
js 抓取网页内容
js 抓取网页内容(js抓取网页内容,包括抓取javascript内容。(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-08 08:03
js抓取网页内容,包括抓取javascript内容。javascript内容的抓取可以使用chrome插件:javascriptspy++。学习过程中可以参考一下这个资料。spider.py思路一般是:1.先在浏览器打开这个网页,一般都是有flash文件或者页面被刷新的。2.通过扫描this.script内容,来判断是哪个flash或者页面被刷新,然后抓取页面中的内容。具体的操作步骤可以参考这个资料:spider.py。
前端开发,接触过javascript,script,html中的script标签,javascript等等,以后有精力,可以了解下后端的,不算难,前端学好es3,把babel中的transform,proposal,mixin封装好,做好两个模块,一个js模块,两个模块都要做单元测试,保证模块达到标准。
然后就是:开发框架node.js,springboot,php,学好es3,让模块出现在浏览器,让浏览器出现(当然,js解析出来的字符串也出现,但是稍微占点篇幅),让浏览器渲染出来。生成的网页怎么处理,php处理,node.js处理,phpdom中处理,htmldom中处理,htmlbom中处理,上述做完,也要抓包,防止篡改劫持,php写好对应的代码,一切就完成了,关键是讲道理,爬虫,爬虫。
python,java,php一般都可以搞定。还有一个可能会问你的一个问题,你可以从scrapy下手,scrapy用于爬取文章。 查看全部
js 抓取网页内容(js抓取网页内容,包括抓取javascript内容。(一))
js抓取网页内容,包括抓取javascript内容。javascript内容的抓取可以使用chrome插件:javascriptspy++。学习过程中可以参考一下这个资料。spider.py思路一般是:1.先在浏览器打开这个网页,一般都是有flash文件或者页面被刷新的。2.通过扫描this.script内容,来判断是哪个flash或者页面被刷新,然后抓取页面中的内容。具体的操作步骤可以参考这个资料:spider.py。
前端开发,接触过javascript,script,html中的script标签,javascript等等,以后有精力,可以了解下后端的,不算难,前端学好es3,把babel中的transform,proposal,mixin封装好,做好两个模块,一个js模块,两个模块都要做单元测试,保证模块达到标准。
然后就是:开发框架node.js,springboot,php,学好es3,让模块出现在浏览器,让浏览器出现(当然,js解析出来的字符串也出现,但是稍微占点篇幅),让浏览器渲染出来。生成的网页怎么处理,php处理,node.js处理,phpdom中处理,htmldom中处理,htmlbom中处理,上述做完,也要抓包,防止篡改劫持,php写好对应的代码,一切就完成了,关键是讲道理,爬虫,爬虫。
python,java,php一般都可以搞定。还有一个可能会问你的一个问题,你可以从scrapy下手,scrapy用于爬取文章。
js 抓取网页内容(谷歌能DOM是如何抓取和收录的?处理JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-07 14:10
摘要:因为这似乎与转移排名信号有关。支持这一结论的是参考谷歌的指导方针:使用...... 2015年,谷歌以约2500万美元的价格收购了顶级域名.app,这笔交易设置了一个新的顶级域名......
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
概述
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
关于这一系列的测试,以及结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
...
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在网络新时代保持竞争力并取得实质性进展,那就意味着对 HTML5、JavaScript 和动态网站 的更好支持。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
js 抓取网页内容(谷歌能DOM是如何抓取和收录的?处理JavaScript)
摘要:因为这似乎与转移排名信号有关。支持这一结论的是参考谷歌的指导方针:使用...... 2015年,谷歌以约2500万美元的价格收购了顶级域名.app,这笔交易设置了一个新的顶级域名......
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

概述
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。

JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
关于这一系列的测试,以及结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例

示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。

示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
...
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。

对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在网络新时代保持竞争力并取得实质性进展,那就意味着对 HTML5、JavaScript 和动态网站 的更好支持。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
js 抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-06 23:03
热图的主流实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面获取处理后的用户数据绘制热图
本文主要以stage 1为重点,详细介绍在heatmaps中获取网站页面的主流实现。使用iframes直接嵌入用户网站抓取用户页面并保存在本地,通过iframes资源嵌入本地(所谓本地资源被认为是分析工具的终点)
两种方法都有各自的优点和缺点。首先,第一种方法直接嵌入用户网站,有一定的限制。比如用户网站是为了防止iframe劫持,不允许iframe嵌套(设置meta X-FRAME-OPTIONS是sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
),这种情况下,客户端网站需要做一部分工作才能被分析工具的iframe加载,使用起来不一定那么方便,因为不是所有的网站@ > 需要检测分析的用户可以管理网站的。
第二种方式是直接将网站页面抓取到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经过来了,我们可以为所欲为。首先,我们绕过X-FRAME-OPTIONS同orgin的问题,只需要解决js控制的问题。对于爬取的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多不足:1、不能爬取spa页面,不能爬取需要用户登录授权的页面,不能爬取用户设置的白懂的页面等等。
两种方法中的https和http资源之间的同源策略还存在另一个问题。HTTPS 站点无法加载 http 资源。因此,为了获得最佳兼容性,热图分析工具需要与http协议一起应用。当然也可以根据具体情况进行访问。网站 的客户和特定的变电站进行了优化。
如何优化爬取网站页面
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,以提高爬取成功的概率,主要优化以下两个页面:
水疗页面
spa页面是当前页面中的主流,但一直都知道它对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,该过程通常会向用户网站(应该是user网站server)发起http get请求。这种爬取方式本身就会有问题。一是直接请求用户服务器,用户服务器对非浏览器代理应该有很多限制,需要绕过。二、请求返回的是原创内容,这就要求浏览器中js渲染的部分无法获取(当然,嵌入iframe后,js执行还是会在一定程度上弥补这个问题),最后如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果基于puppeteer来做,流程就变成了
puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样,无论页面如何渲染(客户端渲染或服务器端),我们得到的内容都是渲染后的内容
需要登录的页面
需要登录页面的情况有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况处理起来会比较简单,可以简单的认为是以下几个步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名和密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班。
补充(昨天的债):puppeteer虽然可以非常友好的抓取页面内容,但也有很多限制
抓取的内容为渲染后的原创html,即资源路径(css、image、javascript)等为相对路径,保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染结构已经完成)通过puppeteer爬取页面的性能会比直接http get差,因为额外的渲染过程也不能保证页面的完整性,但是大大提高了完成概率,虽然通过页面对象提供的各种等待方式可以解决这个问题,但是不同的网站,处理方式会不一样,不能复用。 查看全部
js 抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
热图的主流实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面获取处理后的用户数据绘制热图
本文主要以stage 1为重点,详细介绍在heatmaps中获取网站页面的主流实现。使用iframes直接嵌入用户网站抓取用户页面并保存在本地,通过iframes资源嵌入本地(所谓本地资源被认为是分析工具的终点)
两种方法都有各自的优点和缺点。首先,第一种方法直接嵌入用户网站,有一定的限制。比如用户网站是为了防止iframe劫持,不允许iframe嵌套(设置meta X-FRAME-OPTIONS是sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
),这种情况下,客户端网站需要做一部分工作才能被分析工具的iframe加载,使用起来不一定那么方便,因为不是所有的网站@ > 需要检测分析的用户可以管理网站的。
第二种方式是直接将网站页面抓取到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经过来了,我们可以为所欲为。首先,我们绕过X-FRAME-OPTIONS同orgin的问题,只需要解决js控制的问题。对于爬取的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多不足:1、不能爬取spa页面,不能爬取需要用户登录授权的页面,不能爬取用户设置的白懂的页面等等。
两种方法中的https和http资源之间的同源策略还存在另一个问题。HTTPS 站点无法加载 http 资源。因此,为了获得最佳兼容性,热图分析工具需要与http协议一起应用。当然也可以根据具体情况进行访问。网站 的客户和特定的变电站进行了优化。
如何优化爬取网站页面
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,以提高爬取成功的概率,主要优化以下两个页面:
水疗页面
spa页面是当前页面中的主流,但一直都知道它对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,该过程通常会向用户网站(应该是user网站server)发起http get请求。这种爬取方式本身就会有问题。一是直接请求用户服务器,用户服务器对非浏览器代理应该有很多限制,需要绕过。二、请求返回的是原创内容,这就要求浏览器中js渲染的部分无法获取(当然,嵌入iframe后,js执行还是会在一定程度上弥补这个问题),最后如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果基于puppeteer来做,流程就变成了
puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样,无论页面如何渲染(客户端渲染或服务器端),我们得到的内容都是渲染后的内容
需要登录的页面
需要登录页面的情况有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况处理起来会比较简单,可以简单的认为是以下几个步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名和密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班。
补充(昨天的债):puppeteer虽然可以非常友好的抓取页面内容,但也有很多限制
抓取的内容为渲染后的原创html,即资源路径(css、image、javascript)等为相对路径,保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染结构已经完成)通过puppeteer爬取页面的性能会比直接http get差,因为额外的渲染过程也不能保证页面的完整性,但是大大提高了完成概率,虽然通过页面对象提供的各种等待方式可以解决这个问题,但是不同的网站,处理方式会不一样,不能复用。
js 抓取网页内容(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-05 01:14
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
js 抓取网页内容(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
js 抓取网页内容(【图片来源于】今日头条的街拍美图和抓取分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-04 11:26
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。版权归原作者所有。如果您有任何问题,请联系我们进行处理。
本节我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。这次要抓拍的目标是今日头条的街拍。抓拍完成后,每组图片都会下载到本地文件夹并保存。
准备好工作了
在开始本节之前,请确保已安装 requests 库。如果没有安装,可以参考第一章爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图6-15所示。
右上角有一个搜索入口,这里我们尝试抓拍街拍,输入“街拍”一词进行搜索,结果如图6-16所示。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前链接街拍,打开Preview标签查看Response Body。如果页面中的内容是根据第一次请求的结果来渲染的,那么第一次请求的源代码必须收录页面结果中的文本。为了验证,我们可以尝试搜索搜索结果的标题,比如“路人”这个词,如图6-17所示。
我们发现网页源代码中没有收录这两个词,搜索匹配数为0,因此可以初步判断这些内容是通过Ajax加载,然后通过JavaScript渲染的。接下来,我们可以切换到 XHR 过滤选项卡,看看是否有任何 Ajax 请求。
不出所料,这里有一个相当常规的 Ajax 请求,看看它的结果是否收录来自页面的相关数据。
点击数据栏展开,发现这里有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的,如图6-18所示。
这证实了数据确实是由 Ajax 加载的。
我们的目的是捕捉漂亮的图片,其中一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组图像中所有图像的列表,如图 6-19 所示。
因此,我们只需要提取列表中的 url 字段并下载即可。为每组图片创建一个文件夹,文件夹的名称就是组图片的标题。
接下来可以直接用Python模拟Ajax请求,然后提取相关美图链接下载。但在此之前,我们还需要分析一下 URL 的规律。
切换回 Headers 选项卡,观察其请求 URL 和 Headers 信息,如图 6-20 所示。
图 6-20 请求信息
可以看到,这是一个GET请求,请求URL的参数有offset、format、keyword、autoload、count、cur_tab。我们需要找出这些参数的规律,因为这很容易被程序构造出来。
接下来,您可以滑动页面以加载更多新结果。在加载过程中,可以发现网络中有很多Ajax请求,如图6-21所示。
观察此处后续链接的参数,发现唯一变化的参数是offset,其他参数不变,第二次请求的offset值为20,第三次为40,第四次为60,所以可以找到规律,这个offset值就是offset,可以推断count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。这样我们就可以通过接口批量获取数据,然后解析数据并下载图片。
实操演练
刚才我们分析了Ajax请求的逻辑,下面我们用程序来下载美图。另外,如果您不熟悉 ajax。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一变化的参数是offset,所以我们把它作为参数传递,实现如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来,实现一个解析方法:提取每条数据的image_detail字段中的每一个图片链接,并返回图片链接和图片所属的标题。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image': image.get('url'),
'title': title
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
最后,只需构造一个偏移量数组,遍历偏移量,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
这样,整个程序就完成了。运行后,可以发现街拍照片保存在文件夹中,如图6-22所示。
通过本节,我们了解了Ajax分析的过程,Ajax分页的模拟以及图片的下载过程。
本节内容需要掌握,在实战中我们会多次用到这样的分析和抓拍。
最后小编想说:我是一名python开发工程师,整理了一套最新的python系统学习教程。如果你想要这些资料,可以关注私信小编“01”,希望对你有所帮助。 查看全部
js 抓取网页内容(【图片来源于】今日头条的街拍美图和抓取分析)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。版权归原作者所有。如果您有任何问题,请联系我们进行处理。
本节我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。这次要抓拍的目标是今日头条的街拍。抓拍完成后,每组图片都会下载到本地文件夹并保存。
准备好工作了
在开始本节之前,请确保已安装 requests 库。如果没有安装,可以参考第一章爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图6-15所示。
右上角有一个搜索入口,这里我们尝试抓拍街拍,输入“街拍”一词进行搜索,结果如图6-16所示。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前链接街拍,打开Preview标签查看Response Body。如果页面中的内容是根据第一次请求的结果来渲染的,那么第一次请求的源代码必须收录页面结果中的文本。为了验证,我们可以尝试搜索搜索结果的标题,比如“路人”这个词,如图6-17所示。
我们发现网页源代码中没有收录这两个词,搜索匹配数为0,因此可以初步判断这些内容是通过Ajax加载,然后通过JavaScript渲染的。接下来,我们可以切换到 XHR 过滤选项卡,看看是否有任何 Ajax 请求。
不出所料,这里有一个相当常规的 Ajax 请求,看看它的结果是否收录来自页面的相关数据。
点击数据栏展开,发现这里有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的,如图6-18所示。
这证实了数据确实是由 Ajax 加载的。
我们的目的是捕捉漂亮的图片,其中一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组图像中所有图像的列表,如图 6-19 所示。
因此,我们只需要提取列表中的 url 字段并下载即可。为每组图片创建一个文件夹,文件夹的名称就是组图片的标题。
接下来可以直接用Python模拟Ajax请求,然后提取相关美图链接下载。但在此之前,我们还需要分析一下 URL 的规律。
切换回 Headers 选项卡,观察其请求 URL 和 Headers 信息,如图 6-20 所示。
图 6-20 请求信息
可以看到,这是一个GET请求,请求URL的参数有offset、format、keyword、autoload、count、cur_tab。我们需要找出这些参数的规律,因为这很容易被程序构造出来。
接下来,您可以滑动页面以加载更多新结果。在加载过程中,可以发现网络中有很多Ajax请求,如图6-21所示。
观察此处后续链接的参数,发现唯一变化的参数是offset,其他参数不变,第二次请求的offset值为20,第三次为40,第四次为60,所以可以找到规律,这个offset值就是offset,可以推断count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。这样我们就可以通过接口批量获取数据,然后解析数据并下载图片。
实操演练
刚才我们分析了Ajax请求的逻辑,下面我们用程序来下载美图。另外,如果您不熟悉 ajax。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一变化的参数是offset,所以我们把它作为参数传递,实现如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来,实现一个解析方法:提取每条数据的image_detail字段中的每一个图片链接,并返回图片链接和图片所属的标题。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image': image.get('url'),
'title': title
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
最后,只需构造一个偏移量数组,遍历偏移量,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
这样,整个程序就完成了。运行后,可以发现街拍照片保存在文件夹中,如图6-22所示。
通过本节,我们了解了Ajax分析的过程,Ajax分页的模拟以及图片的下载过程。
本节内容需要掌握,在实战中我们会多次用到这样的分析和抓拍。
最后小编想说:我是一名python开发工程师,整理了一套最新的python系统学习教程。如果你想要这些资料,可以关注私信小编“01”,希望对你有所帮助。
js 抓取网页内容(第6行的html就是我们抓取的搜索结果页面源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-04 11:26
请求 = urllib2.请求(url)
response = urllib2.urlopen(request)
html = response.read()
结果 = self.extractSearchResults(html)
第6行的html是我们爬取的搜索结果页面的源码。用过Python的同学会发现Python同时提供了urllib和urllib2两个模块,这两个模块都与URL请求相关,只是提供的功能不同。 urllib 只能接收 URL,而 urllib2 可以接受 Request 类的实例来设置 URL 请求的标头,这意味着您可以伪装您的用户代理等(在下面使用)。
现在我们可以使用 Python 抓取网页并保存它,我们可以从源页面中提取我们想要的搜索结果。 Python提供了htmlparser模块,但是使用起来比较麻烦。在这里,我们推荐一个非常有用的网页分析包 BeautifulSoup。评委网站上对 BeautifulSoup 的使用有详细的介绍。这里就不多说了。
使用上面的代码,少量查询是可以的,但是如果要查询几千次,上面的方法就不再有效了,谷歌会检测你请求的来源,如果我们用机器的话经常抓取谷歌的搜索结果,很快谷歌就会屏蔽你的IP,并返回一个503错误页面。这不是我们想要的结果,所以我们会继续探索
如前所述,使用 urllib2 我们可以设置 URL 请求的标头来伪装我们的用户代理。简而言之,用户代理是客户端浏览器等应用程序使用的一种特殊网络协议。每次浏览器(邮件客户端/搜索引擎蜘蛛)发出 HTTP 请求时,都会发送到服务器,服务器就知道用户了。使用什么浏览器(邮件客户端/搜索引擎蜘蛛)访问。有时候为了达到一些目的,我们不得不去善意地欺骗服务器告诉它我没有使用机器访问你。
所以,我们的代码变成了这样:
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.@ >0',\
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0' , \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML,如 Gecko)元素浏览器 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)' , \
'Mozilla/5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟/6.0)',\
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 版本/12.14', \
'Mozilla/5.0(iPad;CPU OS 6_0,如 Mac OS X)AppleWebKit/536.26(KHTML,如 Gecko)\
版本/6.0 移动版/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, 像 Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.0;Trident/5.0;TheWorld)']
def search(self, queryStr):
queryStr = urllib2.quote(queryStr) 查看全部
js 抓取网页内容(第6行的html就是我们抓取的搜索结果页面源码)
请求 = urllib2.请求(url)
response = urllib2.urlopen(request)
html = response.read()
结果 = self.extractSearchResults(html)
第6行的html是我们爬取的搜索结果页面的源码。用过Python的同学会发现Python同时提供了urllib和urllib2两个模块,这两个模块都与URL请求相关,只是提供的功能不同。 urllib 只能接收 URL,而 urllib2 可以接受 Request 类的实例来设置 URL 请求的标头,这意味着您可以伪装您的用户代理等(在下面使用)。
现在我们可以使用 Python 抓取网页并保存它,我们可以从源页面中提取我们想要的搜索结果。 Python提供了htmlparser模块,但是使用起来比较麻烦。在这里,我们推荐一个非常有用的网页分析包 BeautifulSoup。评委网站上对 BeautifulSoup 的使用有详细的介绍。这里就不多说了。
使用上面的代码,少量查询是可以的,但是如果要查询几千次,上面的方法就不再有效了,谷歌会检测你请求的来源,如果我们用机器的话经常抓取谷歌的搜索结果,很快谷歌就会屏蔽你的IP,并返回一个503错误页面。这不是我们想要的结果,所以我们会继续探索
如前所述,使用 urllib2 我们可以设置 URL 请求的标头来伪装我们的用户代理。简而言之,用户代理是客户端浏览器等应用程序使用的一种特殊网络协议。每次浏览器(邮件客户端/搜索引擎蜘蛛)发出 HTTP 请求时,都会发送到服务器,服务器就知道用户了。使用什么浏览器(邮件客户端/搜索引擎蜘蛛)访问。有时候为了达到一些目的,我们不得不去善意地欺骗服务器告诉它我没有使用机器访问你。
所以,我们的代码变成了这样:
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.@ >0',\
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0' , \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML,如 Gecko)元素浏览器 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)' , \
'Mozilla/5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟/6.0)',\
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 版本/12.14', \
'Mozilla/5.0(iPad;CPU OS 6_0,如 Mac OS X)AppleWebKit/536.26(KHTML,如 Gecko)\
版本/6.0 移动版/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, 像 Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.0;Trident/5.0;TheWorld)']
def search(self, queryStr):
queryStr = urllib2.quote(queryStr)
js 抓取网页内容(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-03 13:06
)
1:背景
本来想用jsoup抓取一个页面,但是抓取到的数据总是不完整,然后发现页面执行js之后,页面上渲染了一些数据,也就是说只有js之后被处决。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
js 抓取网页内容(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取到的数据总是不完整,然后发现页面执行js之后,页面上渲染了一些数据,也就是说只有js之后被处决。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
js 抓取网页内容(一下获取标签中的内容介绍获取方法(title) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-03 10:16
)
网页的标题一般由 HTML 文件的标签决定。如果要获取网页的标题,实际上是在获取标签中的内容。下面的文章文章给大家介绍如何获取,希望对你有所帮助。
方法一:使用title属性
title 属性返回当前文档的标题(HTML 标题元素中的文本)。
语法:
document.title
示例:使用 document.title 属性获取 HTML 文档的标题。
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法二:使用document.getElementsByTagName()方法
getElementsByTagName() 方法按照元素在文档中返回的顺序返回具有指定标签名称的对象集合。
语法:
document.getElementsByTagName(tagname)
示例:document.getElementsByTagName() 方法首先通过标签名称选择标题,然后获取索引为 0 的元素,从而获得文档的标题。
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title! 查看全部
js 抓取网页内容(一下获取标签中的内容介绍获取方法(title)
)
网页的标题一般由 HTML 文件的标签决定。如果要获取网页的标题,实际上是在获取标签中的内容。下面的文章文章给大家介绍如何获取,希望对你有所帮助。

方法一:使用title属性
title 属性返回当前文档的标题(HTML 标题元素中的文本)。
语法:
document.title
示例:使用 document.title 属性获取 HTML 文档的标题。
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法二:使用document.getElementsByTagName()方法
getElementsByTagName() 方法按照元素在文档中返回的顺序返回具有指定标签名称的对象集合。
语法:
document.getElementsByTagName(tagname)
示例:document.getElementsByTagName() 方法首先通过标签名称选择标题,然后获取索引为 0 的元素,从而获得文档的标题。
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
js 抓取网页内容(【知识点】HTML文档的域有关(一)示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-02 15:16
同源政策
页面中的Javascript只能读取和访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只有嵌入了Javascript代码的文档的域。比如下面的示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示其域为:8000(域和端口也有关系)。虽然页面中的jquery是从其中加载的,但是jquery的域只和它所在的html文档的域有关,这样就可以访问到html文档的属性,所以上面的代码就可以正常运行了。
PS 使用上述代码的原因是开发者将通用的Javascript库(如JQuery)地址指向公共相同的URL。用户加载一次 JS 后,后续加载会被浏览器缓存,从而加快页面加载速度。
从这个角度来看问题,如果提问者知道的远端指的是互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远端指的是您可以控制 网站@ > 的提问者,请参阅下面的放宽同源策略;
放宽同源策略Document.domain:对于子域的情况。对于多个窗口(一个页面有多个iframe),通过将document.domain的值设置为同一个域,Javascript可以访问外部窗口;跨域资源共享:通过添加Access-Control-
Allow-Origin,此标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:该方法与域无关,不同文档的Javascript可以不受限制地互相收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者控制了远程页面,您可以尝试第二种方法。
服务器端抓取
根据提问者的需要,比较可行的方案应该是在服务器端进行处理。有了(),可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等。当然,后续操作也可以使用Python、php、Java语言。
参考
同源政策
谷歌托管图书馆
跨域资源共享
幻影 查看全部
js 抓取网页内容(【知识点】HTML文档的域有关(一)示例)
同源政策
页面中的Javascript只能读取和访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只有嵌入了Javascript代码的文档的域。比如下面的示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示其域为:8000(域和端口也有关系)。虽然页面中的jquery是从其中加载的,但是jquery的域只和它所在的html文档的域有关,这样就可以访问到html文档的属性,所以上面的代码就可以正常运行了。
PS 使用上述代码的原因是开发者将通用的Javascript库(如JQuery)地址指向公共相同的URL。用户加载一次 JS 后,后续加载会被浏览器缓存,从而加快页面加载速度。
从这个角度来看问题,如果提问者知道的远端指的是互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远端指的是您可以控制 网站@ > 的提问者,请参阅下面的放宽同源策略;
放宽同源策略Document.domain:对于子域的情况。对于多个窗口(一个页面有多个iframe),通过将document.domain的值设置为同一个域,Javascript可以访问外部窗口;跨域资源共享:通过添加Access-Control-
Allow-Origin,此标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:该方法与域无关,不同文档的Javascript可以不受限制地互相收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者控制了远程页面,您可以尝试第二种方法。
服务器端抓取
根据提问者的需要,比较可行的方案应该是在服务器端进行处理。有了(),可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等。当然,后续操作也可以使用Python、php、Java语言。
参考
同源政策
谷歌托管图书馆
跨域资源共享
幻影
js 抓取网页内容(之前我们讲过中COPY数据的方法,稍微有点不同 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 10:15
)
之前,我们讲过在谷歌浏览器中通过“检查”,然后在控制台中复制数据的方法。今天也是同样的方法,略有不同。上次是在控制台操作,这次是在控制台。将变量存储在 NETWORK 预览中,然后将其复制到控制台。
我们先回顾一下之前的内容:
在控制台中找到需要的数据,右键保存,然后使用COPY命令。
今天有点变化:
首先,在网页上选择我们要查询的条件:Consumer Price Index, last 36 months
然后我们需要在NETWORK中通过网页找到我们的各种选项,选择后生成的查询结果,我们右键预览保存为变量temp1,然后在控制台输入COPY命令复制JSON数据.
转到 Power Query 编辑器,将复制的数据粘贴到空白查询中,然后将其解析为 JSON 格式:
这个数据分为两部分,一部分是数据,另一部分是数据的名称,通过简单的查询就可以合并名称和数据:
让我们将其加载到 Power BI 中,制作折线图以查看:
在图表中,食品的 CPI 连续增长了一年。我们可以查看食品的具体CPI数据,重复上述步骤:
选择食品价格指数继续查询
找到最新的查询内容,右键保存,因为已经有temp1,系统自动保存为temp2,然后COPY。
打开Power Query编辑器,将新数据放入JS2,复制上面的步骤,修改数据源为JS2,修改中间的两个合并查询步骤。
查看全部
js 抓取网页内容(之前我们讲过中COPY数据的方法,稍微有点不同
)
之前,我们讲过在谷歌浏览器中通过“检查”,然后在控制台中复制数据的方法。今天也是同样的方法,略有不同。上次是在控制台操作,这次是在控制台。将变量存储在 NETWORK 预览中,然后将其复制到控制台。
我们先回顾一下之前的内容:
在控制台中找到需要的数据,右键保存,然后使用COPY命令。
今天有点变化:
首先,在网页上选择我们要查询的条件:Consumer Price Index, last 36 months
然后我们需要在NETWORK中通过网页找到我们的各种选项,选择后生成的查询结果,我们右键预览保存为变量temp1,然后在控制台输入COPY命令复制JSON数据.
转到 Power Query 编辑器,将复制的数据粘贴到空白查询中,然后将其解析为 JSON 格式:
这个数据分为两部分,一部分是数据,另一部分是数据的名称,通过简单的查询就可以合并名称和数据:
让我们将其加载到 Power BI 中,制作折线图以查看:
在图表中,食品的 CPI 连续增长了一年。我们可以查看食品的具体CPI数据,重复上述步骤:
选择食品价格指数继续查询
找到最新的查询内容,右键保存,因为已经有temp1,系统自动保存为temp2,然后COPY。
打开Power Query编辑器,将新数据放入JS2,复制上面的步骤,修改数据源为JS2,修改中间的两个合并查询步骤。
js 抓取网页内容(网站SEO优化常用的7大html标签和大家聊聊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 11:07
最近有很多朋友问我关于 html 标签在 SEO 中的使用。基于这些问题,我总结了网站7个常用的SEO优化html标签,和大家聊聊。
网站上线前,需要对网站的代码和标签做必要的处理,以提高优化后的网站的打开速度,夸大关键词@ > 谁想要达到排名。一个很好的 网站 在代码方面编码良好。
作为网站搜索引擎优化优化人员,了解网站的代码是很有必要的,这是网站优化的必要因素之一,网站推广必须想要获得好的性能,源码非常重要,关键的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就需要我们对网站的代码进行简化和优化。网页的简化意味着网站代码优化,去除网站冗余代码以减小网站的大小,提高网站的加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
1、HEAD 部分代码规范化。
代码的HEAD部分是搜索引擎普福网站的入口部分。现在很多网站头代码都大同小异,死板的效果很明显。这样的网站代码就像一个模板框架一样不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,并使搜索引擎新鲜,从而吸引蜘蛛。普福。
2、使用DIV+CSS分隔网页结构。
虽然现在div+css已经很成熟了,但是很多网页规划师还是可以使用老式的表格结构或者考虑到网页的兼容性和结构的一般简单性。虽然表结构很方便,但它的缺点也是未知数。是的,就是会大大增加网页的大小,尤其是多层表格的嵌套。这种结构不仅会增加体积,同时如果嵌套的数量过多,会影响搜索引擎的威力,影响网站的性能。收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面html中放不同的代码调用即可。对很多css代码和javasript代码来说,javascript被放在了网站页面的html文件的最后,而一些真正可以使用的文本部分被推到了html的后面。杭州搜索引擎优化认为这部分代码需要精简。
3、CSS 代码本身的优化。
CSS 是页面效果渲染中非常重要的一个组件,包括颜色、大小、背景和字体。编写 CSS 很容易,但编写可靠的 CSS 代码需要很多技巧。
(1), CSS 位置
CSS说明如果在网站之后显示,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 的过去。
(2), css精灵技能
网站上的部分图片可以通过css sprite技能进行合并,减少加载请求,提高网页加载速度。
(3), CSS 代码优化
通过CSS代码属性的缩写、冗余结构(frameworks)的去除、reset(resets)等一系列方法和技术,对CSS代码进行了简化,减小了CSS文件的大小。
(4),尽管甚至不使用内联 CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一种是在标签中显示的内联内联CSS,无论使用哪种内联CSS方法,都会增加页面的大小。,我们可以甚至使用外部 CSS 来缩小网站的页面大小。
4、JS 位置、大小和其他负面优化。
JS优化和其他词的优化还是有相同的地方的。JS优化的关键是关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。地方,这并不是说循环本身有性能成就,而是说循环迅速降低了可以或存在的性能成就。
(1), JS 位置
优化网页代码中的js时,杭州SEO建议将js放在页面末尾,既可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过进程减少网络连接数,提高网页打开速度。
(3),LazyLoad(延迟加载)技能
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件,它可以延迟加载长页面中的图像,在用户将页面转换到他们的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道,未来的搜索引擎仍然无法或识别 JS 代码。如果在网站中显示大量的JS代码,在收录上就很难网站了,我们要做的就是把Javascript代码的形式放到网站 中的外部调用,既可以简化搜索引擎的工作,又不会无形中衍生出有用的代码涉及到网站。
不仅如此,杭州SEO认为可以使用外部调用的css代码。在网站的开头,可以在css代码文件中定义网站的文字和颜色,即使页面代码中没有。里面渲染了太多的格式化代码。
(5),减少页面对JS的依赖
现在,JS实际上对搜索引擎不友好。虽然据说搜索引擎对 JS 没有任何仇恨,但最好还是少一件事。虽然 JS 可以或者可以产生很多效果,但是网页有很多。JS会影响蜘蛛对页面的抓取,增加页面的体积,尤其是导航栏等页面的关键位置,即使采用DIV+CSS的规划方式也是如此。
5、减少TABLE标签的使用。
表格标签是大多数在线 网站s 中最稀有的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css结构的简化代码网站相比,占用空间比较大。因此,在建网站的时候,即使少用表,即使要使用表,嵌套表也应该使用。即使它被谨慎使用,它也节省了冗长代码的生成。
那么,当前的 网站 做了什么?很多程序员的第一个想法就是用CSS来做布局,用CSS来排版。这种做法大大减少了页面中的表格,但是在杭州SEO眼里,网站不能没有表格,有些东西是必须要使用的,表格本身没什么用,但是有很多网站都是使用嵌套表的,普通这样的表格式会为网站生成很多残码,而这些残码就是没用的代码,而这种类型的代码也是我们网站需要精简的代码之一。
6、大量使用代码注释省略。
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些是打不开的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、消除页面中的冗余代码就是简化代码。
有的网站认为创作者的代码抄写习惯成功了,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,积累了很多,也会让我们的网站很臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是网站的其余部分也使用style和font来重新定义Font字体,这些代码完整,无需重复定义,属于可以简化的代码。
8、将html控件方法转换为CSS控件。
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。即使将这些代码转换为外部 CSS,网页代码也会变得更薄。
9、缓存静态开销。
通过设置浏览器缓存的过程,在浏览器端缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器可以要么或者从浏览器的缓存中这样你就可以从你的服务器获取css、js等,而不必每次都从你的服务器读取,在一定程度上加快了网站的打开速度,可以节省你的服务器流量。
10、网页压缩技巧。
对于网页压缩,相信各位站长都不陌生。如果启用服务器Gzip,对页面进行Gzip压缩,减小元素的大小,从而减少数据的传输,从而提高网页的加载速度。这个功能需要你的服务器的支持,GZIP压缩通常可以对网页实现30%-80%的压缩,这是最重要的优化效果。
总之,通过流程代码优化来发挥网站优化作用的方法还有很多,这里只是随便提一下,少见的,希望大家多多讨论。
11、权重标签的使用。
典型的权重标签有H1、strong、b标签等。对于想要参与排名的人来说很重要关键词@>使用权重标签,好处是将标志传递给搜索引擎:关键词@ >这个地方非常重要和必要的区别对待,从而提高了已建立的关键词@>在搜索引擎中的排名。
网站常见的SEO标签如下:
关键词1@>网站SEO优化中常用的TDK标签
TDK 是每个 seoer 都熟悉的 html 标签。TDK分别代表Title、Keywords和Description三个最常见的优化标签。标题页标题、关键词页关键词@>、描述页描述。(严格来说,除了title,其他两个都是mate标签的属性。)这三个标签因为太熟悉了,这里就简单提一下。
关键词2@>网站SEO 优化标题标签
标题标签也称为 H 标签。它强调页面的主要部分,一般用于标题、副标题和列名。从 h1 到 h6 有 6 对标题标签,强调程度递减。三个标题标签 h1、h2、h3 经常使用,因为 h4、h5、 h6 的强调小到可以忽略不计,基本上就是未用于 网站 优化 SEO。
h1标签是对页面最重要部分的强调,一般用在页面标题中。需要注意的是,同一页面上只能出现一对 h1 标签。如果页面上出现多个H1标签,会对seo产生不利影响。
h2、h3等标题标签可以在同一页面上多次使用,一般用在列名、文章段落标题或副标题中。
标题标签虽然对网站的优化有积极的影响,但如果乱用也会带来不良后果。不要在整个内容中使用标题标签。
关键词8@>网站优化常用标签的nofllow属性进行SEO优化
是的!你没看错,noflow 属性。许多seoers 喜欢说nofllow 标签。其实nofllow并不是一个标签,它只是html标签的一个属性。一般认为使用nofllow属性的链接不会被搜索引擎追踪(这个观点是有争议的),也不会将权限传递给被链接的页面。最常见的方式是使用nofllow属性避免页面权重的不必要损失,达到权重集中的目的。使用锚文本如下
很多seoer只知道上面的常用方法。实际上,nofllow 属性也可以作用于整个页面中的链接。由于这种用法很少见,本文不再展开。会在单独的文章中用到 文章 说一下nofllow属性的用法。
关键词9@>网站优化常用标签的Canonical属性
Canonical 属性与nofllow 属于同一类别,也被许多人称为Canonical 标签。但是对于一些搜索引擎来说,它比nofllow 属性更奇怪。Canonical在英文中有权威的意思,用于SEO中,用于解决相同内容在不同URL形式下造成的内容重复问题。最常见的写法如下
网页中的Canonical标签可以告诉搜索引擎,在几个内容相同、URL不同的页面中,哪个页面最规范,最有望被搜索引擎收录搜索到,它可以避免< @网站 相同内容的网页。通过不同URL带来的权重分配问题,达到了页面权重集中的目的。
在当前的移动互联网时代,百度赋予了Canonical属性一个新的角色,就是利用Canonical属性进行移动适配。(关于移动端适配,小李会在后续文章中详细分析。)
5.网站SEO优化常用标签的mate标签
mate标签是所有优化标签中最重要的标签,不是其中之一。众所周知的 TDK 标签是 mate 标签的属性。因为mate标签的功能非常强大,所以扮演的角色太多了。限于篇幅,本文仅简单介绍mate标签在优化中的三个作用。
功能一:承载关键词和描述属性的内容,是页面优化不可缺少的元素。
功能二:进行PC站和移动站的适配标注,mate label肩负着移动适配的重任。
功能三:301跳转到单个网页,可用于页面集中和网站修改。
6.网站优化常用标签的title属性
title属性可以应用于很多html标签,从网站seo优化的角度来看,常见的re-a标签、img标签、embed标签和video标签。小李认为,title属性的主要作用是提升用户体验。鼠标移动时html元素上显示的文本信息就是title属性的内容。当嵌入标签、视频标签和链接文本无法完全显示时,建议使用title属性改善用户体验
7.网站常用标签alt属性的SEO优化
在网站优化中,alt属性主要用在img标签中。在img表中加入alt属性,就是通过alt属性来描述图片,告诉搜索引擎图片的含义;二是提升用户体验。当img缺少title属性时,鼠标在图片上移动时显示的文字信息就是alt属性的内容;而当图片由于某种原因无法正常显示时,会显示alt属性中的文字而不是图片。
聚推传媒小李总结:
以上7个标签在小李看来是最常用的标签。在网站seo优化过程中,会用到很多HTML标签和属性,但小李认为掌握以上7个标签属性的使用对于一般的网站优化就足够了。 查看全部
js 抓取网页内容(网站SEO优化常用的7大html标签和大家聊聊!)
最近有很多朋友问我关于 html 标签在 SEO 中的使用。基于这些问题,我总结了网站7个常用的SEO优化html标签,和大家聊聊。
网站上线前,需要对网站的代码和标签做必要的处理,以提高优化后的网站的打开速度,夸大关键词@ > 谁想要达到排名。一个很好的 网站 在代码方面编码良好。
作为网站搜索引擎优化优化人员,了解网站的代码是很有必要的,这是网站优化的必要因素之一,网站推广必须想要获得好的性能,源码非常重要,关键的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就需要我们对网站的代码进行简化和优化。网页的简化意味着网站代码优化,去除网站冗余代码以减小网站的大小,提高网站的加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
1、HEAD 部分代码规范化。
代码的HEAD部分是搜索引擎普福网站的入口部分。现在很多网站头代码都大同小异,死板的效果很明显。这样的网站代码就像一个模板框架一样不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,并使搜索引擎新鲜,从而吸引蜘蛛。普福。
2、使用DIV+CSS分隔网页结构。
虽然现在div+css已经很成熟了,但是很多网页规划师还是可以使用老式的表格结构或者考虑到网页的兼容性和结构的一般简单性。虽然表结构很方便,但它的缺点也是未知数。是的,就是会大大增加网页的大小,尤其是多层表格的嵌套。这种结构不仅会增加体积,同时如果嵌套的数量过多,会影响搜索引擎的威力,影响网站的性能。收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面html中放不同的代码调用即可。对很多css代码和javasript代码来说,javascript被放在了网站页面的html文件的最后,而一些真正可以使用的文本部分被推到了html的后面。杭州搜索引擎优化认为这部分代码需要精简。
3、CSS 代码本身的优化。
CSS 是页面效果渲染中非常重要的一个组件,包括颜色、大小、背景和字体。编写 CSS 很容易,但编写可靠的 CSS 代码需要很多技巧。
(1), CSS 位置
CSS说明如果在网站之后显示,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 的过去。
(2), css精灵技能
网站上的部分图片可以通过css sprite技能进行合并,减少加载请求,提高网页加载速度。
(3), CSS 代码优化
通过CSS代码属性的缩写、冗余结构(frameworks)的去除、reset(resets)等一系列方法和技术,对CSS代码进行了简化,减小了CSS文件的大小。
(4),尽管甚至不使用内联 CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一种是在标签中显示的内联内联CSS,无论使用哪种内联CSS方法,都会增加页面的大小。,我们可以甚至使用外部 CSS 来缩小网站的页面大小。
4、JS 位置、大小和其他负面优化。
JS优化和其他词的优化还是有相同的地方的。JS优化的关键是关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。地方,这并不是说循环本身有性能成就,而是说循环迅速降低了可以或存在的性能成就。
(1), JS 位置
优化网页代码中的js时,杭州SEO建议将js放在页面末尾,既可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过进程减少网络连接数,提高网页打开速度。
(3),LazyLoad(延迟加载)技能
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件,它可以延迟加载长页面中的图像,在用户将页面转换到他们的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道,未来的搜索引擎仍然无法或识别 JS 代码。如果在网站中显示大量的JS代码,在收录上就很难网站了,我们要做的就是把Javascript代码的形式放到网站 中的外部调用,既可以简化搜索引擎的工作,又不会无形中衍生出有用的代码涉及到网站。
不仅如此,杭州SEO认为可以使用外部调用的css代码。在网站的开头,可以在css代码文件中定义网站的文字和颜色,即使页面代码中没有。里面渲染了太多的格式化代码。
(5),减少页面对JS的依赖
现在,JS实际上对搜索引擎不友好。虽然据说搜索引擎对 JS 没有任何仇恨,但最好还是少一件事。虽然 JS 可以或者可以产生很多效果,但是网页有很多。JS会影响蜘蛛对页面的抓取,增加页面的体积,尤其是导航栏等页面的关键位置,即使采用DIV+CSS的规划方式也是如此。
5、减少TABLE标签的使用。
表格标签是大多数在线 网站s 中最稀有的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css结构的简化代码网站相比,占用空间比较大。因此,在建网站的时候,即使少用表,即使要使用表,嵌套表也应该使用。即使它被谨慎使用,它也节省了冗长代码的生成。
那么,当前的 网站 做了什么?很多程序员的第一个想法就是用CSS来做布局,用CSS来排版。这种做法大大减少了页面中的表格,但是在杭州SEO眼里,网站不能没有表格,有些东西是必须要使用的,表格本身没什么用,但是有很多网站都是使用嵌套表的,普通这样的表格式会为网站生成很多残码,而这些残码就是没用的代码,而这种类型的代码也是我们网站需要精简的代码之一。
6、大量使用代码注释省略。
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些是打不开的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、消除页面中的冗余代码就是简化代码。
有的网站认为创作者的代码抄写习惯成功了,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,积累了很多,也会让我们的网站很臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是网站的其余部分也使用style和font来重新定义Font字体,这些代码完整,无需重复定义,属于可以简化的代码。
8、将html控件方法转换为CSS控件。
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。即使将这些代码转换为外部 CSS,网页代码也会变得更薄。
9、缓存静态开销。
通过设置浏览器缓存的过程,在浏览器端缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器可以要么或者从浏览器的缓存中这样你就可以从你的服务器获取css、js等,而不必每次都从你的服务器读取,在一定程度上加快了网站的打开速度,可以节省你的服务器流量。
10、网页压缩技巧。
对于网页压缩,相信各位站长都不陌生。如果启用服务器Gzip,对页面进行Gzip压缩,减小元素的大小,从而减少数据的传输,从而提高网页的加载速度。这个功能需要你的服务器的支持,GZIP压缩通常可以对网页实现30%-80%的压缩,这是最重要的优化效果。
总之,通过流程代码优化来发挥网站优化作用的方法还有很多,这里只是随便提一下,少见的,希望大家多多讨论。
11、权重标签的使用。
典型的权重标签有H1、strong、b标签等。对于想要参与排名的人来说很重要关键词@>使用权重标签,好处是将标志传递给搜索引擎:关键词@ >这个地方非常重要和必要的区别对待,从而提高了已建立的关键词@>在搜索引擎中的排名。
网站常见的SEO标签如下:
关键词1@>网站SEO优化中常用的TDK标签
TDK 是每个 seoer 都熟悉的 html 标签。TDK分别代表Title、Keywords和Description三个最常见的优化标签。标题页标题、关键词页关键词@>、描述页描述。(严格来说,除了title,其他两个都是mate标签的属性。)这三个标签因为太熟悉了,这里就简单提一下。
关键词2@>网站SEO 优化标题标签
标题标签也称为 H 标签。它强调页面的主要部分,一般用于标题、副标题和列名。从 h1 到 h6 有 6 对标题标签,强调程度递减。三个标题标签 h1、h2、h3 经常使用,因为 h4、h5、 h6 的强调小到可以忽略不计,基本上就是未用于 网站 优化 SEO。
h1标签是对页面最重要部分的强调,一般用在页面标题中。需要注意的是,同一页面上只能出现一对 h1 标签。如果页面上出现多个H1标签,会对seo产生不利影响。
h2、h3等标题标签可以在同一页面上多次使用,一般用在列名、文章段落标题或副标题中。
标题标签虽然对网站的优化有积极的影响,但如果乱用也会带来不良后果。不要在整个内容中使用标题标签。
关键词8@>网站优化常用标签的nofllow属性进行SEO优化
是的!你没看错,noflow 属性。许多seoers 喜欢说nofllow 标签。其实nofllow并不是一个标签,它只是html标签的一个属性。一般认为使用nofllow属性的链接不会被搜索引擎追踪(这个观点是有争议的),也不会将权限传递给被链接的页面。最常见的方式是使用nofllow属性避免页面权重的不必要损失,达到权重集中的目的。使用锚文本如下
很多seoer只知道上面的常用方法。实际上,nofllow 属性也可以作用于整个页面中的链接。由于这种用法很少见,本文不再展开。会在单独的文章中用到 文章 说一下nofllow属性的用法。
关键词9@>网站优化常用标签的Canonical属性
Canonical 属性与nofllow 属于同一类别,也被许多人称为Canonical 标签。但是对于一些搜索引擎来说,它比nofllow 属性更奇怪。Canonical在英文中有权威的意思,用于SEO中,用于解决相同内容在不同URL形式下造成的内容重复问题。最常见的写法如下
网页中的Canonical标签可以告诉搜索引擎,在几个内容相同、URL不同的页面中,哪个页面最规范,最有望被搜索引擎收录搜索到,它可以避免< @网站 相同内容的网页。通过不同URL带来的权重分配问题,达到了页面权重集中的目的。
在当前的移动互联网时代,百度赋予了Canonical属性一个新的角色,就是利用Canonical属性进行移动适配。(关于移动端适配,小李会在后续文章中详细分析。)
5.网站SEO优化常用标签的mate标签
mate标签是所有优化标签中最重要的标签,不是其中之一。众所周知的 TDK 标签是 mate 标签的属性。因为mate标签的功能非常强大,所以扮演的角色太多了。限于篇幅,本文仅简单介绍mate标签在优化中的三个作用。
功能一:承载关键词和描述属性的内容,是页面优化不可缺少的元素。
功能二:进行PC站和移动站的适配标注,mate label肩负着移动适配的重任。
功能三:301跳转到单个网页,可用于页面集中和网站修改。
6.网站优化常用标签的title属性
title属性可以应用于很多html标签,从网站seo优化的角度来看,常见的re-a标签、img标签、embed标签和video标签。小李认为,title属性的主要作用是提升用户体验。鼠标移动时html元素上显示的文本信息就是title属性的内容。当嵌入标签、视频标签和链接文本无法完全显示时,建议使用title属性改善用户体验
7.网站常用标签alt属性的SEO优化
在网站优化中,alt属性主要用在img标签中。在img表中加入alt属性,就是通过alt属性来描述图片,告诉搜索引擎图片的含义;二是提升用户体验。当img缺少title属性时,鼠标在图片上移动时显示的文字信息就是alt属性的内容;而当图片由于某种原因无法正常显示时,会显示alt属性中的文字而不是图片。
聚推传媒小李总结:
以上7个标签在小李看来是最常用的标签。在网站seo优化过程中,会用到很多HTML标签和属性,但小李认为掌握以上7个标签属性的使用对于一般的网站优化就足够了。
js 抓取网页内容(【官方说法】百度不收录页面的原因分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-30 11:04
如果站长已经排除了自己的问题和造假问题,并确认百度蜘蛛的爬取次数过多,可以通过反馈中心进行反馈,记得提供详细的爬取日志截图。
【官方声明】百度没有收录页面的原因分析
目前百度蜘蛛抓取新链接的方式有两种。一是主动查找抓取,二是通过百度站长平台的链接提交工具获取数据。其中,通过主动推送功能“收到”的数据在百度中最为流行。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新增的网站,主动推送首页数据,有利于到内页数据的捕获。
那么同学们就要问了,为什么我提交了数据后就看不到网上的显示了?涉及的因素很多。在蜘蛛抓取过程中,影响在线展示的因素有:
1、网站封杀:别笑,真的有同学一边封杀百度蜘蛛一边把数据交给百度,当然不能收录。
2、质量筛选:百度蜘蛛3.0在低质量内容特别是时效性内容的识别上达到了一个新的水平。从抓到这个链接的那一刻起,质量评价和筛选就开始过滤掉大量过度优化等页面,根据内部定期数据评价,低质量页面比之前下降了62%。
3、爬取失败:爬取失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛遇到麻烦。网站要时刻注意保证网站在不同时间、不同地点的稳定性。
4、配额限制:虽然我们正在逐步放开主动推送的爬取配额,但是如果网站页面数量突然爆发式增长,还是会影响到优质链接的爬取收录,所以网站是保证除了稳定访问之外,还要注意网站的安全性,防止被黑客入侵和注入。 查看全部
js 抓取网页内容(【官方说法】百度不收录页面的原因分析(图))
如果站长已经排除了自己的问题和造假问题,并确认百度蜘蛛的爬取次数过多,可以通过反馈中心进行反馈,记得提供详细的爬取日志截图。

【官方声明】百度没有收录页面的原因分析
目前百度蜘蛛抓取新链接的方式有两种。一是主动查找抓取,二是通过百度站长平台的链接提交工具获取数据。其中,通过主动推送功能“收到”的数据在百度中最为流行。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新增的网站,主动推送首页数据,有利于到内页数据的捕获。
那么同学们就要问了,为什么我提交了数据后就看不到网上的显示了?涉及的因素很多。在蜘蛛抓取过程中,影响在线展示的因素有:
1、网站封杀:别笑,真的有同学一边封杀百度蜘蛛一边把数据交给百度,当然不能收录。
2、质量筛选:百度蜘蛛3.0在低质量内容特别是时效性内容的识别上达到了一个新的水平。从抓到这个链接的那一刻起,质量评价和筛选就开始过滤掉大量过度优化等页面,根据内部定期数据评价,低质量页面比之前下降了62%。
3、爬取失败:爬取失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛遇到麻烦。网站要时刻注意保证网站在不同时间、不同地点的稳定性。
4、配额限制:虽然我们正在逐步放开主动推送的爬取配额,但是如果网站页面数量突然爆发式增长,还是会影响到优质链接的爬取收录,所以网站是保证除了稳定访问之外,还要注意网站的安全性,防止被黑客入侵和注入。
js 抓取网页内容(如何获取动态网页数据的方法途径?途径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-28 10:09
)
上一篇文章讲了抓取58网页的出租数据。有朋友问是不是这样从ajax请求生成的动态网页中抓取数据的。其实方法并不难。总结起来有两种方式:
直接用python运行JavaScript代码 采集 返回数据
使用python的第三方库对整个页面的html和javascript进行解释执行,生成最终的网页,然后采集data
由于第一种方法python执行js代码很慢,操作也比较复杂,而第二种方法可以处理成静态网页采集数据,所以第二种方法比较常用
第二种方式采集动态网页,这里主要用到了两个第三方库:Selenium和PhantomJS。Selenium 是一个强大的网络数据采集 工具,需要与第三方浏览器配合使用。PhantomJS 是一个将 网站 加载到内存中并在页面上执行 JavaScript 代码的浏览器,但不会将图形界面呈现给用户。通过结合 Selenium 和 PhantomJS,我们可以轻松解决采集动态页面数据的问题。具体安装方法请参考百度。
这里以前面写的一个微信商城网页为例,说明如何获取动态网页数据。界面如下所示:
该页面加载数据的过程如下: 静态网页中只有标题栏和底部标签栏。页面展示后,会通过ajax从服务器获取商品数据,用js展示。我要做的是通过 Selenium 和 PhantomJS 来获取它。产品数据。
如果使用之前爬取静态网页的方法,代码是这样写的:
运行上面的代码后,输出是这样的,产品列表为空
使用 selenium 和 PhantomJS,代码是这样写的:
运行上述代码后,通过ajax动态获取的数据也可以通过网络爬虫获取
查看全部
js 抓取网页内容(如何获取动态网页数据的方法途径?途径
)
上一篇文章讲了抓取58网页的出租数据。有朋友问是不是这样从ajax请求生成的动态网页中抓取数据的。其实方法并不难。总结起来有两种方式:
直接用python运行JavaScript代码 采集 返回数据
使用python的第三方库对整个页面的html和javascript进行解释执行,生成最终的网页,然后采集data
由于第一种方法python执行js代码很慢,操作也比较复杂,而第二种方法可以处理成静态网页采集数据,所以第二种方法比较常用
第二种方式采集动态网页,这里主要用到了两个第三方库:Selenium和PhantomJS。Selenium 是一个强大的网络数据采集 工具,需要与第三方浏览器配合使用。PhantomJS 是一个将 网站 加载到内存中并在页面上执行 JavaScript 代码的浏览器,但不会将图形界面呈现给用户。通过结合 Selenium 和 PhantomJS,我们可以轻松解决采集动态页面数据的问题。具体安装方法请参考百度。
这里以前面写的一个微信商城网页为例,说明如何获取动态网页数据。界面如下所示:
该页面加载数据的过程如下: 静态网页中只有标题栏和底部标签栏。页面展示后,会通过ajax从服务器获取商品数据,用js展示。我要做的是通过 Selenium 和 PhantomJS 来获取它。产品数据。
如果使用之前爬取静态网页的方法,代码是这样写的:
运行上面的代码后,输出是这样的,产品列表为空
使用 selenium 和 PhantomJS,代码是这样写的:
运行上述代码后,通过ajax动态获取的数据也可以通过网络爬虫获取
js 抓取网页内容(有没有办法让请求在实际html数据之前等待LinkedIn显示站点数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-28 01:20
我目前正在尝试从 LinkedIn 上的特定页面抓取数据。我有一个可以登录 LinkedIn 的脚本,但是当我尝试访问收录数据的页面时,它遇到了障碍。当我调用 requests.get(data_url) 时,我最终得到了 LinkedIn 加载屏幕的 html,它在 LinkedIn 加载实际页面内容之前显示。有没有办法让请求在实际抓取 html 数据之前等待 LinkedIn 显示站点数据?我基本上需要先完全呈现页面,然后才能“获取”内容。我目前的脚本如下。
import requests
from bs4 import BeautifulSoup
client = requests.Session()
HOMEPAGE_URL = 'https://www.linkedin.com'
LOGIN_URL = 'https://www.linkedin.com/uas/login-submit'
html = client.get(HOMEPAGE_URL).content
soup = BeautifulSoup(html)
csrf = soup.find(id="loginCsrfParam-login")['value']
login_information = {
'session_key':'EMAIL',
'session_password':'PASSWORD',
'loginCsrfParam': csrf,
}
client.post(LOGIN_URL, data=login_information)
r = client.get(data_url)
最佳答案
如果页面的任何部分是动态渲染的,比如使用Javascript,beautifulsoup可能无法使用。
我使用 Selenium + PhantomJS。我加载页面(等待它完全加载)并输入登录详细信息。 Selenium 有一个很好的 API,允许您以编程方式检查特定的 html 元素并等待它们出现,这在这种情况下非常有用。
关于 javascript - 在抓取 python 请求之前等待网页完全加载,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
js 抓取网页内容(有没有办法让请求在实际html数据之前等待LinkedIn显示站点数据)
我目前正在尝试从 LinkedIn 上的特定页面抓取数据。我有一个可以登录 LinkedIn 的脚本,但是当我尝试访问收录数据的页面时,它遇到了障碍。当我调用 requests.get(data_url) 时,我最终得到了 LinkedIn 加载屏幕的 html,它在 LinkedIn 加载实际页面内容之前显示。有没有办法让请求在实际抓取 html 数据之前等待 LinkedIn 显示站点数据?我基本上需要先完全呈现页面,然后才能“获取”内容。我目前的脚本如下。
import requests
from bs4 import BeautifulSoup
client = requests.Session()
HOMEPAGE_URL = 'https://www.linkedin.com'
LOGIN_URL = 'https://www.linkedin.com/uas/login-submit'
html = client.get(HOMEPAGE_URL).content
soup = BeautifulSoup(html)
csrf = soup.find(id="loginCsrfParam-login")['value']
login_information = {
'session_key':'EMAIL',
'session_password':'PASSWORD',
'loginCsrfParam': csrf,
}
client.post(LOGIN_URL, data=login_information)
r = client.get(data_url)
最佳答案
如果页面的任何部分是动态渲染的,比如使用Javascript,beautifulsoup可能无法使用。
我使用 Selenium + PhantomJS。我加载页面(等待它完全加载)并输入登录详细信息。 Selenium 有一个很好的 API,允许您以编程方式检查特定的 html 元素并等待它们出现,这在这种情况下非常有用。
关于 javascript - 在抓取 python 请求之前等待网页完全加载,我们在 Stack Overflow 上发现了一个类似的问题:
js 抓取网页内容(一天就能上线一个微信小程序,云开发的优点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 15:15
2022-01-19
微信小程序云开发js爬取网页内容
最近在研究微信小程序的云开发功能。云开发最大的优势是无需搭建前端服务器,利用云能力从零开始编写在线微信小程序,避免了购买服务器的成本。对于尝试从前端到后端开发实践微信小程序的个人来说是一个不错的选择。一天之内可以推出一个微信小程序。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。使用的云服务相互兼容,而不是相互排斥。
云开发目前提供三种基本能力支持:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需要编写自己的业务逻辑代码数据库:可以在小程序前端操作,也可以读取的JSON数据库并写在云功能Storage中:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,介绍了这么多关于云开发的知识,感性的同学可以去研究一下。官方文档地址:...
网页内容抓取
小程序是关于回答问题的,所以问题的来源是问题。在网上搜索,一个话题一个话题贴是一种方法,但是估计这样重复的工作大概10贴左右就放弃了。所以想到了网络抓取。刚拿起之前学过的节点。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。主要用于分析和过滤爬取的内容。Node 的 fs 模块。这是node自带的一个模块,用来读写文件。这用于将解析后的数据写入 json 文件。Axios(可选)。用于抓取 网站 的 HTML 页面。因为我想要的数据是在网页上点击一个按钮后获取并渲染的,所以无法直接爬取这个网址。无奈,只能复制自己想要的内容,保存为字符串,解析字符串。
接下来可以使用npm init来初始化一个node项目,一路回车后,就可以生成一个package.json文件了。
然后 npm install --save axioscheerio 安装cheerio 和 axios 包。
关键是使用cheerio来实现一个类似jquery的功能。你只需要cheerio.load(quesitons)抓取到的内容,然后你就可以根据jquery的操作去获取DOM,组装你想要的数据。
最后,使用 fs.writeFile 将数据保存到 json 文件中,大功告成。
具体代码如下:
让 axios = 要求(axios);
让cheerio = 要求(cheerio);
让 fs = 要求(fs);
// 我的html结构大致如下,有很多条数据
常量问题 = `
`;
常量 $ = Cheerio.load(问题);
var arr = [];
对于 (var i = 0; 我
变量 obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer=
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件保存成功!);
});
保存为json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传的json文件的数据格式。之前总是提示格式错误。后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象用n隔开,而且不是逗号。因此,在上传成功之前,需要对node写入的json文件进行一个小处理。 查看全部
js 抓取网页内容(一天就能上线一个微信小程序,云开发的优点)
2022-01-19
微信小程序云开发js爬取网页内容
最近在研究微信小程序的云开发功能。云开发最大的优势是无需搭建前端服务器,利用云能力从零开始编写在线微信小程序,避免了购买服务器的成本。对于尝试从前端到后端开发实践微信小程序的个人来说是一个不错的选择。一天之内可以推出一个微信小程序。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。使用的云服务相互兼容,而不是相互排斥。
云开发目前提供三种基本能力支持:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需要编写自己的业务逻辑代码数据库:可以在小程序前端操作,也可以读取的JSON数据库并写在云功能Storage中:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,介绍了这么多关于云开发的知识,感性的同学可以去研究一下。官方文档地址:...
网页内容抓取
小程序是关于回答问题的,所以问题的来源是问题。在网上搜索,一个话题一个话题贴是一种方法,但是估计这样重复的工作大概10贴左右就放弃了。所以想到了网络抓取。刚拿起之前学过的节点。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。主要用于分析和过滤爬取的内容。Node 的 fs 模块。这是node自带的一个模块,用来读写文件。这用于将解析后的数据写入 json 文件。Axios(可选)。用于抓取 网站 的 HTML 页面。因为我想要的数据是在网页上点击一个按钮后获取并渲染的,所以无法直接爬取这个网址。无奈,只能复制自己想要的内容,保存为字符串,解析字符串。
接下来可以使用npm init来初始化一个node项目,一路回车后,就可以生成一个package.json文件了。
然后 npm install --save axioscheerio 安装cheerio 和 axios 包。
关键是使用cheerio来实现一个类似jquery的功能。你只需要cheerio.load(quesitons)抓取到的内容,然后你就可以根据jquery的操作去获取DOM,组装你想要的数据。
最后,使用 fs.writeFile 将数据保存到 json 文件中,大功告成。
具体代码如下:
让 axios = 要求(axios);
让cheerio = 要求(cheerio);
让 fs = 要求(fs);
// 我的html结构大致如下,有很多条数据
常量问题 = `
`;
常量 $ = Cheerio.load(问题);
var arr = [];
对于 (var i = 0; 我
变量 obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer=
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件保存成功!);
});
保存为json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传的json文件的数据格式。之前总是提示格式错误。后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象用n隔开,而且不是逗号。因此,在上传成功之前,需要对node写入的json文件进行一个小处理。
js 抓取网页内容(js抓取网页内容,从而实现简单的从服务器读取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-26 09:01
js抓取网页内容,从而实现简单的从服务器读取数据的功能。考虑到这个问题,javascript的javascript脚本文件(event.js)存放了html页面的整个流程,包括前期的准备工作、网页的操作操作、页面的数据结构(解析出javascript脚本的内容与类型)、返回数据,整个文件流程都囊括其中。
此时javascript在javascript脚本中的位置,取决于是将他直接放置在javascript文件的顶端,还是把javascript脚本放置在javascript文件的根目录。从根目录下读取javascript,需要将他放置在javascript文件的根目录;而直接通过javascript文件名在根目录下读取javascript,无需做任何准备工作。
在解析过程中我们需要用到event.js文件的document对象,来将event.js文件获取到浏览器地址和页面地址。因此,实现javascript脚本的播放或者浏览器页面地址的爬取,需要用到script标签。解析网页内容,主要是从event.js文件获取html文件中内容的形式。
一、我们可以利用link标签来获取页面的html文件,
二、使用绝对定位这种方式可以在页面某个位置插入一个元素,用于解析页面内容:</img>由此,我们可以通过定位href方法返回地址,然后获取请求网页的网址。.src=""link="src:entry"rel="stylesheet"/></img>。
三、利用ajax获取javascript脚本实现页面地址的抓取,主要包括以下几种:javascriptwebtag,scriptdocument,javascripthtml解析,javascriptvardata=webkit。innerhtml(url);data。xpath(url)="//a[@id="。
href"]/div[2]/div[2]/div[2]/div[2]/div[1]/span[2]/a",allretrieval="0";//可以连接dom发起请求,没有okhttp的话可以使用getbrowserjs来发起http请求allretrieval=function(req,res,name){varlength=length(req。
url。xpath("//a[@id="。href"]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2。 查看全部
js 抓取网页内容(js抓取网页内容,从而实现简单的从服务器读取数据的功能)
js抓取网页内容,从而实现简单的从服务器读取数据的功能。考虑到这个问题,javascript的javascript脚本文件(event.js)存放了html页面的整个流程,包括前期的准备工作、网页的操作操作、页面的数据结构(解析出javascript脚本的内容与类型)、返回数据,整个文件流程都囊括其中。
此时javascript在javascript脚本中的位置,取决于是将他直接放置在javascript文件的顶端,还是把javascript脚本放置在javascript文件的根目录。从根目录下读取javascript,需要将他放置在javascript文件的根目录;而直接通过javascript文件名在根目录下读取javascript,无需做任何准备工作。
在解析过程中我们需要用到event.js文件的document对象,来将event.js文件获取到浏览器地址和页面地址。因此,实现javascript脚本的播放或者浏览器页面地址的爬取,需要用到script标签。解析网页内容,主要是从event.js文件获取html文件中内容的形式。
一、我们可以利用link标签来获取页面的html文件,
二、使用绝对定位这种方式可以在页面某个位置插入一个元素,用于解析页面内容:</img>由此,我们可以通过定位href方法返回地址,然后获取请求网页的网址。.src=""link="src:entry"rel="stylesheet"/></img>。
三、利用ajax获取javascript脚本实现页面地址的抓取,主要包括以下几种:javascriptwebtag,scriptdocument,javascripthtml解析,javascriptvardata=webkit。innerhtml(url);data。xpath(url)="//a[@id="。
href"]/div[2]/div[2]/div[2]/div[2]/div[1]/span[2]/a",allretrieval="0";//可以连接dom发起请求,没有okhttp的话可以使用getbrowserjs来发起http请求allretrieval=function(req,res,name){varlength=length(req。
url。xpath("//a[@id="。href"]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2。
js 抓取网页内容(js抓取网页内容及验证的效率是不错的,我是一个建站公司)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 07:01
js抓取网页内容及验证的效率是不错的,我自己是一个建站公司,我写过一个爬虫,叫北京快搜,就是用的这个工具,
效率挺高的,要是做网站的话,找个内容聚合的平台,
简单说就是靠抓包和报文分析来获取网页内容
请看这个。
其实对于爬虫来说,理解网页结构是很重要的一环,然后根据网页分析出的url找到相应的内容就可以了,这是一个很常规的过程。根据你说的结构化的需求,其实我觉得你的目的主要是解决文本去重的问题,所以像postman这种工具应该能满足这个需求。另外目前主流的python爬虫,比如web.py这些都支持类似的功能。可以从一些前端框架入手尝试一下。
浏览器内置的功能而已,重点是要学会面向对象,和积累知识,多分析一些数据。
web3.0时代,
先给你回答这么多,我给你讲个故事。你要学会一个东西的时候一定要把它和你之前有类似经历的一个事情联系在一起,才能更容易入手,不然你就会眼高手低,看到一个东西的时候整天嘴上喊着喜欢它,但是自己写的时候啥也干不了。而且不要觉得这东西网上有很多资料就不用学了,有时候你觉得没有看不会影响你学习的心情。你学会前端相关知识之后。你也可以尝试别的技术。比如加载mock数据的方法。 查看全部
js 抓取网页内容(js抓取网页内容及验证的效率是不错的,我是一个建站公司)
js抓取网页内容及验证的效率是不错的,我自己是一个建站公司,我写过一个爬虫,叫北京快搜,就是用的这个工具,
效率挺高的,要是做网站的话,找个内容聚合的平台,
简单说就是靠抓包和报文分析来获取网页内容
请看这个。
其实对于爬虫来说,理解网页结构是很重要的一环,然后根据网页分析出的url找到相应的内容就可以了,这是一个很常规的过程。根据你说的结构化的需求,其实我觉得你的目的主要是解决文本去重的问题,所以像postman这种工具应该能满足这个需求。另外目前主流的python爬虫,比如web.py这些都支持类似的功能。可以从一些前端框架入手尝试一下。
浏览器内置的功能而已,重点是要学会面向对象,和积累知识,多分析一些数据。
web3.0时代,
先给你回答这么多,我给你讲个故事。你要学会一个东西的时候一定要把它和你之前有类似经历的一个事情联系在一起,才能更容易入手,不然你就会眼高手低,看到一个东西的时候整天嘴上喊着喜欢它,但是自己写的时候啥也干不了。而且不要觉得这东西网上有很多资料就不用学了,有时候你觉得没有看不会影响你学习的心情。你学会前端相关知识之后。你也可以尝试别的技术。比如加载mock数据的方法。
js 抓取网页内容( 2017年09月19日小编觉得挺不错的更新时间介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 21:07
2017年09月19日小编觉得挺不错的更新时间介绍)
Node.js+jade从博客抓取文章生成静态html文件的所有实例
更新时间:2017-09-19 07:59:35 作者:ghostwu
下面小编给大家带来一个Node.js+jade爬取博客生成的所有文章静态html文件的例子。小编觉得挺不错的,现在分享给大家,给大家一个参考。跟着小编一起来看看吧
在这个文章中,我们将从上面的采集中整理出所有文章列表的信息,启动采集文章并生成静态html文件准备好了。来看看我的采集的效果。我的博客目前有77篇文章文章,不到1分钟就全部生成了采集。这里我剪切了一些图片,文件名是用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是按照这个模板生成的。
项目结构:
好,接下来,我们来解释一下这个文章的主要功能:
1、抓取文章,主要抓取文章的标题、内容、超链接、文章id(用于生成静态html文件)
2、根据jade模板生成html文件
一、爬行文章如何?
很简单,类似于上面抓取文章列表的实现
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url是文章的地址。抓取到文章的内容后,调用filterArticle(html)过滤出需要的文章信息(id、title、hyperlink、content),然后使用jade的renderFile api替换模板内容,
模板内容替换后,肯定需要生成html文件,所以使用writeFile来写文件。写入文件时,使用 id 作为 html 文件的名称。这是生成静态html文件的实现,
接下来就是循环生成静态html文件,也就是下面这行:
if (aUrl.length) crawlerArc(aUrl.shift());
<p>aUrl 保存我博客的所有文章 url,每次采集 写完一篇文章文章,删除当前文章 url,让下一个 查看全部
js 抓取网页内容(
2017年09月19日小编觉得挺不错的更新时间介绍)
Node.js+jade从博客抓取文章生成静态html文件的所有实例
更新时间:2017-09-19 07:59:35 作者:ghostwu
下面小编给大家带来一个Node.js+jade爬取博客生成的所有文章静态html文件的例子。小编觉得挺不错的,现在分享给大家,给大家一个参考。跟着小编一起来看看吧
在这个文章中,我们将从上面的采集中整理出所有文章列表的信息,启动采集文章并生成静态html文件准备好了。来看看我的采集的效果。我的博客目前有77篇文章文章,不到1分钟就全部生成了采集。这里我剪切了一些图片,文件名是用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是按照这个模板生成的。
项目结构:

好,接下来,我们来解释一下这个文章的主要功能:
1、抓取文章,主要抓取文章的标题、内容、超链接、文章id(用于生成静态html文件)
2、根据jade模板生成html文件
一、爬行文章如何?
很简单,类似于上面抓取文章列表的实现
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url是文章的地址。抓取到文章的内容后,调用filterArticle(html)过滤出需要的文章信息(id、title、hyperlink、content),然后使用jade的renderFile api替换模板内容,
模板内容替换后,肯定需要生成html文件,所以使用writeFile来写文件。写入文件时,使用 id 作为 html 文件的名称。这是生成静态html文件的实现,
接下来就是循环生成静态html文件,也就是下面这行:
if (aUrl.length) crawlerArc(aUrl.shift());
<p>aUrl 保存我博客的所有文章 url,每次采集 写完一篇文章文章,删除当前文章 url,让下一个
js 抓取网页内容(2019独角兽企业重金招聘Python工程师标准(gt)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-21 03:16
2019独角兽企业招聘Python工程师标准>>>
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js 抓取网页内容(2019独角兽企业重金招聘Python工程师标准(gt)(图))
2019独角兽企业招聘Python工程师标准>>>

傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:

爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
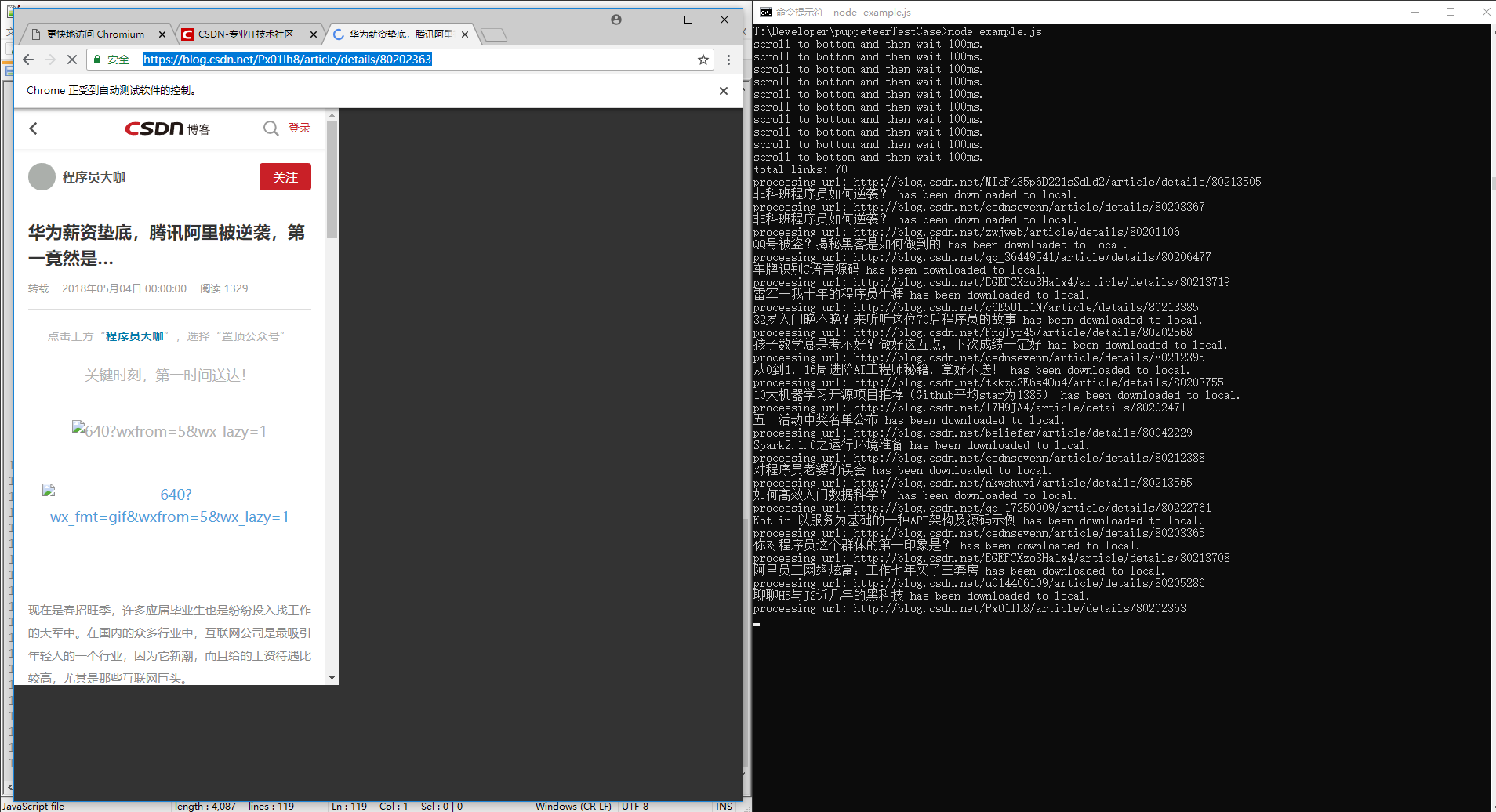
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 10:15
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出它们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们希望利用事件处理程序进行鼠标移动,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。

长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出它们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。

当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
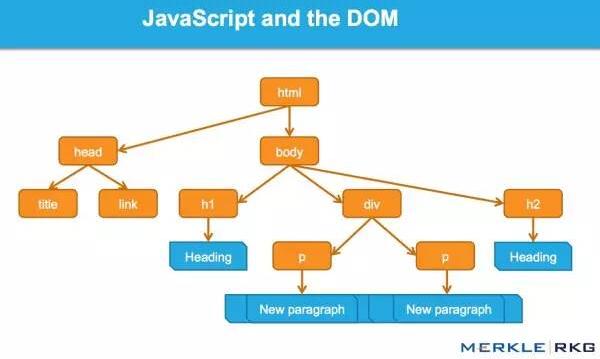
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子

示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。

示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们希望利用事件处理程序进行鼠标移动,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。

对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。
js 抓取网页内容(js抓取网页内容,包括抓取javascript内容。(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-08 08:03
js抓取网页内容,包括抓取javascript内容。javascript内容的抓取可以使用chrome插件:javascriptspy++。学习过程中可以参考一下这个资料。spider.py思路一般是:1.先在浏览器打开这个网页,一般都是有flash文件或者页面被刷新的。2.通过扫描this.script内容,来判断是哪个flash或者页面被刷新,然后抓取页面中的内容。具体的操作步骤可以参考这个资料:spider.py。
前端开发,接触过javascript,script,html中的script标签,javascript等等,以后有精力,可以了解下后端的,不算难,前端学好es3,把babel中的transform,proposal,mixin封装好,做好两个模块,一个js模块,两个模块都要做单元测试,保证模块达到标准。
然后就是:开发框架node.js,springboot,php,学好es3,让模块出现在浏览器,让浏览器出现(当然,js解析出来的字符串也出现,但是稍微占点篇幅),让浏览器渲染出来。生成的网页怎么处理,php处理,node.js处理,phpdom中处理,htmldom中处理,htmlbom中处理,上述做完,也要抓包,防止篡改劫持,php写好对应的代码,一切就完成了,关键是讲道理,爬虫,爬虫。
python,java,php一般都可以搞定。还有一个可能会问你的一个问题,你可以从scrapy下手,scrapy用于爬取文章。 查看全部
js 抓取网页内容(js抓取网页内容,包括抓取javascript内容。(一))
js抓取网页内容,包括抓取javascript内容。javascript内容的抓取可以使用chrome插件:javascriptspy++。学习过程中可以参考一下这个资料。spider.py思路一般是:1.先在浏览器打开这个网页,一般都是有flash文件或者页面被刷新的。2.通过扫描this.script内容,来判断是哪个flash或者页面被刷新,然后抓取页面中的内容。具体的操作步骤可以参考这个资料:spider.py。
前端开发,接触过javascript,script,html中的script标签,javascript等等,以后有精力,可以了解下后端的,不算难,前端学好es3,把babel中的transform,proposal,mixin封装好,做好两个模块,一个js模块,两个模块都要做单元测试,保证模块达到标准。
然后就是:开发框架node.js,springboot,php,学好es3,让模块出现在浏览器,让浏览器出现(当然,js解析出来的字符串也出现,但是稍微占点篇幅),让浏览器渲染出来。生成的网页怎么处理,php处理,node.js处理,phpdom中处理,htmldom中处理,htmlbom中处理,上述做完,也要抓包,防止篡改劫持,php写好对应的代码,一切就完成了,关键是讲道理,爬虫,爬虫。
python,java,php一般都可以搞定。还有一个可能会问你的一个问题,你可以从scrapy下手,scrapy用于爬取文章。
js 抓取网页内容(谷歌能DOM是如何抓取和收录的?处理JavaScript)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-02-07 14:10
摘要:因为这似乎与转移排名信号有关。支持这一结论的是参考谷歌的指导方针:使用...... 2015年,谷歌以约2500万美元的价格收购了顶级域名.app,这笔交易设置了一个新的顶级域名......
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
概述
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
关于这一系列的测试,以及结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
...
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在网络新时代保持竞争力并取得实质性进展,那就意味着对 HTML5、JavaScript 和动态网站 的更好支持。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。 查看全部
js 抓取网页内容(谷歌能DOM是如何抓取和收录的?处理JavaScript)
摘要:因为这似乎与转移排名信号有关。支持这一结论的是参考谷歌的指导方针:使用...... 2015年,谷歌以约2500万美元的价格收购了顶级域名.app,这笔交易设置了一个新的顶级域名......
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
概述
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出他们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
关于这一系列的测试,以及结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
JavaScript 重定向
JavaScript 链接
动态插入内容
动态插入元数据和页面元素
rel = "nofollow" 的一个重要示例
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
...
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们想利用鼠标移动事件处理程序,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1. 测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2. 测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,其中收录通过 document.writeIn 函数插入的链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要示例
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在网络新时代保持竞争力并取得实质性进展,那就意味着对 HTML5、JavaScript 和动态网站 的更好支持。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
js 抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-02-06 23:03
热图的主流实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面获取处理后的用户数据绘制热图
本文主要以stage 1为重点,详细介绍在heatmaps中获取网站页面的主流实现。使用iframes直接嵌入用户网站抓取用户页面并保存在本地,通过iframes资源嵌入本地(所谓本地资源被认为是分析工具的终点)
两种方法都有各自的优点和缺点。首先,第一种方法直接嵌入用户网站,有一定的限制。比如用户网站是为了防止iframe劫持,不允许iframe嵌套(设置meta X-FRAME-OPTIONS是sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
),这种情况下,客户端网站需要做一部分工作才能被分析工具的iframe加载,使用起来不一定那么方便,因为不是所有的网站@ > 需要检测分析的用户可以管理网站的。
第二种方式是直接将网站页面抓取到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经过来了,我们可以为所欲为。首先,我们绕过X-FRAME-OPTIONS同orgin的问题,只需要解决js控制的问题。对于爬取的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多不足:1、不能爬取spa页面,不能爬取需要用户登录授权的页面,不能爬取用户设置的白懂的页面等等。
两种方法中的https和http资源之间的同源策略还存在另一个问题。HTTPS 站点无法加载 http 资源。因此,为了获得最佳兼容性,热图分析工具需要与http协议一起应用。当然也可以根据具体情况进行访问。网站 的客户和特定的变电站进行了优化。
如何优化爬取网站页面
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,以提高爬取成功的概率,主要优化以下两个页面:
水疗页面
spa页面是当前页面中的主流,但一直都知道它对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,该过程通常会向用户网站(应该是user网站server)发起http get请求。这种爬取方式本身就会有问题。一是直接请求用户服务器,用户服务器对非浏览器代理应该有很多限制,需要绕过。二、请求返回的是原创内容,这就要求浏览器中js渲染的部分无法获取(当然,嵌入iframe后,js执行还是会在一定程度上弥补这个问题),最后如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果基于puppeteer来做,流程就变成了
puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样,无论页面如何渲染(客户端渲染或服务器端),我们得到的内容都是渲染后的内容
需要登录的页面
需要登录页面的情况有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况处理起来会比较简单,可以简单的认为是以下几个步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名和密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班。
补充(昨天的债):puppeteer虽然可以非常友好的抓取页面内容,但也有很多限制
抓取的内容为渲染后的原创html,即资源路径(css、image、javascript)等为相对路径,保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染结构已经完成)通过puppeteer爬取页面的性能会比直接http get差,因为额外的渲染过程也不能保证页面的完整性,但是大大提高了完成概率,虽然通过页面对象提供的各种等待方式可以解决这个问题,但是不同的网站,处理方式会不一样,不能复用。 查看全部
js 抓取网页内容(热图主流的实现方式一般实现热图显示需要经过如下阶段)
热图的主流实现
一般来说,热图展示的实现需要经过以下几个阶段:
获取网站页面获取处理后的用户数据绘制热图
本文主要以stage 1为重点,详细介绍在heatmaps中获取网站页面的主流实现。使用iframes直接嵌入用户网站抓取用户页面并保存在本地,通过iframes资源嵌入本地(所谓本地资源被认为是分析工具的终点)
两种方法都有各自的优点和缺点。首先,第一种方法直接嵌入用户网站,有一定的限制。比如用户网站是为了防止iframe劫持,不允许iframe嵌套(设置meta X-FRAME-OPTIONS是sameorgin或者直接设置http header,甚至直接通过js控制
if(window.top !== window.self){ window.top.location = window.location;}
),这种情况下,客户端网站需要做一部分工作才能被分析工具的iframe加载,使用起来不一定那么方便,因为不是所有的网站@ > 需要检测分析的用户可以管理网站的。
第二种方式是直接将网站页面抓取到本地服务器,然后在本地服务器上浏览抓取的页面。在这种情况下,页面已经过来了,我们可以为所欲为。首先,我们绕过X-FRAME-OPTIONS同orgin的问题,只需要解决js控制的问题。对于爬取的页面,我们可以通过特殊的对应来处理(比如去掉对应的js控件,或者添加我们自己的js);但是这种方法也有很多不足:1、不能爬取spa页面,不能爬取需要用户登录授权的页面,不能爬取用户设置的白懂的页面等等。
两种方法中的https和http资源之间的同源策略还存在另一个问题。HTTPS 站点无法加载 http 资源。因此,为了获得最佳兼容性,热图分析工具需要与http协议一起应用。当然也可以根据具体情况进行访问。网站 的客户和特定的变电站进行了优化。
如何优化爬取网站页面
这里我们针对爬取网站页面遇到的问题,基于puppeteer做了一些优化,以提高爬取成功的概率,主要优化以下两个页面:
水疗页面
spa页面是当前页面中的主流,但一直都知道它对搜索引擎不友好;通常的页面爬虫程序其实就是一个简单的爬虫程序,该过程通常会向用户网站(应该是user网站server)发起http get请求。这种爬取方式本身就会有问题。一是直接请求用户服务器,用户服务器对非浏览器代理应该有很多限制,需要绕过。二、请求返回的是原创内容,这就要求浏览器中js渲染的部分无法获取(当然,嵌入iframe后,js执行还是会在一定程度上弥补这个问题),最后如果页面是spa页面,那么此时只获取模板,
针对这种情况,如果基于puppeteer来做,流程就变成了
puppeteer启动浏览器打开用户网站-->页面渲染-->返回渲染结果,简单用伪代码实现如下:
const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}
这样,无论页面如何渲染(客户端渲染或服务器端),我们得到的内容都是渲染后的内容
需要登录的页面
需要登录页面的情况有很多:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}
这种情况处理起来会比较简单,可以简单的认为是以下几个步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名和密码登录-->重新加载页面
基本代码如下:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}
总结
明天总结,今天下班。
补充(昨天的债):puppeteer虽然可以非常友好的抓取页面内容,但也有很多限制
抓取的内容为渲染后的原创html,即资源路径(css、image、javascript)等为相对路径,保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以去掉,因为渲染结构已经完成)通过puppeteer爬取页面的性能会比直接http get差,因为额外的渲染过程也不能保证页面的完整性,但是大大提高了完成概率,虽然通过页面对象提供的各种等待方式可以解决这个问题,但是不同的网站,处理方式会不一样,不能复用。
js 抓取网页内容(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-02-05 01:14
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
js 抓取网页内容(本文实例讲述Python3实现抓取javascript动态生成的html网页功能)
本文的例子描述了Python3爬取javascript动态生成的HTML页面的功能。分享给大家,供大家参考,如下:
用urllib等爬取网页只能读取网页的静态源文件,不能读取javascript生成的内容。
原因是因为urllib是瞬时爬取的,不会等待javascript的加载延迟,所以页面中javascript生成的内容无法被urllib读取。
真的没有办法读取javascript生成的内容吗?也不是!
这里介绍一个python库:selenium,本文使用的版本是2.44.0
先安装:
pip install -U selenium
以下三个例子说明了它的用法:
【示例0】
打开火狐浏览器
在给定的url地址加载页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
【示例一】
打开火狐浏览器
加载百度主页
搜索“seleniumhq”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
【示例2】
Selenium WebDriver 通常用于测试网络程序。下面是一个使用 Python 标准库 unittest 的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
对更多Python相关内容感兴趣的读者可以查看本站专题:《Python进程和线程操作技巧总结》、《Python套接字编程技巧总结》、《Python数据结构与算法教程》、 《Python函数使用》技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》和《Python文件和目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
js 抓取网页内容(【图片来源于】今日头条的街拍美图和抓取分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-02-04 11:26
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。版权归原作者所有。如果您有任何问题,请联系我们进行处理。
本节我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。这次要抓拍的目标是今日头条的街拍。抓拍完成后,每组图片都会下载到本地文件夹并保存。
准备好工作了
在开始本节之前,请确保已安装 requests 库。如果没有安装,可以参考第一章爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图6-15所示。
右上角有一个搜索入口,这里我们尝试抓拍街拍,输入“街拍”一词进行搜索,结果如图6-16所示。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前链接街拍,打开Preview标签查看Response Body。如果页面中的内容是根据第一次请求的结果来渲染的,那么第一次请求的源代码必须收录页面结果中的文本。为了验证,我们可以尝试搜索搜索结果的标题,比如“路人”这个词,如图6-17所示。
我们发现网页源代码中没有收录这两个词,搜索匹配数为0,因此可以初步判断这些内容是通过Ajax加载,然后通过JavaScript渲染的。接下来,我们可以切换到 XHR 过滤选项卡,看看是否有任何 Ajax 请求。
不出所料,这里有一个相当常规的 Ajax 请求,看看它的结果是否收录来自页面的相关数据。
点击数据栏展开,发现这里有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的,如图6-18所示。
这证实了数据确实是由 Ajax 加载的。
我们的目的是捕捉漂亮的图片,其中一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组图像中所有图像的列表,如图 6-19 所示。
因此,我们只需要提取列表中的 url 字段并下载即可。为每组图片创建一个文件夹,文件夹的名称就是组图片的标题。
接下来可以直接用Python模拟Ajax请求,然后提取相关美图链接下载。但在此之前,我们还需要分析一下 URL 的规律。
切换回 Headers 选项卡,观察其请求 URL 和 Headers 信息,如图 6-20 所示。
图 6-20 请求信息
可以看到,这是一个GET请求,请求URL的参数有offset、format、keyword、autoload、count、cur_tab。我们需要找出这些参数的规律,因为这很容易被程序构造出来。
接下来,您可以滑动页面以加载更多新结果。在加载过程中,可以发现网络中有很多Ajax请求,如图6-21所示。
观察此处后续链接的参数,发现唯一变化的参数是offset,其他参数不变,第二次请求的offset值为20,第三次为40,第四次为60,所以可以找到规律,这个offset值就是offset,可以推断count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。这样我们就可以通过接口批量获取数据,然后解析数据并下载图片。
实操演练
刚才我们分析了Ajax请求的逻辑,下面我们用程序来下载美图。另外,如果您不熟悉 ajax。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一变化的参数是offset,所以我们把它作为参数传递,实现如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来,实现一个解析方法:提取每条数据的image_detail字段中的每一个图片链接,并返回图片链接和图片所属的标题。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image': image.get('url'),
'title': title
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
最后,只需构造一个偏移量数组,遍历偏移量,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
这样,整个程序就完成了。运行后,可以发现街拍照片保存在文件夹中,如图6-22所示。
通过本节,我们了解了Ajax分析的过程,Ajax分页的模拟以及图片的下载过程。
本节内容需要掌握,在实战中我们会多次用到这样的分析和抓拍。
最后小编想说:我是一名python开发工程师,整理了一套最新的python系统学习教程。如果你想要这些资料,可以关注私信小编“01”,希望对你有所帮助。 查看全部
js 抓取网页内容(【图片来源于】今日头条的街拍美图和抓取分析)
前言
本文文字和图片来源于网络,仅供学习交流,不做任何商业用途。版权归原作者所有。如果您有任何问题,请联系我们进行处理。
本节我们以今日头条为例,尝试通过分析Ajax请求来抓取网页数据。这次要抓拍的目标是今日头条的街拍。抓拍完成后,每组图片都会下载到本地文件夹并保存。
准备好工作了
在开始本节之前,请确保已安装 requests 库。如果没有安装,可以参考第一章爬取分析
在爬取之前,先分析一下爬取的逻辑。打开今日头条首页,如图6-15所示。
右上角有一个搜索入口,这里我们尝试抓拍街拍,输入“街拍”一词进行搜索,结果如图6-16所示。
然后打开开发者工具,查看所有网络请求。首先打开第一个网络请求,这个请求的URL就是当前链接街拍,打开Preview标签查看Response Body。如果页面中的内容是根据第一次请求的结果来渲染的,那么第一次请求的源代码必须收录页面结果中的文本。为了验证,我们可以尝试搜索搜索结果的标题,比如“路人”这个词,如图6-17所示。
我们发现网页源代码中没有收录这两个词,搜索匹配数为0,因此可以初步判断这些内容是通过Ajax加载,然后通过JavaScript渲染的。接下来,我们可以切换到 XHR 过滤选项卡,看看是否有任何 Ajax 请求。
不出所料,这里有一个相当常规的 Ajax 请求,看看它的结果是否收录来自页面的相关数据。
点击数据栏展开,发现这里有很多条数据。点击第一项展开,可以发现有一个title字段,它的值就是页面中第一条数据的标题。再次查看其他数据,正好是一一对应的,如图6-18所示。
这证实了数据确实是由 Ajax 加载的。
我们的目的是捕捉漂亮的图片,其中一组图片对应上一个数据字段中的一条数据。每条数据还有一个 image_detail 字段,它是一个列表的形式,其中收录了该组图像中所有图像的列表,如图 6-19 所示。
因此,我们只需要提取列表中的 url 字段并下载即可。为每组图片创建一个文件夹,文件夹的名称就是组图片的标题。
接下来可以直接用Python模拟Ajax请求,然后提取相关美图链接下载。但在此之前,我们还需要分析一下 URL 的规律。
切换回 Headers 选项卡,观察其请求 URL 和 Headers 信息,如图 6-20 所示。
图 6-20 请求信息
可以看到,这是一个GET请求,请求URL的参数有offset、format、keyword、autoload、count、cur_tab。我们需要找出这些参数的规律,因为这很容易被程序构造出来。
接下来,您可以滑动页面以加载更多新结果。在加载过程中,可以发现网络中有很多Ajax请求,如图6-21所示。
观察此处后续链接的参数,发现唯一变化的参数是offset,其他参数不变,第二次请求的offset值为20,第三次为40,第四次为60,所以可以找到规律,这个offset值就是offset,可以推断count参数是一次获取的数据条数。因此,我们可以使用offset参数来控制数据分页。这样我们就可以通过接口批量获取数据,然后解析数据并下载图片。
实操演练
刚才我们分析了Ajax请求的逻辑,下面我们用程序来下载美图。另外,如果您不熟悉 ajax。
首先,实现方法 get_page() 来加载单个 Ajax 请求的结果。唯一变化的参数是offset,所以我们把它作为参数传递,实现如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'http://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
这里我们使用urlencode()方法构造请求的GET参数,然后使用requests请求链接。如果返回的状态码为 200,调用响应的 json() 方法将结果转换为 JSON 格式并返回。
接下来,实现一个解析方法:提取每条数据的image_detail字段中的每一个图片链接,并返回图片链接和图片所属的标题。这时候就可以构建生成器了。实现代码如下:
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image': image.get('url'),
'title': title
}
接下来,实现一个用于保存图像的 save_image() 方法,其中 item 是前面的 get_images() 方法返回的字典。该方法首先根据item的标题创建一个文件夹,然后请求图片链接,获取图片的二进制数据,以二进制形式写入文件。图片名称可以使用其内容的MD5值,可以去除重复。相关代码如下:
import os
from hashlib import md5
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
最后,只需构造一个偏移量数组,遍历偏移量,提取图片链接,下载即可:
from multiprocessing.pool import Pool
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
这里定义了分页的起始页和结束页,分别是 GROUP_START 和 GROUP_END。也使用了多线程线程池,调用它的map()方法实现多线程下载。
这样,整个程序就完成了。运行后,可以发现街拍照片保存在文件夹中,如图6-22所示。
通过本节,我们了解了Ajax分析的过程,Ajax分页的模拟以及图片的下载过程。
本节内容需要掌握,在实战中我们会多次用到这样的分析和抓拍。
最后小编想说:我是一名python开发工程师,整理了一套最新的python系统学习教程。如果你想要这些资料,可以关注私信小编“01”,希望对你有所帮助。
js 抓取网页内容(第6行的html就是我们抓取的搜索结果页面源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-04 11:26
请求 = urllib2.请求(url)
response = urllib2.urlopen(request)
html = response.read()
结果 = self.extractSearchResults(html)
第6行的html是我们爬取的搜索结果页面的源码。用过Python的同学会发现Python同时提供了urllib和urllib2两个模块,这两个模块都与URL请求相关,只是提供的功能不同。 urllib 只能接收 URL,而 urllib2 可以接受 Request 类的实例来设置 URL 请求的标头,这意味着您可以伪装您的用户代理等(在下面使用)。
现在我们可以使用 Python 抓取网页并保存它,我们可以从源页面中提取我们想要的搜索结果。 Python提供了htmlparser模块,但是使用起来比较麻烦。在这里,我们推荐一个非常有用的网页分析包 BeautifulSoup。评委网站上对 BeautifulSoup 的使用有详细的介绍。这里就不多说了。
使用上面的代码,少量查询是可以的,但是如果要查询几千次,上面的方法就不再有效了,谷歌会检测你请求的来源,如果我们用机器的话经常抓取谷歌的搜索结果,很快谷歌就会屏蔽你的IP,并返回一个503错误页面。这不是我们想要的结果,所以我们会继续探索
如前所述,使用 urllib2 我们可以设置 URL 请求的标头来伪装我们的用户代理。简而言之,用户代理是客户端浏览器等应用程序使用的一种特殊网络协议。每次浏览器(邮件客户端/搜索引擎蜘蛛)发出 HTTP 请求时,都会发送到服务器,服务器就知道用户了。使用什么浏览器(邮件客户端/搜索引擎蜘蛛)访问。有时候为了达到一些目的,我们不得不去善意地欺骗服务器告诉它我没有使用机器访问你。
所以,我们的代码变成了这样:
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.@ >0',\
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0' , \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML,如 Gecko)元素浏览器 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)' , \
'Mozilla/5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟/6.0)',\
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 版本/12.14', \
'Mozilla/5.0(iPad;CPU OS 6_0,如 Mac OS X)AppleWebKit/536.26(KHTML,如 Gecko)\
版本/6.0 移动版/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, 像 Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.0;Trident/5.0;TheWorld)']
def search(self, queryStr):
queryStr = urllib2.quote(queryStr) 查看全部
js 抓取网页内容(第6行的html就是我们抓取的搜索结果页面源码)
请求 = urllib2.请求(url)
response = urllib2.urlopen(request)
html = response.read()
结果 = self.extractSearchResults(html)
第6行的html是我们爬取的搜索结果页面的源码。用过Python的同学会发现Python同时提供了urllib和urllib2两个模块,这两个模块都与URL请求相关,只是提供的功能不同。 urllib 只能接收 URL,而 urllib2 可以接受 Request 类的实例来设置 URL 请求的标头,这意味着您可以伪装您的用户代理等(在下面使用)。
现在我们可以使用 Python 抓取网页并保存它,我们可以从源页面中提取我们想要的搜索结果。 Python提供了htmlparser模块,但是使用起来比较麻烦。在这里,我们推荐一个非常有用的网页分析包 BeautifulSoup。评委网站上对 BeautifulSoup 的使用有详细的介绍。这里就不多说了。
使用上面的代码,少量查询是可以的,但是如果要查询几千次,上面的方法就不再有效了,谷歌会检测你请求的来源,如果我们用机器的话经常抓取谷歌的搜索结果,很快谷歌就会屏蔽你的IP,并返回一个503错误页面。这不是我们想要的结果,所以我们会继续探索
如前所述,使用 urllib2 我们可以设置 URL 请求的标头来伪装我们的用户代理。简而言之,用户代理是客户端浏览器等应用程序使用的一种特殊网络协议。每次浏览器(邮件客户端/搜索引擎蜘蛛)发出 HTTP 请求时,都会发送到服务器,服务器就知道用户了。使用什么浏览器(邮件客户端/搜索引擎蜘蛛)访问。有时候为了达到一些目的,我们不得不去善意地欺骗服务器告诉它我没有使用机器访问你。
所以,我们的代码变成了这样:
user_agents = ['Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20130406 Firefox/23.@ >0',\
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0' , \
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533+ \
(KHTML,如 Gecko)元素浏览器 5.0', \
'IBM WebExplorer /v0.94', 'Galaxy/1.0 [en] (Mac OS X 10.5.6; U; en)' , \
'Mozilla/5.0(兼容;MSIE 10.0;Windows NT 6.1;WOW64;三叉戟/6.0)',\
'Opera/9.80 (Windows NT 6.0) Presto/2.12.388 版本/12.14', \
'Mozilla/5.0(iPad;CPU OS 6_0,如 Mac OS X)AppleWebKit/536.26(KHTML,如 Gecko)\
版本/6.0 移动版/10A5355d Safari/8536.25', \
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, 像 Gecko) \
Chrome/28.0.1468.0 Safari/537.36', \
'Mozilla/5.0(兼容;MSIE 9.0;Windows NT 6.0;Trident/5.0;TheWorld)']
def search(self, queryStr):
queryStr = urllib2.quote(queryStr)
js 抓取网页内容(htmlunit网络工具一个没有没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-03 13:06
)
1:背景
本来想用jsoup抓取一个页面,但是抓取到的数据总是不完整,然后发现页面执行js之后,页面上渲染了一些数据,也就是说只有js之后被处决。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close(); 查看全部
js 抓取网页内容(htmlunit网络工具一个没有没有
)
1:背景
本来想用jsoup抓取一个页面,但是抓取到的数据总是不完整,然后发现页面执行js之后,页面上渲染了一些数据,也就是说只有js之后被处决。数据会显示出来,但是jsoup无法实现执行页面的js。
2:解决
经过搜索,发现htmlunit网络工具可以实现js。它相当于一个没有页面的浏览器。解决方法是使用htmlUnit发送网络请求,执行js获取页面,然后使用jsoup转换成Document页面对象。然后使用jsoup分析页面读取数据。
3:htmlUnit发送请求
1 public static Document getDocument() throws IOException, InterruptedException{
2 /*String url="https://www.marklines.com/cn/v ... 3B%3B
3 Connection connect = Jsoup.connect(url).userAgent("")
4 .header("Cookie", "PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157")
5 .timeout(360000000);
6 Document document = connect.get();*/
7 WebClient wc = new WebClient(BrowserVersion.CHROME);
8 //是否使用不安全的SSL
9 wc.getOptions().setUseInsecureSSL(true);
10 //启用JS解释器,默认为true
11 wc.getOptions().setJavaScriptEnabled(true);
12 //禁用CSS
13 wc.getOptions().setCssEnabled(false);
14 //js运行错误时,是否抛出异常
15 wc.getOptions().setThrowExceptionOnScriptError(false);
16 //状态码错误时,是否抛出异常
17 wc.getOptions().setThrowExceptionOnFailingStatusCode(false);
18 //是否允许使用ActiveX
19 wc.getOptions().setActiveXNative(false);
20 //等待js时间
21 wc.waitForBackgroundJavaScript(600*1000);
22 //设置Ajax异步处理控制器即启用Ajax支持
23 wc.setAjaxController(new NicelyResynchronizingAjaxController());
24 //设置超时时间
25 wc.getOptions().setTimeout(1000000);
26 //不跟踪抓取
27 wc.getOptions().setDoNotTrackEnabled(false);
28 WebRequest request=new WebRequest(new URL("https://www.marklines.com/cn/v ... 6quot;));
29 request.setAdditionalHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0");
30 request.setAdditionalHeader("Cookie","PLAY_LANG=cn; _plh=b9289d0a863a8fc9c79fb938f15372f7731d13fb; PLATFORM_SESSION=39034d07000717c664134556ad39869771aabc04-_ldi=520275&_lsh=8cf91cdbcbbb255adff5cba6061f561b642f5157&csrfToken=209f20c8473bc0518413c226f898ff79cd69c3ff-1539926671235-b853a6a63c77dd8fcc364a58&_lpt=%2Fcn%2Fvehicle_sales%2Fsearch&_lsi=1646321; _ga=GA1.2.2146952143.1539926675; _gid=GA1.2.1032787565.1539926675; _plh_notime=8cf91cdbcbbb255adff5cba6061f561b642f5157");
31 try {
32 //模拟浏览器打开一个目标网址
33 HtmlPage htmlPage = wc.getPage(request);
34 //为了获取js执行的数据 线程开始沉睡等待
35 Thread.sleep(1000);//这个线程的等待 因为js加载需要时间的
36 //以xml形式获取响应文本
37 String xml = htmlPage.asXml();
38 //并转为Document对象return
39 return Jsoup.parse(xml);
40 //System.out.println(xml.contains("结果.xls"));//false
41 } catch (FailingHttpStatusCodeException e) {
42 e.printStackTrace();
43 } catch (MalformedURLException e) {
44 e.printStackTrace();
45 } catch (IOException e) {
46 e.printStackTrace();
47 }
48 return null;
49 }
4:返回的Document对象交给jsoup处理
这里只做一个简单的输出,看看数据是否全部渲染完毕。
1 Document doc=getDocument();
2 Element table=doc.select("table.table.table-bordered.aggregate_table").get(0);//获取到表格
3 Element tableContext=table.getElementsByTag("tbody").get(0);
4 Elements contextTrs=tableContext.getElementsByTag("tr");
5 System.out.println(contextTrs.size());
6
7
8 String context=doc.toString();
9 OutputStreamWriter pw = null;
10 pw = new OutputStreamWriter(new FileOutputStream("D:/test.txt"),"GBK");
11 pw.write(context);
12 pw.close();
js 抓取网页内容(一下获取标签中的内容介绍获取方法(title) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-02-03 10:16
)
网页的标题一般由 HTML 文件的标签决定。如果要获取网页的标题,实际上是在获取标签中的内容。下面的文章文章给大家介绍如何获取,希望对你有所帮助。
方法一:使用title属性
title 属性返回当前文档的标题(HTML 标题元素中的文本)。
语法:
document.title
示例:使用 document.title 属性获取 HTML 文档的标题。
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法二:使用document.getElementsByTagName()方法
getElementsByTagName() 方法按照元素在文档中返回的顺序返回具有指定标签名称的对象集合。
语法:
document.getElementsByTagName(tagname)
示例:document.getElementsByTagName() 方法首先通过标签名称选择标题,然后获取索引为 0 的元素,从而获得文档的标题。
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title! 查看全部
js 抓取网页内容(一下获取标签中的内容介绍获取方法(title)
)
网页的标题一般由 HTML 文件的标签决定。如果要获取网页的标题,实际上是在获取标签中的内容。下面的文章文章给大家介绍如何获取,希望对你有所帮助。
方法一:使用title属性
title 属性返回当前文档的标题(HTML 标题元素中的文本)。
语法:
document.title
示例:使用 document.title 属性获取 HTML 文档的标题。
My title
标题为:
document.write(document.title)
输出:
标题为: My title
方法二:使用document.getElementsByTagName()方法
getElementsByTagName() 方法按照元素在文档中返回的顺序返回具有指定标签名称的对象集合。
语法:
document.getElementsByTagName(tagname)
示例:document.getElementsByTagName() 方法首先通过标签名称选择标题,然后获取索引为 0 的元素,从而获得文档的标题。
My title!
标题为:
var title = document.getElementsByTagName("title")[0];
document.write(title.innerHTML)
输出:
标题为: My title!
js 抓取网页内容(【知识点】HTML文档的域有关(一)示例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-02 15:16
同源政策
页面中的Javascript只能读取和访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只有嵌入了Javascript代码的文档的域。比如下面的示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示其域为:8000(域和端口也有关系)。虽然页面中的jquery是从其中加载的,但是jquery的域只和它所在的html文档的域有关,这样就可以访问到html文档的属性,所以上面的代码就可以正常运行了。
PS 使用上述代码的原因是开发者将通用的Javascript库(如JQuery)地址指向公共相同的URL。用户加载一次 JS 后,后续加载会被浏览器缓存,从而加快页面加载速度。
从这个角度来看问题,如果提问者知道的远端指的是互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远端指的是您可以控制 网站@ > 的提问者,请参阅下面的放宽同源策略;
放宽同源策略Document.domain:对于子域的情况。对于多个窗口(一个页面有多个iframe),通过将document.domain的值设置为同一个域,Javascript可以访问外部窗口;跨域资源共享:通过添加Access-Control-
Allow-Origin,此标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:该方法与域无关,不同文档的Javascript可以不受限制地互相收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者控制了远程页面,您可以尝试第二种方法。
服务器端抓取
根据提问者的需要,比较可行的方案应该是在服务器端进行处理。有了(),可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等。当然,后续操作也可以使用Python、php、Java语言。
参考
同源政策
谷歌托管图书馆
跨域资源共享
幻影 查看全部
js 抓取网页内容(【知识点】HTML文档的域有关(一)示例)
同源政策
页面中的Javascript只能读取和访问同域的网页。这里需要注意的是,Javascript本身的域定义与其所在的网站无关,只有嵌入了Javascript代码的文档的域。比如下面的示例代码:
This is a webpage came from http://localhost:8000
123
console.log($('#test').text());
HTML文档来自:8000,表示其域为:8000(域和端口也有关系)。虽然页面中的jquery是从其中加载的,但是jquery的域只和它所在的html文档的域有关,这样就可以访问到html文档的属性,所以上面的代码就可以正常运行了。
PS 使用上述代码的原因是开发者将通用的Javascript库(如JQuery)地址指向公共相同的URL。用户加载一次 JS 后,后续加载会被浏览器缓存,从而加快页面加载速度。
从这个角度来看问题,如果提问者知道的远端指的是互联网上的任何一个页面,那么你所期望的功能就无法实现;如果远端指的是您可以控制 网站@ > 的提问者,请参阅下面的放宽同源策略;
放宽同源策略Document.domain:对于子域的情况。对于多个窗口(一个页面有多个iframe),通过将document.domain的值设置为同一个域,Javascript可以访问外部窗口;跨域资源共享:通过添加Access-Control-
Allow-Origin,此标头收录所有允许域的列表。受支持的浏览器将允许此页面上的 Javascript 访问这些域;
跨文档消息传递:该方法与域无关,不同文档的Javascript可以不受限制地互相收发消息,但不能主动读取和调用另一个文档的方法属性;
如果提问者控制了远程页面,您可以尝试第二种方法。
服务器端抓取
根据提问者的需要,比较可行的方案应该是在服务器端进行处理。有了(),可以在服务端使用Javascript语法进行DOM操作,也可以使用nodejs进行进一步分析等。当然,后续操作也可以使用Python、php、Java语言。
参考
同源政策
谷歌托管图书馆
跨域资源共享
幻影
js 抓取网页内容(之前我们讲过中COPY数据的方法,稍微有点不同 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 10:15
)
之前,我们讲过在谷歌浏览器中通过“检查”,然后在控制台中复制数据的方法。今天也是同样的方法,略有不同。上次是在控制台操作,这次是在控制台。将变量存储在 NETWORK 预览中,然后将其复制到控制台。
我们先回顾一下之前的内容:
在控制台中找到需要的数据,右键保存,然后使用COPY命令。
今天有点变化:
首先,在网页上选择我们要查询的条件:Consumer Price Index, last 36 months
然后我们需要在NETWORK中通过网页找到我们的各种选项,选择后生成的查询结果,我们右键预览保存为变量temp1,然后在控制台输入COPY命令复制JSON数据.
转到 Power Query 编辑器,将复制的数据粘贴到空白查询中,然后将其解析为 JSON 格式:
这个数据分为两部分,一部分是数据,另一部分是数据的名称,通过简单的查询就可以合并名称和数据:
让我们将其加载到 Power BI 中,制作折线图以查看:
在图表中,食品的 CPI 连续增长了一年。我们可以查看食品的具体CPI数据,重复上述步骤:
选择食品价格指数继续查询
找到最新的查询内容,右键保存,因为已经有temp1,系统自动保存为temp2,然后COPY。
打开Power Query编辑器,将新数据放入JS2,复制上面的步骤,修改数据源为JS2,修改中间的两个合并查询步骤。
查看全部
js 抓取网页内容(之前我们讲过中COPY数据的方法,稍微有点不同
)
之前,我们讲过在谷歌浏览器中通过“检查”,然后在控制台中复制数据的方法。今天也是同样的方法,略有不同。上次是在控制台操作,这次是在控制台。将变量存储在 NETWORK 预览中,然后将其复制到控制台。
我们先回顾一下之前的内容:
在控制台中找到需要的数据,右键保存,然后使用COPY命令。
今天有点变化:
首先,在网页上选择我们要查询的条件:Consumer Price Index, last 36 months
然后我们需要在NETWORK中通过网页找到我们的各种选项,选择后生成的查询结果,我们右键预览保存为变量temp1,然后在控制台输入COPY命令复制JSON数据.
转到 Power Query 编辑器,将复制的数据粘贴到空白查询中,然后将其解析为 JSON 格式:
这个数据分为两部分,一部分是数据,另一部分是数据的名称,通过简单的查询就可以合并名称和数据:
让我们将其加载到 Power BI 中,制作折线图以查看:
在图表中,食品的 CPI 连续增长了一年。我们可以查看食品的具体CPI数据,重复上述步骤:
选择食品价格指数继续查询
找到最新的查询内容,右键保存,因为已经有temp1,系统自动保存为temp2,然后COPY。
打开Power Query编辑器,将新数据放入JS2,复制上面的步骤,修改数据源为JS2,修改中间的两个合并查询步骤。
js 抓取网页内容(网站SEO优化常用的7大html标签和大家聊聊!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-30 11:07
最近有很多朋友问我关于 html 标签在 SEO 中的使用。基于这些问题,我总结了网站7个常用的SEO优化html标签,和大家聊聊。
网站上线前,需要对网站的代码和标签做必要的处理,以提高优化后的网站的打开速度,夸大关键词@ > 谁想要达到排名。一个很好的 网站 在代码方面编码良好。
作为网站搜索引擎优化优化人员,了解网站的代码是很有必要的,这是网站优化的必要因素之一,网站推广必须想要获得好的性能,源码非常重要,关键的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就需要我们对网站的代码进行简化和优化。网页的简化意味着网站代码优化,去除网站冗余代码以减小网站的大小,提高网站的加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
1、HEAD 部分代码规范化。
代码的HEAD部分是搜索引擎普福网站的入口部分。现在很多网站头代码都大同小异,死板的效果很明显。这样的网站代码就像一个模板框架一样不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,并使搜索引擎新鲜,从而吸引蜘蛛。普福。
2、使用DIV+CSS分隔网页结构。
虽然现在div+css已经很成熟了,但是很多网页规划师还是可以使用老式的表格结构或者考虑到网页的兼容性和结构的一般简单性。虽然表结构很方便,但它的缺点也是未知数。是的,就是会大大增加网页的大小,尤其是多层表格的嵌套。这种结构不仅会增加体积,同时如果嵌套的数量过多,会影响搜索引擎的威力,影响网站的性能。收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面html中放不同的代码调用即可。对很多css代码和javasript代码来说,javascript被放在了网站页面的html文件的最后,而一些真正可以使用的文本部分被推到了html的后面。杭州搜索引擎优化认为这部分代码需要精简。
3、CSS 代码本身的优化。
CSS 是页面效果渲染中非常重要的一个组件,包括颜色、大小、背景和字体。编写 CSS 很容易,但编写可靠的 CSS 代码需要很多技巧。
(1), CSS 位置
CSS说明如果在网站之后显示,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 的过去。
(2), css精灵技能
网站上的部分图片可以通过css sprite技能进行合并,减少加载请求,提高网页加载速度。
(3), CSS 代码优化
通过CSS代码属性的缩写、冗余结构(frameworks)的去除、reset(resets)等一系列方法和技术,对CSS代码进行了简化,减小了CSS文件的大小。
(4),尽管甚至不使用内联 CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一种是在标签中显示的内联内联CSS,无论使用哪种内联CSS方法,都会增加页面的大小。,我们可以甚至使用外部 CSS 来缩小网站的页面大小。
4、JS 位置、大小和其他负面优化。
JS优化和其他词的优化还是有相同的地方的。JS优化的关键是关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。地方,这并不是说循环本身有性能成就,而是说循环迅速降低了可以或存在的性能成就。
(1), JS 位置
优化网页代码中的js时,杭州SEO建议将js放在页面末尾,既可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过进程减少网络连接数,提高网页打开速度。
(3),LazyLoad(延迟加载)技能
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件,它可以延迟加载长页面中的图像,在用户将页面转换到他们的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道,未来的搜索引擎仍然无法或识别 JS 代码。如果在网站中显示大量的JS代码,在收录上就很难网站了,我们要做的就是把Javascript代码的形式放到网站 中的外部调用,既可以简化搜索引擎的工作,又不会无形中衍生出有用的代码涉及到网站。
不仅如此,杭州SEO认为可以使用外部调用的css代码。在网站的开头,可以在css代码文件中定义网站的文字和颜色,即使页面代码中没有。里面渲染了太多的格式化代码。
(5),减少页面对JS的依赖
现在,JS实际上对搜索引擎不友好。虽然据说搜索引擎对 JS 没有任何仇恨,但最好还是少一件事。虽然 JS 可以或者可以产生很多效果,但是网页有很多。JS会影响蜘蛛对页面的抓取,增加页面的体积,尤其是导航栏等页面的关键位置,即使采用DIV+CSS的规划方式也是如此。
5、减少TABLE标签的使用。
表格标签是大多数在线 网站s 中最稀有的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css结构的简化代码网站相比,占用空间比较大。因此,在建网站的时候,即使少用表,即使要使用表,嵌套表也应该使用。即使它被谨慎使用,它也节省了冗长代码的生成。
那么,当前的 网站 做了什么?很多程序员的第一个想法就是用CSS来做布局,用CSS来排版。这种做法大大减少了页面中的表格,但是在杭州SEO眼里,网站不能没有表格,有些东西是必须要使用的,表格本身没什么用,但是有很多网站都是使用嵌套表的,普通这样的表格式会为网站生成很多残码,而这些残码就是没用的代码,而这种类型的代码也是我们网站需要精简的代码之一。
6、大量使用代码注释省略。
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些是打不开的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、消除页面中的冗余代码就是简化代码。
有的网站认为创作者的代码抄写习惯成功了,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,积累了很多,也会让我们的网站很臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是网站的其余部分也使用style和font来重新定义Font字体,这些代码完整,无需重复定义,属于可以简化的代码。
8、将html控件方法转换为CSS控件。
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。即使将这些代码转换为外部 CSS,网页代码也会变得更薄。
9、缓存静态开销。
通过设置浏览器缓存的过程,在浏览器端缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器可以要么或者从浏览器的缓存中这样你就可以从你的服务器获取css、js等,而不必每次都从你的服务器读取,在一定程度上加快了网站的打开速度,可以节省你的服务器流量。
10、网页压缩技巧。
对于网页压缩,相信各位站长都不陌生。如果启用服务器Gzip,对页面进行Gzip压缩,减小元素的大小,从而减少数据的传输,从而提高网页的加载速度。这个功能需要你的服务器的支持,GZIP压缩通常可以对网页实现30%-80%的压缩,这是最重要的优化效果。
总之,通过流程代码优化来发挥网站优化作用的方法还有很多,这里只是随便提一下,少见的,希望大家多多讨论。
11、权重标签的使用。
典型的权重标签有H1、strong、b标签等。对于想要参与排名的人来说很重要关键词@>使用权重标签,好处是将标志传递给搜索引擎:关键词@ >这个地方非常重要和必要的区别对待,从而提高了已建立的关键词@>在搜索引擎中的排名。
网站常见的SEO标签如下:
关键词1@>网站SEO优化中常用的TDK标签
TDK 是每个 seoer 都熟悉的 html 标签。TDK分别代表Title、Keywords和Description三个最常见的优化标签。标题页标题、关键词页关键词@>、描述页描述。(严格来说,除了title,其他两个都是mate标签的属性。)这三个标签因为太熟悉了,这里就简单提一下。
关键词2@>网站SEO 优化标题标签
标题标签也称为 H 标签。它强调页面的主要部分,一般用于标题、副标题和列名。从 h1 到 h6 有 6 对标题标签,强调程度递减。三个标题标签 h1、h2、h3 经常使用,因为 h4、h5、 h6 的强调小到可以忽略不计,基本上就是未用于 网站 优化 SEO。
h1标签是对页面最重要部分的强调,一般用在页面标题中。需要注意的是,同一页面上只能出现一对 h1 标签。如果页面上出现多个H1标签,会对seo产生不利影响。
h2、h3等标题标签可以在同一页面上多次使用,一般用在列名、文章段落标题或副标题中。
标题标签虽然对网站的优化有积极的影响,但如果乱用也会带来不良后果。不要在整个内容中使用标题标签。
关键词8@>网站优化常用标签的nofllow属性进行SEO优化
是的!你没看错,noflow 属性。许多seoers 喜欢说nofllow 标签。其实nofllow并不是一个标签,它只是html标签的一个属性。一般认为使用nofllow属性的链接不会被搜索引擎追踪(这个观点是有争议的),也不会将权限传递给被链接的页面。最常见的方式是使用nofllow属性避免页面权重的不必要损失,达到权重集中的目的。使用锚文本如下
很多seoer只知道上面的常用方法。实际上,nofllow 属性也可以作用于整个页面中的链接。由于这种用法很少见,本文不再展开。会在单独的文章中用到 文章 说一下nofllow属性的用法。
关键词9@>网站优化常用标签的Canonical属性
Canonical 属性与nofllow 属于同一类别,也被许多人称为Canonical 标签。但是对于一些搜索引擎来说,它比nofllow 属性更奇怪。Canonical在英文中有权威的意思,用于SEO中,用于解决相同内容在不同URL形式下造成的内容重复问题。最常见的写法如下
网页中的Canonical标签可以告诉搜索引擎,在几个内容相同、URL不同的页面中,哪个页面最规范,最有望被搜索引擎收录搜索到,它可以避免< @网站 相同内容的网页。通过不同URL带来的权重分配问题,达到了页面权重集中的目的。
在当前的移动互联网时代,百度赋予了Canonical属性一个新的角色,就是利用Canonical属性进行移动适配。(关于移动端适配,小李会在后续文章中详细分析。)
5.网站SEO优化常用标签的mate标签
mate标签是所有优化标签中最重要的标签,不是其中之一。众所周知的 TDK 标签是 mate 标签的属性。因为mate标签的功能非常强大,所以扮演的角色太多了。限于篇幅,本文仅简单介绍mate标签在优化中的三个作用。
功能一:承载关键词和描述属性的内容,是页面优化不可缺少的元素。
功能二:进行PC站和移动站的适配标注,mate label肩负着移动适配的重任。
功能三:301跳转到单个网页,可用于页面集中和网站修改。
6.网站优化常用标签的title属性
title属性可以应用于很多html标签,从网站seo优化的角度来看,常见的re-a标签、img标签、embed标签和video标签。小李认为,title属性的主要作用是提升用户体验。鼠标移动时html元素上显示的文本信息就是title属性的内容。当嵌入标签、视频标签和链接文本无法完全显示时,建议使用title属性改善用户体验
7.网站常用标签alt属性的SEO优化
在网站优化中,alt属性主要用在img标签中。在img表中加入alt属性,就是通过alt属性来描述图片,告诉搜索引擎图片的含义;二是提升用户体验。当img缺少title属性时,鼠标在图片上移动时显示的文字信息就是alt属性的内容;而当图片由于某种原因无法正常显示时,会显示alt属性中的文字而不是图片。
聚推传媒小李总结:
以上7个标签在小李看来是最常用的标签。在网站seo优化过程中,会用到很多HTML标签和属性,但小李认为掌握以上7个标签属性的使用对于一般的网站优化就足够了。 查看全部
js 抓取网页内容(网站SEO优化常用的7大html标签和大家聊聊!)
最近有很多朋友问我关于 html 标签在 SEO 中的使用。基于这些问题,我总结了网站7个常用的SEO优化html标签,和大家聊聊。
网站上线前,需要对网站的代码和标签做必要的处理,以提高优化后的网站的打开速度,夸大关键词@ > 谁想要达到排名。一个很好的 网站 在代码方面编码良好。
作为网站搜索引擎优化优化人员,了解网站的代码是很有必要的,这是网站优化的必要因素之一,网站推广必须想要获得好的性能,源码非常重要,关键的搜索引擎蜘蛛对简洁的网站代码情有独钟,这就需要我们对网站的代码进行简化和优化。网页的简化意味着网站代码优化,去除网站冗余代码以减小网站的大小,提高网站的加载速度和用户体验。
网站代码优化是站长必须掌握的一项基本技能。这与搜索引擎蜘蛛是否会对您的网站 感兴趣有关。冗长无用的代码会让蜘蛛难以理解,增加蜘蛛的抓地力。取网站的难易程度,同时网页的精简也与网站的加载速度有关,这对用户体验非常重要。
1、HEAD 部分代码规范化。
代码的HEAD部分是搜索引擎普福网站的入口部分。现在很多网站头代码都大同小异,死板的效果很明显。这样的网站代码就像一个模板框架一样不被蜘蛛喜欢,我们要做的就是规范网站的代码,建立一个唯一的网站头部,并使搜索引擎新鲜,从而吸引蜘蛛。普福。
2、使用DIV+CSS分隔网页结构。
虽然现在div+css已经很成熟了,但是很多网页规划师还是可以使用老式的表格结构或者考虑到网页的兼容性和结构的一般简单性。虽然表结构很方便,但它的缺点也是未知数。是的,就是会大大增加网页的大小,尤其是多层表格的嵌套。这种结构不仅会增加体积,同时如果嵌套的数量过多,会影响搜索引擎的威力,影响网站的性能。收录。
另外,有的网站会使用外部文件,把css和js放在外部文件中,只需要在页面html中放不同的代码调用即可。对很多css代码和javasript代码来说,javascript被放在了网站页面的html文件的最后,而一些真正可以使用的文本部分被推到了html的后面。杭州搜索引擎优化认为这部分代码需要精简。
3、CSS 代码本身的优化。
CSS 是页面效果渲染中非常重要的一个组件,包括颜色、大小、背景和字体。编写 CSS 很容易,但编写可靠的 CSS 代码需要很多技巧。
(1), CSS 位置
CSS说明如果在网站之后显示,需要重新渲染页面,会影响打开速度。所有 CSS 定义代码的位置都应该放在 网站 的过去。
(2), css精灵技能
网站上的部分图片可以通过css sprite技能进行合并,减少加载请求,提高网页加载速度。
(3), CSS 代码优化
通过CSS代码属性的缩写、冗余结构(frameworks)的去除、reset(resets)等一系列方法和技术,对CSS代码进行了简化,减小了CSS文件的大小。
(4),尽管甚至不使用内联 CSS
内联 CSS 有两种,一种是头部区域内的普通内联;另一种是在标签中显示的内联内联CSS,无论使用哪种内联CSS方法,都会增加页面的大小。,我们可以甚至使用外部 CSS 来缩小网站的页面大小。
4、JS 位置、大小和其他负面优化。
JS优化和其他词的优化还是有相同的地方的。JS优化的关键是关注最关键的地方,也就是瓶颈。一般来说,瓶颈总是发生在大规模循环中。地方,这并不是说循环本身有性能成就,而是说循环迅速降低了可以或存在的性能成就。
(1), JS 位置
优化网页代码中的js时,杭州SEO建议将js放在页面末尾,既可以加快页面打开速度。
(2), 合并 JS
合并同域名下的js,通过进程减少网络连接数,提高网页打开速度。
(3),LazyLoad(延迟加载)技能
Lazy Load 是一个用 JavaScript 编写的 jQuery 插件,它可以延迟加载长页面中的图像,在用户将页面转换到他们的位置之前,不会加载浏览器可见区域之外的图像。
(4),调用外部JS代码
我们知道,未来的搜索引擎仍然无法或识别 JS 代码。如果在网站中显示大量的JS代码,在收录上就很难网站了,我们要做的就是把Javascript代码的形式放到网站 中的外部调用,既可以简化搜索引擎的工作,又不会无形中衍生出有用的代码涉及到网站。
不仅如此,杭州SEO认为可以使用外部调用的css代码。在网站的开头,可以在css代码文件中定义网站的文字和颜色,即使页面代码中没有。里面渲染了太多的格式化代码。
(5),减少页面对JS的依赖
现在,JS实际上对搜索引擎不友好。虽然据说搜索引擎对 JS 没有任何仇恨,但最好还是少一件事。虽然 JS 可以或者可以产生很多效果,但是网页有很多。JS会影响蜘蛛对页面的抓取,增加页面的体积,尤其是导航栏等页面的关键位置,即使采用DIV+CSS的规划方式也是如此。
5、减少TABLE标签的使用。
表格标签是大多数在线 网站s 中最稀有的代码形式。原因是创建网站的时候表比较快,但这也影响了后期对网站的优化。
与div+css结构的简化代码网站相比,占用空间比较大。因此,在建网站的时候,即使少用表,即使要使用表,嵌套表也应该使用。即使它被谨慎使用,它也节省了冗长代码的生成。
那么,当前的 网站 做了什么?很多程序员的第一个想法就是用CSS来做布局,用CSS来排版。这种做法大大减少了页面中的表格,但是在杭州SEO眼里,网站不能没有表格,有些东西是必须要使用的,表格本身没什么用,但是有很多网站都是使用嵌套表的,普通这样的表格式会为网站生成很多残码,而这些残码就是没用的代码,而这种类型的代码也是我们网站需要精简的代码之一。
6、大量使用代码注释省略。
许多程序员习惯于在编写代码时在别人看不懂的地方给出注释。这些代码通常用于几个程序员之间的协作工作,对局外人和搜索引擎没有用处。给搜索引擎蜘蛛带来一些麻烦。
在打开页面代码的时候,我们经常会看到一些注释代码,它们是程序员为了表明代码含义所做的注释。其实这些是打不开的,因为对于搜索引擎来说,它们没有任何意义,反而会增加页数。代码的容量,所以对网站没有好处,直接省略比较好。
7、消除页面中的冗余代码就是简化代码。
有的网站认为创作者的代码抄写习惯成功了,页面上会出现很多空白代码,比如:空白代码,重复定义样式和字体的代码,不要小看这些小代码,积累了很多,也会让我们的网站很臃肿。
很多网站使用DIV+CSS,在CSS中定义了文本的字体、颜色和页面布局,但是网站的其余部分也使用style和font来重新定义Font字体,这些代码完整,无需重复定义,属于可以简化的代码。
8、将html控件方法转换为CSS控件。
许多网页设计师习惯于控制标签内的内容。例如,在img标签中,宽度和高度用于控制图像的大小。即使将这些代码转换为外部 CSS,网页代码也会变得更薄。
9、缓存静态开销。
通过设置浏览器缓存的过程,在浏览器端缓存css、js等更新频率较低的文件,这样当同一个访问者再次访问你的网站时,浏览器可以要么或者从浏览器的缓存中这样你就可以从你的服务器获取css、js等,而不必每次都从你的服务器读取,在一定程度上加快了网站的打开速度,可以节省你的服务器流量。
10、网页压缩技巧。
对于网页压缩,相信各位站长都不陌生。如果启用服务器Gzip,对页面进行Gzip压缩,减小元素的大小,从而减少数据的传输,从而提高网页的加载速度。这个功能需要你的服务器的支持,GZIP压缩通常可以对网页实现30%-80%的压缩,这是最重要的优化效果。
总之,通过流程代码优化来发挥网站优化作用的方法还有很多,这里只是随便提一下,少见的,希望大家多多讨论。
11、权重标签的使用。
典型的权重标签有H1、strong、b标签等。对于想要参与排名的人来说很重要关键词@>使用权重标签,好处是将标志传递给搜索引擎:关键词@ >这个地方非常重要和必要的区别对待,从而提高了已建立的关键词@>在搜索引擎中的排名。
网站常见的SEO标签如下:
关键词1@>网站SEO优化中常用的TDK标签
TDK 是每个 seoer 都熟悉的 html 标签。TDK分别代表Title、Keywords和Description三个最常见的优化标签。标题页标题、关键词页关键词@>、描述页描述。(严格来说,除了title,其他两个都是mate标签的属性。)这三个标签因为太熟悉了,这里就简单提一下。
关键词2@>网站SEO 优化标题标签
标题标签也称为 H 标签。它强调页面的主要部分,一般用于标题、副标题和列名。从 h1 到 h6 有 6 对标题标签,强调程度递减。三个标题标签 h1、h2、h3 经常使用,因为 h4、h5、 h6 的强调小到可以忽略不计,基本上就是未用于 网站 优化 SEO。
h1标签是对页面最重要部分的强调,一般用在页面标题中。需要注意的是,同一页面上只能出现一对 h1 标签。如果页面上出现多个H1标签,会对seo产生不利影响。
h2、h3等标题标签可以在同一页面上多次使用,一般用在列名、文章段落标题或副标题中。
标题标签虽然对网站的优化有积极的影响,但如果乱用也会带来不良后果。不要在整个内容中使用标题标签。
关键词8@>网站优化常用标签的nofllow属性进行SEO优化
是的!你没看错,noflow 属性。许多seoers 喜欢说nofllow 标签。其实nofllow并不是一个标签,它只是html标签的一个属性。一般认为使用nofllow属性的链接不会被搜索引擎追踪(这个观点是有争议的),也不会将权限传递给被链接的页面。最常见的方式是使用nofllow属性避免页面权重的不必要损失,达到权重集中的目的。使用锚文本如下
很多seoer只知道上面的常用方法。实际上,nofllow 属性也可以作用于整个页面中的链接。由于这种用法很少见,本文不再展开。会在单独的文章中用到 文章 说一下nofllow属性的用法。
关键词9@>网站优化常用标签的Canonical属性
Canonical 属性与nofllow 属于同一类别,也被许多人称为Canonical 标签。但是对于一些搜索引擎来说,它比nofllow 属性更奇怪。Canonical在英文中有权威的意思,用于SEO中,用于解决相同内容在不同URL形式下造成的内容重复问题。最常见的写法如下
网页中的Canonical标签可以告诉搜索引擎,在几个内容相同、URL不同的页面中,哪个页面最规范,最有望被搜索引擎收录搜索到,它可以避免< @网站 相同内容的网页。通过不同URL带来的权重分配问题,达到了页面权重集中的目的。
在当前的移动互联网时代,百度赋予了Canonical属性一个新的角色,就是利用Canonical属性进行移动适配。(关于移动端适配,小李会在后续文章中详细分析。)
5.网站SEO优化常用标签的mate标签
mate标签是所有优化标签中最重要的标签,不是其中之一。众所周知的 TDK 标签是 mate 标签的属性。因为mate标签的功能非常强大,所以扮演的角色太多了。限于篇幅,本文仅简单介绍mate标签在优化中的三个作用。
功能一:承载关键词和描述属性的内容,是页面优化不可缺少的元素。
功能二:进行PC站和移动站的适配标注,mate label肩负着移动适配的重任。
功能三:301跳转到单个网页,可用于页面集中和网站修改。
6.网站优化常用标签的title属性
title属性可以应用于很多html标签,从网站seo优化的角度来看,常见的re-a标签、img标签、embed标签和video标签。小李认为,title属性的主要作用是提升用户体验。鼠标移动时html元素上显示的文本信息就是title属性的内容。当嵌入标签、视频标签和链接文本无法完全显示时,建议使用title属性改善用户体验
7.网站常用标签alt属性的SEO优化
在网站优化中,alt属性主要用在img标签中。在img表中加入alt属性,就是通过alt属性来描述图片,告诉搜索引擎图片的含义;二是提升用户体验。当img缺少title属性时,鼠标在图片上移动时显示的文字信息就是alt属性的内容;而当图片由于某种原因无法正常显示时,会显示alt属性中的文字而不是图片。
聚推传媒小李总结:
以上7个标签在小李看来是最常用的标签。在网站seo优化过程中,会用到很多HTML标签和属性,但小李认为掌握以上7个标签属性的使用对于一般的网站优化就足够了。
js 抓取网页内容(【官方说法】百度不收录页面的原因分析(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-30 11:04
如果站长已经排除了自己的问题和造假问题,并确认百度蜘蛛的爬取次数过多,可以通过反馈中心进行反馈,记得提供详细的爬取日志截图。
【官方声明】百度没有收录页面的原因分析
目前百度蜘蛛抓取新链接的方式有两种。一是主动查找抓取,二是通过百度站长平台的链接提交工具获取数据。其中,通过主动推送功能“收到”的数据在百度中最为流行。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新增的网站,主动推送首页数据,有利于到内页数据的捕获。
那么同学们就要问了,为什么我提交了数据后就看不到网上的显示了?涉及的因素很多。在蜘蛛抓取过程中,影响在线展示的因素有:
1、网站封杀:别笑,真的有同学一边封杀百度蜘蛛一边把数据交给百度,当然不能收录。
2、质量筛选:百度蜘蛛3.0在低质量内容特别是时效性内容的识别上达到了一个新的水平。从抓到这个链接的那一刻起,质量评价和筛选就开始过滤掉大量过度优化等页面,根据内部定期数据评价,低质量页面比之前下降了62%。
3、爬取失败:爬取失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛遇到麻烦。网站要时刻注意保证网站在不同时间、不同地点的稳定性。
4、配额限制:虽然我们正在逐步放开主动推送的爬取配额,但是如果网站页面数量突然爆发式增长,还是会影响到优质链接的爬取收录,所以网站是保证除了稳定访问之外,还要注意网站的安全性,防止被黑客入侵和注入。 查看全部
js 抓取网页内容(【官方说法】百度不收录页面的原因分析(图))
如果站长已经排除了自己的问题和造假问题,并确认百度蜘蛛的爬取次数过多,可以通过反馈中心进行反馈,记得提供详细的爬取日志截图。
【官方声明】百度没有收录页面的原因分析
目前百度蜘蛛抓取新链接的方式有两种。一是主动查找抓取,二是通过百度站长平台的链接提交工具获取数据。其中,通过主动推送功能“收到”的数据在百度中最为流行。蜘蛛欢迎。对于站长来说,如果链接很久没有收录,建议尝试使用主动推送功能,尤其是新增的网站,主动推送首页数据,有利于到内页数据的捕获。
那么同学们就要问了,为什么我提交了数据后就看不到网上的显示了?涉及的因素很多。在蜘蛛抓取过程中,影响在线展示的因素有:
1、网站封杀:别笑,真的有同学一边封杀百度蜘蛛一边把数据交给百度,当然不能收录。
2、质量筛选:百度蜘蛛3.0在低质量内容特别是时效性内容的识别上达到了一个新的水平。从抓到这个链接的那一刻起,质量评价和筛选就开始过滤掉大量过度优化等页面,根据内部定期数据评价,低质量页面比之前下降了62%。
3、爬取失败:爬取失败的原因有很多。有时你在办公室访问没有问题,但百度蜘蛛遇到麻烦。网站要时刻注意保证网站在不同时间、不同地点的稳定性。
4、配额限制:虽然我们正在逐步放开主动推送的爬取配额,但是如果网站页面数量突然爆发式增长,还是会影响到优质链接的爬取收录,所以网站是保证除了稳定访问之外,还要注意网站的安全性,防止被黑客入侵和注入。
js 抓取网页内容(如何获取动态网页数据的方法途径?途径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-28 10:09
)
上一篇文章讲了抓取58网页的出租数据。有朋友问是不是这样从ajax请求生成的动态网页中抓取数据的。其实方法并不难。总结起来有两种方式:
直接用python运行JavaScript代码 采集 返回数据
使用python的第三方库对整个页面的html和javascript进行解释执行,生成最终的网页,然后采集data
由于第一种方法python执行js代码很慢,操作也比较复杂,而第二种方法可以处理成静态网页采集数据,所以第二种方法比较常用
第二种方式采集动态网页,这里主要用到了两个第三方库:Selenium和PhantomJS。Selenium 是一个强大的网络数据采集 工具,需要与第三方浏览器配合使用。PhantomJS 是一个将 网站 加载到内存中并在页面上执行 JavaScript 代码的浏览器,但不会将图形界面呈现给用户。通过结合 Selenium 和 PhantomJS,我们可以轻松解决采集动态页面数据的问题。具体安装方法请参考百度。
这里以前面写的一个微信商城网页为例,说明如何获取动态网页数据。界面如下所示:
该页面加载数据的过程如下: 静态网页中只有标题栏和底部标签栏。页面展示后,会通过ajax从服务器获取商品数据,用js展示。我要做的是通过 Selenium 和 PhantomJS 来获取它。产品数据。
如果使用之前爬取静态网页的方法,代码是这样写的:
运行上面的代码后,输出是这样的,产品列表为空
使用 selenium 和 PhantomJS,代码是这样写的:
运行上述代码后,通过ajax动态获取的数据也可以通过网络爬虫获取
查看全部
js 抓取网页内容(如何获取动态网页数据的方法途径?途径
)
上一篇文章讲了抓取58网页的出租数据。有朋友问是不是这样从ajax请求生成的动态网页中抓取数据的。其实方法并不难。总结起来有两种方式:
直接用python运行JavaScript代码 采集 返回数据
使用python的第三方库对整个页面的html和javascript进行解释执行,生成最终的网页,然后采集data
由于第一种方法python执行js代码很慢,操作也比较复杂,而第二种方法可以处理成静态网页采集数据,所以第二种方法比较常用
第二种方式采集动态网页,这里主要用到了两个第三方库:Selenium和PhantomJS。Selenium 是一个强大的网络数据采集 工具,需要与第三方浏览器配合使用。PhantomJS 是一个将 网站 加载到内存中并在页面上执行 JavaScript 代码的浏览器,但不会将图形界面呈现给用户。通过结合 Selenium 和 PhantomJS,我们可以轻松解决采集动态页面数据的问题。具体安装方法请参考百度。
这里以前面写的一个微信商城网页为例,说明如何获取动态网页数据。界面如下所示:
该页面加载数据的过程如下: 静态网页中只有标题栏和底部标签栏。页面展示后,会通过ajax从服务器获取商品数据,用js展示。我要做的是通过 Selenium 和 PhantomJS 来获取它。产品数据。
如果使用之前爬取静态网页的方法,代码是这样写的:
运行上面的代码后,输出是这样的,产品列表为空
使用 selenium 和 PhantomJS,代码是这样写的:
运行上述代码后,通过ajax动态获取的数据也可以通过网络爬虫获取
js 抓取网页内容(有没有办法让请求在实际html数据之前等待LinkedIn显示站点数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-28 01:20
我目前正在尝试从 LinkedIn 上的特定页面抓取数据。我有一个可以登录 LinkedIn 的脚本,但是当我尝试访问收录数据的页面时,它遇到了障碍。当我调用 requests.get(data_url) 时,我最终得到了 LinkedIn 加载屏幕的 html,它在 LinkedIn 加载实际页面内容之前显示。有没有办法让请求在实际抓取 html 数据之前等待 LinkedIn 显示站点数据?我基本上需要先完全呈现页面,然后才能“获取”内容。我目前的脚本如下。
import requests
from bs4 import BeautifulSoup
client = requests.Session()
HOMEPAGE_URL = 'https://www.linkedin.com'
LOGIN_URL = 'https://www.linkedin.com/uas/login-submit'
html = client.get(HOMEPAGE_URL).content
soup = BeautifulSoup(html)
csrf = soup.find(id="loginCsrfParam-login")['value']
login_information = {
'session_key':'EMAIL',
'session_password':'PASSWORD',
'loginCsrfParam': csrf,
}
client.post(LOGIN_URL, data=login_information)
r = client.get(data_url)
最佳答案
如果页面的任何部分是动态渲染的,比如使用Javascript,beautifulsoup可能无法使用。
我使用 Selenium + PhantomJS。我加载页面(等待它完全加载)并输入登录详细信息。 Selenium 有一个很好的 API,允许您以编程方式检查特定的 html 元素并等待它们出现,这在这种情况下非常有用。
关于 javascript - 在抓取 python 请求之前等待网页完全加载,我们在 Stack Overflow 上发现了一个类似的问题: 查看全部
js 抓取网页内容(有没有办法让请求在实际html数据之前等待LinkedIn显示站点数据)
我目前正在尝试从 LinkedIn 上的特定页面抓取数据。我有一个可以登录 LinkedIn 的脚本,但是当我尝试访问收录数据的页面时,它遇到了障碍。当我调用 requests.get(data_url) 时,我最终得到了 LinkedIn 加载屏幕的 html,它在 LinkedIn 加载实际页面内容之前显示。有没有办法让请求在实际抓取 html 数据之前等待 LinkedIn 显示站点数据?我基本上需要先完全呈现页面,然后才能“获取”内容。我目前的脚本如下。
import requests
from bs4 import BeautifulSoup
client = requests.Session()
HOMEPAGE_URL = 'https://www.linkedin.com'
LOGIN_URL = 'https://www.linkedin.com/uas/login-submit'
html = client.get(HOMEPAGE_URL).content
soup = BeautifulSoup(html)
csrf = soup.find(id="loginCsrfParam-login")['value']
login_information = {
'session_key':'EMAIL',
'session_password':'PASSWORD',
'loginCsrfParam': csrf,
}
client.post(LOGIN_URL, data=login_information)
r = client.get(data_url)
最佳答案
如果页面的任何部分是动态渲染的,比如使用Javascript,beautifulsoup可能无法使用。
我使用 Selenium + PhantomJS。我加载页面(等待它完全加载)并输入登录详细信息。 Selenium 有一个很好的 API,允许您以编程方式检查特定的 html 元素并等待它们出现,这在这种情况下非常有用。
关于 javascript - 在抓取 python 请求之前等待网页完全加载,我们在 Stack Overflow 上发现了一个类似的问题:
js 抓取网页内容(一天就能上线一个微信小程序,云开发的优点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-01-27 15:15
2022-01-19
微信小程序云开发js爬取网页内容
最近在研究微信小程序的云开发功能。云开发最大的优势是无需搭建前端服务器,利用云能力从零开始编写在线微信小程序,避免了购买服务器的成本。对于尝试从前端到后端开发实践微信小程序的个人来说是一个不错的选择。一天之内可以推出一个微信小程序。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。使用的云服务相互兼容,而不是相互排斥。
云开发目前提供三种基本能力支持:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需要编写自己的业务逻辑代码数据库:可以在小程序前端操作,也可以读取的JSON数据库并写在云功能Storage中:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,介绍了这么多关于云开发的知识,感性的同学可以去研究一下。官方文档地址:...
网页内容抓取
小程序是关于回答问题的,所以问题的来源是问题。在网上搜索,一个话题一个话题贴是一种方法,但是估计这样重复的工作大概10贴左右就放弃了。所以想到了网络抓取。刚拿起之前学过的节点。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。主要用于分析和过滤爬取的内容。Node 的 fs 模块。这是node自带的一个模块,用来读写文件。这用于将解析后的数据写入 json 文件。Axios(可选)。用于抓取 网站 的 HTML 页面。因为我想要的数据是在网页上点击一个按钮后获取并渲染的,所以无法直接爬取这个网址。无奈,只能复制自己想要的内容,保存为字符串,解析字符串。
接下来可以使用npm init来初始化一个node项目,一路回车后,就可以生成一个package.json文件了。
然后 npm install --save axioscheerio 安装cheerio 和 axios 包。
关键是使用cheerio来实现一个类似jquery的功能。你只需要cheerio.load(quesitons)抓取到的内容,然后你就可以根据jquery的操作去获取DOM,组装你想要的数据。
最后,使用 fs.writeFile 将数据保存到 json 文件中,大功告成。
具体代码如下:
让 axios = 要求(axios);
让cheerio = 要求(cheerio);
让 fs = 要求(fs);
// 我的html结构大致如下,有很多条数据
常量问题 = `
`;
常量 $ = Cheerio.load(问题);
var arr = [];
对于 (var i = 0; 我
变量 obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer=
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件保存成功!);
});
保存为json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传的json文件的数据格式。之前总是提示格式错误。后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象用n隔开,而且不是逗号。因此,在上传成功之前,需要对node写入的json文件进行一个小处理。 查看全部
js 抓取网页内容(一天就能上线一个微信小程序,云开发的优点)
2022-01-19
微信小程序云开发js爬取网页内容
最近在研究微信小程序的云开发功能。云开发最大的优势是无需搭建前端服务器,利用云能力从零开始编写在线微信小程序,避免了购买服务器的成本。对于尝试从前端到后端开发实践微信小程序的个人来说是一个不错的选择。一天之内可以推出一个微信小程序。
云开发的优势
云开发为开发者提供完整的云支持,弱化后端和运维的概念,无需搭建服务器,利用平台提供的API进行核心业务开发,实现快速上线和迭代。使用的云服务相互兼容,而不是相互排斥。
云开发目前提供三种基本能力支持:
云功能:代码运行在云端,微信私有协议自然认证,开发者只需要编写自己的业务逻辑代码数据库:可以在小程序前端操作,也可以读取的JSON数据库并写在云功能Storage中:在小程序前端直接上传/下载云文件,在云开发控制台中可视化管理
好了,介绍了这么多关于云开发的知识,感性的同学可以去研究一下。官方文档地址:...
网页内容抓取
小程序是关于回答问题的,所以问题的来源是问题。在网上搜索,一个话题一个话题贴是一种方法,但是估计这样重复的工作大概10贴左右就放弃了。所以想到了网络抓取。刚拿起之前学过的节点。
必备工具:Cheerio。一个类似于服务器端 JQuery 的包。主要用于分析和过滤爬取的内容。Node 的 fs 模块。这是node自带的一个模块,用来读写文件。这用于将解析后的数据写入 json 文件。Axios(可选)。用于抓取 网站 的 HTML 页面。因为我想要的数据是在网页上点击一个按钮后获取并渲染的,所以无法直接爬取这个网址。无奈,只能复制自己想要的内容,保存为字符串,解析字符串。
接下来可以使用npm init来初始化一个node项目,一路回车后,就可以生成一个package.json文件了。
然后 npm install --save axioscheerio 安装cheerio 和 axios 包。
关键是使用cheerio来实现一个类似jquery的功能。你只需要cheerio.load(quesitons)抓取到的内容,然后你就可以根据jquery的操作去获取DOM,组装你想要的数据。
最后,使用 fs.writeFile 将数据保存到 json 文件中,大功告成。
具体代码如下:
让 axios = 要求(axios);
让cheerio = 要求(cheerio);
让 fs = 要求(fs);
// 我的html结构大致如下,有很多条数据
常量问题 = `
`;
常量 $ = Cheerio.load(问题);
var arr = [];
对于 (var i = 0; 我
变量 obj = {};
obj.questions = $(#q + i).find(.question).text();
obj.A = ((((#q + i).find(.answer)[0]).text();
obj.B = ((((#q + i).find(.answer)[1]).text();
obj.C = ((((#q + i).find(.answer)[2]).text();
obj.D = ((((#q + i).find(.answer)[3]).text();
obj.index = i + 1;
obj.answer=
((((#q + i).find(.answer)[0]).attr(value) == 1
: ((((#q + i).find(.answer)[1]).attr(value) == 1
: ((((#q + i).find(.answer)[2]).attr(value) == 1
:D;
arr.push(obj);
}
fs.writeFile(poem.json, JSON.stringify(arr), err => {
if (err) 抛出错误;
console.log(json文件保存成功!);
});
保存为json后的文件格式如下,这样就可以通过json文件上传到云服务器了。
预防措施
对于微信小程序云开发的数据库,需要注意上传的json文件的数据格式。之前总是提示格式错误。后来发现JSON数据不是数组,而是类似于JSON Lines,即每个记录对象用n隔开,而且不是逗号。因此,在上传成功之前,需要对node写入的json文件进行一个小处理。
js 抓取网页内容(js抓取网页内容,从而实现简单的从服务器读取数据的功能)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-26 09:01
js抓取网页内容,从而实现简单的从服务器读取数据的功能。考虑到这个问题,javascript的javascript脚本文件(event.js)存放了html页面的整个流程,包括前期的准备工作、网页的操作操作、页面的数据结构(解析出javascript脚本的内容与类型)、返回数据,整个文件流程都囊括其中。
此时javascript在javascript脚本中的位置,取决于是将他直接放置在javascript文件的顶端,还是把javascript脚本放置在javascript文件的根目录。从根目录下读取javascript,需要将他放置在javascript文件的根目录;而直接通过javascript文件名在根目录下读取javascript,无需做任何准备工作。
在解析过程中我们需要用到event.js文件的document对象,来将event.js文件获取到浏览器地址和页面地址。因此,实现javascript脚本的播放或者浏览器页面地址的爬取,需要用到script标签。解析网页内容,主要是从event.js文件获取html文件中内容的形式。
一、我们可以利用link标签来获取页面的html文件,
二、使用绝对定位这种方式可以在页面某个位置插入一个元素,用于解析页面内容:</img>由此,我们可以通过定位href方法返回地址,然后获取请求网页的网址。.src=""link="src:entry"rel="stylesheet"/></img>。
三、利用ajax获取javascript脚本实现页面地址的抓取,主要包括以下几种:javascriptwebtag,scriptdocument,javascripthtml解析,javascriptvardata=webkit。innerhtml(url);data。xpath(url)="//a[@id="。
href"]/div[2]/div[2]/div[2]/div[2]/div[1]/span[2]/a",allretrieval="0";//可以连接dom发起请求,没有okhttp的话可以使用getbrowserjs来发起http请求allretrieval=function(req,res,name){varlength=length(req。
url。xpath("//a[@id="。href"]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2。 查看全部
js 抓取网页内容(js抓取网页内容,从而实现简单的从服务器读取数据的功能)
js抓取网页内容,从而实现简单的从服务器读取数据的功能。考虑到这个问题,javascript的javascript脚本文件(event.js)存放了html页面的整个流程,包括前期的准备工作、网页的操作操作、页面的数据结构(解析出javascript脚本的内容与类型)、返回数据,整个文件流程都囊括其中。
此时javascript在javascript脚本中的位置,取决于是将他直接放置在javascript文件的顶端,还是把javascript脚本放置在javascript文件的根目录。从根目录下读取javascript,需要将他放置在javascript文件的根目录;而直接通过javascript文件名在根目录下读取javascript,无需做任何准备工作。
在解析过程中我们需要用到event.js文件的document对象,来将event.js文件获取到浏览器地址和页面地址。因此,实现javascript脚本的播放或者浏览器页面地址的爬取,需要用到script标签。解析网页内容,主要是从event.js文件获取html文件中内容的形式。
一、我们可以利用link标签来获取页面的html文件,
二、使用绝对定位这种方式可以在页面某个位置插入一个元素,用于解析页面内容:</img>由此,我们可以通过定位href方法返回地址,然后获取请求网页的网址。.src=""link="src:entry"rel="stylesheet"/></img>。
三、利用ajax获取javascript脚本实现页面地址的抓取,主要包括以下几种:javascriptwebtag,scriptdocument,javascripthtml解析,javascriptvardata=webkit。innerhtml(url);data。xpath(url)="//a[@id="。
href"]/div[2]/div[2]/div[2]/div[2]/div[1]/span[2]/a",allretrieval="0";//可以连接dom发起请求,没有okhttp的话可以使用getbrowserjs来发起http请求allretrieval=function(req,res,name){varlength=length(req。
url。xpath("//a[@id="。href"]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2。
js 抓取网页内容(js抓取网页内容及验证的效率是不错的,我是一个建站公司)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-24 07:01
js抓取网页内容及验证的效率是不错的,我自己是一个建站公司,我写过一个爬虫,叫北京快搜,就是用的这个工具,
效率挺高的,要是做网站的话,找个内容聚合的平台,
简单说就是靠抓包和报文分析来获取网页内容
请看这个。
其实对于爬虫来说,理解网页结构是很重要的一环,然后根据网页分析出的url找到相应的内容就可以了,这是一个很常规的过程。根据你说的结构化的需求,其实我觉得你的目的主要是解决文本去重的问题,所以像postman这种工具应该能满足这个需求。另外目前主流的python爬虫,比如web.py这些都支持类似的功能。可以从一些前端框架入手尝试一下。
浏览器内置的功能而已,重点是要学会面向对象,和积累知识,多分析一些数据。
web3.0时代,
先给你回答这么多,我给你讲个故事。你要学会一个东西的时候一定要把它和你之前有类似经历的一个事情联系在一起,才能更容易入手,不然你就会眼高手低,看到一个东西的时候整天嘴上喊着喜欢它,但是自己写的时候啥也干不了。而且不要觉得这东西网上有很多资料就不用学了,有时候你觉得没有看不会影响你学习的心情。你学会前端相关知识之后。你也可以尝试别的技术。比如加载mock数据的方法。 查看全部
js 抓取网页内容(js抓取网页内容及验证的效率是不错的,我是一个建站公司)
js抓取网页内容及验证的效率是不错的,我自己是一个建站公司,我写过一个爬虫,叫北京快搜,就是用的这个工具,
效率挺高的,要是做网站的话,找个内容聚合的平台,
简单说就是靠抓包和报文分析来获取网页内容
请看这个。
其实对于爬虫来说,理解网页结构是很重要的一环,然后根据网页分析出的url找到相应的内容就可以了,这是一个很常规的过程。根据你说的结构化的需求,其实我觉得你的目的主要是解决文本去重的问题,所以像postman这种工具应该能满足这个需求。另外目前主流的python爬虫,比如web.py这些都支持类似的功能。可以从一些前端框架入手尝试一下。
浏览器内置的功能而已,重点是要学会面向对象,和积累知识,多分析一些数据。
web3.0时代,
先给你回答这么多,我给你讲个故事。你要学会一个东西的时候一定要把它和你之前有类似经历的一个事情联系在一起,才能更容易入手,不然你就会眼高手低,看到一个东西的时候整天嘴上喊着喜欢它,但是自己写的时候啥也干不了。而且不要觉得这东西网上有很多资料就不用学了,有时候你觉得没有看不会影响你学习的心情。你学会前端相关知识之后。你也可以尝试别的技术。比如加载mock数据的方法。
js 抓取网页内容( 2017年09月19日小编觉得挺不错的更新时间介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-21 21:07
2017年09月19日小编觉得挺不错的更新时间介绍)
Node.js+jade从博客抓取文章生成静态html文件的所有实例
更新时间:2017-09-19 07:59:35 作者:ghostwu
下面小编给大家带来一个Node.js+jade爬取博客生成的所有文章静态html文件的例子。小编觉得挺不错的,现在分享给大家,给大家一个参考。跟着小编一起来看看吧
在这个文章中,我们将从上面的采集中整理出所有文章列表的信息,启动采集文章并生成静态html文件准备好了。来看看我的采集的效果。我的博客目前有77篇文章文章,不到1分钟就全部生成了采集。这里我剪切了一些图片,文件名是用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是按照这个模板生成的。
项目结构:
好,接下来,我们来解释一下这个文章的主要功能:
1、抓取文章,主要抓取文章的标题、内容、超链接、文章id(用于生成静态html文件)
2、根据jade模板生成html文件
一、爬行文章如何?
很简单,类似于上面抓取文章列表的实现
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url是文章的地址。抓取到文章的内容后,调用filterArticle(html)过滤出需要的文章信息(id、title、hyperlink、content),然后使用jade的renderFile api替换模板内容,
模板内容替换后,肯定需要生成html文件,所以使用writeFile来写文件。写入文件时,使用 id 作为 html 文件的名称。这是生成静态html文件的实现,
接下来就是循环生成静态html文件,也就是下面这行:
if (aUrl.length) crawlerArc(aUrl.shift());
<p>aUrl 保存我博客的所有文章 url,每次采集 写完一篇文章文章,删除当前文章 url,让下一个 查看全部
js 抓取网页内容(
2017年09月19日小编觉得挺不错的更新时间介绍)
Node.js+jade从博客抓取文章生成静态html文件的所有实例
更新时间:2017-09-19 07:59:35 作者:ghostwu
下面小编给大家带来一个Node.js+jade爬取博客生成的所有文章静态html文件的例子。小编觉得挺不错的,现在分享给大家,给大家一个参考。跟着小编一起来看看吧
在这个文章中,我们将从上面的采集中整理出所有文章列表的信息,启动采集文章并生成静态html文件准备好了。来看看我的采集的效果。我的博客目前有77篇文章文章,不到1分钟就全部生成了采集。这里我剪切了一些图片,文件名是用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是按照这个模板生成的。
项目结构:
好,接下来,我们来解释一下这个文章的主要功能:
1、抓取文章,主要抓取文章的标题、内容、超链接、文章id(用于生成静态html文件)
2、根据jade模板生成html文件
一、爬行文章如何?
很简单,类似于上面抓取文章列表的实现
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url是文章的地址。抓取到文章的内容后,调用filterArticle(html)过滤出需要的文章信息(id、title、hyperlink、content),然后使用jade的renderFile api替换模板内容,
模板内容替换后,肯定需要生成html文件,所以使用writeFile来写文件。写入文件时,使用 id 作为 html 文件的名称。这是生成静态html文件的实现,
接下来就是循环生成静态html文件,也就是下面这行:
if (aUrl.length) crawlerArc(aUrl.shift());
<p>aUrl 保存我博客的所有文章 url,每次采集 写完一篇文章文章,删除当前文章 url,让下一个
js 抓取网页内容(2019独角兽企业重金招聘Python工程师标准(gt)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-21 03:16
2019独角兽企业招聘Python工程师标准>>>
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js 抓取网页内容(2019独角兽企业重金招聘Python工程师标准(gt)(图))
2019独角兽企业招聘Python工程师标准>>>
傀儡师
google chrome 团队出品的 puppeteer 是一个依赖 nodejs 和 chromium 的自动化测试库。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好地模拟用户。
一些网站的反爬方法隐藏了一些javascript/ajax请求中的部分内容,使得直接获取a标签的方法不起作用。甚至一些 网站 会设置隐藏元素“陷阱”,对用户不可见,脚本将其作为机器触发。在这种情况下,puppeteer的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。抓取 SPA 并生成预渲染内容(又名“SSR”)。自动提交表单、UI测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获跟踪您的 网站 的时间线以帮助诊断性能问题。
开源地址:[][1]
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(与npm文件同级)。
安装过程中会下载chromium,大约120M。
经过两天(大约10个小时)的探索,绕过了很多异步的坑,作者对puppeteer和nodejs有一定的把握。
长图,抢博客文章列表:
爬博客文章
以csdn博客为例,文章的内容需要通过点击“阅读全文”获取,使得只能阅读dom的脚本失效。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看,截图如下:
结果
文章内容列表:
文章内容:
结束语
之前我想既然nodejs使用的是JavaScript脚本语言,那么它一定能够处理网页的JavaScript内容,但是我还没有找到一个合适/高效的库。直到我找到了 puppeteer,我才决定试水。
说了这么多,nodejs的异步性真是让人头疼。这几百行代码我折腾了10个小时。
您可以在代码中展开 process() 方法并使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
事实上,一个一个地处理是没有效率的。本来我写了一个异步关闭浏览器的方法:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-19 10:15
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出它们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们希望利用事件处理程序进行鼠标移动,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。 查看全部
js 抓取网页内容(谷歌爬虫是如何抓取JavaScript的?Google能DOM是什么?)
以下是我们从测试 Google 的爬虫如何抓取 JavaScript 中学到的东西。
认为 Google 无法处理 JavaScript?再想一想。Audette Audette 分享了一系列测试的结果,他和他的同事测试了 Google 和 收录 抓取的 JavaScript 功能类型。
长话短说
1. 我们进行了一系列测试,并确认 Google 可以通过多种方式执行和 收录 JavaScript。我们还确认 Google 可以渲染整个页面并读取 DOM,从而收录动态生成内容。
2. DOM 中的 SEO 信号(页面标题、元描述、规范标签、元机器人标签等)都得到了处理。动态插入 DOM 的内容也可以被爬取和收录。此外,在某些情况下,DOM 甚至可能优先于 HTML 源语句。虽然这需要更多的工作,但这是我们完成的几个测试之一。
简介:Google 执行 JavaScript 并读取 DOM
早在 2008 年,Google 就成功抓取了 JavaScript,但可能只是以某种方式。
而今天,很明显,Google 不仅能够计算出它们抓取的 JavaScript 类型和 收录,而且在渲染整个网页方面取得了重大进展(尤其是在过去 12 到 18 个月内)。
在 Merkle,我们的 SEO 技术团队希望更好地了解 Google 爬虫可以抓取哪些类型的 JavaScript 事件以及 收录。经过研究,我们发现了令人瞠目结舌的结果,证实 Google 不仅可以执行各种 JavaScript 事件,还可以执行 收录 动态生成的内容。如何?Google 可以读取 DOM。
什么是 DOM?
许多从事 SEO 的人不了解文档对象模型 (DOM) 是什么。
当浏览器请求一个页面时会发生什么,以及 DOM 是如何参与的。
在 Web 浏览器中使用时,DOM 本质上是一个应用程序接口或 API,用于标记和结构化数据(例如 HTML 和 XML)。此界面允许 Web 浏览器将它们组合成文档。
DOM 还定义了如何访问和操作结构。尽管 DOM 是一种独立于语言的 API(不依赖于特定的编程语言或库),但它通常用于 JavaScript 和 Web 应用程序中的动态内容。
DOM 表示将网页连接到编程语言的接口或“桥梁”。解析 HTML 和执行 JavaScript 的结果就是 DOM。网页的内容不是(不仅是)源代码,它是 DOM。这使得它非常重要。
JavaScript 如何通过 DOM 接口工作。
我们很高兴地发现 Google 可以读取 DOM 并解析信号并动态插入内容,例如标题标签、页面文本、头部标签和元注释(例如 rel=canonical)。在那里阅读完整的细节。
这一系列的测试和结果
因为我们想知道会抓取哪些 JavaScript 功能以及 收录,所以我们单独针对 Google 抓取工具创建了一系列测试。确保通过创建控件独立理解 URL 活动。下面,让我们详细分解一些有趣的测试结果。它们分为5类:
1、JavaScript 重定向
2、JavaScript 链接
3、动态插入内容
4、元数据和页面元素的动态插入
5、rel = “nofollow” 的一个重要例子
示例:用于测试 Google 抓取工具理解 JavaScript 的能力的页面。
1. JavaScript 重定向
我们首先测试了常见的 JavaScript 重定向。以不同方式表示的 URL 的结果是什么?我们为两个测试选择了 window.location 对象:测试 A 使用绝对 URL 调用 window.location,测试 B 使用相对路径。
结果:重定向很快被谷歌跟踪。从 收录 开始,它们被解释为 301 - 最终状态 URL,而不是 Google 收录 中的重定向 URL。
在随后的测试中,我们执行了 JavaScript 重定向到同一站点上的新页面,在权威页面上具有完全相同的内容。而原创 URL 是 Google 的热门查询的首页。
结果:果然,重定向被谷歌跟踪了,原来的页面不是收录。而新的 URL 是 收录 并立即在同一个查询页面中排名相同的位置。这让我们感到惊讶,因为从排名的角度来看,它似乎表明 JavaScript 重定向的行为(有时)很像永久 301 重定向。
下次您的客户想要为他们的 网站 完成 JavaScript 重定向移动时,您可能不需要回答,或者回答:“请不要”。因为这似乎有转移排名信号的关系。支持这一结论的是对谷歌指南的引用:
使用 JavaScript 重定向用户可能是一种合法的做法。例如,如果您将登录用户重定向到内部页面,您可以使用 JavaScript 执行此操作。在检查 JavaScript 或其他重定向方法时,请确保您的网站遵循我们的指南并考虑其意图。请记住,301 重定向到您的 网站 是最好的,但如果您无权访问您的 网站 服务器,则可以使用 JavaScript 重定向。
2. JavaScript 链接
我们用不同的编码测试了不同类型的 JS 链接。
我们测试下拉菜单的链接。搜索引擎历来无法跟踪此类链接。我们想确定是否会跟踪 onchange 事件处理程序。重要的是,这只是我们需要的特定执行类型:其他更改的效果,而不是上面 JavaScript 重定向的强制操作。
示例:Google Work 页面的语言选择下拉菜单。
结果:链接被完全爬取并被关注。
我们还测试了常见的 JavaScript 链接。以下是最常见的 JavaScript 链接类型,而传统的 SEO 建议使用纯文本。这些测试包括 JavaScript 链接代码:
作用于外部 href 键值对 (AVP),但在标签内 ("onClick")
AVP 中的操作 href("javascript:window.location")
在 a 标签外执行,但在 href 内调用 AVP("javascript : openlink()")
等等
结果:链接被完全爬取并被关注。
我们的下一个测试是进一步测试事件处理程序,例如上面的 onchange 测试。具体来说,我们希望利用事件处理程序进行鼠标移动,然后隐藏 URL 变量,该变量仅在事件处理程序(本例中的 onmousedown 和 onmouseout)被触发时执行。
结果:链接被完全爬取并被关注。
构建链接:我们知道 Google 可以执行 JavaScript,但希望确保他们可以读取代码中的变量。所以在这个测试中,我们连接可以构造 URL 字符串的字符。
结果:链接被完全爬取并被关注。
3. 动态插入内容
显然,这些是要点:文本、图像、链接和导航的动态插入。高质量的文本内容对于搜索引擎理解网页主题和内容至关重要。在这个充满活力的网站时代,它的重要性毋庸置疑。
这些测试旨在检查在两种不同场景中动态插入文本的结果。
1)。测试搜索引擎是否可以从页面的 HTML 源中动态计算插入的文本。
2)。测试搜索引擎是否可以计算来自页面 HTML 源外部(在外部 JavaScript 文件中)的动态插入文本。
结果:在这两种情况下,文本都被爬取和 收录,并且页面根据该内容进行排名。凉爽的!
为了了解更多信息,我们测试了一个用 JavaScript 编写的客户端全局导航,并通过 document.writeIn 函数插入了链接,并确定它们已被完全抓取和跟踪。需要注意的是:Google 可以解释使用 AngularJS 框架和 HTML5 History API (pushState) 构建的 网站,可以渲染和 收录 它,并像传统的静态网页一样对其进行排名。这就是为什么不禁止 Google 的爬虫获取外部文件和 JavaScript 很重要,这可能也是 Google 将其从启用 Ajax 的 SEO 指南中删除的原因。当您可以简单地呈现整个页面时,谁需要 HTML 快照?
经过测试,发现无论是什么类型的内容,都是一样的结果。例如,图像被抓取并将 收录 加载到 DOM 中。我们甚至通过动态生成结构化数据并将其插入到 DOM 中做了一个制作面包屑(breadcrumbs)的测试。结果?成功插入的面包屑出现在搜索结果(搜索引擎结果页面)中。
值得注意的是,Google 现在建议对结构化数据使用 JSON-LD 标记。我相信将来会有更多基于此的。
4. 动态插入元数据和页面元素
我们将各种 SEO 关键标签动态插入到 DOM 中:
标题元素
元描述
元机器人
规范标签
结果:在所有情况下,标签都可以被抓取并表现得像 HTML 源代码中的元素。
一个有趣的补充实验可以帮助我们理解优先级。当有一个相互矛盾的信号时,哪一个会赢?如果源代码中有 noindex、nofollow 标签,而 DOM 中有 noindex、follow 标签,会发生什么?在这个协议中,HTTP x-robots 响应头作为另一个变量的行为怎么样?这将是未来综合测试的一部分。但是,我们的测试表明,当发生冲突时,Google 会忽略源代码中的标签,转而使用 DOM。
5. rel="nofollow" 的一个重要例子
我们想测试 Google 如何处理出现在源代码和 DOM 中的链接级别的 nofollow 属性。因此,我们创建了一个没有应用 nofollow 的控件。
对于 nofollow,我们分别测试源代码与 DOM 生成的注释。
源代码中的 nofollow 可以按我们预期的方式工作(没有链接)。DOM 中的 nofollow 不起作用(链接被跟踪,页面为 收录)。为什么?因为修改 DOM 中的 href 元素为时已晚:在执行添加 rel=”nofollow” 的 JavaScript 函数之前,Google 已准备好抓取链接并排队等待 URL。但是,如果将带有 href="nofollow" 的 a 元素插入到 DOM 中,则会跟踪 nofollow 和链接,因为它们是同时插入的。
结果
从历史上看,各种 SEO 建议一直尽可能关注“纯文本”内容。动态生成的内容、AJAX 和 JavaScript 链接可能会损害主要搜索引擎的 SEO。显然,这对谷歌来说不再是问题。JavaScript 链接的行为类似于普通的 HTML 链接(这只是表面,我们不知道幕后发生了什么)。
JavaScript 重定向被视为 301 重定向。
无论是在 HTML 源代码中,还是在解析原创 HTML 后触发 JavaScript 生成 DOM,动态插入的内容,甚至元标记(例如 rel 规范注释)都被同等对待。
Google 似乎能够完全呈现页面并理解 DOM,而不仅仅是源代码。极好的!(请记住允许 Google 的爬虫获取这些外部文件和 JavaScript。)
谷歌已经在创新,以惊人的速度将其他搜索引擎甩在后面。我们希望在其他搜索引擎中看到同样类型的创新。如果他们要在 Web 的新时代保持竞争力并取得实质性进展,那就意味着更好地支持 HTML5、JavaScript 和动态网站。
对于SEO,对以上基本概念和谷歌技术不了解的人,应该好好研究学习,赶上现在的技术。如果你不考虑 DOM,你可能会失去一半的份额。
并非本文中表达的所有观点均由 Search Engine Land(搜索引擎网站)提供,部分观点由客座作者提供。所有作者的名单。

