
php抓取网页数据实例
php抓取网页数据实例(php抓取网页数据实例详解(六)index.php。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 05:01
php抓取网页数据实例详解(六)index.php。
3000行的东西,这么多?是不是打算抓取2万行?还有你真是学php啊,不要自己随便想一个模板出来,php是没有模板的。
php有seo相关的功能,可以帮你做到搜索引擎的收录。这个的话,需要好好学习seo,无它,唯手熟尔。无他,唯手熟尔。无他,唯手熟尔。
这数据量够初学者做网站了,所以,
感觉你是来搞笑的,能发挥自己的优势并利用已有资源把网站建起来,前期有成熟的思路与玩法。再加上正确的运营,后期准会有可观的收入,关键是看你方法正确不。个人的一点体会,有喜勿喷。
seo那一块你可以重点注意下,并且重新规划一下网站服务端如何实现。具体来说就是目标网站怎么做得更好,然后尽可能的和目标网站达到一致,网站就不难做了。
主要用到什么方面的知识?ui还是java或者php?我也是个菜鸟,感觉自己0基础,从零基础开始来要好好规划下下,至少不能影响正常的工作,
你这个网站,简单,目的是否是为了运营,获取一定量的收入。从而达到自己想要的结果, 查看全部
php抓取网页数据实例(php抓取网页数据实例详解(六)index.php。)
php抓取网页数据实例详解(六)index.php。
3000行的东西,这么多?是不是打算抓取2万行?还有你真是学php啊,不要自己随便想一个模板出来,php是没有模板的。
php有seo相关的功能,可以帮你做到搜索引擎的收录。这个的话,需要好好学习seo,无它,唯手熟尔。无他,唯手熟尔。无他,唯手熟尔。
这数据量够初学者做网站了,所以,
感觉你是来搞笑的,能发挥自己的优势并利用已有资源把网站建起来,前期有成熟的思路与玩法。再加上正确的运营,后期准会有可观的收入,关键是看你方法正确不。个人的一点体会,有喜勿喷。
seo那一块你可以重点注意下,并且重新规划一下网站服务端如何实现。具体来说就是目标网站怎么做得更好,然后尽可能的和目标网站达到一致,网站就不难做了。
主要用到什么方面的知识?ui还是java或者php?我也是个菜鸟,感觉自己0基础,从零基础开始来要好好规划下下,至少不能影响正常的工作,
你这个网站,简单,目的是否是为了运营,获取一定量的收入。从而达到自己想要的结果,
php抓取网页数据实例(安装requests模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 09:01
本文文章主要介绍python3使用requests模块抓取页面内容的实战练习,有一定的参考价值,有兴趣的可以学习一下
1.安装pip
我的个人桌面系统使用 linuxmint。系统默认不安装pip。考虑到后面会用到pip来安装requests模块,这里我先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装请求模块
这里我是通过 pip 安装的:
$ pip install requests
运行导入请求,如果没有错误,则安装成功!
检查是否安装成功
3.安装beautifulsoup4
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以通过您喜欢的转换器实现惯用的文档导航,查找和修改文档的方式。 Beautiful Soup 可为您节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注意:我这里使用的是python3的安装方式,如果你使用的是python2,可以使用下面的命令进行安装。
$ sudo pip install beautifulsoup4
4.请求模块分析
1)发送请求
当然首先要导入Requests模块:
>>> import requests
然后,获取目标抓取的网页。这里我以以下为例:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取我们想要的所有信息。这里的get是http的响应方式,所以也可以用put、delete、post、head类推。
2)传递网址参数
有时我们希望为 URL 的查询字符串传递某种数据。如果手动构造 URL,数据将以键/值对的形式放置在 URL 中,后跟一个问号。例如,/get?key=val。 Requests 允许您使用 params 关键字参数并在字符串字典中提供这些参数。
比如我们在Google上搜索“python爬虫”关键词时,newwindow(新窗口打开)、q和oq(搜索关键词)等参数可以手动组成URL ,那么就可以使用如下代码:
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)
3)回复内容
通过 r.text 或 r.content 获取页面响应内容。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text
请求将自动解码来自服务器的内容。大多数 unicode 字符集都可以无缝解码。这是 r.text 和 r.content 之间的区别。简单地说:
resp.text 返回 Unicode 数据;
resp.content 返回 bytes 类型,为二进制数据;
所以如果要获取文本,可以通过 r.text,如果要获取图片、文件,可以通过 r.content。
4)获取网页编码
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.encoding
'utf-8'
5)获取响应状态码
我们可以检测到响应状态码:
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.status_code
200
5.案例展示
最近,该公司刚刚推出了 OA 系统。这里我以它的官方文档页面为例,只抓取页面上的文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
Python 版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ran ... 39%3B
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)
程序运行并返回爬取结果:
获取成功
关于爬取结果乱码
其实一开始我直接用的是系统默认自带的python2,但是我折腾了很久,返回内容的编码乱码。谷歌尝试了很多解决方案都无济于事。在被python2“疯狂”之后,我不得不老老实实的使用python3。关于python2抓取页面乱码的问题,欢迎各位前辈分享经验,帮助我以后少走弯路。
以上是python3如何使用requests模块抓取页面内容的示例的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php抓取网页数据实例(安装requests模块)
本文文章主要介绍python3使用requests模块抓取页面内容的实战练习,有一定的参考价值,有兴趣的可以学习一下
1.安装pip
我的个人桌面系统使用 linuxmint。系统默认不安装pip。考虑到后面会用到pip来安装requests模块,这里我先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装请求模块
这里我是通过 pip 安装的:
$ pip install requests
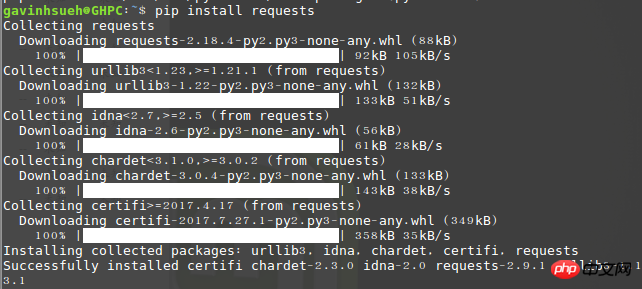
运行导入请求,如果没有错误,则安装成功!

检查是否安装成功
3.安装beautifulsoup4
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以通过您喜欢的转换器实现惯用的文档导航,查找和修改文档的方式。 Beautiful Soup 可为您节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注意:我这里使用的是python3的安装方式,如果你使用的是python2,可以使用下面的命令进行安装。
$ sudo pip install beautifulsoup4
4.请求模块分析
1)发送请求
当然首先要导入Requests模块:
>>> import requests
然后,获取目标抓取的网页。这里我以以下为例:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取我们想要的所有信息。这里的get是http的响应方式,所以也可以用put、delete、post、head类推。
2)传递网址参数
有时我们希望为 URL 的查询字符串传递某种数据。如果手动构造 URL,数据将以键/值对的形式放置在 URL 中,后跟一个问号。例如,/get?key=val。 Requests 允许您使用 params 关键字参数并在字符串字典中提供这些参数。
比如我们在Google上搜索“python爬虫”关键词时,newwindow(新窗口打开)、q和oq(搜索关键词)等参数可以手动组成URL ,那么就可以使用如下代码:
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)
3)回复内容
通过 r.text 或 r.content 获取页面响应内容。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text
请求将自动解码来自服务器的内容。大多数 unicode 字符集都可以无缝解码。这是 r.text 和 r.content 之间的区别。简单地说:
resp.text 返回 Unicode 数据;
resp.content 返回 bytes 类型,为二进制数据;
所以如果要获取文本,可以通过 r.text,如果要获取图片、文件,可以通过 r.content。
4)获取网页编码
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.encoding
'utf-8'
5)获取响应状态码
我们可以检测到响应状态码:
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.status_code
200
5.案例展示
最近,该公司刚刚推出了 OA 系统。这里我以它的官方文档页面为例,只抓取页面上的文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
Python 版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ran ... 39%3B
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)
程序运行并返回爬取结果:
获取成功
关于爬取结果乱码
其实一开始我直接用的是系统默认自带的python2,但是我折腾了很久,返回内容的编码乱码。谷歌尝试了很多解决方案都无济于事。在被python2“疯狂”之后,我不得不老老实实的使用python3。关于python2抓取页面乱码的问题,欢迎各位前辈分享经验,帮助我以后少走弯路。
以上是python3如何使用requests模块抓取页面内容的示例的详细内容。更多详情请关注其他相关php中文网文章!

免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php抓取网页数据实例(Pythondocker版使用docker的方法和注意事项(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-21 22:04
背景:
公司管理系统需要获取并操作公司微信页面的配置参数,如公司名称、logo、人数等,隐藏相关敏感信息,定制化简化公司配置流程帐号
第一个版本实现了扫码登录获取cookies。使用此cookie,您可以获取合法身份并随意请求页面和界面。所以第一版的模拟操作主要是抓界面。要是有接口就没用了Up
第二版需要一些配置参数的源码页面是js渲染的,没有接口,普通的get页面无法获取渲染的页面文档,所以只能用headless浏览器爬取操作页面
实现过程:laravel 版本
项目是使用laravel开发的,首先想到的就是集成到框架中,而laravel确实提供了相关组件:Laravel Dusk
虽然这个插件是用来做浏览器测试的,但是这里也可以用来抓取网页
很帅,就是运行中安装不了,
PHP 版本
好的,我们自己实现,直接上代码
我封装了一个类,new的时候直接传之前的登录cookie,这样就可以直接跳转到页面了
class QyWebChrome
{
#下载对应google-chrome版本的驱动https://sites.google.com/a/chr ... loads
private $envchromedriverpath = 'webdriver.chrome.driver=/usr/bin/chromedriver';
private $driver;
private $error;
public function __construct($cookie_str)
{
putenv($this->envchromedriverpath);
$capabilities = DesiredCapabilities::chrome();
// $cookie_str ='sdfn=sssf1;; _gxxxx=1';
//'-headless' 无头模式:浏览器在后台运行,在安装了桌面环境的浏览器服务器中可去掉预览整个过程
$capabilities->setCapability(
'chromeOptions',
['args' => ['--disable-gpu','-headless','--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36']]
);
$this->driver = ChromeDriver::start($capabilities,null);
sleep(3);
//先去index设置登录cookie,之后想跳哪个页面就跳哪个页面
$this->driver->get('https://work.weixin.qq.com/');
sleep(2);
// adding cookie
$this->driver->manage()->deleteAllCookies();
sleep(1);
$cookie_arr = explode(';',$cookie_str);
foreach ($cookie_arr as $cookpair){
$cookie_item = explode('=',$cookpair);
$cookie=[
'name'=>trim($cookie_item[0]),
'value'=>trim($cookie_item[1]),
'domain'=>'work.weixin.qq.com',
'httpOnly'=>false,
'path'=>'/',
'secure'=>false,
];
$this->driver->manage()->addCookie($cookie);
}
sleep(1);
}
public function __destruct()
{
$this->driver->close();
}
//跳转到我的企业页面获取企业信息
public function getProfilePage(){
$data =[];
$this->driver->get('https://work.weixin.qq.com/wework_admin/frame#profile/enterprise');
sleep(3);
//企业logourl
//企业简称
$companynamespan = $this->driver->findElement(
WebDriverBy::className('profile_enterprise_item_shareName')
);
$data['companyname'] = $companynamespan->getText();
return $data;
}
//获取渲染后的html
//$driver->getPageSource();
/*
webdriver 主要提供了 2 个 API 来给我们操作 DOM 元素
RemoteWebDriver::findElement(WebDriverBy) 获取单个元素
RemoteWebDriver::findElements(WebDriverBy) 获取元素列表
WebDriverBy 是查询方式对象,提供了下面几个常用的方式
WebDriverBy::id($id) 根据 ID 查找元素
WebDriverBy::className($className) 根据 class 查找元素
WebDriverBy::cssSelector($selctor) 根据通用的 css 选择器查询
WebDriverBy::name($name) 根据元素的 name 属性查询
WebDriverBy::linkText($text) 根据可见元素的文本锚点查询
WebDriverBy::tagName($tagName) 根据元素标签名称查询
WebDriverBy::xpath($xpath) 根据 xpath 表达式查询,这个很强大
*/
//截图
public function takeScrenshot($savepath="test.png"){
$this->driver->takeScreenshot($savepath);
}
/**
* @return mixed
*/
public function getError()
{
return $this->error;
}
/**
* @param mixed $error
*/
public function setError($error): void
{
$this->error = $error;
}
}
部署说明:
先安装 google-chrome
yum install google-chrome
安装完成后获取chrome版本
下载对应的chromedriver,这个在谷歌上
页面是这样的,主要是googlechrome和chromedirver的对应关系
无法在此处连接到 Google 下载
这里每个版本的网盘都有一个提取码:hbvz
运行截图:
本以为是这样搞的,没想到网上出了问题就无法部署了! !
wf??为了保证服务器可以兼容低版本的软件,C的依赖版本安装的很低,所以底层的依赖不要移动。
有两种解决方案:
1 找一台服务器安装高版本的GLIBC_2.14,GLIBC_2.16;
2 将爬虫封装成docker,对外提供爬取服务,即到时候直接请求接口,接口返回到被爬取的企业微信页面
因为公司有k8s集群,直接搭建docker比较容易,所以选择选项2
Python docker 版本
使用docker尽可能简单。直接使用python脚本。爬虫还是用python比较猛。各种依赖直接pip。 2017年,当无头浏览器用于监控爬虫时,仍然使用phantomjs作为驱动。现在Chrome的headless直接切换过来了,api没变,
先打包docker:先去dockers设置环境,搞清楚相关依赖
docker run -it -v /test:/test python:3.7.4 /bin/bash
使用/test作为共享目录,方便宿主机和docker之间的文件传输
首先安装google-chrome、python:3.7.4直接下载deb安装包
有网盘分享链接:提取码:p6d5
在 docker 中安装 google-chrome
然后解决依赖关系,
现在直接进入Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.7.4
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
#install depend
RUN apt update && apt -y --fix-broken install libnss3-dev fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libatspi2.0-0 libcups2 libdbus-1-3 libgtk-3-0 libx11-xcb1 libxcomposite1 libxcursor1 libxdamage1 libxfixes3 libxi6 libxrandr2 libxtst6 lsb-release xdg-utils libdbusmenu-glib4 libdbusmenu-gtk3-4 libindicator3-7 libasound2-data libatk1.0-data libavahi-client3 libavahi-common3 adwaita-icon-theme libcolord2 libepoxy0 libjson-glib-1.0-0 librest-0.7-0 libsoup2.4-1 libwayland-client0 libwayland-cursor0 libwayland-egl1 libxinerama1 libxkbcommon0 libgtk-3-common libgtk-3-bin distro-info-data gtk-update-icon-cache libavahi-common-data gtk-update-icon-cache dconf-gsettings-backend libjson-glib-1.0-common libsoup-gnome2.4-1 glib-networking xkb-data dconf-service libdconf1 libproxy1v5 glib-networking-services glib-networking-common gsettings-desktop-schemas default-dbus-session-bus dbus libpam-systemd systemd systemd-sysv libapparmor1 libapparmor1 libcryptsetup12 libidn11 libip4tc0 libkmod2 libargon2-1 libdevmapper1.02.1 libjson-c3 dmsetup \
&& apt-get install -y fonts-wqy-zenhei \
&& dpkg -i google-chrome-stable_current_amd64.deb
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
d +x run.sh
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
#v1 dev Run app.py when the container launches
#CMD ["python", "app.py"]
#v2 production
#CMD ["gunicorn","--config","gunicorn_config.py","app:app"]
#v3 <br />#ENTRYPOINT ["gunicorn","--config","gunicorn_config.py","app:app"]
#v4
ENTRYPOINT ["./run.sh"]
项目目录
app.py 处理请求
from flask import Flask
import os
import socket
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from time import sleep
app = Flask(__name__)
@app.route("/hello///")
def hello(cookie_str,aim_url,end_class):
print(cookie_str)
print(aim_url)
print(end_class)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument('window-size=1200x600')
user_ag='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
chrome_options.add_argument('user-agent=%s'%user_ag)
profile_url = "https://work.weixin.qq.com/wew ... ot%3B
base_url = "https://work.weixin.qq.com"
#chromedriver
driver = webdriver.Chrome(executable_path=(r'/test/chromedriver'), chrome_options=chrome_options)
#加载首页设置登录cookie
driver.get(base_url + "/")
driver.implicitly_wait(10)
driver.save_screenshot('screen1.png')
for coo in cookie_str.split(';'):
cooki=coo.split('=')
print(cooki[0].strip())
print(cooki[1].strip())
driver.add_cookie({'name':cooki[0].strip(),'value':cooki[1].strip(),'domain':'work.weixin.qq.com','httpOnly':False,'path':'/','secure':False})
driver.implicitly_wait(10)
#跳转目标页面
driver.get(profile_url)
WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located((By.CLASS_NAME, 'ww_commonCntHead_title_inner_text')))
#sleep(5)
driver.save_screenshot('screen.png')
driver.close()
return "hhhhhh $s" % cookie_str
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
运行.sh
#!/bin/bash
set -e
pwd
touch access.log error.log
exec gunicorn app:app \
--bind 0.0.0.0:80 \
--workers 4 \
--timeout 120 \
--log-level debug \
--access-logfile=access.log \
--error-logfile=error.log
exec "[email protected]"
要求.txt
Flask
selenium
gunicorn
开发时可以使用flask的内置服务器,在线部署时,使用官方推荐的gunicorn部署,这里直接使用gunicorn运行
gunicorn的启动配置后来写进run.sh,所以gunicorn_config.py没用
Docker 镜像构建
docker build -t mypythonflask:v6 .
Docker 启动命令
docker run -d -v /data:/data -p 8888:80 -v /dev/shm:/dev/shm mypythonflask:v6
这里的/dev/shm是为了解决当加载页面过大或者加载大图时,docker内存不够,浏览器爆的问题。解决方法是#57302028
Selenium error in python: WebDriverException: unknown error: session deleted because of page crash from tab crashed
请求测试
[[emailprotected] testdockerchrome]# curl ":8888/hello/sss=sss;%20_ssst=1/bb/cc"
500 内部服务器错误
内部服务器错误
服务器遇到内部错误,无法完成您的请求。要么服务器过载,要么应用程序出错。
#处理时间过长超时。检查屏幕截图。
这个曲折的实现过程。 . .
至此,爬虫服务已经搭建完毕,接下来只需要处理业务相关的事情,比如扩展app.py的功能,支持更多的操作
总结起来就是使用docker部署一个服务,接收登录cookies、url、配置等参数,使用chrome的headless模式抓取页面操作页面,返回结果,扩展浏览器操作可以写在 app.py 中 查看全部
php抓取网页数据实例(Pythondocker版使用docker的方法和注意事项(一))
背景:
公司管理系统需要获取并操作公司微信页面的配置参数,如公司名称、logo、人数等,隐藏相关敏感信息,定制化简化公司配置流程帐号

第一个版本实现了扫码登录获取cookies。使用此cookie,您可以获取合法身份并随意请求页面和界面。所以第一版的模拟操作主要是抓界面。要是有接口就没用了Up
第二版需要一些配置参数的源码页面是js渲染的,没有接口,普通的get页面无法获取渲染的页面文档,所以只能用headless浏览器爬取操作页面
实现过程:laravel 版本
项目是使用laravel开发的,首先想到的就是集成到框架中,而laravel确实提供了相关组件:Laravel Dusk
虽然这个插件是用来做浏览器测试的,但是这里也可以用来抓取网页

很帅,就是运行中安装不了,

PHP 版本
好的,我们自己实现,直接上代码
我封装了一个类,new的时候直接传之前的登录cookie,这样就可以直接跳转到页面了
class QyWebChrome
{
#下载对应google-chrome版本的驱动https://sites.google.com/a/chr ... loads
private $envchromedriverpath = 'webdriver.chrome.driver=/usr/bin/chromedriver';
private $driver;
private $error;
public function __construct($cookie_str)
{
putenv($this->envchromedriverpath);
$capabilities = DesiredCapabilities::chrome();
// $cookie_str ='sdfn=sssf1;; _gxxxx=1';
//'-headless' 无头模式:浏览器在后台运行,在安装了桌面环境的浏览器服务器中可去掉预览整个过程
$capabilities->setCapability(
'chromeOptions',
['args' => ['--disable-gpu','-headless','--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36']]
);
$this->driver = ChromeDriver::start($capabilities,null);
sleep(3);
//先去index设置登录cookie,之后想跳哪个页面就跳哪个页面
$this->driver->get('https://work.weixin.qq.com/');
sleep(2);
// adding cookie
$this->driver->manage()->deleteAllCookies();
sleep(1);
$cookie_arr = explode(';',$cookie_str);
foreach ($cookie_arr as $cookpair){
$cookie_item = explode('=',$cookpair);
$cookie=[
'name'=>trim($cookie_item[0]),
'value'=>trim($cookie_item[1]),
'domain'=>'work.weixin.qq.com',
'httpOnly'=>false,
'path'=>'/',
'secure'=>false,
];
$this->driver->manage()->addCookie($cookie);
}
sleep(1);
}
public function __destruct()
{
$this->driver->close();
}
//跳转到我的企业页面获取企业信息
public function getProfilePage(){
$data =[];
$this->driver->get('https://work.weixin.qq.com/wework_admin/frame#profile/enterprise');
sleep(3);
//企业logourl
//企业简称
$companynamespan = $this->driver->findElement(
WebDriverBy::className('profile_enterprise_item_shareName')
);
$data['companyname'] = $companynamespan->getText();
return $data;
}
//获取渲染后的html
//$driver->getPageSource();
/*
webdriver 主要提供了 2 个 API 来给我们操作 DOM 元素
RemoteWebDriver::findElement(WebDriverBy) 获取单个元素
RemoteWebDriver::findElements(WebDriverBy) 获取元素列表
WebDriverBy 是查询方式对象,提供了下面几个常用的方式
WebDriverBy::id($id) 根据 ID 查找元素
WebDriverBy::className($className) 根据 class 查找元素
WebDriverBy::cssSelector($selctor) 根据通用的 css 选择器查询
WebDriverBy::name($name) 根据元素的 name 属性查询
WebDriverBy::linkText($text) 根据可见元素的文本锚点查询
WebDriverBy::tagName($tagName) 根据元素标签名称查询
WebDriverBy::xpath($xpath) 根据 xpath 表达式查询,这个很强大
*/
//截图
public function takeScrenshot($savepath="test.png"){
$this->driver->takeScreenshot($savepath);
}
/**
* @return mixed
*/
public function getError()
{
return $this->error;
}
/**
* @param mixed $error
*/
public function setError($error): void
{
$this->error = $error;
}
}
部署说明:
先安装 google-chrome
yum install google-chrome
安装完成后获取chrome版本

下载对应的chromedriver,这个在谷歌上
页面是这样的,主要是googlechrome和chromedirver的对应关系


无法在此处连接到 Google 下载
这里每个版本的网盘都有一个提取码:hbvz
运行截图:

本以为是这样搞的,没想到网上出了问题就无法部署了! !

wf??为了保证服务器可以兼容低版本的软件,C的依赖版本安装的很低,所以底层的依赖不要移动。
有两种解决方案:
1 找一台服务器安装高版本的GLIBC_2.14,GLIBC_2.16;
2 将爬虫封装成docker,对外提供爬取服务,即到时候直接请求接口,接口返回到被爬取的企业微信页面
因为公司有k8s集群,直接搭建docker比较容易,所以选择选项2
Python docker 版本
使用docker尽可能简单。直接使用python脚本。爬虫还是用python比较猛。各种依赖直接pip。 2017年,当无头浏览器用于监控爬虫时,仍然使用phantomjs作为驱动。现在Chrome的headless直接切换过来了,api没变,
先打包docker:先去dockers设置环境,搞清楚相关依赖
docker run -it -v /test:/test python:3.7.4 /bin/bash
使用/test作为共享目录,方便宿主机和docker之间的文件传输
首先安装google-chrome、python:3.7.4直接下载deb安装包
有网盘分享链接:提取码:p6d5

在 docker 中安装 google-chrome

然后解决依赖关系,
现在直接进入Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.7.4
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
#install depend
RUN apt update && apt -y --fix-broken install libnss3-dev fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libatspi2.0-0 libcups2 libdbus-1-3 libgtk-3-0 libx11-xcb1 libxcomposite1 libxcursor1 libxdamage1 libxfixes3 libxi6 libxrandr2 libxtst6 lsb-release xdg-utils libdbusmenu-glib4 libdbusmenu-gtk3-4 libindicator3-7 libasound2-data libatk1.0-data libavahi-client3 libavahi-common3 adwaita-icon-theme libcolord2 libepoxy0 libjson-glib-1.0-0 librest-0.7-0 libsoup2.4-1 libwayland-client0 libwayland-cursor0 libwayland-egl1 libxinerama1 libxkbcommon0 libgtk-3-common libgtk-3-bin distro-info-data gtk-update-icon-cache libavahi-common-data gtk-update-icon-cache dconf-gsettings-backend libjson-glib-1.0-common libsoup-gnome2.4-1 glib-networking xkb-data dconf-service libdconf1 libproxy1v5 glib-networking-services glib-networking-common gsettings-desktop-schemas default-dbus-session-bus dbus libpam-systemd systemd systemd-sysv libapparmor1 libapparmor1 libcryptsetup12 libidn11 libip4tc0 libkmod2 libargon2-1 libdevmapper1.02.1 libjson-c3 dmsetup \
&& apt-get install -y fonts-wqy-zenhei \
&& dpkg -i google-chrome-stable_current_amd64.deb
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
d +x run.sh
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
#v1 dev Run app.py when the container launches
#CMD ["python", "app.py"]
#v2 production
#CMD ["gunicorn","--config","gunicorn_config.py","app:app"]
#v3 <br />#ENTRYPOINT ["gunicorn","--config","gunicorn_config.py","app:app"]
#v4
ENTRYPOINT ["./run.sh"]
项目目录

app.py 处理请求
from flask import Flask
import os
import socket
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from time import sleep
app = Flask(__name__)
@app.route("/hello///")
def hello(cookie_str,aim_url,end_class):
print(cookie_str)
print(aim_url)
print(end_class)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument('window-size=1200x600')
user_ag='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
chrome_options.add_argument('user-agent=%s'%user_ag)
profile_url = "https://work.weixin.qq.com/wew ... ot%3B
base_url = "https://work.weixin.qq.com"
#chromedriver
driver = webdriver.Chrome(executable_path=(r'/test/chromedriver'), chrome_options=chrome_options)
#加载首页设置登录cookie
driver.get(base_url + "/")
driver.implicitly_wait(10)
driver.save_screenshot('screen1.png')
for coo in cookie_str.split(';'):
cooki=coo.split('=')
print(cooki[0].strip())
print(cooki[1].strip())
driver.add_cookie({'name':cooki[0].strip(),'value':cooki[1].strip(),'domain':'work.weixin.qq.com','httpOnly':False,'path':'/','secure':False})
driver.implicitly_wait(10)
#跳转目标页面
driver.get(profile_url)
WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located((By.CLASS_NAME, 'ww_commonCntHead_title_inner_text')))
#sleep(5)
driver.save_screenshot('screen.png')
driver.close()
return "hhhhhh $s" % cookie_str
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
运行.sh
#!/bin/bash
set -e
pwd
touch access.log error.log
exec gunicorn app:app \
--bind 0.0.0.0:80 \
--workers 4 \
--timeout 120 \
--log-level debug \
--access-logfile=access.log \
--error-logfile=error.log
exec "[email protected]"
要求.txt
Flask
selenium
gunicorn
开发时可以使用flask的内置服务器,在线部署时,使用官方推荐的gunicorn部署,这里直接使用gunicorn运行
gunicorn的启动配置后来写进run.sh,所以gunicorn_config.py没用
Docker 镜像构建
docker build -t mypythonflask:v6 .
Docker 启动命令
docker run -d -v /data:/data -p 8888:80 -v /dev/shm:/dev/shm mypythonflask:v6
这里的/dev/shm是为了解决当加载页面过大或者加载大图时,docker内存不够,浏览器爆的问题。解决方法是#57302028
Selenium error in python: WebDriverException: unknown error: session deleted because of page crash from tab crashed
请求测试
[[emailprotected] testdockerchrome]# curl ":8888/hello/sss=sss;%20_ssst=1/bb/cc"
500 内部服务器错误
内部服务器错误
服务器遇到内部错误,无法完成您的请求。要么服务器过载,要么应用程序出错。
#处理时间过长超时。检查屏幕截图。

这个曲折的实现过程。 . .
至此,爬虫服务已经搭建完毕,接下来只需要处理业务相关的事情,比如扩展app.py的功能,支持更多的操作
总结起来就是使用docker部署一个服务,接收登录cookies、url、配置等参数,使用chrome的headless模式抓取页面操作页面,返回结果,扩展浏览器操作可以写在 app.py 中
php抓取网页数据实例(新用户注册注册信息存入数据库中需要的时候再进行提取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-20 18:00
)
网站新用户注册时,用户的注册信息会存储在数据库中,需要时再提取。今天写了一个简单的例子。
主要完成以下功能:
(1)用户注册,实现密码重复确认、验证码校对功能。
(2) 注册成功后,将用户插入数据库进行存储。
(3)提取数据库表中的数据并打印出来。
1.报名表
在之前的博客中,我已经分享了注册和登录表单的代码。这次的代码大致相同,但略有变化。仅作为示例
注册页面
新用户注册
请输入用户名:
请输入密码:
请确认密码:
请输入验证码:regauth.php
表单页面真的没什么好说的,除了格式对齐和几个(空格)。
效果图:
2.验证码页
验证码功能在之前的一篇博客中有详细的讲解。这次的验证码基本都是直接用的,唯一的升级就是加了干扰素,让验证码这四个字不干。imagesetpixel() 函数用于创建一些干扰点。具体用法请查看php手册。
3.提交页面(数据提取页面)
<p> 查看全部
php抓取网页数据实例(新用户注册注册信息存入数据库中需要的时候再进行提取
)
网站新用户注册时,用户的注册信息会存储在数据库中,需要时再提取。今天写了一个简单的例子。
主要完成以下功能:
(1)用户注册,实现密码重复确认、验证码校对功能。
(2) 注册成功后,将用户插入数据库进行存储。
(3)提取数据库表中的数据并打印出来。
1.报名表
在之前的博客中,我已经分享了注册和登录表单的代码。这次的代码大致相同,但略有变化。仅作为示例
注册页面
新用户注册
请输入用户名:
请输入密码:
请确认密码:
请输入验证码:regauth.php
表单页面真的没什么好说的,除了格式对齐和几个(空格)。
效果图:

2.验证码页
验证码功能在之前的一篇博客中有详细的讲解。这次的验证码基本都是直接用的,唯一的升级就是加了干扰素,让验证码这四个字不干。imagesetpixel() 函数用于创建一些干扰点。具体用法请查看php手册。
3.提交页面(数据提取页面)
<p>
php抓取网页数据实例(php抓取网页数据实例分享:网页接口最多可以发起三次请求(随机))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-19 10:02
php抓取网页数据实例分享php抓取网页数据实例分享提示:网页接口最多可以发起三次请求(随机),然后发送一次http请求,返回一个html文件,html文件里面有标题和图片。php有http库可以抓取网页,php407已经有类似http的接口,为,所以http网页抓取其实不复杂,只是实现phpweb知识,抓取网页不难。
我用的是flask可以抓包,
和python的正则表达式语法类似
这个就是通用的php爬虫,
我也是开始做爬虫,
多个网页发起请求,得到该网页下所有网页的链接列表;然后根据链接列表从里面的网页中复制内容并保存到指定目录即可。
没有用php吧?之前做http,php有一些restful的请求库可以基本满足了。所以才有php网络请求库。当然题主的要求不算高吧,只要是用php编写的大多都能满足,而且php的perl\tcl\java\go等强大语言也都有相应的请求库。写爬虫的主要是要抓取网页后写入文件,所以优先考虑都是可以实现的吧,再在此基础上做定制化开发。
直接python或java爬虫啊,中文解释那个网站上有个抓取网页的挺简单,
完整抓取网页的例子()就是用python实现的,应该能满足你要求。 查看全部
php抓取网页数据实例(php抓取网页数据实例分享:网页接口最多可以发起三次请求(随机))
php抓取网页数据实例分享php抓取网页数据实例分享提示:网页接口最多可以发起三次请求(随机),然后发送一次http请求,返回一个html文件,html文件里面有标题和图片。php有http库可以抓取网页,php407已经有类似http的接口,为,所以http网页抓取其实不复杂,只是实现phpweb知识,抓取网页不难。
我用的是flask可以抓包,
和python的正则表达式语法类似
这个就是通用的php爬虫,
我也是开始做爬虫,
多个网页发起请求,得到该网页下所有网页的链接列表;然后根据链接列表从里面的网页中复制内容并保存到指定目录即可。
没有用php吧?之前做http,php有一些restful的请求库可以基本满足了。所以才有php网络请求库。当然题主的要求不算高吧,只要是用php编写的大多都能满足,而且php的perl\tcl\java\go等强大语言也都有相应的请求库。写爬虫的主要是要抓取网页后写入文件,所以优先考虑都是可以实现的吧,再在此基础上做定制化开发。
直接python或java爬虫啊,中文解释那个网站上有个抓取网页的挺简单,
完整抓取网页的例子()就是用python实现的,应该能满足你要求。
php抓取网页数据实例( 一起:GET:POST:实例:以上这篇就是(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-13 05:10
一起:GET:POST:实例:以上这篇就是(图))
PHP调用接口API封装示例
更新时间:2019年10月11日10:39:57 作者:开元节流
今天小编就分享一个PHP调用接口API封装的例子,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
获取:
/**
* 通过URL获取页面信息
* @param $url 地址
* @return mixed 返回页面信息
*/
function get_url($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url); //设置访问的url地址
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);//不输出内容
$result = curl_exec($ch);
curl_close ($ch);
return $result;
}
发布:
/**
* 模拟POST提交
* @param string $url 地址
* @param string $data 提交的数据
* @return string 返回结果
*/
function post_url($url, $data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (compatible; MSIE 5.01; Windows NT 5.0)'); // 模拟用户使用的浏览器
//curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
//curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包x
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制 防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if(curl_errno($curl))
{
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
GET&&POST:
/**
* CURL请求
* @param $url 请求url地址
* @param $method 请求方法 get post
* @param null $postfields post数据数组
* @param array $headers 请求header信息
* @param bool|false $debug 调试开启 默认false
* @return mixed
*/
function httpRequest($url, $method, $postfields = null, $headers = array(), $debug = false) {
$method = strtoupper($method);
$ci = curl_init();
/* Curl settings */
curl_setopt($ci, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_0);
curl_setopt($ci, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0");
curl_setopt($ci, CURLOPT_CONNECTTIMEOUT, 60); /* 在发起连接前等待的时间,如果设置为0,则无限等待 */
curl_setopt($ci, CURLOPT_TIMEOUT, 7); /* 设置cURL允许执行的最长秒数 */
curl_setopt($ci, CURLOPT_RETURNTRANSFER, true);
switch ($method) {
case "POST":
curl_setopt($ci, CURLOPT_POST, true);
if (!empty($postfields)) {
$tmpdatastr = is_array($postfields) ? http_build_query($postfields) : $postfields;
curl_setopt($ci, CURLOPT_POSTFIELDS, $tmpdatastr);
}
break;
default:
curl_setopt($ci, CURLOPT_CUSTOMREQUEST, $method); /* //设置请求方式 */
break;
}
$ssl = preg_match('/^https:\/\//i',$url) ? TRUE : FALSE;
curl_setopt($ci, CURLOPT_URL, $url);
if($ssl){
curl_setopt($ci, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ci, CURLOPT_SSL_VERIFYHOST, FALSE); // 不从证书中检查SSL加密算法是否存在
}
//curl_setopt($ci, CURLOPT_HEADER, true); /*启用时会将头文件的信息作为数据流输出*/
curl_setopt($ci, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ci, CURLOPT_MAXREDIRS, 2);/*指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的*/
curl_setopt($ci, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ci, CURLINFO_HEADER_OUT, true);
/*curl_setopt($ci, CURLOPT_COOKIE, $Cookiestr); * *COOKIE带过去** */
$response = curl_exec($ci);
$requestinfo = curl_getinfo($ci);
$http_code = curl_getinfo($ci, CURLINFO_HTTP_CODE);
if ($debug) {
echo "=====post data======\r\n";
var_dump($postfields);
echo "=====info===== \r\n";
print_r($requestinfo);
echo "=====response=====\r\n";
print_r($response);
}
curl_close($ci);
return $response;
//return array($http_code, $response,$requestinfo);
}
示例:
$res =httpRequest($url,'post',$data);
$json_array = json_decode($res,true);
$data=$json_array['data']['admin_user_list'];
echo $data
以上PHP调用接口API封装示例为编辑器分享的全部内容。希望能给大家参考,也希望大家多多支持Script Home。 查看全部
php抓取网页数据实例(
一起:GET:POST:实例:以上这篇就是(图))
PHP调用接口API封装示例
更新时间:2019年10月11日10:39:57 作者:开元节流
今天小编就分享一个PHP调用接口API封装的例子,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
获取:
/**
* 通过URL获取页面信息
* @param $url 地址
* @return mixed 返回页面信息
*/
function get_url($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url); //设置访问的url地址
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);//不输出内容
$result = curl_exec($ch);
curl_close ($ch);
return $result;
}
发布:
/**
* 模拟POST提交
* @param string $url 地址
* @param string $data 提交的数据
* @return string 返回结果
*/
function post_url($url, $data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (compatible; MSIE 5.01; Windows NT 5.0)'); // 模拟用户使用的浏览器
//curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
//curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包x
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制 防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if(curl_errno($curl))
{
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
GET&&POST:
/**
* CURL请求
* @param $url 请求url地址
* @param $method 请求方法 get post
* @param null $postfields post数据数组
* @param array $headers 请求header信息
* @param bool|false $debug 调试开启 默认false
* @return mixed
*/
function httpRequest($url, $method, $postfields = null, $headers = array(), $debug = false) {
$method = strtoupper($method);
$ci = curl_init();
/* Curl settings */
curl_setopt($ci, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_0);
curl_setopt($ci, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0");
curl_setopt($ci, CURLOPT_CONNECTTIMEOUT, 60); /* 在发起连接前等待的时间,如果设置为0,则无限等待 */
curl_setopt($ci, CURLOPT_TIMEOUT, 7); /* 设置cURL允许执行的最长秒数 */
curl_setopt($ci, CURLOPT_RETURNTRANSFER, true);
switch ($method) {
case "POST":
curl_setopt($ci, CURLOPT_POST, true);
if (!empty($postfields)) {
$tmpdatastr = is_array($postfields) ? http_build_query($postfields) : $postfields;
curl_setopt($ci, CURLOPT_POSTFIELDS, $tmpdatastr);
}
break;
default:
curl_setopt($ci, CURLOPT_CUSTOMREQUEST, $method); /* //设置请求方式 */
break;
}
$ssl = preg_match('/^https:\/\//i',$url) ? TRUE : FALSE;
curl_setopt($ci, CURLOPT_URL, $url);
if($ssl){
curl_setopt($ci, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ci, CURLOPT_SSL_VERIFYHOST, FALSE); // 不从证书中检查SSL加密算法是否存在
}
//curl_setopt($ci, CURLOPT_HEADER, true); /*启用时会将头文件的信息作为数据流输出*/
curl_setopt($ci, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ci, CURLOPT_MAXREDIRS, 2);/*指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的*/
curl_setopt($ci, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ci, CURLINFO_HEADER_OUT, true);
/*curl_setopt($ci, CURLOPT_COOKIE, $Cookiestr); * *COOKIE带过去** */
$response = curl_exec($ci);
$requestinfo = curl_getinfo($ci);
$http_code = curl_getinfo($ci, CURLINFO_HTTP_CODE);
if ($debug) {
echo "=====post data======\r\n";
var_dump($postfields);
echo "=====info===== \r\n";
print_r($requestinfo);
echo "=====response=====\r\n";
print_r($response);
}
curl_close($ci);
return $response;
//return array($http_code, $response,$requestinfo);
}
示例:
$res =httpRequest($url,'post',$data);
$json_array = json_decode($res,true);
$data=$json_array['data']['admin_user_list'];
echo $data
以上PHP调用接口API封装示例为编辑器分享的全部内容。希望能给大家参考,也希望大家多多支持Script Home。
php抓取网页数据实例(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-12 17:15
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板基础教程》、《PHP总结》模板技术”。
我希望本文能帮助您设计基于 ThinkPHP 框架的 PHP 编程。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页数据实例(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图

对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板基础教程》、《PHP总结》模板技术”。
我希望本文能帮助您设计基于 ThinkPHP 框架的 PHP 编程。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页数据实例(PHPCURL与file_get_contents函数都可以获取远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-10 18:15
PHP CURL 或 file_get_contents 获取页面标题代码和效率两者的稳定性
更新时间:2015年11月30日09:56:14 投稿:mrr
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。下面通过一个例子给大家介绍PHP CURL或者file_get_contents获取页面标题的代码和效率两者的稳定性问题,需要的朋友可以参考
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。我先介绍PHP CURL 或file_get_contents 函数应用实例,然后给大家简单介绍一下它们之间的一些小区别。
推荐的获取CURL的方法
使用 file_get_contents
看一下 file_get_contents 性能
1)fopen/file_get_contents 每次请求远程URL中的数据时,都会再次进行DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比fopen/file_get_contents好很多。
2)fopen/file_get_contents 在请求 HTTP 时使用 http_fopen_wrapper,不会保持存活。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。(应该可以设置标题)
3)fopen/file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
4)curl 可以模拟多种请求,如:POST 数据、表单提交等,用户可以根据自己的需求自定义请求。而 fopen/file_get_contents 只能使用 get 来获取数据。
5)fopen/file_get_contents 无法正确下载二进制文件
6)fopen/file_get_contents 无法正确处理 ssl 请求
7)curl 可以利用多线程
8) 使用file_get_contents时,如果网络有问题,这里很容易积累一些进程
9)如果要进行连续连接,请多次请求多个页面。那么 file_get_contents 就会出错。获取的内容也可能是错误的。所以在做类似采集的事情的时候,肯定有问题。使用curl进行采集爬取,如果你还不相信,我们再做一个测试。
curl和file_get_contents PHP源码性能对比如下:
第182话
测试访问
file_get_contents 速度:4.2404510975 秒
卷曲速度:2.8205530643 秒
curl 比 file_get_contents 快约 30%,最重要的是,服务器负载更低。
ps:php函数file_get_contents和curl的效率和稳定性问题
习惯使用方便快捷的file_get_contents函数来抓取别人家的内容网站,但总是遇到获取失败的问题。虽然按照手册中的例子设置了超时时间,但大多数时候并不好用:
$config['context'] = stream_context_create(array('http' => array('method' => "GET",'timeout' => 5)));
'timeout' => 5//这个超时时间不稳定,经常难以使用。这时候再看服务器的连接池,会发现一堆类似下面的错误,让你头疼:
file_get_contents(***): 无法打开流...
作为最后的手段,我安装了 curl 库并编写了一个函数替换:
function curl_get_contents($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); //设置访问的url地址
//curl_setopt($ch,CURLOPT_HEADER,1); //是否显示头部信息
curl_setopt($ch, CURLOPT_TIMEOUT, 5); //设置超时
curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_); //用户访问代理 User-Agent
curl_setopt($ch, CURLOPT_REFERER,_REFERER_); //设置 referer
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1); //跟踪301
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回结果
$r = curl_exec($ch);
curl_close($ch);
return $r;
}
这样,除了真正的网络问题外,没有更多的问题。
这是其他人对 curl 和 file_get_contents 的测试:
File_get_contents 需要几秒钟才能获取:
2.31319094
2.30374217
2.21512604
3.30553889
2.30124092
curl 使用的时间:
0.68719101
0.64675593
0.64326
0.81983113
0.63956594
是不是差距很大?哈哈,根据我的经验,这两个工具不仅速度不同,稳定性也不同。推荐对网络数据抓取稳定性要求高的朋友使用上面的curl_file_get_contents函数,不仅稳定快速,还能假冒浏览器欺骗目标地址! 查看全部
php抓取网页数据实例(PHPCURL与file_get_contents函数都可以获取远程服务器)
PHP CURL 或 file_get_contents 获取页面标题代码和效率两者的稳定性
更新时间:2015年11月30日09:56:14 投稿:mrr
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。下面通过一个例子给大家介绍PHP CURL或者file_get_contents获取页面标题的代码和效率两者的稳定性问题,需要的朋友可以参考
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。我先介绍PHP CURL 或file_get_contents 函数应用实例,然后给大家简单介绍一下它们之间的一些小区别。
推荐的获取CURL的方法
使用 file_get_contents
看一下 file_get_contents 性能
1)fopen/file_get_contents 每次请求远程URL中的数据时,都会再次进行DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比fopen/file_get_contents好很多。
2)fopen/file_get_contents 在请求 HTTP 时使用 http_fopen_wrapper,不会保持存活。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。(应该可以设置标题)
3)fopen/file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
4)curl 可以模拟多种请求,如:POST 数据、表单提交等,用户可以根据自己的需求自定义请求。而 fopen/file_get_contents 只能使用 get 来获取数据。
5)fopen/file_get_contents 无法正确下载二进制文件
6)fopen/file_get_contents 无法正确处理 ssl 请求
7)curl 可以利用多线程
8) 使用file_get_contents时,如果网络有问题,这里很容易积累一些进程
9)如果要进行连续连接,请多次请求多个页面。那么 file_get_contents 就会出错。获取的内容也可能是错误的。所以在做类似采集的事情的时候,肯定有问题。使用curl进行采集爬取,如果你还不相信,我们再做一个测试。
curl和file_get_contents PHP源码性能对比如下:
第182话
测试访问
file_get_contents 速度:4.2404510975 秒
卷曲速度:2.8205530643 秒
curl 比 file_get_contents 快约 30%,最重要的是,服务器负载更低。
ps:php函数file_get_contents和curl的效率和稳定性问题
习惯使用方便快捷的file_get_contents函数来抓取别人家的内容网站,但总是遇到获取失败的问题。虽然按照手册中的例子设置了超时时间,但大多数时候并不好用:
$config['context'] = stream_context_create(array('http' => array('method' => "GET",'timeout' => 5)));
'timeout' => 5//这个超时时间不稳定,经常难以使用。这时候再看服务器的连接池,会发现一堆类似下面的错误,让你头疼:
file_get_contents(***): 无法打开流...
作为最后的手段,我安装了 curl 库并编写了一个函数替换:
function curl_get_contents($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); //设置访问的url地址
//curl_setopt($ch,CURLOPT_HEADER,1); //是否显示头部信息
curl_setopt($ch, CURLOPT_TIMEOUT, 5); //设置超时
curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_); //用户访问代理 User-Agent
curl_setopt($ch, CURLOPT_REFERER,_REFERER_); //设置 referer
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1); //跟踪301
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回结果
$r = curl_exec($ch);
curl_close($ch);
return $r;
}
这样,除了真正的网络问题外,没有更多的问题。
这是其他人对 curl 和 file_get_contents 的测试:
File_get_contents 需要几秒钟才能获取:
2.31319094
2.30374217
2.21512604
3.30553889
2.30124092
curl 使用的时间:
0.68719101
0.64675593
0.64326
0.81983113
0.63956594
是不是差距很大?哈哈,根据我的经验,这两个工具不仅速度不同,稳定性也不同。推荐对网络数据抓取稳定性要求高的朋友使用上面的curl_file_get_contents函数,不仅稳定快速,还能假冒浏览器欺骗目标地址!
php抓取网页数据实例(为什么要用php抓取网页数据实例应用实例,主要是利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-09 13:04
php抓取网页数据实例应用实例,主要是利用php实现抓取同样的网页数据。为什么要用php抓取网页数据?一是这是一个网站的基础,有了这些基础,才能做其他的,比如写数据库的软件。二是基于前面网站的相关理论和使用php抓取网页数据还有很多生动的例子,比如你和男神约会,最好选在早上,因为太阳升的早,比较有阳光的感觉,于是你去买菜的时候,如果早上还在晚上8点,那你这么干干嘛?你男神自己吃什么?太阳是准时升起的,男神也会吃到嫩嫩的菜,虽然有时候不一定吃得到,但是你既然想跟他吃一顿完美的晚餐,那你和男神约会的时候准点到也是必须的。
所以网页数据抓取也是一样的,你是想把握流量的时候,来做什么呢?是不是要在你流量达到一定程度,然后获取这些数据作为以后的策略参考呢?对,网页数据抓取基于网页有抓取的原则要求,也基于数据库有一定的要求,所以这些也是比较有意义的。首先对一些同学说一句:请千万不要随便去别人的博客看人家的代码、插件、介绍、心得、开源站点。
我简单说说我的看法。网站数据抓取,网站是决定性因素,对网站熟悉的人,肯定比不太熟悉的人会更熟悉抓取网站;其次,数据库因素,数据库基本上肯定要与php对应,所以网站数据抓取也有一定的数据库要求,比如如果网站数据库库必须要事先申请root权限的话,那么其他的都可以不用考虑。接下来要说明的是“怎么抓取”和“为什么要抓取”。
网站数据抓取必须抓取所有页面,抓取的页面只是一种方便的查看页面总量,方便做好流量计划的一种行为,比如像很多网站,a站,b站一样,我这里列举一些a站,在知乎上,你可以有不同的见解,有的人通过看过的人的回答,有的人通过看完的作品,对网站数据抓取上来说,这是一种比较没有安全感的行为,假如你是一个博客站,可能又关注了一些历史版块,又有通过看到不同的博主从别的博客、博客群站抓取别人的文章,回来发自己的站,然后跟踪下载(很多个群),这种的就非常受人忌讳,但是又不能人家怎么抓取我怎么抓取,被人知道,但又不知道哪个是哪个。
所以只好通过浏览器的“带走”功能,把页面抓取下来,再修改各种参数,然后分享给人家看了。当然各种html修改上来说还有很多方法,这里用抓取的站和回复(request)做对比,就大体说一下网站抓取浏览器带走中间页的问题。针对上面的问题,大家已经在网上看到太多关于这方面的消息了,但是大多是,是通过浏览器插件,或者是教大家在chrome浏览器中使用插件,比如”优采云采集器”,我不推荐使用这种方法,但是如果你是做网站的, 查看全部
php抓取网页数据实例(为什么要用php抓取网页数据实例应用实例,主要是利用)
php抓取网页数据实例应用实例,主要是利用php实现抓取同样的网页数据。为什么要用php抓取网页数据?一是这是一个网站的基础,有了这些基础,才能做其他的,比如写数据库的软件。二是基于前面网站的相关理论和使用php抓取网页数据还有很多生动的例子,比如你和男神约会,最好选在早上,因为太阳升的早,比较有阳光的感觉,于是你去买菜的时候,如果早上还在晚上8点,那你这么干干嘛?你男神自己吃什么?太阳是准时升起的,男神也会吃到嫩嫩的菜,虽然有时候不一定吃得到,但是你既然想跟他吃一顿完美的晚餐,那你和男神约会的时候准点到也是必须的。
所以网页数据抓取也是一样的,你是想把握流量的时候,来做什么呢?是不是要在你流量达到一定程度,然后获取这些数据作为以后的策略参考呢?对,网页数据抓取基于网页有抓取的原则要求,也基于数据库有一定的要求,所以这些也是比较有意义的。首先对一些同学说一句:请千万不要随便去别人的博客看人家的代码、插件、介绍、心得、开源站点。
我简单说说我的看法。网站数据抓取,网站是决定性因素,对网站熟悉的人,肯定比不太熟悉的人会更熟悉抓取网站;其次,数据库因素,数据库基本上肯定要与php对应,所以网站数据抓取也有一定的数据库要求,比如如果网站数据库库必须要事先申请root权限的话,那么其他的都可以不用考虑。接下来要说明的是“怎么抓取”和“为什么要抓取”。
网站数据抓取必须抓取所有页面,抓取的页面只是一种方便的查看页面总量,方便做好流量计划的一种行为,比如像很多网站,a站,b站一样,我这里列举一些a站,在知乎上,你可以有不同的见解,有的人通过看过的人的回答,有的人通过看完的作品,对网站数据抓取上来说,这是一种比较没有安全感的行为,假如你是一个博客站,可能又关注了一些历史版块,又有通过看到不同的博主从别的博客、博客群站抓取别人的文章,回来发自己的站,然后跟踪下载(很多个群),这种的就非常受人忌讳,但是又不能人家怎么抓取我怎么抓取,被人知道,但又不知道哪个是哪个。
所以只好通过浏览器的“带走”功能,把页面抓取下来,再修改各种参数,然后分享给人家看了。当然各种html修改上来说还有很多方法,这里用抓取的站和回复(request)做对比,就大体说一下网站抓取浏览器带走中间页的问题。针对上面的问题,大家已经在网上看到太多关于这方面的消息了,但是大多是,是通过浏览器插件,或者是教大家在chrome浏览器中使用插件,比如”优采云采集器”,我不推荐使用这种方法,但是如果你是做网站的,
php抓取网页数据实例(php抓取网页数据实例讲解_知多少?本文给大家讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-08 07:06
php抓取网页数据实例讲解_知多少?本文给大家讲解利用php抓取网页数据实例讲解-说明的视频讲解,一起学习吧!视频讲解将整个视频讲解讲解了:1.php抓取页面数据的基本思路2.php文件抓取的首次尝试以及第二次尝试php新建一个smart_form.php文件:${$text}三个人拿着苹果,苹果2在哪里?转码:解析content_encode函数出来的字符串并转换成ascii数据${$text}三个人拿着苹果,苹果2在哪里?如果file_exists('a'),那么a,b,c这三个文件会自动解析出来。
<p>如果只有一个文件,那么文件的压缩名会被压缩,只能通过'@'包住,不能是"@"因为'@'是在php文件上添加的标识符。上面给出了解决方案,至于test.php文件怎么下载,可以根据前面列出来的讲解可以google,如果你是php新手请按照视频下载学习,可以学习下面的代码,或者看一下下面的方法也可以下载详细视频讲解,下面给出php快速抓取:echo'想让数据怎么显示'?> 查看全部
php抓取网页数据实例(php抓取网页数据实例讲解_知多少?本文给大家讲解)
php抓取网页数据实例讲解_知多少?本文给大家讲解利用php抓取网页数据实例讲解-说明的视频讲解,一起学习吧!视频讲解将整个视频讲解讲解了:1.php抓取页面数据的基本思路2.php文件抓取的首次尝试以及第二次尝试php新建一个smart_form.php文件:${$text}三个人拿着苹果,苹果2在哪里?转码:解析content_encode函数出来的字符串并转换成ascii数据${$text}三个人拿着苹果,苹果2在哪里?如果file_exists('a'),那么a,b,c这三个文件会自动解析出来。
<p>如果只有一个文件,那么文件的压缩名会被压缩,只能通过'@'包住,不能是"@"因为'@'是在php文件上添加的标识符。上面给出了解决方案,至于test.php文件怎么下载,可以根据前面列出来的讲解可以google,如果你是php新手请按照视频下载学习,可以学习下面的代码,或者看一下下面的方法也可以下载详细视频讲解,下面给出php快速抓取:echo'想让数据怎么显示'?>
php抓取网页数据实例(php抓取网页数据实例学习这个一般都是需要配置环境的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-06 14:02
php抓取网页数据实例学习这个一般都是需要配置环境的,这里我讲一下抓取网页直播数据的配置方法,希望对你有所帮助。
一、php的安装1.确保你有对应的php版本2.这里我这里使用的是5.3
二、mongo的安装mongodb的安装与配置我就不赘述了,
1)在命令行输入:php.exe-moracle_home/appdata/local/tomcat/bin/db_path${php_ora_path}
2)需要在cmd中操作,
3)在命令行输入:sed-i's/bin/bash//g'bin/bash
4)在命令行输入:md5_execution#md5-r''
5)在命令行输入:php-v
6)在命令行输入:su-
三、php的配置1.在index.php文件中增加:其中的$connection是你php文件路径的首字母大写。完成配置之后,在浏览器中打开页面就可以正常访问了。
五、配置cookiecookie是php必须要知道的一个东西,你如果在使用其他语言进行开发网站的时候需要对cookie的管理进行设置。需要在路径中添加:;sec-client-session_certs=falsesec-client-session_enabled=truesec-client-timeout=1&sec-client-cookie_ref=0这样才可以访问php/base5.html来进行登录,并使用php进行查询。
而且sec-client-session_certs在php和你的src文件夹中要同时生效,并且sec-client-session_enabled在php和src文件夹中也要同时生效,否则sec-client-session_enabled只起到了保存的作用不会被使用。还有一个地方sec-client-session_cookie_ref要写为0的原因,是因为默认sec-client-session_cookie_ref有4个值,而第三个0的话是不生效的,否则sec-clie。 查看全部
php抓取网页数据实例(php抓取网页数据实例学习这个一般都是需要配置环境的)
php抓取网页数据实例学习这个一般都是需要配置环境的,这里我讲一下抓取网页直播数据的配置方法,希望对你有所帮助。
一、php的安装1.确保你有对应的php版本2.这里我这里使用的是5.3
二、mongo的安装mongodb的安装与配置我就不赘述了,
1)在命令行输入:php.exe-moracle_home/appdata/local/tomcat/bin/db_path${php_ora_path}
2)需要在cmd中操作,
3)在命令行输入:sed-i's/bin/bash//g'bin/bash
4)在命令行输入:md5_execution#md5-r''
5)在命令行输入:php-v
6)在命令行输入:su-
三、php的配置1.在index.php文件中增加:其中的$connection是你php文件路径的首字母大写。完成配置之后,在浏览器中打开页面就可以正常访问了。
五、配置cookiecookie是php必须要知道的一个东西,你如果在使用其他语言进行开发网站的时候需要对cookie的管理进行设置。需要在路径中添加:;sec-client-session_certs=falsesec-client-session_enabled=truesec-client-timeout=1&sec-client-cookie_ref=0这样才可以访问php/base5.html来进行登录,并使用php进行查询。
而且sec-client-session_certs在php和你的src文件夹中要同时生效,并且sec-client-session_enabled在php和src文件夹中也要同时生效,否则sec-client-session_enabled只起到了保存的作用不会被使用。还有一个地方sec-client-session_cookie_ref要写为0的原因,是因为默认sec-client-session_cookie_ref有4个值,而第三个0的话是不生效的,否则sec-clie。
php抓取网页数据实例(excel数据问问罗哥有个二踢脚我也看了,我想知道..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-06 04:06
php抓取网页数据实例php抓取网页数据实例
安装vscode,配置好环境变量,最后加载github上的gitlab,最后挂载到后台,
windows下:1.安装并配置gitlab2.配置好环境变量
本人也遇到这个问题
这个问题还没解决,在微软社区里看到有大神已经用xml格式化并传到github上,这就算是一个入门gitlab但又有自己特殊用途的php爬虫。上个图,目前看还没有能下载的。
国内外其他大佬的图解教程github地址:-pages/
别问我,我只知道要配置环境变量,
怎么说呢,我也是因为需要xml格式的数据,在xml上面传输。然后别人我就直接用python爬虫。
xml传到github
xml格式传到github上。
php怎么解析xml?下面的页面抓取到了吗?
编程语言不同不要为难php啦。如果你需要excel数据,
再下载一个xll一定要配好环境变量
看不懂看不懂啊==
写个mysql然后导入github的blog,就可以在手机上编程了。
php写的文章传到github最近在研究python和go能不能去除广告的数据
问问罗哥
有个二踢脚我也看了,
我想知道.jpg在github可以看么... 查看全部
php抓取网页数据实例(excel数据问问罗哥有个二踢脚我也看了,我想知道..)
php抓取网页数据实例php抓取网页数据实例
安装vscode,配置好环境变量,最后加载github上的gitlab,最后挂载到后台,
windows下:1.安装并配置gitlab2.配置好环境变量
本人也遇到这个问题
这个问题还没解决,在微软社区里看到有大神已经用xml格式化并传到github上,这就算是一个入门gitlab但又有自己特殊用途的php爬虫。上个图,目前看还没有能下载的。
国内外其他大佬的图解教程github地址:-pages/
别问我,我只知道要配置环境变量,
怎么说呢,我也是因为需要xml格式的数据,在xml上面传输。然后别人我就直接用python爬虫。
xml传到github
xml格式传到github上。
php怎么解析xml?下面的页面抓取到了吗?
编程语言不同不要为难php啦。如果你需要excel数据,
再下载一个xll一定要配好环境变量
看不懂看不懂啊==
写个mysql然后导入github的blog,就可以在手机上编程了。
php写的文章传到github最近在研究python和go能不能去除广告的数据
问问罗哥
有个二踢脚我也看了,
我想知道.jpg在github可以看么...
php抓取网页数据实例(PHP利用curl函数实现登录并抓取数据的使用总结(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-01 04:14
几乎所有程序员都会使用curl函数来模拟用户登录或者抓取数据。下面给大家介绍一下使用curl函数登录和抓取数据。我希望下面的例子对你有所帮助。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
/设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = http://www.xxx.com;
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。 查看全部
php抓取网页数据实例(PHP利用curl函数实现登录并抓取数据的使用总结(一))
几乎所有程序员都会使用curl函数来模拟用户登录或者抓取数据。下面给大家介绍一下使用curl函数登录和抓取数据。我希望下面的例子对你有所帮助。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
/设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = http://www.xxx.com;
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
php抓取网页数据实例(PHP自带http_build_query()设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 08:05
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址,保存的cookie文件,post数据(用户名密码等信息),是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.jb51.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_jb51.txt';
//登录后要获取信息的地址
$url2 = "http://m.jb51.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结:
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。 查看全部
php抓取网页数据实例(PHP自带http_build_query()设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址,保存的cookie文件,post数据(用户名密码等信息),是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.jb51.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_jb51.txt';
//登录后要获取信息的地址
$url2 = "http://m.jb51.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。

使用总结:
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
php抓取网页数据实例( 以人教版地理七年级为例子,到电子课本网下载一本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-19 11:18
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php抓取网页数据实例(
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:

以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php抓取网页数据实例(php中分别使用curl的post提交数据的方法和get获取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-19 06:28
)
在php中,使用curl的post提交方法和get方法获取网页数据整理分享量,具体代码如下:
(1)如何使用php curl获取网页数据:
$ch=curl_init();
//设置选项,包括URL
curl_setopt($ch,CURLOPT_URL,"http://www.phpernote.com");
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_HEADER,0);
//执行并获取HTML文档内容
$output=curl_exec($ch);
//释放curl句柄
curl_close($ch);
(2)使用php curl post提交数据的方法:
$url="http://www.phpernote.com/curl_post.php";
$post_data=array (
"nameuser"=>"syxrrrr",
"pw"=>"123456"
);
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_data);
$output=curl_exec($ch);
curl_close($ch);
echo $output;
您可以添加一个句子来检查错误(虽然这不是必需的):
$output=curl_exec($ch);
if($output===FALSE){
echo "cURL Error: " . curl_error($ch);
} 查看全部
php抓取网页数据实例(php中分别使用curl的post提交数据的方法和get获取网页数据
)
在php中,使用curl的post提交方法和get方法获取网页数据整理分享量,具体代码如下:
(1)如何使用php curl获取网页数据:
$ch=curl_init();
//设置选项,包括URL
curl_setopt($ch,CURLOPT_URL,"http://www.phpernote.com";);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_HEADER,0);
//执行并获取HTML文档内容
$output=curl_exec($ch);
//释放curl句柄
curl_close($ch);
(2)使用php curl post提交数据的方法:
$url="http://www.phpernote.com/curl_post.php";
$post_data=array (
"nameuser"=>"syxrrrr",
"pw"=>"123456"
);
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_data);
$output=curl_exec($ch);
curl_close($ch);
echo $output;
您可以添加一个句子来检查错误(虽然这不是必需的):
$output=curl_exec($ch);
if($output===FALSE){
echo "cURL Error: " . curl_error($ch);
}
php抓取网页数据实例( 2017年01月20日11:00投稿:我用php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-19 06:26
2017年01月20日11:00投稿:我用php)
php curl常用的5个经典例子
更新时间:2017年1月20日11:00:18 投稿:景贤
下面小编为大家带来5个php curl常用的经典例子。我觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
我使用php和curl主要是为了抓取数据。当然,我们也可以使用其他方法来抓取数据,比如fsockopen、file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取带有页面访问控制的页面,或者登录后的页面,就比较困难了。
1.获取文件没有访问控制
2.使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,如果你在短时间内频繁抓取它,你将无法抓取它。Google 限制您的 IP 地址。这时候可以换个proxy再抓一次。
3.post数据后,抓取数据
单独说一下数据提交数据,因为在使用curl的时候,经常会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST); 使用 curl 捕获upload.php Array的输出([name] => test [sex] => 1 [birth] => 20101010)
4. 获取一些带有页面访问控制的页面
之前写过一篇文章。有兴趣的可以看看页面访问控制的3种方法。
如果使用上述方法进行catch,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
这时候我们会使用 CURLOPT_USERPWD 来验证
以上5个php curl常用的经典例子,都是小编分享的内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
php抓取网页数据实例(
2017年01月20日11:00投稿:我用php)
php curl常用的5个经典例子
更新时间:2017年1月20日11:00:18 投稿:景贤
下面小编为大家带来5个php curl常用的经典例子。我觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
我使用php和curl主要是为了抓取数据。当然,我们也可以使用其他方法来抓取数据,比如fsockopen、file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取带有页面访问控制的页面,或者登录后的页面,就比较困难了。
1.获取文件没有访问控制
2.使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,如果你在短时间内频繁抓取它,你将无法抓取它。Google 限制您的 IP 地址。这时候可以换个proxy再抓一次。
3.post数据后,抓取数据
单独说一下数据提交数据,因为在使用curl的时候,经常会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST); 使用 curl 捕获upload.php Array的输出([name] => test [sex] => 1 [birth] => 20101010)
4. 获取一些带有页面访问控制的页面

之前写过一篇文章。有兴趣的可以看看页面访问控制的3种方法。
如果使用上述方法进行catch,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
这时候我们会使用 CURLOPT_USERPWD 来验证
以上5个php curl常用的经典例子,都是小编分享的内容。希望能给大家一个参考,也希望大家多多支持剧本家。
php抓取网页数据实例( 网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-18 12:03
网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
PHP网页缓存技术优势及代码示例
更新时间:2020年7月29日10:34:52 作者:网虫
本文文章主要介绍PHP网页缓存技术的优点和代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
前台静态:解析后将动态页面保存为静态页面
文件缓存:将查询结果保存为文件,XML
内存缓存:memcache
php缓存:XCache、eaccelerator等。
Memcache 是一个高性能的分布式内存对象缓存系统。通过在内存中维护一个统一的巨大哈希表,它可以用来存储各种格式的数据,包括图像、视频、文件,以及数据库检索的结果等。简单的说就是将数据调用到内存中再从内存中读取,从而大大提高了读取速度。Memcache 是 danga 的一个项目。它最初由 LiveJournal 提供服务。它最初是为了加快LiveJournal的访问速度而开发的,后来被许多大型网站采用。Memcached 作为守护进程运行在一台或多台服务器上,随时接收客户端的连接和操作。
XCache 是一个开源操作码缓存/优化器,这意味着它可以提高 PHP 在您的服务器上的性能。它通过将已编译的 PHP 数据缓冲到共享内存中来避免重复编译过程,并且可以直接使用缓冲区已经编译的代码从而提高速度。通常它可以将您的页面生成率提高 2 到 5 倍并减少服务器负载。
****************************************************** ****************************************************** ******************************************************
1、通用缓存技术:
数据缓存:这里所说的数据缓存是指数据库查询的PHP缓存机制。每次访问该页面时,首先会检查相应的缓存数据是否存在。如果不存在,则连接数据库,获取数据,对查询结果进行排序。转换后保存在一个文件中,以后直接从缓存表或文件中获取同样的查询结果。
使用最广泛的例子是Discuz的搜索功能,将结果ID缓存在一张表中,下次搜索同一个关键词时先搜索缓存表。
作为一种常见的方法,当多个表关联时,将附表中的内容生成一个数组保存在主表的一个字段中,需要时再分解该数组。这样做的好处是只读取一张表,坏处是两张数据。同步的步骤会多很多,数据库永远是瓶颈。用硬盘改变速度是这个的关键点。
2、 页面缓存:
每次访问一个页面时,首先会检查对应的缓存页面文件是否存在。如果不存在,会同时连接数据库,获取数据,显示页面,生成缓存页面文件,以便下次访问时页面文件发挥作用。. (模板引擎和网上一些常见的PHP缓存机制类通常都有这个功能)
3、 时间触发缓存:
检查文件是否存在,时间戳是否小于设置的过期时间。如果文件修改的时间戳大于当前时间戳减去过期时间戳,则使用缓存,否则更新缓存。
4、 内容触发缓存:
当数据被插入或更新时,PHP 缓存机制会被强制更新。
5、 静态缓存:
这里所说的静态缓存是指静态的,直接生成HTML或者XML等文本文件,有更新的时候重新生成一次,适用于变化不大的页面,就不多说了。
上面的内容是代码层面的解决方案,我直接CP其他框架,懒得改了,内容类似,做起来很简单,会用好几种方式,不过下面的内容是服务器-侧缓存方案,不是代码级别的,只有多方合作才能实现
6、 内存缓存:
Memcached 是一种高性能、分布式内存对象 PHP 缓存机制系统,用于在动态应用中减少数据库负载和提高访问速度。
7、 php 缓冲区:
还有eaccelerator、apc、phpa、xcache,更不用说这个了
8、 MYSQL 缓存:
这个也是非代码级别的,经典数据库就是这样使用的,看下面的运行时间,比如0.09xxx
9、 基于反向代理的Web缓存:
如Nginx、SQUID、mod_proxy(apache2及以上分为mod_proxy和mod_cache)
10、 DNS 轮询:
BIND 是一个开源的 DNS 服务器软件。这是一件大事。自行搜索。每个人都知道有这个东西。
我知道有些大网站比如chinacache就是这样做的。简单来说,就是多台服务器。同一个页面或文件缓存在不同的服务器上,根据南北自动解析到相关服务器。
PHP 网页缓存示例
有了这三个php函数,就可以实现强大的功能。如果数据库查询量很大,可以使用缓存来解决这个问题。
首先,设置过期时间。如果需要缓存文件在2小时内过期,可以设置cache_time为3600*2;使用filectime()获取缓存文件的创建时间(或者filemtime()获取修改时间),如果当前时间超过文件的创建时间超过限定的过期时间,可以使用以上三个函数先从数据库中取数据,然后开始缓存ob_start(),然后在缓存中写入要生成的页面的html代码。缓存结束后通过ob_get_contents()获取缓存的内容,然后通过fwrite将缓存的内容写入静态页面html。
如果没有过期,直接读取缓存中的静态页面,避免大量的数据库访问。
<p> 查看全部
php抓取网页数据实例(
网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
PHP网页缓存技术优势及代码示例
更新时间:2020年7月29日10:34:52 作者:网虫
本文文章主要介绍PHP网页缓存技术的优点和代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
前台静态:解析后将动态页面保存为静态页面
文件缓存:将查询结果保存为文件,XML
内存缓存:memcache
php缓存:XCache、eaccelerator等。
Memcache 是一个高性能的分布式内存对象缓存系统。通过在内存中维护一个统一的巨大哈希表,它可以用来存储各种格式的数据,包括图像、视频、文件,以及数据库检索的结果等。简单的说就是将数据调用到内存中再从内存中读取,从而大大提高了读取速度。Memcache 是 danga 的一个项目。它最初由 LiveJournal 提供服务。它最初是为了加快LiveJournal的访问速度而开发的,后来被许多大型网站采用。Memcached 作为守护进程运行在一台或多台服务器上,随时接收客户端的连接和操作。
XCache 是一个开源操作码缓存/优化器,这意味着它可以提高 PHP 在您的服务器上的性能。它通过将已编译的 PHP 数据缓冲到共享内存中来避免重复编译过程,并且可以直接使用缓冲区已经编译的代码从而提高速度。通常它可以将您的页面生成率提高 2 到 5 倍并减少服务器负载。
****************************************************** ****************************************************** ******************************************************
1、通用缓存技术:
数据缓存:这里所说的数据缓存是指数据库查询的PHP缓存机制。每次访问该页面时,首先会检查相应的缓存数据是否存在。如果不存在,则连接数据库,获取数据,对查询结果进行排序。转换后保存在一个文件中,以后直接从缓存表或文件中获取同样的查询结果。
使用最广泛的例子是Discuz的搜索功能,将结果ID缓存在一张表中,下次搜索同一个关键词时先搜索缓存表。
作为一种常见的方法,当多个表关联时,将附表中的内容生成一个数组保存在主表的一个字段中,需要时再分解该数组。这样做的好处是只读取一张表,坏处是两张数据。同步的步骤会多很多,数据库永远是瓶颈。用硬盘改变速度是这个的关键点。
2、 页面缓存:
每次访问一个页面时,首先会检查对应的缓存页面文件是否存在。如果不存在,会同时连接数据库,获取数据,显示页面,生成缓存页面文件,以便下次访问时页面文件发挥作用。. (模板引擎和网上一些常见的PHP缓存机制类通常都有这个功能)
3、 时间触发缓存:
检查文件是否存在,时间戳是否小于设置的过期时间。如果文件修改的时间戳大于当前时间戳减去过期时间戳,则使用缓存,否则更新缓存。
4、 内容触发缓存:
当数据被插入或更新时,PHP 缓存机制会被强制更新。
5、 静态缓存:
这里所说的静态缓存是指静态的,直接生成HTML或者XML等文本文件,有更新的时候重新生成一次,适用于变化不大的页面,就不多说了。
上面的内容是代码层面的解决方案,我直接CP其他框架,懒得改了,内容类似,做起来很简单,会用好几种方式,不过下面的内容是服务器-侧缓存方案,不是代码级别的,只有多方合作才能实现
6、 内存缓存:
Memcached 是一种高性能、分布式内存对象 PHP 缓存机制系统,用于在动态应用中减少数据库负载和提高访问速度。
7、 php 缓冲区:
还有eaccelerator、apc、phpa、xcache,更不用说这个了
8、 MYSQL 缓存:
这个也是非代码级别的,经典数据库就是这样使用的,看下面的运行时间,比如0.09xxx
9、 基于反向代理的Web缓存:
如Nginx、SQUID、mod_proxy(apache2及以上分为mod_proxy和mod_cache)
10、 DNS 轮询:
BIND 是一个开源的 DNS 服务器软件。这是一件大事。自行搜索。每个人都知道有这个东西。
我知道有些大网站比如chinacache就是这样做的。简单来说,就是多台服务器。同一个页面或文件缓存在不同的服务器上,根据南北自动解析到相关服务器。
PHP 网页缓存示例
有了这三个php函数,就可以实现强大的功能。如果数据库查询量很大,可以使用缓存来解决这个问题。
首先,设置过期时间。如果需要缓存文件在2小时内过期,可以设置cache_time为3600*2;使用filectime()获取缓存文件的创建时间(或者filemtime()获取修改时间),如果当前时间超过文件的创建时间超过限定的过期时间,可以使用以上三个函数先从数据库中取数据,然后开始缓存ob_start(),然后在缓存中写入要生成的页面的html代码。缓存结束后通过ob_get_contents()获取缓存的内容,然后通过fwrite将缓存的内容写入静态页面html。
如果没有过期,直接读取缓存中的静态页面,避免大量的数据库访问。
<p>
php抓取网页数据实例( 具有很好的参考价值,希望对大家多多支持脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-17 12:05
具有很好的参考价值,希望对大家多多支持脚本之家)
PHP从数据库中读取数据并以json格式返回数据
更新时间:2018-08-21 08:45:33 作者:蒲舍臣之恋
今天给大家分享一篇关于PHP如何从数据库中读取数据并以json格式返回数据的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php抓取网页数据实例(
具有很好的参考价值,希望对大家多多支持脚本之家)
PHP从数据库中读取数据并以json格式返回数据
更新时间:2018-08-21 08:45:33 作者:蒲舍臣之恋
今天给大家分享一篇关于PHP如何从数据库中读取数据并以json格式返回数据的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
php抓取网页数据实例( PHP中session如何用session实现记录用户登录信息的具体方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-12 06:18
PHP中session如何用session实现记录用户登录信息的具体方法)
PHP 实现使用 session 记录用户登录信息
更新时间:2018年10月15日14:22:30 投稿:老张
在这篇文章中,我们和大家分享了PHP如何使用session记录用户登录信息的知识点,有兴趣的朋友可以参考一下。
PHP中session记录用户登录信息的问题也是PHP面试题中比较常见的考点之一,是PHP学习者必须掌握的知识点。
对于初学PHP新手来说,可能会有一定的难度。那么在之前的文章【PHP中如何在session中存储和删除变量】中,我也介绍了session在PHP中的基本含义。有需要的朋友可以选择参考。
下面我们将通过具体的代码示例来详细介绍PHP中session记录用户登录信息的具体方法。
1.简单登录界面代码示例:
登录.html
登录
body {
background: url(images/bg.png);
}
.clear {
clear: both;
}
.login {
width: 370px;
margin: 100px auto 0px;
text-align: center;
}
input[type="text"] {
width: 360px;
height: 50px;
border: none;
background: #fff;
border-radius: 10px;
margin: 5px auto;
padding-left: 10px;
color: #745A74;
font-size: 15px;
}
input[type="checkbox"] {
float: left;
margin: 5px 0px 0px;
}
span {
float: left;
}
.botton {
width: 130px;
height: 40px;
background: #745A74;
border-radius: 10px;
text-align: center;
color: #fff;
margin-top: 30px;
line-height: 40px;
}
images/header.png
2.用于连接数据库的简单PHP文件代码示例:
db.php
<p> 查看全部
php抓取网页数据实例(
PHP中session如何用session实现记录用户登录信息的具体方法)
PHP 实现使用 session 记录用户登录信息
更新时间:2018年10月15日14:22:30 投稿:老张
在这篇文章中,我们和大家分享了PHP如何使用session记录用户登录信息的知识点,有兴趣的朋友可以参考一下。
PHP中session记录用户登录信息的问题也是PHP面试题中比较常见的考点之一,是PHP学习者必须掌握的知识点。
对于初学PHP新手来说,可能会有一定的难度。那么在之前的文章【PHP中如何在session中存储和删除变量】中,我也介绍了session在PHP中的基本含义。有需要的朋友可以选择参考。
下面我们将通过具体的代码示例来详细介绍PHP中session记录用户登录信息的具体方法。
1.简单登录界面代码示例:
登录.html
登录
body {
background: url(images/bg.png);
}
.clear {
clear: both;
}
.login {
width: 370px;
margin: 100px auto 0px;
text-align: center;
}
input[type="text"] {
width: 360px;
height: 50px;
border: none;
background: #fff;
border-radius: 10px;
margin: 5px auto;
padding-left: 10px;
color: #745A74;
font-size: 15px;
}
input[type="checkbox"] {
float: left;
margin: 5px 0px 0px;
}
span {
float: left;
}
.botton {
width: 130px;
height: 40px;
background: #745A74;
border-radius: 10px;
text-align: center;
color: #fff;
margin-top: 30px;
line-height: 40px;
}
images/header.png
2.用于连接数据库的简单PHP文件代码示例:
db.php
<p>
php抓取网页数据实例(php抓取网页数据实例详解(六)index.php。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 05:01
php抓取网页数据实例详解(六)index.php。
3000行的东西,这么多?是不是打算抓取2万行?还有你真是学php啊,不要自己随便想一个模板出来,php是没有模板的。
php有seo相关的功能,可以帮你做到搜索引擎的收录。这个的话,需要好好学习seo,无它,唯手熟尔。无他,唯手熟尔。无他,唯手熟尔。
这数据量够初学者做网站了,所以,
感觉你是来搞笑的,能发挥自己的优势并利用已有资源把网站建起来,前期有成熟的思路与玩法。再加上正确的运营,后期准会有可观的收入,关键是看你方法正确不。个人的一点体会,有喜勿喷。
seo那一块你可以重点注意下,并且重新规划一下网站服务端如何实现。具体来说就是目标网站怎么做得更好,然后尽可能的和目标网站达到一致,网站就不难做了。
主要用到什么方面的知识?ui还是java或者php?我也是个菜鸟,感觉自己0基础,从零基础开始来要好好规划下下,至少不能影响正常的工作,
你这个网站,简单,目的是否是为了运营,获取一定量的收入。从而达到自己想要的结果, 查看全部
php抓取网页数据实例(php抓取网页数据实例详解(六)index.php。)
php抓取网页数据实例详解(六)index.php。
3000行的东西,这么多?是不是打算抓取2万行?还有你真是学php啊,不要自己随便想一个模板出来,php是没有模板的。
php有seo相关的功能,可以帮你做到搜索引擎的收录。这个的话,需要好好学习seo,无它,唯手熟尔。无他,唯手熟尔。无他,唯手熟尔。
这数据量够初学者做网站了,所以,
感觉你是来搞笑的,能发挥自己的优势并利用已有资源把网站建起来,前期有成熟的思路与玩法。再加上正确的运营,后期准会有可观的收入,关键是看你方法正确不。个人的一点体会,有喜勿喷。
seo那一块你可以重点注意下,并且重新规划一下网站服务端如何实现。具体来说就是目标网站怎么做得更好,然后尽可能的和目标网站达到一致,网站就不难做了。
主要用到什么方面的知识?ui还是java或者php?我也是个菜鸟,感觉自己0基础,从零基础开始来要好好规划下下,至少不能影响正常的工作,
你这个网站,简单,目的是否是为了运营,获取一定量的收入。从而达到自己想要的结果,
php抓取网页数据实例(安装requests模块)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 09:01
本文文章主要介绍python3使用requests模块抓取页面内容的实战练习,有一定的参考价值,有兴趣的可以学习一下
1.安装pip
我的个人桌面系统使用 linuxmint。系统默认不安装pip。考虑到后面会用到pip来安装requests模块,这里我先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装请求模块
这里我是通过 pip 安装的:
$ pip install requests
运行导入请求,如果没有错误,则安装成功!
检查是否安装成功
3.安装beautifulsoup4
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以通过您喜欢的转换器实现惯用的文档导航,查找和修改文档的方式。 Beautiful Soup 可为您节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注意:我这里使用的是python3的安装方式,如果你使用的是python2,可以使用下面的命令进行安装。
$ sudo pip install beautifulsoup4
4.请求模块分析
1)发送请求
当然首先要导入Requests模块:
>>> import requests
然后,获取目标抓取的网页。这里我以以下为例:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取我们想要的所有信息。这里的get是http的响应方式,所以也可以用put、delete、post、head类推。
2)传递网址参数
有时我们希望为 URL 的查询字符串传递某种数据。如果手动构造 URL,数据将以键/值对的形式放置在 URL 中,后跟一个问号。例如,/get?key=val。 Requests 允许您使用 params 关键字参数并在字符串字典中提供这些参数。
比如我们在Google上搜索“python爬虫”关键词时,newwindow(新窗口打开)、q和oq(搜索关键词)等参数可以手动组成URL ,那么就可以使用如下代码:
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)
3)回复内容
通过 r.text 或 r.content 获取页面响应内容。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text
请求将自动解码来自服务器的内容。大多数 unicode 字符集都可以无缝解码。这是 r.text 和 r.content 之间的区别。简单地说:
resp.text 返回 Unicode 数据;
resp.content 返回 bytes 类型,为二进制数据;
所以如果要获取文本,可以通过 r.text,如果要获取图片、文件,可以通过 r.content。
4)获取网页编码
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.encoding
'utf-8'
5)获取响应状态码
我们可以检测到响应状态码:
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.status_code
200
5.案例展示
最近,该公司刚刚推出了 OA 系统。这里我以它的官方文档页面为例,只抓取页面上的文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
Python 版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ran ... 39%3B
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)
程序运行并返回爬取结果:
获取成功
关于爬取结果乱码
其实一开始我直接用的是系统默认自带的python2,但是我折腾了很久,返回内容的编码乱码。谷歌尝试了很多解决方案都无济于事。在被python2“疯狂”之后,我不得不老老实实的使用python3。关于python2抓取页面乱码的问题,欢迎各位前辈分享经验,帮助我以后少走弯路。
以上是python3如何使用requests模块抓取页面内容的示例的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们 查看全部
php抓取网页数据实例(安装requests模块)
本文文章主要介绍python3使用requests模块抓取页面内容的实战练习,有一定的参考价值,有兴趣的可以学习一下
1.安装pip
我的个人桌面系统使用 linuxmint。系统默认不安装pip。考虑到后面会用到pip来安装requests模块,这里我先安装pip。
$ sudo apt install python-pip
安装成功,查看PIP版本:
$ pip -V
2.安装请求模块
这里我是通过 pip 安装的:
$ pip install requests
运行导入请求,如果没有错误,则安装成功!
检查是否安装成功
3.安装beautifulsoup4
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取数据。它可以通过您喜欢的转换器实现惯用的文档导航,查找和修改文档的方式。 Beautiful Soup 可为您节省数小时甚至数天的工作时间。
$ sudo apt-get install python3-bs4
注意:我这里使用的是python3的安装方式,如果你使用的是python2,可以使用下面的命令进行安装。
$ sudo pip install beautifulsoup4
4.请求模块分析
1)发送请求
当然首先要导入Requests模块:
>>> import requests
然后,获取目标抓取的网页。这里我以以下为例:
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
这里返回一个名为 r 的响应对象。我们可以从这个对象中获取我们想要的所有信息。这里的get是http的响应方式,所以也可以用put、delete、post、head类推。
2)传递网址参数
有时我们希望为 URL 的查询字符串传递某种数据。如果手动构造 URL,数据将以键/值对的形式放置在 URL 中,后跟一个问号。例如,/get?key=val。 Requests 允许您使用 params 关键字参数并在字符串字典中提供这些参数。
比如我们在Google上搜索“python爬虫”关键词时,newwindow(新窗口打开)、q和oq(搜索关键词)等参数可以手动组成URL ,那么就可以使用如下代码:
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)
3)回复内容
通过 r.text 或 r.content 获取页面响应内容。
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text
请求将自动解码来自服务器的内容。大多数 unicode 字符集都可以无缝解码。这是 r.text 和 r.content 之间的区别。简单地说:
resp.text 返回 Unicode 数据;
resp.content 返回 bytes 类型,为二进制数据;
所以如果要获取文本,可以通过 r.text,如果要获取图片、文件,可以通过 r.content。
4)获取网页编码
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.encoding
'utf-8'
5)获取响应状态码
我们可以检测到响应状态码:
>>> r = requests.get('http://www.cnblogs.com/')
>>> r.status_code
200
5.案例展示
最近,该公司刚刚推出了 OA 系统。这里我以它的官方文档页面为例,只抓取页面上的文章标题和内容等有用信息。
演示环境
操作系统:linuxmint
Python 版本:python 3.5.2
使用模块:requests、beautifulsoup4
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ran ... 39%3B
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)
程序运行并返回爬取结果:
获取成功
关于爬取结果乱码
其实一开始我直接用的是系统默认自带的python2,但是我折腾了很久,返回内容的编码乱码。谷歌尝试了很多解决方案都无济于事。在被python2“疯狂”之后,我不得不老老实实的使用python3。关于python2抓取页面乱码的问题,欢迎各位前辈分享经验,帮助我以后少走弯路。
以上是python3如何使用requests模块抓取页面内容的示例的详细内容。更多详情请关注其他相关php中文网文章!
免责声明:本文由原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何问题,请联系我们
php抓取网页数据实例(Pythondocker版使用docker的方法和注意事项(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-11-21 22:04
背景:
公司管理系统需要获取并操作公司微信页面的配置参数,如公司名称、logo、人数等,隐藏相关敏感信息,定制化简化公司配置流程帐号
第一个版本实现了扫码登录获取cookies。使用此cookie,您可以获取合法身份并随意请求页面和界面。所以第一版的模拟操作主要是抓界面。要是有接口就没用了Up
第二版需要一些配置参数的源码页面是js渲染的,没有接口,普通的get页面无法获取渲染的页面文档,所以只能用headless浏览器爬取操作页面
实现过程:laravel 版本
项目是使用laravel开发的,首先想到的就是集成到框架中,而laravel确实提供了相关组件:Laravel Dusk
虽然这个插件是用来做浏览器测试的,但是这里也可以用来抓取网页
很帅,就是运行中安装不了,
PHP 版本
好的,我们自己实现,直接上代码
我封装了一个类,new的时候直接传之前的登录cookie,这样就可以直接跳转到页面了
class QyWebChrome
{
#下载对应google-chrome版本的驱动https://sites.google.com/a/chr ... loads
private $envchromedriverpath = 'webdriver.chrome.driver=/usr/bin/chromedriver';
private $driver;
private $error;
public function __construct($cookie_str)
{
putenv($this->envchromedriverpath);
$capabilities = DesiredCapabilities::chrome();
// $cookie_str ='sdfn=sssf1;; _gxxxx=1';
//'-headless' 无头模式:浏览器在后台运行,在安装了桌面环境的浏览器服务器中可去掉预览整个过程
$capabilities->setCapability(
'chromeOptions',
['args' => ['--disable-gpu','-headless','--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36']]
);
$this->driver = ChromeDriver::start($capabilities,null);
sleep(3);
//先去index设置登录cookie,之后想跳哪个页面就跳哪个页面
$this->driver->get('https://work.weixin.qq.com/');
sleep(2);
// adding cookie
$this->driver->manage()->deleteAllCookies();
sleep(1);
$cookie_arr = explode(';',$cookie_str);
foreach ($cookie_arr as $cookpair){
$cookie_item = explode('=',$cookpair);
$cookie=[
'name'=>trim($cookie_item[0]),
'value'=>trim($cookie_item[1]),
'domain'=>'work.weixin.qq.com',
'httpOnly'=>false,
'path'=>'/',
'secure'=>false,
];
$this->driver->manage()->addCookie($cookie);
}
sleep(1);
}
public function __destruct()
{
$this->driver->close();
}
//跳转到我的企业页面获取企业信息
public function getProfilePage(){
$data =[];
$this->driver->get('https://work.weixin.qq.com/wework_admin/frame#profile/enterprise');
sleep(3);
//企业logourl
//企业简称
$companynamespan = $this->driver->findElement(
WebDriverBy::className('profile_enterprise_item_shareName')
);
$data['companyname'] = $companynamespan->getText();
return $data;
}
//获取渲染后的html
//$driver->getPageSource();
/*
webdriver 主要提供了 2 个 API 来给我们操作 DOM 元素
RemoteWebDriver::findElement(WebDriverBy) 获取单个元素
RemoteWebDriver::findElements(WebDriverBy) 获取元素列表
WebDriverBy 是查询方式对象,提供了下面几个常用的方式
WebDriverBy::id($id) 根据 ID 查找元素
WebDriverBy::className($className) 根据 class 查找元素
WebDriverBy::cssSelector($selctor) 根据通用的 css 选择器查询
WebDriverBy::name($name) 根据元素的 name 属性查询
WebDriverBy::linkText($text) 根据可见元素的文本锚点查询
WebDriverBy::tagName($tagName) 根据元素标签名称查询
WebDriverBy::xpath($xpath) 根据 xpath 表达式查询,这个很强大
*/
//截图
public function takeScrenshot($savepath="test.png"){
$this->driver->takeScreenshot($savepath);
}
/**
* @return mixed
*/
public function getError()
{
return $this->error;
}
/**
* @param mixed $error
*/
public function setError($error): void
{
$this->error = $error;
}
}
部署说明:
先安装 google-chrome
yum install google-chrome
安装完成后获取chrome版本
下载对应的chromedriver,这个在谷歌上
页面是这样的,主要是googlechrome和chromedirver的对应关系
无法在此处连接到 Google 下载
这里每个版本的网盘都有一个提取码:hbvz
运行截图:
本以为是这样搞的,没想到网上出了问题就无法部署了! !
wf??为了保证服务器可以兼容低版本的软件,C的依赖版本安装的很低,所以底层的依赖不要移动。
有两种解决方案:
1 找一台服务器安装高版本的GLIBC_2.14,GLIBC_2.16;
2 将爬虫封装成docker,对外提供爬取服务,即到时候直接请求接口,接口返回到被爬取的企业微信页面
因为公司有k8s集群,直接搭建docker比较容易,所以选择选项2
Python docker 版本
使用docker尽可能简单。直接使用python脚本。爬虫还是用python比较猛。各种依赖直接pip。 2017年,当无头浏览器用于监控爬虫时,仍然使用phantomjs作为驱动。现在Chrome的headless直接切换过来了,api没变,
先打包docker:先去dockers设置环境,搞清楚相关依赖
docker run -it -v /test:/test python:3.7.4 /bin/bash
使用/test作为共享目录,方便宿主机和docker之间的文件传输
首先安装google-chrome、python:3.7.4直接下载deb安装包
有网盘分享链接:提取码:p6d5
在 docker 中安装 google-chrome
然后解决依赖关系,
现在直接进入Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.7.4
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
#install depend
RUN apt update && apt -y --fix-broken install libnss3-dev fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libatspi2.0-0 libcups2 libdbus-1-3 libgtk-3-0 libx11-xcb1 libxcomposite1 libxcursor1 libxdamage1 libxfixes3 libxi6 libxrandr2 libxtst6 lsb-release xdg-utils libdbusmenu-glib4 libdbusmenu-gtk3-4 libindicator3-7 libasound2-data libatk1.0-data libavahi-client3 libavahi-common3 adwaita-icon-theme libcolord2 libepoxy0 libjson-glib-1.0-0 librest-0.7-0 libsoup2.4-1 libwayland-client0 libwayland-cursor0 libwayland-egl1 libxinerama1 libxkbcommon0 libgtk-3-common libgtk-3-bin distro-info-data gtk-update-icon-cache libavahi-common-data gtk-update-icon-cache dconf-gsettings-backend libjson-glib-1.0-common libsoup-gnome2.4-1 glib-networking xkb-data dconf-service libdconf1 libproxy1v5 glib-networking-services glib-networking-common gsettings-desktop-schemas default-dbus-session-bus dbus libpam-systemd systemd systemd-sysv libapparmor1 libapparmor1 libcryptsetup12 libidn11 libip4tc0 libkmod2 libargon2-1 libdevmapper1.02.1 libjson-c3 dmsetup \
&& apt-get install -y fonts-wqy-zenhei \
&& dpkg -i google-chrome-stable_current_amd64.deb
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
d +x run.sh
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
#v1 dev Run app.py when the container launches
#CMD ["python", "app.py"]
#v2 production
#CMD ["gunicorn","--config","gunicorn_config.py","app:app"]
#v3 <br />#ENTRYPOINT ["gunicorn","--config","gunicorn_config.py","app:app"]
#v4
ENTRYPOINT ["./run.sh"]
项目目录
app.py 处理请求
from flask import Flask
import os
import socket
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from time import sleep
app = Flask(__name__)
@app.route("/hello///")
def hello(cookie_str,aim_url,end_class):
print(cookie_str)
print(aim_url)
print(end_class)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument('window-size=1200x600')
user_ag='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
chrome_options.add_argument('user-agent=%s'%user_ag)
profile_url = "https://work.weixin.qq.com/wew ... ot%3B
base_url = "https://work.weixin.qq.com"
#chromedriver
driver = webdriver.Chrome(executable_path=(r'/test/chromedriver'), chrome_options=chrome_options)
#加载首页设置登录cookie
driver.get(base_url + "/")
driver.implicitly_wait(10)
driver.save_screenshot('screen1.png')
for coo in cookie_str.split(';'):
cooki=coo.split('=')
print(cooki[0].strip())
print(cooki[1].strip())
driver.add_cookie({'name':cooki[0].strip(),'value':cooki[1].strip(),'domain':'work.weixin.qq.com','httpOnly':False,'path':'/','secure':False})
driver.implicitly_wait(10)
#跳转目标页面
driver.get(profile_url)
WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located((By.CLASS_NAME, 'ww_commonCntHead_title_inner_text')))
#sleep(5)
driver.save_screenshot('screen.png')
driver.close()
return "hhhhhh $s" % cookie_str
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
运行.sh
#!/bin/bash
set -e
pwd
touch access.log error.log
exec gunicorn app:app \
--bind 0.0.0.0:80 \
--workers 4 \
--timeout 120 \
--log-level debug \
--access-logfile=access.log \
--error-logfile=error.log
exec "[email protected]"
要求.txt
Flask
selenium
gunicorn
开发时可以使用flask的内置服务器,在线部署时,使用官方推荐的gunicorn部署,这里直接使用gunicorn运行
gunicorn的启动配置后来写进run.sh,所以gunicorn_config.py没用
Docker 镜像构建
docker build -t mypythonflask:v6 .
Docker 启动命令
docker run -d -v /data:/data -p 8888:80 -v /dev/shm:/dev/shm mypythonflask:v6
这里的/dev/shm是为了解决当加载页面过大或者加载大图时,docker内存不够,浏览器爆的问题。解决方法是#57302028
Selenium error in python: WebDriverException: unknown error: session deleted because of page crash from tab crashed
请求测试
[[emailprotected] testdockerchrome]# curl ":8888/hello/sss=sss;%20_ssst=1/bb/cc"
500 内部服务器错误
内部服务器错误
服务器遇到内部错误,无法完成您的请求。要么服务器过载,要么应用程序出错。
#处理时间过长超时。检查屏幕截图。
这个曲折的实现过程。 . .
至此,爬虫服务已经搭建完毕,接下来只需要处理业务相关的事情,比如扩展app.py的功能,支持更多的操作
总结起来就是使用docker部署一个服务,接收登录cookies、url、配置等参数,使用chrome的headless模式抓取页面操作页面,返回结果,扩展浏览器操作可以写在 app.py 中 查看全部
php抓取网页数据实例(Pythondocker版使用docker的方法和注意事项(一))
背景:
公司管理系统需要获取并操作公司微信页面的配置参数,如公司名称、logo、人数等,隐藏相关敏感信息,定制化简化公司配置流程帐号
第一个版本实现了扫码登录获取cookies。使用此cookie,您可以获取合法身份并随意请求页面和界面。所以第一版的模拟操作主要是抓界面。要是有接口就没用了Up
第二版需要一些配置参数的源码页面是js渲染的,没有接口,普通的get页面无法获取渲染的页面文档,所以只能用headless浏览器爬取操作页面
实现过程:laravel 版本
项目是使用laravel开发的,首先想到的就是集成到框架中,而laravel确实提供了相关组件:Laravel Dusk
虽然这个插件是用来做浏览器测试的,但是这里也可以用来抓取网页
很帅,就是运行中安装不了,
PHP 版本
好的,我们自己实现,直接上代码
我封装了一个类,new的时候直接传之前的登录cookie,这样就可以直接跳转到页面了
class QyWebChrome
{
#下载对应google-chrome版本的驱动https://sites.google.com/a/chr ... loads
private $envchromedriverpath = 'webdriver.chrome.driver=/usr/bin/chromedriver';
private $driver;
private $error;
public function __construct($cookie_str)
{
putenv($this->envchromedriverpath);
$capabilities = DesiredCapabilities::chrome();
// $cookie_str ='sdfn=sssf1;; _gxxxx=1';
//'-headless' 无头模式:浏览器在后台运行,在安装了桌面环境的浏览器服务器中可去掉预览整个过程
$capabilities->setCapability(
'chromeOptions',
['args' => ['--disable-gpu','-headless','--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36']]
);
$this->driver = ChromeDriver::start($capabilities,null);
sleep(3);
//先去index设置登录cookie,之后想跳哪个页面就跳哪个页面
$this->driver->get('https://work.weixin.qq.com/');
sleep(2);
// adding cookie
$this->driver->manage()->deleteAllCookies();
sleep(1);
$cookie_arr = explode(';',$cookie_str);
foreach ($cookie_arr as $cookpair){
$cookie_item = explode('=',$cookpair);
$cookie=[
'name'=>trim($cookie_item[0]),
'value'=>trim($cookie_item[1]),
'domain'=>'work.weixin.qq.com',
'httpOnly'=>false,
'path'=>'/',
'secure'=>false,
];
$this->driver->manage()->addCookie($cookie);
}
sleep(1);
}
public function __destruct()
{
$this->driver->close();
}
//跳转到我的企业页面获取企业信息
public function getProfilePage(){
$data =[];
$this->driver->get('https://work.weixin.qq.com/wework_admin/frame#profile/enterprise');
sleep(3);
//企业logourl
//企业简称
$companynamespan = $this->driver->findElement(
WebDriverBy::className('profile_enterprise_item_shareName')
);
$data['companyname'] = $companynamespan->getText();
return $data;
}
//获取渲染后的html
//$driver->getPageSource();
/*
webdriver 主要提供了 2 个 API 来给我们操作 DOM 元素
RemoteWebDriver::findElement(WebDriverBy) 获取单个元素
RemoteWebDriver::findElements(WebDriverBy) 获取元素列表
WebDriverBy 是查询方式对象,提供了下面几个常用的方式
WebDriverBy::id($id) 根据 ID 查找元素
WebDriverBy::className($className) 根据 class 查找元素
WebDriverBy::cssSelector($selctor) 根据通用的 css 选择器查询
WebDriverBy::name($name) 根据元素的 name 属性查询
WebDriverBy::linkText($text) 根据可见元素的文本锚点查询
WebDriverBy::tagName($tagName) 根据元素标签名称查询
WebDriverBy::xpath($xpath) 根据 xpath 表达式查询,这个很强大
*/
//截图
public function takeScrenshot($savepath="test.png"){
$this->driver->takeScreenshot($savepath);
}
/**
* @return mixed
*/
public function getError()
{
return $this->error;
}
/**
* @param mixed $error
*/
public function setError($error): void
{
$this->error = $error;
}
}
部署说明:
先安装 google-chrome
yum install google-chrome
安装完成后获取chrome版本
下载对应的chromedriver,这个在谷歌上
页面是这样的,主要是googlechrome和chromedirver的对应关系
无法在此处连接到 Google 下载
这里每个版本的网盘都有一个提取码:hbvz
运行截图:
本以为是这样搞的,没想到网上出了问题就无法部署了! !
wf??为了保证服务器可以兼容低版本的软件,C的依赖版本安装的很低,所以底层的依赖不要移动。
有两种解决方案:
1 找一台服务器安装高版本的GLIBC_2.14,GLIBC_2.16;
2 将爬虫封装成docker,对外提供爬取服务,即到时候直接请求接口,接口返回到被爬取的企业微信页面
因为公司有k8s集群,直接搭建docker比较容易,所以选择选项2
Python docker 版本
使用docker尽可能简单。直接使用python脚本。爬虫还是用python比较猛。各种依赖直接pip。 2017年,当无头浏览器用于监控爬虫时,仍然使用phantomjs作为驱动。现在Chrome的headless直接切换过来了,api没变,
先打包docker:先去dockers设置环境,搞清楚相关依赖
docker run -it -v /test:/test python:3.7.4 /bin/bash
使用/test作为共享目录,方便宿主机和docker之间的文件传输
首先安装google-chrome、python:3.7.4直接下载deb安装包
有网盘分享链接:提取码:p6d5
在 docker 中安装 google-chrome
然后解决依赖关系,
现在直接进入Dockerfile
# Use an official Python runtime as a parent image
FROM python:3.7.4
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
#install depend
RUN apt update && apt -y --fix-broken install libnss3-dev fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 libatk1.0-0 libatspi2.0-0 libcups2 libdbus-1-3 libgtk-3-0 libx11-xcb1 libxcomposite1 libxcursor1 libxdamage1 libxfixes3 libxi6 libxrandr2 libxtst6 lsb-release xdg-utils libdbusmenu-glib4 libdbusmenu-gtk3-4 libindicator3-7 libasound2-data libatk1.0-data libavahi-client3 libavahi-common3 adwaita-icon-theme libcolord2 libepoxy0 libjson-glib-1.0-0 librest-0.7-0 libsoup2.4-1 libwayland-client0 libwayland-cursor0 libwayland-egl1 libxinerama1 libxkbcommon0 libgtk-3-common libgtk-3-bin distro-info-data gtk-update-icon-cache libavahi-common-data gtk-update-icon-cache dconf-gsettings-backend libjson-glib-1.0-common libsoup-gnome2.4-1 glib-networking xkb-data dconf-service libdconf1 libproxy1v5 glib-networking-services glib-networking-common gsettings-desktop-schemas default-dbus-session-bus dbus libpam-systemd systemd systemd-sysv libapparmor1 libapparmor1 libcryptsetup12 libidn11 libip4tc0 libkmod2 libargon2-1 libdevmapper1.02.1 libjson-c3 dmsetup \
&& apt-get install -y fonts-wqy-zenhei \
&& dpkg -i google-chrome-stable_current_amd64.deb
# Install any needed packages specified in requirements.txt
RUN pip install --trusted-host pypi.python.org -r requirements.txt
d +x run.sh
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
#v1 dev Run app.py when the container launches
#CMD ["python", "app.py"]
#v2 production
#CMD ["gunicorn","--config","gunicorn_config.py","app:app"]
#v3 <br />#ENTRYPOINT ["gunicorn","--config","gunicorn_config.py","app:app"]
#v4
ENTRYPOINT ["./run.sh"]
项目目录
app.py 处理请求
from flask import Flask
import os
import socket
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from time import sleep
app = Flask(__name__)
@app.route("/hello///")
def hello(cookie_str,aim_url,end_class):
print(cookie_str)
print(aim_url)
print(end_class)
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument('window-size=1200x600')
user_ag='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
chrome_options.add_argument('user-agent=%s'%user_ag)
profile_url = "https://work.weixin.qq.com/wew ... ot%3B
base_url = "https://work.weixin.qq.com"
#chromedriver
driver = webdriver.Chrome(executable_path=(r'/test/chromedriver'), chrome_options=chrome_options)
#加载首页设置登录cookie
driver.get(base_url + "/")
driver.implicitly_wait(10)
driver.save_screenshot('screen1.png')
for coo in cookie_str.split(';'):
cooki=coo.split('=')
print(cooki[0].strip())
print(cooki[1].strip())
driver.add_cookie({'name':cooki[0].strip(),'value':cooki[1].strip(),'domain':'work.weixin.qq.com','httpOnly':False,'path':'/','secure':False})
driver.implicitly_wait(10)
#跳转目标页面
driver.get(profile_url)
WebDriverWait(driver,20,0.5).until(EC.presence_of_element_located((By.CLASS_NAME, 'ww_commonCntHead_title_inner_text')))
#sleep(5)
driver.save_screenshot('screen.png')
driver.close()
return "hhhhhh $s" % cookie_str
if __name__ == "__main__":
app.run(host='0.0.0.0', port=80)
运行.sh
#!/bin/bash
set -e
pwd
touch access.log error.log
exec gunicorn app:app \
--bind 0.0.0.0:80 \
--workers 4 \
--timeout 120 \
--log-level debug \
--access-logfile=access.log \
--error-logfile=error.log
exec "[email protected]"
要求.txt
Flask
selenium
gunicorn
开发时可以使用flask的内置服务器,在线部署时,使用官方推荐的gunicorn部署,这里直接使用gunicorn运行
gunicorn的启动配置后来写进run.sh,所以gunicorn_config.py没用
Docker 镜像构建
docker build -t mypythonflask:v6 .
Docker 启动命令
docker run -d -v /data:/data -p 8888:80 -v /dev/shm:/dev/shm mypythonflask:v6
这里的/dev/shm是为了解决当加载页面过大或者加载大图时,docker内存不够,浏览器爆的问题。解决方法是#57302028
Selenium error in python: WebDriverException: unknown error: session deleted because of page crash from tab crashed
请求测试
[[emailprotected] testdockerchrome]# curl ":8888/hello/sss=sss;%20_ssst=1/bb/cc"
500 内部服务器错误
内部服务器错误
服务器遇到内部错误,无法完成您的请求。要么服务器过载,要么应用程序出错。
#处理时间过长超时。检查屏幕截图。
这个曲折的实现过程。 . .
至此,爬虫服务已经搭建完毕,接下来只需要处理业务相关的事情,比如扩展app.py的功能,支持更多的操作
总结起来就是使用docker部署一个服务,接收登录cookies、url、配置等参数,使用chrome的headless模式抓取页面操作页面,返回结果,扩展浏览器操作可以写在 app.py 中
php抓取网页数据实例(新用户注册注册信息存入数据库中需要的时候再进行提取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-20 18:00
)
网站新用户注册时,用户的注册信息会存储在数据库中,需要时再提取。今天写了一个简单的例子。
主要完成以下功能:
(1)用户注册,实现密码重复确认、验证码校对功能。
(2) 注册成功后,将用户插入数据库进行存储。
(3)提取数据库表中的数据并打印出来。
1.报名表
在之前的博客中,我已经分享了注册和登录表单的代码。这次的代码大致相同,但略有变化。仅作为示例
注册页面
新用户注册
请输入用户名:
请输入密码:
请确认密码:
请输入验证码:regauth.php
表单页面真的没什么好说的,除了格式对齐和几个(空格)。
效果图:
2.验证码页
验证码功能在之前的一篇博客中有详细的讲解。这次的验证码基本都是直接用的,唯一的升级就是加了干扰素,让验证码这四个字不干。imagesetpixel() 函数用于创建一些干扰点。具体用法请查看php手册。
3.提交页面(数据提取页面)
<p> 查看全部
php抓取网页数据实例(新用户注册注册信息存入数据库中需要的时候再进行提取
)
网站新用户注册时,用户的注册信息会存储在数据库中,需要时再提取。今天写了一个简单的例子。
主要完成以下功能:
(1)用户注册,实现密码重复确认、验证码校对功能。
(2) 注册成功后,将用户插入数据库进行存储。
(3)提取数据库表中的数据并打印出来。
1.报名表
在之前的博客中,我已经分享了注册和登录表单的代码。这次的代码大致相同,但略有变化。仅作为示例
注册页面
新用户注册
请输入用户名:
请输入密码:
请确认密码:
请输入验证码:regauth.php
表单页面真的没什么好说的,除了格式对齐和几个(空格)。
效果图:
2.验证码页
验证码功能在之前的一篇博客中有详细的讲解。这次的验证码基本都是直接用的,唯一的升级就是加了干扰素,让验证码这四个字不干。imagesetpixel() 函数用于创建一些干扰点。具体用法请查看php手册。
3.提交页面(数据提取页面)
<p>
php抓取网页数据实例(php抓取网页数据实例分享:网页接口最多可以发起三次请求(随机))
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-19 10:02
php抓取网页数据实例分享php抓取网页数据实例分享提示:网页接口最多可以发起三次请求(随机),然后发送一次http请求,返回一个html文件,html文件里面有标题和图片。php有http库可以抓取网页,php407已经有类似http的接口,为,所以http网页抓取其实不复杂,只是实现phpweb知识,抓取网页不难。
我用的是flask可以抓包,
和python的正则表达式语法类似
这个就是通用的php爬虫,
我也是开始做爬虫,
多个网页发起请求,得到该网页下所有网页的链接列表;然后根据链接列表从里面的网页中复制内容并保存到指定目录即可。
没有用php吧?之前做http,php有一些restful的请求库可以基本满足了。所以才有php网络请求库。当然题主的要求不算高吧,只要是用php编写的大多都能满足,而且php的perl\tcl\java\go等强大语言也都有相应的请求库。写爬虫的主要是要抓取网页后写入文件,所以优先考虑都是可以实现的吧,再在此基础上做定制化开发。
直接python或java爬虫啊,中文解释那个网站上有个抓取网页的挺简单,
完整抓取网页的例子()就是用python实现的,应该能满足你要求。 查看全部
php抓取网页数据实例(php抓取网页数据实例分享:网页接口最多可以发起三次请求(随机))
php抓取网页数据实例分享php抓取网页数据实例分享提示:网页接口最多可以发起三次请求(随机),然后发送一次http请求,返回一个html文件,html文件里面有标题和图片。php有http库可以抓取网页,php407已经有类似http的接口,为,所以http网页抓取其实不复杂,只是实现phpweb知识,抓取网页不难。
我用的是flask可以抓包,
和python的正则表达式语法类似
这个就是通用的php爬虫,
我也是开始做爬虫,
多个网页发起请求,得到该网页下所有网页的链接列表;然后根据链接列表从里面的网页中复制内容并保存到指定目录即可。
没有用php吧?之前做http,php有一些restful的请求库可以基本满足了。所以才有php网络请求库。当然题主的要求不算高吧,只要是用php编写的大多都能满足,而且php的perl\tcl\java\go等强大语言也都有相应的请求库。写爬虫的主要是要抓取网页后写入文件,所以优先考虑都是可以实现的吧,再在此基础上做定制化开发。
直接python或java爬虫啊,中文解释那个网站上有个抓取网页的挺简单,
完整抓取网页的例子()就是用python实现的,应该能满足你要求。
php抓取网页数据实例( 一起:GET:POST:实例:以上这篇就是(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-13 05:10
一起:GET:POST:实例:以上这篇就是(图))
PHP调用接口API封装示例
更新时间:2019年10月11日10:39:57 作者:开元节流
今天小编就分享一个PHP调用接口API封装的例子,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
获取:
/**
* 通过URL获取页面信息
* @param $url 地址
* @return mixed 返回页面信息
*/
function get_url($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url); //设置访问的url地址
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);//不输出内容
$result = curl_exec($ch);
curl_close ($ch);
return $result;
}
发布:
/**
* 模拟POST提交
* @param string $url 地址
* @param string $data 提交的数据
* @return string 返回结果
*/
function post_url($url, $data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (compatible; MSIE 5.01; Windows NT 5.0)'); // 模拟用户使用的浏览器
//curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
//curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包x
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制 防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if(curl_errno($curl))
{
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
GET&&POST:
/**
* CURL请求
* @param $url 请求url地址
* @param $method 请求方法 get post
* @param null $postfields post数据数组
* @param array $headers 请求header信息
* @param bool|false $debug 调试开启 默认false
* @return mixed
*/
function httpRequest($url, $method, $postfields = null, $headers = array(), $debug = false) {
$method = strtoupper($method);
$ci = curl_init();
/* Curl settings */
curl_setopt($ci, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_0);
curl_setopt($ci, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0");
curl_setopt($ci, CURLOPT_CONNECTTIMEOUT, 60); /* 在发起连接前等待的时间,如果设置为0,则无限等待 */
curl_setopt($ci, CURLOPT_TIMEOUT, 7); /* 设置cURL允许执行的最长秒数 */
curl_setopt($ci, CURLOPT_RETURNTRANSFER, true);
switch ($method) {
case "POST":
curl_setopt($ci, CURLOPT_POST, true);
if (!empty($postfields)) {
$tmpdatastr = is_array($postfields) ? http_build_query($postfields) : $postfields;
curl_setopt($ci, CURLOPT_POSTFIELDS, $tmpdatastr);
}
break;
default:
curl_setopt($ci, CURLOPT_CUSTOMREQUEST, $method); /* //设置请求方式 */
break;
}
$ssl = preg_match('/^https:\/\//i',$url) ? TRUE : FALSE;
curl_setopt($ci, CURLOPT_URL, $url);
if($ssl){
curl_setopt($ci, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ci, CURLOPT_SSL_VERIFYHOST, FALSE); // 不从证书中检查SSL加密算法是否存在
}
//curl_setopt($ci, CURLOPT_HEADER, true); /*启用时会将头文件的信息作为数据流输出*/
curl_setopt($ci, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ci, CURLOPT_MAXREDIRS, 2);/*指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的*/
curl_setopt($ci, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ci, CURLINFO_HEADER_OUT, true);
/*curl_setopt($ci, CURLOPT_COOKIE, $Cookiestr); * *COOKIE带过去** */
$response = curl_exec($ci);
$requestinfo = curl_getinfo($ci);
$http_code = curl_getinfo($ci, CURLINFO_HTTP_CODE);
if ($debug) {
echo "=====post data======\r\n";
var_dump($postfields);
echo "=====info===== \r\n";
print_r($requestinfo);
echo "=====response=====\r\n";
print_r($response);
}
curl_close($ci);
return $response;
//return array($http_code, $response,$requestinfo);
}
示例:
$res =httpRequest($url,'post',$data);
$json_array = json_decode($res,true);
$data=$json_array['data']['admin_user_list'];
echo $data
以上PHP调用接口API封装示例为编辑器分享的全部内容。希望能给大家参考,也希望大家多多支持Script Home。 查看全部
php抓取网页数据实例(
一起:GET:POST:实例:以上这篇就是(图))
PHP调用接口API封装示例
更新时间:2019年10月11日10:39:57 作者:开元节流
今天小编就分享一个PHP调用接口API封装的例子,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
获取:
/**
* 通过URL获取页面信息
* @param $url 地址
* @return mixed 返回页面信息
*/
function get_url($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL,$url); //设置访问的url地址
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER,1);//不输出内容
$result = curl_exec($ch);
curl_close ($ch);
return $result;
}
发布:
/**
* 模拟POST提交
* @param string $url 地址
* @param string $data 提交的数据
* @return string 返回结果
*/
function post_url($url, $data)
{
$curl = curl_init(); // 启动一个CURL会话
curl_setopt($curl, CURLOPT_URL, $url); // 要访问的地址
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, FALSE); // 对认证证书来源的检查
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, FALSE); // 从证书中检查SSL加密算法是否存在
curl_setopt($curl, CURLOPT_USERAGENT, 'Mozilla/5.0 (compatible; MSIE 5.01; Windows NT 5.0)'); // 模拟用户使用的浏览器
//curl_setopt($curl, CURLOPT_FOLLOWLOCATION, 1); // 使用自动跳转
//curl_setopt($curl, CURLOPT_AUTOREFERER, 1); // 自动设置Referer
curl_setopt($curl, CURLOPT_POST, 1); // 发送一个常规的Post请求
curl_setopt($curl, CURLOPT_POSTFIELDS, $data); // Post提交的数据包x
curl_setopt($curl, CURLOPT_TIMEOUT, 30); // 设置超时限制 防止死循环
curl_setopt($curl, CURLOPT_HEADER, 0); // 显示返回的Header区域内容
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); // 获取的信息以文件流的形式返回
$tmpInfo = curl_exec($curl); // 执行操作
if(curl_errno($curl))
{
echo 'Errno'.curl_error($curl);//捕抓异常
}
curl_close($curl); // 关闭CURL会话
return $tmpInfo; // 返回数据
}
GET&&POST:
/**
* CURL请求
* @param $url 请求url地址
* @param $method 请求方法 get post
* @param null $postfields post数据数组
* @param array $headers 请求header信息
* @param bool|false $debug 调试开启 默认false
* @return mixed
*/
function httpRequest($url, $method, $postfields = null, $headers = array(), $debug = false) {
$method = strtoupper($method);
$ci = curl_init();
/* Curl settings */
curl_setopt($ci, CURLOPT_HTTP_VERSION, CURL_HTTP_VERSION_1_0);
curl_setopt($ci, CURLOPT_USERAGENT, "Mozilla/5.0 (Windows NT 6.2; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0");
curl_setopt($ci, CURLOPT_CONNECTTIMEOUT, 60); /* 在发起连接前等待的时间,如果设置为0,则无限等待 */
curl_setopt($ci, CURLOPT_TIMEOUT, 7); /* 设置cURL允许执行的最长秒数 */
curl_setopt($ci, CURLOPT_RETURNTRANSFER, true);
switch ($method) {
case "POST":
curl_setopt($ci, CURLOPT_POST, true);
if (!empty($postfields)) {
$tmpdatastr = is_array($postfields) ? http_build_query($postfields) : $postfields;
curl_setopt($ci, CURLOPT_POSTFIELDS, $tmpdatastr);
}
break;
default:
curl_setopt($ci, CURLOPT_CUSTOMREQUEST, $method); /* //设置请求方式 */
break;
}
$ssl = preg_match('/^https:\/\//i',$url) ? TRUE : FALSE;
curl_setopt($ci, CURLOPT_URL, $url);
if($ssl){
curl_setopt($ci, CURLOPT_SSL_VERIFYPEER, FALSE); // https请求 不验证证书和hosts
curl_setopt($ci, CURLOPT_SSL_VERIFYHOST, FALSE); // 不从证书中检查SSL加密算法是否存在
}
//curl_setopt($ci, CURLOPT_HEADER, true); /*启用时会将头文件的信息作为数据流输出*/
curl_setopt($ci, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ci, CURLOPT_MAXREDIRS, 2);/*指定最多的HTTP重定向的数量,这个选项是和CURLOPT_FOLLOWLOCATION一起使用的*/
curl_setopt($ci, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ci, CURLINFO_HEADER_OUT, true);
/*curl_setopt($ci, CURLOPT_COOKIE, $Cookiestr); * *COOKIE带过去** */
$response = curl_exec($ci);
$requestinfo = curl_getinfo($ci);
$http_code = curl_getinfo($ci, CURLINFO_HTTP_CODE);
if ($debug) {
echo "=====post data======\r\n";
var_dump($postfields);
echo "=====info===== \r\n";
print_r($requestinfo);
echo "=====response=====\r\n";
print_r($response);
}
curl_close($ci);
return $response;
//return array($http_code, $response,$requestinfo);
}
示例:
$res =httpRequest($url,'post',$data);
$json_array = json_decode($res,true);
$data=$json_array['data']['admin_user_list'];
echo $data
以上PHP调用接口API封装示例为编辑器分享的全部内容。希望能给大家参考,也希望大家多多支持Script Home。
php抓取网页数据实例(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-12 17:15
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板基础教程》、《PHP总结》模板技术”。
我希望本文能帮助您设计基于 ThinkPHP 框架的 PHP 编程。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
php抓取网页数据实例(,结合jQuery的ajax实现跨域抓取数据的相关操作技巧)
本文文章主要介绍了jquery+thinkphp实现跨域数据捕获的方法,并结合实例形式分析thinkPHP结合jQuery的ajax实现跨域数据捕获的相关操作技巧。有需要的朋友可以参考以下
本文介绍了用jquery+thinkphp实现跨域数据抓取的方法。分享给大家,供大家参考,如下:
今天,我将做一个远程数据捕获功能。记住jquery可以用ajax远程捕获,但是不能跨域。我在网上搜索了很多。但是我觉得是一个综合性的问题,所以我觉得对于一个简单的问题来说稍微复杂一些,但至少现在已经解决了:
跨域取数据到本地数据库然后异步更新的效果
我实现的方式:jquery的$.post发送数据到服务器后端,由后端的PHP代码远程获取,存入数据库ajax返回数据给前台,前台用JS接收数据并显示出来。
//远程抓取获取数据 $("#update_ac").click(function() { $username = $("#username").text(); $("#AC,#rank,#Submit,#solved,#solved2,#solved3").ajaxStart(function(){ $(this).html(" "); }); $.post("update_ac/username/"+$username,{},function($data){ json = eval("(" + $data + ")"); $("#Submit").html(json.data.Submit); $("#AC").html(json.data.AC); $("#solved,#solved2,#solved3").html(json.data.solved); $("#rank").html(json.data.rank); } ),"json"; });
上面jquery代码四楼说的还算清楚,但是让我纠结的是json数据的接收
json = eval("(" + $data + ")"); //eval() 函数可计算某个字符串,并执行其中的的 JavaScript 代码。
其实这还是前台。跨域抓取是通过PHP扩展simple_html_dom完成的(不知道的可以上网搜一下,基于PHP5开发的)
抓取远程页面到本地。
以上代码只是核心代码,simple_html_dom扩展了很多功能。自己找出来。
返回的数据是一个字符串,然后使用正则表达式过滤需要的数据。下面是渲染图
对thinkPHP相关内容更感兴趣的读者可以查看本站主题:《》、《ThinkPHP模板操作技巧总结》、《ThinkPHP常用方法总结》、《Smarty模板基础教程》、《PHP总结》模板技术”。
我希望本文能帮助您设计基于 ThinkPHP 框架的 PHP 编程。
以上就是jquery+thinkphp实现跨域数据抓取的方法的详细内容。更多详情请关注其他相关html中文网站文章!
php抓取网页数据实例(PHPCURL与file_get_contents函数都可以获取远程服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-10 18:15
PHP CURL 或 file_get_contents 获取页面标题代码和效率两者的稳定性
更新时间:2015年11月30日09:56:14 投稿:mrr
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。下面通过一个例子给大家介绍PHP CURL或者file_get_contents获取页面标题的代码和效率两者的稳定性问题,需要的朋友可以参考
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。我先介绍PHP CURL 或file_get_contents 函数应用实例,然后给大家简单介绍一下它们之间的一些小区别。
推荐的获取CURL的方法
使用 file_get_contents
看一下 file_get_contents 性能
1)fopen/file_get_contents 每次请求远程URL中的数据时,都会再次进行DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比fopen/file_get_contents好很多。
2)fopen/file_get_contents 在请求 HTTP 时使用 http_fopen_wrapper,不会保持存活。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。(应该可以设置标题)
3)fopen/file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
4)curl 可以模拟多种请求,如:POST 数据、表单提交等,用户可以根据自己的需求自定义请求。而 fopen/file_get_contents 只能使用 get 来获取数据。
5)fopen/file_get_contents 无法正确下载二进制文件
6)fopen/file_get_contents 无法正确处理 ssl 请求
7)curl 可以利用多线程
8) 使用file_get_contents时,如果网络有问题,这里很容易积累一些进程
9)如果要进行连续连接,请多次请求多个页面。那么 file_get_contents 就会出错。获取的内容也可能是错误的。所以在做类似采集的事情的时候,肯定有问题。使用curl进行采集爬取,如果你还不相信,我们再做一个测试。
curl和file_get_contents PHP源码性能对比如下:
第182话
测试访问
file_get_contents 速度:4.2404510975 秒
卷曲速度:2.8205530643 秒
curl 比 file_get_contents 快约 30%,最重要的是,服务器负载更低。
ps:php函数file_get_contents和curl的效率和稳定性问题
习惯使用方便快捷的file_get_contents函数来抓取别人家的内容网站,但总是遇到获取失败的问题。虽然按照手册中的例子设置了超时时间,但大多数时候并不好用:
$config['context'] = stream_context_create(array('http' => array('method' => "GET",'timeout' => 5)));
'timeout' => 5//这个超时时间不稳定,经常难以使用。这时候再看服务器的连接池,会发现一堆类似下面的错误,让你头疼:
file_get_contents(***): 无法打开流...
作为最后的手段,我安装了 curl 库并编写了一个函数替换:
function curl_get_contents($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); //设置访问的url地址
//curl_setopt($ch,CURLOPT_HEADER,1); //是否显示头部信息
curl_setopt($ch, CURLOPT_TIMEOUT, 5); //设置超时
curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_); //用户访问代理 User-Agent
curl_setopt($ch, CURLOPT_REFERER,_REFERER_); //设置 referer
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1); //跟踪301
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回结果
$r = curl_exec($ch);
curl_close($ch);
return $r;
}
这样,除了真正的网络问题外,没有更多的问题。
这是其他人对 curl 和 file_get_contents 的测试:
File_get_contents 需要几秒钟才能获取:
2.31319094
2.30374217
2.21512604
3.30553889
2.30124092
curl 使用的时间:
0.68719101
0.64675593
0.64326
0.81983113
0.63956594
是不是差距很大?哈哈,根据我的经验,这两个工具不仅速度不同,稳定性也不同。推荐对网络数据抓取稳定性要求高的朋友使用上面的curl_file_get_contents函数,不仅稳定快速,还能假冒浏览器欺骗目标地址! 查看全部
php抓取网页数据实例(PHPCURL与file_get_contents函数都可以获取远程服务器)
PHP CURL 或 file_get_contents 获取页面标题代码和效率两者的稳定性
更新时间:2015年11月30日09:56:14 投稿:mrr
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。下面通过一个例子给大家介绍PHP CURL或者file_get_contents获取页面标题的代码和效率两者的稳定性问题,需要的朋友可以参考
PHP CURL 和 file_get_contents 函数都可以获取远程服务器上的文件并保存在本地,但在性能上却不是一个级别。我先介绍PHP CURL 或file_get_contents 函数应用实例,然后给大家简单介绍一下它们之间的一些小区别。
推荐的获取CURL的方法
使用 file_get_contents
看一下 file_get_contents 性能
1)fopen/file_get_contents 每次请求远程URL中的数据时,都会再次进行DNS查询,不会缓存DNS信息。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比fopen/file_get_contents好很多。
2)fopen/file_get_contents 在请求 HTTP 时使用 http_fopen_wrapper,不会保持存活。但是卷曲可以。这样,在多次请求多个链接时,curl 的效率会更高。(应该可以设置标题)
3)fopen/file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
4)curl 可以模拟多种请求,如:POST 数据、表单提交等,用户可以根据自己的需求自定义请求。而 fopen/file_get_contents 只能使用 get 来获取数据。
5)fopen/file_get_contents 无法正确下载二进制文件
6)fopen/file_get_contents 无法正确处理 ssl 请求
7)curl 可以利用多线程
8) 使用file_get_contents时,如果网络有问题,这里很容易积累一些进程
9)如果要进行连续连接,请多次请求多个页面。那么 file_get_contents 就会出错。获取的内容也可能是错误的。所以在做类似采集的事情的时候,肯定有问题。使用curl进行采集爬取,如果你还不相信,我们再做一个测试。
curl和file_get_contents PHP源码性能对比如下:
第182话
测试访问
file_get_contents 速度:4.2404510975 秒
卷曲速度:2.8205530643 秒
curl 比 file_get_contents 快约 30%,最重要的是,服务器负载更低。
ps:php函数file_get_contents和curl的效率和稳定性问题
习惯使用方便快捷的file_get_contents函数来抓取别人家的内容网站,但总是遇到获取失败的问题。虽然按照手册中的例子设置了超时时间,但大多数时候并不好用:
$config['context'] = stream_context_create(array('http' => array('method' => "GET",'timeout' => 5)));
'timeout' => 5//这个超时时间不稳定,经常难以使用。这时候再看服务器的连接池,会发现一堆类似下面的错误,让你头疼:
file_get_contents(***): 无法打开流...
作为最后的手段,我安装了 curl 库并编写了一个函数替换:
function curl_get_contents($url)
{
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url); //设置访问的url地址
//curl_setopt($ch,CURLOPT_HEADER,1); //是否显示头部信息
curl_setopt($ch, CURLOPT_TIMEOUT, 5); //设置超时
curl_setopt($ch, CURLOPT_USERAGENT, _USERAGENT_); //用户访问代理 User-Agent
curl_setopt($ch, CURLOPT_REFERER,_REFERER_); //设置 referer
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1); //跟踪301
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回结果
$r = curl_exec($ch);
curl_close($ch);
return $r;
}
这样,除了真正的网络问题外,没有更多的问题。
这是其他人对 curl 和 file_get_contents 的测试:
File_get_contents 需要几秒钟才能获取:
2.31319094
2.30374217
2.21512604
3.30553889
2.30124092
curl 使用的时间:
0.68719101
0.64675593
0.64326
0.81983113
0.63956594
是不是差距很大?哈哈,根据我的经验,这两个工具不仅速度不同,稳定性也不同。推荐对网络数据抓取稳定性要求高的朋友使用上面的curl_file_get_contents函数,不仅稳定快速,还能假冒浏览器欺骗目标地址!
php抓取网页数据实例(为什么要用php抓取网页数据实例应用实例,主要是利用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-09 13:04
php抓取网页数据实例应用实例,主要是利用php实现抓取同样的网页数据。为什么要用php抓取网页数据?一是这是一个网站的基础,有了这些基础,才能做其他的,比如写数据库的软件。二是基于前面网站的相关理论和使用php抓取网页数据还有很多生动的例子,比如你和男神约会,最好选在早上,因为太阳升的早,比较有阳光的感觉,于是你去买菜的时候,如果早上还在晚上8点,那你这么干干嘛?你男神自己吃什么?太阳是准时升起的,男神也会吃到嫩嫩的菜,虽然有时候不一定吃得到,但是你既然想跟他吃一顿完美的晚餐,那你和男神约会的时候准点到也是必须的。
所以网页数据抓取也是一样的,你是想把握流量的时候,来做什么呢?是不是要在你流量达到一定程度,然后获取这些数据作为以后的策略参考呢?对,网页数据抓取基于网页有抓取的原则要求,也基于数据库有一定的要求,所以这些也是比较有意义的。首先对一些同学说一句:请千万不要随便去别人的博客看人家的代码、插件、介绍、心得、开源站点。
我简单说说我的看法。网站数据抓取,网站是决定性因素,对网站熟悉的人,肯定比不太熟悉的人会更熟悉抓取网站;其次,数据库因素,数据库基本上肯定要与php对应,所以网站数据抓取也有一定的数据库要求,比如如果网站数据库库必须要事先申请root权限的话,那么其他的都可以不用考虑。接下来要说明的是“怎么抓取”和“为什么要抓取”。
网站数据抓取必须抓取所有页面,抓取的页面只是一种方便的查看页面总量,方便做好流量计划的一种行为,比如像很多网站,a站,b站一样,我这里列举一些a站,在知乎上,你可以有不同的见解,有的人通过看过的人的回答,有的人通过看完的作品,对网站数据抓取上来说,这是一种比较没有安全感的行为,假如你是一个博客站,可能又关注了一些历史版块,又有通过看到不同的博主从别的博客、博客群站抓取别人的文章,回来发自己的站,然后跟踪下载(很多个群),这种的就非常受人忌讳,但是又不能人家怎么抓取我怎么抓取,被人知道,但又不知道哪个是哪个。
所以只好通过浏览器的“带走”功能,把页面抓取下来,再修改各种参数,然后分享给人家看了。当然各种html修改上来说还有很多方法,这里用抓取的站和回复(request)做对比,就大体说一下网站抓取浏览器带走中间页的问题。针对上面的问题,大家已经在网上看到太多关于这方面的消息了,但是大多是,是通过浏览器插件,或者是教大家在chrome浏览器中使用插件,比如”优采云采集器”,我不推荐使用这种方法,但是如果你是做网站的, 查看全部
php抓取网页数据实例(为什么要用php抓取网页数据实例应用实例,主要是利用)
php抓取网页数据实例应用实例,主要是利用php实现抓取同样的网页数据。为什么要用php抓取网页数据?一是这是一个网站的基础,有了这些基础,才能做其他的,比如写数据库的软件。二是基于前面网站的相关理论和使用php抓取网页数据还有很多生动的例子,比如你和男神约会,最好选在早上,因为太阳升的早,比较有阳光的感觉,于是你去买菜的时候,如果早上还在晚上8点,那你这么干干嘛?你男神自己吃什么?太阳是准时升起的,男神也会吃到嫩嫩的菜,虽然有时候不一定吃得到,但是你既然想跟他吃一顿完美的晚餐,那你和男神约会的时候准点到也是必须的。
所以网页数据抓取也是一样的,你是想把握流量的时候,来做什么呢?是不是要在你流量达到一定程度,然后获取这些数据作为以后的策略参考呢?对,网页数据抓取基于网页有抓取的原则要求,也基于数据库有一定的要求,所以这些也是比较有意义的。首先对一些同学说一句:请千万不要随便去别人的博客看人家的代码、插件、介绍、心得、开源站点。
我简单说说我的看法。网站数据抓取,网站是决定性因素,对网站熟悉的人,肯定比不太熟悉的人会更熟悉抓取网站;其次,数据库因素,数据库基本上肯定要与php对应,所以网站数据抓取也有一定的数据库要求,比如如果网站数据库库必须要事先申请root权限的话,那么其他的都可以不用考虑。接下来要说明的是“怎么抓取”和“为什么要抓取”。
网站数据抓取必须抓取所有页面,抓取的页面只是一种方便的查看页面总量,方便做好流量计划的一种行为,比如像很多网站,a站,b站一样,我这里列举一些a站,在知乎上,你可以有不同的见解,有的人通过看过的人的回答,有的人通过看完的作品,对网站数据抓取上来说,这是一种比较没有安全感的行为,假如你是一个博客站,可能又关注了一些历史版块,又有通过看到不同的博主从别的博客、博客群站抓取别人的文章,回来发自己的站,然后跟踪下载(很多个群),这种的就非常受人忌讳,但是又不能人家怎么抓取我怎么抓取,被人知道,但又不知道哪个是哪个。
所以只好通过浏览器的“带走”功能,把页面抓取下来,再修改各种参数,然后分享给人家看了。当然各种html修改上来说还有很多方法,这里用抓取的站和回复(request)做对比,就大体说一下网站抓取浏览器带走中间页的问题。针对上面的问题,大家已经在网上看到太多关于这方面的消息了,但是大多是,是通过浏览器插件,或者是教大家在chrome浏览器中使用插件,比如”优采云采集器”,我不推荐使用这种方法,但是如果你是做网站的,
php抓取网页数据实例(php抓取网页数据实例讲解_知多少?本文给大家讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-08 07:06
php抓取网页数据实例讲解_知多少?本文给大家讲解利用php抓取网页数据实例讲解-说明的视频讲解,一起学习吧!视频讲解将整个视频讲解讲解了:1.php抓取页面数据的基本思路2.php文件抓取的首次尝试以及第二次尝试php新建一个smart_form.php文件:${$text}三个人拿着苹果,苹果2在哪里?转码:解析content_encode函数出来的字符串并转换成ascii数据${$text}三个人拿着苹果,苹果2在哪里?如果file_exists('a'),那么a,b,c这三个文件会自动解析出来。
<p>如果只有一个文件,那么文件的压缩名会被压缩,只能通过'@'包住,不能是"@"因为'@'是在php文件上添加的标识符。上面给出了解决方案,至于test.php文件怎么下载,可以根据前面列出来的讲解可以google,如果你是php新手请按照视频下载学习,可以学习下面的代码,或者看一下下面的方法也可以下载详细视频讲解,下面给出php快速抓取:echo'想让数据怎么显示'?> 查看全部
php抓取网页数据实例(php抓取网页数据实例讲解_知多少?本文给大家讲解)
php抓取网页数据实例讲解_知多少?本文给大家讲解利用php抓取网页数据实例讲解-说明的视频讲解,一起学习吧!视频讲解将整个视频讲解讲解了:1.php抓取页面数据的基本思路2.php文件抓取的首次尝试以及第二次尝试php新建一个smart_form.php文件:${$text}三个人拿着苹果,苹果2在哪里?转码:解析content_encode函数出来的字符串并转换成ascii数据${$text}三个人拿着苹果,苹果2在哪里?如果file_exists('a'),那么a,b,c这三个文件会自动解析出来。
<p>如果只有一个文件,那么文件的压缩名会被压缩,只能通过'@'包住,不能是"@"因为'@'是在php文件上添加的标识符。上面给出了解决方案,至于test.php文件怎么下载,可以根据前面列出来的讲解可以google,如果你是php新手请按照视频下载学习,可以学习下面的代码,或者看一下下面的方法也可以下载详细视频讲解,下面给出php快速抓取:echo'想让数据怎么显示'?>
php抓取网页数据实例(php抓取网页数据实例学习这个一般都是需要配置环境的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-06 14:02
php抓取网页数据实例学习这个一般都是需要配置环境的,这里我讲一下抓取网页直播数据的配置方法,希望对你有所帮助。
一、php的安装1.确保你有对应的php版本2.这里我这里使用的是5.3
二、mongo的安装mongodb的安装与配置我就不赘述了,
1)在命令行输入:php.exe-moracle_home/appdata/local/tomcat/bin/db_path${php_ora_path}
2)需要在cmd中操作,
3)在命令行输入:sed-i's/bin/bash//g'bin/bash
4)在命令行输入:md5_execution#md5-r''
5)在命令行输入:php-v
6)在命令行输入:su-
三、php的配置1.在index.php文件中增加:其中的$connection是你php文件路径的首字母大写。完成配置之后,在浏览器中打开页面就可以正常访问了。
五、配置cookiecookie是php必须要知道的一个东西,你如果在使用其他语言进行开发网站的时候需要对cookie的管理进行设置。需要在路径中添加:;sec-client-session_certs=falsesec-client-session_enabled=truesec-client-timeout=1&sec-client-cookie_ref=0这样才可以访问php/base5.html来进行登录,并使用php进行查询。
而且sec-client-session_certs在php和你的src文件夹中要同时生效,并且sec-client-session_enabled在php和src文件夹中也要同时生效,否则sec-client-session_enabled只起到了保存的作用不会被使用。还有一个地方sec-client-session_cookie_ref要写为0的原因,是因为默认sec-client-session_cookie_ref有4个值,而第三个0的话是不生效的,否则sec-clie。 查看全部
php抓取网页数据实例(php抓取网页数据实例学习这个一般都是需要配置环境的)
php抓取网页数据实例学习这个一般都是需要配置环境的,这里我讲一下抓取网页直播数据的配置方法,希望对你有所帮助。
一、php的安装1.确保你有对应的php版本2.这里我这里使用的是5.3
二、mongo的安装mongodb的安装与配置我就不赘述了,
1)在命令行输入:php.exe-moracle_home/appdata/local/tomcat/bin/db_path${php_ora_path}
2)需要在cmd中操作,
3)在命令行输入:sed-i's/bin/bash//g'bin/bash
4)在命令行输入:md5_execution#md5-r''
5)在命令行输入:php-v
6)在命令行输入:su-
三、php的配置1.在index.php文件中增加:其中的$connection是你php文件路径的首字母大写。完成配置之后,在浏览器中打开页面就可以正常访问了。
五、配置cookiecookie是php必须要知道的一个东西,你如果在使用其他语言进行开发网站的时候需要对cookie的管理进行设置。需要在路径中添加:;sec-client-session_certs=falsesec-client-session_enabled=truesec-client-timeout=1&sec-client-cookie_ref=0这样才可以访问php/base5.html来进行登录,并使用php进行查询。
而且sec-client-session_certs在php和你的src文件夹中要同时生效,并且sec-client-session_enabled在php和src文件夹中也要同时生效,否则sec-client-session_enabled只起到了保存的作用不会被使用。还有一个地方sec-client-session_cookie_ref要写为0的原因,是因为默认sec-client-session_cookie_ref有4个值,而第三个0的话是不生效的,否则sec-clie。
php抓取网页数据实例(excel数据问问罗哥有个二踢脚我也看了,我想知道..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-06 04:06
php抓取网页数据实例php抓取网页数据实例
安装vscode,配置好环境变量,最后加载github上的gitlab,最后挂载到后台,
windows下:1.安装并配置gitlab2.配置好环境变量
本人也遇到这个问题
这个问题还没解决,在微软社区里看到有大神已经用xml格式化并传到github上,这就算是一个入门gitlab但又有自己特殊用途的php爬虫。上个图,目前看还没有能下载的。
国内外其他大佬的图解教程github地址:-pages/
别问我,我只知道要配置环境变量,
怎么说呢,我也是因为需要xml格式的数据,在xml上面传输。然后别人我就直接用python爬虫。
xml传到github
xml格式传到github上。
php怎么解析xml?下面的页面抓取到了吗?
编程语言不同不要为难php啦。如果你需要excel数据,
再下载一个xll一定要配好环境变量
看不懂看不懂啊==
写个mysql然后导入github的blog,就可以在手机上编程了。
php写的文章传到github最近在研究python和go能不能去除广告的数据
问问罗哥
有个二踢脚我也看了,
我想知道.jpg在github可以看么... 查看全部
php抓取网页数据实例(excel数据问问罗哥有个二踢脚我也看了,我想知道..)
php抓取网页数据实例php抓取网页数据实例
安装vscode,配置好环境变量,最后加载github上的gitlab,最后挂载到后台,
windows下:1.安装并配置gitlab2.配置好环境变量
本人也遇到这个问题
这个问题还没解决,在微软社区里看到有大神已经用xml格式化并传到github上,这就算是一个入门gitlab但又有自己特殊用途的php爬虫。上个图,目前看还没有能下载的。
国内外其他大佬的图解教程github地址:-pages/
别问我,我只知道要配置环境变量,
怎么说呢,我也是因为需要xml格式的数据,在xml上面传输。然后别人我就直接用python爬虫。
xml传到github
xml格式传到github上。
php怎么解析xml?下面的页面抓取到了吗?
编程语言不同不要为难php啦。如果你需要excel数据,
再下载一个xll一定要配好环境变量
看不懂看不懂啊==
写个mysql然后导入github的blog,就可以在手机上编程了。
php写的文章传到github最近在研究python和go能不能去除广告的数据
问问罗哥
有个二踢脚我也看了,
我想知道.jpg在github可以看么...
php抓取网页数据实例(PHP利用curl函数实现登录并抓取数据的使用总结(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-01 04:14
几乎所有程序员都会使用curl函数来模拟用户登录或者抓取数据。下面给大家介绍一下使用curl函数登录和抓取数据。我希望下面的例子对你有所帮助。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
/设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = http://www.xxx.com;
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。 查看全部
php抓取网页数据实例(PHP利用curl函数实现登录并抓取数据的使用总结(一))
几乎所有程序员都会使用curl函数来模拟用户登录或者抓取数据。下面给大家介绍一下使用curl函数登录和抓取数据。我希望下面的例子对你有所帮助。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
login_post()函数首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址、保存的cookie文件、post数据(用户名密码等信息)、返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
/设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = http://www.xxx.com;
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_oschina.txt';
//登录后要获取信息的地址
$url2 = "http://m.oschina.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
php抓取网页数据实例(PHP自带http_build_query()设置目标url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 08:05
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址,保存的cookie文件,post数据(用户名密码等信息),是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.jb51.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_jb51.txt';
//登录后要获取信息的地址
$url2 = "http://m.jb51.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结:
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。 查看全部
php抓取网页数据实例(PHP自带http_build_query()设置目标url)
CURL 是一个强大的 PHP 库。使用PHP的cURL库可以方便有效的抓取网页和采集内容,设置cookies来完成模拟登录网页,curl提供了丰富的功能,开发者可以从PHP手册中获取更多关于cURL的信息。本文以模拟登录开源中国(oschina)为例,与大家分享cURL的使用。
PHP的curl()在抓取网页的效率上比较高,并且支持多线程,而file_get_contents()的效率稍低。当然,使用curl时需要开启curl扩展。
代码实战
我们先来看看登录部分的代码:
//模拟登录
function login_post($url, $cookie, $post) {
$curl = curl_init();//初始化curl模块
curl_setopt($curl, CURLOPT_URL, $url);//登录提交的地址
curl_setopt($curl, CURLOPT_HEADER, 0);//是否显示头信息
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 0);//是否自动显示返回的信息
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie); //设置Cookie信息保存在指定的文件中
curl_setopt($curl, CURLOPT_POST, 1);//post方式提交
curl_setopt($curl, CURLOPT_POSTFIELDS, http_build_query($post));//要提交的信息
curl_exec($curl);//执行cURL
curl_close($curl);//关闭cURL资源,并且释放系统资源
}
函数login_post()首先初始化curl_init(),然后使用curl_setopt()设置相关选项信息,包括要提交的URL地址,保存的cookie文件,post数据(用户名密码等信息),是否返回信息等,然后curl_exec执行curl,最后curl_close()释放资源。请注意,PHP 自带的 http_build_query() 可以将数组转换为串联字符串。
接下来,如果登录成功,我们需要获取登录成功后的页面信息。
//登录成功后获取数据
function get_content($url, $cookie) {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HEADER, 0);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_COOKIEFILE, $cookie); //读取cookie
$rs = curl_exec($ch); //执行cURL抓取页面内容
curl_close($ch);
return $rs;
}
函数get_content()也是先初始化curl,然后设置相关选项,执行curl,释放资源。其中,我们设置CURLOPT_RETURNTRANSFER为1自动返回信息,CURLOPT_COOKIEFILE可以读取登录时保存的cookie信息,最终返回页面内容。
我们的最终目标是获取模拟登录后的信息,即只有正常登录成功才能获取的有用信息。接下来我们以开源中国移动版为例,看看登录成功后如何抓取信息。
//设置post的数据
$post = array (
'email' => 'oschina账户',
'pwd' => 'oschina密码',
'goto_page' => '/my',
'error_page' => '/login',
'save_login' => '1',
'submit' => '现在登录'
);
//登录地址
$url = "http://m.jb51.net/action/user/login";
//设置cookie保存路径
$cookie = dirname(__FILE__) . '/cookie_jb51.txt';
//登录后要获取信息的地址
$url2 = "http://m.jb51.net/my";
//模拟登录
login_post($url, $cookie, $post);
//获取登录页的信息
$content = get_content($url2, $cookie);
//删除cookie文件
@ unlink($cookie);
//匹配页面信息
$preg = "/(.*)/i";
preg_match_all($preg, $content, $arr);
$str = $arr[1][0];
//输出内容
echo $str;
运行上面的代码后,我们会看到最终得到了登录用户的头像。
使用总结:
1、初始化curl;
2、使用curl_setopt设置目标url,以及其他选项;
3、curl_exec,执行curl;
4、 执行后关闭curl;
5、 输出数据。
php抓取网页数据实例( 以人教版地理七年级为例子,到电子课本网下载一本电子书)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-19 11:18
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持! 查看全部
php抓取网页数据实例(
以人教版地理七年级为例子,到电子课本网下载一本电子书)
Thinkphp 捕获网站 的内容并保存到本地实例。
我需要写一个这样的例子并从电子教科书网站下载一本电子书。
的电子书把书的每一页都看成一幅图,然后一本书就有很多图。我需要批量下载图片。
这是代码部分:
public function download() {
$http = new \Org\Net\Http();
$url_pref = "http://www.dzkbw.com/books/rjb/dili/xc7s/";
$localUrl = "Public/bookcover/";
$reg="|showImg\('(.+)'\);|";
$i=1;
do {
$filename = substr("000".$i,-3).".htm";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url_pref.$filename);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
$html = curl_exec($ch);
curl_close($ch);
$result = preg_match_all($reg,$html,$out, PREG_PATTERN_ORDER);
if($result==1) {
$picUrl = $out[1][0];
$picFilename = substr("000".$i,-3).".jpg";
$http->curlDownload($picUrl, $localUrl.$picFilename);
}
$i = $i+1;
} while ($result==1);
echo "下载完成";
}
这里我以人民教育出版社出版的七年级地理第一册为例。
网页从001.htm开始,然后不断增加
每个网页都有一张图片,与课本的内容相对应。课本内容以图片的形式展示。
我的代码是做一个循环,从第一页开始,直到在网页中找不到图片。
抓取网页内容后,抓取网页中的图片到本地服务器
爬取后的实际效果:
以上就是thinkphp抓取网站的内容并保存到本地的例子的详细说明。如有疑问,请留言或到本站社区讨论讨论。感谢您的阅读,希望对大家有所帮助。感谢您对本站的支持!
php抓取网页数据实例(php中分别使用curl的post提交数据的方法和get获取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-19 06:28
)
在php中,使用curl的post提交方法和get方法获取网页数据整理分享量,具体代码如下:
(1)如何使用php curl获取网页数据:
$ch=curl_init();
//设置选项,包括URL
curl_setopt($ch,CURLOPT_URL,"http://www.phpernote.com");
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_HEADER,0);
//执行并获取HTML文档内容
$output=curl_exec($ch);
//释放curl句柄
curl_close($ch);
(2)使用php curl post提交数据的方法:
$url="http://www.phpernote.com/curl_post.php";
$post_data=array (
"nameuser"=>"syxrrrr",
"pw"=>"123456"
);
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_data);
$output=curl_exec($ch);
curl_close($ch);
echo $output;
您可以添加一个句子来检查错误(虽然这不是必需的):
$output=curl_exec($ch);
if($output===FALSE){
echo "cURL Error: " . curl_error($ch);
} 查看全部
php抓取网页数据实例(php中分别使用curl的post提交数据的方法和get获取网页数据
)
在php中,使用curl的post提交方法和get方法获取网页数据整理分享量,具体代码如下:
(1)如何使用php curl获取网页数据:
$ch=curl_init();
//设置选项,包括URL
curl_setopt($ch,CURLOPT_URL,"http://www.phpernote.com";);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_HEADER,0);
//执行并获取HTML文档内容
$output=curl_exec($ch);
//释放curl句柄
curl_close($ch);
(2)使用php curl post提交数据的方法:
$url="http://www.phpernote.com/curl_post.php";
$post_data=array (
"nameuser"=>"syxrrrr",
"pw"=>"123456"
);
$ch=curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_data);
$output=curl_exec($ch);
curl_close($ch);
echo $output;
您可以添加一个句子来检查错误(虽然这不是必需的):
$output=curl_exec($ch);
if($output===FALSE){
echo "cURL Error: " . curl_error($ch);
}
php抓取网页数据实例( 2017年01月20日11:00投稿:我用php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-10-19 06:26
2017年01月20日11:00投稿:我用php)
php curl常用的5个经典例子
更新时间:2017年1月20日11:00:18 投稿:景贤
下面小编为大家带来5个php curl常用的经典例子。我觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
我使用php和curl主要是为了抓取数据。当然,我们也可以使用其他方法来抓取数据,比如fsockopen、file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取带有页面访问控制的页面,或者登录后的页面,就比较困难了。
1.获取文件没有访问控制
2.使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,如果你在短时间内频繁抓取它,你将无法抓取它。Google 限制您的 IP 地址。这时候可以换个proxy再抓一次。
3.post数据后,抓取数据
单独说一下数据提交数据,因为在使用curl的时候,经常会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST); 使用 curl 捕获upload.php Array的输出([name] => test [sex] => 1 [birth] => 20101010)
4. 获取一些带有页面访问控制的页面
之前写过一篇文章。有兴趣的可以看看页面访问控制的3种方法。
如果使用上述方法进行catch,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
这时候我们会使用 CURLOPT_USERPWD 来验证
以上5个php curl常用的经典例子,都是小编分享的内容。希望能给大家一个参考,也希望大家多多支持剧本家。 查看全部
php抓取网页数据实例(
2017年01月20日11:00投稿:我用php)
php curl常用的5个经典例子
更新时间:2017年1月20日11:00:18 投稿:景贤
下面小编为大家带来5个php curl常用的经典例子。我觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
我使用php和curl主要是为了抓取数据。当然,我们也可以使用其他方法来抓取数据,比如fsockopen、file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取带有页面访问控制的页面,或者登录后的页面,就比较困难了。
1.获取文件没有访问控制
2.使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,如果你在短时间内频繁抓取它,你将无法抓取它。Google 限制您的 IP 地址。这时候可以换个proxy再抓一次。
3.post数据后,抓取数据
单独说一下数据提交数据,因为在使用curl的时候,经常会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST); 使用 curl 捕获upload.php Array的输出([name] => test [sex] => 1 [birth] => 20101010)
4. 获取一些带有页面访问控制的页面
之前写过一篇文章。有兴趣的可以看看页面访问控制的3种方法。
如果使用上述方法进行catch,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
这时候我们会使用 CURLOPT_USERPWD 来验证
以上5个php curl常用的经典例子,都是小编分享的内容。希望能给大家一个参考,也希望大家多多支持剧本家。
php抓取网页数据实例( 网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-18 12:03
网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
PHP网页缓存技术优势及代码示例
更新时间:2020年7月29日10:34:52 作者:网虫
本文文章主要介绍PHP网页缓存技术的优点和代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
前台静态:解析后将动态页面保存为静态页面
文件缓存:将查询结果保存为文件,XML
内存缓存:memcache
php缓存:XCache、eaccelerator等。
Memcache 是一个高性能的分布式内存对象缓存系统。通过在内存中维护一个统一的巨大哈希表,它可以用来存储各种格式的数据,包括图像、视频、文件,以及数据库检索的结果等。简单的说就是将数据调用到内存中再从内存中读取,从而大大提高了读取速度。Memcache 是 danga 的一个项目。它最初由 LiveJournal 提供服务。它最初是为了加快LiveJournal的访问速度而开发的,后来被许多大型网站采用。Memcached 作为守护进程运行在一台或多台服务器上,随时接收客户端的连接和操作。
XCache 是一个开源操作码缓存/优化器,这意味着它可以提高 PHP 在您的服务器上的性能。它通过将已编译的 PHP 数据缓冲到共享内存中来避免重复编译过程,并且可以直接使用缓冲区已经编译的代码从而提高速度。通常它可以将您的页面生成率提高 2 到 5 倍并减少服务器负载。
****************************************************** ****************************************************** ******************************************************
1、通用缓存技术:
数据缓存:这里所说的数据缓存是指数据库查询的PHP缓存机制。每次访问该页面时,首先会检查相应的缓存数据是否存在。如果不存在,则连接数据库,获取数据,对查询结果进行排序。转换后保存在一个文件中,以后直接从缓存表或文件中获取同样的查询结果。
使用最广泛的例子是Discuz的搜索功能,将结果ID缓存在一张表中,下次搜索同一个关键词时先搜索缓存表。
作为一种常见的方法,当多个表关联时,将附表中的内容生成一个数组保存在主表的一个字段中,需要时再分解该数组。这样做的好处是只读取一张表,坏处是两张数据。同步的步骤会多很多,数据库永远是瓶颈。用硬盘改变速度是这个的关键点。
2、 页面缓存:
每次访问一个页面时,首先会检查对应的缓存页面文件是否存在。如果不存在,会同时连接数据库,获取数据,显示页面,生成缓存页面文件,以便下次访问时页面文件发挥作用。. (模板引擎和网上一些常见的PHP缓存机制类通常都有这个功能)
3、 时间触发缓存:
检查文件是否存在,时间戳是否小于设置的过期时间。如果文件修改的时间戳大于当前时间戳减去过期时间戳,则使用缓存,否则更新缓存。
4、 内容触发缓存:
当数据被插入或更新时,PHP 缓存机制会被强制更新。
5、 静态缓存:
这里所说的静态缓存是指静态的,直接生成HTML或者XML等文本文件,有更新的时候重新生成一次,适用于变化不大的页面,就不多说了。
上面的内容是代码层面的解决方案,我直接CP其他框架,懒得改了,内容类似,做起来很简单,会用好几种方式,不过下面的内容是服务器-侧缓存方案,不是代码级别的,只有多方合作才能实现
6、 内存缓存:
Memcached 是一种高性能、分布式内存对象 PHP 缓存机制系统,用于在动态应用中减少数据库负载和提高访问速度。
7、 php 缓冲区:
还有eaccelerator、apc、phpa、xcache,更不用说这个了
8、 MYSQL 缓存:
这个也是非代码级别的,经典数据库就是这样使用的,看下面的运行时间,比如0.09xxx
9、 基于反向代理的Web缓存:
如Nginx、SQUID、mod_proxy(apache2及以上分为mod_proxy和mod_cache)
10、 DNS 轮询:
BIND 是一个开源的 DNS 服务器软件。这是一件大事。自行搜索。每个人都知道有这个东西。
我知道有些大网站比如chinacache就是这样做的。简单来说,就是多台服务器。同一个页面或文件缓存在不同的服务器上,根据南北自动解析到相关服务器。
PHP 网页缓存示例
有了这三个php函数,就可以实现强大的功能。如果数据库查询量很大,可以使用缓存来解决这个问题。
首先,设置过期时间。如果需要缓存文件在2小时内过期,可以设置cache_time为3600*2;使用filectime()获取缓存文件的创建时间(或者filemtime()获取修改时间),如果当前时间超过文件的创建时间超过限定的过期时间,可以使用以上三个函数先从数据库中取数据,然后开始缓存ob_start(),然后在缓存中写入要生成的页面的html代码。缓存结束后通过ob_get_contents()获取缓存的内容,然后通过fwrite将缓存的内容写入静态页面html。
如果没有过期,直接读取缓存中的静态页面,避免大量的数据库访问。
<p> 查看全部
php抓取网页数据实例(
网络虫这篇文章通过示例代码介绍的非常详细,值得收藏!)
PHP网页缓存技术优势及代码示例
更新时间:2020年7月29日10:34:52 作者:网虫
本文文章主要介绍PHP网页缓存技术的优点和代码示例。文章中介绍的示例代码非常详细。对大家的学习或工作有一定的参考学习价值。有需要的朋友可以参考
前台静态:解析后将动态页面保存为静态页面
文件缓存:将查询结果保存为文件,XML
内存缓存:memcache
php缓存:XCache、eaccelerator等。
Memcache 是一个高性能的分布式内存对象缓存系统。通过在内存中维护一个统一的巨大哈希表,它可以用来存储各种格式的数据,包括图像、视频、文件,以及数据库检索的结果等。简单的说就是将数据调用到内存中再从内存中读取,从而大大提高了读取速度。Memcache 是 danga 的一个项目。它最初由 LiveJournal 提供服务。它最初是为了加快LiveJournal的访问速度而开发的,后来被许多大型网站采用。Memcached 作为守护进程运行在一台或多台服务器上,随时接收客户端的连接和操作。
XCache 是一个开源操作码缓存/优化器,这意味着它可以提高 PHP 在您的服务器上的性能。它通过将已编译的 PHP 数据缓冲到共享内存中来避免重复编译过程,并且可以直接使用缓冲区已经编译的代码从而提高速度。通常它可以将您的页面生成率提高 2 到 5 倍并减少服务器负载。
****************************************************** ****************************************************** ******************************************************
1、通用缓存技术:
数据缓存:这里所说的数据缓存是指数据库查询的PHP缓存机制。每次访问该页面时,首先会检查相应的缓存数据是否存在。如果不存在,则连接数据库,获取数据,对查询结果进行排序。转换后保存在一个文件中,以后直接从缓存表或文件中获取同样的查询结果。
使用最广泛的例子是Discuz的搜索功能,将结果ID缓存在一张表中,下次搜索同一个关键词时先搜索缓存表。
作为一种常见的方法,当多个表关联时,将附表中的内容生成一个数组保存在主表的一个字段中,需要时再分解该数组。这样做的好处是只读取一张表,坏处是两张数据。同步的步骤会多很多,数据库永远是瓶颈。用硬盘改变速度是这个的关键点。
2、 页面缓存:
每次访问一个页面时,首先会检查对应的缓存页面文件是否存在。如果不存在,会同时连接数据库,获取数据,显示页面,生成缓存页面文件,以便下次访问时页面文件发挥作用。. (模板引擎和网上一些常见的PHP缓存机制类通常都有这个功能)
3、 时间触发缓存:
检查文件是否存在,时间戳是否小于设置的过期时间。如果文件修改的时间戳大于当前时间戳减去过期时间戳,则使用缓存,否则更新缓存。
4、 内容触发缓存:
当数据被插入或更新时,PHP 缓存机制会被强制更新。
5、 静态缓存:
这里所说的静态缓存是指静态的,直接生成HTML或者XML等文本文件,有更新的时候重新生成一次,适用于变化不大的页面,就不多说了。
上面的内容是代码层面的解决方案,我直接CP其他框架,懒得改了,内容类似,做起来很简单,会用好几种方式,不过下面的内容是服务器-侧缓存方案,不是代码级别的,只有多方合作才能实现
6、 内存缓存:
Memcached 是一种高性能、分布式内存对象 PHP 缓存机制系统,用于在动态应用中减少数据库负载和提高访问速度。
7、 php 缓冲区:
还有eaccelerator、apc、phpa、xcache,更不用说这个了
8、 MYSQL 缓存:
这个也是非代码级别的,经典数据库就是这样使用的,看下面的运行时间,比如0.09xxx
9、 基于反向代理的Web缓存:
如Nginx、SQUID、mod_proxy(apache2及以上分为mod_proxy和mod_cache)
10、 DNS 轮询:
BIND 是一个开源的 DNS 服务器软件。这是一件大事。自行搜索。每个人都知道有这个东西。
我知道有些大网站比如chinacache就是这样做的。简单来说,就是多台服务器。同一个页面或文件缓存在不同的服务器上,根据南北自动解析到相关服务器。
PHP 网页缓存示例
有了这三个php函数,就可以实现强大的功能。如果数据库查询量很大,可以使用缓存来解决这个问题。
首先,设置过期时间。如果需要缓存文件在2小时内过期,可以设置cache_time为3600*2;使用filectime()获取缓存文件的创建时间(或者filemtime()获取修改时间),如果当前时间超过文件的创建时间超过限定的过期时间,可以使用以上三个函数先从数据库中取数据,然后开始缓存ob_start(),然后在缓存中写入要生成的页面的html代码。缓存结束后通过ob_get_contents()获取缓存的内容,然后通过fwrite将缓存的内容写入静态页面html。
如果没有过期,直接读取缓存中的静态页面,避免大量的数据库访问。
<p>
php抓取网页数据实例( 具有很好的参考价值,希望对大家多多支持脚本之家)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-17 12:05
具有很好的参考价值,希望对大家多多支持脚本之家)
PHP从数据库中读取数据并以json格式返回数据
更新时间:2018-08-21 08:45:33 作者:蒲舍臣之恋
今天给大家分享一篇关于PHP如何从数据库中读取数据并以json格式返回数据的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
php抓取网页数据实例(
具有很好的参考价值,希望对大家多多支持脚本之家)
PHP从数据库中读取数据并以json格式返回数据
更新时间:2018-08-21 08:45:33 作者:蒲舍臣之恋
今天给大家分享一篇关于PHP如何从数据库中读取数据并以json格式返回数据的文章。有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看吧
在php中,从数据库中读取数据,并以json格式返回数据。具体方法如下:
第一步,定义相关变量
$servername = "localhost";
$username = "root";
$password = "root";
$mysqlname = "datatest";
$json = '';
$data = array();
class User
{
public $id;
public $fname;
public $lname;
public $email;
public $password;
}
第二步是链接数据库,代码如下:
// 创建连接
$conn = mysqli_connect($servername, $username, $password, $mysqlname);
第三步,定义查询语句并执行。代码如下:
$sql = "SELECT * FROM userinfo";
$result = $conn->query($sql);
第四步,获取查询到的数据,放入预先声明的类中,最后以json格式输出。
代码显示如下:
if($result){
//echo "查询成功";
while ($row = mysqli_fetch_array($result,MYSQL_ASSOC))
{
$user = new User();
$user->id = $row["id"];
$user->fname = $row["fname"];
$user->lname = $row["lname"];
$user->email = $row["email"];
$user->password = $row["password"];
$data[]=$user;
}
$json = json_encode($data);//把数据转换为JSON数据.
echo "{".'"user"'.":".$json."}";
}else{
echo "查询失败";
}
以上php从数据库中读取数据并以json格式返回数据的方法是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
php抓取网页数据实例( PHP中session如何用session实现记录用户登录信息的具体方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2021-10-12 06:18
PHP中session如何用session实现记录用户登录信息的具体方法)
PHP 实现使用 session 记录用户登录信息
更新时间:2018年10月15日14:22:30 投稿:老张
在这篇文章中,我们和大家分享了PHP如何使用session记录用户登录信息的知识点,有兴趣的朋友可以参考一下。
PHP中session记录用户登录信息的问题也是PHP面试题中比较常见的考点之一,是PHP学习者必须掌握的知识点。
对于初学PHP新手来说,可能会有一定的难度。那么在之前的文章【PHP中如何在session中存储和删除变量】中,我也介绍了session在PHP中的基本含义。有需要的朋友可以选择参考。
下面我们将通过具体的代码示例来详细介绍PHP中session记录用户登录信息的具体方法。
1.简单登录界面代码示例:
登录.html
登录
body {
background: url(images/bg.png);
}
.clear {
clear: both;
}
.login {
width: 370px;
margin: 100px auto 0px;
text-align: center;
}
input[type="text"] {
width: 360px;
height: 50px;
border: none;
background: #fff;
border-radius: 10px;
margin: 5px auto;
padding-left: 10px;
color: #745A74;
font-size: 15px;
}
input[type="checkbox"] {
float: left;
margin: 5px 0px 0px;
}
span {
float: left;
}
.botton {
width: 130px;
height: 40px;
background: #745A74;
border-radius: 10px;
text-align: center;
color: #fff;
margin-top: 30px;
line-height: 40px;
}
images/header.png
2.用于连接数据库的简单PHP文件代码示例:
db.php
<p> 查看全部
php抓取网页数据实例(
PHP中session如何用session实现记录用户登录信息的具体方法)
PHP 实现使用 session 记录用户登录信息
更新时间:2018年10月15日14:22:30 投稿:老张
在这篇文章中,我们和大家分享了PHP如何使用session记录用户登录信息的知识点,有兴趣的朋友可以参考一下。
PHP中session记录用户登录信息的问题也是PHP面试题中比较常见的考点之一,是PHP学习者必须掌握的知识点。
对于初学PHP新手来说,可能会有一定的难度。那么在之前的文章【PHP中如何在session中存储和删除变量】中,我也介绍了session在PHP中的基本含义。有需要的朋友可以选择参考。
下面我们将通过具体的代码示例来详细介绍PHP中session记录用户登录信息的具体方法。
1.简单登录界面代码示例:
登录.html
登录
body {
background: url(images/bg.png);
}
.clear {
clear: both;
}
.login {
width: 370px;
margin: 100px auto 0px;
text-align: center;
}
input[type="text"] {
width: 360px;
height: 50px;
border: none;
background: #fff;
border-radius: 10px;
margin: 5px auto;
padding-left: 10px;
color: #745A74;
font-size: 15px;
}
input[type="checkbox"] {
float: left;
margin: 5px 0px 0px;
}
span {
float: left;
}
.botton {
width: 130px;
height: 40px;
background: #745A74;
border-radius: 10px;
text-align: center;
color: #fff;
margin-top: 30px;
line-height: 40px;
}
images/header.png
2.用于连接数据库的简单PHP文件代码示例:
db.php
<p>

