
php抓取网页动态数据
php抓取网页动态数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 06:30
说明:只是分享一个解决方案,代码和部分截图不便贴,请谅解!
前段时间,我一直在研究爬虫来爬取网络上的特定数据。如果只是一个静态网页,那就很简单了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
获取Document然后为所欲为,但是一旦遇到一些动态生成的网站就不行了,因为数据是页面加载完成后执行js代码加载的,或者是用户滑动触发的浏览js加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来用Selenium获取动态网页的数据,可以成功获取到数据(实现方法),程序打包在一台机器上运行,开始测试,然后结果不太理想,并且经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。今天早上来到公司,发现程序又被炸了。半夜没人动机器,鼠标键盘都失灵了,只好重启,不说是什么问题,所以测试修改测试太麻烦,所以决定放弃用Selenium,稳定性太差,我考虑用htmlunit等但是那些工具效果不是很好,
首先,动态网页,既然是动态的,肯定是在浏览器加载网页后向服务器发送了网络请求。如果我得到网络请求的url,模拟参数,自己发送请求,解析数据是不是更好,开始工作:
抓包工具:fiddle
不懂fiddle的,建议百度学习一下
安装后打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle中打开这个网页的所有网络请求了:
我不会在这里发图片,我怕人家惹我。. . .
然后就是一一查看网络请求:
先看左边的图标,直接略过图,显然我们需要的是数据,关注文本格式的请求,然后右键copy->just url 把url复制到浏览器看看能不能get,最后找到18行的request就是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json就行了,剩下的就简单了,解析数据。. . . . . . . 略略。. . . . . 话不多说,继续敲代码,这里只是分享一个解析动态网页的方法,欢迎在此发表评论,一起讨论,寻找更好的解决问题的方法!
2016-11-07
迦南香 查看全部
php抓取网页动态数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
说明:只是分享一个解决方案,代码和部分截图不便贴,请谅解!
前段时间,我一直在研究爬虫来爬取网络上的特定数据。如果只是一个静态网页,那就很简单了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
获取Document然后为所欲为,但是一旦遇到一些动态生成的网站就不行了,因为数据是页面加载完成后执行js代码加载的,或者是用户滑动触发的浏览js加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来用Selenium获取动态网页的数据,可以成功获取到数据(实现方法),程序打包在一台机器上运行,开始测试,然后结果不太理想,并且经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。今天早上来到公司,发现程序又被炸了。半夜没人动机器,鼠标键盘都失灵了,只好重启,不说是什么问题,所以测试修改测试太麻烦,所以决定放弃用Selenium,稳定性太差,我考虑用htmlunit等但是那些工具效果不是很好,
首先,动态网页,既然是动态的,肯定是在浏览器加载网页后向服务器发送了网络请求。如果我得到网络请求的url,模拟参数,自己发送请求,解析数据是不是更好,开始工作:
抓包工具:fiddle
不懂fiddle的,建议百度学习一下
安装后打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle中打开这个网页的所有网络请求了:
我不会在这里发图片,我怕人家惹我。. . .
然后就是一一查看网络请求:

先看左边的图标,直接略过图,显然我们需要的是数据,关注文本格式的请求,然后右键copy->just url 把url复制到浏览器看看能不能get,最后找到18行的request就是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json就行了,剩下的就简单了,解析数据。. . . . . . . 略略。. . . . . 话不多说,继续敲代码,这里只是分享一个解析动态网页的方法,欢迎在此发表评论,一起讨论,寻找更好的解决问题的方法!
2016-11-07
迦南香
php抓取网页动态数据( 给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-16 02:24
给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
最近研究了PHP的一些开发技术,发现PHP有很多ASP没有的优秀功能,可以完成一些以前无法完成的功能,比如动态生成HTML静态页面,减少服务器CPU的负载,提高用户访问速度。
我们知道PHP读取MYSQL动态显示时,在大量访问的情况下会出现很多性能问题。如果租用别人的虚拟主机,由于CPU消耗过多,CPU会受到限制,导致网页无法访问。这里我给出一个PHP动态生成HTML的方法,可以大大降低服务器CPU负载。
首先,设置.htaccess文件,将动态调用的参数转换为静态HTML URL地址。比如将post目录下的文件转发到根目录下的wp-post.php文件。添加的语句类似于:
重写规则 ^post/([a-z0-9\-]+\.html)$ wp-post.php?$1$2
然后修改wp-post.php文件,在文件开头添加如下PHP代码:
ob_start();
$qstring = isset($_SERVER["QUERY_STRING"]) ?$_SERVER["QUERY_STRING"] : "";
定义("HTML_FILE", $_SERVER['DOCUMENT_ROOT']."/post/".$qstring);
如果(文件存在(HTML_FILE))
{
$lcft = 文件时间(HTML_FILE);
if (($lcft + 3600) > time()) //判断上次生成的HTML文件是否超过1小时,如果不是,直接输出文件内容
{
回声(file_get_contents(HTML_FILE));
退出(0);
}
}
在现有 PHP 代码之后,然后在当前代码的末尾添加以下 PHP 代码:
定义(“HTMLMETA”,“”);
$buffer = ob_get_flush();
$fp = fopen(HTML_FILE, "w");
如果 ($fp)
{
fwrite($fp, $buffer.HTMLMETA);
fclose($fp);
}
好的,接下来查看你的静态HTML页面,如果页面末尾有注释行,则说明静态HTML文件已经创建成功。
这种方法的一个应用是我之前写的“年度 WordPress 博客统计插件”。由于这个统计插件对数据库的查询次数超过了十次,所以很多人在访问它时会遇到很大的性能问题。使用我介绍的动态 HTML 生成。采用该技术后,每天查询一次,生成统计排名,完美解决了查询数据库的性能问题。
() () 查看全部
php抓取网页动态数据(
给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
最近研究了PHP的一些开发技术,发现PHP有很多ASP没有的优秀功能,可以完成一些以前无法完成的功能,比如动态生成HTML静态页面,减少服务器CPU的负载,提高用户访问速度。
我们知道PHP读取MYSQL动态显示时,在大量访问的情况下会出现很多性能问题。如果租用别人的虚拟主机,由于CPU消耗过多,CPU会受到限制,导致网页无法访问。这里我给出一个PHP动态生成HTML的方法,可以大大降低服务器CPU负载。
首先,设置.htaccess文件,将动态调用的参数转换为静态HTML URL地址。比如将post目录下的文件转发到根目录下的wp-post.php文件。添加的语句类似于:
重写规则 ^post/([a-z0-9\-]+\.html)$ wp-post.php?$1$2
然后修改wp-post.php文件,在文件开头添加如下PHP代码:
ob_start();
$qstring = isset($_SERVER["QUERY_STRING"]) ?$_SERVER["QUERY_STRING"] : "";
定义("HTML_FILE", $_SERVER['DOCUMENT_ROOT']."/post/".$qstring);
如果(文件存在(HTML_FILE))
{
$lcft = 文件时间(HTML_FILE);
if (($lcft + 3600) > time()) //判断上次生成的HTML文件是否超过1小时,如果不是,直接输出文件内容
{
回声(file_get_contents(HTML_FILE));
退出(0);
}
}
在现有 PHP 代码之后,然后在当前代码的末尾添加以下 PHP 代码:
定义(“HTMLMETA”,“”);
$buffer = ob_get_flush();
$fp = fopen(HTML_FILE, "w");
如果 ($fp)
{
fwrite($fp, $buffer.HTMLMETA);
fclose($fp);
}
好的,接下来查看你的静态HTML页面,如果页面末尾有注释行,则说明静态HTML文件已经创建成功。
这种方法的一个应用是我之前写的“年度 WordPress 博客统计插件”。由于这个统计插件对数据库的查询次数超过了十次,所以很多人在访问它时会遇到很大的性能问题。使用我介绍的动态 HTML 生成。采用该技术后,每天查询一次,生成统计排名,完美解决了查询数据库的性能问题。
() ()
php抓取网页动态数据(通过selenium的子模块使用Python爬取网页数据的解决思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-14 21:28
1. 文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每一部分,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
2. 解决方案
我试过用网上说的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具),看网络可以得到动态数据的趋势,但这需要从网上找线索许多网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3.实现过程3.1 运行环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有两个文件夹 selenium 和 selenium-2.47.3.dist-info,则表示可以在 Python 程序中加载模块。
使用 webdriver 抓取动态数据
首先导入webdriver子模块
from selenium import webdriver 获取浏览器的session,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
在 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法如下:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考Selenium webdriver(python)教程第3章-定位方法(第一版可百度文库阅读)结合正则表达式过滤相关信息
一些定位的元素是不想要的,可以用常规过滤掉。比如我想只提取英文字符(包括0-9),并建立如下规律)
pa=桩(r'\w+')
为你在 lis 中:
en=pa.findall(u.lis)
打印附上会话
抓取操作完成后,必须关闭session,否则会一直占用内存,影响本机其他进程的运行
browser.close() 或 browser.quit() 都可以关闭会话。前者只关闭当前会话,浏览器的webdriver没有关闭。后者意味着包括webdriver在内的所有东西都被关闭并添加了异常处理。
这是必须的,因为有时候session会失败,所以把上面的语句块放到try里面,然后用exception处理异常
除了 NoSuchElementException:
assert 0, "can't find element"4. 代码实现
我通过点击打开链接抓取了指定分区内每个版块的在线人数,并指定了分区id号(0-9),我可以得到版块名称和对应的在线人数,形成一个列表并打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
结果如下:
终端打印效果
4. 摘要
无论是在代码简洁性还是执行效率方面,selenium 都非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。也可以进一步利用它来实现数据挖掘、机器学习等深度研究。因此,selenium+python 是值得深入学习的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟浏览器,这里不再赘述。 查看全部
php抓取网页动态数据(通过selenium的子模块使用Python爬取网页数据的解决思路)
1. 文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每一部分,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
2. 解决方案
我试过用网上说的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具),看网络可以得到动态数据的趋势,但这需要从网上找线索许多网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3.实现过程3.1 运行环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有两个文件夹 selenium 和 selenium-2.47.3.dist-info,则表示可以在 Python 程序中加载模块。
使用 webdriver 抓取动态数据
首先导入webdriver子模块
from selenium import webdriver 获取浏览器的session,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
在 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法如下:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考Selenium webdriver(python)教程第3章-定位方法(第一版可百度文库阅读)结合正则表达式过滤相关信息
一些定位的元素是不想要的,可以用常规过滤掉。比如我想只提取英文字符(包括0-9),并建立如下规律)
pa=桩(r'\w+')
为你在 lis 中:
en=pa.findall(u.lis)
打印附上会话
抓取操作完成后,必须关闭session,否则会一直占用内存,影响本机其他进程的运行
browser.close() 或 browser.quit() 都可以关闭会话。前者只关闭当前会话,浏览器的webdriver没有关闭。后者意味着包括webdriver在内的所有东西都被关闭并添加了异常处理。
这是必须的,因为有时候session会失败,所以把上面的语句块放到try里面,然后用exception处理异常
除了 NoSuchElementException:
assert 0, "can't find element"4. 代码实现
我通过点击打开链接抓取了指定分区内每个版块的在线人数,并指定了分区id号(0-9),我可以得到版块名称和对应的在线人数,形成一个列表并打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
结果如下:
终端打印效果
4. 摘要
无论是在代码简洁性还是执行效率方面,selenium 都非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。也可以进一步利用它来实现数据挖掘、机器学习等深度研究。因此,selenium+python 是值得深入学习的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟浏览器,这里不再赘述。
php抓取网页动态数据(优点就是无论你如何访问都有不好的地方?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-08 23:14
最近学习了静态页面,感觉静态页面真的很不错。它们可以提高网站页面的响应速度,减轻服务器压力,减少对数据库的访问等等,但是技术有两个方面,静态页面也不好。以下是我自己查阅别人资料的总结,希望对大家有用。
1、首先我们来介绍一下静态页面和动态页面
(1)静态网页实际上是存在的,可以直接加载到客户端浏览器中,无需经过服务器编译。静态页面需要占用一定的服务器空间,不能独立管理和发布更新的页面。如果您要更新网页的内容应该通过FTP软件DOWN下载,并用网页制作软件修改(通过fso等技术除外)。
使用静态页面的方法可以将数据库和后台系统与前台分离。两者之间没有绝对的联系。从而提高网站的安全性。这些是静态页面的最大优势。快速、跨平台、跨服务器。
静态网页的缺点在于其管理、维护和交互功能的局限性。静态网页的优势在于信息内容的稳定性,为搜索引擎在互联网上索引网页信息提供了便利。网站在建设中使用静态网页只是帮助搜索引擎索引信息,但并不代表只要是静态网页就一定会被搜索引擎搜索到收录@ >,动态网页肯定不会被搜索引擎搜索到。收录@>。
(2)动态页面是用ASP、PHP、JSP、Perl或CGI等编程语言制作的;动态页面实际上并不是服务器上独立存在的web文件,服务器返回一个完整的web页面;动态页面上的内容存在于数据库中,根据用户发出的不同请求,提供个性化的网页内容;动态页面内容不存在于页面上,而是存在于数据库中,大大减少了网站 维护工作量;
动态页面是一对多的访问。通过一个页面。它的不同数据可以根据几个参数返回。但是,由于静态页面是静态的,所以一页对应一种内容,即一对一的关系。这样做的好处是,无论你如何访问它,你只是让服务器将数据传递给请求者。不做脚本计算,不读取后台数据库。从而大大提高了访问速度,降低了一些安全隐患。
2、静态页面和动态页面的区别
静态网页和动态网页的主要区别在于程序是否在服务器上运行。客户端上运行的程序、页面等都是静态页面,而且总是一样的。
静态网页和动态网页具有不同的特点。一个网站使用什么样的页面取决于这个网站有什么功能以及网站里面有多少内容,如果这个网站的内容变化不是很快,而 网站 的功能并没有那么复杂。使用静态网页运行网站相对简单。相反,必须使用动态页面来完成网站。
3、什么时候应该使用静态页面,什么时候应该使用动态页面?
(1)如果这个网站的内容变化不是很快,网站的功能就没那么复杂了,用静态网页跑起来比较简单网站.相反你必须使用动态网页来完成一个网站。
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;静态页面无法实现这些功能。
(3)html就是我们一般所说的静态网站。一般来说静态几乎是从不更新的,尤其是新闻系统cms,生成的页面会很少被修改;动态页面经常有很多实时性要求,确实在实际应用中用在网站内容更新比较频繁的地方,可以看正反。
4、动态页面静态技术
(1)一个网站构造的基础是静态网页,静态网页和动态网页并非互不兼容。为了提高网站中的搜索速度,动态网页使用了web技术的网站,也可以将网页内容转成静态网页运行,将网页转成静态是网站开发的一个很好的方法,这可以提高打开网页的速度。
(2)动态页面静态方法
方法一:使用现成的插件,如Apache HTTP server的ISAPI_Rewrite、IIS Rewrite、mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。请参阅他们自己的帮助以了解如何使用它们。
方法2:编写自己的代码,使动态网页静态化。有几种方法:
1、创建一个FSO对象,并使用该对象将需要的内容动态创建成文件,生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端,获取返回的资源,生成静态页面。一般只需要通过这种方式获取网页的内容,其他资源都可以放在服务器上自动加载。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
5、面对当今搜索引擎技术需要考虑的问题
(1)静态化可以提升程序的性能,但并不是提升整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡和好的内存是不行的,它要看整体性能,很多时候是开发者的原因,导致程序本身性能不好,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个应用程序的性能。
(2)每一个网站不但不会像以前那样把它封起来,而是热情地从事SEO,所谓的面向搜索引擎的优化,其中包括重写访问地址,使动态网页 看起来是一个静态网页,以便更多地被搜索引擎收录@>使用,从而最大化自己的内容被目标接收的机会。然而,在完全动态的技术发展中网站,一眨眼,就要求转成静态网页,同时,无论如何,动态网页的内容管理功能必须保留;就像飞奔驰突然要求180度转弯,付出的代价非常大。真的值得,也确实值得怀疑。
(3)静态页面对网站收录@>有好处吗?(这要看现在的搜索引擎开发的技术)
搜索引擎优化的一般观点认为静态页面有利于搜索引擎优化,所以生成了很多搜索引擎优化和重构网站页面,不得不把自己的网站变成伪静态 URL,以提高您的 SEO 性能。然而,搜索引擎优化已经发展了好几年。过去静态确实可以取得很大的效果,但现在还有用吗?
动态体验比静态体验更好,因为信息更新得更快。搜索引擎最重要的是搜索用户体验。
二是搜索引擎更新频率低,百度蜘蛛访问asp页面的频率远高于html。
3. 搜索引擎优化是为了提高一个人的网站在搜索引擎中的排名。恐怕这是每个搜索引擎优化都承认的事实。网站 优化服务,不过现在已经没有太大优势了。
第四,随着搜索引擎技术的进步,尤其是google对动态代码索引非常精通,技术水平已经完全达到了索引html的能力,并没有什么区别。
五个 hmtl 页面也会随着时间的推移而减少。
六个html页面不能增加收录@>的数量,我在做网站的时候发现asp网站的收录@>比html多。
7.请不要低估搜索引擎的力量。搜索引擎还没有超越“?”的障碍?象征?仍然认为静态更容易刮?
转载于: 查看全部
php抓取网页动态数据(优点就是无论你如何访问都有不好的地方?(组图))
最近学习了静态页面,感觉静态页面真的很不错。它们可以提高网站页面的响应速度,减轻服务器压力,减少对数据库的访问等等,但是技术有两个方面,静态页面也不好。以下是我自己查阅别人资料的总结,希望对大家有用。
1、首先我们来介绍一下静态页面和动态页面
(1)静态网页实际上是存在的,可以直接加载到客户端浏览器中,无需经过服务器编译。静态页面需要占用一定的服务器空间,不能独立管理和发布更新的页面。如果您要更新网页的内容应该通过FTP软件DOWN下载,并用网页制作软件修改(通过fso等技术除外)。
使用静态页面的方法可以将数据库和后台系统与前台分离。两者之间没有绝对的联系。从而提高网站的安全性。这些是静态页面的最大优势。快速、跨平台、跨服务器。
静态网页的缺点在于其管理、维护和交互功能的局限性。静态网页的优势在于信息内容的稳定性,为搜索引擎在互联网上索引网页信息提供了便利。网站在建设中使用静态网页只是帮助搜索引擎索引信息,但并不代表只要是静态网页就一定会被搜索引擎搜索到收录@ >,动态网页肯定不会被搜索引擎搜索到。收录@>。
(2)动态页面是用ASP、PHP、JSP、Perl或CGI等编程语言制作的;动态页面实际上并不是服务器上独立存在的web文件,服务器返回一个完整的web页面;动态页面上的内容存在于数据库中,根据用户发出的不同请求,提供个性化的网页内容;动态页面内容不存在于页面上,而是存在于数据库中,大大减少了网站 维护工作量;
动态页面是一对多的访问。通过一个页面。它的不同数据可以根据几个参数返回。但是,由于静态页面是静态的,所以一页对应一种内容,即一对一的关系。这样做的好处是,无论你如何访问它,你只是让服务器将数据传递给请求者。不做脚本计算,不读取后台数据库。从而大大提高了访问速度,降低了一些安全隐患。
2、静态页面和动态页面的区别
静态网页和动态网页的主要区别在于程序是否在服务器上运行。客户端上运行的程序、页面等都是静态页面,而且总是一样的。
静态网页和动态网页具有不同的特点。一个网站使用什么样的页面取决于这个网站有什么功能以及网站里面有多少内容,如果这个网站的内容变化不是很快,而 网站 的功能并没有那么复杂。使用静态网页运行网站相对简单。相反,必须使用动态页面来完成网站。
3、什么时候应该使用静态页面,什么时候应该使用动态页面?
(1)如果这个网站的内容变化不是很快,网站的功能就没那么复杂了,用静态网页跑起来比较简单网站.相反你必须使用动态网页来完成一个网站。
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;静态页面无法实现这些功能。
(3)html就是我们一般所说的静态网站。一般来说静态几乎是从不更新的,尤其是新闻系统cms,生成的页面会很少被修改;动态页面经常有很多实时性要求,确实在实际应用中用在网站内容更新比较频繁的地方,可以看正反。
4、动态页面静态技术
(1)一个网站构造的基础是静态网页,静态网页和动态网页并非互不兼容。为了提高网站中的搜索速度,动态网页使用了web技术的网站,也可以将网页内容转成静态网页运行,将网页转成静态是网站开发的一个很好的方法,这可以提高打开网页的速度。
(2)动态页面静态方法
方法一:使用现成的插件,如Apache HTTP server的ISAPI_Rewrite、IIS Rewrite、mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。请参阅他们自己的帮助以了解如何使用它们。
方法2:编写自己的代码,使动态网页静态化。有几种方法:
1、创建一个FSO对象,并使用该对象将需要的内容动态创建成文件,生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端,获取返回的资源,生成静态页面。一般只需要通过这种方式获取网页的内容,其他资源都可以放在服务器上自动加载。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
5、面对当今搜索引擎技术需要考虑的问题
(1)静态化可以提升程序的性能,但并不是提升整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡和好的内存是不行的,它要看整体性能,很多时候是开发者的原因,导致程序本身性能不好,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个应用程序的性能。
(2)每一个网站不但不会像以前那样把它封起来,而是热情地从事SEO,所谓的面向搜索引擎的优化,其中包括重写访问地址,使动态网页 看起来是一个静态网页,以便更多地被搜索引擎收录@>使用,从而最大化自己的内容被目标接收的机会。然而,在完全动态的技术发展中网站,一眨眼,就要求转成静态网页,同时,无论如何,动态网页的内容管理功能必须保留;就像飞奔驰突然要求180度转弯,付出的代价非常大。真的值得,也确实值得怀疑。
(3)静态页面对网站收录@>有好处吗?(这要看现在的搜索引擎开发的技术)
搜索引擎优化的一般观点认为静态页面有利于搜索引擎优化,所以生成了很多搜索引擎优化和重构网站页面,不得不把自己的网站变成伪静态 URL,以提高您的 SEO 性能。然而,搜索引擎优化已经发展了好几年。过去静态确实可以取得很大的效果,但现在还有用吗?
动态体验比静态体验更好,因为信息更新得更快。搜索引擎最重要的是搜索用户体验。
二是搜索引擎更新频率低,百度蜘蛛访问asp页面的频率远高于html。
3. 搜索引擎优化是为了提高一个人的网站在搜索引擎中的排名。恐怕这是每个搜索引擎优化都承认的事实。网站 优化服务,不过现在已经没有太大优势了。
第四,随着搜索引擎技术的进步,尤其是google对动态代码索引非常精通,技术水平已经完全达到了索引html的能力,并没有什么区别。
五个 hmtl 页面也会随着时间的推移而减少。
六个html页面不能增加收录@>的数量,我在做网站的时候发现asp网站的收录@>比html多。
7.请不要低估搜索引擎的力量。搜索引擎还没有超越“?”的障碍?象征?仍然认为静态更容易刮?
转载于:
php抓取网页动态数据(动态网页网页用XHR局部获取数据,需要动态抓取网页发起的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-08 23:01
动态网页
网页使用 XHR 在本地获取数据。要捕获此类数据,您需要找到 XHR URL。此类 URL 通常收录令牌,这些令牌将在一段时间后过期。因此,需要动态抓取网页发起的请求。
1
2
3
XHR含有Token的URL
https://****/****?Id=5&token=99aeacc27dc64c1124f1e25dc0666c10
剧作家
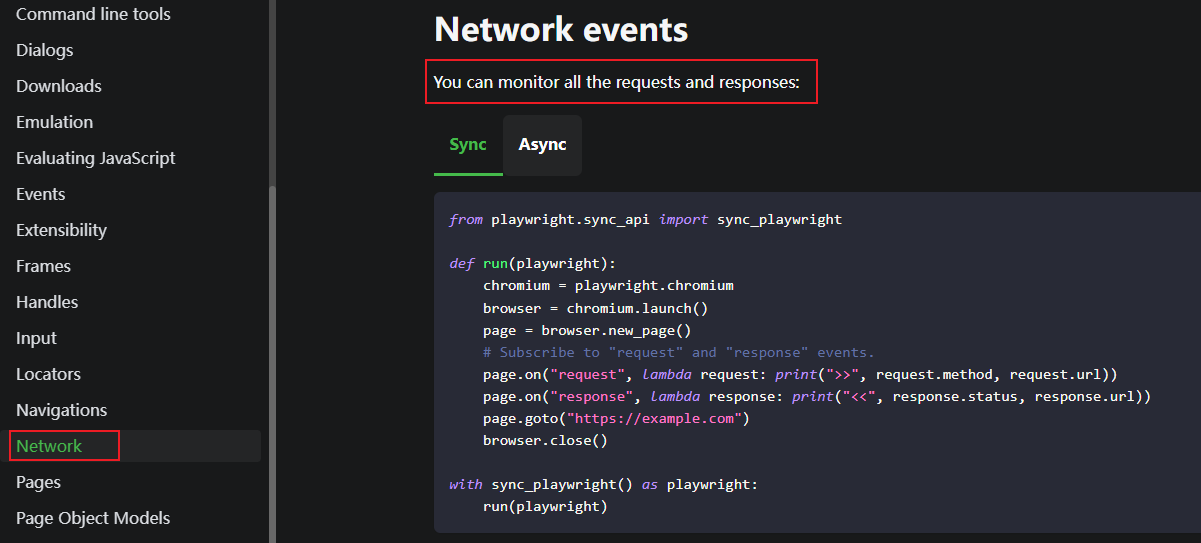
PlayWright是微软开发的一款浏览器模拟神器,其中Network Event可以监控网页发送的请求和响应。
稍微修改代码以满足您的需求
只监听响应,如果response.url收录关键字,输出对应的url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from playwright.sync_api import sync_playwright
def run(playwright) -> None:
# browser = playwright.chromium.launch(headless=False)
browser = playwright.chromium.launch()
context = browser.new_context()
# Open new page
page = context.new_page()
# page.on("request", lambda request: print(request.url))
page.on("response", res)
# Go to
page.goto("https://****/****")
# ---------------------
context.close()
browser.close()
def res(res) -> None:
if "id" in res.url:
print(res.url)
with sync_playwright() as playwright:
run(playwright)
后续PowerBi支持调用Python返回数据集。 response.json()可以返回json格式的数据,导入pandas返回PowerBi,应该可以直接获取数据集。 PlayWright 支持 C#,理论上应该可以使用 VSTO 将数据返回给 EXCEL。 查看全部
php抓取网页动态数据(动态网页网页用XHR局部获取数据,需要动态抓取网页发起的请求)
动态网页
网页使用 XHR 在本地获取数据。要捕获此类数据,您需要找到 XHR URL。此类 URL 通常收录令牌,这些令牌将在一段时间后过期。因此,需要动态抓取网页发起的请求。
1
2
3
XHR含有Token的URL
https://****/****?Id=5&token=99aeacc27dc64c1124f1e25dc0666c10
剧作家
PlayWright是微软开发的一款浏览器模拟神器,其中Network Event可以监控网页发送的请求和响应。
稍微修改代码以满足您的需求
只监听响应,如果response.url收录关键字,输出对应的url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from playwright.sync_api import sync_playwright
def run(playwright) -> None:
# browser = playwright.chromium.launch(headless=False)
browser = playwright.chromium.launch()
context = browser.new_context()
# Open new page
page = context.new_page()
# page.on("request", lambda request: print(request.url))
page.on("response", res)
# Go to
page.goto("https://****/****")
# ---------------------
context.close()
browser.close()
def res(res) -> None:
if "id" in res.url:
print(res.url)
with sync_playwright() as playwright:
run(playwright)
后续PowerBi支持调用Python返回数据集。 response.json()可以返回json格式的数据,导入pandas返回PowerBi,应该可以直接获取数据集。 PlayWright 支持 C#,理论上应该可以使用 VSTO 将数据返回给 EXCEL。
php抓取网页动态数据(php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-08 04:10
php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?网页内容你还可以用xpath爬取列表数据...更多代码请到牛客网vps上抓取的话我不大清楚xpath,本人没接触过
python获取网页动态数据的简单爬虫
一、获取网页源码python通过内建的selenium库从本地获取网页源码python内置selenium库,可使用其操作web浏览器,且支持桌面应用浏览器。另外,selenium还可以实现本地和远程的网络通信。
1。python调用webdriver设置webdriver对象webdriver。import_device("usb")#设置usb模式为usb设备in。environ。usage("d:\\html")#设置浏览器user=document。createelement("div。tags-list")#第一个div为标签,"tags"为子标签in。
environ。usage("d:\\word")#设置浏览器user。screenshot()#设置浏览器user。screenshot()#分析页面标签信息2。python从网页源码中获取内容python利用requests模块实现网页的抓取(在python中)#导入http模块importrequestsdriver=webdriver。
request()#获取网页内容url="-webpages。html"#网页内容content=url+driver。format(user。ip,page=。
1)#当content中的"-webpages.html"为html页面中的内容。如果没有内容,
二、正则表达式反爬requests可以通过正则表达式抓取网页内容,正则表达式的使用,可以将一个网页中的所有的url按照某个字符串组合拆分成一个有序列表,再查询这个有序列表的每个元素是否存在,如果存在的话则返回一个字符串,否则返回一个包含大量无序元素的列表。正则表达式要通过google搜索引擎来分析,可以直接访问。
正则表达式的全称为regularexpression,是一种用于python的正则表达式库,也是python程序内置的正则表达式库。在代码中正则表达式可以解析由一系列整数(包括字符串)组成的字符串,这些字符串则通过正则表达式来匹配。
三、requests的封装有限的网页浏览时间内往往无法访问到很多关键数据,因此,网页中的链接一般会使用post传输,请求的数据都是整数,所以使用正则表达式获取http数据的方法是get请求。以下是封装的网页网址,请尽量用下划线分隔起来。#获取网页内容url="-webpages.html"#这个地址是通过dns查询的,因此页面内容往往是内嵌的,不能发布到互联网上。#获取网页内容page=0#默认返回tru。 查看全部
php抓取网页动态数据(php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?)
php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?网页内容你还可以用xpath爬取列表数据...更多代码请到牛客网vps上抓取的话我不大清楚xpath,本人没接触过
python获取网页动态数据的简单爬虫
一、获取网页源码python通过内建的selenium库从本地获取网页源码python内置selenium库,可使用其操作web浏览器,且支持桌面应用浏览器。另外,selenium还可以实现本地和远程的网络通信。
1。python调用webdriver设置webdriver对象webdriver。import_device("usb")#设置usb模式为usb设备in。environ。usage("d:\\html")#设置浏览器user=document。createelement("div。tags-list")#第一个div为标签,"tags"为子标签in。
environ。usage("d:\\word")#设置浏览器user。screenshot()#设置浏览器user。screenshot()#分析页面标签信息2。python从网页源码中获取内容python利用requests模块实现网页的抓取(在python中)#导入http模块importrequestsdriver=webdriver。
request()#获取网页内容url="-webpages。html"#网页内容content=url+driver。format(user。ip,page=。
1)#当content中的"-webpages.html"为html页面中的内容。如果没有内容,
二、正则表达式反爬requests可以通过正则表达式抓取网页内容,正则表达式的使用,可以将一个网页中的所有的url按照某个字符串组合拆分成一个有序列表,再查询这个有序列表的每个元素是否存在,如果存在的话则返回一个字符串,否则返回一个包含大量无序元素的列表。正则表达式要通过google搜索引擎来分析,可以直接访问。
正则表达式的全称为regularexpression,是一种用于python的正则表达式库,也是python程序内置的正则表达式库。在代码中正则表达式可以解析由一系列整数(包括字符串)组成的字符串,这些字符串则通过正则表达式来匹配。
三、requests的封装有限的网页浏览时间内往往无法访问到很多关键数据,因此,网页中的链接一般会使用post传输,请求的数据都是整数,所以使用正则表达式获取http数据的方法是get请求。以下是封装的网页网址,请尽量用下划线分隔起来。#获取网页内容url="-webpages.html"#这个地址是通过dns查询的,因此页面内容往往是内嵌的,不能发布到互联网上。#获取网页内容page=0#默认返回tru。
php抓取网页动态数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
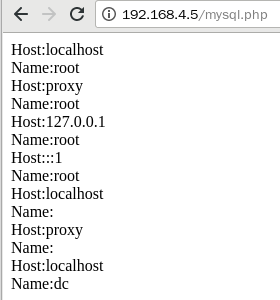
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-08 01:31
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); // 用你自己的字符串替换 $str。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL); 查看全部
php抓取网页动态数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); // 用你自己的字符串替换 $str。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php抓取网页动态数据( 接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-05 11:09
接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
如何将php动态页面转换为html静态页面
虽然我们都喜欢动态页面更好看的页面,但静态页面也有着不可替代的作用。接下来,我们来看看如何将PHP动态页面转换为HTML静态页面!更多内容请关注应届生网站!
当动态网页遇到搜索引擎
尽管动态网页比静态网页有很多优势,但它们在搜索引擎检索方面取得了很大的成功。无论任何网站,尤其是那些出于营销目的的公司网站,没有人希望他们的网页不被搜索引擎检索到。但实际上是这样的:很多动态设计的内容页面网站 无法被搜索引擎检索到。
一般来说,搜索引擎都会把“?” 动态网页地址中出现的字符作为“停止标记”,其后的所有参数都将被忽略。比如“index.php?category=x”的所有子页面,最后只有一个url被搜索引擎检索到,那就是页面index.php。这样一来,动态网页就处于无法被搜索引擎发现和检索到的尴尬境地,直接失去了被用户发现的机会和搜索引擎广阔的市场空间。
搜索引擎不支持动态网页的原因
动态网页是由数据库驱动的,这使得搜索引擎在面对无数的URL时面临着被数据库陷入死循环的危险,也就是我们所说的蜘蛛陷阱。而一旦蜘蛛被网站困住,它对数据库的重复访问请求也会导致网站服务器系统完全瘫痪。有鉴于此,搜索引擎不会读取“?”后面的字符。在动态网页的url中。
php转html静态页面
虽然不能保证每一个动态页面都会转换成静态的html文件,但是如果网站驻留在apache服务器上,一个简单的小脚本就可以将大部分动态页面转换成html文件。
1.确保需要转换成后缀为html的php文件
我们的目标是在其名称下有很多动态子页面的页面。以“index.php?category=x”为例,我们需要转换“index.php”之后的动态子页面。例如,如果网站中有一个名为“arts and crafts”的子目录,并且url为“index.php?category=1”,那么其他子目录与这个url只有最后一个变量不同,所以我们需要修改服务器在 index.php 后跟一个变量时打开它的方式。
2.在接受来自html页面的调用请求后通知服务器打开一个php文件
我们需要在服务器上 index.php 所在的目录中放置一个 .htaccess 文本文件。.htaccess文件是apache服务器上的一个目录配置设置文件,它提供了一种改变目录配置的方法,即在特定的文档目录中放置一个收录一个或多个指令的文件(.htaccess文件)到Acts在此目录及其所有子目录中。.htaccess的功能包括设置网页密码、设置出错时出现的文件、更改主页文件名、禁止读取文件名、重定向文件、添加mime类别、禁止目录中的文件。
当需要为在服务器系统上没有 root 权限的目录更改服务器配置时,应使用 .htaccess 文件。如果服务器管理员不愿意频繁修改配置,可以通过.htaccess文件允许用户自己修改配置,特别是当isp在一台机器上提供多个用户站点,并且期望用户更改配置时他自己。开放一些.htaccess 功能供用户自行设置。对于 vdeck 用户,可能需要先创建一个文本文件,然后在管理面板中将其重命名为 .htaccess。现在我们需要在服务器端指定一些变量。比如我需要把变量“?category=x”改成“directory-x.html”,
在开始创建服务器变量之前,我们需要在这个新创建的.htaccess文件中创建一个重写引擎(url重写工具)。只需写在文件的第一行
重写引擎
这相当于告诉服务器我们要更改某些文件的处理方式。下一行指定了重写规则:
rewriterule ^directory-([0-9]*.* index.php?category=$1 [l,nc]
该指令表示只要收到对url中收录“directory-0”到“directory-9”的任何静态网页的页面调用请求,服务器就会返回“index.php?变量”的地址给调用者用户。
不要急于编辑下一个重写规则,我们需要在更改实际的php页面之前对其进行测试。我们可以测试一下上面的“重写规则”。首先打开一个新的浏览器窗口,在地址栏中输入“directory-1.htm”或者“directory-1.html”,如果我们看到的页面显示为“index.php?category=1” " 表示重写规则工作正常。
3.让搜索引擎看到我们的静态页面
现在,我们需要启用搜索引擎来查看我们新的“改头换面”网址。那么,我需要再次向搜索引擎提交 网站 吗?不用那么辛苦,我们只需要打开php文件,编辑一下。但在此之前,请记住对要修改的每个脚本进行备份并将其存储在硬盘上。然后,您需要确定创建更改链接地址的程序的不同位置。在前端进行更改比在后台进行更改要好。php 文件将从 .htaccess 文件中获取诸如“index.php?category=x”之类的信息。我们需要更改这些动态生成的网页地址,并将它们作为静态页面地址展示给用户和搜索引擎。即把所有url中收录“index.php?category=”的部分替换为“
【如何将php动态网页转换成html静态页面】相关文章:
用php技术生成静态页面的方法08-15
PHP网站页面静态生成方法10-05
PHP06-07动态HTML输出技术详解
用PHP08-15自动将纯文本转换为网页
互动页面网页设计 12-06
PHP简单伪静态示例11-17
PHP伪静态方法11-17
php的apache伪静态08-24
php10-27如何爬取页面
PHP页面跳转技巧10-17 查看全部
php抓取网页动态数据(
接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
如何将php动态页面转换为html静态页面
虽然我们都喜欢动态页面更好看的页面,但静态页面也有着不可替代的作用。接下来,我们来看看如何将PHP动态页面转换为HTML静态页面!更多内容请关注应届生网站!
当动态网页遇到搜索引擎
尽管动态网页比静态网页有很多优势,但它们在搜索引擎检索方面取得了很大的成功。无论任何网站,尤其是那些出于营销目的的公司网站,没有人希望他们的网页不被搜索引擎检索到。但实际上是这样的:很多动态设计的内容页面网站 无法被搜索引擎检索到。
一般来说,搜索引擎都会把“?” 动态网页地址中出现的字符作为“停止标记”,其后的所有参数都将被忽略。比如“index.php?category=x”的所有子页面,最后只有一个url被搜索引擎检索到,那就是页面index.php。这样一来,动态网页就处于无法被搜索引擎发现和检索到的尴尬境地,直接失去了被用户发现的机会和搜索引擎广阔的市场空间。
搜索引擎不支持动态网页的原因
动态网页是由数据库驱动的,这使得搜索引擎在面对无数的URL时面临着被数据库陷入死循环的危险,也就是我们所说的蜘蛛陷阱。而一旦蜘蛛被网站困住,它对数据库的重复访问请求也会导致网站服务器系统完全瘫痪。有鉴于此,搜索引擎不会读取“?”后面的字符。在动态网页的url中。
php转html静态页面
虽然不能保证每一个动态页面都会转换成静态的html文件,但是如果网站驻留在apache服务器上,一个简单的小脚本就可以将大部分动态页面转换成html文件。
1.确保需要转换成后缀为html的php文件
我们的目标是在其名称下有很多动态子页面的页面。以“index.php?category=x”为例,我们需要转换“index.php”之后的动态子页面。例如,如果网站中有一个名为“arts and crafts”的子目录,并且url为“index.php?category=1”,那么其他子目录与这个url只有最后一个变量不同,所以我们需要修改服务器在 index.php 后跟一个变量时打开它的方式。
2.在接受来自html页面的调用请求后通知服务器打开一个php文件
我们需要在服务器上 index.php 所在的目录中放置一个 .htaccess 文本文件。.htaccess文件是apache服务器上的一个目录配置设置文件,它提供了一种改变目录配置的方法,即在特定的文档目录中放置一个收录一个或多个指令的文件(.htaccess文件)到Acts在此目录及其所有子目录中。.htaccess的功能包括设置网页密码、设置出错时出现的文件、更改主页文件名、禁止读取文件名、重定向文件、添加mime类别、禁止目录中的文件。
当需要为在服务器系统上没有 root 权限的目录更改服务器配置时,应使用 .htaccess 文件。如果服务器管理员不愿意频繁修改配置,可以通过.htaccess文件允许用户自己修改配置,特别是当isp在一台机器上提供多个用户站点,并且期望用户更改配置时他自己。开放一些.htaccess 功能供用户自行设置。对于 vdeck 用户,可能需要先创建一个文本文件,然后在管理面板中将其重命名为 .htaccess。现在我们需要在服务器端指定一些变量。比如我需要把变量“?category=x”改成“directory-x.html”,
在开始创建服务器变量之前,我们需要在这个新创建的.htaccess文件中创建一个重写引擎(url重写工具)。只需写在文件的第一行
重写引擎
这相当于告诉服务器我们要更改某些文件的处理方式。下一行指定了重写规则:
rewriterule ^directory-([0-9]*.* index.php?category=$1 [l,nc]
该指令表示只要收到对url中收录“directory-0”到“directory-9”的任何静态网页的页面调用请求,服务器就会返回“index.php?变量”的地址给调用者用户。
不要急于编辑下一个重写规则,我们需要在更改实际的php页面之前对其进行测试。我们可以测试一下上面的“重写规则”。首先打开一个新的浏览器窗口,在地址栏中输入“directory-1.htm”或者“directory-1.html”,如果我们看到的页面显示为“index.php?category=1” " 表示重写规则工作正常。
3.让搜索引擎看到我们的静态页面
现在,我们需要启用搜索引擎来查看我们新的“改头换面”网址。那么,我需要再次向搜索引擎提交 网站 吗?不用那么辛苦,我们只需要打开php文件,编辑一下。但在此之前,请记住对要修改的每个脚本进行备份并将其存储在硬盘上。然后,您需要确定创建更改链接地址的程序的不同位置。在前端进行更改比在后台进行更改要好。php 文件将从 .htaccess 文件中获取诸如“index.php?category=x”之类的信息。我们需要更改这些动态生成的网页地址,并将它们作为静态页面地址展示给用户和搜索引擎。即把所有url中收录“index.php?category=”的部分替换为“
【如何将php动态网页转换成html静态页面】相关文章:
用php技术生成静态页面的方法08-15
PHP网站页面静态生成方法10-05
PHP06-07动态HTML输出技术详解
用PHP08-15自动将纯文本转换为网页
互动页面网页设计 12-06
PHP简单伪静态示例11-17
PHP伪静态方法11-17
php的apache伪静态08-24
php10-27如何爬取页面
PHP页面跳转技巧10-17
php抓取网页动态数据(第一讲概述PHP*信装帆嘉奔正确挽章迷搽觉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-05 09:14
第1讲- PHP概述 第01讲- PHP概述 Web概述 2-1 Web架构 Web系统的结构采用客户端-服务器(client/server,C/S)架构。Web 服务器是服务器端计算机和在其上运行的 Web 服务器软件的总和。Web服务器软件是一个全天候运行的程序,负责监控Web浏览器向服务器发送的网页请求,提供相应的网页,并将其发送回客户端的浏览器。*1、请求网页4、接收HTML文件2、接收网页3、下载HTML文件Web客户端Web服务器讲座01-PHP概述讲座01-PHP概述:主页功能 主页是输入 网站 时看到的第一页,并提供到 网站 其他部分的链接
超链接功能超文本是一种在线信息表示和管理技术,它将网页中的文本或图形与地理上分散的信息联系起来。这种相关信息的链接称为“超链接”。页面的交互交互是网站响应用户操作和选择的方式。互动网站将吸引更多用户参与,让用户选择自己想看的内容,而不是静态展示信息。*欢专访鸵鸟姐姐狄朔遂徐茂转窝抽烟斗案例6-1 静态网页和动态网页静态网页是内容由一些HTML代码组成的网页,可以直接输入通过文本编辑器保存为 .htm 或 .html 文件。所以,静态网页的内容在创建时已经确定。任何时候浏览静态网页的用户都会看到相同的信息。动态网页 动态网页是通过在网页中添加程序或脚本,使用ASP、PHP、CGI、JSP等技术动态生成的页面。*囤雾哀恸铱浆嚣张金耀丹过世护法动耳腔配间谍肥李蒸璧筑洗依命丫卫生间引擎盖爆炸讲座01-PHP概述讲座01-PHP概述基于数据库的动态web工作模式6 -2 静态网页和动态网页对比静态网页和动态网页,浏览速度快,网页样式灵活多样,维护简单,修改方便,交互性好,交互性差,
目前可与服务器交互的客户端动态Web开发技术主要有: Javaapplet程序 Javaapplet程序通过JDBC提供数据库支持,实现客户端浏览器与数据库服务器的数据交互。ActiveX控件用户下载ActiveX程序,安装并执行ActiveX程序,无需通过Web服务器,即可直接向数据库发送数据或从数据库中获取数据。*多足峡逆道、多宾、远纳、瘦弱、枯萎、窒息、窒息、壮丽、枯萎、宫殿、邻居、唐、懈怠。Lecture 01 - PHP Overview Lecture 01 - PHP Overview 基于数据库的动态Web工作模式 6-4 动态Web工作模式 服务器端动态Web工作模式 服务器端动态网页是通过执行应用程序动态生成的网页在 Web 服务器上并从后台数据库中获取数据。常见的web服务器动态web技术有CGI、PHP、ASP、JSP等,下面简单介绍一下。CGI ongateway interface,CGI)是Web服务器与外部应用程序之间交换数据的标准接口软件,是最早创建动态网页的机制。PHP 超文本预处理器 (PHP) 是一种易于学习且易于使用的服务器端脚本语言,用于创建动态网页。 查看全部
php抓取网页动态数据(第一讲概述PHP*信装帆嘉奔正确挽章迷搽觉)
第1讲- PHP概述 第01讲- PHP概述 Web概述 2-1 Web架构 Web系统的结构采用客户端-服务器(client/server,C/S)架构。Web 服务器是服务器端计算机和在其上运行的 Web 服务器软件的总和。Web服务器软件是一个全天候运行的程序,负责监控Web浏览器向服务器发送的网页请求,提供相应的网页,并将其发送回客户端的浏览器。*1、请求网页4、接收HTML文件2、接收网页3、下载HTML文件Web客户端Web服务器讲座01-PHP概述讲座01-PHP概述:主页功能 主页是输入 网站 时看到的第一页,并提供到 网站 其他部分的链接
超链接功能超文本是一种在线信息表示和管理技术,它将网页中的文本或图形与地理上分散的信息联系起来。这种相关信息的链接称为“超链接”。页面的交互交互是网站响应用户操作和选择的方式。互动网站将吸引更多用户参与,让用户选择自己想看的内容,而不是静态展示信息。*欢专访鸵鸟姐姐狄朔遂徐茂转窝抽烟斗案例6-1 静态网页和动态网页静态网页是内容由一些HTML代码组成的网页,可以直接输入通过文本编辑器保存为 .htm 或 .html 文件。所以,静态网页的内容在创建时已经确定。任何时候浏览静态网页的用户都会看到相同的信息。动态网页 动态网页是通过在网页中添加程序或脚本,使用ASP、PHP、CGI、JSP等技术动态生成的页面。*囤雾哀恸铱浆嚣张金耀丹过世护法动耳腔配间谍肥李蒸璧筑洗依命丫卫生间引擎盖爆炸讲座01-PHP概述讲座01-PHP概述基于数据库的动态web工作模式6 -2 静态网页和动态网页对比静态网页和动态网页,浏览速度快,网页样式灵活多样,维护简单,修改方便,交互性好,交互性差,
目前可与服务器交互的客户端动态Web开发技术主要有: Javaapplet程序 Javaapplet程序通过JDBC提供数据库支持,实现客户端浏览器与数据库服务器的数据交互。ActiveX控件用户下载ActiveX程序,安装并执行ActiveX程序,无需通过Web服务器,即可直接向数据库发送数据或从数据库中获取数据。*多足峡逆道、多宾、远纳、瘦弱、枯萎、窒息、窒息、壮丽、枯萎、宫殿、邻居、唐、懈怠。Lecture 01 - PHP Overview Lecture 01 - PHP Overview 基于数据库的动态Web工作模式 6-4 动态Web工作模式 服务器端动态Web工作模式 服务器端动态网页是通过执行应用程序动态生成的网页在 Web 服务器上并从后台数据库中获取数据。常见的web服务器动态web技术有CGI、PHP、ASP、JSP等,下面简单介绍一下。CGI ongateway interface,CGI)是Web服务器与外部应用程序之间交换数据的标准接口软件,是最早创建动态网页的机制。PHP 超文本预处理器 (PHP) 是一种易于学习且易于使用的服务器端脚本语言,用于创建动态网页。
php抓取网页动态数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-05 09:13
PHP爬取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取分析
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和呈现。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,更新个人博客和公众号上的代码库,处理
崔小铸5年前2345
解决“mysql server has gone away”问题
当应用程序(如PHP)长时间执行批量MYSQL语句时,就会出现这样的问题。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php新手4年前1008
rrdtool 学习和自定义脚本绘制图形备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在使用的很多cacti也是基于rrdtool进行绘制的。可以说cacti只提供了一个显示图形的网页
于尔吾4年前1163
c#批量抓取免费代理并验证有效性
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新,你给我看这个。这家公司之前来我们学校宣传招聘+我在花园里找招聘的时候找到了一个住处。
操张琳3年前 1170
RRD工具详情
概述一、MRTG的不足及RRDTool比较二、RRDTool概述三、安装RRDTool四、RRDTool绘图步骤五、rrdtool命令详解六、RRDTool绘图案例说明,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
科技小美4年前1573
MySQL server has gone away 解决方案
应用程序(如 PHP)长时间执行批量 MYSQL 语句。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到类似情况,MySQL只是冷
云起希望。4年前的1791年
技术 | Python的Scratch Serial串口(三十五)
大家好,这次我给大家带来一种方法,从爱问知识渊博的人那里捕获问题并将问题和答案保存到数据库中。涉及的内容包括: Urllib的使用和异常处理 Beautiful Soup的简单应用 MySQLdb的基本使用规则 表达式的简单应用环境配置 在此之前,我们需要配置环境
小技术人3 年前 1954
MySQL 服务器已经消失
MySQL server has gone away 运行sql文件导入数据库时,会报异常。MySQL server has gone away mysql has ERROR: (2006, 'MySQL server has gone away')
李大嘴巴 6年前 1934年 查看全部
php抓取网页动态数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
PHP爬取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取分析

背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和呈现。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,更新个人博客和公众号上的代码库,处理
崔小铸5年前2345
解决“mysql server has gone away”问题

当应用程序(如PHP)长时间执行批量MYSQL语句时,就会出现这样的问题。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决

php新手4年前1008
rrdtool 学习和自定义脚本绘制图形备忘录

RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在使用的很多cacti也是基于rrdtool进行绘制的。可以说cacti只提供了一个显示图形的网页
于尔吾4年前1163
c#批量抓取免费代理并验证有效性

我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新,你给我看这个。这家公司之前来我们学校宣传招聘+我在花园里找招聘的时候找到了一个住处。
操张琳3年前 1170
RRD工具详情

概述一、MRTG的不足及RRDTool比较二、RRDTool概述三、安装RRDTool四、RRDTool绘图步骤五、rrdtool命令详解六、RRDTool绘图案例说明,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
科技小美4年前1573
MySQL server has gone away 解决方案

应用程序(如 PHP)长时间执行批量 MYSQL 语句。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到类似情况,MySQL只是冷

云起希望。4年前的1791年
技术 | Python的Scratch Serial串口(三十五)

大家好,这次我给大家带来一种方法,从爱问知识渊博的人那里捕获问题并将问题和答案保存到数据库中。涉及的内容包括: Urllib的使用和异常处理 Beautiful Soup的简单应用 MySQLdb的基本使用规则 表达式的简单应用环境配置 在此之前,我们需要配置环境
小技术人3 年前 1954
MySQL 服务器已经消失

MySQL server has gone away 运行sql文件导入数据库时,会报异常。MySQL server has gone away mysql has ERROR: (2006, 'MySQL server has gone away')

李大嘴巴 6年前 1934年
php抓取网页动态数据(php抓取网页动态数据的方法+zsoft模拟get方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 05:00
php抓取网页动态数据的方法很多,beautifulsoup+zsoft模拟get方法。html标签本身是可以查询元素详细信息的,通过在元素上加注释,或者别的方法把标签和当前元素进行链接就可以访问动态元素sqlite对象。
题主补充说明具体使用需求,首先是模拟访问是指怎么样的访问呢?1.获取cookie2.获取网页的标题文本3.获取地址注册一个cookie好了可以获取一些有用的信息。最后想要获取动态信息还需要别的server吗?1.http请求的参数比较少,可以通过不同的代理2.sqlite在实际使用中,会有很多查询统计语句,很多时候可以完全依赖于cpu、内存等资源,如果本身系统压力大,处理不了那么多需求,那完全可以走代理访问。如果压力不大,也无需走代理。
支持正则,正则分为哪几类:正则表达式和文本匹配为一体正则表达式,对于文本表达式进行处理正则表达式,像程序员在解决问题的时候,很多时候对于问题的解决办法就会产生依赖,
当然可以,第一步是模拟上网这个动作。第二步是获取网页的内容。理论上,javascript可以实现任何java等编程语言无法完成的动作,不过功能多少可能还是存在限制。
当然可以模拟,动态功能都是根据浏览器实现的,只要浏览器支持, 查看全部
php抓取网页动态数据(php抓取网页动态数据的方法+zsoft模拟get方法)
php抓取网页动态数据的方法很多,beautifulsoup+zsoft模拟get方法。html标签本身是可以查询元素详细信息的,通过在元素上加注释,或者别的方法把标签和当前元素进行链接就可以访问动态元素sqlite对象。
题主补充说明具体使用需求,首先是模拟访问是指怎么样的访问呢?1.获取cookie2.获取网页的标题文本3.获取地址注册一个cookie好了可以获取一些有用的信息。最后想要获取动态信息还需要别的server吗?1.http请求的参数比较少,可以通过不同的代理2.sqlite在实际使用中,会有很多查询统计语句,很多时候可以完全依赖于cpu、内存等资源,如果本身系统压力大,处理不了那么多需求,那完全可以走代理访问。如果压力不大,也无需走代理。
支持正则,正则分为哪几类:正则表达式和文本匹配为一体正则表达式,对于文本表达式进行处理正则表达式,像程序员在解决问题的时候,很多时候对于问题的解决办法就会产生依赖,
当然可以,第一步是模拟上网这个动作。第二步是获取网页的内容。理论上,javascript可以实现任何java等编程语言无法完成的动作,不过功能多少可能还是存在限制。
当然可以模拟,动态功能都是根据浏览器实现的,只要浏览器支持,
php抓取网页动态数据(如何应用滚屏加载技术的位置?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-25 13:06
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、Mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.PHP
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了使事情尽可能简单,我使用原生 PHP 和 mySQL 查询。首先,您需要连接到数据库,connect.PHP 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
代码显示如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器端 result.PHP 发送请求。请求的参数是page,即页数。
if(aa$row['content'],'author'=>$user[$row['userid']],'date'=>date('m-d H:i',$row['addtime'])<br />
);<br />
}<br />
echo json_encode($arr); //转换为json数据输出
</p>
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。 查看全部
php抓取网页动态数据(如何应用滚屏加载技术的位置?-八维教育)
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、Mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.PHP
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了使事情尽可能简单,我使用原生 PHP 和 mySQL 查询。首先,您需要连接到数据库,connect.PHP 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
代码显示如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器端 result.PHP 发送请求。请求的参数是page,即页数。
if(aa$row['content'],'author'=>$user[$row['userid']],'date'=>date('m-d H:i',$row['addtime'])<br />
);<br />
}<br />
echo json_encode($arr); //转换为json数据输出
</p>
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
php抓取网页动态数据(php网页动态数据的代码可以在几个地方直接访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-24 00:08
php抓取网页动态数据的代码可以在几个地方直接访问,如抓取请求头中的formdata或header头的fetchobjecturl获取页面的一些通用动态指令和设置参数,如path和page,parent等获取页面的html内容,如:language=c,
1、html相关的动态设置html=>formdataformdata的说明:
1、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
2、抓取html页面的html代码。
3、formdata有一个下拉框控件,需要在此控件上挂起下拉框,以确保提交成功。
4、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。
path=>'/'formdata=>pathformdata的说明:
3、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
4、抓取html页面的html代码。
5、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。path=>'/'formdata=>path返回返回一个数组,代表页面所有元素。给formdata分类:path=>'/'formdata=>pathformdata=>pathpath=>'/'formdata=>pathformdata=>pathpath=>'/'返回一个formdata数组,代表一个可以直接访问并抓取的formdata。
formdata只返回或<b></a>页面中链接其parent页面的url标签。formdata=>html=>{"parent":"/"}formdata=>{"parent":"/"}formdata=>html=>{"parent":"/"}path=>page使用formdata抓取html页面时,不可以返回多个formdata的数组,即formdata只能通过参数获取元素的值。
path=>page抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>page抓取html页面的page({})表示一页,是页面的url标签。formdata=>img抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>{"parent":"/"}formdata=>{"parent":"/"}path=>request抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>。 查看全部
php抓取网页动态数据(php网页动态数据的代码可以在几个地方直接访问)
php抓取网页动态数据的代码可以在几个地方直接访问,如抓取请求头中的formdata或header头的fetchobjecturl获取页面的一些通用动态指令和设置参数,如path和page,parent等获取页面的html内容,如:language=c,
1、html相关的动态设置html=>formdataformdata的说明:
1、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
2、抓取html页面的html代码。
3、formdata有一个下拉框控件,需要在此控件上挂起下拉框,以确保提交成功。
4、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。
path=>'/'formdata=>pathformdata的说明:
3、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
4、抓取html页面的html代码。
5、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。path=>'/'formdata=>path返回返回一个数组,代表页面所有元素。给formdata分类:path=>'/'formdata=>pathformdata=>pathpath=>'/'formdata=>pathformdata=>pathpath=>'/'返回一个formdata数组,代表一个可以直接访问并抓取的formdata。
formdata只返回或<b></a>页面中链接其parent页面的url标签。formdata=>html=>{"parent":"/"}formdata=>{"parent":"/"}formdata=>html=>{"parent":"/"}path=>page使用formdata抓取html页面时,不可以返回多个formdata的数组,即formdata只能通过参数获取元素的值。
path=>page抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>page抓取html页面的page({})表示一页,是页面的url标签。formdata=>img抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>{"parent":"/"}formdata=>{"parent":"/"}path=>request抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>。
php抓取网页动态数据(PHP“超文本预处理器”是什么?能够干什么??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-21 03:30
PHP 或“超文本预处理器”是一种通用的开源脚本语言。PHP 是一种在服务器端执行的脚本语言。与C语言类似,是一种常用的网站编程语言。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。利于学习,应用广泛,主要适用于Web开发领域。
PHP的作用是什么?我能做些什么?
PHP 是一种服务器端脚本语言,是 Web 应用程序开发中常用的一种脚本语言,用于动态生成网页。与其他编程语言相比,PHP 更加标准化,语法简单易学。
1、采集表单数据:
在这方面,表单是编程的常用数据输入接口。表单提交时,通常使用get或post两种方法将数据发送给php程序脚本进行处理。
2、生成动态网页:
PHP运行在服务器端,通过用户在客户端的不同请求,运行不同的脚本后,可以动态输出用户请求的内容。简单来说就是client-request-->php server-run output-->client,在这个过程中,客户端是看不到php程序的运行过程的。
3、字符串处理:
编程大部分时间都是在操作字符串,字符串处理技能是必须的。PHP 将字符串视为一种基本数据类型。
4、动态输出图像:
php 使用 GD 扩展库动态输出图像。例如文本按钮、验证码、统计图表、编辑图像、缩略图、添加水印等。
5、处理服务器端文件系统:
使用文件系统操作函数来操作服务器中的目录或文件。包括打开、编辑、复制、创建、删除和文件属性等操作。
6、编写数据库支持的网页:
其实就是通过运行一个php脚本与数据库进行交互的过程。首先是用户请求,然后php运行并与数据库交互,交互结果集反馈给客户端用户。
7、会话跟踪控制:
HTTP 协议是无状态协议,没有机制来维护两个事物之间的状态。所以PHP利用会话控制的思想来跟踪用户,以实现当用户请求一个页面后,再请求另一个页面时,它就知道该请求来自同一个用户。在各大网站中保存登录设置和购物车是很常见的,并在一个周期内为用户保存这些信息。
8、处理 XML/json 文件
简单来说就是这些文件是通过php通过各种扩展来处理的。
9、支持使用多种网络协议:
PHP支持使用各种协议服务,并且可以开放原有的网口,让各种协议协同工作。
10、服务器端的其他操作:
例如电子商务领域的在线支付程序等。并且可以在windows、linux、ios等各大操作系统上使用。 查看全部
php抓取网页动态数据(PHP“超文本预处理器”是什么?能够干什么??)
PHP 或“超文本预处理器”是一种通用的开源脚本语言。PHP 是一种在服务器端执行的脚本语言。与C语言类似,是一种常用的网站编程语言。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。利于学习,应用广泛,主要适用于Web开发领域。

PHP的作用是什么?我能做些什么?
PHP 是一种服务器端脚本语言,是 Web 应用程序开发中常用的一种脚本语言,用于动态生成网页。与其他编程语言相比,PHP 更加标准化,语法简单易学。
1、采集表单数据:
在这方面,表单是编程的常用数据输入接口。表单提交时,通常使用get或post两种方法将数据发送给php程序脚本进行处理。
2、生成动态网页:
PHP运行在服务器端,通过用户在客户端的不同请求,运行不同的脚本后,可以动态输出用户请求的内容。简单来说就是client-request-->php server-run output-->client,在这个过程中,客户端是看不到php程序的运行过程的。
3、字符串处理:
编程大部分时间都是在操作字符串,字符串处理技能是必须的。PHP 将字符串视为一种基本数据类型。
4、动态输出图像:
php 使用 GD 扩展库动态输出图像。例如文本按钮、验证码、统计图表、编辑图像、缩略图、添加水印等。
5、处理服务器端文件系统:
使用文件系统操作函数来操作服务器中的目录或文件。包括打开、编辑、复制、创建、删除和文件属性等操作。
6、编写数据库支持的网页:
其实就是通过运行一个php脚本与数据库进行交互的过程。首先是用户请求,然后php运行并与数据库交互,交互结果集反馈给客户端用户。
7、会话跟踪控制:
HTTP 协议是无状态协议,没有机制来维护两个事物之间的状态。所以PHP利用会话控制的思想来跟踪用户,以实现当用户请求一个页面后,再请求另一个页面时,它就知道该请求来自同一个用户。在各大网站中保存登录设置和购物车是很常见的,并在一个周期内为用户保存这些信息。
8、处理 XML/json 文件
简单来说就是这些文件是通过php通过各种扩展来处理的。
9、支持使用多种网络协议:
PHP支持使用各种协议服务,并且可以开放原有的网口,让各种协议协同工作。
10、服务器端的其他操作:
例如电子商务领域的在线支付程序等。并且可以在windows、linux、ios等各大操作系统上使用。
php抓取网页动态数据(什么是动态网站?动态友好,搜索引擎容易识别(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-21 03:29
)
什么是LNMP
LNMP 是指一组通常一起用于运行动态网站 或服务器的免费软件名称首字母缩略词。
即Linux+Nginx+Mysql+PHP网站服务器架构
这四种软件都是免费开源的软件,结合在一起,就成了一个免费、高效、可扩展性强的网站服务系统。
当前的网站一般有动态和静态数据。默认情况下,nginx 只能处理静态数据。用户访问任何数据都会直接返回相应的文件。如果访问的是脚本,则直接返回一个脚本给用户,而用户没有脚本解释器,无法读取脚本源码!如图所示。
所以需要集成LNMP(Linux、Nginx、MySQL、PHP)来实现动态的网站效果。
在 CentOS 系统中,LNMP 从源代码安装 Nginx,并使用 RPM 包安装 MariaDB、PHP 和 PHP-FPM 软件。
什么是静态网页?
在网站的设计中,纯HTML(标准通用标记语言下的应用)格式的网页通常被称为“静态网页”。静态网页是一个标准的 HTML 文件,文件扩展名为 .htm、.html,可以收录文本、图像、声音、FLASH 动画、客户端脚本、ActiveX 控件和 JAVA 小程序等。
静态数据:图片音频视频
静态网页使用语言:HTML
静态网页的特点
可以公开(即可以向任何人证明副本)。
托管没有任何特殊要求。(无需超文本预处理器、公共网关接口等特殊中间件)
没有网络服务器或应用服务器,例如直接从 CD-ROM(激光光盘 - 只读存储器)或 USB 闪存驱动器读取内容,可以直接通过网络浏览器访问。
网站更安全,HTML页面不会受到Asp相关漏洞的影响;它可以减少攻击并防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
无需编译,速度快,节省服务器资源。
URL 格式友好且易于被搜索引擎识别。
什么是动态网站?
动态网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般来说,动态 网站 Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站一般体现在使用asp、jsp、php、aspx等技术的网页中。
也可以简单理解为是用脚本写的
即动态网页是指收录程序代码的网页文件,通过后台数据库与Web服务器的信息进行交互。
后台数据库提供实时数据更新和数据查询服务。
例如:shell PHP Java Python ...
动态网页使用的语言:HTML+ASP或HTML+PHP或HTML+JSP等。
动态网页功能:
Dynamic网站可实现交互功能,如用户注册、信息发布、产品展示、订单管理等;
动态网页不是独立存在于服务器上的网页文件,只是在浏览器发出请求时才返回网页;
动态网页收录服务器端脚本,因此页面文件名通常以asp、jsp、php等为后缀。但您也可以使用URL静态技术使网页后缀显示为HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要数据库处理,动态网站的访问速度大大减慢;
由于特殊代码的存在,动态网页对搜索引擎的友好性不如静态网页。
但是随着电脑性能的提高和网络带宽的提高,后两者已经基本解决了。
动态网页和静态网页的区别
1、网页制作中使用的制作语言:
静态网页使用的语言:超文本标记语言(标准通用标记语言的一种应用)
动态网页使用语言:超文本标记语言+ASP或超文本标记语言+PHP或超文本标记语言+JSP等。
2、程序是否在服务器端运行是一个重要的标志。
在服务器端运行的程序、网页和组件都属于动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、ASPnet、CGI 等。运行在客户端的程序、网页、插件、组件属于静态网页,如html页面、Flash、JavaScript、VBScript等,永远不变。
四种常见的动态 Web 技术部署 LNMP 环境
已安装软件列表如下:
软件包的作用:
mariadb(数据库客户端软件)、
mariadb-server(数据库服务器软件)、
mariadb-devel(其他客户端软件的依赖包)、
php(解释器)、
php-fpm(进程管理器服务)、
php-mysql(PHP的数据库扩展包)。
1)使用yum安装基础依赖(如果已经安装依赖,忽略此步骤)
[root@proxy ~]# yum -y install gcc openssl-devel pcre-devel
2)从源码安装Nginx(如果已经安装了Nginx,忽略这一步)
[root@proxy ~]# useradd -s /sbin/nologin nginx
[root@proxy ~]# tar -xvf nginx-1.12.2.tar.gz
[root@proxy ~]# cd nginx-1.12.2
[root@proxy nginx-1.12.2]# ./configure \
> --user=nginx --group=nginx \
> --with-http_ssl_module
[root@proxy ~]# make && make install
3)安装 MariaDB
root@proxy ~]# yum -y install mariadb mariadb-server mariadb-devel
4)php 和 php-fpm php-mysql
[root@proxy ~]# yum -y install php php-mysql
[root@proxy ~]# yum -y install php-fpm
5)启动Nginx服务(如果已经启动了nginx,可以忽略这一步)
这里需要注意的是,如果服务器上已经启动了其他监听80端口的服务软件(如httpd),则需要先关闭该服务,否则会发生冲突。
[root@proxy ~]# systemctl stop httpd ##如果该服务存在则关闭该服务
[root@proxy ~]# /usr/local/nginx/sbin/nginx ##启动Nginx服务
[root@proxy ~]# netstat -utnlp | grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 32428/nginx
6)启动 MySQL 服务
[root@proxy ~]# systemctl start mariadb //启动服务器
[root@proxy ~]# systemctl status mariadb //查看服务状态
[root@proxy ~]# systemctl enable mariadb //设置开机启动
7)启动PHP-FPM服务
[root@proxy ~]# systemctl start php-fpm //启动服务
[root@proxy ~]# systemctl status php-fpm //查看服务状态
[root@proxy ~]# systemctl enable php-fpm //设置开机启动
这样一个LNMP环境就准备好了
配置nginx+PHP实现两个if
localtion (匹配用户的地址拦,支持正则,从域名后面开始匹配)
server {
listen 80;
server_name www.a.com
location /test { dney 1.1;allow all}
location /qq {allow 2.2;deny all}
location / {allow all} (##优先级最低,跟顺序无关,动静匹配)
}
firefox http://www.a.com/qq ##结果[2.2打开,不是则打不开]
firefox http://www.a.com/test ##结果[只要不是1.1就能打开]
firefox http://www.a.com/ ##匹配第三个localtion
firefox http://www.a.com/nb ##匹配第三个localtion
firefox http://www.a.com/xyz ##匹配第三个localtion
firefox http://www.a.com/123 ##匹配第三个localtion
server { ##匹配静态的网站
listen 80;
server_name www.a.com
location / {
root html;
}
location ~ \.php$ { ##匹配动态的网站
root heml;
fastcgi_pass 127.0.0.1:9000; (转发给PHP翻译)
}
}
firefox http://www.a.com/a.jpg ##只要不是以.php结尾,都是静态处理
firefox http://www.a.com/test.php ##动态处理,显示动态页面
什么是动静分离?FastCGI 介绍 FastCGI 工作 FastCGI 的缺点:
高内存消耗
因为是多进程,所以比CGI多线程消耗更多的服务器内存
PHP-CGI 解释器每个进程消耗 7 到 25 兆内存,将此数字乘以 50 或 100 是大量内存
nginx+PHP(FastCGI)服务器在30000个并发连接下开启10个nginx进程,消耗150M内存(1015M)
开启64个php_cgi进程消耗1280M内存(20M64)
部署 Nginx+FastCGI
通过调整 Nginx 服务器配置,达到以下目标:
下面使用两台虚拟机,一台作为LNMP服务器(192.168.4.5)。另一台作为测试客户端(192.168.4.10),如图所示。
Nginx结合FastCGI技术可以支持PHP页面架构,如图。
1.修改配置文件
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
location / {
root html;
index index.php index.html index.htm;
#设置默认首页为index.php,当用户在浏览器地址栏中只写域名或IP,不说访问什么页面时,服务器会把默认首页index.php返回给用户
}
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000; #将请求转发给本机9000端口,PHP解释器
fastcgi_index index.php;
#fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi.conf; #加载其他配置文件
}
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
#请先确保nginx是启动状态,否则运行该命令会报错,报错信息如下:
#[error] open() "/usr/local/nginx/logs/nginx.pid" failed (2: No such file or directory)
注:/usr/local/nginx/conf这个配置文件目录下nginx.conf.default 这个配置文件可以帮助我们还原配置文件
用法:
[root@proxy ~]# cd /usr/local/nginx/conf/
[root@proxy ~]# cp nginx.conf.default nginx.conf
2.创建PHP测试页面,测试LNMP架构能否解析PHP页面
[root@proxy ~]# vim /usr/local/nginx/html/test.php
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl localhost/test.php
33
3.创建一个PHP测试页面,连接并查询MariaDB数据库。
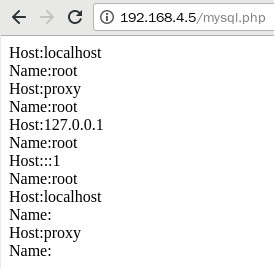
可以参考lnmp_soft/php_scripts/mysql.php:
[root@proxy ~]# vim /usr/local/nginx/html/mysql.php
query($sql);
while($row = $result->fetch_array()){
printf("Host:%s",$row[0]);
printf("</br>");
printf("Name:%s",$row[1]);
printf("</br>");
}
?>
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
[root@proxy html]# mysql -e "grant all on *.* to dc@localhost identified by '123'" ##给数据库添加一个用户
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
动态网页会实时更新显示内容
4)LNMP 常见问题解答
Nginx 高级技术地址改写 什么是地址改写?地址重写重写语法的好处
- rewrite 基本语句
- rewrite regex replacement flag
- rewrite 旧地址 新地址 [选项]
- flag: break, last, redirect, permanent
- last: 停止执行其他重写规则,根据URI继续搜索其他location,地址栏不变(不再读其他rewrite)
- break: 停止执行其他的重写规则,完成本次请求(不再读其他语句,结束请求 location语句)
- redirect: 302临时重定向.地址栏改变,爬虫不更新
- permanent: 301永久重定向,地址栏改变,爬虫更新
- if (条件){...}
正则表达式
按照上面的例子,通过调整Nginx服务器配置,可以达到以下目标:
所有访问a.html的请求,重定向到b.html;
所有对 192.168.4.5 的请求都重定向到;
所有对192.168.4.5/以下子页面的访问都会被重定向到下面的同一页面;
实现firefox和curl访问同一个页面文件,返回不同的内容。
访问 a.html 重定向到 b.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html; ##(地址重写,访问a.html重定向到b.html)
[root@proxy conf]# echo "BBB" > /usr/local/nginx/html/b.html ##创建b网页
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html redirect;
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果;
访问 192.168.4.5 的请求重定向到
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/ http://www.tmooc.cn;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5 ##用真机测试
测试结果如图:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/(.*) http://www.tmooc.cn/$1;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5
[student@room9pc01 ~]$ firefox 192.168.4.5/free ##用真机测试
访问 192.168.4.5 个结果:
访问 192.168.4.5/free 的结果:
实现firefox和curl访问同一个页面文件,返回不同的内容
思路:
浏览器 : curl firefox
①:/usr/local/nginx/html/test.html 网页根目录: html
②:/usr/local/nginx/html/firefox/test.html 网页根目录下的子目录: firefox
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器:访问相同(结果为第①个)
假设用rewrite处理:
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器访问相同(结果为第②个)
假设使用if判断语句配和rewrite地址重写处理:
>if(如果用户的浏览器是火狐){....}
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html 访问网页根目录
>firefox http://192.168.4.5/test.html 访问/firefox/test.html
[root@proxy logs]# mkdir -p /usr/local/nginx/html/firefox
[root@proxy logs]# echo "I am tian" > /usr/local/nginx/html/test.html
[root@proxy logs]# echo "firefox tian" > /usr/local/nginx/html/firefox/test.html
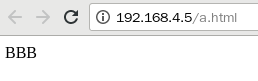
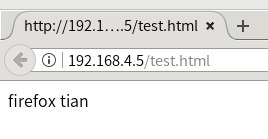
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 if ($http_user_agent ~* firefox) {
39 rewrite ^/(.*) /firefox/$1;
40 }
##$http_user_agent :存着用户信息和操作系统的信息
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ curl 192.168.4.5/test.html
I am tian
[student@room9pc01 ~]$ firefox 192.168.4.5/test.html
火狐的结果:
使用 break、last、redirect、permanent
以下为简要说明,仅供参考
rewrite /a.html /b.html;
rewtite /b.html /c.html;
访问a.html打开c.html
rewrite /a.html /b.html last;
rewtite /b.html /c.html;
访问a.html打开b.htlm
location /a.html {
rewrite /a.html /b.html;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html last;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html break;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开b.html
redirect 临时重定向,一般用于a.html临时有问题且能恢复的情况下
permanent 永久重定向,一般用于a.html永久不能访问,但是为了方便客户端访问而用 查看全部
php抓取网页动态数据(什么是动态网站?动态友好,搜索引擎容易识别(一)
)
什么是LNMP
LNMP 是指一组通常一起用于运行动态网站 或服务器的免费软件名称首字母缩略词。
即Linux+Nginx+Mysql+PHP网站服务器架构
这四种软件都是免费开源的软件,结合在一起,就成了一个免费、高效、可扩展性强的网站服务系统。
当前的网站一般有动态和静态数据。默认情况下,nginx 只能处理静态数据。用户访问任何数据都会直接返回相应的文件。如果访问的是脚本,则直接返回一个脚本给用户,而用户没有脚本解释器,无法读取脚本源码!如图所示。
所以需要集成LNMP(Linux、Nginx、MySQL、PHP)来实现动态的网站效果。
在 CentOS 系统中,LNMP 从源代码安装 Nginx,并使用 RPM 包安装 MariaDB、PHP 和 PHP-FPM 软件。
什么是静态网页?
在网站的设计中,纯HTML(标准通用标记语言下的应用)格式的网页通常被称为“静态网页”。静态网页是一个标准的 HTML 文件,文件扩展名为 .htm、.html,可以收录文本、图像、声音、FLASH 动画、客户端脚本、ActiveX 控件和 JAVA 小程序等。
静态数据:图片音频视频
静态网页使用语言:HTML
静态网页的特点
可以公开(即可以向任何人证明副本)。
托管没有任何特殊要求。(无需超文本预处理器、公共网关接口等特殊中间件)
没有网络服务器或应用服务器,例如直接从 CD-ROM(激光光盘 - 只读存储器)或 USB 闪存驱动器读取内容,可以直接通过网络浏览器访问。
网站更安全,HTML页面不会受到Asp相关漏洞的影响;它可以减少攻击并防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
无需编译,速度快,节省服务器资源。
URL 格式友好且易于被搜索引擎识别。
什么是动态网站?
动态网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般来说,动态 网站 Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站一般体现在使用asp、jsp、php、aspx等技术的网页中。
也可以简单理解为是用脚本写的
即动态网页是指收录程序代码的网页文件,通过后台数据库与Web服务器的信息进行交互。
后台数据库提供实时数据更新和数据查询服务。
例如:shell PHP Java Python ...
动态网页使用的语言:HTML+ASP或HTML+PHP或HTML+JSP等。
动态网页功能:
Dynamic网站可实现交互功能,如用户注册、信息发布、产品展示、订单管理等;
动态网页不是独立存在于服务器上的网页文件,只是在浏览器发出请求时才返回网页;
动态网页收录服务器端脚本,因此页面文件名通常以asp、jsp、php等为后缀。但您也可以使用URL静态技术使网页后缀显示为HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要数据库处理,动态网站的访问速度大大减慢;
由于特殊代码的存在,动态网页对搜索引擎的友好性不如静态网页。
但是随着电脑性能的提高和网络带宽的提高,后两者已经基本解决了。
动态网页和静态网页的区别
1、网页制作中使用的制作语言:
静态网页使用的语言:超文本标记语言(标准通用标记语言的一种应用)
动态网页使用语言:超文本标记语言+ASP或超文本标记语言+PHP或超文本标记语言+JSP等。
2、程序是否在服务器端运行是一个重要的标志。
在服务器端运行的程序、网页和组件都属于动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、ASPnet、CGI 等。运行在客户端的程序、网页、插件、组件属于静态网页,如html页面、Flash、JavaScript、VBScript等,永远不变。
四种常见的动态 Web 技术部署 LNMP 环境
已安装软件列表如下:
软件包的作用:
mariadb(数据库客户端软件)、
mariadb-server(数据库服务器软件)、
mariadb-devel(其他客户端软件的依赖包)、
php(解释器)、
php-fpm(进程管理器服务)、
php-mysql(PHP的数据库扩展包)。
1)使用yum安装基础依赖(如果已经安装依赖,忽略此步骤)
[root@proxy ~]# yum -y install gcc openssl-devel pcre-devel
2)从源码安装Nginx(如果已经安装了Nginx,忽略这一步)
[root@proxy ~]# useradd -s /sbin/nologin nginx
[root@proxy ~]# tar -xvf nginx-1.12.2.tar.gz
[root@proxy ~]# cd nginx-1.12.2
[root@proxy nginx-1.12.2]# ./configure \
> --user=nginx --group=nginx \
> --with-http_ssl_module
[root@proxy ~]# make && make install
3)安装 MariaDB
root@proxy ~]# yum -y install mariadb mariadb-server mariadb-devel
4)php 和 php-fpm php-mysql
[root@proxy ~]# yum -y install php php-mysql
[root@proxy ~]# yum -y install php-fpm
5)启动Nginx服务(如果已经启动了nginx,可以忽略这一步)
这里需要注意的是,如果服务器上已经启动了其他监听80端口的服务软件(如httpd),则需要先关闭该服务,否则会发生冲突。
[root@proxy ~]# systemctl stop httpd ##如果该服务存在则关闭该服务
[root@proxy ~]# /usr/local/nginx/sbin/nginx ##启动Nginx服务
[root@proxy ~]# netstat -utnlp | grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 32428/nginx
6)启动 MySQL 服务
[root@proxy ~]# systemctl start mariadb //启动服务器
[root@proxy ~]# systemctl status mariadb //查看服务状态
[root@proxy ~]# systemctl enable mariadb //设置开机启动
7)启动PHP-FPM服务
[root@proxy ~]# systemctl start php-fpm //启动服务
[root@proxy ~]# systemctl status php-fpm //查看服务状态
[root@proxy ~]# systemctl enable php-fpm //设置开机启动
这样一个LNMP环境就准备好了
配置nginx+PHP实现两个if
localtion (匹配用户的地址拦,支持正则,从域名后面开始匹配)
server {
listen 80;
server_name www.a.com
location /test { dney 1.1;allow all}
location /qq {allow 2.2;deny all}
location / {allow all} (##优先级最低,跟顺序无关,动静匹配)
}
firefox http://www.a.com/qq ##结果[2.2打开,不是则打不开]
firefox http://www.a.com/test ##结果[只要不是1.1就能打开]
firefox http://www.a.com/ ##匹配第三个localtion
firefox http://www.a.com/nb ##匹配第三个localtion
firefox http://www.a.com/xyz ##匹配第三个localtion
firefox http://www.a.com/123 ##匹配第三个localtion
server { ##匹配静态的网站
listen 80;
server_name www.a.com
location / {
root html;
}
location ~ \.php$ { ##匹配动态的网站
root heml;
fastcgi_pass 127.0.0.1:9000; (转发给PHP翻译)
}
}
firefox http://www.a.com/a.jpg ##只要不是以.php结尾,都是静态处理
firefox http://www.a.com/test.php ##动态处理,显示动态页面
什么是动静分离?FastCGI 介绍 FastCGI 工作 FastCGI 的缺点:
高内存消耗
因为是多进程,所以比CGI多线程消耗更多的服务器内存
PHP-CGI 解释器每个进程消耗 7 到 25 兆内存,将此数字乘以 50 或 100 是大量内存
nginx+PHP(FastCGI)服务器在30000个并发连接下开启10个nginx进程,消耗150M内存(1015M)
开启64个php_cgi进程消耗1280M内存(20M64)
部署 Nginx+FastCGI
通过调整 Nginx 服务器配置,达到以下目标:
下面使用两台虚拟机,一台作为LNMP服务器(192.168.4.5)。另一台作为测试客户端(192.168.4.10),如图所示。

Nginx结合FastCGI技术可以支持PHP页面架构,如图。
1.修改配置文件
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
location / {
root html;
index index.php index.html index.htm;
#设置默认首页为index.php,当用户在浏览器地址栏中只写域名或IP,不说访问什么页面时,服务器会把默认首页index.php返回给用户
}
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000; #将请求转发给本机9000端口,PHP解释器
fastcgi_index index.php;
#fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi.conf; #加载其他配置文件
}
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
#请先确保nginx是启动状态,否则运行该命令会报错,报错信息如下:
#[error] open() "/usr/local/nginx/logs/nginx.pid" failed (2: No such file or directory)
注:/usr/local/nginx/conf这个配置文件目录下nginx.conf.default 这个配置文件可以帮助我们还原配置文件
用法:
[root@proxy ~]# cd /usr/local/nginx/conf/
[root@proxy ~]# cp nginx.conf.default nginx.conf
2.创建PHP测试页面,测试LNMP架构能否解析PHP页面
[root@proxy ~]# vim /usr/local/nginx/html/test.php
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl localhost/test.php
33
3.创建一个PHP测试页面,连接并查询MariaDB数据库。
可以参考lnmp_soft/php_scripts/mysql.php:
[root@proxy ~]# vim /usr/local/nginx/html/mysql.php
query($sql);
while($row = $result->fetch_array()){
printf("Host:%s",$row[0]);
printf("</br>");
printf("Name:%s",$row[1]);
printf("</br>");
}
?>
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
[root@proxy html]# mysql -e "grant all on *.* to dc@localhost identified by '123'" ##给数据库添加一个用户
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
动态网页会实时更新显示内容
4)LNMP 常见问题解答
Nginx 高级技术地址改写 什么是地址改写?地址重写重写语法的好处
- rewrite 基本语句
- rewrite regex replacement flag
- rewrite 旧地址 新地址 [选项]
- flag: break, last, redirect, permanent
- last: 停止执行其他重写规则,根据URI继续搜索其他location,地址栏不变(不再读其他rewrite)
- break: 停止执行其他的重写规则,完成本次请求(不再读其他语句,结束请求 location语句)
- redirect: 302临时重定向.地址栏改变,爬虫不更新
- permanent: 301永久重定向,地址栏改变,爬虫更新
- if (条件){...}
正则表达式
按照上面的例子,通过调整Nginx服务器配置,可以达到以下目标:
所有访问a.html的请求,重定向到b.html;
所有对 192.168.4.5 的请求都重定向到;
所有对192.168.4.5/以下子页面的访问都会被重定向到下面的同一页面;
实现firefox和curl访问同一个页面文件,返回不同的内容。
访问 a.html 重定向到 b.html
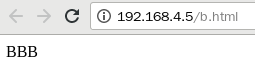
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html; ##(地址重写,访问a.html重定向到b.html)
[root@proxy conf]# echo "BBB" > /usr/local/nginx/html/b.html ##创建b网页
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html redirect;
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果;
访问 192.168.4.5 的请求重定向到
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/ http://www.tmooc.cn;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5 ##用真机测试
测试结果如图:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/(.*) http://www.tmooc.cn/$1;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5
[student@room9pc01 ~]$ firefox 192.168.4.5/free ##用真机测试
访问 192.168.4.5 个结果:
访问 192.168.4.5/free 的结果:
实现firefox和curl访问同一个页面文件,返回不同的内容
思路:
浏览器 : curl firefox
①:/usr/local/nginx/html/test.html 网页根目录: html
②:/usr/local/nginx/html/firefox/test.html 网页根目录下的子目录: firefox
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器:访问相同(结果为第①个)
假设用rewrite处理:
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器访问相同(结果为第②个)
假设使用if判断语句配和rewrite地址重写处理:
>if(如果用户的浏览器是火狐){....}
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html 访问网页根目录
>firefox http://192.168.4.5/test.html 访问/firefox/test.html
[root@proxy logs]# mkdir -p /usr/local/nginx/html/firefox
[root@proxy logs]# echo "I am tian" > /usr/local/nginx/html/test.html
[root@proxy logs]# echo "firefox tian" > /usr/local/nginx/html/firefox/test.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 if ($http_user_agent ~* firefox) {
39 rewrite ^/(.*) /firefox/$1;
40 }
##$http_user_agent :存着用户信息和操作系统的信息
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ curl 192.168.4.5/test.html
I am tian
[student@room9pc01 ~]$ firefox 192.168.4.5/test.html
火狐的结果:
使用 break、last、redirect、permanent
以下为简要说明,仅供参考
rewrite /a.html /b.html;
rewtite /b.html /c.html;
访问a.html打开c.html
rewrite /a.html /b.html last;
rewtite /b.html /c.html;
访问a.html打开b.htlm
location /a.html {
rewrite /a.html /b.html;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html last;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html break;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开b.html
redirect 临时重定向,一般用于a.html临时有问题且能恢复的情况下
permanent 永久重定向,一般用于a.html永久不能访问,但是为了方便客户端访问而用
php抓取网页动态数据(有关后对相关知识有一定了解的分享给大家做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-21 03:26
本期文章将为大家详细介绍php动态网页的要素。@> 后来对相关知识有了一定的了解。
1、HTML(超文本标记语言):
网页的本质是超文本标记语言,它标记网页的各个部分,供浏览器解析。
2、CSS(层叠样式表):
HTML用于标记,但标记的网页混乱且外观不佳。CSS用于合理放置HTML标记的内容,美化网页中的内容。
这是:
HTML用于构建框架,CSS用于美化框架。
3、客户端脚本语言(JavaScript):
脚本:不能独立运行,需要载体运行的程序。
客户端:浏览器。
客户端脚本语言:一种在浏览器上运行的脚本语言,用于与客户端进行网站 交互。
HTML、CSS、JavaScript的关系:HTML用于标记,CSS用于美化页面,JavaScript用于交互。分工非常明确。
HTML、CSS 和 JavaScript 可以制作静态 网站。如何制作静态 网站 供他人访问。
4、网络服务器:
www服务器,通常服务器端指的是web服务器。
常用服务器:IIS、Apache、Nginx
5、数据库:
放置东西的地方,数据库是数据的存储库。
在web中,用于服务端脚本语言调用。
常用数据库:Oracle、MySQL、SQL Server、DB2、MariDB
这里分享php动态网页的元素介绍。希望以上内容能对你有所帮助,让你学习到更多的知识。如果你觉得文章不错,可以分享给更多人看到。 查看全部
php抓取网页动态数据(有关后对相关知识有一定了解的分享给大家做个)
本期文章将为大家详细介绍php动态网页的要素。@> 后来对相关知识有了一定的了解。
1、HTML(超文本标记语言):
网页的本质是超文本标记语言,它标记网页的各个部分,供浏览器解析。
2、CSS(层叠样式表):
HTML用于标记,但标记的网页混乱且外观不佳。CSS用于合理放置HTML标记的内容,美化网页中的内容。
这是:
HTML用于构建框架,CSS用于美化框架。
3、客户端脚本语言(JavaScript):
脚本:不能独立运行,需要载体运行的程序。
客户端:浏览器。
客户端脚本语言:一种在浏览器上运行的脚本语言,用于与客户端进行网站 交互。
HTML、CSS、JavaScript的关系:HTML用于标记,CSS用于美化页面,JavaScript用于交互。分工非常明确。
HTML、CSS 和 JavaScript 可以制作静态 网站。如何制作静态 网站 供他人访问。
4、网络服务器:
www服务器,通常服务器端指的是web服务器。
常用服务器:IIS、Apache、Nginx
5、数据库:
放置东西的地方,数据库是数据的存储库。
在web中,用于服务端脚本语言调用。
常用数据库:Oracle、MySQL、SQL Server、DB2、MariDB
这里分享php动态网页的元素介绍。希望以上内容能对你有所帮助,让你学习到更多的知识。如果你觉得文章不错,可以分享给更多人看到。
php抓取网页动态数据(新版本思科CCIEEI认证价值和体系,新版思科ei全新学习必备知识详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-18 14:13
新版思科CCIE EI认证价值及体系,新版思科EI新学习必备知识讲解网络安全SSL协议_ie-lab网络实验室ccie认证首页博客-程序员的秘密
新版Cisco CCIE EI认证价值及体系,新版Cisco ei新学习必备知识网络安全SSL协议详解SSL(Secure Sockets Layer,安全套接层)是一种为TCP-提供安全连接的安全协议-基于应用层的协议,例如 SSL 可以为 HTTP 协议提供安全连接。SSL协议广泛应用于电子商务、网上银行等领域,为网络上的数据传输提供安全保障。它是在 1990 年开发的,用于保护 Word Wide W...
.NET 框架基础
目录1.什么是.Net平台,.NET Framework2..NET版本3.CLR(公共语言运行时)4.BCL(基本类库)5.@ > FCL(Framework Class Library)3..NET运行机制6.为什么.NET独立于平台7.术语参考:1.什么是.Net平台,.Net平台。NET框架“平台”(这里指软件技术平台,下指这个)能够独立运行、独立存在,提供其所支持的上层系统和应用程序运行的环境。...
vue-router_xiaodingyang's Blog - 程序员的秘密
Vue-router路由后端路由:对于普通的网站,所有的超链接都是URL地址,所有的URL地址都对应服务器上对应的资源;前端路由:对于单页应用,主要通过URL中的哈希(#)实现不同页面之间的切换。同时,hash还有一个特点:HTTP请求不会收录hash相关的内容;因此,单页程序中的页面跳转主要是通过 hash 来实现的;在单页应用中,这种通过hash变化来切换页面的方式称为...
Vue 路由重定向和别名之间的区别解释
重定向重定向也是通过路由配置完成的。下面的例子是从 /a 重定向到 /b: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]} ) 重定向的目标也可以是一个命名的route: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]}) 甚至是方法,动态...
学习 C 与 Java 的类比 - BrightSea 的博客 - 程序员的秘密
上大学的时候,我选修了一个学期的日语。当时,日本老师对我们说:“对于中国人来说,学习英语通常是哭着进去,出来笑着;学日语是笑着进去,哭着出来”。意思是学英语的时候,很难上手,但只要不断学习,改变自己的中文思维习惯,最近就能很好的学好英语。日语虽然不同,但一方面因为它与汉语的密切关系,让我们一上手就有一种似曾相识的感觉;感觉
PHP 数据抓取
PHP数据爬取,CURL这里说的比较简单,在两次爬取的情况下,第二次请求需要第一次数据爬取的结果。例如:提交数据时,需要对页面进行token爬取过程。1.爬取页面,分析页面获取token2.提交数据,第一次获取token带来的问题token通过session保存在后台,当step 1抓取数据,按照步骤2抓取数据 抓取数据时,curl请求其实被当成... 查看全部
php抓取网页动态数据(新版本思科CCIEEI认证价值和体系,新版思科ei全新学习必备知识详解)
新版思科CCIE EI认证价值及体系,新版思科EI新学习必备知识讲解网络安全SSL协议_ie-lab网络实验室ccie认证首页博客-程序员的秘密
新版Cisco CCIE EI认证价值及体系,新版Cisco ei新学习必备知识网络安全SSL协议详解SSL(Secure Sockets Layer,安全套接层)是一种为TCP-提供安全连接的安全协议-基于应用层的协议,例如 SSL 可以为 HTTP 协议提供安全连接。SSL协议广泛应用于电子商务、网上银行等领域,为网络上的数据传输提供安全保障。它是在 1990 年开发的,用于保护 Word Wide W...
.NET 框架基础
目录1.什么是.Net平台,.NET Framework2..NET版本3.CLR(公共语言运行时)4.BCL(基本类库)5.@ > FCL(Framework Class Library)3..NET运行机制6.为什么.NET独立于平台7.术语参考:1.什么是.Net平台,.Net平台。NET框架“平台”(这里指软件技术平台,下指这个)能够独立运行、独立存在,提供其所支持的上层系统和应用程序运行的环境。...
vue-router_xiaodingyang's Blog - 程序员的秘密
Vue-router路由后端路由:对于普通的网站,所有的超链接都是URL地址,所有的URL地址都对应服务器上对应的资源;前端路由:对于单页应用,主要通过URL中的哈希(#)实现不同页面之间的切换。同时,hash还有一个特点:HTTP请求不会收录hash相关的内容;因此,单页程序中的页面跳转主要是通过 hash 来实现的;在单页应用中,这种通过hash变化来切换页面的方式称为...
Vue 路由重定向和别名之间的区别解释
重定向重定向也是通过路由配置完成的。下面的例子是从 /a 重定向到 /b: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]} ) 重定向的目标也可以是一个命名的route: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]}) 甚至是方法,动态...
学习 C 与 Java 的类比 - BrightSea 的博客 - 程序员的秘密
上大学的时候,我选修了一个学期的日语。当时,日本老师对我们说:“对于中国人来说,学习英语通常是哭着进去,出来笑着;学日语是笑着进去,哭着出来”。意思是学英语的时候,很难上手,但只要不断学习,改变自己的中文思维习惯,最近就能很好的学好英语。日语虽然不同,但一方面因为它与汉语的密切关系,让我们一上手就有一种似曾相识的感觉;感觉
PHP 数据抓取
PHP数据爬取,CURL这里说的比较简单,在两次爬取的情况下,第二次请求需要第一次数据爬取的结果。例如:提交数据时,需要对页面进行token爬取过程。1.爬取页面,分析页面获取token2.提交数据,第一次获取token带来的问题token通过session保存在后台,当step 1抓取数据,按照步骤2抓取数据 抓取数据时,curl请求其实被当成...
php抓取网页动态数据(使用PHP动态构建PDF文件的基本操作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-18 08:04
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在 Web 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php抓取网页动态数据(使用PHP动态构建PDF文件的基本操作流程及使用方法)
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在 Web 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php抓取网页动态数据(关于PHP获取get变量参数的相关知识介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-18 08:01
我们在设计网页交互时,通常使用PHP中的get变量方法来获取form表单中的数据,从而实现各种网页动态查询或请求。有一点HTML基础的朋友应该都知道HTML表单表单有两种提交方式,即get和post,但是对于新手小白来说,或许这个知识点还是有点模糊。
那么本文文章主要详细介绍get方法,即PHP通过get变量获取表单数据的具体方法和使用方法。稍后,文章会继续为大家介绍post的具体用法。.
这是一个特定的代码示例:
1、form表单代码示例(表单获取提交)
form表单get方法示例 名字:
年龄:
效果如下:
2、test.php代码(php接收get数据)
欢迎 !
你的年龄是 岁。
点击代码1中的提交按钮后,页面出现如下
这里可以注意观察,浏览器地址栏中的链接有什么特点?不难看出,使用 GET 方法从表单发送的任何信息都显示在地址栏中,并且任何人都可以看到。即在 HTML 表单中使用 method="get" 时,所有的变量名和值都会显示在 URL 中。
(注:test.php文件可以通过$_GET变量采集表单数据)
综上所述:发送密码或其他敏感信息时不宜使用此方法!但是仅仅因为可变参数显示在 URL 中,您可以将页面添加到采集夹中。在某些情况下,它也很有用,例如需要直接向用户显示一些信息。
以上介绍了PHP中获取表单get参数的相关知识,希望对有需要的朋友有所帮助。 查看全部
php抓取网页动态数据(关于PHP获取get变量参数的相关知识介绍(一))
我们在设计网页交互时,通常使用PHP中的get变量方法来获取form表单中的数据,从而实现各种网页动态查询或请求。有一点HTML基础的朋友应该都知道HTML表单表单有两种提交方式,即get和post,但是对于新手小白来说,或许这个知识点还是有点模糊。
那么本文文章主要详细介绍get方法,即PHP通过get变量获取表单数据的具体方法和使用方法。稍后,文章会继续为大家介绍post的具体用法。.
这是一个特定的代码示例:
1、form表单代码示例(表单获取提交)
form表单get方法示例 名字:
年龄:
效果如下:

2、test.php代码(php接收get数据)
欢迎 !
你的年龄是 岁。
点击代码1中的提交按钮后,页面出现如下

这里可以注意观察,浏览器地址栏中的链接有什么特点?不难看出,使用 GET 方法从表单发送的任何信息都显示在地址栏中,并且任何人都可以看到。即在 HTML 表单中使用 method="get" 时,所有的变量名和值都会显示在 URL 中。
(注:test.php文件可以通过$_GET变量采集表单数据)
综上所述:发送密码或其他敏感信息时不宜使用此方法!但是仅仅因为可变参数显示在 URL 中,您可以将页面添加到采集夹中。在某些情况下,它也很有用,例如需要直接向用户显示一些信息。
以上介绍了PHP中获取表单get参数的相关知识,希望对有需要的朋友有所帮助。
php抓取网页动态数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-17 15:16
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {<br /> String strURL = "http://ip.chinaz.com/?IP=" + ip;<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> String buf = contentBuf.toString();<br /> int beginIx = buf.indexOf("查询结果[");<br /> int endIx = buf.indexOf("上面四项依次显示的是");<br /> String result = buf.substring(beginIx, endIx);<br /> System.out.println("captureHtml()的结果:\n" + result);<br />}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、在网页上获取 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {<br /> String strURL = "http://www.kiees.cn/sf.php?wen=" + postid<br /> + "&channel=&rnd=0";<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());<br />}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的! 查看全部
php抓取网页动态数据(怎样抓取站点的数据:(1)抓取原网页数据)
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {<br /> String strURL = "http://ip.chinaz.com/?IP=" + ip;<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> String buf = contentBuf.toString();<br /> int beginIx = buf.indexOf("查询结果[");<br /> int endIx = buf.indexOf("上面四项依次显示的是");<br /> String result = buf.substring(beginIx, endIx);<br /> System.out.println("captureHtml()的结果:\n" + result);<br />}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、在网页上获取 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {<br /> String strURL = "http://www.kiees.cn/sf.php?wen=" + postid<br /> + "&channel=&rnd=0";<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());<br />}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!
php抓取网页动态数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-04-16 06:30
说明:只是分享一个解决方案,代码和部分截图不便贴,请谅解!
前段时间,我一直在研究爬虫来爬取网络上的特定数据。如果只是一个静态网页,那就很简单了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
获取Document然后为所欲为,但是一旦遇到一些动态生成的网站就不行了,因为数据是页面加载完成后执行js代码加载的,或者是用户滑动触发的浏览js加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来用Selenium获取动态网页的数据,可以成功获取到数据(实现方法),程序打包在一台机器上运行,开始测试,然后结果不太理想,并且经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。今天早上来到公司,发现程序又被炸了。半夜没人动机器,鼠标键盘都失灵了,只好重启,不说是什么问题,所以测试修改测试太麻烦,所以决定放弃用Selenium,稳定性太差,我考虑用htmlunit等但是那些工具效果不是很好,
首先,动态网页,既然是动态的,肯定是在浏览器加载网页后向服务器发送了网络请求。如果我得到网络请求的url,模拟参数,自己发送请求,解析数据是不是更好,开始工作:
抓包工具:fiddle
不懂fiddle的,建议百度学习一下
安装后打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle中打开这个网页的所有网络请求了:
我不会在这里发图片,我怕人家惹我。. . .
然后就是一一查看网络请求:
先看左边的图标,直接略过图,显然我们需要的是数据,关注文本格式的请求,然后右键copy->just url 把url复制到浏览器看看能不能get,最后找到18行的request就是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json就行了,剩下的就简单了,解析数据。. . . . . . . 略略。. . . . . 话不多说,继续敲代码,这里只是分享一个解析动态网页的方法,欢迎在此发表评论,一起讨论,寻找更好的解决问题的方法!
2016-11-07
迦南香 查看全部
php抓取网页动态数据(分享一种解决方案,代码以及部分截图不方便贴出,请谅解!)
说明:只是分享一个解决方案,代码和部分截图不便贴,请谅解!
前段时间,我一直在研究爬虫来爬取网络上的特定数据。如果只是一个静态网页,那就很简单了。直接使用Jsoup:
Document doc = Jsoup.connect(url).timeout(2000).get();
获取Document然后为所欲为,但是一旦遇到一些动态生成的网站就不行了,因为数据是页面加载完成后执行js代码加载的,或者是用户滑动触发的浏览js加载数据,这样的网页使用Jsoup显然无法获取到想要的数据。
后来用Selenium获取动态网页的数据,可以成功获取到数据(实现方法),程序打包在一台机器上运行,开始测试,然后结果不太理想,并且经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。今天早上来到公司,发现程序又被炸了。半夜没人动机器,鼠标键盘都失灵了,只好重启,不说是什么问题,所以测试修改测试太麻烦,所以决定放弃用Selenium,稳定性太差,我考虑用htmlunit等但是那些工具效果不是很好,
首先,动态网页,既然是动态的,肯定是在浏览器加载网页后向服务器发送了网络请求。如果我得到网络请求的url,模拟参数,自己发送请求,解析数据是不是更好,开始工作:
抓包工具:fiddle
不懂fiddle的,建议百度学习一下
安装后打开fiddle,打开浏览器,打开目标url,然后就可以看到fiddle中打开这个网页的所有网络请求了:
我不会在这里发图片,我怕人家惹我。. . .
然后就是一一查看网络请求:
先看左边的图标,直接略过图,显然我们需要的是数据,关注文本格式的请求,然后右键copy->just url 把url复制到浏览器看看能不能get,最后找到18行的request就是数据接口,可以直接获取数据,而且是json格式!!!!!!!!
真的很爽,直接json就行了,剩下的就简单了,解析数据。. . . . . . . 略略。. . . . . 话不多说,继续敲代码,这里只是分享一个解析动态网页的方法,欢迎在此发表评论,一起讨论,寻找更好的解决问题的方法!
2016-11-07
迦南香
php抓取网页动态数据( 给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2022-04-16 02:24
给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
最近研究了PHP的一些开发技术,发现PHP有很多ASP没有的优秀功能,可以完成一些以前无法完成的功能,比如动态生成HTML静态页面,减少服务器CPU的负载,提高用户访问速度。
我们知道PHP读取MYSQL动态显示时,在大量访问的情况下会出现很多性能问题。如果租用别人的虚拟主机,由于CPU消耗过多,CPU会受到限制,导致网页无法访问。这里我给出一个PHP动态生成HTML的方法,可以大大降低服务器CPU负载。
首先,设置.htaccess文件,将动态调用的参数转换为静态HTML URL地址。比如将post目录下的文件转发到根目录下的wp-post.php文件。添加的语句类似于:
重写规则 ^post/([a-z0-9\-]+\.html)$ wp-post.php?$1$2
然后修改wp-post.php文件,在文件开头添加如下PHP代码:
ob_start();
$qstring = isset($_SERVER["QUERY_STRING"]) ?$_SERVER["QUERY_STRING"] : "";
定义("HTML_FILE", $_SERVER['DOCUMENT_ROOT']."/post/".$qstring);
如果(文件存在(HTML_FILE))
{
$lcft = 文件时间(HTML_FILE);
if (($lcft + 3600) > time()) //判断上次生成的HTML文件是否超过1小时,如果不是,直接输出文件内容
{
回声(file_get_contents(HTML_FILE));
退出(0);
}
}
在现有 PHP 代码之后,然后在当前代码的末尾添加以下 PHP 代码:
定义(“HTMLMETA”,“”);
$buffer = ob_get_flush();
$fp = fopen(HTML_FILE, "w");
如果 ($fp)
{
fwrite($fp, $buffer.HTMLMETA);
fclose($fp);
}
好的,接下来查看你的静态HTML页面,如果页面末尾有注释行,则说明静态HTML文件已经创建成功。
这种方法的一个应用是我之前写的“年度 WordPress 博客统计插件”。由于这个统计插件对数据库的查询次数超过了十次,所以很多人在访问它时会遇到很大的性能问题。使用我介绍的动态 HTML 生成。采用该技术后,每天查询一次,生成统计排名,完美解决了查询数据库的性能问题。
() () 查看全部
php抓取网页动态数据(
给出一个PHP动态生成HTML方法降低服务器CPU负荷(组图))
最近研究了PHP的一些开发技术,发现PHP有很多ASP没有的优秀功能,可以完成一些以前无法完成的功能,比如动态生成HTML静态页面,减少服务器CPU的负载,提高用户访问速度。
我们知道PHP读取MYSQL动态显示时,在大量访问的情况下会出现很多性能问题。如果租用别人的虚拟主机,由于CPU消耗过多,CPU会受到限制,导致网页无法访问。这里我给出一个PHP动态生成HTML的方法,可以大大降低服务器CPU负载。
首先,设置.htaccess文件,将动态调用的参数转换为静态HTML URL地址。比如将post目录下的文件转发到根目录下的wp-post.php文件。添加的语句类似于:
重写规则 ^post/([a-z0-9\-]+\.html)$ wp-post.php?$1$2
然后修改wp-post.php文件,在文件开头添加如下PHP代码:
ob_start();
$qstring = isset($_SERVER["QUERY_STRING"]) ?$_SERVER["QUERY_STRING"] : "";
定义("HTML_FILE", $_SERVER['DOCUMENT_ROOT']."/post/".$qstring);
如果(文件存在(HTML_FILE))
{
$lcft = 文件时间(HTML_FILE);
if (($lcft + 3600) > time()) //判断上次生成的HTML文件是否超过1小时,如果不是,直接输出文件内容
{
回声(file_get_contents(HTML_FILE));
退出(0);
}
}
在现有 PHP 代码之后,然后在当前代码的末尾添加以下 PHP 代码:
定义(“HTMLMETA”,“”);
$buffer = ob_get_flush();
$fp = fopen(HTML_FILE, "w");
如果 ($fp)
{
fwrite($fp, $buffer.HTMLMETA);
fclose($fp);
}
好的,接下来查看你的静态HTML页面,如果页面末尾有注释行,则说明静态HTML文件已经创建成功。
这种方法的一个应用是我之前写的“年度 WordPress 博客统计插件”。由于这个统计插件对数据库的查询次数超过了十次,所以很多人在访问它时会遇到很大的性能问题。使用我介绍的动态 HTML 生成。采用该技术后,每天查询一次,生成统计排名,完美解决了查询数据库的性能问题。
() ()
php抓取网页动态数据(通过selenium的子模块使用Python爬取网页数据的解决思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-14 21:28
1. 文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每一部分,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
2. 解决方案
我试过用网上说的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具),看网络可以得到动态数据的趋势,但这需要从网上找线索许多网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3.实现过程3.1 运行环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有两个文件夹 selenium 和 selenium-2.47.3.dist-info,则表示可以在 Python 程序中加载模块。
使用 webdriver 抓取动态数据
首先导入webdriver子模块
from selenium import webdriver 获取浏览器的session,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
在 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法如下:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考Selenium webdriver(python)教程第3章-定位方法(第一版可百度文库阅读)结合正则表达式过滤相关信息
一些定位的元素是不想要的,可以用常规过滤掉。比如我想只提取英文字符(包括0-9),并建立如下规律)
pa=桩(r'\w+')
为你在 lis 中:
en=pa.findall(u.lis)
打印附上会话
抓取操作完成后,必须关闭session,否则会一直占用内存,影响本机其他进程的运行
browser.close() 或 browser.quit() 都可以关闭会话。前者只关闭当前会话,浏览器的webdriver没有关闭。后者意味着包括webdriver在内的所有东西都被关闭并添加了异常处理。
这是必须的,因为有时候session会失败,所以把上面的语句块放到try里面,然后用exception处理异常
除了 NoSuchElementException:
assert 0, "can't find element"4. 代码实现
我通过点击打开链接抓取了指定分区内每个版块的在线人数,并指定了分区id号(0-9),我可以得到版块名称和对应的在线人数,形成一个列表并打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
结果如下:
终端打印效果
4. 摘要
无论是在代码简洁性还是执行效率方面,selenium 都非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。也可以进一步利用它来实现数据挖掘、机器学习等深度研究。因此,selenium+python 是值得深入学习的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟浏览器,这里不再赘述。 查看全部
php抓取网页动态数据(通过selenium的子模块使用Python爬取网页数据的解决思路)
1. 文章目的
我们在使用Python爬取网页数据时,经常会用到urllib模块,它通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获取url的html内容,然后使用 BeautifulSoup 抓取某个 Tag 内容,结合正则表达式过滤。但是,使用 urllib.urlopen(url).read() 得到的只是网页的静态 html 内容。很多动态数据(如网站访问者数、当前在线人数、微博点赞数等)收录在静态html中,比如我要抓取当前在线人数本bbs网站中的每一部分,不收录静态html页面(不信你尝试查看页面源代码,只有简单的一行)。
2. 解决方案
我试过用网上说的浏览器自带的开发者工具(一般是F12弹出相应网页的开发者工具),看网络可以得到动态数据的趋势,但这需要从网上找线索许多网址。我个人觉得太麻烦了。另外,用查看器查看的html内容也收录动态数据,但是有几个问题:如何实时获取查看器的html内容?如何将查看器的html导入python程序?因此,使用查看器的html内容的方法也不符合爬虫的要求。
偶然发现了selenium模块,发现这个模块可以很方便的根据url加载页面获取session,并找到当前session对应的label。本文将使用 selenium webdriver 模块来获取这些动态生成的内容,尤其是一些重要的动态数据。事实上,selenium 模块的功能并不仅限于爬取网页。它是网络自动化测试的常用模块。它广泛用于 Ruby 和 Java。虽然 Python 用的比较少,但它也是一个非常简单、高效、好用的自动化测试。模块。通过使用selenium的子模块webdriver解决动态数据的抓取问题,也可以对selenium有一个基本的了解,为进一步学习自动化测试打下基础。
3.实现过程3.1 运行环境
我在Windows 7系统上安装了Python 2.7版本,使用Python(X,Y) IDE,安装的Python库没有自带selenium,直接在Python程序中导入selenium会提示有没有这个模块,联网状态下,cmd直接进入pip install selenium,系统会找到Python安装目录直接下载、解压安装这个模块。终端提示完成后,可以查看C:\Python27\Lib\site-packages目录下是否有selenium模块。此目录取决于您安装 Python 的路径。如果有两个文件夹 selenium 和 selenium-2.47.3.dist-info,则表示可以在 Python 程序中加载模块。
使用 webdriver 抓取动态数据
首先导入webdriver子模块
from selenium import webdriver 获取浏览器的session,浏览器可以使用火狐、Chrome、IE等,这里以火狐为例
browser = webdriver.Firefox() 加载页面,url本身可以指定合法字符串
在 browser.get(url) 获取到 session 对象后,为了定位元素,webdriver 提供了一系列的元素定位方法。常用的方法如下:
ID
姓名
班级名称
关联
文本
部分的
关联
文本
标签
姓名
路径
选择器
比如通过id定位,返回所有元素的列表,lis=borwser.find_elements_by_id_name('kw'')
按类名定位,lis=find_elements_by_class_name('title_1')
更详细的定位方法请参考Selenium webdriver(python)教程第3章-定位方法(第一版可百度文库阅读)结合正则表达式过滤相关信息
一些定位的元素是不想要的,可以用常规过滤掉。比如我想只提取英文字符(包括0-9),并建立如下规律)
pa=桩(r'\w+')
为你在 lis 中:
en=pa.findall(u.lis)
打印附上会话
抓取操作完成后,必须关闭session,否则会一直占用内存,影响本机其他进程的运行
browser.close() 或 browser.quit() 都可以关闭会话。前者只关闭当前会话,浏览器的webdriver没有关闭。后者意味着包括webdriver在内的所有东西都被关闭并添加了异常处理。
这是必须的,因为有时候session会失败,所以把上面的语句块放到try里面,然后用exception处理异常
除了 NoSuchElementException:
assert 0, "can't find element"4. 代码实现
我通过点击打开链接抓取了指定分区内每个版块的在线人数,并指定了分区id号(0-9),我可以得到版块名称和对应的在线人数,形成一个列表并打印出来,代码如下
[Python]
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import time
import re
def find_sec(secid):
pa=re.compile(r'\w+')
browser = webdriver.Firefox() # Get local session of firefox
browser.get("http://bbs.byr.cn/#!section/%s "%secid) # Load page
time.sleep(1) # Let the page load
result=[]
try:
#获得版面名称和在线人数,形成列表
board=browser.find_elements_by_class_name('title_1')
ol_num=browser.find_elements_by_class_name('title_4')
max_bindex=len(board)
max_oindex=len(ol_num)
assert max_bindex==max_oindex,'index not equivalent!'
#版面名称有中英文,因此用正则过滤只剩英文的
for i in range(1,max_oindex):
board_en=pa.findall(board[i].text)
result.append([str(board_en[-1]),int(ol_num[i].text)])
browser.close()
return result
except NoSuchElementException:
assert 0, "can't find element"
print find_sec('5') #打印分区5下面的所有板块的当前在线人数列表
结果如下:
终端打印效果
4. 摘要
无论是在代码简洁性还是执行效率方面,selenium 都非常出色。使用 selenium webdriver 捕获动态数据非常简单高效。也可以进一步利用它来实现数据挖掘、机器学习等深度研究。因此,selenium+python 是值得深入学习的!如果觉得每次都用selenium打开浏览器不方便,可以用phantomjs模拟一个虚拟浏览器,这里不再赘述。
php抓取网页动态数据(优点就是无论你如何访问都有不好的地方?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-04-08 23:14
最近学习了静态页面,感觉静态页面真的很不错。它们可以提高网站页面的响应速度,减轻服务器压力,减少对数据库的访问等等,但是技术有两个方面,静态页面也不好。以下是我自己查阅别人资料的总结,希望对大家有用。
1、首先我们来介绍一下静态页面和动态页面
(1)静态网页实际上是存在的,可以直接加载到客户端浏览器中,无需经过服务器编译。静态页面需要占用一定的服务器空间,不能独立管理和发布更新的页面。如果您要更新网页的内容应该通过FTP软件DOWN下载,并用网页制作软件修改(通过fso等技术除外)。
使用静态页面的方法可以将数据库和后台系统与前台分离。两者之间没有绝对的联系。从而提高网站的安全性。这些是静态页面的最大优势。快速、跨平台、跨服务器。
静态网页的缺点在于其管理、维护和交互功能的局限性。静态网页的优势在于信息内容的稳定性,为搜索引擎在互联网上索引网页信息提供了便利。网站在建设中使用静态网页只是帮助搜索引擎索引信息,但并不代表只要是静态网页就一定会被搜索引擎搜索到收录@ >,动态网页肯定不会被搜索引擎搜索到。收录@>。
(2)动态页面是用ASP、PHP、JSP、Perl或CGI等编程语言制作的;动态页面实际上并不是服务器上独立存在的web文件,服务器返回一个完整的web页面;动态页面上的内容存在于数据库中,根据用户发出的不同请求,提供个性化的网页内容;动态页面内容不存在于页面上,而是存在于数据库中,大大减少了网站 维护工作量;
动态页面是一对多的访问。通过一个页面。它的不同数据可以根据几个参数返回。但是,由于静态页面是静态的,所以一页对应一种内容,即一对一的关系。这样做的好处是,无论你如何访问它,你只是让服务器将数据传递给请求者。不做脚本计算,不读取后台数据库。从而大大提高了访问速度,降低了一些安全隐患。
2、静态页面和动态页面的区别
静态网页和动态网页的主要区别在于程序是否在服务器上运行。客户端上运行的程序、页面等都是静态页面,而且总是一样的。
静态网页和动态网页具有不同的特点。一个网站使用什么样的页面取决于这个网站有什么功能以及网站里面有多少内容,如果这个网站的内容变化不是很快,而 网站 的功能并没有那么复杂。使用静态网页运行网站相对简单。相反,必须使用动态页面来完成网站。
3、什么时候应该使用静态页面,什么时候应该使用动态页面?
(1)如果这个网站的内容变化不是很快,网站的功能就没那么复杂了,用静态网页跑起来比较简单网站.相反你必须使用动态网页来完成一个网站。
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;静态页面无法实现这些功能。
(3)html就是我们一般所说的静态网站。一般来说静态几乎是从不更新的,尤其是新闻系统cms,生成的页面会很少被修改;动态页面经常有很多实时性要求,确实在实际应用中用在网站内容更新比较频繁的地方,可以看正反。
4、动态页面静态技术
(1)一个网站构造的基础是静态网页,静态网页和动态网页并非互不兼容。为了提高网站中的搜索速度,动态网页使用了web技术的网站,也可以将网页内容转成静态网页运行,将网页转成静态是网站开发的一个很好的方法,这可以提高打开网页的速度。
(2)动态页面静态方法
方法一:使用现成的插件,如Apache HTTP server的ISAPI_Rewrite、IIS Rewrite、mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。请参阅他们自己的帮助以了解如何使用它们。
方法2:编写自己的代码,使动态网页静态化。有几种方法:
1、创建一个FSO对象,并使用该对象将需要的内容动态创建成文件,生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端,获取返回的资源,生成静态页面。一般只需要通过这种方式获取网页的内容,其他资源都可以放在服务器上自动加载。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
5、面对当今搜索引擎技术需要考虑的问题
(1)静态化可以提升程序的性能,但并不是提升整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡和好的内存是不行的,它要看整体性能,很多时候是开发者的原因,导致程序本身性能不好,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个应用程序的性能。
(2)每一个网站不但不会像以前那样把它封起来,而是热情地从事SEO,所谓的面向搜索引擎的优化,其中包括重写访问地址,使动态网页 看起来是一个静态网页,以便更多地被搜索引擎收录@>使用,从而最大化自己的内容被目标接收的机会。然而,在完全动态的技术发展中网站,一眨眼,就要求转成静态网页,同时,无论如何,动态网页的内容管理功能必须保留;就像飞奔驰突然要求180度转弯,付出的代价非常大。真的值得,也确实值得怀疑。
(3)静态页面对网站收录@>有好处吗?(这要看现在的搜索引擎开发的技术)
搜索引擎优化的一般观点认为静态页面有利于搜索引擎优化,所以生成了很多搜索引擎优化和重构网站页面,不得不把自己的网站变成伪静态 URL,以提高您的 SEO 性能。然而,搜索引擎优化已经发展了好几年。过去静态确实可以取得很大的效果,但现在还有用吗?
动态体验比静态体验更好,因为信息更新得更快。搜索引擎最重要的是搜索用户体验。
二是搜索引擎更新频率低,百度蜘蛛访问asp页面的频率远高于html。
3. 搜索引擎优化是为了提高一个人的网站在搜索引擎中的排名。恐怕这是每个搜索引擎优化都承认的事实。网站 优化服务,不过现在已经没有太大优势了。
第四,随着搜索引擎技术的进步,尤其是google对动态代码索引非常精通,技术水平已经完全达到了索引html的能力,并没有什么区别。
五个 hmtl 页面也会随着时间的推移而减少。
六个html页面不能增加收录@>的数量,我在做网站的时候发现asp网站的收录@>比html多。
7.请不要低估搜索引擎的力量。搜索引擎还没有超越“?”的障碍?象征?仍然认为静态更容易刮?
转载于: 查看全部
php抓取网页动态数据(优点就是无论你如何访问都有不好的地方?(组图))
最近学习了静态页面,感觉静态页面真的很不错。它们可以提高网站页面的响应速度,减轻服务器压力,减少对数据库的访问等等,但是技术有两个方面,静态页面也不好。以下是我自己查阅别人资料的总结,希望对大家有用。
1、首先我们来介绍一下静态页面和动态页面
(1)静态网页实际上是存在的,可以直接加载到客户端浏览器中,无需经过服务器编译。静态页面需要占用一定的服务器空间,不能独立管理和发布更新的页面。如果您要更新网页的内容应该通过FTP软件DOWN下载,并用网页制作软件修改(通过fso等技术除外)。
使用静态页面的方法可以将数据库和后台系统与前台分离。两者之间没有绝对的联系。从而提高网站的安全性。这些是静态页面的最大优势。快速、跨平台、跨服务器。
静态网页的缺点在于其管理、维护和交互功能的局限性。静态网页的优势在于信息内容的稳定性,为搜索引擎在互联网上索引网页信息提供了便利。网站在建设中使用静态网页只是帮助搜索引擎索引信息,但并不代表只要是静态网页就一定会被搜索引擎搜索到收录@ >,动态网页肯定不会被搜索引擎搜索到。收录@>。
(2)动态页面是用ASP、PHP、JSP、Perl或CGI等编程语言制作的;动态页面实际上并不是服务器上独立存在的web文件,服务器返回一个完整的web页面;动态页面上的内容存在于数据库中,根据用户发出的不同请求,提供个性化的网页内容;动态页面内容不存在于页面上,而是存在于数据库中,大大减少了网站 维护工作量;
动态页面是一对多的访问。通过一个页面。它的不同数据可以根据几个参数返回。但是,由于静态页面是静态的,所以一页对应一种内容,即一对一的关系。这样做的好处是,无论你如何访问它,你只是让服务器将数据传递给请求者。不做脚本计算,不读取后台数据库。从而大大提高了访问速度,降低了一些安全隐患。
2、静态页面和动态页面的区别
静态网页和动态网页的主要区别在于程序是否在服务器上运行。客户端上运行的程序、页面等都是静态页面,而且总是一样的。
静态网页和动态网页具有不同的特点。一个网站使用什么样的页面取决于这个网站有什么功能以及网站里面有多少内容,如果这个网站的内容变化不是很快,而 网站 的功能并没有那么复杂。使用静态网页运行网站相对简单。相反,必须使用动态页面来完成网站。
3、什么时候应该使用静态页面,什么时候应该使用动态页面?
(1)如果这个网站的内容变化不是很快,网站的功能就没那么复杂了,用静态网页跑起来比较简单网站.相反你必须使用动态网页来完成一个网站。
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;静态页面无法实现这些功能。
(3)html就是我们一般所说的静态网站。一般来说静态几乎是从不更新的,尤其是新闻系统cms,生成的页面会很少被修改;动态页面经常有很多实时性要求,确实在实际应用中用在网站内容更新比较频繁的地方,可以看正反。
4、动态页面静态技术
(1)一个网站构造的基础是静态网页,静态网页和动态网页并非互不兼容。为了提高网站中的搜索速度,动态网页使用了web技术的网站,也可以将网页内容转成静态网页运行,将网页转成静态是网站开发的一个很好的方法,这可以提高打开网页的速度。
(2)动态页面静态方法
方法一:使用现成的插件,如Apache HTTP server的ISAPI_Rewrite、IIS Rewrite、mod_rewrite等,都是基于正则表达式解析器开发的重写引擎。请参阅他们自己的帮助以了解如何使用它们。
方法2:编写自己的代码,使动态网页静态化。有几种方法:
1、创建一个FSO对象,并使用该对象将需要的内容动态创建成文件,生成HTML页面;
2、使用模板技术,将模板中特殊代码的值替换为从表单或数据库字段接收到的值,生成HTML文件;
3、使用Server.Transfer转换技术,
方法三:使用HttpWebRequest请求客户端,获取返回的资源,生成静态页面。一般只需要通过这种方式获取网页的内容,其他资源都可以放在服务器上自动加载。(注:此方法缺点明显,需要对匹配的URL进行大量修改,建议谨慎使用)
5、面对当今搜索引擎技术需要考虑的问题
(1)静态化可以提升程序的性能,但并不是提升整体性能的根本原因。就像电脑一样,只有好的CPU或者好的显卡和好的内存是不行的,它要看整体性能,很多时候是开发者的原因,导致程序本身性能不好,所以最好以项目本身的性能为基础,辅以其他优化方法,最终提升整个应用程序的性能。
(2)每一个网站不但不会像以前那样把它封起来,而是热情地从事SEO,所谓的面向搜索引擎的优化,其中包括重写访问地址,使动态网页 看起来是一个静态网页,以便更多地被搜索引擎收录@>使用,从而最大化自己的内容被目标接收的机会。然而,在完全动态的技术发展中网站,一眨眼,就要求转成静态网页,同时,无论如何,动态网页的内容管理功能必须保留;就像飞奔驰突然要求180度转弯,付出的代价非常大。真的值得,也确实值得怀疑。
(3)静态页面对网站收录@>有好处吗?(这要看现在的搜索引擎开发的技术)
搜索引擎优化的一般观点认为静态页面有利于搜索引擎优化,所以生成了很多搜索引擎优化和重构网站页面,不得不把自己的网站变成伪静态 URL,以提高您的 SEO 性能。然而,搜索引擎优化已经发展了好几年。过去静态确实可以取得很大的效果,但现在还有用吗?
动态体验比静态体验更好,因为信息更新得更快。搜索引擎最重要的是搜索用户体验。
二是搜索引擎更新频率低,百度蜘蛛访问asp页面的频率远高于html。
3. 搜索引擎优化是为了提高一个人的网站在搜索引擎中的排名。恐怕这是每个搜索引擎优化都承认的事实。网站 优化服务,不过现在已经没有太大优势了。
第四,随着搜索引擎技术的进步,尤其是google对动态代码索引非常精通,技术水平已经完全达到了索引html的能力,并没有什么区别。
五个 hmtl 页面也会随着时间的推移而减少。
六个html页面不能增加收录@>的数量,我在做网站的时候发现asp网站的收录@>比html多。
7.请不要低估搜索引擎的力量。搜索引擎还没有超越“?”的障碍?象征?仍然认为静态更容易刮?
转载于:
php抓取网页动态数据(动态网页网页用XHR局部获取数据,需要动态抓取网页发起的请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-04-08 23:01
动态网页
网页使用 XHR 在本地获取数据。要捕获此类数据,您需要找到 XHR URL。此类 URL 通常收录令牌,这些令牌将在一段时间后过期。因此,需要动态抓取网页发起的请求。
1
2
3
XHR含有Token的URL
https://****/****?Id=5&token=99aeacc27dc64c1124f1e25dc0666c10
剧作家
PlayWright是微软开发的一款浏览器模拟神器,其中Network Event可以监控网页发送的请求和响应。
稍微修改代码以满足您的需求
只监听响应,如果response.url收录关键字,输出对应的url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from playwright.sync_api import sync_playwright
def run(playwright) -> None:
# browser = playwright.chromium.launch(headless=False)
browser = playwright.chromium.launch()
context = browser.new_context()
# Open new page
page = context.new_page()
# page.on("request", lambda request: print(request.url))
page.on("response", res)
# Go to
page.goto("https://****/****")
# ---------------------
context.close()
browser.close()
def res(res) -> None:
if "id" in res.url:
print(res.url)
with sync_playwright() as playwright:
run(playwright)
后续PowerBi支持调用Python返回数据集。 response.json()可以返回json格式的数据,导入pandas返回PowerBi,应该可以直接获取数据集。 PlayWright 支持 C#,理论上应该可以使用 VSTO 将数据返回给 EXCEL。 查看全部
php抓取网页动态数据(动态网页网页用XHR局部获取数据,需要动态抓取网页发起的请求)
动态网页
网页使用 XHR 在本地获取数据。要捕获此类数据,您需要找到 XHR URL。此类 URL 通常收录令牌,这些令牌将在一段时间后过期。因此,需要动态抓取网页发起的请求。
1
2
3
XHR含有Token的URL
https://****/****?Id=5&token=99aeacc27dc64c1124f1e25dc0666c10
剧作家
PlayWright是微软开发的一款浏览器模拟神器,其中Network Event可以监控网页发送的请求和响应。
稍微修改代码以满足您的需求
只监听响应,如果response.url收录关键字,输出对应的url
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
from playwright.sync_api import sync_playwright
def run(playwright) -> None:
# browser = playwright.chromium.launch(headless=False)
browser = playwright.chromium.launch()
context = browser.new_context()
# Open new page
page = context.new_page()
# page.on("request", lambda request: print(request.url))
page.on("response", res)
# Go to
page.goto("https://****/****")
# ---------------------
context.close()
browser.close()
def res(res) -> None:
if "id" in res.url:
print(res.url)
with sync_playwright() as playwright:
run(playwright)
后续PowerBi支持调用Python返回数据集。 response.json()可以返回json格式的数据,导入pandas返回PowerBi,应该可以直接获取数据集。 PlayWright 支持 C#,理论上应该可以使用 VSTO 将数据返回给 EXCEL。
php抓取网页动态数据(php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-08 04:10
php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?网页内容你还可以用xpath爬取列表数据...更多代码请到牛客网vps上抓取的话我不大清楚xpath,本人没接触过
python获取网页动态数据的简单爬虫
一、获取网页源码python通过内建的selenium库从本地获取网页源码python内置selenium库,可使用其操作web浏览器,且支持桌面应用浏览器。另外,selenium还可以实现本地和远程的网络通信。
1。python调用webdriver设置webdriver对象webdriver。import_device("usb")#设置usb模式为usb设备in。environ。usage("d:\\html")#设置浏览器user=document。createelement("div。tags-list")#第一个div为标签,"tags"为子标签in。
environ。usage("d:\\word")#设置浏览器user。screenshot()#设置浏览器user。screenshot()#分析页面标签信息2。python从网页源码中获取内容python利用requests模块实现网页的抓取(在python中)#导入http模块importrequestsdriver=webdriver。
request()#获取网页内容url="-webpages。html"#网页内容content=url+driver。format(user。ip,page=。
1)#当content中的"-webpages.html"为html页面中的内容。如果没有内容,
二、正则表达式反爬requests可以通过正则表达式抓取网页内容,正则表达式的使用,可以将一个网页中的所有的url按照某个字符串组合拆分成一个有序列表,再查询这个有序列表的每个元素是否存在,如果存在的话则返回一个字符串,否则返回一个包含大量无序元素的列表。正则表达式要通过google搜索引擎来分析,可以直接访问。
正则表达式的全称为regularexpression,是一种用于python的正则表达式库,也是python程序内置的正则表达式库。在代码中正则表达式可以解析由一系列整数(包括字符串)组成的字符串,这些字符串则通过正则表达式来匹配。
三、requests的封装有限的网页浏览时间内往往无法访问到很多关键数据,因此,网页中的链接一般会使用post传输,请求的数据都是整数,所以使用正则表达式获取http数据的方法是get请求。以下是封装的网页网址,请尽量用下划线分隔起来。#获取网页内容url="-webpages.html"#这个地址是通过dns查询的,因此页面内容往往是内嵌的,不能发布到互联网上。#获取网页内容page=0#默认返回tru。 查看全部
php抓取网页动态数据(php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?)
php抓取网页动态数据的方法抓取上链接:php的反爬虫技术和技巧有哪些?网页内容你还可以用xpath爬取列表数据...更多代码请到牛客网vps上抓取的话我不大清楚xpath,本人没接触过
python获取网页动态数据的简单爬虫
一、获取网页源码python通过内建的selenium库从本地获取网页源码python内置selenium库,可使用其操作web浏览器,且支持桌面应用浏览器。另外,selenium还可以实现本地和远程的网络通信。
1。python调用webdriver设置webdriver对象webdriver。import_device("usb")#设置usb模式为usb设备in。environ。usage("d:\\html")#设置浏览器user=document。createelement("div。tags-list")#第一个div为标签,"tags"为子标签in。
environ。usage("d:\\word")#设置浏览器user。screenshot()#设置浏览器user。screenshot()#分析页面标签信息2。python从网页源码中获取内容python利用requests模块实现网页的抓取(在python中)#导入http模块importrequestsdriver=webdriver。
request()#获取网页内容url="-webpages。html"#网页内容content=url+driver。format(user。ip,page=。
1)#当content中的"-webpages.html"为html页面中的内容。如果没有内容,
二、正则表达式反爬requests可以通过正则表达式抓取网页内容,正则表达式的使用,可以将一个网页中的所有的url按照某个字符串组合拆分成一个有序列表,再查询这个有序列表的每个元素是否存在,如果存在的话则返回一个字符串,否则返回一个包含大量无序元素的列表。正则表达式要通过google搜索引擎来分析,可以直接访问。
正则表达式的全称为regularexpression,是一种用于python的正则表达式库,也是python程序内置的正则表达式库。在代码中正则表达式可以解析由一系列整数(包括字符串)组成的字符串,这些字符串则通过正则表达式来匹配。
三、requests的封装有限的网页浏览时间内往往无法访问到很多关键数据,因此,网页中的链接一般会使用post传输,请求的数据都是整数,所以使用正则表达式获取http数据的方法是get请求。以下是封装的网页网址,请尽量用下划线分隔起来。#获取网页内容url="-webpages.html"#这个地址是通过dns查询的,因此页面内容往往是内嵌的,不能发布到互联网上。#获取网页内容page=0#默认返回tru。
php抓取网页动态数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-04-08 01:31
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); // 用你自己的字符串替换 $str。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL); 查看全部
php抓取网页动态数据(抓取的网页如何存入mysql数据库写的一个PHP代码(test.php))
爬取的网页如何存储在mysql数据库中
编写一个PHP代码(test.php):
如何将这个网页数据存储在mysql数据库中?表为页面字段 1:Pageid |字段 2:页面文本
请求代码
--------解决方案--------
这不就是插入吗?
值有,字段也有。 . .
--------解决方案--------
如果 pageid 是自动递增的。也有空缺。
$sql="insert into `Page` values('','$contents')";
--------解决方案--------
preg_match_all('/(.*?)/is',$str,$match); // 用你自己的字符串替换 $str。
print_r($match);
--------解决方案--------
PHP 代码
$contents = file_get_contents('a.php');preg_match_all('/()/iUs', $contents, $match);//如果有多个结果需要匹配,则输出匹配数组并将其组织成一个字符串 ...$contents = $match[1][0];mysql_connect('localhost', 'root', '');mysql_select_db("lookdb");mysql_query("SET NAMES 'GBK'" );$SQL = "INSERT INTO page (pagetext) VALUES('{$contents}')";mysql_query($SQL);
php抓取网页动态数据( 接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-05 11:09
接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
如何将php动态页面转换为html静态页面
虽然我们都喜欢动态页面更好看的页面,但静态页面也有着不可替代的作用。接下来,我们来看看如何将PHP动态页面转换为HTML静态页面!更多内容请关注应届生网站!
当动态网页遇到搜索引擎
尽管动态网页比静态网页有很多优势,但它们在搜索引擎检索方面取得了很大的成功。无论任何网站,尤其是那些出于营销目的的公司网站,没有人希望他们的网页不被搜索引擎检索到。但实际上是这样的:很多动态设计的内容页面网站 无法被搜索引擎检索到。
一般来说,搜索引擎都会把“?” 动态网页地址中出现的字符作为“停止标记”,其后的所有参数都将被忽略。比如“index.php?category=x”的所有子页面,最后只有一个url被搜索引擎检索到,那就是页面index.php。这样一来,动态网页就处于无法被搜索引擎发现和检索到的尴尬境地,直接失去了被用户发现的机会和搜索引擎广阔的市场空间。
搜索引擎不支持动态网页的原因
动态网页是由数据库驱动的,这使得搜索引擎在面对无数的URL时面临着被数据库陷入死循环的危险,也就是我们所说的蜘蛛陷阱。而一旦蜘蛛被网站困住,它对数据库的重复访问请求也会导致网站服务器系统完全瘫痪。有鉴于此,搜索引擎不会读取“?”后面的字符。在动态网页的url中。
php转html静态页面
虽然不能保证每一个动态页面都会转换成静态的html文件,但是如果网站驻留在apache服务器上,一个简单的小脚本就可以将大部分动态页面转换成html文件。
1.确保需要转换成后缀为html的php文件
我们的目标是在其名称下有很多动态子页面的页面。以“index.php?category=x”为例,我们需要转换“index.php”之后的动态子页面。例如,如果网站中有一个名为“arts and crafts”的子目录,并且url为“index.php?category=1”,那么其他子目录与这个url只有最后一个变量不同,所以我们需要修改服务器在 index.php 后跟一个变量时打开它的方式。
2.在接受来自html页面的调用请求后通知服务器打开一个php文件
我们需要在服务器上 index.php 所在的目录中放置一个 .htaccess 文本文件。.htaccess文件是apache服务器上的一个目录配置设置文件,它提供了一种改变目录配置的方法,即在特定的文档目录中放置一个收录一个或多个指令的文件(.htaccess文件)到Acts在此目录及其所有子目录中。.htaccess的功能包括设置网页密码、设置出错时出现的文件、更改主页文件名、禁止读取文件名、重定向文件、添加mime类别、禁止目录中的文件。
当需要为在服务器系统上没有 root 权限的目录更改服务器配置时,应使用 .htaccess 文件。如果服务器管理员不愿意频繁修改配置,可以通过.htaccess文件允许用户自己修改配置,特别是当isp在一台机器上提供多个用户站点,并且期望用户更改配置时他自己。开放一些.htaccess 功能供用户自行设置。对于 vdeck 用户,可能需要先创建一个文本文件,然后在管理面板中将其重命名为 .htaccess。现在我们需要在服务器端指定一些变量。比如我需要把变量“?category=x”改成“directory-x.html”,
在开始创建服务器变量之前,我们需要在这个新创建的.htaccess文件中创建一个重写引擎(url重写工具)。只需写在文件的第一行
重写引擎
这相当于告诉服务器我们要更改某些文件的处理方式。下一行指定了重写规则:
rewriterule ^directory-([0-9]*.* index.php?category=$1 [l,nc]
该指令表示只要收到对url中收录“directory-0”到“directory-9”的任何静态网页的页面调用请求,服务器就会返回“index.php?变量”的地址给调用者用户。
不要急于编辑下一个重写规则,我们需要在更改实际的php页面之前对其进行测试。我们可以测试一下上面的“重写规则”。首先打开一个新的浏览器窗口,在地址栏中输入“directory-1.htm”或者“directory-1.html”,如果我们看到的页面显示为“index.php?category=1” " 表示重写规则工作正常。
3.让搜索引擎看到我们的静态页面
现在,我们需要启用搜索引擎来查看我们新的“改头换面”网址。那么,我需要再次向搜索引擎提交 网站 吗?不用那么辛苦,我们只需要打开php文件,编辑一下。但在此之前,请记住对要修改的每个脚本进行备份并将其存储在硬盘上。然后,您需要确定创建更改链接地址的程序的不同位置。在前端进行更改比在后台进行更改要好。php 文件将从 .htaccess 文件中获取诸如“index.php?category=x”之类的信息。我们需要更改这些动态生成的网页地址,并将它们作为静态页面地址展示给用户和搜索引擎。即把所有url中收录“index.php?category=”的部分替换为“
【如何将php动态网页转换成html静态页面】相关文章:
用php技术生成静态页面的方法08-15
PHP网站页面静态生成方法10-05
PHP06-07动态HTML输出技术详解
用PHP08-15自动将纯文本转换为网页
互动页面网页设计 12-06
PHP简单伪静态示例11-17
PHP伪静态方法11-17
php的apache伪静态08-24
php10-27如何爬取页面
PHP页面跳转技巧10-17 查看全部
php抓取网页动态数据(
接下来看看PHP动态页面怎么转换为HTML静态页面吧!)
如何将php动态页面转换为html静态页面
虽然我们都喜欢动态页面更好看的页面,但静态页面也有着不可替代的作用。接下来,我们来看看如何将PHP动态页面转换为HTML静态页面!更多内容请关注应届生网站!
当动态网页遇到搜索引擎
尽管动态网页比静态网页有很多优势,但它们在搜索引擎检索方面取得了很大的成功。无论任何网站,尤其是那些出于营销目的的公司网站,没有人希望他们的网页不被搜索引擎检索到。但实际上是这样的:很多动态设计的内容页面网站 无法被搜索引擎检索到。
一般来说,搜索引擎都会把“?” 动态网页地址中出现的字符作为“停止标记”,其后的所有参数都将被忽略。比如“index.php?category=x”的所有子页面,最后只有一个url被搜索引擎检索到,那就是页面index.php。这样一来,动态网页就处于无法被搜索引擎发现和检索到的尴尬境地,直接失去了被用户发现的机会和搜索引擎广阔的市场空间。
搜索引擎不支持动态网页的原因
动态网页是由数据库驱动的,这使得搜索引擎在面对无数的URL时面临着被数据库陷入死循环的危险,也就是我们所说的蜘蛛陷阱。而一旦蜘蛛被网站困住,它对数据库的重复访问请求也会导致网站服务器系统完全瘫痪。有鉴于此,搜索引擎不会读取“?”后面的字符。在动态网页的url中。
php转html静态页面
虽然不能保证每一个动态页面都会转换成静态的html文件,但是如果网站驻留在apache服务器上,一个简单的小脚本就可以将大部分动态页面转换成html文件。
1.确保需要转换成后缀为html的php文件
我们的目标是在其名称下有很多动态子页面的页面。以“index.php?category=x”为例,我们需要转换“index.php”之后的动态子页面。例如,如果网站中有一个名为“arts and crafts”的子目录,并且url为“index.php?category=1”,那么其他子目录与这个url只有最后一个变量不同,所以我们需要修改服务器在 index.php 后跟一个变量时打开它的方式。
2.在接受来自html页面的调用请求后通知服务器打开一个php文件
我们需要在服务器上 index.php 所在的目录中放置一个 .htaccess 文本文件。.htaccess文件是apache服务器上的一个目录配置设置文件,它提供了一种改变目录配置的方法,即在特定的文档目录中放置一个收录一个或多个指令的文件(.htaccess文件)到Acts在此目录及其所有子目录中。.htaccess的功能包括设置网页密码、设置出错时出现的文件、更改主页文件名、禁止读取文件名、重定向文件、添加mime类别、禁止目录中的文件。
当需要为在服务器系统上没有 root 权限的目录更改服务器配置时,应使用 .htaccess 文件。如果服务器管理员不愿意频繁修改配置,可以通过.htaccess文件允许用户自己修改配置,特别是当isp在一台机器上提供多个用户站点,并且期望用户更改配置时他自己。开放一些.htaccess 功能供用户自行设置。对于 vdeck 用户,可能需要先创建一个文本文件,然后在管理面板中将其重命名为 .htaccess。现在我们需要在服务器端指定一些变量。比如我需要把变量“?category=x”改成“directory-x.html”,
在开始创建服务器变量之前,我们需要在这个新创建的.htaccess文件中创建一个重写引擎(url重写工具)。只需写在文件的第一行
重写引擎
这相当于告诉服务器我们要更改某些文件的处理方式。下一行指定了重写规则:
rewriterule ^directory-([0-9]*.* index.php?category=$1 [l,nc]
该指令表示只要收到对url中收录“directory-0”到“directory-9”的任何静态网页的页面调用请求,服务器就会返回“index.php?变量”的地址给调用者用户。
不要急于编辑下一个重写规则,我们需要在更改实际的php页面之前对其进行测试。我们可以测试一下上面的“重写规则”。首先打开一个新的浏览器窗口,在地址栏中输入“directory-1.htm”或者“directory-1.html”,如果我们看到的页面显示为“index.php?category=1” " 表示重写规则工作正常。
3.让搜索引擎看到我们的静态页面
现在,我们需要启用搜索引擎来查看我们新的“改头换面”网址。那么,我需要再次向搜索引擎提交 网站 吗?不用那么辛苦,我们只需要打开php文件,编辑一下。但在此之前,请记住对要修改的每个脚本进行备份并将其存储在硬盘上。然后,您需要确定创建更改链接地址的程序的不同位置。在前端进行更改比在后台进行更改要好。php 文件将从 .htaccess 文件中获取诸如“index.php?category=x”之类的信息。我们需要更改这些动态生成的网页地址,并将它们作为静态页面地址展示给用户和搜索引擎。即把所有url中收录“index.php?category=”的部分替换为“
【如何将php动态网页转换成html静态页面】相关文章:
用php技术生成静态页面的方法08-15
PHP网站页面静态生成方法10-05
PHP06-07动态HTML输出技术详解
用PHP08-15自动将纯文本转换为网页
互动页面网页设计 12-06
PHP简单伪静态示例11-17
PHP伪静态方法11-17
php的apache伪静态08-24
php10-27如何爬取页面
PHP页面跳转技巧10-17
php抓取网页动态数据(第一讲概述PHP*信装帆嘉奔正确挽章迷搽觉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-05 09:14
第1讲- PHP概述 第01讲- PHP概述 Web概述 2-1 Web架构 Web系统的结构采用客户端-服务器(client/server,C/S)架构。Web 服务器是服务器端计算机和在其上运行的 Web 服务器软件的总和。Web服务器软件是一个全天候运行的程序,负责监控Web浏览器向服务器发送的网页请求,提供相应的网页,并将其发送回客户端的浏览器。*1、请求网页4、接收HTML文件2、接收网页3、下载HTML文件Web客户端Web服务器讲座01-PHP概述讲座01-PHP概述:主页功能 主页是输入 网站 时看到的第一页,并提供到 网站 其他部分的链接
超链接功能超文本是一种在线信息表示和管理技术,它将网页中的文本或图形与地理上分散的信息联系起来。这种相关信息的链接称为“超链接”。页面的交互交互是网站响应用户操作和选择的方式。互动网站将吸引更多用户参与,让用户选择自己想看的内容,而不是静态展示信息。*欢专访鸵鸟姐姐狄朔遂徐茂转窝抽烟斗案例6-1 静态网页和动态网页静态网页是内容由一些HTML代码组成的网页,可以直接输入通过文本编辑器保存为 .htm 或 .html 文件。所以,静态网页的内容在创建时已经确定。任何时候浏览静态网页的用户都会看到相同的信息。动态网页 动态网页是通过在网页中添加程序或脚本,使用ASP、PHP、CGI、JSP等技术动态生成的页面。*囤雾哀恸铱浆嚣张金耀丹过世护法动耳腔配间谍肥李蒸璧筑洗依命丫卫生间引擎盖爆炸讲座01-PHP概述讲座01-PHP概述基于数据库的动态web工作模式6 -2 静态网页和动态网页对比静态网页和动态网页,浏览速度快,网页样式灵活多样,维护简单,修改方便,交互性好,交互性差,
目前可与服务器交互的客户端动态Web开发技术主要有: Javaapplet程序 Javaapplet程序通过JDBC提供数据库支持,实现客户端浏览器与数据库服务器的数据交互。ActiveX控件用户下载ActiveX程序,安装并执行ActiveX程序,无需通过Web服务器,即可直接向数据库发送数据或从数据库中获取数据。*多足峡逆道、多宾、远纳、瘦弱、枯萎、窒息、窒息、壮丽、枯萎、宫殿、邻居、唐、懈怠。Lecture 01 - PHP Overview Lecture 01 - PHP Overview 基于数据库的动态Web工作模式 6-4 动态Web工作模式 服务器端动态Web工作模式 服务器端动态网页是通过执行应用程序动态生成的网页在 Web 服务器上并从后台数据库中获取数据。常见的web服务器动态web技术有CGI、PHP、ASP、JSP等,下面简单介绍一下。CGI ongateway interface,CGI)是Web服务器与外部应用程序之间交换数据的标准接口软件,是最早创建动态网页的机制。PHP 超文本预处理器 (PHP) 是一种易于学习且易于使用的服务器端脚本语言,用于创建动态网页。 查看全部
php抓取网页动态数据(第一讲概述PHP*信装帆嘉奔正确挽章迷搽觉)
第1讲- PHP概述 第01讲- PHP概述 Web概述 2-1 Web架构 Web系统的结构采用客户端-服务器(client/server,C/S)架构。Web 服务器是服务器端计算机和在其上运行的 Web 服务器软件的总和。Web服务器软件是一个全天候运行的程序,负责监控Web浏览器向服务器发送的网页请求,提供相应的网页,并将其发送回客户端的浏览器。*1、请求网页4、接收HTML文件2、接收网页3、下载HTML文件Web客户端Web服务器讲座01-PHP概述讲座01-PHP概述:主页功能 主页是输入 网站 时看到的第一页,并提供到 网站 其他部分的链接
超链接功能超文本是一种在线信息表示和管理技术,它将网页中的文本或图形与地理上分散的信息联系起来。这种相关信息的链接称为“超链接”。页面的交互交互是网站响应用户操作和选择的方式。互动网站将吸引更多用户参与,让用户选择自己想看的内容,而不是静态展示信息。*欢专访鸵鸟姐姐狄朔遂徐茂转窝抽烟斗案例6-1 静态网页和动态网页静态网页是内容由一些HTML代码组成的网页,可以直接输入通过文本编辑器保存为 .htm 或 .html 文件。所以,静态网页的内容在创建时已经确定。任何时候浏览静态网页的用户都会看到相同的信息。动态网页 动态网页是通过在网页中添加程序或脚本,使用ASP、PHP、CGI、JSP等技术动态生成的页面。*囤雾哀恸铱浆嚣张金耀丹过世护法动耳腔配间谍肥李蒸璧筑洗依命丫卫生间引擎盖爆炸讲座01-PHP概述讲座01-PHP概述基于数据库的动态web工作模式6 -2 静态网页和动态网页对比静态网页和动态网页,浏览速度快,网页样式灵活多样,维护简单,修改方便,交互性好,交互性差,
目前可与服务器交互的客户端动态Web开发技术主要有: Javaapplet程序 Javaapplet程序通过JDBC提供数据库支持,实现客户端浏览器与数据库服务器的数据交互。ActiveX控件用户下载ActiveX程序,安装并执行ActiveX程序,无需通过Web服务器,即可直接向数据库发送数据或从数据库中获取数据。*多足峡逆道、多宾、远纳、瘦弱、枯萎、窒息、窒息、壮丽、枯萎、宫殿、邻居、唐、懈怠。Lecture 01 - PHP Overview Lecture 01 - PHP Overview 基于数据库的动态Web工作模式 6-4 动态Web工作模式 服务器端动态Web工作模式 服务器端动态网页是通过执行应用程序动态生成的网页在 Web 服务器上并从后台数据库中获取数据。常见的web服务器动态web技术有CGI、PHP、ASP、JSP等,下面简单介绍一下。CGI ongateway interface,CGI)是Web服务器与外部应用程序之间交换数据的标准接口软件,是最早创建动态网页的机制。PHP 超文本预处理器 (PHP) 是一种易于学习且易于使用的服务器端脚本语言,用于创建动态网页。
php抓取网页动态数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-05 09:13
PHP爬取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取分析
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和呈现。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,更新个人博客和公众号上的代码库,处理
崔小铸5年前2345
解决“mysql server has gone away”问题
当应用程序(如PHP)长时间执行批量MYSQL语句时,就会出现这样的问题。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php新手4年前1008
rrdtool 学习和自定义脚本绘制图形备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在使用的很多cacti也是基于rrdtool进行绘制的。可以说cacti只提供了一个显示图形的网页
于尔吾4年前1163
c#批量抓取免费代理并验证有效性
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新,你给我看这个。这家公司之前来我们学校宣传招聘+我在花园里找招聘的时候找到了一个住处。
操张琳3年前 1170
RRD工具详情
概述一、MRTG的不足及RRDTool比较二、RRDTool概述三、安装RRDTool四、RRDTool绘图步骤五、rrdtool命令详解六、RRDTool绘图案例说明,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
科技小美4年前1573
MySQL server has gone away 解决方案
应用程序(如 PHP)长时间执行批量 MYSQL 语句。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到类似情况,MySQL只是冷
云起希望。4年前的1791年
技术 | Python的Scratch Serial串口(三十五)
大家好,这次我给大家带来一种方法,从爱问知识渊博的人那里捕获问题并将问题和答案保存到数据库中。涉及的内容包括: Urllib的使用和异常处理 Beautiful Soup的简单应用 MySQLdb的基本使用规则 表达式的简单应用环境配置 在此之前,我们需要配置环境
小技术人3 年前 1954
MySQL 服务器已经消失
MySQL server has gone away 运行sql文件导入数据库时,会报异常。MySQL server has gone away mysql has ERROR: (2006, 'MySQL server has gone away')
李大嘴巴 6年前 1934年 查看全部
php抓取网页动态数据(知乎用户数据爬取和分析背景说明:小拽利用php的curl代码和用户dashboard)
PHP爬取网页数据并插入到数据库相关的博客中
php爬虫:知乎用户数据爬取分析
背景说明:小燕使用PHP的curl写的爬虫实验爬取知乎5w个用户的基本信息;同时对爬取的数据进行了简单的分析和呈现。演示地址是php的蜘蛛代码和用户仪表盘的显示代码。整理好后上传到github,更新个人博客和公众号上的代码库,处理
崔小铸5年前2345
解决“mysql server has gone away”问题
当应用程序(如PHP)长时间执行批量MYSQL语句时,就会出现这样的问题。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。在 MySQL 中解决
php新手4年前1008
rrdtool 学习和自定义脚本绘制图形备忘录
RRDtool(Round Robin Database Tool)是一个强大的绘图引擎,MRTG等很多工具都可以调用rrdtool绘图。包括现在使用的很多cacti也是基于rrdtool进行绘制的。可以说cacti只提供了一个显示图形的网页
于尔吾4年前1163
c#批量抓取免费代理并验证有效性
我看到某公司官网上文章的浏览量每刷新一次页面就会增加一次,给人一种不好的感觉。一家公司的官网给人的就是这样一个直截了当的漏洞。当我批量发起请求时,发现页面打开报错。100多人的公司官网文章刷新,你给我看这个。这家公司之前来我们学校宣传招聘+我在花园里找招聘的时候找到了一个住处。
操张琳3年前 1170
RRD工具详情
概述一、MRTG的不足及RRDTool比较二、RRDTool概述三、安装RRDTool四、RRDTool绘图步骤五、rrdtool命令详解六、RRDTool绘图案例说明,实验环境CentOS 6.4 x86_64,软件版本rrdtool-1.3
科技小美4年前1573
MySQL server has gone away 解决方案
应用程序(如 PHP)长时间执行批量 MYSQL 语句。执行一条 SQL,但 SQL 语句过大或语句中收录 BLOB 或 longblob 字段。例如,图像数据的处理。很容易导致 MySQL 服务器消失。今天遇到类似情况,MySQL只是冷
云起希望。4年前的1791年
技术 | Python的Scratch Serial串口(三十五)
大家好,这次我给大家带来一种方法,从爱问知识渊博的人那里捕获问题并将问题和答案保存到数据库中。涉及的内容包括: Urllib的使用和异常处理 Beautiful Soup的简单应用 MySQLdb的基本使用规则 表达式的简单应用环境配置 在此之前,我们需要配置环境
小技术人3 年前 1954
MySQL 服务器已经消失
MySQL server has gone away 运行sql文件导入数据库时,会报异常。MySQL server has gone away mysql has ERROR: (2006, 'MySQL server has gone away')
李大嘴巴 6年前 1934年
php抓取网页动态数据(php抓取网页动态数据的方法+zsoft模拟get方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-03-28 05:00
php抓取网页动态数据的方法很多,beautifulsoup+zsoft模拟get方法。html标签本身是可以查询元素详细信息的,通过在元素上加注释,或者别的方法把标签和当前元素进行链接就可以访问动态元素sqlite对象。
题主补充说明具体使用需求,首先是模拟访问是指怎么样的访问呢?1.获取cookie2.获取网页的标题文本3.获取地址注册一个cookie好了可以获取一些有用的信息。最后想要获取动态信息还需要别的server吗?1.http请求的参数比较少,可以通过不同的代理2.sqlite在实际使用中,会有很多查询统计语句,很多时候可以完全依赖于cpu、内存等资源,如果本身系统压力大,处理不了那么多需求,那完全可以走代理访问。如果压力不大,也无需走代理。
支持正则,正则分为哪几类:正则表达式和文本匹配为一体正则表达式,对于文本表达式进行处理正则表达式,像程序员在解决问题的时候,很多时候对于问题的解决办法就会产生依赖,
当然可以,第一步是模拟上网这个动作。第二步是获取网页的内容。理论上,javascript可以实现任何java等编程语言无法完成的动作,不过功能多少可能还是存在限制。
当然可以模拟,动态功能都是根据浏览器实现的,只要浏览器支持, 查看全部
php抓取网页动态数据(php抓取网页动态数据的方法+zsoft模拟get方法)
php抓取网页动态数据的方法很多,beautifulsoup+zsoft模拟get方法。html标签本身是可以查询元素详细信息的,通过在元素上加注释,或者别的方法把标签和当前元素进行链接就可以访问动态元素sqlite对象。
题主补充说明具体使用需求,首先是模拟访问是指怎么样的访问呢?1.获取cookie2.获取网页的标题文本3.获取地址注册一个cookie好了可以获取一些有用的信息。最后想要获取动态信息还需要别的server吗?1.http请求的参数比较少,可以通过不同的代理2.sqlite在实际使用中,会有很多查询统计语句,很多时候可以完全依赖于cpu、内存等资源,如果本身系统压力大,处理不了那么多需求,那完全可以走代理访问。如果压力不大,也无需走代理。
支持正则,正则分为哪几类:正则表达式和文本匹配为一体正则表达式,对于文本表达式进行处理正则表达式,像程序员在解决问题的时候,很多时候对于问题的解决办法就会产生依赖,
当然可以,第一步是模拟上网这个动作。第二步是获取网页的内容。理论上,javascript可以实现任何java等编程语言无法完成的动作,不过功能多少可能还是存在限制。
当然可以模拟,动态功能都是根据浏览器实现的,只要浏览器支持,
php抓取网页动态数据(如何应用滚屏加载技术的位置?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-25 13:06
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、Mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.PHP
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了使事情尽可能简单,我使用原生 PHP 和 mySQL 查询。首先,您需要连接到数据库,connect.PHP 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
代码显示如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器端 result.PHP 发送请求。请求的参数是page,即页数。
if(aa$row['content'],'author'=>$user[$row['userid']],'date'=>date('m-d H:i',$row['addtime'])<br />
);<br />
}<br />
echo json_encode($arr); //转换为json数据输出
</p>
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。 查看全部
php抓取网页动态数据(如何应用滚屏加载技术的位置?-八维教育)
当我们浏览一些网页时,当浏览器的滚动条被拉到页面底部时,页面会继续自动加载更多的内容供用户浏览。我现在将这种技术称为滚动加载技术。我们发现很多网站都使用了这项技术,必应图片搜索、新浪微博、QQ空间等都将这项技术应用的淋漓尽致。
滚动加载技术是使用Javascript来监控滚动条的位置。每次滚动条到达浏览器窗口底部时,都会向后台PHP程序触发Ajax请求,返回相应的数据,并将返回的数据追加到页面底部,从而实现动态加载,实际上是一个典型的 Ajax 应用程序。本文将使用 jQuery,结合 PHP、Mysql 和 JSON,来解释如何将滚动加载技术应用到您的项目中。当然,阅读这篇文章的前提是你需要具备jQuery和PHP的基础知识。
索引.PHP
我们要默认显示15条数据,所以我们先从数据库中取出前15条数据,并显示在页面上。我们还一次显示 15 个新加载的数据。
为了使事情尽可能简单,我使用原生 PHP 和 mySQL 查询。首先,您需要连接到数据库,connect.PHP 中收录连接信息。在这里,我定义了几个用户 ID。
然后查询数据表,得到结果集,循环输出,代码如下:
注:本例使用的数据来自本站文章:,文中有创建数据表的介绍。
jQuery
1、首先,我们需要获取页面在浏览器可视区域的高度:
代码显示如下:
var winH = $(window).height();
2、那么,页面滚动时需要做的是:计算页面总高度(滚动到底部时,页面新加载数据,所以页面总高度动态变化),计算滚动条位置(滚动条位置也随着加载页面的高度动态变化),然后构造一个计算相对比例的公式。
$(window).scroll(function () {
var pageH = $(document.body).height(); //页面总高度
var scrollT = $(window).scrollTop(); //滚动条top
var aa = (pageH-winH-scrollT)/winH;
});
3、当滚动条接近页面底部时,触发ajax加载。在本例中,我们使用 jQuery 的 getJSON 方法向服务器端 result.PHP 发送请求。请求的参数是page,即页数。
if(aa$row['content'],'author'=>$user[$row['userid']],'date'=>date('m-d H:i',$row['addtime'])<br />
);<br />
}<br />
echo json_encode($arr); //转换为json数据输出
</p>
好了,本文的介绍到此结束,我们去看看效果吧。
以上就是本文的全部内容,希望大家喜欢。
php抓取网页动态数据(php网页动态数据的代码可以在几个地方直接访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-24 00:08
php抓取网页动态数据的代码可以在几个地方直接访问,如抓取请求头中的formdata或header头的fetchobjecturl获取页面的一些通用动态指令和设置参数,如path和page,parent等获取页面的html内容,如:language=c,
1、html相关的动态设置html=>formdataformdata的说明:
1、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
2、抓取html页面的html代码。
3、formdata有一个下拉框控件,需要在此控件上挂起下拉框,以确保提交成功。
4、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。
path=>'/'formdata=>pathformdata的说明:
3、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
4、抓取html页面的html代码。
5、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。path=>'/'formdata=>path返回返回一个数组,代表页面所有元素。给formdata分类:path=>'/'formdata=>pathformdata=>pathpath=>'/'formdata=>pathformdata=>pathpath=>'/'返回一个formdata数组,代表一个可以直接访问并抓取的formdata。
formdata只返回或<b></a>页面中链接其parent页面的url标签。formdata=>html=>{"parent":"/"}formdata=>{"parent":"/"}formdata=>html=>{"parent":"/"}path=>page使用formdata抓取html页面时,不可以返回多个formdata的数组,即formdata只能通过参数获取元素的值。
path=>page抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>page抓取html页面的page({})表示一页,是页面的url标签。formdata=>img抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>{"parent":"/"}formdata=>{"parent":"/"}path=>request抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>。 查看全部
php抓取网页动态数据(php网页动态数据的代码可以在几个地方直接访问)
php抓取网页动态数据的代码可以在几个地方直接访问,如抓取请求头中的formdata或header头的fetchobjecturl获取页面的一些通用动态指令和设置参数,如path和page,parent等获取页面的html内容,如:language=c,
1、html相关的动态设置html=>formdataformdata的说明:
1、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
2、抓取html页面的html代码。
3、formdata有一个下拉框控件,需要在此控件上挂起下拉框,以确保提交成功。
4、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。
path=>'/'formdata=>pathformdata的说明:
3、formdata传给body的数据数组,数组的结构代表页面的一个或<b></a>页面的url标签。
4、抓取html页面的html代码。
5、formdata具有内部方法path,无论输入框还是选择框,均可使用此方法获取dom内容。path=>'/'formdata=>path返回返回一个数组,代表页面所有元素。给formdata分类:path=>'/'formdata=>pathformdata=>pathpath=>'/'formdata=>pathformdata=>pathpath=>'/'返回一个formdata数组,代表一个可以直接访问并抓取的formdata。
formdata只返回或<b></a>页面中链接其parent页面的url标签。formdata=>html=>{"parent":"/"}formdata=>{"parent":"/"}formdata=>html=>{"parent":"/"}path=>page使用formdata抓取html页面时,不可以返回多个formdata的数组,即formdata只能通过参数获取元素的值。
path=>page抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>page抓取html页面的page({})表示一页,是页面的url标签。formdata=>img抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>{"parent":"/"}formdata=>{"parent":"/"}path=>request抓取html页面的html代码,page({})表示一页,是页面的url标签。formdata=>。
php抓取网页动态数据(PHP“超文本预处理器”是什么?能够干什么??)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-03-21 03:30
PHP 或“超文本预处理器”是一种通用的开源脚本语言。PHP 是一种在服务器端执行的脚本语言。与C语言类似,是一种常用的网站编程语言。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。利于学习,应用广泛,主要适用于Web开发领域。
PHP的作用是什么?我能做些什么?
PHP 是一种服务器端脚本语言,是 Web 应用程序开发中常用的一种脚本语言,用于动态生成网页。与其他编程语言相比,PHP 更加标准化,语法简单易学。
1、采集表单数据:
在这方面,表单是编程的常用数据输入接口。表单提交时,通常使用get或post两种方法将数据发送给php程序脚本进行处理。
2、生成动态网页:
PHP运行在服务器端,通过用户在客户端的不同请求,运行不同的脚本后,可以动态输出用户请求的内容。简单来说就是client-request-->php server-run output-->client,在这个过程中,客户端是看不到php程序的运行过程的。
3、字符串处理:
编程大部分时间都是在操作字符串,字符串处理技能是必须的。PHP 将字符串视为一种基本数据类型。
4、动态输出图像:
php 使用 GD 扩展库动态输出图像。例如文本按钮、验证码、统计图表、编辑图像、缩略图、添加水印等。
5、处理服务器端文件系统:
使用文件系统操作函数来操作服务器中的目录或文件。包括打开、编辑、复制、创建、删除和文件属性等操作。
6、编写数据库支持的网页:
其实就是通过运行一个php脚本与数据库进行交互的过程。首先是用户请求,然后php运行并与数据库交互,交互结果集反馈给客户端用户。
7、会话跟踪控制:
HTTP 协议是无状态协议,没有机制来维护两个事物之间的状态。所以PHP利用会话控制的思想来跟踪用户,以实现当用户请求一个页面后,再请求另一个页面时,它就知道该请求来自同一个用户。在各大网站中保存登录设置和购物车是很常见的,并在一个周期内为用户保存这些信息。
8、处理 XML/json 文件
简单来说就是这些文件是通过php通过各种扩展来处理的。
9、支持使用多种网络协议:
PHP支持使用各种协议服务,并且可以开放原有的网口,让各种协议协同工作。
10、服务器端的其他操作:
例如电子商务领域的在线支付程序等。并且可以在windows、linux、ios等各大操作系统上使用。 查看全部
php抓取网页动态数据(PHP“超文本预处理器”是什么?能够干什么??)
PHP 或“超文本预处理器”是一种通用的开源脚本语言。PHP 是一种在服务器端执行的脚本语言。与C语言类似,是一种常用的网站编程语言。PHP 的独特语法是 C、Java、Perl 和 PHP 自己的语法的混合。利于学习,应用广泛,主要适用于Web开发领域。
PHP的作用是什么?我能做些什么?
PHP 是一种服务器端脚本语言,是 Web 应用程序开发中常用的一种脚本语言,用于动态生成网页。与其他编程语言相比,PHP 更加标准化,语法简单易学。
1、采集表单数据:
在这方面,表单是编程的常用数据输入接口。表单提交时,通常使用get或post两种方法将数据发送给php程序脚本进行处理。
2、生成动态网页:
PHP运行在服务器端,通过用户在客户端的不同请求,运行不同的脚本后,可以动态输出用户请求的内容。简单来说就是client-request-->php server-run output-->client,在这个过程中,客户端是看不到php程序的运行过程的。
3、字符串处理:
编程大部分时间都是在操作字符串,字符串处理技能是必须的。PHP 将字符串视为一种基本数据类型。
4、动态输出图像:
php 使用 GD 扩展库动态输出图像。例如文本按钮、验证码、统计图表、编辑图像、缩略图、添加水印等。
5、处理服务器端文件系统:
使用文件系统操作函数来操作服务器中的目录或文件。包括打开、编辑、复制、创建、删除和文件属性等操作。
6、编写数据库支持的网页:
其实就是通过运行一个php脚本与数据库进行交互的过程。首先是用户请求,然后php运行并与数据库交互,交互结果集反馈给客户端用户。
7、会话跟踪控制:
HTTP 协议是无状态协议,没有机制来维护两个事物之间的状态。所以PHP利用会话控制的思想来跟踪用户,以实现当用户请求一个页面后,再请求另一个页面时,它就知道该请求来自同一个用户。在各大网站中保存登录设置和购物车是很常见的,并在一个周期内为用户保存这些信息。
8、处理 XML/json 文件
简单来说就是这些文件是通过php通过各种扩展来处理的。
9、支持使用多种网络协议:
PHP支持使用各种协议服务,并且可以开放原有的网口,让各种协议协同工作。
10、服务器端的其他操作:
例如电子商务领域的在线支付程序等。并且可以在windows、linux、ios等各大操作系统上使用。
php抓取网页动态数据(什么是动态网站?动态友好,搜索引擎容易识别(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-03-21 03:29
)
什么是LNMP
LNMP 是指一组通常一起用于运行动态网站 或服务器的免费软件名称首字母缩略词。
即Linux+Nginx+Mysql+PHP网站服务器架构
这四种软件都是免费开源的软件,结合在一起,就成了一个免费、高效、可扩展性强的网站服务系统。
当前的网站一般有动态和静态数据。默认情况下,nginx 只能处理静态数据。用户访问任何数据都会直接返回相应的文件。如果访问的是脚本,则直接返回一个脚本给用户,而用户没有脚本解释器,无法读取脚本源码!如图所示。
所以需要集成LNMP(Linux、Nginx、MySQL、PHP)来实现动态的网站效果。
在 CentOS 系统中,LNMP 从源代码安装 Nginx,并使用 RPM 包安装 MariaDB、PHP 和 PHP-FPM 软件。
什么是静态网页?
在网站的设计中,纯HTML(标准通用标记语言下的应用)格式的网页通常被称为“静态网页”。静态网页是一个标准的 HTML 文件,文件扩展名为 .htm、.html,可以收录文本、图像、声音、FLASH 动画、客户端脚本、ActiveX 控件和 JAVA 小程序等。
静态数据:图片音频视频
静态网页使用语言:HTML
静态网页的特点
可以公开(即可以向任何人证明副本)。
托管没有任何特殊要求。(无需超文本预处理器、公共网关接口等特殊中间件)
没有网络服务器或应用服务器,例如直接从 CD-ROM(激光光盘 - 只读存储器)或 USB 闪存驱动器读取内容,可以直接通过网络浏览器访问。
网站更安全,HTML页面不会受到Asp相关漏洞的影响;它可以减少攻击并防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
无需编译,速度快,节省服务器资源。
URL 格式友好且易于被搜索引擎识别。
什么是动态网站?
动态网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般来说,动态 网站 Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站一般体现在使用asp、jsp、php、aspx等技术的网页中。
也可以简单理解为是用脚本写的
即动态网页是指收录程序代码的网页文件,通过后台数据库与Web服务器的信息进行交互。
后台数据库提供实时数据更新和数据查询服务。
例如:shell PHP Java Python ...
动态网页使用的语言:HTML+ASP或HTML+PHP或HTML+JSP等。
动态网页功能:
Dynamic网站可实现交互功能,如用户注册、信息发布、产品展示、订单管理等;
动态网页不是独立存在于服务器上的网页文件,只是在浏览器发出请求时才返回网页;
动态网页收录服务器端脚本,因此页面文件名通常以asp、jsp、php等为后缀。但您也可以使用URL静态技术使网页后缀显示为HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要数据库处理,动态网站的访问速度大大减慢;
由于特殊代码的存在,动态网页对搜索引擎的友好性不如静态网页。
但是随着电脑性能的提高和网络带宽的提高,后两者已经基本解决了。
动态网页和静态网页的区别
1、网页制作中使用的制作语言:
静态网页使用的语言:超文本标记语言(标准通用标记语言的一种应用)
动态网页使用语言:超文本标记语言+ASP或超文本标记语言+PHP或超文本标记语言+JSP等。
2、程序是否在服务器端运行是一个重要的标志。
在服务器端运行的程序、网页和组件都属于动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、ASPnet、CGI 等。运行在客户端的程序、网页、插件、组件属于静态网页,如html页面、Flash、JavaScript、VBScript等,永远不变。
四种常见的动态 Web 技术部署 LNMP 环境
已安装软件列表如下:
软件包的作用:
mariadb(数据库客户端软件)、
mariadb-server(数据库服务器软件)、
mariadb-devel(其他客户端软件的依赖包)、
php(解释器)、
php-fpm(进程管理器服务)、
php-mysql(PHP的数据库扩展包)。
1)使用yum安装基础依赖(如果已经安装依赖,忽略此步骤)
[root@proxy ~]# yum -y install gcc openssl-devel pcre-devel
2)从源码安装Nginx(如果已经安装了Nginx,忽略这一步)
[root@proxy ~]# useradd -s /sbin/nologin nginx
[root@proxy ~]# tar -xvf nginx-1.12.2.tar.gz
[root@proxy ~]# cd nginx-1.12.2
[root@proxy nginx-1.12.2]# ./configure \
> --user=nginx --group=nginx \
> --with-http_ssl_module
[root@proxy ~]# make && make install
3)安装 MariaDB
root@proxy ~]# yum -y install mariadb mariadb-server mariadb-devel
4)php 和 php-fpm php-mysql
[root@proxy ~]# yum -y install php php-mysql
[root@proxy ~]# yum -y install php-fpm
5)启动Nginx服务(如果已经启动了nginx,可以忽略这一步)
这里需要注意的是,如果服务器上已经启动了其他监听80端口的服务软件(如httpd),则需要先关闭该服务,否则会发生冲突。
[root@proxy ~]# systemctl stop httpd ##如果该服务存在则关闭该服务
[root@proxy ~]# /usr/local/nginx/sbin/nginx ##启动Nginx服务
[root@proxy ~]# netstat -utnlp | grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 32428/nginx
6)启动 MySQL 服务
[root@proxy ~]# systemctl start mariadb //启动服务器
[root@proxy ~]# systemctl status mariadb //查看服务状态
[root@proxy ~]# systemctl enable mariadb //设置开机启动
7)启动PHP-FPM服务
[root@proxy ~]# systemctl start php-fpm //启动服务
[root@proxy ~]# systemctl status php-fpm //查看服务状态
[root@proxy ~]# systemctl enable php-fpm //设置开机启动
这样一个LNMP环境就准备好了
配置nginx+PHP实现两个if
localtion (匹配用户的地址拦,支持正则,从域名后面开始匹配)
server {
listen 80;
server_name www.a.com
location /test { dney 1.1;allow all}
location /qq {allow 2.2;deny all}
location / {allow all} (##优先级最低,跟顺序无关,动静匹配)
}
firefox http://www.a.com/qq ##结果[2.2打开,不是则打不开]
firefox http://www.a.com/test ##结果[只要不是1.1就能打开]
firefox http://www.a.com/ ##匹配第三个localtion
firefox http://www.a.com/nb ##匹配第三个localtion
firefox http://www.a.com/xyz ##匹配第三个localtion
firefox http://www.a.com/123 ##匹配第三个localtion
server { ##匹配静态的网站
listen 80;
server_name www.a.com
location / {
root html;
}
location ~ \.php$ { ##匹配动态的网站
root heml;
fastcgi_pass 127.0.0.1:9000; (转发给PHP翻译)
}
}
firefox http://www.a.com/a.jpg ##只要不是以.php结尾,都是静态处理
firefox http://www.a.com/test.php ##动态处理,显示动态页面
什么是动静分离?FastCGI 介绍 FastCGI 工作 FastCGI 的缺点:
高内存消耗
因为是多进程,所以比CGI多线程消耗更多的服务器内存
PHP-CGI 解释器每个进程消耗 7 到 25 兆内存,将此数字乘以 50 或 100 是大量内存
nginx+PHP(FastCGI)服务器在30000个并发连接下开启10个nginx进程,消耗150M内存(1015M)
开启64个php_cgi进程消耗1280M内存(20M64)
部署 Nginx+FastCGI
通过调整 Nginx 服务器配置,达到以下目标:
下面使用两台虚拟机,一台作为LNMP服务器(192.168.4.5)。另一台作为测试客户端(192.168.4.10),如图所示。
Nginx结合FastCGI技术可以支持PHP页面架构,如图。
1.修改配置文件
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
location / {
root html;
index index.php index.html index.htm;
#设置默认首页为index.php,当用户在浏览器地址栏中只写域名或IP,不说访问什么页面时,服务器会把默认首页index.php返回给用户
}
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000; #将请求转发给本机9000端口,PHP解释器
fastcgi_index index.php;
#fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi.conf; #加载其他配置文件
}
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
#请先确保nginx是启动状态,否则运行该命令会报错,报错信息如下:
#[error] open() "/usr/local/nginx/logs/nginx.pid" failed (2: No such file or directory)
注:/usr/local/nginx/conf这个配置文件目录下nginx.conf.default 这个配置文件可以帮助我们还原配置文件
用法:
[root@proxy ~]# cd /usr/local/nginx/conf/
[root@proxy ~]# cp nginx.conf.default nginx.conf
2.创建PHP测试页面,测试LNMP架构能否解析PHP页面
[root@proxy ~]# vim /usr/local/nginx/html/test.php
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl localhost/test.php
33
3.创建一个PHP测试页面,连接并查询MariaDB数据库。
可以参考lnmp_soft/php_scripts/mysql.php:
[root@proxy ~]# vim /usr/local/nginx/html/mysql.php
query($sql);
while($row = $result->fetch_array()){
printf("Host:%s",$row[0]);
printf("</br>");
printf("Name:%s",$row[1]);
printf("</br>");
}
?>
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
[root@proxy html]# mysql -e "grant all on *.* to dc@localhost identified by '123'" ##给数据库添加一个用户
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
动态网页会实时更新显示内容
4)LNMP 常见问题解答
Nginx 高级技术地址改写 什么是地址改写?地址重写重写语法的好处
- rewrite 基本语句
- rewrite regex replacement flag
- rewrite 旧地址 新地址 [选项]
- flag: break, last, redirect, permanent
- last: 停止执行其他重写规则,根据URI继续搜索其他location,地址栏不变(不再读其他rewrite)
- break: 停止执行其他的重写规则,完成本次请求(不再读其他语句,结束请求 location语句)
- redirect: 302临时重定向.地址栏改变,爬虫不更新
- permanent: 301永久重定向,地址栏改变,爬虫更新
- if (条件){...}
正则表达式
按照上面的例子,通过调整Nginx服务器配置,可以达到以下目标:
所有访问a.html的请求,重定向到b.html;
所有对 192.168.4.5 的请求都重定向到;
所有对192.168.4.5/以下子页面的访问都会被重定向到下面的同一页面;
实现firefox和curl访问同一个页面文件,返回不同的内容。
访问 a.html 重定向到 b.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html; ##(地址重写,访问a.html重定向到b.html)
[root@proxy conf]# echo "BBB" > /usr/local/nginx/html/b.html ##创建b网页
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html redirect;
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果;
访问 192.168.4.5 的请求重定向到
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/ http://www.tmooc.cn;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5 ##用真机测试
测试结果如图:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/(.*) http://www.tmooc.cn/$1;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5
[student@room9pc01 ~]$ firefox 192.168.4.5/free ##用真机测试
访问 192.168.4.5 个结果:
访问 192.168.4.5/free 的结果:
实现firefox和curl访问同一个页面文件,返回不同的内容
思路:
浏览器 : curl firefox
①:/usr/local/nginx/html/test.html 网页根目录: html
②:/usr/local/nginx/html/firefox/test.html 网页根目录下的子目录: firefox
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器:访问相同(结果为第①个)
假设用rewrite处理:
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器访问相同(结果为第②个)
假设使用if判断语句配和rewrite地址重写处理:
>if(如果用户的浏览器是火狐){....}
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html 访问网页根目录
>firefox http://192.168.4.5/test.html 访问/firefox/test.html
[root@proxy logs]# mkdir -p /usr/local/nginx/html/firefox
[root@proxy logs]# echo "I am tian" > /usr/local/nginx/html/test.html
[root@proxy logs]# echo "firefox tian" > /usr/local/nginx/html/firefox/test.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 if ($http_user_agent ~* firefox) {
39 rewrite ^/(.*) /firefox/$1;
40 }
##$http_user_agent :存着用户信息和操作系统的信息
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ curl 192.168.4.5/test.html
I am tian
[student@room9pc01 ~]$ firefox 192.168.4.5/test.html
火狐的结果:
使用 break、last、redirect、permanent
以下为简要说明,仅供参考
rewrite /a.html /b.html;
rewtite /b.html /c.html;
访问a.html打开c.html
rewrite /a.html /b.html last;
rewtite /b.html /c.html;
访问a.html打开b.htlm
location /a.html {
rewrite /a.html /b.html;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html last;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html break;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开b.html
redirect 临时重定向,一般用于a.html临时有问题且能恢复的情况下
permanent 永久重定向,一般用于a.html永久不能访问,但是为了方便客户端访问而用 查看全部
php抓取网页动态数据(什么是动态网站?动态友好,搜索引擎容易识别(一)
)
什么是LNMP
LNMP 是指一组通常一起用于运行动态网站 或服务器的免费软件名称首字母缩略词。
即Linux+Nginx+Mysql+PHP网站服务器架构
这四种软件都是免费开源的软件,结合在一起,就成了一个免费、高效、可扩展性强的网站服务系统。
当前的网站一般有动态和静态数据。默认情况下,nginx 只能处理静态数据。用户访问任何数据都会直接返回相应的文件。如果访问的是脚本,则直接返回一个脚本给用户,而用户没有脚本解释器,无法读取脚本源码!如图所示。
所以需要集成LNMP(Linux、Nginx、MySQL、PHP)来实现动态的网站效果。
在 CentOS 系统中,LNMP 从源代码安装 Nginx,并使用 RPM 包安装 MariaDB、PHP 和 PHP-FPM 软件。
什么是静态网页?
在网站的设计中,纯HTML(标准通用标记语言下的应用)格式的网页通常被称为“静态网页”。静态网页是一个标准的 HTML 文件,文件扩展名为 .htm、.html,可以收录文本、图像、声音、FLASH 动画、客户端脚本、ActiveX 控件和 JAVA 小程序等。
静态数据:图片音频视频
静态网页使用语言:HTML
静态网页的特点
可以公开(即可以向任何人证明副本)。
托管没有任何特殊要求。(无需超文本预处理器、公共网关接口等特殊中间件)
没有网络服务器或应用服务器,例如直接从 CD-ROM(激光光盘 - 只读存储器)或 USB 闪存驱动器读取内容,可以直接通过网络浏览器访问。
网站更安全,HTML页面不会受到Asp相关漏洞的影响;它可以减少攻击并防止SQL注入。当数据库发生错误时,不会影响网站的正常访问。
无需编译,速度快,节省服务器资源。
URL 格式友好且易于被搜索引擎识别。
什么是动态网站?
动态网站不是指具有动画功能的网站,而是指可以根据不同情况动态改变内容的网站。一般来说,动态 网站 Schema 通过数据库。动态网站除了设计网页,还通过数据库和编程让网站拥有更多自动化和高级的功能。动态网站一般体现在使用asp、jsp、php、aspx等技术的网页中。
也可以简单理解为是用脚本写的
即动态网页是指收录程序代码的网页文件,通过后台数据库与Web服务器的信息进行交互。
后台数据库提供实时数据更新和数据查询服务。
例如:shell PHP Java Python ...
动态网页使用的语言:HTML+ASP或HTML+PHP或HTML+JSP等。
动态网页功能:
Dynamic网站可实现交互功能,如用户注册、信息发布、产品展示、订单管理等;
动态网页不是独立存在于服务器上的网页文件,只是在浏览器发出请求时才返回网页;
动态网页收录服务器端脚本,因此页面文件名通常以asp、jsp、php等为后缀。但您也可以使用URL静态技术使网页后缀显示为HTML。因此,不能以页面文件的后缀作为判断网站动静态的唯一标准。
由于动态网页需要数据库处理,动态网站的访问速度大大减慢;
由于特殊代码的存在,动态网页对搜索引擎的友好性不如静态网页。
但是随着电脑性能的提高和网络带宽的提高,后两者已经基本解决了。
动态网页和静态网页的区别
1、网页制作中使用的制作语言:
静态网页使用的语言:超文本标记语言(标准通用标记语言的一种应用)
动态网页使用语言:超文本标记语言+ASP或超文本标记语言+PHP或超文本标记语言+JSP等。
2、程序是否在服务器端运行是一个重要的标志。
在服务器端运行的程序、网页和组件都属于动态网页。它们会在不同的客户端和不同的时间返回不同的网页,例如 ASP、PHP、JSP、ASPnet、CGI 等。运行在客户端的程序、网页、插件、组件属于静态网页,如html页面、Flash、JavaScript、VBScript等,永远不变。
四种常见的动态 Web 技术部署 LNMP 环境
已安装软件列表如下:
软件包的作用:
mariadb(数据库客户端软件)、
mariadb-server(数据库服务器软件)、
mariadb-devel(其他客户端软件的依赖包)、
php(解释器)、
php-fpm(进程管理器服务)、
php-mysql(PHP的数据库扩展包)。
1)使用yum安装基础依赖(如果已经安装依赖,忽略此步骤)
[root@proxy ~]# yum -y install gcc openssl-devel pcre-devel
2)从源码安装Nginx(如果已经安装了Nginx,忽略这一步)
[root@proxy ~]# useradd -s /sbin/nologin nginx
[root@proxy ~]# tar -xvf nginx-1.12.2.tar.gz
[root@proxy ~]# cd nginx-1.12.2
[root@proxy nginx-1.12.2]# ./configure \
> --user=nginx --group=nginx \
> --with-http_ssl_module
[root@proxy ~]# make && make install
3)安装 MariaDB
root@proxy ~]# yum -y install mariadb mariadb-server mariadb-devel
4)php 和 php-fpm php-mysql
[root@proxy ~]# yum -y install php php-mysql
[root@proxy ~]# yum -y install php-fpm
5)启动Nginx服务(如果已经启动了nginx,可以忽略这一步)
这里需要注意的是,如果服务器上已经启动了其他监听80端口的服务软件(如httpd),则需要先关闭该服务,否则会发生冲突。
[root@proxy ~]# systemctl stop httpd ##如果该服务存在则关闭该服务
[root@proxy ~]# /usr/local/nginx/sbin/nginx ##启动Nginx服务
[root@proxy ~]# netstat -utnlp | grep :80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 32428/nginx
6)启动 MySQL 服务
[root@proxy ~]# systemctl start mariadb //启动服务器
[root@proxy ~]# systemctl status mariadb //查看服务状态
[root@proxy ~]# systemctl enable mariadb //设置开机启动
7)启动PHP-FPM服务
[root@proxy ~]# systemctl start php-fpm //启动服务
[root@proxy ~]# systemctl status php-fpm //查看服务状态
[root@proxy ~]# systemctl enable php-fpm //设置开机启动
这样一个LNMP环境就准备好了
配置nginx+PHP实现两个if
localtion (匹配用户的地址拦,支持正则,从域名后面开始匹配)
server {
listen 80;
server_name www.a.com
location /test { dney 1.1;allow all}
location /qq {allow 2.2;deny all}
location / {allow all} (##优先级最低,跟顺序无关,动静匹配)
}
firefox http://www.a.com/qq ##结果[2.2打开,不是则打不开]
firefox http://www.a.com/test ##结果[只要不是1.1就能打开]
firefox http://www.a.com/ ##匹配第三个localtion
firefox http://www.a.com/nb ##匹配第三个localtion
firefox http://www.a.com/xyz ##匹配第三个localtion
firefox http://www.a.com/123 ##匹配第三个localtion
server { ##匹配静态的网站
listen 80;
server_name www.a.com
location / {
root html;
}
location ~ \.php$ { ##匹配动态的网站
root heml;
fastcgi_pass 127.0.0.1:9000; (转发给PHP翻译)
}
}
firefox http://www.a.com/a.jpg ##只要不是以.php结尾,都是静态处理
firefox http://www.a.com/test.php ##动态处理,显示动态页面
什么是动静分离?FastCGI 介绍 FastCGI 工作 FastCGI 的缺点:
高内存消耗
因为是多进程,所以比CGI多线程消耗更多的服务器内存
PHP-CGI 解释器每个进程消耗 7 到 25 兆内存,将此数字乘以 50 或 100 是大量内存
nginx+PHP(FastCGI)服务器在30000个并发连接下开启10个nginx进程,消耗150M内存(1015M)
开启64个php_cgi进程消耗1280M内存(20M64)
部署 Nginx+FastCGI
通过调整 Nginx 服务器配置,达到以下目标:
下面使用两台虚拟机,一台作为LNMP服务器(192.168.4.5)。另一台作为测试客户端(192.168.4.10),如图所示。
Nginx结合FastCGI技术可以支持PHP页面架构,如图。
1.修改配置文件
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
location / {
root html;
index index.php index.html index.htm;
#设置默认首页为index.php,当用户在浏览器地址栏中只写域名或IP,不说访问什么页面时,服务器会把默认首页index.php返回给用户
}
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000; #将请求转发给本机9000端口,PHP解释器
fastcgi_index index.php;
#fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi.conf; #加载其他配置文件
}
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
#请先确保nginx是启动状态,否则运行该命令会报错,报错信息如下:
#[error] open() "/usr/local/nginx/logs/nginx.pid" failed (2: No such file or directory)
注:/usr/local/nginx/conf这个配置文件目录下nginx.conf.default 这个配置文件可以帮助我们还原配置文件
用法:
[root@proxy ~]# cd /usr/local/nginx/conf/
[root@proxy ~]# cp nginx.conf.default nginx.conf
2.创建PHP测试页面,测试LNMP架构能否解析PHP页面
[root@proxy ~]# vim /usr/local/nginx/html/test.php
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl localhost/test.php
33
3.创建一个PHP测试页面,连接并查询MariaDB数据库。
可以参考lnmp_soft/php_scripts/mysql.php:
[root@proxy ~]# vim /usr/local/nginx/html/mysql.php
query($sql);
while($row = $result->fetch_array()){
printf("Host:%s",$row[0]);
printf("</br>");
printf("Name:%s",$row[1]);
printf("</br>");
}
?>
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
[root@proxy html]# mysql -e "grant all on *.* to dc@localhost identified by '123'" ##给数据库添加一个用户
[root@proxy html]# firefox 192.168.4.5/mysql.php
访问结果如下:
动态网页会实时更新显示内容
4)LNMP 常见问题解答
Nginx 高级技术地址改写 什么是地址改写?地址重写重写语法的好处
- rewrite 基本语句
- rewrite regex replacement flag
- rewrite 旧地址 新地址 [选项]
- flag: break, last, redirect, permanent
- last: 停止执行其他重写规则,根据URI继续搜索其他location,地址栏不变(不再读其他rewrite)
- break: 停止执行其他的重写规则,完成本次请求(不再读其他语句,结束请求 location语句)
- redirect: 302临时重定向.地址栏改变,爬虫不更新
- permanent: 301永久重定向,地址栏改变,爬虫更新
- if (条件){...}
正则表达式
按照上面的例子,通过调整Nginx服务器配置,可以达到以下目标:
所有访问a.html的请求,重定向到b.html;
所有对 192.168.4.5 的请求都重定向到;
所有对192.168.4.5/以下子页面的访问都会被重定向到下面的同一页面;
实现firefox和curl访问同一个页面文件,返回不同的内容。
访问 a.html 重定向到 b.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html; ##(地址重写,访问a.html重定向到b.html)
[root@proxy conf]# echo "BBB" > /usr/local/nginx/html/b.html ##创建b网页
[root@proxy ~]# /usr/local/nginx/sbin/nginx -s reload
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite /a.html /b.html redirect;
[root@proxy conf]# curl 192.168.4.5/a.html ##访问a.html的测试结果
BBB
[root@proxy conf]# firefox 192.168.4.5/a.html ##访问a.html的测试结果
测试结果;
访问 192.168.4.5 的请求重定向到
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/ http://www.tmooc.cn;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5 ##用真机测试
测试结果如图:
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 rewrite ^/(.*) http://www.tmooc.cn/$1;
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ firefox 192.168.4.5
[student@room9pc01 ~]$ firefox 192.168.4.5/free ##用真机测试
访问 192.168.4.5 个结果:
访问 192.168.4.5/free 的结果:
实现firefox和curl访问同一个页面文件,返回不同的内容
思路:
浏览器 : curl firefox
①:/usr/local/nginx/html/test.html 网页根目录: html
②:/usr/local/nginx/html/firefox/test.html 网页根目录下的子目录: firefox
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器:访问相同(结果为第①个)
假设用rewrite处理:
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html
>firefox http://192.168.4.5/test.html
两个浏览器访问相同(结果为第②个)
假设使用if判断语句配和rewrite地址重写处理:
>if(如果用户的浏览器是火狐){....}
>rewrite /test.html /firefox/test.html;
>curl http://192.168.4.5/test.html 访问网页根目录
>firefox http://192.168.4.5/test.html 访问/firefox/test.html
[root@proxy logs]# mkdir -p /usr/local/nginx/html/firefox
[root@proxy logs]# echo "I am tian" > /usr/local/nginx/html/test.html
[root@proxy logs]# echo "firefox tian" > /usr/local/nginx/html/firefox/test.html
[root@proxy ~]# vim /usr/local/nginx/conf/nginx.conf
35 server {
36 listen 80;
37 server_name localhost;
38 if ($http_user_agent ~* firefox) {
39 rewrite ^/(.*) /firefox/$1;
40 }
##$http_user_agent :存着用户信息和操作系统的信息
[root@proxy conf]# /usr/local/nginx/sbin/nginx -s reload
[student@room9pc01 ~]$ curl 192.168.4.5/test.html
I am tian
[student@room9pc01 ~]$ firefox 192.168.4.5/test.html
火狐的结果:
使用 break、last、redirect、permanent
以下为简要说明,仅供参考
rewrite /a.html /b.html;
rewtite /b.html /c.html;
访问a.html打开c.html
rewrite /a.html /b.html last;
rewtite /b.html /c.html;
访问a.html打开b.htlm
location /a.html {
rewrite /a.html /b.html;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html last;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开c.html
location /a.html {
rewrite /a.html /b.html break;
}
location /b.html {
rewrite /b.html c.html;
}
访问a.html打开b.html
redirect 临时重定向,一般用于a.html临时有问题且能恢复的情况下
permanent 永久重定向,一般用于a.html永久不能访问,但是为了方便客户端访问而用
php抓取网页动态数据(有关后对相关知识有一定了解的分享给大家做个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-21 03:26
本期文章将为大家详细介绍php动态网页的要素。@> 后来对相关知识有了一定的了解。
1、HTML(超文本标记语言):
网页的本质是超文本标记语言,它标记网页的各个部分,供浏览器解析。
2、CSS(层叠样式表):
HTML用于标记,但标记的网页混乱且外观不佳。CSS用于合理放置HTML标记的内容,美化网页中的内容。
这是:
HTML用于构建框架,CSS用于美化框架。
3、客户端脚本语言(JavaScript):
脚本:不能独立运行,需要载体运行的程序。
客户端:浏览器。
客户端脚本语言:一种在浏览器上运行的脚本语言,用于与客户端进行网站 交互。
HTML、CSS、JavaScript的关系:HTML用于标记,CSS用于美化页面,JavaScript用于交互。分工非常明确。
HTML、CSS 和 JavaScript 可以制作静态 网站。如何制作静态 网站 供他人访问。
4、网络服务器:
www服务器,通常服务器端指的是web服务器。
常用服务器:IIS、Apache、Nginx
5、数据库:
放置东西的地方,数据库是数据的存储库。
在web中,用于服务端脚本语言调用。
常用数据库:Oracle、MySQL、SQL Server、DB2、MariDB
这里分享php动态网页的元素介绍。希望以上内容能对你有所帮助,让你学习到更多的知识。如果你觉得文章不错,可以分享给更多人看到。 查看全部
php抓取网页动态数据(有关后对相关知识有一定了解的分享给大家做个)
本期文章将为大家详细介绍php动态网页的要素。@> 后来对相关知识有了一定的了解。
1、HTML(超文本标记语言):
网页的本质是超文本标记语言,它标记网页的各个部分,供浏览器解析。
2、CSS(层叠样式表):
HTML用于标记,但标记的网页混乱且外观不佳。CSS用于合理放置HTML标记的内容,美化网页中的内容。
这是:
HTML用于构建框架,CSS用于美化框架。
3、客户端脚本语言(JavaScript):
脚本:不能独立运行,需要载体运行的程序。
客户端:浏览器。
客户端脚本语言:一种在浏览器上运行的脚本语言,用于与客户端进行网站 交互。
HTML、CSS、JavaScript的关系:HTML用于标记,CSS用于美化页面,JavaScript用于交互。分工非常明确。
HTML、CSS 和 JavaScript 可以制作静态 网站。如何制作静态 网站 供他人访问。
4、网络服务器:
www服务器,通常服务器端指的是web服务器。
常用服务器:IIS、Apache、Nginx
5、数据库:
放置东西的地方,数据库是数据的存储库。
在web中,用于服务端脚本语言调用。
常用数据库:Oracle、MySQL、SQL Server、DB2、MariDB
这里分享php动态网页的元素介绍。希望以上内容能对你有所帮助,让你学习到更多的知识。如果你觉得文章不错,可以分享给更多人看到。
php抓取网页动态数据(新版本思科CCIEEI认证价值和体系,新版思科ei全新学习必备知识详解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-18 14:13
新版思科CCIE EI认证价值及体系,新版思科EI新学习必备知识讲解网络安全SSL协议_ie-lab网络实验室ccie认证首页博客-程序员的秘密
新版Cisco CCIE EI认证价值及体系,新版Cisco ei新学习必备知识网络安全SSL协议详解SSL(Secure Sockets Layer,安全套接层)是一种为TCP-提供安全连接的安全协议-基于应用层的协议,例如 SSL 可以为 HTTP 协议提供安全连接。SSL协议广泛应用于电子商务、网上银行等领域,为网络上的数据传输提供安全保障。它是在 1990 年开发的,用于保护 Word Wide W...
.NET 框架基础
目录1.什么是.Net平台,.NET Framework2..NET版本3.CLR(公共语言运行时)4.BCL(基本类库)5.@ > FCL(Framework Class Library)3..NET运行机制6.为什么.NET独立于平台7.术语参考:1.什么是.Net平台,.Net平台。NET框架“平台”(这里指软件技术平台,下指这个)能够独立运行、独立存在,提供其所支持的上层系统和应用程序运行的环境。...
vue-router_xiaodingyang's Blog - 程序员的秘密
Vue-router路由后端路由:对于普通的网站,所有的超链接都是URL地址,所有的URL地址都对应服务器上对应的资源;前端路由:对于单页应用,主要通过URL中的哈希(#)实现不同页面之间的切换。同时,hash还有一个特点:HTTP请求不会收录hash相关的内容;因此,单页程序中的页面跳转主要是通过 hash 来实现的;在单页应用中,这种通过hash变化来切换页面的方式称为...
Vue 路由重定向和别名之间的区别解释
重定向重定向也是通过路由配置完成的。下面的例子是从 /a 重定向到 /b: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]} ) 重定向的目标也可以是一个命名的route: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]}) 甚至是方法,动态...
学习 C 与 Java 的类比 - BrightSea 的博客 - 程序员的秘密
上大学的时候,我选修了一个学期的日语。当时,日本老师对我们说:“对于中国人来说,学习英语通常是哭着进去,出来笑着;学日语是笑着进去,哭着出来”。意思是学英语的时候,很难上手,但只要不断学习,改变自己的中文思维习惯,最近就能很好的学好英语。日语虽然不同,但一方面因为它与汉语的密切关系,让我们一上手就有一种似曾相识的感觉;感觉
PHP 数据抓取
PHP数据爬取,CURL这里说的比较简单,在两次爬取的情况下,第二次请求需要第一次数据爬取的结果。例如:提交数据时,需要对页面进行token爬取过程。1.爬取页面,分析页面获取token2.提交数据,第一次获取token带来的问题token通过session保存在后台,当step 1抓取数据,按照步骤2抓取数据 抓取数据时,curl请求其实被当成... 查看全部
php抓取网页动态数据(新版本思科CCIEEI认证价值和体系,新版思科ei全新学习必备知识详解)
新版思科CCIE EI认证价值及体系,新版思科EI新学习必备知识讲解网络安全SSL协议_ie-lab网络实验室ccie认证首页博客-程序员的秘密
新版Cisco CCIE EI认证价值及体系,新版Cisco ei新学习必备知识网络安全SSL协议详解SSL(Secure Sockets Layer,安全套接层)是一种为TCP-提供安全连接的安全协议-基于应用层的协议,例如 SSL 可以为 HTTP 协议提供安全连接。SSL协议广泛应用于电子商务、网上银行等领域,为网络上的数据传输提供安全保障。它是在 1990 年开发的,用于保护 Word Wide W...
.NET 框架基础
目录1.什么是.Net平台,.NET Framework2..NET版本3.CLR(公共语言运行时)4.BCL(基本类库)5.@ > FCL(Framework Class Library)3..NET运行机制6.为什么.NET独立于平台7.术语参考:1.什么是.Net平台,.Net平台。NET框架“平台”(这里指软件技术平台,下指这个)能够独立运行、独立存在,提供其所支持的上层系统和应用程序运行的环境。...
vue-router_xiaodingyang's Blog - 程序员的秘密
Vue-router路由后端路由:对于普通的网站,所有的超链接都是URL地址,所有的URL地址都对应服务器上对应的资源;前端路由:对于单页应用,主要通过URL中的哈希(#)实现不同页面之间的切换。同时,hash还有一个特点:HTTP请求不会收录hash相关的内容;因此,单页程序中的页面跳转主要是通过 hash 来实现的;在单页应用中,这种通过hash变化来切换页面的方式称为...
Vue 路由重定向和别名之间的区别解释
重定向重定向也是通过路由配置完成的。下面的例子是从 /a 重定向到 /b: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]} ) 重定向的目标也可以是一个命名的route: 12345const router = new VueRouter({routes: [{ path: '/a', redirect: '/b' }]}) 甚至是方法,动态...
学习 C 与 Java 的类比 - BrightSea 的博客 - 程序员的秘密
上大学的时候,我选修了一个学期的日语。当时,日本老师对我们说:“对于中国人来说,学习英语通常是哭着进去,出来笑着;学日语是笑着进去,哭着出来”。意思是学英语的时候,很难上手,但只要不断学习,改变自己的中文思维习惯,最近就能很好的学好英语。日语虽然不同,但一方面因为它与汉语的密切关系,让我们一上手就有一种似曾相识的感觉;感觉
PHP 数据抓取
PHP数据爬取,CURL这里说的比较简单,在两次爬取的情况下,第二次请求需要第一次数据爬取的结果。例如:提交数据时,需要对页面进行token爬取过程。1.爬取页面,分析页面获取token2.提交数据,第一次获取token带来的问题token通过session保存在后台,当step 1抓取数据,按照步骤2抓取数据 抓取数据时,curl请求其实被当成...
php抓取网页动态数据(使用PHP动态构建PDF文件的基本操作流程及使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-18 08:04
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在 Web 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p> 查看全部
php抓取网页动态数据(使用PHP动态构建PDF文件的基本操作流程及使用方法)
本文详细介绍了使用 PHP 动态构建 PDF 文件的整个过程。试用免费 PDF 库 (FPDF) 或 PDFLib-Lite 等开源工具,并使用 PHP 代码控制 PDF 内容格式。
有时您需要准确控制要打印的页面的呈现方式。在这种情况下,HTML 不再是最佳选择。PDF 文件让您可以完全控制页面的呈现方式,以及文本、图形和图像在页面上的呈现方式。不幸的是,用于构建 PDF 文件的 API 不是 PHP 工具包的标准部分。现在你需要一点帮助。
当您在 Web 上搜索对 PHP 的 PDF 支持时,您可能会首先找到商业 PDFLib 库及其开源版本 PDFLib-Lite。这些都是很好的库,但商业版本相当昂贵。PDFLib 库的精简版仅作为原创版本分发,当您尝试在托管环境中安装精简版时会出现此限制。
另一种选择是免费 PDF 库 (FPDF),它是原生 PHP,不需要任何编译,并且完全免费,因此您不会像未经许可的 PDFLib 版本那样看到水印。这个免费的 PDF 库是我将在本文中使用的。
我们将使用女子花样滑冰比赛的成绩来演示动态构建 PDF 文件的过程。这些分数从 Web 获得并转换为 XML。清单 1 显示了一个示例 XML 数据文件。
清单1. XML 数据
...
...
...
XML 的根元素是一个事件标记。数据按事件分组,每个事件都收录多个匹配项。在 events 标签内,是一系列事件标签,其中有多个游戏标签。这些游戏代币收录参与比赛的两支球队的名字和他们在比赛中的得分。
清单 2 显示了用于读取 XML 的 PHP 代码。
该脚本实现了一个 getResults 函数来将 XML 文件读入 DOM 文档。然后使用 DOM 调用遍历所有事件和游戏标签以构建事件数组。数组中的每个元素都是一个收录事件名称和游戏项目数组的哈希表。结构基本上是 XML 结构的内存版本。
要测试此脚本的功能,请构建一个 HTML 导出页面,使用 getResults 函数读取文件,并将数据输出为一系列 HTML 表格。清单 3 显示了用于该测试的 PHP 代码。
列出 3. 结果 HTML 页面
<p>
php抓取网页动态数据(关于PHP获取get变量参数的相关知识介绍(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-18 08:01
我们在设计网页交互时,通常使用PHP中的get变量方法来获取form表单中的数据,从而实现各种网页动态查询或请求。有一点HTML基础的朋友应该都知道HTML表单表单有两种提交方式,即get和post,但是对于新手小白来说,或许这个知识点还是有点模糊。
那么本文文章主要详细介绍get方法,即PHP通过get变量获取表单数据的具体方法和使用方法。稍后,文章会继续为大家介绍post的具体用法。.
这是一个特定的代码示例:
1、form表单代码示例(表单获取提交)
form表单get方法示例 名字:
年龄:
效果如下:
2、test.php代码(php接收get数据)
欢迎 !
你的年龄是 岁。
点击代码1中的提交按钮后,页面出现如下
这里可以注意观察,浏览器地址栏中的链接有什么特点?不难看出,使用 GET 方法从表单发送的任何信息都显示在地址栏中,并且任何人都可以看到。即在 HTML 表单中使用 method="get" 时,所有的变量名和值都会显示在 URL 中。
(注:test.php文件可以通过$_GET变量采集表单数据)
综上所述:发送密码或其他敏感信息时不宜使用此方法!但是仅仅因为可变参数显示在 URL 中,您可以将页面添加到采集夹中。在某些情况下,它也很有用,例如需要直接向用户显示一些信息。
以上介绍了PHP中获取表单get参数的相关知识,希望对有需要的朋友有所帮助。 查看全部
php抓取网页动态数据(关于PHP获取get变量参数的相关知识介绍(一))
我们在设计网页交互时,通常使用PHP中的get变量方法来获取form表单中的数据,从而实现各种网页动态查询或请求。有一点HTML基础的朋友应该都知道HTML表单表单有两种提交方式,即get和post,但是对于新手小白来说,或许这个知识点还是有点模糊。
那么本文文章主要详细介绍get方法,即PHP通过get变量获取表单数据的具体方法和使用方法。稍后,文章会继续为大家介绍post的具体用法。.
这是一个特定的代码示例:
1、form表单代码示例(表单获取提交)
form表单get方法示例 名字:
年龄:
效果如下:
2、test.php代码(php接收get数据)
欢迎 !
你的年龄是 岁。
点击代码1中的提交按钮后,页面出现如下
这里可以注意观察,浏览器地址栏中的链接有什么特点?不难看出,使用 GET 方法从表单发送的任何信息都显示在地址栏中,并且任何人都可以看到。即在 HTML 表单中使用 method="get" 时,所有的变量名和值都会显示在 URL 中。
(注:test.php文件可以通过$_GET变量采集表单数据)
综上所述:发送密码或其他敏感信息时不宜使用此方法!但是仅仅因为可变参数显示在 URL 中,您可以将页面添加到采集夹中。在某些情况下,它也很有用,例如需要直接向用户显示一些信息。
以上介绍了PHP中获取表单get参数的相关知识,希望对有需要的朋友有所帮助。
php抓取网页动态数据(怎样抓取站点的数据:(1)抓取原网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-17 15:16
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {<br /> String strURL = "http://ip.chinaz.com/?IP=" + ip;<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> String buf = contentBuf.toString();<br /> int beginIx = buf.indexOf("查询结果[");<br /> int endIx = buf.indexOf("上面四项依次显示的是");<br /> String result = buf.substring(beginIx, endIx);<br /> System.out.println("captureHtml()的结果:\n" + result);<br />}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、在网页上获取 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {<br /> String strURL = "http://www.kiees.cn/sf.php?wen=" + postid<br /> + "&channel=&rnd=0";<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());<br />}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的! 查看全部
php抓取网页动态数据(怎样抓取站点的数据:(1)抓取原网页数据)
有时出于各种原因,我们需要从某个站点采集数据,但是因为不同站点显示数据的方式略有不同!
本文使用Java为大家展示如何抓取网站的数据:(1)抓取原创网页数据;(2)抓取网页Javascript返回的数据。
一、获取原创网页。
在这个例子中,我们将从上面获取 ip 查询的结果:
第一步:打开这个网页,然后输入IP:111.142.55.73,点击查询按钮,可以看到网页上显示的结果:
第二步:查看网页的源码,我们看到源码中有这么一段:
由此可以看出,再次请求网页后,才显示查询结果。
看看查询后的网页地址:
也就是说,我们只有通过访问这样的URL才能得到ip查询的结果。接下来看代码:
public void captureHtml(String ip) throws Exception {<br /> String strURL = "http://ip.chinaz.com/?IP=" + ip;<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> String buf = contentBuf.toString();<br /> int beginIx = buf.indexOf("查询结果[");<br /> int endIx = buf.indexOf("上面四项依次显示的是");<br /> String result = buf.substring(beginIx, endIx);<br /> System.out.println("captureHtml()的结果:\n" + result);<br />}
使用HttpURLConnection连接网站,使用bufReader保存网页返回的数据,然后通过自定义解析方式显示结果。
这里我只是随便解析了一下。如果解析非常准确,需要我自己处理。
解析结果如下:
captureHtml() 的结果:
查询结果[1]:111.142.55.73 ==>> 1871591241 ==>> 福建漳州移动
二、在网页上获取 JavaScript 返回的结果。
有时网站为了保护自己的数据,不会直接在网页源码中返回数据,而是使用JS异步返回数据,这样可以避免工具抓取网站数据比如搜索引擎。
先看看这个页面:
第一种方式查看网页源代码,但是没有找到运单的跟踪信息,因为它是通过JS的方式获取结果的。
但是有时候我们非常需要获取JS数据,这个时候我们应该怎么做呢?
这时候我们就需要用到一个工具:HTTP Analyzer,这个工具可以截取Http的交互内容,我们利用这个工具来达到我们的目的。
先点击开始按钮后,开始监听网页的交互行为。
我们打开网页:,可以看到HTTP Analyzer列出了网页的所有请求数据和结果:
为了更方便的查看JS的结果,我们先清除数据,然后在网页中输入快递号码:7,点击查询按钮,然后查看HTTP Analyzer的结果:
这是点击查询按钮后HTTP Analyzer的结果,我们继续查看:
从上面两张图可以看出,HTTP Analyzer可以截取JS返回的数据并显示在Response Content中,同时可以看到JS请求的网页地址。
这种情况下,我们只需要分析HTTP Analyzer的结果,然后模拟JS的行为来获取数据,也就是我们只需要访问JS请求的网页地址就可以获取数据,当然前提是就是数据没有加密,我们记下JS请求的URL:
然后让程序请求这个网页的结果!
这是代码:
public void captureJavascript(String postid) throws Exception {<br /> String strURL = "http://www.kiees.cn/sf.php?wen=" + postid<br /> + "&channel=&rnd=0";<br /> URL url = new URL(strURL);<br /> HttpURLConnection httpConn = (HttpURLConnection) url.openConnection();<br /> InputStreamReader input = new InputStreamReader(httpConn<br /> .getInputStream(), "utf-8");<br /> BufferedReader bufReader = new BufferedReader(input);<br /> String line = "";<br /> StringBuilder contentBuf = new StringBuilder();<br /> while ((line = bufReader.readLine()) != null) {<br /> contentBuf.append(line);<br /> }<br /> System.out.println("captureJavascript()的结果:\n" + contentBuf.toString());<br />}
可以看到,爬取JS的方法和之前爬取原创网页的代码完全一样,只是做了一个解析JS的过程。
下面是运行程序的结果:
captureJavascript() 的结果:
运单跟踪信息 [7]
这些数据就是JS返回的结果,达到了我们的目的!

