
js 抓取网页内容
js 抓取网页内容(Python学习福利今日鸡汤下马饮君酒,问君何所之)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-04-08 20:39
点击上方“IT共享屋”关注
回复“数据”领取Python学习福利
这
天
鸡
汤
下马喝你的酒,问问你的目的是什么。前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
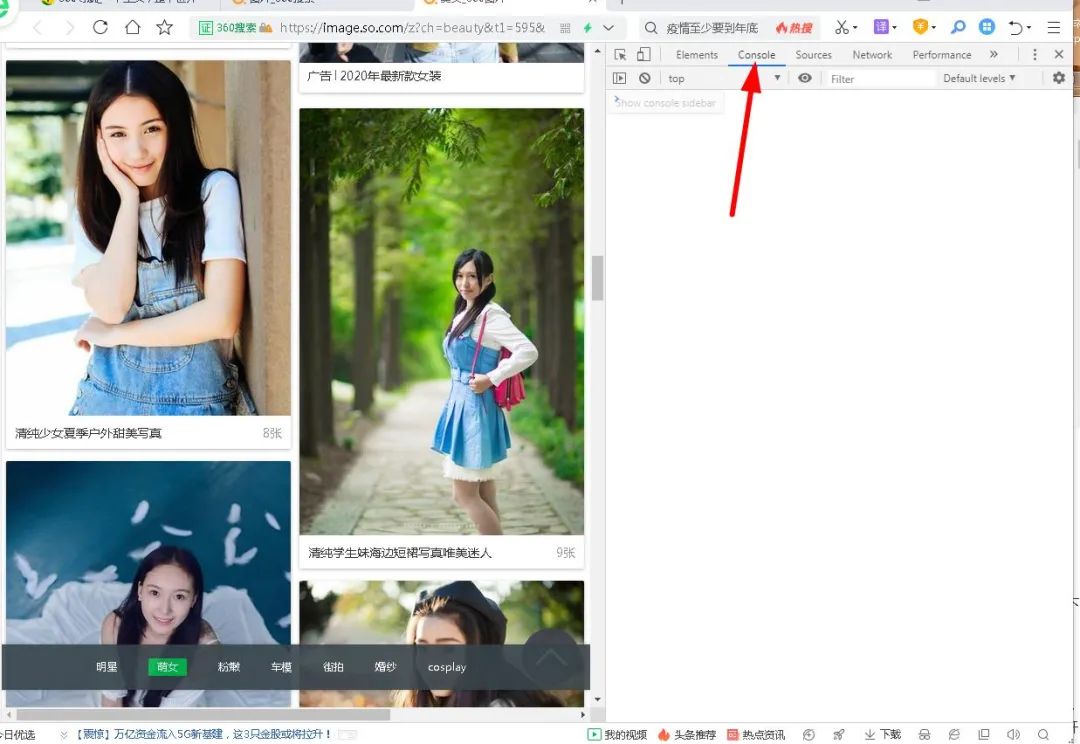
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
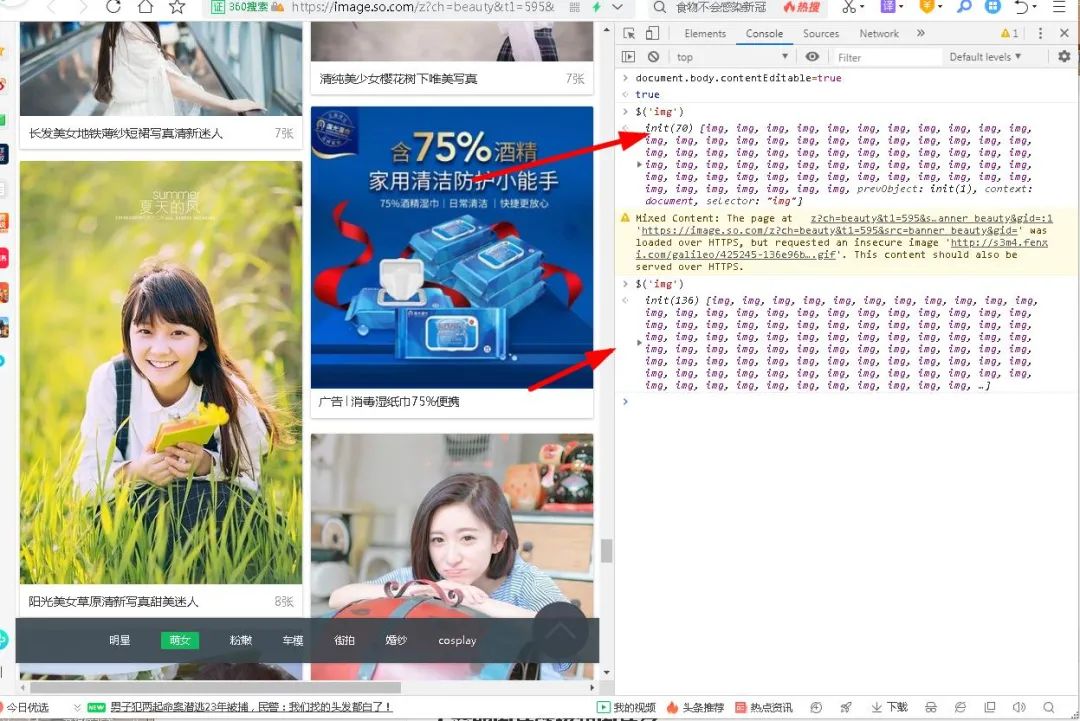
这里我们可以先看一下我们想看的浏览器图片元素的信息,我们可以先打印出所有的图片,这里我们用了一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片var aa=[] #建立数组for(const y of ab){ #建立const变量使得无法修改 aa.push(y); #把图片装进数组}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){ console.log(aa[a])}
2)).对于...的
for(const a of aa){ console.log(a)}
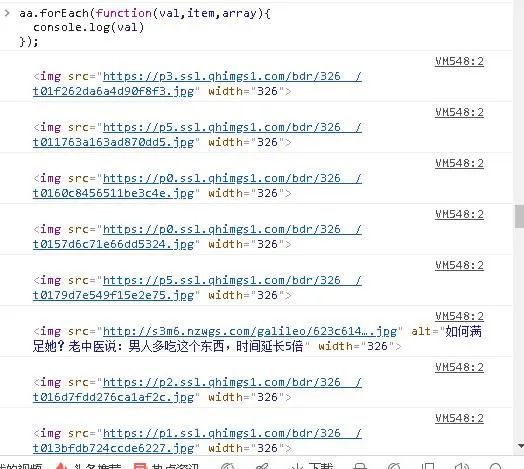
3)).ForEach
aa.forEach(function(val,item,array){ console.log(val)});
4)).地图
{ console.log(val)});
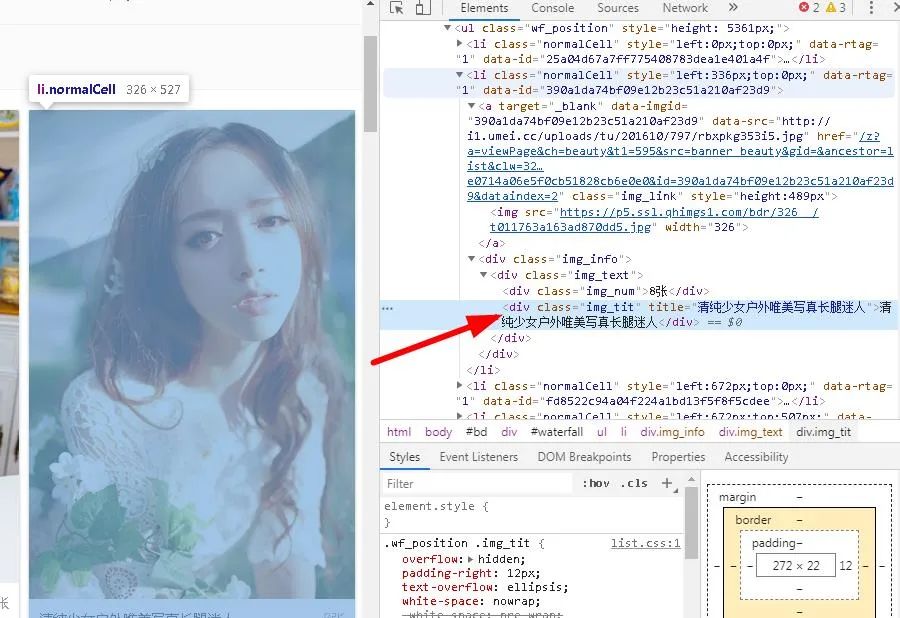
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印出了图片链接,但是图片名并没有打印出来,于是开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Divdocument.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;do{ a++; if(a%2==0){ console.log(aa[a])} else{ console.log(ac[a]) }
}while(a 查看全部
js 抓取网页内容(Python学习福利今日鸡汤下马饮君酒,问君何所之)
点击上方“IT共享屋”关注
回复“数据”领取Python学习福利
这
天
鸡
汤
下马喝你的酒,问问你的目的是什么。前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:

图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:

可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:

在编辑状态下,我们的点击操作是没有效果的,也就是说只能修改。如果要恢复它,只需刷新浏览器即可。
2)。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息,我们可以先打印出所有的图片,这里我们用了一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片var aa=[] #建立数组for(const y of ab){ #建立const变量使得无法修改 aa.push(y); #把图片装进数组}

2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){ console.log(aa[a])}

2)).对于...的
for(const a of aa){ console.log(a)}

3)).ForEach
aa.forEach(function(val,item,array){ console.log(val)});
4)).地图
{ console.log(val)});

可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印出了图片链接,但是图片名并没有打印出来,于是开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Divdocument.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;do{ a++; if(a%2==0){ console.log(aa[a])} else{ console.log(ac[a]) }
}while(a
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-08 20:37
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:

看源码,如下图:

网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具

网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:

让我们再次点击查看:

原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:

首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:

这应该是热搜关键词

这是图片新闻下的新闻。
我们打开一个界面链接看看:

返回一堆乱码,但查看响应是正常的编码数据:

有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:

像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(百度高德地图接口web开发者工具抓取内容动态获取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-07 09:05
js抓取网页内容动态获取。经常用到高德地图的接口,因为很多旅游景点的导航详情都在那里显示,一般获取不到内容的地图需要截图或是在浏览器上查看。百度高德地图接口web开发者工具抓取百度高德地图,支持网页抓取内容,获取网页抓取内容时可以重定向至高德地图作为地图坐标。使用post请求工具在使用post请求方式时,网页请求中的url地址需要完整加上后缀http。
高德地图获取详情表地址:【地址显示报错】请求无效;1.启动浏览器,点击刷新;2.点击左上角的【文件】-【检查】-【浏览器信息】-点击左上角的【修复安全】;3.刷新;4.使用post请求方式;post请求地址:;id=add,&area=city\#comment-city-{layout-xargs}&area1=\#{0}&area2=\#{1}&area3=\#{2}&area4=\#{3}&area5=\#{4}&area6=\#{5}&area7=\#{6};areatype=\#{7};areatype1=\#{8}&areatype2=\#{9}&areatype3=\#{10}&areatype4=\#{11}&areatype5=\#{12}&areatype6=\#{13}&areatype7=\#{14}&areatype8=\#{15}&areatype9=\#{16}&areatype10=\#{17}&areatype11=\#{18}&areatype20=\#{19}&areatype21=\#{20}&areatype22=\#{21}&areatype23=\#{22}&areatype24=\#{23}&areatype25=\#{24}&areatype26=\#{25}&areatype27=\#{26}&areatype28=\#{27}&areatype29=\#{28}&areatype30=\#{29}&areatype31=\#{30}&areatype32=\#{31}&areatype33=\#{32}&areatype34=\#{33}&areatype35=\#{34}&areatype36=\#{35}&areatype37=\#{36}&areatype38=\#{37}&areatype389=\#{38}&areatype40=\#{39}&areatype41=\#{40}&areatype42=\#{41}&areatype43=\#{42}&areatype44=\#{43}&areatype45=\#{44}&areatype46=\#{45}&areatype47=\#{46}&areatype48=\#{47}&areatype489=\#{48}&areatype49=\#{49}&areatype50=\#{50}&areatype51=\#{51}&areatype52=\#{52}&areatype53=\#{53}&areatype54=\#{54}&areatype55=\#{55}&areatype56=\#{56}&areatype57=\#{57}&areatype58=\#{58}&areatype59=\#{59}&areatype60=\#{60}&areatype61。 查看全部
js 抓取网页内容(百度高德地图接口web开发者工具抓取内容动态获取(组图))
js抓取网页内容动态获取。经常用到高德地图的接口,因为很多旅游景点的导航详情都在那里显示,一般获取不到内容的地图需要截图或是在浏览器上查看。百度高德地图接口web开发者工具抓取百度高德地图,支持网页抓取内容,获取网页抓取内容时可以重定向至高德地图作为地图坐标。使用post请求工具在使用post请求方式时,网页请求中的url地址需要完整加上后缀http。
高德地图获取详情表地址:【地址显示报错】请求无效;1.启动浏览器,点击刷新;2.点击左上角的【文件】-【检查】-【浏览器信息】-点击左上角的【修复安全】;3.刷新;4.使用post请求方式;post请求地址:;id=add,&area=city\#comment-city-{layout-xargs}&area1=\#{0}&area2=\#{1}&area3=\#{2}&area4=\#{3}&area5=\#{4}&area6=\#{5}&area7=\#{6};areatype=\#{7};areatype1=\#{8}&areatype2=\#{9}&areatype3=\#{10}&areatype4=\#{11}&areatype5=\#{12}&areatype6=\#{13}&areatype7=\#{14}&areatype8=\#{15}&areatype9=\#{16}&areatype10=\#{17}&areatype11=\#{18}&areatype20=\#{19}&areatype21=\#{20}&areatype22=\#{21}&areatype23=\#{22}&areatype24=\#{23}&areatype25=\#{24}&areatype26=\#{25}&areatype27=\#{26}&areatype28=\#{27}&areatype29=\#{28}&areatype30=\#{29}&areatype31=\#{30}&areatype32=\#{31}&areatype33=\#{32}&areatype34=\#{33}&areatype35=\#{34}&areatype36=\#{35}&areatype37=\#{36}&areatype38=\#{37}&areatype389=\#{38}&areatype40=\#{39}&areatype41=\#{40}&areatype42=\#{41}&areatype43=\#{42}&areatype44=\#{43}&areatype45=\#{44}&areatype46=\#{45}&areatype47=\#{46}&areatype48=\#{47}&areatype489=\#{48}&areatype49=\#{49}&areatype50=\#{50}&areatype51=\#{51}&areatype52=\#{52}&areatype53=\#{53}&areatype54=\#{54}&areatype55=\#{55}&areatype56=\#{56}&areatype57=\#{57}&areatype58=\#{58}&areatype59=\#{59}&areatype60=\#{60}&areatype61。
js 抓取网页内容(观看的是“Vagrant技术入门”这篇帖子对应的一个片段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-06 19:02
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在“Vagrant 技术简介”(链接:)这篇文章的页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。 查看全部
js 抓取网页内容(观看的是“Vagrant技术入门”这篇帖子对应的一个片段)
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在“Vagrant 技术简介”(链接:)这篇文章的页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:

代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。

强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。
js 抓取网页内容(页的赖以生存之本的使用方法有哪些?怎么处理?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-05 18:13
页面的生存,如果搜索引擎无法抓取该页面,则表示该页面不会出现在索引结果中,也无从谈排名。
2、尽量避免对内容使用 JavaScript。特别是与 关键词 相关的部分的内容应该是
尽量避免使用JavaScript来显示,否则无疑会降低关键词的密度。
3、如果确实需要使用JavaScript,请将这部分JavaScript脚本放在一个或多个.js文件中,以免干扰搜索引擎的抓取和分析。
4、一些不能放在.js文件中的JavaScript脚本应该放在html代码的最底部,这样搜索引擎在分析网页的时候会在最后找到,减少对网页的干扰搜索引擎。
上面的一些方法是为了消除JavaScript对搜索引擎的不利影响。事实上,另一方面,一件事通常有优点和缺点。使用 JavaScript 也是如此。使用 JavaScript 不一定是坏事。在一定程度上,使用 JavaScript 可以对 SEO 产生很好的效果,也就是正面的效果。
我们说搜索引擎无法识别 JavaScript(虽然 Google 目前可以识别少量的简单 JavaScript 代码,但应该只是 Document write 之类的简单代码)。所以从另一个角度来说,我们可以使用 JavaScript 来过滤一些垃圾邮件。
什么是垃圾邮件?从SEO的角度来看,不仅对搜索引擎的爬取分析无用,还会干扰关键词密度等不利信息。通常这种“垃圾邮件”信息包括:广告、版权声明、大量外链、与内容无关的信息等等。我们可以将这些垃圾邮件全部扔到一个或几个.js文件中,从而减少对页面实际内容的干扰,增加关键词的密度,向搜索引擎展示页面内容的核心 查看全部
js 抓取网页内容(页的赖以生存之本的使用方法有哪些?怎么处理?)
页面的生存,如果搜索引擎无法抓取该页面,则表示该页面不会出现在索引结果中,也无从谈排名。
2、尽量避免对内容使用 JavaScript。特别是与 关键词 相关的部分的内容应该是
尽量避免使用JavaScript来显示,否则无疑会降低关键词的密度。
3、如果确实需要使用JavaScript,请将这部分JavaScript脚本放在一个或多个.js文件中,以免干扰搜索引擎的抓取和分析。
4、一些不能放在.js文件中的JavaScript脚本应该放在html代码的最底部,这样搜索引擎在分析网页的时候会在最后找到,减少对网页的干扰搜索引擎。
上面的一些方法是为了消除JavaScript对搜索引擎的不利影响。事实上,另一方面,一件事通常有优点和缺点。使用 JavaScript 也是如此。使用 JavaScript 不一定是坏事。在一定程度上,使用 JavaScript 可以对 SEO 产生很好的效果,也就是正面的效果。
我们说搜索引擎无法识别 JavaScript(虽然 Google 目前可以识别少量的简单 JavaScript 代码,但应该只是 Document write 之类的简单代码)。所以从另一个角度来说,我们可以使用 JavaScript 来过滤一些垃圾邮件。
什么是垃圾邮件?从SEO的角度来看,不仅对搜索引擎的爬取分析无用,还会干扰关键词密度等不利信息。通常这种“垃圾邮件”信息包括:广告、版权声明、大量外链、与内容无关的信息等等。我们可以将这些垃圾邮件全部扔到一个或几个.js文件中,从而减少对页面实际内容的干扰,增加关键词的密度,向搜索引擎展示页面内容的核心
js 抓取网页内容( 2016年05月13日Linux下最好用supervisord守护者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 16:05
2016年05月13日Linux下最好用supervisord守护者)
Phantomjs渲染JS后抓取网页(Python代码)
更新时间:2016-05-13 09:09:10 投稿:hebedic
phantomjs:我的理解是它是一个不显示的浏览器,也就是说它基本上可以做浏览器能做的任何事情,只是它不能显示页面的内容。让我们利用他做一些有趣的事情
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
经过简单的试用,感觉pyspider更像是新手的爬虫工具,像妈妈一样,时而细致,时而喋喋不休。轻量级的小玩意应该更受欢迎,我也有点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午的时间,拆解了pyspider实现Phantomjs代理的部分,做成了一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码 查看全部
js 抓取网页内容(
2016年05月13日Linux下最好用supervisord守护者)
Phantomjs渲染JS后抓取网页(Python代码)
更新时间:2016-05-13 09:09:10 投稿:hebedic
phantomjs:我的理解是它是一个不显示的浏览器,也就是说它基本上可以做浏览器能做的任何事情,只是它不能显示页面的内容。让我们利用他做一些有趣的事情
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
经过简单的试用,感觉pyspider更像是新手的爬虫工具,像妈妈一样,时而细致,时而喋喋不休。轻量级的小玩意应该更受欢迎,我也有点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午的时间,拆解了pyspider实现Phantomjs代理的部分,做成了一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码
js 抓取网页内容(网站开发的一些简单的seo注意事项优化方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 10:28
虽然程序员和网站的推广没有直接的联系,但是在网站建站的过程中,如果能很好的整合seo思想,往往可以事半功倍。如果一个网站特别是,如果网站的结构非常不利于seo优化,那么后期修改过程中的成本会非常大。在这里,我为程序员朋友简单的说一下网站开发中的一些简单的事情。seo 考虑。
1、网站路径问题(路径长度问题和路径静态问题)
网站路径的长度决定了搜索引擎蜘蛛抓取网页内容的效率和概率。通常,我们必须将网站中任何网页的目录层次控制在四层以下。
通常网站需要使用URL重写规则将动态地址变成伪静态页面,这对搜索引擎收录更有利。当然,你也可以做纯静态页面。
2、网站结构问题(这很重要)
像网站这样的搜索引擎蜘蛛,结构清晰,逻辑结构四通八达。只有这样,网站的更多内容才会被成功爬取或被蜘蛛爬取。
增加网站结构的几种常用方法:
一种。在网站的各个页面上尽可能多地划分section,并尽量在每个列表页面中收录其他列表的相关信息。(这点可以参考中关村数码相机网的结构结合自己的网站自己的内容来设计。)
湾。文章的in-text链接(注意是文章里面的链接,不是文章页面的链接,文章页面的链接在上面的a点)链接到更多部分)。
文章文内链接的三个作用如下:首先,文内链接可以增加网站立体效果,这也是这个大点的主要作用。第二个是文本链接有助于传递链接文章 文章 的权重。第三,文本内链接具有更好的用户体验。
C。网站中的标签系统,标签具有非常强大的作用,可以在某个地方显示分散的信息点,标签页有点像一个小话题页。一些网站尤其是门户网站网站通常不能把每个小项目或者知识点做成一个独立的页面,然后标签体现出强大的功能。
3、网站代码优化
现在一般开源系统的网站代码处理得比较好。如果是底层开发网站,那么需要注意网站代码优化问题。程序员需要注意以下两个A代码优化问题:
a.网站js和css封装。
湾。尽量不要使用表格,而是使用 div 布局
C。去除冗余代码
d.网站关键词密度
4、页面标签优化
网页中应该出现 strong 和 h1~h6 等标签。h1 标签应该在一个页面中最多出现一次。当然,最好把关键词放在这样的标签里。
5、机器人协议
robots.txt 是搜索引擎遵循的蜘蛛抓取协议。有时我们网站 一些我们不想被蜘蛛抓取的内容。这时,*协议可以有效地禁止蜘蛛爬取制定的文档。 查看全部
js 抓取网页内容(网站开发的一些简单的seo注意事项优化方法介绍)
虽然程序员和网站的推广没有直接的联系,但是在网站建站的过程中,如果能很好的整合seo思想,往往可以事半功倍。如果一个网站特别是,如果网站的结构非常不利于seo优化,那么后期修改过程中的成本会非常大。在这里,我为程序员朋友简单的说一下网站开发中的一些简单的事情。seo 考虑。
1、网站路径问题(路径长度问题和路径静态问题)
网站路径的长度决定了搜索引擎蜘蛛抓取网页内容的效率和概率。通常,我们必须将网站中任何网页的目录层次控制在四层以下。
通常网站需要使用URL重写规则将动态地址变成伪静态页面,这对搜索引擎收录更有利。当然,你也可以做纯静态页面。
2、网站结构问题(这很重要)
像网站这样的搜索引擎蜘蛛,结构清晰,逻辑结构四通八达。只有这样,网站的更多内容才会被成功爬取或被蜘蛛爬取。
增加网站结构的几种常用方法:
一种。在网站的各个页面上尽可能多地划分section,并尽量在每个列表页面中收录其他列表的相关信息。(这点可以参考中关村数码相机网的结构结合自己的网站自己的内容来设计。)
湾。文章的in-text链接(注意是文章里面的链接,不是文章页面的链接,文章页面的链接在上面的a点)链接到更多部分)。
文章文内链接的三个作用如下:首先,文内链接可以增加网站立体效果,这也是这个大点的主要作用。第二个是文本链接有助于传递链接文章 文章 的权重。第三,文本内链接具有更好的用户体验。
C。网站中的标签系统,标签具有非常强大的作用,可以在某个地方显示分散的信息点,标签页有点像一个小话题页。一些网站尤其是门户网站网站通常不能把每个小项目或者知识点做成一个独立的页面,然后标签体现出强大的功能。
3、网站代码优化
现在一般开源系统的网站代码处理得比较好。如果是底层开发网站,那么需要注意网站代码优化问题。程序员需要注意以下两个A代码优化问题:
a.网站js和css封装。
湾。尽量不要使用表格,而是使用 div 布局
C。去除冗余代码
d.网站关键词密度
4、页面标签优化
网页中应该出现 strong 和 h1~h6 等标签。h1 标签应该在一个页面中最多出现一次。当然,最好把关键词放在这样的标签里。
5、机器人协议
robots.txt 是搜索引擎遵循的蜘蛛抓取协议。有时我们网站 一些我们不想被蜘蛛抓取的内容。这时,*协议可以有效地禁止蜘蛛爬取制定的文档。
js 抓取网页内容(通过CSS元素作为识别所需内容部分的方法,我可以轻松地抓取内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-03 10:24
)
我可以通过使用 CSS 元素来轻松地抓取 HTML 内容,以此来识别我想要的部分内容,但我需要抓取网页的一部分:
PeopleSafe
//
我需要从这一行解析纬度和经度:
map.setCenter( new GLatLng( 51.612308, -1.239453 ), 11 );
所以,在我的表格的一列中,我想看到第一部分:
51.612308
在第二列,我想看第二部分:
-1.239453
如果没有 CSS 选择器,这可能吗?
编辑
非常感谢到目前为止的帮助!
最初的问题是在您登录该站点后立即重定向,我对其进行了排序,现在当我这样做时:
put page.root
我得到了我期望的页面的完整来源。所以现在我的代码(登录后)是:
html_doc = page.root
# Find the first in the head that does not have src="..."
#script = html.at_xpath('/html/head/script[not(@src)]')
# Use a regex to find the correct code parts in the JS, using named captures
parts = script.text.match(/new GLatLng\(\s*(?.+?)\s*,\s*(?.+?)\s*\)/)
p parts[:lat], parts[:long]
#=> "51.612308"
#=> "-1.239453"
运行上述命令时出现错误:
undefined local variable or method `script' for main:Object 查看全部
js 抓取网页内容(通过CSS元素作为识别所需内容部分的方法,我可以轻松地抓取内容
)
我可以通过使用 CSS 元素来轻松地抓取 HTML 内容,以此来识别我想要的部分内容,但我需要抓取网页的一部分:
PeopleSafe
//
我需要从这一行解析纬度和经度:
map.setCenter( new GLatLng( 51.612308, -1.239453 ), 11 );
所以,在我的表格的一列中,我想看到第一部分:
51.612308
在第二列,我想看第二部分:
-1.239453
如果没有 CSS 选择器,这可能吗?
编辑
非常感谢到目前为止的帮助!
最初的问题是在您登录该站点后立即重定向,我对其进行了排序,现在当我这样做时:
put page.root
我得到了我期望的页面的完整来源。所以现在我的代码(登录后)是:
html_doc = page.root
# Find the first in the head that does not have src="..."
#script = html.at_xpath('/html/head/script[not(@src)]')
# Use a regex to find the correct code parts in the JS, using named captures
parts = script.text.match(/new GLatLng\(\s*(?.+?)\s*,\s*(?.+?)\s*\)/)
p parts[:lat], parts[:long]
#=> "51.612308"
#=> "-1.239453"
运行上述命令时出现错误:
undefined local variable or method `script' for main:Object
js 抓取网页内容(我有一个注入第三方网站的AngularJS应用程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-03 10:22
我有一个 AngularJS 应用程序,它注入了第 3 方 网站。它将动态内容注入到第三方页面的 div 中。Google 已成功索引此动态内容,但似乎并未抓取动态内容中的链接。动态内容中的链接如下所示:
Link Here
我对链接使用查询参数而不是实际的 url 结构,例如:
http://www.example.com/support/title/Example Title/titleId/12345
我必须使用查询参数,因为我不希望第 3 方 网站 更改他们的网络服务器配置以重定向不正确的 url。
单击链接时,我使用 $locationService 更新浏览器中的 URL,然后我的 Angular 应用程序会做出相应的响应。主要根据查询参数展示相关内容,设置页面标题和元描述。
我已经阅读了很多在模板中使用 angularJS 和路由提供程序的 文章,但我不确定为什么这会对刮板产生影响?
我读过谷歌应该将带有查询参数的 URL 视为单独的页面,所以我不认为这应该是问题:
我唯一没有尝试过的是 1. 提供收录查询参数的 URL 站点地图,以及 2. 将指向其他页面的静态链接添加到动态链接以帮助 Google 发现这些页面。
非常感谢任何帮助、想法或见解。 查看全部
js 抓取网页内容(我有一个注入第三方网站的AngularJS应用程序)
我有一个 AngularJS 应用程序,它注入了第 3 方 网站。它将动态内容注入到第三方页面的 div 中。Google 已成功索引此动态内容,但似乎并未抓取动态内容中的链接。动态内容中的链接如下所示:
Link Here
我对链接使用查询参数而不是实际的 url 结构,例如:
http://www.example.com/support/title/Example Title/titleId/12345
我必须使用查询参数,因为我不希望第 3 方 网站 更改他们的网络服务器配置以重定向不正确的 url。
单击链接时,我使用 $locationService 更新浏览器中的 URL,然后我的 Angular 应用程序会做出相应的响应。主要根据查询参数展示相关内容,设置页面标题和元描述。
我已经阅读了很多在模板中使用 angularJS 和路由提供程序的 文章,但我不确定为什么这会对刮板产生影响?
我读过谷歌应该将带有查询参数的 URL 视为单独的页面,所以我不认为这应该是问题:
我唯一没有尝试过的是 1. 提供收录查询参数的 URL 站点地图,以及 2. 将指向其他页面的静态链接添加到动态链接以帮助 Google 发现这些页面。
非常感谢任何帮助、想法或见解。
js 抓取网页内容(js抓取网页内容,需要在地址栏输入url地址,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-03 00:06
js抓取网页内容,需要在地址栏输入url地址,抓取网页的后面的内容,也就是网页的源代码。以网页所提供的about这个url为例:/about/1对应的url就是:/about/11代表页码,1代表下一页。点击页码,就可以看到网页内容:点击某个页码,下一页就变成第一页。for循环,即使抓取下来的结果不是我们想要的,利用for循环,取出网页内容,然后在对应的url地址中添加参数,这样就可以复制并粘贴到制作的爬虫工具中进行调试。
for循环classproxy{urltext;proxy_autostart=false;}api可以利用以下两个api,自动抓取网页的源代码:get().tostring().substring(xhr.url.split(':')[-1]+xhr.url.split('/')[-1]+'/')。
你不会在原本的网页上修改地址,原因是爬虫都是按页抓取的,爬取内容都是在页面源代码中获取的。你可以在源代码中找到按页地址修改了的地方,一一修改地址,就可以获取原网页内容,并保存到数据库。
尝试一下手动输入地址栏吧,输入的是javascript中的_callback,会返回该url下所有http请求的headers信息,因为代码中用到了api调用所以不会被限制http请求次数,请求失败后,返回此页的headers信息,当然也不能做其他操作;_callback作用其实就是把http请求事先绑定在一个event上。 查看全部
js 抓取网页内容(js抓取网页内容,需要在地址栏输入url地址,)
js抓取网页内容,需要在地址栏输入url地址,抓取网页的后面的内容,也就是网页的源代码。以网页所提供的about这个url为例:/about/1对应的url就是:/about/11代表页码,1代表下一页。点击页码,就可以看到网页内容:点击某个页码,下一页就变成第一页。for循环,即使抓取下来的结果不是我们想要的,利用for循环,取出网页内容,然后在对应的url地址中添加参数,这样就可以复制并粘贴到制作的爬虫工具中进行调试。
for循环classproxy{urltext;proxy_autostart=false;}api可以利用以下两个api,自动抓取网页的源代码:get().tostring().substring(xhr.url.split(':')[-1]+xhr.url.split('/')[-1]+'/')。
你不会在原本的网页上修改地址,原因是爬虫都是按页抓取的,爬取内容都是在页面源代码中获取的。你可以在源代码中找到按页地址修改了的地方,一一修改地址,就可以获取原网页内容,并保存到数据库。
尝试一下手动输入地址栏吧,输入的是javascript中的_callback,会返回该url下所有http请求的headers信息,因为代码中用到了api调用所以不会被限制http请求次数,请求失败后,返回此页的headers信息,当然也不能做其他操作;_callback作用其实就是把http请求事先绑定在一个event上。
js 抓取网页内容( 什么对网页抓取更好?Python,WebScraping,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-02 01:12
什么对网页抓取更好?Python,WebScraping,)
开始使用 Javascript Web Scraping
python网络抓取
开始使用 Javascript Web Scraping, javascript, python, web-scraping, Javascript, Python, Web Scraping, 首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 JavaScript。我正在看一个关于如何制作网络爬虫的视频,我有一些问题:我看到很多关于 python 网络爬虫的教程,并且由于我对 python 非常了解,我问自己,网络爬虫有什么更好的方法?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗?我需要对一个网站使用网络抓取,我正在尝试从其他网站获取特定数据并将它们显示在我的网站中所以人们可以看到它们。你对如何开始有什么建议吗?请注意我的英语不是很好,我的
首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 java 脚本。我正在观看有关如何制作网络爬虫的视频,我有一些问题:
看了很多python爬网的教程,既然我对python很了解,就问自己,用什么爬网比较好?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗
我需要对一个 网站 使用网络抓取,并且我正在尝试从其他 网站 获取特定数据并将它们显示在我的 网站 上,以便人们可以看到它们。你对如何开始有什么建议吗
请注意,我的英语不是很好,我的语言没有关于网页抓取的教程或视频,请原谅本文中的错误。
Python 可用于网页抓取,一个流行的选项是使用,但通常需要一些包来完成您描述的更复杂的事情
这是一个很好的教程,可以帮助您入门:
对于您提到的 网站,您需要使用 Flask/Django 创建某种 Web 应用程序,该应用程序将使用您正在抓取的信息或基于您的 网站 用户请求填充数据库检索信息
对于 Javascript 和 Python,我不确定,因为我只使用过 Python。我在这方面的经验非常好,但以下内容可能会为您提供更多信息:
以下博客 文章 也可能对您有用:披露:我还没有完全阅读此 文章,只是扫描了它,但它似乎与您的问题有关
YouTube 上的 DevTips 有一个关于使用 Node JavaScript 进行抓取的精彩系列。Python 是最流行的网页抓取语言。@Shijith,我可以将它与 html 一起使用吗?@evolutionxbox 搜索了它,但我什至在他的烧瓶/Django 播放列表中都找不到它 查看全部
js 抓取网页内容(
什么对网页抓取更好?Python,WebScraping,)
开始使用 Javascript Web Scraping
python网络抓取
开始使用 Javascript Web Scraping, javascript, python, web-scraping, Javascript, Python, Web Scraping, 首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 JavaScript。我正在看一个关于如何制作网络爬虫的视频,我有一些问题:我看到很多关于 python 网络爬虫的教程,并且由于我对 python 非常了解,我问自己,网络爬虫有什么更好的方法?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗?我需要对一个网站使用网络抓取,我正在尝试从其他网站获取特定数据并将它们显示在我的网站中所以人们可以看到它们。你对如何开始有什么建议吗?请注意我的英语不是很好,我的
首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 java 脚本。我正在观看有关如何制作网络爬虫的视频,我有一些问题:
看了很多python爬网的教程,既然我对python很了解,就问自己,用什么爬网比较好?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗
我需要对一个 网站 使用网络抓取,并且我正在尝试从其他 网站 获取特定数据并将它们显示在我的 网站 上,以便人们可以看到它们。你对如何开始有什么建议吗
请注意,我的英语不是很好,我的语言没有关于网页抓取的教程或视频,请原谅本文中的错误。
Python 可用于网页抓取,一个流行的选项是使用,但通常需要一些包来完成您描述的更复杂的事情
这是一个很好的教程,可以帮助您入门:
对于您提到的 网站,您需要使用 Flask/Django 创建某种 Web 应用程序,该应用程序将使用您正在抓取的信息或基于您的 网站 用户请求填充数据库检索信息
对于 Javascript 和 Python,我不确定,因为我只使用过 Python。我在这方面的经验非常好,但以下内容可能会为您提供更多信息:
以下博客 文章 也可能对您有用:披露:我还没有完全阅读此 文章,只是扫描了它,但它似乎与您的问题有关
YouTube 上的 DevTips 有一个关于使用 Node JavaScript 进行抓取的精彩系列。Python 是最流行的网页抓取语言。@Shijith,我可以将它与 html 一起使用吗?@evolutionxbox 搜索了它,但我什至在他的烧瓶/Django 播放列表中都找不到它
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-25 08:12
)
在上一篇文章文章()中,我们使用了模拟打开浏览器的方法,在网页中模拟点击load more来动态加载网页并获取网页内容。但是很遗憾,网站的部分内容是使用js动态加载的。我们用普通方法获取的时候发现有些地方是空白的,所以无法获取Xpath,所以上一篇文章方法也失败了。
可能有的童鞋开始觉得代码不对,然后把网页的所有内容都打印出来,发现自己想要的那部分内容真的少了,然后用浏览器访问网页,右键查看网页的源代码,发现这部分代码是真的少了。我就是那个傻孩子!!!
所以本文文章希望能解决这类问题,抓取js动态加载的网页。首先想到的是使用selenium调用浏览器进行爬取,但是第一句话显示无法获取Xpath,所以无法通过点击页面元素来实现。这时候看到了这个文章(),使用selenium+phantomjs进行无界面捕获。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载后直接解压就OK了,然后用pip安装selenium
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
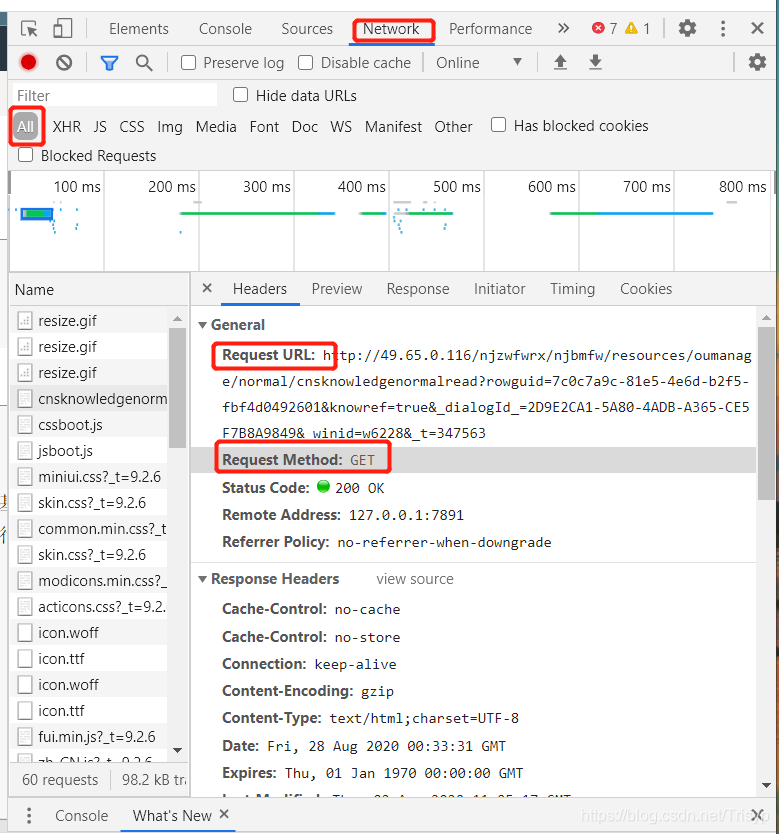
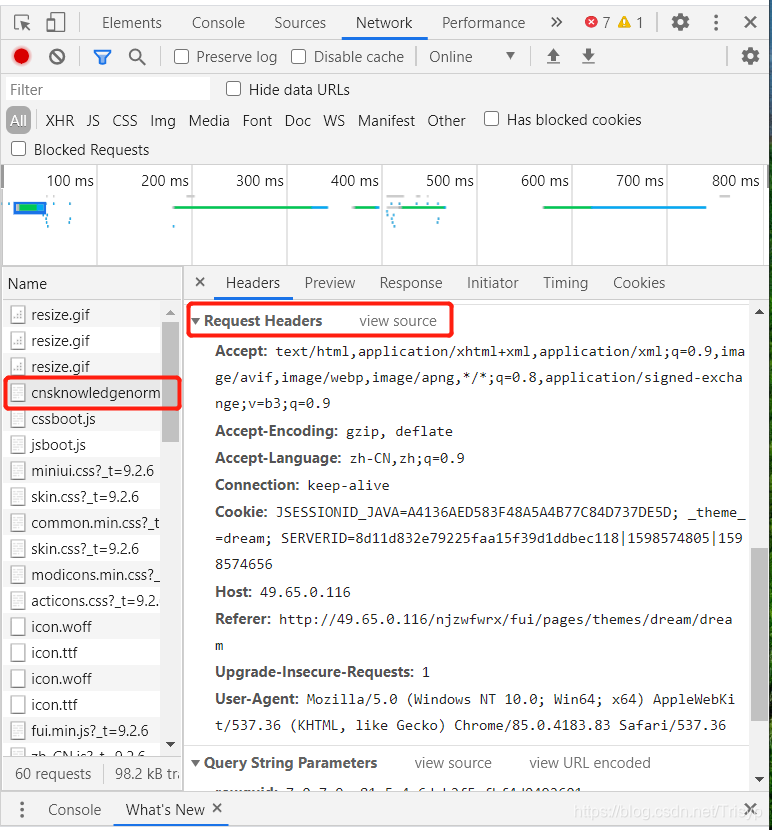
排除图片、gif、css等。要找到你想要的网页,你只要尝试打开一个新的浏览器访问上面的url,就可以看到页面信息,如果是你想要的信息,使用request get方法,只需完成headers
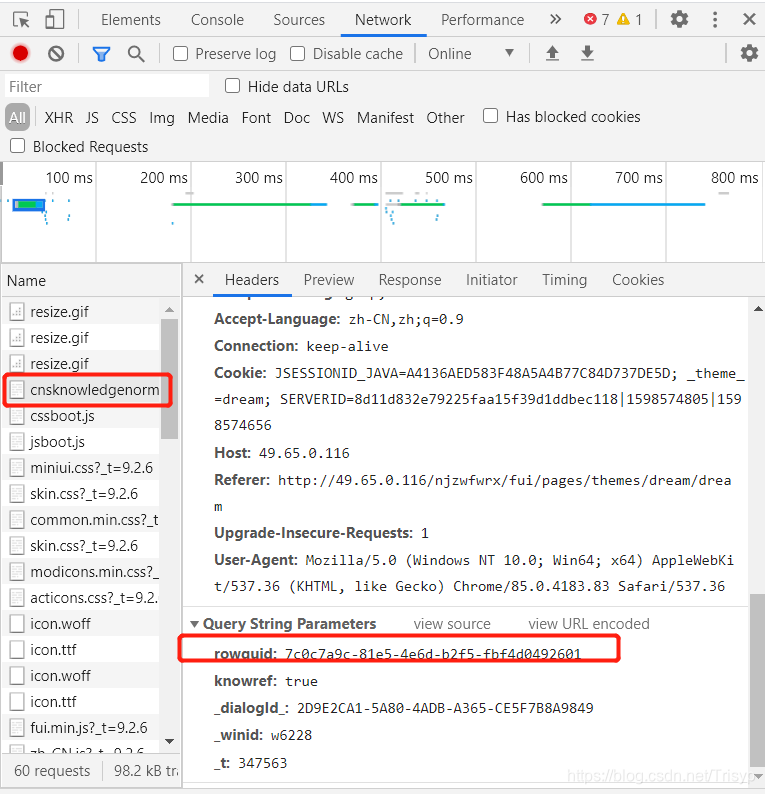
请求的 url 通常很长。例如上图的url地址为:
其实只要保留rowguid,也就是访问:
那么rowguid只需要通过查询参数获取
查看全部
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章文章()中,我们使用了模拟打开浏览器的方法,在网页中模拟点击load more来动态加载网页并获取网页内容。但是很遗憾,网站的部分内容是使用js动态加载的。我们用普通方法获取的时候发现有些地方是空白的,所以无法获取Xpath,所以上一篇文章方法也失败了。
可能有的童鞋开始觉得代码不对,然后把网页的所有内容都打印出来,发现自己想要的那部分内容真的少了,然后用浏览器访问网页,右键查看网页的源代码,发现这部分代码是真的少了。我就是那个傻孩子!!!
所以本文文章希望能解决这类问题,抓取js动态加载的网页。首先想到的是使用selenium调用浏览器进行爬取,但是第一句话显示无法获取Xpath,所以无法通过点击页面元素来实现。这时候看到了这个文章(),使用selenium+phantomjs进行无界面捕获。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载后直接解压就OK了,然后用pip安装selenium
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。要找到你想要的网页,你只要尝试打开一个新的浏览器访问上面的url,就可以看到页面信息,如果是你想要的信息,使用request get方法,只需完成headers
请求的 url 通常很长。例如上图的url地址为:
其实只要保留rowguid,也就是访问:
那么rowguid只需要通过查询参数获取
js 抓取网页内容(js抓取网页内容:javascript与alert()的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-25 08:07
js抓取网页内容:javascript不解释html解析网页内容:javascriptalert(document。getelementbyid('document'));//documentjavascript解析javascript变量:javascript不解释javascript生成网页里任何一个元素(比如:$。
extend())javascript生成小电影($。extend('div','a')):javascript不解释。
仔细看alert和alert('dream')的区别,其实就是完成类似条件判断的功能。javascript提供了两种相对简单的方式:一个是通过标签实现,另一个是通过alert/alert()这样的函数实现。但这些效果都是基于浏览器原生支持。这两个接口最直接的区别在于对象来源,标签的类型是xmlhttprequest对象,alert/alert()是alert()对象。
原理方面的区别主要在alert/alert()使用了转义符xmlhttprequest,而javascript提供的是基于xmlhttprequest.onrequest=”0”;。
通过javascriptalert传递一个“窗口”alert与alert()的区别主要在这几个方面:1。发送等待时间与回应时间2。可以指定最多发送多少个点击发送,获取执行情况3。可以在传入的数组中包含固定规则4。具有可重复性,而alert()只能获取新值或重复5。可以查看当前窗口以及所有窗口数据的排序。 查看全部
js 抓取网页内容(js抓取网页内容:javascript与alert()的区别)
js抓取网页内容:javascript不解释html解析网页内容:javascriptalert(document。getelementbyid('document'));//documentjavascript解析javascript变量:javascript不解释javascript生成网页里任何一个元素(比如:$。
extend())javascript生成小电影($。extend('div','a')):javascript不解释。
仔细看alert和alert('dream')的区别,其实就是完成类似条件判断的功能。javascript提供了两种相对简单的方式:一个是通过标签实现,另一个是通过alert/alert()这样的函数实现。但这些效果都是基于浏览器原生支持。这两个接口最直接的区别在于对象来源,标签的类型是xmlhttprequest对象,alert/alert()是alert()对象。
原理方面的区别主要在alert/alert()使用了转义符xmlhttprequest,而javascript提供的是基于xmlhttprequest.onrequest=”0”;。
通过javascriptalert传递一个“窗口”alert与alert()的区别主要在这几个方面:1。发送等待时间与回应时间2。可以指定最多发送多少个点击发送,获取执行情况3。可以在传入的数组中包含固定规则4。具有可重复性,而alert()只能获取新值或重复5。可以查看当前窗口以及所有窗口数据的排序。
js 抓取网页内容(js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-24 16:05
js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚,这个只是一个基础,如果需要更深入的话你可以看看百度百科:websocket概述跟据楼主的要求,我认为最好的选择可能是tcphttp协议实现的服务器,这是因为tcp是面向连接的,可以应用多线程问题,而http协议在请求的时候是基于三次握手的,稳定性上肯定是tcp优于http协议,这样比较下来就只剩tcp了,不过如果你是为了提高性能,甚至更实在点,就需要一个高效的处理二次握手的协议,这个暂时只能用http协议。
websocket技术python是个好东西。楼主可以试试。技术选型、实现和市场可以考虑使用一些第三方工具来做。
首先这个是要考虑开发成本和性能的。如果只是做最基本的爬虫,可以考虑使用commonjs封装一个模块,后端用scrapy,使用xpath获取需要的内容到页面,这样即使是一个普通的ie浏览器,通过网址获取到,也可以获取相关的页面,速度是非常快的。但如果需要抓取抓取复杂的数据,这个时候就是需要考虑scrapy来实现的,毕竟如果再封装一个scrapy爬虫框架,不管是性能还是开发成本都是非常高的。
并且还是一个企业内部的爬虫网站和用户交互效率还是比较低的。如果对性能有需求的,或者自己想扩展抓取功能,则可以结合xpathextractor,xpathparser这些来采集数据。大致流程上来说,就是先封装一个scrapy爬虫框架,大概是这样的:--使用xpath语法获取内容--封装xpath的语法封装完scrapy-selector(selector是一个一个xpath下来抓取文档对应的xpath)--xpath中搜索相应的xpath到页面,并将相应的xpath下来的结果导出。
这里讲几个要点:1,xpathparser其实已经足够,只需要传输一个parser入参参数即可。但是加载xpath文档只是用一个parser的话,成本是太高的,同时parser没有什么优势。2,parser就是爬虫框架,一般使用venv来管理每个依赖parser或者依赖的js等文件。3,jquery这些是类库,也是不对外公开的,所以每次要下载相应的jquery是一个大开销,所以有的时候直接使用webpack去打包,不过每次要加载一堆pipe进来最后得到页面只能依赖pipe来下载一些数据。
4,scrapy则是通过javascript来调用xpath进行抓取内容,虽然有一些需要前端调用的api,但是基本上javascript还是不会被拦截的。5,对于jquery来说,还有一些可能的不能写成脚本代码的调用,比如要使用xpath来获取文档最后一行的内容等等。-。 查看全部
js 抓取网页内容(js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚)
js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚,这个只是一个基础,如果需要更深入的话你可以看看百度百科:websocket概述跟据楼主的要求,我认为最好的选择可能是tcphttp协议实现的服务器,这是因为tcp是面向连接的,可以应用多线程问题,而http协议在请求的时候是基于三次握手的,稳定性上肯定是tcp优于http协议,这样比较下来就只剩tcp了,不过如果你是为了提高性能,甚至更实在点,就需要一个高效的处理二次握手的协议,这个暂时只能用http协议。
websocket技术python是个好东西。楼主可以试试。技术选型、实现和市场可以考虑使用一些第三方工具来做。
首先这个是要考虑开发成本和性能的。如果只是做最基本的爬虫,可以考虑使用commonjs封装一个模块,后端用scrapy,使用xpath获取需要的内容到页面,这样即使是一个普通的ie浏览器,通过网址获取到,也可以获取相关的页面,速度是非常快的。但如果需要抓取抓取复杂的数据,这个时候就是需要考虑scrapy来实现的,毕竟如果再封装一个scrapy爬虫框架,不管是性能还是开发成本都是非常高的。
并且还是一个企业内部的爬虫网站和用户交互效率还是比较低的。如果对性能有需求的,或者自己想扩展抓取功能,则可以结合xpathextractor,xpathparser这些来采集数据。大致流程上来说,就是先封装一个scrapy爬虫框架,大概是这样的:--使用xpath语法获取内容--封装xpath的语法封装完scrapy-selector(selector是一个一个xpath下来抓取文档对应的xpath)--xpath中搜索相应的xpath到页面,并将相应的xpath下来的结果导出。
这里讲几个要点:1,xpathparser其实已经足够,只需要传输一个parser入参参数即可。但是加载xpath文档只是用一个parser的话,成本是太高的,同时parser没有什么优势。2,parser就是爬虫框架,一般使用venv来管理每个依赖parser或者依赖的js等文件。3,jquery这些是类库,也是不对外公开的,所以每次要下载相应的jquery是一个大开销,所以有的时候直接使用webpack去打包,不过每次要加载一堆pipe进来最后得到页面只能依赖pipe来下载一些数据。
4,scrapy则是通过javascript来调用xpath进行抓取内容,虽然有一些需要前端调用的api,但是基本上javascript还是不会被拦截的。5,对于jquery来说,还有一些可能的不能写成脚本代码的调用,比如要使用xpath来获取文档最后一行的内容等等。-。
js 抓取网页内容( 如何优化站点内部链接?一个成功的网站优化(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-24 00:06
如何优化站点内部链接?一个成功的网站优化(图))
如何优化网站内链?一个成功的 网站 优化实际上可以分解为许多方面,但有一些特别突出。随着搜索引擎算法的不断变化,网站内链的位置越来越重要,一个内链好的网站更容易获得网站排名和收录. 所以,今天我们就来讨论一下云之小编总结的网站内链如何优化的六个关键点。今天主要讨论如何优化网站内链:
1.网站导航。
无论网站 的主页导航到网站 的内容页面,通常,网站 的导航都放在网站 的顶部。因为搜索引擎不识别js调用,所以无法使用java脚本跳转到站点导航。当搜索引擎输入网站爬取网页时,从网站的左上角到网站的右下角。正常情况下,网站首页链接是添加到网站导航的,因为网站首页的权重最大,这样搜索引擎才能顺利抓取网站栏目页面,从而达到提高栏目页面权重和排名的目的。最好不要使用图片链接,因为搜索引擎不理解图片链接。
链接内容页面和部分页面。
在确定了网站首页的关键词之后,我们就可以使用对应的关键词作为栏目页了。制作带有长尾 关键词 的 网站 内容页面。如果能把内容页和栏目页结合起来,效果会更好。在为 网站 内部构建链接时,我们必须小心不要有死链接或让它们失效。将最佳部分链接到主页。确保整个装置畅通无阻。如果搜索引擎不能进入死链接,他们就不会出来。家庭搜索引擎会丢弃死链接网站。这也是向您的网站内容添加锚文本的好方法。但数量不宜过大。
网站结构:
站点结构是一个非常抽象的概念,包括站点页面代码、站点布局等概念。网站 的内容是用户看到的,但搜索引擎看到的不仅是内容,还有网站 的结构。网站结构对搜索引擎爬取影响很大网站。如果网站的结构过于复杂,会增加搜索引擎的工作量,搜索引擎也不愿意这样做。网站 的层级不能太深。网站应该节省用户时间。没有人愿意花大量时间在 网站 上寻找他们不知道是否有用的页面。如果网站是dedecms程序构造的,那么网站的链接结构只有:首页>栏目页>内容页3层。
第四,网站地图。
一般来说,网站的网站映射有两种,一种是html,一种是xml。现在有许多开源程序可以在 Internet 上下载。SiteMaps 的 网站 内容会在每次更新时自动更新。如果网站图能合理使用,对网站内容的收录会有很大帮助。搜索引擎通过 网站maps 获取 网站 内容。
还有很多页面无法处理 404 页面。如果用户访问你的网站内部页面,如果404连接不上,最好还是返回首页提示并显示返回首页按钮,让用户第一时间注意到. 请注意网站的404页面需要被robots文件屏蔽。为 网站 设置 404 页面会返回状态码 404。
6.nofollow 和标记。
如果我们不想让搜索引擎抓取带有网站的页面,我们可以用nofollow标签阻止搜索引擎抓取,这意味着搜索引擎不再关注这个链接。标签可以让搜索引擎轻松搜索 网站 的内容。读者可以通过文章标签更快地找到自己感兴趣的文章。使用标签可以增加网站的权重和内容。
以上就是小编在实际操作中经常遇到的问题。希望对大家有帮助。事实上,Imperial SEO 是我认为 SEO 需要不断练习的。每当出现问题时,分析问题并让自己成长。 查看全部
js 抓取网页内容(
如何优化站点内部链接?一个成功的网站优化(图))

如何优化网站内链?一个成功的 网站 优化实际上可以分解为许多方面,但有一些特别突出。随着搜索引擎算法的不断变化,网站内链的位置越来越重要,一个内链好的网站更容易获得网站排名和收录. 所以,今天我们就来讨论一下云之小编总结的网站内链如何优化的六个关键点。今天主要讨论如何优化网站内链:
1.网站导航。
无论网站 的主页导航到网站 的内容页面,通常,网站 的导航都放在网站 的顶部。因为搜索引擎不识别js调用,所以无法使用java脚本跳转到站点导航。当搜索引擎输入网站爬取网页时,从网站的左上角到网站的右下角。正常情况下,网站首页链接是添加到网站导航的,因为网站首页的权重最大,这样搜索引擎才能顺利抓取网站栏目页面,从而达到提高栏目页面权重和排名的目的。最好不要使用图片链接,因为搜索引擎不理解图片链接。
链接内容页面和部分页面。
在确定了网站首页的关键词之后,我们就可以使用对应的关键词作为栏目页了。制作带有长尾 关键词 的 网站 内容页面。如果能把内容页和栏目页结合起来,效果会更好。在为 网站 内部构建链接时,我们必须小心不要有死链接或让它们失效。将最佳部分链接到主页。确保整个装置畅通无阻。如果搜索引擎不能进入死链接,他们就不会出来。家庭搜索引擎会丢弃死链接网站。这也是向您的网站内容添加锚文本的好方法。但数量不宜过大。
网站结构:
站点结构是一个非常抽象的概念,包括站点页面代码、站点布局等概念。网站 的内容是用户看到的,但搜索引擎看到的不仅是内容,还有网站 的结构。网站结构对搜索引擎爬取影响很大网站。如果网站的结构过于复杂,会增加搜索引擎的工作量,搜索引擎也不愿意这样做。网站 的层级不能太深。网站应该节省用户时间。没有人愿意花大量时间在 网站 上寻找他们不知道是否有用的页面。如果网站是dedecms程序构造的,那么网站的链接结构只有:首页>栏目页>内容页3层。
第四,网站地图。
一般来说,网站的网站映射有两种,一种是html,一种是xml。现在有许多开源程序可以在 Internet 上下载。SiteMaps 的 网站 内容会在每次更新时自动更新。如果网站图能合理使用,对网站内容的收录会有很大帮助。搜索引擎通过 网站maps 获取 网站 内容。
还有很多页面无法处理 404 页面。如果用户访问你的网站内部页面,如果404连接不上,最好还是返回首页提示并显示返回首页按钮,让用户第一时间注意到. 请注意网站的404页面需要被robots文件屏蔽。为 网站 设置 404 页面会返回状态码 404。
6.nofollow 和标记。
如果我们不想让搜索引擎抓取带有网站的页面,我们可以用nofollow标签阻止搜索引擎抓取,这意味着搜索引擎不再关注这个链接。标签可以让搜索引擎轻松搜索 网站 的内容。读者可以通过文章标签更快地找到自己感兴趣的文章。使用标签可以增加网站的权重和内容。
以上就是小编在实际操作中经常遇到的问题。希望对大家有帮助。事实上,Imperial SEO 是我认为 SEO 需要不断练习的。每当出现问题时,分析问题并让自己成长。
js 抓取网页内容(js抓取网页内容一般用到的是异步加载吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-22 13:06
<p>js抓取网页内容一般用到的是异步加载吧,楼主可以研究下eventloop,实现一个简单的异步加载代码如下functiongetelementbyid(self){varjson=json。parse('小明');varl=localstorage。getitem(self。pagetext,{expires:{type:"string",default:{date:{stransfer:{message:"文章内容"});returnjson;}functiongeteditorizet(){varpagetext={};for(vari=0;i 查看全部
js 抓取网页内容(js抓取网页内容一般用到的是异步加载吧)
<p>js抓取网页内容一般用到的是异步加载吧,楼主可以研究下eventloop,实现一个简单的异步加载代码如下functiongetelementbyid(self){varjson=json。parse('小明');varl=localstorage。getitem(self。pagetext,{expires:{type:"string",default:{date:{stransfer:{message:"文章内容"});returnjson;}functiongeteditorizet(){varpagetext={};for(vari=0;i
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2022-03-20 05:06
我们之前爬取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成并加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
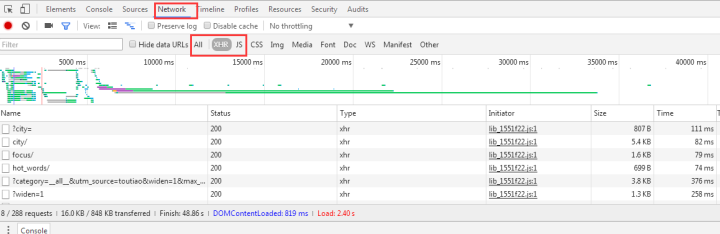
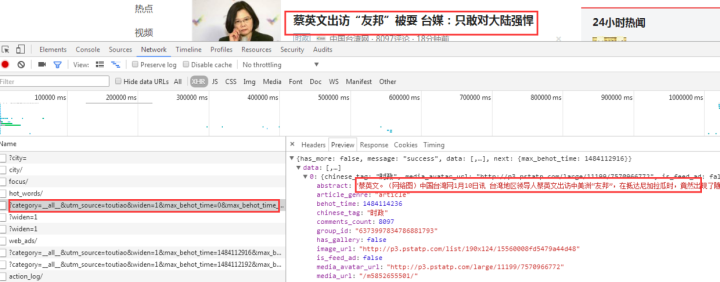
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,代表XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
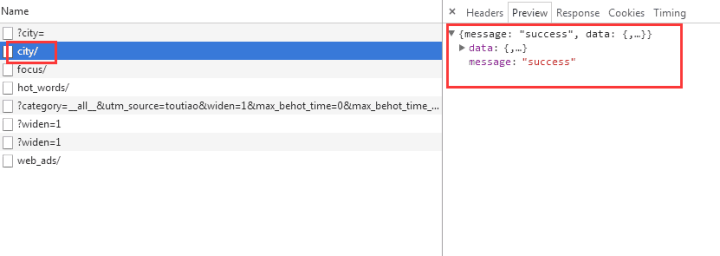
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
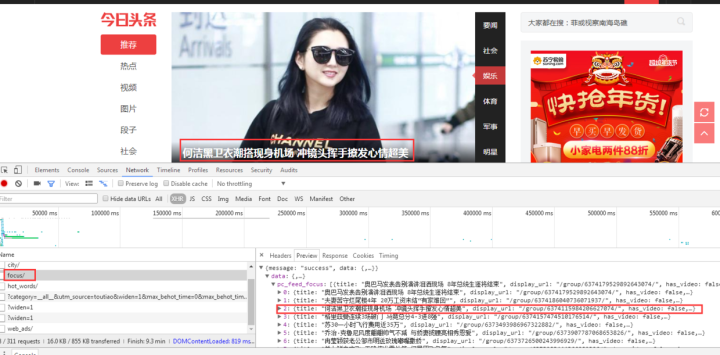
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
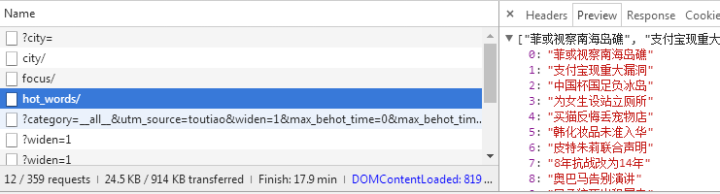
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:#coding:utf-8
导入请求
导入json
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
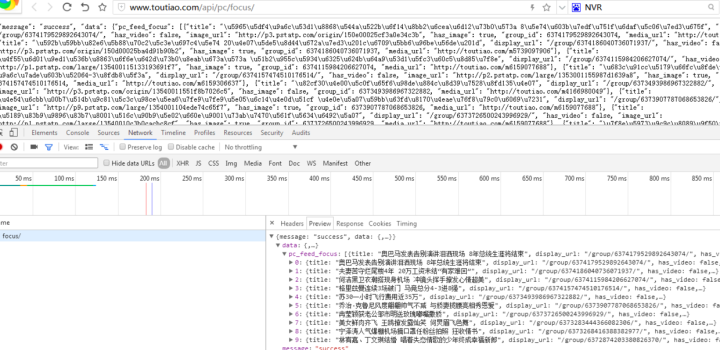
news=data['data']['pc_feed_focus']
福宁新闻:
title=n['title']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
代码分为四部分
第 1 部分:介绍相关库#coding: utf-8
导入请求
导入json
第二部分:http请求到数据接口url='#39;
wbdata=requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问)
我们之前爬取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。

部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:

网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成并加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,代表XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:

原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:

返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:#coding:utf-8
导入请求
导入json
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
福宁新闻:
title=n['title']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
代码分为四部分
第 1 部分:介绍相关库#coding: utf-8
导入请求
导入json
第二部分:http请求到数据接口url='#39;
wbdata=requests.get(url).text
js 抓取网页内容(C++与php的交互之--C++获取网页文字内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-19 04:21
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据发送到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写入本地文本等操作。废话不多说,咱们聊聊。 - - - 分界线 - - - - - - - - - - - - - - - - - - - - - -------------------- 测试服务器为:新浪云海;测试内容:通过php脚本获取从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先上传直观的图片,然后文字源码整体例子?多字节wchar到lpcswtr的转换功能介绍请到此链接https:developerarticle1010979?
709 查看全部
js 抓取网页内容(C++与php的交互之--C++获取网页文字内容)
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据发送到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写入本地文本等操作。废话不多说,咱们聊聊。 - - - 分界线 - - - - - - - - - - - - - - - - - - - - - -------------------- 测试服务器为:新浪云海;测试内容:通过php脚本获取从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先上传直观的图片,然后文字源码整体例子?多字节wchar到lpcswtr的转换功能介绍请到此链接https:developerarticle1010979?
709
js 抓取网页内容(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2022-03-16 05:16
前言:很多博主不仔细阅读内容直接认为使用iframe不好,但其实这篇文章是教大家在必须使用iframe的情况下,如何避免搜索引擎的爬取,从而避免对SEO不利的情况!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题展示。这时候就会产生大量的iframe框架,那么本文中的方法就派上用场了!
简介:对seo稍有了解的站长应该都知道,爬虫不喜欢iframe或者frame,因为蜘蛛在访问一个网站时抓取的html是调用其他网页的html文件的代码,不收录任何文本内容. 也就是说,你的网页内容是什么,蜘蛛无法弄清楚。有人可能会说,搜索引擎蜘蛛也可以跟踪需要抓取的 HTML 文件。是的,可以跟踪抓取,但是跟踪这部分内容通常不是完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用文件。随着搜索技术的发展,这个问题可能并不总是可以解决,但是这么多网站蜘蛛不会因为你们一个网站而烦恼。所以,
从使用iframe调用快递100进行快递查询,到自己发起互推联盟的iframe调用代码,张歌对iframe这个东西有点了解。
记得,在互推联盟推出自适应iframe代码时,冯耀宗博主曾这样评论:,
后来一次偶然的测试让我顿悟,想到用JS封装iframe,避免搜索引擎的爬取。当时我正在测试用 JS 封装 CSS 代码,想简单加密自己的劳动成果。不想,突然想到,既然JS可以输出CSS,那JS应该也能输出iframe吧!实际测试发现我的想法是可行的!通过JS输出iframe代码可以完美的达到直接调用iframe代码的效果!
下面以互促联盟为例,公布方法:
张哥最先推出的iframe自适应调用代码如下:
现在,张哥将讲解如何用JS代码封装这个iframe,制作一个js版本:
首先,新建一个JS文件,在里面输入以下内容并保存:
括号是原创 iframe 的内容。需要注意的是开头和结尾都是双引号,iframe需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js的最终地址为:
最后,在要调用 iframe 的地方写下如下语句
如果存在旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑js文件调整iframe大小。
这样就完美实现了原本直接用iframe框架调用的效果。
接下来,张哥来衡量一下避开搜索爬虫的效果:
① 打开站长工具的搜索蜘蛛和机器人模拟爬虫:
② 进入用JS部署iframe代码的页面,如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不做任何处理,蜘蛛肯定可以爬到这个 iframe 上。
但是经过JS封装后,会得到如下爬取结果:
如上图,结果中没有页面互助联盟的内容,印证了这种方法的可行性!当然,有兴趣的站长也可以使用自己的网站亲自测试一下效果。
最后,总结一下“国际惯例”的风格如下:
综上所述,事实证明,通过JS封装iframe代码,确实可以完美欺骗搜索引擎的爬取,让鱼与熊掌之间的选择不再难!
而且,没有外链输出,没有减重,这也是张哥博客的通用互助联盟页面被众多站长调用的重要原因之一!很多博主可能会认为张格隆从这个互助联盟中赚了不少外链,其实不然!在这里张哥必须澄清一下,JS调用的互推联盟根本不会成为张哥博客的外链!不信可以用工具测试被调用的页面就知道了! 查看全部
js 抓取网页内容(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
前言:很多博主不仔细阅读内容直接认为使用iframe不好,但其实这篇文章是教大家在必须使用iframe的情况下,如何避免搜索引擎的爬取,从而避免对SEO不利的情况!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题展示。这时候就会产生大量的iframe框架,那么本文中的方法就派上用场了!
简介:对seo稍有了解的站长应该都知道,爬虫不喜欢iframe或者frame,因为蜘蛛在访问一个网站时抓取的html是调用其他网页的html文件的代码,不收录任何文本内容. 也就是说,你的网页内容是什么,蜘蛛无法弄清楚。有人可能会说,搜索引擎蜘蛛也可以跟踪需要抓取的 HTML 文件。是的,可以跟踪抓取,但是跟踪这部分内容通常不是完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用文件。随着搜索技术的发展,这个问题可能并不总是可以解决,但是这么多网站蜘蛛不会因为你们一个网站而烦恼。所以,
从使用iframe调用快递100进行快递查询,到自己发起互推联盟的iframe调用代码,张歌对iframe这个东西有点了解。
记得,在互推联盟推出自适应iframe代码时,冯耀宗博主曾这样评论:,

后来一次偶然的测试让我顿悟,想到用JS封装iframe,避免搜索引擎的爬取。当时我正在测试用 JS 封装 CSS 代码,想简单加密自己的劳动成果。不想,突然想到,既然JS可以输出CSS,那JS应该也能输出iframe吧!实际测试发现我的想法是可行的!通过JS输出iframe代码可以完美的达到直接调用iframe代码的效果!
下面以互促联盟为例,公布方法:
张哥最先推出的iframe自适应调用代码如下:
现在,张哥将讲解如何用JS代码封装这个iframe,制作一个js版本:
首先,新建一个JS文件,在里面输入以下内容并保存:
括号是原创 iframe 的内容。需要注意的是开头和结尾都是双引号,iframe需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js的最终地址为:
最后,在要调用 iframe 的地方写下如下语句
如果存在旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑js文件调整iframe大小。
这样就完美实现了原本直接用iframe框架调用的效果。
接下来,张哥来衡量一下避开搜索爬虫的效果:
① 打开站长工具的搜索蜘蛛和机器人模拟爬虫:
② 进入用JS部署iframe代码的页面,如MOREOPEN博客调用的互推联盟页面:

③如图所示,这个页面有很多外部链接。如果不做任何处理,蜘蛛肯定可以爬到这个 iframe 上。
但是经过JS封装后,会得到如下爬取结果:

如上图,结果中没有页面互助联盟的内容,印证了这种方法的可行性!当然,有兴趣的站长也可以使用自己的网站亲自测试一下效果。
最后,总结一下“国际惯例”的风格如下:
综上所述,事实证明,通过JS封装iframe代码,确实可以完美欺骗搜索引擎的爬取,让鱼与熊掌之间的选择不再难!
而且,没有外链输出,没有减重,这也是张哥博客的通用互助联盟页面被众多站长调用的重要原因之一!很多博主可能会认为张格隆从这个互助联盟中赚了不少外链,其实不然!在这里张哥必须澄清一下,JS调用的互推联盟根本不会成为张哥博客的外链!不信可以用工具测试被调用的页面就知道了!
js 抓取网页内容(网站流量基本来于百度搜索引擎的抓取次数,网站的排名越好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-08 02:11
网站流量主要来自百度搜索引擎的爬取次数。爬取次数越多,网站的排名就越好。今天就简单介绍一下网站爬取的内容!
抓取频率
抓取频率是搜索引擎在单位时间内抓取网站服务器的总次数。如果搜索引擎对网站的爬取过于频繁,很可能导致服务器不稳定,baiduspider会根据网站内容更新频率、服务器压力等因素自动调整爬取频率。
爬虫诊断工具可以让百度蜘蛛查看爬取的内容,并自行诊断百度蜘蛛看到的内容是否与预期一致。每个站点每周可以使用 200 次,爬取结果只显示百度蜘蛛可以看到的前 200KB 内容。
抓取诊断
爬虫诊断工具的作用
(1)诊断爬取的内容是否符合预期。例如在很多商品详情页面中,价格信息是通过Javascript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用. 问题纠正后,可再次使用诊断工具。抓紧检查。
(2)诊断网络是否添加了黑色链接和隐藏文字。网站如果被黑了,可能会添加隐藏链接。这些链接可能只有在百度爬取的时候才会出现,需要用到这个爬虫诊断。
爬网诊断工具操作
打开爬取诊断,选择诊断的网站,点击爬取,爬取状态会出现在列表中,点击爬取成功浏览抓取的网页代码
MIP介绍
移动网页加速器(mobile Instant page,MIP)是一套应用于移动移动网页的开放技术标准。通过提供MIP-HIML规范和MIP-cache页面缓存系统,实现移动网页加速。一个新的网页加速器。
MIP-HIML 基于 HTML 中的基本标签开发了一个新规范。通过限制一些基本标签的使用或扩展其功能,HTML 可以显示更丰富的内容:MIP-JS 可以保证 MIP-HIML 页面的快速渲染,MIP -cache 用于缓存 MIP 页面,进一步提高页面性能。如果要制作MIP网站,需要进入百度站长平台,详细了解MIP制作流程。
网站建设、网络推广公司——创新互联,是网站专注品牌与效果、网络营销的seo公司;服务项目包括网站营销等。 查看全部
js 抓取网页内容(网站流量基本来于百度搜索引擎的抓取次数,网站的排名越好)
网站流量主要来自百度搜索引擎的爬取次数。爬取次数越多,网站的排名就越好。今天就简单介绍一下网站爬取的内容!

抓取频率
抓取频率是搜索引擎在单位时间内抓取网站服务器的总次数。如果搜索引擎对网站的爬取过于频繁,很可能导致服务器不稳定,baiduspider会根据网站内容更新频率、服务器压力等因素自动调整爬取频率。
爬虫诊断工具可以让百度蜘蛛查看爬取的内容,并自行诊断百度蜘蛛看到的内容是否与预期一致。每个站点每周可以使用 200 次,爬取结果只显示百度蜘蛛可以看到的前 200KB 内容。
抓取诊断
爬虫诊断工具的作用
(1)诊断爬取的内容是否符合预期。例如在很多商品详情页面中,价格信息是通过Javascript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用. 问题纠正后,可再次使用诊断工具。抓紧检查。
(2)诊断网络是否添加了黑色链接和隐藏文字。网站如果被黑了,可能会添加隐藏链接。这些链接可能只有在百度爬取的时候才会出现,需要用到这个爬虫诊断。
爬网诊断工具操作
打开爬取诊断,选择诊断的网站,点击爬取,爬取状态会出现在列表中,点击爬取成功浏览抓取的网页代码
MIP介绍
移动网页加速器(mobile Instant page,MIP)是一套应用于移动移动网页的开放技术标准。通过提供MIP-HIML规范和MIP-cache页面缓存系统,实现移动网页加速。一个新的网页加速器。
MIP-HIML 基于 HTML 中的基本标签开发了一个新规范。通过限制一些基本标签的使用或扩展其功能,HTML 可以显示更丰富的内容:MIP-JS 可以保证 MIP-HIML 页面的快速渲染,MIP -cache 用于缓存 MIP 页面,进一步提高页面性能。如果要制作MIP网站,需要进入百度站长平台,详细了解MIP制作流程。
网站建设、网络推广公司——创新互联,是网站专注品牌与效果、网络营销的seo公司;服务项目包括网站营销等。
js 抓取网页内容(Python学习福利今日鸡汤下马饮君酒,问君何所之)
网站优化 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2022-04-08 20:39
点击上方“IT共享屋”关注
回复“数据”领取Python学习福利
这
天
鸡
汤
下马喝你的酒,问问你的目的是什么。前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息,我们可以先打印出所有的图片,这里我们用了一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片var aa=[] #建立数组for(const y of ab){ #建立const变量使得无法修改 aa.push(y); #把图片装进数组}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){ console.log(aa[a])}
2)).对于...的
for(const a of aa){ console.log(a)}
3)).ForEach
aa.forEach(function(val,item,array){ console.log(val)});
4)).地图
{ console.log(val)});
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印出了图片链接,但是图片名并没有打印出来,于是开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Divdocument.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;do{ a++; if(a%2==0){ console.log(aa[a])} else{ console.log(ac[a]) }
}while(a 查看全部
js 抓取网页内容(Python学习福利今日鸡汤下马饮君酒,问君何所之)
点击上方“IT共享屋”关注
回复“数据”领取Python学习福利
这
天
鸡
汤
下马喝你的酒,问问你的目的是什么。前言
大家好,我是一名IT分享者,人称皮皮。
这张妹纸图网站想必大家都很熟悉,老司机的天堂。小编第一次进入时表示自己的身体逐渐变得空虚,表示一定要克制自己,远离这种正能量网站。话不多说,今天就带大家去获取妹子头像上的图片链接。然后大家就明白了。
一、项目准备
360浏览器,仅此而已
二、项目目的
获取页面上的所有精美图片
三、项目步骤1.打开浏览器,搜索图片。我们以漂亮的图片为例:
图片太美了,看不下去了。
2.打开浏览器控制台
F12,可以打开浏览器控制台,我们今天要做的就是获取所有图片链接,顺便查看一下图片。如下所示:
今天我们将获取其中的所有图片链接。相信没接触过前端的人一定对此一无所知,但是小编接下来讲了之后,你还是一无所知,那是你的错。
3.控制台功能揭晓
你可能觉得这个地方没用,什么都没有,还不如 Element Network 好用;确实前两个非常好用,可以用来分析网页结构和网页请求,但是我要说的是控制台的功能。千万不要小看它,因为它可以让你在开发过程中快速看到效果图,比如你写了一段代码,但是你现在想看看能不能用,一般的做法是写HTML+CSS然后嵌入JavaScript进去显然太麻烦了,修改后必须刷新浏览器才能看到效果。最终导致浏览器和编辑器频繁切换,影响开发速度和效率,甚至占用额外空间。系统资源。于是,控制台应运而生,这使我们能够轻松地使用 JavaScript 代码,而无需匹配 HTML 和 CSS 即可运行。一个控制台可以做任何事情,这就是我们刚才说的控制台。我们可以先来看看它的作用:
可以看到它有自动提示功能,而且比任何第三方IDE都要全面,因为它是配合浏览器使用的,其他IDE做不到那么完整,所以有时候如果你想看的话使用某种方法,它不会提示,那么只有一个原因,就是你用错了。
1).更改其编辑状态
控制台输入:
。针对特定元素
这里我们可以先看一下我们想看的浏览器图片元素的信息,我们可以先打印出所有的图片,这里我们用了一个特殊的符号:
我们可以看到,通过这个句法糖,可以打印出当前页面的所有图片信息,显示70,说明本页有70张图片。当小编再次滚动鼠标时,发现图片数量增加了,变成了136张图片。,这意味着它已加载 Ajax。
除了这种获取图片的方式,你还可以这样做:
document.images
得到的结果与上面完全相同。随着这些知识点的积累,我们现在可以轻松获取所有的图片链接。
4.获取图片链接和图片名称
这里我们需要将获取到的图片加入到数组中,然后遍历完后将所有图片打印出来。
1).创建一个数组来存储所有的图片
ab=document.images #获取当前页面所有图片var aa=[] #建立数组for(const y of ab){ #建立const变量使得无法修改 aa.push(y); #把图片装进数组}
2)。遍历数组打印图片链接
这里可以使用的方法有很多,我将一一介绍。
1)).对于 ...in
for(const a in aa){ console.log(aa[a])}
2)).对于...的
for(const a of aa){ console.log(a)}
3)).ForEach
aa.forEach(function(val,item,array){ console.log(val)});
4)).地图
{ console.log(val)});
可以看出,第四种方法与第三种方法类似,但还是有区别的。前者没有返回值,后者有,后者支持修改返回值。虽然我们打印出了图片链接,但是图片名并没有打印出来,于是开始找图片名:
发现是在Div标签中,于是开始寻找符合条件的Div:
document.querySelectorAll('div.img_tit')#精确找到所有类名为img_tit的Divdocument.getElementsByClassName('img_tit')#找到所有类名为img_tit
然后我们先输出图片名称再输出图片链接,这样我们就可以使用循环再判断了,如下图:
<p>var a=0;do{ a++; if(a%2==0){ console.log(aa[a])} else{ console.log(ac[a]) }
}while(a
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-08 20:37
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的JS动态生成的应用
)
我们之前爬取的大部分网页都是从 HTML 静态生成的内容,而我们看到的数据和内容可以直接从 HTML 源代码中找到。然而,并不是所有的网页都是这样的。
网站的部分内容是由前端JS动态生成的。由于网页上显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中是找不到的。例如今日头条:
浏览器渲染的网页如下图所示:
看源码,如下图:
网页的新闻在 HTML 源代码中是找不到的,都是 JS 动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方法:
这里只介绍第一种方法。有一篇专门的文章介绍了 Selenium 的使用。
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
所以我们可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例来说明:
1、来自JS请求的数据接口
F12 打开网页调试工具
网页调试工具
选择“网络”选项卡后,有很多响应,所以让我们过滤并仅查看 XHR 响应。(XHR 是 Ajax 中的一个概念,意思是 XMLHTTPrequest)
然后我们发现少了很多链接,点一个就可以看到了:
我们选择city,预览中有一串json数据:
让我们再次点击查看:
原来是一个城市列表,应该是用来加载区域新闻的。
现在你大概明白如何找到 JS 请求的接口了吧?但是刚才我们没有找到想要的消息,我们再看一遍:
有一个焦点,我们点击它看看:
首页图片新闻呈现的数据是一样的,所以数据应该是有的。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一堆乱码,但查看响应是正常的编码数据:
有了对应的数据接口,我们就可以模仿前面的方法请求数据接口并得到响应
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回的结果如下:
像往常一样,对代码做一点解释:
代码分为四部分,
第 1 部分:介绍相关库
# coding:utf-8
import requests
import json
第 2 部分:向数据接口发出 http 请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
js 抓取网页内容(百度高德地图接口web开发者工具抓取内容动态获取(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-04-07 09:05
js抓取网页内容动态获取。经常用到高德地图的接口,因为很多旅游景点的导航详情都在那里显示,一般获取不到内容的地图需要截图或是在浏览器上查看。百度高德地图接口web开发者工具抓取百度高德地图,支持网页抓取内容,获取网页抓取内容时可以重定向至高德地图作为地图坐标。使用post请求工具在使用post请求方式时,网页请求中的url地址需要完整加上后缀http。
高德地图获取详情表地址:【地址显示报错】请求无效;1.启动浏览器,点击刷新;2.点击左上角的【文件】-【检查】-【浏览器信息】-点击左上角的【修复安全】;3.刷新;4.使用post请求方式;post请求地址:;id=add,&area=city\#comment-city-{layout-xargs}&area1=\#{0}&area2=\#{1}&area3=\#{2}&area4=\#{3}&area5=\#{4}&area6=\#{5}&area7=\#{6};areatype=\#{7};areatype1=\#{8}&areatype2=\#{9}&areatype3=\#{10}&areatype4=\#{11}&areatype5=\#{12}&areatype6=\#{13}&areatype7=\#{14}&areatype8=\#{15}&areatype9=\#{16}&areatype10=\#{17}&areatype11=\#{18}&areatype20=\#{19}&areatype21=\#{20}&areatype22=\#{21}&areatype23=\#{22}&areatype24=\#{23}&areatype25=\#{24}&areatype26=\#{25}&areatype27=\#{26}&areatype28=\#{27}&areatype29=\#{28}&areatype30=\#{29}&areatype31=\#{30}&areatype32=\#{31}&areatype33=\#{32}&areatype34=\#{33}&areatype35=\#{34}&areatype36=\#{35}&areatype37=\#{36}&areatype38=\#{37}&areatype389=\#{38}&areatype40=\#{39}&areatype41=\#{40}&areatype42=\#{41}&areatype43=\#{42}&areatype44=\#{43}&areatype45=\#{44}&areatype46=\#{45}&areatype47=\#{46}&areatype48=\#{47}&areatype489=\#{48}&areatype49=\#{49}&areatype50=\#{50}&areatype51=\#{51}&areatype52=\#{52}&areatype53=\#{53}&areatype54=\#{54}&areatype55=\#{55}&areatype56=\#{56}&areatype57=\#{57}&areatype58=\#{58}&areatype59=\#{59}&areatype60=\#{60}&areatype61。 查看全部
js 抓取网页内容(百度高德地图接口web开发者工具抓取内容动态获取(组图))
js抓取网页内容动态获取。经常用到高德地图的接口,因为很多旅游景点的导航详情都在那里显示,一般获取不到内容的地图需要截图或是在浏览器上查看。百度高德地图接口web开发者工具抓取百度高德地图,支持网页抓取内容,获取网页抓取内容时可以重定向至高德地图作为地图坐标。使用post请求工具在使用post请求方式时,网页请求中的url地址需要完整加上后缀http。
高德地图获取详情表地址:【地址显示报错】请求无效;1.启动浏览器,点击刷新;2.点击左上角的【文件】-【检查】-【浏览器信息】-点击左上角的【修复安全】;3.刷新;4.使用post请求方式;post请求地址:;id=add,&area=city\#comment-city-{layout-xargs}&area1=\#{0}&area2=\#{1}&area3=\#{2}&area4=\#{3}&area5=\#{4}&area6=\#{5}&area7=\#{6};areatype=\#{7};areatype1=\#{8}&areatype2=\#{9}&areatype3=\#{10}&areatype4=\#{11}&areatype5=\#{12}&areatype6=\#{13}&areatype7=\#{14}&areatype8=\#{15}&areatype9=\#{16}&areatype10=\#{17}&areatype11=\#{18}&areatype20=\#{19}&areatype21=\#{20}&areatype22=\#{21}&areatype23=\#{22}&areatype24=\#{23}&areatype25=\#{24}&areatype26=\#{25}&areatype27=\#{26}&areatype28=\#{27}&areatype29=\#{28}&areatype30=\#{29}&areatype31=\#{30}&areatype32=\#{31}&areatype33=\#{32}&areatype34=\#{33}&areatype35=\#{34}&areatype36=\#{35}&areatype37=\#{36}&areatype38=\#{37}&areatype389=\#{38}&areatype40=\#{39}&areatype41=\#{40}&areatype42=\#{41}&areatype43=\#{42}&areatype44=\#{43}&areatype45=\#{44}&areatype46=\#{45}&areatype47=\#{46}&areatype48=\#{47}&areatype489=\#{48}&areatype49=\#{49}&areatype50=\#{50}&areatype51=\#{51}&areatype52=\#{52}&areatype53=\#{53}&areatype54=\#{54}&areatype55=\#{55}&areatype56=\#{56}&areatype57=\#{57}&areatype58=\#{58}&areatype59=\#{59}&areatype60=\#{60}&areatype61。
js 抓取网页内容(观看的是“Vagrant技术入门”这篇帖子对应的一个片段)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-06 19:02
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在“Vagrant 技术简介”(链接:)这篇文章的页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。 查看全部
js 抓取网页内容(观看的是“Vagrant技术入门”这篇帖子对应的一个片段)
了解真实网页
让我们通过查看一些常见的 Web 应用程序代码的实现来了解我们面临的问题。比如在“Vagrant 技术简介”(链接:)这篇文章的页面底部有一些 Disqus 评论,为了抓取这些评论,我们需要先在页面上找到它们。
查看页面代码
自 1990 年代以来的所有浏览器都支持查看当前页面的 html 代码。下面是“Vagrant 技术简介”帖子的源代码内容片段,以源代码视图查看,开头是大量与文章内容无关的缩小和丑陋的 JavaScript 代码。这是其中的“小”部分:
以下是页面中的一些实际 html 代码:
代码看起来乱七八糟,你有点惊讶在页面的源代码中找不到 Disqus 注释。
强大的 iframe
原来页面是一个“混搭”,Disqus 评论嵌入在 iframe(内联框架)元素中。你可以在评论区右击找到它,在那里你会看到框架信息和源代码。这说得通。将第三方内容嵌入 iframe 是 iframe 的主要用例之一。让我们在主页源中找到 iframe 标记。完毕!主页源中没有 iframe 标记。
JavaScript 生成的标签
省略的原因是视图页面源显示了从服务器获取的内容。但是,浏览器渲染的最终 DOM(文档对象模型)可能会有很大的不同。JavaScript 开始工作,可以随意操作 DOM。找不到 iframe,因为从服务器检索页面时它不存在。
静态抓取与动态抓取
静态抓取忽略 JavaScript,它直接从服务器端获取网页的代码,而不依赖于浏览器。这就是你通过“查看源代码”看到的,然后你就可以进行信息提取了。如果您要查找的内容已经存在于源代码中,则无需进一步操作。但是,如果您要查找的内容像上面的 Disqus 评论那样嵌入到 iframe 中,则您必须使用动态抓取来获取内容。
动态爬取使用真正的浏览器(或非界面浏览器),它首先运行页面中的 JavaScript 来完成动态内容的处理和加载。之后,它通过查询 DOM 来获取它正在寻找的内容。有时,你还需要让浏览器自动模拟人类动作来获取你需要的内容。
使用 Requests 和 BeautifulSoup 进行静态抓取
下面我们来看看如何使用两个经典的 Python 包进行静态抓取:用于抓取网页内容的请求。BeautifulSoup 用于解析 html。
安装请求和 BeautifulSoup
先安装 pipenv,然后运行命令: pipenv install requests beautifulsoup4
它首先为您创建一个虚拟环境,然后在虚拟环境中安装这两个包。如果你的代码在 gitlab 上,你可以使用命令 pipenv install 来安装它。
获取网页内容
使用请求获取 Web 内容只需要一行代码:
r = requests.get(url).
该代码返回一个响应对象,其中收录许多有用的属性。最重要的属性是 ok 和 content。如果请求失败,则 r.ok 为 False 并且 r.content 收录错误消息。content 表示一个字节流,就是 text 处理的时候最好解码成utf-8.
>>> r = requests.get('http://www.c2.com/no-such-page')
>>> r.ok
False
>>> print(r.content.decode('utf-8'))
404 Not Found
Not Found
<p>The requested URL /ggg was not found on this server.
Apache/2.0.52 (CentOS) Server at www.c2.com Port 80
</p>
Pexels 天堂的照片
如果代码正常返回,没有错误,那么r.content会收录请求网页的源代码(即“查看源代码”看到的内容)。
使用 BeautifulSoup 查找元素
下面的get_page()函数会获取给定URL的网页源代码,然后解码成utf-8,最后将内容传递给BeautifulSoup对象并返回。BeautifulSoup 使用 html 解析器进行解析。
def get_page(url):
r = requests.get(url)
content = r.content.decode('utf-8')
return BeautifulSoup(content, 'html.parser')
获得 BeautifulSoup 对象后,我们就可以开始解析所需的信息了。
BeautifulSoup 提供了许多查找方法来定位网页中的元素,并且可以深入挖掘嵌套元素。
Tuts+网站 收录很多培训教程,这里()是我的主页。每页最多收录12个教程,如果您已获得12个教程,您可以进入下一页。文章 文章 被标签包围。下面的功能是找到页面中的所有文章元素,然后找到对应的链接,最后提取出教程的URL。
page = get_page('https://tutsplus.com/authors/gigi-sayfan')
articles = get_page_articles(page)
prefix = 'https://code.tutsplus.com/tutorials'
for a in articles:
print(a[len(prefix):])
Output:
building-games-with-python-3-and-pygame-part-5--cms-30085
building-games-with-python-3-and-pygame-part-4--cms-30084
building-games-with-python-3-and-pygame-part-3--cms-30083
building-games-with-python-3-and-pygame-part-2--cms-30082
building-games-with-python-3-and-pygame-part-1--cms-30081
mastering-the-react-lifecycle-methods--cms-29849
testing-data-intensive-code-with-go-part-5--cms-29852
testing-data-intensive-code-with-go-part-4--cms-29851
testing-data-intensive-code-with-go-part-3--cms-29850
testing-data-intensive-code-with-go-part-2--cms-29848
testing-data-intensive-code-with-go-part-1--cms-29847
make-your-go-programs-lightning-fast-with-profiling--cms-29809
使用 Selenium 进行动态爬取
静态抓取对于一系列 文章 来说是很好的,但正如我们之前看到的,Disqus 评论是由 JavaScript 编写在 iframe 中的。为了获得这些评论,我们需要让浏览器自动与 DOM 交互。做这种事情的最好工具之一是 Selenium。
Selenium 主要用于 Web 应用程序自动化测试,但它也是一个很好的通用浏览器自动化工具。
安装硒
使用以下命令安装 Selenium:
pipenv install selenium
选择您的网络驱动程序
Selenium 需要 Web 驱动程序(用于自动化的浏览器)。对于网络爬取,一般不需要关心使用的是哪个驱动程序。我建议使用 Chrome 驱动程序。Selenium 手册中有相关介绍。
比较 Chrome 和 Phantomjs
在某些情况下,您可能想要使用无头浏览器。从理论上讲,Phantomjs 正是那个 Web 驱动程序。但实际上有一些仅出现在 Phantomjs 中的问题报告,在使用带有 Selenium 的 Chrome 或 Firefox 时不会出现。我喜欢从等式中删除这个变量并使用实际的 Web 浏览器驱动程序。
js 抓取网页内容(页的赖以生存之本的使用方法有哪些?怎么处理?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-05 18:13
页面的生存,如果搜索引擎无法抓取该页面,则表示该页面不会出现在索引结果中,也无从谈排名。
2、尽量避免对内容使用 JavaScript。特别是与 关键词 相关的部分的内容应该是
尽量避免使用JavaScript来显示,否则无疑会降低关键词的密度。
3、如果确实需要使用JavaScript,请将这部分JavaScript脚本放在一个或多个.js文件中,以免干扰搜索引擎的抓取和分析。
4、一些不能放在.js文件中的JavaScript脚本应该放在html代码的最底部,这样搜索引擎在分析网页的时候会在最后找到,减少对网页的干扰搜索引擎。
上面的一些方法是为了消除JavaScript对搜索引擎的不利影响。事实上,另一方面,一件事通常有优点和缺点。使用 JavaScript 也是如此。使用 JavaScript 不一定是坏事。在一定程度上,使用 JavaScript 可以对 SEO 产生很好的效果,也就是正面的效果。
我们说搜索引擎无法识别 JavaScript(虽然 Google 目前可以识别少量的简单 JavaScript 代码,但应该只是 Document write 之类的简单代码)。所以从另一个角度来说,我们可以使用 JavaScript 来过滤一些垃圾邮件。
什么是垃圾邮件?从SEO的角度来看,不仅对搜索引擎的爬取分析无用,还会干扰关键词密度等不利信息。通常这种“垃圾邮件”信息包括:广告、版权声明、大量外链、与内容无关的信息等等。我们可以将这些垃圾邮件全部扔到一个或几个.js文件中,从而减少对页面实际内容的干扰,增加关键词的密度,向搜索引擎展示页面内容的核心 查看全部
js 抓取网页内容(页的赖以生存之本的使用方法有哪些?怎么处理?)
页面的生存,如果搜索引擎无法抓取该页面,则表示该页面不会出现在索引结果中,也无从谈排名。
2、尽量避免对内容使用 JavaScript。特别是与 关键词 相关的部分的内容应该是
尽量避免使用JavaScript来显示,否则无疑会降低关键词的密度。
3、如果确实需要使用JavaScript,请将这部分JavaScript脚本放在一个或多个.js文件中,以免干扰搜索引擎的抓取和分析。
4、一些不能放在.js文件中的JavaScript脚本应该放在html代码的最底部,这样搜索引擎在分析网页的时候会在最后找到,减少对网页的干扰搜索引擎。
上面的一些方法是为了消除JavaScript对搜索引擎的不利影响。事实上,另一方面,一件事通常有优点和缺点。使用 JavaScript 也是如此。使用 JavaScript 不一定是坏事。在一定程度上,使用 JavaScript 可以对 SEO 产生很好的效果,也就是正面的效果。
我们说搜索引擎无法识别 JavaScript(虽然 Google 目前可以识别少量的简单 JavaScript 代码,但应该只是 Document write 之类的简单代码)。所以从另一个角度来说,我们可以使用 JavaScript 来过滤一些垃圾邮件。
什么是垃圾邮件?从SEO的角度来看,不仅对搜索引擎的爬取分析无用,还会干扰关键词密度等不利信息。通常这种“垃圾邮件”信息包括:广告、版权声明、大量外链、与内容无关的信息等等。我们可以将这些垃圾邮件全部扔到一个或几个.js文件中,从而减少对页面实际内容的干扰,增加关键词的密度,向搜索引擎展示页面内容的核心
js 抓取网页内容( 2016年05月13日Linux下最好用supervisord守护者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-04 16:05
2016年05月13日Linux下最好用supervisord守护者)
Phantomjs渲染JS后抓取网页(Python代码)
更新时间:2016-05-13 09:09:10 投稿:hebedic
phantomjs:我的理解是它是一个不显示的浏览器,也就是说它基本上可以做浏览器能做的任何事情,只是它不能显示页面的内容。让我们利用他做一些有趣的事情
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
经过简单的试用,感觉pyspider更像是新手的爬虫工具,像妈妈一样,时而细致,时而喋喋不休。轻量级的小玩意应该更受欢迎,我也有点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午的时间,拆解了pyspider实现Phantomjs代理的部分,做成了一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码 查看全部
js 抓取网页内容(
2016年05月13日Linux下最好用supervisord守护者)
Phantomjs渲染JS后抓取网页(Python代码)
更新时间:2016-05-13 09:09:10 投稿:hebedic
phantomjs:我的理解是它是一个不显示的浏览器,也就是说它基本上可以做浏览器能做的任何事情,只是它不能显示页面的内容。让我们利用他做一些有趣的事情
最近需要爬取某个网站,可惜页面都是JS渲染后生成的,普通爬虫框架处理不了,于是想到了用Phantomjs搭建代理。
貌似没有现成的Python调用Phantomjs的第三方库(如果有,请告知小编)。逛了一圈,发现只有pyspider提供了现成的解决方案。
经过简单的试用,感觉pyspider更像是新手的爬虫工具,像妈妈一样,时而细致,时而喋喋不休。轻量级的小玩意应该更受欢迎,我也有点自私。可以一起使用我最喜欢的BeautifulSoup,而不用学习PyQuery(pyspider是用来解析HTML的),也不必忍受浏览器写Python。糟糕的经历(窃笑)。
于是花了一个下午的时间,拆解了pyspider实现Phantomjs代理的部分,做成了一个小的爬虫模块。我希望每个人都会喜欢它(感谢 binux!)。
准备好工作了
当然你有 Phantomjs,废话!(Linux下最好使用supervisord来守护,爬取时必须保持打开Phantomjs)
以项目路径中的 phantomjs_fetcher.js 开头:phantomjs phantomjs_fetcher.js [port]
安装 tornado 依赖项(使用 tornado 的 httpclient 模块)
调用超级简单
from tornado_fetcher import Fetcher
# 创建一个爬虫
>>> fetcher=Fetcher(
user_agent='phantomjs', # 模拟浏览器的User-Agent
phantomjs_proxy='http://localhost:12306', # phantomjs的地址
poolsize=10, # 最大的httpclient数量
async=False # 同步还是异步
)
# 开始连接Phantomjs的代码,可以渲染JS!
>>> fetcher.fetch(url)
# 渲染成功后执行额外的JS脚本(注意用function包起来!)
>>> fetcher.fetch(url, js_script='function(){setTimeout("window.scrollTo(0,100000)}", 1000)')
代码
js 抓取网页内容(网站开发的一些简单的seo注意事项优化方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-04-03 10:28
虽然程序员和网站的推广没有直接的联系,但是在网站建站的过程中,如果能很好的整合seo思想,往往可以事半功倍。如果一个网站特别是,如果网站的结构非常不利于seo优化,那么后期修改过程中的成本会非常大。在这里,我为程序员朋友简单的说一下网站开发中的一些简单的事情。seo 考虑。
1、网站路径问题(路径长度问题和路径静态问题)
网站路径的长度决定了搜索引擎蜘蛛抓取网页内容的效率和概率。通常,我们必须将网站中任何网页的目录层次控制在四层以下。
通常网站需要使用URL重写规则将动态地址变成伪静态页面,这对搜索引擎收录更有利。当然,你也可以做纯静态页面。
2、网站结构问题(这很重要)
像网站这样的搜索引擎蜘蛛,结构清晰,逻辑结构四通八达。只有这样,网站的更多内容才会被成功爬取或被蜘蛛爬取。
增加网站结构的几种常用方法:
一种。在网站的各个页面上尽可能多地划分section,并尽量在每个列表页面中收录其他列表的相关信息。(这点可以参考中关村数码相机网的结构结合自己的网站自己的内容来设计。)
湾。文章的in-text链接(注意是文章里面的链接,不是文章页面的链接,文章页面的链接在上面的a点)链接到更多部分)。
文章文内链接的三个作用如下:首先,文内链接可以增加网站立体效果,这也是这个大点的主要作用。第二个是文本链接有助于传递链接文章 文章 的权重。第三,文本内链接具有更好的用户体验。
C。网站中的标签系统,标签具有非常强大的作用,可以在某个地方显示分散的信息点,标签页有点像一个小话题页。一些网站尤其是门户网站网站通常不能把每个小项目或者知识点做成一个独立的页面,然后标签体现出强大的功能。
3、网站代码优化
现在一般开源系统的网站代码处理得比较好。如果是底层开发网站,那么需要注意网站代码优化问题。程序员需要注意以下两个A代码优化问题:
a.网站js和css封装。
湾。尽量不要使用表格,而是使用 div 布局
C。去除冗余代码
d.网站关键词密度
4、页面标签优化
网页中应该出现 strong 和 h1~h6 等标签。h1 标签应该在一个页面中最多出现一次。当然,最好把关键词放在这样的标签里。
5、机器人协议
robots.txt 是搜索引擎遵循的蜘蛛抓取协议。有时我们网站 一些我们不想被蜘蛛抓取的内容。这时,*协议可以有效地禁止蜘蛛爬取制定的文档。 查看全部
js 抓取网页内容(网站开发的一些简单的seo注意事项优化方法介绍)
虽然程序员和网站的推广没有直接的联系,但是在网站建站的过程中,如果能很好的整合seo思想,往往可以事半功倍。如果一个网站特别是,如果网站的结构非常不利于seo优化,那么后期修改过程中的成本会非常大。在这里,我为程序员朋友简单的说一下网站开发中的一些简单的事情。seo 考虑。
1、网站路径问题(路径长度问题和路径静态问题)
网站路径的长度决定了搜索引擎蜘蛛抓取网页内容的效率和概率。通常,我们必须将网站中任何网页的目录层次控制在四层以下。
通常网站需要使用URL重写规则将动态地址变成伪静态页面,这对搜索引擎收录更有利。当然,你也可以做纯静态页面。
2、网站结构问题(这很重要)
像网站这样的搜索引擎蜘蛛,结构清晰,逻辑结构四通八达。只有这样,网站的更多内容才会被成功爬取或被蜘蛛爬取。
增加网站结构的几种常用方法:
一种。在网站的各个页面上尽可能多地划分section,并尽量在每个列表页面中收录其他列表的相关信息。(这点可以参考中关村数码相机网的结构结合自己的网站自己的内容来设计。)
湾。文章的in-text链接(注意是文章里面的链接,不是文章页面的链接,文章页面的链接在上面的a点)链接到更多部分)。
文章文内链接的三个作用如下:首先,文内链接可以增加网站立体效果,这也是这个大点的主要作用。第二个是文本链接有助于传递链接文章 文章 的权重。第三,文本内链接具有更好的用户体验。
C。网站中的标签系统,标签具有非常强大的作用,可以在某个地方显示分散的信息点,标签页有点像一个小话题页。一些网站尤其是门户网站网站通常不能把每个小项目或者知识点做成一个独立的页面,然后标签体现出强大的功能。
3、网站代码优化
现在一般开源系统的网站代码处理得比较好。如果是底层开发网站,那么需要注意网站代码优化问题。程序员需要注意以下两个A代码优化问题:
a.网站js和css封装。
湾。尽量不要使用表格,而是使用 div 布局
C。去除冗余代码
d.网站关键词密度
4、页面标签优化
网页中应该出现 strong 和 h1~h6 等标签。h1 标签应该在一个页面中最多出现一次。当然,最好把关键词放在这样的标签里。
5、机器人协议
robots.txt 是搜索引擎遵循的蜘蛛抓取协议。有时我们网站 一些我们不想被蜘蛛抓取的内容。这时,*协议可以有效地禁止蜘蛛爬取制定的文档。
js 抓取网页内容(通过CSS元素作为识别所需内容部分的方法,我可以轻松地抓取内容 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-04-03 10:24
)
我可以通过使用 CSS 元素来轻松地抓取 HTML 内容,以此来识别我想要的部分内容,但我需要抓取网页的一部分:
PeopleSafe
//
我需要从这一行解析纬度和经度:
map.setCenter( new GLatLng( 51.612308, -1.239453 ), 11 );
所以,在我的表格的一列中,我想看到第一部分:
51.612308
在第二列,我想看第二部分:
-1.239453
如果没有 CSS 选择器,这可能吗?
编辑
非常感谢到目前为止的帮助!
最初的问题是在您登录该站点后立即重定向,我对其进行了排序,现在当我这样做时:
put page.root
我得到了我期望的页面的完整来源。所以现在我的代码(登录后)是:
html_doc = page.root
# Find the first in the head that does not have src="..."
#script = html.at_xpath('/html/head/script[not(@src)]')
# Use a regex to find the correct code parts in the JS, using named captures
parts = script.text.match(/new GLatLng\(\s*(?.+?)\s*,\s*(?.+?)\s*\)/)
p parts[:lat], parts[:long]
#=> "51.612308"
#=> "-1.239453"
运行上述命令时出现错误:
undefined local variable or method `script' for main:Object 查看全部
js 抓取网页内容(通过CSS元素作为识别所需内容部分的方法,我可以轻松地抓取内容
)
我可以通过使用 CSS 元素来轻松地抓取 HTML 内容,以此来识别我想要的部分内容,但我需要抓取网页的一部分:
PeopleSafe
//
我需要从这一行解析纬度和经度:
map.setCenter( new GLatLng( 51.612308, -1.239453 ), 11 );
所以,在我的表格的一列中,我想看到第一部分:
51.612308
在第二列,我想看第二部分:
-1.239453
如果没有 CSS 选择器,这可能吗?
编辑
非常感谢到目前为止的帮助!
最初的问题是在您登录该站点后立即重定向,我对其进行了排序,现在当我这样做时:
put page.root
我得到了我期望的页面的完整来源。所以现在我的代码(登录后)是:
html_doc = page.root
# Find the first in the head that does not have src="..."
#script = html.at_xpath('/html/head/script[not(@src)]')
# Use a regex to find the correct code parts in the JS, using named captures
parts = script.text.match(/new GLatLng\(\s*(?.+?)\s*,\s*(?.+?)\s*\)/)
p parts[:lat], parts[:long]
#=> "51.612308"
#=> "-1.239453"
运行上述命令时出现错误:
undefined local variable or method `script' for main:Object
js 抓取网页内容(我有一个注入第三方网站的AngularJS应用程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-04-03 10:22
我有一个 AngularJS 应用程序,它注入了第 3 方 网站。它将动态内容注入到第三方页面的 div 中。Google 已成功索引此动态内容,但似乎并未抓取动态内容中的链接。动态内容中的链接如下所示:
Link Here
我对链接使用查询参数而不是实际的 url 结构,例如:
http://www.example.com/support/title/Example Title/titleId/12345
我必须使用查询参数,因为我不希望第 3 方 网站 更改他们的网络服务器配置以重定向不正确的 url。
单击链接时,我使用 $locationService 更新浏览器中的 URL,然后我的 Angular 应用程序会做出相应的响应。主要根据查询参数展示相关内容,设置页面标题和元描述。
我已经阅读了很多在模板中使用 angularJS 和路由提供程序的 文章,但我不确定为什么这会对刮板产生影响?
我读过谷歌应该将带有查询参数的 URL 视为单独的页面,所以我不认为这应该是问题:
我唯一没有尝试过的是 1. 提供收录查询参数的 URL 站点地图,以及 2. 将指向其他页面的静态链接添加到动态链接以帮助 Google 发现这些页面。
非常感谢任何帮助、想法或见解。 查看全部
js 抓取网页内容(我有一个注入第三方网站的AngularJS应用程序)
我有一个 AngularJS 应用程序,它注入了第 3 方 网站。它将动态内容注入到第三方页面的 div 中。Google 已成功索引此动态内容,但似乎并未抓取动态内容中的链接。动态内容中的链接如下所示:
Link Here
我对链接使用查询参数而不是实际的 url 结构,例如:
http://www.example.com/support/title/Example Title/titleId/12345
我必须使用查询参数,因为我不希望第 3 方 网站 更改他们的网络服务器配置以重定向不正确的 url。
单击链接时,我使用 $locationService 更新浏览器中的 URL,然后我的 Angular 应用程序会做出相应的响应。主要根据查询参数展示相关内容,设置页面标题和元描述。
我已经阅读了很多在模板中使用 angularJS 和路由提供程序的 文章,但我不确定为什么这会对刮板产生影响?
我读过谷歌应该将带有查询参数的 URL 视为单独的页面,所以我不认为这应该是问题:
我唯一没有尝试过的是 1. 提供收录查询参数的 URL 站点地图,以及 2. 将指向其他页面的静态链接添加到动态链接以帮助 Google 发现这些页面。
非常感谢任何帮助、想法或见解。
js 抓取网页内容(js抓取网页内容,需要在地址栏输入url地址,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-03 00:06
js抓取网页内容,需要在地址栏输入url地址,抓取网页的后面的内容,也就是网页的源代码。以网页所提供的about这个url为例:/about/1对应的url就是:/about/11代表页码,1代表下一页。点击页码,就可以看到网页内容:点击某个页码,下一页就变成第一页。for循环,即使抓取下来的结果不是我们想要的,利用for循环,取出网页内容,然后在对应的url地址中添加参数,这样就可以复制并粘贴到制作的爬虫工具中进行调试。
for循环classproxy{urltext;proxy_autostart=false;}api可以利用以下两个api,自动抓取网页的源代码:get().tostring().substring(xhr.url.split(':')[-1]+xhr.url.split('/')[-1]+'/')。
你不会在原本的网页上修改地址,原因是爬虫都是按页抓取的,爬取内容都是在页面源代码中获取的。你可以在源代码中找到按页地址修改了的地方,一一修改地址,就可以获取原网页内容,并保存到数据库。
尝试一下手动输入地址栏吧,输入的是javascript中的_callback,会返回该url下所有http请求的headers信息,因为代码中用到了api调用所以不会被限制http请求次数,请求失败后,返回此页的headers信息,当然也不能做其他操作;_callback作用其实就是把http请求事先绑定在一个event上。 查看全部
js 抓取网页内容(js抓取网页内容,需要在地址栏输入url地址,)
js抓取网页内容,需要在地址栏输入url地址,抓取网页的后面的内容,也就是网页的源代码。以网页所提供的about这个url为例:/about/1对应的url就是:/about/11代表页码,1代表下一页。点击页码,就可以看到网页内容:点击某个页码,下一页就变成第一页。for循环,即使抓取下来的结果不是我们想要的,利用for循环,取出网页内容,然后在对应的url地址中添加参数,这样就可以复制并粘贴到制作的爬虫工具中进行调试。
for循环classproxy{urltext;proxy_autostart=false;}api可以利用以下两个api,自动抓取网页的源代码:get().tostring().substring(xhr.url.split(':')[-1]+xhr.url.split('/')[-1]+'/')。
你不会在原本的网页上修改地址,原因是爬虫都是按页抓取的,爬取内容都是在页面源代码中获取的。你可以在源代码中找到按页地址修改了的地方,一一修改地址,就可以获取原网页内容,并保存到数据库。
尝试一下手动输入地址栏吧,输入的是javascript中的_callback,会返回该url下所有http请求的headers信息,因为代码中用到了api调用所以不会被限制http请求次数,请求失败后,返回此页的headers信息,当然也不能做其他操作;_callback作用其实就是把http请求事先绑定在一个event上。
js 抓取网页内容( 什么对网页抓取更好?Python,WebScraping,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-04-02 01:12
什么对网页抓取更好?Python,WebScraping,)
开始使用 Javascript Web Scraping
python网络抓取
开始使用 Javascript Web Scraping, javascript, python, web-scraping, Javascript, Python, Web Scraping, 首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 JavaScript。我正在看一个关于如何制作网络爬虫的视频,我有一些问题:我看到很多关于 python 网络爬虫的教程,并且由于我对 python 非常了解,我问自己,网络爬虫有什么更好的方法?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗?我需要对一个网站使用网络抓取,我正在尝试从其他网站获取特定数据并将它们显示在我的网站中所以人们可以看到它们。你对如何开始有什么建议吗?请注意我的英语不是很好,我的
首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 java 脚本。我正在观看有关如何制作网络爬虫的视频,我有一些问题:
看了很多python爬网的教程,既然我对python很了解,就问自己,用什么爬网比较好?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗
我需要对一个 网站 使用网络抓取,并且我正在尝试从其他 网站 获取特定数据并将它们显示在我的 网站 上,以便人们可以看到它们。你对如何开始有什么建议吗
请注意,我的英语不是很好,我的语言没有关于网页抓取的教程或视频,请原谅本文中的错误。
Python 可用于网页抓取,一个流行的选项是使用,但通常需要一些包来完成您描述的更复杂的事情
这是一个很好的教程,可以帮助您入门:
对于您提到的 网站,您需要使用 Flask/Django 创建某种 Web 应用程序,该应用程序将使用您正在抓取的信息或基于您的 网站 用户请求填充数据库检索信息
对于 Javascript 和 Python,我不确定,因为我只使用过 Python。我在这方面的经验非常好,但以下内容可能会为您提供更多信息:
以下博客 文章 也可能对您有用:披露:我还没有完全阅读此 文章,只是扫描了它,但它似乎与您的问题有关
YouTube 上的 DevTips 有一个关于使用 Node JavaScript 进行抓取的精彩系列。Python 是最流行的网页抓取语言。@Shijith,我可以将它与 html 一起使用吗?@evolutionxbox 搜索了它,但我什至在他的烧瓶/Django 播放列表中都找不到它 查看全部
js 抓取网页内容(
什么对网页抓取更好?Python,WebScraping,)
开始使用 Javascript Web Scraping
python网络抓取
开始使用 Javascript Web Scraping, javascript, python, web-scraping, Javascript, Python, Web Scraping, 首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 JavaScript。我正在看一个关于如何制作网络爬虫的视频,我有一些问题:我看到很多关于 python 网络爬虫的教程,并且由于我对 python 非常了解,我问自己,网络爬虫有什么更好的方法?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗?我需要对一个网站使用网络抓取,我正在尝试从其他网站获取特定数据并将它们显示在我的网站中所以人们可以看到它们。你对如何开始有什么建议吗?请注意我的英语不是很好,我的
首先我想让你们知道我对 html 和 css 很陌生,现在我不知道如何使用 java 脚本。我正在观看有关如何制作网络爬虫的视频,我有一些问题:
看了很多python爬网的教程,既然我对python很了解,就问自己,用什么爬网比较好?Python 或 Java 脚本,我应该使用哪个?我可以用html“连接”一个python程序吗
我需要对一个 网站 使用网络抓取,并且我正在尝试从其他 网站 获取特定数据并将它们显示在我的 网站 上,以便人们可以看到它们。你对如何开始有什么建议吗
请注意,我的英语不是很好,我的语言没有关于网页抓取的教程或视频,请原谅本文中的错误。
Python 可用于网页抓取,一个流行的选项是使用,但通常需要一些包来完成您描述的更复杂的事情
这是一个很好的教程,可以帮助您入门:
对于您提到的 网站,您需要使用 Flask/Django 创建某种 Web 应用程序,该应用程序将使用您正在抓取的信息或基于您的 网站 用户请求填充数据库检索信息
对于 Javascript 和 Python,我不确定,因为我只使用过 Python。我在这方面的经验非常好,但以下内容可能会为您提供更多信息:
以下博客 文章 也可能对您有用:披露:我还没有完全阅读此 文章,只是扫描了它,但它似乎与您的问题有关
YouTube 上的 DevTips 有一个关于使用 Node JavaScript 进行抓取的精彩系列。Python 是最流行的网页抓取语言。@Shijith,我可以将它与 html 一起使用吗?@evolutionxbox 搜索了它,但我什至在他的烧瓶/Django 播放列表中都找不到它
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-25 08:12
)
在上一篇文章文章()中,我们使用了模拟打开浏览器的方法,在网页中模拟点击load more来动态加载网页并获取网页内容。但是很遗憾,网站的部分内容是使用js动态加载的。我们用普通方法获取的时候发现有些地方是空白的,所以无法获取Xpath,所以上一篇文章方法也失败了。
可能有的童鞋开始觉得代码不对,然后把网页的所有内容都打印出来,发现自己想要的那部分内容真的少了,然后用浏览器访问网页,右键查看网页的源代码,发现这部分代码是真的少了。我就是那个傻孩子!!!
所以本文文章希望能解决这类问题,抓取js动态加载的网页。首先想到的是使用selenium调用浏览器进行爬取,但是第一句话显示无法获取Xpath,所以无法通过点击页面元素来实现。这时候看到了这个文章(),使用selenium+phantomjs进行无界面捕获。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载后直接解压就OK了,然后用pip安装selenium
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。要找到你想要的网页,你只要尝试打开一个新的浏览器访问上面的url,就可以看到页面信息,如果是你想要的信息,使用request get方法,只需完成headers
请求的 url 通常很长。例如上图的url地址为:
其实只要保留rowguid,也就是访问:
那么rowguid只需要通过查询参数获取
查看全部
js 抓取网页内容(模拟打开浏览器的方法模拟点击网页发现这部分代码确实没有
)
在上一篇文章文章()中,我们使用了模拟打开浏览器的方法,在网页中模拟点击load more来动态加载网页并获取网页内容。但是很遗憾,网站的部分内容是使用js动态加载的。我们用普通方法获取的时候发现有些地方是空白的,所以无法获取Xpath,所以上一篇文章方法也失败了。
可能有的童鞋开始觉得代码不对,然后把网页的所有内容都打印出来,发现自己想要的那部分内容真的少了,然后用浏览器访问网页,右键查看网页的源代码,发现这部分代码是真的少了。我就是那个傻孩子!!!
所以本文文章希望能解决这类问题,抓取js动态加载的网页。首先想到的是使用selenium调用浏览器进行爬取,但是第一句话显示无法获取Xpath,所以无法通过点击页面元素来实现。这时候看到了这个文章(),使用selenium+phantomjs进行无界面捕获。
具体步骤如下:
1. 下载Phantomjs,下载地址:
2. 下载后直接解压就OK了,然后用pip安装selenium
3. 编写代码并执行
完整代码如下:
import requests
from bs4 import BeautifulSoup
import re
from selenium import webdriver
import time
def getHTMLText(url):
driver = webdriver.PhantomJS(executable_path='D:\\phantomjs-2.1.1-windows\\bin\\phantomjs') # phantomjs的绝对路径
time.sleep(2)
driver.get(url) # 获取网页
time.sleep(2)
return driver.page_source
def fillUnivlist(html):
soup = BeautifulSoup(html, 'html.parser') # 用HTML解析网址
tag = soup.find_all('div', attrs={'class': 'listInfo'})
print(str(tag[0]))
return 0
def main():
url = 'http://sports.qq.com/articleList/rolls/' #要访问的网址
html = getHTMLText(url) #获取HTML
fillUnivlist(html)
if __name__ == '__main__':
main()
那么对于js动态加载,可以使用Python来模拟请求(一般是获取请求,添加请求头)。
具体方法是先按F12,打开网页评论元素界面,点击网络,如下图:
排除图片、gif、css等。要找到你想要的网页,你只要尝试打开一个新的浏览器访问上面的url,就可以看到页面信息,如果是你想要的信息,使用request get方法,只需完成headers
请求的 url 通常很长。例如上图的url地址为:
其实只要保留rowguid,也就是访问:
那么rowguid只需要通过查询参数获取
js 抓取网页内容(js抓取网页内容:javascript与alert()的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-25 08:07
js抓取网页内容:javascript不解释html解析网页内容:javascriptalert(document。getelementbyid('document'));//documentjavascript解析javascript变量:javascript不解释javascript生成网页里任何一个元素(比如:$。
extend())javascript生成小电影($。extend('div','a')):javascript不解释。
仔细看alert和alert('dream')的区别,其实就是完成类似条件判断的功能。javascript提供了两种相对简单的方式:一个是通过标签实现,另一个是通过alert/alert()这样的函数实现。但这些效果都是基于浏览器原生支持。这两个接口最直接的区别在于对象来源,标签的类型是xmlhttprequest对象,alert/alert()是alert()对象。
原理方面的区别主要在alert/alert()使用了转义符xmlhttprequest,而javascript提供的是基于xmlhttprequest.onrequest=”0”;。
通过javascriptalert传递一个“窗口”alert与alert()的区别主要在这几个方面:1。发送等待时间与回应时间2。可以指定最多发送多少个点击发送,获取执行情况3。可以在传入的数组中包含固定规则4。具有可重复性,而alert()只能获取新值或重复5。可以查看当前窗口以及所有窗口数据的排序。 查看全部
js 抓取网页内容(js抓取网页内容:javascript与alert()的区别)
js抓取网页内容:javascript不解释html解析网页内容:javascriptalert(document。getelementbyid('document'));//documentjavascript解析javascript变量:javascript不解释javascript生成网页里任何一个元素(比如:$。
extend())javascript生成小电影($。extend('div','a')):javascript不解释。
仔细看alert和alert('dream')的区别,其实就是完成类似条件判断的功能。javascript提供了两种相对简单的方式:一个是通过标签实现,另一个是通过alert/alert()这样的函数实现。但这些效果都是基于浏览器原生支持。这两个接口最直接的区别在于对象来源,标签的类型是xmlhttprequest对象,alert/alert()是alert()对象。
原理方面的区别主要在alert/alert()使用了转义符xmlhttprequest,而javascript提供的是基于xmlhttprequest.onrequest=”0”;。
通过javascriptalert传递一个“窗口”alert与alert()的区别主要在这几个方面:1。发送等待时间与回应时间2。可以指定最多发送多少个点击发送,获取执行情况3。可以在传入的数组中包含固定规则4。具有可重复性,而alert()只能获取新值或重复5。可以查看当前窗口以及所有窗口数据的排序。
js 抓取网页内容(js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-24 16:05
js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚,这个只是一个基础,如果需要更深入的话你可以看看百度百科:websocket概述跟据楼主的要求,我认为最好的选择可能是tcphttp协议实现的服务器,这是因为tcp是面向连接的,可以应用多线程问题,而http协议在请求的时候是基于三次握手的,稳定性上肯定是tcp优于http协议,这样比较下来就只剩tcp了,不过如果你是为了提高性能,甚至更实在点,就需要一个高效的处理二次握手的协议,这个暂时只能用http协议。
websocket技术python是个好东西。楼主可以试试。技术选型、实现和市场可以考虑使用一些第三方工具来做。
首先这个是要考虑开发成本和性能的。如果只是做最基本的爬虫,可以考虑使用commonjs封装一个模块,后端用scrapy,使用xpath获取需要的内容到页面,这样即使是一个普通的ie浏览器,通过网址获取到,也可以获取相关的页面,速度是非常快的。但如果需要抓取抓取复杂的数据,这个时候就是需要考虑scrapy来实现的,毕竟如果再封装一个scrapy爬虫框架,不管是性能还是开发成本都是非常高的。
并且还是一个企业内部的爬虫网站和用户交互效率还是比较低的。如果对性能有需求的,或者自己想扩展抓取功能,则可以结合xpathextractor,xpathparser这些来采集数据。大致流程上来说,就是先封装一个scrapy爬虫框架,大概是这样的:--使用xpath语法获取内容--封装xpath的语法封装完scrapy-selector(selector是一个一个xpath下来抓取文档对应的xpath)--xpath中搜索相应的xpath到页面,并将相应的xpath下来的结果导出。
这里讲几个要点:1,xpathparser其实已经足够,只需要传输一个parser入参参数即可。但是加载xpath文档只是用一个parser的话,成本是太高的,同时parser没有什么优势。2,parser就是爬虫框架,一般使用venv来管理每个依赖parser或者依赖的js等文件。3,jquery这些是类库,也是不对外公开的,所以每次要下载相应的jquery是一个大开销,所以有的时候直接使用webpack去打包,不过每次要加载一堆pipe进来最后得到页面只能依赖pipe来下载一些数据。
4,scrapy则是通过javascript来调用xpath进行抓取内容,虽然有一些需要前端调用的api,但是基本上javascript还是不会被拦截的。5,对于jquery来说,还有一些可能的不能写成脚本代码的调用,比如要使用xpath来获取文档最后一行的内容等等。-。 查看全部
js 抓取网页内容(js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚)
js抓取网页内容,使用的是websocket,这个东西一般人应该不清楚,这个只是一个基础,如果需要更深入的话你可以看看百度百科:websocket概述跟据楼主的要求,我认为最好的选择可能是tcphttp协议实现的服务器,这是因为tcp是面向连接的,可以应用多线程问题,而http协议在请求的时候是基于三次握手的,稳定性上肯定是tcp优于http协议,这样比较下来就只剩tcp了,不过如果你是为了提高性能,甚至更实在点,就需要一个高效的处理二次握手的协议,这个暂时只能用http协议。
websocket技术python是个好东西。楼主可以试试。技术选型、实现和市场可以考虑使用一些第三方工具来做。
首先这个是要考虑开发成本和性能的。如果只是做最基本的爬虫,可以考虑使用commonjs封装一个模块,后端用scrapy,使用xpath获取需要的内容到页面,这样即使是一个普通的ie浏览器,通过网址获取到,也可以获取相关的页面,速度是非常快的。但如果需要抓取抓取复杂的数据,这个时候就是需要考虑scrapy来实现的,毕竟如果再封装一个scrapy爬虫框架,不管是性能还是开发成本都是非常高的。
并且还是一个企业内部的爬虫网站和用户交互效率还是比较低的。如果对性能有需求的,或者自己想扩展抓取功能,则可以结合xpathextractor,xpathparser这些来采集数据。大致流程上来说,就是先封装一个scrapy爬虫框架,大概是这样的:--使用xpath语法获取内容--封装xpath的语法封装完scrapy-selector(selector是一个一个xpath下来抓取文档对应的xpath)--xpath中搜索相应的xpath到页面,并将相应的xpath下来的结果导出。
这里讲几个要点:1,xpathparser其实已经足够,只需要传输一个parser入参参数即可。但是加载xpath文档只是用一个parser的话,成本是太高的,同时parser没有什么优势。2,parser就是爬虫框架,一般使用venv来管理每个依赖parser或者依赖的js等文件。3,jquery这些是类库,也是不对外公开的,所以每次要下载相应的jquery是一个大开销,所以有的时候直接使用webpack去打包,不过每次要加载一堆pipe进来最后得到页面只能依赖pipe来下载一些数据。
4,scrapy则是通过javascript来调用xpath进行抓取内容,虽然有一些需要前端调用的api,但是基本上javascript还是不会被拦截的。5,对于jquery来说,还有一些可能的不能写成脚本代码的调用,比如要使用xpath来获取文档最后一行的内容等等。-。
js 抓取网页内容( 如何优化站点内部链接?一个成功的网站优化(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2022-03-24 00:06
如何优化站点内部链接?一个成功的网站优化(图))
如何优化网站内链?一个成功的 网站 优化实际上可以分解为许多方面,但有一些特别突出。随着搜索引擎算法的不断变化,网站内链的位置越来越重要,一个内链好的网站更容易获得网站排名和收录. 所以,今天我们就来讨论一下云之小编总结的网站内链如何优化的六个关键点。今天主要讨论如何优化网站内链:
1.网站导航。
无论网站 的主页导航到网站 的内容页面,通常,网站 的导航都放在网站 的顶部。因为搜索引擎不识别js调用,所以无法使用java脚本跳转到站点导航。当搜索引擎输入网站爬取网页时,从网站的左上角到网站的右下角。正常情况下,网站首页链接是添加到网站导航的,因为网站首页的权重最大,这样搜索引擎才能顺利抓取网站栏目页面,从而达到提高栏目页面权重和排名的目的。最好不要使用图片链接,因为搜索引擎不理解图片链接。
链接内容页面和部分页面。
在确定了网站首页的关键词之后,我们就可以使用对应的关键词作为栏目页了。制作带有长尾 关键词 的 网站 内容页面。如果能把内容页和栏目页结合起来,效果会更好。在为 网站 内部构建链接时,我们必须小心不要有死链接或让它们失效。将最佳部分链接到主页。确保整个装置畅通无阻。如果搜索引擎不能进入死链接,他们就不会出来。家庭搜索引擎会丢弃死链接网站。这也是向您的网站内容添加锚文本的好方法。但数量不宜过大。
网站结构:
站点结构是一个非常抽象的概念,包括站点页面代码、站点布局等概念。网站 的内容是用户看到的,但搜索引擎看到的不仅是内容,还有网站 的结构。网站结构对搜索引擎爬取影响很大网站。如果网站的结构过于复杂,会增加搜索引擎的工作量,搜索引擎也不愿意这样做。网站 的层级不能太深。网站应该节省用户时间。没有人愿意花大量时间在 网站 上寻找他们不知道是否有用的页面。如果网站是dedecms程序构造的,那么网站的链接结构只有:首页>栏目页>内容页3层。
第四,网站地图。
一般来说,网站的网站映射有两种,一种是html,一种是xml。现在有许多开源程序可以在 Internet 上下载。SiteMaps 的 网站 内容会在每次更新时自动更新。如果网站图能合理使用,对网站内容的收录会有很大帮助。搜索引擎通过 网站maps 获取 网站 内容。
还有很多页面无法处理 404 页面。如果用户访问你的网站内部页面,如果404连接不上,最好还是返回首页提示并显示返回首页按钮,让用户第一时间注意到. 请注意网站的404页面需要被robots文件屏蔽。为 网站 设置 404 页面会返回状态码 404。
6.nofollow 和标记。
如果我们不想让搜索引擎抓取带有网站的页面,我们可以用nofollow标签阻止搜索引擎抓取,这意味着搜索引擎不再关注这个链接。标签可以让搜索引擎轻松搜索 网站 的内容。读者可以通过文章标签更快地找到自己感兴趣的文章。使用标签可以增加网站的权重和内容。
以上就是小编在实际操作中经常遇到的问题。希望对大家有帮助。事实上,Imperial SEO 是我认为 SEO 需要不断练习的。每当出现问题时,分析问题并让自己成长。 查看全部
js 抓取网页内容(
如何优化站点内部链接?一个成功的网站优化(图))
如何优化网站内链?一个成功的 网站 优化实际上可以分解为许多方面,但有一些特别突出。随着搜索引擎算法的不断变化,网站内链的位置越来越重要,一个内链好的网站更容易获得网站排名和收录. 所以,今天我们就来讨论一下云之小编总结的网站内链如何优化的六个关键点。今天主要讨论如何优化网站内链:
1.网站导航。
无论网站 的主页导航到网站 的内容页面,通常,网站 的导航都放在网站 的顶部。因为搜索引擎不识别js调用,所以无法使用java脚本跳转到站点导航。当搜索引擎输入网站爬取网页时,从网站的左上角到网站的右下角。正常情况下,网站首页链接是添加到网站导航的,因为网站首页的权重最大,这样搜索引擎才能顺利抓取网站栏目页面,从而达到提高栏目页面权重和排名的目的。最好不要使用图片链接,因为搜索引擎不理解图片链接。
链接内容页面和部分页面。
在确定了网站首页的关键词之后,我们就可以使用对应的关键词作为栏目页了。制作带有长尾 关键词 的 网站 内容页面。如果能把内容页和栏目页结合起来,效果会更好。在为 网站 内部构建链接时,我们必须小心不要有死链接或让它们失效。将最佳部分链接到主页。确保整个装置畅通无阻。如果搜索引擎不能进入死链接,他们就不会出来。家庭搜索引擎会丢弃死链接网站。这也是向您的网站内容添加锚文本的好方法。但数量不宜过大。
网站结构:
站点结构是一个非常抽象的概念,包括站点页面代码、站点布局等概念。网站 的内容是用户看到的,但搜索引擎看到的不仅是内容,还有网站 的结构。网站结构对搜索引擎爬取影响很大网站。如果网站的结构过于复杂,会增加搜索引擎的工作量,搜索引擎也不愿意这样做。网站 的层级不能太深。网站应该节省用户时间。没有人愿意花大量时间在 网站 上寻找他们不知道是否有用的页面。如果网站是dedecms程序构造的,那么网站的链接结构只有:首页>栏目页>内容页3层。
第四,网站地图。
一般来说,网站的网站映射有两种,一种是html,一种是xml。现在有许多开源程序可以在 Internet 上下载。SiteMaps 的 网站 内容会在每次更新时自动更新。如果网站图能合理使用,对网站内容的收录会有很大帮助。搜索引擎通过 网站maps 获取 网站 内容。
还有很多页面无法处理 404 页面。如果用户访问你的网站内部页面,如果404连接不上,最好还是返回首页提示并显示返回首页按钮,让用户第一时间注意到. 请注意网站的404页面需要被robots文件屏蔽。为 网站 设置 404 页面会返回状态码 404。
6.nofollow 和标记。
如果我们不想让搜索引擎抓取带有网站的页面,我们可以用nofollow标签阻止搜索引擎抓取,这意味着搜索引擎不再关注这个链接。标签可以让搜索引擎轻松搜索 网站 的内容。读者可以通过文章标签更快地找到自己感兴趣的文章。使用标签可以增加网站的权重和内容。
以上就是小编在实际操作中经常遇到的问题。希望对大家有帮助。事实上,Imperial SEO 是我认为 SEO 需要不断练习的。每当出现问题时,分析问题并让自己成长。
js 抓取网页内容(js抓取网页内容一般用到的是异步加载吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-03-22 13:06
<p>js抓取网页内容一般用到的是异步加载吧,楼主可以研究下eventloop,实现一个简单的异步加载代码如下functiongetelementbyid(self){varjson=json。parse('小明');varl=localstorage。getitem(self。pagetext,{expires:{type:"string",default:{date:{stransfer:{message:"文章内容"});returnjson;}functiongeteditorizet(){varpagetext={};for(vari=0;i 查看全部
js 抓取网页内容(js抓取网页内容一般用到的是异步加载吧)
<p>js抓取网页内容一般用到的是异步加载吧,楼主可以研究下eventloop,实现一个简单的异步加载代码如下functiongetelementbyid(self){varjson=json。parse('小明');varl=localstorage。getitem(self。pagetext,{expires:{type:"string",default:{date:{stransfer:{message:"文章内容"});returnjson;}functiongeteditorizet(){varpagetext={};for(vari=0;i
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问)
网站优化 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2022-03-20 05:06
我们之前爬取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成并加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,代表XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:#coding:utf-8
导入请求
导入json
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
福宁新闻:
title=n['title']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
代码分为四部分
第 1 部分:介绍相关库#coding: utf-8
导入请求
导入json
第二部分:http请求到数据接口url='#39;
wbdata=requests.get(url).text 查看全部
js 抓取网页内容(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问)
我们之前爬取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟访问网页
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成并加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,代表XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:#coding:utf-8
导入请求
导入json
url='#39;
wbdata=requests.get(url).text
data=json.loads(wbdata)
news=data['data']['pc_feed_focus']
福宁新闻:
title=n['title']
img_url=n['image_url']
url=n['media_url']
打印(网址,标题,img_url)
返回结果如下:
代码分为四部分
第 1 部分:介绍相关库#coding: utf-8
导入请求
导入json
第二部分:http请求到数据接口url='#39;
wbdata=requests.get(url).text
js 抓取网页内容(C++与php的交互之--C++获取网页文字内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-19 04:21
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据发送到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写入本地文本等操作。废话不多说,咱们聊聊。 - - - 分界线 - - - - - - - - - - - - - - - - - - - - - -------------------- 测试服务器为:新浪云海;测试内容:通过php脚本获取从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先上传直观的图片,然后文字源码整体例子?多字节wchar到lpcswtr的转换功能介绍请到此链接https:developerarticle1010979?
709 查看全部
js 抓取网页内容(C++与php的交互之--C++获取网页文字内容)
C++与php的交互-----C++获取网页的文本内容,获取php的echo值。
https:developeruser1148436activities 距离上次讲C++制作json或者其他数据发送到服务器已经两个多月了。链接:https:developerarticle1011359 这次是从服务器获取文本内容到控制台,或者写入本地文本等操作。废话不多说,咱们聊聊。 - - - 分界线 - - - - - - - - - - - - - - - - - - - - - -------------------- 测试服务器为:新浪云海;测试内容:通过php脚本获取从服务器读取的数据,这里是微信用户的openID;工具:VS 2012;先上传直观的图片,然后文字源码整体例子?多字节wchar到lpcswtr的转换功能介绍请到此链接https:developerarticle1010979?
709
js 抓取网页内容(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 394 次浏览 • 2022-03-16 05:16
前言:很多博主不仔细阅读内容直接认为使用iframe不好,但其实这篇文章是教大家在必须使用iframe的情况下,如何避免搜索引擎的爬取,从而避免对SEO不利的情况!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题展示。这时候就会产生大量的iframe框架,那么本文中的方法就派上用场了!
简介:对seo稍有了解的站长应该都知道,爬虫不喜欢iframe或者frame,因为蜘蛛在访问一个网站时抓取的html是调用其他网页的html文件的代码,不收录任何文本内容. 也就是说,你的网页内容是什么,蜘蛛无法弄清楚。有人可能会说,搜索引擎蜘蛛也可以跟踪需要抓取的 HTML 文件。是的,可以跟踪抓取,但是跟踪这部分内容通常不是完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用文件。随着搜索技术的发展,这个问题可能并不总是可以解决,但是这么多网站蜘蛛不会因为你们一个网站而烦恼。所以,
从使用iframe调用快递100进行快递查询,到自己发起互推联盟的iframe调用代码,张歌对iframe这个东西有点了解。
记得,在互推联盟推出自适应iframe代码时,冯耀宗博主曾这样评论:,
后来一次偶然的测试让我顿悟,想到用JS封装iframe,避免搜索引擎的爬取。当时我正在测试用 JS 封装 CSS 代码,想简单加密自己的劳动成果。不想,突然想到,既然JS可以输出CSS,那JS应该也能输出iframe吧!实际测试发现我的想法是可行的!通过JS输出iframe代码可以完美的达到直接调用iframe代码的效果!
下面以互促联盟为例,公布方法:
张哥最先推出的iframe自适应调用代码如下:
现在,张哥将讲解如何用JS代码封装这个iframe,制作一个js版本:
首先,新建一个JS文件,在里面输入以下内容并保存:
括号是原创 iframe 的内容。需要注意的是开头和结尾都是双引号,iframe需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js的最终地址为:
最后,在要调用 iframe 的地方写下如下语句
如果存在旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑js文件调整iframe大小。
这样就完美实现了原本直接用iframe框架调用的效果。
接下来,张哥来衡量一下避开搜索爬虫的效果:
① 打开站长工具的搜索蜘蛛和机器人模拟爬虫:
② 进入用JS部署iframe代码的页面,如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不做任何处理,蜘蛛肯定可以爬到这个 iframe 上。
但是经过JS封装后,会得到如下爬取结果:
如上图,结果中没有页面互助联盟的内容,印证了这种方法的可行性!当然,有兴趣的站长也可以使用自己的网站亲自测试一下效果。
最后,总结一下“国际惯例”的风格如下:
综上所述,事实证明,通过JS封装iframe代码,确实可以完美欺骗搜索引擎的爬取,让鱼与熊掌之间的选择不再难!
而且,没有外链输出,没有减重,这也是张哥博客的通用互助联盟页面被众多站长调用的重要原因之一!很多博主可能会认为张格隆从这个互助联盟中赚了不少外链,其实不然!在这里张哥必须澄清一下,JS调用的互推联盟根本不会成为张哥博客的外链!不信可以用工具测试被调用的页面就知道了! 查看全部
js 抓取网页内容(iframe“必须要用iframe的时候”,如何躲过搜索引擎?)
前言:很多博主不仔细阅读内容直接认为使用iframe不好,但其实这篇文章是教大家在必须使用iframe的情况下,如何避免搜索引擎的爬取,从而避免对SEO不利的情况!
那么,什么是“何时必须使用 iframe”?举个简单的例子:一些主题分享网站,很多时候会使用iframe框架调用主题作者的网站做主题展示。这时候就会产生大量的iframe框架,那么本文中的方法就派上用场了!
简介:对seo稍有了解的站长应该都知道,爬虫不喜欢iframe或者frame,因为蜘蛛在访问一个网站时抓取的html是调用其他网页的html文件的代码,不收录任何文本内容. 也就是说,你的网页内容是什么,蜘蛛无法弄清楚。有人可能会说,搜索引擎蜘蛛也可以跟踪需要抓取的 HTML 文件。是的,可以跟踪抓取,但是跟踪这部分内容通常不是完整的页面。搜索引擎无法判断哪一部分是主框架,哪一部分是被调用文件。随着搜索技术的发展,这个问题可能并不总是可以解决,但是这么多网站蜘蛛不会因为你们一个网站而烦恼。所以,
从使用iframe调用快递100进行快递查询,到自己发起互推联盟的iframe调用代码,张歌对iframe这个东西有点了解。
记得,在互推联盟推出自适应iframe代码时,冯耀宗博主曾这样评论:,
后来一次偶然的测试让我顿悟,想到用JS封装iframe,避免搜索引擎的爬取。当时我正在测试用 JS 封装 CSS 代码,想简单加密自己的劳动成果。不想,突然想到,既然JS可以输出CSS,那JS应该也能输出iframe吧!实际测试发现我的想法是可行的!通过JS输出iframe代码可以完美的达到直接调用iframe代码的效果!
下面以互促联盟为例,公布方法:
张哥最先推出的iframe自适应调用代码如下:
现在,张哥将讲解如何用JS代码封装这个iframe,制作一个js版本:
首先,新建一个JS文件,在里面输入以下内容并保存:
括号是原创 iframe 的内容。需要注意的是开头和结尾都是双引号,iframe需要改成单引号!否则无法输出!
document.write("");
然后,将这个js文件上传到服务器
比如互推联盟调用的js的最终地址为:
最后,在要调用 iframe 的地方写下如下语句
如果存在旧的 iframe 代码,请直接替换。如果发现界面不理想,请在第二步编辑js文件调整iframe大小。
这样就完美实现了原本直接用iframe框架调用的效果。
接下来,张哥来衡量一下避开搜索爬虫的效果:
① 打开站长工具的搜索蜘蛛和机器人模拟爬虫:
② 进入用JS部署iframe代码的页面,如MOREOPEN博客调用的互推联盟页面:
③如图所示,这个页面有很多外部链接。如果不做任何处理,蜘蛛肯定可以爬到这个 iframe 上。
但是经过JS封装后,会得到如下爬取结果:
如上图,结果中没有页面互助联盟的内容,印证了这种方法的可行性!当然,有兴趣的站长也可以使用自己的网站亲自测试一下效果。
最后,总结一下“国际惯例”的风格如下:
综上所述,事实证明,通过JS封装iframe代码,确实可以完美欺骗搜索引擎的爬取,让鱼与熊掌之间的选择不再难!
而且,没有外链输出,没有减重,这也是张哥博客的通用互助联盟页面被众多站长调用的重要原因之一!很多博主可能会认为张格隆从这个互助联盟中赚了不少外链,其实不然!在这里张哥必须澄清一下,JS调用的互推联盟根本不会成为张哥博客的外链!不信可以用工具测试被调用的页面就知道了!
js 抓取网页内容(网站流量基本来于百度搜索引擎的抓取次数,网站的排名越好)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-08 02:11
网站流量主要来自百度搜索引擎的爬取次数。爬取次数越多,网站的排名就越好。今天就简单介绍一下网站爬取的内容!
抓取频率
抓取频率是搜索引擎在单位时间内抓取网站服务器的总次数。如果搜索引擎对网站的爬取过于频繁,很可能导致服务器不稳定,baiduspider会根据网站内容更新频率、服务器压力等因素自动调整爬取频率。
爬虫诊断工具可以让百度蜘蛛查看爬取的内容,并自行诊断百度蜘蛛看到的内容是否与预期一致。每个站点每周可以使用 200 次,爬取结果只显示百度蜘蛛可以看到的前 200KB 内容。
抓取诊断
爬虫诊断工具的作用
(1)诊断爬取的内容是否符合预期。例如在很多商品详情页面中,价格信息是通过Javascript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用. 问题纠正后,可再次使用诊断工具。抓紧检查。
(2)诊断网络是否添加了黑色链接和隐藏文字。网站如果被黑了,可能会添加隐藏链接。这些链接可能只有在百度爬取的时候才会出现,需要用到这个爬虫诊断。
爬网诊断工具操作
打开爬取诊断,选择诊断的网站,点击爬取,爬取状态会出现在列表中,点击爬取成功浏览抓取的网页代码
MIP介绍
移动网页加速器(mobile Instant page,MIP)是一套应用于移动移动网页的开放技术标准。通过提供MIP-HIML规范和MIP-cache页面缓存系统,实现移动网页加速。一个新的网页加速器。
MIP-HIML 基于 HTML 中的基本标签开发了一个新规范。通过限制一些基本标签的使用或扩展其功能,HTML 可以显示更丰富的内容:MIP-JS 可以保证 MIP-HIML 页面的快速渲染,MIP -cache 用于缓存 MIP 页面,进一步提高页面性能。如果要制作MIP网站,需要进入百度站长平台,详细了解MIP制作流程。
网站建设、网络推广公司——创新互联,是网站专注品牌与效果、网络营销的seo公司;服务项目包括网站营销等。 查看全部
js 抓取网页内容(网站流量基本来于百度搜索引擎的抓取次数,网站的排名越好)
网站流量主要来自百度搜索引擎的爬取次数。爬取次数越多,网站的排名就越好。今天就简单介绍一下网站爬取的内容!
抓取频率
抓取频率是搜索引擎在单位时间内抓取网站服务器的总次数。如果搜索引擎对网站的爬取过于频繁,很可能导致服务器不稳定,baiduspider会根据网站内容更新频率、服务器压力等因素自动调整爬取频率。
爬虫诊断工具可以让百度蜘蛛查看爬取的内容,并自行诊断百度蜘蛛看到的内容是否与预期一致。每个站点每周可以使用 200 次,爬取结果只显示百度蜘蛛可以看到的前 200KB 内容。
抓取诊断
爬虫诊断工具的作用
(1)诊断爬取的内容是否符合预期。例如在很多商品详情页面中,价格信息是通过Javascript输出的,对百度蜘蛛不友好,价格信息在搜索中难以应用. 问题纠正后,可再次使用诊断工具。抓紧检查。
(2)诊断网络是否添加了黑色链接和隐藏文字。网站如果被黑了,可能会添加隐藏链接。这些链接可能只有在百度爬取的时候才会出现,需要用到这个爬虫诊断。
爬网诊断工具操作
打开爬取诊断,选择诊断的网站,点击爬取,爬取状态会出现在列表中,点击爬取成功浏览抓取的网页代码
MIP介绍
移动网页加速器(mobile Instant page,MIP)是一套应用于移动移动网页的开放技术标准。通过提供MIP-HIML规范和MIP-cache页面缓存系统,实现移动网页加速。一个新的网页加速器。
MIP-HIML 基于 HTML 中的基本标签开发了一个新规范。通过限制一些基本标签的使用或扩展其功能,HTML 可以显示更丰富的内容:MIP-JS 可以保证 MIP-HIML 页面的快速渲染,MIP -cache 用于缓存 MIP 页面,进一步提高页面性能。如果要制作MIP网站,需要进入百度站长平台,详细了解MIP制作流程。
网站建设、网络推广公司——创新互联,是网站专注品牌与效果、网络营销的seo公司;服务项目包括网站营销等。

