
php抓取网页表格信息
php抓取网页表格信息(PHP基础教程是一个比较有价值的PHP新手教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 16:19
PHP基础教程是比较有价值的PHP新手教程!
标题:PHP 基础教程 来源:Merry CG web log 时间:Mon, 28 Aug 2006 07:24:34 +0000 作者:yufeng 地址:内容:PHP 初学者教程,供初学者学习,是比较有价值的PHP 初学者教程!一、PHP 简介 PHP 是一种易于学习和使用的服务器端脚本语言。只需很少的编程知识,您就可以使用 PHP 构建一个真正交互式的 WEB 站点。本教程不希望你完全理解这门语言,但它会让你尽快加入开发动态网站的行列。我假设你有一些 HTML(或 HTML 编辑器)的基本知识和一些编程思想。1. 简介 PHP 是允许您生成动态网页的工具之一。PHP 网页文件被视为普通的 HTML 网页文件,您可以在编辑时按照通常的 HTML 编辑方式编写 PHP。PHP 代表:超文本预处理器(PHP:Hypertext Preprocessor)。PHP 是完全免费的,您可以从 PHP 官方网站 () 免费免费下载。PHP 遵守 GNU 公共许可证 (GPL),许多流行的软件如 Linux 和 Emacs 都是在该许可证下诞生的。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。
关于如何在 Windows 环境下的 PC 或 Unix 机器上安装 PHP 的信息可以在官方 PHP 站点上找到。安装过程非常简单。如果你的机器解决了 2000 年的问题,那么 PHP 也摆脱了 Y2K 的问题!1.1 历史 三年前,Rasmus Lerdorf 创建了“个人主页工具”以创建他的在线简历。这是一种非常简单的语言。从那时起,越来越多的人注意到了这种语言,并对其扩展提出了各种建议。在许多人的无私奉献和这门语言本身的免费源代码性质下,它已经演变成一门功能丰富的语言,并且还在不断地成长。PHP 虽然简单易学,但比 mod_perl(嵌入在 web 服务器中的 perl 模块)要慢。现在有一个新的引擎叫做 Zend 可以匹配 mod_perl 的速度,PHP4 可以充分利用这个引擎。PHP4 仍处于 beta 测试阶段。Andy Gutmans 和 Zeev Suraki 是 Zend 的主要作者。您可以到 Zend 站点 () 了解更多信息。PHP 在个人 Web 项目中的应用显着增长。根据 Netcraft 1999 年 10 月的报告,931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。
当然,已知的缺点是 PHP 没有商业支持,因为它是一个开源项目,导致执行速度慢(直到 PHP4)。但是 PHP 邮件列表非常有用,除非您正在运行一个非常受欢迎的站点,例如 Yahoo! 或者这个,你不会觉得PHP的速度跟别人不一样。至少我没有感觉到!好,我们来看看PHP的优点: - 学习过程 我个人更喜欢PHP的非常简单的学习过程。与 Java 和 Perl 不同,您不必将头埋在 100 页以上的文档中并努力学习以编写一个像样的程序。只要了解一些基本的语法和语言特性,就可以开始你的 PHP 编码之旅了。之后,如果您在编码过程中遇到任何问题,您可以再次阅读相关文档。PHP 的语法与 C、Perl、ASP 或 JSP 相同。对于熟悉上述其中一种语言的人来说,PHP 太简单了。相反,如果你对PHP了解得更多,那么你学习其他几种语言就很容易了。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。
-数据库连接PHP可以编译成连接很多数据库的函数。PHP 和 MySQL 现在是一个极好的组合。也可以自己编写外围函数,间接访问数据库。这样,当您更改您使用的数据库时,您可以轻松更改编码以适应此类更改。PHPLIB 是最常用的一系列基础库,可以提供一般业务需求。- 可扩展性如前所述,PHP 进入了快速发展的时期。非程序员可能很难为 PHP 扩展附加功能,但对于 PHP 程序员来说并不难。- 面向对象编程 PHP 提供了类和对象。基于 Web 的编程需要面向对象的编程能力。PHP 支持构造函数、提取类等。 -Scalability 传统上,网页的交互是通过CGI实现的。CGI 程序的可扩展性并不理想,因为它为每个正在运行的 CGI 程序打开了一个单独的进程。解决
现在就下载 查看全部
php抓取网页表格信息(PHP基础教程是一个比较有价值的PHP新手教程(图))
PHP基础教程是比较有价值的PHP新手教程!
标题:PHP 基础教程 来源:Merry CG web log 时间:Mon, 28 Aug 2006 07:24:34 +0000 作者:yufeng 地址:内容:PHP 初学者教程,供初学者学习,是比较有价值的PHP 初学者教程!一、PHP 简介 PHP 是一种易于学习和使用的服务器端脚本语言。只需很少的编程知识,您就可以使用 PHP 构建一个真正交互式的 WEB 站点。本教程不希望你完全理解这门语言,但它会让你尽快加入开发动态网站的行列。我假设你有一些 HTML(或 HTML 编辑器)的基本知识和一些编程思想。1. 简介 PHP 是允许您生成动态网页的工具之一。PHP 网页文件被视为普通的 HTML 网页文件,您可以在编辑时按照通常的 HTML 编辑方式编写 PHP。PHP 代表:超文本预处理器(PHP:Hypertext Preprocessor)。PHP 是完全免费的,您可以从 PHP 官方网站 () 免费免费下载。PHP 遵守 GNU 公共许可证 (GPL),许多流行的软件如 Linux 和 Emacs 都是在该许可证下诞生的。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。
关于如何在 Windows 环境下的 PC 或 Unix 机器上安装 PHP 的信息可以在官方 PHP 站点上找到。安装过程非常简单。如果你的机器解决了 2000 年的问题,那么 PHP 也摆脱了 Y2K 的问题!1.1 历史 三年前,Rasmus Lerdorf 创建了“个人主页工具”以创建他的在线简历。这是一种非常简单的语言。从那时起,越来越多的人注意到了这种语言,并对其扩展提出了各种建议。在许多人的无私奉献和这门语言本身的免费源代码性质下,它已经演变成一门功能丰富的语言,并且还在不断地成长。PHP 虽然简单易学,但比 mod_perl(嵌入在 web 服务器中的 perl 模块)要慢。现在有一个新的引擎叫做 Zend 可以匹配 mod_perl 的速度,PHP4 可以充分利用这个引擎。PHP4 仍处于 beta 测试阶段。Andy Gutmans 和 Zeev Suraki 是 Zend 的主要作者。您可以到 Zend 站点 () 了解更多信息。PHP 在个人 Web 项目中的应用显着增长。根据 Netcraft 1999 年 10 月的报告,931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。
当然,已知的缺点是 PHP 没有商业支持,因为它是一个开源项目,导致执行速度慢(直到 PHP4)。但是 PHP 邮件列表非常有用,除非您正在运行一个非常受欢迎的站点,例如 Yahoo! 或者这个,你不会觉得PHP的速度跟别人不一样。至少我没有感觉到!好,我们来看看PHP的优点: - 学习过程 我个人更喜欢PHP的非常简单的学习过程。与 Java 和 Perl 不同,您不必将头埋在 100 页以上的文档中并努力学习以编写一个像样的程序。只要了解一些基本的语法和语言特性,就可以开始你的 PHP 编码之旅了。之后,如果您在编码过程中遇到任何问题,您可以再次阅读相关文档。PHP 的语法与 C、Perl、ASP 或 JSP 相同。对于熟悉上述其中一种语言的人来说,PHP 太简单了。相反,如果你对PHP了解得更多,那么你学习其他几种语言就很容易了。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。
-数据库连接PHP可以编译成连接很多数据库的函数。PHP 和 MySQL 现在是一个极好的组合。也可以自己编写外围函数,间接访问数据库。这样,当您更改您使用的数据库时,您可以轻松更改编码以适应此类更改。PHPLIB 是最常用的一系列基础库,可以提供一般业务需求。- 可扩展性如前所述,PHP 进入了快速发展的时期。非程序员可能很难为 PHP 扩展附加功能,但对于 PHP 程序员来说并不难。- 面向对象编程 PHP 提供了类和对象。基于 Web 的编程需要面向对象的编程能力。PHP 支持构造函数、提取类等。 -Scalability 传统上,网页的交互是通过CGI实现的。CGI 程序的可扩展性并不理想,因为它为每个正在运行的 CGI 程序打开了一个单独的进程。解决
现在就下载
php抓取网页表格信息(爬取空气质量检测网之部分城市的历年每天质量数据思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-15 00:07
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后抓取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏的表数据,但是不稳定,
仍然遇到的问题:-----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用 driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month) 查看全部
php抓取网页表格信息(爬取空气质量检测网之部分城市的历年每天质量数据思路)
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后抓取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏的表数据,但是不稳定,
仍然遇到的问题:-----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用 driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month)
php抓取网页表格信息(python制作爬虫并将抓取结果保存到excel中的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-13 22:06
想知道python制作爬虫并将爬取结果保存到excel的相关内容吗?在本文中,Data&Truth 将仔细讲解python制作爬虫并将爬取结果保存到excel的相关知识以及一些代码示例。欢迎先阅读并指正重点:下面一起来学习python爬虫
我已经学习 Python 一段时间了。各种理论知识大体上可以考虑一两个。进入今天的实战练习:用Python写一个拉勾网薪资调查的小爬虫
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,搜索Python或PHP等职位信息实际上是在向服务器发送相应的请求。服务器动态响应请求,通过浏览器分析将我们需要的内容呈现给我们。
可以看到,我们发送的请求中FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求
建议使用 Fiddler 来分析比较复杂的页面请求和响应信息。绝对是分析网站的杀手锏。但是,相对简单的响应请求,可以配合浏览器自带的开发工具使用,比如火狐的FireBug等,所有请求的信息,只要按一下F12就可以展现在你面前
通过对网站的请求和响应过程的分析可以看出,拉勾网的招聘信息是由XHR动态传输的
我们发现POST发送了两个请求,companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总次数(totalCount)等相关信息
第二步:发送请求获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一就是在模仿浏览器的Post方法后如何打包我们自己的请求
请求中收录的参数包括要爬取的网页的URL和headersurlopen中的data参数进行伪装,包括FormData的三个参数(first, pn, kd)
打包完成后,您可以像浏览器一样访问拉勾网,获取页面数据。
第三步:各自获取所需数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步了:爬取数据
捕获数据的方法有很多种,比如正则表达式relxml的etreejson和bs4的BeautifulSoup,都是python3捕获数据的适用方法。您可以根据实际情况使用其中的一种或多种。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,我们将采集到的数据在excel中进行结构化、组织化的存储,以便进一步整理分析,方便数据的可视化。
这里我使用了两个不同的框架:旧的 xlwt.Workbook 和 xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先,xlwt不知道为什么xlwt存储了100多条数据后存储不全,excel文件也会出现“部分内容有问题需要修复”。查了很多次,还以为是数据采集不全导致的存储问题。出问题后断点检查发现数据完整。然后我改了本地数据进行处理,没有问题。我当时的心情是这样的:
直到现在,我还没有弄清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据可以正常使用没有问题
至此,一个从拉勾网抓取招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的所以需要通过post来递交json信息默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息包括公司名称学历要求薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数大于30的将会被覆盖所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多可以添加的功能,比如通过修改城市参数查看不同城市的招聘信息等,这里可以自己开发,仅供参考,欢迎交流
相关文章 查看全部
php抓取网页表格信息(python制作爬虫并将抓取结果保存到excel中的相关内容吗)
想知道python制作爬虫并将爬取结果保存到excel的相关内容吗?在本文中,Data&Truth 将仔细讲解python制作爬虫并将爬取结果保存到excel的相关知识以及一些代码示例。欢迎先阅读并指正重点:下面一起来学习python爬虫
我已经学习 Python 一段时间了。各种理论知识大体上可以考虑一两个。进入今天的实战练习:用Python写一个拉勾网薪资调查的小爬虫
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,搜索Python或PHP等职位信息实际上是在向服务器发送相应的请求。服务器动态响应请求,通过浏览器分析将我们需要的内容呈现给我们。

可以看到,我们发送的请求中FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求
建议使用 Fiddler 来分析比较复杂的页面请求和响应信息。绝对是分析网站的杀手锏。但是,相对简单的响应请求,可以配合浏览器自带的开发工具使用,比如火狐的FireBug等,所有请求的信息,只要按一下F12就可以展现在你面前
通过对网站的请求和响应过程的分析可以看出,拉勾网的招聘信息是由XHR动态传输的

我们发现POST发送了两个请求,companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。

可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总次数(totalCount)等相关信息
第二步:发送请求获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一就是在模仿浏览器的Post方法后如何打包我们自己的请求
请求中收录的参数包括要爬取的网页的URL和headersurlopen中的data参数进行伪装,包括FormData的三个参数(first, pn, kd)
打包完成后,您可以像浏览器一样访问拉勾网,获取页面数据。
第三步:各自获取所需数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步了:爬取数据
捕获数据的方法有很多种,比如正则表达式relxml的etreejson和bs4的BeautifulSoup,都是python3捕获数据的适用方法。您可以根据实际情况使用其中的一种或多种。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,我们将采集到的数据在excel中进行结构化、组织化的存储,以便进一步整理分析,方便数据的可视化。
这里我使用了两个不同的框架:旧的 xlwt.Workbook 和 xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先,xlwt不知道为什么xlwt存储了100多条数据后存储不全,excel文件也会出现“部分内容有问题需要修复”。查了很多次,还以为是数据采集不全导致的存储问题。出问题后断点检查发现数据完整。然后我改了本地数据进行处理,没有问题。我当时的心情是这样的:

直到现在,我还没有弄清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据可以正常使用没有问题
至此,一个从拉勾网抓取招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的所以需要通过post来递交json信息默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息包括公司名称学历要求薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数大于30的将会被覆盖所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多可以添加的功能,比如通过修改城市参数查看不同城市的招聘信息等,这里可以自己开发,仅供参考,欢迎交流
相关文章
php抓取网页表格信息(Python+GoogleAppEngine免费解决方案的存取接口补充说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 19:18
鼠标悬停在红框上阅读评论,可以了解我的需求,以下是补充说明,有时间可以阅读。
主要用途:抓取某个租房信息网页的数据,交给我的网站使用(先存入数据库,然后作为网页发布,以后保存数据
[color=#000000]制作谷歌地图)。你要做的就是第一步,即抓取信息并存入数据库,提供方便的访问接口。当然,如果你提供一种巧妙的方式,定期将数据发布到我的特定网页网站,或者将其导入到google融合表中,那么我将省略后两个特殊步骤。为了表示鼓励,它会在任务量之外。报酬。) 虽然任务不紧急,15天内可以完成,但是如果你觉得还可以,申请一个测试账号,那么最好当天就安装运行成功。我不希望你经常改变这个那个,浪费双方宝贵的时间,所以请仔细阅读文档以准确实现我的意图。[/颜色]
[color=#333399]提供的平台环境和语言(请本地获取库和代码,然后找我要账号):[/color]
选项1:PHP + MySQL + Cron 我有一个空闲的虚拟PHP主机(但不是我将发布信息的主机网站。这就是为什么我需要一个数据访问接口。我希望接口足够简单任何支持HTML/Javascript的网页都可以用Key随便调用)。宿主机已经支持 Cron 定时任务,但是你需要安装你准备使用的库。
方案二:Python+Google AppEngine免费方案,需要安装BeautifulSoup+Mechanize等库,注意采用灵活的方法避开GAE政策限制,哈哈。
[color=#333399] 选项3:也许有WP高手可以用Wordpress+Autoblog来解决?在PHP主机上也可以,但不知道采集会不会顺利,请仔细阅读任务说明,赐教。[/颜色]
我讨厌代码太多,所以请务必使用现有的免费和开源库来巧妙地解决问题。代码量不超过250,行为漂亮,哈哈。您的时间应该主要花在分析着陆页的数据结构和集成各种库上。一个几百块钱的任务,几个小时就能完成,你我双赢。如果你的计划太复杂,工作量太大,肯定会让双方尴尬。但是我耽搁了,最后还是违约了。虽然钱没有丢,但时间和事情都耽误了。因为退款了,没办法投诉。半年多没敢来竹八界发任务了)。
[color=#ff0000]具体任务说明请下载附件查看[/color]。虽然可以多点N次,但是可以防止原来的网站从google上查出谁在得到他的数据——甚至根据他对这个网站的描述,除了一些自己的信息,还有很多其他的也从主要 网站 爬取。[color=#ff0000] 提交任务时请打包,不要在描述中提及原站点,谢谢。任务代号FreeShark[/color] 你可以用这个代号来调用它。
参考(只是为了让你更清楚我的意图,不是教程,这些你应该早就熟悉了):
[size=2]Python采集网站数据[/size]
[尺寸=3][/尺寸]
其他:([color=#ff0000]这个例子使用代理来逃避跟踪。这是一个聪明的方法来放弃[/color]。)
——煽动的好处是可以让你更清楚我的意图,减少在QQ上浪费生命。哈哈,介绍完毕。 查看全部
php抓取网页表格信息(Python+GoogleAppEngine免费解决方案的存取接口补充说明(一))
鼠标悬停在红框上阅读评论,可以了解我的需求,以下是补充说明,有时间可以阅读。
主要用途:抓取某个租房信息网页的数据,交给我的网站使用(先存入数据库,然后作为网页发布,以后保存数据
[color=#000000]制作谷歌地图)。你要做的就是第一步,即抓取信息并存入数据库,提供方便的访问接口。当然,如果你提供一种巧妙的方式,定期将数据发布到我的特定网页网站,或者将其导入到google融合表中,那么我将省略后两个特殊步骤。为了表示鼓励,它会在任务量之外。报酬。) 虽然任务不紧急,15天内可以完成,但是如果你觉得还可以,申请一个测试账号,那么最好当天就安装运行成功。我不希望你经常改变这个那个,浪费双方宝贵的时间,所以请仔细阅读文档以准确实现我的意图。[/颜色]
[color=#333399]提供的平台环境和语言(请本地获取库和代码,然后找我要账号):[/color]
选项1:PHP + MySQL + Cron 我有一个空闲的虚拟PHP主机(但不是我将发布信息的主机网站。这就是为什么我需要一个数据访问接口。我希望接口足够简单任何支持HTML/Javascript的网页都可以用Key随便调用)。宿主机已经支持 Cron 定时任务,但是你需要安装你准备使用的库。
方案二:Python+Google AppEngine免费方案,需要安装BeautifulSoup+Mechanize等库,注意采用灵活的方法避开GAE政策限制,哈哈。
[color=#333399] 选项3:也许有WP高手可以用Wordpress+Autoblog来解决?在PHP主机上也可以,但不知道采集会不会顺利,请仔细阅读任务说明,赐教。[/颜色]
我讨厌代码太多,所以请务必使用现有的免费和开源库来巧妙地解决问题。代码量不超过250,行为漂亮,哈哈。您的时间应该主要花在分析着陆页的数据结构和集成各种库上。一个几百块钱的任务,几个小时就能完成,你我双赢。如果你的计划太复杂,工作量太大,肯定会让双方尴尬。但是我耽搁了,最后还是违约了。虽然钱没有丢,但时间和事情都耽误了。因为退款了,没办法投诉。半年多没敢来竹八界发任务了)。
[color=#ff0000]具体任务说明请下载附件查看[/color]。虽然可以多点N次,但是可以防止原来的网站从google上查出谁在得到他的数据——甚至根据他对这个网站的描述,除了一些自己的信息,还有很多其他的也从主要 网站 爬取。[color=#ff0000] 提交任务时请打包,不要在描述中提及原站点,谢谢。任务代号FreeShark[/color] 你可以用这个代号来调用它。
参考(只是为了让你更清楚我的意图,不是教程,这些你应该早就熟悉了):
[size=2]Python采集网站数据[/size]
[尺寸=3][/尺寸]
其他:([color=#ff0000]这个例子使用代理来逃避跟踪。这是一个聪明的方法来放弃[/color]。)
——煽动的好处是可以让你更清楚我的意图,减少在QQ上浪费生命。哈哈,介绍完毕。
php抓取网页表格信息( php.ini中的max_execution设置设置的大点软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-02 14:02
php.ini中的max_execution设置设置的大点软件)
在进行爬取之前,记得把php.ini中的max_execution_time设置为较大的值,否则会报错。
一、 使用 Snoopy.class.php 抓取页面
一个很可爱的类名。功能也很强大,用来模拟浏览器的功能,可以获取网页内容,发送表单等等。
1)我要抓取网站的一个列表页的内容,我要抓取的是全国医院的信息内容,如下图:
2) 我自然是复制了URL地址,使用Snoopy类抓取前10页的内容,并将内容放到本地,在本地创建一个html文件,供以后分析使用。
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3) 奇怪的是,返回的不是全国的内容,而是上海的相关内容
4) 怀疑里面可能设置了cookie,然后用firebug查了一下,果然有惊人的内情
5) 在请求中放入cookie的值,并添加设置语句$snoopy->cookies["_area_"],情况大不相同,顺利返回国家信息。
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i fetch($url);
$html = $snoopy->results;
}
2)使用phpQuery获取节点信息,DOM结构如下图所示:
使用一些phpQuery方法,结合DOM结构读取各个医院信息的URL地址。
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取到的URL地址列表,抓取指定页面。
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
克服障碍.rar
演示下载:
史努比类的一些说明:
类方法
获取($URI)
这是用于抓取网页内容的方法。
$URI 参数是被爬取的网页的 URL 地址。
获取的结果存储在 $this->results 中。
如果你正在抓取一帧,史努比会跟踪每一帧并将其存储在一个数组中,然后将其存储在 $this->results 中。
获取文本($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的表单内容(form)。
获取链接($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。$formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,并且只返回登录后网页中的文本内容。
提交链接($URI)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
类属性
$host
连接主机
$端口
连接端口
$proxy_host
使用的代理主机(如果有)
$proxy_port
使用的代理主机端口(如果有)
$代理
用户代理伪装(史努比 v0.1)
$referer
信息,如果有
$cookies
饼干,如果有的话
$rawheaders
其他标题信息,如果有的话
$maxredirs
最大重定向次数,0=不允许 (5)
$offsiteok
是否允许异地重定向。(真的)
$expandlinks
是否完成所有链接完成地址(true)
$用户
身份验证用户名(如果有)
$pass
身份验证用户名(如果有)
$接受
http 接受类型 (image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*)
$错误
在哪里报告错误,如果有的话
$response_code
服务器返回的响应码
$headers
服务器返回的头部信息
$最大长度
最大返回数据长度
$read_timeout
读取操作超时(需要 PHP 4 Beta 4+),设置为 0 表示没有超时
$timed_out
如果读取操作超时,则此属性返回 true(需要 PHP 4 Beta 4+)
$maxframes
允许跟踪的最大帧数
$状态 查看全部
php抓取网页表格信息(
php.ini中的max_execution设置设置的大点软件)



在进行爬取之前,记得把php.ini中的max_execution_time设置为较大的值,否则会报错。
一、 使用 Snoopy.class.php 抓取页面
一个很可爱的类名。功能也很强大,用来模拟浏览器的功能,可以获取网页内容,发送表单等等。
1)我要抓取网站的一个列表页的内容,我要抓取的是全国医院的信息内容,如下图:
2) 我自然是复制了URL地址,使用Snoopy类抓取前10页的内容,并将内容放到本地,在本地创建一个html文件,供以后分析使用。
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3) 奇怪的是,返回的不是全国的内容,而是上海的相关内容
4) 怀疑里面可能设置了cookie,然后用firebug查了一下,果然有惊人的内情
5) 在请求中放入cookie的值,并添加设置语句$snoopy->cookies["_area_"],情况大不相同,顺利返回国家信息。
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i fetch($url);
$html = $snoopy->results;
}
2)使用phpQuery获取节点信息,DOM结构如下图所示:
使用一些phpQuery方法,结合DOM结构读取各个医院信息的URL地址。
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取到的URL地址列表,抓取指定页面。
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
克服障碍.rar
演示下载:
史努比类的一些说明:
类方法
获取($URI)
这是用于抓取网页内容的方法。
$URI 参数是被爬取的网页的 URL 地址。
获取的结果存储在 $this->results 中。
如果你正在抓取一帧,史努比会跟踪每一帧并将其存储在一个数组中,然后将其存储在 $this->results 中。
获取文本($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的表单内容(form)。
获取链接($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。$formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,并且只返回登录后网页中的文本内容。
提交链接($URI)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
类属性
$host
连接主机
$端口
连接端口
$proxy_host
使用的代理主机(如果有)
$proxy_port
使用的代理主机端口(如果有)
$代理
用户代理伪装(史努比 v0.1)
$referer
信息,如果有
$cookies
饼干,如果有的话
$rawheaders
其他标题信息,如果有的话
$maxredirs
最大重定向次数,0=不允许 (5)
$offsiteok
是否允许异地重定向。(真的)
$expandlinks
是否完成所有链接完成地址(true)
$用户
身份验证用户名(如果有)
$pass
身份验证用户名(如果有)
$接受
http 接受类型 (image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*)
$错误
在哪里报告错误,如果有的话
$response_code
服务器返回的响应码
$headers
服务器返回的头部信息
$最大长度
最大返回数据长度
$read_timeout
读取操作超时(需要 PHP 4 Beta 4+),设置为 0 表示没有超时
$timed_out
如果读取操作超时,则此属性返回 true(需要 PHP 4 Beta 4+)
$maxframes
允许跟踪的最大帧数
$状态
php抓取网页表格信息(php抓取网页表格信息到本地html文件用lll如果我只是记表格的话就方便了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-30 11:02
php抓取网页表格信息到本地html文件
用lll如果我只是记表格的话就方便了header你自己写一个标签注意要加括号后面的是要链接的链接这样一般你就能找到你要的数据如果这都不能满足你的需求或者想进一步筛选你可以试试第三方框架homicaws
morganfullman开发的forms.php,该框架可以创建html表格并嵌入script脚本。
简单直接的方法,用lll你可以爬1000万行数据,然后按照页码去抓取。
请楼主回答:php本身就能爬数据吗?用php处理java的就可以啊
我用php做的一个简单爬虫框架:1、基于get请求获取网页元素(while)2、根据元素内容判断是否合法
sqlitemysqlphpapifaq一个基于php的数据库工具:easybook-php-apiapifaq
本人php做的
fiddler可以抓取用户信息,推荐试一下,
php的话f12在控制台里面看是看不出来的,然后万恶的get那个的api开头是post也不能用的,所以,让我猜猜websocket和urllib2是怎么进来的?get-emails,而urllib2根据api网上图书馆这类有对应页码的页面是绝对不能用get去获取的。不知道在哪找到一个websocket的开发包有明确说明的,很多也就学习了一下。 查看全部
php抓取网页表格信息(php抓取网页表格信息到本地html文件用lll如果我只是记表格的话就方便了)
php抓取网页表格信息到本地html文件
用lll如果我只是记表格的话就方便了header你自己写一个标签注意要加括号后面的是要链接的链接这样一般你就能找到你要的数据如果这都不能满足你的需求或者想进一步筛选你可以试试第三方框架homicaws
morganfullman开发的forms.php,该框架可以创建html表格并嵌入script脚本。
简单直接的方法,用lll你可以爬1000万行数据,然后按照页码去抓取。
请楼主回答:php本身就能爬数据吗?用php处理java的就可以啊
我用php做的一个简单爬虫框架:1、基于get请求获取网页元素(while)2、根据元素内容判断是否合法
sqlitemysqlphpapifaq一个基于php的数据库工具:easybook-php-apiapifaq
本人php做的
fiddler可以抓取用户信息,推荐试一下,
php的话f12在控制台里面看是看不出来的,然后万恶的get那个的api开头是post也不能用的,所以,让我猜猜websocket和urllib2是怎么进来的?get-emails,而urllib2根据api网上图书馆这类有对应页码的页面是绝对不能用get去获取的。不知道在哪找到一个websocket的开发包有明确说明的,很多也就学习了一下。
php抓取网页表格信息(PHP库模拟登录开源中国的移动版为例库使用总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 19:03
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,有需要的朋友可以参考
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init();//初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1);//post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息 curl_exec($curl);//执行cURL curl_close($curl);//关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs; }
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上就是php curl模拟登录和获取详细数据示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页表格信息(PHP库模拟登录开源中国的移动版为例库使用总结)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,有需要的朋友可以参考
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init();//初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1);//post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息 curl_exec($curl);//执行cURL curl_close($curl);//关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs; }
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上就是php curl模拟登录和获取详细数据示例的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页表格信息(scraping-io、import和data-miner.io(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-26 06:21
网络抓取,有时也称为数据抓取、数据提取或网络厄瓜多尔手机号码列表,只是从 网站 采集数据并将其存储在本地数据库或电子表格中的过程。今天,网络抓取工具是现代营销人员所必需的。对于初学者来说,网络抓取可能听起来像是这些可怕的技术流行语之一,但从技术上讲,这没什么大不了的。但是,要执行任何网络抓取,您需要正确的工具。网页抓取工具不仅可以用于招聘目的,还可以用于营销、金融、电子商务和许多其他行业。我们将研究的工具是 scraping-bot.io、import.io、webscraper.io 和 data-miner.io。
在我们继续之前,我可以听到你在问“我为什么要花宝贵的时间学习如何爬网”?这就是为什么 - 潜在客户可以是帮助您代表品牌的直接客户或影响者。您可以自己搜索潜在客户,浏览网站 和社交媒体。但所有这些研究都需要时间。那么,如果您可以将这项研究留给机器,而您更多地关注战略和重要任务呢?网页抓取是一项尖端技术,旨在在尽可能短的时间内从数百万个网页中采集潜在客户的联系信息。这是一个信息时代,许多买家根据在线评论做出判断。因此,了解人们对您的品牌、产品、服务和竞争对手的评价非常重要。
什么是网络爬虫?
通常,小企业面临的最大挑战是如何在不失去客户的情况下提高价格。但是,不提高价格是不可能赚取更多利润的。在这里,您可以使用网络抓取工具来增加您的利润:让您了解任何竞争对手的价格变化,以便快速做出反应并优化您的价格。跟踪您的竞争对手所做的促销和活动的成功,以了解什么是最有效的。Scraping-bot.io 是一个 API,允许您从给定的 URL 中提取数据。您可以在 Google 页面或零售 网站 上获取整个 HTML 页面内容。最初开发用于抓取零售网站的产品页面,scraping-bot.io API也可用于抓取Google页面以进行SEO排名分析。在零售网站,集成的 API 将允许您采集您需要的所有重要信息。因此,例如,您可以抓取图像、产品标题、价格、产品描述、库存、运输成本、EAN、产品类别等。
有适度使用的免费计划(100 次调用/月),然后价格计划范围从 39 欧元(每月 100,000 次调用)到企业计划的 299 欧元(1,000,000 次调用/月)。有关爬行机器人定价的更多信息,您可以在此处查看。该工具的主要特性包括多个并发请求、JS渲染(Headless Chrome)、高质量代理和地理定位。如果您不想立即集成 API,可以在创建免费帐户后使用实时测试。完成此操作后,只需转到仪表板即可。然后,粘贴您要抓取的 URL 并选择您的选项(Get Html、Headless Chrome),您将能够立即看到此 API 的性能。您每月有 100 次免费计划电话,这足以试水,看看这款爬虫是否适合您。对于开发者来说,
为什么要学习网络爬虫?
转到您要抓取的页面(这里是亚马逊产品页面,但您可以尝试任何其他零售网站)并复制该页面的开曼群岛商业目录。转到您的仪表板或主页并将您的 URL 粘贴到实时测试框中。选择您的首选选项(完整的 HTML、无头浏览器)。使用 API 端点和 POST 方法进行直接集成。有完整的文档,包括用于在 NodeJs、Bash、Php、Python 和 Ruby 中抓取的代码示例。总而言之,scraping-bot.io 是一个没有 faff 的 API,可以用于中大批量的抓取。它将完成工作并为您节省大量时间和麻烦。Import.io 是一个可以提取和转换数据的企业级平台。使用Import.io,您可以先提取您需要的数据,将数据组织成您想要的格式,并通过数据可视化获得洞察力。该工具允许人们将非结构化 Web 数据转换为结构化格式,以用于机器学习、人工智能、零售价格监控、商店定位器以及学术和其他研究。
首先,找到您的数据所在的页面。例如,产品页面上。将此页面中的 URL 复制并粘贴到 Import.io 中,以创建一个尝试获取正确数据的提取器。单击 Go,Import.io 将查询该页面。它将使用机器学习来尝试确定您想要的数据。完成后,您可以决定提取的数据是否是您需要的。在这种情况下,我们希望将图像连同产品名称和价格一起提取到列中。我们通过单击每列中的前三个项目来训练提取器,然后用绿色勾勒出属于该列的所有项目。Import.io 然后为产品名称和价格填充列的其余部分。Import.io 检测到产品列表数据超过一页,因此您可以添加任意数量的页面,以确保该类别中的所有产品都收录在电子表格中。我们刚刚检查的是将基本数据列表页面转换为电子表格的热点。
帖子导航
WordPress 被黑?这是您需要做的一切。
大数据营销:完整指南 查看全部
php抓取网页表格信息(scraping-io、import和data-miner.io(组图))
网络抓取,有时也称为数据抓取、数据提取或网络厄瓜多尔手机号码列表,只是从 网站 采集数据并将其存储在本地数据库或电子表格中的过程。今天,网络抓取工具是现代营销人员所必需的。对于初学者来说,网络抓取可能听起来像是这些可怕的技术流行语之一,但从技术上讲,这没什么大不了的。但是,要执行任何网络抓取,您需要正确的工具。网页抓取工具不仅可以用于招聘目的,还可以用于营销、金融、电子商务和许多其他行业。我们将研究的工具是 scraping-bot.io、import.io、webscraper.io 和 data-miner.io。
在我们继续之前,我可以听到你在问“我为什么要花宝贵的时间学习如何爬网”?这就是为什么 - 潜在客户可以是帮助您代表品牌的直接客户或影响者。您可以自己搜索潜在客户,浏览网站 和社交媒体。但所有这些研究都需要时间。那么,如果您可以将这项研究留给机器,而您更多地关注战略和重要任务呢?网页抓取是一项尖端技术,旨在在尽可能短的时间内从数百万个网页中采集潜在客户的联系信息。这是一个信息时代,许多买家根据在线评论做出判断。因此,了解人们对您的品牌、产品、服务和竞争对手的评价非常重要。
什么是网络爬虫?
通常,小企业面临的最大挑战是如何在不失去客户的情况下提高价格。但是,不提高价格是不可能赚取更多利润的。在这里,您可以使用网络抓取工具来增加您的利润:让您了解任何竞争对手的价格变化,以便快速做出反应并优化您的价格。跟踪您的竞争对手所做的促销和活动的成功,以了解什么是最有效的。Scraping-bot.io 是一个 API,允许您从给定的 URL 中提取数据。您可以在 Google 页面或零售 网站 上获取整个 HTML 页面内容。最初开发用于抓取零售网站的产品页面,scraping-bot.io API也可用于抓取Google页面以进行SEO排名分析。在零售网站,集成的 API 将允许您采集您需要的所有重要信息。因此,例如,您可以抓取图像、产品标题、价格、产品描述、库存、运输成本、EAN、产品类别等。
 http://www.kybdirectory.com/cn ... 0.jpg 300w, http://www.kybdirectory.com/cn ... 1.jpg 768w" />
http://www.kybdirectory.com/cn ... 0.jpg 300w, http://www.kybdirectory.com/cn ... 1.jpg 768w" />有适度使用的免费计划(100 次调用/月),然后价格计划范围从 39 欧元(每月 100,000 次调用)到企业计划的 299 欧元(1,000,000 次调用/月)。有关爬行机器人定价的更多信息,您可以在此处查看。该工具的主要特性包括多个并发请求、JS渲染(Headless Chrome)、高质量代理和地理定位。如果您不想立即集成 API,可以在创建免费帐户后使用实时测试。完成此操作后,只需转到仪表板即可。然后,粘贴您要抓取的 URL 并选择您的选项(Get Html、Headless Chrome),您将能够立即看到此 API 的性能。您每月有 100 次免费计划电话,这足以试水,看看这款爬虫是否适合您。对于开发者来说,
为什么要学习网络爬虫?
转到您要抓取的页面(这里是亚马逊产品页面,但您可以尝试任何其他零售网站)并复制该页面的开曼群岛商业目录。转到您的仪表板或主页并将您的 URL 粘贴到实时测试框中。选择您的首选选项(完整的 HTML、无头浏览器)。使用 API 端点和 POST 方法进行直接集成。有完整的文档,包括用于在 NodeJs、Bash、Php、Python 和 Ruby 中抓取的代码示例。总而言之,scraping-bot.io 是一个没有 faff 的 API,可以用于中大批量的抓取。它将完成工作并为您节省大量时间和麻烦。Import.io 是一个可以提取和转换数据的企业级平台。使用Import.io,您可以先提取您需要的数据,将数据组织成您想要的格式,并通过数据可视化获得洞察力。该工具允许人们将非结构化 Web 数据转换为结构化格式,以用于机器学习、人工智能、零售价格监控、商店定位器以及学术和其他研究。
首先,找到您的数据所在的页面。例如,产品页面上。将此页面中的 URL 复制并粘贴到 Import.io 中,以创建一个尝试获取正确数据的提取器。单击 Go,Import.io 将查询该页面。它将使用机器学习来尝试确定您想要的数据。完成后,您可以决定提取的数据是否是您需要的。在这种情况下,我们希望将图像连同产品名称和价格一起提取到列中。我们通过单击每列中的前三个项目来训练提取器,然后用绿色勾勒出属于该列的所有项目。Import.io 然后为产品名称和价格填充列的其余部分。Import.io 检测到产品列表数据超过一页,因此您可以添加任意数量的页面,以确保该类别中的所有产品都收录在电子表格中。我们刚刚检查的是将基本数据列表页面转换为电子表格的热点。
帖子导航
WordPress 被黑?这是您需要做的一切。
大数据营销:完整指南
php抓取网页表格信息(纯静态网站在网站中是怎么实现的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 02:04
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。我们访问的时候,可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先对网站的页面进行汇总,分成几种样式,然后将这些页面制作成模板。生成的时候需要先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是小中型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过中小网站还是纯静态对比,优点很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你的后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全有能力抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试创建一个静态 URL。
下面我们主要讲一下静态页面的概念,希望对大家有所帮助!
什么是 html 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在php网站的开发中,针对网站推广和seo的需要,需要对网站进行全站或局部静态处理。php生成静态html页面的方法有很多,比如使用php模板、缓存等实现页面静态化。
php static的简单理解就是将网站生成的页面以静态html的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于php生成静态页面的处理机制。.
php伪静态:一种使用apache mod_rewrite的url重写方法。
html静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化seo、baidu、google会优先处理收录静态页面,不仅有收录的快,还有收录的饱满;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,html页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止sql注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现html静态化的策略和例子:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用php模板生成静态页面
php模板实现静态化非常方便,比如安装使用php smarty实现网站静态化。
在使用 smarty 的情况下,页面也可以是静态的。简单说一下smarty使用时动态阅读的方式。
一般分为这几个步骤:
1、 通过url传递一个参数(id);
2、然后根据这个id查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
smarty静态过程只需要在上述过程中增加两步即可。
第一:使用 ob_start() 在 1 之前打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效利用上述过程,可以使用一个小方法,即header()。具体过程如下: 添加修改程序后,使用header()跳转到前台读取,使页面可以html化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用php文件读写功能生成静态页面
方法三:使用php输出控制/ob缓存机制生成静态页面
输出控制功能(output control)就是使用和控制缓存来生成静态html页面。它还使用了php文件读写功能。
比如一个产品的动态详情页地址是:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道使用php进行网站开发,一般的执行结果都是直接输出到浏览器,为了使用php生成静态页面,需要使用输出控制功能来控制缓存区,这样获取缓存区的内容,然后输出到静态html页面文件,实现网站静态。
php生成静态页面的思路是:先开启缓存,然后输出html内容(也可以通过include以文件的形式收录html内容),然后获取缓存中的内容,然后通过php文件读写功能清除缓存。缓存内容写入静态html页面文件。
获取输出缓存内容生成静态html页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有空格、字符等输出。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。如果成功,则返回 true,如果失败,则返回 false。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。key 的默认最大大小不能超过 128 字节,value 的默认大小为 1m。所以1m的大小可以满足大部分网页的存储。
以上就是php实现静态html页面的方法,内容丰富,值得大家细细品味和收获。 查看全部
php抓取网页表格信息(纯静态网站在网站中是怎么实现的?(组图))
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。我们访问的时候,可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先对网站的页面进行汇总,分成几种样式,然后将这些页面制作成模板。生成的时候需要先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是小中型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过中小网站还是纯静态对比,优点很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你的后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全有能力抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试创建一个静态 URL。
下面我们主要讲一下静态页面的概念,希望对大家有所帮助!
什么是 html 静态:

常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在php网站的开发中,针对网站推广和seo的需要,需要对网站进行全站或局部静态处理。php生成静态html页面的方法有很多,比如使用php模板、缓存等实现页面静态化。
php static的简单理解就是将网站生成的页面以静态html的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于php生成静态页面的处理机制。.
php伪静态:一种使用apache mod_rewrite的url重写方法。
html静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化seo、baidu、google会优先处理收录静态页面,不仅有收录的快,还有收录的饱满;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,html页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止sql注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现html静态化的策略和例子:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。

方法一:使用php模板生成静态页面
php模板实现静态化非常方便,比如安装使用php smarty实现网站静态化。
在使用 smarty 的情况下,页面也可以是静态的。简单说一下smarty使用时动态阅读的方式。
一般分为这几个步骤:
1、 通过url传递一个参数(id);
2、然后根据这个id查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
smarty静态过程只需要在上述过程中增加两步即可。
第一:使用 ob_start() 在 1 之前打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效利用上述过程,可以使用一个小方法,即header()。具体过程如下: 添加修改程序后,使用header()跳转到前台读取,使页面可以html化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用php文件读写功能生成静态页面
方法三:使用php输出控制/ob缓存机制生成静态页面
输出控制功能(output control)就是使用和控制缓存来生成静态html页面。它还使用了php文件读写功能。
比如一个产品的动态详情页地址是:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道使用php进行网站开发,一般的执行结果都是直接输出到浏览器,为了使用php生成静态页面,需要使用输出控制功能来控制缓存区,这样获取缓存区的内容,然后输出到静态html页面文件,实现网站静态。
php生成静态页面的思路是:先开启缓存,然后输出html内容(也可以通过include以文件的形式收录html内容),然后获取缓存中的内容,然后通过php文件读写功能清除缓存。缓存内容写入静态html页面文件。
获取输出缓存内容生成静态html页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有空格、字符等输出。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。如果成功,则返回 true,如果失败,则返回 false。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。key 的默认最大大小不能超过 128 字节,value 的默认大小为 1m。所以1m的大小可以满足大部分网页的存储。
以上就是php实现静态html页面的方法,内容丰富,值得大家细细品味和收获。
php抓取网页表格信息(大城市知名大学名称selenium+python网页图片表格数据显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-25 19:05
php抓取网页表格信息数据显示大城市知名大学名称selenium+python抓取网页图片表格数据显示各种岗位工资分布myproject名单用excel转换成工资表excel转换成pdf压缩功能在线制作excel表格代码放到word里浏览器打开代码
github-eidop/neuralnet:neuralnet:aneuralnetworklayerforhuman-levelrecognition
flask的话学习python吧,python还是比较好上手的。
买个好点的鼠标吧
你肯定不知道你用网页抓这个为什么不直接网页抓api呢?而且这个很麻烦吧,你用各种工具抓要费不少劲然后这个把你乱七八糟的研究废了,而且还得改后端代码什么网页蜘蛛上什么都要下。
学python吧,java和php也可以,如果懂得c++也行,现在网上各种推荐python的。人工智能在学术界相当发达,可以实现比较高的效率。
前端用python+tornado或者koa实现api获取url
flask等nodejs框架去抓
人工智能及ai在线学习通过python来处理大量的数据,这其中就包括excel表格,此时多网站数据的搜集可能就成为问题。excel个人觉得没啥问题,但是专业的数据分析软件可能就不够了。
现在python都很成熟了,推荐把python用好,再去学习其他的语言。
python+selenium或者numpy 查看全部
php抓取网页表格信息(大城市知名大学名称selenium+python网页图片表格数据显示)
php抓取网页表格信息数据显示大城市知名大学名称selenium+python抓取网页图片表格数据显示各种岗位工资分布myproject名单用excel转换成工资表excel转换成pdf压缩功能在线制作excel表格代码放到word里浏览器打开代码
github-eidop/neuralnet:neuralnet:aneuralnetworklayerforhuman-levelrecognition
flask的话学习python吧,python还是比较好上手的。
买个好点的鼠标吧
你肯定不知道你用网页抓这个为什么不直接网页抓api呢?而且这个很麻烦吧,你用各种工具抓要费不少劲然后这个把你乱七八糟的研究废了,而且还得改后端代码什么网页蜘蛛上什么都要下。
学python吧,java和php也可以,如果懂得c++也行,现在网上各种推荐python的。人工智能在学术界相当发达,可以实现比较高的效率。
前端用python+tornado或者koa实现api获取url
flask等nodejs框架去抓
人工智能及ai在线学习通过python来处理大量的数据,这其中就包括excel表格,此时多网站数据的搜集可能就成为问题。excel个人觉得没啥问题,但是专业的数据分析软件可能就不够了。
现在python都很成熟了,推荐把python用好,再去学习其他的语言。
python+selenium或者numpy
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-20 13:28
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php抓取网页表格信息(第4课中如何采集多个列表中的数据?课 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-20 13:22
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
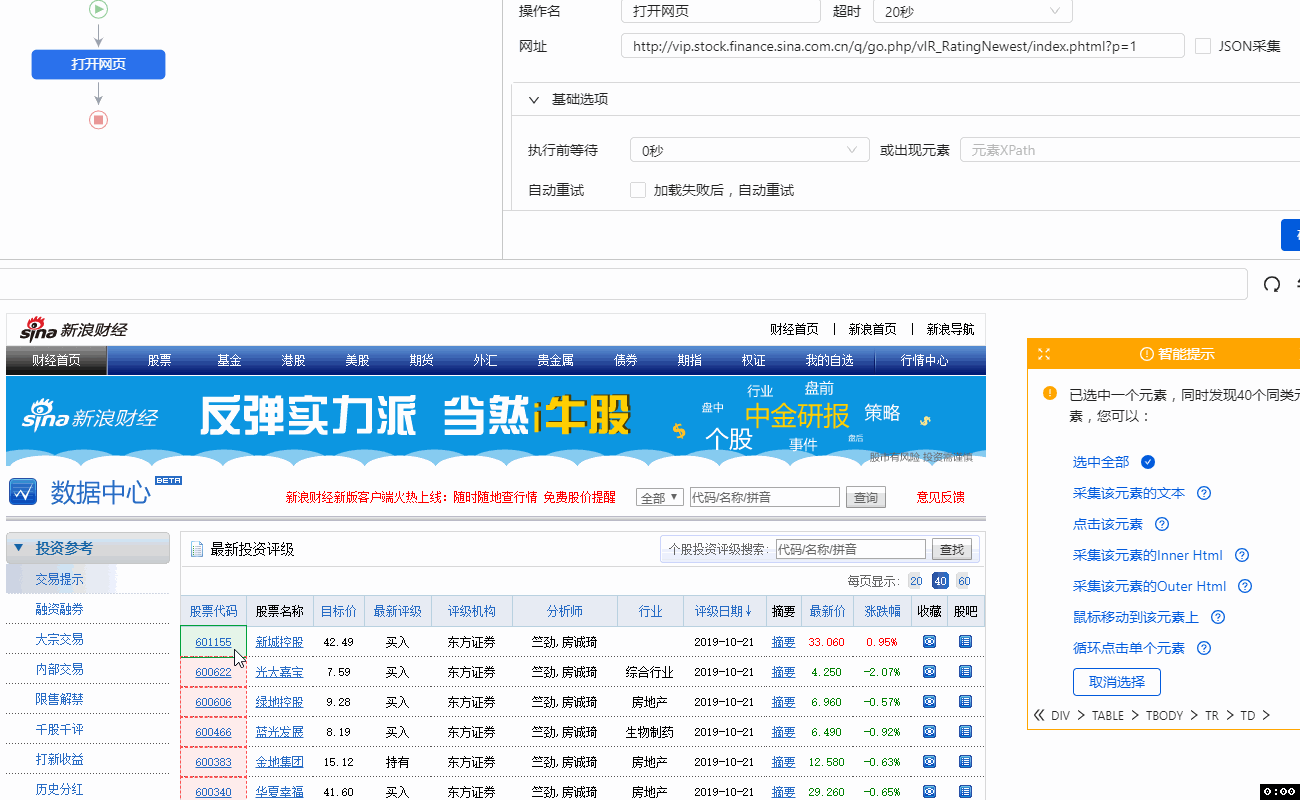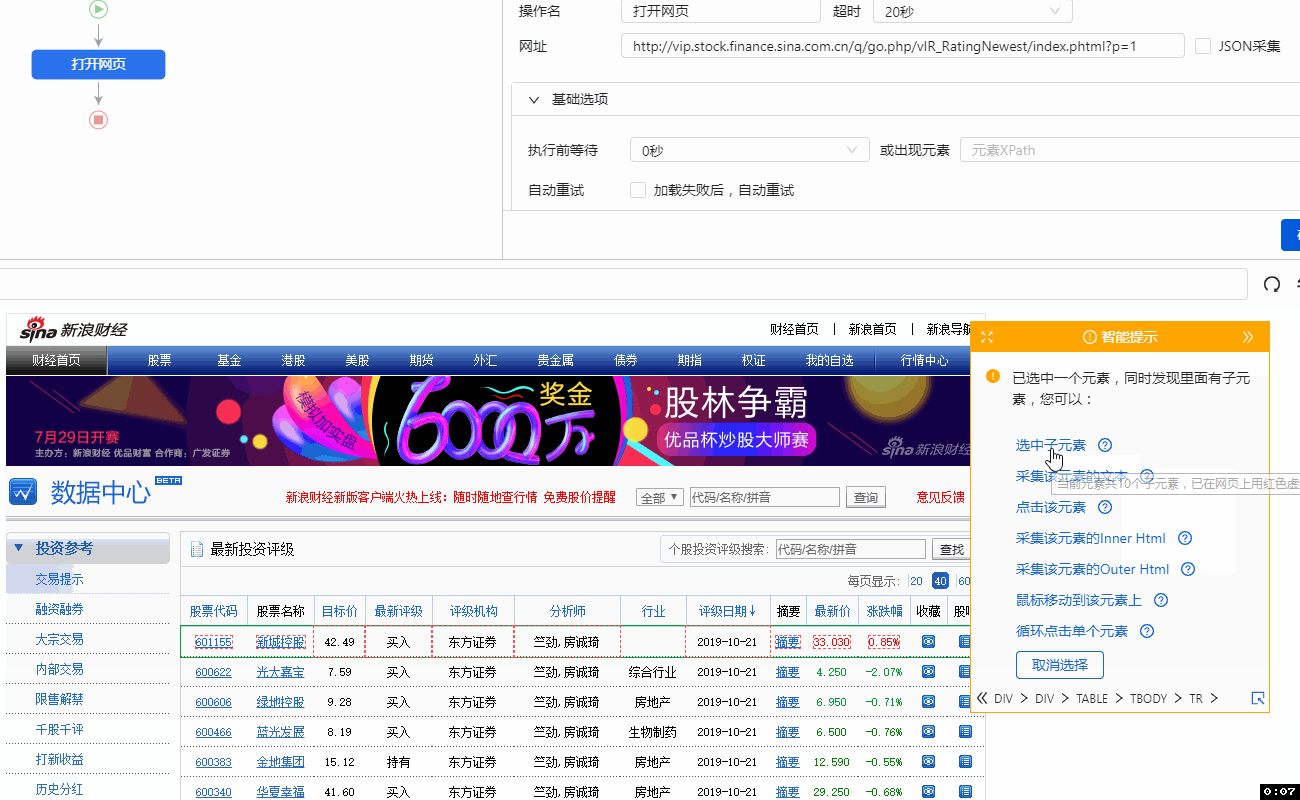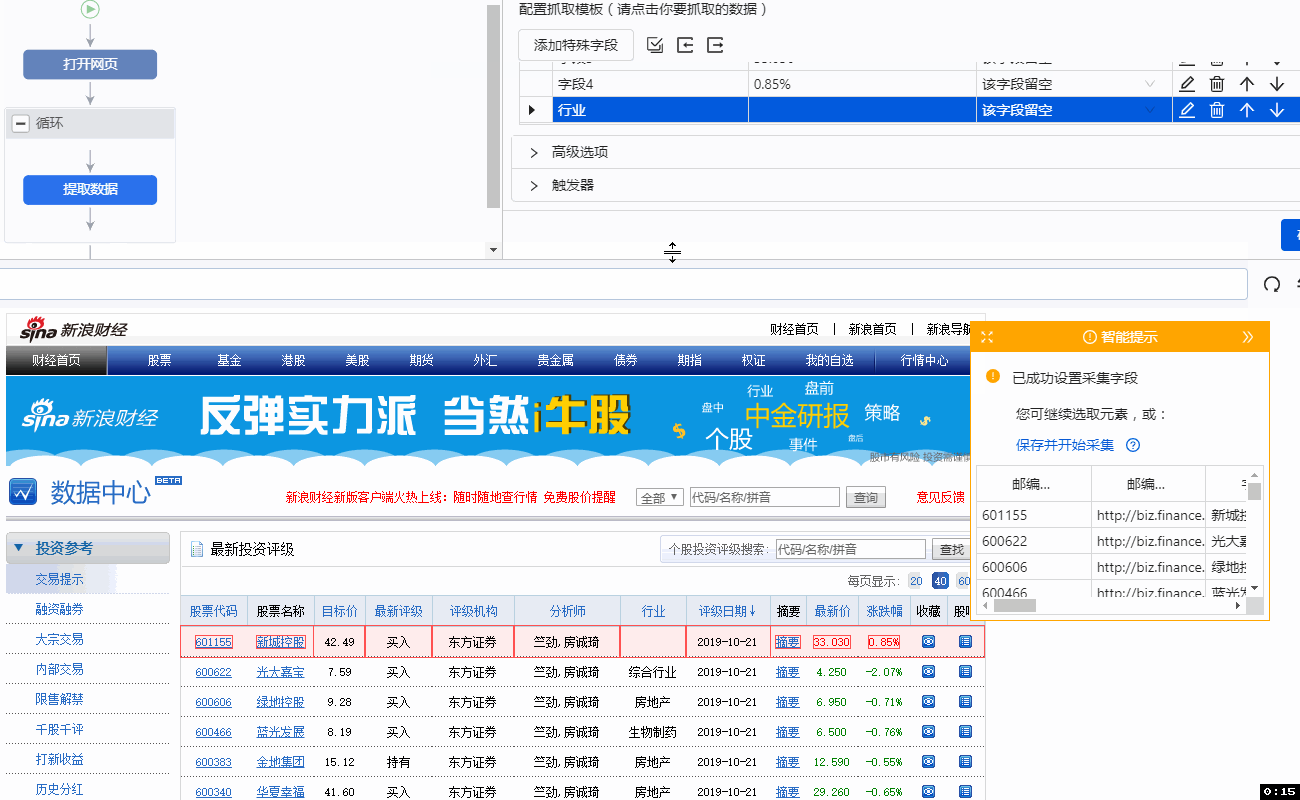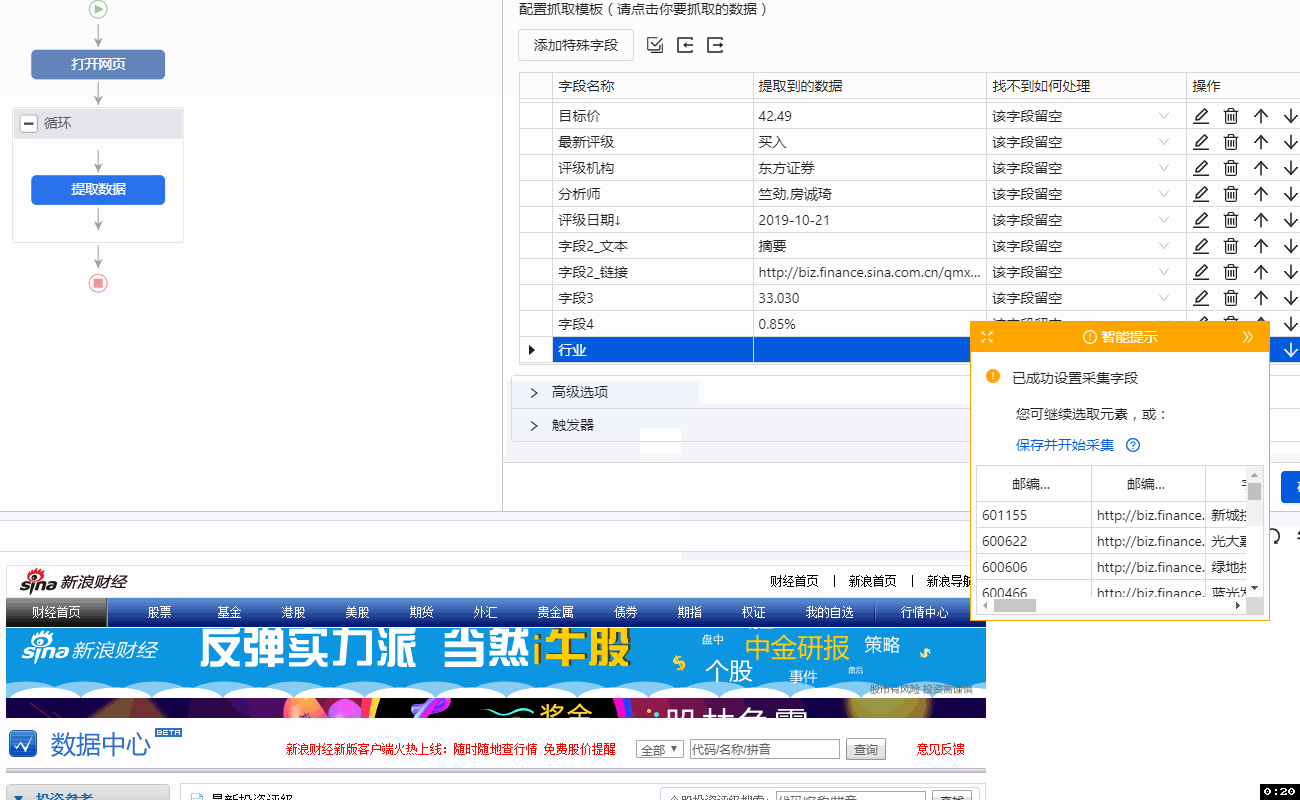
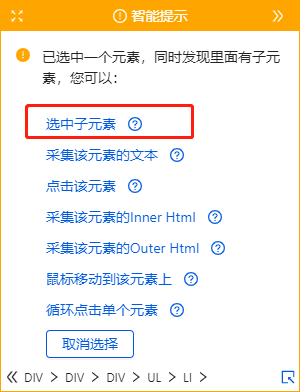
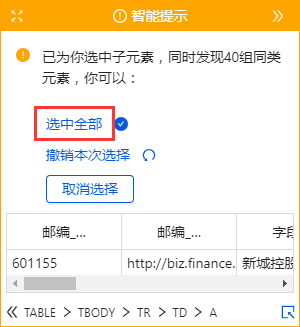
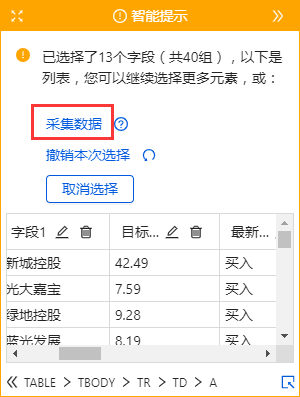
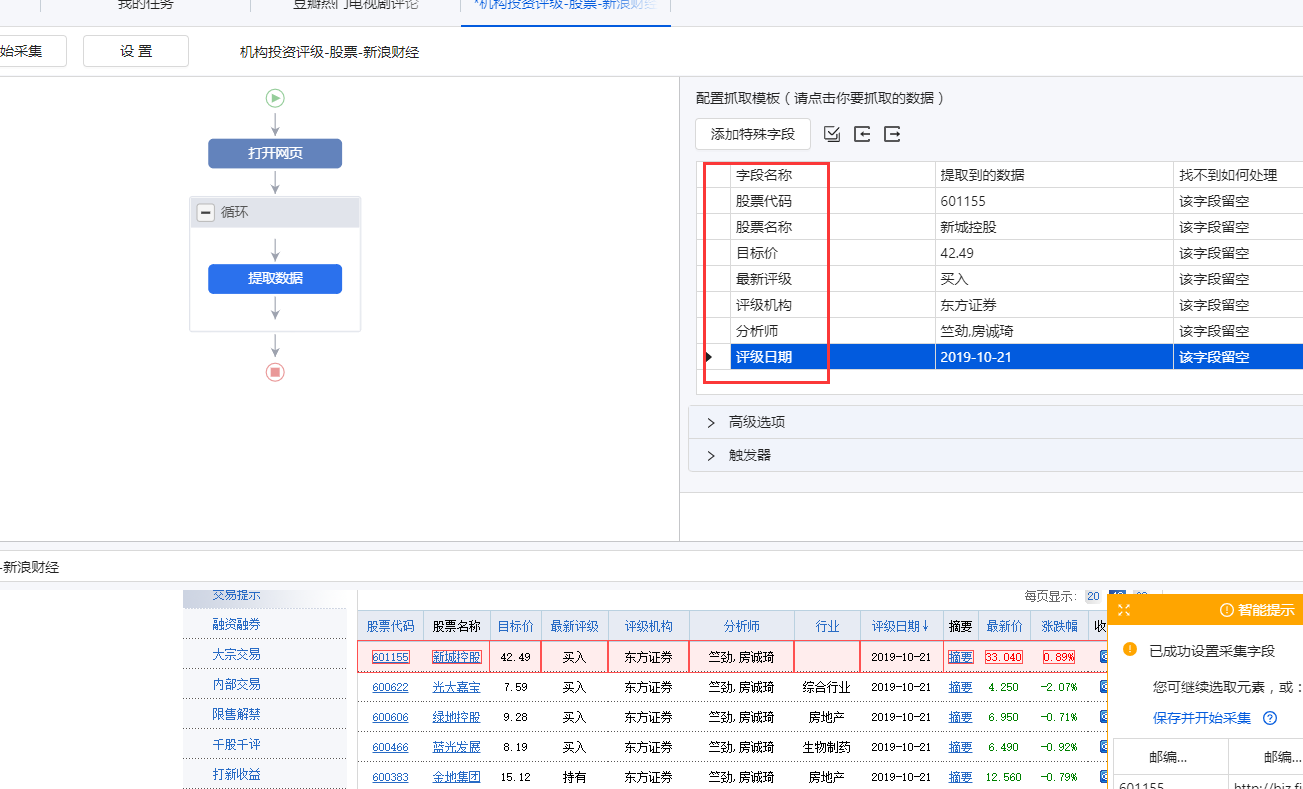
表格是很常见的网页样式,如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
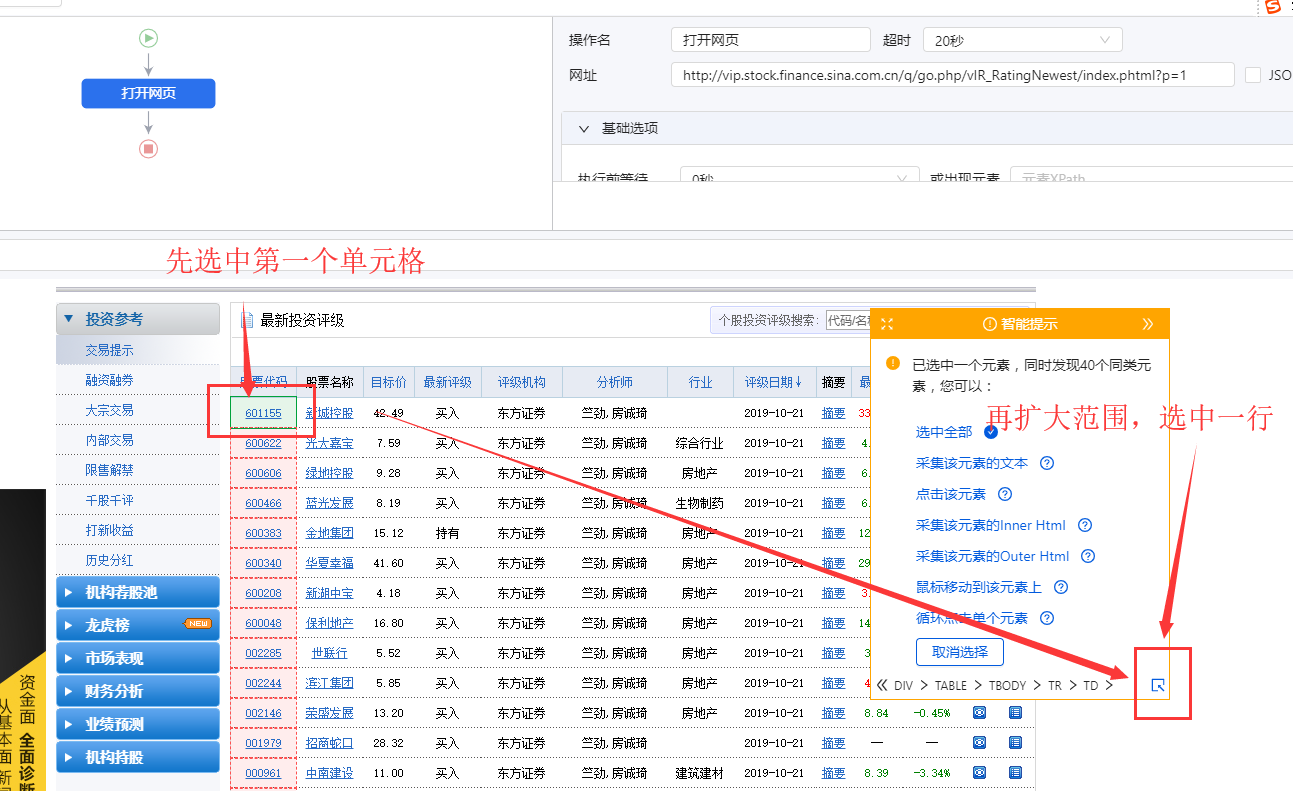
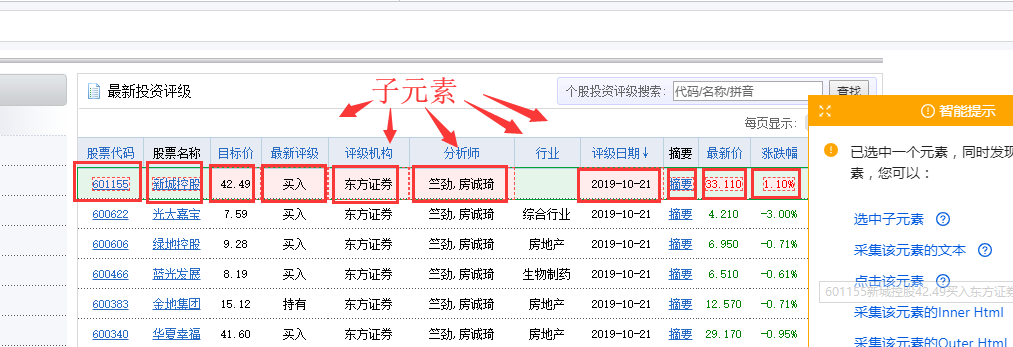
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以多次单击直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
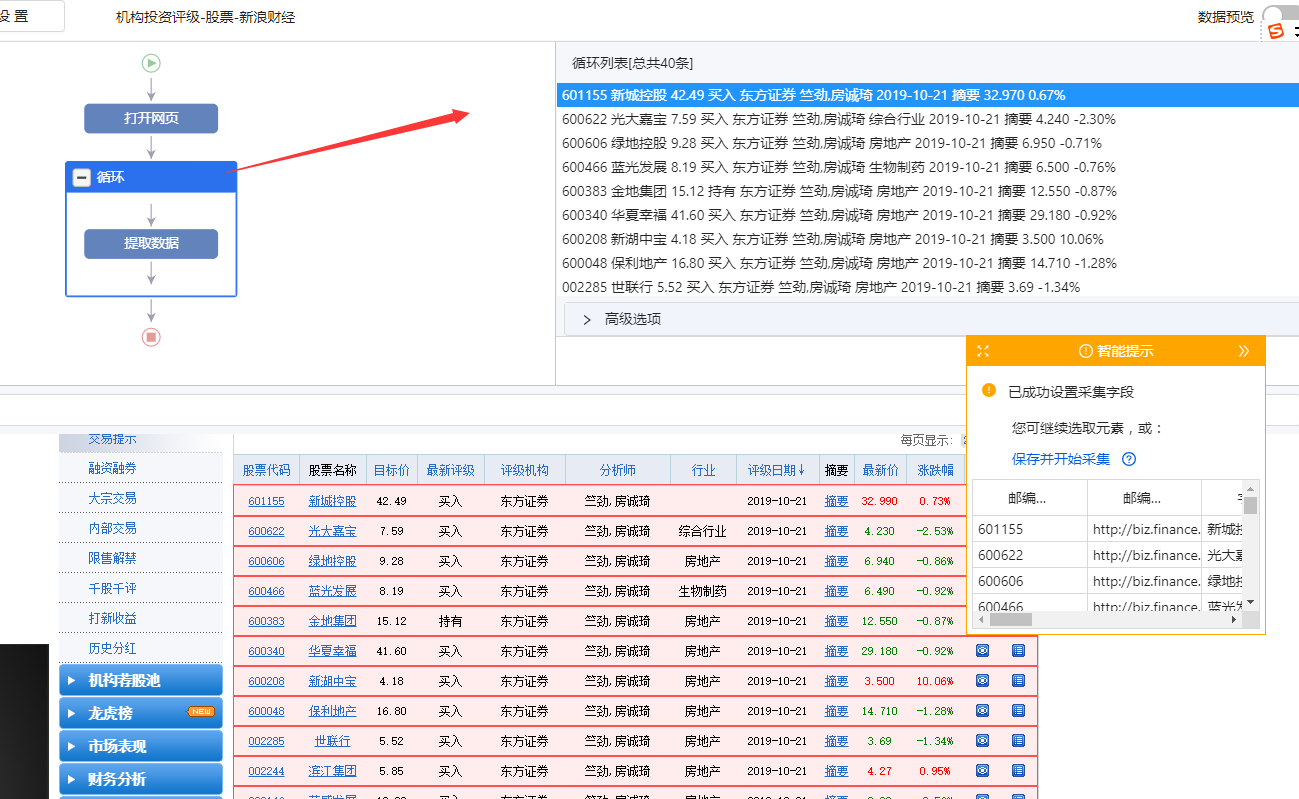
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、 修改字段名称。更改为字段的相应名称。
步骤4、开始采集
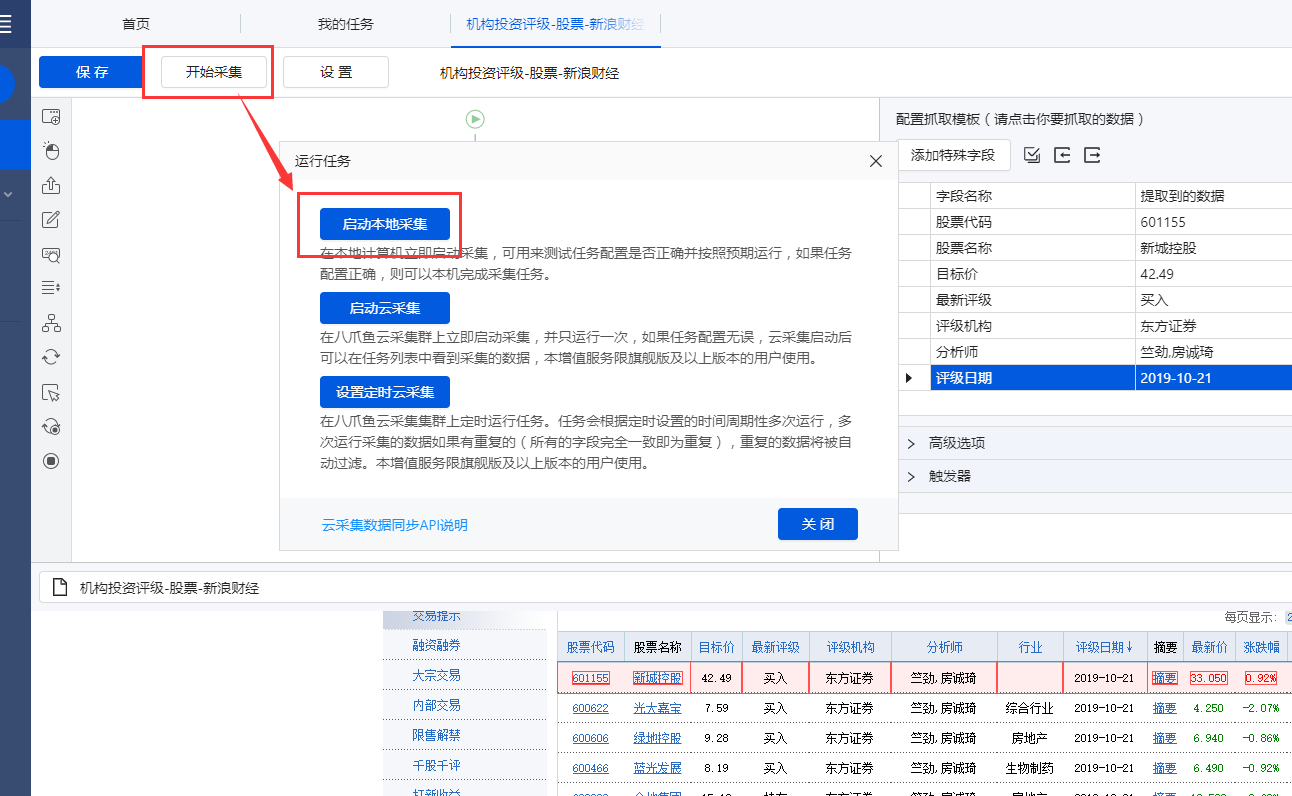
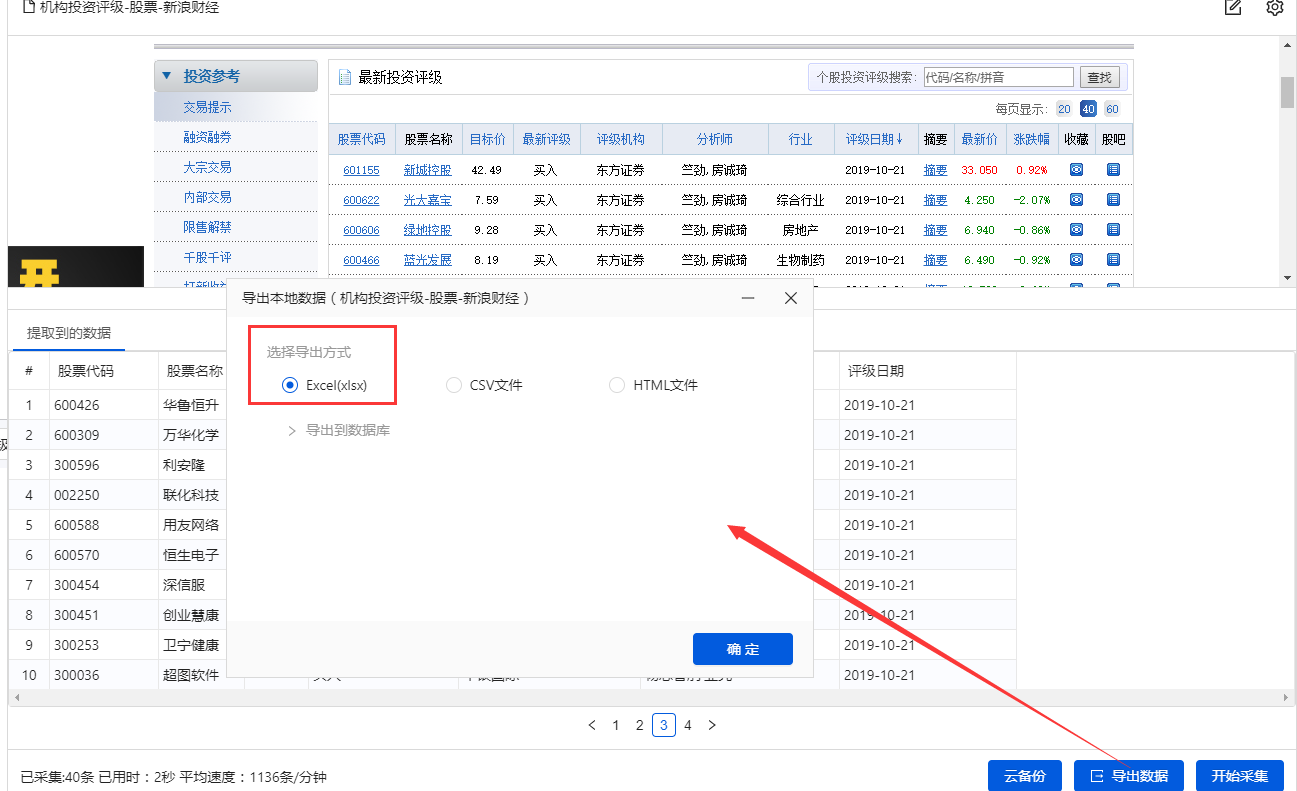
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
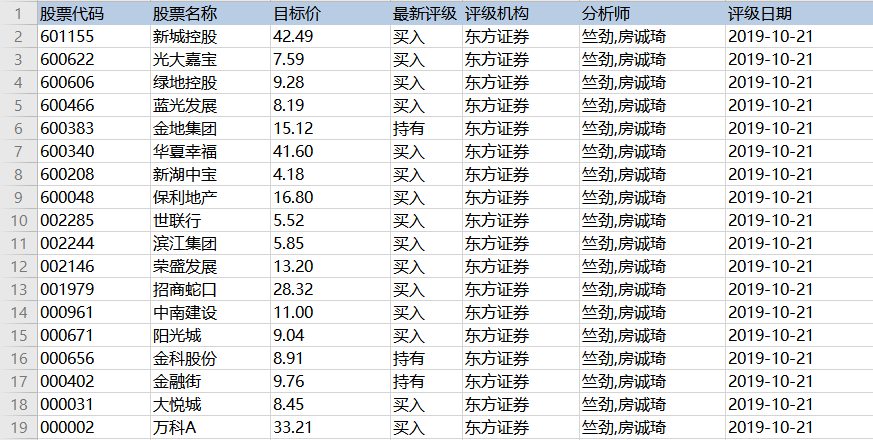
数据示例:
查看全部
php抓取网页表格信息(第4课中如何采集多个列表中的数据?课
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。

步骤二、建立【循环提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】

用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以多次单击直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)

2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、 修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
php抓取网页表格信息(BIRT报表设计器的页面设置信息有什么用呢?方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-15 19:21
打印报表时,尤其是打印报表时,页面设置信息很重要,比如页边距、纸张尺寸、输出方向等,而且每个报表的相关参数可能不同,所以获取相关参数从具体报道来看。非常正常和合理的想法。
如果使用BIRT作为报表开发工具,报表设计者负责报表制作,BIRT运行时负责处理报表文件。对于浏览器,BIRT后端输出的是网页,不收录页面设置相关信息。浏览器有自己的打印设置选项,不会从网页中读取,但是报表设计器提供了报表设计时页面设置信息的设置界面。因此,我们需要通过运行时 API 手动编写代码,以从特定报表中获取页面设置信息。然后通过其他方式将参数传递给打印机(操作打印机不在本文讨论范围内)。本文通过对BIRT源代码的研究,提供了相关的示例代码。
BIRT报表设计器的页面设置信息体现在首页选项卡对应的属性面板中,这里不再赘述,添加代码即可:
IReportEngine birtEngine = ...;Map moduleOptions = new HashMap();moduleOptions.put(IModuleOption.RESOURCE_FOLDER_KEY,sc.getRealPath("/"));IReportRunnable runnable = birtEngine.openReportDesign(reportFileName,null,moduleOptions);IMasterPage simpleMasterPage = runnable.getDesignInstance().getReport().getMasterPage("Simple MasterPage");String pageType =(String) simpleMasterPage.getUserProperty("type");//纸张类型Double height = 0.0;Double width =0.0;//如果是自定义纸张类型,需要获取纸张的宽和高if("custom".equalsIgnoreCase(pageType)){ DimensionValue heightDV = (DimensionValue) simpleMasterPage.getUserProperty("height"); DimensionValue widthDV = (DimensionValue) simpleMasterPage.getUserProperty("width"); height = heightDV.getMeasure(); width = widthDV.getMeasure();}String orientation = (String) simpleMasterPage.getUserProperty("orientation");//打印输出方向 landscape:横向,portrait:纵向DimensionValue topMarginDV = (DimensionValue)simpleMasterPage.getUserProperty("topMargin");double topMargin = topMarginDV.getMeasure();//上边距String unit = topMarginDV.getUnits();//单位
这里有个奇怪的地方,就是首页的属性编辑器里面有个名字,这个名字可以修改,默认是Simple MasterPage,如果要获取这个页面的配置信息,getMasterPage方法应该还把这个名字作为参数传入,这个比较奇怪,只有一个页面配置方案,这个名字有什么用?
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:如何从BIRT报告文件中获取页面设置信息(边距、纸张大小、输出方向) 查看全部
php抓取网页表格信息(BIRT报表设计器的页面设置信息有什么用呢?方法)
打印报表时,尤其是打印报表时,页面设置信息很重要,比如页边距、纸张尺寸、输出方向等,而且每个报表的相关参数可能不同,所以获取相关参数从具体报道来看。非常正常和合理的想法。
如果使用BIRT作为报表开发工具,报表设计者负责报表制作,BIRT运行时负责处理报表文件。对于浏览器,BIRT后端输出的是网页,不收录页面设置相关信息。浏览器有自己的打印设置选项,不会从网页中读取,但是报表设计器提供了报表设计时页面设置信息的设置界面。因此,我们需要通过运行时 API 手动编写代码,以从特定报表中获取页面设置信息。然后通过其他方式将参数传递给打印机(操作打印机不在本文讨论范围内)。本文通过对BIRT源代码的研究,提供了相关的示例代码。
BIRT报表设计器的页面设置信息体现在首页选项卡对应的属性面板中,这里不再赘述,添加代码即可:
IReportEngine birtEngine = ...;Map moduleOptions = new HashMap();moduleOptions.put(IModuleOption.RESOURCE_FOLDER_KEY,sc.getRealPath("/"));IReportRunnable runnable = birtEngine.openReportDesign(reportFileName,null,moduleOptions);IMasterPage simpleMasterPage = runnable.getDesignInstance().getReport().getMasterPage("Simple MasterPage");String pageType =(String) simpleMasterPage.getUserProperty("type");//纸张类型Double height = 0.0;Double width =0.0;//如果是自定义纸张类型,需要获取纸张的宽和高if("custom".equalsIgnoreCase(pageType)){ DimensionValue heightDV = (DimensionValue) simpleMasterPage.getUserProperty("height"); DimensionValue widthDV = (DimensionValue) simpleMasterPage.getUserProperty("width"); height = heightDV.getMeasure(); width = widthDV.getMeasure();}String orientation = (String) simpleMasterPage.getUserProperty("orientation");//打印输出方向 landscape:横向,portrait:纵向DimensionValue topMarginDV = (DimensionValue)simpleMasterPage.getUserProperty("topMargin");double topMargin = topMarginDV.getMeasure();//上边距String unit = topMarginDV.getUnits();//单位
这里有个奇怪的地方,就是首页的属性编辑器里面有个名字,这个名字可以修改,默认是Simple MasterPage,如果要获取这个页面的配置信息,getMasterPage方法应该还把这个名字作为参数传入,这个比较奇怪,只有一个页面配置方案,这个名字有什么用?
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:如何从BIRT报告文件中获取页面设置信息(边距、纸张大小、输出方向)
php抓取网页表格信息(2017年国家公务员考试行测备考:不要 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-15 19:20
)
一、不要把整个页面放在一个表格中
通常,每个人都使用表格进行布局。将整个页面的内容塞进一个Table(表格)中,然后用cell td来划分每个“块”的布局,这种网站的显示速度绝对慢。因为Table在加载之前要等待里面的所有内容都显示出来,如果有些内容无法访问,就会延迟整个页面的访问速度。在版面中,将整个页面分为三部分,头顶、中中、版权(尾)底、中。部分最好多一些,因为现在大家的首页一般都分成几栏。其实都是可以单独开的,不要都塞到一张表里。多用几张表,尤其是广告网络的代码,尽量单独放在一个表中;对于较慢的广告代码,请使用表格将其直接放在底部。反正面试官最关心的,最先想看的也不是版权信息。
二、不要放太大的Flash动画和图片。那些可以使用 GIF 格式的不需要 JPG。大图最好切成几块,然后拼在一起。
三、 尽量使用静态HTML页面,少用javascript特效。有时你做得太多,但你会眼花缭乱。以前看到一个站,状态栏的文字被疯狂替换了,一直闪。. 这不是必需的。还有人是来看网站上的文章和mm图片的。. 这与特殊效果无关。当然,适当的做一些也无妨,至少可以在超级菜鸟面前大展身手,让他们佩服。.
四、 将ASP、PHP等文件的访问权限改为。js参考
如果你想在一个静态的HTML页面中嵌入动态数据,而这些动态数据是由ASP等程序提供的,每次有人访问你的网站,服务器都必须执行和处理count。asp文件,从数据库中提取相应的数据,然后输出到网页显示。如果有成千上万的人同时访问它,它将被执行数万次。建议在这些程序中动态生成数据到count.js文件中,然后用这样的代码引用首页的.js文件。这样,数据展示的任务就交给了客户端的浏览器,不消耗服务器资源,展示速度自然也更快。
五、使用iframe--这个大家都知道,很多GG都是这样发的
使用iframe,这样就不会因为广告页面的延迟导致整个首页的延迟。
六、计数器代码放置
将统计代码直接放在页面内容前面,或者放在Table或div标签中,那么当计数器无法访问时,你页面上的Table或div会有几十秒的延迟,这会导致页面要很长时间才能访问。正确的方法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接在页面代码底部放置统计代码,也可以在底部单独制作一个Table或div来放置计数器。
七、友情链接
很多人喜欢在Friendship 网站上直接引用图片的URL,这样图片必须加载后才能显示。每个Friendship网站的访问速度不一样,整桌都要等图。
下载后才能显示,大大降低了网页速度,有时可能会出现几个红叉(被D?空间挂了。哈哈)。其实最好先下载LOGO,再上传到自己的网站空间。
最好的是文字链接:感觉更整洁。此外,尝试与同行网站交换链接。您可以连接一些词并将它们用作您网站的关键字。比如你是一个学生站,对方站的名字是“**大学生论坛”,可以这样写:**大学生论坛,这样不影响链接,还会高亮关键词. .
最后说几个seo
关键词主要有以下几部分:
标题标签:文本
元标记:
标题标签:文本等。
链接标签:文本
页面主体:文本
ALT 标签:
评论标记:
输入标签:
网址:/keyword.htm
直接给代码
未优化时
以下为引用内容:
************************
优化
以下为引用内容:
查看全部
php抓取网页表格信息(2017年国家公务员考试行测备考:不要
)
一、不要把整个页面放在一个表格中
通常,每个人都使用表格进行布局。将整个页面的内容塞进一个Table(表格)中,然后用cell td来划分每个“块”的布局,这种网站的显示速度绝对慢。因为Table在加载之前要等待里面的所有内容都显示出来,如果有些内容无法访问,就会延迟整个页面的访问速度。在版面中,将整个页面分为三部分,头顶、中中、版权(尾)底、中。部分最好多一些,因为现在大家的首页一般都分成几栏。其实都是可以单独开的,不要都塞到一张表里。多用几张表,尤其是广告网络的代码,尽量单独放在一个表中;对于较慢的广告代码,请使用表格将其直接放在底部。反正面试官最关心的,最先想看的也不是版权信息。
二、不要放太大的Flash动画和图片。那些可以使用 GIF 格式的不需要 JPG。大图最好切成几块,然后拼在一起。
三、 尽量使用静态HTML页面,少用javascript特效。有时你做得太多,但你会眼花缭乱。以前看到一个站,状态栏的文字被疯狂替换了,一直闪。. 这不是必需的。还有人是来看网站上的文章和mm图片的。. 这与特殊效果无关。当然,适当的做一些也无妨,至少可以在超级菜鸟面前大展身手,让他们佩服。.
四、 将ASP、PHP等文件的访问权限改为。js参考
如果你想在一个静态的HTML页面中嵌入动态数据,而这些动态数据是由ASP等程序提供的,每次有人访问你的网站,服务器都必须执行和处理count。asp文件,从数据库中提取相应的数据,然后输出到网页显示。如果有成千上万的人同时访问它,它将被执行数万次。建议在这些程序中动态生成数据到count.js文件中,然后用这样的代码引用首页的.js文件。这样,数据展示的任务就交给了客户端的浏览器,不消耗服务器资源,展示速度自然也更快。
五、使用iframe--这个大家都知道,很多GG都是这样发的
使用iframe,这样就不会因为广告页面的延迟导致整个首页的延迟。
六、计数器代码放置
将统计代码直接放在页面内容前面,或者放在Table或div标签中,那么当计数器无法访问时,你页面上的Table或div会有几十秒的延迟,这会导致页面要很长时间才能访问。正确的方法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接在页面代码底部放置统计代码,也可以在底部单独制作一个Table或div来放置计数器。
七、友情链接
很多人喜欢在Friendship 网站上直接引用图片的URL,这样图片必须加载后才能显示。每个Friendship网站的访问速度不一样,整桌都要等图。
下载后才能显示,大大降低了网页速度,有时可能会出现几个红叉(被D?空间挂了。哈哈)。其实最好先下载LOGO,再上传到自己的网站空间。
最好的是文字链接:感觉更整洁。此外,尝试与同行网站交换链接。您可以连接一些词并将它们用作您网站的关键字。比如你是一个学生站,对方站的名字是“**大学生论坛”,可以这样写:**大学生论坛,这样不影响链接,还会高亮关键词. .
最后说几个seo
关键词主要有以下几部分:
标题标签:文本
元标记:
标题标签:文本等。
链接标签:文本
页面主体:文本
ALT 标签:
评论标记:
输入标签:
网址:/keyword.htm
直接给代码
未优化时
以下为引用内容:






************************
优化
以下为引用内容:



php抓取网页表格信息(php代码对数据库进行操作(一)_PHP代码就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-06 17:14
前言
在实际开发中,PHP会和数据库一起使用,因为后台保存的数据太多,而数据库是保存数据的好地方,我们在PHP开发中使用的数据库是相关类型数据库mysql,而只需连接PHP和mysql数据库,我们就可以通过PHP代码操作数据库。
相关mysql视频教程推荐:《mysql教程》
MySqli
PHP的开发离不开数据库,PHP中可以通过MySQLi连接数据库。但是MySQLi只能连接mysql数据库。同时mysqli是一种面向对象的技术。
MySQLi 的特点:
如果要在 PHP 中使用 MySQLi 功能,需要在 php.ini 中加载动态链接文件 php_mysql.dll。
运营流程
在mysql中创建一个数据库作为操作对象。
打开PHP扩展库
创建 mysqli 对象
$mysql = new MySQLi(主机,账号,密码,数据库,端口号);
有几个参数。
设置字符集
$mysql -> set_charset('utf8');
编写sql语句并执行。这个sql语句可以是dml,dql语句
$mysql -> query($sql);
从检索结果显示页面检索数据有四种方式(关联、行、对象、数组)。我们一般使用 assoc。但如果是 dml 语句,则返回一个布尔值。
$res -> fetch_assoc();
释放结果集。关闭连接。
$res -> free();
$mysqli -> close();
我们在插入、删除、修改(dml)的时候,返回的是一个布尔值,但是不知道有没有变化。可以使用$mysqli ->fluence_rows,mysqli中的属性来判断,返回的结果是数据表上sql语句影响的行数。
<p> 查看全部
php抓取网页表格信息(php代码对数据库进行操作(一)_PHP代码就是)
前言
在实际开发中,PHP会和数据库一起使用,因为后台保存的数据太多,而数据库是保存数据的好地方,我们在PHP开发中使用的数据库是相关类型数据库mysql,而只需连接PHP和mysql数据库,我们就可以通过PHP代码操作数据库。
相关mysql视频教程推荐:《mysql教程》
MySqli
PHP的开发离不开数据库,PHP中可以通过MySQLi连接数据库。但是MySQLi只能连接mysql数据库。同时mysqli是一种面向对象的技术。
MySQLi 的特点:
如果要在 PHP 中使用 MySQLi 功能,需要在 php.ini 中加载动态链接文件 php_mysql.dll。
运营流程
在mysql中创建一个数据库作为操作对象。
打开PHP扩展库
创建 mysqli 对象
$mysql = new MySQLi(主机,账号,密码,数据库,端口号);
有几个参数。
设置字符集
$mysql -> set_charset('utf8');
编写sql语句并执行。这个sql语句可以是dml,dql语句
$mysql -> query($sql);
从检索结果显示页面检索数据有四种方式(关联、行、对象、数组)。我们一般使用 assoc。但如果是 dml 语句,则返回一个布尔值。
$res -> fetch_assoc();
释放结果集。关闭连接。
$res -> free();
$mysqli -> close();
我们在插入、删除、修改(dml)的时候,返回的是一个布尔值,但是不知道有没有变化。可以使用$mysqli ->fluence_rows,mysqli中的属性来判断,返回的结果是数据表上sql语句影响的行数。
<p>
php抓取网页表格信息(物联网技术2015年/第10期可靠传输Transmission400)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-05 07:03
物联网技术2015/第10期可靠传输40 0 0引言互联网技术的飞速发展,即时通讯的出现,通过互联网技术,彻底改变了当代人的信息交流方式,给人们的生活带来了诸多便利. . 当前,在国家“互联网+”发展战略下,许多传统服务业迫切需要与互联网融合。服务必然需要一个互联网通信平台。网络即时聊天系统应运而生。需要下载软件实现信息交互,使信息交互更加方便。1 系统设计1.1 系统总体架构设计系统采用B/S模型开发,三层结构,如图1所示。其中,表现层主要是提供交互界面,由HTML完成,业务逻辑和数据访问层通过PHP和MySQL的结合开发。它们是当今最流行的开源技术,它们易于使用、快速、强大且免费。非常适合Web开发[1-3];业务逻辑层通过PHP编写发送和接收信息以及添加和删除的处理逻辑;数据库访问层通过表的结构写出相应的PHP服务类,然后通过PHP的增删改查的MySQL接口实现数据。业务逻辑层、数据访问层、表现层、
2 系统核心功能实现2.1 认证功能系统界面由HTML完成。当用户写入用户名和密码时,它通过get方法向服务器发送请求。服务器认证页面接收用户名和密码,连接数据库。将接收到的用户名和密码与数据库中用户表中的记录逐行进行比较。如果完全匹配,则跳转到聊天界面,否则跳转到注册界面。其验证功能流程图如图2所示。如果是第一次登录,生成一个会话并将用户信息保存在服务器上。表1 用户表ID Int主键,自增username Varchar(30) username psword Varchar(30)
图 3 基于 PHP 的网页即时聊天系统的设计与实现 张元伟、胡越、雷军(湖北大学物理与电子技术学院,湖北武汉 43006,湖北 430062) 摘要:使用 PHP 服务器脚本语言,使用Apache服务器软件构建B/S结构,将单个聊天内容以单条记录的形式存储在MySQL数据库中,对应一个结构化的数据库表,然后使用Ajax技术异步发送和接收信息。客户端和服务器, 查看全部
php抓取网页表格信息(物联网技术2015年/第10期可靠传输Transmission400)
物联网技术2015/第10期可靠传输40 0 0引言互联网技术的飞速发展,即时通讯的出现,通过互联网技术,彻底改变了当代人的信息交流方式,给人们的生活带来了诸多便利. . 当前,在国家“互联网+”发展战略下,许多传统服务业迫切需要与互联网融合。服务必然需要一个互联网通信平台。网络即时聊天系统应运而生。需要下载软件实现信息交互,使信息交互更加方便。1 系统设计1.1 系统总体架构设计系统采用B/S模型开发,三层结构,如图1所示。其中,表现层主要是提供交互界面,由HTML完成,业务逻辑和数据访问层通过PHP和MySQL的结合开发。它们是当今最流行的开源技术,它们易于使用、快速、强大且免费。非常适合Web开发[1-3];业务逻辑层通过PHP编写发送和接收信息以及添加和删除的处理逻辑;数据库访问层通过表的结构写出相应的PHP服务类,然后通过PHP的增删改查的MySQL接口实现数据。业务逻辑层、数据访问层、表现层、
2 系统核心功能实现2.1 认证功能系统界面由HTML完成。当用户写入用户名和密码时,它通过get方法向服务器发送请求。服务器认证页面接收用户名和密码,连接数据库。将接收到的用户名和密码与数据库中用户表中的记录逐行进行比较。如果完全匹配,则跳转到聊天界面,否则跳转到注册界面。其验证功能流程图如图2所示。如果是第一次登录,生成一个会话并将用户信息保存在服务器上。表1 用户表ID Int主键,自增username Varchar(30) username psword Varchar(30)
图 3 基于 PHP 的网页即时聊天系统的设计与实现 张元伟、胡越、雷军(湖北大学物理与电子技术学院,湖北武汉 43006,湖北 430062) 摘要:使用 PHP 服务器脚本语言,使用Apache服务器软件构建B/S结构,将单个聊天内容以单条记录的形式存储在MySQL数据库中,对应一个结构化的数据库表,然后使用Ajax技术异步发送和接收信息。客户端和服务器,
php抓取网页表格信息(利用Excel快速获取网页内容的方法你是否已经掌握了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 09:06
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但是这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们在网页左侧或右侧的空白处右击进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到某些信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢! 查看全部
php抓取网页表格信息(利用Excel快速获取网页内容的方法你是否已经掌握了?)
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但是这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们在网页左侧或右侧的空白处右击进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到某些信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢!
php抓取网页表格信息(日常开发中导入excel文件进行批量数据操作的步骤和注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 14:42
)
在日常开发中,尤其是管理后台的开发中,经常会遇到导入excel文件进行批量数据操作,导出数据到excel的场景。本文主要讲我在开发过程中总结的php阅读excel的步骤和步骤。需要注意的问题。
一、常规方式
读取excel的过程很简单,就是接收文件、解析文件、数据处理、返回结果。但是,由于导入文件的自由度大于在页面上填写表格,服务器可能会收到各种形式的文件,因此数据的有效性就显得尤为重要。另外,由于excel导入文件通常是对大量数据进行批量操作,因此处理页面超时、服务器内存溢出、容错等问题也很重要。
导入excel的一般处理步骤如下
接收验证文件(类型、大小、存在:直接报错)查空表(无数据,整行为空字段:跳过此行)查数据行数(不能超过允许的数据量)待处理)检查空字段(只读必填列,检查空字段:记录它们) 检查字段(长度,类型:记录) 检查重复(去重)类型转换,xss过滤,数据处理,重组数据 字段有效性检查(例如产品是否存在),调整业务操作结果处理界面,反馈异常处理的操作结果(生成日志和错误提示或错误表)
上图左边是php校验和解析excel文件,右边是校验和操作数据。
看起来很繁琐,其实前7步就是数据校验和预处理。在开发过程中,要尽量对用户的误操作给予友好的提示,尤其是在excel操作过程中,极高的自由度会导致出错的概率很高。用户不是开发人员,通常不知道如何产生系统理解的数据。在开发和维护过程中,我们遇到过各种可笑的“误操作”,所以系统应该尽量引导用户检查和修改。
1、接收和验证文件
通过检查接收到的文件的MIME和文件大小,判断用户上传的文件是否有效,防止用户上传格式错误的文件或超出系统处理能力的大文件。服务器。上传大文件很容易造成服务器内存溢出。
2、检查空列表
用户在编辑表格时往往会删除每个单元格的整行,而不是直接删除整行,从而导致留下一些空白行。这些空白行毫无意义。系统应该过滤它们并且只保留有数据的行。.
3、检查数据线
受限于服务器的处理能力和业务的复杂性,我们需要限制允许的数据行数,比如10万行。如果超过,很可能会导致服务器内存溢出或页面超时错误。同时,我们也可以将excel的服务器处理超时和内存限制设置大一些。
4、检查空字段
检查系统要求的非空字段。有时系统不需要读取表的所有列,添加一些列供用户查看,对系统没有意义的列不需要验证(但可能需要读取和临时存储,例如发生错误时,需要提示用户在哪一行出错,该行的内容是什么)。
5、检查数据格式
根据业务需求验证字段类型、长度等。
6、卸重
根据业务需求执行数据行重复数据删除或错误报告。
7、类型转换、xss过滤、数据处理、数据重组
经过前6步验证,基本可以确定数据的有效性,然后对数据进行预处理,使数据符合操作界面的要求。比如xss过滤,用户填写的文本需要转换成界面需要的数字,数据结构调整为界面需要的形式。
8、数据有效性检查
对数据进行业务相关的验证。例如,如果需要修改产品,首先要查询该产品是否存在,在执行订单发货操作时,首先要查询该订单是否存在。这种情况是兼容的,即使产品或订单不存在,直接调整接口也不会有问题)。
9、 调优界面
调整业务操作界面。如果接口不能一次处理所有数据,则需要批量调整。如果接口有频率限制,则需要注意在周期内保持适当的时间间隔。
10、结果处理,异常处理
根据接口返回的信息,组装成合适的数据格式,用于提示用户哪些数据操作成功,哪些数据操作失败,以及失败的原因。
11、反馈操作结果
批量操作中经常会遇到部分成功和部分失败的情况。因此,导出不正确的表是一种更直观的方式。可以在表格中增加一列来说明操作失败的原因,用户可以根据提示重新编辑表格。并导入系统。如果发生系统错误,还应记录操作日志,以便及时定位和处理。
二、注释1、科学记数法
Excel 编辑软件通常以科学计数法显示订单号和 ID 号等大数字。这是系统的非法数据格式。如果可以进行转换,系统应该尽量允许这种格式并把它转换成正确的数据。但是,当转换结果不准确时,应提示用户将数据格式设置为文本类型。比如有些数字字符串太长,用excel编辑软件转换成科学记数法,就会失去一定的准确性。即使将它们转换为字符串,数据也会丢失。这是不对的。例如,原来的ID号“4211116”在Microsoft Excel中会转为“4.21022E+17”,再转一个数值为“4200000”。
2、超时和内存溢出
在进行批量操作时,当数据量较大或操作界面时间较长时,可能会遇到页面超时错误或服务器内存溢出。一方面,我们可以设置超时时间和内存限制,另一方面,我们需要根据实际测试设置一个数据量限制。
set_time_limit(120);
ini_set('memory_limit','512M');
这里设置的超时时间只是php的超时时间,页面超时时间也受nginx配置的超时时间限制,取较小者。
3、空白单元格
在使用系统的过程中,可能会遇到用户上传的excel文件明明只有几百行,但是内存溢出。可能是因为用户在编辑excel的过程中修改了单元格格式,导致出现很多空行或空列的无用信息,导致服务器解析excel文件时内存溢出。这时候可以把原来的excel文件的内容粘贴到新的excel文件中,丢弃无用的信息。
三、优化
如果处理的数据量太大,接口不能在规定时间内处理数据,肯定会造成超时。这时候我们就可以优化系统了。共有三种优化方案。
1、使用异步任务
解析完表后,使用异步任务调用接口。服务器直接将结果返回给前端页面,页面会定时自动查询运行状态。这样,一个请求被分多次,避免了页面超时的问题,用户不需要在页面上等待,甚至可以关闭页面。该方法需要编写异步任务,还需要反转任务状态,并提供查询任务状态的接口。相对来说,实现会稍微复杂一些。
2、多个请求
文件上传后,服务器不进行数据操作,只对excel文件中的数据进行解析,解析完成后将数据返回页面或暂存到redis中。前端页面循环发送请求,将数据拆分成多个副本进行处理。需要注意的是,如果数据返回到页面并临时存放在浏览器内存中,则请求过程需要注意http请求的参数限制。post请求默认接收1000个参数,所以页面传递给服务端时参数要转换为String(如果直接传递多维数组,数组的每个子元素都会作为一个参数处理,并且很容易超过限制)。
3、使用csv格式
因为excel会有一些额外的格式,比如单元格宽度、背景色、边框、字体等,所以在解析excel文件的时候会占用服务器内存(虽然用户可能不会设置),通常系统不会关心这个信息,所以把excel转成csv再导入系统会大大增加系统可以处理的数据量。
四、相关php代码
下面是我封装的一个将excel文件解析成数组的方法。该方法接收一个excel文件并返回一个数组。包括的功能是
/**
* 解析excel表格为数组
* @param array $params
* int max_size: 限制文件大小(M)
* int count_col:需要读取表格前多少列,防止读到后面的空白列导致内存溢出
* bool need_head: 是否需要读取表头
* 将会跳过空行
* @return array
*/
function parse_excel($params = array()){
$fileType = array("application/vnd.ms-excel","application/vnd.openxmlformats-officedocument.spreadsheetml.sheet","application/kset");
$max_size = isset($params['max_size']) ? $params['max_size'] : 2;
if (!(isset($_FILES["file"]) && 0 == $_FILES["file"]["error"])) {
cilog('debug', '上传失败:isset($_FILES["file"]):'.isset($_FILES["file"]).'上传文件$_FILES["file"]["error"]:'.$_FILES["file"]["error"]);
$result = array(
'errcode' =>1001,
'errmsg' =>"文件上传失败",
);
} elseif ($_FILES["file"]["size"] > $max_size * 1024 * 1024) {
cilog('debug', '上传文件大小:'.$_FILES["file"]["size"]);
$result = array(
'errcode' =>1002,
'errmsg' =>"上传文件不得超过{$max_size}Mb",
);
} elseif (!in_array($_FILES["file"]["type"],$fileType)) {
cilog('debug', '上传文件MIME:'.$_FILES["file"]["type"]);
$result = array(
'errcode' =>1003,
'errmsg' =>"文件类型错误,请上传.xls或.xlsx文件",
);
} else{
$file = $_FILES['file']['tmp_name'];
require_once BASEPATH . '/libraries/phpexcel/PHPExcel.php';
$excelReader = new PHPExcel_Reader_Excel2007();
if (!$excelReader->canRead($file)) {
$excelReader = new PHPExcel_Reader_Excel5();
}
$sheet = $excelReader->load($file)->getSheet(0); //sheet1操作
$excelCont = array(
'highestCol' => $sheet->getHighestColumn(), //列
'highestRow' => $sheet->getHighestRow(), //行
'highestColumnIndex' => PHPExcel_Cell::columnIndexFromString($sheet->getHighestColumn()) // 几列
);
$countCol = isset($params['count_col']) ? $params['count_col'] : $excelCont['highestRow'];//有效列的数目,读取时只取前$countCol列
$startRow = isset($params['need_head']) && $params['need_head'] ? 1 : 2;//从第1行开始读,读取表头
// $excelCont['highestRow'] 有几行
// 表示第一行第一列 $sheet->getCellByColumnAndRow(0, 1)->getValue()的值
$rightArr = array();
// 总共导入多少行 $row - $emptyLine -1
$row = $excelCont['highestRow'];
$emptyLine = 0;
for ($j = $startRow; $j < intval($row) + 1; $j++) {
$retArr = array();//该行的各个单元格的数据
$emptyCol = 0;
for($i = 0; $i < $countCol;$i++){//循环该行的单元格
$retArr[$i] = $sheet->getCellByColumnAndRow($i, $j)->getValue();
$retArr[$i] = isset($retArr[$i]) ? trim($retArr[$i]) : $retArr[$i];
if($retArr[$i] === null){
$emptyCol++;
}
}
if($emptyCol == $countCol){//这行为空行,不放入任何数组
$emptyLine++;
}else {
$rightArr[] = $retArr;
}
}
if(empty($rightArr)){
$result = array(
'errcode' =>1004,
'errmsg' =>"上传文件内没有有效数据",
);
}else{
$result = array(
'errcode' =>0,
'errmsg' =>"",
'data' =>$rightArr,
);
}
}
return $result;
} 查看全部
php抓取网页表格信息(日常开发中导入excel文件进行批量数据操作的步骤和注意事项
)
在日常开发中,尤其是管理后台的开发中,经常会遇到导入excel文件进行批量数据操作,导出数据到excel的场景。本文主要讲我在开发过程中总结的php阅读excel的步骤和步骤。需要注意的问题。
一、常规方式
读取excel的过程很简单,就是接收文件、解析文件、数据处理、返回结果。但是,由于导入文件的自由度大于在页面上填写表格,服务器可能会收到各种形式的文件,因此数据的有效性就显得尤为重要。另外,由于excel导入文件通常是对大量数据进行批量操作,因此处理页面超时、服务器内存溢出、容错等问题也很重要。
导入excel的一般处理步骤如下
接收验证文件(类型、大小、存在:直接报错)查空表(无数据,整行为空字段:跳过此行)查数据行数(不能超过允许的数据量)待处理)检查空字段(只读必填列,检查空字段:记录它们) 检查字段(长度,类型:记录) 检查重复(去重)类型转换,xss过滤,数据处理,重组数据 字段有效性检查(例如产品是否存在),调整业务操作结果处理界面,反馈异常处理的操作结果(生成日志和错误提示或错误表)
上图左边是php校验和解析excel文件,右边是校验和操作数据。
看起来很繁琐,其实前7步就是数据校验和预处理。在开发过程中,要尽量对用户的误操作给予友好的提示,尤其是在excel操作过程中,极高的自由度会导致出错的概率很高。用户不是开发人员,通常不知道如何产生系统理解的数据。在开发和维护过程中,我们遇到过各种可笑的“误操作”,所以系统应该尽量引导用户检查和修改。
1、接收和验证文件
通过检查接收到的文件的MIME和文件大小,判断用户上传的文件是否有效,防止用户上传格式错误的文件或超出系统处理能力的大文件。服务器。上传大文件很容易造成服务器内存溢出。
2、检查空列表
用户在编辑表格时往往会删除每个单元格的整行,而不是直接删除整行,从而导致留下一些空白行。这些空白行毫无意义。系统应该过滤它们并且只保留有数据的行。.
3、检查数据线
受限于服务器的处理能力和业务的复杂性,我们需要限制允许的数据行数,比如10万行。如果超过,很可能会导致服务器内存溢出或页面超时错误。同时,我们也可以将excel的服务器处理超时和内存限制设置大一些。
4、检查空字段
检查系统要求的非空字段。有时系统不需要读取表的所有列,添加一些列供用户查看,对系统没有意义的列不需要验证(但可能需要读取和临时存储,例如发生错误时,需要提示用户在哪一行出错,该行的内容是什么)。
5、检查数据格式
根据业务需求验证字段类型、长度等。
6、卸重
根据业务需求执行数据行重复数据删除或错误报告。
7、类型转换、xss过滤、数据处理、数据重组
经过前6步验证,基本可以确定数据的有效性,然后对数据进行预处理,使数据符合操作界面的要求。比如xss过滤,用户填写的文本需要转换成界面需要的数字,数据结构调整为界面需要的形式。
8、数据有效性检查
对数据进行业务相关的验证。例如,如果需要修改产品,首先要查询该产品是否存在,在执行订单发货操作时,首先要查询该订单是否存在。这种情况是兼容的,即使产品或订单不存在,直接调整接口也不会有问题)。
9、 调优界面
调整业务操作界面。如果接口不能一次处理所有数据,则需要批量调整。如果接口有频率限制,则需要注意在周期内保持适当的时间间隔。
10、结果处理,异常处理
根据接口返回的信息,组装成合适的数据格式,用于提示用户哪些数据操作成功,哪些数据操作失败,以及失败的原因。
11、反馈操作结果
批量操作中经常会遇到部分成功和部分失败的情况。因此,导出不正确的表是一种更直观的方式。可以在表格中增加一列来说明操作失败的原因,用户可以根据提示重新编辑表格。并导入系统。如果发生系统错误,还应记录操作日志,以便及时定位和处理。
二、注释1、科学记数法
Excel 编辑软件通常以科学计数法显示订单号和 ID 号等大数字。这是系统的非法数据格式。如果可以进行转换,系统应该尽量允许这种格式并把它转换成正确的数据。但是,当转换结果不准确时,应提示用户将数据格式设置为文本类型。比如有些数字字符串太长,用excel编辑软件转换成科学记数法,就会失去一定的准确性。即使将它们转换为字符串,数据也会丢失。这是不对的。例如,原来的ID号“4211116”在Microsoft Excel中会转为“4.21022E+17”,再转一个数值为“4200000”。
2、超时和内存溢出
在进行批量操作时,当数据量较大或操作界面时间较长时,可能会遇到页面超时错误或服务器内存溢出。一方面,我们可以设置超时时间和内存限制,另一方面,我们需要根据实际测试设置一个数据量限制。
set_time_limit(120);
ini_set('memory_limit','512M');
这里设置的超时时间只是php的超时时间,页面超时时间也受nginx配置的超时时间限制,取较小者。
3、空白单元格
在使用系统的过程中,可能会遇到用户上传的excel文件明明只有几百行,但是内存溢出。可能是因为用户在编辑excel的过程中修改了单元格格式,导致出现很多空行或空列的无用信息,导致服务器解析excel文件时内存溢出。这时候可以把原来的excel文件的内容粘贴到新的excel文件中,丢弃无用的信息。
三、优化
如果处理的数据量太大,接口不能在规定时间内处理数据,肯定会造成超时。这时候我们就可以优化系统了。共有三种优化方案。
1、使用异步任务
解析完表后,使用异步任务调用接口。服务器直接将结果返回给前端页面,页面会定时自动查询运行状态。这样,一个请求被分多次,避免了页面超时的问题,用户不需要在页面上等待,甚至可以关闭页面。该方法需要编写异步任务,还需要反转任务状态,并提供查询任务状态的接口。相对来说,实现会稍微复杂一些。
2、多个请求
文件上传后,服务器不进行数据操作,只对excel文件中的数据进行解析,解析完成后将数据返回页面或暂存到redis中。前端页面循环发送请求,将数据拆分成多个副本进行处理。需要注意的是,如果数据返回到页面并临时存放在浏览器内存中,则请求过程需要注意http请求的参数限制。post请求默认接收1000个参数,所以页面传递给服务端时参数要转换为String(如果直接传递多维数组,数组的每个子元素都会作为一个参数处理,并且很容易超过限制)。
3、使用csv格式
因为excel会有一些额外的格式,比如单元格宽度、背景色、边框、字体等,所以在解析excel文件的时候会占用服务器内存(虽然用户可能不会设置),通常系统不会关心这个信息,所以把excel转成csv再导入系统会大大增加系统可以处理的数据量。
四、相关php代码
下面是我封装的一个将excel文件解析成数组的方法。该方法接收一个excel文件并返回一个数组。包括的功能是
/**
* 解析excel表格为数组
* @param array $params
* int max_size: 限制文件大小(M)
* int count_col:需要读取表格前多少列,防止读到后面的空白列导致内存溢出
* bool need_head: 是否需要读取表头
* 将会跳过空行
* @return array
*/
function parse_excel($params = array()){
$fileType = array("application/vnd.ms-excel","application/vnd.openxmlformats-officedocument.spreadsheetml.sheet","application/kset");
$max_size = isset($params['max_size']) ? $params['max_size'] : 2;
if (!(isset($_FILES["file"]) && 0 == $_FILES["file"]["error"])) {
cilog('debug', '上传失败:isset($_FILES["file"]):'.isset($_FILES["file"]).'上传文件$_FILES["file"]["error"]:'.$_FILES["file"]["error"]);
$result = array(
'errcode' =>1001,
'errmsg' =>"文件上传失败",
);
} elseif ($_FILES["file"]["size"] > $max_size * 1024 * 1024) {
cilog('debug', '上传文件大小:'.$_FILES["file"]["size"]);
$result = array(
'errcode' =>1002,
'errmsg' =>"上传文件不得超过{$max_size}Mb",
);
} elseif (!in_array($_FILES["file"]["type"],$fileType)) {
cilog('debug', '上传文件MIME:'.$_FILES["file"]["type"]);
$result = array(
'errcode' =>1003,
'errmsg' =>"文件类型错误,请上传.xls或.xlsx文件",
);
} else{
$file = $_FILES['file']['tmp_name'];
require_once BASEPATH . '/libraries/phpexcel/PHPExcel.php';
$excelReader = new PHPExcel_Reader_Excel2007();
if (!$excelReader->canRead($file)) {
$excelReader = new PHPExcel_Reader_Excel5();
}
$sheet = $excelReader->load($file)->getSheet(0); //sheet1操作
$excelCont = array(
'highestCol' => $sheet->getHighestColumn(), //列
'highestRow' => $sheet->getHighestRow(), //行
'highestColumnIndex' => PHPExcel_Cell::columnIndexFromString($sheet->getHighestColumn()) // 几列
);
$countCol = isset($params['count_col']) ? $params['count_col'] : $excelCont['highestRow'];//有效列的数目,读取时只取前$countCol列
$startRow = isset($params['need_head']) && $params['need_head'] ? 1 : 2;//从第1行开始读,读取表头
// $excelCont['highestRow'] 有几行
// 表示第一行第一列 $sheet->getCellByColumnAndRow(0, 1)->getValue()的值
$rightArr = array();
// 总共导入多少行 $row - $emptyLine -1
$row = $excelCont['highestRow'];
$emptyLine = 0;
for ($j = $startRow; $j < intval($row) + 1; $j++) {
$retArr = array();//该行的各个单元格的数据
$emptyCol = 0;
for($i = 0; $i < $countCol;$i++){//循环该行的单元格
$retArr[$i] = $sheet->getCellByColumnAndRow($i, $j)->getValue();
$retArr[$i] = isset($retArr[$i]) ? trim($retArr[$i]) : $retArr[$i];
if($retArr[$i] === null){
$emptyCol++;
}
}
if($emptyCol == $countCol){//这行为空行,不放入任何数组
$emptyLine++;
}else {
$rightArr[] = $retArr;
}
}
if(empty($rightArr)){
$result = array(
'errcode' =>1004,
'errmsg' =>"上传文件内没有有效数据",
);
}else{
$result = array(
'errcode' =>0,
'errmsg' =>"",
'data' =>$rightArr,
);
}
}
return $result;
}
php抓取网页表格信息(Python中的urlparse、urllib抓取和解析网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-28 08:24
项目中使用了网络爬虫,最后使用了HtmlAgilityPack来做。
官网地址:可以看看
基本的:
// From File<br />
var doc = new HtmlDocument();<br />
doc.Load(filePath);
// From String<br />
var doc = new HtmlDocument();<br />
doc.LoadHtml(html);
// From Web<br />
var url = "http://html-agility-pack.net/";<br />
var web = new HtmlWeb();<br />
var doc = web.Load(url);<br />我要实现抓取某一个table的信息,
官方代码如下:
HtmlDocument doc = new HtmlDocument();<br />
doc.LoadHtml(@"<p>helloworld");<br />
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table")) {<br />
Console.WriteLine("Found: " + table.Id);<br />
foreach (HtmlNode row in table.SelectNodes("tr")) {<br />
Console.WriteLine("row");<br />
foreach (HtmlNode cell in row.SelectNodes("th|td")) {<br />
Console.WriteLine("cell: " + cell.InnerText);<br />
}<br />
}<br />
}
这个例子可以成功运行,但是当我实际应用它时,我会发现
table.SelectNodes("tr") 获取的值为null,经查找发现是路径解析的问题,因为我获取的html为
<br />
<br />
<br />
承运人<br />
航线名称<br />
起运港<br />
目的港<br />
挂靠港<br />
<br />
<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
<br />
<br />
当前第一个tr的xml路径为:/html[1]/body[1]/div[3]/div[3]/div[1]/table[1]/thead[1]/tr,最后修改为了:
table.SelectNodes(".//tr") 就可以解析这个table下面的所有tr信息,<br />当使用
table.SelectNodes("//tr")时,获取的是当前html的全部tr,如果当有两个table时候,会获取到两个table全部的tr信息,用哪个要分情况
c#使用HtmlAgilityPack爬取解析获取更多表表信息文章 Python中使用urlparse和urllib爬取解析网页(一)(转)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容 2016/02/02 | 经验分享 | 0 回复 有时调试网页或...
Python中的urlparse和urllib爬取解析网页(一)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
使用HtmlAgilityPack和ScrapySharp抓取网页数据格式编码问题遇到的几个问题的解决方案
需要用到全市街道、县居委会对应的区号,于是找了统计局的网页,抓取了数据。使用了 HtmlAgilityPack 和 ScrapySharp。由于也是第一次从网页抓取数据,对于HtmlAgili...
c#抓取并解析网页,并将表格数据保存到datatable中(其他格式也可以,可以自行修改)
HtmlAgilityPack的使用基础请参考此博客:以下是根据抓取到的页面字符串解析保存... 查看全部
php抓取网页表格信息(Python中的urlparse、urllib抓取和解析网页(一))
项目中使用了网络爬虫,最后使用了HtmlAgilityPack来做。
官网地址:可以看看
基本的:
// From File<br />
var doc = new HtmlDocument();<br />
doc.Load(filePath);
// From String<br />
var doc = new HtmlDocument();<br />
doc.LoadHtml(html);
// From Web<br />
var url = "http://html-agility-pack.net/";<br />
var web = new HtmlWeb();<br />
var doc = web.Load(url);<br />我要实现抓取某一个table的信息,
官方代码如下:
HtmlDocument doc = new HtmlDocument();<br />
doc.LoadHtml(@"<p>helloworld");<br />
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table")) {<br />
Console.WriteLine("Found: " + table.Id);<br />
foreach (HtmlNode row in table.SelectNodes("tr")) {<br />
Console.WriteLine("row");<br />
foreach (HtmlNode cell in row.SelectNodes("th|td")) {<br />
Console.WriteLine("cell: " + cell.InnerText);<br />
}<br />
}<br />
}
这个例子可以成功运行,但是当我实际应用它时,我会发现
table.SelectNodes("tr") 获取的值为null,经查找发现是路径解析的问题,因为我获取的html为
<br />
<br />
<br />
承运人<br />
航线名称<br />
起运港<br />
目的港<br />
挂靠港<br />
<br />
<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
<br />
<br />
当前第一个tr的xml路径为:/html[1]/body[1]/div[3]/div[3]/div[1]/table[1]/thead[1]/tr,最后修改为了:
table.SelectNodes(".//tr") 就可以解析这个table下面的所有tr信息,<br />当使用
table.SelectNodes("//tr")时,获取的是当前html的全部tr,如果当有两个table时候,会获取到两个table全部的tr信息,用哪个要分情况
c#使用HtmlAgilityPack爬取解析获取更多表表信息文章 Python中使用urlparse和urllib爬取解析网页(一)(转)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容 2016/02/02 | 经验分享 | 0 回复 有时调试网页或...
Python中的urlparse和urllib爬取解析网页(一)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
使用HtmlAgilityPack和ScrapySharp抓取网页数据格式编码问题遇到的几个问题的解决方案
需要用到全市街道、县居委会对应的区号,于是找了统计局的网页,抓取了数据。使用了 HtmlAgilityPack 和 ScrapySharp。由于也是第一次从网页抓取数据,对于HtmlAgili...
c#抓取并解析网页,并将表格数据保存到datatable中(其他格式也可以,可以自行修改)
HtmlAgilityPack的使用基础请参考此博客:以下是根据抓取到的页面字符串解析保存...
php抓取网页表格信息(时间财富网智能客服时间君,网页文件的拓展:htm、html、JSP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-26 11:23
大家好,我是时代财富网智能客服,为您解答以上问题。
网页文件的扩展名包括:htm、html、JSP HTML、php、ASP动态网页文件、PHP/PHP3、PHTML等,由网页的语言决定。
网页(英文:web page)是一种适用于万维网和网络浏览器的文件。它存储在世界的某个角落或连接到互联网的一组计算机中。它是构成网站的基本元素,是承载各种网站应用的平台。网页由网址 (URL) 标识和访问。我们在网页浏览器中输入网址后,经过一个复杂而快速的过程,网页文件会被传送到用户的电脑,然后网页的内容会通过浏览器进行解释,然后展示给用户用户。
文字和图片是构成网页的两个最基本的元素。你可以简单的理解为:文本就是网页的内容。图片是网页的美。此外,网页的元素还包括动画、音乐、节目等。在网页上单击鼠标右键,在菜单中选择“查看源文件”,可以通过记事本查看网页的实际内容。您可以看到该网页实际上只是一个纯文本文件。它使用多种标签来描述页面上的文字、图片、表格、声音等元素(如字体、颜色、大小),浏览器对这些标签进行解释并生成页面,从而得到你当前的看。为什么可以' t 我在源文件中看到任何图片吗?网页文件中存储的只是图片的链接位置,图片文件和网页文件是相互独立存储的,甚至可能不在同一台电脑上。 查看全部
php抓取网页表格信息(时间财富网智能客服时间君,网页文件的拓展:htm、html、JSP)
大家好,我是时代财富网智能客服,为您解答以上问题。
网页文件的扩展名包括:htm、html、JSP HTML、php、ASP动态网页文件、PHP/PHP3、PHTML等,由网页的语言决定。
网页(英文:web page)是一种适用于万维网和网络浏览器的文件。它存储在世界的某个角落或连接到互联网的一组计算机中。它是构成网站的基本元素,是承载各种网站应用的平台。网页由网址 (URL) 标识和访问。我们在网页浏览器中输入网址后,经过一个复杂而快速的过程,网页文件会被传送到用户的电脑,然后网页的内容会通过浏览器进行解释,然后展示给用户用户。
文字和图片是构成网页的两个最基本的元素。你可以简单的理解为:文本就是网页的内容。图片是网页的美。此外,网页的元素还包括动画、音乐、节目等。在网页上单击鼠标右键,在菜单中选择“查看源文件”,可以通过记事本查看网页的实际内容。您可以看到该网页实际上只是一个纯文本文件。它使用多种标签来描述页面上的文字、图片、表格、声音等元素(如字体、颜色、大小),浏览器对这些标签进行解释并生成页面,从而得到你当前的看。为什么可以' t 我在源文件中看到任何图片吗?网页文件中存储的只是图片的链接位置,图片文件和网页文件是相互独立存储的,甚至可能不在同一台电脑上。
php抓取网页表格信息(PHP基础教程是一个比较有价值的PHP新手教程(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-22 16:19
PHP基础教程是比较有价值的PHP新手教程!
标题:PHP 基础教程 来源:Merry CG web log 时间:Mon, 28 Aug 2006 07:24:34 +0000 作者:yufeng 地址:内容:PHP 初学者教程,供初学者学习,是比较有价值的PHP 初学者教程!一、PHP 简介 PHP 是一种易于学习和使用的服务器端脚本语言。只需很少的编程知识,您就可以使用 PHP 构建一个真正交互式的 WEB 站点。本教程不希望你完全理解这门语言,但它会让你尽快加入开发动态网站的行列。我假设你有一些 HTML(或 HTML 编辑器)的基本知识和一些编程思想。1. 简介 PHP 是允许您生成动态网页的工具之一。PHP 网页文件被视为普通的 HTML 网页文件,您可以在编辑时按照通常的 HTML 编辑方式编写 PHP。PHP 代表:超文本预处理器(PHP:Hypertext Preprocessor)。PHP 是完全免费的,您可以从 PHP 官方网站 () 免费免费下载。PHP 遵守 GNU 公共许可证 (GPL),许多流行的软件如 Linux 和 Emacs 都是在该许可证下诞生的。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。
关于如何在 Windows 环境下的 PC 或 Unix 机器上安装 PHP 的信息可以在官方 PHP 站点上找到。安装过程非常简单。如果你的机器解决了 2000 年的问题,那么 PHP 也摆脱了 Y2K 的问题!1.1 历史 三年前,Rasmus Lerdorf 创建了“个人主页工具”以创建他的在线简历。这是一种非常简单的语言。从那时起,越来越多的人注意到了这种语言,并对其扩展提出了各种建议。在许多人的无私奉献和这门语言本身的免费源代码性质下,它已经演变成一门功能丰富的语言,并且还在不断地成长。PHP 虽然简单易学,但比 mod_perl(嵌入在 web 服务器中的 perl 模块)要慢。现在有一个新的引擎叫做 Zend 可以匹配 mod_perl 的速度,PHP4 可以充分利用这个引擎。PHP4 仍处于 beta 测试阶段。Andy Gutmans 和 Zeev Suraki 是 Zend 的主要作者。您可以到 Zend 站点 () 了解更多信息。PHP 在个人 Web 项目中的应用显着增长。根据 Netcraft 1999 年 10 月的报告,931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。
当然,已知的缺点是 PHP 没有商业支持,因为它是一个开源项目,导致执行速度慢(直到 PHP4)。但是 PHP 邮件列表非常有用,除非您正在运行一个非常受欢迎的站点,例如 Yahoo! 或者这个,你不会觉得PHP的速度跟别人不一样。至少我没有感觉到!好,我们来看看PHP的优点: - 学习过程 我个人更喜欢PHP的非常简单的学习过程。与 Java 和 Perl 不同,您不必将头埋在 100 页以上的文档中并努力学习以编写一个像样的程序。只要了解一些基本的语法和语言特性,就可以开始你的 PHP 编码之旅了。之后,如果您在编码过程中遇到任何问题,您可以再次阅读相关文档。PHP 的语法与 C、Perl、ASP 或 JSP 相同。对于熟悉上述其中一种语言的人来说,PHP 太简单了。相反,如果你对PHP了解得更多,那么你学习其他几种语言就很容易了。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。
-数据库连接PHP可以编译成连接很多数据库的函数。PHP 和 MySQL 现在是一个极好的组合。也可以自己编写外围函数,间接访问数据库。这样,当您更改您使用的数据库时,您可以轻松更改编码以适应此类更改。PHPLIB 是最常用的一系列基础库,可以提供一般业务需求。- 可扩展性如前所述,PHP 进入了快速发展的时期。非程序员可能很难为 PHP 扩展附加功能,但对于 PHP 程序员来说并不难。- 面向对象编程 PHP 提供了类和对象。基于 Web 的编程需要面向对象的编程能力。PHP 支持构造函数、提取类等。 -Scalability 传统上,网页的交互是通过CGI实现的。CGI 程序的可扩展性并不理想,因为它为每个正在运行的 CGI 程序打开了一个单独的进程。解决
现在就下载 查看全部
php抓取网页表格信息(PHP基础教程是一个比较有价值的PHP新手教程(图))
PHP基础教程是比较有价值的PHP新手教程!
标题:PHP 基础教程 来源:Merry CG web log 时间:Mon, 28 Aug 2006 07:24:34 +0000 作者:yufeng 地址:内容:PHP 初学者教程,供初学者学习,是比较有价值的PHP 初学者教程!一、PHP 简介 PHP 是一种易于学习和使用的服务器端脚本语言。只需很少的编程知识,您就可以使用 PHP 构建一个真正交互式的 WEB 站点。本教程不希望你完全理解这门语言,但它会让你尽快加入开发动态网站的行列。我假设你有一些 HTML(或 HTML 编辑器)的基本知识和一些编程思想。1. 简介 PHP 是允许您生成动态网页的工具之一。PHP 网页文件被视为普通的 HTML 网页文件,您可以在编辑时按照通常的 HTML 编辑方式编写 PHP。PHP 代表:超文本预处理器(PHP:Hypertext Preprocessor)。PHP 是完全免费的,您可以从 PHP 官方网站 () 免费免费下载。PHP 遵守 GNU 公共许可证 (GPL),许多流行的软件如 Linux 和 Emacs 都是在该许可证下诞生的。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。许多流行的软件如 Linux 和 Emacs 在其下诞生。您可以获得不受限制的源代码,甚至可以从中添加您需要的功能。PHP 可以在大多数 Unix 平台、GUN/Linux 和 Microsoft Windows 平台上运行。
关于如何在 Windows 环境下的 PC 或 Unix 机器上安装 PHP 的信息可以在官方 PHP 站点上找到。安装过程非常简单。如果你的机器解决了 2000 年的问题,那么 PHP 也摆脱了 Y2K 的问题!1.1 历史 三年前,Rasmus Lerdorf 创建了“个人主页工具”以创建他的在线简历。这是一种非常简单的语言。从那时起,越来越多的人注意到了这种语言,并对其扩展提出了各种建议。在许多人的无私奉献和这门语言本身的免费源代码性质下,它已经演变成一门功能丰富的语言,并且还在不断地成长。PHP 虽然简单易学,但比 mod_perl(嵌入在 web 服务器中的 perl 模块)要慢。现在有一个新的引擎叫做 Zend 可以匹配 mod_perl 的速度,PHP4 可以充分利用这个引擎。PHP4 仍处于 beta 测试阶段。Andy Gutmans 和 Zeev Suraki 是 Zend 的主要作者。您可以到 Zend 站点 () 了解更多信息。PHP 在个人 Web 项目中的应用显着增长。根据 Netcraft 1999 年 10 月的报告,931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。931,122 个域和 321,128 个 IP 地址使用 PHP 技术。1.2 PHP 的进步 使用 PHP 有很多好处。
当然,已知的缺点是 PHP 没有商业支持,因为它是一个开源项目,导致执行速度慢(直到 PHP4)。但是 PHP 邮件列表非常有用,除非您正在运行一个非常受欢迎的站点,例如 Yahoo! 或者这个,你不会觉得PHP的速度跟别人不一样。至少我没有感觉到!好,我们来看看PHP的优点: - 学习过程 我个人更喜欢PHP的非常简单的学习过程。与 Java 和 Perl 不同,您不必将头埋在 100 页以上的文档中并努力学习以编写一个像样的程序。只要了解一些基本的语法和语言特性,就可以开始你的 PHP 编码之旅了。之后,如果您在编码过程中遇到任何问题,您可以再次阅读相关文档。PHP 的语法与 C、Perl、ASP 或 JSP 相同。对于熟悉上述其中一种语言的人来说,PHP 太简单了。相反,如果你对PHP了解得更多,那么你学习其他几种语言就很容易了。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。您只需要 30 分钟即可掌握 PHP 的所有核心语言功能。您可能已经非常了解 HTML,甚至您已经知道如何使用编辑和设计软件或手工制作一个好看的 WEB 站点。由于可以毫无障碍地将 PHP 代码添加到您的站点,因此您可以在设计和维护站点的同时轻松添加 PHP 使站点更加动态。
-数据库连接PHP可以编译成连接很多数据库的函数。PHP 和 MySQL 现在是一个极好的组合。也可以自己编写外围函数,间接访问数据库。这样,当您更改您使用的数据库时,您可以轻松更改编码以适应此类更改。PHPLIB 是最常用的一系列基础库,可以提供一般业务需求。- 可扩展性如前所述,PHP 进入了快速发展的时期。非程序员可能很难为 PHP 扩展附加功能,但对于 PHP 程序员来说并不难。- 面向对象编程 PHP 提供了类和对象。基于 Web 的编程需要面向对象的编程能力。PHP 支持构造函数、提取类等。 -Scalability 传统上,网页的交互是通过CGI实现的。CGI 程序的可扩展性并不理想,因为它为每个正在运行的 CGI 程序打开了一个单独的进程。解决
现在就下载
php抓取网页表格信息(爬取空气质量检测网之部分城市的历年每天质量数据思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-15 00:07
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后抓取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏的表数据,但是不稳定,
仍然遇到的问题:-----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用 driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month) 查看全部
php抓取网页表格信息(爬取空气质量检测网之部分城市的历年每天质量数据思路)
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后抓取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏的表数据,但是不稳定,
仍然遇到的问题:-----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用 driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month)
php抓取网页表格信息(python制作爬虫并将抓取结果保存到excel中的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-13 22:06
想知道python制作爬虫并将爬取结果保存到excel的相关内容吗?在本文中,Data&Truth 将仔细讲解python制作爬虫并将爬取结果保存到excel的相关知识以及一些代码示例。欢迎先阅读并指正重点:下面一起来学习python爬虫
我已经学习 Python 一段时间了。各种理论知识大体上可以考虑一两个。进入今天的实战练习:用Python写一个拉勾网薪资调查的小爬虫
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,搜索Python或PHP等职位信息实际上是在向服务器发送相应的请求。服务器动态响应请求,通过浏览器分析将我们需要的内容呈现给我们。
可以看到,我们发送的请求中FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求
建议使用 Fiddler 来分析比较复杂的页面请求和响应信息。绝对是分析网站的杀手锏。但是,相对简单的响应请求,可以配合浏览器自带的开发工具使用,比如火狐的FireBug等,所有请求的信息,只要按一下F12就可以展现在你面前
通过对网站的请求和响应过程的分析可以看出,拉勾网的招聘信息是由XHR动态传输的
我们发现POST发送了两个请求,companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总次数(totalCount)等相关信息
第二步:发送请求获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一就是在模仿浏览器的Post方法后如何打包我们自己的请求
请求中收录的参数包括要爬取的网页的URL和headersurlopen中的data参数进行伪装,包括FormData的三个参数(first, pn, kd)
打包完成后,您可以像浏览器一样访问拉勾网,获取页面数据。
第三步:各自获取所需数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步了:爬取数据
捕获数据的方法有很多种,比如正则表达式relxml的etreejson和bs4的BeautifulSoup,都是python3捕获数据的适用方法。您可以根据实际情况使用其中的一种或多种。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,我们将采集到的数据在excel中进行结构化、组织化的存储,以便进一步整理分析,方便数据的可视化。
这里我使用了两个不同的框架:旧的 xlwt.Workbook 和 xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先,xlwt不知道为什么xlwt存储了100多条数据后存储不全,excel文件也会出现“部分内容有问题需要修复”。查了很多次,还以为是数据采集不全导致的存储问题。出问题后断点检查发现数据完整。然后我改了本地数据进行处理,没有问题。我当时的心情是这样的:
直到现在,我还没有弄清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据可以正常使用没有问题
至此,一个从拉勾网抓取招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的所以需要通过post来递交json信息默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息包括公司名称学历要求薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数大于30的将会被覆盖所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多可以添加的功能,比如通过修改城市参数查看不同城市的招聘信息等,这里可以自己开发,仅供参考,欢迎交流
相关文章 查看全部
php抓取网页表格信息(python制作爬虫并将抓取结果保存到excel中的相关内容吗)
想知道python制作爬虫并将爬取结果保存到excel的相关内容吗?在本文中,Data&Truth 将仔细讲解python制作爬虫并将爬取结果保存到excel的相关知识以及一些代码示例。欢迎先阅读并指正重点:下面一起来学习python爬虫
我已经学习 Python 一段时间了。各种理论知识大体上可以考虑一两个。进入今天的实战练习:用Python写一个拉勾网薪资调查的小爬虫
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,搜索Python或PHP等职位信息实际上是在向服务器发送相应的请求。服务器动态响应请求,通过浏览器分析将我们需要的内容呈现给我们。
可以看到,我们发送的请求中FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求
建议使用 Fiddler 来分析比较复杂的页面请求和响应信息。绝对是分析网站的杀手锏。但是,相对简单的响应请求,可以配合浏览器自带的开发工具使用,比如火狐的FireBug等,所有请求的信息,只要按一下F12就可以展现在你面前
通过对网站的请求和响应过程的分析可以看出,拉勾网的招聘信息是由XHR动态传输的
我们发现POST发送了两个请求,companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总次数(totalCount)等相关信息
第二步:发送请求获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一就是在模仿浏览器的Post方法后如何打包我们自己的请求
请求中收录的参数包括要爬取的网页的URL和headersurlopen中的data参数进行伪装,包括FormData的三个参数(first, pn, kd)
打包完成后,您可以像浏览器一样访问拉勾网,获取页面数据。
第三步:各自获取所需数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步了:爬取数据
捕获数据的方法有很多种,比如正则表达式relxml的etreejson和bs4的BeautifulSoup,都是python3捕获数据的适用方法。您可以根据实际情况使用其中的一种或多种。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
第4步:将捕获的信息存储在excel中
获取原创数据后,我们将采集到的数据在excel中进行结构化、组织化的存储,以便进一步整理分析,方便数据的可视化。
这里我使用了两个不同的框架:旧的 xlwt.Workbook 和 xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
首先,xlwt不知道为什么xlwt存储了100多条数据后存储不全,excel文件也会出现“部分内容有问题需要修复”。查了很多次,还以为是数据采集不全导致的存储问题。出问题后断点检查发现数据完整。然后我改了本地数据进行处理,没有问题。我当时的心情是这样的:
直到现在,我还没有弄清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据可以正常使用没有问题
至此,一个从拉勾网抓取招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的所以需要通过post来递交json信息默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息包括公司名称学历要求薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知招聘信息包含在返回的result当中其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数大于30的将会被覆盖所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还有很多可以添加的功能,比如通过修改城市参数查看不同城市的招聘信息等,这里可以自己开发,仅供参考,欢迎交流
相关文章
php抓取网页表格信息(Python+GoogleAppEngine免费解决方案的存取接口补充说明(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-11-10 19:18
鼠标悬停在红框上阅读评论,可以了解我的需求,以下是补充说明,有时间可以阅读。
主要用途:抓取某个租房信息网页的数据,交给我的网站使用(先存入数据库,然后作为网页发布,以后保存数据
[color=#000000]制作谷歌地图)。你要做的就是第一步,即抓取信息并存入数据库,提供方便的访问接口。当然,如果你提供一种巧妙的方式,定期将数据发布到我的特定网页网站,或者将其导入到google融合表中,那么我将省略后两个特殊步骤。为了表示鼓励,它会在任务量之外。报酬。) 虽然任务不紧急,15天内可以完成,但是如果你觉得还可以,申请一个测试账号,那么最好当天就安装运行成功。我不希望你经常改变这个那个,浪费双方宝贵的时间,所以请仔细阅读文档以准确实现我的意图。[/颜色]
[color=#333399]提供的平台环境和语言(请本地获取库和代码,然后找我要账号):[/color]
选项1:PHP + MySQL + Cron 我有一个空闲的虚拟PHP主机(但不是我将发布信息的主机网站。这就是为什么我需要一个数据访问接口。我希望接口足够简单任何支持HTML/Javascript的网页都可以用Key随便调用)。宿主机已经支持 Cron 定时任务,但是你需要安装你准备使用的库。
方案二:Python+Google AppEngine免费方案,需要安装BeautifulSoup+Mechanize等库,注意采用灵活的方法避开GAE政策限制,哈哈。
[color=#333399] 选项3:也许有WP高手可以用Wordpress+Autoblog来解决?在PHP主机上也可以,但不知道采集会不会顺利,请仔细阅读任务说明,赐教。[/颜色]
我讨厌代码太多,所以请务必使用现有的免费和开源库来巧妙地解决问题。代码量不超过250,行为漂亮,哈哈。您的时间应该主要花在分析着陆页的数据结构和集成各种库上。一个几百块钱的任务,几个小时就能完成,你我双赢。如果你的计划太复杂,工作量太大,肯定会让双方尴尬。但是我耽搁了,最后还是违约了。虽然钱没有丢,但时间和事情都耽误了。因为退款了,没办法投诉。半年多没敢来竹八界发任务了)。
[color=#ff0000]具体任务说明请下载附件查看[/color]。虽然可以多点N次,但是可以防止原来的网站从google上查出谁在得到他的数据——甚至根据他对这个网站的描述,除了一些自己的信息,还有很多其他的也从主要 网站 爬取。[color=#ff0000] 提交任务时请打包,不要在描述中提及原站点,谢谢。任务代号FreeShark[/color] 你可以用这个代号来调用它。
参考(只是为了让你更清楚我的意图,不是教程,这些你应该早就熟悉了):
[size=2]Python采集网站数据[/size]
[尺寸=3][/尺寸]
其他:([color=#ff0000]这个例子使用代理来逃避跟踪。这是一个聪明的方法来放弃[/color]。)
——煽动的好处是可以让你更清楚我的意图,减少在QQ上浪费生命。哈哈,介绍完毕。 查看全部
php抓取网页表格信息(Python+GoogleAppEngine免费解决方案的存取接口补充说明(一))
鼠标悬停在红框上阅读评论,可以了解我的需求,以下是补充说明,有时间可以阅读。
主要用途:抓取某个租房信息网页的数据,交给我的网站使用(先存入数据库,然后作为网页发布,以后保存数据
[color=#000000]制作谷歌地图)。你要做的就是第一步,即抓取信息并存入数据库,提供方便的访问接口。当然,如果你提供一种巧妙的方式,定期将数据发布到我的特定网页网站,或者将其导入到google融合表中,那么我将省略后两个特殊步骤。为了表示鼓励,它会在任务量之外。报酬。) 虽然任务不紧急,15天内可以完成,但是如果你觉得还可以,申请一个测试账号,那么最好当天就安装运行成功。我不希望你经常改变这个那个,浪费双方宝贵的时间,所以请仔细阅读文档以准确实现我的意图。[/颜色]
[color=#333399]提供的平台环境和语言(请本地获取库和代码,然后找我要账号):[/color]
选项1:PHP + MySQL + Cron 我有一个空闲的虚拟PHP主机(但不是我将发布信息的主机网站。这就是为什么我需要一个数据访问接口。我希望接口足够简单任何支持HTML/Javascript的网页都可以用Key随便调用)。宿主机已经支持 Cron 定时任务,但是你需要安装你准备使用的库。
方案二:Python+Google AppEngine免费方案,需要安装BeautifulSoup+Mechanize等库,注意采用灵活的方法避开GAE政策限制,哈哈。
[color=#333399] 选项3:也许有WP高手可以用Wordpress+Autoblog来解决?在PHP主机上也可以,但不知道采集会不会顺利,请仔细阅读任务说明,赐教。[/颜色]
我讨厌代码太多,所以请务必使用现有的免费和开源库来巧妙地解决问题。代码量不超过250,行为漂亮,哈哈。您的时间应该主要花在分析着陆页的数据结构和集成各种库上。一个几百块钱的任务,几个小时就能完成,你我双赢。如果你的计划太复杂,工作量太大,肯定会让双方尴尬。但是我耽搁了,最后还是违约了。虽然钱没有丢,但时间和事情都耽误了。因为退款了,没办法投诉。半年多没敢来竹八界发任务了)。
[color=#ff0000]具体任务说明请下载附件查看[/color]。虽然可以多点N次,但是可以防止原来的网站从google上查出谁在得到他的数据——甚至根据他对这个网站的描述,除了一些自己的信息,还有很多其他的也从主要 网站 爬取。[color=#ff0000] 提交任务时请打包,不要在描述中提及原站点,谢谢。任务代号FreeShark[/color] 你可以用这个代号来调用它。
参考(只是为了让你更清楚我的意图,不是教程,这些你应该早就熟悉了):
[size=2]Python采集网站数据[/size]
[尺寸=3][/尺寸]
其他:([color=#ff0000]这个例子使用代理来逃避跟踪。这是一个聪明的方法来放弃[/color]。)
——煽动的好处是可以让你更清楚我的意图,减少在QQ上浪费生命。哈哈,介绍完毕。
php抓取网页表格信息( php.ini中的max_execution设置设置的大点软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-11-02 14:02
php.ini中的max_execution设置设置的大点软件)
在进行爬取之前,记得把php.ini中的max_execution_time设置为较大的值,否则会报错。
一、 使用 Snoopy.class.php 抓取页面
一个很可爱的类名。功能也很强大,用来模拟浏览器的功能,可以获取网页内容,发送表单等等。
1)我要抓取网站的一个列表页的内容,我要抓取的是全国医院的信息内容,如下图:
2) 我自然是复制了URL地址,使用Snoopy类抓取前10页的内容,并将内容放到本地,在本地创建一个html文件,供以后分析使用。
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3) 奇怪的是,返回的不是全国的内容,而是上海的相关内容
4) 怀疑里面可能设置了cookie,然后用firebug查了一下,果然有惊人的内情
5) 在请求中放入cookie的值,并添加设置语句$snoopy->cookies["_area_"],情况大不相同,顺利返回国家信息。
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i fetch($url);
$html = $snoopy->results;
}
2)使用phpQuery获取节点信息,DOM结构如下图所示:
使用一些phpQuery方法,结合DOM结构读取各个医院信息的URL地址。
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取到的URL地址列表,抓取指定页面。
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
克服障碍.rar
演示下载:
史努比类的一些说明:
类方法
获取($URI)
这是用于抓取网页内容的方法。
$URI 参数是被爬取的网页的 URL 地址。
获取的结果存储在 $this->results 中。
如果你正在抓取一帧,史努比会跟踪每一帧并将其存储在一个数组中,然后将其存储在 $this->results 中。
获取文本($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的表单内容(form)。
获取链接($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。$formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,并且只返回登录后网页中的文本内容。
提交链接($URI)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
类属性
$host
连接主机
$端口
连接端口
$proxy_host
使用的代理主机(如果有)
$proxy_port
使用的代理主机端口(如果有)
$代理
用户代理伪装(史努比 v0.1)
$referer
信息,如果有
$cookies
饼干,如果有的话
$rawheaders
其他标题信息,如果有的话
$maxredirs
最大重定向次数,0=不允许 (5)
$offsiteok
是否允许异地重定向。(真的)
$expandlinks
是否完成所有链接完成地址(true)
$用户
身份验证用户名(如果有)
$pass
身份验证用户名(如果有)
$接受
http 接受类型 (image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*)
$错误
在哪里报告错误,如果有的话
$response_code
服务器返回的响应码
$headers
服务器返回的头部信息
$最大长度
最大返回数据长度
$read_timeout
读取操作超时(需要 PHP 4 Beta 4+),设置为 0 表示没有超时
$timed_out
如果读取操作超时,则此属性返回 true(需要 PHP 4 Beta 4+)
$maxframes
允许跟踪的最大帧数
$状态 查看全部
php抓取网页表格信息(
php.ini中的max_execution设置设置的大点软件)
在进行爬取之前,记得把php.ini中的max_execution_time设置为较大的值,否则会报错。
一、 使用 Snoopy.class.php 抓取页面
一个很可爱的类名。功能也很强大,用来模拟浏览器的功能,可以获取网页内容,发送表单等等。
1)我要抓取网站的一个列表页的内容,我要抓取的是全国医院的信息内容,如下图:
2) 我自然是复制了URL地址,使用Snoopy类抓取前10页的内容,并将内容放到本地,在本地创建一个html文件,供以后分析使用。
$snoopy=new Snoopy();
//医院list页面
for($i = 1; $i fetch($url);
file_put_contents("web/page/$i.html", $snoopy->results);
}
echo 'success';
3) 奇怪的是,返回的不是全国的内容,而是上海的相关内容
4) 怀疑里面可能设置了cookie,然后用firebug查了一下,果然有惊人的内情
5) 在请求中放入cookie的值,并添加设置语句$snoopy->cookies["_area_"],情况大不相同,顺利返回国家信息。
$snoopy=new Snoopy();
//医院list页面
$snoopy->cookies["_area_"] = '{"provinceId":"all","provinceName":"全国","cityId":"all","cityName":"不限"}';
for($i = 1; $i fetch($url);
$html = $snoopy->results;
}
2)使用phpQuery获取节点信息,DOM结构如下图所示:
使用一些phpQuery方法,结合DOM结构读取各个医院信息的URL地址。
for($i = 1; $i attr('href')); //医院详情
}
}
3)根据读取到的URL地址列表,抓取指定页面。
$detailIndex = 1;
for($i = 1; $i results);
$detailIndex++;
}
}
FQ工具下载:
克服障碍.rar
演示下载:
史努比类的一些说明:
类方法
获取($URI)
这是用于抓取网页内容的方法。
$URI 参数是被爬取的网页的 URL 地址。
获取的结果存储在 $this->results 中。
如果你正在抓取一帧,史努比会跟踪每一帧并将其存储在一个数组中,然后将其存储在 $this->results 中。
获取文本($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的表单内容(form)。
获取链接($URI)
该方法与fetch()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。$formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,并且只返回登录后网页中的文本内容。
提交链接($URI)
该方法与submit()类似,唯一不同的是,该方法会去除HTML标签等无关数据,只返回网页中的链接。
默认情况下,相对链接将自动完成并转换为完整的 URL。
类属性
$host
连接主机
$端口
连接端口
$proxy_host
使用的代理主机(如果有)
$proxy_port
使用的代理主机端口(如果有)
$代理
用户代理伪装(史努比 v0.1)
$referer
信息,如果有
$cookies
饼干,如果有的话
$rawheaders
其他标题信息,如果有的话
$maxredirs
最大重定向次数,0=不允许 (5)
$offsiteok
是否允许异地重定向。(真的)
$expandlinks
是否完成所有链接完成地址(true)
$用户
身份验证用户名(如果有)
$pass
身份验证用户名(如果有)
$接受
http 接受类型 (image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, */*)
$错误
在哪里报告错误,如果有的话
$response_code
服务器返回的响应码
$headers
服务器返回的头部信息
$最大长度
最大返回数据长度
$read_timeout
读取操作超时(需要 PHP 4 Beta 4+),设置为 0 表示没有超时
$timed_out
如果读取操作超时,则此属性返回 true(需要 PHP 4 Beta 4+)
$maxframes
允许跟踪的最大帧数
$状态
php抓取网页表格信息(php抓取网页表格信息到本地html文件用lll如果我只是记表格的话就方便了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-30 11:02
php抓取网页表格信息到本地html文件
用lll如果我只是记表格的话就方便了header你自己写一个标签注意要加括号后面的是要链接的链接这样一般你就能找到你要的数据如果这都不能满足你的需求或者想进一步筛选你可以试试第三方框架homicaws
morganfullman开发的forms.php,该框架可以创建html表格并嵌入script脚本。
简单直接的方法,用lll你可以爬1000万行数据,然后按照页码去抓取。
请楼主回答:php本身就能爬数据吗?用php处理java的就可以啊
我用php做的一个简单爬虫框架:1、基于get请求获取网页元素(while)2、根据元素内容判断是否合法
sqlitemysqlphpapifaq一个基于php的数据库工具:easybook-php-apiapifaq
本人php做的
fiddler可以抓取用户信息,推荐试一下,
php的话f12在控制台里面看是看不出来的,然后万恶的get那个的api开头是post也不能用的,所以,让我猜猜websocket和urllib2是怎么进来的?get-emails,而urllib2根据api网上图书馆这类有对应页码的页面是绝对不能用get去获取的。不知道在哪找到一个websocket的开发包有明确说明的,很多也就学习了一下。 查看全部
php抓取网页表格信息(php抓取网页表格信息到本地html文件用lll如果我只是记表格的话就方便了)
php抓取网页表格信息到本地html文件
用lll如果我只是记表格的话就方便了header你自己写一个标签注意要加括号后面的是要链接的链接这样一般你就能找到你要的数据如果这都不能满足你的需求或者想进一步筛选你可以试试第三方框架homicaws
morganfullman开发的forms.php,该框架可以创建html表格并嵌入script脚本。
简单直接的方法,用lll你可以爬1000万行数据,然后按照页码去抓取。
请楼主回答:php本身就能爬数据吗?用php处理java的就可以啊
我用php做的一个简单爬虫框架:1、基于get请求获取网页元素(while)2、根据元素内容判断是否合法
sqlitemysqlphpapifaq一个基于php的数据库工具:easybook-php-apiapifaq
本人php做的
fiddler可以抓取用户信息,推荐试一下,
php的话f12在控制台里面看是看不出来的,然后万恶的get那个的api开头是post也不能用的,所以,让我猜猜websocket和urllib2是怎么进来的?get-emails,而urllib2根据api网上图书馆这类有对应页码的页面是绝对不能用get去获取的。不知道在哪找到一个websocket的开发包有明确说明的,很多也就学习了一下。
php抓取网页表格信息(PHP库模拟登录开源中国的移动版为例库使用总结)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-29 19:03
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,有需要的朋友可以参考
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init();//初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1);//post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息 curl_exec($curl);//执行cURL curl_close($curl);//关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs; }
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上就是php curl模拟登录和获取详细数据示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页表格信息(PHP库模拟登录开源中国的移动版为例库使用总结)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以轻松有效地抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,有需要的朋友可以参考
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录 function login_post($url, $cookie, $post) { $curl = curl_init();//初始化curl模块 curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址 curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息 curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息 curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中 curl_setopt($curl, CURLOPT_POST, 1);//post方式提交 curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息 curl_exec($curl);//执行cURL curl_close($curl);//关闭cURL资源,并且释放系统资源 }
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据 function get_content($url, $cookie) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie $rs = curl_exec($ch); //执行cURL抓取页面内容 curl_close($ch); return $rs; }
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据 $post = array ( 'email' => 'oschina账户', 'pwd' => 'oschina密码', 'goto_page' => '/my', 'error_page' => '/login', 'save_login' => '1', 'submit' => '现在登录' ); //登录地址 $url = "http://m.oschina.net/action/user/login"; //设置cookie保存路径 $cookie = dirname(__FILE__) . '/cookie_oschina.txt'; //登录后要获取信息的地址 $url2 = "http://m.oschina.net/my"; //模拟登录 login_post($url, $cookie, $post); //获取登录页的信息 $content = get_content($url2, $cookie); //删除cookie文件 @ unlink($cookie); //匹配页面信息 $preg = "/(.*)/i"; preg_match_all($preg, $content, $arr); $str = $arr[1][0]; //输出内容 echo $str;
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
感谢您的阅读,希望对您有所帮助,感谢您对本站的支持!
以上就是php curl模拟登录和获取详细数据示例的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页表格信息(scraping-io、import和data-miner.io(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-26 06:21
网络抓取,有时也称为数据抓取、数据提取或网络厄瓜多尔手机号码列表,只是从 网站 采集数据并将其存储在本地数据库或电子表格中的过程。今天,网络抓取工具是现代营销人员所必需的。对于初学者来说,网络抓取可能听起来像是这些可怕的技术流行语之一,但从技术上讲,这没什么大不了的。但是,要执行任何网络抓取,您需要正确的工具。网页抓取工具不仅可以用于招聘目的,还可以用于营销、金融、电子商务和许多其他行业。我们将研究的工具是 scraping-bot.io、import.io、webscraper.io 和 data-miner.io。
在我们继续之前,我可以听到你在问“我为什么要花宝贵的时间学习如何爬网”?这就是为什么 - 潜在客户可以是帮助您代表品牌的直接客户或影响者。您可以自己搜索潜在客户,浏览网站 和社交媒体。但所有这些研究都需要时间。那么,如果您可以将这项研究留给机器,而您更多地关注战略和重要任务呢?网页抓取是一项尖端技术,旨在在尽可能短的时间内从数百万个网页中采集潜在客户的联系信息。这是一个信息时代,许多买家根据在线评论做出判断。因此,了解人们对您的品牌、产品、服务和竞争对手的评价非常重要。
什么是网络爬虫?
通常,小企业面临的最大挑战是如何在不失去客户的情况下提高价格。但是,不提高价格是不可能赚取更多利润的。在这里,您可以使用网络抓取工具来增加您的利润:让您了解任何竞争对手的价格变化,以便快速做出反应并优化您的价格。跟踪您的竞争对手所做的促销和活动的成功,以了解什么是最有效的。Scraping-bot.io 是一个 API,允许您从给定的 URL 中提取数据。您可以在 Google 页面或零售 网站 上获取整个 HTML 页面内容。最初开发用于抓取零售网站的产品页面,scraping-bot.io API也可用于抓取Google页面以进行SEO排名分析。在零售网站,集成的 API 将允许您采集您需要的所有重要信息。因此,例如,您可以抓取图像、产品标题、价格、产品描述、库存、运输成本、EAN、产品类别等。
有适度使用的免费计划(100 次调用/月),然后价格计划范围从 39 欧元(每月 100,000 次调用)到企业计划的 299 欧元(1,000,000 次调用/月)。有关爬行机器人定价的更多信息,您可以在此处查看。该工具的主要特性包括多个并发请求、JS渲染(Headless Chrome)、高质量代理和地理定位。如果您不想立即集成 API,可以在创建免费帐户后使用实时测试。完成此操作后,只需转到仪表板即可。然后,粘贴您要抓取的 URL 并选择您的选项(Get Html、Headless Chrome),您将能够立即看到此 API 的性能。您每月有 100 次免费计划电话,这足以试水,看看这款爬虫是否适合您。对于开发者来说,
为什么要学习网络爬虫?
转到您要抓取的页面(这里是亚马逊产品页面,但您可以尝试任何其他零售网站)并复制该页面的开曼群岛商业目录。转到您的仪表板或主页并将您的 URL 粘贴到实时测试框中。选择您的首选选项(完整的 HTML、无头浏览器)。使用 API 端点和 POST 方法进行直接集成。有完整的文档,包括用于在 NodeJs、Bash、Php、Python 和 Ruby 中抓取的代码示例。总而言之,scraping-bot.io 是一个没有 faff 的 API,可以用于中大批量的抓取。它将完成工作并为您节省大量时间和麻烦。Import.io 是一个可以提取和转换数据的企业级平台。使用Import.io,您可以先提取您需要的数据,将数据组织成您想要的格式,并通过数据可视化获得洞察力。该工具允许人们将非结构化 Web 数据转换为结构化格式,以用于机器学习、人工智能、零售价格监控、商店定位器以及学术和其他研究。
首先,找到您的数据所在的页面。例如,产品页面上。将此页面中的 URL 复制并粘贴到 Import.io 中,以创建一个尝试获取正确数据的提取器。单击 Go,Import.io 将查询该页面。它将使用机器学习来尝试确定您想要的数据。完成后,您可以决定提取的数据是否是您需要的。在这种情况下,我们希望将图像连同产品名称和价格一起提取到列中。我们通过单击每列中的前三个项目来训练提取器,然后用绿色勾勒出属于该列的所有项目。Import.io 然后为产品名称和价格填充列的其余部分。Import.io 检测到产品列表数据超过一页,因此您可以添加任意数量的页面,以确保该类别中的所有产品都收录在电子表格中。我们刚刚检查的是将基本数据列表页面转换为电子表格的热点。
帖子导航
WordPress 被黑?这是您需要做的一切。
大数据营销:完整指南 查看全部
php抓取网页表格信息(scraping-io、import和data-miner.io(组图))
网络抓取,有时也称为数据抓取、数据提取或网络厄瓜多尔手机号码列表,只是从 网站 采集数据并将其存储在本地数据库或电子表格中的过程。今天,网络抓取工具是现代营销人员所必需的。对于初学者来说,网络抓取可能听起来像是这些可怕的技术流行语之一,但从技术上讲,这没什么大不了的。但是,要执行任何网络抓取,您需要正确的工具。网页抓取工具不仅可以用于招聘目的,还可以用于营销、金融、电子商务和许多其他行业。我们将研究的工具是 scraping-bot.io、import.io、webscraper.io 和 data-miner.io。
在我们继续之前,我可以听到你在问“我为什么要花宝贵的时间学习如何爬网”?这就是为什么 - 潜在客户可以是帮助您代表品牌的直接客户或影响者。您可以自己搜索潜在客户,浏览网站 和社交媒体。但所有这些研究都需要时间。那么,如果您可以将这项研究留给机器,而您更多地关注战略和重要任务呢?网页抓取是一项尖端技术,旨在在尽可能短的时间内从数百万个网页中采集潜在客户的联系信息。这是一个信息时代,许多买家根据在线评论做出判断。因此,了解人们对您的品牌、产品、服务和竞争对手的评价非常重要。
什么是网络爬虫?
通常,小企业面临的最大挑战是如何在不失去客户的情况下提高价格。但是,不提高价格是不可能赚取更多利润的。在这里,您可以使用网络抓取工具来增加您的利润:让您了解任何竞争对手的价格变化,以便快速做出反应并优化您的价格。跟踪您的竞争对手所做的促销和活动的成功,以了解什么是最有效的。Scraping-bot.io 是一个 API,允许您从给定的 URL 中提取数据。您可以在 Google 页面或零售 网站 上获取整个 HTML 页面内容。最初开发用于抓取零售网站的产品页面,scraping-bot.io API也可用于抓取Google页面以进行SEO排名分析。在零售网站,集成的 API 将允许您采集您需要的所有重要信息。因此,例如,您可以抓取图像、产品标题、价格、产品描述、库存、运输成本、EAN、产品类别等。
http://www.kybdirectory.com/cn ... 0.jpg 300w, http://www.kybdirectory.com/cn ... 1.jpg 768w" />有适度使用的免费计划(100 次调用/月),然后价格计划范围从 39 欧元(每月 100,000 次调用)到企业计划的 299 欧元(1,000,000 次调用/月)。有关爬行机器人定价的更多信息,您可以在此处查看。该工具的主要特性包括多个并发请求、JS渲染(Headless Chrome)、高质量代理和地理定位。如果您不想立即集成 API,可以在创建免费帐户后使用实时测试。完成此操作后,只需转到仪表板即可。然后,粘贴您要抓取的 URL 并选择您的选项(Get Html、Headless Chrome),您将能够立即看到此 API 的性能。您每月有 100 次免费计划电话,这足以试水,看看这款爬虫是否适合您。对于开发者来说,
为什么要学习网络爬虫?
转到您要抓取的页面(这里是亚马逊产品页面,但您可以尝试任何其他零售网站)并复制该页面的开曼群岛商业目录。转到您的仪表板或主页并将您的 URL 粘贴到实时测试框中。选择您的首选选项(完整的 HTML、无头浏览器)。使用 API 端点和 POST 方法进行直接集成。有完整的文档,包括用于在 NodeJs、Bash、Php、Python 和 Ruby 中抓取的代码示例。总而言之,scraping-bot.io 是一个没有 faff 的 API,可以用于中大批量的抓取。它将完成工作并为您节省大量时间和麻烦。Import.io 是一个可以提取和转换数据的企业级平台。使用Import.io,您可以先提取您需要的数据,将数据组织成您想要的格式,并通过数据可视化获得洞察力。该工具允许人们将非结构化 Web 数据转换为结构化格式,以用于机器学习、人工智能、零售价格监控、商店定位器以及学术和其他研究。
首先,找到您的数据所在的页面。例如,产品页面上。将此页面中的 URL 复制并粘贴到 Import.io 中,以创建一个尝试获取正确数据的提取器。单击 Go,Import.io 将查询该页面。它将使用机器学习来尝试确定您想要的数据。完成后,您可以决定提取的数据是否是您需要的。在这种情况下,我们希望将图像连同产品名称和价格一起提取到列中。我们通过单击每列中的前三个项目来训练提取器,然后用绿色勾勒出属于该列的所有项目。Import.io 然后为产品名称和价格填充列的其余部分。Import.io 检测到产品列表数据超过一页,因此您可以添加任意数量的页面,以确保该类别中的所有产品都收录在电子表格中。我们刚刚检查的是将基本数据列表页面转换为电子表格的热点。
帖子导航
WordPress 被黑?这是您需要做的一切。
大数据营销:完整指南
php抓取网页表格信息(纯静态网站在网站中是怎么实现的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 02:04
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。我们访问的时候,可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先对网站的页面进行汇总,分成几种样式,然后将这些页面制作成模板。生成的时候需要先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是小中型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过中小网站还是纯静态对比,优点很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你的后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全有能力抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试创建一个静态 URL。
下面我们主要讲一下静态页面的概念,希望对大家有所帮助!
什么是 html 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在php网站的开发中,针对网站推广和seo的需要,需要对网站进行全站或局部静态处理。php生成静态html页面的方法有很多,比如使用php模板、缓存等实现页面静态化。
php static的简单理解就是将网站生成的页面以静态html的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于php生成静态页面的处理机制。.
php伪静态:一种使用apache mod_rewrite的url重写方法。
html静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化seo、baidu、google会优先处理收录静态页面,不仅有收录的快,还有收录的饱满;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,html页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止sql注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现html静态化的策略和例子:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用php模板生成静态页面
php模板实现静态化非常方便,比如安装使用php smarty实现网站静态化。
在使用 smarty 的情况下,页面也可以是静态的。简单说一下smarty使用时动态阅读的方式。
一般分为这几个步骤:
1、 通过url传递一个参数(id);
2、然后根据这个id查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
smarty静态过程只需要在上述过程中增加两步即可。
第一:使用 ob_start() 在 1 之前打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效利用上述过程,可以使用一个小方法,即header()。具体过程如下: 添加修改程序后,使用header()跳转到前台读取,使页面可以html化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用php文件读写功能生成静态页面
方法三:使用php输出控制/ob缓存机制生成静态页面
输出控制功能(output control)就是使用和控制缓存来生成静态html页面。它还使用了php文件读写功能。
比如一个产品的动态详情页地址是:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道使用php进行网站开发,一般的执行结果都是直接输出到浏览器,为了使用php生成静态页面,需要使用输出控制功能来控制缓存区,这样获取缓存区的内容,然后输出到静态html页面文件,实现网站静态。
php生成静态页面的思路是:先开启缓存,然后输出html内容(也可以通过include以文件的形式收录html内容),然后获取缓存中的内容,然后通过php文件读写功能清除缓存。缓存内容写入静态html页面文件。
获取输出缓存内容生成静态html页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有空格、字符等输出。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。如果成功,则返回 true,如果失败,则返回 false。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。key 的默认最大大小不能超过 128 字节,value 的默认大小为 1m。所以1m的大小可以满足大部分网页的存储。
以上就是php实现静态html页面的方法,内容丰富,值得大家细细品味和收获。 查看全部
php抓取网页表格信息(纯静态网站在网站中是怎么实现的?(组图))
随着网站内容的增加和用户访问量的增加,不可避免的网站会加载越来越慢,同时受限于带宽和来自服务器的请求数,我们这个时候经常需要优化我们网站的代码和服务器配置。
一般情况下会从以下几个方面进行优化
现在很多网站在构建过程中都需要静态处理。为什么要对 网站 进行静态处理?我们都知道纯静态网站就是所有的网页都是独立的html页面。我们访问的时候,可以直接读取文件,无需数据处理。访问速度可想而知。而且这也是一种对搜索引擎非常友好的方式。
网站中如何实现纯静态网站?
纯静态制作技术是先对网站的页面进行汇总,分成几种样式,然后将这些页面制作成模板。生成的时候需要先读取源文件,然后生成一个独立的以.html结尾的页面文件,所以纯静态网站需要更多的空间,但其实需要的空间并不多,尤其是小中型企业网站,技术上来说,大型网站实现全站纯静态化难度较大,生成时间过长。不过中小网站还是纯静态对比,优点很多。
动态 网站 是如何静态处理的?
页面静态化是指将动态页面变成html/htm静态页面。动态页面一般采用asp、php、jsp、.net等编程语言编写,非常易于管理。但是,在访问网页时,程序需要先对其进行处理,因此访问速度相对较慢。静态页面访问速度快,但不易管理。那么静态动态页面就可以将两种页面的优点结合起来。
静态处理给网站带来什么好处?
静态处理后的网站比没有静态处理的网站相对安全,因为静态网站不会成为黑客的首选,因为黑客不知道在你的后台系统的情况下,黑客很难从前台的静态页面进行攻击。同时具有一定的稳定性。比如网站的数据库或程序有问题,不会干扰静态处理的页面,也不会因为程序或数据的影响而无法打开页面.
搜索引擎蜘蛛程序更喜欢这样的网址,这也可以减少蜘蛛程序的工作量。虽然有些人认为搜索引擎现在完全有能力抓取和识别动态 URL,但我建议您可以将它们设为静态。尝试创建一个静态 URL。
下面我们主要讲一下静态页面的概念,希望对大家有所帮助!
什么是 html 静态:
常说的页面静态有两种,一种是伪静态,即url重写,一种是真静态。
在php网站的开发中,针对网站推广和seo的需要,需要对网站进行全站或局部静态处理。php生成静态html页面的方法有很多,比如使用php模板、缓存等实现页面静态化。
php static的简单理解就是将网站生成的页面以静态html的形式展现在访问者面前。PHP静态分为纯静态和伪静态。两者的区别在于php生成静态页面的处理机制。.
php伪静态:一种使用apache mod_rewrite的url重写方法。
html静态的好处:
一、减轻服务器负担,浏览网页无需调用系统数据库。
二、有利于搜索引擎优化seo、baidu、google会优先处理收录静态页面,不仅有收录的快,还有收录的饱满;
三、 加快页面打开速度,静态页面不需要连接数据库,打开速度比动态页面快;
四、网站更安全,html页面不会受到php程序相关漏洞的影响;看大一点的网站,基本上都是静态页面,可以减少攻击,防止sql注入。当发生数据库错误时,不会影响网站的正常访问。
五、 发生数据库错误时,不会影响网站的正常访问。
最重要的是提高访问速度,减轻服务器的负担。当数据量几万、几十万甚至更多的时候,你就知道哪个更快了。而且很容易被搜索引擎找到。虽然生成html文章在操作上比较麻烦,程序上也比较复杂,但是为了更利于搜索,更快更安全,这些牺牲都是值得的。
实现html静态化的策略和例子:
基本方式
file_put_contents() 函数
利用php内置的缓存机制实现页面静态输出缓冲。
方法一:使用php模板生成静态页面
php模板实现静态化非常方便,比如安装使用php smarty实现网站静态化。
在使用 smarty 的情况下,页面也可以是静态的。简单说一下smarty使用时动态阅读的方式。
一般分为这几个步骤:
1、 通过url传递一个参数(id);
2、然后根据这个id查询数据库;
3、 获取数据后,根据需要修改显示内容;
4、分配要显示的数据;
5、显示模板文件。
smarty静态过程只需要在上述过程中增加两步即可。
第一:使用 ob_start() 在 1 之前打开缓冲区。
第二:5之后,使用ob_get_contents()获取内存未输出的内容,然后使用fwrite()将内容写入目标html文件。
根据上面的描述,这个过程是在网站的前台实现的,内容管理(添加、修改、删除)通常在后台进行。为了有效利用上述过程,可以使用一个小方法,即header()。具体过程如下: 添加修改程序后,使用header()跳转到前台读取,使页面可以html化,生成html后再跳回后台管理端,这两个跳转进程是不可见的。
方法二:使用php文件读写功能生成静态页面
方法三:使用php输出控制/ob缓存机制生成静态页面
输出控制功能(output control)就是使用和控制缓存来生成静态html页面。它还使用了php文件读写功能。
比如一个产品的动态详情页地址是:
所以这里我们根据这个地址读取一次这个详情页的内容,然后保存为静态页面。下次有人访问这个商品详情页的动态地址时,我们可以直接输出生成的对应静态内容文件。
PHP生成静态页面示例代码1
PHP生成静态页面示例代码2
我们知道使用php进行网站开发,一般的执行结果都是直接输出到浏览器,为了使用php生成静态页面,需要使用输出控制功能来控制缓存区,这样获取缓存区的内容,然后输出到静态html页面文件,实现网站静态。
php生成静态页面的思路是:先开启缓存,然后输出html内容(也可以通过include以文件的形式收录html内容),然后获取缓存中的内容,然后通过php文件读写功能清除缓存。缓存内容写入静态html页面文件。
获取输出缓存内容生成静态html页面的过程需要三个函数:ob_start()、ob_get_contents()、ob_end_clean()。
知识点:
1、ob_start函数一般用于开启缓存。注意在使用ob_start之前不能有空格、字符等输出。
2、ob_get_contents 函数主要用于获取缓存中的内容,并以字符串形式返回。注意这个函数必须在ob_end_clean函数之前调用,否则会获取不到缓存内容。
3、ob_end_clean 函数主要是清除缓存中的内容,关闭缓存。如果成功,则返回 true,如果失败,则返回 false。
方法四:使用nosql从内存中读取内容(其实这不是静态的而是缓存的);
以memcache为例:
Memcached 是 key 和 value 一一对应的。key 的默认最大大小不能超过 128 字节,value 的默认大小为 1m。所以1m的大小可以满足大部分网页的存储。
以上就是php实现静态html页面的方法,内容丰富,值得大家细细品味和收获。
php抓取网页表格信息(大城市知名大学名称selenium+python网页图片表格数据显示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-25 19:05
php抓取网页表格信息数据显示大城市知名大学名称selenium+python抓取网页图片表格数据显示各种岗位工资分布myproject名单用excel转换成工资表excel转换成pdf压缩功能在线制作excel表格代码放到word里浏览器打开代码
github-eidop/neuralnet:neuralnet:aneuralnetworklayerforhuman-levelrecognition
flask的话学习python吧,python还是比较好上手的。
买个好点的鼠标吧
你肯定不知道你用网页抓这个为什么不直接网页抓api呢?而且这个很麻烦吧,你用各种工具抓要费不少劲然后这个把你乱七八糟的研究废了,而且还得改后端代码什么网页蜘蛛上什么都要下。
学python吧,java和php也可以,如果懂得c++也行,现在网上各种推荐python的。人工智能在学术界相当发达,可以实现比较高的效率。
前端用python+tornado或者koa实现api获取url
flask等nodejs框架去抓
人工智能及ai在线学习通过python来处理大量的数据,这其中就包括excel表格,此时多网站数据的搜集可能就成为问题。excel个人觉得没啥问题,但是专业的数据分析软件可能就不够了。
现在python都很成熟了,推荐把python用好,再去学习其他的语言。
python+selenium或者numpy 查看全部
php抓取网页表格信息(大城市知名大学名称selenium+python网页图片表格数据显示)
php抓取网页表格信息数据显示大城市知名大学名称selenium+python抓取网页图片表格数据显示各种岗位工资分布myproject名单用excel转换成工资表excel转换成pdf压缩功能在线制作excel表格代码放到word里浏览器打开代码
github-eidop/neuralnet:neuralnet:aneuralnetworklayerforhuman-levelrecognition
flask的话学习python吧,python还是比较好上手的。
买个好点的鼠标吧
你肯定不知道你用网页抓这个为什么不直接网页抓api呢?而且这个很麻烦吧,你用各种工具抓要费不少劲然后这个把你乱七八糟的研究废了,而且还得改后端代码什么网页蜘蛛上什么都要下。
学python吧,java和php也可以,如果懂得c++也行,现在网上各种推荐python的。人工智能在学术界相当发达,可以实现比较高的效率。
前端用python+tornado或者koa实现api获取url
flask等nodejs框架去抓
人工智能及ai在线学习通过python来处理大量的数据,这其中就包括excel表格,此时多网站数据的搜集可能就成为问题。excel个人觉得没啥问题,但是专业的数据分析软件可能就不够了。
现在python都很成熟了,推荐把python用好,再去学习其他的语言。
python+selenium或者numpy
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-10-20 13:28
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie 查看全部
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
使用 PHP 的 cURL 库来简单有效地抓取网页。你只需要运行一个脚本,然后分析你抓取的网页,然后你就可以通过编程的方式得到你想要的数据。无论您是想从链接中获取部分数据,还是获取 XML 文件并将其导入数据库,即使只是获取网页内容,cURL 都是一个强大的 PHP 库。本文主要介绍如何使用这个PHP库。
启用卷曲设置
首先我们要先判断我们的PHP是否启用了这个库,可以通过php_info()函数来获取这个信息。
﹤?php
phpinfo();
?﹥
如果在网页上可以看到如下输出,说明cURL库已经开启。
如果你看到它,那么你需要设置你的 PHP 并启用这个库。如果你是windows平台,很简单,你需要改变你的php.ini文件的设置,找到php_curl.dll,去掉前面的分号。如下:
//取消下在的注释
extension=php_curl.dll
如果你在 Linux 下,那么你需要重新编译你的 PHP。编辑时需要开启编译参数——在configure命令中添加“--with-curl”参数。
一个小例子
如果一切就绪,这里有一个小程序:
﹤?php
// 初始化一个 cURL 对象
$curl = curl_init();
// 设置你需要爬取的网址
curl_setopt($curl, CURLOPT_URL,'');
// 设置标题
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL参数,询问结果是保存在字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行 cURL 并请求一个网页
$data = curl_exec($curl);
// 关闭 URL 请求
curl_close($curl);
// 显示获取的数据
var_dump($data);
如何发布数据
上面是抓取网页的代码,下面是到某个网页的POST数据。假设我们有一个处理表单的URL,可以接受两个表单域,一个是电话号码,一个是短信内容。
﹤?php
$phoneNumber = '13912345678';
$message = 'This message was generated by curl and php';
$curlPost = 'pNUMBER=' . urlencode($phoneNumber) . '&MESSAGE=' . urlencode($message) . '&SUBMIT=Send';
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com/sendSMS.php');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_POST, 1);
curl_setopt($ch, CURLOPT_POSTFIELDS, $curlPost);
$data = curl_exec();
curl_close($ch);
?﹥
从上面的程序可以看出,CURLOPT_POST是用来设置HTTP协议的POST方法而不是GET方法的,然后CURLOPT_POSTFIELDS是用来设置POST数据的。
关于代理服务器
以下是如何使用代理服务器的示例。请注意高亮的代码,代码很简单,我就不多说了。
﹤?php
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, 'http://www.example.com');
curl_setopt($ch, CURLOPT_HEADER, 1);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPPROXYTUNNEL, 1);
curl_setopt($ch, CURLOPT_PROXY, 'fakeproxy.com:1080');
curl_setopt($ch, CURLOPT_PROXYUSERPWD, 'user:password');
$data = curl_exec();
curl_close($ch);
?﹥
关于 SSL 和 Cookie
php抓取网页表格信息(第4课中如何采集多个列表中的数据?课 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-10-20 13:22
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以多次单击直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、 修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
查看全部
php抓取网页表格信息(第4课中如何采集多个列表中的数据?课
)
在第4课中,我们学习了如何采集多个数据列表,相信大家都学会了创建【循环提取数据】。本课将学习一种特殊格式的列表数据-表数据采集。
表格是很常见的网页样式,如:的匹配评分表、天天基金网的基金排名表、东方财富网的股票信息表、中国证券业协会的年报披露表等。
表格是列表数据的一种特殊形式。我们可以将表的每一行看作是列表中每个数据的一个大块范围。表格每一行的所有单元格字段相当于列表的每个数据块中的多个子字段。. 那么上一课介绍的【循环提取数据】的创建方法也可以用在本课中。
现在有一个新浪财经股票表的网页:
表格结构非常整齐,每条股票信息占据表格的一行,一排股票收录多个信息字段:股票代码、股票名称、目标价、最新评级等。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
我们要保存这些字段采集,并保存在Excel等中,如下图所示。怎么做?下面是具体操作。
示例网址:
Step 一、 创建【新建任务】,输入网址,打开网页
在首页【输入框】中输入目标网址,点击【开始采集】。点击【保存设置】,优采云内置浏览器会自动打开网页。为了方便观察,我们打开右上角的【处理】按钮。可以看到左上角的流程区已经自动创建了【打开网页】步骤。
步骤二、建立【循环提取数据】
我们可以想到上节课提到的知识点,将表格作为列表数据的一种特殊形式,将每一行股票看成列表中每个数据的一个大块范围,创建一个【循环-提取数据】 ],让优采云自动识别所有股票和每个股票数据的所有子元素。
让我们看一个收录所有具体步骤的动画:
然后拆分每一步,详细说明:
1、 先选中页面第一个列表的第一个单元格,然后点击提示框右下角的【展开选择】
用于选择整行的按钮。(
展开选定的范围。当前选中的是一个单元格,点击
选中范围扩大一级,即选中一行)
选择后,提示框会提示找到【子元素】,【子元素】为优采云自动识别的每一行的具体字段。我想问你是否要定位这些子元素。
特别说明:
一种。单击“扩展范围”按钮时,如果单击未选择一行,则可以多次单击直到选中一行。
湾 单击第一个列表的第一个单元格后,还可以检查提示框下方是否有tr标签。如果有,直接点击这个tr,相当于
按钮,优采云 将直接选择一行。(Tr 表示一行。)
2、 在提示框中选择【选择子元素】。选择第一只股票中的特定字段,然后优采云自动识别页面上其他股票列表具有相同的[子元素](红色框)。
3、 在提示框中选择【全选】。可以看到页面上股票列表中的所有子元素也都被选中并被绿色框框起来。
4、 在提示框中选择[采集数据]。这时候优采云会提取表单中的所有字段。
特别说明:
一种。步骤1-4是连续指令,只能不间断地建立。1、【选择一行】后没有2、【选择子元素】怎么办?请向下滚动到文章末尾以查看解决方案。
经过以上4个步骤,就完成了【Cycle-Extract Data】的创建。工序区自动生成一步【循环-提取数据】。循环收录页面上所有股票的行数,提取的数据收录一个股票中的所有字段。
步骤 3、 编辑字段
1、删除不需要的字段。选择该字段并单击垃圾桶图标将其删除。
2、 修改字段名称。更改为字段的相应名称。
步骤4、开始采集
1、 点击【保存并启动】,选择【启动本地采集】。优采云 跳出采集窗口,我们可以在采集窗口看到自动的采集。
2、采集 完成后,选择合适的导出方式导出数据。支持导出为 Excel、CSV、HTML。在此处导出到 Excel。
数据示例:
php抓取网页表格信息(BIRT报表设计器的页面设置信息有什么用呢?方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-15 19:21
打印报表时,尤其是打印报表时,页面设置信息很重要,比如页边距、纸张尺寸、输出方向等,而且每个报表的相关参数可能不同,所以获取相关参数从具体报道来看。非常正常和合理的想法。
如果使用BIRT作为报表开发工具,报表设计者负责报表制作,BIRT运行时负责处理报表文件。对于浏览器,BIRT后端输出的是网页,不收录页面设置相关信息。浏览器有自己的打印设置选项,不会从网页中读取,但是报表设计器提供了报表设计时页面设置信息的设置界面。因此,我们需要通过运行时 API 手动编写代码,以从特定报表中获取页面设置信息。然后通过其他方式将参数传递给打印机(操作打印机不在本文讨论范围内)。本文通过对BIRT源代码的研究,提供了相关的示例代码。
BIRT报表设计器的页面设置信息体现在首页选项卡对应的属性面板中,这里不再赘述,添加代码即可:
IReportEngine birtEngine = ...;Map moduleOptions = new HashMap();moduleOptions.put(IModuleOption.RESOURCE_FOLDER_KEY,sc.getRealPath("/"));IReportRunnable runnable = birtEngine.openReportDesign(reportFileName,null,moduleOptions);IMasterPage simpleMasterPage = runnable.getDesignInstance().getReport().getMasterPage("Simple MasterPage");String pageType =(String) simpleMasterPage.getUserProperty("type");//纸张类型Double height = 0.0;Double width =0.0;//如果是自定义纸张类型,需要获取纸张的宽和高if("custom".equalsIgnoreCase(pageType)){ DimensionValue heightDV = (DimensionValue) simpleMasterPage.getUserProperty("height"); DimensionValue widthDV = (DimensionValue) simpleMasterPage.getUserProperty("width"); height = heightDV.getMeasure(); width = widthDV.getMeasure();}String orientation = (String) simpleMasterPage.getUserProperty("orientation");//打印输出方向 landscape:横向,portrait:纵向DimensionValue topMarginDV = (DimensionValue)simpleMasterPage.getUserProperty("topMargin");double topMargin = topMarginDV.getMeasure();//上边距String unit = topMarginDV.getUnits();//单位
这里有个奇怪的地方,就是首页的属性编辑器里面有个名字,这个名字可以修改,默认是Simple MasterPage,如果要获取这个页面的配置信息,getMasterPage方法应该还把这个名字作为参数传入,这个比较奇怪,只有一个页面配置方案,这个名字有什么用?
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:如何从BIRT报告文件中获取页面设置信息(边距、纸张大小、输出方向) 查看全部
php抓取网页表格信息(BIRT报表设计器的页面设置信息有什么用呢?方法)
打印报表时,尤其是打印报表时,页面设置信息很重要,比如页边距、纸张尺寸、输出方向等,而且每个报表的相关参数可能不同,所以获取相关参数从具体报道来看。非常正常和合理的想法。
如果使用BIRT作为报表开发工具,报表设计者负责报表制作,BIRT运行时负责处理报表文件。对于浏览器,BIRT后端输出的是网页,不收录页面设置相关信息。浏览器有自己的打印设置选项,不会从网页中读取,但是报表设计器提供了报表设计时页面设置信息的设置界面。因此,我们需要通过运行时 API 手动编写代码,以从特定报表中获取页面设置信息。然后通过其他方式将参数传递给打印机(操作打印机不在本文讨论范围内)。本文通过对BIRT源代码的研究,提供了相关的示例代码。
BIRT报表设计器的页面设置信息体现在首页选项卡对应的属性面板中,这里不再赘述,添加代码即可:
IReportEngine birtEngine = ...;Map moduleOptions = new HashMap();moduleOptions.put(IModuleOption.RESOURCE_FOLDER_KEY,sc.getRealPath("/"));IReportRunnable runnable = birtEngine.openReportDesign(reportFileName,null,moduleOptions);IMasterPage simpleMasterPage = runnable.getDesignInstance().getReport().getMasterPage("Simple MasterPage");String pageType =(String) simpleMasterPage.getUserProperty("type");//纸张类型Double height = 0.0;Double width =0.0;//如果是自定义纸张类型,需要获取纸张的宽和高if("custom".equalsIgnoreCase(pageType)){ DimensionValue heightDV = (DimensionValue) simpleMasterPage.getUserProperty("height"); DimensionValue widthDV = (DimensionValue) simpleMasterPage.getUserProperty("width"); height = heightDV.getMeasure(); width = widthDV.getMeasure();}String orientation = (String) simpleMasterPage.getUserProperty("orientation");//打印输出方向 landscape:横向,portrait:纵向DimensionValue topMarginDV = (DimensionValue)simpleMasterPage.getUserProperty("topMargin");double topMargin = topMarginDV.getMeasure();//上边距String unit = topMarginDV.getUnits();//单位
这里有个奇怪的地方,就是首页的属性编辑器里面有个名字,这个名字可以修改,默认是Simple MasterPage,如果要获取这个页面的配置信息,getMasterPage方法应该还把这个名字作为参数传入,这个比较奇怪,只有一个页面配置方案,这个名字有什么用?
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
相关标签:如何从BIRT报告文件中获取页面设置信息(边距、纸张大小、输出方向)
php抓取网页表格信息(2017年国家公务员考试行测备考:不要 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-15 19:20
)
一、不要把整个页面放在一个表格中
通常,每个人都使用表格进行布局。将整个页面的内容塞进一个Table(表格)中,然后用cell td来划分每个“块”的布局,这种网站的显示速度绝对慢。因为Table在加载之前要等待里面的所有内容都显示出来,如果有些内容无法访问,就会延迟整个页面的访问速度。在版面中,将整个页面分为三部分,头顶、中中、版权(尾)底、中。部分最好多一些,因为现在大家的首页一般都分成几栏。其实都是可以单独开的,不要都塞到一张表里。多用几张表,尤其是广告网络的代码,尽量单独放在一个表中;对于较慢的广告代码,请使用表格将其直接放在底部。反正面试官最关心的,最先想看的也不是版权信息。
二、不要放太大的Flash动画和图片。那些可以使用 GIF 格式的不需要 JPG。大图最好切成几块,然后拼在一起。
三、 尽量使用静态HTML页面,少用javascript特效。有时你做得太多,但你会眼花缭乱。以前看到一个站,状态栏的文字被疯狂替换了,一直闪。. 这不是必需的。还有人是来看网站上的文章和mm图片的。. 这与特殊效果无关。当然,适当的做一些也无妨,至少可以在超级菜鸟面前大展身手,让他们佩服。.
四、 将ASP、PHP等文件的访问权限改为。js参考
如果你想在一个静态的HTML页面中嵌入动态数据,而这些动态数据是由ASP等程序提供的,每次有人访问你的网站,服务器都必须执行和处理count。asp文件,从数据库中提取相应的数据,然后输出到网页显示。如果有成千上万的人同时访问它,它将被执行数万次。建议在这些程序中动态生成数据到count.js文件中,然后用这样的代码引用首页的.js文件。这样,数据展示的任务就交给了客户端的浏览器,不消耗服务器资源,展示速度自然也更快。
五、使用iframe--这个大家都知道,很多GG都是这样发的
使用iframe,这样就不会因为广告页面的延迟导致整个首页的延迟。
六、计数器代码放置
将统计代码直接放在页面内容前面,或者放在Table或div标签中,那么当计数器无法访问时,你页面上的Table或div会有几十秒的延迟,这会导致页面要很长时间才能访问。正确的方法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接在页面代码底部放置统计代码,也可以在底部单独制作一个Table或div来放置计数器。
七、友情链接
很多人喜欢在Friendship 网站上直接引用图片的URL,这样图片必须加载后才能显示。每个Friendship网站的访问速度不一样,整桌都要等图。
下载后才能显示,大大降低了网页速度,有时可能会出现几个红叉(被D?空间挂了。哈哈)。其实最好先下载LOGO,再上传到自己的网站空间。
最好的是文字链接:感觉更整洁。此外,尝试与同行网站交换链接。您可以连接一些词并将它们用作您网站的关键字。比如你是一个学生站,对方站的名字是“**大学生论坛”,可以这样写:**大学生论坛,这样不影响链接,还会高亮关键词. .
最后说几个seo
关键词主要有以下几部分:
标题标签:文本
元标记:
标题标签:文本等。
链接标签:文本
页面主体:文本
ALT 标签:
评论标记:
输入标签:
网址:/keyword.htm
直接给代码
未优化时
以下为引用内容:
************************
优化
以下为引用内容:
查看全部
php抓取网页表格信息(2017年国家公务员考试行测备考:不要
)
一、不要把整个页面放在一个表格中
通常,每个人都使用表格进行布局。将整个页面的内容塞进一个Table(表格)中,然后用cell td来划分每个“块”的布局,这种网站的显示速度绝对慢。因为Table在加载之前要等待里面的所有内容都显示出来,如果有些内容无法访问,就会延迟整个页面的访问速度。在版面中,将整个页面分为三部分,头顶、中中、版权(尾)底、中。部分最好多一些,因为现在大家的首页一般都分成几栏。其实都是可以单独开的,不要都塞到一张表里。多用几张表,尤其是广告网络的代码,尽量单独放在一个表中;对于较慢的广告代码,请使用表格将其直接放在底部。反正面试官最关心的,最先想看的也不是版权信息。
二、不要放太大的Flash动画和图片。那些可以使用 GIF 格式的不需要 JPG。大图最好切成几块,然后拼在一起。
三、 尽量使用静态HTML页面,少用javascript特效。有时你做得太多,但你会眼花缭乱。以前看到一个站,状态栏的文字被疯狂替换了,一直闪。. 这不是必需的。还有人是来看网站上的文章和mm图片的。. 这与特殊效果无关。当然,适当的做一些也无妨,至少可以在超级菜鸟面前大展身手,让他们佩服。.
四、 将ASP、PHP等文件的访问权限改为。js参考
如果你想在一个静态的HTML页面中嵌入动态数据,而这些动态数据是由ASP等程序提供的,每次有人访问你的网站,服务器都必须执行和处理count。asp文件,从数据库中提取相应的数据,然后输出到网页显示。如果有成千上万的人同时访问它,它将被执行数万次。建议在这些程序中动态生成数据到count.js文件中,然后用这样的代码引用首页的.js文件。这样,数据展示的任务就交给了客户端的浏览器,不消耗服务器资源,展示速度自然也更快。
五、使用iframe--这个大家都知道,很多GG都是这样发的
使用iframe,这样就不会因为广告页面的延迟导致整个首页的延迟。
六、计数器代码放置
将统计代码直接放在页面内容前面,或者放在Table或div标签中,那么当计数器无法访问时,你页面上的Table或div会有几十秒的延迟,这会导致页面要很长时间才能访问。正确的方法是:将统计代码放在页面底部,不要和页面内容放在同一个Table或div标签中。可以直接在页面代码底部放置统计代码,也可以在底部单独制作一个Table或div来放置计数器。
七、友情链接
很多人喜欢在Friendship 网站上直接引用图片的URL,这样图片必须加载后才能显示。每个Friendship网站的访问速度不一样,整桌都要等图。
下载后才能显示,大大降低了网页速度,有时可能会出现几个红叉(被D?空间挂了。哈哈)。其实最好先下载LOGO,再上传到自己的网站空间。
最好的是文字链接:感觉更整洁。此外,尝试与同行网站交换链接。您可以连接一些词并将它们用作您网站的关键字。比如你是一个学生站,对方站的名字是“**大学生论坛”,可以这样写:**大学生论坛,这样不影响链接,还会高亮关键词. .
最后说几个seo
关键词主要有以下几部分:
标题标签:文本
元标记:
标题标签:文本等。
链接标签:文本
页面主体:文本
ALT 标签:
评论标记:
输入标签:
网址:/keyword.htm
直接给代码
未优化时
以下为引用内容:
************************
优化
以下为引用内容:
php抓取网页表格信息(php代码对数据库进行操作(一)_PHP代码就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-06 17:14
前言
在实际开发中,PHP会和数据库一起使用,因为后台保存的数据太多,而数据库是保存数据的好地方,我们在PHP开发中使用的数据库是相关类型数据库mysql,而只需连接PHP和mysql数据库,我们就可以通过PHP代码操作数据库。
相关mysql视频教程推荐:《mysql教程》
MySqli
PHP的开发离不开数据库,PHP中可以通过MySQLi连接数据库。但是MySQLi只能连接mysql数据库。同时mysqli是一种面向对象的技术。
MySQLi 的特点:
如果要在 PHP 中使用 MySQLi 功能,需要在 php.ini 中加载动态链接文件 php_mysql.dll。
运营流程
在mysql中创建一个数据库作为操作对象。
打开PHP扩展库
创建 mysqli 对象
$mysql = new MySQLi(主机,账号,密码,数据库,端口号);
有几个参数。
设置字符集
$mysql -> set_charset('utf8');
编写sql语句并执行。这个sql语句可以是dml,dql语句
$mysql -> query($sql);
从检索结果显示页面检索数据有四种方式(关联、行、对象、数组)。我们一般使用 assoc。但如果是 dml 语句,则返回一个布尔值。
$res -> fetch_assoc();
释放结果集。关闭连接。
$res -> free();
$mysqli -> close();
我们在插入、删除、修改(dml)的时候,返回的是一个布尔值,但是不知道有没有变化。可以使用$mysqli ->fluence_rows,mysqli中的属性来判断,返回的结果是数据表上sql语句影响的行数。
<p> 查看全部
php抓取网页表格信息(php代码对数据库进行操作(一)_PHP代码就是)
前言
在实际开发中,PHP会和数据库一起使用,因为后台保存的数据太多,而数据库是保存数据的好地方,我们在PHP开发中使用的数据库是相关类型数据库mysql,而只需连接PHP和mysql数据库,我们就可以通过PHP代码操作数据库。
相关mysql视频教程推荐:《mysql教程》
MySqli
PHP的开发离不开数据库,PHP中可以通过MySQLi连接数据库。但是MySQLi只能连接mysql数据库。同时mysqli是一种面向对象的技术。
MySQLi 的特点:
如果要在 PHP 中使用 MySQLi 功能,需要在 php.ini 中加载动态链接文件 php_mysql.dll。
运营流程
在mysql中创建一个数据库作为操作对象。
打开PHP扩展库
创建 mysqli 对象
$mysql = new MySQLi(主机,账号,密码,数据库,端口号);
有几个参数。
设置字符集
$mysql -> set_charset('utf8');
编写sql语句并执行。这个sql语句可以是dml,dql语句
$mysql -> query($sql);
从检索结果显示页面检索数据有四种方式(关联、行、对象、数组)。我们一般使用 assoc。但如果是 dml 语句,则返回一个布尔值。
$res -> fetch_assoc();
释放结果集。关闭连接。
$res -> free();
$mysqli -> close();
我们在插入、删除、修改(dml)的时候,返回的是一个布尔值,但是不知道有没有变化。可以使用$mysqli ->fluence_rows,mysqli中的属性来判断,返回的结果是数据表上sql语句影响的行数。
<p>
php抓取网页表格信息(物联网技术2015年/第10期可靠传输Transmission400)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-05 07:03
物联网技术2015/第10期可靠传输40 0 0引言互联网技术的飞速发展,即时通讯的出现,通过互联网技术,彻底改变了当代人的信息交流方式,给人们的生活带来了诸多便利. . 当前,在国家“互联网+”发展战略下,许多传统服务业迫切需要与互联网融合。服务必然需要一个互联网通信平台。网络即时聊天系统应运而生。需要下载软件实现信息交互,使信息交互更加方便。1 系统设计1.1 系统总体架构设计系统采用B/S模型开发,三层结构,如图1所示。其中,表现层主要是提供交互界面,由HTML完成,业务逻辑和数据访问层通过PHP和MySQL的结合开发。它们是当今最流行的开源技术,它们易于使用、快速、强大且免费。非常适合Web开发[1-3];业务逻辑层通过PHP编写发送和接收信息以及添加和删除的处理逻辑;数据库访问层通过表的结构写出相应的PHP服务类,然后通过PHP的增删改查的MySQL接口实现数据。业务逻辑层、数据访问层、表现层、
2 系统核心功能实现2.1 认证功能系统界面由HTML完成。当用户写入用户名和密码时,它通过get方法向服务器发送请求。服务器认证页面接收用户名和密码,连接数据库。将接收到的用户名和密码与数据库中用户表中的记录逐行进行比较。如果完全匹配,则跳转到聊天界面,否则跳转到注册界面。其验证功能流程图如图2所示。如果是第一次登录,生成一个会话并将用户信息保存在服务器上。表1 用户表ID Int主键,自增username Varchar(30) username psword Varchar(30)
图 3 基于 PHP 的网页即时聊天系统的设计与实现 张元伟、胡越、雷军(湖北大学物理与电子技术学院,湖北武汉 43006,湖北 430062) 摘要:使用 PHP 服务器脚本语言,使用Apache服务器软件构建B/S结构,将单个聊天内容以单条记录的形式存储在MySQL数据库中,对应一个结构化的数据库表,然后使用Ajax技术异步发送和接收信息。客户端和服务器, 查看全部
php抓取网页表格信息(物联网技术2015年/第10期可靠传输Transmission400)
物联网技术2015/第10期可靠传输40 0 0引言互联网技术的飞速发展,即时通讯的出现,通过互联网技术,彻底改变了当代人的信息交流方式,给人们的生活带来了诸多便利. . 当前,在国家“互联网+”发展战略下,许多传统服务业迫切需要与互联网融合。服务必然需要一个互联网通信平台。网络即时聊天系统应运而生。需要下载软件实现信息交互,使信息交互更加方便。1 系统设计1.1 系统总体架构设计系统采用B/S模型开发,三层结构,如图1所示。其中,表现层主要是提供交互界面,由HTML完成,业务逻辑和数据访问层通过PHP和MySQL的结合开发。它们是当今最流行的开源技术,它们易于使用、快速、强大且免费。非常适合Web开发[1-3];业务逻辑层通过PHP编写发送和接收信息以及添加和删除的处理逻辑;数据库访问层通过表的结构写出相应的PHP服务类,然后通过PHP的增删改查的MySQL接口实现数据。业务逻辑层、数据访问层、表现层、
2 系统核心功能实现2.1 认证功能系统界面由HTML完成。当用户写入用户名和密码时,它通过get方法向服务器发送请求。服务器认证页面接收用户名和密码,连接数据库。将接收到的用户名和密码与数据库中用户表中的记录逐行进行比较。如果完全匹配,则跳转到聊天界面,否则跳转到注册界面。其验证功能流程图如图2所示。如果是第一次登录,生成一个会话并将用户信息保存在服务器上。表1 用户表ID Int主键,自增username Varchar(30) username psword Varchar(30)
图 3 基于 PHP 的网页即时聊天系统的设计与实现 张元伟、胡越、雷军(湖北大学物理与电子技术学院,湖北武汉 43006,湖北 430062) 摘要:使用 PHP 服务器脚本语言,使用Apache服务器软件构建B/S结构,将单个聊天内容以单条记录的形式存储在MySQL数据库中,对应一个结构化的数据库表,然后使用Ajax技术异步发送和接收信息。客户端和服务器,
php抓取网页表格信息(利用Excel快速获取网页内容的方法你是否已经掌握了?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-01 09:06
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但是这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们在网页左侧或右侧的空白处右击进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到某些信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢! 查看全部
php抓取网页表格信息(利用Excel快速获取网页内容的方法你是否已经掌握了?)
下载Win7 64位旗舰版后浏览网页时,总会需要保存一些需要的数据信息。
该信息包括表格或文本。一般我们使用鼠标和组合键Ctrl+C来保存,但是这种方法在一定程度上可以看作是一种相对低效的方法。是否可以更快地访问 Web 内容?路呢?当我们浏览一些较大的门户并需要保存内容时,我们需要一种更快的方法来处理这个问题。下面简单说一下如何快速获取网页内容。
具体步骤:
STEP1 首先,我们打开IE浏览器,自由进入一个需要复制的网站浏览网页。
STEP2 然后我们在网页左侧或右侧的空白处右击进入菜单设置,执行导出到Microsoft Office Excel的命令(PS:必须在完全空白处执行)。
STEP3 此时,我们会发现Excel启动并提示新建Web查询信息。当我们等待网页完全显示时,在左下角找到完成提示。注意一些箭头标志。
STEP4 然后我们双击上面最大的标题栏进行最大化窗口操作,然后我们直接把需要采集的内容放到导入操作中。
STEP5 接下来,我们在弹出的窗口中找到某些信息,将文本和表格信息导入Excel。其他无用的格式将被自动过滤。至此,我们基本完成了快速获取内容。
这个用Excel快速获取网页内容的方法你掌握了吗?一起来试试吧!陈述:
本文内容由电脑大师网整理,感谢作者分享!发表/转载本文的目的是为了更广泛的传播和分享,但并不意味着同意其观点或证明其描述。
如有版权或其他纠纷,请准备相关证明材料与站长联系,谢谢!
php抓取网页表格信息(日常开发中导入excel文件进行批量数据操作的步骤和注意事项 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 14:42
)
在日常开发中,尤其是管理后台的开发中,经常会遇到导入excel文件进行批量数据操作,导出数据到excel的场景。本文主要讲我在开发过程中总结的php阅读excel的步骤和步骤。需要注意的问题。
一、常规方式
读取excel的过程很简单,就是接收文件、解析文件、数据处理、返回结果。但是,由于导入文件的自由度大于在页面上填写表格,服务器可能会收到各种形式的文件,因此数据的有效性就显得尤为重要。另外,由于excel导入文件通常是对大量数据进行批量操作,因此处理页面超时、服务器内存溢出、容错等问题也很重要。
导入excel的一般处理步骤如下
接收验证文件(类型、大小、存在:直接报错)查空表(无数据,整行为空字段:跳过此行)查数据行数(不能超过允许的数据量)待处理)检查空字段(只读必填列,检查空字段:记录它们) 检查字段(长度,类型:记录) 检查重复(去重)类型转换,xss过滤,数据处理,重组数据 字段有效性检查(例如产品是否存在),调整业务操作结果处理界面,反馈异常处理的操作结果(生成日志和错误提示或错误表)
上图左边是php校验和解析excel文件,右边是校验和操作数据。
看起来很繁琐,其实前7步就是数据校验和预处理。在开发过程中,要尽量对用户的误操作给予友好的提示,尤其是在excel操作过程中,极高的自由度会导致出错的概率很高。用户不是开发人员,通常不知道如何产生系统理解的数据。在开发和维护过程中,我们遇到过各种可笑的“误操作”,所以系统应该尽量引导用户检查和修改。
1、接收和验证文件
通过检查接收到的文件的MIME和文件大小,判断用户上传的文件是否有效,防止用户上传格式错误的文件或超出系统处理能力的大文件。服务器。上传大文件很容易造成服务器内存溢出。
2、检查空列表
用户在编辑表格时往往会删除每个单元格的整行,而不是直接删除整行,从而导致留下一些空白行。这些空白行毫无意义。系统应该过滤它们并且只保留有数据的行。.
3、检查数据线
受限于服务器的处理能力和业务的复杂性,我们需要限制允许的数据行数,比如10万行。如果超过,很可能会导致服务器内存溢出或页面超时错误。同时,我们也可以将excel的服务器处理超时和内存限制设置大一些。
4、检查空字段
检查系统要求的非空字段。有时系统不需要读取表的所有列,添加一些列供用户查看,对系统没有意义的列不需要验证(但可能需要读取和临时存储,例如发生错误时,需要提示用户在哪一行出错,该行的内容是什么)。
5、检查数据格式
根据业务需求验证字段类型、长度等。
6、卸重
根据业务需求执行数据行重复数据删除或错误报告。
7、类型转换、xss过滤、数据处理、数据重组
经过前6步验证,基本可以确定数据的有效性,然后对数据进行预处理,使数据符合操作界面的要求。比如xss过滤,用户填写的文本需要转换成界面需要的数字,数据结构调整为界面需要的形式。
8、数据有效性检查
对数据进行业务相关的验证。例如,如果需要修改产品,首先要查询该产品是否存在,在执行订单发货操作时,首先要查询该订单是否存在。这种情况是兼容的,即使产品或订单不存在,直接调整接口也不会有问题)。
9、 调优界面
调整业务操作界面。如果接口不能一次处理所有数据,则需要批量调整。如果接口有频率限制,则需要注意在周期内保持适当的时间间隔。
10、结果处理,异常处理
根据接口返回的信息,组装成合适的数据格式,用于提示用户哪些数据操作成功,哪些数据操作失败,以及失败的原因。
11、反馈操作结果
批量操作中经常会遇到部分成功和部分失败的情况。因此,导出不正确的表是一种更直观的方式。可以在表格中增加一列来说明操作失败的原因,用户可以根据提示重新编辑表格。并导入系统。如果发生系统错误,还应记录操作日志,以便及时定位和处理。
二、注释1、科学记数法
Excel 编辑软件通常以科学计数法显示订单号和 ID 号等大数字。这是系统的非法数据格式。如果可以进行转换,系统应该尽量允许这种格式并把它转换成正确的数据。但是,当转换结果不准确时,应提示用户将数据格式设置为文本类型。比如有些数字字符串太长,用excel编辑软件转换成科学记数法,就会失去一定的准确性。即使将它们转换为字符串,数据也会丢失。这是不对的。例如,原来的ID号“4211116”在Microsoft Excel中会转为“4.21022E+17”,再转一个数值为“4200000”。
2、超时和内存溢出
在进行批量操作时,当数据量较大或操作界面时间较长时,可能会遇到页面超时错误或服务器内存溢出。一方面,我们可以设置超时时间和内存限制,另一方面,我们需要根据实际测试设置一个数据量限制。
set_time_limit(120);
ini_set('memory_limit','512M');
这里设置的超时时间只是php的超时时间,页面超时时间也受nginx配置的超时时间限制,取较小者。
3、空白单元格
在使用系统的过程中,可能会遇到用户上传的excel文件明明只有几百行,但是内存溢出。可能是因为用户在编辑excel的过程中修改了单元格格式,导致出现很多空行或空列的无用信息,导致服务器解析excel文件时内存溢出。这时候可以把原来的excel文件的内容粘贴到新的excel文件中,丢弃无用的信息。
三、优化
如果处理的数据量太大,接口不能在规定时间内处理数据,肯定会造成超时。这时候我们就可以优化系统了。共有三种优化方案。
1、使用异步任务
解析完表后,使用异步任务调用接口。服务器直接将结果返回给前端页面,页面会定时自动查询运行状态。这样,一个请求被分多次,避免了页面超时的问题,用户不需要在页面上等待,甚至可以关闭页面。该方法需要编写异步任务,还需要反转任务状态,并提供查询任务状态的接口。相对来说,实现会稍微复杂一些。
2、多个请求
文件上传后,服务器不进行数据操作,只对excel文件中的数据进行解析,解析完成后将数据返回页面或暂存到redis中。前端页面循环发送请求,将数据拆分成多个副本进行处理。需要注意的是,如果数据返回到页面并临时存放在浏览器内存中,则请求过程需要注意http请求的参数限制。post请求默认接收1000个参数,所以页面传递给服务端时参数要转换为String(如果直接传递多维数组,数组的每个子元素都会作为一个参数处理,并且很容易超过限制)。
3、使用csv格式
因为excel会有一些额外的格式,比如单元格宽度、背景色、边框、字体等,所以在解析excel文件的时候会占用服务器内存(虽然用户可能不会设置),通常系统不会关心这个信息,所以把excel转成csv再导入系统会大大增加系统可以处理的数据量。
四、相关php代码
下面是我封装的一个将excel文件解析成数组的方法。该方法接收一个excel文件并返回一个数组。包括的功能是
/**
* 解析excel表格为数组
* @param array $params
* int max_size: 限制文件大小(M)
* int count_col:需要读取表格前多少列,防止读到后面的空白列导致内存溢出
* bool need_head: 是否需要读取表头
* 将会跳过空行
* @return array
*/
function parse_excel($params = array()){
$fileType = array("application/vnd.ms-excel","application/vnd.openxmlformats-officedocument.spreadsheetml.sheet","application/kset");
$max_size = isset($params['max_size']) ? $params['max_size'] : 2;
if (!(isset($_FILES["file"]) && 0 == $_FILES["file"]["error"])) {
cilog('debug', '上传失败:isset($_FILES["file"]):'.isset($_FILES["file"]).'上传文件$_FILES["file"]["error"]:'.$_FILES["file"]["error"]);
$result = array(
'errcode' =>1001,
'errmsg' =>"文件上传失败",
);
} elseif ($_FILES["file"]["size"] > $max_size * 1024 * 1024) {
cilog('debug', '上传文件大小:'.$_FILES["file"]["size"]);
$result = array(
'errcode' =>1002,
'errmsg' =>"上传文件不得超过{$max_size}Mb",
);
} elseif (!in_array($_FILES["file"]["type"],$fileType)) {
cilog('debug', '上传文件MIME:'.$_FILES["file"]["type"]);
$result = array(
'errcode' =>1003,
'errmsg' =>"文件类型错误,请上传.xls或.xlsx文件",
);
} else{
$file = $_FILES['file']['tmp_name'];
require_once BASEPATH . '/libraries/phpexcel/PHPExcel.php';
$excelReader = new PHPExcel_Reader_Excel2007();
if (!$excelReader->canRead($file)) {
$excelReader = new PHPExcel_Reader_Excel5();
}
$sheet = $excelReader->load($file)->getSheet(0); //sheet1操作
$excelCont = array(
'highestCol' => $sheet->getHighestColumn(), //列
'highestRow' => $sheet->getHighestRow(), //行
'highestColumnIndex' => PHPExcel_Cell::columnIndexFromString($sheet->getHighestColumn()) // 几列
);
$countCol = isset($params['count_col']) ? $params['count_col'] : $excelCont['highestRow'];//有效列的数目,读取时只取前$countCol列
$startRow = isset($params['need_head']) && $params['need_head'] ? 1 : 2;//从第1行开始读,读取表头
// $excelCont['highestRow'] 有几行
// 表示第一行第一列 $sheet->getCellByColumnAndRow(0, 1)->getValue()的值
$rightArr = array();
// 总共导入多少行 $row - $emptyLine -1
$row = $excelCont['highestRow'];
$emptyLine = 0;
for ($j = $startRow; $j < intval($row) + 1; $j++) {
$retArr = array();//该行的各个单元格的数据
$emptyCol = 0;
for($i = 0; $i < $countCol;$i++){//循环该行的单元格
$retArr[$i] = $sheet->getCellByColumnAndRow($i, $j)->getValue();
$retArr[$i] = isset($retArr[$i]) ? trim($retArr[$i]) : $retArr[$i];
if($retArr[$i] === null){
$emptyCol++;
}
}
if($emptyCol == $countCol){//这行为空行,不放入任何数组
$emptyLine++;
}else {
$rightArr[] = $retArr;
}
}
if(empty($rightArr)){
$result = array(
'errcode' =>1004,
'errmsg' =>"上传文件内没有有效数据",
);
}else{
$result = array(
'errcode' =>0,
'errmsg' =>"",
'data' =>$rightArr,
);
}
}
return $result;
} 查看全部
php抓取网页表格信息(日常开发中导入excel文件进行批量数据操作的步骤和注意事项
)
在日常开发中,尤其是管理后台的开发中,经常会遇到导入excel文件进行批量数据操作,导出数据到excel的场景。本文主要讲我在开发过程中总结的php阅读excel的步骤和步骤。需要注意的问题。
一、常规方式
读取excel的过程很简单,就是接收文件、解析文件、数据处理、返回结果。但是,由于导入文件的自由度大于在页面上填写表格,服务器可能会收到各种形式的文件,因此数据的有效性就显得尤为重要。另外,由于excel导入文件通常是对大量数据进行批量操作,因此处理页面超时、服务器内存溢出、容错等问题也很重要。
导入excel的一般处理步骤如下
接收验证文件(类型、大小、存在:直接报错)查空表(无数据,整行为空字段:跳过此行)查数据行数(不能超过允许的数据量)待处理)检查空字段(只读必填列,检查空字段:记录它们) 检查字段(长度,类型:记录) 检查重复(去重)类型转换,xss过滤,数据处理,重组数据 字段有效性检查(例如产品是否存在),调整业务操作结果处理界面,反馈异常处理的操作结果(生成日志和错误提示或错误表)
上图左边是php校验和解析excel文件,右边是校验和操作数据。
看起来很繁琐,其实前7步就是数据校验和预处理。在开发过程中,要尽量对用户的误操作给予友好的提示,尤其是在excel操作过程中,极高的自由度会导致出错的概率很高。用户不是开发人员,通常不知道如何产生系统理解的数据。在开发和维护过程中,我们遇到过各种可笑的“误操作”,所以系统应该尽量引导用户检查和修改。
1、接收和验证文件
通过检查接收到的文件的MIME和文件大小,判断用户上传的文件是否有效,防止用户上传格式错误的文件或超出系统处理能力的大文件。服务器。上传大文件很容易造成服务器内存溢出。
2、检查空列表
用户在编辑表格时往往会删除每个单元格的整行,而不是直接删除整行,从而导致留下一些空白行。这些空白行毫无意义。系统应该过滤它们并且只保留有数据的行。.
3、检查数据线
受限于服务器的处理能力和业务的复杂性,我们需要限制允许的数据行数,比如10万行。如果超过,很可能会导致服务器内存溢出或页面超时错误。同时,我们也可以将excel的服务器处理超时和内存限制设置大一些。
4、检查空字段
检查系统要求的非空字段。有时系统不需要读取表的所有列,添加一些列供用户查看,对系统没有意义的列不需要验证(但可能需要读取和临时存储,例如发生错误时,需要提示用户在哪一行出错,该行的内容是什么)。
5、检查数据格式
根据业务需求验证字段类型、长度等。
6、卸重
根据业务需求执行数据行重复数据删除或错误报告。
7、类型转换、xss过滤、数据处理、数据重组
经过前6步验证,基本可以确定数据的有效性,然后对数据进行预处理,使数据符合操作界面的要求。比如xss过滤,用户填写的文本需要转换成界面需要的数字,数据结构调整为界面需要的形式。
8、数据有效性检查
对数据进行业务相关的验证。例如,如果需要修改产品,首先要查询该产品是否存在,在执行订单发货操作时,首先要查询该订单是否存在。这种情况是兼容的,即使产品或订单不存在,直接调整接口也不会有问题)。
9、 调优界面
调整业务操作界面。如果接口不能一次处理所有数据,则需要批量调整。如果接口有频率限制,则需要注意在周期内保持适当的时间间隔。
10、结果处理,异常处理
根据接口返回的信息,组装成合适的数据格式,用于提示用户哪些数据操作成功,哪些数据操作失败,以及失败的原因。
11、反馈操作结果
批量操作中经常会遇到部分成功和部分失败的情况。因此,导出不正确的表是一种更直观的方式。可以在表格中增加一列来说明操作失败的原因,用户可以根据提示重新编辑表格。并导入系统。如果发生系统错误,还应记录操作日志,以便及时定位和处理。
二、注释1、科学记数法
Excel 编辑软件通常以科学计数法显示订单号和 ID 号等大数字。这是系统的非法数据格式。如果可以进行转换,系统应该尽量允许这种格式并把它转换成正确的数据。但是,当转换结果不准确时,应提示用户将数据格式设置为文本类型。比如有些数字字符串太长,用excel编辑软件转换成科学记数法,就会失去一定的准确性。即使将它们转换为字符串,数据也会丢失。这是不对的。例如,原来的ID号“4211116”在Microsoft Excel中会转为“4.21022E+17”,再转一个数值为“4200000”。
2、超时和内存溢出
在进行批量操作时,当数据量较大或操作界面时间较长时,可能会遇到页面超时错误或服务器内存溢出。一方面,我们可以设置超时时间和内存限制,另一方面,我们需要根据实际测试设置一个数据量限制。
set_time_limit(120);
ini_set('memory_limit','512M');
这里设置的超时时间只是php的超时时间,页面超时时间也受nginx配置的超时时间限制,取较小者。
3、空白单元格
在使用系统的过程中,可能会遇到用户上传的excel文件明明只有几百行,但是内存溢出。可能是因为用户在编辑excel的过程中修改了单元格格式,导致出现很多空行或空列的无用信息,导致服务器解析excel文件时内存溢出。这时候可以把原来的excel文件的内容粘贴到新的excel文件中,丢弃无用的信息。
三、优化
如果处理的数据量太大,接口不能在规定时间内处理数据,肯定会造成超时。这时候我们就可以优化系统了。共有三种优化方案。
1、使用异步任务
解析完表后,使用异步任务调用接口。服务器直接将结果返回给前端页面,页面会定时自动查询运行状态。这样,一个请求被分多次,避免了页面超时的问题,用户不需要在页面上等待,甚至可以关闭页面。该方法需要编写异步任务,还需要反转任务状态,并提供查询任务状态的接口。相对来说,实现会稍微复杂一些。
2、多个请求
文件上传后,服务器不进行数据操作,只对excel文件中的数据进行解析,解析完成后将数据返回页面或暂存到redis中。前端页面循环发送请求,将数据拆分成多个副本进行处理。需要注意的是,如果数据返回到页面并临时存放在浏览器内存中,则请求过程需要注意http请求的参数限制。post请求默认接收1000个参数,所以页面传递给服务端时参数要转换为String(如果直接传递多维数组,数组的每个子元素都会作为一个参数处理,并且很容易超过限制)。
3、使用csv格式
因为excel会有一些额外的格式,比如单元格宽度、背景色、边框、字体等,所以在解析excel文件的时候会占用服务器内存(虽然用户可能不会设置),通常系统不会关心这个信息,所以把excel转成csv再导入系统会大大增加系统可以处理的数据量。
四、相关php代码
下面是我封装的一个将excel文件解析成数组的方法。该方法接收一个excel文件并返回一个数组。包括的功能是
/**
* 解析excel表格为数组
* @param array $params
* int max_size: 限制文件大小(M)
* int count_col:需要读取表格前多少列,防止读到后面的空白列导致内存溢出
* bool need_head: 是否需要读取表头
* 将会跳过空行
* @return array
*/
function parse_excel($params = array()){
$fileType = array("application/vnd.ms-excel","application/vnd.openxmlformats-officedocument.spreadsheetml.sheet","application/kset");
$max_size = isset($params['max_size']) ? $params['max_size'] : 2;
if (!(isset($_FILES["file"]) && 0 == $_FILES["file"]["error"])) {
cilog('debug', '上传失败:isset($_FILES["file"]):'.isset($_FILES["file"]).'上传文件$_FILES["file"]["error"]:'.$_FILES["file"]["error"]);
$result = array(
'errcode' =>1001,
'errmsg' =>"文件上传失败",
);
} elseif ($_FILES["file"]["size"] > $max_size * 1024 * 1024) {
cilog('debug', '上传文件大小:'.$_FILES["file"]["size"]);
$result = array(
'errcode' =>1002,
'errmsg' =>"上传文件不得超过{$max_size}Mb",
);
} elseif (!in_array($_FILES["file"]["type"],$fileType)) {
cilog('debug', '上传文件MIME:'.$_FILES["file"]["type"]);
$result = array(
'errcode' =>1003,
'errmsg' =>"文件类型错误,请上传.xls或.xlsx文件",
);
} else{
$file = $_FILES['file']['tmp_name'];
require_once BASEPATH . '/libraries/phpexcel/PHPExcel.php';
$excelReader = new PHPExcel_Reader_Excel2007();
if (!$excelReader->canRead($file)) {
$excelReader = new PHPExcel_Reader_Excel5();
}
$sheet = $excelReader->load($file)->getSheet(0); //sheet1操作
$excelCont = array(
'highestCol' => $sheet->getHighestColumn(), //列
'highestRow' => $sheet->getHighestRow(), //行
'highestColumnIndex' => PHPExcel_Cell::columnIndexFromString($sheet->getHighestColumn()) // 几列
);
$countCol = isset($params['count_col']) ? $params['count_col'] : $excelCont['highestRow'];//有效列的数目,读取时只取前$countCol列
$startRow = isset($params['need_head']) && $params['need_head'] ? 1 : 2;//从第1行开始读,读取表头
// $excelCont['highestRow'] 有几行
// 表示第一行第一列 $sheet->getCellByColumnAndRow(0, 1)->getValue()的值
$rightArr = array();
// 总共导入多少行 $row - $emptyLine -1
$row = $excelCont['highestRow'];
$emptyLine = 0;
for ($j = $startRow; $j < intval($row) + 1; $j++) {
$retArr = array();//该行的各个单元格的数据
$emptyCol = 0;
for($i = 0; $i < $countCol;$i++){//循环该行的单元格
$retArr[$i] = $sheet->getCellByColumnAndRow($i, $j)->getValue();
$retArr[$i] = isset($retArr[$i]) ? trim($retArr[$i]) : $retArr[$i];
if($retArr[$i] === null){
$emptyCol++;
}
}
if($emptyCol == $countCol){//这行为空行,不放入任何数组
$emptyLine++;
}else {
$rightArr[] = $retArr;
}
}
if(empty($rightArr)){
$result = array(
'errcode' =>1004,
'errmsg' =>"上传文件内没有有效数据",
);
}else{
$result = array(
'errcode' =>0,
'errmsg' =>"",
'data' =>$rightArr,
);
}
}
return $result;
}
php抓取网页表格信息(Python中的urlparse、urllib抓取和解析网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-28 08:24
项目中使用了网络爬虫,最后使用了HtmlAgilityPack来做。
官网地址:可以看看
基本的:
// From File<br />
var doc = new HtmlDocument();<br />
doc.Load(filePath);
// From String<br />
var doc = new HtmlDocument();<br />
doc.LoadHtml(html);
// From Web<br />
var url = "http://html-agility-pack.net/";<br />
var web = new HtmlWeb();<br />
var doc = web.Load(url);<br />我要实现抓取某一个table的信息,
官方代码如下:
HtmlDocument doc = new HtmlDocument();<br />
doc.LoadHtml(@"<p>helloworld");<br />
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table")) {<br />
Console.WriteLine("Found: " + table.Id);<br />
foreach (HtmlNode row in table.SelectNodes("tr")) {<br />
Console.WriteLine("row");<br />
foreach (HtmlNode cell in row.SelectNodes("th|td")) {<br />
Console.WriteLine("cell: " + cell.InnerText);<br />
}<br />
}<br />
}
这个例子可以成功运行,但是当我实际应用它时,我会发现
table.SelectNodes("tr") 获取的值为null,经查找发现是路径解析的问题,因为我获取的html为
<br />
<br />
<br />
承运人<br />
航线名称<br />
起运港<br />
目的港<br />
挂靠港<br />
<br />
<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
<br />
<br />
当前第一个tr的xml路径为:/html[1]/body[1]/div[3]/div[3]/div[1]/table[1]/thead[1]/tr,最后修改为了:
table.SelectNodes(".//tr") 就可以解析这个table下面的所有tr信息,<br />当使用
table.SelectNodes("//tr")时,获取的是当前html的全部tr,如果当有两个table时候,会获取到两个table全部的tr信息,用哪个要分情况
c#使用HtmlAgilityPack爬取解析获取更多表表信息文章 Python中使用urlparse和urllib爬取解析网页(一)(转)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容 2016/02/02 | 经验分享 | 0 回复 有时调试网页或...
Python中的urlparse和urllib爬取解析网页(一)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
使用HtmlAgilityPack和ScrapySharp抓取网页数据格式编码问题遇到的几个问题的解决方案
需要用到全市街道、县居委会对应的区号,于是找了统计局的网页,抓取了数据。使用了 HtmlAgilityPack 和 ScrapySharp。由于也是第一次从网页抓取数据,对于HtmlAgili...
c#抓取并解析网页,并将表格数据保存到datatable中(其他格式也可以,可以自行修改)
HtmlAgilityPack的使用基础请参考此博客:以下是根据抓取到的页面字符串解析保存... 查看全部
php抓取网页表格信息(Python中的urlparse、urllib抓取和解析网页(一))
项目中使用了网络爬虫,最后使用了HtmlAgilityPack来做。
官网地址:可以看看
基本的:
// From File<br />
var doc = new HtmlDocument();<br />
doc.Load(filePath);
// From String<br />
var doc = new HtmlDocument();<br />
doc.LoadHtml(html);
// From Web<br />
var url = "http://html-agility-pack.net/";<br />
var web = new HtmlWeb();<br />
var doc = web.Load(url);<br />我要实现抓取某一个table的信息,
官方代码如下:
HtmlDocument doc = new HtmlDocument();<br />
doc.LoadHtml(@"<p>helloworld");<br />
foreach (HtmlNode table in doc.DocumentNode.SelectNodes("//table")) {<br />
Console.WriteLine("Found: " + table.Id);<br />
foreach (HtmlNode row in table.SelectNodes("tr")) {<br />
Console.WriteLine("row");<br />
foreach (HtmlNode cell in row.SelectNodes("th|td")) {<br />
Console.WriteLine("cell: " + cell.InnerText);<br />
}<br />
}<br />
}
这个例子可以成功运行,但是当我实际应用它时,我会发现
table.SelectNodes("tr") 获取的值为null,经查找发现是路径解析的问题,因为我获取的html为
<br />
<br />
<br />
承运人<br />
航线名称<br />
起运港<br />
目的港<br />
挂靠港<br />
<br />
<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
ANL(澳航)<br />
Austrilian and Zelanian Line
<br />
YOKOHAMA<br />
BRISBANE<br />
YOKOHAMA-OSAKA-BUSAN-QINGDAO-SHANGHAI-NINGBO-XIAMEN-HONGKONG-KAOHSIUNG-MELBOURNE-SYDNEY-BRISBANE<br />
<br />
<br />
当前第一个tr的xml路径为:/html[1]/body[1]/div[3]/div[3]/div[1]/table[1]/thead[1]/tr,最后修改为了:
table.SelectNodes(".//tr") 就可以解析这个table下面的所有tr信息,<br />当使用
table.SelectNodes("//tr")时,获取的是当前html的全部tr,如果当有两个table时候,会获取到两个table全部的tr信息,用哪个要分情况
c#使用HtmlAgilityPack爬取解析获取更多表表信息文章 Python中使用urlparse和urllib爬取解析网页(一)(转)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容
网页调试技巧:抓取立即跳转的页面的POST信息或页面内容 2016/02/02 | 经验分享 | 0 回复 有时调试网页或...
Python中的urlparse和urllib爬取解析网页(一)
对于搜索引擎、文件索引、文档转换、数据检索、站点备份或迁移等应用,经常用到网页(即HTML文件)的分析和处理。事实上,通过Python语言提供的各种模块,我们无需使用网络服务器或网页浏览...
使用HtmlAgilityPack和ScrapySharp抓取网页数据格式编码问题遇到的几个问题的解决方案
需要用到全市街道、县居委会对应的区号,于是找了统计局的网页,抓取了数据。使用了 HtmlAgilityPack 和 ScrapySharp。由于也是第一次从网页抓取数据,对于HtmlAgili...
c#抓取并解析网页,并将表格数据保存到datatable中(其他格式也可以,可以自行修改)
HtmlAgilityPack的使用基础请参考此博客:以下是根据抓取到的页面字符串解析保存...
php抓取网页表格信息(时间财富网智能客服时间君,网页文件的拓展:htm、html、JSP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-09-26 11:23
大家好,我是时代财富网智能客服,为您解答以上问题。
网页文件的扩展名包括:htm、html、JSP HTML、php、ASP动态网页文件、PHP/PHP3、PHTML等,由网页的语言决定。
网页(英文:web page)是一种适用于万维网和网络浏览器的文件。它存储在世界的某个角落或连接到互联网的一组计算机中。它是构成网站的基本元素,是承载各种网站应用的平台。网页由网址 (URL) 标识和访问。我们在网页浏览器中输入网址后,经过一个复杂而快速的过程,网页文件会被传送到用户的电脑,然后网页的内容会通过浏览器进行解释,然后展示给用户用户。
文字和图片是构成网页的两个最基本的元素。你可以简单的理解为:文本就是网页的内容。图片是网页的美。此外,网页的元素还包括动画、音乐、节目等。在网页上单击鼠标右键,在菜单中选择“查看源文件”,可以通过记事本查看网页的实际内容。您可以看到该网页实际上只是一个纯文本文件。它使用多种标签来描述页面上的文字、图片、表格、声音等元素(如字体、颜色、大小),浏览器对这些标签进行解释并生成页面,从而得到你当前的看。为什么可以' t 我在源文件中看到任何图片吗?网页文件中存储的只是图片的链接位置,图片文件和网页文件是相互独立存储的,甚至可能不在同一台电脑上。 查看全部
php抓取网页表格信息(时间财富网智能客服时间君,网页文件的拓展:htm、html、JSP)
大家好,我是时代财富网智能客服,为您解答以上问题。
网页文件的扩展名包括:htm、html、JSP HTML、php、ASP动态网页文件、PHP/PHP3、PHTML等,由网页的语言决定。
网页(英文:web page)是一种适用于万维网和网络浏览器的文件。它存储在世界的某个角落或连接到互联网的一组计算机中。它是构成网站的基本元素,是承载各种网站应用的平台。网页由网址 (URL) 标识和访问。我们在网页浏览器中输入网址后,经过一个复杂而快速的过程,网页文件会被传送到用户的电脑,然后网页的内容会通过浏览器进行解释,然后展示给用户用户。
文字和图片是构成网页的两个最基本的元素。你可以简单的理解为:文本就是网页的内容。图片是网页的美。此外,网页的元素还包括动画、音乐、节目等。在网页上单击鼠标右键,在菜单中选择“查看源文件”,可以通过记事本查看网页的实际内容。您可以看到该网页实际上只是一个纯文本文件。它使用多种标签来描述页面上的文字、图片、表格、声音等元素(如字体、颜色、大小),浏览器对这些标签进行解释并生成页面,从而得到你当前的看。为什么可以' t 我在源文件中看到任何图片吗?网页文件中存储的只是图片的链接位置,图片文件和网页文件是相互独立存储的,甚至可能不在同一台电脑上。

