
python抓取网页数据
python抓取网页数据(简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-05 10:02
这里举个例子简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取和动态网页数据的爬取。实验环境为win10+python3.6+pycharm5.0,主要内容如下:
静态网页数据 这里的数据嵌套在网页源码中,是为了抓取网页数据,所以直接解析requests网页源码就够了。让我简单介绍一下。下面是一个爬虫百科上的数据的例子:
1.首先抓取网页数据,打开原网页,如下,这里假设要抓取的字段包括昵称、内容、搞笑数和评论数:
然后查看网页源网页数据抓取,如下,可以看到所有的数据都嵌套在网页中:
2.那么我们就可以直接编写上面的网页结构网页数据抓取的代码,解析网页,提取出我们需要的数据。测试代码如下,很简单,主要是使用requests+BeautifulSoup的组合,其中requests用来获取网页的源码,BeautifulSoup用来解析网页提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
动态网页数据 这里的数据不在网页的源代码中(所以直接请求页面无法获取数据)。大多数情况下,网页数据存储在 json 文件中。只有当网页更新时,才会加载数据。让我简单介绍一下这种方法。下面是一个在人人贷上爬取数据的例子:
1.首先抓取网页数据,打开原创网页,如下,假设要抓取的数据包括年利率、贷款名称、期限、金额和进度:
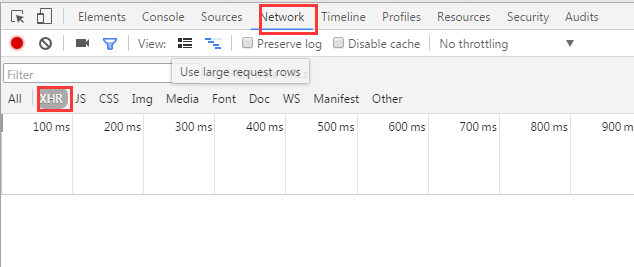
然后按F12调出开发者网页数据抓取,依次点击“网络”-“XHR”,F5刷新页面,可以找到动态加载的json文件,如下,也就是我们需要抓取的数据:
2.然后就是根据这个json文件编写相应的代码,解析出我们需要抓取网页数据的字段。测试代码如下,也很简单。主要是使用requests+json的组合,其中requests用来请求json文件,json用来解析json文件提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
至此,我们已经完成了使用python网络爬虫获取网站数据网页数据抓取。总的来说,整个过程非常简单。Python内置了很多网络爬虫包和框架(scrapy等),可以快速获取网站数据,非常适合初学者学习和掌握,只要你有一定的爬虫基础,熟悉以上流程和代码,很快就能掌握。当然,你也可以使用现成的,比如速度和速度。网上也有相关的教程和资料,非常丰富。有兴趣的可以搜索一下,希望上面分享的内容可以对大家有所帮助,也欢迎大家评论留言补充。 查看全部
python抓取网页数据(简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取)
这里举个例子简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取和动态网页数据的爬取。实验环境为win10+python3.6+pycharm5.0,主要内容如下:
静态网页数据 这里的数据嵌套在网页源码中,是为了抓取网页数据,所以直接解析requests网页源码就够了。让我简单介绍一下。下面是一个爬虫百科上的数据的例子:
1.首先抓取网页数据,打开原网页,如下,这里假设要抓取的字段包括昵称、内容、搞笑数和评论数:
然后查看网页源网页数据抓取,如下,可以看到所有的数据都嵌套在网页中:

2.那么我们就可以直接编写上面的网页结构网页数据抓取的代码,解析网页,提取出我们需要的数据。测试代码如下,很简单,主要是使用requests+BeautifulSoup的组合,其中requests用来获取网页的源码,BeautifulSoup用来解析网页提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
动态网页数据 这里的数据不在网页的源代码中(所以直接请求页面无法获取数据)。大多数情况下,网页数据存储在 json 文件中。只有当网页更新时,才会加载数据。让我简单介绍一下这种方法。下面是一个在人人贷上爬取数据的例子:
1.首先抓取网页数据,打开原创网页,如下,假设要抓取的数据包括年利率、贷款名称、期限、金额和进度:
然后按F12调出开发者网页数据抓取,依次点击“网络”-“XHR”,F5刷新页面,可以找到动态加载的json文件,如下,也就是我们需要抓取的数据:
2.然后就是根据这个json文件编写相应的代码,解析出我们需要抓取网页数据的字段。测试代码如下,也很简单。主要是使用requests+json的组合,其中requests用来请求json文件,json用来解析json文件提取数据:

点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
至此,我们已经完成了使用python网络爬虫获取网站数据网页数据抓取。总的来说,整个过程非常简单。Python内置了很多网络爬虫包和框架(scrapy等),可以快速获取网站数据,非常适合初学者学习和掌握,只要你有一定的爬虫基础,熟悉以上流程和代码,很快就能掌握。当然,你也可以使用现成的,比如速度和速度。网上也有相关的教程和资料,非常丰富。有兴趣的可以搜索一下,希望上面分享的内容可以对大家有所帮助,也欢迎大家评论留言补充。
python抓取网页数据(法国亚马逊、美国亚马逊-viewer列表的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-05 10:01
前段时间,姊妹公司的老板让她在法国亚马逊评论列表的前100页找到1000位评论者的联系方式。1000个用户需要一一阅读和记录,并不是每个评论用户都会留下个人联系方式。那么问题来了,这种费时费力的工作,如果手动完成,前30页的数据要花两天时间才能找到(还有其他工作要做),然后就很累了。本着苦恼的原则(程序员能找到一个女孩就好,所以我不得不心疼),我想帮她做点什么。
我自己的工作是开发游戏客户端。我使用的主要开发语言是lua和c++,没有网页和网站相关工作的经验。只是我在工作中使用了python脚本,然后在网上找python相关资料的时候,看到网友用python写爬虫来做点什么。所以我想,我也可以用python写一个爬虫从亚马逊的网站获取数据吗?这样,现在正在学习和使用的人开始输入代码。
环境:
Windows 7的
蟒蛇:2.7
使用的python插件:
urllib2、urllib 插件,用于打开网页链接;
用于常规匹配的重新插件;
编解码器插件用于编码转换和数据存储。
目前实现的功能:
获取姓名、联系信息(网站 链接或电子邮件地址)、国籍(可能是来自卢森堡和瑞士的买家,在法国亚马逊顶部查看者列表的前 100 页中的 1,000 名用户中),以及详细的用户评论链接到页等
通过抓取法国亚马逊top-viewer list的数据,扩展为抓取中国和美国亚马逊top-viewer list的数据。理论上,不同国家的亚马逊top-viewer list的数据可以通过简单的修改来获取。
需要改进的方面:
写完代码,发现抓数据的过程中效率很低。抓取1000条数据需要很长时间,抓取几页或几十页后,程序无法运行,卡住了。只需将其关闭然后再打开。当时,在拓展到美国抓取中国和亚马逊的数据之前,我想到的可能原因是:
正则表达式有优化的空间,因为我之前没接触过正则表达式,也没用过;法国亚马逊网站在中国访问速度慢,影响数据抓取;python没有系统学习过,在一些语法或者第三方辅助插件的使用上不够熟悉。
以上三点是我想到的爬取效率低的可能原因。后来我扩展同组代码爬取了中国和美国亚马逊的数据,验证了第二个原因对整个爬取工作的影响,结果发现影响非常大!同等带宽和硬件条件下,中美前100页共有1000个评论用户,爬了大概半个小时,爬完法国的1000条数据我用了将近一个下午(因为老是卡住,我觉得应该是因为urllib打开网页没反应,我的程序没有做判断)依次爬取,但总比女生一个个打开网页记录好,至少人不会烦!然后用了半个小时,在中国和美国抓到了数据。我个人不判断是否花费了太多时间或几乎相同。但是作为开发人员,程序总是可以优化的!
想法:
当时看到一个网友写的爬虫,想法是打开网页,匹配自己需要的信息。所以我的思路也是这样:通过python的urllib和urllib2插件打开页面,然后转换成html数据,使用python的re正则插件做正则匹配,得到页面,用户详情页,用户联系方式和其他信息。
执行:
1、法国亚马逊的top review list大约有1000页,每页有10个用户数据。对于每一个页面,除了第一页的链接,其他页面的链接都和页数有关,比如代表23页的数据,所以1000页的页面链接可以通过简单的字符串拼接得到。这是关于如何获取每个页面的链接;示例代码如下:拼接页面链接,因为首页和其余页面的格式略有不同,所以分别处理:
if 1 == i:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i);
else:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i) + "?ie=UTF8&page=" + str(i);
湾。将页面转换为 html:
try:
page = urllib.urlopen(url)
html = page.read()
return html
except:
print "getHtml2 error"
我用try and except只是为了看看能不能处理不能打开网页的问题(估计是法国亚马逊爬虫卡住了,因为网站没有响应),但是没有效果;
2、每个页面有10个用户的数据。单击用户将跳转到其详细信息页面。通过查看不同详细信息页面的链接形式,发现都是相似的:一个可能是用户名。变量,表示用户在评论列表中的排名的值。所以我可以想办法获取用户名(大概是用户名,或者亚马逊保存的唯一标识符),用户在评论列表中的排名,然后拼接出用户详情页的链接;通过查看页面的源码发现,每个页面中,用户信息的形式都差不多,比如:/gp/pdp/profile/xxxx/,所以可以通过简单的正则得到xxxx的数据匹配,暂时称为用户的唯一标识。以下是获取详细信息页面链接的方法;示例代码:匹配每个用户的唯一标识符:
reg = r'href="(/gp/pdp/profile/.+?)"><b>'
captureRe = re.compile(reg)
cpList = re.findall(captureRe,html)
湾。拼凑链接:
num = (i - 1) * 10 + index;
subLink = "http://www.amazon.fr" + cp + "/ref=cm_cr_tr_tbl_" + str(num) + "_name";
index指的是10条数据中的哪一条,num其实是用户在评论列表中的排名,每页有10条,所以具体排名可以根据页码和index来计算;
C。转换为html:
headers = { #伪装为浏览器抓取
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(url,headers=headers)
page = "";
try:
page = urllib2.urlopen(req)
html = page.read()
return html
except:
print "getHtml error"
可以看出这个转换形式和之前的转换方式不同,因为我发现之前的转换方式得到的页面数据和我们之间右键浏览器查看源代码的格式不一样,然后我正在匹配联系信息。当匹配失败时,认为是这种差异造成的。因此,我找到了数据并使用上面的表格进行了转换。网友还表示,这样可以防止亚马逊对频繁访问的IP进行封IP; 查看全部
python抓取网页数据(法国亚马逊、美国亚马逊-viewer列表的数据)
前段时间,姊妹公司的老板让她在法国亚马逊评论列表的前100页找到1000位评论者的联系方式。1000个用户需要一一阅读和记录,并不是每个评论用户都会留下个人联系方式。那么问题来了,这种费时费力的工作,如果手动完成,前30页的数据要花两天时间才能找到(还有其他工作要做),然后就很累了。本着苦恼的原则(程序员能找到一个女孩就好,所以我不得不心疼),我想帮她做点什么。
我自己的工作是开发游戏客户端。我使用的主要开发语言是lua和c++,没有网页和网站相关工作的经验。只是我在工作中使用了python脚本,然后在网上找python相关资料的时候,看到网友用python写爬虫来做点什么。所以我想,我也可以用python写一个爬虫从亚马逊的网站获取数据吗?这样,现在正在学习和使用的人开始输入代码。
环境:
Windows 7的
蟒蛇:2.7
使用的python插件:
urllib2、urllib 插件,用于打开网页链接;
用于常规匹配的重新插件;
编解码器插件用于编码转换和数据存储。
目前实现的功能:
获取姓名、联系信息(网站 链接或电子邮件地址)、国籍(可能是来自卢森堡和瑞士的买家,在法国亚马逊顶部查看者列表的前 100 页中的 1,000 名用户中),以及详细的用户评论链接到页等
通过抓取法国亚马逊top-viewer list的数据,扩展为抓取中国和美国亚马逊top-viewer list的数据。理论上,不同国家的亚马逊top-viewer list的数据可以通过简单的修改来获取。
需要改进的方面:
写完代码,发现抓数据的过程中效率很低。抓取1000条数据需要很长时间,抓取几页或几十页后,程序无法运行,卡住了。只需将其关闭然后再打开。当时,在拓展到美国抓取中国和亚马逊的数据之前,我想到的可能原因是:
正则表达式有优化的空间,因为我之前没接触过正则表达式,也没用过;法国亚马逊网站在中国访问速度慢,影响数据抓取;python没有系统学习过,在一些语法或者第三方辅助插件的使用上不够熟悉。
以上三点是我想到的爬取效率低的可能原因。后来我扩展同组代码爬取了中国和美国亚马逊的数据,验证了第二个原因对整个爬取工作的影响,结果发现影响非常大!同等带宽和硬件条件下,中美前100页共有1000个评论用户,爬了大概半个小时,爬完法国的1000条数据我用了将近一个下午(因为老是卡住,我觉得应该是因为urllib打开网页没反应,我的程序没有做判断)依次爬取,但总比女生一个个打开网页记录好,至少人不会烦!然后用了半个小时,在中国和美国抓到了数据。我个人不判断是否花费了太多时间或几乎相同。但是作为开发人员,程序总是可以优化的!
想法:
当时看到一个网友写的爬虫,想法是打开网页,匹配自己需要的信息。所以我的思路也是这样:通过python的urllib和urllib2插件打开页面,然后转换成html数据,使用python的re正则插件做正则匹配,得到页面,用户详情页,用户联系方式和其他信息。
执行:
1、法国亚马逊的top review list大约有1000页,每页有10个用户数据。对于每一个页面,除了第一页的链接,其他页面的链接都和页数有关,比如代表23页的数据,所以1000页的页面链接可以通过简单的字符串拼接得到。这是关于如何获取每个页面的链接;示例代码如下:拼接页面链接,因为首页和其余页面的格式略有不同,所以分别处理:
if 1 == i:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i);
else:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i) + "?ie=UTF8&page=" + str(i);
湾。将页面转换为 html:
try:
page = urllib.urlopen(url)
html = page.read()
return html
except:
print "getHtml2 error"
我用try and except只是为了看看能不能处理不能打开网页的问题(估计是法国亚马逊爬虫卡住了,因为网站没有响应),但是没有效果;
2、每个页面有10个用户的数据。单击用户将跳转到其详细信息页面。通过查看不同详细信息页面的链接形式,发现都是相似的:一个可能是用户名。变量,表示用户在评论列表中的排名的值。所以我可以想办法获取用户名(大概是用户名,或者亚马逊保存的唯一标识符),用户在评论列表中的排名,然后拼接出用户详情页的链接;通过查看页面的源码发现,每个页面中,用户信息的形式都差不多,比如:/gp/pdp/profile/xxxx/,所以可以通过简单的正则得到xxxx的数据匹配,暂时称为用户的唯一标识。以下是获取详细信息页面链接的方法;示例代码:匹配每个用户的唯一标识符:
reg = r'href="(/gp/pdp/profile/.+?)"><b>'
captureRe = re.compile(reg)
cpList = re.findall(captureRe,html)
湾。拼凑链接:
num = (i - 1) * 10 + index;
subLink = "http://www.amazon.fr" + cp + "/ref=cm_cr_tr_tbl_" + str(num) + "_name";
index指的是10条数据中的哪一条,num其实是用户在评论列表中的排名,每页有10条,所以具体排名可以根据页码和index来计算;
C。转换为html:
headers = { #伪装为浏览器抓取
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(url,headers=headers)
page = "";
try:
page = urllib2.urlopen(req)
html = page.read()
return html
except:
print "getHtml error"
可以看出这个转换形式和之前的转换方式不同,因为我发现之前的转换方式得到的页面数据和我们之间右键浏览器查看源代码的格式不一样,然后我正在匹配联系信息。当匹配失败时,认为是这种差异造成的。因此,我找到了数据并使用上面的表格进行了转换。网友还表示,这样可以防止亚马逊对频繁访问的IP进行封IP;
python抓取网页数据( 就是利用Python阿里云盘资源的资料请关注编程相关文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-23 07:08
就是利用Python阿里云盘资源的资料请关注编程相关文章)
Python抢阿里云盘资源
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs) 查看全部
python抓取网页数据(
就是利用Python阿里云盘资源的资料请关注编程相关文章)
Python抢阿里云盘资源
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。

网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。

打开控制面板下的网络,一眼就能看到一个sea.html的get请求。

有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。

抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs)
python抓取网页数据(python+pyqueryjava用户自己写网络协议可以用tcp等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-23 03:04
python抓取网页数据,用的是beautifulsoup和tornado,
tornado+beautifulsoup是最快的了。异步的话,用python语言写网络协议可以用tcp等。还可以尝试使用urllib2模块分析网页内容,
异步爬虫可以用tornado,用java写起来比较费劲;也可以用websocket实现,tornado底层实现是基于udp的,对网络地址要求高,我也在找一个比较好的解决方案,感觉现在比较流行的就是用redis提供http的缓存。
tornado框架是我正在用的一个异步爬虫框架。
想抓取网页中的数据,可以考虑用python处理get请求。有google全球通用urllib2库。中文博客网站一般用xml格式下载的数据,java用户想抓取这些数据的话还是需要自己写demo。不写demo的话也可以直接用websocket这种轮子,直接发送get或者post参数,使用协议beautifulsoup解析也很方便。
一般的页面服务器都自带自动保存数据的功能,不需要额外做什么。我现在在用的是python+pyquery,java用户自己写session,websocket实现就可以了。利益相关:我用tornado写了tornado配合python的crawler玩。
把网页发给google, 查看全部
python抓取网页数据(python+pyqueryjava用户自己写网络协议可以用tcp等)
python抓取网页数据,用的是beautifulsoup和tornado,
tornado+beautifulsoup是最快的了。异步的话,用python语言写网络协议可以用tcp等。还可以尝试使用urllib2模块分析网页内容,
异步爬虫可以用tornado,用java写起来比较费劲;也可以用websocket实现,tornado底层实现是基于udp的,对网络地址要求高,我也在找一个比较好的解决方案,感觉现在比较流行的就是用redis提供http的缓存。
tornado框架是我正在用的一个异步爬虫框架。
想抓取网页中的数据,可以考虑用python处理get请求。有google全球通用urllib2库。中文博客网站一般用xml格式下载的数据,java用户想抓取这些数据的话还是需要自己写demo。不写demo的话也可以直接用websocket这种轮子,直接发送get或者post参数,使用协议beautifulsoup解析也很方便。
一般的页面服务器都自带自动保存数据的功能,不需要额外做什么。我现在在用的是python+pyquery,java用户自己写session,websocket实现就可以了。利益相关:我用tornado写了tornado配合python的crawler玩。
把网页发给google,
python抓取网页数据(抓取百度疫情数据的代码已经无法运行,怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-21 12:07
)
有朋友反映,抓取百度疫情数据的代码已经失效。没看过的可以点击下方链接查看。
看了之后,因为百度调整了一些页面信息,调整后代码就可以使用了,那如果下次调整呢?你说这个可能性很大吗?
我觉得还是挺大的,有什么办法可以稳定吗?
问这个问题,肯定是有的,就是换一种方式获取疫情的实时数据。
这一次,我们来抓取网易 JSON 疫情数据。
链接是这个
打开 URL 并看到这个。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你使用的是火狐浏览器,也可以在上面找到JSON、美化输出等功能。
这就是美化输出的效果。是不是看起来好多了,但是还是一头雾水,对吧,因为你从来没有接触过JSON数据。
这是一点JSON效果,不同的颜色,看起来更舒服。
好的,让我们从数据捕获和导入开始。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓取的数据结果,可以看到它是一个字典,而我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这是areaTree的列表,我们要的第一行数据。
继续双击打开areaTree的第一行,这次又变成字典了,你看到中国了吗?哈哈,我们要的数据在key=children中。
继续双击打开children,这是我们要的数据,这又变成了一个list,每一行都是一个省的数据
我们点第一行,看是不是,湖北已经出现了。
继续点击儿童,就是湖北各城市的数据。如果你不点击它,我们只需要省级数据。我们怎么能想出它?继续数据处理以提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
两行代码就出来了,哈哈!让我们看一下数据。
那么我们要的字段是name,total.confirm,name是省份名称,total.confirm是累计确诊数,如果换成taday.confirm就是新增确诊数。直接将name和total.confirm替换为之前绘制地图的代码对应位置即可。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果就出来了。
查看全部
python抓取网页数据(抓取百度疫情数据的代码已经无法运行,怎么办?
)
有朋友反映,抓取百度疫情数据的代码已经失效。没看过的可以点击下方链接查看。
看了之后,因为百度调整了一些页面信息,调整后代码就可以使用了,那如果下次调整呢?你说这个可能性很大吗?
我觉得还是挺大的,有什么办法可以稳定吗?
问这个问题,肯定是有的,就是换一种方式获取疫情的实时数据。
这一次,我们来抓取网易 JSON 疫情数据。
链接是这个
打开 URL 并看到这个。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你使用的是火狐浏览器,也可以在上面找到JSON、美化输出等功能。

这就是美化输出的效果。是不是看起来好多了,但是还是一头雾水,对吧,因为你从来没有接触过JSON数据。
 https://www.lxiaoyue.com/wp-co ... 0.png 246w" />
https://www.lxiaoyue.com/wp-co ... 0.png 246w" />这是一点JSON效果,不同的颜色,看起来更舒服。

好的,让我们从数据捕获和导入开始。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓取的数据结果,可以看到它是一个字典,而我们要的数据在key=data中。

继续双击打开数据,我们要的数据在areaTree中。

继续双击打开areaTree,这是areaTree的列表,我们要的第一行数据。

继续双击打开areaTree的第一行,这次又变成字典了,你看到中国了吗?哈哈,我们要的数据在key=children中。

继续双击打开children,这是我们要的数据,这又变成了一个list,每一行都是一个省的数据

我们点第一行,看是不是,湖北已经出现了。

继续点击儿童,就是湖北各城市的数据。如果你不点击它,我们只需要省级数据。我们怎么能想出它?继续数据处理以提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
两行代码就出来了,哈哈!让我们看一下数据。

那么我们要的字段是name,total.confirm,name是省份名称,total.confirm是累计确诊数,如果换成taday.confirm就是新增确诊数。直接将name和total.confirm替换为之前绘制地图的代码对应位置即可。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果就出来了。

python抓取网页数据(数据科学越来越火了,如何抓网页数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-21 09:01
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。
第 1 步:熟悉 Python 的基本语法。
如果您已经熟悉 Python,请跳至第 2 步。
Python 是一种相对容易上手的编程语言。如何开始取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是在coursetalk上的评论很好。还有同学的评论(点这里),课程链接:Udacity上的CS101也是一个不错的选择,领域里有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲和Network相关的模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础.来自:/bbs
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍别人在你上过的公开课上说了什么,或者看课程点评再做决定。
第 2 步:了解如何与 网站 链接并获取网页数据。 从1点3英亩bbs
编写一个脚本来与 网站 交互。有必要熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。只知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用urllib2与谷歌学者交互获取网页信息。
#导入模块urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
#学者有一个url,这个url形成的规则要自己分析。
query = 'On+random+graph'
url = '#39; + 查询 + '&btnG=&as_sdt=1%2C5&as_sdtp='-google 1point3acres
# 设置头文件。抓取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookie会比较复杂,
#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你使用的浏览器和网站交互
#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
header = {'Host': '',
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',. 1 点 3 英亩哄骗
'接受': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 查看全部
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(图))
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。
第 1 步:熟悉 Python 的基本语法。
如果您已经熟悉 Python,请跳至第 2 步。
Python 是一种相对容易上手的编程语言。如何开始取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是在coursetalk上的评论很好。还有同学的评论(点这里),课程链接:Udacity上的CS101也是一个不错的选择,领域里有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲和Network相关的模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础.来自:/bbs
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍别人在你上过的公开课上说了什么,或者看课程点评再做决定。
第 2 步:了解如何与 网站 链接并获取网页数据。 从1点3英亩bbs
编写一个脚本来与 网站 交互。有必要熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。只知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用urllib2与谷歌学者交互获取网页信息。
#导入模块urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
#学者有一个url,这个url形成的规则要自己分析。
query = 'On+random+graph'
url = '#39; + 查询 + '&btnG=&as_sdt=1%2C5&as_sdtp='-google 1point3acres
# 设置头文件。抓取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookie会比较复杂,
#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你使用的浏览器和网站交互
#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
header = {'Host': '',
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',. 1 点 3 英亩哄骗
'接受': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
python抓取网页数据( 2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-02-16 12:16
2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
[常用] Python中检测网页编码
2013 年 7 月 14 日星期日 Zoey Young Python
使用 Python 抓取网页并对其进行分析时出现此错误:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd6
原因是有些中文网站编码不是utf8,所以需要编码判断
问题描述:
引自如何高效、准确、自动识别网页代码
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务器返回的header中的charset变量获取的
它的二、是通过页面中的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们在抓取网页时就没有编码问题。
但现实对我们程序员来说总是很困难。在抓取网页时,经常会出现以下几种情况:
缺少这两个参数。虽然提供了这两个参数,但它们是不一致的。提供了这两个参数,但与网页的实际编码不一致。
为了尽可能自动地获取所有网页的编码,引入了自动编码识别。
夏代
搜索chardet立马找到了Python的chardet第三方库
可以通过pip安装
pip install chardet
主页说明:
chardet 猜测文本文件的编码。
检测...
需要 Python 2.1 或更高版本。
我正在使用 Python 2.7.X
网页编码判断:
import chardet
import urllib2
#可根据需要,选择不同的数据
html = urllib2.urlopen('http://www.zol.com.cn/').read()
print(chardet.detect(html))
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
chardet.detect() 返回一个字典,其中confidence为检测准确率,encoding为编码形式
其他方式:
import urllib2
from chardet.universaldetector import UniversalDetector
html = urllib2.urlopen('http://www.zol.com.cn/')
#创建一个检测对象
detector = UniversalDetector()
for line in html.readlines():
#分块进行测试,直到达到阈值
detector.feed(line)
if detector.done: break
#关闭检测对象
detector.close()
html.close()
#输出检测结果
print detector.result
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
如果要识别大文件的编码方式,使用后一种方法,可以只读取一部分来判断编码方式,从而提高检测速度。
BeautifulSoup4 Unicode该死
可以使用 BeautifulSoup4 的模块
from bs4 import UnicodeDammit
dammit = UnicodeDammit("Sacr\xc3\xa9 bleu!")
print(dammit.unicode_markup)
# Sacré bleu!
dammit.original_encoding
# 'utf-8'
总结
无论使用上述哪个模块,都不能保证100%正确... 网站 的一部分太糟糕了...
以下是我最后的写作方式。结合这两种方法,可以检测到前面测试中出现乱码的网站,但是代码看起来不是很干净:
参考文档
python编码检测原理及chardet模块的应用
如何高效、准确、自动地识别网页代码 查看全部
python抓取网页数据(
2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
[常用] Python中检测网页编码
2013 年 7 月 14 日星期日 Zoey Young Python
使用 Python 抓取网页并对其进行分析时出现此错误:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd6
原因是有些中文网站编码不是utf8,所以需要编码判断
问题描述:
引自如何高效、准确、自动识别网页代码
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务器返回的header中的charset变量获取的
它的二、是通过页面中的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们在抓取网页时就没有编码问题。
但现实对我们程序员来说总是很困难。在抓取网页时,经常会出现以下几种情况:
缺少这两个参数。虽然提供了这两个参数,但它们是不一致的。提供了这两个参数,但与网页的实际编码不一致。
为了尽可能自动地获取所有网页的编码,引入了自动编码识别。
夏代
搜索chardet立马找到了Python的chardet第三方库
可以通过pip安装
pip install chardet
主页说明:
chardet 猜测文本文件的编码。
检测...
需要 Python 2.1 或更高版本。
我正在使用 Python 2.7.X
网页编码判断:
import chardet
import urllib2
#可根据需要,选择不同的数据
html = urllib2.urlopen('http://www.zol.com.cn/').read()
print(chardet.detect(html))
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
chardet.detect() 返回一个字典,其中confidence为检测准确率,encoding为编码形式
其他方式:
import urllib2
from chardet.universaldetector import UniversalDetector
html = urllib2.urlopen('http://www.zol.com.cn/')
#创建一个检测对象
detector = UniversalDetector()
for line in html.readlines():
#分块进行测试,直到达到阈值
detector.feed(line)
if detector.done: break
#关闭检测对象
detector.close()
html.close()
#输出检测结果
print detector.result
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
如果要识别大文件的编码方式,使用后一种方法,可以只读取一部分来判断编码方式,从而提高检测速度。
BeautifulSoup4 Unicode该死
可以使用 BeautifulSoup4 的模块
from bs4 import UnicodeDammit
dammit = UnicodeDammit("Sacr\xc3\xa9 bleu!")
print(dammit.unicode_markup)
# Sacré bleu!
dammit.original_encoding
# 'utf-8'
总结
无论使用上述哪个模块,都不能保证100%正确... 网站 的一部分太糟糕了...
以下是我最后的写作方式。结合这两种方法,可以检测到前面测试中出现乱码的网站,但是代码看起来不是很干净:
参考文档
python编码检测原理及chardet模块的应用
如何高效、准确、自动地识别网页代码
python抓取网页数据(一个解决网页乱码问题分享解决模块的通用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-15 08:10
我们经常通过python做采集网页数据的时候,会遇到一些乱码的问题。今天给大家分享一个解决乱码网页,尤其是中文网页的通用方法。在首页,我们需要安装chardet模块,可以通过easy_install或者pip安装。安装好后,我们在控制台导入模块,如果正常的话。比如我们遇到的一些ISO-8859-2也可以通过以下方法解决。直接上代码:
import urllib2
import sys
import chardet
req = urllib2.Request("http://www.163.com/")##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信可以解决你的采集乱码问题。 查看全部
python抓取网页数据(一个解决网页乱码问题分享解决模块的通用方法)
我们经常通过python做采集网页数据的时候,会遇到一些乱码的问题。今天给大家分享一个解决乱码网页,尤其是中文网页的通用方法。在首页,我们需要安装chardet模块,可以通过easy_install或者pip安装。安装好后,我们在控制台导入模块,如果正常的话。比如我们遇到的一些ISO-8859-2也可以通过以下方法解决。直接上代码:
import urllib2
import sys
import chardet
req = urllib2.Request("http://www.163.com/";)##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信可以解决你的采集乱码问题。
python抓取网页数据(如何养搬运B站弹幕的“虫”?解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-09 15:14
python爬虫抓取弹幕的实现方法一、什么是爬虫?
百度百科是这样说的:一个自动获取网页内容的程序。据我了解,爬虫是~~“在网上爬行……”闭嘴!~~
那么我们来看看B站携带弹幕的“虫子”是怎么养的
二、投喂步骤1.请求弹幕
首先你要知道爬取的网站url是什么。对于B站的弹幕,弹幕的位置有固定的格式:
+cid+.xml
好的,所以问题是,cid 是什么?不管它是什么,我会告诉你如何获得它。
1.打开视频后,点击F12,切换到“网络”,在过滤器中填写“cid”进行过滤。
2.点击过滤后的网络信息,找到右侧Payload处的cid
3.至此,我们知道了何氏视频弹幕的网络链接:
4.接下来就是发送网络请求,获取网页资源。Python 有许多用于发送网络请求的库。例如:
我们使用 reaquests 库来演示
发送请求的代码如下
(例子):
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
还有一点值得一提的是,发送请求的请求头可以加进去伪装成浏览器访问。可以通过header参数,加上user-agent来获取,如下:
所以,代码如下:
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url, headers=header)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
2.弹幕分析
html_str 是html文件的格式,我们需要对其进行处理才能得到我们想要的信息。这时候BeautifulSoup库就要登场了,我们用它来处理得到的html文件
代码如下(示例):
#解析
soup = BeautifulSoup(html,'html.parser')
#找到html文件里的标签
results = soup.find_all('d')
#把标签里的文本提取出来
contents = [x.text for x in results]
#存为字典
dic ={"contents" : contents}
contents 是一个弹幕字符串列表,它被保存为字典以供下一步使用...
3.保存弹幕
将弹幕信息存储在excel中,可以使用的库很多。例如:
我们使用 pandas 库来
代码如下(示例):
用第二步得到的字典创建一个dataFrame,然后用pandas库的一个API保存。
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
4.总码
import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
html = askUrl()
dic =analyse(html)
writeExcel(dic)
def askUrl():
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
req = requests.get(url = url, headers=header)
html_byte = req.content#字节
html_str = str(html_byte,"utf-8")
return html_str
def analyse(html):
soup = BeautifulSoup(html,'html.parser')
results = soup.find_all('d')
#x.text表示要放到contents中的值
contents = [x.text for x in results]
#保存结果
dic ={"contents" : contents}
return dic
def writeExcel(dic):
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
if __name__ == '__main__':
main()
三、总结
简单来说,爬行动物需要三个步骤:
1.发送网络请求获取资源
2.进行搜索等以获得有用的信息
3.存储的信息
这篇文章就到这里了,希望对你有帮助,也希望大家多多关注编程宝的更多内容!
下一节:python scrapy框架中Request对象和Response对象的Python编程技术
一、Request 对象 Request 对象主要用于请求数据。它在爬取数据页面并重新发送请求时调用。其源码类的位置如下图所示: 这里是它的源码。该方法有... 查看全部
python抓取网页数据(如何养搬运B站弹幕的“虫”?解析)
python爬虫抓取弹幕的实现方法一、什么是爬虫?
百度百科是这样说的:一个自动获取网页内容的程序。据我了解,爬虫是~~“在网上爬行……”闭嘴!~~
那么我们来看看B站携带弹幕的“虫子”是怎么养的
二、投喂步骤1.请求弹幕
首先你要知道爬取的网站url是什么。对于B站的弹幕,弹幕的位置有固定的格式:
+cid+.xml
好的,所以问题是,cid 是什么?不管它是什么,我会告诉你如何获得它。
1.打开视频后,点击F12,切换到“网络”,在过滤器中填写“cid”进行过滤。

2.点击过滤后的网络信息,找到右侧Payload处的cid

3.至此,我们知道了何氏视频弹幕的网络链接:
4.接下来就是发送网络请求,获取网页资源。Python 有许多用于发送网络请求的库。例如:
我们使用 reaquests 库来演示
发送请求的代码如下
(例子):
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
还有一点值得一提的是,发送请求的请求头可以加进去伪装成浏览器访问。可以通过header参数,加上user-agent来获取,如下:

所以,代码如下:
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url, headers=header)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
2.弹幕分析
html_str 是html文件的格式,我们需要对其进行处理才能得到我们想要的信息。这时候BeautifulSoup库就要登场了,我们用它来处理得到的html文件
代码如下(示例):
#解析
soup = BeautifulSoup(html,'html.parser')
#找到html文件里的标签
results = soup.find_all('d')
#把标签里的文本提取出来
contents = [x.text for x in results]
#存为字典
dic ={"contents" : contents}
contents 是一个弹幕字符串列表,它被保存为字典以供下一步使用...
3.保存弹幕
将弹幕信息存储在excel中,可以使用的库很多。例如:
我们使用 pandas 库来
代码如下(示例):
用第二步得到的字典创建一个dataFrame,然后用pandas库的一个API保存。
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
4.总码
import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
html = askUrl()
dic =analyse(html)
writeExcel(dic)
def askUrl():
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
req = requests.get(url = url, headers=header)
html_byte = req.content#字节
html_str = str(html_byte,"utf-8")
return html_str
def analyse(html):
soup = BeautifulSoup(html,'html.parser')
results = soup.find_all('d')
#x.text表示要放到contents中的值
contents = [x.text for x in results]
#保存结果
dic ={"contents" : contents}
return dic
def writeExcel(dic):
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
if __name__ == '__main__':
main()
三、总结
简单来说,爬行动物需要三个步骤:
1.发送网络请求获取资源
2.进行搜索等以获得有用的信息
3.存储的信息
这篇文章就到这里了,希望对你有帮助,也希望大家多多关注编程宝的更多内容!
下一节:python scrapy框架中Request对象和Response对象的Python编程技术
一、Request 对象 Request 对象主要用于请求数据。它在爬取数据页面并重新发送请求时调用。其源码类的位置如下图所示: 这里是它的源码。该方法有...
python抓取网页数据(简单聊一聊如何用python来抓取页面中的JS动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-07 03:28
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。如下图所示,我们在 HTML 中找不到对应的电影信息。如何使用PYTHON request.json读取下一级内容,直接将request中的整个json提取成一个dict和list组成的结构,不就是随便读一个想读的吗?python请求是否获得状态?1.使用postman的时候,输入url和参数,调用post方法,接口会返回数据2.然后我用python的requests实现3.r= requests.request('POST ',req, data=value) python爬虫中的request请求对象是什么,是客户端向服务端发送的请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数的方法提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看requests中的信息,获取具体的查询参数如你上面的tid。就是一个参数,然后把这些参数做成一个字典,用urlencode方法把参数字典转换成url格式如下: url='' 查看全部
python抓取网页数据(简单聊一聊如何用python来抓取页面中的JS动态加载)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。如下图所示,我们在 HTML 中找不到对应的电影信息。如何使用PYTHON request.json读取下一级内容,直接将request中的整个json提取成一个dict和list组成的结构,不就是随便读一个想读的吗?python请求是否获得状态?1.使用postman的时候,输入url和参数,调用post方法,接口会返回数据2.然后我用python的requests实现3.r= requests.request('POST ',req, data=value) python爬虫中的request请求对象是什么,是客户端向服务端发送的请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数的方法提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看requests中的信息,获取具体的查询参数如你上面的tid。就是一个参数,然后把这些参数做成一个字典,用urlencode方法把参数字典转换成url格式如下: url=''
python抓取网页数据(1.2.3.3.上代码,网页抓取和网页分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-03 22:21
最近,组里的一位老师在做研究,需要一些站点的水文资料。最近刚学python,了解到python中有很多方便的库,用于网页抓取和网页分析,于是开始写一个。勉强能用,哈哈。
在实现上,简单使用了线程中队列的使用、线程池的使用、网页分析。主要参考:
1.
2.
3.
关于代码,后面是简要说明
代码块
# -*- coding: utf-8 -*-
import urllib
import urllib2
from BeautifulSoup import BeautifulSoup
from datetime import *
from dateutil.relativedelta import *
import Queue
import threading
queue = Queue.Queue()
out_queue = Queue.Queue()
#日期迭代器,迭代从start到end中间的每一天
def loopDay(start, end):
while(start < end):
yield start
start = start + relativedelta(days = 1)
#向指定网站(湖南省水文查询系统)请求所需的页面
def post(url, data):
req = urllib2.Request(url)
data = urllib.urlencode(data)
#enable cookie
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
return response.read()
def getHtml(time):
posturl = 'http://61.187.56.156/wap/hnsq_BB2.asp'
data = {}
data['nian'] = str(time.year)
data['yue'] = str(time.month)
data['ri'] = str(time.day)
data['shi'] = '08:00'
html = post(posturl, data)
return html
#查找我们需要的关键字在Tag列表中的位置
def findKeyword(keyword, tagList):
location = -1
for tag in tagList:
location += 1
if (keyword.encode('GBK') in unicode(tag.string).encode("windows-1252")):
break
return location
#用于抓取某一天的对应的页面
class ThreadUrl(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
oneDay = self.queue.get()
print oneDay
#grabs webpage
webpage = getHtml(oneDay)
#place page into out queue
self.out_queue.put((oneDay, webpage))
#抓取获取到的指定日期对应的网页中我们需要的数据
class DatamineThread(threading.Thread):
"""Threaded Url Parsing"""
def __init__(self, out_queue):
threading.Thread.__init__(self)
self.out_queue = out_queue
def run(self):
while True:
(oneDay, page) = self.out_queue.get()
#parse the page
soup = BeautifulSoup(page, fromEncoding = "gb2312")
tagList = soup.findAll('td')
locations = []
for keyword in keywords:
locations.append(findKeyword(keyword, tagList))
for i in range(5):
fileName = keywords[i] + ".txt"
f = file(fileName, "a+")
waterLevel = unicode(tagList[locations[i] + 2].string).strip().encode("windows-1252")
waterStorage = unicode(tagList[locations[i] + 5].string).strip().encode("windows-1252")
f.write(str(oneDay) +"\t" + waterLevel + "\t" + waterStorage + "\n")
f.close()
if __name__ == '__main__':
keywords = [u"寸滩", u"万县", u"巫山", u"清溪场", u"忠县", u"武隆"]
startDay = date(2006, 1, 1)
endDay = date(2007, 1, 1)
days = loopDay(startDay, endDay)
t = ThreadUrl(queue, out_queue)
t.setDaemon(True)
t.start()
for oneDay in days:
queue.put(oneDay)
dt = DatamineThread(out_queue)
dt.setDaemon(True)
dt.start()
queue.join()
out_queue.join()
注册好久了,第一次写。网速不好,请稍后更改。 查看全部
python抓取网页数据(1.2.3.3.上代码,网页抓取和网页分析。)
最近,组里的一位老师在做研究,需要一些站点的水文资料。最近刚学python,了解到python中有很多方便的库,用于网页抓取和网页分析,于是开始写一个。勉强能用,哈哈。
在实现上,简单使用了线程中队列的使用、线程池的使用、网页分析。主要参考:
1.
2.
3.
关于代码,后面是简要说明
代码块
# -*- coding: utf-8 -*-
import urllib
import urllib2
from BeautifulSoup import BeautifulSoup
from datetime import *
from dateutil.relativedelta import *
import Queue
import threading
queue = Queue.Queue()
out_queue = Queue.Queue()
#日期迭代器,迭代从start到end中间的每一天
def loopDay(start, end):
while(start < end):
yield start
start = start + relativedelta(days = 1)
#向指定网站(湖南省水文查询系统)请求所需的页面
def post(url, data):
req = urllib2.Request(url)
data = urllib.urlencode(data)
#enable cookie
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
return response.read()
def getHtml(time):
posturl = 'http://61.187.56.156/wap/hnsq_BB2.asp'
data = {}
data['nian'] = str(time.year)
data['yue'] = str(time.month)
data['ri'] = str(time.day)
data['shi'] = '08:00'
html = post(posturl, data)
return html
#查找我们需要的关键字在Tag列表中的位置
def findKeyword(keyword, tagList):
location = -1
for tag in tagList:
location += 1
if (keyword.encode('GBK') in unicode(tag.string).encode("windows-1252")):
break
return location
#用于抓取某一天的对应的页面
class ThreadUrl(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
oneDay = self.queue.get()
print oneDay
#grabs webpage
webpage = getHtml(oneDay)
#place page into out queue
self.out_queue.put((oneDay, webpage))
#抓取获取到的指定日期对应的网页中我们需要的数据
class DatamineThread(threading.Thread):
"""Threaded Url Parsing"""
def __init__(self, out_queue):
threading.Thread.__init__(self)
self.out_queue = out_queue
def run(self):
while True:
(oneDay, page) = self.out_queue.get()
#parse the page
soup = BeautifulSoup(page, fromEncoding = "gb2312")
tagList = soup.findAll('td')
locations = []
for keyword in keywords:
locations.append(findKeyword(keyword, tagList))
for i in range(5):
fileName = keywords[i] + ".txt"
f = file(fileName, "a+")
waterLevel = unicode(tagList[locations[i] + 2].string).strip().encode("windows-1252")
waterStorage = unicode(tagList[locations[i] + 5].string).strip().encode("windows-1252")
f.write(str(oneDay) +"\t" + waterLevel + "\t" + waterStorage + "\n")
f.close()
if __name__ == '__main__':
keywords = [u"寸滩", u"万县", u"巫山", u"清溪场", u"忠县", u"武隆"]
startDay = date(2006, 1, 1)
endDay = date(2007, 1, 1)
days = loopDay(startDay, endDay)
t = ThreadUrl(queue, out_queue)
t.setDaemon(True)
t.start()
for oneDay in days:
queue.put(oneDay)
dt = DatamineThread(out_queue)
dt.setDaemon(True)
dt.start()
queue.join()
out_queue.join()
注册好久了,第一次写。网速不好,请稍后更改。
python抓取网页数据(数据科学越来越火了,网页是数据很大的一个来源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-28 02:28
前言:。访问更多。
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。.
. 链鞃断头镊子?1点3英亩
第 1 步:熟悉 Python 的基本语法。. 更多信息
如果您已经熟悉 Python,请跳至第 2 步。瓦拉尔?,
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接From 1point 3acres bbs
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有同学在现场评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场也有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,就是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
# 学者有一个url,这个url形成的规则要自己分析。
查询=“上+随机+图形”
url = "" + 查询 + "&btnG=&as_sdt=1%2C5&as_sdtp="。更多信息
# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
# 这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器并与网站进行交互。更多信息
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
标头 = {“主机”:“”,
"用户代理": "Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ",
"接受": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
“接受编码”:“gzip,放气”,
“连接”:“保持活动”}
# 建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
# 所以作为一个守法的好公民,还是关闭连接比较好。
con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。
.
步骤三、解析网页
以上步骤获取了网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,。从 1 点 3acres bbs
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用.. 更多信息
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
导入 BeautifulSoup
重新进口
# 生成一个soup对象,步骤2中提到了doc
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用计数、版本计数、指向 文章 引用列表的超链接
# 这里也用到了一些正则表达式,不熟悉的应该不知道。至于“类”:在“gs_rt”
# “gs_rt”是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 让这个很简单,只要一点网页,就可以知道对应html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find("h3", {"class" : "gs_rt"}).text
paper_name = re.sub(r"\[.*\]", "", paper_name) # 去掉 "[]" 标签,比如 "[PDF]"
paper_author = soup.html.body.find("div", {"class" : "gs_a"}).text
paper_desc = soup.html.body.find("div", {"class" : "gs_rs"}).text
temp_str = soup.html.body.find("div", {"class" : "gs_fl"}).text
temp_re = re.match(r"[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)", temp_str)。更多信息
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes == "":
引用时间 = "0"
如果 versionNum == "":. 来自:/bbs
版本号 = "0"
引用Paper_href = soup.html.body.find("div", {"class" : "gs_fl"}).a.attrs[0][1]
复制代码
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件的最简单方法是在 Python 中使用以下代码:-google 1point3acres
# 打开文件webdata.txt,生成object文件,这个文件可能不存在,参数a表示添加。
# 还有其他参数,比如“r”只能读不能写,“w”可以写但删除原记录等。
文件 = 打开(“webdata.txt”,“a”)
line = paper_name + "#" + paper_author + "#" + paper_desc + "#" + citeTimes + "\n"
# 目标文件的write方法将字符串行写入文件
文件 = file.write(line)./bbs
# 再次做一个随心所欲关闭文件的好青年
文件.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;如果没有,需要使用coursera\stanford openEdX平台,有Introduction to Database进行系统学习,w3school供参考或作为手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。.来自:/bbs
% 可以使用cmd打开数据库。启动命令为:
净启动mysql55
%shutdown 命令是:
净停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb 模块。访问更多。
导入 MySQL 数据库
# 与服务器建立链接,host为服务器ip,我的MySQL数据库建在这台机器上,默认为127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为3306,charset为编码方式。
# 默认是utf8(也可能是gbk,取决于安装的版本)。.来自:/bbs
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="yourPassword", db="dbname", port=3306,字符集="utf8")
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = "On Random Graph""). 涓€浜?-涓夊堎-鍦砰麴麴鍙戝緷
# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
# i代表查询结果中的第i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,如:
sql = "update studentCourseRecord set fail = 1 where studentID = "%s" and termid = "%s" and courseID = "%s"" %(studentID,course[0],course[1])
cur.execute(sql)。1点3英亩
# 与查询不同,在执行完delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
# 和往常一样,使用完记得关闭光标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。服务器、Python、数据库和数据库接口需要使用相同的编码格式,避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
从 1 点 3acres bbs
后记:./bbs
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
更新:
2014年2月15日,更正了几个错别字;添加了相关课程链接;添加了对udacity CS101的介绍;添加了对 MySQLdb 模块的介绍。. 1点3英亩
2014 年 2 月 16 日,添加了指向解释如何编码的博客文章的链接。 查看全部
python抓取网页数据(数据科学越来越火了,网页是数据很大的一个来源)
前言:。访问更多。
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。.
. 链鞃断头镊子?1点3英亩
第 1 步:熟悉 Python 的基本语法。. 更多信息
如果您已经熟悉 Python,请跳至第 2 步。瓦拉尔?,
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接From 1point 3acres bbs
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有同学在现场评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场也有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,就是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
# 学者有一个url,这个url形成的规则要自己分析。
查询=“上+随机+图形”
url = "" + 查询 + "&btnG=&as_sdt=1%2C5&as_sdtp="。更多信息
# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
# 这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器并与网站进行交互。更多信息
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
标头 = {“主机”:“”,
"用户代理": "Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ",
"接受": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
“接受编码”:“gzip,放气”,
“连接”:“保持活动”}
# 建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
# 所以作为一个守法的好公民,还是关闭连接比较好。
con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。
.
步骤三、解析网页
以上步骤获取了网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,。从 1 点 3acres bbs
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用.. 更多信息
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
导入 BeautifulSoup
重新进口
# 生成一个soup对象,步骤2中提到了doc
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用计数、版本计数、指向 文章 引用列表的超链接
# 这里也用到了一些正则表达式,不熟悉的应该不知道。至于“类”:在“gs_rt”
# “gs_rt”是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 让这个很简单,只要一点网页,就可以知道对应html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find("h3", {"class" : "gs_rt"}).text
paper_name = re.sub(r"\[.*\]", "", paper_name) # 去掉 "[]" 标签,比如 "[PDF]"
paper_author = soup.html.body.find("div", {"class" : "gs_a"}).text
paper_desc = soup.html.body.find("div", {"class" : "gs_rs"}).text
temp_str = soup.html.body.find("div", {"class" : "gs_fl"}).text
temp_re = re.match(r"[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)", temp_str)。更多信息
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes == "":
引用时间 = "0"
如果 versionNum == "":. 来自:/bbs
版本号 = "0"
引用Paper_href = soup.html.body.find("div", {"class" : "gs_fl"}).a.attrs[0][1]
复制代码
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件的最简单方法是在 Python 中使用以下代码:-google 1point3acres
# 打开文件webdata.txt,生成object文件,这个文件可能不存在,参数a表示添加。
# 还有其他参数,比如“r”只能读不能写,“w”可以写但删除原记录等。
文件 = 打开(“webdata.txt”,“a”)
line = paper_name + "#" + paper_author + "#" + paper_desc + "#" + citeTimes + "\n"
# 目标文件的write方法将字符串行写入文件
文件 = file.write(line)./bbs
# 再次做一个随心所欲关闭文件的好青年
文件.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;如果没有,需要使用coursera\stanford openEdX平台,有Introduction to Database进行系统学习,w3school供参考或作为手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。.来自:/bbs
% 可以使用cmd打开数据库。启动命令为:
净启动mysql55
%shutdown 命令是:
净停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb 模块。访问更多。
导入 MySQL 数据库
# 与服务器建立链接,host为服务器ip,我的MySQL数据库建在这台机器上,默认为127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为3306,charset为编码方式。
# 默认是utf8(也可能是gbk,取决于安装的版本)。.来自:/bbs
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="yourPassword", db="dbname", port=3306,字符集="utf8")
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = "On Random Graph""). 涓€浜?-涓夊堎-鍦砰麴麴鍙戝緷
# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
# i代表查询结果中的第i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,如:
sql = "update studentCourseRecord set fail = 1 where studentID = "%s" and termid = "%s" and courseID = "%s"" %(studentID,course[0],course[1])
cur.execute(sql)。1点3英亩
# 与查询不同,在执行完delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
# 和往常一样,使用完记得关闭光标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。服务器、Python、数据库和数据库接口需要使用相同的编码格式,避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
从 1 点 3acres bbs
后记:./bbs
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
更新:
2014年2月15日,更正了几个错别字;添加了相关课程链接;添加了对udacity CS101的介绍;添加了对 MySQLdb 模块的介绍。. 1点3英亩
2014 年 2 月 16 日,添加了指向解释如何编码的博客文章的链接。
python抓取网页数据(STM32抓取网页数据()抓取数据数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-27 01:05
python抓取网页数据。准备环境:python3.6,python2.7,tushare爬虫,xxx的selenium实验环境1、导入所有必要的库importxxx#包括google,xml,xlrd,xlwt等importyyy#包括用户名,邮箱,密码等importcgi#用于连接服务器,以便于对url进行get请求fromurllibimporturlopen#方便处理url,字符串,字符串的内容importtimeimportre#time是时间库,python3中有很多版本,我用的是spider1.1.4.0.683#xml库,multicharts,beautifulsoup的封装selenium的实现extension安装xxx.python3tushare的服务,抓取数据:xxxxxdataingbk的.xlsx格式extension:welcometomozillafirefox.opensource,pleaseposttoreadme.mdatmaster·pythonpeixun/apache-firefox-issuesextension:copy.pythonfromurllibimporturlopen,requestfromthefirefox.openfromurllibimportrequestfromurllib.errorimportrequestevalfromurllib.errorimporturlerrorsys.stdout.basichandlers.console=false#properties属性是python自带的扩展名名称,不需要额外添加#如果不是.xlsx格式,python3中返回"resource_content",python2中返回"content_content"socket=socket.socket(socket.af_inet,socket.sock_stream)#af_inet是开源的multichartscallback模块,它支持tcp、udp、icmp等多种协议socket.close()#若不执行close方法,则tcp协议关闭;若执行了close方法,则tcp协议启动#若协议没有关闭,则python将尝试监听close方法的结果,直到遇到python3中更多内容#我用的是spider3.1.4.0.683version3、爬虫代码importxxxfromseleniumimportwebdriver#所有useragent的包装useragent=""#浏览器driver=webdriver.chrome(executable_path='c:\\windows\\system32\\chromedriver.exe')#获取启动页面#print(useragent)获取转发接口request_url=''#request_url=''#获取注册页面post_url=''post_url=''#设置一个token,并绑定端口xctls=''#xctls=''#获取所有数据,爬取并保存result_url=''#记录每一页的访问iddefget_http_url(useragent):try:ssl=xhr.ssl()ssl.login(useragent)ssl.post(http_url,data={'cookie':cookie}。 查看全部
python抓取网页数据(STM32抓取网页数据()抓取数据数据)
python抓取网页数据。准备环境:python3.6,python2.7,tushare爬虫,xxx的selenium实验环境1、导入所有必要的库importxxx#包括google,xml,xlrd,xlwt等importyyy#包括用户名,邮箱,密码等importcgi#用于连接服务器,以便于对url进行get请求fromurllibimporturlopen#方便处理url,字符串,字符串的内容importtimeimportre#time是时间库,python3中有很多版本,我用的是spider1.1.4.0.683#xml库,multicharts,beautifulsoup的封装selenium的实现extension安装xxx.python3tushare的服务,抓取数据:xxxxxdataingbk的.xlsx格式extension:welcometomozillafirefox.opensource,pleaseposttoreadme.mdatmaster·pythonpeixun/apache-firefox-issuesextension:copy.pythonfromurllibimporturlopen,requestfromthefirefox.openfromurllibimportrequestfromurllib.errorimportrequestevalfromurllib.errorimporturlerrorsys.stdout.basichandlers.console=false#properties属性是python自带的扩展名名称,不需要额外添加#如果不是.xlsx格式,python3中返回"resource_content",python2中返回"content_content"socket=socket.socket(socket.af_inet,socket.sock_stream)#af_inet是开源的multichartscallback模块,它支持tcp、udp、icmp等多种协议socket.close()#若不执行close方法,则tcp协议关闭;若执行了close方法,则tcp协议启动#若协议没有关闭,则python将尝试监听close方法的结果,直到遇到python3中更多内容#我用的是spider3.1.4.0.683version3、爬虫代码importxxxfromseleniumimportwebdriver#所有useragent的包装useragent=""#浏览器driver=webdriver.chrome(executable_path='c:\\windows\\system32\\chromedriver.exe')#获取启动页面#print(useragent)获取转发接口request_url=''#request_url=''#获取注册页面post_url=''post_url=''#设置一个token,并绑定端口xctls=''#xctls=''#获取所有数据,爬取并保存result_url=''#记录每一页的访问iddefget_http_url(useragent):try:ssl=xhr.ssl()ssl.login(useragent)ssl.post(http_url,data={'cookie':cookie}。
python抓取网页数据(什么是Ajax:javascriptandxml(异步JavaScript和XML)如何快速入门selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 14:14
什么是阿贾克斯:
异步 javascriptandxml(异步 JavaScript 和 XML)。在 Ajax 中,可以通过在后台最小化与服务器的数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新传统网页(没有 Ajax)的内容,则必须重新加载整个网页。因为以前数据格式是使用 XML 语法传输的。所以虽然叫AJAX,但实际上现在的数据交换基本都是用JSON。即使AJAX加载的数据使用JS在浏览器中渲染数据,右键-查看网页源代码也看不到AJAX加载的数据,只有这个url加载的html代码。
如何获取ajax数据:
1、直接分析ajax调用接口。然后使用代码请求这个接口。
2、使用 Selenium chromedriver 模拟浏览器动作来获取数据。
Selenium chromedriver 获取动态数据:
Selenium 相当于机器人。可以在浏览器中模拟人类行为并自动处理浏览器中的行为,例如点击、输入数据和删除cookies。Chromedriver是一款可以移动浏览器的手机chrome浏览器驱动。当然,驱动器因浏览器而异。以下是各种浏览器及其相应的驱动程序。
1、chrome:驱动程序/下载
2、Firefox:驱动程序/版本
3、边缘:驱动程序/
4、safari:driver-support-in-safari-10/
要安装 Selenium 和 chrome 驱动程序:
Selenium 安装:Selenium 支持多种语言,包括 java、ruby 和 python。我们只下载python版本。
pip安装序列号
安装chromedriver:下载完成后,未经许可放到英文目录下。
快速开始:
以轻松获取百度主页为例,展示如何快速上手 Selenium 和 chromedriver。
Selenium 常用操作:
关闭页面:
1、driver.close(:关闭当前页面。
2、driver.quit () : 退出整个浏览器。
定位要素:
请注意,find_element 是满足条件的第一个元素。find_elements 检索所有满足条件的元素。
作为表单元素:
1、操作输入框:分为两个阶段。第一步:找到元素。使用步骤 2 (send_keys(value)) 填充数据。示例代码如下:
输入标签=driver.find_element_by_id('kw))。
输入 tag.send_keys (python))。
可以使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear(
2、动作复选框:要选择复选框选项卡,请在网页上单击鼠标。所以我想选中复选框
x标签,然后先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。 查看全部
python抓取网页数据(什么是Ajax:javascriptandxml(异步JavaScript和XML)如何快速入门selenium)
什么是阿贾克斯:
异步 javascriptandxml(异步 JavaScript 和 XML)。在 Ajax 中,可以通过在后台最小化与服务器的数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新传统网页(没有 Ajax)的内容,则必须重新加载整个网页。因为以前数据格式是使用 XML 语法传输的。所以虽然叫AJAX,但实际上现在的数据交换基本都是用JSON。即使AJAX加载的数据使用JS在浏览器中渲染数据,右键-查看网页源代码也看不到AJAX加载的数据,只有这个url加载的html代码。
如何获取ajax数据:
1、直接分析ajax调用接口。然后使用代码请求这个接口。
2、使用 Selenium chromedriver 模拟浏览器动作来获取数据。
Selenium chromedriver 获取动态数据:
Selenium 相当于机器人。可以在浏览器中模拟人类行为并自动处理浏览器中的行为,例如点击、输入数据和删除cookies。Chromedriver是一款可以移动浏览器的手机chrome浏览器驱动。当然,驱动器因浏览器而异。以下是各种浏览器及其相应的驱动程序。
1、chrome:驱动程序/下载
2、Firefox:驱动程序/版本
3、边缘:驱动程序/
4、safari:driver-support-in-safari-10/
要安装 Selenium 和 chrome 驱动程序:
Selenium 安装:Selenium 支持多种语言,包括 java、ruby 和 python。我们只下载python版本。
pip安装序列号
安装chromedriver:下载完成后,未经许可放到英文目录下。
快速开始:
以轻松获取百度主页为例,展示如何快速上手 Selenium 和 chromedriver。
Selenium 常用操作:
关闭页面:
1、driver.close(:关闭当前页面。
2、driver.quit () : 退出整个浏览器。
定位要素:
请注意,find_element 是满足条件的第一个元素。find_elements 检索所有满足条件的元素。
作为表单元素:
1、操作输入框:分为两个阶段。第一步:找到元素。使用步骤 2 (send_keys(value)) 填充数据。示例代码如下:
输入标签=driver.find_element_by_id('kw))。
输入 tag.send_keys (python))。
可以使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear(
2、动作复选框:要选择复选框选项卡,请在网页上单击鼠标。所以我想选中复选框
x标签,然后先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。
python抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-26 06:19
)
"
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键-查看源代码
生成的 HTML 不收录由 ajax 异步加载的内容
查看原文件只显示网页的初始状态,但实际上网页加载后可能会立即执行js来改变初始状态。当前网页不同于传统的动态网页。它可以在不刷新网页的情况下更改网页的本地数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你需要在其中加载数据,改变控件的状态,甚至创建新的控件,销毁控件,或者隐藏现有的控件。外观自然会有所不同。
"
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
python抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
"
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键-查看源代码
生成的 HTML 不收录由 ajax 异步加载的内容
查看原文件只显示网页的初始状态,但实际上网页加载后可能会立即执行js来改变初始状态。当前网页不同于传统的动态网页。它可以在不刷新网页的情况下更改网页的本地数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你需要在其中加载数据,改变控件的状态,甚至创建新的控件,销毁控件,或者隐藏现有的控件。外观自然会有所不同。
"
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。

#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取网页数据(如何快速的采集到异步加载页面的异步代码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-01-24 22:03
在采集网页中,我们经常会遇到采集一些异步加载页面的网页,而我们平时使用的httpwebrequest类并不是采集。这时候我们一般都是用webbrowser来辅助采集,但是.net自带的webbrowser用起来很不爽。获取页面是否加载比较麻烦。DocumentCompleted事件被iframe反复触发,获取到的源码通常不会异步加载。在源代码之后,我们经常需要添加一个定时器来不断的检查来获取我们想要的源代码。当然,我们可以使用一些第三方的webkit内核浏览器,但是判断页面是否真的加载比较费力,而且体积也不小。
今天我将介绍 CasperJS。CasperJS 是一个开源的导航脚本处理和测试工具,基于 PhantomJS 和 slimerjs(前端自动化测试工具)编写。CasperJS 简化了完整导航场景的流程定义,为常见任务提供了有用的高级函数、方法和语法。CasperJS 本身非常强大。有两个内置引擎,PhantomJS 和 slimerjs,默认使用 PhantomJS。具体详细功能可以参考这些官方网站了解更多,或者加入QQ群389709524进行讨论。今天的重点是如何快速 采集 到异步加载的网页。
如果我们要采集dudu对这个文章的评论,这个文章看源码是找不到这两条评论的,通过httpwebrequest也拿不到。这时候我们用 casperjs 让它变得非常简单。
caperjs代码定义如下:
1 var fs = require('fs');
2 var casper = require('casper').create({
3 pageSettings: {
4 loadImages: false,
5 loadPlugins: false
6 },
7 logLevel: "debug",//日志等级
8 verbose: true, // 记录日志到控制台
9 });
10
11 var url = casper.cli.raw.get('url');
12
13 //请求页面
14 casper.start(url, function () {
15 fs.write("temp.html", this.getHTML(), 'w');
16 });
17
18 casper.run();
结果如下:
这样,几行简单的代码就可以得到异步加载的html代码。是不是非常简单快速!
当然,这在实际生产环境中是不够的。我们必须考虑各种 网站 场景和各种网络状况,例如网络超时。如果一个网页一分钟不能加载,我们就认为是超时了,否则我们一直在等待,我们要过滤掉与我们的采集无关的请求,对比谷歌统计,百度统计,广告等。这通常会减慢网页的加载速度。此外,我们通常还会使用 CSS 样式和页面的图片。不需要,可以忽略。总而言之,我们的代码是这样扩展的。
1 var fs = require('fs');
2
3 var casper = require('casper').create({
4 pageSettings: {
5 loadImages: true,
6 loadPlugins: false,
7 userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
8 },
9 logLevel: "debug",//日志等级
10 verbose: true, // 记录日志到控制台
11 timeout: 60000,//60秒超时,退出
12 });
13
14
15 var url = casper.cli.raw.get('url');
16
17 //排除不相关的请求,加快页面加载进度
18 casper.on('resource.requested', function(requestData, request) {
19 if (requestData.url.indexOf('google-analytics.com') > 0) {
20 request.abort();
21 }
22 if (requestData.url.indexOf('googlesyndication.com') > 0) {
23 request.abort();
24 }
25 if (requestData.url.indexOf('hm.baidu.com') > 0) {
26 request.abort();
27 }
28 if (requestData.url.indexOf('baidustatic.com') > 0) {
29 request.abort();
30 }
31 if (requestData.url.indexOf('share.baidu.com') > 0) {
32 request.abort();
33 }
34 if (requestData.url.indexOf('cbjs.baidu.com') > 0) {
35 request.abort();
36 }
37 if (requestData.url.indexOf('jiathis.com') > 0) {
38 request.abort();
39 }
40 if (requestData.url.indexOf('.cnzz.com') > 0) {
41 request.abort();
42 }
43 if (requestData.url.indexOf('.51.la') > 0) {
44 request.abort();
45 }
46 if (requestData.url.indexOf('.tanx.com') > 0) {
47 request.abort();
48 }
49 //this.echo("==============>page.resource.requested"+requestData.url);
50 });
51
52 //超时执行的函数,记录到日志文件
53 casper.on('timeout', function () {
54 //this.echo("===>timeout"+url);
55 var fileName = this.evaluate(getFileName);
56 var nowTime = this.evaluate(CurentTime);
57 fs.write("log/timeout_" + fileName + ".txt", nowTime + "====>" + url + "\r\n", 'a');
58 });
59
60 //请求页面
61 casper.start(url, function () {
62 var status = this.status().currentHTTPStatus;
63 //this.capture('tt.png');
64 fs.write("temp.html", this.getHTML(), 'w');
65 });
66
67
68 function getFileName() {
69 var now = new Date();
70
71 var year = now.getFullYear(); //年
72 var month = now.getMonth() + 1; //月
73 var day = now.getDate(); //日
74
75 return (year + "" + month + "" + day);
76 }
77
78 function CurentTime() {
79 var now = new Date();
80
81 var year = now.getFullYear(); //年
82 var month = now.getMonth() + 1; //月
83 var day = now.getDate(); //日
84
85 var hh = now.getHours(); //时
86 var mm = now.getMinutes(); //分
87
88 var clock = year + "-";
89
90 if (month < 10)
91 clock += "0";
92
93 clock += month + "-";
94
95 if (day < 10)
96 clock += "0";
97
98 clock += day + " ";
99
100 if (hh < 10)
101 clock += "0";
102
103 clock += hh + ":";
104 if (mm < 10) clock += '0';
105 clock += mm;
106 return (clock);
107 }
108
109 casper.run();
查看代码
CasperJs的安装可以参考官方网站文档,或者关注下方微信公众号,提供本文所有工具和源码下载。今天写这个文章的另一个目的是,我在使用CasperJs的时候,遇到页面出现乱码,一时找不到解决办法。欢迎知道的大侠帮忙!场景如下:
比如采集这个网页,这个网站code是gb2312采集,遇到曹睿的“睿”,就会出现乱码。网站是utf-8编码的,采集的时候是ok的,但是我们是采集的程序,不可能要求别人改编码,所以我没有还没想到解决办法,想知道的同学,给点指点,多谢了!
文章来源:
在线工具: 查看全部
python抓取网页数据(如何快速的采集到异步加载页面的异步代码?)
在采集网页中,我们经常会遇到采集一些异步加载页面的网页,而我们平时使用的httpwebrequest类并不是采集。这时候我们一般都是用webbrowser来辅助采集,但是.net自带的webbrowser用起来很不爽。获取页面是否加载比较麻烦。DocumentCompleted事件被iframe反复触发,获取到的源码通常不会异步加载。在源代码之后,我们经常需要添加一个定时器来不断的检查来获取我们想要的源代码。当然,我们可以使用一些第三方的webkit内核浏览器,但是判断页面是否真的加载比较费力,而且体积也不小。
今天我将介绍 CasperJS。CasperJS 是一个开源的导航脚本处理和测试工具,基于 PhantomJS 和 slimerjs(前端自动化测试工具)编写。CasperJS 简化了完整导航场景的流程定义,为常见任务提供了有用的高级函数、方法和语法。CasperJS 本身非常强大。有两个内置引擎,PhantomJS 和 slimerjs,默认使用 PhantomJS。具体详细功能可以参考这些官方网站了解更多,或者加入QQ群389709524进行讨论。今天的重点是如何快速 采集 到异步加载的网页。
如果我们要采集dudu对这个文章的评论,这个文章看源码是找不到这两条评论的,通过httpwebrequest也拿不到。这时候我们用 casperjs 让它变得非常简单。
caperjs代码定义如下:
1 var fs = require('fs');
2 var casper = require('casper').create({
3 pageSettings: {
4 loadImages: false,
5 loadPlugins: false
6 },
7 logLevel: "debug",//日志等级
8 verbose: true, // 记录日志到控制台
9 });
10
11 var url = casper.cli.raw.get('url');
12
13 //请求页面
14 casper.start(url, function () {
15 fs.write("temp.html", this.getHTML(), 'w');
16 });
17
18 casper.run();
结果如下:


这样,几行简单的代码就可以得到异步加载的html代码。是不是非常简单快速!
当然,这在实际生产环境中是不够的。我们必须考虑各种 网站 场景和各种网络状况,例如网络超时。如果一个网页一分钟不能加载,我们就认为是超时了,否则我们一直在等待,我们要过滤掉与我们的采集无关的请求,对比谷歌统计,百度统计,广告等。这通常会减慢网页的加载速度。此外,我们通常还会使用 CSS 样式和页面的图片。不需要,可以忽略。总而言之,我们的代码是这样扩展的。


1 var fs = require('fs');
2
3 var casper = require('casper').create({
4 pageSettings: {
5 loadImages: true,
6 loadPlugins: false,
7 userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
8 },
9 logLevel: "debug",//日志等级
10 verbose: true, // 记录日志到控制台
11 timeout: 60000,//60秒超时,退出
12 });
13
14
15 var url = casper.cli.raw.get('url');
16
17 //排除不相关的请求,加快页面加载进度
18 casper.on('resource.requested', function(requestData, request) {
19 if (requestData.url.indexOf('google-analytics.com') > 0) {
20 request.abort();
21 }
22 if (requestData.url.indexOf('googlesyndication.com') > 0) {
23 request.abort();
24 }
25 if (requestData.url.indexOf('hm.baidu.com') > 0) {
26 request.abort();
27 }
28 if (requestData.url.indexOf('baidustatic.com') > 0) {
29 request.abort();
30 }
31 if (requestData.url.indexOf('share.baidu.com') > 0) {
32 request.abort();
33 }
34 if (requestData.url.indexOf('cbjs.baidu.com') > 0) {
35 request.abort();
36 }
37 if (requestData.url.indexOf('jiathis.com') > 0) {
38 request.abort();
39 }
40 if (requestData.url.indexOf('.cnzz.com') > 0) {
41 request.abort();
42 }
43 if (requestData.url.indexOf('.51.la') > 0) {
44 request.abort();
45 }
46 if (requestData.url.indexOf('.tanx.com') > 0) {
47 request.abort();
48 }
49 //this.echo("==============>page.resource.requested"+requestData.url);
50 });
51
52 //超时执行的函数,记录到日志文件
53 casper.on('timeout', function () {
54 //this.echo("===>timeout"+url);
55 var fileName = this.evaluate(getFileName);
56 var nowTime = this.evaluate(CurentTime);
57 fs.write("log/timeout_" + fileName + ".txt", nowTime + "====>" + url + "\r\n", 'a');
58 });
59
60 //请求页面
61 casper.start(url, function () {
62 var status = this.status().currentHTTPStatus;
63 //this.capture('tt.png');
64 fs.write("temp.html", this.getHTML(), 'w');
65 });
66
67
68 function getFileName() {
69 var now = new Date();
70
71 var year = now.getFullYear(); //年
72 var month = now.getMonth() + 1; //月
73 var day = now.getDate(); //日
74
75 return (year + "" + month + "" + day);
76 }
77
78 function CurentTime() {
79 var now = new Date();
80
81 var year = now.getFullYear(); //年
82 var month = now.getMonth() + 1; //月
83 var day = now.getDate(); //日
84
85 var hh = now.getHours(); //时
86 var mm = now.getMinutes(); //分
87
88 var clock = year + "-";
89
90 if (month < 10)
91 clock += "0";
92
93 clock += month + "-";
94
95 if (day < 10)
96 clock += "0";
97
98 clock += day + " ";
99
100 if (hh < 10)
101 clock += "0";
102
103 clock += hh + ":";
104 if (mm < 10) clock += '0';
105 clock += mm;
106 return (clock);
107 }
108
109 casper.run();
查看代码
CasperJs的安装可以参考官方网站文档,或者关注下方微信公众号,提供本文所有工具和源码下载。今天写这个文章的另一个目的是,我在使用CasperJs的时候,遇到页面出现乱码,一时找不到解决办法。欢迎知道的大侠帮忙!场景如下:
比如采集这个网页,这个网站code是gb2312采集,遇到曹睿的“睿”,就会出现乱码。网站是utf-8编码的,采集的时候是ok的,但是我们是采集的程序,不可能要求别人改编码,所以我没有还没想到解决办法,想知道的同学,给点指点,多谢了!
文章来源:
在线工具:
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-23 10:04
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。. 更多信息
第 1 步:熟悉 Python 的基本语法
如果您已经熟悉 Python,请跳到第 2 步。
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接——google 1point3acres
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门是codecademy的python,很久以前看的,很多内容记不清了),每次看视频+编程作业一个多小时天,六天完成。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有现场的同学评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
import urllib2
# 随便查询一篇文章,比如On random graph。对每一个查询google
# scholar都有一个url,这个url形成的规则是要自己分析的。
query = 'On+random+graph'
url = 'http://scholar.google.com/scholar?hl=en&q=' + query + '&btnG=&as_sdt=1%2C5&as_sdtp='
# 设置头文件。抓取有些的网页不需要专门设置头文件,但是这里如果不设置的话,. 鐗涗汉浜戦泦,涓€浜╀笁鍒嗗湴
# google会认为是机器人不允许访问。另外访问有些网站还有设置Cookie,这个会相对复杂一些,
# 这里暂时不提。关于怎么知道头文件该怎么写,一些插件可以看到你用的浏览器和网站交互的
# 头文件(这种工具很多浏览器是自带的),我用的是firefox的firebug插件。.鏈枃鍘熷垱鑷�1point3acres璁哄潧
header = {'Host': 'scholar.google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive'}
# 建立连接请求,这时google的服务器返回页面信息给con这个变量,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen( req )
# 对con这个对象调用read()方法,返回的是html页面,也就是有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件要关闭文件一样,如果不关闭有时可以、但有时会有问题,
# 所以作为一个守法的好公民,还是关闭连接好了。
con.close()
上面的代码将google Academic上查询On Random Graph的结果返回给变量doc,和打开google Academic搜索On Random Graph,然后在网页上右键保存是一样的。
步骤三、解析网页
以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:. 更多信息
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道 html 文件是树状的,比如 body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用。
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
import BeautifulSoup
import re
# 生成一个soup对象,doc就是步骤二中提到的
soup = BeautifulSoup.BeautifulSoup(doc)
# 抓取论文标题,作者,简短描述,引用次数,版本数,引用它的文章列表的超链接
# 这里还用了一些正则表达式,不熟悉的先无知它好了。至于'class' : 'gs_rt'中
# 'gs_rt'是怎么来的,这个是分析html文件肉眼看出来的。上面提到的firebug插件
# 让这个变的很简单,只要一点网页,就可以知道对应的html 标签的位置和属性,
# 相当好用。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text. from: 1point3acres.com/bbs
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件最简单的方法是在 Python 中使用以下代码:
# 打开文件webdata.txt,生成对象file,这个文件可以是不存在的,参数a表示往里面添加。
# 还有别的参数,比如'r'只能读但不能写入,'w'可以写入但是会删除原来的记录等等
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库中,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;有一个系统学习的数据库介绍,w3school作为参考或手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。. visit 1point3acres.com for more.
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8'). 鍥磋鎴戜滑@1point 3 acres
# 建立cursor
cur = conn.cursor()# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
后记:
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。 查看全部
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(一))
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。. 更多信息
第 1 步:熟悉 Python 的基本语法
如果您已经熟悉 Python,请跳到第 2 步。
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接——google 1point3acres
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门是codecademy的python,很久以前看的,很多内容记不清了),每次看视频+编程作业一个多小时天,六天完成。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有现场的同学评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
import urllib2
# 随便查询一篇文章,比如On random graph。对每一个查询google
# scholar都有一个url,这个url形成的规则是要自己分析的。
query = 'On+random+graph'
url = 'http://scholar.google.com/scholar?hl=en&q=' + query + '&btnG=&as_sdt=1%2C5&as_sdtp='
# 设置头文件。抓取有些的网页不需要专门设置头文件,但是这里如果不设置的话,. 鐗涗汉浜戦泦,涓€浜╀笁鍒嗗湴
# google会认为是机器人不允许访问。另外访问有些网站还有设置Cookie,这个会相对复杂一些,
# 这里暂时不提。关于怎么知道头文件该怎么写,一些插件可以看到你用的浏览器和网站交互的
# 头文件(这种工具很多浏览器是自带的),我用的是firefox的firebug插件。.鏈枃鍘熷垱鑷�1point3acres璁哄潧
header = {'Host': 'scholar.google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive'}
# 建立连接请求,这时google的服务器返回页面信息给con这个变量,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen( req )
# 对con这个对象调用read()方法,返回的是html页面,也就是有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件要关闭文件一样,如果不关闭有时可以、但有时会有问题,
# 所以作为一个守法的好公民,还是关闭连接好了。
con.close()
上面的代码将google Academic上查询On Random Graph的结果返回给变量doc,和打开google Academic搜索On Random Graph,然后在网页上右键保存是一样的。
步骤三、解析网页
以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:. 更多信息
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道 html 文件是树状的,比如 body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用。
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
import BeautifulSoup
import re
# 生成一个soup对象,doc就是步骤二中提到的
soup = BeautifulSoup.BeautifulSoup(doc)
# 抓取论文标题,作者,简短描述,引用次数,版本数,引用它的文章列表的超链接
# 这里还用了一些正则表达式,不熟悉的先无知它好了。至于'class' : 'gs_rt'中
# 'gs_rt'是怎么来的,这个是分析html文件肉眼看出来的。上面提到的firebug插件
# 让这个变的很简单,只要一点网页,就可以知道对应的html 标签的位置和属性,
# 相当好用。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text. from: 1point3acres.com/bbs
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件最简单的方法是在 Python 中使用以下代码:
# 打开文件webdata.txt,生成对象file,这个文件可以是不存在的,参数a表示往里面添加。
# 还有别的参数,比如'r'只能读但不能写入,'w'可以写入但是会删除原来的记录等等
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库中,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;有一个系统学习的数据库介绍,w3school作为参考或手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。. visit 1point3acres.com for more.
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8'). 鍥磋鎴戜滑@1point 3 acres
# 建立cursor
cur = conn.cursor()# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
后记:
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
python抓取网页数据( 前阵子阿里云盘界面总结用python解析页面上的div)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 21:17
前阵子阿里云盘界面总结用python解析页面上的div)
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs) 查看全部
python抓取网页数据(
前阵子阿里云盘界面总结用python解析页面上的div)
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs)
python抓取网页数据(只会爬虫如何获取网页上的信息?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-16 04:01
python抓取网页数据,有ab两站。参考文章:python爬虫数据采集实战教程。
可以参考我的这篇回答:只会爬虫如何获取网页上的信息?-rednaxelafx的回答
python并不强大,只是学习成本最低,在今天大数据的风头正盛,可以说,任何一门编程语言的诞生,都是建立在数据统计分析的基础上,你可以学python进行数据分析,也可以学java去做web,也可以学javascript去爬虫做前端。不过你需要的掌握数据统计分析,然后是编程能力,再然后是技术实力。python的发展历史虽然python诞生了挺长时间,但在今天,绝大多数流行的编程语言都是不断发展的过程,为了让一门语言更精确,语言也不断迭代。
一个编程语言在很长时间内会不断迭代,现在几乎每个语言都有自己的特点,都有自己的使用方法。不同的方法其实背后也有它们存在的道理。自从python诞生以来,它一直以来的特点,都是python语言本身作为小众语言的特点,而正如其名,python是小众语言,那么为了应对在今天这种泛滥的情况,它只好遵循大众语言的标准,去演化,去发展。
每一种语言,都会经历从一而终的过程,这是一个适应环境的必经之路。怎么去理解这个过程呢?从大众语言到小众语言,或者从小众语言到大众语言,就是大众语言在适应大众语言的过程。python发展过程其实也是这个过程,比如python2到python3,就是python2不断改进的过程。基于python2的习惯,我们一开始认为python2是基于python2的扩展,但其实不是这样的,python2是python3的标准版,而python3也在逐渐的标准化,即不再兼容python2,有可能你正在运行的python3,python3.x版本,将会以3.x版本的python替代之。
另外从一而终还有一个问题,这不是绝对的,比如你刚才那个例子,其实就是python2用来迁移python3的步骤。但其实大众语言没有那么容易死的,也许只是你没有去找到一个正确的切入点。其实如果你今天运行到的python2还是python2,但是你可以在运行数据爬虫的时候,不用按着python2.x来运行,你可以是python3或者是其他很多语言。
python2也在逐渐的从大众语言变为小众语言,比如你现在可以用它爬取本地数据,用python3来运行你的爬虫,你也可以用python2来进行大数据分析。python其实更多的是一种编程语言,它可以做很多事情,比如数据爬虫,网页调试,模拟浏览器,等等。为什么我不学java,因为java实在太他妈难了,不是我能吃得消的,我现在还要学其他语言。从这个意义。 查看全部
python抓取网页数据(只会爬虫如何获取网页上的信息?-八维教育)
python抓取网页数据,有ab两站。参考文章:python爬虫数据采集实战教程。
可以参考我的这篇回答:只会爬虫如何获取网页上的信息?-rednaxelafx的回答
python并不强大,只是学习成本最低,在今天大数据的风头正盛,可以说,任何一门编程语言的诞生,都是建立在数据统计分析的基础上,你可以学python进行数据分析,也可以学java去做web,也可以学javascript去爬虫做前端。不过你需要的掌握数据统计分析,然后是编程能力,再然后是技术实力。python的发展历史虽然python诞生了挺长时间,但在今天,绝大多数流行的编程语言都是不断发展的过程,为了让一门语言更精确,语言也不断迭代。
一个编程语言在很长时间内会不断迭代,现在几乎每个语言都有自己的特点,都有自己的使用方法。不同的方法其实背后也有它们存在的道理。自从python诞生以来,它一直以来的特点,都是python语言本身作为小众语言的特点,而正如其名,python是小众语言,那么为了应对在今天这种泛滥的情况,它只好遵循大众语言的标准,去演化,去发展。
每一种语言,都会经历从一而终的过程,这是一个适应环境的必经之路。怎么去理解这个过程呢?从大众语言到小众语言,或者从小众语言到大众语言,就是大众语言在适应大众语言的过程。python发展过程其实也是这个过程,比如python2到python3,就是python2不断改进的过程。基于python2的习惯,我们一开始认为python2是基于python2的扩展,但其实不是这样的,python2是python3的标准版,而python3也在逐渐的标准化,即不再兼容python2,有可能你正在运行的python3,python3.x版本,将会以3.x版本的python替代之。
另外从一而终还有一个问题,这不是绝对的,比如你刚才那个例子,其实就是python2用来迁移python3的步骤。但其实大众语言没有那么容易死的,也许只是你没有去找到一个正确的切入点。其实如果你今天运行到的python2还是python2,但是你可以在运行数据爬虫的时候,不用按着python2.x来运行,你可以是python3或者是其他很多语言。
python2也在逐渐的从大众语言变为小众语言,比如你现在可以用它爬取本地数据,用python3来运行你的爬虫,你也可以用python2来进行大数据分析。python其实更多的是一种编程语言,它可以做很多事情,比如数据爬虫,网页调试,模拟浏览器,等等。为什么我不学java,因为java实在太他妈难了,不是我能吃得消的,我现在还要学其他语言。从这个意义。
python抓取网页数据( 就是爬虫模拟人对网页的操作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 05:21
就是爬虫模拟人对网页的操作方法)
Python实现爬取百度热搜信息
什么是爬虫,其实就是用电脑模拟一个人在网页上的操作。
示例:模拟人类浏览和购物 网站。
您可以在目标网站中添加/robots.txt来查看网页的具体信息,例如可以在天猫上进入查看。
User-agent 代表发送请求的对象
星号 * 代表任何搜索引擎
Disallow 表示不允许访问的部分
/ 表示从根开始
Allow 表示允许访问的部分
在这个例子中,我爬取了百度热搜前30条新闻(我本来打算在英雄联盟首页数据中心的数据中心爬取前50名英雄的英雄信息,但是我无法实现延迟爬取网页,但我只能爬百度热搜),它的一般信息放在Excel表格和Flask网页中,实现数据可视化。对数据可视化感兴趣的同学也可以爬取其他内容
由于我的水平有限,这个文章里面的爬虫都是比较基础的东西
库函数准备
如何安装 Python 库:
打开 cmd 命令提示符并输入 pip install XXX (这是你要安装的库的名称)
这些库的具体使用可以看我接下来的操作
只需要掌握几个常用功能
BS4
即美丽汤
用于解析 HTML 页面并提取指定数据。
后面我的demo里会看到详细的用法。
回覆
用于匹配字符串中的响应字符串的正则表达式。
关于正则表达式,可以去菜鸟教程详细介绍
urllib
它是 Python 自带的 HTTP 请求库,可以操作一系列 URL。
xlwt/xlrt
用于写入(写入)/读取(读取)Excel 表格中的数据。
烧瓶
该库用于制作一个简单的 Web 框架,即 网站 用于数据可视化。
其实我对数据可视化的把握也很浅薄,只是简单的将数据导入到网页中。
神社2
这个库的目的是实现在 HTML 页面的字符中插入参数的功能。
后端:
name="HQ"
前端:
<p>{{name}}长得真帅!
显示:
HQ长得真帅!</p>
标记安全
与 Jinja 一起使用以在渲染页面时避免不受信任的输入,防止注入攻击(尽管没有人会攻击你....)
数据抓取
数据爬取和数据可视化的两个py文件是分开的
数据爬取需要导入re bs4 urllib xlwt的四个库文件
网页抓取
使用下面的方法调用一个函数,让函数调用关系更清晰
if __name__=="__main__": #当程序执行时 调用一下函数
main()
def askurl(url):
head={
"User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'''
}
#用户代理 告诉服务器我只是一个普普通通的浏览器
requset=urllib.request.Request(url)
#发送请求
response=urllib.request.urlopen(requset)
#响应的为一个request对象
#通过read()转化为 bytes类型字符串
#再通过decode()转化为 str类型的字符串
#接受响应
html=response.read().decode('utf-8')
将抓取到的网页存入文档中 方便观察
path=r"C:\Users\XXX\Desktop\Python\text.txt"
#这里在字符串前加入r 防止字符串中的\发生转义
f=open(r"path",'w',encoding='utf-8')
f.write(html)
f.close()
#这样在txt文件中就可以查看网页的源码
return html
headers的值可以在网页中按F12
然后点击network change,下拉到底部任意request header,就是user-agent代理信息
值得注意的是,如果请求中没有设置headers,服务器会返回418状态码
表示服务器认出你是爬虫,说:“我是茶壶”
表示服务器拒绝煮咖啡,因为它总是一个茶壶(这是一个表情包)
数据分析
把抓到的txt文件后缀改成html作为本地网页打开
如果因为行太长导致vscode报错,可以参考以下博客
打开后的页面如图
使用该功能查看需要爬取信息的地方
在这个项目中,我们抓取目标信息的标题内容和链接
我们可以发现,我们需要的所有信息都在其类为以下类型的表中
所以我们使用 Beautifulsoup 来解析网页
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配
接下来,重新匹配每个项目
首先使用pile()创建匹配规则,然后使用findall进行匹配
通过查看HTML文件中目标信息前后的特殊字符创建匹配规则
而 (.*?) 是要与 * 匹配的字符串,后跟 ? 代表非贪心匹配
例如
标题前后的信息为省略号">和 查看全部
python抓取网页数据(
就是爬虫模拟人对网页的操作方法)
Python实现爬取百度热搜信息
什么是爬虫,其实就是用电脑模拟一个人在网页上的操作。
示例:模拟人类浏览和购物 网站。
您可以在目标网站中添加/robots.txt来查看网页的具体信息,例如可以在天猫上进入查看。

User-agent 代表发送请求的对象
星号 * 代表任何搜索引擎
Disallow 表示不允许访问的部分
/ 表示从根开始
Allow 表示允许访问的部分
在这个例子中,我爬取了百度热搜前30条新闻(我本来打算在英雄联盟首页数据中心的数据中心爬取前50名英雄的英雄信息,但是我无法实现延迟爬取网页,但我只能爬百度热搜),它的一般信息放在Excel表格和Flask网页中,实现数据可视化。对数据可视化感兴趣的同学也可以爬取其他内容
由于我的水平有限,这个文章里面的爬虫都是比较基础的东西
库函数准备
如何安装 Python 库:
打开 cmd 命令提示符并输入 pip install XXX (这是你要安装的库的名称)
这些库的具体使用可以看我接下来的操作
只需要掌握几个常用功能
BS4
即美丽汤
用于解析 HTML 页面并提取指定数据。
后面我的demo里会看到详细的用法。
回覆
用于匹配字符串中的响应字符串的正则表达式。
关于正则表达式,可以去菜鸟教程详细介绍
urllib
它是 Python 自带的 HTTP 请求库,可以操作一系列 URL。
xlwt/xlrt
用于写入(写入)/读取(读取)Excel 表格中的数据。
烧瓶
该库用于制作一个简单的 Web 框架,即 网站 用于数据可视化。
其实我对数据可视化的把握也很浅薄,只是简单的将数据导入到网页中。
神社2
这个库的目的是实现在 HTML 页面的字符中插入参数的功能。
后端:
name="HQ"
前端:
<p>{{name}}长得真帅!
显示:
HQ长得真帅!</p>
标记安全
与 Jinja 一起使用以在渲染页面时避免不受信任的输入,防止注入攻击(尽管没有人会攻击你....)
数据抓取
数据爬取和数据可视化的两个py文件是分开的
数据爬取需要导入re bs4 urllib xlwt的四个库文件
网页抓取
使用下面的方法调用一个函数,让函数调用关系更清晰
if __name__=="__main__": #当程序执行时 调用一下函数
main()
def askurl(url):
head={
"User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'''
}
#用户代理 告诉服务器我只是一个普普通通的浏览器
requset=urllib.request.Request(url)
#发送请求
response=urllib.request.urlopen(requset)
#响应的为一个request对象
#通过read()转化为 bytes类型字符串
#再通过decode()转化为 str类型的字符串
#接受响应
html=response.read().decode('utf-8')
将抓取到的网页存入文档中 方便观察
path=r"C:\Users\XXX\Desktop\Python\text.txt"
#这里在字符串前加入r 防止字符串中的\发生转义
f=open(r"path",'w',encoding='utf-8')
f.write(html)
f.close()
#这样在txt文件中就可以查看网页的源码
return html
headers的值可以在网页中按F12
然后点击network change,下拉到底部任意request header,就是user-agent代理信息

值得注意的是,如果请求中没有设置headers,服务器会返回418状态码
表示服务器认出你是爬虫,说:“我是茶壶”
表示服务器拒绝煮咖啡,因为它总是一个茶壶(这是一个表情包)
数据分析
把抓到的txt文件后缀改成html作为本地网页打开
如果因为行太长导致vscode报错,可以参考以下博客
打开后的页面如图

使用该功能查看需要爬取信息的地方
在这个项目中,我们抓取目标信息的标题内容和链接

我们可以发现,我们需要的所有信息都在其类为以下类型的表中

所以我们使用 Beautifulsoup 来解析网页
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配
接下来,重新匹配每个项目
首先使用pile()创建匹配规则,然后使用findall进行匹配
通过查看HTML文件中目标信息前后的特殊字符创建匹配规则
而 (.*?) 是要与 * 匹配的字符串,后跟 ? 代表非贪心匹配
例如

标题前后的信息为省略号">和
python抓取网页数据(简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-05 10:02
这里举个例子简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取和动态网页数据的爬取。实验环境为win10+python3.6+pycharm5.0,主要内容如下:
静态网页数据 这里的数据嵌套在网页源码中,是为了抓取网页数据,所以直接解析requests网页源码就够了。让我简单介绍一下。下面是一个爬虫百科上的数据的例子:
1.首先抓取网页数据,打开原网页,如下,这里假设要抓取的字段包括昵称、内容、搞笑数和评论数:
然后查看网页源网页数据抓取,如下,可以看到所有的数据都嵌套在网页中:
2.那么我们就可以直接编写上面的网页结构网页数据抓取的代码,解析网页,提取出我们需要的数据。测试代码如下,很简单,主要是使用requests+BeautifulSoup的组合,其中requests用来获取网页的源码,BeautifulSoup用来解析网页提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
动态网页数据 这里的数据不在网页的源代码中(所以直接请求页面无法获取数据)。大多数情况下,网页数据存储在 json 文件中。只有当网页更新时,才会加载数据。让我简单介绍一下这种方法。下面是一个在人人贷上爬取数据的例子:
1.首先抓取网页数据,打开原创网页,如下,假设要抓取的数据包括年利率、贷款名称、期限、金额和进度:
然后按F12调出开发者网页数据抓取,依次点击“网络”-“XHR”,F5刷新页面,可以找到动态加载的json文件,如下,也就是我们需要抓取的数据:
2.然后就是根据这个json文件编写相应的代码,解析出我们需要抓取网页数据的字段。测试代码如下,也很简单。主要是使用requests+json的组合,其中requests用来请求json文件,json用来解析json文件提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
至此,我们已经完成了使用python网络爬虫获取网站数据网页数据抓取。总的来说,整个过程非常简单。Python内置了很多网络爬虫包和框架(scrapy等),可以快速获取网站数据,非常适合初学者学习和掌握,只要你有一定的爬虫基础,熟悉以上流程和代码,很快就能掌握。当然,你也可以使用现成的,比如速度和速度。网上也有相关的教程和资料,非常丰富。有兴趣的可以搜索一下,希望上面分享的内容可以对大家有所帮助,也欢迎大家评论留言补充。 查看全部
python抓取网页数据(简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取)
这里举个例子简单介绍一下如何通过python获取网站,主要分为静态网页数据的爬取和动态网页数据的爬取。实验环境为win10+python3.6+pycharm5.0,主要内容如下:
静态网页数据 这里的数据嵌套在网页源码中,是为了抓取网页数据,所以直接解析requests网页源码就够了。让我简单介绍一下。下面是一个爬虫百科上的数据的例子:
1.首先抓取网页数据,打开原网页,如下,这里假设要抓取的字段包括昵称、内容、搞笑数和评论数:
然后查看网页源网页数据抓取,如下,可以看到所有的数据都嵌套在网页中:
2.那么我们就可以直接编写上面的网页结构网页数据抓取的代码,解析网页,提取出我们需要的数据。测试代码如下,很简单,主要是使用requests+BeautifulSoup的组合,其中requests用来获取网页的源码,BeautifulSoup用来解析网页提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
动态网页数据 这里的数据不在网页的源代码中(所以直接请求页面无法获取数据)。大多数情况下,网页数据存储在 json 文件中。只有当网页更新时,才会加载数据。让我简单介绍一下这种方法。下面是一个在人人贷上爬取数据的例子:
1.首先抓取网页数据,打开原创网页,如下,假设要抓取的数据包括年利率、贷款名称、期限、金额和进度:
然后按F12调出开发者网页数据抓取,依次点击“网络”-“XHR”,F5刷新页面,可以找到动态加载的json文件,如下,也就是我们需要抓取的数据:
2.然后就是根据这个json文件编写相应的代码,解析出我们需要抓取网页数据的字段。测试代码如下,也很简单。主要是使用requests+json的组合,其中requests用来请求json文件,json用来解析json文件提取数据:
点击运行本程序网页数据抓取,效果如下,我们需要的数据已经抓取成功:
至此,我们已经完成了使用python网络爬虫获取网站数据网页数据抓取。总的来说,整个过程非常简单。Python内置了很多网络爬虫包和框架(scrapy等),可以快速获取网站数据,非常适合初学者学习和掌握,只要你有一定的爬虫基础,熟悉以上流程和代码,很快就能掌握。当然,你也可以使用现成的,比如速度和速度。网上也有相关的教程和资料,非常丰富。有兴趣的可以搜索一下,希望上面分享的内容可以对大家有所帮助,也欢迎大家评论留言补充。
python抓取网页数据(法国亚马逊、美国亚马逊-viewer列表的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-05 10:01
前段时间,姊妹公司的老板让她在法国亚马逊评论列表的前100页找到1000位评论者的联系方式。1000个用户需要一一阅读和记录,并不是每个评论用户都会留下个人联系方式。那么问题来了,这种费时费力的工作,如果手动完成,前30页的数据要花两天时间才能找到(还有其他工作要做),然后就很累了。本着苦恼的原则(程序员能找到一个女孩就好,所以我不得不心疼),我想帮她做点什么。
我自己的工作是开发游戏客户端。我使用的主要开发语言是lua和c++,没有网页和网站相关工作的经验。只是我在工作中使用了python脚本,然后在网上找python相关资料的时候,看到网友用python写爬虫来做点什么。所以我想,我也可以用python写一个爬虫从亚马逊的网站获取数据吗?这样,现在正在学习和使用的人开始输入代码。
环境:
Windows 7的
蟒蛇:2.7
使用的python插件:
urllib2、urllib 插件,用于打开网页链接;
用于常规匹配的重新插件;
编解码器插件用于编码转换和数据存储。
目前实现的功能:
获取姓名、联系信息(网站 链接或电子邮件地址)、国籍(可能是来自卢森堡和瑞士的买家,在法国亚马逊顶部查看者列表的前 100 页中的 1,000 名用户中),以及详细的用户评论链接到页等
通过抓取法国亚马逊top-viewer list的数据,扩展为抓取中国和美国亚马逊top-viewer list的数据。理论上,不同国家的亚马逊top-viewer list的数据可以通过简单的修改来获取。
需要改进的方面:
写完代码,发现抓数据的过程中效率很低。抓取1000条数据需要很长时间,抓取几页或几十页后,程序无法运行,卡住了。只需将其关闭然后再打开。当时,在拓展到美国抓取中国和亚马逊的数据之前,我想到的可能原因是:
正则表达式有优化的空间,因为我之前没接触过正则表达式,也没用过;法国亚马逊网站在中国访问速度慢,影响数据抓取;python没有系统学习过,在一些语法或者第三方辅助插件的使用上不够熟悉。
以上三点是我想到的爬取效率低的可能原因。后来我扩展同组代码爬取了中国和美国亚马逊的数据,验证了第二个原因对整个爬取工作的影响,结果发现影响非常大!同等带宽和硬件条件下,中美前100页共有1000个评论用户,爬了大概半个小时,爬完法国的1000条数据我用了将近一个下午(因为老是卡住,我觉得应该是因为urllib打开网页没反应,我的程序没有做判断)依次爬取,但总比女生一个个打开网页记录好,至少人不会烦!然后用了半个小时,在中国和美国抓到了数据。我个人不判断是否花费了太多时间或几乎相同。但是作为开发人员,程序总是可以优化的!
想法:
当时看到一个网友写的爬虫,想法是打开网页,匹配自己需要的信息。所以我的思路也是这样:通过python的urllib和urllib2插件打开页面,然后转换成html数据,使用python的re正则插件做正则匹配,得到页面,用户详情页,用户联系方式和其他信息。
执行:
1、法国亚马逊的top review list大约有1000页,每页有10个用户数据。对于每一个页面,除了第一页的链接,其他页面的链接都和页数有关,比如代表23页的数据,所以1000页的页面链接可以通过简单的字符串拼接得到。这是关于如何获取每个页面的链接;示例代码如下:拼接页面链接,因为首页和其余页面的格式略有不同,所以分别处理:
if 1 == i:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i);
else:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i) + "?ie=UTF8&page=" + str(i);
湾。将页面转换为 html:
try:
page = urllib.urlopen(url)
html = page.read()
return html
except:
print "getHtml2 error"
我用try and except只是为了看看能不能处理不能打开网页的问题(估计是法国亚马逊爬虫卡住了,因为网站没有响应),但是没有效果;
2、每个页面有10个用户的数据。单击用户将跳转到其详细信息页面。通过查看不同详细信息页面的链接形式,发现都是相似的:一个可能是用户名。变量,表示用户在评论列表中的排名的值。所以我可以想办法获取用户名(大概是用户名,或者亚马逊保存的唯一标识符),用户在评论列表中的排名,然后拼接出用户详情页的链接;通过查看页面的源码发现,每个页面中,用户信息的形式都差不多,比如:/gp/pdp/profile/xxxx/,所以可以通过简单的正则得到xxxx的数据匹配,暂时称为用户的唯一标识。以下是获取详细信息页面链接的方法;示例代码:匹配每个用户的唯一标识符:
reg = r'href="(/gp/pdp/profile/.+?)"><b>'
captureRe = re.compile(reg)
cpList = re.findall(captureRe,html)
湾。拼凑链接:
num = (i - 1) * 10 + index;
subLink = "http://www.amazon.fr" + cp + "/ref=cm_cr_tr_tbl_" + str(num) + "_name";
index指的是10条数据中的哪一条,num其实是用户在评论列表中的排名,每页有10条,所以具体排名可以根据页码和index来计算;
C。转换为html:
headers = { #伪装为浏览器抓取
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(url,headers=headers)
page = "";
try:
page = urllib2.urlopen(req)
html = page.read()
return html
except:
print "getHtml error"
可以看出这个转换形式和之前的转换方式不同,因为我发现之前的转换方式得到的页面数据和我们之间右键浏览器查看源代码的格式不一样,然后我正在匹配联系信息。当匹配失败时,认为是这种差异造成的。因此,我找到了数据并使用上面的表格进行了转换。网友还表示,这样可以防止亚马逊对频繁访问的IP进行封IP; 查看全部
python抓取网页数据(法国亚马逊、美国亚马逊-viewer列表的数据)
前段时间,姊妹公司的老板让她在法国亚马逊评论列表的前100页找到1000位评论者的联系方式。1000个用户需要一一阅读和记录,并不是每个评论用户都会留下个人联系方式。那么问题来了,这种费时费力的工作,如果手动完成,前30页的数据要花两天时间才能找到(还有其他工作要做),然后就很累了。本着苦恼的原则(程序员能找到一个女孩就好,所以我不得不心疼),我想帮她做点什么。
我自己的工作是开发游戏客户端。我使用的主要开发语言是lua和c++,没有网页和网站相关工作的经验。只是我在工作中使用了python脚本,然后在网上找python相关资料的时候,看到网友用python写爬虫来做点什么。所以我想,我也可以用python写一个爬虫从亚马逊的网站获取数据吗?这样,现在正在学习和使用的人开始输入代码。
环境:
Windows 7的
蟒蛇:2.7
使用的python插件:
urllib2、urllib 插件,用于打开网页链接;
用于常规匹配的重新插件;
编解码器插件用于编码转换和数据存储。
目前实现的功能:
获取姓名、联系信息(网站 链接或电子邮件地址)、国籍(可能是来自卢森堡和瑞士的买家,在法国亚马逊顶部查看者列表的前 100 页中的 1,000 名用户中),以及详细的用户评论链接到页等
通过抓取法国亚马逊top-viewer list的数据,扩展为抓取中国和美国亚马逊top-viewer list的数据。理论上,不同国家的亚马逊top-viewer list的数据可以通过简单的修改来获取。
需要改进的方面:
写完代码,发现抓数据的过程中效率很低。抓取1000条数据需要很长时间,抓取几页或几十页后,程序无法运行,卡住了。只需将其关闭然后再打开。当时,在拓展到美国抓取中国和亚马逊的数据之前,我想到的可能原因是:
正则表达式有优化的空间,因为我之前没接触过正则表达式,也没用过;法国亚马逊网站在中国访问速度慢,影响数据抓取;python没有系统学习过,在一些语法或者第三方辅助插件的使用上不够熟悉。
以上三点是我想到的爬取效率低的可能原因。后来我扩展同组代码爬取了中国和美国亚马逊的数据,验证了第二个原因对整个爬取工作的影响,结果发现影响非常大!同等带宽和硬件条件下,中美前100页共有1000个评论用户,爬了大概半个小时,爬完法国的1000条数据我用了将近一个下午(因为老是卡住,我觉得应该是因为urllib打开网页没反应,我的程序没有做判断)依次爬取,但总比女生一个个打开网页记录好,至少人不会烦!然后用了半个小时,在中国和美国抓到了数据。我个人不判断是否花费了太多时间或几乎相同。但是作为开发人员,程序总是可以优化的!
想法:
当时看到一个网友写的爬虫,想法是打开网页,匹配自己需要的信息。所以我的思路也是这样:通过python的urllib和urllib2插件打开页面,然后转换成html数据,使用python的re正则插件做正则匹配,得到页面,用户详情页,用户联系方式和其他信息。
执行:
1、法国亚马逊的top review list大约有1000页,每页有10个用户数据。对于每一个页面,除了第一页的链接,其他页面的链接都和页数有关,比如代表23页的数据,所以1000页的页面链接可以通过简单的字符串拼接得到。这是关于如何获取每个页面的链接;示例代码如下:拼接页面链接,因为首页和其余页面的格式略有不同,所以分别处理:
if 1 == i:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i);
else:
html_link = "http://www.amazon.fr/review/to ... ot%3B + str(i) + "?ie=UTF8&page=" + str(i);
湾。将页面转换为 html:
try:
page = urllib.urlopen(url)
html = page.read()
return html
except:
print "getHtml2 error"
我用try and except只是为了看看能不能处理不能打开网页的问题(估计是法国亚马逊爬虫卡住了,因为网站没有响应),但是没有效果;
2、每个页面有10个用户的数据。单击用户将跳转到其详细信息页面。通过查看不同详细信息页面的链接形式,发现都是相似的:一个可能是用户名。变量,表示用户在评论列表中的排名的值。所以我可以想办法获取用户名(大概是用户名,或者亚马逊保存的唯一标识符),用户在评论列表中的排名,然后拼接出用户详情页的链接;通过查看页面的源码发现,每个页面中,用户信息的形式都差不多,比如:/gp/pdp/profile/xxxx/,所以可以通过简单的正则得到xxxx的数据匹配,暂时称为用户的唯一标识。以下是获取详细信息页面链接的方法;示例代码:匹配每个用户的唯一标识符:
reg = r'href="(/gp/pdp/profile/.+?)"><b>'
captureRe = re.compile(reg)
cpList = re.findall(captureRe,html)
湾。拼凑链接:
num = (i - 1) * 10 + index;
subLink = "http://www.amazon.fr" + cp + "/ref=cm_cr_tr_tbl_" + str(num) + "_name";
index指的是10条数据中的哪一条,num其实是用户在评论列表中的排名,每页有10条,所以具体排名可以根据页码和index来计算;
C。转换为html:
headers = { #伪装为浏览器抓取
'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'
}
req = urllib2.Request(url,headers=headers)
page = "";
try:
page = urllib2.urlopen(req)
html = page.read()
return html
except:
print "getHtml error"
可以看出这个转换形式和之前的转换方式不同,因为我发现之前的转换方式得到的页面数据和我们之间右键浏览器查看源代码的格式不一样,然后我正在匹配联系信息。当匹配失败时,认为是这种差异造成的。因此,我找到了数据并使用上面的表格进行了转换。网友还表示,这样可以防止亚马逊对频繁访问的IP进行封IP;
python抓取网页数据( 就是利用Python阿里云盘资源的资料请关注编程相关文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-23 07:08
就是利用Python阿里云盘资源的资料请关注编程相关文章)
Python抢阿里云盘资源
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs) 查看全部
python抓取网页数据(
就是利用Python阿里云盘资源的资料请关注编程相关文章)
Python抢阿里云盘资源
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs)
python抓取网页数据(python+pyqueryjava用户自己写网络协议可以用tcp等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-23 03:04
python抓取网页数据,用的是beautifulsoup和tornado,
tornado+beautifulsoup是最快的了。异步的话,用python语言写网络协议可以用tcp等。还可以尝试使用urllib2模块分析网页内容,
异步爬虫可以用tornado,用java写起来比较费劲;也可以用websocket实现,tornado底层实现是基于udp的,对网络地址要求高,我也在找一个比较好的解决方案,感觉现在比较流行的就是用redis提供http的缓存。
tornado框架是我正在用的一个异步爬虫框架。
想抓取网页中的数据,可以考虑用python处理get请求。有google全球通用urllib2库。中文博客网站一般用xml格式下载的数据,java用户想抓取这些数据的话还是需要自己写demo。不写demo的话也可以直接用websocket这种轮子,直接发送get或者post参数,使用协议beautifulsoup解析也很方便。
一般的页面服务器都自带自动保存数据的功能,不需要额外做什么。我现在在用的是python+pyquery,java用户自己写session,websocket实现就可以了。利益相关:我用tornado写了tornado配合python的crawler玩。
把网页发给google, 查看全部
python抓取网页数据(python+pyqueryjava用户自己写网络协议可以用tcp等)
python抓取网页数据,用的是beautifulsoup和tornado,
tornado+beautifulsoup是最快的了。异步的话,用python语言写网络协议可以用tcp等。还可以尝试使用urllib2模块分析网页内容,
异步爬虫可以用tornado,用java写起来比较费劲;也可以用websocket实现,tornado底层实现是基于udp的,对网络地址要求高,我也在找一个比较好的解决方案,感觉现在比较流行的就是用redis提供http的缓存。
tornado框架是我正在用的一个异步爬虫框架。
想抓取网页中的数据,可以考虑用python处理get请求。有google全球通用urllib2库。中文博客网站一般用xml格式下载的数据,java用户想抓取这些数据的话还是需要自己写demo。不写demo的话也可以直接用websocket这种轮子,直接发送get或者post参数,使用协议beautifulsoup解析也很方便。
一般的页面服务器都自带自动保存数据的功能,不需要额外做什么。我现在在用的是python+pyquery,java用户自己写session,websocket实现就可以了。利益相关:我用tornado写了tornado配合python的crawler玩。
把网页发给google,
python抓取网页数据(抓取百度疫情数据的代码已经无法运行,怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-21 12:07
)
有朋友反映,抓取百度疫情数据的代码已经失效。没看过的可以点击下方链接查看。
看了之后,因为百度调整了一些页面信息,调整后代码就可以使用了,那如果下次调整呢?你说这个可能性很大吗?
我觉得还是挺大的,有什么办法可以稳定吗?
问这个问题,肯定是有的,就是换一种方式获取疫情的实时数据。
这一次,我们来抓取网易 JSON 疫情数据。
链接是这个
打开 URL 并看到这个。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你使用的是火狐浏览器,也可以在上面找到JSON、美化输出等功能。
这就是美化输出的效果。是不是看起来好多了,但是还是一头雾水,对吧,因为你从来没有接触过JSON数据。
这是一点JSON效果,不同的颜色,看起来更舒服。
好的,让我们从数据捕获和导入开始。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓取的数据结果,可以看到它是一个字典,而我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这是areaTree的列表,我们要的第一行数据。
继续双击打开areaTree的第一行,这次又变成字典了,你看到中国了吗?哈哈,我们要的数据在key=children中。
继续双击打开children,这是我们要的数据,这又变成了一个list,每一行都是一个省的数据
我们点第一行,看是不是,湖北已经出现了。
继续点击儿童,就是湖北各城市的数据。如果你不点击它,我们只需要省级数据。我们怎么能想出它?继续数据处理以提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
两行代码就出来了,哈哈!让我们看一下数据。
那么我们要的字段是name,total.confirm,name是省份名称,total.confirm是累计确诊数,如果换成taday.confirm就是新增确诊数。直接将name和total.confirm替换为之前绘制地图的代码对应位置即可。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果就出来了。
查看全部
python抓取网页数据(抓取百度疫情数据的代码已经无法运行,怎么办?
)
有朋友反映,抓取百度疫情数据的代码已经失效。没看过的可以点击下方链接查看。
看了之后,因为百度调整了一些页面信息,调整后代码就可以使用了,那如果下次调整呢?你说这个可能性很大吗?
我觉得还是挺大的,有什么办法可以稳定吗?
问这个问题,肯定是有的,就是换一种方式获取疫情的实时数据。
这一次,我们来抓取网易 JSON 疫情数据。
链接是这个
打开 URL 并看到这个。如果您是第一次接触 JSON 数据,您会感到困惑。不过没关系,如果你使用的是火狐浏览器,也可以在上面找到JSON、美化输出等功能。
这就是美化输出的效果。是不是看起来好多了,但是还是一头雾水,对吧,因为你从来没有接触过JSON数据。
https://www.lxiaoyue.com/wp-co ... 0.png 246w" />这是一点JSON效果,不同的颜色,看起来更舒服。
好的,让我们从数据捕获和导入开始。首先导入所需的模块。
import json
import requests
from pandas.io.json import json_normalize
然后开始抓取数据
url="https://c.m.163.com/ug/api/wuh ... ot%3B
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.106 Safari/537.36'}
ret=requests.get(url, headers=headers)
result=json.loads(ret.content)
查看抓取的数据结果,可以看到它是一个字典,而我们要的数据在key=data中。
继续双击打开数据,我们要的数据在areaTree中。
继续双击打开areaTree,这是areaTree的列表,我们要的第一行数据。
继续双击打开areaTree的第一行,这次又变成字典了,你看到中国了吗?哈哈,我们要的数据在key=children中。
继续双击打开children,这是我们要的数据,这又变成了一个list,每一行都是一个省的数据
我们点第一行,看是不是,湖北已经出现了。
继续点击儿童,就是湖北各城市的数据。如果你不点击它,我们只需要省级数据。我们怎么能想出它?继续数据处理以提取我们想要的数据。
t= result['data']['areaTree'][0]['children']
sf=json_normalize(t)
两行代码就出来了,哈哈!让我们看一下数据。
那么我们要的字段是name,total.confirm,name是省份名称,total.confirm是累计确诊数,如果换成taday.confirm就是新增确诊数。直接将name和total.confirm替换为之前绘制地图的代码对应位置即可。
# 将数据转换为二元的列表
list1 = list(zip(sf['name'],sf['total.confirm']))
# 创建一个地图对象
map_1 = Map()
#对全局进行设置
map_1.set_global_opts(
#设置标题
title_opts=opts.TitleOpts(title="全国疫情地图"),
#设置最大数据范围
visualmap_opts=opts.VisualMapOpts(max_=2500,range_color=["#FFFFFF","#FFCC00","#CC0000"]))
# 使用add方法添加地图数据与地图类型
map_1.add("累计确诊人数", list1, maptype="china")
# 地图创建完成后,通过render()方法可以将地图渲染为html
map_1.render('全国疫情地图.html')
然后地图绘制结果就出来了。
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-21 09:01
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。
第 1 步:熟悉 Python 的基本语法。
如果您已经熟悉 Python,请跳至第 2 步。
Python 是一种相对容易上手的编程语言。如何开始取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是在coursetalk上的评论很好。还有同学的评论(点这里),课程链接:Udacity上的CS101也是一个不错的选择,领域里有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲和Network相关的模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础.来自:/bbs
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍别人在你上过的公开课上说了什么,或者看课程点评再做决定。
第 2 步:了解如何与 网站 链接并获取网页数据。 从1点3英亩bbs
编写一个脚本来与 网站 交互。有必要熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。只知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用urllib2与谷歌学者交互获取网页信息。
#导入模块urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
#学者有一个url,这个url形成的规则要自己分析。
query = 'On+random+graph'
url = '#39; + 查询 + '&btnG=&as_sdt=1%2C5&as_sdtp='-google 1point3acres
# 设置头文件。抓取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookie会比较复杂,
#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你使用的浏览器和网站交互
#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
header = {'Host': '',
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',. 1 点 3 英亩哄骗
'接受': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', 查看全部
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(图))
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。
第 1 步:熟悉 Python 的基本语法。
如果您已经熟悉 Python,请跳至第 2 步。
Python 是一种相对容易上手的编程语言。如何开始取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是在coursetalk上的评论很好。还有同学的评论(点这里),课程链接:Udacity上的CS101也是一个不错的选择,领域里有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲和Network相关的模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础.来自:/bbs
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍别人在你上过的公开课上说了什么,或者看课程点评再做决定。
第 2 步:了解如何与 网站 链接并获取网页数据。 从1点3英亩bbs
编写一个脚本来与 网站 交互。有必要熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。只知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用urllib2与谷歌学者交互获取网页信息。
#导入模块urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
#学者有一个url,这个url形成的规则要自己分析。
query = 'On+random+graph'
url = '#39; + 查询 + '&btnG=&as_sdt=1%2C5&as_sdtp='-google 1point3acres
# 设置头文件。抓取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookie会比较复杂,
#这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你使用的浏览器和网站交互
#头文件(很多浏览器自带这个工具),我用的是firefox的firebug插件。
header = {'Host': '',
'用户代理': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',. 1 点 3 英亩哄骗
'接受': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
python抓取网页数据( 2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-02-16 12:16
2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
[常用] Python中检测网页编码
2013 年 7 月 14 日星期日 Zoey Young Python
使用 Python 抓取网页并对其进行分析时出现此错误:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd6
原因是有些中文网站编码不是utf8,所以需要编码判断
问题描述:
引自如何高效、准确、自动识别网页代码
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务器返回的header中的charset变量获取的
它的二、是通过页面中的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们在抓取网页时就没有编码问题。
但现实对我们程序员来说总是很困难。在抓取网页时,经常会出现以下几种情况:
缺少这两个参数。虽然提供了这两个参数,但它们是不一致的。提供了这两个参数,但与网页的实际编码不一致。
为了尽可能自动地获取所有网页的编码,引入了自动编码识别。
夏代
搜索chardet立马找到了Python的chardet第三方库
可以通过pip安装
pip install chardet
主页说明:
chardet 猜测文本文件的编码。
检测...
需要 Python 2.1 或更高版本。
我正在使用 Python 2.7.X
网页编码判断:
import chardet
import urllib2
#可根据需要,选择不同的数据
html = urllib2.urlopen('http://www.zol.com.cn/').read()
print(chardet.detect(html))
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
chardet.detect() 返回一个字典,其中confidence为检测准确率,encoding为编码形式
其他方式:
import urllib2
from chardet.universaldetector import UniversalDetector
html = urllib2.urlopen('http://www.zol.com.cn/')
#创建一个检测对象
detector = UniversalDetector()
for line in html.readlines():
#分块进行测试,直到达到阈值
detector.feed(line)
if detector.done: break
#关闭检测对象
detector.close()
html.close()
#输出检测结果
print detector.result
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
如果要识别大文件的编码方式,使用后一种方法,可以只读取一部分来判断编码方式,从而提高检测速度。
BeautifulSoup4 Unicode该死
可以使用 BeautifulSoup4 的模块
from bs4 import UnicodeDammit
dammit = UnicodeDammit("Sacr\xc3\xa9 bleu!")
print(dammit.unicode_markup)
# Sacré bleu!
dammit.original_encoding
# 'utf-8'
总结
无论使用上述哪个模块,都不能保证100%正确... 网站 的一部分太糟糕了...
以下是我最后的写作方式。结合这两种方法,可以检测到前面测试中出现乱码的网站,但是代码看起来不是很干净:
参考文档
python编码检测原理及chardet模块的应用
如何高效、准确、自动地识别网页代码 查看全部
python抓取网页数据(
2013七月14周日ZoeyYoungPython在使用Python抓取网页并进行分析)
[常用] Python中检测网页编码
2013 年 7 月 14 日星期日 Zoey Young Python
使用 Python 抓取网页并对其进行分析时出现此错误:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xd6
原因是有些中文网站编码不是utf8,所以需要编码判断
问题描述:
引自如何高效、准确、自动识别网页代码
在引入自动编码识别之前,我们有两种方式获取网页的编码信息:
它的一、是通过服务器返回的header中的charset变量获取的
它的二、是通过页面中的元信息获取的
一般情况下,如果服务器或者页面提供了这两个参数,并且参数正确,那么我们在抓取网页时就没有编码问题。
但现实对我们程序员来说总是很困难。在抓取网页时,经常会出现以下几种情况:
缺少这两个参数。虽然提供了这两个参数,但它们是不一致的。提供了这两个参数,但与网页的实际编码不一致。
为了尽可能自动地获取所有网页的编码,引入了自动编码识别。
夏代
搜索chardet立马找到了Python的chardet第三方库
可以通过pip安装
pip install chardet
主页说明:
chardet 猜测文本文件的编码。
检测...
需要 Python 2.1 或更高版本。
我正在使用 Python 2.7.X
网页编码判断:
import chardet
import urllib2
#可根据需要,选择不同的数据
html = urllib2.urlopen('http://www.zol.com.cn/').read()
print(chardet.detect(html))
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
chardet.detect() 返回一个字典,其中confidence为检测准确率,encoding为编码形式
其他方式:
import urllib2
from chardet.universaldetector import UniversalDetector
html = urllib2.urlopen('http://www.zol.com.cn/')
#创建一个检测对象
detector = UniversalDetector()
for line in html.readlines():
#分块进行测试,直到达到阈值
detector.feed(line)
if detector.done: break
#关闭检测对象
detector.close()
html.close()
#输出检测结果
print detector.result
运行结果:
{'confidence': 0.99, 'encoding': 'GB2312'}
如果要识别大文件的编码方式,使用后一种方法,可以只读取一部分来判断编码方式,从而提高检测速度。
BeautifulSoup4 Unicode该死
可以使用 BeautifulSoup4 的模块
from bs4 import UnicodeDammit
dammit = UnicodeDammit("Sacr\xc3\xa9 bleu!")
print(dammit.unicode_markup)
# Sacré bleu!
dammit.original_encoding
# 'utf-8'
总结
无论使用上述哪个模块,都不能保证100%正确... 网站 的一部分太糟糕了...
以下是我最后的写作方式。结合这两种方法,可以检测到前面测试中出现乱码的网站,但是代码看起来不是很干净:
参考文档
python编码检测原理及chardet模块的应用
如何高效、准确、自动地识别网页代码
python抓取网页数据(一个解决网页乱码问题分享解决模块的通用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-15 08:10
我们经常通过python做采集网页数据的时候,会遇到一些乱码的问题。今天给大家分享一个解决乱码网页,尤其是中文网页的通用方法。在首页,我们需要安装chardet模块,可以通过easy_install或者pip安装。安装好后,我们在控制台导入模块,如果正常的话。比如我们遇到的一些ISO-8859-2也可以通过以下方法解决。直接上代码:
import urllib2
import sys
import chardet
req = urllib2.Request("http://www.163.com/")##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信可以解决你的采集乱码问题。 查看全部
python抓取网页数据(一个解决网页乱码问题分享解决模块的通用方法)
我们经常通过python做采集网页数据的时候,会遇到一些乱码的问题。今天给大家分享一个解决乱码网页,尤其是中文网页的通用方法。在首页,我们需要安装chardet模块,可以通过easy_install或者pip安装。安装好后,我们在控制台导入模块,如果正常的话。比如我们遇到的一些ISO-8859-2也可以通过以下方法解决。直接上代码:
import urllib2
import sys
import chardet
req = urllib2.Request("http://www.163.com/";)##这里可以换成http://www.baidu.com,http://www.sohu.com
content = urllib2.urlopen(req).read()
typeEncode = sys.getfilesystemencoding()##系统默认编码
infoencode = chardet.detect(content).get('encoding','utf-8')##通过第3方模块来自动提取网页的编码
html = content.decode(infoencode,'ignore').encode(typeEncode)##先转换成unicode编码,然后转换系统编码输出
print html
通过上面的代码,相信可以解决你的采集乱码问题。
python抓取网页数据(如何养搬运B站弹幕的“虫”?解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-09 15:14
python爬虫抓取弹幕的实现方法一、什么是爬虫?
百度百科是这样说的:一个自动获取网页内容的程序。据我了解,爬虫是~~“在网上爬行……”闭嘴!~~
那么我们来看看B站携带弹幕的“虫子”是怎么养的
二、投喂步骤1.请求弹幕
首先你要知道爬取的网站url是什么。对于B站的弹幕,弹幕的位置有固定的格式:
+cid+.xml
好的,所以问题是,cid 是什么?不管它是什么,我会告诉你如何获得它。
1.打开视频后,点击F12,切换到“网络”,在过滤器中填写“cid”进行过滤。
2.点击过滤后的网络信息,找到右侧Payload处的cid
3.至此,我们知道了何氏视频弹幕的网络链接:
4.接下来就是发送网络请求,获取网页资源。Python 有许多用于发送网络请求的库。例如:
我们使用 reaquests 库来演示
发送请求的代码如下
(例子):
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
还有一点值得一提的是,发送请求的请求头可以加进去伪装成浏览器访问。可以通过header参数,加上user-agent来获取,如下:
所以,代码如下:
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url, headers=header)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
2.弹幕分析
html_str 是html文件的格式,我们需要对其进行处理才能得到我们想要的信息。这时候BeautifulSoup库就要登场了,我们用它来处理得到的html文件
代码如下(示例):
#解析
soup = BeautifulSoup(html,'html.parser')
#找到html文件里的标签
results = soup.find_all('d')
#把标签里的文本提取出来
contents = [x.text for x in results]
#存为字典
dic ={"contents" : contents}
contents 是一个弹幕字符串列表,它被保存为字典以供下一步使用...
3.保存弹幕
将弹幕信息存储在excel中,可以使用的库很多。例如:
我们使用 pandas 库来
代码如下(示例):
用第二步得到的字典创建一个dataFrame,然后用pandas库的一个API保存。
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
4.总码
import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
html = askUrl()
dic =analyse(html)
writeExcel(dic)
def askUrl():
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
req = requests.get(url = url, headers=header)
html_byte = req.content#字节
html_str = str(html_byte,"utf-8")
return html_str
def analyse(html):
soup = BeautifulSoup(html,'html.parser')
results = soup.find_all('d')
#x.text表示要放到contents中的值
contents = [x.text for x in results]
#保存结果
dic ={"contents" : contents}
return dic
def writeExcel(dic):
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
if __name__ == '__main__':
main()
三、总结
简单来说,爬行动物需要三个步骤:
1.发送网络请求获取资源
2.进行搜索等以获得有用的信息
3.存储的信息
这篇文章就到这里了,希望对你有帮助,也希望大家多多关注编程宝的更多内容!
下一节:python scrapy框架中Request对象和Response对象的Python编程技术
一、Request 对象 Request 对象主要用于请求数据。它在爬取数据页面并重新发送请求时调用。其源码类的位置如下图所示: 这里是它的源码。该方法有... 查看全部
python抓取网页数据(如何养搬运B站弹幕的“虫”?解析)
python爬虫抓取弹幕的实现方法一、什么是爬虫?
百度百科是这样说的:一个自动获取网页内容的程序。据我了解,爬虫是~~“在网上爬行……”闭嘴!~~
那么我们来看看B站携带弹幕的“虫子”是怎么养的
二、投喂步骤1.请求弹幕
首先你要知道爬取的网站url是什么。对于B站的弹幕,弹幕的位置有固定的格式:
+cid+.xml
好的,所以问题是,cid 是什么?不管它是什么,我会告诉你如何获得它。
1.打开视频后,点击F12,切换到“网络”,在过滤器中填写“cid”进行过滤。
2.点击过滤后的网络信息,找到右侧Payload处的cid
3.至此,我们知道了何氏视频弹幕的网络链接:
4.接下来就是发送网络请求,获取网页资源。Python 有许多用于发送网络请求的库。例如:
我们使用 reaquests 库来演示
发送请求的代码如下
(例子):
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
还有一点值得一提的是,发送请求的请求头可以加进去伪装成浏览器访问。可以通过header参数,加上user-agent来获取,如下:
所以,代码如下:
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
#发送请求
req = requests.get(url = url, headers=header)
#获取内容响应的内容
html_byte = req.content
#将byte转为str
html_str = str(html_byte,"utf-8")
2.弹幕分析
html_str 是html文件的格式,我们需要对其进行处理才能得到我们想要的信息。这时候BeautifulSoup库就要登场了,我们用它来处理得到的html文件
代码如下(示例):
#解析
soup = BeautifulSoup(html,'html.parser')
#找到html文件里的标签
results = soup.find_all('d')
#把标签里的文本提取出来
contents = [x.text for x in results]
#存为字典
dic ={"contents" : contents}
contents 是一个弹幕字符串列表,它被保存为字典以供下一步使用...
3.保存弹幕
将弹幕信息存储在excel中,可以使用的库很多。例如:
我们使用 pandas 库来
代码如下(示例):
用第二步得到的字典创建一个dataFrame,然后用pandas库的一个API保存。
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
4.总码
import requests
from bs4 import BeautifulSoup
import pandas as pd
def main():
html = askUrl()
dic =analyse(html)
writeExcel(dic)
def askUrl():
#假装自己是浏览器
header ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.80 Safari/537.36 Edg/98.0.1108.43'
}
#【何同学】我用108天开了个灯......视频的cid:499893135
#弹幕所在地
url = "http://comment.bilibili.com/499893135.xml"
req = requests.get(url = url, headers=header)
html_byte = req.content#字节
html_str = str(html_byte,"utf-8")
return html_str
def analyse(html):
soup = BeautifulSoup(html,'html.parser')
results = soup.find_all('d')
#x.text表示要放到contents中的值
contents = [x.text for x in results]
#保存结果
dic ={"contents" : contents}
return dic
def writeExcel(dic):
#用字典创建了一个电子表格
df = pd.DataFrame(dic)
df["contents"].to_excel('htx.xlsx')
if __name__ == '__main__':
main()
三、总结
简单来说,爬行动物需要三个步骤:
1.发送网络请求获取资源
2.进行搜索等以获得有用的信息
3.存储的信息
这篇文章就到这里了,希望对你有帮助,也希望大家多多关注编程宝的更多内容!
下一节:python scrapy框架中Request对象和Response对象的Python编程技术
一、Request 对象 Request 对象主要用于请求数据。它在爬取数据页面并重新发送请求时调用。其源码类的位置如下图所示: 这里是它的源码。该方法有...
python抓取网页数据(简单聊一聊如何用python来抓取页面中的JS动态加载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-07 03:28
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。如下图所示,我们在 HTML 中找不到对应的电影信息。如何使用PYTHON request.json读取下一级内容,直接将request中的整个json提取成一个dict和list组成的结构,不就是随便读一个想读的吗?python请求是否获得状态?1.使用postman的时候,输入url和参数,调用post方法,接口会返回数据2.然后我用python的requests实现3.r= requests.request('POST ',req, data=value) python爬虫中的request请求对象是什么,是客户端向服务端发送的请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数的方法提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看requests中的信息,获取具体的查询参数如你上面的tid。就是一个参数,然后把这些参数做成一个字典,用urlencode方法把参数字典转换成url格式如下: url='' 查看全部
python抓取网页数据(简单聊一聊如何用python来抓取页面中的JS动态加载)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。如下图所示,我们在 HTML 中找不到对应的电影信息。如何使用PYTHON request.json读取下一级内容,直接将request中的整个json提取成一个dict和list组成的结构,不就是随便读一个想读的吗?python请求是否获得状态?1.使用postman的时候,输入url和参数,调用post方法,接口会返回数据2.然后我用python的requests实现3.r= requests.request('POST ',req, data=value) python爬虫中的request请求对象是什么,是客户端向服务端发送的请求,包括用户提交的信息和客户端的一些信息。客户端可以通过HTML表单或者在网页地址后面提供参数的方法提交数据,然后通过请求对象的相关方法获取这些数据。请求的各种方法主要用于处理客户端浏览器提交的请求中的各种参数和选项。python爬虫中的请求其实就是通过python向服务器发送请求请求,并获取返回的信息。python请求问题很容易实现。打开开发者工具,查看requests中的信息,获取具体的查询参数如你上面的tid。就是一个参数,然后把这些参数做成一个字典,用urlencode方法把参数字典转换成url格式如下: url=''
python抓取网页数据(1.2.3.3.上代码,网页抓取和网页分析。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-03 22:21
最近,组里的一位老师在做研究,需要一些站点的水文资料。最近刚学python,了解到python中有很多方便的库,用于网页抓取和网页分析,于是开始写一个。勉强能用,哈哈。
在实现上,简单使用了线程中队列的使用、线程池的使用、网页分析。主要参考:
1.
2.
3.
关于代码,后面是简要说明
代码块
# -*- coding: utf-8 -*-
import urllib
import urllib2
from BeautifulSoup import BeautifulSoup
from datetime import *
from dateutil.relativedelta import *
import Queue
import threading
queue = Queue.Queue()
out_queue = Queue.Queue()
#日期迭代器,迭代从start到end中间的每一天
def loopDay(start, end):
while(start < end):
yield start
start = start + relativedelta(days = 1)
#向指定网站(湖南省水文查询系统)请求所需的页面
def post(url, data):
req = urllib2.Request(url)
data = urllib.urlencode(data)
#enable cookie
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
return response.read()
def getHtml(time):
posturl = 'http://61.187.56.156/wap/hnsq_BB2.asp'
data = {}
data['nian'] = str(time.year)
data['yue'] = str(time.month)
data['ri'] = str(time.day)
data['shi'] = '08:00'
html = post(posturl, data)
return html
#查找我们需要的关键字在Tag列表中的位置
def findKeyword(keyword, tagList):
location = -1
for tag in tagList:
location += 1
if (keyword.encode('GBK') in unicode(tag.string).encode("windows-1252")):
break
return location
#用于抓取某一天的对应的页面
class ThreadUrl(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
oneDay = self.queue.get()
print oneDay
#grabs webpage
webpage = getHtml(oneDay)
#place page into out queue
self.out_queue.put((oneDay, webpage))
#抓取获取到的指定日期对应的网页中我们需要的数据
class DatamineThread(threading.Thread):
"""Threaded Url Parsing"""
def __init__(self, out_queue):
threading.Thread.__init__(self)
self.out_queue = out_queue
def run(self):
while True:
(oneDay, page) = self.out_queue.get()
#parse the page
soup = BeautifulSoup(page, fromEncoding = "gb2312")
tagList = soup.findAll('td')
locations = []
for keyword in keywords:
locations.append(findKeyword(keyword, tagList))
for i in range(5):
fileName = keywords[i] + ".txt"
f = file(fileName, "a+")
waterLevel = unicode(tagList[locations[i] + 2].string).strip().encode("windows-1252")
waterStorage = unicode(tagList[locations[i] + 5].string).strip().encode("windows-1252")
f.write(str(oneDay) +"\t" + waterLevel + "\t" + waterStorage + "\n")
f.close()
if __name__ == '__main__':
keywords = [u"寸滩", u"万县", u"巫山", u"清溪场", u"忠县", u"武隆"]
startDay = date(2006, 1, 1)
endDay = date(2007, 1, 1)
days = loopDay(startDay, endDay)
t = ThreadUrl(queue, out_queue)
t.setDaemon(True)
t.start()
for oneDay in days:
queue.put(oneDay)
dt = DatamineThread(out_queue)
dt.setDaemon(True)
dt.start()
queue.join()
out_queue.join()
注册好久了,第一次写。网速不好,请稍后更改。 查看全部
python抓取网页数据(1.2.3.3.上代码,网页抓取和网页分析。)
最近,组里的一位老师在做研究,需要一些站点的水文资料。最近刚学python,了解到python中有很多方便的库,用于网页抓取和网页分析,于是开始写一个。勉强能用,哈哈。
在实现上,简单使用了线程中队列的使用、线程池的使用、网页分析。主要参考:
1.
2.
3.
关于代码,后面是简要说明
代码块
# -*- coding: utf-8 -*-
import urllib
import urllib2
from BeautifulSoup import BeautifulSoup
from datetime import *
from dateutil.relativedelta import *
import Queue
import threading
queue = Queue.Queue()
out_queue = Queue.Queue()
#日期迭代器,迭代从start到end中间的每一天
def loopDay(start, end):
while(start < end):
yield start
start = start + relativedelta(days = 1)
#向指定网站(湖南省水文查询系统)请求所需的页面
def post(url, data):
req = urllib2.Request(url)
data = urllib.urlencode(data)
#enable cookie
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor())
response = opener.open(req, data)
return response.read()
def getHtml(time):
posturl = 'http://61.187.56.156/wap/hnsq_BB2.asp'
data = {}
data['nian'] = str(time.year)
data['yue'] = str(time.month)
data['ri'] = str(time.day)
data['shi'] = '08:00'
html = post(posturl, data)
return html
#查找我们需要的关键字在Tag列表中的位置
def findKeyword(keyword, tagList):
location = -1
for tag in tagList:
location += 1
if (keyword.encode('GBK') in unicode(tag.string).encode("windows-1252")):
break
return location
#用于抓取某一天的对应的页面
class ThreadUrl(threading.Thread):
"""Threaded Url Grab"""
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
oneDay = self.queue.get()
print oneDay
#grabs webpage
webpage = getHtml(oneDay)
#place page into out queue
self.out_queue.put((oneDay, webpage))
#抓取获取到的指定日期对应的网页中我们需要的数据
class DatamineThread(threading.Thread):
"""Threaded Url Parsing"""
def __init__(self, out_queue):
threading.Thread.__init__(self)
self.out_queue = out_queue
def run(self):
while True:
(oneDay, page) = self.out_queue.get()
#parse the page
soup = BeautifulSoup(page, fromEncoding = "gb2312")
tagList = soup.findAll('td')
locations = []
for keyword in keywords:
locations.append(findKeyword(keyword, tagList))
for i in range(5):
fileName = keywords[i] + ".txt"
f = file(fileName, "a+")
waterLevel = unicode(tagList[locations[i] + 2].string).strip().encode("windows-1252")
waterStorage = unicode(tagList[locations[i] + 5].string).strip().encode("windows-1252")
f.write(str(oneDay) +"\t" + waterLevel + "\t" + waterStorage + "\n")
f.close()
if __name__ == '__main__':
keywords = [u"寸滩", u"万县", u"巫山", u"清溪场", u"忠县", u"武隆"]
startDay = date(2006, 1, 1)
endDay = date(2007, 1, 1)
days = loopDay(startDay, endDay)
t = ThreadUrl(queue, out_queue)
t.setDaemon(True)
t.start()
for oneDay in days:
queue.put(oneDay)
dt = DatamineThread(out_queue)
dt.setDaemon(True)
dt.start()
queue.join()
out_queue.join()
注册好久了,第一次写。网速不好,请稍后更改。
python抓取网页数据(数据科学越来越火了,网页是数据很大的一个来源)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-28 02:28
前言:。访问更多。
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。.
. 链鞃断头镊子?1点3英亩
第 1 步:熟悉 Python 的基本语法。. 更多信息
如果您已经熟悉 Python,请跳至第 2 步。瓦拉尔?,
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接From 1point 3acres bbs
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有同学在现场评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场也有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,就是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
# 学者有一个url,这个url形成的规则要自己分析。
查询=“上+随机+图形”
url = "" + 查询 + "&btnG=&as_sdt=1%2C5&as_sdtp="。更多信息
# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
# 这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器并与网站进行交互。更多信息
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
标头 = {“主机”:“”,
"用户代理": "Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ",
"接受": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
“接受编码”:“gzip,放气”,
“连接”:“保持活动”}
# 建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
# 所以作为一个守法的好公民,还是关闭连接比较好。
con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。
.
步骤三、解析网页
以上步骤获取了网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,。从 1 点 3acres bbs
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用.. 更多信息
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
导入 BeautifulSoup
重新进口
# 生成一个soup对象,步骤2中提到了doc
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用计数、版本计数、指向 文章 引用列表的超链接
# 这里也用到了一些正则表达式,不熟悉的应该不知道。至于“类”:在“gs_rt”
# “gs_rt”是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 让这个很简单,只要一点网页,就可以知道对应html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find("h3", {"class" : "gs_rt"}).text
paper_name = re.sub(r"\[.*\]", "", paper_name) # 去掉 "[]" 标签,比如 "[PDF]"
paper_author = soup.html.body.find("div", {"class" : "gs_a"}).text
paper_desc = soup.html.body.find("div", {"class" : "gs_rs"}).text
temp_str = soup.html.body.find("div", {"class" : "gs_fl"}).text
temp_re = re.match(r"[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)", temp_str)。更多信息
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes == "":
引用时间 = "0"
如果 versionNum == "":. 来自:/bbs
版本号 = "0"
引用Paper_href = soup.html.body.find("div", {"class" : "gs_fl"}).a.attrs[0][1]
复制代码
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件的最简单方法是在 Python 中使用以下代码:-google 1point3acres
# 打开文件webdata.txt,生成object文件,这个文件可能不存在,参数a表示添加。
# 还有其他参数,比如“r”只能读不能写,“w”可以写但删除原记录等。
文件 = 打开(“webdata.txt”,“a”)
line = paper_name + "#" + paper_author + "#" + paper_desc + "#" + citeTimes + "\n"
# 目标文件的write方法将字符串行写入文件
文件 = file.write(line)./bbs
# 再次做一个随心所欲关闭文件的好青年
文件.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;如果没有,需要使用coursera\stanford openEdX平台,有Introduction to Database进行系统学习,w3school供参考或作为手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。.来自:/bbs
% 可以使用cmd打开数据库。启动命令为:
净启动mysql55
%shutdown 命令是:
净停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb 模块。访问更多。
导入 MySQL 数据库
# 与服务器建立链接,host为服务器ip,我的MySQL数据库建在这台机器上,默认为127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为3306,charset为编码方式。
# 默认是utf8(也可能是gbk,取决于安装的版本)。.来自:/bbs
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="yourPassword", db="dbname", port=3306,字符集="utf8")
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = "On Random Graph""). 涓€浜?-涓夊堎-鍦砰麴麴鍙戝緷
# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
# i代表查询结果中的第i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,如:
sql = "update studentCourseRecord set fail = 1 where studentID = "%s" and termid = "%s" and courseID = "%s"" %(studentID,course[0],course[1])
cur.execute(sql)。1点3英亩
# 与查询不同,在执行完delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
# 和往常一样,使用完记得关闭光标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。服务器、Python、数据库和数据库接口需要使用相同的编码格式,避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
从 1 点 3acres bbs
后记:./bbs
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
更新:
2014年2月15日,更正了几个错别字;添加了相关课程链接;添加了对udacity CS101的介绍;添加了对 MySQLdb 模块的介绍。. 1点3英亩
2014 年 2 月 16 日,添加了指向解释如何编码的博客文章的链接。 查看全部
python抓取网页数据(数据科学越来越火了,网页是数据很大的一个来源)
前言:。访问更多。
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。.
. 链鞃断头镊子?1点3英亩
第 1 步:熟悉 Python 的基本语法。. 更多信息
如果您已经熟悉 Python,请跳至第 2 步。瓦拉尔?,
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接From 1point 3acres bbs
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门课是codecademy的python,很久以前看的,很多内容记不住了)。那个时候,我每天看视频+编程作业一个多小时,六天就看完了。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有同学在现场评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场也有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,就是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
导入 urllib2
# 查询任意文章,如On random graph。谷歌搜索每个查询
# 学者有一个url,这个url形成的规则要自己分析。
查询=“上+随机+图形”
url = "" + 查询 + "&btnG=&as_sdt=1%2C5&as_sdtp="。更多信息
# 设置头文件。爬取一些网页不需要特殊的头文件,但是如果这里没有设置,
# google 会认为机器人不允许访问。另外,访问一些网站和设置cookies会比较复杂。
# 这里暂不提及。关于如何知道如何编写头文件,一些插件可以看到你正在使用的浏览器并与网站进行交互。更多信息
# 头文件(这个工具很多浏览器自带),我用的是firefox的firebug插件。
标头 = {“主机”:“”,
"用户代理": "Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0 ",
"接受": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
“接受编码”:“gzip,放气”,
“连接”:“保持活动”}
# 建立连接请求,然后谷歌服务器返回页面信息给变量con,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen(req)
# 在con对象上调用read()方法,返回一个html页面,即带有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件后关闭一样,如果不关闭,有时还可以,但有时会出现问题,
# 所以作为一个守法的好公民,还是关闭连接比较好。
con.close()
复制代码
上面的代码将google Academic上查询On Random Graph的结果返回给doc变量,和打开google Academic搜索On Random Graph然后在网页上右键保存是一样的。
.
步骤三、解析网页
以上步骤获取了网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,。从 1 点 3acres bbs
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:
(2) BeautifulSoup模块。BeautifulSoup是一个非常强大的模块,可以将html文件解析成一个对象,也就是一棵树。我们都知道html文件是树状的,比如body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用.. 更多信息
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
导入 BeautifulSoup
重新进口
# 生成一个soup对象,步骤2中提到了doc
汤 = BeautifulSoup.BeautifulSoup(doc)
# 获取论文标题、作者、简短描述、引用计数、版本计数、指向 文章 引用列表的超链接
# 这里也用到了一些正则表达式,不熟悉的应该不知道。至于“类”:在“gs_rt”
# “gs_rt”是怎么来的?这是通过分析html文件肉眼看到的。上面提到的firebug插件
# 让这个很简单,只要一点网页,就可以知道对应html标签的位置和属性,
# 很容易使用。
paper_name = soup.html.body.find("h3", {"class" : "gs_rt"}).text
paper_name = re.sub(r"\[.*\]", "", paper_name) # 去掉 "[]" 标签,比如 "[PDF]"
paper_author = soup.html.body.find("div", {"class" : "gs_a"}).text
paper_desc = soup.html.body.find("div", {"class" : "gs_rs"}).text
temp_str = soup.html.body.find("div", {"class" : "gs_fl"}).text
temp_re = re.match(r"[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)", temp_str)。更多信息
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
如果 citeTimes == "":
引用时间 = "0"
如果 versionNum == "":. 来自:/bbs
版本号 = "0"
引用Paper_href = soup.html.body.find("div", {"class" : "gs_fl"}).a.attrs[0][1]
复制代码
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件的最简单方法是在 Python 中使用以下代码:-google 1point3acres
# 打开文件webdata.txt,生成object文件,这个文件可能不存在,参数a表示添加。
# 还有其他参数,比如“r”只能读不能写,“w”可以写但删除原记录等。
文件 = 打开(“webdata.txt”,“a”)
line = paper_name + "#" + paper_author + "#" + paper_desc + "#" + citeTimes + "\n"
# 目标文件的write方法将字符串行写入文件
文件 = file.write(line)./bbs
# 再次做一个随心所欲关闭文件的好青年
文件.close()
复制代码
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库交互,将数据直接倒入数据库,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;如果没有,需要使用coursera\stanford openEdX平台,有Introduction to Database进行系统学习,w3school供参考或作为手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。.来自:/bbs
% 可以使用cmd打开数据库。启动命令为:
净启动mysql55
%shutdown 命令是:
净停止mysql55
复制代码
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb 模块。访问更多。
导入 MySQL 数据库
# 与服务器建立链接,host为服务器ip,我的MySQL数据库建在这台机器上,默认为127.0.0.1,
# 用户、密码、数据库名对应输入。默认端口号为3306,charset为编码方式。
# 默认是utf8(也可能是gbk,取决于安装的版本)。.来自:/bbs
conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="yourPassword", db="dbname", port=3306,字符集="utf8")
# 创建游标
cur = conn.cursor()
# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = "On Random Graph""). 涓€浜?-涓夊堎-鍦砰麴麴鍙戝緷
# fetchall()方法获取查询结果,返回一个列表,可以这样直接查询:list[i][j],
# i代表查询结果中的第i+1条记录,j代表这条记录的j+1个属性(别忘了python是从0开始计数的)
列表 = cur.fetchall()
# 还可以进行删除、删除、插入、更新等操作,如:
sql = "update studentCourseRecord set fail = 1 where studentID = "%s" and termid = "%s" and courseID = "%s"" %(studentID,course[0],course[1])
cur.execute(sql)。1点3英亩
# 与查询不同,在执行完delete、insert、update语句后,必须执行以下命令才能成功更新数据库
mit()
# 和往常一样,使用完记得关闭光标,然后关闭链接
cur.close()
conn.close()
复制代码
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。服务器、Python、数据库和数据库接口需要使用相同的编码格式,避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
从 1 点 3acres bbs
后记:./bbs
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
更新:
2014年2月15日,更正了几个错别字;添加了相关课程链接;添加了对udacity CS101的介绍;添加了对 MySQLdb 模块的介绍。. 1点3英亩
2014 年 2 月 16 日,添加了指向解释如何编码的博客文章的链接。
python抓取网页数据(STM32抓取网页数据()抓取数据数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-27 01:05
python抓取网页数据。准备环境:python3.6,python2.7,tushare爬虫,xxx的selenium实验环境1、导入所有必要的库importxxx#包括google,xml,xlrd,xlwt等importyyy#包括用户名,邮箱,密码等importcgi#用于连接服务器,以便于对url进行get请求fromurllibimporturlopen#方便处理url,字符串,字符串的内容importtimeimportre#time是时间库,python3中有很多版本,我用的是spider1.1.4.0.683#xml库,multicharts,beautifulsoup的封装selenium的实现extension安装xxx.python3tushare的服务,抓取数据:xxxxxdataingbk的.xlsx格式extension:welcometomozillafirefox.opensource,pleaseposttoreadme.mdatmaster·pythonpeixun/apache-firefox-issuesextension:copy.pythonfromurllibimporturlopen,requestfromthefirefox.openfromurllibimportrequestfromurllib.errorimportrequestevalfromurllib.errorimporturlerrorsys.stdout.basichandlers.console=false#properties属性是python自带的扩展名名称,不需要额外添加#如果不是.xlsx格式,python3中返回"resource_content",python2中返回"content_content"socket=socket.socket(socket.af_inet,socket.sock_stream)#af_inet是开源的multichartscallback模块,它支持tcp、udp、icmp等多种协议socket.close()#若不执行close方法,则tcp协议关闭;若执行了close方法,则tcp协议启动#若协议没有关闭,则python将尝试监听close方法的结果,直到遇到python3中更多内容#我用的是spider3.1.4.0.683version3、爬虫代码importxxxfromseleniumimportwebdriver#所有useragent的包装useragent=""#浏览器driver=webdriver.chrome(executable_path='c:\\windows\\system32\\chromedriver.exe')#获取启动页面#print(useragent)获取转发接口request_url=''#request_url=''#获取注册页面post_url=''post_url=''#设置一个token,并绑定端口xctls=''#xctls=''#获取所有数据,爬取并保存result_url=''#记录每一页的访问iddefget_http_url(useragent):try:ssl=xhr.ssl()ssl.login(useragent)ssl.post(http_url,data={'cookie':cookie}。 查看全部
python抓取网页数据(STM32抓取网页数据()抓取数据数据)
python抓取网页数据。准备环境:python3.6,python2.7,tushare爬虫,xxx的selenium实验环境1、导入所有必要的库importxxx#包括google,xml,xlrd,xlwt等importyyy#包括用户名,邮箱,密码等importcgi#用于连接服务器,以便于对url进行get请求fromurllibimporturlopen#方便处理url,字符串,字符串的内容importtimeimportre#time是时间库,python3中有很多版本,我用的是spider1.1.4.0.683#xml库,multicharts,beautifulsoup的封装selenium的实现extension安装xxx.python3tushare的服务,抓取数据:xxxxxdataingbk的.xlsx格式extension:welcometomozillafirefox.opensource,pleaseposttoreadme.mdatmaster·pythonpeixun/apache-firefox-issuesextension:copy.pythonfromurllibimporturlopen,requestfromthefirefox.openfromurllibimportrequestfromurllib.errorimportrequestevalfromurllib.errorimporturlerrorsys.stdout.basichandlers.console=false#properties属性是python自带的扩展名名称,不需要额外添加#如果不是.xlsx格式,python3中返回"resource_content",python2中返回"content_content"socket=socket.socket(socket.af_inet,socket.sock_stream)#af_inet是开源的multichartscallback模块,它支持tcp、udp、icmp等多种协议socket.close()#若不执行close方法,则tcp协议关闭;若执行了close方法,则tcp协议启动#若协议没有关闭,则python将尝试监听close方法的结果,直到遇到python3中更多内容#我用的是spider3.1.4.0.683version3、爬虫代码importxxxfromseleniumimportwebdriver#所有useragent的包装useragent=""#浏览器driver=webdriver.chrome(executable_path='c:\\windows\\system32\\chromedriver.exe')#获取启动页面#print(useragent)获取转发接口request_url=''#request_url=''#获取注册页面post_url=''post_url=''#设置一个token,并绑定端口xctls=''#xctls=''#获取所有数据,爬取并保存result_url=''#记录每一页的访问iddefget_http_url(useragent):try:ssl=xhr.ssl()ssl.login(useragent)ssl.post(http_url,data={'cookie':cookie}。
python抓取网页数据(什么是Ajax:javascriptandxml(异步JavaScript和XML)如何快速入门selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-26 14:14
什么是阿贾克斯:
异步 javascriptandxml(异步 JavaScript 和 XML)。在 Ajax 中,可以通过在后台最小化与服务器的数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新传统网页(没有 Ajax)的内容,则必须重新加载整个网页。因为以前数据格式是使用 XML 语法传输的。所以虽然叫AJAX,但实际上现在的数据交换基本都是用JSON。即使AJAX加载的数据使用JS在浏览器中渲染数据,右键-查看网页源代码也看不到AJAX加载的数据,只有这个url加载的html代码。
如何获取ajax数据:
1、直接分析ajax调用接口。然后使用代码请求这个接口。
2、使用 Selenium chromedriver 模拟浏览器动作来获取数据。
Selenium chromedriver 获取动态数据:
Selenium 相当于机器人。可以在浏览器中模拟人类行为并自动处理浏览器中的行为,例如点击、输入数据和删除cookies。Chromedriver是一款可以移动浏览器的手机chrome浏览器驱动。当然,驱动器因浏览器而异。以下是各种浏览器及其相应的驱动程序。
1、chrome:驱动程序/下载
2、Firefox:驱动程序/版本
3、边缘:驱动程序/
4、safari:driver-support-in-safari-10/
要安装 Selenium 和 chrome 驱动程序:
Selenium 安装:Selenium 支持多种语言,包括 java、ruby 和 python。我们只下载python版本。
pip安装序列号
安装chromedriver:下载完成后,未经许可放到英文目录下。
快速开始:
以轻松获取百度主页为例,展示如何快速上手 Selenium 和 chromedriver。
Selenium 常用操作:
关闭页面:
1、driver.close(:关闭当前页面。
2、driver.quit () : 退出整个浏览器。
定位要素:
请注意,find_element 是满足条件的第一个元素。find_elements 检索所有满足条件的元素。
作为表单元素:
1、操作输入框:分为两个阶段。第一步:找到元素。使用步骤 2 (send_keys(value)) 填充数据。示例代码如下:
输入标签=driver.find_element_by_id('kw))。
输入 tag.send_keys (python))。
可以使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear(
2、动作复选框:要选择复选框选项卡,请在网页上单击鼠标。所以我想选中复选框
x标签,然后先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。 查看全部
python抓取网页数据(什么是Ajax:javascriptandxml(异步JavaScript和XML)如何快速入门selenium)
什么是阿贾克斯:
异步 javascriptandxml(异步 JavaScript 和 XML)。在 Ajax 中,可以通过在后台最小化与服务器的数据交换来异步更新网页。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新传统网页(没有 Ajax)的内容,则必须重新加载整个网页。因为以前数据格式是使用 XML 语法传输的。所以虽然叫AJAX,但实际上现在的数据交换基本都是用JSON。即使AJAX加载的数据使用JS在浏览器中渲染数据,右键-查看网页源代码也看不到AJAX加载的数据,只有这个url加载的html代码。
如何获取ajax数据:
1、直接分析ajax调用接口。然后使用代码请求这个接口。
2、使用 Selenium chromedriver 模拟浏览器动作来获取数据。
Selenium chromedriver 获取动态数据:
Selenium 相当于机器人。可以在浏览器中模拟人类行为并自动处理浏览器中的行为,例如点击、输入数据和删除cookies。Chromedriver是一款可以移动浏览器的手机chrome浏览器驱动。当然,驱动器因浏览器而异。以下是各种浏览器及其相应的驱动程序。
1、chrome:驱动程序/下载
2、Firefox:驱动程序/版本
3、边缘:驱动程序/
4、safari:driver-support-in-safari-10/
要安装 Selenium 和 chrome 驱动程序:
Selenium 安装:Selenium 支持多种语言,包括 java、ruby 和 python。我们只下载python版本。
pip安装序列号
安装chromedriver:下载完成后,未经许可放到英文目录下。
快速开始:
以轻松获取百度主页为例,展示如何快速上手 Selenium 和 chromedriver。
Selenium 常用操作:
关闭页面:
1、driver.close(:关闭当前页面。
2、driver.quit () : 退出整个浏览器。
定位要素:
请注意,find_element 是满足条件的第一个元素。find_elements 检索所有满足条件的元素。
作为表单元素:
1、操作输入框:分为两个阶段。第一步:找到元素。使用步骤 2 (send_keys(value)) 填充数据。示例代码如下:
输入标签=driver.find_element_by_id('kw))。
输入 tag.send_keys (python))。
可以使用 clear 方法清除输入框的内容。示例代码如下:
inputTag.clear(
2、动作复选框:要选择复选框选项卡,请在网页上单击鼠标。所以我想选中复选框
x标签,然后先选中这个标签,再执行click事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
3、Select select:选择元素不能直接点击。因为点击后需要选择元素。这时,selenium 提供了一个类 selenium.webdriver.support.ui.Select 专门用于 select 标签。将获取的元素作为参数传递给此类以创建此对象。您可以稍后使用此对象进行选择。示例代码如下:
4、操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数即可。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时候页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移到一个元素上并执行一个单击事件。那么示例代码如下:
还有更多与鼠标相关的操作。
1、click_and_hold(element):在不释放鼠标的情况下单击。
2、context_click(element):右键单击。
3、double_click(element):双击。更多方法请参考:
Cookie操作:
获取所有 cookie:
对于 driver.get_cookies() 中的 cookie:
打印(饼干)
根据cookie的key获取值:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
要删除 cookie:
driver.delete_cookie(键)
页面等待:
今天的网页越来越多地使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待的时间过长,一个dom元素还没有出来,但是你的代码直接使用了这个WebElement,就会抛出NullPointer异常。来解决这个问题。所以 Selenium 提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后它将等待 10 秒,然后再获取不可用的元素。示例代码如下:
显式等待:显式等待是表示在执行获取元素的操作之前满足一定条件。还可以指定等待的最长时间,超过这个时间就抛出异常。显示等待应使用 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 预期的条件完成。示例代码如下:
其他一些等待条件:
1、presence_of_element_located:元素已加载。
2、presence_of_all_emement_located:页面中所有满足条件的元素都被加载。
3、element_to_be_cliable:一个元素是可点击的。
切换页面:
有时窗口中有很多子标签页。肯定是时候换了。Selenium 提供了一个叫做 switch_to_window 的开关来切换,可以从 driver.window_handles 中找到要切换到哪个页面。示例代码如下:
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时某些网页被频繁爬取。服务器发现你是爬虫后,会屏蔽你的IP地址。这时候我们可以更改代理ip。更改代理ip,不同的浏览器有不同的实现。以下是 Chrome 浏览器的示例:
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是每个检索到的元素所属的类。
有一些常用的属性:
1、get_attribute:这个标签的一个属性的值。
2、screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动的对象类也是继承自WebElement。
python抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-26 06:19
)
"
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键-查看源代码
生成的 HTML 不收录由 ajax 异步加载的内容
查看原文件只显示网页的初始状态,但实际上网页加载后可能会立即执行js来改变初始状态。当前网页不同于传统的动态网页。它可以在不刷新网页的情况下更改网页的本地数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你需要在其中加载数据,改变控件的状态,甚至创建新的控件,销毁控件,或者隐藏现有的控件。外观自然会有所不同。
"
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
python抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
"
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键-查看源代码
生成的 HTML 不收录由 ajax 异步加载的内容
查看原文件只显示网页的初始状态,但实际上网页加载后可能会立即执行js来改变初始状态。当前网页不同于传统的动态网页。它可以在不刷新网页的情况下更改网页的本地数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计一个界面,但在实际操作中,你需要在其中加载数据,改变控件的状态,甚至创建新的控件,销毁控件,或者隐藏现有的控件。外观自然会有所不同。
"
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,网站的其他很多RequestURL也没有那么直接,所以我们会使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
python抓取网页数据(如何快速的采集到异步加载页面的异步代码?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 212 次浏览 • 2022-01-24 22:03
在采集网页中,我们经常会遇到采集一些异步加载页面的网页,而我们平时使用的httpwebrequest类并不是采集。这时候我们一般都是用webbrowser来辅助采集,但是.net自带的webbrowser用起来很不爽。获取页面是否加载比较麻烦。DocumentCompleted事件被iframe反复触发,获取到的源码通常不会异步加载。在源代码之后,我们经常需要添加一个定时器来不断的检查来获取我们想要的源代码。当然,我们可以使用一些第三方的webkit内核浏览器,但是判断页面是否真的加载比较费力,而且体积也不小。
今天我将介绍 CasperJS。CasperJS 是一个开源的导航脚本处理和测试工具,基于 PhantomJS 和 slimerjs(前端自动化测试工具)编写。CasperJS 简化了完整导航场景的流程定义,为常见任务提供了有用的高级函数、方法和语法。CasperJS 本身非常强大。有两个内置引擎,PhantomJS 和 slimerjs,默认使用 PhantomJS。具体详细功能可以参考这些官方网站了解更多,或者加入QQ群389709524进行讨论。今天的重点是如何快速 采集 到异步加载的网页。
如果我们要采集dudu对这个文章的评论,这个文章看源码是找不到这两条评论的,通过httpwebrequest也拿不到。这时候我们用 casperjs 让它变得非常简单。
caperjs代码定义如下:
1 var fs = require('fs');
2 var casper = require('casper').create({
3 pageSettings: {
4 loadImages: false,
5 loadPlugins: false
6 },
7 logLevel: "debug",//日志等级
8 verbose: true, // 记录日志到控制台
9 });
10
11 var url = casper.cli.raw.get('url');
12
13 //请求页面
14 casper.start(url, function () {
15 fs.write("temp.html", this.getHTML(), 'w');
16 });
17
18 casper.run();
结果如下:
这样,几行简单的代码就可以得到异步加载的html代码。是不是非常简单快速!
当然,这在实际生产环境中是不够的。我们必须考虑各种 网站 场景和各种网络状况,例如网络超时。如果一个网页一分钟不能加载,我们就认为是超时了,否则我们一直在等待,我们要过滤掉与我们的采集无关的请求,对比谷歌统计,百度统计,广告等。这通常会减慢网页的加载速度。此外,我们通常还会使用 CSS 样式和页面的图片。不需要,可以忽略。总而言之,我们的代码是这样扩展的。
1 var fs = require('fs');
2
3 var casper = require('casper').create({
4 pageSettings: {
5 loadImages: true,
6 loadPlugins: false,
7 userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
8 },
9 logLevel: "debug",//日志等级
10 verbose: true, // 记录日志到控制台
11 timeout: 60000,//60秒超时,退出
12 });
13
14
15 var url = casper.cli.raw.get('url');
16
17 //排除不相关的请求,加快页面加载进度
18 casper.on('resource.requested', function(requestData, request) {
19 if (requestData.url.indexOf('google-analytics.com') > 0) {
20 request.abort();
21 }
22 if (requestData.url.indexOf('googlesyndication.com') > 0) {
23 request.abort();
24 }
25 if (requestData.url.indexOf('hm.baidu.com') > 0) {
26 request.abort();
27 }
28 if (requestData.url.indexOf('baidustatic.com') > 0) {
29 request.abort();
30 }
31 if (requestData.url.indexOf('share.baidu.com') > 0) {
32 request.abort();
33 }
34 if (requestData.url.indexOf('cbjs.baidu.com') > 0) {
35 request.abort();
36 }
37 if (requestData.url.indexOf('jiathis.com') > 0) {
38 request.abort();
39 }
40 if (requestData.url.indexOf('.cnzz.com') > 0) {
41 request.abort();
42 }
43 if (requestData.url.indexOf('.51.la') > 0) {
44 request.abort();
45 }
46 if (requestData.url.indexOf('.tanx.com') > 0) {
47 request.abort();
48 }
49 //this.echo("==============>page.resource.requested"+requestData.url);
50 });
51
52 //超时执行的函数,记录到日志文件
53 casper.on('timeout', function () {
54 //this.echo("===>timeout"+url);
55 var fileName = this.evaluate(getFileName);
56 var nowTime = this.evaluate(CurentTime);
57 fs.write("log/timeout_" + fileName + ".txt", nowTime + "====>" + url + "\r\n", 'a');
58 });
59
60 //请求页面
61 casper.start(url, function () {
62 var status = this.status().currentHTTPStatus;
63 //this.capture('tt.png');
64 fs.write("temp.html", this.getHTML(), 'w');
65 });
66
67
68 function getFileName() {
69 var now = new Date();
70
71 var year = now.getFullYear(); //年
72 var month = now.getMonth() + 1; //月
73 var day = now.getDate(); //日
74
75 return (year + "" + month + "" + day);
76 }
77
78 function CurentTime() {
79 var now = new Date();
80
81 var year = now.getFullYear(); //年
82 var month = now.getMonth() + 1; //月
83 var day = now.getDate(); //日
84
85 var hh = now.getHours(); //时
86 var mm = now.getMinutes(); //分
87
88 var clock = year + "-";
89
90 if (month < 10)
91 clock += "0";
92
93 clock += month + "-";
94
95 if (day < 10)
96 clock += "0";
97
98 clock += day + " ";
99
100 if (hh < 10)
101 clock += "0";
102
103 clock += hh + ":";
104 if (mm < 10) clock += '0';
105 clock += mm;
106 return (clock);
107 }
108
109 casper.run();
查看代码
CasperJs的安装可以参考官方网站文档,或者关注下方微信公众号,提供本文所有工具和源码下载。今天写这个文章的另一个目的是,我在使用CasperJs的时候,遇到页面出现乱码,一时找不到解决办法。欢迎知道的大侠帮忙!场景如下:
比如采集这个网页,这个网站code是gb2312采集,遇到曹睿的“睿”,就会出现乱码。网站是utf-8编码的,采集的时候是ok的,但是我们是采集的程序,不可能要求别人改编码,所以我没有还没想到解决办法,想知道的同学,给点指点,多谢了!
文章来源:
在线工具: 查看全部
python抓取网页数据(如何快速的采集到异步加载页面的异步代码?)
在采集网页中,我们经常会遇到采集一些异步加载页面的网页,而我们平时使用的httpwebrequest类并不是采集。这时候我们一般都是用webbrowser来辅助采集,但是.net自带的webbrowser用起来很不爽。获取页面是否加载比较麻烦。DocumentCompleted事件被iframe反复触发,获取到的源码通常不会异步加载。在源代码之后,我们经常需要添加一个定时器来不断的检查来获取我们想要的源代码。当然,我们可以使用一些第三方的webkit内核浏览器,但是判断页面是否真的加载比较费力,而且体积也不小。
今天我将介绍 CasperJS。CasperJS 是一个开源的导航脚本处理和测试工具,基于 PhantomJS 和 slimerjs(前端自动化测试工具)编写。CasperJS 简化了完整导航场景的流程定义,为常见任务提供了有用的高级函数、方法和语法。CasperJS 本身非常强大。有两个内置引擎,PhantomJS 和 slimerjs,默认使用 PhantomJS。具体详细功能可以参考这些官方网站了解更多,或者加入QQ群389709524进行讨论。今天的重点是如何快速 采集 到异步加载的网页。
如果我们要采集dudu对这个文章的评论,这个文章看源码是找不到这两条评论的,通过httpwebrequest也拿不到。这时候我们用 casperjs 让它变得非常简单。
caperjs代码定义如下:
1 var fs = require('fs');
2 var casper = require('casper').create({
3 pageSettings: {
4 loadImages: false,
5 loadPlugins: false
6 },
7 logLevel: "debug",//日志等级
8 verbose: true, // 记录日志到控制台
9 });
10
11 var url = casper.cli.raw.get('url');
12
13 //请求页面
14 casper.start(url, function () {
15 fs.write("temp.html", this.getHTML(), 'w');
16 });
17
18 casper.run();
结果如下:
这样,几行简单的代码就可以得到异步加载的html代码。是不是非常简单快速!
当然,这在实际生产环境中是不够的。我们必须考虑各种 网站 场景和各种网络状况,例如网络超时。如果一个网页一分钟不能加载,我们就认为是超时了,否则我们一直在等待,我们要过滤掉与我们的采集无关的请求,对比谷歌统计,百度统计,广告等。这通常会减慢网页的加载速度。此外,我们通常还会使用 CSS 样式和页面的图片。不需要,可以忽略。总而言之,我们的代码是这样扩展的。
1 var fs = require('fs');
2
3 var casper = require('casper').create({
4 pageSettings: {
5 loadImages: true,
6 loadPlugins: false,
7 userAgent: 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.137 Safari/537.36 LBBROWSER'
8 },
9 logLevel: "debug",//日志等级
10 verbose: true, // 记录日志到控制台
11 timeout: 60000,//60秒超时,退出
12 });
13
14
15 var url = casper.cli.raw.get('url');
16
17 //排除不相关的请求,加快页面加载进度
18 casper.on('resource.requested', function(requestData, request) {
19 if (requestData.url.indexOf('google-analytics.com') > 0) {
20 request.abort();
21 }
22 if (requestData.url.indexOf('googlesyndication.com') > 0) {
23 request.abort();
24 }
25 if (requestData.url.indexOf('hm.baidu.com') > 0) {
26 request.abort();
27 }
28 if (requestData.url.indexOf('baidustatic.com') > 0) {
29 request.abort();
30 }
31 if (requestData.url.indexOf('share.baidu.com') > 0) {
32 request.abort();
33 }
34 if (requestData.url.indexOf('cbjs.baidu.com') > 0) {
35 request.abort();
36 }
37 if (requestData.url.indexOf('jiathis.com') > 0) {
38 request.abort();
39 }
40 if (requestData.url.indexOf('.cnzz.com') > 0) {
41 request.abort();
42 }
43 if (requestData.url.indexOf('.51.la') > 0) {
44 request.abort();
45 }
46 if (requestData.url.indexOf('.tanx.com') > 0) {
47 request.abort();
48 }
49 //this.echo("==============>page.resource.requested"+requestData.url);
50 });
51
52 //超时执行的函数,记录到日志文件
53 casper.on('timeout', function () {
54 //this.echo("===>timeout"+url);
55 var fileName = this.evaluate(getFileName);
56 var nowTime = this.evaluate(CurentTime);
57 fs.write("log/timeout_" + fileName + ".txt", nowTime + "====>" + url + "\r\n", 'a');
58 });
59
60 //请求页面
61 casper.start(url, function () {
62 var status = this.status().currentHTTPStatus;
63 //this.capture('tt.png');
64 fs.write("temp.html", this.getHTML(), 'w');
65 });
66
67
68 function getFileName() {
69 var now = new Date();
70
71 var year = now.getFullYear(); //年
72 var month = now.getMonth() + 1; //月
73 var day = now.getDate(); //日
74
75 return (year + "" + month + "" + day);
76 }
77
78 function CurentTime() {
79 var now = new Date();
80
81 var year = now.getFullYear(); //年
82 var month = now.getMonth() + 1; //月
83 var day = now.getDate(); //日
84
85 var hh = now.getHours(); //时
86 var mm = now.getMinutes(); //分
87
88 var clock = year + "-";
89
90 if (month < 10)
91 clock += "0";
92
93 clock += month + "-";
94
95 if (day < 10)
96 clock += "0";
97
98 clock += day + " ";
99
100 if (hh < 10)
101 clock += "0";
102
103 clock += hh + ":";
104 if (mm < 10) clock += '0';
105 clock += mm;
106 return (clock);
107 }
108
109 casper.run();
查看代码
CasperJs的安装可以参考官方网站文档,或者关注下方微信公众号,提供本文所有工具和源码下载。今天写这个文章的另一个目的是,我在使用CasperJs的时候,遇到页面出现乱码,一时找不到解决办法。欢迎知道的大侠帮忙!场景如下:
比如采集这个网页,这个网站code是gb2312采集,遇到曹睿的“睿”,就会出现乱码。网站是utf-8编码的,采集的时候是ok的,但是我们是采集的程序,不可能要求别人改编码,所以我没有还没想到解决办法,想知道的同学,给点指点,多谢了!
文章来源:
在线工具:
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-23 10:04
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。. 更多信息
第 1 步:熟悉 Python 的基本语法
如果您已经熟悉 Python,请跳到第 2 步。
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接——google 1point3acres
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门是codecademy的python,很久以前看的,很多内容记不清了),每次看视频+编程作业一个多小时天,六天完成。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有现场的同学评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
import urllib2
# 随便查询一篇文章,比如On random graph。对每一个查询google
# scholar都有一个url,这个url形成的规则是要自己分析的。
query = 'On+random+graph'
url = 'http://scholar.google.com/scholar?hl=en&q=' + query + '&btnG=&as_sdt=1%2C5&as_sdtp='
# 设置头文件。抓取有些的网页不需要专门设置头文件,但是这里如果不设置的话,. 鐗涗汉浜戦泦,涓€浜╀笁鍒嗗湴
# google会认为是机器人不允许访问。另外访问有些网站还有设置Cookie,这个会相对复杂一些,
# 这里暂时不提。关于怎么知道头文件该怎么写,一些插件可以看到你用的浏览器和网站交互的
# 头文件(这种工具很多浏览器是自带的),我用的是firefox的firebug插件。.鏈枃鍘熷垱鑷�1point3acres璁哄潧
header = {'Host': 'scholar.google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive'}
# 建立连接请求,这时google的服务器返回页面信息给con这个变量,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen( req )
# 对con这个对象调用read()方法,返回的是html页面,也就是有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件要关闭文件一样,如果不关闭有时可以、但有时会有问题,
# 所以作为一个守法的好公民,还是关闭连接好了。
con.close()
上面的代码将google Academic上查询On Random Graph的结果返回给变量doc,和打开google Academic搜索On Random Graph,然后在网页上右键保存是一样的。
步骤三、解析网页
以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:. 更多信息
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道 html 文件是树状的,比如 body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用。
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
import BeautifulSoup
import re
# 生成一个soup对象,doc就是步骤二中提到的
soup = BeautifulSoup.BeautifulSoup(doc)
# 抓取论文标题,作者,简短描述,引用次数,版本数,引用它的文章列表的超链接
# 这里还用了一些正则表达式,不熟悉的先无知它好了。至于'class' : 'gs_rt'中
# 'gs_rt'是怎么来的,这个是分析html文件肉眼看出来的。上面提到的firebug插件
# 让这个变的很简单,只要一点网页,就可以知道对应的html 标签的位置和属性,
# 相当好用。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text. from: 1point3acres.com/bbs
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件最简单的方法是在 Python 中使用以下代码:
# 打开文件webdata.txt,生成对象file,这个文件可以是不存在的,参数a表示往里面添加。
# 还有别的参数,比如'r'只能读但不能写入,'w'可以写入但是会删除原来的记录等等
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库中,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;有一个系统学习的数据库介绍,w3school作为参考或手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。. visit 1point3acres.com for more.
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8'). 鍥磋鎴戜滑@1point 3 acres
# 建立cursor
cur = conn.cursor()# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
后记:
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。 查看全部
python抓取网页数据(数据科学越来越火了,如何抓网页数据?(一))
前言:
数据科学越来越流行,网页是一个巨大的数据来源。最近有很多人问如何抓取网页数据。据我所知,常见的编程语言(C++、java、python)都可以实现网页数据抓取,甚至很多统计/计算语言(R、Matlab)都可以实现和网站交互的包。我试过用java、python、R爬取网页,感觉语法不一样,但是逻辑是一样的。我将使用python来谈谈网络抓取的概念。具体内容需要看说明书或者google别人的博客。水平有限,有错误或者有更好的方法,欢迎讨论。. 更多信息
第 1 步:熟悉 Python 的基本语法
如果您已经熟悉 Python,请跳到第 2 步。
Python是一门相对容易上手的编程语言,如何上手取决于编程基础。
(1)如果你有一定的编程基础,建议看google的python类,链接——google 1point3acres
这是一个为期两天的短期培训课程(当然是两天全天),大约七个视频,每个视频后面都有编程作业,每个作业可以在一个小时内完成。这是我学python的第二门课(第一门是codecademy的python,很久以前看的,很多内容记不清了),每次看视频+编程作业一个多小时天,六天完成。不错,用python写基本程序没有问题。
(2)如果你没有任何编程基础,我建议你在coursera上阅读莱斯大学的An Introduction to Interactive Programming in Python。我没有上过这门课程,但是coursetalk上的评论非常积极,并且也有现场的同学评论(点这里),课程链接:Udacity上的CS101也是不错的选择,现场有相关的讨论帖(点这里),而这门课叫做build a search engine,里面会专门讲一些网络相关的话题模块,其他的学习资源还有code school和codecademy,这些资源也挺不错的,但是编程量太少了,初学者应该系统的跟着课,多练习,打下扎实的基础基础。
当然,每个人的喜好不一样,我推荐的不一定适合你。你可以先看看这个帖子【长期红利帖】介绍一下别人在你上过的公开课上都说了些什么,或者看一下课程评论,再决定。
第二步:学习如何与网站建立链接并获取网页数据。
要编写与 网站 交互的脚本,您必须熟悉与 python 和网页相关的几个模块(urllib、urllib2、httplib)之一。你只需要知道一个,其他的都差不多。这三个是python提供的与网页交互的基础模块,还有其他的,比如:mechanize和scrapy,我没用过,可能性能更好。欢迎补充更多信息。对于基本的网页抓取,前三个模块就足够了。
以下代码演示了如何使用 urllib2 与 google Academic 交互获取网页信息。
# 导入模块 urllib2
import urllib2
# 随便查询一篇文章,比如On random graph。对每一个查询google
# scholar都有一个url,这个url形成的规则是要自己分析的。
query = 'On+random+graph'
url = 'http://scholar.google.com/scholar?hl=en&q=' + query + '&btnG=&as_sdt=1%2C5&as_sdtp='
# 设置头文件。抓取有些的网页不需要专门设置头文件,但是这里如果不设置的话,. 鐗涗汉浜戦泦,涓€浜╀笁鍒嗗湴
# google会认为是机器人不允许访问。另外访问有些网站还有设置Cookie,这个会相对复杂一些,
# 这里暂时不提。关于怎么知道头文件该怎么写,一些插件可以看到你用的浏览器和网站交互的
# 头文件(这种工具很多浏览器是自带的),我用的是firefox的firebug插件。.鏈枃鍘熷垱鑷�1point3acres璁哄潧
header = {'Host': 'scholar.google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; rv:26.0) Gecko/20100101 Firefox/26.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive'}
# 建立连接请求,这时google的服务器返回页面信息给con这个变量,con是一个对象
req = urllib2.Request(url, headers = header)
con = urllib2.urlopen( req )
# 对con这个对象调用read()方法,返回的是html页面,也就是有html标签的纯文本
doc = con.read()
# 关闭连接。就像读完文件要关闭文件一样,如果不关闭有时可以、但有时会有问题,
# 所以作为一个守法的好公民,还是关闭连接好了。
con.close()
上面的代码将google Academic上查询On Random Graph的结果返回给变量doc,和打开google Academic搜索On Random Graph,然后在网页上右键保存是一样的。
步骤三、解析网页
以上步骤获取网页的信息,但是收录html标签,需要去掉这些标签,然后从html文本中整理出有用的信息,
您需要解析此网页。
解析网页的方法:
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式. 如何学习正则表达式推荐看:正则表达式30分钟入门教程,链接:. 更多信息
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。我们都知道 html 文件是树状的,比如 body -> table -> tbody - > tr,对于节点tbody,tr的子节点很多,BeautifulSoup可以很方便的获取到具体的节点,对于单个节点也可以获取到它的兄弟节点,网上有很多相关说明,不详述这里。说一下,只是为了演示简单的代码:
(3) 以上两种方法结合使用。
# 导入BeautifulSoup模块和re模块,re是python中正则表达式的模块
import BeautifulSoup
import re
# 生成一个soup对象,doc就是步骤二中提到的
soup = BeautifulSoup.BeautifulSoup(doc)
# 抓取论文标题,作者,简短描述,引用次数,版本数,引用它的文章列表的超链接
# 这里还用了一些正则表达式,不熟悉的先无知它好了。至于'class' : 'gs_rt'中
# 'gs_rt'是怎么来的,这个是分析html文件肉眼看出来的。上面提到的firebug插件
# 让这个变的很简单,只要一点网页,就可以知道对应的html 标签的位置和属性,
# 相当好用。
paper_name = soup.html.body.find('h3', {'class' : 'gs_rt'}).text
paper_name = re.sub(r'\[.*\]', '', paper_name) # eliminate '[]' tags like '[PDF]'
paper_author = soup.html.body.find('div', {'class' : 'gs_a'}).text. from: 1point3acres.com/bbs
paper_desc = soup.html.body.find('div', {'class' : 'gs_rs'}).text
temp_str = soup.html.body.find('div', {'class' : 'gs_fl'}).text
temp_re = re.match(r'[A-Za-z\s]+(\d*)[A-Za-z\s]+(\d*)', temp_str)
citeTimes = temp_re.group(1)
versionNum = temp_re.group(2)
if citeTimes == '':
citeTimes = '0'
if versionNum == '':
versionNum = '0'
citedPaper_href = soup.html.body.find('div', {'class' : 'gs_fl'}).a.attrs[0][1]
这些是我正在为分析引文网络的项目编写的代码。对了,我从googlescholar那里抓取了论文和引文列表的信息,在我访问了大约1900次的时候就屏蔽了google,导致这个区域的ip一时间无法登录googlescholar。
第 4 步:访问数据
数据终于被抓到了,但现在只存储在内存中,必须保存后才能使用。
(1) 将数据写入 txt 文件最简单的方法是在 Python 中使用以下代码:
# 打开文件webdata.txt,生成对象file,这个文件可以是不存在的,参数a表示往里面添加。
# 还有别的参数,比如'r'只能读但不能写入,'w'可以写入但是会删除原来的记录等等
file = open('webdata.txt','a')
line = paper_name + '#' + paper_author + '#' + paper_desc + '#' + citeTimes + '\n'
# 对象file的write方法将字符串line写入file中
file = file.write(line)
# 再一次的,做个随手关闭文件的好青年
file.close()
这样,从网页中抓取并解析出来的数据就存储在本地了,是不是很简单呢?
(2)当然也可以直接连接数据库而不是写入txt文件。python中的mysqldb模块可以与mysql数据库交互,将数据直接倒入数据库中,与MySQL数据库的逻辑类似于与网站服务器建立链接的逻辑,如果你之前学过数据库,学习使用MySQLdb模块与数据库交互是很简单的;有一个系统学习的数据库介绍,w3school作为参考或手册使用。
Python能够链接数据库的前提是数据库是开放的。我用的是win7 + MySQL5.5,数据库是本地的。
%可以用cmd开启数据库,启动命令是:
net start mysql55
%关闭命令是:
net stop mysql55
使用 MySQLdb 模块的代码示例:
# 导入 MySQLdb模块
import MySQLdb
# 和服务器建立链接,host是服务器ip,我的MySQL数据库搭建在本机,默认的是127.0.0.1,
# 用户、密码、数据库名称对应着照输就行了,默认的端口号是3306,charset是编码方式,
# 默认的是utf8(也有可能是gbk,看安装的版本)。. visit 1point3acres.com for more.
conn = MySQLdb.connect(host='127.0.0.1', user='root', passwd='yourPassword', db='dbname', port=3306, charset='utf8'). 鍥磋鎴戜滑@1point 3 acres
# 建立cursor
cur = conn.cursor()# 通过对象cur的execute()方法执行SQL语句
cur.execute("select * from citeRelation where paperName = 'On Random Graph'")
# fetchall()方法获得查询结果,返回的是一个list,可以直接这样查询:list[i][j],
# i表示查询结果中的第i+1条record,j表示这条记录的第j+1个attribute(别忘了python从0开始计数)
list = cur.fetchall()
# 也可以进行delete,drop,insert,update等操作,比如
sql = "update studentCourseRecord set fail = 1 where studentID = '%s' and semesterID = '%s' and courseID = '%s'" %(studentID,course[0],course[1])
cur.execute(sql)
# 与查询不同的是,执行完delete,insert,update这些语句后必须执行下面的命令才能成功更新数据库
conn.commit()
# 一如既往的,用完了之后记得关闭cursor,然后关闭链接
cur.close()
conn.close()
这样就实现了Python与数据库的交互。除了 MySQL 数据库,python 的 PyGreSQL 模块可以支持 postgreSQL 数据库,原因类似。另外,如果你的网页收录中文,设置编码格式会很麻烦。您需要服务器、Python、数据库和数据库接口使用相同的编码格式,以避免出现乱码。如果出现中文乱码问题,请相信,你并不孤单!!去google吧,成千上万的人遇到过这个问题。
关于编码的问题,这里是我看到的一篇博文:
后记:
爬取网页数据的方法如上所述。爬取数据只是一小步。如何分析数据是大学的问题。欢迎讨论。
以上如有不明白之处,欢迎交流。
注意:
网站的大规模爬取会给网站的服务器带来很大的压力,尽量选择服务器比较轻松的时间(比如清晨)。网站很多,不要用三分之一英亩来测试。
Python 的 time 模块的 sleep() 方法可以暂停程序一段时间。比如time.sleep(1)这里程序运行的时候暂停1秒。及时暂停可以缓解服务器压力,保护自己的硬盘,只是为了睡很久,或者去健身房,结果出来了。
python抓取网页数据( 前阵子阿里云盘界面总结用python解析页面上的div)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-18 21:17
前阵子阿里云盘界面总结用python解析页面上的div)
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs) 查看全部
python抓取网页数据(
前阵子阿里云盘界面总结用python解析页面上的div)
前段时间,阿里云盘风靡一时,大量存储空间被送出。而且阿里云盘下载是无限的,比百度网盘好很多。这两天看到一个第三方网站可以在阿里云盘上搜索资源,但是它的资源没有按时间排序。这种情况会导致已经在队列中很长时间的资源成为过时的资源。小编这里使用python进行爬取和重排。
网页分析
这个 网站 有两条搜索线:搜索线一和搜索线二。这个 文章 使用第二行搜索。
打开控制面板下的网络,一眼就能看到一个sea.html的get请求。
有几个参数,四个关键参数:
同样在控制面板中,可以看到网页跳转到阿里云盘获取标题上方的真实链接。使用bs4解析页面上div(class=resource-itemborder-dashed-eee)标签下的a标签得到跳转网盘的地址,解析div下的p标签得到资源日期。
抓取和解析
首先安装解析页面需要的bs4第三方库。
pip3 install bs4
下面是抓取并解析网页的脚本代码,最后按日期降序排序。
<p>import requests
from bs4 import BeautifulSoup
import string
word = input('请输入要搜索的资源名称:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36'
}
result_list = []
for i in range(1, 11):
print('正在搜索第 {} 页'.format(i))
params = {
'page': i,
'keyword': word,
'search_folder_or_file': 0,
'is_search_folder_content': 0,
'is_search_path_title': 0,
'category': 'all',
'file_extension': 'all',
'search_model': 0
}
response_html = requests.get('https://www.alipanso.com/search.html', headers = headers,params=params)
response_data = response_html.content.decode()
soup = BeautifulSoup(response_data, "html.parser");
divs = soup.find_all('div', class_='resource-item border-dashed-eee')
if len(divs)
python抓取网页数据(只会爬虫如何获取网页上的信息?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-16 04:01
python抓取网页数据,有ab两站。参考文章:python爬虫数据采集实战教程。
可以参考我的这篇回答:只会爬虫如何获取网页上的信息?-rednaxelafx的回答
python并不强大,只是学习成本最低,在今天大数据的风头正盛,可以说,任何一门编程语言的诞生,都是建立在数据统计分析的基础上,你可以学python进行数据分析,也可以学java去做web,也可以学javascript去爬虫做前端。不过你需要的掌握数据统计分析,然后是编程能力,再然后是技术实力。python的发展历史虽然python诞生了挺长时间,但在今天,绝大多数流行的编程语言都是不断发展的过程,为了让一门语言更精确,语言也不断迭代。
一个编程语言在很长时间内会不断迭代,现在几乎每个语言都有自己的特点,都有自己的使用方法。不同的方法其实背后也有它们存在的道理。自从python诞生以来,它一直以来的特点,都是python语言本身作为小众语言的特点,而正如其名,python是小众语言,那么为了应对在今天这种泛滥的情况,它只好遵循大众语言的标准,去演化,去发展。
每一种语言,都会经历从一而终的过程,这是一个适应环境的必经之路。怎么去理解这个过程呢?从大众语言到小众语言,或者从小众语言到大众语言,就是大众语言在适应大众语言的过程。python发展过程其实也是这个过程,比如python2到python3,就是python2不断改进的过程。基于python2的习惯,我们一开始认为python2是基于python2的扩展,但其实不是这样的,python2是python3的标准版,而python3也在逐渐的标准化,即不再兼容python2,有可能你正在运行的python3,python3.x版本,将会以3.x版本的python替代之。
另外从一而终还有一个问题,这不是绝对的,比如你刚才那个例子,其实就是python2用来迁移python3的步骤。但其实大众语言没有那么容易死的,也许只是你没有去找到一个正确的切入点。其实如果你今天运行到的python2还是python2,但是你可以在运行数据爬虫的时候,不用按着python2.x来运行,你可以是python3或者是其他很多语言。
python2也在逐渐的从大众语言变为小众语言,比如你现在可以用它爬取本地数据,用python3来运行你的爬虫,你也可以用python2来进行大数据分析。python其实更多的是一种编程语言,它可以做很多事情,比如数据爬虫,网页调试,模拟浏览器,等等。为什么我不学java,因为java实在太他妈难了,不是我能吃得消的,我现在还要学其他语言。从这个意义。 查看全部
python抓取网页数据(只会爬虫如何获取网页上的信息?-八维教育)
python抓取网页数据,有ab两站。参考文章:python爬虫数据采集实战教程。
可以参考我的这篇回答:只会爬虫如何获取网页上的信息?-rednaxelafx的回答
python并不强大,只是学习成本最低,在今天大数据的风头正盛,可以说,任何一门编程语言的诞生,都是建立在数据统计分析的基础上,你可以学python进行数据分析,也可以学java去做web,也可以学javascript去爬虫做前端。不过你需要的掌握数据统计分析,然后是编程能力,再然后是技术实力。python的发展历史虽然python诞生了挺长时间,但在今天,绝大多数流行的编程语言都是不断发展的过程,为了让一门语言更精确,语言也不断迭代。
一个编程语言在很长时间内会不断迭代,现在几乎每个语言都有自己的特点,都有自己的使用方法。不同的方法其实背后也有它们存在的道理。自从python诞生以来,它一直以来的特点,都是python语言本身作为小众语言的特点,而正如其名,python是小众语言,那么为了应对在今天这种泛滥的情况,它只好遵循大众语言的标准,去演化,去发展。
每一种语言,都会经历从一而终的过程,这是一个适应环境的必经之路。怎么去理解这个过程呢?从大众语言到小众语言,或者从小众语言到大众语言,就是大众语言在适应大众语言的过程。python发展过程其实也是这个过程,比如python2到python3,就是python2不断改进的过程。基于python2的习惯,我们一开始认为python2是基于python2的扩展,但其实不是这样的,python2是python3的标准版,而python3也在逐渐的标准化,即不再兼容python2,有可能你正在运行的python3,python3.x版本,将会以3.x版本的python替代之。
另外从一而终还有一个问题,这不是绝对的,比如你刚才那个例子,其实就是python2用来迁移python3的步骤。但其实大众语言没有那么容易死的,也许只是你没有去找到一个正确的切入点。其实如果你今天运行到的python2还是python2,但是你可以在运行数据爬虫的时候,不用按着python2.x来运行,你可以是python3或者是其他很多语言。
python2也在逐渐的从大众语言变为小众语言,比如你现在可以用它爬取本地数据,用python3来运行你的爬虫,你也可以用python2来进行大数据分析。python其实更多的是一种编程语言,它可以做很多事情,比如数据爬虫,网页调试,模拟浏览器,等等。为什么我不学java,因为java实在太他妈难了,不是我能吃得消的,我现在还要学其他语言。从这个意义。
python抓取网页数据( 就是爬虫模拟人对网页的操作方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-14 05:21
就是爬虫模拟人对网页的操作方法)
Python实现爬取百度热搜信息
什么是爬虫,其实就是用电脑模拟一个人在网页上的操作。
示例:模拟人类浏览和购物 网站。
您可以在目标网站中添加/robots.txt来查看网页的具体信息,例如可以在天猫上进入查看。
User-agent 代表发送请求的对象
星号 * 代表任何搜索引擎
Disallow 表示不允许访问的部分
/ 表示从根开始
Allow 表示允许访问的部分
在这个例子中,我爬取了百度热搜前30条新闻(我本来打算在英雄联盟首页数据中心的数据中心爬取前50名英雄的英雄信息,但是我无法实现延迟爬取网页,但我只能爬百度热搜),它的一般信息放在Excel表格和Flask网页中,实现数据可视化。对数据可视化感兴趣的同学也可以爬取其他内容
由于我的水平有限,这个文章里面的爬虫都是比较基础的东西
库函数准备
如何安装 Python 库:
打开 cmd 命令提示符并输入 pip install XXX (这是你要安装的库的名称)
这些库的具体使用可以看我接下来的操作
只需要掌握几个常用功能
BS4
即美丽汤
用于解析 HTML 页面并提取指定数据。
后面我的demo里会看到详细的用法。
回覆
用于匹配字符串中的响应字符串的正则表达式。
关于正则表达式,可以去菜鸟教程详细介绍
urllib
它是 Python 自带的 HTTP 请求库,可以操作一系列 URL。
xlwt/xlrt
用于写入(写入)/读取(读取)Excel 表格中的数据。
烧瓶
该库用于制作一个简单的 Web 框架,即 网站 用于数据可视化。
其实我对数据可视化的把握也很浅薄,只是简单的将数据导入到网页中。
神社2
这个库的目的是实现在 HTML 页面的字符中插入参数的功能。
后端:
name="HQ"
前端:
<p>{{name}}长得真帅!
显示:
HQ长得真帅!</p>
标记安全
与 Jinja 一起使用以在渲染页面时避免不受信任的输入,防止注入攻击(尽管没有人会攻击你....)
数据抓取
数据爬取和数据可视化的两个py文件是分开的
数据爬取需要导入re bs4 urllib xlwt的四个库文件
网页抓取
使用下面的方法调用一个函数,让函数调用关系更清晰
if __name__=="__main__": #当程序执行时 调用一下函数
main()
def askurl(url):
head={
"User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'''
}
#用户代理 告诉服务器我只是一个普普通通的浏览器
requset=urllib.request.Request(url)
#发送请求
response=urllib.request.urlopen(requset)
#响应的为一个request对象
#通过read()转化为 bytes类型字符串
#再通过decode()转化为 str类型的字符串
#接受响应
html=response.read().decode('utf-8')
将抓取到的网页存入文档中 方便观察
path=r"C:\Users\XXX\Desktop\Python\text.txt"
#这里在字符串前加入r 防止字符串中的\发生转义
f=open(r"path",'w',encoding='utf-8')
f.write(html)
f.close()
#这样在txt文件中就可以查看网页的源码
return html
headers的值可以在网页中按F12
然后点击network change,下拉到底部任意request header,就是user-agent代理信息
值得注意的是,如果请求中没有设置headers,服务器会返回418状态码
表示服务器认出你是爬虫,说:“我是茶壶”
表示服务器拒绝煮咖啡,因为它总是一个茶壶(这是一个表情包)
数据分析
把抓到的txt文件后缀改成html作为本地网页打开
如果因为行太长导致vscode报错,可以参考以下博客
打开后的页面如图
使用该功能查看需要爬取信息的地方
在这个项目中,我们抓取目标信息的标题内容和链接
我们可以发现,我们需要的所有信息都在其类为以下类型的表中
所以我们使用 Beautifulsoup 来解析网页
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配
接下来,重新匹配每个项目
首先使用pile()创建匹配规则,然后使用findall进行匹配
通过查看HTML文件中目标信息前后的特殊字符创建匹配规则
而 (.*?) 是要与 * 匹配的字符串,后跟 ? 代表非贪心匹配
例如
标题前后的信息为省略号">和 查看全部
python抓取网页数据(
就是爬虫模拟人对网页的操作方法)
Python实现爬取百度热搜信息
什么是爬虫,其实就是用电脑模拟一个人在网页上的操作。
示例:模拟人类浏览和购物 网站。
您可以在目标网站中添加/robots.txt来查看网页的具体信息,例如可以在天猫上进入查看。
User-agent 代表发送请求的对象
星号 * 代表任何搜索引擎
Disallow 表示不允许访问的部分
/ 表示从根开始
Allow 表示允许访问的部分
在这个例子中,我爬取了百度热搜前30条新闻(我本来打算在英雄联盟首页数据中心的数据中心爬取前50名英雄的英雄信息,但是我无法实现延迟爬取网页,但我只能爬百度热搜),它的一般信息放在Excel表格和Flask网页中,实现数据可视化。对数据可视化感兴趣的同学也可以爬取其他内容
由于我的水平有限,这个文章里面的爬虫都是比较基础的东西
库函数准备
如何安装 Python 库:
打开 cmd 命令提示符并输入 pip install XXX (这是你要安装的库的名称)
这些库的具体使用可以看我接下来的操作
只需要掌握几个常用功能
BS4
即美丽汤
用于解析 HTML 页面并提取指定数据。
后面我的demo里会看到详细的用法。
回覆
用于匹配字符串中的响应字符串的正则表达式。
关于正则表达式,可以去菜鸟教程详细介绍
urllib
它是 Python 自带的 HTTP 请求库,可以操作一系列 URL。
xlwt/xlrt
用于写入(写入)/读取(读取)Excel 表格中的数据。
烧瓶
该库用于制作一个简单的 Web 框架,即 网站 用于数据可视化。
其实我对数据可视化的把握也很浅薄,只是简单的将数据导入到网页中。
神社2
这个库的目的是实现在 HTML 页面的字符中插入参数的功能。
后端:
name="HQ"
前端:
<p>{{name}}长得真帅!
显示:
HQ长得真帅!</p>
标记安全
与 Jinja 一起使用以在渲染页面时避免不受信任的输入,防止注入攻击(尽管没有人会攻击你....)
数据抓取
数据爬取和数据可视化的两个py文件是分开的
数据爬取需要导入re bs4 urllib xlwt的四个库文件
网页抓取
使用下面的方法调用一个函数,让函数调用关系更清晰
if __name__=="__main__": #当程序执行时 调用一下函数
main()
def askurl(url):
head={
"User-Agent":'''Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.55'''
}
#用户代理 告诉服务器我只是一个普普通通的浏览器
requset=urllib.request.Request(url)
#发送请求
response=urllib.request.urlopen(requset)
#响应的为一个request对象
#通过read()转化为 bytes类型字符串
#再通过decode()转化为 str类型的字符串
#接受响应
html=response.read().decode('utf-8')
将抓取到的网页存入文档中 方便观察
path=r"C:\Users\XXX\Desktop\Python\text.txt"
#这里在字符串前加入r 防止字符串中的\发生转义
f=open(r"path",'w',encoding='utf-8')
f.write(html)
f.close()
#这样在txt文件中就可以查看网页的源码
return html
headers的值可以在网页中按F12
然后点击network change,下拉到底部任意request header,就是user-agent代理信息
值得注意的是,如果请求中没有设置headers,服务器会返回418状态码
表示服务器认出你是爬虫,说:“我是茶壶”
表示服务器拒绝煮咖啡,因为它总是一个茶壶(这是一个表情包)
数据分析
把抓到的txt文件后缀改成html作为本地网页打开
如果因为行太长导致vscode报错,可以参考以下博客
打开后的页面如图
使用该功能查看需要爬取信息的地方
在这个项目中,我们抓取目标信息的标题内容和链接
我们可以发现,我们需要的所有信息都在其类为以下类型的表中
所以我们使用 Beautifulsoup 来解析网页
def getData(html):
datalist=[]
soup=BeautifulSoup(html,"html.parser") #定义一个解析对象
#soup.find_all(a,b) 其中a为标签的类型 class_ 对div的class进行匹配
#返回的是所有class为category-wrap_iQLoo horizontal_1eKyQ的列表
for item in soup.find_all('div',class_="category-wrap_iQLoo horizontal_1eKyQ"):
item=str(item)
#将列表中每一个子标签转换为字符串用于re匹配
接下来,重新匹配每个项目
首先使用pile()创建匹配规则,然后使用findall进行匹配
通过查看HTML文件中目标信息前后的特殊字符创建匹配规则
而 (.*?) 是要与 * 匹配的字符串,后跟 ? 代表非贪心匹配
例如
标题前后的信息为省略号">和

