
python抓取网页数据
使用 Excel和 Python从互联网获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-09-10 11:29
互联网上有极其丰富的数据资源可以使用。使用Excel可以自动读取部分网页中的表格数据,使用Python编写爬虫程序可以读取网页的内容。
本节通过Python编写测试用Web应用程序,然后使用Excel和Python从编写的Web网站上获取数据。
1,构建测试用网站数据
通过Python Flask Web框架分别构建一个Web网站和一个WebAPI服务。
1.构建Web网站
新建一个名为“5-5-WebTable.py”的Python脚本,创建一个包含表格的简单网页。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装flask包。
pip install flask
(2)构建包含表格的网页。
from flask import Flask<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /><br /># 将路由“/”映射到table_info函数,函数返回HTML代码@app.route('/')def table_info(): return """HTML表格实例,用于提供给Excel和Python读取 用户信息表 姓名 性别 年龄 小米 女 22 ………. """<br /><br />if __name__ == '__main__': app.debug = True # 启用调试模式 app.run() # 运行,网站端口默认为5000
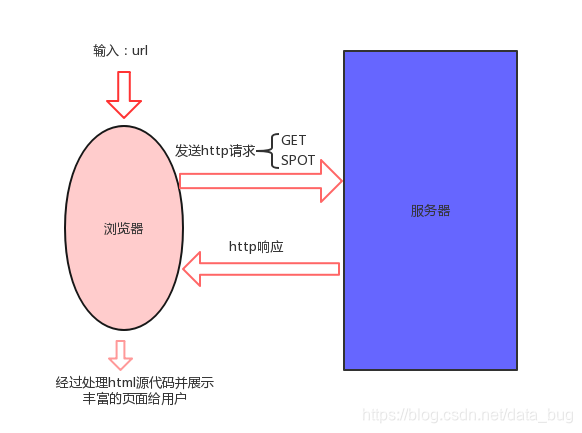
通过命令“python./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,出现如图1所示的网页内容。
图1 使用Flask构建的测试网站
2.构建Web API服务
新建一个名为“5-5-WebAPI.py”的Python脚本,使用flask_restplus包构建WebAPI服务。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开WebAPI服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库与初始化应用对象。
from flask import Flask# Api类是Web API应用的入口,需要用Flask应用程序初始化from flask_restplus import Api<br /># Resource类是HTTP请求的资源的基类from flask_restplus import Resource<br /># fields类用于定义数据的类型和格式from flask_restplus import fields<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /># 在flask应用的基础上构建flask_restplus Api对象api = Api(app, version='1.0', title='Excel集成Python数据分析-测试用WebAPI', description='测试用WebAPI', )<br /># 使用namespace函数生成命名空间,用于为资源分组ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')# 使用api.model函数生成模型对象todo = api.model('task_model', { 'id': fields.Integer(readonly=True, description='ETL任务唯一标识'), 'task': fields.String(required=True, description='ETL任务详情')})
(3)WebAPI数据操作类,包含增、删、改、查等方法。
class TodoDAO(object):<br /> def __init__(self): self.counter = 0 self.todos = []<br /> def get(self, id): for todo in self.todos: if todo['id'] == id: return todo api.abort(404, "ETL任务 {} 不存在".format(id))<br /> def create(self, data): todo = data todo['id'] = self.counter = self.counter + 1 self.todos.append(todo) return todo<br /><br /># 实例化数据操作,创建3条测试数据DAO = TodoDAO()DAO.create({'task': 'ETL-抽取数据操作'})DAO.create({'task': 'ETL-数据清洗转换'})DAO.create({'task': 'ETL-数据加载操作'})
(4)构建Web API的路由映射。
HTTP资源请求类从Resource类继承,然后映射到不同的路由,同时指定可使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求class TodoList(Resource): @ns.doc('list_todos') # @doc装饰器对应API文档的信息 @ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出 def get(self): # 定义get方法获取所有的任务信息 return DAO.todos<br /> @ns.doc('create_todo') @ns.expect(todo) @ns.marshal_with(todo, code=201) def post(self): # 定义post方法获取所有的任务信息 return DAO.create(api.payload), 201<br /><br /># 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求@ns.route('/')@ns.response(404, '未发现相关ETL任务')@ns.param('id', 'ETL任务ID号')class Todo(Resource): @ns.doc('get_todo') @ns.marshal_with(todo) def get(self, id): return DAO.get(id)<br /> @ns.doc('delete_todo') @ns.response(204, 'ETL任务已经删除') def delete(self, id): DAO.delete(id) return '', 204<br /> @ns.expect(todo) @ns.marshal_with(todo) def put(self, id): return DAO.update(id, api.payload)<br /><br />if __name__ == '__main__': app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)开启Web API服务。
通过命令“python./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”
将出现如图5-23所示的Web API服务请求方法列表。
图2WebAPI服务请求方法列表
2,抓取用网页数据
Excel可以通过“数据”选项卡下的“自网站”功能抓取网页数据。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架抓取网页数据。
1.通过Excel抓取
单击“数据”→“自其他源”→“自网站”功能。Excel可读取的网页数据有局限:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)单击“数据”→“自其他源”→“自网站”功能。
(2)确保在5.5.1节中编写的Web网站已经开启。
(3)输入网站URL地址“:5000/”
单击“高级”按钮可配置更详细的HTTP请求信息,然后单击“确定”按钮,如图3所示。
图3 配置要读取网站的URL
(4)在“导航器”窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表名后单击“加载”按钮即可。
图4Excel自动识别网页中的表格数据
2.使用Python抓取
下面演示使用requests库抓取整个网页中的数据,然后使用Beautiful Soup解析网页。读者可参考本书代码素材文件“5-5-web.ipynb”进行学习。
(1)通过requests读取网页数据。
import requests #导入requests包url ='http://127.0.0.1:5000/'<br />strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过BeautifulSoup解析网页。
from bs4 import BeautifulSoup<br />soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象table = soup.find('table') # 查找网页中的table元素table_body = table.find('tbody') # 查找table元素中的tbody元素data = []rows = table_body.find_all('tr') # 查找表中的所有tr元素<br />for row in rows: # 遍历数据 cols = row.find_all('td') cols = [ele.text.strip() for ele in cols]data.append([ele for ele in cols if ele])# 结果输出:[[],['小米', '女', '22'],['小明','男','23'],……
3,调用Web API服务
Excel可以通过“数据”选项卡下的“自网站”功能调用Web API服务。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架调用Web API获取数据。
1.使用Excel调用
(1)确保5.5.1节中编写的Web API服务已经开启。
(2)输入Web API方法对应的URL:
:8000/ExcelPythonTest/。
(3)处理返回的数据。
调用Web API服务后数据以JSON格式返回,按照5.4.3小节中介绍的方法处理JSON数据。
2.使用Python调用
使用requests库调用Web API方法,然后对返回的JSON数据进行处理,读者可参考本书代码素材文件“5-5-api.ipynb”进行学习。
import requests #导入requests包url ='http://127.0.0.1:8000/ExcelPythonTest/'<br />strhtml= requests.get(url) #使用get方法获取网页数据<br />import pandas as pd<br />frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数print(frame)#结果输出:id task0 1 ETL-抽取数据操作1 2 ETL-数据清洗转换2 3 ETL-数据加载操作
3,Excel和Python抓取互联网数据方法对比
表1所示为Excel和Python抓取互联网数据方法的对比。需要注意Excel从互联网抓取数据的功能并不完善。
表1Excel和Python抓取互联网数据方法对比
声明:本文选自北京大学出版社的《从零开始利用Excel与Python进行数据分析》一书,略有修改,经出版社授权刊登于此。
文末赠书<p style="margin-bottom: 24px;outline: 0px;max-width: 100%;font-family: system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">内容简介
《从零开始利用Excel与Python进行数据分析》介绍了数据分析的方法和步骤,并分别通过Excel和Python实施和对比。通过《从零开始利用Excel与Python进行数据分析》一方面可以拓宽对Excel功能的认识,另一方面可以学习和掌握Python的基础操作。
规则
后台回复: 送书 ,参与抽奖
<br /><br />推荐阅读 点击标题可跳转用 Python 破解 WiFi 密码,太刺激了JetBrains 如何看待自己的软件在中国被频繁破解抛弃for循环,让 Python 代码更 pythonic </p> 查看全部
使用 Excel和 Python从互联网获取数据
互联网上有极其丰富的数据资源可以使用。使用Excel可以自动读取部分网页中的表格数据,使用Python编写爬虫程序可以读取网页的内容。
本节通过Python编写测试用Web应用程序,然后使用Excel和Python从编写的Web网站上获取数据。
1,构建测试用网站数据
通过Python Flask Web框架分别构建一个Web网站和一个WebAPI服务。
1.构建Web网站
新建一个名为“5-5-WebTable.py”的Python脚本,创建一个包含表格的简单网页。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装flask包。
pip install flask
(2)构建包含表格的网页。
from flask import Flask<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /><br /># 将路由“/”映射到table_info函数,函数返回HTML代码@app.route('/')def table_info(): return """HTML表格实例,用于提供给Excel和Python读取 用户信息表 姓名 性别 年龄 小米 女 22 ………. """<br /><br />if __name__ == '__main__': app.debug = True # 启用调试模式 app.run() # 运行,网站端口默认为5000
通过命令“python./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,出现如图1所示的网页内容。
图1 使用Flask构建的测试网站
2.构建Web API服务
新建一个名为“5-5-WebAPI.py”的Python脚本,使用flask_restplus包构建WebAPI服务。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开WebAPI服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库与初始化应用对象。
from flask import Flask# Api类是Web API应用的入口,需要用Flask应用程序初始化from flask_restplus import Api<br /># Resource类是HTTP请求的资源的基类from flask_restplus import Resource<br /># fields类用于定义数据的类型和格式from flask_restplus import fields<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /># 在flask应用的基础上构建flask_restplus Api对象api = Api(app, version='1.0', title='Excel集成Python数据分析-测试用WebAPI', description='测试用WebAPI', )<br /># 使用namespace函数生成命名空间,用于为资源分组ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')# 使用api.model函数生成模型对象todo = api.model('task_model', { 'id': fields.Integer(readonly=True, description='ETL任务唯一标识'), 'task': fields.String(required=True, description='ETL任务详情')})
(3)WebAPI数据操作类,包含增、删、改、查等方法。
class TodoDAO(object):<br /> def __init__(self): self.counter = 0 self.todos = []<br /> def get(self, id): for todo in self.todos: if todo['id'] == id: return todo api.abort(404, "ETL任务 {} 不存在".format(id))<br /> def create(self, data): todo = data todo['id'] = self.counter = self.counter + 1 self.todos.append(todo) return todo<br /><br /># 实例化数据操作,创建3条测试数据DAO = TodoDAO()DAO.create({'task': 'ETL-抽取数据操作'})DAO.create({'task': 'ETL-数据清洗转换'})DAO.create({'task': 'ETL-数据加载操作'})

(4)构建Web API的路由映射。
HTTP资源请求类从Resource类继承,然后映射到不同的路由,同时指定可使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求class TodoList(Resource): @ns.doc('list_todos') # @doc装饰器对应API文档的信息 @ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出 def get(self): # 定义get方法获取所有的任务信息 return DAO.todos<br /> @ns.doc('create_todo') @ns.expect(todo) @ns.marshal_with(todo, code=201) def post(self): # 定义post方法获取所有的任务信息 return DAO.create(api.payload), 201<br /><br /># 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求@ns.route('/')@ns.response(404, '未发现相关ETL任务')@ns.param('id', 'ETL任务ID号')class Todo(Resource): @ns.doc('get_todo') @ns.marshal_with(todo) def get(self, id): return DAO.get(id)<br /> @ns.doc('delete_todo') @ns.response(204, 'ETL任务已经删除') def delete(self, id): DAO.delete(id) return '', 204<br /> @ns.expect(todo) @ns.marshal_with(todo) def put(self, id): return DAO.update(id, api.payload)<br /><br />if __name__ == '__main__': app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)开启Web API服务。
通过命令“python./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”
将出现如图5-23所示的Web API服务请求方法列表。
图2WebAPI服务请求方法列表
2,抓取用网页数据
Excel可以通过“数据”选项卡下的“自网站”功能抓取网页数据。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架抓取网页数据。
1.通过Excel抓取
单击“数据”→“自其他源”→“自网站”功能。Excel可读取的网页数据有局限:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)单击“数据”→“自其他源”→“自网站”功能。
(2)确保在5.5.1节中编写的Web网站已经开启。
(3)输入网站URL地址“:5000/”
单击“高级”按钮可配置更详细的HTTP请求信息,然后单击“确定”按钮,如图3所示。
图3 配置要读取网站的URL
(4)在“导航器”窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表名后单击“加载”按钮即可。
图4Excel自动识别网页中的表格数据

2.使用Python抓取
下面演示使用requests库抓取整个网页中的数据,然后使用Beautiful Soup解析网页。读者可参考本书代码素材文件“5-5-web.ipynb”进行学习。
(1)通过requests读取网页数据。
import requests #导入requests包url ='http://127.0.0.1:5000/'<br />strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过BeautifulSoup解析网页。
from bs4 import BeautifulSoup<br />soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象table = soup.find('table') # 查找网页中的table元素table_body = table.find('tbody') # 查找table元素中的tbody元素data = []rows = table_body.find_all('tr') # 查找表中的所有tr元素<br />for row in rows: # 遍历数据 cols = row.find_all('td') cols = [ele.text.strip() for ele in cols]data.append([ele for ele in cols if ele])# 结果输出:[[],['小米', '女', '22'],['小明','男','23'],……
3,调用Web API服务
Excel可以通过“数据”选项卡下的“自网站”功能调用Web API服务。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架调用Web API获取数据。
1.使用Excel调用
(1)确保5.5.1节中编写的Web API服务已经开启。
(2)输入Web API方法对应的URL:
:8000/ExcelPythonTest/。
(3)处理返回的数据。
调用Web API服务后数据以JSON格式返回,按照5.4.3小节中介绍的方法处理JSON数据。
2.使用Python调用
使用requests库调用Web API方法,然后对返回的JSON数据进行处理,读者可参考本书代码素材文件“5-5-api.ipynb”进行学习。
import requests #导入requests包url ='http://127.0.0.1:8000/ExcelPythonTest/'<br />strhtml= requests.get(url) #使用get方法获取网页数据<br />import pandas as pd<br />frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数print(frame)#结果输出:id task0 1 ETL-抽取数据操作1 2 ETL-数据清洗转换2 3 ETL-数据加载操作
3,Excel和Python抓取互联网数据方法对比
表1所示为Excel和Python抓取互联网数据方法的对比。需要注意Excel从互联网抓取数据的功能并不完善。
表1Excel和Python抓取互联网数据方法对比
声明:本文选自北京大学出版社的《从零开始利用Excel与Python进行数据分析》一书,略有修改,经出版社授权刊登于此。
文末赠书<p style="margin-bottom: 24px;outline: 0px;max-width: 100%;font-family: system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">内容简介
《从零开始利用Excel与Python进行数据分析》介绍了数据分析的方法和步骤,并分别通过Excel和Python实施和对比。通过《从零开始利用Excel与Python进行数据分析》一方面可以拓宽对Excel功能的认识,另一方面可以学习和掌握Python的基础操作。
规则
后台回复: 送书 ,参与抽奖
<br /><br />推荐阅读 点击标题可跳转用 Python 破解 WiFi 密码,太刺激了JetBrains 如何看待自己的软件在中国被频繁破解抛弃for循环,让 Python 代码更 pythonic </p>
python抓取网页数据抓取到的是一个抖音用户的简介
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-09-08 21:15
python抓取网页数据这里抓取到的是一个抖音用户的简介。简介是这样的:作者:neo用户年龄:18禁欲系爱好:听radio看剧目前:已进行过两次付费服务两个月地址:提取码:uhi后来又发现这个用户名字带有you'llneverfallinlovewithxxxx当然,可能是个恶意用户,因为他会在视频里说这种话。我觉得这个数据挺有用的,所以总结一下。python爬取网页数据。
现在懂技术的多数转向,爬虫。把几千条数据根据你要发布的主题分割成数十万几百万条数据,进行高频抓取进行分析,基本上都要写爬虫代码,这个比起写c++要容易很多。根据数据量基本一个字典就足够了,然后selenium,
因为是开放教育平台,所以我们用c++爬取了数据,大概抓取的网站有上千个。网页抓取不是一个简单的动作,包括头程序、分析器、分包处理、数据库、web服务等等。如何给爬虫设置合理的语言和界面之间关系,是非常复杂的。因此,我们作为网站管理者(包括前端设计师)、前端工程师都非常重视这个问题。常规的做法:用java、python、js等前端语言爬取不同网站发布的链接数据,然后合并起来。
也有一些直接用php转成脚本后用scrapy抓取。我们根据自己爬取的链接,对数据进行分析,提取用户画像,数据量都挺多的。大概就是这些。 查看全部
python抓取网页数据抓取到的是一个抖音用户的简介
python抓取网页数据这里抓取到的是一个抖音用户的简介。简介是这样的:作者:neo用户年龄:18禁欲系爱好:听radio看剧目前:已进行过两次付费服务两个月地址:提取码:uhi后来又发现这个用户名字带有you'llneverfallinlovewithxxxx当然,可能是个恶意用户,因为他会在视频里说这种话。我觉得这个数据挺有用的,所以总结一下。python爬取网页数据。

现在懂技术的多数转向,爬虫。把几千条数据根据你要发布的主题分割成数十万几百万条数据,进行高频抓取进行分析,基本上都要写爬虫代码,这个比起写c++要容易很多。根据数据量基本一个字典就足够了,然后selenium,

因为是开放教育平台,所以我们用c++爬取了数据,大概抓取的网站有上千个。网页抓取不是一个简单的动作,包括头程序、分析器、分包处理、数据库、web服务等等。如何给爬虫设置合理的语言和界面之间关系,是非常复杂的。因此,我们作为网站管理者(包括前端设计师)、前端工程师都非常重视这个问题。常规的做法:用java、python、js等前端语言爬取不同网站发布的链接数据,然后合并起来。
也有一些直接用php转成脚本后用scrapy抓取。我们根据自己爬取的链接,对数据进行分析,提取用户画像,数据量都挺多的。大概就是这些。
python抓取网页数据库django中控制文章中数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-07-16 13:01
python抓取网页数据库django中控制文章django中数据库没有django2的多变表的配置抓取以前发表的文章对旧文章进行删除对新文章进行添加在文章列表页面添加相关字段username和passwordpassword为文章的密码post表单请求网站posturl=''#headertype='text/plain'method='post'#添加版权信息content-type='application/x-www-form-urlencoded'#发送多重域名请求时指定url的类型postmethod='locate'postsuccesskey='xxx'#responseheaders={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responseheaders={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responsebody={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/53 查看全部
python抓取网页数据库django中控制文章中数据
python抓取网页数据库django中控制文章django中数据库没有django2的多变表的配置抓取以前发表的文章对旧文章进行删除对新文章进行添加在文章列表页面添加相关字段username和passwordpassword为文章的密码post表单请求网站posturl=''#headertype='text/plain'method='post'#添加版权信息content-type='application/x-www-form-urlencoded'#发送多重域名请求时指定url的类型postmethod='locate'postsuccesskey='xxx'#responseheaders={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。

4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responseheaders={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responsebody={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/53
Python爬虫入门教程 21-100 网易云课堂课程数据抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-06-18 13:16
网易云课堂课程数据-写在前面
今天咱们抓取一下网易云课堂的课程数据,这个网站的数据量并不是很大,我们只需要使用requests就可以快速的抓取到这部分数据了。 你第一步要做的是打开全部课程的地址,找出爬虫规律,
地址如下:
我简单的看了一下,页面数据是基于这个地址进行异步加载的。你自己尝试的时候需要借助开发者工具进行多次尝试,抓取到这个地址的数据为准。
还有一个地方需要注意,这次是post提交方式,并且提交数据是payload类型的,这个原因导致我们的代码和以前的略微有一些不同的地方。
提取post关键字,看一下各个参数的意思,如果你爬取的网站足够多,那么训练出来的敏感度能够快速的分析这些参数
<p>{"pageIndex":55, # 页码
"pageSize":50, # 每页数据大小
"relativeOffset":2700,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":"" # 搜索相关
}</p>
好了,可以开始编写代码了,核心的代码就是通过requests模块发送post请求
<p>def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageIndex":index,
"pageSize":50,
"relativeOffset":50,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":""
}
headers = {"Accept":"application/json",
"Host":"study.163.com",
"Origin":"https://study.163.com",
"Content-Type":"application/json",
"Referer":"https://study.163.com/courses",
"User-Agent":"自己去找个浏览器UA"
}
try:
# 请注意这个地方发送的是post请求
# CSDN 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except Exception as e:
print("出现BUG了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]</p>
因为获取到的数据是json类型的,所以,数据可以快速的保存到mongodb里面,保存数据的代码我依旧留空,希望你自己可以完善。
通过很短的时间,我们就捕获到了3000门课程
好了,需要代码和数据,请评论留下我能联系你的方式即可。
选哪个长按哪个二维码即可
小小的备注:如果你发现在手机上看源码不是很方便,可以点击收藏,然后在电脑端微信就可以查阅啦~ 完美格式呈现
欢迎关注:非本科程序员 公众账号
查看全部
Python爬虫入门教程 21-100 网易云课堂课程数据抓取
网易云课堂课程数据-写在前面
今天咱们抓取一下网易云课堂的课程数据,这个网站的数据量并不是很大,我们只需要使用requests就可以快速的抓取到这部分数据了。 你第一步要做的是打开全部课程的地址,找出爬虫规律,
地址如下:
我简单的看了一下,页面数据是基于这个地址进行异步加载的。你自己尝试的时候需要借助开发者工具进行多次尝试,抓取到这个地址的数据为准。
还有一个地方需要注意,这次是post提交方式,并且提交数据是payload类型的,这个原因导致我们的代码和以前的略微有一些不同的地方。
提取post关键字,看一下各个参数的意思,如果你爬取的网站足够多,那么训练出来的敏感度能够快速的分析这些参数
<p>{"pageIndex":55, # 页码
"pageSize":50, # 每页数据大小
"relativeOffset":2700,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":"" # 搜索相关
}</p>
好了,可以开始编写代码了,核心的代码就是通过requests模块发送post请求
<p>def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageIndex":index,
"pageSize":50,
"relativeOffset":50,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":""
}
headers = {"Accept":"application/json",
"Host":"study.163.com",
"Origin":"https://study.163.com",
"Content-Type":"application/json",
"Referer":"https://study.163.com/courses",
"User-Agent":"自己去找个浏览器UA"
}
try:
# 请注意这个地方发送的是post请求
# CSDN 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except Exception as e:
print("出现BUG了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]</p>
因为获取到的数据是json类型的,所以,数据可以快速的保存到mongodb里面,保存数据的代码我依旧留空,希望你自己可以完善。
通过很短的时间,我们就捕获到了3000门课程
好了,需要代码和数据,请评论留下我能联系你的方式即可。
选哪个长按哪个二维码即可
小小的备注:如果你发现在手机上看源码不是很方便,可以点击收藏,然后在电脑端微信就可以查阅啦~ 完美格式呈现
欢迎关注:非本科程序员 公众账号
介绍python 数据抓取三种方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-06-04 23:49
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = ''page_content = download(url)country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('
(.*?)
', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = ''html = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = ''page_content = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。 查看全部
介绍python 数据抓取三种方法
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = ''page_content = download(url)country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('
(.*?)
', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = ''html = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = ''page_content = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
用 Python 抓取 bilibili 弹幕并分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-01 03:29
作者| GitPython
时隔一年,嵩哥带来他的新作《雨幕》。
他依旧认真创作,追求高品质,作品在发表之前已听了五百遍以上。
如此高品质的音乐,大家如何评价呢?通过哔哩哔哩上的视频弹幕,感受一下。
01实现思路
首先,利用哔哩哔哩的弹幕接口,把数据保存到本地。接着,对数据进行分词。最后,做了评论的可视化。
02弹幕数据
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的。
比如:
一个固定的url地址 + 视频的cid + .xml
只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?
右键网页,打开网页源代码,搜索 "cid":就能找到:
03保存数据到本地
有了数据的接口链接,我们就可以利用request模块,获取数据了。
然后,再利用xpath简单的解析xml,就可以把所有的弹幕信息汇总到一个列表里了。最后,把列表转化成dataframe,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 许嵩新歌《雨幕》<br /># bilibili视频弹幕文件<br />url = 'https://comment.bilibili.com/123072475.xml'<br /><br /># 发送请求<br />response = requests.get(url)<br />xml = etree.fromstring(response.content)<br /><br /># 解析数据<br />dm = xml.xpath("/i/d/text()")<br />print(dm) # list<br /><br /># 把列表转换成 dataframe<br />dm_df = pd.DataFrame(dm, columns=['弹幕内容'])<br />print(dm_df)<br /><br /># 存到本地<br /># 解决了中文乱码问题<br />dm_df.to_csv('雨幕-弹幕.csv', encoding='utf_8_sig')<br /></p>
保存的csv数据:
04对数据进行分词
制作词云前,需要把弹幕数据进行分词。
关于jieba分词,可以参考:
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># jieba分词<br />dm_str = " ".join(dm)<br />words_list = jieba.lcut(dm_str) # 切分的是字符串,返回的是列表<br />words_str = " ".join(words_list)<br /></p>
05词云可视化
通过创建词云对象、设置词云参数,最终生成图片,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 读取本地文件<br />backgroud_Image = plt.imread('1.jpg')<br /><br /># 创建词云<br />wc = WordCloud(<br /> background_color='white',<br /> mask=backgroud_Image,<br /> font_path='./SourceHanSerifCN-Medium.otf', # 设置本地字体<br /><br /> max_words=2000,<br /> max_font_size=100,<br /> min_font_size=10,<br /> color_func=random_color_func,<br /> random_state=50,<br />)<br /><br />word_cloud = wc.generate(words_str) # 产生词云<br />word_cloud.to_file("yumu.jpg") #保存图片<br /></p>
<p style="margin-right: 16px;margin-left: 16px;white-space: normal;line-height: 1.75em;"><br />
</p> 查看全部
用 Python 抓取 bilibili 弹幕并分析
作者| GitPython
时隔一年,嵩哥带来他的新作《雨幕》。
他依旧认真创作,追求高品质,作品在发表之前已听了五百遍以上。
如此高品质的音乐,大家如何评价呢?通过哔哩哔哩上的视频弹幕,感受一下。
01实现思路
首先,利用哔哩哔哩的弹幕接口,把数据保存到本地。接着,对数据进行分词。最后,做了评论的可视化。
02弹幕数据
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的。
比如:
一个固定的url地址 + 视频的cid + .xml
只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?
右键网页,打开网页源代码,搜索 "cid":就能找到:
03保存数据到本地
有了数据的接口链接,我们就可以利用request模块,获取数据了。
然后,再利用xpath简单的解析xml,就可以把所有的弹幕信息汇总到一个列表里了。最后,把列表转化成dataframe,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 许嵩新歌《雨幕》<br /># bilibili视频弹幕文件<br />url = 'https://comment.bilibili.com/123072475.xml'<br /><br /># 发送请求<br />response = requests.get(url)<br />xml = etree.fromstring(response.content)<br /><br /># 解析数据<br />dm = xml.xpath("/i/d/text()")<br />print(dm) # list<br /><br /># 把列表转换成 dataframe<br />dm_df = pd.DataFrame(dm, columns=['弹幕内容'])<br />print(dm_df)<br /><br /># 存到本地<br /># 解决了中文乱码问题<br />dm_df.to_csv('雨幕-弹幕.csv', encoding='utf_8_sig')<br /></p>
保存的csv数据:
04对数据进行分词
制作词云前,需要把弹幕数据进行分词。
关于jieba分词,可以参考:
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># jieba分词<br />dm_str = " ".join(dm)<br />words_list = jieba.lcut(dm_str) # 切分的是字符串,返回的是列表<br />words_str = " ".join(words_list)<br /></p>
05词云可视化
通过创建词云对象、设置词云参数,最终生成图片,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 读取本地文件<br />backgroud_Image = plt.imread('1.jpg')<br /><br /># 创建词云<br />wc = WordCloud(<br /> background_color='white',<br /> mask=backgroud_Image,<br /> font_path='./SourceHanSerifCN-Medium.otf', # 设置本地字体<br /><br /> max_words=2000,<br /> max_font_size=100,<br /> min_font_size=10,<br /> color_func=random_color_func,<br /> random_state=50,<br />)<br /><br />word_cloud = wc.generate(words_str) # 产生词云<br />word_cloud.to_file("yumu.jpg") #保存图片<br /></p>
<p style="margin-right: 16px;margin-left: 16px;white-space: normal;line-height: 1.75em;"><br />
用Python爬网页需要了解什么背景知识
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 22:36
在知乎上有一位同学提出的问题:用Python爬网页需要了解什么背景知识,恰好我对爬虫有所了解,所以昨天晚上做了回答,今天放到公众号上面希望对大家有所帮助,如有帮助欢迎转发。
文中涉及到一些教程链接在本篇文章无法打开,可以点击阅读原文查看我在知乎上的原回答,也欢迎大家给我的回答点赞。
要学会使用Python爬取网页信息无外乎以下几点内容:
1、要会Python
2、知道网页信息如何呈现
3、了解网页信息如何产生
4、学会如何提取网页信息
第一步Python是工具,所以你必须熟练掌握它,要掌握到什么程度呢?如果你只想写一写简单的爬虫,不要炫技不考虑爬虫效率,你只需要掌握:
你甚至不需要掌握函数、异步、多线程、多进程,当然如果想要提高自己小爬虫的爬虫效率,提高数据的精确性,那么记住最好的方式是去系统的学习一遍Python,去哪儿学习?Python教程
假设你已经熟悉了最基础的Python知识,那么进入第二步:知道网页信息如何呈现?你首先要知道所需要抓取的数据是怎样的呈现的,就像是你想要学做一幅画,在开始之前你要知道这幅画是用什么画出来的,铅笔还是水彩笔...等等,可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:
1、HTML (HTML 简介)
2、JSON (JSON 简介)
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
假设你现在知道了数据是由HTML和JSON呈现出来的,那么我们紧接着第三步:数据怎么来?数据当然是从服务器反馈给你的,为什么要反馈给你?因为你发出了请求。
“Hi~ ,服务器我要这个资源”
“正在传输中...”
“已经收到HTML或者JSON格式的数据”
这是什么请求?要搞清楚这一点你需要了解一下http的基础知识,更加精确来说你需要去了解GET和POST是什么,区别是什么。也许你可以看看这个:浅谈HTTP中Get与Post的区别 - hyddd - 博客园
很高兴你使用的是Python,那么你只需要去掌握好快速上手 - Requests 2.10.0 文档,requests可以帮你模拟发出GET和POST请求,这真是太棒了。
饭菜已经备好,两菜一汤美味佳肴,下面就是好好享受了。现在我们已经拿到了数据,我们需要在这些错乱的数据中提取我们需要的数据,这时候我们有两个选择。
第一招:万能钥匙
Python正则表达式指南 ,再大再乱的内容,哪怕是大海捞针,只要告诉我这个针的样子我都能从茫茫大海中捞出来,强大的正则表达式是你提取数据的不二之选。
第二招:笑里藏刀
Beautiful Soup 4.2.0 文档,或许我们有更好的选择,我们把原始数据和我们想要的数据的样子扔个这个Beautifulsoup,然后让它帮我们去寻找,这也是一个不错的方案,但是论灵活性,第二招还是略逊于第一招。
第三招:双剑合璧
最厉害的招式莫过于结合第一招和第二招了,打破天下无敌手。
基础知识我都会,可是我还是写不了一个爬虫啊!
客观别急,这还没完。
以下这些项目,你拿来学习学习练练手。
两个教学项目你值得拥有:
还不够?这儿有很多:
偶遇一个段子
查看全部
用Python爬网页需要了解什么背景知识
在知乎上有一位同学提出的问题:用Python爬网页需要了解什么背景知识,恰好我对爬虫有所了解,所以昨天晚上做了回答,今天放到公众号上面希望对大家有所帮助,如有帮助欢迎转发。
文中涉及到一些教程链接在本篇文章无法打开,可以点击阅读原文查看我在知乎上的原回答,也欢迎大家给我的回答点赞。
要学会使用Python爬取网页信息无外乎以下几点内容:
1、要会Python
2、知道网页信息如何呈现
3、了解网页信息如何产生
4、学会如何提取网页信息
第一步Python是工具,所以你必须熟练掌握它,要掌握到什么程度呢?如果你只想写一写简单的爬虫,不要炫技不考虑爬虫效率,你只需要掌握:
你甚至不需要掌握函数、异步、多线程、多进程,当然如果想要提高自己小爬虫的爬虫效率,提高数据的精确性,那么记住最好的方式是去系统的学习一遍Python,去哪儿学习?Python教程
假设你已经熟悉了最基础的Python知识,那么进入第二步:知道网页信息如何呈现?你首先要知道所需要抓取的数据是怎样的呈现的,就像是你想要学做一幅画,在开始之前你要知道这幅画是用什么画出来的,铅笔还是水彩笔...等等,可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:
1、HTML (HTML 简介)
2、JSON (JSON 简介)
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
假设你现在知道了数据是由HTML和JSON呈现出来的,那么我们紧接着第三步:数据怎么来?数据当然是从服务器反馈给你的,为什么要反馈给你?因为你发出了请求。
“Hi~ ,服务器我要这个资源”
“正在传输中...”
“已经收到HTML或者JSON格式的数据”
这是什么请求?要搞清楚这一点你需要了解一下http的基础知识,更加精确来说你需要去了解GET和POST是什么,区别是什么。也许你可以看看这个:浅谈HTTP中Get与Post的区别 - hyddd - 博客园
很高兴你使用的是Python,那么你只需要去掌握好快速上手 - Requests 2.10.0 文档,requests可以帮你模拟发出GET和POST请求,这真是太棒了。
饭菜已经备好,两菜一汤美味佳肴,下面就是好好享受了。现在我们已经拿到了数据,我们需要在这些错乱的数据中提取我们需要的数据,这时候我们有两个选择。
第一招:万能钥匙
Python正则表达式指南 ,再大再乱的内容,哪怕是大海捞针,只要告诉我这个针的样子我都能从茫茫大海中捞出来,强大的正则表达式是你提取数据的不二之选。
第二招:笑里藏刀
Beautiful Soup 4.2.0 文档,或许我们有更好的选择,我们把原始数据和我们想要的数据的样子扔个这个Beautifulsoup,然后让它帮我们去寻找,这也是一个不错的方案,但是论灵活性,第二招还是略逊于第一招。
第三招:双剑合璧
最厉害的招式莫过于结合第一招和第二招了,打破天下无敌手。
基础知识我都会,可是我还是写不了一个爬虫啊!
客观别急,这还没完。
以下这些项目,你拿来学习学习练练手。
两个教学项目你值得拥有:
还不够?这儿有很多:
偶遇一个段子
python数据抓取3种方法总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-09 04:31
这篇文章主要给大家介绍了关于python数据抓取的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
三种数据抓取的方法
*利用之前构建的下载网页函数,获取目标网页的html,我们以为例,获取html。
<p>from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)</p>
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
<p>from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])</p>
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.BeautifulSoup(bs4)
<p>from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)</p>
3.lxml
<p>from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')</p>
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
扫下方二维码加老师微信 查看全部
python数据抓取3种方法总结
这篇文章主要给大家介绍了关于python数据抓取的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
三种数据抓取的方法
*利用之前构建的下载网页函数,获取目标网页的html,我们以为例,获取html。
<p>from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)</p>
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
<p>from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])</p>
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.BeautifulSoup(bs4)
<p>from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)</p>
3.lxml
<p>from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')</p>
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
扫下方二维码加老师微信
Python使用xslt提取网页数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-09 04:30
1 引言
在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml格式。
2 用lxml库实现网页内容提取
lxml是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
这2天测试了在python中通过xslt来提取网页内容,记录如下:
2.1 抓取目标
假设要提取集搜客官网旧版论坛的帖子标题和回复数,如下图,要把整个列表提取出来,存成xml格式
2.2 源代码1:
只抓当前页,结果显示在控制台
Python的优势是用很少量代码就能解决一个问题,请注意下面的代码看起来很长,其实python函数调用没有几个,大篇幅被一个xslt脚本占去了,在这段代码中,只是一个好长的字符串而已,至于为什么选择xslt,而不是离散的xpath或者让人挠头的正则表达式,请参看Python即时网络爬虫项目启动说明,我们期望通过这个架构,把程序员的时间节省下来一大半。
可以拷贝运行下面的代码(在windows10, python3.2下测试通过):
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeurl="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)doc = etree.HTML(conn.read())xslt_root = etree.XML("""\""")transform = etree.XSLT(xslt_root)result_tree = transform(doc)print(result_tree)<br /></p>
源代码下载地址请见文章末尾的GitHub源。
2.3 抓取结果
得到的抓取结果如下图:
2.4 源代码2:
翻页抓取,结果存入文件
我们对2.2的代码再做进一步修改,增加翻页抓取和存结果文件功能,代码如下:
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeimport timexslt_root = etree.XML("""\""")baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):<br /> url = baseurl + "?page=" + str(count)<br /> conn = request.urlopen(url)<br /> doc = etree.HTML(conn.read())<br /> transform = etree.XSLT(xslt_root)<br /> result_tree = transform(doc)<br /> print(str(result_tree))<br /> file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')<br /> file_obj.write(str(result_tree))<br /> file_obj.close()<br /> count += 1<br /> time.sleep(2)<br /></p>
我们增加了写文件的代码,还增加了一个循环,构造每个翻页的网址,但是,如果翻页过程中网址总是不变怎么办?其实这就是动态网页内容,下面会讨论这个问题。
3总结
这是开源Python通用爬虫项目的验证过程,在一个爬虫框架里面,其它部分都容易做成通用的,就是网页内容提取和转换成结构化的操作难于通用,我们称之为提取器。但是,借助GooSeeker可视化提取规则生成器MS谋数台 ,提取器的生成过程将变得很便捷,而且可以标准化插入,从而实现通用爬虫,在后续的文章中会专门讲解MS谋数台与Python配合的具体方法。
End.
作者:fullerhua(中国统计网特邀认证作者)
本文为中国统计网原创文章,需要转载请联系中国统计网( ),转载时请注明作者及出处,并保留本文链接。
更多精彩,长按下方图片中的二维码,下载APP查看。
查看全部
Python使用xslt提取网页数据
1 引言
在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml格式。
2 用lxml库实现网页内容提取
lxml是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
这2天测试了在python中通过xslt来提取网页内容,记录如下:
2.1 抓取目标
假设要提取集搜客官网旧版论坛的帖子标题和回复数,如下图,要把整个列表提取出来,存成xml格式
2.2 源代码1:
只抓当前页,结果显示在控制台
Python的优势是用很少量代码就能解决一个问题,请注意下面的代码看起来很长,其实python函数调用没有几个,大篇幅被一个xslt脚本占去了,在这段代码中,只是一个好长的字符串而已,至于为什么选择xslt,而不是离散的xpath或者让人挠头的正则表达式,请参看Python即时网络爬虫项目启动说明,我们期望通过这个架构,把程序员的时间节省下来一大半。
可以拷贝运行下面的代码(在windows10, python3.2下测试通过):
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeurl="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)doc = etree.HTML(conn.read())xslt_root = etree.XML("""\""")transform = etree.XSLT(xslt_root)result_tree = transform(doc)print(result_tree)<br /></p>
源代码下载地址请见文章末尾的GitHub源。
2.3 抓取结果
得到的抓取结果如下图:
2.4 源代码2:
翻页抓取,结果存入文件
我们对2.2的代码再做进一步修改,增加翻页抓取和存结果文件功能,代码如下:
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeimport timexslt_root = etree.XML("""\""")baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):<br /> url = baseurl + "?page=" + str(count)<br /> conn = request.urlopen(url)<br /> doc = etree.HTML(conn.read())<br /> transform = etree.XSLT(xslt_root)<br /> result_tree = transform(doc)<br /> print(str(result_tree))<br /> file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')<br /> file_obj.write(str(result_tree))<br /> file_obj.close()<br /> count += 1<br /> time.sleep(2)<br /></p>
我们增加了写文件的代码,还增加了一个循环,构造每个翻页的网址,但是,如果翻页过程中网址总是不变怎么办?其实这就是动态网页内容,下面会讨论这个问题。
3总结
这是开源Python通用爬虫项目的验证过程,在一个爬虫框架里面,其它部分都容易做成通用的,就是网页内容提取和转换成结构化的操作难于通用,我们称之为提取器。但是,借助GooSeeker可视化提取规则生成器MS谋数台 ,提取器的生成过程将变得很便捷,而且可以标准化插入,从而实现通用爬虫,在后续的文章中会专门讲解MS谋数台与Python配合的具体方法。
End.
作者:fullerhua(中国统计网特邀认证作者)
本文为中国统计网原创文章,需要转载请联系中国统计网( ),转载时请注明作者及出处,并保留本文链接。
更多精彩,长按下方图片中的二维码,下载APP查看。
python抓取网页数据 “经阅Sharing”|第一期活动回顾
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-05-04 02:40
2022年4月30日晚,由经济学院研究生会主办的第一期“经阅Sharing”学术分享活动在线上举办。本次活动中,经济学院2020级博士研究生赵文天以“Python爬虫实用技能——从入门到进阶”为主题进行了分享。
主讲人首先介绍了爬虫的基本功能和实现原理:爬虫是一种从众多公开网站中抓取数据的程序,在现今各个领域的学术研究中被广泛地应用。其次介绍了浏览器、HTML与web请求过程:浏览器将承载着包括对象、属性和过程等信息的HTML语言,翻译成人们可阅读的网页信息。这一过程可以分解为两步:第一步客户端向服务器发送请求信息;第二步服务器向客户端返回请求信息所要求的网页代码(HTML)和数据。
随后,主讲人为我们介绍了爬虫程序实现思路。核心就是用程序模拟浏览器的行为,向服务器发送请求,并接收对应的信息,最终再提取出我们想要的数据。主讲人以百度网页为例,向我们展示了在我们如何获取浏览器向服务器发送的请求指令,以及如何从指令中寻找规律,得到我们想要的结果。
之后,主讲人开始演示爬虫的具体操作,分别以百度网页和中国知网为例,详细地介绍了利用requests库爬取同步加载和异步加载数据的主要思路,以及在这过程中可能遇到的问题和解决方式。
除此之外,主讲人还介绍了另一种爬虫库——selenium,比对了两种爬虫库在应用上的不同与优劣,并且还向我们介绍了re正则表达式语言,展示了该语言与requests相结合进行爬虫的主要方法。
最后,主讲人与同学们就平时学习以及实践过程中的疑问进行交流,和同学们分享了自己在爬虫方面的诸多经验。本次“经阅Sharing”在大家的热烈讨论中结束。
本学期首次“经阅Sharing”举办活动圆满成功,之后会陆续推出技能介绍与经验分享等学术活动,欢迎大家持续关注!
文案|杨惠婷
经济学院研究生会学术部供稿
查看全部
python抓取网页数据 “经阅Sharing”|第一期活动回顾
2022年4月30日晚,由经济学院研究生会主办的第一期“经阅Sharing”学术分享活动在线上举办。本次活动中,经济学院2020级博士研究生赵文天以“Python爬虫实用技能——从入门到进阶”为主题进行了分享。
主讲人首先介绍了爬虫的基本功能和实现原理:爬虫是一种从众多公开网站中抓取数据的程序,在现今各个领域的学术研究中被广泛地应用。其次介绍了浏览器、HTML与web请求过程:浏览器将承载着包括对象、属性和过程等信息的HTML语言,翻译成人们可阅读的网页信息。这一过程可以分解为两步:第一步客户端向服务器发送请求信息;第二步服务器向客户端返回请求信息所要求的网页代码(HTML)和数据。
随后,主讲人为我们介绍了爬虫程序实现思路。核心就是用程序模拟浏览器的行为,向服务器发送请求,并接收对应的信息,最终再提取出我们想要的数据。主讲人以百度网页为例,向我们展示了在我们如何获取浏览器向服务器发送的请求指令,以及如何从指令中寻找规律,得到我们想要的结果。
之后,主讲人开始演示爬虫的具体操作,分别以百度网页和中国知网为例,详细地介绍了利用requests库爬取同步加载和异步加载数据的主要思路,以及在这过程中可能遇到的问题和解决方式。
除此之外,主讲人还介绍了另一种爬虫库——selenium,比对了两种爬虫库在应用上的不同与优劣,并且还向我们介绍了re正则表达式语言,展示了该语言与requests相结合进行爬虫的主要方法。
最后,主讲人与同学们就平时学习以及实践过程中的疑问进行交流,和同学们分享了自己在爬虫方面的诸多经验。本次“经阅Sharing”在大家的热烈讨论中结束。
本学期首次“经阅Sharing”举办活动圆满成功,之后会陆续推出技能介绍与经验分享等学术活动,欢迎大家持续关注!
文案|杨惠婷
经济学院研究生会学术部供稿
用python绘制一张炫酷的玫瑰图!
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-05-03 04:10
网上冲浪时看到了一张很炫酷的南丁格尔玫瑰图,显示了国外主流流媒体平台的订阅人数排行,顿时来了兴趣,咱也用python 来绘制一张!
话不多说,先上原图:
再来看下代码复现的效果:
可以看到,图形主体得到了完美的复现,仅需要在此基础上增加标题、文字说明和服务商logo即可,这些步骤可以在PS 或 AI 中进行,修图可以让你的玫瑰图更完美!
本文介绍使用pyecharts 绘制南丁格尔玫瑰图的过程,即代码实现部分,不过在绘制之前需要获取网页数据,所以,整篇文章分为数据获取和图形绘制两部分。预计阅读时间9分钟。
01
获取网页数据
以上是图表和数据来源网页,其数据是以分页形式展示的,需要进行翻页,点击next 看到所有数据。
这里,我们获取网页数据的工具是Selenium, 这是一款超级好用的自动化测试工具,可以模拟人类对浏览器的操作,实现对所有网页元素的定位和抓取,即可见即可得。
首先安装 selenium(pip install selenium)和浏览器驱动程序webdriver(建议下载与谷歌浏览器和对应版本的chrome webdriver)。
安装好之后,对数据的获取可以分3步走:
启动webdriver, 打开网页
定位标题和下载图片
获取当前页数据,并实现翻页,获取所有数据
代码展示:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport requestsimport csvimport time# 01. 启动 webdirver, 打开网页browser = webdriver.Chrome('/usr/local/chromedriver')# 此处填入自己的webdriver exe 的文件路径browser.get('https://www.visualcapitalist.com/which-streaming-service-has-the-most-subscriptions/')browser.implicitly_wait(5) # 等待内容加载完毕# 02. 获取标题和下载图片title = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > h1').text + '.jpg'pic = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > span > p:nth-child(1) > img').get_attribute('src')res = requests.get(pic).contentimagepath = './' + titlewith open(imagepath, 'wb') as fp: fp.write(res)time.sleep(2)# 03. 点击翻页,获取所有数据with open('./data.csv', 'a') as f: writer = csv.writer(f) writer.writerow(['services', 'subscribers','types'])for i in range(1,4): services = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-1') types = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-2') subscribers = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-3') column1 = [] column2 = [] column3 = [] for service in services: column1.append(service.text.strip()) for subscriber in subscribers: column2.append(subscriber.text.strip()) for type in types: column3.append(type.text.strip()) lis = [] for i in zip(column1, column2,column3): lis.append(list(i)) with open('./data.csv','a') as f: writer = csv.writer(f) writer.writerows(lis) next_button =browser.find_element(By.XPATH,'//*[@id="tablepress-1461_next"]') next_button.click()# 以上两行实现翻页,获取所有数据print('数据成功获取')browser.quit()# 获取完毕,关闭网页
成功获取的数据存在csv 文件中:
02
绘制玫瑰图
有了数据,自然就可以使用工具来绘制玫瑰图了,这里我们使用的是pyecharts里的饼图类 Pie.
import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as opts<br /># 01. 读取并整理数据data = pd.read_csv('data.csv',header=1)data = data.drop_duplicates(keep=False)data = data.reset_index(drop=True)data['subscribers'] = data['subscribers'].str.replace('M','')data['subscribers'] = data['subscribers'].astype('float').round()x_data = data['services']y_data = data['subscribers']# 自定义颜色,根据服务商类型提供4种颜色,可以在ps中打开原图,获取颜色的十六进制代码color_dic = {'Video':'#fbf3dc', 'Audio':'#1b1718', 'Video/Audio':'#833100', 'News':'#f1a15c' }data['colors'] = data['types'].map(color_dic)# 准备数据对data_pairdf = [list(z) for z in zip(x_data,y_data)]# print(df)# 02. 使用 pyecharts Pie 绘制玫瑰图pie = Pie(init_opts=opts.InitOpts(bg_color='#d66f0a',width='650px',height='1000px'))pie.add(series_name='services', data_pair=df, radius=['12%','200%'],#设置内圆和外圆的半径 center=['35%','70%'], #设置圆的位置 rosetype='area',) # 关键步骤!设置类型为area, 会展示为玫瑰图pie.set_global_opts( legend_opts=opts.LegendOpts(is_show=False), #不显示图例 )pie.set_series_opts( label_opts=opts.LabelOpts(position='inside', # 标签位置 rotate = 45, font_size = 14, # 字体大小 formatter="{c}",color = '#d66f0a') # 标签格式 )pie.set_colors(list(data['colors'])) # 渲染颜色pie.render('streaming war.html') #出图<br />
至此,就可以得到一张网页图形,后续可使用PS AI PPT等工具进行图表元素的完善,本文不作展示。想要追求100%复现的同学可以自行探索~
03
总结一下
实现炫酷的玫瑰图,可以分为两步:
获取数据,难点在于使用selenium 定位全部数据,需要用for 循环配合点击Next 按钮完成。
绘制数据,关键在于数据格式的整理,以及将饼图的rosetype 设为area 。
欢迎关注本号,可私信获取源码和数据~
END
查看全部
用python绘制一张炫酷的玫瑰图!
网上冲浪时看到了一张很炫酷的南丁格尔玫瑰图,显示了国外主流流媒体平台的订阅人数排行,顿时来了兴趣,咱也用python 来绘制一张!
话不多说,先上原图:
再来看下代码复现的效果:
可以看到,图形主体得到了完美的复现,仅需要在此基础上增加标题、文字说明和服务商logo即可,这些步骤可以在PS 或 AI 中进行,修图可以让你的玫瑰图更完美!
本文介绍使用pyecharts 绘制南丁格尔玫瑰图的过程,即代码实现部分,不过在绘制之前需要获取网页数据,所以,整篇文章分为数据获取和图形绘制两部分。预计阅读时间9分钟。
01
获取网页数据
以上是图表和数据来源网页,其数据是以分页形式展示的,需要进行翻页,点击next 看到所有数据。
这里,我们获取网页数据的工具是Selenium, 这是一款超级好用的自动化测试工具,可以模拟人类对浏览器的操作,实现对所有网页元素的定位和抓取,即可见即可得。
首先安装 selenium(pip install selenium)和浏览器驱动程序webdriver(建议下载与谷歌浏览器和对应版本的chrome webdriver)。
安装好之后,对数据的获取可以分3步走:
启动webdriver, 打开网页
定位标题和下载图片
获取当前页数据,并实现翻页,获取所有数据
代码展示:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport requestsimport csvimport time# 01. 启动 webdirver, 打开网页browser = webdriver.Chrome('/usr/local/chromedriver')# 此处填入自己的webdriver exe 的文件路径browser.get('https://www.visualcapitalist.com/which-streaming-service-has-the-most-subscriptions/')browser.implicitly_wait(5) # 等待内容加载完毕# 02. 获取标题和下载图片title = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > h1').text + '.jpg'pic = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > span > p:nth-child(1) > img').get_attribute('src')res = requests.get(pic).contentimagepath = './' + titlewith open(imagepath, 'wb') as fp: fp.write(res)time.sleep(2)# 03. 点击翻页,获取所有数据with open('./data.csv', 'a') as f: writer = csv.writer(f) writer.writerow(['services', 'subscribers','types'])for i in range(1,4): services = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-1') types = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-2') subscribers = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-3') column1 = [] column2 = [] column3 = [] for service in services: column1.append(service.text.strip()) for subscriber in subscribers: column2.append(subscriber.text.strip()) for type in types: column3.append(type.text.strip()) lis = [] for i in zip(column1, column2,column3): lis.append(list(i)) with open('./data.csv','a') as f: writer = csv.writer(f) writer.writerows(lis) next_button =browser.find_element(By.XPATH,'//*[@id="tablepress-1461_next"]') next_button.click()# 以上两行实现翻页,获取所有数据print('数据成功获取')browser.quit()# 获取完毕,关闭网页
成功获取的数据存在csv 文件中:
02
绘制玫瑰图
有了数据,自然就可以使用工具来绘制玫瑰图了,这里我们使用的是pyecharts里的饼图类 Pie.
import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as opts<br /># 01. 读取并整理数据data = pd.read_csv('data.csv',header=1)data = data.drop_duplicates(keep=False)data = data.reset_index(drop=True)data['subscribers'] = data['subscribers'].str.replace('M','')data['subscribers'] = data['subscribers'].astype('float').round()x_data = data['services']y_data = data['subscribers']# 自定义颜色,根据服务商类型提供4种颜色,可以在ps中打开原图,获取颜色的十六进制代码color_dic = {'Video':'#fbf3dc', 'Audio':'#1b1718', 'Video/Audio':'#833100', 'News':'#f1a15c' }data['colors'] = data['types'].map(color_dic)# 准备数据对data_pairdf = [list(z) for z in zip(x_data,y_data)]# print(df)# 02. 使用 pyecharts Pie 绘制玫瑰图pie = Pie(init_opts=opts.InitOpts(bg_color='#d66f0a',width='650px',height='1000px'))pie.add(series_name='services', data_pair=df, radius=['12%','200%'],#设置内圆和外圆的半径 center=['35%','70%'], #设置圆的位置 rosetype='area',) # 关键步骤!设置类型为area, 会展示为玫瑰图pie.set_global_opts( legend_opts=opts.LegendOpts(is_show=False), #不显示图例 )pie.set_series_opts( label_opts=opts.LabelOpts(position='inside', # 标签位置 rotate = 45, font_size = 14, # 字体大小 formatter="{c}",color = '#d66f0a') # 标签格式 )pie.set_colors(list(data['colors'])) # 渲染颜色pie.render('streaming war.html') #出图<br />
至此,就可以得到一张网页图形,后续可使用PS AI PPT等工具进行图表元素的完善,本文不作展示。想要追求100%复现的同学可以自行探索~
03
总结一下
实现炫酷的玫瑰图,可以分为两步:
获取数据,难点在于使用selenium 定位全部数据,需要用for 循环配合点击Next 按钮完成。
绘制数据,关键在于数据格式的整理,以及将饼图的rosetype 设为area 。
欢迎关注本号,可私信获取源码和数据~
END
Python之父推荐!《Python 3网络爬虫开发实战》
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-02 19:15
何谓爬虫?网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。要学爬虫,首推的就是 Python 语言,简单快速易上手,且 Python 语言的爬虫生态极其丰富。
随着爬虫技术的不断进步,一些新兴技术的不断兴起,许多书中的一些案例网站和服务早已经改版或者停止维护,很多代码已经不能正常运行。目前市面上的爬虫书,其他的书跟这本书相比,内容方面这本《Python 3网络爬虫开发实战》算是最全的,没有之一。能将最前沿的爬虫技术比如异步、JavaScript 逆向、安卓逆向、智能解析、WebAssembly、Kubernetes 等技术都涵盖的。
为什么说这本书适合小白呢?
1、这本书介绍了学习爬虫之前需要了解的基础知识。如 HTTP、爬虫、代理、网页结构、多进程多线程等内容,可以让我们要做的事情有个了解。
2、深入浅出的介绍了爬虫的“基操”(基本的爬虫操作),最基本的请求库(urllib、requests、httpx)、页面解析库(Beautiful Soup、XPath、pyquery、parsel)和正则表达式的基本用法。
3、还有数据存储的知识介绍:包括 TXT、JSON、CSV 各种文件的存储,以及关系型数据库 MySQL 和非关系型数据库 MongoDB、Redis 的基本存取操作。
这样即便是没有基础,也可以看懂
对比现在市场存在很久的书籍技术过时问题,新上市的《Python3网络爬虫开发实战》可以让我们掌握最新的知识,比较新技术代表效率的提升。
书籍展示:
浅尝目录:
平台限制,需要这本豆瓣评分9.0,科技类人气排行榜第一名的《Python3网络爬虫开发实战》电子书的朋友下图自行领取~ 查看全部
Python之父推荐!《Python 3网络爬虫开发实战》
何谓爬虫?网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。要学爬虫,首推的就是 Python 语言,简单快速易上手,且 Python 语言的爬虫生态极其丰富。
随着爬虫技术的不断进步,一些新兴技术的不断兴起,许多书中的一些案例网站和服务早已经改版或者停止维护,很多代码已经不能正常运行。目前市面上的爬虫书,其他的书跟这本书相比,内容方面这本《Python 3网络爬虫开发实战》算是最全的,没有之一。能将最前沿的爬虫技术比如异步、JavaScript 逆向、安卓逆向、智能解析、WebAssembly、Kubernetes 等技术都涵盖的。
为什么说这本书适合小白呢?
1、这本书介绍了学习爬虫之前需要了解的基础知识。如 HTTP、爬虫、代理、网页结构、多进程多线程等内容,可以让我们要做的事情有个了解。
2、深入浅出的介绍了爬虫的“基操”(基本的爬虫操作),最基本的请求库(urllib、requests、httpx)、页面解析库(Beautiful Soup、XPath、pyquery、parsel)和正则表达式的基本用法。
3、还有数据存储的知识介绍:包括 TXT、JSON、CSV 各种文件的存储,以及关系型数据库 MySQL 和非关系型数据库 MongoDB、Redis 的基本存取操作。
这样即便是没有基础,也可以看懂
对比现在市场存在很久的书籍技术过时问题,新上市的《Python3网络爬虫开发实战》可以让我们掌握最新的知识,比较新技术代表效率的提升。
书籍展示:
浅尝目录:
平台限制,需要这本豆瓣评分9.0,科技类人气排行榜第一名的《Python3网络爬虫开发实战》电子书的朋友下图自行领取~
专业解码 | 爬虫的基本原理:爬虫概述及爬取过程
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-30 01:09
最新
动态
实时
资讯
部门
通知
专业
速递
导语✦
爱学习的小伙伴们,在学习专业知识的你们,是否有过困惑与不解,不要着急,本栏目致力于为同学们指路迷津!
《专业速递》——带你了解大数据的魅力!
一、什么是爬虫
爬虫就是获取网页并提取和保存信息的自动化程序。
1)我们可以把互联网比作一张大网,而爬虫(网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
2)虽然不使用爬虫我们通过手工方式也可以提取网页中的信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序的。爬虫就是代替我们来完成这份工作的自动化程序,它可以在抓取过程中进行各种异常、错误重试等操作,确保爬取持续高效地运行。
二、爬虫爬取过程
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,其主要有如下三个步骤:
1.获取网页:爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息。爬虫首先向网站的服务器发送一个请求,返回的响应体便是网页源代码。Python中提供了许多库(如urllib、requests)来帮助我们实现这个操作,我们可以用这些库来帮助我们实现HTTP请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的Body部分即可,即得到网页的源代码。
2.提取信息:获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
3.保存数据:提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL和MongoDB等,也可以保存至远程服务器,如借助SFTP进行操作等。
今日的爬虫介绍就先告一段落啦,最后感谢大家的阅读,希望同学们在课后能够自主学习,扩展有关爬虫方面的相关知识。 查看全部
专业解码 | 爬虫的基本原理:爬虫概述及爬取过程
最新
动态
实时
资讯
部门
通知
专业
速递
导语✦
爱学习的小伙伴们,在学习专业知识的你们,是否有过困惑与不解,不要着急,本栏目致力于为同学们指路迷津!
《专业速递》——带你了解大数据的魅力!
一、什么是爬虫
爬虫就是获取网页并提取和保存信息的自动化程序。
1)我们可以把互联网比作一张大网,而爬虫(网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
2)虽然不使用爬虫我们通过手工方式也可以提取网页中的信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序的。爬虫就是代替我们来完成这份工作的自动化程序,它可以在抓取过程中进行各种异常、错误重试等操作,确保爬取持续高效地运行。
二、爬虫爬取过程
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,其主要有如下三个步骤:
1.获取网页:爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息。爬虫首先向网站的服务器发送一个请求,返回的响应体便是网页源代码。Python中提供了许多库(如urllib、requests)来帮助我们实现这个操作,我们可以用这些库来帮助我们实现HTTP请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的Body部分即可,即得到网页的源代码。
2.提取信息:获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
3.保存数据:提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL和MongoDB等,也可以保存至远程服务器,如借助SFTP进行操作等。
今日的爬虫介绍就先告一段落啦,最后感谢大家的阅读,希望同学们在课后能够自主学习,扩展有关爬虫方面的相关知识。
python零基础小白也能学习
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-30 01:08
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
用什么语言写爬虫?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
查看全部
python零基础小白也能学习
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
用什么语言写爬虫?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
python抓取网页数据(Python数据抓取技术与实战(一)-Python语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-19 16:31
编辑评论:
Python数据采集技术与实践主要介绍了使用Python语言及相关工具进行数据采集的方法,并通过实例演示了数据采集过程中常见问题的解决方案。通过本书的学习,读者可以根据自己的需要,快速编写出符合要求的爬虫程序。
前言
大数据技术是当前工程和科技领域的热门研究课题。数据科学研究通常包括四个主要环节,即数据获取、数据存储、数据分析和数据可视化。本书主要侧重于数据采集。这是其他链接的基础。及时准确地获取丰富、详细的数据,为后续工作打下坚实的基础,提高分析结论的可信度和可靠性。
互联网的开放性给数据的获取带来了极大的便利。本书以Python语言的数据捕获技术为基础,主要介绍如何快速、准确地从网络中获取所需数据,构建符合要求的数据集或大数据集。 Python 语言是一种通用的编程语言,可用于各种编程领域,也是数据科学领域非常流行的语言。本书使用Python作为数据采集技术的实现语言,利用Python丰富的模块支持和语言特性解决了数据采集中经常遇到的大部分问题。为了让不了解 Python 语言的读者快速入门,第 1 章介绍了阅读本书所需的 Python 语言基础知识。本书介绍了数据采集中涉及的各种技术问题和解决方案,并按章节进行组织。每章内容基本独立,使读者在遇到问题时能够快速定位问题。本书的内容侧重于应用现有成熟的理论原理和流行的框架来解决数据采集的实际问题。在写的过程中,我们只关注应用于数据采集的应用方法,并没有详细描述一些原理和框架。有兴趣的读者可以进一步搜索相关文献资料,加深对概念和理论的理解。读者在阅读时可以运行书中的示例代码,看到现象后再回去分析,有助于更好地理解相关概念和原理,为进一步研究打下基础。
本书主要面向初学者。读者可以根据书中运行的例子进行改造,设计出符合自己需求的数据采集程序。本书可快速应用于实战,可供高校相关专业工程技术人员和本科生参考。
感谢总策划付军的辛勤工作!感谢赵星驰老师在外文技术资料方面的帮助与合作!
如果读者在阅读中发现问题,请及时联系我们,希望大家批评指正。
python基础
Python 是一种动态类型的脚本语言,具有简洁的语法和强大的表达能力。它是目前数据科学领域的主流编程语言。其丰富的包和模块支持可以让 Python 在几乎所有领域都变得实用。
本书使用 Python 作为数据抓取的编程实现语言。
本章主要介绍Python编程语言的基础知识以及Python语言的安装和基本使用。通过两个引人入胜的例子,描述了Python的基本语法和后续章节中将用到的语法知识。
语言版本选择Python3.4+作为开发语言,使用Python 3及以上版本进行字符串处理更方便。如果不使用 Python3 及以上版本引入的新特性,可以在字符串处理并稍作改动后使用 Python2.7+ 执行。随着Python3的发展,很多Python2.7可以使用的库和模块都可以被Python3使用。因此,建议没有使用过Python的读者可以直接安装3以上版本进行学习开发。
在操作系统选择方面,本书中的大部分例子都是在Ubuntu 14.04可信赖的64位桌面系统下编写和运行的。如果Python版本相同,可以直接在Windows下运行书中的代码。使用Windows系统的读者可以使用Vmware虚拟机环境在虚拟机中搭建Ubuntu系统来学习和使用书中的代码。
缩进样式
在get-content函数的定义形式中引入了Python语言的一个非常特殊的特性,即缩进。
下面简单介绍一下Python中的缩进问题。
与大多数编程语言不同,Python 使用缩进来表示逻辑级别,而不是“1 1”括号。具有相同缩进的语句块代表相同的逻辑级别。例如,在上面的get-content函数中,函数体中的两行代码应该在同一个缩进级别。如果在编辑器中输入这两行代码,要保证这两行代码在句首和def中保持一定的缩进,并且缩进的程度是一样的。
注意缩进的程度是一样的,缩进多和少没有区别。此外,不同的 IDE 可能有不同的代码编辑设置。例如,在 Pycharm IDE 中,您可以设置一个 tab 键等于 4 个空格,然后在这个 IDE 中使用一个 tab 缩进和 4 个空格缩进。 ,效果是一样的。但是,将代码复制到其他IDE时,制表符和空格数的对应关系可能不是1:4,所以可能会出现缩进的问题。最好在编码的方式上统一,或者使用tab或者空格来解决这个问题。 查看全部
python抓取网页数据(Python数据抓取技术与实战(一)-Python语言)
编辑评论:
Python数据采集技术与实践主要介绍了使用Python语言及相关工具进行数据采集的方法,并通过实例演示了数据采集过程中常见问题的解决方案。通过本书的学习,读者可以根据自己的需要,快速编写出符合要求的爬虫程序。

前言
大数据技术是当前工程和科技领域的热门研究课题。数据科学研究通常包括四个主要环节,即数据获取、数据存储、数据分析和数据可视化。本书主要侧重于数据采集。这是其他链接的基础。及时准确地获取丰富、详细的数据,为后续工作打下坚实的基础,提高分析结论的可信度和可靠性。
互联网的开放性给数据的获取带来了极大的便利。本书以Python语言的数据捕获技术为基础,主要介绍如何快速、准确地从网络中获取所需数据,构建符合要求的数据集或大数据集。 Python 语言是一种通用的编程语言,可用于各种编程领域,也是数据科学领域非常流行的语言。本书使用Python作为数据采集技术的实现语言,利用Python丰富的模块支持和语言特性解决了数据采集中经常遇到的大部分问题。为了让不了解 Python 语言的读者快速入门,第 1 章介绍了阅读本书所需的 Python 语言基础知识。本书介绍了数据采集中涉及的各种技术问题和解决方案,并按章节进行组织。每章内容基本独立,使读者在遇到问题时能够快速定位问题。本书的内容侧重于应用现有成熟的理论原理和流行的框架来解决数据采集的实际问题。在写的过程中,我们只关注应用于数据采集的应用方法,并没有详细描述一些原理和框架。有兴趣的读者可以进一步搜索相关文献资料,加深对概念和理论的理解。读者在阅读时可以运行书中的示例代码,看到现象后再回去分析,有助于更好地理解相关概念和原理,为进一步研究打下基础。
本书主要面向初学者。读者可以根据书中运行的例子进行改造,设计出符合自己需求的数据采集程序。本书可快速应用于实战,可供高校相关专业工程技术人员和本科生参考。
感谢总策划付军的辛勤工作!感谢赵星驰老师在外文技术资料方面的帮助与合作!
如果读者在阅读中发现问题,请及时联系我们,希望大家批评指正。
python基础
Python 是一种动态类型的脚本语言,具有简洁的语法和强大的表达能力。它是目前数据科学领域的主流编程语言。其丰富的包和模块支持可以让 Python 在几乎所有领域都变得实用。
本书使用 Python 作为数据抓取的编程实现语言。
本章主要介绍Python编程语言的基础知识以及Python语言的安装和基本使用。通过两个引人入胜的例子,描述了Python的基本语法和后续章节中将用到的语法知识。
语言版本选择Python3.4+作为开发语言,使用Python 3及以上版本进行字符串处理更方便。如果不使用 Python3 及以上版本引入的新特性,可以在字符串处理并稍作改动后使用 Python2.7+ 执行。随着Python3的发展,很多Python2.7可以使用的库和模块都可以被Python3使用。因此,建议没有使用过Python的读者可以直接安装3以上版本进行学习开发。
在操作系统选择方面,本书中的大部分例子都是在Ubuntu 14.04可信赖的64位桌面系统下编写和运行的。如果Python版本相同,可以直接在Windows下运行书中的代码。使用Windows系统的读者可以使用Vmware虚拟机环境在虚拟机中搭建Ubuntu系统来学习和使用书中的代码。
缩进样式
在get-content函数的定义形式中引入了Python语言的一个非常特殊的特性,即缩进。
下面简单介绍一下Python中的缩进问题。
与大多数编程语言不同,Python 使用缩进来表示逻辑级别,而不是“1 1”括号。具有相同缩进的语句块代表相同的逻辑级别。例如,在上面的get-content函数中,函数体中的两行代码应该在同一个缩进级别。如果在编辑器中输入这两行代码,要保证这两行代码在句首和def中保持一定的缩进,并且缩进的程度是一样的。
注意缩进的程度是一样的,缩进多和少没有区别。此外,不同的 IDE 可能有不同的代码编辑设置。例如,在 Pycharm IDE 中,您可以设置一个 tab 键等于 4 个空格,然后在这个 IDE 中使用一个 tab 缩进和 4 个空格缩进。 ,效果是一样的。但是,将代码复制到其他IDE时,制表符和空格数的对应关系可能不是1:4,所以可能会出现缩进的问题。最好在编码的方式上统一,或者使用tab或者空格来解决这个问题。
python抓取网页数据(如何使用Python对天猫的评论数据进行评论(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-04-18 06:00
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接。接下来,你只需要复制这个链接,把这个地址粘贴到浏览器中,你就会发现这些评论都隐藏在这个地方了。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以概括为这种形式:每次更改最后一个 currentPage 值时,都可以捕获到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append(';spuId=345965243&sellerId=2106525799&order=1¤tPage=%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall(''displayUserNick':'(.*?)'',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile(''rateContent':'(.*?)','rateDate''),content))
ratingate.extend(re.findall(pile(''rateDate':'(.*?)','reply''),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'\n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
温馨的提示:
天山智能是中国商业智能BI、数据分析、大数据领域最大的社区。欢迎您访问天山学院,有更多免费的行业专家数据库、商业智能BI、数据分析、大数据、数据挖掘视频和好文章分享。.
12 月 29 日 8:30 pm Oracle Oracle BI 银行和保险业大数据应用
参 查看全部
python抓取网页数据(如何使用Python对天猫的评论数据进行评论(图))
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,

然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。

如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:

你会发现有一个请求连接。接下来,你只需要复制这个链接,把这个地址粘贴到浏览器中,你就会发现这些评论都隐藏在这个地方了。. .

哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以概括为这种形式:每次更改最后一个 currentPage 值时,都可以捕获到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append(';spuId=345965243&sellerId=2106525799&order=1¤tPage=%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall(''displayUserNick':'(.*?)'',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile(''rateContent':'(.*?)','rateDate''),content))
ratingate.extend(re.findall(pile(''rateDate':'(.*?)','reply''),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'\n')
文件.close()
最终爬虫结果如下:

今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
温馨的提示:
天山智能是中国商业智能BI、数据分析、大数据领域最大的社区。欢迎您访问天山学院,有更多免费的行业专家数据库、商业智能BI、数据分析、大数据、数据挖掘视频和好文章分享。.
12 月 29 日 8:30 pm Oracle Oracle BI 银行和保险业大数据应用

参
python抓取网页数据(是不是突然感觉网络爬虫很简单?代码就完全解决了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2022-04-18 01:12
网络爬虫对于大数据专业的同学可能并不陌生,所以在说网络爬虫之前,博主先给大家介绍一下我们平时使用的浏览器的工作原理,只要你了解普通浏览器的工作原理,那么网络爬虫就变得简单了。
下图是浏览器正常工作原理的流程图:
首先我们可以看到有四个进程:
(1)我们先在浏览器中输入url(网址);
(2)浏览器会向指定的服务器发送一个HTTP请求。请求的方式有两种:一种是get,另一种是:spot。那么这两者有什么区别呢?大家可以这样理解: get是指从服务器下载我们需要的数据,spot是我们上传(粘贴)到服务器的数据;
(3)服务器收到浏览器的请求后,会生成一个http响应给服务器;
(4)其实html的源码一般人是看不懂的,所以浏览器会处理,最后给我们展示一个丰富漂亮的网页!!!
介绍完普通浏览器的工作流程后,我们启动我们的网络爬虫。网络爬虫:模拟浏览器网页,下载我们需要的网络资源的程序,其实本质上就是一个假的http请求。好的,开始我们的代码部分(说明:使用python环境)
首先我们在python中加载第三方库:re、urllib、json、time,三个库
#加载第三方库
import urllib
import re
import json
import time
###
#输入网站
url = 'https://sclub.jd.com/comment/p ... 39%3B
#1:模拟浏览器的http请求部分
#html = urllib.request.urlopen(url)
#2:模拟响应过程
#html = urllib.request.urlopen(url).read()
#我们可以打印print(html)看,如果源码出现乱码,我们再响应过程部分进行编码设置:常用的编码有:utf-8,gbk,gb18030
#完整的模拟浏览器的http请求过程和http响应的过程
html = urllib.request.urlopen(url).read().decode('gbk')#此处已经经请求和响应过程合并
print(html)
#由于读取到的源码不是标准的 JSON 格式,因此需要使用进行处理
json_data = re.search('{.+}', html).group()#正则表达式处理
data = json.loads(json_data)# 将json格式数据转为字典格式(反序列化)
现在爬取1页评论数据,代码运行:
#忘记每行代码的目的,请看上面备注
import pandas as pd
import urllib
import requests
import re
import json
import random
url = 'https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
json_data = re.search('{.+}', html).group()
data = json.loads(json_data)
data['comments']
运行之后,我们就可以得到我们需要的数据评论数据了。
是不是突然觉得爬网很容易?几行代码就可以彻底解决,但别忘了这只是爬取一页数据。如果我们需要爬取多个页面,则需要我们自己编写和爬取。为了大家方便,博主自己也写了一个循环爬虫的代码如下:
all_url = []
for i in range(0,10):
all_url.append('https://sclub.jd.com/comment/p ... 2Bstr(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
allh_data = pd.DataFrame()
for k in range(0,10): #爬取10页的数据
print("正在打印第{}页的评论数据".format(k+1))
html_data = urllib.request.urlopen(all_url[k]).read().decode('gb18030')
json_data = re.search('{.+}', html_data).group()
all_data = json.loads(json_data)
alls_data = all_data['comments']
referenceName = [x['referenceName'] for x in alls_data] # 提取商品的品牌名
nickname = [x['nickname'] for x in alls_data] # 提取商品购买用户的昵称
creationTime = [x['creationTime'] for x in alls_data] # 提取购物时间
content = [x['content'] for x in alls_data] # 发表时间
all_data_hp = pd.DataFrame({'referenceName': referenceName,
'nickname': nickname,
'creationTime': creationTime,
'content': content})
allh_data = allh_data.append(all_data_hp)
time.sleep(random.randint(2, 3))
print(">>>爬取第{}结束.......".format(k+1))
allh_data.index = range(len(allh_data))#重设dateframe的index
然后最后可以得到以下数据:
如有任何问题,请发表评论,博主将尽力解答。 查看全部
python抓取网页数据(是不是突然感觉网络爬虫很简单?代码就完全解决了)
网络爬虫对于大数据专业的同学可能并不陌生,所以在说网络爬虫之前,博主先给大家介绍一下我们平时使用的浏览器的工作原理,只要你了解普通浏览器的工作原理,那么网络爬虫就变得简单了。
下图是浏览器正常工作原理的流程图:
首先我们可以看到有四个进程:
(1)我们先在浏览器中输入url(网址);
(2)浏览器会向指定的服务器发送一个HTTP请求。请求的方式有两种:一种是get,另一种是:spot。那么这两者有什么区别呢?大家可以这样理解: get是指从服务器下载我们需要的数据,spot是我们上传(粘贴)到服务器的数据;
(3)服务器收到浏览器的请求后,会生成一个http响应给服务器;
(4)其实html的源码一般人是看不懂的,所以浏览器会处理,最后给我们展示一个丰富漂亮的网页!!!
介绍完普通浏览器的工作流程后,我们启动我们的网络爬虫。网络爬虫:模拟浏览器网页,下载我们需要的网络资源的程序,其实本质上就是一个假的http请求。好的,开始我们的代码部分(说明:使用python环境)
首先我们在python中加载第三方库:re、urllib、json、time,三个库
#加载第三方库
import urllib
import re
import json
import time
###
#输入网站
url = 'https://sclub.jd.com/comment/p ... 39%3B
#1:模拟浏览器的http请求部分
#html = urllib.request.urlopen(url)
#2:模拟响应过程
#html = urllib.request.urlopen(url).read()
#我们可以打印print(html)看,如果源码出现乱码,我们再响应过程部分进行编码设置:常用的编码有:utf-8,gbk,gb18030
#完整的模拟浏览器的http请求过程和http响应的过程
html = urllib.request.urlopen(url).read().decode('gbk')#此处已经经请求和响应过程合并
print(html)
#由于读取到的源码不是标准的 JSON 格式,因此需要使用进行处理
json_data = re.search('{.+}', html).group()#正则表达式处理
data = json.loads(json_data)# 将json格式数据转为字典格式(反序列化)
现在爬取1页评论数据,代码运行:
#忘记每行代码的目的,请看上面备注
import pandas as pd
import urllib
import requests
import re
import json
import random
url = 'https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
json_data = re.search('{.+}', html).group()
data = json.loads(json_data)
data['comments']
运行之后,我们就可以得到我们需要的数据评论数据了。
是不是突然觉得爬网很容易?几行代码就可以彻底解决,但别忘了这只是爬取一页数据。如果我们需要爬取多个页面,则需要我们自己编写和爬取。为了大家方便,博主自己也写了一个循环爬虫的代码如下:
all_url = []
for i in range(0,10):
all_url.append('https://sclub.jd.com/comment/p ... 2Bstr(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
allh_data = pd.DataFrame()
for k in range(0,10): #爬取10页的数据
print("正在打印第{}页的评论数据".format(k+1))
html_data = urllib.request.urlopen(all_url[k]).read().decode('gb18030')
json_data = re.search('{.+}', html_data).group()
all_data = json.loads(json_data)
alls_data = all_data['comments']
referenceName = [x['referenceName'] for x in alls_data] # 提取商品的品牌名
nickname = [x['nickname'] for x in alls_data] # 提取商品购买用户的昵称
creationTime = [x['creationTime'] for x in alls_data] # 提取购物时间
content = [x['content'] for x in alls_data] # 发表时间
all_data_hp = pd.DataFrame({'referenceName': referenceName,
'nickname': nickname,
'creationTime': creationTime,
'content': content})
allh_data = allh_data.append(all_data_hp)
time.sleep(random.randint(2, 3))
print(">>>爬取第{}结束.......".format(k+1))
allh_data.index = range(len(allh_data))#重设dateframe的index
然后最后可以得到以下数据:
如有任何问题,请发表评论,博主将尽力解答。
python抓取网页数据(炉石传说爬虫前不要的暂停时间是怎么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-17 18:15
然后就用requests来获取网页的源代码
使用BeautifulSoup/正则表达式/pyQuery解析元素并遍历对应img的url进行下载
教训:不要在爬虫之前根据网页的操作来实现相应的代码爬取。不要有这样的心态。首先要做的是浏览和分析整个网页的源代码。再加工
炉石卡链接:
网站 通过下拉右侧的滚动条不断加载新卡片
与上一个网站不同的是,最后一个网站一次写了所有卡片,但它被隐藏了
网站是js动态加载渲染的卡片,无法直接从源码中获取所有卡片信息。
然后用selenium来模拟下拉滚动条(selenium是家里必备神器)
使用selenium执行js脚本每次下拉1000个单位的滚动条90次
为什么在 90 次测试中大约有 90 次被拉到最后?
注意:此处为网页渲染添加 1~3 秒的暂停时间
第一次没设置停留时间,拿不到新数据,怀疑自己,怀疑人生
根据前端/后端朋友L的提示,需要增加暂停时间,这样才能获取到加载渲染后的数据。
browser.page_source 获取动态加载的所有数据
有了数据之后,通过正则匹配得到对应的url下载就很简单了。
终于拿到了800幅原画和1324张卡片
既然获得了这么多卡牌和原画,那就不能浪费了,拿来拼图吧!
向玩了几年的炉石致敬
只拼女神
完全的 查看全部
python抓取网页数据(炉石传说爬虫前不要的暂停时间是怎么样的?)
然后就用requests来获取网页的源代码
使用BeautifulSoup/正则表达式/pyQuery解析元素并遍历对应img的url进行下载
教训:不要在爬虫之前根据网页的操作来实现相应的代码爬取。不要有这样的心态。首先要做的是浏览和分析整个网页的源代码。再加工
炉石卡链接:
网站 通过下拉右侧的滚动条不断加载新卡片
与上一个网站不同的是,最后一个网站一次写了所有卡片,但它被隐藏了
网站是js动态加载渲染的卡片,无法直接从源码中获取所有卡片信息。
然后用selenium来模拟下拉滚动条(selenium是家里必备神器)
使用selenium执行js脚本每次下拉1000个单位的滚动条90次
为什么在 90 次测试中大约有 90 次被拉到最后?
注意:此处为网页渲染添加 1~3 秒的暂停时间
第一次没设置停留时间,拿不到新数据,怀疑自己,怀疑人生
根据前端/后端朋友L的提示,需要增加暂停时间,这样才能获取到加载渲染后的数据。
browser.page_source 获取动态加载的所有数据
有了数据之后,通过正则匹配得到对应的url下载就很简单了。
终于拿到了800幅原画和1324张卡片
既然获得了这么多卡牌和原画,那就不能浪费了,拿来拼图吧!
向玩了几年的炉石致敬

只拼女神


完全的
python抓取网页数据( 小编来一起学习学习吧三种数据抓取的3种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-17 08:06
小编来一起学习学习吧三种数据抓取的3种方法)
python数据抓取的3种方法总结
更新时间:2021-02-07 12:16:01 作者:呵呵
本篇文章主要介绍python数据抓取的3种方法。文中介绍的示例代码非常详细,对您的学习或工作有一定的参考和学习价值。有需要的朋友请按照以下说明进行操作。来和我一起学习
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
总结
至此,这篇关于python数据抓取的3种方法的文章文章就介绍到这里了。更多相关python数据抓取内容,请搜索脚本之家往期文章或继续浏览下方相关话题。文章希望您以后多多支持 Scripting House! 查看全部
python抓取网页数据(
小编来一起学习学习吧三种数据抓取的3种方法)
python数据抓取的3种方法总结
更新时间:2021-02-07 12:16:01 作者:呵呵
本篇文章主要介绍python数据抓取的3种方法。文中介绍的示例代码非常详细,对您的学习或工作有一定的参考和学习价值。有需要的朋友请按照以下说明进行操作。来和我一起学习
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。

from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:

最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:

仅供参考。
总结
至此,这篇关于python数据抓取的3种方法的文章文章就介绍到这里了。更多相关python数据抓取内容,请搜索脚本之家往期文章或继续浏览下方相关话题。文章希望您以后多多支持 Scripting House!
python抓取网页数据(python抓取网页数据的技巧分享什么是双抓取抓取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-12 10:00
python抓取网页数据的技巧分享什么是双抓取?双抓取实质上就是网页中可抓取的资源有“多页”,“多方向”(多页,多方向,多广度,多深度)等,是通过技术手段进行多维度进行网页探测和抓取的,就是多维数据抓取。大家可以简单看一下通常的爬虫,都是需要深入到每一个页面的每一个链接后再去提取数据。在这种情况下,我们就不得不为了保证我们的数据不断更新,我们需要重复进行这些抓取和提取,是比较耗费时间的。
然而,对于一些业务部门来说,会遇到业务分析会以某种角度需要在后台上线产品。那么,这种时候,如果可以直接对网页进行抓取,且这些网页没有重复提取的功能。比如,每次可以直接下载产品页面内的所有产品列表,并存入数据库。双抓取系统介绍以整站抓取为例,接下来,我将介绍一下整站抓取系统的功能。可以根据人员和业务的需要,创建两组文件系统,一组叫做web抓取,一组叫做生产抓取。
下面简单列出工作流程。1.按照业务的需要创建一个生产抓取系统的实验例子,之所以这么干是因为我们没有给他太多的约束,可以根据业务的需要加入一些数据提取的功能,系统提供集成机器学习,大数据计算等更高级的功能,这些功能我们完全可以根据实际业务进行安排。2.在python里,很多库就已经提供了生产抓取系统的工具。
例如pandas库和itertools库等,如果数据量超大的时候,基本需要两遍抓取。numpy库里有一个基于矩阵的矩阵采样,这个是很多抓取的首选,抓取到的数据有些很大也有些很小,这个能满足我们的需求。3.每个抓取的文件,存放在相应的目录下,这个目录里,所有文件都是按照生产抓取里的保存格式存放的。我们只需要按照我们的格式来存放对应的文件。如果这个文件多不过来的时候,可以用一个更小的文件。 查看全部
python抓取网页数据(python抓取网页数据的技巧分享什么是双抓取抓取?)
python抓取网页数据的技巧分享什么是双抓取?双抓取实质上就是网页中可抓取的资源有“多页”,“多方向”(多页,多方向,多广度,多深度)等,是通过技术手段进行多维度进行网页探测和抓取的,就是多维数据抓取。大家可以简单看一下通常的爬虫,都是需要深入到每一个页面的每一个链接后再去提取数据。在这种情况下,我们就不得不为了保证我们的数据不断更新,我们需要重复进行这些抓取和提取,是比较耗费时间的。
然而,对于一些业务部门来说,会遇到业务分析会以某种角度需要在后台上线产品。那么,这种时候,如果可以直接对网页进行抓取,且这些网页没有重复提取的功能。比如,每次可以直接下载产品页面内的所有产品列表,并存入数据库。双抓取系统介绍以整站抓取为例,接下来,我将介绍一下整站抓取系统的功能。可以根据人员和业务的需要,创建两组文件系统,一组叫做web抓取,一组叫做生产抓取。
下面简单列出工作流程。1.按照业务的需要创建一个生产抓取系统的实验例子,之所以这么干是因为我们没有给他太多的约束,可以根据业务的需要加入一些数据提取的功能,系统提供集成机器学习,大数据计算等更高级的功能,这些功能我们完全可以根据实际业务进行安排。2.在python里,很多库就已经提供了生产抓取系统的工具。
例如pandas库和itertools库等,如果数据量超大的时候,基本需要两遍抓取。numpy库里有一个基于矩阵的矩阵采样,这个是很多抓取的首选,抓取到的数据有些很大也有些很小,这个能满足我们的需求。3.每个抓取的文件,存放在相应的目录下,这个目录里,所有文件都是按照生产抓取里的保存格式存放的。我们只需要按照我们的格式来存放对应的文件。如果这个文件多不过来的时候,可以用一个更小的文件。
使用 Excel和 Python从互联网获取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-09-10 11:29
互联网上有极其丰富的数据资源可以使用。使用Excel可以自动读取部分网页中的表格数据,使用Python编写爬虫程序可以读取网页的内容。
本节通过Python编写测试用Web应用程序,然后使用Excel和Python从编写的Web网站上获取数据。
1,构建测试用网站数据
通过Python Flask Web框架分别构建一个Web网站和一个WebAPI服务。
1.构建Web网站
新建一个名为“5-5-WebTable.py”的Python脚本,创建一个包含表格的简单网页。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装flask包。
pip install flask
(2)构建包含表格的网页。
from flask import Flask<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /><br /># 将路由“/”映射到table_info函数,函数返回HTML代码@app.route('/')def table_info(): return """HTML表格实例,用于提供给Excel和Python读取 用户信息表 姓名 性别 年龄 小米 女 22 ………. """<br /><br />if __name__ == '__main__': app.debug = True # 启用调试模式 app.run() # 运行,网站端口默认为5000
通过命令“python./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,出现如图1所示的网页内容。
图1 使用Flask构建的测试网站
2.构建Web API服务
新建一个名为“5-5-WebAPI.py”的Python脚本,使用flask_restplus包构建WebAPI服务。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开WebAPI服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库与初始化应用对象。
from flask import Flask# Api类是Web API应用的入口,需要用Flask应用程序初始化from flask_restplus import Api<br /># Resource类是HTTP请求的资源的基类from flask_restplus import Resource<br /># fields类用于定义数据的类型和格式from flask_restplus import fields<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /># 在flask应用的基础上构建flask_restplus Api对象api = Api(app, version='1.0', title='Excel集成Python数据分析-测试用WebAPI', description='测试用WebAPI', )<br /># 使用namespace函数生成命名空间,用于为资源分组ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')# 使用api.model函数生成模型对象todo = api.model('task_model', { 'id': fields.Integer(readonly=True, description='ETL任务唯一标识'), 'task': fields.String(required=True, description='ETL任务详情')})
(3)WebAPI数据操作类,包含增、删、改、查等方法。
class TodoDAO(object):<br /> def __init__(self): self.counter = 0 self.todos = []<br /> def get(self, id): for todo in self.todos: if todo['id'] == id: return todo api.abort(404, "ETL任务 {} 不存在".format(id))<br /> def create(self, data): todo = data todo['id'] = self.counter = self.counter + 1 self.todos.append(todo) return todo<br /><br /># 实例化数据操作,创建3条测试数据DAO = TodoDAO()DAO.create({'task': 'ETL-抽取数据操作'})DAO.create({'task': 'ETL-数据清洗转换'})DAO.create({'task': 'ETL-数据加载操作'})
(4)构建Web API的路由映射。
HTTP资源请求类从Resource类继承,然后映射到不同的路由,同时指定可使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求class TodoList(Resource): @ns.doc('list_todos') # @doc装饰器对应API文档的信息 @ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出 def get(self): # 定义get方法获取所有的任务信息 return DAO.todos<br /> @ns.doc('create_todo') @ns.expect(todo) @ns.marshal_with(todo, code=201) def post(self): # 定义post方法获取所有的任务信息 return DAO.create(api.payload), 201<br /><br /># 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求@ns.route('/')@ns.response(404, '未发现相关ETL任务')@ns.param('id', 'ETL任务ID号')class Todo(Resource): @ns.doc('get_todo') @ns.marshal_with(todo) def get(self, id): return DAO.get(id)<br /> @ns.doc('delete_todo') @ns.response(204, 'ETL任务已经删除') def delete(self, id): DAO.delete(id) return '', 204<br /> @ns.expect(todo) @ns.marshal_with(todo) def put(self, id): return DAO.update(id, api.payload)<br /><br />if __name__ == '__main__': app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)开启Web API服务。
通过命令“python./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”
将出现如图5-23所示的Web API服务请求方法列表。
图2WebAPI服务请求方法列表
2,抓取用网页数据
Excel可以通过“数据”选项卡下的“自网站”功能抓取网页数据。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架抓取网页数据。
1.通过Excel抓取
单击“数据”→“自其他源”→“自网站”功能。Excel可读取的网页数据有局限:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)单击“数据”→“自其他源”→“自网站”功能。
(2)确保在5.5.1节中编写的Web网站已经开启。
(3)输入网站URL地址“:5000/”
单击“高级”按钮可配置更详细的HTTP请求信息,然后单击“确定”按钮,如图3所示。
图3 配置要读取网站的URL
(4)在“导航器”窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表名后单击“加载”按钮即可。
图4Excel自动识别网页中的表格数据
2.使用Python抓取
下面演示使用requests库抓取整个网页中的数据,然后使用Beautiful Soup解析网页。读者可参考本书代码素材文件“5-5-web.ipynb”进行学习。
(1)通过requests读取网页数据。
import requests #导入requests包url ='http://127.0.0.1:5000/'<br />strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过BeautifulSoup解析网页。
from bs4 import BeautifulSoup<br />soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象table = soup.find('table') # 查找网页中的table元素table_body = table.find('tbody') # 查找table元素中的tbody元素data = []rows = table_body.find_all('tr') # 查找表中的所有tr元素<br />for row in rows: # 遍历数据 cols = row.find_all('td') cols = [ele.text.strip() for ele in cols]data.append([ele for ele in cols if ele])# 结果输出:[[],['小米', '女', '22'],['小明','男','23'],……
3,调用Web API服务
Excel可以通过“数据”选项卡下的“自网站”功能调用Web API服务。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架调用Web API获取数据。
1.使用Excel调用
(1)确保5.5.1节中编写的Web API服务已经开启。
(2)输入Web API方法对应的URL:
:8000/ExcelPythonTest/。
(3)处理返回的数据。
调用Web API服务后数据以JSON格式返回,按照5.4.3小节中介绍的方法处理JSON数据。
2.使用Python调用
使用requests库调用Web API方法,然后对返回的JSON数据进行处理,读者可参考本书代码素材文件“5-5-api.ipynb”进行学习。
import requests #导入requests包url ='http://127.0.0.1:8000/ExcelPythonTest/'<br />strhtml= requests.get(url) #使用get方法获取网页数据<br />import pandas as pd<br />frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数print(frame)#结果输出:id task0 1 ETL-抽取数据操作1 2 ETL-数据清洗转换2 3 ETL-数据加载操作
3,Excel和Python抓取互联网数据方法对比
表1所示为Excel和Python抓取互联网数据方法的对比。需要注意Excel从互联网抓取数据的功能并不完善。
表1Excel和Python抓取互联网数据方法对比
声明:本文选自北京大学出版社的《从零开始利用Excel与Python进行数据分析》一书,略有修改,经出版社授权刊登于此。
文末赠书<p style="margin-bottom: 24px;outline: 0px;max-width: 100%;font-family: system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">内容简介
《从零开始利用Excel与Python进行数据分析》介绍了数据分析的方法和步骤,并分别通过Excel和Python实施和对比。通过《从零开始利用Excel与Python进行数据分析》一方面可以拓宽对Excel功能的认识,另一方面可以学习和掌握Python的基础操作。
规则
后台回复: 送书 ,参与抽奖
<br /><br />推荐阅读 点击标题可跳转用 Python 破解 WiFi 密码,太刺激了JetBrains 如何看待自己的软件在中国被频繁破解抛弃for循环,让 Python 代码更 pythonic </p> 查看全部
使用 Excel和 Python从互联网获取数据
互联网上有极其丰富的数据资源可以使用。使用Excel可以自动读取部分网页中的表格数据,使用Python编写爬虫程序可以读取网页的内容。
本节通过Python编写测试用Web应用程序,然后使用Excel和Python从编写的Web网站上获取数据。
1,构建测试用网站数据
通过Python Flask Web框架分别构建一个Web网站和一个WebAPI服务。
1.构建Web网站
新建一个名为“5-5-WebTable.py”的Python脚本,创建一个包含表格的简单网页。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebTable.py”打开网站。
(1)安装flask包。
pip install flask
(2)构建包含表格的网页。
from flask import Flask<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /><br /># 将路由“/”映射到table_info函数,函数返回HTML代码@app.route('/')def table_info(): return """HTML表格实例,用于提供给Excel和Python读取 用户信息表 姓名 性别 年龄 小米 女 22 ………. """<br /><br />if __name__ == '__main__': app.debug = True # 启用调试模式 app.run() # 运行,网站端口默认为5000
通过命令“python./5-5-WebTable.py”启动网站,然后在浏览器中输入:5000/,出现如图1所示的网页内容。
图1 使用Flask构建的测试网站
2.构建Web API服务
新建一个名为“5-5-WebAPI.py”的Python脚本,使用flask_restplus包构建WebAPI服务。如果读者对构建方法不感兴趣,可跳过以下代码,直接执行脚本“5-5-WebAPI.py”打开WebAPI服务。
(1)安装flask_restplus包。
pip install flask-restplus
(2)导入必要的库与初始化应用对象。
from flask import Flask# Api类是Web API应用的入口,需要用Flask应用程序初始化from flask_restplus import Api<br /># Resource类是HTTP请求的资源的基类from flask_restplus import Resource<br /># fields类用于定义数据的类型和格式from flask_restplus import fields<br />app = Flask(__name__) # 创建Falsk Web应用实例<br /># 在flask应用的基础上构建flask_restplus Api对象api = Api(app, version='1.0', title='Excel集成Python数据分析-测试用WebAPI', description='测试用WebAPI', )<br /># 使用namespace函数生成命名空间,用于为资源分组ns = api.namespace('ExcelPythonTest', description='Excel与Python Web API测试')# 使用api.model函数生成模型对象todo = api.model('task_model', { 'id': fields.Integer(readonly=True, description='ETL任务唯一标识'), 'task': fields.String(required=True, description='ETL任务详情')})
(3)WebAPI数据操作类,包含增、删、改、查等方法。
class TodoDAO(object):<br /> def __init__(self): self.counter = 0 self.todos = []<br /> def get(self, id): for todo in self.todos: if todo['id'] == id: return todo api.abort(404, "ETL任务 {} 不存在".format(id))<br /> def create(self, data): todo = data todo['id'] = self.counter = self.counter + 1 self.todos.append(todo) return todo<br /><br /># 实例化数据操作,创建3条测试数据DAO = TodoDAO()DAO.create({'task': 'ETL-抽取数据操作'})DAO.create({'task': 'ETL-数据清洗转换'})DAO.create({'task': 'ETL-数据加载操作'})
(4)构建Web API的路由映射。
HTTP资源请求类从Resource类继承,然后映射到不同的路由,同时指定可使用HTTP方法。
@ns.route('/') # 路由“/”对应的资源类为TodoList,可使用get方法和post方法进行请求class TodoList(Resource): @ns.doc('list_todos') # @doc装饰器对应API文档的信息 @ns.marshal_list_with(todo) # @marshal_xxx装饰器对模型数据进行格式转换与输出 def get(self): # 定义get方法获取所有的任务信息 return DAO.todos<br /> @ns.doc('create_todo') @ns.expect(todo) @ns.marshal_with(todo, code=201) def post(self): # 定义post方法获取所有的任务信息 return DAO.create(api.payload), 201<br /><br /># 路由/对应的资源类为Todo,可使用get、delete、put方法进行请求@ns.route('/')@ns.response(404, '未发现相关ETL任务')@ns.param('id', 'ETL任务ID号')class Todo(Resource): @ns.doc('get_todo') @ns.marshal_with(todo) def get(self, id): return DAO.get(id)<br /> @ns.doc('delete_todo') @ns.response(204, 'ETL任务已经删除') def delete(self, id): DAO.delete(id) return '', 204<br /> @ns.expect(todo) @ns.marshal_with(todo) def put(self, id): return DAO.update(id, api.payload)<br /><br />if __name__ == '__main__': app.run(debug=True, port=8000) # 启动Web API服务,端口为8000
(4)开启Web API服务。
通过命令“python./5-5-WebAPI.py”启动Web API服务,在浏览器中输入“:8000/”
将出现如图5-23所示的Web API服务请求方法列表。
图2WebAPI服务请求方法列表
2,抓取用网页数据
Excel可以通过“数据”选项卡下的“自网站”功能抓取网页数据。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架抓取网页数据。
1.通过Excel抓取
单击“数据”→“自其他源”→“自网站”功能。Excel可读取的网页数据有局限:动态网页数据无法自动识别,非表格数据无法自动识别。
(1)单击“数据”→“自其他源”→“自网站”功能。
(2)确保在5.5.1节中编写的Web网站已经开启。
(3)输入网站URL地址“:5000/”
单击“高级”按钮可配置更详细的HTTP请求信息,然后单击“确定”按钮,如图3所示。
图3 配置要读取网站的URL
(4)在“导航器”窗口中选择导入数据。
如图4所示,Excel自动识别网页中的表格数据,选择表名后单击“加载”按钮即可。
图4Excel自动识别网页中的表格数据
2.使用Python抓取
下面演示使用requests库抓取整个网页中的数据,然后使用Beautiful Soup解析网页。读者可参考本书代码素材文件“5-5-web.ipynb”进行学习。
(1)通过requests读取网页数据。
import requests #导入requests包url ='http://127.0.0.1:5000/'<br />strhtml= requests.get(url) #使用get方法请求网页数据
(2)通过BeautifulSoup解析网页。
from bs4 import BeautifulSoup<br />soup = BeautifulSoup(strhtml.text) # 将网页内容作为参数,创建soup对象table = soup.find('table') # 查找网页中的table元素table_body = table.find('tbody') # 查找table元素中的tbody元素data = []rows = table_body.find_all('tr') # 查找表中的所有tr元素<br />for row in rows: # 遍历数据 cols = row.find_all('td') cols = [ele.text.strip() for ele in cols]data.append([ele for ele in cols if ele])# 结果输出:[[],['小米', '女', '22'],['小明','男','23'],……
3,调用Web API服务
Excel可以通过“数据”选项卡下的“自网站”功能调用Web API服务。Python可以使用 requests 库、Beautiful Soup包、Scrapy框架调用Web API获取数据。
1.使用Excel调用
(1)确保5.5.1节中编写的Web API服务已经开启。
(2)输入Web API方法对应的URL:
:8000/ExcelPythonTest/。
(3)处理返回的数据。
调用Web API服务后数据以JSON格式返回,按照5.4.3小节中介绍的方法处理JSON数据。
2.使用Python调用
使用requests库调用Web API方法,然后对返回的JSON数据进行处理,读者可参考本书代码素材文件“5-5-api.ipynb”进行学习。
import requests #导入requests包url ='http://127.0.0.1:8000/ExcelPythonTest/'<br />strhtml= requests.get(url) #使用get方法获取网页数据<br />import pandas as pd<br />frame= pd.read_json(strhtml.text) #使用Pandas包中的read_json函数print(frame)#结果输出:id task0 1 ETL-抽取数据操作1 2 ETL-数据清洗转换2 3 ETL-数据加载操作
3,Excel和Python抓取互联网数据方法对比
表1所示为Excel和Python抓取互联网数据方法的对比。需要注意Excel从互联网抓取数据的功能并不完善。
表1Excel和Python抓取互联网数据方法对比
声明:本文选自北京大学出版社的《从零开始利用Excel与Python进行数据分析》一书,略有修改,经出版社授权刊登于此。
文末赠书<p style="margin-bottom: 24px;outline: 0px;max-width: 100%;font-family: system-ui, -apple-system, BlinkMacSystemFont, "Helvetica Neue", "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei UI", "Microsoft YaHei", Arial, sans-serif;letter-spacing: 0.544px;white-space: normal;text-align: center;box-sizing: border-box !important;overflow-wrap: break-word !important;">内容简介
《从零开始利用Excel与Python进行数据分析》介绍了数据分析的方法和步骤,并分别通过Excel和Python实施和对比。通过《从零开始利用Excel与Python进行数据分析》一方面可以拓宽对Excel功能的认识,另一方面可以学习和掌握Python的基础操作。
规则
后台回复: 送书 ,参与抽奖
<br /><br />推荐阅读 点击标题可跳转用 Python 破解 WiFi 密码,太刺激了JetBrains 如何看待自己的软件在中国被频繁破解抛弃for循环,让 Python 代码更 pythonic </p>
python抓取网页数据抓取到的是一个抖音用户的简介
网站优化 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-09-08 21:15
python抓取网页数据这里抓取到的是一个抖音用户的简介。简介是这样的:作者:neo用户年龄:18禁欲系爱好:听radio看剧目前:已进行过两次付费服务两个月地址:提取码:uhi后来又发现这个用户名字带有you'llneverfallinlovewithxxxx当然,可能是个恶意用户,因为他会在视频里说这种话。我觉得这个数据挺有用的,所以总结一下。python爬取网页数据。
现在懂技术的多数转向,爬虫。把几千条数据根据你要发布的主题分割成数十万几百万条数据,进行高频抓取进行分析,基本上都要写爬虫代码,这个比起写c++要容易很多。根据数据量基本一个字典就足够了,然后selenium,
因为是开放教育平台,所以我们用c++爬取了数据,大概抓取的网站有上千个。网页抓取不是一个简单的动作,包括头程序、分析器、分包处理、数据库、web服务等等。如何给爬虫设置合理的语言和界面之间关系,是非常复杂的。因此,我们作为网站管理者(包括前端设计师)、前端工程师都非常重视这个问题。常规的做法:用java、python、js等前端语言爬取不同网站发布的链接数据,然后合并起来。
也有一些直接用php转成脚本后用scrapy抓取。我们根据自己爬取的链接,对数据进行分析,提取用户画像,数据量都挺多的。大概就是这些。 查看全部
python抓取网页数据抓取到的是一个抖音用户的简介
python抓取网页数据这里抓取到的是一个抖音用户的简介。简介是这样的:作者:neo用户年龄:18禁欲系爱好:听radio看剧目前:已进行过两次付费服务两个月地址:提取码:uhi后来又发现这个用户名字带有you'llneverfallinlovewithxxxx当然,可能是个恶意用户,因为他会在视频里说这种话。我觉得这个数据挺有用的,所以总结一下。python爬取网页数据。
现在懂技术的多数转向,爬虫。把几千条数据根据你要发布的主题分割成数十万几百万条数据,进行高频抓取进行分析,基本上都要写爬虫代码,这个比起写c++要容易很多。根据数据量基本一个字典就足够了,然后selenium,
因为是开放教育平台,所以我们用c++爬取了数据,大概抓取的网站有上千个。网页抓取不是一个简单的动作,包括头程序、分析器、分包处理、数据库、web服务等等。如何给爬虫设置合理的语言和界面之间关系,是非常复杂的。因此,我们作为网站管理者(包括前端设计师)、前端工程师都非常重视这个问题。常规的做法:用java、python、js等前端语言爬取不同网站发布的链接数据,然后合并起来。
也有一些直接用php转成脚本后用scrapy抓取。我们根据自己爬取的链接,对数据进行分析,提取用户画像,数据量都挺多的。大概就是这些。
python抓取网页数据库django中控制文章中数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-07-16 13:01
python抓取网页数据库django中控制文章django中数据库没有django2的多变表的配置抓取以前发表的文章对旧文章进行删除对新文章进行添加在文章列表页面添加相关字段username和passwordpassword为文章的密码post表单请求网站posturl=''#headertype='text/plain'method='post'#添加版权信息content-type='application/x-www-form-urlencoded'#发送多重域名请求时指定url的类型postmethod='locate'postsuccesskey='xxx'#responseheaders={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responseheaders={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responsebody={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/53 查看全部
python抓取网页数据库django中控制文章中数据
python抓取网页数据库django中控制文章django中数据库没有django2的多变表的配置抓取以前发表的文章对旧文章进行删除对新文章进行添加在文章列表页面添加相关字段username和passwordpassword为文章的密码post表单请求网站posturl=''#headertype='text/plain'method='post'#添加版权信息content-type='application/x-www-form-urlencoded'#发送多重域名请求时指定url的类型postmethod='locate'postsuccesskey='xxx'#responseheaders={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responseheaders={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537.36(khtml,likegecko)chrome/75.0.2838.116safari/537.36'}responsebody={'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/53
Python爬虫入门教程 21-100 网易云课堂课程数据抓取
网站优化 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-06-18 13:16
网易云课堂课程数据-写在前面
今天咱们抓取一下网易云课堂的课程数据,这个网站的数据量并不是很大,我们只需要使用requests就可以快速的抓取到这部分数据了。 你第一步要做的是打开全部课程的地址,找出爬虫规律,
地址如下:
我简单的看了一下,页面数据是基于这个地址进行异步加载的。你自己尝试的时候需要借助开发者工具进行多次尝试,抓取到这个地址的数据为准。
还有一个地方需要注意,这次是post提交方式,并且提交数据是payload类型的,这个原因导致我们的代码和以前的略微有一些不同的地方。
提取post关键字,看一下各个参数的意思,如果你爬取的网站足够多,那么训练出来的敏感度能够快速的分析这些参数
<p>{"pageIndex":55, # 页码
"pageSize":50, # 每页数据大小
"relativeOffset":2700,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":"" # 搜索相关
}</p>
好了,可以开始编写代码了,核心的代码就是通过requests模块发送post请求
<p>def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageIndex":index,
"pageSize":50,
"relativeOffset":50,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":""
}
headers = {"Accept":"application/json",
"Host":"study.163.com",
"Origin":"https://study.163.com",
"Content-Type":"application/json",
"Referer":"https://study.163.com/courses",
"User-Agent":"自己去找个浏览器UA"
}
try:
# 请注意这个地方发送的是post请求
# CSDN 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except Exception as e:
print("出现BUG了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]</p>
因为获取到的数据是json类型的,所以,数据可以快速的保存到mongodb里面,保存数据的代码我依旧留空,希望你自己可以完善。
通过很短的时间,我们就捕获到了3000门课程
好了,需要代码和数据,请评论留下我能联系你的方式即可。
选哪个长按哪个二维码即可
小小的备注:如果你发现在手机上看源码不是很方便,可以点击收藏,然后在电脑端微信就可以查阅啦~ 完美格式呈现
欢迎关注:非本科程序员 公众账号
查看全部
Python爬虫入门教程 21-100 网易云课堂课程数据抓取
网易云课堂课程数据-写在前面
今天咱们抓取一下网易云课堂的课程数据,这个网站的数据量并不是很大,我们只需要使用requests就可以快速的抓取到这部分数据了。 你第一步要做的是打开全部课程的地址,找出爬虫规律,
地址如下:
我简单的看了一下,页面数据是基于这个地址进行异步加载的。你自己尝试的时候需要借助开发者工具进行多次尝试,抓取到这个地址的数据为准。
还有一个地方需要注意,这次是post提交方式,并且提交数据是payload类型的,这个原因导致我们的代码和以前的略微有一些不同的地方。
提取post关键字,看一下各个参数的意思,如果你爬取的网站足够多,那么训练出来的敏感度能够快速的分析这些参数
<p>{"pageIndex":55, # 页码
"pageSize":50, # 每页数据大小
"relativeOffset":2700,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":"" # 搜索相关
}</p>
好了,可以开始编写代码了,核心的代码就是通过requests模块发送post请求
<p>def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageIndex":index,
"pageSize":50,
"relativeOffset":50,
"frontCategoryId":-1,
"searchTimeType":-1,
"orderType":50,
"priceType":-1,
"activityId":0,
"keyword":""
}
headers = {"Accept":"application/json",
"Host":"study.163.com",
"Origin":"https://study.163.com",
"Content-Type":"application/json",
"Referer":"https://study.163.com/courses",
"User-Agent":"自己去找个浏览器UA"
}
try:
# 请注意这个地方发送的是post请求
# CSDN 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except Exception as e:
print("出现BUG了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]</p>
因为获取到的数据是json类型的,所以,数据可以快速的保存到mongodb里面,保存数据的代码我依旧留空,希望你自己可以完善。
通过很短的时间,我们就捕获到了3000门课程
好了,需要代码和数据,请评论留下我能联系你的方式即可。
选哪个长按哪个二维码即可
小小的备注:如果你发现在手机上看源码不是很方便,可以点击收藏,然后在电脑端微信就可以查阅啦~ 完美格式呈现
欢迎关注:非本科程序员 公众账号
介绍python 数据抓取三种方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-06-04 23:49
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = ''page_content = download(url)country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('
(.*?)
', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = ''html = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = ''page_content = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。 查看全部
介绍python 数据抓取三种方法
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = ''page_content = download(url)country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('
(.*?)
', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)
2.BeautifulSoup(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = ''html = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = ''page_content = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
用 Python 抓取 bilibili 弹幕并分析
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-01 03:29
作者| GitPython
时隔一年,嵩哥带来他的新作《雨幕》。
他依旧认真创作,追求高品质,作品在发表之前已听了五百遍以上。
如此高品质的音乐,大家如何评价呢?通过哔哩哔哩上的视频弹幕,感受一下。
01实现思路
首先,利用哔哩哔哩的弹幕接口,把数据保存到本地。接着,对数据进行分词。最后,做了评论的可视化。
02弹幕数据
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的。
比如:
一个固定的url地址 + 视频的cid + .xml
只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?
右键网页,打开网页源代码,搜索 "cid":就能找到:
03保存数据到本地
有了数据的接口链接,我们就可以利用request模块,获取数据了。
然后,再利用xpath简单的解析xml,就可以把所有的弹幕信息汇总到一个列表里了。最后,把列表转化成dataframe,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 许嵩新歌《雨幕》<br /># bilibili视频弹幕文件<br />url = 'https://comment.bilibili.com/123072475.xml'<br /><br /># 发送请求<br />response = requests.get(url)<br />xml = etree.fromstring(response.content)<br /><br /># 解析数据<br />dm = xml.xpath("/i/d/text()")<br />print(dm) # list<br /><br /># 把列表转换成 dataframe<br />dm_df = pd.DataFrame(dm, columns=['弹幕内容'])<br />print(dm_df)<br /><br /># 存到本地<br /># 解决了中文乱码问题<br />dm_df.to_csv('雨幕-弹幕.csv', encoding='utf_8_sig')<br /></p>
保存的csv数据:
04对数据进行分词
制作词云前,需要把弹幕数据进行分词。
关于jieba分词,可以参考:
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># jieba分词<br />dm_str = " ".join(dm)<br />words_list = jieba.lcut(dm_str) # 切分的是字符串,返回的是列表<br />words_str = " ".join(words_list)<br /></p>
05词云可视化
通过创建词云对象、设置词云参数,最终生成图片,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 读取本地文件<br />backgroud_Image = plt.imread('1.jpg')<br /><br /># 创建词云<br />wc = WordCloud(<br /> background_color='white',<br /> mask=backgroud_Image,<br /> font_path='./SourceHanSerifCN-Medium.otf', # 设置本地字体<br /><br /> max_words=2000,<br /> max_font_size=100,<br /> min_font_size=10,<br /> color_func=random_color_func,<br /> random_state=50,<br />)<br /><br />word_cloud = wc.generate(words_str) # 产生词云<br />word_cloud.to_file("yumu.jpg") #保存图片<br /></p>
<p style="margin-right: 16px;margin-left: 16px;white-space: normal;line-height: 1.75em;"><br />
</p> 查看全部
用 Python 抓取 bilibili 弹幕并分析
作者| GitPython
时隔一年,嵩哥带来他的新作《雨幕》。
他依旧认真创作,追求高品质,作品在发表之前已听了五百遍以上。
如此高品质的音乐,大家如何评价呢?通过哔哩哔哩上的视频弹幕,感受一下。
01实现思路
首先,利用哔哩哔哩的弹幕接口,把数据保存到本地。接着,对数据进行分词。最后,做了评论的可视化。
02弹幕数据
平常我们在看视频时,弹幕是出现在视频上的。实际上在网页中,弹幕是被隐藏在源代码中,以XML的数据格式进行加载的。
比如:
一个固定的url地址 + 视频的cid + .xml
只要找到你想要的视频cid,替换这个url就可以爬取所有弹幕了(b站大部分网页给出的字幕限制是1000条)。
一个视频的cid在哪里呢?
右键网页,打开网页源代码,搜索 "cid":就能找到:
03保存数据到本地
有了数据的接口链接,我们就可以利用request模块,获取数据了。
然后,再利用xpath简单的解析xml,就可以把所有的弹幕信息汇总到一个列表里了。最后,把列表转化成dataframe,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 许嵩新歌《雨幕》<br /># bilibili视频弹幕文件<br />url = 'https://comment.bilibili.com/123072475.xml'<br /><br /># 发送请求<br />response = requests.get(url)<br />xml = etree.fromstring(response.content)<br /><br /># 解析数据<br />dm = xml.xpath("/i/d/text()")<br />print(dm) # list<br /><br /># 把列表转换成 dataframe<br />dm_df = pd.DataFrame(dm, columns=['弹幕内容'])<br />print(dm_df)<br /><br /># 存到本地<br /># 解决了中文乱码问题<br />dm_df.to_csv('雨幕-弹幕.csv', encoding='utf_8_sig')<br /></p>
保存的csv数据:
04对数据进行分词
制作词云前,需要把弹幕数据进行分词。
关于jieba分词,可以参考:
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># jieba分词<br />dm_str = " ".join(dm)<br />words_list = jieba.lcut(dm_str) # 切分的是字符串,返回的是列表<br />words_str = " ".join(words_list)<br /></p>
05词云可视化
通过创建词云对象、设置词云参数,最终生成图片,保存到本地。
<p style="font-size: 14px;letter-spacing: 0px;font-family: Consolas, Inconsolata, Courier, monospace;border-radius: 0px;color: rgb(169, 183, 198);background: rgb(40, 43, 46);padding: 0.5em;text-align: justify;margin-left: 16px;margin-right: 16px;line-height: 1.75em;overflow-wrap: normal !important;word-break: normal !important;overflow: auto !important;display: -webkit-box !important;"># 读取本地文件<br />backgroud_Image = plt.imread('1.jpg')<br /><br /># 创建词云<br />wc = WordCloud(<br /> background_color='white',<br /> mask=backgroud_Image,<br /> font_path='./SourceHanSerifCN-Medium.otf', # 设置本地字体<br /><br /> max_words=2000,<br /> max_font_size=100,<br /> min_font_size=10,<br /> color_func=random_color_func,<br /> random_state=50,<br />)<br /><br />word_cloud = wc.generate(words_str) # 产生词云<br />word_cloud.to_file("yumu.jpg") #保存图片<br /></p>
<p style="margin-right: 16px;margin-left: 16px;white-space: normal;line-height: 1.75em;"><br />
用Python爬网页需要了解什么背景知识
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 22:36
在知乎上有一位同学提出的问题:用Python爬网页需要了解什么背景知识,恰好我对爬虫有所了解,所以昨天晚上做了回答,今天放到公众号上面希望对大家有所帮助,如有帮助欢迎转发。
文中涉及到一些教程链接在本篇文章无法打开,可以点击阅读原文查看我在知乎上的原回答,也欢迎大家给我的回答点赞。
要学会使用Python爬取网页信息无外乎以下几点内容:
1、要会Python
2、知道网页信息如何呈现
3、了解网页信息如何产生
4、学会如何提取网页信息
第一步Python是工具,所以你必须熟练掌握它,要掌握到什么程度呢?如果你只想写一写简单的爬虫,不要炫技不考虑爬虫效率,你只需要掌握:
你甚至不需要掌握函数、异步、多线程、多进程,当然如果想要提高自己小爬虫的爬虫效率,提高数据的精确性,那么记住最好的方式是去系统的学习一遍Python,去哪儿学习?Python教程
假设你已经熟悉了最基础的Python知识,那么进入第二步:知道网页信息如何呈现?你首先要知道所需要抓取的数据是怎样的呈现的,就像是你想要学做一幅画,在开始之前你要知道这幅画是用什么画出来的,铅笔还是水彩笔...等等,可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:
1、HTML (HTML 简介)
2、JSON (JSON 简介)
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
假设你现在知道了数据是由HTML和JSON呈现出来的,那么我们紧接着第三步:数据怎么来?数据当然是从服务器反馈给你的,为什么要反馈给你?因为你发出了请求。
“Hi~ ,服务器我要这个资源”
“正在传输中...”
“已经收到HTML或者JSON格式的数据”
这是什么请求?要搞清楚这一点你需要了解一下http的基础知识,更加精确来说你需要去了解GET和POST是什么,区别是什么。也许你可以看看这个:浅谈HTTP中Get与Post的区别 - hyddd - 博客园
很高兴你使用的是Python,那么你只需要去掌握好快速上手 - Requests 2.10.0 文档,requests可以帮你模拟发出GET和POST请求,这真是太棒了。
饭菜已经备好,两菜一汤美味佳肴,下面就是好好享受了。现在我们已经拿到了数据,我们需要在这些错乱的数据中提取我们需要的数据,这时候我们有两个选择。
第一招:万能钥匙
Python正则表达式指南 ,再大再乱的内容,哪怕是大海捞针,只要告诉我这个针的样子我都能从茫茫大海中捞出来,强大的正则表达式是你提取数据的不二之选。
第二招:笑里藏刀
Beautiful Soup 4.2.0 文档,或许我们有更好的选择,我们把原始数据和我们想要的数据的样子扔个这个Beautifulsoup,然后让它帮我们去寻找,这也是一个不错的方案,但是论灵活性,第二招还是略逊于第一招。
第三招:双剑合璧
最厉害的招式莫过于结合第一招和第二招了,打破天下无敌手。
基础知识我都会,可是我还是写不了一个爬虫啊!
客观别急,这还没完。
以下这些项目,你拿来学习学习练练手。
两个教学项目你值得拥有:
还不够?这儿有很多:
偶遇一个段子
查看全部
用Python爬网页需要了解什么背景知识
在知乎上有一位同学提出的问题:用Python爬网页需要了解什么背景知识,恰好我对爬虫有所了解,所以昨天晚上做了回答,今天放到公众号上面希望对大家有所帮助,如有帮助欢迎转发。
文中涉及到一些教程链接在本篇文章无法打开,可以点击阅读原文查看我在知乎上的原回答,也欢迎大家给我的回答点赞。
要学会使用Python爬取网页信息无外乎以下几点内容:
1、要会Python
2、知道网页信息如何呈现
3、了解网页信息如何产生
4、学会如何提取网页信息
第一步Python是工具,所以你必须熟练掌握它,要掌握到什么程度呢?如果你只想写一写简单的爬虫,不要炫技不考虑爬虫效率,你只需要掌握:
你甚至不需要掌握函数、异步、多线程、多进程,当然如果想要提高自己小爬虫的爬虫效率,提高数据的精确性,那么记住最好的方式是去系统的学习一遍Python,去哪儿学习?Python教程
假设你已经熟悉了最基础的Python知识,那么进入第二步:知道网页信息如何呈现?你首先要知道所需要抓取的数据是怎样的呈现的,就像是你想要学做一幅画,在开始之前你要知道这幅画是用什么画出来的,铅笔还是水彩笔...等等,可能种类是多样的,但是放到网页信息来说这儿只有两种呈现方式:
1、HTML (HTML 简介)
2、JSON (JSON 简介)
HTML是用来描述网页的一种语言
JSON是一种轻量级的数据交换格式
假设你现在知道了数据是由HTML和JSON呈现出来的,那么我们紧接着第三步:数据怎么来?数据当然是从服务器反馈给你的,为什么要反馈给你?因为你发出了请求。
“Hi~ ,服务器我要这个资源”
“正在传输中...”
“已经收到HTML或者JSON格式的数据”
这是什么请求?要搞清楚这一点你需要了解一下http的基础知识,更加精确来说你需要去了解GET和POST是什么,区别是什么。也许你可以看看这个:浅谈HTTP中Get与Post的区别 - hyddd - 博客园
很高兴你使用的是Python,那么你只需要去掌握好快速上手 - Requests 2.10.0 文档,requests可以帮你模拟发出GET和POST请求,这真是太棒了。
饭菜已经备好,两菜一汤美味佳肴,下面就是好好享受了。现在我们已经拿到了数据,我们需要在这些错乱的数据中提取我们需要的数据,这时候我们有两个选择。
第一招:万能钥匙
Python正则表达式指南 ,再大再乱的内容,哪怕是大海捞针,只要告诉我这个针的样子我都能从茫茫大海中捞出来,强大的正则表达式是你提取数据的不二之选。
第二招:笑里藏刀
Beautiful Soup 4.2.0 文档,或许我们有更好的选择,我们把原始数据和我们想要的数据的样子扔个这个Beautifulsoup,然后让它帮我们去寻找,这也是一个不错的方案,但是论灵活性,第二招还是略逊于第一招。
第三招:双剑合璧
最厉害的招式莫过于结合第一招和第二招了,打破天下无敌手。
基础知识我都会,可是我还是写不了一个爬虫啊!
客观别急,这还没完。
以下这些项目,你拿来学习学习练练手。
两个教学项目你值得拥有:
还不够?这儿有很多:
偶遇一个段子
python数据抓取3种方法总结
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-05-09 04:31
这篇文章主要给大家介绍了关于python数据抓取的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
三种数据抓取的方法
*利用之前构建的下载网页函数,获取目标网页的html,我们以为例,获取html。
<p>from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)</p>
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
<p>from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])</p>
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.BeautifulSoup(bs4)
<p>from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)</p>
3.lxml
<p>from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')</p>
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
扫下方二维码加老师微信 查看全部
python数据抓取3种方法总结
这篇文章主要给大家介绍了关于python数据抓取的3种方法,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
三种数据抓取的方法
*利用之前构建的下载网页函数,获取目标网页的html,我们以为例,获取html。
<p>from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)</p>
*假设我们需要爬取该网页中的国家名称和概况,我们依次使用这三种数据抓取的方法实现数据抓取。
1.正则表达式
<p>from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])</p>
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)</p>
2.BeautifulSoup(bs4)
<p>from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)</p>
3.lxml
<p>from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')</p>
运行结果:
最后,引用《用python写网络爬虫》中对三种方法的性能对比,如下图:
仅供参考。
扫下方二维码加老师微信
Python使用xslt提取网页数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-05-09 04:30
1 引言
在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml格式。
2 用lxml库实现网页内容提取
lxml是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
这2天测试了在python中通过xslt来提取网页内容,记录如下:
2.1 抓取目标
假设要提取集搜客官网旧版论坛的帖子标题和回复数,如下图,要把整个列表提取出来,存成xml格式
2.2 源代码1:
只抓当前页,结果显示在控制台
Python的优势是用很少量代码就能解决一个问题,请注意下面的代码看起来很长,其实python函数调用没有几个,大篇幅被一个xslt脚本占去了,在这段代码中,只是一个好长的字符串而已,至于为什么选择xslt,而不是离散的xpath或者让人挠头的正则表达式,请参看Python即时网络爬虫项目启动说明,我们期望通过这个架构,把程序员的时间节省下来一大半。
可以拷贝运行下面的代码(在windows10, python3.2下测试通过):
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeurl="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)doc = etree.HTML(conn.read())xslt_root = etree.XML("""\""")transform = etree.XSLT(xslt_root)result_tree = transform(doc)print(result_tree)<br /></p>
源代码下载地址请见文章末尾的GitHub源。
2.3 抓取结果
得到的抓取结果如下图:
2.4 源代码2:
翻页抓取,结果存入文件
我们对2.2的代码再做进一步修改,增加翻页抓取和存结果文件功能,代码如下:
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeimport timexslt_root = etree.XML("""\""")baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):<br /> url = baseurl + "?page=" + str(count)<br /> conn = request.urlopen(url)<br /> doc = etree.HTML(conn.read())<br /> transform = etree.XSLT(xslt_root)<br /> result_tree = transform(doc)<br /> print(str(result_tree))<br /> file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')<br /> file_obj.write(str(result_tree))<br /> file_obj.close()<br /> count += 1<br /> time.sleep(2)<br /></p>
我们增加了写文件的代码,还增加了一个循环,构造每个翻页的网址,但是,如果翻页过程中网址总是不变怎么办?其实这就是动态网页内容,下面会讨论这个问题。
3总结
这是开源Python通用爬虫项目的验证过程,在一个爬虫框架里面,其它部分都容易做成通用的,就是网页内容提取和转换成结构化的操作难于通用,我们称之为提取器。但是,借助GooSeeker可视化提取规则生成器MS谋数台 ,提取器的生成过程将变得很便捷,而且可以标准化插入,从而实现通用爬虫,在后续的文章中会专门讲解MS谋数台与Python配合的具体方法。
End.
作者:fullerhua(中国统计网特邀认证作者)
本文为中国统计网原创文章,需要转载请联系中国统计网( ),转载时请注明作者及出处,并保留本文链接。
更多精彩,长按下方图片中的二维码,下载APP查看。
查看全部
Python使用xslt提取网页数据
1 引言
在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor。本文记录了确定gsExtractor的技术路线过程中所做的编程实验。这是第一部分,实验了用xslt方式一次性提取静态网页内容并转换成xml格式。
2 用lxml库实现网页内容提取
lxml是python的一个库,可以迅速、灵活地处理 XML。它支持 XML Path Language (XPath) 和 Extensible Stylesheet Language Transformation (XSLT),并且实现了常见的 ElementTree API。
这2天测试了在python中通过xslt来提取网页内容,记录如下:
2.1 抓取目标
假设要提取集搜客官网旧版论坛的帖子标题和回复数,如下图,要把整个列表提取出来,存成xml格式
2.2 源代码1:
只抓当前页,结果显示在控制台
Python的优势是用很少量代码就能解决一个问题,请注意下面的代码看起来很长,其实python函数调用没有几个,大篇幅被一个xslt脚本占去了,在这段代码中,只是一个好长的字符串而已,至于为什么选择xslt,而不是离散的xpath或者让人挠头的正则表达式,请参看Python即时网络爬虫项目启动说明,我们期望通过这个架构,把程序员的时间节省下来一大半。
可以拷贝运行下面的代码(在windows10, python3.2下测试通过):
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeurl="http://www.gooseeker.com/cn/forum/7"conn = request.urlopen(url)doc = etree.HTML(conn.read())xslt_root = etree.XML("""\""")transform = etree.XSLT(xslt_root)result_tree = transform(doc)print(result_tree)<br /></p>
源代码下载地址请见文章末尾的GitHub源。
2.3 抓取结果
得到的抓取结果如下图:
2.4 源代码2:
翻页抓取,结果存入文件
我们对2.2的代码再做进一步修改,增加翻页抓取和存结果文件功能,代码如下:
<p style="margin-top: 5px; margin-bottom: 5px; line-height: 1.5em;">from urllib import requestfrom lxml import etreeimport timexslt_root = etree.XML("""\""")baseurl = "http://www.gooseeker.com/cn/fo ... begin = "jsk_bbs_"basefileend = ".xml"count = 1while (count < 12):<br /> url = baseurl + "?page=" + str(count)<br /> conn = request.urlopen(url)<br /> doc = etree.HTML(conn.read())<br /> transform = etree.XSLT(xslt_root)<br /> result_tree = transform(doc)<br /> print(str(result_tree))<br /> file_obj = open(basefilebegin+str(count)+basefileend,'w',encoding='UTF-8')<br /> file_obj.write(str(result_tree))<br /> file_obj.close()<br /> count += 1<br /> time.sleep(2)<br /></p>
我们增加了写文件的代码,还增加了一个循环,构造每个翻页的网址,但是,如果翻页过程中网址总是不变怎么办?其实这就是动态网页内容,下面会讨论这个问题。
3总结
这是开源Python通用爬虫项目的验证过程,在一个爬虫框架里面,其它部分都容易做成通用的,就是网页内容提取和转换成结构化的操作难于通用,我们称之为提取器。但是,借助GooSeeker可视化提取规则生成器MS谋数台 ,提取器的生成过程将变得很便捷,而且可以标准化插入,从而实现通用爬虫,在后续的文章中会专门讲解MS谋数台与Python配合的具体方法。
End.
作者:fullerhua(中国统计网特邀认证作者)
本文为中国统计网原创文章,需要转载请联系中国统计网( ),转载时请注明作者及出处,并保留本文链接。
更多精彩,长按下方图片中的二维码,下载APP查看。
python抓取网页数据 “经阅Sharing”|第一期活动回顾
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-05-04 02:40
2022年4月30日晚,由经济学院研究生会主办的第一期“经阅Sharing”学术分享活动在线上举办。本次活动中,经济学院2020级博士研究生赵文天以“Python爬虫实用技能——从入门到进阶”为主题进行了分享。
主讲人首先介绍了爬虫的基本功能和实现原理:爬虫是一种从众多公开网站中抓取数据的程序,在现今各个领域的学术研究中被广泛地应用。其次介绍了浏览器、HTML与web请求过程:浏览器将承载着包括对象、属性和过程等信息的HTML语言,翻译成人们可阅读的网页信息。这一过程可以分解为两步:第一步客户端向服务器发送请求信息;第二步服务器向客户端返回请求信息所要求的网页代码(HTML)和数据。
随后,主讲人为我们介绍了爬虫程序实现思路。核心就是用程序模拟浏览器的行为,向服务器发送请求,并接收对应的信息,最终再提取出我们想要的数据。主讲人以百度网页为例,向我们展示了在我们如何获取浏览器向服务器发送的请求指令,以及如何从指令中寻找规律,得到我们想要的结果。
之后,主讲人开始演示爬虫的具体操作,分别以百度网页和中国知网为例,详细地介绍了利用requests库爬取同步加载和异步加载数据的主要思路,以及在这过程中可能遇到的问题和解决方式。
除此之外,主讲人还介绍了另一种爬虫库——selenium,比对了两种爬虫库在应用上的不同与优劣,并且还向我们介绍了re正则表达式语言,展示了该语言与requests相结合进行爬虫的主要方法。
最后,主讲人与同学们就平时学习以及实践过程中的疑问进行交流,和同学们分享了自己在爬虫方面的诸多经验。本次“经阅Sharing”在大家的热烈讨论中结束。
本学期首次“经阅Sharing”举办活动圆满成功,之后会陆续推出技能介绍与经验分享等学术活动,欢迎大家持续关注!
文案|杨惠婷
经济学院研究生会学术部供稿
查看全部
python抓取网页数据 “经阅Sharing”|第一期活动回顾
2022年4月30日晚,由经济学院研究生会主办的第一期“经阅Sharing”学术分享活动在线上举办。本次活动中,经济学院2020级博士研究生赵文天以“Python爬虫实用技能——从入门到进阶”为主题进行了分享。
主讲人首先介绍了爬虫的基本功能和实现原理:爬虫是一种从众多公开网站中抓取数据的程序,在现今各个领域的学术研究中被广泛地应用。其次介绍了浏览器、HTML与web请求过程:浏览器将承载着包括对象、属性和过程等信息的HTML语言,翻译成人们可阅读的网页信息。这一过程可以分解为两步:第一步客户端向服务器发送请求信息;第二步服务器向客户端返回请求信息所要求的网页代码(HTML)和数据。
随后,主讲人为我们介绍了爬虫程序实现思路。核心就是用程序模拟浏览器的行为,向服务器发送请求,并接收对应的信息,最终再提取出我们想要的数据。主讲人以百度网页为例,向我们展示了在我们如何获取浏览器向服务器发送的请求指令,以及如何从指令中寻找规律,得到我们想要的结果。
之后,主讲人开始演示爬虫的具体操作,分别以百度网页和中国知网为例,详细地介绍了利用requests库爬取同步加载和异步加载数据的主要思路,以及在这过程中可能遇到的问题和解决方式。
除此之外,主讲人还介绍了另一种爬虫库——selenium,比对了两种爬虫库在应用上的不同与优劣,并且还向我们介绍了re正则表达式语言,展示了该语言与requests相结合进行爬虫的主要方法。
最后,主讲人与同学们就平时学习以及实践过程中的疑问进行交流,和同学们分享了自己在爬虫方面的诸多经验。本次“经阅Sharing”在大家的热烈讨论中结束。
本学期首次“经阅Sharing”举办活动圆满成功,之后会陆续推出技能介绍与经验分享等学术活动,欢迎大家持续关注!
文案|杨惠婷
经济学院研究生会学术部供稿
用python绘制一张炫酷的玫瑰图!
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-05-03 04:10
网上冲浪时看到了一张很炫酷的南丁格尔玫瑰图,显示了国外主流流媒体平台的订阅人数排行,顿时来了兴趣,咱也用python 来绘制一张!
话不多说,先上原图:
再来看下代码复现的效果:
可以看到,图形主体得到了完美的复现,仅需要在此基础上增加标题、文字说明和服务商logo即可,这些步骤可以在PS 或 AI 中进行,修图可以让你的玫瑰图更完美!
本文介绍使用pyecharts 绘制南丁格尔玫瑰图的过程,即代码实现部分,不过在绘制之前需要获取网页数据,所以,整篇文章分为数据获取和图形绘制两部分。预计阅读时间9分钟。
01
获取网页数据
以上是图表和数据来源网页,其数据是以分页形式展示的,需要进行翻页,点击next 看到所有数据。
这里,我们获取网页数据的工具是Selenium, 这是一款超级好用的自动化测试工具,可以模拟人类对浏览器的操作,实现对所有网页元素的定位和抓取,即可见即可得。
首先安装 selenium(pip install selenium)和浏览器驱动程序webdriver(建议下载与谷歌浏览器和对应版本的chrome webdriver)。
安装好之后,对数据的获取可以分3步走:
启动webdriver, 打开网页
定位标题和下载图片
获取当前页数据,并实现翻页,获取所有数据
代码展示:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport requestsimport csvimport time# 01. 启动 webdirver, 打开网页browser = webdriver.Chrome('/usr/local/chromedriver')# 此处填入自己的webdriver exe 的文件路径browser.get('https://www.visualcapitalist.com/which-streaming-service-has-the-most-subscriptions/')browser.implicitly_wait(5) # 等待内容加载完毕# 02. 获取标题和下载图片title = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > h1').text + '.jpg'pic = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > span > p:nth-child(1) > img').get_attribute('src')res = requests.get(pic).contentimagepath = './' + titlewith open(imagepath, 'wb') as fp: fp.write(res)time.sleep(2)# 03. 点击翻页,获取所有数据with open('./data.csv', 'a') as f: writer = csv.writer(f) writer.writerow(['services', 'subscribers','types'])for i in range(1,4): services = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-1') types = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-2') subscribers = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-3') column1 = [] column2 = [] column3 = [] for service in services: column1.append(service.text.strip()) for subscriber in subscribers: column2.append(subscriber.text.strip()) for type in types: column3.append(type.text.strip()) lis = [] for i in zip(column1, column2,column3): lis.append(list(i)) with open('./data.csv','a') as f: writer = csv.writer(f) writer.writerows(lis) next_button =browser.find_element(By.XPATH,'//*[@id="tablepress-1461_next"]') next_button.click()# 以上两行实现翻页,获取所有数据print('数据成功获取')browser.quit()# 获取完毕,关闭网页
成功获取的数据存在csv 文件中:
02
绘制玫瑰图
有了数据,自然就可以使用工具来绘制玫瑰图了,这里我们使用的是pyecharts里的饼图类 Pie.
import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as opts<br /># 01. 读取并整理数据data = pd.read_csv('data.csv',header=1)data = data.drop_duplicates(keep=False)data = data.reset_index(drop=True)data['subscribers'] = data['subscribers'].str.replace('M','')data['subscribers'] = data['subscribers'].astype('float').round()x_data = data['services']y_data = data['subscribers']# 自定义颜色,根据服务商类型提供4种颜色,可以在ps中打开原图,获取颜色的十六进制代码color_dic = {'Video':'#fbf3dc', 'Audio':'#1b1718', 'Video/Audio':'#833100', 'News':'#f1a15c' }data['colors'] = data['types'].map(color_dic)# 准备数据对data_pairdf = [list(z) for z in zip(x_data,y_data)]# print(df)# 02. 使用 pyecharts Pie 绘制玫瑰图pie = Pie(init_opts=opts.InitOpts(bg_color='#d66f0a',width='650px',height='1000px'))pie.add(series_name='services', data_pair=df, radius=['12%','200%'],#设置内圆和外圆的半径 center=['35%','70%'], #设置圆的位置 rosetype='area',) # 关键步骤!设置类型为area, 会展示为玫瑰图pie.set_global_opts( legend_opts=opts.LegendOpts(is_show=False), #不显示图例 )pie.set_series_opts( label_opts=opts.LabelOpts(position='inside', # 标签位置 rotate = 45, font_size = 14, # 字体大小 formatter="{c}",color = '#d66f0a') # 标签格式 )pie.set_colors(list(data['colors'])) # 渲染颜色pie.render('streaming war.html') #出图<br />
至此,就可以得到一张网页图形,后续可使用PS AI PPT等工具进行图表元素的完善,本文不作展示。想要追求100%复现的同学可以自行探索~
03
总结一下
实现炫酷的玫瑰图,可以分为两步:
获取数据,难点在于使用selenium 定位全部数据,需要用for 循环配合点击Next 按钮完成。
绘制数据,关键在于数据格式的整理,以及将饼图的rosetype 设为area 。
欢迎关注本号,可私信获取源码和数据~
END
查看全部
用python绘制一张炫酷的玫瑰图!
网上冲浪时看到了一张很炫酷的南丁格尔玫瑰图,显示了国外主流流媒体平台的订阅人数排行,顿时来了兴趣,咱也用python 来绘制一张!
话不多说,先上原图:
再来看下代码复现的效果:
可以看到,图形主体得到了完美的复现,仅需要在此基础上增加标题、文字说明和服务商logo即可,这些步骤可以在PS 或 AI 中进行,修图可以让你的玫瑰图更完美!
本文介绍使用pyecharts 绘制南丁格尔玫瑰图的过程,即代码实现部分,不过在绘制之前需要获取网页数据,所以,整篇文章分为数据获取和图形绘制两部分。预计阅读时间9分钟。
01
获取网页数据
以上是图表和数据来源网页,其数据是以分页形式展示的,需要进行翻页,点击next 看到所有数据。
这里,我们获取网页数据的工具是Selenium, 这是一款超级好用的自动化测试工具,可以模拟人类对浏览器的操作,实现对所有网页元素的定位和抓取,即可见即可得。
首先安装 selenium(pip install selenium)和浏览器驱动程序webdriver(建议下载与谷歌浏览器和对应版本的chrome webdriver)。
安装好之后,对数据的获取可以分3步走:
启动webdriver, 打开网页
定位标题和下载图片
获取当前页数据,并实现翻页,获取所有数据
代码展示:
from selenium import webdriverfrom selenium.webdriver.common.by import Byimport requestsimport csvimport time# 01. 启动 webdirver, 打开网页browser = webdriver.Chrome('/usr/local/chromedriver')# 此处填入自己的webdriver exe 的文件路径browser.get('https://www.visualcapitalist.com/which-streaming-service-has-the-most-subscriptions/')browser.implicitly_wait(5) # 等待内容加载完毕# 02. 获取标题和下载图片title = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > h1').text + '.jpg'pic = browser.find_element(By.CSS_SELECTOR,'#mvp-post-head > span > p:nth-child(1) > img').get_attribute('src')res = requests.get(pic).contentimagepath = './' + titlewith open(imagepath, 'wb') as fp: fp.write(res)time.sleep(2)# 03. 点击翻页,获取所有数据with open('./data.csv', 'a') as f: writer = csv.writer(f) writer.writerow(['services', 'subscribers','types'])for i in range(1,4): services = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-1') types = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-2') subscribers = browser.find_elements(By.CSS_SELECTOR, '#tablepress-1461 > tbody > tr > td.column-3') column1 = [] column2 = [] column3 = [] for service in services: column1.append(service.text.strip()) for subscriber in subscribers: column2.append(subscriber.text.strip()) for type in types: column3.append(type.text.strip()) lis = [] for i in zip(column1, column2,column3): lis.append(list(i)) with open('./data.csv','a') as f: writer = csv.writer(f) writer.writerows(lis) next_button =browser.find_element(By.XPATH,'//*[@id="tablepress-1461_next"]') next_button.click()# 以上两行实现翻页,获取所有数据print('数据成功获取')browser.quit()# 获取完毕,关闭网页
成功获取的数据存在csv 文件中:
02
绘制玫瑰图
有了数据,自然就可以使用工具来绘制玫瑰图了,这里我们使用的是pyecharts里的饼图类 Pie.
import pandas as pdfrom pyecharts.charts import Piefrom pyecharts import options as opts<br /># 01. 读取并整理数据data = pd.read_csv('data.csv',header=1)data = data.drop_duplicates(keep=False)data = data.reset_index(drop=True)data['subscribers'] = data['subscribers'].str.replace('M','')data['subscribers'] = data['subscribers'].astype('float').round()x_data = data['services']y_data = data['subscribers']# 自定义颜色,根据服务商类型提供4种颜色,可以在ps中打开原图,获取颜色的十六进制代码color_dic = {'Video':'#fbf3dc', 'Audio':'#1b1718', 'Video/Audio':'#833100', 'News':'#f1a15c' }data['colors'] = data['types'].map(color_dic)# 准备数据对data_pairdf = [list(z) for z in zip(x_data,y_data)]# print(df)# 02. 使用 pyecharts Pie 绘制玫瑰图pie = Pie(init_opts=opts.InitOpts(bg_color='#d66f0a',width='650px',height='1000px'))pie.add(series_name='services', data_pair=df, radius=['12%','200%'],#设置内圆和外圆的半径 center=['35%','70%'], #设置圆的位置 rosetype='area',) # 关键步骤!设置类型为area, 会展示为玫瑰图pie.set_global_opts( legend_opts=opts.LegendOpts(is_show=False), #不显示图例 )pie.set_series_opts( label_opts=opts.LabelOpts(position='inside', # 标签位置 rotate = 45, font_size = 14, # 字体大小 formatter="{c}",color = '#d66f0a') # 标签格式 )pie.set_colors(list(data['colors'])) # 渲染颜色pie.render('streaming war.html') #出图<br />
至此,就可以得到一张网页图形,后续可使用PS AI PPT等工具进行图表元素的完善,本文不作展示。想要追求100%复现的同学可以自行探索~
03
总结一下
实现炫酷的玫瑰图,可以分为两步:
获取数据,难点在于使用selenium 定位全部数据,需要用for 循环配合点击Next 按钮完成。
绘制数据,关键在于数据格式的整理,以及将饼图的rosetype 设为area 。
欢迎关注本号,可私信获取源码和数据~
END
Python之父推荐!《Python 3网络爬虫开发实战》
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-02 19:15
何谓爬虫?网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。要学爬虫,首推的就是 Python 语言,简单快速易上手,且 Python 语言的爬虫生态极其丰富。
随着爬虫技术的不断进步,一些新兴技术的不断兴起,许多书中的一些案例网站和服务早已经改版或者停止维护,很多代码已经不能正常运行。目前市面上的爬虫书,其他的书跟这本书相比,内容方面这本《Python 3网络爬虫开发实战》算是最全的,没有之一。能将最前沿的爬虫技术比如异步、JavaScript 逆向、安卓逆向、智能解析、WebAssembly、Kubernetes 等技术都涵盖的。
为什么说这本书适合小白呢?
1、这本书介绍了学习爬虫之前需要了解的基础知识。如 HTTP、爬虫、代理、网页结构、多进程多线程等内容,可以让我们要做的事情有个了解。
2、深入浅出的介绍了爬虫的“基操”(基本的爬虫操作),最基本的请求库(urllib、requests、httpx)、页面解析库(Beautiful Soup、XPath、pyquery、parsel)和正则表达式的基本用法。
3、还有数据存储的知识介绍:包括 TXT、JSON、CSV 各种文件的存储,以及关系型数据库 MySQL 和非关系型数据库 MongoDB、Redis 的基本存取操作。
这样即便是没有基础,也可以看懂
对比现在市场存在很久的书籍技术过时问题,新上市的《Python3网络爬虫开发实战》可以让我们掌握最新的知识,比较新技术代表效率的提升。
书籍展示:
浅尝目录:
平台限制,需要这本豆瓣评分9.0,科技类人气排行榜第一名的《Python3网络爬虫开发实战》电子书的朋友下图自行领取~ 查看全部
Python之父推荐!《Python 3网络爬虫开发实战》
何谓爬虫?网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。要学爬虫,首推的就是 Python 语言,简单快速易上手,且 Python 语言的爬虫生态极其丰富。
随着爬虫技术的不断进步,一些新兴技术的不断兴起,许多书中的一些案例网站和服务早已经改版或者停止维护,很多代码已经不能正常运行。目前市面上的爬虫书,其他的书跟这本书相比,内容方面这本《Python 3网络爬虫开发实战》算是最全的,没有之一。能将最前沿的爬虫技术比如异步、JavaScript 逆向、安卓逆向、智能解析、WebAssembly、Kubernetes 等技术都涵盖的。
为什么说这本书适合小白呢?
1、这本书介绍了学习爬虫之前需要了解的基础知识。如 HTTP、爬虫、代理、网页结构、多进程多线程等内容,可以让我们要做的事情有个了解。
2、深入浅出的介绍了爬虫的“基操”(基本的爬虫操作),最基本的请求库(urllib、requests、httpx)、页面解析库(Beautiful Soup、XPath、pyquery、parsel)和正则表达式的基本用法。
3、还有数据存储的知识介绍:包括 TXT、JSON、CSV 各种文件的存储,以及关系型数据库 MySQL 和非关系型数据库 MongoDB、Redis 的基本存取操作。
这样即便是没有基础,也可以看懂
对比现在市场存在很久的书籍技术过时问题,新上市的《Python3网络爬虫开发实战》可以让我们掌握最新的知识,比较新技术代表效率的提升。
书籍展示:
浅尝目录:
平台限制,需要这本豆瓣评分9.0,科技类人气排行榜第一名的《Python3网络爬虫开发实战》电子书的朋友下图自行领取~
专业解码 | 爬虫的基本原理:爬虫概述及爬取过程
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-30 01:09
最新
动态
实时
资讯
部门
通知
专业
速递
导语✦
爱学习的小伙伴们,在学习专业知识的你们,是否有过困惑与不解,不要着急,本栏目致力于为同学们指路迷津!
《专业速递》——带你了解大数据的魅力!
一、什么是爬虫
爬虫就是获取网页并提取和保存信息的自动化程序。
1)我们可以把互联网比作一张大网,而爬虫(网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
2)虽然不使用爬虫我们通过手工方式也可以提取网页中的信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序的。爬虫就是代替我们来完成这份工作的自动化程序,它可以在抓取过程中进行各种异常、错误重试等操作,确保爬取持续高效地运行。
二、爬虫爬取过程
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,其主要有如下三个步骤:
1.获取网页:爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息。爬虫首先向网站的服务器发送一个请求,返回的响应体便是网页源代码。Python中提供了许多库(如urllib、requests)来帮助我们实现这个操作,我们可以用这些库来帮助我们实现HTTP请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的Body部分即可,即得到网页的源代码。
2.提取信息:获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
3.保存数据:提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL和MongoDB等,也可以保存至远程服务器,如借助SFTP进行操作等。
今日的爬虫介绍就先告一段落啦,最后感谢大家的阅读,希望同学们在课后能够自主学习,扩展有关爬虫方面的相关知识。 查看全部
专业解码 | 爬虫的基本原理:爬虫概述及爬取过程
最新
动态
实时
资讯
部门
通知
专业
速递
导语✦
爱学习的小伙伴们,在学习专业知识的你们,是否有过困惑与不解,不要着急,本栏目致力于为同学们指路迷津!
《专业速递》——带你了解大数据的魅力!
一、什么是爬虫
爬虫就是获取网页并提取和保存信息的自动化程序。
1)我们可以把互联网比作一张大网,而爬虫(网络爬虫)便是在网上爬行的蜘蛛。把网的节点比作一个个网页,爬虫爬到这就相当于访问了该页面,获取了其信息。可以把节点间的连线比作网页与网页之间的链接关系,这样蜘蛛通过一个节点后,可以顺着节点连线继续爬行到达下一个节点,即通过一个网页继续获取后续的网页,这样整个网的节点便可以被蜘蛛全部爬行到,网站的数据就可以被抓取下来了。
2)虽然不使用爬虫我们通过手工方式也可以提取网页中的信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序的。爬虫就是代替我们来完成这份工作的自动化程序,它可以在抓取过程中进行各种异常、错误重试等操作,确保爬取持续高效地运行。
二、爬虫爬取过程
简单来说,爬虫就是获取网页并提取和保存信息的自动化程序,其主要有如下三个步骤:
1.获取网页:爬虫首先要做的工作就是获取网页,这里就是获取网页的源代码。源代码里包含了网页的部分有用信息。爬虫首先向网站的服务器发送一个请求,返回的响应体便是网页源代码。Python中提供了许多库(如urllib、requests)来帮助我们实现这个操作,我们可以用这些库来帮助我们实现HTTP请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的Body部分即可,即得到网页的源代码。
2.提取信息:获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。首先,最通用的方法便是采用正则表达式提取。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS选择器或XPath来提取网页信息的库,如Beautiful Soup、pyquery、lxml等。提取信息是爬虫非常重要的部分,它可以使杂乱的数据变得条理清晰,以便我们后续处理和分析数据。
3.保存数据:提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为TXT文本或JSON文本,也可以保存到数据库,如MySQL和MongoDB等,也可以保存至远程服务器,如借助SFTP进行操作等。
今日的爬虫介绍就先告一段落啦,最后感谢大家的阅读,希望同学们在课后能够自主学习,扩展有关爬虫方面的相关知识。
python零基础小白也能学习
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-30 01:08
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
用什么语言写爬虫?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
查看全部
python零基础小白也能学习
在学习Python之前,我们要知道,Python的用途,学习它可以给我们带来什么?
python主要有网络爬虫,网站开发,人工智能,自动化运维
在这里我们主要看一看网络爬虫,什么叫网络爬虫?
网络爬虫又称网络蜘蛛,是指按照某种规则在网络上爬取所需内容的脚本程序。众所周知,每个网页通常包含其他网页的入口,网络爬虫则通过一个网址依次进入其他网址获取所需内容。
爬虫有什么用?
做垂直搜索引擎(google,baidu等).
科学研究:在线人类行为,在线社群演化,人类动力学研究,计量社会学,复杂网络,数据挖掘,等领域的实证研究都需要大量数据,网络爬虫是收集相关数据的利器。
偷窥,hacking,发垃圾邮件……
爬虫是搜索引擎的第一步也是最容易的一步。
用什么语言写爬虫?
C,C++。高效率,快速,适合通用搜索引擎做全网爬取。缺点,开发慢,写起来又臭又长,例如:天网搜索源代码。
脚本语言:Perl, Python, Java, Ruby。简单,易学,良好的文本处理能方便网页内容的细致提取,但效率往往不高,适合对少量网站的聚焦爬取
为什么眼下最火的是Python?
个人用c#,java都写过爬虫。区别不大,原理就是利用好正则表达式。只不过是平台问题。后来了解到很多爬虫都是用python写的,于是便一发不可收拾。Python优势很多,总结两个要点:
1)抓取网页本身的接口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的接口更简洁;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是很好的选择)
此外,抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,譬如模拟用户登陆、模拟session/cookie的存储和设置。在python里都有非常优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。Life is short, u need python.
END
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜。
python抓取网页数据(Python数据抓取技术与实战(一)-Python语言)
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-04-19 16:31
编辑评论:
Python数据采集技术与实践主要介绍了使用Python语言及相关工具进行数据采集的方法,并通过实例演示了数据采集过程中常见问题的解决方案。通过本书的学习,读者可以根据自己的需要,快速编写出符合要求的爬虫程序。
前言
大数据技术是当前工程和科技领域的热门研究课题。数据科学研究通常包括四个主要环节,即数据获取、数据存储、数据分析和数据可视化。本书主要侧重于数据采集。这是其他链接的基础。及时准确地获取丰富、详细的数据,为后续工作打下坚实的基础,提高分析结论的可信度和可靠性。
互联网的开放性给数据的获取带来了极大的便利。本书以Python语言的数据捕获技术为基础,主要介绍如何快速、准确地从网络中获取所需数据,构建符合要求的数据集或大数据集。 Python 语言是一种通用的编程语言,可用于各种编程领域,也是数据科学领域非常流行的语言。本书使用Python作为数据采集技术的实现语言,利用Python丰富的模块支持和语言特性解决了数据采集中经常遇到的大部分问题。为了让不了解 Python 语言的读者快速入门,第 1 章介绍了阅读本书所需的 Python 语言基础知识。本书介绍了数据采集中涉及的各种技术问题和解决方案,并按章节进行组织。每章内容基本独立,使读者在遇到问题时能够快速定位问题。本书的内容侧重于应用现有成熟的理论原理和流行的框架来解决数据采集的实际问题。在写的过程中,我们只关注应用于数据采集的应用方法,并没有详细描述一些原理和框架。有兴趣的读者可以进一步搜索相关文献资料,加深对概念和理论的理解。读者在阅读时可以运行书中的示例代码,看到现象后再回去分析,有助于更好地理解相关概念和原理,为进一步研究打下基础。
本书主要面向初学者。读者可以根据书中运行的例子进行改造,设计出符合自己需求的数据采集程序。本书可快速应用于实战,可供高校相关专业工程技术人员和本科生参考。
感谢总策划付军的辛勤工作!感谢赵星驰老师在外文技术资料方面的帮助与合作!
如果读者在阅读中发现问题,请及时联系我们,希望大家批评指正。
python基础
Python 是一种动态类型的脚本语言,具有简洁的语法和强大的表达能力。它是目前数据科学领域的主流编程语言。其丰富的包和模块支持可以让 Python 在几乎所有领域都变得实用。
本书使用 Python 作为数据抓取的编程实现语言。
本章主要介绍Python编程语言的基础知识以及Python语言的安装和基本使用。通过两个引人入胜的例子,描述了Python的基本语法和后续章节中将用到的语法知识。
语言版本选择Python3.4+作为开发语言,使用Python 3及以上版本进行字符串处理更方便。如果不使用 Python3 及以上版本引入的新特性,可以在字符串处理并稍作改动后使用 Python2.7+ 执行。随着Python3的发展,很多Python2.7可以使用的库和模块都可以被Python3使用。因此,建议没有使用过Python的读者可以直接安装3以上版本进行学习开发。
在操作系统选择方面,本书中的大部分例子都是在Ubuntu 14.04可信赖的64位桌面系统下编写和运行的。如果Python版本相同,可以直接在Windows下运行书中的代码。使用Windows系统的读者可以使用Vmware虚拟机环境在虚拟机中搭建Ubuntu系统来学习和使用书中的代码。
缩进样式
在get-content函数的定义形式中引入了Python语言的一个非常特殊的特性,即缩进。
下面简单介绍一下Python中的缩进问题。
与大多数编程语言不同,Python 使用缩进来表示逻辑级别,而不是“1 1”括号。具有相同缩进的语句块代表相同的逻辑级别。例如,在上面的get-content函数中,函数体中的两行代码应该在同一个缩进级别。如果在编辑器中输入这两行代码,要保证这两行代码在句首和def中保持一定的缩进,并且缩进的程度是一样的。
注意缩进的程度是一样的,缩进多和少没有区别。此外,不同的 IDE 可能有不同的代码编辑设置。例如,在 Pycharm IDE 中,您可以设置一个 tab 键等于 4 个空格,然后在这个 IDE 中使用一个 tab 缩进和 4 个空格缩进。 ,效果是一样的。但是,将代码复制到其他IDE时,制表符和空格数的对应关系可能不是1:4,所以可能会出现缩进的问题。最好在编码的方式上统一,或者使用tab或者空格来解决这个问题。 查看全部
python抓取网页数据(Python数据抓取技术与实战(一)-Python语言)
编辑评论:
Python数据采集技术与实践主要介绍了使用Python语言及相关工具进行数据采集的方法,并通过实例演示了数据采集过程中常见问题的解决方案。通过本书的学习,读者可以根据自己的需要,快速编写出符合要求的爬虫程序。
前言
大数据技术是当前工程和科技领域的热门研究课题。数据科学研究通常包括四个主要环节,即数据获取、数据存储、数据分析和数据可视化。本书主要侧重于数据采集。这是其他链接的基础。及时准确地获取丰富、详细的数据,为后续工作打下坚实的基础,提高分析结论的可信度和可靠性。
互联网的开放性给数据的获取带来了极大的便利。本书以Python语言的数据捕获技术为基础,主要介绍如何快速、准确地从网络中获取所需数据,构建符合要求的数据集或大数据集。 Python 语言是一种通用的编程语言,可用于各种编程领域,也是数据科学领域非常流行的语言。本书使用Python作为数据采集技术的实现语言,利用Python丰富的模块支持和语言特性解决了数据采集中经常遇到的大部分问题。为了让不了解 Python 语言的读者快速入门,第 1 章介绍了阅读本书所需的 Python 语言基础知识。本书介绍了数据采集中涉及的各种技术问题和解决方案,并按章节进行组织。每章内容基本独立,使读者在遇到问题时能够快速定位问题。本书的内容侧重于应用现有成熟的理论原理和流行的框架来解决数据采集的实际问题。在写的过程中,我们只关注应用于数据采集的应用方法,并没有详细描述一些原理和框架。有兴趣的读者可以进一步搜索相关文献资料,加深对概念和理论的理解。读者在阅读时可以运行书中的示例代码,看到现象后再回去分析,有助于更好地理解相关概念和原理,为进一步研究打下基础。
本书主要面向初学者。读者可以根据书中运行的例子进行改造,设计出符合自己需求的数据采集程序。本书可快速应用于实战,可供高校相关专业工程技术人员和本科生参考。
感谢总策划付军的辛勤工作!感谢赵星驰老师在外文技术资料方面的帮助与合作!
如果读者在阅读中发现问题,请及时联系我们,希望大家批评指正。
python基础
Python 是一种动态类型的脚本语言,具有简洁的语法和强大的表达能力。它是目前数据科学领域的主流编程语言。其丰富的包和模块支持可以让 Python 在几乎所有领域都变得实用。
本书使用 Python 作为数据抓取的编程实现语言。
本章主要介绍Python编程语言的基础知识以及Python语言的安装和基本使用。通过两个引人入胜的例子,描述了Python的基本语法和后续章节中将用到的语法知识。
语言版本选择Python3.4+作为开发语言,使用Python 3及以上版本进行字符串处理更方便。如果不使用 Python3 及以上版本引入的新特性,可以在字符串处理并稍作改动后使用 Python2.7+ 执行。随着Python3的发展,很多Python2.7可以使用的库和模块都可以被Python3使用。因此,建议没有使用过Python的读者可以直接安装3以上版本进行学习开发。
在操作系统选择方面,本书中的大部分例子都是在Ubuntu 14.04可信赖的64位桌面系统下编写和运行的。如果Python版本相同,可以直接在Windows下运行书中的代码。使用Windows系统的读者可以使用Vmware虚拟机环境在虚拟机中搭建Ubuntu系统来学习和使用书中的代码。
缩进样式
在get-content函数的定义形式中引入了Python语言的一个非常特殊的特性,即缩进。
下面简单介绍一下Python中的缩进问题。
与大多数编程语言不同,Python 使用缩进来表示逻辑级别,而不是“1 1”括号。具有相同缩进的语句块代表相同的逻辑级别。例如,在上面的get-content函数中,函数体中的两行代码应该在同一个缩进级别。如果在编辑器中输入这两行代码,要保证这两行代码在句首和def中保持一定的缩进,并且缩进的程度是一样的。
注意缩进的程度是一样的,缩进多和少没有区别。此外,不同的 IDE 可能有不同的代码编辑设置。例如,在 Pycharm IDE 中,您可以设置一个 tab 键等于 4 个空格,然后在这个 IDE 中使用一个 tab 缩进和 4 个空格缩进。 ,效果是一样的。但是,将代码复制到其他IDE时,制表符和空格数的对应关系可能不是1:4,所以可能会出现缩进的问题。最好在编码的方式上统一,或者使用tab或者空格来解决这个问题。
python抓取网页数据(如何使用Python对天猫的评论数据进行评论(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 262 次浏览 • 2022-04-18 06:00
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接。接下来,你只需要复制这个链接,把这个地址粘贴到浏览器中,你就会发现这些评论都隐藏在这个地方了。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以概括为这种形式:每次更改最后一个 currentPage 值时,都可以捕获到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append(';spuId=345965243&sellerId=2106525799&order=1¤tPage=%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall(''displayUserNick':'(.*?)'',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile(''rateContent':'(.*?)','rateDate''),content))
ratingate.extend(re.findall(pile(''rateDate':'(.*?)','reply''),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'\n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
温馨的提示:
天山智能是中国商业智能BI、数据分析、大数据领域最大的社区。欢迎您访问天山学院,有更多免费的行业专家数据库、商业智能BI、数据分析、大数据、数据挖掘视频和好文章分享。.
12 月 29 日 8:30 pm Oracle Oracle BI 银行和保险业大数据应用
参 查看全部
python抓取网页数据(如何使用Python对天猫的评论数据进行评论(图))
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接。接下来,你只需要复制这个链接,把这个地址粘贴到浏览器中,你就会发现这些评论都隐藏在这个地方了。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以概括为这种形式:每次更改最后一个 currentPage 值时,都可以捕获到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append(';spuId=345965243&sellerId=2106525799&order=1¤tPage=%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall(''displayUserNick':'(.*?)'',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile(''rateContent':'(.*?)','rateDate''),content))
ratingate.extend(re.findall(pile(''rateDate':'(.*?)','reply''),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'\n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
温馨的提示:
天山智能是中国商业智能BI、数据分析、大数据领域最大的社区。欢迎您访问天山学院,有更多免费的行业专家数据库、商业智能BI、数据分析、大数据、数据挖掘视频和好文章分享。.
12 月 29 日 8:30 pm Oracle Oracle BI 银行和保险业大数据应用
参
python抓取网页数据(是不是突然感觉网络爬虫很简单?代码就完全解决了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 274 次浏览 • 2022-04-18 01:12
网络爬虫对于大数据专业的同学可能并不陌生,所以在说网络爬虫之前,博主先给大家介绍一下我们平时使用的浏览器的工作原理,只要你了解普通浏览器的工作原理,那么网络爬虫就变得简单了。
下图是浏览器正常工作原理的流程图:
首先我们可以看到有四个进程:
(1)我们先在浏览器中输入url(网址);
(2)浏览器会向指定的服务器发送一个HTTP请求。请求的方式有两种:一种是get,另一种是:spot。那么这两者有什么区别呢?大家可以这样理解: get是指从服务器下载我们需要的数据,spot是我们上传(粘贴)到服务器的数据;
(3)服务器收到浏览器的请求后,会生成一个http响应给服务器;
(4)其实html的源码一般人是看不懂的,所以浏览器会处理,最后给我们展示一个丰富漂亮的网页!!!
介绍完普通浏览器的工作流程后,我们启动我们的网络爬虫。网络爬虫:模拟浏览器网页,下载我们需要的网络资源的程序,其实本质上就是一个假的http请求。好的,开始我们的代码部分(说明:使用python环境)
首先我们在python中加载第三方库:re、urllib、json、time,三个库
#加载第三方库
import urllib
import re
import json
import time
###
#输入网站
url = 'https://sclub.jd.com/comment/p ... 39%3B
#1:模拟浏览器的http请求部分
#html = urllib.request.urlopen(url)
#2:模拟响应过程
#html = urllib.request.urlopen(url).read()
#我们可以打印print(html)看,如果源码出现乱码,我们再响应过程部分进行编码设置:常用的编码有:utf-8,gbk,gb18030
#完整的模拟浏览器的http请求过程和http响应的过程
html = urllib.request.urlopen(url).read().decode('gbk')#此处已经经请求和响应过程合并
print(html)
#由于读取到的源码不是标准的 JSON 格式,因此需要使用进行处理
json_data = re.search('{.+}', html).group()#正则表达式处理
data = json.loads(json_data)# 将json格式数据转为字典格式(反序列化)
现在爬取1页评论数据,代码运行:
#忘记每行代码的目的,请看上面备注
import pandas as pd
import urllib
import requests
import re
import json
import random
url = 'https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
json_data = re.search('{.+}', html).group()
data = json.loads(json_data)
data['comments']
运行之后,我们就可以得到我们需要的数据评论数据了。
是不是突然觉得爬网很容易?几行代码就可以彻底解决,但别忘了这只是爬取一页数据。如果我们需要爬取多个页面,则需要我们自己编写和爬取。为了大家方便,博主自己也写了一个循环爬虫的代码如下:
all_url = []
for i in range(0,10):
all_url.append('https://sclub.jd.com/comment/p ... 2Bstr(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
allh_data = pd.DataFrame()
for k in range(0,10): #爬取10页的数据
print("正在打印第{}页的评论数据".format(k+1))
html_data = urllib.request.urlopen(all_url[k]).read().decode('gb18030')
json_data = re.search('{.+}', html_data).group()
all_data = json.loads(json_data)
alls_data = all_data['comments']
referenceName = [x['referenceName'] for x in alls_data] # 提取商品的品牌名
nickname = [x['nickname'] for x in alls_data] # 提取商品购买用户的昵称
creationTime = [x['creationTime'] for x in alls_data] # 提取购物时间
content = [x['content'] for x in alls_data] # 发表时间
all_data_hp = pd.DataFrame({'referenceName': referenceName,
'nickname': nickname,
'creationTime': creationTime,
'content': content})
allh_data = allh_data.append(all_data_hp)
time.sleep(random.randint(2, 3))
print(">>>爬取第{}结束.......".format(k+1))
allh_data.index = range(len(allh_data))#重设dateframe的index
然后最后可以得到以下数据:
如有任何问题,请发表评论,博主将尽力解答。 查看全部
python抓取网页数据(是不是突然感觉网络爬虫很简单?代码就完全解决了)
网络爬虫对于大数据专业的同学可能并不陌生,所以在说网络爬虫之前,博主先给大家介绍一下我们平时使用的浏览器的工作原理,只要你了解普通浏览器的工作原理,那么网络爬虫就变得简单了。
下图是浏览器正常工作原理的流程图:
首先我们可以看到有四个进程:
(1)我们先在浏览器中输入url(网址);
(2)浏览器会向指定的服务器发送一个HTTP请求。请求的方式有两种:一种是get,另一种是:spot。那么这两者有什么区别呢?大家可以这样理解: get是指从服务器下载我们需要的数据,spot是我们上传(粘贴)到服务器的数据;
(3)服务器收到浏览器的请求后,会生成一个http响应给服务器;
(4)其实html的源码一般人是看不懂的,所以浏览器会处理,最后给我们展示一个丰富漂亮的网页!!!
介绍完普通浏览器的工作流程后,我们启动我们的网络爬虫。网络爬虫:模拟浏览器网页,下载我们需要的网络资源的程序,其实本质上就是一个假的http请求。好的,开始我们的代码部分(说明:使用python环境)
首先我们在python中加载第三方库:re、urllib、json、time,三个库
#加载第三方库
import urllib
import re
import json
import time
###
#输入网站
url = 'https://sclub.jd.com/comment/p ... 39%3B
#1:模拟浏览器的http请求部分
#html = urllib.request.urlopen(url)
#2:模拟响应过程
#html = urllib.request.urlopen(url).read()
#我们可以打印print(html)看,如果源码出现乱码,我们再响应过程部分进行编码设置:常用的编码有:utf-8,gbk,gb18030
#完整的模拟浏览器的http请求过程和http响应的过程
html = urllib.request.urlopen(url).read().decode('gbk')#此处已经经请求和响应过程合并
print(html)
#由于读取到的源码不是标准的 JSON 格式,因此需要使用进行处理
json_data = re.search('{.+}', html).group()#正则表达式处理
data = json.loads(json_data)# 将json格式数据转为字典格式(反序列化)
现在爬取1页评论数据,代码运行:
#忘记每行代码的目的,请看上面备注
import pandas as pd
import urllib
import requests
import re
import json
import random
url = 'https://sclub.jd.com/comment/p ... 39%3B
html = urllib.request.urlopen(url).read().decode('gbk')
print(html)
json_data = re.search('{.+}', html).group()
data = json.loads(json_data)
data['comments']
运行之后,我们就可以得到我们需要的数据评论数据了。
是不是突然觉得爬网很容易?几行代码就可以彻底解决,但别忘了这只是爬取一页数据。如果我们需要爬取多个页面,则需要我们自己编写和爬取。为了大家方便,博主自己也写了一个循环爬虫的代码如下:
all_url = []
for i in range(0,10):
all_url.append('https://sclub.jd.com/comment/p ... 2Bstr(i)+'&pageSize=10&isShadowSku=0&rid=0&fold=1')
allh_data = pd.DataFrame()
for k in range(0,10): #爬取10页的数据
print("正在打印第{}页的评论数据".format(k+1))
html_data = urllib.request.urlopen(all_url[k]).read().decode('gb18030')
json_data = re.search('{.+}', html_data).group()
all_data = json.loads(json_data)
alls_data = all_data['comments']
referenceName = [x['referenceName'] for x in alls_data] # 提取商品的品牌名
nickname = [x['nickname'] for x in alls_data] # 提取商品购买用户的昵称
creationTime = [x['creationTime'] for x in alls_data] # 提取购物时间
content = [x['content'] for x in alls_data] # 发表时间
all_data_hp = pd.DataFrame({'referenceName': referenceName,
'nickname': nickname,
'creationTime': creationTime,
'content': content})
allh_data = allh_data.append(all_data_hp)
time.sleep(random.randint(2, 3))
print(">>>爬取第{}结束.......".format(k+1))
allh_data.index = range(len(allh_data))#重设dateframe的index
然后最后可以得到以下数据:
如有任何问题,请发表评论,博主将尽力解答。
python抓取网页数据(炉石传说爬虫前不要的暂停时间是怎么样的?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-17 18:15
然后就用requests来获取网页的源代码
使用BeautifulSoup/正则表达式/pyQuery解析元素并遍历对应img的url进行下载
教训:不要在爬虫之前根据网页的操作来实现相应的代码爬取。不要有这样的心态。首先要做的是浏览和分析整个网页的源代码。再加工
炉石卡链接:
网站 通过下拉右侧的滚动条不断加载新卡片
与上一个网站不同的是,最后一个网站一次写了所有卡片,但它被隐藏了
网站是js动态加载渲染的卡片,无法直接从源码中获取所有卡片信息。
然后用selenium来模拟下拉滚动条(selenium是家里必备神器)
使用selenium执行js脚本每次下拉1000个单位的滚动条90次
为什么在 90 次测试中大约有 90 次被拉到最后?
注意:此处为网页渲染添加 1~3 秒的暂停时间
第一次没设置停留时间,拿不到新数据,怀疑自己,怀疑人生
根据前端/后端朋友L的提示,需要增加暂停时间,这样才能获取到加载渲染后的数据。
browser.page_source 获取动态加载的所有数据
有了数据之后,通过正则匹配得到对应的url下载就很简单了。
终于拿到了800幅原画和1324张卡片
既然获得了这么多卡牌和原画,那就不能浪费了,拿来拼图吧!
向玩了几年的炉石致敬
只拼女神
完全的 查看全部
python抓取网页数据(炉石传说爬虫前不要的暂停时间是怎么样的?)
然后就用requests来获取网页的源代码
使用BeautifulSoup/正则表达式/pyQuery解析元素并遍历对应img的url进行下载
教训:不要在爬虫之前根据网页的操作来实现相应的代码爬取。不要有这样的心态。首先要做的是浏览和分析整个网页的源代码。再加工
炉石卡链接:
网站 通过下拉右侧的滚动条不断加载新卡片
与上一个网站不同的是,最后一个网站一次写了所有卡片,但它被隐藏了
网站是js动态加载渲染的卡片,无法直接从源码中获取所有卡片信息。
然后用selenium来模拟下拉滚动条(selenium是家里必备神器)
使用selenium执行js脚本每次下拉1000个单位的滚动条90次
为什么在 90 次测试中大约有 90 次被拉到最后?
注意:此处为网页渲染添加 1~3 秒的暂停时间
第一次没设置停留时间,拿不到新数据,怀疑自己,怀疑人生
根据前端/后端朋友L的提示,需要增加暂停时间,这样才能获取到加载渲染后的数据。
browser.page_source 获取动态加载的所有数据
有了数据之后,通过正则匹配得到对应的url下载就很简单了。
终于拿到了800幅原画和1324张卡片
既然获得了这么多卡牌和原画,那就不能浪费了,拿来拼图吧!
向玩了几年的炉石致敬
只拼女神
完全的
python抓取网页数据( 小编来一起学习学习吧三种数据抓取的3种方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-04-17 08:06
小编来一起学习学习吧三种数据抓取的3种方法)
python数据抓取的3种方法总结
更新时间:2021-02-07 12:16:01 作者:呵呵
本篇文章主要介绍python数据抓取的3种方法。文中介绍的示例代码非常详细,对您的学习或工作有一定的参考和学习价值。有需要的朋友请按照以下说明进行操作。来和我一起学习
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
总结
至此,这篇关于python数据抓取的3种方法的文章文章就介绍到这里了。更多相关python数据抓取内容,请搜索脚本之家往期文章或继续浏览下方相关话题。文章希望您以后多多支持 Scripting House! 查看全部
python抓取网页数据(
小编来一起学习学习吧三种数据抓取的3种方法)
python数据抓取的3种方法总结
更新时间:2021-02-07 12:16:01 作者:呵呵
本篇文章主要介绍python数据抓取的3种方法。文中介绍的示例代码非常详细,对您的学习或工作有一定的参考和学习价值。有需要的朋友请按照以下说明进行操作。来和我一起学习
三种数据采集方法
*使用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import download
import re
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
country = re.findall('class="h2dabiaoti">(.*?)', page_content) #注意返回的是list
survey_data = re.findall('(.*?)', page_content)
survey_info_list = re.findall('<p> (.*?)', survey_data[0])
survey_info = ''.join(survey_info_list)
print(country[0],survey_info)
</p>
2.美汤(bs4)
from get_html import download
from bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
html = download(url)
#创建 beautifulsoup 对象
soup = BeautifulSoup(html,"html.parser")
#搜索
country = soup.find(attrs={'class':'h2dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).text
print(country,survey_info)
3.lxml
from get_html import download
from lxml import etree #解析树
url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/'
page_content = download(url)
selector = etree.HTML(page_content)#可进行xpath解析
country_select = selector.xpath('//*[@id="main_content"]/h2') #返回列表
for country in country_select:
print(country.text)
survey_select = selector.xpath('//*[@id="wzneirong"]/p')
for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
总结
至此,这篇关于python数据抓取的3种方法的文章文章就介绍到这里了。更多相关python数据抓取内容,请搜索脚本之家往期文章或继续浏览下方相关话题。文章希望您以后多多支持 Scripting House!
python抓取网页数据(python抓取网页数据的技巧分享什么是双抓取抓取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-12 10:00
python抓取网页数据的技巧分享什么是双抓取?双抓取实质上就是网页中可抓取的资源有“多页”,“多方向”(多页,多方向,多广度,多深度)等,是通过技术手段进行多维度进行网页探测和抓取的,就是多维数据抓取。大家可以简单看一下通常的爬虫,都是需要深入到每一个页面的每一个链接后再去提取数据。在这种情况下,我们就不得不为了保证我们的数据不断更新,我们需要重复进行这些抓取和提取,是比较耗费时间的。
然而,对于一些业务部门来说,会遇到业务分析会以某种角度需要在后台上线产品。那么,这种时候,如果可以直接对网页进行抓取,且这些网页没有重复提取的功能。比如,每次可以直接下载产品页面内的所有产品列表,并存入数据库。双抓取系统介绍以整站抓取为例,接下来,我将介绍一下整站抓取系统的功能。可以根据人员和业务的需要,创建两组文件系统,一组叫做web抓取,一组叫做生产抓取。
下面简单列出工作流程。1.按照业务的需要创建一个生产抓取系统的实验例子,之所以这么干是因为我们没有给他太多的约束,可以根据业务的需要加入一些数据提取的功能,系统提供集成机器学习,大数据计算等更高级的功能,这些功能我们完全可以根据实际业务进行安排。2.在python里,很多库就已经提供了生产抓取系统的工具。
例如pandas库和itertools库等,如果数据量超大的时候,基本需要两遍抓取。numpy库里有一个基于矩阵的矩阵采样,这个是很多抓取的首选,抓取到的数据有些很大也有些很小,这个能满足我们的需求。3.每个抓取的文件,存放在相应的目录下,这个目录里,所有文件都是按照生产抓取里的保存格式存放的。我们只需要按照我们的格式来存放对应的文件。如果这个文件多不过来的时候,可以用一个更小的文件。 查看全部
python抓取网页数据(python抓取网页数据的技巧分享什么是双抓取抓取?)
python抓取网页数据的技巧分享什么是双抓取?双抓取实质上就是网页中可抓取的资源有“多页”,“多方向”(多页,多方向,多广度,多深度)等,是通过技术手段进行多维度进行网页探测和抓取的,就是多维数据抓取。大家可以简单看一下通常的爬虫,都是需要深入到每一个页面的每一个链接后再去提取数据。在这种情况下,我们就不得不为了保证我们的数据不断更新,我们需要重复进行这些抓取和提取,是比较耗费时间的。
然而,对于一些业务部门来说,会遇到业务分析会以某种角度需要在后台上线产品。那么,这种时候,如果可以直接对网页进行抓取,且这些网页没有重复提取的功能。比如,每次可以直接下载产品页面内的所有产品列表,并存入数据库。双抓取系统介绍以整站抓取为例,接下来,我将介绍一下整站抓取系统的功能。可以根据人员和业务的需要,创建两组文件系统,一组叫做web抓取,一组叫做生产抓取。
下面简单列出工作流程。1.按照业务的需要创建一个生产抓取系统的实验例子,之所以这么干是因为我们没有给他太多的约束,可以根据业务的需要加入一些数据提取的功能,系统提供集成机器学习,大数据计算等更高级的功能,这些功能我们完全可以根据实际业务进行安排。2.在python里,很多库就已经提供了生产抓取系统的工具。
例如pandas库和itertools库等,如果数据量超大的时候,基本需要两遍抓取。numpy库里有一个基于矩阵的矩阵采样,这个是很多抓取的首选,抓取到的数据有些很大也有些很小,这个能满足我们的需求。3.每个抓取的文件,存放在相应的目录下,这个目录里,所有文件都是按照生产抓取里的保存格式存放的。我们只需要按照我们的格式来存放对应的文件。如果这个文件多不过来的时候,可以用一个更小的文件。

