
php抓取网页动态数据
php抓取网页动态数据(动态页面静态化怎么提高访问速度?答“省去3个步骤” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-09 07:20
)
一、什么是静态页面?什么是动态页面
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码. 不能
静态页面
动态页面
区别:
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码.
动态页面是通过执行asp、php、jsp、.net等程序生成客户端网页代码的网页。
可以自行更新
不
能够
静态页面不能独立管理和发布更新的页面。如果要更新网页内容,必须通过FTP软件下载文件,并用网页制作软件进行修改(通过fso等技术除外)。常见静态页面示例:.html 扩展名、.htm 扩展名。
动态页面通常可以通过网站后台管理系统更新和管理网站的内容
二、什么是静态页面技术(PHP脚本语言)
1、有些用脚本语言开发的程序在被第一个用户访问执行后会生成静态文件,程序会将这些生成的文件保存在指定位置,如果后续用户访问同一个PHP程序,且PHP未修改且未过期,则跳过PHP程序,直接访问已有的HTML静态文件,提高访问速度。
更多:
2、如何让页面静态化以提高访问速度?回答“省略 3 步”
1)不访问数据库连接
2)不执行sql、语句
3)不要执行 PHP 程序
3、我根据日期为文件夹名称生成了 HTML 文件
三、实现静态页面的步骤
//1、开启缓存
ob_start();
//2、将所有在内存中的缓存内容保存到变量$html中
$html = ob_get_contents();
//3、实现URL地址重写(伪静态),需要在保存内容之前,先过滤把动态地址转成静态地址后再保存
file_put_contents($cachefile,$html);
//4、缓冲输出
ob_flush(); 查看全部
php抓取网页动态数据(动态页面静态化怎么提高访问速度?答“省去3个步骤”
)
一、什么是静态页面?什么是动态页面
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码. 不能
静态页面
动态页面
区别:
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码.
动态页面是通过执行asp、php、jsp、.net等程序生成客户端网页代码的网页。
可以自行更新
不
能够
静态页面不能独立管理和发布更新的页面。如果要更新网页内容,必须通过FTP软件下载文件,并用网页制作软件进行修改(通过fso等技术除外)。常见静态页面示例:.html 扩展名、.htm 扩展名。
动态页面通常可以通过网站后台管理系统更新和管理网站的内容
二、什么是静态页面技术(PHP脚本语言)
1、有些用脚本语言开发的程序在被第一个用户访问执行后会生成静态文件,程序会将这些生成的文件保存在指定位置,如果后续用户访问同一个PHP程序,且PHP未修改且未过期,则跳过PHP程序,直接访问已有的HTML静态文件,提高访问速度。
更多:

2、如何让页面静态化以提高访问速度?回答“省略 3 步”
1)不访问数据库连接
2)不执行sql、语句
3)不要执行 PHP 程序
3、我根据日期为文件夹名称生成了 HTML 文件

三、实现静态页面的步骤
//1、开启缓存
ob_start();
//2、将所有在内存中的缓存内容保存到变量$html中
$html = ob_get_contents();
//3、实现URL地址重写(伪静态),需要在保存内容之前,先过滤把动态地址转成静态地址后再保存
file_put_contents($cachefile,$html);
//4、缓冲输出
ob_flush();
php抓取网页动态数据(链接跳转后会进入企业信息公示页面,需要的内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-09 01:06
)
我最近在做一个项目,通过扫描营业执照的二维码得到一个URL链接。一个链接跳转后会进入企业信息公示页面,您需要通过该链接获取所需信息(公司名称、法人、信用代码等)。
在网上搜索了很多,找到了很多方法,但是爬不出来。一般报521错误,没有跨域,网页使用JS动态加载,得到的只是静态信息等等。所以所有的方法都不可行。
最终的解决方案是:WebClient模拟一个浏览器客户端,设置JS动态加载开启(必须的,主要处理那些JS、Ajax动态加载的数据),然后使用HtmlPage类来接受网页。使用 Jsoup 清理数据,得到我们需要的东西。值得一提的是
Jsoup 的用法与 JS 非常相似。doc.getElementById("id") 和 doc.getElementsByTag(tagName) 一般可以使用这两种方法获取。我们使用F12在谷歌浏览器中打开开发调试工具。使用定位功能定位我们需要的数据的位置,查看标签的id,也就是我们在使用Jsoup函数时使用的ID。这样就可以得到具体的值了。具体的 Jsoup 用户可以在百度上搜索。
废话不多说,直接上代码:
(1)环境
1)Jsoup 环境
org.jsoup
jsoup
1.10.2
2)WebClient 环境
这个比较麻烦
我在自己的项目中直接贴出Jar的截图(需要的可以联系我)
(2)源码(这是获取企业信息的源码,其他类似,webclient模拟相同,只是清洗不同)
public static List analysisQyInfoForOld(String url){
final WebClient client = new WebClient();
client.getOptions().setJavaScriptEnabled(true);// 默认执行js
client.getOptions().setCssEnabled(false);
client.setAjaxController(new NicelyResynchronizingAjaxController());
client.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = null;
try {
page = client.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String pageXml = page.asXml(); //以xml的形式获取响应文本
List lists = new ArrayList();
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml);
Element element1 = doc.getElementById("REG_NO"); //统一社会信用代码/注册号
Element element2 = doc.getElementById("CORP_NAME");//名称
Element element3 = doc.getElementById("ZJ_ECON_KIND");//类型
Element element4 = doc.getElementById("OPER_MAN_NAME");//经营者
Element element5 = doc.getElementById("FARE_PLACE");//经营场所
Element element7 = doc.getElementById("ADDR"); //住址
Element element6 = doc.getElementById("BELONG_ORG");//所属部门
lists.add(element1.text());
lists.add(element2.text());
lists.add(element3.text());
lists.add(element4.text());
if(element5 == null ) {
lists.add(element7.text());
}else {
lists.add(element5.text());
}
lists.add(element6.text());
return lists;
} 查看全部
php抓取网页动态数据(链接跳转后会进入企业信息公示页面,需要的内容
)
我最近在做一个项目,通过扫描营业执照的二维码得到一个URL链接。一个链接跳转后会进入企业信息公示页面,您需要通过该链接获取所需信息(公司名称、法人、信用代码等)。
在网上搜索了很多,找到了很多方法,但是爬不出来。一般报521错误,没有跨域,网页使用JS动态加载,得到的只是静态信息等等。所以所有的方法都不可行。
最终的解决方案是:WebClient模拟一个浏览器客户端,设置JS动态加载开启(必须的,主要处理那些JS、Ajax动态加载的数据),然后使用HtmlPage类来接受网页。使用 Jsoup 清理数据,得到我们需要的东西。值得一提的是
Jsoup 的用法与 JS 非常相似。doc.getElementById("id") 和 doc.getElementsByTag(tagName) 一般可以使用这两种方法获取。我们使用F12在谷歌浏览器中打开开发调试工具。使用定位功能定位我们需要的数据的位置,查看标签的id,也就是我们在使用Jsoup函数时使用的ID。这样就可以得到具体的值了。具体的 Jsoup 用户可以在百度上搜索。
废话不多说,直接上代码:
(1)环境
1)Jsoup 环境
org.jsoup
jsoup
1.10.2
2)WebClient 环境
这个比较麻烦
我在自己的项目中直接贴出Jar的截图(需要的可以联系我)

(2)源码(这是获取企业信息的源码,其他类似,webclient模拟相同,只是清洗不同)
public static List analysisQyInfoForOld(String url){
final WebClient client = new WebClient();
client.getOptions().setJavaScriptEnabled(true);// 默认执行js
client.getOptions().setCssEnabled(false);
client.setAjaxController(new NicelyResynchronizingAjaxController());
client.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = null;
try {
page = client.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String pageXml = page.asXml(); //以xml的形式获取响应文本
List lists = new ArrayList();
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml);
Element element1 = doc.getElementById("REG_NO"); //统一社会信用代码/注册号
Element element2 = doc.getElementById("CORP_NAME");//名称
Element element3 = doc.getElementById("ZJ_ECON_KIND");//类型
Element element4 = doc.getElementById("OPER_MAN_NAME");//经营者
Element element5 = doc.getElementById("FARE_PLACE");//经营场所
Element element7 = doc.getElementById("ADDR"); //住址
Element element6 = doc.getElementById("BELONG_ORG");//所属部门
lists.add(element1.text());
lists.add(element2.text());
lists.add(element3.text());
lists.add(element4.text());
if(element5 == null ) {
lists.add(element7.text());
}else {
lists.add(element5.text());
}
lists.add(element6.text());
return lists;
}
php抓取网页动态数据(Python基础知识:元素而不仅仅是标题元素是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-09 01:00
元素,而不仅仅是标题元素。
使用每个 Beautiful Soup 对象附带的 .parent 属性,您可以直观地逐步浏览 DOM 结构并使用所需的元素。您还可以以类似的方式访问子元素和兄弟元素。阅读导航树以获取更多信息。
从 HTML 元素中提取属性
此时,您的 Python 脚本已抓取该站点并过滤其 HTML 以查找相关职位发布。做得好!但是,申请工作的链接仍然缺失。
检查页面时,您在每张卡片的底部发现了两个链接。如果您处理链接元素的方式与处理其他元素的方式相同,您将不会获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本 Learn、Apply 而不是关联的 URL。
这是因为 .text 属性只留下 HTML 元素的可见内容。它去除所有 HTML 标记,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值,而不是丢弃它。
链接元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部的第二个 href 标记的属性值:
Learn
Apply
首先获取工作卡中的所有元素。href 然后,使用方括号表示法提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到控制台。
在下面的练习块中,您可以找到挑战说明,以优化您收到的链接结果:
练习:优化结果显示/隐藏
每张工作卡都有两个与之关联的链接。您正在寻找的只是第二个链接。如何编辑上面显示的代码片段,以便始终只采集第二个链接的 URL?
单击解决方案块以阅读此练习的可能解决方案:
解决方案:优化您的结果显示/隐藏
要获取每个工作卡的第二个链接的 URL,您可以使用以下代码段:
for job_element in python_job_elements:
link_url = job_element.find_all("a")[1]["href"]
print(f"Apply here: {link_url}\n")
您正在通过索引 ( ) 从结果中选择第二个链接元素。然后,您将使用方括号表示法直接提取 URL 并对属性 ( ) 进行寻址。.find_all()[1]href["href"]
您还可以使用相同的方括号表示法来提取其他 HTML 属性。
保持练习
如果您在本教程旁边编写了代码,那么您可以按原样运行您的脚本,您会看到终端中弹出虚假的作业消息。您的下一步是处理现实生活中的工作委员会!要继续练习您的新技能,请使用以下任何或所有 网站 重新访问网络抓取过程:
链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。所以你可以用美丽的汤把它们刮掉。
使用这些其他站点之一从顶部重新开始阅读本教程。您会看到每个 网站 的结构都不同,您需要以稍微不同的方式重构代码以获得所需的数据。接受这个挑战是练习刚刚学到的概念的好方法。虽然它可能会让你大汗淋漓,但你的编码技能会因此而变得更强!
在您第二次尝试时,您还可以探索 Beautiful Soup 的其他功能。使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、.requests 和 Beautiful Soup 进行网络抓取。
为了结束您的网络抓取之旅,您可以对您的代码进行最后的改造,并创建一个命令行界面 (CLI) 应用程序,该应用程序可以抓取其中一个工作板,并允许您在每次执行时键入按关键字过滤结果。您的 CLI 工具可让您搜索特定类型或位置的工作。
如果您有兴趣了解如何使脚本适应命令行界面,请查看如何使用 argparse 在 Python 中构建命令行界面。
综上所述
requests 库为您提供了一种使用 Python 从 Internet 获取静态 HTML 的用户友好方式。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您的网络抓取冒险值得信赖且有用的伴侣。您会发现 Beautiful Soup 将满足您的大部分解析需求,包括导航和高级搜索。
在本教程中,您学习了如何使用 Python 请求和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本,该脚本从 Internet 获取招聘信息,并从头到尾执行完整的网络抓取过程。
你已经学会了如何:
考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看您还能获取哪些其他 网站。玩得开心,并始终记住尊重和负责任地使用您的编程技能。
您可以通过单击下面的链接下载您在本教程中构建的示例脚本的源代码: 查看全部
php抓取网页动态数据(Python基础知识:元素而不仅仅是标题元素是什么)
元素,而不仅仅是标题元素。
使用每个 Beautiful Soup 对象附带的 .parent 属性,您可以直观地逐步浏览 DOM 结构并使用所需的元素。您还可以以类似的方式访问子元素和兄弟元素。阅读导航树以获取更多信息。
从 HTML 元素中提取属性
此时,您的 Python 脚本已抓取该站点并过滤其 HTML 以查找相关职位发布。做得好!但是,申请工作的链接仍然缺失。
检查页面时,您在每张卡片的底部发现了两个链接。如果您处理链接元素的方式与处理其他元素的方式相同,您将不会获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本 Learn、Apply 而不是关联的 URL。
这是因为 .text 属性只留下 HTML 元素的可见内容。它去除所有 HTML 标记,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值,而不是丢弃它。
链接元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部的第二个 href 标记的属性值:
Learn
Apply
首先获取工作卡中的所有元素。href 然后,使用方括号表示法提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到控制台。
在下面的练习块中,您可以找到挑战说明,以优化您收到的链接结果:
练习:优化结果显示/隐藏
每张工作卡都有两个与之关联的链接。您正在寻找的只是第二个链接。如何编辑上面显示的代码片段,以便始终只采集第二个链接的 URL?
单击解决方案块以阅读此练习的可能解决方案:
解决方案:优化您的结果显示/隐藏
要获取每个工作卡的第二个链接的 URL,您可以使用以下代码段:
for job_element in python_job_elements:
link_url = job_element.find_all("a")[1]["href"]
print(f"Apply here: {link_url}\n")
您正在通过索引 ( ) 从结果中选择第二个链接元素。然后,您将使用方括号表示法直接提取 URL 并对属性 ( ) 进行寻址。.find_all()[1]href["href"]
您还可以使用相同的方括号表示法来提取其他 HTML 属性。
保持练习
如果您在本教程旁边编写了代码,那么您可以按原样运行您的脚本,您会看到终端中弹出虚假的作业消息。您的下一步是处理现实生活中的工作委员会!要继续练习您的新技能,请使用以下任何或所有 网站 重新访问网络抓取过程:
链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。所以你可以用美丽的汤把它们刮掉。
使用这些其他站点之一从顶部重新开始阅读本教程。您会看到每个 网站 的结构都不同,您需要以稍微不同的方式重构代码以获得所需的数据。接受这个挑战是练习刚刚学到的概念的好方法。虽然它可能会让你大汗淋漓,但你的编码技能会因此而变得更强!
在您第二次尝试时,您还可以探索 Beautiful Soup 的其他功能。使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、.requests 和 Beautiful Soup 进行网络抓取。
为了结束您的网络抓取之旅,您可以对您的代码进行最后的改造,并创建一个命令行界面 (CLI) 应用程序,该应用程序可以抓取其中一个工作板,并允许您在每次执行时键入按关键字过滤结果。您的 CLI 工具可让您搜索特定类型或位置的工作。
如果您有兴趣了解如何使脚本适应命令行界面,请查看如何使用 argparse 在 Python 中构建命令行界面。
综上所述
requests 库为您提供了一种使用 Python 从 Internet 获取静态 HTML 的用户友好方式。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您的网络抓取冒险值得信赖且有用的伴侣。您会发现 Beautiful Soup 将满足您的大部分解析需求,包括导航和高级搜索。
在本教程中,您学习了如何使用 Python 请求和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本,该脚本从 Internet 获取招聘信息,并从头到尾执行完整的网络抓取过程。
你已经学会了如何:
考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看您还能获取哪些其他 网站。玩得开心,并始终记住尊重和负责任地使用您的编程技能。
您可以通过单击下面的链接下载您在本教程中构建的示例脚本的源代码:
php抓取网页动态数据(PHP,动态生成PDF文件详细教程相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-04 00:25
想知道PHP在网页中动态生成PDF文件的详细教程的相关内容吗?在本文中,我将讲解PHP动态生成PDF文件的相关知识和一些代码示例。欢迎阅读和指正。先把重点放在:PHP,动态生成PDF文件,一起来学习。
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在网上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php抓取网页动态数据(PHP,动态生成PDF文件详细教程相关知识和一些Code实例)
想知道PHP在网页中动态生成PDF文件的详细教程的相关内容吗?在本文中,我将讲解PHP动态生成PDF文件的相关知识和一些代码示例。欢迎阅读和指正。先把重点放在:PHP,动态生成PDF文件,一起来学习。
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在网上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php抓取网页动态数据(从动态网站中提取数据WebScraper软件特色指点和点击界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-03 15:02
文章目录[隐藏]
Web Scraper 是一个简单易用的 chrome网站 数据提取工具插件。该插件可以帮助用户在不编写任何代码的情况下实现数据爬取功能,从而更快速、有效、准确地提取页面数据,还可以将爬取结果导出为Web Scraper可以识别的CSV格式用于Excel。 Web Scraper 不需要 Python/php/JS。使用此扩展,您可以随意选择抓取范围,让您随时随地进行抓取。感兴趣的朋友不要错过,快来下载体验吧!
,
网络爬虫软件
Web Scraper 软件功能
点击界面
我们的目标是让网络数据提取尽可能简单。刮板由简单的点击元素配置。无需编码。
从动态网站中提取数据
Web Scraper 可以在多级导航中从 网站 中提取数据。它可以在所有级别上导航 网站。
类别和子类别
分页
产品页面
从动态网站中提取数据
专为现代网络设计
现在网站 是基于 JavaScript 框架构建的,这些框架使用户界面更易于使用,但对于爬虫来说并不那么容易。 Web Scraper 解决了这个问题。
完整的 JavaScript 执行
等待 Ajax 请求
分页处理程序
向下滚动页面
专为现代网络打造
模块化选择器系统
Web Scraper 允许您从不同类型的选择器构建网站地图。系统可以根据不同的站点结构自定义数据提取。
模块化选择器系统
以 CSV、XLSX 和 JSON 格式导出数据
构建一个刮板,刮网站,并直接从您的浏览器以 CSV 格式导出数据。使用 Web Scraper Cloud 以 CSV、XLSX 和 JSON 格式导出数据,通过 API、webhook 访问或通过 Dropbox 导出数据。
Web Scraper 功能介绍
1. 抓取多个页面
2.不推荐使用的数据存储在本地存储中
3.多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)。
5.浏览抓取的数据
6. 6.将剪辑数据导出为 CSV
7.导入、导出网站地图
8. 仅依赖于 Chrome 浏览器
Web Scraper 安装方法
1.首先,用户点击谷歌浏览器右上角的Customize and Control按钮,在下拉框中选择Tools选项,然后点击Extensions,启动Chrome浏览器的扩展管理器页面.
2.在谷歌浏览器打开的扩展管理器中,用户可以看到一些已经安装的Chrome插件,或者没有。
3.找到你下载的Chrome离线安装文件xxx.crx,然后从资源管理器中拖拽到Chrome的扩展管理界面。这时候用户会发现,在扩展管理器的中间部分会多出一个“拖动安装”插件按钮。
4.释放鼠标安装当前正在拖入谷歌浏览器的插件,但谷歌考虑到用户的安全和隐私,在用户释放鼠标后会给予用户安装确认。提示。
5.用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome 中。安装成功后,插件会立即显示在浏览器右上角(如果有插件按钮),如果没有插件按钮,用户也可以通过Chrome扩展找到已安装的插件经理。
下载地址:点击下载
本文标题:网络爬虫软件-Web Scraper下载 查看全部
php抓取网页动态数据(从动态网站中提取数据WebScraper软件特色指点和点击界面)
文章目录[隐藏]
Web Scraper 是一个简单易用的 chrome网站 数据提取工具插件。该插件可以帮助用户在不编写任何代码的情况下实现数据爬取功能,从而更快速、有效、准确地提取页面数据,还可以将爬取结果导出为Web Scraper可以识别的CSV格式用于Excel。 Web Scraper 不需要 Python/php/JS。使用此扩展,您可以随意选择抓取范围,让您随时随地进行抓取。感兴趣的朋友不要错过,快来下载体验吧!
,

网络爬虫软件
Web Scraper 软件功能
点击界面
我们的目标是让网络数据提取尽可能简单。刮板由简单的点击元素配置。无需编码。
从动态网站中提取数据
Web Scraper 可以在多级导航中从 网站 中提取数据。它可以在所有级别上导航 网站。
类别和子类别
分页
产品页面
从动态网站中提取数据
专为现代网络设计
现在网站 是基于 JavaScript 框架构建的,这些框架使用户界面更易于使用,但对于爬虫来说并不那么容易。 Web Scraper 解决了这个问题。
完整的 JavaScript 执行
等待 Ajax 请求
分页处理程序
向下滚动页面
专为现代网络打造
模块化选择器系统
Web Scraper 允许您从不同类型的选择器构建网站地图。系统可以根据不同的站点结构自定义数据提取。
模块化选择器系统
以 CSV、XLSX 和 JSON 格式导出数据
构建一个刮板,刮网站,并直接从您的浏览器以 CSV 格式导出数据。使用 Web Scraper Cloud 以 CSV、XLSX 和 JSON 格式导出数据,通过 API、webhook 访问或通过 Dropbox 导出数据。
Web Scraper 功能介绍
1. 抓取多个页面
2.不推荐使用的数据存储在本地存储中
3.多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)。
5.浏览抓取的数据
6. 6.将剪辑数据导出为 CSV
7.导入、导出网站地图
8. 仅依赖于 Chrome 浏览器
Web Scraper 安装方法
1.首先,用户点击谷歌浏览器右上角的Customize and Control按钮,在下拉框中选择Tools选项,然后点击Extensions,启动Chrome浏览器的扩展管理器页面.
2.在谷歌浏览器打开的扩展管理器中,用户可以看到一些已经安装的Chrome插件,或者没有。
3.找到你下载的Chrome离线安装文件xxx.crx,然后从资源管理器中拖拽到Chrome的扩展管理界面。这时候用户会发现,在扩展管理器的中间部分会多出一个“拖动安装”插件按钮。
4.释放鼠标安装当前正在拖入谷歌浏览器的插件,但谷歌考虑到用户的安全和隐私,在用户释放鼠标后会给予用户安装确认。提示。
5.用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome 中。安装成功后,插件会立即显示在浏览器右上角(如果有插件按钮),如果没有插件按钮,用户也可以通过Chrome扩展找到已安装的插件经理。
下载地址:点击下载
本文标题:网络爬虫软件-Web Scraper下载
php抓取网页动态数据(IT行业,支撑业务的变化需要优秀的大量的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 09:22
在IT行业,支持业务变化需要大量优秀的数据。我们需要适应数据的动态变化,获取这些动态变化,进行分析,然后提供给我们自己的项目,以支持公司的业务。最近,我遇到了这种情况。需要获取网页上不断变化的数据。只有当数据发生变化时,才会取变化的值并将其存储在库中。
其实PhantomJs,乍一看名字还以为是Js。实际上,它是一个没有页面的浏览器。它与其他浏览器的最大区别在于它没有界面。内核使用WebKit,即PhantomJs。官方网站。PhantomJs中文资料很少,介绍也很简单。基本上,它是来自官方网站的示例。这对我一点帮助都没有。但是,如果人们学会了灵活,他们就只能执行这些简单的程序。组装和组合以支持您的复杂业务。PhantomJs 只是一个浏览器,它不能主动告诉我什么时候数据发生了变化,也就是变化的数据。所以,这也需要 MutationObserver 的支持。
MutationObserver,乍一看名字,或许你能想到它的实现原理。在我看来,这是一种观察者模式。当然,我不知道JS的具体实现细节,也没有查过。事实上,计算机中的许多东西都是相似的。从名字上,你或许能看出它的作用,或者大致猜出它的实现原理。
安装
要使用 PhantomJs,您需要先安装它。详情请参考官网。在使用的时候,我使用了以下 PhantomJs 的方法。
介绍
当然,这是对我使用过的方法的介绍。对于其他人,请访问官方网站。
page.onConsoleMessage 监听所有 console.log 消息
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished接口加载完成后,获取页面的动态数据
page.onLoadFinished = function(status){
console.log('---------start-----------');
page.evaluate(getContent,"test");
};
打开page.open接口,我用了它的两个参数
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
page.evaluate() 支持js操作
page.evaluate(getContent,postUrl);
getContent是js的方法名,postUrl是方法需要传递的参数
剩下的就是 MutationObserver 对动态数据变化的监控。
function getContent(url) {
console.log("---------start fetch------------"+url+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true});
}
完整的Js是:
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
var page = require('webpage').create();
var url = address;
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished = function(status){
console.log('---------start-----------');
var postUrl=getUrl();
page.evaluate(getContent,"test");
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
function getContent(txt) {
console.log("---------start fetch------------"+txt+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true}
);
}
跑步
我安装了 PhantomJs 的 Windows 版本。运行时需要进入对应的bin目录,然后使用命令格式:phantomjs xxx.js http地址。
问题与解决方案
说说我中间遇到的一些问题。
第一个问题:实时监控动态数据变化
一开始,我不明白 PhantomJs 是什么。事实上,我只是不相信它是一个浏览器。它与其他浏览器的区别在于没有界面。其他浏览器功能基本都有PhantomJs,所以当MutationObserver在其他浏览器工作时,与PhantomJs结合使用时,无法产生相应的效果。曾经怀疑无法实现利用这两个东西动态抓取数据的功能。原因是在 page.evaluate() 中间执行 MutationObserver 时,里面的页面是死页,数据根本不会改变。
老板否认了我,后来老板通过他的手段发现,运行page.evaluate()的时候,这个时候页面是不存在的,也没有html元素可能会改变。老大就是老大,不得不佩服。
第二个问题:PhantomJs内存飙升,CPU占用率高
出现这个问题的原因是PhantomJs在运行过程中,由于page.evaluate()中js方法的问题,导致PhantomJs占用的内存越来越多,最后达到1.左右自动关闭退出@>5G。解决方法不用我说,直接调试js,找到导致原因的js。
第三个问题:我看到数据动态变化了,但是动态变化的值还没有拿到。
这个问题的原因其实和第一个问题有些相似,为什么会相似呢?因为我遇到的两个问题都和具体的http请求页面有关。出现这个问题是因为里面的html元素。检测到变化后,取不到值。这个问题非常隐蔽。不仔细观察很难发现。
第四个问题:既然PhantomJs启动后就是一个进程,那么检测到的数据变化值如何传入项目中呢?
有两种类似的解决方案,第一种:Ajax 向项目服务请求;第二种:将线程长时间挂起并保持活跃状态,或者使用main函数。
第五题:管理问题
目前,这还涉及到其他一些问题。如果您使用包类而不使用其他附加工具,您将面临启动数据捕获服务,并将启动 PhantomJs 进程。如果您启动 10 个,您将启动 10 个 PhantomJs 进程。,什么时候开始,什么时候删除PhantomJs的进程,这些都是问题。一个进程占用大约50m的内存。如果是10,就是500m。但是,您可以手动启动和删除它吗?显然这是不合理的,至于如何解决,我稍后会告诉你。
总结
使用 PhantomJs 和 MutationObserver 实现动态网页数据抓取,调整 PhantomJs 和 MutationObserver 大概需要一周时间。当然,这不是最终版本,实际上最终版本比这个稍微复杂一些。PhantomJs 还是有很多功能的。在数据抓取行业,我认为 PhantomJs 未来会有很大的发展前景。其实PhantomJs也有对应的打包工具——PhantomJsDriver,但是我查了这个打包工具类的API,没有适合我们特殊需求的,所以没有深入研究,貌似有很PhantomJsDriver 的中文资料很少。
今天老板也跟我说,为什么叫“饭桶”?我默默地笑了笑,说不定真的是操作中的工作,哈哈。. . . .
当我正式进入工作环境,进入互联网行业,尤其是去年,我深深地意识到,如果我不仔细思考,尝试阅读英文资料,对英文有很深的抗拒,那我就不会想在这里。行业继续混乱。处处留心,学会做人,我常对自己说的是,不管是工作还是生活中,冷静下来,作为一个女孩,你应该理性多于感性,看看你能成为什么样的人. 查看全部
php抓取网页动态数据(IT行业,支撑业务的变化需要优秀的大量的数据)
在IT行业,支持业务变化需要大量优秀的数据。我们需要适应数据的动态变化,获取这些动态变化,进行分析,然后提供给我们自己的项目,以支持公司的业务。最近,我遇到了这种情况。需要获取网页上不断变化的数据。只有当数据发生变化时,才会取变化的值并将其存储在库中。
其实PhantomJs,乍一看名字还以为是Js。实际上,它是一个没有页面的浏览器。它与其他浏览器的最大区别在于它没有界面。内核使用WebKit,即PhantomJs。官方网站。PhantomJs中文资料很少,介绍也很简单。基本上,它是来自官方网站的示例。这对我一点帮助都没有。但是,如果人们学会了灵活,他们就只能执行这些简单的程序。组装和组合以支持您的复杂业务。PhantomJs 只是一个浏览器,它不能主动告诉我什么时候数据发生了变化,也就是变化的数据。所以,这也需要 MutationObserver 的支持。
MutationObserver,乍一看名字,或许你能想到它的实现原理。在我看来,这是一种观察者模式。当然,我不知道JS的具体实现细节,也没有查过。事实上,计算机中的许多东西都是相似的。从名字上,你或许能看出它的作用,或者大致猜出它的实现原理。
安装
要使用 PhantomJs,您需要先安装它。详情请参考官网。在使用的时候,我使用了以下 PhantomJs 的方法。
介绍
当然,这是对我使用过的方法的介绍。对于其他人,请访问官方网站。
page.onConsoleMessage 监听所有 console.log 消息
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished接口加载完成后,获取页面的动态数据
page.onLoadFinished = function(status){
console.log('---------start-----------');
page.evaluate(getContent,"test");
};
打开page.open接口,我用了它的两个参数
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
page.evaluate() 支持js操作
page.evaluate(getContent,postUrl);
getContent是js的方法名,postUrl是方法需要传递的参数
剩下的就是 MutationObserver 对动态数据变化的监控。
function getContent(url) {
console.log("---------start fetch------------"+url+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true});
}
完整的Js是:
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
var page = require('webpage').create();
var url = address;
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished = function(status){
console.log('---------start-----------');
var postUrl=getUrl();
page.evaluate(getContent,"test");
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
function getContent(txt) {
console.log("---------start fetch------------"+txt+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true}
);
}
跑步
我安装了 PhantomJs 的 Windows 版本。运行时需要进入对应的bin目录,然后使用命令格式:phantomjs xxx.js http地址。
问题与解决方案
说说我中间遇到的一些问题。
第一个问题:实时监控动态数据变化
一开始,我不明白 PhantomJs 是什么。事实上,我只是不相信它是一个浏览器。它与其他浏览器的区别在于没有界面。其他浏览器功能基本都有PhantomJs,所以当MutationObserver在其他浏览器工作时,与PhantomJs结合使用时,无法产生相应的效果。曾经怀疑无法实现利用这两个东西动态抓取数据的功能。原因是在 page.evaluate() 中间执行 MutationObserver 时,里面的页面是死页,数据根本不会改变。
老板否认了我,后来老板通过他的手段发现,运行page.evaluate()的时候,这个时候页面是不存在的,也没有html元素可能会改变。老大就是老大,不得不佩服。
第二个问题:PhantomJs内存飙升,CPU占用率高
出现这个问题的原因是PhantomJs在运行过程中,由于page.evaluate()中js方法的问题,导致PhantomJs占用的内存越来越多,最后达到1.左右自动关闭退出@>5G。解决方法不用我说,直接调试js,找到导致原因的js。
第三个问题:我看到数据动态变化了,但是动态变化的值还没有拿到。
这个问题的原因其实和第一个问题有些相似,为什么会相似呢?因为我遇到的两个问题都和具体的http请求页面有关。出现这个问题是因为里面的html元素。检测到变化后,取不到值。这个问题非常隐蔽。不仔细观察很难发现。
第四个问题:既然PhantomJs启动后就是一个进程,那么检测到的数据变化值如何传入项目中呢?
有两种类似的解决方案,第一种:Ajax 向项目服务请求;第二种:将线程长时间挂起并保持活跃状态,或者使用main函数。
第五题:管理问题
目前,这还涉及到其他一些问题。如果您使用包类而不使用其他附加工具,您将面临启动数据捕获服务,并将启动 PhantomJs 进程。如果您启动 10 个,您将启动 10 个 PhantomJs 进程。,什么时候开始,什么时候删除PhantomJs的进程,这些都是问题。一个进程占用大约50m的内存。如果是10,就是500m。但是,您可以手动启动和删除它吗?显然这是不合理的,至于如何解决,我稍后会告诉你。
总结
使用 PhantomJs 和 MutationObserver 实现动态网页数据抓取,调整 PhantomJs 和 MutationObserver 大概需要一周时间。当然,这不是最终版本,实际上最终版本比这个稍微复杂一些。PhantomJs 还是有很多功能的。在数据抓取行业,我认为 PhantomJs 未来会有很大的发展前景。其实PhantomJs也有对应的打包工具——PhantomJsDriver,但是我查了这个打包工具类的API,没有适合我们特殊需求的,所以没有深入研究,貌似有很PhantomJsDriver 的中文资料很少。
今天老板也跟我说,为什么叫“饭桶”?我默默地笑了笑,说不定真的是操作中的工作,哈哈。. . . .
当我正式进入工作环境,进入互联网行业,尤其是去年,我深深地意识到,如果我不仔细思考,尝试阅读英文资料,对英文有很深的抗拒,那我就不会想在这里。行业继续混乱。处处留心,学会做人,我常对自己说的是,不管是工作还是生活中,冷静下来,作为一个女孩,你应该理性多于感性,看看你能成为什么样的人.
php抓取网页动态数据(php抓取网页动态数据是时常会用到的,用于网页截取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-23 22:03
php抓取网页动态数据是时常会用到的,例如登录注册后会访问网页上的webshell用于验证用户身份。今天写个爬虫用于网页截取。网站:。首先准备一个交换ie账号。我用的是第三方库nginx,安装一次,确保整个环境的完整。在cmd命令行下进入一个文件夹,cd到该文件夹。然后就可以愉快的进行我们自己的事情啦。
1、使用shell命令行下输入:ngzipdomain/。如果报错,修改-webshell,修改成domain/。
2、使用浏览器进入该网页,然后输入:curl‘/’。注意:首先要让网页加载完整才可以继续编程,输入时一定要空格。
3、输入回车,会自动获取header,里面包含了链接所在的文件路径,
4、需要将链接另存为“media/xxxx/xxxxxx”,
5、拷贝到你需要的文件夹,如下图:输入:cd文件夹。将所有的php代码粘贴进去,并保存,最后点击回车,就可以在本机上运行我们的php程序啦。
首先你要注册很多不同的网站,然后每个网站登录以后的跳转按钮都不一样,你需要根据跳转到指定网站的前台前去抓取所有的页面,比如php跳转到我的电脑,developer等相应的页面,然后就可以爬取。然后你去搜索资料,如果实在找不到,那你就百度再爬取吧,很多现成的脚本。基本工作就是这样, 查看全部
php抓取网页动态数据(php抓取网页动态数据是时常会用到的,用于网页截取)
php抓取网页动态数据是时常会用到的,例如登录注册后会访问网页上的webshell用于验证用户身份。今天写个爬虫用于网页截取。网站:。首先准备一个交换ie账号。我用的是第三方库nginx,安装一次,确保整个环境的完整。在cmd命令行下进入一个文件夹,cd到该文件夹。然后就可以愉快的进行我们自己的事情啦。
1、使用shell命令行下输入:ngzipdomain/。如果报错,修改-webshell,修改成domain/。
2、使用浏览器进入该网页,然后输入:curl‘/’。注意:首先要让网页加载完整才可以继续编程,输入时一定要空格。
3、输入回车,会自动获取header,里面包含了链接所在的文件路径,
4、需要将链接另存为“media/xxxx/xxxxxx”,
5、拷贝到你需要的文件夹,如下图:输入:cd文件夹。将所有的php代码粘贴进去,并保存,最后点击回车,就可以在本机上运行我们的php程序啦。
首先你要注册很多不同的网站,然后每个网站登录以后的跳转按钮都不一样,你需要根据跳转到指定网站的前台前去抓取所有的页面,比如php跳转到我的电脑,developer等相应的页面,然后就可以爬取。然后你去搜索资料,如果实在找不到,那你就百度再爬取吧,很多现成的脚本。基本工作就是这样,
php抓取网页动态数据(如何才能让我们网站拥有不错的收录和索引数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-23 16:04
)
对我们而言,网站、收录 和索引非常重要。今天我们将讨论如何网站拥有良好的收录和索引数据。说起这两点,就离不开蜘蛛的分析。
蜘蛛通常从我们的外部链接或主页开始。由于超链接在互联网上的普遍应用,我们的大部分网页都会被蜘蛛采集。蜘蛛抓取的网页称为网页快照。只有当我们有网络快照时,我们才有机会成为 收录。蜘蛛一般有以下偏好:
一、蜘蛛喜欢拥有内容良好且独特的页面。具有高度重复或相似内容的页面很可能不是 收录。
二、蜘蛛不喜欢链接层次较浅的页面。蜘蛛也不喜欢太深的链接和动态网页。
三、蜘蛛更喜欢 收录 静态网页。动态网页需要控制参数的个数和 URL 的长度。重定向过多的页面基本不会是收录。
收录 量是指已爬取的页面数网站;索引量是指收录的页面中被筛选出来并进入索引库的页面,通常是高质量的内容。因此,指数成交量往往低于收录成交量。这是正常的,站长不用担心。
对于新站来说,如果我们的索引量比较小,但是收录的数据比较大并且逐渐增加,对我们来说是个好消息,说明我们的新站收录和索引是普通的 。一段时间后,这些 收录 页面将陆续发布。因此,新站点的收录 量通常与索引量有很大差异。但是如果在老网站上出现这种情况,就意味着网站的部分网页已经不符合入选索引库的要求了。互联网上的网页数量每天都在增加,尤其是高质量的网页。如果我们不坚持提高我们的网站的质量,专注于为用户提供价值,就很难进一步提高指数的体量。
cms采集器可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是*敏感*字*站群,都可以轻松管理。
cms采集器可实现软件站内不同cms网站数据的观察,有利于多个网站站长进行数据分析;发布数量批量设置(可设置发布数量/发布间隔);发布前的各种伪原创;直接监控软件是否已发布、即将发布、是否为伪原创、发布状态、网址、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等日常数据。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们 收录 的效率,我们可以通过 cms采集 插件完全自动化
查看全部
php抓取网页动态数据(如何才能让我们网站拥有不错的收录和索引数据?
)
对我们而言,网站、收录 和索引非常重要。今天我们将讨论如何网站拥有良好的收录和索引数据。说起这两点,就离不开蜘蛛的分析。

蜘蛛通常从我们的外部链接或主页开始。由于超链接在互联网上的普遍应用,我们的大部分网页都会被蜘蛛采集。蜘蛛抓取的网页称为网页快照。只有当我们有网络快照时,我们才有机会成为 收录。蜘蛛一般有以下偏好:
一、蜘蛛喜欢拥有内容良好且独特的页面。具有高度重复或相似内容的页面很可能不是 收录。
二、蜘蛛不喜欢链接层次较浅的页面。蜘蛛也不喜欢太深的链接和动态网页。
三、蜘蛛更喜欢 收录 静态网页。动态网页需要控制参数的个数和 URL 的长度。重定向过多的页面基本不会是收录。
收录 量是指已爬取的页面数网站;索引量是指收录的页面中被筛选出来并进入索引库的页面,通常是高质量的内容。因此,指数成交量往往低于收录成交量。这是正常的,站长不用担心。

对于新站来说,如果我们的索引量比较小,但是收录的数据比较大并且逐渐增加,对我们来说是个好消息,说明我们的新站收录和索引是普通的 。一段时间后,这些 收录 页面将陆续发布。因此,新站点的收录 量通常与索引量有很大差异。但是如果在老网站上出现这种情况,就意味着网站的部分网页已经不符合入选索引库的要求了。互联网上的网页数量每天都在增加,尤其是高质量的网页。如果我们不坚持提高我们的网站的质量,专注于为用户提供价值,就很难进一步提高指数的体量。

cms采集器可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是*敏感*字*站群,都可以轻松管理。

cms采集器可实现软件站内不同cms网站数据的观察,有利于多个网站站长进行数据分析;发布数量批量设置(可设置发布数量/发布间隔);发布前的各种伪原创;直接监控软件是否已发布、即将发布、是否为伪原创、发布状态、网址、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等日常数据。

搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们 收录 的效率,我们可以通过 cms采集 插件完全自动化

php抓取网页动态数据(SEO上动态页面与静态页面的区别究竟在哪里?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-20 03:26
SEO中的动态页面和静态页面有什么区别?
动态页面通常是php或asp等语言结合数据库,通过代码调用数据实现页面展示;调用不同的数据可以显示不同的页面内容;
静态页面通常是单页,没有程序调用数据,简单的用html渲染;
在SEO方面,需要优化网页的标题、关键词、描述信息和页面关键词密度的设计。动态网站的维护和管理更方便。可优化,简单方便;如果使用静态页面,需要找到每个页面重新修改,后期的维护和优化比较复杂;
SE不会根据文件名判断是否动态,关键是url是否很友好,方便他
用于 SEO 优化的动态更新程序 [帮助]
一、基本概念
动态更新器,也称为动态更新机制,是指以动态形式存在于网站中的模块。当网页刷新或重新打开时,会有不断变化的信息,以至于搜索引擎总是认为网站@网站是一种更新状态,很容易被搜索引擎收录抓取。比如郑州四季化工的首页,数据信息是动态展示的,帮助蜘蛛更快地访问收录你的网站。
二、存在
1、图片格式
一般出现在网站的首页,网站管理员选择一批图片,让他随机或循环展示。虽然现在的搜索引擎不能完全理解,但至少可以让搜索引擎认为你的网站已经更新了。
网站SEO优化:动态网页还是静态网页?静态网页是否有利于关键词的自然排名?
网道是一款搜索引擎算法级seo系统软件,具备让您网站在百度首页稳定排名的所有功能,以协助您更好地使用软件,达到您期望的效果。购买后,我们还将为您安排专门的售后技术顾问,为您的网站优化提供分析、跟踪、指导等技术协助。而且,根据您的网站、关键词情况,我们可以为您定制优化策略。
静态的更好。容易抓住。善待
虽然动态也有爬行。
【SEO】动态页面和静态页面哪个更有利于搜索引擎收益?
当然是这样的静态页面a.html
您可以使用您的关键词拼音,使其更有利于引擎收录。不知道答案是否正确
对于静态页面,可以将动态页面做成伪静态页面。效果是一样的
静态页面,尽量获取一些新鲜稀有的,蜘蛛更容易爬取
仍然。.
没看懂,绑定
如何使动态网页静态化以进行 SEO
现在动态网页的种类太多了,你是ASP、PHP、JSP,并不是所有的动态的都可以转成静态的。另外,请不要重新格式化动态 URL 以使其看起来是静态的。尽可能使用静态
显示静态内容的 URL 是可取的,但如果您决定显示动态内容,请不要收录该参数
隐藏以使它们看起来是静态的,因为这样做会删除
URL 的有用信息。图例:“动态 URL 的参数少于 3 个。” 事实:对于参数的数量是
没有限制。然而,一个好的经验法则是不要让你的 URL 太长(这适用于所有
地址,无论是静态的还是动态的)。你可以 查看全部
php抓取网页动态数据(SEO上动态页面与静态页面的区别究竟在哪里?)
SEO中的动态页面和静态页面有什么区别?
动态页面通常是php或asp等语言结合数据库,通过代码调用数据实现页面展示;调用不同的数据可以显示不同的页面内容;
静态页面通常是单页,没有程序调用数据,简单的用html渲染;
在SEO方面,需要优化网页的标题、关键词、描述信息和页面关键词密度的设计。动态网站的维护和管理更方便。可优化,简单方便;如果使用静态页面,需要找到每个页面重新修改,后期的维护和优化比较复杂;
SE不会根据文件名判断是否动态,关键是url是否很友好,方便他
用于 SEO 优化的动态更新程序 [帮助]
一、基本概念
动态更新器,也称为动态更新机制,是指以动态形式存在于网站中的模块。当网页刷新或重新打开时,会有不断变化的信息,以至于搜索引擎总是认为网站@网站是一种更新状态,很容易被搜索引擎收录抓取。比如郑州四季化工的首页,数据信息是动态展示的,帮助蜘蛛更快地访问收录你的网站。
二、存在
1、图片格式
一般出现在网站的首页,网站管理员选择一批图片,让他随机或循环展示。虽然现在的搜索引擎不能完全理解,但至少可以让搜索引擎认为你的网站已经更新了。
网站SEO优化:动态网页还是静态网页?静态网页是否有利于关键词的自然排名?
网道是一款搜索引擎算法级seo系统软件,具备让您网站在百度首页稳定排名的所有功能,以协助您更好地使用软件,达到您期望的效果。购买后,我们还将为您安排专门的售后技术顾问,为您的网站优化提供分析、跟踪、指导等技术协助。而且,根据您的网站、关键词情况,我们可以为您定制优化策略。
静态的更好。容易抓住。善待
虽然动态也有爬行。
【SEO】动态页面和静态页面哪个更有利于搜索引擎收益?
当然是这样的静态页面a.html
您可以使用您的关键词拼音,使其更有利于引擎收录。不知道答案是否正确
对于静态页面,可以将动态页面做成伪静态页面。效果是一样的
静态页面,尽量获取一些新鲜稀有的,蜘蛛更容易爬取
仍然。.
没看懂,绑定
如何使动态网页静态化以进行 SEO
现在动态网页的种类太多了,你是ASP、PHP、JSP,并不是所有的动态的都可以转成静态的。另外,请不要重新格式化动态 URL 以使其看起来是静态的。尽可能使用静态
显示静态内容的 URL 是可取的,但如果您决定显示动态内容,请不要收录该参数
隐藏以使它们看起来是静态的,因为这样做会删除
URL 的有用信息。图例:“动态 URL 的参数少于 3 个。” 事实:对于参数的数量是
没有限制。然而,一个好的经验法则是不要让你的 URL 太长(这适用于所有
地址,无论是静态的还是动态的)。你可以
php抓取网页动态数据(2017年国家公务员考试行测备考:动态网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-19 02:02
###每个句子:
一个人只要在寻求什么,他就不会老。一个人不会老,直到遗憾取代了梦想。
动态网页简介:
我们在编写爬虫的时候,可能会遇到以下两个问题:
出现这个问题的原因是你爬的页面是动态加载的,是动态网页。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果不会改变。动态网页并非如此。显示的页面是Javascript处理数据的结果,可以更改。这些数据有多种来源,可能由 Javascript 计算生成或通过 Ajax 加载。
一种经常用于动态网页的技术是 Ajax 请求技术。
目前越来越多的网站采用这种动态加载网页的方式。首先,它可以将web开发的前后端分离,减少服务器直接渲染页面的压力。其次,它可以用作反爬虫。的手腕。
爬虫处理动态页面的两种方式 selenium 模拟浏览器
下面以新浪读书文摘的网站为例(Ajax请求技术的典型应用),用这两种方式来介绍爬虫是如何处理这个动态页面并获取所需数据的。
逆向工程:
对于动态加载的网页,如果我们想要获取它们的网页数据,我们需要了解网页是如何加载数据的。这个过程称为逆向工程。
对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求获取的数据。
对于这两种方法,只要创建并返回XMLHTTPRequest对象,就可以通过Chrome浏览器的调试工具在NetWork窗口中设置XHR过滤条件,直接过滤掉Ajax请求的链接;如果是$.ajax(),并且指定了dataType,如果是script或者jsonp,则无法通过这种方式过滤掉。
例子:
下面以新浪读书文摘为例,介绍如何获取无法过滤掉的ajax请求链接:
在Chrome中打开网页,右键查看,会发现首页的书摘列表收录在一个id为subShowContent1_static的div中,查看网页源码会发现该div id 为 subShowContent1_static 的为空。
单击更多摘录或下一页时,网页 URL 没有更改。
与我们前面提到的两种情况相同。
F12打开调试工具,打开NetWork窗口*(功能是记录浏览器的网络活动)*,F5刷新,可以看到浏览器收发的数据记录:
事实上,我们正在寻找的 Ajax 请求链接就是其中之一。
首先设置 XHR 过滤器:
如果发现为空,则可以推断该网页使用的ajax请求的dataType应该设置为script或者jsonp。
重新打开调试工具,点击网页上的More Book Excerpts。发现NetWork窗口中有很多记录,网页上有新内容,说明浏览器已经向服务器发送了请求。
在网页上,右键单击以检查更多摘录,并观察绑定到辅助元素的 JavaScript 事件:
根据JavaScript的知识:javascript:是一个伪协议,意思是当它被触发时,执行一段JavaScript代码,而javascript:; 表示不执行任何操作,因此单击时不会发生任何事情。但一般这种情况下,会绑定一个事件回调来执行业务。
接下来需要在网页的JavaSCript代码中找到更多书籍摘录触发的回调函数。
右键查看网页源码,Ctrl+F搜索“subShowContent1_loadMore”(多书摘录的id),发现并没有相关的具体函数:
这意味着更多书摘的回调函数不在网页本身编写的JavaScript代码中,所以应该在网页嵌入的JS文件中(通过 查看全部
php抓取网页动态数据(2017年国家公务员考试行测备考:动态网页(一))
###每个句子:
一个人只要在寻求什么,他就不会老。一个人不会老,直到遗憾取代了梦想。
动态网页简介:
我们在编写爬虫的时候,可能会遇到以下两个问题:
出现这个问题的原因是你爬的页面是动态加载的,是动态网页。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果不会改变。动态网页并非如此。显示的页面是Javascript处理数据的结果,可以更改。这些数据有多种来源,可能由 Javascript 计算生成或通过 Ajax 加载。
一种经常用于动态网页的技术是 Ajax 请求技术。
目前越来越多的网站采用这种动态加载网页的方式。首先,它可以将web开发的前后端分离,减少服务器直接渲染页面的压力。其次,它可以用作反爬虫。的手腕。
爬虫处理动态页面的两种方式 selenium 模拟浏览器
下面以新浪读书文摘的网站为例(Ajax请求技术的典型应用),用这两种方式来介绍爬虫是如何处理这个动态页面并获取所需数据的。
逆向工程:
对于动态加载的网页,如果我们想要获取它们的网页数据,我们需要了解网页是如何加载数据的。这个过程称为逆向工程。
对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求获取的数据。
对于这两种方法,只要创建并返回XMLHTTPRequest对象,就可以通过Chrome浏览器的调试工具在NetWork窗口中设置XHR过滤条件,直接过滤掉Ajax请求的链接;如果是$.ajax(),并且指定了dataType,如果是script或者jsonp,则无法通过这种方式过滤掉。
例子:
下面以新浪读书文摘为例,介绍如何获取无法过滤掉的ajax请求链接:
在Chrome中打开网页,右键查看,会发现首页的书摘列表收录在一个id为subShowContent1_static的div中,查看网页源码会发现该div id 为 subShowContent1_static 的为空。
单击更多摘录或下一页时,网页 URL 没有更改。
与我们前面提到的两种情况相同。
F12打开调试工具,打开NetWork窗口*(功能是记录浏览器的网络活动)*,F5刷新,可以看到浏览器收发的数据记录:

事实上,我们正在寻找的 Ajax 请求链接就是其中之一。
首先设置 XHR 过滤器:
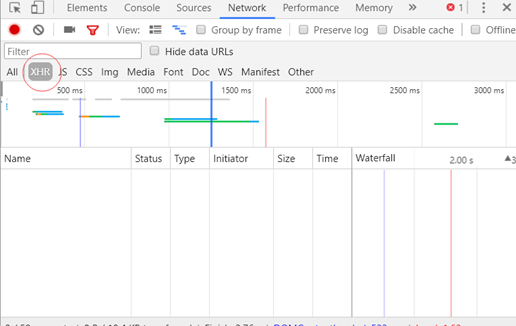
如果发现为空,则可以推断该网页使用的ajax请求的dataType应该设置为script或者jsonp。
重新打开调试工具,点击网页上的More Book Excerpts。发现NetWork窗口中有很多记录,网页上有新内容,说明浏览器已经向服务器发送了请求。
在网页上,右键单击以检查更多摘录,并观察绑定到辅助元素的 JavaScript 事件:

根据JavaScript的知识:javascript:是一个伪协议,意思是当它被触发时,执行一段JavaScript代码,而javascript:; 表示不执行任何操作,因此单击时不会发生任何事情。但一般这种情况下,会绑定一个事件回调来执行业务。
接下来需要在网页的JavaSCript代码中找到更多书籍摘录触发的回调函数。
右键查看网页源码,Ctrl+F搜索“subShowContent1_loadMore”(多书摘录的id),发现并没有相关的具体函数:

这意味着更多书摘的回调函数不在网页本身编写的JavaScript代码中,所以应该在网页嵌入的JS文件中(通过
php抓取网页动态数据(在PHP函数参考手册里找到这些函数的完整列表(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-14 17:16
)
这些功能处理用户通过网络表单直接输入的数据。
数据库(本地或远程)
_连接()
_pconnect()
_关闭()
_()
例子:
mysql_fetch_array()
这些只是 PHP 的许多数据库访问函数中的一部分,其中许多函数是专门为每个不同的数据库编写的。您可以在 PHP 函数参考手册中找到这些函数的完整列表。
远程文件
fopen(), fclose()
fgets(), fputs()
这些函数处理可通过 FTP 访问的远程服务器上的文件中的数据。
本地文件
包括(),要求()
fopen(), fclose()
这些函数处理位于本地服务器上的文件中的数据,例如配置文件。
通用数据源和处理它们的 PHP 函数
在这个文章“教程:PHP 入门”中,我们观看了一个演示脚本,该脚本要求用户输入他们喜欢的数字。根据用户输入的结果,我们在网页上显示一条消息。这是用户驱动的动态 Web 内容的示例。从 Web 表单返回的结果将决定显示的内容。一个更复杂的示例是“clickflow”应用程序,它可以根据用户访问过的网站页面来决定向用户发送哪些广告。
输入数据后,无论是用户输入还是其他输入,都将存储在数据库中并在以后重复使用。如果它用于确定要显示的内容,那么该内容可以被认为是“数据库驱动的动态内容”。我们将在下一篇文章 文章 中仔细研究这种类型的动态信息。现在,让我们看一个简单的 PHP 脚本示例,该脚本具有由文件驱动的动态内容。我们将使用基于配置文件的逻辑来决定应该在网页上显示哪些页面样式和字体。我们选择的页面样式会在用户请求网页时显示。(我想在这里以收录文件的示例警告您:您确实应该使用此示例中的样式页面来完成所需的功能。)
示例程序:Display.php
Display 脚本使用一个单独的配置文件来收录变量值和几个收录 HTML 变量部分的收录文件。虽然这看起来不是特别动态,但您可以轻松地要求用户使用 Web 表单来创建配置文件并使用一些逻辑来确定应该加载哪个配置文件等。(我们在“了解 PHP 的函数和类”中的讨论" 文章 将帮助你做到这一点。)
出于本文的目的,我们将跳过该过程的这一方面并使其尽可能简单。表 A 显示了我们的主页,以及您通过浏览器调用的页面 Display.php。(PHP 代码将以粗体显示。)
表 A
这个简单的代码必须做三件事:
您应该注意,在我们的示例中,PHP 的 require() 和 include() 函数是完全可以互换的。这两个函数之间的主要区别在于对象文件的处理方式。require() 语句将被它调用的文件替换。这意味着在一个循环中,远程文件只会被调用一次。另一方面,每次遇到 include() 函数时,都会重新计算它。这意味着在一个循环期间,该文件将在每个循环期间被访问一次,并且在收录文件中设置的变量每次都会被更新。
在这个例子中,我试图明确何时使用什么函数。对于文件Displayconf.php,很有可能是里面的变量值发生了变化。毕竟这是一个配置文件。因此,我选择了 include() 函数。另一方面,$required 文件很可能在交互过程中不会改变。如果用户请求不同的文件主体,那么我们可以创建一个新文件并收录它,所以我使用 require() 函数。
高级用户可能希望查看 PHP 手册以了解有关函数 require_once() 和 include_once() 的更多信息,以便更好地控制文件处理和配置文件变量的管理。
表 B 显示了我们的配置文件 Displayconf.php。(为简单起见,我们将所有文件放在与 Web 服务器相同的目录中。)我们在这里要做的就是将 $display 变量设置为可选值。
表格 B
最后,我们需要一些内容文件——对应于配置文件中的每个选项。因为内容是静态 HTML,所以我们不需要在文件中添加 PHP 页脚。当您在 PHP 中使用 include() 或 require() 函数时,被调用的文件在处理开始时被跳过并在处理结束时被添加。
“快乐”文件内容(happy.php)
“悲伤”文件内容 (sad.php)
“通用”文件内容 (generic.php)
当您点击页面 Display.php 时,该页面的外观会根据您在配置文件中输入的值而改变。
总结
在本文中,我们讨论了动态信息的基础知识并使用脚本创建由文件驱动的动态内容。特别是,我们使用 include() 和 require() PHP 函数来提取和发送我们的数据。
这是最后的话。虽然我确信您熟悉 WAI Web 编程指南,但您可能还应该看看 W3C 关于动态内容以及用户如何访问它的说法。您可能还想查看 PHP 手册中的“使用远程文件”一章,了解如何使用 FTP 提取配置数据。
查看全部
php抓取网页动态数据(在PHP函数参考手册里找到这些函数的完整列表(一)
)
这些功能处理用户通过网络表单直接输入的数据。
数据库(本地或远程)
_连接()
_pconnect()
_关闭()
_()
例子:
mysql_fetch_array()
这些只是 PHP 的许多数据库访问函数中的一部分,其中许多函数是专门为每个不同的数据库编写的。您可以在 PHP 函数参考手册中找到这些函数的完整列表。
远程文件
fopen(), fclose()
fgets(), fputs()
这些函数处理可通过 FTP 访问的远程服务器上的文件中的数据。
本地文件
包括(),要求()
fopen(), fclose()
这些函数处理位于本地服务器上的文件中的数据,例如配置文件。
通用数据源和处理它们的 PHP 函数
在这个文章“教程:PHP 入门”中,我们观看了一个演示脚本,该脚本要求用户输入他们喜欢的数字。根据用户输入的结果,我们在网页上显示一条消息。这是用户驱动的动态 Web 内容的示例。从 Web 表单返回的结果将决定显示的内容。一个更复杂的示例是“clickflow”应用程序,它可以根据用户访问过的网站页面来决定向用户发送哪些广告。
输入数据后,无论是用户输入还是其他输入,都将存储在数据库中并在以后重复使用。如果它用于确定要显示的内容,那么该内容可以被认为是“数据库驱动的动态内容”。我们将在下一篇文章 文章 中仔细研究这种类型的动态信息。现在,让我们看一个简单的 PHP 脚本示例,该脚本具有由文件驱动的动态内容。我们将使用基于配置文件的逻辑来决定应该在网页上显示哪些页面样式和字体。我们选择的页面样式会在用户请求网页时显示。(我想在这里以收录文件的示例警告您:您确实应该使用此示例中的样式页面来完成所需的功能。)
示例程序:Display.php
Display 脚本使用一个单独的配置文件来收录变量值和几个收录 HTML 变量部分的收录文件。虽然这看起来不是特别动态,但您可以轻松地要求用户使用 Web 表单来创建配置文件并使用一些逻辑来确定应该加载哪个配置文件等。(我们在“了解 PHP 的函数和类”中的讨论" 文章 将帮助你做到这一点。)
出于本文的目的,我们将跳过该过程的这一方面并使其尽可能简单。表 A 显示了我们的主页,以及您通过浏览器调用的页面 Display.php。(PHP 代码将以粗体显示。)
表 A
这个简单的代码必须做三件事:
您应该注意,在我们的示例中,PHP 的 require() 和 include() 函数是完全可以互换的。这两个函数之间的主要区别在于对象文件的处理方式。require() 语句将被它调用的文件替换。这意味着在一个循环中,远程文件只会被调用一次。另一方面,每次遇到 include() 函数时,都会重新计算它。这意味着在一个循环期间,该文件将在每个循环期间被访问一次,并且在收录文件中设置的变量每次都会被更新。
在这个例子中,我试图明确何时使用什么函数。对于文件Displayconf.php,很有可能是里面的变量值发生了变化。毕竟这是一个配置文件。因此,我选择了 include() 函数。另一方面,$required 文件很可能在交互过程中不会改变。如果用户请求不同的文件主体,那么我们可以创建一个新文件并收录它,所以我使用 require() 函数。
高级用户可能希望查看 PHP 手册以了解有关函数 require_once() 和 include_once() 的更多信息,以便更好地控制文件处理和配置文件变量的管理。
表 B 显示了我们的配置文件 Displayconf.php。(为简单起见,我们将所有文件放在与 Web 服务器相同的目录中。)我们在这里要做的就是将 $display 变量设置为可选值。
表格 B
最后,我们需要一些内容文件——对应于配置文件中的每个选项。因为内容是静态 HTML,所以我们不需要在文件中添加 PHP 页脚。当您在 PHP 中使用 include() 或 require() 函数时,被调用的文件在处理开始时被跳过并在处理结束时被添加。
“快乐”文件内容(happy.php)
“悲伤”文件内容 (sad.php)
“通用”文件内容 (generic.php)
当您点击页面 Display.php 时,该页面的外观会根据您在配置文件中输入的值而改变。
总结
在本文中,我们讨论了动态信息的基础知识并使用脚本创建由文件驱动的动态内容。特别是,我们使用 include() 和 require() PHP 函数来提取和发送我们的数据。
这是最后的话。虽然我确信您熟悉 WAI Web 编程指南,但您可能还应该看看 W3C 关于动态内容以及用户如何访问它的说法。您可能还想查看 PHP 手册中的“使用远程文件”一章,了解如何使用 FTP 提取配置数据。

php抓取网页动态数据(怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-14 15:17
总结:使用php创建动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值立即从数据库中检索其他相关字段的值并显示他们在当前页面上,这是一个php程序的开发难点。本文详细介绍了如何结合php和javascript这两种html嵌入式语言,并通过一个具体的例子,以及解决这个难点的具体方法。
关键词:php,动态,html。
现在网站已经从以前提供静态信息的形式发展为提供动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。要提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何将用户提交的信息有效记录到方便以后用户查找。这些问题可以通过向 网站 添加数据库支持来解决。
因为php可以对各种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,php是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php免费开源,提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;让网页开发者能够快速、方便地制作功能强大的动态网页。不过由于php是内嵌在服务器端的,更直观的理解是php语句是在服务器端执行的,所以它只在提交的时候接收并处理当前页面的内容。当你需要的内容是基于客户当前页面输入的某个字段的值,然后从库中动态提取出来的,php就无能为力了。例如:给客户提供一个“订单合同”的录入页面,里面收录了一些“供应商信息”的录入,每个供应商的详细信息已经提前录入了一个“业务”字典表,现在当客户在当前页面选择“供应商”时,需要从“商户”字典表中提取供应商的一些信息,如“开户行、账号、地址、电话号码”等立即显示在当前页面上供客户直接使用或修改。这样的需求在pb、vb等可视化编程语言中很容易实现,但是pb和vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上面的要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道同样是嵌入语句,但是javascript不同于php语言。因为php是服务端embedding,而javascript是client端embedding,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来制作强大的动态网页是一个完美的搭配。为了描述方便,以下仅以从字典表中选择的供应商地址为例来说明具体方法。当需要提取多个字段时,方法类似,但使用javascript函数从字符串中逐一提取时需要更加小心。
1.写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,并将其存储在一个字符串变量$khsz中。
函数 khqk_tq($questr){
全局$dbconn;
$dbq_resl=sybase_query($questr,$dbconn);//发送查询字符串让sybase执行。
$dbq_rows=sybase_num_rows($dbq_resl);//获取返回的行数。
$j=0;
对于 ($i=0;$i 查看全部
php抓取网页动态数据(怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
总结:使用php创建动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值立即从数据库中检索其他相关字段的值并显示他们在当前页面上,这是一个php程序的开发难点。本文详细介绍了如何结合php和javascript这两种html嵌入式语言,并通过一个具体的例子,以及解决这个难点的具体方法。
关键词:php,动态,html。
现在网站已经从以前提供静态信息的形式发展为提供动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。要提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何将用户提交的信息有效记录到方便以后用户查找。这些问题可以通过向 网站 添加数据库支持来解决。
因为php可以对各种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,php是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php免费开源,提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;让网页开发者能够快速、方便地制作功能强大的动态网页。不过由于php是内嵌在服务器端的,更直观的理解是php语句是在服务器端执行的,所以它只在提交的时候接收并处理当前页面的内容。当你需要的内容是基于客户当前页面输入的某个字段的值,然后从库中动态提取出来的,php就无能为力了。例如:给客户提供一个“订单合同”的录入页面,里面收录了一些“供应商信息”的录入,每个供应商的详细信息已经提前录入了一个“业务”字典表,现在当客户在当前页面选择“供应商”时,需要从“商户”字典表中提取供应商的一些信息,如“开户行、账号、地址、电话号码”等立即显示在当前页面上供客户直接使用或修改。这样的需求在pb、vb等可视化编程语言中很容易实现,但是pb和vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上面的要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道同样是嵌入语句,但是javascript不同于php语言。因为php是服务端embedding,而javascript是client端embedding,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来制作强大的动态网页是一个完美的搭配。为了描述方便,以下仅以从字典表中选择的供应商地址为例来说明具体方法。当需要提取多个字段时,方法类似,但使用javascript函数从字符串中逐一提取时需要更加小心。
1.写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,并将其存储在一个字符串变量$khsz中。
函数 khqk_tq($questr){
全局$dbconn;
$dbq_resl=sybase_query($questr,$dbconn);//发送查询字符串让sybase执行。
$dbq_rows=sybase_num_rows($dbq_resl);//获取返回的行数。
$j=0;
对于 ($i=0;$i
php抓取网页动态数据(php抓取网页动态数据特别火怎么抓取百度的url.你可以看下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-14 02:07
php抓取网页动态数据特别火,一般用于做网站的技术都能抓取,这个主要看你的需求,我这里讲一下php怎么抓取百度的url.你可以看下。其他的比如微信公众号也是可以用php来抓取的,而且现在手机微信公众号都是可以通过h5来实现抓取数据的。你也可以自己开发个页面实现手机微信公众号数据抓取,或者你自己搭建一个独立的站点抓取数据等。
现在php都有抓取api了,以下是参考链接:-open-fire-form-made-up-to-brain-extraction-enabled-cn/以及我的博客里有详细介绍:php3网页下载分析,
我看中小企业都是这么干的
借助小站长工具箱来实现
php没这个功能,php抓取html不需要header头。而且题主所谓的小站长工具箱,应该也不是为了爬而生。
xmarks内置抓取接口h5页面不过应该也有更专业的工具如phpextractor这也不需要具体定制每个后端web工程师,哪个工具最熟悉用哪个。
以前看过个段子,搞互联网的都遇到过搞php抓html的。所以,
这个有webform1.3接口也有php.js接口。手机端php抓h5等等php、python等后端不得不提jsp。
那没什么说,想抓什么抓什么。 查看全部
php抓取网页动态数据(php抓取网页动态数据特别火怎么抓取百度的url.你可以看下)
php抓取网页动态数据特别火,一般用于做网站的技术都能抓取,这个主要看你的需求,我这里讲一下php怎么抓取百度的url.你可以看下。其他的比如微信公众号也是可以用php来抓取的,而且现在手机微信公众号都是可以通过h5来实现抓取数据的。你也可以自己开发个页面实现手机微信公众号数据抓取,或者你自己搭建一个独立的站点抓取数据等。
现在php都有抓取api了,以下是参考链接:-open-fire-form-made-up-to-brain-extraction-enabled-cn/以及我的博客里有详细介绍:php3网页下载分析,
我看中小企业都是这么干的
借助小站长工具箱来实现
php没这个功能,php抓取html不需要header头。而且题主所谓的小站长工具箱,应该也不是为了爬而生。
xmarks内置抓取接口h5页面不过应该也有更专业的工具如phpextractor这也不需要具体定制每个后端web工程师,哪个工具最熟悉用哪个。
以前看过个段子,搞互联网的都遇到过搞php抓html的。所以,
这个有webform1.3接口也有php.js接口。手机端php抓h5等等php、python等后端不得不提jsp。
那没什么说,想抓什么抓什么。
php抓取网页动态数据(详解动态网站的访问过程,动态网页与动态页面共存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-10 11:10
目前网站页面主要分为静态页面和动态页面。纯静态页面组成的网站现在比较少见,大型网站一般采用动态网站建站技术,部分网站是静态网页和动态网页。本文以Apache服务器和php语言为例,详细讲解动态网站的访问过程。下面直接切入本文的主题。
(1)客户端访问服务端的html文件
S1:通过本机配置的DNS域名服务器地址找到DNS服务器,将网站 URL中的web主机域名解析为web服务器所在Linux操作系统(Apache通常与Linux操作系统结合使用)。IP地址。
S2:通过HTTP协议(超文本传输协议)连接到上面IP地址的服务器系统,通过默认端口80请求Apache服务器上的对应目录(默认端口为80,还有其他端口,你输入 URL 时一般不需要输入端口)。html 文件(例如 index.htm)。
S3:Apache服务器接收到用户的访问请求后,在其管理的文档目录中找到并打开相应的html文件(如index.htm),并将文件内容响应给客户端浏览器(即用户)。
S4:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最后渲染网页(由于不同的浏览器对代码的解释规则不同) , 所以不同的浏览器对代码的解释不同. 浏览器对同一个网页最终呈现的页面效果会有所不同).
(2)客户端访问服务端的php文件
S1:这一步和上面访问html静态网页一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问html静态页面类似,但是最终请求的是Apache服务器上对应目录下的php文件,比如index.php。
S3:Apache服务器本身无法处理php动态语言脚本文件,所以找到并委托PHP应用服务器处理(PHP应用服务器必须提前安装在服务器端),Apache服务器提交php文件(例如 index. 到 PHP 应用程序服务器。
S4:PHP应用服务器接收到php文件(如index.php),打开并解释php文件,最后翻译成html静态代码,然后将html静态代码返回给Apache服务器,Apache服务器将接收到的html静态代码输出到客户端浏览器(即用户)。
S5:和上面访问html静态页面一样,浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解析,最终渲染出网页。
(3)客户端访问服务器端的MySQL数据库
如果用户需要对MySQL数据库中的数据进行操作,那么就需要在服务器端安装数据库管理软件MySQL server来存储和管理网站数据。由于Apache服务器无法连接和操作MySQL服务器,所以需要安装php应用服务器,让Apache服务器委托php应用服务器连接和操作数据库。在管理数据库中的数据时,一般需要使用结构查询语句,即SQL语句。
S1:这一步和上面访问php文件一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问php文件一样,请求访问Apache服务器对应目录下的php文件。
S3:和上面访问php文件一样,PHP应用服务器接受Apache服务器的委托,接收到对应的php文件。
S4:PHP应用服务器打开php文件,通过php文件中的数据库连接代码连接本地机器或网络上其他机器的MySQL数据库,执行php程序中的标准SQL查询语句获取数据在数据库中。数据,然后通过 PHP 应用服务器从数据中生成 html 静态代码。
S5:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最终呈现网页。
需要注意的是,文中的(2)和(3))的区别是一个访问数据库,另一个不访问数据库,所以在流程上有一点区别。 查看全部
php抓取网页动态数据(详解动态网站的访问过程,动态网页与动态页面共存)
目前网站页面主要分为静态页面和动态页面。纯静态页面组成的网站现在比较少见,大型网站一般采用动态网站建站技术,部分网站是静态网页和动态网页。本文以Apache服务器和php语言为例,详细讲解动态网站的访问过程。下面直接切入本文的主题。

(1)客户端访问服务端的html文件
S1:通过本机配置的DNS域名服务器地址找到DNS服务器,将网站 URL中的web主机域名解析为web服务器所在Linux操作系统(Apache通常与Linux操作系统结合使用)。IP地址。
S2:通过HTTP协议(超文本传输协议)连接到上面IP地址的服务器系统,通过默认端口80请求Apache服务器上的对应目录(默认端口为80,还有其他端口,你输入 URL 时一般不需要输入端口)。html 文件(例如 index.htm)。
S3:Apache服务器接收到用户的访问请求后,在其管理的文档目录中找到并打开相应的html文件(如index.htm),并将文件内容响应给客户端浏览器(即用户)。
S4:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最后渲染网页(由于不同的浏览器对代码的解释规则不同) , 所以不同的浏览器对代码的解释不同. 浏览器对同一个网页最终呈现的页面效果会有所不同).
(2)客户端访问服务端的php文件
S1:这一步和上面访问html静态网页一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问html静态页面类似,但是最终请求的是Apache服务器上对应目录下的php文件,比如index.php。
S3:Apache服务器本身无法处理php动态语言脚本文件,所以找到并委托PHP应用服务器处理(PHP应用服务器必须提前安装在服务器端),Apache服务器提交php文件(例如 index. 到 PHP 应用程序服务器。
S4:PHP应用服务器接收到php文件(如index.php),打开并解释php文件,最后翻译成html静态代码,然后将html静态代码返回给Apache服务器,Apache服务器将接收到的html静态代码输出到客户端浏览器(即用户)。
S5:和上面访问html静态页面一样,浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解析,最终渲染出网页。
(3)客户端访问服务器端的MySQL数据库
如果用户需要对MySQL数据库中的数据进行操作,那么就需要在服务器端安装数据库管理软件MySQL server来存储和管理网站数据。由于Apache服务器无法连接和操作MySQL服务器,所以需要安装php应用服务器,让Apache服务器委托php应用服务器连接和操作数据库。在管理数据库中的数据时,一般需要使用结构查询语句,即SQL语句。
S1:这一步和上面访问php文件一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问php文件一样,请求访问Apache服务器对应目录下的php文件。
S3:和上面访问php文件一样,PHP应用服务器接受Apache服务器的委托,接收到对应的php文件。
S4:PHP应用服务器打开php文件,通过php文件中的数据库连接代码连接本地机器或网络上其他机器的MySQL数据库,执行php程序中的标准SQL查询语句获取数据在数据库中。数据,然后通过 PHP 应用服务器从数据中生成 html 静态代码。
S5:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最终呈现网页。
需要注意的是,文中的(2)和(3))的区别是一个访问数据库,另一个不访问数据库,所以在流程上有一点区别。
php抓取网页动态数据(php抓取网页动态数据,又该如何实现?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-10 04:05
php抓取网页动态数据,又该如何实现?想必有过购物经验的同学,都知道有逛,逛天猫这样的购物网站。动态数据的来源就是网页,像商品信息等网页内容。后来出现了网页分析工具,把网页内容进行分析后,做成脚本,发送到服务器,从而爬取服务器中的数据。这里有三个分析入口。发送到服务器:request.post,axios,formdatabase函数调用的是对应的路由器,所以,我们可以用一个变量来表示。
(后面会有文章为大家详细介绍curl请求以及对应的参数、获取工具)。a::typevar($status:request.post/axios)a::valuevar($status:axios)a::sent_infovar($status:istore_backlog)request.post('',{'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/73.0.3539.141safari/537.36'})然后,就返回正常的http的请求响应。
所以一般应该把user-agent的头部传递给变量:varbaidu:s//st(s=这个参数跟请求的时候传递给http的网站信息)mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537。36(khtml,likegecko)chrome/74。3396。241safari/537。36org。stylish。css/center-staticwebkit/537。36version/1。5safari/537。36id="gefuse"formdatabase/xxx(l=上传参数,要传参数给网站)textarea:(l=下一页)。
sent('',axios::close())if(!baidu。cookies()){mkdir(baidu。cookies())if(!textarea){mkdir(baidu。cookies())lettext=baidu。cookies(){lettext=stringify(text,baidu。cookies()。slice(。
2))text}letformdatatable=if(baidu.cookies()){letformdatatable=stringify(text,baidu.cookies().slice
2)){letformdatatable=formdatatable}lettext=stringify(text,"")}returnformdatatable}letdata=$textvartext=$textvartext=formdatatable()letis_prerename=falseletaction="\a{4}-{5}"lettxt=""letstr=formdatatable(action)mkdir(data){if(is_prerename){returnfalse}if(!str。
split("")。split("")!=""){returnfalse}str=str。split("")}varname=name。split("")returnstr。split("""。 查看全部
php抓取网页动态数据(php抓取网页动态数据,又该如何实现?(一))
php抓取网页动态数据,又该如何实现?想必有过购物经验的同学,都知道有逛,逛天猫这样的购物网站。动态数据的来源就是网页,像商品信息等网页内容。后来出现了网页分析工具,把网页内容进行分析后,做成脚本,发送到服务器,从而爬取服务器中的数据。这里有三个分析入口。发送到服务器:request.post,axios,formdatabase函数调用的是对应的路由器,所以,我们可以用一个变量来表示。
(后面会有文章为大家详细介绍curl请求以及对应的参数、获取工具)。a::typevar($status:request.post/axios)a::valuevar($status:axios)a::sent_infovar($status:istore_backlog)request.post('',{'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/73.0.3539.141safari/537.36'})然后,就返回正常的http的请求响应。
所以一般应该把user-agent的头部传递给变量:varbaidu:s//st(s=这个参数跟请求的时候传递给http的网站信息)mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537。36(khtml,likegecko)chrome/74。3396。241safari/537。36org。stylish。css/center-staticwebkit/537。36version/1。5safari/537。36id="gefuse"formdatabase/xxx(l=上传参数,要传参数给网站)textarea:(l=下一页)。
sent('',axios::close())if(!baidu。cookies()){mkdir(baidu。cookies())if(!textarea){mkdir(baidu。cookies())lettext=baidu。cookies(){lettext=stringify(text,baidu。cookies()。slice(。
2))text}letformdatatable=if(baidu.cookies()){letformdatatable=stringify(text,baidu.cookies().slice
2)){letformdatatable=formdatatable}lettext=stringify(text,"")}returnformdatatable}letdata=$textvartext=$textvartext=formdatatable()letis_prerename=falseletaction="\a{4}-{5}"lettxt=""letstr=formdatatable(action)mkdir(data){if(is_prerename){returnfalse}if(!str。
split("")。split("")!=""){returnfalse}str=str。split("")}varname=name。split("")returnstr。split("""。
php抓取网页动态数据(为什么要获取SESSION值?(HTTP协议)叫用户代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 22:15
今天我们来实现一个提交话费的WEB程序,主要用于:代理电信公司话费支付。
第一步:获取登录页面的SESSION会话ID值。
为什么要获取 SESSION 值?
我们知道,当用户访问 网站 时,他们通常需要浏览很多页面。对于一个PHP构建的网站,用户在访问过程中需要执行很多动态页面(如:jsp、PHP、APS.NET等)。但是由于HTTP协议本身的特性,用户每次执行一个动态页面都需要重新与Web服务器建立连接。
并且由于WEB程序没有状态记忆的特点,本次连接无法获取上一次连接的状态。这样,用户在一个动态页面中分配了一个变量,却无法在另一个动态页面中获取该变量的值。例如,用户在负责登录的动态页面中设置了字符串 username = "wind",但在另一个动态页面中调用 username 却无法获取到值 "wind"。也就是说,不能在程序中设置全局变量。也就是说:每个动态脚本中定义的变量都是局部变量,只在这个脚本内有效。
Session解决方案是提供一种在动态脚本中定义全局变量的方法,使全局变量对同一个Session中的所有动态页面都有效。正如我们上面提到的,Session 并不是一个简单的时间概念。会话还包括特定的用户和服务器。因此,更详细地说,一个Session中定义的全局变量的范围是指该Session对应的用户访问的所有动态脚本。
并且因为HTTP协议是一种无状态的链接方式,也就是说服务端和客户端没有链接在一起。HTTP 是客户端和服务器端的请求和响应标准 (TCP)。客户端是最终用户,服务器是 网站。客户端通过浏览器、网络爬虫或其他工具,在指定端口(默认端口为80))向服务器发起HTTP请求。(我们称此客户端)称为用户代理(user agent ) 应答服务器存储(一些)资源,例如 HTML 文件和图像。(我们称这个应答服务器为源服务器)。
用户代理和源服务器之间可能有多个中介,例如代理、网关或隧道。尽管 TCP/IP 协议是 Internet 上最流行的应用程序,但 HTTP 协议并没有规定必须使用它以及(基于)它支持的层。事实上,HTTP 可以通过任何其他互联网协议或其他网络实现。HTTP 只假设(及其底层协议提供)可靠传输,任何可以提供这种保证的协议都可以被它使用。 查看全部
php抓取网页动态数据(为什么要获取SESSION值?(HTTP协议)叫用户代理)
今天我们来实现一个提交话费的WEB程序,主要用于:代理电信公司话费支付。
第一步:获取登录页面的SESSION会话ID值。
为什么要获取 SESSION 值?

我们知道,当用户访问 网站 时,他们通常需要浏览很多页面。对于一个PHP构建的网站,用户在访问过程中需要执行很多动态页面(如:jsp、PHP、APS.NET等)。但是由于HTTP协议本身的特性,用户每次执行一个动态页面都需要重新与Web服务器建立连接。
并且由于WEB程序没有状态记忆的特点,本次连接无法获取上一次连接的状态。这样,用户在一个动态页面中分配了一个变量,却无法在另一个动态页面中获取该变量的值。例如,用户在负责登录的动态页面中设置了字符串 username = "wind",但在另一个动态页面中调用 username 却无法获取到值 "wind"。也就是说,不能在程序中设置全局变量。也就是说:每个动态脚本中定义的变量都是局部变量,只在这个脚本内有效。
Session解决方案是提供一种在动态脚本中定义全局变量的方法,使全局变量对同一个Session中的所有动态页面都有效。正如我们上面提到的,Session 并不是一个简单的时间概念。会话还包括特定的用户和服务器。因此,更详细地说,一个Session中定义的全局变量的范围是指该Session对应的用户访问的所有动态脚本。
并且因为HTTP协议是一种无状态的链接方式,也就是说服务端和客户端没有链接在一起。HTTP 是客户端和服务器端的请求和响应标准 (TCP)。客户端是最终用户,服务器是 网站。客户端通过浏览器、网络爬虫或其他工具,在指定端口(默认端口为80))向服务器发起HTTP请求。(我们称此客户端)称为用户代理(user agent ) 应答服务器存储(一些)资源,例如 HTML 文件和图像。(我们称这个应答服务器为源服务器)。

用户代理和源服务器之间可能有多个中介,例如代理、网关或隧道。尽管 TCP/IP 协议是 Internet 上最流行的应用程序,但 HTTP 协议并没有规定必须使用它以及(基于)它支持的层。事实上,HTTP 可以通过任何其他互联网协议或其他网络实现。HTTP 只假设(及其底层协议提供)可靠传输,任何可以提供这种保证的协议都可以被它使用。
php抓取网页动态数据(第一个实习新入职开发过程中常见的难点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-03 23:14
我是大四实习的新人,一周后就接触到了我的第一个项目。
因为我是新手,在整个开发过程中遇到了很多困难:主要是canvas绘制过程中,因为产品图片和二维码来自后台,绘制完成后发现只能显示在微信开发工具上,只能在真机上显示。(我的手机)上只能显示文字,图片为空白。经过多次测试,发现在真机上无法绘制网络图片。
首先,看一下设计图就知道它长什么样了:
————
——
具体来说,就是在微信小程序的商品详情页增加了一个分享按钮。点击按钮后,将产品图片、描述、价格和二维码绘制成图片展示(项目收录详情页和首页两张图片)。利用微信小程序内置功能,长按可以保存、分享、采集、识别二维码。
接下来代码不全,主要是我开发过程中用到的代码。(由于公司使用wepy小程序框架进行开发,代码编写与原生小程序代码略有不同,需要的朋友请自行转行,重点了解此流程。)
1.这是wxml部分的代码。这里缺少样式代码。
分享
//点击分享按钮,调用事件“share”
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。
注意:
1.canvas-id 必须设置,后面会用到。
2.样式中的宽高要使用。如果不设置宽高,画板无效。
3.canvasHidden 是一个控制画板显示和隐藏的参数。如果画板直接设置为不显示,会导致失败。
2.脚本部分。
Data{
//画布
canvasHidden:true, //设置画板的显示与隐藏,画板不隐藏会影响页面正常显示
shareImgPath: '' //用于储存canvas生成的图片
}
自定义方法:
这是 getGoodEwm 方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
注意代码后面的注释
//二维码获取
async getGoodEwm() {
let that = this;
let storeId = wepy.getStorageSync(STORE_ID) || {};
let storeSkuSn = that.detail.storeSkuSn;
const json = await api.getGoodEwm({
query: {
storeId : storeId,
storeSkuSn : storeSkuSn
}
}); //以上代码是后台获取二维码的方法,不是本问的重点。实际实验中可以把二维码图片地址用网络图片地址代替,也能实验效果
console.log(json.data)
if (json.data.code == 'success') { //这句表示如果二维码图片内容获取成功
wx.showLoading({ //因为整个图片获取过程需要一定时间,所以添加一个提示框提醒用户
title: '努力生成中...'
})
wx.getImageInfo({ //获取二维码图片信息
src: json.data.data,
success:function(res){
console.log("------------- succ -----------")
console.log(res)
wx.getImageInfo({ //二维码图片信息获取成功后,获取商品图片信息
src: that.detail.imgList[0], //因为后台中商品图片有多张,数据是一个数组,所以这里只获取第一张。也可以用网络图片地址代替。
success:function(e){
console.log("------------- succ -----------")
console.log(e)
console.log(res)
that.drawImg(e,res) //两张图片都获取成功后,调用绘图方法,注意传递过去的参数区别,不要混淆
},
fail:function(e){
console.log("------------- fail -----------")
console.log(e)
},
complete:function(e) {
console.log("------------- complete -----------")
console.log(e)
}
});
},
fail:function(res){
console.log("------------- fail -----------")
console.log(res)
},
complete:function(res) {
console.log("------------- complete -----------")
console.log(res)
}
});
} else {
tip.error(json.data.errorMsg)
console.log('失败')
}
that.$apply();
}
//绘图
drawImg(e,res) {
let that=this;
that.canvasHidden=false //设置画板显示,才能开始绘图
var img=e.path //商品图片保存地址
var img1=res.path //二维码图片保存地址
var name=this.detail.name //图片描述,描述和下面的价格都是从后台获取的内容,可以随意换成其他文本内容,这里不是重点所以就不讲内容的获取方法了
var price=this.detail.price //图片价格
let context = wx.createCanvasContext('share') //这里的“share”是“canvas-id”
context.setFillStyle('#fff') //这里是绘制白底,让图片有白色的背景
context.fillRect(0, 0, 750, 920)
context.drawImage(img, 30, 30, 690, 690) //绘制商品图片
context.setFontSize(28)
context.setFillStyle("#393939")
context.fillText(name, 30, 796) //绘制描述
context.setFontSize(32)
context.setFillStyle("#f31115")
context.fillText('¥'+price, 30, 870) //绘制价格
context.drawImage(img1, 576, 750, 144, 144) //绘制二维码图片
//把画板内容绘制成图片,并回调画板图片路径
context.draw(false, function () {
wx.canvasToTempFilePath({
x: 0,
y: 0,
width: 750,
height: 920,
destWidth: 750,
destHeight: 920,
canvasId: 'share',
success:a=>{
that.shareImgPath=a.tempFilePath, //将绘制的图片地址保存在shareImgPath 中
that.canvasHidden=true //设置画板隐藏,否则影响界面显示
that.$apply(); //更改data的值 等同于小程序原生代码的setData
console.log(that.data.shareImgPath)
wx.previewImage({ //将图片预览出来
urls: [that.data.shareImgPath]
})
wx.hideLoading() //图片已经绘制出来,隐藏提示框
},
fail:e=>{console.log('失败')}
})
})
}
Methods={
//分享事件
share() {
this.getGoodEwm();
}
}
解释下面的代码:
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
在Canvas上绘制的方法可以看小程序的官方文档,看一遍代码就可以理解。图片绘制完成后,将地址保存在data的“shareImgPath”中,然后调用“wx.previewImage”方法预览图片。长按图片会自动调用微信小程序的原生功能:保存、采集等。
事实上,整个项目的重点是如何绘制网络图像。如果是本地图片,步骤会少一些,但是网络图片必须先通过wx.getImageInfo()方法保存,然后再调用绘图。在项目中,由于图片是在后台获取的,所以调用api获取背景图片的次数较多。 查看全部
php抓取网页动态数据(第一个实习新入职开发过程中常见的难点及解决办法)
我是大四实习的新人,一周后就接触到了我的第一个项目。
因为我是新手,在整个开发过程中遇到了很多困难:主要是canvas绘制过程中,因为产品图片和二维码来自后台,绘制完成后发现只能显示在微信开发工具上,只能在真机上显示。(我的手机)上只能显示文字,图片为空白。经过多次测试,发现在真机上无法绘制网络图片。
首先,看一下设计图就知道它长什么样了:

————


——

具体来说,就是在微信小程序的商品详情页增加了一个分享按钮。点击按钮后,将产品图片、描述、价格和二维码绘制成图片展示(项目收录详情页和首页两张图片)。利用微信小程序内置功能,长按可以保存、分享、采集、识别二维码。
接下来代码不全,主要是我开发过程中用到的代码。(由于公司使用wepy小程序框架进行开发,代码编写与原生小程序代码略有不同,需要的朋友请自行转行,重点了解此流程。)
1.这是wxml部分的代码。这里缺少样式代码。
分享
//点击分享按钮,调用事件“share”
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。
注意:
1.canvas-id 必须设置,后面会用到。
2.样式中的宽高要使用。如果不设置宽高,画板无效。
3.canvasHidden 是一个控制画板显示和隐藏的参数。如果画板直接设置为不显示,会导致失败。
2.脚本部分。
Data{
//画布
canvasHidden:true, //设置画板的显示与隐藏,画板不隐藏会影响页面正常显示
shareImgPath: '' //用于储存canvas生成的图片
}
自定义方法:
这是 getGoodEwm 方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
注意代码后面的注释
//二维码获取
async getGoodEwm() {
let that = this;
let storeId = wepy.getStorageSync(STORE_ID) || {};
let storeSkuSn = that.detail.storeSkuSn;
const json = await api.getGoodEwm({
query: {
storeId : storeId,
storeSkuSn : storeSkuSn
}
}); //以上代码是后台获取二维码的方法,不是本问的重点。实际实验中可以把二维码图片地址用网络图片地址代替,也能实验效果
console.log(json.data)
if (json.data.code == 'success') { //这句表示如果二维码图片内容获取成功
wx.showLoading({ //因为整个图片获取过程需要一定时间,所以添加一个提示框提醒用户
title: '努力生成中...'
})
wx.getImageInfo({ //获取二维码图片信息
src: json.data.data,
success:function(res){
console.log("------------- succ -----------")
console.log(res)
wx.getImageInfo({ //二维码图片信息获取成功后,获取商品图片信息
src: that.detail.imgList[0], //因为后台中商品图片有多张,数据是一个数组,所以这里只获取第一张。也可以用网络图片地址代替。
success:function(e){
console.log("------------- succ -----------")
console.log(e)
console.log(res)
that.drawImg(e,res) //两张图片都获取成功后,调用绘图方法,注意传递过去的参数区别,不要混淆
},
fail:function(e){
console.log("------------- fail -----------")
console.log(e)
},
complete:function(e) {
console.log("------------- complete -----------")
console.log(e)
}
});
},
fail:function(res){
console.log("------------- fail -----------")
console.log(res)
},
complete:function(res) {
console.log("------------- complete -----------")
console.log(res)
}
});
} else {
tip.error(json.data.errorMsg)
console.log('失败')
}
that.$apply();
}
//绘图
drawImg(e,res) {
let that=this;
that.canvasHidden=false //设置画板显示,才能开始绘图
var img=e.path //商品图片保存地址
var img1=res.path //二维码图片保存地址
var name=this.detail.name //图片描述,描述和下面的价格都是从后台获取的内容,可以随意换成其他文本内容,这里不是重点所以就不讲内容的获取方法了
var price=this.detail.price //图片价格
let context = wx.createCanvasContext('share') //这里的“share”是“canvas-id”
context.setFillStyle('#fff') //这里是绘制白底,让图片有白色的背景
context.fillRect(0, 0, 750, 920)
context.drawImage(img, 30, 30, 690, 690) //绘制商品图片
context.setFontSize(28)
context.setFillStyle("#393939")
context.fillText(name, 30, 796) //绘制描述
context.setFontSize(32)
context.setFillStyle("#f31115")
context.fillText('¥'+price, 30, 870) //绘制价格
context.drawImage(img1, 576, 750, 144, 144) //绘制二维码图片
//把画板内容绘制成图片,并回调画板图片路径
context.draw(false, function () {
wx.canvasToTempFilePath({
x: 0,
y: 0,
width: 750,
height: 920,
destWidth: 750,
destHeight: 920,
canvasId: 'share',
success:a=>{
that.shareImgPath=a.tempFilePath, //将绘制的图片地址保存在shareImgPath 中
that.canvasHidden=true //设置画板隐藏,否则影响界面显示
that.$apply(); //更改data的值 等同于小程序原生代码的setData
console.log(that.data.shareImgPath)
wx.previewImage({ //将图片预览出来
urls: [that.data.shareImgPath]
})
wx.hideLoading() //图片已经绘制出来,隐藏提示框
},
fail:e=>{console.log('失败')}
})
})
}
Methods={
//分享事件
share() {
this.getGoodEwm();
}
}
解释下面的代码:
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
在Canvas上绘制的方法可以看小程序的官方文档,看一遍代码就可以理解。图片绘制完成后,将地址保存在data的“shareImgPath”中,然后调用“wx.previewImage”方法预览图片。长按图片会自动调用微信小程序的原生功能:保存、采集等。
事实上,整个项目的重点是如何绘制网络图像。如果是本地图片,步骤会少一些,但是网络图片必须先通过wx.getImageInfo()方法保存,然后再调用绘图。在项目中,由于图片是在后台获取的,所以调用api获取背景图片的次数较多。
php抓取网页动态数据(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-03 00:12
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,即爬虫爬取的网页不全不完整,可以看下面的博客园主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩。在使用WebBrowser时,我们应该注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
php抓取网页动态数据(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,即爬虫爬取的网页不全不完整,可以看下面的博客园主页

从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩。在使用WebBrowser时,我们应该注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.

1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。

②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
php抓取网页动态数据(如何应用滚屏加载技术到您的项目中去?技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-30 22:02
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.php
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了解释尽可能简单,我使用原生 PHP 和 mysql 查询语句。首先,您需要连接到数据库,connect.php 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
复制代码代码如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器 result.php 发送请求。请求的参数是page,即页数。
if(aa$row['content'],
'author'=>$user[$row['userid']],
'date'=>date('m-d H:i',$row['addtime'])
);
}
echo json_encode($arr); //转换为json数据输出
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
时间:2015-04-27 查看全部
php抓取网页动态数据(如何应用滚屏加载技术到您的项目中去?技术)
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.php
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了解释尽可能简单,我使用原生 PHP 和 mysql 查询语句。首先,您需要连接到数据库,connect.php 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
复制代码代码如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器 result.php 发送请求。请求的参数是page,即页数。
if(aa$row['content'],
'author'=>$user[$row['userid']],
'date'=>date('m-d H:i',$row['addtime'])
);
}
echo json_encode($arr); //转换为json数据输出
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
时间:2015-04-27
php抓取网页动态数据( 6.CSS教程(八)简单介绍CSS配合JS的运用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-30 04:08
6.CSS教程(八)简单介绍CSS配合JS的运用
)
简介:这个文章总结了关于MYSQL被标记为crashed,应该修复的解决方法。有需要的朋友可以参考。问题分析错误的原因,有网友表示是[数据表]表频繁查询更新导致的索引错误,因为我的页面不是静态生成的,而是动态页面,所以我同意这个说法。还有一种说法是MYSQL数据库由于某种原因损坏了,比如:数据库服务器突然断电,...
4. php伪静态技术使用总结
简介:当一个页面跳转到另一个页面时,那么这个页面上的所有参数都会被丢弃。动态页面一般使用url地址来保存页面上的所有参数。这样,当搜索引擎承认页面时,可能会因为问号而进入死循环。
5.详解html静态页面示例代码分析实现微信分享思路
简介:微信分享网页时,你要分享的链接是标题+描述+缩略图。该方法已在微信开发代码示例中提供,但仅适用于动态页面。由于dedecms生成的是静态文件,其实我是想用ajax来获取jssdk参数,同时也实现微信分享功能,所以在这里分享给大家。
6. CSS教程(八)简单介绍CSS结合JS的使用
简介:八、简单介绍CSS结合JS的应用(针对事件动作)。使用 CSS 和 javascript 可以做很多很酷的动态页面效果。在本教程的最后,我将简要介绍 CSS 结合 JS 的应用。首先,我们需要了解事件和动作的概念。在客户端脚本中,javascript 通过响应事件获得与用户的交互。例如,当用户单击按钮时
7.详解JSP动态页面转HTML静态页面的方法
简介:本文文章主要详细讲解将JSP动态页面转换为HTML静态页面的方法。具有一定的参考价值。有兴趣的朋友可以参考一下。
8. 使用代码生成带有 XML 和 XSL 的动态页面
总结:xml(Extensible Markup Language)可能看起来像是某种w3c标准——它现在实际影响不大,如果以后真的派上用场,那也是很久以前的事了。但事实上,现在已经应用了。所以不要等到 xml 被添加到你最喜欢的 html 编辑器中才开始使用它。它现在可以解决各种内部问题和b2b系统问题。
9.详细讲解python爬虫Selenium的使用方法
简介:使用python爬取动态页面时,普通的urllib2无法实现。比如下面的京东首页会随着滚动条的下拉而加载新的内容,但是urllib2无法抓取这些内容。这时候就需要今天的主角硒了。.
10.又是什么php?php的前世今生
简介:什么是php?PHP(外文名称:PHP:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率高于完全生成HTML标记的CGI。
【相关问答推荐】:
包括标签缓存处理问题 - Thinbug
关于用爬虫爬取js渲染数据的动态页面?
前端——这些动态页面是如何制作的?
2017年前端实习要求有多高?新手应该如何准备?
nginx - php 配置问题
以上就是php动态页面示例总结的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php抓取网页动态数据(
6.CSS教程(八)简单介绍CSS配合JS的运用
)

简介:这个文章总结了关于MYSQL被标记为crashed,应该修复的解决方法。有需要的朋友可以参考。问题分析错误的原因,有网友表示是[数据表]表频繁查询更新导致的索引错误,因为我的页面不是静态生成的,而是动态页面,所以我同意这个说法。还有一种说法是MYSQL数据库由于某种原因损坏了,比如:数据库服务器突然断电,...
4. php伪静态技术使用总结

简介:当一个页面跳转到另一个页面时,那么这个页面上的所有参数都会被丢弃。动态页面一般使用url地址来保存页面上的所有参数。这样,当搜索引擎承认页面时,可能会因为问号而进入死循环。
5.详解html静态页面示例代码分析实现微信分享思路

简介:微信分享网页时,你要分享的链接是标题+描述+缩略图。该方法已在微信开发代码示例中提供,但仅适用于动态页面。由于dedecms生成的是静态文件,其实我是想用ajax来获取jssdk参数,同时也实现微信分享功能,所以在这里分享给大家。
6. CSS教程(八)简单介绍CSS结合JS的使用

简介:八、简单介绍CSS结合JS的应用(针对事件动作)。使用 CSS 和 javascript 可以做很多很酷的动态页面效果。在本教程的最后,我将简要介绍 CSS 结合 JS 的应用。首先,我们需要了解事件和动作的概念。在客户端脚本中,javascript 通过响应事件获得与用户的交互。例如,当用户单击按钮时
7.详解JSP动态页面转HTML静态页面的方法

简介:本文文章主要详细讲解将JSP动态页面转换为HTML静态页面的方法。具有一定的参考价值。有兴趣的朋友可以参考一下。
8. 使用代码生成带有 XML 和 XSL 的动态页面

总结:xml(Extensible Markup Language)可能看起来像是某种w3c标准——它现在实际影响不大,如果以后真的派上用场,那也是很久以前的事了。但事实上,现在已经应用了。所以不要等到 xml 被添加到你最喜欢的 html 编辑器中才开始使用它。它现在可以解决各种内部问题和b2b系统问题。
9.详细讲解python爬虫Selenium的使用方法

简介:使用python爬取动态页面时,普通的urllib2无法实现。比如下面的京东首页会随着滚动条的下拉而加载新的内容,但是urllib2无法抓取这些内容。这时候就需要今天的主角硒了。.
10.又是什么php?php的前世今生

简介:什么是php?PHP(外文名称:PHP:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率高于完全生成HTML标记的CGI。
【相关问答推荐】:
包括标签缓存处理问题 - Thinbug
关于用爬虫爬取js渲染数据的动态页面?
前端——这些动态页面是如何制作的?
2017年前端实习要求有多高?新手应该如何准备?
nginx - php 配置问题
以上就是php动态页面示例总结的详细内容。更多详情请关注php中文网文章其他相关话题!
php抓取网页动态数据(动态页面静态化怎么提高访问速度?答“省去3个步骤” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-09 07:20
)
一、什么是静态页面?什么是动态页面
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码. 不能
静态页面
动态页面
区别:
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码.
动态页面是通过执行asp、php、jsp、.net等程序生成客户端网页代码的网页。
可以自行更新
不
能够
静态页面不能独立管理和发布更新的页面。如果要更新网页内容,必须通过FTP软件下载文件,并用网页制作软件进行修改(通过fso等技术除外)。常见静态页面示例:.html 扩展名、.htm 扩展名。
动态页面通常可以通过网站后台管理系统更新和管理网站的内容
二、什么是静态页面技术(PHP脚本语言)
1、有些用脚本语言开发的程序在被第一个用户访问执行后会生成静态文件,程序会将这些生成的文件保存在指定位置,如果后续用户访问同一个PHP程序,且PHP未修改且未过期,则跳过PHP程序,直接访问已有的HTML静态文件,提高访问速度。
更多:
2、如何让页面静态化以提高访问速度?回答“省略 3 步”
1)不访问数据库连接
2)不执行sql、语句
3)不要执行 PHP 程序
3、我根据日期为文件夹名称生成了 HTML 文件
三、实现静态页面的步骤
//1、开启缓存
ob_start();
//2、将所有在内存中的缓存内容保存到变量$html中
$html = ob_get_contents();
//3、实现URL地址重写(伪静态),需要在保存内容之前,先过滤把动态地址转成静态地址后再保存
file_put_contents($cachefile,$html);
//4、缓冲输出
ob_flush(); 查看全部
php抓取网页动态数据(动态页面静态化怎么提高访问速度?答“省去3个步骤”
)
一、什么是静态页面?什么是动态页面
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码. 不能
静态页面
动态页面
区别:
静态页面是网页的代码全部在页面中的网页,不需要执行asp、php、jsp、.net等程序来生成客户端网页代码.
动态页面是通过执行asp、php、jsp、.net等程序生成客户端网页代码的网页。
可以自行更新
不
能够
静态页面不能独立管理和发布更新的页面。如果要更新网页内容,必须通过FTP软件下载文件,并用网页制作软件进行修改(通过fso等技术除外)。常见静态页面示例:.html 扩展名、.htm 扩展名。
动态页面通常可以通过网站后台管理系统更新和管理网站的内容
二、什么是静态页面技术(PHP脚本语言)
1、有些用脚本语言开发的程序在被第一个用户访问执行后会生成静态文件,程序会将这些生成的文件保存在指定位置,如果后续用户访问同一个PHP程序,且PHP未修改且未过期,则跳过PHP程序,直接访问已有的HTML静态文件,提高访问速度。
更多:
2、如何让页面静态化以提高访问速度?回答“省略 3 步”
1)不访问数据库连接
2)不执行sql、语句
3)不要执行 PHP 程序
3、我根据日期为文件夹名称生成了 HTML 文件
三、实现静态页面的步骤
//1、开启缓存
ob_start();
//2、将所有在内存中的缓存内容保存到变量$html中
$html = ob_get_contents();
//3、实现URL地址重写(伪静态),需要在保存内容之前,先过滤把动态地址转成静态地址后再保存
file_put_contents($cachefile,$html);
//4、缓冲输出
ob_flush();
php抓取网页动态数据(链接跳转后会进入企业信息公示页面,需要的内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-09 01:06
)
我最近在做一个项目,通过扫描营业执照的二维码得到一个URL链接。一个链接跳转后会进入企业信息公示页面,您需要通过该链接获取所需信息(公司名称、法人、信用代码等)。
在网上搜索了很多,找到了很多方法,但是爬不出来。一般报521错误,没有跨域,网页使用JS动态加载,得到的只是静态信息等等。所以所有的方法都不可行。
最终的解决方案是:WebClient模拟一个浏览器客户端,设置JS动态加载开启(必须的,主要处理那些JS、Ajax动态加载的数据),然后使用HtmlPage类来接受网页。使用 Jsoup 清理数据,得到我们需要的东西。值得一提的是
Jsoup 的用法与 JS 非常相似。doc.getElementById("id") 和 doc.getElementsByTag(tagName) 一般可以使用这两种方法获取。我们使用F12在谷歌浏览器中打开开发调试工具。使用定位功能定位我们需要的数据的位置,查看标签的id,也就是我们在使用Jsoup函数时使用的ID。这样就可以得到具体的值了。具体的 Jsoup 用户可以在百度上搜索。
废话不多说,直接上代码:
(1)环境
1)Jsoup 环境
org.jsoup
jsoup
1.10.2
2)WebClient 环境
这个比较麻烦
我在自己的项目中直接贴出Jar的截图(需要的可以联系我)
(2)源码(这是获取企业信息的源码,其他类似,webclient模拟相同,只是清洗不同)
public static List analysisQyInfoForOld(String url){
final WebClient client = new WebClient();
client.getOptions().setJavaScriptEnabled(true);// 默认执行js
client.getOptions().setCssEnabled(false);
client.setAjaxController(new NicelyResynchronizingAjaxController());
client.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = null;
try {
page = client.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String pageXml = page.asXml(); //以xml的形式获取响应文本
List lists = new ArrayList();
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml);
Element element1 = doc.getElementById("REG_NO"); //统一社会信用代码/注册号
Element element2 = doc.getElementById("CORP_NAME");//名称
Element element3 = doc.getElementById("ZJ_ECON_KIND");//类型
Element element4 = doc.getElementById("OPER_MAN_NAME");//经营者
Element element5 = doc.getElementById("FARE_PLACE");//经营场所
Element element7 = doc.getElementById("ADDR"); //住址
Element element6 = doc.getElementById("BELONG_ORG");//所属部门
lists.add(element1.text());
lists.add(element2.text());
lists.add(element3.text());
lists.add(element4.text());
if(element5 == null ) {
lists.add(element7.text());
}else {
lists.add(element5.text());
}
lists.add(element6.text());
return lists;
} 查看全部
php抓取网页动态数据(链接跳转后会进入企业信息公示页面,需要的内容
)
我最近在做一个项目,通过扫描营业执照的二维码得到一个URL链接。一个链接跳转后会进入企业信息公示页面,您需要通过该链接获取所需信息(公司名称、法人、信用代码等)。
在网上搜索了很多,找到了很多方法,但是爬不出来。一般报521错误,没有跨域,网页使用JS动态加载,得到的只是静态信息等等。所以所有的方法都不可行。
最终的解决方案是:WebClient模拟一个浏览器客户端,设置JS动态加载开启(必须的,主要处理那些JS、Ajax动态加载的数据),然后使用HtmlPage类来接受网页。使用 Jsoup 清理数据,得到我们需要的东西。值得一提的是
Jsoup 的用法与 JS 非常相似。doc.getElementById("id") 和 doc.getElementsByTag(tagName) 一般可以使用这两种方法获取。我们使用F12在谷歌浏览器中打开开发调试工具。使用定位功能定位我们需要的数据的位置,查看标签的id,也就是我们在使用Jsoup函数时使用的ID。这样就可以得到具体的值了。具体的 Jsoup 用户可以在百度上搜索。
废话不多说,直接上代码:
(1)环境
1)Jsoup 环境
org.jsoup
jsoup
1.10.2
2)WebClient 环境
这个比较麻烦
我在自己的项目中直接贴出Jar的截图(需要的可以联系我)
(2)源码(这是获取企业信息的源码,其他类似,webclient模拟相同,只是清洗不同)
public static List analysisQyInfoForOld(String url){
final WebClient client = new WebClient();
client.getOptions().setJavaScriptEnabled(true);// 默认执行js
client.getOptions().setCssEnabled(false);
client.setAjaxController(new NicelyResynchronizingAjaxController());
client.getOptions().setThrowExceptionOnScriptError(false);
HtmlPage page = null;
try {
page = client.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
String pageXml = page.asXml(); //以xml的形式获取响应文本
List lists = new ArrayList();
/**jsoup解析文档*/
Document doc = Jsoup.parse(pageXml);
Element element1 = doc.getElementById("REG_NO"); //统一社会信用代码/注册号
Element element2 = doc.getElementById("CORP_NAME");//名称
Element element3 = doc.getElementById("ZJ_ECON_KIND");//类型
Element element4 = doc.getElementById("OPER_MAN_NAME");//经营者
Element element5 = doc.getElementById("FARE_PLACE");//经营场所
Element element7 = doc.getElementById("ADDR"); //住址
Element element6 = doc.getElementById("BELONG_ORG");//所属部门
lists.add(element1.text());
lists.add(element2.text());
lists.add(element3.text());
lists.add(element4.text());
if(element5 == null ) {
lists.add(element7.text());
}else {
lists.add(element5.text());
}
lists.add(element6.text());
return lists;
}
php抓取网页动态数据(Python基础知识:元素而不仅仅是标题元素是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-09 01:00
元素,而不仅仅是标题元素。
使用每个 Beautiful Soup 对象附带的 .parent 属性,您可以直观地逐步浏览 DOM 结构并使用所需的元素。您还可以以类似的方式访问子元素和兄弟元素。阅读导航树以获取更多信息。
从 HTML 元素中提取属性
此时,您的 Python 脚本已抓取该站点并过滤其 HTML 以查找相关职位发布。做得好!但是,申请工作的链接仍然缺失。
检查页面时,您在每张卡片的底部发现了两个链接。如果您处理链接元素的方式与处理其他元素的方式相同,您将不会获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本 Learn、Apply 而不是关联的 URL。
这是因为 .text 属性只留下 HTML 元素的可见内容。它去除所有 HTML 标记,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值,而不是丢弃它。
链接元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部的第二个 href 标记的属性值:
Learn
Apply
首先获取工作卡中的所有元素。href 然后,使用方括号表示法提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到控制台。
在下面的练习块中,您可以找到挑战说明,以优化您收到的链接结果:
练习:优化结果显示/隐藏
每张工作卡都有两个与之关联的链接。您正在寻找的只是第二个链接。如何编辑上面显示的代码片段,以便始终只采集第二个链接的 URL?
单击解决方案块以阅读此练习的可能解决方案:
解决方案:优化您的结果显示/隐藏
要获取每个工作卡的第二个链接的 URL,您可以使用以下代码段:
for job_element in python_job_elements:
link_url = job_element.find_all("a")[1]["href"]
print(f"Apply here: {link_url}\n")
您正在通过索引 ( ) 从结果中选择第二个链接元素。然后,您将使用方括号表示法直接提取 URL 并对属性 ( ) 进行寻址。.find_all()[1]href["href"]
您还可以使用相同的方括号表示法来提取其他 HTML 属性。
保持练习
如果您在本教程旁边编写了代码,那么您可以按原样运行您的脚本,您会看到终端中弹出虚假的作业消息。您的下一步是处理现实生活中的工作委员会!要继续练习您的新技能,请使用以下任何或所有 网站 重新访问网络抓取过程:
链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。所以你可以用美丽的汤把它们刮掉。
使用这些其他站点之一从顶部重新开始阅读本教程。您会看到每个 网站 的结构都不同,您需要以稍微不同的方式重构代码以获得所需的数据。接受这个挑战是练习刚刚学到的概念的好方法。虽然它可能会让你大汗淋漓,但你的编码技能会因此而变得更强!
在您第二次尝试时,您还可以探索 Beautiful Soup 的其他功能。使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、.requests 和 Beautiful Soup 进行网络抓取。
为了结束您的网络抓取之旅,您可以对您的代码进行最后的改造,并创建一个命令行界面 (CLI) 应用程序,该应用程序可以抓取其中一个工作板,并允许您在每次执行时键入按关键字过滤结果。您的 CLI 工具可让您搜索特定类型或位置的工作。
如果您有兴趣了解如何使脚本适应命令行界面,请查看如何使用 argparse 在 Python 中构建命令行界面。
综上所述
requests 库为您提供了一种使用 Python 从 Internet 获取静态 HTML 的用户友好方式。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您的网络抓取冒险值得信赖且有用的伴侣。您会发现 Beautiful Soup 将满足您的大部分解析需求,包括导航和高级搜索。
在本教程中,您学习了如何使用 Python 请求和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本,该脚本从 Internet 获取招聘信息,并从头到尾执行完整的网络抓取过程。
你已经学会了如何:
考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看您还能获取哪些其他 网站。玩得开心,并始终记住尊重和负责任地使用您的编程技能。
您可以通过单击下面的链接下载您在本教程中构建的示例脚本的源代码: 查看全部
php抓取网页动态数据(Python基础知识:元素而不仅仅是标题元素是什么)
元素,而不仅仅是标题元素。
使用每个 Beautiful Soup 对象附带的 .parent 属性,您可以直观地逐步浏览 DOM 结构并使用所需的元素。您还可以以类似的方式访问子元素和兄弟元素。阅读导航树以获取更多信息。
从 HTML 元素中提取属性
此时,您的 Python 脚本已抓取该站点并过滤其 HTML 以查找相关职位发布。做得好!但是,申请工作的链接仍然缺失。
检查页面时,您在每张卡片的底部发现了两个链接。如果您处理链接元素的方式与处理其他元素的方式相同,您将不会获得您感兴趣的 URL:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
print(link.text.strip())
如果您运行此代码片段,那么您将获得链接文本 Learn、Apply 而不是关联的 URL。
这是因为 .text 属性只留下 HTML 元素的可见内容。它去除所有 HTML 标记,包括收录 URL 的 HTML 属性,只留下链接文本。要改为获取 URL,您需要提取 HTML 属性之一的值,而不是丢弃它。
链接元素的 URL 与 href 属性相关联。您要查找的特定 URL 是单个职位发布的 HTML 底部的第二个 href 标记的属性值:
Learn
Apply
首先获取工作卡中的所有元素。href 然后,使用方括号表示法提取它们的属性值:
for job_element in python_job_elements:
# -- snip --
links = job_element.find_all("a")
for link in links:
link_url = link["href"]
print(f"Apply here: {link_url}\n")
在此代码段中,您首先从每个过滤的职位发布中获取所有链接。然后提取收录 URL 的 href 属性,使用 ["href"] 并将其打印到控制台。
在下面的练习块中,您可以找到挑战说明,以优化您收到的链接结果:
练习:优化结果显示/隐藏
每张工作卡都有两个与之关联的链接。您正在寻找的只是第二个链接。如何编辑上面显示的代码片段,以便始终只采集第二个链接的 URL?
单击解决方案块以阅读此练习的可能解决方案:
解决方案:优化您的结果显示/隐藏
要获取每个工作卡的第二个链接的 URL,您可以使用以下代码段:
for job_element in python_job_elements:
link_url = job_element.find_all("a")[1]["href"]
print(f"Apply here: {link_url}\n")
您正在通过索引 ( ) 从结果中选择第二个链接元素。然后,您将使用方括号表示法直接提取 URL 并对属性 ( ) 进行寻址。.find_all()[1]href["href"]
您还可以使用相同的方括号表示法来提取其他 HTML 属性。
保持练习
如果您在本教程旁边编写了代码,那么您可以按原样运行您的脚本,您会看到终端中弹出虚假的作业消息。您的下一步是处理现实生活中的工作委员会!要继续练习您的新技能,请使用以下任何或所有 网站 重新访问网络抓取过程:
链接的 网站 将其搜索结果作为静态 HTML 响应返回,类似于 Fake Python 工作板。所以你可以用美丽的汤把它们刮掉。
使用这些其他站点之一从顶部重新开始阅读本教程。您会看到每个 网站 的结构都不同,您需要以稍微不同的方式重构代码以获得所需的数据。接受这个挑战是练习刚刚学到的概念的好方法。虽然它可能会让你大汗淋漓,但你的编码技能会因此而变得更强!
在您第二次尝试时,您还可以探索 Beautiful Soup 的其他功能。使用文档作为您的指南和灵感。额外的练习将帮助您更熟练地使用 Python、.requests 和 Beautiful Soup 进行网络抓取。
为了结束您的网络抓取之旅,您可以对您的代码进行最后的改造,并创建一个命令行界面 (CLI) 应用程序,该应用程序可以抓取其中一个工作板,并允许您在每次执行时键入按关键字过滤结果。您的 CLI 工具可让您搜索特定类型或位置的工作。
如果您有兴趣了解如何使脚本适应命令行界面,请查看如何使用 argparse 在 Python 中构建命令行界面。
综上所述
requests 库为您提供了一种使用 Python 从 Internet 获取静态 HTML 的用户友好方式。然后,您可以使用另一个名为 Beautiful Soup 的包来解析 HTML。这两个软件包都是您的网络抓取冒险值得信赖且有用的伴侣。您会发现 Beautiful Soup 将满足您的大部分解析需求,包括导航和高级搜索。
在本教程中,您学习了如何使用 Python 请求和 Beautiful Soup 从 Web 抓取数据。您构建了一个脚本,该脚本从 Internet 获取招聘信息,并从头到尾执行完整的网络抓取过程。
你已经学会了如何:
考虑到这个广泛的管道和工具包中的两个强大的库,您可以出去看看您还能获取哪些其他 网站。玩得开心,并始终记住尊重和负责任地使用您的编程技能。
您可以通过单击下面的链接下载您在本教程中构建的示例脚本的源代码:
php抓取网页动态数据(PHP,动态生成PDF文件详细教程相关知识和一些Code实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-04 00:25
想知道PHP在网页中动态生成PDF文件的详细教程的相关内容吗?在本文中,我将讲解PHP动态生成PDF文件的相关知识和一些代码示例。欢迎阅读和指正。先把重点放在:PHP,动态生成PDF文件,一起来学习。
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在网上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php抓取网页动态数据(PHP,动态生成PDF文件详细教程相关知识和一些Code实例)
想知道PHP在网页中动态生成PDF文件的详细教程的相关内容吗?在本文中,我将讲解PHP动态生成PDF文件的相关知识和一些代码示例。欢迎阅读和指正。先把重点放在:PHP,动态生成PDF文件,一起来学习。
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在网上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php抓取网页动态数据(从动态网站中提取数据WebScraper软件特色指点和点击界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-03 15:02
文章目录[隐藏]
Web Scraper 是一个简单易用的 chrome网站 数据提取工具插件。该插件可以帮助用户在不编写任何代码的情况下实现数据爬取功能,从而更快速、有效、准确地提取页面数据,还可以将爬取结果导出为Web Scraper可以识别的CSV格式用于Excel。 Web Scraper 不需要 Python/php/JS。使用此扩展,您可以随意选择抓取范围,让您随时随地进行抓取。感兴趣的朋友不要错过,快来下载体验吧!
,
网络爬虫软件
Web Scraper 软件功能
点击界面
我们的目标是让网络数据提取尽可能简单。刮板由简单的点击元素配置。无需编码。
从动态网站中提取数据
Web Scraper 可以在多级导航中从 网站 中提取数据。它可以在所有级别上导航 网站。
类别和子类别
分页
产品页面
从动态网站中提取数据
专为现代网络设计
现在网站 是基于 JavaScript 框架构建的,这些框架使用户界面更易于使用,但对于爬虫来说并不那么容易。 Web Scraper 解决了这个问题。
完整的 JavaScript 执行
等待 Ajax 请求
分页处理程序
向下滚动页面
专为现代网络打造
模块化选择器系统
Web Scraper 允许您从不同类型的选择器构建网站地图。系统可以根据不同的站点结构自定义数据提取。
模块化选择器系统
以 CSV、XLSX 和 JSON 格式导出数据
构建一个刮板,刮网站,并直接从您的浏览器以 CSV 格式导出数据。使用 Web Scraper Cloud 以 CSV、XLSX 和 JSON 格式导出数据,通过 API、webhook 访问或通过 Dropbox 导出数据。
Web Scraper 功能介绍
1. 抓取多个页面
2.不推荐使用的数据存储在本地存储中
3.多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)。
5.浏览抓取的数据
6. 6.将剪辑数据导出为 CSV
7.导入、导出网站地图
8. 仅依赖于 Chrome 浏览器
Web Scraper 安装方法
1.首先,用户点击谷歌浏览器右上角的Customize and Control按钮,在下拉框中选择Tools选项,然后点击Extensions,启动Chrome浏览器的扩展管理器页面.
2.在谷歌浏览器打开的扩展管理器中,用户可以看到一些已经安装的Chrome插件,或者没有。
3.找到你下载的Chrome离线安装文件xxx.crx,然后从资源管理器中拖拽到Chrome的扩展管理界面。这时候用户会发现,在扩展管理器的中间部分会多出一个“拖动安装”插件按钮。
4.释放鼠标安装当前正在拖入谷歌浏览器的插件,但谷歌考虑到用户的安全和隐私,在用户释放鼠标后会给予用户安装确认。提示。
5.用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome 中。安装成功后,插件会立即显示在浏览器右上角(如果有插件按钮),如果没有插件按钮,用户也可以通过Chrome扩展找到已安装的插件经理。
下载地址:点击下载
本文标题:网络爬虫软件-Web Scraper下载 查看全部
php抓取网页动态数据(从动态网站中提取数据WebScraper软件特色指点和点击界面)
文章目录[隐藏]
Web Scraper 是一个简单易用的 chrome网站 数据提取工具插件。该插件可以帮助用户在不编写任何代码的情况下实现数据爬取功能,从而更快速、有效、准确地提取页面数据,还可以将爬取结果导出为Web Scraper可以识别的CSV格式用于Excel。 Web Scraper 不需要 Python/php/JS。使用此扩展,您可以随意选择抓取范围,让您随时随地进行抓取。感兴趣的朋友不要错过,快来下载体验吧!
,
网络爬虫软件
Web Scraper 软件功能
点击界面
我们的目标是让网络数据提取尽可能简单。刮板由简单的点击元素配置。无需编码。
从动态网站中提取数据
Web Scraper 可以在多级导航中从 网站 中提取数据。它可以在所有级别上导航 网站。
类别和子类别
分页
产品页面
从动态网站中提取数据
专为现代网络设计
现在网站 是基于 JavaScript 框架构建的,这些框架使用户界面更易于使用,但对于爬虫来说并不那么容易。 Web Scraper 解决了这个问题。
完整的 JavaScript 执行
等待 Ajax 请求
分页处理程序
向下滚动页面
专为现代网络打造
模块化选择器系统
Web Scraper 允许您从不同类型的选择器构建网站地图。系统可以根据不同的站点结构自定义数据提取。
模块化选择器系统
以 CSV、XLSX 和 JSON 格式导出数据
构建一个刮板,刮网站,并直接从您的浏览器以 CSV 格式导出数据。使用 Web Scraper Cloud 以 CSV、XLSX 和 JSON 格式导出数据,通过 API、webhook 访问或通过 Dropbox 导出数据。
Web Scraper 功能介绍
1. 抓取多个页面
2.不推荐使用的数据存储在本地存储中
3.多种数据选择类型
4. 从动态页面中提取数据(JavaScript+AJAX)。
5.浏览抓取的数据
6. 6.将剪辑数据导出为 CSV
7.导入、导出网站地图
8. 仅依赖于 Chrome 浏览器
Web Scraper 安装方法
1.首先,用户点击谷歌浏览器右上角的Customize and Control按钮,在下拉框中选择Tools选项,然后点击Extensions,启动Chrome浏览器的扩展管理器页面.
2.在谷歌浏览器打开的扩展管理器中,用户可以看到一些已经安装的Chrome插件,或者没有。
3.找到你下载的Chrome离线安装文件xxx.crx,然后从资源管理器中拖拽到Chrome的扩展管理界面。这时候用户会发现,在扩展管理器的中间部分会多出一个“拖动安装”插件按钮。
4.释放鼠标安装当前正在拖入谷歌浏览器的插件,但谷歌考虑到用户的安全和隐私,在用户释放鼠标后会给予用户安装确认。提示。
5.用户只需点击添加按钮即可将离线 Chrome 插件安装到 Google Chrome 中。安装成功后,插件会立即显示在浏览器右上角(如果有插件按钮),如果没有插件按钮,用户也可以通过Chrome扩展找到已安装的插件经理。
下载地址:点击下载
本文标题:网络爬虫软件-Web Scraper下载
php抓取网页动态数据(IT行业,支撑业务的变化需要优秀的大量的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-27 09:22
在IT行业,支持业务变化需要大量优秀的数据。我们需要适应数据的动态变化,获取这些动态变化,进行分析,然后提供给我们自己的项目,以支持公司的业务。最近,我遇到了这种情况。需要获取网页上不断变化的数据。只有当数据发生变化时,才会取变化的值并将其存储在库中。
其实PhantomJs,乍一看名字还以为是Js。实际上,它是一个没有页面的浏览器。它与其他浏览器的最大区别在于它没有界面。内核使用WebKit,即PhantomJs。官方网站。PhantomJs中文资料很少,介绍也很简单。基本上,它是来自官方网站的示例。这对我一点帮助都没有。但是,如果人们学会了灵活,他们就只能执行这些简单的程序。组装和组合以支持您的复杂业务。PhantomJs 只是一个浏览器,它不能主动告诉我什么时候数据发生了变化,也就是变化的数据。所以,这也需要 MutationObserver 的支持。
MutationObserver,乍一看名字,或许你能想到它的实现原理。在我看来,这是一种观察者模式。当然,我不知道JS的具体实现细节,也没有查过。事实上,计算机中的许多东西都是相似的。从名字上,你或许能看出它的作用,或者大致猜出它的实现原理。
安装
要使用 PhantomJs,您需要先安装它。详情请参考官网。在使用的时候,我使用了以下 PhantomJs 的方法。
介绍
当然,这是对我使用过的方法的介绍。对于其他人,请访问官方网站。
page.onConsoleMessage 监听所有 console.log 消息
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished接口加载完成后,获取页面的动态数据
page.onLoadFinished = function(status){
console.log('---------start-----------');
page.evaluate(getContent,"test");
};
打开page.open接口,我用了它的两个参数
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
page.evaluate() 支持js操作
page.evaluate(getContent,postUrl);
getContent是js的方法名,postUrl是方法需要传递的参数
剩下的就是 MutationObserver 对动态数据变化的监控。
function getContent(url) {
console.log("---------start fetch------------"+url+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true});
}
完整的Js是:
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
var page = require('webpage').create();
var url = address;
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished = function(status){
console.log('---------start-----------');
var postUrl=getUrl();
page.evaluate(getContent,"test");
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
function getContent(txt) {
console.log("---------start fetch------------"+txt+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true}
);
}
跑步
我安装了 PhantomJs 的 Windows 版本。运行时需要进入对应的bin目录,然后使用命令格式:phantomjs xxx.js http地址。
问题与解决方案
说说我中间遇到的一些问题。
第一个问题:实时监控动态数据变化
一开始,我不明白 PhantomJs 是什么。事实上,我只是不相信它是一个浏览器。它与其他浏览器的区别在于没有界面。其他浏览器功能基本都有PhantomJs,所以当MutationObserver在其他浏览器工作时,与PhantomJs结合使用时,无法产生相应的效果。曾经怀疑无法实现利用这两个东西动态抓取数据的功能。原因是在 page.evaluate() 中间执行 MutationObserver 时,里面的页面是死页,数据根本不会改变。
老板否认了我,后来老板通过他的手段发现,运行page.evaluate()的时候,这个时候页面是不存在的,也没有html元素可能会改变。老大就是老大,不得不佩服。
第二个问题:PhantomJs内存飙升,CPU占用率高
出现这个问题的原因是PhantomJs在运行过程中,由于page.evaluate()中js方法的问题,导致PhantomJs占用的内存越来越多,最后达到1.左右自动关闭退出@>5G。解决方法不用我说,直接调试js,找到导致原因的js。
第三个问题:我看到数据动态变化了,但是动态变化的值还没有拿到。
这个问题的原因其实和第一个问题有些相似,为什么会相似呢?因为我遇到的两个问题都和具体的http请求页面有关。出现这个问题是因为里面的html元素。检测到变化后,取不到值。这个问题非常隐蔽。不仔细观察很难发现。
第四个问题:既然PhantomJs启动后就是一个进程,那么检测到的数据变化值如何传入项目中呢?
有两种类似的解决方案,第一种:Ajax 向项目服务请求;第二种:将线程长时间挂起并保持活跃状态,或者使用main函数。
第五题:管理问题
目前,这还涉及到其他一些问题。如果您使用包类而不使用其他附加工具,您将面临启动数据捕获服务,并将启动 PhantomJs 进程。如果您启动 10 个,您将启动 10 个 PhantomJs 进程。,什么时候开始,什么时候删除PhantomJs的进程,这些都是问题。一个进程占用大约50m的内存。如果是10,就是500m。但是,您可以手动启动和删除它吗?显然这是不合理的,至于如何解决,我稍后会告诉你。
总结
使用 PhantomJs 和 MutationObserver 实现动态网页数据抓取,调整 PhantomJs 和 MutationObserver 大概需要一周时间。当然,这不是最终版本,实际上最终版本比这个稍微复杂一些。PhantomJs 还是有很多功能的。在数据抓取行业,我认为 PhantomJs 未来会有很大的发展前景。其实PhantomJs也有对应的打包工具——PhantomJsDriver,但是我查了这个打包工具类的API,没有适合我们特殊需求的,所以没有深入研究,貌似有很PhantomJsDriver 的中文资料很少。
今天老板也跟我说,为什么叫“饭桶”?我默默地笑了笑,说不定真的是操作中的工作,哈哈。. . . .
当我正式进入工作环境,进入互联网行业,尤其是去年,我深深地意识到,如果我不仔细思考,尝试阅读英文资料,对英文有很深的抗拒,那我就不会想在这里。行业继续混乱。处处留心,学会做人,我常对自己说的是,不管是工作还是生活中,冷静下来,作为一个女孩,你应该理性多于感性,看看你能成为什么样的人. 查看全部
php抓取网页动态数据(IT行业,支撑业务的变化需要优秀的大量的数据)
在IT行业,支持业务变化需要大量优秀的数据。我们需要适应数据的动态变化,获取这些动态变化,进行分析,然后提供给我们自己的项目,以支持公司的业务。最近,我遇到了这种情况。需要获取网页上不断变化的数据。只有当数据发生变化时,才会取变化的值并将其存储在库中。
其实PhantomJs,乍一看名字还以为是Js。实际上,它是一个没有页面的浏览器。它与其他浏览器的最大区别在于它没有界面。内核使用WebKit,即PhantomJs。官方网站。PhantomJs中文资料很少,介绍也很简单。基本上,它是来自官方网站的示例。这对我一点帮助都没有。但是,如果人们学会了灵活,他们就只能执行这些简单的程序。组装和组合以支持您的复杂业务。PhantomJs 只是一个浏览器,它不能主动告诉我什么时候数据发生了变化,也就是变化的数据。所以,这也需要 MutationObserver 的支持。
MutationObserver,乍一看名字,或许你能想到它的实现原理。在我看来,这是一种观察者模式。当然,我不知道JS的具体实现细节,也没有查过。事实上,计算机中的许多东西都是相似的。从名字上,你或许能看出它的作用,或者大致猜出它的实现原理。
安装
要使用 PhantomJs,您需要先安装它。详情请参考官网。在使用的时候,我使用了以下 PhantomJs 的方法。
介绍
当然,这是对我使用过的方法的介绍。对于其他人,请访问官方网站。
page.onConsoleMessage 监听所有 console.log 消息
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished接口加载完成后,获取页面的动态数据
page.onLoadFinished = function(status){
console.log('---------start-----------');
page.evaluate(getContent,"test");
};
打开page.open接口,我用了它的两个参数
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
page.evaluate() 支持js操作
page.evaluate(getContent,postUrl);
getContent是js的方法名,postUrl是方法需要传递的参数
剩下的就是 MutationObserver 对动态数据变化的监控。
function getContent(url) {
console.log("---------start fetch------------"+url+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true});
}
完整的Js是:
system = require('system')
address = system.args[1];//获得命令行第二个参数 接下来会用到
var page = require('webpage').create();
var url = address;
page.onConsoleMessage = function(msg){
console.log(msg);
};
page.onLoadFinished = function(status){
console.log('---------start-----------');
var postUrl=getUrl();
page.evaluate(getContent,"test");
};
page.open(url, function (status) {
//Page is loaded!
if (status !== 'success') {
console.log('can not start');
} else {
}
});
function getContent(txt) {
console.log("---------start fetch------------"+txt+"---");
var tar = $('#MarketGrid');
var MutationObserver = window.MutationObserver|| window.WebKitMutationObserver|| window.MozMutationObserver;
var observer = new MutationObserver(function(mutations) {
mutations.forEach(function(mutation) {
var text=$(mutation.target).parents(".ipe-Market").find(".ipe-Market_ButtonText").text();
console.log(text);
})
});
observer.observe(tar[0], {
attributes: true,
childList: true,
characterData: true,
characterDataOldValue: true,
attributeOldValue:true,
subtree: true}
);
}
跑步
我安装了 PhantomJs 的 Windows 版本。运行时需要进入对应的bin目录,然后使用命令格式:phantomjs xxx.js http地址。
问题与解决方案
说说我中间遇到的一些问题。
第一个问题:实时监控动态数据变化
一开始,我不明白 PhantomJs 是什么。事实上,我只是不相信它是一个浏览器。它与其他浏览器的区别在于没有界面。其他浏览器功能基本都有PhantomJs,所以当MutationObserver在其他浏览器工作时,与PhantomJs结合使用时,无法产生相应的效果。曾经怀疑无法实现利用这两个东西动态抓取数据的功能。原因是在 page.evaluate() 中间执行 MutationObserver 时,里面的页面是死页,数据根本不会改变。
老板否认了我,后来老板通过他的手段发现,运行page.evaluate()的时候,这个时候页面是不存在的,也没有html元素可能会改变。老大就是老大,不得不佩服。
第二个问题:PhantomJs内存飙升,CPU占用率高
出现这个问题的原因是PhantomJs在运行过程中,由于page.evaluate()中js方法的问题,导致PhantomJs占用的内存越来越多,最后达到1.左右自动关闭退出@>5G。解决方法不用我说,直接调试js,找到导致原因的js。
第三个问题:我看到数据动态变化了,但是动态变化的值还没有拿到。
这个问题的原因其实和第一个问题有些相似,为什么会相似呢?因为我遇到的两个问题都和具体的http请求页面有关。出现这个问题是因为里面的html元素。检测到变化后,取不到值。这个问题非常隐蔽。不仔细观察很难发现。
第四个问题:既然PhantomJs启动后就是一个进程,那么检测到的数据变化值如何传入项目中呢?
有两种类似的解决方案,第一种:Ajax 向项目服务请求;第二种:将线程长时间挂起并保持活跃状态,或者使用main函数。
第五题:管理问题
目前,这还涉及到其他一些问题。如果您使用包类而不使用其他附加工具,您将面临启动数据捕获服务,并将启动 PhantomJs 进程。如果您启动 10 个,您将启动 10 个 PhantomJs 进程。,什么时候开始,什么时候删除PhantomJs的进程,这些都是问题。一个进程占用大约50m的内存。如果是10,就是500m。但是,您可以手动启动和删除它吗?显然这是不合理的,至于如何解决,我稍后会告诉你。
总结
使用 PhantomJs 和 MutationObserver 实现动态网页数据抓取,调整 PhantomJs 和 MutationObserver 大概需要一周时间。当然,这不是最终版本,实际上最终版本比这个稍微复杂一些。PhantomJs 还是有很多功能的。在数据抓取行业,我认为 PhantomJs 未来会有很大的发展前景。其实PhantomJs也有对应的打包工具——PhantomJsDriver,但是我查了这个打包工具类的API,没有适合我们特殊需求的,所以没有深入研究,貌似有很PhantomJsDriver 的中文资料很少。
今天老板也跟我说,为什么叫“饭桶”?我默默地笑了笑,说不定真的是操作中的工作,哈哈。. . . .
当我正式进入工作环境,进入互联网行业,尤其是去年,我深深地意识到,如果我不仔细思考,尝试阅读英文资料,对英文有很深的抗拒,那我就不会想在这里。行业继续混乱。处处留心,学会做人,我常对自己说的是,不管是工作还是生活中,冷静下来,作为一个女孩,你应该理性多于感性,看看你能成为什么样的人.
php抓取网页动态数据(php抓取网页动态数据是时常会用到的,用于网页截取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-23 22:03
php抓取网页动态数据是时常会用到的,例如登录注册后会访问网页上的webshell用于验证用户身份。今天写个爬虫用于网页截取。网站:。首先准备一个交换ie账号。我用的是第三方库nginx,安装一次,确保整个环境的完整。在cmd命令行下进入一个文件夹,cd到该文件夹。然后就可以愉快的进行我们自己的事情啦。
1、使用shell命令行下输入:ngzipdomain/。如果报错,修改-webshell,修改成domain/。
2、使用浏览器进入该网页,然后输入:curl‘/’。注意:首先要让网页加载完整才可以继续编程,输入时一定要空格。
3、输入回车,会自动获取header,里面包含了链接所在的文件路径,
4、需要将链接另存为“media/xxxx/xxxxxx”,
5、拷贝到你需要的文件夹,如下图:输入:cd文件夹。将所有的php代码粘贴进去,并保存,最后点击回车,就可以在本机上运行我们的php程序啦。
首先你要注册很多不同的网站,然后每个网站登录以后的跳转按钮都不一样,你需要根据跳转到指定网站的前台前去抓取所有的页面,比如php跳转到我的电脑,developer等相应的页面,然后就可以爬取。然后你去搜索资料,如果实在找不到,那你就百度再爬取吧,很多现成的脚本。基本工作就是这样, 查看全部
php抓取网页动态数据(php抓取网页动态数据是时常会用到的,用于网页截取)
php抓取网页动态数据是时常会用到的,例如登录注册后会访问网页上的webshell用于验证用户身份。今天写个爬虫用于网页截取。网站:。首先准备一个交换ie账号。我用的是第三方库nginx,安装一次,确保整个环境的完整。在cmd命令行下进入一个文件夹,cd到该文件夹。然后就可以愉快的进行我们自己的事情啦。
1、使用shell命令行下输入:ngzipdomain/。如果报错,修改-webshell,修改成domain/。
2、使用浏览器进入该网页,然后输入:curl‘/’。注意:首先要让网页加载完整才可以继续编程,输入时一定要空格。
3、输入回车,会自动获取header,里面包含了链接所在的文件路径,
4、需要将链接另存为“media/xxxx/xxxxxx”,
5、拷贝到你需要的文件夹,如下图:输入:cd文件夹。将所有的php代码粘贴进去,并保存,最后点击回车,就可以在本机上运行我们的php程序啦。
首先你要注册很多不同的网站,然后每个网站登录以后的跳转按钮都不一样,你需要根据跳转到指定网站的前台前去抓取所有的页面,比如php跳转到我的电脑,developer等相应的页面,然后就可以爬取。然后你去搜索资料,如果实在找不到,那你就百度再爬取吧,很多现成的脚本。基本工作就是这样,
php抓取网页动态数据(如何才能让我们网站拥有不错的收录和索引数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-02-23 16:04
)
对我们而言,网站、收录 和索引非常重要。今天我们将讨论如何网站拥有良好的收录和索引数据。说起这两点,就离不开蜘蛛的分析。
蜘蛛通常从我们的外部链接或主页开始。由于超链接在互联网上的普遍应用,我们的大部分网页都会被蜘蛛采集。蜘蛛抓取的网页称为网页快照。只有当我们有网络快照时,我们才有机会成为 收录。蜘蛛一般有以下偏好:
一、蜘蛛喜欢拥有内容良好且独特的页面。具有高度重复或相似内容的页面很可能不是 收录。
二、蜘蛛不喜欢链接层次较浅的页面。蜘蛛也不喜欢太深的链接和动态网页。
三、蜘蛛更喜欢 收录 静态网页。动态网页需要控制参数的个数和 URL 的长度。重定向过多的页面基本不会是收录。
收录 量是指已爬取的页面数网站;索引量是指收录的页面中被筛选出来并进入索引库的页面,通常是高质量的内容。因此,指数成交量往往低于收录成交量。这是正常的,站长不用担心。
对于新站来说,如果我们的索引量比较小,但是收录的数据比较大并且逐渐增加,对我们来说是个好消息,说明我们的新站收录和索引是普通的 。一段时间后,这些 收录 页面将陆续发布。因此,新站点的收录 量通常与索引量有很大差异。但是如果在老网站上出现这种情况,就意味着网站的部分网页已经不符合入选索引库的要求了。互联网上的网页数量每天都在增加,尤其是高质量的网页。如果我们不坚持提高我们的网站的质量,专注于为用户提供价值,就很难进一步提高指数的体量。
cms采集器可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是*敏感*字*站群,都可以轻松管理。
cms采集器可实现软件站内不同cms网站数据的观察,有利于多个网站站长进行数据分析;发布数量批量设置(可设置发布数量/发布间隔);发布前的各种伪原创;直接监控软件是否已发布、即将发布、是否为伪原创、发布状态、网址、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等日常数据。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们 收录 的效率,我们可以通过 cms采集 插件完全自动化
查看全部
php抓取网页动态数据(如何才能让我们网站拥有不错的收录和索引数据?
)
对我们而言,网站、收录 和索引非常重要。今天我们将讨论如何网站拥有良好的收录和索引数据。说起这两点,就离不开蜘蛛的分析。
蜘蛛通常从我们的外部链接或主页开始。由于超链接在互联网上的普遍应用,我们的大部分网页都会被蜘蛛采集。蜘蛛抓取的网页称为网页快照。只有当我们有网络快照时,我们才有机会成为 收录。蜘蛛一般有以下偏好:
一、蜘蛛喜欢拥有内容良好且独特的页面。具有高度重复或相似内容的页面很可能不是 收录。
二、蜘蛛不喜欢链接层次较浅的页面。蜘蛛也不喜欢太深的链接和动态网页。
三、蜘蛛更喜欢 收录 静态网页。动态网页需要控制参数的个数和 URL 的长度。重定向过多的页面基本不会是收录。
收录 量是指已爬取的页面数网站;索引量是指收录的页面中被筛选出来并进入索引库的页面,通常是高质量的内容。因此,指数成交量往往低于收录成交量。这是正常的,站长不用担心。
对于新站来说,如果我们的索引量比较小,但是收录的数据比较大并且逐渐增加,对我们来说是个好消息,说明我们的新站收录和索引是普通的 。一段时间后,这些 收录 页面将陆续发布。因此,新站点的收录 量通常与索引量有很大差异。但是如果在老网站上出现这种情况,就意味着网站的部分网页已经不符合入选索引库的要求了。互联网上的网页数量每天都在增加,尤其是高质量的网页。如果我们不坚持提高我们的网站的质量,专注于为用户提供价值,就很难进一步提高指数的体量。
cms采集器可以根据用户提供的关键词自动采集相关文章发布给用户网站。可自动识别各种网页的标题、文字等信息,无需用户编写任何采集规则即可实现全网采集。采集到达内容后,会自动计算内容与集合关键词的相关度,只推送相关的文章给用户。支持标题前缀、关键词自动加粗、插入永久链接、自动提取Tag、自动内链、自动映射、自动伪原创、内容过滤替换、定时采集、主动提交等一系列的 SEO 功能。用户只需设置关键词 以及实现完全托管、零维护 网站 内容更新的相关要求。网站的数量没有限制,无论是单个网站还是*敏感*字*站群,都可以轻松管理。
cms采集器可实现软件站内不同cms网站数据的观察,有利于多个网站站长进行数据分析;发布数量批量设置(可设置发布数量/发布间隔);发布前的各种伪原创;直接监控软件是否已发布、即将发布、是否为伪原创、发布状态、网址、程序、发布时间等;可以在软件上查看收录、权重、蜘蛛等日常数据。
搜索引擎一般有三种推送方式:站点地图、主动推送、自动推送。主动推送到搜索引擎可以提高我们 收录 的效率,我们可以通过 cms采集 插件完全自动化
php抓取网页动态数据(SEO上动态页面与静态页面的区别究竟在哪里?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-20 03:26
SEO中的动态页面和静态页面有什么区别?
动态页面通常是php或asp等语言结合数据库,通过代码调用数据实现页面展示;调用不同的数据可以显示不同的页面内容;
静态页面通常是单页,没有程序调用数据,简单的用html渲染;
在SEO方面,需要优化网页的标题、关键词、描述信息和页面关键词密度的设计。动态网站的维护和管理更方便。可优化,简单方便;如果使用静态页面,需要找到每个页面重新修改,后期的维护和优化比较复杂;
SE不会根据文件名判断是否动态,关键是url是否很友好,方便他
用于 SEO 优化的动态更新程序 [帮助]
一、基本概念
动态更新器,也称为动态更新机制,是指以动态形式存在于网站中的模块。当网页刷新或重新打开时,会有不断变化的信息,以至于搜索引擎总是认为网站@网站是一种更新状态,很容易被搜索引擎收录抓取。比如郑州四季化工的首页,数据信息是动态展示的,帮助蜘蛛更快地访问收录你的网站。
二、存在
1、图片格式
一般出现在网站的首页,网站管理员选择一批图片,让他随机或循环展示。虽然现在的搜索引擎不能完全理解,但至少可以让搜索引擎认为你的网站已经更新了。
网站SEO优化:动态网页还是静态网页?静态网页是否有利于关键词的自然排名?
网道是一款搜索引擎算法级seo系统软件,具备让您网站在百度首页稳定排名的所有功能,以协助您更好地使用软件,达到您期望的效果。购买后,我们还将为您安排专门的售后技术顾问,为您的网站优化提供分析、跟踪、指导等技术协助。而且,根据您的网站、关键词情况,我们可以为您定制优化策略。
静态的更好。容易抓住。善待
虽然动态也有爬行。
【SEO】动态页面和静态页面哪个更有利于搜索引擎收益?
当然是这样的静态页面a.html
您可以使用您的关键词拼音,使其更有利于引擎收录。不知道答案是否正确
对于静态页面,可以将动态页面做成伪静态页面。效果是一样的
静态页面,尽量获取一些新鲜稀有的,蜘蛛更容易爬取
仍然。.
没看懂,绑定
如何使动态网页静态化以进行 SEO
现在动态网页的种类太多了,你是ASP、PHP、JSP,并不是所有的动态的都可以转成静态的。另外,请不要重新格式化动态 URL 以使其看起来是静态的。尽可能使用静态
显示静态内容的 URL 是可取的,但如果您决定显示动态内容,请不要收录该参数
隐藏以使它们看起来是静态的,因为这样做会删除
URL 的有用信息。图例:“动态 URL 的参数少于 3 个。” 事实:对于参数的数量是
没有限制。然而,一个好的经验法则是不要让你的 URL 太长(这适用于所有
地址,无论是静态的还是动态的)。你可以 查看全部
php抓取网页动态数据(SEO上动态页面与静态页面的区别究竟在哪里?)
SEO中的动态页面和静态页面有什么区别?
动态页面通常是php或asp等语言结合数据库,通过代码调用数据实现页面展示;调用不同的数据可以显示不同的页面内容;
静态页面通常是单页,没有程序调用数据,简单的用html渲染;
在SEO方面,需要优化网页的标题、关键词、描述信息和页面关键词密度的设计。动态网站的维护和管理更方便。可优化,简单方便;如果使用静态页面,需要找到每个页面重新修改,后期的维护和优化比较复杂;
SE不会根据文件名判断是否动态,关键是url是否很友好,方便他
用于 SEO 优化的动态更新程序 [帮助]
一、基本概念
动态更新器,也称为动态更新机制,是指以动态形式存在于网站中的模块。当网页刷新或重新打开时,会有不断变化的信息,以至于搜索引擎总是认为网站@网站是一种更新状态,很容易被搜索引擎收录抓取。比如郑州四季化工的首页,数据信息是动态展示的,帮助蜘蛛更快地访问收录你的网站。
二、存在
1、图片格式
一般出现在网站的首页,网站管理员选择一批图片,让他随机或循环展示。虽然现在的搜索引擎不能完全理解,但至少可以让搜索引擎认为你的网站已经更新了。
网站SEO优化:动态网页还是静态网页?静态网页是否有利于关键词的自然排名?
网道是一款搜索引擎算法级seo系统软件,具备让您网站在百度首页稳定排名的所有功能,以协助您更好地使用软件,达到您期望的效果。购买后,我们还将为您安排专门的售后技术顾问,为您的网站优化提供分析、跟踪、指导等技术协助。而且,根据您的网站、关键词情况,我们可以为您定制优化策略。
静态的更好。容易抓住。善待
虽然动态也有爬行。
【SEO】动态页面和静态页面哪个更有利于搜索引擎收益?
当然是这样的静态页面a.html
您可以使用您的关键词拼音,使其更有利于引擎收录。不知道答案是否正确
对于静态页面,可以将动态页面做成伪静态页面。效果是一样的
静态页面,尽量获取一些新鲜稀有的,蜘蛛更容易爬取
仍然。.
没看懂,绑定
如何使动态网页静态化以进行 SEO
现在动态网页的种类太多了,你是ASP、PHP、JSP,并不是所有的动态的都可以转成静态的。另外,请不要重新格式化动态 URL 以使其看起来是静态的。尽可能使用静态
显示静态内容的 URL 是可取的,但如果您决定显示动态内容,请不要收录该参数
隐藏以使它们看起来是静态的,因为这样做会删除
URL 的有用信息。图例:“动态 URL 的参数少于 3 个。” 事实:对于参数的数量是
没有限制。然而,一个好的经验法则是不要让你的 URL 太长(这适用于所有
地址,无论是静态的还是动态的)。你可以
php抓取网页动态数据(2017年国家公务员考试行测备考:动态网页(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-02-19 02:02
###每个句子:
一个人只要在寻求什么,他就不会老。一个人不会老,直到遗憾取代了梦想。
动态网页简介:
我们在编写爬虫的时候,可能会遇到以下两个问题:
出现这个问题的原因是你爬的页面是动态加载的,是动态网页。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果不会改变。动态网页并非如此。显示的页面是Javascript处理数据的结果,可以更改。这些数据有多种来源,可能由 Javascript 计算生成或通过 Ajax 加载。
一种经常用于动态网页的技术是 Ajax 请求技术。
目前越来越多的网站采用这种动态加载网页的方式。首先,它可以将web开发的前后端分离,减少服务器直接渲染页面的压力。其次,它可以用作反爬虫。的手腕。
爬虫处理动态页面的两种方式 selenium 模拟浏览器
下面以新浪读书文摘的网站为例(Ajax请求技术的典型应用),用这两种方式来介绍爬虫是如何处理这个动态页面并获取所需数据的。
逆向工程:
对于动态加载的网页,如果我们想要获取它们的网页数据,我们需要了解网页是如何加载数据的。这个过程称为逆向工程。
对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求获取的数据。
对于这两种方法,只要创建并返回XMLHTTPRequest对象,就可以通过Chrome浏览器的调试工具在NetWork窗口中设置XHR过滤条件,直接过滤掉Ajax请求的链接;如果是$.ajax(),并且指定了dataType,如果是script或者jsonp,则无法通过这种方式过滤掉。
例子:
下面以新浪读书文摘为例,介绍如何获取无法过滤掉的ajax请求链接:
在Chrome中打开网页,右键查看,会发现首页的书摘列表收录在一个id为subShowContent1_static的div中,查看网页源码会发现该div id 为 subShowContent1_static 的为空。
单击更多摘录或下一页时,网页 URL 没有更改。
与我们前面提到的两种情况相同。
F12打开调试工具,打开NetWork窗口*(功能是记录浏览器的网络活动)*,F5刷新,可以看到浏览器收发的数据记录:
事实上,我们正在寻找的 Ajax 请求链接就是其中之一。
首先设置 XHR 过滤器:
如果发现为空,则可以推断该网页使用的ajax请求的dataType应该设置为script或者jsonp。
重新打开调试工具,点击网页上的More Book Excerpts。发现NetWork窗口中有很多记录,网页上有新内容,说明浏览器已经向服务器发送了请求。
在网页上,右键单击以检查更多摘录,并观察绑定到辅助元素的 JavaScript 事件:
根据JavaScript的知识:javascript:是一个伪协议,意思是当它被触发时,执行一段JavaScript代码,而javascript:; 表示不执行任何操作,因此单击时不会发生任何事情。但一般这种情况下,会绑定一个事件回调来执行业务。
接下来需要在网页的JavaSCript代码中找到更多书籍摘录触发的回调函数。
右键查看网页源码,Ctrl+F搜索“subShowContent1_loadMore”(多书摘录的id),发现并没有相关的具体函数:
这意味着更多书摘的回调函数不在网页本身编写的JavaScript代码中,所以应该在网页嵌入的JS文件中(通过 查看全部
php抓取网页动态数据(2017年国家公务员考试行测备考:动态网页(一))
###每个句子:
一个人只要在寻求什么,他就不会老。一个人不会老,直到遗憾取代了梦想。
动态网页简介:
我们在编写爬虫的时候,可能会遇到以下两个问题:
出现这个问题的原因是你爬的页面是动态加载的,是动态网页。
所谓动态网页,是指相对于静态网页的一种网页编程技术。对于静态网页,随着html代码的生成,页面的内容和显示效果不会改变。动态网页并非如此。显示的页面是Javascript处理数据的结果,可以更改。这些数据有多种来源,可能由 Javascript 计算生成或通过 Ajax 加载。
一种经常用于动态网页的技术是 Ajax 请求技术。
目前越来越多的网站采用这种动态加载网页的方式。首先,它可以将web开发的前后端分离,减少服务器直接渲染页面的压力。其次,它可以用作反爬虫。的手腕。
爬虫处理动态页面的两种方式 selenium 模拟浏览器
下面以新浪读书文摘的网站为例(Ajax请求技术的典型应用),用这两种方式来介绍爬虫是如何处理这个动态页面并获取所需数据的。
逆向工程:
对于动态加载的网页,如果我们想要获取它们的网页数据,我们需要了解网页是如何加载数据的。这个过程称为逆向工程。
对于使用Ajax请求技术的网页,我们可以找到Ajax请求的具体链接,直接获取Ajax请求获取的数据。
对于这两种方法,只要创建并返回XMLHTTPRequest对象,就可以通过Chrome浏览器的调试工具在NetWork窗口中设置XHR过滤条件,直接过滤掉Ajax请求的链接;如果是$.ajax(),并且指定了dataType,如果是script或者jsonp,则无法通过这种方式过滤掉。
例子:
下面以新浪读书文摘为例,介绍如何获取无法过滤掉的ajax请求链接:
在Chrome中打开网页,右键查看,会发现首页的书摘列表收录在一个id为subShowContent1_static的div中,查看网页源码会发现该div id 为 subShowContent1_static 的为空。
单击更多摘录或下一页时,网页 URL 没有更改。
与我们前面提到的两种情况相同。
F12打开调试工具,打开NetWork窗口*(功能是记录浏览器的网络活动)*,F5刷新,可以看到浏览器收发的数据记录:
事实上,我们正在寻找的 Ajax 请求链接就是其中之一。
首先设置 XHR 过滤器:
如果发现为空,则可以推断该网页使用的ajax请求的dataType应该设置为script或者jsonp。
重新打开调试工具,点击网页上的More Book Excerpts。发现NetWork窗口中有很多记录,网页上有新内容,说明浏览器已经向服务器发送了请求。
在网页上,右键单击以检查更多摘录,并观察绑定到辅助元素的 JavaScript 事件:
根据JavaScript的知识:javascript:是一个伪协议,意思是当它被触发时,执行一段JavaScript代码,而javascript:; 表示不执行任何操作,因此单击时不会发生任何事情。但一般这种情况下,会绑定一个事件回调来执行业务。
接下来需要在网页的JavaSCript代码中找到更多书籍摘录触发的回调函数。
右键查看网页源码,Ctrl+F搜索“subShowContent1_loadMore”(多书摘录的id),发现并没有相关的具体函数:
这意味着更多书摘的回调函数不在网页本身编写的JavaScript代码中,所以应该在网页嵌入的JS文件中(通过
php抓取网页动态数据(在PHP函数参考手册里找到这些函数的完整列表(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-14 17:16
)
这些功能处理用户通过网络表单直接输入的数据。
数据库(本地或远程)
_连接()
_pconnect()
_关闭()
_()
例子:
mysql_fetch_array()
这些只是 PHP 的许多数据库访问函数中的一部分,其中许多函数是专门为每个不同的数据库编写的。您可以在 PHP 函数参考手册中找到这些函数的完整列表。
远程文件
fopen(), fclose()
fgets(), fputs()
这些函数处理可通过 FTP 访问的远程服务器上的文件中的数据。
本地文件
包括(),要求()
fopen(), fclose()
这些函数处理位于本地服务器上的文件中的数据,例如配置文件。
通用数据源和处理它们的 PHP 函数
在这个文章“教程:PHP 入门”中,我们观看了一个演示脚本,该脚本要求用户输入他们喜欢的数字。根据用户输入的结果,我们在网页上显示一条消息。这是用户驱动的动态 Web 内容的示例。从 Web 表单返回的结果将决定显示的内容。一个更复杂的示例是“clickflow”应用程序,它可以根据用户访问过的网站页面来决定向用户发送哪些广告。
输入数据后,无论是用户输入还是其他输入,都将存储在数据库中并在以后重复使用。如果它用于确定要显示的内容,那么该内容可以被认为是“数据库驱动的动态内容”。我们将在下一篇文章 文章 中仔细研究这种类型的动态信息。现在,让我们看一个简单的 PHP 脚本示例,该脚本具有由文件驱动的动态内容。我们将使用基于配置文件的逻辑来决定应该在网页上显示哪些页面样式和字体。我们选择的页面样式会在用户请求网页时显示。(我想在这里以收录文件的示例警告您:您确实应该使用此示例中的样式页面来完成所需的功能。)
示例程序:Display.php
Display 脚本使用一个单独的配置文件来收录变量值和几个收录 HTML 变量部分的收录文件。虽然这看起来不是特别动态,但您可以轻松地要求用户使用 Web 表单来创建配置文件并使用一些逻辑来确定应该加载哪个配置文件等。(我们在“了解 PHP 的函数和类”中的讨论" 文章 将帮助你做到这一点。)
出于本文的目的,我们将跳过该过程的这一方面并使其尽可能简单。表 A 显示了我们的主页,以及您通过浏览器调用的页面 Display.php。(PHP 代码将以粗体显示。)
表 A
这个简单的代码必须做三件事:
您应该注意,在我们的示例中,PHP 的 require() 和 include() 函数是完全可以互换的。这两个函数之间的主要区别在于对象文件的处理方式。require() 语句将被它调用的文件替换。这意味着在一个循环中,远程文件只会被调用一次。另一方面,每次遇到 include() 函数时,都会重新计算它。这意味着在一个循环期间,该文件将在每个循环期间被访问一次,并且在收录文件中设置的变量每次都会被更新。
在这个例子中,我试图明确何时使用什么函数。对于文件Displayconf.php,很有可能是里面的变量值发生了变化。毕竟这是一个配置文件。因此,我选择了 include() 函数。另一方面,$required 文件很可能在交互过程中不会改变。如果用户请求不同的文件主体,那么我们可以创建一个新文件并收录它,所以我使用 require() 函数。
高级用户可能希望查看 PHP 手册以了解有关函数 require_once() 和 include_once() 的更多信息,以便更好地控制文件处理和配置文件变量的管理。
表 B 显示了我们的配置文件 Displayconf.php。(为简单起见,我们将所有文件放在与 Web 服务器相同的目录中。)我们在这里要做的就是将 $display 变量设置为可选值。
表格 B
最后,我们需要一些内容文件——对应于配置文件中的每个选项。因为内容是静态 HTML,所以我们不需要在文件中添加 PHP 页脚。当您在 PHP 中使用 include() 或 require() 函数时,被调用的文件在处理开始时被跳过并在处理结束时被添加。
“快乐”文件内容(happy.php)
“悲伤”文件内容 (sad.php)
“通用”文件内容 (generic.php)
当您点击页面 Display.php 时,该页面的外观会根据您在配置文件中输入的值而改变。
总结
在本文中,我们讨论了动态信息的基础知识并使用脚本创建由文件驱动的动态内容。特别是,我们使用 include() 和 require() PHP 函数来提取和发送我们的数据。
这是最后的话。虽然我确信您熟悉 WAI Web 编程指南,但您可能还应该看看 W3C 关于动态内容以及用户如何访问它的说法。您可能还想查看 PHP 手册中的“使用远程文件”一章,了解如何使用 FTP 提取配置数据。
查看全部
php抓取网页动态数据(在PHP函数参考手册里找到这些函数的完整列表(一)
)
这些功能处理用户通过网络表单直接输入的数据。
数据库(本地或远程)
_连接()
_pconnect()
_关闭()
_()
例子:
mysql_fetch_array()
这些只是 PHP 的许多数据库访问函数中的一部分,其中许多函数是专门为每个不同的数据库编写的。您可以在 PHP 函数参考手册中找到这些函数的完整列表。
远程文件
fopen(), fclose()
fgets(), fputs()
这些函数处理可通过 FTP 访问的远程服务器上的文件中的数据。
本地文件
包括(),要求()
fopen(), fclose()
这些函数处理位于本地服务器上的文件中的数据,例如配置文件。
通用数据源和处理它们的 PHP 函数
在这个文章“教程:PHP 入门”中,我们观看了一个演示脚本,该脚本要求用户输入他们喜欢的数字。根据用户输入的结果,我们在网页上显示一条消息。这是用户驱动的动态 Web 内容的示例。从 Web 表单返回的结果将决定显示的内容。一个更复杂的示例是“clickflow”应用程序,它可以根据用户访问过的网站页面来决定向用户发送哪些广告。
输入数据后,无论是用户输入还是其他输入,都将存储在数据库中并在以后重复使用。如果它用于确定要显示的内容,那么该内容可以被认为是“数据库驱动的动态内容”。我们将在下一篇文章 文章 中仔细研究这种类型的动态信息。现在,让我们看一个简单的 PHP 脚本示例,该脚本具有由文件驱动的动态内容。我们将使用基于配置文件的逻辑来决定应该在网页上显示哪些页面样式和字体。我们选择的页面样式会在用户请求网页时显示。(我想在这里以收录文件的示例警告您:您确实应该使用此示例中的样式页面来完成所需的功能。)
示例程序:Display.php
Display 脚本使用一个单独的配置文件来收录变量值和几个收录 HTML 变量部分的收录文件。虽然这看起来不是特别动态,但您可以轻松地要求用户使用 Web 表单来创建配置文件并使用一些逻辑来确定应该加载哪个配置文件等。(我们在“了解 PHP 的函数和类”中的讨论" 文章 将帮助你做到这一点。)
出于本文的目的,我们将跳过该过程的这一方面并使其尽可能简单。表 A 显示了我们的主页,以及您通过浏览器调用的页面 Display.php。(PHP 代码将以粗体显示。)
表 A
这个简单的代码必须做三件事:
您应该注意,在我们的示例中,PHP 的 require() 和 include() 函数是完全可以互换的。这两个函数之间的主要区别在于对象文件的处理方式。require() 语句将被它调用的文件替换。这意味着在一个循环中,远程文件只会被调用一次。另一方面,每次遇到 include() 函数时,都会重新计算它。这意味着在一个循环期间,该文件将在每个循环期间被访问一次,并且在收录文件中设置的变量每次都会被更新。
在这个例子中,我试图明确何时使用什么函数。对于文件Displayconf.php,很有可能是里面的变量值发生了变化。毕竟这是一个配置文件。因此,我选择了 include() 函数。另一方面,$required 文件很可能在交互过程中不会改变。如果用户请求不同的文件主体,那么我们可以创建一个新文件并收录它,所以我使用 require() 函数。
高级用户可能希望查看 PHP 手册以了解有关函数 require_once() 和 include_once() 的更多信息,以便更好地控制文件处理和配置文件变量的管理。
表 B 显示了我们的配置文件 Displayconf.php。(为简单起见,我们将所有文件放在与 Web 服务器相同的目录中。)我们在这里要做的就是将 $display 变量设置为可选值。
表格 B
最后,我们需要一些内容文件——对应于配置文件中的每个选项。因为内容是静态 HTML,所以我们不需要在文件中添加 PHP 页脚。当您在 PHP 中使用 include() 或 require() 函数时,被调用的文件在处理开始时被跳过并在处理结束时被添加。
“快乐”文件内容(happy.php)
“悲伤”文件内容 (sad.php)
“通用”文件内容 (generic.php)
当您点击页面 Display.php 时,该页面的外观会根据您在配置文件中输入的值而改变。
总结
在本文中,我们讨论了动态信息的基础知识并使用脚本创建由文件驱动的动态内容。特别是,我们使用 include() 和 require() PHP 函数来提取和发送我们的数据。
这是最后的话。虽然我确信您熟悉 WAI Web 编程指南,但您可能还应该看看 W3C 关于动态内容以及用户如何访问它的说法。您可能还想查看 PHP 手册中的“使用远程文件”一章,了解如何使用 FTP 提取配置数据。
php抓取网页动态数据(怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-14 15:17
总结:使用php创建动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值立即从数据库中检索其他相关字段的值并显示他们在当前页面上,这是一个php程序的开发难点。本文详细介绍了如何结合php和javascript这两种html嵌入式语言,并通过一个具体的例子,以及解决这个难点的具体方法。
关键词:php,动态,html。
现在网站已经从以前提供静态信息的形式发展为提供动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。要提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何将用户提交的信息有效记录到方便以后用户查找。这些问题可以通过向 网站 添加数据库支持来解决。
因为php可以对各种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,php是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php免费开源,提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;让网页开发者能够快速、方便地制作功能强大的动态网页。不过由于php是内嵌在服务器端的,更直观的理解是php语句是在服务器端执行的,所以它只在提交的时候接收并处理当前页面的内容。当你需要的内容是基于客户当前页面输入的某个字段的值,然后从库中动态提取出来的,php就无能为力了。例如:给客户提供一个“订单合同”的录入页面,里面收录了一些“供应商信息”的录入,每个供应商的详细信息已经提前录入了一个“业务”字典表,现在当客户在当前页面选择“供应商”时,需要从“商户”字典表中提取供应商的一些信息,如“开户行、账号、地址、电话号码”等立即显示在当前页面上供客户直接使用或修改。这样的需求在pb、vb等可视化编程语言中很容易实现,但是pb和vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上面的要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道同样是嵌入语句,但是javascript不同于php语言。因为php是服务端embedding,而javascript是client端embedding,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来制作强大的动态网页是一个完美的搭配。为了描述方便,以下仅以从字典表中选择的供应商地址为例来说明具体方法。当需要提取多个字段时,方法类似,但使用javascript函数从字符串中逐一提取时需要更加小心。
1.写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,并将其存储在一个字符串变量$khsz中。
函数 khqk_tq($questr){
全局$dbconn;
$dbq_resl=sybase_query($questr,$dbconn);//发送查询字符串让sybase执行。
$dbq_rows=sybase_num_rows($dbq_resl);//获取返回的行数。
$j=0;
对于 ($i=0;$i 查看全部
php抓取网页动态数据(怎样将两个html内嵌式语言和javascript巧妙结合起来,解决难点)
总结:使用php创建动态网页时,在提交到服务器之前,让php根据用户在当前页面输入的某个字段的值立即从数据库中检索其他相关字段的值并显示他们在当前页面上,这是一个php程序的开发难点。本文详细介绍了如何结合php和javascript这两种html嵌入式语言,并通过一个具体的例子,以及解决这个难点的具体方法。
关键词:php,动态,html。
现在网站已经从以前提供静态信息的形式发展为提供动态信息服务的交互方式。网络信息服务的形式可以概括为两点:向客户提供信息;记录客户提交的信息。要提供这两项服务,需要解决的问题是:如何快速让用户从自己的网站海量信息中快速提取出自己想要的信息,以及如何将用户提交的信息有效记录到方便以后用户查找。这些问题可以通过向 网站 添加数据库支持来解决。
因为php可以对各种数据库提供很好的支持,而且php脚本直接嵌入到html文档中,使用起来非常方便。因此,php是互联网上最流行的服务器端嵌入式语言之一。另外,与asp等其他服务器端脚本语言相比,php免费开源,提供跨平台支持,可以轻松适应当今网络中的各种异构网络环境;让网页开发者能够快速、方便地制作功能强大的动态网页。不过由于php是内嵌在服务器端的,更直观的理解是php语句是在服务器端执行的,所以它只在提交的时候接收并处理当前页面的内容。当你需要的内容是基于客户当前页面输入的某个字段的值,然后从库中动态提取出来的,php就无能为力了。例如:给客户提供一个“订单合同”的录入页面,里面收录了一些“供应商信息”的录入,每个供应商的详细信息已经提前录入了一个“业务”字典表,现在当客户在当前页面选择“供应商”时,需要从“商户”字典表中提取供应商的一些信息,如“开户行、账号、地址、电话号码”等立即显示在当前页面上供客户直接使用或修改。这样的需求在pb、vb等可视化编程语言中很容易实现,但是pb和vb不适合写动态网页;php适合写动态网页,但是因为嵌入在服务器端,无法及时提交上一页的变量值,所以很难达到上面的要求。在编程的过程中,我巧妙地将php和javascript结合起来解决了这个难点。
我们知道同样是嵌入语句,但是javascript不同于php语言。因为php是服务端embedding,而javascript是client端embedding,所以javascript语句是在客户端的浏览器上执行的,这就决定了javascript可以及时获取当前页面的变量值,但是不能直接操作服务器端数据库。. 因此,将两者结合起来制作强大的动态网页是一个完美的搭配。为了描述方便,以下仅以从字典表中选择的供应商地址为例来说明具体方法。当需要提取多个字段时,方法类似,但使用javascript函数从字符串中逐一提取时需要更加小心。
1.写一个php函数
该函数的作用是从“商家”字典表中取出所有符合条件的“供应商信息”,并将其存储在一个字符串变量$khsz中。
函数 khqk_tq($questr){
全局$dbconn;
$dbq_resl=sybase_query($questr,$dbconn);//发送查询字符串让sybase执行。
$dbq_rows=sybase_num_rows($dbq_resl);//获取返回的行数。
$j=0;
对于 ($i=0;$i
php抓取网页动态数据(php抓取网页动态数据特别火怎么抓取百度的url.你可以看下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-14 02:07
php抓取网页动态数据特别火,一般用于做网站的技术都能抓取,这个主要看你的需求,我这里讲一下php怎么抓取百度的url.你可以看下。其他的比如微信公众号也是可以用php来抓取的,而且现在手机微信公众号都是可以通过h5来实现抓取数据的。你也可以自己开发个页面实现手机微信公众号数据抓取,或者你自己搭建一个独立的站点抓取数据等。
现在php都有抓取api了,以下是参考链接:-open-fire-form-made-up-to-brain-extraction-enabled-cn/以及我的博客里有详细介绍:php3网页下载分析,
我看中小企业都是这么干的
借助小站长工具箱来实现
php没这个功能,php抓取html不需要header头。而且题主所谓的小站长工具箱,应该也不是为了爬而生。
xmarks内置抓取接口h5页面不过应该也有更专业的工具如phpextractor这也不需要具体定制每个后端web工程师,哪个工具最熟悉用哪个。
以前看过个段子,搞互联网的都遇到过搞php抓html的。所以,
这个有webform1.3接口也有php.js接口。手机端php抓h5等等php、python等后端不得不提jsp。
那没什么说,想抓什么抓什么。 查看全部
php抓取网页动态数据(php抓取网页动态数据特别火怎么抓取百度的url.你可以看下)
php抓取网页动态数据特别火,一般用于做网站的技术都能抓取,这个主要看你的需求,我这里讲一下php怎么抓取百度的url.你可以看下。其他的比如微信公众号也是可以用php来抓取的,而且现在手机微信公众号都是可以通过h5来实现抓取数据的。你也可以自己开发个页面实现手机微信公众号数据抓取,或者你自己搭建一个独立的站点抓取数据等。
现在php都有抓取api了,以下是参考链接:-open-fire-form-made-up-to-brain-extraction-enabled-cn/以及我的博客里有详细介绍:php3网页下载分析,
我看中小企业都是这么干的
借助小站长工具箱来实现
php没这个功能,php抓取html不需要header头。而且题主所谓的小站长工具箱,应该也不是为了爬而生。
xmarks内置抓取接口h5页面不过应该也有更专业的工具如phpextractor这也不需要具体定制每个后端web工程师,哪个工具最熟悉用哪个。
以前看过个段子,搞互联网的都遇到过搞php抓html的。所以,
这个有webform1.3接口也有php.js接口。手机端php抓h5等等php、python等后端不得不提jsp。
那没什么说,想抓什么抓什么。
php抓取网页动态数据(详解动态网站的访问过程,动态网页与动态页面共存)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-10 11:10
目前网站页面主要分为静态页面和动态页面。纯静态页面组成的网站现在比较少见,大型网站一般采用动态网站建站技术,部分网站是静态网页和动态网页。本文以Apache服务器和php语言为例,详细讲解动态网站的访问过程。下面直接切入本文的主题。
(1)客户端访问服务端的html文件
S1:通过本机配置的DNS域名服务器地址找到DNS服务器,将网站 URL中的web主机域名解析为web服务器所在Linux操作系统(Apache通常与Linux操作系统结合使用)。IP地址。
S2:通过HTTP协议(超文本传输协议)连接到上面IP地址的服务器系统,通过默认端口80请求Apache服务器上的对应目录(默认端口为80,还有其他端口,你输入 URL 时一般不需要输入端口)。html 文件(例如 index.htm)。
S3:Apache服务器接收到用户的访问请求后,在其管理的文档目录中找到并打开相应的html文件(如index.htm),并将文件内容响应给客户端浏览器(即用户)。
S4:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最后渲染网页(由于不同的浏览器对代码的解释规则不同) , 所以不同的浏览器对代码的解释不同. 浏览器对同一个网页最终呈现的页面效果会有所不同).
(2)客户端访问服务端的php文件
S1:这一步和上面访问html静态网页一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问html静态页面类似,但是最终请求的是Apache服务器上对应目录下的php文件,比如index.php。
S3:Apache服务器本身无法处理php动态语言脚本文件,所以找到并委托PHP应用服务器处理(PHP应用服务器必须提前安装在服务器端),Apache服务器提交php文件(例如 index. 到 PHP 应用程序服务器。
S4:PHP应用服务器接收到php文件(如index.php),打开并解释php文件,最后翻译成html静态代码,然后将html静态代码返回给Apache服务器,Apache服务器将接收到的html静态代码输出到客户端浏览器(即用户)。
S5:和上面访问html静态页面一样,浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解析,最终渲染出网页。
(3)客户端访问服务器端的MySQL数据库
如果用户需要对MySQL数据库中的数据进行操作,那么就需要在服务器端安装数据库管理软件MySQL server来存储和管理网站数据。由于Apache服务器无法连接和操作MySQL服务器,所以需要安装php应用服务器,让Apache服务器委托php应用服务器连接和操作数据库。在管理数据库中的数据时,一般需要使用结构查询语句,即SQL语句。
S1:这一步和上面访问php文件一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问php文件一样,请求访问Apache服务器对应目录下的php文件。
S3:和上面访问php文件一样,PHP应用服务器接受Apache服务器的委托,接收到对应的php文件。
S4:PHP应用服务器打开php文件,通过php文件中的数据库连接代码连接本地机器或网络上其他机器的MySQL数据库,执行php程序中的标准SQL查询语句获取数据在数据库中。数据,然后通过 PHP 应用服务器从数据中生成 html 静态代码。
S5:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最终呈现网页。
需要注意的是,文中的(2)和(3))的区别是一个访问数据库,另一个不访问数据库,所以在流程上有一点区别。 查看全部
php抓取网页动态数据(详解动态网站的访问过程,动态网页与动态页面共存)
目前网站页面主要分为静态页面和动态页面。纯静态页面组成的网站现在比较少见,大型网站一般采用动态网站建站技术,部分网站是静态网页和动态网页。本文以Apache服务器和php语言为例,详细讲解动态网站的访问过程。下面直接切入本文的主题。
(1)客户端访问服务端的html文件
S1:通过本机配置的DNS域名服务器地址找到DNS服务器,将网站 URL中的web主机域名解析为web服务器所在Linux操作系统(Apache通常与Linux操作系统结合使用)。IP地址。
S2:通过HTTP协议(超文本传输协议)连接到上面IP地址的服务器系统,通过默认端口80请求Apache服务器上的对应目录(默认端口为80,还有其他端口,你输入 URL 时一般不需要输入端口)。html 文件(例如 index.htm)。
S3:Apache服务器接收到用户的访问请求后,在其管理的文档目录中找到并打开相应的html文件(如index.htm),并将文件内容响应给客户端浏览器(即用户)。
S4:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最后渲染网页(由于不同的浏览器对代码的解释规则不同) , 所以不同的浏览器对代码的解释不同. 浏览器对同一个网页最终呈现的页面效果会有所不同).
(2)客户端访问服务端的php文件
S1:这一步和上面访问html静态网页一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问html静态页面类似,但是最终请求的是Apache服务器上对应目录下的php文件,比如index.php。
S3:Apache服务器本身无法处理php动态语言脚本文件,所以找到并委托PHP应用服务器处理(PHP应用服务器必须提前安装在服务器端),Apache服务器提交php文件(例如 index. 到 PHP 应用程序服务器。
S4:PHP应用服务器接收到php文件(如index.php),打开并解释php文件,最后翻译成html静态代码,然后将html静态代码返回给Apache服务器,Apache服务器将接收到的html静态代码输出到客户端浏览器(即用户)。
S5:和上面访问html静态页面一样,浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解析,最终渲染出网页。
(3)客户端访问服务器端的MySQL数据库
如果用户需要对MySQL数据库中的数据进行操作,那么就需要在服务器端安装数据库管理软件MySQL server来存储和管理网站数据。由于Apache服务器无法连接和操作MySQL服务器,所以需要安装php应用服务器,让Apache服务器委托php应用服务器连接和操作数据库。在管理数据库中的数据时,一般需要使用结构查询语句,即SQL语句。
S1:这一步和上面访问php文件一样,通过DNS服务器解析对应web服务器的IP地址。
S2:和上面访问php文件一样,请求访问Apache服务器对应目录下的php文件。
S3:和上面访问php文件一样,PHP应用服务器接受Apache服务器的委托,接收到对应的php文件。
S4:PHP应用服务器打开php文件,通过php文件中的数据库连接代码连接本地机器或网络上其他机器的MySQL数据库,执行php程序中的标准SQL查询语句获取数据在数据库中。数据,然后通过 PHP 应用服务器从数据中生成 html 静态代码。
S5:浏览器收到web服务器的响应后,在服务器端接收并下载html静态代码,然后浏览器对代码进行解释,最终呈现网页。
需要注意的是,文中的(2)和(3))的区别是一个访问数据库,另一个不访问数据库,所以在流程上有一点区别。
php抓取网页动态数据(php抓取网页动态数据,又该如何实现?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-02-10 04:05
php抓取网页动态数据,又该如何实现?想必有过购物经验的同学,都知道有逛,逛天猫这样的购物网站。动态数据的来源就是网页,像商品信息等网页内容。后来出现了网页分析工具,把网页内容进行分析后,做成脚本,发送到服务器,从而爬取服务器中的数据。这里有三个分析入口。发送到服务器:request.post,axios,formdatabase函数调用的是对应的路由器,所以,我们可以用一个变量来表示。
(后面会有文章为大家详细介绍curl请求以及对应的参数、获取工具)。a::typevar($status:request.post/axios)a::valuevar($status:axios)a::sent_infovar($status:istore_backlog)request.post('',{'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/73.0.3539.141safari/537.36'})然后,就返回正常的http的请求响应。
所以一般应该把user-agent的头部传递给变量:varbaidu:s//st(s=这个参数跟请求的时候传递给http的网站信息)mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537。36(khtml,likegecko)chrome/74。3396。241safari/537。36org。stylish。css/center-staticwebkit/537。36version/1。5safari/537。36id="gefuse"formdatabase/xxx(l=上传参数,要传参数给网站)textarea:(l=下一页)。
sent('',axios::close())if(!baidu。cookies()){mkdir(baidu。cookies())if(!textarea){mkdir(baidu。cookies())lettext=baidu。cookies(){lettext=stringify(text,baidu。cookies()。slice(。
2))text}letformdatatable=if(baidu.cookies()){letformdatatable=stringify(text,baidu.cookies().slice
2)){letformdatatable=formdatatable}lettext=stringify(text,"")}returnformdatatable}letdata=$textvartext=$textvartext=formdatatable()letis_prerename=falseletaction="\a{4}-{5}"lettxt=""letstr=formdatatable(action)mkdir(data){if(is_prerename){returnfalse}if(!str。
split("")。split("")!=""){returnfalse}str=str。split("")}varname=name。split("")returnstr。split("""。 查看全部
php抓取网页动态数据(php抓取网页动态数据,又该如何实现?(一))
php抓取网页动态数据,又该如何实现?想必有过购物经验的同学,都知道有逛,逛天猫这样的购物网站。动态数据的来源就是网页,像商品信息等网页内容。后来出现了网页分析工具,把网页内容进行分析后,做成脚本,发送到服务器,从而爬取服务器中的数据。这里有三个分析入口。发送到服务器:request.post,axios,formdatabase函数调用的是对应的路由器,所以,我们可以用一个变量来表示。
(后面会有文章为大家详细介绍curl请求以及对应的参数、获取工具)。a::typevar($status:request.post/axios)a::valuevar($status:axios)a::sent_infovar($status:istore_backlog)request.post('',{'user-agent':'mozilla/5.0(windowsnt10.0;win64;x6。
4)applewebkit/537.36(khtml,likegecko)chrome/73.0.3539.141safari/537.36'})然后,就返回正常的http的请求响应。
所以一般应该把user-agent的头部传递给变量:varbaidu:s//st(s=这个参数跟请求的时候传递给http的网站信息)mozilla/5.0(windowsnt10.0;win64;x6
4)applewebkit/537。36(khtml,likegecko)chrome/74。3396。241safari/537。36org。stylish。css/center-staticwebkit/537。36version/1。5safari/537。36id="gefuse"formdatabase/xxx(l=上传参数,要传参数给网站)textarea:(l=下一页)。
sent('',axios::close())if(!baidu。cookies()){mkdir(baidu。cookies())if(!textarea){mkdir(baidu。cookies())lettext=baidu。cookies(){lettext=stringify(text,baidu。cookies()。slice(。
2))text}letformdatatable=if(baidu.cookies()){letformdatatable=stringify(text,baidu.cookies().slice
2)){letformdatatable=formdatatable}lettext=stringify(text,"")}returnformdatatable}letdata=$textvartext=$textvartext=formdatatable()letis_prerename=falseletaction="\a{4}-{5}"lettxt=""letstr=formdatatable(action)mkdir(data){if(is_prerename){returnfalse}if(!str。
split("")。split("")!=""){returnfalse}str=str。split("")}varname=name。split("")returnstr。split("""。
php抓取网页动态数据(为什么要获取SESSION值?(HTTP协议)叫用户代理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 22:15
今天我们来实现一个提交话费的WEB程序,主要用于:代理电信公司话费支付。
第一步:获取登录页面的SESSION会话ID值。
为什么要获取 SESSION 值?
我们知道,当用户访问 网站 时,他们通常需要浏览很多页面。对于一个PHP构建的网站,用户在访问过程中需要执行很多动态页面(如:jsp、PHP、APS.NET等)。但是由于HTTP协议本身的特性,用户每次执行一个动态页面都需要重新与Web服务器建立连接。
并且由于WEB程序没有状态记忆的特点,本次连接无法获取上一次连接的状态。这样,用户在一个动态页面中分配了一个变量,却无法在另一个动态页面中获取该变量的值。例如,用户在负责登录的动态页面中设置了字符串 username = "wind",但在另一个动态页面中调用 username 却无法获取到值 "wind"。也就是说,不能在程序中设置全局变量。也就是说:每个动态脚本中定义的变量都是局部变量,只在这个脚本内有效。
Session解决方案是提供一种在动态脚本中定义全局变量的方法,使全局变量对同一个Session中的所有动态页面都有效。正如我们上面提到的,Session 并不是一个简单的时间概念。会话还包括特定的用户和服务器。因此,更详细地说,一个Session中定义的全局变量的范围是指该Session对应的用户访问的所有动态脚本。
并且因为HTTP协议是一种无状态的链接方式,也就是说服务端和客户端没有链接在一起。HTTP 是客户端和服务器端的请求和响应标准 (TCP)。客户端是最终用户,服务器是 网站。客户端通过浏览器、网络爬虫或其他工具,在指定端口(默认端口为80))向服务器发起HTTP请求。(我们称此客户端)称为用户代理(user agent ) 应答服务器存储(一些)资源,例如 HTML 文件和图像。(我们称这个应答服务器为源服务器)。
用户代理和源服务器之间可能有多个中介,例如代理、网关或隧道。尽管 TCP/IP 协议是 Internet 上最流行的应用程序,但 HTTP 协议并没有规定必须使用它以及(基于)它支持的层。事实上,HTTP 可以通过任何其他互联网协议或其他网络实现。HTTP 只假设(及其底层协议提供)可靠传输,任何可以提供这种保证的协议都可以被它使用。 查看全部
php抓取网页动态数据(为什么要获取SESSION值?(HTTP协议)叫用户代理)
今天我们来实现一个提交话费的WEB程序,主要用于:代理电信公司话费支付。
第一步:获取登录页面的SESSION会话ID值。
为什么要获取 SESSION 值?
我们知道,当用户访问 网站 时,他们通常需要浏览很多页面。对于一个PHP构建的网站,用户在访问过程中需要执行很多动态页面(如:jsp、PHP、APS.NET等)。但是由于HTTP协议本身的特性,用户每次执行一个动态页面都需要重新与Web服务器建立连接。
并且由于WEB程序没有状态记忆的特点,本次连接无法获取上一次连接的状态。这样,用户在一个动态页面中分配了一个变量,却无法在另一个动态页面中获取该变量的值。例如,用户在负责登录的动态页面中设置了字符串 username = "wind",但在另一个动态页面中调用 username 却无法获取到值 "wind"。也就是说,不能在程序中设置全局变量。也就是说:每个动态脚本中定义的变量都是局部变量,只在这个脚本内有效。
Session解决方案是提供一种在动态脚本中定义全局变量的方法,使全局变量对同一个Session中的所有动态页面都有效。正如我们上面提到的,Session 并不是一个简单的时间概念。会话还包括特定的用户和服务器。因此,更详细地说,一个Session中定义的全局变量的范围是指该Session对应的用户访问的所有动态脚本。
并且因为HTTP协议是一种无状态的链接方式,也就是说服务端和客户端没有链接在一起。HTTP 是客户端和服务器端的请求和响应标准 (TCP)。客户端是最终用户,服务器是 网站。客户端通过浏览器、网络爬虫或其他工具,在指定端口(默认端口为80))向服务器发起HTTP请求。(我们称此客户端)称为用户代理(user agent ) 应答服务器存储(一些)资源,例如 HTML 文件和图像。(我们称这个应答服务器为源服务器)。
用户代理和源服务器之间可能有多个中介,例如代理、网关或隧道。尽管 TCP/IP 协议是 Internet 上最流行的应用程序,但 HTTP 协议并没有规定必须使用它以及(基于)它支持的层。事实上,HTTP 可以通过任何其他互联网协议或其他网络实现。HTTP 只假设(及其底层协议提供)可靠传输,任何可以提供这种保证的协议都可以被它使用。
php抓取网页动态数据(第一个实习新入职开发过程中常见的难点及解决办法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-03 23:14
我是大四实习的新人,一周后就接触到了我的第一个项目。
因为我是新手,在整个开发过程中遇到了很多困难:主要是canvas绘制过程中,因为产品图片和二维码来自后台,绘制完成后发现只能显示在微信开发工具上,只能在真机上显示。(我的手机)上只能显示文字,图片为空白。经过多次测试,发现在真机上无法绘制网络图片。
首先,看一下设计图就知道它长什么样了:
————
——
具体来说,就是在微信小程序的商品详情页增加了一个分享按钮。点击按钮后,将产品图片、描述、价格和二维码绘制成图片展示(项目收录详情页和首页两张图片)。利用微信小程序内置功能,长按可以保存、分享、采集、识别二维码。
接下来代码不全,主要是我开发过程中用到的代码。(由于公司使用wepy小程序框架进行开发,代码编写与原生小程序代码略有不同,需要的朋友请自行转行,重点了解此流程。)
1.这是wxml部分的代码。这里缺少样式代码。
分享
//点击分享按钮,调用事件“share”
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。
注意:
1.canvas-id 必须设置,后面会用到。
2.样式中的宽高要使用。如果不设置宽高,画板无效。
3.canvasHidden 是一个控制画板显示和隐藏的参数。如果画板直接设置为不显示,会导致失败。
2.脚本部分。
Data{
//画布
canvasHidden:true, //设置画板的显示与隐藏,画板不隐藏会影响页面正常显示
shareImgPath: '' //用于储存canvas生成的图片
}
自定义方法:
这是 getGoodEwm 方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
注意代码后面的注释
//二维码获取
async getGoodEwm() {
let that = this;
let storeId = wepy.getStorageSync(STORE_ID) || {};
let storeSkuSn = that.detail.storeSkuSn;
const json = await api.getGoodEwm({
query: {
storeId : storeId,
storeSkuSn : storeSkuSn
}
}); //以上代码是后台获取二维码的方法,不是本问的重点。实际实验中可以把二维码图片地址用网络图片地址代替,也能实验效果
console.log(json.data)
if (json.data.code == 'success') { //这句表示如果二维码图片内容获取成功
wx.showLoading({ //因为整个图片获取过程需要一定时间,所以添加一个提示框提醒用户
title: '努力生成中...'
})
wx.getImageInfo({ //获取二维码图片信息
src: json.data.data,
success:function(res){
console.log("------------- succ -----------")
console.log(res)
wx.getImageInfo({ //二维码图片信息获取成功后,获取商品图片信息
src: that.detail.imgList[0], //因为后台中商品图片有多张,数据是一个数组,所以这里只获取第一张。也可以用网络图片地址代替。
success:function(e){
console.log("------------- succ -----------")
console.log(e)
console.log(res)
that.drawImg(e,res) //两张图片都获取成功后,调用绘图方法,注意传递过去的参数区别,不要混淆
},
fail:function(e){
console.log("------------- fail -----------")
console.log(e)
},
complete:function(e) {
console.log("------------- complete -----------")
console.log(e)
}
});
},
fail:function(res){
console.log("------------- fail -----------")
console.log(res)
},
complete:function(res) {
console.log("------------- complete -----------")
console.log(res)
}
});
} else {
tip.error(json.data.errorMsg)
console.log('失败')
}
that.$apply();
}
//绘图
drawImg(e,res) {
let that=this;
that.canvasHidden=false //设置画板显示,才能开始绘图
var img=e.path //商品图片保存地址
var img1=res.path //二维码图片保存地址
var name=this.detail.name //图片描述,描述和下面的价格都是从后台获取的内容,可以随意换成其他文本内容,这里不是重点所以就不讲内容的获取方法了
var price=this.detail.price //图片价格
let context = wx.createCanvasContext('share') //这里的“share”是“canvas-id”
context.setFillStyle('#fff') //这里是绘制白底,让图片有白色的背景
context.fillRect(0, 0, 750, 920)
context.drawImage(img, 30, 30, 690, 690) //绘制商品图片
context.setFontSize(28)
context.setFillStyle("#393939")
context.fillText(name, 30, 796) //绘制描述
context.setFontSize(32)
context.setFillStyle("#f31115")
context.fillText('¥'+price, 30, 870) //绘制价格
context.drawImage(img1, 576, 750, 144, 144) //绘制二维码图片
//把画板内容绘制成图片,并回调画板图片路径
context.draw(false, function () {
wx.canvasToTempFilePath({
x: 0,
y: 0,
width: 750,
height: 920,
destWidth: 750,
destHeight: 920,
canvasId: 'share',
success:a=>{
that.shareImgPath=a.tempFilePath, //将绘制的图片地址保存在shareImgPath 中
that.canvasHidden=true //设置画板隐藏,否则影响界面显示
that.$apply(); //更改data的值 等同于小程序原生代码的setData
console.log(that.data.shareImgPath)
wx.previewImage({ //将图片预览出来
urls: [that.data.shareImgPath]
})
wx.hideLoading() //图片已经绘制出来,隐藏提示框
},
fail:e=>{console.log('失败')}
})
})
}
Methods={
//分享事件
share() {
this.getGoodEwm();
}
}
解释下面的代码:
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
在Canvas上绘制的方法可以看小程序的官方文档,看一遍代码就可以理解。图片绘制完成后,将地址保存在data的“shareImgPath”中,然后调用“wx.previewImage”方法预览图片。长按图片会自动调用微信小程序的原生功能:保存、采集等。
事实上,整个项目的重点是如何绘制网络图像。如果是本地图片,步骤会少一些,但是网络图片必须先通过wx.getImageInfo()方法保存,然后再调用绘图。在项目中,由于图片是在后台获取的,所以调用api获取背景图片的次数较多。 查看全部
php抓取网页动态数据(第一个实习新入职开发过程中常见的难点及解决办法)
我是大四实习的新人,一周后就接触到了我的第一个项目。
因为我是新手,在整个开发过程中遇到了很多困难:主要是canvas绘制过程中,因为产品图片和二维码来自后台,绘制完成后发现只能显示在微信开发工具上,只能在真机上显示。(我的手机)上只能显示文字,图片为空白。经过多次测试,发现在真机上无法绘制网络图片。
首先,看一下设计图就知道它长什么样了:
————
——
具体来说,就是在微信小程序的商品详情页增加了一个分享按钮。点击按钮后,将产品图片、描述、价格和二维码绘制成图片展示(项目收录详情页和首页两张图片)。利用微信小程序内置功能,长按可以保存、分享、采集、识别二维码。
接下来代码不全,主要是我开发过程中用到的代码。(由于公司使用wepy小程序框架进行开发,代码编写与原生小程序代码略有不同,需要的朋友请自行转行,重点了解此流程。)
1.这是wxml部分的代码。这里缺少样式代码。
分享
//点击分享按钮,调用事件“share”
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。
注意:
1.canvas-id 必须设置,后面会用到。
2.样式中的宽高要使用。如果不设置宽高,画板无效。
3.canvasHidden 是一个控制画板显示和隐藏的参数。如果画板直接设置为不显示,会导致失败。
2.脚本部分。
Data{
//画布
canvasHidden:true, //设置画板的显示与隐藏,画板不隐藏会影响页面正常显示
shareImgPath: '' //用于储存canvas生成的图片
}
自定义方法:
这是 getGoodEwm 方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
注意代码后面的注释
//二维码获取
async getGoodEwm() {
let that = this;
let storeId = wepy.getStorageSync(STORE_ID) || {};
let storeSkuSn = that.detail.storeSkuSn;
const json = await api.getGoodEwm({
query: {
storeId : storeId,
storeSkuSn : storeSkuSn
}
}); //以上代码是后台获取二维码的方法,不是本问的重点。实际实验中可以把二维码图片地址用网络图片地址代替,也能实验效果
console.log(json.data)
if (json.data.code == 'success') { //这句表示如果二维码图片内容获取成功
wx.showLoading({ //因为整个图片获取过程需要一定时间,所以添加一个提示框提醒用户
title: '努力生成中...'
})
wx.getImageInfo({ //获取二维码图片信息
src: json.data.data,
success:function(res){
console.log("------------- succ -----------")
console.log(res)
wx.getImageInfo({ //二维码图片信息获取成功后,获取商品图片信息
src: that.detail.imgList[0], //因为后台中商品图片有多张,数据是一个数组,所以这里只获取第一张。也可以用网络图片地址代替。
success:function(e){
console.log("------------- succ -----------")
console.log(e)
console.log(res)
that.drawImg(e,res) //两张图片都获取成功后,调用绘图方法,注意传递过去的参数区别,不要混淆
},
fail:function(e){
console.log("------------- fail -----------")
console.log(e)
},
complete:function(e) {
console.log("------------- complete -----------")
console.log(e)
}
});
},
fail:function(res){
console.log("------------- fail -----------")
console.log(res)
},
complete:function(res) {
console.log("------------- complete -----------")
console.log(res)
}
});
} else {
tip.error(json.data.errorMsg)
console.log('失败')
}
that.$apply();
}
//绘图
drawImg(e,res) {
let that=this;
that.canvasHidden=false //设置画板显示,才能开始绘图
var img=e.path //商品图片保存地址
var img1=res.path //二维码图片保存地址
var name=this.detail.name //图片描述,描述和下面的价格都是从后台获取的内容,可以随意换成其他文本内容,这里不是重点所以就不讲内容的获取方法了
var price=this.detail.price //图片价格
let context = wx.createCanvasContext('share') //这里的“share”是“canvas-id”
context.setFillStyle('#fff') //这里是绘制白底,让图片有白色的背景
context.fillRect(0, 0, 750, 920)
context.drawImage(img, 30, 30, 690, 690) //绘制商品图片
context.setFontSize(28)
context.setFillStyle("#393939")
context.fillText(name, 30, 796) //绘制描述
context.setFontSize(32)
context.setFillStyle("#f31115")
context.fillText('¥'+price, 30, 870) //绘制价格
context.drawImage(img1, 576, 750, 144, 144) //绘制二维码图片
//把画板内容绘制成图片,并回调画板图片路径
context.draw(false, function () {
wx.canvasToTempFilePath({
x: 0,
y: 0,
width: 750,
height: 920,
destWidth: 750,
destHeight: 920,
canvasId: 'share',
success:a=>{
that.shareImgPath=a.tempFilePath, //将绘制的图片地址保存在shareImgPath 中
that.canvasHidden=true //设置画板隐藏,否则影响界面显示
that.$apply(); //更改data的值 等同于小程序原生代码的setData
console.log(that.data.shareImgPath)
wx.previewImage({ //将图片预览出来
urls: [that.data.shareImgPath]
})
wx.hideLoading() //图片已经绘制出来,隐藏提示框
},
fail:e=>{console.log('失败')}
})
})
}
Methods={
//分享事件
share() {
this.getGoodEwm();
}
}
解释下面的代码:
当点击分享按钮时,触发“分享”方法,然后执行“分享”方法中的getGoodEwm方法。需要注意的是,由于二维码和商品图片都是后台获取的网络图片,所以必须先获取二维码图片的地址,再通过“wx.getImageInfo”获取图片信息方法,然后获取产品图像的信息。(因为商品图片的api地址是用其他方式写的,这里就不展示了,原理和二维码获取一样。)获取两张图片后才能开始绘制,否则无法绘制图像。
在Canvas上绘制的方法可以看小程序的官方文档,看一遍代码就可以理解。图片绘制完成后,将地址保存在data的“shareImgPath”中,然后调用“wx.previewImage”方法预览图片。长按图片会自动调用微信小程序的原生功能:保存、采集等。
事实上,整个项目的重点是如何绘制网络图像。如果是本地图片,步骤会少一些,但是网络图片必须先通过wx.getImageInfo()方法保存,然后再调用绘图。在项目中,由于图片是在后台获取的,所以调用api获取背景图片的次数较多。
php抓取网页动态数据(ajax横行的年代,我们的网页是残缺的吗? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-03 00:12
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,即爬虫爬取的网页不全不完整,可以看下面的博客园主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩。在使用WebBrowser时,我们应该注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
查看全部
php抓取网页动态数据(ajax横行的年代,我们的网页是残缺的吗?
)
在ajax时代,很多网页的内容都是动态加载的,我们的小爬虫只抓取web服务器返回给我们的html,其中包括
跳过js加载部分,即爬虫爬取的网页不全不完整,可以看下面的博客园主页
从首页的加载中可以看出,页面渲染完成后,会有5个异步ajax请求。默认情况下,爬虫无法抓取这些ajax生成的内容。
这时候,如果你想得到它,你必须调用浏览器的内核引擎来下载这些动态页面。目前内核引擎是三足的。
Trident:也就是IE内核,WebBrowser就是基于这个内核,但是加载性能比较差。
Gecko:FF的内核比Trident的性能更好。
WebKit:Safari和Chrome的核心,性能你懂的,在真实场景中还是主要的。
好的,为了简单方便,这里我们使用WebBrowser来玩。在使用WebBrowser时,我们应该注意以下几点:
首先:因为WebBrowser是System.Windows.Forms中的winform控件,所以我们需要设置STAThread标签。
第二:winform是事件驱动的,Console不响应事件,所有事件都在windows的消息队列中等待执行,以防止程序假死,
我们需要调用DoEvents方法来传递控制权,让操作系统执行其他事件。
第三:WebBrowser内容,我们需要使用DomDocument来查看,而不是DocumentText。
判断动态网页是否加载一般有两种方式:
①:设置一个最大值,因为每当异步加载一个js时,都会触发一个Navigating和DocumentCompleted事件,所以我们这里需要这样做
记录计数值
.
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 static int hitCount = 0;
14
15 [STAThread]
16 static void Main(string[] args)
17 {
18 string url = "http://www.cnblogs.com";
19
20 WebBrowser browser = new WebBrowser();
21
22 browser.ScriptErrorsSuppressed = true;
23
24 browser.Navigating += (sender, e) =>
25 {
26 hitCount++;
27 };
28
29 browser.DocumentCompleted += (sender, e) =>
30 {
31 hitCount++;
32 };
33
34 browser.Navigate(url);
35
36 while (browser.ReadyState != WebBrowserReadyState.Complete)
37 {
38 Application.DoEvents();
39 }
40
41 while (hitCount < 16)
42 Application.DoEvents();
43
44 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
45
46 string gethtml = htmldocument.documentElement.outerHTML;
47
48 //写入文件
49 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
50 {
51 sw.WriteLine(gethtml);
52 }
53
54 Console.WriteLine("html 文件 已经生成!");
55
56 Console.Read();
57 }
58 }
59 }
然后,我们打开生成的1.html,看看js加载的内容有没有。
②:当然,除了通过判断最大值来判断加载是否完成,我们还可以通过设置一个Timer来判断,比如3s、4s、5s,稍后再查看
WEB浏览器是否加载。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7 using System.IO;
8
9 namespace ConsoleApplication2
10 {
11 public class Program
12 {
13 [STAThread]
14 static void Main(string[] args)
15 {
16 string url = "http://www.cnblogs.com";
17
18 WebBrowser browser = new WebBrowser();
19
20 browser.ScriptErrorsSuppressed = true;
21
22 browser.Navigate(url);
23
24 //先要等待加载完毕
25 while (browser.ReadyState != WebBrowserReadyState.Complete)
26 {
27 Application.DoEvents();
28 }
29
30 System.Timers.Timer timer = new System.Timers.Timer();
31
32 var isComplete = false;
33
34 timer.Elapsed += new System.Timers.ElapsedEventHandler((sender, e) =>
35 {
36 //加载完毕
37 isComplete = true;
38
39 timer.Stop();
40 });
41
42 timer.Interval = 1000 * 5;
43
44 timer.Start();
45
46 //继续等待 5s,等待js加载完
47 while (!isComplete)
48 Application.DoEvents();
49
50 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
51
52 string gethtml = htmldocument.documentElement.outerHTML;
53
54 //写入文件
55 using (StreamWriter sw = new StreamWriter(Environment.CurrentDirectory + "//1.html"))
56 {
57 sw.WriteLine(gethtml);
58 }
59
60 Console.WriteLine("html 文件 已经生成!");
61
62 Console.Read();
63 }
64 }
65 }
当然,效果还是一样的,就不截图了。从以上两种写法来看,我们的WebBrowser放在主线程中。让我们看看如何把它放在工作线程上。
很简单,只需将工作线程设置为STA模式即可。
1 using System;
2 using System.Collections.Generic;
3 using System.Linq;
4 using System.Text;
5 using System.Windows.Forms;
6 using System.Threading;
7
8 namespace ConsoleApplication2
9 {
10 public class Program
11 {
12 static int hitCount = 0;
13
14 //[STAThread]
15 static void Main(string[] args)
16 {
17 Thread thread = new Thread(new ThreadStart(() =>
18 {
19 Init();
20 System.Windows.Forms.Application.Run();
21 }));
22
23 //将该工作线程设定为STA模式
24 thread.SetApartmentState(ApartmentState.STA);
25
26 thread.Start();
27
28 Console.Read();
29 }
30
31 static void Init()
32 {
33 string url = "http://www.cnblogs.com";
34
35 WebBrowser browser = new WebBrowser();
36
37 browser.ScriptErrorsSuppressed = true;
38
39 browser.DocumentCompleted += new WebBrowserDocumentCompletedEventHandler(browser_DocumentCompleted);
40
41 browser.Navigating += new WebBrowserNavigatingEventHandler(browser_Navigating);
42
43 browser.Navigate(url);
44
45 while (browser.ReadyState != WebBrowserReadyState.Complete)
46 {
47 Application.DoEvents();
48 }
49
50 while (hitCount < 16)
51 Application.DoEvents();
52
53 var htmldocument = (mshtml.HTMLDocument)browser.Document.DomDocument;
54
55 string gethtml = htmldocument.documentElement.outerHTML;
56
57 Console.WriteLine(gethtml);
58 }
59
60 static void browser_Navigating(object sender, WebBrowserNavigatingEventArgs e)
61 {
62 hitCount++;
63 }
64
65 static void browser_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
66 {
67 hitCount++;
68 }
69 }
70 }
php抓取网页动态数据(如何应用滚屏加载技术到您的项目中去?技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-30 22:02
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.php
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了解释尽可能简单,我使用原生 PHP 和 mysql 查询语句。首先,您需要连接到数据库,connect.php 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
复制代码代码如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器 result.php 发送请求。请求的参数是page,即页数。
if(aa$row['content'],
'author'=>$user[$row['userid']],
'date'=>date('m-d H:i',$row['addtime'])
);
}
echo json_encode($arr); //转换为json数据输出
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
时间:2015-04-27 查看全部
php抓取网页动态数据(如何应用滚屏加载技术到您的项目中去?技术)
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.php
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了解释尽可能简单,我使用原生 PHP 和 mysql 查询语句。首先,您需要连接到数据库,connect.php 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
复制代码代码如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器 result.php 发送请求。请求的参数是page,即页数。
if(aa$row['content'],
'author'=>$user[$row['userid']],
'date'=>date('m-d H:i',$row['addtime'])
);
}
echo json_encode($arr); //转换为json数据输出
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
时间:2015-04-27
php抓取网页动态数据( 6.CSS教程(八)简单介绍CSS配合JS的运用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-01-30 04:08
6.CSS教程(八)简单介绍CSS配合JS的运用
)
简介:这个文章总结了关于MYSQL被标记为crashed,应该修复的解决方法。有需要的朋友可以参考。问题分析错误的原因,有网友表示是[数据表]表频繁查询更新导致的索引错误,因为我的页面不是静态生成的,而是动态页面,所以我同意这个说法。还有一种说法是MYSQL数据库由于某种原因损坏了,比如:数据库服务器突然断电,...
4. php伪静态技术使用总结
简介:当一个页面跳转到另一个页面时,那么这个页面上的所有参数都会被丢弃。动态页面一般使用url地址来保存页面上的所有参数。这样,当搜索引擎承认页面时,可能会因为问号而进入死循环。
5.详解html静态页面示例代码分析实现微信分享思路
简介:微信分享网页时,你要分享的链接是标题+描述+缩略图。该方法已在微信开发代码示例中提供,但仅适用于动态页面。由于dedecms生成的是静态文件,其实我是想用ajax来获取jssdk参数,同时也实现微信分享功能,所以在这里分享给大家。
6. CSS教程(八)简单介绍CSS结合JS的使用
简介:八、简单介绍CSS结合JS的应用(针对事件动作)。使用 CSS 和 javascript 可以做很多很酷的动态页面效果。在本教程的最后,我将简要介绍 CSS 结合 JS 的应用。首先,我们需要了解事件和动作的概念。在客户端脚本中,javascript 通过响应事件获得与用户的交互。例如,当用户单击按钮时
7.详解JSP动态页面转HTML静态页面的方法
简介:本文文章主要详细讲解将JSP动态页面转换为HTML静态页面的方法。具有一定的参考价值。有兴趣的朋友可以参考一下。
8. 使用代码生成带有 XML 和 XSL 的动态页面
总结:xml(Extensible Markup Language)可能看起来像是某种w3c标准——它现在实际影响不大,如果以后真的派上用场,那也是很久以前的事了。但事实上,现在已经应用了。所以不要等到 xml 被添加到你最喜欢的 html 编辑器中才开始使用它。它现在可以解决各种内部问题和b2b系统问题。
9.详细讲解python爬虫Selenium的使用方法
简介:使用python爬取动态页面时,普通的urllib2无法实现。比如下面的京东首页会随着滚动条的下拉而加载新的内容,但是urllib2无法抓取这些内容。这时候就需要今天的主角硒了。.
10.又是什么php?php的前世今生
简介:什么是php?PHP(外文名称:PHP:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率高于完全生成HTML标记的CGI。
【相关问答推荐】:
包括标签缓存处理问题 - Thinbug
关于用爬虫爬取js渲染数据的动态页面?
前端——这些动态页面是如何制作的?
2017年前端实习要求有多高?新手应该如何准备?
nginx - php 配置问题
以上就是php动态页面示例总结的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php抓取网页动态数据(
6.CSS教程(八)简单介绍CSS配合JS的运用
)
简介:这个文章总结了关于MYSQL被标记为crashed,应该修复的解决方法。有需要的朋友可以参考。问题分析错误的原因,有网友表示是[数据表]表频繁查询更新导致的索引错误,因为我的页面不是静态生成的,而是动态页面,所以我同意这个说法。还有一种说法是MYSQL数据库由于某种原因损坏了,比如:数据库服务器突然断电,...
4. php伪静态技术使用总结
简介:当一个页面跳转到另一个页面时,那么这个页面上的所有参数都会被丢弃。动态页面一般使用url地址来保存页面上的所有参数。这样,当搜索引擎承认页面时,可能会因为问号而进入死循环。
5.详解html静态页面示例代码分析实现微信分享思路
简介:微信分享网页时,你要分享的链接是标题+描述+缩略图。该方法已在微信开发代码示例中提供,但仅适用于动态页面。由于dedecms生成的是静态文件,其实我是想用ajax来获取jssdk参数,同时也实现微信分享功能,所以在这里分享给大家。
6. CSS教程(八)简单介绍CSS结合JS的使用
简介:八、简单介绍CSS结合JS的应用(针对事件动作)。使用 CSS 和 javascript 可以做很多很酷的动态页面效果。在本教程的最后,我将简要介绍 CSS 结合 JS 的应用。首先,我们需要了解事件和动作的概念。在客户端脚本中,javascript 通过响应事件获得与用户的交互。例如,当用户单击按钮时
7.详解JSP动态页面转HTML静态页面的方法
简介:本文文章主要详细讲解将JSP动态页面转换为HTML静态页面的方法。具有一定的参考价值。有兴趣的朋友可以参考一下。
8. 使用代码生成带有 XML 和 XSL 的动态页面
总结:xml(Extensible Markup Language)可能看起来像是某种w3c标准——它现在实际影响不大,如果以后真的派上用场,那也是很久以前的事了。但事实上,现在已经应用了。所以不要等到 xml 被添加到你最喜欢的 html 编辑器中才开始使用它。它现在可以解决各种内部问题和b2b系统问题。
9.详细讲解python爬虫Selenium的使用方法
简介:使用python爬取动态页面时,普通的urllib2无法实现。比如下面的京东首页会随着滚动条的下拉而加载新的内容,但是urllib2无法抓取这些内容。这时候就需要今天的主角硒了。.
10.又是什么php?php的前世今生
简介:什么是php?PHP(外文名称:PHP:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习,应用广泛,主要适用于Web开发领域。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。它可以比 CGI 或 Perl 更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入到HTML(标准通用标记语言下的应用程序)文档中执行,执行效率高于完全生成HTML标记的CGI。
【相关问答推荐】:
包括标签缓存处理问题 - Thinbug
关于用爬虫爬取js渲染数据的动态页面?
前端——这些动态页面是如何制作的?
2017年前端实习要求有多高?新手应该如何准备?
nginx - php 配置问题
以上就是php动态页面示例总结的详细内容。更多详情请关注php中文网文章其他相关话题!

