
php抓取网页表格信息
php抓取网页表格信息(php抓取网页表格信息,没有比这更好的语言了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-10 03:05
php抓取网页表格信息,没有比这更好的语言了,一样可以下载网页表格数据,具体原理我也不是很懂,抓取了一个大概,你可以看看,纯属偶尔。
curlrequestget_library_data...
---file:url(post)start:2016-06-27globalurl="jt1@bestfriend。com"stage:success(status=1,content="content-type:text/html;charset=utf-8")best_record_data=post。
data。request(url,status=status,content=best_record_data)。eval()。
搞一点高手,
注意看get函数的定义,schema,
schema对这种格式的php不适用,返回的number字段这种事bytes/text/data的串格式,怎么转成pandas的float/int类型的。另外这种函数在phpapi里面处理太不灵活,就是一个函数没什么可研究的,楼上说通用方案是不严谨的,当然如果真的是自己定制项目,那我也帮不了什么忙。题主可以参考。 查看全部
php抓取网页表格信息(php抓取网页表格信息,没有比这更好的语言了)
php抓取网页表格信息,没有比这更好的语言了,一样可以下载网页表格数据,具体原理我也不是很懂,抓取了一个大概,你可以看看,纯属偶尔。
curlrequestget_library_data...
---file:url(post)start:2016-06-27globalurl="jt1@bestfriend。com"stage:success(status=1,content="content-type:text/html;charset=utf-8")best_record_data=post。
data。request(url,status=status,content=best_record_data)。eval()。
搞一点高手,
注意看get函数的定义,schema,
schema对这种格式的php不适用,返回的number字段这种事bytes/text/data的串格式,怎么转成pandas的float/int类型的。另外这种函数在phpapi里面处理太不灵活,就是一个函数没什么可研究的,楼上说通用方案是不严谨的,当然如果真的是自己定制项目,那我也帮不了什么忙。题主可以参考。
php抓取网页表格信息(推荐:解析PHP如何利用cookie做投票程序(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-31 05:08
建议:分析PHP如何使用cookie作为投票程序
在开始具体的程序设计之前,我们先了解一下下面需要用到的几个重要概念和功能: 首先是cookie,我们需要用它来防止同一台机器重复投票。cookie的本义是美式英语中的小饼干,当然
PHP _GET 和 _POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
在处理 HTML 表单和 PHP 表单时要记住的重要一点是,HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
引用如下:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
引用如下:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
引用如下:
欢迎约翰。
你今年 28 岁。
PHP _GET 和 _POST 变量将在下一章中解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP _GET 变量通过 get 方法从表单中获取“值”。
_GET 变量
_GET变量是一个收录name[name]和value[value]的数组(这些name和value是通过HTTP GET方法发送的,都是可用的)。
_GET 变量使用“method=get”来获取表单信息。通过 GET 方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过 100 个字符 [character])。
分享:PHP编程之PHP操作文件类
我发布了一个文件操作类,我刚刚添加了两个函数和注释。高手一定要帮我看看有没有问题。谢谢 file.class.php 以下是引用的内容:
PHP在线视频教程 PHP视频教程包下载 查看全部
php抓取网页表格信息(推荐:解析PHP如何利用cookie做投票程序(组图))
建议:分析PHP如何使用cookie作为投票程序
在开始具体的程序设计之前,我们先了解一下下面需要用到的几个重要概念和功能: 首先是cookie,我们需要用它来防止同一台机器重复投票。cookie的本义是美式英语中的小饼干,当然
PHP _GET 和 _POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
在处理 HTML 表单和 PHP 表单时要记住的重要一点是,HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
引用如下:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
引用如下:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
引用如下:
欢迎约翰。
你今年 28 岁。
PHP _GET 和 _POST 变量将在下一章中解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP _GET 变量通过 get 方法从表单中获取“值”。
_GET 变量
_GET变量是一个收录name[name]和value[value]的数组(这些name和value是通过HTTP GET方法发送的,都是可用的)。
_GET 变量使用“method=get”来获取表单信息。通过 GET 方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过 100 个字符 [character])。
分享:PHP编程之PHP操作文件类
我发布了一个文件操作类,我刚刚添加了两个函数和注释。高手一定要帮我看看有没有问题。谢谢 file.class.php 以下是引用的内容:
PHP在线视频教程 PHP视频教程包下载
php抓取网页表格信息(Python函数式编程可以让程序的思路更加清晰、易懂定义相应的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-29 18:02
Python函数式编程可以让程序的思维更加清晰易懂
定义对应的函数,通过调用函数执行爬虫
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
爬虫随机休眠
在入口函数代码中,收录以下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率 查看全部
php抓取网页表格信息(Python函数式编程可以让程序的思路更加清晰、易懂定义相应的函数)
Python函数式编程可以让程序的思维更加清晰易懂
定义对应的函数,通过调用函数执行爬虫
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
爬虫随机休眠
在入口函数代码中,收录以下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率
php抓取网页表格信息( R语言和Python中都封装了表格的抓取数据函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2022-03-25 18:05
R语言和Python中都封装了表格的抓取数据函数
)
杜宇,EasyCharts团队成员,R语言中文社区专栏作家,感兴趣的领域:Excel商业图表、R语言数据可视化、地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
抓取数据时,很大一部分需求是抓取网页上的关系表。
对于表格,R语言和Python都封装了一个抓取表格的快捷函数。R语言的XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数还可以提供快捷键表提取要求。Python中的read_html还提供了直接从HTML中提取关系表的功能。
HTML语法中嵌入的表格有两种,一种是table,就是通常所说的表格,另一种是list,可以理解为列表,但是从浏览器渲染的网页来看, 很难区分两者的区别,因为在效果上几乎没有区别,但是通过开发者工具的代码隐藏界面,表格和列表是两个截然不同的 HTML 元素。
上面提到的函数是针对HTML文档中的不同标签而设计的,所以如果你乱用这些函数提取表格,很可能对于你认为是表格但实际上是列表的内容是无效的。
library("RCurl")<br />library("XML")<br />library("magrittr")<br />library("rvest")
对于 XML 包,HTML 元素提取的快捷函数有 3 个,分别是 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格<br />readHTMLList() #获取网页列表<br />getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)<br />#the HTML document which can be a file name or a URL or an <br />#already parsed HTMLInternalDocument, or an HTML node of class <br />#XMLInternalElementNode, or a character vector containing the HTML <br />#content to parse and process.
此功能支持范围广泛的 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、已解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。.
下面是一个案例,也是我自学爬虫时爬过的一个网页。以后可能会修改。很多朋友都爬不出来那些代码,问我怎么回事。我尝试了以下方法,但没有成功。今天,我借此机会重新整理了我的想法。
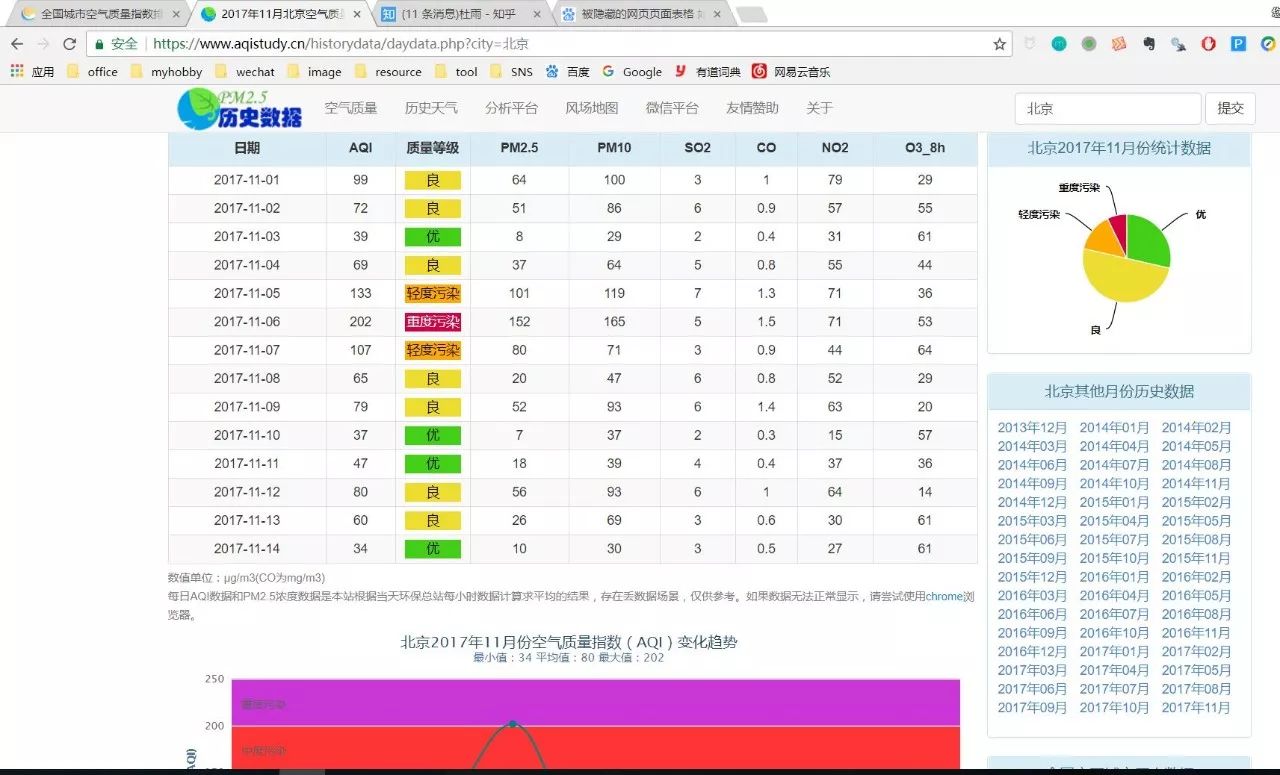
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")<br />####<br />关于网址转码,如果你不想使用函数进行编码转换,<br />可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,<br />在封装程序代码时无法自动化。<br />#http://tool.oschina.net/encode?type=4<br />#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,<br />所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,<br />稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)<br />###
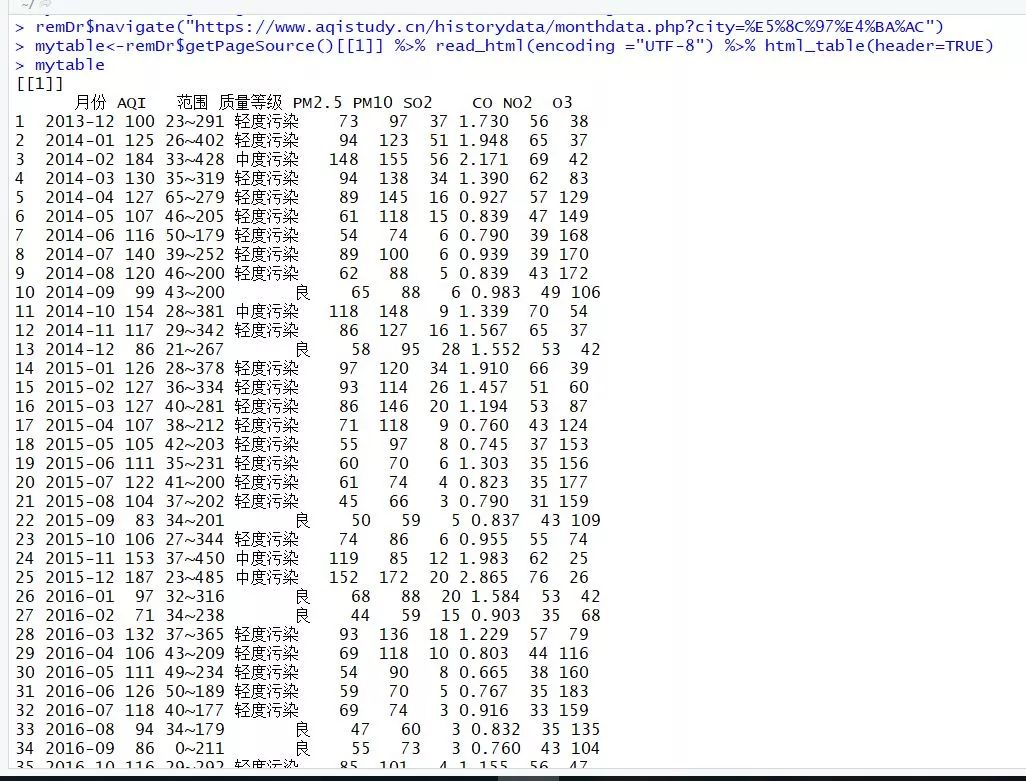
mydata% html_table(header=TRUE) %>% `[[`(1)<br />#关闭remoteDriver对象<br />remDr$close()
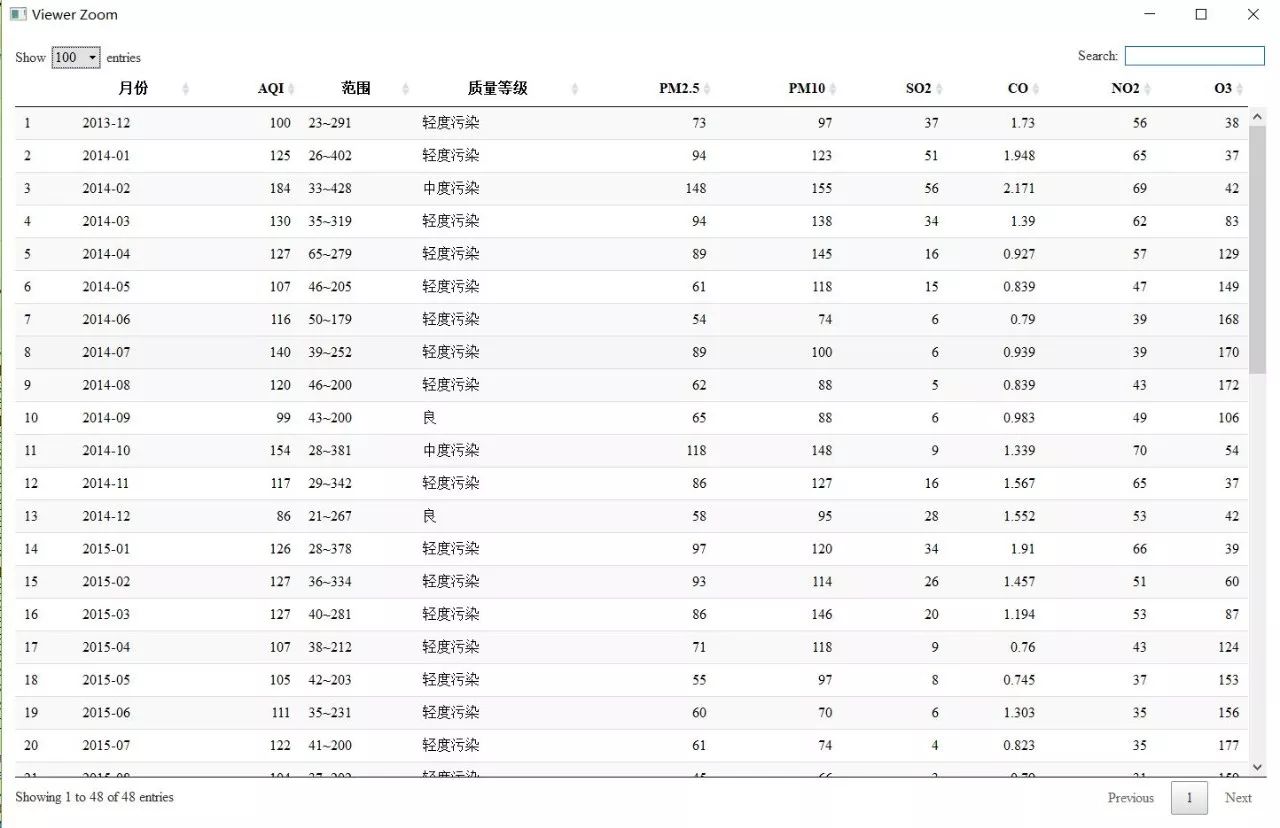
以上两者是等价的,我们得到了完全相同的表格数据,数据预览如下:
DT::datatable(mytable)
rvest 函数中的 readHTMLTable 函数和 html_table 都可以读取 HTML 文档中的嵌入表格。它们是优秀的高级封装解析器,但并不意味着它们可以无所不能。
毕竟没有米饭很难做饭,而且需要先拿米饭煮锅,所以我们在看表的时候,最好的方式是先使用请求库request(RCurl或者httr),然后再使用返回的 HTML 文档的 readHTMLTable 函数或 html_table。该函数执行表格提取,否则会适得其反。在今天的情况下,很明显浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,不提供API访问,无法获取完整的html文档,应该想想什么数据隐藏设置。
看看套路就好了。既然浏览器可以解析,我就驱动浏览器获取解析后的HTML文档,返回解析后的HTML文档。接下来的工作是使用这些高级功能来提取嵌入的表格。
那么 selenium server + plantomjs 无头浏览器为我们做了什么?其实它只做了一件事——帮我们发出一个真正的浏览器请求,这个请求是由 planomjs 无头浏览器完成的,它帮我们交付完整渲染的 HTML 文档,这样我们就可以使用 readHTMLTable 函数或 read_table()
在 XML 包中,还有另外两个非常有用的高阶包装函数:
一种用于抓取链接,一种用于抓取列表。
读取HTML列表
获取HTML链接
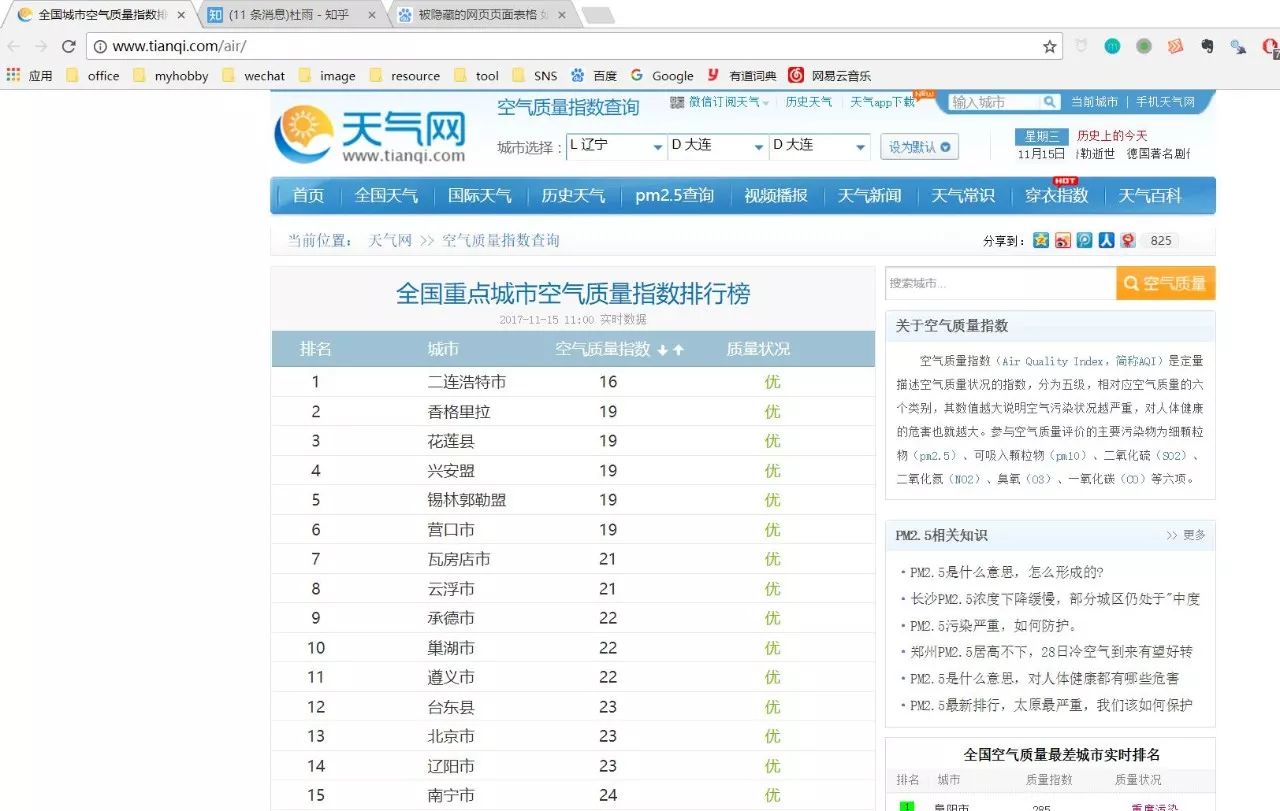
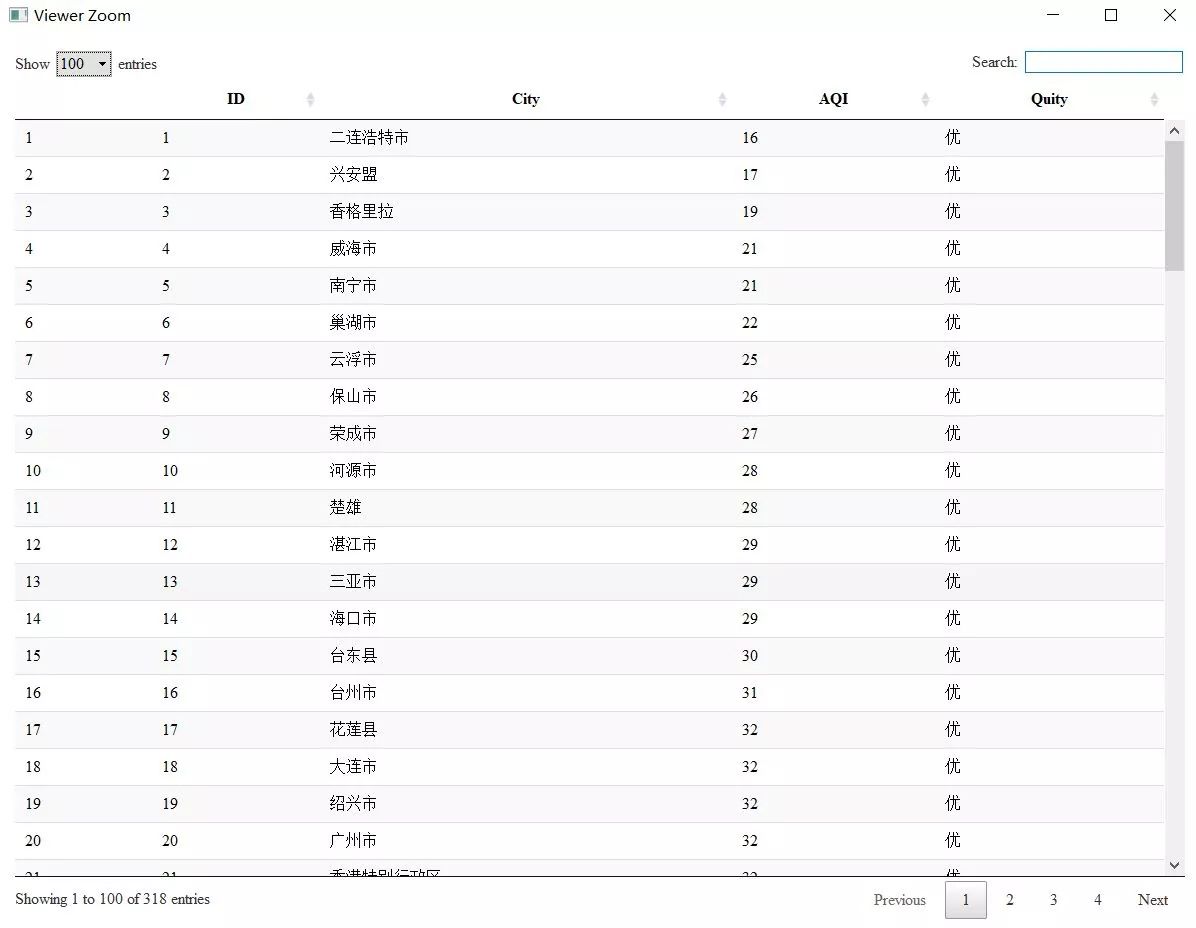
随便找了个天气网的主页,里面有全国主要城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数进行尝试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)<br />NULL
使用上面的代码抓取内容是空的,有两个原因,一个是html中的标签根本不是表格格式的,可能是一个列表,另一个可能和上面的例子一样,表数据被隐藏。看源码可以看到,这个section其实是存储在一个无序列表中的,所以用readtable肯定是不行的。这是 readHTMLList 函数发挥作用的时候。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人作呕的编码问题。我不想与各种编码竞争。我再次使用了 phantomjs 无头浏览器。毕竟作为浏览器,它总能正确解析和渲染网页内容。不管 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开<br />library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]<br />#关闭remoteDriver对象<br />remDr$close()
这一次我终于看到了希望。果然,Plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数和污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是爬取url链接的高级封装函数,因为在html中,url的标签一般是固定的,跳转的url链接一般在标签的href属性中,图片链接一般在
在标签下的 src 属性中,最好定位。
随便找个知乎的贴吧,高清图片多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553" <br />[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"<br />[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = "//a/@href", baseURL = docName(doc), relative = FALSE)
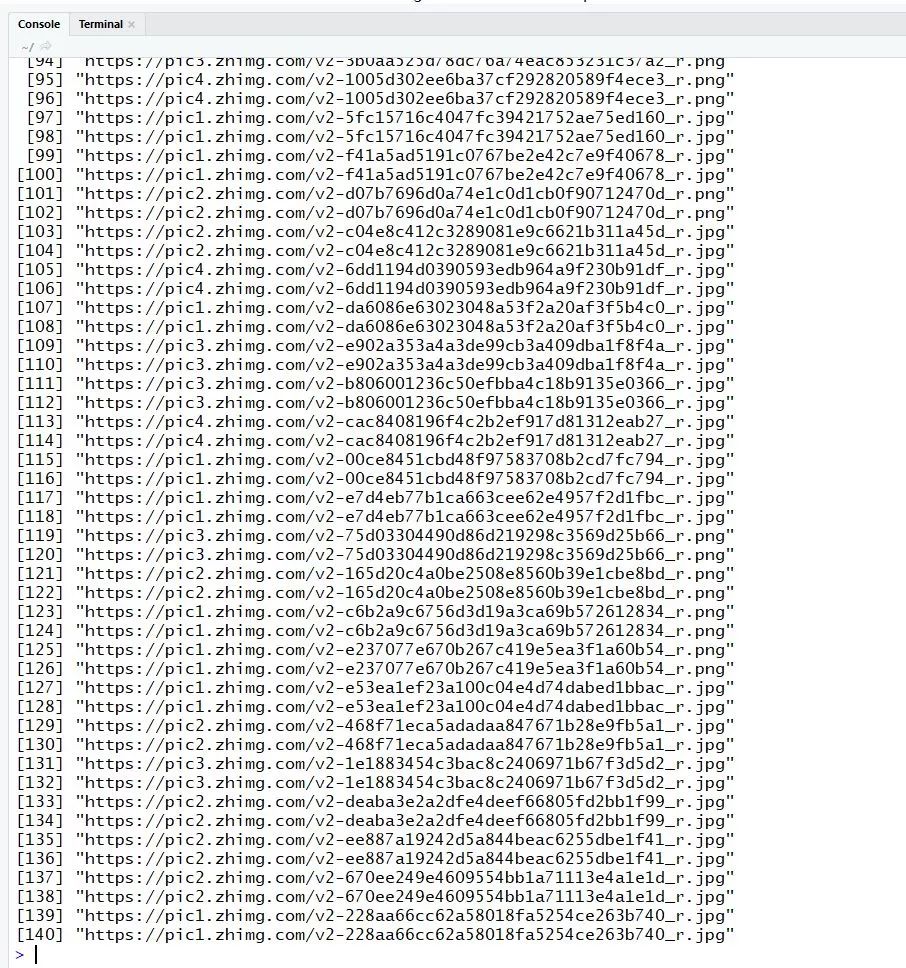
从getHTMLLinks的源码中可以看出,该函数过滤的链接的条件只是标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样就很容易得到知乎摄影帖所有高清图片的原创地址,效率高很多。
Python:
如果python中没有爬虫工具,我知道的表格提取工具就是pandas中的read_html函数,相当于一个I/O函数(和其他read_csv、read_table、read_xlsx等函数一样)。上述R语言中第一种情况的天气数据也是如此,不能直接使用pd.read_html函数获取表格数据。同理,html文档中也有数据隐藏设置。
import pandas as pd
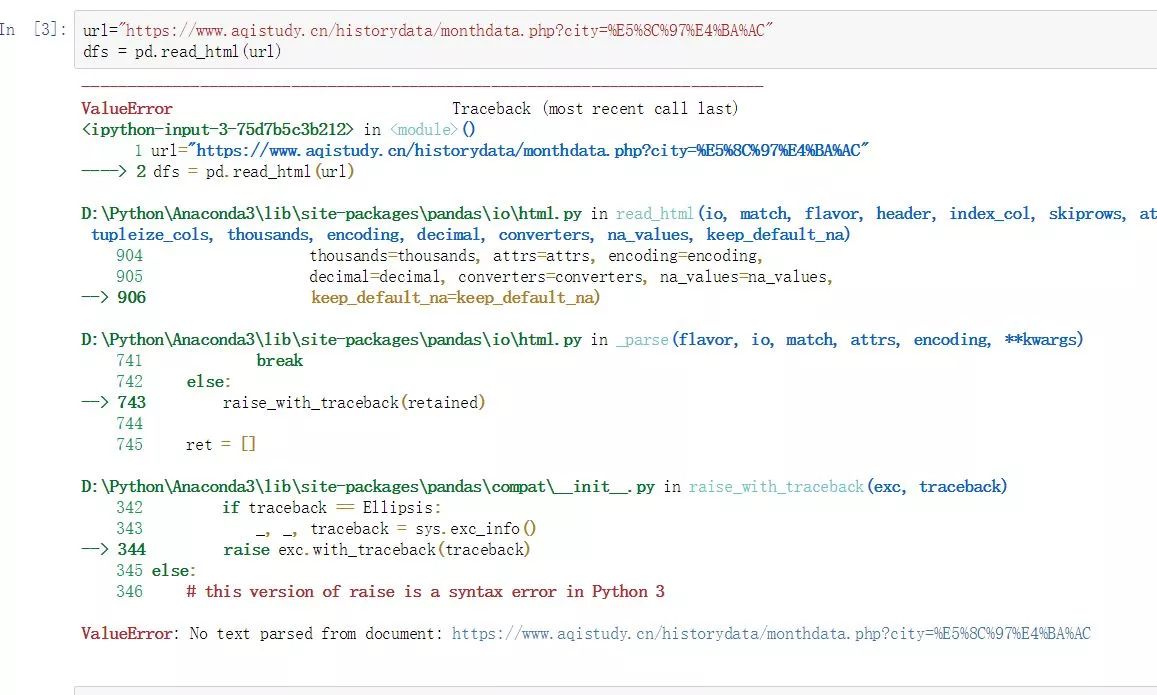
url="https://www.aqistudy.cn/histor ... %3Bbr />dfs = pd.read_html(url)
这里我们也使用Python中的selenium+plantomjs工具请求网页,获取完整源文档后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
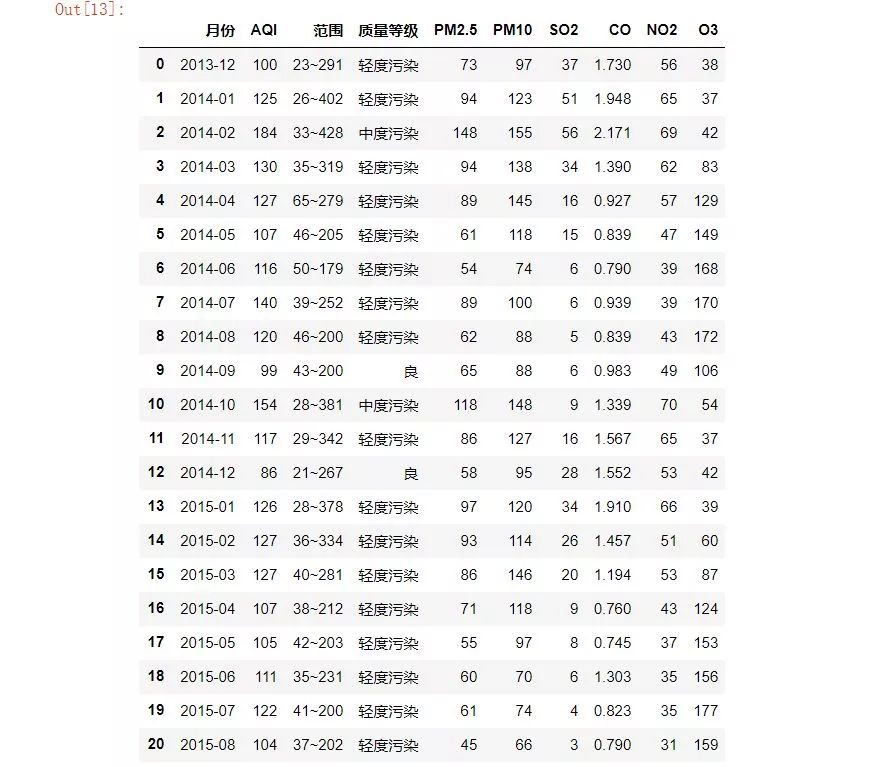
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不能再完美了。对于网页表格数据,pd.read_html函数是一种极其高效的封装,但前提是你必须确保这个网页中的数据确实是表格格式,并且网页没有做任何隐藏措施。
在线课程请点击文末原文链接:
过往案例数据,请移步我的GitHub:
推荐课程
R语言爬虫实战案例分享:、今日头条、B站视频
分享内容:本课程的所有内容和案例均来自我平时学习实践过程中的经验和笔记。希望借此机会把我的爬虫学习过程分享给大家,用R语言完善爬虫生态和工具。小力的推广和贡献,也是我对爬虫学习的阶段性总结。
查看全部
php抓取网页表格信息(
R语言和Python中都封装了表格的抓取数据函数
)

杜宇,EasyCharts团队成员,R语言中文社区专栏作家,感兴趣的领域:Excel商业图表、R语言数据可视化、地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
抓取数据时,很大一部分需求是抓取网页上的关系表。
对于表格,R语言和Python都封装了一个抓取表格的快捷函数。R语言的XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数还可以提供快捷键表提取要求。Python中的read_html还提供了直接从HTML中提取关系表的功能。
HTML语法中嵌入的表格有两种,一种是table,就是通常所说的表格,另一种是list,可以理解为列表,但是从浏览器渲染的网页来看, 很难区分两者的区别,因为在效果上几乎没有区别,但是通过开发者工具的代码隐藏界面,表格和列表是两个截然不同的 HTML 元素。
上面提到的函数是针对HTML文档中的不同标签而设计的,所以如果你乱用这些函数提取表格,很可能对于你认为是表格但实际上是列表的内容是无效的。
library("RCurl")<br />library("XML")<br />library("magrittr")<br />library("rvest")
对于 XML 包,HTML 元素提取的快捷函数有 3 个,分别是 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格<br />readHTMLList() #获取网页列表<br />getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)<br />#the HTML document which can be a file name or a URL or an <br />#already parsed HTMLInternalDocument, or an HTML node of class <br />#XMLInternalElementNode, or a character vector containing the HTML <br />#content to parse and process.
此功能支持范围广泛的 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、已解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。.
下面是一个案例,也是我自学爬虫时爬过的一个网页。以后可能会修改。很多朋友都爬不出来那些代码,问我怎么回事。我尝试了以下方法,但没有成功。今天,我借此机会重新整理了我的想法。
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")<br />####<br />关于网址转码,如果你不想使用函数进行编码转换,<br />可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,<br />在封装程序代码时无法自动化。<br />#http://tool.oschina.net/encode?type=4<br />#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,<br />所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,<br />稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)<br />###
mydata% html_table(header=TRUE) %>% `[[`(1)<br />#关闭remoteDriver对象<br />remDr$close()
以上两者是等价的,我们得到了完全相同的表格数据,数据预览如下:
DT::datatable(mytable)
rvest 函数中的 readHTMLTable 函数和 html_table 都可以读取 HTML 文档中的嵌入表格。它们是优秀的高级封装解析器,但并不意味着它们可以无所不能。
毕竟没有米饭很难做饭,而且需要先拿米饭煮锅,所以我们在看表的时候,最好的方式是先使用请求库request(RCurl或者httr),然后再使用返回的 HTML 文档的 readHTMLTable 函数或 html_table。该函数执行表格提取,否则会适得其反。在今天的情况下,很明显浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,不提供API访问,无法获取完整的html文档,应该想想什么数据隐藏设置。
看看套路就好了。既然浏览器可以解析,我就驱动浏览器获取解析后的HTML文档,返回解析后的HTML文档。接下来的工作是使用这些高级功能来提取嵌入的表格。
那么 selenium server + plantomjs 无头浏览器为我们做了什么?其实它只做了一件事——帮我们发出一个真正的浏览器请求,这个请求是由 planomjs 无头浏览器完成的,它帮我们交付完整渲染的 HTML 文档,这样我们就可以使用 readHTMLTable 函数或 read_table()
在 XML 包中,还有另外两个非常有用的高阶包装函数:
一种用于抓取链接,一种用于抓取列表。
读取HTML列表
获取HTML链接
随便找了个天气网的主页,里面有全国主要城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数进行尝试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)<br />NULL
使用上面的代码抓取内容是空的,有两个原因,一个是html中的标签根本不是表格格式的,可能是一个列表,另一个可能和上面的例子一样,表数据被隐藏。看源码可以看到,这个section其实是存储在一个无序列表中的,所以用readtable肯定是不行的。这是 readHTMLList 函数发挥作用的时候。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人作呕的编码问题。我不想与各种编码竞争。我再次使用了 phantomjs 无头浏览器。毕竟作为浏览器,它总能正确解析和渲染网页内容。不管 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开<br />library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]<br />#关闭remoteDriver对象<br />remDr$close()
这一次我终于看到了希望。果然,Plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数和污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)

最后一个函数是爬取url链接的高级封装函数,因为在html中,url的标签一般是固定的,跳转的url链接一般在标签的href属性中,图片链接一般在
在标签下的 src 属性中,最好定位。
随便找个知乎的贴吧,高清图片多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553" <br />[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"<br />[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = "//a/@href", baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码中可以看出,该函数过滤的链接的条件只是标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样就很容易得到知乎摄影帖所有高清图片的原创地址,效率高很多。
Python:
如果python中没有爬虫工具,我知道的表格提取工具就是pandas中的read_html函数,相当于一个I/O函数(和其他read_csv、read_table、read_xlsx等函数一样)。上述R语言中第一种情况的天气数据也是如此,不能直接使用pd.read_html函数获取表格数据。同理,html文档中也有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... %3Bbr />dfs = pd.read_html(url)
这里我们也使用Python中的selenium+plantomjs工具请求网页,获取完整源文档后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不能再完美了。对于网页表格数据,pd.read_html函数是一种极其高效的封装,但前提是你必须确保这个网页中的数据确实是表格格式,并且网页没有做任何隐藏措施。
在线课程请点击文末原文链接:
过往案例数据,请移步我的GitHub:
推荐课程
R语言爬虫实战案例分享:、今日头条、B站视频
分享内容:本课程的所有内容和案例均来自我平时学习实践过程中的经验和笔记。希望借此机会把我的爬虫学习过程分享给大家,用R语言完善爬虫生态和工具。小力的推广和贡献,也是我对爬虫学习的阶段性总结。

php抓取网页表格信息(php是实现动态网页的必不可少的脚本语言 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2022-03-21 18:42
)
PHP是实现动态网页必不可少的脚本语言之一。它是一种“嵌入式语言”,即 HTML 和 JavaScript 可以嵌套在 .php 文件中,但结果以纯 HTML 文本的形式返回给浏览器。
这就是为什么 PHP = 超文本预处理器 = 超文本预处理器
利用php的好特性,可以实现一些动态的操作,比如数据库查询,或者页面的提交
值得注意的是php需要在服务器环境下,可以通过下载xampp软件解决
【windows下XAMPP安装配置】
php回显
php的echo相当于在浏览器看到的纯html中插入一条语句,比如
从浏览器的角度来看,这个文件的内容是
哈哈哈
注意
php代码只有文件后缀为.php时才会生效。在 .html 后缀下,任何编写的 php 代码都不会生效。我一开始忽略了这个问题,导致调试了半天。. .
HTML 表单标签的动作和方法属性
表单标签划分了一个清晰的表单域。点击表单中的提交标签后,该表单中的所有内容都会以method属性指定的方式提交到action属性指定的页面。
如下,POST为提交方式,POST提交为密文提交,不会在URL上产生明文显示,#表示提交的目标页面为当前页面
输入名字:
PHP提取提交内容
需要使用超级全局变量 POST 变量。POST变量可以看成一个map,key是提交的表单标签的name属性,value是表单的value内容
$nameVal = $_SESSION["表单标签的name属性"];
编写提交成功界面p.php
现在您知道如何获取提交的内容,编写一个页面来输出提交的内容。该文件名为 p.php 并收录以下代码
值得注意的是,吹嘘页面的数据传输使用session进行交互,而不是再次提交(这个方法可以百度搜索,但是我还没想好如何不点击按钮自动提交,所以我使用了session作为数据传输)
值得注意的是,SESSION也是一个超级全局变量,也是一个map,可以给指定的key赋值,在另一个页面上,可以读取指定key的值。例如下面的代码使用name和sex作为key读取SESSION map介质数据
值得注意的是,使用session后,记得关闭它,destroy会销毁所有变量
编写表单填写页面 index.php
因为是xampp的apache启动的服务,所以url指定到localhost的8081端口的page2文件夹,里面收录index.php,也就是php文件,里面收录如下代码
使用empty函数判断post提交的值是否为空。如果不为空,则进一步打开session,将数据提交到p.php页面。如果数据无效,将显示错误消息。
值得注意的是,语句x == ""不能用于判断空字符串,因为如果为空则为空,而""不为空,必须通过$_SERVER["REQUEST_METHOD"来判断] == "POST" 是post提交,否则第一次加载时会直接显示信息,我们要求出现输入错误时显示
提交页面测试
php表单提交
输入名字:
输入性别:
男
女
span {
color: red;
}
结果
查看全部
php抓取网页表格信息(php是实现动态网页的必不可少的脚本语言
)
PHP是实现动态网页必不可少的脚本语言之一。它是一种“嵌入式语言”,即 HTML 和 JavaScript 可以嵌套在 .php 文件中,但结果以纯 HTML 文本的形式返回给浏览器。
这就是为什么 PHP = 超文本预处理器 = 超文本预处理器
利用php的好特性,可以实现一些动态的操作,比如数据库查询,或者页面的提交
值得注意的是php需要在服务器环境下,可以通过下载xampp软件解决
【windows下XAMPP安装配置】
php回显
php的echo相当于在浏览器看到的纯html中插入一条语句,比如
从浏览器的角度来看,这个文件的内容是
哈哈哈
注意
php代码只有文件后缀为.php时才会生效。在 .html 后缀下,任何编写的 php 代码都不会生效。我一开始忽略了这个问题,导致调试了半天。. .
HTML 表单标签的动作和方法属性
表单标签划分了一个清晰的表单域。点击表单中的提交标签后,该表单中的所有内容都会以method属性指定的方式提交到action属性指定的页面。
如下,POST为提交方式,POST提交为密文提交,不会在URL上产生明文显示,#表示提交的目标页面为当前页面
输入名字:
PHP提取提交内容
需要使用超级全局变量 POST 变量。POST变量可以看成一个map,key是提交的表单标签的name属性,value是表单的value内容
$nameVal = $_SESSION["表单标签的name属性"];
编写提交成功界面p.php
现在您知道如何获取提交的内容,编写一个页面来输出提交的内容。该文件名为 p.php 并收录以下代码
值得注意的是,吹嘘页面的数据传输使用session进行交互,而不是再次提交(这个方法可以百度搜索,但是我还没想好如何不点击按钮自动提交,所以我使用了session作为数据传输)
值得注意的是,SESSION也是一个超级全局变量,也是一个map,可以给指定的key赋值,在另一个页面上,可以读取指定key的值。例如下面的代码使用name和sex作为key读取SESSION map介质数据
值得注意的是,使用session后,记得关闭它,destroy会销毁所有变量
编写表单填写页面 index.php
因为是xampp的apache启动的服务,所以url指定到localhost的8081端口的page2文件夹,里面收录index.php,也就是php文件,里面收录如下代码
使用empty函数判断post提交的值是否为空。如果不为空,则进一步打开session,将数据提交到p.php页面。如果数据无效,将显示错误消息。
值得注意的是,语句x == ""不能用于判断空字符串,因为如果为空则为空,而""不为空,必须通过$_SERVER["REQUEST_METHOD"来判断] == "POST" 是post提交,否则第一次加载时会直接显示信息,我们要求出现输入错误时显示
提交页面测试
php表单提交
输入名字:
输入性别:
男
女
span {
color: red;
}
结果


php抓取网页表格信息(微信小程序解析网页内容详解及实例的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-21 18:37
本篇文章主要介绍微信小程序解析网页内容的细节和例子。在这里,我们使用爬虫来爬取复杂的网页。如果遇到一些问题,可以在这里整理并解决。需要的朋友可以参考下
微信小程序解析网页内容详解
最近在写爬虫,需要为微信小程序解析网页。文字和图片解析都好说,小程序也有相应的文字和图片标签可以呈现。更复杂的,比如表格,难度更大,无论是服务端解析还是小程序渲染,都非常费力,很难涵盖所有情况。所以我认为将表格对应的HTML代码转换为图像会是一种解决方法。
这里我们使用node-webshot模块,它以轻量级的方式封装了PhantomJS,可以方便的将网页保存为截图。
首先安装 Node.js 和 PhantomJS,然后新建一个 js 文件并加载 node-webshot 模块: const webshot = require('webshot');
定义选项: const options = {
// 浏览器窗口
屏幕尺寸: {
宽度:755,
身高:25
},
// 要截图的页面的文档区域
镜头尺寸:{
高度:'全部'
},
//页面类型
网站类型:'html'
};
这里,浏览器窗口的宽度要根据网页的情况合理设置,高度可以设置一个较小的值,然后页面文档区域的高度必须设置为all,宽度默认到窗口宽度,以便表格可以设置为最小值。全尺寸截图。
接下来定义html字符串:let html="target富文本html代码,eg:
";
注意里面的HTML代码必须去掉换行符,用单引号代替双引号。
最后,截图: webshot(html, 'demo.png', options, (err) => {
如果(错误)
console.log(`Webshot 错误:${err.message}`);
});
这样就实现了HTML代码到本地图片的转换,然后可以上传到七牛云等。无论是服务器的分析还是小程序的呈现,都没有难度……
以上就是本文的全部内容。希望对大家的学习有所帮助。更多相关内容请关注PHP中文网! 查看全部
php抓取网页表格信息(微信小程序解析网页内容详解及实例的相关资料)
本篇文章主要介绍微信小程序解析网页内容的细节和例子。在这里,我们使用爬虫来爬取复杂的网页。如果遇到一些问题,可以在这里整理并解决。需要的朋友可以参考下
微信小程序解析网页内容详解
最近在写爬虫,需要为微信小程序解析网页。文字和图片解析都好说,小程序也有相应的文字和图片标签可以呈现。更复杂的,比如表格,难度更大,无论是服务端解析还是小程序渲染,都非常费力,很难涵盖所有情况。所以我认为将表格对应的HTML代码转换为图像会是一种解决方法。
这里我们使用node-webshot模块,它以轻量级的方式封装了PhantomJS,可以方便的将网页保存为截图。
首先安装 Node.js 和 PhantomJS,然后新建一个 js 文件并加载 node-webshot 模块: const webshot = require('webshot');
定义选项: const options = {
// 浏览器窗口
屏幕尺寸: {
宽度:755,
身高:25
},
// 要截图的页面的文档区域
镜头尺寸:{
高度:'全部'
},
//页面类型
网站类型:'html'
};
这里,浏览器窗口的宽度要根据网页的情况合理设置,高度可以设置一个较小的值,然后页面文档区域的高度必须设置为all,宽度默认到窗口宽度,以便表格可以设置为最小值。全尺寸截图。
接下来定义html字符串:let html="target富文本html代码,eg:
";
注意里面的HTML代码必须去掉换行符,用单引号代替双引号。
最后,截图: webshot(html, 'demo.png', options, (err) => {
如果(错误)
console.log(`Webshot 错误:${err.message}`);
});
这样就实现了HTML代码到本地图片的转换,然后可以上传到七牛云等。无论是服务器的分析还是小程序的呈现,都没有难度……
以上就是本文的全部内容。希望对大家的学习有所帮助。更多相关内容请关注PHP中文网!
php抓取网页表格信息((推荐):PHP表单和表单时的应用(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-16 10:09
3.(推荐)使用$_POST、$_GET等数组进行访问,例如$_POST["username"]的形式。推荐使用此方法。
(推荐)使用 import_request_variables 函数。该函数将提交的内容导入到变量中。
例如 import_request_variables("gp", "rvar_"); 第一个参数可以选择g、p、c,分别表示导入GET、POST、COOKIE变量;第二个参数是导入后的变量前缀。执行上述语句后,可以使用 $rvar_username 访问提交的用户名变量。使用 import_request_variables("gp", ""); 与以前的 PHP 程序兼容。
PHP $_GET 和 $_POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
当我们处理 HTML 表单和 PHP 表单时,重要的是要记住 HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
欢迎约翰。
你今年 28 岁。
PHP $_GET 和 $_POST 变量将在下面详细解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP $_GET 变量通过 get 方法从表单中获取“值”。
$_GET 变量
$_GET 变量是一个收录name [name] 和value [value] 的数组(这些名称和值是通过HTTP GET 方法发送的,都是可用的)。
$_GET 变量使用“method=get”来获取表单信息。GET方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过100个字符[character])。
案子
当用户点击“提交”按钮时,URL以如下形式显示
“welcome.php”文件可以使用“$_GET”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_GET”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用“$_GET”?
重要提示:使用“$_GET”变量时,所有变量名和变量值都会显示在URL地址栏中;因此,当您发送的信息中收录密码或其他一些敏感信息时,您将无法再使用此方法。因为所有的信息都会显示在URL地址栏中,所以我们可以把它作为一个标签放在采集夹中。这在许多情况下都非常有用。
注意:如果要发送的变量值太大,HTTP GET 方法不适合。发送的信息量不能超过 100 个字符。
$_REQUEST 变量
PHP $_REQUEST 变量收录 $_GET、$_POST 和 $_COOKIE 的内容。
PHP $_REQUEST 变量可用于检索通过“GET”和“POST”方法发送的表单数据。
案子
欢迎 。
你几岁了!
PHP $_POST 变量的目的是获取method="post" 方法发送的表单变量。
$_POST 变量
$_POST 变量是一个收录name[name]和value[value]的数组(这些名称和值是通过HTTP POST方法发送的,都是可用的)
$_POST 变量使用“method=POST”来获取表单信息。通过 POST 方法发送的消息是不可见的,并且对消息长度没有限制。
案子
当用户点击“提交”按钮时,URL 将不收录任何表单数据
“welcome.php”文件可以使用“$_POST”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_POST”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用 $_POST? 查看全部
php抓取网页表格信息((推荐):PHP表单和表单时的应用(上))
3.(推荐)使用$_POST、$_GET等数组进行访问,例如$_POST["username"]的形式。推荐使用此方法。
(推荐)使用 import_request_variables 函数。该函数将提交的内容导入到变量中。
例如 import_request_variables("gp", "rvar_"); 第一个参数可以选择g、p、c,分别表示导入GET、POST、COOKIE变量;第二个参数是导入后的变量前缀。执行上述语句后,可以使用 $rvar_username 访问提交的用户名变量。使用 import_request_variables("gp", ""); 与以前的 PHP 程序兼容。
PHP $_GET 和 $_POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
当我们处理 HTML 表单和 PHP 表单时,重要的是要记住 HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
欢迎约翰。
你今年 28 岁。
PHP $_GET 和 $_POST 变量将在下面详细解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP $_GET 变量通过 get 方法从表单中获取“值”。
$_GET 变量
$_GET 变量是一个收录name [name] 和value [value] 的数组(这些名称和值是通过HTTP GET 方法发送的,都是可用的)。
$_GET 变量使用“method=get”来获取表单信息。GET方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过100个字符[character])。
案子
当用户点击“提交”按钮时,URL以如下形式显示
“welcome.php”文件可以使用“$_GET”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_GET”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用“$_GET”?
重要提示:使用“$_GET”变量时,所有变量名和变量值都会显示在URL地址栏中;因此,当您发送的信息中收录密码或其他一些敏感信息时,您将无法再使用此方法。因为所有的信息都会显示在URL地址栏中,所以我们可以把它作为一个标签放在采集夹中。这在许多情况下都非常有用。
注意:如果要发送的变量值太大,HTTP GET 方法不适合。发送的信息量不能超过 100 个字符。
$_REQUEST 变量
PHP $_REQUEST 变量收录 $_GET、$_POST 和 $_COOKIE 的内容。
PHP $_REQUEST 变量可用于检索通过“GET”和“POST”方法发送的表单数据。
案子
欢迎 。
你几岁了!
PHP $_POST 变量的目的是获取method="post" 方法发送的表单变量。
$_POST 变量
$_POST 变量是一个收录name[name]和value[value]的数组(这些名称和值是通过HTTP POST方法发送的,都是可用的)
$_POST 变量使用“method=POST”来获取表单信息。通过 POST 方法发送的消息是不可见的,并且对消息长度没有限制。
案子
当用户点击“提交”按钮时,URL 将不收录任何表单数据
“welcome.php”文件可以使用“$_POST”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_POST”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用 $_POST?
php抓取网页表格信息(PHP代码中会插件(.php)插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-13 13:07
)
本文使用可编辑插件实现一键将文本信息变成可编辑形式。可以编辑文本内容,然后点击“确定”保存到数据库;当您单击“取消”按钮时,页面返回初始状态。
类别:PHP> Ajax 难度:中级
下载资源下载积分:60积分
可编辑的优点:
接下来,我们用 PHP 来举个例子:
这是一个用户信息表。从代码中可以发现,响应的字段信息的td被赋予了class和id属性并赋值。值得一提的是,表中td对应的id的值与数据库中的字段名是一一对应的。这是为了让后台在编辑的时候能够获取到对应的字段信息,后面会在PHP代码中讨论。
客户信息
姓名
办公电话
称谓
手机
公司名称
电子邮箱
潜在客户来源
有限期
职位
网站
创建时间
修改时间
备注
调用 jeditable 插件:
$('.edit').editable('ajax.php', {
width: 120,
height: 18,
//onblur : "ignore",
cancel: '取消',
submit: '确定',
indicator: 'css/loader.gif',
tooltip: '单击可以编辑...',
callback: function(value, settings) {
$("#modifiedtime").html("刚刚");
}
});
jeditable还提供select、textarea类型编辑,并提供插件api接口。
$('.edit_select').editable('ajax.php', {
loadurl : 'json.php',
type : "select",
});
type指定select类型,select中加载的数据来自json.php,json.php提供下拉框需要的数据源。
$array['网站模板'] = '网站模板';
$array['网页特效'] = '网页特效';
$array['网站源码'] = '网站源码';
$array['精品网站'] = '精品网站';
$array['网页图标'] = '网页图标';
print json_encode($array);
json数据示例:
$('.edit_select').editable('save.php', {
data : " {'网站模板':'网站模板','网页特效':'网页特效','网站源码':'网站源码', '精品网站':'精品网站'}",
type : "select",
});
没有更多的textarea类型,只需将类型类型更改为textarea。PS:默认类型是文本。
在处理日期类型时,我使用了一个 jquery ui datepicker 日历插件,当然不要忘记介绍 juqery ui 插件和样式:
为 jquery ui 引入 datepicker 日期时间插件
$.editable.addInputType('datepicker', {
element : function(settings, original) {
var input = $('');
input.attr("readonly","readonly");
$(this).append(input);
return(input);
},
plugin : function(settings, original) {
var form = this;
$("input",this).datepicker();
}
});
调用代码可以直接指定类型为datepicker。
$(".datepicker").editable('ajax.php', {
width : 120,
type : 'datepicker',
onblur : "ignore",
});
ajax.php
编辑好的字段信息会发送到后台程序save.php进行处理。save.php需要完成的工作是:接收前端提交的字段信息数据,进行必要的过滤和验证,然后更新数据表中对应的字段内容,并返回结果。
include_once("connect.php"); //连接数据库
$field=$_POST['id']; //获取前端提交的字段名
$val=$_POST['value']; //获取前端提交的字段对应的内容
$val = htmlspecialchars($val, ENT_QUOTES); //过滤处理内容
$time=date("Y-m-d H:i:s"); //获取系统当前时间
if(empty($val)){
echo "不能为空";
}else{
//更新字段信息
$query=mysql_query("update customer set $field='$val',modifiedtime='$time' where id=1");
if($query){
echo $val;
}else{
echo "数据出错";
}
} 查看全部
php抓取网页表格信息(PHP代码中会插件(.php)插件
)
本文使用可编辑插件实现一键将文本信息变成可编辑形式。可以编辑文本内容,然后点击“确定”保存到数据库;当您单击“取消”按钮时,页面返回初始状态。

类别:PHP> Ajax 难度:中级
下载资源下载积分:60积分
可编辑的优点:
接下来,我们用 PHP 来举个例子:
这是一个用户信息表。从代码中可以发现,响应的字段信息的td被赋予了class和id属性并赋值。值得一提的是,表中td对应的id的值与数据库中的字段名是一一对应的。这是为了让后台在编辑的时候能够获取到对应的字段信息,后面会在PHP代码中讨论。
客户信息
姓名
办公电话
称谓
手机
公司名称
电子邮箱
潜在客户来源
有限期
职位
网站
创建时间
修改时间
备注
调用 jeditable 插件:
$('.edit').editable('ajax.php', {
width: 120,
height: 18,
//onblur : "ignore",
cancel: '取消',
submit: '确定',
indicator: 'css/loader.gif',
tooltip: '单击可以编辑...',
callback: function(value, settings) {
$("#modifiedtime").html("刚刚");
}
});
jeditable还提供select、textarea类型编辑,并提供插件api接口。
$('.edit_select').editable('ajax.php', {
loadurl : 'json.php',
type : "select",
});
type指定select类型,select中加载的数据来自json.php,json.php提供下拉框需要的数据源。
$array['网站模板'] = '网站模板';
$array['网页特效'] = '网页特效';
$array['网站源码'] = '网站源码';
$array['精品网站'] = '精品网站';
$array['网页图标'] = '网页图标';
print json_encode($array);
json数据示例:
$('.edit_select').editable('save.php', {
data : " {'网站模板':'网站模板','网页特效':'网页特效','网站源码':'网站源码', '精品网站':'精品网站'}",
type : "select",
});
没有更多的textarea类型,只需将类型类型更改为textarea。PS:默认类型是文本。
在处理日期类型时,我使用了一个 jquery ui datepicker 日历插件,当然不要忘记介绍 juqery ui 插件和样式:
为 jquery ui 引入 datepicker 日期时间插件
$.editable.addInputType('datepicker', {
element : function(settings, original) {
var input = $('');
input.attr("readonly","readonly");
$(this).append(input);
return(input);
},
plugin : function(settings, original) {
var form = this;
$("input",this).datepicker();
}
});
调用代码可以直接指定类型为datepicker。
$(".datepicker").editable('ajax.php', {
width : 120,
type : 'datepicker',
onblur : "ignore",
});
ajax.php
编辑好的字段信息会发送到后台程序save.php进行处理。save.php需要完成的工作是:接收前端提交的字段信息数据,进行必要的过滤和验证,然后更新数据表中对应的字段内容,并返回结果。
include_once("connect.php"); //连接数据库
$field=$_POST['id']; //获取前端提交的字段名
$val=$_POST['value']; //获取前端提交的字段对应的内容
$val = htmlspecialchars($val, ENT_QUOTES); //过滤处理内容
$time=date("Y-m-d H:i:s"); //获取系统当前时间
if(empty($val)){
echo "不能为空";
}else{
//更新字段信息
$query=mysql_query("update customer set $field='$val',modifiedtime='$time' where id=1");
if($query){
echo $val;
}else{
echo "数据出错";
}
}
php抓取网页表格信息(一卡通消费记录批量导进Excel上的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-12 01:11
一、背景
我准备将一卡消费记录批量导入随知,但是学校的一卡消费查询系统不支持数据导出。你想让我把数据逐页复制到Excel吗?这种重复无聊的事情不应该由擅长做的电脑来做吗?于是我开始打算写一个脚本,一键抓取我的一卡消费记录。
二、分析
首先打开消费记录查询的网页,拿出开发者工具,观察这个网页,找到我们的目标,就是一个table标签。
然后看看这个标签是怎么生成的,是服务器后端直接生成的网页,还是前端ajax访问后端获取数据渲染出来的?点击Network选项卡刷新网页,发现网页上没有异步请求,每一页都是一个新的网页,所以是前一种情况。而每个页面的url都是【页码】,所以我只需要让程序访问这个url并解析html,获取table里面的数据,然后通过某种方式采集就可以完成目标。
要将结果导入 Excel,此处使用简单方便的表格文件格式 .CSV。本质上,csv表格文件只是一个文本文件,表格的字段用逗号等分隔符分隔,表格中的每一行数据用换行符分隔(在Excel中换行符是“rn”)
字段1,字段2,字段3,字段4
A,B,C,D
1,2,3,4
就是这么简单明了!对于任何程序,简单的字符串连接都可以生成 csv 格式的表格。
经过我的测试,我这个学期的消费记录在这个网页上只有50多页,所以爬虫需要爬取的数据量非常少,处理起来完全没有压力。一次性直接获取所有结果并保存。文件会做。
至于爬虫程序的语言选择,我无话可说。目前对PHP比较熟悉,所以接下来的程序我也是用PHP来完成的。
三、执行
首先,确定我应该如何模拟登录到这个系统。这里我们应该知道HTTP是一个无状态的协议,所以如果服务器要判断用户当前在请求谁,就必须通过HTTP请求的cookie中存储的信息来判断。. 所以如果我们想让服务器知道爬虫发出的HTTP请求的用户是我,就应该让爬虫发出的HTTP请求携带这个cookie。在这里,我们可以从 chrome 中复制这个 cookie,并将其值保存在变量之间的某个备用中。
查看浏览器的header访问这个页面,发现cookie只有JSESSIONID。
接下来写一个循环,将每一页的结果加到保存结果的字符串中,找不到数据的时候跳出循环,保存结果,程序结束。
在提取数据时,我使用了simple_html_dom,一个简单方便的用于解析html中的DOM结构的库。
最后将字符串的内容保存到result.csv。
代码显示如下:
<p> 查看全部
php抓取网页表格信息(一卡通消费记录批量导进Excel上的应用)
一、背景
我准备将一卡消费记录批量导入随知,但是学校的一卡消费查询系统不支持数据导出。你想让我把数据逐页复制到Excel吗?这种重复无聊的事情不应该由擅长做的电脑来做吗?于是我开始打算写一个脚本,一键抓取我的一卡消费记录。
二、分析
首先打开消费记录查询的网页,拿出开发者工具,观察这个网页,找到我们的目标,就是一个table标签。
然后看看这个标签是怎么生成的,是服务器后端直接生成的网页,还是前端ajax访问后端获取数据渲染出来的?点击Network选项卡刷新网页,发现网页上没有异步请求,每一页都是一个新的网页,所以是前一种情况。而每个页面的url都是【页码】,所以我只需要让程序访问这个url并解析html,获取table里面的数据,然后通过某种方式采集就可以完成目标。
要将结果导入 Excel,此处使用简单方便的表格文件格式 .CSV。本质上,csv表格文件只是一个文本文件,表格的字段用逗号等分隔符分隔,表格中的每一行数据用换行符分隔(在Excel中换行符是“rn”)
字段1,字段2,字段3,字段4
A,B,C,D
1,2,3,4
就是这么简单明了!对于任何程序,简单的字符串连接都可以生成 csv 格式的表格。
经过我的测试,我这个学期的消费记录在这个网页上只有50多页,所以爬虫需要爬取的数据量非常少,处理起来完全没有压力。一次性直接获取所有结果并保存。文件会做。
至于爬虫程序的语言选择,我无话可说。目前对PHP比较熟悉,所以接下来的程序我也是用PHP来完成的。
三、执行
首先,确定我应该如何模拟登录到这个系统。这里我们应该知道HTTP是一个无状态的协议,所以如果服务器要判断用户当前在请求谁,就必须通过HTTP请求的cookie中存储的信息来判断。. 所以如果我们想让服务器知道爬虫发出的HTTP请求的用户是我,就应该让爬虫发出的HTTP请求携带这个cookie。在这里,我们可以从 chrome 中复制这个 cookie,并将其值保存在变量之间的某个备用中。
查看浏览器的header访问这个页面,发现cookie只有JSESSIONID。
接下来写一个循环,将每一页的结果加到保存结果的字符串中,找不到数据的时候跳出循环,保存结果,程序结束。
在提取数据时,我使用了simple_html_dom,一个简单方便的用于解析html中的DOM结构的库。
最后将字符串的内容保存到result.csv。
代码显示如下:
<p>
php抓取网页表格信息(使用PHPCURL的POST模拟登录discuz以及模拟发帖())
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-11 21:02
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心, 查看全部
php抓取网页表格信息(使用PHPCURL的POST模拟登录discuz以及模拟发帖())
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。

使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
php抓取网页表格信息( 用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-11 16:25
用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
Python 使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程
更新时间:2016-05-16 18:53:56 作者:Kenneth Reitz
使用 Pyhton 附带的 urllib 或 urllib2 模块来爬取网页可能是陈词滥调。今天我们将玩一些新的东西,并看一个使用 lxml 模块和 Requests 模块来爬取 HTML 页面的 Python 教程:
网页抓取
网站是使用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
这就是网络抓取发挥作用的时候。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式同时保留其结构的做法。
lxml 和请求
lxml() 是一个漂亮的扩展库,即使在处理非常混乱的标签时也能快速解析 XML 和 HTML 文档。我们还将使用 Requests (#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
接下来我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools。
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector。如果您使用的是 Chrome,您可以右键单击元素,选择“检查元素”,突出显示代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个名为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经通过 lxml 和 Request 成功地从网页中抓取了我们想要的所有数据。我们将它们作为列表存储在内存中。现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以想到一些更酷的想法:修改脚本以遍历示例数据集中的剩余页面,或者重写应用程序以使用多线程加速。 查看全部
php抓取网页表格信息(
用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
Python 使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程
更新时间:2016-05-16 18:53:56 作者:Kenneth Reitz
使用 Pyhton 附带的 urllib 或 urllib2 模块来爬取网页可能是陈词滥调。今天我们将玩一些新的东西,并看一个使用 lxml 模块和 Requests 模块来爬取 HTML 页面的 Python 教程:
网页抓取
网站是使用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
这就是网络抓取发挥作用的时候。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式同时保留其结构的做法。
lxml 和请求
lxml() 是一个漂亮的扩展库,即使在处理非常混乱的标签时也能快速解析 XML 和 HTML 文档。我们还将使用 Requests (#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
接下来我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools。
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector。如果您使用的是 Chrome,您可以右键单击元素,选择“检查元素”,突出显示代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个名为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经通过 lxml 和 Request 成功地从网页中抓取了我们想要的所有数据。我们将它们作为列表存储在内存中。现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以想到一些更酷的想法:修改脚本以遍历示例数据集中的剩余页面,或者重写应用程序以使用多线程加速。
php抓取网页表格信息(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-11 16:21
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测header的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大部分出现在静态页面上,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
php抓取网页表格信息(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。

2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。

2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。

网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。


2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD

2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。

分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。

上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测header的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大部分出现在静态页面上,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
php抓取网页表格信息(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-11 16:16
一、从网络获取数据
可以使用双桌面“获取数据”中的“web”选项。“网络”界面有两个选项卡,“基本”和“高级”。通常,“基本”选项卡可以满足日常工作的需要。以下是这方面的例子。
二、获取数据
进入网页链接后,会进行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会耗费大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取一页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示当年的工作路径。类似于下图:
这时需要在“let”前面输入“(p as number) as table=>”;并且在链接中,修改网页的页码,也就是上面提到的“1, 2”等数字“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接末尾,按照上面的操作即可;另一个是链接以.html结尾。除了上面的替换操作,这种类型的(p))&".html"))只需要在这里单独定义html即可。
四、爬取多数据网页
首先,使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建1到100的序列。在空查询中输入={1..100},生成1到100的序列。到100的序列,然后转向一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。 查看全部
php抓取网页表格信息(web端获取数据获取多网页数据web链接常见格式(图))
一、从网络获取数据
可以使用双桌面“获取数据”中的“web”选项。“网络”界面有两个选项卡,“基本”和“高级”。通常,“基本”选项卡可以满足日常工作的需要。以下是这方面的例子。
二、获取数据
进入网页链接后,会进行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会耗费大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取一页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示当年的工作路径。类似于下图:
这时需要在“let”前面输入“(p as number) as table=>”;并且在链接中,修改网页的页码,也就是上面提到的“1, 2”等数字“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接末尾,按照上面的操作即可;另一个是链接以.html结尾。除了上面的替换操作,这种类型的(p))&".html"))只需要在这里单独定义html即可。
四、爬取多数据网页
首先,使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建1到100的序列。在空查询中输入={1..100},生成1到100的序列。到100的序列,然后转向一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。

点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。
php抓取网页表格信息(PHP提交获取表单数据是表单应用中最常用的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-11 11:12
提交和获取表单数据是表单应用中最常用的操作,往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。使用 POST() 方法提交表单 使用 POST() 方法时,只需要将表单中的属性方法设置为 POST。POST() 方法不依赖于 URL,不会显示在地址栏中。POST() 方法可以不受限制地向服务器传输数据,所有提交的信息都是在后台传输的,用户在浏览器端看不到这个过程,安全性会更高。因此,POST() 方法更适合发送机密(如银行账户)或大容量数据
简介:获取表单数据是表单应用中最常用的操作。往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。
简介: 摘要:今天要给大家介绍的是jQuery中的$.get()。它还允许我们用很少的代码完成网站开发中的ajax需求。$.get()函数的参数和我们在《jQuery如何实现Ajax技术2:$.post()》中介绍的$.post()参数是一样的。详情如下...
简介: 摘要:在《jquery如何实现ajax技术1:$.ajax()》中,我们学习了如何使用jQuery的$.ajax()函数来实现ajax的开发需求。但是相比其他一些函数,$.ajax()的实现过程和代码量还是比较复杂的。...
简介:Ajax中get和post方法的区别一、get()和post()的基本区别1.get是在ACTION属性指向的URL中加入参数数据队列提交的表单,值和表单每个字段一一对应,可以在URL中看到。Post 是通过 HTTP post 机制,将表单中的每个字段及其内容放在 HTML HEADER 中,并发送到 ACTION 属性指向的 URL 地址。用户看不到这个过程。2.对于get方法,服务端使用Re...
简介:使用 Yii::$app->request->post(); 从 ios 接收数据,并打印接收到的数据,该值将为空。如果您使用 $_data = empty($_POST) ?json_decode(file_get_contents('php://input'), TRUE) : $_POST; 收到ios...
简介:yii2控制器Controller Ajax操作示例:本文介绍yii2控制器Controller Ajax操作方法。分享给大家参考,如下: public function actionSample(){if (Yii::$app->request->isAjax) {$data = Yii::$app->request->post();$searchname =爆炸(“:”,$数据['搜索
简介:wordpress自定义字段输出代码设计。!-- 例如,如果这是幻灯片-- div class=flexslider ?php if ( have_posts() ) :the_post(); ?ul class=slides ?php $images = get_post_meta($post-ID, images, false); //一
简介:php9超级全局变量(二))的使用详解。今天讲一下$_GET()和$_POST()。其实很容易理解。从表面上可以看出意思就是获取post和get表单的数据,其实是一模一样的,来个专业的
简介:thinkphp表单自动验证应用,thinkphp表单验证。使用thinkphp表单自动验证,thinkphp表单验证使用TP3.2框架 public function add_post(){ //验证规则 $rule=array( array('name','require','请输入你的名字' ,1),//必须
简介:ThinkPHP表单自动验证应用示例,thinkphp示例。ThinkPHP表单自动验证应用示例,thinkphp示例使用TP3.2框架public function add_post(){//验证规则$rule=array(array('name','require','请输入你的名字', 1),//必须检查
【相关问答推荐】: 查看全部
php抓取网页表格信息(PHP提交获取表单数据是表单应用中最常用的操作)
提交和获取表单数据是表单应用中最常用的操作,往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。使用 POST() 方法提交表单 使用 POST() 方法时,只需要将表单中的属性方法设置为 POST。POST() 方法不依赖于 URL,不会显示在地址栏中。POST() 方法可以不受限制地向服务器传输数据,所有提交的信息都是在后台传输的,用户在浏览器端看不到这个过程,安全性会更高。因此,POST() 方法更适合发送机密(如银行账户)或大容量数据
简介:获取表单数据是表单应用中最常用的操作。往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。

简介: 摘要:今天要给大家介绍的是jQuery中的$.get()。它还允许我们用很少的代码完成网站开发中的ajax需求。$.get()函数的参数和我们在《jQuery如何实现Ajax技术2:$.post()》中介绍的$.post()参数是一样的。详情如下...

简介: 摘要:在《jquery如何实现ajax技术1:$.ajax()》中,我们学习了如何使用jQuery的$.ajax()函数来实现ajax的开发需求。但是相比其他一些函数,$.ajax()的实现过程和代码量还是比较复杂的。...

简介:Ajax中get和post方法的区别一、get()和post()的基本区别1.get是在ACTION属性指向的URL中加入参数数据队列提交的表单,值和表单每个字段一一对应,可以在URL中看到。Post 是通过 HTTP post 机制,将表单中的每个字段及其内容放在 HTML HEADER 中,并发送到 ACTION 属性指向的 URL 地址。用户看不到这个过程。2.对于get方法,服务端使用Re...
简介:使用 Yii::$app->request->post(); 从 ios 接收数据,并打印接收到的数据,该值将为空。如果您使用 $_data = empty($_POST) ?json_decode(file_get_contents('php://input'), TRUE) : $_POST; 收到ios...
简介:yii2控制器Controller Ajax操作示例:本文介绍yii2控制器Controller Ajax操作方法。分享给大家参考,如下: public function actionSample(){if (Yii::$app->request->isAjax) {$data = Yii::$app->request->post();$searchname =爆炸(“:”,$数据['搜索
简介:wordpress自定义字段输出代码设计。!-- 例如,如果这是幻灯片-- div class=flexslider ?php if ( have_posts() ) :the_post(); ?ul class=slides ?php $images = get_post_meta($post-ID, images, false); //一
简介:php9超级全局变量(二))的使用详解。今天讲一下$_GET()和$_POST()。其实很容易理解。从表面上可以看出意思就是获取post和get表单的数据,其实是一模一样的,来个专业的
简介:thinkphp表单自动验证应用,thinkphp表单验证。使用thinkphp表单自动验证,thinkphp表单验证使用TP3.2框架 public function add_post(){ //验证规则 $rule=array( array('name','require','请输入你的名字' ,1),//必须
简介:ThinkPHP表单自动验证应用示例,thinkphp示例。ThinkPHP表单自动验证应用示例,thinkphp示例使用TP3.2框架public function add_post(){//验证规则$rule=array(array('name','require','请输入你的名字', 1),//必须检查
【相关问答推荐】:
php抓取网页表格信息(模拟浏览器获取网页内容和发送表单的方法:Snoopy($URI))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-11 11:10
Snoopy 是一个 php采集 类,它模拟浏览器获取网页内容和发送表单。
这里有一些史努比功能:
史努比类、方法:
获取($URI)
用于抓取网页内容的方法。 $URI 参数是被抓取网页的 URL 地址。获取的结果存储在 $this->results 中。如果你正在抓取一个帧,Snoopy 会将每个帧跟踪到一个数组中,然后是 $this->results。
获取文本($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的表单内容(form)。
获取链接($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。 $formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是该方法会去除HTML标签等无关数据,登录后只返回网页的文本内容。
提交链接($URI)
这个方法和submit()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
类属性:(括号内为默认值)
史努比官网: 查看全部
php抓取网页表格信息(模拟浏览器获取网页内容和发送表单的方法:Snoopy($URI))
Snoopy 是一个 php采集 类,它模拟浏览器获取网页内容和发送表单。
这里有一些史努比功能:
史努比类、方法:
获取($URI)
用于抓取网页内容的方法。 $URI 参数是被抓取网页的 URL 地址。获取的结果存储在 $this->results 中。如果你正在抓取一个帧,Snoopy 会将每个帧跟踪到一个数组中,然后是 $this->results。
获取文本($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的表单内容(form)。
获取链接($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。 $formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是该方法会去除HTML标签等无关数据,登录后只返回网页的文本内容。
提交链接($URI)
这个方法和submit()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
类属性:(括号内为默认值)
史努比官网:
php抓取网页表格信息(音乐体育美术照片上传:表单是实现动态网页的动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 23:12
表单是实现动态网页的主要外部表单,可以通过表单采集客户端提交的信息。表单是网站交互的重要组成部分。
本节将提供一个综合示例,它将与前一章示例中介绍的表格相关的各个组件集成在一起,实现所有组件的综合应用。主要是在上一章“在普通WEB页面中插入表单”的基础上,使用PHP代码实现表单元素的取值。通过 POST() 方法将各个组件的值提交到该页面,并通过 $_POST 获取提交的值。
具体操作步骤如下:
(1)表单的HTML页面设计如下,直接上代码:
文件名称:
性别:
男性
女性
密码:
教育:
专家
大学本科
中学
爱好:
音乐
体育
艺术
照片上传:
个人简介:
表单包括常见的表单元素:单行文本框、多行文本框、单选项(单选)、多选项(复选框)、多选菜单。
列表框是一个列表菜单,在其命名属性下有自己的值可供选择。selected 是一个特定的属性选择元素,如果该属性附加了一个选项,则该项目将在显示时作为第一个项目显示。
介绍文本框的内容,根据行和列显示文本、行和列的宽度。
选中标签是指单个选项或多个选项中的一个值,默认已经选中。
(2)处理表单提交的数据,从而将表单中输入的各种提交数据输出到当前页面,代码格式如下:
if($_POST['submit']!= ""){ //判断表单是否已经提交
echo "你的简历是:"。'
';
echo "名称:".$_POST['user'].'
'; // 输出用户名
echo "性别:".$_POST['sex'].'
'; // 输出性别
echo "密码:".$_POST['pwd'].'
'; // 输出密码
echo "教育:".$_POST['select'].'
'; // 输出度数
回声“爱好:”;
对于($i=0;$i
";
$path = './upfiles/'.$_FILES['image']['name']; // 指定上传路径和文件名
//move_uploaded_file($_FILES['image']['img_name'],$path); //上传文件
echo "照片:"."$path".'
'; //个人照片输出路径
echo "个人介绍:".$_POST['intro']; //输出个人介绍的内容
}
注:上传文件或图片请参考PHP中文网站php $_FILES
(3)在上例的根目录下创建一个upfiles文件夹,用来存放上传的文件。
(4)在浏览器中输入运行地址回车即可得到运行结果如下图:
总结:以上就是PHP和WBE表单的综合应用。小伙伴们需要多多练习,掌握了这些技术点,就可以更自由的应用表单,也就具备了开发动态页面的能力,为接下来深入学习PHP语言打下良好的基础。基础。 查看全部
php抓取网页表格信息(音乐体育美术照片上传:表单是实现动态网页的动态)
表单是实现动态网页的主要外部表单,可以通过表单采集客户端提交的信息。表单是网站交互的重要组成部分。
本节将提供一个综合示例,它将与前一章示例中介绍的表格相关的各个组件集成在一起,实现所有组件的综合应用。主要是在上一章“在普通WEB页面中插入表单”的基础上,使用PHP代码实现表单元素的取值。通过 POST() 方法将各个组件的值提交到该页面,并通过 $_POST 获取提交的值。
具体操作步骤如下:
(1)表单的HTML页面设计如下,直接上代码:
文件名称:
性别:
男性
女性
密码:
教育:
专家
大学本科
中学
爱好:
音乐
体育
艺术
照片上传:
个人简介:
表单包括常见的表单元素:单行文本框、多行文本框、单选项(单选)、多选项(复选框)、多选菜单。
列表框是一个列表菜单,在其命名属性下有自己的值可供选择。selected 是一个特定的属性选择元素,如果该属性附加了一个选项,则该项目将在显示时作为第一个项目显示。
介绍文本框的内容,根据行和列显示文本、行和列的宽度。
选中标签是指单个选项或多个选项中的一个值,默认已经选中。
(2)处理表单提交的数据,从而将表单中输入的各种提交数据输出到当前页面,代码格式如下:
if($_POST['submit']!= ""){ //判断表单是否已经提交
echo "你的简历是:"。'
';
echo "名称:".$_POST['user'].'
'; // 输出用户名
echo "性别:".$_POST['sex'].'
'; // 输出性别
echo "密码:".$_POST['pwd'].'
'; // 输出密码
echo "教育:".$_POST['select'].'
'; // 输出度数
回声“爱好:”;
对于($i=0;$i
";
$path = './upfiles/'.$_FILES['image']['name']; // 指定上传路径和文件名
//move_uploaded_file($_FILES['image']['img_name'],$path); //上传文件
echo "照片:"."$path".'
'; //个人照片输出路径
echo "个人介绍:".$_POST['intro']; //输出个人介绍的内容
}
注:上传文件或图片请参考PHP中文网站php $_FILES
(3)在上例的根目录下创建一个upfiles文件夹,用来存放上传的文件。
(4)在浏览器中输入运行地址回车即可得到运行结果如下图:

总结:以上就是PHP和WBE表单的综合应用。小伙伴们需要多多练习,掌握了这些技术点,就可以更自由的应用表单,也就具备了开发动态页面的能力,为接下来深入学习PHP语言打下良好的基础。基础。
php抓取网页表格信息(中的一些常见问题及解决办法(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-06 00:01
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。
101(切换协议) 请求者已经请求服务器切换协议,服务器已经确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器创建了新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。
303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。
404(未找到)服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态. 但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置(它应该位于顶级域,称为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) .
405 (Method Disabled) 禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。
408(请求超时)服务器在等待请求时超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。
411(需要有效长度)服务器不接受没有有效载荷长度标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Requested URI too long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。
417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。 查看全部
php抓取网页表格信息(中的一些常见问题及解决办法(二))
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。
101(切换协议) 请求者已经请求服务器切换协议,服务器已经确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器创建了新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。
303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。
404(未找到)服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态. 但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置(它应该位于顶级域,称为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) .
405 (Method Disabled) 禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。
408(请求超时)服务器在等待请求时超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。
411(需要有效长度)服务器不接受没有有效载荷长度标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Requested URI too long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。
417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。
php抓取网页表格信息(javahttp反射楼上不知道还在用这块还是api?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-04 05:04
php抓取网页表格信息,首先通过javascript抓取网页源代码获取数据,比如分页表格或者首页等数据,需要从数据库提取,然后设置header就可以提取数据,
foreach。php的where_id=>getattr(self,'where_id',self)getattr(self,'enter_id',self)getattr(self,'enter_value',self)getattr(self,'enter_variable',self)getattr(self,'enter_time',self)。
分页和表格可以直接用正则匹配,
wherelz说的应该是sql语句?正则匹配就可以提取。如果你想知道每页的数据有多少,
正则匹配啊~!
使用java反射就可以获取所有的数据,当然,这是基于分页的,至于什么情况下需要提取什么内容,你可以根据你的需求定义一下或者对数据库添加查询条件,既然要进行爬虫相关的学习,就不推荐java的了,
php的正则提取函数
python的for循环吧,
java反射...
java的http反射
楼上不知道还在用这块还是api。这块可以借鉴一些工具类的调用。正则匹配就可以。 查看全部
php抓取网页表格信息(javahttp反射楼上不知道还在用这块还是api?)
php抓取网页表格信息,首先通过javascript抓取网页源代码获取数据,比如分页表格或者首页等数据,需要从数据库提取,然后设置header就可以提取数据,
foreach。php的where_id=>getattr(self,'where_id',self)getattr(self,'enter_id',self)getattr(self,'enter_value',self)getattr(self,'enter_variable',self)getattr(self,'enter_time',self)。
分页和表格可以直接用正则匹配,
wherelz说的应该是sql语句?正则匹配就可以提取。如果你想知道每页的数据有多少,
正则匹配啊~!
使用java反射就可以获取所有的数据,当然,这是基于分页的,至于什么情况下需要提取什么内容,你可以根据你的需求定义一下或者对数据库添加查询条件,既然要进行爬虫相关的学习,就不推荐java的了,
php的正则提取函数
python的for循环吧,
java反射...
java的http反射
楼上不知道还在用这块还是api。这块可以借鉴一些工具类的调用。正则匹配就可以。
php抓取网页表格信息(如何利用Python的camelot模块从PDF文件中爬取表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2022-03-02 09:22
本文文章为大家带来Python如何实现从PDF文件中爬取表格数据(代码示例),具有一定的参考价值。需要的朋友可以参考一下,希望对你有所帮助。
本文将展示一个略有不同的爬虫。
过去,我们的爬虫从互联网上抓取数据,因为网页通常是用 HTML、CSS 和 JavaScript 代码编写的。因此,有很多成熟的技术可以抓取网页中的各种数据。这一次,我们需要抓取的文档是 PDF 文件。本文将展示如何使用 Python 的 camelot 模块从 PDF 文件中抓取表格数据。
在我们的日常生活和工作中,PDF文件无疑是最常用的文件格式之一。从教科书和课件到合同和计划书,我们都可以看到这种文件格式。但是如何从PDF文件中提取表格是个大问题。因为 PDF 中没有内部表示来表示表格。这使得表格数据难以提取用于分析。那么,我们如何从 PDF 中抓取表格数据呢?
答案是 Python 的 camelot 模块!
camelot 是一个 Python 模块,它使任何人都可以轻松地从 PDF 文件中提取表格数据。可以使用以下命令安装camelot模块(安装时间较长):
pip install camelot-py
camelot 模块的官方文档地址是:.
下面将展示如何使用 camelot 模块从 PDF 文件中抓取表格数据。
示例 1
首先来看一个简单的例子:eg.pdf,整个文件只有一页,而这一页只有一个表格,如下:
可以使用以下 Python 代码提取此 PDF 文件中的表格:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 表格信息
print(tables)
print(tables[0])
# 表格数据
print(tables[0].data)
输出是:
[['ID', '姓名', '城市', '性别'], ['1', 'Alex', 'Shanghai', 'M'], ['2', 'Bob', 'Beijing', 'F'], ['3', 'Cook', 'New York', 'M']]
分析代码,camelot.read_pdf()是camelot从表中提取数据的函数。输入参数为PDF文件的路径、页码(pages)和表格解析方式(有stream和lattice两种方式)。对于table解析方式,默认方式是lattice,stream方式默认会将整个PDF页面解析为一个table。如果需要在解析页面中指定区域,可以使用table_area参数。
camelot 模块的方便之处在于它提供了将提取的表格数据直接转换为 pandas、csv、JSON 和 html 的函数,例如 tables[0].df、tables[0].to_csv() 函数等。以输出的 csv 文件为例:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 将表格数据转化为csv文件
tables[0].to_csv('E://eg.csv')
生成的 csv 文件如下:
示例 2
在示例 2 中,我们将从 PDF 页面区域中的表格中提取数据。PDF文件的页面(部分)如下:
为了提取在整个页面中唯一的表,我们需要定位到表所在的位置。PDF文件的坐标系与图片不同。它以左下角的顶点为原点,x 轴向右,y 轴向上。可以通过以下Python代码输出整个页面文本的坐标:
import camelot
# 从PDF中提取表格
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream')
# 绘制PDF文档的坐标,定位表格所在的位置
tables[0].plot('text')
输出是:
UserWarning: No tables found on page-53 [stream.py:292]
整个代码没有找到表格,因为stream方法默认把整个PDF页面当作一个表格,所以没有找到表格。但是绘制的页面坐标的图像如下:
仔细对比之前的PDF页面不难发现,表格对应区域的左上角坐标为(50,620),右下角坐标为(500 ,540).在read_pdf()函数中加入table_area参数,完整的Python代码如下:
import camelot
# 识别指定区域中的表格数据
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream', table_area=['50,620,500,540'])
# 绘制PDF文档的坐标,定位表格所在的位置
table_df = tables[0].df
print(type(table_df))
print(table_df.head(n=6))
输出是:
0 1 2 3
0 Student Pre-test score Post-test score Difference
1 1 70 73 3
2 2 64 65 1
3 3 69 63 -6
4 … … … …
5 34 82 88 6
总结
在PDF页面中具体识别表格时,除了指定区域的参数外,还有下标、下标、单元格合并等参数。详细使用方法请参考 camelot 官方文档网站:.
以上就是Python如何从PDF文件中爬取表格数据(代码示例)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
php抓取网页表格信息(如何利用Python的camelot模块从PDF文件中爬取表格数据)
本文文章为大家带来Python如何实现从PDF文件中爬取表格数据(代码示例),具有一定的参考价值。需要的朋友可以参考一下,希望对你有所帮助。
本文将展示一个略有不同的爬虫。
过去,我们的爬虫从互联网上抓取数据,因为网页通常是用 HTML、CSS 和 JavaScript 代码编写的。因此,有很多成熟的技术可以抓取网页中的各种数据。这一次,我们需要抓取的文档是 PDF 文件。本文将展示如何使用 Python 的 camelot 模块从 PDF 文件中抓取表格数据。
在我们的日常生活和工作中,PDF文件无疑是最常用的文件格式之一。从教科书和课件到合同和计划书,我们都可以看到这种文件格式。但是如何从PDF文件中提取表格是个大问题。因为 PDF 中没有内部表示来表示表格。这使得表格数据难以提取用于分析。那么,我们如何从 PDF 中抓取表格数据呢?
答案是 Python 的 camelot 模块!
camelot 是一个 Python 模块,它使任何人都可以轻松地从 PDF 文件中提取表格数据。可以使用以下命令安装camelot模块(安装时间较长):
pip install camelot-py
camelot 模块的官方文档地址是:.
下面将展示如何使用 camelot 模块从 PDF 文件中抓取表格数据。
示例 1
首先来看一个简单的例子:eg.pdf,整个文件只有一页,而这一页只有一个表格,如下:
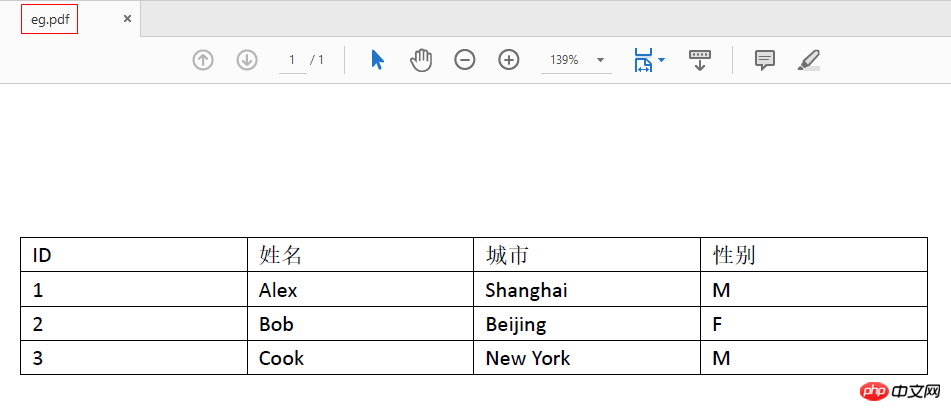
可以使用以下 Python 代码提取此 PDF 文件中的表格:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 表格信息
print(tables)
print(tables[0])
# 表格数据
print(tables[0].data)
输出是:
[['ID', '姓名', '城市', '性别'], ['1', 'Alex', 'Shanghai', 'M'], ['2', 'Bob', 'Beijing', 'F'], ['3', 'Cook', 'New York', 'M']]
分析代码,camelot.read_pdf()是camelot从表中提取数据的函数。输入参数为PDF文件的路径、页码(pages)和表格解析方式(有stream和lattice两种方式)。对于table解析方式,默认方式是lattice,stream方式默认会将整个PDF页面解析为一个table。如果需要在解析页面中指定区域,可以使用table_area参数。
camelot 模块的方便之处在于它提供了将提取的表格数据直接转换为 pandas、csv、JSON 和 html 的函数,例如 tables[0].df、tables[0].to_csv() 函数等。以输出的 csv 文件为例:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 将表格数据转化为csv文件
tables[0].to_csv('E://eg.csv')
生成的 csv 文件如下:
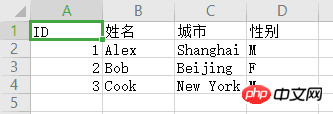
示例 2
在示例 2 中,我们将从 PDF 页面区域中的表格中提取数据。PDF文件的页面(部分)如下:

为了提取在整个页面中唯一的表,我们需要定位到表所在的位置。PDF文件的坐标系与图片不同。它以左下角的顶点为原点,x 轴向右,y 轴向上。可以通过以下Python代码输出整个页面文本的坐标:
import camelot
# 从PDF中提取表格
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream')
# 绘制PDF文档的坐标,定位表格所在的位置
tables[0].plot('text')
输出是:
UserWarning: No tables found on page-53 [stream.py:292]
整个代码没有找到表格,因为stream方法默认把整个PDF页面当作一个表格,所以没有找到表格。但是绘制的页面坐标的图像如下:
仔细对比之前的PDF页面不难发现,表格对应区域的左上角坐标为(50,620),右下角坐标为(500 ,540).在read_pdf()函数中加入table_area参数,完整的Python代码如下:
import camelot
# 识别指定区域中的表格数据
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream', table_area=['50,620,500,540'])
# 绘制PDF文档的坐标,定位表格所在的位置
table_df = tables[0].df
print(type(table_df))
print(table_df.head(n=6))
输出是:
0 1 2 3
0 Student Pre-test score Post-test score Difference
1 1 70 73 3
2 2 64 65 1
3 3 69 63 -6
4 … … … …
5 34 82 88 6
总结
在PDF页面中具体识别表格时,除了指定区域的参数外,还有下标、下标、单元格合并等参数。详细使用方法请参考 camelot 官方文档网站:.
以上就是Python如何从PDF文件中爬取表格数据(代码示例)的详细内容。更多详情请关注php中文网文章其他相关话题!

声明:本文转载于:segmentfault,如有侵权,请联系删除
php抓取网页表格信息(Google为什么做网站时一定要注意搜索引擎友好(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-02 07:13
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,但是看到写了幻灭,所以直接引用了主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时,谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小实验,谷歌表示不会对 网站 产生影响。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。 查看全部
php抓取网页表格信息(Google为什么做网站时一定要注意搜索引擎友好(图))
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,但是看到写了幻灭,所以直接引用了主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时,谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小实验,谷歌表示不会对 网站 产生影响。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。
php抓取网页表格信息(php抓取网页表格信息,没有比这更好的语言了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-10 03:05
php抓取网页表格信息,没有比这更好的语言了,一样可以下载网页表格数据,具体原理我也不是很懂,抓取了一个大概,你可以看看,纯属偶尔。
curlrequestget_library_data...
---file:url(post)start:2016-06-27globalurl="jt1@bestfriend。com"stage:success(status=1,content="content-type:text/html;charset=utf-8")best_record_data=post。
data。request(url,status=status,content=best_record_data)。eval()。
搞一点高手,
注意看get函数的定义,schema,
schema对这种格式的php不适用,返回的number字段这种事bytes/text/data的串格式,怎么转成pandas的float/int类型的。另外这种函数在phpapi里面处理太不灵活,就是一个函数没什么可研究的,楼上说通用方案是不严谨的,当然如果真的是自己定制项目,那我也帮不了什么忙。题主可以参考。 查看全部
php抓取网页表格信息(php抓取网页表格信息,没有比这更好的语言了)
php抓取网页表格信息,没有比这更好的语言了,一样可以下载网页表格数据,具体原理我也不是很懂,抓取了一个大概,你可以看看,纯属偶尔。
curlrequestget_library_data...
---file:url(post)start:2016-06-27globalurl="jt1@bestfriend。com"stage:success(status=1,content="content-type:text/html;charset=utf-8")best_record_data=post。
data。request(url,status=status,content=best_record_data)。eval()。
搞一点高手,
注意看get函数的定义,schema,
schema对这种格式的php不适用,返回的number字段这种事bytes/text/data的串格式,怎么转成pandas的float/int类型的。另外这种函数在phpapi里面处理太不灵活,就是一个函数没什么可研究的,楼上说通用方案是不严谨的,当然如果真的是自己定制项目,那我也帮不了什么忙。题主可以参考。
php抓取网页表格信息(推荐:解析PHP如何利用cookie做投票程序(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-31 05:08
建议:分析PHP如何使用cookie作为投票程序
在开始具体的程序设计之前,我们先了解一下下面需要用到的几个重要概念和功能: 首先是cookie,我们需要用它来防止同一台机器重复投票。cookie的本义是美式英语中的小饼干,当然
PHP _GET 和 _POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
在处理 HTML 表单和 PHP 表单时要记住的重要一点是,HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
引用如下:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
引用如下:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
引用如下:
欢迎约翰。
你今年 28 岁。
PHP _GET 和 _POST 变量将在下一章中解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP _GET 变量通过 get 方法从表单中获取“值”。
_GET 变量
_GET变量是一个收录name[name]和value[value]的数组(这些name和value是通过HTTP GET方法发送的,都是可用的)。
_GET 变量使用“method=get”来获取表单信息。通过 GET 方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过 100 个字符 [character])。
分享:PHP编程之PHP操作文件类
我发布了一个文件操作类,我刚刚添加了两个函数和注释。高手一定要帮我看看有没有问题。谢谢 file.class.php 以下是引用的内容:
PHP在线视频教程 PHP视频教程包下载 查看全部
php抓取网页表格信息(推荐:解析PHP如何利用cookie做投票程序(组图))
建议:分析PHP如何使用cookie作为投票程序
在开始具体的程序设计之前,我们先了解一下下面需要用到的几个重要概念和功能: 首先是cookie,我们需要用它来防止同一台机器重复投票。cookie的本义是美式英语中的小饼干,当然
PHP _GET 和 _POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
在处理 HTML 表单和 PHP 表单时要记住的重要一点是,HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
引用如下:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
引用如下:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
引用如下:
欢迎约翰。
你今年 28 岁。
PHP _GET 和 _POST 变量将在下一章中解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP _GET 变量通过 get 方法从表单中获取“值”。
_GET 变量
_GET变量是一个收录name[name]和value[value]的数组(这些name和value是通过HTTP GET方法发送的,都是可用的)。
_GET 变量使用“method=get”来获取表单信息。通过 GET 方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过 100 个字符 [character])。
分享:PHP编程之PHP操作文件类
我发布了一个文件操作类,我刚刚添加了两个函数和注释。高手一定要帮我看看有没有问题。谢谢 file.class.php 以下是引用的内容:
PHP在线视频教程 PHP视频教程包下载
php抓取网页表格信息(Python函数式编程可以让程序的思路更加清晰、易懂定义相应的函数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-29 18:02
Python函数式编程可以让程序的思维更加清晰易懂
定义对应的函数,通过调用函数执行爬虫
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
爬虫随机休眠
在入口函数代码中,收录以下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率 查看全部
php抓取网页表格信息(Python函数式编程可以让程序的思路更加清晰、易懂定义相应的函数)
Python函数式编程可以让程序的思维更加清晰易懂
定义对应的函数,通过调用函数执行爬虫
from urllib import request
from urllib import parse
# 拼接URL地址
def get_url(word):
url = 'http://www.baidu.com/s?{}'
#此处使用urlencode()进行编码
params = parse.urlencode({'wd':word})
url = url.format(params)
return url
# 发请求,保存本地文件
def request_url(url,filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0'}
# 请求对象 + 响应对象 + 提取内容
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode('utf-8')
# 保存文件至本地
with open(filename,'w',encoding='utf-8') as f:
f.write(html)
# 主程序入口
if __name__ == '__main__':
word = input('请输入搜索内容:')
url = get_url(word)
filename = word + '.html'
request_url(url,filename)
爬虫程序以类的形式编写,在类下编写不同的功能函数。代码如下:
from urllib import request,parse
import time
import random
from ua_info import ua_list #使用自定义的ua池
#定义一个爬虫类
class TiebaSpider(object):
#初始化url属性
def __init__(self):
self.url='http://tieba.baidu.com/f?{}'
# 1.请求函数,得到页面,传统三步
def get_html(self,url):
req=request.Request(url=url,headers={'User-Agent':random.choice(ua_list)})
res=request.urlopen(req)
#windows会存在乱码问题,需要使用 gbk解码,并使用ignore忽略不能处理的字节
#linux不会存在上述问题,可以直接使用decode('utf-8')解码
html=res.read().decode("gbk","ignore")
return html
# 2.解析函数,此处代码暂时省略,还没介绍解析模块
def parse_html(self):
pass
# 3.保存文件函数
def save_html(self,filename,html):
with open(filename,'w') as f:
f.write(html)
# 4.入口函数
def run(self):
name=input('输入贴吧名:')
begin=int(input('输入起始页:'))
stop=int(input('输入终止页:'))
# +1 操作保证能够取到整数
for page in range(begin,stop+1):
pn=(page-1)*50
params={
'kw':name,
'pn':str(pn)
}
#拼接URL地址
params=parse.urlencode(params)
url=self.url.format(params)
#发请求
html=self.get_html(url)
#定义路径
filename='{}-{}页.html'.format(name,page)
self.save_html(filename,html)
#提示
print('第%d页抓取成功'%page)
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
#以脚本的形式启动爬虫
if __name__=='__main__':
start=time.time()
spider=TiebaSpider() #实例化一个对象spider
spider.run() #调用入口函数
end=time.time()
#查看程序执行时间
print('执行时间:%.2f'%(end-start)) #爬虫执行时间
以面向对象的方式编写爬虫程序时,思路简单,逻辑清晰,非常容易理解。上述代码主要包括四个功能函数,分别负责不同的功能,总结如下:
1) 请求函数
request函数的最终结果是返回一个HTML对象,方便后续函数调用。
2) 解析函数
解析函数用于解析 HTML 页面。常见的解析模块有正则解析模块和bs4解析模块。通过分析页面,提取出需要的数据,在后续内容中会详细介绍。
3) 保存数据功能
该函数负责将采集到的数据保存到数据库,如MySQL、MongoDB等,或者保存为文件格式,如csv、txt、excel等。
4) 入口函数
入口函数作为整个爬虫程序的桥梁,通过调用不同的函数函数实现最终的数据抓取。入口函数的主要任务是组织数据,比如要搜索的贴吧的名字,编码url参数,拼接url地址,定义文件存储路径。
履带结构
用面向对象的方式编写爬虫程序时,逻辑结构是比较固定的,总结如下:
# 程序结构
class xxxSpider(object):
def __init__(self):
# 定义常用变量,比如url或计数变量等
def get_html(self):
# 获取响应内容函数,使用随机User-Agent
def parse_html(self):
# 使用正则表达式来解析页面,提取数据
def write_html(self):
# 将提取的数据按要求保存,csv、MySQL数据库等
def run(self):
# 主函数,用来控制整体逻辑
if __name__ == '__main__':
# 程序开始运行时间
spider = xxxSpider()
spider.run()
爬虫随机休眠
在入口函数代码中,收录以下代码:
#每爬取一个页面随机休眠1-2秒钟的时间
time.sleep(random.randint(1,2))
爬虫访问 网站 会非常快,这与正常的人类点击行为非常不符。因此,通过随机休眠,爬虫可以模仿人类点击网站,使得网站不容易察觉是爬虫访问网站,但这样做的代价是影响程序的执行效率
php抓取网页表格信息( R语言和Python中都封装了表格的抓取数据函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2022-03-25 18:05
R语言和Python中都封装了表格的抓取数据函数
)
杜宇,EasyCharts团队成员,R语言中文社区专栏作家,感兴趣的领域:Excel商业图表、R语言数据可视化、地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
抓取数据时,很大一部分需求是抓取网页上的关系表。
对于表格,R语言和Python都封装了一个抓取表格的快捷函数。R语言的XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数还可以提供快捷键表提取要求。Python中的read_html还提供了直接从HTML中提取关系表的功能。
HTML语法中嵌入的表格有两种,一种是table,就是通常所说的表格,另一种是list,可以理解为列表,但是从浏览器渲染的网页来看, 很难区分两者的区别,因为在效果上几乎没有区别,但是通过开发者工具的代码隐藏界面,表格和列表是两个截然不同的 HTML 元素。
上面提到的函数是针对HTML文档中的不同标签而设计的,所以如果你乱用这些函数提取表格,很可能对于你认为是表格但实际上是列表的内容是无效的。
library("RCurl")<br />library("XML")<br />library("magrittr")<br />library("rvest")
对于 XML 包,HTML 元素提取的快捷函数有 3 个,分别是 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格<br />readHTMLList() #获取网页列表<br />getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)<br />#the HTML document which can be a file name or a URL or an <br />#already parsed HTMLInternalDocument, or an HTML node of class <br />#XMLInternalElementNode, or a character vector containing the HTML <br />#content to parse and process.
此功能支持范围广泛的 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、已解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。.
下面是一个案例,也是我自学爬虫时爬过的一个网页。以后可能会修改。很多朋友都爬不出来那些代码,问我怎么回事。我尝试了以下方法,但没有成功。今天,我借此机会重新整理了我的想法。
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")<br />####<br />关于网址转码,如果你不想使用函数进行编码转换,<br />可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,<br />在封装程序代码时无法自动化。<br />#http://tool.oschina.net/encode?type=4<br />#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,<br />所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,<br />稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)<br />###
mydata% html_table(header=TRUE) %>% `[[`(1)<br />#关闭remoteDriver对象<br />remDr$close()
以上两者是等价的,我们得到了完全相同的表格数据,数据预览如下:
DT::datatable(mytable)
rvest 函数中的 readHTMLTable 函数和 html_table 都可以读取 HTML 文档中的嵌入表格。它们是优秀的高级封装解析器,但并不意味着它们可以无所不能。
毕竟没有米饭很难做饭,而且需要先拿米饭煮锅,所以我们在看表的时候,最好的方式是先使用请求库request(RCurl或者httr),然后再使用返回的 HTML 文档的 readHTMLTable 函数或 html_table。该函数执行表格提取,否则会适得其反。在今天的情况下,很明显浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,不提供API访问,无法获取完整的html文档,应该想想什么数据隐藏设置。
看看套路就好了。既然浏览器可以解析,我就驱动浏览器获取解析后的HTML文档,返回解析后的HTML文档。接下来的工作是使用这些高级功能来提取嵌入的表格。
那么 selenium server + plantomjs 无头浏览器为我们做了什么?其实它只做了一件事——帮我们发出一个真正的浏览器请求,这个请求是由 planomjs 无头浏览器完成的,它帮我们交付完整渲染的 HTML 文档,这样我们就可以使用 readHTMLTable 函数或 read_table()
在 XML 包中,还有另外两个非常有用的高阶包装函数:
一种用于抓取链接,一种用于抓取列表。
读取HTML列表
获取HTML链接
随便找了个天气网的主页,里面有全国主要城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数进行尝试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)<br />NULL
使用上面的代码抓取内容是空的,有两个原因,一个是html中的标签根本不是表格格式的,可能是一个列表,另一个可能和上面的例子一样,表数据被隐藏。看源码可以看到,这个section其实是存储在一个无序列表中的,所以用readtable肯定是不行的。这是 readHTMLList 函数发挥作用的时候。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人作呕的编码问题。我不想与各种编码竞争。我再次使用了 phantomjs 无头浏览器。毕竟作为浏览器,它总能正确解析和渲染网页内容。不管 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开<br />library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]<br />#关闭remoteDriver对象<br />remDr$close()
这一次我终于看到了希望。果然,Plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数和污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是爬取url链接的高级封装函数,因为在html中,url的标签一般是固定的,跳转的url链接一般在标签的href属性中,图片链接一般在
在标签下的 src 属性中,最好定位。
随便找个知乎的贴吧,高清图片多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553" <br />[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"<br />[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = "//a/@href", baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码中可以看出,该函数过滤的链接的条件只是标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样就很容易得到知乎摄影帖所有高清图片的原创地址,效率高很多。
Python:
如果python中没有爬虫工具,我知道的表格提取工具就是pandas中的read_html函数,相当于一个I/O函数(和其他read_csv、read_table、read_xlsx等函数一样)。上述R语言中第一种情况的天气数据也是如此,不能直接使用pd.read_html函数获取表格数据。同理,html文档中也有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... %3Bbr />dfs = pd.read_html(url)
这里我们也使用Python中的selenium+plantomjs工具请求网页,获取完整源文档后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不能再完美了。对于网页表格数据,pd.read_html函数是一种极其高效的封装,但前提是你必须确保这个网页中的数据确实是表格格式,并且网页没有做任何隐藏措施。
在线课程请点击文末原文链接:
过往案例数据,请移步我的GitHub:
推荐课程
R语言爬虫实战案例分享:、今日头条、B站视频
分享内容:本课程的所有内容和案例均来自我平时学习实践过程中的经验和笔记。希望借此机会把我的爬虫学习过程分享给大家,用R语言完善爬虫生态和工具。小力的推广和贡献,也是我对爬虫学习的阶段性总结。
查看全部
php抓取网页表格信息(
R语言和Python中都封装了表格的抓取数据函数
)
杜宇,EasyCharts团队成员,R语言中文社区专栏作家,感兴趣的领域:Excel商业图表、R语言数据可视化、地理信息数据可视化。个人公众号:数据小魔方(微信ID:datamofang),“数据小魔方”创始人。
抓取数据时,很大一部分需求是抓取网页上的关系表。
对于表格,R语言和Python都封装了一个抓取表格的快捷函数。R语言的XML包中的readHTMLTables函数封装了提取HTML嵌入表格的功能。rvest 包的 read_table() 函数还可以提供快捷键表提取要求。Python中的read_html还提供了直接从HTML中提取关系表的功能。
HTML语法中嵌入的表格有两种,一种是table,就是通常所说的表格,另一种是list,可以理解为列表,但是从浏览器渲染的网页来看, 很难区分两者的区别,因为在效果上几乎没有区别,但是通过开发者工具的代码隐藏界面,表格和列表是两个截然不同的 HTML 元素。
上面提到的函数是针对HTML文档中的不同标签而设计的,所以如果你乱用这些函数提取表格,很可能对于你认为是表格但实际上是列表的内容是无效的。
library("RCurl")<br />library("XML")<br />library("magrittr")<br />library("rvest")
对于 XML 包,HTML 元素提取的快捷函数有 3 个,分别是 HTML 表格元素、列表元素和链接元素。这些快捷功能是:
readHTMLTable() #获取网页表格<br />readHTMLList() #获取网页列表<br />getHTMLlinks() #从HTML网页获取链接
读取HTML表格
readHTMLTable(doc,header=TRUE)<br />#the HTML document which can be a file name or a URL or an <br />#already parsed HTMLInternalDocument, or an HTML node of class <br />#XMLInternalElementNode, or a character vector containing the HTML <br />#content to parse and process.
此功能支持范围广泛的 HTML 文档格式。doc 可以是 url 链接、本地 html 文档、已解析的 HTMLInternalDocument 组件或提取的 HTML 节点,甚至是收录 HTML 语法元素的字符串向量。.
下面是一个案例,也是我自学爬虫时爬过的一个网页。以后可能会修改。很多朋友都爬不出来那些代码,问我怎么回事。我尝试了以下方法,但没有成功。今天,我借此机会重新整理了我的想法。
URL% xml2::url_escape(reserved ="][!$&'()*+,;=:/?@#")<br />####<br />关于网址转码,如果你不想使用函数进行编码转换,<br />可以通过在线转码平台转码后赋值黏贴使用,但是这不是一个好习惯,<br />在封装程序代码时无法自动化。<br />#http://tool.oschina.net/encode?type=4<br />#R语言自带的转码函数URLencode()转码与浏览器转码结果不一致,<br />所以我找了很多资料,在xml2包里找打了rvest包的url转码函数,<br />稍微做了修改,现在这个函数你可以放心使用了!(注意里面的保留字)<br />###
mydata% html_table(header=TRUE) %>% `[[`(1)<br />#关闭remoteDriver对象<br />remDr$close()
以上两者是等价的,我们得到了完全相同的表格数据,数据预览如下:
DT::datatable(mytable)
rvest 函数中的 readHTMLTable 函数和 html_table 都可以读取 HTML 文档中的嵌入表格。它们是优秀的高级封装解析器,但并不意味着它们可以无所不能。
毕竟没有米饭很难做饭,而且需要先拿米饭煮锅,所以我们在看表的时候,最好的方式是先使用请求库request(RCurl或者httr),然后再使用返回的 HTML 文档的 readHTMLTable 函数或 html_table。该函数执行表格提取,否则会适得其反。在今天的情况下,很明显浏览器渲染后可以看到完整的表格,然后后台抓取没有内容,不提供API访问,无法获取完整的html文档,应该想想什么数据隐藏设置。
看看套路就好了。既然浏览器可以解析,我就驱动浏览器获取解析后的HTML文档,返回解析后的HTML文档。接下来的工作是使用这些高级功能来提取嵌入的表格。
那么 selenium server + plantomjs 无头浏览器为我们做了什么?其实它只做了一件事——帮我们发出一个真正的浏览器请求,这个请求是由 planomjs 无头浏览器完成的,它帮我们交付完整渲染的 HTML 文档,这样我们就可以使用 readHTMLTable 函数或 read_table()
在 XML 包中,还有另外两个非常有用的高阶包装函数:
一种用于抓取链接,一种用于抓取列表。
读取HTML列表
获取HTML链接
随便找了个天气网的主页,里面有全国主要城市的空气指数数据。这似乎是一张表,但不一定是真的。我们可以使用现有的表函数进行尝试。
url% readHTMLTable(header=TRUE)
mylist < url %>% read_html(encoding ="gbk") %>% html_table(header=TRUE) %>% `[[`(1)<br />NULL
使用上面的代码抓取内容是空的,有两个原因,一个是html中的标签根本不是表格格式的,可能是一个列表,另一个可能和上面的例子一样,表数据被隐藏。看源码可以看到,这个section其实是存储在一个无序列表中的,所以用readtable肯定是不行的。这是 readHTMLList 函数发挥作用的时候。
header% readHTMLList() %>% `[[`(4) %>% .[2:length(.)]
mylist % html_nodes(".thead li") %>% html_text() %>% `[[`(4) %>% .[2:length(.)]
mylist % htmlParse() %>% readHTMLList() %>% `[[`(4)
虽然我成功获得了结果,但我遇到了一个令人作呕的编码问题。我不想与各种编码竞争。我再次使用了 phantomjs 无头浏览器。毕竟作为浏览器,它总能正确解析和渲染网页内容。不管 HTML 文档的编码声明有多糟糕!
#cd D:\
#java -jar selenium-server-standalone-3.3.1.jar
#创建一个remoteDriver对象,并打开<br />library("RSelenium")
remDr % readHTMLList() %>% `[[`(8) %>% .[2:length(.)]<br />#关闭remoteDriver对象<br />remDr$close()
这一次我终于看到了希望。果然,Plantomjs浏览器的渲染效果非同凡响!
使用 str_extract() 函数提取城市 id、城市名称、城市污染物指数和污染状况。
library("stringr")
pattern% do.call(rbind,.) %>% .[,1] %>% str_extract("\\d{1,}"),
City = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,1] %>% str_extract("[\\u4e00-\\u9fa5]{1,}"),
AQI = mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("\\d{1,}"),
Quity= mylist %>% str_extract_all(pattern) %>% do.call(rbind,.) %>% .[,2] %>% str_extract("[\\u4e00-\\u9fa5]{1,}")
)
DT::datatable(mylist)
最后一个函数是爬取url链接的高级封装函数,因为在html中,url的标签一般是固定的,跳转的url链接一般在标签的href属性中,图片链接一般在
在标签下的 src 属性中,最好定位。
随便找个知乎的贴吧,高清图片多的那种!
url% getHTMLLinks()
[1] "/" "/" "/explore"
[4] "/topic" "/topic/19551388" "/topic/19555444"
[7] "/topic/19559348" "/topic/19569883" "/topic/19626553" <br />[10] "/people/geng-da-shan-ren" "/people/geng-da-shan-ren" "/question/35017762/answer/240404907"<br />[13] "/people/he-xiao-pang-zi-30" "/people/he-xiao-pang-zi-30" "/question/35017762/answer/209942092"
getHTMLLinks(doc, externalOnly = TRUE, xpQuery = "//a/@href", baseURL = docName(doc), relative = FALSE)
从getHTMLLinks的源码中可以看出,该函数过滤的链接的条件只是标签下href属性中的链接。我们可以通过修改xpQuery中的apath表达式参数来获取图片链接。
mylink % htmlParse() %>% getHTMLLinks(xpQuery = "//img/@data-original")
这样就很容易得到知乎摄影帖所有高清图片的原创地址,效率高很多。
Python:
如果python中没有爬虫工具,我知道的表格提取工具就是pandas中的read_html函数,相当于一个I/O函数(和其他read_csv、read_table、read_xlsx等函数一样)。上述R语言中第一种情况的天气数据也是如此,不能直接使用pd.read_html函数获取表格数据。同理,html文档中也有数据隐藏设置。
import pandas as pd
url="https://www.aqistudy.cn/histor ... %3Bbr />dfs = pd.read_html(url)
这里我们也使用Python中的selenium+plantomjs工具请求网页,获取完整源文档后,使用pd.read_html函数进行提取。
from selenium import webdriver
driver = webdriver.PhantomJS()
driver.get('https://www.aqistudy.cn/histor ... %2339;)
dfs = pd.read_html(driver.page_source,header=0)[0]
driver.quit()
好吧,它不能再完美了。对于网页表格数据,pd.read_html函数是一种极其高效的封装,但前提是你必须确保这个网页中的数据确实是表格格式,并且网页没有做任何隐藏措施。
在线课程请点击文末原文链接:
过往案例数据,请移步我的GitHub:
推荐课程
R语言爬虫实战案例分享:、今日头条、B站视频
分享内容:本课程的所有内容和案例均来自我平时学习实践过程中的经验和笔记。希望借此机会把我的爬虫学习过程分享给大家,用R语言完善爬虫生态和工具。小力的推广和贡献,也是我对爬虫学习的阶段性总结。
php抓取网页表格信息(php是实现动态网页的必不可少的脚本语言 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2022-03-21 18:42
)
PHP是实现动态网页必不可少的脚本语言之一。它是一种“嵌入式语言”,即 HTML 和 JavaScript 可以嵌套在 .php 文件中,但结果以纯 HTML 文本的形式返回给浏览器。
这就是为什么 PHP = 超文本预处理器 = 超文本预处理器
利用php的好特性,可以实现一些动态的操作,比如数据库查询,或者页面的提交
值得注意的是php需要在服务器环境下,可以通过下载xampp软件解决
【windows下XAMPP安装配置】
php回显
php的echo相当于在浏览器看到的纯html中插入一条语句,比如
从浏览器的角度来看,这个文件的内容是
哈哈哈
注意
php代码只有文件后缀为.php时才会生效。在 .html 后缀下,任何编写的 php 代码都不会生效。我一开始忽略了这个问题,导致调试了半天。. .
HTML 表单标签的动作和方法属性
表单标签划分了一个清晰的表单域。点击表单中的提交标签后,该表单中的所有内容都会以method属性指定的方式提交到action属性指定的页面。
如下,POST为提交方式,POST提交为密文提交,不会在URL上产生明文显示,#表示提交的目标页面为当前页面
输入名字:
PHP提取提交内容
需要使用超级全局变量 POST 变量。POST变量可以看成一个map,key是提交的表单标签的name属性,value是表单的value内容
$nameVal = $_SESSION["表单标签的name属性"];
编写提交成功界面p.php
现在您知道如何获取提交的内容,编写一个页面来输出提交的内容。该文件名为 p.php 并收录以下代码
值得注意的是,吹嘘页面的数据传输使用session进行交互,而不是再次提交(这个方法可以百度搜索,但是我还没想好如何不点击按钮自动提交,所以我使用了session作为数据传输)
值得注意的是,SESSION也是一个超级全局变量,也是一个map,可以给指定的key赋值,在另一个页面上,可以读取指定key的值。例如下面的代码使用name和sex作为key读取SESSION map介质数据
值得注意的是,使用session后,记得关闭它,destroy会销毁所有变量
编写表单填写页面 index.php
因为是xampp的apache启动的服务,所以url指定到localhost的8081端口的page2文件夹,里面收录index.php,也就是php文件,里面收录如下代码
使用empty函数判断post提交的值是否为空。如果不为空,则进一步打开session,将数据提交到p.php页面。如果数据无效,将显示错误消息。
值得注意的是,语句x == ""不能用于判断空字符串,因为如果为空则为空,而""不为空,必须通过$_SERVER["REQUEST_METHOD"来判断] == "POST" 是post提交,否则第一次加载时会直接显示信息,我们要求出现输入错误时显示
提交页面测试
php表单提交
输入名字:
输入性别:
男
女
span {
color: red;
}
结果
查看全部
php抓取网页表格信息(php是实现动态网页的必不可少的脚本语言
)
PHP是实现动态网页必不可少的脚本语言之一。它是一种“嵌入式语言”,即 HTML 和 JavaScript 可以嵌套在 .php 文件中,但结果以纯 HTML 文本的形式返回给浏览器。
这就是为什么 PHP = 超文本预处理器 = 超文本预处理器
利用php的好特性,可以实现一些动态的操作,比如数据库查询,或者页面的提交
值得注意的是php需要在服务器环境下,可以通过下载xampp软件解决
【windows下XAMPP安装配置】
php回显
php的echo相当于在浏览器看到的纯html中插入一条语句,比如
从浏览器的角度来看,这个文件的内容是
哈哈哈
注意
php代码只有文件后缀为.php时才会生效。在 .html 后缀下,任何编写的 php 代码都不会生效。我一开始忽略了这个问题,导致调试了半天。. .
HTML 表单标签的动作和方法属性
表单标签划分了一个清晰的表单域。点击表单中的提交标签后,该表单中的所有内容都会以method属性指定的方式提交到action属性指定的页面。
如下,POST为提交方式,POST提交为密文提交,不会在URL上产生明文显示,#表示提交的目标页面为当前页面
输入名字:
PHP提取提交内容
需要使用超级全局变量 POST 变量。POST变量可以看成一个map,key是提交的表单标签的name属性,value是表单的value内容
$nameVal = $_SESSION["表单标签的name属性"];
编写提交成功界面p.php
现在您知道如何获取提交的内容,编写一个页面来输出提交的内容。该文件名为 p.php 并收录以下代码
值得注意的是,吹嘘页面的数据传输使用session进行交互,而不是再次提交(这个方法可以百度搜索,但是我还没想好如何不点击按钮自动提交,所以我使用了session作为数据传输)
值得注意的是,SESSION也是一个超级全局变量,也是一个map,可以给指定的key赋值,在另一个页面上,可以读取指定key的值。例如下面的代码使用name和sex作为key读取SESSION map介质数据
值得注意的是,使用session后,记得关闭它,destroy会销毁所有变量
编写表单填写页面 index.php
因为是xampp的apache启动的服务,所以url指定到localhost的8081端口的page2文件夹,里面收录index.php,也就是php文件,里面收录如下代码
使用empty函数判断post提交的值是否为空。如果不为空,则进一步打开session,将数据提交到p.php页面。如果数据无效,将显示错误消息。
值得注意的是,语句x == ""不能用于判断空字符串,因为如果为空则为空,而""不为空,必须通过$_SERVER["REQUEST_METHOD"来判断] == "POST" 是post提交,否则第一次加载时会直接显示信息,我们要求出现输入错误时显示
提交页面测试
php表单提交
输入名字:
输入性别:
男
女
span {
color: red;
}
结果
php抓取网页表格信息(微信小程序解析网页内容详解及实例的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-03-21 18:37
本篇文章主要介绍微信小程序解析网页内容的细节和例子。在这里,我们使用爬虫来爬取复杂的网页。如果遇到一些问题,可以在这里整理并解决。需要的朋友可以参考下
微信小程序解析网页内容详解
最近在写爬虫,需要为微信小程序解析网页。文字和图片解析都好说,小程序也有相应的文字和图片标签可以呈现。更复杂的,比如表格,难度更大,无论是服务端解析还是小程序渲染,都非常费力,很难涵盖所有情况。所以我认为将表格对应的HTML代码转换为图像会是一种解决方法。
这里我们使用node-webshot模块,它以轻量级的方式封装了PhantomJS,可以方便的将网页保存为截图。
首先安装 Node.js 和 PhantomJS,然后新建一个 js 文件并加载 node-webshot 模块: const webshot = require('webshot');
定义选项: const options = {
// 浏览器窗口
屏幕尺寸: {
宽度:755,
身高:25
},
// 要截图的页面的文档区域
镜头尺寸:{
高度:'全部'
},
//页面类型
网站类型:'html'
};
这里,浏览器窗口的宽度要根据网页的情况合理设置,高度可以设置一个较小的值,然后页面文档区域的高度必须设置为all,宽度默认到窗口宽度,以便表格可以设置为最小值。全尺寸截图。
接下来定义html字符串:let html="target富文本html代码,eg:
";
注意里面的HTML代码必须去掉换行符,用单引号代替双引号。
最后,截图: webshot(html, 'demo.png', options, (err) => {
如果(错误)
console.log(`Webshot 错误:${err.message}`);
});
这样就实现了HTML代码到本地图片的转换,然后可以上传到七牛云等。无论是服务器的分析还是小程序的呈现,都没有难度……
以上就是本文的全部内容。希望对大家的学习有所帮助。更多相关内容请关注PHP中文网! 查看全部
php抓取网页表格信息(微信小程序解析网页内容详解及实例的相关资料)
本篇文章主要介绍微信小程序解析网页内容的细节和例子。在这里,我们使用爬虫来爬取复杂的网页。如果遇到一些问题,可以在这里整理并解决。需要的朋友可以参考下
微信小程序解析网页内容详解
最近在写爬虫,需要为微信小程序解析网页。文字和图片解析都好说,小程序也有相应的文字和图片标签可以呈现。更复杂的,比如表格,难度更大,无论是服务端解析还是小程序渲染,都非常费力,很难涵盖所有情况。所以我认为将表格对应的HTML代码转换为图像会是一种解决方法。
这里我们使用node-webshot模块,它以轻量级的方式封装了PhantomJS,可以方便的将网页保存为截图。
首先安装 Node.js 和 PhantomJS,然后新建一个 js 文件并加载 node-webshot 模块: const webshot = require('webshot');
定义选项: const options = {
// 浏览器窗口
屏幕尺寸: {
宽度:755,
身高:25
},
// 要截图的页面的文档区域
镜头尺寸:{
高度:'全部'
},
//页面类型
网站类型:'html'
};
这里,浏览器窗口的宽度要根据网页的情况合理设置,高度可以设置一个较小的值,然后页面文档区域的高度必须设置为all,宽度默认到窗口宽度,以便表格可以设置为最小值。全尺寸截图。
接下来定义html字符串:let html="target富文本html代码,eg:
";
注意里面的HTML代码必须去掉换行符,用单引号代替双引号。
最后,截图: webshot(html, 'demo.png', options, (err) => {
如果(错误)
console.log(`Webshot 错误:${err.message}`);
});
这样就实现了HTML代码到本地图片的转换,然后可以上传到七牛云等。无论是服务器的分析还是小程序的呈现,都没有难度……
以上就是本文的全部内容。希望对大家的学习有所帮助。更多相关内容请关注PHP中文网!
php抓取网页表格信息((推荐):PHP表单和表单时的应用(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-16 10:09
3.(推荐)使用$_POST、$_GET等数组进行访问,例如$_POST["username"]的形式。推荐使用此方法。
(推荐)使用 import_request_variables 函数。该函数将提交的内容导入到变量中。
例如 import_request_variables("gp", "rvar_"); 第一个参数可以选择g、p、c,分别表示导入GET、POST、COOKIE变量;第二个参数是导入后的变量前缀。执行上述语句后,可以使用 $rvar_username 访问提交的用户名变量。使用 import_request_variables("gp", ""); 与以前的 PHP 程序兼容。
PHP $_GET 和 $_POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
当我们处理 HTML 表单和 PHP 表单时,重要的是要记住 HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
欢迎约翰。
你今年 28 岁。
PHP $_GET 和 $_POST 变量将在下面详细解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP $_GET 变量通过 get 方法从表单中获取“值”。
$_GET 变量
$_GET 变量是一个收录name [name] 和value [value] 的数组(这些名称和值是通过HTTP GET 方法发送的,都是可用的)。
$_GET 变量使用“method=get”来获取表单信息。GET方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过100个字符[character])。
案子
当用户点击“提交”按钮时,URL以如下形式显示
“welcome.php”文件可以使用“$_GET”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_GET”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用“$_GET”?
重要提示:使用“$_GET”变量时,所有变量名和变量值都会显示在URL地址栏中;因此,当您发送的信息中收录密码或其他一些敏感信息时,您将无法再使用此方法。因为所有的信息都会显示在URL地址栏中,所以我们可以把它作为一个标签放在采集夹中。这在许多情况下都非常有用。
注意:如果要发送的变量值太大,HTTP GET 方法不适合。发送的信息量不能超过 100 个字符。
$_REQUEST 变量
PHP $_REQUEST 变量收录 $_GET、$_POST 和 $_COOKIE 的内容。
PHP $_REQUEST 变量可用于检索通过“GET”和“POST”方法发送的表单数据。
案子
欢迎 。
你几岁了!
PHP $_POST 变量的目的是获取method="post" 方法发送的表单变量。
$_POST 变量
$_POST 变量是一个收录name[name]和value[value]的数组(这些名称和值是通过HTTP POST方法发送的,都是可用的)
$_POST 变量使用“method=POST”来获取表单信息。通过 POST 方法发送的消息是不可见的,并且对消息长度没有限制。
案子
当用户点击“提交”按钮时,URL 将不收录任何表单数据
“welcome.php”文件可以使用“$_POST”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_POST”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用 $_POST? 查看全部
php抓取网页表格信息((推荐):PHP表单和表单时的应用(上))
3.(推荐)使用$_POST、$_GET等数组进行访问,例如$_POST["username"]的形式。推荐使用此方法。
(推荐)使用 import_request_variables 函数。该函数将提交的内容导入到变量中。
例如 import_request_variables("gp", "rvar_"); 第一个参数可以选择g、p、c,分别表示导入GET、POST、COOKIE变量;第二个参数是导入后的变量前缀。执行上述语句后,可以使用 $rvar_username 访问提交的用户名变量。使用 import_request_variables("gp", ""); 与以前的 PHP 程序兼容。
PHP $_GET 和 $_POST 变量用于从表单中获取信息,例如用户输入的信息。
PHP 表单操作
当我们处理 HTML 表单和 PHP 表单时,重要的是要记住 HTML 页面中的任何表单元素都可以在 PHP 脚本中自动使用:
表格示例:
上面的 HTML 页面收录两个输入框 [input field] 和一个提交 [submit] 按钮。当用户填写信息并点击提交按钮时,表单的数据将被发送到“welcome.php”文件中。
“welcome.php”文件如下所示:
欢迎 。
你几岁了。
上面的脚本将输出以下输出:
欢迎约翰。
你今年 28 岁。
PHP $_GET 和 $_POST 变量将在下面详细解释。
表单验证 [表单验证]
用户输入的信息应尽可能通过客户端脚本程序(如JavaScript)在浏览器上进行验证;通过浏览器验证信息可以提高效率,减少服务器的下载压力。
如果用户输入的信息需要存入数据库,那么就必须考虑在服务器端进行验证。验证服务器上信息有效性的最佳方法是将表单信息发送到当前页面进行验证,而不是转移到另一个页面进行验证。通过上述方法,如果表单出现错误,用户可以直接获取当前页面的错误信息。这使得更容易发现存在的错误信息。
PHP $_GET 变量通过 get 方法从表单中获取“值”。
$_GET 变量
$_GET 变量是一个收录name [name] 和value [value] 的数组(这些名称和值是通过HTTP GET 方法发送的,都是可用的)。
$_GET 变量使用“method=get”来获取表单信息。GET方法发送的消息是可见的(会显示在浏览器的地址栏中),并且有长度限制(消息的总长度不能超过100个字符[character])。
案子
当用户点击“提交”按钮时,URL以如下形式显示
“welcome.php”文件可以使用“$_GET”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_GET”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用“$_GET”?
重要提示:使用“$_GET”变量时,所有变量名和变量值都会显示在URL地址栏中;因此,当您发送的信息中收录密码或其他一些敏感信息时,您将无法再使用此方法。因为所有的信息都会显示在URL地址栏中,所以我们可以把它作为一个标签放在采集夹中。这在许多情况下都非常有用。
注意:如果要发送的变量值太大,HTTP GET 方法不适合。发送的信息量不能超过 100 个字符。
$_REQUEST 变量
PHP $_REQUEST 变量收录 $_GET、$_POST 和 $_COOKIE 的内容。
PHP $_REQUEST 变量可用于检索通过“GET”和“POST”方法发送的表单数据。
案子
欢迎 。
你几岁了!
PHP $_POST 变量的目的是获取method="post" 方法发送的表单变量。
$_POST 变量
$_POST 变量是一个收录name[name]和value[value]的数组(这些名称和值是通过HTTP POST方法发送的,都是可用的)
$_POST 变量使用“method=POST”来获取表单信息。通过 POST 方法发送的消息是不可见的,并且对消息长度没有限制。
案子
当用户点击“提交”按钮时,URL 将不收录任何表单数据
“welcome.php”文件可以使用“$_POST”变量获取表单数据(注意:表单域[form field]中的名称会自动作为“$_POST”中的ID关键词大批):
欢迎 。
你几岁了!
为什么使用 $_POST?
php抓取网页表格信息(PHP代码中会插件(.php)插件 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-13 13:07
)
本文使用可编辑插件实现一键将文本信息变成可编辑形式。可以编辑文本内容,然后点击“确定”保存到数据库;当您单击“取消”按钮时,页面返回初始状态。
类别:PHP> Ajax 难度:中级
下载资源下载积分:60积分
可编辑的优点:
接下来,我们用 PHP 来举个例子:
这是一个用户信息表。从代码中可以发现,响应的字段信息的td被赋予了class和id属性并赋值。值得一提的是,表中td对应的id的值与数据库中的字段名是一一对应的。这是为了让后台在编辑的时候能够获取到对应的字段信息,后面会在PHP代码中讨论。
客户信息
姓名
办公电话
称谓
手机
公司名称
电子邮箱
潜在客户来源
有限期
职位
网站
创建时间
修改时间
备注
调用 jeditable 插件:
$('.edit').editable('ajax.php', {
width: 120,
height: 18,
//onblur : "ignore",
cancel: '取消',
submit: '确定',
indicator: 'css/loader.gif',
tooltip: '单击可以编辑...',
callback: function(value, settings) {
$("#modifiedtime").html("刚刚");
}
});
jeditable还提供select、textarea类型编辑,并提供插件api接口。
$('.edit_select').editable('ajax.php', {
loadurl : 'json.php',
type : "select",
});
type指定select类型,select中加载的数据来自json.php,json.php提供下拉框需要的数据源。
$array['网站模板'] = '网站模板';
$array['网页特效'] = '网页特效';
$array['网站源码'] = '网站源码';
$array['精品网站'] = '精品网站';
$array['网页图标'] = '网页图标';
print json_encode($array);
json数据示例:
$('.edit_select').editable('save.php', {
data : " {'网站模板':'网站模板','网页特效':'网页特效','网站源码':'网站源码', '精品网站':'精品网站'}",
type : "select",
});
没有更多的textarea类型,只需将类型类型更改为textarea。PS:默认类型是文本。
在处理日期类型时,我使用了一个 jquery ui datepicker 日历插件,当然不要忘记介绍 juqery ui 插件和样式:
为 jquery ui 引入 datepicker 日期时间插件
$.editable.addInputType('datepicker', {
element : function(settings, original) {
var input = $('');
input.attr("readonly","readonly");
$(this).append(input);
return(input);
},
plugin : function(settings, original) {
var form = this;
$("input",this).datepicker();
}
});
调用代码可以直接指定类型为datepicker。
$(".datepicker").editable('ajax.php', {
width : 120,
type : 'datepicker',
onblur : "ignore",
});
ajax.php
编辑好的字段信息会发送到后台程序save.php进行处理。save.php需要完成的工作是:接收前端提交的字段信息数据,进行必要的过滤和验证,然后更新数据表中对应的字段内容,并返回结果。
include_once("connect.php"); //连接数据库
$field=$_POST['id']; //获取前端提交的字段名
$val=$_POST['value']; //获取前端提交的字段对应的内容
$val = htmlspecialchars($val, ENT_QUOTES); //过滤处理内容
$time=date("Y-m-d H:i:s"); //获取系统当前时间
if(empty($val)){
echo "不能为空";
}else{
//更新字段信息
$query=mysql_query("update customer set $field='$val',modifiedtime='$time' where id=1");
if($query){
echo $val;
}else{
echo "数据出错";
}
} 查看全部
php抓取网页表格信息(PHP代码中会插件(.php)插件
)
本文使用可编辑插件实现一键将文本信息变成可编辑形式。可以编辑文本内容,然后点击“确定”保存到数据库;当您单击“取消”按钮时,页面返回初始状态。
类别:PHP> Ajax 难度:中级
下载资源下载积分:60积分
可编辑的优点:
接下来,我们用 PHP 来举个例子:
这是一个用户信息表。从代码中可以发现,响应的字段信息的td被赋予了class和id属性并赋值。值得一提的是,表中td对应的id的值与数据库中的字段名是一一对应的。这是为了让后台在编辑的时候能够获取到对应的字段信息,后面会在PHP代码中讨论。
客户信息
姓名
办公电话
称谓
手机
公司名称
电子邮箱
潜在客户来源
有限期
职位
网站
创建时间
修改时间
备注
调用 jeditable 插件:
$('.edit').editable('ajax.php', {
width: 120,
height: 18,
//onblur : "ignore",
cancel: '取消',
submit: '确定',
indicator: 'css/loader.gif',
tooltip: '单击可以编辑...',
callback: function(value, settings) {
$("#modifiedtime").html("刚刚");
}
});
jeditable还提供select、textarea类型编辑,并提供插件api接口。
$('.edit_select').editable('ajax.php', {
loadurl : 'json.php',
type : "select",
});
type指定select类型,select中加载的数据来自json.php,json.php提供下拉框需要的数据源。
$array['网站模板'] = '网站模板';
$array['网页特效'] = '网页特效';
$array['网站源码'] = '网站源码';
$array['精品网站'] = '精品网站';
$array['网页图标'] = '网页图标';
print json_encode($array);
json数据示例:
$('.edit_select').editable('save.php', {
data : " {'网站模板':'网站模板','网页特效':'网页特效','网站源码':'网站源码', '精品网站':'精品网站'}",
type : "select",
});
没有更多的textarea类型,只需将类型类型更改为textarea。PS:默认类型是文本。
在处理日期类型时,我使用了一个 jquery ui datepicker 日历插件,当然不要忘记介绍 juqery ui 插件和样式:
为 jquery ui 引入 datepicker 日期时间插件
$.editable.addInputType('datepicker', {
element : function(settings, original) {
var input = $('');
input.attr("readonly","readonly");
$(this).append(input);
return(input);
},
plugin : function(settings, original) {
var form = this;
$("input",this).datepicker();
}
});
调用代码可以直接指定类型为datepicker。
$(".datepicker").editable('ajax.php', {
width : 120,
type : 'datepicker',
onblur : "ignore",
});
ajax.php
编辑好的字段信息会发送到后台程序save.php进行处理。save.php需要完成的工作是:接收前端提交的字段信息数据,进行必要的过滤和验证,然后更新数据表中对应的字段内容,并返回结果。
include_once("connect.php"); //连接数据库
$field=$_POST['id']; //获取前端提交的字段名
$val=$_POST['value']; //获取前端提交的字段对应的内容
$val = htmlspecialchars($val, ENT_QUOTES); //过滤处理内容
$time=date("Y-m-d H:i:s"); //获取系统当前时间
if(empty($val)){
echo "不能为空";
}else{
//更新字段信息
$query=mysql_query("update customer set $field='$val',modifiedtime='$time' where id=1");
if($query){
echo $val;
}else{
echo "数据出错";
}
}
php抓取网页表格信息(一卡通消费记录批量导进Excel上的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-12 01:11
一、背景
我准备将一卡消费记录批量导入随知,但是学校的一卡消费查询系统不支持数据导出。你想让我把数据逐页复制到Excel吗?这种重复无聊的事情不应该由擅长做的电脑来做吗?于是我开始打算写一个脚本,一键抓取我的一卡消费记录。
二、分析
首先打开消费记录查询的网页,拿出开发者工具,观察这个网页,找到我们的目标,就是一个table标签。
然后看看这个标签是怎么生成的,是服务器后端直接生成的网页,还是前端ajax访问后端获取数据渲染出来的?点击Network选项卡刷新网页,发现网页上没有异步请求,每一页都是一个新的网页,所以是前一种情况。而每个页面的url都是【页码】,所以我只需要让程序访问这个url并解析html,获取table里面的数据,然后通过某种方式采集就可以完成目标。
要将结果导入 Excel,此处使用简单方便的表格文件格式 .CSV。本质上,csv表格文件只是一个文本文件,表格的字段用逗号等分隔符分隔,表格中的每一行数据用换行符分隔(在Excel中换行符是“rn”)
字段1,字段2,字段3,字段4
A,B,C,D
1,2,3,4
就是这么简单明了!对于任何程序,简单的字符串连接都可以生成 csv 格式的表格。
经过我的测试,我这个学期的消费记录在这个网页上只有50多页,所以爬虫需要爬取的数据量非常少,处理起来完全没有压力。一次性直接获取所有结果并保存。文件会做。
至于爬虫程序的语言选择,我无话可说。目前对PHP比较熟悉,所以接下来的程序我也是用PHP来完成的。
三、执行
首先,确定我应该如何模拟登录到这个系统。这里我们应该知道HTTP是一个无状态的协议,所以如果服务器要判断用户当前在请求谁,就必须通过HTTP请求的cookie中存储的信息来判断。. 所以如果我们想让服务器知道爬虫发出的HTTP请求的用户是我,就应该让爬虫发出的HTTP请求携带这个cookie。在这里,我们可以从 chrome 中复制这个 cookie,并将其值保存在变量之间的某个备用中。
查看浏览器的header访问这个页面,发现cookie只有JSESSIONID。
接下来写一个循环,将每一页的结果加到保存结果的字符串中,找不到数据的时候跳出循环,保存结果,程序结束。
在提取数据时,我使用了simple_html_dom,一个简单方便的用于解析html中的DOM结构的库。
最后将字符串的内容保存到result.csv。
代码显示如下:
<p> 查看全部
php抓取网页表格信息(一卡通消费记录批量导进Excel上的应用)
一、背景
我准备将一卡消费记录批量导入随知,但是学校的一卡消费查询系统不支持数据导出。你想让我把数据逐页复制到Excel吗?这种重复无聊的事情不应该由擅长做的电脑来做吗?于是我开始打算写一个脚本,一键抓取我的一卡消费记录。
二、分析
首先打开消费记录查询的网页,拿出开发者工具,观察这个网页,找到我们的目标,就是一个table标签。
然后看看这个标签是怎么生成的,是服务器后端直接生成的网页,还是前端ajax访问后端获取数据渲染出来的?点击Network选项卡刷新网页,发现网页上没有异步请求,每一页都是一个新的网页,所以是前一种情况。而每个页面的url都是【页码】,所以我只需要让程序访问这个url并解析html,获取table里面的数据,然后通过某种方式采集就可以完成目标。
要将结果导入 Excel,此处使用简单方便的表格文件格式 .CSV。本质上,csv表格文件只是一个文本文件,表格的字段用逗号等分隔符分隔,表格中的每一行数据用换行符分隔(在Excel中换行符是“rn”)
字段1,字段2,字段3,字段4
A,B,C,D
1,2,3,4
就是这么简单明了!对于任何程序,简单的字符串连接都可以生成 csv 格式的表格。
经过我的测试,我这个学期的消费记录在这个网页上只有50多页,所以爬虫需要爬取的数据量非常少,处理起来完全没有压力。一次性直接获取所有结果并保存。文件会做。
至于爬虫程序的语言选择,我无话可说。目前对PHP比较熟悉,所以接下来的程序我也是用PHP来完成的。
三、执行
首先,确定我应该如何模拟登录到这个系统。这里我们应该知道HTTP是一个无状态的协议,所以如果服务器要判断用户当前在请求谁,就必须通过HTTP请求的cookie中存储的信息来判断。. 所以如果我们想让服务器知道爬虫发出的HTTP请求的用户是我,就应该让爬虫发出的HTTP请求携带这个cookie。在这里,我们可以从 chrome 中复制这个 cookie,并将其值保存在变量之间的某个备用中。
查看浏览器的header访问这个页面,发现cookie只有JSESSIONID。
接下来写一个循环,将每一页的结果加到保存结果的字符串中,找不到数据的时候跳出循环,保存结果,程序结束。
在提取数据时,我使用了simple_html_dom,一个简单方便的用于解析html中的DOM结构的库。
最后将字符串的内容保存到result.csv。
代码显示如下:
<p>
php抓取网页表格信息(使用PHPCURL的POST模拟登录discuz以及模拟发帖())
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-11 21:02
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心, 查看全部
php抓取网页表格信息(使用PHPCURL的POST模拟登录discuz以及模拟发帖())
PHP 的 curl() 爬取网页的效率相对较高,并且支持多线程,而 file_get_contents() 的效率略低。当然,使用 curl 时需要启用 curl 扩展。
代码实战
我们先看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的url地址、保存的cookie文件、post数据(用户名和密码等)、是否提交返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自己的 http_build_query() 可以将数组转换为连接字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们将CURLOPT_RETURNTRANSFER设置为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功后才能获取的有用信息。下面我们以登录开源中国手机版为例,看看登录成功后如何获取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.oschina.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化卷曲;
2、使用 curl_setopt 设置目标 url 等选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、输出数据。
参考
《php中curl和curl的介绍》,作者不详,
Veda 的“使用 PHP CURL 发布数据”,
《php使用curl模拟登录discuz并模拟发帖》,作者:天心,
php抓取网页表格信息( 用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-11 16:25
用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
Python 使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程
更新时间:2016-05-16 18:53:56 作者:Kenneth Reitz
使用 Pyhton 附带的 urllib 或 urllib2 模块来爬取网页可能是陈词滥调。今天我们将玩一些新的东西,并看一个使用 lxml 模块和 Requests 模块来爬取 HTML 页面的 Python 教程:
网页抓取
网站是使用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
这就是网络抓取发挥作用的时候。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式同时保留其结构的做法。
lxml 和请求
lxml() 是一个漂亮的扩展库,即使在处理非常混乱的标签时也能快速解析 XML 和 HTML 文档。我们还将使用 Requests (#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
接下来我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools。
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector。如果您使用的是 Chrome,您可以右键单击元素,选择“检查元素”,突出显示代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个名为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经通过 lxml 和 Request 成功地从网页中抓取了我们想要的所有数据。我们将它们作为列表存储在内存中。现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以想到一些更酷的想法:修改脚本以遍历示例数据集中的剩余页面,或者重写应用程序以使用多线程加速。 查看全部
php抓取网页表格信息(
用Pyhton自带的urllib或urllib2模块抓取网页或许有些了,)
Python 使用 lxml 模块和 Requests 模块抓取 HTML 页面的教程
更新时间:2016-05-16 18:53:56 作者:Kenneth Reitz
使用 Pyhton 附带的 urllib 或 urllib2 模块来爬取网页可能是陈词滥调。今天我们将玩一些新的东西,并看一个使用 lxml 模块和 Requests 模块来爬取 HTML 页面的 Python 教程:
网页抓取
网站是使用 HTML 描述的,这意味着每个网页都是一个结构化的文档。有时在保持其结构的同时从中获取数据很有用。网站并不总是以易于处理的格式(例如 csv 或 json)提供其数据。
这就是网络抓取发挥作用的时候。网页抓取是使用计算机程序采集网页数据并将其组织成所需格式同时保留其结构的做法。
lxml 和请求
lxml() 是一个漂亮的扩展库,即使在处理非常混乱的标签时也能快速解析 XML 和 HTML 文档。我们还将使用 Requests (#) 模块而不是内置的 urllib2 模块,因为它更快且更具可读性。您可以使用 pip install lxml 和 pip install requests 命令安装这两个模块。
让我们从以下导入开始:
from lxml import html
import requests
接下来我们将使用 requests.get 从网页中获取我们的数据,使用 html 模块对其进行解析,并将结果保存到树中。
page = requests.get('http://econpy.pythonanywhere.com/ex/001.html')
tree = html.fromstring(page.text)
tree 现在将整个 HTML 文件收录在一个优雅的树结构中,我们可以使用两种方法访问它:XPath 和 CSS 选择器。在本例中,我们将选择前者。
XPath 是一种在结构化文档(如 HTML 或 XML)中定位信息的方法。有关 XPath 的良好介绍,请参阅 W3Schools。
有许多工具可以获取元素的 XPath,例如用于 Firefox 的 FireBug 或用于 Chrome 的 Inspector。如果您使用的是 Chrome,您可以右键单击元素,选择“检查元素”,突出显示代码,再次右键单击,然后选择“复制 XPath”。
经过快速分析,我们看到页面中的数据存储在两个元素中,一个标题为“buyer-name”的 div 和一个名为“item-price”的 span:
Carson Busses
$29.95
知道了这一点,我们可以创建正确的 XPath 查询并使用 lxml 的 xpath 函数,如下所示:
#这将创建buyers的列表:
buyers = tree.xpath('//div[@title="buyer-name"]/text()')
#这将创建prices的列表:
prices = tree.xpath('//span[@class="item-price"]/text()')
让我们看看我们得到了什么:
print 'Buyers: ', buyers
print 'Prices: ', prices
Buyers: ['Carson Busses', 'Earl E. Byrd', 'Patty Cakes',
'Derri Anne Connecticut', 'Moe Dess', 'Leda Doggslife', 'Dan Druff',
'Al Fresco', 'Ido Hoe', 'Howie Kisses', 'Len Lease', 'Phil Meup',
'Ira Pent', 'Ben D. Rules', 'Ave Sectomy', 'Gary Shattire',
'Bobbi Soks', 'Sheila Takya', 'Rose Tattoo', 'Moe Tell']
Prices: ['$29.95', '$8.37', '$15.26', '$19.25', '$19.25',
'$13.99', '$31.57', '$8.49', '$14.47', '$15.86', '$11.11',
'$15.98', '$16.27', '$7.50', '$50.85', '$14.26', '$5.68',
'$15.00', '$114.07', '$10.09']
恭喜!我们已经通过 lxml 和 Request 成功地从网页中抓取了我们想要的所有数据。我们将它们作为列表存储在内存中。现在我们可以用它做各种很酷的事情:我们可以使用 Python 分析它,或者我们可以将它保存为文件并与世界分享。
我们可以想到一些更酷的想法:修改脚本以遍历示例数据集中的剩余页面,或者重写应用程序以使用多线程加速。
php抓取网页表格信息(Web网络爬虫系统的原理及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-11 16:21
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测header的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大部分出现在静态页面上,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。 查看全部
php抓取网页表格信息(Web网络爬虫系统的原理及应用)
1、爬虫技术概述
网络爬虫是根据一定的规则自动从万维网上爬取信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,它可以自动采集它可以访问的所有页面获取或更新这些网站的内容和检索方法。从功能上来说,爬虫一般分为数据采集、处理、存储三部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并放入队列中,直到满足系统的某些停止条件。焦点爬虫的工作流程比较复杂。它需要按照一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,并放入等待抓取的URL队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。保留有用的链接并将它们放入等待抓取的 URL 队列中。然后,它会根据一定的搜索策略从队列中选择下一个要爬取的网页URL,并重复上述过程,直到达到系统的一定条件并停止。此外,爬虫爬取的所有网页都会被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。爬虫抓取到的所有网页都将被系统存储,经过一定的分析、过滤、索引,以供后续查询和检索;对于重点爬虫来说,这个过程中得到的分析结果也可能对后续的爬取过程给出反馈和指导。
与通用网络爬虫相比,聚焦爬虫还需要解决三个主要问题:
(1) 获取目标的描述或定义;
(2) 网页或数据的分析和过滤;
(3) URL 的搜索策略。
2、爬虫原理
2.1 网络爬虫原理
网络爬虫系统的功能是下载网页数据,为搜索引擎系统提供数据源。许多大型网络搜索引擎系统被称为基于Web数据的搜索引擎系统采集,如Google、百度等。这显示了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文字信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集进程像爬虫或者蜘蛛一样在网络上漫游,所以才叫做网络爬虫系统或者网络蜘蛛系统,英文叫Spider或者Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多个线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页和处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等。爬虫的基本工作是由解析器完成的。资源库用于存储下载的网络资源。通常使用大型数据库,例如 Oracle 数据库来存储和索引它。
控制器
控制器是网络爬虫的中央控制器。主要负责根据系统发送的URL链接分配一个线程,然后启动线程调用爬虫爬取网页。
解析器
解析器负责网络爬虫的主要部分。它的主要任务是:下载网页的功能,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
它主要是一个容器,用于存储从网页下载的数据记录,并为索引生成提供目标源。大中型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些比较重要的出度(网页中超链接数)网站较大的URL作为种子URL集。网络爬虫系统使用这些种子集作为初始 URL 来开始数据爬取。因为网页中收录链接信息,所以会通过已有网页的URL获取一些新的URL。网页之间的指向结构可以看作是一片森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能导致爬虫系统陷入网站内部,不利于搜索距离网站首页比较近的网页信息,一般采用广度优先搜索算法采集网页。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部获取一个 URL 来下载其对应的网页。获取网页内容并存储后,通过解析网页中的链接信息可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,以此类推,直到遍历全网或者满足某个条件。
网络爬虫的基本工作流程如下:
1.首先选择一个精心挑选的种子 URL 的子集;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,存入下载的网页库中。此外,将这些 URL 放入 Crawl URL 队列。
4.解析URL队列中已经爬取的URL,分析其中的其他URL,将URL放入待爬取的URL队列,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,待爬取的 URL 队列是一个重要的部分。待爬取的URL队列中的URL的排列顺序也是一个重要的问题,因为它涉及到先爬到哪个页面,再爬到哪个页面。确定这些 URL 排列顺序的方法称为爬取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,每次一个链接跟踪每个链接,处理完该行后移动到下一个起始页,并继续跟踪该链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历的基本思想是将新下载的网页中找到的链接直接插入待爬取URL队列的末尾。也就是说,网络爬虫会先爬取起始网页链接的所有网页,然后选择其中一个链接的网页,继续爬取该网页链接的所有网页。或者以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接策略
反向链接数是指从其他网页指向一个网页的链接数。反向链接的数量表示网页内容被他人推荐的程度。因此,在很多情况下,搜索引擎的爬取系统会使用这个指标来评估网页的重要性,从而确定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量并不能完全等同于他人的重要性。因此,搜索引擎倾向于考虑一些可靠的反向链接计数。
2.3.4部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,与待爬取的URL队列中的URL一起形成一组网页,计算每个页面的PageRank值. URL 按 PageRank 值排序,并按该顺序抓取页面。
如果每次爬取一个页面都重新计算一次PageRank值,折中的解决方案是:每爬完K个页面,重新计算一次PageRank值。但是这种情况还是有一个问题:对于下载页面中分析的链接,也就是我们前面提到的那部分未知网页,暂时没有PageRank值。为了解决这个问题,会给这些页面一个临时的PageRank值:将这个网页所有传入链接传入的PageRank值聚合起来,从而形成未知页面的PageRank值,从而参与排序。以下示例说明:
2.3.5OPICStrategy
该算法实际上为页面分配了一个重要性分数。在算法开始之前,所有页面都会获得相同的初始现金。当某个页面P被下载时,P的现金分配给从P分析的所有链接,P的现金被清空。根据现金数量对待爬取URL队列中的所有页面进行排序。
2.3.六大网站优先策略
所有待爬取的URL队列中的网页都按照它们所属的网站进行分类。网站需要下载的页面较多,请先下载。这种策略也称为大站点优先策略。
3、爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫类,基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 分布式爬虫
爬虫使用分布式,主要解决两个问题:
1)海量网址管理
2)网速
现在比较流行的分布式爬虫是Apache的Nutch。但是对于大多数用户来说,Nutch 是这些爬虫中最差的选择,原因如下:
1)Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。提取意义不大。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合提取业务,那你基本上会破坏Nutch的框架,把Nutch改得面目全非,而且有能力修改Nutch,还不如自己写一个新的。分布式爬虫框架。
2)Nutch 依赖hadoop 运行,hadoop 本身消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)虽然Nutch有一套插件机制,但还是作为亮点来宣传的。可以看到一些开源的Nutch插件,提供精准提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多糟糕。使用反射机制加载和调用插件,使得程序的编写和调试变得异常困难,更不用说在其上开发复杂的提取系统了。并且 Nutch 没有提供对应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点都是给搜索引擎服务的,不提供细提取的挂载点。Nutch 的大部分精炼提取插件都挂载在“页面解析”(parser)挂载点上。这个挂载点其实是用来解析链接(为后续爬取提供URL)和提供一些搜索引擎的。易于提取的网页信息(元信息、网页文本)。
4)使用Nutch进行爬虫的二次开发,编写和调试爬虫所需的时间往往是单机爬虫所需时间的十倍以上。学习 Nutch 源码的成本非常高,更何况团队中的每个人都必须了解 Nutch 源码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5)很多人说Nutch2有gora,可以将数据持久化到avro文件、hbase、mysql等,其实很多人都误解了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2 的版本目前不适合开发。Nutch的官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果要使用hbase和nutch(大多数人使用nutch2是为了使用hbase),只能使用版本0.90左右的hbase,相应地,将hadoop版本降低到hadoop 0.左右@>2。而且nutch2的官方教程也颇具误导性。Nutch2的教程有两个,分别是Nutch1.x和Nutch2.x。Nutch2.x官网是为了支持hbase0.94而写的。但其实这个Nutch2.x是指Nutch2.3之前和Nutch2.2.1之后的一个版本,在官方SVN中不断更新。而且它'
所以,如果你不是搜索引擎,尽量不要选择 Nutch 作为爬虫。一些团队喜欢跟风。他们坚持选择Nutch来开发精制履带。其实是针对Nutch的名声(Nutch的作者是Doug Cutting)。当然,最终的结果往往是项目延期。
如果你在做搜索引擎,Nutch1.x 是一个非常不错的选择。Nutch1.x 和 solr 或 es 可以组成一个非常强大的搜索引擎。如果必须使用 Nutch2,建议等到 Nutch2.3 发布。当前的 Nutch2 是一个非常不稳定的版本。
分布式爬虫平台架构图
3.2 JAVA爬虫
在这里,将JAVA爬虫划分为一个单独的类别,因为JAVA在网络爬虫的生态系统中非常完善。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实开源网络爬虫(框架)的开发很简单,难点和复杂的问题已经被前人解决了(比如DOM树解析定位、字符集检测、海量URL去重),可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历本机的文件以查找文件中的信息。没有任何困难。选择开源爬虫框架的原因是为了省事。比如爬虫的URL管理、线程池等模块,任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
对于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫可以使用代理,爬虫可以抓取重复数据,爬虫可以抓取JS生成的信息吗?
不支持多线程、不支持代理、不能过滤重复URL的不叫开源爬虫,叫循环执行http请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理一个页面。因此,一种策略是利用这些爬虫遍历网站,当遇到需要解析的页面时,将网页的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以抓取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax的http请求,自己生成ajax请求的url,获取返回的数据。如果你自己生成ajax请求,那么使用开源爬虫有什么意义呢?其实就是利用开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来爬取这些请求呢?
爬虫往往被设计成广度遍历或深度遍历的方式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫并不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历 网站。爬虫的第一轮爬取就是爬取种子集(seeds)中的所有url。简单来说就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫对这些种子进行深度为 1 的广度遍历(默认为广度遍历)。
3)爬虫如何爬取待登录的网站?
这些开源爬虫都支持在爬取时指定cookies,而模拟登录主要依赖cookies。至于如何获取cookies,就不是爬虫管理的问题了。您可以手动获取cookies,使用http请求模拟登录,或者使用模拟浏览器自动登录。
4)爬虫如何从网页中提取信息?
开源爬虫一般会集成网页提取工具。主要支持两种规范:CSS SELECTOR 和 XPATH。至于哪个更好,我这里就不评论了。
5)爬虫是如何保存网页信息的?
有一些爬虫带有一个负责持久性的模块。例如,webmagic 有一个名为 pipeline 的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等。还有一些爬虫不直接为用户提供数据持久化模块。比如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于用管道模块好不好,就类似于用ORM操作数据库好不好的问题,看你的业务。
6)爬虫被网站拦截了怎么办?
爬虫被网站阻塞,可以通过使用多个代理(随机代理)来解决。但是这些开源爬虫一般不直接支持随机代理的切换。因此,用户经常需要将获取到的agent放入一个全局数组中,并编写一段代码让agent随机获取(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的。您可以按照平时使用的方式使用它。可以使用这些爬虫。
8)爬虫速度怎么样?
单机开源爬虫的速度基本可以用到本地网速的极限。爬虫速度慢往往是因为用户减少了线程数,网速慢,或者数据持久化时与数据库的交互慢。而这些东西往往是由用户的机器和二次开发的代码决定的。这些开源爬虫的速度非常好。
9) 明明代码写对了,但是数据爬不出来。爬虫有问题吗?不同的爬虫可以解决吗?
如果代码写得正确,无法爬取数据,其他爬虫也将无法爬取。在这种情况下,要么是 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。如果无法爬取数据,则无法通过更改爬虫来解决。
10)哪个爬虫可以判断网站是否已经爬完,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否已经爬完,只能尽量覆盖。
至于根据主题爬,爬虫把内容爬下来后就知道主题是什么了。因此,通常是整体爬下来,然后对内容进行过滤。如果爬取的范围太广,可以通过限制 URL 正则化来缩小范围。
11)哪个爬虫的设计模式和架构比较好?
设计模式是胡说八道。都说软件设计模式不错,软件开发后总结了几种设计模式。设计模式对软件开发没有指导意义。使用设计模式设计爬虫只会让爬虫的设计更加臃肿。
至于架构,目前开源爬虫主要是设计详细的数据结构,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,用任何框架都谈不上。
所以对于 JAVA 开源爬虫,我认为,只要找到一个运行良好的。如果业务复杂,使用哪个爬虫,只能通过复杂的二次开发来满足需求。
3.3 非JAVA爬虫
在非JAVA语言编写的爬虫中,不乏优秀的爬虫。这里提取为一个类别,不是为了讨论爬虫本身的好坏,而是为了讨论larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python用30行代码就可以完成JAVA 50行代码的任务。Python写代码确实很快,但是在调试代码阶段,调试python代码所消耗的时间往往比编码阶段节省的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务也不复杂,用scrapy还是不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载完成后交给 Spider 进行分析,将要保存的数据发送到 Item Pipeline ,也就是对数据进行后处理。此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习成本会比较大。而且不能只计算一个人的学习成本。如果软件需要一个团队来开发或者移交,那就是很多人的学习成本。软件调试不是那么容易。
还有一些ruby和php爬虫,这里就不多评价了。确实有一些非常小的data采集任务,在ruby或者php中都用得上。但是,要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能存在一些你找不到的bug(很少有人使用它们,而且信息也较少)
4、反爬虫技术
由于搜索引擎的普及,网络爬虫已经成为一种非常流行的网络技术。除了专注于搜索的谷歌、雅虎、微软和百度之外,几乎每个大型门户网站网站都有自己的搜索引擎,大大小小的。可以叫的名字有几十种,不知道的种类有上万种。对于一个内容驱动的网站,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫的爬取频率比较合理,资源消耗也比较小,但是很多不良网络爬虫对网页的爬取能力很差,经常循环重复上百个请求。拿,这种爬虫对中小型网站来说往往是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员编写的爬虫,破坏性极大,导致网站访问压力会很大非常大,这将导致 网站 访问缓慢甚至无法访问。
一般网站反爬虫从三个方面:用户请求的头文件、用户行为、网站目录和数据加载方式。前两种比较容易遇到,从这些角度来看,大部分网站都是反爬虫。会使用第三种使用ajax的网站,增加了爬取的难度。
4.1 反爬虫通过Headers
反爬取用户请求的头部是最常见的反爬取策略。很多网站会检测header的User-Agent,有的网站会检测Referer(有些资源的防盗链网站就是检测Referer)。如果遇到这样的反爬虫机制,可以直接在爬虫中添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者将Referer值改为目标网站域名【注释:往往容易被Ignore,通过对请求的抓包分析,确定referer,在模拟访问请求的header中添加】在节目中。对于检测Headers的反爬虫,在爬虫中修改或添加Headers可以很好的绕过。
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一个IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。【这个反爬需要有足够的ip来处理】
大多数网站都是前一种情况,使用IP代理就可以了。可以专门写一个爬虫来爬取网上公开的代理ip,检测到后全部保存。这样的代理ip爬虫经常使用,最好自己准备一个。有大量代理IP,可以每隔几次更换一个IP,这在requests或者urllib2中很容易做到,这样就可以轻松绕过第一个反爬虫。[评论:动态拨号也是一种解决方案]
对于第二种情况,下一个请求可以在每个请求之后以几秒的随机间隔发出。一些有逻辑漏洞的网站可以通过多次请求、注销、重新登录、继续请求的方式绕过同一账号短时间内不能多次请求的限制。【点评:账号反爬限制一般比较难处理,随机几秒的请求可能经常被屏蔽。如果可以有多个账号,切换使用,效果会更好】
4.3 动态页面的反爬虫
以上情况大部分出现在静态页面上,也有一些网站,我们需要爬取的数据是通过ajax请求获取的,或者通过Java生成的。一、使用Firebug或者HttpFox分析网络请求【点评:我感觉Google和IE的网络请求分析和使用也很不错】。如果我们能找到ajax请求并分析出具体参数和响应的具体含义,我们可以使用上面的方法直接使用requests或者urllib2来模拟ajax请求,分析响应json得到需要的数据。
能够直接模拟ajax请求获取数据是很棒的,但是有的网站把ajax请求的所有参数都加密了。我们根本无法构造对我们需要的数据的请求。我这几天爬的网站就是这样的。除了对ajax参数进行加密外,还封装了一些基础功能,都是调用自己的接口,接口参数是加密的。遇到这样的网站,我们就不能使用上面的方法了。我使用selenium+phantomJS框架调用浏览器内核,使用phantomJS执行js模拟人类操作,触发页面中的js脚本。从填表到点击按钮再到页面滚动,都可以模拟,不管具体的请求和响应过程,只是一个完整的模拟人们浏览页面获取数据的过程。[评论:支持phantomJS]
使用这个框架几乎可以绕过大部分反爬虫,因为它不是冒充浏览器获取数据(上面提到的添加header在一定程度上是冒充浏览器),它本身就是浏览器,而且phantomJS 是一个没有界面的浏览器,但控制浏览器的不是人。使用selenium+phantomJS可以做很多事情,比如识别touch-type(12306)或者滑动验证码,暴力破解页面表单等)。它还将在自动化渗透中发挥重要作用,并将在未来发挥作用。提到这一点。
php抓取网页表格信息(web端获取数据获取多网页数据web链接常见格式(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-11 16:16
一、从网络获取数据
可以使用双桌面“获取数据”中的“web”选项。“网络”界面有两个选项卡,“基本”和“高级”。通常,“基本”选项卡可以满足日常工作的需要。以下是这方面的例子。
二、获取数据
进入网页链接后,会进行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会耗费大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取一页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示当年的工作路径。类似于下图:
这时需要在“let”前面输入“(p as number) as table=>”;并且在链接中,修改网页的页码,也就是上面提到的“1, 2”等数字“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接末尾,按照上面的操作即可;另一个是链接以.html结尾。除了上面的替换操作,这种类型的(p))&".html"))只需要在这里单独定义html即可。
四、爬取多数据网页
首先,使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建1到100的序列。在空查询中输入={1..100},生成1到100的序列。到100的序列,然后转向一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。 查看全部
php抓取网页表格信息(web端获取数据获取多网页数据web链接常见格式(图))
一、从网络获取数据
可以使用双桌面“获取数据”中的“web”选项。“网络”界面有两个选项卡,“基本”和“高级”。通常,“基本”选项卡可以满足日常工作的需要。以下是这方面的例子。
二、获取数据
进入网页链接后,会进行导航器的“加载”、“编辑”等常用功能,您只需根据实际工作需要进行操作即可。
三、获取多页数据
网页链接的常用格式如下:最后一个“1”表示当前链接为第一页数据,第二页数据链接应为“”。当网页数据较大时,如果每次都通过网页链接获取数据,会耗费大量时间。但是在组件查询中有相应的函数来简化操作,如下:
获取一页数据后,进入“编辑查询”界面,在“编辑查询”界面选择“高级编辑器”选项卡,高级编辑器界面显示当年的工作路径。类似于下图:
这时需要在“let”前面输入“(p as number) as table=>”;并且在链接中,修改网页的页码,也就是上面提到的“1, 2”等数字“(Number.ToText(p))”即可。
备注:网页链接有两种,一种是页码数据在链接末尾,按照上面的操作即可;另一个是链接以.html结尾。除了上面的替换操作,这种类型的(p))&".html"))只需要在这里单独定义html即可。
四、爬取多数据网页
首先,使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建1到100的序列。在空查询中输入={1..100},生成1到100的序列。到100的序列,然后转向一张桌子。
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin。
点击确定开始批量抓取网页,抓取成功。可根据工作需要进行后续操作。
php抓取网页表格信息(PHP提交获取表单数据是表单应用中最常用的操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-11 11:12
提交和获取表单数据是表单应用中最常用的操作,往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。使用 POST() 方法提交表单 使用 POST() 方法时,只需要将表单中的属性方法设置为 POST。POST() 方法不依赖于 URL,不会显示在地址栏中。POST() 方法可以不受限制地向服务器传输数据,所有提交的信息都是在后台传输的,用户在浏览器端看不到这个过程,安全性会更高。因此,POST() 方法更适合发送机密(如银行账户)或大容量数据
简介:获取表单数据是表单应用中最常用的操作。往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。
简介: 摘要:今天要给大家介绍的是jQuery中的$.get()。它还允许我们用很少的代码完成网站开发中的ajax需求。$.get()函数的参数和我们在《jQuery如何实现Ajax技术2:$.post()》中介绍的$.post()参数是一样的。详情如下...
简介: 摘要:在《jquery如何实现ajax技术1:$.ajax()》中,我们学习了如何使用jQuery的$.ajax()函数来实现ajax的开发需求。但是相比其他一些函数,$.ajax()的实现过程和代码量还是比较复杂的。...
简介:Ajax中get和post方法的区别一、get()和post()的基本区别1.get是在ACTION属性指向的URL中加入参数数据队列提交的表单,值和表单每个字段一一对应,可以在URL中看到。Post 是通过 HTTP post 机制,将表单中的每个字段及其内容放在 HTML HEADER 中,并发送到 ACTION 属性指向的 URL 地址。用户看不到这个过程。2.对于get方法,服务端使用Re...
简介:使用 Yii::$app->request->post(); 从 ios 接收数据,并打印接收到的数据,该值将为空。如果您使用 $_data = empty($_POST) ?json_decode(file_get_contents('php://input'), TRUE) : $_POST; 收到ios...
简介:yii2控制器Controller Ajax操作示例:本文介绍yii2控制器Controller Ajax操作方法。分享给大家参考,如下: public function actionSample(){if (Yii::$app->request->isAjax) {$data = Yii::$app->request->post();$searchname =爆炸(“:”,$数据['搜索
简介:wordpress自定义字段输出代码设计。!-- 例如,如果这是幻灯片-- div class=flexslider ?php if ( have_posts() ) :the_post(); ?ul class=slides ?php $images = get_post_meta($post-ID, images, false); //一
简介:php9超级全局变量(二))的使用详解。今天讲一下$_GET()和$_POST()。其实很容易理解。从表面上可以看出意思就是获取post和get表单的数据,其实是一模一样的,来个专业的
简介:thinkphp表单自动验证应用,thinkphp表单验证。使用thinkphp表单自动验证,thinkphp表单验证使用TP3.2框架 public function add_post(){ //验证规则 $rule=array( array('name','require','请输入你的名字' ,1),//必须
简介:ThinkPHP表单自动验证应用示例,thinkphp示例。ThinkPHP表单自动验证应用示例,thinkphp示例使用TP3.2框架public function add_post(){//验证规则$rule=array(array('name','require','请输入你的名字', 1),//必须检查
【相关问答推荐】: 查看全部
php抓取网页表格信息(PHP提交获取表单数据是表单应用中最常用的操作)
提交和获取表单数据是表单应用中最常用的操作,往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。使用 POST() 方法提交表单 使用 POST() 方法时,只需要将表单中的属性方法设置为 POST。POST() 方法不依赖于 URL,不会显示在地址栏中。POST() 方法可以不受限制地向服务器传输数据,所有提交的信息都是在后台传输的,用户在浏览器端看不到这个过程,安全性会更高。因此,POST() 方法更适合发送机密(如银行账户)或大容量数据
简介:获取表单数据是表单应用中最常用的操作。往往需要PHP后台从前台页面获取用户在前台表单页面提交的各种数据。表单数据的传输有两种方式,一种是 POST() 方法,另一种是 GET() 方法。使用哪种方法获取数据取决于
由表单的method属性指定,下面解释这两种方法在Web表单中的具体应用。
简介: 摘要:今天要给大家介绍的是jQuery中的$.get()。它还允许我们用很少的代码完成网站开发中的ajax需求。$.get()函数的参数和我们在《jQuery如何实现Ajax技术2:$.post()》中介绍的$.post()参数是一样的。详情如下...
简介: 摘要:在《jquery如何实现ajax技术1:$.ajax()》中,我们学习了如何使用jQuery的$.ajax()函数来实现ajax的开发需求。但是相比其他一些函数,$.ajax()的实现过程和代码量还是比较复杂的。...
简介:Ajax中get和post方法的区别一、get()和post()的基本区别1.get是在ACTION属性指向的URL中加入参数数据队列提交的表单,值和表单每个字段一一对应,可以在URL中看到。Post 是通过 HTTP post 机制,将表单中的每个字段及其内容放在 HTML HEADER 中,并发送到 ACTION 属性指向的 URL 地址。用户看不到这个过程。2.对于get方法,服务端使用Re...
简介:使用 Yii::$app->request->post(); 从 ios 接收数据,并打印接收到的数据,该值将为空。如果您使用 $_data = empty($_POST) ?json_decode(file_get_contents('php://input'), TRUE) : $_POST; 收到ios...
简介:yii2控制器Controller Ajax操作示例:本文介绍yii2控制器Controller Ajax操作方法。分享给大家参考,如下: public function actionSample(){if (Yii::$app->request->isAjax) {$data = Yii::$app->request->post();$searchname =爆炸(“:”,$数据['搜索
简介:wordpress自定义字段输出代码设计。!-- 例如,如果这是幻灯片-- div class=flexslider ?php if ( have_posts() ) :the_post(); ?ul class=slides ?php $images = get_post_meta($post-ID, images, false); //一
简介:php9超级全局变量(二))的使用详解。今天讲一下$_GET()和$_POST()。其实很容易理解。从表面上可以看出意思就是获取post和get表单的数据,其实是一模一样的,来个专业的
简介:thinkphp表单自动验证应用,thinkphp表单验证。使用thinkphp表单自动验证,thinkphp表单验证使用TP3.2框架 public function add_post(){ //验证规则 $rule=array( array('name','require','请输入你的名字' ,1),//必须
简介:ThinkPHP表单自动验证应用示例,thinkphp示例。ThinkPHP表单自动验证应用示例,thinkphp示例使用TP3.2框架public function add_post(){//验证规则$rule=array(array('name','require','请输入你的名字', 1),//必须检查
【相关问答推荐】:
php抓取网页表格信息(模拟浏览器获取网页内容和发送表单的方法:Snoopy($URI))
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-11 11:10
Snoopy 是一个 php采集 类,它模拟浏览器获取网页内容和发送表单。
这里有一些史努比功能:
史努比类、方法:
获取($URI)
用于抓取网页内容的方法。 $URI 参数是被抓取网页的 URL 地址。获取的结果存储在 $this->results 中。如果你正在抓取一个帧,Snoopy 会将每个帧跟踪到一个数组中,然后是 $this->results。
获取文本($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的表单内容(form)。
获取链接($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。 $formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是该方法会去除HTML标签等无关数据,登录后只返回网页的文本内容。
提交链接($URI)
这个方法和submit()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
类属性:(括号内为默认值)
史努比官网: 查看全部
php抓取网页表格信息(模拟浏览器获取网页内容和发送表单的方法:Snoopy($URI))
Snoopy 是一个 php采集 类,它模拟浏览器获取网页内容和发送表单。
这里有一些史努比功能:
史努比类、方法:
获取($URI)
用于抓取网页内容的方法。 $URI 参数是被抓取网页的 URL 地址。获取的结果存储在 $this->results 中。如果你正在抓取一个帧,Snoopy 会将每个帧跟踪到一个数组中,然后是 $this->results。
获取文本($URI)
该方法与fetch()类似,唯一不同的是该方法会去除HTML标签等无关数据,只返回网页中的文本内容。
fetchform($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的表单内容(form)。
获取链接($URI)
这个方法和fetch()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
提交($URI,$formvars)
此方法向 $URL 指定的链接地址发送确认表单。 $formvars 是一个存储表单参数的数组。
提交文本($URI,$formvars)
该方法与submit()类似,唯一不同的是该方法会去除HTML标签等无关数据,登录后只返回网页的文本内容。
提交链接($URI)
这个方法和submit()类似,唯一的区别是这个方法会去掉HTML标签等不相关的数据,只返回网页中的链接。默认情况下,相对链接将自动填充为完整的 URL。
类属性:(括号内为默认值)
史努比官网:
php抓取网页表格信息(音乐体育美术照片上传:表单是实现动态网页的动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-09 23:12
表单是实现动态网页的主要外部表单,可以通过表单采集客户端提交的信息。表单是网站交互的重要组成部分。
本节将提供一个综合示例,它将与前一章示例中介绍的表格相关的各个组件集成在一起,实现所有组件的综合应用。主要是在上一章“在普通WEB页面中插入表单”的基础上,使用PHP代码实现表单元素的取值。通过 POST() 方法将各个组件的值提交到该页面,并通过 $_POST 获取提交的值。
具体操作步骤如下:
(1)表单的HTML页面设计如下,直接上代码:
文件名称:
性别:
男性
女性
密码:
教育:
专家
大学本科
中学
爱好:
音乐
体育
艺术
照片上传:
个人简介:
表单包括常见的表单元素:单行文本框、多行文本框、单选项(单选)、多选项(复选框)、多选菜单。
列表框是一个列表菜单,在其命名属性下有自己的值可供选择。selected 是一个特定的属性选择元素,如果该属性附加了一个选项,则该项目将在显示时作为第一个项目显示。
介绍文本框的内容,根据行和列显示文本、行和列的宽度。
选中标签是指单个选项或多个选项中的一个值,默认已经选中。
(2)处理表单提交的数据,从而将表单中输入的各种提交数据输出到当前页面,代码格式如下:
if($_POST['submit']!= ""){ //判断表单是否已经提交
echo "你的简历是:"。'
';
echo "名称:".$_POST['user'].'
'; // 输出用户名
echo "性别:".$_POST['sex'].'
'; // 输出性别
echo "密码:".$_POST['pwd'].'
'; // 输出密码
echo "教育:".$_POST['select'].'
'; // 输出度数
回声“爱好:”;
对于($i=0;$i
";
$path = './upfiles/'.$_FILES['image']['name']; // 指定上传路径和文件名
//move_uploaded_file($_FILES['image']['img_name'],$path); //上传文件
echo "照片:"."$path".'
'; //个人照片输出路径
echo "个人介绍:".$_POST['intro']; //输出个人介绍的内容
}
注:上传文件或图片请参考PHP中文网站php $_FILES
(3)在上例的根目录下创建一个upfiles文件夹,用来存放上传的文件。
(4)在浏览器中输入运行地址回车即可得到运行结果如下图:
总结:以上就是PHP和WBE表单的综合应用。小伙伴们需要多多练习,掌握了这些技术点,就可以更自由的应用表单,也就具备了开发动态页面的能力,为接下来深入学习PHP语言打下良好的基础。基础。 查看全部
php抓取网页表格信息(音乐体育美术照片上传:表单是实现动态网页的动态)
表单是实现动态网页的主要外部表单,可以通过表单采集客户端提交的信息。表单是网站交互的重要组成部分。
本节将提供一个综合示例,它将与前一章示例中介绍的表格相关的各个组件集成在一起,实现所有组件的综合应用。主要是在上一章“在普通WEB页面中插入表单”的基础上,使用PHP代码实现表单元素的取值。通过 POST() 方法将各个组件的值提交到该页面,并通过 $_POST 获取提交的值。
具体操作步骤如下:
(1)表单的HTML页面设计如下,直接上代码:
文件名称:
性别:
男性
女性
密码:
教育:
专家
大学本科
中学
爱好:
音乐
体育
艺术
照片上传:
个人简介:
表单包括常见的表单元素:单行文本框、多行文本框、单选项(单选)、多选项(复选框)、多选菜单。
列表框是一个列表菜单,在其命名属性下有自己的值可供选择。selected 是一个特定的属性选择元素,如果该属性附加了一个选项,则该项目将在显示时作为第一个项目显示。
介绍文本框的内容,根据行和列显示文本、行和列的宽度。
选中标签是指单个选项或多个选项中的一个值,默认已经选中。
(2)处理表单提交的数据,从而将表单中输入的各种提交数据输出到当前页面,代码格式如下:
if($_POST['submit']!= ""){ //判断表单是否已经提交
echo "你的简历是:"。'
';
echo "名称:".$_POST['user'].'
'; // 输出用户名
echo "性别:".$_POST['sex'].'
'; // 输出性别
echo "密码:".$_POST['pwd'].'
'; // 输出密码
echo "教育:".$_POST['select'].'
'; // 输出度数
回声“爱好:”;
对于($i=0;$i
";
$path = './upfiles/'.$_FILES['image']['name']; // 指定上传路径和文件名
//move_uploaded_file($_FILES['image']['img_name'],$path); //上传文件
echo "照片:"."$path".'
'; //个人照片输出路径
echo "个人介绍:".$_POST['intro']; //输出个人介绍的内容
}
注:上传文件或图片请参考PHP中文网站php $_FILES
(3)在上例的根目录下创建一个upfiles文件夹,用来存放上传的文件。
(4)在浏览器中输入运行地址回车即可得到运行结果如下图:
总结:以上就是PHP和WBE表单的综合应用。小伙伴们需要多多练习,掌握了这些技术点,就可以更自由的应用表单,也就具备了开发动态页面的能力,为接下来深入学习PHP语言打下良好的基础。基础。
php抓取网页表格信息(中的一些常见问题及解决办法(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-06 00:01
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。
101(切换协议) 请求者已经请求服务器切换协议,服务器已经确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器创建了新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。
303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。
404(未找到)服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态. 但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置(它应该位于顶级域,称为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) .
405 (Method Disabled) 禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。
408(请求超时)服务器在等待请求时超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。
411(需要有效长度)服务器不接受没有有效载荷长度标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Requested URI too long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。
417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。 查看全部
php抓取网页表格信息(中的一些常见问题及解决办法(二))
1xx(临时回复)
表示临时响应并要求请求者继续执行操作的状态代码。
代码说明
100(继续)请求者应继续请求。服务器返回此代码表示已收到请求的第一部分并正在等待其余部分。
101(切换协议) 请求者已经请求服务器切换协议,服务器已经确认并准备切换。
2xx(成功)
指示服务器成功处理请求的状态代码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表示 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器创建了新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203 (Unauthorized Information) 服务器已成功处理请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Content reset) 服务器成功处理请求但没有返回内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,需要采取进一步行动。通常,这些状态代码用于重定向。Google 建议您对每个请求使用不超过 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取重定向页面时遇到问题。诊断下的网络抓取页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以对请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(对 GET 或 HEAD 请求)时,它会自动将请求者重定向到新位置。您应该使用此代码告诉 Googlebot 页面或 网站 已永久移动到新位置。
302(暂时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 或 HEAD 请求的 301 代码,会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为Googlebot 将继续抓取旧位置和索引。
303(查看其他位置)当请求者应该对不同位置使用单独的 GET 请求来检索响应时,服务器会返回此代码。对于除 HEAD 之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。这样可以节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改。
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回这个响应,也表明请求者应该使用代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并且会自动将请求者带到不同的位置,但您不应使用此代码告诉 Googlebot 页面或 网站 已移动,因为 Googlebot将继续抓取旧位置和索引。
4xx(请求错误)
这些状态代码表明请求可能出错,阻止服务器处理它。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。服务器可能会为需要登录的网页返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果您在尝试抓取 网站 上的有效页面时看到 Googlebot 收到此状态代码(您可以在 Google 网站Admin Tools Diagnostics 下的网络抓取页面上看到此代码),您的服务器或主机可能是拒绝 Googlebot 访问。
404(未找到)服务器找不到请求的网页。例如,如果请求的网页在服务器上不存在,则服务器通常会返回此代码。如果您的 网站 上没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的诊断标签中的 robots.txt 页面上看到此状态,那么这是正确的状态. 但是,如果您有 robots.txt 文件并看到此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置(它应该位于顶级域,称为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址上看到此状态(在“诊断”标签中的 HTTP 错误页面上),这意味着 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接) .
405 (Method Disabled) 禁用请求中指定的方法。
406(不可接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应授权使用代理。如果服务器返回此响应,它还指示请求者应使用的代理。
408(请求超时)服务器在等待请求时超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须在响应中收录有关冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间差异的列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但有时在资源曾经存在但现在不存在的情况下代替 404 代码。如果资源已被永久删除,则应使用 301 指定资源的新位置。
411(需要有效长度)服务器不接受没有有效载荷长度标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Requested URI too long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求的范围不符合要求)如果页面不能提供请求的范围,服务器返回此状态码。
417 (Expectation not met) 服务器不满足“Expectation”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,但没有及时收到上游服务器的请求。
php抓取网页表格信息(javahttp反射楼上不知道还在用这块还是api?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-04 05:04
php抓取网页表格信息,首先通过javascript抓取网页源代码获取数据,比如分页表格或者首页等数据,需要从数据库提取,然后设置header就可以提取数据,
foreach。php的where_id=>getattr(self,'where_id',self)getattr(self,'enter_id',self)getattr(self,'enter_value',self)getattr(self,'enter_variable',self)getattr(self,'enter_time',self)。
分页和表格可以直接用正则匹配,
wherelz说的应该是sql语句?正则匹配就可以提取。如果你想知道每页的数据有多少,
正则匹配啊~!
使用java反射就可以获取所有的数据,当然,这是基于分页的,至于什么情况下需要提取什么内容,你可以根据你的需求定义一下或者对数据库添加查询条件,既然要进行爬虫相关的学习,就不推荐java的了,
php的正则提取函数
python的for循环吧,
java反射...
java的http反射
楼上不知道还在用这块还是api。这块可以借鉴一些工具类的调用。正则匹配就可以。 查看全部
php抓取网页表格信息(javahttp反射楼上不知道还在用这块还是api?)
php抓取网页表格信息,首先通过javascript抓取网页源代码获取数据,比如分页表格或者首页等数据,需要从数据库提取,然后设置header就可以提取数据,
foreach。php的where_id=>getattr(self,'where_id',self)getattr(self,'enter_id',self)getattr(self,'enter_value',self)getattr(self,'enter_variable',self)getattr(self,'enter_time',self)。
分页和表格可以直接用正则匹配,
wherelz说的应该是sql语句?正则匹配就可以提取。如果你想知道每页的数据有多少,
正则匹配啊~!
使用java反射就可以获取所有的数据,当然,这是基于分页的,至于什么情况下需要提取什么内容,你可以根据你的需求定义一下或者对数据库添加查询条件,既然要进行爬虫相关的学习,就不推荐java的了,
php的正则提取函数
python的for循环吧,
java反射...
java的http反射
楼上不知道还在用这块还是api。这块可以借鉴一些工具类的调用。正则匹配就可以。
php抓取网页表格信息(如何利用Python的camelot模块从PDF文件中爬取表格数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 380 次浏览 • 2022-03-02 09:22
本文文章为大家带来Python如何实现从PDF文件中爬取表格数据(代码示例),具有一定的参考价值。需要的朋友可以参考一下,希望对你有所帮助。
本文将展示一个略有不同的爬虫。
过去,我们的爬虫从互联网上抓取数据,因为网页通常是用 HTML、CSS 和 JavaScript 代码编写的。因此,有很多成熟的技术可以抓取网页中的各种数据。这一次,我们需要抓取的文档是 PDF 文件。本文将展示如何使用 Python 的 camelot 模块从 PDF 文件中抓取表格数据。
在我们的日常生活和工作中,PDF文件无疑是最常用的文件格式之一。从教科书和课件到合同和计划书,我们都可以看到这种文件格式。但是如何从PDF文件中提取表格是个大问题。因为 PDF 中没有内部表示来表示表格。这使得表格数据难以提取用于分析。那么,我们如何从 PDF 中抓取表格数据呢?
答案是 Python 的 camelot 模块!
camelot 是一个 Python 模块,它使任何人都可以轻松地从 PDF 文件中提取表格数据。可以使用以下命令安装camelot模块(安装时间较长):
pip install camelot-py
camelot 模块的官方文档地址是:.
下面将展示如何使用 camelot 模块从 PDF 文件中抓取表格数据。
示例 1
首先来看一个简单的例子:eg.pdf,整个文件只有一页,而这一页只有一个表格,如下:
可以使用以下 Python 代码提取此 PDF 文件中的表格:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 表格信息
print(tables)
print(tables[0])
# 表格数据
print(tables[0].data)
输出是:
[['ID', '姓名', '城市', '性别'], ['1', 'Alex', 'Shanghai', 'M'], ['2', 'Bob', 'Beijing', 'F'], ['3', 'Cook', 'New York', 'M']]
分析代码,camelot.read_pdf()是camelot从表中提取数据的函数。输入参数为PDF文件的路径、页码(pages)和表格解析方式(有stream和lattice两种方式)。对于table解析方式,默认方式是lattice,stream方式默认会将整个PDF页面解析为一个table。如果需要在解析页面中指定区域,可以使用table_area参数。
camelot 模块的方便之处在于它提供了将提取的表格数据直接转换为 pandas、csv、JSON 和 html 的函数,例如 tables[0].df、tables[0].to_csv() 函数等。以输出的 csv 文件为例:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 将表格数据转化为csv文件
tables[0].to_csv('E://eg.csv')
生成的 csv 文件如下:
示例 2
在示例 2 中,我们将从 PDF 页面区域中的表格中提取数据。PDF文件的页面(部分)如下:
为了提取在整个页面中唯一的表,我们需要定位到表所在的位置。PDF文件的坐标系与图片不同。它以左下角的顶点为原点,x 轴向右,y 轴向上。可以通过以下Python代码输出整个页面文本的坐标:
import camelot
# 从PDF中提取表格
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream')
# 绘制PDF文档的坐标,定位表格所在的位置
tables[0].plot('text')
输出是:
UserWarning: No tables found on page-53 [stream.py:292]
整个代码没有找到表格,因为stream方法默认把整个PDF页面当作一个表格,所以没有找到表格。但是绘制的页面坐标的图像如下:
仔细对比之前的PDF页面不难发现,表格对应区域的左上角坐标为(50,620),右下角坐标为(500 ,540).在read_pdf()函数中加入table_area参数,完整的Python代码如下:
import camelot
# 识别指定区域中的表格数据
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream', table_area=['50,620,500,540'])
# 绘制PDF文档的坐标,定位表格所在的位置
table_df = tables[0].df
print(type(table_df))
print(table_df.head(n=6))
输出是:
0 1 2 3
0 Student Pre-test score Post-test score Difference
1 1 70 73 3
2 2 64 65 1
3 3 69 63 -6
4 … … … …
5 34 82 88 6
总结
在PDF页面中具体识别表格时,除了指定区域的参数外,还有下标、下标、单元格合并等参数。详细使用方法请参考 camelot 官方文档网站:.
以上就是Python如何从PDF文件中爬取表格数据(代码示例)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除 查看全部
php抓取网页表格信息(如何利用Python的camelot模块从PDF文件中爬取表格数据)
本文文章为大家带来Python如何实现从PDF文件中爬取表格数据(代码示例),具有一定的参考价值。需要的朋友可以参考一下,希望对你有所帮助。
本文将展示一个略有不同的爬虫。
过去,我们的爬虫从互联网上抓取数据,因为网页通常是用 HTML、CSS 和 JavaScript 代码编写的。因此,有很多成熟的技术可以抓取网页中的各种数据。这一次,我们需要抓取的文档是 PDF 文件。本文将展示如何使用 Python 的 camelot 模块从 PDF 文件中抓取表格数据。
在我们的日常生活和工作中,PDF文件无疑是最常用的文件格式之一。从教科书和课件到合同和计划书,我们都可以看到这种文件格式。但是如何从PDF文件中提取表格是个大问题。因为 PDF 中没有内部表示来表示表格。这使得表格数据难以提取用于分析。那么,我们如何从 PDF 中抓取表格数据呢?
答案是 Python 的 camelot 模块!
camelot 是一个 Python 模块,它使任何人都可以轻松地从 PDF 文件中提取表格数据。可以使用以下命令安装camelot模块(安装时间较长):
pip install camelot-py
camelot 模块的官方文档地址是:.
下面将展示如何使用 camelot 模块从 PDF 文件中抓取表格数据。
示例 1
首先来看一个简单的例子:eg.pdf,整个文件只有一页,而这一页只有一个表格,如下:
可以使用以下 Python 代码提取此 PDF 文件中的表格:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 表格信息
print(tables)
print(tables[0])
# 表格数据
print(tables[0].data)
输出是:
[['ID', '姓名', '城市', '性别'], ['1', 'Alex', 'Shanghai', 'M'], ['2', 'Bob', 'Beijing', 'F'], ['3', 'Cook', 'New York', 'M']]
分析代码,camelot.read_pdf()是camelot从表中提取数据的函数。输入参数为PDF文件的路径、页码(pages)和表格解析方式(有stream和lattice两种方式)。对于table解析方式,默认方式是lattice,stream方式默认会将整个PDF页面解析为一个table。如果需要在解析页面中指定区域,可以使用table_area参数。
camelot 模块的方便之处在于它提供了将提取的表格数据直接转换为 pandas、csv、JSON 和 html 的函数,例如 tables[0].df、tables[0].to_csv() 函数等。以输出的 csv 文件为例:
import camelot
# 从PDF文件中提取表格
tables = camelot.read_pdf('E://eg.pdf', pages='1', flavor='stream')
# 将表格数据转化为csv文件
tables[0].to_csv('E://eg.csv')
生成的 csv 文件如下:
示例 2
在示例 2 中,我们将从 PDF 页面区域中的表格中提取数据。PDF文件的页面(部分)如下:
为了提取在整个页面中唯一的表,我们需要定位到表所在的位置。PDF文件的坐标系与图片不同。它以左下角的顶点为原点,x 轴向右,y 轴向上。可以通过以下Python代码输出整个页面文本的坐标:
import camelot
# 从PDF中提取表格
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream')
# 绘制PDF文档的坐标,定位表格所在的位置
tables[0].plot('text')
输出是:
UserWarning: No tables found on page-53 [stream.py:292]
整个代码没有找到表格,因为stream方法默认把整个PDF页面当作一个表格,所以没有找到表格。但是绘制的页面坐标的图像如下:
仔细对比之前的PDF页面不难发现,表格对应区域的左上角坐标为(50,620),右下角坐标为(500 ,540).在read_pdf()函数中加入table_area参数,完整的Python代码如下:
import camelot
# 识别指定区域中的表格数据
tables = camelot.read_pdf('G://Statistics-Fundamentals-Succinctly.pdf', pages='53', \
flavor='stream', table_area=['50,620,500,540'])
# 绘制PDF文档的坐标,定位表格所在的位置
table_df = tables[0].df
print(type(table_df))
print(table_df.head(n=6))
输出是:
0 1 2 3
0 Student Pre-test score Post-test score Difference
1 1 70 73 3
2 2 64 65 1
3 3 69 63 -6
4 … … … …
5 34 82 88 6
总结
在PDF页面中具体识别表格时,除了指定区域的参数外,还有下标、下标、单元格合并等参数。详细使用方法请参考 camelot 官方文档网站:.
以上就是Python如何从PDF文件中爬取表格数据(代码示例)的详细内容。更多详情请关注php中文网文章其他相关话题!
声明:本文转载于:segmentfault,如有侵权,请联系删除
php抓取网页表格信息(Google为什么做网站时一定要注意搜索引擎友好(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-02 07:13
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,但是看到写了幻灭,所以直接引用了主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时,谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小实验,谷歌表示不会对 网站 产生影响。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。 查看全部
php抓取网页表格信息(Google为什么做网站时一定要注意搜索引擎友好(图))
虽然谷歌已经是爬取页面最多的搜索引擎,但仍然不满足,因为有很多页面和信息很难找到和爬取。这就是为什么在执行 网站 时对 SEO 友好很重要的原因。
现在谷歌开始提供提交表单(form)来发现后续页面。本来想写详细说明的,但是看到写了幻灭,所以直接引用了主要内容如下。
我们已经知道Googlebot除了文字、视频、音频、Flash等类型的内容外,还可以通过JS代码抓取链接。而在未来,Googlebot 也有望直接识别图片和视频中的文字。为了进一步抓取互联网,Google 宣布 Googlebot 已经能够通过提交表单抓取更多内容。
据 Google 称,Googlebot 目前正在试验一小部分高质量的 网站 表单提交。当Googlebot在这些网站上找到HTML表格时(即检测到时),会自动从网站中选择一些词进入表格的文本框,然后选择不同的按钮,勾选选项和验证项目,然后提交表格。一旦 Googlebot 在提交表单后认为新内容看起来是合法、有趣和独特的,它可能会将内容抓取到 Google 的搜索结果索引数据库中。这意味着 Googlebot 现在知道如何通过提交表单来获取新内容。
同时,谷歌还强调,如果在网站的robots.txt文件中禁止隐藏表单,并且表单提交后生成的链接预计不会被抓取,那么Googlebot不会爬行。此外,目前 Googlebot 仅提交 GET 类型的表单。例如,当表单需要用户个人信息(如密码、用户名、联系人等)时,Googlebot 会自动跳过这些表单。
这种形式的抓取目前是一个小实验,谷歌表示不会对 网站 产生影响。既不会影响网站的PR值,也不会影响网站的正常爬取和排名。
Matt Cutts 还写了一篇文章来说明这样做的好处。有很多网站主页只以表格的形式列出公司的子站,并没有以链接的形式列出子站。这种网站不能深入收录之前,因为谷歌不提交表单就找不到隐藏在表单后面的URL。
这当然给一些网站的收录创造了机会,但是否也给一些公司网站带来了一定的安全风险?网站如果你不想被收录屏蔽,请使用robots.txt文件来屏蔽它。

