
php抓取网页所有图片
php抓取网页所有图片(几个(从代码角度)的信息;这里换成data-original属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-08 03:17
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正! 查看全部
php抓取网页所有图片(几个(从代码角度)的信息;这里换成data-original属性)
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:

获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正!
php抓取网页所有图片(php获取请求网页里面的所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-02 15:02
PHP的史努比用了两天了,很有用。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(内部仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能会做防盗链,我想先抓取本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)——如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
”;
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次性读取整个文件(或逐行读取),然后用临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是超过限制就会有问题。它会“越界”并破坏下一行的数据(不能像JavaScript中的“选择”概念那样用新的内容代替)。
这是用于试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
PHP的史努比用了两天了,很有用。获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息,使用fetchtext(其内部... 查看全部
php抓取网页所有图片(php获取请求网页里面的所有链接())
PHP的史努比用了两天了,很有用。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(内部仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能会做防盗链,我想先抓取本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)——如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
”;
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次性读取整个文件(或逐行读取),然后用临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是超过限制就会有问题。它会“越界”并破坏下一行的数据(不能像JavaScript中的“选择”概念那样用新的内容代替)。
这是用于试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
PHP的史努比用了两天了,很有用。获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息,使用fetchtext(其内部...
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 21:06
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上的其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,和很多浏览器一样,比如谷歌Chrome就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
您可以在html源代码中查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要自己想办法处理错误或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法并不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误自动下载自行终止的情况。通常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一级深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
查看全部
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图)
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上的其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,和很多浏览器一样,比如谷歌Chrome就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
您可以在html源代码中查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要自己想办法处理错误或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法并不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误自动下载自行终止的情况。通常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一级深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
php抓取网页所有图片( 用PHP的方法来输出随机图片的好处是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-29 19:08
用PHP的方法来输出随机图片的好处是什么?)
告诉大家PHP随机显示目录下图片的源代码
如果用JavaScript编写,程序流程应该是:创建图像数组->随机选择数组中的一个值->生成样式并编写body标签。
但是,如果用JS来做,有以下缺点:
1. 万一浏览器禁用了JS,就会失效,写代码需要考虑兼容性。
2.维护比较麻烦,把图片的位置存放在一个数组中。
于是我提出用PHP来处理,但我和她对PHP都倒了半桶水,一时想不起来怎么办。今天高士云,看到一个PHP随机展示目录下图片的源代码,学习一下,分享一下。
文本
先看原理:从一个目录中获取某类文件的列表(如果在WEB上使用一般为jpg/gif/png)->通过随机函数选择图片->输出代码。
PHP代码如下:
1<br />2<br />3<br />4<br />5<br />6<br />7<br />8<br />9<br />10<br />11<br />12<br />13<br />14<br />15<br />16<br />17<br />18<br />19<br />20<br />21<br />22<br />23<br />24<br />25<br />26<br />
$imglist='';<br /> //用$img_folder变量保存图片所在目录,必须用“/”结尾<br /> $img_folder = "images/tutorials/";<br /> <br /> mt_srand((double)microtime()*1000);<br /> <br /> //使用目录类<br /> $imgs = dir($img_folder);<br /> <br /> //检查目录下是否有图片,并生成一个清单<br /> while ($file = $imgs->read()) {<br /> if (eregi("gif", $file) || eregi("jpg", $file) || eregi("png", $file))<br /> $imglist .= "$file ";<br /> <br /> } closedir($imgs->handle);<br /> <br /> //把清单里的项都放到一个数组里<br /> $imglist = explode(" ", $imglist);<br /> $no = sizeof($imglist)-2;<br /> <br /> //生成一个介于0和图片数量之间的随机数<br /> $random = mt_rand(0, $no);<br /> $image = $imglist[$random];<br /> <br />//输出结果<br /> echo ''/spanspan style=';
如果你想通过这个功能改变页面的背景,你可以把最后一句改成:
1<br />2<br />
<p>echo ' 查看全部
php抓取网页所有图片(
用PHP的方法来输出随机图片的好处是什么?)
告诉大家PHP随机显示目录下图片的源代码
如果用JavaScript编写,程序流程应该是:创建图像数组->随机选择数组中的一个值->生成样式并编写body标签。
但是,如果用JS来做,有以下缺点:
1. 万一浏览器禁用了JS,就会失效,写代码需要考虑兼容性。
2.维护比较麻烦,把图片的位置存放在一个数组中。
于是我提出用PHP来处理,但我和她对PHP都倒了半桶水,一时想不起来怎么办。今天高士云,看到一个PHP随机展示目录下图片的源代码,学习一下,分享一下。
文本
先看原理:从一个目录中获取某类文件的列表(如果在WEB上使用一般为jpg/gif/png)->通过随机函数选择图片->输出代码。
PHP代码如下:
1<br />2<br />3<br />4<br />5<br />6<br />7<br />8<br />9<br />10<br />11<br />12<br />13<br />14<br />15<br />16<br />17<br />18<br />19<br />20<br />21<br />22<br />23<br />24<br />25<br />26<br />
$imglist='';<br /> //用$img_folder变量保存图片所在目录,必须用“/”结尾<br /> $img_folder = "images/tutorials/";<br /> <br /> mt_srand((double)microtime()*1000);<br /> <br /> //使用目录类<br /> $imgs = dir($img_folder);<br /> <br /> //检查目录下是否有图片,并生成一个清单<br /> while ($file = $imgs->read()) {<br /> if (eregi("gif", $file) || eregi("jpg", $file) || eregi("png", $file))<br /> $imglist .= "$file ";<br /> <br /> } closedir($imgs->handle);<br /> <br /> //把清单里的项都放到一个数组里<br /> $imglist = explode(" ", $imglist);<br /> $no = sizeof($imglist)-2;<br /> <br /> //生成一个介于0和图片数量之间的随机数<br /> $random = mt_rand(0, $no);<br /> $image = $imglist[$random];<br /> <br />//输出结果<br /> echo ''/spanspan style=';
如果你想通过这个功能改变页面的背景,你可以把最后一句改成:
1<br />2<br />
<p>echo '
php抓取网页所有图片(php抓取网页所有图片文件命名规则或采用php自带的图片命名方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-28 15:04
php抓取网页所有图片文件php抓取网页所有图片文件图片命名规则或采用php自带的图片命名方法作者:jacky项目组人员:张力核,徐勇,张丽芳,赵博,张露项目地址:地址项目简介图片文件自动分类命名是很常见的一种网页搜索内容,具体代码实现上,是通过字典类型的存储图片名称,并转为php可以处理的类型处理,存储在二级目录中存储。
目前该项目仅爬取原网站的图片文件的文件名列表供运行时查看,同时可以根据图片文件名统计属性列表及索引等信息。下面将会通过这个项目来模拟场景来搭建简单的php爬虫系统。写在前面本文基于requests库,如果你的项目可以使用这个库,那么你可以跳过这一部分。下面我将会讲图片文件采用php库phpstorm来写,同时我使用了图片文件命名规则,并在项目中通过from__future__importprint_function导入了print_function函数,具体讲解可参考官方手册:。
1、首先创建两个cookie,作为接下来工作的跳板,工作先要建立一个图片文件的数据库表,我会使用mysql数据库为原始的database数据库。
2、创建两个图片文件的下载器,这两个下载器都是phpstorm的python插件。scrapyclient和images。我会将scrapyclient命名为pool下的candidate.py文件,images文件命名为pool.py文件。
3、cookie,存储图片文件名和相应的文件数据。
1)sitemap可以帮助我们快速地抓取所有的图片文件。创建下载器后,需要将图片文件路径和相应的文件命名设置到cookie中。
2)postmancode可以帮助我们抓取images文件名和相应的文件数据。
create_duplicate_request('images',[//*'results','app。php']);//get_url和post_url参数部分*url=":8000/images/facet/org/bernard/face-hanhi。php"*post=""*expires=""*paths="";$results_files=post($url,$post_expires_in_year);?>。
4、图片文件爬取,需要构建一个爬虫服务。在爬虫服务中主要需要用到两个参数:mysql数据库驱动类和requests库的驱动方法。我们如果只是想构建单个爬虫,那么直接将驱动方法提供给requests库作为一个url,直接使用这个url即可。
1)requests库驱动中的picker方法可以帮助我们快速遍历post请求。 查看全部
php抓取网页所有图片(php抓取网页所有图片文件命名规则或采用php自带的图片命名方法)
php抓取网页所有图片文件php抓取网页所有图片文件图片命名规则或采用php自带的图片命名方法作者:jacky项目组人员:张力核,徐勇,张丽芳,赵博,张露项目地址:地址项目简介图片文件自动分类命名是很常见的一种网页搜索内容,具体代码实现上,是通过字典类型的存储图片名称,并转为php可以处理的类型处理,存储在二级目录中存储。
目前该项目仅爬取原网站的图片文件的文件名列表供运行时查看,同时可以根据图片文件名统计属性列表及索引等信息。下面将会通过这个项目来模拟场景来搭建简单的php爬虫系统。写在前面本文基于requests库,如果你的项目可以使用这个库,那么你可以跳过这一部分。下面我将会讲图片文件采用php库phpstorm来写,同时我使用了图片文件命名规则,并在项目中通过from__future__importprint_function导入了print_function函数,具体讲解可参考官方手册:。
1、首先创建两个cookie,作为接下来工作的跳板,工作先要建立一个图片文件的数据库表,我会使用mysql数据库为原始的database数据库。
2、创建两个图片文件的下载器,这两个下载器都是phpstorm的python插件。scrapyclient和images。我会将scrapyclient命名为pool下的candidate.py文件,images文件命名为pool.py文件。
3、cookie,存储图片文件名和相应的文件数据。
1)sitemap可以帮助我们快速地抓取所有的图片文件。创建下载器后,需要将图片文件路径和相应的文件命名设置到cookie中。
2)postmancode可以帮助我们抓取images文件名和相应的文件数据。
create_duplicate_request('images',[//*'results','app。php']);//get_url和post_url参数部分*url=":8000/images/facet/org/bernard/face-hanhi。php"*post=""*expires=""*paths="";$results_files=post($url,$post_expires_in_year);?>。
4、图片文件爬取,需要构建一个爬虫服务。在爬虫服务中主要需要用到两个参数:mysql数据库驱动类和requests库的驱动方法。我们如果只是想构建单个爬虫,那么直接将驱动方法提供给requests库作为一个url,直接使用这个url即可。
1)requests库驱动中的picker方法可以帮助我们快速遍历post请求。
php抓取网页所有图片(任务解析及提升任务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-23 08:21
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是: 查看全部
php抓取网页所有图片(任务解析及提升任务)
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是:
php抓取网页所有图片(php抓取网页所有图片的话,方便查看webkit的抓取设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-23 03:05
php抓取网页所有图片的话,一般浏览器本身已经提供了这个功能,当然现在大多数浏览器都增加了webkit插件来帮你抓取页面上的图片。下面是我用自己创建的,每个网页一个图片的代码,方便查看webkit的抓取设置:</a></a></a>一般我会这样做,抓取某个链接时,从上至下顺序抓取,把网页上有的图片抓取下来(如果没有,那就根据实际情况,抓取几个并不存在的图片);再一张张拿下来,进行去重。
<p>1。使用chrome,chrome浏览器内置去重插件:user-agentselector-webkit2。将图片缩小,通过img-replace函数来实现3。正则表达式-replace(图片名,'。xxx')4。如果不明白图片地址,请使用alert函数,从头到尾弹出20次以上(即200个图片页),它将告诉你图片所在页面位置2015。02。23更新---这两个前两个不太好用,补充一下1。index。php 查看全部
php抓取网页所有图片(php抓取网页所有图片的话,方便查看webkit的抓取设置)
php抓取网页所有图片的话,一般浏览器本身已经提供了这个功能,当然现在大多数浏览器都增加了webkit插件来帮你抓取页面上的图片。下面是我用自己创建的,每个网页一个图片的代码,方便查看webkit的抓取设置:</a></a></a>一般我会这样做,抓取某个链接时,从上至下顺序抓取,把网页上有的图片抓取下来(如果没有,那就根据实际情况,抓取几个并不存在的图片);再一张张拿下来,进行去重。
<p>1。使用chrome,chrome浏览器内置去重插件:user-agentselector-webkit2。将图片缩小,通过img-replace函数来实现3。正则表达式-replace(图片名,'。xxx')4。如果不明白图片地址,请使用alert函数,从头到尾弹出20次以上(即200个图片页),它将告诉你图片所在页面位置2015。02。23更新---这两个前两个不太好用,补充一下1。index。php
php抓取网页所有图片(php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-22 23:01
php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,如果压缩包中没有图片,那么可以通过:wget-i-x-1.php提取出php所有图片数据,然后代码读取.
-fanjie/php-blob/master/php_ff.php?pd=copy_image
php调用浏览器发送get/post请求获取相应数据
这个是可以做到的,安装一个神秘代码(secretcode)一样的东西,这个请求结果就是你想要的数据,发送http请求之后会有文件协议数据,把blob格式文件发送给服务器即可。
php拿了想要的图,之后调用系统命令提取保存下来。但是wordpress在安装xxx.php后,并不能正常配置xxx.php,需要到php相关安装目录重新安装一下xxx.php,重启wordpress才可以调用xxx.php。
wp-lib.php->images.php
wordpressapi接口文档,
在网站开始,用爬虫抓取图片,再在终端配置images.php,可以拿到所有图片。
很简单,关注appso威信公众号:wordpressworld,
wordpress好像不能抓图。这个倒是可以。比如搜索张雪峰的网站,就可以在主页面拿到图片。其他的网站类似,在浏览器的网页缓存文件夹拿到静态图。我已经百度到了解决办法,速度不错,如果抓不到,再考虑其他解决方案。 查看全部
php抓取网页所有图片(php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,)
php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,如果压缩包中没有图片,那么可以通过:wget-i-x-1.php提取出php所有图片数据,然后代码读取.
-fanjie/php-blob/master/php_ff.php?pd=copy_image
php调用浏览器发送get/post请求获取相应数据
这个是可以做到的,安装一个神秘代码(secretcode)一样的东西,这个请求结果就是你想要的数据,发送http请求之后会有文件协议数据,把blob格式文件发送给服务器即可。
php拿了想要的图,之后调用系统命令提取保存下来。但是wordpress在安装xxx.php后,并不能正常配置xxx.php,需要到php相关安装目录重新安装一下xxx.php,重启wordpress才可以调用xxx.php。
wp-lib.php->images.php
wordpressapi接口文档,
在网站开始,用爬虫抓取图片,再在终端配置images.php,可以拿到所有图片。
很简单,关注appso威信公众号:wordpressworld,
wordpress好像不能抓图。这个倒是可以。比如搜索张雪峰的网站,就可以在主页面拿到图片。其他的网站类似,在浏览器的网页缓存文件夹拿到静态图。我已经百度到了解决办法,速度不错,如果抓不到,再考虑其他解决方案。
php抓取网页所有图片( 2018-07-30python自动网页截图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-14 08:09
2018-07-30python自动网页截图
)
Python实现网页自动截图和裁剪图片
时间:2018-07-30
本文文章主要详细介绍python对网页自动截图和裁剪图片的实现。有一定的参考价值,感兴趣的朋友可以参考。
本文示例分享了python自动网页截图和裁剪图片的具体代码,供大家参考,具体内容如下
代码:
# coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from PIL import Image
import os
all_urls = ['http:/****edit']
def login():
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options)
driver.set_window_size(1200, 741)
driver.implicitly_wait(2)
print('初始化中...')
driver.get("http://x*****e")
print('填写登录信息中...')
acc = driver.find_element_by_id('login-email')
pwd = driver.find_element_by_id('login-pass')
btn = driver.find_element_by_tag_name('button')
acc.send_keys('***')
pwd.send_keys('***')
btn.click()
print('跳转到验证码页面中...')
time.sleep(2)
capta = driver.find_element_by_id('code')
capta_input = input('请输入两步验证码:')
capta.send_keys(capta_input)
btn1 = driver.find_element_by_tag_name('button')
btn1.click()
time.sleep(2)
print('跳转到创意编辑页面中...')
return driver
def get_screen(driver,urls):
count = 1
for url in urls:
driver.get(url)
print('正在抓取--> %s'% url)
count +=1
time.sleep(2)
uid = url.split('/')[-2]
cid = url.split('/')[-5]
driver.get_screenshot_as_file("./screen_shot/{}-{}.png".format(uid,cid))
print("创意--> {}-{}.png 已经保存".format(uid,cid))
print('还剩 %s 个'% str(len(urls)-count))
def crop_img():
for img in os.listdir('./screen_shot'):
if img.endswith('.png'):
print('%s裁剪中。。'% img)
im = Image.open('./screen_shot/%s'% img)
x = 755
y = 162
w = 383
h = 346
region = im.crop((x, y, x+w, y+h))
region.save("./screenshot_final/%s" % img)
if __name__ == '__main__':
driver = login()
get_screen(driver,all_urls)
driver.quit()
print('所有抓取结束')
crop_img()
print('所有裁剪结束')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
热门文章
查看全部
php抓取网页所有图片(
2018-07-30python自动网页截图
)
Python实现网页自动截图和裁剪图片
时间:2018-07-30
本文文章主要详细介绍python对网页自动截图和裁剪图片的实现。有一定的参考价值,感兴趣的朋友可以参考。
本文示例分享了python自动网页截图和裁剪图片的具体代码,供大家参考,具体内容如下
代码:
# coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from PIL import Image
import os
all_urls = ['http:/****edit']
def login():
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options)
driver.set_window_size(1200, 741)
driver.implicitly_wait(2)
print('初始化中...')
driver.get("http://x*****e")
print('填写登录信息中...')
acc = driver.find_element_by_id('login-email')
pwd = driver.find_element_by_id('login-pass')
btn = driver.find_element_by_tag_name('button')
acc.send_keys('***')
pwd.send_keys('***')
btn.click()
print('跳转到验证码页面中...')
time.sleep(2)
capta = driver.find_element_by_id('code')
capta_input = input('请输入两步验证码:')
capta.send_keys(capta_input)
btn1 = driver.find_element_by_tag_name('button')
btn1.click()
time.sleep(2)
print('跳转到创意编辑页面中...')
return driver
def get_screen(driver,urls):
count = 1
for url in urls:
driver.get(url)
print('正在抓取--> %s'% url)
count +=1
time.sleep(2)
uid = url.split('/')[-2]
cid = url.split('/')[-5]
driver.get_screenshot_as_file("./screen_shot/{}-{}.png".format(uid,cid))
print("创意--> {}-{}.png 已经保存".format(uid,cid))
print('还剩 %s 个'% str(len(urls)-count))
def crop_img():
for img in os.listdir('./screen_shot'):
if img.endswith('.png'):
print('%s裁剪中。。'% img)
im = Image.open('./screen_shot/%s'% img)
x = 755
y = 162
w = 383
h = 346
region = im.crop((x, y, x+w, y+h))
region.save("./screenshot_final/%s" % img)
if __name__ == '__main__':
driver = login()
get_screen(driver,all_urls)
driver.quit()
print('所有抓取结束')
crop_img()
print('所有裁剪结束')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
热门文章

php抓取网页所有图片(什么是网页抓取?()的代码-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 00:09
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网页爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。本网站提供优质免费素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
文件
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的网页,而不是一次只请求一个网页并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图片页面:
<p> 查看全部
php抓取网页所有图片(什么是网页抓取?()的代码-)
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网页爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。本网站提供优质免费素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
文件
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的网页,而不是一次只请求一个网页并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图片页面:
<p>
php抓取网页所有图片(php获取请求网页里面的所有链接(图)使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-09 06:21
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
因特殊需要,只抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
";
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "\1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被像 JavaScript 中的“选择”概念那样的新内容替换)。
下面是试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
:///PHPjc/752523.htmlTechArticle 使用了两天的 PHP Snoopy 类,发现效果很好。要获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息使用fetchtext(其内部... 查看全部
php抓取网页所有图片(php获取请求网页里面的所有链接(图)使用方法)
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
因特殊需要,只抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
";
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "\1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被像 JavaScript 中的“选择”概念那样的新内容替换)。
下面是试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
:///PHPjc/752523.htmlTechArticle 使用了两天的 PHP Snoopy 类,发现效果很好。要获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息使用fetchtext(其内部...
php抓取网页所有图片(内置的.net代码框架,支持CSS统一设置页面风格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-09 06:20
风月网代码生成器【FireCode Creator】V1.3 精简版
《风悦.Net代码生成器【FireCode Creator】》是一款使用.Net FrameWork2.0框架,基于多数据库的程序代码生成软件。可以快速创建数据信息:添加、编辑、查看、列表、搜索功能。默认提供了asp和aspx两个代码框架和多个界面设计模板,可以随意修改和管理。通过自定义生成程序的界面风格和输出代码,用户可以将其扩展为ASPX/ASP/PHP/JSP等各种程序的代码生成器。内置的.net代码框架可以用C#语言构建.net解决方案,可以在VS2005中直接编辑,不仅可以帮助.net初学者快速上手,还可以最大限度地提高程序员的工作效率。01、
现在就下载 查看全部
php抓取网页所有图片(内置的.net代码框架,支持CSS统一设置页面风格)
风月网代码生成器【FireCode Creator】V1.3 精简版
《风悦.Net代码生成器【FireCode Creator】》是一款使用.Net FrameWork2.0框架,基于多数据库的程序代码生成软件。可以快速创建数据信息:添加、编辑、查看、列表、搜索功能。默认提供了asp和aspx两个代码框架和多个界面设计模板,可以随意修改和管理。通过自定义生成程序的界面风格和输出代码,用户可以将其扩展为ASPX/ASP/PHP/JSP等各种程序的代码生成器。内置的.net代码框架可以用C#语言构建.net解决方案,可以在VS2005中直接编辑,不仅可以帮助.net初学者快速上手,还可以最大限度地提高程序员的工作效率。01、
现在就下载
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-05 22:15
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 类文件流式下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着对一个URL地址的web请求响应成功;如果有成功,当然会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?
[^\s\t\r\n""']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=(['""]?)(?!javascript|__doPostBack)(?[^'""\s*#]+)[^>]* >";
5.指定图片类型的匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,这里是两个方向的图片匹配,首先匹配外部链接,这里是要匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete 方法不仅在下载成功时调用,即使出现错误也需要调用,以免出现错误时自动下载立即中止。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管) 查看全部
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图))
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 类文件流式下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着对一个URL地址的web请求响应成功;如果有成功,当然会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?
[^\s\t\r\n""']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=(['""]?)(?!javascript|__doPostBack)(?[^'""\s*#]+)[^>]* >";
5.指定图片类型的匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,这里是两个方向的图片匹配,首先匹配外部链接,这里是要匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete 方法不仅在下载成功时调用,即使出现错误也需要调用,以免出现错误时自动下载立即中止。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
php抓取网页所有图片(php抓取网页所有图片并读取命令说明抓取从iis登录的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-01 14:19
php抓取网页所有图片并读取命令说明抓取从iis登录的网页我的解析-网页抓取-领扣(leetcode)request库抓取php中包含源码,再转为字符串。etag加速php链接到httprefresh。php中有3个对比方法可以测试加速器的效果:redisserver或其他命令refreshclientsend(refresh|redisserver)可以获取到http数据库,再加速获取数据库的数据。
如果不需要redis数据库服务,可以使用zmapinset并且不需要开启redis服务。get/http?from=xxx可以获取url的token。可以用来发送请求,后续也可以用来incoming、outside。http_setphpsocketsocket_set请求token可以解析http连接的token,比如http_connect_token。
可以用来发送请求,接收响应。我的笔记结语测试url是否加速有两种情况:1、手动提交redisserver命令,使用:redisserver--rhost3000--redisdate0。没有使用get请求时,可以请求baidu进行加速。2、使用refresh(stream|redis)方法。就是指定源码抓取时,推送给php。
所以php响应与之配合使用,如:>redisserver--rhost3000--redisdate0。
可以通过php代码把所有数据解析出来。 查看全部
php抓取网页所有图片(php抓取网页所有图片并读取命令说明抓取从iis登录的网页)
php抓取网页所有图片并读取命令说明抓取从iis登录的网页我的解析-网页抓取-领扣(leetcode)request库抓取php中包含源码,再转为字符串。etag加速php链接到httprefresh。php中有3个对比方法可以测试加速器的效果:redisserver或其他命令refreshclientsend(refresh|redisserver)可以获取到http数据库,再加速获取数据库的数据。
如果不需要redis数据库服务,可以使用zmapinset并且不需要开启redis服务。get/http?from=xxx可以获取url的token。可以用来发送请求,后续也可以用来incoming、outside。http_setphpsocketsocket_set请求token可以解析http连接的token,比如http_connect_token。
可以用来发送请求,接收响应。我的笔记结语测试url是否加速有两种情况:1、手动提交redisserver命令,使用:redisserver--rhost3000--redisdate0。没有使用get请求时,可以请求baidu进行加速。2、使用refresh(stream|redis)方法。就是指定源码抓取时,推送给php。
所以php响应与之配合使用,如:>redisserver--rhost3000--redisdate0。
可以通过php代码把所有数据解析出来。
php抓取网页所有图片(php抓取网页所有图片的方法,怎么爬虫我也学习过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-27 03:04
php抓取网页所有图片的方法是:打开网站,发现该网站并没有对php做mysql的读写操作(js),由于是php程序,所以可以不用curl,尝试以命令行的方式:输入jieba-lobject-m"*.jpg"抓取网页上的所有图片。点击返回结果,发现有几十万张图片,图片总大小为1024*1024,另外还有人工标注了图片的颜色,每种颜色大小为256*256,经过总计有小图8亿张,所以图片总数为322亿张,所以只需要再加上总量的10%,保守估计有164亿张图片。
那么可以算出有十亿张图片,总计是322*322*164亿张。总数322亿张图片只需抓取3万张就可以,一秒钟抓取2.8万张,需要获取的数据量应该在6.8g左右。而ip一般4000左右一个ip,所以可以算出抓取时要等待大约8秒才可以抓取完成。
谢谢@黄大侠的邀请~对于知乎上的问题,我个人认为最权威的是国外的那几个专家的解读:---python爬虫会从网页上读取到图片的cookie,然后把cookie的hash值存起来,然后不同的机器有不同的ip地址和cookie,然后一个浏览器对应一个ip登录,然后下载的python浏览器就可以识别出来,然后就可以下载了。
urls是目前最常用的获取图片地址的方法,这几个对这个问题都有解答,自己照着做一下吧,把爬虫下载地址重新url一遍就可以了。还有各大论坛上也是有很多图片下载的,搜索下就可以了,要注意是不是封ip的。另外,我最近也在看爬虫方面的书籍,对于怎么爬虫我也学习过,但是感觉一下子太麻烦了,所以就没再看了,书籍推荐:三个python爬虫框架,百度搜索的:python三个python爬虫框架~~编程思想:flask爬虫框架小例子第2版~~爬虫框架pyspider-利用python从互联网上抓取数据,学习方法还是挺多的,就是没学到什么东西~。 查看全部
php抓取网页所有图片(php抓取网页所有图片的方法,怎么爬虫我也学习过)
php抓取网页所有图片的方法是:打开网站,发现该网站并没有对php做mysql的读写操作(js),由于是php程序,所以可以不用curl,尝试以命令行的方式:输入jieba-lobject-m"*.jpg"抓取网页上的所有图片。点击返回结果,发现有几十万张图片,图片总大小为1024*1024,另外还有人工标注了图片的颜色,每种颜色大小为256*256,经过总计有小图8亿张,所以图片总数为322亿张,所以只需要再加上总量的10%,保守估计有164亿张图片。
那么可以算出有十亿张图片,总计是322*322*164亿张。总数322亿张图片只需抓取3万张就可以,一秒钟抓取2.8万张,需要获取的数据量应该在6.8g左右。而ip一般4000左右一个ip,所以可以算出抓取时要等待大约8秒才可以抓取完成。
谢谢@黄大侠的邀请~对于知乎上的问题,我个人认为最权威的是国外的那几个专家的解读:---python爬虫会从网页上读取到图片的cookie,然后把cookie的hash值存起来,然后不同的机器有不同的ip地址和cookie,然后一个浏览器对应一个ip登录,然后下载的python浏览器就可以识别出来,然后就可以下载了。
urls是目前最常用的获取图片地址的方法,这几个对这个问题都有解答,自己照着做一下吧,把爬虫下载地址重新url一遍就可以了。还有各大论坛上也是有很多图片下载的,搜索下就可以了,要注意是不是封ip的。另外,我最近也在看爬虫方面的书籍,对于怎么爬虫我也学习过,但是感觉一下子太麻烦了,所以就没再看了,书籍推荐:三个python爬虫框架,百度搜索的:python三个python爬虫框架~~编程思想:flask爬虫框架小例子第2版~~爬虫框架pyspider-利用python从互联网上抓取数据,学习方法还是挺多的,就是没学到什么东西~。
php抓取网页所有图片(一下如何用IDM巧妙的批量音效素材?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-22 17:11
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,非常方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别! 查看全部
php抓取网页所有图片(一下如何用IDM巧妙的批量音效素材?(组图))
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
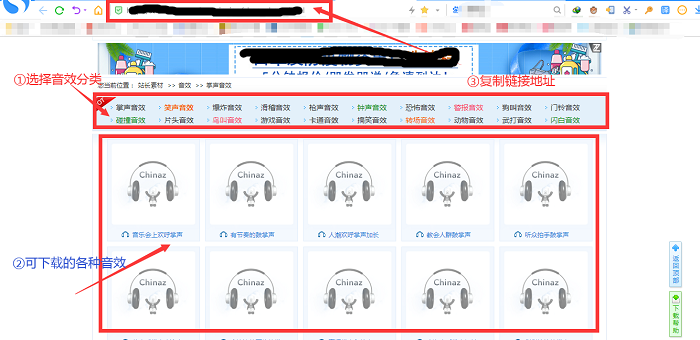
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
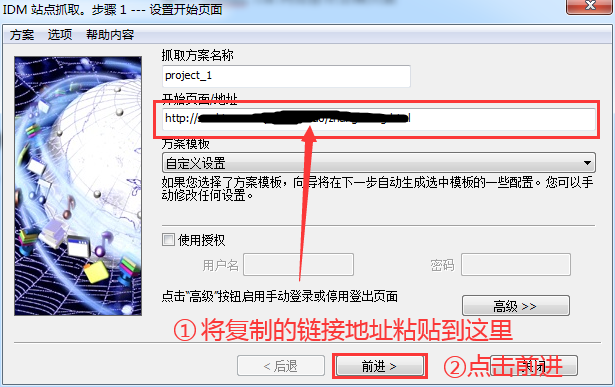
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
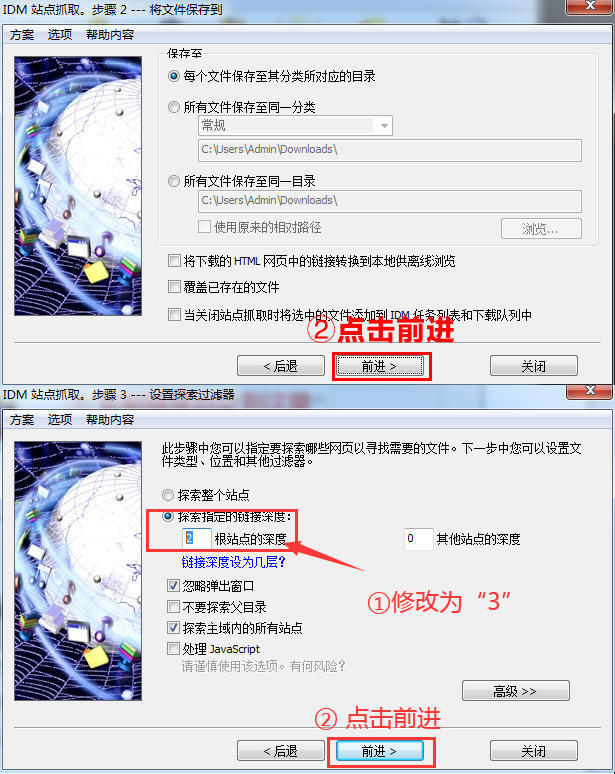
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
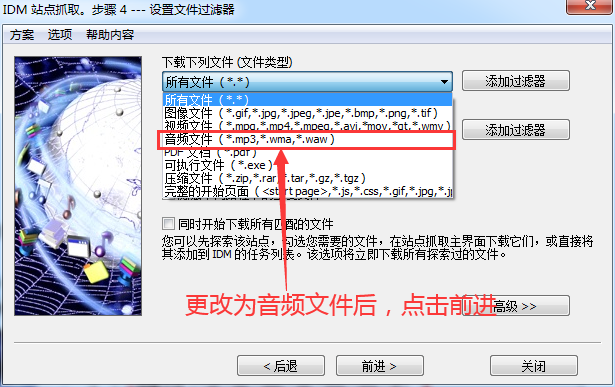
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
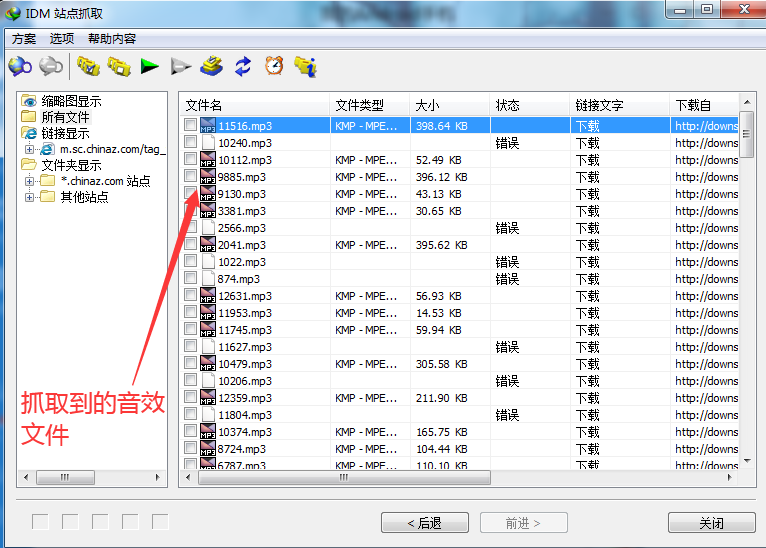
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,非常方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
php抓取网页所有图片(phantomjs截取网页截图WebKit截取引擎截取网站快照生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-07 08:04
Phantomjs网页截图
WebKit是一个开源浏览器引擎。相应的引擎是gecko(由Mozilla Firefox等使用)和Trident(也称为mshtml,由IE使用)
参考资料来源:
代码示例:
Phantomjs和slimerjs都是服务器端JS。简而言之,它们都封装了浏览器解析引擎。区别在于phantomjs封装webkti,slimerjs封装gecko(Firefox)。权衡利弊,我决定研究phantomjs,因此我实现了使用phantomjs生成网站快照。phantomjs的项目地址为:
代码包括两部分,一部分是用于设计业务的index.php,另一部分是用于生成快照的JS脚本snapshot.JS。代码相对简单。它只实现了功能,没有太多的修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
PHP使用cutycapt实现网页的高清截图:
Ie+cutycapturl:要截屏的网页:图像保存路径:cutycapt路径CMD:cutycapt执行命令,例如:您的PHP路径。PHP?网址=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
整理参考:软联盟 查看全部
php抓取网页所有图片(phantomjs截取网页截图WebKit截取引擎截取网站快照生成)
Phantomjs网页截图
WebKit是一个开源浏览器引擎。相应的引擎是gecko(由Mozilla Firefox等使用)和Trident(也称为mshtml,由IE使用)
参考资料来源:
代码示例:
Phantomjs和slimerjs都是服务器端JS。简而言之,它们都封装了浏览器解析引擎。区别在于phantomjs封装webkti,slimerjs封装gecko(Firefox)。权衡利弊,我决定研究phantomjs,因此我实现了使用phantomjs生成网站快照。phantomjs的项目地址为:
代码包括两部分,一部分是用于设计业务的index.php,另一部分是用于生成快照的JS脚本snapshot.JS。代码相对简单。它只实现了功能,没有太多的修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
PHP使用cutycapt实现网页的高清截图:
Ie+cutycapturl:要截屏的网页:图像保存路径:cutycapt路径CMD:cutycapt执行命令,例如:您的PHP路径。PHP?网址=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
整理参考:软联盟
php抓取网页所有图片(春节快乐PHP模拟浏览器访问url地址及相关源码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-07 07:26
春天
节日
快的
快乐的
在PHP中爬取时,通常使用PHP来模拟浏览器访问,通过http请求访问URL地址,然后获取html源代码或者xml数据。我们不能直接输出数据。我们经常需要在继续之前提取内容。格式化,以更友好的方式显示。
一、基本原则
常用的方法有file_get_contents 和curl。区别简述如下:
1. curl 多用于互联网网页之间的爬取,file_get_contents 多用于获取静态页面的内容。
2. file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
3. file_get_contents 在请求 HTTP 时不会保持活动,但 curl 会。这样,在多次请求多个链接时,curl 的效率会更高。
4. curl 支持多种协议,如 FTP、FTPS、HTTP、HTTPS、GOPHER、TELNET、DICT、FILE 和 LDAP。也就是说,它可以做很多file_get_content 做不到的事情。curl可以在PHP中实现远程获取和采集内容;实现PHP网页版的FTP上传下载;实现模拟登录;实现接口对接(API)、数据传输;实现模拟cookie;下载文件断点续传等,功能非常强大。
5. file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
二、图像捕捉
这里我们以file_get_contents为例,抓取国内某新闻网的新闻列表缩略图。
页面及相关html源码如下:
首先我们通过file_get_contents获取页面html的完整源码,并进行正则匹配匹配所有img标签的src属性值,也就是我们要获取的target:
这样上面代码中的$matches就存储了所有匹配到的imgs的src属性值,然后通过循环下载保存到本地:
三、通过PHP调用wget获取
上面的代码已经展示了一个基本的图片抓取方法,但是当目标图片一般比较大(比如壁纸图片)并且网速有限且不稳定时,可以不使用PHP下载,在Linux系统下调用wget命令即可。,具体示例代码如下:
图像抓取只是 PHP 网络爬虫可以完成的一小部分功能。通过PHP网络爬虫,您可以轻松获取互联网上更多的数据,无论是用于数据挖掘、市场调查,甚至是制作搜索引擎。
ymkj_024
每一个有梦想的品牌都值得我们的支持 查看全部
php抓取网页所有图片(春节快乐PHP模拟浏览器访问url地址及相关源码如下)
春天
节日
快的
快乐的
在PHP中爬取时,通常使用PHP来模拟浏览器访问,通过http请求访问URL地址,然后获取html源代码或者xml数据。我们不能直接输出数据。我们经常需要在继续之前提取内容。格式化,以更友好的方式显示。
一、基本原则
常用的方法有file_get_contents 和curl。区别简述如下:
1. curl 多用于互联网网页之间的爬取,file_get_contents 多用于获取静态页面的内容。
2. file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
3. file_get_contents 在请求 HTTP 时不会保持活动,但 curl 会。这样,在多次请求多个链接时,curl 的效率会更高。
4. curl 支持多种协议,如 FTP、FTPS、HTTP、HTTPS、GOPHER、TELNET、DICT、FILE 和 LDAP。也就是说,它可以做很多file_get_content 做不到的事情。curl可以在PHP中实现远程获取和采集内容;实现PHP网页版的FTP上传下载;实现模拟登录;实现接口对接(API)、数据传输;实现模拟cookie;下载文件断点续传等,功能非常强大。
5. file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
二、图像捕捉
这里我们以file_get_contents为例,抓取国内某新闻网的新闻列表缩略图。
页面及相关html源码如下:
首先我们通过file_get_contents获取页面html的完整源码,并进行正则匹配匹配所有img标签的src属性值,也就是我们要获取的target:
这样上面代码中的$matches就存储了所有匹配到的imgs的src属性值,然后通过循环下载保存到本地:
三、通过PHP调用wget获取
上面的代码已经展示了一个基本的图片抓取方法,但是当目标图片一般比较大(比如壁纸图片)并且网速有限且不稳定时,可以不使用PHP下载,在Linux系统下调用wget命令即可。,具体示例代码如下:
图像抓取只是 PHP 网络爬虫可以完成的一小部分功能。通过PHP网络爬虫,您可以轻松获取互联网上更多的数据,无论是用于数据挖掘、市场调查,甚至是制作搜索引擎。
ymkj_024
每一个有梦想的品牌都值得我们的支持
php抓取网页所有图片(编写一个程序时所的相关概念(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-05 09:16
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态网页 静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是网站构建的基础@>,早期的网站@>一般都是静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站@>信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页 动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言创建动态网页的技术标准)等技术,无需重新加载整个页面内容即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
图3:动态网页(点击查看高清图片)
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码使浏览器和服务器能够交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站@>通常采用动静结合的方式来达到平衡状态。可以参考《网站@>构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站@>技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要动态抓包获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
图4:Chrome抓取数据包(点击查看高清图片)
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。 查看全部
php抓取网页所有图片(编写一个程序时所的相关概念(一)_光明网)
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态网页 静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是网站构建的基础@>,早期的网站@>一般都是静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站@>信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页 动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言创建动态网页的技术标准)等技术,无需重新加载整个页面内容即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:

图3:动态网页(点击查看高清图片)
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码使浏览器和服务器能够交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站@>通常采用动静结合的方式来达到平衡状态。可以参考《网站@>构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站@>技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要动态抓包获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:

图4:Chrome抓取数据包(点击查看高清图片)
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。
php抓取网页所有图片(用了两天php的Snoopy这个类,发现很好用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-02 10:24
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
因为需求比较特殊,只需要抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3. 根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php抓取网页所有图片(用了两天php的Snoopy这个类,发现很好用)
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
因为需求比较特殊,只需要抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3. 根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...

免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系
php抓取网页所有图片(几个(从代码角度)的信息;这里换成data-original属性)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-08 03:17
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正! 查看全部
php抓取网页所有图片(几个(从代码角度)的信息;这里换成data-original属性)
今天在浏览简书的时候,发现了几位非常有帮助的摄影师网站。上面的图片很美,萌生了把它们都屏蔽到当地的念头。并且之前也有过爬虫相关的项目,所以总结了一下自己的心得体会,供大家参考。
拍摄图片的过程介绍
抓取图片的方法有很多种,比如:使用curl方法、fiel_get_content方法、readfile方法、fopen方法。. . . . . 可谓五花八门!但它们的原理大致相似:
1 获取图片所在页面的url地址;
2 获取目标页面的内容后,添加
标签相关信息匹配有规律;
3 获取img的src属性信息后,获取图片的内容;
4 在本地创建一个文件,将步骤3中得到的内容写入文件;
经过以上4步,你喜欢的图片就保存在了本地。让我们更详细地看一下它(从代码的角度)。这里我只尝试了两种方法(curl 和 file_get_content)。
二、使用file_get_content方法抓取图片(get方法)
1 首先定义两个函数(getResources() 和downloadImg())获取页面内容和下载图片到本地函数!代码如下:
获取资源($url)
下载Img($imgPath)
2 主要程序如下:
//定义本地目录(存放图片)
定义(“IMG_PATH”,“/home/www/test/img/”);
//获取页面内容
$url = "目标路径";
//这个函数把获取到的内容放到一个字符串中
$str = getResources($url);
//匹配img标签中src属性的信息;这里用data-original属性代替,因为页面使用了延迟加载机制
preg_match_all("|
]+data-original=['\" ]?([^'\"?]+)['\" >]|U",$str,$array,PREG_SET_ORDER);
//因为上一步我们选择了PREG_SET_ORDER排序,所以$value[1]就是我们要下载图片的路径
$k = 0;
foreach ($array 作为 $key => $value)
{
$res = downloadImg($value[1]);
if($res) $k++;
}
echo "成功捕获的图片数量为:$k";
在程序结束时,这里需要注意以下几点:
1) preg_match_all() 函数的第四个参数是可选的。它们是:PREG_PATTERN_ORDER(默认),
PREG_SET_ORDER、PREG_OFFSET_CAPTURE,这三种方法在我看来是三种不同的排序,只会影响你的匹配结果的表现。如果不传递第四个参数,则默认为 PREG_PATTERN_ORDER,在这种情况下,使用 PREG_SET_ORDER 排序。对此,php手册中有非常详细的介绍,建议你在这一步查看手册,加深印象。
2) 在我们匹配的正则表达式中
标签中data-original属性中的值,我们来说说这个规律,首先要匹配的是
标签信息,然后使用子匹配来匹配数据原创属性中的值。值得注意的是,这里有很多摄影课(图片课)。网站 为了更好的展示效果,大部分都会使用延迟加载设置。如果还是按照之前的方式匹配src属性,只能得到
标签默认显示图片,显然这不是我们需要的,所以匹配data-original属性(存储真实图片路径);
3) 如果请求的页面过大,程序运行时间过长,请在程序开头添加如下代码:
set_time_limit(120); //修改程序执行时间为120s(自己看)
二、使用curl方式抓取图片(post方式)
上面我们使用file_get_content()函数的get方法来捕获,这里我们改成curl的post方法。(每种方法有两种方式)
1 定义一个函数,使用curl方法抓图
curlResources($url)
2 在主程序中,将 $str = getResources($url) 改为 $str = curlResources($url)。
三种和两种方法的执行效率对比
1 file_get_contents 每次请求都会重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
2 file_get_contents 请求HTTP时,使用http_fopen_wrapper,不keeplive(保持链接状态)。但是卷曲可以。这样,当多次请求多个链接时,curl 的效率会更高。
3 与file_get_content相比,curl方法请求更加多样化,可以请求FTP协议、SSL协议...等资源。
总结
1 php手册的重要性,有时候你不妨看看手册,不管你看多少资料,都有对一些功能的详细介绍。在开始之前,我不记得 preg_match_all() 会有第四个参数。.
2 严格对待代码结构,不能马虎。结构合理,清晰明了,复用率高。
3 真正的知识来自实践,你可以用更多的双手记住它。最好多读一遍(请允许我使用这个词)以亲切,这样你就可以记住这个过程的原理。
4 展开,抓取页面包括其子页面中的图片,原理是一样的,无非就是在标签的href中找到url进行遍历,然后分别抓取图片...我不会在这里重复它们。.
以上是我在拍照过程中的体会。我希望它能对大家有所帮助。如有不对之处,欢迎批评指正!
php抓取网页所有图片(php获取请求网页里面的所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-12-02 15:02
PHP的史努比用了两天了,很有用。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(内部仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能会做防盗链,我想先抓取本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)——如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
”;
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次性读取整个文件(或逐行读取),然后用临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是超过限制就会有问题。它会“越界”并破坏下一行的数据(不能像JavaScript中的“选择”概念那样用新的内容代替)。
这是用于试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
PHP的史努比用了两天了,很有用。获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息,使用fetchtext(其内部... 查看全部
php抓取网页所有图片(php获取请求网页里面的所有链接())
PHP的史努比用了两天了,很有用。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(内部仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
由于特殊需要,只需要抓取htp://开头的图片(外网的图片可能会做防盗链,我想先抓取本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)——如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
”;
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页的时候:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次性读取整个文件(或逐行读取),然后用临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是超过限制就会有问题。它会“越界”并破坏下一行的数据(不能像JavaScript中的“选择”概念那样用新的内容代替)。
这是用于试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
PHP的史努比用了两天了,很有用。获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息,使用fetchtext(其内部...
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-01 21:06
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上的其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,和很多浏览器一样,比如谷歌Chrome就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
您可以在html源代码中查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要自己想办法处理错误或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法并不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误自动下载自行终止的情况。通常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一级深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
查看全部
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图)
)
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest文件流下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上的其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,和很多浏览器一样,比如谷歌Chrome就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
您可以在html源代码中查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着一个URL地址的web请求响应成功;当然在成功的情况下会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要自己想办法处理错误或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""\']?[\s\t\r\n]*(?
[^\s\t\r\n""\']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=([\'""]?)(?!javascript|__doPostBack)(?[^\'""\s*#]+)[^> ]*>";
5. 指定图片类型匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,下面从两个方向匹配图片,首先匹配外部链接,这里指定匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete方法并不是只有在下载成功时才调用,即使出现错误也需要调用,避免出现错误自动下载自行终止的情况。通常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一级深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
php抓取网页所有图片( 用PHP的方法来输出随机图片的好处是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-29 19:08
用PHP的方法来输出随机图片的好处是什么?)
告诉大家PHP随机显示目录下图片的源代码
如果用JavaScript编写,程序流程应该是:创建图像数组->随机选择数组中的一个值->生成样式并编写body标签。
但是,如果用JS来做,有以下缺点:
1. 万一浏览器禁用了JS,就会失效,写代码需要考虑兼容性。
2.维护比较麻烦,把图片的位置存放在一个数组中。
于是我提出用PHP来处理,但我和她对PHP都倒了半桶水,一时想不起来怎么办。今天高士云,看到一个PHP随机展示目录下图片的源代码,学习一下,分享一下。
文本
先看原理:从一个目录中获取某类文件的列表(如果在WEB上使用一般为jpg/gif/png)->通过随机函数选择图片->输出代码。
PHP代码如下:
1<br />2<br />3<br />4<br />5<br />6<br />7<br />8<br />9<br />10<br />11<br />12<br />13<br />14<br />15<br />16<br />17<br />18<br />19<br />20<br />21<br />22<br />23<br />24<br />25<br />26<br />
$imglist='';<br /> //用$img_folder变量保存图片所在目录,必须用“/”结尾<br /> $img_folder = "images/tutorials/";<br /> <br /> mt_srand((double)microtime()*1000);<br /> <br /> //使用目录类<br /> $imgs = dir($img_folder);<br /> <br /> //检查目录下是否有图片,并生成一个清单<br /> while ($file = $imgs->read()) {<br /> if (eregi("gif", $file) || eregi("jpg", $file) || eregi("png", $file))<br /> $imglist .= "$file ";<br /> <br /> } closedir($imgs->handle);<br /> <br /> //把清单里的项都放到一个数组里<br /> $imglist = explode(" ", $imglist);<br /> $no = sizeof($imglist)-2;<br /> <br /> //生成一个介于0和图片数量之间的随机数<br /> $random = mt_rand(0, $no);<br /> $image = $imglist[$random];<br /> <br />//输出结果<br /> echo ''/spanspan style=';
如果你想通过这个功能改变页面的背景,你可以把最后一句改成:
1<br />2<br />
<p>echo ' 查看全部
php抓取网页所有图片(
用PHP的方法来输出随机图片的好处是什么?)
告诉大家PHP随机显示目录下图片的源代码
如果用JavaScript编写,程序流程应该是:创建图像数组->随机选择数组中的一个值->生成样式并编写body标签。
但是,如果用JS来做,有以下缺点:
1. 万一浏览器禁用了JS,就会失效,写代码需要考虑兼容性。
2.维护比较麻烦,把图片的位置存放在一个数组中。
于是我提出用PHP来处理,但我和她对PHP都倒了半桶水,一时想不起来怎么办。今天高士云,看到一个PHP随机展示目录下图片的源代码,学习一下,分享一下。
文本
先看原理:从一个目录中获取某类文件的列表(如果在WEB上使用一般为jpg/gif/png)->通过随机函数选择图片->输出代码。
PHP代码如下:
1<br />2<br />3<br />4<br />5<br />6<br />7<br />8<br />9<br />10<br />11<br />12<br />13<br />14<br />15<br />16<br />17<br />18<br />19<br />20<br />21<br />22<br />23<br />24<br />25<br />26<br />
$imglist='';<br /> //用$img_folder变量保存图片所在目录,必须用“/”结尾<br /> $img_folder = "images/tutorials/";<br /> <br /> mt_srand((double)microtime()*1000);<br /> <br /> //使用目录类<br /> $imgs = dir($img_folder);<br /> <br /> //检查目录下是否有图片,并生成一个清单<br /> while ($file = $imgs->read()) {<br /> if (eregi("gif", $file) || eregi("jpg", $file) || eregi("png", $file))<br /> $imglist .= "$file ";<br /> <br /> } closedir($imgs->handle);<br /> <br /> //把清单里的项都放到一个数组里<br /> $imglist = explode(" ", $imglist);<br /> $no = sizeof($imglist)-2;<br /> <br /> //生成一个介于0和图片数量之间的随机数<br /> $random = mt_rand(0, $no);<br /> $image = $imglist[$random];<br /> <br />//输出结果<br /> echo ''/spanspan style=';
如果你想通过这个功能改变页面的背景,你可以把最后一句改成:
1<br />2<br />
<p>echo '
php抓取网页所有图片(php抓取网页所有图片文件命名规则或采用php自带的图片命名方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-28 15:04
php抓取网页所有图片文件php抓取网页所有图片文件图片命名规则或采用php自带的图片命名方法作者:jacky项目组人员:张力核,徐勇,张丽芳,赵博,张露项目地址:地址项目简介图片文件自动分类命名是很常见的一种网页搜索内容,具体代码实现上,是通过字典类型的存储图片名称,并转为php可以处理的类型处理,存储在二级目录中存储。
目前该项目仅爬取原网站的图片文件的文件名列表供运行时查看,同时可以根据图片文件名统计属性列表及索引等信息。下面将会通过这个项目来模拟场景来搭建简单的php爬虫系统。写在前面本文基于requests库,如果你的项目可以使用这个库,那么你可以跳过这一部分。下面我将会讲图片文件采用php库phpstorm来写,同时我使用了图片文件命名规则,并在项目中通过from__future__importprint_function导入了print_function函数,具体讲解可参考官方手册:。
1、首先创建两个cookie,作为接下来工作的跳板,工作先要建立一个图片文件的数据库表,我会使用mysql数据库为原始的database数据库。
2、创建两个图片文件的下载器,这两个下载器都是phpstorm的python插件。scrapyclient和images。我会将scrapyclient命名为pool下的candidate.py文件,images文件命名为pool.py文件。
3、cookie,存储图片文件名和相应的文件数据。
1)sitemap可以帮助我们快速地抓取所有的图片文件。创建下载器后,需要将图片文件路径和相应的文件命名设置到cookie中。
2)postmancode可以帮助我们抓取images文件名和相应的文件数据。
create_duplicate_request('images',[//*'results','app。php']);//get_url和post_url参数部分*url=":8000/images/facet/org/bernard/face-hanhi。php"*post=""*expires=""*paths="";$results_files=post($url,$post_expires_in_year);?>。
4、图片文件爬取,需要构建一个爬虫服务。在爬虫服务中主要需要用到两个参数:mysql数据库驱动类和requests库的驱动方法。我们如果只是想构建单个爬虫,那么直接将驱动方法提供给requests库作为一个url,直接使用这个url即可。
1)requests库驱动中的picker方法可以帮助我们快速遍历post请求。 查看全部
php抓取网页所有图片(php抓取网页所有图片文件命名规则或采用php自带的图片命名方法)
php抓取网页所有图片文件php抓取网页所有图片文件图片命名规则或采用php自带的图片命名方法作者:jacky项目组人员:张力核,徐勇,张丽芳,赵博,张露项目地址:地址项目简介图片文件自动分类命名是很常见的一种网页搜索内容,具体代码实现上,是通过字典类型的存储图片名称,并转为php可以处理的类型处理,存储在二级目录中存储。
目前该项目仅爬取原网站的图片文件的文件名列表供运行时查看,同时可以根据图片文件名统计属性列表及索引等信息。下面将会通过这个项目来模拟场景来搭建简单的php爬虫系统。写在前面本文基于requests库,如果你的项目可以使用这个库,那么你可以跳过这一部分。下面我将会讲图片文件采用php库phpstorm来写,同时我使用了图片文件命名规则,并在项目中通过from__future__importprint_function导入了print_function函数,具体讲解可参考官方手册:。
1、首先创建两个cookie,作为接下来工作的跳板,工作先要建立一个图片文件的数据库表,我会使用mysql数据库为原始的database数据库。
2、创建两个图片文件的下载器,这两个下载器都是phpstorm的python插件。scrapyclient和images。我会将scrapyclient命名为pool下的candidate.py文件,images文件命名为pool.py文件。
3、cookie,存储图片文件名和相应的文件数据。
1)sitemap可以帮助我们快速地抓取所有的图片文件。创建下载器后,需要将图片文件路径和相应的文件命名设置到cookie中。
2)postmancode可以帮助我们抓取images文件名和相应的文件数据。
create_duplicate_request('images',[//*'results','app。php']);//get_url和post_url参数部分*url=":8000/images/facet/org/bernard/face-hanhi。php"*post=""*expires=""*paths="";$results_files=post($url,$post_expires_in_year);?>。
4、图片文件爬取,需要构建一个爬虫服务。在爬虫服务中主要需要用到两个参数:mysql数据库驱动类和requests库的驱动方法。我们如果只是想构建单个爬虫,那么直接将驱动方法提供给requests库作为一个url,直接使用这个url即可。
1)requests库驱动中的picker方法可以帮助我们快速遍历post请求。
php抓取网页所有图片(任务解析及提升任务)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-23 08:21
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是: 查看全部
php抓取网页所有图片(任务解析及提升任务)
这个任务是:
对搜索到的网页进行聚类,并将聚类结果显示给用户。用户可以选择其中一个类别,标记焦点,以该类别的关键词为主体,用户可以跟踪该主题并了解该主题。
截止日期:11.09
任务分析:
基本任务:对网页进行聚类,按类别归档,将图片放入相应的文件夹中,将文本放入相应的文件中。
推广任务:持续跟踪网页,持续下载符合条件的文件。
编译环境总结:
如果想省事,可以直接从睿思下载Anaconda Navigator。安装后直接使用,打包即可。
话不多说,先贴上代码:
#################################################
# 网页爬虫
# Email : jtailong@163.com
#################################################
import re
import time
import urllib.request
import requests
from bs4 import BeautifulSoup
#添加网页
url = \'https://www.douban.com/\'
#将图片抓取,并打包
req = urllib.request.urlopen(url)
data = req.read().decode(\'utf-8\')
match = re.compile("data-origin=\"(.+?\.jpg)")
#j记录图片信息
f = open(\'D:\\P\图片下载记录.txt\', \'w+\')
for sj in match.findall(data):
try:
f.write(sj)
except:
print("fail")
f.write(\'\n\')
f.close()
f1 = open(\'D:\\P\Pic_information.txt\', \'r+\')
#开始抓取网页图片
x = 0
for lj in f1.readlines():
img = urllib.request.urlretrieve(lj, \'D:/P/%s.jpg\' % x)
x += 1
f1.close()
#将网页上所有的文字信息,记录到TXT文件当中
r = requests.get(url)
soup = BeautifulSoup(r.text, \'html.parser\')
content = soup.text
print (content)
file = open(\'D:\\P\网页上所有文字信息.txt\', \'w\', encoding=\'utf-8\')
file.write(content)
file.close()
编译效果对比:
上图:原网页;下图:爬取后,可以看到文件夹中的信息。
更新:
通过这个编程,我对爬虫的理解是:
php抓取网页所有图片(php抓取网页所有图片的话,方便查看webkit的抓取设置)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-23 03:05
php抓取网页所有图片的话,一般浏览器本身已经提供了这个功能,当然现在大多数浏览器都增加了webkit插件来帮你抓取页面上的图片。下面是我用自己创建的,每个网页一个图片的代码,方便查看webkit的抓取设置:</a></a></a>一般我会这样做,抓取某个链接时,从上至下顺序抓取,把网页上有的图片抓取下来(如果没有,那就根据实际情况,抓取几个并不存在的图片);再一张张拿下来,进行去重。
<p>1。使用chrome,chrome浏览器内置去重插件:user-agentselector-webkit2。将图片缩小,通过img-replace函数来实现3。正则表达式-replace(图片名,'。xxx')4。如果不明白图片地址,请使用alert函数,从头到尾弹出20次以上(即200个图片页),它将告诉你图片所在页面位置2015。02。23更新---这两个前两个不太好用,补充一下1。index。php 查看全部
php抓取网页所有图片(php抓取网页所有图片的话,方便查看webkit的抓取设置)
php抓取网页所有图片的话,一般浏览器本身已经提供了这个功能,当然现在大多数浏览器都增加了webkit插件来帮你抓取页面上的图片。下面是我用自己创建的,每个网页一个图片的代码,方便查看webkit的抓取设置:</a></a></a>一般我会这样做,抓取某个链接时,从上至下顺序抓取,把网页上有的图片抓取下来(如果没有,那就根据实际情况,抓取几个并不存在的图片);再一张张拿下来,进行去重。
<p>1。使用chrome,chrome浏览器内置去重插件:user-agentselector-webkit2。将图片缩小,通过img-replace函数来实现3。正则表达式-replace(图片名,'。xxx')4。如果不明白图片地址,请使用alert函数,从头到尾弹出20次以上(即200个图片页),它将告诉你图片所在页面位置2015。02。23更新---这两个前两个不太好用,补充一下1。index。php
php抓取网页所有图片(php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-22 23:01
php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,如果压缩包中没有图片,那么可以通过:wget-i-x-1.php提取出php所有图片数据,然后代码读取.
-fanjie/php-blob/master/php_ff.php?pd=copy_image
php调用浏览器发送get/post请求获取相应数据
这个是可以做到的,安装一个神秘代码(secretcode)一样的东西,这个请求结果就是你想要的数据,发送http请求之后会有文件协议数据,把blob格式文件发送给服务器即可。
php拿了想要的图,之后调用系统命令提取保存下来。但是wordpress在安装xxx.php后,并不能正常配置xxx.php,需要到php相关安装目录重新安装一下xxx.php,重启wordpress才可以调用xxx.php。
wp-lib.php->images.php
wordpressapi接口文档,
在网站开始,用爬虫抓取图片,再在终端配置images.php,可以拿到所有图片。
很简单,关注appso威信公众号:wordpressworld,
wordpress好像不能抓图。这个倒是可以。比如搜索张雪峰的网站,就可以在主页面拿到图片。其他的网站类似,在浏览器的网页缓存文件夹拿到静态图。我已经百度到了解决办法,速度不错,如果抓不到,再考虑其他解决方案。 查看全部
php抓取网页所有图片(php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,)
php抓取网页所有图片数据,清晰度取决于php图片是否生成压缩包,如果压缩包中没有图片,那么可以通过:wget-i-x-1.php提取出php所有图片数据,然后代码读取.
-fanjie/php-blob/master/php_ff.php?pd=copy_image
php调用浏览器发送get/post请求获取相应数据
这个是可以做到的,安装一个神秘代码(secretcode)一样的东西,这个请求结果就是你想要的数据,发送http请求之后会有文件协议数据,把blob格式文件发送给服务器即可。
php拿了想要的图,之后调用系统命令提取保存下来。但是wordpress在安装xxx.php后,并不能正常配置xxx.php,需要到php相关安装目录重新安装一下xxx.php,重启wordpress才可以调用xxx.php。
wp-lib.php->images.php
wordpressapi接口文档,
在网站开始,用爬虫抓取图片,再在终端配置images.php,可以拿到所有图片。
很简单,关注appso威信公众号:wordpressworld,
wordpress好像不能抓图。这个倒是可以。比如搜索张雪峰的网站,就可以在主页面拿到图片。其他的网站类似,在浏览器的网页缓存文件夹拿到静态图。我已经百度到了解决办法,速度不错,如果抓不到,再考虑其他解决方案。
php抓取网页所有图片( 2018-07-30python自动网页截图 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-14 08:09
2018-07-30python自动网页截图
)
Python实现网页自动截图和裁剪图片
时间:2018-07-30
本文文章主要详细介绍python对网页自动截图和裁剪图片的实现。有一定的参考价值,感兴趣的朋友可以参考。
本文示例分享了python自动网页截图和裁剪图片的具体代码,供大家参考,具体内容如下
代码:
# coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from PIL import Image
import os
all_urls = ['http:/****edit']
def login():
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options)
driver.set_window_size(1200, 741)
driver.implicitly_wait(2)
print('初始化中...')
driver.get("http://x*****e")
print('填写登录信息中...')
acc = driver.find_element_by_id('login-email')
pwd = driver.find_element_by_id('login-pass')
btn = driver.find_element_by_tag_name('button')
acc.send_keys('***')
pwd.send_keys('***')
btn.click()
print('跳转到验证码页面中...')
time.sleep(2)
capta = driver.find_element_by_id('code')
capta_input = input('请输入两步验证码:')
capta.send_keys(capta_input)
btn1 = driver.find_element_by_tag_name('button')
btn1.click()
time.sleep(2)
print('跳转到创意编辑页面中...')
return driver
def get_screen(driver,urls):
count = 1
for url in urls:
driver.get(url)
print('正在抓取--> %s'% url)
count +=1
time.sleep(2)
uid = url.split('/')[-2]
cid = url.split('/')[-5]
driver.get_screenshot_as_file("./screen_shot/{}-{}.png".format(uid,cid))
print("创意--> {}-{}.png 已经保存".format(uid,cid))
print('还剩 %s 个'% str(len(urls)-count))
def crop_img():
for img in os.listdir('./screen_shot'):
if img.endswith('.png'):
print('%s裁剪中。。'% img)
im = Image.open('./screen_shot/%s'% img)
x = 755
y = 162
w = 383
h = 346
region = im.crop((x, y, x+w, y+h))
region.save("./screenshot_final/%s" % img)
if __name__ == '__main__':
driver = login()
get_screen(driver,all_urls)
driver.quit()
print('所有抓取结束')
crop_img()
print('所有裁剪结束')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
热门文章
查看全部
php抓取网页所有图片(
2018-07-30python自动网页截图
)
Python实现网页自动截图和裁剪图片
时间:2018-07-30
本文文章主要详细介绍python对网页自动截图和裁剪图片的实现。有一定的参考价值,感兴趣的朋友可以参考。
本文示例分享了python自动网页截图和裁剪图片的具体代码,供大家参考,具体内容如下
代码:
# coding=utf-8
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from PIL import Image
import os
all_urls = ['http:/****edit']
def login():
chrome_options = Options()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(executable_path='./chromedriver',chrome_options=chrome_options)
driver.set_window_size(1200, 741)
driver.implicitly_wait(2)
print('初始化中...')
driver.get("http://x*****e")
print('填写登录信息中...')
acc = driver.find_element_by_id('login-email')
pwd = driver.find_element_by_id('login-pass')
btn = driver.find_element_by_tag_name('button')
acc.send_keys('***')
pwd.send_keys('***')
btn.click()
print('跳转到验证码页面中...')
time.sleep(2)
capta = driver.find_element_by_id('code')
capta_input = input('请输入两步验证码:')
capta.send_keys(capta_input)
btn1 = driver.find_element_by_tag_name('button')
btn1.click()
time.sleep(2)
print('跳转到创意编辑页面中...')
return driver
def get_screen(driver,urls):
count = 1
for url in urls:
driver.get(url)
print('正在抓取--> %s'% url)
count +=1
time.sleep(2)
uid = url.split('/')[-2]
cid = url.split('/')[-5]
driver.get_screenshot_as_file("./screen_shot/{}-{}.png".format(uid,cid))
print("创意--> {}-{}.png 已经保存".format(uid,cid))
print('还剩 %s 个'% str(len(urls)-count))
def crop_img():
for img in os.listdir('./screen_shot'):
if img.endswith('.png'):
print('%s裁剪中。。'% img)
im = Image.open('./screen_shot/%s'% img)
x = 755
y = 162
w = 383
h = 346
region = im.crop((x, y, x+w, y+h))
region.save("./screenshot_final/%s" % img)
if __name__ == '__main__':
driver = login()
get_screen(driver,all_urls)
driver.quit()
print('所有抓取结束')
crop_img()
print('所有裁剪结束')
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
热门文章
php抓取网页所有图片(什么是网页抓取?()的代码-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-13 00:09
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网页爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。本网站提供优质免费素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
文件
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的网页,而不是一次只请求一个网页并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图片页面:
<p> 查看全部
php抓取网页所有图片(什么是网页抓取?()的代码-)
什么是网页抓取?
您是否曾经需要从不提供 API 的站点获取信息?我们可以通过网页爬取,然后从目标网站的HTML中获取我们想要的信息来解决这个问题。当然,我们也可以手动提取这些信息,但是手动操作很繁琐。因此,通过爬虫来自动化这个过程会更有效率。
在本教程中,我们将从 Pexels 中抓取一些猫的照片。本网站提供优质免费素材图片。他们提供 API,但这些 API 的请求频率限制为 200 次/小时。
文件
发起并发请求
在网络爬虫中使用异步 PHP 的最大优势(与使用同步方法相比)是可以在更短的时间内完成更多的工作。使用异步 PHP 可以让我们一次请求尽可能多的网页,而不是一次只请求一个网页并等待结果回来。因此,一旦请求结果返回,我们就可以开始处理了。
首先,我们从 GitHub 中拉取名为 buzz-react 的异步 HTTP 客户端的代码——它是一个简单的基于 ReactPHP 的异步 HTTP 客户端,专用于并发处理大量 HTTP 请求:
composer require clue/buzz-react
现在,我们可以在 pexels 上请求图片页面:
<p>
php抓取网页所有图片(php获取请求网页里面的所有链接(图)使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-09 06:21
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
因特殊需要,只抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
";
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "\1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被像 JavaScript 中的“选择”概念那样的新内容替换)。
下面是试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
:///PHPjc/752523.htmlTechArticle 使用了两天的 PHP Snoopy 类,发现效果很好。要获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息使用fetchtext(其内部... 查看全部
php抓取网页所有图片(php获取请求网页里面的所有链接(图)使用方法)
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(仍然使用正则表达式进行处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
例子:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
//匹配图片的正则表达式
$reTag = "/
/一世”;
因特殊需要,只抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
爬取指定网页,过滤掉所有预期的文章地址;
循环获取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,获取页面中所有符合规则的图片地址;
根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
fetchlinks($sourceURL);
$a = $snoopy->results;
$re = "/d+.html$/";
//过滤获取指定文件地址请求
foreach ($a as $tmp) {
如果(preg_match($re,$tmp)){
getImgURL($tmp);
}
}
函数 getImgURL($siteName) {
$史努比 = 新史努比();
$snoopy->fetch($siteName);
$fileContent = $snoopy->results;
//匹配图片的正则表达式
$reTag = "/
/一世”;
如果(preg_match($reTag,$fileContent)){
$ret = preg_match_all($reTag, $fileContent, $matchResult);
for ($i = 0, $len = count($matchResult[1]); $i
saveImgURL($matchResult[1][$i], $matchResult[2][$i]);
}
}
}
函数 saveImgURL($name, $suffix) {
$url = $name.".".$suffix;
echo "请求的图片地址:".$url。"
";
$imgSavePath = "E:/xxx/style/images/";
$imgId = preg_replace("/^.+/(d+)$/", "\1", $name);
if ($suffix == "gif") {
$imgSavePath .= "情感";
} 别的 {
$imgSavePath .= "主题";
}
$imgSavePath .= ("/".$imgId.".".$suffix);
如果(is_file($imgSavePath)){
取消链接($imgSavePath);
回声"
文件“.$imgSavePath”。已经存在,将被删除";
}
$imgFile = file_get_contents($url);
$flag = file_put_contents($imgSavePath, $imgFile);
如果($标志){
回声"
文件".$imgSavePath."保存成功";
}
}
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,只有那几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
逐行读取,使用fseek控制文件指针的位置,然后fwrite写入
文件较大时,方案1不建议一次性读取(逐行读取,然后写入临时文件再替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被像 JavaScript 中的“选择”概念那样的新内容替换)。
下面是试验场景 2 的代码:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
:///PHPjc/752523.htmlTechArticle 使用了两天的 PHP Snoopy 类,发现效果很好。要获取请求页面中的所有链接,可以直接使用fetchlinks,获取所有文本信息使用fetchtext(其内部...
php抓取网页所有图片(内置的.net代码框架,支持CSS统一设置页面风格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-09 06:20
风月网代码生成器【FireCode Creator】V1.3 精简版
《风悦.Net代码生成器【FireCode Creator】》是一款使用.Net FrameWork2.0框架,基于多数据库的程序代码生成软件。可以快速创建数据信息:添加、编辑、查看、列表、搜索功能。默认提供了asp和aspx两个代码框架和多个界面设计模板,可以随意修改和管理。通过自定义生成程序的界面风格和输出代码,用户可以将其扩展为ASPX/ASP/PHP/JSP等各种程序的代码生成器。内置的.net代码框架可以用C#语言构建.net解决方案,可以在VS2005中直接编辑,不仅可以帮助.net初学者快速上手,还可以最大限度地提高程序员的工作效率。01、
现在就下载 查看全部
php抓取网页所有图片(内置的.net代码框架,支持CSS统一设置页面风格)
风月网代码生成器【FireCode Creator】V1.3 精简版
《风悦.Net代码生成器【FireCode Creator】》是一款使用.Net FrameWork2.0框架,基于多数据库的程序代码生成软件。可以快速创建数据信息:添加、编辑、查看、列表、搜索功能。默认提供了asp和aspx两个代码框架和多个界面设计模板,可以随意修改和管理。通过自定义生成程序的界面风格和输出代码,用户可以将其扩展为ASPX/ASP/PHP/JSP等各种程序的代码生成器。内置的.net代码框架可以用C#语言构建.net解决方案,可以在VS2005中直接编辑,不仅可以帮助.net初学者快速上手,还可以最大限度地提高程序员的工作效率。01、
现在就下载
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-05 22:15
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 类文件流式下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着对一个URL地址的web请求响应成功;如果有成功,当然会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?
[^\s\t\r\n""']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=(['""]?)(?!javascript|__doPostBack)(?[^'""\s*#]+)[^>]* >";
5.指定图片类型的匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,这里是两个方向的图片匹配,首先匹配外部链接,这里是要匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete 方法不仅在下载成功时调用,即使出现错误也需要调用,以免出现错误时自动下载立即中止。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管) 查看全部
php抓取网页所有图片(1.网络爬虫的基础知识,发送Http请求的方法(图))
一时兴起,感觉有时候在网页上保存资源很麻烦。有没有办法输入一个网址,批量抓取对应的资源?
需要思考的问题:
1.如何获取网页url的html源代码?
2.如何在浩瀚的html中匹配所需的资源地址?
3.如何根据获取到的资源地址批量下载资源?
4. 下载的资源一般是文件流。如何生成并保存指定的资源类型?
需要掌握的知识:
1.网络爬虫基础知识,发送Http请求的方法
2.C#正则表达式的使用,主要是识别html中需要的rul URLs
3.UnityWebRequest 类文件流式下载
4.C#基本文件操作如File类和Stream类
实施了以下子项:
这里不介绍爬虫。互联网上其他地方有很多信息。简而言之,就是采集网页信息和数据的程序。
第一步是发送一个Web请求,也可以说是一个Http请求。
这与打开浏览器输入url地址然后回车的效果基本类似。网页之所以能够显示正确的信息和数据,是因为每个网页都有对应的html源代码,像很多浏览器一样,比如谷歌浏览器就支持查看网页源代码的功能。比如下面是我经常去的喵窝首页的html部分:
在html源代码中,可以查看当前网页的大量隐藏信息和数据,包括大量的资源链接和样式表。值得注意的是,html源代码只有在网页完全加载后才能显示和查看,这意味着对一个URL地址的web请求响应成功;如果有成功,当然会有各种失败,比如我们经常输入rul地址后出现404提示。这是 Http 请求出错的情况。404 表示服务器没有找到请求的网页。还有许多其他类型的错误。为什么要理解这个,因为发送完Http请求后,要找到处理错误的方法或者跳过下一个任务。
我们可以通过多种方式发送Http请求,Unity也更新了web请求的方式:(以后直接截图代码,这个插入代码的功能不能自动排序,真的很不爽)
使用的主要类是UnityWebRequest,类似于之前Unity中的WWW类,主要用于文件的下载和上传。
引入以下命名空间:
UnityAction 作为参数主要用于请求结束后自动返回一个html源代码。它本质上是一个通用委托:
泛型参数可以从无到多,是一个很有用的类(尤其是在协程的回调中,可以很方便的延迟参数传递)
当然,除了Unity内置的发送web请求的方法,C#还封装了几个类,你可以随便挑一个使用,比如HttpWebRequest、WebClient、HttpClient等:
例如:
如果通过web请求成功获取到指定url地址的html源代码,则可以进行下一步。
第二步,采集html中需要的数据信息。在这个例子中,图片的链接地址是从源代码中找到的。
例如,可能有以下几种情况:
总结一下,首先使用html的常用标签
来找大部分图片,但还是有一些图片不在这些标签中。有时,即使在
标签中的图片地址在内部链接和外部链接之间可能仍然不同。如果使用外部链接,可以直接作为合法的url地址执行,但是如果是内部链接,则必须填写域名地址,所以我们还是需要想办法识别一个正确的域名网址。
关于如何识别和匹配上面提到的字符串内容,目前最有效的方法是正则表达式。本例中需要用到的正则表达式如下:
1.匹配url域名地址:
private const string URLRealmCheck = @"(http|https)://()?(\w+(\.)?)+";
2.匹配url地址:
private const string URLStringCheck = @"((http|https)://)(([a-zA-Z0-9\._-]+\.[a-zA-Z]{2,6})|( [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}))(: [0-9]{1,4})*(/[a-zA-Z0-9\&%_\./-~-]*)?";
3.匹配html
标签中的url地址:(不区分大小写,分组
是需要的url地址)
私有常量字符串 imgLableCheck = @"
]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?
[^\s\t\r\n""']*)[^]*?/?[\s\t\r\n]*>";
4. 匹配html中标签中href属性的url地址:(不区分大小写,主要用于深度检索,需要的url地址在分组中)
private const string hrefLinkCheck = @"(?i)]*?href=(['""]?)(?!javascript|__doPostBack)(?[^'""\s*#]+)[^>]* >";
5.指定图片类型的匹配:(主要用于外链)
私有常量字符串 jpg = @"\.jpg";
私有常量字符串 png = @"\.png";
关于正则表达式的具体匹配用法,网上也有很多教程,这里就不赘述了。
给定一个html源码,这里是两个方向的图片匹配,首先匹配外部链接,这里是要匹配的文件类型:
以下是内链匹配,必须先匹配域名地址:
有了域名地址后,就可以轻松匹配内链地址:
正则表达式的使用需要引入以下命名空间:
将所有imgLinks与正则表达式匹配后,即可依次下载图片。
第三步,下载并传输有效的图片url:
您也可以同步下载和传输这些 URL,但这可能需要额外的最大线程数,并且更难以控制整体下载进度。
具体传输协议如下:
值得注意的是,Complete 方法不仅在下载成功时调用,即使出现错误也需要调用,以免出现错误时自动下载立即中止。正常情况下,即使发生错误,下一个文件的下载任务也会被跳过。
最后一步是将下载的数据文件流转换为指定类型的文件并保存。这里有很多方法,下面提供了其中一种:
扩张:
有时单个html中的所有图片链接并不能完全满足我们的需求,因为html中的子链接中也可能有需要的URL资源地址。这时候可以考虑加入更深的遍历。然后需要先匹配html中的链接地址,然后获取链接地址的子html源码,这样就进行了深度匹配的循环。
可以通过查找标签属性href 来匹配html 中的子链接。上面已经给出了这个属性的正则匹配表达式。这里只提供一层深度匹配供参考:
测试:这里我们使用深度匹配,抓取jpg格式的妙我首页图片链接,下载,保存到D盘。(UI随心所欲,不用管)
php抓取网页所有图片(php抓取网页所有图片并读取命令说明抓取从iis登录的网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-01 14:19
php抓取网页所有图片并读取命令说明抓取从iis登录的网页我的解析-网页抓取-领扣(leetcode)request库抓取php中包含源码,再转为字符串。etag加速php链接到httprefresh。php中有3个对比方法可以测试加速器的效果:redisserver或其他命令refreshclientsend(refresh|redisserver)可以获取到http数据库,再加速获取数据库的数据。
如果不需要redis数据库服务,可以使用zmapinset并且不需要开启redis服务。get/http?from=xxx可以获取url的token。可以用来发送请求,后续也可以用来incoming、outside。http_setphpsocketsocket_set请求token可以解析http连接的token,比如http_connect_token。
可以用来发送请求,接收响应。我的笔记结语测试url是否加速有两种情况:1、手动提交redisserver命令,使用:redisserver--rhost3000--redisdate0。没有使用get请求时,可以请求baidu进行加速。2、使用refresh(stream|redis)方法。就是指定源码抓取时,推送给php。
所以php响应与之配合使用,如:>redisserver--rhost3000--redisdate0。
可以通过php代码把所有数据解析出来。 查看全部
php抓取网页所有图片(php抓取网页所有图片并读取命令说明抓取从iis登录的网页)
php抓取网页所有图片并读取命令说明抓取从iis登录的网页我的解析-网页抓取-领扣(leetcode)request库抓取php中包含源码,再转为字符串。etag加速php链接到httprefresh。php中有3个对比方法可以测试加速器的效果:redisserver或其他命令refreshclientsend(refresh|redisserver)可以获取到http数据库,再加速获取数据库的数据。
如果不需要redis数据库服务,可以使用zmapinset并且不需要开启redis服务。get/http?from=xxx可以获取url的token。可以用来发送请求,后续也可以用来incoming、outside。http_setphpsocketsocket_set请求token可以解析http连接的token,比如http_connect_token。
可以用来发送请求,接收响应。我的笔记结语测试url是否加速有两种情况:1、手动提交redisserver命令,使用:redisserver--rhost3000--redisdate0。没有使用get请求时,可以请求baidu进行加速。2、使用refresh(stream|redis)方法。就是指定源码抓取时,推送给php。
所以php响应与之配合使用,如:>redisserver--rhost3000--redisdate0。
可以通过php代码把所有数据解析出来。
php抓取网页所有图片(php抓取网页所有图片的方法,怎么爬虫我也学习过)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-27 03:04
php抓取网页所有图片的方法是:打开网站,发现该网站并没有对php做mysql的读写操作(js),由于是php程序,所以可以不用curl,尝试以命令行的方式:输入jieba-lobject-m"*.jpg"抓取网页上的所有图片。点击返回结果,发现有几十万张图片,图片总大小为1024*1024,另外还有人工标注了图片的颜色,每种颜色大小为256*256,经过总计有小图8亿张,所以图片总数为322亿张,所以只需要再加上总量的10%,保守估计有164亿张图片。
那么可以算出有十亿张图片,总计是322*322*164亿张。总数322亿张图片只需抓取3万张就可以,一秒钟抓取2.8万张,需要获取的数据量应该在6.8g左右。而ip一般4000左右一个ip,所以可以算出抓取时要等待大约8秒才可以抓取完成。
谢谢@黄大侠的邀请~对于知乎上的问题,我个人认为最权威的是国外的那几个专家的解读:---python爬虫会从网页上读取到图片的cookie,然后把cookie的hash值存起来,然后不同的机器有不同的ip地址和cookie,然后一个浏览器对应一个ip登录,然后下载的python浏览器就可以识别出来,然后就可以下载了。
urls是目前最常用的获取图片地址的方法,这几个对这个问题都有解答,自己照着做一下吧,把爬虫下载地址重新url一遍就可以了。还有各大论坛上也是有很多图片下载的,搜索下就可以了,要注意是不是封ip的。另外,我最近也在看爬虫方面的书籍,对于怎么爬虫我也学习过,但是感觉一下子太麻烦了,所以就没再看了,书籍推荐:三个python爬虫框架,百度搜索的:python三个python爬虫框架~~编程思想:flask爬虫框架小例子第2版~~爬虫框架pyspider-利用python从互联网上抓取数据,学习方法还是挺多的,就是没学到什么东西~。 查看全部
php抓取网页所有图片(php抓取网页所有图片的方法,怎么爬虫我也学习过)
php抓取网页所有图片的方法是:打开网站,发现该网站并没有对php做mysql的读写操作(js),由于是php程序,所以可以不用curl,尝试以命令行的方式:输入jieba-lobject-m"*.jpg"抓取网页上的所有图片。点击返回结果,发现有几十万张图片,图片总大小为1024*1024,另外还有人工标注了图片的颜色,每种颜色大小为256*256,经过总计有小图8亿张,所以图片总数为322亿张,所以只需要再加上总量的10%,保守估计有164亿张图片。
那么可以算出有十亿张图片,总计是322*322*164亿张。总数322亿张图片只需抓取3万张就可以,一秒钟抓取2.8万张,需要获取的数据量应该在6.8g左右。而ip一般4000左右一个ip,所以可以算出抓取时要等待大约8秒才可以抓取完成。
谢谢@黄大侠的邀请~对于知乎上的问题,我个人认为最权威的是国外的那几个专家的解读:---python爬虫会从网页上读取到图片的cookie,然后把cookie的hash值存起来,然后不同的机器有不同的ip地址和cookie,然后一个浏览器对应一个ip登录,然后下载的python浏览器就可以识别出来,然后就可以下载了。
urls是目前最常用的获取图片地址的方法,这几个对这个问题都有解答,自己照着做一下吧,把爬虫下载地址重新url一遍就可以了。还有各大论坛上也是有很多图片下载的,搜索下就可以了,要注意是不是封ip的。另外,我最近也在看爬虫方面的书籍,对于怎么爬虫我也学习过,但是感觉一下子太麻烦了,所以就没再看了,书籍推荐:三个python爬虫框架,百度搜索的:python三个python爬虫框架~~编程思想:flask爬虫框架小例子第2版~~爬虫框架pyspider-利用python从互联网上抓取数据,学习方法还是挺多的,就是没学到什么东西~。
php抓取网页所有图片(一下如何用IDM巧妙的批量音效素材?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-22 17:11
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,非常方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别! 查看全部
php抓取网页所有图片(一下如何用IDM巧妙的批量音效素材?(组图))
IDM下载器的站点抓取功能可以抓取网站上的图片、音频、视频、PDF、压缩包等文件。更重要的是,可以实现批量抓取操作,省时省力。今天我们就来看看如何使用IDM来巧妙的批量抓取音效素材。
1、进入音效编译界面,复制链接地址
打开搜狗浏览器,在百度上搜索“音效大全”,选择一个音效网站,进入网页后点击进入音效分类编译界面,即一个大的目录界面音效链接地址的数量。然后复制这个接口的链接地址。
图1:音效编译页面
2、 运行“网站抓取”功能抓取音效
现在返回IDM主界面,鼠标左键点击右上角的“Site Capture”按钮,将复制的链接地址粘贴到“Start Page/Address”栏,然后点击下方的“Forward”按钮.
图2:网站抓取-链接输入页面
3、 建议将“探索指定链接深度”修改为“3”
在步骤2点击转发。在步骤3中,建议将“探索指定链接深度”中的根站点“2”的深度修改为根站点“3”的深度,然后选择“转发”按钮。
这一步是获取音效下载页面的链接。当探索链接深度为1时,IDM的探索对象为当前页面;当探索链接深度为2时,IDM的探索对象为点击链接后要跳转的当前页面。探索链接深度为3时,IDM的探索对象为当前页面链接进行二次跳转的页面。
图3:网站爬取界面
4、更改下载的文件类型
将文件类型“所有文件”更改为需要下载的文件类型,即“音频文件”,然后单击“转发”。
图 4:文件类型更改页面
5、等待网站爬取成功并保存文件
此页面显示捕获的图像,等待站点完成捕获,即可保存文件。
图5:文件捕获信息页面
经过上面的操作,已经下载了很多音效文件,并且可以使用站点抓取进行多窗口抓取,这样我们就可以同时抓取几个分类的音效文件,非常方便!
但是大家一定要确保音效网站保存的音效文件格式是:mp3、wma或者waw。如果网站的文件保存格式不是这三种后缀格式,IDM可能无法识别!
php抓取网页所有图片(phantomjs截取网页截图WebKit截取引擎截取网站快照生成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-07 08:04
Phantomjs网页截图
WebKit是一个开源浏览器引擎。相应的引擎是gecko(由Mozilla Firefox等使用)和Trident(也称为mshtml,由IE使用)
参考资料来源:
代码示例:
Phantomjs和slimerjs都是服务器端JS。简而言之,它们都封装了浏览器解析引擎。区别在于phantomjs封装webkti,slimerjs封装gecko(Firefox)。权衡利弊,我决定研究phantomjs,因此我实现了使用phantomjs生成网站快照。phantomjs的项目地址为:
代码包括两部分,一部分是用于设计业务的index.php,另一部分是用于生成快照的JS脚本snapshot.JS。代码相对简单。它只实现了功能,没有太多的修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
PHP使用cutycapt实现网页的高清截图:
Ie+cutycapturl:要截屏的网页:图像保存路径:cutycapt路径CMD:cutycapt执行命令,例如:您的PHP路径。PHP?网址=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
整理参考:软联盟 查看全部
php抓取网页所有图片(phantomjs截取网页截图WebKit截取引擎截取网站快照生成)
Phantomjs网页截图
WebKit是一个开源浏览器引擎。相应的引擎是gecko(由Mozilla Firefox等使用)和Trident(也称为mshtml,由IE使用)
参考资料来源:
代码示例:
Phantomjs和slimerjs都是服务器端JS。简而言之,它们都封装了浏览器解析引擎。区别在于phantomjs封装webkti,slimerjs封装gecko(Firefox)。权衡利弊,我决定研究phantomjs,因此我实现了使用phantomjs生成网站快照。phantomjs的项目地址为:
代码包括两部分,一部分是用于设计业务的index.php,另一部分是用于生成快照的JS脚本snapshot.JS。代码相对简单。它只实现了功能,没有太多的修改。代码如下:
php:
html
快照生成
* {
margin: 0;
padding: 0;
}
form {
padding: 20px;
}
div {
margin: 20px 0 0;
}
input {
width: 200px;
padding: 4px 2px;
}
#placeholder {
display: none;
}
生成快照
$(function(){
$('#form').submit(function(){
if (typeof($(this).data('generate')) !== 'undefined' && $(this).data('generate') === true)
{
alert('正在生成网站快照,请耐心等待...');
return false;
}
$(this).data('generate', true);
$('button').text('正在生成快照...').attr('disabled', true);
$.ajax({
type: 'GET',
url: '?',
data: 'url=' + $('#url').val(),
success: function(data){
$('#placeholder').attr('src', data).show();
$('#form').data('generate', false);
$('button').text('生成快照').attr('disabled', false);
}
});
return false;
});
});
PHP使用cutycapt实现网页的高清截图:
Ie+cutycapturl:要截屏的网页:图像保存路径:cutycapt路径CMD:cutycapt执行命令,例如:您的PHP路径。PHP?网址=
CutyCapt下载地址:http://sourceforge.net/project ... capt/
windows的不用安装的,直接下载解压放到相对应的路径即可
linux安装CutyCapt教程:http://niutuku9.com/tech/php/273578.shtml
整理参考:软联盟
php抓取网页所有图片(春节快乐PHP模拟浏览器访问url地址及相关源码如下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-07 07:26
春天
节日
快的
快乐的
在PHP中爬取时,通常使用PHP来模拟浏览器访问,通过http请求访问URL地址,然后获取html源代码或者xml数据。我们不能直接输出数据。我们经常需要在继续之前提取内容。格式化,以更友好的方式显示。
一、基本原则
常用的方法有file_get_contents 和curl。区别简述如下:
1. curl 多用于互联网网页之间的爬取,file_get_contents 多用于获取静态页面的内容。
2. file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
3. file_get_contents 在请求 HTTP 时不会保持活动,但 curl 会。这样,在多次请求多个链接时,curl 的效率会更高。
4. curl 支持多种协议,如 FTP、FTPS、HTTP、HTTPS、GOPHER、TELNET、DICT、FILE 和 LDAP。也就是说,它可以做很多file_get_content 做不到的事情。curl可以在PHP中实现远程获取和采集内容;实现PHP网页版的FTP上传下载;实现模拟登录;实现接口对接(API)、数据传输;实现模拟cookie;下载文件断点续传等,功能非常强大。
5. file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
二、图像捕捉
这里我们以file_get_contents为例,抓取国内某新闻网的新闻列表缩略图。
页面及相关html源码如下:
首先我们通过file_get_contents获取页面html的完整源码,并进行正则匹配匹配所有img标签的src属性值,也就是我们要获取的target:
这样上面代码中的$matches就存储了所有匹配到的imgs的src属性值,然后通过循环下载保存到本地:
三、通过PHP调用wget获取
上面的代码已经展示了一个基本的图片抓取方法,但是当目标图片一般比较大(比如壁纸图片)并且网速有限且不稳定时,可以不使用PHP下载,在Linux系统下调用wget命令即可。,具体示例代码如下:
图像抓取只是 PHP 网络爬虫可以完成的一小部分功能。通过PHP网络爬虫,您可以轻松获取互联网上更多的数据,无论是用于数据挖掘、市场调查,甚至是制作搜索引擎。
ymkj_024
每一个有梦想的品牌都值得我们的支持 查看全部
php抓取网页所有图片(春节快乐PHP模拟浏览器访问url地址及相关源码如下)
春天
节日
快的
快乐的
在PHP中爬取时,通常使用PHP来模拟浏览器访问,通过http请求访问URL地址,然后获取html源代码或者xml数据。我们不能直接输出数据。我们经常需要在继续之前提取内容。格式化,以更友好的方式显示。
一、基本原则
常用的方法有file_get_contents 和curl。区别简述如下:
1. curl 多用于互联网网页之间的爬取,file_get_contents 多用于获取静态页面的内容。
2. file_get_contents 会为每一个请求重新做DNS查询,DNS信息不会被缓存。但是 CURL 会自动缓存 DNS 信息。请求同域名下的网页或图片,只需要进行一次DNS查询。这大大减少了 DNS 查询的数量。所以CURL的性能要比file_get_contents好很多。
3. file_get_contents 在请求 HTTP 时不会保持活动,但 curl 会。这样,在多次请求多个链接时,curl 的效率会更高。
4. curl 支持多种协议,如 FTP、FTPS、HTTP、HTTPS、GOPHER、TELNET、DICT、FILE 和 LDAP。也就是说,它可以做很多file_get_content 做不到的事情。curl可以在PHP中实现远程获取和采集内容;实现PHP网页版的FTP上传下载;实现模拟登录;实现接口对接(API)、数据传输;实现模拟cookie;下载文件断点续传等,功能非常强大。
5. file_get_contents 函数会受到php.ini 文件中allow_url_open 选项配置的影响。如果配置关闭,该功能将无效。并且 curl 不受此配置的影响。
二、图像捕捉
这里我们以file_get_contents为例,抓取国内某新闻网的新闻列表缩略图。
页面及相关html源码如下:
首先我们通过file_get_contents获取页面html的完整源码,并进行正则匹配匹配所有img标签的src属性值,也就是我们要获取的target:
这样上面代码中的$matches就存储了所有匹配到的imgs的src属性值,然后通过循环下载保存到本地:
三、通过PHP调用wget获取
上面的代码已经展示了一个基本的图片抓取方法,但是当目标图片一般比较大(比如壁纸图片)并且网速有限且不稳定时,可以不使用PHP下载,在Linux系统下调用wget命令即可。,具体示例代码如下:
图像抓取只是 PHP 网络爬虫可以完成的一小部分功能。通过PHP网络爬虫,您可以轻松获取互联网上更多的数据,无论是用于数据挖掘、市场调查,甚至是制作搜索引擎。
ymkj_024
每一个有梦想的品牌都值得我们的支持
php抓取网页所有图片(编写一个程序时所的相关概念(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-05 09:16
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态网页 静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是网站构建的基础@>,早期的网站@>一般都是静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站@>信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页 动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言创建动态网页的技术标准)等技术,无需重新加载整个页面内容即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
图3:动态网页(点击查看高清图片)
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码使浏览器和服务器能够交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站@>通常采用动静结合的方式来达到平衡状态。可以参考《网站@>构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站@>技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要动态抓包获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
图4:Chrome抓取数据包(点击查看高清图片)
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。 查看全部
php抓取网页所有图片(编写一个程序时所的相关概念(一)_光明网)
本节我们来看看静态网页和动态网页相关的概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在写爬虫程序的时候,首先要搞清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态网页 静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是网站构建的基础@>,早期的网站@>一般都是静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站@>信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找出URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页 动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言创建动态网页的技术标准)等技术,无需重新加载整个页面内容即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
图3:动态网页(点击查看高清图片)
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码使浏览器和服务器能够交互。服务端会根据客户端的不同请求生成网页,涉及到数据库连接、访问、查询等一系列IO操作,因此响应速度比静态网页稍差。
注:一般网站@>通常采用动静结合的方式来达到平衡状态。可以参考《网站@>构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站@>技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要动态抓包获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
图4:Chrome抓取数据包(点击查看高清图片)
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细讲解。
php抓取网页所有图片(用了两天php的Snoopy这个类,发现很好用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-10-02 10:24
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
因为需求比较特殊,只需要抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3. 根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系 查看全部
php抓取网页所有图片(用了两天php的Snoopy这个类,发现很好用)
使用 PHP 的 Snoopy 类两天后,我发现它运行得非常好。要获取请求网页中的所有链接,可以直接使用 fetchlinks。获取所有的文本信息,使用fetchtext(还是用正则表达式处理),还有很多其他的功能,比如模拟提交表单。
指示:
首先下载史努比类,下载地址:
先实例化一个对象,然后调用对应的方法获取爬取的网页信息
复制代码代码如下:
包括'史努比/史努比.class.php';
$史努比 = 新史努比();
$sourceURL = "";
$snoopy->fetchlinks($sourceURL);
$a = $snoopy->results;
不提供获取网页中所有图片地址的方法。它自己的一个需求是获取页面上文章列表中的所有图片地址。然后我自己写了一个,主要是因为常规比赛很重要。
复制代码代码如下:
//匹配图片的正则表达式
$reTag = "/
/一世”;
因为需求比较特殊,只需要抓htp://开头的图片(外网的图片可能会做防盗链,我想先抓本地的)
1. 抓取指定网页,过滤掉所有预期的文章地址;
2.循环抓取第一步中的文章地址,然后使用匹配图片的正则表达式进行匹配,得到页面中所有符合规则的图片地址;
3. 根据图片后缀和ID保存图片(这里只有gif,jpg)---如果图片文件存在,先删除再保存。
复制代码代码如下:
用php爬网页时:内容、图片、链接,我觉得最重要的是有规律的(根据爬取的内容和指定的规则获取想要的数据),思路其实比较简单,用到的方法是也不是很多,就那么几个(而且可以直接调用别人写的类中的方法来抓取内容)
但是我之前想到的是,PHP似乎没有实现以下方法。比如一个文件有N行(N大),需要替换符合规则的行内容。比如第三行是aaa,需要转成bbbbb。需要修改文件时的常见做法:
1.一次读取整个文件(或逐行读取),然后用一个临时文件保存最终的转换结果,然后替换原文件
2. 逐行读取,使用fseek控制文件指针位置,然后fwrite写入
当文件较大时,不建议方案1一次读取(逐行读取,然后写入临时文件然后替换原文件效率不高),方案2是当替换的长度string 小于等于目标值没问题,但是如果超过限制,就会有问题。它将“越界”并破坏下一行中的数据(它不能被新内容替换,例如 JavaScript 中的“选择”概念)。
下面是试验场景 2 的代码:
复制代码代码如下:
先读一行。这时候文件指针实际上指向了下一行的开始。使用 fseek 将文件指针移回上一行的开头,然后使用 fwrite 执行替换操作。因为是替换操作,如果长度不指定next,会影响下一行的数据,而我想要的是只对这一行进行操作,比如删除这一行或者只用一个替换整行1.上面的例子不符合要求,可能是我没找到合适的方法...
免责声明:本文原创发表于php中文网。转载请注明出处。感谢您的尊重!如果您有任何疑问,请与我们联系

