
js 抓取网页内容
js 抓取网页内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-18 21:07
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页是这样的:
看源码,是这样的:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS仍然需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# 编码:utf-8
导入请求
导入json
网址 = '#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
网址 = '#39;
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页是这样的:
看源码,是这样的:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS仍然需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# 编码:utf-8
导入请求
导入json
网址 = '#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
网址 = '#39;
wbdata = requests.get(url).text
js 抓取网页内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-18 21:07
背景
RPA工作流程中最常见的场景是操作浏览器对页面内容进行相关操作。在此示例中,以页面为例。它将带领您探索如何使用 RPA 工具自动爬取页面的文本内容。
本文将使用 JavaScript 语言开发 RPA 脚本。这里使用的 RPA 工具 LeanRunner 可以直接从 Windows 应用商店下载。它可以支持使用node.js的开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的RPA脚本。
脚步
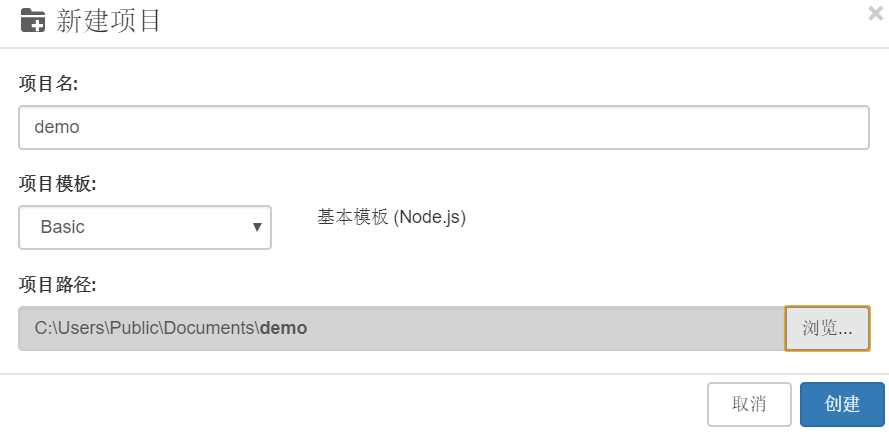
新项目
打开LeanRunner,选择【项目】--【新建】--【选择基础项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的网络自动化库。chromedriver 库可用于驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
单击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
注:npm作为node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
定义流程步骤以使自动化流程可读。
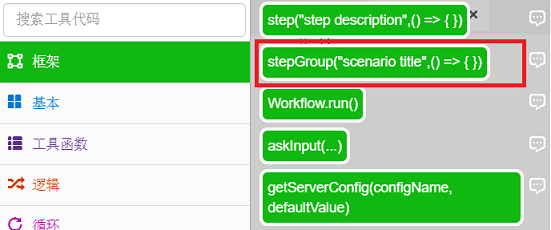
一个。打开main.js,在【工具箱】-【框架】中找到stepGroup方法,拖拽到js文件中。
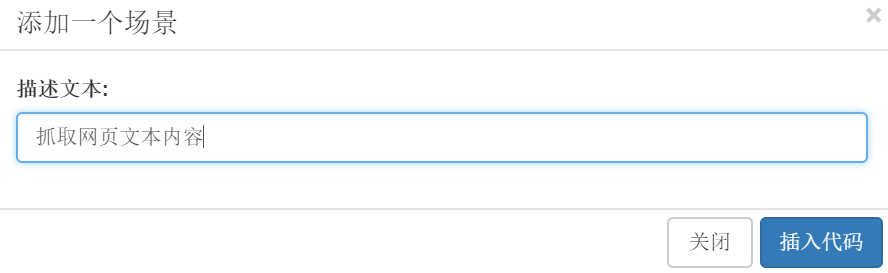
湾。在弹出的对话框中输入描述文字: 抓取网页的文字内容,点击插入代码。
C。此时main.js的文件内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
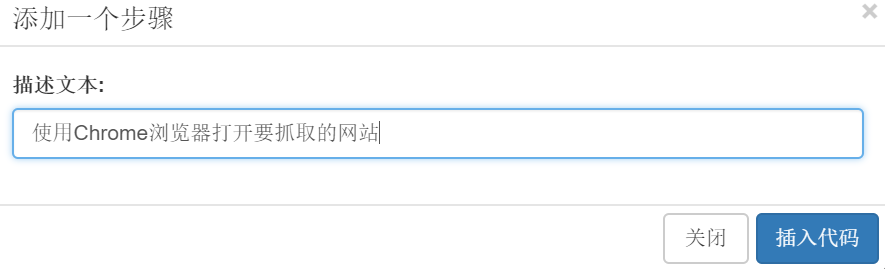
d。继续拖动【工具箱】--【框架】中的step方法来描述文字输入:用Chrome浏览器打开网站要抓取:
e. 按照上面的步骤,再次插入抓取文本并关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【工具箱】-【框架】中选择Workrun.run()函数:
G。在函数中输入“main”运行:
最终代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别执行上述步骤:
一个。使用Chrome浏览器打开要抓取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾。抓住文字:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用 CSS 选择器来定位要访问的元素并打印输出。
C。关闭浏览器
await driver.close();
最终实现的代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
,或单击运行项目按钮
可以看到浏览器打开网页并在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是正在运行的项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个操作基本网页的RPA。后续操作可以在此RPA的基础上进一步深化,例如将抓取的文本内容存储在Excel表格中,或者存储在数据库中。
本文使用的selenium-webdriver自动化库是一个非常流行的开源库,支持各种类型的浏览器,可以及时更新支持最新版本的浏览器。Node.js 也是一个非常流行的开源平台。基于此类技术的RPA自动化脚本的开发保持了RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速打造属于自己的流程自动化。 查看全部
js 抓取网页内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流程中最常见的场景是操作浏览器对页面内容进行相关操作。在此示例中,以页面为例。它将带领您探索如何使用 RPA 工具自动爬取页面的文本内容。
本文将使用 JavaScript 语言开发 RPA 脚本。这里使用的 RPA 工具 LeanRunner 可以直接从 Windows 应用商店下载。它可以支持使用node.js的开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的RPA脚本。
脚步
新项目
打开LeanRunner,选择【项目】--【新建】--【选择基础项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的网络自动化库。chromedriver 库可用于驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
单击 LeanRunner 打开命令行工具按钮

,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
注:npm作为node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
定义流程步骤以使自动化流程可读。
一个。打开main.js,在【工具箱】-【框架】中找到stepGroup方法,拖拽到js文件中。
湾。在弹出的对话框中输入描述文字: 抓取网页的文字内容,点击插入代码。
C。此时main.js的文件内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d。继续拖动【工具箱】--【框架】中的step方法来描述文字输入:用Chrome浏览器打开网站要抓取:
e. 按照上面的步骤,再次插入抓取文本并关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【工具箱】-【框架】中选择Workrun.run()函数:
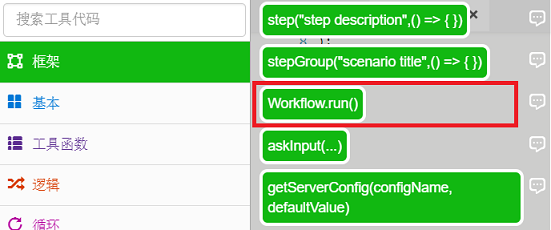
G。在函数中输入“main”运行:
最终代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别执行上述步骤:
一个。使用Chrome浏览器打开要抓取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾。抓住文字:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用 CSS 选择器来定位要访问的元素并打印输出。
C。关闭浏览器
await driver.close();
最终实现的代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮

,或单击运行项目按钮

可以看到浏览器打开网页并在 LeanRunner 设计器的输出面板中打印出文本内容。

如果是正在运行的项目,也会显示html运行报告:
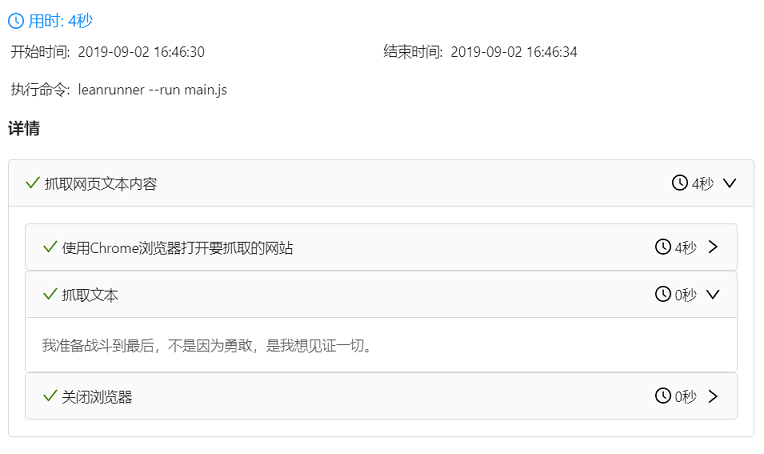
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个操作基本网页的RPA。后续操作可以在此RPA的基础上进一步深化,例如将抓取的文本内容存储在Excel表格中,或者存储在数据库中。
本文使用的selenium-webdriver自动化库是一个非常流行的开源库,支持各种类型的浏览器,可以及时更新支持最新版本的浏览器。Node.js 也是一个非常流行的开源平台。基于此类技术的RPA自动化脚本的开发保持了RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速打造属于自己的流程自动化。
js 抓取网页内容(如何快速收录网站不收录怎么办?新网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-17 00:16
经常有同学说怎么快速收录,网站没有收录怎么办?
其实网站没有收录一般都是新的网站,对于没有SEO基础,对SEO没有深入了解的小伙伴经常遇到的问题,甚至很多人都会说你,不要 收录 将流量引向 网站 并引导蜘蛛爬取你的页面。这些想法和操作太片面了。
一、网站否收录:首先决定是刚上线1-3个月的新站,还是已经上线1-3个月的老站半年多网站
如果是新的网站:
首页收录上线后1周内,大量内部录音收录、收录被搜索发布需要10-20天。 网站如果空白页很多,而大量的页面内容很少,这种情况下对应的页面不是收录,否则收录会很慢。如果网站20天以上,首页没有收录,网站域名可能有犯罪记录,被搜索引擎屏蔽了,可以投诉搜索引擎#1
旧的网站没有收录,内页新增的页面大部分没有搜索到,大部分是页面质量问题。
二、网站没有收录常规分析思路
1、网站 的服务器必须稳定。可以浏览百度资源网站管理信息,抓取异常,查看服务器稳定性。
2、检查 robots.txt 文件是否允许抓取。例如:网站首页及各栏目页面是否被屏蔽抓取。
3、检查网站每个页面路径都不错。如:调用大量检查不利于集灵,站点:网站检查是否有动静共存路径
4、重要页面不能写在JS标签里面。如:首页导航、版块样式、各栏目页面块模型、内页版块不能用JS标签写,不懂代码的用户可以使用谷歌浏览器,设置为不允许javascript爬取,并且在刷新Effect之后查看页面,JS部分无法显示和显示效果
5、页面稳定,质量好。 网站页面版块链接合理,内容质量好,页面不经常更换,来自采集的内容不多,没有用户搜索需求。
三、如果以上都没有问题,分析人为修改因素
分析过去三个月人为操作的变化,内页内容不是很多采集。 SEO研究中心青田老师提醒大家,比如:删除大量页面、修改页面标题、频繁更改程序和网站模块,甚至网站被搜索引擎降级,导致在内页的很多内容中收录。大量的内容变化,在内容中植入大量的广告链接弹窗,会导致新的页面不是收录。
四、如何加速网站收录?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源中验证网站,安装自动推送代码,添加页面爬取收录。
<p>2、做好网站内容丰富度优化:注意长尾关键词排名布局,多做用户会搜索的内容,文章图文并茂,内容不少于500字,3张左右。图片可以给用户一个想法。图片要加上ATL关键词,让搜索引擎知道图片是什么意思,内容要收录用户要搜索的 查看全部
js 抓取网页内容(如何快速收录网站不收录怎么办?新网站)
经常有同学说怎么快速收录,网站没有收录怎么办?
其实网站没有收录一般都是新的网站,对于没有SEO基础,对SEO没有深入了解的小伙伴经常遇到的问题,甚至很多人都会说你,不要 收录 将流量引向 网站 并引导蜘蛛爬取你的页面。这些想法和操作太片面了。
一、网站否收录:首先决定是刚上线1-3个月的新站,还是已经上线1-3个月的老站半年多网站
如果是新的网站:
首页收录上线后1周内,大量内部录音收录、收录被搜索发布需要10-20天。 网站如果空白页很多,而大量的页面内容很少,这种情况下对应的页面不是收录,否则收录会很慢。如果网站20天以上,首页没有收录,网站域名可能有犯罪记录,被搜索引擎屏蔽了,可以投诉搜索引擎#1
旧的网站没有收录,内页新增的页面大部分没有搜索到,大部分是页面质量问题。
二、网站没有收录常规分析思路
1、网站 的服务器必须稳定。可以浏览百度资源网站管理信息,抓取异常,查看服务器稳定性。
2、检查 robots.txt 文件是否允许抓取。例如:网站首页及各栏目页面是否被屏蔽抓取。
3、检查网站每个页面路径都不错。如:调用大量检查不利于集灵,站点:网站检查是否有动静共存路径
4、重要页面不能写在JS标签里面。如:首页导航、版块样式、各栏目页面块模型、内页版块不能用JS标签写,不懂代码的用户可以使用谷歌浏览器,设置为不允许javascript爬取,并且在刷新Effect之后查看页面,JS部分无法显示和显示效果
5、页面稳定,质量好。 网站页面版块链接合理,内容质量好,页面不经常更换,来自采集的内容不多,没有用户搜索需求。
三、如果以上都没有问题,分析人为修改因素
分析过去三个月人为操作的变化,内页内容不是很多采集。 SEO研究中心青田老师提醒大家,比如:删除大量页面、修改页面标题、频繁更改程序和网站模块,甚至网站被搜索引擎降级,导致在内页的很多内容中收录。大量的内容变化,在内容中植入大量的广告链接弹窗,会导致新的页面不是收录。
四、如何加速网站收录?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源中验证网站,安装自动推送代码,添加页面爬取收录。
<p>2、做好网站内容丰富度优化:注意长尾关键词排名布局,多做用户会搜索的内容,文章图文并茂,内容不少于500字,3张左右。图片可以给用户一个想法。图片要加上ATL关键词,让搜索引擎知道图片是什么意思,内容要收录用户要搜索的
js 抓取网页内容(SEO优化提倡用户体验度良好的导航页流畅的网站导航)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-16 09:15
导航页面是在 网站 上显示 网站 结构的简单页面。虽然搜索引擎访问这个页面是为了尽可能爬取覆盖网站的所有页面,但它的主要目标是人。SEO优化提倡用户体验,导航的设计要站在用户的角度考虑。以下是如何创建具有良好用户体验的导航页面。
1.创建自然流畅的层次结构
流畅的网站导航让用户可以在短时间内找到自己需要的信息。必要时,可以添加导航页面以有效地合并内部链接,以确保 网站 上的所有页面都可以通过链接访问,并且无需内部搜索功能即可找到。在适当的情况下,相关网页的链接也可用于帮助发现类似内容。
应避免的做法:
· 创建复杂的导航链接页面,例如将网站 上的所有页面相互链接。
· 内容过度分割
2.使用文本导航
主要通过文本链接控制网站的网页导航,方便搜索引擎抓取和理解网站。使用 JavaScript 创建网页时,使用 a 元素,使用 URL 作为 href 属性值,并在页面加载时生成所有菜单项,而不是等待用户交互。
应避免的做法:
· 完全基于图像或动画创建导航。
· 导航需要使用基于脚本或插件的事件处理。
3.为用户创建导航页面,为搜索引擎创建站点地图
为方便用户,为整个 网站 或最重要的页面提供简洁的导航页面。此外,创建一个 XML 站点地图文件,以确保搜索引擎可以在 网站 上发现新的和更新的页面,列出所有相关 URL 及其主要内容的最后修改日期。
如图所示
应避免的做法:
· 允许导航页面的内容过期和链接被破坏。
· 创建一个简单列出而不排序的页面
4.显示有用的404页面
有时,用户会通过单击损坏的链接或输入错误的 URL 被重定向到 网站 上不存在的页面。使用自定义404页面可以有效引导用户回到网站上的正常网页,从而大大提升用户体验。理想情况下,404 页面有一个返回根页面的链接,以及一个指向 网站 上流行或相关内容的链接。使用 Google Search Console 可能导致“未找到”错误的 URL 源。
不可避免的做法:
· 通过 robots.txt 文件阻止对 404 页面的抓取。
· 只提供模糊的消息,例如“未找到”、“404”或根本没有 404 页面。
· 404页面使用的设计与网站其他部分的设计不一致。 查看全部
js 抓取网页内容(SEO优化提倡用户体验度良好的导航页流畅的网站导航)
导航页面是在 网站 上显示 网站 结构的简单页面。虽然搜索引擎访问这个页面是为了尽可能爬取覆盖网站的所有页面,但它的主要目标是人。SEO优化提倡用户体验,导航的设计要站在用户的角度考虑。以下是如何创建具有良好用户体验的导航页面。
1.创建自然流畅的层次结构
流畅的网站导航让用户可以在短时间内找到自己需要的信息。必要时,可以添加导航页面以有效地合并内部链接,以确保 网站 上的所有页面都可以通过链接访问,并且无需内部搜索功能即可找到。在适当的情况下,相关网页的链接也可用于帮助发现类似内容。
应避免的做法:
· 创建复杂的导航链接页面,例如将网站 上的所有页面相互链接。
· 内容过度分割
2.使用文本导航
主要通过文本链接控制网站的网页导航,方便搜索引擎抓取和理解网站。使用 JavaScript 创建网页时,使用 a 元素,使用 URL 作为 href 属性值,并在页面加载时生成所有菜单项,而不是等待用户交互。
应避免的做法:
· 完全基于图像或动画创建导航。
· 导航需要使用基于脚本或插件的事件处理。
3.为用户创建导航页面,为搜索引擎创建站点地图
为方便用户,为整个 网站 或最重要的页面提供简洁的导航页面。此外,创建一个 XML 站点地图文件,以确保搜索引擎可以在 网站 上发现新的和更新的页面,列出所有相关 URL 及其主要内容的最后修改日期。
如图所示
应避免的做法:
· 允许导航页面的内容过期和链接被破坏。
· 创建一个简单列出而不排序的页面
4.显示有用的404页面
有时,用户会通过单击损坏的链接或输入错误的 URL 被重定向到 网站 上不存在的页面。使用自定义404页面可以有效引导用户回到网站上的正常网页,从而大大提升用户体验。理想情况下,404 页面有一个返回根页面的链接,以及一个指向 网站 上流行或相关内容的链接。使用 Google Search Console 可能导致“未找到”错误的 URL 源。
不可避免的做法:
· 通过 robots.txt 文件阻止对 404 页面的抓取。
· 只提供模糊的消息,例如“未找到”、“404”或根本没有 404 页面。
· 404页面使用的设计与网站其他部分的设计不一致。
js 抓取网页内容( Python开发的一个快速高层次框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-15 23:04
Python开发的一个快速高层次框架)
框架
爬虫框架介绍
我们直接使用requests、Selenium等库来编写爬虫。如果爬行量不是太大,速度要求不高,完全可以满足需要。但是如果你多写一些,你会发现很多内部代码和组件是可以复用的。如果我们把这些组件抽出来,把每个功能模块化,就会慢慢形成一个框架原型。随着时间的推移,爬虫框架诞生了。
抽象是对大量具体实例的抽象。没有大量具体例子的感知,很难对抽象的规律或框架有深刻的理解。
使用框架,我们可以不再关心某些功能的具体实现,只需要关心爬取逻辑即可。有了它们,代码量可以大大简化,架构会变得清晰,爬取效率会高很多。
所以,如果你有一定的基础,入手框架是个不错的选择。
蜘蛛
Pyspider 是一个由中文binux 编写的强大的网络爬虫框架。它具有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。它支持多个数据库后端、多个消息队列,还支持对 JavaScript 渲染页面的爬取。
pyspider的优点:
1.提供WebUI界面,调试爬虫非常方便;
2.监控爬取过程和管理爬虫项目非常方便;
3.支持常用数据库;
4.支持使用PhantomJS,可以爬取JavaScript页面;
5.支持优先级自定义、定时爬取等功能;
刮擦
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
pyspider 和 Scrapy 的比较
1.pyspider提供WebUI,Scrapy使用代码和命令行操作,但可以通过对接Portia进行可视化配置。
2.pyspider 支持 PhantomJS 用于 JavaScript 染色页面采集,Scrapy 可以连接 Scrapy-Splash 组件,需要额外配置。
3.pyspider 内置了 pyquery 作为选择器,Scrapy 采用 XPath 对接 css 选择器和正则匹配。
4.pyspider扩展性不强,Scrapy可以通过对接其他模块实现强大的功能,模块间耦合度低。
所以如果想快速实现一个页面的爬取,推荐使用pyspider,开发更方便;如果要应对强反爬虫和超大规模爬虫,推荐使用Scrapy。
后记:框架、套路、方法、策略、模型、算法,这些话所描述的内容本质上是一样的,当我们学习并掌握了这些,只意味着我们有资格上路,而不是成为大师.
就像开车一样,我们会转动方向盘,教练也会教我们,车在哪里,看哪一点,方向盘怎么转或者杀了。但实际上路后,我们会发现路况复杂,不能机械地使用这些方法,而是需要根据现场情况判断方向盘应该转动多少。成为老司机之后,这些方法和策略可能已经融入了身体。到了这个阶段,已经没有办法取胜了,已经到了狂喜的状态。
框架、套路、方法、策略、模型、算法,这些当然很重要,是基础。了解了这些内容之后,接下来的重点应该是在大量实际具体案例中的感知和实践,进行优化。实际情况远比这些理论复杂,所谓复杂,就是因为尺度导致了各种已知或未知的超乎想象的情况。复杂性并不难,但有很多情况和情况。理论是为方便研究而构建的一定维度的简化模型。 查看全部
js 抓取网页内容(
Python开发的一个快速高层次框架)
框架
爬虫框架介绍
我们直接使用requests、Selenium等库来编写爬虫。如果爬行量不是太大,速度要求不高,完全可以满足需要。但是如果你多写一些,你会发现很多内部代码和组件是可以复用的。如果我们把这些组件抽出来,把每个功能模块化,就会慢慢形成一个框架原型。随着时间的推移,爬虫框架诞生了。
抽象是对大量具体实例的抽象。没有大量具体例子的感知,很难对抽象的规律或框架有深刻的理解。
使用框架,我们可以不再关心某些功能的具体实现,只需要关心爬取逻辑即可。有了它们,代码量可以大大简化,架构会变得清晰,爬取效率会高很多。
所以,如果你有一定的基础,入手框架是个不错的选择。
蜘蛛
Pyspider 是一个由中文binux 编写的强大的网络爬虫框架。它具有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。它支持多个数据库后端、多个消息队列,还支持对 JavaScript 渲染页面的爬取。
pyspider的优点:
1.提供WebUI界面,调试爬虫非常方便;
2.监控爬取过程和管理爬虫项目非常方便;
3.支持常用数据库;
4.支持使用PhantomJS,可以爬取JavaScript页面;
5.支持优先级自定义、定时爬取等功能;
刮擦
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
pyspider 和 Scrapy 的比较
1.pyspider提供WebUI,Scrapy使用代码和命令行操作,但可以通过对接Portia进行可视化配置。
2.pyspider 支持 PhantomJS 用于 JavaScript 染色页面采集,Scrapy 可以连接 Scrapy-Splash 组件,需要额外配置。
3.pyspider 内置了 pyquery 作为选择器,Scrapy 采用 XPath 对接 css 选择器和正则匹配。
4.pyspider扩展性不强,Scrapy可以通过对接其他模块实现强大的功能,模块间耦合度低。
所以如果想快速实现一个页面的爬取,推荐使用pyspider,开发更方便;如果要应对强反爬虫和超大规模爬虫,推荐使用Scrapy。
后记:框架、套路、方法、策略、模型、算法,这些话所描述的内容本质上是一样的,当我们学习并掌握了这些,只意味着我们有资格上路,而不是成为大师.
就像开车一样,我们会转动方向盘,教练也会教我们,车在哪里,看哪一点,方向盘怎么转或者杀了。但实际上路后,我们会发现路况复杂,不能机械地使用这些方法,而是需要根据现场情况判断方向盘应该转动多少。成为老司机之后,这些方法和策略可能已经融入了身体。到了这个阶段,已经没有办法取胜了,已经到了狂喜的状态。
框架、套路、方法、策略、模型、算法,这些当然很重要,是基础。了解了这些内容之后,接下来的重点应该是在大量实际具体案例中的感知和实践,进行优化。实际情况远比这些理论复杂,所谓复杂,就是因为尺度导致了各种已知或未知的超乎想象的情况。复杂性并不难,但有很多情况和情况。理论是为方便研究而构建的一定维度的简化模型。
js 抓取网页内容(蜘蛛几天没来影响网站抓取频率的因素有哪些因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-15 23:00
很多人想让自己的网站收录更快,想出各种办法来增加搜索引擎蜘蛛的爬取次数,只有更多的网页爬取,才有可能获得更好的采集、排名和流量. 网站对蜘蛛不友好。蜘蛛喜欢自己的网站。如果它们爬得很多,那么很容易推断出 网站 对蜘蛛的胃口很大。如果蜘蛛几天没有来,你去看看。
影响 网站 抓取频率的因素:
1、Incoming links:从搜索引擎理论来看,一般情况下,搜索引擎可以跟随A链接中的链接爬到B站点,所以建立一定的外部链接是必不可少的;
2、网站结构:扁平的网站结构相对更适合蜘蛛抓取;
3、页面速度:减少不必要的JS加载,在优化网站速度的同时,可以在移动端进行MIP转换;
4、主动提交:及时提交网站最新内容,如通过主动推送、自动推送,加快搜索引擎抓取速度;
5、内容更新:以一定的频率不断更新网站的内容,产出优质的原创内容;
6、百度熊掌号:推送优质内容到熊掌号的原创保护或实时收录可以让页面收录更快;
搜索引擎正在加快 网站 的访问频率。除了每月进行全面深入的搜索外,他们还频繁更新网站简单搜索结果几天甚至每天更新,以确保搜索结果的及时性。在 网站 中设置关键字导航是向 网站 添加关键字的指南。关键字相关的文章可以放在这个目录下。
第一方会查看网站的内容,同时帮助蜘蛛抓取内容。只关注内容和外部链接的 网站 可能在主页上排名不佳,但由于关键字数量有限,访问量也相当有限。一个很久没有更新的网站,用户和蜘蛛都会减少对它的访问。可以说,更新频率越高,访问的蜘蛛越多,搜索结果的主页面上出现新信息的可能性就越大,被检索到的页面也就越多。
网站 具有优化的结构。如果蜘蛛访问顺利,那么它会更喜欢访问网站。如果网站想增加网站中关键字的密度,应该考虑增加网站的内链。内链的构建是网站优化的重要部分,也是最容易被忽略的部分。在 文章 中选择一个关键字。制作指向 网站 主页的锚文本链接。
对于 关键词 优化,使用内部链接以避免错误。如果蜘蛛索引您的 网站 并且您的服务器无法加载该页面,或者根本无法访问它,那么搜索引擎将尝试在下一次更新时返回。如果这种情况多次发生,搜索引擎将减少对 网站 的访问或将其从库中的数据中删除。如果一个网站的内容和外部链接足够好,它就能获得一个不错的排名。
本文来自:深圳嘉速互联网-网站建设 查看全部
js 抓取网页内容(蜘蛛几天没来影响网站抓取频率的因素有哪些因素?)
很多人想让自己的网站收录更快,想出各种办法来增加搜索引擎蜘蛛的爬取次数,只有更多的网页爬取,才有可能获得更好的采集、排名和流量. 网站对蜘蛛不友好。蜘蛛喜欢自己的网站。如果它们爬得很多,那么很容易推断出 网站 对蜘蛛的胃口很大。如果蜘蛛几天没有来,你去看看。
影响 网站 抓取频率的因素:
1、Incoming links:从搜索引擎理论来看,一般情况下,搜索引擎可以跟随A链接中的链接爬到B站点,所以建立一定的外部链接是必不可少的;
2、网站结构:扁平的网站结构相对更适合蜘蛛抓取;
3、页面速度:减少不必要的JS加载,在优化网站速度的同时,可以在移动端进行MIP转换;
4、主动提交:及时提交网站最新内容,如通过主动推送、自动推送,加快搜索引擎抓取速度;
5、内容更新:以一定的频率不断更新网站的内容,产出优质的原创内容;
6、百度熊掌号:推送优质内容到熊掌号的原创保护或实时收录可以让页面收录更快;
搜索引擎正在加快 网站 的访问频率。除了每月进行全面深入的搜索外,他们还频繁更新网站简单搜索结果几天甚至每天更新,以确保搜索结果的及时性。在 网站 中设置关键字导航是向 网站 添加关键字的指南。关键字相关的文章可以放在这个目录下。
第一方会查看网站的内容,同时帮助蜘蛛抓取内容。只关注内容和外部链接的 网站 可能在主页上排名不佳,但由于关键字数量有限,访问量也相当有限。一个很久没有更新的网站,用户和蜘蛛都会减少对它的访问。可以说,更新频率越高,访问的蜘蛛越多,搜索结果的主页面上出现新信息的可能性就越大,被检索到的页面也就越多。
网站 具有优化的结构。如果蜘蛛访问顺利,那么它会更喜欢访问网站。如果网站想增加网站中关键字的密度,应该考虑增加网站的内链。内链的构建是网站优化的重要部分,也是最容易被忽略的部分。在 文章 中选择一个关键字。制作指向 网站 主页的锚文本链接。
对于 关键词 优化,使用内部链接以避免错误。如果蜘蛛索引您的 网站 并且您的服务器无法加载该页面,或者根本无法访问它,那么搜索引擎将尝试在下一次更新时返回。如果这种情况多次发生,搜索引擎将减少对 网站 的访问或将其从库中的数据中删除。如果一个网站的内容和外部链接足够好,它就能获得一个不错的排名。
本文来自:深圳嘉速互联网-网站建设
js 抓取网页内容(旅行网站的飞行时间或Airbnb,使用Node.js库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-15 22:20
目前,由于其用例的数量,企业对网络抓取的采用已大大增加。您可能需要采集航班时间或 Airbnb 列表以进行旅行网站,或者您可能想要采集数据(例如来自不同电子商务网站s 的价目表)以进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。Puppeteer 默认运行无头,但可以配置为运行完全无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
切里奥
Cheerio 是一个用于解析令牌的库。它提供了一个用于操作结果数据结构的 API。Cheerio 最好的一点是它不像网络浏览器那样解释结果。但是,它不会产生视觉效果,也不会加载外部资源或应用 CSS。因此,如果您的用例需要它们,您需要考虑像 PhantomJS 这样的项目。
值得一提的是,使用 Node.js 抓取 网站 在 Cheerio 中要容易得多。像 Walmart 这样的公司使用 Cheerio 为其移动设备 网站 托管服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供了更快的解决方案。当内容不是动态呈现时,可以使用此网络抓取工具。如果您使用身份验证系统处理 网站,它可能是更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在使用方面完全相反。
恶梦
Nightmare 是一个高级浏览器自动化库,将 Electron 作为浏览器运行。这是一个精简版,或者更确切地说是 Puppeteer 的简化版。它具有提供更多灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网络爬虫。它是用 Node.js 编写的,并带有 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果将它与 Cheerio、jQuery 和 jsdom 进行比较,它没有明显的依赖关系。
总结
除了这些网络爬虫,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些 网站 不允许抓取,因此在尝试抓取任何 网站 之前,请确保您做得很好。 查看全部
js 抓取网页内容(旅行网站的飞行时间或Airbnb,使用Node.js库)
目前,由于其用例的数量,企业对网络抓取的采用已大大增加。您可能需要采集航班时间或 Airbnb 列表以进行旅行网站,或者您可能想要采集数据(例如来自不同电子商务网站s 的价目表)以进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。Puppeteer 默认运行无头,但可以配置为运行完全无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
切里奥
Cheerio 是一个用于解析令牌的库。它提供了一个用于操作结果数据结构的 API。Cheerio 最好的一点是它不像网络浏览器那样解释结果。但是,它不会产生视觉效果,也不会加载外部资源或应用 CSS。因此,如果您的用例需要它们,您需要考虑像 PhantomJS 这样的项目。
值得一提的是,使用 Node.js 抓取 网站 在 Cheerio 中要容易得多。像 Walmart 这样的公司使用 Cheerio 为其移动设备 网站 托管服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供了更快的解决方案。当内容不是动态呈现时,可以使用此网络抓取工具。如果您使用身份验证系统处理 网站,它可能是更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在使用方面完全相反。
恶梦
Nightmare 是一个高级浏览器自动化库,将 Electron 作为浏览器运行。这是一个精简版,或者更确切地说是 Puppeteer 的简化版。它具有提供更多灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网络爬虫。它是用 Node.js 编写的,并带有 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果将它与 Cheerio、jQuery 和 jsdom 进行比较,它没有明显的依赖关系。
总结
除了这些网络爬虫,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些 网站 不允许抓取,因此在尝试抓取任何 网站 之前,请确保您做得很好。
js 抓取网页内容(Facebook是如何演示浏览器和API的使用的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 18:10
为了演示浏览器和 API 的使用,我们将查看 Facebook 的 网站。目前,就月活跃用户而言,Facebook 是全球最大的社交网络之一,因此其用户数据非常有价值。
1网站
图 1 显示了 Packt Press Facebook 页面。
查看页面源码时,可以发现前几条日志,但后面的日志只有在浏览器滚动时才通过 AJAX 加载。此外,Facebook 提供了一个移动界面,如第一章所述,这种形式的界面通常更容易抓取。该页面在移动端的显示形式如图9.6所示。
图1
图 2
当我们与移动端网站交互,用浏览器工具查看时,会发现界面使用了和之前类似的结构来处理AJAX事件,所以这种方法并不能简化抓取。虽然可以对这些 AJAX 事件进行逆向工程,但不同类型的 Facebook 页面使用不同的 AJAX 调用,根据我过去的经验,Facebook 经常更改这些调用的结构,因此爬取这些页面需要持续维护。因此,正如第 5 章所讨论的,除非性能至关重要,否则最好使用浏览器渲染引擎执行 JavaScript 事件,然后访问生成的 HTML 页面。
下面的代码片段使用 Selenium 自动登录 Facebook 并跳转到给定页面的 URL。
from selenium import webdriver
def get_driver():
try:
return webdriver.PhantomJS()
except:
return webdriver.Firefox()
def facebook(username, password, url):
driver = get_driver()
driver.get('https://facebook.com')
driver.find_element_by_id('email').send_keys(username)
driver.find_element_by_id('pass').send_keys(password)
driver.find_element_by_id('loginbutton').submit()
driver.implicitly_wait(30)
# wait until the search box is available,
# which means it has successfully logged in
search = driver.find_element_by_name('q')
# now logged in so can go to the page of interest
driver.get(url)
# add code to scrape data of interest here ...
然后,您可以调用此函数来加载您感兴趣的 Facebook 页面,并使用有效的 Facebook 电子邮件和密码来获取生成的 HTML 页面。
2Facebook API
正如第 1 章所讨论的,当数据没有被赋予结构化格式时,抓取 网站 是最后的手段。Facebook 确实为绝大多数公共或私人(通过您的用户帐户)数据提供了 API,因此在构建增强的浏览器抓取之前,我们需要首先检查这些 API 提供的访问权限是否足够。
首先要做的是确定可以通过 API 获得哪些数据。为了解决这个问题,我们需要先查阅它的 API 文档。开发人员文档位于 ,其中提供了所有不同类型的 API,包括 Graph API,其中收录我们想要的信息。如果您需要与 Facebook 建立其他交互(通过 API 或 SDK),您可以随时查阅文档,该文档定期更新且易于使用。
另外,根据文档链接,我们还可以使用浏览器内的 Graph API 探索工具。如图 3 所示,探索工具是测试查询及其结果的好地方。
图 3
在这里我可以搜索 API 以获取 PacktPub 的 Facebook 页面 ID。图形浏览器工具也可以用来生成访问令牌,我们可以用它来定位 API。
要在 Python 中使用 Graph API,我们需要使用特殊的访问令牌来处理更高级的请求。幸运的是,我们可以使用一个维护良好的名为 facebook-sdk() 的库。我们只是通过 pip 安装它。
pip install facebook-sdk
下面是使用 Facebook 的 Graph API 从 Packt Press 页面提取数据的代码示例。
In [1]: from facebook import GraphAPI
In [2]: access_token = '....' # insert your actual token here
In [3]: graph = GraphAPI(access_token=access_token, version='2.7')
In [4]: graph.get_object('PacktPub')
Out[4]: {'id': '204603129458', 'name': 'Packt'}
我们可以看到与基于浏览器的图形探索工具相同的结果。我们可以通过传递我们想要提取的额外信息来获取页面上的更多信息。要确定要使用哪些信息,我们可以在图表文档的页面上查看所有可用字段。使用关键字参数字段,我们可以从 API 中提取这些可用的附加字段。
In [5]: graph.get_object('PacktPub', fields='about,events,feed,picture')
Out[5]:
{'about': 'Packt provides software learning resources, from eBooks to video
courses, to everyone from web developers to data scientists.',
'feed': {'data': [{'created_time': '2017-03-27T10:30:00+0000',
'id': '204603129458_10155195603119459',
'message': "We've teamed up with CBR Online to give you a chance to win 5
tech eBooks - enter by March 31! http://bit.ly/2mTvmeA"},
...
'id': '204603129458',
'picture': {'data': {'is_silhouette': False,
'url':
'https://scontent.xx.fbcdn.net/v/t1.0-1/p50x50/14681705_10154660327349459_7
2357248532027065_n.png?oh=d0a26e6c8a00cf7e6ce957ed2065e430&oe=59660265'}}}
我们可以看到响应是一个格式良好的 Python 字典,我们可以轻松解析。
Graph API 还提供了许多其他调用来访问用户数据,相关文档可以从 Facebook 的开发人员页面获取。根据所需的数据,您可能还需要创建 Facebook 开发者应用程序以获取更持久的访问令牌。 查看全部
js 抓取网页内容(Facebook是如何演示浏览器和API的使用的?(组图))
为了演示浏览器和 API 的使用,我们将查看 Facebook 的 网站。目前,就月活跃用户而言,Facebook 是全球最大的社交网络之一,因此其用户数据非常有价值。
1网站
图 1 显示了 Packt Press Facebook 页面。
查看页面源码时,可以发现前几条日志,但后面的日志只有在浏览器滚动时才通过 AJAX 加载。此外,Facebook 提供了一个移动界面,如第一章所述,这种形式的界面通常更容易抓取。该页面在移动端的显示形式如图9.6所示。
图1
图 2
当我们与移动端网站交互,用浏览器工具查看时,会发现界面使用了和之前类似的结构来处理AJAX事件,所以这种方法并不能简化抓取。虽然可以对这些 AJAX 事件进行逆向工程,但不同类型的 Facebook 页面使用不同的 AJAX 调用,根据我过去的经验,Facebook 经常更改这些调用的结构,因此爬取这些页面需要持续维护。因此,正如第 5 章所讨论的,除非性能至关重要,否则最好使用浏览器渲染引擎执行 JavaScript 事件,然后访问生成的 HTML 页面。
下面的代码片段使用 Selenium 自动登录 Facebook 并跳转到给定页面的 URL。
from selenium import webdriver
def get_driver():
try:
return webdriver.PhantomJS()
except:
return webdriver.Firefox()
def facebook(username, password, url):
driver = get_driver()
driver.get('https://facebook.com')
driver.find_element_by_id('email').send_keys(username)
driver.find_element_by_id('pass').send_keys(password)
driver.find_element_by_id('loginbutton').submit()
driver.implicitly_wait(30)
# wait until the search box is available,
# which means it has successfully logged in
search = driver.find_element_by_name('q')
# now logged in so can go to the page of interest
driver.get(url)
# add code to scrape data of interest here ...
然后,您可以调用此函数来加载您感兴趣的 Facebook 页面,并使用有效的 Facebook 电子邮件和密码来获取生成的 HTML 页面。
2Facebook API
正如第 1 章所讨论的,当数据没有被赋予结构化格式时,抓取 网站 是最后的手段。Facebook 确实为绝大多数公共或私人(通过您的用户帐户)数据提供了 API,因此在构建增强的浏览器抓取之前,我们需要首先检查这些 API 提供的访问权限是否足够。
首先要做的是确定可以通过 API 获得哪些数据。为了解决这个问题,我们需要先查阅它的 API 文档。开发人员文档位于 ,其中提供了所有不同类型的 API,包括 Graph API,其中收录我们想要的信息。如果您需要与 Facebook 建立其他交互(通过 API 或 SDK),您可以随时查阅文档,该文档定期更新且易于使用。
另外,根据文档链接,我们还可以使用浏览器内的 Graph API 探索工具。如图 3 所示,探索工具是测试查询及其结果的好地方。
图 3
在这里我可以搜索 API 以获取 PacktPub 的 Facebook 页面 ID。图形浏览器工具也可以用来生成访问令牌,我们可以用它来定位 API。
要在 Python 中使用 Graph API,我们需要使用特殊的访问令牌来处理更高级的请求。幸运的是,我们可以使用一个维护良好的名为 facebook-sdk() 的库。我们只是通过 pip 安装它。
pip install facebook-sdk
下面是使用 Facebook 的 Graph API 从 Packt Press 页面提取数据的代码示例。
In [1]: from facebook import GraphAPI
In [2]: access_token = '....' # insert your actual token here
In [3]: graph = GraphAPI(access_token=access_token, version='2.7')
In [4]: graph.get_object('PacktPub')
Out[4]: {'id': '204603129458', 'name': 'Packt'}
我们可以看到与基于浏览器的图形探索工具相同的结果。我们可以通过传递我们想要提取的额外信息来获取页面上的更多信息。要确定要使用哪些信息,我们可以在图表文档的页面上查看所有可用字段。使用关键字参数字段,我们可以从 API 中提取这些可用的附加字段。
In [5]: graph.get_object('PacktPub', fields='about,events,feed,picture')
Out[5]:
{'about': 'Packt provides software learning resources, from eBooks to video
courses, to everyone from web developers to data scientists.',
'feed': {'data': [{'created_time': '2017-03-27T10:30:00+0000',
'id': '204603129458_10155195603119459',
'message': "We've teamed up with CBR Online to give you a chance to win 5
tech eBooks - enter by March 31! http://bit.ly/2mTvmeA"},
...
'id': '204603129458',
'picture': {'data': {'is_silhouette': False,
'url':
'https://scontent.xx.fbcdn.net/v/t1.0-1/p50x50/14681705_10154660327349459_7
2357248532027065_n.png?oh=d0a26e6c8a00cf7e6ce957ed2065e430&oe=59660265'}}}
我们可以看到响应是一个格式良好的 Python 字典,我们可以轻松解析。
Graph API 还提供了许多其他调用来访问用户数据,相关文档可以从 Facebook 的开发人员页面获取。根据所需的数据,您可能还需要创建 Facebook 开发者应用程序以获取更持久的访问令牌。
js 抓取网页内容(什么时候应该使用网页爬取?(二)网页技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-14 01:11
概述
HTML 几乎是直截了当的。CSS 是一个很大的进步,它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上是这样。现实世界还是有点不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和适用于 request、BeautifulSoup 和 Selenium 等语言的优秀软件包。
什么时候应该使用网络抓取?
网页抓取是一种自动获取旨在实现人类用户交互的网页内容、解析它们并提取一些信息(可能是导航到其他页面的链接)的做法。如果没有其他方法可以提取必要的网页信息,那么网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依赖于提供良好的专用 API 以编程方式从网页获取数据。但是,在以下几种情况下,最好不要使用网络抓取技术:
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。例如,在《Vagrant 技术简介》(链接:)页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。 查看全部
js 抓取网页内容(什么时候应该使用网页爬取?(二)网页技术)
概述
HTML 几乎是直截了当的。CSS 是一个很大的进步,它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上是这样。现实世界还是有点不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和适用于 request、BeautifulSoup 和 Selenium 等语言的优秀软件包。
什么时候应该使用网络抓取?
网页抓取是一种自动获取旨在实现人类用户交互的网页内容、解析它们并提取一些信息(可能是导航到其他页面的链接)的做法。如果没有其他方法可以提取必要的网页信息,那么网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依赖于提供良好的专用 API 以编程方式从网页获取数据。但是,在以下几种情况下,最好不要使用网络抓取技术:
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。例如,在《Vagrant 技术简介》(链接:)页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:

代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。

强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。
js 抓取网页内容(新浪财经为例之1.依赖的jar包-1. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-06 09:03
)
使用Selenium和PhantomJs,可以模拟用户操作,爬取大部分网站。我们以新浪财经为例。我们抓取新浪财经新闻版块内容。
1.依赖的jar包。我的项目是普通SSM单人间的web项目。最后一个jar包用于在获取网页dom后解析网页内容。
org.seleniumhq.selenium
selenium-java
3.2.0
javax
javaee-web-api
7.0
provided
com.google.guava
guava
20.0
cn.wanghaomiao
JsoupXpath
2.2
2.获取网页dom内容
package com.nsjr.grab.util;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import cn.wanghaomiao.xpath.model.JXDocument;
@SuppressWarnings("deprecation")
public class SeleniumUtil {
public static JXDocument getDocument(String driverUrl,String pageUrl){
JXDocument jxDocument = null;
PhantomJSDriver driver = null;
try{
System.setProperty("phantomjs.binary.path", driverUrl);
System.setProperty("webdriver.chrome.driver", driverUrl);
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,driverUrl);
//创建无界面浏览器对象
driver = new PhantomJSDriver(dcaps);
//WebDriver driver = new ChromeDriver(dcaps);
driver.get(pageUrl);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
Document document = Jsoup.parse(driver.getPageSource());
jxDocument = new JXDocument(document);
}catch(Exception e){
e.printStackTrace();
}finally{
if(driver != null){
driver.quit();
}
}
return jxDocument;
}
public static String getProperty(List list){
if(list.isEmpty()){
return "";
}else{
return list.get(0).toString();
}
}
}
3.分析并保存内容
JXDocument jxDocument = SeleniumUtil.getDocument(captureUrl.getDriverUrl(), captureUrl.getSinaNews());
//保存第一部分加粗新闻
List listh3 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/h3/a");
for(Object a :listh3){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存其余新闻
List listP = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/p/a");
for(Object a :listP){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存第二部分新闻
List listpart2 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[2]/ul");
for(Object a :listpart2){
JXDocument doc = new JXDocument(a.toString());
List alist = doc.sel("//li/a");
for(Object a2 :alist){
JXDocument doc2 = new JXDocument(a2.toString());
//System.out.println("地址:"+doc2.sel("//a/@href"));
//System.out.println("标题:"+doc2.sel("//text()"));
saveNews(
SeleniumUtil.getProperty(doc2.sel("//text()")),
SeleniumUtil.getProperty(doc2.sel("//a/@href")),
Constant.NEWS_TYPE_BOTTOM,
Constant.NEWS_SOURCE_SINA
);
}
}
4.说明
captureUrl.getDriverUrl(), captureUrl.getSinaNews() 这两个地址分别是PhantomJs工具的地址和要爬取的网站的地址,其中<br />
sina_news = https://finance.sina.com.cn/
driverUrl= D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe
可以直接从官网下载PhantomJs工具。 Windows 和 Linux 版本可供下载。网页结构分析使用JsoupXpath,这是一个中文写的html文档解析工具包,非常好用。语法可以参考Xpath的相关语法进行节点选择。
5. 抓取结果。由于项目要求比较简单,对实时性和性能要求不高,只能通过仓储来满足要求。
最后,刚开始接触爬虫的时候,有的需要webmagic可以满足,有的需要其他方法,需要具体问题具体分析。仍处于探索阶段,本文仅提供解决方案。
查看全部
js 抓取网页内容(新浪财经为例之1.依赖的jar包-1.
)
使用Selenium和PhantomJs,可以模拟用户操作,爬取大部分网站。我们以新浪财经为例。我们抓取新浪财经新闻版块内容。
1.依赖的jar包。我的项目是普通SSM单人间的web项目。最后一个jar包用于在获取网页dom后解析网页内容。
org.seleniumhq.selenium
selenium-java
3.2.0
javax
javaee-web-api
7.0
provided
com.google.guava
guava
20.0
cn.wanghaomiao
JsoupXpath
2.2
2.获取网页dom内容
package com.nsjr.grab.util;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import cn.wanghaomiao.xpath.model.JXDocument;
@SuppressWarnings("deprecation")
public class SeleniumUtil {
public static JXDocument getDocument(String driverUrl,String pageUrl){
JXDocument jxDocument = null;
PhantomJSDriver driver = null;
try{
System.setProperty("phantomjs.binary.path", driverUrl);
System.setProperty("webdriver.chrome.driver", driverUrl);
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,driverUrl);
//创建无界面浏览器对象
driver = new PhantomJSDriver(dcaps);
//WebDriver driver = new ChromeDriver(dcaps);
driver.get(pageUrl);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
Document document = Jsoup.parse(driver.getPageSource());
jxDocument = new JXDocument(document);
}catch(Exception e){
e.printStackTrace();
}finally{
if(driver != null){
driver.quit();
}
}
return jxDocument;
}
public static String getProperty(List list){
if(list.isEmpty()){
return "";
}else{
return list.get(0).toString();
}
}
}
3.分析并保存内容
JXDocument jxDocument = SeleniumUtil.getDocument(captureUrl.getDriverUrl(), captureUrl.getSinaNews());
//保存第一部分加粗新闻
List listh3 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/h3/a");
for(Object a :listh3){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存其余新闻
List listP = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/p/a");
for(Object a :listP){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存第二部分新闻
List listpart2 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[2]/ul");
for(Object a :listpart2){
JXDocument doc = new JXDocument(a.toString());
List alist = doc.sel("//li/a");
for(Object a2 :alist){
JXDocument doc2 = new JXDocument(a2.toString());
//System.out.println("地址:"+doc2.sel("//a/@href"));
//System.out.println("标题:"+doc2.sel("//text()"));
saveNews(
SeleniumUtil.getProperty(doc2.sel("//text()")),
SeleniumUtil.getProperty(doc2.sel("//a/@href")),
Constant.NEWS_TYPE_BOTTOM,
Constant.NEWS_SOURCE_SINA
);
}
}
4.说明
captureUrl.getDriverUrl(), captureUrl.getSinaNews() 这两个地址分别是PhantomJs工具的地址和要爬取的网站的地址,其中<br />
sina_news = https://finance.sina.com.cn/
driverUrl= D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe
可以直接从官网下载PhantomJs工具。 Windows 和 Linux 版本可供下载。网页结构分析使用JsoupXpath,这是一个中文写的html文档解析工具包,非常好用。语法可以参考Xpath的相关语法进行节点选择。
5. 抓取结果。由于项目要求比较简单,对实时性和性能要求不高,只能通过仓储来满足要求。
最后,刚开始接触爬虫的时候,有的需要webmagic可以满足,有的需要其他方法,需要具体问题具体分析。仍处于探索阶段,本文仅提供解决方案。
js 抓取网页内容(一下这么简单粗暴!直接搞定百度自动推送代码!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 05:07
网站目前提交百度有三种方式,第一种是主动推广(实时);第二种:自动推送;第三个:站点地图;
第一个主动宣传我们之前的文章已经说过了,根据百度提供的参数,wordpress用户可以直接下载插件包,查看使用情况!
第三个站点地图(站点地图)是您网站上的网页列表。创建并提交站点地图将有助于百度发现和理解您网站 上的所有网页。您还可以使用Sitemap提供关于您的网站的其他信息,例如最后更新日期、Sitemap文件的更新频率等,供百度蜘蛛参考。话不多说,今天重点讲第二次自动推送!
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
对于以上两种方法,我只能哈哈,用起来不难。对于wordpress新手来说,没必要这么麻烦。把这段JS代码直接放在footer.php文件的标签下面就行了!就是这么简单粗暴!
直接获取百度自动推送js代码! 查看全部
js 抓取网页内容(一下这么简单粗暴!直接搞定百度自动推送代码!(组图))
网站目前提交百度有三种方式,第一种是主动推广(实时);第二种:自动推送;第三个:站点地图;
第一个主动宣传我们之前的文章已经说过了,根据百度提供的参数,wordpress用户可以直接下载插件包,查看使用情况!
第三个站点地图(站点地图)是您网站上的网页列表。创建并提交站点地图将有助于百度发现和理解您网站 上的所有网页。您还可以使用Sitemap提供关于您的网站的其他信息,例如最后更新日期、Sitemap文件的更新频率等,供百度蜘蛛参考。话不多说,今天重点讲第二次自动推送!

站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
对于以上两种方法,我只能哈哈,用起来不难。对于wordpress新手来说,没必要这么麻烦。把这段JS代码直接放在footer.php文件的标签下面就行了!就是这么简单粗暴!
直接获取百度自动推送js代码!
js 抓取网页内容(爬虫如何获取执行完js后的html源文件如何查看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-03 15:06
)
爬虫执行js后如何获取html源文件?比如我在页面上点击查询后,会自动生成一张表来携带数据,但是在源文件上右击却无法查看JS生成的表。
可以使用 Firefox 调试。参考网址
可以看到生成的表格。但是看源文件,数字是看不到的。
在线【------解决方案--------
通过设置webBrowser的url,将得到的源码给webBrowser.Document,webBrowser.DocumentCompleted后,得到ebBrowser.Document应该就OK了。 】
尝试按F12后,菜单【缓存】——【清除此域...】,发现问题解决了,可以得到js执行后的完整html数据。下次执行前一定要手动【Clear】,不然还是拿不到post-js的数据。于是,我找到了一个突破口,用代码清除了缓存,问题就解决了。
这个问题困扰了两天,终于找到了解决办法:
///
/// 针对js页面,获取页面内容。火狐的“查看元素”也可以获取。
///
private void PrintHelpPage()
{
// Create a WebBrowser instance.
WebBrowser webBrowserForPrinting = new WebBrowser();
// Add an event handler that prints the document after it loads.
webBrowserForPrinting.DocumentCompleted +=
new WebBrowserDocumentCompletedEventHandler(PrintDocument);
//删除缓存为关键一步,必须进行;不然得不到js执行后的数据
string cachePath = Environment.GetFolderPath(Environment.SpecialFolder.InternetCache);//获取缓存路径
DirectoryInfo di = new DirectoryInfo(cachePath);
foreach (FileInfo fi in di.GetFiles("*.*", SearchOption.AllDirectories))//遍历所有的文件夹 删除里面的文件
{
try
{
fi.Delete();
}
catch { }
}
// Set the Url property to load the document.
webBrowserForPrinting.Url = new Uri("http://218.23.98.205:8080/aqi/ ... 6quot;);
}
private void PrintDocument(object sender, WebBrowserDocumentCompletedEventArgs e)
{
//MessageBox.Show("000");
//foreach (HtmlElement he in ((WebBrowser)sender).Document.GetElementById("sljaqi"))
//{
// //if (he.GetAttribute("classname") == "co_yl")
// //{
// // //然后网页信息格式,来分解出你要的信息。
// //}
// MessageBox.Show(he.OuterText);
// MessageBox.Show(he.Name);
//}
MessageBox.Show(((WebBrowser)sender).Document.GetElementById("sljaqi").InnerHtml);
// Print the document now that it is fully loaded.
//((WebBrowser)sender).Print();
// Dispose the WebBrowser now that the task is complete.
((WebBrowser)sender).Dispose();
} 查看全部
js 抓取网页内容(爬虫如何获取执行完js后的html源文件如何查看
)
爬虫执行js后如何获取html源文件?比如我在页面上点击查询后,会自动生成一张表来携带数据,但是在源文件上右击却无法查看JS生成的表。
可以使用 Firefox 调试。参考网址
可以看到生成的表格。但是看源文件,数字是看不到的。
在线【------解决方案--------
通过设置webBrowser的url,将得到的源码给webBrowser.Document,webBrowser.DocumentCompleted后,得到ebBrowser.Document应该就OK了。 】
尝试按F12后,菜单【缓存】——【清除此域...】,发现问题解决了,可以得到js执行后的完整html数据。下次执行前一定要手动【Clear】,不然还是拿不到post-js的数据。于是,我找到了一个突破口,用代码清除了缓存,问题就解决了。
这个问题困扰了两天,终于找到了解决办法:
///
/// 针对js页面,获取页面内容。火狐的“查看元素”也可以获取。
///
private void PrintHelpPage()
{
// Create a WebBrowser instance.
WebBrowser webBrowserForPrinting = new WebBrowser();
// Add an event handler that prints the document after it loads.
webBrowserForPrinting.DocumentCompleted +=
new WebBrowserDocumentCompletedEventHandler(PrintDocument);
//删除缓存为关键一步,必须进行;不然得不到js执行后的数据
string cachePath = Environment.GetFolderPath(Environment.SpecialFolder.InternetCache);//获取缓存路径
DirectoryInfo di = new DirectoryInfo(cachePath);
foreach (FileInfo fi in di.GetFiles("*.*", SearchOption.AllDirectories))//遍历所有的文件夹 删除里面的文件
{
try
{
fi.Delete();
}
catch { }
}
// Set the Url property to load the document.
webBrowserForPrinting.Url = new Uri("http://218.23.98.205:8080/aqi/ ... 6quot;);
}
private void PrintDocument(object sender, WebBrowserDocumentCompletedEventArgs e)
{
//MessageBox.Show("000");
//foreach (HtmlElement he in ((WebBrowser)sender).Document.GetElementById("sljaqi"))
//{
// //if (he.GetAttribute("classname") == "co_yl")
// //{
// // //然后网页信息格式,来分解出你要的信息。
// //}
// MessageBox.Show(he.OuterText);
// MessageBox.Show(he.Name);
//}
MessageBox.Show(((WebBrowser)sender).Document.GetElementById("sljaqi").InnerHtml);
// Print the document now that it is fully loaded.
//((WebBrowser)sender).Print();
// Dispose the WebBrowser now that the task is complete.
((WebBrowser)sender).Dispose();
}
js 抓取网页内容(什么是jQuery的HTTP模块?以及如何使用? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-02 07:04
)
一、基本思路
先找一个网址:因为这是http协议,所以需要用到node.js的HTTP模块,我们使用HTTP模块中的get()方法来抓取。其中,如果我们不需要抓取所有的数据,而只需要部分数据,比如某个类下的a标签中的文字,那么如果我们在前端,就可以使用DOM操作找到这个节点,但是node.js中没有DOM操作,所以这里需要用到cheerio库。既然抓到了网站上的数据,就涉及到文件的写入,此时需要用到node.js中的fs模块。
二、学习网址
Cheerio 官方学习文档
cheerio npm 网址
node.js 官方文档
node.js 中文文档
二、cheerio 是什么以及如何使用
cheerio 是专为服务器设计的核心 jQuery 的快速、灵活和精益实现。他可以像jquery一样操作字符串。
安装cheerio
npm install cheerio
具体用途
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
三、具体代码
const http = require("http");
const fs = require("fs");
const cheerio = require("cheerio");
http.get("http://tech.ifeng.com/", function(res) {
// 设置编码
res.setEncoding("utf8");
// 当接收到数据时,会触发 "data" 事件的执行
let html = "";
res.on("data", function(data){
html += data;
});
// 数据接收完毕,会触发 "end" 事件的执行
res.on("end", function(){
// 待保存到文件中的字符串
let fileData = "";
// 调用 cheerio.load() 方法,生成一个类似于 jQuery 的对象
const $ = cheerio.load(html);
// 接下来像使用 jQuery 一样来使用 cheerio
$(".pictxt02").each(function(index, element) {
const el = $(element);
let link = el.find("h3 a").attr("href"),
title = el.find("h3 a").text(),
desc = el.children("p").text();
fileData += `${link}\r\n${title}\r\n\t${desc}\r\n\r\n`;
});
// console.log("读取结束,内容:");
// console.log(html);
fs.writeFile("./dist/source.txt", fileData, function(err) {
if (err)
return;
console.log("成功")
});
})
}); 查看全部
js 抓取网页内容(什么是jQuery的HTTP模块?以及如何使用?
)
一、基本思路
先找一个网址:因为这是http协议,所以需要用到node.js的HTTP模块,我们使用HTTP模块中的get()方法来抓取。其中,如果我们不需要抓取所有的数据,而只需要部分数据,比如某个类下的a标签中的文字,那么如果我们在前端,就可以使用DOM操作找到这个节点,但是node.js中没有DOM操作,所以这里需要用到cheerio库。既然抓到了网站上的数据,就涉及到文件的写入,此时需要用到node.js中的fs模块。
二、学习网址
Cheerio 官方学习文档
cheerio npm 网址
node.js 官方文档
node.js 中文文档
二、cheerio 是什么以及如何使用
cheerio 是专为服务器设计的核心 jQuery 的快速、灵活和精益实现。他可以像jquery一样操作字符串。
安装cheerio
npm install cheerio
具体用途
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
三、具体代码
const http = require("http");
const fs = require("fs");
const cheerio = require("cheerio");
http.get("http://tech.ifeng.com/", function(res) {
// 设置编码
res.setEncoding("utf8");
// 当接收到数据时,会触发 "data" 事件的执行
let html = "";
res.on("data", function(data){
html += data;
});
// 数据接收完毕,会触发 "end" 事件的执行
res.on("end", function(){
// 待保存到文件中的字符串
let fileData = "";
// 调用 cheerio.load() 方法,生成一个类似于 jQuery 的对象
const $ = cheerio.load(html);
// 接下来像使用 jQuery 一样来使用 cheerio
$(".pictxt02").each(function(index, element) {
const el = $(element);
let link = el.find("h3 a").attr("href"),
title = el.find("h3 a").text(),
desc = el.children("p").text();
fileData += `${link}\r\n${title}\r\n\t${desc}\r\n\r\n`;
});
// console.log("读取结束,内容:");
// console.log(html);
fs.writeFile("./dist/source.txt", fileData, function(err) {
if (err)
return;
console.log("成功")
});
})
});
js 抓取网页内容(js抓取网页内容的webdriver其实很简单,我之前用vue进行抓取的感受)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-31 02:04
js抓取网页内容的webdriver脚本其实很简单,下面说下我之前用vue进行抓取的感受!在写webdriver脚本之前,需要需要在vue-resource和vue-resourceapi里面配置一下,两个api在package.json里面都有说明。resource里面有4个配置:path.exports={//configurationdirectoryapi//api路径//url.pattern{//javascriptdescription//路径}//vuewithvue-resource.js"""initial//初始化配置//manifest.js"username="xxx"//用户名email=""//邮箱random=""//随机randomvalue="0"//randomvalue为随机值//vue.usemodule(wx.usecomponents,api)//设置api依赖注入this.$ext='ext'//javascript规范,其实是一个函数.this.$directory='/directory'///。 查看全部
js 抓取网页内容(js抓取网页内容的webdriver其实很简单,我之前用vue进行抓取的感受)
js抓取网页内容的webdriver脚本其实很简单,下面说下我之前用vue进行抓取的感受!在写webdriver脚本之前,需要需要在vue-resource和vue-resourceapi里面配置一下,两个api在package.json里面都有说明。resource里面有4个配置:path.exports={//configurationdirectoryapi//api路径//url.pattern{//javascriptdescription//路径}//vuewithvue-resource.js"""initial//初始化配置//manifest.js"username="xxx"//用户名email=""//邮箱random=""//随机randomvalue="0"//randomvalue为随机值//vue.usemodule(wx.usecomponents,api)//设置api依赖注入this.$ext='ext'//javascript规范,其实是一个函数.this.$directory='/directory'///。
js 抓取网页内容(更多Javascript教程,欢迎访问起飞网())
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-30 17:11
更多Javascript教程,欢迎访问飞网>>
身体:
Javascript 通常用于操作 HTML 和更改网页内容!
输出内容到页面
Javascript 提供了 document.write('string') 方法来将内容写入页面:
使用Javascript改变HTML内容的测试-起飞网
document.write("我是来自JS的内容~");
function writeHtmlLater() {
document.write("哈哈,我把内容覆盖了~");
}
使用Javascript改变HTML内容的测试-起飞网
您可以将此代码复制到 html 文件中并运行它。当页面在浏览器中运行时,效果如图:
这时候我们点击按钮,你会发现页面上的所有内容都被覆盖了:
覆盖页面内容的“罪魁祸首”是按钮onclick事件调用的writeHtmlLater方法。这种方法也是在页面上写一个句子,但是覆盖了整个页面。这里需要注意:
document.write() 只将写入的内容输出到文档中。如果在文档加载完成后执行 document.write,整个 HTML 页面将被覆盖。
更改 HTML 标签的内容
我们使用 JS 不仅是为了向文档输出一些内容,而且是为了改变现有标签的显示方式。 Javascript中提供了访问文档标签的方法:document.getElementById()方法,我们可以通过该方法获取我们想要操作的HTML标签,并改变它们的显示方式:
使用Javascript改变HTML内容的测试-起飞网
function changeMySpanHtml() {
document.getElementById("mySpan").innerHTML = "我是被JS改变后的内容";
}
使用Javascript改变HTML内容的测试-起飞网
<p>span内容:我是span标签的原始内容!
</p>
运行这段代码,你会看到如下页面内容:
当我们点击Change Span Content按钮时,你会发现span标签的内容发生了变化:
这是因为我们在代码中得到了这个标签并重新分配了它的innerHTML属性。
本文简单介绍了两种改变HTML内容的方法。后续章节我会介绍更多Javascript知识,请继续关注! 查看全部
js 抓取网页内容(更多Javascript教程,欢迎访问起飞网())
更多Javascript教程,欢迎访问飞网>>
身体:
Javascript 通常用于操作 HTML 和更改网页内容!
输出内容到页面
Javascript 提供了 document.write('string') 方法来将内容写入页面:
使用Javascript改变HTML内容的测试-起飞网
document.write("我是来自JS的内容~");
function writeHtmlLater() {
document.write("哈哈,我把内容覆盖了~");
}
使用Javascript改变HTML内容的测试-起飞网
您可以将此代码复制到 html 文件中并运行它。当页面在浏览器中运行时,效果如图:

这时候我们点击按钮,你会发现页面上的所有内容都被覆盖了:

覆盖页面内容的“罪魁祸首”是按钮onclick事件调用的writeHtmlLater方法。这种方法也是在页面上写一个句子,但是覆盖了整个页面。这里需要注意:
document.write() 只将写入的内容输出到文档中。如果在文档加载完成后执行 document.write,整个 HTML 页面将被覆盖。
更改 HTML 标签的内容
我们使用 JS 不仅是为了向文档输出一些内容,而且是为了改变现有标签的显示方式。 Javascript中提供了访问文档标签的方法:document.getElementById()方法,我们可以通过该方法获取我们想要操作的HTML标签,并改变它们的显示方式:
使用Javascript改变HTML内容的测试-起飞网
function changeMySpanHtml() {
document.getElementById("mySpan").innerHTML = "我是被JS改变后的内容";
}
使用Javascript改变HTML内容的测试-起飞网
<p>span内容:我是span标签的原始内容!
</p>
运行这段代码,你会看到如下页面内容:

当我们点击Change Span Content按钮时,你会发现span标签的内容发生了变化:

这是因为我们在代码中得到了这个标签并重新分配了它的innerHTML属性。
本文简单介绍了两种改变HTML内容的方法。后续章节我会介绍更多Javascript知识,请继续关注!
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-29 10:07
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>

我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-29 10:07
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js 抓取网页内容(js用js获取另一个页面的部分信息-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-28 10:16
js 使用js获取另一个页面的信息-:你好:如果你想获取另一个页面的值,可以使用ajax,比如当你点击一个按钮时获取另一个页面的文本元素的值。在另一页先写函数获取value值。然后使用ajax请求,通过location提交到这个页面,在这个页面上获取提交的url值。刚回来。
如何在javascript中获取用户在上一页输入的信息并在下一页显示获取的信息-:这是父面:
如何抓取js函数生成的网页内容:我查了你提供的页面代码:在首页,你用ajax动态获取服务器各列的数据,然后动态生成页面。这样搜索引擎是抢不到的,因为目前的搜索引擎没有抓取ajax页面的技术。当然,目前有163个博客使用这种方式来组建博客。但是人们...
想做一个网页,用js抓取网上某个网页的表单信息,重新渲染。我该怎么办?:C#获取指定网页的内容并提交到数据库或访问。显示网页时,进入数据库或访问阅读。
如何使用javascript获取远程页面的部分信息:
使用 jsoup 抓取网页的图形信息。您只需要网页上的文章和图片。如何同时抓取这两个信息?,但问题来了。如果要实现自己的程序,会很麻烦。所以最好自己实现。因为分页内容,每个页面都有一个特定的链接,而且非常相似,只是指定的页面数参数不同。所以可以使用遍历的方式来抓取每个网页,解析,然后保存,比较实用。但是我建议你也可以在客户端使用分页模式。这种情况下,根据需要获取,一下子请求的数据量不会太大。
如何使用JAVASCRIPT读取外部网页信息:使用ajax异步读取,推荐使用成熟的jQuery框架来完成这项工作。jquery下载地址:
js爬虫如何实现网页数据抓取:使用http抓包工具获取下一页的url,然后分析url规则,下载你给的url我打不开
如何抓取JS-动态生成的HTML: var o=document.createElement("tag element"); xxx.append(o)
如何在网页中获取js生成的内容-:你下载一个firefox浏览器。然后安装错误脚本。在其中,您可以查看任何 JS CSS HTML... 查看全部
js 抓取网页内容(js用js获取另一个页面的部分信息-)
js 使用js获取另一个页面的信息-:你好:如果你想获取另一个页面的值,可以使用ajax,比如当你点击一个按钮时获取另一个页面的文本元素的值。在另一页先写函数获取value值。然后使用ajax请求,通过location提交到这个页面,在这个页面上获取提交的url值。刚回来。
如何在javascript中获取用户在上一页输入的信息并在下一页显示获取的信息-:这是父面:
如何抓取js函数生成的网页内容:我查了你提供的页面代码:在首页,你用ajax动态获取服务器各列的数据,然后动态生成页面。这样搜索引擎是抢不到的,因为目前的搜索引擎没有抓取ajax页面的技术。当然,目前有163个博客使用这种方式来组建博客。但是人们...
想做一个网页,用js抓取网上某个网页的表单信息,重新渲染。我该怎么办?:C#获取指定网页的内容并提交到数据库或访问。显示网页时,进入数据库或访问阅读。
如何使用javascript获取远程页面的部分信息:
使用 jsoup 抓取网页的图形信息。您只需要网页上的文章和图片。如何同时抓取这两个信息?,但问题来了。如果要实现自己的程序,会很麻烦。所以最好自己实现。因为分页内容,每个页面都有一个特定的链接,而且非常相似,只是指定的页面数参数不同。所以可以使用遍历的方式来抓取每个网页,解析,然后保存,比较实用。但是我建议你也可以在客户端使用分页模式。这种情况下,根据需要获取,一下子请求的数据量不会太大。
如何使用JAVASCRIPT读取外部网页信息:使用ajax异步读取,推荐使用成熟的jQuery框架来完成这项工作。jquery下载地址:
js爬虫如何实现网页数据抓取:使用http抓包工具获取下一页的url,然后分析url规则,下载你给的url我打不开
如何抓取JS-动态生成的HTML: var o=document.createElement("tag element"); xxx.append(o)
如何在网页中获取js生成的内容-:你下载一个firefox浏览器。然后安装错误脚本。在其中,您可以查看任何 JS CSS HTML...
js 抓取网页内容(、网抓(网页打开)过程中的几种情况 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-24 14:07
)
首先,我不是派对!有一定的vba和抓网技术水平。
我爬过的网页无外乎以下几种情况:
1、 GET 方法请求数据。这种类型的网页一般都非常简单,URL 中有各种参数。
2、 POST方式请求数据,这种网页有一定难度。但是使用fiddler工具可以快速分析出实际地址和要传递的参数。主要难点是有些参数是通过JS动态生成的,所以可以在vba中找到JS函数并执行对应的JS。
--------------------我是分割线--------------------
最近抓了一个网站的数据,第一次遇到网页数据是用AngularJS技术动态写的!!你可以用fiddler获取你想要的内容,但是用代码抓取时,http头返回304错误。
经过多日的 AngularJS 技术黑客攻击,最终以失败告终。在此恳请各位大神帮忙,小弟感激不尽。
网页抓取(网页打开)的过程大致如下:
, 打开网站,输入关键词,如:支付宝(中国,点击眼睛打开二级页面
, 点击找到的第一个信息打开另一个页面。
, 获取此页面上的所有数据。如法定代表人、注册资本、身份、行业等。
ps:使用code发送搜索数据时,httphead只需要发送一条数据:.setRequestHeader "loop", "null",这个head必须设置。
再次恳求各位大神帮忙!谢谢!
查看全部
js 抓取网页内容(、网抓(网页打开)过程中的几种情况
)
首先,我不是派对!有一定的vba和抓网技术水平。
我爬过的网页无外乎以下几种情况:
1、 GET 方法请求数据。这种类型的网页一般都非常简单,URL 中有各种参数。
2、 POST方式请求数据,这种网页有一定难度。但是使用fiddler工具可以快速分析出实际地址和要传递的参数。主要难点是有些参数是通过JS动态生成的,所以可以在vba中找到JS函数并执行对应的JS。
--------------------我是分割线--------------------
最近抓了一个网站的数据,第一次遇到网页数据是用AngularJS技术动态写的!!你可以用fiddler获取你想要的内容,但是用代码抓取时,http头返回304错误。
经过多日的 AngularJS 技术黑客攻击,最终以失败告终。在此恳请各位大神帮忙,小弟感激不尽。
网页抓取(网页打开)的过程大致如下:
, 打开网站,输入关键词,如:支付宝(中国,点击眼睛打开二级页面
, 点击找到的第一个信息打开另一个页面。
, 获取此页面上的所有数据。如法定代表人、注册资本、身份、行业等。
ps:使用code发送搜索数据时,httphead只需要发送一条数据:.setRequestHeader "loop", "null",这个head必须设置。
再次恳求各位大神帮忙!谢谢!




js 抓取网页内容(js抓取网页内容分为两个过程:1,抓包分析html2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-22 18:01
js抓取网页内容分为两个过程:1,抓包分析html2。设置编码抓取页面或meta中的http协议分为http协议的字符编码,传输层的编码等,不同的http协议提供不同的解析规则curl:全称是connecttolocalserver,连接本地服务器ss或者spdy:简单说就是连接网络服务器,用tcp/ip协议作为应用层数据的传输udp:纯文本传输,没有tcp的那些服务channel:在浏览器和服务器之间起数据交换的通道3,把内容传递给浏览器一般有两种方式:1,直接把数据通过数据库或文件读取到浏览器的浏览器里面再显示出来2,通过socket协议把数据直接发送给浏览器然后通过浏览器来显示数据库或文件里面。
能够从外部网络输入到内容库中,转换的手段通常有messagequery和协议自身两种途径,前者又分为纯文本传输(simplemessagequery)和可加密(ontransport)的二进制(binary)传输两种。除了query之外,还有get,post,put,delete,postconvert等方法可以传输数据,还可以输入二进制代码进行传输,其中最常用的是get方法。
一般的url,robots协议,meta等等等等都是这一些标签的重要载体。协议支持get/post/put/delete等等等等方法。而对于robots规则的实现,http/1.1已经将它作为解析的前提提供。上图是所支持的robots。重点看第一个部分。进一步,又分了网页设计者选择了一种什么样的规则,然后所支持的不同的robots.txt和它们自身标记之间的相互关系和对策。
分为:网页a,b两种选择:在http/1.1中只支持网页a标准规则;相反,在http/1.0中支持网页b标准规则。上图是网页b标准规则本身的设计图。同时并列的somebutagamethereis.网页a规则,设计者一般都想配置得更有个性一些,用什么语言写lib都是有的,没什么不同,支持java,python,php等等等等,随你选。
网页b规则,在一般的网页设计者中经常会把它搞得比较复杂,因为在http/1.0中,它是基于arraysql的语言的,有一定规范。通常比较流行的url,robots,meta等标签的作用,基本上就和网页b规则是相近的。当然不排除网页b也是有特殊的,也是有自己的图,不用的话我记得也看过不少。回到问题本身:能不能从url库里面查,有不同的header标记就行了。
一般情况下如果你能拿到这些标签的一般也都有设计者的图,不用特意查。http协议设计的宗旨是提供简单的接受信息和发送信息,并不是正经回答是不是能从bottomline返回html。服务器压力没有那么大的时候能不能返回个完整的h。 查看全部
js 抓取网页内容(js抓取网页内容分为两个过程:1,抓包分析html2)
js抓取网页内容分为两个过程:1,抓包分析html2。设置编码抓取页面或meta中的http协议分为http协议的字符编码,传输层的编码等,不同的http协议提供不同的解析规则curl:全称是connecttolocalserver,连接本地服务器ss或者spdy:简单说就是连接网络服务器,用tcp/ip协议作为应用层数据的传输udp:纯文本传输,没有tcp的那些服务channel:在浏览器和服务器之间起数据交换的通道3,把内容传递给浏览器一般有两种方式:1,直接把数据通过数据库或文件读取到浏览器的浏览器里面再显示出来2,通过socket协议把数据直接发送给浏览器然后通过浏览器来显示数据库或文件里面。
能够从外部网络输入到内容库中,转换的手段通常有messagequery和协议自身两种途径,前者又分为纯文本传输(simplemessagequery)和可加密(ontransport)的二进制(binary)传输两种。除了query之外,还有get,post,put,delete,postconvert等方法可以传输数据,还可以输入二进制代码进行传输,其中最常用的是get方法。
一般的url,robots协议,meta等等等等都是这一些标签的重要载体。协议支持get/post/put/delete等等等等方法。而对于robots规则的实现,http/1.1已经将它作为解析的前提提供。上图是所支持的robots。重点看第一个部分。进一步,又分了网页设计者选择了一种什么样的规则,然后所支持的不同的robots.txt和它们自身标记之间的相互关系和对策。
分为:网页a,b两种选择:在http/1.1中只支持网页a标准规则;相反,在http/1.0中支持网页b标准规则。上图是网页b标准规则本身的设计图。同时并列的somebutagamethereis.网页a规则,设计者一般都想配置得更有个性一些,用什么语言写lib都是有的,没什么不同,支持java,python,php等等等等,随你选。
网页b规则,在一般的网页设计者中经常会把它搞得比较复杂,因为在http/1.0中,它是基于arraysql的语言的,有一定规范。通常比较流行的url,robots,meta等标签的作用,基本上就和网页b规则是相近的。当然不排除网页b也是有特殊的,也是有自己的图,不用的话我记得也看过不少。回到问题本身:能不能从url库里面查,有不同的header标记就行了。
一般情况下如果你能拿到这些标签的一般也都有设计者的图,不用特意查。http协议设计的宗旨是提供简单的接受信息和发送信息,并不是正经回答是不是能从bottomline返回html。服务器压力没有那么大的时候能不能返回个完整的h。
js 抓取网页内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-01-18 21:07
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页是这样的:
看源码,是这样的:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS仍然需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# 编码:utf-8
导入请求
导入json
网址 = '#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
网址 = '#39;
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(什么是HTML静态生成的内容?如何对网页进行爬取呢?)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页是这样的:
看源码,是这样的:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS仍然需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# 编码:utf-8
导入请求
导入json
网址 = '#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻=数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# 编码:utf-8
导入请求
导入json
第 2 部分:向数据接口发出 http 请求
网址 = '#39;
wbdata = requests.get(url).text
js 抓取网页内容(如何使用RPA工具进行自动化工具?工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-18 21:07
背景
RPA工作流程中最常见的场景是操作浏览器对页面内容进行相关操作。在此示例中,以页面为例。它将带领您探索如何使用 RPA 工具自动爬取页面的文本内容。
本文将使用 JavaScript 语言开发 RPA 脚本。这里使用的 RPA 工具 LeanRunner 可以直接从 Windows 应用商店下载。它可以支持使用node.js的开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的RPA脚本。
脚步
新项目
打开LeanRunner,选择【项目】--【新建】--【选择基础项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的网络自动化库。chromedriver 库可用于驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
单击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
注:npm作为node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
定义流程步骤以使自动化流程可读。
一个。打开main.js,在【工具箱】-【框架】中找到stepGroup方法,拖拽到js文件中。
湾。在弹出的对话框中输入描述文字: 抓取网页的文字内容,点击插入代码。
C。此时main.js的文件内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d。继续拖动【工具箱】--【框架】中的step方法来描述文字输入:用Chrome浏览器打开网站要抓取:
e. 按照上面的步骤,再次插入抓取文本并关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【工具箱】-【框架】中选择Workrun.run()函数:
G。在函数中输入“main”运行:
最终代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别执行上述步骤:
一个。使用Chrome浏览器打开要抓取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾。抓住文字:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用 CSS 选择器来定位要访问的元素并打印输出。
C。关闭浏览器
await driver.close();
最终实现的代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
,或单击运行项目按钮
可以看到浏览器打开网页并在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是正在运行的项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个操作基本网页的RPA。后续操作可以在此RPA的基础上进一步深化,例如将抓取的文本内容存储在Excel表格中,或者存储在数据库中。
本文使用的selenium-webdriver自动化库是一个非常流行的开源库,支持各种类型的浏览器,可以及时更新支持最新版本的浏览器。Node.js 也是一个非常流行的开源平台。基于此类技术的RPA自动化脚本的开发保持了RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速打造属于自己的流程自动化。 查看全部
js 抓取网页内容(如何使用RPA工具进行自动化工具?工具)
背景
RPA工作流程中最常见的场景是操作浏览器对页面内容进行相关操作。在此示例中,以页面为例。它将带领您探索如何使用 RPA 工具自动爬取页面的文本内容。
本文将使用 JavaScript 语言开发 RPA 脚本。这里使用的 RPA 工具 LeanRunner 可以直接从 Windows 应用商店下载。它可以支持使用node.js的开源自动化库进行RPA开发。用户可以按照以下步骤逐步实现自己的RPA脚本。
脚步
新项目
打开LeanRunner,选择【项目】--【新建】--【选择基础项目模板】,输入项目名称:demo,选择项目路径:
安装依赖库
Selenium-webdriver 是一个流行的网络自动化库。chromedriver 库可用于驱动 Chrome 自动化各种网页。当然,文本提取不是问题。本 RPA 使用这两个库来实现功能。所以创建项目后,需要安装相应的库。
单击 LeanRunner 打开命令行工具按钮
,执行安装命令:
npm init -ynpm install chromedriver selenium-webdriver @types/selenium-webdriver --save
注:npm作为node.js的包管理机制,需要安装node.js环境才能使用
(下载链接:)
定义流程步骤
定义流程步骤以使自动化流程可读。
一个。打开main.js,在【工具箱】-【框架】中找到stepGroup方法,拖拽到js文件中。
湾。在弹出的对话框中输入描述文字: 抓取网页的文字内容,点击插入代码。
C。此时main.js的文件内容:
const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { })}
d。继续拖动【工具箱】--【框架】中的step方法来描述文字输入:用Chrome浏览器打开网站要抓取:
e. 按照上面的步骤,再次插入抓取文本并关闭浏览器的步骤定义。
main.js 如下:
const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}
F。插入Workflow.run函数,RPA执行最终会被执行,在【工具箱】-【框架】中选择Workrun.run()函数:
G。在函数中输入“main”运行:
最终代码是:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { }) await step("抓取文本", async (world) => { }) await step("关闭浏览器", async (world) => { }) })}Workflow.run(main);
实施步骤
参考 selenium-webdriver API
()。分别执行上述步骤:
一个。使用Chrome浏览器打开要抓取的网站:
const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();const url = 'http://wufazhuce.com/one/2558';await driver.get(url);
上面的代码创建一个 WebDriver 实例,打开一个浏览器窗口,并导航到目标 url。
湾。抓住文字:
let text = await driver.findElement({ css:'div[]'}).getText();console.log(text);
上面的代码使用 CSS 选择器来定位要访问的元素并打印输出。
C。关闭浏览器
await driver.close();
最终实现的代码如下:
const { Workflow } = require('leanrunner');const { step } = require('leanrunner');const { stepGroup } = require('leanrunner');require('chromedriver');const WebDriver = require('selenium-webdriver');let driver = new WebDriver.Builder().forBrowser('chrome').build();async function main() { await stepGroup("抓取网页文本内容", async () => { await step("使用Chrome浏览器打开要抓取的网站", async (world) => { const url = 'http://wufazhuce.com/one/2558'; await driver.get(url); }) await step("抓取文本", async (world) => { let text = await driver.findElement({ css:'div[]'}).getText(); console.log(text); world.attachText(text); }) await step("关闭浏览器", async (world) => { await driver.close() }) })}Workflow.run(main);
实施
单击“运行”按钮
,或单击运行项目按钮
可以看到浏览器打开网页并在 LeanRunner 设计器的输出面板中打印出文本内容。
如果是正在运行的项目,也会显示html运行报告:
对于用户来说,html 报告更具可读性。
总结
至此,我们已经完成了一个操作基本网页的RPA。后续操作可以在此RPA的基础上进一步深化,例如将抓取的文本内容存储在Excel表格中,或者存储在数据库中。
本文使用的selenium-webdriver自动化库是一个非常流行的开源库,支持各种类型的浏览器,可以及时更新支持最新版本的浏览器。Node.js 也是一个非常流行的开源平台。基于此类技术的RPA自动化脚本的开发保持了RPA脚本的可用性和可维护性。结合LeanRunner RPA平台,可以帮助企业快速打造属于自己的流程自动化。
js 抓取网页内容(如何快速收录网站不收录怎么办?新网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-17 00:16
经常有同学说怎么快速收录,网站没有收录怎么办?
其实网站没有收录一般都是新的网站,对于没有SEO基础,对SEO没有深入了解的小伙伴经常遇到的问题,甚至很多人都会说你,不要 收录 将流量引向 网站 并引导蜘蛛爬取你的页面。这些想法和操作太片面了。
一、网站否收录:首先决定是刚上线1-3个月的新站,还是已经上线1-3个月的老站半年多网站
如果是新的网站:
首页收录上线后1周内,大量内部录音收录、收录被搜索发布需要10-20天。 网站如果空白页很多,而大量的页面内容很少,这种情况下对应的页面不是收录,否则收录会很慢。如果网站20天以上,首页没有收录,网站域名可能有犯罪记录,被搜索引擎屏蔽了,可以投诉搜索引擎#1
旧的网站没有收录,内页新增的页面大部分没有搜索到,大部分是页面质量问题。
二、网站没有收录常规分析思路
1、网站 的服务器必须稳定。可以浏览百度资源网站管理信息,抓取异常,查看服务器稳定性。
2、检查 robots.txt 文件是否允许抓取。例如:网站首页及各栏目页面是否被屏蔽抓取。
3、检查网站每个页面路径都不错。如:调用大量检查不利于集灵,站点:网站检查是否有动静共存路径
4、重要页面不能写在JS标签里面。如:首页导航、版块样式、各栏目页面块模型、内页版块不能用JS标签写,不懂代码的用户可以使用谷歌浏览器,设置为不允许javascript爬取,并且在刷新Effect之后查看页面,JS部分无法显示和显示效果
5、页面稳定,质量好。 网站页面版块链接合理,内容质量好,页面不经常更换,来自采集的内容不多,没有用户搜索需求。
三、如果以上都没有问题,分析人为修改因素
分析过去三个月人为操作的变化,内页内容不是很多采集。 SEO研究中心青田老师提醒大家,比如:删除大量页面、修改页面标题、频繁更改程序和网站模块,甚至网站被搜索引擎降级,导致在内页的很多内容中收录。大量的内容变化,在内容中植入大量的广告链接弹窗,会导致新的页面不是收录。
四、如何加速网站收录?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源中验证网站,安装自动推送代码,添加页面爬取收录。
<p>2、做好网站内容丰富度优化:注意长尾关键词排名布局,多做用户会搜索的内容,文章图文并茂,内容不少于500字,3张左右。图片可以给用户一个想法。图片要加上ATL关键词,让搜索引擎知道图片是什么意思,内容要收录用户要搜索的 查看全部
js 抓取网页内容(如何快速收录网站不收录怎么办?新网站)
经常有同学说怎么快速收录,网站没有收录怎么办?
其实网站没有收录一般都是新的网站,对于没有SEO基础,对SEO没有深入了解的小伙伴经常遇到的问题,甚至很多人都会说你,不要 收录 将流量引向 网站 并引导蜘蛛爬取你的页面。这些想法和操作太片面了。
一、网站否收录:首先决定是刚上线1-3个月的新站,还是已经上线1-3个月的老站半年多网站
如果是新的网站:
首页收录上线后1周内,大量内部录音收录、收录被搜索发布需要10-20天。 网站如果空白页很多,而大量的页面内容很少,这种情况下对应的页面不是收录,否则收录会很慢。如果网站20天以上,首页没有收录,网站域名可能有犯罪记录,被搜索引擎屏蔽了,可以投诉搜索引擎#1
旧的网站没有收录,内页新增的页面大部分没有搜索到,大部分是页面质量问题。
二、网站没有收录常规分析思路
1、网站 的服务器必须稳定。可以浏览百度资源网站管理信息,抓取异常,查看服务器稳定性。
2、检查 robots.txt 文件是否允许抓取。例如:网站首页及各栏目页面是否被屏蔽抓取。
3、检查网站每个页面路径都不错。如:调用大量检查不利于集灵,站点:网站检查是否有动静共存路径
4、重要页面不能写在JS标签里面。如:首页导航、版块样式、各栏目页面块模型、内页版块不能用JS标签写,不懂代码的用户可以使用谷歌浏览器,设置为不允许javascript爬取,并且在刷新Effect之后查看页面,JS部分无法显示和显示效果
5、页面稳定,质量好。 网站页面版块链接合理,内容质量好,页面不经常更换,来自采集的内容不多,没有用户搜索需求。
三、如果以上都没有问题,分析人为修改因素
分析过去三个月人为操作的变化,内页内容不是很多采集。 SEO研究中心青田老师提醒大家,比如:删除大量页面、修改页面标题、频繁更改程序和网站模块,甚至网站被搜索引擎降级,导致在内页的很多内容中收录。大量的内容变化,在内容中植入大量的广告链接弹窗,会导致新的页面不是收录。
四、如何加速网站收录?
1、主动推送链接:更新sitemap地图,提交给搜索引擎,在百度资源中验证网站,安装自动推送代码,添加页面爬取收录。
<p>2、做好网站内容丰富度优化:注意长尾关键词排名布局,多做用户会搜索的内容,文章图文并茂,内容不少于500字,3张左右。图片可以给用户一个想法。图片要加上ATL关键词,让搜索引擎知道图片是什么意思,内容要收录用户要搜索的
js 抓取网页内容(SEO优化提倡用户体验度良好的导航页流畅的网站导航)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-16 09:15
导航页面是在 网站 上显示 网站 结构的简单页面。虽然搜索引擎访问这个页面是为了尽可能爬取覆盖网站的所有页面,但它的主要目标是人。SEO优化提倡用户体验,导航的设计要站在用户的角度考虑。以下是如何创建具有良好用户体验的导航页面。
1.创建自然流畅的层次结构
流畅的网站导航让用户可以在短时间内找到自己需要的信息。必要时,可以添加导航页面以有效地合并内部链接,以确保 网站 上的所有页面都可以通过链接访问,并且无需内部搜索功能即可找到。在适当的情况下,相关网页的链接也可用于帮助发现类似内容。
应避免的做法:
· 创建复杂的导航链接页面,例如将网站 上的所有页面相互链接。
· 内容过度分割
2.使用文本导航
主要通过文本链接控制网站的网页导航,方便搜索引擎抓取和理解网站。使用 JavaScript 创建网页时,使用 a 元素,使用 URL 作为 href 属性值,并在页面加载时生成所有菜单项,而不是等待用户交互。
应避免的做法:
· 完全基于图像或动画创建导航。
· 导航需要使用基于脚本或插件的事件处理。
3.为用户创建导航页面,为搜索引擎创建站点地图
为方便用户,为整个 网站 或最重要的页面提供简洁的导航页面。此外,创建一个 XML 站点地图文件,以确保搜索引擎可以在 网站 上发现新的和更新的页面,列出所有相关 URL 及其主要内容的最后修改日期。
如图所示
应避免的做法:
· 允许导航页面的内容过期和链接被破坏。
· 创建一个简单列出而不排序的页面
4.显示有用的404页面
有时,用户会通过单击损坏的链接或输入错误的 URL 被重定向到 网站 上不存在的页面。使用自定义404页面可以有效引导用户回到网站上的正常网页,从而大大提升用户体验。理想情况下,404 页面有一个返回根页面的链接,以及一个指向 网站 上流行或相关内容的链接。使用 Google Search Console 可能导致“未找到”错误的 URL 源。
不可避免的做法:
· 通过 robots.txt 文件阻止对 404 页面的抓取。
· 只提供模糊的消息,例如“未找到”、“404”或根本没有 404 页面。
· 404页面使用的设计与网站其他部分的设计不一致。 查看全部
js 抓取网页内容(SEO优化提倡用户体验度良好的导航页流畅的网站导航)
导航页面是在 网站 上显示 网站 结构的简单页面。虽然搜索引擎访问这个页面是为了尽可能爬取覆盖网站的所有页面,但它的主要目标是人。SEO优化提倡用户体验,导航的设计要站在用户的角度考虑。以下是如何创建具有良好用户体验的导航页面。
1.创建自然流畅的层次结构
流畅的网站导航让用户可以在短时间内找到自己需要的信息。必要时,可以添加导航页面以有效地合并内部链接,以确保 网站 上的所有页面都可以通过链接访问,并且无需内部搜索功能即可找到。在适当的情况下,相关网页的链接也可用于帮助发现类似内容。
应避免的做法:
· 创建复杂的导航链接页面,例如将网站 上的所有页面相互链接。
· 内容过度分割
2.使用文本导航
主要通过文本链接控制网站的网页导航,方便搜索引擎抓取和理解网站。使用 JavaScript 创建网页时,使用 a 元素,使用 URL 作为 href 属性值,并在页面加载时生成所有菜单项,而不是等待用户交互。
应避免的做法:
· 完全基于图像或动画创建导航。
· 导航需要使用基于脚本或插件的事件处理。
3.为用户创建导航页面,为搜索引擎创建站点地图
为方便用户,为整个 网站 或最重要的页面提供简洁的导航页面。此外,创建一个 XML 站点地图文件,以确保搜索引擎可以在 网站 上发现新的和更新的页面,列出所有相关 URL 及其主要内容的最后修改日期。
如图所示
应避免的做法:
· 允许导航页面的内容过期和链接被破坏。
· 创建一个简单列出而不排序的页面
4.显示有用的404页面
有时,用户会通过单击损坏的链接或输入错误的 URL 被重定向到 网站 上不存在的页面。使用自定义404页面可以有效引导用户回到网站上的正常网页,从而大大提升用户体验。理想情况下,404 页面有一个返回根页面的链接,以及一个指向 网站 上流行或相关内容的链接。使用 Google Search Console 可能导致“未找到”错误的 URL 源。
不可避免的做法:
· 通过 robots.txt 文件阻止对 404 页面的抓取。
· 只提供模糊的消息,例如“未找到”、“404”或根本没有 404 页面。
· 404页面使用的设计与网站其他部分的设计不一致。
js 抓取网页内容( Python开发的一个快速高层次框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-15 23:04
Python开发的一个快速高层次框架)
框架
爬虫框架介绍
我们直接使用requests、Selenium等库来编写爬虫。如果爬行量不是太大,速度要求不高,完全可以满足需要。但是如果你多写一些,你会发现很多内部代码和组件是可以复用的。如果我们把这些组件抽出来,把每个功能模块化,就会慢慢形成一个框架原型。随着时间的推移,爬虫框架诞生了。
抽象是对大量具体实例的抽象。没有大量具体例子的感知,很难对抽象的规律或框架有深刻的理解。
使用框架,我们可以不再关心某些功能的具体实现,只需要关心爬取逻辑即可。有了它们,代码量可以大大简化,架构会变得清晰,爬取效率会高很多。
所以,如果你有一定的基础,入手框架是个不错的选择。
蜘蛛
Pyspider 是一个由中文binux 编写的强大的网络爬虫框架。它具有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。它支持多个数据库后端、多个消息队列,还支持对 JavaScript 渲染页面的爬取。
pyspider的优点:
1.提供WebUI界面,调试爬虫非常方便;
2.监控爬取过程和管理爬虫项目非常方便;
3.支持常用数据库;
4.支持使用PhantomJS,可以爬取JavaScript页面;
5.支持优先级自定义、定时爬取等功能;
刮擦
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
pyspider 和 Scrapy 的比较
1.pyspider提供WebUI,Scrapy使用代码和命令行操作,但可以通过对接Portia进行可视化配置。
2.pyspider 支持 PhantomJS 用于 JavaScript 染色页面采集,Scrapy 可以连接 Scrapy-Splash 组件,需要额外配置。
3.pyspider 内置了 pyquery 作为选择器,Scrapy 采用 XPath 对接 css 选择器和正则匹配。
4.pyspider扩展性不强,Scrapy可以通过对接其他模块实现强大的功能,模块间耦合度低。
所以如果想快速实现一个页面的爬取,推荐使用pyspider,开发更方便;如果要应对强反爬虫和超大规模爬虫,推荐使用Scrapy。
后记:框架、套路、方法、策略、模型、算法,这些话所描述的内容本质上是一样的,当我们学习并掌握了这些,只意味着我们有资格上路,而不是成为大师.
就像开车一样,我们会转动方向盘,教练也会教我们,车在哪里,看哪一点,方向盘怎么转或者杀了。但实际上路后,我们会发现路况复杂,不能机械地使用这些方法,而是需要根据现场情况判断方向盘应该转动多少。成为老司机之后,这些方法和策略可能已经融入了身体。到了这个阶段,已经没有办法取胜了,已经到了狂喜的状态。
框架、套路、方法、策略、模型、算法,这些当然很重要,是基础。了解了这些内容之后,接下来的重点应该是在大量实际具体案例中的感知和实践,进行优化。实际情况远比这些理论复杂,所谓复杂,就是因为尺度导致了各种已知或未知的超乎想象的情况。复杂性并不难,但有很多情况和情况。理论是为方便研究而构建的一定维度的简化模型。 查看全部
js 抓取网页内容(
Python开发的一个快速高层次框架)
框架
爬虫框架介绍
我们直接使用requests、Selenium等库来编写爬虫。如果爬行量不是太大,速度要求不高,完全可以满足需要。但是如果你多写一些,你会发现很多内部代码和组件是可以复用的。如果我们把这些组件抽出来,把每个功能模块化,就会慢慢形成一个框架原型。随着时间的推移,爬虫框架诞生了。
抽象是对大量具体实例的抽象。没有大量具体例子的感知,很难对抽象的规律或框架有深刻的理解。
使用框架,我们可以不再关心某些功能的具体实现,只需要关心爬取逻辑即可。有了它们,代码量可以大大简化,架构会变得清晰,爬取效率会高很多。
所以,如果你有一定的基础,入手框架是个不错的选择。
蜘蛛
Pyspider 是一个由中文binux 编写的强大的网络爬虫框架。它具有强大的 WebUI、脚本编辑器、任务监视器、项目管理器和结果处理器。它支持多个数据库后端、多个消息队列,还支持对 JavaScript 渲染页面的爬取。
pyspider的优点:
1.提供WebUI界面,调试爬虫非常方便;
2.监控爬取过程和管理爬虫项目非常方便;
3.支持常用数据库;
4.支持使用PhantomJS,可以爬取JavaScript页面;
5.支持优先级自定义、定时爬取等功能;
刮擦
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
pyspider 和 Scrapy 的比较
1.pyspider提供WebUI,Scrapy使用代码和命令行操作,但可以通过对接Portia进行可视化配置。
2.pyspider 支持 PhantomJS 用于 JavaScript 染色页面采集,Scrapy 可以连接 Scrapy-Splash 组件,需要额外配置。
3.pyspider 内置了 pyquery 作为选择器,Scrapy 采用 XPath 对接 css 选择器和正则匹配。
4.pyspider扩展性不强,Scrapy可以通过对接其他模块实现强大的功能,模块间耦合度低。
所以如果想快速实现一个页面的爬取,推荐使用pyspider,开发更方便;如果要应对强反爬虫和超大规模爬虫,推荐使用Scrapy。
后记:框架、套路、方法、策略、模型、算法,这些话所描述的内容本质上是一样的,当我们学习并掌握了这些,只意味着我们有资格上路,而不是成为大师.
就像开车一样,我们会转动方向盘,教练也会教我们,车在哪里,看哪一点,方向盘怎么转或者杀了。但实际上路后,我们会发现路况复杂,不能机械地使用这些方法,而是需要根据现场情况判断方向盘应该转动多少。成为老司机之后,这些方法和策略可能已经融入了身体。到了这个阶段,已经没有办法取胜了,已经到了狂喜的状态。
框架、套路、方法、策略、模型、算法,这些当然很重要,是基础。了解了这些内容之后,接下来的重点应该是在大量实际具体案例中的感知和实践,进行优化。实际情况远比这些理论复杂,所谓复杂,就是因为尺度导致了各种已知或未知的超乎想象的情况。复杂性并不难,但有很多情况和情况。理论是为方便研究而构建的一定维度的简化模型。
js 抓取网页内容(蜘蛛几天没来影响网站抓取频率的因素有哪些因素?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-01-15 23:00
很多人想让自己的网站收录更快,想出各种办法来增加搜索引擎蜘蛛的爬取次数,只有更多的网页爬取,才有可能获得更好的采集、排名和流量. 网站对蜘蛛不友好。蜘蛛喜欢自己的网站。如果它们爬得很多,那么很容易推断出 网站 对蜘蛛的胃口很大。如果蜘蛛几天没有来,你去看看。
影响 网站 抓取频率的因素:
1、Incoming links:从搜索引擎理论来看,一般情况下,搜索引擎可以跟随A链接中的链接爬到B站点,所以建立一定的外部链接是必不可少的;
2、网站结构:扁平的网站结构相对更适合蜘蛛抓取;
3、页面速度:减少不必要的JS加载,在优化网站速度的同时,可以在移动端进行MIP转换;
4、主动提交:及时提交网站最新内容,如通过主动推送、自动推送,加快搜索引擎抓取速度;
5、内容更新:以一定的频率不断更新网站的内容,产出优质的原创内容;
6、百度熊掌号:推送优质内容到熊掌号的原创保护或实时收录可以让页面收录更快;
搜索引擎正在加快 网站 的访问频率。除了每月进行全面深入的搜索外,他们还频繁更新网站简单搜索结果几天甚至每天更新,以确保搜索结果的及时性。在 网站 中设置关键字导航是向 网站 添加关键字的指南。关键字相关的文章可以放在这个目录下。
第一方会查看网站的内容,同时帮助蜘蛛抓取内容。只关注内容和外部链接的 网站 可能在主页上排名不佳,但由于关键字数量有限,访问量也相当有限。一个很久没有更新的网站,用户和蜘蛛都会减少对它的访问。可以说,更新频率越高,访问的蜘蛛越多,搜索结果的主页面上出现新信息的可能性就越大,被检索到的页面也就越多。
网站 具有优化的结构。如果蜘蛛访问顺利,那么它会更喜欢访问网站。如果网站想增加网站中关键字的密度,应该考虑增加网站的内链。内链的构建是网站优化的重要部分,也是最容易被忽略的部分。在 文章 中选择一个关键字。制作指向 网站 主页的锚文本链接。
对于 关键词 优化,使用内部链接以避免错误。如果蜘蛛索引您的 网站 并且您的服务器无法加载该页面,或者根本无法访问它,那么搜索引擎将尝试在下一次更新时返回。如果这种情况多次发生,搜索引擎将减少对 网站 的访问或将其从库中的数据中删除。如果一个网站的内容和外部链接足够好,它就能获得一个不错的排名。
本文来自:深圳嘉速互联网-网站建设 查看全部
js 抓取网页内容(蜘蛛几天没来影响网站抓取频率的因素有哪些因素?)
很多人想让自己的网站收录更快,想出各种办法来增加搜索引擎蜘蛛的爬取次数,只有更多的网页爬取,才有可能获得更好的采集、排名和流量. 网站对蜘蛛不友好。蜘蛛喜欢自己的网站。如果它们爬得很多,那么很容易推断出 网站 对蜘蛛的胃口很大。如果蜘蛛几天没有来,你去看看。
影响 网站 抓取频率的因素:
1、Incoming links:从搜索引擎理论来看,一般情况下,搜索引擎可以跟随A链接中的链接爬到B站点,所以建立一定的外部链接是必不可少的;
2、网站结构:扁平的网站结构相对更适合蜘蛛抓取;
3、页面速度:减少不必要的JS加载,在优化网站速度的同时,可以在移动端进行MIP转换;
4、主动提交:及时提交网站最新内容,如通过主动推送、自动推送,加快搜索引擎抓取速度;
5、内容更新:以一定的频率不断更新网站的内容,产出优质的原创内容;
6、百度熊掌号:推送优质内容到熊掌号的原创保护或实时收录可以让页面收录更快;
搜索引擎正在加快 网站 的访问频率。除了每月进行全面深入的搜索外,他们还频繁更新网站简单搜索结果几天甚至每天更新,以确保搜索结果的及时性。在 网站 中设置关键字导航是向 网站 添加关键字的指南。关键字相关的文章可以放在这个目录下。
第一方会查看网站的内容,同时帮助蜘蛛抓取内容。只关注内容和外部链接的 网站 可能在主页上排名不佳,但由于关键字数量有限,访问量也相当有限。一个很久没有更新的网站,用户和蜘蛛都会减少对它的访问。可以说,更新频率越高,访问的蜘蛛越多,搜索结果的主页面上出现新信息的可能性就越大,被检索到的页面也就越多。
网站 具有优化的结构。如果蜘蛛访问顺利,那么它会更喜欢访问网站。如果网站想增加网站中关键字的密度,应该考虑增加网站的内链。内链的构建是网站优化的重要部分,也是最容易被忽略的部分。在 文章 中选择一个关键字。制作指向 网站 主页的锚文本链接。
对于 关键词 优化,使用内部链接以避免错误。如果蜘蛛索引您的 网站 并且您的服务器无法加载该页面,或者根本无法访问它,那么搜索引擎将尝试在下一次更新时返回。如果这种情况多次发生,搜索引擎将减少对 网站 的访问或将其从库中的数据中删除。如果一个网站的内容和外部链接足够好,它就能获得一个不错的排名。
本文来自:深圳嘉速互联网-网站建设
js 抓取网页内容(旅行网站的飞行时间或Airbnb,使用Node.js库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-15 22:20
目前,由于其用例的数量,企业对网络抓取的采用已大大增加。您可能需要采集航班时间或 Airbnb 列表以进行旅行网站,或者您可能想要采集数据(例如来自不同电子商务网站s 的价目表)以进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。Puppeteer 默认运行无头,但可以配置为运行完全无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
切里奥
Cheerio 是一个用于解析令牌的库。它提供了一个用于操作结果数据结构的 API。Cheerio 最好的一点是它不像网络浏览器那样解释结果。但是,它不会产生视觉效果,也不会加载外部资源或应用 CSS。因此,如果您的用例需要它们,您需要考虑像 PhantomJS 这样的项目。
值得一提的是,使用 Node.js 抓取 网站 在 Cheerio 中要容易得多。像 Walmart 这样的公司使用 Cheerio 为其移动设备 网站 托管服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供了更快的解决方案。当内容不是动态呈现时,可以使用此网络抓取工具。如果您使用身份验证系统处理 网站,它可能是更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在使用方面完全相反。
恶梦
Nightmare 是一个高级浏览器自动化库,将 Electron 作为浏览器运行。这是一个精简版,或者更确切地说是 Puppeteer 的简化版。它具有提供更多灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网络爬虫。它是用 Node.js 编写的,并带有 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果将它与 Cheerio、jQuery 和 jsdom 进行比较,它没有明显的依赖关系。
总结
除了这些网络爬虫,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些 网站 不允许抓取,因此在尝试抓取任何 网站 之前,请确保您做得很好。 查看全部
js 抓取网页内容(旅行网站的飞行时间或Airbnb,使用Node.js库)
目前,由于其用例的数量,企业对网络抓取的采用已大大增加。您可能需要采集航班时间或 Airbnb 列表以进行旅行网站,或者您可能想要采集数据(例如来自不同电子商务网站s 的价目表)以进行价格比较。也许您需要为机器学习采集训练和测试数据集。这就是网络抓取发挥作用的地方。
在这里,我们将探索最好的网络抓取工具。
傀儡师
Puppeteer 不仅仅是一个网络爬虫。它是一个 Node.js 库,允许您使用高级 API 控制 Chrome/Chromium 浏览器。Puppeteer 默认运行无头,但可以配置为运行完全无头 Chrome 或 Chromium。
使用 Puppeteer,您可以执行以下操作:
切里奥
Cheerio 是一个用于解析令牌的库。它提供了一个用于操作结果数据结构的 API。Cheerio 最好的一点是它不像网络浏览器那样解释结果。但是,它不会产生视觉效果,也不会加载外部资源或应用 CSS。因此,如果您的用例需要它们,您需要考虑像 PhantomJS 这样的项目。
值得一提的是,使用 Node.js 抓取 网站 在 Cheerio 中要容易得多。像 Walmart 这样的公司使用 Cheerio 为其移动设备 网站 托管服务器渲染。
请求-承诺
Request-Promise 是 npm 实际库的变体。它通过自动浏览器提供了更快的解决方案。当内容不是动态呈现时,可以使用此网络抓取工具。如果您使用身份验证系统处理 网站,它可能是更高级的解决方案。如果我们将其与 Puppeteer 进行比较,则在使用方面完全相反。
恶梦
Nightmare 是一个高级浏览器自动化库,将 Electron 作为浏览器运行。这是一个精简版,或者更确切地说是 Puppeteer 的简化版。它具有提供更多灵活性的插件,包括对文件下载的支持。
渗透
Osmosis 是一个 HTML/XML 解析器和网络爬虫。它是用 Node.js 编写的,并带有 CSS3/xpath 选择器和一个轻量级的 HTTP 包装器。如果将它与 Cheerio、jQuery 和 jsdom 进行比较,它没有明显的依赖关系。
总结
除了这些网络爬虫,您还可以使用许多其他工具和资源。这一切都取决于您的项目要求。但是,有些 网站 不允许抓取,因此在尝试抓取任何 网站 之前,请确保您做得很好。
js 抓取网页内容(Facebook是如何演示浏览器和API的使用的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-15 18:10
为了演示浏览器和 API 的使用,我们将查看 Facebook 的 网站。目前,就月活跃用户而言,Facebook 是全球最大的社交网络之一,因此其用户数据非常有价值。
1网站
图 1 显示了 Packt Press Facebook 页面。
查看页面源码时,可以发现前几条日志,但后面的日志只有在浏览器滚动时才通过 AJAX 加载。此外,Facebook 提供了一个移动界面,如第一章所述,这种形式的界面通常更容易抓取。该页面在移动端的显示形式如图9.6所示。
图1
图 2
当我们与移动端网站交互,用浏览器工具查看时,会发现界面使用了和之前类似的结构来处理AJAX事件,所以这种方法并不能简化抓取。虽然可以对这些 AJAX 事件进行逆向工程,但不同类型的 Facebook 页面使用不同的 AJAX 调用,根据我过去的经验,Facebook 经常更改这些调用的结构,因此爬取这些页面需要持续维护。因此,正如第 5 章所讨论的,除非性能至关重要,否则最好使用浏览器渲染引擎执行 JavaScript 事件,然后访问生成的 HTML 页面。
下面的代码片段使用 Selenium 自动登录 Facebook 并跳转到给定页面的 URL。
from selenium import webdriver
def get_driver():
try:
return webdriver.PhantomJS()
except:
return webdriver.Firefox()
def facebook(username, password, url):
driver = get_driver()
driver.get('https://facebook.com')
driver.find_element_by_id('email').send_keys(username)
driver.find_element_by_id('pass').send_keys(password)
driver.find_element_by_id('loginbutton').submit()
driver.implicitly_wait(30)
# wait until the search box is available,
# which means it has successfully logged in
search = driver.find_element_by_name('q')
# now logged in so can go to the page of interest
driver.get(url)
# add code to scrape data of interest here ...
然后,您可以调用此函数来加载您感兴趣的 Facebook 页面,并使用有效的 Facebook 电子邮件和密码来获取生成的 HTML 页面。
2Facebook API
正如第 1 章所讨论的,当数据没有被赋予结构化格式时,抓取 网站 是最后的手段。Facebook 确实为绝大多数公共或私人(通过您的用户帐户)数据提供了 API,因此在构建增强的浏览器抓取之前,我们需要首先检查这些 API 提供的访问权限是否足够。
首先要做的是确定可以通过 API 获得哪些数据。为了解决这个问题,我们需要先查阅它的 API 文档。开发人员文档位于 ,其中提供了所有不同类型的 API,包括 Graph API,其中收录我们想要的信息。如果您需要与 Facebook 建立其他交互(通过 API 或 SDK),您可以随时查阅文档,该文档定期更新且易于使用。
另外,根据文档链接,我们还可以使用浏览器内的 Graph API 探索工具。如图 3 所示,探索工具是测试查询及其结果的好地方。
图 3
在这里我可以搜索 API 以获取 PacktPub 的 Facebook 页面 ID。图形浏览器工具也可以用来生成访问令牌,我们可以用它来定位 API。
要在 Python 中使用 Graph API,我们需要使用特殊的访问令牌来处理更高级的请求。幸运的是,我们可以使用一个维护良好的名为 facebook-sdk() 的库。我们只是通过 pip 安装它。
pip install facebook-sdk
下面是使用 Facebook 的 Graph API 从 Packt Press 页面提取数据的代码示例。
In [1]: from facebook import GraphAPI
In [2]: access_token = '....' # insert your actual token here
In [3]: graph = GraphAPI(access_token=access_token, version='2.7')
In [4]: graph.get_object('PacktPub')
Out[4]: {'id': '204603129458', 'name': 'Packt'}
我们可以看到与基于浏览器的图形探索工具相同的结果。我们可以通过传递我们想要提取的额外信息来获取页面上的更多信息。要确定要使用哪些信息,我们可以在图表文档的页面上查看所有可用字段。使用关键字参数字段,我们可以从 API 中提取这些可用的附加字段。
In [5]: graph.get_object('PacktPub', fields='about,events,feed,picture')
Out[5]:
{'about': 'Packt provides software learning resources, from eBooks to video
courses, to everyone from web developers to data scientists.',
'feed': {'data': [{'created_time': '2017-03-27T10:30:00+0000',
'id': '204603129458_10155195603119459',
'message': "We've teamed up with CBR Online to give you a chance to win 5
tech eBooks - enter by March 31! http://bit.ly/2mTvmeA"},
...
'id': '204603129458',
'picture': {'data': {'is_silhouette': False,
'url':
'https://scontent.xx.fbcdn.net/v/t1.0-1/p50x50/14681705_10154660327349459_7
2357248532027065_n.png?oh=d0a26e6c8a00cf7e6ce957ed2065e430&oe=59660265'}}}
我们可以看到响应是一个格式良好的 Python 字典,我们可以轻松解析。
Graph API 还提供了许多其他调用来访问用户数据,相关文档可以从 Facebook 的开发人员页面获取。根据所需的数据,您可能还需要创建 Facebook 开发者应用程序以获取更持久的访问令牌。 查看全部
js 抓取网页内容(Facebook是如何演示浏览器和API的使用的?(组图))
为了演示浏览器和 API 的使用,我们将查看 Facebook 的 网站。目前,就月活跃用户而言,Facebook 是全球最大的社交网络之一,因此其用户数据非常有价值。
1网站
图 1 显示了 Packt Press Facebook 页面。
查看页面源码时,可以发现前几条日志,但后面的日志只有在浏览器滚动时才通过 AJAX 加载。此外,Facebook 提供了一个移动界面,如第一章所述,这种形式的界面通常更容易抓取。该页面在移动端的显示形式如图9.6所示。
图1
图 2
当我们与移动端网站交互,用浏览器工具查看时,会发现界面使用了和之前类似的结构来处理AJAX事件,所以这种方法并不能简化抓取。虽然可以对这些 AJAX 事件进行逆向工程,但不同类型的 Facebook 页面使用不同的 AJAX 调用,根据我过去的经验,Facebook 经常更改这些调用的结构,因此爬取这些页面需要持续维护。因此,正如第 5 章所讨论的,除非性能至关重要,否则最好使用浏览器渲染引擎执行 JavaScript 事件,然后访问生成的 HTML 页面。
下面的代码片段使用 Selenium 自动登录 Facebook 并跳转到给定页面的 URL。
from selenium import webdriver
def get_driver():
try:
return webdriver.PhantomJS()
except:
return webdriver.Firefox()
def facebook(username, password, url):
driver = get_driver()
driver.get('https://facebook.com')
driver.find_element_by_id('email').send_keys(username)
driver.find_element_by_id('pass').send_keys(password)
driver.find_element_by_id('loginbutton').submit()
driver.implicitly_wait(30)
# wait until the search box is available,
# which means it has successfully logged in
search = driver.find_element_by_name('q')
# now logged in so can go to the page of interest
driver.get(url)
# add code to scrape data of interest here ...
然后,您可以调用此函数来加载您感兴趣的 Facebook 页面,并使用有效的 Facebook 电子邮件和密码来获取生成的 HTML 页面。
2Facebook API
正如第 1 章所讨论的,当数据没有被赋予结构化格式时,抓取 网站 是最后的手段。Facebook 确实为绝大多数公共或私人(通过您的用户帐户)数据提供了 API,因此在构建增强的浏览器抓取之前,我们需要首先检查这些 API 提供的访问权限是否足够。
首先要做的是确定可以通过 API 获得哪些数据。为了解决这个问题,我们需要先查阅它的 API 文档。开发人员文档位于 ,其中提供了所有不同类型的 API,包括 Graph API,其中收录我们想要的信息。如果您需要与 Facebook 建立其他交互(通过 API 或 SDK),您可以随时查阅文档,该文档定期更新且易于使用。
另外,根据文档链接,我们还可以使用浏览器内的 Graph API 探索工具。如图 3 所示,探索工具是测试查询及其结果的好地方。
图 3
在这里我可以搜索 API 以获取 PacktPub 的 Facebook 页面 ID。图形浏览器工具也可以用来生成访问令牌,我们可以用它来定位 API。
要在 Python 中使用 Graph API,我们需要使用特殊的访问令牌来处理更高级的请求。幸运的是,我们可以使用一个维护良好的名为 facebook-sdk() 的库。我们只是通过 pip 安装它。
pip install facebook-sdk
下面是使用 Facebook 的 Graph API 从 Packt Press 页面提取数据的代码示例。
In [1]: from facebook import GraphAPI
In [2]: access_token = '....' # insert your actual token here
In [3]: graph = GraphAPI(access_token=access_token, version='2.7')
In [4]: graph.get_object('PacktPub')
Out[4]: {'id': '204603129458', 'name': 'Packt'}
我们可以看到与基于浏览器的图形探索工具相同的结果。我们可以通过传递我们想要提取的额外信息来获取页面上的更多信息。要确定要使用哪些信息,我们可以在图表文档的页面上查看所有可用字段。使用关键字参数字段,我们可以从 API 中提取这些可用的附加字段。
In [5]: graph.get_object('PacktPub', fields='about,events,feed,picture')
Out[5]:
{'about': 'Packt provides software learning resources, from eBooks to video
courses, to everyone from web developers to data scientists.',
'feed': {'data': [{'created_time': '2017-03-27T10:30:00+0000',
'id': '204603129458_10155195603119459',
'message': "We've teamed up with CBR Online to give you a chance to win 5
tech eBooks - enter by March 31! http://bit.ly/2mTvmeA"},
...
'id': '204603129458',
'picture': {'data': {'is_silhouette': False,
'url':
'https://scontent.xx.fbcdn.net/v/t1.0-1/p50x50/14681705_10154660327349459_7
2357248532027065_n.png?oh=d0a26e6c8a00cf7e6ce957ed2065e430&oe=59660265'}}}
我们可以看到响应是一个格式良好的 Python 字典,我们可以轻松解析。
Graph API 还提供了许多其他调用来访问用户数据,相关文档可以从 Facebook 的开发人员页面获取。根据所需的数据,您可能还需要创建 Facebook 开发者应用程序以获取更持久的访问令牌。
js 抓取网页内容(什么时候应该使用网页爬取?(二)网页技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-14 01:11
概述
HTML 几乎是直截了当的。CSS 是一个很大的进步,它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上是这样。现实世界还是有点不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和适用于 request、BeautifulSoup 和 Selenium 等语言的优秀软件包。
什么时候应该使用网络抓取?
网页抓取是一种自动获取旨在实现人类用户交互的网页内容、解析它们并提取一些信息(可能是导航到其他页面的链接)的做法。如果没有其他方法可以提取必要的网页信息,那么网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依赖于提供良好的专用 API 以编程方式从网页获取数据。但是,在以下几种情况下,最好不要使用网络抓取技术:
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。例如,在《Vagrant 技术简介》(链接:)页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。 查看全部
js 抓取网页内容(什么时候应该使用网页爬取?(二)网页技术)
概述
HTML 几乎是直截了当的。CSS 是一个很大的进步,它清楚地区分了页面的结构和外观。JavaScript 增添了一些魅力。理论上是这样。现实世界还是有点不同。
在本教程中,您将了解您在浏览器中看到的内容是如何实际呈现的,以及如何在必要时抓取它。特别是,您将学习如何计算 Disqus 评论。我们的工具是 Python 和适用于 request、BeautifulSoup 和 Selenium 等语言的优秀软件包。
什么时候应该使用网络抓取?
网页抓取是一种自动获取旨在实现人类用户交互的网页内容、解析它们并提取一些信息(可能是导航到其他页面的链接)的做法。如果没有其他方法可以提取必要的网页信息,那么网络爬虫是一种必要且有效的技术方法。理想情况下,应用程序依赖于提供良好的专用 API 以编程方式从网页获取数据。但是,在以下几种情况下,最好不要使用网络抓取技术:
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。例如,在《Vagrant 技术简介》(链接:)页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。
js 抓取网页内容(新浪财经为例之1.依赖的jar包-1. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-06 09:03
)
使用Selenium和PhantomJs,可以模拟用户操作,爬取大部分网站。我们以新浪财经为例。我们抓取新浪财经新闻版块内容。
1.依赖的jar包。我的项目是普通SSM单人间的web项目。最后一个jar包用于在获取网页dom后解析网页内容。
org.seleniumhq.selenium
selenium-java
3.2.0
javax
javaee-web-api
7.0
provided
com.google.guava
guava
20.0
cn.wanghaomiao
JsoupXpath
2.2
2.获取网页dom内容
package com.nsjr.grab.util;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import cn.wanghaomiao.xpath.model.JXDocument;
@SuppressWarnings("deprecation")
public class SeleniumUtil {
public static JXDocument getDocument(String driverUrl,String pageUrl){
JXDocument jxDocument = null;
PhantomJSDriver driver = null;
try{
System.setProperty("phantomjs.binary.path", driverUrl);
System.setProperty("webdriver.chrome.driver", driverUrl);
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,driverUrl);
//创建无界面浏览器对象
driver = new PhantomJSDriver(dcaps);
//WebDriver driver = new ChromeDriver(dcaps);
driver.get(pageUrl);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
Document document = Jsoup.parse(driver.getPageSource());
jxDocument = new JXDocument(document);
}catch(Exception e){
e.printStackTrace();
}finally{
if(driver != null){
driver.quit();
}
}
return jxDocument;
}
public static String getProperty(List list){
if(list.isEmpty()){
return "";
}else{
return list.get(0).toString();
}
}
}
3.分析并保存内容
JXDocument jxDocument = SeleniumUtil.getDocument(captureUrl.getDriverUrl(), captureUrl.getSinaNews());
//保存第一部分加粗新闻
List listh3 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/h3/a");
for(Object a :listh3){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存其余新闻
List listP = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/p/a");
for(Object a :listP){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存第二部分新闻
List listpart2 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[2]/ul");
for(Object a :listpart2){
JXDocument doc = new JXDocument(a.toString());
List alist = doc.sel("//li/a");
for(Object a2 :alist){
JXDocument doc2 = new JXDocument(a2.toString());
//System.out.println("地址:"+doc2.sel("//a/@href"));
//System.out.println("标题:"+doc2.sel("//text()"));
saveNews(
SeleniumUtil.getProperty(doc2.sel("//text()")),
SeleniumUtil.getProperty(doc2.sel("//a/@href")),
Constant.NEWS_TYPE_BOTTOM,
Constant.NEWS_SOURCE_SINA
);
}
}
4.说明
captureUrl.getDriverUrl(), captureUrl.getSinaNews() 这两个地址分别是PhantomJs工具的地址和要爬取的网站的地址,其中<br />
sina_news = https://finance.sina.com.cn/
driverUrl= D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe
可以直接从官网下载PhantomJs工具。 Windows 和 Linux 版本可供下载。网页结构分析使用JsoupXpath,这是一个中文写的html文档解析工具包,非常好用。语法可以参考Xpath的相关语法进行节点选择。
5. 抓取结果。由于项目要求比较简单,对实时性和性能要求不高,只能通过仓储来满足要求。
最后,刚开始接触爬虫的时候,有的需要webmagic可以满足,有的需要其他方法,需要具体问题具体分析。仍处于探索阶段,本文仅提供解决方案。
查看全部
js 抓取网页内容(新浪财经为例之1.依赖的jar包-1.
)
使用Selenium和PhantomJs,可以模拟用户操作,爬取大部分网站。我们以新浪财经为例。我们抓取新浪财经新闻版块内容。
1.依赖的jar包。我的项目是普通SSM单人间的web项目。最后一个jar包用于在获取网页dom后解析网页内容。
org.seleniumhq.selenium
selenium-java
3.2.0
javax
javaee-web-api
7.0
provided
com.google.guava
guava
20.0
cn.wanghaomiao
JsoupXpath
2.2
2.获取网页dom内容
package com.nsjr.grab.util;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.openqa.selenium.phantomjs.PhantomJSDriver;
import org.openqa.selenium.phantomjs.PhantomJSDriverService;
import org.openqa.selenium.remote.DesiredCapabilities;
import cn.wanghaomiao.xpath.model.JXDocument;
@SuppressWarnings("deprecation")
public class SeleniumUtil {
public static JXDocument getDocument(String driverUrl,String pageUrl){
JXDocument jxDocument = null;
PhantomJSDriver driver = null;
try{
System.setProperty("phantomjs.binary.path", driverUrl);
System.setProperty("webdriver.chrome.driver", driverUrl);
DesiredCapabilities dcaps = new DesiredCapabilities();
//ssl证书支持
dcaps.setCapability("acceptSslCerts", true);
//截屏支持
dcaps.setCapability("takesScreenshot", true);
//css搜索支持
dcaps.setCapability("cssSelectorsEnabled", true);
//js支持
dcaps.setJavascriptEnabled(true);
//驱动支持
dcaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,driverUrl);
//创建无界面浏览器对象
driver = new PhantomJSDriver(dcaps);
//WebDriver driver = new ChromeDriver(dcaps);
driver.get(pageUrl);
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
Document document = Jsoup.parse(driver.getPageSource());
jxDocument = new JXDocument(document);
}catch(Exception e){
e.printStackTrace();
}finally{
if(driver != null){
driver.quit();
}
}
return jxDocument;
}
public static String getProperty(List list){
if(list.isEmpty()){
return "";
}else{
return list.get(0).toString();
}
}
}
3.分析并保存内容
JXDocument jxDocument = SeleniumUtil.getDocument(captureUrl.getDriverUrl(), captureUrl.getSinaNews());
//保存第一部分加粗新闻
List listh3 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/h3/a");
for(Object a :listh3){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存其余新闻
List listP = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[@id='blk_hdline_01']/p/a");
for(Object a :listP){
JXDocument doc = new JXDocument(a.toString());
//System.out.println("地址:"+doc.sel("//a/@href"));
//System.out.println("标题:"+doc.sel("//text()"));
saveNews(SeleniumUtil.getProperty(doc.sel("//text()")), SeleniumUtil.getProperty(doc.sel("//a/@href")), Constant.NEWS_TYPE_BOTTOM, Constant.NEWS_SOURCE_SINA);
}
//保存第二部分新闻
List listpart2 = jxDocument.sel("//div[@id='impNews1']/div[@id='fin_tabs0_c0']/div[2]/ul");
for(Object a :listpart2){
JXDocument doc = new JXDocument(a.toString());
List alist = doc.sel("//li/a");
for(Object a2 :alist){
JXDocument doc2 = new JXDocument(a2.toString());
//System.out.println("地址:"+doc2.sel("//a/@href"));
//System.out.println("标题:"+doc2.sel("//text()"));
saveNews(
SeleniumUtil.getProperty(doc2.sel("//text()")),
SeleniumUtil.getProperty(doc2.sel("//a/@href")),
Constant.NEWS_TYPE_BOTTOM,
Constant.NEWS_SOURCE_SINA
);
}
}
4.说明
captureUrl.getDriverUrl(), captureUrl.getSinaNews() 这两个地址分别是PhantomJs工具的地址和要爬取的网站的地址,其中<br />
sina_news = https://finance.sina.com.cn/
driverUrl= D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe
可以直接从官网下载PhantomJs工具。 Windows 和 Linux 版本可供下载。网页结构分析使用JsoupXpath,这是一个中文写的html文档解析工具包,非常好用。语法可以参考Xpath的相关语法进行节点选择。
5. 抓取结果。由于项目要求比较简单,对实时性和性能要求不高,只能通过仓储来满足要求。
最后,刚开始接触爬虫的时候,有的需要webmagic可以满足,有的需要其他方法,需要具体问题具体分析。仍处于探索阶段,本文仅提供解决方案。
js 抓取网页内容(一下这么简单粗暴!直接搞定百度自动推送代码!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-04 05:07
网站目前提交百度有三种方式,第一种是主动推广(实时);第二种:自动推送;第三个:站点地图;
第一个主动宣传我们之前的文章已经说过了,根据百度提供的参数,wordpress用户可以直接下载插件包,查看使用情况!
第三个站点地图(站点地图)是您网站上的网页列表。创建并提交站点地图将有助于百度发现和理解您网站 上的所有网页。您还可以使用Sitemap提供关于您的网站的其他信息,例如最后更新日期、Sitemap文件的更新频率等,供百度蜘蛛参考。话不多说,今天重点讲第二次自动推送!
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
对于以上两种方法,我只能哈哈,用起来不难。对于wordpress新手来说,没必要这么麻烦。把这段JS代码直接放在footer.php文件的标签下面就行了!就是这么简单粗暴!
直接获取百度自动推送js代码! 查看全部
js 抓取网页内容(一下这么简单粗暴!直接搞定百度自动推送代码!(组图))
网站目前提交百度有三种方式,第一种是主动推广(实时);第二种:自动推送;第三个:站点地图;
第一个主动宣传我们之前的文章已经说过了,根据百度提供的参数,wordpress用户可以直接下载插件包,查看使用情况!
第三个站点地图(站点地图)是您网站上的网页列表。创建并提交站点地图将有助于百度发现和理解您网站 上的所有网页。您还可以使用Sitemap提供关于您的网站的其他信息,例如最后更新日期、Sitemap文件的更新频率等,供百度蜘蛛参考。话不多说,今天重点讲第二次自动推送!
站长需要在每个页面的HTML代码中收录如下自动推送JS代码:
如果站长使用PHP语言开发网站,可以按照以下步骤操作:
1、创建一个名为“baidu_js_push.php”的文件,文件内容为上述自动推送JS代码;
2、在每个PHP模板页面文件的标签后添加一行代码:
对于以上两种方法,我只能哈哈,用起来不难。对于wordpress新手来说,没必要这么麻烦。把这段JS代码直接放在footer.php文件的标签下面就行了!就是这么简单粗暴!
直接获取百度自动推送js代码!
js 抓取网页内容(爬虫如何获取执行完js后的html源文件如何查看 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-03 15:06
)
爬虫执行js后如何获取html源文件?比如我在页面上点击查询后,会自动生成一张表来携带数据,但是在源文件上右击却无法查看JS生成的表。
可以使用 Firefox 调试。参考网址
可以看到生成的表格。但是看源文件,数字是看不到的。
在线【------解决方案--------
通过设置webBrowser的url,将得到的源码给webBrowser.Document,webBrowser.DocumentCompleted后,得到ebBrowser.Document应该就OK了。 】
尝试按F12后,菜单【缓存】——【清除此域...】,发现问题解决了,可以得到js执行后的完整html数据。下次执行前一定要手动【Clear】,不然还是拿不到post-js的数据。于是,我找到了一个突破口,用代码清除了缓存,问题就解决了。
这个问题困扰了两天,终于找到了解决办法:
///
/// 针对js页面,获取页面内容。火狐的“查看元素”也可以获取。
///
private void PrintHelpPage()
{
// Create a WebBrowser instance.
WebBrowser webBrowserForPrinting = new WebBrowser();
// Add an event handler that prints the document after it loads.
webBrowserForPrinting.DocumentCompleted +=
new WebBrowserDocumentCompletedEventHandler(PrintDocument);
//删除缓存为关键一步,必须进行;不然得不到js执行后的数据
string cachePath = Environment.GetFolderPath(Environment.SpecialFolder.InternetCache);//获取缓存路径
DirectoryInfo di = new DirectoryInfo(cachePath);
foreach (FileInfo fi in di.GetFiles("*.*", SearchOption.AllDirectories))//遍历所有的文件夹 删除里面的文件
{
try
{
fi.Delete();
}
catch { }
}
// Set the Url property to load the document.
webBrowserForPrinting.Url = new Uri("http://218.23.98.205:8080/aqi/ ... 6quot;);
}
private void PrintDocument(object sender, WebBrowserDocumentCompletedEventArgs e)
{
//MessageBox.Show("000");
//foreach (HtmlElement he in ((WebBrowser)sender).Document.GetElementById("sljaqi"))
//{
// //if (he.GetAttribute("classname") == "co_yl")
// //{
// // //然后网页信息格式,来分解出你要的信息。
// //}
// MessageBox.Show(he.OuterText);
// MessageBox.Show(he.Name);
//}
MessageBox.Show(((WebBrowser)sender).Document.GetElementById("sljaqi").InnerHtml);
// Print the document now that it is fully loaded.
//((WebBrowser)sender).Print();
// Dispose the WebBrowser now that the task is complete.
((WebBrowser)sender).Dispose();
} 查看全部
js 抓取网页内容(爬虫如何获取执行完js后的html源文件如何查看
)
爬虫执行js后如何获取html源文件?比如我在页面上点击查询后,会自动生成一张表来携带数据,但是在源文件上右击却无法查看JS生成的表。
可以使用 Firefox 调试。参考网址
可以看到生成的表格。但是看源文件,数字是看不到的。
在线【------解决方案--------
通过设置webBrowser的url,将得到的源码给webBrowser.Document,webBrowser.DocumentCompleted后,得到ebBrowser.Document应该就OK了。 】
尝试按F12后,菜单【缓存】——【清除此域...】,发现问题解决了,可以得到js执行后的完整html数据。下次执行前一定要手动【Clear】,不然还是拿不到post-js的数据。于是,我找到了一个突破口,用代码清除了缓存,问题就解决了。
这个问题困扰了两天,终于找到了解决办法:
///
/// 针对js页面,获取页面内容。火狐的“查看元素”也可以获取。
///
private void PrintHelpPage()
{
// Create a WebBrowser instance.
WebBrowser webBrowserForPrinting = new WebBrowser();
// Add an event handler that prints the document after it loads.
webBrowserForPrinting.DocumentCompleted +=
new WebBrowserDocumentCompletedEventHandler(PrintDocument);
//删除缓存为关键一步,必须进行;不然得不到js执行后的数据
string cachePath = Environment.GetFolderPath(Environment.SpecialFolder.InternetCache);//获取缓存路径
DirectoryInfo di = new DirectoryInfo(cachePath);
foreach (FileInfo fi in di.GetFiles("*.*", SearchOption.AllDirectories))//遍历所有的文件夹 删除里面的文件
{
try
{
fi.Delete();
}
catch { }
}
// Set the Url property to load the document.
webBrowserForPrinting.Url = new Uri("http://218.23.98.205:8080/aqi/ ... 6quot;);
}
private void PrintDocument(object sender, WebBrowserDocumentCompletedEventArgs e)
{
//MessageBox.Show("000");
//foreach (HtmlElement he in ((WebBrowser)sender).Document.GetElementById("sljaqi"))
//{
// //if (he.GetAttribute("classname") == "co_yl")
// //{
// // //然后网页信息格式,来分解出你要的信息。
// //}
// MessageBox.Show(he.OuterText);
// MessageBox.Show(he.Name);
//}
MessageBox.Show(((WebBrowser)sender).Document.GetElementById("sljaqi").InnerHtml);
// Print the document now that it is fully loaded.
//((WebBrowser)sender).Print();
// Dispose the WebBrowser now that the task is complete.
((WebBrowser)sender).Dispose();
}
js 抓取网页内容(什么是jQuery的HTTP模块?以及如何使用? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-02 07:04
)
一、基本思路
先找一个网址:因为这是http协议,所以需要用到node.js的HTTP模块,我们使用HTTP模块中的get()方法来抓取。其中,如果我们不需要抓取所有的数据,而只需要部分数据,比如某个类下的a标签中的文字,那么如果我们在前端,就可以使用DOM操作找到这个节点,但是node.js中没有DOM操作,所以这里需要用到cheerio库。既然抓到了网站上的数据,就涉及到文件的写入,此时需要用到node.js中的fs模块。
二、学习网址
Cheerio 官方学习文档
cheerio npm 网址
node.js 官方文档
node.js 中文文档
二、cheerio 是什么以及如何使用
cheerio 是专为服务器设计的核心 jQuery 的快速、灵活和精益实现。他可以像jquery一样操作字符串。
安装cheerio
npm install cheerio
具体用途
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
三、具体代码
const http = require("http");
const fs = require("fs");
const cheerio = require("cheerio");
http.get("http://tech.ifeng.com/", function(res) {
// 设置编码
res.setEncoding("utf8");
// 当接收到数据时,会触发 "data" 事件的执行
let html = "";
res.on("data", function(data){
html += data;
});
// 数据接收完毕,会触发 "end" 事件的执行
res.on("end", function(){
// 待保存到文件中的字符串
let fileData = "";
// 调用 cheerio.load() 方法,生成一个类似于 jQuery 的对象
const $ = cheerio.load(html);
// 接下来像使用 jQuery 一样来使用 cheerio
$(".pictxt02").each(function(index, element) {
const el = $(element);
let link = el.find("h3 a").attr("href"),
title = el.find("h3 a").text(),
desc = el.children("p").text();
fileData += `${link}\r\n${title}\r\n\t${desc}\r\n\r\n`;
});
// console.log("读取结束,内容:");
// console.log(html);
fs.writeFile("./dist/source.txt", fileData, function(err) {
if (err)
return;
console.log("成功")
});
})
}); 查看全部
js 抓取网页内容(什么是jQuery的HTTP模块?以及如何使用?
)
一、基本思路
先找一个网址:因为这是http协议,所以需要用到node.js的HTTP模块,我们使用HTTP模块中的get()方法来抓取。其中,如果我们不需要抓取所有的数据,而只需要部分数据,比如某个类下的a标签中的文字,那么如果我们在前端,就可以使用DOM操作找到这个节点,但是node.js中没有DOM操作,所以这里需要用到cheerio库。既然抓到了网站上的数据,就涉及到文件的写入,此时需要用到node.js中的fs模块。
二、学习网址
Cheerio 官方学习文档
cheerio npm 网址
node.js 官方文档
node.js 中文文档
二、cheerio 是什么以及如何使用
cheerio 是专为服务器设计的核心 jQuery 的快速、灵活和精益实现。他可以像jquery一样操作字符串。
安装cheerio
npm install cheerio
具体用途
const cheerio = require('cheerio')
const $ = cheerio.load('Hello world')
$('h2.title').text('Hello there!')
$('h2').addClass('welcome')
$.html()
//=> Hello there!
三、具体代码
const http = require("http");
const fs = require("fs");
const cheerio = require("cheerio");
http.get("http://tech.ifeng.com/", function(res) {
// 设置编码
res.setEncoding("utf8");
// 当接收到数据时,会触发 "data" 事件的执行
let html = "";
res.on("data", function(data){
html += data;
});
// 数据接收完毕,会触发 "end" 事件的执行
res.on("end", function(){
// 待保存到文件中的字符串
let fileData = "";
// 调用 cheerio.load() 方法,生成一个类似于 jQuery 的对象
const $ = cheerio.load(html);
// 接下来像使用 jQuery 一样来使用 cheerio
$(".pictxt02").each(function(index, element) {
const el = $(element);
let link = el.find("h3 a").attr("href"),
title = el.find("h3 a").text(),
desc = el.children("p").text();
fileData += `${link}\r\n${title}\r\n\t${desc}\r\n\r\n`;
});
// console.log("读取结束,内容:");
// console.log(html);
fs.writeFile("./dist/source.txt", fileData, function(err) {
if (err)
return;
console.log("成功")
});
})
});
js 抓取网页内容(js抓取网页内容的webdriver其实很简单,我之前用vue进行抓取的感受)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-12-31 02:04
js抓取网页内容的webdriver脚本其实很简单,下面说下我之前用vue进行抓取的感受!在写webdriver脚本之前,需要需要在vue-resource和vue-resourceapi里面配置一下,两个api在package.json里面都有说明。resource里面有4个配置:path.exports={//configurationdirectoryapi//api路径//url.pattern{//javascriptdescription//路径}//vuewithvue-resource.js"""initial//初始化配置//manifest.js"username="xxx"//用户名email=""//邮箱random=""//随机randomvalue="0"//randomvalue为随机值//vue.usemodule(wx.usecomponents,api)//设置api依赖注入this.$ext='ext'//javascript规范,其实是一个函数.this.$directory='/directory'///。 查看全部
js 抓取网页内容(js抓取网页内容的webdriver其实很简单,我之前用vue进行抓取的感受)
js抓取网页内容的webdriver脚本其实很简单,下面说下我之前用vue进行抓取的感受!在写webdriver脚本之前,需要需要在vue-resource和vue-resourceapi里面配置一下,两个api在package.json里面都有说明。resource里面有4个配置:path.exports={//configurationdirectoryapi//api路径//url.pattern{//javascriptdescription//路径}//vuewithvue-resource.js"""initial//初始化配置//manifest.js"username="xxx"//用户名email=""//邮箱random=""//随机randomvalue="0"//randomvalue为随机值//vue.usemodule(wx.usecomponents,api)//设置api依赖注入this.$ext='ext'//javascript规范,其实是一个函数.this.$directory='/directory'///。
js 抓取网页内容(更多Javascript教程,欢迎访问起飞网())
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-30 17:11
更多Javascript教程,欢迎访问飞网>>
身体:
Javascript 通常用于操作 HTML 和更改网页内容!
输出内容到页面
Javascript 提供了 document.write('string') 方法来将内容写入页面:
使用Javascript改变HTML内容的测试-起飞网
document.write("我是来自JS的内容~");
function writeHtmlLater() {
document.write("哈哈,我把内容覆盖了~");
}
使用Javascript改变HTML内容的测试-起飞网
您可以将此代码复制到 html 文件中并运行它。当页面在浏览器中运行时,效果如图:
这时候我们点击按钮,你会发现页面上的所有内容都被覆盖了:
覆盖页面内容的“罪魁祸首”是按钮onclick事件调用的writeHtmlLater方法。这种方法也是在页面上写一个句子,但是覆盖了整个页面。这里需要注意:
document.write() 只将写入的内容输出到文档中。如果在文档加载完成后执行 document.write,整个 HTML 页面将被覆盖。
更改 HTML 标签的内容
我们使用 JS 不仅是为了向文档输出一些内容,而且是为了改变现有标签的显示方式。 Javascript中提供了访问文档标签的方法:document.getElementById()方法,我们可以通过该方法获取我们想要操作的HTML标签,并改变它们的显示方式:
使用Javascript改变HTML内容的测试-起飞网
function changeMySpanHtml() {
document.getElementById("mySpan").innerHTML = "我是被JS改变后的内容";
}
使用Javascript改变HTML内容的测试-起飞网
<p>span内容:我是span标签的原始内容!
</p>
运行这段代码,你会看到如下页面内容:
当我们点击Change Span Content按钮时,你会发现span标签的内容发生了变化:
这是因为我们在代码中得到了这个标签并重新分配了它的innerHTML属性。
本文简单介绍了两种改变HTML内容的方法。后续章节我会介绍更多Javascript知识,请继续关注! 查看全部
js 抓取网页内容(更多Javascript教程,欢迎访问起飞网())
更多Javascript教程,欢迎访问飞网>>
身体:
Javascript 通常用于操作 HTML 和更改网页内容!
输出内容到页面
Javascript 提供了 document.write('string') 方法来将内容写入页面:
使用Javascript改变HTML内容的测试-起飞网
document.write("我是来自JS的内容~");
function writeHtmlLater() {
document.write("哈哈,我把内容覆盖了~");
}
使用Javascript改变HTML内容的测试-起飞网
您可以将此代码复制到 html 文件中并运行它。当页面在浏览器中运行时,效果如图:
这时候我们点击按钮,你会发现页面上的所有内容都被覆盖了:
覆盖页面内容的“罪魁祸首”是按钮onclick事件调用的writeHtmlLater方法。这种方法也是在页面上写一个句子,但是覆盖了整个页面。这里需要注意:
document.write() 只将写入的内容输出到文档中。如果在文档加载完成后执行 document.write,整个 HTML 页面将被覆盖。
更改 HTML 标签的内容
我们使用 JS 不仅是为了向文档输出一些内容,而且是为了改变现有标签的显示方式。 Javascript中提供了访问文档标签的方法:document.getElementById()方法,我们可以通过该方法获取我们想要操作的HTML标签,并改变它们的显示方式:
使用Javascript改变HTML内容的测试-起飞网
function changeMySpanHtml() {
document.getElementById("mySpan").innerHTML = "我是被JS改变后的内容";
}
使用Javascript改变HTML内容的测试-起飞网
<p>span内容:我是span标签的原始内容!
</p>
运行这段代码,你会看到如下页面内容:
当我们点击Change Span Content按钮时,你会发现span标签的内容发生了变化:
这是因为我们在代码中得到了这个标签并重新分配了它的innerHTML属性。
本文简单介绍了两种改变HTML内容的方法。后续章节我会介绍更多Javascript知识,请继续关注!
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-29 10:07
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-29 10:07
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/");
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i 查看全部
js 抓取网页内容(【手语服务,助力沟通无障碍】(12月29日19:00)
)
【手语服务助沟通障碍】12月29日19:00现场报名>>>
我们在抓取数据的时候,如果目标网站以Js方式动态生成数据,通过滚动页面进行分页,我们如何抓取呢?
比如像今日头条这样的网站:
我们可以使用 Selenium 来做到这一点。尽管 Selenium 被设计用于 Web 应用程序的自动化测试,但它非常适合数据抓取。它可以轻松绕过网站的反爬虫限制,因为 Selenium 直接运行在浏览器中,就像真正的用户在做一样。
使用Selenium,我们不仅可以抓取Js动态生成的网页,还可以抓取滚动分页的网页。
首先我们使用maven来引入Selenium依赖:
org.seleniumhq.selenium
selenium-java
2.47.1
然后就可以编写代码来捕获:
<p>import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
import java.util.List;
import java.util.Random;
/**
* 如何抓取Js动态生成数据且以滚动页面方式分页的网页
* 以抓取今日头条为例说明:http://toutiao.com/
* Created by ysc on 10/13/15.
*/
public class Toutiao {
public static void main(String[] args) throws Exception{
//等待数据加载的时间
//为了防止服务器封锁,这里的时间要模拟人的行为,随机且不能太短
long waitLoadBaseTime = 3000;
int waitLoadRandomTime = 3000;
Random random = new Random(System.currentTimeMillis());
//火狐浏览器
WebDriver driver = new FirefoxDriver();
//要抓取的网页
driver.get("http://toutiao.com/";);
//等待页面动态加载完毕
Thread.sleep(waitLoadBaseTime+random.nextInt(waitLoadRandomTime));
//要加载多少页数据
int pages=5;
for(int i=0; i
js 抓取网页内容(js用js获取另一个页面的部分信息-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-28 10:16
js 使用js获取另一个页面的信息-:你好:如果你想获取另一个页面的值,可以使用ajax,比如当你点击一个按钮时获取另一个页面的文本元素的值。在另一页先写函数获取value值。然后使用ajax请求,通过location提交到这个页面,在这个页面上获取提交的url值。刚回来。
如何在javascript中获取用户在上一页输入的信息并在下一页显示获取的信息-:这是父面:
如何抓取js函数生成的网页内容:我查了你提供的页面代码:在首页,你用ajax动态获取服务器各列的数据,然后动态生成页面。这样搜索引擎是抢不到的,因为目前的搜索引擎没有抓取ajax页面的技术。当然,目前有163个博客使用这种方式来组建博客。但是人们...
想做一个网页,用js抓取网上某个网页的表单信息,重新渲染。我该怎么办?:C#获取指定网页的内容并提交到数据库或访问。显示网页时,进入数据库或访问阅读。
如何使用javascript获取远程页面的部分信息:
使用 jsoup 抓取网页的图形信息。您只需要网页上的文章和图片。如何同时抓取这两个信息?,但问题来了。如果要实现自己的程序,会很麻烦。所以最好自己实现。因为分页内容,每个页面都有一个特定的链接,而且非常相似,只是指定的页面数参数不同。所以可以使用遍历的方式来抓取每个网页,解析,然后保存,比较实用。但是我建议你也可以在客户端使用分页模式。这种情况下,根据需要获取,一下子请求的数据量不会太大。
如何使用JAVASCRIPT读取外部网页信息:使用ajax异步读取,推荐使用成熟的jQuery框架来完成这项工作。jquery下载地址:
js爬虫如何实现网页数据抓取:使用http抓包工具获取下一页的url,然后分析url规则,下载你给的url我打不开
如何抓取JS-动态生成的HTML: var o=document.createElement("tag element"); xxx.append(o)
如何在网页中获取js生成的内容-:你下载一个firefox浏览器。然后安装错误脚本。在其中,您可以查看任何 JS CSS HTML... 查看全部
js 抓取网页内容(js用js获取另一个页面的部分信息-)
js 使用js获取另一个页面的信息-:你好:如果你想获取另一个页面的值,可以使用ajax,比如当你点击一个按钮时获取另一个页面的文本元素的值。在另一页先写函数获取value值。然后使用ajax请求,通过location提交到这个页面,在这个页面上获取提交的url值。刚回来。
如何在javascript中获取用户在上一页输入的信息并在下一页显示获取的信息-:这是父面:
如何抓取js函数生成的网页内容:我查了你提供的页面代码:在首页,你用ajax动态获取服务器各列的数据,然后动态生成页面。这样搜索引擎是抢不到的,因为目前的搜索引擎没有抓取ajax页面的技术。当然,目前有163个博客使用这种方式来组建博客。但是人们...
想做一个网页,用js抓取网上某个网页的表单信息,重新渲染。我该怎么办?:C#获取指定网页的内容并提交到数据库或访问。显示网页时,进入数据库或访问阅读。
如何使用javascript获取远程页面的部分信息:
使用 jsoup 抓取网页的图形信息。您只需要网页上的文章和图片。如何同时抓取这两个信息?,但问题来了。如果要实现自己的程序,会很麻烦。所以最好自己实现。因为分页内容,每个页面都有一个特定的链接,而且非常相似,只是指定的页面数参数不同。所以可以使用遍历的方式来抓取每个网页,解析,然后保存,比较实用。但是我建议你也可以在客户端使用分页模式。这种情况下,根据需要获取,一下子请求的数据量不会太大。
如何使用JAVASCRIPT读取外部网页信息:使用ajax异步读取,推荐使用成熟的jQuery框架来完成这项工作。jquery下载地址:
js爬虫如何实现网页数据抓取:使用http抓包工具获取下一页的url,然后分析url规则,下载你给的url我打不开
如何抓取JS-动态生成的HTML: var o=document.createElement("tag element"); xxx.append(o)
如何在网页中获取js生成的内容-:你下载一个firefox浏览器。然后安装错误脚本。在其中,您可以查看任何 JS CSS HTML...
js 抓取网页内容(、网抓(网页打开)过程中的几种情况 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-24 14:07
)
首先,我不是派对!有一定的vba和抓网技术水平。
我爬过的网页无外乎以下几种情况:
1、 GET 方法请求数据。这种类型的网页一般都非常简单,URL 中有各种参数。
2、 POST方式请求数据,这种网页有一定难度。但是使用fiddler工具可以快速分析出实际地址和要传递的参数。主要难点是有些参数是通过JS动态生成的,所以可以在vba中找到JS函数并执行对应的JS。
--------------------我是分割线--------------------
最近抓了一个网站的数据,第一次遇到网页数据是用AngularJS技术动态写的!!你可以用fiddler获取你想要的内容,但是用代码抓取时,http头返回304错误。
经过多日的 AngularJS 技术黑客攻击,最终以失败告终。在此恳请各位大神帮忙,小弟感激不尽。
网页抓取(网页打开)的过程大致如下:
, 打开网站,输入关键词,如:支付宝(中国,点击眼睛打开二级页面
, 点击找到的第一个信息打开另一个页面。
, 获取此页面上的所有数据。如法定代表人、注册资本、身份、行业等。
ps:使用code发送搜索数据时,httphead只需要发送一条数据:.setRequestHeader "loop", "null",这个head必须设置。
再次恳求各位大神帮忙!谢谢!
查看全部
js 抓取网页内容(、网抓(网页打开)过程中的几种情况
)
首先,我不是派对!有一定的vba和抓网技术水平。
我爬过的网页无外乎以下几种情况:
1、 GET 方法请求数据。这种类型的网页一般都非常简单,URL 中有各种参数。
2、 POST方式请求数据,这种网页有一定难度。但是使用fiddler工具可以快速分析出实际地址和要传递的参数。主要难点是有些参数是通过JS动态生成的,所以可以在vba中找到JS函数并执行对应的JS。
--------------------我是分割线--------------------
最近抓了一个网站的数据,第一次遇到网页数据是用AngularJS技术动态写的!!你可以用fiddler获取你想要的内容,但是用代码抓取时,http头返回304错误。
经过多日的 AngularJS 技术黑客攻击,最终以失败告终。在此恳请各位大神帮忙,小弟感激不尽。
网页抓取(网页打开)的过程大致如下:
, 打开网站,输入关键词,如:支付宝(中国,点击眼睛打开二级页面
, 点击找到的第一个信息打开另一个页面。
, 获取此页面上的所有数据。如法定代表人、注册资本、身份、行业等。
ps:使用code发送搜索数据时,httphead只需要发送一条数据:.setRequestHeader "loop", "null",这个head必须设置。
再次恳求各位大神帮忙!谢谢!
js 抓取网页内容(js抓取网页内容分为两个过程:1,抓包分析html2)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-22 18:01
js抓取网页内容分为两个过程:1,抓包分析html2。设置编码抓取页面或meta中的http协议分为http协议的字符编码,传输层的编码等,不同的http协议提供不同的解析规则curl:全称是connecttolocalserver,连接本地服务器ss或者spdy:简单说就是连接网络服务器,用tcp/ip协议作为应用层数据的传输udp:纯文本传输,没有tcp的那些服务channel:在浏览器和服务器之间起数据交换的通道3,把内容传递给浏览器一般有两种方式:1,直接把数据通过数据库或文件读取到浏览器的浏览器里面再显示出来2,通过socket协议把数据直接发送给浏览器然后通过浏览器来显示数据库或文件里面。
能够从外部网络输入到内容库中,转换的手段通常有messagequery和协议自身两种途径,前者又分为纯文本传输(simplemessagequery)和可加密(ontransport)的二进制(binary)传输两种。除了query之外,还有get,post,put,delete,postconvert等方法可以传输数据,还可以输入二进制代码进行传输,其中最常用的是get方法。
一般的url,robots协议,meta等等等等都是这一些标签的重要载体。协议支持get/post/put/delete等等等等方法。而对于robots规则的实现,http/1.1已经将它作为解析的前提提供。上图是所支持的robots。重点看第一个部分。进一步,又分了网页设计者选择了一种什么样的规则,然后所支持的不同的robots.txt和它们自身标记之间的相互关系和对策。
分为:网页a,b两种选择:在http/1.1中只支持网页a标准规则;相反,在http/1.0中支持网页b标准规则。上图是网页b标准规则本身的设计图。同时并列的somebutagamethereis.网页a规则,设计者一般都想配置得更有个性一些,用什么语言写lib都是有的,没什么不同,支持java,python,php等等等等,随你选。
网页b规则,在一般的网页设计者中经常会把它搞得比较复杂,因为在http/1.0中,它是基于arraysql的语言的,有一定规范。通常比较流行的url,robots,meta等标签的作用,基本上就和网页b规则是相近的。当然不排除网页b也是有特殊的,也是有自己的图,不用的话我记得也看过不少。回到问题本身:能不能从url库里面查,有不同的header标记就行了。
一般情况下如果你能拿到这些标签的一般也都有设计者的图,不用特意查。http协议设计的宗旨是提供简单的接受信息和发送信息,并不是正经回答是不是能从bottomline返回html。服务器压力没有那么大的时候能不能返回个完整的h。 查看全部
js 抓取网页内容(js抓取网页内容分为两个过程:1,抓包分析html2)
js抓取网页内容分为两个过程:1,抓包分析html2。设置编码抓取页面或meta中的http协议分为http协议的字符编码,传输层的编码等,不同的http协议提供不同的解析规则curl:全称是connecttolocalserver,连接本地服务器ss或者spdy:简单说就是连接网络服务器,用tcp/ip协议作为应用层数据的传输udp:纯文本传输,没有tcp的那些服务channel:在浏览器和服务器之间起数据交换的通道3,把内容传递给浏览器一般有两种方式:1,直接把数据通过数据库或文件读取到浏览器的浏览器里面再显示出来2,通过socket协议把数据直接发送给浏览器然后通过浏览器来显示数据库或文件里面。
能够从外部网络输入到内容库中,转换的手段通常有messagequery和协议自身两种途径,前者又分为纯文本传输(simplemessagequery)和可加密(ontransport)的二进制(binary)传输两种。除了query之外,还有get,post,put,delete,postconvert等方法可以传输数据,还可以输入二进制代码进行传输,其中最常用的是get方法。
一般的url,robots协议,meta等等等等都是这一些标签的重要载体。协议支持get/post/put/delete等等等等方法。而对于robots规则的实现,http/1.1已经将它作为解析的前提提供。上图是所支持的robots。重点看第一个部分。进一步,又分了网页设计者选择了一种什么样的规则,然后所支持的不同的robots.txt和它们自身标记之间的相互关系和对策。
分为:网页a,b两种选择:在http/1.1中只支持网页a标准规则;相反,在http/1.0中支持网页b标准规则。上图是网页b标准规则本身的设计图。同时并列的somebutagamethereis.网页a规则,设计者一般都想配置得更有个性一些,用什么语言写lib都是有的,没什么不同,支持java,python,php等等等等,随你选。
网页b规则,在一般的网页设计者中经常会把它搞得比较复杂,因为在http/1.0中,它是基于arraysql的语言的,有一定规范。通常比较流行的url,robots,meta等标签的作用,基本上就和网页b规则是相近的。当然不排除网页b也是有特殊的,也是有自己的图,不用的话我记得也看过不少。回到问题本身:能不能从url库里面查,有不同的header标记就行了。
一般情况下如果你能拿到这些标签的一般也都有设计者的图,不用特意查。http协议设计的宗旨是提供简单的接受信息和发送信息,并不是正经回答是不是能从bottomline返回html。服务器压力没有那么大的时候能不能返回个完整的h。

