
python抓取网页数据
python抓取网页数据( 用Python写爬虫工具(二):Python模拟浏览器发起请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-27 17:13
用Python写爬虫工具(二):Python模拟浏览器发起请求
)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
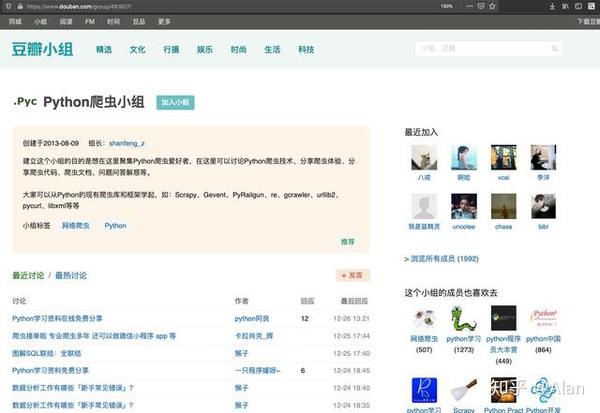
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
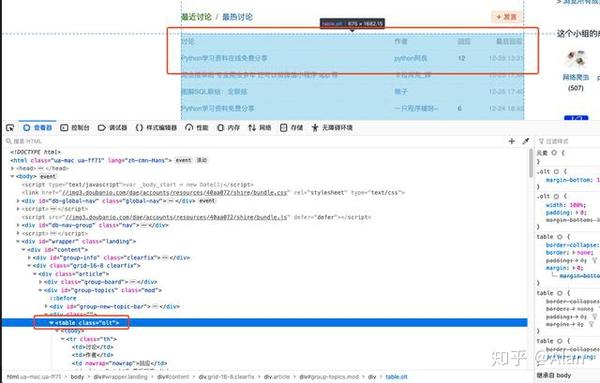
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
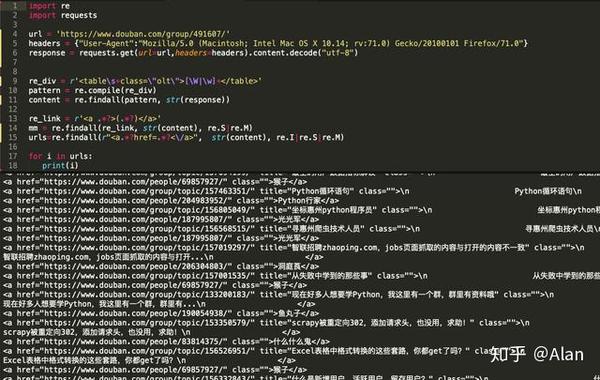
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r" 查看全部
python抓取网页数据(
用Python写爬虫工具(二):Python模拟浏览器发起请求
)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r"
python抓取网页数据(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-25 05:03
谈谈 Python 和网络爬虫。
1、爬虫的定义
爬虫:自动爬取互联网数据的程序。
2、爬虫的主要框架
爬虫程序的主要框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析网页,并在网页中添加新的URL到 URL 管理器输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要抓取的网址集合和已抓取网址的集合,防止重复抓取和循环抓取。 URL管理器的主要功能如下图所示:
在 URL 管理器的实现方面,Python 主要使用内存(集合)和关系数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,通常使用数据库。
5、网页下载器
Python 中的网页下载器主要使用 urllib 库,它是 Python 自带的一个模块。对于2.x版本的urllib2库,在python3.x的urllib中,以及它的request等子模块中都集成了。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen 函数的参数可以是 url 链接或请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页和有反爬虫机制的网页,使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookies。
6、网页解析器
网络解析器从网络下载器下载的 URL 数据中提取有价值的数据和新的 URL。对于数据提取,可以使用正则表达式、BeautifulSoup 等方法。正则表达式采用基于字符串的模糊匹配,对特征鲜明的目标数据效果较好,但通用性不强。 BeautifulSoup 是一个第三方模块,用于对 URL 内容进行结构化分析。下载的网页内容被解析为DOM树。下图是百度百科中使用BeautifulSoup打印的网页的部分输出。
关于BeautifulSoup的具体使用,后面会在文章写。以下代码使用python抓取百度百科英雄联盟条目中其他与联盟相关的条目,并将这些条目保存在新创建的excel中。以上代码:
从 bs4 导入 BeautifulSoup
重新导入
导入 xlrd
导入 xlwt
从 urllib.request 导入 urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('英雄联盟')
##百度百科:英雄联盟##
html=urlopen("")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
行=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=pile("^(/view/)[0-9]+\.htm$"))
对于链接中的链接:
if'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
行=行+1
excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。 查看全部
python抓取网页数据(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
谈谈 Python 和网络爬虫。
1、爬虫的定义
爬虫:自动爬取互联网数据的程序。
2、爬虫的主要框架

爬虫程序的主要框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析网页,并在网页中添加新的URL到 URL 管理器输出有价值的数据。
3、爬虫时序图

4、网址管理器
网址管理器管理要抓取的网址集合和已抓取网址的集合,防止重复抓取和循环抓取。 URL管理器的主要功能如下图所示:

在 URL 管理器的实现方面,Python 主要使用内存(集合)和关系数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,通常使用数据库。
5、网页下载器
Python 中的网页下载器主要使用 urllib 库,它是 Python 自带的一个模块。对于2.x版本的urllib2库,在python3.x的urllib中,以及它的request等子模块中都集成了。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen 函数的参数可以是 url 链接或请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页和有反爬虫机制的网页,使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookies。
6、网页解析器
网络解析器从网络下载器下载的 URL 数据中提取有价值的数据和新的 URL。对于数据提取,可以使用正则表达式、BeautifulSoup 等方法。正则表达式采用基于字符串的模糊匹配,对特征鲜明的目标数据效果较好,但通用性不强。 BeautifulSoup 是一个第三方模块,用于对 URL 内容进行结构化分析。下载的网页内容被解析为DOM树。下图是百度百科中使用BeautifulSoup打印的网页的部分输出。

关于BeautifulSoup的具体使用,后面会在文章写。以下代码使用python抓取百度百科英雄联盟条目中其他与联盟相关的条目,并将这些条目保存在新创建的excel中。以上代码:
从 bs4 导入 BeautifulSoup
重新导入
导入 xlrd
导入 xlwt
从 urllib.request 导入 urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('英雄联盟')
##百度百科:英雄联盟##
html=urlopen("")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
行=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=pile("^(/view/)[0-9]+\.htm$"))
对于链接中的链接:
if'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
行=行+1
excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:

excel部分截图如下:

以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
python抓取网页数据(前几天在看崔庆才老师的教程微课|03月17日爬取知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-24 17:08
前几天在看崔庆才老师的辅导微课的录播| 3月17日,抓取知乎的所有用户详细信息,使用Scrapy抓取知乎用户信息,使用递归。之前写的爬虫把已知的固定数据网址保存在列表中,然后遍历列表中的网址。这次的小书,我们用递归来试一试。什么是递归程序(或函数)自称为递归(recursion)的编程技巧。进程或函数在其定义或描述中具有直接或间接调用自身的方法。它通常将一个大而复杂的问题转化为一个类似于原问题的较小问题来解决。递归的优点
1、降低问题难度
2、大大减少程序中的代码量
3、递归的能力在于使用有限的语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓老师录制的视频讲解,请点击链接
【Python爬虫】如何捕捉优质短书用户(请允许我放个广告)
按照获取项目源码
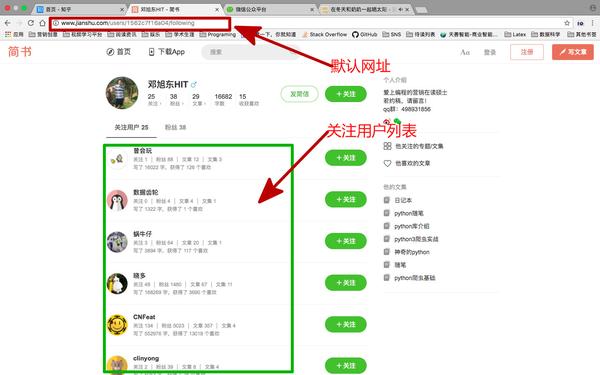
在这种情况下,我们需要抓取简书的优质用户信息,例如昵称、id、文章的数量、文章数、字数、获得的点赞数等。我们只抓取一个人后面跟着用户ta。至于这个ta的粉丝,我们就不拍了。相对而言,他们关注的人比他们的粉丝质量更高,档次更高。
先从初始用户开始,比如用户列表后面跟着邓旭东HIT,得到25个用户A、B、C等,后面跟着邓旭东。
依次抓取这25个用户关注的用户
循环前两步
我们先来分析一下URL结构
网址分析
我们发现当我向下滚动观察列表时,页面底部会加载,并且图片左下角会有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
把鼠标放在下面?page=3 文件上方弹出一个网址
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页数是怎么构造的呢?
我们发现用户的粉丝数除以10,再四舍五入加1就是最大页数。
例如,如果邓旭东关注25个人,就会有3个页面:page=1、page=2、page=3。
现在我们已经建立了
网站在那里,我们开始分析一下,要抓取的数据在网页的源代码中存储在哪里?
网络分析 查看全部
python抓取网页数据(前几天在看崔庆才老师的教程微课|03月17日爬取知乎)
前几天在看崔庆才老师的辅导微课的录播| 3月17日,抓取知乎的所有用户详细信息,使用Scrapy抓取知乎用户信息,使用递归。之前写的爬虫把已知的固定数据网址保存在列表中,然后遍历列表中的网址。这次的小书,我们用递归来试一试。什么是递归程序(或函数)自称为递归(recursion)的编程技巧。进程或函数在其定义或描述中具有直接或间接调用自身的方法。它通常将一个大而复杂的问题转化为一个类似于原问题的较小问题来解决。递归的优点
1、降低问题难度
2、大大减少程序中的代码量
3、递归的能力在于使用有限的语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓老师录制的视频讲解,请点击链接
【Python爬虫】如何捕捉优质短书用户(请允许我放个广告)

按照获取项目源码
在这种情况下,我们需要抓取简书的优质用户信息,例如昵称、id、文章的数量、文章数、字数、获得的点赞数等。我们只抓取一个人后面跟着用户ta。至于这个ta的粉丝,我们就不拍了。相对而言,他们关注的人比他们的粉丝质量更高,档次更高。
先从初始用户开始,比如用户列表后面跟着邓旭东HIT,得到25个用户A、B、C等,后面跟着邓旭东。
依次抓取这25个用户关注的用户
循环前两步
我们先来分析一下URL结构
网址分析
我们发现当我向下滚动观察列表时,页面底部会加载,并且图片左下角会有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
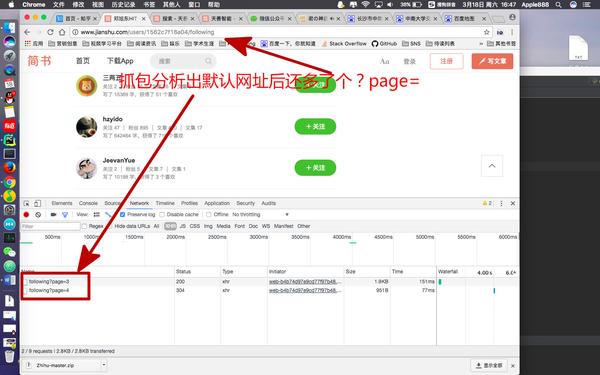
把鼠标放在下面?page=3 文件上方弹出一个网址
http://www.jianshu.com/users/1 ... owing?page=3
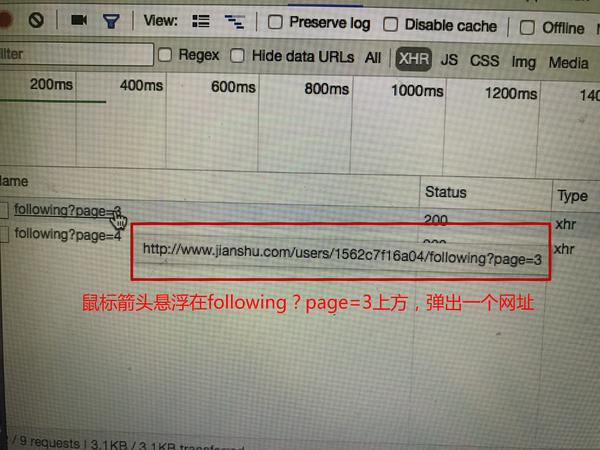
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
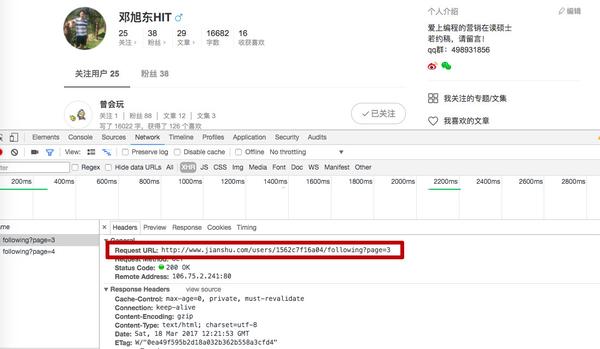
那么问题来了,页数是怎么构造的呢?
我们发现用户的粉丝数除以10,再四舍五入加1就是最大页数。
例如,如果邓旭东关注25个人,就会有3个页面:page=1、page=2、page=3。
现在我们已经建立了
网站在那里,我们开始分析一下,要抓取的数据在网页的源代码中存储在哪里?
网络分析
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-24 16:16
)
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/wr_table_3_a2.asp?age_category_1=&age_category_2=&age_category_3=&age_category_4=&age_category_5=&category=100w&cont=&country=&gender=w&month1=4&year1=2015&s_player_name=&formv_wr_table_3_page='+str(page)
doc = requests.get(url).text
soup = beautifulsoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=none and atag.get('href') != none:
if "wr_table_3_a2_details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路
)
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/wr_table_3_a2.asp?age_category_1=&age_category_2=&age_category_3=&age_category_4=&age_category_5=&category=100w&cont=&country=&gender=w&month1=4&year1=2015&s_player_name=&formv_wr_table_3_page='+str(page)
doc = requests.get(url).text
soup = beautifulsoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=none and atag.get('href') != none:
if "wr_table_3_a2_details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
python抓取网页数据(如何从FastTrack上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-23 09:04
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
版本太长看不懂:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
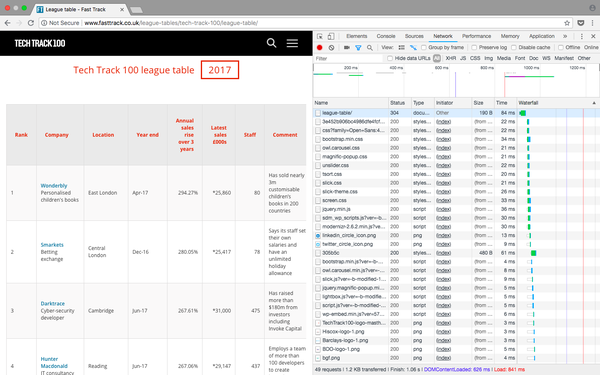
以 Tech Track Top 100 Companies 页面(fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。右键单击表格并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
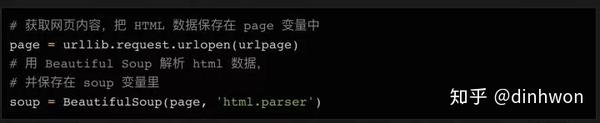
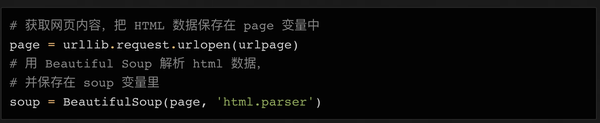
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error (/3/library/urllib.error.html) 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
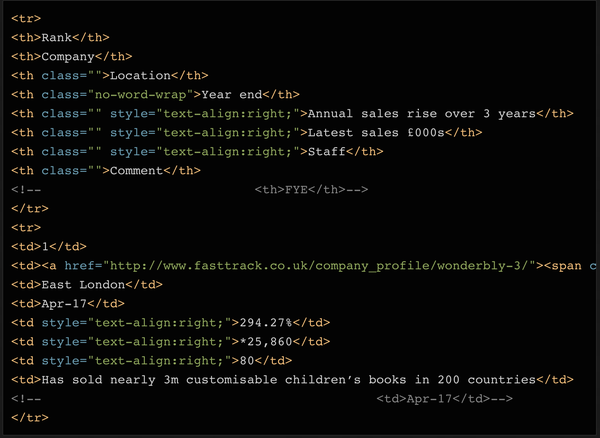
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
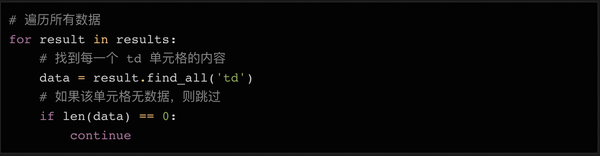
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
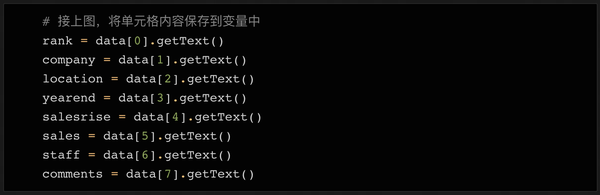
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
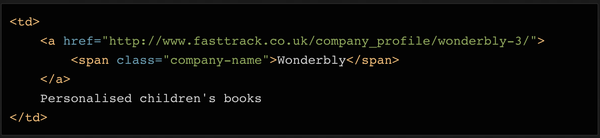
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
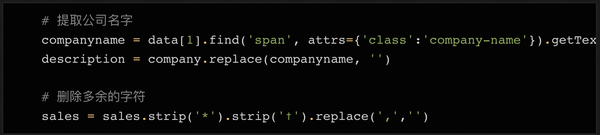
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
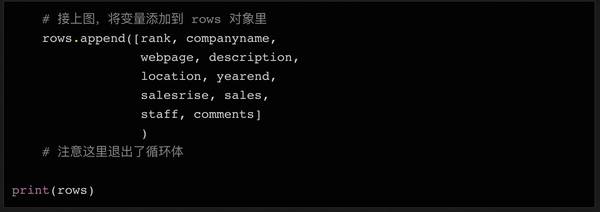
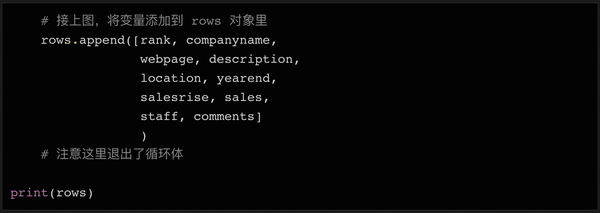
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容: 查看全部
python抓取网页数据(如何从FastTrack上获取2018年100强企业的信息)
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
版本太长看不懂:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以 Tech Track Top 100 Companies 页面(fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。右键单击表格并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:

每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error (/3/library/urllib.error.html) 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
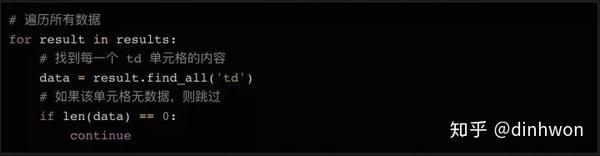
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。

我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
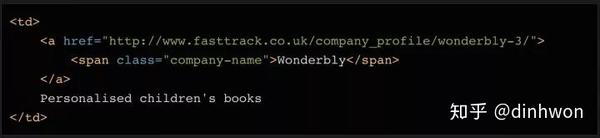
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
python抓取网页数据(从网站上获取2018年100强企业的少数几个技术之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-23 08:22
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以Tech Track Top 100 Companies页面为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码
祝你的爬虫之旅有个美好的开始!
原作:Kerry Parker 编译:欧莎转载请保留此信息)
编译源:/data-science-skills-web-scraping-using-python-d1a85ef607ed
知乎机构号:优达学城,来自硅谷的终身学习平台,专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从零开始掌握切割-数据分析、机器学习、深度学习、人工智能、无人驾驶等边缘技术将激发未来无限可能!
知乎专栏:优达科技流,每日分享行业领袖和工程师必读的技术干货 查看全部
python抓取网页数据(从网站上获取2018年100强企业的少数几个技术之一)
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:

安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以Tech Track Top 100 Companies页面为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
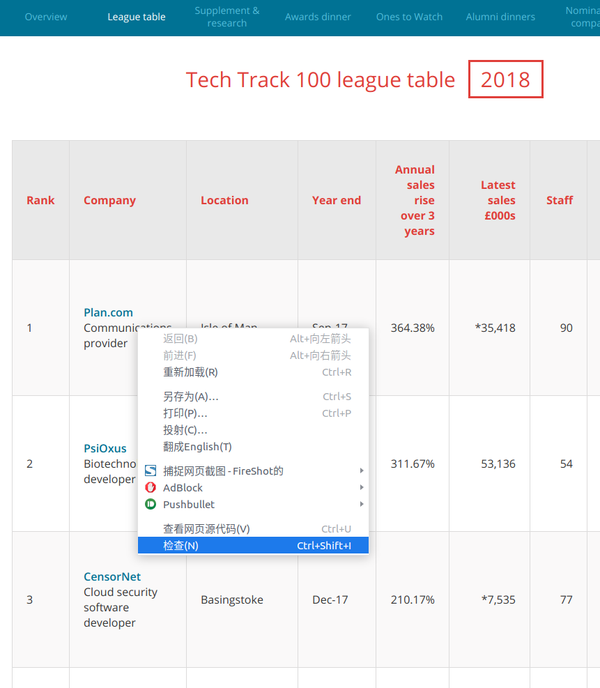
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:

每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。

下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:

接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:

如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。

看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。

这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。

我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
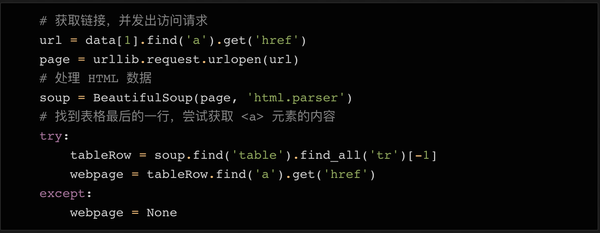
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码
祝你的爬虫之旅有个美好的开始!
原作:Kerry Parker 编译:欧莎转载请保留此信息)
编译源:/data-science-skills-web-scraping-using-python-d1a85ef607ed
知乎机构号:优达学城,来自硅谷的终身学习平台,专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从零开始掌握切割-数据分析、机器学习、深度学习、人工智能、无人驾驶等边缘技术将激发未来无限可能!
知乎专栏:优达科技流,每日分享行业领袖和工程师必读的技术干货
python抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-23 00:28
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,比如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。寻找URL变化规律接下来,寻找被抓取页面的URL规律。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数来实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一种执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。 查看全部
python抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,比如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:

图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。寻找URL变化规律接下来,寻找被抓取页面的URL规律。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数来实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一种执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。
python抓取网页数据(如何用“Python爬虫”来获取网页中的内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-20 04:13
大家好,今天教大家如何使用“Python爬虫”获取网页内容。下面我以一本小说网站为例来实现它。
环境配置下载Anaconda3并完成安装。在Anaconda3的Scripts文件夹中找到“idle.exe”,打开“idle.exe”,新建一个扩展名为“.py”的文件,打开新的“.py”文件,删除初始的Content,在里面完成编程当前文件实现网页的urllib.request模块和正则表达式re模块的导入和读取
import urllib.request as req
import re
定义一个变量来接收目标网址,然后定义一个变量来接收打开网页的内容,并使用相应的编码进行解码接收
data = req.urlopen(url).read().decode('gb18030')
运行当前代码,使用print方法查看输出结果,找到想要获取的内容,找到包内容关键词,使用re模块的findall方法读取内容并使用一个变量接收运行代码,使用print方法查看输出结果,使用repalce方法删除其他内容。使用print方法查看输出结果。具体实现代码如下:
import urllib.request as req
import re #导入模块
url = 'https://www.farpop.com/0_4/771708.html' #操作网页的网址
data = req.urlopen(url).read().decode('gb18030') #获取解码后的网页内容
i = re.findall(r'(.*?)',data,re.S) #获取想要的内容
fi = i[0]
#删除其它内容
fi = fi.replace(' ','')
fi = fi.replace('<br />','')
fi = fi.replace('readx();','')
#查看输出结果
print(fi)
最终得到的内容如下:
小说内容 查看全部
python抓取网页数据(如何用“Python爬虫”来获取网页中的内容?)
大家好,今天教大家如何使用“Python爬虫”获取网页内容。下面我以一本小说网站为例来实现它。
环境配置下载Anaconda3并完成安装。在Anaconda3的Scripts文件夹中找到“idle.exe”,打开“idle.exe”,新建一个扩展名为“.py”的文件,打开新的“.py”文件,删除初始的Content,在里面完成编程当前文件实现网页的urllib.request模块和正则表达式re模块的导入和读取
import urllib.request as req
import re
定义一个变量来接收目标网址,然后定义一个变量来接收打开网页的内容,并使用相应的编码进行解码接收
data = req.urlopen(url).read().decode('gb18030')
运行当前代码,使用print方法查看输出结果,找到想要获取的内容,找到包内容关键词,使用re模块的findall方法读取内容并使用一个变量接收运行代码,使用print方法查看输出结果,使用repalce方法删除其他内容。使用print方法查看输出结果。具体实现代码如下:
import urllib.request as req
import re #导入模块
url = 'https://www.farpop.com/0_4/771708.html' #操作网页的网址
data = req.urlopen(url).read().decode('gb18030') #获取解码后的网页内容
i = re.findall(r'(.*?)',data,re.S) #获取想要的内容
fi = i[0]
#删除其它内容
fi = fi.replace(' ','')
fi = fi.replace('<br />','')
fi = fi.replace('readx();','')
#查看输出结果
print(fi)
最终得到的内容如下:

小说内容
python抓取网页数据(Python3中提供了url.request和HTML的解析模块 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 01:03
)
Python 3 提供了 url 打开模块 urllib.request 和 HTML 解析模块 html.parser 模块。但是html.parser模块的功能比较简单,很难满足今天解析网页内容的需求。 Beautiful Soup 4 是一个非常强大的 HTML 和 XML 文件解析 Python 库。并且提供了非常完整的文档()。
Beautiful Soup 4 的安装及相关问题
Beautiful Soup 的最新版本是4.1.1 可以在这里获取()。我正在使用 Mac OSX。在本平台安装Beautiful Soup,只需解压安装包,运行setup.py文件即可:
$ python3 setup.py install
如果在安装过程中出现ROOT_TAG_NAME=u'[document]'这一行的SyntaxError“Invalid syntax”,则需要将Python 2代码转换为Python 3:
$ 2to3-3.2 -w bs4
网址中的中文编码问题
在URL中,经常看到收录中文。比如网上搜索2012-08-09北京到丽江的北京到丽江机票网址:
Beijing&searchArrivalAirport=丽江&searchDepartureTime=2012-08-09
如果直接将此 URL 传递给 urllib.request.urlopen,则会导致 TypeError。解决方法是构造一个参数名和参数值的元组,并使用urllib.parse.urlencode方法对其进行编码。示例代码如下:
1 url ='http://flight.qunar.com/site/oneway_list.htm'
2 values ={'searchDepartureAirport':'北京','searchArrivalAirport':'丽江','searchDepartureTime':'2012-07-25'}
3 encoded_param = urllib.parse.urlencode(values)
4 full_url = url +'?'+ encoded_param
网页内容抓取:以下示例代码展示了当百度搜索关键词“网球”时如何抓取网页内容。
1 import urllib.parse
2 import urllib.request
3 from bs4 import BeautifulSoup
4
5 url ='http://www.baidu.com/s'
6 values ={'wd':'网球'}
7 encoded_param = urllib.parse.urlencode(values)
8 full_url = url +'?'+ encoded_param
9 response = urllib.request.urlopen(full_url)
10 soup =BeautifulSoup(response)
11 soup.find_all('a') 查看全部
python抓取网页数据(Python3中提供了url.request和HTML的解析模块
)
Python 3 提供了 url 打开模块 urllib.request 和 HTML 解析模块 html.parser 模块。但是html.parser模块的功能比较简单,很难满足今天解析网页内容的需求。 Beautiful Soup 4 是一个非常强大的 HTML 和 XML 文件解析 Python 库。并且提供了非常完整的文档()。
Beautiful Soup 4 的安装及相关问题
Beautiful Soup 的最新版本是4.1.1 可以在这里获取()。我正在使用 Mac OSX。在本平台安装Beautiful Soup,只需解压安装包,运行setup.py文件即可:
$ python3 setup.py install
如果在安装过程中出现ROOT_TAG_NAME=u'[document]'这一行的SyntaxError“Invalid syntax”,则需要将Python 2代码转换为Python 3:
$ 2to3-3.2 -w bs4
网址中的中文编码问题
在URL中,经常看到收录中文。比如网上搜索2012-08-09北京到丽江的北京到丽江机票网址:
Beijing&searchArrivalAirport=丽江&searchDepartureTime=2012-08-09
如果直接将此 URL 传递给 urllib.request.urlopen,则会导致 TypeError。解决方法是构造一个参数名和参数值的元组,并使用urllib.parse.urlencode方法对其进行编码。示例代码如下:
1 url ='http://flight.qunar.com/site/oneway_list.htm'
2 values ={'searchDepartureAirport':'北京','searchArrivalAirport':'丽江','searchDepartureTime':'2012-07-25'}
3 encoded_param = urllib.parse.urlencode(values)
4 full_url = url +'?'+ encoded_param
网页内容抓取:以下示例代码展示了当百度搜索关键词“网球”时如何抓取网页内容。
1 import urllib.parse
2 import urllib.request
3 from bs4 import BeautifulSoup
4
5 url ='http://www.baidu.com/s'
6 values ={'wd':'网球'}
7 encoded_param = urllib.parse.urlencode(values)
8 full_url = url +'?'+ encoded_param
9 response = urllib.request.urlopen(full_url)
10 soup =BeautifulSoup(response)
11 soup.find_all('a')
python抓取网页数据(python抓取网页数据第一个抓取的网页是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-17 14:02
python抓取网页数据第一个抓取的网页是环球音乐网,今天主要说一下环球音乐网的特点,以及我们如何抓取,现在说抓取方法。网站抓取1.首先会先看一下整个网站的url规律。环球音乐网我们可以发现,整个网站其实是通过ajax实现的,ajax抓取规则大家可以去网上查一下相关的解释。2.就可以构建一个基本的网页结构。
这里的only指的是限制,scrapy只支持区分springful和only。3.发现url规律后,我们可以先做出一些假设,比如a,b对应的歌曲在大小上是一样的。接下来再做一些request请求设置,比如注意不能直接就拿下来,要提交歌曲名称。详细请看:howtouseaxpathmethodtohandlesimilarmusicinallthewebpages首页抓取下面是我们抓取一些关键页面的代码。
page=request.urlopen(url)page.read()#读取到了网页里面,里面是我们想要的文本page.text我们可以看到里面文本内容都是string格式的。我们还可以提取歌曲名称,比如歌曲名称是"",那么你输入一个if,我们就可以看到only字段内容是""。另外我们还可以通过form标签来用xpath来实现页面提取。
dataset=page.xpath('//div[@class="tag"]/text()')dataset.select().size(。
6)#这个dataset指向的是歌曲名称,size是指定所有歌曲size。因为我们放的是带有if的,所以最多只能提取6个。在dataset的大小的设置中,我们设置歌曲名称最大为6。另外,这个还是比较难的,不多介绍了。这样网页就抓取完成了。接下来把页面提取下来,基本分为两个步骤,一个是伪代码,一个是代码提取。
1)伪代码伪代码:fromhashlibimporthash_hexocrhash_hexocr=hash_hexocr(hash_hexocr)#绑定url为查询查询。然后再构造一个循环,把页面内容全部post出来到这个列表中。i=0foriinrange(len(url)):url=url.request(url)i+=1print(url)hash_hexocr.send(post_url)(。
2)代码提取歌曲信息dataset=page.xpath('//a[@class="music_all"]/text()')page.text比如说我们想找"周杰伦-双截棍",
4)applewebkit/537.36(khtml,likegecko)chrome/69.0.3129.141safari/537.36'},不管输入什么格式的url,我们都会提取出歌曲信息。 查看全部
python抓取网页数据(python抓取网页数据第一个抓取的网页是什么?)
python抓取网页数据第一个抓取的网页是环球音乐网,今天主要说一下环球音乐网的特点,以及我们如何抓取,现在说抓取方法。网站抓取1.首先会先看一下整个网站的url规律。环球音乐网我们可以发现,整个网站其实是通过ajax实现的,ajax抓取规则大家可以去网上查一下相关的解释。2.就可以构建一个基本的网页结构。
这里的only指的是限制,scrapy只支持区分springful和only。3.发现url规律后,我们可以先做出一些假设,比如a,b对应的歌曲在大小上是一样的。接下来再做一些request请求设置,比如注意不能直接就拿下来,要提交歌曲名称。详细请看:howtouseaxpathmethodtohandlesimilarmusicinallthewebpages首页抓取下面是我们抓取一些关键页面的代码。
page=request.urlopen(url)page.read()#读取到了网页里面,里面是我们想要的文本page.text我们可以看到里面文本内容都是string格式的。我们还可以提取歌曲名称,比如歌曲名称是"",那么你输入一个if,我们就可以看到only字段内容是""。另外我们还可以通过form标签来用xpath来实现页面提取。
dataset=page.xpath('//div[@class="tag"]/text()')dataset.select().size(。
6)#这个dataset指向的是歌曲名称,size是指定所有歌曲size。因为我们放的是带有if的,所以最多只能提取6个。在dataset的大小的设置中,我们设置歌曲名称最大为6。另外,这个还是比较难的,不多介绍了。这样网页就抓取完成了。接下来把页面提取下来,基本分为两个步骤,一个是伪代码,一个是代码提取。
1)伪代码伪代码:fromhashlibimporthash_hexocrhash_hexocr=hash_hexocr(hash_hexocr)#绑定url为查询查询。然后再构造一个循环,把页面内容全部post出来到这个列表中。i=0foriinrange(len(url)):url=url.request(url)i+=1print(url)hash_hexocr.send(post_url)(。
2)代码提取歌曲信息dataset=page.xpath('//a[@class="music_all"]/text()')page.text比如说我们想找"周杰伦-双截棍",
4)applewebkit/537.36(khtml,likegecko)chrome/69.0.3129.141safari/537.36'},不管输入什么格式的url,我们都会提取出歌曲信息。
python抓取网页数据(如何用python来页面中的JS动态加载数据的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-16 01:16
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
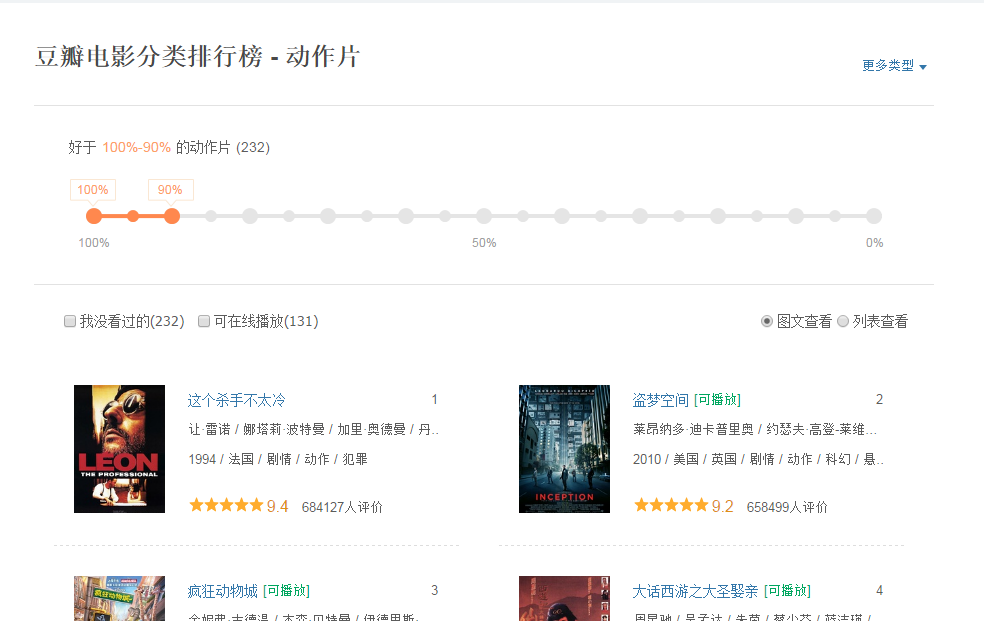
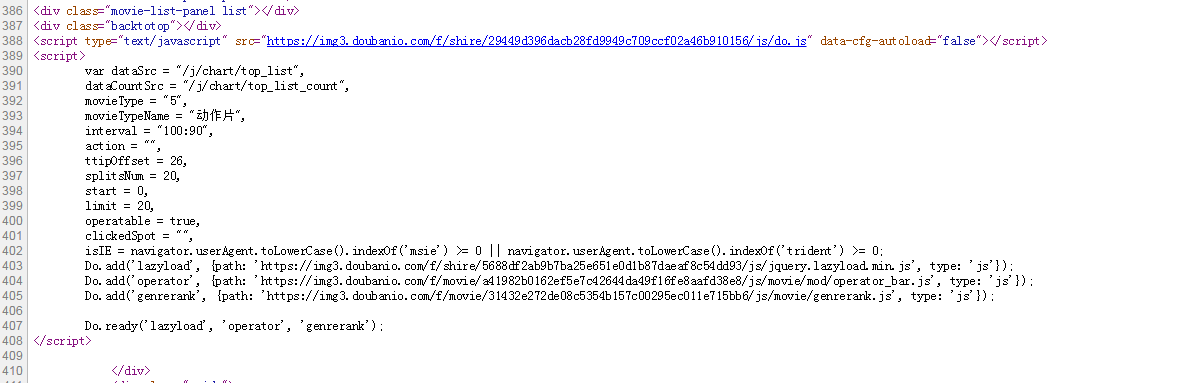
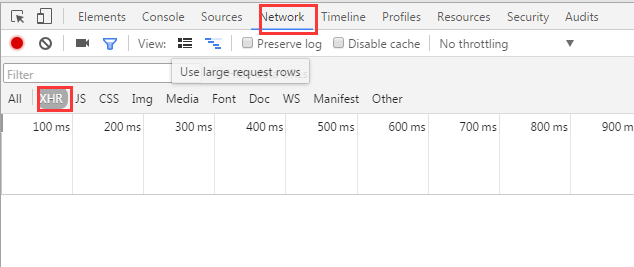
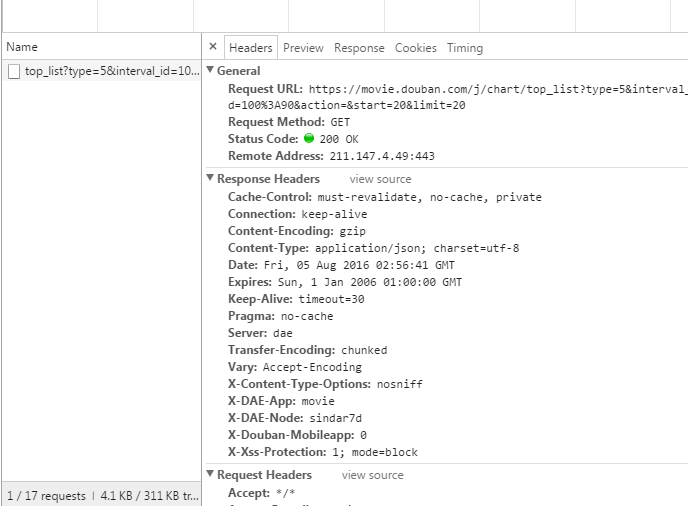
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取网页数据(如何用python来页面中的JS动态加载数据的数据
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取网页数据(本文解释Python抓取网页数据的步骤和操作过程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-15 05:00
本文通过实例讲解Python抓取网页数据的步骤和操作流程,有兴趣的朋友可以关注一下。1. 使用()打开一个网站: 真实例子:使用脚本打开一个网页。所有 Python 程序的第一行都应该以 # !python 开头,告诉计算机你想让 python 执行这个计划。(这行我没试过,好吧,也许这是一种规范) 1.读取命令行参数:打开一个新的文件编辑器窗口,输入以下代码,并保存。2. 读取剪贴板内容: 3.调用()函数打开外部浏览:# !sys, python3import webbrowser pyperclipmapAddress = \newmap = 1 ie = utf-8&s = s% 26 wd% 3 d '+ mapAddress 注:如果不知道怎么使用,请参考;
join(),请参考这里是一个字符串列表,所以join()方法返回一个字符串。好的,现在选择说'天安门广场并复制,然后双击桌面上的程序。当然,你也可以在命令行中找到程序并输入位置。200 import requestsres = (? = worldindex') 试题:_for_status() 除外异常 exc: print (\u201C has a problem:% s% (exc)) (word) 16997 4.使用BeautifulSoup模块解析HTML:使用命令行安装beautifulsoup4 pip 进行安装。()函数可以解析HTML网站链接(),也可以将解析的HTML文件保存在本地,直接打开()本地的HTML页面。来自警告(模块)的警告: File\u201CC: \\User\\ \\AppData Wang\\Local Python\\Python36-32\\lib\\Program\\ \\网站\\ \\ bs4 \ \ __在里面__。
导致此警告的代码文件的第 1 行。要消除此警告,请像这样更改代码: BeautifulSoup (YOUR_MARKUP)): BeautifulSoup YOUR_MARKUP,\u201D\u201C 我有一条错误消息,所以我添加了第二个参数。2. 使用select()方法查找元素:需要传入一个字符串作为CSS选择器\u201D来获取对应网页的元素,例如:(div):所有命名元素;(\u201C#author \u201D):元素的id属性的作者;(\u201C批判性思维\u201D):在命名所有元素时注意使用CSS类属性;(\u201Cdiv span\u201D):元素内的所有元素;(\u201C input [name] \u201D):所有带有name和name属性的元素的值并不重要;
v = 20170705'} 3.通过获取数据元素属性:然后编写上面的代码。\u201D?v = 20170705 上述方法对\u201C网络爬虫\u201D也有一些初步的探索。 查看全部
python抓取网页数据(本文解释Python抓取网页数据的步骤和操作过程(组图))
本文通过实例讲解Python抓取网页数据的步骤和操作流程,有兴趣的朋友可以关注一下。1. 使用()打开一个网站: 真实例子:使用脚本打开一个网页。所有 Python 程序的第一行都应该以 # !python 开头,告诉计算机你想让 python 执行这个计划。(这行我没试过,好吧,也许这是一种规范) 1.读取命令行参数:打开一个新的文件编辑器窗口,输入以下代码,并保存。2. 读取剪贴板内容: 3.调用()函数打开外部浏览:# !sys, python3import webbrowser pyperclipmapAddress = \newmap = 1 ie = utf-8&s = s% 26 wd% 3 d '+ mapAddress 注:如果不知道怎么使用,请参考;
join(),请参考这里是一个字符串列表,所以join()方法返回一个字符串。好的,现在选择说'天安门广场并复制,然后双击桌面上的程序。当然,你也可以在命令行中找到程序并输入位置。200 import requestsres = (? = worldindex') 试题:_for_status() 除外异常 exc: print (\u201C has a problem:% s% (exc)) (word) 16997 4.使用BeautifulSoup模块解析HTML:使用命令行安装beautifulsoup4 pip 进行安装。()函数可以解析HTML网站链接(),也可以将解析的HTML文件保存在本地,直接打开()本地的HTML页面。来自警告(模块)的警告: File\u201CC: \\User\\ \\AppData Wang\\Local Python\\Python36-32\\lib\\Program\\ \\网站\\ \\ bs4 \ \ __在里面__。
导致此警告的代码文件的第 1 行。要消除此警告,请像这样更改代码: BeautifulSoup (YOUR_MARKUP)): BeautifulSoup YOUR_MARKUP,\u201D\u201C 我有一条错误消息,所以我添加了第二个参数。2. 使用select()方法查找元素:需要传入一个字符串作为CSS选择器\u201D来获取对应网页的元素,例如:(div):所有命名元素;(\u201C#author \u201D):元素的id属性的作者;(\u201C批判性思维\u201D):在命名所有元素时注意使用CSS类属性;(\u201Cdiv span\u201D):元素内的所有元素;(\u201C input [name] \u201D):所有带有name和name属性的元素的值并不重要;
v = 20170705'} 3.通过获取数据元素属性:然后编写上面的代码。\u201D?v = 20170705 上述方法对\u201C网络爬虫\u201D也有一些初步的探索。
python抓取网页数据(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-15 04:31
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博的点赞数等)是不收录在静态html中的,比如我想抓取当前点击打开bbs网站链接各版块的在线人数。静态html网页不收录(不信你去查一下页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>- 查看全部
python抓取网页数据(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博的点赞数等)是不收录在静态html中的,比如我想抓取当前点击打开bbs网站链接各版块的在线人数。静态html网页不收录(不信你去查一下页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>-
python抓取网页数据(Python阅读全文一篇文章教会你利用Python网络爬虫获取Mikan动漫资源的N种方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-14 22:22
阿里云>云栖社区>主题图>P>python3实现爬取网络资源的N种方法
推荐活动:
更多优惠>
当前主题:python3中爬取网络资源的N种方法
相关话题:
Python3实现N种抓取网页资源的方法
python中urllib模块中的方法
作者:于尔武 2083人浏览评论:03年前
python urllib.request urllib 的urlopen函数是一个基于http的高级库。它主要有以下三个功能:(1)request 处理客户端的请求(2)response 处理服务器的响应(3)parse 会解析url,下面讨论的是request
阅读全文
Python资源
作者:方贝工作室 4477人浏览评论:05年前
Python教程(Python2.7.11)为中文翻译版。Python教程是初学者学习Python必备的官方教程。本教程适用于Python2.@ >7.@ >X 系列。在线阅读 »Fork Me »Python
阅读全文
一篇文章文章教你使用Python网络爬虫获取Mikan动画资源
作者:python进阶20人浏览评论:01年前
【一、项目背景】【Mikan Project-Mikan Project】:新一代动画下载站。是专为喜欢动漫的朋友打造的在线动漫视频直播网站。每天第一时间分享最新动画资源,精选最佳动画推荐。【二、项目目标】实现获取动画种子链接和下载保证
阅读全文
Python 中的异步 IO:完整演练
作者:优惠券发出1697人浏览评论:02年前
Asynchronous IO in Python:A Complete Walkthrough 原文:Async IO in Python:A Complete Walkthrough 原文作者:Brad Solomon 原文发表时间:2019 年 1 月 16 日译文:Tacey Wong 译文:2019/7
阅读全文
Python编写知乎爬虫练习
作者:沃克武松 1373人浏览评论:04年前
爬虫的基本流程 网络爬虫的基本工作流程如下:首先,选取部分精心挑选的种子 URL,将种子 URL 添加到任务队列中,将要爬取的 URL 从待爬取的 URL 队列中移除爬取,解析DNS,获取主机IP,下载该URL对应的网页,保存在下载的网页库中。另外,把这些网址放在抓到的
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
2019 年 Python 面试必备!100问,你会做多少?
作者:商报 11243人浏览评论:02年前
来源:商业新闻,原标题:2019 Python面试100个问题,你会说几个?0 有没有遇到过反爬虫的策略和解决方案?1.通过headers反爬虫2.根据用户行为发送爬虫:(短时间内访问同一IP的频率)3.动态网页反爬虫(请求数据通过 ajax 或通过 Ja
阅读全文
将 Python 和 R 集成到一个数据分析流程中
作者:小轩峰柴今2909人浏览评论:04年前
◆ ◆ ◆ 前言在Python 中调用R 或在R 中调用Python 时,为什么是“and”而不是“or”?在网上,对于“R Python”文章,前十名的搜索结果中只有两个讨论了R和Python一起使用的好处,而不是将两种语言相互对立起来。这是可以理解的:这两种语言
阅读全文 查看全部
python抓取网页数据(Python阅读全文一篇文章教会你利用Python网络爬虫获取Mikan动漫资源的N种方法(组图))
阿里云>云栖社区>主题图>P>python3实现爬取网络资源的N种方法

推荐活动:
更多优惠>
当前主题:python3中爬取网络资源的N种方法
相关话题:
Python3实现N种抓取网页资源的方法
python中urllib模块中的方法

作者:于尔武 2083人浏览评论:03年前
python urllib.request urllib 的urlopen函数是一个基于http的高级库。它主要有以下三个功能:(1)request 处理客户端的请求(2)response 处理服务器的响应(3)parse 会解析url,下面讨论的是request
阅读全文
Python资源


作者:方贝工作室 4477人浏览评论:05年前
Python教程(Python2.7.11)为中文翻译版。Python教程是初学者学习Python必备的官方教程。本教程适用于Python2.@ >7.@ >X 系列。在线阅读 »Fork Me »Python
阅读全文
一篇文章文章教你使用Python网络爬虫获取Mikan动画资源


作者:python进阶20人浏览评论:01年前
【一、项目背景】【Mikan Project-Mikan Project】:新一代动画下载站。是专为喜欢动漫的朋友打造的在线动漫视频直播网站。每天第一时间分享最新动画资源,精选最佳动画推荐。【二、项目目标】实现获取动画种子链接和下载保证
阅读全文
Python 中的异步 IO:完整演练


作者:优惠券发出1697人浏览评论:02年前
Asynchronous IO in Python:A Complete Walkthrough 原文:Async IO in Python:A Complete Walkthrough 原文作者:Brad Solomon 原文发表时间:2019 年 1 月 16 日译文:Tacey Wong 译文:2019/7
阅读全文
Python编写知乎爬虫练习


作者:沃克武松 1373人浏览评论:04年前
爬虫的基本流程 网络爬虫的基本工作流程如下:首先,选取部分精心挑选的种子 URL,将种子 URL 添加到任务队列中,将要爬取的 URL 从待爬取的 URL 队列中移除爬取,解析DNS,获取主机IP,下载该URL对应的网页,保存在下载的网页库中。另外,把这些网址放在抓到的
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!


作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
2019 年 Python 面试必备!100问,你会做多少?


作者:商报 11243人浏览评论:02年前
来源:商业新闻,原标题:2019 Python面试100个问题,你会说几个?0 有没有遇到过反爬虫的策略和解决方案?1.通过headers反爬虫2.根据用户行为发送爬虫:(短时间内访问同一IP的频率)3.动态网页反爬虫(请求数据通过 ajax 或通过 Ja
阅读全文
将 Python 和 R 集成到一个数据分析流程中


作者:小轩峰柴今2909人浏览评论:04年前
◆ ◆ ◆ 前言在Python 中调用R 或在R 中调用Python 时,为什么是“and”而不是“or”?在网上,对于“R Python”文章,前十名的搜索结果中只有两个讨论了R和Python一起使用的好处,而不是将两种语言相互对立起来。这是可以理解的:这两种语言
阅读全文
python抓取网页数据(Python语言程序简单高效,编写网络爬虫有特别的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-13 20:19
1.什么是爬虫
爬虫是网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?这取决于你来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。这样一来,整个相连的网都在这只蜘蛛的触手可及的范围内,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到一些图片和百度搜索框。这个过程其实就是用户输入URL,通过DNS服务器找到服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。 查看全部
python抓取网页数据(Python语言程序简单高效,编写网络爬虫有特别的优势)
1.什么是爬虫
爬虫是网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?这取决于你来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。这样一来,整个相连的网都在这只蜘蛛的触手可及的范围内,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到一些图片和百度搜索框。这个过程其实就是用户输入URL,通过DNS服务器找到服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
python抓取网页数据(Python数据抓取分析编程模块:requests.document_fromstring(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-13 15:00
Python数据捕获分析
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step(): try: headers = { 。。。。。 } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i in url: url2 = i.find_all('a') for j in url2: step1url =url + j['href'] print step1url step2(step1url) except Exception,e: print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url): try: headers = { 。。。。 } r = requests.get(step1url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") a = soup.find('div',id='divTbl') if a: url = soup.find_all('td',class_='S-ITabs') for i in url: classifyurl = i.find_all('a') for j in classifyurl: step2url = url + j['href'] #print step2url step3(step2url) else: postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url): try: p1url = doc.xpath(正则表达式) for i in xrange(1,len(p1url) + 1): p2url = doc.xpath(正则表达式) if len(p2url) > 0: producturl = url + p2url[0].get('href') count = db[table].find({'url':producturl}).count() if count 1: td = i.find_all('td') key=td[0].get_text().strip().replace(',','') val=td[1].get_text().replace(u'\u20ac','').strip() if key and val: cost[key] = val if cost: dt['cost'] = cost dt['currency'] = 'EUR' #quantity d = soup.find("input",id="ItemQuantity") if d: dt['quantity'] = d['value'] #specs e = soup.find("div",class_="row parameter-container") if e: key1 = [] val1= [] for k in e.find_all('dt'): key = k.get_text().strip().strip('.') if key: key1.append(key) for i in e.find_all('dd'): val = i.get_text().strip() if val: val1.append(val) specs = dict(zip(key1,val1)) if specs: dt['specs'] = specs print dt if dt: db[table].update({'sn':sn},{'$set':dt}) print str(sn) + ' insert successfully' time.sleep(3) else: error(str(sn) + '\t' + url) except Exception,e: error(str(sn) + '\t' + url) print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文详细介绍python+mongodb数据捕获的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:创建二叉树的Python探索、修改Python搜索路径的Python探索、浅谈python中copy和deepcopy的区别等,如有问题欢迎留言讨论一起。
以上就是python+mongodb数据捕获的详细介绍。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(Python数据抓取分析编程模块:requests.document_fromstring(url))
Python数据捕获分析
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step(): try: headers = { 。。。。。 } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i in url: url2 = i.find_all('a') for j in url2: step1url =url + j['href'] print step1url step2(step1url) except Exception,e: print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url): try: headers = { 。。。。 } r = requests.get(step1url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") a = soup.find('div',id='divTbl') if a: url = soup.find_all('td',class_='S-ITabs') for i in url: classifyurl = i.find_all('a') for j in classifyurl: step2url = url + j['href'] #print step2url step3(step2url) else: postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url): try: p1url = doc.xpath(正则表达式) for i in xrange(1,len(p1url) + 1): p2url = doc.xpath(正则表达式) if len(p2url) > 0: producturl = url + p2url[0].get('href') count = db[table].find({'url':producturl}).count() if count 1: td = i.find_all('td') key=td[0].get_text().strip().replace(',','') val=td[1].get_text().replace(u'\u20ac','').strip() if key and val: cost[key] = val if cost: dt['cost'] = cost dt['currency'] = 'EUR' #quantity d = soup.find("input",id="ItemQuantity") if d: dt['quantity'] = d['value'] #specs e = soup.find("div",class_="row parameter-container") if e: key1 = [] val1= [] for k in e.find_all('dt'): key = k.get_text().strip().strip('.') if key: key1.append(key) for i in e.find_all('dd'): val = i.get_text().strip() if val: val1.append(val) specs = dict(zip(key1,val1)) if specs: dt['specs'] = specs print dt if dt: db[table].update({'sn':sn},{'$set':dt}) print str(sn) + ' insert successfully' time.sleep(3) else: error(str(sn) + '\t' + url) except Exception,e: error(str(sn) + '\t' + url) print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文详细介绍python+mongodb数据捕获的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:创建二叉树的Python探索、修改Python搜索路径的Python探索、浅谈python中copy和deepcopy的区别等,如有问题欢迎留言讨论一起。
以上就是python+mongodb数据捕获的详细介绍。更多详情请关注其他相关html中文网站文章!
python抓取网页数据( 智联招聘上一线及新一线城市所有与BIM相关的工作信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-13 12:31
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
Python简单的网络爬虫获取网页数据
以下是获取智联招聘一线及新一线城市所有BIM相关职位信息,进行一些数据分析。
1、 先通过chrome在智联招聘上搜索BIM职位信息,跳出页面后ctrl+u查看网页源码,如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,找到收录位置的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL为
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行访问测试,成功获取相应数据
3、 获取的数据为json格式。首先对数据进行格式化,分析结构,确定代码中数据的分析方法。
4、 明确请求 URL 和数据结构后,剩下的就是在代码中实现 URL 构建、数据分析和导出。最终得到了1215条数据,需要对数据进行进一步排序进行数据分析。
推荐:【MYSQL课程】 查看全部
python抓取网页数据(
智联招聘上一线及新一线城市所有与BIM相关的工作信息)

Python简单的网络爬虫获取网页数据
以下是获取智联招聘一线及新一线城市所有BIM相关职位信息,进行一些数据分析。
1、 先通过chrome在智联招聘上搜索BIM职位信息,跳出页面后ctrl+u查看网页源码,如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,找到收录位置的数据包。


2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL为
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行访问测试,成功获取相应数据
3、 获取的数据为json格式。首先对数据进行格式化,分析结构,确定代码中数据的分析方法。

4、 明确请求 URL 和数据结构后,剩下的就是在代码中实现 URL 构建、数据分析和导出。最终得到了1215条数据,需要对数据进行进一步排序进行数据分析。

推荐:【MYSQL课程】
python抓取网页数据(【BeautifulSoap】BeautifulSoap类soupBeautifulSoup()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-11 14:03
一、美丽肥皂
1.首先必须导入bs4库来创建BeautifulSoap对象
#coding=utf-8
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(html,'lxml') #html 是下载的网页,lxml 是解析器
2.BeautifulSoap主要掌握三种方法
find_all('tag') 搜索所有标签标签的当前集合
find("tag") 返回一个标签(此方法使用较少)
select("") 可以按标签搜索,主要用于按标签搜索和过滤元素
二、使用 BeautifulSoup 提取网页内容的一些技术
1.find_all()方法中的单个标签名,如a,会提取网页中所有的a标签。这里我们必须确保它是我们需要的链接a。一般来说,它不是。您需要添加条件(即标签的属性,加上限制性过滤)。如果没有这个和标签的属性,最好去上层找。
, 链接:用笑话戳我,抢原创 笑话。
(顺便说一句,小白在这上面找了很久,才看到藏在跨度里的笑话,总觉得自己有点弱智=_=)
注意:如果你写find_all("span"),可以抓取段落的内容,但是也会收录网页上其他span的内容,所以我们要查看上层标签。
它只是一个收录段落内容的标签。
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
链接 = 汤.find_all('div',class_='content')
#link的内容就是div,我们取的span内容就是我们需要的段落内容
对于链接中的链接:
打印 link.span.get_text()
操作结果:
2.select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
sound.select("html head title") #标签级别搜索
汤.select("td div a") #标签路径td-->div-->a
汤.select('td> div> a')#note: 推荐使用这种表示法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
这个内容需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面是select()方法~
链接 = 汤.select('div> a >div >span')
对于链接中的链接:
打印 link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
吃饭的时候没发~
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
--------------------- 查看全部
python抓取网页数据(【BeautifulSoap】BeautifulSoap类soupBeautifulSoup()())
一、美丽肥皂
1.首先必须导入bs4库来创建BeautifulSoap对象
#coding=utf-8
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(html,'lxml') #html 是下载的网页,lxml 是解析器
2.BeautifulSoap主要掌握三种方法
find_all('tag') 搜索所有标签标签的当前集合
find("tag") 返回一个标签(此方法使用较少)
select("") 可以按标签搜索,主要用于按标签搜索和过滤元素
二、使用 BeautifulSoup 提取网页内容的一些技术
1.find_all()方法中的单个标签名,如a,会提取网页中所有的a标签。这里我们必须确保它是我们需要的链接a。一般来说,它不是。您需要添加条件(即标签的属性,加上限制性过滤)。如果没有这个和标签的属性,最好去上层找。
, 链接:用笑话戳我,抢原创 笑话。
(顺便说一句,小白在这上面找了很久,才看到藏在跨度里的笑话,总觉得自己有点弱智=_=)
注意:如果你写find_all("span"),可以抓取段落的内容,但是也会收录网页上其他span的内容,所以我们要查看上层标签。
它只是一个收录段落内容的标签。
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
链接 = 汤.find_all('div',class_='content')
#link的内容就是div,我们取的span内容就是我们需要的段落内容
对于链接中的链接:
打印 link.span.get_text()
操作结果:
2.select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
sound.select("html head title") #标签级别搜索
汤.select("td div a") #标签路径td-->div-->a
汤.select('td> div> a')#note: 推荐使用这种表示法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
这个内容需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面是select()方法~
链接 = 汤.select('div> a >div >span')
对于链接中的链接:
打印 link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
吃饭的时候没发~
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
---------------------
python抓取网页数据( 介绍网页抓取是了解数据的最常用技术之一Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-09 14:37
介绍网页抓取是了解数据的最常用技术之一Python)
介绍
网页抓取是理解 Internet 数据最常用的技术之一。它是一种从网页中提取有价值和需要的数据的技术,这些数据被视为执行各种计算操作以生成有用信息的输入值。在本文中,我们将学习如何采集发布在任何网页上的电子邮件数据。我们使用最流行的编程语言之一 Python 来提取数据元素值,因为它具有丰富的库,可以帮助执行各种所需的活动。
以下步骤将帮助您了解如何在任何网页上查找电子邮件。
第1步
我们需要为我们的程序导入所有必要的库。
#import packages
from bs4 import BeautifulSoup
import requests
import requests.exceptions
from urllib.parse import urlsplit
from collections import deque
import re
第2步
选择用于从给定 URL 提取电子邮件的 URL。
# 要抓取的 url 队列
new_urls = deque(['https://www.gtu.ac.in/page.aspx?p=ContactUsA'])
第 3 步
我们只需要处理给定的 URL 一次,因此请跟踪您处理的 URL。
# a set of urls that we have already crawled
processed_urls = set()
第四步
在抓取给定 URL 时,我们可能会遇到多个电子邮件 ID,因此将它们保留在集合中。
# a set of crawled emails
emails = set()
第 5 步
是时候开始爬行了。我们需要爬取队列中所有的URL,维护爬取过的URL列表,从网页中获取页面内容。如果您遇到任何错误,请移至下一页。
# process urls one by one until we exhaust the queue
while len(new_urls):
# move next url from the queue to the set of processed urls
url = new_urls.popleft()
processed_urls.add(url)
# get url's content
print("Processing %s" % url)
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors
continue
第 6 步
现在我们需要提取当前 URL 的一些基本部分,这是将文档中的相对链接转换为绝对链接的重要部分:
# extract base url and path to resolve relative links
parts = urlsplit(url)
base_url = "{0.scheme}://{0.netloc}".format(parts)
path = url[:url.rfind('/')+1] if '/' in parts.path else url
第 7 步
从页面内容中提取电子邮件并将其添加到电子邮件集合中。
# extract all email addresses and add them into the resulting set
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", response.text, re.I))
emails.update(new_emails)
第 8 步
处理完当前页面后,就可以搜索到其他页面的链接,加入到URL队列中(这就是爬行的魅力所在)。获取一个 Beautifulsoup 对象来解析 HTML 页面。
# create a beutiful soup for the html document
soup = BeautifulSoup(response.text)
步骤 9
汤对象收录 HTML 元素。现在找到所有带有 href 属性的锚标记来解析相关链接并保留处理过的 URL 的记录。
# find and process all the anchors in the document
for anchor in soup.find_all("a"):
# extract link url from the anchor
link = anchor.attrs["href"] if "href" in anchor.attrs else ''
# resolve relative links
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
# add the new url to the queue if it was not enqueued nor processed yet
if not link in new_urls and not link in processed_urls:
new_urls.append(link)
第 10 步
列出从给定 URL 中提取的所有电子邮件 ID。
for email in emails:
print(email)
总结
本文解释了如何执行网页抓取,尤其是当您使用诸如 BeautifulSoup、采集s、requests、re 和 urllib.parse 等 Python 包来定位 HTML 页面上的任何数据时。 查看全部
python抓取网页数据(
介绍网页抓取是了解数据的最常用技术之一Python)
 https://www.muyuanzhan.com/wp- ... 8.jpg 300w, https://www.muyuanzhan.com/wp- ... 4.jpg 150w" />
https://www.muyuanzhan.com/wp- ... 8.jpg 300w, https://www.muyuanzhan.com/wp- ... 4.jpg 150w" />介绍
网页抓取是理解 Internet 数据最常用的技术之一。它是一种从网页中提取有价值和需要的数据的技术,这些数据被视为执行各种计算操作以生成有用信息的输入值。在本文中,我们将学习如何采集发布在任何网页上的电子邮件数据。我们使用最流行的编程语言之一 Python 来提取数据元素值,因为它具有丰富的库,可以帮助执行各种所需的活动。
以下步骤将帮助您了解如何在任何网页上查找电子邮件。
第1步
我们需要为我们的程序导入所有必要的库。
#import packages
from bs4 import BeautifulSoup
import requests
import requests.exceptions
from urllib.parse import urlsplit
from collections import deque
import re
第2步
选择用于从给定 URL 提取电子邮件的 URL。
# 要抓取的 url 队列
new_urls = deque(['https://www.gtu.ac.in/page.aspx?p=ContactUsA'])
第 3 步
我们只需要处理给定的 URL 一次,因此请跟踪您处理的 URL。
# a set of urls that we have already crawled
processed_urls = set()
第四步
在抓取给定 URL 时,我们可能会遇到多个电子邮件 ID,因此将它们保留在集合中。
# a set of crawled emails
emails = set()
第 5 步
是时候开始爬行了。我们需要爬取队列中所有的URL,维护爬取过的URL列表,从网页中获取页面内容。如果您遇到任何错误,请移至下一页。
# process urls one by one until we exhaust the queue
while len(new_urls):
# move next url from the queue to the set of processed urls
url = new_urls.popleft()
processed_urls.add(url)
# get url's content
print("Processing %s" % url)
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors
continue
第 6 步
现在我们需要提取当前 URL 的一些基本部分,这是将文档中的相对链接转换为绝对链接的重要部分:
# extract base url and path to resolve relative links
parts = urlsplit(url)
base_url = "{0.scheme}://{0.netloc}".format(parts)
path = url[:url.rfind('/')+1] if '/' in parts.path else url
第 7 步
从页面内容中提取电子邮件并将其添加到电子邮件集合中。
# extract all email addresses and add them into the resulting set
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", response.text, re.I))
emails.update(new_emails)
第 8 步
处理完当前页面后,就可以搜索到其他页面的链接,加入到URL队列中(这就是爬行的魅力所在)。获取一个 Beautifulsoup 对象来解析 HTML 页面。
# create a beutiful soup for the html document
soup = BeautifulSoup(response.text)
步骤 9
汤对象收录 HTML 元素。现在找到所有带有 href 属性的锚标记来解析相关链接并保留处理过的 URL 的记录。
# find and process all the anchors in the document
for anchor in soup.find_all("a"):
# extract link url from the anchor
link = anchor.attrs["href"] if "href" in anchor.attrs else ''
# resolve relative links
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
# add the new url to the queue if it was not enqueued nor processed yet
if not link in new_urls and not link in processed_urls:
new_urls.append(link)
第 10 步
列出从给定 URL 中提取的所有电子邮件 ID。
for email in emails:
print(email)
总结
本文解释了如何执行网页抓取,尤其是当您使用诸如 BeautifulSoup、采集s、requests、re 和 urllib.parse 等 Python 包来定位 HTML 页面上的任何数据时。
python抓取网页数据(“微信运动”能够向朋友分享一个的网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-09 14:32
)
“微信运动”可以与朋友分享一个收录运动数据的网页,网页中收录我们需要的数据。url类似于:用户的openid,它有微信体育唯一使用的openid。打开 fiddler 来抓包。先打开fiddler,再打开微信体育,点击我的主页,如下:
微信通过请求头来区分请求是否是通过微信浏览器发出的。如果直接用浏览器打开链接,会出现如下错误提示,说明不是通过微信浏览器打开的,被微信拦截了:
通过Fiddler的抓包数据,我们可以通过伪造Request Headers请求头来抓数据
Fiddler 捕获数据包并显示:
通过邮递员伪造请求头来模拟微信浏览器。伪造请求头后,在浏览器中成功获取到相应的网页内容:
Python实现代码:
import requests
import re
import json
class WechatSprot(object):
def __init__(self, openid):
self.openid = openid
def getInfo(self):
url = "http://hw.weixin.qq.com/stepra ... ot%3B
querystring = {"openid": self.openid}
headers = {
\'host\': "hw.weixin.qq.com",
\'connection\': "keep-alive",
\'accept\': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
\'user-agent\': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.691.400 QQBrowser/9.0.2524.400",
\'accept-encoding\': "gzip, deflate",
\'accept-language\': "zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4",
\'cookie\': "hwstepranksk=JxMBWw1sxQhxnMgsJnnLh-r0VFzLH6RtJWv5b_j3z8MPs6-J; pass_ticket=p9R%2FqjIh%2BlXt%2BoxP7GIWrqm3Sbf1Minisk%2FNUz5zra4ReETR2ATI8H57zkEERCvG",
}
response = requests.request("GET", url, headers=headers, params=querystring)
res = re.findall(\'window.json = (.+);\', response.text)
# print(res)
# exit()
return json.loads(res[0])
if __name__ == "__main__":
obj = WechatSprot(用户的openid)
print(obj.getInfo()) 查看全部
python抓取网页数据(“微信运动”能够向朋友分享一个的网页数据
)
“微信运动”可以与朋友分享一个收录运动数据的网页,网页中收录我们需要的数据。url类似于:用户的openid,它有微信体育唯一使用的openid。打开 fiddler 来抓包。先打开fiddler,再打开微信体育,点击我的主页,如下:
微信通过请求头来区分请求是否是通过微信浏览器发出的。如果直接用浏览器打开链接,会出现如下错误提示,说明不是通过微信浏览器打开的,被微信拦截了:
通过Fiddler的抓包数据,我们可以通过伪造Request Headers请求头来抓数据
Fiddler 捕获数据包并显示:
通过邮递员伪造请求头来模拟微信浏览器。伪造请求头后,在浏览器中成功获取到相应的网页内容:
Python实现代码:
import requests
import re
import json
class WechatSprot(object):
def __init__(self, openid):
self.openid = openid
def getInfo(self):
url = "http://hw.weixin.qq.com/stepra ... ot%3B
querystring = {"openid": self.openid}
headers = {
\'host\': "hw.weixin.qq.com",
\'connection\': "keep-alive",
\'accept\': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
\'user-agent\': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.691.400 QQBrowser/9.0.2524.400",
\'accept-encoding\': "gzip, deflate",
\'accept-language\': "zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4",
\'cookie\': "hwstepranksk=JxMBWw1sxQhxnMgsJnnLh-r0VFzLH6RtJWv5b_j3z8MPs6-J; pass_ticket=p9R%2FqjIh%2BlXt%2BoxP7GIWrqm3Sbf1Minisk%2FNUz5zra4ReETR2ATI8H57zkEERCvG",
}
response = requests.request("GET", url, headers=headers, params=querystring)
res = re.findall(\'window.json = (.+);\', response.text)
# print(res)
# exit()
return json.loads(res[0])
if __name__ == "__main__":
obj = WechatSprot(用户的openid)
print(obj.getInfo())
python抓取网页数据( 用Python写爬虫工具(二):Python模拟浏览器发起请求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-27 17:13
用Python写爬虫工具(二):Python模拟浏览器发起请求
)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r" 查看全部
python抓取网页数据(
用Python写爬虫工具(二):Python模拟浏览器发起请求
)
用 Python 编写爬虫工具现在已经司空见惯。每个人都希望能够编写一个程序来获取互联网上的一些信息进行数据分析或其他事情。
我们知道,爬虫的原理无非就是下载目标URL的内容并存入内存。这时候它的内容其实就是一堆HTML,然后根据自己的想法解析HTML内容,提取出想要的数据。,所以今天我们主要讲四种在Python中解析网页HTML内容的方法,各有千秋,适用于不同的场合。
首先,我们随机找了一个网站,然后豆瓣网站闪过我的脑海。好吧,网站毕竟是用Python构建的,所以我们用它作为演示。
我们找到了豆瓣的Python爬虫群主页,如下图。
让我们使用浏览器开发人员工具查看 HTML 代码并找到所需的内容。我们想要获取讨论组中的所有帖子标题和链接。
通过分析,我们发现其实我们想要的内容就在整个HTML代码的这个区域,那么我们只需要想办法取出这个区域的内容即可。
现在开始编写代码。
1:正则表达式大法
正则表达式通常用于检索和替换符合某种模式的文本,因此我们可以利用这个原理来提取我们想要的信息。
参考以下代码。
代码第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求。否则,豆瓣会将我们的请求视为正常请求并返回 HTTP 418 错误。
在第 7 行中,我们直接使用 requests 库的 get 方法发出请求。获取到内容后,我们需要进行编码格式转换。这也是豆瓣页面渲染机制的问题。一般情况下,可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}
response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则化的优点是写起来麻烦,不容易理解,但是匹配效率很高。但是,在如今现成的HTMl内容解析库太多之后,我个人不建议使用正则化来手动匹配内容,费时费力。.
主要分析代码:
<p>re_div = r'[\W|\w]+'
pattern = re.compile(re_div)
content = re.findall(pattern, str(response))
re_link = r'<a .*?>(.*?)</a>'
mm = re.findall(re_link, str(content), re.S|re.M)
urls=re.findall(r"
python抓取网页数据(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-10-25 05:03
谈谈 Python 和网络爬虫。
1、爬虫的定义
爬虫:自动爬取互联网数据的程序。
2、爬虫的主要框架
爬虫程序的主要框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析网页,并在网页中添加新的URL到 URL 管理器输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要抓取的网址集合和已抓取网址的集合,防止重复抓取和循环抓取。 URL管理器的主要功能如下图所示:
在 URL 管理器的实现方面,Python 主要使用内存(集合)和关系数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,通常使用数据库。
5、网页下载器
Python 中的网页下载器主要使用 urllib 库,它是 Python 自带的一个模块。对于2.x版本的urllib2库,在python3.x的urllib中,以及它的request等子模块中都集成了。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen 函数的参数可以是 url 链接或请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页和有反爬虫机制的网页,使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookies。
6、网页解析器
网络解析器从网络下载器下载的 URL 数据中提取有价值的数据和新的 URL。对于数据提取,可以使用正则表达式、BeautifulSoup 等方法。正则表达式采用基于字符串的模糊匹配,对特征鲜明的目标数据效果较好,但通用性不强。 BeautifulSoup 是一个第三方模块,用于对 URL 内容进行结构化分析。下载的网页内容被解析为DOM树。下图是百度百科中使用BeautifulSoup打印的网页的部分输出。
关于BeautifulSoup的具体使用,后面会在文章写。以下代码使用python抓取百度百科英雄联盟条目中其他与联盟相关的条目,并将这些条目保存在新创建的excel中。以上代码:
从 bs4 导入 BeautifulSoup
重新导入
导入 xlrd
导入 xlwt
从 urllib.request 导入 urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('英雄联盟')
##百度百科:英雄联盟##
html=urlopen("")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
行=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=pile("^(/view/)[0-9]+\.htm$"))
对于链接中的链接:
if'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
行=行+1
excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。 查看全部
python抓取网页数据(聊一聊Python与网络爬虫的主要框架程序的特点及应用)
谈谈 Python 和网络爬虫。
1、爬虫的定义
爬虫:自动爬取互联网数据的程序。
2、爬虫的主要框架
爬虫程序的主要框架如上图所示。爬虫调度器通过URL管理器获取要爬取的URL链接。如果URL管理器中存在需要爬取的URL链接,爬虫调度器调用网页下载器下载对应的网页,然后调用网页解析器解析网页,并在网页中添加新的URL到 URL 管理器输出有价值的数据。
3、爬虫时序图
4、网址管理器
网址管理器管理要抓取的网址集合和已抓取网址的集合,防止重复抓取和循环抓取。 URL管理器的主要功能如下图所示:
在 URL 管理器的实现方面,Python 主要使用内存(集合)和关系数据库(MySQL)。对于小程序,一般在内存中实现,Python 内置的 set() 类型可以自动判断元素是否重复。对于较大的程序,通常使用数据库。
5、网页下载器
Python 中的网页下载器主要使用 urllib 库,它是 Python 自带的一个模块。对于2.x版本的urllib2库,在python3.x的urllib中,以及它的request等子模块中都集成了。 urllib 中的 urlopen 函数用于打开 url 并获取 url 数据。 urlopen 函数的参数可以是 url 链接或请求对象。对于简单的网页,直接使用url字符串作为参数就足够了,但是对于复杂的网页和有反爬虫机制的网页,使用urlopen函数时,需要添加http头。对于有登录机制的网页,需要设置cookies。
6、网页解析器
网络解析器从网络下载器下载的 URL 数据中提取有价值的数据和新的 URL。对于数据提取,可以使用正则表达式、BeautifulSoup 等方法。正则表达式采用基于字符串的模糊匹配,对特征鲜明的目标数据效果较好,但通用性不强。 BeautifulSoup 是一个第三方模块,用于对 URL 内容进行结构化分析。下载的网页内容被解析为DOM树。下图是百度百科中使用BeautifulSoup打印的网页的部分输出。
关于BeautifulSoup的具体使用,后面会在文章写。以下代码使用python抓取百度百科英雄联盟条目中其他与联盟相关的条目,并将这些条目保存在新创建的excel中。以上代码:
从 bs4 导入 BeautifulSoup
重新导入
导入 xlrd
导入 xlwt
从 urllib.request 导入 urlopen
excelFile=xlwt.Workbook()
sheet=excelFile.add_sheet('英雄联盟')
##百度百科:英雄联盟##
html=urlopen("")
bsObj=BeautifulSoup(html.read(),"html.parser")
#print(bsObj.prettify())
行=0
for node in bsObj.find("div",{"class":"main-content"}).findAll("div",{"class":"para"}):
links=node.findAll("a",href=pile("^(/view/)[0-9]+\.htm$"))
对于链接中的链接:
if'href' in link.attrs:
print(link.attrs['href'],link.get_text())
sheet.write(row,0,link.attrs['href'])
sheet.write(row,1,link.get_text())
行=行+1
excelFile.save('E:\Project\Python\lol.xls')
部分输出截图如下:
excel部分截图如下:
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助。
python抓取网页数据(前几天在看崔庆才老师的教程微课|03月17日爬取知乎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-24 17:08
前几天在看崔庆才老师的辅导微课的录播| 3月17日,抓取知乎的所有用户详细信息,使用Scrapy抓取知乎用户信息,使用递归。之前写的爬虫把已知的固定数据网址保存在列表中,然后遍历列表中的网址。这次的小书,我们用递归来试一试。什么是递归程序(或函数)自称为递归(recursion)的编程技巧。进程或函数在其定义或描述中具有直接或间接调用自身的方法。它通常将一个大而复杂的问题转化为一个类似于原问题的较小问题来解决。递归的优点
1、降低问题难度
2、大大减少程序中的代码量
3、递归的能力在于使用有限的语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓老师录制的视频讲解,请点击链接
【Python爬虫】如何捕捉优质短书用户(请允许我放个广告)
按照获取项目源码
在这种情况下,我们需要抓取简书的优质用户信息,例如昵称、id、文章的数量、文章数、字数、获得的点赞数等。我们只抓取一个人后面跟着用户ta。至于这个ta的粉丝,我们就不拍了。相对而言,他们关注的人比他们的粉丝质量更高,档次更高。
先从初始用户开始,比如用户列表后面跟着邓旭东HIT,得到25个用户A、B、C等,后面跟着邓旭东。
依次抓取这25个用户关注的用户
循环前两步
我们先来分析一下URL结构
网址分析
我们发现当我向下滚动观察列表时,页面底部会加载,并且图片左下角会有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
把鼠标放在下面?page=3 文件上方弹出一个网址
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页数是怎么构造的呢?
我们发现用户的粉丝数除以10,再四舍五入加1就是最大页数。
例如,如果邓旭东关注25个人,就会有3个页面:page=1、page=2、page=3。
现在我们已经建立了
网站在那里,我们开始分析一下,要抓取的数据在网页的源代码中存储在哪里?
网络分析 查看全部
python抓取网页数据(前几天在看崔庆才老师的教程微课|03月17日爬取知乎)
前几天在看崔庆才老师的辅导微课的录播| 3月17日,抓取知乎的所有用户详细信息,使用Scrapy抓取知乎用户信息,使用递归。之前写的爬虫把已知的固定数据网址保存在列表中,然后遍历列表中的网址。这次的小书,我们用递归来试一试。什么是递归程序(或函数)自称为递归(recursion)的编程技巧。进程或函数在其定义或描述中具有直接或间接调用自身的方法。它通常将一个大而复杂的问题转化为一个类似于原问题的较小问题来解决。递归的优点
1、降低问题难度
2、大大减少程序中的代码量
3、递归的能力在于使用有限的语句来定义无限的对象集
这个案例
如果看图麻烦,可以先看邓老师录制的视频讲解,请点击链接
【Python爬虫】如何捕捉优质短书用户(请允许我放个广告)
按照获取项目源码
在这种情况下,我们需要抓取简书的优质用户信息,例如昵称、id、文章的数量、文章数、字数、获得的点赞数等。我们只抓取一个人后面跟着用户ta。至于这个ta的粉丝,我们就不拍了。相对而言,他们关注的人比他们的粉丝质量更高,档次更高。
先从初始用户开始,比如用户列表后面跟着邓旭东HIT,得到25个用户A、B、C等,后面跟着邓旭东。
依次抓取这25个用户关注的用户
循环前两步
我们先来分析一下URL结构
网址分析
我们发现当我向下滚动观察列表时,页面底部会加载,并且图片左下角会有更多
下列的?page=3 及以下?page=4 两个 xhr 类型的文件。
把鼠标放在下面?page=3 文件上方弹出一个网址
http://www.jianshu.com/users/1 ... owing?page=3
我们用鼠标点击下面的?page=3,点击Headers,发现请求的url是
http://www.jianshu.com/users/1 ... owing?page=3
那么问题来了,页数是怎么构造的呢?
我们发现用户的粉丝数除以10,再四舍五入加1就是最大页数。
例如,如果邓旭东关注25个人,就会有3个页面:page=1、page=2、page=3。
现在我们已经建立了
网站在那里,我们开始分析一下,要抓取的数据在网页的源代码中存储在哪里?
网络分析
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-10-24 16:16
)
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/wr_table_3_a2.asp?age_category_1=&age_category_2=&age_category_3=&age_category_4=&age_category_5=&category=100w&cont=&country=&gender=w&month1=4&year1=2015&s_player_name=&formv_wr_table_3_page='+str(page)
doc = requests.get(url).text
soup = beautifulsoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=none and atag.get('href') != none:
if "wr_table_3_a2_details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close() 查看全部
python抓取网页数据(抓取网页数据的思路有好,抓取抓取数据思路
)
抓取网页数据的方法很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等。本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接取网页的文字,一句话就可以做到:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/wr_table_3_a2.asp?age_category_1=&age_category_2=&age_category_3=&age_category_4=&age_category_5=&category=100w&cont=&country=&gender=w&month1=4&year1=2015&s_player_name=&formv_wr_table_3_page='+str(page)
doc = requests.get(url).text
soup = beautifulsoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=none and atag.get('href') != none:
if "wr_table_3_a2_details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
python抓取网页数据(如何从FastTrack上获取2018年100强企业的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-23 09:04
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
版本太长看不懂:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以 Tech Track Top 100 Companies 页面(fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。右键单击表格并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error (/3/library/urllib.error.html) 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容: 查看全部
python抓取网页数据(如何从FastTrack上获取2018年100强企业的信息)
作为数据科学家的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
版本太长看不懂:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以 Tech Track Top 100 Companies 页面(fasttrack.co.uk/league-tables/tech-track-100/league-table/)为例。右键单击表格并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入CSV文件并保存在本地硬盘上,因此我们需要导入csv库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error (/3/library/urllib.error.html) 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
python抓取网页数据(从网站上获取2018年100强企业的少数几个技术之一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-23 08:22
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以Tech Track Top 100 Companies页面为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码
祝你的爬虫之旅有个美好的开始!
原作:Kerry Parker 编译:欧莎转载请保留此信息)
编译源:/data-science-skills-web-scraping-using-python-d1a85ef607ed
知乎机构号:优达学城,来自硅谷的终身学习平台,专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从零开始掌握切割-数据分析、机器学习、深度学习、人工智能、无人驾驶等边缘技术将激发未来无限可能!
知乎专栏:优达科技流,每日分享行业领袖和工程师必读的技术干货 查看全部
python抓取网页数据(从网站上获取2018年100强企业的少数几个技术之一)
作为数据科学家,我的第一项任务是进行网络爬虫。那时,我对使用代码从网站获取数据的技术一无所知。这是最合乎逻辑和最简单的数据来源。经过几次尝试,网络爬虫对我来说几乎是本能的。今天,它已成为我几乎每天都在使用的少数技术之一。
在今天的文章中,我会用几个简单的例子来给大家展示一下如何爬取一个网站——比如从Fast Track获取2018年100强企业的信息。使用脚本来自动化获取信息的过程,不仅可以节省人工整理的时间,还可以将所有企业数据组织在一个结构化的文件中,以便进一步分析和查询。
看版本太长了:如果你只是想要一个最基本的Python爬虫程序的示例代码,本文用到的所有代码都在GitHub上,欢迎大家来取。
准备好工作了
每次你打算用 Python 做某事时,你问的第一个问题应该是:“我需要使用什么库?”
有几个不同的库可用于网络爬虫,包括:
今天我们计划使用 Beautiful Soup 库。您只需要使用 pip(Python 包管理工具)即可轻松将其安装到您的计算机上:
安装完成后,我们就可以开始了!
检查网页
为了确定要抓取网页的哪些元素,首先需要检查网页的结构。
以Tech Track Top 100 Companies页面为例。右键单击表单并选择“检查”。在弹出的“开发者工具”中,我们可以看到页面上的每个元素以及其中收录的内容。
右击要查看的网页元素,选择“勾选”,可以看到具体的HTML元素内容
由于数据存储在表中,因此只需几行代码即可直接获取完整信息。如果您想自己练习抓取网页内容,这是一个很好的例子。但请记住,实际情况往往并非如此简单。
在此示例中,所有 100 个结果都收录在同一页面上,并按标签分隔成行。但是,在实际的爬取过程中,很多数据往往分布在多个不同的页面上。您需要调整每个页面显示的结果总数或遍历所有页面以捕获完整数据。
在表格页面上,您可以看到一个收录所有 100 条数据的表格。右键单击它并选择“检查”。您可以轻松查看 HTML 表格的结构。收录内容的表的主体在此标记中:
每一行都在一个标签中,即我们不需要太复杂的代码,只需一个循环,就可以读取所有的表数据并保存到文件中。
注意:您也可以通过检查当前页面是否发送了HTTP GET请求并获取该请求的返回值来获取页面显示的信息。因为 HTTP GET 请求往往可以返回结构化数据,例如 JSON 或 XML 格式的数据,以方便后续处理。您可以在开发者工具中点击Network类别(如果需要,您只能查看XHR标签的内容)。这时候可以刷新页面,这样页面上加载的所有请求和返回的内容都会在Network中列出。此外,您还可以使用某种 REST 客户端(例如 Insomnia)来发起请求并输出返回值。
刷新页面后,更新Network选项卡的内容
使用 Beautiful Soup 库处理网页的 HTML 内容
熟悉了网页的结构,了解了需要爬取的内容后,我们终于拿起代码开始工作了~
首先要做的是导入代码中需要用到的各个模块。我们上面已经提到过 BeautifulSoup,这个模块可以帮助我们处理 HTML 结构。下一个要导入的模块是urllib,负责连接目标地址,获取网页内容。最后,我们需要能够将数据写入 CSV 文件并保存在本地硬盘上,因此我们需要导入 csv 库。当然,这不是唯一的选择。如果要将数据保存为json文件,则需要相应地导入json库。
下一步,我们需要准备好需要爬取的目标网址。如上所述,这个页面已经收录了我们需要的所有内容,所以我们只需要复制完整的 URL 并将其分配给变量:
接下来我们可以使用urllib连接这个URL,将内容保存在page变量中,然后使用BeautifulSoup对页面进行处理,并将处理结果保存在soup变量中:
这时候可以尝试打印soup变量,看看处理后的html数据是什么样子的:
如果变量内容为空或返回一些错误信息,则表示可能无法正确获取网页数据。您可能需要在 urllib.error 模块中使用一些错误捕获代码来查找可能的问题。
查找 HTML 元素
由于所有的内容都在表(标签)中,我们可以在soup对象中搜索需要的表,然后使用find_all方法遍历表中的每一行数据。
如果您尝试打印出所有行,则应该有 101 行-100 行内容,加上一个标题。
看打印出来的内容,如果没有问题,我们可以用一个循环来获取所有的数据。
如果打印出soup对象的前2行,可以看到每行的结构是这样的:
可以看到,表中一共有8列,分别是Rank(排名)、Company(公司)、Location(地址)、Year End(财政年度结束)、Annual Sales Rise(年度销售额增长)、Latest Sales(当年销售额)、Staff(员工人数)和 Comments(备注)。
这些就是我们需要的数据。
这种结构在整个网页中是一致的(但在其他网站上可能没有那么简单!),所以我们可以再次使用find_all方法通过搜索元素逐行提取数据,并存储在一个变量中,方便以后写入csv或json文件。
循环遍历所有元素并将它们存储在变量中
在 Python 中,如果要处理大量数据,需要写入文件,列表对象非常有用。我们可以先声明一个空列表,填入初始头部(以备将来在CSV文件中使用),后续数据只需要调用列表对象的append方法即可。
这将打印出我们刚刚添加到列表对象行中的第一行标题。
您可能会注意到,我输入的标题中的列名称比网页上的表格多几个,例如网页和描述。请仔细查看上面打印的汤变量数据-否。在数据的第二行第二列,不仅有公司名称,还有公司网址和简要说明。所以我们需要这些额外的列来存储这些数据。
接下来,我们遍历所有 100 行数据,提取内容,并将其保存到列表中。
循环读取数据的方法:
因为第一行数据是html表的表头,我们可以不看就跳过。因为header使用了标签,没有标签,所以我们简单地查询标签中的数据,丢弃空值。
接下来,我们读出数据的内容并赋值给变量:
如上代码所示,我们将8列的内容依次存入8个变量中。当然,有些数据的内容需要清理,去除多余的字符,导出需要的数据。
数据清洗
如果我们把company变量的内容打印出来,可以发现它不仅收录了公司名称,还收录了include和description。如果我们把sales变量的内容打印出来,可以发现里面还收录了一些备注等需要清除的字符。
我们要将公司变量的内容拆分为两部分:公司名称和描述。这可以在几行代码中完成。看看对应的html代码,你会发现这个单元格里还有一个元素,里面只有公司名。此外,还有一个链接元素,其中收录指向公司详细信息页面的链接。我们以后会用到!
为了区分公司名称和描述这两个字段,我们然后使用find方法读取元素中的内容,然后删除或替换公司变量中的对应内容,这样变量中就只剩下描述了.
为了删除 sales 变量中多余的字符,我们使用了一次 strip 方法。
我们要保存的最后一件事是公司的链接网站。如上所述,在第二列中有一个指向公司详细信息页面的链接。每个公司的详细信息页面上都有一个表格。在大多数情况下,表单中有指向公司 网站 的链接。
检查公司详细信息页面上表格中的链接
为了抓取每个表中的 URL 并将其保存在变量中,我们需要执行以下步骤:
如上图所示,看了几个公司详情页,你会发现公司的网址基本都在表格的最后一行。所以我们可以在表格的最后一行找到元素。
同样,也有可能最后一行没有链接。所以我们添加了一个 try...except 语句,如果找不到 URL,则将该变量设置为 None。在我们将所有需要的数据存储在变量中后(仍在循环体中),我们可以将所有变量集成到一个列表中,然后将这个列表附加到我们上面初始化的行对象的末尾。
在上面代码的最后,我们在循环体完成后打印了行的内容,以便您在将数据写入文件之前再次检查。
写入外部文件
最后,我们将上面得到的数据写入外部文件,方便后续的分析处理。在 Python 中,我们只需要几行简单的代码即可将列表对象保存为文件。
最后,让我们运行这个python代码。如果一切顺利,您会发现目录中出现一个收录 100 行数据的 csv 文件。您可以使用 python 轻松阅读和处理它。
总结
在这个简单的 Python 教程中,我们采取了以下步骤来抓取网页内容:
如果有什么不清楚的,请在下方留言,我会尽力解答!
附:本文所有代码
祝你的爬虫之旅有个美好的开始!
原作:Kerry Parker 编译:欧莎转载请保留此信息)
编译源:/data-science-skills-web-scraping-using-python-d1a85ef607ed
知乎机构号:优达学城,来自硅谷的终身学习平台,专注技能提升和求职规则,让你在家关注谷歌、Facebook、IBM等行业大咖,从零开始掌握切割-数据分析、机器学习、深度学习、人工智能、无人驾驶等边缘技术将激发未来无限可能!
知乎专栏:优达科技流,每日分享行业领袖和工程师必读的技术干货
python抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-10-23 00:28
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,比如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。寻找URL变化规律接下来,寻找被抓取页面的URL规律。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数来实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一种执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。 查看全部
python抓取网页数据(本节继续讲解Python爬虫实战案例(图:抓取百度贴吧))
本节继续讲解Python爬虫的实际案例:爬取百度贴吧()页面,如Python爬虫栏、编程栏,只爬取贴吧的前5页。在本节中,我们将使用面向对象的编程方法来编写程序。
通过简单分析判断页面类型,可以知道待抓取的百度贴吧页面为静态网页。分析方法很简单:打开百度贴吧,搜索“Python爬虫”,在出现的页面复制任意一条信息,比如“爬虫需要http代理的原因”,然后对-单击选择查看源代码,使用Ctrl+F快捷键在源代码页搜索刚刚复制的数据,如下图:
图1:静态网页分析判断(点击查看高清图片)
从上图可以看出,页面中的所有信息都收录在源页面中,不需要从数据库单独加载数据,所以页面是静态页面。寻找URL变化规律接下来,寻找被抓取页面的URL规律。搜索“Python爬虫”后,贴吧的第一页url如下:
爬虫&fr=搜索
点击第二页,其url信息如下:
爬虫&ie=utf-8&pn=50
点击第三页,url信息如下:
爬虫&ie=utf-8&pn=100
再次点击第一页,url信息如下:
爬虫&ie=utf-8&pn=0
如果您不确定,可以继续浏览更多页面。最后你发现url有两个查询参数kw和pn,pn参数有规律,如下图:
第n页:pn=(n-1)*50
#参数params
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
url地址可以简写为:
爬虫(&pn)=450
编写爬虫程序 爬虫程序以类的形式编写,在类下编写了不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
程序执行后,抓取到的文件会保存到Pycharm的当前工作目录下,输出为:
输入贴吧名:python爬虫
输入起始页:1
输入终止页:2
第1页抓取成功
第2页抓取成功
执行时间:12.25
用面向对象的方法写爬虫程序的时候,思路简单,逻辑清晰,很容易理解。上面的代码主要收录四个function函数,分别负责不同的功能。总结如下: 1) Request function Request function final 结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数解析函数用于解析HTML页面。常用的解析模块有正则解析模块和bs4解析模块。通过对页面的分析,提取出需要的数据,在后续的内容中会详细介绍。
3) 保存数据功能 该功能负责将抓取到的数据保存到数据库中,如MySQL、MongoDB等,或保存为文件格式,如csv、txt、excel等。
4) 入口函数入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数来实现数据的最终抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧名称,编码url参数,拼接url地址,定义文件保存路径。爬虫程序结构 用面向对象的方法写爬虫程序时,逻辑结构比较固定,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
注:掌握以上编程逻辑有助于后续学习。爬虫程序在入口函数代码中随机休眠,包括如下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫程序访问网站的速度非常快,与正常的人类点击行为非常不符。因此,爬虫程序可以通过随机休眠来模仿人类。点击网站,这样网站不容易检测到爬虫访问了网站,但这样做的代价是影响程序的执行效率。
聚焦爬虫是一种执行效率低的程序。提高其性能是业界一直关注的问题。由此,一个更高效的 Python 爬虫框架 Scrapy 诞生了。
python抓取网页数据(如何用“Python爬虫”来获取网页中的内容?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-20 04:13
大家好,今天教大家如何使用“Python爬虫”获取网页内容。下面我以一本小说网站为例来实现它。
环境配置下载Anaconda3并完成安装。在Anaconda3的Scripts文件夹中找到“idle.exe”,打开“idle.exe”,新建一个扩展名为“.py”的文件,打开新的“.py”文件,删除初始的Content,在里面完成编程当前文件实现网页的urllib.request模块和正则表达式re模块的导入和读取
import urllib.request as req
import re
定义一个变量来接收目标网址,然后定义一个变量来接收打开网页的内容,并使用相应的编码进行解码接收
data = req.urlopen(url).read().decode('gb18030')
运行当前代码,使用print方法查看输出结果,找到想要获取的内容,找到包内容关键词,使用re模块的findall方法读取内容并使用一个变量接收运行代码,使用print方法查看输出结果,使用repalce方法删除其他内容。使用print方法查看输出结果。具体实现代码如下:
import urllib.request as req
import re #导入模块
url = 'https://www.farpop.com/0_4/771708.html' #操作网页的网址
data = req.urlopen(url).read().decode('gb18030') #获取解码后的网页内容
i = re.findall(r'(.*?)',data,re.S) #获取想要的内容
fi = i[0]
#删除其它内容
fi = fi.replace(' ','')
fi = fi.replace('<br />','')
fi = fi.replace('readx();','')
#查看输出结果
print(fi)
最终得到的内容如下:
小说内容 查看全部
python抓取网页数据(如何用“Python爬虫”来获取网页中的内容?)
大家好,今天教大家如何使用“Python爬虫”获取网页内容。下面我以一本小说网站为例来实现它。
环境配置下载Anaconda3并完成安装。在Anaconda3的Scripts文件夹中找到“idle.exe”,打开“idle.exe”,新建一个扩展名为“.py”的文件,打开新的“.py”文件,删除初始的Content,在里面完成编程当前文件实现网页的urllib.request模块和正则表达式re模块的导入和读取
import urllib.request as req
import re
定义一个变量来接收目标网址,然后定义一个变量来接收打开网页的内容,并使用相应的编码进行解码接收
data = req.urlopen(url).read().decode('gb18030')
运行当前代码,使用print方法查看输出结果,找到想要获取的内容,找到包内容关键词,使用re模块的findall方法读取内容并使用一个变量接收运行代码,使用print方法查看输出结果,使用repalce方法删除其他内容。使用print方法查看输出结果。具体实现代码如下:
import urllib.request as req
import re #导入模块
url = 'https://www.farpop.com/0_4/771708.html' #操作网页的网址
data = req.urlopen(url).read().decode('gb18030') #获取解码后的网页内容
i = re.findall(r'(.*?)',data,re.S) #获取想要的内容
fi = i[0]
#删除其它内容
fi = fi.replace(' ','')
fi = fi.replace('<br />','')
fi = fi.replace('readx();','')
#查看输出结果
print(fi)
最终得到的内容如下:
小说内容
python抓取网页数据(Python3中提供了url.request和HTML的解析模块 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-19 01:03
)
Python 3 提供了 url 打开模块 urllib.request 和 HTML 解析模块 html.parser 模块。但是html.parser模块的功能比较简单,很难满足今天解析网页内容的需求。 Beautiful Soup 4 是一个非常强大的 HTML 和 XML 文件解析 Python 库。并且提供了非常完整的文档()。
Beautiful Soup 4 的安装及相关问题
Beautiful Soup 的最新版本是4.1.1 可以在这里获取()。我正在使用 Mac OSX。在本平台安装Beautiful Soup,只需解压安装包,运行setup.py文件即可:
$ python3 setup.py install
如果在安装过程中出现ROOT_TAG_NAME=u'[document]'这一行的SyntaxError“Invalid syntax”,则需要将Python 2代码转换为Python 3:
$ 2to3-3.2 -w bs4
网址中的中文编码问题
在URL中,经常看到收录中文。比如网上搜索2012-08-09北京到丽江的北京到丽江机票网址:
Beijing&searchArrivalAirport=丽江&searchDepartureTime=2012-08-09
如果直接将此 URL 传递给 urllib.request.urlopen,则会导致 TypeError。解决方法是构造一个参数名和参数值的元组,并使用urllib.parse.urlencode方法对其进行编码。示例代码如下:
1 url ='http://flight.qunar.com/site/oneway_list.htm'
2 values ={'searchDepartureAirport':'北京','searchArrivalAirport':'丽江','searchDepartureTime':'2012-07-25'}
3 encoded_param = urllib.parse.urlencode(values)
4 full_url = url +'?'+ encoded_param
网页内容抓取:以下示例代码展示了当百度搜索关键词“网球”时如何抓取网页内容。
1 import urllib.parse
2 import urllib.request
3 from bs4 import BeautifulSoup
4
5 url ='http://www.baidu.com/s'
6 values ={'wd':'网球'}
7 encoded_param = urllib.parse.urlencode(values)
8 full_url = url +'?'+ encoded_param
9 response = urllib.request.urlopen(full_url)
10 soup =BeautifulSoup(response)
11 soup.find_all('a') 查看全部
python抓取网页数据(Python3中提供了url.request和HTML的解析模块
)
Python 3 提供了 url 打开模块 urllib.request 和 HTML 解析模块 html.parser 模块。但是html.parser模块的功能比较简单,很难满足今天解析网页内容的需求。 Beautiful Soup 4 是一个非常强大的 HTML 和 XML 文件解析 Python 库。并且提供了非常完整的文档()。
Beautiful Soup 4 的安装及相关问题
Beautiful Soup 的最新版本是4.1.1 可以在这里获取()。我正在使用 Mac OSX。在本平台安装Beautiful Soup,只需解压安装包,运行setup.py文件即可:
$ python3 setup.py install
如果在安装过程中出现ROOT_TAG_NAME=u'[document]'这一行的SyntaxError“Invalid syntax”,则需要将Python 2代码转换为Python 3:
$ 2to3-3.2 -w bs4
网址中的中文编码问题
在URL中,经常看到收录中文。比如网上搜索2012-08-09北京到丽江的北京到丽江机票网址:
Beijing&searchArrivalAirport=丽江&searchDepartureTime=2012-08-09
如果直接将此 URL 传递给 urllib.request.urlopen,则会导致 TypeError。解决方法是构造一个参数名和参数值的元组,并使用urllib.parse.urlencode方法对其进行编码。示例代码如下:
1 url ='http://flight.qunar.com/site/oneway_list.htm'
2 values ={'searchDepartureAirport':'北京','searchArrivalAirport':'丽江','searchDepartureTime':'2012-07-25'}
3 encoded_param = urllib.parse.urlencode(values)
4 full_url = url +'?'+ encoded_param
网页内容抓取:以下示例代码展示了当百度搜索关键词“网球”时如何抓取网页内容。
1 import urllib.parse
2 import urllib.request
3 from bs4 import BeautifulSoup
4
5 url ='http://www.baidu.com/s'
6 values ={'wd':'网球'}
7 encoded_param = urllib.parse.urlencode(values)
8 full_url = url +'?'+ encoded_param
9 response = urllib.request.urlopen(full_url)
10 soup =BeautifulSoup(response)
11 soup.find_all('a')
python抓取网页数据(python抓取网页数据第一个抓取的网页是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-17 14:02
python抓取网页数据第一个抓取的网页是环球音乐网,今天主要说一下环球音乐网的特点,以及我们如何抓取,现在说抓取方法。网站抓取1.首先会先看一下整个网站的url规律。环球音乐网我们可以发现,整个网站其实是通过ajax实现的,ajax抓取规则大家可以去网上查一下相关的解释。2.就可以构建一个基本的网页结构。
这里的only指的是限制,scrapy只支持区分springful和only。3.发现url规律后,我们可以先做出一些假设,比如a,b对应的歌曲在大小上是一样的。接下来再做一些request请求设置,比如注意不能直接就拿下来,要提交歌曲名称。详细请看:howtouseaxpathmethodtohandlesimilarmusicinallthewebpages首页抓取下面是我们抓取一些关键页面的代码。
page=request.urlopen(url)page.read()#读取到了网页里面,里面是我们想要的文本page.text我们可以看到里面文本内容都是string格式的。我们还可以提取歌曲名称,比如歌曲名称是"",那么你输入一个if,我们就可以看到only字段内容是""。另外我们还可以通过form标签来用xpath来实现页面提取。
dataset=page.xpath('//div[@class="tag"]/text()')dataset.select().size(。
6)#这个dataset指向的是歌曲名称,size是指定所有歌曲size。因为我们放的是带有if的,所以最多只能提取6个。在dataset的大小的设置中,我们设置歌曲名称最大为6。另外,这个还是比较难的,不多介绍了。这样网页就抓取完成了。接下来把页面提取下来,基本分为两个步骤,一个是伪代码,一个是代码提取。
1)伪代码伪代码:fromhashlibimporthash_hexocrhash_hexocr=hash_hexocr(hash_hexocr)#绑定url为查询查询。然后再构造一个循环,把页面内容全部post出来到这个列表中。i=0foriinrange(len(url)):url=url.request(url)i+=1print(url)hash_hexocr.send(post_url)(。
2)代码提取歌曲信息dataset=page.xpath('//a[@class="music_all"]/text()')page.text比如说我们想找"周杰伦-双截棍",
4)applewebkit/537.36(khtml,likegecko)chrome/69.0.3129.141safari/537.36'},不管输入什么格式的url,我们都会提取出歌曲信息。 查看全部
python抓取网页数据(python抓取网页数据第一个抓取的网页是什么?)
python抓取网页数据第一个抓取的网页是环球音乐网,今天主要说一下环球音乐网的特点,以及我们如何抓取,现在说抓取方法。网站抓取1.首先会先看一下整个网站的url规律。环球音乐网我们可以发现,整个网站其实是通过ajax实现的,ajax抓取规则大家可以去网上查一下相关的解释。2.就可以构建一个基本的网页结构。
这里的only指的是限制,scrapy只支持区分springful和only。3.发现url规律后,我们可以先做出一些假设,比如a,b对应的歌曲在大小上是一样的。接下来再做一些request请求设置,比如注意不能直接就拿下来,要提交歌曲名称。详细请看:howtouseaxpathmethodtohandlesimilarmusicinallthewebpages首页抓取下面是我们抓取一些关键页面的代码。
page=request.urlopen(url)page.read()#读取到了网页里面,里面是我们想要的文本page.text我们可以看到里面文本内容都是string格式的。我们还可以提取歌曲名称,比如歌曲名称是"",那么你输入一个if,我们就可以看到only字段内容是""。另外我们还可以通过form标签来用xpath来实现页面提取。
dataset=page.xpath('//div[@class="tag"]/text()')dataset.select().size(。
6)#这个dataset指向的是歌曲名称,size是指定所有歌曲size。因为我们放的是带有if的,所以最多只能提取6个。在dataset的大小的设置中,我们设置歌曲名称最大为6。另外,这个还是比较难的,不多介绍了。这样网页就抓取完成了。接下来把页面提取下来,基本分为两个步骤,一个是伪代码,一个是代码提取。
1)伪代码伪代码:fromhashlibimporthash_hexocrhash_hexocr=hash_hexocr(hash_hexocr)#绑定url为查询查询。然后再构造一个循环,把页面内容全部post出来到这个列表中。i=0foriinrange(len(url)):url=url.request(url)i+=1print(url)hash_hexocr.send(post_url)(。
2)代码提取歌曲信息dataset=page.xpath('//a[@class="music_all"]/text()')page.text比如说我们想找"周杰伦-双截棍",
4)applewebkit/537.36(khtml,likegecko)chrome/69.0.3129.141safari/537.36'},不管输入什么格式的url,我们都会提取出歌曲信息。
python抓取网页数据(如何用python来页面中的JS动态加载数据的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-16 01:16
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
python抓取网页数据(如何用python来页面中的JS动态加载数据的数据
)
本文文章与大家分享使用python抓取网页动态数据的方法。小编觉得很实用,分享给大家参考。跟着小编一起来看看吧。
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这不是很自动,很多其他的网站 RequestURL 也不是那么直接,所以我们将使用python 进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取网页数据(本文解释Python抓取网页数据的步骤和操作过程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-10-15 05:00
本文通过实例讲解Python抓取网页数据的步骤和操作流程,有兴趣的朋友可以关注一下。1. 使用()打开一个网站: 真实例子:使用脚本打开一个网页。所有 Python 程序的第一行都应该以 # !python 开头,告诉计算机你想让 python 执行这个计划。(这行我没试过,好吧,也许这是一种规范) 1.读取命令行参数:打开一个新的文件编辑器窗口,输入以下代码,并保存。2. 读取剪贴板内容: 3.调用()函数打开外部浏览:# !sys, python3import webbrowser pyperclipmapAddress = \newmap = 1 ie = utf-8&s = s% 26 wd% 3 d '+ mapAddress 注:如果不知道怎么使用,请参考;
join(),请参考这里是一个字符串列表,所以join()方法返回一个字符串。好的,现在选择说'天安门广场并复制,然后双击桌面上的程序。当然,你也可以在命令行中找到程序并输入位置。200 import requestsres = (? = worldindex') 试题:_for_status() 除外异常 exc: print (\u201C has a problem:% s% (exc)) (word) 16997 4.使用BeautifulSoup模块解析HTML:使用命令行安装beautifulsoup4 pip 进行安装。()函数可以解析HTML网站链接(),也可以将解析的HTML文件保存在本地,直接打开()本地的HTML页面。来自警告(模块)的警告: File\u201CC: \\User\\ \\AppData Wang\\Local Python\\Python36-32\\lib\\Program\\ \\网站\\ \\ bs4 \ \ __在里面__。
导致此警告的代码文件的第 1 行。要消除此警告,请像这样更改代码: BeautifulSoup (YOUR_MARKUP)): BeautifulSoup YOUR_MARKUP,\u201D\u201C 我有一条错误消息,所以我添加了第二个参数。2. 使用select()方法查找元素:需要传入一个字符串作为CSS选择器\u201D来获取对应网页的元素,例如:(div):所有命名元素;(\u201C#author \u201D):元素的id属性的作者;(\u201C批判性思维\u201D):在命名所有元素时注意使用CSS类属性;(\u201Cdiv span\u201D):元素内的所有元素;(\u201C input [name] \u201D):所有带有name和name属性的元素的值并不重要;
v = 20170705'} 3.通过获取数据元素属性:然后编写上面的代码。\u201D?v = 20170705 上述方法对\u201C网络爬虫\u201D也有一些初步的探索。 查看全部
python抓取网页数据(本文解释Python抓取网页数据的步骤和操作过程(组图))
本文通过实例讲解Python抓取网页数据的步骤和操作流程,有兴趣的朋友可以关注一下。1. 使用()打开一个网站: 真实例子:使用脚本打开一个网页。所有 Python 程序的第一行都应该以 # !python 开头,告诉计算机你想让 python 执行这个计划。(这行我没试过,好吧,也许这是一种规范) 1.读取命令行参数:打开一个新的文件编辑器窗口,输入以下代码,并保存。2. 读取剪贴板内容: 3.调用()函数打开外部浏览:# !sys, python3import webbrowser pyperclipmapAddress = \newmap = 1 ie = utf-8&s = s% 26 wd% 3 d '+ mapAddress 注:如果不知道怎么使用,请参考;
join(),请参考这里是一个字符串列表,所以join()方法返回一个字符串。好的,现在选择说'天安门广场并复制,然后双击桌面上的程序。当然,你也可以在命令行中找到程序并输入位置。200 import requestsres = (? = worldindex') 试题:_for_status() 除外异常 exc: print (\u201C has a problem:% s% (exc)) (word) 16997 4.使用BeautifulSoup模块解析HTML:使用命令行安装beautifulsoup4 pip 进行安装。()函数可以解析HTML网站链接(),也可以将解析的HTML文件保存在本地,直接打开()本地的HTML页面。来自警告(模块)的警告: File\u201CC: \\User\\ \\AppData Wang\\Local Python\\Python36-32\\lib\\Program\\ \\网站\\ \\ bs4 \ \ __在里面__。
导致此警告的代码文件的第 1 行。要消除此警告,请像这样更改代码: BeautifulSoup (YOUR_MARKUP)): BeautifulSoup YOUR_MARKUP,\u201D\u201C 我有一条错误消息,所以我添加了第二个参数。2. 使用select()方法查找元素:需要传入一个字符串作为CSS选择器\u201D来获取对应网页的元素,例如:(div):所有命名元素;(\u201C#author \u201D):元素的id属性的作者;(\u201C批判性思维\u201D):在命名所有元素时注意使用CSS类属性;(\u201Cdiv span\u201D):元素内的所有元素;(\u201C input [name] \u201D):所有带有name和name属性的元素的值并不重要;
v = 20170705'} 3.通过获取数据元素属性:然后编写上面的代码。\u201D?v = 20170705 上述方法对\u201C网络爬虫\u201D也有一些初步的探索。
python抓取网页数据(通过利用selenium的子模块解决动态数据的html内容的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-10-15 04:31
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博的点赞数等)是不收录在静态html中的,比如我想抓取当前点击打开bbs网站链接各版块的在线人数。静态html网页不收录(不信你去查一下页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>- 查看全部
python抓取网页数据(通过利用selenium的子模块解决动态数据的html内容的方式)
文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取网页的html内容url,然后使用 BeautifulSoup 抓取某个 Label 内容,结合正则表达式过滤。但是,你用urllib.urlopen(url).read()得到的只是网页的静态html内容,还有很多动态数据(比如网站的访问者数,当前在线用户数、微博的点赞数等)是不收录在静态html中的,比如我想抓取当前点击打开bbs网站链接各版块的在线人数。静态html网页不收录(不信你去查一下页面源码,只有简单的一行)。此类动态数据更多是由JavaScript、JQuery、PHP等语言动态生成的,因此不宜采用抓取静态html内容的方法。
解决方案
我已经尝试了网上说的使用浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具)查看网上动态数据的趋势,但这需要从多方面寻找线索网址。个人觉得太麻烦。另外,查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,找到当前session对应的tag。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能不仅限于抓取网页。它是网络自动化测试的常用模块。它在 Ruby 和 Java 中被广泛使用。Python虽然使用的相对较少,但它也是一个非常简单、高效、易用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的捕获问题,你也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
实施过程
操作环境
我在windows 7系统上安装了Python2.7版本,使用的是Python(X,Y)的IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示没有这样的模块,在联网状态下,cmd直接输入pip install selenium,系统会找到Python的安装目录,直接下载解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。这个目录取决于你安装 Python 的路径。如果有 selenium 和 selenium-2.47.3.dist-info 两个文件夹,则可以在 Python 程序中加载模块。
使用 webdriver 捕获动态数据
1.首先导入webdriver子模块
从硒导入网络驱动程序
2.获取浏览器会话,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
浏览器 = webdriver.Firefox()
3.加载页面并在URL中指定有效字符串
browser.get(url)
4. 获取到session对象后,为了定位元素,webdriver提供了一系列的元素定位方法。常用的方法有以下几种:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
css选择器
比如通过id定位,返回一个所有元素组成的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考《博客园-昆虫大师》selenium webdriver(python)教程第三章——定位方法部分(第一版可在百度文库阅读,第二版将收费。>-
python抓取网页数据(Python阅读全文一篇文章教会你利用Python网络爬虫获取Mikan动漫资源的N种方法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-10-14 22:22
阿里云>云栖社区>主题图>P>python3实现爬取网络资源的N种方法
推荐活动:
更多优惠>
当前主题:python3中爬取网络资源的N种方法
相关话题:
Python3实现N种抓取网页资源的方法
python中urllib模块中的方法
作者:于尔武 2083人浏览评论:03年前
python urllib.request urllib 的urlopen函数是一个基于http的高级库。它主要有以下三个功能:(1)request 处理客户端的请求(2)response 处理服务器的响应(3)parse 会解析url,下面讨论的是request
阅读全文
Python资源
作者:方贝工作室 4477人浏览评论:05年前
Python教程(Python2.7.11)为中文翻译版。Python教程是初学者学习Python必备的官方教程。本教程适用于Python2.@ >7.@ >X 系列。在线阅读 »Fork Me »Python
阅读全文
一篇文章文章教你使用Python网络爬虫获取Mikan动画资源
作者:python进阶20人浏览评论:01年前
【一、项目背景】【Mikan Project-Mikan Project】:新一代动画下载站。是专为喜欢动漫的朋友打造的在线动漫视频直播网站。每天第一时间分享最新动画资源,精选最佳动画推荐。【二、项目目标】实现获取动画种子链接和下载保证
阅读全文
Python 中的异步 IO:完整演练
作者:优惠券发出1697人浏览评论:02年前
Asynchronous IO in Python:A Complete Walkthrough 原文:Async IO in Python:A Complete Walkthrough 原文作者:Brad Solomon 原文发表时间:2019 年 1 月 16 日译文:Tacey Wong 译文:2019/7
阅读全文
Python编写知乎爬虫练习
作者:沃克武松 1373人浏览评论:04年前
爬虫的基本流程 网络爬虫的基本工作流程如下:首先,选取部分精心挑选的种子 URL,将种子 URL 添加到任务队列中,将要爬取的 URL 从待爬取的 URL 队列中移除爬取,解析DNS,获取主机IP,下载该URL对应的网页,保存在下载的网页库中。另外,把这些网址放在抓到的
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
2019 年 Python 面试必备!100问,你会做多少?
作者:商报 11243人浏览评论:02年前
来源:商业新闻,原标题:2019 Python面试100个问题,你会说几个?0 有没有遇到过反爬虫的策略和解决方案?1.通过headers反爬虫2.根据用户行为发送爬虫:(短时间内访问同一IP的频率)3.动态网页反爬虫(请求数据通过 ajax 或通过 Ja
阅读全文
将 Python 和 R 集成到一个数据分析流程中
作者:小轩峰柴今2909人浏览评论:04年前
◆ ◆ ◆ 前言在Python 中调用R 或在R 中调用Python 时,为什么是“and”而不是“or”?在网上,对于“R Python”文章,前十名的搜索结果中只有两个讨论了R和Python一起使用的好处,而不是将两种语言相互对立起来。这是可以理解的:这两种语言
阅读全文 查看全部
python抓取网页数据(Python阅读全文一篇文章教会你利用Python网络爬虫获取Mikan动漫资源的N种方法(组图))
阿里云>云栖社区>主题图>P>python3实现爬取网络资源的N种方法
推荐活动:
更多优惠>
当前主题:python3中爬取网络资源的N种方法
相关话题:
Python3实现N种抓取网页资源的方法
python中urllib模块中的方法
作者:于尔武 2083人浏览评论:03年前
python urllib.request urllib 的urlopen函数是一个基于http的高级库。它主要有以下三个功能:(1)request 处理客户端的请求(2)response 处理服务器的响应(3)parse 会解析url,下面讨论的是request
阅读全文
Python资源
作者:方贝工作室 4477人浏览评论:05年前
Python教程(Python2.7.11)为中文翻译版。Python教程是初学者学习Python必备的官方教程。本教程适用于Python2.@ >7.@ >X 系列。在线阅读 »Fork Me »Python
阅读全文
一篇文章文章教你使用Python网络爬虫获取Mikan动画资源
作者:python进阶20人浏览评论:01年前
【一、项目背景】【Mikan Project-Mikan Project】:新一代动画下载站。是专为喜欢动漫的朋友打造的在线动漫视频直播网站。每天第一时间分享最新动画资源,精选最佳动画推荐。【二、项目目标】实现获取动画种子链接和下载保证
阅读全文
Python 中的异步 IO:完整演练
作者:优惠券发出1697人浏览评论:02年前
Asynchronous IO in Python:A Complete Walkthrough 原文:Async IO in Python:A Complete Walkthrough 原文作者:Brad Solomon 原文发表时间:2019 年 1 月 16 日译文:Tacey Wong 译文:2019/7
阅读全文
Python编写知乎爬虫练习
作者:沃克武松 1373人浏览评论:04年前
爬虫的基本流程 网络爬虫的基本工作流程如下:首先,选取部分精心挑选的种子 URL,将种子 URL 添加到任务队列中,将要爬取的 URL 从待爬取的 URL 队列中移除爬取,解析DNS,获取主机IP,下载该URL对应的网页,保存在下载的网页库中。另外,把这些网址放在抓到的
阅读全文
博士生导师用了十天时间整理了所有的Python库。只希望学好后能找到一份高薪的工作!
作者:yunqi2 浏览评论人数:13年前
导演的辛苦也辜负了!让我们直接开始主题。需要资料可以私信我回复01,还可以得到大量PDF书籍和视频!Python常用库简单介绍fuzzywuzzy,模糊字符串匹配。esmre,正则表达式的加速器。colorama 主要用于文本
阅读全文
2019 年 Python 面试必备!100问,你会做多少?
作者:商报 11243人浏览评论:02年前
来源:商业新闻,原标题:2019 Python面试100个问题,你会说几个?0 有没有遇到过反爬虫的策略和解决方案?1.通过headers反爬虫2.根据用户行为发送爬虫:(短时间内访问同一IP的频率)3.动态网页反爬虫(请求数据通过 ajax 或通过 Ja
阅读全文
将 Python 和 R 集成到一个数据分析流程中
作者:小轩峰柴今2909人浏览评论:04年前
◆ ◆ ◆ 前言在Python 中调用R 或在R 中调用Python 时,为什么是“and”而不是“or”?在网上,对于“R Python”文章,前十名的搜索结果中只有两个讨论了R和Python一起使用的好处,而不是将两种语言相互对立起来。这是可以理解的:这两种语言
阅读全文
python抓取网页数据(Python语言程序简单高效,编写网络爬虫有特别的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-13 20:19
1.什么是爬虫
爬虫是网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?这取决于你来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。这样一来,整个相连的网都在这只蜘蛛的触手可及的范围内,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到一些图片和百度搜索框。这个过程其实就是用户输入URL,通过DNS服务器找到服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。 查看全部
python抓取网页数据(Python语言程序简单高效,编写网络爬虫有特别的优势)
1.什么是爬虫
爬虫是网络爬虫。大家可以把它理解为在互联网上爬行的蜘蛛。互联网就像一个大网,爬虫就是在这个网上爬来爬去的蜘蛛。如果它遇到资源,那么它会被爬下来。你想爬什么?这取决于你来控制它。比如它在爬一个网页,他在这个网上找到了一条路,其实就是一个网页的超链接,然后就可以爬到另一个网页上获取数据了。这样一来,整个相连的网都在这只蜘蛛的触手可及的范围内,分分钟爬下来也不成问题。
网络爬虫是一组可以自动从网站的相关网页中搜索和提取数据的程序。提取和存储这些数据是进一步数据分析的关键和前提。Python语言程序简单高效,编写网络爬虫有特殊优势。尤其是业界有各种专门为Python编写的爬虫程序框架,使得爬虫程序的编写更加简单高效。
Python 是一种面向对象的解释型计算机编程语言。该语言开源、免费、功能强大,语法简单明了,库丰富而强大,是目前广泛使用的编程语言。
2.浏览网页的过程
在用户浏览网页的过程中,我们可能会看到很多漂亮的图片,比如我们会看到一些图片和百度搜索框。这个过程其实就是用户输入URL,通过DNS服务器找到服务器主机之后。向服务器发送请求。服务器解析后,将浏览器的HTML、JS、CSS等文件发送给用户。浏览器解析出来,用户可以看到各种图片。
因此,用户看到的网页本质上是由HTML代码组成的,爬虫爬取这个内容。通过对这些HTML代码进行分析和过滤,可以获得图片、文字等资源。
python抓取网页数据(Python数据抓取分析编程模块:requests.document_fromstring(url))
网站优化 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-10-13 15:00
Python数据捕获分析
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step(): try: headers = { 。。。。。 } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i in url: url2 = i.find_all('a') for j in url2: step1url =url + j['href'] print step1url step2(step1url) except Exception,e: print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url): try: headers = { 。。。。 } r = requests.get(step1url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") a = soup.find('div',id='divTbl') if a: url = soup.find_all('td',class_='S-ITabs') for i in url: classifyurl = i.find_all('a') for j in classifyurl: step2url = url + j['href'] #print step2url step3(step2url) else: postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url): try: p1url = doc.xpath(正则表达式) for i in xrange(1,len(p1url) + 1): p2url = doc.xpath(正则表达式) if len(p2url) > 0: producturl = url + p2url[0].get('href') count = db[table].find({'url':producturl}).count() if count 1: td = i.find_all('td') key=td[0].get_text().strip().replace(',','') val=td[1].get_text().replace(u'\u20ac','').strip() if key and val: cost[key] = val if cost: dt['cost'] = cost dt['currency'] = 'EUR' #quantity d = soup.find("input",id="ItemQuantity") if d: dt['quantity'] = d['value'] #specs e = soup.find("div",class_="row parameter-container") if e: key1 = [] val1= [] for k in e.find_all('dt'): key = k.get_text().strip().strip('.') if key: key1.append(key) for i in e.find_all('dd'): val = i.get_text().strip() if val: val1.append(val) specs = dict(zip(key1,val1)) if specs: dt['specs'] = specs print dt if dt: db[table].update({'sn':sn},{'$set':dt}) print str(sn) + ' insert successfully' time.sleep(3) else: error(str(sn) + '\t' + url) except Exception,e: error(str(sn) + '\t' + url) print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文详细介绍python+mongodb数据捕获的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:创建二叉树的Python探索、修改Python搜索路径的Python探索、浅谈python中copy和deepcopy的区别等,如有问题欢迎留言讨论一起。
以上就是python+mongodb数据捕获的详细介绍。更多详情请关注其他相关html中文网站文章! 查看全部
python抓取网页数据(Python数据抓取分析编程模块:requests.document_fromstring(url))
Python数据捕获分析
编程模块:requests、lxml、pymongo、time、BeautifulSoup
首先获取所有产品的类别 URL:
def step(): try: headers = { 。。。。。 } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i in url: url2 = i.find_all('a') for j in url2: step1url =url + j['href'] print step1url step2(step1url) except Exception,e: print e
我们在对产品进行分类时,需要判断我们访问的地址是一个产品还是另一个分类的产品地址(所以我们需要判断我们访问的地址是否收录if判断标志):
def step2(step1url): try: headers = { 。。。。 } r = requests.get(step1url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") a = soup.find('div',id='divTbl') if a: url = soup.find_all('td',class_='S-ITabs') for i in url: classifyurl = i.find_all('a') for j in classifyurl: step2url = url + j['href'] #print step2url step3(step2url) else: postdata(step1url)
当我们的if判断为true时,我们将获取第二页的类别URL(第一步),否则我们将执行postdata函数来抓取网页的产品地址!
def producturl(url): try: p1url = doc.xpath(正则表达式) for i in xrange(1,len(p1url) + 1): p2url = doc.xpath(正则表达式) if len(p2url) > 0: producturl = url + p2url[0].get('href') count = db[table].find({'url':producturl}).count() if count 1: td = i.find_all('td') key=td[0].get_text().strip().replace(',','') val=td[1].get_text().replace(u'\u20ac','').strip() if key and val: cost[key] = val if cost: dt['cost'] = cost dt['currency'] = 'EUR' #quantity d = soup.find("input",id="ItemQuantity") if d: dt['quantity'] = d['value'] #specs e = soup.find("div",class_="row parameter-container") if e: key1 = [] val1= [] for k in e.find_all('dt'): key = k.get_text().strip().strip('.') if key: key1.append(key) for i in e.find_all('dd'): val = i.get_text().strip() if val: val1.append(val) specs = dict(zip(key1,val1)) if specs: dt['specs'] = specs print dt if dt: db[table].update({'sn':sn},{'$set':dt}) print str(sn) + ' insert successfully' time.sleep(3) else: error(str(sn) + '\t' + url) except Exception,e: error(str(sn) + '\t' + url) print "Don't data!"
最后运行所有程序,对数值数据进行分析处理并存入数据库!
以上就是本文详细介绍python+mongodb数据捕获的全部内容,希望对大家有所帮助。有兴趣的朋友可以继续参考本站:创建二叉树的Python探索、修改Python搜索路径的Python探索、浅谈python中copy和deepcopy的区别等,如有问题欢迎留言讨论一起。
以上就是python+mongodb数据捕获的详细介绍。更多详情请关注其他相关html中文网站文章!
python抓取网页数据( 智联招聘上一线及新一线城市所有与BIM相关的工作信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-13 12:31
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
Python简单的网络爬虫获取网页数据
以下是获取智联招聘一线及新一线城市所有BIM相关职位信息,进行一些数据分析。
1、 先通过chrome在智联招聘上搜索BIM职位信息,跳出页面后ctrl+u查看网页源码,如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,找到收录位置的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL为
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行访问测试,成功获取相应数据
3、 获取的数据为json格式。首先对数据进行格式化,分析结构,确定代码中数据的分析方法。
4、 明确请求 URL 和数据结构后,剩下的就是在代码中实现 URL 构建、数据分析和导出。最终得到了1215条数据,需要对数据进行进一步排序进行数据分析。
推荐:【MYSQL课程】 查看全部
python抓取网页数据(
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
Python简单的网络爬虫获取网页数据
以下是获取智联招聘一线及新一线城市所有BIM相关职位信息,进行一些数据分析。
1、 先通过chrome在智联招聘上搜索BIM职位信息,跳出页面后ctrl+u查看网页源码,如果没有找到当前页面的职位信息。然后快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,找到收录位置的数据包。
2、查看这个文件的请求URL,分析其结构,发现数据包的请求URL为
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行访问测试,成功获取相应数据
3、 获取的数据为json格式。首先对数据进行格式化,分析结构,确定代码中数据的分析方法。
4、 明确请求 URL 和数据结构后,剩下的就是在代码中实现 URL 构建、数据分析和导出。最终得到了1215条数据,需要对数据进行进一步排序进行数据分析。
推荐:【MYSQL课程】
python抓取网页数据(【BeautifulSoap】BeautifulSoap类soupBeautifulSoup()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-10-11 14:03
一、美丽肥皂
1.首先必须导入bs4库来创建BeautifulSoap对象
#coding=utf-8
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(html,'lxml') #html 是下载的网页,lxml 是解析器
2.BeautifulSoap主要掌握三种方法
find_all('tag') 搜索所有标签标签的当前集合
find("tag") 返回一个标签(此方法使用较少)
select("") 可以按标签搜索,主要用于按标签搜索和过滤元素
二、使用 BeautifulSoup 提取网页内容的一些技术
1.find_all()方法中的单个标签名,如a,会提取网页中所有的a标签。这里我们必须确保它是我们需要的链接a。一般来说,它不是。您需要添加条件(即标签的属性,加上限制性过滤)。如果没有这个和标签的属性,最好去上层找。
, 链接:用笑话戳我,抢原创 笑话。
(顺便说一句,小白在这上面找了很久,才看到藏在跨度里的笑话,总觉得自己有点弱智=_=)
注意:如果你写find_all("span"),可以抓取段落的内容,但是也会收录网页上其他span的内容,所以我们要查看上层标签。
它只是一个收录段落内容的标签。
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
链接 = 汤.find_all('div',class_='content')
#link的内容就是div,我们取的span内容就是我们需要的段落内容
对于链接中的链接:
打印 link.span.get_text()
操作结果:
2.select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
sound.select("html head title") #标签级别搜索
汤.select("td div a") #标签路径td-->div-->a
汤.select('td> div> a')#note: 推荐使用这种表示法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
这个内容需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面是select()方法~
链接 = 汤.select('div> a >div >span')
对于链接中的链接:
打印 link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
吃饭的时候没发~
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
--------------------- 查看全部
python抓取网页数据(【BeautifulSoap】BeautifulSoap类soupBeautifulSoup()())
一、美丽肥皂
1.首先必须导入bs4库来创建BeautifulSoap对象
#coding=utf-8
从 bs4 导入 BeautifulSoup
汤 = BeautifulSoup(html,'lxml') #html 是下载的网页,lxml 是解析器
2.BeautifulSoap主要掌握三种方法
find_all('tag') 搜索所有标签标签的当前集合
find("tag") 返回一个标签(此方法使用较少)
select("") 可以按标签搜索,主要用于按标签搜索和过滤元素
二、使用 BeautifulSoup 提取网页内容的一些技术
1.find_all()方法中的单个标签名,如a,会提取网页中所有的a标签。这里我们必须确保它是我们需要的链接a。一般来说,它不是。您需要添加条件(即标签的属性,加上限制性过滤)。如果没有这个和标签的属性,最好去上层找。
, 链接:用笑话戳我,抢原创 笑话。
(顺便说一句,小白在这上面找了很久,才看到藏在跨度里的笑话,总觉得自己有点弱智=_=)
注意:如果你写find_all("span"),可以抓取段落的内容,但是也会收录网页上其他span的内容,所以我们要查看上层标签。
它只是一个收录段落内容的标签。
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
链接 = 汤.find_all('div',class_='content')
#link的内容就是div,我们取的span内容就是我们需要的段落内容
对于链接中的链接:
打印 link.span.get_text()
操作结果:
2.select() 方法
我们需要的内容可以逐层查找。这个特别方便,也就是定位,防止单个标签无法定位到我们需要的内容元素。
sound.select("html head title") #标签级别搜索
汤.select("td div a") #标签路径td-->div-->a
汤.select('td> div> a')#note: 推荐使用这种表示法
选择谷歌浏览器,右键复制--复制选择器
获取内容的任务:
#qiushi_tag_120529403> a> div> span:nth-child(1)
这个内容需要改一下~按标签顺序搜索
div> a> div> span(我在运行的时候发现了一个问题,>前后必须有空格,否则会报错)
然后代码如下:(和前面的代码区别只有最后三行)
#coding=utf-8
从 bs4 导入 BeautifulSoup
进口请求
#使用requests抓取页面内容并将响应赋值给page变量
html = requests.get('')
#使用content属性获取页面的源页面
#使用BeautifulSoap进行解析,并将内容传递给BeautifulSoap类
汤 = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面是select()方法~
链接 = 汤.select('div> a >div >span')
对于链接中的链接:
打印 link.get_text()
操作结果:
啊哦~有没有发现和上面操作的结果不一样?评论也在这里匹配,所以:
我们还需要修改定位使其更加精确,从标签a开始,并添加其class属性。a.contentHerf 写在 select 方法中。
具体是这样的:a.contentHerf>div>span(改成代码第三行再运行一次~)
吃饭的时候没发~
注意:1)示例只介绍了一页的内容
2)代码在python中运行2.7
---------------------
python抓取网页数据( 介绍网页抓取是了解数据的最常用技术之一Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-09 14:37
介绍网页抓取是了解数据的最常用技术之一Python)
介绍
网页抓取是理解 Internet 数据最常用的技术之一。它是一种从网页中提取有价值和需要的数据的技术,这些数据被视为执行各种计算操作以生成有用信息的输入值。在本文中,我们将学习如何采集发布在任何网页上的电子邮件数据。我们使用最流行的编程语言之一 Python 来提取数据元素值,因为它具有丰富的库,可以帮助执行各种所需的活动。
以下步骤将帮助您了解如何在任何网页上查找电子邮件。
第1步
我们需要为我们的程序导入所有必要的库。
#import packages
from bs4 import BeautifulSoup
import requests
import requests.exceptions
from urllib.parse import urlsplit
from collections import deque
import re
第2步
选择用于从给定 URL 提取电子邮件的 URL。
# 要抓取的 url 队列
new_urls = deque(['https://www.gtu.ac.in/page.aspx?p=ContactUsA'])
第 3 步
我们只需要处理给定的 URL 一次,因此请跟踪您处理的 URL。
# a set of urls that we have already crawled
processed_urls = set()
第四步
在抓取给定 URL 时,我们可能会遇到多个电子邮件 ID,因此将它们保留在集合中。
# a set of crawled emails
emails = set()
第 5 步
是时候开始爬行了。我们需要爬取队列中所有的URL,维护爬取过的URL列表,从网页中获取页面内容。如果您遇到任何错误,请移至下一页。
# process urls one by one until we exhaust the queue
while len(new_urls):
# move next url from the queue to the set of processed urls
url = new_urls.popleft()
processed_urls.add(url)
# get url's content
print("Processing %s" % url)
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors
continue
第 6 步
现在我们需要提取当前 URL 的一些基本部分,这是将文档中的相对链接转换为绝对链接的重要部分:
# extract base url and path to resolve relative links
parts = urlsplit(url)
base_url = "{0.scheme}://{0.netloc}".format(parts)
path = url[:url.rfind('/')+1] if '/' in parts.path else url
第 7 步
从页面内容中提取电子邮件并将其添加到电子邮件集合中。
# extract all email addresses and add them into the resulting set
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", response.text, re.I))
emails.update(new_emails)
第 8 步
处理完当前页面后,就可以搜索到其他页面的链接,加入到URL队列中(这就是爬行的魅力所在)。获取一个 Beautifulsoup 对象来解析 HTML 页面。
# create a beutiful soup for the html document
soup = BeautifulSoup(response.text)
步骤 9
汤对象收录 HTML 元素。现在找到所有带有 href 属性的锚标记来解析相关链接并保留处理过的 URL 的记录。
# find and process all the anchors in the document
for anchor in soup.find_all("a"):
# extract link url from the anchor
link = anchor.attrs["href"] if "href" in anchor.attrs else ''
# resolve relative links
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
# add the new url to the queue if it was not enqueued nor processed yet
if not link in new_urls and not link in processed_urls:
new_urls.append(link)
第 10 步
列出从给定 URL 中提取的所有电子邮件 ID。
for email in emails:
print(email)
总结
本文解释了如何执行网页抓取,尤其是当您使用诸如 BeautifulSoup、采集s、requests、re 和 urllib.parse 等 Python 包来定位 HTML 页面上的任何数据时。 查看全部
python抓取网页数据(
介绍网页抓取是了解数据的最常用技术之一Python)
https://www.muyuanzhan.com/wp- ... 8.jpg 300w, https://www.muyuanzhan.com/wp- ... 4.jpg 150w" />介绍
网页抓取是理解 Internet 数据最常用的技术之一。它是一种从网页中提取有价值和需要的数据的技术,这些数据被视为执行各种计算操作以生成有用信息的输入值。在本文中,我们将学习如何采集发布在任何网页上的电子邮件数据。我们使用最流行的编程语言之一 Python 来提取数据元素值,因为它具有丰富的库,可以帮助执行各种所需的活动。
以下步骤将帮助您了解如何在任何网页上查找电子邮件。
第1步
我们需要为我们的程序导入所有必要的库。
#import packages
from bs4 import BeautifulSoup
import requests
import requests.exceptions
from urllib.parse import urlsplit
from collections import deque
import re
第2步
选择用于从给定 URL 提取电子邮件的 URL。
# 要抓取的 url 队列
new_urls = deque(['https://www.gtu.ac.in/page.aspx?p=ContactUsA'])
第 3 步
我们只需要处理给定的 URL 一次,因此请跟踪您处理的 URL。
# a set of urls that we have already crawled
processed_urls = set()
第四步
在抓取给定 URL 时,我们可能会遇到多个电子邮件 ID,因此将它们保留在集合中。
# a set of crawled emails
emails = set()
第 5 步
是时候开始爬行了。我们需要爬取队列中所有的URL,维护爬取过的URL列表,从网页中获取页面内容。如果您遇到任何错误,请移至下一页。
# process urls one by one until we exhaust the queue
while len(new_urls):
# move next url from the queue to the set of processed urls
url = new_urls.popleft()
processed_urls.add(url)
# get url's content
print("Processing %s" % url)
try:
response = requests.get(url)
except (requests.exceptions.MissingSchema, requests.exceptions.ConnectionError):
# ignore pages with errors
continue
第 6 步
现在我们需要提取当前 URL 的一些基本部分,这是将文档中的相对链接转换为绝对链接的重要部分:
# extract base url and path to resolve relative links
parts = urlsplit(url)
base_url = "{0.scheme}://{0.netloc}".format(parts)
path = url[:url.rfind('/')+1] if '/' in parts.path else url
第 7 步
从页面内容中提取电子邮件并将其添加到电子邮件集合中。
# extract all email addresses and add them into the resulting set
new_emails = set(re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", response.text, re.I))
emails.update(new_emails)
第 8 步
处理完当前页面后,就可以搜索到其他页面的链接,加入到URL队列中(这就是爬行的魅力所在)。获取一个 Beautifulsoup 对象来解析 HTML 页面。
# create a beutiful soup for the html document
soup = BeautifulSoup(response.text)
步骤 9
汤对象收录 HTML 元素。现在找到所有带有 href 属性的锚标记来解析相关链接并保留处理过的 URL 的记录。
# find and process all the anchors in the document
for anchor in soup.find_all("a"):
# extract link url from the anchor
link = anchor.attrs["href"] if "href" in anchor.attrs else ''
# resolve relative links
if link.startswith('/'):
link = base_url + link
elif not link.startswith('http'):
link = path + link
# add the new url to the queue if it was not enqueued nor processed yet
if not link in new_urls and not link in processed_urls:
new_urls.append(link)
第 10 步
列出从给定 URL 中提取的所有电子邮件 ID。
for email in emails:
print(email)
总结
本文解释了如何执行网页抓取,尤其是当您使用诸如 BeautifulSoup、采集s、requests、re 和 urllib.parse 等 Python 包来定位 HTML 页面上的任何数据时。
python抓取网页数据(“微信运动”能够向朋友分享一个的网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-09 14:32
)
“微信运动”可以与朋友分享一个收录运动数据的网页,网页中收录我们需要的数据。url类似于:用户的openid,它有微信体育唯一使用的openid。打开 fiddler 来抓包。先打开fiddler,再打开微信体育,点击我的主页,如下:
微信通过请求头来区分请求是否是通过微信浏览器发出的。如果直接用浏览器打开链接,会出现如下错误提示,说明不是通过微信浏览器打开的,被微信拦截了:
通过Fiddler的抓包数据,我们可以通过伪造Request Headers请求头来抓数据
Fiddler 捕获数据包并显示:
通过邮递员伪造请求头来模拟微信浏览器。伪造请求头后,在浏览器中成功获取到相应的网页内容:
Python实现代码:
import requests
import re
import json
class WechatSprot(object):
def __init__(self, openid):
self.openid = openid
def getInfo(self):
url = "http://hw.weixin.qq.com/stepra ... ot%3B
querystring = {"openid": self.openid}
headers = {
\'host\': "hw.weixin.qq.com",
\'connection\': "keep-alive",
\'accept\': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
\'user-agent\': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.691.400 QQBrowser/9.0.2524.400",
\'accept-encoding\': "gzip, deflate",
\'accept-language\': "zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4",
\'cookie\': "hwstepranksk=JxMBWw1sxQhxnMgsJnnLh-r0VFzLH6RtJWv5b_j3z8MPs6-J; pass_ticket=p9R%2FqjIh%2BlXt%2BoxP7GIWrqm3Sbf1Minisk%2FNUz5zra4ReETR2ATI8H57zkEERCvG",
}
response = requests.request("GET", url, headers=headers, params=querystring)
res = re.findall(\'window.json = (.+);\', response.text)
# print(res)
# exit()
return json.loads(res[0])
if __name__ == "__main__":
obj = WechatSprot(用户的openid)
print(obj.getInfo()) 查看全部
python抓取网页数据(“微信运动”能够向朋友分享一个的网页数据
)
“微信运动”可以与朋友分享一个收录运动数据的网页,网页中收录我们需要的数据。url类似于:用户的openid,它有微信体育唯一使用的openid。打开 fiddler 来抓包。先打开fiddler,再打开微信体育,点击我的主页,如下:
微信通过请求头来区分请求是否是通过微信浏览器发出的。如果直接用浏览器打开链接,会出现如下错误提示,说明不是通过微信浏览器打开的,被微信拦截了:
通过Fiddler的抓包数据,我们可以通过伪造Request Headers请求头来抓数据
Fiddler 捕获数据包并显示:
通过邮递员伪造请求头来模拟微信浏览器。伪造请求头后,在浏览器中成功获取到相应的网页内容:
Python实现代码:
import requests
import re
import json
class WechatSprot(object):
def __init__(self, openid):
self.openid = openid
def getInfo(self):
url = "http://hw.weixin.qq.com/stepra ... ot%3B
querystring = {"openid": self.openid}
headers = {
\'host\': "hw.weixin.qq.com",
\'connection\': "keep-alive",
\'accept\': "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
\'user-agent\': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 MicroMessenger/6.5.2.501 NetType/WIFI WindowsWechat QBCore/3.43.691.400 QQBrowser/9.0.2524.400",
\'accept-encoding\': "gzip, deflate",
\'accept-language\': "zh-CN,zh;q=0.8,en-us;q=0.6,en;q=0.5;q=0.4",
\'cookie\': "hwstepranksk=JxMBWw1sxQhxnMgsJnnLh-r0VFzLH6RtJWv5b_j3z8MPs6-J; pass_ticket=p9R%2FqjIh%2BlXt%2BoxP7GIWrqm3Sbf1Minisk%2FNUz5zra4ReETR2ATI8H57zkEERCvG",
}
response = requests.request("GET", url, headers=headers, params=querystring)
res = re.findall(\'window.json = (.+);\', response.text)
# print(res)
# exit()
return json.loads(res[0])
if __name__ == "__main__":
obj = WechatSprot(用户的openid)
print(obj.getInfo())

