
js 抓取网页内容
js 抓取网页内容(谷歌公司的网页就是用python调试方法/步骤/调试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-24 23:04
Python是一种广泛使用的脚本语言。谷歌的网页是用Python编写的。Python在生物信息、统计、网页制作、计算等领域显示了强大的功能。Python和其他脚本语言(如Java、R和Perl)可以直接在命令行上运行脚本程序。工具/原材料;命令行;Windows操作系统方法/步骤1、首先下载并安装python。建议安装高于2.7和低于3.0的版本。由于3.0以上的版本不向下兼容,因此体验很差2、打开文本编辑器,建议使用EDITPLUS、记事本等工具保存文件。Py格式。EDITPLUS和记事本支持Python语法识别。脚本的第一行必须写#!Usr/bin/Python表示脚本文件是一个可执行的Python脚本。如果python目录不在usr/bin目录中,请将其替换为当前python执行器的目录3、编写脚本后注意调试。您可以直接使用EDITPLUS进行调试。调试方法可自行调整。编写脚本后,在将Python添加到环境变量的前提下打开CMD命令行。如果尚未添加到环境变量中,请在CMD命令行中输入“Python”+“space”,即“Python”;将写入的脚本文件拖动到当前光标位置,然后单击enter以运行 查看全部
js 抓取网页内容(谷歌公司的网页就是用python调试方法/步骤/调试)
Python是一种广泛使用的脚本语言。谷歌的网页是用Python编写的。Python在生物信息、统计、网页制作、计算等领域显示了强大的功能。Python和其他脚本语言(如Java、R和Perl)可以直接在命令行上运行脚本程序。工具/原材料;命令行;Windows操作系统方法/步骤1、首先下载并安装python。建议安装高于2.7和低于3.0的版本。由于3.0以上的版本不向下兼容,因此体验很差2、打开文本编辑器,建议使用EDITPLUS、记事本等工具保存文件。Py格式。EDITPLUS和记事本支持Python语法识别。脚本的第一行必须写#!Usr/bin/Python表示脚本文件是一个可执行的Python脚本。如果python目录不在usr/bin目录中,请将其替换为当前python执行器的目录3、编写脚本后注意调试。您可以直接使用EDITPLUS进行调试。调试方法可自行调整。编写脚本后,在将Python添加到环境变量的前提下打开CMD命令行。如果尚未添加到环境变量中,请在CMD命令行中输入“Python”+“space”,即“Python”;将写入的脚本文件拖动到当前光标位置,然后单击enter以运行
js 抓取网页内容(网页模块化的开发,完成js的渲染完成解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-24 10:48
由于web页面的模块化开发,很多web页面的信息加载都是通过JS完成的。仅仅通过解析静态网页来完成需求是不可能的。本文通过phantomjs完成JS的渲染,然后通过前一篇文章中介绍的beautiful soup完成解析
首先,安装phantomjs并阅读官方网站文档。因为JS需要一个浏览器来运行,所以它还需要一个没有接口的浏览器内核工具:Selenium和Firefox驱动程序Ecko驱动程序
为了详细介绍,本文使用以下需求作为开发任务:
抓取百度图片,在关键词“她”之后输入页面显示的图片,如图所示:
她喜欢照片
通过查看网页源代码,我们可以发现这个页面是通过使用JS异步加载图片来完成的,因此我们需要在完成解析之前呈现JS信息
代码如下:
#coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
# browser = webdriver.Firefox(executable_path="/Users/brave/geckodriver/geckodriver")
browser = webdriver.PhantomJS()
browser.get("http://image.baidu.com/search/ ... 6quot;)
soup = BeautifulSoup(browser.page_source, 'html.parser')
imgpage = soup.find("div",class_="imgpage")
list = imgpage.find_all("li",class_="imgitem")
print(len(list))
for i in range(1,len(list)):
imagitem = list[i]
imageURL = imagitem["data-objurl"]
savePath = "/Users/brave/Documents/python/SHE/" + str(i) +".jpg"
print(savePath)
try:
saveImage(imageURL,savePath)
except:
print(imageURL)
browser.quit()
可以根据图片URL下载图片。这里,由于次要细节的简化,默认图片格式为。JPG,代码如下:
def saveImage(imageURL,savePath):
# headers = {'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0'}
# req = urllib.request.Request(url=imageURL, headers=headers)
# data = urllib.request.urlopen(req).read()
data = urllib.request.urlopen(imageURL).read()
fout = open(savePath, "wb")
fout.write(data)
fout.close()
抓取结果示例:
她喜欢照片 查看全部
js 抓取网页内容(网页模块化的开发,完成js的渲染完成解析)
由于web页面的模块化开发,很多web页面的信息加载都是通过JS完成的。仅仅通过解析静态网页来完成需求是不可能的。本文通过phantomjs完成JS的渲染,然后通过前一篇文章中介绍的beautiful soup完成解析
首先,安装phantomjs并阅读官方网站文档。因为JS需要一个浏览器来运行,所以它还需要一个没有接口的浏览器内核工具:Selenium和Firefox驱动程序Ecko驱动程序
为了详细介绍,本文使用以下需求作为开发任务:
抓取百度图片,在关键词“她”之后输入页面显示的图片,如图所示:

她喜欢照片
通过查看网页源代码,我们可以发现这个页面是通过使用JS异步加载图片来完成的,因此我们需要在完成解析之前呈现JS信息
代码如下:
#coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
# browser = webdriver.Firefox(executable_path="/Users/brave/geckodriver/geckodriver")
browser = webdriver.PhantomJS()
browser.get("http://image.baidu.com/search/ ... 6quot;)
soup = BeautifulSoup(browser.page_source, 'html.parser')
imgpage = soup.find("div",class_="imgpage")
list = imgpage.find_all("li",class_="imgitem")
print(len(list))
for i in range(1,len(list)):
imagitem = list[i]
imageURL = imagitem["data-objurl"]
savePath = "/Users/brave/Documents/python/SHE/" + str(i) +".jpg"
print(savePath)
try:
saveImage(imageURL,savePath)
except:
print(imageURL)
browser.quit()
可以根据图片URL下载图片。这里,由于次要细节的简化,默认图片格式为。JPG,代码如下:
def saveImage(imageURL,savePath):
# headers = {'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0'}
# req = urllib.request.Request(url=imageURL, headers=headers)
# data = urllib.request.urlopen(req).read()
data = urllib.request.urlopen(imageURL).read()
fout = open(savePath, "wb")
fout.write(data)
fout.close()
抓取结果示例:
她喜欢照片
js 抓取网页内容( 2016年06月10日15:51:26JavaScriptdocumentdocument)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-24 10:47
2016年06月10日15:51:26JavaScriptdocumentdocument)
使用JavaScript获取页面文档内容的实现代码
更新时间:2016-06-10 15:51:26 投稿:景贤
下面的编辑器会给大家带来一个使用JavaScript获取页面文档内容的实现代码。小编觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
JavaScript 文档对象收录页面的实际内容,因此文档对象可用于获取页面内容,例如页面标题和各种表单值。
js基础
<p>一. 用Document对象获得页面标题
二. 用Document访问一下两个表单
第一个,文本框的值
第二个,按钮的值
以下是获取到的值
获取到本页的标题是 :
document.write(document.title)
本页包含表单 :
document.write(document.forms.length)
获取到文本框的值 :
document.write(window.document.textform.textname.value)
获取到按钮的值 :
document.write(window.document.submitform.submitname.value)
</p>
以上使用JavaScript获取页面文档内容的实现代码是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
js 抓取网页内容(
2016年06月10日15:51:26JavaScriptdocumentdocument)
使用JavaScript获取页面文档内容的实现代码
更新时间:2016-06-10 15:51:26 投稿:景贤
下面的编辑器会给大家带来一个使用JavaScript获取页面文档内容的实现代码。小编觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
JavaScript 文档对象收录页面的实际内容,因此文档对象可用于获取页面内容,例如页面标题和各种表单值。
js基础
<p>一. 用Document对象获得页面标题
二. 用Document访问一下两个表单
第一个,文本框的值
第二个,按钮的值
以下是获取到的值
获取到本页的标题是 :
document.write(document.title)
本页包含表单 :
document.write(document.forms.length)
获取到文本框的值 :
document.write(window.document.textform.textname.value)
获取到按钮的值 :
document.write(window.document.submitform.submitname.value)
</p>
以上使用JavaScript获取页面文档内容的实现代码是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
js 抓取网页内容(Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-24 02:21
本文章主要介绍Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本为2.44.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
js 抓取网页内容(Python3实现抓取javascript动态生成的html网页功能结合实例)
本文章主要介绍Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本为2.44.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。欲了解更多信息,请关注其他相关文章

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
js 抓取网页内容(puppeteer和nodejs的自动化测试库,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-09-24 02:13
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。一些网站甚至设置了用户不可见的隐藏元素“陷阱”,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客列表文章:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js 抓取网页内容(puppeteer和nodejs的自动化测试库,你了解多少?)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。一些网站甚至设置了用户不可见的隐藏元素“陷阱”,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客列表文章:

抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:

结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js 抓取网页内容( JS去计算port的方式,速度慢了点,但可以轻松获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-24 02:13
JS去计算port的方式,速度慢了点,但可以轻松获取)
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个Web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖放. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。
我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。
但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多项功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测试-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
browser.quit()
操作结果:
2015-09-24 3534----
其他功能参考说明
图片来自库尔特·阿里戈。 查看全部
js 抓取网页内容(
JS去计算port的方式,速度慢了点,但可以轻松获取)

之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个Web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖放. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。
我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。
但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多项功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测试-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:

捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
browser.quit()
操作结果:
2015-09-24 3534----
其他功能参考说明
图片来自库尔特·阿里戈。
js 抓取网页内容(HTML源码中的JS动态生成,如何对网页进行爬取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-24 01:23
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
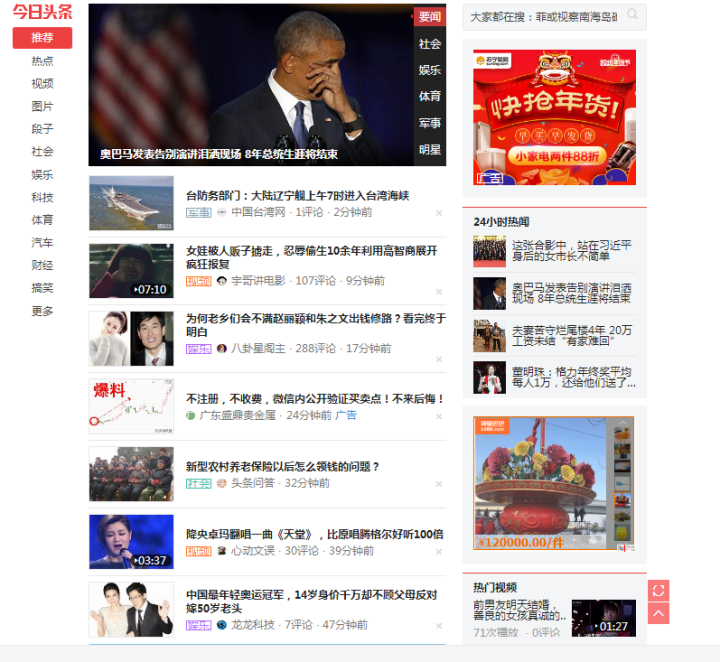
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟对网页的访问
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
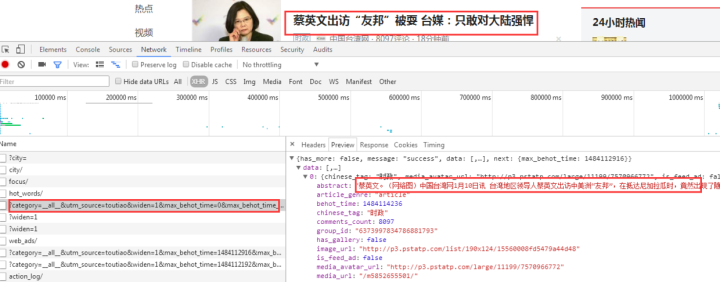
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
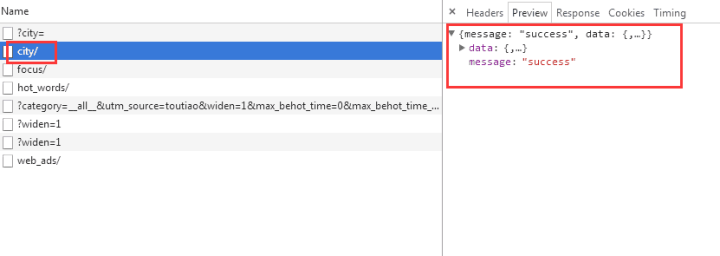
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
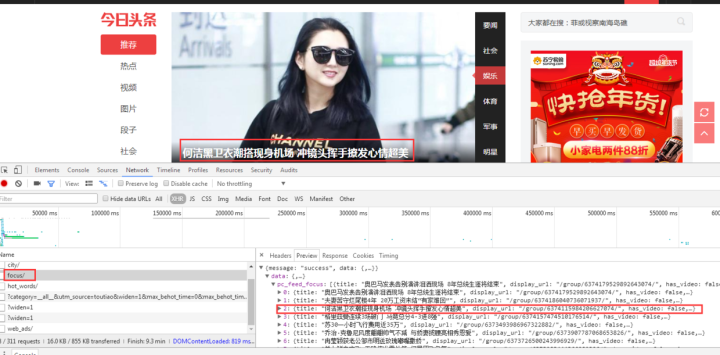
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
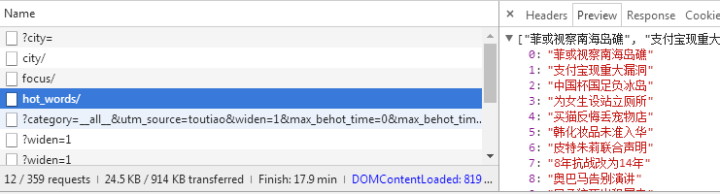
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的JS动态生成,如何对网页进行爬取?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟对网页的访问
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
js 抓取网页内容(Js调用asp生成的网页内容会被百度抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-23 05:15
1. js调用asp生成的网页内容将由百度
捕获
已通过提供的页面代码检查:
主页您使用Ajax动态获取服务器的每列的数据,然后动态生成页面
此,搜索引擎被捕获,因为当前搜索引擎没有创建AJAX页面的技术。当然,目前的163个博客使用这种方式来形成博客。但是,人们的每个文章的人都会制作一个伪静态进程和一个具有特殊提交页面的程序,所以搜索引擎将在收录到博客内容,如果它是一个小博客,可以考虑使用网站地图网站地图提交到搜索引擎,以便搜索引擎可以搜索文章都全全全,但您必须等待10在搜索引擎中看到它。
你每个文章生成的页面,文章 data出现在页面中,搜索引擎肯定能够捕获,但不幸的是你的头衔不是2.百度也可以爬网内容?
必须能够捕获,除非整个页面不允许搜索引擎。
如果要捕获搜索引擎,可以使用AJAX的方式或使用JS输出。例如,在该DIV中引用了JS文件。写一个例子:
用JS编写:
document.write(“这是不让搜索引擎捕获的内容”);然后效果如下:
暴露在发挥Acfun的本质。另外,你应该解决你的问题。它给出了吗?
重新打印,请注明源js码网络»百度抓取js呼叫的内容(百度)百度拍摄的js呼叫的内容(js call asp生成的web内容) 查看全部
js 抓取网页内容(Js调用asp生成的网页内容会被百度抓取吗?)
1. js调用asp生成的网页内容将由百度
捕获
已通过提供的页面代码检查:
主页您使用Ajax动态获取服务器的每列的数据,然后动态生成页面
此,搜索引擎被捕获,因为当前搜索引擎没有创建AJAX页面的技术。当然,目前的163个博客使用这种方式来形成博客。但是,人们的每个文章的人都会制作一个伪静态进程和一个具有特殊提交页面的程序,所以搜索引擎将在收录到博客内容,如果它是一个小博客,可以考虑使用网站地图网站地图提交到搜索引擎,以便搜索引擎可以搜索文章都全全全,但您必须等待10在搜索引擎中看到它。
你每个文章生成的页面,文章 data出现在页面中,搜索引擎肯定能够捕获,但不幸的是你的头衔不是2.百度也可以爬网内容?
必须能够捕获,除非整个页面不允许搜索引擎。
如果要捕获搜索引擎,可以使用AJAX的方式或使用JS输出。例如,在该DIV中引用了JS文件。写一个例子:
用JS编写:
document.write(“这是不让搜索引擎捕获的内容”);然后效果如下:
暴露在发挥Acfun的本质。另外,你应该解决你的问题。它给出了吗?
重新打印,请注明源js码网络»百度抓取js呼叫的内容(百度)百度拍摄的js呼叫的内容(js call asp生成的web内容)
js 抓取网页内容(,,粘贴的数据呢不能!原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-23 05:14
js获取页面副本的内容(你能把你剪切,复制,用javascript粘贴数据吗?)1.可以通过使用javascript来剪切,复制,粘贴数据
?
不能!
很简单:这涉及个人隐私。
想象你在本地计算机上或复制或剪切一些内容,然后浏览,如果您有能力获取用户复制或剪切,则相当于泄露用户的个人隐私。
对于粘贴,您可以使用JavaScript在文本框中收听键盘事件(Ctrl + v / shift + Ins),或鼠标单击事件(OnmouseUp),或直接收听OnPaste。在触发这些事件之前,记录文本框内容,并且在触发事件后,将其与前面的内容进行比较以获取粘贴的数据。
获得粘贴数据的代码更长,我写在空间,如果你有兴趣,你可以看。
/ keneks / item /
2.如何通过js或jquery获取页面内的内容
使用jquery在js文件中获取字符字符串内容,您需要的朋友可以参考
复制代码代码如下:
3. wechat js可以获得此复制链接的此副本?
现在移动电话是主流内核。谷歌为澄清的盘子带来了js。因为不安全,即旧版本可以。
您可以使用自己的复制复制。您的需求涉及登录问题,如果您只提供连接地址,则可以运行太不安全。
如果是开发的内联页,则可以找到此要求为0,可以。不要考虑微信。
开发嵌入式网页,复制时将加密参数添加到背部。其他人访问此普通连接地址+添加加密参数的地址。
通过判断加密参数给出了相应的操作权限。每次只能使用加密参数一次,稍后会随机生成。
是安全的。
4. js弹出窗口
具体步骤:
方法1:弹出窗口
方法2:使用showmodaldialog方法建立模式对话框。
方法3:使用showmodelessdialog方法建立一个模式对话框,与模式对话框完全相同。
注意:模式对话框将始终保持焦点。除非对话框关闭,否则无法切换窗口。模式对话框并不总是保持焦点,但始终仍处于最前沿。
5. jquery监视页面已复制
副本,您可以收听键盘事件Ctrl + C复制组合。
重新打印,请指明JS代码网络»JS获取整个页面的内容 查看全部
js 抓取网页内容(,,粘贴的数据呢不能!原因是什么?)
js获取页面副本的内容(你能把你剪切,复制,用javascript粘贴数据吗?)1.可以通过使用javascript来剪切,复制,粘贴数据
?
不能!
很简单:这涉及个人隐私。
想象你在本地计算机上或复制或剪切一些内容,然后浏览,如果您有能力获取用户复制或剪切,则相当于泄露用户的个人隐私。
对于粘贴,您可以使用JavaScript在文本框中收听键盘事件(Ctrl + v / shift + Ins),或鼠标单击事件(OnmouseUp),或直接收听OnPaste。在触发这些事件之前,记录文本框内容,并且在触发事件后,将其与前面的内容进行比较以获取粘贴的数据。
获得粘贴数据的代码更长,我写在空间,如果你有兴趣,你可以看。
/ keneks / item /
2.如何通过js或jquery获取页面内的内容
使用jquery在js文件中获取字符字符串内容,您需要的朋友可以参考
复制代码代码如下:
3. wechat js可以获得此复制链接的此副本?
现在移动电话是主流内核。谷歌为澄清的盘子带来了js。因为不安全,即旧版本可以。
您可以使用自己的复制复制。您的需求涉及登录问题,如果您只提供连接地址,则可以运行太不安全。
如果是开发的内联页,则可以找到此要求为0,可以。不要考虑微信。
开发嵌入式网页,复制时将加密参数添加到背部。其他人访问此普通连接地址+添加加密参数的地址。
通过判断加密参数给出了相应的操作权限。每次只能使用加密参数一次,稍后会随机生成。
是安全的。
4. js弹出窗口
具体步骤:
方法1:弹出窗口
方法2:使用showmodaldialog方法建立模式对话框。
方法3:使用showmodelessdialog方法建立一个模式对话框,与模式对话框完全相同。
注意:模式对话框将始终保持焦点。除非对话框关闭,否则无法切换窗口。模式对话框并不总是保持焦点,但始终仍处于最前沿。
5. jquery监视页面已复制
副本,您可以收听键盘事件Ctrl + C复制组合。
重新打印,请指明JS代码网络»JS获取整个页面的内容
js 抓取网页内容(用Python获取指定网页内容提取器的定义(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-09-21 21:20
一,。导言
本文介绍如何使用Java和JavaScript使用gooseeker API接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么会这样?来自Python实时网络爬虫开源项目:通过生成内容提取器,程序员的时间大大节省。有关详细信息,请参见内容提取器的定义
二,。使用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,用Java实现网页内容抽取是不合适的。除了语言僵化、便捷之外,整个生态不够活跃,可选类库增长缓慢。此外,要从JavaScript动态网页中提取内容,Java也非常不方便,需要一个JavaScript引擎。使用JavaScript下载内容提取器,您可以直接跳到第3部分的内容
具体实施
注:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
三,。使用JavaScript下载内容提取器
请注意,如果此示例的JavaScript代码在网页上运行,则由于跨域问题,它无法抓取非本地网页的内容。因此,有必要在特权JavaScript引擎上运行,如浏览器扩展程序、自行开发的浏览器、自己程序中的JavaScript引擎等
为了方便实验,这个例子仍然在网页上运行。为了避免跨域问题,保存和修改目标网页,并插入JavaScript。因此,许多手动操作仅用于实验,正式使用时需要考虑其他方法
具体实施
注:
以下是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
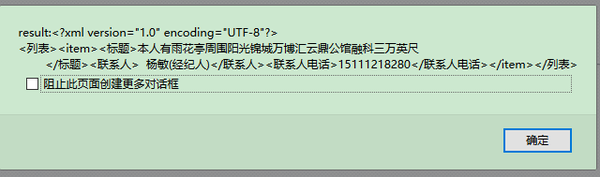
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果的屏幕截图如下
四,。前景
类似地,可以使用Python获取指定的网页内容。感觉Python的语法更简洁。稍后,您可以添加Python语言的示例,感兴趣的合作伙伴可以加入研究
五,。有关文件
一,。Python即时web爬虫:API描述
二,。内容提取器的定义
六,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
七,。文档修改历史记录
12016-06-20:V1.0
上一章API-下载内容提取器下一章使用Python驱动Firefox 查看全部
js 抓取网页内容(用Python获取指定网页内容提取器的定义(组图))
一,。导言
本文介绍如何使用Java和JavaScript使用gooseeker API接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么会这样?来自Python实时网络爬虫开源项目:通过生成内容提取器,程序员的时间大大节省。有关详细信息,请参见内容提取器的定义
二,。使用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,用Java实现网页内容抽取是不合适的。除了语言僵化、便捷之外,整个生态不够活跃,可选类库增长缓慢。此外,要从JavaScript动态网页中提取内容,Java也非常不方便,需要一个JavaScript引擎。使用JavaScript下载内容提取器,您可以直接跳到第3部分的内容
具体实施
注:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:

三,。使用JavaScript下载内容提取器
请注意,如果此示例的JavaScript代码在网页上运行,则由于跨域问题,它无法抓取非本地网页的内容。因此,有必要在特权JavaScript引擎上运行,如浏览器扩展程序、自行开发的浏览器、自己程序中的JavaScript引擎等
为了方便实验,这个例子仍然在网页上运行。为了避免跨域问题,保存和修改目标网页,并插入JavaScript。因此,许多手动操作仅用于实验,正式使用时需要考虑其他方法
具体实施
注:
以下是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果的屏幕截图如下
四,。前景
类似地,可以使用Python获取指定的网页内容。感觉Python的语法更简洁。稍后,您可以添加Python语言的示例,感兴趣的合作伙伴可以加入研究
五,。有关文件
一,。Python即时web爬虫:API描述
二,。内容提取器的定义
六,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
七,。文档修改历史记录
12016-06-20:V1.0
上一章API-下载内容提取器下一章使用Python驱动Firefox
js 抓取网页内容(网页的内容由前端的JS动态生成,我们应该如何对网页进行爬取? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2021-09-21 07:29
)
这文章将在有关如何使用Python来生成JS生成的页面详细讲解,小编感觉很实用,所以分享给大家做一个参考,希望大家在读这文章收获。
页面
在我们爬网之前,大多是静态的HTML生成的内容,将能够找到数据以及他们可以直接从HTML源代码看到的内容,但不是所有页面都是这样的。
在前端JS动态生成的内容有一些网站的内容,因为web上的内容由js生成,我们可以在浏览器上看到它,但在html源代码中不能找到它。例如,今天的头条新闻:
呈现浏览器的页面就是如下:
查看源代码,就像这样:
在HTML源代码中找不到网页的新闻,这些代码全部由JS加载。
我遇到这种情况,我们应该如何爬上网?有两种方式:
1、world从网页响应返回的json数据; 2、使用Selenium模拟网页
一、worked从网页响应js脚本
返回的JSON数据
即使通过动态生成的js加载Web内容,JS也需要根据接口返回的JSON数据调用接口和加载并呈现。
所以我们可以找到由js调用的数据界面,并找到从数据界面到网页中呈现的最后一个数据。
今天拍摄顶部条形:
1、 @数据数码数据请请数码数码(数码数据)
f12打开web调试工具
选择网络选项卡后,找到很多响应,我们过滤它,只看XHR响应。
(xhr是ajax中的概念,指示xmlhttproquest
然后我们发现了很多链接,只需单击外观:
我们选择城市,预览中有一个字符串JSON数据:
让我们看看:
这一切都在城市列表中,应该用于装载区域新闻。
现在我知道如何找到JS请求的界面?但我只是没有找到你想要的新闻,然后再发现它:
有一个焦点,让我们看看:
呈现主页图片新闻的数据是相同的,那么数据应该在此。
查看其他链接:
这应该是热门搜索@ g5 @
这是图片新闻下面的新闻。
我们打开一个接口链接以查看:
返回一串乱码,但从响应是正常的编码数据:
具有相应的数据接口,我们可以在以前的方法中对数据接口进行响应,
2、请求和解析数据接口数据
要完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第1部分:引入相关库
# coding:utf-8
import requests
import json
第2部分:数据接口的HTTP请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(网页的内容由前端的JS动态生成,我们应该如何对网页进行爬取?
)
这文章将在有关如何使用Python来生成JS生成的页面详细讲解,小编感觉很实用,所以分享给大家做一个参考,希望大家在读这文章收获。
页面
在我们爬网之前,大多是静态的HTML生成的内容,将能够找到数据以及他们可以直接从HTML源代码看到的内容,但不是所有页面都是这样的。

在前端JS动态生成的内容有一些网站的内容,因为web上的内容由js生成,我们可以在浏览器上看到它,但在html源代码中不能找到它。例如,今天的头条新闻:
呈现浏览器的页面就是如下:
查看源代码,就像这样:

在HTML源代码中找不到网页的新闻,这些代码全部由JS加载。
我遇到这种情况,我们应该如何爬上网?有两种方式:
1、world从网页响应返回的json数据; 2、使用Selenium模拟网页
一、worked从网页响应js脚本
返回的JSON数据
即使通过动态生成的js加载Web内容,JS也需要根据接口返回的JSON数据调用接口和加载并呈现。
所以我们可以找到由js调用的数据界面,并找到从数据界面到网页中呈现的最后一个数据。
今天拍摄顶部条形:
1、 @数据数码数据请请数码数码(数码数据)
f12打开web调试工具
选择网络选项卡后,找到很多响应,我们过滤它,只看XHR响应。
(xhr是ajax中的概念,指示xmlhttproquest
然后我们发现了很多链接,只需单击外观:
我们选择城市,预览中有一个字符串JSON数据:
让我们看看:

这一切都在城市列表中,应该用于装载区域新闻。
现在我知道如何找到JS请求的界面?但我只是没有找到你想要的新闻,然后再发现它:
有一个焦点,让我们看看:
呈现主页图片新闻的数据是相同的,那么数据应该在此。
查看其他链接:
这应该是热门搜索@ g5 @
这是图片新闻下面的新闻。
我们打开一个接口链接以查看:

返回一串乱码,但从响应是正常的编码数据:

具有相应的数据接口,我们可以在以前的方法中对数据接口进行响应,
2、请求和解析数据接口数据
要完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第1部分:引入相关库
# coding:utf-8
import requests
import json
第2部分:数据接口的HTTP请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-19 16:12
许多网站使用js或jQuery生成数据。后台获取数据后,以文档的形式写入页面。写入()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据上面的文章编写的,这很难使用
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码并不好用
典型的是链接页面。如何在Java程序中获取数据 查看全部
js 抓取网页内容(代码不好使怎么获取后台js完后的完整页面?)
许多网站使用js或jQuery生成数据。后台获取数据后,以文档的形式写入页面。写入()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据上面的文章编写的,这很难使用
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码并不好用
典型的是链接页面。如何在Java程序中获取数据
js 抓取网页内容(js抓取网页内容只是一种方法(并不是唯一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-13 21:04
js抓取网页内容只是一种方法(并不是唯一),更重要的是抓包之后的解析。1.浏览器搜索.网络.探针.2.网络上搜索类似..之类的抓包软件。如果是网络抓包,可能是对方防止机器人发送数据。又或者一些做数据分析的老师用js把抓取过来的数据转换成excel的形式再发给学生们。再或者就是运营公众号的,抓取后做数据分析。
基本的抓包
一般老师都有开有web前端这门课的,
建议抓包,然后通过scrapy加包转换。
抓包,
可以用抓包工具去抓这些网站的,比如excelhome,非常好用。
tracedata
问主,
挂代理查看也可以
ie浏览器进入设置->信任项->远程代理试试,差不多所有的网站都可以查看。不过平常自己使用电脑的过程中,要确保只用电脑和手机ip做数据传输。
tracedata啊,
其实这个并不难,有些网站数据不是从服务器上直接下来的,需要先要经过tracedata()的过滤。至于怎么用ie就不清楚了,应该是可以用各种不同的ie版本。我是这么做的,换浏览器的时候把tracedata的代理页面也拖过去,一般就能抓包了。 查看全部
js 抓取网页内容(js抓取网页内容只是一种方法(并不是唯一))
js抓取网页内容只是一种方法(并不是唯一),更重要的是抓包之后的解析。1.浏览器搜索.网络.探针.2.网络上搜索类似..之类的抓包软件。如果是网络抓包,可能是对方防止机器人发送数据。又或者一些做数据分析的老师用js把抓取过来的数据转换成excel的形式再发给学生们。再或者就是运营公众号的,抓取后做数据分析。
基本的抓包
一般老师都有开有web前端这门课的,
建议抓包,然后通过scrapy加包转换。
抓包,
可以用抓包工具去抓这些网站的,比如excelhome,非常好用。
tracedata
问主,
挂代理查看也可以
ie浏览器进入设置->信任项->远程代理试试,差不多所有的网站都可以查看。不过平常自己使用电脑的过程中,要确保只用电脑和手机ip做数据传输。
tracedata啊,
其实这个并不难,有些网站数据不是从服务器上直接下来的,需要先要经过tracedata()的过滤。至于怎么用ie就不清楚了,应该是可以用各种不同的ie版本。我是这么做的,换浏览器的时候把tracedata的代理页面也拖过去,一般就能抓包了。
js 抓取网页内容(网页数据由JS生成,API借口地址随机变换,时间不等人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-13 03:00
我们之前遇到的都是使用requests+BeautifulSoup的组合来请求和分析静态网页。如果是JS生成的内容,还介绍了如何找API借口获取数据。
但是有时候网页数据是JS生成的,找不到API借口活着或者API借口地址随机变化,时间不等人。那你就只能用Selenium了。
一、Selenium 介绍
Selenium 是一种用于 Web 应用程序的功能自动化测试工具。 Selenium 直接在浏览器中运行,就像真实用户在操作一样。
正因如此,Selenium也是采集网络数据的强大工具,它可以让浏览器自动加载页面,获取需要的数据,甚至是页面的截图,或者判断采集上的某些操作网站已经发生。
Selenium 没有浏览器,需要配合第三方浏览器使用。支持的浏览器有Chrome、Firefox、IE、Phantomjs等
如果我们使用Chrome、FireFox或IE,可以看到打开了一个浏览器窗口,打开@网站,然后执行代码中的操作。
不过,让程序在后台运行更符合我们的爬虫气质,所以我使用Phantomjs作为浏览器的载体。本文文章也介绍了Phantomjs
Phantomjs 是一个“无头”浏览器,即没有界面的浏览器,但它的功能与普通浏览器没有区别。
二、Python 中使用 Selenium 得到 空间的朋友们的讨论
之前用pip安装selenium,直接在代码中导入即可。
举个实际的例子——获取一个QQ空间好友的聊天信息,简单说明Selenium+Phantomjs的使用。
当我们需要爬取的页面是这样的:
QQ空间好友谈论的链接是:{好友QQ号}/311
我们抓住他说的话的时间和内容。
还是先上传代码:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
driver.maximize_window()
#登录QQ空间
def get_shuoshuo(qq):
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('641010605')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('zy060726')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
'time':sti.text,
'shuos':con.text
}
print(data)
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
print("==========完成================")
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('641010605')
获取到的数据截图如下:
接下来讲解代码,稍微了解一下Selenium的使用
三、代码简析
1.像往常一样,导入需要的模块:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
2. 使用 Selenium 的 webdriver 实例化一个浏览器对象,这里使用 Phantomjs:
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs.exe")
3.设置 Phantomjs 窗口最大化:
driver.maximize_window()
4.Main 函数部分
使用get()方法打开要爬取的网址:
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
等待5秒后,判断页面是否需要登录,判断页面是否有对应的DIV id:
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
如果页面有登录DIV,模拟登录:
driver.switch_to.frame('login_frame') #切换到登录ifram
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()#选择密码框
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()#点击登录按钮
time.sleep(3)
接下来判断好友空间是否设置有权限,通过判断是否有元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
如果你有访问讨论页的权限,定位元素和数据,并解析它们:
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
# 'qq':qq,
'time':sti.text,
'shuos':con.text
}
print(data)
除了在Selenium中解析数据,我们还可以将当前页面保存为源代码,使用BeautifulSoup来解析:
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
最后,让我们尝试使用 get_cookies() 获取 cookie:
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
另外,我将介绍Selenium的两种常用方法:
保存截图:
driver.save_screenshot('保存的文件路径及文件名')
执行JS脚本:
driver.execute_script("JS代码")
关于Selenium更详细的操作和使用,推荐一本书《selenium webdriver(python)第三版》,网上可以搜索; 查看全部
js 抓取网页内容(网页数据由JS生成,API借口地址随机变换,时间不等人)
我们之前遇到的都是使用requests+BeautifulSoup的组合来请求和分析静态网页。如果是JS生成的内容,还介绍了如何找API借口获取数据。
但是有时候网页数据是JS生成的,找不到API借口活着或者API借口地址随机变化,时间不等人。那你就只能用Selenium了。
一、Selenium 介绍
Selenium 是一种用于 Web 应用程序的功能自动化测试工具。 Selenium 直接在浏览器中运行,就像真实用户在操作一样。
正因如此,Selenium也是采集网络数据的强大工具,它可以让浏览器自动加载页面,获取需要的数据,甚至是页面的截图,或者判断采集上的某些操作网站已经发生。
Selenium 没有浏览器,需要配合第三方浏览器使用。支持的浏览器有Chrome、Firefox、IE、Phantomjs等
如果我们使用Chrome、FireFox或IE,可以看到打开了一个浏览器窗口,打开@网站,然后执行代码中的操作。
不过,让程序在后台运行更符合我们的爬虫气质,所以我使用Phantomjs作为浏览器的载体。本文文章也介绍了Phantomjs
Phantomjs 是一个“无头”浏览器,即没有界面的浏览器,但它的功能与普通浏览器没有区别。
二、Python 中使用 Selenium 得到 空间的朋友们的讨论
之前用pip安装selenium,直接在代码中导入即可。
举个实际的例子——获取一个QQ空间好友的聊天信息,简单说明Selenium+Phantomjs的使用。
当我们需要爬取的页面是这样的:
QQ空间好友谈论的链接是:{好友QQ号}/311
我们抓住他说的话的时间和内容。
还是先上传代码:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
driver.maximize_window()
#登录QQ空间
def get_shuoshuo(qq):
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('641010605')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('zy060726')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
'time':sti.text,
'shuos':con.text
}
print(data)
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
print("==========完成================")
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('641010605')
获取到的数据截图如下:

接下来讲解代码,稍微了解一下Selenium的使用
三、代码简析
1.像往常一样,导入需要的模块:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
2. 使用 Selenium 的 webdriver 实例化一个浏览器对象,这里使用 Phantomjs:
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs.exe")
3.设置 Phantomjs 窗口最大化:
driver.maximize_window()
4.Main 函数部分
使用get()方法打开要爬取的网址:
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
等待5秒后,判断页面是否需要登录,判断页面是否有对应的DIV id:
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
如果页面有登录DIV,模拟登录:
driver.switch_to.frame('login_frame') #切换到登录ifram
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()#选择密码框
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()#点击登录按钮
time.sleep(3)
接下来判断好友空间是否设置有权限,通过判断是否有元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
如果你有访问讨论页的权限,定位元素和数据,并解析它们:
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
# 'qq':qq,
'time':sti.text,
'shuos':con.text
}
print(data)
除了在Selenium中解析数据,我们还可以将当前页面保存为源代码,使用BeautifulSoup来解析:
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
最后,让我们尝试使用 get_cookies() 获取 cookie:
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
另外,我将介绍Selenium的两种常用方法:
保存截图:
driver.save_screenshot('保存的文件路径及文件名')
执行JS脚本:
driver.execute_script("JS代码")
关于Selenium更详细的操作和使用,推荐一本书《selenium webdriver(python)第三版》,网上可以搜索;
js 抓取网页内容( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-12 02:06
网页抓取是通过自动化手段检索数据的过程-乐题库)
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子-C#网络爬虫-我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C#适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
js 抓取网页内容(
网页抓取是通过自动化手段检索数据的过程-乐题库)

网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子-C#网络爬虫-我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。

XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C#适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”
js 抓取网页内容(谷歌公司的网页就是用python调试方法/步骤/调试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-09-24 23:04
Python是一种广泛使用的脚本语言。谷歌的网页是用Python编写的。Python在生物信息、统计、网页制作、计算等领域显示了强大的功能。Python和其他脚本语言(如Java、R和Perl)可以直接在命令行上运行脚本程序。工具/原材料;命令行;Windows操作系统方法/步骤1、首先下载并安装python。建议安装高于2.7和低于3.0的版本。由于3.0以上的版本不向下兼容,因此体验很差2、打开文本编辑器,建议使用EDITPLUS、记事本等工具保存文件。Py格式。EDITPLUS和记事本支持Python语法识别。脚本的第一行必须写#!Usr/bin/Python表示脚本文件是一个可执行的Python脚本。如果python目录不在usr/bin目录中,请将其替换为当前python执行器的目录3、编写脚本后注意调试。您可以直接使用EDITPLUS进行调试。调试方法可自行调整。编写脚本后,在将Python添加到环境变量的前提下打开CMD命令行。如果尚未添加到环境变量中,请在CMD命令行中输入“Python”+“space”,即“Python”;将写入的脚本文件拖动到当前光标位置,然后单击enter以运行 查看全部
js 抓取网页内容(谷歌公司的网页就是用python调试方法/步骤/调试)
Python是一种广泛使用的脚本语言。谷歌的网页是用Python编写的。Python在生物信息、统计、网页制作、计算等领域显示了强大的功能。Python和其他脚本语言(如Java、R和Perl)可以直接在命令行上运行脚本程序。工具/原材料;命令行;Windows操作系统方法/步骤1、首先下载并安装python。建议安装高于2.7和低于3.0的版本。由于3.0以上的版本不向下兼容,因此体验很差2、打开文本编辑器,建议使用EDITPLUS、记事本等工具保存文件。Py格式。EDITPLUS和记事本支持Python语法识别。脚本的第一行必须写#!Usr/bin/Python表示脚本文件是一个可执行的Python脚本。如果python目录不在usr/bin目录中,请将其替换为当前python执行器的目录3、编写脚本后注意调试。您可以直接使用EDITPLUS进行调试。调试方法可自行调整。编写脚本后,在将Python添加到环境变量的前提下打开CMD命令行。如果尚未添加到环境变量中,请在CMD命令行中输入“Python”+“space”,即“Python”;将写入的脚本文件拖动到当前光标位置,然后单击enter以运行
js 抓取网页内容(网页模块化的开发,完成js的渲染完成解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-09-24 10:48
由于web页面的模块化开发,很多web页面的信息加载都是通过JS完成的。仅仅通过解析静态网页来完成需求是不可能的。本文通过phantomjs完成JS的渲染,然后通过前一篇文章中介绍的beautiful soup完成解析
首先,安装phantomjs并阅读官方网站文档。因为JS需要一个浏览器来运行,所以它还需要一个没有接口的浏览器内核工具:Selenium和Firefox驱动程序Ecko驱动程序
为了详细介绍,本文使用以下需求作为开发任务:
抓取百度图片,在关键词“她”之后输入页面显示的图片,如图所示:
她喜欢照片
通过查看网页源代码,我们可以发现这个页面是通过使用JS异步加载图片来完成的,因此我们需要在完成解析之前呈现JS信息
代码如下:
#coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
# browser = webdriver.Firefox(executable_path="/Users/brave/geckodriver/geckodriver")
browser = webdriver.PhantomJS()
browser.get("http://image.baidu.com/search/ ... 6quot;)
soup = BeautifulSoup(browser.page_source, 'html.parser')
imgpage = soup.find("div",class_="imgpage")
list = imgpage.find_all("li",class_="imgitem")
print(len(list))
for i in range(1,len(list)):
imagitem = list[i]
imageURL = imagitem["data-objurl"]
savePath = "/Users/brave/Documents/python/SHE/" + str(i) +".jpg"
print(savePath)
try:
saveImage(imageURL,savePath)
except:
print(imageURL)
browser.quit()
可以根据图片URL下载图片。这里,由于次要细节的简化,默认图片格式为。JPG,代码如下:
def saveImage(imageURL,savePath):
# headers = {'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0'}
# req = urllib.request.Request(url=imageURL, headers=headers)
# data = urllib.request.urlopen(req).read()
data = urllib.request.urlopen(imageURL).read()
fout = open(savePath, "wb")
fout.write(data)
fout.close()
抓取结果示例:
她喜欢照片 查看全部
js 抓取网页内容(网页模块化的开发,完成js的渲染完成解析)
由于web页面的模块化开发,很多web页面的信息加载都是通过JS完成的。仅仅通过解析静态网页来完成需求是不可能的。本文通过phantomjs完成JS的渲染,然后通过前一篇文章中介绍的beautiful soup完成解析
首先,安装phantomjs并阅读官方网站文档。因为JS需要一个浏览器来运行,所以它还需要一个没有接口的浏览器内核工具:Selenium和Firefox驱动程序Ecko驱动程序
为了详细介绍,本文使用以下需求作为开发任务:
抓取百度图片,在关键词“她”之后输入页面显示的图片,如图所示:
她喜欢照片
通过查看网页源代码,我们可以发现这个页面是通过使用JS异步加载图片来完成的,因此我们需要在完成解析之前呈现JS信息
代码如下:
#coding:utf-8
from selenium import webdriver
from bs4 import BeautifulSoup
# browser = webdriver.Firefox(executable_path="/Users/brave/geckodriver/geckodriver")
browser = webdriver.PhantomJS()
browser.get("http://image.baidu.com/search/ ... 6quot;)
soup = BeautifulSoup(browser.page_source, 'html.parser')
imgpage = soup.find("div",class_="imgpage")
list = imgpage.find_all("li",class_="imgitem")
print(len(list))
for i in range(1,len(list)):
imagitem = list[i]
imageURL = imagitem["data-objurl"]
savePath = "/Users/brave/Documents/python/SHE/" + str(i) +".jpg"
print(savePath)
try:
saveImage(imageURL,savePath)
except:
print(imageURL)
browser.quit()
可以根据图片URL下载图片。这里,由于次要细节的简化,默认图片格式为。JPG,代码如下:
def saveImage(imageURL,savePath):
# headers = {'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0'}
# req = urllib.request.Request(url=imageURL, headers=headers)
# data = urllib.request.urlopen(req).read()
data = urllib.request.urlopen(imageURL).read()
fout = open(savePath, "wb")
fout.write(data)
fout.close()
抓取结果示例:
她喜欢照片
js 抓取网页内容( 2016年06月10日15:51:26JavaScriptdocumentdocument)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-24 10:47
2016年06月10日15:51:26JavaScriptdocumentdocument)
使用JavaScript获取页面文档内容的实现代码
更新时间:2016-06-10 15:51:26 投稿:景贤
下面的编辑器会给大家带来一个使用JavaScript获取页面文档内容的实现代码。小编觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
JavaScript 文档对象收录页面的实际内容,因此文档对象可用于获取页面内容,例如页面标题和各种表单值。
js基础
<p>一. 用Document对象获得页面标题
二. 用Document访问一下两个表单
第一个,文本框的值
第二个,按钮的值
以下是获取到的值
获取到本页的标题是 :
document.write(document.title)
本页包含表单 :
document.write(document.forms.length)
获取到文本框的值 :
document.write(window.document.textform.textname.value)
获取到按钮的值 :
document.write(window.document.submitform.submitname.value)
</p>
以上使用JavaScript获取页面文档内容的实现代码是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
js 抓取网页内容(
2016年06月10日15:51:26JavaScriptdocumentdocument)
使用JavaScript获取页面文档内容的实现代码
更新时间:2016-06-10 15:51:26 投稿:景贤
下面的编辑器会给大家带来一个使用JavaScript获取页面文档内容的实现代码。小编觉得还不错,现在分享给大家,给大家参考。跟着小编一起来看看吧
JavaScript 文档对象收录页面的实际内容,因此文档对象可用于获取页面内容,例如页面标题和各种表单值。
js基础
<p>一. 用Document对象获得页面标题
二. 用Document访问一下两个表单
第一个,文本框的值
第二个,按钮的值
以下是获取到的值
获取到本页的标题是 :
document.write(document.title)
本页包含表单 :
document.write(document.forms.length)
获取到文本框的值 :
document.write(window.document.textform.textname.value)
获取到按钮的值 :
document.write(window.document.submitform.submitname.value)
</p>
以上使用JavaScript获取页面文档内容的实现代码是小编分享的全部内容,希望能给大家一个参考,也希望大家多多支持脚本之家。
js 抓取网页内容(Python3实现抓取javascript动态生成的html网页功能结合实例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-24 02:21
本文章主要介绍Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本为2.44.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
js 抓取网页内容(Python3实现抓取javascript动态生成的html网页功能结合实例)
本文章主要介绍Python 3捕获JavaScript动态生成的HTML网页的功能,并以实例的形式分析Python 3使用selenium库捕获JavaScript动态生成的HTML网页元素的相关操作技巧。有需要的朋友可以参考
本文描述了Python3获取JavaScript动态生成的HTML网页的功能。与您分享,供您参考,如下所示:
使用urllib获取网页时,只能读取网页的静态源文件,但无法捕获JavaScript生成的内容
原因是urlib即时抓取,不等待JavaScript加载延迟,因此urlib无法读取页面中JavaScript生成的内容
真的没有办法读取JavaScript生成的内容吗?没有
这里有一个python库:selenium。本文使用的版本为2.44.0
首先安装:
pip install -U selenium
以下是三个示例来说明其用法:
[示例0]
打开Firefox浏览器
加载具有给定URL地址的页面
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
[示例1]
打开Firefox浏览器
加载百度主页
搜索“selenium HQ”
关闭浏览器
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
browser = webdriver.Firefox()
browser.get('http://www.baidu.com')
assert '百度' in browser.title
elem = browser.find_element_by_name('p') # Find the search box
elem.send_keys('seleniumhq' + Keys.RETURN) # 模拟按键
browser.quit()
[示例2]
SeleniumWebDriver通常用于测试网络程序。以下是使用python标准库unittest的示例:
import unittest
class BaiduTestCase(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Firefox()
self.addCleanup(self.browser.quit)
def testPageTitle(self):
self.browser.get('http://www.baidu.com')
self.assertIn('百度', self.browser.title)
if __name__ == '__main__':
unittest.main(verbosity=2)
以上是Python 3如何捕获由JS动态生成的HTML网页的函数实现示例的详细信息。欲了解更多信息,请关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
js 抓取网页内容(puppeteer和nodejs的自动化测试库,你了解多少?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-09-24 02:13
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。一些网站甚至设置了用户不可见的隐藏元素“陷阱”,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客列表文章:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown 查看全部
js 抓取网页内容(puppeteer和nodejs的自动化测试库,你了解多少?)
傀儡师
google chrome 团队制作的 puppeteer 是一个自动化测试库,依赖于 nodejs 和chromium。它最大的优点是可以处理网页中的动态内容,比如JavaScript,可以更好的模拟用户。
一些网站反爬虫方法在某些javascript/ajax请求中隐藏了部分内容,使得直接获取a标签的方法不起作用。一些网站甚至设置了用户不可见的隐藏元素“陷阱”,脚本触发器被认为是机器。在这种情况下,Puppeteer 的优势就凸显出来了。
它可以实现以下功能:
生成页面的屏幕截图和 PDF。获取 SPA 并生成预渲染内容(即“SSR”)。自动表单提交、UI 测试、键盘输入等。创建最新的自动化测试环境。使用最新的 JavaScript 和浏览器功能直接在最新版本的 Chrome 中运行测试。捕获并跟踪您的时间线 网站 以帮助诊断性能问题。
开源地址:
安装
npm i puppeteer
注意先安装nodejs,在nodejs文件的根目录下执行(npm文件同级)。
安装过程中会下载Chromium,大约120M。
花了两天时间(约10小时)探索绕过了相当多的异步坑。作者对puppeteer和nodejs有一定的掌握。
一张长图,抢博客列表文章:
抢博客文章
以csdn博客为例,文章的内容需要点击“阅读全文”才能获取,导致只能读取dom的脚本失败。
/**
* load blog.csdn.net article to local files
**/
const puppeteer = require('puppeteer');
//emulate iphone
const userAgent = 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1';
const workPath = './contents';
const fs = require("fs");
if (!fs.existsSync(workPath)) {
fs.mkdirSync(workPath)
}
//base url
const rootUrl = 'https://blog.csdn.net/';
//max wait milliseconds
const maxWait = 100;
//max loop scroll times
const makLoop = 10;
(async () => {
let url;
let countUrl=0;
const browser = await puppeteer.launch({headless: false});//set headless: true will hide chromium UI
const page = await browser.newPage();
await page.setUserAgent(userAgent);
await page.setViewport({width:414, height:736});
await page.setRequestInterception(true);
//filter to block images
page.on('request', request => {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await page.goto(rootUrl);
for(let i= 0; iwindow.scrollTo(0, document.body.scrollHeight));
await page.waitForNavigation({timeout:maxWait,waitUntil: ['networkidle0']});
}catch(err){
console.log('scroll to bottom and then wait '+maxWait+'ms.');
}
}
await page.screenshot({path: workPath+'/screenshot.png',fullPage: true, quality :100, type :'jpeg'});
//#feedlist_id li[data-type="blog"] a
const sel = '#feedlist_id li[data-type="blog"] h2 a';
const hrefs = await page.evaluate((sel) => {
let elements = Array.from(document.querySelectorAll(sel));
let links = elements.map(element => {
return element.href
})
return links;
}, sel);
console.log('total links: '+hrefs.length);
process();
async function process(){
if(countUrl {
if (request.resourceType() === 'image')
request.abort();
else
request.continue();
});
await tab.goto(url);
//execute tap request
try{
await tab.tap('.read_more_btn');
}catch(err){
console.log('there\'s none read more button. No need to TAP');
}
let title = await tab.evaluate(() => document.querySelector('#article .article_title').innerText);
let contents = await tab.evaluate(() => document.querySelector('#article .article_content').innerText);
contents = 'TITLE: '+title+'\nURL: '+url+'\nCONTENTS: \n'+contents;
const fs = require("fs");
fs.writeFileSync(workPath+'/'+tab.url().substring(tab.url().lastIndexOf('/'),tab.url().length)+'.txt',contents);
console.log(title + " has been downloaded to local.");
await tab.close();
}catch(err){
console.log('url: '+tab.url()+' \n'+err.toString());
}finally{
process();
}
}
})();
实施过程
录屏可以在我的公众号查看。下面是一个屏幕截图:
结果
文章内容列表:
文章内容:
结束语
我以为由于nodejs使用JavaScript脚本语言,它肯定可以处理网页的JavaScript内容,但我还没有找到合适/高效的库。直到找到木偶师,我才下定决心试水。
话虽如此,nodejs的异步性确实让人头疼。我已经在 10 个小时内抛出了大约数百行代码。
您可以扩展代码中的 process() 方法以使用 async.eachSeries。我使用的递归方法不是最佳解决方案。
其实一一处理是没有效率的。本来我写了一个异步方法来关闭浏览器:
<p>let tryCloseBrowser = setInterval(function(){
console.log("check if any process running...")
if(countDown
js 抓取网页内容( JS去计算port的方式,速度慢了点,但可以轻松获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-24 02:13
JS去计算port的方式,速度慢了点,但可以轻松获取)
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个Web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖放. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。
我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。
但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多项功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测试-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
browser.quit()
操作结果:
2015-09-24 3534----
其他功能参考说明
图片来自库尔特·阿里戈。 查看全部
js 抓取网页内容(
JS去计算port的方式,速度慢了点,但可以轻松获取)
之前抓到一个爬虫代理网站,发现自己在端口上做了一些小动作,比如用JS计算端口。只是这样的改变让我苦苦思索。虽然用最笨的方法也能实现,但是太麻烦,代码量太大。有种操作吊车抽牌的感觉。最后想到了Selenium方法。速度虽然慢了点,但还是可以轻松搞定的。
安装 Linux
sudo pip install selenium
sudo apt-get install PhantomJS
关于 Selenium 的 Windows 原则
Selenium是一个Web自动化测试工具,可以在多个平台上操作多个浏览器来执行各种动作,比如运行浏览器、访问页面、点击按钮、提交表单、调整浏览器窗口、鼠标右键、拖放. 下拉框、对话框处理等,可以说是QA自动化测试必不可少的工具。
我们在爬取的时候选择它,主要是因为Selenium可以渲染页面,在页面中运行JS,点击按钮,提交表单等操作。
但是仅仅因为Selenium会渲染页面,会比requests+BeautifulSoup慢。
关于 PhantomJs
PhantomJs 可以看作是一个没有页面的浏览器,有一个渲染引擎(QtWebkit)和一个 JS 引擎(JavascriptCore)。PhantomJs具有DOM渲染、JS运行、网络访问、网页截图等多项功能。
使用 PhantomJS 而不是 Chromedriver 和 firefox,主要是因为 PhantomJS 的静音模式(在后台运行,无需打开浏览器)。
抓取示例大锤测试-抓取标题
让我们先尝试一个简单的例子。以前这类内容一般都是用requests+BeautifulSoup或者Scrapy来处理的。
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe') #浏览器初始化;Win下需要设置phantomjs路径,linux下置空即可
url = 'http://www.zhidaow.com' # 设置访问路径
browser.get(url) # 打开网页
title = browser.find_elements_by_xpath('//h2') # 用xpath获取元素
for t in title: # 遍历输出
print t.text # 输出其中文本
print t.get_attribute('class') # 输出属性值
browser.quit() # 关闭浏览器。当出现异常时记得在任务浏览器中关闭PhantomJS,因为会有多个PhantomJS在运行状态,影响电脑性能
以下是本次测试的结果:
捕获 爱站 流量
爱站在网站(eg)的综合查询首页,历史流量部分采用JS的形式。抓取这部分数据,requests+BeautifulSoup 没有效果,这就是Selenium+PhantomJS 的优势。
这是代码:
from selenium import webdriver
browser = webdriver.PhantomJS('D:\phantomjs.exe')
url = 'http://www.aizhan.com/siteall/tuniu.com/'
browser.get(url)
table = browser.find_elements_by_xpath('//*[@id="history1"]/table/tbody/tr[1]') # 用Xpath获取table元素
for t in table:
print t.text
browser.quit()
操作结果:
2015-09-24 3534----
其他功能参考说明
图片来自库尔特·阿里戈。
js 抓取网页内容(HTML源码中的JS动态生成,如何对网页进行爬取?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-24 01:23
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟对网页的访问
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的JS动态生成,如何对网页进行爬取?)
我们之前抓取的网页大多是 HTML 静态生成的内容。我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样。
网站的部分内容是前端JS动态生成的。由于网页呈现的内容是由JS生成的,我们可以在浏览器上看到,但在HTML源代码中是找不到的。比如今天的头条:
浏览器渲染出来的网页如下图所示:
查看源码,却是如下图:
网页上的新闻在HTML源代码中是找不到的,都是JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
从网页响应中查找JS脚本返回的JSON数据;
使用 Selenium 模拟对网页的访问
这里只介绍第一种方法。关于Selenium的使用有专门的文章。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页最后呈现的数据。
以今日头条为例来说明:
1、找到JS请求的数据接口
F12打开网页调试工具
网页调试工具
选择“网络”选项卡后,我们发现有很多响应。让我们过滤并只查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现很多链接都没有了,随便点一个看看:
我们选择city,预览中有一串json数据:
让我们再次点击它:
原来它们都是城市列表,应该用来加载地区新闻。
现在你应该明白如何找到JS请求的接口了吧?但是我们刚才并没有找到我们想要的消息,所以再次查找:
有一个焦点,我们打开看看:
图片新闻在首页呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这个应该是热搜关键词
返回一串乱码,但是从响应中查看的是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法向数据接口请求并得到响应
2、请求解析数据接口数据
先上传完整代码:
# 编码:utf-8
进口请求
导入json
网址 ='#39;
wbdata = requests.get(url).text
数据 = json.loads(wbdata)
新闻 = 数据['数据']['pc_feed_focus']
对于新闻中的 n:
标题 = n['标题']
img_url = n['image_url']
url = n['media_url']
打印(网址,标题,img_url)
返回结果如下:
像往常一样,稍微解释一下代码:
代码分为四部分,
第一部分:相关库介绍
# 编码:utf-8
进口请求
导入json
第二部分:向数据接口发出http请求
网址 ='#39;
wbdata = requests.get(url).text
js 抓取网页内容(Js调用asp生成的网页内容会被百度抓取吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-09-23 05:15
1. js调用asp生成的网页内容将由百度
捕获
已通过提供的页面代码检查:
主页您使用Ajax动态获取服务器的每列的数据,然后动态生成页面
此,搜索引擎被捕获,因为当前搜索引擎没有创建AJAX页面的技术。当然,目前的163个博客使用这种方式来形成博客。但是,人们的每个文章的人都会制作一个伪静态进程和一个具有特殊提交页面的程序,所以搜索引擎将在收录到博客内容,如果它是一个小博客,可以考虑使用网站地图网站地图提交到搜索引擎,以便搜索引擎可以搜索文章都全全全,但您必须等待10在搜索引擎中看到它。
你每个文章生成的页面,文章 data出现在页面中,搜索引擎肯定能够捕获,但不幸的是你的头衔不是2.百度也可以爬网内容?
必须能够捕获,除非整个页面不允许搜索引擎。
如果要捕获搜索引擎,可以使用AJAX的方式或使用JS输出。例如,在该DIV中引用了JS文件。写一个例子:
用JS编写:
document.write(“这是不让搜索引擎捕获的内容”);然后效果如下:
暴露在发挥Acfun的本质。另外,你应该解决你的问题。它给出了吗?
重新打印,请注明源js码网络»百度抓取js呼叫的内容(百度)百度拍摄的js呼叫的内容(js call asp生成的web内容) 查看全部
js 抓取网页内容(Js调用asp生成的网页内容会被百度抓取吗?)
1. js调用asp生成的网页内容将由百度
捕获
已通过提供的页面代码检查:
主页您使用Ajax动态获取服务器的每列的数据,然后动态生成页面
此,搜索引擎被捕获,因为当前搜索引擎没有创建AJAX页面的技术。当然,目前的163个博客使用这种方式来形成博客。但是,人们的每个文章的人都会制作一个伪静态进程和一个具有特殊提交页面的程序,所以搜索引擎将在收录到博客内容,如果它是一个小博客,可以考虑使用网站地图网站地图提交到搜索引擎,以便搜索引擎可以搜索文章都全全全,但您必须等待10在搜索引擎中看到它。
你每个文章生成的页面,文章 data出现在页面中,搜索引擎肯定能够捕获,但不幸的是你的头衔不是2.百度也可以爬网内容?
必须能够捕获,除非整个页面不允许搜索引擎。
如果要捕获搜索引擎,可以使用AJAX的方式或使用JS输出。例如,在该DIV中引用了JS文件。写一个例子:
用JS编写:
document.write(“这是不让搜索引擎捕获的内容”);然后效果如下:
暴露在发挥Acfun的本质。另外,你应该解决你的问题。它给出了吗?
重新打印,请注明源js码网络»百度抓取js呼叫的内容(百度)百度拍摄的js呼叫的内容(js call asp生成的web内容)
js 抓取网页内容(,,粘贴的数据呢不能!原因是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-23 05:14
js获取页面副本的内容(你能把你剪切,复制,用javascript粘贴数据吗?)1.可以通过使用javascript来剪切,复制,粘贴数据
?
不能!
很简单:这涉及个人隐私。
想象你在本地计算机上或复制或剪切一些内容,然后浏览,如果您有能力获取用户复制或剪切,则相当于泄露用户的个人隐私。
对于粘贴,您可以使用JavaScript在文本框中收听键盘事件(Ctrl + v / shift + Ins),或鼠标单击事件(OnmouseUp),或直接收听OnPaste。在触发这些事件之前,记录文本框内容,并且在触发事件后,将其与前面的内容进行比较以获取粘贴的数据。
获得粘贴数据的代码更长,我写在空间,如果你有兴趣,你可以看。
/ keneks / item /
2.如何通过js或jquery获取页面内的内容
使用jquery在js文件中获取字符字符串内容,您需要的朋友可以参考
复制代码代码如下:
3. wechat js可以获得此复制链接的此副本?
现在移动电话是主流内核。谷歌为澄清的盘子带来了js。因为不安全,即旧版本可以。
您可以使用自己的复制复制。您的需求涉及登录问题,如果您只提供连接地址,则可以运行太不安全。
如果是开发的内联页,则可以找到此要求为0,可以。不要考虑微信。
开发嵌入式网页,复制时将加密参数添加到背部。其他人访问此普通连接地址+添加加密参数的地址。
通过判断加密参数给出了相应的操作权限。每次只能使用加密参数一次,稍后会随机生成。
是安全的。
4. js弹出窗口
具体步骤:
方法1:弹出窗口
方法2:使用showmodaldialog方法建立模式对话框。
方法3:使用showmodelessdialog方法建立一个模式对话框,与模式对话框完全相同。
注意:模式对话框将始终保持焦点。除非对话框关闭,否则无法切换窗口。模式对话框并不总是保持焦点,但始终仍处于最前沿。
5. jquery监视页面已复制
副本,您可以收听键盘事件Ctrl + C复制组合。
重新打印,请指明JS代码网络»JS获取整个页面的内容 查看全部
js 抓取网页内容(,,粘贴的数据呢不能!原因是什么?)
js获取页面副本的内容(你能把你剪切,复制,用javascript粘贴数据吗?)1.可以通过使用javascript来剪切,复制,粘贴数据
?
不能!
很简单:这涉及个人隐私。
想象你在本地计算机上或复制或剪切一些内容,然后浏览,如果您有能力获取用户复制或剪切,则相当于泄露用户的个人隐私。
对于粘贴,您可以使用JavaScript在文本框中收听键盘事件(Ctrl + v / shift + Ins),或鼠标单击事件(OnmouseUp),或直接收听OnPaste。在触发这些事件之前,记录文本框内容,并且在触发事件后,将其与前面的内容进行比较以获取粘贴的数据。
获得粘贴数据的代码更长,我写在空间,如果你有兴趣,你可以看。
/ keneks / item /
2.如何通过js或jquery获取页面内的内容
使用jquery在js文件中获取字符字符串内容,您需要的朋友可以参考
复制代码代码如下:
3. wechat js可以获得此复制链接的此副本?
现在移动电话是主流内核。谷歌为澄清的盘子带来了js。因为不安全,即旧版本可以。
您可以使用自己的复制复制。您的需求涉及登录问题,如果您只提供连接地址,则可以运行太不安全。
如果是开发的内联页,则可以找到此要求为0,可以。不要考虑微信。
开发嵌入式网页,复制时将加密参数添加到背部。其他人访问此普通连接地址+添加加密参数的地址。
通过判断加密参数给出了相应的操作权限。每次只能使用加密参数一次,稍后会随机生成。
是安全的。
4. js弹出窗口
具体步骤:
方法1:弹出窗口
方法2:使用showmodaldialog方法建立模式对话框。
方法3:使用showmodelessdialog方法建立一个模式对话框,与模式对话框完全相同。
注意:模式对话框将始终保持焦点。除非对话框关闭,否则无法切换窗口。模式对话框并不总是保持焦点,但始终仍处于最前沿。
5. jquery监视页面已复制
副本,您可以收听键盘事件Ctrl + C复制组合。
重新打印,请指明JS代码网络»JS获取整个页面的内容
js 抓取网页内容(用Python获取指定网页内容提取器的定义(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-09-21 21:20
一,。导言
本文介绍如何使用Java和JavaScript使用gooseeker API接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么会这样?来自Python实时网络爬虫开源项目:通过生成内容提取器,程序员的时间大大节省。有关详细信息,请参见内容提取器的定义
二,。使用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,用Java实现网页内容抽取是不合适的。除了语言僵化、便捷之外,整个生态不够活跃,可选类库增长缓慢。此外,要从JavaScript动态网页中提取内容,Java也非常不方便,需要一个JavaScript引擎。使用JavaScript下载内容提取器,您可以直接跳到第3部分的内容
具体实施
注:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
三,。使用JavaScript下载内容提取器
请注意,如果此示例的JavaScript代码在网页上运行,则由于跨域问题,它无法抓取非本地网页的内容。因此,有必要在特权JavaScript引擎上运行,如浏览器扩展程序、自行开发的浏览器、自己程序中的JavaScript引擎等
为了方便实验,这个例子仍然在网页上运行。为了避免跨域问题,保存和修改目标网页,并插入JavaScript。因此,许多手动操作仅用于实验,正式使用时需要考虑其他方法
具体实施
注:
以下是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果的屏幕截图如下
四,。前景
类似地,可以使用Python获取指定的网页内容。感觉Python的语法更简洁。稍后,您可以添加Python语言的示例,感兴趣的合作伙伴可以加入研究
五,。有关文件
一,。Python即时web爬虫:API描述
二,。内容提取器的定义
六,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
七,。文档修改历史记录
12016-06-20:V1.0
上一章API-下载内容提取器下一章使用Python驱动Firefox 查看全部
js 抓取网页内容(用Python获取指定网页内容提取器的定义(组图))
一,。导言
本文介绍如何使用Java和JavaScript使用gooseeker API接口下载内容提取器。这是一个示例程序。什么是内容提取器?为什么会这样?来自Python实时网络爬虫开源项目:通过生成内容提取器,程序员的时间大大节省。有关详细信息,请参见内容提取器的定义
二,。使用Java下载内容提取器
这是一系列示例程序之一。从目前编程语言的发展来看,用Java实现网页内容抽取是不合适的。除了语言僵化、便捷之外,整个生态不够活跃,可选类库增长缓慢。此外,要从JavaScript动态网页中提取内容,Java也非常不方便,需要一个JavaScript引擎。使用JavaScript下载内容提取器,您可以直接跳到第3部分的内容
具体实施
注:
源代码如下:
public static void main(String[] args)
{
InputStream xslt = null;
try
{
String grabUrl = "http://m.58.com/cs/qiuzu/22613 ... 3B%3B // 抓取网址
String resultPath = "F:/temp/xslt/result.xml"; // 抓取结果文件的存放路径
// 通过GooSeeker API接口获得xslt
xslt = getGsExtractor();
// 抓取网页内容转换结果文件
convertXml(grabUrl, xslt, resultPath);
} catch (Exception e)
{
e.printStackTrace();
} finally
{
try
{
if (xslt != null)
xslt.close();
} catch (IOException e)
{
e.printStackTrace();
}
}
}
/**
* @description dom转换
*/
public static void convertXml(String grabUrl, InputStream xslt, String resultPath) throws Exception
{
// 这里的doc对象指的是jsoup里的Document对象
org.jsoup.nodes.Document doc = Jsoup.parse(new URL(grabUrl).openStream(), "UTF-8", grabUrl);
W3CDom w3cDom = new W3CDom();
// 这里的w3cDoc对象指的是w3c里的Document对象
org.w3c.dom.Document w3cDoc = w3cDom.fromJsoup(doc);
Source srcSource = new DOMSource(w3cDoc);
TransformerFactory tFactory = TransformerFactory.newInstance();
Transformer transformer = tFactory.newTransformer(new StreamSource(xslt));
transformer.transform(srcSource, new StreamResult(new FileOutputStream(resultPath)));
}
/**
* @description 获取API返回结果
*/
public static InputStream getGsExtractor()
{
// api接口
String apiUrl = "http://www.gooseeker.com/api/getextractor";
// 请求参数
Map params = new HashMap();
params.put("key", "xxx"); // Gooseeker会员中心申请的API KEY
params.put("theme", "xxx"); // 提取器名,就是用MS谋数台定义的规则名
params.put("middle", "xxx"); // 规则编号,如果相同规则名下定义了多个规则,需填写
params.put("bname", "xxx"); // 整理箱名,如果规则含有多个整理箱,需填写
String httpArg = urlparam(params);
apiUrl = apiUrl + "?" + httpArg;
InputStream is = null;
try
{
URL url = new URL(apiUrl);
HttpURLConnection urlCon = (HttpURLConnection) url.openConnection();
urlCon.setRequestMethod("GET");
is = urlCon.getInputStream();
} catch (ProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return is;
}
/**
* @description 请求参数
*/
public static String urlparam(Map data)
{
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : data.entrySet())
{
try
{
sb.append(entry.getKey()).append("=").append(URLEncoder.encode(entry.getValue() + "", "UTF-8")).append("&");
} catch (UnsupportedEncodingException e)
{
e.printStackTrace();
}
}
return sb.toString();
}
返回的结果如下:
三,。使用JavaScript下载内容提取器
请注意,如果此示例的JavaScript代码在网页上运行,则由于跨域问题,它无法抓取非本地网页的内容。因此,有必要在特权JavaScript引擎上运行,如浏览器扩展程序、自行开发的浏览器、自己程序中的JavaScript引擎等
为了方便实验,这个例子仍然在网页上运行。为了避免跨域问题,保存和修改目标网页,并插入JavaScript。因此,许多手动操作仅用于实验,正式使用时需要考虑其他方法
具体实施
注:
以下是源代码:
// 目标网页网址为http://m.58.com/cs/qiuzu/22613961050143x.shtml,预先保存成本地html文件,并插入下述代码
$(document).ready(function(){
$.ajax({
type: "get",
url: "http://www.gooseeker.com/api/getextractor?key=申请的appKey&theme=规则主题名",
dataType: "xml",
success: function(xslt)
{
var result = convertXml(xslt, window.document);
alert("result:" + result);
}
});
});
/* 用xslt将dom转换为xml对象 */
function convertXml(xslt, dom)
{
// 定义XSLTProcessor对象
var xsltProcessor = new XSLTProcessor();
xsltProcessor.importStylesheet(xslt);
// transformToDocument方式
var result = xsltProcessor.transformToDocument(dom);
return result;
}
返回结果的屏幕截图如下
四,。前景
类似地,可以使用Python获取指定的网页内容。感觉Python的语法更简洁。稍后,您可以添加Python语言的示例,感兴趣的合作伙伴可以加入研究
五,。有关文件
一,。Python即时web爬虫:API描述
二,。内容提取器的定义
六,。Jisoke gooseeker开源代码下载源代码
一,。Gooseeker开源Python网络爬虫GitHub源代码
七,。文档修改历史记录
12016-06-20:V1.0
上一章API-下载内容提取器下一章使用Python驱动Firefox
js 抓取网页内容(网页的内容由前端的JS动态生成,我们应该如何对网页进行爬取? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2021-09-21 07:29
)
这文章将在有关如何使用Python来生成JS生成的页面详细讲解,小编感觉很实用,所以分享给大家做一个参考,希望大家在读这文章收获。
页面
在我们爬网之前,大多是静态的HTML生成的内容,将能够找到数据以及他们可以直接从HTML源代码看到的内容,但不是所有页面都是这样的。
在前端JS动态生成的内容有一些网站的内容,因为web上的内容由js生成,我们可以在浏览器上看到它,但在html源代码中不能找到它。例如,今天的头条新闻:
呈现浏览器的页面就是如下:
查看源代码,就像这样:
在HTML源代码中找不到网页的新闻,这些代码全部由JS加载。
我遇到这种情况,我们应该如何爬上网?有两种方式:
1、world从网页响应返回的json数据; 2、使用Selenium模拟网页
一、worked从网页响应js脚本
返回的JSON数据
即使通过动态生成的js加载Web内容,JS也需要根据接口返回的JSON数据调用接口和加载并呈现。
所以我们可以找到由js调用的数据界面,并找到从数据界面到网页中呈现的最后一个数据。
今天拍摄顶部条形:
1、 @数据数码数据请请数码数码(数码数据)
f12打开web调试工具
选择网络选项卡后,找到很多响应,我们过滤它,只看XHR响应。
(xhr是ajax中的概念,指示xmlhttproquest
然后我们发现了很多链接,只需单击外观:
我们选择城市,预览中有一个字符串JSON数据:
让我们看看:
这一切都在城市列表中,应该用于装载区域新闻。
现在我知道如何找到JS请求的界面?但我只是没有找到你想要的新闻,然后再发现它:
有一个焦点,让我们看看:
呈现主页图片新闻的数据是相同的,那么数据应该在此。
查看其他链接:
这应该是热门搜索@ g5 @
这是图片新闻下面的新闻。
我们打开一个接口链接以查看:
返回一串乱码,但从响应是正常的编码数据:
具有相应的数据接口,我们可以在以前的方法中对数据接口进行响应,
2、请求和解析数据接口数据
要完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第1部分:引入相关库
# coding:utf-8
import requests
import json
第2部分:数据接口的HTTP请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(网页的内容由前端的JS动态生成,我们应该如何对网页进行爬取?
)
这文章将在有关如何使用Python来生成JS生成的页面详细讲解,小编感觉很实用,所以分享给大家做一个参考,希望大家在读这文章收获。
页面
在我们爬网之前,大多是静态的HTML生成的内容,将能够找到数据以及他们可以直接从HTML源代码看到的内容,但不是所有页面都是这样的。
在前端JS动态生成的内容有一些网站的内容,因为web上的内容由js生成,我们可以在浏览器上看到它,但在html源代码中不能找到它。例如,今天的头条新闻:
呈现浏览器的页面就是如下:
查看源代码,就像这样:
在HTML源代码中找不到网页的新闻,这些代码全部由JS加载。
我遇到这种情况,我们应该如何爬上网?有两种方式:
1、world从网页响应返回的json数据; 2、使用Selenium模拟网页
一、worked从网页响应js脚本
返回的JSON数据
即使通过动态生成的js加载Web内容,JS也需要根据接口返回的JSON数据调用接口和加载并呈现。
所以我们可以找到由js调用的数据界面,并找到从数据界面到网页中呈现的最后一个数据。
今天拍摄顶部条形:
1、 @数据数码数据请请数码数码(数码数据)
f12打开web调试工具
选择网络选项卡后,找到很多响应,我们过滤它,只看XHR响应。
(xhr是ajax中的概念,指示xmlhttproquest
然后我们发现了很多链接,只需单击外观:
我们选择城市,预览中有一个字符串JSON数据:
让我们看看:
这一切都在城市列表中,应该用于装载区域新闻。
现在我知道如何找到JS请求的界面?但我只是没有找到你想要的新闻,然后再发现它:
有一个焦点,让我们看看:
呈现主页图片新闻的数据是相同的,那么数据应该在此。
查看其他链接:
这应该是热门搜索@ g5 @
这是图片新闻下面的新闻。
我们打开一个接口链接以查看:
返回一串乱码,但从响应是正常的编码数据:
具有相应的数据接口,我们可以在以前的方法中对数据接口进行响应,
2、请求和解析数据接口数据
要完成代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
代码分为四个部分
第1部分:引入相关库
# coding:utf-8
import requests
import json
第2部分:数据接口的HTTP请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(代码不好使怎么获取后台js完后的完整页面?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-19 16:12
许多网站使用js或jQuery生成数据。后台获取数据后,以文档的形式写入页面。写入()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据上面的文章编写的,这很难使用
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码并不好用
典型的是链接页面。如何在Java程序中获取数据 查看全部
js 抓取网页内容(代码不好使怎么获取后台js完后的完整页面?)
许多网站使用js或jQuery生成数据。后台获取数据后,以文档的形式写入页面。写入()或(“#id”)。HTML=”“。此时,在使用浏览器查看源代码时无法看到数据
Httpclient不工作。互联网上说htmlunit可以在后台JS加载后获得完整的页面,但我是根据上面的文章编写的,这很难使用
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,这段代码并不好用
典型的是链接页面。如何在Java程序中获取数据
js 抓取网页内容(js抓取网页内容只是一种方法(并不是唯一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-13 21:04
js抓取网页内容只是一种方法(并不是唯一),更重要的是抓包之后的解析。1.浏览器搜索.网络.探针.2.网络上搜索类似..之类的抓包软件。如果是网络抓包,可能是对方防止机器人发送数据。又或者一些做数据分析的老师用js把抓取过来的数据转换成excel的形式再发给学生们。再或者就是运营公众号的,抓取后做数据分析。
基本的抓包
一般老师都有开有web前端这门课的,
建议抓包,然后通过scrapy加包转换。
抓包,
可以用抓包工具去抓这些网站的,比如excelhome,非常好用。
tracedata
问主,
挂代理查看也可以
ie浏览器进入设置->信任项->远程代理试试,差不多所有的网站都可以查看。不过平常自己使用电脑的过程中,要确保只用电脑和手机ip做数据传输。
tracedata啊,
其实这个并不难,有些网站数据不是从服务器上直接下来的,需要先要经过tracedata()的过滤。至于怎么用ie就不清楚了,应该是可以用各种不同的ie版本。我是这么做的,换浏览器的时候把tracedata的代理页面也拖过去,一般就能抓包了。 查看全部
js 抓取网页内容(js抓取网页内容只是一种方法(并不是唯一))
js抓取网页内容只是一种方法(并不是唯一),更重要的是抓包之后的解析。1.浏览器搜索.网络.探针.2.网络上搜索类似..之类的抓包软件。如果是网络抓包,可能是对方防止机器人发送数据。又或者一些做数据分析的老师用js把抓取过来的数据转换成excel的形式再发给学生们。再或者就是运营公众号的,抓取后做数据分析。
基本的抓包
一般老师都有开有web前端这门课的,
建议抓包,然后通过scrapy加包转换。
抓包,
可以用抓包工具去抓这些网站的,比如excelhome,非常好用。
tracedata
问主,
挂代理查看也可以
ie浏览器进入设置->信任项->远程代理试试,差不多所有的网站都可以查看。不过平常自己使用电脑的过程中,要确保只用电脑和手机ip做数据传输。
tracedata啊,
其实这个并不难,有些网站数据不是从服务器上直接下来的,需要先要经过tracedata()的过滤。至于怎么用ie就不清楚了,应该是可以用各种不同的ie版本。我是这么做的,换浏览器的时候把tracedata的代理页面也拖过去,一般就能抓包了。
js 抓取网页内容(网页数据由JS生成,API借口地址随机变换,时间不等人)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-09-13 03:00
我们之前遇到的都是使用requests+BeautifulSoup的组合来请求和分析静态网页。如果是JS生成的内容,还介绍了如何找API借口获取数据。
但是有时候网页数据是JS生成的,找不到API借口活着或者API借口地址随机变化,时间不等人。那你就只能用Selenium了。
一、Selenium 介绍
Selenium 是一种用于 Web 应用程序的功能自动化测试工具。 Selenium 直接在浏览器中运行,就像真实用户在操作一样。
正因如此,Selenium也是采集网络数据的强大工具,它可以让浏览器自动加载页面,获取需要的数据,甚至是页面的截图,或者判断采集上的某些操作网站已经发生。
Selenium 没有浏览器,需要配合第三方浏览器使用。支持的浏览器有Chrome、Firefox、IE、Phantomjs等
如果我们使用Chrome、FireFox或IE,可以看到打开了一个浏览器窗口,打开@网站,然后执行代码中的操作。
不过,让程序在后台运行更符合我们的爬虫气质,所以我使用Phantomjs作为浏览器的载体。本文文章也介绍了Phantomjs
Phantomjs 是一个“无头”浏览器,即没有界面的浏览器,但它的功能与普通浏览器没有区别。
二、Python 中使用 Selenium 得到 空间的朋友们的讨论
之前用pip安装selenium,直接在代码中导入即可。
举个实际的例子——获取一个QQ空间好友的聊天信息,简单说明Selenium+Phantomjs的使用。
当我们需要爬取的页面是这样的:
QQ空间好友谈论的链接是:{好友QQ号}/311
我们抓住他说的话的时间和内容。
还是先上传代码:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
driver.maximize_window()
#登录QQ空间
def get_shuoshuo(qq):
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('641010605')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('zy060726')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
'time':sti.text,
'shuos':con.text
}
print(data)
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
print("==========完成================")
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('641010605')
获取到的数据截图如下:
接下来讲解代码,稍微了解一下Selenium的使用
三、代码简析
1.像往常一样,导入需要的模块:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
2. 使用 Selenium 的 webdriver 实例化一个浏览器对象,这里使用 Phantomjs:
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs.exe")
3.设置 Phantomjs 窗口最大化:
driver.maximize_window()
4.Main 函数部分
使用get()方法打开要爬取的网址:
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
等待5秒后,判断页面是否需要登录,判断页面是否有对应的DIV id:
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
如果页面有登录DIV,模拟登录:
driver.switch_to.frame('login_frame') #切换到登录ifram
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()#选择密码框
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()#点击登录按钮
time.sleep(3)
接下来判断好友空间是否设置有权限,通过判断是否有元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
如果你有访问讨论页的权限,定位元素和数据,并解析它们:
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
# 'qq':qq,
'time':sti.text,
'shuos':con.text
}
print(data)
除了在Selenium中解析数据,我们还可以将当前页面保存为源代码,使用BeautifulSoup来解析:
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
最后,让我们尝试使用 get_cookies() 获取 cookie:
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
另外,我将介绍Selenium的两种常用方法:
保存截图:
driver.save_screenshot('保存的文件路径及文件名')
执行JS脚本:
driver.execute_script("JS代码")
关于Selenium更详细的操作和使用,推荐一本书《selenium webdriver(python)第三版》,网上可以搜索; 查看全部
js 抓取网页内容(网页数据由JS生成,API借口地址随机变换,时间不等人)
我们之前遇到的都是使用requests+BeautifulSoup的组合来请求和分析静态网页。如果是JS生成的内容,还介绍了如何找API借口获取数据。
但是有时候网页数据是JS生成的,找不到API借口活着或者API借口地址随机变化,时间不等人。那你就只能用Selenium了。
一、Selenium 介绍
Selenium 是一种用于 Web 应用程序的功能自动化测试工具。 Selenium 直接在浏览器中运行,就像真实用户在操作一样。
正因如此,Selenium也是采集网络数据的强大工具,它可以让浏览器自动加载页面,获取需要的数据,甚至是页面的截图,或者判断采集上的某些操作网站已经发生。
Selenium 没有浏览器,需要配合第三方浏览器使用。支持的浏览器有Chrome、Firefox、IE、Phantomjs等
如果我们使用Chrome、FireFox或IE,可以看到打开了一个浏览器窗口,打开@网站,然后执行代码中的操作。
不过,让程序在后台运行更符合我们的爬虫气质,所以我使用Phantomjs作为浏览器的载体。本文文章也介绍了Phantomjs
Phantomjs 是一个“无头”浏览器,即没有界面的浏览器,但它的功能与普通浏览器没有区别。
二、Python 中使用 Selenium 得到 空间的朋友们的讨论
之前用pip安装selenium,直接在代码中导入即可。
举个实际的例子——获取一个QQ空间好友的聊天信息,简单说明Selenium+Phantomjs的使用。
当我们需要爬取的页面是这样的:
QQ空间好友谈论的链接是:{好友QQ号}/311
我们抓住他说的话的时间和内容。
还是先上传代码:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
#使用selenium
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe")
driver.maximize_window()
#登录QQ空间
def get_shuoshuo(qq):
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
time.sleep(5)
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
if a == True:
driver.switch_to.frame('login_frame')
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('641010605')
driver.find_element_by_id('p').clear()
driver.find_element_by_id('p').send_keys('zy060726')
driver.find_element_by_id('login_button').click()
time.sleep(3)
driver.implicitly_wait(3)
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
'time':sti.text,
'shuos':con.text
}
print(data)
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
print("==========完成================")
driver.close()
driver.quit()
if __name__ == '__main__':
get_shuoshuo('641010605')
获取到的数据截图如下:
接下来讲解代码,稍微了解一下Selenium的使用
三、代码简析
1.像往常一样,导入需要的模块:
from bs4 import BeautifulSoup
from selenium import webdriver
import time
2. 使用 Selenium 的 webdriver 实例化一个浏览器对象,这里使用 Phantomjs:
driver = webdriver.PhantomJS(executable_path="D:\\phantomjs.exe")
3.设置 Phantomjs 窗口最大化:
driver.maximize_window()
4.Main 函数部分
使用get()方法打开要爬取的网址:
driver.get('http://user.qzone.qq.com/{}/311'.format(qq))
等待5秒后,判断页面是否需要登录,判断页面是否有对应的DIV id:
try:
driver.find_element_by_id('login_div')
a = True
except:
a = False
如果页面有登录DIV,模拟登录:
driver.switch_to.frame('login_frame') #切换到登录ifram
driver.find_element_by_id('switcher_plogin').click()
driver.find_element_by_id('u').clear()#选择用户名框
driver.find_element_by_id('u').send_keys('QQ号')
driver.find_element_by_id('p').clear()#选择密码框
driver.find_element_by_id('p').send_keys('QQ密码')
driver.find_element_by_id('login_button').click()#点击登录按钮
time.sleep(3)
接下来判断好友空间是否设置有权限,通过判断是否有元素ID:QM_OwnerInfo_Icon
try:
driver.find_element_by_id('QM_OwnerInfo_Icon')
b = True
except:
b = False
如果你有访问讨论页的权限,定位元素和数据,并解析它们:
if b == True:
driver.switch_to.frame('app_canvas_frame')
content = driver.find_elements_by_css_selector('.content')
stime = driver.find_elements_by_css_selector('.c_tx.c_tx3.goDetail')
for con,sti in zip(content,stime):
data = {
# 'qq':qq,
'time':sti.text,
'shuos':con.text
}
print(data)
除了在Selenium中解析数据,我们还可以将当前页面保存为源代码,使用BeautifulSoup来解析:
pages = driver.page_source
soup = BeautifulSoup(pages,'lxml')
最后,让我们尝试使用 get_cookies() 获取 cookie:
cookie = driver.get_cookies()
cookie_dict = []
for c in cookie:
ck = "{0}={1};".format(c['name'],c['value'])
cookie_dict.append(ck)
i = ''
for c in cookie_dict:
i += c
print('Cookies:',i)
另外,我将介绍Selenium的两种常用方法:
保存截图:
driver.save_screenshot('保存的文件路径及文件名')
执行JS脚本:
driver.execute_script("JS代码")
关于Selenium更详细的操作和使用,推荐一本书《selenium webdriver(python)第三版》,网上可以搜索;
js 抓取网页内容( 网页抓取是通过自动化手段检索数据的过程-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-09-12 02:06
网页抓取是通过自动化手段检索数据的过程-乐题库)
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子-C#网络爬虫-我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C#适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?” 查看全部
js 抓取网页内容(
网页抓取是通过自动化手段检索数据的过程-乐题库)
网络抓取是通过自动化手段检索数据的过程。在很多场景中都是不可缺少的,比如竞争对手价格监控、房产挂牌、潜在客户和舆情监控、新闻文章或金融数据聚合等。
在编写网络抓取代码时,您必须做出的第一个决定是选择您的编程语言。您可以使用多种语言进行编写,例如 Python、JavaScript、Java、Ruby 或 C#。所有提到的语言都提供了强大的网页抓取功能。
在本文中,我们将探索 C# 并向您展示如何创建一个真正的 C# 公共网络爬虫。请记住,即使我们使用 C#,您也可以将此信息调整为 .NET 平台支持的所有语言,包括 VB.NET 和 F#。
01.C#网络爬虫
在编写任何代码之前,第一步是选择合适的 C# 库或包。这些 C# 库或包将能够下载 HTML 页面、解析它们并从这些页面中提取所需的数据。一些最流行的 C# 包如下:
●ScrapySharp
●Puppeteer Sharp
●Html 敏捷包
Html Agility Pack 是最流行的 C# 包,仅 Nuget 就有近 5000 万次下载。其流行的原因有很多,其中最重要的是HTML解析器可以直接下载网页,也可以使用浏览器下载。这个包可以容忍格式错误的 HTML 并支持 XPath。此外,它甚至可以解析本地 HTML 文件;因此,我们将在本文中进一步使用此包。
ScrapySharp 为 C# 编程添加了更多功能。这个包支持 CSS 选择器,可以模拟 Web 浏览器。尽管 ScrapySharp 被认为是一个强大的 C# 包,但程序员使用它进行维护的概率并不是很高。
Puppeteer Sharp 是著名的 Node.js Puppeteer 项目的 .NET 端口。它使用相同的 Chromium 浏览器来加载页面。此外,该包使用 async-await 风格的代码来支持异步和预操作管理。如果您已经熟悉这个 C# 包并且需要浏览器来渲染页面,那么 Puppeteer Sharp 可能是一个不错的选择。
02.使用C#搭建网络爬虫
如前所述,现在我们将演示如何编写将使用 Html Agility Pack 的 C# 公共网络爬虫代码。我们将使用 .NET 5 SDK 和 Visual Studio Code。此代码已在 .NET Core 3 和 .NET 5 上进行了测试,它应该适用于其他版本的 .NET。
我们将建立一个假设场景:抓取在线书店并采集书名和价格。
在编写C#网络爬虫之前,我们先搭建好开发环境。
03.搭建开发环境
对于C#开发环境,请安装Visual Studio Code。请注意,如果您使用 Visual Studio 和 Visual Studio Code 编写 C# 代码,则需要注意它们是两个完全不同的应用程序。
安装 Visual Studio Code 后,安装 .NET 5.0 或更高版本。您还可以使用 .NET Core 3.1。安装完成后,打开终端并运行以下命令以验证 .NET CLI 或命令行界面是否正常工作:
dotnet --version
这行命令会输出安装的.NET的版本号。
04.项目结构和依赖
代码将成为 .NET 项目的一部分。为简单起见,创建一个控制台应用程序。然后,创建一个文件夹,您将在其中编写 C# 代码。打开终端并导航到该文件夹。输入以下命令:
dotnet new console
这个命令的输出应该是控制台应用已经成功创建的信息。
是时候安装所需的软件包了。使用C#抓取公共网页,Html Agility Pack会是一个不错的选择。您可以使用以下命令为该项目安装它:
dotnet add package HtmlAgilityPack
安装另一个包,以便我们可以轻松地将捕获的数据导出到 CSV 文件:
dotnet add package CsvHelper
如果您使用的是 Visual Studio 而不是 Visual Studio Code,请单击“文件”,选择“新建解决方案”,然后按“控制台应用程序”按钮。要安装依赖项,请按照以下步骤操作:
●选择一个项目;
●单击以管理项目依赖项。这将打开 NuGet 包窗口;
●搜索HtmlAgilityPack并选择它;
●最后,搜索CsvHelper,选择它,然后点击添加包。
Visual Studio 中的 Nuget 包管理器
安装完这些包后,我们就可以继续编写爬取网上书店的代码了。
05.下载并解析网页数据
任何网页抓取程序的第一步都是下载网页的 HTML。这个HTML会是一个字符串,你需要把它转换成一个可以进一步处理的对象,这是第二步,这部分叫做解析。 Html Agility Pack 可以从本地文件、HTML 字符串、任何 URL 和浏览器读取和解析文件。
在我们的示例中,我们需要做的就是从 URL 中获取 HTML。 Html Agility Pack 不使用.NET 原生功能,而是提供了一个方便的类-HtmlWeb。这个类提供了一个Load函数,它可以接受一个URL,并返回一个HtmlDocument类的实例,这也是我们使用Part的包。有了这些信息,我们就可以编写一个接受 URL 并返回 HtmlDocument 实例的函数。
打开Program.cs文件,在类中输入这个函数Program:
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument (string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
这样,代码的第一步就完成了。下一步是解析文档。
06.Parse HTML:获取书籍链接
在这部分代码中,我们将从网页中提取所需的信息。在这个阶段,文档现在是一个 HtmlDocument 类型的对象。这个类公开了两个函数来选择元素。这两个函数都接受 XPath 输入并返回 HtmlNode 或 HtmlNode采集。
这是这两个函数的签名:
public HtmlNodeCollection SelectNodes(string xpath);
public HtmlNode SelectSingleNode(string xpath);
让我们先讨论 SelectNodes。
对于这个例子-C#网络爬虫-我们将从这个页面抓取所有书籍的详细信息。
首先,需要对其进行解析,以便可以提取到所有书籍的链接。在浏览器中打开上述书店页面,右键单击任一图书链接,然后单击“检查”按钮。开发者工具将打开。
了解标记后,您要选择的 XPath 应如下所示:
//h3/a
现在可以将此 XPath 传递给 SelectNodes 函数。
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
请注意,SelectNodes 函数是由
创建的
由 HtmlDocument 的 DocumentNode 属性调用。
变量linkNodes 是一个集合。我们可以写一个foreach循环,从每个链接中一一获取href值。我们只需要解决一个小问题——即页面上的链接是相对链接。因此,在抓取这些提取的链接之前,我们需要将它们转换为绝对网址。
为了转换相对链接,我们可以使用 Uri 类。我们使用这个构造函数来获取具有绝对 URL 的 Uri 对象。
dotnet --version
一旦我们有了 Uri 对象,我们就可以简单地检查 AbsoluteUri 属性来获取完整的 URL。
我们将所有这些都写在一个函数中,以保持代码井井有条。
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
在这个函数中,我们从一个空的 List 对象开始。在 foreach 循环中,我们将所有链接添加到该对象并返回。
现在,我们可以修改 Main() 函数,以便我们可以测试到目前为止编写的 C# 代码。修改后的函数如下:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
}
要运行此代码,请打开终端并导航到收录此文件的目录,然后键入以下内容:
dotnet run
输出应如下所示:
Found 20 links
然后我们进入下一部分,我们将处理所有链接以获取图书数据。
07.Parse HTML:获取详细书籍信息
此时,我们有一个收录书籍 URL 的字符串列表。我们可以简单的写一个循环,先用我们写的GetDocument函数来获取文档。之后,我们将使用 SelectSingleNode 函数来提取图书的标题和价格。
为了让数据清晰、有条理,我们从一个类开始。这个类将代表一本书并且有两个属性——标题和价格。示例如下:
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
然后,在浏览器中打开 Title-//h1 的书页。为价格创建 XPath 有点棘手,因为相同的类应用于底部的附加书籍。
XPath 价格
价格的 XPath 将如下所示:
//div[contains(@class,"product_main")]/p[@class="price_color"]
请注意 XPath 收录双引号。我们必须通过在它们前面加上反斜杠来转义这些字符。
现在我们可以使用 SelectSingleNode 函数获取节点,然后使用 InnerText 属性获取元素中收录的文本。我们可以将所有内容放在一个函数中,如下所示:
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode (priceXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
此函数将返回一个 Book 对象列表。是时候更新 Main() 函数了:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
这个网络抓取项目的最后一部分是将数据导出为 CSV。
08.导出数据
如果你还没有安装CsvHelper,可以通过
dotnet add package CsvHelper
在终端中运行命令以完成此操作。
导出功能很简单。首先,我们需要创建一个 StreamWriter 并将 CSV 文件名作为参数发送。接下来,我们将使用这个对象来创建一个 CsvWriter。最后,我们可以使用 WriteRecords 函数在一行代码中编写所有书籍。
为了确保所有资源都被正确关闭,我们可以使用 using 块。我们也可以将所有东西都包装在一个函数中,如下所示:
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
最后,我们可以从 Main() 函数中调用这个函数:
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/cata ... 6quot;);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
要运行此代码,请打开终端并运行以下命令:
dotnet run
几秒钟后,您将创建一个 books.csv 文件。
09.conclusion
如果你想用C#写一个网络爬虫,你可以使用多个包。在本文中,我们展示了如何使用 Html Agility Pack,这是一个功能强大且易于使用的包。也是一个简单的例子,可以进一步增强;例如,您可以尝试将上述逻辑添加到此代码中以处理多个页面。
如果您想详细了解使用其他编程语言进行网页抓取的工作原理,可以查看使用 Python 进行网页抓取的指南。我们还有一个
常见问题
问:C#适合爬网吗?
A:与 Python 类似,C# 被广泛用于网络爬虫。在决定选择哪种编程语言时,选择您最熟悉的一种很重要。但是您将能够在 Python 和 C# 中找到示例网络爬虫。
问:网络抓取合法吗?
A:如果在不违反任何法律的情况下使用代理,它们可能是合法的。但是,在与代理人进行任何活动之前,您应该就您的具体案件获得专业的法律建议。请参考我们的文章“网络抓取合法吗?”

