params构造URL。
例如:
import requests
key = {
'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
操作结果:
(2)自定义请求头
请求标头 Headers 提供有关其他实体的请求、响应或发送的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法获得正确的结果。我们如何获取网页的请求头?
我们以()为例,进入网页检查页面,下图中箭头所指的部分就是网页的请求头部分(Requests Headers)
提取重要部分,编写代码:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
(3)超时
有时候爬虫会遇到服务器长时间不返回,那么程序就会一直等待,导致程序执行不顺畅。因此,您可以在超时参数设置为等待秒数后,使用Requests 停止等待响应。(我们一般把这个值设置为20秒)
这里我们设置秒数为0.0001秒,看看会抛出什么异常:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers, timeout=0.0001)
print("响应状态码:", req.status_code)
操作结果:

三.项目实践
举个例子来练习,目的是获取起点中文网月票榜上一百本书的名字。
1.网站分析
打开起点中文网站月票列表的网页,使用“check”查看网页的请求头,写上我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一页只有 20 本书信息。如果要获取全部 100 本书的信息,总共需要获取 5 页。
python抓取网页数据( WebScraperswithPython你会学到什么是刮刀和蜘蛛?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 08:09
WebScraperswithPython你会学到什么是刮刀和蜘蛛?)
使用 Python 构建的尖端网络抓取技术开始您的大数据项目
刮地球!使用 Python 构建 Web 爬虫
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建刮板
如何构建一个多线程、复杂的scraper
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原版英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
描述
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。股票价格和加密货币趋势等金融数据、数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据以馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都希望学习如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
关于查找易查找教程网 查看全部
python抓取网页数据(
WebScraperswithPython你会学到什么是刮刀和蜘蛛?)


使用 Python 构建的尖端网络抓取技术开始您的大数据项目
刮地球!使用 Python 构建 Web 爬虫
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建刮板
如何构建一个多线程、复杂的scraper
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原版英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m

描述
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。股票价格和加密货币趋势等金融数据、数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据以馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都希望学习如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。


关于查找易查找教程网
python抓取网页数据(soup()如何依靠类标签找到数据的位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-27 00:26
.
同样,如果将光标放在名称“标准普尔指数”上并单击,则可以看到控制台中的此信息收录在标签中。
现在我们知道如何依靠类标签来查找我们需要的数据了。
学习代码 现在我们知道了我们需要的数据的位置,我们可以开始编写代码来构建我们的网络爬虫。现在请打开您的文本编辑工具!
首先,我们必须导入我们想要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并赋值给网站的URL链接。
#赋值网站链接
quote_page =':IND'
接下来使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索网站并得到html代码,保存在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析为 BeautifulSoup 格式,以便我们可以使用 BeautifulSoup 库来分析网页。
# 使用beautifulSoup解析HTML代码并将其存储在变量“soup”中`
汤 = BeautifulSoup(page,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在一个独特的层次结构中。BeautifulSoup 库中的 find() 函数可以帮助我们进入不同的层次来提取内容。我们需要的 HTML 类型“名称”在整个网页中是唯一的,所以我们可以简单地找到
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
拿到label后,我们可以使用name_box的text属性来获取对应的值
name = name_box.text.strip() #strip()函数用于去除前后空格
印刷名称
使用类似的方法,我们可以得到股票指数价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
印刷价格
当您运行程序时,您应该能够看到程序输出标准普尔 500 指数的当前价格。
以Excel CSV 格式导出数据我们已经学习了如何获取数据,现在我们将学习如何存储数据。Excel 的逗号分隔数据格式 (CSV) 是一个不错的选择。这样,我们就可以在 Excel 中打开数据文件进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码底部,添加将数据写入 CSV 文件的代码。
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称, 价格, datetime.now()])
现在,如果您运行该程序,您应该能够导出一个 index.csv 文件。可以在Excel中打开文件,看到如图所示的一行数据。
所以如果你每天运行这个程序,你就可以轻松获得标准普尔指数价格,而不必像以前那样在网站上搜索。
进一步(高级用法)多个股票指数
抓取一个股指信息对你来说还不够,对吧?我们可以尝试同时提取多个股指信息。首先,我们需要修改quote_page 将其定义为一个URL 数组。
quote_page = [':IND',':IND']
然后我们把代码的数据提取部分改成了for循环。这个循环可以一个一个地处理URL,并将变量data中的所有数据以元组类型存储。
# for 循环
数据 = []
对于quote_page 中的pg:
# 检索网站并返回HTML代码,并将其存储在变量'page'中
页 = urllib2.urlopen(pg)
# 使用beautifulSoup解析HTML代码并将其存储在变量`soup`中
汤 = BeautifulSoup(page,'html.parser')
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 使用元组类型存储数据
数据.附加((名称,价格))
并且,修改保存部分,逐行保存数据
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称, 价格, datetime.now()])
重新运行程序,应该可以同时提取两个股指价格信息了!
BeautifulSoup 库,一种先进的爬取技术,使用方便,可以很好地执行少量的网站爬取。但是如果你对大量的爬取信息感兴趣,可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据捕获框架。
2. 您可以尝试将一些公共应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法远比网络爬行高效。例如,您可以尝试 Facebook Graph API。该 API 可以帮助您获取 Facebook 网站 上未显示的隐藏信息。
3. 如果数据量太大,可以考虑使用类似于MySQL的数据库后端来存储数据。
采取“不要重复”的方法
DRY 是英语中“不要重复你做过的事情”的缩写。您可以尝试像链接中的人一样自动化您的日常工作。同时,你也可以考虑其他有趣的项目,比如掌握你的 Facebook 好友的在线时间(当然他们同意),或者在论坛中获取演讲主题列表来尝试自然语言处理(这是当前人工智能的热门话题)!
原文链接: 查看全部
python抓取网页数据(soup()如何依靠类标签找到数据的位置?)
.
同样,如果将光标放在名称“标准普尔指数”上并单击,则可以看到控制台中的此信息收录在标签中。

现在我们知道如何依靠类标签来查找我们需要的数据了。
学习代码 现在我们知道了我们需要的数据的位置,我们可以开始编写代码来构建我们的网络爬虫。现在请打开您的文本编辑工具!
首先,我们必须导入我们想要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并赋值给网站的URL链接。
#赋值网站链接
quote_page =':IND'
接下来使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索网站并得到html代码,保存在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析为 BeautifulSoup 格式,以便我们可以使用 BeautifulSoup 库来分析网页。
# 使用beautifulSoup解析HTML代码并将其存储在变量“soup”中`
汤 = BeautifulSoup(page,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在一个独特的层次结构中。BeautifulSoup 库中的 find() 函数可以帮助我们进入不同的层次来提取内容。我们需要的 HTML 类型“名称”在整个网页中是唯一的,所以我们可以简单地找到
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
拿到label后,我们可以使用name_box的text属性来获取对应的值
name = name_box.text.strip() #strip()函数用于去除前后空格
印刷名称
使用类似的方法,我们可以得到股票指数价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
印刷价格

当您运行程序时,您应该能够看到程序输出标准普尔 500 指数的当前价格。
以Excel CSV 格式导出数据我们已经学习了如何获取数据,现在我们将学习如何存储数据。Excel 的逗号分隔数据格式 (CSV) 是一个不错的选择。这样,我们就可以在 Excel 中打开数据文件进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码底部,添加将数据写入 CSV 文件的代码。
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称, 价格, datetime.now()])

现在,如果您运行该程序,您应该能够导出一个 index.csv 文件。可以在Excel中打开文件,看到如图所示的一行数据。
所以如果你每天运行这个程序,你就可以轻松获得标准普尔指数价格,而不必像以前那样在网站上搜索。
进一步(高级用法)多个股票指数
抓取一个股指信息对你来说还不够,对吧?我们可以尝试同时提取多个股指信息。首先,我们需要修改quote_page 将其定义为一个URL 数组。
quote_page = [':IND',':IND']
然后我们把代码的数据提取部分改成了for循环。这个循环可以一个一个地处理URL,并将变量data中的所有数据以元组类型存储。
# for 循环
数据 = []
对于quote_page 中的pg:
# 检索网站并返回HTML代码,并将其存储在变量'page'中
页 = urllib2.urlopen(pg)
# 使用beautifulSoup解析HTML代码并将其存储在变量`soup`中
汤 = BeautifulSoup(page,'html.parser')
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 使用元组类型存储数据
数据.附加((名称,价格))
并且,修改保存部分,逐行保存数据
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称, 价格, datetime.now()])
重新运行程序,应该可以同时提取两个股指价格信息了!
BeautifulSoup 库,一种先进的爬取技术,使用方便,可以很好地执行少量的网站爬取。但是如果你对大量的爬取信息感兴趣,可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据捕获框架。
2. 您可以尝试将一些公共应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法远比网络爬行高效。例如,您可以尝试 Facebook Graph API。该 API 可以帮助您获取 Facebook 网站 上未显示的隐藏信息。
3. 如果数据量太大,可以考虑使用类似于MySQL的数据库后端来存储数据。
采取“不要重复”的方法

DRY 是英语中“不要重复你做过的事情”的缩写。您可以尝试像链接中的人一样自动化您的日常工作。同时,你也可以考虑其他有趣的项目,比如掌握你的 Facebook 好友的在线时间(当然他们同意),或者在论坛中获取演讲主题列表来尝试自然语言处理(这是当前人工智能的热门话题)!
原文链接:
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 17:14
抓取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
以上代码思路:先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子页面,从而获取span保存的访问量子页面中的标签。
打开下面的本地文件,pandas会分析数据,然后pyecharts会实现图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,有知道的朋友帮忙解答一下:
1.第一段代码保存的xlsx格式,实际保存后显示损坏。用xml打开就没问题,用xls格式打开也没问题。
2. 访问次数过多会报错。我使用了睡眠,但实际上,访问次数是间歇性地读取值。为什么有些人无法读取值?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表格的第一行,不知道为什么
我觉得还需要加强1)pandas的数据处理方式,比如分组排序。
2)正则表达式提取
3)Pyecharts 图形绘制
4)遇到网页反爬等情况时的虚拟ip设置
记录我的python学习路径,大家一起努力~~ 查看全部
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
抓取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
以上代码思路:先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子页面,从而获取span保存的访问量子页面中的标签。
打开下面的本地文件,pandas会分析数据,然后pyecharts会实现图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果

同时还有很多问题,有知道的朋友帮忙解答一下:
1.第一段代码保存的xlsx格式,实际保存后显示损坏。用xml打开就没问题,用xls格式打开也没问题。
2. 访问次数过多会报错。我使用了睡眠,但实际上,访问次数是间歇性地读取值。为什么有些人无法读取值?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表格的第一行,不知道为什么
我觉得还需要加强1)pandas的数据处理方式,比如分组排序。
2)正则表达式提取
3)Pyecharts 图形绘制
4)遇到网页反爬等情况时的虚拟ip设置
记录我的python学习路径,大家一起努力~~
python抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-18 12:12
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
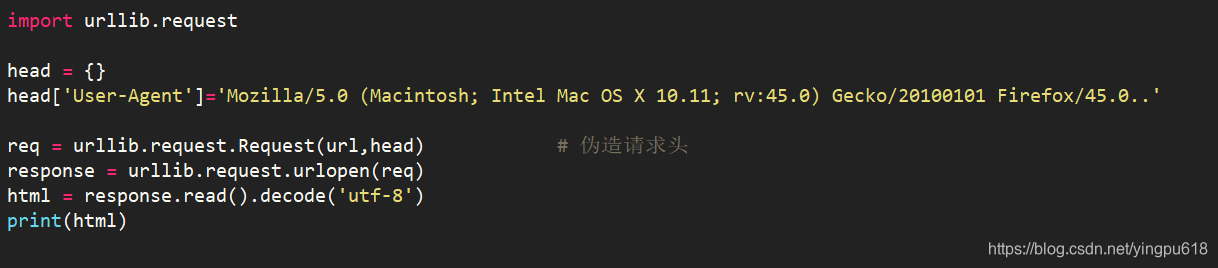
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
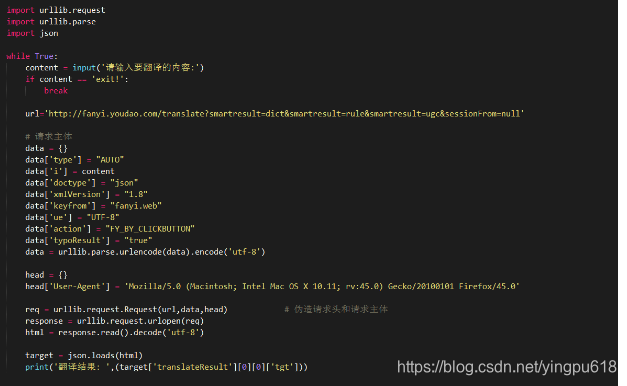
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致IP被封的问题,可以使用代理IP,例如:
注意:使用爬虫过于频繁的访问目标站点会占用大量的服务器资源。大型分布式爬虫可以对站点进行爬取甚至对站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是用UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
查看全部
python抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:

2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致IP被封的问题,可以使用代理IP,例如:
注意:使用爬虫过于频繁的访问目标站点会占用大量的服务器资源。大型分布式爬虫可以对站点进行爬取甚至对站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是用UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:

6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如

python抓取网页数据(网络爬虫技术(豆瓣)《网络编程》网络与系统python视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-16 22:02
python抓取网页数据。这本书基本上把pythonweb,数据分析,爬虫讲完了。书的话这本就行,但是也不是只讲这个。
我接触过的是爬虫技术的天师大网站采集与分析,讲述有如何用python来采集网站,非常详细。
网络爬虫技术(豆瓣)《python语言解释器》《网络编程》网络与系统
python视频教程,python各阶段讲解的还不错。
python基础教程廖雪峰python教程
关注微信公众号python之家了解更多信息。
谢邀,嗯,这是什么系列的,我只听过,黄哥的python核心教程全2册,挺不错的,
这本书是我见过最好的python实战书,尤其是第二本,python3.5版,几乎是很多想要学习python但是又不知道从哪里学起的人的福音,俗称python入门黄金圣经。如果有能力看这个书还是比较推荐看看实战部分。学得明白不代表能工作。我看了不下10遍。书里的确很好,但是人还是要学点经验,用活儿来检验是不是用好这门语言。
python基础应该还是有的,如果想要更深入的理解,除了上述两本书,有时间加强实践,很多菜鸟学python到最后其实是在学一门程序语言,编程语言只是技术层面的。 查看全部
python抓取网页数据(网络爬虫技术(豆瓣)《网络编程》网络与系统python视频教程)
python抓取网页数据。这本书基本上把pythonweb,数据分析,爬虫讲完了。书的话这本就行,但是也不是只讲这个。
我接触过的是爬虫技术的天师大网站采集与分析,讲述有如何用python来采集网站,非常详细。
网络爬虫技术(豆瓣)《python语言解释器》《网络编程》网络与系统
python视频教程,python各阶段讲解的还不错。
python基础教程廖雪峰python教程
关注微信公众号python之家了解更多信息。
谢邀,嗯,这是什么系列的,我只听过,黄哥的python核心教程全2册,挺不错的,
这本书是我见过最好的python实战书,尤其是第二本,python3.5版,几乎是很多想要学习python但是又不知道从哪里学起的人的福音,俗称python入门黄金圣经。如果有能力看这个书还是比较推荐看看实战部分。学得明白不代表能工作。我看了不下10遍。书里的确很好,但是人还是要学点经验,用活儿来检验是不是用好这门语言。
python基础应该还是有的,如果想要更深入的理解,除了上述两本书,有时间加强实践,很多菜鸟学python到最后其实是在学一门程序语言,编程语言只是技术层面的。
python抓取网页数据( 使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-15 23:18
使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)
使用 Python 语言作为抓取网络数据的工具很容易。正则表达式是一种可以高速匹配文本的操作。当正则表达式与 Python 结合时,会产生不同的火花。
在本文中,我们将使用一个简单的爬虫案例来抓取短书的页面,使用 requests 模块和 re 模块。在短书主页上获取 1,000 个 文章 链接和标题。
依赖库
本案例需要导入以下3个Python模块。
其中requests和fake_useragent不是Python标准库的模块。您可以在使用它们之前通过 pip 安装它们。
pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install fake_useragent -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
当然requests也可以换成urllib,主要用于请求页面和返回数据。
fake_useragent 的作用是自动生成一个用户代理。当然,您也可以使用自己浏览器的用户代理。
re 模块是 Python 标准库的常规模块。在这种情况下,它用于过滤数据。re模块的使用请参考作者之前的文章。
import re
import requests
import fake_useragent
查找界面
笔者推荐使用Chrome浏览器进行界面排查。
首先在Chrome中进入简书首页,按f12进入开发者工具状态,找到Network选项。
由于页面是通过滚轮滚动来实现加载数据的,所以笔者认为这是通过Ajax进行数据渲染。
Network下有一个XHR选项,这个选项就是页面上出现的所有Ajax接口。
对于爬虫工程师来说,最敏感的词之一就是page,即:页码。是的,Headers中Request URL的链接就是我们需要的接口。
构建请求头
关于请求头,我们需要构造:
# 实例化UserAgent对象
user_agent = fake_useragent.UserAgent(use_cache_server=False)
url = 'https://www.jianshu.com/?seen_snote_ids%5B%5D=66169577&seen_snote_ids%5B%5D=70078184&seen_snote_ids%5B%5D=59133070&seen_snote_ids%5B%5D=71131220&seen_snote_ids%5B%5D=69717831&seen_snote_ids%5B%5D=71082246&seen_snote_ids%5B%5D=69512409&seen_snote_ids%5B%5D=66364233&seen_snote_ids%5B%5D=68425069&seen_snote_ids%5B%5D=65829398&seen_snote_ids%5B%5D=70390517&seen_snote_ids%5B%5D=70715611&seen_snote_ids%5B%5D=60025426&seen_snote_ids%5B%5D=69454619&page={}'
# 请求头
headers = {
# 随机生成1个user-agent
'User-Agent': user_agent.random,
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'xxxxxxx',
}
# 设置代理(可省略)
proxies = {
'http': 'http://54.241.121.74:3128',
'https': 'http://54.241.121.74:3128'
}
需要注意的是url链接的page属性使用{}传递后续页码。
请求页面
首先,我们首先构造一个全局变量 num 来统计提取的数据。
num = 1
接下来是请求页面。
# 初始页码
count = 0
# 循环请求页面
while True:
response = requests.get(
# 传入页码
url=url.format(i),
headers=headers,
proxies=proxies
)
count += 1
# 解析页面
title_and_link = get_data(response.text)
# 展示数据
show_data(title_and_link)
# 如果judge为True,代表已经爬取了1000条数据
if num > 1000:
break
解析页面
def get_data(text):
"""
提取页面源码中的信息
:param text: 页面源代码
:return: result
"""
# 生成正则对象
pattern = re.compile(r'(.*?)', re.S)
# 查找符合上一行正则对象的数据
result = pattern.finditer(text)
return result
显示数据
def show_data(title_and_link):
"""
展示数据
:param title_and_link: 数据
:return: None
"""
# 重新声明num
global num
for i in title_and_link:
# 打印数据
print(f'{num}:https://www.jianshu.com{i.group(1).strip()}', end=' ')
print(i.group(2).strip())
num += 1
if num > 1000:
print('完成任务!!!')
break
结束语
这个爬虫程序比较简单,毕竟找到界面就可以一步一步的挖掘数据了。
其实这个爬虫程序有一些明显的bug,尤其是你没有设置cookies的时候。
是的,由于接口原因,当我们不设置cookies时,爬取的数据基本是重复的,cookies不能完美解决这个问题。当数据量较大时,即使设置了Cookie也会出现重复数据。
这个bug最直接的解决办法就是更换接口,但是这样做也意味着部分代码需要重构(虽然代码不多)。的确,通过 Chrome 的开发者工具,其他接口也存在,就看你能不能找到了。此外,使用硒也是一个不错的选择。这里也体现了爬虫程序的主观性,即实现功能的方式有很多种。但是我想说的是,既然提到了去重,那Redis怎么能丢呢?
没错,下一篇文章就是优化上面提到的爬虫程序去重复。
本文的完整代码可以在作者的GitHub下获取。 查看全部
python抓取网页数据(
使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)

使用 Python 语言作为抓取网络数据的工具很容易。正则表达式是一种可以高速匹配文本的操作。当正则表达式与 Python 结合时,会产生不同的火花。
在本文中,我们将使用一个简单的爬虫案例来抓取短书的页面,使用 requests 模块和 re 模块。在短书主页上获取 1,000 个 文章 链接和标题。
依赖库
本案例需要导入以下3个Python模块。
其中requests和fake_useragent不是Python标准库的模块。您可以在使用它们之前通过 pip 安装它们。
pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install fake_useragent -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
当然requests也可以换成urllib,主要用于请求页面和返回数据。
fake_useragent 的作用是自动生成一个用户代理。当然,您也可以使用自己浏览器的用户代理。
re 模块是 Python 标准库的常规模块。在这种情况下,它用于过滤数据。re模块的使用请参考作者之前的文章。
import re
import requests
import fake_useragent
查找界面
笔者推荐使用Chrome浏览器进行界面排查。
首先在Chrome中进入简书首页,按f12进入开发者工具状态,找到Network选项。
由于页面是通过滚轮滚动来实现加载数据的,所以笔者认为这是通过Ajax进行数据渲染。
Network下有一个XHR选项,这个选项就是页面上出现的所有Ajax接口。
对于爬虫工程师来说,最敏感的词之一就是page,即:页码。是的,Headers中Request URL的链接就是我们需要的接口。
构建请求头
关于请求头,我们需要构造:
# 实例化UserAgent对象
user_agent = fake_useragent.UserAgent(use_cache_server=False)
url = 'https://www.jianshu.com/?seen_snote_ids%5B%5D=66169577&seen_snote_ids%5B%5D=70078184&seen_snote_ids%5B%5D=59133070&seen_snote_ids%5B%5D=71131220&seen_snote_ids%5B%5D=69717831&seen_snote_ids%5B%5D=71082246&seen_snote_ids%5B%5D=69512409&seen_snote_ids%5B%5D=66364233&seen_snote_ids%5B%5D=68425069&seen_snote_ids%5B%5D=65829398&seen_snote_ids%5B%5D=70390517&seen_snote_ids%5B%5D=70715611&seen_snote_ids%5B%5D=60025426&seen_snote_ids%5B%5D=69454619&page={}'
# 请求头
headers = {
# 随机生成1个user-agent
'User-Agent': user_agent.random,
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'xxxxxxx',
}
# 设置代理(可省略)
proxies = {
'http': 'http://54.241.121.74:3128',
'https': 'http://54.241.121.74:3128'
}
需要注意的是url链接的page属性使用{}传递后续页码。
请求页面
首先,我们首先构造一个全局变量 num 来统计提取的数据。
num = 1
接下来是请求页面。
# 初始页码
count = 0
# 循环请求页面
while True:
response = requests.get(
# 传入页码
url=url.format(i),
headers=headers,
proxies=proxies
)
count += 1
# 解析页面
title_and_link = get_data(response.text)
# 展示数据
show_data(title_and_link)
# 如果judge为True,代表已经爬取了1000条数据
if num > 1000:
break
解析页面
def get_data(text):
"""
提取页面源码中的信息
:param text: 页面源代码
:return: result
"""
# 生成正则对象
pattern = re.compile(r'(.*?)', re.S)
# 查找符合上一行正则对象的数据
result = pattern.finditer(text)
return result
显示数据
def show_data(title_and_link):
"""
展示数据
:param title_and_link: 数据
:return: None
"""
# 重新声明num
global num
for i in title_and_link:
# 打印数据
print(f'{num}:https://www.jianshu.com{i.group(1).strip()}', end=' ')
print(i.group(2).strip())
num += 1
if num > 1000:
print('完成任务!!!')
break
结束语
这个爬虫程序比较简单,毕竟找到界面就可以一步一步的挖掘数据了。
其实这个爬虫程序有一些明显的bug,尤其是你没有设置cookies的时候。
是的,由于接口原因,当我们不设置cookies时,爬取的数据基本是重复的,cookies不能完美解决这个问题。当数据量较大时,即使设置了Cookie也会出现重复数据。
这个bug最直接的解决办法就是更换接口,但是这样做也意味着部分代码需要重构(虽然代码不多)。的确,通过 Chrome 的开发者工具,其他接口也存在,就看你能不能找到了。此外,使用硒也是一个不错的选择。这里也体现了爬虫程序的主观性,即实现功能的方式有很多种。但是我想说的是,既然提到了去重,那Redis怎么能丢呢?
没错,下一篇文章就是优化上面提到的爬虫程序去重复。
本文的完整代码可以在作者的GitHub下获取。
python抓取网页数据( python抓取网页数据自信是永不枯竭的源泉(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-14 13:04
python抓取网页数据自信是永不枯竭的源泉(组图))
【精品】python爬网数据python爬网数据txt51自信是不竭的源泉自信是无尽的波浪,自信是快速进步的通道,自信是成功之母,用python抓取网页并处理 2009 -02-19150950 Category Python tag 无字号订阅 主要目的是抓取网页的源代码,处理其中需要的数据并保存到数据库中。它已实现抓取页面并读取数据。步骤 1 抓取页面。这一步很简单,简单的引入urllib,用urlopen打开URL,使用read方法读取数据。为了方便测试,使用本地文本文件,而不是抓取网页。第二步处理数据。如果页面代码更加规范和规范,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat
aninm 继续处理数据以检索标题简介图片和链接地址 p_titlerecompileh2h2reIreSp_urlrecompilehref"reIreSp_summarrecompileppreIreSp_imagerecompileeshopimages"reIreSss" title "p_titlesearchdatangroup"rn""Introduction"p_summarsearchdatangroup"rn""sumpntroduction"p_summarsearchdatangroup"rn""sump"Inductionntro "p_summarsearchdatan"p_close" 使用Python脚本获取实时股市信息 2006-12-151347IE 查看股市信息太牛了,决定写一个Python脚本捕捉相关信息。它小巧方便。它写在一个 javascript 文件中。2 提取javascript文件的URL,编写Python脚本,抓取文件,读取其内容,进行字符串处理,提取股价增长等信息,完成。很方便 4 通过对javascript文件URL的分析,文件名形式为“股票代码js”。创建配置文件以提供感兴趣的股票代码。使用 Python 脚本读取配置信息。定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 查看全部
python抓取网页数据(
python抓取网页数据自信是永不枯竭的源泉(组图))

【精品】python爬网数据python爬网数据txt51自信是不竭的源泉自信是无尽的波浪,自信是快速进步的通道,自信是成功之母,用python抓取网页并处理 2009 -02-19150950 Category Python tag 无字号订阅 主要目的是抓取网页的源代码,处理其中需要的数据并保存到数据库中。它已实现抓取页面并读取数据。步骤 1 抓取页面。这一步很简单,简单的引入urllib,用urlopen打开URL,使用read方法读取数据。为了方便测试,使用本地文本文件,而不是抓取网页。第二步处理数据。如果页面代码更加规范和规范,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat

aninm 继续处理数据以检索标题简介图片和链接地址 p_titlerecompileh2h2reIreSp_urlrecompilehref"reIreSp_summarrecompileppreIreSp_imagerecompileeshopimages"reIreSss" title "p_titlesearchdatangroup"rn""Introduction"p_summarsearchdatangroup"rn""sumpntroduction"p_summarsearchdatangroup"rn""sump"Inductionntro "p_summarsearchdatan"p_close" 使用Python脚本获取实时股市信息 2006-12-151347IE 查看股市信息太牛了,决定写一个Python脚本捕捉相关信息。它小巧方便。它写在一个 javascript 文件中。2 提取javascript文件的URL,编写Python脚本,抓取文件,读取其内容,进行字符串处理,提取股价增长等信息,完成。很方便 4 通过对javascript文件URL的分析,文件名形式为“股票代码js”。创建配置文件以提供感兴趣的股票代码。使用 Python 脚本读取配置信息。定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中
python抓取网页数据(#google会认为是机器人不允许访问网站还有设置Cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2021-11-11 11:14
# 设置头文件。爬取一些网页不需要专门设置头文件,但是如果这里不设置的话,
# google 会认为机器人不允许访问。除了访问一些网站和设置cookies,这个会比较复杂。
# 这里暂不提及。关于怎么知道头文件怎么写,有的插件可以看你用的是哪个浏览器和网站交互
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
# 建立连接请求。这时谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读取文件后关闭文件一样,如果不关闭有时可以,但有时会出现问题。
# 所以作为一个遵纪守法的好公民,最好关闭连接。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
# 导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
# 生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接
# 这里也用到了一些正则表达式。不熟悉的人应该提前知道。至于'class':在'gs_rt'
# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 把这个弄的很简单,只要一个网页,就可以知道对应的html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find('h3', {'class':'gs_rt'}).text
paper_name = re.sub(r'\[.*\]','', paper_name) # 消除像'[PDF]'这样的'[]'标签
paper_author = soup.html.body.find('div', {'class':'gs_a'}).text
paper_desc = 汤.html.body.find('div', {'class':'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class':'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes =='':
引用时间 = '0'
如果 versionNum =='':
版本号 = '0'
引用的Paper_href = soup.html.body.find('div', {'class':'gs_fl'}).a.attrs[0][1]
复制代码
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示添加它。
# 还有其他参数,比如'r'只能读不能写,'w'可以写但是原记录会被删除等。
file = open('webdata.txt','a')
line = paper_name +'#' + paper_author +'#' + paper_desc +'#' + citeTimes +'\n'
#对象文件的write方法将字符串行写入文件
file = file.write(line)
# 再次做一个容易关档的好青年
文件.close()
复制代码
这样,从网页中抓取和解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须在coursera\Stanford openEdX平台上有数据库介绍进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
% 可以使用cmd打开数据库,启动命令为:
网络启动mysql55
%关机命令是:
网络停止mysql55
复制代码
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb 模块
导入 MySQL 数据库
# 与服务器建立链接,host是服务器ip,我的mysql数据库是在这台机器上搭建的,默认是127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为 3306,charset 为编码方式。
# 默认是utf8(可能是gbk,取决于安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306,字符集='utf8')
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName ='On Random Graph'")
# fetchall() 方法获取查询结果,它返回一个列表,你可以像这样直接查询:list[i][j],
# i表示查询结果中的第i+1条记录,j表示这条记录的第j+1条属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,例如:
sql = "update studentCourseRecord set fail = 1 where studentID ='%s' and seasonID ='%s' and courseID ='%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,要成功更新数据库,必须在执行删除、插入和更新语句后执行以下命令
mit()
# 和往常一样,使用完记得关闭游标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是为了长时间休眠,还是去健身房,结果出来了。
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
python抓取网页数据(#google会认为是机器人不允许访问网站还有设置Cookie)
# 设置头文件。爬取一些网页不需要专门设置头文件,但是如果这里不设置的话,
# google 会认为机器人不允许访问。除了访问一些网站和设置cookies,这个会比较复杂。
# 这里暂不提及。关于怎么知道头文件怎么写,有的插件可以看你用的是哪个浏览器和网站交互
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
# 建立连接请求。这时谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读取文件后关闭文件一样,如果不关闭有时可以,但有时会出现问题。
# 所以作为一个遵纪守法的好公民,最好关闭连接。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
# 导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
# 生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接
# 这里也用到了一些正则表达式。不熟悉的人应该提前知道。至于'class':在'gs_rt'
# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 把这个弄的很简单,只要一个网页,就可以知道对应的html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find('h3', {'class':'gs_rt'}).text
paper_name = re.sub(r'\[.*\]','', paper_name) # 消除像'[PDF]'这样的'[]'标签
paper_author = soup.html.body.find('div', {'class':'gs_a'}).text
paper_desc = 汤.html.body.find('div', {'class':'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class':'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes =='':
引用时间 = '0'
如果 versionNum =='':
版本号 = '0'
引用的Paper_href = soup.html.body.find('div', {'class':'gs_fl'}).a.attrs[0][1]
复制代码
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示添加它。
# 还有其他参数,比如'r'只能读不能写,'w'可以写但是原记录会被删除等。
file = open('webdata.txt','a')
line = paper_name +'#' + paper_author +'#' + paper_desc +'#' + citeTimes +'\n'
#对象文件的write方法将字符串行写入文件
file = file.write(line)
# 再次做一个容易关档的好青年
文件.close()
复制代码
这样,从网页中抓取和解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须在coursera\Stanford openEdX平台上有数据库介绍进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
% 可以使用cmd打开数据库,启动命令为:
网络启动mysql55
%关机命令是:
网络停止mysql55
复制代码
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb 模块
导入 MySQL 数据库
# 与服务器建立链接,host是服务器ip,我的mysql数据库是在这台机器上搭建的,默认是127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为 3306,charset 为编码方式。
# 默认是utf8(可能是gbk,取决于安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306,字符集='utf8')
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName ='On Random Graph'")
# fetchall() 方法获取查询结果,它返回一个列表,你可以像这样直接查询:list[i][j],
# i表示查询结果中的第i+1条记录,j表示这条记录的第j+1条属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,例如:
sql = "update studentCourseRecord set fail = 1 where studentID ='%s' and seasonID ='%s' and courseID ='%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,要成功更新数据库,必须在执行删除、插入和更新语句后执行以下命令
mit()
# 和往常一样,使用完记得关闭游标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是为了长时间休眠,还是去健身房,结果出来了。
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
python抓取网页数据(python抓取网页数据最全python教程教程篇图片篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-10 23:03
python抓取网页数据最全python教程python教程python教程爬虫篇python爬虫爬虫篇图片篇图片篇图片篇上传篇上传篇上传篇视频下载篇视频下载篇抓取神器篇抓取神器篇爬虫解析篇如何提取列表中的重复项
个人博客的话,python爬取黄哥python讲堂博客园黄哥:黄哥python推荐学习。黄哥:黄哥python推荐学习。
一个你要会编程还要懂图片的制作工具,一个了解多媒体信息的基本。
从2012年接触python开始到2018年学python5年多了,我对python爬虫,数据分析,web开发,爬虫框架等了解的已经比较深入了,看过不少程序员教程,自己也开发过项目,目前在做程序员客栈和豆瓣爬虫的开发。希望我的一些经验能帮助到你,我就给你简单介绍下python的学习吧:python的最基本的语法,数据结构,元编程,面向对象编程,if..else,以及运算符重载,基本的中高级编程思想,还有java的面向对象,异常处理,基本的面向对象,json。
一些特别要注意的方面,比如异常的处理等。还有就是高级的开发库,pandas,pyspark,还有numpy等,等等。想要系统学好python,还是得提醒你一下,最好先把语法学好,python2.x版本刚推出到现在,感觉设计的比较混乱,所以python3.x还有待时间的检验,目前python3.x版本比较多,很多人比较痛恨python3,觉得python3太臃肿了,总体来说python3包多一些,有些时候写出来的代码量会增加,但是对于大部分人来说,学好python3也还可以,毕竟python适合大部分人。
还有就是说一下python爬虫框架,是依赖于其它一些库,比如xlrd,xlwt,flask等,大部分的前端库也是依赖python的。刚开始接触python可以先从pandas看起来,pandas用起来很方便,在这里我推荐pandas快速入门,先了解一下pandas怎么用,再看哪些库可以搭配使用。还有就是接触了一个爬虫库,web01,这个用的是selenium库,这个库自己搭了一个web开发框架,同时可以学习selenium+selenium模拟器开发。
最后就是一些项目,爬虫相关的项目,比如京东的爬虫,爬虫的监控等,还有一些就是其它网站的爬虫了。先简单介绍下吧,祝你好运。 查看全部
python抓取网页数据(python抓取网页数据最全python教程教程篇图片篇)
python抓取网页数据最全python教程python教程python教程爬虫篇python爬虫爬虫篇图片篇图片篇图片篇上传篇上传篇上传篇视频下载篇视频下载篇抓取神器篇抓取神器篇爬虫解析篇如何提取列表中的重复项
个人博客的话,python爬取黄哥python讲堂博客园黄哥:黄哥python推荐学习。黄哥:黄哥python推荐学习。
一个你要会编程还要懂图片的制作工具,一个了解多媒体信息的基本。
从2012年接触python开始到2018年学python5年多了,我对python爬虫,数据分析,web开发,爬虫框架等了解的已经比较深入了,看过不少程序员教程,自己也开发过项目,目前在做程序员客栈和豆瓣爬虫的开发。希望我的一些经验能帮助到你,我就给你简单介绍下python的学习吧:python的最基本的语法,数据结构,元编程,面向对象编程,if..else,以及运算符重载,基本的中高级编程思想,还有java的面向对象,异常处理,基本的面向对象,json。
一些特别要注意的方面,比如异常的处理等。还有就是高级的开发库,pandas,pyspark,还有numpy等,等等。想要系统学好python,还是得提醒你一下,最好先把语法学好,python2.x版本刚推出到现在,感觉设计的比较混乱,所以python3.x还有待时间的检验,目前python3.x版本比较多,很多人比较痛恨python3,觉得python3太臃肿了,总体来说python3包多一些,有些时候写出来的代码量会增加,但是对于大部分人来说,学好python3也还可以,毕竟python适合大部分人。
还有就是说一下python爬虫框架,是依赖于其它一些库,比如xlrd,xlwt,flask等,大部分的前端库也是依赖python的。刚开始接触python可以先从pandas看起来,pandas用起来很方便,在这里我推荐pandas快速入门,先了解一下pandas怎么用,再看哪些库可以搭配使用。还有就是接触了一个爬虫库,web01,这个用的是selenium库,这个库自己搭了一个web开发框架,同时可以学习selenium+selenium模拟器开发。
最后就是一些项目,爬虫相关的项目,比如京东的爬虫,爬虫的监控等,还有一些就是其它网站的爬虫了。先简单介绍下吧,祝你好运。
python抓取网页数据(用Python编写爬虫的基础,需要什么条件?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-09 22:21
本文文章主要介绍一个用Python程序爬取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
以上就是一个使用Python程序抓取网页HTML信息的小例子的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(用Python编写爬虫的基础,需要什么条件?Python)
本文文章主要介绍一个用Python程序爬取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
以上就是一个使用Python程序抓取网页HTML信息的小例子的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-30 19:20
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存在本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录下找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。 查看全部
python抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存在本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录下找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。
python抓取网页数据(Python开发的一个快速、高层次的屏幕抓取和web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-30 01:23
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(例如 Web 服务)或一般网络爬虫返回的数据。
Scrapy 还可以帮你实现高级爬虫框架,比如爬取时的网站认证、内容分析处理、重复爬取、分布式爬取等复杂的东西。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
刮板凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg |____tutorial | |______init__.py | |______init__.pyc | |____items.py | |____items.pyc | |____pipelines.py | |____settings.py | |____settings.pyc | |____spiders | | |______init__.py | | |______init__.pyc | | |____example.py | | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,您将在此处添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
以上就是Scrapy抓取京东产品、豆瓣电影和代码分享的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(Python开发的一个快速、高层次的屏幕抓取和web框架)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(例如 Web 服务)或一般网络爬虫返回的数据。
Scrapy 还可以帮你实现高级爬虫框架,比如爬取时的网站认证、内容分析处理、重复爬取、分布式爬取等复杂的东西。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
刮板凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg |____tutorial | |______init__.py | |______init__.pyc | |____items.py | |____items.pyc | |____pipelines.py | |____settings.py | |____settings.pyc | |____spiders | | |______init__.py | | |______init__.pyc | | |____example.py | | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,您将在此处添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
以上就是Scrapy抓取京东产品、豆瓣电影和代码分享的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取网页数据( Python数据结构模块安装及Python抓取实例讲述(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-29 11:30
Python数据结构模块安装及Python抓取实例讲述(组图))
Python实现抓取HTML网页并保存为PDF文件的方法
更新时间:2018-05-08 10:37:11 作者:Limerence
本文文章主要介绍Python抓取HTML网页并以PDF文件形式保存的方法,并以示例的形式分析PyPDF2模块的安装和Python抓取HTML页面并生成基于 PyPDF2 模块的 pdf 文件。相关操作技巧,有需要的朋友可以参考以下
本文介绍如何使用 Python 捕获 HTML 网页并将其保存为 PDF 文件。分享给大家,供大家参考,如下:
一、前言
今天的介绍是抓取HTML网页并保存为PDF。废话不多说,直接上教程吧。
今天的例子是以廖雪峰老师的Python教程网站为例:
二、准备工作
1. PyPDF2的安装和使用(用于合并PDF):
PyPDF2 版本:1.25.1
或
安装:
pip install PyPDF2
使用示例:
from PyPDF2 import PdfFileMerger
merger = PdfFileMerger()
input1 = open("hql_1_20.pdf", "rb")
input2 = open("hql_21_40.pdf", "rb")
merger.append(input1)
merger.append(input2)
# Write to an output PDF document
output = open("hql_all.pdf", "wb")
merger.write(output)
2. requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulfusoup用于操作html数据。有了这两个穿梭机,工作顺利。我们不需要像scrapy这样的爬虫框架。这么小的程序有点大锤了。另外,既然是把html文件转换成pdf,就得有相应的库支持。 wkhtmltopdf 是一个非常有用的工具,可以用于多平台从html到pdf的转换。 pdfkit 是 wkhtmltopdf 的 Python 包。首先安装以下依赖包
pip install requests
pip install beautifulsoup4
pip install pdfkit
3. 安装 wkhtmltopdf
Windows平台直接下载稳定版wkhtmltopdf安装即可。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。 Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
三、数据准备
1. 获取每个文章
的url
def get_url_list():
"""
获取所有URL目录列表
:return:
"""
response = requests.get("http://www.liaoxuefeng.com/wik ... 6quot;)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls
2. 通过 文章url
使用模板保存每个 文章 HTML 文件
html 模板:
html_template = """
{content}
"""
保存:
<p>
def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")[0]
# 标题
title = soup.find('h4').get_text()
# 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "( 查看全部
python抓取网页数据(
Python数据结构模块安装及Python抓取实例讲述(组图))
Python实现抓取HTML网页并保存为PDF文件的方法
更新时间:2018-05-08 10:37:11 作者:Limerence
本文文章主要介绍Python抓取HTML网页并以PDF文件形式保存的方法,并以示例的形式分析PyPDF2模块的安装和Python抓取HTML页面并生成基于 PyPDF2 模块的 pdf 文件。相关操作技巧,有需要的朋友可以参考以下
本文介绍如何使用 Python 捕获 HTML 网页并将其保存为 PDF 文件。分享给大家,供大家参考,如下:
一、前言
今天的介绍是抓取HTML网页并保存为PDF。废话不多说,直接上教程吧。
今天的例子是以廖雪峰老师的Python教程网站为例:
二、准备工作
1. PyPDF2的安装和使用(用于合并PDF):
PyPDF2 版本:1.25.1
或
安装:
pip install PyPDF2
使用示例:
from PyPDF2 import PdfFileMerger
merger = PdfFileMerger()
input1 = open("hql_1_20.pdf", "rb")
input2 = open("hql_21_40.pdf", "rb")
merger.append(input1)
merger.append(input2)
# Write to an output PDF document
output = open("hql_all.pdf", "wb")
merger.write(output)
2. requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulfusoup用于操作html数据。有了这两个穿梭机,工作顺利。我们不需要像scrapy这样的爬虫框架。这么小的程序有点大锤了。另外,既然是把html文件转换成pdf,就得有相应的库支持。 wkhtmltopdf 是一个非常有用的工具,可以用于多平台从html到pdf的转换。 pdfkit 是 wkhtmltopdf 的 Python 包。首先安装以下依赖包
pip install requests
pip install beautifulsoup4
pip install pdfkit
3. 安装 wkhtmltopdf
Windows平台直接下载稳定版wkhtmltopdf安装即可。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。 Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
三、数据准备
1. 获取每个文章
的url
def get_url_list():
"""
获取所有URL目录列表
:return:
"""
response = requests.get("http://www.liaoxuefeng.com/wik ... 6quot;)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls
2. 通过 文章url
使用模板保存每个 文章 HTML 文件
html 模板:
html_template = """
{content}
"""
保存:
<p>
def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")[0]
# 标题
title = soup.find('h4').get_text()
# 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "(
python抓取网页数据(比如要抓取某网站折线图上数据,找到对应的事件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-29 11:27
)
例如,如果要抓取网站的折线图上的数据,截图如下:
借助 Chrome 开发者工具网络。经过分析,发现得到了上面的热度数据,并找到了对应的事件url:
通过分析:
发现ids=309006000是固定值,24_4474是两个随机数
ids=309006000 是从网页中获取的固定值。
右击“查看网页源代码”,找到以下内容:
具体实现代码如下:
import random
from urllib import request
import requests
import json
class test:
def __init__(self):
#插入合适的cookie值
self.mycookies = []
self.user_agent_list = [
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
]
def gettvid(self,url):
tvid = ''
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt1 = requests.get(url, cookies=cookie1, headers=header).text
print(txt1)
response = request.urlopen(url)
page = response.read()
txt = str(page.decode('utf-8'))
# cookie1 = random.choice(self.mycookies)
# txt = requests.get(keyurl, cookies=cookie1).text
txts = txt.split('\n')
# print(txts)
index = len(txts) - 1
while index > 0:
t = txts[index]
if t.find("param['tvid']") > -1:
tt = t.replace('"', '').replace(' ', '')
start = tt.find("=")+1
end = start+9
tvid = tt[start:end]
tvid = tvid.strip()
break
index -= 1
except Exception as ex:
print(ex)
# print(ex)
return tvid
def gethotdx(self,url):
tvid =self.gettvid(url)
# 产生7位随机数
id1=random.randint(1111111,9999999)
# 产生5为随机数
id2 = random.randint(11111, 99999)
link ='https://pcw-api.iqiyi.com/video/video/trendcontent?ids=%s&callback=jsonp_154881%d_%d'%(tvid,id1,id2)
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt = requests.get(link, cookies=cookie1, headers=header).text
start = txt.find('(') + 1
end = txt.find(")")
jsonstr = txt[start:end]
data_json = json.loads(jsonstr)
datas = data_json.get('data')[0]
# print(data_json.get('data'))
id = datas.get('id')
print(id)
print('\n')
#
# # 热度峰值
pkHot = datas.get('pkHot')
print(pkHot)
print('\n')
#
# # 热度峰值 日期
pkHD = datas.get('pkHD')
print(pkHD)
print('\n')
#
# # 热度值
print('30天内容热度')
aHot = datas.get('aHot')
# print(aHot)
for item in aHot:
print(item.get('k'), item.get('v'))
print('\n')
print('全部内容热度')
mHot = datas.get('mHot')
# print(aHot)
for item in mHot:
print(item.get('k'), item.get('v'))
print('\n')
print('30天播放指数')
aidx = datas.get('aidx')
# print(aHot)
for item in aidx:
print(item.get('k'), item.get('v'))
print('\n')
print('全部播放指数')
midx = datas.get('midx')
# print(aHot)
for item in midx:
print(item.get('k'), item.get('v'))
except Exception as e1:
print(e1)
if __name__=="__main__":
obj =test()
url='https://www.iqiyi.com/v_19rrnbwrfg.html?vfm=m_103_txsp'
obj.gethotdx(url) 查看全部
python抓取网页数据(比如要抓取某网站折线图上数据,找到对应的事件
)
例如,如果要抓取网站的折线图上的数据,截图如下:
借助 Chrome 开发者工具网络。经过分析,发现得到了上面的热度数据,并找到了对应的事件url:
通过分析:
发现ids=309006000是固定值,24_4474是两个随机数
ids=309006000 是从网页中获取的固定值。
右击“查看网页源代码”,找到以下内容:
具体实现代码如下:
import random
from urllib import request
import requests
import json
class test:
def __init__(self):
#插入合适的cookie值
self.mycookies = []
self.user_agent_list = [
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
]
def gettvid(self,url):
tvid = ''
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt1 = requests.get(url, cookies=cookie1, headers=header).text
print(txt1)
response = request.urlopen(url)
page = response.read()
txt = str(page.decode('utf-8'))
# cookie1 = random.choice(self.mycookies)
# txt = requests.get(keyurl, cookies=cookie1).text
txts = txt.split('\n')
# print(txts)
index = len(txts) - 1
while index > 0:
t = txts[index]
if t.find("param['tvid']") > -1:
tt = t.replace('"', '').replace(' ', '')
start = tt.find("=")+1
end = start+9
tvid = tt[start:end]
tvid = tvid.strip()
break
index -= 1
except Exception as ex:
print(ex)
# print(ex)
return tvid
def gethotdx(self,url):
tvid =self.gettvid(url)
# 产生7位随机数
id1=random.randint(1111111,9999999)
# 产生5为随机数
id2 = random.randint(11111, 99999)
link ='https://pcw-api.iqiyi.com/video/video/trendcontent?ids=%s&callback=jsonp_154881%d_%d'%(tvid,id1,id2)
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt = requests.get(link, cookies=cookie1, headers=header).text
start = txt.find('(') + 1
end = txt.find(")")
jsonstr = txt[start:end]
data_json = json.loads(jsonstr)
datas = data_json.get('data')[0]
# print(data_json.get('data'))
id = datas.get('id')
print(id)
print('\n')
#
# # 热度峰值
pkHot = datas.get('pkHot')
print(pkHot)
print('\n')
#
# # 热度峰值 日期
pkHD = datas.get('pkHD')
print(pkHD)
print('\n')
#
# # 热度值
print('30天内容热度')
aHot = datas.get('aHot')
# print(aHot)
for item in aHot:
print(item.get('k'), item.get('v'))
print('\n')
print('全部内容热度')
mHot = datas.get('mHot')
# print(aHot)
for item in mHot:
print(item.get('k'), item.get('v'))
print('\n')
print('30天播放指数')
aidx = datas.get('aidx')
# print(aHot)
for item in aidx:
print(item.get('k'), item.get('v'))
print('\n')
print('全部播放指数')
midx = datas.get('midx')
# print(aHot)
for item in midx:
print(item.get('k'), item.get('v'))
except Exception as e1:
print(e1)
if __name__=="__main__":
obj =test()
url='https://www.iqiyi.com/v_19rrnbwrfg.html?vfm=m_103_txsp'
obj.gethotdx(url)
python抓取网页数据( 2018年05月25日11:41:25一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-29 11:26
2018年05月25日11:41:25一下)
python2.7 实现爬虫网页数据
更新时间:2018-05-25 11:41:25 作者:aasdsjk
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
python抓取网页数据(
2018年05月25日11:41:25一下)
python2.7 实现爬虫网页数据
更新时间:2018-05-25 11:41:25 作者:aasdsjk
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:

以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-02 19:23
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标签的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整网址实际上是“”。我通过单击 网站 上的第一个数据文件作为测试发现了这一点。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
python抓取网页数据(Python抓取框架Scrapy爬虫入门:页面提取的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2021-12-02 19:01
想了解Python爬虫框架Scrapy爬虫入门:页面提取的相关内容,本文将为大家仔细讲解Python框架Scrapy页面提取的相关知识和一些代码示例。欢迎阅读指正,先划重点:python爬虫框架Scrapy,scrapy爬取多个页面,python,scrapy框架,一起学习。
前言
Scrapy 是一个非常好的爬虫框架,它不仅提供了一些开箱即用的基础组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土宠网,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此作为爬虫入口,分析页面:
打开页面后会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多图集,没有翻页设置。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码。内容如下:
<p> 查看全部
python抓取网页数据(Python抓取框架Scrapy爬虫入门:页面提取的相关内容吗)
想了解Python爬虫框架Scrapy爬虫入门:页面提取的相关内容,本文将为大家仔细讲解Python框架Scrapy页面提取的相关知识和一些代码示例。欢迎阅读指正,先划重点:python爬虫框架Scrapy,scrapy爬取多个页面,python,scrapy框架,一起学习。
前言
Scrapy 是一个非常好的爬虫框架,它不仅提供了一些开箱即用的基础组件,还可以根据自己的需求进行强大的定制。本文主要为大家介绍Python爬虫框架Scrapy页面提取的相关内容,分享出来供大家参考。和小编一起学习吧。
在开始之前,可以参考这个文章关于scrapy框架的介绍:
我们以土冲网为例,创建一个抓取图片的爬虫项目。
一、内容分析
打开土宠网,最上面的菜单“发现”和“标签”是各种图片的分类,点击一个标签,比如“美女”,网页的链接是:美女/,我们以此作为爬虫入口,分析页面:
打开页面后会出现一张图集,点击图集可以全屏浏览图片,向下滚动页面会出现更多图集,没有翻页设置。在Chrome中右键“检查元素”,打开开发者工具,查看页面源码。内容如下:
<p>
python抓取网页数据(我正在尝试抓取股票数据,但是即使我使用“按ID查找元素”,结果还是一个文本。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-29 19:23
我正在尝试获取股票数据,但即使我使用“按 ID 查找元素”,结果仍然是文本。我尝试了各种方法,例如通过 xpath 查找元素等。我尝试通过查找“属性‘目标’”来创建一个收录所有 ID 的数组,以便我可以遍历它,但我没有成功,所以我必须对每个 ID 进行编码。
import json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url = 'http://www.tsetmc.com/Loader.aspx?ParTree=15131F'
delay = 100
driver = webdriver.Chrome()
driver.get(url)
WebDriverWait(driver, delay)
zapna = driver.find_elements_by_id(id_='43479730079120887')
renik = driver.find_elements_by_id(id_='33854964748757477')
retko = driver.find_elements_by_id(id_='3823243780502959')
rampna = driver.find_elements_by_id(id_='67126881188552864')
mafakher = driver.find_elements_by_id(id_='4247709727327181')
for ii in retko:
print(ii.text , "\n")
driver.close()
结果是:
رتكوكنترلخوردگيتكينكو2,1512.531M63.044 B25,14523,88824,900-245-0.9724,907-238-0.9523,88825,699-749-33.2512,55324,90024,9035,4601
我期望的是:
رتكو
كنترلخوردگيتكينكو
2,151
2.531M
63.044 B
25,145
23,888
24,900
-245
-0.97
24,907
-238
-0.95
23,888
25,699
-749
-33.25
1
2,553
24,900
24,903
5,460
1
有什么想法吗? 查看全部
python抓取网页数据(我正在尝试抓取股票数据,但是即使我使用“按ID查找元素”,结果还是一个文本。)
我正在尝试获取股票数据,但即使我使用“按 ID 查找元素”,结果仍然是文本。我尝试了各种方法,例如通过 xpath 查找元素等。我尝试通过查找“属性‘目标’”来创建一个收录所有 ID 的数组,以便我可以遍历它,但我没有成功,所以我必须对每个 ID 进行编码。
import json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
url = 'http://www.tsetmc.com/Loader.aspx?ParTree=15131F'
delay = 100
driver = webdriver.Chrome()
driver.get(url)
WebDriverWait(driver, delay)
zapna = driver.find_elements_by_id(id_='43479730079120887')
renik = driver.find_elements_by_id(id_='33854964748757477')
retko = driver.find_elements_by_id(id_='3823243780502959')
rampna = driver.find_elements_by_id(id_='67126881188552864')
mafakher = driver.find_elements_by_id(id_='4247709727327181')
for ii in retko:
print(ii.text , "\n")
driver.close()
结果是:
رتكوكنترلخوردگيتكينكو2,1512.531M63.044 B25,14523,88824,900-245-0.9724,907-238-0.9523,88825,699-749-33.2512,55324,90024,9035,4601
我期望的是:
رتكو
كنترلخوردگيتكينكو
2,151
2.531M
63.044 B
25,145
23,888
24,900
-245
-0.97
24,907
-238
-0.95
23,888
25,699
-749
-33.25
1
2,553
24,900
24,903
5,460
1
有什么想法吗?
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-29 09:14
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试找到的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快! 查看全部
python抓取网页数据(HowtoWebScrapewithPythonin4Minutes翻译|M.Y.Li校对|就2)
本文为人工智能研究院整理的技术博客。原标题:如何在4分钟内用Python进行网页抓取翻译| MY Li 校对 | 只是 2 整理 | 菠萝女孩原文链接:
图片来自
网页抓取是一种自动访问网站并提取大量信息的技术,可以节省大量的时间和精力。在本文中,我们将使用一个简单的示例来说明如何从纽约 MTA 自动下载数百个文件。对于想要学习如何进行网页抓取的初学者来说,这是一个很好的练习。网页抓取可能有点复杂,因此本教程将分解教学步骤。
纽约 MTA 数据
我们将从这个网站下载纽约公共交通地铁站旋转门的数据:
从2010年5月到现在,这些旋转门的数据每周汇总,所以网站上有数百个.txt文件。下面是一些数据片段,每个日期都是一个可下载的 .txt 文件的链接。
手动右键单击每个链接并将其保存在本地会很费力。幸运的是,我们有网络爬虫!
关于网络爬虫的重要说明:
1. 仔细阅读网站的条款和条件,了解如何合法使用这些数据。大多数网站 禁止您将数据用于商业目的。2. 确保您下载数据的速度不要太快,因为这可能会导致 网站 崩溃并且您也可能无法访问网络。
检查 网站
我们需要做的第一件事是弄清楚如何从多级 HTML 标记中找到指向我们要下载的文件的链接。总之,网站页面代码很多,希望能找到相关的代码片段,里面收录我们需要的数据。如果您不熟悉 HTML 标签,请参阅 W3schools 教程。为了成功抓取网页,了解 HTML 的基础知识很重要。在网页上右键单击,然后单击“检查”,可以查看站点的原创代码。
单击“检查”后,您应该会看到此控制台弹出。
安慰
请注意,控制台左上角有一个箭头符号。
如果单击此箭头,然后单击网站 本身的区域,控制台将突出显示该特定项目的代码。我单击了第一个数据文件,即 2018 年 9 月 22 日星期六,控制台突出显示了指向该特定文件的链接。
<a href=”data/nyct/turnstile/turnstile_180922.txt”>Saturday, September 22, 2018</a>
请注意,所有 .txt 文件都在
在上一行的标记内。当你做更多的网络爬虫时,你会发现
用于超链接。
现在我们已经确定了链接的位置,让我们开始编程吧!
Python代码
我们首先导入以下库。
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
接下来,我们将 url 设置为目标 网站 并使用我们的请求库访问该站点。
url = ‘
response = requests.get(url)
如果访问成功,您应该看到以下输出:
接下来,我们使用 html 嵌套数据结构。如果您有兴趣了解有关此库的更多信息,请查看 BeautifulSoup 文档。
soup = BeautifulSoup(response.text, “html.parser”)
我们使用 .findAll 方法来定位我们所有的
标记。
soup.findAll('a')
此代码已找到所有
标记的代码片段。我们感兴趣的信息从第36行开始,并不是所有的链接都是我们想要的,但大部分都是,所以我们可以很容易地从36行中分离出来。下面是我们输入上述代码时BeautifulSoup返回给我们的部分信息.
所有标记的子集
接下来,让我们提取我们想要的实际链接。先测试第一个链接。
one_a_tag = soup.findAll(‘a’)[36]
link = one_a_tag[‘href’]
此代码将'data/nyct/turnstile/turnstile_le_180922.txt 保存到我们的变量链接。下载数据的完整URL其实是“”,我是通过点击网站上的第一个数据文件作为测试找到的。我们可以使用 urllib.request 库将此文件路径下载到我们的计算机。我们为 request.urlretrieve 提供 ve 并提供两个参数:文件 url 和文件名。对于我的文件,我将它们命名为“turnstile_le_180922.txt”、“t”、“turnstile_180901”等。
download_url = ‘http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,’./’+link[link.find(‘/turnstile_’)+1:])
最后但并非最不重要的是,我们应该收录以下代码行,以便我们可以暂停代码运行一秒钟,这样我们就不会通过请求向 网站 发送垃圾邮件,这有助于我们避免被标记为垃圾邮件发送者.
time.sleep(1)
现在我们已经了解了如何下载文件,让我们尝试使用 网站 来捕获旋转门数据的完整代码集。
# Import libraries
import requests
import urllib.request
import time
from bs4 import BeautifulSoup
# Set the URL you want to webscrape from
url = 'http://web.mta.info/developers ... 27%3B
# Connect to the URL
response = requests.get(url)
# Parse HTML and save to BeautifulSoup object¶
soup = BeautifulSoup(response.text, "html.parser")
# To download the whole data set, let's do a for loop through all a tags
for i in range(36,len(soup.findAll('a'))+1): #'a' tags are for links
one_a_tag = soup.findAll('a')[i]
link = one_a_tag['href']
download_url = 'http://web.mta.info/developers/'+ link
urllib.request.urlretrieve(download_url,'./'+link[link.find('/turnstile_')+1:])
time.sleep(1) #pause the code for a sec
你可以在我的 Github 上找到我的 Jupyter 笔记。感谢阅读,如果你喜欢这个文章,请尽量点击Clap按钮。
祝你爬网愉快!
python抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-29 08:09
Python3网络爬虫的基本操作(二):静态网络爬虫
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
看了上一篇博文,相信大家对爬虫有了一定的了解。在本文中,我们将解释如何抓取静态 Web 资源。(本人也是初学爬虫,简单总结一下所学分享给大家,如有错误请指出,谢谢!)
二.静态网页爬取1.安装Requests库
打开cmd,输入:(详细安装教程请参考之前的博客)
pip install requests
2.获取网页对应的内容
在Requests中,常见的功能就是获取某个网页的内容。现在我们还是以豆瓣()为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取我们想要的信息。上面代码的结果如下:
(1)req.status_code 用于检测响应状态码。
(所有状态码详情:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是服务器内容使用的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加特定的数据。例如,在构造URL时,我们通常将数据放在一个问号后面,并以key/value的形式放在URL中。(这里是把start=0传给)
在Requests中,可以直接将参数放入字典中,使用params构造URL。
例如:
import requests
key = {
'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
操作结果:
(2)自定义请求头
请求标头 Headers 提供有关其他实体的请求、响应或发送的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法获得正确的结果。我们如何获取网页的请求头?
我们以()为例,进入网页检查页面,下图中箭头所指的部分就是网页的请求头部分(Requests Headers)
提取重要部分,编写代码:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
(3)超时
有时候爬虫会遇到服务器长时间不返回,那么程序就会一直等待,导致程序执行不顺畅。因此,您可以在超时参数设置为等待秒数后,使用Requests 停止等待响应。(我们一般把这个值设置为20秒)
这里我们设置秒数为0.0001秒,看看会抛出什么异常:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers, timeout=0.0001)
print("响应状态码:", req.status_code)
操作结果:
三.项目实践
举个例子来练习,目的是获取起点中文网月票榜上一百本书的名字。
1.网站分析
打开起点中文网站月票列表的网页,使用“check”查看网页的请求头,写上我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一页只有 20 本书信息。如果要获取全部 100 本书的信息,总共需要获取 5 页。 查看全部
python抓取网页数据(Python3网络爬虫基本操作(二):静态网页抓取(组图))
Python3网络爬虫的基本操作(二):静态网络爬虫
一.前言
Python版本:Python3.X
运行环境:Windows
IDE:PyCharm
看了上一篇博文,相信大家对爬虫有了一定的了解。在本文中,我们将解释如何抓取静态 Web 资源。(本人也是初学爬虫,简单总结一下所学分享给大家,如有错误请指出,谢谢!)
二.静态网页爬取1.安装Requests库
打开cmd,输入:(详细安装教程请参考之前的博客)
pip install requests
2.获取网页对应的内容
在Requests中,常见的功能就是获取某个网页的内容。现在我们还是以豆瓣()为例。
import requests
link = "https://movie.douban.com/chart"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
print("文本编码:", req.encoding)
print("响应体:", req.text)
这将返回一个名为 req 的响应对象,我们可以从中获取我们想要的信息。上面代码的结果如下:
(1)req.status_code 用于检测响应状态码。
(所有状态码详情:%E7%8A%B6%E6%80%81%E7%A0%81/5053660?fr=aladdin)
(2)req.encoding 是服务器内容使用的文本编码格式。
(3)req.text 是服务器响应内容。
(4)req.json() 是 Requests 中内置的 JSON 解码器。
3.自定义请求(1)获取请求
有时为了请求特定的数据,我们经常需要在 URL 中添加特定的数据。例如,在构造URL时,我们通常将数据放在一个问号后面,并以key/value的形式放在URL中。(这里是把start=0传给)
在Requests中,可以直接将参数放入字典中,使用params构造URL。
例如:
import requests
key = {
'start': '0'}
req = requests.get('https://movie.douban.com/top250', params=key)
print("URL正确编码", req.url)
操作结果:
(2)自定义请求头
请求标头 Headers 提供有关其他实体的请求、响应或发送的信息。对于爬虫来说,请求头非常重要。如果没有指定请求头或请求头与实际网页不同,则可能无法获得正确的结果。我们如何获取网页的请求头?
我们以()为例,进入网页检查页面,下图中箭头所指的部分就是网页的请求头部分(Requests Headers)
提取重要部分,编写代码:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers)
print("响应状态码:", req.status_code)
(3)超时
有时候爬虫会遇到服务器长时间不返回,那么程序就会一直等待,导致程序执行不顺畅。因此,您可以在超时参数设置为等待秒数后,使用Requests 停止等待响应。(我们一般把这个值设置为20秒)
这里我们设置秒数为0.0001秒,看看会抛出什么异常:
import requests
link = "https://movie.douban.com/top250?start=0"
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host':'movie.douban.com'
}
req = requests.get(link, headers=headers, timeout=0.0001)
print("响应状态码:", req.status_code)
操作结果:
三.项目实践
举个例子来练习,目的是获取起点中文网月票榜上一百本书的名字。
1.网站分析
打开起点中文网站月票列表的网页,使用“check”查看网页的请求头,写上我们的请求头。
请求头:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Host': 'www.qidian.com'
}
第一页只有 20 本书信息。如果要获取全部 100 本书的信息,总共需要获取 5 页。
python抓取网页数据( WebScraperswithPython你会学到什么是刮刀和蜘蛛?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-11-29 08:09
WebScraperswithPython你会学到什么是刮刀和蜘蛛?)
使用 Python 构建的尖端网络抓取技术开始您的大数据项目
刮地球!使用 Python 构建 Web 爬虫
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建刮板
如何构建一个多线程、复杂的scraper
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原版英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
描述
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。股票价格和加密货币趋势等金融数据、数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据以馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都希望学习如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
关于查找易查找教程网 查看全部
python抓取网页数据(
WebScraperswithPython你会学到什么是刮刀和蜘蛛?)
使用 Python 构建的尖端网络抓取技术开始您的大数据项目
刮地球!使用 Python 构建 Web 爬虫
你会学到什么
如何理论化和开发用于数据分析和研究的网络爬虫和蜘蛛
什么是刮板和蜘蛛?
刮刀和蜘蛛有什么区别?
研究中如何使用刮刀和蜘蛛?
如何使用请求和美化库构建刮板
如何构建一个多线程、复杂的scraper
类型:电子学习 | MP4 | 视频:h264, 1280×720 | 音频:AAC,48.0 KHz
语言:英文+中英文字幕(根据原版英文字幕机器翻译更准确|解压后大小:9GB|时长:10h 26m
描述
网络中充满了极其强大的数据,这些数据存储在数十亿个不同的 网站、数据库和应用程序编程接口中。股票价格和加密货币趋势等金融数据、数十个国家/地区数千个不同城市的天气数据,以及您最喜欢的演员或女演员的有趣传记信息:所有这些信息都触手可及,但无需一点帮助和自动化,不可能真正使用这些信息!
Scrapers 和 Spider 是非常强大的程序,允许开发人员、大数据分析师和研究人员利用所有这些惊人的数据并将其用于大量不同的应用程序,从创建数据馈送到采集数据以馈送机器学习和人工智能算法。本课程为构建真实可用的蜘蛛提供了一种实用的方法,用于在真实情况下进行财务分析、链接图构建和社交媒体研究。在本课程结束时,学生将能够使用 Python 从头开始开发蜘蛛和爬虫,并且只会受到自己的想象力的限制。通过学习如何开发一个自动爬虫,互联网的巨大力量就在你的掌握之中!
本课程专为初学者设计。尽管以前的 Python 编程经验很有帮助,但您无需编写任何代码即可开始本课程。
本课程适用于:
各行各业的互联网研究人员都希望学习如何利用互联网上的信息为更大的利益服务。
对数据科学和网络抓取感兴趣的人。
对数据采集和管理感兴趣的人。
初级 Python 开发人员。
关于查找易查找教程网
python抓取网页数据(soup()如何依靠类标签找到数据的位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-27 00:26
.
同样,如果将光标放在名称“标准普尔指数”上并单击,则可以看到控制台中的此信息收录在标签中。
现在我们知道如何依靠类标签来查找我们需要的数据了。
学习代码 现在我们知道了我们需要的数据的位置,我们可以开始编写代码来构建我们的网络爬虫。现在请打开您的文本编辑工具!
首先,我们必须导入我们想要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并赋值给网站的URL链接。
#赋值网站链接
quote_page =':IND'
接下来使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索网站并得到html代码,保存在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析为 BeautifulSoup 格式,以便我们可以使用 BeautifulSoup 库来分析网页。
# 使用beautifulSoup解析HTML代码并将其存储在变量“soup”中`
汤 = BeautifulSoup(page,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在一个独特的层次结构中。BeautifulSoup 库中的 find() 函数可以帮助我们进入不同的层次来提取内容。我们需要的 HTML 类型“名称”在整个网页中是唯一的,所以我们可以简单地找到
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
拿到label后,我们可以使用name_box的text属性来获取对应的值
name = name_box.text.strip() #strip()函数用于去除前后空格
印刷名称
使用类似的方法,我们可以得到股票指数价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
印刷价格
当您运行程序时,您应该能够看到程序输出标准普尔 500 指数的当前价格。
以Excel CSV 格式导出数据我们已经学习了如何获取数据,现在我们将学习如何存储数据。Excel 的逗号分隔数据格式 (CSV) 是一个不错的选择。这样,我们就可以在 Excel 中打开数据文件进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码底部,添加将数据写入 CSV 文件的代码。
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称, 价格, datetime.now()])
现在,如果您运行该程序,您应该能够导出一个 index.csv 文件。可以在Excel中打开文件,看到如图所示的一行数据。
所以如果你每天运行这个程序,你就可以轻松获得标准普尔指数价格,而不必像以前那样在网站上搜索。
进一步(高级用法)多个股票指数
抓取一个股指信息对你来说还不够,对吧?我们可以尝试同时提取多个股指信息。首先,我们需要修改quote_page 将其定义为一个URL 数组。
quote_page = [':IND',':IND']
然后我们把代码的数据提取部分改成了for循环。这个循环可以一个一个地处理URL,并将变量data中的所有数据以元组类型存储。
# for 循环
数据 = []
对于quote_page 中的pg:
# 检索网站并返回HTML代码,并将其存储在变量'page'中
页 = urllib2.urlopen(pg)
# 使用beautifulSoup解析HTML代码并将其存储在变量`soup`中
汤 = BeautifulSoup(page,'html.parser')
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 使用元组类型存储数据
数据.附加((名称,价格))
并且,修改保存部分,逐行保存数据
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称, 价格, datetime.now()])
重新运行程序,应该可以同时提取两个股指价格信息了!
BeautifulSoup 库,一种先进的爬取技术,使用方便,可以很好地执行少量的网站爬取。但是如果你对大量的爬取信息感兴趣,可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据捕获框架。
2. 您可以尝试将一些公共应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法远比网络爬行高效。例如,您可以尝试 Facebook Graph API。该 API 可以帮助您获取 Facebook 网站 上未显示的隐藏信息。
3. 如果数据量太大,可以考虑使用类似于MySQL的数据库后端来存储数据。
采取“不要重复”的方法
DRY 是英语中“不要重复你做过的事情”的缩写。您可以尝试像链接中的人一样自动化您的日常工作。同时,你也可以考虑其他有趣的项目,比如掌握你的 Facebook 好友的在线时间(当然他们同意),或者在论坛中获取演讲主题列表来尝试自然语言处理(这是当前人工智能的热门话题)!
原文链接: 查看全部
python抓取网页数据(soup()如何依靠类标签找到数据的位置?)
.
同样,如果将光标放在名称“标准普尔指数”上并单击,则可以看到控制台中的此信息收录在标签中。
现在我们知道如何依靠类标签来查找我们需要的数据了。
学习代码 现在我们知道了我们需要的数据的位置,我们可以开始编写代码来构建我们的网络爬虫。现在请打开您的文本编辑工具!
首先,我们必须导入我们想要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并赋值给网站的URL链接。
#赋值网站链接
quote_page =':IND'
接下来使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索网站并得到html代码,保存在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析为 BeautifulSoup 格式,以便我们可以使用 BeautifulSoup 库来分析网页。
# 使用beautifulSoup解析HTML代码并将其存储在变量“soup”中`
汤 = BeautifulSoup(page,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在一个独特的层次结构中。BeautifulSoup 库中的 find() 函数可以帮助我们进入不同的层次来提取内容。我们需要的 HTML 类型“名称”在整个网页中是唯一的,所以我们可以简单地找到
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
拿到label后,我们可以使用name_box的text属性来获取对应的值
name = name_box.text.strip() #strip()函数用于去除前后空格
印刷名称
使用类似的方法,我们可以得到股票指数价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
印刷价格
当您运行程序时,您应该能够看到程序输出标准普尔 500 指数的当前价格。
以Excel CSV 格式导出数据我们已经学习了如何获取数据,现在我们将学习如何存储数据。Excel 的逗号分隔数据格式 (CSV) 是一个不错的选择。这样,我们就可以在 Excel 中打开数据文件进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码底部,添加将数据写入 CSV 文件的代码。
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称, 价格, datetime.now()])
现在,如果您运行该程序,您应该能够导出一个 index.csv 文件。可以在Excel中打开文件,看到如图所示的一行数据。
所以如果你每天运行这个程序,你就可以轻松获得标准普尔指数价格,而不必像以前那样在网站上搜索。
进一步(高级用法)多个股票指数
抓取一个股指信息对你来说还不够,对吧?我们可以尝试同时提取多个股指信息。首先,我们需要修改quote_page 将其定义为一个URL 数组。
quote_page = [':IND',':IND']
然后我们把代码的数据提取部分改成了for循环。这个循环可以一个一个地处理URL,并将变量data中的所有数据以元组类型存储。
# for 循环
数据 = []
对于quote_page 中的pg:
# 检索网站并返回HTML代码,并将其存储在变量'page'中
页 = urllib2.urlopen(pg)
# 使用beautifulSoup解析HTML代码并将其存储在变量`soup`中
汤 = BeautifulSoup(page,'html.parser')
# 获取“名称”类别
代码段并提取对应值
name_box = soup.find('h1', attrs={'class':'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 使用元组类型存储数据
数据.附加((名称,价格))
并且,修改保存部分,逐行保存数据
#以“添加”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv','a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称, 价格, datetime.now()])
重新运行程序,应该可以同时提取两个股指价格信息了!
BeautifulSoup 库,一种先进的爬取技术,使用方便,可以很好地执行少量的网站爬取。但是如果你对大量的爬取信息感兴趣,可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据捕获框架。
2. 您可以尝试将一些公共应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法远比网络爬行高效。例如,您可以尝试 Facebook Graph API。该 API 可以帮助您获取 Facebook 网站 上未显示的隐藏信息。
3. 如果数据量太大,可以考虑使用类似于MySQL的数据库后端来存储数据。
采取“不要重复”的方法
DRY 是英语中“不要重复你做过的事情”的缩写。您可以尝试像链接中的人一样自动化您的日常工作。同时,你也可以考虑其他有趣的项目,比如掌握你的 Facebook 好友的在线时间(当然他们同意),或者在论坛中获取演讲主题列表来尝试自然语言处理(这是当前人工智能的热门话题)!
原文链接:
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-20 17:14
抓取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
以上代码思路:先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子页面,从而获取span保存的访问量子页面中的标签。
打开下面的本地文件,pandas会分析数据,然后pyecharts会实现图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,有知道的朋友帮忙解答一下:
1.第一段代码保存的xlsx格式,实际保存后显示损坏。用xml打开就没问题,用xls格式打开也没问题。
2. 访问次数过多会报错。我使用了睡眠,但实际上,访问次数是间歇性地读取值。为什么有些人无法读取值?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表格的第一行,不知道为什么
我觉得还需要加强1)pandas的数据处理方式,比如分组排序。
2)正则表达式提取
3)Pyecharts 图形绘制
4)遇到网页反爬等情况时的虚拟ip设置
记录我的python学习路径,大家一起努力~~ 查看全部
python抓取网页数据(利用sort_values对count列进行排序取前3的思路)
抓取文章的链接,将流量保存到本地
1 #coding=utf-8
2 import requests as req
3 import re
4 import urllib
5 from bs4 import BeautifulSoup
6 import sys
7 import codecs
8 import time
9
10
11 r=req.get('https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000',
12 headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
13 content=r.text
14 #print(content)
15 soup=BeautifulSoup(content,'html.parser')
16
17 #下面2行内容解决UnicodeEncodeError: 'ascii' codec can't encode characters in position 63-64问题,但是加了后print就打印不出来了,需要查原因
18 reload(sys)
19 sys.setdefaultencoding('utf-8')
20
21 i=0
22 for tag in soup.find_all(re.compile(r'^a{1}'),{'class':'x-wiki-index-item'}):
23 i=i+1
24 if i%3==0:
25 time.sleep(30)
26 name=tag.get_text()
27 href='https://www.liaoxuefeng.com'+tag['href']
28 req2=req.get(href,headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36'})
29 time.sleep(3)
30 soup2=BeautifulSoup(req2.text,'html.parser')
31 count=soup2.find_all('div',{'class':'x-wiki-info'})
32 try:
33 co=count[0].find('span').get_text()
34 co=co[7:]
35 except IndexError as e:
36 co='0'
37 with open('E:/sg_articles.xlsx', 'a+') as f:
38 f.write(codecs.BOM_UTF8)#解决写入csv后乱码问题
39 f.write(name+','+href+','+co+'\n')
40 '''
41 睡眠是因为网页访问过多就会报503 Service Unavailable for Bot网站超过了iis限制造成的由于2003的操作系统在提示IIS过多时并非像2000系统提示“链接人数过多”
42 http://www.51testing.com/html/ ... .html --数据可视化
43 http://www.cnblogs.com/xxoome/p/5880693.html --python引入模块时import与from ... import的区别
44 https://www.cnblogs.com/amou/p/9184614.html --讲解几种爬取网页的匹配方式
45 https://www.cnblogs.com/yinheyi/p/6043571.html --python基本语法
46 '''
以上代码思路:先获取主网页,然后遍历主网页上的文章链接,请求这些链接进入子页面,从而获取span保存的访问量子页面中的标签。
打开下面的本地文件,pandas会分析数据,然后pyecharts会实现图形
1 #coding=utf-8
2 from pyecharts import Bar
3 import pandas as pd
4
5 p=pd.read_excel('E:\sg_articles.xls',names=["title","href","count"])
6 a=p.sort_values(by='count',ascending=False)[0:3]
7 title=a['title']
8 count=a['count']
9 bar=Bar("点击量TOP3", title_pos='center', title_top='18', width=800, height=400)
10 bar.add("", title, count, is_convert=True, xaxis_min=10, yaxis_rotate=30, yaxis_label_textsize=10, is_yaxis_boundarygap=True, yaxis_interval=0,
11 is_label_show=True, is_legend_show=False, label_pos='right',is_yaxis_inverse=True, is_splitline_show=False)
12 bar.render("E:\点击量TOP3.html")
最终结果
同时还有很多问题,有知道的朋友帮忙解答一下:
1.第一段代码保存的xlsx格式,实际保存后显示损坏。用xml打开就没问题,用xls格式打开也没问题。
2. 访问次数过多会报错。我使用了睡眠,但实际上,访问次数是间歇性地读取值。为什么有些人无法读取值?
3.使用sort_values对count列进行排序,取前3,这样会自动排除excel表格的第一行,不知道为什么
我觉得还需要加强1)pandas的数据处理方式,比如分组排序。
2)正则表达式提取
3)Pyecharts 图形绘制
4)遇到网页反爬等情况时的虚拟ip设置
记录我的python学习路径,大家一起努力~~
python抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-18 12:12
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致IP被封的问题,可以使用代理IP,例如:
注意:使用爬虫过于频繁的访问目标站点会占用大量的服务器资源。大型分布式爬虫可以对站点进行爬取甚至对站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是用UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
查看全部
python抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?
)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免采集爬虫过于频繁导致IP被封的问题,可以使用代理IP,例如:
注意:使用爬虫过于频繁的访问目标站点会占用大量的服务器资源。大型分布式爬虫可以对站点进行爬取甚至对站点发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是用UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
python抓取网页数据(网络爬虫技术(豆瓣)《网络编程》网络与系统python视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-16 22:02
python抓取网页数据。这本书基本上把pythonweb,数据分析,爬虫讲完了。书的话这本就行,但是也不是只讲这个。
我接触过的是爬虫技术的天师大网站采集与分析,讲述有如何用python来采集网站,非常详细。
网络爬虫技术(豆瓣)《python语言解释器》《网络编程》网络与系统
python视频教程,python各阶段讲解的还不错。
python基础教程廖雪峰python教程
关注微信公众号python之家了解更多信息。
谢邀,嗯,这是什么系列的,我只听过,黄哥的python核心教程全2册,挺不错的,
这本书是我见过最好的python实战书,尤其是第二本,python3.5版,几乎是很多想要学习python但是又不知道从哪里学起的人的福音,俗称python入门黄金圣经。如果有能力看这个书还是比较推荐看看实战部分。学得明白不代表能工作。我看了不下10遍。书里的确很好,但是人还是要学点经验,用活儿来检验是不是用好这门语言。
python基础应该还是有的,如果想要更深入的理解,除了上述两本书,有时间加强实践,很多菜鸟学python到最后其实是在学一门程序语言,编程语言只是技术层面的。 查看全部
python抓取网页数据(网络爬虫技术(豆瓣)《网络编程》网络与系统python视频教程)
python抓取网页数据。这本书基本上把pythonweb,数据分析,爬虫讲完了。书的话这本就行,但是也不是只讲这个。
我接触过的是爬虫技术的天师大网站采集与分析,讲述有如何用python来采集网站,非常详细。
网络爬虫技术(豆瓣)《python语言解释器》《网络编程》网络与系统
python视频教程,python各阶段讲解的还不错。
python基础教程廖雪峰python教程
关注微信公众号python之家了解更多信息。
谢邀,嗯,这是什么系列的,我只听过,黄哥的python核心教程全2册,挺不错的,
这本书是我见过最好的python实战书,尤其是第二本,python3.5版,几乎是很多想要学习python但是又不知道从哪里学起的人的福音,俗称python入门黄金圣经。如果有能力看这个书还是比较推荐看看实战部分。学得明白不代表能工作。我看了不下10遍。书里的确很好,但是人还是要学点经验,用活儿来检验是不是用好这门语言。
python基础应该还是有的,如果想要更深入的理解,除了上述两本书,有时间加强实践,很多菜鸟学python到最后其实是在学一门程序语言,编程语言只是技术层面的。
python抓取网页数据( 使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-15 23:18
使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)
使用 Python 语言作为抓取网络数据的工具很容易。正则表达式是一种可以高速匹配文本的操作。当正则表达式与 Python 结合时,会产生不同的火花。
在本文中,我们将使用一个简单的爬虫案例来抓取短书的页面,使用 requests 模块和 re 模块。在短书主页上获取 1,000 个 文章 链接和标题。
依赖库
本案例需要导入以下3个Python模块。
其中requests和fake_useragent不是Python标准库的模块。您可以在使用它们之前通过 pip 安装它们。
pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install fake_useragent -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
当然requests也可以换成urllib,主要用于请求页面和返回数据。
fake_useragent 的作用是自动生成一个用户代理。当然,您也可以使用自己浏览器的用户代理。
re 模块是 Python 标准库的常规模块。在这种情况下,它用于过滤数据。re模块的使用请参考作者之前的文章。
import re
import requests
import fake_useragent
查找界面
笔者推荐使用Chrome浏览器进行界面排查。
首先在Chrome中进入简书首页,按f12进入开发者工具状态,找到Network选项。
由于页面是通过滚轮滚动来实现加载数据的,所以笔者认为这是通过Ajax进行数据渲染。
Network下有一个XHR选项,这个选项就是页面上出现的所有Ajax接口。
对于爬虫工程师来说,最敏感的词之一就是page,即:页码。是的,Headers中Request URL的链接就是我们需要的接口。
构建请求头
关于请求头,我们需要构造:
# 实例化UserAgent对象
user_agent = fake_useragent.UserAgent(use_cache_server=False)
url = 'https://www.jianshu.com/?seen_snote_ids%5B%5D=66169577&seen_snote_ids%5B%5D=70078184&seen_snote_ids%5B%5D=59133070&seen_snote_ids%5B%5D=71131220&seen_snote_ids%5B%5D=69717831&seen_snote_ids%5B%5D=71082246&seen_snote_ids%5B%5D=69512409&seen_snote_ids%5B%5D=66364233&seen_snote_ids%5B%5D=68425069&seen_snote_ids%5B%5D=65829398&seen_snote_ids%5B%5D=70390517&seen_snote_ids%5B%5D=70715611&seen_snote_ids%5B%5D=60025426&seen_snote_ids%5B%5D=69454619&page={}'
# 请求头
headers = {
# 随机生成1个user-agent
'User-Agent': user_agent.random,
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'xxxxxxx',
}
# 设置代理(可省略)
proxies = {
'http': 'http://54.241.121.74:3128',
'https': 'http://54.241.121.74:3128'
}
需要注意的是url链接的page属性使用{}传递后续页码。
请求页面
首先,我们首先构造一个全局变量 num 来统计提取的数据。
num = 1
接下来是请求页面。
# 初始页码
count = 0
# 循环请求页面
while True:
response = requests.get(
# 传入页码
url=url.format(i),
headers=headers,
proxies=proxies
)
count += 1
# 解析页面
title_and_link = get_data(response.text)
# 展示数据
show_data(title_and_link)
# 如果judge为True,代表已经爬取了1000条数据
if num > 1000:
break
解析页面
def get_data(text):
"""
提取页面源码中的信息
:param text: 页面源代码
:return: result
"""
# 生成正则对象
pattern = re.compile(r'(.*?)', re.S)
# 查找符合上一行正则对象的数据
result = pattern.finditer(text)
return result
显示数据
def show_data(title_and_link):
"""
展示数据
:param title_and_link: 数据
:return: None
"""
# 重新声明num
global num
for i in title_and_link:
# 打印数据
print(f'{num}:https://www.jianshu.com{i.group(1).strip()}', end=' ')
print(i.group(2).strip())
num += 1
if num > 1000:
print('完成任务!!!')
break
结束语
这个爬虫程序比较简单,毕竟找到界面就可以一步一步的挖掘数据了。
其实这个爬虫程序有一些明显的bug,尤其是你没有设置cookies的时候。
是的,由于接口原因,当我们不设置cookies时,爬取的数据基本是重复的,cookies不能完美解决这个问题。当数据量较大时,即使设置了Cookie也会出现重复数据。
这个bug最直接的解决办法就是更换接口,但是这样做也意味着部分代码需要重构(虽然代码不多)。的确,通过 Chrome 的开发者工具,其他接口也存在,就看你能不能找到了。此外,使用硒也是一个不错的选择。这里也体现了爬虫程序的主观性,即实现功能的方式有很多种。但是我想说的是,既然提到了去重,那Redis怎么能丢呢?
没错,下一篇文章就是优化上面提到的爬虫程序去重复。
本文的完整代码可以在作者的GitHub下获取。 查看全部
python抓取网页数据(
使用Python语言的3个Python模块,抓取简书首页1000条文章与标题)
使用 Python 语言作为抓取网络数据的工具很容易。正则表达式是一种可以高速匹配文本的操作。当正则表达式与 Python 结合时,会产生不同的火花。
在本文中,我们将使用一个简单的爬虫案例来抓取短书的页面,使用 requests 模块和 re 模块。在短书主页上获取 1,000 个 文章 链接和标题。
依赖库
本案例需要导入以下3个Python模块。
其中requests和fake_useragent不是Python标准库的模块。您可以在使用它们之前通过 pip 安装它们。
pip install requests -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install fake_useragent -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
当然requests也可以换成urllib,主要用于请求页面和返回数据。
fake_useragent 的作用是自动生成一个用户代理。当然,您也可以使用自己浏览器的用户代理。
re 模块是 Python 标准库的常规模块。在这种情况下,它用于过滤数据。re模块的使用请参考作者之前的文章。
import re
import requests
import fake_useragent
查找界面
笔者推荐使用Chrome浏览器进行界面排查。
首先在Chrome中进入简书首页,按f12进入开发者工具状态,找到Network选项。
由于页面是通过滚轮滚动来实现加载数据的,所以笔者认为这是通过Ajax进行数据渲染。
Network下有一个XHR选项,这个选项就是页面上出现的所有Ajax接口。
对于爬虫工程师来说,最敏感的词之一就是page,即:页码。是的,Headers中Request URL的链接就是我们需要的接口。
构建请求头
关于请求头,我们需要构造:
# 实例化UserAgent对象
user_agent = fake_useragent.UserAgent(use_cache_server=False)
url = 'https://www.jianshu.com/?seen_snote_ids%5B%5D=66169577&seen_snote_ids%5B%5D=70078184&seen_snote_ids%5B%5D=59133070&seen_snote_ids%5B%5D=71131220&seen_snote_ids%5B%5D=69717831&seen_snote_ids%5B%5D=71082246&seen_snote_ids%5B%5D=69512409&seen_snote_ids%5B%5D=66364233&seen_snote_ids%5B%5D=68425069&seen_snote_ids%5B%5D=65829398&seen_snote_ids%5B%5D=70390517&seen_snote_ids%5B%5D=70715611&seen_snote_ids%5B%5D=60025426&seen_snote_ids%5B%5D=69454619&page={}'
# 请求头
headers = {
# 随机生成1个user-agent
'User-Agent': user_agent.random,
'X-Requested-With': 'XMLHttpRequest',
'Cookie': 'xxxxxxx',
}
# 设置代理(可省略)
proxies = {
'http': 'http://54.241.121.74:3128',
'https': 'http://54.241.121.74:3128'
}
需要注意的是url链接的page属性使用{}传递后续页码。
请求页面
首先,我们首先构造一个全局变量 num 来统计提取的数据。
num = 1
接下来是请求页面。
# 初始页码
count = 0
# 循环请求页面
while True:
response = requests.get(
# 传入页码
url=url.format(i),
headers=headers,
proxies=proxies
)
count += 1
# 解析页面
title_and_link = get_data(response.text)
# 展示数据
show_data(title_and_link)
# 如果judge为True,代表已经爬取了1000条数据
if num > 1000:
break
解析页面
def get_data(text):
"""
提取页面源码中的信息
:param text: 页面源代码
:return: result
"""
# 生成正则对象
pattern = re.compile(r'(.*?)', re.S)
# 查找符合上一行正则对象的数据
result = pattern.finditer(text)
return result
显示数据
def show_data(title_and_link):
"""
展示数据
:param title_and_link: 数据
:return: None
"""
# 重新声明num
global num
for i in title_and_link:
# 打印数据
print(f'{num}:https://www.jianshu.com{i.group(1).strip()}', end=' ')
print(i.group(2).strip())
num += 1
if num > 1000:
print('完成任务!!!')
break
结束语
这个爬虫程序比较简单,毕竟找到界面就可以一步一步的挖掘数据了。
其实这个爬虫程序有一些明显的bug,尤其是你没有设置cookies的时候。
是的,由于接口原因,当我们不设置cookies时,爬取的数据基本是重复的,cookies不能完美解决这个问题。当数据量较大时,即使设置了Cookie也会出现重复数据。
这个bug最直接的解决办法就是更换接口,但是这样做也意味着部分代码需要重构(虽然代码不多)。的确,通过 Chrome 的开发者工具,其他接口也存在,就看你能不能找到了。此外,使用硒也是一个不错的选择。这里也体现了爬虫程序的主观性,即实现功能的方式有很多种。但是我想说的是,既然提到了去重,那Redis怎么能丢呢?
没错,下一篇文章就是优化上面提到的爬虫程序去重复。
本文的完整代码可以在作者的GitHub下获取。
python抓取网页数据( python抓取网页数据自信是永不枯竭的源泉(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 40 次浏览 • 2021-11-14 13:04
python抓取网页数据自信是永不枯竭的源泉(组图))
【精品】python爬网数据python爬网数据txt51自信是不竭的源泉自信是无尽的波浪,自信是快速进步的通道,自信是成功之母,用python抓取网页并处理 2009 -02-19150950 Category Python tag 无字号订阅 主要目的是抓取网页的源代码,处理其中需要的数据并保存到数据库中。它已实现抓取页面并读取数据。步骤 1 抓取页面。这一步很简单,简单的引入urllib,用urlopen打开URL,使用read方法读取数据。为了方便测试,使用本地文本文件,而不是抓取网页。第二步处理数据。如果页面代码更加规范和规范,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat
aninm 继续处理数据以检索标题简介图片和链接地址 p_titlerecompileh2h2reIreSp_urlrecompilehref"reIreSp_summarrecompileppreIreSp_imagerecompileeshopimages"reIreSss" title "p_titlesearchdatangroup"rn""Introduction"p_summarsearchdatangroup"rn""sumpntroduction"p_summarsearchdatangroup"rn""sump"Inductionntro "p_summarsearchdatan"p_close" 使用Python脚本获取实时股市信息 2006-12-151347IE 查看股市信息太牛了,决定写一个Python脚本捕捉相关信息。它小巧方便。它写在一个 javascript 文件中。2 提取javascript文件的URL,编写Python脚本,抓取文件,读取其内容,进行字符串处理,提取股价增长等信息,完成。很方便 4 通过对javascript文件URL的分析,文件名形式为“股票代码js”。创建配置文件以提供感兴趣的股票代码。使用 Python 脚本读取配置信息。定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 查看全部
python抓取网页数据(
python抓取网页数据自信是永不枯竭的源泉(组图))
【精品】python爬网数据python爬网数据txt51自信是不竭的源泉自信是无尽的波浪,自信是快速进步的通道,自信是成功之母,用python抓取网页并处理 2009 -02-19150950 Category Python tag 无字号订阅 主要目的是抓取网页的源代码,处理其中需要的数据并保存到数据库中。它已实现抓取页面并读取数据。步骤 1 抓取页面。这一步很简单,简单的引入urllib,用urlopen打开URL,使用read方法读取数据。为了方便测试,使用本地文本文件,而不是抓取网页。第二步处理数据。如果页面代码更加规范和规范,可以使用HTMLParser进行简单处理,但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 但具体情况需要具体分析。顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 顺便练习一下刚刚学的正则表达式。其实正则表达式也是一种比较简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 正则表达式也是一种相对简单的语言。符号比较晦涩难懂。它只能是更多的练习和练习。步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat 步骤3 将处理后的数据保存到数据库中,使用pymssql。可以在这里处理,只需将其保存为文本文件并展开即可。此功能还可用于捕获整个 网站 图像并自动声明站点地图文件。接下来的任务是研究python的socket函数 --codinggbk--importurllibimportrepagerurlliburlopendatapagerreadpagerclosefopenr" D2txt "datafreadfclose 处理数据 precompileclassonedivreIreSmpfindalldatas""fordat
aninm 继续处理数据以检索标题简介图片和链接地址 p_titlerecompileh2h2reIreSp_urlrecompilehref"reIreSp_summarrecompileppreIreSp_imagerecompileeshopimages"reIreSss" title "p_titlesearchdatangroup"rn""Introduction"p_summarsearchdatangroup"rn""sumpntroduction"p_summarsearchdatangroup"rn""sump"Inductionntro "p_summarsearchdatan"p_close" 使用Python脚本获取实时股市信息 2006-12-151347IE 查看股市信息太牛了,决定写一个Python脚本捕捉相关信息。它小巧方便。它写在一个 javascript 文件中。2 提取javascript文件的URL,编写Python脚本,抓取文件,读取其内容,进行字符串处理,提取股价增长等信息,完成。很方便 4 通过对javascript文件URL的分析,文件名形式为“股票代码js”。创建配置文件以提供感兴趣的股票代码。使用 Python 脚本读取配置信息。定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中 定期阅读所需的实时信息。5 定义每日市场状况。格式存储在 XML 中
python抓取网页数据(#google会认为是机器人不允许访问网站还有设置Cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 452 次浏览 • 2021-11-11 11:14
# 设置头文件。爬取一些网页不需要专门设置头文件,但是如果这里不设置的话,
# google 会认为机器人不允许访问。除了访问一些网站和设置cookies,这个会比较复杂。
# 这里暂不提及。关于怎么知道头文件怎么写,有的插件可以看你用的是哪个浏览器和网站交互
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
# 建立连接请求。这时谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读取文件后关闭文件一样,如果不关闭有时可以,但有时会出现问题。
# 所以作为一个遵纪守法的好公民,最好关闭连接。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
# 导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
# 生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接
# 这里也用到了一些正则表达式。不熟悉的人应该提前知道。至于'class':在'gs_rt'
# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 把这个弄的很简单,只要一个网页,就可以知道对应的html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find('h3', {'class':'gs_rt'}).text
paper_name = re.sub(r'\[.*\]','', paper_name) # 消除像'[PDF]'这样的'[]'标签
paper_author = soup.html.body.find('div', {'class':'gs_a'}).text
paper_desc = 汤.html.body.find('div', {'class':'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class':'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes =='':
引用时间 = '0'
如果 versionNum =='':
版本号 = '0'
引用的Paper_href = soup.html.body.find('div', {'class':'gs_fl'}).a.attrs[0][1]
复制代码
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示添加它。
# 还有其他参数,比如'r'只能读不能写,'w'可以写但是原记录会被删除等。
file = open('webdata.txt','a')
line = paper_name +'#' + paper_author +'#' + paper_desc +'#' + citeTimes +'\n'
#对象文件的write方法将字符串行写入文件
file = file.write(line)
# 再次做一个容易关档的好青年
文件.close()
复制代码
这样,从网页中抓取和解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须在coursera\Stanford openEdX平台上有数据库介绍进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
% 可以使用cmd打开数据库,启动命令为:
网络启动mysql55
%关机命令是:
网络停止mysql55
复制代码
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb 模块
导入 MySQL 数据库
# 与服务器建立链接,host是服务器ip,我的mysql数据库是在这台机器上搭建的,默认是127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为 3306,charset 为编码方式。
# 默认是utf8(可能是gbk,取决于安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306,字符集='utf8')
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName ='On Random Graph'")
# fetchall() 方法获取查询结果,它返回一个列表,你可以像这样直接查询:list[i][j],
# i表示查询结果中的第i+1条记录,j表示这条记录的第j+1条属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,例如:
sql = "update studentCourseRecord set fail = 1 where studentID ='%s' and seasonID ='%s' and courseID ='%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,要成功更新数据库,必须在执行删除、插入和更新语句后执行以下命令
mit()
# 和往常一样,使用完记得关闭游标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是为了长时间休眠,还是去健身房,结果出来了。
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。 查看全部
python抓取网页数据(#google会认为是机器人不允许访问网站还有设置Cookie)
# 设置头文件。爬取一些网页不需要专门设置头文件,但是如果这里不设置的话,
# google 会认为机器人不允许访问。除了访问一些网站和设置cookies,这个会比较复杂。
# 这里暂不提及。关于怎么知道头文件怎么写,有的插件可以看你用的是哪个浏览器和网站交互
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
header = {'Host':'',
'用户代理':'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ',
'接受':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'接受编码':'gzip,放气',
'连接':'保持活动'}
# 建立连接请求。这时谷歌服务器将页面信息返回给变量con,该变量是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 调用con对象的read()方法,返回html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读取文件后关闭文件一样,如果不关闭有时可以,但有时会出现问题。
# 所以作为一个遵纪守法的好公民,最好关闭连接。
关闭()
复制代码
上面的代码将googlescholar上查询On Random Graph的结果返回给变量doc,这和打开googlescholar搜索On Random Graph然后右键保存网页是一样的。
Step 三、 解析网页
上面的步骤是得到了网页的信息,但是收录了html标签,你得把这些标签去掉,然后从html文本中整理出有用的信息,
您需要解析此页面。
解析网页的方法:
(1) 正则表达式。正则表达式非常有用,熟悉起来可以节省很多时间。有时候清洗数据不需要写脚本,也不需要对数据库进行查询,只是正则表达式的组合在记事本++上。如何学习正则表达式的建议:关于正则表达式的 30 分钟介绍性教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr.对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点,也可以获取到它的兄弟节点,网上有很多相关的说明,不过我会这里就不细说了,简单的代码演示一下:
(3) 结合以上两种方法。
# 导入BeautifulSoup模块和re模块,re是python中的正则表达式模块
进口美汤
进口重新
# 生成一个soup对象,doc在第二步有提到
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用次数、版本数以及指向引用它的 文章 列表的超链接
# 这里也用到了一些正则表达式。不熟悉的人应该提前知道。至于'class':在'gs_rt'
# 'gs_rt' 是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 把这个弄的很简单,只要一个网页,就可以知道对应的html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find('h3', {'class':'gs_rt'}).text
paper_name = re.sub(r'\[.*\]','', paper_name) # 消除像'[PDF]'这样的'[]'标签
paper_author = soup.html.body.find('div', {'class':'gs_a'}).text
paper_desc = 汤.html.body.find('div', {'class':'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class':'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes =='':
引用时间 = '0'
如果 versionNum =='':
版本号 = '0'
引用的Paper_href = soup.html.body.find('div', {'class':'gs_fl'}).a.attrs[0][1]
复制代码
这些是我正在分析引文网络的项目的代码。顺便说一下,我从googlescholar那里抓取了论文信息和引文列表信息,在访问了大约1900次后交给了google block,导致这个区的ip暂时无法登录googlescholar。
第 4 步:访问数据
最后抓取到数据后,只存储在内存中,必须保存后才能使用。
(1) 最简单的将数据写入txt文件的方式,Python可以使用如下代码实现:
# 打开文件webdata.txt,生成目标文件。该文件可能不存在。参数 a 表示添加它。
# 还有其他参数,比如'r'只能读不能写,'w'可以写但是原记录会被删除等。
file = open('webdata.txt','a')
line = paper_name +'#' + paper_author +'#' + paper_desc +'#' + citeTimes +'\n'
#对象文件的write方法将字符串行写入文件
file = file.write(line)
# 再次做一个容易关档的好青年
文件.close()
复制代码
这样,从网页中抓取和解析出来的数据就存储在本地了。是不是很简单?
(2)当然也可以不写txt文件直接连接数据库。python中的MySQLdb模块可以与MySQL数据库交互,直接将数据倒入数据库,建立与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果之前学过数据库,学习使用MySQLdb模块与数据库交互非常简单;如果没有,必须在coursera\Stanford openEdX平台上有数据库介绍进行系统学习,w3school仅供参考或作为手册使用。
Python能够链接到数据库的前提是数据库是开放的。我用的是win7+MySQL5.5,数据库是本地的。
% 可以使用cmd打开数据库,启动命令为:
网络启动mysql55
%关机命令是:
网络停止mysql55
复制代码
使用 MySQLdb 模块代码的示例:
# 导入 MySQLdb 模块
导入 MySQL 数据库
# 与服务器建立链接,host是服务器ip,我的mysql数据库是在这台机器上搭建的,默认是127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为 3306,charset 为编码方式。
# 默认是utf8(可能是gbk,取决于安装的版本)。
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306,字符集='utf8')
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName ='On Random Graph'")
# fetchall() 方法获取查询结果,它返回一个列表,你可以像这样直接查询:list[i][j],
# i表示查询结果中的第i+1条记录,j表示这条记录的第j+1条属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,例如:
sql = "update studentCourseRecord set fail = 1 where studentID ='%s' and seasonID ='%s' and courseID ='%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,要成功更新数据库,必须在执行删除、插入和更新语句后执行以下命令
mit()
# 和往常一样,使用完记得关闭游标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python和数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,道理类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。需要对服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信你不是一个人!!去谷歌吧,成千上万的人都遇到过这种问题。
关于编码问题,附上我看到的一篇博文
:
后记:
上面介绍了抓取网页数据的方法。数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上有不清楚的地方,欢迎交流。
请注意:
网站的大规模爬取会给网站的服务器带来很大的压力。尽量选择服务器比较放松的时间(比如清晨)。网站很多,不要用一亩三分地作为实验。
Python 的 time 模块的 sleep() 方法可以让程序暂停一段时间。比如time.sleep(1)在这里运行时暂停程序1秒。及时暂停可以缓解服务器压力,保护自己。硬盘,只是为了长时间休眠,还是去健身房,结果出来了。
更新:
2014年2月15日,修改了几个打字错误;添加了相关课程链接;加入udacity CS101;添加了 MySQLdb 模块的介绍。
2014 年 2 月 16 日,添加了指向介绍编码方法的博客文章的链接。
python抓取网页数据(python抓取网页数据最全python教程教程篇图片篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-10 23:03
python抓取网页数据最全python教程python教程python教程爬虫篇python爬虫爬虫篇图片篇图片篇图片篇上传篇上传篇上传篇视频下载篇视频下载篇抓取神器篇抓取神器篇爬虫解析篇如何提取列表中的重复项
个人博客的话,python爬取黄哥python讲堂博客园黄哥:黄哥python推荐学习。黄哥:黄哥python推荐学习。
一个你要会编程还要懂图片的制作工具,一个了解多媒体信息的基本。
从2012年接触python开始到2018年学python5年多了,我对python爬虫,数据分析,web开发,爬虫框架等了解的已经比较深入了,看过不少程序员教程,自己也开发过项目,目前在做程序员客栈和豆瓣爬虫的开发。希望我的一些经验能帮助到你,我就给你简单介绍下python的学习吧:python的最基本的语法,数据结构,元编程,面向对象编程,if..else,以及运算符重载,基本的中高级编程思想,还有java的面向对象,异常处理,基本的面向对象,json。
一些特别要注意的方面,比如异常的处理等。还有就是高级的开发库,pandas,pyspark,还有numpy等,等等。想要系统学好python,还是得提醒你一下,最好先把语法学好,python2.x版本刚推出到现在,感觉设计的比较混乱,所以python3.x还有待时间的检验,目前python3.x版本比较多,很多人比较痛恨python3,觉得python3太臃肿了,总体来说python3包多一些,有些时候写出来的代码量会增加,但是对于大部分人来说,学好python3也还可以,毕竟python适合大部分人。
还有就是说一下python爬虫框架,是依赖于其它一些库,比如xlrd,xlwt,flask等,大部分的前端库也是依赖python的。刚开始接触python可以先从pandas看起来,pandas用起来很方便,在这里我推荐pandas快速入门,先了解一下pandas怎么用,再看哪些库可以搭配使用。还有就是接触了一个爬虫库,web01,这个用的是selenium库,这个库自己搭了一个web开发框架,同时可以学习selenium+selenium模拟器开发。
最后就是一些项目,爬虫相关的项目,比如京东的爬虫,爬虫的监控等,还有一些就是其它网站的爬虫了。先简单介绍下吧,祝你好运。 查看全部
python抓取网页数据(python抓取网页数据最全python教程教程篇图片篇)
python抓取网页数据最全python教程python教程python教程爬虫篇python爬虫爬虫篇图片篇图片篇图片篇上传篇上传篇上传篇视频下载篇视频下载篇抓取神器篇抓取神器篇爬虫解析篇如何提取列表中的重复项
个人博客的话,python爬取黄哥python讲堂博客园黄哥:黄哥python推荐学习。黄哥:黄哥python推荐学习。
一个你要会编程还要懂图片的制作工具,一个了解多媒体信息的基本。
从2012年接触python开始到2018年学python5年多了,我对python爬虫,数据分析,web开发,爬虫框架等了解的已经比较深入了,看过不少程序员教程,自己也开发过项目,目前在做程序员客栈和豆瓣爬虫的开发。希望我的一些经验能帮助到你,我就给你简单介绍下python的学习吧:python的最基本的语法,数据结构,元编程,面向对象编程,if..else,以及运算符重载,基本的中高级编程思想,还有java的面向对象,异常处理,基本的面向对象,json。
一些特别要注意的方面,比如异常的处理等。还有就是高级的开发库,pandas,pyspark,还有numpy等,等等。想要系统学好python,还是得提醒你一下,最好先把语法学好,python2.x版本刚推出到现在,感觉设计的比较混乱,所以python3.x还有待时间的检验,目前python3.x版本比较多,很多人比较痛恨python3,觉得python3太臃肿了,总体来说python3包多一些,有些时候写出来的代码量会增加,但是对于大部分人来说,学好python3也还可以,毕竟python适合大部分人。
还有就是说一下python爬虫框架,是依赖于其它一些库,比如xlrd,xlwt,flask等,大部分的前端库也是依赖python的。刚开始接触python可以先从pandas看起来,pandas用起来很方便,在这里我推荐pandas快速入门,先了解一下pandas怎么用,再看哪些库可以搭配使用。还有就是接触了一个爬虫库,web01,这个用的是selenium库,这个库自己搭了一个web开发框架,同时可以学习selenium+selenium模拟器开发。
最后就是一些项目,爬虫相关的项目,比如京东的爬虫,爬虫的监控等,还有一些就是其它网站的爬虫了。先简单介绍下吧,祝你好运。
python抓取网页数据(用Python编写爬虫的基础,需要什么条件?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-09 22:21
本文文章主要介绍一个用Python程序爬取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
以上就是一个使用Python程序抓取网页HTML信息的小例子的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(用Python编写爬虫的基础,需要什么条件?Python)
本文文章主要介绍一个用Python程序爬取网页HTML信息的小例子。使用的方法也是用Python编写爬虫的基础。有需要的朋友可以参考
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page) doc = requests.get(url).text soup = BeautifulSoup(doc) atags = soup.find_all('a') rank_link_pre = 'http://www.ittf.com/ittf_ranking/' mlfile = open(linkfile,'a') for atag in atags: #print atag if atag!=None and atag.get('href') != None: if "WR_Table_3_A2_Details.asp" in atag['href']: link = rank_link_pre + atag['href'] links.append(link) mlfile.write(link+'\n') print 'fetch link: '+link mlfile.close()
以上就是一个使用Python程序抓取网页HTML信息的小例子的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-30 19:20
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存在本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录下找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。 查看全部
python抓取网页数据(本节讲解第一个Python爬虫实战案例:抓取您想要的网页)
本节讲解第一个实际的 Python 爬虫案例:抓取你想要的网页并将其保存到本地计算机。
首先我们简单分析一下要编写的爬虫程序。程序可以分为以下三个部分:
理清逻辑后,我们就可以正式编写爬虫程序了。导入需要的模块本节内容使用urllib库编写爬虫,导入程序用到的模块如下:
from urllib import request
from urllib import parse
拼接url地址定义了url变量,拼接url地址。代码如下:
url = 'http://www.baidu.com/s?wd={}'
#想要搜索的内容
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
向 URL 发送请求发送请求主要分为以下几个步骤:
代码如下:
#重构请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
#创建请求对应
req = request.Request(url=full_url,headers=headers)
#获取响应对象
res = request.urlopen(req)
#获取响应内容
html = res.read().decode("utf-8")
保存为本地文件将抓取到的照片保存在本地,这里需要使用Python编程的文件IO操作,代码如下:
filename = word + '.html'
with open(filename,'w', encoding='utf-8') as f:
f.write(html)
完整的程序如下:
from urllib import request,parse
# 1.拼url地址
url = 'http://www.baidu.com/s?wd={}'
word = input('请输入搜索内容:')
params = parse.quote(word)
full_url = url.format(params)
# 2.发请求保存到本地
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
req = request.Request(url=full_url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 3.保存文件至当前目录
filename = word + '.html'
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
尝试运行程序,输入编程帮助,确认搜索,就会在Pycharm当前工作目录下找到“programming help.html”文件。函数式编程修改程序 Python函数式编程可以让程序的思想更加清晰易懂。接下来,利用函数式编程的思想,对上面的代码进行修改。
定义相应的函数,通过调用函数执行爬虫程序。修改后的代码如下:
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
除了使用函数式编程,还可以使用面向对象的编程方法(本教程主要使用这种方法),后续内容中会介绍。
python抓取网页数据(Python开发的一个快速、高层次的屏幕抓取和web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-10-30 01:23
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(例如 Web 服务)或一般网络爬虫返回的数据。
Scrapy 还可以帮你实现高级爬虫框架,比如爬取时的网站认证、内容分析处理、重复爬取、分布式爬取等复杂的东西。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
刮板凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg |____tutorial | |______init__.py | |______init__.pyc | |____items.py | |____items.pyc | |____pipelines.py | |____settings.py | |____settings.pyc | |____spiders | | |______init__.py | | |______init__.pyc | | |____example.py | | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,您将在此处添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
以上就是Scrapy抓取京东产品、豆瓣电影和代码分享的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(Python开发的一个快速、高层次的屏幕抓取和web框架)
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
1.scrapy的基本理解
Scrapy是一个为爬取网站数据和提取结构化数据而编写的应用框架。它可用于包括数据挖掘、信息处理或存储历史数据在内的一系列程序。它最初是为页面抓取(更准确地说,网络抓取)而设计的,也可以用于检索 API(例如 Web 服务)或一般网络爬虫返回的数据。
Scrapy 还可以帮你实现高级爬虫框架,比如爬取时的网站认证、内容分析处理、重复爬取、分布式爬取等复杂的东西。
Scrapy主要包括以下组件:
Scrapy的运行过程大致如下:
1.首先,引擎从调度器中获取一个链接(URL),用于下一次抓取
2. 引擎将URL封装成请求(Request)发送给下载器,下载器下载资源并封装成响应包(Response)
3.然后,爬虫解析Response
4.如果实体(Item)被解析,就会交给实体管道做进一步处理。
5.如果解析出来的是一个链接(URL),那么这个URL就会交给Scheduler等待爬取
2.安装scrapy
虚拟环境安装:
sudo pip install virtualenv #安装虚拟环境工具
virtualenv ENV #创建虚拟环境目录
source ./ENV/bin/active #激活虚拟环境
pip install Scrapy #验证是否安装成功
pip list #验证安装
可以进行如下测试:
刮板凳
3.使用scrapy
在爬取之前,您需要创建一个新的 Scrapy 项目。输入要保存代码的目录,然后执行:
$ scrapy startproject 教程
该命令会在当前目录下新建一个目录tutorial,其结构如下:
|____scrapy.cfg |____tutorial | |______init__.py | |______init__.pyc | |____items.py | |____items.pyc | |____pipelines.py | |____settings.py | |____settings.pyc | |____spiders | | |______init__.py | | |______init__.pyc | | |____example.py | | |____example.pyc
这些文件主要是:
scrapy.cfg:项目配置文件
教程/:项目python模块,您将在此处添加代码
教程/items.py:项目项目文件
教程/pipelines.py:项目管道文件
tutorial/settings.py:项目配置文件
教程/蜘蛛:放置蜘蛛的目录
3.1. 定义项
items 是将加载捕获数据的容器。它的工作原理类似于 Python 中的字典,但它提供了更多保护,例如填充未定义的字段以防止拼写错误。创建一个scrapy.Item类,定义类型为scrapy.Field的class属性声明了一个Item。我们为所需的项目建模。在教程目录中的 items.py 文件中进行编辑。
3.2. 写作蜘蛛
Spider 是一个用户编写的类,用于从域(或域组)中抓取信息,定义用于下载的初步 URL 列表,如何跟踪链接,以及如何解析这些网页的内容以提取项目。
要创建 Spider,请继承 scrapy.Spider 基类,并确定三个主要的强制性属性:
name:爬虫的标识名。它必须是独一无二的。您必须在不同的爬虫中定义不同的名称。
start_urls:收录Spider启动时抓取的URL列表。因此,要检索的第一页将是其中之一。从初始 URL 获得的数据中提取后续 URL。我们可以使用正则表达式来定义和过滤需要跟进的链接。
parse():是spider的一种方法。调用时,在下载每个初始 URL 后生成的 Response 对象将作为唯一参数传递给函数。该方法负责解析返回的数据(响应数据),提取数据(生成项),生成需要进一步处理的URL的Request对象。
该方法负责解析返回的数据,匹配捕获的数据(解析为item),跟踪更多的URL。
在/tutorial/tutorial/spiders目录下创建
例子.py
3.3。爬行
进入项目根目录,运行命令
$scrapy 爬取示例
完整代码参考:标题中有抓取京东和豆瓣的方法。
以上就是Scrapy抓取京东产品、豆瓣电影和代码分享的详细内容。更多详情请关注其他相关html中文网站文章!
python抓取网页数据( Python数据结构模块安装及Python抓取实例讲述(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-29 11:30
Python数据结构模块安装及Python抓取实例讲述(组图))
Python实现抓取HTML网页并保存为PDF文件的方法
更新时间:2018-05-08 10:37:11 作者:Limerence
本文文章主要介绍Python抓取HTML网页并以PDF文件形式保存的方法,并以示例的形式分析PyPDF2模块的安装和Python抓取HTML页面并生成基于 PyPDF2 模块的 pdf 文件。相关操作技巧,有需要的朋友可以参考以下
本文介绍如何使用 Python 捕获 HTML 网页并将其保存为 PDF 文件。分享给大家,供大家参考,如下:
一、前言
今天的介绍是抓取HTML网页并保存为PDF。废话不多说,直接上教程吧。
今天的例子是以廖雪峰老师的Python教程网站为例:
二、准备工作
1. PyPDF2的安装和使用(用于合并PDF):
PyPDF2 版本:1.25.1
或
安装:
pip install PyPDF2
使用示例:
from PyPDF2 import PdfFileMerger
merger = PdfFileMerger()
input1 = open("hql_1_20.pdf", "rb")
input2 = open("hql_21_40.pdf", "rb")
merger.append(input1)
merger.append(input2)
# Write to an output PDF document
output = open("hql_all.pdf", "wb")
merger.write(output)
2. requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulfusoup用于操作html数据。有了这两个穿梭机,工作顺利。我们不需要像scrapy这样的爬虫框架。这么小的程序有点大锤了。另外,既然是把html文件转换成pdf,就得有相应的库支持。 wkhtmltopdf 是一个非常有用的工具,可以用于多平台从html到pdf的转换。 pdfkit 是 wkhtmltopdf 的 Python 包。首先安装以下依赖包
pip install requests
pip install beautifulsoup4
pip install pdfkit
3. 安装 wkhtmltopdf
Windows平台直接下载稳定版wkhtmltopdf安装即可。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。 Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
三、数据准备
1. 获取每个文章
的url
def get_url_list():
"""
获取所有URL目录列表
:return:
"""
response = requests.get("http://www.liaoxuefeng.com/wik ... 6quot;)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls
2. 通过 文章url
使用模板保存每个 文章 HTML 文件
html 模板:
html_template = """
{content}
"""
保存:
<p>
def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")[0]
# 标题
title = soup.find('h4').get_text()
# 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "( 查看全部
python抓取网页数据(
Python数据结构模块安装及Python抓取实例讲述(组图))
Python实现抓取HTML网页并保存为PDF文件的方法
更新时间:2018-05-08 10:37:11 作者:Limerence
本文文章主要介绍Python抓取HTML网页并以PDF文件形式保存的方法,并以示例的形式分析PyPDF2模块的安装和Python抓取HTML页面并生成基于 PyPDF2 模块的 pdf 文件。相关操作技巧,有需要的朋友可以参考以下
本文介绍如何使用 Python 捕获 HTML 网页并将其保存为 PDF 文件。分享给大家,供大家参考,如下:
一、前言
今天的介绍是抓取HTML网页并保存为PDF。废话不多说,直接上教程吧。
今天的例子是以廖雪峰老师的Python教程网站为例:
二、准备工作
1. PyPDF2的安装和使用(用于合并PDF):
PyPDF2 版本:1.25.1
或
安装:
pip install PyPDF2
使用示例:
from PyPDF2 import PdfFileMerger
merger = PdfFileMerger()
input1 = open("hql_1_20.pdf", "rb")
input2 = open("hql_21_40.pdf", "rb")
merger.append(input1)
merger.append(input2)
# Write to an output PDF document
output = open("hql_all.pdf", "wb")
merger.write(output)
2. requests和beautifulsoup是爬虫的两大神器,reuqests用于网络请求,beautifulfusoup用于操作html数据。有了这两个穿梭机,工作顺利。我们不需要像scrapy这样的爬虫框架。这么小的程序有点大锤了。另外,既然是把html文件转换成pdf,就得有相应的库支持。 wkhtmltopdf 是一个非常有用的工具,可以用于多平台从html到pdf的转换。 pdfkit 是 wkhtmltopdf 的 Python 包。首先安装以下依赖包
pip install requests
pip install beautifulsoup4
pip install pdfkit
3. 安装 wkhtmltopdf
Windows平台直接下载稳定版wkhtmltopdf安装即可。安装完成后,将程序的执行路径添加到系统环境$PATH变量中,否则pdfkit将找不到wkhtmltopdf并出现“No wkhtmltopdf executable found”的错误提示。 Ubuntu 和 CentOS 可以直接从命令行安装
$ sudo apt-get install wkhtmltopdf # ubuntu
$ sudo yum intsall wkhtmltopdf # centos
三、数据准备
1. 获取每个文章
的url
def get_url_list():
"""
获取所有URL目录列表
:return:
"""
response = requests.get("http://www.liaoxuefeng.com/wik ... 6quot;)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urls
2. 通过 文章url
使用模板保存每个 文章 HTML 文件
html 模板:
html_template = """
{content}
"""
保存:
<p>
def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")[0]
# 标题
title = soup.find('h4').get_text()
# 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(1, title_tag)
body.insert(1, center_tag)
html = str(body)
# body中的img标签的src相对路径的改成绝对路径
pattern = "(
python抓取网页数据(比如要抓取某网站折线图上数据,找到对应的事件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-29 11:27
)
例如,如果要抓取网站的折线图上的数据,截图如下:
借助 Chrome 开发者工具网络。经过分析,发现得到了上面的热度数据,并找到了对应的事件url:
通过分析:
发现ids=309006000是固定值,24_4474是两个随机数
ids=309006000 是从网页中获取的固定值。
右击“查看网页源代码”,找到以下内容:
具体实现代码如下:
import random
from urllib import request
import requests
import json
class test:
def __init__(self):
#插入合适的cookie值
self.mycookies = []
self.user_agent_list = [
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
]
def gettvid(self,url):
tvid = ''
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt1 = requests.get(url, cookies=cookie1, headers=header).text
print(txt1)
response = request.urlopen(url)
page = response.read()
txt = str(page.decode('utf-8'))
# cookie1 = random.choice(self.mycookies)
# txt = requests.get(keyurl, cookies=cookie1).text
txts = txt.split('\n')
# print(txts)
index = len(txts) - 1
while index > 0:
t = txts[index]
if t.find("param['tvid']") > -1:
tt = t.replace('"', '').replace(' ', '')
start = tt.find("=")+1
end = start+9
tvid = tt[start:end]
tvid = tvid.strip()
break
index -= 1
except Exception as ex:
print(ex)
# print(ex)
return tvid
def gethotdx(self,url):
tvid =self.gettvid(url)
# 产生7位随机数
id1=random.randint(1111111,9999999)
# 产生5为随机数
id2 = random.randint(11111, 99999)
link ='https://pcw-api.iqiyi.com/video/video/trendcontent?ids=%s&callback=jsonp_154881%d_%d'%(tvid,id1,id2)
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt = requests.get(link, cookies=cookie1, headers=header).text
start = txt.find('(') + 1
end = txt.find(")")
jsonstr = txt[start:end]
data_json = json.loads(jsonstr)
datas = data_json.get('data')[0]
# print(data_json.get('data'))
id = datas.get('id')
print(id)
print('\n')
#
# # 热度峰值
pkHot = datas.get('pkHot')
print(pkHot)
print('\n')
#
# # 热度峰值 日期
pkHD = datas.get('pkHD')
print(pkHD)
print('\n')
#
# # 热度值
print('30天内容热度')
aHot = datas.get('aHot')
# print(aHot)
for item in aHot:
print(item.get('k'), item.get('v'))
print('\n')
print('全部内容热度')
mHot = datas.get('mHot')
# print(aHot)
for item in mHot:
print(item.get('k'), item.get('v'))
print('\n')
print('30天播放指数')
aidx = datas.get('aidx')
# print(aHot)
for item in aidx:
print(item.get('k'), item.get('v'))
print('\n')
print('全部播放指数')
midx = datas.get('midx')
# print(aHot)
for item in midx:
print(item.get('k'), item.get('v'))
except Exception as e1:
print(e1)
if __name__=="__main__":
obj =test()
url='https://www.iqiyi.com/v_19rrnbwrfg.html?vfm=m_103_txsp'
obj.gethotdx(url) 查看全部
python抓取网页数据(比如要抓取某网站折线图上数据,找到对应的事件
)
例如,如果要抓取网站的折线图上的数据,截图如下:
借助 Chrome 开发者工具网络。经过分析,发现得到了上面的热度数据,并找到了对应的事件url:
通过分析:
发现ids=309006000是固定值,24_4474是两个随机数
ids=309006000 是从网页中获取的固定值。
右击“查看网页源代码”,找到以下内容:
具体实现代码如下:
import random
from urllib import request
import requests
import json
class test:
def __init__(self):
#插入合适的cookie值
self.mycookies = []
self.user_agent_list = [
'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1464.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.16 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.3319.102 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1667.0 Safari/537.36',
'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0) Gecko/20100101 Firefox/17.0.6',
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36',
'Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
]
def gettvid(self,url):
tvid = ''
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt1 = requests.get(url, cookies=cookie1, headers=header).text
print(txt1)
response = request.urlopen(url)
page = response.read()
txt = str(page.decode('utf-8'))
# cookie1 = random.choice(self.mycookies)
# txt = requests.get(keyurl, cookies=cookie1).text
txts = txt.split('\n')
# print(txts)
index = len(txts) - 1
while index > 0:
t = txts[index]
if t.find("param['tvid']") > -1:
tt = t.replace('"', '').replace(' ', '')
start = tt.find("=")+1
end = start+9
tvid = tt[start:end]
tvid = tvid.strip()
break
index -= 1
except Exception as ex:
print(ex)
# print(ex)
return tvid
def gethotdx(self,url):
tvid =self.gettvid(url)
# 产生7位随机数
id1=random.randint(1111111,9999999)
# 产生5为随机数
id2 = random.randint(11111, 99999)
link ='https://pcw-api.iqiyi.com/video/video/trendcontent?ids=%s&callback=jsonp_154881%d_%d'%(tvid,id1,id2)
try:
cookie1 = random.choice(self.mycookies)
# print(cookie1)
UserAgent = random.choice(self.user_agent_list)
header = {'User-Agent': UserAgent}
# print(header)
txt = requests.get(link, cookies=cookie1, headers=header).text
start = txt.find('(') + 1
end = txt.find(")")
jsonstr = txt[start:end]
data_json = json.loads(jsonstr)
datas = data_json.get('data')[0]
# print(data_json.get('data'))
id = datas.get('id')
print(id)
print('\n')
#
# # 热度峰值
pkHot = datas.get('pkHot')
print(pkHot)
print('\n')
#
# # 热度峰值 日期
pkHD = datas.get('pkHD')
print(pkHD)
print('\n')
#
# # 热度值
print('30天内容热度')
aHot = datas.get('aHot')
# print(aHot)
for item in aHot:
print(item.get('k'), item.get('v'))
print('\n')
print('全部内容热度')
mHot = datas.get('mHot')
# print(aHot)
for item in mHot:
print(item.get('k'), item.get('v'))
print('\n')
print('30天播放指数')
aidx = datas.get('aidx')
# print(aHot)
for item in aidx:
print(item.get('k'), item.get('v'))
print('\n')
print('全部播放指数')
midx = datas.get('midx')
# print(aHot)
for item in midx:
print(item.get('k'), item.get('v'))
except Exception as e1:
print(e1)
if __name__=="__main__":
obj =test()
url='https://www.iqiyi.com/v_19rrnbwrfg.html?vfm=m_103_txsp'
obj.gethotdx(url)
python抓取网页数据( 2018年05月25日11:41:25一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-10-29 11:26
2018年05月25日11:41:25一下)
python2.7 实现爬虫网页数据
更新时间:2018-05-25 11:41:25 作者:aasdsjk
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
python抓取网页数据(
2018年05月25日11:41:25一下)
python2.7 实现爬虫网页数据
更新时间:2018-05-25 11:41:25 作者:aasdsjk
本文文章主要介绍python2.7,详细实现爬虫网页数据。有一定的参考价值,感兴趣的朋友可以参考
最近刚学了Python,做了一个简单的爬虫。作为一个简单的demo,希望对我这样的初学者有所帮助。
代码使用python制作的爬虫2.7抓取51job上的职位名称、公司名称、薪水、发布时间等。
直接上代码。代码中的注释相当清楚。如果没有安装mysql,需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式抓取的网页数据格式如下:
以上是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Scripthome。

