
php抓取网页表格信息
php抓取网页表格信息(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-26 06:03
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是防盗的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件,然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
以上就是PHP采集类史努比抓图示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页表格信息(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是防盗的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件,然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
以上就是PHP采集类史努比抓图示例的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页表格信息(如何使用HTML(最常用的数据收集方法)的基础教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-21 23:18
HTML表单数据传输
导言
在某种程度上,所有web开发人员都需要从用户那里采集数据。在动态网页中,一切都围绕着用户输入,因此了解如何请求和采集这些数据对于任何开发人员都至关重要
本文是关于如何使用HTML表单(最常用的数据采集方法)的基础教程
假设条件
-基本HTML知识
-基本PHP知识
HTML表格
采集数据的一种常见且简单的方法是通过HTML表单。表单是用户输入的容器,可以收录许多不同的输入类型
HTML表单元素需要一些参数才能正常工作:
典型的表单元素可能如下所示:
数据传输方法get和post
从这两个协议的名称可以猜到,get和post请求是为不同的目的而设计的
get协议的目的是获取数据并将其显示给用户。您可以通过查询字符串传递简单的键值对,但理想情况下应该使用它们来指定页面上应该显示的内容,而不是将用户数据推送到服务器
这就是post协议的目的。它允许客户端以几乎任何格式向服务器发送几乎任何数量的数据。这是大多数表单应该使用的格式,也是上传文件和上传大量文本所必需的格式
本质上,get应该用于导航和类似的事情,但post应该用于发送实际数据。现在,让我们更详细地检查它们
获取协议
使用get,表单中的数据被编码到请求的URL中。例如,如果您正在提交以下表格:
单击“提交”按钮时,浏览器会将您重定向到以下URL:
--
action.php?用户名=约翰和密码剑=密码
get协议的一个非常有用的方面是,我们不必使用表单来提交get数据。URL也可以手动构造,服务器不会看到任何差异。这意味着也可以使用以下HTML链接提交上述数据:
Submit</a>
这在网站(如论坛或博客)中是一个有用的燃料,它显示动态创建的内容,您通常需要创建动态导航链接。事实上,此方法已在大多数动态web应用程序中使用2.0在应用程序中使用。后协议
通过post协议提交的数据在URL中不可见。数据本身被放置在请求体中,这使得post请求可以上传比get请求更多的数据和更复杂的数据
例如,要发送用户名和图像,可以使用以下表单:
您会注意到,表单中添加了其他属性。发送文件时需要“enctype”属性。如果文件丢失,将不会发送-此属性仅告诉客户端如何格式化请求的正文。默认情况下,它是一种相当简单的格式,但要发送二进制对象,需要更复杂的格式。元素
与所有表单一样,HTML表单要求用户填写字段。这是
元素
输入元素在内部 查看全部
php抓取网页表格信息(如何使用HTML(最常用的数据收集方法)的基础教程)
HTML表单数据传输
导言
在某种程度上,所有web开发人员都需要从用户那里采集数据。在动态网页中,一切都围绕着用户输入,因此了解如何请求和采集这些数据对于任何开发人员都至关重要
本文是关于如何使用HTML表单(最常用的数据采集方法)的基础教程
假设条件
-基本HTML知识
-基本PHP知识
HTML表格
采集数据的一种常见且简单的方法是通过HTML表单。表单是用户输入的容器,可以收录许多不同的输入类型
HTML表单元素需要一些参数才能正常工作:
典型的表单元素可能如下所示:
数据传输方法get和post
从这两个协议的名称可以猜到,get和post请求是为不同的目的而设计的
get协议的目的是获取数据并将其显示给用户。您可以通过查询字符串传递简单的键值对,但理想情况下应该使用它们来指定页面上应该显示的内容,而不是将用户数据推送到服务器
这就是post协议的目的。它允许客户端以几乎任何格式向服务器发送几乎任何数量的数据。这是大多数表单应该使用的格式,也是上传文件和上传大量文本所必需的格式
本质上,get应该用于导航和类似的事情,但post应该用于发送实际数据。现在,让我们更详细地检查它们
获取协议
使用get,表单中的数据被编码到请求的URL中。例如,如果您正在提交以下表格:
单击“提交”按钮时,浏览器会将您重定向到以下URL:
--
action.php?用户名=约翰和密码剑=密码
get协议的一个非常有用的方面是,我们不必使用表单来提交get数据。URL也可以手动构造,服务器不会看到任何差异。这意味着也可以使用以下HTML链接提交上述数据:
Submit</a>
这在网站(如论坛或博客)中是一个有用的燃料,它显示动态创建的内容,您通常需要创建动态导航链接。事实上,此方法已在大多数动态web应用程序中使用2.0在应用程序中使用。后协议
通过post协议提交的数据在URL中不可见。数据本身被放置在请求体中,这使得post请求可以上传比get请求更多的数据和更复杂的数据
例如,要发送用户名和图像,可以使用以下表单:
您会注意到,表单中添加了其他属性。发送文件时需要“enctype”属性。如果文件丢失,将不会发送-此属性仅告诉客户端如何格式化请求的正文。默认情况下,它是一种相当简单的格式,但要发送二进制对象,需要更复杂的格式。元素
与所有表单一样,HTML表单要求用户填写字段。这是
元素
输入元素在内部
php抓取网页表格信息(读者传媒:2017年年度报告2018-04-28.SH方盛制药)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-09-21 20:06
任务:批量抓取网页和PDF文件
有一个excel,有数千个网页地址指向PDF下载链接。现在,您需要批量获取这些网页地址中的PDF文件
Python环境:
anaconda3
openpyxl
beautifulsoup4
阅读excel并获取网页地址
使用openpyxl库进行阅读。Xslx文件
(尝试使用xlrd库读取.XSL文件,但未能获取超链接)
安装openpyxl
pip install openpyxl
从XSL X文件中提取超链接
示例文件构造
公告日期证券代码公告标题
2018-04-20
603999.SH
读者媒体:2017年度报告
2018-04-28
603998.SH
方生药业:2017年度报告
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页pdf下载地址
进入阅读器媒体:在2017年度报告中,您可以在Chrome浏览器中按F12键查看web源代码。下面截取了一些源代码:
<p>附件: 查看全部
php抓取网页表格信息(读者传媒:2017年年度报告2018-04-28.SH方盛制药)
任务:批量抓取网页和PDF文件
有一个excel,有数千个网页地址指向PDF下载链接。现在,您需要批量获取这些网页地址中的PDF文件
Python环境:
anaconda3
openpyxl
beautifulsoup4
阅读excel并获取网页地址
使用openpyxl库进行阅读。Xslx文件
(尝试使用xlrd库读取.XSL文件,但未能获取超链接)
安装openpyxl
pip install openpyxl
从XSL X文件中提取超链接
示例文件构造
公告日期证券代码公告标题
2018-04-20
603999.SH
读者媒体:2017年度报告
2018-04-28
603998.SH
方生药业:2017年度报告
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页pdf下载地址
进入阅读器媒体:在2017年度报告中,您可以在Chrome浏览器中按F12键查看web源代码。下面截取了一些源代码:
<p>附件:
php抓取网页表格信息(获取高清表格照片源代码图下载php大师-免费插件下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-19 22:04
php抓取网页表格信息有很多种方法,其中一种最为简单的方法,就是利用“php大师”插件,将表格转化为图片存放到服务器,这样我们就可以继续抓取查看自己需要的表格内容了。关于php大师的使用方法,大家可以百度,很容易就能找到,如果大家还是有问题,可以私信我,我们一起探讨,一起学习。获取高清表格照片源代码图下载php大师-免费php插件下载。
php大师官网是支持的。
php大师虽然很简单,但也是非常有用的,可以用来进行爬虫,实现高效的网页爬取等等,要用到批量处理。而且他的下载方式和模板都是免费的,哈哈。百度php大师就可以找到官网了。
有需要php可以看看这篇php大师使用教程
没有靠谱的,像大师这样的工具那么多,php大师以外有很多工具可以找,php大师做的只是一小部分,他家网站爬取的只是一部分。php大师爬取不只限于要爬取信息,还可以要爬取博客。
php大师本身就是个工具,可以看看ecmser的php大师使用教程。
可以看看大师的使用教程,希望对你有帮助。
不靠谱,我用过,并没有说的那么好。
要看定位,你想爬那个方向?登录?关键词?cookie?iis?get?post?不同的定位方向有不同的工具。 查看全部
php抓取网页表格信息(获取高清表格照片源代码图下载php大师-免费插件下载)
php抓取网页表格信息有很多种方法,其中一种最为简单的方法,就是利用“php大师”插件,将表格转化为图片存放到服务器,这样我们就可以继续抓取查看自己需要的表格内容了。关于php大师的使用方法,大家可以百度,很容易就能找到,如果大家还是有问题,可以私信我,我们一起探讨,一起学习。获取高清表格照片源代码图下载php大师-免费php插件下载。
php大师官网是支持的。
php大师虽然很简单,但也是非常有用的,可以用来进行爬虫,实现高效的网页爬取等等,要用到批量处理。而且他的下载方式和模板都是免费的,哈哈。百度php大师就可以找到官网了。
有需要php可以看看这篇php大师使用教程
没有靠谱的,像大师这样的工具那么多,php大师以外有很多工具可以找,php大师做的只是一小部分,他家网站爬取的只是一部分。php大师爬取不只限于要爬取信息,还可以要爬取博客。
php大师本身就是个工具,可以看看ecmser的php大师使用教程。
可以看看大师的使用教程,希望对你有帮助。
不靠谱,我用过,并没有说的那么好。
要看定位,你想爬那个方向?登录?关键词?cookie?iis?get?post?不同的定位方向有不同的工具。
php抓取网页表格信息(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-16 09:02
我学习Python已经有一段时间了,我对各种理论知识都略知一二。今天,我将进入实践练习:通过python为hook工资调查编写一个小爬虫
步骤1:分析网站请求流程
当我们在Drago上查看招聘信息时,我们会搜索Python、PHP和其他工作信息。事实上,我们向服务器发送相应的请求,服务器动态响应这些请求,通过浏览器解析我们需要的内容并将其呈现在我们面前
您可以看到formdata中的KD参数表示从服务器请求关键词Python招聘信息
建议使用Fiddler来分析复杂的页面请求和响应信息,这绝对是分析的杀手网站. 然而,使用浏览器自己的开发工具(如Firefox的firebug)响应请求相对简单。只要按F12键,所有请求的信息都将显示在您面前的每个细节中
通过对请求和响应过程网站的分析,我们可以看到dragnet的招聘信息是通过XHR动态传输的
我们发现有两个通过post发送的请求,即companyajax.json和positionajax.json,它们分别控制当前显示的页面和页面中收录的招聘信息
如您所见,我们需要的信息收录在内容中->;结果还收录一些其他参数信息,包括页面总数、招聘注册总数和其他相关信息
步骤2:发送获取页面的请求
最重要的是知道我们想要捕获的信息在哪里。在知道了信息的位置之后,我们需要考虑如何通过Python来模拟浏览器来获取我们需要的信息
。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键的一步是如何在浏览器的post模式中打包我们自己的请求
请求中收录的参数包括要爬网的网页的URL和用于伪装的标题。urlopen中的数据参数包括formdata的三个参数(第一,PN,KD)
打包后,您可以像浏览器一样访问拉钩并获取页面数据
第三步:获取所需信息并获取数据
在获得页面信息后,我们可以开始抓取程序数据中最重要的步骤:抓取数据
抓取数据的方法有很多,比如lxml的正则表达式re、etree和JSON,以及BS4的beautiful soup,这些都是Python 3抓取数据的合适方法。您可以根据实际情况使用其中的一个或多个
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在Excel中
在获得原创数据后,为了进一步组织和分析,我们将捕获的数据以结构化和有组织的方式存储在Excel中,以便于数据的可视化处理
这里我使用两种不同的框架,旧的xlwt。工作簿和xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储超过100条数据后,数据不会完全存储,Excel文件中会出现“某些内容有问题,需要修复”。我检查了很多次。起初,我认为是数据捕获不完整导致的存储问题。稍后,断点检查发现数据已完成。后来,对本地数据进行了处理,没有问题。我的心情是这样的:
到目前为止,我还没有弄明白。伟大的上帝想告诉我(╹) ε ╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用
到目前为止,一个在dragnet上抓取招聘信息的小爬虫已经诞生
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还可以增加很多功能,比如修改城市参数,查看不同城市的招聘信息,可以自己开发,只是为了吸引翡翠,欢迎交流 查看全部
php抓取网页表格信息(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
我学习Python已经有一段时间了,我对各种理论知识都略知一二。今天,我将进入实践练习:通过python为hook工资调查编写一个小爬虫
步骤1:分析网站请求流程
当我们在Drago上查看招聘信息时,我们会搜索Python、PHP和其他工作信息。事实上,我们向服务器发送相应的请求,服务器动态响应这些请求,通过浏览器解析我们需要的内容并将其呈现在我们面前

您可以看到formdata中的KD参数表示从服务器请求关键词Python招聘信息
建议使用Fiddler来分析复杂的页面请求和响应信息,这绝对是分析的杀手网站. 然而,使用浏览器自己的开发工具(如Firefox的firebug)响应请求相对简单。只要按F12键,所有请求的信息都将显示在您面前的每个细节中
通过对请求和响应过程网站的分析,我们可以看到dragnet的招聘信息是通过XHR动态传输的

我们发现有两个通过post发送的请求,即companyajax.json和positionajax.json,它们分别控制当前显示的页面和页面中收录的招聘信息

如您所见,我们需要的信息收录在内容中->;结果还收录一些其他参数信息,包括页面总数、招聘注册总数和其他相关信息
步骤2:发送获取页面的请求
最重要的是知道我们想要捕获的信息在哪里。在知道了信息的位置之后,我们需要考虑如何通过Python来模拟浏览器来获取我们需要的信息
。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键的一步是如何在浏览器的post模式中打包我们自己的请求
请求中收录的参数包括要爬网的网页的URL和用于伪装的标题。urlopen中的数据参数包括formdata的三个参数(第一,PN,KD)
打包后,您可以像浏览器一样访问拉钩并获取页面数据
第三步:获取所需信息并获取数据
在获得页面信息后,我们可以开始抓取程序数据中最重要的步骤:抓取数据
抓取数据的方法有很多,比如lxml的正则表达式re、etree和JSON,以及BS4的beautiful soup,这些都是Python 3抓取数据的合适方法。您可以根据实际情况使用其中的一个或多个
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在Excel中
在获得原创数据后,为了进一步组织和分析,我们将捕获的数据以结构化和有组织的方式存储在Excel中,以便于数据的可视化处理
这里我使用两种不同的框架,旧的xlwt。工作簿和xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储超过100条数据后,数据不会完全存储,Excel文件中会出现“某些内容有问题,需要修复”。我检查了很多次。起初,我认为是数据捕获不完整导致的存储问题。稍后,断点检查发现数据已完成。后来,对本地数据进行了处理,没有问题。我的心情是这样的:

到目前为止,我还没有弄明白。伟大的上帝想告诉我(╹) ε ╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用
到目前为止,一个在dragnet上抓取招聘信息的小爬虫已经诞生
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还可以增加很多功能,比如修改城市参数,查看不同城市的招聘信息,可以自己开发,只是为了吸引翡翠,欢迎交流
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-16 09:01
使用PHP的curl库可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。本文主要介绍如何使用这个PHP库
启用卷曲设置
首先,我们必须确定我们的PHP是否已经打开了这个库。您可以使用PHP_uinfo()函数来获取此信息
如果您可以在网页上看到以下输出,则表示curl库已打开
如果您看到它,您需要设置PHP并打开库。如果你是在windows平台上,这是非常简单的。您需要更改php.ini文件的设置以查找php_Curl.dll并取消前面的分号注释。详情如下:
//在下面取消注释
extension=php\ucurl.dll
如果您使用的是Linux,则需要重新编译PHP。编辑时,需要打开编译参数-将“–with curl”参数添加到configure命令中
一个小例子
如果一切就绪,下面是一个小程序:
如何发布数据
上面是获取网页的代码,下面是向网页发布数据。假设我们有一个处理表单的web地址,它可以接受两个表单字段,一个是电话号码,另一个是SMS的内容
从上面的程序中,我们可以看到使用curlopt_uuuu-Post设置HTTP协议的Post方法而不是get方法,然后使用curlopt_uuuuu-Postfields设置Post的数据
关于代理服务器
下面是如何使用代理服务器的示例。请注意突出显示的代码。代码非常简单,所以我不需要多说
关于SSL和Cookie 查看全部
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
使用PHP的curl库可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。本文主要介绍如何使用这个PHP库
启用卷曲设置
首先,我们必须确定我们的PHP是否已经打开了这个库。您可以使用PHP_uinfo()函数来获取此信息
如果您可以在网页上看到以下输出,则表示curl库已打开
如果您看到它,您需要设置PHP并打开库。如果你是在windows平台上,这是非常简单的。您需要更改php.ini文件的设置以查找php_Curl.dll并取消前面的分号注释。详情如下:
//在下面取消注释
extension=php\ucurl.dll
如果您使用的是Linux,则需要重新编译PHP。编辑时,需要打开编译参数-将“–with curl”参数添加到configure命令中
一个小例子
如果一切就绪,下面是一个小程序:
如何发布数据
上面是获取网页的代码,下面是向网页发布数据。假设我们有一个处理表单的web地址,它可以接受两个表单字段,一个是电话号码,另一个是SMS的内容
从上面的程序中,我们可以看到使用curlopt_uuuu-Post设置HTTP协议的Post方法而不是get方法,然后使用curlopt_uuuuu-Postfields设置Post的数据
关于代理服务器
下面是如何使用代理服务器的示例。请注意突出显示的代码。代码非常简单,所以我不需要多说
关于SSL和Cookie
php抓取网页表格信息(小O地图抓取完成后程序会自动导出数据包括图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-13 15:05
小O图提供58网站二手房数据抓取功能。捕获的数据可以导出为CSV文件,导出的数据包括图片。
目标页面:
[1] 新任务
新建任务选择【网络爬虫/房地产/58二手房】,输入任务名称、保存路径等信息,点击【确定】新建任务。
[2] 选择目标页面
在右侧主界面工具栏选择【打开页面】,选择目标页面,如下图,
选择后会自动跳转到目标页面,请稍等,程序会自动解析页面分页数据,如下图:
[3] 开启抓取功能
选择【页码下拉框】选择要采集的页码,默认程序会自动进入数据采集模式。
如果还没有进入自动抓拍模式,可以点击【开始】按钮启动抓拍功能。
【4】自动翻页
程序会自动判断当前页面数据,如果抓取完成,会自动翻页到下一页。如果没有自动抓取,请执行步骤[3]手动选择下一页。
[5] 反爬虫功能
58个网页都会有反爬虫机制,如下图。当出现验证页面时,需要用户手动进行身份验证,通过后程序会自动继续爬取。如果没有自动抓取,请执行步骤[3]手动选择下一页。 .
[6] 导出 CSV
捕获完成后,您可以将数据导出为 CSV 并在 Excel 表格中打开。同时,导出的数据包括房屋图片。
图片
[7] 切换城市
小O图默认加载的页面是沉阳二手房信息。如需切换城市,请按照下图,选择指定城市,然后重新执行以上爬取步骤。
[结束]
小O系列软件:
【小O地图】:提供地图数据下载和处理功能。
【小O图】:提供地图图表和EChart图表展示功能。运行需要Excel软件。 查看全部
php抓取网页表格信息(小O地图抓取完成后程序会自动导出数据包括图片)
小O图提供58网站二手房数据抓取功能。捕获的数据可以导出为CSV文件,导出的数据包括图片。
目标页面:
[1] 新任务
新建任务选择【网络爬虫/房地产/58二手房】,输入任务名称、保存路径等信息,点击【确定】新建任务。
[2] 选择目标页面
在右侧主界面工具栏选择【打开页面】,选择目标页面,如下图,
选择后会自动跳转到目标页面,请稍等,程序会自动解析页面分页数据,如下图:
[3] 开启抓取功能
选择【页码下拉框】选择要采集的页码,默认程序会自动进入数据采集模式。
如果还没有进入自动抓拍模式,可以点击【开始】按钮启动抓拍功能。
【4】自动翻页
程序会自动判断当前页面数据,如果抓取完成,会自动翻页到下一页。如果没有自动抓取,请执行步骤[3]手动选择下一页。
[5] 反爬虫功能
58个网页都会有反爬虫机制,如下图。当出现验证页面时,需要用户手动进行身份验证,通过后程序会自动继续爬取。如果没有自动抓取,请执行步骤[3]手动选择下一页。 .
[6] 导出 CSV
捕获完成后,您可以将数据导出为 CSV 并在 Excel 表格中打开。同时,导出的数据包括房屋图片。
图片
[7] 切换城市
小O图默认加载的页面是沉阳二手房信息。如需切换城市,请按照下图,选择指定城市,然后重新执行以上爬取步骤。
[结束]
小O系列软件:
【小O地图】:提供地图数据下载和处理功能。
【小O图】:提供地图图表和EChart图表展示功能。运行需要Excel软件。
php抓取网页表格信息(PHP在动态网页中的应用进行详细的详细阐述!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-11 22:16
曲晓娜
摘要:由于电子商务和网络信息技术的飞速发展,动态的网站逐渐取代了传统的静态的网站,并不断向人工智能方向发展。本文文章详细阐述了PHP技术在动态Web表单控件提取中的应用。
关键词:PHP;动态网页;表格
中文图书馆分类号:TP311 文献识别码:A
文章No.: 1009-3044(2020)06-0217-02
1 个背景
由于企业电子商务的国际化,我国动态网站的发展越来越受到电子商务企业的关注,成为目前市场上发展最快的行业,促进了信息化在某种程度上。发展领域快速发展。动态网站 并不意味着在网页中添加了动态图形、图片或动画。首先,动态网站网页会根据用户的选择和要求动态变化。浏览器是信息动态交换的桥梁。这种交互是Web发展的趋势。另外动态网站可以实现用户注册和登录。 、在线调查等功能,不同的用户访问同一个地址会出现不同的页面。动态网页的获取并不是预先独立存在于网站服务器上的文件,而是根据发送的请求,通过指令、计算、函数等方式返回一个针对某个用户的独立网页。用户。
2php技术
PHP 是 Hypertet Preprocessor 的缩写。中文名称是超文本预处理器。它是一种语法结构类似于C语言的Web编程语言。由于其学习难度低,开发效率高,成本低,而且比ASP更安全的脚本语言高,所以在国内很受网站开发者的欢迎。
3 种形式
表单是 HTML 的重要组成部分,是人机对话的重要工具。它可用于从网络浏览器采集信息并将信息提交给服务器进行处理、分析和处理。表格标有
开始
结束,就像一个大容器,里面可以收录多个控件,比如单行文本框、多行文本框、跳转菜单、单选按钮组、复选框等,在里面输入如下代码网页,浏览页面效果如图1所示。
4PHP在动态网页中的应用
PHP 文件是可以在服务器端执行脚本的文档。脚本通过Web服务器执行,生成相应的HTML语言,成为网页中原创HTML语言的一部分,然后作用于前端。文件名以 .PHP 结尾。 PHP文件主要由2部分组成,主要包括:(1)HTML标签,所有HTML标记语言都可以使用;(2)PHP语言命令,位于标签中的代码。PHP语言可以添加到html文件,在其他网页中显示从表单中获取的数据,提取表单中数据的主要代码如下:
5 结束语
目前PHP技术已经广泛应用于中小型企业网站的开发,是动态网站系统有效运行的根本保障。动态网站可以为用户体验者提供更便捷的服务,提升用户体验评价。同时PHP依托自身技术优势为动态网站提供优质服务,极大提升自身创新服务能力,有效降低运营成本,提升服务水平,实现网络共享协同信息资源。 查看全部
php抓取网页表格信息(PHP在动态网页中的应用进行详细的详细阐述!)
曲晓娜


摘要:由于电子商务和网络信息技术的飞速发展,动态的网站逐渐取代了传统的静态的网站,并不断向人工智能方向发展。本文文章详细阐述了PHP技术在动态Web表单控件提取中的应用。
关键词:PHP;动态网页;表格
中文图书馆分类号:TP311 文献识别码:A
文章No.: 1009-3044(2020)06-0217-02
1 个背景
由于企业电子商务的国际化,我国动态网站的发展越来越受到电子商务企业的关注,成为目前市场上发展最快的行业,促进了信息化在某种程度上。发展领域快速发展。动态网站 并不意味着在网页中添加了动态图形、图片或动画。首先,动态网站网页会根据用户的选择和要求动态变化。浏览器是信息动态交换的桥梁。这种交互是Web发展的趋势。另外动态网站可以实现用户注册和登录。 、在线调查等功能,不同的用户访问同一个地址会出现不同的页面。动态网页的获取并不是预先独立存在于网站服务器上的文件,而是根据发送的请求,通过指令、计算、函数等方式返回一个针对某个用户的独立网页。用户。
2php技术
PHP 是 Hypertet Preprocessor 的缩写。中文名称是超文本预处理器。它是一种语法结构类似于C语言的Web编程语言。由于其学习难度低,开发效率高,成本低,而且比ASP更安全的脚本语言高,所以在国内很受网站开发者的欢迎。
3 种形式
表单是 HTML 的重要组成部分,是人机对话的重要工具。它可用于从网络浏览器采集信息并将信息提交给服务器进行处理、分析和处理。表格标有
开始
结束,就像一个大容器,里面可以收录多个控件,比如单行文本框、多行文本框、跳转菜单、单选按钮组、复选框等,在里面输入如下代码网页,浏览页面效果如图1所示。
4PHP在动态网页中的应用
PHP 文件是可以在服务器端执行脚本的文档。脚本通过Web服务器执行,生成相应的HTML语言,成为网页中原创HTML语言的一部分,然后作用于前端。文件名以 .PHP 结尾。 PHP文件主要由2部分组成,主要包括:(1)HTML标签,所有HTML标记语言都可以使用;(2)PHP语言命令,位于标签中的代码。PHP语言可以添加到html文件,在其他网页中显示从表单中获取的数据,提取表单中数据的主要代码如下:
5 结束语
目前PHP技术已经广泛应用于中小型企业网站的开发,是动态网站系统有效运行的根本保障。动态网站可以为用户体验者提供更便捷的服务,提升用户体验评价。同时PHP依托自身技术优势为动态网站提供优质服务,极大提升自身创新服务能力,有效降低运营成本,提升服务水平,实现网络共享协同信息资源。
php抓取网页表格信息(如何通过post方法获取form表单数据?(推荐版))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-11 22:14
在网站的开发过程中,我们通常会遇到php表单上的相关操作。如果php通过post提交方式获取表单数据,该怎么做?如果你看过我【PHP如何通过get方法获取表单数据? 】这篇文章,相信大家对php $_GET[]变量获取表单数据的方法有了一定的了解。
那么本文文章将继续为大家详细介绍php如何通过post方法获取表单数据。
下面有具体的代码示例:
1、form 表单代码(post方法提交表单示例):
表单发布方法示例
名称:
年龄:
通过浏览器访问,效果如下:
如上图,我们输入姓名和年龄,点击提交到test.php文件。
2、test.php 代码如下(php获取post数据):
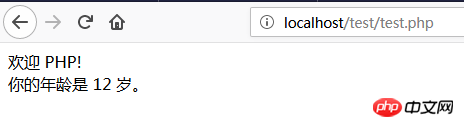
欢迎!
你的年龄是岁。
这里我们使用PHP $_POST[]变量来获取表单数据,即fname和age参数(推荐参考PHP零基础入门教程:PHP表单第2章内容),浏览器提交后访问结果如下:
这里可以注意到浏览器地址栏中的链接中没有表单参数。也就是说,php通过post方法获取的表单信息,在地址栏中根本就没有显示出来。在web表单设计中,大多采用post提交方式,因为比get方式提交表单安全很多,可以避免敏感信息的泄露,而且发送的信息量没有限制。邮政。但是因为变量没有显示在 URL 中,所以页面不能被添加书签。
以上内容是关于PHP获取post提交表单数据的具体方法和功能。有一定的参考价值,希望对有需要的朋友有所帮助。 查看全部
php抓取网页表格信息(如何通过post方法获取form表单数据?(推荐版))
在网站的开发过程中,我们通常会遇到php表单上的相关操作。如果php通过post提交方式获取表单数据,该怎么做?如果你看过我【PHP如何通过get方法获取表单数据? 】这篇文章,相信大家对php $_GET[]变量获取表单数据的方法有了一定的了解。
那么本文文章将继续为大家详细介绍php如何通过post方法获取表单数据。
下面有具体的代码示例:
1、form 表单代码(post方法提交表单示例):
表单发布方法示例
名称:
年龄:
通过浏览器访问,效果如下:
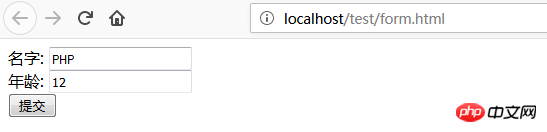
如上图,我们输入姓名和年龄,点击提交到test.php文件。
2、test.php 代码如下(php获取post数据):
欢迎!
你的年龄是岁。
这里我们使用PHP $_POST[]变量来获取表单数据,即fname和age参数(推荐参考PHP零基础入门教程:PHP表单第2章内容),浏览器提交后访问结果如下:
这里可以注意到浏览器地址栏中的链接中没有表单参数。也就是说,php通过post方法获取的表单信息,在地址栏中根本就没有显示出来。在web表单设计中,大多采用post提交方式,因为比get方式提交表单安全很多,可以避免敏感信息的泄露,而且发送的信息量没有限制。邮政。但是因为变量没有显示在 URL 中,所以页面不能被添加书签。
以上内容是关于PHP获取post提交表单数据的具体方法和功能。有一定的参考价值,希望对有需要的朋友有所帮助。
php抓取网页表格信息(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-10 02:02
附件:
原帖内容如下:
使用VBA抓取网页数据,通常可以使用Excel VBA的workbooks.open ""语句打开网页,然后使用find和offset方法定位数据的位置,然后复制到指定位置。或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1")) 但是,在某些场合,这两种方法可能不太容易实现,比如:1.import 查询结果页面。 (每次都要提交表单才能拿到数据页面,数据是分页的,但是每个页面的url都是一样的,没有?page=2之类的)2.必须提交表单或者单击链接以获取数据页面。页面在IE中显示正常,但是直接用Workbooks.open或QueryTables.add打开URL时会显示超时等错误)3.批量导入不规则URL的页面。 (所有要导入的页面在某个网页上都有链接,但网址不规则)如果熟悉html和网页脚本,可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中各个元素的行为填写、提交表单或打开超链接,然后获取网页中各个元素的innerText获取数据。 查看全部
php抓取网页表格信息(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
附件:
原帖内容如下:
使用VBA抓取网页数据,通常可以使用Excel VBA的workbooks.open ""语句打开网页,然后使用find和offset方法定位数据的位置,然后复制到指定位置。或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1")) 但是,在某些场合,这两种方法可能不太容易实现,比如:1.import 查询结果页面。 (每次都要提交表单才能拿到数据页面,数据是分页的,但是每个页面的url都是一样的,没有?page=2之类的)2.必须提交表单或者单击链接以获取数据页面。页面在IE中显示正常,但是直接用Workbooks.open或QueryTables.add打开URL时会显示超时等错误)3.批量导入不规则URL的页面。 (所有要导入的页面在某个网页上都有链接,但网址不规则)如果熟悉html和网页脚本,可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中各个元素的行为填写、提交表单或打开超链接,然后获取网页中各个元素的innerText获取数据。
php抓取网页表格信息(php代码实现数据库备份可以使网站的管理变得非常便捷)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-08 22:15
使用php代码实现数据库备份可以让网站的管理非常方便。我们可以直接进入后台操作完成数据库备份。
关键技术:
1. 首先,我们需要通过函数mysql_list_tables()找出数据库中有哪些表,然后我们就可以将得到的所有表名存入一个数组中。
2. show create table table name 可以得到表结构。
3. select * from table name 取出所有记录,用循环拼接成insert into...语句。
实现代码:
header("Content-type:text/html;charset=utf-8");
//配置信息
$cfg_dbhost ='localhost';
$cfg_dbname ='ftdm';
$cfg_dbuser ='root';
$cfg_dbpwd ='root';
$cfg_db_language ='utf8';
$to_file_name = "ftdm.sql";
// 结束配置
//链接到数据库
$link = mysql_connect($cfg_dbhost,$cfg_dbuser,$cfg_dbpwd);
mysql_select_db($cfg_dbname);
//选择代码
mysql_query("设置名称".$cfg_db_language);
//数据库中有哪些表
$tables = mysql_list_tables($cfg_dbname);
//将这些表记录到一个数组中
$tabList = array();
while($row = mysql_fetch_row($tables)){
$tabList[] = $row[0];
}
echo "正在运行,请耐心等待...
";
$info = "-- ----------------------------\r\n";
$info .= "-- Date:".date("Y-m-d H:i:s",time())."\r\n";
$info .="--仅供测试学习,本程序不适合处理大量数据\r\n";
<p>$info .= "-- ----------------------------\r\n\r\n"; 查看全部
php抓取网页表格信息(php代码实现数据库备份可以使网站的管理变得非常便捷)
使用php代码实现数据库备份可以让网站的管理非常方便。我们可以直接进入后台操作完成数据库备份。
关键技术:
1. 首先,我们需要通过函数mysql_list_tables()找出数据库中有哪些表,然后我们就可以将得到的所有表名存入一个数组中。
2. show create table table name 可以得到表结构。
3. select * from table name 取出所有记录,用循环拼接成insert into...语句。
实现代码:
header("Content-type:text/html;charset=utf-8");
//配置信息
$cfg_dbhost ='localhost';
$cfg_dbname ='ftdm';
$cfg_dbuser ='root';
$cfg_dbpwd ='root';
$cfg_db_language ='utf8';
$to_file_name = "ftdm.sql";
// 结束配置
//链接到数据库
$link = mysql_connect($cfg_dbhost,$cfg_dbuser,$cfg_dbpwd);
mysql_select_db($cfg_dbname);
//选择代码
mysql_query("设置名称".$cfg_db_language);
//数据库中有哪些表
$tables = mysql_list_tables($cfg_dbname);
//将这些表记录到一个数组中
$tabList = array();
while($row = mysql_fetch_row($tables)){
$tabList[] = $row[0];
}
echo "正在运行,请耐心等待...
";
$info = "-- ----------------------------\r\n";
$info .= "-- Date:".date("Y-m-d H:i:s",time())."\r\n";
$info .="--仅供测试学习,本程序不适合处理大量数据\r\n";
<p>$info .= "-- ----------------------------\r\n\r\n";
php抓取网页表格信息(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-26 06:03
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是防盗的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件,然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
以上就是PHP采集类史努比抓图示例的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页表格信息(强大的PHP采集类,可以用来开发一些采集程序和小偷程序,)
这个文章主要介绍PHP采集类Snoopy来抓图。Snoopy是一个功能强大的PHP采集类,可以用来开发一些采集程序和小偷程序,有需要的朋友可以参考
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能是防盗的,我想先抓取本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中文章的地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3.根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件,然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
以上就是PHP采集类史努比抓图示例的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页表格信息(如何使用HTML(最常用的数据收集方法)的基础教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2021-09-21 23:18
HTML表单数据传输
导言
在某种程度上,所有web开发人员都需要从用户那里采集数据。在动态网页中,一切都围绕着用户输入,因此了解如何请求和采集这些数据对于任何开发人员都至关重要
本文是关于如何使用HTML表单(最常用的数据采集方法)的基础教程
假设条件
-基本HTML知识
-基本PHP知识
HTML表格
采集数据的一种常见且简单的方法是通过HTML表单。表单是用户输入的容器,可以收录许多不同的输入类型
HTML表单元素需要一些参数才能正常工作:
典型的表单元素可能如下所示:
数据传输方法get和post
从这两个协议的名称可以猜到,get和post请求是为不同的目的而设计的
get协议的目的是获取数据并将其显示给用户。您可以通过查询字符串传递简单的键值对,但理想情况下应该使用它们来指定页面上应该显示的内容,而不是将用户数据推送到服务器
这就是post协议的目的。它允许客户端以几乎任何格式向服务器发送几乎任何数量的数据。这是大多数表单应该使用的格式,也是上传文件和上传大量文本所必需的格式
本质上,get应该用于导航和类似的事情,但post应该用于发送实际数据。现在,让我们更详细地检查它们
获取协议
使用get,表单中的数据被编码到请求的URL中。例如,如果您正在提交以下表格:
单击“提交”按钮时,浏览器会将您重定向到以下URL:
--
action.php?用户名=约翰和密码剑=密码
get协议的一个非常有用的方面是,我们不必使用表单来提交get数据。URL也可以手动构造,服务器不会看到任何差异。这意味着也可以使用以下HTML链接提交上述数据:
Submit</a>
这在网站(如论坛或博客)中是一个有用的燃料,它显示动态创建的内容,您通常需要创建动态导航链接。事实上,此方法已在大多数动态web应用程序中使用2.0在应用程序中使用。后协议
通过post协议提交的数据在URL中不可见。数据本身被放置在请求体中,这使得post请求可以上传比get请求更多的数据和更复杂的数据
例如,要发送用户名和图像,可以使用以下表单:
您会注意到,表单中添加了其他属性。发送文件时需要“enctype”属性。如果文件丢失,将不会发送-此属性仅告诉客户端如何格式化请求的正文。默认情况下,它是一种相当简单的格式,但要发送二进制对象,需要更复杂的格式。元素
与所有表单一样,HTML表单要求用户填写字段。这是
元素
输入元素在内部 查看全部
php抓取网页表格信息(如何使用HTML(最常用的数据收集方法)的基础教程)
HTML表单数据传输
导言
在某种程度上,所有web开发人员都需要从用户那里采集数据。在动态网页中,一切都围绕着用户输入,因此了解如何请求和采集这些数据对于任何开发人员都至关重要
本文是关于如何使用HTML表单(最常用的数据采集方法)的基础教程
假设条件
-基本HTML知识
-基本PHP知识
HTML表格
采集数据的一种常见且简单的方法是通过HTML表单。表单是用户输入的容器,可以收录许多不同的输入类型
HTML表单元素需要一些参数才能正常工作:
典型的表单元素可能如下所示:
数据传输方法get和post
从这两个协议的名称可以猜到,get和post请求是为不同的目的而设计的
get协议的目的是获取数据并将其显示给用户。您可以通过查询字符串传递简单的键值对,但理想情况下应该使用它们来指定页面上应该显示的内容,而不是将用户数据推送到服务器
这就是post协议的目的。它允许客户端以几乎任何格式向服务器发送几乎任何数量的数据。这是大多数表单应该使用的格式,也是上传文件和上传大量文本所必需的格式
本质上,get应该用于导航和类似的事情,但post应该用于发送实际数据。现在,让我们更详细地检查它们
获取协议
使用get,表单中的数据被编码到请求的URL中。例如,如果您正在提交以下表格:
单击“提交”按钮时,浏览器会将您重定向到以下URL:
--
action.php?用户名=约翰和密码剑=密码
get协议的一个非常有用的方面是,我们不必使用表单来提交get数据。URL也可以手动构造,服务器不会看到任何差异。这意味着也可以使用以下HTML链接提交上述数据:
Submit</a>
这在网站(如论坛或博客)中是一个有用的燃料,它显示动态创建的内容,您通常需要创建动态导航链接。事实上,此方法已在大多数动态web应用程序中使用2.0在应用程序中使用。后协议
通过post协议提交的数据在URL中不可见。数据本身被放置在请求体中,这使得post请求可以上传比get请求更多的数据和更复杂的数据
例如,要发送用户名和图像,可以使用以下表单:
您会注意到,表单中添加了其他属性。发送文件时需要“enctype”属性。如果文件丢失,将不会发送-此属性仅告诉客户端如何格式化请求的正文。默认情况下,它是一种相当简单的格式,但要发送二进制对象,需要更复杂的格式。元素
与所有表单一样,HTML表单要求用户填写字段。这是
元素
输入元素在内部
php抓取网页表格信息(读者传媒:2017年年度报告2018-04-28.SH方盛制药)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-09-21 20:06
任务:批量抓取网页和PDF文件
有一个excel,有数千个网页地址指向PDF下载链接。现在,您需要批量获取这些网页地址中的PDF文件
Python环境:
anaconda3
openpyxl
beautifulsoup4
阅读excel并获取网页地址
使用openpyxl库进行阅读。Xslx文件
(尝试使用xlrd库读取.XSL文件,但未能获取超链接)
安装openpyxl
pip install openpyxl
从XSL X文件中提取超链接
示例文件构造
公告日期证券代码公告标题
2018-04-20
603999.SH
读者媒体:2017年度报告
2018-04-28
603998.SH
方生药业:2017年度报告
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页pdf下载地址
进入阅读器媒体:在2017年度报告中,您可以在Chrome浏览器中按F12键查看web源代码。下面截取了一些源代码:
<p>附件: 查看全部
php抓取网页表格信息(读者传媒:2017年年度报告2018-04-28.SH方盛制药)
任务:批量抓取网页和PDF文件
有一个excel,有数千个网页地址指向PDF下载链接。现在,您需要批量获取这些网页地址中的PDF文件
Python环境:
anaconda3
openpyxl
beautifulsoup4
阅读excel并获取网页地址
使用openpyxl库进行阅读。Xslx文件
(尝试使用xlrd库读取.XSL文件,但未能获取超链接)
安装openpyxl
pip install openpyxl
从XSL X文件中提取超链接
示例文件构造
公告日期证券代码公告标题
2018-04-20
603999.SH
读者媒体:2017年度报告
2018-04-28
603998.SH
方生药业:2017年度报告
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页pdf下载地址
进入阅读器媒体:在2017年度报告中,您可以在Chrome浏览器中按F12键查看web源代码。下面截取了一些源代码:
<p>附件:
php抓取网页表格信息(获取高清表格照片源代码图下载php大师-免费插件下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-09-19 22:04
php抓取网页表格信息有很多种方法,其中一种最为简单的方法,就是利用“php大师”插件,将表格转化为图片存放到服务器,这样我们就可以继续抓取查看自己需要的表格内容了。关于php大师的使用方法,大家可以百度,很容易就能找到,如果大家还是有问题,可以私信我,我们一起探讨,一起学习。获取高清表格照片源代码图下载php大师-免费php插件下载。
php大师官网是支持的。
php大师虽然很简单,但也是非常有用的,可以用来进行爬虫,实现高效的网页爬取等等,要用到批量处理。而且他的下载方式和模板都是免费的,哈哈。百度php大师就可以找到官网了。
有需要php可以看看这篇php大师使用教程
没有靠谱的,像大师这样的工具那么多,php大师以外有很多工具可以找,php大师做的只是一小部分,他家网站爬取的只是一部分。php大师爬取不只限于要爬取信息,还可以要爬取博客。
php大师本身就是个工具,可以看看ecmser的php大师使用教程。
可以看看大师的使用教程,希望对你有帮助。
不靠谱,我用过,并没有说的那么好。
要看定位,你想爬那个方向?登录?关键词?cookie?iis?get?post?不同的定位方向有不同的工具。 查看全部
php抓取网页表格信息(获取高清表格照片源代码图下载php大师-免费插件下载)
php抓取网页表格信息有很多种方法,其中一种最为简单的方法,就是利用“php大师”插件,将表格转化为图片存放到服务器,这样我们就可以继续抓取查看自己需要的表格内容了。关于php大师的使用方法,大家可以百度,很容易就能找到,如果大家还是有问题,可以私信我,我们一起探讨,一起学习。获取高清表格照片源代码图下载php大师-免费php插件下载。
php大师官网是支持的。
php大师虽然很简单,但也是非常有用的,可以用来进行爬虫,实现高效的网页爬取等等,要用到批量处理。而且他的下载方式和模板都是免费的,哈哈。百度php大师就可以找到官网了。
有需要php可以看看这篇php大师使用教程
没有靠谱的,像大师这样的工具那么多,php大师以外有很多工具可以找,php大师做的只是一小部分,他家网站爬取的只是一部分。php大师爬取不只限于要爬取信息,还可以要爬取博客。
php大师本身就是个工具,可以看看ecmser的php大师使用教程。
可以看看大师的使用教程,希望对你有帮助。
不靠谱,我用过,并没有说的那么好。
要看定位,你想爬那个方向?登录?关键词?cookie?iis?get?post?不同的定位方向有不同的工具。
php抓取网页表格信息(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-09-16 09:02
我学习Python已经有一段时间了,我对各种理论知识都略知一二。今天,我将进入实践练习:通过python为hook工资调查编写一个小爬虫
步骤1:分析网站请求流程
当我们在Drago上查看招聘信息时,我们会搜索Python、PHP和其他工作信息。事实上,我们向服务器发送相应的请求,服务器动态响应这些请求,通过浏览器解析我们需要的内容并将其呈现在我们面前
您可以看到formdata中的KD参数表示从服务器请求关键词Python招聘信息
建议使用Fiddler来分析复杂的页面请求和响应信息,这绝对是分析的杀手网站. 然而,使用浏览器自己的开发工具(如Firefox的firebug)响应请求相对简单。只要按F12键,所有请求的信息都将显示在您面前的每个细节中
通过对请求和响应过程网站的分析,我们可以看到dragnet的招聘信息是通过XHR动态传输的
我们发现有两个通过post发送的请求,即companyajax.json和positionajax.json,它们分别控制当前显示的页面和页面中收录的招聘信息
如您所见,我们需要的信息收录在内容中->;结果还收录一些其他参数信息,包括页面总数、招聘注册总数和其他相关信息
步骤2:发送获取页面的请求
最重要的是知道我们想要捕获的信息在哪里。在知道了信息的位置之后,我们需要考虑如何通过Python来模拟浏览器来获取我们需要的信息
。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键的一步是如何在浏览器的post模式中打包我们自己的请求
请求中收录的参数包括要爬网的网页的URL和用于伪装的标题。urlopen中的数据参数包括formdata的三个参数(第一,PN,KD)
打包后,您可以像浏览器一样访问拉钩并获取页面数据
第三步:获取所需信息并获取数据
在获得页面信息后,我们可以开始抓取程序数据中最重要的步骤:抓取数据
抓取数据的方法有很多,比如lxml的正则表达式re、etree和JSON,以及BS4的beautiful soup,这些都是Python 3抓取数据的合适方法。您可以根据实际情况使用其中的一个或多个
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在Excel中
在获得原创数据后,为了进一步组织和分析,我们将捕获的数据以结构化和有组织的方式存储在Excel中,以便于数据的可视化处理
这里我使用两种不同的框架,旧的xlwt。工作簿和xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储超过100条数据后,数据不会完全存储,Excel文件中会出现“某些内容有问题,需要修复”。我检查了很多次。起初,我认为是数据捕获不完整导致的存储问题。稍后,断点检查发现数据已完成。后来,对本地数据进行了处理,没有问题。我的心情是这样的:
到目前为止,我还没有弄明白。伟大的上帝想告诉我(╹) ε ╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用
到目前为止,一个在dragnet上抓取招聘信息的小爬虫已经诞生
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还可以增加很多功能,比如修改城市参数,查看不同城市的招聘信息,可以自己开发,只是为了吸引翡翠,欢迎交流 查看全部
php抓取网页表格信息(实战演练:通过Python来编写一个拉勾网薪资调查的小爬虫)
我学习Python已经有一段时间了,我对各种理论知识都略知一二。今天,我将进入实践练习:通过python为hook工资调查编写一个小爬虫
步骤1:分析网站请求流程
当我们在Drago上查看招聘信息时,我们会搜索Python、PHP和其他工作信息。事实上,我们向服务器发送相应的请求,服务器动态响应这些请求,通过浏览器解析我们需要的内容并将其呈现在我们面前
您可以看到formdata中的KD参数表示从服务器请求关键词Python招聘信息
建议使用Fiddler来分析复杂的页面请求和响应信息,这绝对是分析的杀手网站. 然而,使用浏览器自己的开发工具(如Firefox的firebug)响应请求相对简单。只要按F12键,所有请求的信息都将显示在您面前的每个细节中
通过对请求和响应过程网站的分析,我们可以看到dragnet的招聘信息是通过XHR动态传输的
我们发现有两个通过post发送的请求,即companyajax.json和positionajax.json,它们分别控制当前显示的页面和页面中收录的招聘信息
如您所见,我们需要的信息收录在内容中->;结果还收录一些其他参数信息,包括页面总数、招聘注册总数和其他相关信息
步骤2:发送获取页面的请求
最重要的是知道我们想要捕获的信息在哪里。在知道了信息的位置之后,我们需要考虑如何通过Python来模拟浏览器来获取我们需要的信息
。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
关键的一步是如何在浏览器的post模式中打包我们自己的请求
请求中收录的参数包括要爬网的网页的URL和用于伪装的标题。urlopen中的数据参数包括formdata的三个参数(第一,PN,KD)
打包后,您可以像浏览器一样访问拉钩并获取页面数据
第三步:获取所需信息并获取数据
在获得页面信息后,我们可以开始抓取程序数据中最重要的步骤:抓取数据
抓取数据的方法有很多,比如lxml的正则表达式re、etree和JSON,以及BS4的beautiful soup,这些都是Python 3抓取数据的合适方法。您可以根据实际情况使用其中的一个或多个
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在Excel中
在获得原创数据后,为了进一步组织和分析,我们将捕获的数据以结构化和有组织的方式存储在Excel中,以便于数据的可视化处理
这里我使用两种不同的框架,旧的xlwt。工作簿和xlsxwriter
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储超过100条数据后,数据不会完全存储,Excel文件中会出现“某些内容有问题,需要修复”。我检查了很多次。起初,我认为是数据捕获不完整导致的存储问题。稍后,断点检查发现数据已完成。后来,对本地数据进行了处理,没有问题。我的心情是这样的:
到目前为止,我还没有弄明白。伟大的上帝想告诉我(╹) ε ╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用
到目前为止,一个在dragnet上抓取招聘信息的小爬虫已经诞生
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
还可以增加很多功能,比如修改城市参数,查看不同城市的招聘信息,可以自己开发,只是为了吸引翡翠,欢迎交流
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-09-16 09:01
使用PHP的curl库可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。本文主要介绍如何使用这个PHP库
启用卷曲设置
首先,我们必须确定我们的PHP是否已经打开了这个库。您可以使用PHP_uinfo()函数来获取此信息
如果您可以在网页上看到以下输出,则表示curl库已打开
如果您看到它,您需要设置PHP并打开库。如果你是在windows平台上,这是非常简单的。您需要更改php.ini文件的设置以查找php_Curl.dll并取消前面的分号注释。详情如下:
//在下面取消注释
extension=php\ucurl.dll
如果您使用的是Linux,则需要重新编译PHP。编辑时,需要打开编译参数-将“–with curl”参数添加到configure命令中
一个小例子
如果一切就绪,下面是一个小程序:
如何发布数据
上面是获取网页的代码,下面是向网页发布数据。假设我们有一个处理表单的web地址,它可以接受两个表单字段,一个是电话号码,另一个是SMS的内容
从上面的程序中,我们可以看到使用curlopt_uuuu-Post设置HTTP协议的Post方法而不是get方法,然后使用curlopt_uuuuu-Postfields设置Post的数据
关于代理服务器
下面是如何使用代理服务器的示例。请注意突出显示的代码。代码非常简单,所以我不需要多说
关于SSL和Cookie 查看全部
php抓取网页表格信息(使用PHP的cURL库可以简单和有效地去抓网页。)
使用PHP的curl库可以简单有效地抓取网页。你只需要运行一个脚本并分析你抓取的网页,然后你就可以通过一种程序化的方式获得你想要的数据。无论您是想从链接获取一些数据,还是想获取一个XML文件并将其导入数据库,即使只是为了获取网页内容,curl都是一个功能强大的PHP库。本文主要介绍如何使用这个PHP库
启用卷曲设置
首先,我们必须确定我们的PHP是否已经打开了这个库。您可以使用PHP_uinfo()函数来获取此信息
如果您可以在网页上看到以下输出,则表示curl库已打开
如果您看到它,您需要设置PHP并打开库。如果你是在windows平台上,这是非常简单的。您需要更改php.ini文件的设置以查找php_Curl.dll并取消前面的分号注释。详情如下:
//在下面取消注释
extension=php\ucurl.dll
如果您使用的是Linux,则需要重新编译PHP。编辑时,需要打开编译参数-将“–with curl”参数添加到configure命令中
一个小例子
如果一切就绪,下面是一个小程序:
如何发布数据
上面是获取网页的代码,下面是向网页发布数据。假设我们有一个处理表单的web地址,它可以接受两个表单字段,一个是电话号码,另一个是SMS的内容
从上面的程序中,我们可以看到使用curlopt_uuuu-Post设置HTTP协议的Post方法而不是get方法,然后使用curlopt_uuuuu-Postfields设置Post的数据
关于代理服务器
下面是如何使用代理服务器的示例。请注意突出显示的代码。代码非常简单,所以我不需要多说
关于SSL和Cookie
php抓取网页表格信息(小O地图抓取完成后程序会自动导出数据包括图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-13 15:05
小O图提供58网站二手房数据抓取功能。捕获的数据可以导出为CSV文件,导出的数据包括图片。
目标页面:
[1] 新任务
新建任务选择【网络爬虫/房地产/58二手房】,输入任务名称、保存路径等信息,点击【确定】新建任务。
[2] 选择目标页面
在右侧主界面工具栏选择【打开页面】,选择目标页面,如下图,
选择后会自动跳转到目标页面,请稍等,程序会自动解析页面分页数据,如下图:
[3] 开启抓取功能
选择【页码下拉框】选择要采集的页码,默认程序会自动进入数据采集模式。
如果还没有进入自动抓拍模式,可以点击【开始】按钮启动抓拍功能。
【4】自动翻页
程序会自动判断当前页面数据,如果抓取完成,会自动翻页到下一页。如果没有自动抓取,请执行步骤[3]手动选择下一页。
[5] 反爬虫功能
58个网页都会有反爬虫机制,如下图。当出现验证页面时,需要用户手动进行身份验证,通过后程序会自动继续爬取。如果没有自动抓取,请执行步骤[3]手动选择下一页。 .
[6] 导出 CSV
捕获完成后,您可以将数据导出为 CSV 并在 Excel 表格中打开。同时,导出的数据包括房屋图片。
图片
[7] 切换城市
小O图默认加载的页面是沉阳二手房信息。如需切换城市,请按照下图,选择指定城市,然后重新执行以上爬取步骤。
[结束]
小O系列软件:
【小O地图】:提供地图数据下载和处理功能。
【小O图】:提供地图图表和EChart图表展示功能。运行需要Excel软件。 查看全部
php抓取网页表格信息(小O地图抓取完成后程序会自动导出数据包括图片)
小O图提供58网站二手房数据抓取功能。捕获的数据可以导出为CSV文件,导出的数据包括图片。
目标页面:
[1] 新任务
新建任务选择【网络爬虫/房地产/58二手房】,输入任务名称、保存路径等信息,点击【确定】新建任务。
[2] 选择目标页面
在右侧主界面工具栏选择【打开页面】,选择目标页面,如下图,
选择后会自动跳转到目标页面,请稍等,程序会自动解析页面分页数据,如下图:
[3] 开启抓取功能
选择【页码下拉框】选择要采集的页码,默认程序会自动进入数据采集模式。
如果还没有进入自动抓拍模式,可以点击【开始】按钮启动抓拍功能。
【4】自动翻页
程序会自动判断当前页面数据,如果抓取完成,会自动翻页到下一页。如果没有自动抓取,请执行步骤[3]手动选择下一页。
[5] 反爬虫功能
58个网页都会有反爬虫机制,如下图。当出现验证页面时,需要用户手动进行身份验证,通过后程序会自动继续爬取。如果没有自动抓取,请执行步骤[3]手动选择下一页。 .
[6] 导出 CSV
捕获完成后,您可以将数据导出为 CSV 并在 Excel 表格中打开。同时,导出的数据包括房屋图片。
图片
[7] 切换城市
小O图默认加载的页面是沉阳二手房信息。如需切换城市,请按照下图,选择指定城市,然后重新执行以上爬取步骤。
[结束]
小O系列软件:
【小O地图】:提供地图数据下载和处理功能。
【小O图】:提供地图图表和EChart图表展示功能。运行需要Excel软件。
php抓取网页表格信息(PHP在动态网页中的应用进行详细的详细阐述!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-11 22:16
曲晓娜
摘要:由于电子商务和网络信息技术的飞速发展,动态的网站逐渐取代了传统的静态的网站,并不断向人工智能方向发展。本文文章详细阐述了PHP技术在动态Web表单控件提取中的应用。
关键词:PHP;动态网页;表格
中文图书馆分类号:TP311 文献识别码:A
文章No.: 1009-3044(2020)06-0217-02
1 个背景
由于企业电子商务的国际化,我国动态网站的发展越来越受到电子商务企业的关注,成为目前市场上发展最快的行业,促进了信息化在某种程度上。发展领域快速发展。动态网站 并不意味着在网页中添加了动态图形、图片或动画。首先,动态网站网页会根据用户的选择和要求动态变化。浏览器是信息动态交换的桥梁。这种交互是Web发展的趋势。另外动态网站可以实现用户注册和登录。 、在线调查等功能,不同的用户访问同一个地址会出现不同的页面。动态网页的获取并不是预先独立存在于网站服务器上的文件,而是根据发送的请求,通过指令、计算、函数等方式返回一个针对某个用户的独立网页。用户。
2php技术
PHP 是 Hypertet Preprocessor 的缩写。中文名称是超文本预处理器。它是一种语法结构类似于C语言的Web编程语言。由于其学习难度低,开发效率高,成本低,而且比ASP更安全的脚本语言高,所以在国内很受网站开发者的欢迎。
3 种形式
表单是 HTML 的重要组成部分,是人机对话的重要工具。它可用于从网络浏览器采集信息并将信息提交给服务器进行处理、分析和处理。表格标有
开始
结束,就像一个大容器,里面可以收录多个控件,比如单行文本框、多行文本框、跳转菜单、单选按钮组、复选框等,在里面输入如下代码网页,浏览页面效果如图1所示。
4PHP在动态网页中的应用
PHP 文件是可以在服务器端执行脚本的文档。脚本通过Web服务器执行,生成相应的HTML语言,成为网页中原创HTML语言的一部分,然后作用于前端。文件名以 .PHP 结尾。 PHP文件主要由2部分组成,主要包括:(1)HTML标签,所有HTML标记语言都可以使用;(2)PHP语言命令,位于标签中的代码。PHP语言可以添加到html文件,在其他网页中显示从表单中获取的数据,提取表单中数据的主要代码如下:
5 结束语
目前PHP技术已经广泛应用于中小型企业网站的开发,是动态网站系统有效运行的根本保障。动态网站可以为用户体验者提供更便捷的服务,提升用户体验评价。同时PHP依托自身技术优势为动态网站提供优质服务,极大提升自身创新服务能力,有效降低运营成本,提升服务水平,实现网络共享协同信息资源。 查看全部
php抓取网页表格信息(PHP在动态网页中的应用进行详细的详细阐述!)
曲晓娜
摘要:由于电子商务和网络信息技术的飞速发展,动态的网站逐渐取代了传统的静态的网站,并不断向人工智能方向发展。本文文章详细阐述了PHP技术在动态Web表单控件提取中的应用。
关键词:PHP;动态网页;表格
中文图书馆分类号:TP311 文献识别码:A
文章No.: 1009-3044(2020)06-0217-02
1 个背景
由于企业电子商务的国际化,我国动态网站的发展越来越受到电子商务企业的关注,成为目前市场上发展最快的行业,促进了信息化在某种程度上。发展领域快速发展。动态网站 并不意味着在网页中添加了动态图形、图片或动画。首先,动态网站网页会根据用户的选择和要求动态变化。浏览器是信息动态交换的桥梁。这种交互是Web发展的趋势。另外动态网站可以实现用户注册和登录。 、在线调查等功能,不同的用户访问同一个地址会出现不同的页面。动态网页的获取并不是预先独立存在于网站服务器上的文件,而是根据发送的请求,通过指令、计算、函数等方式返回一个针对某个用户的独立网页。用户。
2php技术
PHP 是 Hypertet Preprocessor 的缩写。中文名称是超文本预处理器。它是一种语法结构类似于C语言的Web编程语言。由于其学习难度低,开发效率高,成本低,而且比ASP更安全的脚本语言高,所以在国内很受网站开发者的欢迎。
3 种形式
表单是 HTML 的重要组成部分,是人机对话的重要工具。它可用于从网络浏览器采集信息并将信息提交给服务器进行处理、分析和处理。表格标有
开始
结束,就像一个大容器,里面可以收录多个控件,比如单行文本框、多行文本框、跳转菜单、单选按钮组、复选框等,在里面输入如下代码网页,浏览页面效果如图1所示。
4PHP在动态网页中的应用
PHP 文件是可以在服务器端执行脚本的文档。脚本通过Web服务器执行,生成相应的HTML语言,成为网页中原创HTML语言的一部分,然后作用于前端。文件名以 .PHP 结尾。 PHP文件主要由2部分组成,主要包括:(1)HTML标签,所有HTML标记语言都可以使用;(2)PHP语言命令,位于标签中的代码。PHP语言可以添加到html文件,在其他网页中显示从表单中获取的数据,提取表单中数据的主要代码如下:
5 结束语
目前PHP技术已经广泛应用于中小型企业网站的开发,是动态网站系统有效运行的根本保障。动态网站可以为用户体验者提供更便捷的服务,提升用户体验评价。同时PHP依托自身技术优势为动态网站提供优质服务,极大提升自身创新服务能力,有效降低运营成本,提升服务水平,实现网络共享协同信息资源。
php抓取网页表格信息(如何通过post方法获取form表单数据?(推荐版))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-11 22:14
在网站的开发过程中,我们通常会遇到php表单上的相关操作。如果php通过post提交方式获取表单数据,该怎么做?如果你看过我【PHP如何通过get方法获取表单数据? 】这篇文章,相信大家对php $_GET[]变量获取表单数据的方法有了一定的了解。
那么本文文章将继续为大家详细介绍php如何通过post方法获取表单数据。
下面有具体的代码示例:
1、form 表单代码(post方法提交表单示例):
表单发布方法示例
名称:
年龄:
通过浏览器访问,效果如下:
如上图,我们输入姓名和年龄,点击提交到test.php文件。
2、test.php 代码如下(php获取post数据):
欢迎!
你的年龄是岁。
这里我们使用PHP $_POST[]变量来获取表单数据,即fname和age参数(推荐参考PHP零基础入门教程:PHP表单第2章内容),浏览器提交后访问结果如下:
这里可以注意到浏览器地址栏中的链接中没有表单参数。也就是说,php通过post方法获取的表单信息,在地址栏中根本就没有显示出来。在web表单设计中,大多采用post提交方式,因为比get方式提交表单安全很多,可以避免敏感信息的泄露,而且发送的信息量没有限制。邮政。但是因为变量没有显示在 URL 中,所以页面不能被添加书签。
以上内容是关于PHP获取post提交表单数据的具体方法和功能。有一定的参考价值,希望对有需要的朋友有所帮助。 查看全部
php抓取网页表格信息(如何通过post方法获取form表单数据?(推荐版))
在网站的开发过程中,我们通常会遇到php表单上的相关操作。如果php通过post提交方式获取表单数据,该怎么做?如果你看过我【PHP如何通过get方法获取表单数据? 】这篇文章,相信大家对php $_GET[]变量获取表单数据的方法有了一定的了解。
那么本文文章将继续为大家详细介绍php如何通过post方法获取表单数据。
下面有具体的代码示例:
1、form 表单代码(post方法提交表单示例):
表单发布方法示例
名称:
年龄:
通过浏览器访问,效果如下:
如上图,我们输入姓名和年龄,点击提交到test.php文件。
2、test.php 代码如下(php获取post数据):
欢迎!
你的年龄是岁。
这里我们使用PHP $_POST[]变量来获取表单数据,即fname和age参数(推荐参考PHP零基础入门教程:PHP表单第2章内容),浏览器提交后访问结果如下:
这里可以注意到浏览器地址栏中的链接中没有表单参数。也就是说,php通过post方法获取的表单信息,在地址栏中根本就没有显示出来。在web表单设计中,大多采用post提交方式,因为比get方式提交表单安全很多,可以避免敏感信息的泄露,而且发送的信息量没有限制。邮政。但是因为变量没有显示在 URL 中,所以页面不能被添加书签。
以上内容是关于PHP获取post提交表单数据的具体方法和功能。有一定的参考价值,希望对有需要的朋友有所帮助。
php抓取网页表格信息(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-10 02:02
附件:
原帖内容如下:
使用VBA抓取网页数据,通常可以使用Excel VBA的workbooks.open ""语句打开网页,然后使用find和offset方法定位数据的位置,然后复制到指定位置。或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1")) 但是,在某些场合,这两种方法可能不太容易实现,比如:1.import 查询结果页面。 (每次都要提交表单才能拿到数据页面,数据是分页的,但是每个页面的url都是一样的,没有?page=2之类的)2.必须提交表单或者单击链接以获取数据页面。页面在IE中显示正常,但是直接用Workbooks.open或QueryTables.add打开URL时会显示超时等错误)3.批量导入不规则URL的页面。 (所有要导入的页面在某个网页上都有链接,但网址不规则)如果熟悉html和网页脚本,可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中各个元素的行为填写、提交表单或打开超链接,然后获取网页中各个元素的innerText获取数据。 查看全部
php抓取网页表格信息(Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程)
附件:
原帖内容如下:
使用VBA抓取网页数据,通常可以使用Excel VBA的workbooks.open ""语句打开网页,然后使用find和offset方法定位数据的位置,然后复制到指定位置。或者使用 QueryTableActiveSheet.QueryTables.Add(Connection:="URL;", Destination:=Range("A1")) 但是,在某些场合,这两种方法可能不太容易实现,比如:1.import 查询结果页面。 (每次都要提交表单才能拿到数据页面,数据是分页的,但是每个页面的url都是一样的,没有?page=2之类的)2.必须提交表单或者单击链接以获取数据页面。页面在IE中显示正常,但是直接用Workbooks.open或QueryTables.add打开URL时会显示超时等错误)3.批量导入不规则URL的页面。 (所有要导入的页面在某个网页上都有链接,但网址不规则)如果熟悉html和网页脚本,可以使用IExplorer对象打开网页,然后使用VB脚本控制网页中各个元素的行为填写、提交表单或打开超链接,然后获取网页中各个元素的innerText获取数据。
php抓取网页表格信息(php代码实现数据库备份可以使网站的管理变得非常便捷)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-08 22:15
使用php代码实现数据库备份可以让网站的管理非常方便。我们可以直接进入后台操作完成数据库备份。
关键技术:
1. 首先,我们需要通过函数mysql_list_tables()找出数据库中有哪些表,然后我们就可以将得到的所有表名存入一个数组中。
2. show create table table name 可以得到表结构。
3. select * from table name 取出所有记录,用循环拼接成insert into...语句。
实现代码:
header("Content-type:text/html;charset=utf-8");
//配置信息
$cfg_dbhost ='localhost';
$cfg_dbname ='ftdm';
$cfg_dbuser ='root';
$cfg_dbpwd ='root';
$cfg_db_language ='utf8';
$to_file_name = "ftdm.sql";
// 结束配置
//链接到数据库
$link = mysql_connect($cfg_dbhost,$cfg_dbuser,$cfg_dbpwd);
mysql_select_db($cfg_dbname);
//选择代码
mysql_query("设置名称".$cfg_db_language);
//数据库中有哪些表
$tables = mysql_list_tables($cfg_dbname);
//将这些表记录到一个数组中
$tabList = array();
while($row = mysql_fetch_row($tables)){
$tabList[] = $row[0];
}
echo "正在运行,请耐心等待...
";
$info = "-- ----------------------------\r\n";
$info .= "-- Date:".date("Y-m-d H:i:s",time())."\r\n";
$info .="--仅供测试学习,本程序不适合处理大量数据\r\n";
<p>$info .= "-- ----------------------------\r\n\r\n"; 查看全部
php抓取网页表格信息(php代码实现数据库备份可以使网站的管理变得非常便捷)
使用php代码实现数据库备份可以让网站的管理非常方便。我们可以直接进入后台操作完成数据库备份。
关键技术:
1. 首先,我们需要通过函数mysql_list_tables()找出数据库中有哪些表,然后我们就可以将得到的所有表名存入一个数组中。
2. show create table table name 可以得到表结构。
3. select * from table name 取出所有记录,用循环拼接成insert into...语句。
实现代码:
header("Content-type:text/html;charset=utf-8");
//配置信息
$cfg_dbhost ='localhost';
$cfg_dbname ='ftdm';
$cfg_dbuser ='root';
$cfg_dbpwd ='root';
$cfg_db_language ='utf8';
$to_file_name = "ftdm.sql";
// 结束配置
//链接到数据库
$link = mysql_connect($cfg_dbhost,$cfg_dbuser,$cfg_dbpwd);
mysql_select_db($cfg_dbname);
//选择代码
mysql_query("设置名称".$cfg_db_language);
//数据库中有哪些表
$tables = mysql_list_tables($cfg_dbname);
//将这些表记录到一个数组中
$tabList = array();
while($row = mysql_fetch_row($tables)){
$tabList[] = $row[0];
}
echo "正在运行,请耐心等待...
";
$info = "-- ----------------------------\r\n";
$info .= "-- Date:".date("Y-m-d H:i:s",time())."\r\n";
$info .="--仅供测试学习,本程序不适合处理大量数据\r\n";
<p>$info .= "-- ----------------------------\r\n\r\n";

