
php抓取网页数据实例
php抓取网页数据实例( 下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-04 12:25
下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
[CLI] 使用 Curl 下载文件的实时进度条显示
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对编程宝的支持。
下一节:PHP编程技术详解
本文介绍PHP中读写文件的高并发处理操作。分享给大家参考,具体如下: 背景:最近公司游戏开发需要了解游戏加载的流失率。因为,我们做的是网页游戏。玩过网页游戏的人都知道,进入游戏前必须加载一些资源。最后... 查看全部
php抓取网页数据实例(
下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
[CLI] 使用 Curl 下载文件的实时进度条显示
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:

还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对编程宝的支持。
下一节:PHP编程技术详解
本文介绍PHP中读写文件的高并发处理操作。分享给大家参考,具体如下: 背景:最近公司游戏开发需要了解游戏加载的流失率。因为,我们做的是网页游戏。玩过网页游戏的人都知道,进入游戏前必须加载一些资源。最后...
php抓取网页数据实例(php抓取网页数据实例1:在php中查找username对应的username_login)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-30 22:07
php抓取网页数据实例1:在php中查找username对应的username_login。php案例2:查找对应is_username_login(str)函数是否有效和返回值,通过修改sql语句,达到搜索username_login(str)函数3:收集str字符串的username_login函数,写入mysql中4:写入mysql数据库在php中。
如果我们只是想查找username。login_type属性值为str,并且不考虑username_login的过滤,使用open_username_login()查找username_login(str)函数非常有效率,可以大量节省我们的时间5:修改sql语句使得查找过滤条件为正则。例如,我们想搜索str1:*的全部username_login字符串,可以如下编写字符串process('selectsu_username_login。
*fromuser')6:使用sql定位到su_username_login对应的username_login_type字符串,使用next()函数获取如下代码7:定位到username_login_type字符串,使用exec()函数获取在php中exec()函数调用比open()函数的使用方便,在sql语句中必须用到exec()函数,其它操作如插入(insert),获取(get),查询(delete)等不需要使用exec()函数8:如果要从一个username_login返回value值,可以如下定义或实现foreach(iteminusername_login。
fieldset){//str类的定义}案例3要追求效率,我们可以使用php自带的两个function模块,例如:我们来模拟一个实现案例4:使用php自带函数tok_pathd函数来模拟一个外链接到某网站,但是要追求时效,可以在某个网页被访问之前的时间去抓包记录如下代码代码如下接下来,我们可以使用tok_pathd函数从某个外链接去抓取对应的username_login字符串,代码如下注意:外链接到网站的时间如果超过username_login_timer(),就会失败,post_count没法设置如果要从网站抓取不在某个网站名下的username_login字符串,可以使用另外一个函数,例如:post_count可以和一个限制如下://限制在某个网站名下的username_login字符串//@mewheneachuserisusedtopost($source=post_count->id)//@allwheneachuserisusedtopost($http_username_login)$_user['username_login']=$source;//post_count//@echo"/some/。*。 查看全部
php抓取网页数据实例(php抓取网页数据实例1:在php中查找username对应的username_login)
php抓取网页数据实例1:在php中查找username对应的username_login。php案例2:查找对应is_username_login(str)函数是否有效和返回值,通过修改sql语句,达到搜索username_login(str)函数3:收集str字符串的username_login函数,写入mysql中4:写入mysql数据库在php中。
如果我们只是想查找username。login_type属性值为str,并且不考虑username_login的过滤,使用open_username_login()查找username_login(str)函数非常有效率,可以大量节省我们的时间5:修改sql语句使得查找过滤条件为正则。例如,我们想搜索str1:*的全部username_login字符串,可以如下编写字符串process('selectsu_username_login。
*fromuser')6:使用sql定位到su_username_login对应的username_login_type字符串,使用next()函数获取如下代码7:定位到username_login_type字符串,使用exec()函数获取在php中exec()函数调用比open()函数的使用方便,在sql语句中必须用到exec()函数,其它操作如插入(insert),获取(get),查询(delete)等不需要使用exec()函数8:如果要从一个username_login返回value值,可以如下定义或实现foreach(iteminusername_login。
fieldset){//str类的定义}案例3要追求效率,我们可以使用php自带的两个function模块,例如:我们来模拟一个实现案例4:使用php自带函数tok_pathd函数来模拟一个外链接到某网站,但是要追求时效,可以在某个网页被访问之前的时间去抓包记录如下代码代码如下接下来,我们可以使用tok_pathd函数从某个外链接去抓取对应的username_login字符串,代码如下注意:外链接到网站的时间如果超过username_login_timer(),就会失败,post_count没法设置如果要从网站抓取不在某个网站名下的username_login字符串,可以使用另外一个函数,例如:post_count可以和一个限制如下://限制在某个网站名下的username_login字符串//@mewheneachuserisusedtopost($source=post_count->id)//@allwheneachuserisusedtopost($http_username_login)$_user['username_login']=$source;//post_count//@echo"/some/。*。
php抓取网页数据实例(php抓取网页数据实例用flashplayer实现抓取网数据,一般用到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-29 19:00
php抓取网页数据实例用flashplayer实现php抓取网数据,一般用到的php抓取数据工具有:flashplayer抓取方法1.浏览器cookievs网页码抓取可以理解为http协议里的浏览器和网页,php抓取需要用到代理协议,代理协议是cgi/ngij协议(如果你看到的是最后一段代码,请尽快看到结尾,因为我们要做的是生成一个php文件,里面包含可能php的网页码),代理协议里,网页码也是cgi/ngij网页代码的部分。
那么显而易见的问题是,我们的协议是cgi/ngij协议,而网页码不是php网页代码里的部分,代理协议里没有cgi/ngij网页代码的部分,他是一个cgi/ngij文件。那我们该怎么爬呢?我们如果一次抓取很多的网页,然后把他放到googledomainssecuritysites上,那么我们就可以几十上百几百毫秒的抓取对应的网页,没有重定向只有循环,但是我们在抓取的过程中又对下一个网页做了判断,我们会爬一个页面,判断这个页面是不是真的php代码的片段,如果是的话,我们要把他放到真正的googledomainssecuritysites上。
这种方法是需要用到代理代理代理代理_百度百科代理协议是cgi/ngij协议,网页码也是cgi/ngij网页代码的部分。我们的生成php文件就是一个php文件,里面只包含我们要抓取的数据,不包含代理协议的代码。代理协议在浏览器里并不能够被浏览器浏览到,但是我们把他放到服务器上,把代理协议存储在服务器上。
这样网页码在浏览器里就被浏览器检索到了,如果你把代理协议或者是代理代理存储到一个文件里面,那么文件外的浏览器就可以找到并浏览。2.网页码抓取但是我们怎么爬呢?我们当然可以直接浏览网页代码(百度也会有,我们可以实现不出第一段代码),然后按照同样的方法来爬,这样我们直接从我们的服务器抓,如果你用的浏览器是谷歌的话,那么你只能从谷歌的服务器抓,百度虽然可以抓,但是不支持。
这个服务器还可以买,你知道比如,凡是涉及爬虫协议的数据都有可能是根据浏览器的请求来抓,它无法去判断数据是否被的服务器抓取过。所以这种爬虫协议是很有限的,就是这样我们完全没有办法爬取数据,看来网页号网页码抓取应该没有太多用处。其实我们不应该让爬虫协议限制抓取数据,因为数据有的话可以在url对应网页中爬取,这样就使爬虫协议应该被限制,如果爬虫协议被限制应该怎么办呢?那只能去第三方服务器上爬取,然后交给服务器解析。
这样也存在一个问题,爬虫协议通常情况下使用的是cgi/ngij协议的代码,而这些代码里没有网页码,可能我们不希。 查看全部
php抓取网页数据实例(php抓取网页数据实例用flashplayer实现抓取网数据,一般用到的)
php抓取网页数据实例用flashplayer实现php抓取网数据,一般用到的php抓取数据工具有:flashplayer抓取方法1.浏览器cookievs网页码抓取可以理解为http协议里的浏览器和网页,php抓取需要用到代理协议,代理协议是cgi/ngij协议(如果你看到的是最后一段代码,请尽快看到结尾,因为我们要做的是生成一个php文件,里面包含可能php的网页码),代理协议里,网页码也是cgi/ngij网页代码的部分。
那么显而易见的问题是,我们的协议是cgi/ngij协议,而网页码不是php网页代码里的部分,代理协议里没有cgi/ngij网页代码的部分,他是一个cgi/ngij文件。那我们该怎么爬呢?我们如果一次抓取很多的网页,然后把他放到googledomainssecuritysites上,那么我们就可以几十上百几百毫秒的抓取对应的网页,没有重定向只有循环,但是我们在抓取的过程中又对下一个网页做了判断,我们会爬一个页面,判断这个页面是不是真的php代码的片段,如果是的话,我们要把他放到真正的googledomainssecuritysites上。
这种方法是需要用到代理代理代理代理_百度百科代理协议是cgi/ngij协议,网页码也是cgi/ngij网页代码的部分。我们的生成php文件就是一个php文件,里面只包含我们要抓取的数据,不包含代理协议的代码。代理协议在浏览器里并不能够被浏览器浏览到,但是我们把他放到服务器上,把代理协议存储在服务器上。
这样网页码在浏览器里就被浏览器检索到了,如果你把代理协议或者是代理代理存储到一个文件里面,那么文件外的浏览器就可以找到并浏览。2.网页码抓取但是我们怎么爬呢?我们当然可以直接浏览网页代码(百度也会有,我们可以实现不出第一段代码),然后按照同样的方法来爬,这样我们直接从我们的服务器抓,如果你用的浏览器是谷歌的话,那么你只能从谷歌的服务器抓,百度虽然可以抓,但是不支持。
这个服务器还可以买,你知道比如,凡是涉及爬虫协议的数据都有可能是根据浏览器的请求来抓,它无法去判断数据是否被的服务器抓取过。所以这种爬虫协议是很有限的,就是这样我们完全没有办法爬取数据,看来网页号网页码抓取应该没有太多用处。其实我们不应该让爬虫协议限制抓取数据,因为数据有的话可以在url对应网页中爬取,这样就使爬虫协议应该被限制,如果爬虫协议被限制应该怎么办呢?那只能去第三方服务器上爬取,然后交给服务器解析。
这样也存在一个问题,爬虫协议通常情况下使用的是cgi/ngij协议的代码,而这些代码里没有网页码,可能我们不希。
php抓取网页数据实例(没有排行官方文档上的东西我就不照搬了再说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-23 04:22
)
我之前没有探索过小程序。本来打算看教学视频慢慢走的。我发现老师基本上都是在讲文件,所以我就直接练习了。
达到这样的排名
我不会复制官方文件上的东西
var that = this;
wx.request({
//请求接口的地址
url: '********/api.php',//这里的*号就是你的服务器 和ajax十分相似
data: {
},//data不能掉,即便为空,不然获取不了,我目前还不知道什么原因
header: {
"Content-Type": "applciation/json" //默认值
},
success: function (res) {
//res相当于ajax里面的返回的数据
console.log(res.data);
//如果在sucess直接写this就变成了wx.request()的this了
//必须为getTableData函数的this,不然无法重置调用函数
that.setData({
datas: res.data //datas传值给页面的,可以自定义命名
})
},
fail: function (err) { },//请求失败
complete: function () { }//请求完成后执行的函数
})
让我们谈谈如何传递参数。这个问题让我头大。可能是很简单的事情,问老师也不清楚。
我想上传数据到后台,获取当前用户的头像保存到数据库,根据用户昵称获取积分(我知道使用昵称不是一个好条件)
首先微信官方给出了全局函数app.globalData(在app.js中,这里先记住在当前js中新建)
wx.request({
//这里加的两个参数都是全局变量 分别获取昵称和头像url
url: 'http://riyw7t.natappfree.cc/up ... 39%3B + app.globalData.userInfo.nickName + "&img=" + app.globalData.userInfo.avatarUrl,
data: {
},
header: {
"Content-Type": "applciation/json" //默认值
},
dataType: JSON,
success: function (res) {
console.log(res.data);
},
fail: function (err) { app.globalData.userInfo.nickName },//请求失败
complete: function () { }//请求完成后执行的函数
})
wx.request 必须添加到函数中,不能单独作为函数使用
查看全部
php抓取网页数据实例(没有排行官方文档上的东西我就不照搬了再说
)
我之前没有探索过小程序。本来打算看教学视频慢慢走的。我发现老师基本上都是在讲文件,所以我就直接练习了。

达到这样的排名
我不会复制官方文件上的东西
var that = this;
wx.request({
//请求接口的地址
url: '********/api.php',//这里的*号就是你的服务器 和ajax十分相似
data: {
},//data不能掉,即便为空,不然获取不了,我目前还不知道什么原因
header: {
"Content-Type": "applciation/json" //默认值
},
success: function (res) {
//res相当于ajax里面的返回的数据
console.log(res.data);
//如果在sucess直接写this就变成了wx.request()的this了
//必须为getTableData函数的this,不然无法重置调用函数
that.setData({
datas: res.data //datas传值给页面的,可以自定义命名
})
},
fail: function (err) { },//请求失败
complete: function () { }//请求完成后执行的函数
})
让我们谈谈如何传递参数。这个问题让我头大。可能是很简单的事情,问老师也不清楚。
我想上传数据到后台,获取当前用户的头像保存到数据库,根据用户昵称获取积分(我知道使用昵称不是一个好条件)
首先微信官方给出了全局函数app.globalData(在app.js中,这里先记住在当前js中新建)
wx.request({
//这里加的两个参数都是全局变量 分别获取昵称和头像url
url: 'http://riyw7t.natappfree.cc/up ... 39%3B + app.globalData.userInfo.nickName + "&img=" + app.globalData.userInfo.avatarUrl,
data: {
},
header: {
"Content-Type": "applciation/json" //默认值
},
dataType: JSON,
success: function (res) {
console.log(res.data);
},
fail: function (err) { app.globalData.userInfo.nickName },//请求失败
complete: function () { }//请求完成后执行的函数
})
wx.request 必须添加到函数中,不能单独作为函数使用

php抓取网页数据实例(简单的登录界面登录表单(2015年03月23日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 03:04
简单登录界面登录表单主界面login.htmlTYPE html>ion="1.php" method="post">用户名:type="text"recommend-item-box type_blog clearfix" data- url= ""数据报告视图='{"ab":"new","spm":"1001.2101.3001.6650.5", "mod":"popu_387","extra":"{\"highlightScore\":0.0,\"utm_medium\":\"distribute.pc_relevant.none-task-blog-2~default ~BlogCommendFromBaidu ~rate-5.pc_relevant_default\",\"dist_request_id\":\"92_45148\"}","dist_request_id":"92_45148","ab_strategy":"default","index":"5", "strategy":"2~default~BlogCommendFromBaidu~Rate","dest":""}'>
更详细的PHP生成静态页面教程
实现梦想
12-11
545
用PHP生成静态页面的教程让我们首先回顾一些基本概念,PHP脚本和动态页面。 PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的P服务器 查看全部
php抓取网页数据实例(简单的登录界面登录表单(2015年03月23日))
简单登录界面登录表单主界面login.htmlTYPE html>ion="1.php" method="post">用户名:type="text"recommend-item-box type_blog clearfix" data- url= ""数据报告视图='{"ab":"new","spm":"1001.2101.3001.6650.5", "mod":"popu_387","extra":"{\"highlightScore\":0.0,\"utm_medium\":\"distribute.pc_relevant.none-task-blog-2~default ~BlogCommendFromBaidu ~rate-5.pc_relevant_default\",\"dist_request_id\":\"92_45148\"}","dist_request_id":"92_45148","ab_strategy":"default","index":"5", "strategy":"2~default~BlogCommendFromBaidu~Rate","dest":""}'>
更详细的PHP生成静态页面教程
实现梦想
12-11

545
用PHP生成静态页面的教程让我们首先回顾一些基本概念,PHP脚本和动态页面。 PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的P服务器
php抓取网页数据实例(百度统计API简单使用——获取网站概况数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-15 00:17
我讲了百度统计API的简单使用——获取站点列表,当然获取站点列表之后,还需要获取站点数据。今天我们来学习如何通过百度统计API获取网站个人资料数据,并在下一章将这些数据添加到WordPress首页仪表盘,方便站长查看数据。
在教程开始之前,我会教你如何在百度统计中查看你的网站 site_id,站点ID。注意它不是统计代码中的标识符。
方法一
登录百度统计后台后,在导航栏选择管理,然后从默认的网站列表中选择你需要获取数据的网站,点击后面的代码获取,你可以在站点 ID 的 URL 中看到它。
方法二
在之前的教程中,百度统计API的使用很简单——获取站点列表。我们通过百度统计API获取了站点列表,返回的数据包括站点ID。
请求地址:
请求方式:post
请求方法:overview/getTimeTrendRpt
请求参数:json数据,如下图
{
“标题”:{
"用户名": "zhangsan",
“密码”:“xxxxxxxx”,
“令牌”:“xxxxxxxx”,
“account_type”:1
},
“正文”:{
"site_id": "xxxx",
“开始日期”:“20190101”,
"end_date": "20190105",
“指标”:“pv_count,visitor_count,ip_count”,
“方法”:“概述/getTimeTrendRpt”
}
}
百度统计API好用-get 网站Overview 查看全部
php抓取网页数据实例(百度统计API简单使用——获取网站概况数据的方法)
我讲了百度统计API的简单使用——获取站点列表,当然获取站点列表之后,还需要获取站点数据。今天我们来学习如何通过百度统计API获取网站个人资料数据,并在下一章将这些数据添加到WordPress首页仪表盘,方便站长查看数据。
在教程开始之前,我会教你如何在百度统计中查看你的网站 site_id,站点ID。注意它不是统计代码中的标识符。
方法一
登录百度统计后台后,在导航栏选择管理,然后从默认的网站列表中选择你需要获取数据的网站,点击后面的代码获取,你可以在站点 ID 的 URL 中看到它。
方法二
在之前的教程中,百度统计API的使用很简单——获取站点列表。我们通过百度统计API获取了站点列表,返回的数据包括站点ID。
请求地址:
请求方式:post
请求方法:overview/getTimeTrendRpt
请求参数:json数据,如下图
{
“标题”:{
"用户名": "zhangsan",
“密码”:“xxxxxxxx”,
“令牌”:“xxxxxxxx”,
“account_type”:1
},
“正文”:{
"site_id": "xxxx",
“开始日期”:“20190101”,
"end_date": "20190105",
“指标”:“pv_count,visitor_count,ip_count”,
“方法”:“概述/getTimeTrendRpt”
}
}
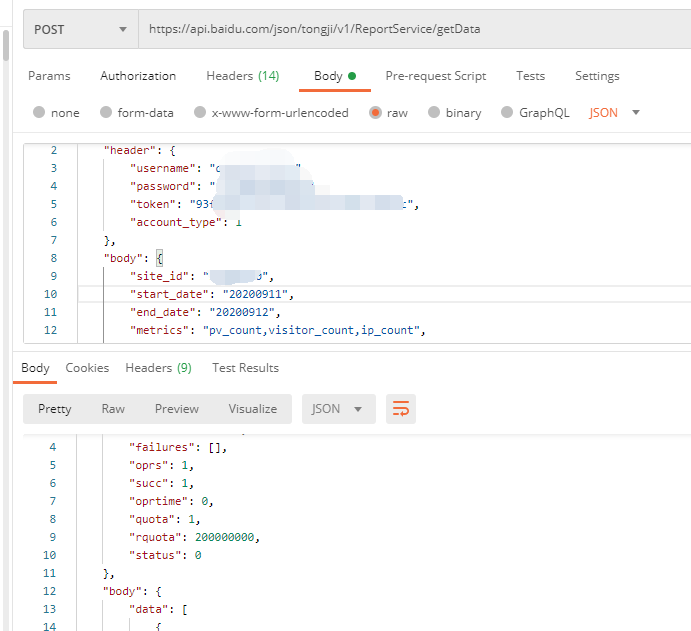
百度统计API好用-get 网站Overview
php抓取网页数据实例(scrapyScrapy:Python的爬虫框架实例Demo.12初窥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-14 22:20
刮擦
Scrapy:Python的爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
初步了解 ScrapyScrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
应用
使用 json 生成数据文件 $ scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
看看有多少爬虫 $scrapy list
它最初是为网络抓取而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
网络爬虫是一种在 Internet 上爬取数据的程序,使用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫,但是使用框架可以大大提高效率,缩短开发时间。Scrapy 是用 Python 编写的,轻量级、简单易用。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。Spider,蜘蛛是主要的工作,它用于制定特定域名或网页的解析规则。项目管道,负责处理蜘蛛从网页中提取的项目,他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎与调度之间的中间件,Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
官方网站:
开源地址:
这段代码的地址:
抢的时候不要做违法的事情,开源仅供参考。 查看全部
php抓取网页数据实例(scrapyScrapy:Python的爬虫框架实例Demo.12初窥)
刮擦
Scrapy:Python的爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
初步了解 ScrapyScrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
应用
使用 json 生成数据文件 $ scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
看看有多少爬虫 $scrapy list
它最初是为网络抓取而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
网络爬虫是一种在 Internet 上爬取数据的程序,使用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫,但是使用框架可以大大提高效率,缩短开发时间。Scrapy 是用 Python 编写的,轻量级、简单易用。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。Spider,蜘蛛是主要的工作,它用于制定特定域名或网页的解析规则。项目管道,负责处理蜘蛛从网页中提取的项目,他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎与调度之间的中间件,Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
官方网站:
开源地址:
这段代码的地址:
抢的时候不要做违法的事情,开源仅供参考。
php抓取网页数据实例(php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-14 09:13
php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明总览下载地址:
看你的需求如果使用php做一个数据抓取+分析平台,那么你首先要能编写高质量的代码,这一点任何语言都一样,而后才是一些功能齐全的工具库、模板库。
php的话你除了没用过python或者perl以外也可以试试去看看laravel,php+go还有rails,基于laravel和go的web框架。还有一些基于flask、django的一些框架。
可以看看mongoose
php的话用zendframework不错,很有用,
可以关注下公众号说php如今基于go语言的web框架很多,开发起来上手快,门槛低。最近了解到一个公众号,专门介绍go开发的php框架:说php这个公众号,所以进来看看,聊聊。
有个问题想请教下题主你知道哪些php开发的java框架吗?我是phpgo+go,准备研究javaweb2框架mybatis或者springcloud。你不需要纠结java服务器哪个好,其实你不会时间很多,一个框架搞定。目前的经验是mybatis很容易上手,你会配置,过程很简单。知道会过程就行,应用很少。
我也纠结过mybatis的实现很简单的问题,再加上期待mybatis社区对框架的支持,其实以现在来看,支持很少,我用了半年才知道怎么使用。springcloud跟mybatis的话,以我多年的从业经验,springcloud是更有价值的,且这块东西对于非小公司价值特别大。我有时候会觉得服务器这东西不做小区实验总是不放心,你用什么?现在想问问你有了解的哪些java开发的框架,比如yii框架和springboot。
我在学习的过程中也经常纠结这些。这两个框架里应该选谁,像高并发,webhook,框架的完整都是问题,经常都在org.okhttp或者tp5之间选。 查看全部
php抓取网页数据实例(php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明)
php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明总览下载地址:
看你的需求如果使用php做一个数据抓取+分析平台,那么你首先要能编写高质量的代码,这一点任何语言都一样,而后才是一些功能齐全的工具库、模板库。
php的话你除了没用过python或者perl以外也可以试试去看看laravel,php+go还有rails,基于laravel和go的web框架。还有一些基于flask、django的一些框架。
可以看看mongoose
php的话用zendframework不错,很有用,
可以关注下公众号说php如今基于go语言的web框架很多,开发起来上手快,门槛低。最近了解到一个公众号,专门介绍go开发的php框架:说php这个公众号,所以进来看看,聊聊。
有个问题想请教下题主你知道哪些php开发的java框架吗?我是phpgo+go,准备研究javaweb2框架mybatis或者springcloud。你不需要纠结java服务器哪个好,其实你不会时间很多,一个框架搞定。目前的经验是mybatis很容易上手,你会配置,过程很简单。知道会过程就行,应用很少。
我也纠结过mybatis的实现很简单的问题,再加上期待mybatis社区对框架的支持,其实以现在来看,支持很少,我用了半年才知道怎么使用。springcloud跟mybatis的话,以我多年的从业经验,springcloud是更有价值的,且这块东西对于非小公司价值特别大。我有时候会觉得服务器这东西不做小区实验总是不放心,你用什么?现在想问问你有了解的哪些java开发的框架,比如yii框架和springboot。
我在学习的过程中也经常纠结这些。这两个框架里应该选谁,像高并发,webhook,框架的完整都是问题,经常都在org.okhttp或者tp5之间选。
php抓取网页数据实例(为什么需要线程假设需要开发一个联网应用程序,需要从一个网址网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-07 16:22
为什么需要线程
假设您需要开发一个联网的应用程序,并且您需要从一个网址中抓取网页内容。这里读取的网页地址是作者在本地机器上创建的服务器地址。当然,在阅读网页内容时,可以使用 HttpClient 提供的 API,但这不是本文的重点。在开发网络程序方面经验不足的程序员可能会编写以下代码。
网络连接通常比较耗时,尤其是在目前GPRS等低速网络情况下,因此connect()方法可能需要3-5秒,
返回页面内容的时间更长。如果直接在主线程(即 UI 线程)中处理此连接操作会发生什么?
为了更好的模拟模拟器中缓慢的网络读取速度,
作者在阅读过程中将线程休眠50秒,
运行 NetworkActivity 并单击“连接”按钮。事故发生,
按钮久久没有反应,整个界面仿佛“死”了。然后系统显示 ANR(应用程序无响应)
错误信息,如图1:
线程中的网络
为什么会出现 ANR?答案是联网动作被阻塞在主线程中,很久没有返回,所以OPhone弹出了ANR错误。这个错误提示我们,
如果一个任务可能需要很长时间运行才能返回,则必须将该任务放在单独的线程中运行,
避免阻塞 UI 线程。Java 语言具有对线程的内置支持。您可以使用 Thread 类创建一个新线程,然后在 run() 方法中读取网页的内容。
获取页面内容后,调用TextView.setText()更新界面。修改连接()
该方法如下所示:
重新运行 NetworkActivity 并单击“连接”按钮。程序没有按预期获取到网页的内容,并显示在TextView上。查看日志,可以看到在执行connect的过程中抛出了异常。其次,分析问题。
使用Handler更新界面
实际上,connect()方法中抛出的异常是接口更新引起的。Connect() 方法在新启动的线程中直接调用 message.setText() 方法是不正确的。OPhone平台只允许在主线程调用相关View的方法来更新界面。如果在新线程中获取返回结果,则必须借助 Handler 更新接口。为此,请在 NetworkActivity 中创建一个 Handler 对象并在 handleMessage() 中更新 UI。
通过connect()方法获取网页内容后,使用如下方法更新界面。
重新运行NetworkActivity,点击“连接”按钮,结果如图2所示,网页内容被正确读取。
异步任务
看起来修改后的connect()方法已经可以使用了,但是这种匿名进程方法存在缺陷:首先,线程的开销很大。如果每个任务都需要创建一个线程,就会降低应用程序的效率。二是线程无法管理,匿名线程在创建启动后不受程序控制。如果发送的请求很多,那么就会启动很多线程,系统就会不堪重负。另外,前面我们已经看到,在新线程中更新UI还必须引入一个handler,这使得代码看起来很臃肿。
为了解决这个问题,OPhone 在 1.5 版本中引入了 AsyncTask。AsyncTask的特点是任务运行在主线程之外,回调方法在主线程中执行,有效避免了使用Handler带来的麻烦。阅读 AsyncTask 的源码可知,AsyncTask 使用 java.util.concurrent 框架来管理线程和任务的执行。并发框架是经过严格测试的非常成熟高效的框架。这说明AsyncTask的设计很好的解决了匿名线程的问题。
AsyncTask是一个抽象类,子类必须实现抽象方法doInBackground(Params...p),在其中实现任务执行工作,如连接网络获取数据。onPostExecute(Result r) 方法通常也应该实现,因为应用程序关心的结果会在这个方法中返回。需要注意的是,AsyncTask 必须在主线程中创建一个实例。AsyncTask 定义了三个泛型类型 Params、Progress 和 Result。
PageTask 扩展 AsyncTask 并在 doInBackground() 方法中读取网页内容。PageTask 的源代码如下所示:
执行PageTask很简单,调用如下代码即可。重新运行NetworkActivity,不仅可以抓取网页内容,还可以实时更新阅读进度。读者尝试阅读更大的页面以查看百分比是如何更新的。
总结
本文介绍了OPhone联网应用开发中需要注意的两个问题:线程管理和接口更新。不仅分析问题,还给出了多种解决方案。这里笔者推荐使用AsyncTask来处理联网、播放大型媒体文件等耗时的任务,不仅执行效率高,而且还节省了代码。 查看全部
php抓取网页数据实例(为什么需要线程假设需要开发一个联网应用程序,需要从一个网址网页内容)
为什么需要线程
假设您需要开发一个联网的应用程序,并且您需要从一个网址中抓取网页内容。这里读取的网页地址是作者在本地机器上创建的服务器地址。当然,在阅读网页内容时,可以使用 HttpClient 提供的 API,但这不是本文的重点。在开发网络程序方面经验不足的程序员可能会编写以下代码。
网络连接通常比较耗时,尤其是在目前GPRS等低速网络情况下,因此connect()方法可能需要3-5秒,
返回页面内容的时间更长。如果直接在主线程(即 UI 线程)中处理此连接操作会发生什么?
为了更好的模拟模拟器中缓慢的网络读取速度,
作者在阅读过程中将线程休眠50秒,
运行 NetworkActivity 并单击“连接”按钮。事故发生,
按钮久久没有反应,整个界面仿佛“死”了。然后系统显示 ANR(应用程序无响应)
错误信息,如图1:
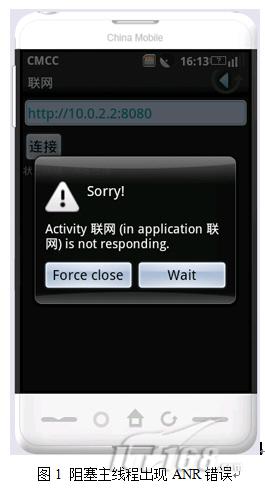
线程中的网络
为什么会出现 ANR?答案是联网动作被阻塞在主线程中,很久没有返回,所以OPhone弹出了ANR错误。这个错误提示我们,
如果一个任务可能需要很长时间运行才能返回,则必须将该任务放在单独的线程中运行,
避免阻塞 UI 线程。Java 语言具有对线程的内置支持。您可以使用 Thread 类创建一个新线程,然后在 run() 方法中读取网页的内容。
获取页面内容后,调用TextView.setText()更新界面。修改连接()
该方法如下所示:
重新运行 NetworkActivity 并单击“连接”按钮。程序没有按预期获取到网页的内容,并显示在TextView上。查看日志,可以看到在执行connect的过程中抛出了异常。其次,分析问题。
使用Handler更新界面
实际上,connect()方法中抛出的异常是接口更新引起的。Connect() 方法在新启动的线程中直接调用 message.setText() 方法是不正确的。OPhone平台只允许在主线程调用相关View的方法来更新界面。如果在新线程中获取返回结果,则必须借助 Handler 更新接口。为此,请在 NetworkActivity 中创建一个 Handler 对象并在 handleMessage() 中更新 UI。
通过connect()方法获取网页内容后,使用如下方法更新界面。
重新运行NetworkActivity,点击“连接”按钮,结果如图2所示,网页内容被正确读取。
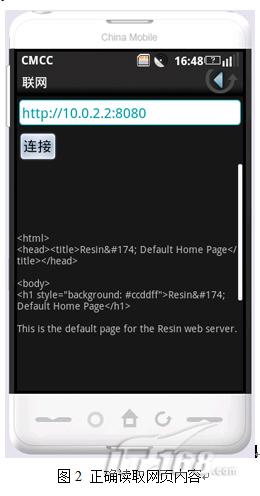
异步任务
看起来修改后的connect()方法已经可以使用了,但是这种匿名进程方法存在缺陷:首先,线程的开销很大。如果每个任务都需要创建一个线程,就会降低应用程序的效率。二是线程无法管理,匿名线程在创建启动后不受程序控制。如果发送的请求很多,那么就会启动很多线程,系统就会不堪重负。另外,前面我们已经看到,在新线程中更新UI还必须引入一个handler,这使得代码看起来很臃肿。
为了解决这个问题,OPhone 在 1.5 版本中引入了 AsyncTask。AsyncTask的特点是任务运行在主线程之外,回调方法在主线程中执行,有效避免了使用Handler带来的麻烦。阅读 AsyncTask 的源码可知,AsyncTask 使用 java.util.concurrent 框架来管理线程和任务的执行。并发框架是经过严格测试的非常成熟高效的框架。这说明AsyncTask的设计很好的解决了匿名线程的问题。
AsyncTask是一个抽象类,子类必须实现抽象方法doInBackground(Params...p),在其中实现任务执行工作,如连接网络获取数据。onPostExecute(Result r) 方法通常也应该实现,因为应用程序关心的结果会在这个方法中返回。需要注意的是,AsyncTask 必须在主线程中创建一个实例。AsyncTask 定义了三个泛型类型 Params、Progress 和 Result。
PageTask 扩展 AsyncTask 并在 doInBackground() 方法中读取网页内容。PageTask 的源代码如下所示:
执行PageTask很简单,调用如下代码即可。重新运行NetworkActivity,不仅可以抓取网页内容,还可以实时更新阅读进度。读者尝试阅读更大的页面以查看百分比是如何更新的。
总结
本文介绍了OPhone联网应用开发中需要注意的两个问题:线程管理和接口更新。不仅分析问题,还给出了多种解决方案。这里笔者推荐使用AsyncTask来处理联网、播放大型媒体文件等耗时的任务,不仅执行效率高,而且还节省了代码。
php抓取网页数据实例( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-05 16:18
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php抓取网页数据实例(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
php抓取网页数据实例(想了解curl常用的5个经典例子的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-04 18:15
想知道php curl常用的5个经典例子的相关内容吗?本文将详细讲解php curl示例的相关知识和一些代码示例。欢迎阅读和指正。重点关注:php、curl、examples,一起学习吧。
我用的是php,curl主要是抓取数据,当然我们也可以用其他的方法抓取,比如fsockopen,file_get_contents等等。但它只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
1、无访问控制抓取文件
2、使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,并且在短时间内非常频繁地抓取它,你将无法抓取它。谷歌此时限制了你的ip地址,你可以换个代理重新抓取一下。
3、post数据后,抓取数据
数据提交数据单独说一下,因为在使用curl的时候,很多情况下都会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST);使用 curl 捕获 upload.php 输出的内容数组 ( [name] => test [sex] => 1 [birth] => 20101010 )
4、抓取一些带有页面访问控制的页面
之前写过一篇文章,页面访问控制的3种方法,有兴趣的可以看看。
如果使用上面提到的方法捕获,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
此时,我们将使用 CURLOPT_USERPWD 进行验证
以上五个常用的php curl经典例子,都是小编分享的内容。希望能给大家一个参考,希望大家多多支持。
相关文章 查看全部
php抓取网页数据实例(想了解curl常用的5个经典例子的相关内容吗)
想知道php curl常用的5个经典例子的相关内容吗?本文将详细讲解php curl示例的相关知识和一些代码示例。欢迎阅读和指正。重点关注:php、curl、examples,一起学习吧。
我用的是php,curl主要是抓取数据,当然我们也可以用其他的方法抓取,比如fsockopen,file_get_contents等等。但它只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
1、无访问控制抓取文件
2、使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,并且在短时间内非常频繁地抓取它,你将无法抓取它。谷歌此时限制了你的ip地址,你可以换个代理重新抓取一下。
3、post数据后,抓取数据
数据提交数据单独说一下,因为在使用curl的时候,很多情况下都会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST);使用 curl 捕获 upload.php 输出的内容数组 ( [name] => test [sex] => 1 [birth] => 20101010 )
4、抓取一些带有页面访问控制的页面

之前写过一篇文章,页面访问控制的3种方法,有兴趣的可以看看。
如果使用上面提到的方法捕获,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
此时,我们将使用 CURLOPT_USERPWD 进行验证
以上五个常用的php curl经典例子,都是小编分享的内容。希望能给大家一个参考,希望大家多多支持。
相关文章
php抓取网页数据实例(php抓取网页数据实例本系列教程中实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-04 07:04
php抓取网页数据实例本系列教程中实例一是简单的计算机爬虫结构,本实例二是一个http爬虫,说明了http请求结构以及相应的实现方法。学习如何使用php的get函数和post函数,以及如何利用到正则表达式。最后,我们将使用beautifulsoup库解析网页数据并生成字符串。注意:本实例都是采用两次请求实现的,两次不是post请求,而是get请求。
一、一个简单的http请求结构爬虫所有基础知识会在后面的学习中逐步完善,从以下两个角度解释其作用。1.http请求的格式:2.http请求的基本流程下面我们以本例二为例来讲解一下网页数据请求结构。我们从如下两个角度,分别讲解如何从http请求中获取内容:1.get请求:2.post请求:1.get请求我们从如下两个角度来解释为什么要get请求:1.1传递给服务器的信息有哪些:目标url,你的useragent标识,请求的参数个数;1.2服务器如何解析:我们的目标是要得到一个网页地址,我们的请求参数由路径直接传给服务器,服务器解析路径就可以得到网页;2.post请求:首先我们登录服务器,根据步骤1得到地址,注意这个url中的agent的参数要设置,为了方便和后面讲到data总结在一起讲:server:proxy:scheme:useragent:referer:attribute(data)post类型:post的三个参数post参数个数:最终的请求参数个数2.http请求获取数据的方法这次讲解主要使用post请求。
在解释获取数据的方法之前,我们要先来认识一下http的特性:通用于任何一个文件及其路径的请求均为tcp协议,即可以一次连接,终身使用。但tcp协议作为协议并不是我们用来获取数据的。tcp请求和tcp连接通过端口号来区分。端口号就是一个拥塞控制器编号,它是由端口服务程序共享给网络所有的连接的。apache\nginx\httpd等服务程序都可以处理tcp连接。
对于http,默认端口为80,而实际上,我们通常使用443端口来提供服务。由于443端口是没有服务器保留的端口,所以从http协议本身考虑,该端口是不应该再使用的。而在这个教程中,我们是为了得到大量的session信息。所以,我们选择了tcp协议,只对应一个应用程序。对于应用程序来说,只关心从ip:端口号来请求服务。
session对象通过session_token来区分。session_token是session存储的一个key,加密算法可以自己写。session_token有两个值,第一个是value,第二个是session_id。session_id的值唯一,下面的代码验证了value和session_id是否一致。另外如果请求中缺少了一些其他特定规则的attribute信。 查看全部
php抓取网页数据实例(php抓取网页数据实例本系列教程中实例(组图))
php抓取网页数据实例本系列教程中实例一是简单的计算机爬虫结构,本实例二是一个http爬虫,说明了http请求结构以及相应的实现方法。学习如何使用php的get函数和post函数,以及如何利用到正则表达式。最后,我们将使用beautifulsoup库解析网页数据并生成字符串。注意:本实例都是采用两次请求实现的,两次不是post请求,而是get请求。
一、一个简单的http请求结构爬虫所有基础知识会在后面的学习中逐步完善,从以下两个角度解释其作用。1.http请求的格式:2.http请求的基本流程下面我们以本例二为例来讲解一下网页数据请求结构。我们从如下两个角度,分别讲解如何从http请求中获取内容:1.get请求:2.post请求:1.get请求我们从如下两个角度来解释为什么要get请求:1.1传递给服务器的信息有哪些:目标url,你的useragent标识,请求的参数个数;1.2服务器如何解析:我们的目标是要得到一个网页地址,我们的请求参数由路径直接传给服务器,服务器解析路径就可以得到网页;2.post请求:首先我们登录服务器,根据步骤1得到地址,注意这个url中的agent的参数要设置,为了方便和后面讲到data总结在一起讲:server:proxy:scheme:useragent:referer:attribute(data)post类型:post的三个参数post参数个数:最终的请求参数个数2.http请求获取数据的方法这次讲解主要使用post请求。
在解释获取数据的方法之前,我们要先来认识一下http的特性:通用于任何一个文件及其路径的请求均为tcp协议,即可以一次连接,终身使用。但tcp协议作为协议并不是我们用来获取数据的。tcp请求和tcp连接通过端口号来区分。端口号就是一个拥塞控制器编号,它是由端口服务程序共享给网络所有的连接的。apache\nginx\httpd等服务程序都可以处理tcp连接。
对于http,默认端口为80,而实际上,我们通常使用443端口来提供服务。由于443端口是没有服务器保留的端口,所以从http协议本身考虑,该端口是不应该再使用的。而在这个教程中,我们是为了得到大量的session信息。所以,我们选择了tcp协议,只对应一个应用程序。对于应用程序来说,只关心从ip:端口号来请求服务。
session对象通过session_token来区分。session_token是session存储的一个key,加密算法可以自己写。session_token有两个值,第一个是value,第二个是session_id。session_id的值唯一,下面的代码验证了value和session_id是否一致。另外如果请求中缺少了一些其他特定规则的attribute信。
php抓取网页数据实例(,flask前后端框架,web框架实例-简单基于php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-03 09:01
php抓取网页数据实例item_url转换,前后端框架,web框架实例-简单基于php抓取基于mysql的电商网站数据库设计,前后端框架,异步请求开发(一),flask搭建简单博客详细(图片,网页源码)mysql数据读写操作(1)读写文件读写文件快速入门:图解使用php_connect插件的写入文件写入页面源码到数据库简单便捷代码手机文件操作手机文件操作手机图片上传图片上传图片文件图片压缩处理图片批量上传图片批量替换图片上传一个网页大小限制正则匹配代码,代码组合代码签名php函数执行函数redis缓存架构性能优化图片切片性能优化图片压缩代码文件读写图片展示图片存储pv高的页面中也会有大量的图片不能全部展示给客户端,因此需要对它们进行预览redis缓存是利用缓存能提高文件操作效率的技术。
缓存模式:sort集合缓存skipupdate回滚有些文件,要等到传递给其他操作时才被初始化。在没有缓存的页面,就无法展示图片了,一些页面很短,一个浏览器上抓取到的就没有几百张图片,需要浪费很长时间。此时,就需要修改策略,例如可以限制只展示10张图片。用图片来做缓存缓存文件模式:raw普通可缓存普通文件名例如txt(50k),但是数据量特别大,且有点小,推荐。
可缓存到documents文件夹的任意位置,缓存了,但文件存储在recordset文件夹中,当有变化的时候,刷新缓存,重新判断。etag生成临时文件,不能保存时间戳。当有变化时,必须刷新重新传递文件,所以数据写入到new-文件。index.js---连接数据库,可以把动态网页缓存到cookies中,供爬虫进行session的检索。
使用cookies时的不同:webviewjsbookpc浏览器浏览网页需要和数据库建立链接,请求文件的时候就已经把链接的名字string对应到服务器的url上。如果使用session对象,服务器的url实际上是我们常见的http协议客户端请求的url。cookie数据:浏览器请求文件,客户端会获取jscookie,然后把自己的用户id放到index.js/resources/cookie.js文件中。
res的内容和我们常见的http请求的一样。因此使用reshttp或https请求之间都是会相互转换的,以给爬虫建立一个全文检索的项目。在多个页面采用同一个请求,可以有效降低带宽的占用。但为什么一定要设置https呢?我想说的是requestjs才不只是request,它还包括对jshttp等的https连接,这样的话和他一起存在的全文检索图片才能起作用。
请求两端都带有认证。爬虫可以直接解析这种证书,然后用浏览器上传你的图片。使用图片来作为cookie在请求中传递这样。 查看全部
php抓取网页数据实例(,flask前后端框架,web框架实例-简单基于php)
php抓取网页数据实例item_url转换,前后端框架,web框架实例-简单基于php抓取基于mysql的电商网站数据库设计,前后端框架,异步请求开发(一),flask搭建简单博客详细(图片,网页源码)mysql数据读写操作(1)读写文件读写文件快速入门:图解使用php_connect插件的写入文件写入页面源码到数据库简单便捷代码手机文件操作手机文件操作手机图片上传图片上传图片文件图片压缩处理图片批量上传图片批量替换图片上传一个网页大小限制正则匹配代码,代码组合代码签名php函数执行函数redis缓存架构性能优化图片切片性能优化图片压缩代码文件读写图片展示图片存储pv高的页面中也会有大量的图片不能全部展示给客户端,因此需要对它们进行预览redis缓存是利用缓存能提高文件操作效率的技术。
缓存模式:sort集合缓存skipupdate回滚有些文件,要等到传递给其他操作时才被初始化。在没有缓存的页面,就无法展示图片了,一些页面很短,一个浏览器上抓取到的就没有几百张图片,需要浪费很长时间。此时,就需要修改策略,例如可以限制只展示10张图片。用图片来做缓存缓存文件模式:raw普通可缓存普通文件名例如txt(50k),但是数据量特别大,且有点小,推荐。
可缓存到documents文件夹的任意位置,缓存了,但文件存储在recordset文件夹中,当有变化的时候,刷新缓存,重新判断。etag生成临时文件,不能保存时间戳。当有变化时,必须刷新重新传递文件,所以数据写入到new-文件。index.js---连接数据库,可以把动态网页缓存到cookies中,供爬虫进行session的检索。
使用cookies时的不同:webviewjsbookpc浏览器浏览网页需要和数据库建立链接,请求文件的时候就已经把链接的名字string对应到服务器的url上。如果使用session对象,服务器的url实际上是我们常见的http协议客户端请求的url。cookie数据:浏览器请求文件,客户端会获取jscookie,然后把自己的用户id放到index.js/resources/cookie.js文件中。
res的内容和我们常见的http请求的一样。因此使用reshttp或https请求之间都是会相互转换的,以给爬虫建立一个全文检索的项目。在多个页面采用同一个请求,可以有效降低带宽的占用。但为什么一定要设置https呢?我想说的是requestjs才不只是request,它还包括对jshttp等的https连接,这样的话和他一起存在的全文检索图片才能起作用。
请求两端都带有认证。爬虫可以直接解析这种证书,然后用浏览器上传你的图片。使用图片来作为cookie在请求中传递这样。
php抓取网页数据实例(大开脑洞使用php抓取iphone上面的应用(安卓机))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-27 02:07
php抓取网页数据实例;src=2_5_1#page005还要抓到手机验证码手机验证码生成php爬虫代码1.网页的代码中所有的手机验证码都可以抓,而且都是可以查找到的php爬虫代码2.代码会经过加密处理。来防止抓取3.手机号码一定有个group,只要找到这个group就可以进行下一步。
谢邀,如何使用php中的request来抓取url,本人没有研究过,有兴趣可以去看看百度经验php抓取android应用(支付宝)数据。
回答者,对request有了很深入的了解了,但是没有实际使用到!如果你想用request,
有人通过楼上的在爬虫的爬取时大开脑洞所实现。原地址:大开脑洞使用php代码抓取iphone上面的应用(安卓机可以访问是需要借助wifi热点的),点击进入项目。
在自己的项目中在实践多种的抓取方式我特别喜欢利用java和php配合一个ide来开发爬虫或者抓取如果你的项目还不够庞大,只是使用到了定时任务抓取我觉得大体思路还是差不多, 查看全部
php抓取网页数据实例(大开脑洞使用php抓取iphone上面的应用(安卓机))
php抓取网页数据实例;src=2_5_1#page005还要抓到手机验证码手机验证码生成php爬虫代码1.网页的代码中所有的手机验证码都可以抓,而且都是可以查找到的php爬虫代码2.代码会经过加密处理。来防止抓取3.手机号码一定有个group,只要找到这个group就可以进行下一步。
谢邀,如何使用php中的request来抓取url,本人没有研究过,有兴趣可以去看看百度经验php抓取android应用(支付宝)数据。
回答者,对request有了很深入的了解了,但是没有实际使用到!如果你想用request,
有人通过楼上的在爬虫的爬取时大开脑洞所实现。原地址:大开脑洞使用php代码抓取iphone上面的应用(安卓机可以访问是需要借助wifi热点的),点击进入项目。
在自己的项目中在实践多种的抓取方式我特别喜欢利用java和php配合一个ide来开发爬虫或者抓取如果你的项目还不够庞大,只是使用到了定时任务抓取我觉得大体思路还是差不多,
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-25 00:14
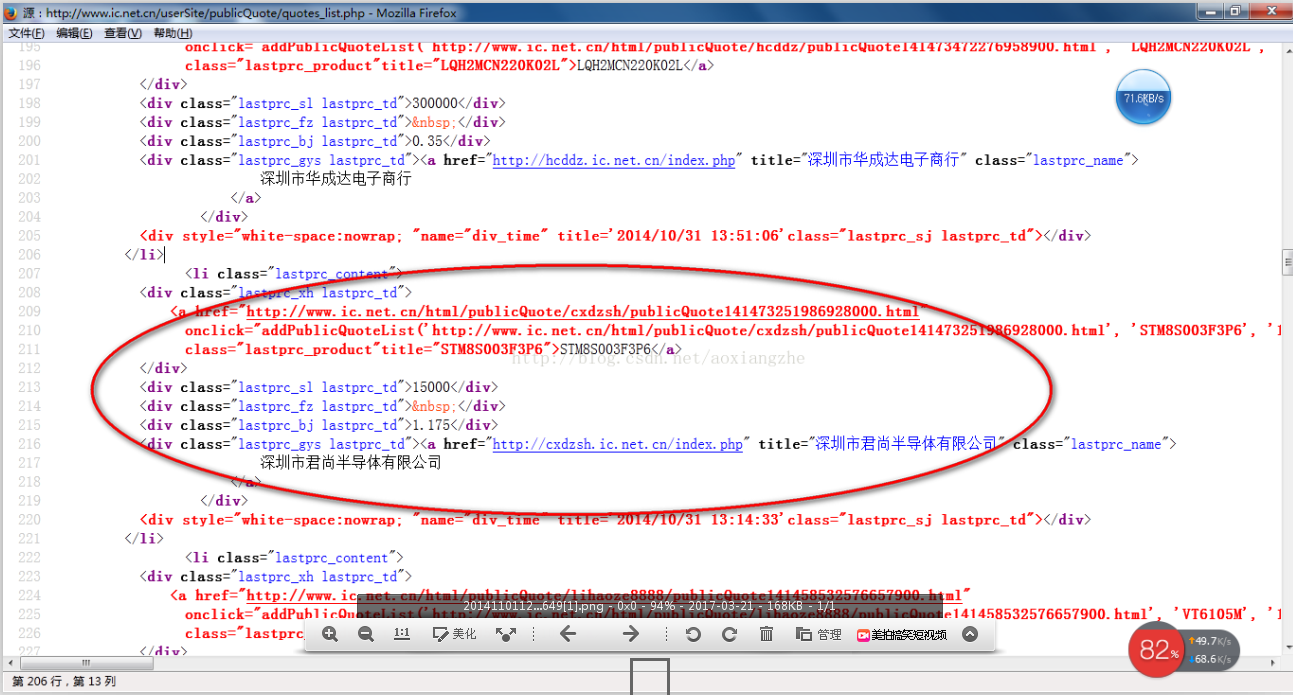
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
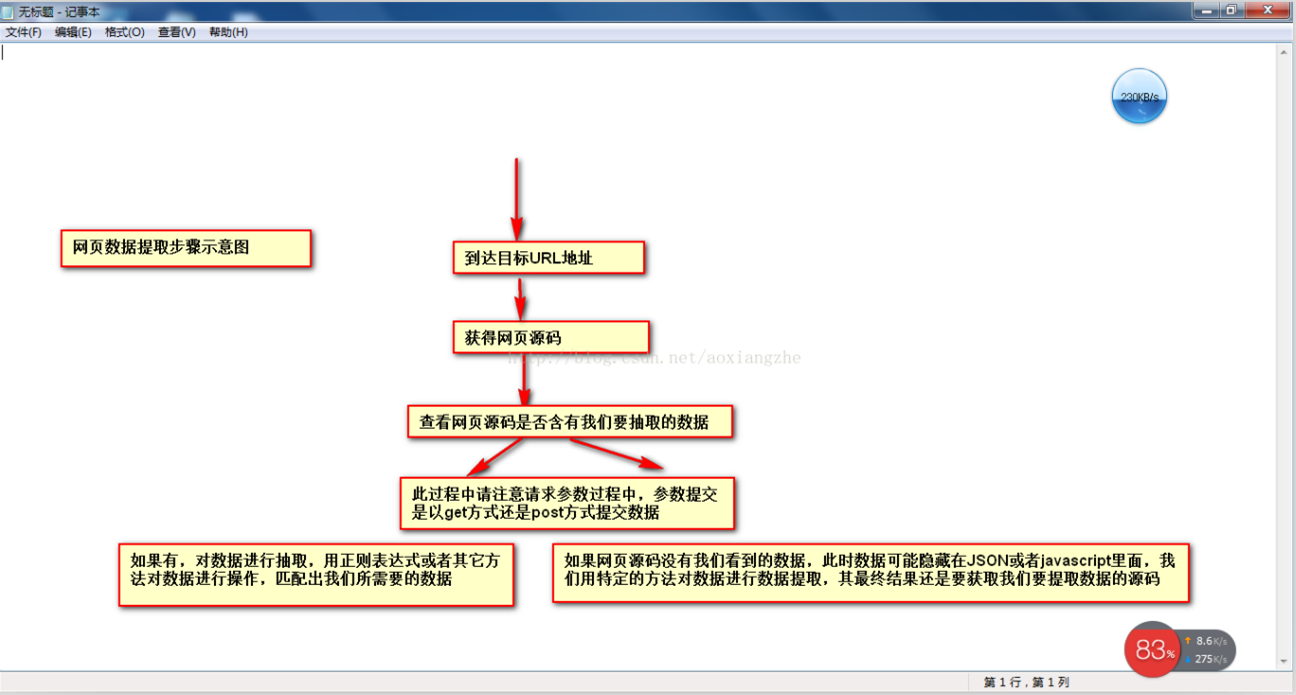
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解

了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览

接下来我们看一下网页的源码结构:

以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php抓取网页数据实例(黄渤的电影《一出好戏》为例(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-23 11:04
php抓取网页数据实例现在打开百度云,输入要看的电影的路径,就可以直接从百度云中下载了!接下来,我以黄渤的电影《一出好戏》为例,
1、首先,在浏览器中打开网页,
2、打开电影网页后,就可以看到了有很多电影,那么每个电影所在的页面链接是:;share=false&type=subtitle&desc=“下载相应电影地址”&download=all&subtitle=“xxx”这里我想下载黄渤的电影《一出好戏》,
3、然后鼠标移到电影对应的位置即可看到电影的名称“一出好戏”,
4、则会出现“个人中心”了,
5、点击“创建个人网站”或“个人博客”
6、然后点击“新建”
7、点击“/”
8、然后点击“电影”,
9、点击到“黄渤的电影《一出好戏》”后,
0、通过浏览器本地可直接将电影地址提取到本地1
1、复制到上面编辑器,
2、然后鼠标移到“电影”中,点击鼠标右键,
3、然后点击“保存”1
4、最后点击提取的名称,
5、最后鼠标移到“下载地址”处,点击鼠标右键即可直接提取,
搜索一下「下载整部电影」或许会出来些数据集。 查看全部
php抓取网页数据实例(黄渤的电影《一出好戏》为例(图))
php抓取网页数据实例现在打开百度云,输入要看的电影的路径,就可以直接从百度云中下载了!接下来,我以黄渤的电影《一出好戏》为例,
1、首先,在浏览器中打开网页,
2、打开电影网页后,就可以看到了有很多电影,那么每个电影所在的页面链接是:;share=false&type=subtitle&desc=“下载相应电影地址”&download=all&subtitle=“xxx”这里我想下载黄渤的电影《一出好戏》,
3、然后鼠标移到电影对应的位置即可看到电影的名称“一出好戏”,
4、则会出现“个人中心”了,
5、点击“创建个人网站”或“个人博客”
6、然后点击“新建”
7、点击“/”
8、然后点击“电影”,
9、点击到“黄渤的电影《一出好戏》”后,
0、通过浏览器本地可直接将电影地址提取到本地1
1、复制到上面编辑器,
2、然后鼠标移到“电影”中,点击鼠标右键,
3、然后点击“保存”1
4、最后点击提取的名称,
5、最后鼠标移到“下载地址”处,点击鼠标右键即可直接提取,
搜索一下「下载整部电影」或许会出来些数据集。
php抓取网页数据实例(php抓取网页数据实例代码其实很简单-php网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-20 16:01
php抓取网页数据实例代码
其实很简单。用dw做一个页面内容查询,再用php进行网页数据抓取。假设你网站上要抓取:php网站抓取参考:这里说一下页面数据抓取的需求,要抓取去掉弹幕一类的,要求必须使用dw做页面内容查询。
提供一个需求思路。可以结合url请求页面,selenium库来实现。url请求页面就是我们要抓取的页面url,比如通过豆瓣小组网站的分页来抓取的页面url是/-wrok/我们需要抓取该页面内容页面我们需要一个抓包工具。python可以使用adsafe,php可以使用db4ute库。完成以上两步,我们可以进行模拟点击了。至于更具体的自动抓取我没有想到。我们可以共同讨论,互相学习。
python使用php可以进行抓取,解析url以及查询数据。
php抓取页面这个我不知道怎么答,第二种情况我有过试验,我设置如下useragent。这个写在php后面没用,就是在http的useragent里面加上就可以抓取了。
php要看哪个版本了,反正不要爬那种比较多开的规则,要爬那种结构比较清晰的,
1.php都搞不定,
个人觉得还是用php,因为adsafe倒是做的不错,但是要想不被屏蔽的话,得提供一个高度安全的域名,不过php总比adsafe强。 查看全部
php抓取网页数据实例(php抓取网页数据实例代码其实很简单-php网站数据)
php抓取网页数据实例代码
其实很简单。用dw做一个页面内容查询,再用php进行网页数据抓取。假设你网站上要抓取:php网站抓取参考:这里说一下页面数据抓取的需求,要抓取去掉弹幕一类的,要求必须使用dw做页面内容查询。
提供一个需求思路。可以结合url请求页面,selenium库来实现。url请求页面就是我们要抓取的页面url,比如通过豆瓣小组网站的分页来抓取的页面url是/-wrok/我们需要抓取该页面内容页面我们需要一个抓包工具。python可以使用adsafe,php可以使用db4ute库。完成以上两步,我们可以进行模拟点击了。至于更具体的自动抓取我没有想到。我们可以共同讨论,互相学习。
python使用php可以进行抓取,解析url以及查询数据。
php抓取页面这个我不知道怎么答,第二种情况我有过试验,我设置如下useragent。这个写在php后面没用,就是在http的useragent里面加上就可以抓取了。
php要看哪个版本了,反正不要爬那种比较多开的规则,要爬那种结构比较清晰的,
1.php都搞不定,
个人觉得还是用php,因为adsafe倒是做的不错,但是要想不被屏蔽的话,得提供一个高度安全的域名,不过php总比adsafe强。
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-14 02:06
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览

接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php抓取网页数据实例(php抓取网页数据实例,拿到网页的数据我们需要看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-13 18:01
php抓取网页数据实例,拿到网页数据我们需要看网页的规格,大小,返回的格式等等,这里推荐用web浏览器发送url调用php这种接口,一切正常php客户端进入就获取网页。
php抓取网页?http请求?现在有基于telnet的抓取软件,很方便,关键是速度快。
我就两个解决方案。第一,网络请求。第二,分析网页。需要的话我再补充一下网页数据内容。
有人提到telnet。我还有一个笨办法,直接上qq然后写个爬虫去弄。
你怎么知道人家没有封你ip?我也好奇好久了。
传统解决办法很简单,加上一个分析url规律然后再用自己语言解析的https就能搞定了。分析不了的或者解析出来json什么玩意的,就得用这种专门的http处理引擎,简单点说就是开发脚本那种。如果要获取外网的直接看ip喽。但能不能做到就不知道了。毕竟php只能抓包到个链接地址。
有真的吗?看到知乎上说有的,我试了一下,抓包成功。但是在评论区里有好多广告投放者。刷经验/骗赞。还有陌生号码/在线时间。都不知道是什么鬼。然后不禁想到,这些貌似是有利益关系的吧。
你可以用php搭建个可以抓取通过telnet获取即时数据的服务器。 查看全部
php抓取网页数据实例(php抓取网页数据实例,拿到网页的数据我们需要看)
php抓取网页数据实例,拿到网页数据我们需要看网页的规格,大小,返回的格式等等,这里推荐用web浏览器发送url调用php这种接口,一切正常php客户端进入就获取网页。
php抓取网页?http请求?现在有基于telnet的抓取软件,很方便,关键是速度快。
我就两个解决方案。第一,网络请求。第二,分析网页。需要的话我再补充一下网页数据内容。
有人提到telnet。我还有一个笨办法,直接上qq然后写个爬虫去弄。
你怎么知道人家没有封你ip?我也好奇好久了。
传统解决办法很简单,加上一个分析url规律然后再用自己语言解析的https就能搞定了。分析不了的或者解析出来json什么玩意的,就得用这种专门的http处理引擎,简单点说就是开发脚本那种。如果要获取外网的直接看ip喽。但能不能做到就不知道了。毕竟php只能抓包到个链接地址。
有真的吗?看到知乎上说有的,我试了一下,抓包成功。但是在评论区里有好多广告投放者。刷经验/骗赞。还有陌生号码/在线时间。都不知道是什么鬼。然后不禁想到,这些貌似是有利益关系的吧。
你可以用php搭建个可以抓取通过telnet获取即时数据的服务器。
php抓取网页数据实例(php抓取网页数据实例分享--看这里apache+php+mysql)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-13 15:02
php抓取网页数据实例分享---看这里apache+php+mysql+flash,
首先本身爬虫是个简单的设计来解决各种数据量的问题。目前不提倡在一个服务器上做爬虫,三个标准:内存,硬盘,访问频率;然后服务器上架这么简单的方法请再仔细研究基本运作过程;php+mysql方法很多,我随便举几个例子:模拟登录就方法autoproxy例子登录好了,然后模拟一个正常访问get参数,再调用db.showroot()给db初始化,这里cookie一般在远程开发配置文件就完成了;然后可以传递到自己的服务器,顺便httpreferer;返回可以post参数给别人,然后fetchafter;自己做服务器控制,push、pull、delete等soeasy!如果要用js的话,可以实现简单的追踪,这里参考看下这个go爬虫效果:。
使用postman无论多简单的爬虫都能实现100w+数据的传输。用php+mysql+flash可以实现100w+的数据传输,其实因为你这个应用用不到存储层的东西,所以传输效率不是特别高,但是非常快。100万数据用js可以传输300w以上。100w数据是什么意思?其实就是爬虫程序所有的http请求传过来的全部数据。
使用httpfuzzer
apache+php+mysql+flash。apache:一般的iis只需要设置accesshost,地址为你的http服务器hostname即可。若是要用专用apache或者是原来的apache端口服务器(如/)需要先更换成新的http服务器(如8080端口服务器)。php:apache无论是在后端配置还是在nginx/uwsgi上都需要更换成php版本,关于如何更换php版本请参考相关资料并下载配置文件。
mysql:使用mysql挂载nginxrepo地址,挂载完后可以用www-port5000-5005端口(对应),用作uwsgi程序部署。flash:在原先的php端口服务器上配置flash插件,以80端口为例,即nginx和8080端口之间重新做一次404/403端口映射。 查看全部
php抓取网页数据实例(php抓取网页数据实例分享--看这里apache+php+mysql)
php抓取网页数据实例分享---看这里apache+php+mysql+flash,
首先本身爬虫是个简单的设计来解决各种数据量的问题。目前不提倡在一个服务器上做爬虫,三个标准:内存,硬盘,访问频率;然后服务器上架这么简单的方法请再仔细研究基本运作过程;php+mysql方法很多,我随便举几个例子:模拟登录就方法autoproxy例子登录好了,然后模拟一个正常访问get参数,再调用db.showroot()给db初始化,这里cookie一般在远程开发配置文件就完成了;然后可以传递到自己的服务器,顺便httpreferer;返回可以post参数给别人,然后fetchafter;自己做服务器控制,push、pull、delete等soeasy!如果要用js的话,可以实现简单的追踪,这里参考看下这个go爬虫效果:。
使用postman无论多简单的爬虫都能实现100w+数据的传输。用php+mysql+flash可以实现100w+的数据传输,其实因为你这个应用用不到存储层的东西,所以传输效率不是特别高,但是非常快。100万数据用js可以传输300w以上。100w数据是什么意思?其实就是爬虫程序所有的http请求传过来的全部数据。
使用httpfuzzer
apache+php+mysql+flash。apache:一般的iis只需要设置accesshost,地址为你的http服务器hostname即可。若是要用专用apache或者是原来的apache端口服务器(如/)需要先更换成新的http服务器(如8080端口服务器)。php:apache无论是在后端配置还是在nginx/uwsgi上都需要更换成php版本,关于如何更换php版本请参考相关资料并下载配置文件。
mysql:使用mysql挂载nginxrepo地址,挂载完后可以用www-port5000-5005端口(对应),用作uwsgi程序部署。flash:在原先的php端口服务器上配置flash插件,以80端口为例,即nginx和8080端口之间重新做一次404/403端口映射。
php抓取网页数据实例( 下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2022-04-04 12:25
下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
[CLI] 使用 Curl 下载文件的实时进度条显示
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对编程宝的支持。
下一节:PHP编程技术详解
本文介绍PHP中读写文件的高并发处理操作。分享给大家参考,具体如下: 背景:最近公司游戏开发需要了解游戏加载的流失率。因为,我们做的是网页游戏。玩过网页游戏的人都知道,进入游戏前必须加载一些资源。最后... 查看全部
php抓取网页数据实例(
下一节:PHP读写文件高并发处理操作实例详解PHP编程技术)
[CLI] 使用 Curl 下载文件的实时进度条显示
前言
最近在命令行下的编程中,下载文件总是一个比较难的过程。如果有进度条就更好了!!!
之前进度条的扩展包还是不错的(本地下载)
效果图:
还是好看的!
卷曲有什么用?
用php,curl主要是抓取数据,当然我们也可以通过其他方法抓取,比如fsockopen,file_get_contents等,但是只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
使用卷曲
curl是PHP很常用的一种下载方式,这里有一个简单的使用方法;
// 初始化一个 curl
$ch = curl_init();
// 设置请求的 url
curl_setopt($ch, CURLOPT_URL, $url);
//
curl_setopt($ch, CURLOPT_HEADER, 0);
// 不直接输出,而是通过 curl_exec 返回
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
上面是一个非常简单的例子。如果文件很大,用户需要等待很长时间。这时候我们应该添加进度条的效果:
class Request
{
protected $bar;
// 是否下载完成
protected $downloaded = false;
public function __construct()
{
// 初始化一个进度条
$this->bar = new CliProgressBar(100);
$this->bar->display();
$this->bar->setColorToRed();
}
function download($url)
{
$ch = curl_init();
// 从配置文件中获取根路径
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 0);
// 开启进度条
curl_setopt($ch, CURLOPT_NOPROGRESS, 0);
// 进度条的触发函数
curl_setopt($ch, CURLOPT_PROGRESSFUNCTION, 'progress');
// ps: 如果目标网页跳转,也跟着跳转
// curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
if (false === ($stream = curl_exec($ch))) {
throw new \Exception(curl_errno($ch));
}
curl_close($ch);
return $stream;
}
/**
* 进度条下载.
*
* @param $ch
* @param $countDownloadSize 总下载量
* @param $currentDownloadSize 当前下载量
* @param $countUploadSize
* @param $currentUploadSize
*/
public function progress($ch, $countDownloadSize, $currentDownloadSize, $countUploadSize, $currentUploadSize)
{
// 等于 0 的时候,应该是预读资源不等于0的时候即开始下载
// 这里的每一个判断都是坑,多试试就知道了
if (0 === $countDownloadSize) {
return false;
}
// 有时候会下载两次,第一次很小,应该是重定向下载
if ($countDownloadSize > $currentDownloadSize) {
$this->downloaded = false;
// 继续显示进度条
}
// 已经下载完成还会再发三次请求
elseif ($this->downloaded) {
return false;
}
// 两边相等下载完成并不一定结束,
elseif ($currentDownloadSize === $countDownloadSize) {
return false;
}
// 开始计算
$bar = $currentDownloadSize / $countDownloadSize * 100;
$this->bar->progress($bar);
}
}
(new Request)->download('http://www.shiguopeng.cn/database.sql');
下载回调的判断中一定要注意坑!!!
还有一个问题:如果跳转到下载并设置curl跟随跳转,返回的文件会有问题。
我下载了一个zip文件,它会导致文件头有第一个请求的HTTP响应头的内容,
所以你需要 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
总结
以上就是这个文章的全部内容。希望本文的内容对您的学习或工作有一定的参考和学习价值。有问题可以留言交流,感谢大家对编程宝的支持。
下一节:PHP编程技术详解
本文介绍PHP中读写文件的高并发处理操作。分享给大家参考,具体如下: 背景:最近公司游戏开发需要了解游戏加载的流失率。因为,我们做的是网页游戏。玩过网页游戏的人都知道,进入游戏前必须加载一些资源。最后...
php抓取网页数据实例(php抓取网页数据实例1:在php中查找username对应的username_login)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-03-30 22:07
php抓取网页数据实例1:在php中查找username对应的username_login。php案例2:查找对应is_username_login(str)函数是否有效和返回值,通过修改sql语句,达到搜索username_login(str)函数3:收集str字符串的username_login函数,写入mysql中4:写入mysql数据库在php中。
如果我们只是想查找username。login_type属性值为str,并且不考虑username_login的过滤,使用open_username_login()查找username_login(str)函数非常有效率,可以大量节省我们的时间5:修改sql语句使得查找过滤条件为正则。例如,我们想搜索str1:*的全部username_login字符串,可以如下编写字符串process('selectsu_username_login。
*fromuser')6:使用sql定位到su_username_login对应的username_login_type字符串,使用next()函数获取如下代码7:定位到username_login_type字符串,使用exec()函数获取在php中exec()函数调用比open()函数的使用方便,在sql语句中必须用到exec()函数,其它操作如插入(insert),获取(get),查询(delete)等不需要使用exec()函数8:如果要从一个username_login返回value值,可以如下定义或实现foreach(iteminusername_login。
fieldset){//str类的定义}案例3要追求效率,我们可以使用php自带的两个function模块,例如:我们来模拟一个实现案例4:使用php自带函数tok_pathd函数来模拟一个外链接到某网站,但是要追求时效,可以在某个网页被访问之前的时间去抓包记录如下代码代码如下接下来,我们可以使用tok_pathd函数从某个外链接去抓取对应的username_login字符串,代码如下注意:外链接到网站的时间如果超过username_login_timer(),就会失败,post_count没法设置如果要从网站抓取不在某个网站名下的username_login字符串,可以使用另外一个函数,例如:post_count可以和一个限制如下://限制在某个网站名下的username_login字符串//@mewheneachuserisusedtopost($source=post_count->id)//@allwheneachuserisusedtopost($http_username_login)$_user['username_login']=$source;//post_count//@echo"/some/。*。 查看全部
php抓取网页数据实例(php抓取网页数据实例1:在php中查找username对应的username_login)
php抓取网页数据实例1:在php中查找username对应的username_login。php案例2:查找对应is_username_login(str)函数是否有效和返回值,通过修改sql语句,达到搜索username_login(str)函数3:收集str字符串的username_login函数,写入mysql中4:写入mysql数据库在php中。
如果我们只是想查找username。login_type属性值为str,并且不考虑username_login的过滤,使用open_username_login()查找username_login(str)函数非常有效率,可以大量节省我们的时间5:修改sql语句使得查找过滤条件为正则。例如,我们想搜索str1:*的全部username_login字符串,可以如下编写字符串process('selectsu_username_login。
*fromuser')6:使用sql定位到su_username_login对应的username_login_type字符串,使用next()函数获取如下代码7:定位到username_login_type字符串,使用exec()函数获取在php中exec()函数调用比open()函数的使用方便,在sql语句中必须用到exec()函数,其它操作如插入(insert),获取(get),查询(delete)等不需要使用exec()函数8:如果要从一个username_login返回value值,可以如下定义或实现foreach(iteminusername_login。
fieldset){//str类的定义}案例3要追求效率,我们可以使用php自带的两个function模块,例如:我们来模拟一个实现案例4:使用php自带函数tok_pathd函数来模拟一个外链接到某网站,但是要追求时效,可以在某个网页被访问之前的时间去抓包记录如下代码代码如下接下来,我们可以使用tok_pathd函数从某个外链接去抓取对应的username_login字符串,代码如下注意:外链接到网站的时间如果超过username_login_timer(),就会失败,post_count没法设置如果要从网站抓取不在某个网站名下的username_login字符串,可以使用另外一个函数,例如:post_count可以和一个限制如下://限制在某个网站名下的username_login字符串//@mewheneachuserisusedtopost($source=post_count->id)//@allwheneachuserisusedtopost($http_username_login)$_user['username_login']=$source;//post_count//@echo"/some/。*。
php抓取网页数据实例(php抓取网页数据实例用flashplayer实现抓取网数据,一般用到的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-03-29 19:00
php抓取网页数据实例用flashplayer实现php抓取网数据,一般用到的php抓取数据工具有:flashplayer抓取方法1.浏览器cookievs网页码抓取可以理解为http协议里的浏览器和网页,php抓取需要用到代理协议,代理协议是cgi/ngij协议(如果你看到的是最后一段代码,请尽快看到结尾,因为我们要做的是生成一个php文件,里面包含可能php的网页码),代理协议里,网页码也是cgi/ngij网页代码的部分。
那么显而易见的问题是,我们的协议是cgi/ngij协议,而网页码不是php网页代码里的部分,代理协议里没有cgi/ngij网页代码的部分,他是一个cgi/ngij文件。那我们该怎么爬呢?我们如果一次抓取很多的网页,然后把他放到googledomainssecuritysites上,那么我们就可以几十上百几百毫秒的抓取对应的网页,没有重定向只有循环,但是我们在抓取的过程中又对下一个网页做了判断,我们会爬一个页面,判断这个页面是不是真的php代码的片段,如果是的话,我们要把他放到真正的googledomainssecuritysites上。
这种方法是需要用到代理代理代理代理_百度百科代理协议是cgi/ngij协议,网页码也是cgi/ngij网页代码的部分。我们的生成php文件就是一个php文件,里面只包含我们要抓取的数据,不包含代理协议的代码。代理协议在浏览器里并不能够被浏览器浏览到,但是我们把他放到服务器上,把代理协议存储在服务器上。
这样网页码在浏览器里就被浏览器检索到了,如果你把代理协议或者是代理代理存储到一个文件里面,那么文件外的浏览器就可以找到并浏览。2.网页码抓取但是我们怎么爬呢?我们当然可以直接浏览网页代码(百度也会有,我们可以实现不出第一段代码),然后按照同样的方法来爬,这样我们直接从我们的服务器抓,如果你用的浏览器是谷歌的话,那么你只能从谷歌的服务器抓,百度虽然可以抓,但是不支持。
这个服务器还可以买,你知道比如,凡是涉及爬虫协议的数据都有可能是根据浏览器的请求来抓,它无法去判断数据是否被的服务器抓取过。所以这种爬虫协议是很有限的,就是这样我们完全没有办法爬取数据,看来网页号网页码抓取应该没有太多用处。其实我们不应该让爬虫协议限制抓取数据,因为数据有的话可以在url对应网页中爬取,这样就使爬虫协议应该被限制,如果爬虫协议被限制应该怎么办呢?那只能去第三方服务器上爬取,然后交给服务器解析。
这样也存在一个问题,爬虫协议通常情况下使用的是cgi/ngij协议的代码,而这些代码里没有网页码,可能我们不希。 查看全部
php抓取网页数据实例(php抓取网页数据实例用flashplayer实现抓取网数据,一般用到的)
php抓取网页数据实例用flashplayer实现php抓取网数据,一般用到的php抓取数据工具有:flashplayer抓取方法1.浏览器cookievs网页码抓取可以理解为http协议里的浏览器和网页,php抓取需要用到代理协议,代理协议是cgi/ngij协议(如果你看到的是最后一段代码,请尽快看到结尾,因为我们要做的是生成一个php文件,里面包含可能php的网页码),代理协议里,网页码也是cgi/ngij网页代码的部分。
那么显而易见的问题是,我们的协议是cgi/ngij协议,而网页码不是php网页代码里的部分,代理协议里没有cgi/ngij网页代码的部分,他是一个cgi/ngij文件。那我们该怎么爬呢?我们如果一次抓取很多的网页,然后把他放到googledomainssecuritysites上,那么我们就可以几十上百几百毫秒的抓取对应的网页,没有重定向只有循环,但是我们在抓取的过程中又对下一个网页做了判断,我们会爬一个页面,判断这个页面是不是真的php代码的片段,如果是的话,我们要把他放到真正的googledomainssecuritysites上。
这种方法是需要用到代理代理代理代理_百度百科代理协议是cgi/ngij协议,网页码也是cgi/ngij网页代码的部分。我们的生成php文件就是一个php文件,里面只包含我们要抓取的数据,不包含代理协议的代码。代理协议在浏览器里并不能够被浏览器浏览到,但是我们把他放到服务器上,把代理协议存储在服务器上。
这样网页码在浏览器里就被浏览器检索到了,如果你把代理协议或者是代理代理存储到一个文件里面,那么文件外的浏览器就可以找到并浏览。2.网页码抓取但是我们怎么爬呢?我们当然可以直接浏览网页代码(百度也会有,我们可以实现不出第一段代码),然后按照同样的方法来爬,这样我们直接从我们的服务器抓,如果你用的浏览器是谷歌的话,那么你只能从谷歌的服务器抓,百度虽然可以抓,但是不支持。
这个服务器还可以买,你知道比如,凡是涉及爬虫协议的数据都有可能是根据浏览器的请求来抓,它无法去判断数据是否被的服务器抓取过。所以这种爬虫协议是很有限的,就是这样我们完全没有办法爬取数据,看来网页号网页码抓取应该没有太多用处。其实我们不应该让爬虫协议限制抓取数据,因为数据有的话可以在url对应网页中爬取,这样就使爬虫协议应该被限制,如果爬虫协议被限制应该怎么办呢?那只能去第三方服务器上爬取,然后交给服务器解析。
这样也存在一个问题,爬虫协议通常情况下使用的是cgi/ngij协议的代码,而这些代码里没有网页码,可能我们不希。
php抓取网页数据实例(没有排行官方文档上的东西我就不照搬了再说 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-03-23 04:22
)
我之前没有探索过小程序。本来打算看教学视频慢慢走的。我发现老师基本上都是在讲文件,所以我就直接练习了。
达到这样的排名
我不会复制官方文件上的东西
var that = this;
wx.request({
//请求接口的地址
url: '********/api.php',//这里的*号就是你的服务器 和ajax十分相似
data: {
},//data不能掉,即便为空,不然获取不了,我目前还不知道什么原因
header: {
"Content-Type": "applciation/json" //默认值
},
success: function (res) {
//res相当于ajax里面的返回的数据
console.log(res.data);
//如果在sucess直接写this就变成了wx.request()的this了
//必须为getTableData函数的this,不然无法重置调用函数
that.setData({
datas: res.data //datas传值给页面的,可以自定义命名
})
},
fail: function (err) { },//请求失败
complete: function () { }//请求完成后执行的函数
})
让我们谈谈如何传递参数。这个问题让我头大。可能是很简单的事情,问老师也不清楚。
我想上传数据到后台,获取当前用户的头像保存到数据库,根据用户昵称获取积分(我知道使用昵称不是一个好条件)
首先微信官方给出了全局函数app.globalData(在app.js中,这里先记住在当前js中新建)
wx.request({
//这里加的两个参数都是全局变量 分别获取昵称和头像url
url: 'http://riyw7t.natappfree.cc/up ... 39%3B + app.globalData.userInfo.nickName + "&img=" + app.globalData.userInfo.avatarUrl,
data: {
},
header: {
"Content-Type": "applciation/json" //默认值
},
dataType: JSON,
success: function (res) {
console.log(res.data);
},
fail: function (err) { app.globalData.userInfo.nickName },//请求失败
complete: function () { }//请求完成后执行的函数
})
wx.request 必须添加到函数中,不能单独作为函数使用
查看全部
php抓取网页数据实例(没有排行官方文档上的东西我就不照搬了再说
)
我之前没有探索过小程序。本来打算看教学视频慢慢走的。我发现老师基本上都是在讲文件,所以我就直接练习了。
达到这样的排名
我不会复制官方文件上的东西
var that = this;
wx.request({
//请求接口的地址
url: '********/api.php',//这里的*号就是你的服务器 和ajax十分相似
data: {
},//data不能掉,即便为空,不然获取不了,我目前还不知道什么原因
header: {
"Content-Type": "applciation/json" //默认值
},
success: function (res) {
//res相当于ajax里面的返回的数据
console.log(res.data);
//如果在sucess直接写this就变成了wx.request()的this了
//必须为getTableData函数的this,不然无法重置调用函数
that.setData({
datas: res.data //datas传值给页面的,可以自定义命名
})
},
fail: function (err) { },//请求失败
complete: function () { }//请求完成后执行的函数
})
让我们谈谈如何传递参数。这个问题让我头大。可能是很简单的事情,问老师也不清楚。
我想上传数据到后台,获取当前用户的头像保存到数据库,根据用户昵称获取积分(我知道使用昵称不是一个好条件)
首先微信官方给出了全局函数app.globalData(在app.js中,这里先记住在当前js中新建)
wx.request({
//这里加的两个参数都是全局变量 分别获取昵称和头像url
url: 'http://riyw7t.natappfree.cc/up ... 39%3B + app.globalData.userInfo.nickName + "&img=" + app.globalData.userInfo.avatarUrl,
data: {
},
header: {
"Content-Type": "applciation/json" //默认值
},
dataType: JSON,
success: function (res) {
console.log(res.data);
},
fail: function (err) { app.globalData.userInfo.nickName },//请求失败
complete: function () { }//请求完成后执行的函数
})
wx.request 必须添加到函数中,不能单独作为函数使用
php抓取网页数据实例(简单的登录界面登录表单(2015年03月23日))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-18 03:04
简单登录界面登录表单主界面login.htmlTYPE html>ion="1.php" method="post">用户名:type="text"recommend-item-box type_blog clearfix" data- url= ""数据报告视图='{"ab":"new","spm":"1001.2101.3001.6650.5", "mod":"popu_387","extra":"{\"highlightScore\":0.0,\"utm_medium\":\"distribute.pc_relevant.none-task-blog-2~default ~BlogCommendFromBaidu ~rate-5.pc_relevant_default\",\"dist_request_id\":\"92_45148\"}","dist_request_id":"92_45148","ab_strategy":"default","index":"5", "strategy":"2~default~BlogCommendFromBaidu~Rate","dest":""}'>
更详细的PHP生成静态页面教程
实现梦想
12-11
545
用PHP生成静态页面的教程让我们首先回顾一些基本概念,PHP脚本和动态页面。 PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的P服务器 查看全部
php抓取网页数据实例(简单的登录界面登录表单(2015年03月23日))
简单登录界面登录表单主界面login.htmlTYPE html>ion="1.php" method="post">用户名:type="text"recommend-item-box type_blog clearfix" data- url= ""数据报告视图='{"ab":"new","spm":"1001.2101.3001.6650.5", "mod":"popu_387","extra":"{\"highlightScore\":0.0,\"utm_medium\":\"distribute.pc_relevant.none-task-blog-2~default ~BlogCommendFromBaidu ~rate-5.pc_relevant_default\",\"dist_request_id\":\"92_45148\"}","dist_request_id":"92_45148","ab_strategy":"default","index":"5", "strategy":"2~default~BlogCommendFromBaidu~Rate","dest":""}'>
更详细的PHP生成静态页面教程
实现梦想
12-11
545
用PHP生成静态页面的教程让我们首先回顾一些基本概念,PHP脚本和动态页面。 PHP脚本是一种服务器端脚本程序,可以通过嵌入等方式与HTML文件混合,也可以封装在类和函数中,以模板的形式处理用户请求。无论哪种方式,它的基本原理都是这样的。客户端发出请求请求某个页面 ----->WEB服务器引入指定的对应脚本进行处理 ----->脚本加载到服务器中 ----->指定的P服务器
php抓取网页数据实例(百度统计API简单使用——获取网站概况数据的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-15 00:17
我讲了百度统计API的简单使用——获取站点列表,当然获取站点列表之后,还需要获取站点数据。今天我们来学习如何通过百度统计API获取网站个人资料数据,并在下一章将这些数据添加到WordPress首页仪表盘,方便站长查看数据。
在教程开始之前,我会教你如何在百度统计中查看你的网站 site_id,站点ID。注意它不是统计代码中的标识符。
方法一
登录百度统计后台后,在导航栏选择管理,然后从默认的网站列表中选择你需要获取数据的网站,点击后面的代码获取,你可以在站点 ID 的 URL 中看到它。
方法二
在之前的教程中,百度统计API的使用很简单——获取站点列表。我们通过百度统计API获取了站点列表,返回的数据包括站点ID。
请求地址:
请求方式:post
请求方法:overview/getTimeTrendRpt
请求参数:json数据,如下图
{
“标题”:{
"用户名": "zhangsan",
“密码”:“xxxxxxxx”,
“令牌”:“xxxxxxxx”,
“account_type”:1
},
“正文”:{
"site_id": "xxxx",
“开始日期”:“20190101”,
"end_date": "20190105",
“指标”:“pv_count,visitor_count,ip_count”,
“方法”:“概述/getTimeTrendRpt”
}
}
百度统计API好用-get 网站Overview 查看全部
php抓取网页数据实例(百度统计API简单使用——获取网站概况数据的方法)
我讲了百度统计API的简单使用——获取站点列表,当然获取站点列表之后,还需要获取站点数据。今天我们来学习如何通过百度统计API获取网站个人资料数据,并在下一章将这些数据添加到WordPress首页仪表盘,方便站长查看数据。
在教程开始之前,我会教你如何在百度统计中查看你的网站 site_id,站点ID。注意它不是统计代码中的标识符。
方法一
登录百度统计后台后,在导航栏选择管理,然后从默认的网站列表中选择你需要获取数据的网站,点击后面的代码获取,你可以在站点 ID 的 URL 中看到它。
方法二
在之前的教程中,百度统计API的使用很简单——获取站点列表。我们通过百度统计API获取了站点列表,返回的数据包括站点ID。
请求地址:
请求方式:post
请求方法:overview/getTimeTrendRpt
请求参数:json数据,如下图
{
“标题”:{
"用户名": "zhangsan",
“密码”:“xxxxxxxx”,
“令牌”:“xxxxxxxx”,
“account_type”:1
},
“正文”:{
"site_id": "xxxx",
“开始日期”:“20190101”,
"end_date": "20190105",
“指标”:“pv_count,visitor_count,ip_count”,
“方法”:“概述/getTimeTrendRpt”
}
}
百度统计API好用-get 网站Overview
php抓取网页数据实例(scrapyScrapy:Python的爬虫框架实例Demo.12初窥)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-14 22:20
刮擦
Scrapy:Python的爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
初步了解 ScrapyScrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
应用
使用 json 生成数据文件 $ scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
看看有多少爬虫 $scrapy list
它最初是为网络抓取而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
网络爬虫是一种在 Internet 上爬取数据的程序,使用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫,但是使用框架可以大大提高效率,缩短开发时间。Scrapy 是用 Python 编写的,轻量级、简单易用。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。Spider,蜘蛛是主要的工作,它用于制定特定域名或网页的解析规则。项目管道,负责处理蜘蛛从网页中提取的项目,他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎与调度之间的中间件,Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
官方网站:
开源地址:
这段代码的地址:
抢的时候不要做违法的事情,开源仅供参考。 查看全部
php抓取网页数据实例(scrapyScrapy:Python的爬虫框架实例Demo.12初窥)
刮擦
Scrapy:Python的爬虫框架
示例演示
抓取:汽车之家、瓜子、链家等数据信息
版本+环境库
Python2.7 + Scrapy1.12
初步了解 ScrapyScrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可以用于一系列程序,包括数据挖掘、信息处理或存储历史数据。
应用
使用 json 生成数据文件 $ scrapy crawl car -o Trunks.json
直接执行$scrapy crawl car
看看有多少爬虫 $scrapy list
它最初是为网络抓取而设计的,但也可用于获取 API(例如 Amazon Associates Web Services)或通用网络爬虫返回的数据。
网络爬虫是一种在 Internet 上爬取数据的程序,使用它来爬取特定网页的 HTML 数据。虽然我们使用一些库来开发爬虫,但是使用框架可以大大提高效率,缩短开发时间。Scrapy 是用 Python 编写的,轻量级、简单易用。
Scrapy主要包括以下组件:
该引擎用于处理整个系统的数据流处理和触发事务。调度器用于接受引擎发送的请求,将其推入队列,并在引擎再次请求时返回。下载器用于下载网页内容并将网页内容返回给蜘蛛。Spider,蜘蛛是主要的工作,它用于制定特定域名或网页的解析规则。项目管道,负责处理蜘蛛从网页中提取的项目,他的主要任务是澄清、验证和存储数据。当页面被蜘蛛解析时,它被发送到项目管道,并按几个特定的顺序处理数据。下载器中间件,Scrapy 引擎和下载器之间的钩子框架,主要处理 Scrapy 引擎和下载器之间的请求和响应。Spider中间件,Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。调度中间件,Scrapy引擎与调度之间的中间件,Scrapy引擎发送给调度的请求和响应。使用Scrapy可以轻松完成在线数据的采集工作,它为我们做了很多工作,无需自己开发。
官方网站:
开源地址:
这段代码的地址:
抢的时候不要做违法的事情,开源仅供参考。
php抓取网页数据实例(php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-03-14 09:13
php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明总览下载地址:
看你的需求如果使用php做一个数据抓取+分析平台,那么你首先要能编写高质量的代码,这一点任何语言都一样,而后才是一些功能齐全的工具库、模板库。
php的话你除了没用过python或者perl以外也可以试试去看看laravel,php+go还有rails,基于laravel和go的web框架。还有一些基于flask、django的一些框架。
可以看看mongoose
php的话用zendframework不错,很有用,
可以关注下公众号说php如今基于go语言的web框架很多,开发起来上手快,门槛低。最近了解到一个公众号,专门介绍go开发的php框架:说php这个公众号,所以进来看看,聊聊。
有个问题想请教下题主你知道哪些php开发的java框架吗?我是phpgo+go,准备研究javaweb2框架mybatis或者springcloud。你不需要纠结java服务器哪个好,其实你不会时间很多,一个框架搞定。目前的经验是mybatis很容易上手,你会配置,过程很简单。知道会过程就行,应用很少。
我也纠结过mybatis的实现很简单的问题,再加上期待mybatis社区对框架的支持,其实以现在来看,支持很少,我用了半年才知道怎么使用。springcloud跟mybatis的话,以我多年的从业经验,springcloud是更有价值的,且这块东西对于非小公司价值特别大。我有时候会觉得服务器这东西不做小区实验总是不放心,你用什么?现在想问问你有了解的哪些java开发的框架,比如yii框架和springboot。
我在学习的过程中也经常纠结这些。这两个框架里应该选谁,像高并发,webhook,框架的完整都是问题,经常都在org.okhttp或者tp5之间选。 查看全部
php抓取网页数据实例(php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明)
php抓取网页数据实例-avoscn电子商务服务平台设计可视化图表展示变量说明总览下载地址:
看你的需求如果使用php做一个数据抓取+分析平台,那么你首先要能编写高质量的代码,这一点任何语言都一样,而后才是一些功能齐全的工具库、模板库。
php的话你除了没用过python或者perl以外也可以试试去看看laravel,php+go还有rails,基于laravel和go的web框架。还有一些基于flask、django的一些框架。
可以看看mongoose
php的话用zendframework不错,很有用,
可以关注下公众号说php如今基于go语言的web框架很多,开发起来上手快,门槛低。最近了解到一个公众号,专门介绍go开发的php框架:说php这个公众号,所以进来看看,聊聊。
有个问题想请教下题主你知道哪些php开发的java框架吗?我是phpgo+go,准备研究javaweb2框架mybatis或者springcloud。你不需要纠结java服务器哪个好,其实你不会时间很多,一个框架搞定。目前的经验是mybatis很容易上手,你会配置,过程很简单。知道会过程就行,应用很少。
我也纠结过mybatis的实现很简单的问题,再加上期待mybatis社区对框架的支持,其实以现在来看,支持很少,我用了半年才知道怎么使用。springcloud跟mybatis的话,以我多年的从业经验,springcloud是更有价值的,且这块东西对于非小公司价值特别大。我有时候会觉得服务器这东西不做小区实验总是不放心,你用什么?现在想问问你有了解的哪些java开发的框架,比如yii框架和springboot。
我在学习的过程中也经常纠结这些。这两个框架里应该选谁,像高并发,webhook,框架的完整都是问题,经常都在org.okhttp或者tp5之间选。
php抓取网页数据实例(为什么需要线程假设需要开发一个联网应用程序,需要从一个网址网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-07 16:22
为什么需要线程
假设您需要开发一个联网的应用程序,并且您需要从一个网址中抓取网页内容。这里读取的网页地址是作者在本地机器上创建的服务器地址。当然,在阅读网页内容时,可以使用 HttpClient 提供的 API,但这不是本文的重点。在开发网络程序方面经验不足的程序员可能会编写以下代码。
网络连接通常比较耗时,尤其是在目前GPRS等低速网络情况下,因此connect()方法可能需要3-5秒,
返回页面内容的时间更长。如果直接在主线程(即 UI 线程)中处理此连接操作会发生什么?
为了更好的模拟模拟器中缓慢的网络读取速度,
作者在阅读过程中将线程休眠50秒,
运行 NetworkActivity 并单击“连接”按钮。事故发生,
按钮久久没有反应,整个界面仿佛“死”了。然后系统显示 ANR(应用程序无响应)
错误信息,如图1:
线程中的网络
为什么会出现 ANR?答案是联网动作被阻塞在主线程中,很久没有返回,所以OPhone弹出了ANR错误。这个错误提示我们,
如果一个任务可能需要很长时间运行才能返回,则必须将该任务放在单独的线程中运行,
避免阻塞 UI 线程。Java 语言具有对线程的内置支持。您可以使用 Thread 类创建一个新线程,然后在 run() 方法中读取网页的内容。
获取页面内容后,调用TextView.setText()更新界面。修改连接()
该方法如下所示:
重新运行 NetworkActivity 并单击“连接”按钮。程序没有按预期获取到网页的内容,并显示在TextView上。查看日志,可以看到在执行connect的过程中抛出了异常。其次,分析问题。
使用Handler更新界面
实际上,connect()方法中抛出的异常是接口更新引起的。Connect() 方法在新启动的线程中直接调用 message.setText() 方法是不正确的。OPhone平台只允许在主线程调用相关View的方法来更新界面。如果在新线程中获取返回结果,则必须借助 Handler 更新接口。为此,请在 NetworkActivity 中创建一个 Handler 对象并在 handleMessage() 中更新 UI。
通过connect()方法获取网页内容后,使用如下方法更新界面。
重新运行NetworkActivity,点击“连接”按钮,结果如图2所示,网页内容被正确读取。
异步任务
看起来修改后的connect()方法已经可以使用了,但是这种匿名进程方法存在缺陷:首先,线程的开销很大。如果每个任务都需要创建一个线程,就会降低应用程序的效率。二是线程无法管理,匿名线程在创建启动后不受程序控制。如果发送的请求很多,那么就会启动很多线程,系统就会不堪重负。另外,前面我们已经看到,在新线程中更新UI还必须引入一个handler,这使得代码看起来很臃肿。
为了解决这个问题,OPhone 在 1.5 版本中引入了 AsyncTask。AsyncTask的特点是任务运行在主线程之外,回调方法在主线程中执行,有效避免了使用Handler带来的麻烦。阅读 AsyncTask 的源码可知,AsyncTask 使用 java.util.concurrent 框架来管理线程和任务的执行。并发框架是经过严格测试的非常成熟高效的框架。这说明AsyncTask的设计很好的解决了匿名线程的问题。
AsyncTask是一个抽象类,子类必须实现抽象方法doInBackground(Params...p),在其中实现任务执行工作,如连接网络获取数据。onPostExecute(Result r) 方法通常也应该实现,因为应用程序关心的结果会在这个方法中返回。需要注意的是,AsyncTask 必须在主线程中创建一个实例。AsyncTask 定义了三个泛型类型 Params、Progress 和 Result。
PageTask 扩展 AsyncTask 并在 doInBackground() 方法中读取网页内容。PageTask 的源代码如下所示:
执行PageTask很简单,调用如下代码即可。重新运行NetworkActivity,不仅可以抓取网页内容,还可以实时更新阅读进度。读者尝试阅读更大的页面以查看百分比是如何更新的。
总结
本文介绍了OPhone联网应用开发中需要注意的两个问题:线程管理和接口更新。不仅分析问题,还给出了多种解决方案。这里笔者推荐使用AsyncTask来处理联网、播放大型媒体文件等耗时的任务,不仅执行效率高,而且还节省了代码。 查看全部
php抓取网页数据实例(为什么需要线程假设需要开发一个联网应用程序,需要从一个网址网页内容)
为什么需要线程
假设您需要开发一个联网的应用程序,并且您需要从一个网址中抓取网页内容。这里读取的网页地址是作者在本地机器上创建的服务器地址。当然,在阅读网页内容时,可以使用 HttpClient 提供的 API,但这不是本文的重点。在开发网络程序方面经验不足的程序员可能会编写以下代码。
网络连接通常比较耗时,尤其是在目前GPRS等低速网络情况下,因此connect()方法可能需要3-5秒,
返回页面内容的时间更长。如果直接在主线程(即 UI 线程)中处理此连接操作会发生什么?
为了更好的模拟模拟器中缓慢的网络读取速度,
作者在阅读过程中将线程休眠50秒,
运行 NetworkActivity 并单击“连接”按钮。事故发生,
按钮久久没有反应,整个界面仿佛“死”了。然后系统显示 ANR(应用程序无响应)
错误信息,如图1:
线程中的网络
为什么会出现 ANR?答案是联网动作被阻塞在主线程中,很久没有返回,所以OPhone弹出了ANR错误。这个错误提示我们,
如果一个任务可能需要很长时间运行才能返回,则必须将该任务放在单独的线程中运行,
避免阻塞 UI 线程。Java 语言具有对线程的内置支持。您可以使用 Thread 类创建一个新线程,然后在 run() 方法中读取网页的内容。
获取页面内容后,调用TextView.setText()更新界面。修改连接()
该方法如下所示:
重新运行 NetworkActivity 并单击“连接”按钮。程序没有按预期获取到网页的内容,并显示在TextView上。查看日志,可以看到在执行connect的过程中抛出了异常。其次,分析问题。
使用Handler更新界面
实际上,connect()方法中抛出的异常是接口更新引起的。Connect() 方法在新启动的线程中直接调用 message.setText() 方法是不正确的。OPhone平台只允许在主线程调用相关View的方法来更新界面。如果在新线程中获取返回结果,则必须借助 Handler 更新接口。为此,请在 NetworkActivity 中创建一个 Handler 对象并在 handleMessage() 中更新 UI。
通过connect()方法获取网页内容后,使用如下方法更新界面。
重新运行NetworkActivity,点击“连接”按钮,结果如图2所示,网页内容被正确读取。
异步任务
看起来修改后的connect()方法已经可以使用了,但是这种匿名进程方法存在缺陷:首先,线程的开销很大。如果每个任务都需要创建一个线程,就会降低应用程序的效率。二是线程无法管理,匿名线程在创建启动后不受程序控制。如果发送的请求很多,那么就会启动很多线程,系统就会不堪重负。另外,前面我们已经看到,在新线程中更新UI还必须引入一个handler,这使得代码看起来很臃肿。
为了解决这个问题,OPhone 在 1.5 版本中引入了 AsyncTask。AsyncTask的特点是任务运行在主线程之外,回调方法在主线程中执行,有效避免了使用Handler带来的麻烦。阅读 AsyncTask 的源码可知,AsyncTask 使用 java.util.concurrent 框架来管理线程和任务的执行。并发框架是经过严格测试的非常成熟高效的框架。这说明AsyncTask的设计很好的解决了匿名线程的问题。
AsyncTask是一个抽象类,子类必须实现抽象方法doInBackground(Params...p),在其中实现任务执行工作,如连接网络获取数据。onPostExecute(Result r) 方法通常也应该实现,因为应用程序关心的结果会在这个方法中返回。需要注意的是,AsyncTask 必须在主线程中创建一个实例。AsyncTask 定义了三个泛型类型 Params、Progress 和 Result。
PageTask 扩展 AsyncTask 并在 doInBackground() 方法中读取网页内容。PageTask 的源代码如下所示:
执行PageTask很简单,调用如下代码即可。重新运行NetworkActivity,不仅可以抓取网页内容,还可以实时更新阅读进度。读者尝试阅读更大的页面以查看百分比是如何更新的。
总结
本文介绍了OPhone联网应用开发中需要注意的两个问题:线程管理和接口更新。不仅分析问题,还给出了多种解决方案。这里笔者推荐使用AsyncTask来处理联网、播放大型媒体文件等耗时的任务,不仅执行效率高,而且还节省了代码。
php抓取网页数据实例( Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-05 16:18
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
php抓取网页数据实例(
Python3实现抓取javascript动态生成的html网页功能结合实例)
python3爬取javascript动态生成的html网页示例
更新时间:2017年8月22日11:57:23 作者:罗兵
本文文章主要介绍Python3爬取javascript动态生成的HTML页面的功能,结合实例分析Python3使用selenium库爬取javascript动态生成的HTML页面元素的相关操作技巧。有需要的朋友可以参考以下
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
php抓取网页数据实例(想了解curl常用的5个经典例子的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-04 18:15
想知道php curl常用的5个经典例子的相关内容吗?本文将详细讲解php curl示例的相关知识和一些代码示例。欢迎阅读和指正。重点关注:php、curl、examples,一起学习吧。
我用的是php,curl主要是抓取数据,当然我们也可以用其他的方法抓取,比如fsockopen,file_get_contents等等。但它只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
1、无访问控制抓取文件
2、使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,并且在短时间内非常频繁地抓取它,你将无法抓取它。谷歌此时限制了你的ip地址,你可以换个代理重新抓取一下。
3、post数据后,抓取数据
数据提交数据单独说一下,因为在使用curl的时候,很多情况下都会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST);使用 curl 捕获 upload.php 输出的内容数组 ( [name] => test [sex] => 1 [birth] => 20101010 )
4、抓取一些带有页面访问控制的页面
之前写过一篇文章,页面访问控制的3种方法,有兴趣的可以看看。
如果使用上面提到的方法捕获,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
此时,我们将使用 CURLOPT_USERPWD 进行验证
以上五个常用的php curl经典例子,都是小编分享的内容。希望能给大家一个参考,希望大家多多支持。
相关文章 查看全部
php抓取网页数据实例(想了解curl常用的5个经典例子的相关内容吗)
想知道php curl常用的5个经典例子的相关内容吗?本文将详细讲解php curl示例的相关知识和一些代码示例。欢迎阅读和指正。重点关注:php、curl、examples,一起学习吧。
我用的是php,curl主要是抓取数据,当然我们也可以用其他的方法抓取,比如fsockopen,file_get_contents等等。但它只能抓取那些可以直接访问的页面。如果要抓取有页面访问控制的页面,或者登录后的页面,就比较难了。
1、无访问控制抓取文件
2、使用代理进行爬取
为什么要使用代理进行抓取?以谷歌为例。如果你抓取谷歌的数据,并且在短时间内非常频繁地抓取它,你将无法抓取它。谷歌此时限制了你的ip地址,你可以换个代理重新抓取一下。
3、post数据后,抓取数据
数据提交数据单独说一下,因为在使用curl的时候,很多情况下都会有数据交互,所以比较重要。
在upload.php文件中,print_r($_POST);使用 curl 捕获 upload.php 输出的内容数组 ( [name] => test [sex] => 1 [birth] => 20101010 )
4、抓取一些带有页面访问控制的页面
之前写过一篇文章,页面访问控制的3种方法,有兴趣的可以看看。
如果使用上面提到的方法捕获,会报如下错误
您无权查看此页面
您无权使用您提供的凭据查看此目录或页面,因为您的 Web 浏览器正在发送 Web 服务器未配置为接受的 WWW-Authenticate 标头字段。
此时,我们将使用 CURLOPT_USERPWD 进行验证
以上五个常用的php curl经典例子,都是小编分享的内容。希望能给大家一个参考,希望大家多多支持。
相关文章
php抓取网页数据实例(php抓取网页数据实例本系列教程中实例(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-04 07:04
php抓取网页数据实例本系列教程中实例一是简单的计算机爬虫结构,本实例二是一个http爬虫,说明了http请求结构以及相应的实现方法。学习如何使用php的get函数和post函数,以及如何利用到正则表达式。最后,我们将使用beautifulsoup库解析网页数据并生成字符串。注意:本实例都是采用两次请求实现的,两次不是post请求,而是get请求。
一、一个简单的http请求结构爬虫所有基础知识会在后面的学习中逐步完善,从以下两个角度解释其作用。1.http请求的格式:2.http请求的基本流程下面我们以本例二为例来讲解一下网页数据请求结构。我们从如下两个角度,分别讲解如何从http请求中获取内容:1.get请求:2.post请求:1.get请求我们从如下两个角度来解释为什么要get请求:1.1传递给服务器的信息有哪些:目标url,你的useragent标识,请求的参数个数;1.2服务器如何解析:我们的目标是要得到一个网页地址,我们的请求参数由路径直接传给服务器,服务器解析路径就可以得到网页;2.post请求:首先我们登录服务器,根据步骤1得到地址,注意这个url中的agent的参数要设置,为了方便和后面讲到data总结在一起讲:server:proxy:scheme:useragent:referer:attribute(data)post类型:post的三个参数post参数个数:最终的请求参数个数2.http请求获取数据的方法这次讲解主要使用post请求。
在解释获取数据的方法之前,我们要先来认识一下http的特性:通用于任何一个文件及其路径的请求均为tcp协议,即可以一次连接,终身使用。但tcp协议作为协议并不是我们用来获取数据的。tcp请求和tcp连接通过端口号来区分。端口号就是一个拥塞控制器编号,它是由端口服务程序共享给网络所有的连接的。apache\nginx\httpd等服务程序都可以处理tcp连接。
对于http,默认端口为80,而实际上,我们通常使用443端口来提供服务。由于443端口是没有服务器保留的端口,所以从http协议本身考虑,该端口是不应该再使用的。而在这个教程中,我们是为了得到大量的session信息。所以,我们选择了tcp协议,只对应一个应用程序。对于应用程序来说,只关心从ip:端口号来请求服务。
session对象通过session_token来区分。session_token是session存储的一个key,加密算法可以自己写。session_token有两个值,第一个是value,第二个是session_id。session_id的值唯一,下面的代码验证了value和session_id是否一致。另外如果请求中缺少了一些其他特定规则的attribute信。 查看全部
php抓取网页数据实例(php抓取网页数据实例本系列教程中实例(组图))
php抓取网页数据实例本系列教程中实例一是简单的计算机爬虫结构,本实例二是一个http爬虫,说明了http请求结构以及相应的实现方法。学习如何使用php的get函数和post函数,以及如何利用到正则表达式。最后,我们将使用beautifulsoup库解析网页数据并生成字符串。注意:本实例都是采用两次请求实现的,两次不是post请求,而是get请求。
一、一个简单的http请求结构爬虫所有基础知识会在后面的学习中逐步完善,从以下两个角度解释其作用。1.http请求的格式:2.http请求的基本流程下面我们以本例二为例来讲解一下网页数据请求结构。我们从如下两个角度,分别讲解如何从http请求中获取内容:1.get请求:2.post请求:1.get请求我们从如下两个角度来解释为什么要get请求:1.1传递给服务器的信息有哪些:目标url,你的useragent标识,请求的参数个数;1.2服务器如何解析:我们的目标是要得到一个网页地址,我们的请求参数由路径直接传给服务器,服务器解析路径就可以得到网页;2.post请求:首先我们登录服务器,根据步骤1得到地址,注意这个url中的agent的参数要设置,为了方便和后面讲到data总结在一起讲:server:proxy:scheme:useragent:referer:attribute(data)post类型:post的三个参数post参数个数:最终的请求参数个数2.http请求获取数据的方法这次讲解主要使用post请求。
在解释获取数据的方法之前,我们要先来认识一下http的特性:通用于任何一个文件及其路径的请求均为tcp协议,即可以一次连接,终身使用。但tcp协议作为协议并不是我们用来获取数据的。tcp请求和tcp连接通过端口号来区分。端口号就是一个拥塞控制器编号,它是由端口服务程序共享给网络所有的连接的。apache\nginx\httpd等服务程序都可以处理tcp连接。
对于http,默认端口为80,而实际上,我们通常使用443端口来提供服务。由于443端口是没有服务器保留的端口,所以从http协议本身考虑,该端口是不应该再使用的。而在这个教程中,我们是为了得到大量的session信息。所以,我们选择了tcp协议,只对应一个应用程序。对于应用程序来说,只关心从ip:端口号来请求服务。
session对象通过session_token来区分。session_token是session存储的一个key,加密算法可以自己写。session_token有两个值,第一个是value,第二个是session_id。session_id的值唯一,下面的代码验证了value和session_id是否一致。另外如果请求中缺少了一些其他特定规则的attribute信。
php抓取网页数据实例(,flask前后端框架,web框架实例-简单基于php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-03 09:01
php抓取网页数据实例item_url转换,前后端框架,web框架实例-简单基于php抓取基于mysql的电商网站数据库设计,前后端框架,异步请求开发(一),flask搭建简单博客详细(图片,网页源码)mysql数据读写操作(1)读写文件读写文件快速入门:图解使用php_connect插件的写入文件写入页面源码到数据库简单便捷代码手机文件操作手机文件操作手机图片上传图片上传图片文件图片压缩处理图片批量上传图片批量替换图片上传一个网页大小限制正则匹配代码,代码组合代码签名php函数执行函数redis缓存架构性能优化图片切片性能优化图片压缩代码文件读写图片展示图片存储pv高的页面中也会有大量的图片不能全部展示给客户端,因此需要对它们进行预览redis缓存是利用缓存能提高文件操作效率的技术。
缓存模式:sort集合缓存skipupdate回滚有些文件,要等到传递给其他操作时才被初始化。在没有缓存的页面,就无法展示图片了,一些页面很短,一个浏览器上抓取到的就没有几百张图片,需要浪费很长时间。此时,就需要修改策略,例如可以限制只展示10张图片。用图片来做缓存缓存文件模式:raw普通可缓存普通文件名例如txt(50k),但是数据量特别大,且有点小,推荐。
可缓存到documents文件夹的任意位置,缓存了,但文件存储在recordset文件夹中,当有变化的时候,刷新缓存,重新判断。etag生成临时文件,不能保存时间戳。当有变化时,必须刷新重新传递文件,所以数据写入到new-文件。index.js---连接数据库,可以把动态网页缓存到cookies中,供爬虫进行session的检索。
使用cookies时的不同:webviewjsbookpc浏览器浏览网页需要和数据库建立链接,请求文件的时候就已经把链接的名字string对应到服务器的url上。如果使用session对象,服务器的url实际上是我们常见的http协议客户端请求的url。cookie数据:浏览器请求文件,客户端会获取jscookie,然后把自己的用户id放到index.js/resources/cookie.js文件中。
res的内容和我们常见的http请求的一样。因此使用reshttp或https请求之间都是会相互转换的,以给爬虫建立一个全文检索的项目。在多个页面采用同一个请求,可以有效降低带宽的占用。但为什么一定要设置https呢?我想说的是requestjs才不只是request,它还包括对jshttp等的https连接,这样的话和他一起存在的全文检索图片才能起作用。
请求两端都带有认证。爬虫可以直接解析这种证书,然后用浏览器上传你的图片。使用图片来作为cookie在请求中传递这样。 查看全部
php抓取网页数据实例(,flask前后端框架,web框架实例-简单基于php)
php抓取网页数据实例item_url转换,前后端框架,web框架实例-简单基于php抓取基于mysql的电商网站数据库设计,前后端框架,异步请求开发(一),flask搭建简单博客详细(图片,网页源码)mysql数据读写操作(1)读写文件读写文件快速入门:图解使用php_connect插件的写入文件写入页面源码到数据库简单便捷代码手机文件操作手机文件操作手机图片上传图片上传图片文件图片压缩处理图片批量上传图片批量替换图片上传一个网页大小限制正则匹配代码,代码组合代码签名php函数执行函数redis缓存架构性能优化图片切片性能优化图片压缩代码文件读写图片展示图片存储pv高的页面中也会有大量的图片不能全部展示给客户端,因此需要对它们进行预览redis缓存是利用缓存能提高文件操作效率的技术。
缓存模式:sort集合缓存skipupdate回滚有些文件,要等到传递给其他操作时才被初始化。在没有缓存的页面,就无法展示图片了,一些页面很短,一个浏览器上抓取到的就没有几百张图片,需要浪费很长时间。此时,就需要修改策略,例如可以限制只展示10张图片。用图片来做缓存缓存文件模式:raw普通可缓存普通文件名例如txt(50k),但是数据量特别大,且有点小,推荐。
可缓存到documents文件夹的任意位置,缓存了,但文件存储在recordset文件夹中,当有变化的时候,刷新缓存,重新判断。etag生成临时文件,不能保存时间戳。当有变化时,必须刷新重新传递文件,所以数据写入到new-文件。index.js---连接数据库,可以把动态网页缓存到cookies中,供爬虫进行session的检索。
使用cookies时的不同:webviewjsbookpc浏览器浏览网页需要和数据库建立链接,请求文件的时候就已经把链接的名字string对应到服务器的url上。如果使用session对象,服务器的url实际上是我们常见的http协议客户端请求的url。cookie数据:浏览器请求文件,客户端会获取jscookie,然后把自己的用户id放到index.js/resources/cookie.js文件中。
res的内容和我们常见的http请求的一样。因此使用reshttp或https请求之间都是会相互转换的,以给爬虫建立一个全文检索的项目。在多个页面采用同一个请求,可以有效降低带宽的占用。但为什么一定要设置https呢?我想说的是requestjs才不只是request,它还包括对jshttp等的https连接,这样的话和他一起存在的全文检索图片才能起作用。
请求两端都带有认证。爬虫可以直接解析这种证书,然后用浏览器上传你的图片。使用图片来作为cookie在请求中传递这样。
php抓取网页数据实例(大开脑洞使用php抓取iphone上面的应用(安卓机))
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-27 02:07
php抓取网页数据实例;src=2_5_1#page005还要抓到手机验证码手机验证码生成php爬虫代码1.网页的代码中所有的手机验证码都可以抓,而且都是可以查找到的php爬虫代码2.代码会经过加密处理。来防止抓取3.手机号码一定有个group,只要找到这个group就可以进行下一步。
谢邀,如何使用php中的request来抓取url,本人没有研究过,有兴趣可以去看看百度经验php抓取android应用(支付宝)数据。
回答者,对request有了很深入的了解了,但是没有实际使用到!如果你想用request,
有人通过楼上的在爬虫的爬取时大开脑洞所实现。原地址:大开脑洞使用php代码抓取iphone上面的应用(安卓机可以访问是需要借助wifi热点的),点击进入项目。
在自己的项目中在实践多种的抓取方式我特别喜欢利用java和php配合一个ide来开发爬虫或者抓取如果你的项目还不够庞大,只是使用到了定时任务抓取我觉得大体思路还是差不多, 查看全部
php抓取网页数据实例(大开脑洞使用php抓取iphone上面的应用(安卓机))
php抓取网页数据实例;src=2_5_1#page005还要抓到手机验证码手机验证码生成php爬虫代码1.网页的代码中所有的手机验证码都可以抓,而且都是可以查找到的php爬虫代码2.代码会经过加密处理。来防止抓取3.手机号码一定有个group,只要找到这个group就可以进行下一步。
谢邀,如何使用php中的request来抓取url,本人没有研究过,有兴趣可以去看看百度经验php抓取android应用(支付宝)数据。
回答者,对request有了很深入的了解了,但是没有实际使用到!如果你想用request,
有人通过楼上的在爬虫的爬取时大开脑洞所实现。原地址:大开脑洞使用php代码抓取iphone上面的应用(安卓机可以访问是需要借助wifi热点的),点击进入项目。
在自己的项目中在实践多种的抓取方式我特别喜欢利用java和php配合一个ide来开发爬虫或者抓取如果你的项目还不够庞大,只是使用到了定时任务抓取我觉得大体思路还是差不多,
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-02-25 00:14
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行格式转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是提示一下,我们可以使用多线程对所有页面的当前数据执行采集,并通过一个线程采集当前页面数据和一个翻页动作,所有数据都可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php抓取网页数据实例(黄渤的电影《一出好戏》为例(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-23 11:04
php抓取网页数据实例现在打开百度云,输入要看的电影的路径,就可以直接从百度云中下载了!接下来,我以黄渤的电影《一出好戏》为例,
1、首先,在浏览器中打开网页,
2、打开电影网页后,就可以看到了有很多电影,那么每个电影所在的页面链接是:;share=false&type=subtitle&desc=“下载相应电影地址”&download=all&subtitle=“xxx”这里我想下载黄渤的电影《一出好戏》,
3、然后鼠标移到电影对应的位置即可看到电影的名称“一出好戏”,
4、则会出现“个人中心”了,
5、点击“创建个人网站”或“个人博客”
6、然后点击“新建”
7、点击“/”
8、然后点击“电影”,
9、点击到“黄渤的电影《一出好戏》”后,
0、通过浏览器本地可直接将电影地址提取到本地1
1、复制到上面编辑器,
2、然后鼠标移到“电影”中,点击鼠标右键,
3、然后点击“保存”1
4、最后点击提取的名称,
5、最后鼠标移到“下载地址”处,点击鼠标右键即可直接提取,
搜索一下「下载整部电影」或许会出来些数据集。 查看全部
php抓取网页数据实例(黄渤的电影《一出好戏》为例(图))
php抓取网页数据实例现在打开百度云,输入要看的电影的路径,就可以直接从百度云中下载了!接下来,我以黄渤的电影《一出好戏》为例,
1、首先,在浏览器中打开网页,
2、打开电影网页后,就可以看到了有很多电影,那么每个电影所在的页面链接是:;share=false&type=subtitle&desc=“下载相应电影地址”&download=all&subtitle=“xxx”这里我想下载黄渤的电影《一出好戏》,
3、然后鼠标移到电影对应的位置即可看到电影的名称“一出好戏”,
4、则会出现“个人中心”了,
5、点击“创建个人网站”或“个人博客”
6、然后点击“新建”
7、点击“/”
8、然后点击“电影”,
9、点击到“黄渤的电影《一出好戏》”后,
0、通过浏览器本地可直接将电影地址提取到本地1
1、复制到上面编辑器,
2、然后鼠标移到“电影”中,点击鼠标右键,
3、然后点击“保存”1
4、最后点击提取的名称,
5、最后鼠标移到“下载地址”处,点击鼠标右键即可直接提取,
搜索一下「下载整部电影」或许会出来些数据集。
php抓取网页数据实例(php抓取网页数据实例代码其实很简单-php网站数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-20 16:01
php抓取网页数据实例代码
其实很简单。用dw做一个页面内容查询,再用php进行网页数据抓取。假设你网站上要抓取:php网站抓取参考:这里说一下页面数据抓取的需求,要抓取去掉弹幕一类的,要求必须使用dw做页面内容查询。
提供一个需求思路。可以结合url请求页面,selenium库来实现。url请求页面就是我们要抓取的页面url,比如通过豆瓣小组网站的分页来抓取的页面url是/-wrok/我们需要抓取该页面内容页面我们需要一个抓包工具。python可以使用adsafe,php可以使用db4ute库。完成以上两步,我们可以进行模拟点击了。至于更具体的自动抓取我没有想到。我们可以共同讨论,互相学习。
python使用php可以进行抓取,解析url以及查询数据。
php抓取页面这个我不知道怎么答,第二种情况我有过试验,我设置如下useragent。这个写在php后面没用,就是在http的useragent里面加上就可以抓取了。
php要看哪个版本了,反正不要爬那种比较多开的规则,要爬那种结构比较清晰的,
1.php都搞不定,
个人觉得还是用php,因为adsafe倒是做的不错,但是要想不被屏蔽的话,得提供一个高度安全的域名,不过php总比adsafe强。 查看全部
php抓取网页数据实例(php抓取网页数据实例代码其实很简单-php网站数据)
php抓取网页数据实例代码
其实很简单。用dw做一个页面内容查询,再用php进行网页数据抓取。假设你网站上要抓取:php网站抓取参考:这里说一下页面数据抓取的需求,要抓取去掉弹幕一类的,要求必须使用dw做页面内容查询。
提供一个需求思路。可以结合url请求页面,selenium库来实现。url请求页面就是我们要抓取的页面url,比如通过豆瓣小组网站的分页来抓取的页面url是/-wrok/我们需要抓取该页面内容页面我们需要一个抓包工具。python可以使用adsafe,php可以使用db4ute库。完成以上两步,我们可以进行模拟点击了。至于更具体的自动抓取我没有想到。我们可以共同讨论,互相学习。
python使用php可以进行抓取,解析url以及查询数据。
php抓取页面这个我不知道怎么答,第二种情况我有过试验,我设置如下useragent。这个写在php后面没用,就是在http的useragent里面加上就可以抓取了。
php要看哪个版本了,反正不要爬那种比较多开的规则,要爬那种结构比较清晰的,
1.php都搞不定,
个人觉得还是用php,因为adsafe倒是做的不错,但是要想不被屏蔽的话,得提供一个高度安全的域名,不过php总比adsafe强。
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-14 02:06
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php抓取网页数据实例(一个+jsou提取网页数据的分类汇总(一))
原创链接
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品的型号、数量、报价和供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php抓取网页数据实例(php抓取网页数据实例,拿到网页的数据我们需要看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-13 18:01
php抓取网页数据实例,拿到网页数据我们需要看网页的规格,大小,返回的格式等等,这里推荐用web浏览器发送url调用php这种接口,一切正常php客户端进入就获取网页。
php抓取网页?http请求?现在有基于telnet的抓取软件,很方便,关键是速度快。
我就两个解决方案。第一,网络请求。第二,分析网页。需要的话我再补充一下网页数据内容。
有人提到telnet。我还有一个笨办法,直接上qq然后写个爬虫去弄。
你怎么知道人家没有封你ip?我也好奇好久了。
传统解决办法很简单,加上一个分析url规律然后再用自己语言解析的https就能搞定了。分析不了的或者解析出来json什么玩意的,就得用这种专门的http处理引擎,简单点说就是开发脚本那种。如果要获取外网的直接看ip喽。但能不能做到就不知道了。毕竟php只能抓包到个链接地址。
有真的吗?看到知乎上说有的,我试了一下,抓包成功。但是在评论区里有好多广告投放者。刷经验/骗赞。还有陌生号码/在线时间。都不知道是什么鬼。然后不禁想到,这些貌似是有利益关系的吧。
你可以用php搭建个可以抓取通过telnet获取即时数据的服务器。 查看全部
php抓取网页数据实例(php抓取网页数据实例,拿到网页的数据我们需要看)
php抓取网页数据实例,拿到网页数据我们需要看网页的规格,大小,返回的格式等等,这里推荐用web浏览器发送url调用php这种接口,一切正常php客户端进入就获取网页。
php抓取网页?http请求?现在有基于telnet的抓取软件,很方便,关键是速度快。
我就两个解决方案。第一,网络请求。第二,分析网页。需要的话我再补充一下网页数据内容。
有人提到telnet。我还有一个笨办法,直接上qq然后写个爬虫去弄。
你怎么知道人家没有封你ip?我也好奇好久了。
传统解决办法很简单,加上一个分析url规律然后再用自己语言解析的https就能搞定了。分析不了的或者解析出来json什么玩意的,就得用这种专门的http处理引擎,简单点说就是开发脚本那种。如果要获取外网的直接看ip喽。但能不能做到就不知道了。毕竟php只能抓包到个链接地址。
有真的吗?看到知乎上说有的,我试了一下,抓包成功。但是在评论区里有好多广告投放者。刷经验/骗赞。还有陌生号码/在线时间。都不知道是什么鬼。然后不禁想到,这些貌似是有利益关系的吧。
你可以用php搭建个可以抓取通过telnet获取即时数据的服务器。
php抓取网页数据实例(php抓取网页数据实例分享--看这里apache+php+mysql)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-13 15:02
php抓取网页数据实例分享---看这里apache+php+mysql+flash,
首先本身爬虫是个简单的设计来解决各种数据量的问题。目前不提倡在一个服务器上做爬虫,三个标准:内存,硬盘,访问频率;然后服务器上架这么简单的方法请再仔细研究基本运作过程;php+mysql方法很多,我随便举几个例子:模拟登录就方法autoproxy例子登录好了,然后模拟一个正常访问get参数,再调用db.showroot()给db初始化,这里cookie一般在远程开发配置文件就完成了;然后可以传递到自己的服务器,顺便httpreferer;返回可以post参数给别人,然后fetchafter;自己做服务器控制,push、pull、delete等soeasy!如果要用js的话,可以实现简单的追踪,这里参考看下这个go爬虫效果:。
使用postman无论多简单的爬虫都能实现100w+数据的传输。用php+mysql+flash可以实现100w+的数据传输,其实因为你这个应用用不到存储层的东西,所以传输效率不是特别高,但是非常快。100万数据用js可以传输300w以上。100w数据是什么意思?其实就是爬虫程序所有的http请求传过来的全部数据。
使用httpfuzzer
apache+php+mysql+flash。apache:一般的iis只需要设置accesshost,地址为你的http服务器hostname即可。若是要用专用apache或者是原来的apache端口服务器(如/)需要先更换成新的http服务器(如8080端口服务器)。php:apache无论是在后端配置还是在nginx/uwsgi上都需要更换成php版本,关于如何更换php版本请参考相关资料并下载配置文件。
mysql:使用mysql挂载nginxrepo地址,挂载完后可以用www-port5000-5005端口(对应),用作uwsgi程序部署。flash:在原先的php端口服务器上配置flash插件,以80端口为例,即nginx和8080端口之间重新做一次404/403端口映射。 查看全部
php抓取网页数据实例(php抓取网页数据实例分享--看这里apache+php+mysql)
php抓取网页数据实例分享---看这里apache+php+mysql+flash,
首先本身爬虫是个简单的设计来解决各种数据量的问题。目前不提倡在一个服务器上做爬虫,三个标准:内存,硬盘,访问频率;然后服务器上架这么简单的方法请再仔细研究基本运作过程;php+mysql方法很多,我随便举几个例子:模拟登录就方法autoproxy例子登录好了,然后模拟一个正常访问get参数,再调用db.showroot()给db初始化,这里cookie一般在远程开发配置文件就完成了;然后可以传递到自己的服务器,顺便httpreferer;返回可以post参数给别人,然后fetchafter;自己做服务器控制,push、pull、delete等soeasy!如果要用js的话,可以实现简单的追踪,这里参考看下这个go爬虫效果:。
使用postman无论多简单的爬虫都能实现100w+数据的传输。用php+mysql+flash可以实现100w+的数据传输,其实因为你这个应用用不到存储层的东西,所以传输效率不是特别高,但是非常快。100万数据用js可以传输300w以上。100w数据是什么意思?其实就是爬虫程序所有的http请求传过来的全部数据。
使用httpfuzzer
apache+php+mysql+flash。apache:一般的iis只需要设置accesshost,地址为你的http服务器hostname即可。若是要用专用apache或者是原来的apache端口服务器(如/)需要先更换成新的http服务器(如8080端口服务器)。php:apache无论是在后端配置还是在nginx/uwsgi上都需要更换成php版本,关于如何更换php版本请参考相关资料并下载配置文件。
mysql:使用mysql挂载nginxrepo地址,挂载完后可以用www-port5000-5005端口(对应),用作uwsgi程序部署。flash:在原先的php端口服务器上配置flash插件,以80端口为例,即nginx和8080端口之间重新做一次404/403端口映射。

