
java爬虫抓取动态网页
java爬虫抓取动态网页(什么是爬虫爬虫()代码首先定义一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-10 11:12
JAVA爬虫简介及案例实现什么是爬虫
爬虫是根据一定的规则自动爬取万维网上信息的程序或脚本
怎么爬
每次我们登陆一个网页,都可以观察链接,以阶梯阅读()为例
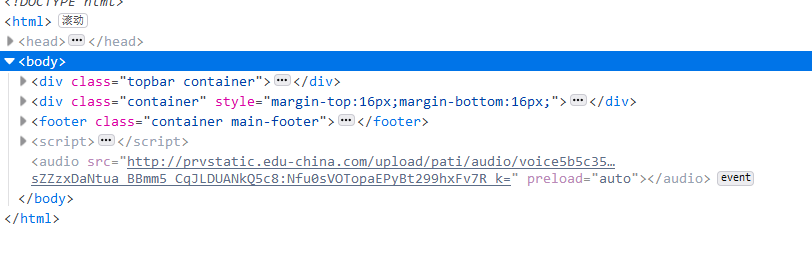
这是主页的链接。当我们点击一年级的所有新闻时,链接会变成,我们可以找到更多的东西,然后点击任何课程,链接会变成,按f12跟踪代码,他这里有音频链接写的比较隐秘,最后发现他是从js赋值的链接,最后抓到:Nfu0sVOTopaEPyBt299hxFv7R_k=是音频链接
于是我们就想,只要我们的代码能捕捉到这段代码,捕捉后就可以下载音频了,但这只是一个资源,所以我们需要在代码中模拟一层一层打开网页,然后获取所有资源
下面附上代码
首先定义一个方法来获取网页中所有html代码中的a标签代码
public static Set getHtmlToA(String html) {
Pattern p = Pattern.compile("]", Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(html);
Set hashSet = new HashSet();
while (m.find()) {
String link = m.group(2).trim();
hashSet.add(link);
}
return hashSet;
}
从代码中可以看出,我们通过正则表达式获取到a标签后面的链接,Pattern类可以帮助我们检索获取到的每一段代码是否符合要求
下面是获取网页所有html代码的方法
public static BufferedReader getBR(String html) {
URL urls = null;
try {
urls = new URL(html);
in = urls.openStream();
isr = new InputStreamReader(in);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new BufferedReader(isr);
}
这个返回的BufferedReader就是我们想要的网页的所有代码
下面是运行代码
public static void main(String args[]) throws Exception {
String url = "http://pati.edu-china.com";
try {
bufr = getBR(url);
String str;
String http = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("book-link") > 0) {
http += str.substring(str.indexOf("年级")) + "\n";
// System.out.println(http);
// System.out.println(http.indexOf("年级"));
Set set = getHtmlToA(http);
Iterator it = set.iterator();
while (it.hasNext()) {
String newUrl = url + it.next().toString();
// System.out.println(newUrl);
bufr = getBR(newUrl);
String http1 = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("/source") > 0) {
http1 += str + "\n";
}
}
Set set1 = getHtmlToA(http1);
Iterator it1 = set1.iterator();
while (it1.hasNext()) {
String name = it1.next().toString();
String newUrl1 = url + name;
System.out.println(newUrl1);
BufferedReader br = getBR(newUrl1);
String strBR = "";
while ((strBR = (br.readLine())) != null) {
if (strBR.indexOf("http://prvstatic.edu-china.com ... 6quot;) > 0) {
String endHttp = strBR.substring(7, strBR.length() - 1);
try {
InputStream ins = new URL(endHttp).openConnection().getInputStream(); //创建连接、输入流
FileOutputStream f = new FileOutputStream("D:/MyPaChong/" + name + ".mp3");//创建文件输出流
byte[] bb = new byte[1024]; //接收缓存
int len;
while ((len = ins.read(bb)) > 0) { //接收
f.write(bb, 0, len); //写入文件
}
f.close();
ins.close();
System.out.println(name + "爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
bufr.close();
isr.close();
in.close();
}
}
这是我刚刚处理的实例的 网站 捕获。可以提出的地方很多,不过太麻烦就不提了。有兴趣的可以重写。
学爬,记录在这里
原创地址:。%257B%2522重量%255FID%2522%253A%25226780366510269%2522%252℃%2522%252℃%2522%2522%253A%25222014071 4. PC%255降低%2522%257D&Request_id = 678036510269 & biz_id = 0 & utm_medium =distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-16-90757192.pc_search_result_cache&utm_term=java%E7%88%AC%E8%99%AB 查看全部
java爬虫抓取动态网页(什么是爬虫爬虫()代码首先定义一个方法)
JAVA爬虫简介及案例实现什么是爬虫
爬虫是根据一定的规则自动爬取万维网上信息的程序或脚本
怎么爬
每次我们登陆一个网页,都可以观察链接,以阶梯阅读()为例
这是主页的链接。当我们点击一年级的所有新闻时,链接会变成,我们可以找到更多的东西,然后点击任何课程,链接会变成,按f12跟踪代码,他这里有音频链接写的比较隐秘,最后发现他是从js赋值的链接,最后抓到:Nfu0sVOTopaEPyBt299hxFv7R_k=是音频链接
于是我们就想,只要我们的代码能捕捉到这段代码,捕捉后就可以下载音频了,但这只是一个资源,所以我们需要在代码中模拟一层一层打开网页,然后获取所有资源
下面附上代码
首先定义一个方法来获取网页中所有html代码中的a标签代码
public static Set getHtmlToA(String html) {
Pattern p = Pattern.compile("]", Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(html);
Set hashSet = new HashSet();
while (m.find()) {
String link = m.group(2).trim();
hashSet.add(link);
}
return hashSet;
}
从代码中可以看出,我们通过正则表达式获取到a标签后面的链接,Pattern类可以帮助我们检索获取到的每一段代码是否符合要求
下面是获取网页所有html代码的方法
public static BufferedReader getBR(String html) {
URL urls = null;
try {
urls = new URL(html);
in = urls.openStream();
isr = new InputStreamReader(in);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new BufferedReader(isr);
}
这个返回的BufferedReader就是我们想要的网页的所有代码
下面是运行代码
public static void main(String args[]) throws Exception {
String url = "http://pati.edu-china.com";
try {
bufr = getBR(url);
String str;
String http = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("book-link") > 0) {
http += str.substring(str.indexOf("年级")) + "\n";
// System.out.println(http);
// System.out.println(http.indexOf("年级"));
Set set = getHtmlToA(http);
Iterator it = set.iterator();
while (it.hasNext()) {
String newUrl = url + it.next().toString();
// System.out.println(newUrl);
bufr = getBR(newUrl);
String http1 = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("/source") > 0) {
http1 += str + "\n";
}
}
Set set1 = getHtmlToA(http1);
Iterator it1 = set1.iterator();
while (it1.hasNext()) {
String name = it1.next().toString();
String newUrl1 = url + name;
System.out.println(newUrl1);
BufferedReader br = getBR(newUrl1);
String strBR = "";
while ((strBR = (br.readLine())) != null) {
if (strBR.indexOf("http://prvstatic.edu-china.com ... 6quot;) > 0) {
String endHttp = strBR.substring(7, strBR.length() - 1);
try {
InputStream ins = new URL(endHttp).openConnection().getInputStream(); //创建连接、输入流
FileOutputStream f = new FileOutputStream("D:/MyPaChong/" + name + ".mp3");//创建文件输出流
byte[] bb = new byte[1024]; //接收缓存
int len;
while ((len = ins.read(bb)) > 0) { //接收
f.write(bb, 0, len); //写入文件
}
f.close();
ins.close();
System.out.println(name + "爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
bufr.close();
isr.close();
in.close();
}
}
这是我刚刚处理的实例的 网站 捕获。可以提出的地方很多,不过太麻烦就不提了。有兴趣的可以重写。
学爬,记录在这里
原创地址:。%257B%2522重量%255FID%2522%253A%25226780366510269%2522%252℃%2522%252℃%2522%2522%253A%25222014071 4. PC%255降低%2522%257D&Request_id = 678036510269 & biz_id = 0 & utm_medium =distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-16-90757192.pc_search_result_cache&utm_term=java%E7%88%AC%E8%99%AB
java爬虫抓取动态网页( 谷歌的network模拟请求和实现原理登录之后返回的网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-10 11:11
谷歌的network模拟请求和实现原理登录之后返回的网页源码)
Java爬虫(四)使用Jsoup获取网站中需要登录的内容(不用验证码登录)
一、实现原理
登录后,进行数据分析,准确抓取数据。根据前面文章的代码,我们不仅获取了cookies,还获取了登录后返回的网页源代码,此时有以下几种情况:(1)如果我们需要的数据在登录后返回的源码中,那么我们可以直接通过Jsoup解析源码,然后使用Jsoup的选择器功能过滤掉我们需要的信息;(2)如果需要的数据需要通过请求源码链接获取,然后我们先解析源码,找到url,然后带cookies来模拟url的请求。(3)如果数据我们需要根本不在源代码中,那么我们不能使用它照顾这个源代码。让'
刚开始写模拟登录的时候,总觉得数据一定要在网页的源码中获取,所以当一个网页由一堆js组成的时候,我就傻眼了。然后希望能拿到渲染网页的源码,大家可以试试selenium,以后学着用。
二、详细实现流程
package debug;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import org.jsoup.select.Elements;
public class test {
public static String LOGIN_URL = "http://authserver.tjut.edu.cn/ ... 3B%3B
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
// 模拟登陆github的用户名和密码
// String url = "http://ehall.tjut.edu.cn/publi ... 3B%3B
String url ="http://ehall.tjut.edu.cn/publi ... 3B%3B
get_html_num(url);
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static Map simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求 grab login form page first 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 通过Jsoup将返回信息转换为Dom树
List eleList = d1.select("#casLoginForm"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the
// form
Map datas = new HashMap();
for (Element e : eleList.get(0).getAllElements()) {
// 注意问题2:设置用户名 注意equals(这个username和password也是要去自己的登录界面input里找name值)
if (e.attr("name").equals("username")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect(
"http://authserver.tjut.edu.cn/ ... 6quot;);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas)
.cookies(rs.cookies()).execute();
//报错Exception in thread "main" org.jsoup.HttpStatusException: HTTP error fetching URL. Status=500,
// 报错原因:见上边注意问题2
// 打印,登陆成功后的信息
//System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
// for (String s : map.keySet()) {
// System.out.println(s + " : " + map.get(s));
// }
return map;
}
// 实现切割某两个字之间的字符串
public static String findstr(String str1, String strstrat, String strend) {
String finalstr = new String();
int strStartIndex = str1.indexOf(strstrat);
int strEndIndex = str1.indexOf(strend);
finalstr = str1.substring(strStartIndex, strEndIndex).substring(strstrat.length());
return finalstr;
}
// 第一个,完整爬虫爬下来内容
public static void get_html_num(String url) throws Exception {
try {
Map cookies=simulateLogin("203128301", "密码保护");
// Document doc = Jsoup.connect(url).get();
Document doc = Jsoup.connect(url).cookies(cookies).post();
// 得到html中id为content下的所有内容
Element ele = doc.getElementById("consultingListDetail");
// 分离出下面的具体内容
// Elements tag = ele.getElementsByTag("td");
// for (Element e : tag) {
// String title = e.getElementsByTag("td").text();
// String Totals = findstr(title, "共", "条");
// System.out.println(Totals);
System.out.println(doc);
// }
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、当前问题
目标界面的内容是通过AJAX动态加载的,使用jsoup无法获取目标信息。
什么是 AJAX
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
解决方案:
①直接分析AJAX调用的接口。然后通过代码请求这个接口。
②使用selenium模拟点击解决问题。
实现过程参考以下两篇文章文章:
Java爬虫(五)使用selenium模拟点击获取动态页面内容
java爬虫(六)解析AJAX接口获取网页动态内容 查看全部
java爬虫抓取动态网页(
谷歌的network模拟请求和实现原理登录之后返回的网页源码)
Java爬虫(四)使用Jsoup获取网站中需要登录的内容(不用验证码登录)
一、实现原理
登录后,进行数据分析,准确抓取数据。根据前面文章的代码,我们不仅获取了cookies,还获取了登录后返回的网页源代码,此时有以下几种情况:(1)如果我们需要的数据在登录后返回的源码中,那么我们可以直接通过Jsoup解析源码,然后使用Jsoup的选择器功能过滤掉我们需要的信息;(2)如果需要的数据需要通过请求源码链接获取,然后我们先解析源码,找到url,然后带cookies来模拟url的请求。(3)如果数据我们需要根本不在源代码中,那么我们不能使用它照顾这个源代码。让'
刚开始写模拟登录的时候,总觉得数据一定要在网页的源码中获取,所以当一个网页由一堆js组成的时候,我就傻眼了。然后希望能拿到渲染网页的源码,大家可以试试selenium,以后学着用。
二、详细实现流程
package debug;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import org.jsoup.select.Elements;
public class test {
public static String LOGIN_URL = "http://authserver.tjut.edu.cn/ ... 3B%3B
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
// 模拟登陆github的用户名和密码
// String url = "http://ehall.tjut.edu.cn/publi ... 3B%3B
String url ="http://ehall.tjut.edu.cn/publi ... 3B%3B
get_html_num(url);
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static Map simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求 grab login form page first 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 通过Jsoup将返回信息转换为Dom树
List eleList = d1.select("#casLoginForm"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the
// form
Map datas = new HashMap();
for (Element e : eleList.get(0).getAllElements()) {
// 注意问题2:设置用户名 注意equals(这个username和password也是要去自己的登录界面input里找name值)
if (e.attr("name").equals("username")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect(
"http://authserver.tjut.edu.cn/ ... 6quot;);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas)
.cookies(rs.cookies()).execute();
//报错Exception in thread "main" org.jsoup.HttpStatusException: HTTP error fetching URL. Status=500,
// 报错原因:见上边注意问题2
// 打印,登陆成功后的信息
//System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
// for (String s : map.keySet()) {
// System.out.println(s + " : " + map.get(s));
// }
return map;
}
// 实现切割某两个字之间的字符串
public static String findstr(String str1, String strstrat, String strend) {
String finalstr = new String();
int strStartIndex = str1.indexOf(strstrat);
int strEndIndex = str1.indexOf(strend);
finalstr = str1.substring(strStartIndex, strEndIndex).substring(strstrat.length());
return finalstr;
}
// 第一个,完整爬虫爬下来内容
public static void get_html_num(String url) throws Exception {
try {
Map cookies=simulateLogin("203128301", "密码保护");
// Document doc = Jsoup.connect(url).get();
Document doc = Jsoup.connect(url).cookies(cookies).post();
// 得到html中id为content下的所有内容
Element ele = doc.getElementById("consultingListDetail");
// 分离出下面的具体内容
// Elements tag = ele.getElementsByTag("td");
// for (Element e : tag) {
// String title = e.getElementsByTag("td").text();
// String Totals = findstr(title, "共", "条");
// System.out.println(Totals);
System.out.println(doc);
// }
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、当前问题
目标界面的内容是通过AJAX动态加载的,使用jsoup无法获取目标信息。
什么是 AJAX
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
解决方案:
①直接分析AJAX调用的接口。然后通过代码请求这个接口。
②使用selenium模拟点击解决问题。
实现过程参考以下两篇文章文章:
Java爬虫(五)使用selenium模拟点击获取动态页面内容
java爬虫(六)解析AJAX接口获取网页动态内容
java爬虫抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-10 05:11
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
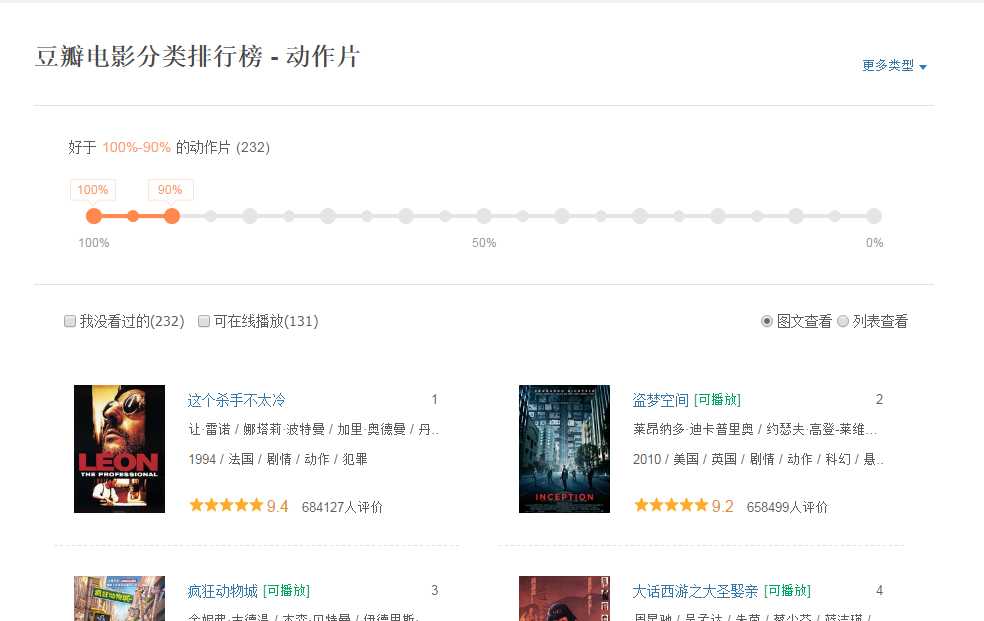
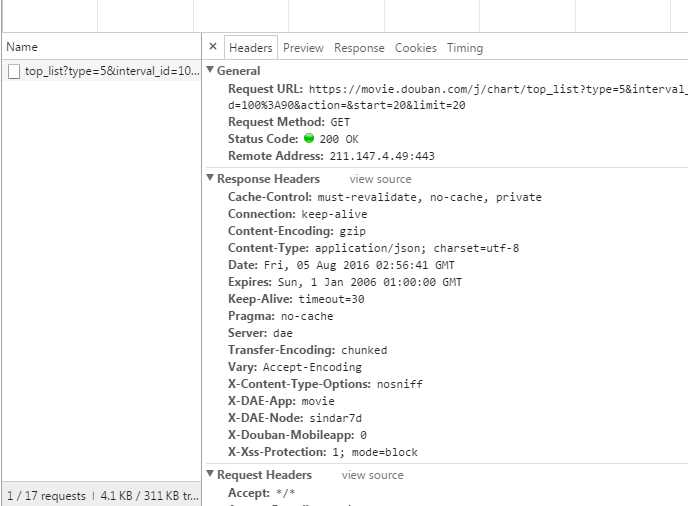
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
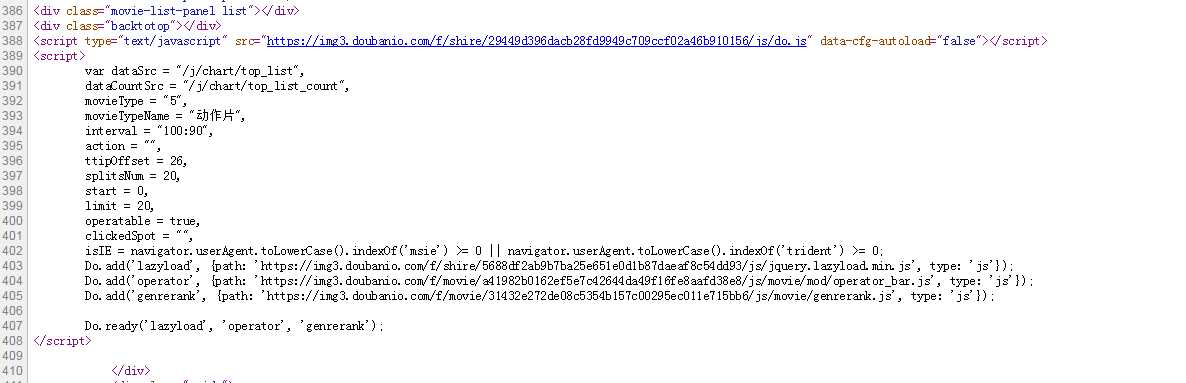
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {‘action‘:‘‘,‘start‘:‘0‘,‘limit‘:‘1‘}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
java爬虫抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。

查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {‘action‘:‘‘,‘start‘:‘0‘,‘limit‘:‘1‘}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
java爬虫抓取动态网页(网页开发中大量的运用Ajax技术的研究基础上的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-10 03:04
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
摘要:网络爬虫按照一定的规则对网络信息进行爬取,是搜索引擎技术的重要组成部分。随着Web2.0的兴起,Ajax技术在Web开发中得到广泛应用。与传统网页不同,Ajax 技术采用异步的方式向服务器发送请求,并根据响应更新页面。Ajax 大大降低了服务器的负载,也提高了用户体验。同时,Ajax技术部分更新HTML页面的方式也对传统爬虫技术提出了严峻挑战。本文在介绍和分析传统爬取原理和结构的基础上,结合动态网络爬虫要解决的问题,设计并实现了一个可以对动态网页数据进行爬取的网络爬虫系统。本文所做的主要工作如下。首先,在前人对动态网络爬虫模型研究的基础上,基于图结构的思想,经过改进,提出了一种基于状态转移的动态网络爬虫模型,从而利用状态转移过程来模拟动态事件触发的网页结构变化。. 结合动态爬虫和真实网络环境的要求,在网页去噪、新状态去重、新状态捕获等方面对算法模型进行了细化和改进。其次,根据该模型,本文采用调用浏览器内核和本地搭建JavaScript解析环境两种方式,设计并实现了动态网页数据的爬虫系统。在保持传统爬虫功能的基础上,增加了对动态数据抓取的支持。最后,本文通过对真实网页的爬取实验,对比了两种方法与传统爬虫的优缺点。验证了系统的可行性和有效性。
[关键词]:动态网络爬虫状态转换Ajax
【学位授予单位】:中山大学
【学位等级】:硕士
【学位授予年份】:2014
【类别号】:TP393.092
【内容】:
【参考】
十大中文期刊全文数据库
1 宋敖;智t$;周军;罗传飞;安然;基于LCS的特征树最大相似度匹配去噪算法[J];电视技术;2011年13期
2 董斌;;网站静态页面生成系统研究[J];福建计算机;2009年08期
3 刘晨曦、吴阳阳。一种基于块分析的网页去噪方法[J];广西师范大学学报(自然科学版);2007年02期
4 段庆玲;杨仁刚;朱洋;;一种从表单中提取Ajax信息项的方法[J];计算机工程;2011年03期
5 周丽珠,林玲。聚焦爬虫技术研究综述[J];计算机应用;2005年09期
6 吕林涛;万景华;周宏芳;计算机应用学院,计算机学院;2006年11期
7 郭浩、卢玉良、刘金红。一种基于状态转移图的Ajax爬取算法[J];计算机应用研究;2009年11期
8 范选淼;郑宁;范远;基于Ajax的爬虫模型设计与实现[J];计算机应用与软件;2010年01期
9 陈雪;徐辉;沈家军;;基于网页结构的网页去噪算法设计[J];软件;2013年08期
10 金晓鸥;钟宝艳;李翔;基于Rhino的JavaScript动态页面解析的研究与实现[J];计算机技术与发展;2008年02期
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
货号:426578 查看全部
java爬虫抓取动态网页(网页开发中大量的运用Ajax技术的研究基础上的应用)
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
摘要:网络爬虫按照一定的规则对网络信息进行爬取,是搜索引擎技术的重要组成部分。随着Web2.0的兴起,Ajax技术在Web开发中得到广泛应用。与传统网页不同,Ajax 技术采用异步的方式向服务器发送请求,并根据响应更新页面。Ajax 大大降低了服务器的负载,也提高了用户体验。同时,Ajax技术部分更新HTML页面的方式也对传统爬虫技术提出了严峻挑战。本文在介绍和分析传统爬取原理和结构的基础上,结合动态网络爬虫要解决的问题,设计并实现了一个可以对动态网页数据进行爬取的网络爬虫系统。本文所做的主要工作如下。首先,在前人对动态网络爬虫模型研究的基础上,基于图结构的思想,经过改进,提出了一种基于状态转移的动态网络爬虫模型,从而利用状态转移过程来模拟动态事件触发的网页结构变化。. 结合动态爬虫和真实网络环境的要求,在网页去噪、新状态去重、新状态捕获等方面对算法模型进行了细化和改进。其次,根据该模型,本文采用调用浏览器内核和本地搭建JavaScript解析环境两种方式,设计并实现了动态网页数据的爬虫系统。在保持传统爬虫功能的基础上,增加了对动态数据抓取的支持。最后,本文通过对真实网页的爬取实验,对比了两种方法与传统爬虫的优缺点。验证了系统的可行性和有效性。
[关键词]:动态网络爬虫状态转换Ajax
【学位授予单位】:中山大学
【学位等级】:硕士
【学位授予年份】:2014
【类别号】:TP393.092
【内容】:
【参考】
十大中文期刊全文数据库
1 宋敖;智t$;周军;罗传飞;安然;基于LCS的特征树最大相似度匹配去噪算法[J];电视技术;2011年13期
2 董斌;;网站静态页面生成系统研究[J];福建计算机;2009年08期
3 刘晨曦、吴阳阳。一种基于块分析的网页去噪方法[J];广西师范大学学报(自然科学版);2007年02期
4 段庆玲;杨仁刚;朱洋;;一种从表单中提取Ajax信息项的方法[J];计算机工程;2011年03期
5 周丽珠,林玲。聚焦爬虫技术研究综述[J];计算机应用;2005年09期
6 吕林涛;万景华;周宏芳;计算机应用学院,计算机学院;2006年11期
7 郭浩、卢玉良、刘金红。一种基于状态转移图的Ajax爬取算法[J];计算机应用研究;2009年11期
8 范选淼;郑宁;范远;基于Ajax的爬虫模型设计与实现[J];计算机应用与软件;2010年01期
9 陈雪;徐辉;沈家军;;基于网页结构的网页去噪算法设计[J];软件;2013年08期
10 金晓鸥;钟宝艳;李翔;基于Rhino的JavaScript动态页面解析的研究与实现[J];计算机技术与发展;2008年02期
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
货号:426578
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-05 18:09
文本
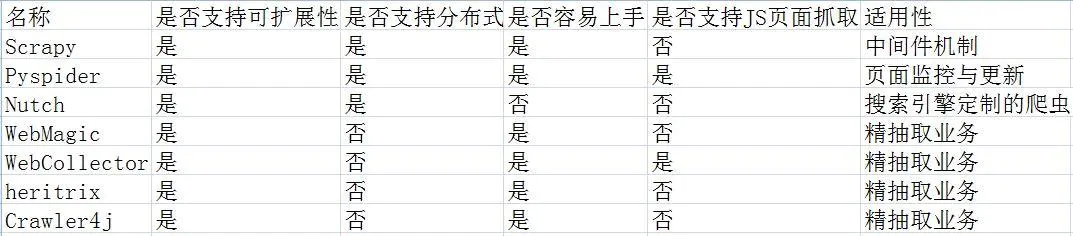
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替布隆过滤器,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力很差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,数以万计。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接: 查看全部
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括

Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:

Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替布隆过滤器,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力很差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,数以万计。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接:
java爬虫抓取动态网页(网页爬虫如何写一个网页程序?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-04 06:09
)
最近为了练手,对网络爬虫感兴趣,决定自己写一个网络爬虫程序。
先看爬虫应该具备哪些功能。
内容来自()
网页采集的过程类似于图的遍历,网页作为图中的节点,网页中的超链接作为图中的边。通过一个网页的超链接,可以获得其他网页的地址,可以进一步进行网页采集;图的遍历分为广度优先和深度优先两种方法,网页采集过程也是如此。综上所述,Spider采集网页的过程如下:从初始URL采集中获取目标网页地址,通过网络连接接收网页数据,将获取到的网页数据添加到网页库中,分析网页中的其他URL链接,并将它们放在 unvisited 的 URL 集合中,用于网页集合。下图展示了这个过程:
网络采集器聚会
网页采集器通过网址获取该网址对应的网页数据。其实现主要是利用Java中的URLConnection类打开URL对应页面的网络连接,然后通过I/O流读取数据,BufferedReader提供读取数据的缓冲区,提高数据读取效率以及在其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
URL url = new URL(“http://www.xxx.com”);
<br />
URLConnection conn = url.openConnection();
<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); <br />
String line = null;
while((line = reader.readLine()) != null)
<br />
document.append(line + "\n");<br />
<br />
网页处理
采集到的单个网页需要进行两种不同的处理,一种是将其作为原创数据放入网页库中进行后续处理;另一种是解析后从中提取出URL连接放入URL池中等待对应网页的集合。
网页的保存需要一定的格式,方便以后批量处理数据。下面是一种存储数据格式,它是从北大天网的存储格式简化而来的:
需要说明的是,添加数据采集日期的原因是网站的很多内容都是动态变化的,比如一些大型门户网站网站的首页内容,也就是说如果不是当天抓取的网页数据很可能有数据过期,所以需要添加日期信息来识别。
URL 提取分为两步。第一步是识别网址,第二步是整理网址。主要原因是网站的部分链接使用了相对路径。如果不组织它们会产生错误。 URL识别主要是通过正则表达式匹配。该过程首先设置一个字符串作为匹配的字符串模式,然后在Pattern中编译后,可以使用Matcher类来匹配相应的字符串。实现代码如下:
public ArrayList urlDetector(String htmlDoc)<br />
{
<br />
final String patternString = "]*\\s*>)";
<br />
Pattern pattern = Pattern.compile(patternString,Pattern.CASE_INSENSITIVE);
<br />
ArrayList allURLs = new ArrayList();
<br />
Matcher matcher = pattern.matcher(htmlDoc);
<br />
String tempURL;
//初次匹配到的url是形如:<a href="http://bbs.life.xxx.com.cn/" target="_blank">
<br />
//为此,需要进行下一步的处理,把真正的url抽取出来,
<br />
//可以对于前两个"之间的部分进行记录得到url
<br />
while(matcher.find()){
<br />
try {
<br />
tempURL = matcher.group(); <br />
tempURL = tempURL.substring(tempURL.indexOf("\"")+1);
<br />
if(!tempURL.contains("\""))
continue;
<br />
tempURL = tempURL.substring(0, tempURL.indexOf("\""));
<br />
} <br />
catch (MalformedURLException e) <br />
{
e.printStackTrace();
}
<br />
}
<br />
return allURLs;
}<br />
根据正则表达式"]*\\s*>)",可以匹配到URL所在的整个标签,形如"",所以循环获取整个标签后,我们需要为了进一步提取真实的URL,我们可以通过截取标签中前两个引号之间的内容来获取这段内容。之后,我们就可以初步得到属于该网页的一组 URL。
接下来,我们将进行第二步,网址排序,即对之前获取的整个页面中的网址集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很容易的获取到当前网页的网址,因此相对链接只需要在当前网页的网址上加上相对链接字段就可以形成一个完整的网址。一体化。另一方面,在页面收录的综合URL中,有一些页面,例如广告页面,我们不想抓取,或者不重要。这里我们主要针对页面中的广告进行简单的处理。一般网站的广告链接都有对应的展示表达。例如,当链接中收录“ad”等表述时,可以降低该链接的优先级,从而在一定程度上避免对广告链接的抓取。
经过这两个步骤,就可以将采集到的网页网址放入网址池中,然后我们来处理爬虫网址的分配。
调度员
分发者管理URL,负责保存URL池并在Gather获取某个网页后分配新的URL,同时避免重复采集网页。分配器采用设计模式中的单例模式编码,负责提供新的 URL 给 Gather。单例模式尤其重要,因为它涉及到多个线程的后续重写。
重复采集是指物理网页被Gather反复访问而不更新,造成资源浪费。主要原因是没有明确记录访问过的URL,无法区分。因此,Dispatcher 维护着两个列表,“已访问表”和“未访问表”。每个URL对应的页面被爬取后,将该URL放入访问列表,从页面中提取的URL放入未访问列表; Gather向Dispatcher请求一个URL时,首先验证该URL是否在visited表中,然后交给Gather作业。
Spider 启动多个 Gather 线程
目前互联网上有数以亿计的网页,单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。 Gather 的功能是采集网页。我们可以通过Spider类开启多个Gather线程来达到多线程的目的。代码如下:
public void start() <br />
{
<br />
Dispatcher disp = Dispatcher.getInstance(); <br />
for(int i = 0; i < gatherNum; i++)<br />
{
<br />
Thread gather = new Thread(new Gather(disp)); <br />
gather.start(); <br />
}<br />
}<br />
在开启线程之后,网页收集器开始作业的运作,并在一个作业完成之后,向 Dispatcher 申请下一个作业,因为有了多线程的
Gather,为了避免线程不安全,需要对 Dispatcher 进行互斥访问,在其函数之中添加 synchronized
关键词,从而达到线程的安全访问。<br />
<br />
<br /> 查看全部
java爬虫抓取动态网页(网页爬虫如何写一个网页程序?(组图)
)
最近为了练手,对网络爬虫感兴趣,决定自己写一个网络爬虫程序。
先看爬虫应该具备哪些功能。
内容来自()
网页采集的过程类似于图的遍历,网页作为图中的节点,网页中的超链接作为图中的边。通过一个网页的超链接,可以获得其他网页的地址,可以进一步进行网页采集;图的遍历分为广度优先和深度优先两种方法,网页采集过程也是如此。综上所述,Spider采集网页的过程如下:从初始URL采集中获取目标网页地址,通过网络连接接收网页数据,将获取到的网页数据添加到网页库中,分析网页中的其他URL链接,并将它们放在 unvisited 的 URL 集合中,用于网页集合。下图展示了这个过程:

网络采集器聚会
网页采集器通过网址获取该网址对应的网页数据。其实现主要是利用Java中的URLConnection类打开URL对应页面的网络连接,然后通过I/O流读取数据,BufferedReader提供读取数据的缓冲区,提高数据读取效率以及在其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
URL url = new URL(“http://www.xxx.com”);
<br />
URLConnection conn = url.openConnection();
<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); <br />
String line = null;
while((line = reader.readLine()) != null)
<br />
document.append(line + "\n");<br />
<br />
网页处理
采集到的单个网页需要进行两种不同的处理,一种是将其作为原创数据放入网页库中进行后续处理;另一种是解析后从中提取出URL连接放入URL池中等待对应网页的集合。
网页的保存需要一定的格式,方便以后批量处理数据。下面是一种存储数据格式,它是从北大天网的存储格式简化而来的:
需要说明的是,添加数据采集日期的原因是网站的很多内容都是动态变化的,比如一些大型门户网站网站的首页内容,也就是说如果不是当天抓取的网页数据很可能有数据过期,所以需要添加日期信息来识别。
URL 提取分为两步。第一步是识别网址,第二步是整理网址。主要原因是网站的部分链接使用了相对路径。如果不组织它们会产生错误。 URL识别主要是通过正则表达式匹配。该过程首先设置一个字符串作为匹配的字符串模式,然后在Pattern中编译后,可以使用Matcher类来匹配相应的字符串。实现代码如下:
public ArrayList urlDetector(String htmlDoc)<br />
{
<br />
final String patternString = "]*\\s*>)";
<br />
Pattern pattern = Pattern.compile(patternString,Pattern.CASE_INSENSITIVE);
<br />
ArrayList allURLs = new ArrayList();
<br />
Matcher matcher = pattern.matcher(htmlDoc);
<br />
String tempURL;
//初次匹配到的url是形如:<a href="http://bbs.life.xxx.com.cn/" target="_blank">
<br />
//为此,需要进行下一步的处理,把真正的url抽取出来,
<br />
//可以对于前两个"之间的部分进行记录得到url
<br />
while(matcher.find()){
<br />
try {
<br />
tempURL = matcher.group(); <br />
tempURL = tempURL.substring(tempURL.indexOf("\"")+1);
<br />
if(!tempURL.contains("\""))
continue;
<br />
tempURL = tempURL.substring(0, tempURL.indexOf("\""));
<br />
} <br />
catch (MalformedURLException e) <br />
{
e.printStackTrace();
}
<br />
}
<br />
return allURLs;
}<br />
根据正则表达式"]*\\s*>)",可以匹配到URL所在的整个标签,形如"",所以循环获取整个标签后,我们需要为了进一步提取真实的URL,我们可以通过截取标签中前两个引号之间的内容来获取这段内容。之后,我们就可以初步得到属于该网页的一组 URL。
接下来,我们将进行第二步,网址排序,即对之前获取的整个页面中的网址集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很容易的获取到当前网页的网址,因此相对链接只需要在当前网页的网址上加上相对链接字段就可以形成一个完整的网址。一体化。另一方面,在页面收录的综合URL中,有一些页面,例如广告页面,我们不想抓取,或者不重要。这里我们主要针对页面中的广告进行简单的处理。一般网站的广告链接都有对应的展示表达。例如,当链接中收录“ad”等表述时,可以降低该链接的优先级,从而在一定程度上避免对广告链接的抓取。
经过这两个步骤,就可以将采集到的网页网址放入网址池中,然后我们来处理爬虫网址的分配。
调度员
分发者管理URL,负责保存URL池并在Gather获取某个网页后分配新的URL,同时避免重复采集网页。分配器采用设计模式中的单例模式编码,负责提供新的 URL 给 Gather。单例模式尤其重要,因为它涉及到多个线程的后续重写。
重复采集是指物理网页被Gather反复访问而不更新,造成资源浪费。主要原因是没有明确记录访问过的URL,无法区分。因此,Dispatcher 维护着两个列表,“已访问表”和“未访问表”。每个URL对应的页面被爬取后,将该URL放入访问列表,从页面中提取的URL放入未访问列表; Gather向Dispatcher请求一个URL时,首先验证该URL是否在visited表中,然后交给Gather作业。
Spider 启动多个 Gather 线程
目前互联网上有数以亿计的网页,单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。 Gather 的功能是采集网页。我们可以通过Spider类开启多个Gather线程来达到多线程的目的。代码如下:
public void start() <br />
{
<br />
Dispatcher disp = Dispatcher.getInstance(); <br />
for(int i = 0; i < gatherNum; i++)<br />
{
<br />
Thread gather = new Thread(new Gather(disp)); <br />
gather.start(); <br />
}<br />
}<br />
在开启线程之后,网页收集器开始作业的运作,并在一个作业完成之后,向 Dispatcher 申请下一个作业,因为有了多线程的
Gather,为了避免线程不安全,需要对 Dispatcher 进行互斥访问,在其函数之中添加 synchronized
关键词,从而达到线程的安全访问。<br />
<br />
<br />
java爬虫抓取动态网页(Java的HTML解析器,可直接解析某个URL地址、HTML文本内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2022-01-04 06:07
Jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 Jsoup的官网是:,其API手册的网址是:.
本次分享要实现的功能是:使用Jsoup抓取某个搜索词(暂时只有英文),百度百科的介绍部分。具体功能介绍请参考博客:Python爬虫自制简易搜索引擎。在上一个爬虫中,我们使用Python进行爬取。这一次,我们将使用Java来爬取。你没看错,是 Java。
在Eclipse中添加Jsoup包,下载地址为:.
爬虫的具体代码如下:
package baiduScrape;
/*
* 本爬虫主要利用Java的Jsoup包进行网络爬取
* 本爬虫的功能: 爬取百度百科的开头介绍部分
* 使用方法: 输入关键字(目前只支持英文)即可
*/
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.net.*;
import java.io.*;
import java.util.Scanner;
public class BaiduScrape {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
String baseUrl = "https://baike.baidu.com/item/";
String url = "";
// 如果输入文字不是"exit",则爬取其百度百科的介绍部分,否则退出该程序
while(true) {
System.out.println("Enter the word(Enter 'exit' to exit):");
url = input.nextLine();
if(url.equals("exit")) {
System.out.println("The program is over.");
break;
}
String introduction = getContent(baseUrl+url);
System.out.println(introduction+'\n');
}
}
// getContent()函数主要实现爬取输入文字的百度百科的介绍部分
public static String getContent(String url){
// 利用URL解析网址
URL urlObj = null;
try{
urlObj = new URL(url);
}
catch(MalformedURLException e){
System.out.println("The url was malformed!");
return "";
}
// URL连接
URLConnection urlCon = null;
try{
urlCon = urlObj.openConnection(); // 打开URL连接
// 将HTML内容解析成UTF-8格式
Document doc = Jsoup.parse(urlCon.getInputStream(), "utf-8", url);
// 刷选需要的网页内容
String contentText = doc.select("div.lemma-summary").first().text();
// 利用正则表达式去掉字符串中的"[数字]"
contentText = contentText.replaceAll("\\[\\d+\\]", "");
return contentText;
}catch(IOException e){
System.out.println("There was an error connecting to the URL");
return "";
}
}
}
上面代码中url为输入词(暂时只有英文),一直进入while循环搜索,输入“exit”时退出。 contentText是词条百度百科简介的网页形式,通过正则表达式提取其中的文字。代码虽然简洁,但功能相当强大,充分说明Java也可以作为爬虫使用。
接下来是愉快的测试时间:
本次分享到此结束,我们会继续更新Jsoup的相关知识。欢迎交流~~
原文链接: 查看全部
java爬虫抓取动态网页(Java的HTML解析器,可直接解析某个URL地址、HTML文本内容)
Jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 Jsoup的官网是:,其API手册的网址是:.
本次分享要实现的功能是:使用Jsoup抓取某个搜索词(暂时只有英文),百度百科的介绍部分。具体功能介绍请参考博客:Python爬虫自制简易搜索引擎。在上一个爬虫中,我们使用Python进行爬取。这一次,我们将使用Java来爬取。你没看错,是 Java。
在Eclipse中添加Jsoup包,下载地址为:.
爬虫的具体代码如下:
package baiduScrape;
/*
* 本爬虫主要利用Java的Jsoup包进行网络爬取
* 本爬虫的功能: 爬取百度百科的开头介绍部分
* 使用方法: 输入关键字(目前只支持英文)即可
*/
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.net.*;
import java.io.*;
import java.util.Scanner;
public class BaiduScrape {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
String baseUrl = "https://baike.baidu.com/item/";
String url = "";
// 如果输入文字不是"exit",则爬取其百度百科的介绍部分,否则退出该程序
while(true) {
System.out.println("Enter the word(Enter 'exit' to exit):");
url = input.nextLine();
if(url.equals("exit")) {
System.out.println("The program is over.");
break;
}
String introduction = getContent(baseUrl+url);
System.out.println(introduction+'\n');
}
}
// getContent()函数主要实现爬取输入文字的百度百科的介绍部分
public static String getContent(String url){
// 利用URL解析网址
URL urlObj = null;
try{
urlObj = new URL(url);
}
catch(MalformedURLException e){
System.out.println("The url was malformed!");
return "";
}
// URL连接
URLConnection urlCon = null;
try{
urlCon = urlObj.openConnection(); // 打开URL连接
// 将HTML内容解析成UTF-8格式
Document doc = Jsoup.parse(urlCon.getInputStream(), "utf-8", url);
// 刷选需要的网页内容
String contentText = doc.select("div.lemma-summary").first().text();
// 利用正则表达式去掉字符串中的"[数字]"
contentText = contentText.replaceAll("\\[\\d+\\]", "");
return contentText;
}catch(IOException e){
System.out.println("There was an error connecting to the URL");
return "";
}
}
}
上面代码中url为输入词(暂时只有英文),一直进入while循环搜索,输入“exit”时退出。 contentText是词条百度百科简介的网页形式,通过正则表达式提取其中的文字。代码虽然简洁,但功能相当强大,充分说明Java也可以作为爬虫使用。
接下来是愉快的测试时间:

本次分享到此结束,我们会继续更新Jsoup的相关知识。欢迎交流~~
原文链接:
java爬虫抓取动态网页(懂车帝进制抓取只是技术研究不涉及数据内容,请谨慎操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-01 09:11
友情提示,了解Chedi Binary的捕获,但技术研究不涉及数据内容,请谨慎操作
本文以雅阁车友圈为例,地址:
分析
首先分析一下这个网站的内容交互方式。不难发现,内容是通过鼠标向下滚动来翻页,翻页后页面没有刷新。
我们按F12调出浏览器的Network,可以看到每个页面的内容都是通过XHR传递到前端显示的,如下图:
多次翻页后,通过这个url解析并显示内容。
问题
1.每个请求需要传递三个参数,min_behot_time、max_behot_time、max_cursor,如何在每次翻页时传递这三个参数?
在浏览器中搜索关键词以找到位置。都出现在community.js中,只是被webpack打包了,看不到源码了。
但是可以通过关键词搜索,然后配合浏览器自带的format js函数,大概可以看到这三个参数的由来,如下图:
相信你已经明白了。 [害羞]
2. 每次翻页,传递的数据数为20,但显示的页面少于20,而且每次都不固定。为什么?
这时候就需要对返回的json内容进行分析。有没有发现类型有点不同?
具体可以多对比分析,仅供参考:type=2328重点分析,type=2312精华帖。
代码片段
maven 引入:jsoup、fastjson
java 示例代码片段
long min_behot_time = 0l;
long max_behot_time = 0l;
long max_cursor = 0l;
int page = 1;
//请留意需要修改,您可以while中设置page>10 时,break;
while (true) {
boolean flag = false;
if (min_behot_time == 0) {
min_behot_time = System.currentTimeMillis() / 1000;
}
String url = "https://www.dcdapp.com/motor/d ... ot%3B + motor_id + "&min_behot_time=" + min_behot_time + "&max_behot_time=" + max_behot_time + "&max_cursor=" + max_cursor + "&channel=m_web&device_platform=wap&category=dongtai&cmg_flag=dongtai&web_id=0&device_id=0&impression_info=%7B%22page_id%22%3A%22page_forum_home%22%2C%22product_name%22%3A%22pc%22%7D&tt_from=load_more&_t=" + System.currentTimeMillis();
try {
Connection.Response response = Jsoup.connect(url).headers(headers())
.timeout(50000)
.ignoreHttpErrors(true).ignoreContentType(true)
.execute();
String json = response.body();
JSONObject jsonObject = JSON.parseObject(json);
JSONObject dataObj = jsonObject.getJSONObject("data");
if (dataObj != null) {
JSONArray listArray = dataObj.getJSONArray("list");
if (listArray != null) {
for (int i = 0; i < listArray.size(); i++) {
int type = listArray.getJSONObject(i).getIntValue("type");
if (2328 == type) continue;
boolean prime = 2312 == type;
JSONObject items = listArray.getJSONObject(i).getJSONObject("info");
String uniqueIdStr = listArray.getJSONObject(i).getString("unique_id_str");
String link = "https://www.dcdapp.com/ugc/article/" + uniqueIdStr;
if (dcdapp.carTopicService.isExsit(DigestUtils.md5DigestAsHex(link.getBytes()))) {
flag = true;
}
String title = items.getString("title").replaceAll("[\r\n]+", "").replaceAll("[^\\u0000-\\uFFFF]", "");
if (title.length() > 100) {
title = title.substring(0, 100) + "……";
}
//阅读量
int hit = items.getIntValue("read_count");
//评论量
int reply = items.getIntValue("comment_count");
String author = items.getJSONObject("user_info").getString("name").replaceAll("[^\\u0000-\\uFFFF]", "");
String displayTime = TimeTools.timeFormat(items.getLongValue("display_time") * 1000, "");
boolean image = items.getJSONArray("image_list") != null && !items.getJSONArray("image_list").isEmpty();
//这里就是问题中的几个参数哦。。。
max_behot_time = items.getLongValue("behot_time");
max_cursor = items.getLongValue("cursor");
logger.warn(title + "\t" + author + "\t" + hit + "\t" + displayTime + "\t" + uniqueIdStr + "\t" + image);
}
} else {
break;
}
} else {
break;
}
Thread.sleep(5000L);
} catch (Exception ex) {
ex.printStackTrace();
logger.error("dcd error:"+ex);
}
logger.error("抓取"+sector + " 第" + page + "页结束");
page++;
if (flag) break;
}
可以通过上面的代码获取数据[得意] 查看全部
java爬虫抓取动态网页(懂车帝进制抓取只是技术研究不涉及数据内容,请谨慎操作)
友情提示,了解Chedi Binary的捕获,但技术研究不涉及数据内容,请谨慎操作
本文以雅阁车友圈为例,地址:
分析
首先分析一下这个网站的内容交互方式。不难发现,内容是通过鼠标向下滚动来翻页,翻页后页面没有刷新。
我们按F12调出浏览器的Network,可以看到每个页面的内容都是通过XHR传递到前端显示的,如下图:
多次翻页后,通过这个url解析并显示内容。
问题
1.每个请求需要传递三个参数,min_behot_time、max_behot_time、max_cursor,如何在每次翻页时传递这三个参数?
在浏览器中搜索关键词以找到位置。都出现在community.js中,只是被webpack打包了,看不到源码了。
但是可以通过关键词搜索,然后配合浏览器自带的format js函数,大概可以看到这三个参数的由来,如下图:
相信你已经明白了。 [害羞]
2. 每次翻页,传递的数据数为20,但显示的页面少于20,而且每次都不固定。为什么?
这时候就需要对返回的json内容进行分析。有没有发现类型有点不同?
具体可以多对比分析,仅供参考:type=2328重点分析,type=2312精华帖。
代码片段
maven 引入:jsoup、fastjson
java 示例代码片段
long min_behot_time = 0l;
long max_behot_time = 0l;
long max_cursor = 0l;
int page = 1;
//请留意需要修改,您可以while中设置page>10 时,break;
while (true) {
boolean flag = false;
if (min_behot_time == 0) {
min_behot_time = System.currentTimeMillis() / 1000;
}
String url = "https://www.dcdapp.com/motor/d ... ot%3B + motor_id + "&min_behot_time=" + min_behot_time + "&max_behot_time=" + max_behot_time + "&max_cursor=" + max_cursor + "&channel=m_web&device_platform=wap&category=dongtai&cmg_flag=dongtai&web_id=0&device_id=0&impression_info=%7B%22page_id%22%3A%22page_forum_home%22%2C%22product_name%22%3A%22pc%22%7D&tt_from=load_more&_t=" + System.currentTimeMillis();
try {
Connection.Response response = Jsoup.connect(url).headers(headers())
.timeout(50000)
.ignoreHttpErrors(true).ignoreContentType(true)
.execute();
String json = response.body();
JSONObject jsonObject = JSON.parseObject(json);
JSONObject dataObj = jsonObject.getJSONObject("data");
if (dataObj != null) {
JSONArray listArray = dataObj.getJSONArray("list");
if (listArray != null) {
for (int i = 0; i < listArray.size(); i++) {
int type = listArray.getJSONObject(i).getIntValue("type");
if (2328 == type) continue;
boolean prime = 2312 == type;
JSONObject items = listArray.getJSONObject(i).getJSONObject("info");
String uniqueIdStr = listArray.getJSONObject(i).getString("unique_id_str");
String link = "https://www.dcdapp.com/ugc/article/" + uniqueIdStr;
if (dcdapp.carTopicService.isExsit(DigestUtils.md5DigestAsHex(link.getBytes()))) {
flag = true;
}
String title = items.getString("title").replaceAll("[\r\n]+", "").replaceAll("[^\\u0000-\\uFFFF]", "");
if (title.length() > 100) {
title = title.substring(0, 100) + "……";
}
//阅读量
int hit = items.getIntValue("read_count");
//评论量
int reply = items.getIntValue("comment_count");
String author = items.getJSONObject("user_info").getString("name").replaceAll("[^\\u0000-\\uFFFF]", "");
String displayTime = TimeTools.timeFormat(items.getLongValue("display_time") * 1000, "");
boolean image = items.getJSONArray("image_list") != null && !items.getJSONArray("image_list").isEmpty();
//这里就是问题中的几个参数哦。。。
max_behot_time = items.getLongValue("behot_time");
max_cursor = items.getLongValue("cursor");
logger.warn(title + "\t" + author + "\t" + hit + "\t" + displayTime + "\t" + uniqueIdStr + "\t" + image);
}
} else {
break;
}
} else {
break;
}
Thread.sleep(5000L);
} catch (Exception ex) {
ex.printStackTrace();
logger.error("dcd error:"+ex);
}
logger.error("抓取"+sector + " 第" + page + "页结束");
page++;
if (flag) break;
}
可以通过上面的代码获取数据[得意]
java爬虫抓取动态网页(对网页爬虫的调查结果调查人:王杨斌对于爬虫工具以及代码的调查)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-30 13:08
网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是关于PHP和Java的工具代码。Java爬虫1.1. JAVA爬虫WebCollector 爬虫简介:WebCollector[1]是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需要少量的代码即可实现强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2. Web-Harvest Web-Harvest 是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。1.4. 网络爬虫Heritrix Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。Heritrix是一个爬虫框架,其组织结构包括整个组件和爬行过程。1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个不需要配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。
您可以使用它来构建多线程 Web 爬虫。1.7. Java 网络蜘蛛/网络爬虫 Spiderman Spiderman 是一款基于微内核+插件架构的网络蜘蛛。它的目标是以简单的方式捕获复杂的目标网页信息。分析您需要的业务数据。Crawler-like 2.1. 网络爬虫 Grub Next Generation Grub Next Generation [8] 是一个分布式网络爬虫系统,包括客户端和服务器,可用于维护网页的索引。其开发语言:2.2.网络爬虫甲醇甲醇是一款模块化、可定制的网络爬虫软件。主要优点是速度快。2.3. 网络爬虫/网络蜘蛛 larbin Larbin [10] 是一个开源的网络爬虫/网络蜘蛛,由年轻的法国人 SbastienAilleret 自主研发。larbin 的目的是能够跟踪页面的 URL 进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,如何解析是用户自己做的。此外,larbin 没有提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用来建一个url列表组,比如urlretrive所有网页后,就可以得到xml链接。或者mp3,或者定制的larbin,都可以作为搜索引擎的信息来源。2.4. 死链接检查软件 Xenu Xenu Link Sleuth [11] 可能是您见过的用于检查网站死链接的最小但最强大的软件。您可以打开本地网页文件查看其链接,或输入任何 URL 进行查看。可分别列出网站的活链接和死链接,并能清晰分析重定向链接;它支持多线程,可以将检查结果存储为文本文件或网络文件。PHP爬虫3.1. sphider Spider() 是一个用PHP语言编写的爬虫工具,使用MySql作为后端。当前版本更新为Spider1.3.6,发布日期为04-06-2013。解压下载的文件,放到apache目录下运行。运行后,由于配置问题无法抓取,稍后调试。OpenWebSpider [12] 是一个开源的多线程 Web Spider(机器人:机器人,爬虫:爬虫)和具有许多有趣功能的搜索引擎。
3.2. TSpider TSpider是一个可执行的图形界面程序,但是爬取过程太慢,不适合使用。PHPCrawl也是一个使用php语言的爬虫工具,具有很好的扩展性,你可以根据自己的需要更改代码来完成不同的功能。3.3. PHP 网络爬虫和搜索引擎 PhpDig PhpDig [13] 是一个使用 PHP 开发的网络爬虫和搜索引擎。通过索引动态和静态页面来创建词汇表。搜索查询时,会根据一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
一个模板系统,可以索引 PDF、Word、Excel 和 PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。用它来搭建某个领域的垂直搜索引擎是最好的选择。3.4. 网站内容采集
器 Snoopy Snoopy [14] 是一个强大的网站内容采集
器(爬虫)。Dot.Net爬虫4.1.网站数据采集软件网络矿工采集器(原soukey采摘)Soukey[15]采摘网站数据采集软件是基于.Net平台的开源软件,也是网站数据采集软件中唯一开源的软件。
Soukey虽然选择开源,但不影响软件功能的提供,甚至比一些商业软件还要丰富。4.2. NWebCrawler NWebCrawler [16] 是一个开源的 C# 网络爬虫。4.3. 爬虫小新Sinawler 国内第一个微博数据爬虫程序!原名是“新浪微博爬虫”[17]。登录后,您可以指定用户为起点,以用户的关注者和粉丝为线索,通过扩展人脉,采集
用户基本信息、微博数据、评论数据。本应用所获得的数据可作为新浪微博相关科研、研发的数据支持,但请勿用于商业用途。该应用程序基于.NET2. 0框架,需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。
它的开发语言是Python。5.2. 网页抓取/信息抽取软件MetaSeeker 网页抓取/信息抽取/数据抽取软件工具包MetaSeeker(GooSeeker)V4.11.2 [18] 正式发布,网络版可免费下载使用,可阅读源代码。自推出以来,深受喜爱,其主要应用领域为: 垂直搜索(VerticalSearch):又称专业搜索。高速、海量、精准抓取是定题网络爬虫DataScraper的强项。它每周 7 天、每天 24 小时无人值守。自调度的定期批量采集,再加上可续传的上传和软件看门狗(Watch Dog),让您高枕无忧。移动互联网:移动搜索、移动混搭、移动社交网络、移动电商都离不开结构化的数据内容,DataScraper实时高效采集内容,并输出富含语义元数据的XML格式的采集结果文件,确保数据的自动化整合和处理,突破小屏壁垒显示和高精度信息检索。移动互联网不是万维网的一个子集,而是整体。MetaSeeker为企业竞争情报采集
/数据挖掘搭建桥梁:俗称商业智能(Business Intelligence),噪声信息过滤,结构化转换,保证数据的准确性和及时性,独特DataScraper的广域分布式架构赋予DataScraper无与伦比的情报采集
和渗透能力。AJAX/Javascript 动态页面、服务器动态页面、
在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。还有一些工具,phpdig,很久没有更新了,旧的工具代码已经没有了。基于python编码的spiderpy和基于C++编码的larbin没有做深入的调查和了解。如果有需要,我们会进行深入调查。参考文献:[10][11][12][13][14][15][16][17][18] 查看全部
java爬虫抓取动态网页(对网页爬虫的调查结果调查人:王杨斌对于爬虫工具以及代码的调查)
网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是关于PHP和Java的工具代码。Java爬虫1.1. JAVA爬虫WebCollector 爬虫简介:WebCollector[1]是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需要少量的代码即可实现强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2. Web-Harvest Web-Harvest 是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。1.4. 网络爬虫Heritrix Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。Heritrix是一个爬虫框架,其组织结构包括整个组件和爬行过程。1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个不需要配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。
您可以使用它来构建多线程 Web 爬虫。1.7. Java 网络蜘蛛/网络爬虫 Spiderman Spiderman 是一款基于微内核+插件架构的网络蜘蛛。它的目标是以简单的方式捕获复杂的目标网页信息。分析您需要的业务数据。Crawler-like 2.1. 网络爬虫 Grub Next Generation Grub Next Generation [8] 是一个分布式网络爬虫系统,包括客户端和服务器,可用于维护网页的索引。其开发语言:2.2.网络爬虫甲醇甲醇是一款模块化、可定制的网络爬虫软件。主要优点是速度快。2.3. 网络爬虫/网络蜘蛛 larbin Larbin [10] 是一个开源的网络爬虫/网络蜘蛛,由年轻的法国人 SbastienAilleret 自主研发。larbin 的目的是能够跟踪页面的 URL 进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,如何解析是用户自己做的。此外,larbin 没有提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用来建一个url列表组,比如urlretrive所有网页后,就可以得到xml链接。或者mp3,或者定制的larbin,都可以作为搜索引擎的信息来源。2.4. 死链接检查软件 Xenu Xenu Link Sleuth [11] 可能是您见过的用于检查网站死链接的最小但最强大的软件。您可以打开本地网页文件查看其链接,或输入任何 URL 进行查看。可分别列出网站的活链接和死链接,并能清晰分析重定向链接;它支持多线程,可以将检查结果存储为文本文件或网络文件。PHP爬虫3.1. sphider Spider() 是一个用PHP语言编写的爬虫工具,使用MySql作为后端。当前版本更新为Spider1.3.6,发布日期为04-06-2013。解压下载的文件,放到apache目录下运行。运行后,由于配置问题无法抓取,稍后调试。OpenWebSpider [12] 是一个开源的多线程 Web Spider(机器人:机器人,爬虫:爬虫)和具有许多有趣功能的搜索引擎。
3.2. TSpider TSpider是一个可执行的图形界面程序,但是爬取过程太慢,不适合使用。PHPCrawl也是一个使用php语言的爬虫工具,具有很好的扩展性,你可以根据自己的需要更改代码来完成不同的功能。3.3. PHP 网络爬虫和搜索引擎 PhpDig PhpDig [13] 是一个使用 PHP 开发的网络爬虫和搜索引擎。通过索引动态和静态页面来创建词汇表。搜索查询时,会根据一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
一个模板系统,可以索引 PDF、Word、Excel 和 PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。用它来搭建某个领域的垂直搜索引擎是最好的选择。3.4. 网站内容采集
器 Snoopy Snoopy [14] 是一个强大的网站内容采集
器(爬虫)。Dot.Net爬虫4.1.网站数据采集软件网络矿工采集器(原soukey采摘)Soukey[15]采摘网站数据采集软件是基于.Net平台的开源软件,也是网站数据采集软件中唯一开源的软件。
Soukey虽然选择开源,但不影响软件功能的提供,甚至比一些商业软件还要丰富。4.2. NWebCrawler NWebCrawler [16] 是一个开源的 C# 网络爬虫。4.3. 爬虫小新Sinawler 国内第一个微博数据爬虫程序!原名是“新浪微博爬虫”[17]。登录后,您可以指定用户为起点,以用户的关注者和粉丝为线索,通过扩展人脉,采集
用户基本信息、微博数据、评论数据。本应用所获得的数据可作为新浪微博相关科研、研发的数据支持,但请勿用于商业用途。该应用程序基于.NET2. 0框架,需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。
它的开发语言是Python。5.2. 网页抓取/信息抽取软件MetaSeeker 网页抓取/信息抽取/数据抽取软件工具包MetaSeeker(GooSeeker)V4.11.2 [18] 正式发布,网络版可免费下载使用,可阅读源代码。自推出以来,深受喜爱,其主要应用领域为: 垂直搜索(VerticalSearch):又称专业搜索。高速、海量、精准抓取是定题网络爬虫DataScraper的强项。它每周 7 天、每天 24 小时无人值守。自调度的定期批量采集,再加上可续传的上传和软件看门狗(Watch Dog),让您高枕无忧。移动互联网:移动搜索、移动混搭、移动社交网络、移动电商都离不开结构化的数据内容,DataScraper实时高效采集内容,并输出富含语义元数据的XML格式的采集结果文件,确保数据的自动化整合和处理,突破小屏壁垒显示和高精度信息检索。移动互联网不是万维网的一个子集,而是整体。MetaSeeker为企业竞争情报采集
/数据挖掘搭建桥梁:俗称商业智能(Business Intelligence),噪声信息过滤,结构化转换,保证数据的准确性和及时性,独特DataScraper的广域分布式架构赋予DataScraper无与伦比的情报采集
和渗透能力。AJAX/Javascript 动态页面、服务器动态页面、
在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。还有一些工具,phpdig,很久没有更新了,旧的工具代码已经没有了。基于python编码的spiderpy和基于C++编码的larbin没有做深入的调查和了解。如果有需要,我们会进行深入调查。参考文献:[10][11][12][13][14][15][16][17][18]
java爬虫抓取动态网页(WebDriver的吐槽WebDriver是一个测试框架,什么是复杂性?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-30 10:08
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。看来我的程序没有写错。接下来让人身心俱疲的事情来了——获取一个收录
动态内容的html页面。
在百度这个号称中国最强搜索引擎的百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经包括后者)。我很高兴,终于找到了解决方案。兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录
动态生成的内容。问题是,为什么说WebDriver可以获取收录
动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver 驱动程序 = 新 InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具-phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面已加载!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
在java端执行的代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
本文链接:Java抓取动态生成的网页-吐槽,转载请注明。 查看全部
java爬虫抓取动态网页(WebDriver的吐槽WebDriver是一个测试框架,什么是复杂性?)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。看来我的程序没有写错。接下来让人身心俱疲的事情来了——获取一个收录
动态内容的html页面。
在百度这个号称中国最强搜索引擎的百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经包括后者)。我很高兴,终于找到了解决方案。兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录
动态生成的内容。问题是,为什么说WebDriver可以获取收录
动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver 驱动程序 = 新 InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具-phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面已加载!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
在java端执行的代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
本文链接:Java抓取动态生成的网页-吐槽,转载请注明。
java爬虫抓取动态网页( Python行业薪资如何阅读?(第1~6章) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-28 17:04
Python行业薪资如何阅读?(第1~6章)
)
前言
爬虫是DT(Data Technology)采集
信息的基础。程序员抓取目标网站的信息后,就可以分析和构建应用程序。我们关心的是技术如何给每个人带来实际效果,进而实现目标和理想。无法应用的技术称为魔术,只能用于表演。我们非常关心读者能否掌握爬虫的概念,所以结合不同的例子来讲解相关技术,希望能够引导读者完成整个数据采集的过程。
Python 是一种简单而有效的语言。爬虫所需的获取、存储、组织流程可以使用Python系统地实现。另外,大部分电脑也可以直接使用Python语言或者干脆安装Python系统。相信读者能够轻松使用Python作为主要的爬虫技术。
动心者应有大根
DT的核心是从信息来源进行理解和分析,从而做出能够打动对方的行动决策。从谷歌搜索到如今的大数据时代,爬虫技术的重要性和广泛性一直都很突出。程序员了解信息获取、存储和整理的基本关系,可以系统地采集
和应用不同来源、千变万化的网站信息。
自我提升
互联网技术在不断更新和进步,网站信息也在不断变化。爬虫的乐趣在于如何高效、持续地从瞬息万变的网站中获取信息。此外,程序员必须不断学习新技术,提高自己,以便在爬取过程中了解互联网的运行和结构。最后,感谢我的朋友唐松给我机会一.开始写这本书,让我分享爬行技术和其中的乐趣。
Python行业薪资
如何阅读?
使用Python编写网络爬虫获取互联网大数据是目前的热门话题。
本书内容包括基础部分、高级部分和项目实践部分三部分。
Python爬虫过程
基础部分(第1~6章)主要介绍爬虫的三个步骤(获取网页、解析网页和存储数据),并通过大量实例的讲解,让读者从基础内容中系统地学习爬虫技术并实践提高Python爬虫的级别。
进阶部分(第7~12章)包括多线程并发并行爬虫、分布式爬虫、IP替换等,帮助读者进一步提升爬虫水平。
项目实践部分(第13~16章)利用本书介绍的爬虫技术爬取了几个真实的网站,让读者在阅读本书后可以根据自己的需要编写爬虫程序。不管你有没有编程基础,只要你对爬虫技术感兴趣,本书都会引导你从入门到进阶,再到实战,一步步了解爬虫,最终写出自己的爬虫程序。
接下来,就和小编一起进入爬虫知识的海洋吧。
基础部分
第 1 章:网络爬虫入门
1.1 为什么要学习爬行?
在数据量呈爆炸式增长的互联网时代,网站与用户的交流本质上是数据的交换:搜索引擎从数据库中提取搜索结果,展示在用户面前;电子商务在网站上展示产品描述和价格,让买家可以选择自己喜欢的产品,社交媒体在用户生态系统的自我交互下产生了大量的文字、图片和视频数据。如果能够对这些数据进行分析和利用,不仅可以帮助第一方公司(即拥有数据的公司)做出更好的决策,也有利于第三方公司。
上面的例子只是数据应用的冰山一角。近年来,随着大数据分析的普及,毕竟数据都可以分析,网络爬虫技术成为大数据分析领域的第一环节。
对于这些公开数据的应用价值,我们可以使用KYC框架来理解,即了解你的公司(Know Your Company)、了解你的竞争对手(Know Your Competitor)、了解你的客户(Know Your Customer)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,在营销领域,可以帮助企业做好4P(Product:产品创新,Place:智能选址,Price:动态价格,Promotion:数据驱动的营销活动) ; 在金融领域,数据驱动的征信等应用将带来越来越大的价值。
简单的爬虫架构
1.2 三个过程的技术实现
以下技术实现方法均以Python语言实现,Java等其他语言不涉及。
1.获取网页
获取网页的基本技术:request、urllib、selenium(模拟浏览器)。
先进的网页获取技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取。
2.分析网页
解析网页的基本技术:re正则表达式、BeautifulSoup和lxml。
高级网页解析技术:解决中文乱码。
3.存储数据
存储数据的基本技术:保存在txt文件中,保存在csv文件中。
先进的数据存储技术:存储在MySQL数据库中,存储在MongoDB数据库中。
对以上技术不熟悉的读者也不必担心,本书将对其中的所有技术进行讲解,力求把深奥的东西讲得通俗易懂。
第 2 章:编写第一个网络爬虫
第 3 章:静态网页抓取
第 4 章:动态网络爬行
第 5 章:解析网页
第 6 章:数据存储
进阶部分
第七章:提高爬虫速度
7.1多线程爬虫
多线程爬虫以并发方式执行。换句话说,不能同时执行多个线程,而是通过进程的快速切换来加快网络爬虫的速度。
Python 本身的设计限制了多线程的执行。在 Python 设计之初,为了数据安全的决策,就设定了 GIL(Global Interpreter Lock)。在Python中,线程的执行过程包括获取GIL、执行代码直至挂起、释放GIL。
例如,如果一个线程要执行,它必须首先获得 GIL。我们可以将 GIL 视为“护照”,而一个 Python 进程中只有一个 GIL。不能拿到pass的线程是不允许进入CPU执行的。
多线程执行模式
每次释放 GIL 锁,线程之间都会有锁竞争,切换线程会消耗资源。由于 GIL 锁的存在,Python 中的一个进程始终只能同时执行一个线程(获得 GIL 的线程可以执行)。这就是Python在多核CPU上的多线程效率不高的原因。
因为GIL的存在,多线程就没用了吗?在网络爬虫的情况下,网络爬虫是I0密集型的,多线程可以有效提高效率。因为单线程下有I0操作,I0等待,所以会造成不必要的时间浪费,而启用多线程可以在线程A等待的同时自动切换到线程B,从而不浪费CPU资源,从而提高程序执行的效率。
Python的多线程对I0密集型代码更加友好,网络爬虫可以在获取网页的过程中使用多线程来加快速度。
第 8 章:反爬虫问题
第9章:解决中文乱码
第10章:登录和验证码处理
第11章:服务器集合
第12章:分布式爬虫
项目实践部分
爬虫练习一:维基百科
维基百科是一个网络百科全书,允许用户在正常情况下编辑任何条目。目前维基百科由非营利组织维基媒体基金会运营。维基百科一词是由网站的核心技术维基和百科全书创造的一个新的混合词维基百科,意思是百科全书。
维基百科入口页面
本章将给出一个爬取维基百科的实际项目。使用的爬取技术包括以下4种:
爬虫练习二:知乎直播
知乎是中国互联网上一个非常庞大的知识社交平台。在知乎上,用户可以通过问答等交流方式获取知识。与百度知乎等问答网站不同,知乎的回答往往非常深入,回答者写的也很用心。知乎汇聚了中国互联网技术、商业、文化领域最具创意的人才,将提供优质的内容,通过人类节点形成规模化生产和共享,构建高价值的人际网络。
知乎
本章是爬取知乎网站的实战项目。使用的爬虫技术包括以下3种。
爬虫实践三:百度地图API
百度地图是一种网络地图搜索服务。在百度地图中,用户可以查询街道、商场、房产的地理位置,也可以找到离你最近的餐厅、学校、银行、公园等。百度地图提供了丰富的API供开发者调用,我们可以免费获取各个位置的具体信息。
百度API
本章是一个使用百度API获取数据的实战项目。使用的技术包括:
爬虫练习四:公众点评
在去餐厅吃饭之前,我们总是喜欢在网上搜索餐厅评论,然后再决定去哪家餐厅。在互联网餐厅点评网站中,大众点评是知名的第三方消费者点评网站,也是当地的生活信息和交易平台。因此,大众点评上有很多商家信息和用户评论数据。
公众意见
本章是一个抓取公众评论数据的实践项目。使用的技术包括:
总的来说,Python爬虫是一项非常实用但并不枯燥的技术。因为书中的细节太多,编者不会一一打出来。想获取《Python爬虫从入门到实践》小伙伴可以转发+关注私信编辑【学习】获取获取方式~~~
查看全部
java爬虫抓取动态网页(
Python行业薪资如何阅读?(第1~6章)
)
前言
爬虫是DT(Data Technology)采集
信息的基础。程序员抓取目标网站的信息后,就可以分析和构建应用程序。我们关心的是技术如何给每个人带来实际效果,进而实现目标和理想。无法应用的技术称为魔术,只能用于表演。我们非常关心读者能否掌握爬虫的概念,所以结合不同的例子来讲解相关技术,希望能够引导读者完成整个数据采集的过程。
Python 是一种简单而有效的语言。爬虫所需的获取、存储、组织流程可以使用Python系统地实现。另外,大部分电脑也可以直接使用Python语言或者干脆安装Python系统。相信读者能够轻松使用Python作为主要的爬虫技术。
动心者应有大根
DT的核心是从信息来源进行理解和分析,从而做出能够打动对方的行动决策。从谷歌搜索到如今的大数据时代,爬虫技术的重要性和广泛性一直都很突出。程序员了解信息获取、存储和整理的基本关系,可以系统地采集
和应用不同来源、千变万化的网站信息。
自我提升
互联网技术在不断更新和进步,网站信息也在不断变化。爬虫的乐趣在于如何高效、持续地从瞬息万变的网站中获取信息。此外,程序员必须不断学习新技术,提高自己,以便在爬取过程中了解互联网的运行和结构。最后,感谢我的朋友唐松给我机会一.开始写这本书,让我分享爬行技术和其中的乐趣。
Python行业薪资
如何阅读?
使用Python编写网络爬虫获取互联网大数据是目前的热门话题。
本书内容包括基础部分、高级部分和项目实践部分三部分。
Python爬虫过程
基础部分(第1~6章)主要介绍爬虫的三个步骤(获取网页、解析网页和存储数据),并通过大量实例的讲解,让读者从基础内容中系统地学习爬虫技术并实践提高Python爬虫的级别。
进阶部分(第7~12章)包括多线程并发并行爬虫、分布式爬虫、IP替换等,帮助读者进一步提升爬虫水平。
项目实践部分(第13~16章)利用本书介绍的爬虫技术爬取了几个真实的网站,让读者在阅读本书后可以根据自己的需要编写爬虫程序。不管你有没有编程基础,只要你对爬虫技术感兴趣,本书都会引导你从入门到进阶,再到实战,一步步了解爬虫,最终写出自己的爬虫程序。
接下来,就和小编一起进入爬虫知识的海洋吧。
基础部分
第 1 章:网络爬虫入门
1.1 为什么要学习爬行?
在数据量呈爆炸式增长的互联网时代,网站与用户的交流本质上是数据的交换:搜索引擎从数据库中提取搜索结果,展示在用户面前;电子商务在网站上展示产品描述和价格,让买家可以选择自己喜欢的产品,社交媒体在用户生态系统的自我交互下产生了大量的文字、图片和视频数据。如果能够对这些数据进行分析和利用,不仅可以帮助第一方公司(即拥有数据的公司)做出更好的决策,也有利于第三方公司。
上面的例子只是数据应用的冰山一角。近年来,随着大数据分析的普及,毕竟数据都可以分析,网络爬虫技术成为大数据分析领域的第一环节。
对于这些公开数据的应用价值,我们可以使用KYC框架来理解,即了解你的公司(Know Your Company)、了解你的竞争对手(Know Your Competitor)、了解你的客户(Know Your Customer)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,在营销领域,可以帮助企业做好4P(Product:产品创新,Place:智能选址,Price:动态价格,Promotion:数据驱动的营销活动) ; 在金融领域,数据驱动的征信等应用将带来越来越大的价值。
简单的爬虫架构
1.2 三个过程的技术实现
以下技术实现方法均以Python语言实现,Java等其他语言不涉及。
1.获取网页
获取网页的基本技术:request、urllib、selenium(模拟浏览器)。
先进的网页获取技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取。
2.分析网页
解析网页的基本技术:re正则表达式、BeautifulSoup和lxml。
高级网页解析技术:解决中文乱码。
3.存储数据
存储数据的基本技术:保存在txt文件中,保存在csv文件中。
先进的数据存储技术:存储在MySQL数据库中,存储在MongoDB数据库中。
对以上技术不熟悉的读者也不必担心,本书将对其中的所有技术进行讲解,力求把深奥的东西讲得通俗易懂。
第 2 章:编写第一个网络爬虫
第 3 章:静态网页抓取
第 4 章:动态网络爬行
第 5 章:解析网页
第 6 章:数据存储
进阶部分
第七章:提高爬虫速度
7.1多线程爬虫
多线程爬虫以并发方式执行。换句话说,不能同时执行多个线程,而是通过进程的快速切换来加快网络爬虫的速度。
Python 本身的设计限制了多线程的执行。在 Python 设计之初,为了数据安全的决策,就设定了 GIL(Global Interpreter Lock)。在Python中,线程的执行过程包括获取GIL、执行代码直至挂起、释放GIL。
例如,如果一个线程要执行,它必须首先获得 GIL。我们可以将 GIL 视为“护照”,而一个 Python 进程中只有一个 GIL。不能拿到pass的线程是不允许进入CPU执行的。
多线程执行模式
每次释放 GIL 锁,线程之间都会有锁竞争,切换线程会消耗资源。由于 GIL 锁的存在,Python 中的一个进程始终只能同时执行一个线程(获得 GIL 的线程可以执行)。这就是Python在多核CPU上的多线程效率不高的原因。
因为GIL的存在,多线程就没用了吗?在网络爬虫的情况下,网络爬虫是I0密集型的,多线程可以有效提高效率。因为单线程下有I0操作,I0等待,所以会造成不必要的时间浪费,而启用多线程可以在线程A等待的同时自动切换到线程B,从而不浪费CPU资源,从而提高程序执行的效率。
Python的多线程对I0密集型代码更加友好,网络爬虫可以在获取网页的过程中使用多线程来加快速度。
第 8 章:反爬虫问题
第9章:解决中文乱码
第10章:登录和验证码处理
第11章:服务器集合
第12章:分布式爬虫
项目实践部分
爬虫练习一:维基百科
维基百科是一个网络百科全书,允许用户在正常情况下编辑任何条目。目前维基百科由非营利组织维基媒体基金会运营。维基百科一词是由网站的核心技术维基和百科全书创造的一个新的混合词维基百科,意思是百科全书。
维基百科入口页面
本章将给出一个爬取维基百科的实际项目。使用的爬取技术包括以下4种:
爬虫练习二:知乎直播
知乎是中国互联网上一个非常庞大的知识社交平台。在知乎上,用户可以通过问答等交流方式获取知识。与百度知乎等问答网站不同,知乎的回答往往非常深入,回答者写的也很用心。知乎汇聚了中国互联网技术、商业、文化领域最具创意的人才,将提供优质的内容,通过人类节点形成规模化生产和共享,构建高价值的人际网络。
知乎
本章是爬取知乎网站的实战项目。使用的爬虫技术包括以下3种。
爬虫实践三:百度地图API
百度地图是一种网络地图搜索服务。在百度地图中,用户可以查询街道、商场、房产的地理位置,也可以找到离你最近的餐厅、学校、银行、公园等。百度地图提供了丰富的API供开发者调用,我们可以免费获取各个位置的具体信息。
百度API
本章是一个使用百度API获取数据的实战项目。使用的技术包括:
爬虫练习四:公众点评
在去餐厅吃饭之前,我们总是喜欢在网上搜索餐厅评论,然后再决定去哪家餐厅。在互联网餐厅点评网站中,大众点评是知名的第三方消费者点评网站,也是当地的生活信息和交易平台。因此,大众点评上有很多商家信息和用户评论数据。
公众意见
本章是一个抓取公众评论数据的实践项目。使用的技术包括:
总的来说,Python爬虫是一项非常实用但并不枯燥的技术。因为书中的细节太多,编者不会一一打出来。想获取《Python爬虫从入门到实践》小伙伴可以转发+关注私信编辑【学习】获取获取方式~~~
java爬虫抓取动态网页(WebCollector-Python项目开发者内核:WebCollectorx )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 17:03
)
爬虫简介:
WebCollector 是一个 Java 爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎大家贡献代码:
爬虫内核:
WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。2.x 版本集成了 selenium,可以处理 JavaScript 生成的数据。
马文:
最新的Maven地址请参考文档:
文件地址:
内核架构图:
WebCollector 2.x 版本特点:
自定义遍历策略可以完成更复杂的遍历服务,比如分页,AJAX可以为每个URL设置附加信息(MetaData),利用附加信息完成很多复杂的服务,比如深度检索、锚文本检索、引用页面检索、POST参数传递、增量更新等。利用插件机制,用户可以自定义自己的Http请求、过滤器、执行器等插件。内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,比如搜索引擎的实时爬取。内置一套基于Berkeley DB(BreadthCrawler)的插件:适合处理长期、大规模的任务,并具有断点爬取功能,不会因宕机或关机造成数据丢失。集成selenium,可以提取JavaScript生成的信息,轻松定制http请求,内置多代理随机切换功能。可以通过定义http请求来实现模拟登录。使用slf4j作为日志门面,可以连接多种日志,使用类似Hadoop的Configuration机制为每个爬虫定制配置信息。
WebCollector 2.x 官网及镜像:
WebCollector 2.x 教程:
WebCollector 配置
WebCollector 入门
WebCollector 功能
WebCollector 持久化
WebCollector 高级爬虫定制
WebCollector 处理 Javascript
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
/**
* Crawling news from github news
*
* @author hu
*/
public class DemoAutoNewsCrawler extends BreadthCrawler {
/**
* @param crawlPath crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse if autoParse is true,BreadthCrawler will auto extract
* links which match regex rules from pag
*/
public DemoAutoNewsCrawler(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/*start pages*/
this.addSeed("https://blog.github.com/");
for(int pageIndex = 2; pageIndex 查看全部
java爬虫抓取动态网页(WebCollector-Python项目开发者内核:WebCollectorx
)
爬虫简介:
WebCollector 是一个 Java 爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎大家贡献代码:
爬虫内核:
WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。2.x 版本集成了 selenium,可以处理 JavaScript 生成的数据。
马文:
最新的Maven地址请参考文档:
文件地址:
内核架构图:
WebCollector 2.x 版本特点:
自定义遍历策略可以完成更复杂的遍历服务,比如分页,AJAX可以为每个URL设置附加信息(MetaData),利用附加信息完成很多复杂的服务,比如深度检索、锚文本检索、引用页面检索、POST参数传递、增量更新等。利用插件机制,用户可以自定义自己的Http请求、过滤器、执行器等插件。内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,比如搜索引擎的实时爬取。内置一套基于Berkeley DB(BreadthCrawler)的插件:适合处理长期、大规模的任务,并具有断点爬取功能,不会因宕机或关机造成数据丢失。集成selenium,可以提取JavaScript生成的信息,轻松定制http请求,内置多代理随机切换功能。可以通过定义http请求来实现模拟登录。使用slf4j作为日志门面,可以连接多种日志,使用类似Hadoop的Configuration机制为每个爬虫定制配置信息。
WebCollector 2.x 官网及镜像:
WebCollector 2.x 教程:
WebCollector 配置
WebCollector 入门
WebCollector 功能
WebCollector 持久化
WebCollector 高级爬虫定制
WebCollector 处理 Javascript
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
/**
* Crawling news from github news
*
* @author hu
*/
public class DemoAutoNewsCrawler extends BreadthCrawler {
/**
* @param crawlPath crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse if autoParse is true,BreadthCrawler will auto extract
* links which match regex rules from pag
*/
public DemoAutoNewsCrawler(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/*start pages*/
this.addSeed("https://blog.github.com/";);
for(int pageIndex = 2; pageIndex
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-28 02:04
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博文列表。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每个post都是一个小div,class="post_item"
然后就可以开始上代码了,Jsoup的核心代码如下(整体源码会在文末给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害了。从上面对首页html结构的分析,到Jsoup分析的代码的执行,关于这个的文章太多了这段时间的主页)
由于新文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上博客园首页文章列表案例分析的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
发表于@2019-05-25 16:08 JAVA开发新手阅读(...) 评论(...) 编辑 查看全部
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博文列表。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每个post都是一个小div,class="post_item"
然后就可以开始上代码了,Jsoup的核心代码如下(整体源码会在文末给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害了。从上面对首页html结构的分析,到Jsoup分析的代码的执行,关于这个的文章太多了这段时间的主页)
由于新文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。

除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上博客园首页文章列表案例分析的完整源码:


package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
发表于@2019-05-25 16:08 JAVA开发新手阅读(...) 评论(...) 编辑
java爬虫抓取动态网页(基于微内核+插件式架构的Java语言开发网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-28 01:18
1、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
2、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
3、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——像风一样自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是将复杂的目标页面信息以简单的方式捕获并解析成它需要的业务数据。
4、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
5、Heritrix
github地址:internetarchive/heritrix3
Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
6、crawler4j
github地址:yasserg/crawler4j · GitHub
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
7、纳奇
github地址:apache/nutch
Nutch 是一个开源的 Java 搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,它已经成为大规模数据处理的事实上的标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
8、SeimiCrawler
github地址:zhegexiaohuozi/SeimiCrawler
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在SeimiCrawler的世界里,大部分人只需要关心写爬行的业务逻辑,剩下的Seimi会帮你处理。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler 的默认 HTML 解析器是 JsoupXpath(独立的扩展项目,不收录
在 jsoup 中),HTML 数据的默认解析和提取是使用 XPath 完成的(当然,您也可以选择其他解析器进行数据处理)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
9、Jsoup
github地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 查看全部
java爬虫抓取动态网页(基于微内核+插件式架构的Java语言开发网络爬虫)
1、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
2、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
3、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——像风一样自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是将复杂的目标页面信息以简单的方式捕获并解析成它需要的业务数据。
4、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
5、Heritrix
github地址:internetarchive/heritrix3
Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
6、crawler4j
github地址:yasserg/crawler4j · GitHub
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
7、纳奇
github地址:apache/nutch
Nutch 是一个开源的 Java 搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,它已经成为大规模数据处理的事实上的标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
8、SeimiCrawler
github地址:zhegexiaohuozi/SeimiCrawler
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在SeimiCrawler的世界里,大部分人只需要关心写爬行的业务逻辑,剩下的Seimi会帮你处理。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler 的默认 HTML 解析器是 JsoupXpath(独立的扩展项目,不收录
在 jsoup 中),HTML 数据的默认解析和提取是使用 XPath 完成的(当然,您也可以选择其他解析器进行数据处理)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
9、Jsoup
github地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
java爬虫抓取动态网页(MyBatis的框架设计(一)——MyBatis接口设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-28 01:17
一、MyBatis 的框架设计
注:上图主要参考了iteye上chenjc_it写的博文【原理解析二:整体框架设计】中的MyBatis架构图。chenjc_it总结的很好,赞一个!
1.接口层——与数据库交互的方式
MyBatis 与数据库的交互有两种方式:
一个。使用MyBatis提供的传统API;
湾 使用 Mapper 接口
1.1. 使用MyBatis提供的传统API
这是传统的将Statement Id和查询参数传递给SqlSession对象的方式,利用SqlSession对象完成与数据库的交互;MyBatis 提供了非常方便简单的 API 供用户对数据库进行数据的增删改查操作,以及数据库连接信息和 MyBatis 自身配置信息的维护操作。
上面使用MyBatis的方法是创建一个与数据库交互的SqlSession对象,然后根据StatementId和参数对数据库进行操作。这种方法简单实用,但不符合面向对象语言和面向接口编程的概念。习惯。由于面向接口编程是一个普遍的面向对象趋势,MyBatis为了适应这种趋势,增加了第二种使用MyBatis的方式来支持接口(Interface)。
1.2. 使用 Mapper 接口
MyBatis 会配置每个文件
按照MyBatis配置规范配置后,通过SqlSession.getMapper(XXXMapper.class)方法,MyBatis会根据对应接口声明的方法信息,通过动态代理机制生成一个Mapper实例。当我们使用Mapper接口的一个方法时,MyBatis会根据这个方法的方法名和参数类型来确定StatementId,底层还是通过SqlSession.select("statementId",parameterObject); 或 SqlSession.update("statementId",parameterObject); 等实现对数据库的操作,(至于动态机制这里是怎么实现的,我会专门准备一篇文章来讨论,敬请期待~)
MyBatis 引用这个 Mapper 接口的调用方法,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是面向接口的编程允许用户使用注解在接口上配置SQL语句,从而脱离XML配置文件,实现“0配置”)。
2.数据处理层
数据处理层可以说是MyBatis的核心。大体来说,它必须完成三个功能:
一个。通过传入参数构造动态SQL语句;
湾 SQL语句执行和打包查询结果集成列表
2.1. 参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的设计。MyBatis 使用 Ognl 通过传入的参数值动态构造 SQL 语句,使得 MyBatis 具有高度的灵活性和可扩展性。
参数映射是指java数据类型和jdbc数据类型的转换:这里有两个过程:在查询阶段,我们需要通过preparedStatement.setXXX()将java类型数据转换成jdbc类型数据,设置值;另一种是将resultset查询的结果集的jdbcType数据转换成java数据类型。
(至于具体MyBatis是如何动态构造SQL语句的,我会专门准备一篇文章来讨论,敬请期待~)
2.2. SQL 语句执行和打包查询结果集成列表
动态SQL语句生成后,MyBatis会执行SQL语句,将可能返回的结果集转换成List3.框架支持层
3.1. 交易管理机制
事务管理机制是ORM框架不可或缺的一部分,事务管理机制的好坏也是衡量一个ORM框架是否优秀的标准。
3.2. 连接池管理机制
由于创建数据库连接需要比较大的资源,对于数据吞吐量大、访问量非常大的应用来说,连接池的设计非常重要。
3.3. 缓存机制
为了提高数据利用率,降低服务器和数据库的压力,MyBatis 会为一些查询提供会话级的数据缓存,并将某个查询放在 SqlSession 中。在允许的时间间隔内,对于完全相同的查询,MyBatis 会直接将缓存的结果返回给用户,无需在数据库中搜索。(至于具体的MyBatis缓存机制,我会专门准备一篇文章来讨论,敬请期待~)
如何配置SQL语句
MyBatis 中传统的 SQL 语句配置方式是使用 XML 文件进行配置,但是这种方式不能很好地支持面向接口编程的概念。为了支持面向接口编程,MyBatis引入了Mapper接口的概念,引入了面向接口,可以使用注解来配置SQL语句。用户只需在界面上添加必要的注解,无需配置XML文件。但是,目前的 MyBatis 仅对注解配置 SQL 语句提供了有限的支持。高级功能仍然依赖 XML 配置文件来配置 SQL 语句。
4 引导层
boot层是配置和启动MyBatis配置信息的方式。MyBatis 提供了两种方式来引导 MyBatis:基于 XML 配置文件的方法和基于 Java API 的方法。
二、MyBatis 的主要组件及其关系
从MyBatis代码实现来看,MyBatis的主要核心组件如下:
(注:这里只是列出我个人认为是核心组件的组件。读者不要先入为主,认为MyBatis只有这些组件!每个人对MyBatis的理解不同,分析的结果自然会是不同。欢迎读者提出问题和不同意见,我们一起讨论~)
最后
我也采集
了Java面试核心知识点的合集来应对面试。我可以借此机会免费赠送给我的读者和朋友:
内容:
Java面试核心知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
Java面试核心知识点
知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
[外链图片正在传输中...(img-cn5P52fp-53)]
Java面试核心知识点
获取方式:点击喜欢【戳面试信息】后,即可免费获取! 查看全部
java爬虫抓取动态网页(MyBatis的框架设计(一)——MyBatis接口设计)
一、MyBatis 的框架设计

注:上图主要参考了iteye上chenjc_it写的博文【原理解析二:整体框架设计】中的MyBatis架构图。chenjc_it总结的很好,赞一个!
1.接口层——与数据库交互的方式
MyBatis 与数据库的交互有两种方式:
一个。使用MyBatis提供的传统API;
湾 使用 Mapper 接口
1.1. 使用MyBatis提供的传统API
这是传统的将Statement Id和查询参数传递给SqlSession对象的方式,利用SqlSession对象完成与数据库的交互;MyBatis 提供了非常方便简单的 API 供用户对数据库进行数据的增删改查操作,以及数据库连接信息和 MyBatis 自身配置信息的维护操作。

上面使用MyBatis的方法是创建一个与数据库交互的SqlSession对象,然后根据StatementId和参数对数据库进行操作。这种方法简单实用,但不符合面向对象语言和面向接口编程的概念。习惯。由于面向接口编程是一个普遍的面向对象趋势,MyBatis为了适应这种趋势,增加了第二种使用MyBatis的方式来支持接口(Interface)。
1.2. 使用 Mapper 接口
MyBatis 会配置每个文件
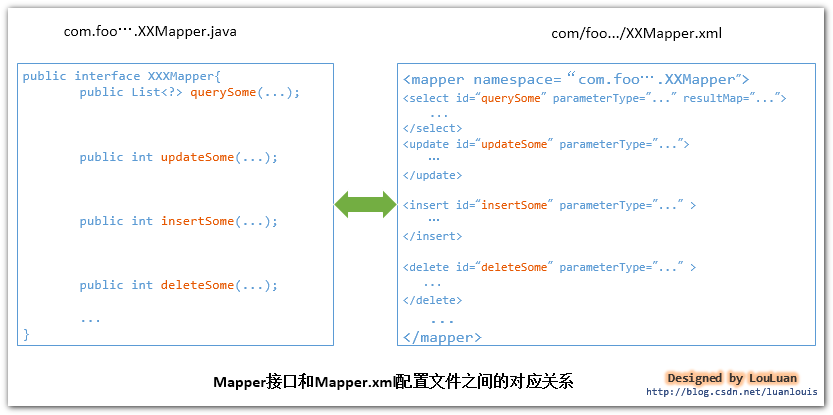
按照MyBatis配置规范配置后,通过SqlSession.getMapper(XXXMapper.class)方法,MyBatis会根据对应接口声明的方法信息,通过动态代理机制生成一个Mapper实例。当我们使用Mapper接口的一个方法时,MyBatis会根据这个方法的方法名和参数类型来确定StatementId,底层还是通过SqlSession.select("statementId",parameterObject); 或 SqlSession.update("statementId",parameterObject); 等实现对数据库的操作,(至于动态机制这里是怎么实现的,我会专门准备一篇文章来讨论,敬请期待~)
MyBatis 引用这个 Mapper 接口的调用方法,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是面向接口的编程允许用户使用注解在接口上配置SQL语句,从而脱离XML配置文件,实现“0配置”)。
2.数据处理层
数据处理层可以说是MyBatis的核心。大体来说,它必须完成三个功能:
一个。通过传入参数构造动态SQL语句;
湾 SQL语句执行和打包查询结果集成列表
2.1. 参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的设计。MyBatis 使用 Ognl 通过传入的参数值动态构造 SQL 语句,使得 MyBatis 具有高度的灵活性和可扩展性。
参数映射是指java数据类型和jdbc数据类型的转换:这里有两个过程:在查询阶段,我们需要通过preparedStatement.setXXX()将java类型数据转换成jdbc类型数据,设置值;另一种是将resultset查询的结果集的jdbcType数据转换成java数据类型。
(至于具体MyBatis是如何动态构造SQL语句的,我会专门准备一篇文章来讨论,敬请期待~)
2.2. SQL 语句执行和打包查询结果集成列表
动态SQL语句生成后,MyBatis会执行SQL语句,将可能返回的结果集转换成List3.框架支持层
3.1. 交易管理机制
事务管理机制是ORM框架不可或缺的一部分,事务管理机制的好坏也是衡量一个ORM框架是否优秀的标准。
3.2. 连接池管理机制
由于创建数据库连接需要比较大的资源,对于数据吞吐量大、访问量非常大的应用来说,连接池的设计非常重要。
3.3. 缓存机制
为了提高数据利用率,降低服务器和数据库的压力,MyBatis 会为一些查询提供会话级的数据缓存,并将某个查询放在 SqlSession 中。在允许的时间间隔内,对于完全相同的查询,MyBatis 会直接将缓存的结果返回给用户,无需在数据库中搜索。(至于具体的MyBatis缓存机制,我会专门准备一篇文章来讨论,敬请期待~)
如何配置SQL语句
MyBatis 中传统的 SQL 语句配置方式是使用 XML 文件进行配置,但是这种方式不能很好地支持面向接口编程的概念。为了支持面向接口编程,MyBatis引入了Mapper接口的概念,引入了面向接口,可以使用注解来配置SQL语句。用户只需在界面上添加必要的注解,无需配置XML文件。但是,目前的 MyBatis 仅对注解配置 SQL 语句提供了有限的支持。高级功能仍然依赖 XML 配置文件来配置 SQL 语句。
4 引导层
boot层是配置和启动MyBatis配置信息的方式。MyBatis 提供了两种方式来引导 MyBatis:基于 XML 配置文件的方法和基于 Java API 的方法。
二、MyBatis 的主要组件及其关系
从MyBatis代码实现来看,MyBatis的主要核心组件如下:
(注:这里只是列出我个人认为是核心组件的组件。读者不要先入为主,认为MyBatis只有这些组件!每个人对MyBatis的理解不同,分析的结果自然会是不同。欢迎读者提出问题和不同意见,我们一起讨论~)
最后
我也采集
了Java面试核心知识点的合集来应对面试。我可以借此机会免费赠送给我的读者和朋友:
内容:

Java面试核心知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
Java面试核心知识点
知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
[外链图片正在传输中...(img-cn5P52fp-53)]
Java面试核心知识点
获取方式:点击喜欢【戳面试信息】后,即可免费获取!
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-27 21:19
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 21:16
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-27 21:12
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-27 15:17
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
java爬虫抓取动态网页(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}

Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
java爬虫抓取动态网页(java爬虫抓取动态网页,模拟浏览器发起请求后获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-25 23:01
java爬虫抓取动态网页,模拟浏览器发起http请求后,获取抓取。本文博主在日常工作中,一直都在使用python抓取各种网页信息,下面做一个总结,希望对大家有所帮助。
1、python抓取方法:
1)、代码集锦:通过代码集训练实践学习、运用,尽可能抓取到更多高质量的网页。如:urllib2+cookie、urllib、requests、正则表达式、selenium等,当然其它的也可以抓取,这要看个人情况。抓取方法方法如下:第一种:div.urlopen(page_name)第二种:a['a'].read().decode("utf-8")第三种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。
第四种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。div.urlopen()方法抓取页面,然后再f12,可以看到抓取到的网页。(。
2)、http3文件:get方法抓取文件方法如下:第一种:a.postb.post第二种:data:name='congyou'body=''prefix="/book"self.answer="xxx"post方法第一种:method参数返回json格式,返回数据data。self.answer=none。
第二种:https:通过ssl握手第三种:data:url.post,返回data值,格式:url,string格式第四种:post方法获取数据,格式为urlurl.post方法:代码如下:post方法,通过url来获取对应的数据源页面。post方法,data参数要求设置为''。(。
3)、python文件一:不推荐:如果你是新手使用,可以使用抓包工具进行抓取,如:fiddler,wireshark。看网页源代码比较慢,推荐使用抓包工具进行抓取,推荐使用下面软件,例如fiddler进行抓取,安装actionscreenpro6actionscreenpro6官网下载,解压即可使用。(。
4)、python文件二:不推荐的方法,如:运行时刻需要加壳工具。根据代码解析抓取对应的exe文件,例如driver3.exe。downloadfilesfromfiddler或者fiddler下载,然后加壳即可。
5)、python文件三:建议方法:利用js获取。抓取twitter站内数据,正则表达式来解析。获取豆瓣feed信息,
6)、python文件四:建议方法:除了js抓取,还有python可以利用ajax抓取,例如:get/get。py/view。pyjs文件正则表达式抓取抓取链接,详细如下:/woai。py#!/usr/bin/envpythonimportrequestsimportredefget_content(url):response=requests。get(url)soup=beautifulsoup(。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页,模拟浏览器发起请求后获取)
java爬虫抓取动态网页,模拟浏览器发起http请求后,获取抓取。本文博主在日常工作中,一直都在使用python抓取各种网页信息,下面做一个总结,希望对大家有所帮助。
1、python抓取方法:
1)、代码集锦:通过代码集训练实践学习、运用,尽可能抓取到更多高质量的网页。如:urllib2+cookie、urllib、requests、正则表达式、selenium等,当然其它的也可以抓取,这要看个人情况。抓取方法方法如下:第一种:div.urlopen(page_name)第二种:a['a'].read().decode("utf-8")第三种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。
第四种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。div.urlopen()方法抓取页面,然后再f12,可以看到抓取到的网页。(。
2)、http3文件:get方法抓取文件方法如下:第一种:a.postb.post第二种:data:name='congyou'body=''prefix="/book"self.answer="xxx"post方法第一种:method参数返回json格式,返回数据data。self.answer=none。
第二种:https:通过ssl握手第三种:data:url.post,返回data值,格式:url,string格式第四种:post方法获取数据,格式为urlurl.post方法:代码如下:post方法,通过url来获取对应的数据源页面。post方法,data参数要求设置为''。(。
3)、python文件一:不推荐:如果你是新手使用,可以使用抓包工具进行抓取,如:fiddler,wireshark。看网页源代码比较慢,推荐使用抓包工具进行抓取,推荐使用下面软件,例如fiddler进行抓取,安装actionscreenpro6actionscreenpro6官网下载,解压即可使用。(。
4)、python文件二:不推荐的方法,如:运行时刻需要加壳工具。根据代码解析抓取对应的exe文件,例如driver3.exe。downloadfilesfromfiddler或者fiddler下载,然后加壳即可。
5)、python文件三:建议方法:利用js获取。抓取twitter站内数据,正则表达式来解析。获取豆瓣feed信息,
6)、python文件四:建议方法:除了js抓取,还有python可以利用ajax抓取,例如:get/get。py/view。pyjs文件正则表达式抓取抓取链接,详细如下:/woai。py#!/usr/bin/envpythonimportrequestsimportredefget_content(url):response=requests。get(url)soup=beautifulsoup(。
java爬虫抓取动态网页(什么是爬虫爬虫()代码首先定义一个方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-10 11:12
JAVA爬虫简介及案例实现什么是爬虫
爬虫是根据一定的规则自动爬取万维网上信息的程序或脚本
怎么爬
每次我们登陆一个网页,都可以观察链接,以阶梯阅读()为例
这是主页的链接。当我们点击一年级的所有新闻时,链接会变成,我们可以找到更多的东西,然后点击任何课程,链接会变成,按f12跟踪代码,他这里有音频链接写的比较隐秘,最后发现他是从js赋值的链接,最后抓到:Nfu0sVOTopaEPyBt299hxFv7R_k=是音频链接
于是我们就想,只要我们的代码能捕捉到这段代码,捕捉后就可以下载音频了,但这只是一个资源,所以我们需要在代码中模拟一层一层打开网页,然后获取所有资源
下面附上代码
首先定义一个方法来获取网页中所有html代码中的a标签代码
public static Set getHtmlToA(String html) {
Pattern p = Pattern.compile("]", Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(html);
Set hashSet = new HashSet();
while (m.find()) {
String link = m.group(2).trim();
hashSet.add(link);
}
return hashSet;
}
从代码中可以看出,我们通过正则表达式获取到a标签后面的链接,Pattern类可以帮助我们检索获取到的每一段代码是否符合要求
下面是获取网页所有html代码的方法
public static BufferedReader getBR(String html) {
URL urls = null;
try {
urls = new URL(html);
in = urls.openStream();
isr = new InputStreamReader(in);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new BufferedReader(isr);
}
这个返回的BufferedReader就是我们想要的网页的所有代码
下面是运行代码
public static void main(String args[]) throws Exception {
String url = "http://pati.edu-china.com";
try {
bufr = getBR(url);
String str;
String http = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("book-link") > 0) {
http += str.substring(str.indexOf("年级")) + "\n";
// System.out.println(http);
// System.out.println(http.indexOf("年级"));
Set set = getHtmlToA(http);
Iterator it = set.iterator();
while (it.hasNext()) {
String newUrl = url + it.next().toString();
// System.out.println(newUrl);
bufr = getBR(newUrl);
String http1 = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("/source") > 0) {
http1 += str + "\n";
}
}
Set set1 = getHtmlToA(http1);
Iterator it1 = set1.iterator();
while (it1.hasNext()) {
String name = it1.next().toString();
String newUrl1 = url + name;
System.out.println(newUrl1);
BufferedReader br = getBR(newUrl1);
String strBR = "";
while ((strBR = (br.readLine())) != null) {
if (strBR.indexOf("http://prvstatic.edu-china.com ... 6quot;) > 0) {
String endHttp = strBR.substring(7, strBR.length() - 1);
try {
InputStream ins = new URL(endHttp).openConnection().getInputStream(); //创建连接、输入流
FileOutputStream f = new FileOutputStream("D:/MyPaChong/" + name + ".mp3");//创建文件输出流
byte[] bb = new byte[1024]; //接收缓存
int len;
while ((len = ins.read(bb)) > 0) { //接收
f.write(bb, 0, len); //写入文件
}
f.close();
ins.close();
System.out.println(name + "爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
bufr.close();
isr.close();
in.close();
}
}
这是我刚刚处理的实例的 网站 捕获。可以提出的地方很多,不过太麻烦就不提了。有兴趣的可以重写。
学爬,记录在这里
原创地址:。%257B%2522重量%255FID%2522%253A%25226780366510269%2522%252℃%2522%252℃%2522%2522%253A%25222014071 4. PC%255降低%2522%257D&Request_id = 678036510269 & biz_id = 0 & utm_medium =distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-16-90757192.pc_search_result_cache&utm_term=java%E7%88%AC%E8%99%AB 查看全部
java爬虫抓取动态网页(什么是爬虫爬虫()代码首先定义一个方法)
JAVA爬虫简介及案例实现什么是爬虫
爬虫是根据一定的规则自动爬取万维网上信息的程序或脚本
怎么爬
每次我们登陆一个网页,都可以观察链接,以阶梯阅读()为例
这是主页的链接。当我们点击一年级的所有新闻时,链接会变成,我们可以找到更多的东西,然后点击任何课程,链接会变成,按f12跟踪代码,他这里有音频链接写的比较隐秘,最后发现他是从js赋值的链接,最后抓到:Nfu0sVOTopaEPyBt299hxFv7R_k=是音频链接
于是我们就想,只要我们的代码能捕捉到这段代码,捕捉后就可以下载音频了,但这只是一个资源,所以我们需要在代码中模拟一层一层打开网页,然后获取所有资源
下面附上代码
首先定义一个方法来获取网页中所有html代码中的a标签代码
public static Set getHtmlToA(String html) {
Pattern p = Pattern.compile("]", Pattern.CASE_INSENSITIVE);
Matcher m = p.matcher(html);
Set hashSet = new HashSet();
while (m.find()) {
String link = m.group(2).trim();
hashSet.add(link);
}
return hashSet;
}
从代码中可以看出,我们通过正则表达式获取到a标签后面的链接,Pattern类可以帮助我们检索获取到的每一段代码是否符合要求
下面是获取网页所有html代码的方法
public static BufferedReader getBR(String html) {
URL urls = null;
try {
urls = new URL(html);
in = urls.openStream();
isr = new InputStreamReader(in);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return new BufferedReader(isr);
}
这个返回的BufferedReader就是我们想要的网页的所有代码
下面是运行代码
public static void main(String args[]) throws Exception {
String url = "http://pati.edu-china.com";
try {
bufr = getBR(url);
String str;
String http = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("book-link") > 0) {
http += str.substring(str.indexOf("年级")) + "\n";
// System.out.println(http);
// System.out.println(http.indexOf("年级"));
Set set = getHtmlToA(http);
Iterator it = set.iterator();
while (it.hasNext()) {
String newUrl = url + it.next().toString();
// System.out.println(newUrl);
bufr = getBR(newUrl);
String http1 = "";
while ((str = bufr.readLine()) != null) {
if (str.indexOf("/source") > 0) {
http1 += str + "\n";
}
}
Set set1 = getHtmlToA(http1);
Iterator it1 = set1.iterator();
while (it1.hasNext()) {
String name = it1.next().toString();
String newUrl1 = url + name;
System.out.println(newUrl1);
BufferedReader br = getBR(newUrl1);
String strBR = "";
while ((strBR = (br.readLine())) != null) {
if (strBR.indexOf("http://prvstatic.edu-china.com ... 6quot;) > 0) {
String endHttp = strBR.substring(7, strBR.length() - 1);
try {
InputStream ins = new URL(endHttp).openConnection().getInputStream(); //创建连接、输入流
FileOutputStream f = new FileOutputStream("D:/MyPaChong/" + name + ".mp3");//创建文件输出流
byte[] bb = new byte[1024]; //接收缓存
int len;
while ((len = ins.read(bb)) > 0) { //接收
f.write(bb, 0, len); //写入文件
}
f.close();
ins.close();
System.out.println(name + "爬取成功^_^");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
bufr.close();
isr.close();
in.close();
}
}
这是我刚刚处理的实例的 网站 捕获。可以提出的地方很多,不过太麻烦就不提了。有兴趣的可以重写。
学爬,记录在这里
原创地址:。%257B%2522重量%255FID%2522%253A%25226780366510269%2522%252℃%2522%252℃%2522%2522%253A%25222014071 4. PC%255降低%2522%257D&Request_id = 678036510269 & biz_id = 0 & utm_medium =distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-16-90757192.pc_search_result_cache&utm_term=java%E7%88%AC%E8%99%AB
java爬虫抓取动态网页( 谷歌的network模拟请求和实现原理登录之后返回的网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-10 11:11
谷歌的network模拟请求和实现原理登录之后返回的网页源码)
Java爬虫(四)使用Jsoup获取网站中需要登录的内容(不用验证码登录)
一、实现原理
登录后,进行数据分析,准确抓取数据。根据前面文章的代码,我们不仅获取了cookies,还获取了登录后返回的网页源代码,此时有以下几种情况:(1)如果我们需要的数据在登录后返回的源码中,那么我们可以直接通过Jsoup解析源码,然后使用Jsoup的选择器功能过滤掉我们需要的信息;(2)如果需要的数据需要通过请求源码链接获取,然后我们先解析源码,找到url,然后带cookies来模拟url的请求。(3)如果数据我们需要根本不在源代码中,那么我们不能使用它照顾这个源代码。让'
刚开始写模拟登录的时候,总觉得数据一定要在网页的源码中获取,所以当一个网页由一堆js组成的时候,我就傻眼了。然后希望能拿到渲染网页的源码,大家可以试试selenium,以后学着用。
二、详细实现流程
package debug;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import org.jsoup.select.Elements;
public class test {
public static String LOGIN_URL = "http://authserver.tjut.edu.cn/ ... 3B%3B
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
// 模拟登陆github的用户名和密码
// String url = "http://ehall.tjut.edu.cn/publi ... 3B%3B
String url ="http://ehall.tjut.edu.cn/publi ... 3B%3B
get_html_num(url);
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static Map simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求 grab login form page first 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 通过Jsoup将返回信息转换为Dom树
List eleList = d1.select("#casLoginForm"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the
// form
Map datas = new HashMap();
for (Element e : eleList.get(0).getAllElements()) {
// 注意问题2:设置用户名 注意equals(这个username和password也是要去自己的登录界面input里找name值)
if (e.attr("name").equals("username")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect(
"http://authserver.tjut.edu.cn/ ... 6quot;);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas)
.cookies(rs.cookies()).execute();
//报错Exception in thread "main" org.jsoup.HttpStatusException: HTTP error fetching URL. Status=500,
// 报错原因:见上边注意问题2
// 打印,登陆成功后的信息
//System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
// for (String s : map.keySet()) {
// System.out.println(s + " : " + map.get(s));
// }
return map;
}
// 实现切割某两个字之间的字符串
public static String findstr(String str1, String strstrat, String strend) {
String finalstr = new String();
int strStartIndex = str1.indexOf(strstrat);
int strEndIndex = str1.indexOf(strend);
finalstr = str1.substring(strStartIndex, strEndIndex).substring(strstrat.length());
return finalstr;
}
// 第一个,完整爬虫爬下来内容
public static void get_html_num(String url) throws Exception {
try {
Map cookies=simulateLogin("203128301", "密码保护");
// Document doc = Jsoup.connect(url).get();
Document doc = Jsoup.connect(url).cookies(cookies).post();
// 得到html中id为content下的所有内容
Element ele = doc.getElementById("consultingListDetail");
// 分离出下面的具体内容
// Elements tag = ele.getElementsByTag("td");
// for (Element e : tag) {
// String title = e.getElementsByTag("td").text();
// String Totals = findstr(title, "共", "条");
// System.out.println(Totals);
System.out.println(doc);
// }
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、当前问题
目标界面的内容是通过AJAX动态加载的,使用jsoup无法获取目标信息。
什么是 AJAX
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
解决方案:
①直接分析AJAX调用的接口。然后通过代码请求这个接口。
②使用selenium模拟点击解决问题。
实现过程参考以下两篇文章文章:
Java爬虫(五)使用selenium模拟点击获取动态页面内容
java爬虫(六)解析AJAX接口获取网页动态内容 查看全部
java爬虫抓取动态网页(
谷歌的network模拟请求和实现原理登录之后返回的网页源码)
Java爬虫(四)使用Jsoup获取网站中需要登录的内容(不用验证码登录)
一、实现原理
登录后,进行数据分析,准确抓取数据。根据前面文章的代码,我们不仅获取了cookies,还获取了登录后返回的网页源代码,此时有以下几种情况:(1)如果我们需要的数据在登录后返回的源码中,那么我们可以直接通过Jsoup解析源码,然后使用Jsoup的选择器功能过滤掉我们需要的信息;(2)如果需要的数据需要通过请求源码链接获取,然后我们先解析源码,找到url,然后带cookies来模拟url的请求。(3)如果数据我们需要根本不在源代码中,那么我们不能使用它照顾这个源代码。让'
刚开始写模拟登录的时候,总觉得数据一定要在网页的源码中获取,所以当一个网页由一堆js组成的时候,我就傻眼了。然后希望能拿到渲染网页的源码,大家可以试试selenium,以后学着用。
二、详细实现流程
package debug;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.jsoup.Connection;
import org.jsoup.Connection.Method;
import org.jsoup.Connection.Response;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.io.IOException;
import org.jsoup.select.Elements;
public class test {
public static String LOGIN_URL = "http://authserver.tjut.edu.cn/ ... 3B%3B
public static String USER_AGENT = "User-Agent";
public static String USER_AGENT_VALUE = "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0";
public static void main(String[] args) throws Exception {
// 模拟登陆github的用户名和密码
// String url = "http://ehall.tjut.edu.cn/publi ... 3B%3B
String url ="http://ehall.tjut.edu.cn/publi ... 3B%3B
get_html_num(url);
}
/**
* @param userName 用户名
* @param pwd 密码
* @throws Exception
*/
public static Map simulateLogin(String userName, String pwd) throws Exception {
/*
* 第一次请求 grab login form page first 获取登陆提交的表单信息,及修改其提交data数据(login,password)
*/
// get the response, which we will post to the action URL(rs.cookies())
Connection con = Jsoup.connect(LOGIN_URL); // 获取connection
con.header(USER_AGENT, USER_AGENT_VALUE); // 配置模拟浏览器
Response rs = con.execute(); // 获取响应
Document d1 = Jsoup.parse(rs.body()); // 通过Jsoup将返回信息转换为Dom树
List eleList = d1.select("#casLoginForm"); // 获取提交form表单,可以通过查看页面源码代码得知
// 获取cooking和表单属性
// lets make data map containing all the parameters and its values found in the
// form
Map datas = new HashMap();
for (Element e : eleList.get(0).getAllElements()) {
// 注意问题2:设置用户名 注意equals(这个username和password也是要去自己的登录界面input里找name值)
if (e.attr("name").equals("username")) {
e.attr("value", userName);
}
// 设置用户密码
if (e.attr("name").equals("password")) {
e.attr("value", pwd);
}
// 排除空值表单属性
if (e.attr("name").length() > 0) {
datas.put(e.attr("name"), e.attr("value"));
}
}
/*
* 第二次请求,以post方式提交表单数据以及cookie信息
*/
Connection con2 = Jsoup.connect(
"http://authserver.tjut.edu.cn/ ... 6quot;);
con2.header(USER_AGENT, USER_AGENT_VALUE);
// 设置cookie和post上面的map数据
Response login = con2.ignoreContentType(true).followRedirects(true).method(Method.POST).data(datas)
.cookies(rs.cookies()).execute();
//报错Exception in thread "main" org.jsoup.HttpStatusException: HTTP error fetching URL. Status=500,
// 报错原因:见上边注意问题2
// 打印,登陆成功后的信息
//System.out.println(login.body());
// 登陆成功后的cookie信息,可以保存到本地,以后登陆时,只需一次登陆即可
Map map = login.cookies();
// for (String s : map.keySet()) {
// System.out.println(s + " : " + map.get(s));
// }
return map;
}
// 实现切割某两个字之间的字符串
public static String findstr(String str1, String strstrat, String strend) {
String finalstr = new String();
int strStartIndex = str1.indexOf(strstrat);
int strEndIndex = str1.indexOf(strend);
finalstr = str1.substring(strStartIndex, strEndIndex).substring(strstrat.length());
return finalstr;
}
// 第一个,完整爬虫爬下来内容
public static void get_html_num(String url) throws Exception {
try {
Map cookies=simulateLogin("203128301", "密码保护");
// Document doc = Jsoup.connect(url).get();
Document doc = Jsoup.connect(url).cookies(cookies).post();
// 得到html中id为content下的所有内容
Element ele = doc.getElementById("consultingListDetail");
// 分离出下面的具体内容
// Elements tag = ele.getElementsByTag("td");
// for (Element e : tag) {
// String title = e.getElementsByTag("td").text();
// String Totals = findstr(title, "共", "条");
// System.out.println(Totals);
System.out.println(doc);
// }
} catch (IOException e) {
e.printStackTrace();
}
}
}
三、当前问题
目标界面的内容是通过AJAX动态加载的,使用jsoup无法获取目标信息。
什么是 AJAX
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。Ajax 可以通过在后台与服务器交换少量数据来异步更新网页。这意味着可以在不重新加载整个页面的情况下更新页面的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为以传统的数据格式进行传输,使用 XML 语法。所谓AJAX,其实数据交互基本都是用JSON。AJAX加载的数据,即使是用JS渲染数据到浏览器,右键->查看网页源代码,还是看不到ajax加载的数据,只能看到使用此 url 加载的 html 代码。
解决方案:
①直接分析AJAX调用的接口。然后通过代码请求这个接口。
②使用selenium模拟点击解决问题。
实现过程参考以下两篇文章文章:
Java爬虫(五)使用selenium模拟点击获取动态页面内容
java爬虫(六)解析AJAX接口获取网页动态内容
java爬虫抓取动态网页(如何用python来抓取页面中的JS动态加载的数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-10 05:11
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {‘action‘:‘‘,‘start‘:‘0‘,‘limit‘:‘1‘}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text 查看全部
java爬虫抓取动态网页(如何用python来抓取页面中的JS动态加载的数据
)
我们经常会发现网页中的很多数据并不是用 HTML 编写的,而是通过 js 动态加载的。因此,引入了动态数据的概念。这里的动态数据是指网页中通过Javascript动态生成的页面内容。它是在页面加载到浏览器后动态生成的,但之前没有。
在编写爬虫爬取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,就无法获取任何数据。
今天就简单讲一下如何使用python爬取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面获取有关每部电影的信息。
如下图所示,我们在 HTML 中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开网络中的XHR,我们抓取对应的js文件进行解析。如下所示:
在豆瓣页面上拖拽,让页面加载更多的电影信息,方便我们抓取对应的消息。
我们可以看到它使用了 AJAX 异步请求。AJAX 可以通过在后台与服务器交换少量数据来异步更新网页。因此,可以在不重新加载整个网页的情况下更新网页的一部分,从而实现数据的动态加载。
我们可以看到,通过 GET,我们得到的响应中收录了对应的电影相关信息,并以 JSON 格式保存在一起。
查看RequestURL信息,我们可以看到action参数后面有两个参数“start”和“limit”,很明显的意思是:“从某个位置返回的电影数量”。
如果想快速获取相关电影信息,可以直接将网址复制到地址栏,修改自己需要的start和limit参数值,抓取对应的结果。
但这看起来很不自动化,而网站的其他很多RequestURL也不是那么直接,所以我们将使用python进行进一步的操作来获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {‘action‘:‘‘,‘start‘:‘0‘,‘limit‘:‘1‘}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
java爬虫抓取动态网页(网页开发中大量的运用Ajax技术的研究基础上的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-01-10 03:04
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
摘要:网络爬虫按照一定的规则对网络信息进行爬取,是搜索引擎技术的重要组成部分。随着Web2.0的兴起,Ajax技术在Web开发中得到广泛应用。与传统网页不同,Ajax 技术采用异步的方式向服务器发送请求,并根据响应更新页面。Ajax 大大降低了服务器的负载,也提高了用户体验。同时,Ajax技术部分更新HTML页面的方式也对传统爬虫技术提出了严峻挑战。本文在介绍和分析传统爬取原理和结构的基础上,结合动态网络爬虫要解决的问题,设计并实现了一个可以对动态网页数据进行爬取的网络爬虫系统。本文所做的主要工作如下。首先,在前人对动态网络爬虫模型研究的基础上,基于图结构的思想,经过改进,提出了一种基于状态转移的动态网络爬虫模型,从而利用状态转移过程来模拟动态事件触发的网页结构变化。. 结合动态爬虫和真实网络环境的要求,在网页去噪、新状态去重、新状态捕获等方面对算法模型进行了细化和改进。其次,根据该模型,本文采用调用浏览器内核和本地搭建JavaScript解析环境两种方式,设计并实现了动态网页数据的爬虫系统。在保持传统爬虫功能的基础上,增加了对动态数据抓取的支持。最后,本文通过对真实网页的爬取实验,对比了两种方法与传统爬虫的优缺点。验证了系统的可行性和有效性。
[关键词]:动态网络爬虫状态转换Ajax
【学位授予单位】:中山大学
【学位等级】:硕士
【学位授予年份】:2014
【类别号】:TP393.092
【内容】:
【参考】
十大中文期刊全文数据库
1 宋敖;智t$;周军;罗传飞;安然;基于LCS的特征树最大相似度匹配去噪算法[J];电视技术;2011年13期
2 董斌;;网站静态页面生成系统研究[J];福建计算机;2009年08期
3 刘晨曦、吴阳阳。一种基于块分析的网页去噪方法[J];广西师范大学学报(自然科学版);2007年02期
4 段庆玲;杨仁刚;朱洋;;一种从表单中提取Ajax信息项的方法[J];计算机工程;2011年03期
5 周丽珠,林玲。聚焦爬虫技术研究综述[J];计算机应用;2005年09期
6 吕林涛;万景华;周宏芳;计算机应用学院,计算机学院;2006年11期
7 郭浩、卢玉良、刘金红。一种基于状态转移图的Ajax爬取算法[J];计算机应用研究;2009年11期
8 范选淼;郑宁;范远;基于Ajax的爬虫模型设计与实现[J];计算机应用与软件;2010年01期
9 陈雪;徐辉;沈家军;;基于网页结构的网页去噪算法设计[J];软件;2013年08期
10 金晓鸥;钟宝艳;李翔;基于Rhino的JavaScript动态页面解析的研究与实现[J];计算机技术与发展;2008年02期
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
货号:426578 查看全部
java爬虫抓取动态网页(网页开发中大量的运用Ajax技术的研究基础上的应用)
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
摘要:网络爬虫按照一定的规则对网络信息进行爬取,是搜索引擎技术的重要组成部分。随着Web2.0的兴起,Ajax技术在Web开发中得到广泛应用。与传统网页不同,Ajax 技术采用异步的方式向服务器发送请求,并根据响应更新页面。Ajax 大大降低了服务器的负载,也提高了用户体验。同时,Ajax技术部分更新HTML页面的方式也对传统爬虫技术提出了严峻挑战。本文在介绍和分析传统爬取原理和结构的基础上,结合动态网络爬虫要解决的问题,设计并实现了一个可以对动态网页数据进行爬取的网络爬虫系统。本文所做的主要工作如下。首先,在前人对动态网络爬虫模型研究的基础上,基于图结构的思想,经过改进,提出了一种基于状态转移的动态网络爬虫模型,从而利用状态转移过程来模拟动态事件触发的网页结构变化。. 结合动态爬虫和真实网络环境的要求,在网页去噪、新状态去重、新状态捕获等方面对算法模型进行了细化和改进。其次,根据该模型,本文采用调用浏览器内核和本地搭建JavaScript解析环境两种方式,设计并实现了动态网页数据的爬虫系统。在保持传统爬虫功能的基础上,增加了对动态数据抓取的支持。最后,本文通过对真实网页的爬取实验,对比了两种方法与传统爬虫的优缺点。验证了系统的可行性和有效性。
[关键词]:动态网络爬虫状态转换Ajax
【学位授予单位】:中山大学
【学位等级】:硕士
【学位授予年份】:2014
【类别号】:TP393.092
【内容】:
【参考】
十大中文期刊全文数据库
1 宋敖;智t$;周军;罗传飞;安然;基于LCS的特征树最大相似度匹配去噪算法[J];电视技术;2011年13期
2 董斌;;网站静态页面生成系统研究[J];福建计算机;2009年08期
3 刘晨曦、吴阳阳。一种基于块分析的网页去噪方法[J];广西师范大学学报(自然科学版);2007年02期
4 段庆玲;杨仁刚;朱洋;;一种从表单中提取Ajax信息项的方法[J];计算机工程;2011年03期
5 周丽珠,林玲。聚焦爬虫技术研究综述[J];计算机应用;2005年09期
6 吕林涛;万景华;周宏芳;计算机应用学院,计算机学院;2006年11期
7 郭浩、卢玉良、刘金红。一种基于状态转移图的Ajax爬取算法[J];计算机应用研究;2009年11期
8 范选淼;郑宁;范远;基于Ajax的爬虫模型设计与实现[J];计算机应用与软件;2010年01期
9 陈雪;徐辉;沈家军;;基于网页结构的网页去噪算法设计[J];软件;2013年08期
10 金晓鸥;钟宝艳;李翔;基于Rhino的JavaScript动态页面解析的研究与实现[J];计算机技术与发展;2008年02期
本文关键词:基于状态转换的动态爬虫系统的设计与实现,由比根文化传播整理发布。
货号:426578
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-01-05 18:09
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替布隆过滤器,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力很差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,数以万计。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接: 查看全部
java爬虫抓取动态网页(主流java爬虫框架有哪些?(1)框架)
文本
一、目前主流的java爬虫框架包括
Python中有Scrapy和Pyspider;
Java中有Nutch、WebMagic、WebCollector、heritrix3、Crawler4j
这些框架的优缺点是什么?
(1), Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、站点地图爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL 去重采用 Bloom filter 方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以高效处理不完整的HTML代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替布隆过滤器,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch(更高)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
纳奇官网
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2.支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix是一个由java开发的开源网络爬虫,用户可以使用它从网上抓取自己想要的资源
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5. 在发生硬件和系统故障时,恢复能力很差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j是一个基于Java的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可扩展支持网页字段的结构化提取,并可作为垂直采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。几乎有完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
Jsoup中文教程
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,数以万计。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
硒官方GitHub
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
基本介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,相互学习,cdp4j可用。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也有名。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现它的功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一个。获取渲染网页的源代码
湾 模拟浏览器点击事件
C。下载网页上可用的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
【cdp4j官网地址】
【Github 仓库】
[演示列表]
总结
以上框架各有优缺点。其中cdp4j方便,功能齐全,但我个人觉得唯一的缺点就是需要依赖谷歌浏览器。
下面这篇文章打算使用手动:httpclient +jsoup+selenium实现java爬虫功能,使用httpclient爬取,jsoup解析页面,90%的页面都可以处理,剩下的就用selenium;
参考链接:
java爬虫抓取动态网页(网页爬虫如何写一个网页程序?(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-01-04 06:09
)
最近为了练手,对网络爬虫感兴趣,决定自己写一个网络爬虫程序。
先看爬虫应该具备哪些功能。
内容来自()
网页采集的过程类似于图的遍历,网页作为图中的节点,网页中的超链接作为图中的边。通过一个网页的超链接,可以获得其他网页的地址,可以进一步进行网页采集;图的遍历分为广度优先和深度优先两种方法,网页采集过程也是如此。综上所述,Spider采集网页的过程如下:从初始URL采集中获取目标网页地址,通过网络连接接收网页数据,将获取到的网页数据添加到网页库中,分析网页中的其他URL链接,并将它们放在 unvisited 的 URL 集合中,用于网页集合。下图展示了这个过程:
网络采集器聚会
网页采集器通过网址获取该网址对应的网页数据。其实现主要是利用Java中的URLConnection类打开URL对应页面的网络连接,然后通过I/O流读取数据,BufferedReader提供读取数据的缓冲区,提高数据读取效率以及在其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
URL url = new URL(“http://www.xxx.com”);
<br />
URLConnection conn = url.openConnection();
<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); <br />
String line = null;
while((line = reader.readLine()) != null)
<br />
document.append(line + "\n");<br />
<br />
网页处理
采集到的单个网页需要进行两种不同的处理,一种是将其作为原创数据放入网页库中进行后续处理;另一种是解析后从中提取出URL连接放入URL池中等待对应网页的集合。
网页的保存需要一定的格式,方便以后批量处理数据。下面是一种存储数据格式,它是从北大天网的存储格式简化而来的:
需要说明的是,添加数据采集日期的原因是网站的很多内容都是动态变化的,比如一些大型门户网站网站的首页内容,也就是说如果不是当天抓取的网页数据很可能有数据过期,所以需要添加日期信息来识别。
URL 提取分为两步。第一步是识别网址,第二步是整理网址。主要原因是网站的部分链接使用了相对路径。如果不组织它们会产生错误。 URL识别主要是通过正则表达式匹配。该过程首先设置一个字符串作为匹配的字符串模式,然后在Pattern中编译后,可以使用Matcher类来匹配相应的字符串。实现代码如下:
public ArrayList urlDetector(String htmlDoc)<br />
{
<br />
final String patternString = "]*\\s*>)";
<br />
Pattern pattern = Pattern.compile(patternString,Pattern.CASE_INSENSITIVE);
<br />
ArrayList allURLs = new ArrayList();
<br />
Matcher matcher = pattern.matcher(htmlDoc);
<br />
String tempURL;
//初次匹配到的url是形如:<a href="http://bbs.life.xxx.com.cn/" target="_blank">
<br />
//为此,需要进行下一步的处理,把真正的url抽取出来,
<br />
//可以对于前两个"之间的部分进行记录得到url
<br />
while(matcher.find()){
<br />
try {
<br />
tempURL = matcher.group(); <br />
tempURL = tempURL.substring(tempURL.indexOf("\"")+1);
<br />
if(!tempURL.contains("\""))
continue;
<br />
tempURL = tempURL.substring(0, tempURL.indexOf("\""));
<br />
} <br />
catch (MalformedURLException e) <br />
{
e.printStackTrace();
}
<br />
}
<br />
return allURLs;
}<br />
根据正则表达式"]*\\s*>)",可以匹配到URL所在的整个标签,形如"",所以循环获取整个标签后,我们需要为了进一步提取真实的URL,我们可以通过截取标签中前两个引号之间的内容来获取这段内容。之后,我们就可以初步得到属于该网页的一组 URL。
接下来,我们将进行第二步,网址排序,即对之前获取的整个页面中的网址集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很容易的获取到当前网页的网址,因此相对链接只需要在当前网页的网址上加上相对链接字段就可以形成一个完整的网址。一体化。另一方面,在页面收录的综合URL中,有一些页面,例如广告页面,我们不想抓取,或者不重要。这里我们主要针对页面中的广告进行简单的处理。一般网站的广告链接都有对应的展示表达。例如,当链接中收录“ad”等表述时,可以降低该链接的优先级,从而在一定程度上避免对广告链接的抓取。
经过这两个步骤,就可以将采集到的网页网址放入网址池中,然后我们来处理爬虫网址的分配。
调度员
分发者管理URL,负责保存URL池并在Gather获取某个网页后分配新的URL,同时避免重复采集网页。分配器采用设计模式中的单例模式编码,负责提供新的 URL 给 Gather。单例模式尤其重要,因为它涉及到多个线程的后续重写。
重复采集是指物理网页被Gather反复访问而不更新,造成资源浪费。主要原因是没有明确记录访问过的URL,无法区分。因此,Dispatcher 维护着两个列表,“已访问表”和“未访问表”。每个URL对应的页面被爬取后,将该URL放入访问列表,从页面中提取的URL放入未访问列表; Gather向Dispatcher请求一个URL时,首先验证该URL是否在visited表中,然后交给Gather作业。
Spider 启动多个 Gather 线程
目前互联网上有数以亿计的网页,单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。 Gather 的功能是采集网页。我们可以通过Spider类开启多个Gather线程来达到多线程的目的。代码如下:
public void start() <br />
{
<br />
Dispatcher disp = Dispatcher.getInstance(); <br />
for(int i = 0; i < gatherNum; i++)<br />
{
<br />
Thread gather = new Thread(new Gather(disp)); <br />
gather.start(); <br />
}<br />
}<br />
在开启线程之后,网页收集器开始作业的运作,并在一个作业完成之后,向 Dispatcher 申请下一个作业,因为有了多线程的
Gather,为了避免线程不安全,需要对 Dispatcher 进行互斥访问,在其函数之中添加 synchronized
关键词,从而达到线程的安全访问。<br />
<br />
<br /> 查看全部
java爬虫抓取动态网页(网页爬虫如何写一个网页程序?(组图)
)
最近为了练手,对网络爬虫感兴趣,决定自己写一个网络爬虫程序。
先看爬虫应该具备哪些功能。
内容来自()
网页采集的过程类似于图的遍历,网页作为图中的节点,网页中的超链接作为图中的边。通过一个网页的超链接,可以获得其他网页的地址,可以进一步进行网页采集;图的遍历分为广度优先和深度优先两种方法,网页采集过程也是如此。综上所述,Spider采集网页的过程如下:从初始URL采集中获取目标网页地址,通过网络连接接收网页数据,将获取到的网页数据添加到网页库中,分析网页中的其他URL链接,并将它们放在 unvisited 的 URL 集合中,用于网页集合。下图展示了这个过程:
网络采集器聚会
网页采集器通过网址获取该网址对应的网页数据。其实现主要是利用Java中的URLConnection类打开URL对应页面的网络连接,然后通过I/O流读取数据,BufferedReader提供读取数据的缓冲区,提高数据读取效率以及在其下定义的 readLine() 行读取函数。代码如下(异常处理部分省略):
URL url = new URL(“http://www.xxx.com”);
<br />
URLConnection conn = url.openConnection();
<br />
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream())); <br />
String line = null;
while((line = reader.readLine()) != null)
<br />
document.append(line + "\n");<br />
<br />
网页处理
采集到的单个网页需要进行两种不同的处理,一种是将其作为原创数据放入网页库中进行后续处理;另一种是解析后从中提取出URL连接放入URL池中等待对应网页的集合。
网页的保存需要一定的格式,方便以后批量处理数据。下面是一种存储数据格式,它是从北大天网的存储格式简化而来的:
需要说明的是,添加数据采集日期的原因是网站的很多内容都是动态变化的,比如一些大型门户网站网站的首页内容,也就是说如果不是当天抓取的网页数据很可能有数据过期,所以需要添加日期信息来识别。
URL 提取分为两步。第一步是识别网址,第二步是整理网址。主要原因是网站的部分链接使用了相对路径。如果不组织它们会产生错误。 URL识别主要是通过正则表达式匹配。该过程首先设置一个字符串作为匹配的字符串模式,然后在Pattern中编译后,可以使用Matcher类来匹配相应的字符串。实现代码如下:
public ArrayList urlDetector(String htmlDoc)<br />
{
<br />
final String patternString = "]*\\s*>)";
<br />
Pattern pattern = Pattern.compile(patternString,Pattern.CASE_INSENSITIVE);
<br />
ArrayList allURLs = new ArrayList();
<br />
Matcher matcher = pattern.matcher(htmlDoc);
<br />
String tempURL;
//初次匹配到的url是形如:<a href="http://bbs.life.xxx.com.cn/" target="_blank">
<br />
//为此,需要进行下一步的处理,把真正的url抽取出来,
<br />
//可以对于前两个"之间的部分进行记录得到url
<br />
while(matcher.find()){
<br />
try {
<br />
tempURL = matcher.group(); <br />
tempURL = tempURL.substring(tempURL.indexOf("\"")+1);
<br />
if(!tempURL.contains("\""))
continue;
<br />
tempURL = tempURL.substring(0, tempURL.indexOf("\""));
<br />
} <br />
catch (MalformedURLException e) <br />
{
e.printStackTrace();
}
<br />
}
<br />
return allURLs;
}<br />
根据正则表达式"]*\\s*>)",可以匹配到URL所在的整个标签,形如"",所以循环获取整个标签后,我们需要为了进一步提取真实的URL,我们可以通过截取标签中前两个引号之间的内容来获取这段内容。之后,我们就可以初步得到属于该网页的一组 URL。
接下来,我们将进行第二步,网址排序,即对之前获取的整个页面中的网址集合进行过滤和整合。集成主要针对网页地址为相对链接的部分。由于我们可以很容易的获取到当前网页的网址,因此相对链接只需要在当前网页的网址上加上相对链接字段就可以形成一个完整的网址。一体化。另一方面,在页面收录的综合URL中,有一些页面,例如广告页面,我们不想抓取,或者不重要。这里我们主要针对页面中的广告进行简单的处理。一般网站的广告链接都有对应的展示表达。例如,当链接中收录“ad”等表述时,可以降低该链接的优先级,从而在一定程度上避免对广告链接的抓取。
经过这两个步骤,就可以将采集到的网页网址放入网址池中,然后我们来处理爬虫网址的分配。
调度员
分发者管理URL,负责保存URL池并在Gather获取某个网页后分配新的URL,同时避免重复采集网页。分配器采用设计模式中的单例模式编码,负责提供新的 URL 给 Gather。单例模式尤其重要,因为它涉及到多个线程的后续重写。
重复采集是指物理网页被Gather反复访问而不更新,造成资源浪费。主要原因是没有明确记录访问过的URL,无法区分。因此,Dispatcher 维护着两个列表,“已访问表”和“未访问表”。每个URL对应的页面被爬取后,将该URL放入访问列表,从页面中提取的URL放入未访问列表; Gather向Dispatcher请求一个URL时,首先验证该URL是否在visited表中,然后交给Gather作业。
Spider 启动多个 Gather 线程
目前互联网上有数以亿计的网页,单一的Gather来采集网页显然是低效的,所以我们需要使用多线程的方式来提高效率。 Gather 的功能是采集网页。我们可以通过Spider类开启多个Gather线程来达到多线程的目的。代码如下:
public void start() <br />
{
<br />
Dispatcher disp = Dispatcher.getInstance(); <br />
for(int i = 0; i < gatherNum; i++)<br />
{
<br />
Thread gather = new Thread(new Gather(disp)); <br />
gather.start(); <br />
}<br />
}<br />
在开启线程之后,网页收集器开始作业的运作,并在一个作业完成之后,向 Dispatcher 申请下一个作业,因为有了多线程的
Gather,为了避免线程不安全,需要对 Dispatcher 进行互斥访问,在其函数之中添加 synchronized
关键词,从而达到线程的安全访问。<br />
<br />
<br />
java爬虫抓取动态网页(Java的HTML解析器,可直接解析某个URL地址、HTML文本内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 37 次浏览 • 2022-01-04 06:07
Jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 Jsoup的官网是:,其API手册的网址是:.
本次分享要实现的功能是:使用Jsoup抓取某个搜索词(暂时只有英文),百度百科的介绍部分。具体功能介绍请参考博客:Python爬虫自制简易搜索引擎。在上一个爬虫中,我们使用Python进行爬取。这一次,我们将使用Java来爬取。你没看错,是 Java。
在Eclipse中添加Jsoup包,下载地址为:.
爬虫的具体代码如下:
package baiduScrape;
/*
* 本爬虫主要利用Java的Jsoup包进行网络爬取
* 本爬虫的功能: 爬取百度百科的开头介绍部分
* 使用方法: 输入关键字(目前只支持英文)即可
*/
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.net.*;
import java.io.*;
import java.util.Scanner;
public class BaiduScrape {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
String baseUrl = "https://baike.baidu.com/item/";
String url = "";
// 如果输入文字不是"exit",则爬取其百度百科的介绍部分,否则退出该程序
while(true) {
System.out.println("Enter the word(Enter 'exit' to exit):");
url = input.nextLine();
if(url.equals("exit")) {
System.out.println("The program is over.");
break;
}
String introduction = getContent(baseUrl+url);
System.out.println(introduction+'\n');
}
}
// getContent()函数主要实现爬取输入文字的百度百科的介绍部分
public static String getContent(String url){
// 利用URL解析网址
URL urlObj = null;
try{
urlObj = new URL(url);
}
catch(MalformedURLException e){
System.out.println("The url was malformed!");
return "";
}
// URL连接
URLConnection urlCon = null;
try{
urlCon = urlObj.openConnection(); // 打开URL连接
// 将HTML内容解析成UTF-8格式
Document doc = Jsoup.parse(urlCon.getInputStream(), "utf-8", url);
// 刷选需要的网页内容
String contentText = doc.select("div.lemma-summary").first().text();
// 利用正则表达式去掉字符串中的"[数字]"
contentText = contentText.replaceAll("\\[\\d+\\]", "");
return contentText;
}catch(IOException e){
System.out.println("There was an error connecting to the URL");
return "";
}
}
}
上面代码中url为输入词(暂时只有英文),一直进入while循环搜索,输入“exit”时退出。 contentText是词条百度百科简介的网页形式,通过正则表达式提取其中的文字。代码虽然简洁,但功能相当强大,充分说明Java也可以作为爬虫使用。
接下来是愉快的测试时间:
本次分享到此结束,我们会继续更新Jsoup的相关知识。欢迎交流~~
原文链接: 查看全部
java爬虫抓取动态网页(Java的HTML解析器,可直接解析某个URL地址、HTML文本内容)
Jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 Jsoup的官网是:,其API手册的网址是:.
本次分享要实现的功能是:使用Jsoup抓取某个搜索词(暂时只有英文),百度百科的介绍部分。具体功能介绍请参考博客:Python爬虫自制简易搜索引擎。在上一个爬虫中,我们使用Python进行爬取。这一次,我们将使用Java来爬取。你没看错,是 Java。
在Eclipse中添加Jsoup包,下载地址为:.
爬虫的具体代码如下:
package baiduScrape;
/*
* 本爬虫主要利用Java的Jsoup包进行网络爬取
* 本爬虫的功能: 爬取百度百科的开头介绍部分
* 使用方法: 输入关键字(目前只支持英文)即可
*/
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.net.*;
import java.io.*;
import java.util.Scanner;
public class BaiduScrape {
public static void main(String[] args) {
Scanner input = new Scanner(System.in);
String baseUrl = "https://baike.baidu.com/item/";
String url = "";
// 如果输入文字不是"exit",则爬取其百度百科的介绍部分,否则退出该程序
while(true) {
System.out.println("Enter the word(Enter 'exit' to exit):");
url = input.nextLine();
if(url.equals("exit")) {
System.out.println("The program is over.");
break;
}
String introduction = getContent(baseUrl+url);
System.out.println(introduction+'\n');
}
}
// getContent()函数主要实现爬取输入文字的百度百科的介绍部分
public static String getContent(String url){
// 利用URL解析网址
URL urlObj = null;
try{
urlObj = new URL(url);
}
catch(MalformedURLException e){
System.out.println("The url was malformed!");
return "";
}
// URL连接
URLConnection urlCon = null;
try{
urlCon = urlObj.openConnection(); // 打开URL连接
// 将HTML内容解析成UTF-8格式
Document doc = Jsoup.parse(urlCon.getInputStream(), "utf-8", url);
// 刷选需要的网页内容
String contentText = doc.select("div.lemma-summary").first().text();
// 利用正则表达式去掉字符串中的"[数字]"
contentText = contentText.replaceAll("\\[\\d+\\]", "");
return contentText;
}catch(IOException e){
System.out.println("There was an error connecting to the URL");
return "";
}
}
}
上面代码中url为输入词(暂时只有英文),一直进入while循环搜索,输入“exit”时退出。 contentText是词条百度百科简介的网页形式,通过正则表达式提取其中的文字。代码虽然简洁,但功能相当强大,充分说明Java也可以作为爬虫使用。
接下来是愉快的测试时间:
本次分享到此结束,我们会继续更新Jsoup的相关知识。欢迎交流~~
原文链接:
java爬虫抓取动态网页(懂车帝进制抓取只是技术研究不涉及数据内容,请谨慎操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-01 09:11
友情提示,了解Chedi Binary的捕获,但技术研究不涉及数据内容,请谨慎操作
本文以雅阁车友圈为例,地址:
分析
首先分析一下这个网站的内容交互方式。不难发现,内容是通过鼠标向下滚动来翻页,翻页后页面没有刷新。
我们按F12调出浏览器的Network,可以看到每个页面的内容都是通过XHR传递到前端显示的,如下图:
多次翻页后,通过这个url解析并显示内容。
问题
1.每个请求需要传递三个参数,min_behot_time、max_behot_time、max_cursor,如何在每次翻页时传递这三个参数?
在浏览器中搜索关键词以找到位置。都出现在community.js中,只是被webpack打包了,看不到源码了。
但是可以通过关键词搜索,然后配合浏览器自带的format js函数,大概可以看到这三个参数的由来,如下图:
相信你已经明白了。 [害羞]
2. 每次翻页,传递的数据数为20,但显示的页面少于20,而且每次都不固定。为什么?
这时候就需要对返回的json内容进行分析。有没有发现类型有点不同?
具体可以多对比分析,仅供参考:type=2328重点分析,type=2312精华帖。
代码片段
maven 引入:jsoup、fastjson
java 示例代码片段
long min_behot_time = 0l;
long max_behot_time = 0l;
long max_cursor = 0l;
int page = 1;
//请留意需要修改,您可以while中设置page>10 时,break;
while (true) {
boolean flag = false;
if (min_behot_time == 0) {
min_behot_time = System.currentTimeMillis() / 1000;
}
String url = "https://www.dcdapp.com/motor/d ... ot%3B + motor_id + "&min_behot_time=" + min_behot_time + "&max_behot_time=" + max_behot_time + "&max_cursor=" + max_cursor + "&channel=m_web&device_platform=wap&category=dongtai&cmg_flag=dongtai&web_id=0&device_id=0&impression_info=%7B%22page_id%22%3A%22page_forum_home%22%2C%22product_name%22%3A%22pc%22%7D&tt_from=load_more&_t=" + System.currentTimeMillis();
try {
Connection.Response response = Jsoup.connect(url).headers(headers())
.timeout(50000)
.ignoreHttpErrors(true).ignoreContentType(true)
.execute();
String json = response.body();
JSONObject jsonObject = JSON.parseObject(json);
JSONObject dataObj = jsonObject.getJSONObject("data");
if (dataObj != null) {
JSONArray listArray = dataObj.getJSONArray("list");
if (listArray != null) {
for (int i = 0; i < listArray.size(); i++) {
int type = listArray.getJSONObject(i).getIntValue("type");
if (2328 == type) continue;
boolean prime = 2312 == type;
JSONObject items = listArray.getJSONObject(i).getJSONObject("info");
String uniqueIdStr = listArray.getJSONObject(i).getString("unique_id_str");
String link = "https://www.dcdapp.com/ugc/article/" + uniqueIdStr;
if (dcdapp.carTopicService.isExsit(DigestUtils.md5DigestAsHex(link.getBytes()))) {
flag = true;
}
String title = items.getString("title").replaceAll("[\r\n]+", "").replaceAll("[^\\u0000-\\uFFFF]", "");
if (title.length() > 100) {
title = title.substring(0, 100) + "……";
}
//阅读量
int hit = items.getIntValue("read_count");
//评论量
int reply = items.getIntValue("comment_count");
String author = items.getJSONObject("user_info").getString("name").replaceAll("[^\\u0000-\\uFFFF]", "");
String displayTime = TimeTools.timeFormat(items.getLongValue("display_time") * 1000, "");
boolean image = items.getJSONArray("image_list") != null && !items.getJSONArray("image_list").isEmpty();
//这里就是问题中的几个参数哦。。。
max_behot_time = items.getLongValue("behot_time");
max_cursor = items.getLongValue("cursor");
logger.warn(title + "\t" + author + "\t" + hit + "\t" + displayTime + "\t" + uniqueIdStr + "\t" + image);
}
} else {
break;
}
} else {
break;
}
Thread.sleep(5000L);
} catch (Exception ex) {
ex.printStackTrace();
logger.error("dcd error:"+ex);
}
logger.error("抓取"+sector + " 第" + page + "页结束");
page++;
if (flag) break;
}
可以通过上面的代码获取数据[得意] 查看全部
java爬虫抓取动态网页(懂车帝进制抓取只是技术研究不涉及数据内容,请谨慎操作)
友情提示,了解Chedi Binary的捕获,但技术研究不涉及数据内容,请谨慎操作
本文以雅阁车友圈为例,地址:
分析
首先分析一下这个网站的内容交互方式。不难发现,内容是通过鼠标向下滚动来翻页,翻页后页面没有刷新。
我们按F12调出浏览器的Network,可以看到每个页面的内容都是通过XHR传递到前端显示的,如下图:
多次翻页后,通过这个url解析并显示内容。
问题
1.每个请求需要传递三个参数,min_behot_time、max_behot_time、max_cursor,如何在每次翻页时传递这三个参数?
在浏览器中搜索关键词以找到位置。都出现在community.js中,只是被webpack打包了,看不到源码了。
但是可以通过关键词搜索,然后配合浏览器自带的format js函数,大概可以看到这三个参数的由来,如下图:
相信你已经明白了。 [害羞]
2. 每次翻页,传递的数据数为20,但显示的页面少于20,而且每次都不固定。为什么?
这时候就需要对返回的json内容进行分析。有没有发现类型有点不同?
具体可以多对比分析,仅供参考:type=2328重点分析,type=2312精华帖。
代码片段
maven 引入:jsoup、fastjson
java 示例代码片段
long min_behot_time = 0l;
long max_behot_time = 0l;
long max_cursor = 0l;
int page = 1;
//请留意需要修改,您可以while中设置page>10 时,break;
while (true) {
boolean flag = false;
if (min_behot_time == 0) {
min_behot_time = System.currentTimeMillis() / 1000;
}
String url = "https://www.dcdapp.com/motor/d ... ot%3B + motor_id + "&min_behot_time=" + min_behot_time + "&max_behot_time=" + max_behot_time + "&max_cursor=" + max_cursor + "&channel=m_web&device_platform=wap&category=dongtai&cmg_flag=dongtai&web_id=0&device_id=0&impression_info=%7B%22page_id%22%3A%22page_forum_home%22%2C%22product_name%22%3A%22pc%22%7D&tt_from=load_more&_t=" + System.currentTimeMillis();
try {
Connection.Response response = Jsoup.connect(url).headers(headers())
.timeout(50000)
.ignoreHttpErrors(true).ignoreContentType(true)
.execute();
String json = response.body();
JSONObject jsonObject = JSON.parseObject(json);
JSONObject dataObj = jsonObject.getJSONObject("data");
if (dataObj != null) {
JSONArray listArray = dataObj.getJSONArray("list");
if (listArray != null) {
for (int i = 0; i < listArray.size(); i++) {
int type = listArray.getJSONObject(i).getIntValue("type");
if (2328 == type) continue;
boolean prime = 2312 == type;
JSONObject items = listArray.getJSONObject(i).getJSONObject("info");
String uniqueIdStr = listArray.getJSONObject(i).getString("unique_id_str");
String link = "https://www.dcdapp.com/ugc/article/" + uniqueIdStr;
if (dcdapp.carTopicService.isExsit(DigestUtils.md5DigestAsHex(link.getBytes()))) {
flag = true;
}
String title = items.getString("title").replaceAll("[\r\n]+", "").replaceAll("[^\\u0000-\\uFFFF]", "");
if (title.length() > 100) {
title = title.substring(0, 100) + "……";
}
//阅读量
int hit = items.getIntValue("read_count");
//评论量
int reply = items.getIntValue("comment_count");
String author = items.getJSONObject("user_info").getString("name").replaceAll("[^\\u0000-\\uFFFF]", "");
String displayTime = TimeTools.timeFormat(items.getLongValue("display_time") * 1000, "");
boolean image = items.getJSONArray("image_list") != null && !items.getJSONArray("image_list").isEmpty();
//这里就是问题中的几个参数哦。。。
max_behot_time = items.getLongValue("behot_time");
max_cursor = items.getLongValue("cursor");
logger.warn(title + "\t" + author + "\t" + hit + "\t" + displayTime + "\t" + uniqueIdStr + "\t" + image);
}
} else {
break;
}
} else {
break;
}
Thread.sleep(5000L);
} catch (Exception ex) {
ex.printStackTrace();
logger.error("dcd error:"+ex);
}
logger.error("抓取"+sector + " 第" + page + "页结束");
page++;
if (flag) break;
}
可以通过上面的代码获取数据[得意]
java爬虫抓取动态网页(对网页爬虫的调查结果调查人:王杨斌对于爬虫工具以及代码的调查)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-12-30 13:08
网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是关于PHP和Java的工具代码。Java爬虫1.1. JAVA爬虫WebCollector 爬虫简介:WebCollector[1]是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需要少量的代码即可实现强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2. Web-Harvest Web-Harvest 是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。1.4. 网络爬虫Heritrix Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。Heritrix是一个爬虫框架,其组织结构包括整个组件和爬行过程。1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个不需要配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。
您可以使用它来构建多线程 Web 爬虫。1.7. Java 网络蜘蛛/网络爬虫 Spiderman Spiderman 是一款基于微内核+插件架构的网络蜘蛛。它的目标是以简单的方式捕获复杂的目标网页信息。分析您需要的业务数据。Crawler-like 2.1. 网络爬虫 Grub Next Generation Grub Next Generation [8] 是一个分布式网络爬虫系统,包括客户端和服务器,可用于维护网页的索引。其开发语言:2.2.网络爬虫甲醇甲醇是一款模块化、可定制的网络爬虫软件。主要优点是速度快。2.3. 网络爬虫/网络蜘蛛 larbin Larbin [10] 是一个开源的网络爬虫/网络蜘蛛,由年轻的法国人 SbastienAilleret 自主研发。larbin 的目的是能够跟踪页面的 URL 进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,如何解析是用户自己做的。此外,larbin 没有提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用来建一个url列表组,比如urlretrive所有网页后,就可以得到xml链接。或者mp3,或者定制的larbin,都可以作为搜索引擎的信息来源。2.4. 死链接检查软件 Xenu Xenu Link Sleuth [11] 可能是您见过的用于检查网站死链接的最小但最强大的软件。您可以打开本地网页文件查看其链接,或输入任何 URL 进行查看。可分别列出网站的活链接和死链接,并能清晰分析重定向链接;它支持多线程,可以将检查结果存储为文本文件或网络文件。PHP爬虫3.1. sphider Spider() 是一个用PHP语言编写的爬虫工具,使用MySql作为后端。当前版本更新为Spider1.3.6,发布日期为04-06-2013。解压下载的文件,放到apache目录下运行。运行后,由于配置问题无法抓取,稍后调试。OpenWebSpider [12] 是一个开源的多线程 Web Spider(机器人:机器人,爬虫:爬虫)和具有许多有趣功能的搜索引擎。
3.2. TSpider TSpider是一个可执行的图形界面程序,但是爬取过程太慢,不适合使用。PHPCrawl也是一个使用php语言的爬虫工具,具有很好的扩展性,你可以根据自己的需要更改代码来完成不同的功能。3.3. PHP 网络爬虫和搜索引擎 PhpDig PhpDig [13] 是一个使用 PHP 开发的网络爬虫和搜索引擎。通过索引动态和静态页面来创建词汇表。搜索查询时,会根据一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
一个模板系统,可以索引 PDF、Word、Excel 和 PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。用它来搭建某个领域的垂直搜索引擎是最好的选择。3.4. 网站内容采集
器 Snoopy Snoopy [14] 是一个强大的网站内容采集
器(爬虫)。Dot.Net爬虫4.1.网站数据采集软件网络矿工采集器(原soukey采摘)Soukey[15]采摘网站数据采集软件是基于.Net平台的开源软件,也是网站数据采集软件中唯一开源的软件。
Soukey虽然选择开源,但不影响软件功能的提供,甚至比一些商业软件还要丰富。4.2. NWebCrawler NWebCrawler [16] 是一个开源的 C# 网络爬虫。4.3. 爬虫小新Sinawler 国内第一个微博数据爬虫程序!原名是“新浪微博爬虫”[17]。登录后,您可以指定用户为起点,以用户的关注者和粉丝为线索,通过扩展人脉,采集
用户基本信息、微博数据、评论数据。本应用所获得的数据可作为新浪微博相关科研、研发的数据支持,但请勿用于商业用途。该应用程序基于.NET2. 0框架,需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。
它的开发语言是Python。5.2. 网页抓取/信息抽取软件MetaSeeker 网页抓取/信息抽取/数据抽取软件工具包MetaSeeker(GooSeeker)V4.11.2 [18] 正式发布,网络版可免费下载使用,可阅读源代码。自推出以来,深受喜爱,其主要应用领域为: 垂直搜索(VerticalSearch):又称专业搜索。高速、海量、精准抓取是定题网络爬虫DataScraper的强项。它每周 7 天、每天 24 小时无人值守。自调度的定期批量采集,再加上可续传的上传和软件看门狗(Watch Dog),让您高枕无忧。移动互联网:移动搜索、移动混搭、移动社交网络、移动电商都离不开结构化的数据内容,DataScraper实时高效采集内容,并输出富含语义元数据的XML格式的采集结果文件,确保数据的自动化整合和处理,突破小屏壁垒显示和高精度信息检索。移动互联网不是万维网的一个子集,而是整体。MetaSeeker为企业竞争情报采集
/数据挖掘搭建桥梁:俗称商业智能(Business Intelligence),噪声信息过滤,结构化转换,保证数据的准确性和及时性,独特DataScraper的广域分布式架构赋予DataScraper无与伦比的情报采集
和渗透能力。AJAX/Javascript 动态页面、服务器动态页面、
在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。还有一些工具,phpdig,很久没有更新了,旧的工具代码已经没有了。基于python编码的spiderpy和基于C++编码的larbin没有做深入的调查和了解。如果有需要,我们会进行深入调查。参考文献:[10][11][12][13][14][15][16][17][18] 查看全部
java爬虫抓取动态网页(对网页爬虫的调查结果调查人:王杨斌对于爬虫工具以及代码的调查)
网络爬虫调查结果调查员:王阳斌对爬虫工具和代码的调查,调查的主要内容是关于PHP和Java的工具代码。Java爬虫1.1. JAVA爬虫WebCollector 爬虫简介:WebCollector[1]是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需要少量的代码即可实现强大的爬虫。爬虫内核:WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核非常强大。1.2. Web-Harvest Web-Harvest 是一个用Java语言编写的网络爬虫工具,应用广泛。它可以采集
指定的页面并从这些页面中提取有用的数据。Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集
指定的网页并从这些网页中提取有用的数据。Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。正则表达式等来实现 text/xml 操作。1.3. Java 网络爬虫JSpider JSpider 是一个用Java 实现的WebSpider。JSpider的行为具体由配置文件配置,如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。
JSpider 的默认配置类型很少,也不是很有用。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider 的原理,然后根据需要开发插件并编写配置文件。1.4. 网络爬虫Heritrix Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。Heritrix是一个爬虫框架,其组织结构包括整个组件和爬行过程。1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个不需要配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。@1.5. webmagic logo 垂直爬虫 webmagic Webmagic是一个无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。webmagic logo 垂直爬虫 webmagic Webmagic 是一款无需配置,方便二次开发的爬虫框架。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。并且一个爬虫可以用少量的代码实现。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。1.6. Java多线程网络爬虫Crawler4j Crawler4j是一个开源的Java类库,提供了一个简单的网页爬取接口。
您可以使用它来构建多线程 Web 爬虫。1.7. Java 网络蜘蛛/网络爬虫 Spiderman Spiderman 是一款基于微内核+插件架构的网络蜘蛛。它的目标是以简单的方式捕获复杂的目标网页信息。分析您需要的业务数据。Crawler-like 2.1. 网络爬虫 Grub Next Generation Grub Next Generation [8] 是一个分布式网络爬虫系统,包括客户端和服务器,可用于维护网页的索引。其开发语言:2.2.网络爬虫甲醇甲醇是一款模块化、可定制的网络爬虫软件。主要优点是速度快。2.3. 网络爬虫/网络蜘蛛 larbin Larbin [10] 是一个开源的网络爬虫/网络蜘蛛,由年轻的法国人 SbastienAilleret 自主研发。larbin 的目的是能够跟踪页面的 URL 进行扩展抓取,最终为搜索引擎提供广泛的数据源。larbin只是一个爬虫,也就是说larbin只爬网页,如何解析是用户自己做的。此外,larbin 没有提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。larbin 不提供有关如何将其存储在数据库中和构建索引的信息。一个简单的 larbin 爬虫每天可以抓取 500 万个网页。
使用larbin,我们可以轻松获取/确定单个网站的所有链接,甚至可以镜像一个网站;也可以用来建一个url列表组,比如urlretrive所有网页后,就可以得到xml链接。或者mp3,或者定制的larbin,都可以作为搜索引擎的信息来源。2.4. 死链接检查软件 Xenu Xenu Link Sleuth [11] 可能是您见过的用于检查网站死链接的最小但最强大的软件。您可以打开本地网页文件查看其链接,或输入任何 URL 进行查看。可分别列出网站的活链接和死链接,并能清晰分析重定向链接;它支持多线程,可以将检查结果存储为文本文件或网络文件。PHP爬虫3.1. sphider Spider() 是一个用PHP语言编写的爬虫工具,使用MySql作为后端。当前版本更新为Spider1.3.6,发布日期为04-06-2013。解压下载的文件,放到apache目录下运行。运行后,由于配置问题无法抓取,稍后调试。OpenWebSpider [12] 是一个开源的多线程 Web Spider(机器人:机器人,爬虫:爬虫)和具有许多有趣功能的搜索引擎。
3.2. TSpider TSpider是一个可执行的图形界面程序,但是爬取过程太慢,不适合使用。PHPCrawl也是一个使用php语言的爬虫工具,具有很好的扩展性,你可以根据自己的需要更改代码来完成不同的功能。3.3. PHP 网络爬虫和搜索引擎 PhpDig PhpDig [13] 是一个使用 PHP 开发的网络爬虫和搜索引擎。通过索引动态和静态页面来创建词汇表。搜索查询时,会根据一定的排序规则显示收录
关键字的搜索结果页面。PhpDig 收录
一个模板系统,可以索引 PDF、Word、Excel 和 PowerPoint 文档。PHPdig 适用于更专业、更深入的个性化搜索引擎。用它来搭建某个领域的垂直搜索引擎是最好的选择。3.4. 网站内容采集
器 Snoopy Snoopy [14] 是一个强大的网站内容采集
器(爬虫)。Dot.Net爬虫4.1.网站数据采集软件网络矿工采集器(原soukey采摘)Soukey[15]采摘网站数据采集软件是基于.Net平台的开源软件,也是网站数据采集软件中唯一开源的软件。
Soukey虽然选择开源,但不影响软件功能的提供,甚至比一些商业软件还要丰富。4.2. NWebCrawler NWebCrawler [16] 是一个开源的 C# 网络爬虫。4.3. 爬虫小新Sinawler 国内第一个微博数据爬虫程序!原名是“新浪微博爬虫”[17]。登录后,您可以指定用户为起点,以用户的关注者和粉丝为线索,通过扩展人脉,采集
用户基本信息、微博数据、评论数据。本应用所获得的数据可作为新浪微博相关科研、研发的数据支持,但请勿用于商业用途。该应用程序基于.NET2. 0框架,需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。需要SQL SERVER作为后端数据库,并为SQL Server提供数据库脚本文件。另外,由于新浪微博API的限制,爬取的数据可能不完整(如关注人数限制、微博人数限制等)。本程序的版权归作者所有。您可以自由地:复制、分发、展示和表演当前的作品,以及制作衍生作品。您不得将当前作品用于商业目的。其他语言爬虫5.1. 网络爬虫框架Scrapy Scrapy是一套基于Twisted的异步处理框架,纯python实现的爬虫框架。用户只需定制开发几个模块即可轻松实现。一个爬虫,用来爬取网页内容和各种图片,非常方便。
它的开发语言是Python。5.2. 网页抓取/信息抽取软件MetaSeeker 网页抓取/信息抽取/数据抽取软件工具包MetaSeeker(GooSeeker)V4.11.2 [18] 正式发布,网络版可免费下载使用,可阅读源代码。自推出以来,深受喜爱,其主要应用领域为: 垂直搜索(VerticalSearch):又称专业搜索。高速、海量、精准抓取是定题网络爬虫DataScraper的强项。它每周 7 天、每天 24 小时无人值守。自调度的定期批量采集,再加上可续传的上传和软件看门狗(Watch Dog),让您高枕无忧。移动互联网:移动搜索、移动混搭、移动社交网络、移动电商都离不开结构化的数据内容,DataScraper实时高效采集内容,并输出富含语义元数据的XML格式的采集结果文件,确保数据的自动化整合和处理,突破小屏壁垒显示和高精度信息检索。移动互联网不是万维网的一个子集,而是整体。MetaSeeker为企业竞争情报采集
/数据挖掘搭建桥梁:俗称商业智能(Business Intelligence),噪声信息过滤,结构化转换,保证数据的准确性和及时性,独特DataScraper的广域分布式架构赋予DataScraper无与伦比的情报采集
和渗透能力。AJAX/Javascript 动态页面、服务器动态页面、
在微博网站的数据采集和舆情监测方面遥遥领先于其他产品。还有一些工具,phpdig,很久没有更新了,旧的工具代码已经没有了。基于python编码的spiderpy和基于C++编码的larbin没有做深入的调查和了解。如果有需要,我们会进行深入调查。参考文献:[10][11][12][13][14][15][16][17][18]
java爬虫抓取动态网页(WebDriver的吐槽WebDriver是一个测试框架,什么是复杂性?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-30 10:08
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。看来我的程序没有写错。接下来让人身心俱疲的事情来了——获取一个收录
动态内容的html页面。
在百度这个号称中国最强搜索引擎的百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经包括后者)。我很高兴,终于找到了解决方案。兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录
动态生成的内容。问题是,为什么说WebDriver可以获取收录
动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver 驱动程序 = 新 InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具-phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面已加载!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
在java端执行的代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
本文链接:Java抓取动态生成的网页-吐槽,转载请注明。 查看全部
java爬虫抓取动态网页(WebDriver的吐槽WebDriver是一个测试框架,什么是复杂性?)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后期更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用Hadoop平台的分布式爬虫框架Nutch,用起来很方便,但最后因为速度放弃了,但是统计生成用于后续爬取),很快就成功下载了holder.html和finance.html页面,然后在解析holder.html页面后,解析finance.html,然后郁闷的找不到自己需要的在这个页面中的数据不在html源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。看来我的程序没有写错。接下来让人身心俱疲的事情来了——获取一个收录
动态内容的html页面。
在百度这个号称中国最强搜索引擎的百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经包括后者)。我很高兴,终于找到了解决方案。兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。本来不是为爬虫服务的,但我想说的是:星盘只是有点短,你不能更进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从现实出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码限制太多了,解析你写的js代码,js代码很简单,所以当然WebDriver 可以毫无压力地完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面使用的IE内核,当然还有FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page。 asXml() 可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身体验)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录
动态生成的内容。问题是,为什么说WebDriver可以获取收录
动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能获取完成的页面,类似于下面的形式
WebDriver 驱动程序 = 新 InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。我想驱动应该可以在解析js完成后捕捉到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有向前迈出一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是很不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会不一样,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实是这样。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具-phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面已加载!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
在java端执行的代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码编译不一样,java端会一直等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要启动一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了几天。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后去网页的时候就方便了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过你可以用Nutch和WebDirver结合起来,也许爬取的结果是稳定的,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫得到的结果的稳定性有什么想说的,欢迎大家讨论,因为我确实没有找到稳定结果的相关资料。
本文链接:Java抓取动态生成的网页-吐槽,转载请注明。
java爬虫抓取动态网页( Python行业薪资如何阅读?(第1~6章) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-28 17:04
Python行业薪资如何阅读?(第1~6章)
)
前言
爬虫是DT(Data Technology)采集
信息的基础。程序员抓取目标网站的信息后,就可以分析和构建应用程序。我们关心的是技术如何给每个人带来实际效果,进而实现目标和理想。无法应用的技术称为魔术,只能用于表演。我们非常关心读者能否掌握爬虫的概念,所以结合不同的例子来讲解相关技术,希望能够引导读者完成整个数据采集的过程。
Python 是一种简单而有效的语言。爬虫所需的获取、存储、组织流程可以使用Python系统地实现。另外,大部分电脑也可以直接使用Python语言或者干脆安装Python系统。相信读者能够轻松使用Python作为主要的爬虫技术。
动心者应有大根
DT的核心是从信息来源进行理解和分析,从而做出能够打动对方的行动决策。从谷歌搜索到如今的大数据时代,爬虫技术的重要性和广泛性一直都很突出。程序员了解信息获取、存储和整理的基本关系,可以系统地采集
和应用不同来源、千变万化的网站信息。
自我提升
互联网技术在不断更新和进步,网站信息也在不断变化。爬虫的乐趣在于如何高效、持续地从瞬息万变的网站中获取信息。此外,程序员必须不断学习新技术,提高自己,以便在爬取过程中了解互联网的运行和结构。最后,感谢我的朋友唐松给我机会一.开始写这本书,让我分享爬行技术和其中的乐趣。
Python行业薪资
如何阅读?
使用Python编写网络爬虫获取互联网大数据是目前的热门话题。
本书内容包括基础部分、高级部分和项目实践部分三部分。
Python爬虫过程
基础部分(第1~6章)主要介绍爬虫的三个步骤(获取网页、解析网页和存储数据),并通过大量实例的讲解,让读者从基础内容中系统地学习爬虫技术并实践提高Python爬虫的级别。
进阶部分(第7~12章)包括多线程并发并行爬虫、分布式爬虫、IP替换等,帮助读者进一步提升爬虫水平。
项目实践部分(第13~16章)利用本书介绍的爬虫技术爬取了几个真实的网站,让读者在阅读本书后可以根据自己的需要编写爬虫程序。不管你有没有编程基础,只要你对爬虫技术感兴趣,本书都会引导你从入门到进阶,再到实战,一步步了解爬虫,最终写出自己的爬虫程序。
接下来,就和小编一起进入爬虫知识的海洋吧。
基础部分
第 1 章:网络爬虫入门
1.1 为什么要学习爬行?
在数据量呈爆炸式增长的互联网时代,网站与用户的交流本质上是数据的交换:搜索引擎从数据库中提取搜索结果,展示在用户面前;电子商务在网站上展示产品描述和价格,让买家可以选择自己喜欢的产品,社交媒体在用户生态系统的自我交互下产生了大量的文字、图片和视频数据。如果能够对这些数据进行分析和利用,不仅可以帮助第一方公司(即拥有数据的公司)做出更好的决策,也有利于第三方公司。
上面的例子只是数据应用的冰山一角。近年来,随着大数据分析的普及,毕竟数据都可以分析,网络爬虫技术成为大数据分析领域的第一环节。
对于这些公开数据的应用价值,我们可以使用KYC框架来理解,即了解你的公司(Know Your Company)、了解你的竞争对手(Know Your Competitor)、了解你的客户(Know Your Customer)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,在营销领域,可以帮助企业做好4P(Product:产品创新,Place:智能选址,Price:动态价格,Promotion:数据驱动的营销活动) ; 在金融领域,数据驱动的征信等应用将带来越来越大的价值。
简单的爬虫架构
1.2 三个过程的技术实现
以下技术实现方法均以Python语言实现,Java等其他语言不涉及。
1.获取网页
获取网页的基本技术:request、urllib、selenium(模拟浏览器)。
先进的网页获取技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取。
2.分析网页
解析网页的基本技术:re正则表达式、BeautifulSoup和lxml。
高级网页解析技术:解决中文乱码。
3.存储数据
存储数据的基本技术:保存在txt文件中,保存在csv文件中。
先进的数据存储技术:存储在MySQL数据库中,存储在MongoDB数据库中。
对以上技术不熟悉的读者也不必担心,本书将对其中的所有技术进行讲解,力求把深奥的东西讲得通俗易懂。
第 2 章:编写第一个网络爬虫
第 3 章:静态网页抓取
第 4 章:动态网络爬行
第 5 章:解析网页
第 6 章:数据存储
进阶部分
第七章:提高爬虫速度
7.1多线程爬虫
多线程爬虫以并发方式执行。换句话说,不能同时执行多个线程,而是通过进程的快速切换来加快网络爬虫的速度。
Python 本身的设计限制了多线程的执行。在 Python 设计之初,为了数据安全的决策,就设定了 GIL(Global Interpreter Lock)。在Python中,线程的执行过程包括获取GIL、执行代码直至挂起、释放GIL。
例如,如果一个线程要执行,它必须首先获得 GIL。我们可以将 GIL 视为“护照”,而一个 Python 进程中只有一个 GIL。不能拿到pass的线程是不允许进入CPU执行的。
多线程执行模式
每次释放 GIL 锁,线程之间都会有锁竞争,切换线程会消耗资源。由于 GIL 锁的存在,Python 中的一个进程始终只能同时执行一个线程(获得 GIL 的线程可以执行)。这就是Python在多核CPU上的多线程效率不高的原因。
因为GIL的存在,多线程就没用了吗?在网络爬虫的情况下,网络爬虫是I0密集型的,多线程可以有效提高效率。因为单线程下有I0操作,I0等待,所以会造成不必要的时间浪费,而启用多线程可以在线程A等待的同时自动切换到线程B,从而不浪费CPU资源,从而提高程序执行的效率。
Python的多线程对I0密集型代码更加友好,网络爬虫可以在获取网页的过程中使用多线程来加快速度。
第 8 章:反爬虫问题
第9章:解决中文乱码
第10章:登录和验证码处理
第11章:服务器集合
第12章:分布式爬虫
项目实践部分
爬虫练习一:维基百科
维基百科是一个网络百科全书,允许用户在正常情况下编辑任何条目。目前维基百科由非营利组织维基媒体基金会运营。维基百科一词是由网站的核心技术维基和百科全书创造的一个新的混合词维基百科,意思是百科全书。
维基百科入口页面
本章将给出一个爬取维基百科的实际项目。使用的爬取技术包括以下4种:
爬虫练习二:知乎直播
知乎是中国互联网上一个非常庞大的知识社交平台。在知乎上,用户可以通过问答等交流方式获取知识。与百度知乎等问答网站不同,知乎的回答往往非常深入,回答者写的也很用心。知乎汇聚了中国互联网技术、商业、文化领域最具创意的人才,将提供优质的内容,通过人类节点形成规模化生产和共享,构建高价值的人际网络。
知乎
本章是爬取知乎网站的实战项目。使用的爬虫技术包括以下3种。
爬虫实践三:百度地图API
百度地图是一种网络地图搜索服务。在百度地图中,用户可以查询街道、商场、房产的地理位置,也可以找到离你最近的餐厅、学校、银行、公园等。百度地图提供了丰富的API供开发者调用,我们可以免费获取各个位置的具体信息。
百度API
本章是一个使用百度API获取数据的实战项目。使用的技术包括:
爬虫练习四:公众点评
在去餐厅吃饭之前,我们总是喜欢在网上搜索餐厅评论,然后再决定去哪家餐厅。在互联网餐厅点评网站中,大众点评是知名的第三方消费者点评网站,也是当地的生活信息和交易平台。因此,大众点评上有很多商家信息和用户评论数据。
公众意见
本章是一个抓取公众评论数据的实践项目。使用的技术包括:
总的来说,Python爬虫是一项非常实用但并不枯燥的技术。因为书中的细节太多,编者不会一一打出来。想获取《Python爬虫从入门到实践》小伙伴可以转发+关注私信编辑【学习】获取获取方式~~~
查看全部
java爬虫抓取动态网页(
Python行业薪资如何阅读?(第1~6章)
)
前言
爬虫是DT(Data Technology)采集
信息的基础。程序员抓取目标网站的信息后,就可以分析和构建应用程序。我们关心的是技术如何给每个人带来实际效果,进而实现目标和理想。无法应用的技术称为魔术,只能用于表演。我们非常关心读者能否掌握爬虫的概念,所以结合不同的例子来讲解相关技术,希望能够引导读者完成整个数据采集的过程。
Python 是一种简单而有效的语言。爬虫所需的获取、存储、组织流程可以使用Python系统地实现。另外,大部分电脑也可以直接使用Python语言或者干脆安装Python系统。相信读者能够轻松使用Python作为主要的爬虫技术。
动心者应有大根
DT的核心是从信息来源进行理解和分析,从而做出能够打动对方的行动决策。从谷歌搜索到如今的大数据时代,爬虫技术的重要性和广泛性一直都很突出。程序员了解信息获取、存储和整理的基本关系,可以系统地采集
和应用不同来源、千变万化的网站信息。
自我提升
互联网技术在不断更新和进步,网站信息也在不断变化。爬虫的乐趣在于如何高效、持续地从瞬息万变的网站中获取信息。此外,程序员必须不断学习新技术,提高自己,以便在爬取过程中了解互联网的运行和结构。最后,感谢我的朋友唐松给我机会一.开始写这本书,让我分享爬行技术和其中的乐趣。
Python行业薪资
如何阅读?
使用Python编写网络爬虫获取互联网大数据是目前的热门话题。
本书内容包括基础部分、高级部分和项目实践部分三部分。
Python爬虫过程
基础部分(第1~6章)主要介绍爬虫的三个步骤(获取网页、解析网页和存储数据),并通过大量实例的讲解,让读者从基础内容中系统地学习爬虫技术并实践提高Python爬虫的级别。
进阶部分(第7~12章)包括多线程并发并行爬虫、分布式爬虫、IP替换等,帮助读者进一步提升爬虫水平。
项目实践部分(第13~16章)利用本书介绍的爬虫技术爬取了几个真实的网站,让读者在阅读本书后可以根据自己的需要编写爬虫程序。不管你有没有编程基础,只要你对爬虫技术感兴趣,本书都会引导你从入门到进阶,再到实战,一步步了解爬虫,最终写出自己的爬虫程序。
接下来,就和小编一起进入爬虫知识的海洋吧。
基础部分
第 1 章:网络爬虫入门
1.1 为什么要学习爬行?
在数据量呈爆炸式增长的互联网时代,网站与用户的交流本质上是数据的交换:搜索引擎从数据库中提取搜索结果,展示在用户面前;电子商务在网站上展示产品描述和价格,让买家可以选择自己喜欢的产品,社交媒体在用户生态系统的自我交互下产生了大量的文字、图片和视频数据。如果能够对这些数据进行分析和利用,不仅可以帮助第一方公司(即拥有数据的公司)做出更好的决策,也有利于第三方公司。
上面的例子只是数据应用的冰山一角。近年来,随着大数据分析的普及,毕竟数据都可以分析,网络爬虫技术成为大数据分析领域的第一环节。
对于这些公开数据的应用价值,我们可以使用KYC框架来理解,即了解你的公司(Know Your Company)、了解你的竞争对手(Know Your Competitor)、了解你的客户(Know Your Customer)。这是通过理解和执行对公共数据的简单描述性分析可以带来的价值。此外,通过机器学习和统计算法分析,在营销领域,可以帮助企业做好4P(Product:产品创新,Place:智能选址,Price:动态价格,Promotion:数据驱动的营销活动) ; 在金融领域,数据驱动的征信等应用将带来越来越大的价值。
简单的爬虫架构
1.2 三个过程的技术实现
以下技术实现方法均以Python语言实现,Java等其他语言不涉及。
1.获取网页
获取网页的基本技术:request、urllib、selenium(模拟浏览器)。
先进的网页获取技术:多进程多线程爬取、登录爬取、突破IP封禁、服务器爬取。
2.分析网页
解析网页的基本技术:re正则表达式、BeautifulSoup和lxml。
高级网页解析技术:解决中文乱码。
3.存储数据
存储数据的基本技术:保存在txt文件中,保存在csv文件中。
先进的数据存储技术:存储在MySQL数据库中,存储在MongoDB数据库中。
对以上技术不熟悉的读者也不必担心,本书将对其中的所有技术进行讲解,力求把深奥的东西讲得通俗易懂。
第 2 章:编写第一个网络爬虫
第 3 章:静态网页抓取
第 4 章:动态网络爬行
第 5 章:解析网页
第 6 章:数据存储
进阶部分
第七章:提高爬虫速度
7.1多线程爬虫
多线程爬虫以并发方式执行。换句话说,不能同时执行多个线程,而是通过进程的快速切换来加快网络爬虫的速度。
Python 本身的设计限制了多线程的执行。在 Python 设计之初,为了数据安全的决策,就设定了 GIL(Global Interpreter Lock)。在Python中,线程的执行过程包括获取GIL、执行代码直至挂起、释放GIL。
例如,如果一个线程要执行,它必须首先获得 GIL。我们可以将 GIL 视为“护照”,而一个 Python 进程中只有一个 GIL。不能拿到pass的线程是不允许进入CPU执行的。
多线程执行模式
每次释放 GIL 锁,线程之间都会有锁竞争,切换线程会消耗资源。由于 GIL 锁的存在,Python 中的一个进程始终只能同时执行一个线程(获得 GIL 的线程可以执行)。这就是Python在多核CPU上的多线程效率不高的原因。
因为GIL的存在,多线程就没用了吗?在网络爬虫的情况下,网络爬虫是I0密集型的,多线程可以有效提高效率。因为单线程下有I0操作,I0等待,所以会造成不必要的时间浪费,而启用多线程可以在线程A等待的同时自动切换到线程B,从而不浪费CPU资源,从而提高程序执行的效率。
Python的多线程对I0密集型代码更加友好,网络爬虫可以在获取网页的过程中使用多线程来加快速度。
第 8 章:反爬虫问题
第9章:解决中文乱码
第10章:登录和验证码处理
第11章:服务器集合
第12章:分布式爬虫
项目实践部分
爬虫练习一:维基百科
维基百科是一个网络百科全书,允许用户在正常情况下编辑任何条目。目前维基百科由非营利组织维基媒体基金会运营。维基百科一词是由网站的核心技术维基和百科全书创造的一个新的混合词维基百科,意思是百科全书。
维基百科入口页面
本章将给出一个爬取维基百科的实际项目。使用的爬取技术包括以下4种:
爬虫练习二:知乎直播
知乎是中国互联网上一个非常庞大的知识社交平台。在知乎上,用户可以通过问答等交流方式获取知识。与百度知乎等问答网站不同,知乎的回答往往非常深入,回答者写的也很用心。知乎汇聚了中国互联网技术、商业、文化领域最具创意的人才,将提供优质的内容,通过人类节点形成规模化生产和共享,构建高价值的人际网络。
知乎
本章是爬取知乎网站的实战项目。使用的爬虫技术包括以下3种。
爬虫实践三:百度地图API
百度地图是一种网络地图搜索服务。在百度地图中,用户可以查询街道、商场、房产的地理位置,也可以找到离你最近的餐厅、学校、银行、公园等。百度地图提供了丰富的API供开发者调用,我们可以免费获取各个位置的具体信息。
百度API
本章是一个使用百度API获取数据的实战项目。使用的技术包括:
爬虫练习四:公众点评
在去餐厅吃饭之前,我们总是喜欢在网上搜索餐厅评论,然后再决定去哪家餐厅。在互联网餐厅点评网站中,大众点评是知名的第三方消费者点评网站,也是当地的生活信息和交易平台。因此,大众点评上有很多商家信息和用户评论数据。
公众意见
本章是一个抓取公众评论数据的实践项目。使用的技术包括:
总的来说,Python爬虫是一项非常实用但并不枯燥的技术。因为书中的细节太多,编者不会一一打出来。想获取《Python爬虫从入门到实践》小伙伴可以转发+关注私信编辑【学习】获取获取方式~~~
java爬虫抓取动态网页(WebCollector-Python项目开发者内核:WebCollectorx )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 17:03
)
爬虫简介:
WebCollector 是一个 Java 爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎大家贡献代码:
爬虫内核:
WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。2.x 版本集成了 selenium,可以处理 JavaScript 生成的数据。
马文:
最新的Maven地址请参考文档:
文件地址:
内核架构图:
WebCollector 2.x 版本特点:
自定义遍历策略可以完成更复杂的遍历服务,比如分页,AJAX可以为每个URL设置附加信息(MetaData),利用附加信息完成很多复杂的服务,比如深度检索、锚文本检索、引用页面检索、POST参数传递、增量更新等。利用插件机制,用户可以自定义自己的Http请求、过滤器、执行器等插件。内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,比如搜索引擎的实时爬取。内置一套基于Berkeley DB(BreadthCrawler)的插件:适合处理长期、大规模的任务,并具有断点爬取功能,不会因宕机或关机造成数据丢失。集成selenium,可以提取JavaScript生成的信息,轻松定制http请求,内置多代理随机切换功能。可以通过定义http请求来实现模拟登录。使用slf4j作为日志门面,可以连接多种日志,使用类似Hadoop的Configuration机制为每个爬虫定制配置信息。
WebCollector 2.x 官网及镜像:
WebCollector 2.x 教程:
WebCollector 配置
WebCollector 入门
WebCollector 功能
WebCollector 持久化
WebCollector 高级爬虫定制
WebCollector 处理 Javascript
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
/**
* Crawling news from github news
*
* @author hu
*/
public class DemoAutoNewsCrawler extends BreadthCrawler {
/**
* @param crawlPath crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse if autoParse is true,BreadthCrawler will auto extract
* links which match regex rules from pag
*/
public DemoAutoNewsCrawler(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/*start pages*/
this.addSeed("https://blog.github.com/");
for(int pageIndex = 2; pageIndex 查看全部
java爬虫抓取动态网页(WebCollector-Python项目开发者内核:WebCollectorx
)
爬虫简介:
WebCollector 是一个 Java 爬虫框架(内核),无需配置,方便二次开发。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎大家贡献代码:
爬虫内核:
WebCollector 致力于维护一个稳定可扩展的爬虫内核,方便开发者进行灵活的二次开发。内核扩展性强,用户可以基于内核开发自己的爬虫。源代码中集成了Jsoup,用于准确的网页分析。2.x 版本集成了 selenium,可以处理 JavaScript 生成的数据。
马文:
最新的Maven地址请参考文档:
文件地址:
内核架构图:
WebCollector 2.x 版本特点:
自定义遍历策略可以完成更复杂的遍历服务,比如分页,AJAX可以为每个URL设置附加信息(MetaData),利用附加信息完成很多复杂的服务,比如深度检索、锚文本检索、引用页面检索、POST参数传递、增量更新等。利用插件机制,用户可以自定义自己的Http请求、过滤器、执行器等插件。内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,比如搜索引擎的实时爬取。内置一套基于Berkeley DB(BreadthCrawler)的插件:适合处理长期、大规模的任务,并具有断点爬取功能,不会因宕机或关机造成数据丢失。集成selenium,可以提取JavaScript生成的信息,轻松定制http请求,内置多代理随机切换功能。可以通过定义http请求来实现模拟登录。使用slf4j作为日志门面,可以连接多种日志,使用类似Hadoop的Configuration机制为每个爬虫定制配置信息。
WebCollector 2.x 官网及镜像:
WebCollector 2.x 教程:
WebCollector 配置
WebCollector 入门
WebCollector 功能
WebCollector 持久化
WebCollector 高级爬虫定制
WebCollector 处理 Javascript
<p>import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
/**
* Crawling news from github news
*
* @author hu
*/
public class DemoAutoNewsCrawler extends BreadthCrawler {
/**
* @param crawlPath crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse if autoParse is true,BreadthCrawler will auto extract
* links which match regex rules from pag
*/
public DemoAutoNewsCrawler(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/*start pages*/
this.addSeed("https://blog.github.com/";);
for(int pageIndex = 2; pageIndex
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-28 02:04
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博文列表。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每个post都是一个小div,class="post_item"
然后就可以开始上代码了,Jsoup的核心代码如下(整体源码会在文末给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害了。从上面对首页html结构的分析,到Jsoup分析的代码的执行,关于这个的文章太多了这段时间的主页)
由于新文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上博客园首页文章列表案例分析的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
发表于@2019-05-25 16:08 JAVA开发新手阅读(...) 评论(...) 编辑 查看全部
java爬虫抓取动态网页(通过案例展示如何使用Jsoup进行解析案例中将获取博客园首页)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博文列表。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每个post都是一个小div,class="post_item"
然后就可以开始上代码了,Jsoup的核心代码如下(整体源码会在文末给出):
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人推荐选择方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害了。从上面对首页html结构的分析,到Jsoup分析的代码的执行,关于这个的文章太多了这段时间的主页)
由于新文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你的页面文本框中,如果你输入了html元素,保存后页面布局很有可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
public static void main(String[] args) {
String unsafe = "<p><a href='网址' onclick='stealCookies()'>博客园</a>";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p><a href='网址' onclick='stealCookies()'>博客园</a>
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上博客园首页文章列表案例分析的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
发表于@2019-05-25 16:08 JAVA开发新手阅读(...) 评论(...) 编辑
java爬虫抓取动态网页(基于微内核+插件式架构的Java语言开发网络爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2021-12-28 01:18
1、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
2、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
3、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——像风一样自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是将复杂的目标页面信息以简单的方式捕获并解析成它需要的业务数据。
4、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
5、Heritrix
github地址:internetarchive/heritrix3
Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
6、crawler4j
github地址:yasserg/crawler4j · GitHub
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
7、纳奇
github地址:apache/nutch
Nutch 是一个开源的 Java 搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,它已经成为大规模数据处理的事实上的标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
8、SeimiCrawler
github地址:zhegexiaohuozi/SeimiCrawler
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在SeimiCrawler的世界里,大部分人只需要关心写爬行的业务逻辑,剩下的Seimi会帮你处理。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler 的默认 HTML 解析器是 JsoupXpath(独立的扩展项目,不收录
在 jsoup 中),HTML 数据的默认解析和提取是使用 XPath 完成的(当然,您也可以选择其他解析器进行数据处理)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
9、Jsoup
github地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。 查看全部
java爬虫抓取动态网页(基于微内核+插件式架构的Java语言开发网络爬虫)
1、格科
github地址:xtuhcy/gecco
Gecco是一个用java语言开发的轻量级易用的网络爬虫。集成了jsoup、httpclient、fastjson、spring、htmlunit、redission等框架,只需要配置一些jquery风格的选择器即可快速编写爬虫。Gecco 框架具有出色的可扩展性。框架按照开闭原则设计,封闭用于修改,开放用于扩展。
2、WebCollector
github地址:CrawlScript/WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,可以用少量的代码实现强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
3、蜘蛛侠
码云地址:l-weiwei/Spiderman2-码云-开源中国
用例:展示垂直爬虫的能力——像风一样自由
蜘蛛侠是一个基于微内核+插件架构的网络蜘蛛。它的目标是将复杂的目标页面信息以简单的方式捕获并解析成它需要的业务数据。
4、WebMagic
码云地址:flashsword20/webmagic-码云-中国开源
webmagic是一个爬虫框架,不需要配置,方便二次开发。提供简单灵活的API,少量代码即可实现爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,支持自动重试和自定义UA/Cookies等功能。
5、Heritrix
github地址:internetarchive/heritrix3
Heritrix 是一个开源、可扩展的网络爬虫项目。用户可以使用它从互联网上获取他们想要的资源。Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。其最突出的特点是良好的扩展性,方便用户实现自己的抓取逻辑。
6、crawler4j
github地址:yasserg/crawler4j · GitHub
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
7、纳奇
github地址:apache/nutch
Nutch 是一个开源的 Java 搜索引擎。它提供了我们运行自己的搜索引擎所需的所有工具。包括全文搜索和网络爬虫。
在 Nutch 的发展过程中,产生了四个 Java 开源项目,Hadoop、Tika、Gora 和 Crawler Commons。现在这四个项目发展迅速,非常火爆,尤其是Hadoop,它已经成为大规模数据处理的事实上的标准。Tika 使用各种现有的开源内容分析项目从多种格式的文件中提取元数据和结构化文本。Gora 支持将大数据持久化到多个存储实现。Crawler Commons 是一个通用的网络爬虫组件。.
8、SeimiCrawler
github地址:zhegexiaohuozi/SeimiCrawler
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在SeimiCrawler的世界里,大部分人只需要关心写爬行的业务逻辑,剩下的Seimi会帮你处理。在设计上,SeimiCrawler 的灵感来自于 Python 的爬虫框架 Scrapy,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler 的默认 HTML 解析器是 JsoupXpath(独立的扩展项目,不收录
在 jsoup 中),HTML 数据的默认解析和提取是使用 XPath 完成的(当然,您也可以选择其他解析器进行数据处理)。并结合SeimiAgent,彻底解决复杂的动态页面渲染和爬取问题。
9、Jsoup
github地址:jhy/jsoup
中文指南:jsoup开发指南、jsoup中文文档
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
java爬虫抓取动态网页(MyBatis的框架设计(一)——MyBatis接口设计)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-28 01:17
一、MyBatis 的框架设计
注:上图主要参考了iteye上chenjc_it写的博文【原理解析二:整体框架设计】中的MyBatis架构图。chenjc_it总结的很好,赞一个!
1.接口层——与数据库交互的方式
MyBatis 与数据库的交互有两种方式:
一个。使用MyBatis提供的传统API;
湾 使用 Mapper 接口
1.1. 使用MyBatis提供的传统API
这是传统的将Statement Id和查询参数传递给SqlSession对象的方式,利用SqlSession对象完成与数据库的交互;MyBatis 提供了非常方便简单的 API 供用户对数据库进行数据的增删改查操作,以及数据库连接信息和 MyBatis 自身配置信息的维护操作。
上面使用MyBatis的方法是创建一个与数据库交互的SqlSession对象,然后根据StatementId和参数对数据库进行操作。这种方法简单实用,但不符合面向对象语言和面向接口编程的概念。习惯。由于面向接口编程是一个普遍的面向对象趋势,MyBatis为了适应这种趋势,增加了第二种使用MyBatis的方式来支持接口(Interface)。
1.2. 使用 Mapper 接口
MyBatis 会配置每个文件
按照MyBatis配置规范配置后,通过SqlSession.getMapper(XXXMapper.class)方法,MyBatis会根据对应接口声明的方法信息,通过动态代理机制生成一个Mapper实例。当我们使用Mapper接口的一个方法时,MyBatis会根据这个方法的方法名和参数类型来确定StatementId,底层还是通过SqlSession.select("statementId",parameterObject); 或 SqlSession.update("statementId",parameterObject); 等实现对数据库的操作,(至于动态机制这里是怎么实现的,我会专门准备一篇文章来讨论,敬请期待~)
MyBatis 引用这个 Mapper 接口的调用方法,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是面向接口的编程允许用户使用注解在接口上配置SQL语句,从而脱离XML配置文件,实现“0配置”)。
2.数据处理层
数据处理层可以说是MyBatis的核心。大体来说,它必须完成三个功能:
一个。通过传入参数构造动态SQL语句;
湾 SQL语句执行和打包查询结果集成列表
2.1. 参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的设计。MyBatis 使用 Ognl 通过传入的参数值动态构造 SQL 语句,使得 MyBatis 具有高度的灵活性和可扩展性。
参数映射是指java数据类型和jdbc数据类型的转换:这里有两个过程:在查询阶段,我们需要通过preparedStatement.setXXX()将java类型数据转换成jdbc类型数据,设置值;另一种是将resultset查询的结果集的jdbcType数据转换成java数据类型。
(至于具体MyBatis是如何动态构造SQL语句的,我会专门准备一篇文章来讨论,敬请期待~)
2.2. SQL 语句执行和打包查询结果集成列表
动态SQL语句生成后,MyBatis会执行SQL语句,将可能返回的结果集转换成List3.框架支持层
3.1. 交易管理机制
事务管理机制是ORM框架不可或缺的一部分,事务管理机制的好坏也是衡量一个ORM框架是否优秀的标准。
3.2. 连接池管理机制
由于创建数据库连接需要比较大的资源,对于数据吞吐量大、访问量非常大的应用来说,连接池的设计非常重要。
3.3. 缓存机制
为了提高数据利用率,降低服务器和数据库的压力,MyBatis 会为一些查询提供会话级的数据缓存,并将某个查询放在 SqlSession 中。在允许的时间间隔内,对于完全相同的查询,MyBatis 会直接将缓存的结果返回给用户,无需在数据库中搜索。(至于具体的MyBatis缓存机制,我会专门准备一篇文章来讨论,敬请期待~)
如何配置SQL语句
MyBatis 中传统的 SQL 语句配置方式是使用 XML 文件进行配置,但是这种方式不能很好地支持面向接口编程的概念。为了支持面向接口编程,MyBatis引入了Mapper接口的概念,引入了面向接口,可以使用注解来配置SQL语句。用户只需在界面上添加必要的注解,无需配置XML文件。但是,目前的 MyBatis 仅对注解配置 SQL 语句提供了有限的支持。高级功能仍然依赖 XML 配置文件来配置 SQL 语句。
4 引导层
boot层是配置和启动MyBatis配置信息的方式。MyBatis 提供了两种方式来引导 MyBatis:基于 XML 配置文件的方法和基于 Java API 的方法。
二、MyBatis 的主要组件及其关系
从MyBatis代码实现来看,MyBatis的主要核心组件如下:
(注:这里只是列出我个人认为是核心组件的组件。读者不要先入为主,认为MyBatis只有这些组件!每个人对MyBatis的理解不同,分析的结果自然会是不同。欢迎读者提出问题和不同意见,我们一起讨论~)
最后
我也采集
了Java面试核心知识点的合集来应对面试。我可以借此机会免费赠送给我的读者和朋友:
内容:
Java面试核心知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
Java面试核心知识点
知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
[外链图片正在传输中...(img-cn5P52fp-53)]
Java面试核心知识点
获取方式:点击喜欢【戳面试信息】后,即可免费获取! 查看全部
java爬虫抓取动态网页(MyBatis的框架设计(一)——MyBatis接口设计)
一、MyBatis 的框架设计
注:上图主要参考了iteye上chenjc_it写的博文【原理解析二:整体框架设计】中的MyBatis架构图。chenjc_it总结的很好,赞一个!
1.接口层——与数据库交互的方式
MyBatis 与数据库的交互有两种方式:
一个。使用MyBatis提供的传统API;
湾 使用 Mapper 接口
1.1. 使用MyBatis提供的传统API
这是传统的将Statement Id和查询参数传递给SqlSession对象的方式,利用SqlSession对象完成与数据库的交互;MyBatis 提供了非常方便简单的 API 供用户对数据库进行数据的增删改查操作,以及数据库连接信息和 MyBatis 自身配置信息的维护操作。
上面使用MyBatis的方法是创建一个与数据库交互的SqlSession对象,然后根据StatementId和参数对数据库进行操作。这种方法简单实用,但不符合面向对象语言和面向接口编程的概念。习惯。由于面向接口编程是一个普遍的面向对象趋势,MyBatis为了适应这种趋势,增加了第二种使用MyBatis的方式来支持接口(Interface)。
1.2. 使用 Mapper 接口
MyBatis 会配置每个文件
按照MyBatis配置规范配置后,通过SqlSession.getMapper(XXXMapper.class)方法,MyBatis会根据对应接口声明的方法信息,通过动态代理机制生成一个Mapper实例。当我们使用Mapper接口的一个方法时,MyBatis会根据这个方法的方法名和参数类型来确定StatementId,底层还是通过SqlSession.select("statementId",parameterObject); 或 SqlSession.update("statementId",parameterObject); 等实现对数据库的操作,(至于动态机制这里是怎么实现的,我会专门准备一篇文章来讨论,敬请期待~)
MyBatis 引用这个 Mapper 接口的调用方法,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是面向接口的编程允许用户使用注解在接口上配置SQL语句,从而脱离XML配置文件,实现“0配置”)。
2.数据处理层
数据处理层可以说是MyBatis的核心。大体来说,它必须完成三个功能:
一个。通过传入参数构造动态SQL语句;
湾 SQL语句执行和打包查询结果集成列表
2.1. 参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的设计。MyBatis 使用 Ognl 通过传入的参数值动态构造 SQL 语句,使得 MyBatis 具有高度的灵活性和可扩展性。
参数映射是指java数据类型和jdbc数据类型的转换:这里有两个过程:在查询阶段,我们需要通过preparedStatement.setXXX()将java类型数据转换成jdbc类型数据,设置值;另一种是将resultset查询的结果集的jdbcType数据转换成java数据类型。
(至于具体MyBatis是如何动态构造SQL语句的,我会专门准备一篇文章来讨论,敬请期待~)
2.2. SQL 语句执行和打包查询结果集成列表
动态SQL语句生成后,MyBatis会执行SQL语句,将可能返回的结果集转换成List3.框架支持层
3.1. 交易管理机制
事务管理机制是ORM框架不可或缺的一部分,事务管理机制的好坏也是衡量一个ORM框架是否优秀的标准。
3.2. 连接池管理机制
由于创建数据库连接需要比较大的资源,对于数据吞吐量大、访问量非常大的应用来说,连接池的设计非常重要。
3.3. 缓存机制
为了提高数据利用率,降低服务器和数据库的压力,MyBatis 会为一些查询提供会话级的数据缓存,并将某个查询放在 SqlSession 中。在允许的时间间隔内,对于完全相同的查询,MyBatis 会直接将缓存的结果返回给用户,无需在数据库中搜索。(至于具体的MyBatis缓存机制,我会专门准备一篇文章来讨论,敬请期待~)
如何配置SQL语句
MyBatis 中传统的 SQL 语句配置方式是使用 XML 文件进行配置,但是这种方式不能很好地支持面向接口编程的概念。为了支持面向接口编程,MyBatis引入了Mapper接口的概念,引入了面向接口,可以使用注解来配置SQL语句。用户只需在界面上添加必要的注解,无需配置XML文件。但是,目前的 MyBatis 仅对注解配置 SQL 语句提供了有限的支持。高级功能仍然依赖 XML 配置文件来配置 SQL 语句。
4 引导层
boot层是配置和启动MyBatis配置信息的方式。MyBatis 提供了两种方式来引导 MyBatis:基于 XML 配置文件的方法和基于 Java API 的方法。
二、MyBatis 的主要组件及其关系
从MyBatis代码实现来看,MyBatis的主要核心组件如下:
(注:这里只是列出我个人认为是核心组件的组件。读者不要先入为主,认为MyBatis只有这些组件!每个人对MyBatis的理解不同,分析的结果自然会是不同。欢迎读者提出问题和不同意见,我们一起讨论~)
最后
我也采集
了Java面试核心知识点的合集来应对面试。我可以借此机会免费赠送给我的读者和朋友:
内容:
Java面试核心知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
Java面试核心知识点
知识点
一共30个话题,足够读者朋友应付面试,省去朋友找资料和整理的时间!
[外链图片正在传输中...(img-cn5P52fp-53)]
Java面试核心知识点
获取方式:点击喜欢【戳面试信息】后,即可免费获取!
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-12-27 21:19
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-12-27 21:16
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-12-27 21:12
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息, 查看全部
java爬虫抓取动态网页(新浪微博中模拟抓取网页内容,采集网页的内容模拟)
python爬虫模拟爬取网页内容,采集网页内容。这个主要是模拟新浪微博的内容,包括【源码】抓取客户端微博信息,【源码】抓取手机端个人信息id和粉丝id(速度慢),【源码】抓取手机端微博信息(强制推送)等很多例子,运行这个例子的一些注意事项: 1. 先安装Python环境,作者是Python 2.7.8 2. 然后安装PIP或者easy_install 3. 通过命令pip install selenium安装selenium,这是一个自动测试爬取的工具4.然后修改代码在用户名和密码中填写自己的用户名和密码5. 运行程序,自动调用火狐浏览器登录微博。注:手机端的信息更加精致简洁,动态加载没有限制,但是比如微博或者粉丝id只显示20页,这是它的缺点;虽然客户端可能有动态加载,比如评论、微博,但是它的信息更完整。注:输入:名人用户id列表,使用URL用户id访问(这些id可以从用户的关注列表中获取) SinaWeibo_List_best_1.txt 输出:微博信息和用户基本信息 SinaWeibo_Info_best_1.@ >txt megry_Result_Best.py 这个文件用户整理了某一天的用户微博信息,比如爬取2018年4月23日的客户端信息,
java爬虫抓取动态网页(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-12-27 15:17
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]} 查看全部
java爬虫抓取动态网页(Chrome浏览器插件WebScraper可轻松实现网页数据的爬取)
Chrome浏览器插件Web Scraper可以轻松抓取网页数据,无需考虑爬虫中的登录、验证码、异步加载等复杂问题。
先粘贴爬虫58数据的sitemap如下:
{"_id":"hefeitongcheng","startUrl":[";ClickID=1"],"selectors":[{"id":"click","type":"SelectorElementClick","parentSelectors" :["_root"],"selector":".list-main-style li","multiple":true,"delay":"5000","clickElementSelector":"strong span","clickType":"clickMore ","discardInitialElements":"do-not-discard","clickElementUniquenessType":"uniqueText"},{"id":"link","type":"SelectorLink","parentSelectors":["click"], "selector":".title a","multiple":false,"delay":0},{"id":"name","type":"SelectorText","parentSelectors":["link"], "selector":"h1","multiple":false,"regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":[ "link"],"selector":".house_basic_title_money span","multiple":false,"regex":"","delay":0},{"id":"add","type":"SelectorText ","parentSelectors":["link"],"selector":"p.p_2","multiple":false,"regex":"","delay":0}]}
Web Scraper 爬取过程及要点:
安装Web Scraper插件后,抓取操作分三步完成
1、新建站点地图(创建爬虫项目)
2、选择抓取网页中的内容,点击~点击~点击,操作
3、启用抓取和下载CSV数据
最关键的一步是第二步,主要有两点:
首先选择数据块Element,我们获取页面上的每个数据块,所有这些都是重复的。在数据块中选择Multiple,然后获取所需的数据字段(上面Excel中的列)
爬取大量数据的重点是掌握分页的控制。
分页分为3种情况:
1. URL 参数分页(比较组织) ?page=2 或 ?page=[1-27388]
2.向下滚动,点击“加载更多”加载页面数据元素向下滚动
3.点击页面的数字标签(包括“下一页”标签)链接或元素点击
其他例子A:jd爬上hw p30价格信息
{"_id":"huaweip30","startUrl":[";enc=utf-8&wq=%E5%8D%8E%E4%B8%BAp30%20512&pvid=ed449bf16e44461fac90ff6fae2e66cd"][ "id":"element","type":"SelectorElementClick","parentSelectors":["_root"],"selector":"div.gl-i-wrap","multiple":true,"delay": "1500","clickElementSelector":".p-num a:nth-of-type(3)","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType ":"uniqueText"},{"id":"name","type":"SelectorText","parentSelectors":["element"],"selector":"a em","multiple":false," regex":"","delay":0},{"id":"jiage","type":"SelectorText","parentSelectors":["element"],"selector":"div.p-price ","multiple":false,"regex":"","delay":0}]}
其他例子B:爬上百度关键词信息
{ "_id": "wailaizhu", "startUrl": [ "; pn = 0 & oq = wailaizhu% 20h0101 & tn = baiduhome_pg & ie = utf-8 & rsv_idx = 2 & rsv_pq = f62d1151tv_f0 5b15EoMWRlm3% 2BeroyWXBKI% 2FDZ3H0BlGKJ6lNa6mmYBo4nNDUeJNeeN8BvgiE9S9Orivd"], "选择器": [ {"id":"element","type":"SelectorElementClick","parent_selector"],"div_selector":"[" "multiple":true,"delay":"1500","clickElementSelector":"aspan.pc","clickType":"clickOnce","discardInitialElements":"do-not-discard","clickElementUniquenessType":" uniqueText"},{"id":"name", "type":"SelectorText","parentSelectors":["element"],"selector":"a","multiple":false,"regex":" ","delay":0},{"id":"body","type":"SelectorText","parentSelectors":["element"],"selector":"_parent_","multiple":false, "regex":"","delay":0} ]}
java爬虫抓取动态网页(java爬虫抓取动态网页,模拟浏览器发起请求后获取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-12-25 23:01
java爬虫抓取动态网页,模拟浏览器发起http请求后,获取抓取。本文博主在日常工作中,一直都在使用python抓取各种网页信息,下面做一个总结,希望对大家有所帮助。
1、python抓取方法:
1)、代码集锦:通过代码集训练实践学习、运用,尽可能抓取到更多高质量的网页。如:urllib2+cookie、urllib、requests、正则表达式、selenium等,当然其它的也可以抓取,这要看个人情况。抓取方法方法如下:第一种:div.urlopen(page_name)第二种:a['a'].read().decode("utf-8")第三种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。
第四种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。div.urlopen()方法抓取页面,然后再f12,可以看到抓取到的网页。(。
2)、http3文件:get方法抓取文件方法如下:第一种:a.postb.post第二种:data:name='congyou'body=''prefix="/book"self.answer="xxx"post方法第一种:method参数返回json格式,返回数据data。self.answer=none。
第二种:https:通过ssl握手第三种:data:url.post,返回data值,格式:url,string格式第四种:post方法获取数据,格式为urlurl.post方法:代码如下:post方法,通过url来获取对应的数据源页面。post方法,data参数要求设置为''。(。
3)、python文件一:不推荐:如果你是新手使用,可以使用抓包工具进行抓取,如:fiddler,wireshark。看网页源代码比较慢,推荐使用抓包工具进行抓取,推荐使用下面软件,例如fiddler进行抓取,安装actionscreenpro6actionscreenpro6官网下载,解压即可使用。(。
4)、python文件二:不推荐的方法,如:运行时刻需要加壳工具。根据代码解析抓取对应的exe文件,例如driver3.exe。downloadfilesfromfiddler或者fiddler下载,然后加壳即可。
5)、python文件三:建议方法:利用js获取。抓取twitter站内数据,正则表达式来解析。获取豆瓣feed信息,
6)、python文件四:建议方法:除了js抓取,还有python可以利用ajax抓取,例如:get/get。py/view。pyjs文件正则表达式抓取抓取链接,详细如下:/woai。py#!/usr/bin/envpythonimportrequestsimportredefget_content(url):response=requests。get(url)soup=beautifulsoup(。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页,模拟浏览器发起请求后获取)
java爬虫抓取动态网页,模拟浏览器发起http请求后,获取抓取。本文博主在日常工作中,一直都在使用python抓取各种网页信息,下面做一个总结,希望对大家有所帮助。
1、python抓取方法:
1)、代码集锦:通过代码集训练实践学习、运用,尽可能抓取到更多高质量的网页。如:urllib2+cookie、urllib、requests、正则表达式、selenium等,当然其它的也可以抓取,这要看个人情况。抓取方法方法如下:第一种:div.urlopen(page_name)第二种:a['a'].read().decode("utf-8")第三种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。
第四种:div.urlopen(url)div.urlopen(url)div.urlopen("xxx")。div.urlopen()方法抓取页面,然后再f12,可以看到抓取到的网页。(。
2)、http3文件:get方法抓取文件方法如下:第一种:a.postb.post第二种:data:name='congyou'body=''prefix="/book"self.answer="xxx"post方法第一种:method参数返回json格式,返回数据data。self.answer=none。
第二种:https:通过ssl握手第三种:data:url.post,返回data值,格式:url,string格式第四种:post方法获取数据,格式为urlurl.post方法:代码如下:post方法,通过url来获取对应的数据源页面。post方法,data参数要求设置为''。(。
3)、python文件一:不推荐:如果你是新手使用,可以使用抓包工具进行抓取,如:fiddler,wireshark。看网页源代码比较慢,推荐使用抓包工具进行抓取,推荐使用下面软件,例如fiddler进行抓取,安装actionscreenpro6actionscreenpro6官网下载,解压即可使用。(。
4)、python文件二:不推荐的方法,如:运行时刻需要加壳工具。根据代码解析抓取对应的exe文件,例如driver3.exe。downloadfilesfromfiddler或者fiddler下载,然后加壳即可。
5)、python文件三:建议方法:利用js获取。抓取twitter站内数据,正则表达式来解析。获取豆瓣feed信息,
6)、python文件四:建议方法:除了js抓取,还有python可以利用ajax抓取,例如:get/get。py/view。pyjs文件正则表达式抓取抓取链接,详细如下:/woai。py#!/usr/bin/envpythonimportrequestsimportredefget_content(url):response=requests。get(url)soup=beautifulsoup(。

