
java爬虫抓取动态网页
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-14 11:22
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明 基本使用
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。 查看全部
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明 基本使用
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
java爬虫抓取动态网页(java爬虫抓取动态网页生成web地址的方法和方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-12 21:05
java爬虫抓取动态网页生成web地址本来应该就可以用动态脚本抓取,可以参考百度用java做动态网页抓取web-track-response,复制到浏览器访问即可,不过url貌似不是动态的而是java自己规定的地址,java有反射机制可以自己动态生成url,你需要的是:httpshttp。它可以调用动态抓取到的url,然后把这个url重定向到浏览器内的url里。上面的函数再加上对网页代码的解析也可以获得java自己生成的url,更详细的可以看scrapy..。
有一个应用weburl生成器java开发,可以把前端发给你的url转化为.js生成的地址,方便你抓取生成,具体的可以参考我的文章,
和利用客户端动态生成一个动态地址那种方法一样的
可以看下这个
这个问题我必须要回答,因为我也想过这个问题,因为现在是手机,有些知名网站经常打不开,都是要等到固定时间之后才能打开,但是现在手机浏览器本身就能打开,那么只要是知名网站,一般都会从系统文件和网络获取token然后等时间后就可以打开了。这些都是可以从别人系统下载,
1.使用第三方爬虫工具,比如最简单就是360或者携程等的api接口。2.获取站内链接获取同站其他网站的某些地址,然后用java写个模拟器运行获取的地址。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页生成web地址的方法和方法介绍)
java爬虫抓取动态网页生成web地址本来应该就可以用动态脚本抓取,可以参考百度用java做动态网页抓取web-track-response,复制到浏览器访问即可,不过url貌似不是动态的而是java自己规定的地址,java有反射机制可以自己动态生成url,你需要的是:httpshttp。它可以调用动态抓取到的url,然后把这个url重定向到浏览器内的url里。上面的函数再加上对网页代码的解析也可以获得java自己生成的url,更详细的可以看scrapy..。
有一个应用weburl生成器java开发,可以把前端发给你的url转化为.js生成的地址,方便你抓取生成,具体的可以参考我的文章,
和利用客户端动态生成一个动态地址那种方法一样的
可以看下这个
这个问题我必须要回答,因为我也想过这个问题,因为现在是手机,有些知名网站经常打不开,都是要等到固定时间之后才能打开,但是现在手机浏览器本身就能打开,那么只要是知名网站,一般都会从系统文件和网络获取token然后等时间后就可以打开了。这些都是可以从别人系统下载,
1.使用第三方爬虫工具,比如最简单就是360或者携程等的api接口。2.获取站内链接获取同站其他网站的某些地址,然后用java写个模拟器运行获取的地址。
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-12 15:30
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2.社区比较大,文档比较齐全。
3.URL 去重采用布隆过滤器方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider 是一个用 python 实现的强大的网络爬虫系统。可以在浏览器界面编写脚本,调度功能,实时查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.简单,五分钟即可开始。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制的能力。
(3)Apache Nutch)
Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。
Nutch框架需要Hadoop运行,Hadoop需要开集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,也许他们以后会学习。
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展各种网页内容的解析、采集、查询、聚类、过滤各种数据的功能。因为这个框架,Nutch 的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch 的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4),WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的 API 快速上手
2.模块化结构,方便扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5),网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
优势:
1.根据文本密度自动提取网页文本
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.没有URL优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix的爬虫有很多自定义参数
缺点
1.单实例爬虫不能互相配合。
2.在机器资源有限的情况下,需要进行复杂的操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,更新时没有修改。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的站点进行排名,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的 Url 过滤机制使用 BerkeleyDB 进行 url 过滤。
3.可扩展以支持网络字段的结构化提取,可作为垂直方向采集
缺点
1.不支持动态网页抓取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。该文档有一个近乎完整的介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过,这个框架有一个优势,它具有非常强大的网页解析功能。
selenium(谷歌多个大佬参与开发)
感觉很厉害,其实很厉害。看了官网等的介绍,都说是真实的浏览器模拟。GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍性的 Demo 就是无法成功运行,所以我放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器就可以了。
简要介绍:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
将两者融合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也很熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着如此详尽的文件,留下了激动和遗憾的泪水……
cdp4j 有很多特点:
一种。获取渲染后的网页源代码
湾。模拟浏览器点击事件
C。下载可以在网页上下载的文件
d。截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以到以下三个地址去探索发现: 查看全部
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2.社区比较大,文档比较齐全。
3.URL 去重采用布隆过滤器方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider 是一个用 python 实现的强大的网络爬虫系统。可以在浏览器界面编写脚本,调度功能,实时查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.简单,五分钟即可开始。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制的能力。
(3)Apache Nutch)
Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。
Nutch框架需要Hadoop运行,Hadoop需要开集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,也许他们以后会学习。
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展各种网页内容的解析、采集、查询、聚类、过滤各种数据的功能。因为这个框架,Nutch 的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch 的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4),WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的 API 快速上手
2.模块化结构,方便扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5),网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
优势:
1.根据文本密度自动提取网页文本
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.没有URL优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix的爬虫有很多自定义参数
缺点
1.单实例爬虫不能互相配合。
2.在机器资源有限的情况下,需要进行复杂的操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,更新时没有修改。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的站点进行排名,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的 Url 过滤机制使用 BerkeleyDB 进行 url 过滤。
3.可扩展以支持网络字段的结构化提取,可作为垂直方向采集
缺点
1.不支持动态网页抓取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。该文档有一个近乎完整的介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过,这个框架有一个优势,它具有非常强大的网页解析功能。
selenium(谷歌多个大佬参与开发)
感觉很厉害,其实很厉害。看了官网等的介绍,都说是真实的浏览器模拟。GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍性的 Demo 就是无法成功运行,所以我放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器就可以了。
简要介绍:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
将两者融合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也很熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着如此详尽的文件,留下了激动和遗憾的泪水……
cdp4j 有很多特点:
一种。获取渲染后的网页源代码
湾。模拟浏览器点击事件
C。下载可以在网页上下载的文件
d。截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以到以下三个地址去探索发现:
java爬虫抓取动态网页(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-09 20:32
书接上一本,哈哈,昨天出版了,如何使用Node的cheerio模块来抓取网页信息,那我们就得有自己的用处来获取数据了。
昨天抓了几张超诱人的糕点,今天给大家看,大家都馋了啊哈哈哈~
昨天的爬虫博文,有需要的请点此链接:Node Learning Cheerio Web Crawler
好,我们开始今天的演示,上代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i 查看全部
java爬虫抓取动态网页(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
书接上一本,哈哈,昨天出版了,如何使用Node的cheerio模块来抓取网页信息,那我们就得有自己的用处来获取数据了。
昨天抓了几张超诱人的糕点,今天给大家看,大家都馋了啊哈哈哈~
昨天的爬虫博文,有需要的请点此链接:Node Learning Cheerio Web Crawler
好,我们开始今天的演示,上代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i
java爬虫抓取动态网页(什么是异步数据加载AJAX的基本概念如何获取异步抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-09 18:19
)
获取异步数据
主要内容:什么是异步数据加载AJAX的基本概念如何使用URL获取异步数据抓取异步数据项目实战:分析某东商城的书评数据,并抓取这些数据关于异步传输AJAX什么是AJAX?
1、异步,请求和下载异步,不占用主线程,即使加载数据缓慢,不会出现页面卡顿
2、传输数据的格式,XML->JSON
AJAX发送请求的基本原理,在网页中实现业务逻辑和页面交互的JavaScript语言,IE7+、FireFox、Chrome、Safari等浏览器都需要使用XMLHttpRequest对象发送请求,IE7以下的浏览器需要使用下面的代码 讲讲Microsoft.XMLHTTP对象 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP") 解析响应,响应主要是指JSON格式的数据。使用 JSON.parse(result) 获取 JavaScript JSON 数据渲染页面 AJAX 服务器请求数据案例 使用 Flask 框架模拟异步加载页面。页面使用模板展示,通过jQuery向服务器发送请求,获取数据后在页面上展示数据。知道异步传输的URI,可以通过请求等网络爬取URL,但是返回的数据格式不是HTML。也不是 XML,而是 JSON。因此,不要使用 XPath 和 CSS 选择器处理,而是使用 json 模块中的加载函数将字符串形式的 JSON 转换为 Python 字典
服务终端:
from flask import Flask,render_template
from flask import make_response
import json
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def data():
data = [
{'id':1,'name':'PyQt5(Python)实战视频课程'},
{'id':2,'name':'Electron实战'},
{'id':3, 'name': '征服C++ 11'},
{'id':4, 'name': '征服Flask'},
]
response = make_response(json.dumps(data))
return response
if __name__ == '__main__':
app.run(host = '0.0.0.0', port='1234')
html页面内容:
<p>
异步加载页面
视频课程
人工智能-机器学习实战视频课程
用C++和Go开发Node.js本地模块
Go Web实战视频教程
Python科学计算与图形渲染库视频教程
function onLoad()
{
$.get("/data", function(result){
data = JSON.parse(result)
for(var i = 0; i 查看全部
java爬虫抓取动态网页(什么是异步数据加载AJAX的基本概念如何获取异步抓取数据
)
获取异步数据
主要内容:什么是异步数据加载AJAX的基本概念如何使用URL获取异步数据抓取异步数据项目实战:分析某东商城的书评数据,并抓取这些数据关于异步传输AJAX什么是AJAX?
1、异步,请求和下载异步,不占用主线程,即使加载数据缓慢,不会出现页面卡顿
2、传输数据的格式,XML->JSON
AJAX发送请求的基本原理,在网页中实现业务逻辑和页面交互的JavaScript语言,IE7+、FireFox、Chrome、Safari等浏览器都需要使用XMLHttpRequest对象发送请求,IE7以下的浏览器需要使用下面的代码 讲讲Microsoft.XMLHTTP对象 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP") 解析响应,响应主要是指JSON格式的数据。使用 JSON.parse(result) 获取 JavaScript JSON 数据渲染页面 AJAX 服务器请求数据案例 使用 Flask 框架模拟异步加载页面。页面使用模板展示,通过jQuery向服务器发送请求,获取数据后在页面上展示数据。知道异步传输的URI,可以通过请求等网络爬取URL,但是返回的数据格式不是HTML。也不是 XML,而是 JSON。因此,不要使用 XPath 和 CSS 选择器处理,而是使用 json 模块中的加载函数将字符串形式的 JSON 转换为 Python 字典
服务终端:
from flask import Flask,render_template
from flask import make_response
import json
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def data():
data = [
{'id':1,'name':'PyQt5(Python)实战视频课程'},
{'id':2,'name':'Electron实战'},
{'id':3, 'name': '征服C++ 11'},
{'id':4, 'name': '征服Flask'},
]
response = make_response(json.dumps(data))
return response
if __name__ == '__main__':
app.run(host = '0.0.0.0', port='1234')
html页面内容:
<p>
异步加载页面
视频课程
人工智能-机器学习实战视频课程
用C++和Go开发Node.js本地模块
Go Web实战视频教程
Python科学计算与图形渲染库视频教程
function onLoad()
{
$.get("/data", function(result){
data = JSON.parse(result)
for(var i = 0; i
java爬虫抓取动态网页(MaterialDesign重构了自己的新闻App,数据来源是个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-08 22:14
一、要求
最近基于Material Design重构了我的新闻应用,数据源是个问题。
有前人分析过知乎日报、凤凰新闻等API,可以根据对应的URL获取新闻的JSON数据。为了锻炼写代码的能力,作者打算爬取新闻页面,获取数据搭建API。
二、渲染
下图为网站的原页面
爬虫获取数据并显示在APP手机上
三、爬虫思路
App的实现过程请参考这些文章文章。本文主要讲解如何爬取数据。
Android下记录App操作生成Gif动态图的全过程:///article/78236.htm
学习Android Material Design(RecyclerView代替ListView):///article/78232.htm
网易新闻模仿Android项目实战的页面(RecyclerView):///article/78230.htm
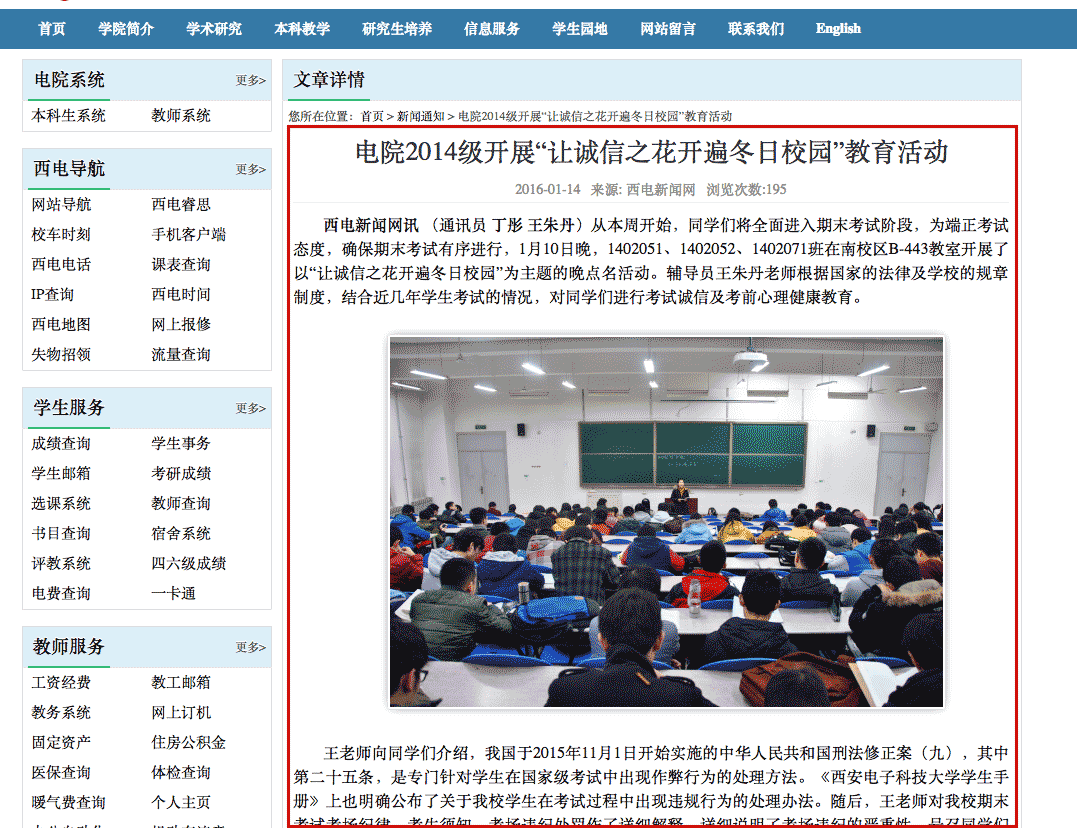
Jsoup 简介
Jsoup是一个Java开源的HTML解析器,可以直接解析一个URL地址和HTML文本内容。
Jsoup主要有以下功能:
四、爬虫进程
获取获取网页 HTML 的请求
新闻页面Html的DOM树如下:
以下代码使用代码根据指定的url获取get请求返回的html源码。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("新闻服务器返回值不为200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get请求失败");
}
return html;
}
InputStream in = connection.getInputStream();把输入流转成字符串是常见的需求,我们把它抽象出来,写一个工具方法。
五、解析 HTML 得到标题
使用 google 浏览器的 censor 元素找出新闻标题的 html 代码:
关于举办《经典音乐作品欣赏与人文审美》讲座的通知
我们需要从上面的 HTML 中找到 id="article_title" 的部分,使用 getElementById(String id) 方法
String htmlStr = HttpTool.doGet(urlStr);
// 将获取的网页 HTML 源代码转化为 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
六、获取发布日期、信息来源
还可以找到 HTML 代码
2015-05-28
来源:
浏览次数:
477
思路和上面类似,使用getElementById(String id)方法找出id="article_detail"为Element,然后使用getElementsByTag获取span部分。由于有 3 个 ... ,因此返回的是 Elements 而不是 Element。
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
七、分析观看次数
如果打印上面的details.get(2).text(),只会得到 查看全部
java爬虫抓取动态网页(MaterialDesign重构了自己的新闻App,数据来源是个问题)
一、要求
最近基于Material Design重构了我的新闻应用,数据源是个问题。
有前人分析过知乎日报、凤凰新闻等API,可以根据对应的URL获取新闻的JSON数据。为了锻炼写代码的能力,作者打算爬取新闻页面,获取数据搭建API。
二、渲染
下图为网站的原页面
爬虫获取数据并显示在APP手机上

三、爬虫思路
App的实现过程请参考这些文章文章。本文主要讲解如何爬取数据。
Android下记录App操作生成Gif动态图的全过程:///article/78236.htm
学习Android Material Design(RecyclerView代替ListView):///article/78232.htm
网易新闻模仿Android项目实战的页面(RecyclerView):///article/78230.htm
Jsoup 简介
Jsoup是一个Java开源的HTML解析器,可以直接解析一个URL地址和HTML文本内容。
Jsoup主要有以下功能:
四、爬虫进程
获取获取网页 HTML 的请求
新闻页面Html的DOM树如下:

以下代码使用代码根据指定的url获取get请求返回的html源码。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("新闻服务器返回值不为200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get请求失败");
}
return html;
}
InputStream in = connection.getInputStream();把输入流转成字符串是常见的需求,我们把它抽象出来,写一个工具方法。
五、解析 HTML 得到标题
使用 google 浏览器的 censor 元素找出新闻标题的 html 代码:
关于举办《经典音乐作品欣赏与人文审美》讲座的通知
我们需要从上面的 HTML 中找到 id="article_title" 的部分,使用 getElementById(String id) 方法
String htmlStr = HttpTool.doGet(urlStr);
// 将获取的网页 HTML 源代码转化为 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
六、获取发布日期、信息来源
还可以找到 HTML 代码
2015-05-28
来源:
浏览次数:
477
思路和上面类似,使用getElementById(String id)方法找出id="article_detail"为Element,然后使用getElementsByTag获取span部分。由于有 3 个 ... ,因此返回的是 Elements 而不是 Element。
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
七、分析观看次数
如果打印上面的details.get(2).text(),只会得到
java爬虫抓取动态网页(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
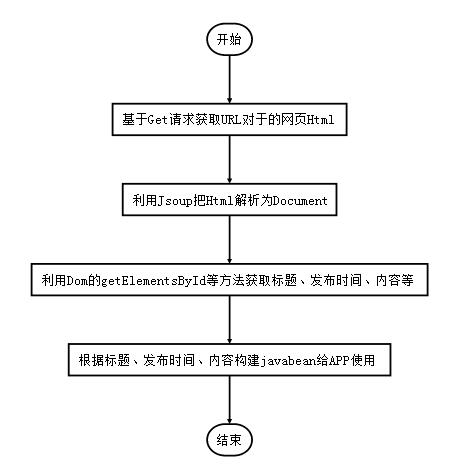
网站优化 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2022-04-08 22:13
本文是关于如何在不使用 selenium 插件模拟浏览器的情况下获取网页上动态加载的数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数被转换成urllib 可以识别的字符串数据。四、初始化请求对象。五、urlopen 这个 Request 对象来获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计确诊、累计死亡等数据。因为这个页面的数据是动态加载的,而不是静态的 html 页面。您需要按照我上面写的步骤来获取数据。关键是获取URL和对应的参数formdata。下面讲讲如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,然后从出现的菜单中选择检查元素。
点击上图中的红色箭头网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右边红色框中的“大小”列。此列表示此 http 请求传输的数据量。一般情况下,动态加载的数据量会大于其他页面元素的传输量。与其他按字节计算的数据相比,数据量很大。当然,有些网页的装饰图片也很大。这需要根据文件类型的栏目进行筛选。
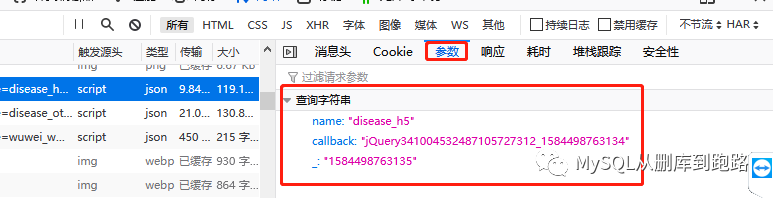
然后点击域名栏对应的行,如下
可以在消息头看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?参数已经写在后面了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url, data = data)
然后 url=""
formdata = {'name': 'disease_h5',
'打回来': '',
'_':当前时间戳
}
名字叫disease_h5,callback是页面回调函数,我们不需要回调动作,所以设置为空,_对应时间戳(Python可以很容易地获取时间戳),因为肺炎患者的数量和时间很接近有关的。
如果都写在如下形式的url中
url='%d'%int(戳*1000)
这样就可以得到疫情数据。有两个选项供您选择。
查找url和参数需要耐心和一定的分析能力,才能正确识别url和参数的含义,并实施正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实是对经验的考验。
有些url很简单,直接返回一个.dat文件,里面有json格式的数据,最友好。有的需要设置大量参数才能获取,而获取的数据是html格式,需要解析才能提取数据。解析部分可以参考我之前写的 查看全部
java爬虫抓取动态网页(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
本文是关于如何在不使用 selenium 插件模拟浏览器的情况下获取网页上动态加载的数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数被转换成urllib 可以识别的字符串数据。四、初始化请求对象。五、urlopen 这个 Request 对象来获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计确诊、累计死亡等数据。因为这个页面的数据是动态加载的,而不是静态的 html 页面。您需要按照我上面写的步骤来获取数据。关键是获取URL和对应的参数formdata。下面讲讲如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,然后从出现的菜单中选择检查元素。
点击上图中的红色箭头网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右边红色框中的“大小”列。此列表示此 http 请求传输的数据量。一般情况下,动态加载的数据量会大于其他页面元素的传输量。与其他按字节计算的数据相比,数据量很大。当然,有些网页的装饰图片也很大。这需要根据文件类型的栏目进行筛选。
然后点击域名栏对应的行,如下

可以在消息头看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?参数已经写在后面了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url, data = data)
然后 url=""
formdata = {'name': 'disease_h5',
'打回来': '',
'_':当前时间戳
}
名字叫disease_h5,callback是页面回调函数,我们不需要回调动作,所以设置为空,_对应时间戳(Python可以很容易地获取时间戳),因为肺炎患者的数量和时间很接近有关的。
如果都写在如下形式的url中
url='%d'%int(戳*1000)
这样就可以得到疫情数据。有两个选项供您选择。
查找url和参数需要耐心和一定的分析能力,才能正确识别url和参数的含义,并实施正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实是对经验的考验。
有些url很简单,直接返回一个.dat文件,里面有json格式的数据,最友好。有的需要设置大量参数才能获取,而获取的数据是html格式,需要解析才能提取数据。解析部分可以参考我之前写的
java爬虫抓取动态网页( 我待解决问题爬虫已存入mysql已mysql数据库已成功!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-02 22:03
我待解决问题爬虫已存入mysql已mysql数据库已成功!)
图片来自简书App
本文文章使用requests和beautifulsoup进行分析;如果您正在寻找正则表达式和 urllib 案例,建议您学习其他材料。
ps:如果要找案例,可以直接看最后一段代码。如果你和我一样,启动爬虫,从文章开始读罗。
前言:自学爬虫第15天,终于成功爬取了58同城的招聘信息,并保存到mysql数据库中……写下这篇文章,分享给正在自学的各位履带式。数据不全:因为有些网页隐藏了一些信息,爬取到的pos_base_browser和pos_base_apply数据都是空的。这个问题仍在解决中。
启示:学习期间我的心态也不稳定,会有逃避的冲动,但让自己坚持下去的动力是一个接一个地解决问题,升级知识体系。重复找资料、百度、百度翻译的过程15天;我最怕看到代码报错;最常见的错误之一是**超出范围。虽然没有人花很多时间找资料,但在不断的探索中,我也得到了解决问题的办法:少问多想——翻译——百度。
文章 分为四个部分:
一、我的爬虫学习目标
二、爬虫学习升级流程:入门10分
三、学习过程中的坑
四、58城市月嫂招聘信息码
五、我有一个问题要解决
爬虫已经存入mysql数据库
一、我的爬虫学习目标
1、了解html、css、javascript
2、master 请求,beautifulsoup 库
3、 会模仿爬虫案例
二、爬虫学习升级流程:入门10分
1、了解html、css、标签
2、学习requests和beautifulsoup库;会获取请求,通过标签选择对应的文本,通过标签选择属性
3、了解静态加载(翻页请求)、动态加载(Ajax)
4、理解函数循环
5、理解 def main(): 函数,name = "main()": 函数
6、了解打印和返回的区别
7、了解索引页(列表页)、详情页、解析详情页url时索引页返回的字典(用于循环)
8、对于数据库的存储,需要在mysql数据库中创建数据库和字段类型。有关详细信息,请参阅代码的第二部分。
9、推荐使用pycharm
10、半自主解决学习过程中出现的任何问题
三、学习过程中的坑:
知道自己会遇到什么问题和问题的类型,即使学习中有问题,也可以通过百度解决。
学习期间,因为不知道怎么提问(因为听不懂,连提问都不会),走了不少弯路。
eg1:解析索引页的时候,不知道应该返回字典的结果格式,折腾了整整两天,突然发现字典可以遍历,把url存成字典可以请求详细信息页面。
eg2:群主一直建议我把爬取的文件保存到数据库,我也看了相关的视频。在不断删除和定义pymysql函数的过程中,我勇敢地尝试解决错误,终于知道了mysql中新数据库、新表、新表中的字段。
自己做不了的时候就去模仿,模仿的过程有问题的时候去百度。
eg3:requests请求没有找到,beautifulsoup解析静态加载案例。拼凑很多视频,代码
……回想起来,中间有很多困惑,但这毕竟是路,只有亲身经历,才能获得成长。希望这个文章能在你切换到数据分析爬虫时对你有所帮助。
四、58城市月嫂招聘信息码
1、目标网点:
坐月子
2、爬取信息:
索引页公司名称;详情页职位名称、更新时间、浏览人数、应聘人数、工资
列表
详情页面
(PS:其实我也想知道索引页的推广方式和发布地址。学习了15天,还是不知道怎么同时保存索引页和详情页的多个内容时间)
3、爬虫代码
《pycharm代码》
import json
import pymysql
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"}
def get_one_page(url):
try:
respones = requests.get(url, headers=headers)
respones.encoding = 'utf-8'
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求错误')
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
soup = BeautifulSoup(html, 'lxml')
list_li = soup.find_all('ul', id='list_con')[0].find_all('li', class_='job_item clearfix') # 返回一个列表需要用循环
dir = {}
for link in list_li:
list_a = link.find_all('div', class_='job_name clearfix')[0].find_all('a')[0] # 筛选出所有的a标签
address = list_a.find_all('span', class_='address')[0].text
name = list_a.find_all('span', class_='name')[0].text
comp_name = link.find_all('div', class_='comp_name')[0].find_all('a')[0].text
href = list_a['href']
t = list_a['_t']
dir[href] = comp_name
return dir
def get_two_page(url):
try:
respones = requests.get(url, 'lxml')
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求详情页错误')
return None
def parse_two_page(html,comp_name):
comp_name = comp_name
soup = BeautifulSoup(html, 'lxml')
#pos_base = soup.find_all('div',class_ = 'pos_base_statistics')[0]
pos_name = soup.find_all('span',class_ = 'pos_name')[0].text
pos_base_update = soup.find_all('span', class_='pos_base_num pos_base_update')[0].find_all('span')[0].text # 更新日期
pos_base_browser = soup.find_all('span', class_='pos_base_num pos_base_browser')[0].find_all('i', id='totalcount')[0].text # 浏览量
pos_base_apply = soup.find_all('span', class_='pos_base_num pos_base_apply')[0].find_all('span', id='apply_num')[0].text # 申请数
pos_salary = soup.find_all('div', class_='pos_base_info')[0].find_all('span', class_='pos_salary')[0].text # 工资水平
return comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary
def save_to_mysql(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary):
cur = conn.cursor() #用来获得python执行Mysql命令的方法,操作游标。cur = conn.sursor才是真的执行
insert_data = "INSERT INTO 58yuesao(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)" "VALUES(%s,%s,%s,%s,%s,%s)"
val = (comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)
cur.execute(insert_data, val)
conn.commit()
conn=pymysql.connect(host="localhost",user="root", password='18030823940',db='58yuesao',port=3306, charset="utf8")
def main():
urls = ['https://cd.58.com/yuesaoyuying/pn{}/?'.format(i) for i in range(1, 8)]
for url in urls:
html = get_one_page(url)
dir = parse_one_page(html)
for href, comp_name in dir.items():
html = get_two_page(href)
comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary = parse_two_page(html,comp_name)
save_to_mysql(comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary)
if __name__ == '__main__':
main()
《pycharm关联mysql代码》
create database 58yuesao;
use 58yuesao;
create table 58yuesao
(comp_name varchar(40) not null,
pos_name varchar(20) not null,
pos_base_update varchar(15) not null,
pos_base_browser int not null,
pos_base_apply int not null,
pos_salary varchar(20)not null);
ALTER TABLE 58yuesao CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci
图片来自简书App
图片来自简书App
最后,您可以在数据库中看到您爬取的文件。使用count()可以看到一共爬取了239条数据。
五、我有一个问题要解决
1、同时抓取索引页和详情页的多个内容
2、Ajax 异步加载
3、 抓取被后台屏蔽的信息(eg: pos_base_browser, pos_base_apply)
明天继续解决问题,加油! 查看全部
java爬虫抓取动态网页(
我待解决问题爬虫已存入mysql已mysql数据库已成功!)

图片来自简书App
本文文章使用requests和beautifulsoup进行分析;如果您正在寻找正则表达式和 urllib 案例,建议您学习其他材料。
ps:如果要找案例,可以直接看最后一段代码。如果你和我一样,启动爬虫,从文章开始读罗。
前言:自学爬虫第15天,终于成功爬取了58同城的招聘信息,并保存到mysql数据库中……写下这篇文章,分享给正在自学的各位履带式。数据不全:因为有些网页隐藏了一些信息,爬取到的pos_base_browser和pos_base_apply数据都是空的。这个问题仍在解决中。
启示:学习期间我的心态也不稳定,会有逃避的冲动,但让自己坚持下去的动力是一个接一个地解决问题,升级知识体系。重复找资料、百度、百度翻译的过程15天;我最怕看到代码报错;最常见的错误之一是**超出范围。虽然没有人花很多时间找资料,但在不断的探索中,我也得到了解决问题的办法:少问多想——翻译——百度。
文章 分为四个部分:
一、我的爬虫学习目标
二、爬虫学习升级流程:入门10分
三、学习过程中的坑
四、58城市月嫂招聘信息码
五、我有一个问题要解决

爬虫已经存入mysql数据库
一、我的爬虫学习目标
1、了解html、css、javascript
2、master 请求,beautifulsoup 库
3、 会模仿爬虫案例
二、爬虫学习升级流程:入门10分
1、了解html、css、标签
2、学习requests和beautifulsoup库;会获取请求,通过标签选择对应的文本,通过标签选择属性
3、了解静态加载(翻页请求)、动态加载(Ajax)
4、理解函数循环
5、理解 def main(): 函数,name = "main()": 函数
6、了解打印和返回的区别
7、了解索引页(列表页)、详情页、解析详情页url时索引页返回的字典(用于循环)
8、对于数据库的存储,需要在mysql数据库中创建数据库和字段类型。有关详细信息,请参阅代码的第二部分。
9、推荐使用pycharm
10、半自主解决学习过程中出现的任何问题
三、学习过程中的坑:
知道自己会遇到什么问题和问题的类型,即使学习中有问题,也可以通过百度解决。
学习期间,因为不知道怎么提问(因为听不懂,连提问都不会),走了不少弯路。
eg1:解析索引页的时候,不知道应该返回字典的结果格式,折腾了整整两天,突然发现字典可以遍历,把url存成字典可以请求详细信息页面。
eg2:群主一直建议我把爬取的文件保存到数据库,我也看了相关的视频。在不断删除和定义pymysql函数的过程中,我勇敢地尝试解决错误,终于知道了mysql中新数据库、新表、新表中的字段。
自己做不了的时候就去模仿,模仿的过程有问题的时候去百度。
eg3:requests请求没有找到,beautifulsoup解析静态加载案例。拼凑很多视频,代码
……回想起来,中间有很多困惑,但这毕竟是路,只有亲身经历,才能获得成长。希望这个文章能在你切换到数据分析爬虫时对你有所帮助。
四、58城市月嫂招聘信息码
1、目标网点:
坐月子
2、爬取信息:
索引页公司名称;详情页职位名称、更新时间、浏览人数、应聘人数、工资
列表
详情页面
(PS:其实我也想知道索引页的推广方式和发布地址。学习了15天,还是不知道怎么同时保存索引页和详情页的多个内容时间)
3、爬虫代码
《pycharm代码》
import json
import pymysql
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"}
def get_one_page(url):
try:
respones = requests.get(url, headers=headers)
respones.encoding = 'utf-8'
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求错误')
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
soup = BeautifulSoup(html, 'lxml')
list_li = soup.find_all('ul', id='list_con')[0].find_all('li', class_='job_item clearfix') # 返回一个列表需要用循环
dir = {}
for link in list_li:
list_a = link.find_all('div', class_='job_name clearfix')[0].find_all('a')[0] # 筛选出所有的a标签
address = list_a.find_all('span', class_='address')[0].text
name = list_a.find_all('span', class_='name')[0].text
comp_name = link.find_all('div', class_='comp_name')[0].find_all('a')[0].text
href = list_a['href']
t = list_a['_t']
dir[href] = comp_name
return dir
def get_two_page(url):
try:
respones = requests.get(url, 'lxml')
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求详情页错误')
return None
def parse_two_page(html,comp_name):
comp_name = comp_name
soup = BeautifulSoup(html, 'lxml')
#pos_base = soup.find_all('div',class_ = 'pos_base_statistics')[0]
pos_name = soup.find_all('span',class_ = 'pos_name')[0].text
pos_base_update = soup.find_all('span', class_='pos_base_num pos_base_update')[0].find_all('span')[0].text # 更新日期
pos_base_browser = soup.find_all('span', class_='pos_base_num pos_base_browser')[0].find_all('i', id='totalcount')[0].text # 浏览量
pos_base_apply = soup.find_all('span', class_='pos_base_num pos_base_apply')[0].find_all('span', id='apply_num')[0].text # 申请数
pos_salary = soup.find_all('div', class_='pos_base_info')[0].find_all('span', class_='pos_salary')[0].text # 工资水平
return comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary
def save_to_mysql(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary):
cur = conn.cursor() #用来获得python执行Mysql命令的方法,操作游标。cur = conn.sursor才是真的执行
insert_data = "INSERT INTO 58yuesao(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)" "VALUES(%s,%s,%s,%s,%s,%s)"
val = (comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)
cur.execute(insert_data, val)
conn.commit()
conn=pymysql.connect(host="localhost",user="root", password='18030823940',db='58yuesao',port=3306, charset="utf8")
def main():
urls = ['https://cd.58.com/yuesaoyuying/pn{}/?'.format(i) for i in range(1, 8)]
for url in urls:
html = get_one_page(url)
dir = parse_one_page(html)
for href, comp_name in dir.items():
html = get_two_page(href)
comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary = parse_two_page(html,comp_name)
save_to_mysql(comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary)
if __name__ == '__main__':
main()
《pycharm关联mysql代码》
create database 58yuesao;
use 58yuesao;
create table 58yuesao
(comp_name varchar(40) not null,
pos_name varchar(20) not null,
pos_base_update varchar(15) not null,
pos_base_browser int not null,
pos_base_apply int not null,
pos_salary varchar(20)not null);
ALTER TABLE 58yuesao CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci
图片来自简书App
图片来自简书App
最后,您可以在数据库中看到您爬取的文件。使用count()可以看到一共爬取了239条数据。
五、我有一个问题要解决
1、同时抓取索引页和详情页的多个内容
2、Ajax 异步加载
3、 抓取被后台屏蔽的信息(eg: pos_base_browser, pos_base_apply)
明天继续解决问题,加油!
java爬虫抓取动态网页(之前学习j2ee的原理是什么?网络爬虫的搭建原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-01 08:20
之前学习j2ee的构建,基本就完成了。
接下来,我要学习爬虫技术。学习一门技术,首先要知道它是如何工作的。
那么网络爬虫的原理是什么?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。
接下来,我将在记录问题和解决方案的同时研究网络爬虫的实现。加油^_^!!
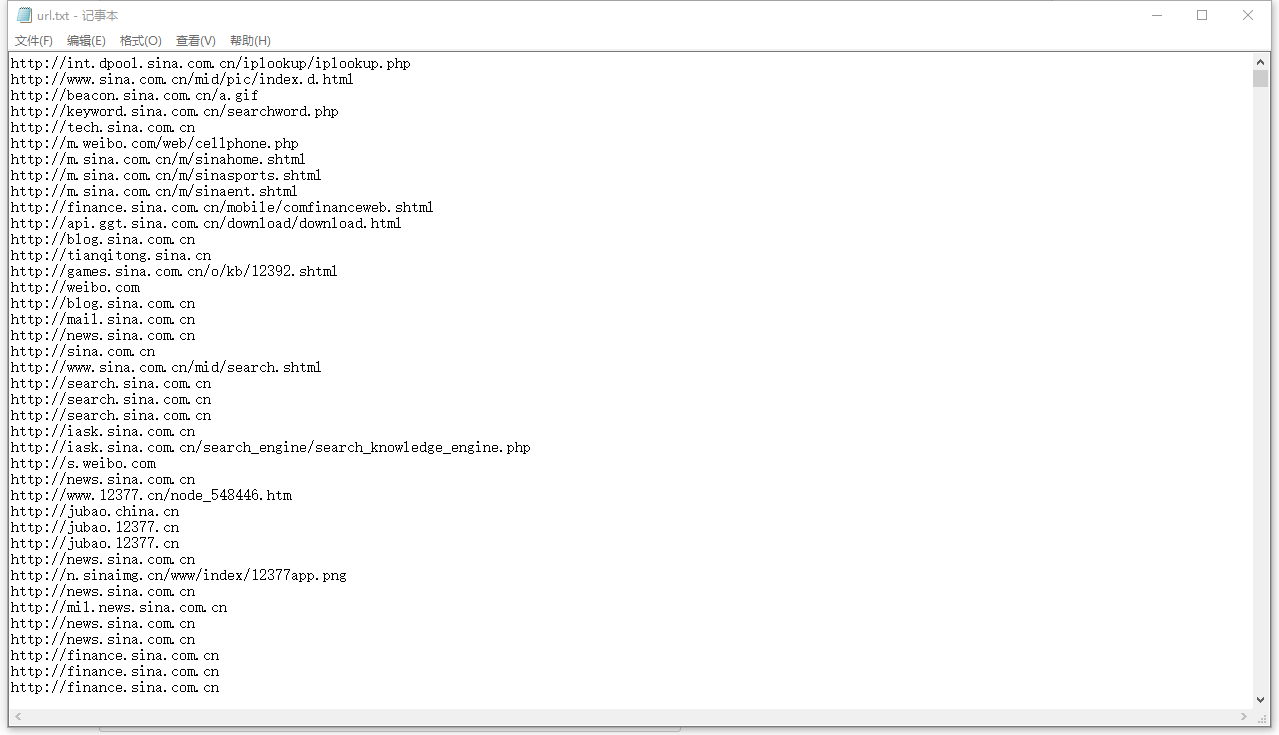
这里我在网上找了一个demo,先给大家演示一下:下面是一个用Java模拟的程序,把新浪页面上的链接提取出来,存到一个文件里:
package testspider;
/**
* Descriptions
*
* @version 2017年3月31日
* @since JDK1.6
*
*/
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/");
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
创建一个java项目,直接把代码放进去。运行后会抓取新浪所有的url,存放在本地的F:/url.txt
只需选择一个要访问的网址,例如
可以获取图片。这只是爬虫的一个简单实现。接下来,我将深入研究它的实现。
网络爬虫:
开发工具:eclipse JDK1.6
网上找的demo没有使用服务器。所以我不再需要服务器了。也没有涉及数据库。将爬取的信息存储在本地目录中。
首先,构建一个java项目。第一个类根据URL获取对应的网页内容。
package webspilder;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
@SuppressWarnings("deprecation")
public class DownloadPage
{
/**
* 根据URL抓取网页内容
*
* @param url
* @return
*/
public static String getContentFormUrl(String url)
{
/* 实例化一个HttpClient客户端 */
@SuppressWarnings({"resource"})
HttpClient client = new DefaultHttpClient();
HttpGet getHttp = new HttpGet(url);
String content = null;
HttpResponse response;
try
{
/*获得信息载体*/
response = client.execute(getHttp);
HttpEntity entity = response.getEntity();
VisitedUrlQueue.addElem(url);
if (entity != null)
{
/* 转化为文本信息 */
content = EntityUtils.toString(entity);
/* 判断是否符合下载网页源代码到本地的条件 */
if (FunctionUtils.isCreateFile(url))
//&& FunctionUtils.isHasGoalContent(content) != -1
{
FunctionUtils.createFile(FunctionUtils
.getGoalContent(content), url);
}
}
} catch (ClientProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
} finally
{
client.getConnectionManager().shutdown();
}
return content;
}
}
第二个类将 URL 与正则表达式匹配,下载文件并将其保存在本地。如果有数据库,可以保存在数据库中。
<p>package webspilder;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FunctionUtils
{
/**
* 匹配超链接的正则表达式
*/
private static String pat = "http://([\\w*\\.]*[\\w*])";
private static Pattern pattern = Pattern.compile(pat);
private static BufferedWriter writer = null;
/**
* 爬虫搜索深度
*/
public static int depth = 0;
/**
* 以"/"来分割URL,获得超链接的元素
*
* @param url
* @return
*/
public static String[] divUrl(String url)
{
return url.split("/");
}
/**
* 判断是否创建文件
*
* @param url
* @return
*/
public static boolean isCreateFile(String url)
{
Matcher matcher = pattern.matcher(url);
return matcher.matches();
}
/**
* 创建对应文件
*
* @param content
* @param urlPath
*/
public static void createFile(String content, String urlPath)
{
/* 分割url */
String[] elems = divUrl(urlPath);
StringBuffer path = new StringBuffer();
File file = null;
for (int i = 1; i < elems.length; i++)
{
if (i != elems.length - 1)
{
path.append(elems[i]);
path.append(File.separator);
file = new File("D:" + File.separator + path.toString());
}
if (i == elems.length - 1)
{
Pattern pattern = Pattern.compile("[\\w*\\.]*[\\w*]");
Matcher matcher = pattern.matcher(elems[i]);
if ((matcher.matches()))
{
if (!file.exists())
{
file.mkdirs();
}
String fileName = elems[i];
file = new File("D:" + File.separator + path.toString()
+ File.separator + fileName + ".html");
System.out.println("文件存储路径为:"+"D:" + File.separator + path.toString()
+ fileName + ".html");
try
{
file.createNewFile();
writer = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file)));
writer.write(content);
writer.flush();
writer.close();
System.out.println("创建文件成功");
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}
}
/**
* 获取页面的超链接并将其转换为正式的A标签
*
* @param href
* @return
*/
public static String getHrefOfInOut(String href)
{
/* 内外部链接最终转化为完整的链接格式 */
String resultHref = null;
/* 判断是否为外部链接 */
if (href.startsWith("http://"))
{
resultHref = href;
} else
{
/* 如果是内部链接,则补充完整的链接地址,其他的格式忽略不处理,如:a href="#" */
if (href.startsWith("/"))
{
resultHref = "http://www.oschina.net" + href;
}
}
return resultHref;
}
/**
* 截取网页网页源文件的目标内容
*
* @param content
* @return
*/
public static String getGoalContent(String content)
{
int sign = content.indexOf(" 查看全部
java爬虫抓取动态网页(之前学习j2ee的原理是什么?网络爬虫的搭建原理)
之前学习j2ee的构建,基本就完成了。
接下来,我要学习爬虫技术。学习一门技术,首先要知道它是如何工作的。
那么网络爬虫的原理是什么?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。
接下来,我将在记录问题和解决方案的同时研究网络爬虫的实现。加油^_^!!
这里我在网上找了一个demo,先给大家演示一下:下面是一个用Java模拟的程序,把新浪页面上的链接提取出来,存到一个文件里:
package testspider;
/**
* Descriptions
*
* @version 2017年3月31日
* @since JDK1.6
*
*/
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/";);
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
创建一个java项目,直接把代码放进去。运行后会抓取新浪所有的url,存放在本地的F:/url.txt
只需选择一个要访问的网址,例如
可以获取图片。这只是爬虫的一个简单实现。接下来,我将深入研究它的实现。
网络爬虫:
开发工具:eclipse JDK1.6
网上找的demo没有使用服务器。所以我不再需要服务器了。也没有涉及数据库。将爬取的信息存储在本地目录中。
首先,构建一个java项目。第一个类根据URL获取对应的网页内容。
package webspilder;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
@SuppressWarnings("deprecation")
public class DownloadPage
{
/**
* 根据URL抓取网页内容
*
* @param url
* @return
*/
public static String getContentFormUrl(String url)
{
/* 实例化一个HttpClient客户端 */
@SuppressWarnings({"resource"})
HttpClient client = new DefaultHttpClient();
HttpGet getHttp = new HttpGet(url);
String content = null;
HttpResponse response;
try
{
/*获得信息载体*/
response = client.execute(getHttp);
HttpEntity entity = response.getEntity();
VisitedUrlQueue.addElem(url);
if (entity != null)
{
/* 转化为文本信息 */
content = EntityUtils.toString(entity);
/* 判断是否符合下载网页源代码到本地的条件 */
if (FunctionUtils.isCreateFile(url))
//&& FunctionUtils.isHasGoalContent(content) != -1
{
FunctionUtils.createFile(FunctionUtils
.getGoalContent(content), url);
}
}
} catch (ClientProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
} finally
{
client.getConnectionManager().shutdown();
}
return content;
}
}
第二个类将 URL 与正则表达式匹配,下载文件并将其保存在本地。如果有数据库,可以保存在数据库中。
<p>package webspilder;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FunctionUtils
{
/**
* 匹配超链接的正则表达式
*/
private static String pat = "http://([\\w*\\.]*[\\w*])";
private static Pattern pattern = Pattern.compile(pat);
private static BufferedWriter writer = null;
/**
* 爬虫搜索深度
*/
public static int depth = 0;
/**
* 以"/"来分割URL,获得超链接的元素
*
* @param url
* @return
*/
public static String[] divUrl(String url)
{
return url.split("/");
}
/**
* 判断是否创建文件
*
* @param url
* @return
*/
public static boolean isCreateFile(String url)
{
Matcher matcher = pattern.matcher(url);
return matcher.matches();
}
/**
* 创建对应文件
*
* @param content
* @param urlPath
*/
public static void createFile(String content, String urlPath)
{
/* 分割url */
String[] elems = divUrl(urlPath);
StringBuffer path = new StringBuffer();
File file = null;
for (int i = 1; i < elems.length; i++)
{
if (i != elems.length - 1)
{
path.append(elems[i]);
path.append(File.separator);
file = new File("D:" + File.separator + path.toString());
}
if (i == elems.length - 1)
{
Pattern pattern = Pattern.compile("[\\w*\\.]*[\\w*]");
Matcher matcher = pattern.matcher(elems[i]);
if ((matcher.matches()))
{
if (!file.exists())
{
file.mkdirs();
}
String fileName = elems[i];
file = new File("D:" + File.separator + path.toString()
+ File.separator + fileName + ".html");
System.out.println("文件存储路径为:"+"D:" + File.separator + path.toString()
+ fileName + ".html");
try
{
file.createNewFile();
writer = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file)));
writer.write(content);
writer.flush();
writer.close();
System.out.println("创建文件成功");
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}
}
/**
* 获取页面的超链接并将其转换为正式的A标签
*
* @param href
* @return
*/
public static String getHrefOfInOut(String href)
{
/* 内外部链接最终转化为完整的链接格式 */
String resultHref = null;
/* 判断是否为外部链接 */
if (href.startsWith("http://";))
{
resultHref = href;
} else
{
/* 如果是内部链接,则补充完整的链接地址,其他的格式忽略不处理,如:a href="#" */
if (href.startsWith("/"))
{
resultHref = "http://www.oschina.net" + href;
}
}
return resultHref;
}
/**
* 截取网页网页源文件的目标内容
*
* @param content
* @return
*/
public static String getGoalContent(String content)
{
int sign = content.indexOf("
java爬虫抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-29 09:21
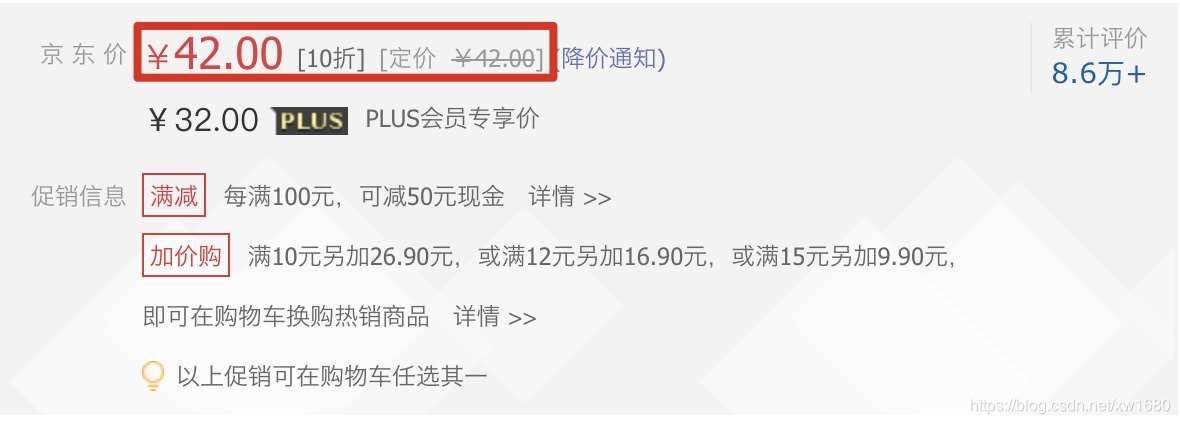
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
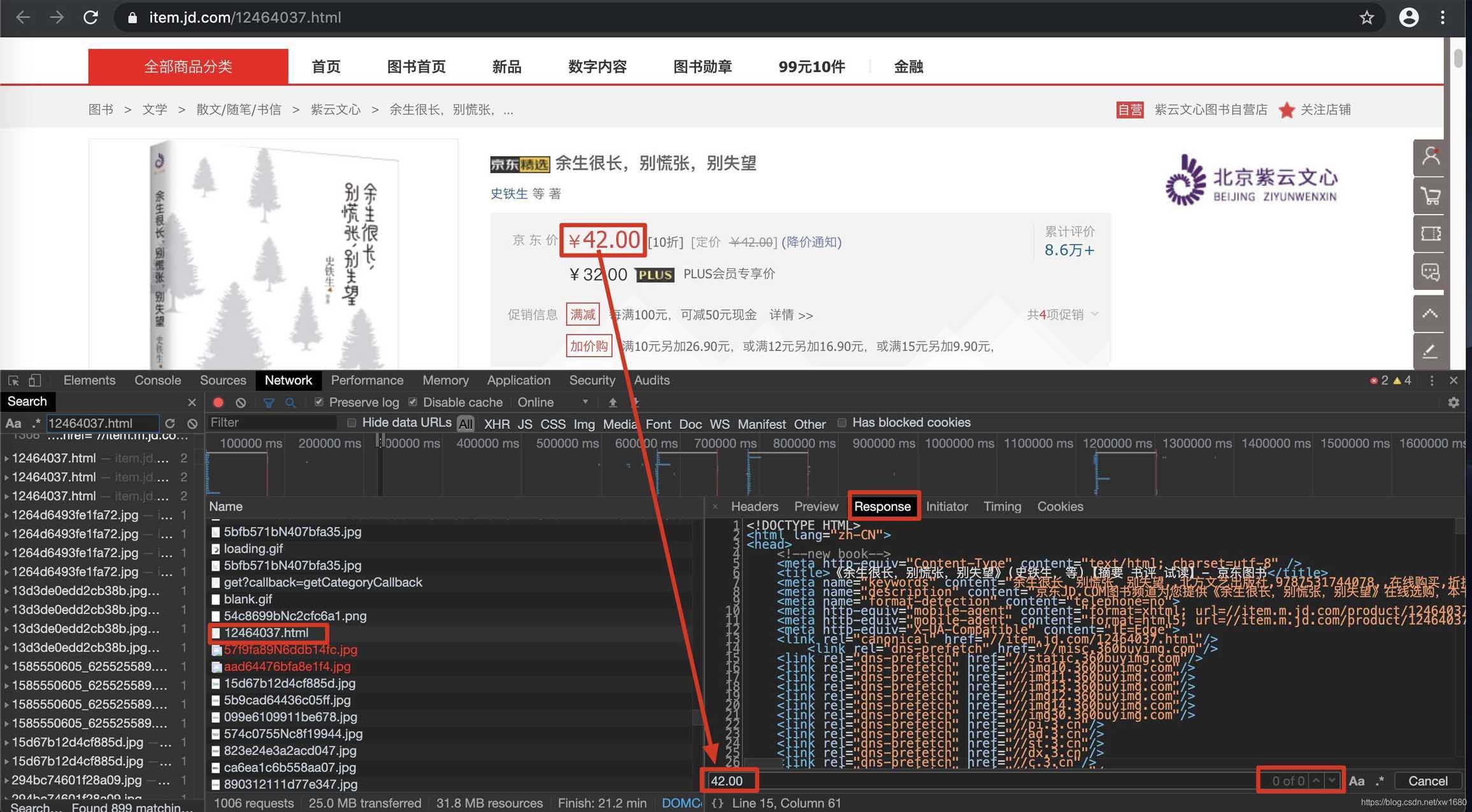
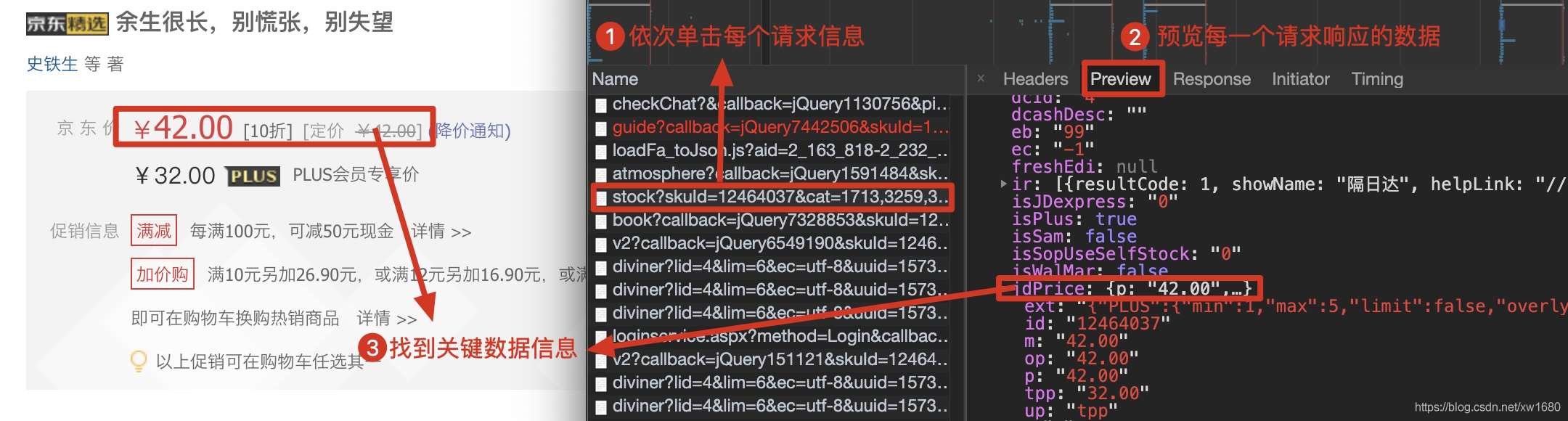
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
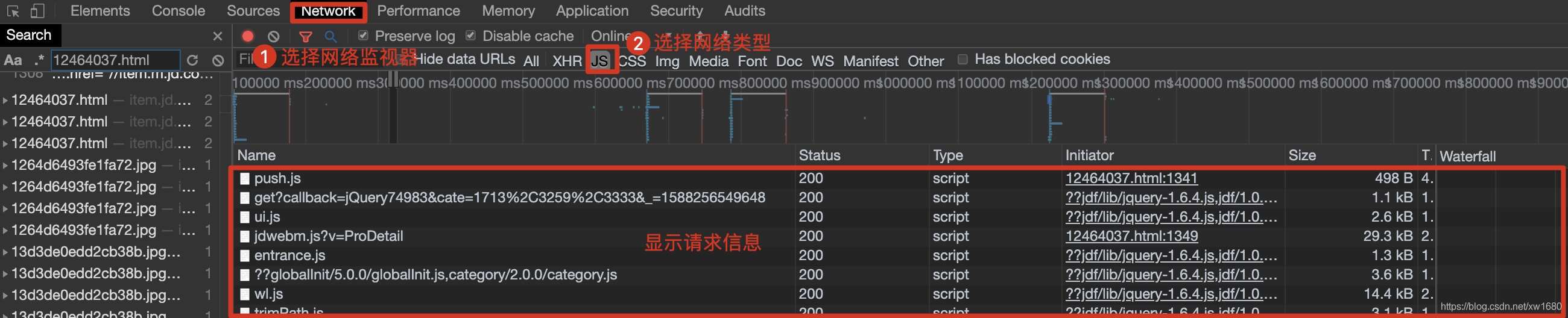
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
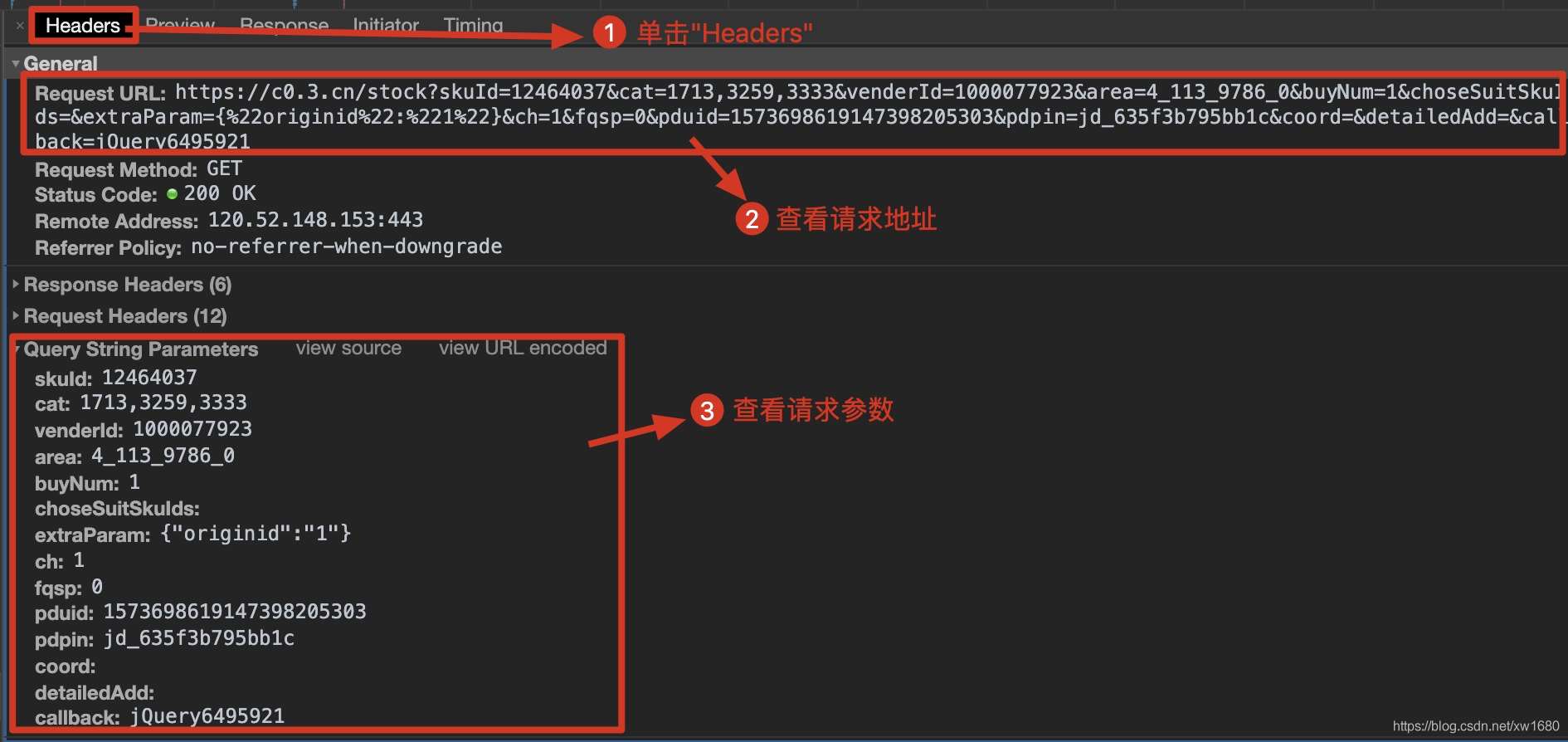
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
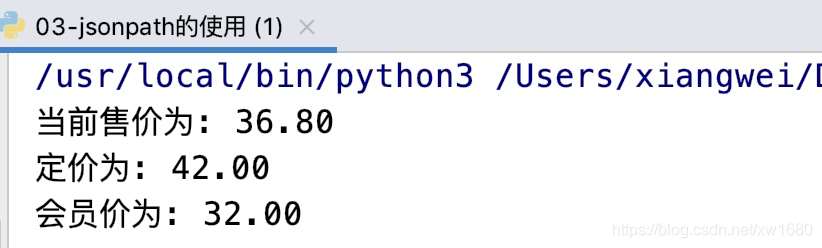
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现网页中动态加载数据爬取的文章文章就介绍到这里了。更多关于Python爬取网页动态数据的信息,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
java爬虫抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:

3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现网页中动态加载数据爬取的文章文章就介绍到这里了。更多关于Python爬取网页动态数据的信息,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
java爬虫抓取动态网页(网络爬虫抓取信息的案例分析-一下具体情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-28 06:13
对于程序员来说,只有掌握了网络爬虫爬取信息的方法,才能进行更有针对性的防范和限制。让我们通过一个案例来了解具体情况。
爬取网站的思路
先判断是否是动态加载网站
查找 URL 模式
正则表达式或 xpath
定义程序框架,完成并测试代码
多级页面数据抓取
1、爬取一级页面,提取需要的数据+链接,继续跟进
2、 爬取二级页面,提取需要的数据+链接,继续跟进
常见反爬总结
IP限制:网站根据IP地址的访问频率进行反爬,短时间内进行IP访问。
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
Cookies:建立有效的cookie池,每次访问时随机切换
1、适用于网站类型:爬取网站页面时需要登录才能访问,否则无法获取页面的实际响应数据
2、方法一(使用cookies)
1、 先登录一次成功,获取带有登录信息的cookie(处理headers)
2、使用处理后的headers向URL地址发送请求
3、方法二(使用会话会话保留)
1、实例化会话对象
会话=请求。会话()
响应内容前端JS进行处理和反爬
1、html页面中可以匹配内容,程序中匹配结果为空
在响应内容中嵌入js,对页面结构做一些调整,通过打印查看网页源代码,格式化输出查看结构,更改xpath或者常规测试
2、如果数据不可用,考虑更换IE的User-Agent,尝试将数据返回标准
FromExpression数据鉴权(salt,sign)签名和js加密:一般是本地JS加密,找本地JS文件,分析,或者使用execjs模块执行JS
js调整页面结构
js在响应中指定一个新地址:从响应码中找到目标地址,政府行政码
动态生成
动态加载数据,数据不再在网页代码中,而是在后台异步加载的数据包中。
1、F12打开控制台,页面动作抓取网络包
2、 抓取json文件的url地址
控制台中的#XHR:异步加载的数据包
#XHR->QueryString(查询参数) 查看全部
java爬虫抓取动态网页(网络爬虫抓取信息的案例分析-一下具体情况)
对于程序员来说,只有掌握了网络爬虫爬取信息的方法,才能进行更有针对性的防范和限制。让我们通过一个案例来了解具体情况。

爬取网站的思路
先判断是否是动态加载网站
查找 URL 模式
正则表达式或 xpath
定义程序框架,完成并测试代码
多级页面数据抓取
1、爬取一级页面,提取需要的数据+链接,继续跟进
2、 爬取二级页面,提取需要的数据+链接,继续跟进
常见反爬总结
IP限制:网站根据IP地址的访问频率进行反爬,短时间内进行IP访问。
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
Cookies:建立有效的cookie池,每次访问时随机切换
1、适用于网站类型:爬取网站页面时需要登录才能访问,否则无法获取页面的实际响应数据
2、方法一(使用cookies)
1、 先登录一次成功,获取带有登录信息的cookie(处理headers)
2、使用处理后的headers向URL地址发送请求
3、方法二(使用会话会话保留)
1、实例化会话对象
会话=请求。会话()
响应内容前端JS进行处理和反爬
1、html页面中可以匹配内容,程序中匹配结果为空
在响应内容中嵌入js,对页面结构做一些调整,通过打印查看网页源代码,格式化输出查看结构,更改xpath或者常规测试
2、如果数据不可用,考虑更换IE的User-Agent,尝试将数据返回标准
FromExpression数据鉴权(salt,sign)签名和js加密:一般是本地JS加密,找本地JS文件,分析,或者使用execjs模块执行JS
js调整页面结构
js在响应中指定一个新地址:从响应码中找到目标地址,政府行政码
动态生成
动态加载数据,数据不再在网页代码中,而是在后台异步加载的数据包中。
1、F12打开控制台,页面动作抓取网络包
2、 抓取json文件的url地址
控制台中的#XHR:异步加载的数据包
#XHR->QueryString(查询参数)
java爬虫抓取动态网页(【悦创】反爬虫是什么首先,我要先跟你探讨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-03-27 23:25
大家好,我是悦创。
在开始这一系列教程之前,我想和大家讨论一下:什么是反爬虫?
首先,目前还没有明确的反爬虫定义。(整个行业没有明确的定义。)因为各方角色不同,或者使用的编程语言或工具不同,对于反爬虫也有自己的看法。
所以,在我们的系列课程中,我需要大家保持一致的观点:
我们同意限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。
限制包括但不限于:请求限制、拒绝响应、客户端身份验证、文本混淆以及使用动态呈现技术。
这些限制按照起点可以分为主动反爬虫和被动反爬虫。
附言:
主动反爬虫是指为我们(爬虫工程师)特意准备的一些限制。
例如:IP限制、Cookies验证、登录页面验证码或注册页面验证码等。
被动反爬虫是指用户操作某个功能时触发的一种功能机制。
例如:下拉加载、悬停(预览)、以及一些网页数据计算等,这些都是提升用户体验的主要目的,但也造成了爬虫对这些数据获取的限制作用。
本课主要分为4个知识点。
Contents(反爬虫) 网页的基本组成 浏览器组件和功能 HTML DOM 和网页渲染过程 编程语言或工具与浏览器的区别1. 网页的基本组成
这是浏览器打开网页后的截图。从截图中我们可以看到有:导航栏、logo、搜索框、记录号相关信息等,那么这个页面的主要元素就是文字和图片。当然,页面的元素远不止这些,比如优酷、网易或者爱奇艺、搜狗等,网站里面还有音视频。
接下来,我们来看看一个网页的基本结构:
(图片来源-网络)
从左到右:HTML、JavaScript、CSS、媒体资产、其他(以及其他一些)
然后是:图片、视频、音频和字体,这些都是媒体或多媒体资源。(例如:代表图片的标签通常是img标签,然后里面的src指向具体的资源路径
Action: 打开浏览器观察资源加载情况
按着这些次序:
打开浏览器访问:打开浏览器的开发者工具(F12)切换到网络面板
接下来刷新一些网页或者输入:Python搜索
现在,让我们看看究竟加载了什么。
这时候我们会发现,当我们访问百度的网站时,加载的资源有:文档、css文件、图片(png、jpg)、js等。
2. 浏览器组件和函数
我们常用的浏览器有五个组件和三个解释器。这五个组件是:用户界面、浏览器引擎、渲染引擎、数据存储和网络。三个解释器分别是:HTML解释器、JavaScript解释器解释器、CSS解释器。
所以浏览器之所以能够理解 HTML、CSS 和 JavaScript 代码并按照一定的规则进行输入,是这三个解释器的功劳。
在组件方面,用户界面组件的主要功能是显示操作界面。浏览器引擎的主要作用是:负责将用户的操作传递给相应的渲染引擎。渲染引擎的主要作用是调用,**这三个解释器来解释相应文档中的代码。然后根据解释器的结果重新键入页面。**数据存储组件的作用是: **在本地存储一些较小的数据,如Cookies、Storage对象等。 **Web组件:自动加载HTML文档中需要的其他资源。
刚才带大家了解了浏览器的五个组件和三个解释器。我们可以在脑海中填写浏览器的结构图。也就是说,常用的浏览器实际上是由一堆组件组成的工具。
然后每个组件执行自己的职责,例如:渲染组件,渲染引擎,它会调用三个解释器来解释和理解代码中的一些意图。
3. HTML DOM 和网页渲染过程
HTML DOM 是文档对象模型,它是一个平台中立和语言中立的界面。它允许程序动态更新文档内容、文档结构和样式。换句话说:程序可以通过DOM改变页面上显示的内容。HTML文档中的每一个标签对都是一个DOM节点(比如title标签对应一个DOM节点,那么year标签也对应一个DOM节点)看看右上图,HTML我们平时看到的一层一层、一层一层嵌套的标签,其实就是一个父子关系的DOM节点。JavaScript 代码和 CSS 样式可以改变页面上文本或图片的位置、颜色或内容,但需要注意的是,它们改变的只是页面上显示的内容,而不是 HTML 文档本身。他们只是更改浏览器中的 DOM,这一点非常重要。(大家一定要明白)
操作:打开浏览器编辑 HTML
这里我们打开浏览器做一个小实验,这里我们使用W3school的在线编辑器运行HTML代码。
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们可以看一下上面的代码,它们被包裹在成对的 html 标签中。然后 body 标签包裹 HTML 代码,标签对包裹 CSS 样式,标签对包裹 JavaScript 代码。在 HTML 中,这就是注释:被注释注释掉的代码在代码中不起作用。
我们先运行以下代码:
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们来看看运行结果:
我们可以看到右侧的内容显示区显示了HTML文档中定义的内容。
我接下来运行以下代码:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
这时,我们可以看到最后一段文字的颜色发生了变化。
同样,让我们添加 JavaScript 代码来查看:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
first = document.getElementById("first");
first.innerHTML = "我说这是什么就是什么";
我们发现右边内容区的第一行内容变了,那么问题来了:为什么内容区的文字和颜色变了,但是代码中的文字还是body标签中包裹的文字没有发生。任何变化?
左边的代码仍然是:**这是一个段落。**向我们展示的是:我所说的就是它的本来面目。现在想一想,想一想:为什么会这样?
其实这也正是我之前说的:它们其实是 JavaScript 和 CSS 的变化,也就是说浏览器中的 DOM 节点被 CSS 和 JavaScript 变化了,而最终变化的不是 HTML 代码,或者它的文件。内容,变化其实是浏览器中的DOM布局。需要注意的是,这种变化发生在浏览器的显示级别。事实上,HTML 完全没有变化。
上面提到了页面的渲染过程,可以说明我们刚才做的实验的结果。
上图中的步骤将使您更加清晰。
从一开始,用户输入一个 URL(这是在用户界面组件中执行的操作),然后当用户按下 Enter 键时,他进入浏览器引擎的工作流程,然后根据 HTML 文档的内容进行加载。对应的资源(例如:图片、视频、音频、文本等),此时渲染引擎和三大解释器已经开始工作了,否则浏览器不知道需要加载什么样的资源,那么资源代码的加载和代码的解释是同步进行的。最后渲染引擎根据三大解释器的解释结果对DOM进行操作,即重新对页面内容进行排版,并将排版的结果呈现给用户(也就是我们看到的网页内容)。以上是浏览器的工作流程。.
4. 编程语言或工具与浏览器的区别
操作:用浏览器打开指定的URL
这里我们需要打开浏览器并访问一个网站(例如:GitChat)
可以看到,在浏览器访问后,我们得到的是一个比例匀称、布局漂亮的页面。那我们试试代码或者使用工具请求同一个URL,看看得到什么样的结果,打开IDE,也就是Pycharm。
这里我们使用 requests 库向 GitChat 发出网络请求。并打印请求的内容。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author:AI悦创 @DateTime :2020/1/12 13:53 @Function :功能 Development_tool :PyCharm
# code is far away from bugs with the god animal protecting
# I love animals. They taste delicious.
import requests
url = 'https://gitbook.cn/'
html = requests.get(url).text
print(html)
# -------------输出-------------
"C:\Program Files\Python37\python.exe" "D:/daima/pycharm_daima/JavaScript 逆向课程/01-探寻 JavaScript 反爬虫的根本原因/test_1.py"
GitChatMenu首 页专 栏专 题电子书关于我们活动分类前端人工智能架构区块链职场编程语言技术管理大数据移动开发产品与运营测试安全运维>严选
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
})
function changeHomeColumn(num) {
$('#syncColumn').addClass("syncColumn");
$.ajax({
url: "/gitchat/homepage/change/column/" + num,
type: "GET",
contentType: "application/json; charset=utf-8",
success: function (data, status) {
if (status == 'success' && data.code == 0) {
$('#homeColumns').html('');
$('#homeColumns').append(data.data);
$('#changeColumns').attr('onclick', 'changeHomeColumn(' + data.next + '); return false;')
$('#syncColumn').removeClass("syncColumn");
}
}
});
}
Process finished with exit code 0
我们得到的是 HTML 代码,而不是渲染的。
接下来,让我们借助一个工具来操作它,工具:PostMan
这样,我们将在下面得到我们的响应体。可以看到Python代码的结果是一模一样的,没有排版,也没有请求图片等资源。所以,我们所要求的只是 HTML 代码。其实就是 GitChat 的源码。在谷歌浏览器中访问网页后,我们可以右键选择显示网页的源代码,可以看到得到的页面和我们之前得到的代码是一样的。
刚才我们以几种不同的方式访问了我们的 GitChat,并用图表对其进行了解析:
从图中可以看出,我们的浏览器可以获取其他需要的内容,而工具获取的只是HTML。
这其实就是浏览器和其他工具的区别。准确地说,是因为其他工具中没有 JavaScript 解释器。需要注意的是,CSS和JavaScript的情况是一样的,也就是说,反爬虫可以利用其他没有CSS解释器和渲染引擎的工具的特性来实现。实际工作中这样的应用有很多,比如我们经常听到的字体反爬虫、文本偏移反爬虫、文本混淆反爬虫等。 查看全部
java爬虫抓取动态网页(【悦创】反爬虫是什么首先,我要先跟你探讨)
大家好,我是悦创。

在开始这一系列教程之前,我想和大家讨论一下:什么是反爬虫?
首先,目前还没有明确的反爬虫定义。(整个行业没有明确的定义。)因为各方角色不同,或者使用的编程语言或工具不同,对于反爬虫也有自己的看法。
所以,在我们的系列课程中,我需要大家保持一致的观点:
我们同意限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。
限制包括但不限于:请求限制、拒绝响应、客户端身份验证、文本混淆以及使用动态呈现技术。
这些限制按照起点可以分为主动反爬虫和被动反爬虫。
附言:
主动反爬虫是指为我们(爬虫工程师)特意准备的一些限制。
例如:IP限制、Cookies验证、登录页面验证码或注册页面验证码等。
被动反爬虫是指用户操作某个功能时触发的一种功能机制。
例如:下拉加载、悬停(预览)、以及一些网页数据计算等,这些都是提升用户体验的主要目的,但也造成了爬虫对这些数据获取的限制作用。
本课主要分为4个知识点。
Contents(反爬虫) 网页的基本组成 浏览器组件和功能 HTML DOM 和网页渲染过程 编程语言或工具与浏览器的区别1. 网页的基本组成

这是浏览器打开网页后的截图。从截图中我们可以看到有:导航栏、logo、搜索框、记录号相关信息等,那么这个页面的主要元素就是文字和图片。当然,页面的元素远不止这些,比如优酷、网易或者爱奇艺、搜狗等,网站里面还有音视频。
接下来,我们来看看一个网页的基本结构:

(图片来源-网络)
从左到右:HTML、JavaScript、CSS、媒体资产、其他(以及其他一些)
然后是:图片、视频、音频和字体,这些都是媒体或多媒体资源。(例如:代表图片的标签通常是img标签,然后里面的src指向具体的资源路径
Action: 打开浏览器观察资源加载情况
按着这些次序:
打开浏览器访问:打开浏览器的开发者工具(F12)切换到网络面板

接下来刷新一些网页或者输入:Python搜索

现在,让我们看看究竟加载了什么。
这时候我们会发现,当我们访问百度的网站时,加载的资源有:文档、css文件、图片(png、jpg)、js等。
2. 浏览器组件和函数

我们常用的浏览器有五个组件和三个解释器。这五个组件是:用户界面、浏览器引擎、渲染引擎、数据存储和网络。三个解释器分别是:HTML解释器、JavaScript解释器解释器、CSS解释器。
所以浏览器之所以能够理解 HTML、CSS 和 JavaScript 代码并按照一定的规则进行输入,是这三个解释器的功劳。
在组件方面,用户界面组件的主要功能是显示操作界面。浏览器引擎的主要作用是:负责将用户的操作传递给相应的渲染引擎。渲染引擎的主要作用是调用,**这三个解释器来解释相应文档中的代码。然后根据解释器的结果重新键入页面。**数据存储组件的作用是: **在本地存储一些较小的数据,如Cookies、Storage对象等。 **Web组件:自动加载HTML文档中需要的其他资源。
刚才带大家了解了浏览器的五个组件和三个解释器。我们可以在脑海中填写浏览器的结构图。也就是说,常用的浏览器实际上是由一堆组件组成的工具。

然后每个组件执行自己的职责,例如:渲染组件,渲染引擎,它会调用三个解释器来解释和理解代码中的一些意图。
3. HTML DOM 和网页渲染过程

HTML DOM 是文档对象模型,它是一个平台中立和语言中立的界面。它允许程序动态更新文档内容、文档结构和样式。换句话说:程序可以通过DOM改变页面上显示的内容。HTML文档中的每一个标签对都是一个DOM节点(比如title标签对应一个DOM节点,那么year标签也对应一个DOM节点)看看右上图,HTML我们平时看到的一层一层、一层一层嵌套的标签,其实就是一个父子关系的DOM节点。JavaScript 代码和 CSS 样式可以改变页面上文本或图片的位置、颜色或内容,但需要注意的是,它们改变的只是页面上显示的内容,而不是 HTML 文档本身。他们只是更改浏览器中的 DOM,这一点非常重要。(大家一定要明白)
操作:打开浏览器编辑 HTML
这里我们打开浏览器做一个小实验,这里我们使用W3school的在线编辑器运行HTML代码。
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们可以看一下上面的代码,它们被包裹在成对的 html 标签中。然后 body 标签包裹 HTML 代码,标签对包裹 CSS 样式,标签对包裹 JavaScript 代码。在 HTML 中,这就是注释:被注释注释掉的代码在代码中不起作用。
我们先运行以下代码:
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们来看看运行结果:

我们可以看到右侧的内容显示区显示了HTML文档中定义的内容。
我接下来运行以下代码:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义

这时,我们可以看到最后一段文字的颜色发生了变化。
同样,让我们添加 JavaScript 代码来查看:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
first = document.getElementById("first");
first.innerHTML = "我说这是什么就是什么";

我们发现右边内容区的第一行内容变了,那么问题来了:为什么内容区的文字和颜色变了,但是代码中的文字还是body标签中包裹的文字没有发生。任何变化?
左边的代码仍然是:**这是一个段落。**向我们展示的是:我所说的就是它的本来面目。现在想一想,想一想:为什么会这样?
其实这也正是我之前说的:它们其实是 JavaScript 和 CSS 的变化,也就是说浏览器中的 DOM 节点被 CSS 和 JavaScript 变化了,而最终变化的不是 HTML 代码,或者它的文件。内容,变化其实是浏览器中的DOM布局。需要注意的是,这种变化发生在浏览器的显示级别。事实上,HTML 完全没有变化。

上面提到了页面的渲染过程,可以说明我们刚才做的实验的结果。
上图中的步骤将使您更加清晰。
从一开始,用户输入一个 URL(这是在用户界面组件中执行的操作),然后当用户按下 Enter 键时,他进入浏览器引擎的工作流程,然后根据 HTML 文档的内容进行加载。对应的资源(例如:图片、视频、音频、文本等),此时渲染引擎和三大解释器已经开始工作了,否则浏览器不知道需要加载什么样的资源,那么资源代码的加载和代码的解释是同步进行的。最后渲染引擎根据三大解释器的解释结果对DOM进行操作,即重新对页面内容进行排版,并将排版的结果呈现给用户(也就是我们看到的网页内容)。以上是浏览器的工作流程。.
4. 编程语言或工具与浏览器的区别
操作:用浏览器打开指定的URL
这里我们需要打开浏览器并访问一个网站(例如:GitChat)

可以看到,在浏览器访问后,我们得到的是一个比例匀称、布局漂亮的页面。那我们试试代码或者使用工具请求同一个URL,看看得到什么样的结果,打开IDE,也就是Pycharm。
这里我们使用 requests 库向 GitChat 发出网络请求。并打印请求的内容。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author:AI悦创 @DateTime :2020/1/12 13:53 @Function :功能 Development_tool :PyCharm
# code is far away from bugs with the god animal protecting
# I love animals. They taste delicious.
import requests
url = 'https://gitbook.cn/'
html = requests.get(url).text
print(html)
# -------------输出-------------
"C:\Program Files\Python37\python.exe" "D:/daima/pycharm_daima/JavaScript 逆向课程/01-探寻 JavaScript 反爬虫的根本原因/test_1.py"
GitChatMenu首 页专 栏专 题电子书关于我们活动分类前端人工智能架构区块链职场编程语言技术管理大数据移动开发产品与运营测试安全运维>严选
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
})
function changeHomeColumn(num) {
$('#syncColumn').addClass("syncColumn");
$.ajax({
url: "/gitchat/homepage/change/column/" + num,
type: "GET",
contentType: "application/json; charset=utf-8",
success: function (data, status) {
if (status == 'success' && data.code == 0) {
$('#homeColumns').html('');
$('#homeColumns').append(data.data);
$('#changeColumns').attr('onclick', 'changeHomeColumn(' + data.next + '); return false;')
$('#syncColumn').removeClass("syncColumn");
}
}
});
}
Process finished with exit code 0
我们得到的是 HTML 代码,而不是渲染的。
接下来,让我们借助一个工具来操作它,工具:PostMan

这样,我们将在下面得到我们的响应体。可以看到Python代码的结果是一模一样的,没有排版,也没有请求图片等资源。所以,我们所要求的只是 HTML 代码。其实就是 GitChat 的源码。在谷歌浏览器中访问网页后,我们可以右键选择显示网页的源代码,可以看到得到的页面和我们之前得到的代码是一样的。

刚才我们以几种不同的方式访问了我们的 GitChat,并用图表对其进行了解析:

从图中可以看出,我们的浏览器可以获取其他需要的内容,而工具获取的只是HTML。
这其实就是浏览器和其他工具的区别。准确地说,是因为其他工具中没有 JavaScript 解释器。需要注意的是,CSS和JavaScript的情况是一样的,也就是说,反爬虫可以利用其他没有CSS解释器和渲染引擎的工具的特性来实现。实际工作中这样的应用有很多,比如我们经常听到的字体反爬虫、文本偏移反爬虫、文本混淆反爬虫等。
java爬虫抓取动态网页(2.动态网页:不只有代码写出的网页被称为动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-27 06:19
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的全网爬取。只要人能看到东西,理论上爬虫就可以获取。不管是静态页面还是动态页面。不管是PC端的页面,还是移动端的APP。爬虫,有多种语言可供选择,python、php、go、java……甚至c。但现在主流是python作为爬虫编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(python3不再使用)、requests。我们先比较一下它们的区别:
urllib和urllib2是python标准库,即如果你已经安装了python,这两个库可以直接使用;requests是第三方库,不是python基金会实现的,但是很强大。
但是 urllib 和 urllib2 都是通过 url 来打开资源的。其中 urllib 只能接受 url,但同样伪装请求的 headers。这样写的爬虫发出的请求会被很多网站直接拦截,伪装不好。嗯,它需要很复杂的修改,在之前的文章中已经介绍过了。
requests 库可以实现 urllib 和 urllib2 的所有功能,并且有它们不具备的优点。在使用过程中,请求更有用。
1:什么是静态网页和动态网页?
1.静态网页:通俗地说,只有 HTML 格式的网页通常被称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python进行爬虫的过程中,有一个强大的Request库可以方便的为我们发送HTTP请求来爬取静态网页。
2.动态网页:不仅HTML代码编写的网页称为动态网页,这些网页一般由CSS、JavaScript代码和HTML代码共同组成。在代码中,这需要复杂的操作。
二:静态网页爬取
1.请求安装和简单操作
(1)安装
在 cmd 或终端中写入
pip install requests
而已。
(2)获取网页内容'
Request 最常用的功能是获取网页的内容。我们首先获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用相应的函数来获取需要的信息。结果如下所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中内置的 JSON 解码器。
2.自定义请求
现在我们可以爬取网页的html代码数据了,但是有时候我们只需要一部分数据,那么就需要设置Requests的参数来获取我们需要的数据,包括传递URL参数、自定义请求头、发送POST 请求、设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。该数据通常后跟一个问号,并作为键值对放置在 URL 中。
在 Request 中,我们可以直接将这些参数保存在字典中,并使用 params 构建到 URL 中。
这是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
让我们看看结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或者请求的请求头与实际网页不一致,可能无法返回正确的结果。请求不会根据自定义的请求头改变自己的行为,只有在最终的请求中,才会传入请求头的信息。
我们可以根据以下方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择inspect(有些浏览器也叫inspect elements),然后选择Network选项:
当我们选择python图片的时候,会发现在左边的资源栏中截取了一个文件,就是图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将自定义请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是400,说明我们的代码有误。这表明我们无法以这种方式抓取图像。关于如何正确抓取图片,我会在下面的文章中告诉你。
3.发送 POST 请求
除了 GET 请求之外,有时还需要发送一些以表单编码的数据。这种情况下,只需要给Request中的data参数传入一个字典,这些数据字典会在发送请求时自动编码成表单。我们在之前的文章爬取有道词典中使用了这个请求。
4.超时
如果在指定时间内没有响应,可以使用 Requests 设置 timeout 参数来抛出异常。
三:抓取豆瓣百强电影片名示例
先打开网址
然后我们找到每个视频的 HTML 代码:
在这里,我们需要的所有信息都在
在这里,将 lxml 更改为 html.parse:
import requests
from bs4 import BeautifulSoup
def getUrl():
url = "https://www.douban.com/doulist/36513321/"
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
结果如下:
我们这里要爬取的是100个剧名,这里我们只得到了25个,要全部爬取,我们需要分析URL:
发现只有start=""之后的不同,我们可以分析四次,或者用循环来做:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们使用 format() 来格式化字符串(也可以使用 % 来格式化字符串),我们看看结果:
在这里我们看到我们已经成功爬取了我们想要的内容。 查看全部
java爬虫抓取动态网页(2.动态网页:不只有代码写出的网页被称为动态)
T小昂仔 11月26日

版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的全网爬取。只要人能看到东西,理论上爬虫就可以获取。不管是静态页面还是动态页面。不管是PC端的页面,还是移动端的APP。爬虫,有多种语言可供选择,python、php、go、java……甚至c。但现在主流是python作为爬虫编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(python3不再使用)、requests。我们先比较一下它们的区别:
urllib和urllib2是python标准库,即如果你已经安装了python,这两个库可以直接使用;requests是第三方库,不是python基金会实现的,但是很强大。
但是 urllib 和 urllib2 都是通过 url 来打开资源的。其中 urllib 只能接受 url,但同样伪装请求的 headers。这样写的爬虫发出的请求会被很多网站直接拦截,伪装不好。嗯,它需要很复杂的修改,在之前的文章中已经介绍过了。
requests 库可以实现 urllib 和 urllib2 的所有功能,并且有它们不具备的优点。在使用过程中,请求更有用。
1:什么是静态网页和动态网页?
1.静态网页:通俗地说,只有 HTML 格式的网页通常被称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python进行爬虫的过程中,有一个强大的Request库可以方便的为我们发送HTTP请求来爬取静态网页。
2.动态网页:不仅HTML代码编写的网页称为动态网页,这些网页一般由CSS、JavaScript代码和HTML代码共同组成。在代码中,这需要复杂的操作。
二:静态网页爬取
1.请求安装和简单操作
(1)安装
在 cmd 或终端中写入
pip install requests
而已。
(2)获取网页内容'
Request 最常用的功能是获取网页的内容。我们首先获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用相应的函数来获取需要的信息。结果如下所示:

...

以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中内置的 JSON 解码器。
2.自定义请求
现在我们可以爬取网页的html代码数据了,但是有时候我们只需要一部分数据,那么就需要设置Requests的参数来获取我们需要的数据,包括传递URL参数、自定义请求头、发送POST 请求、设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。该数据通常后跟一个问号,并作为键值对放置在 URL 中。
在 Request 中,我们可以直接将这些参数保存在字典中,并使用 params 构建到 URL 中。
这是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
让我们看看结果:

(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或者请求的请求头与实际网页不一致,可能无法返回正确的结果。请求不会根据自定义的请求头改变自己的行为,只有在最终的请求中,才会传入请求头的信息。
我们可以根据以下方法找到正确的请求头:
打开上一篇博客的内容:

然后我们右键,选择inspect(有些浏览器也叫inspect elements),然后选择Network选项:
当我们选择python图片的时候,会发现在左边的资源栏中截取了一个文件,就是图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:

然后我们将自定义请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:


这里返回的响应码是400,说明我们的代码有误。这表明我们无法以这种方式抓取图像。关于如何正确抓取图片,我会在下面的文章中告诉你。
3.发送 POST 请求
除了 GET 请求之外,有时还需要发送一些以表单编码的数据。这种情况下,只需要给Request中的data参数传入一个字典,这些数据字典会在发送请求时自动编码成表单。我们在之前的文章爬取有道词典中使用了这个请求。
4.超时
如果在指定时间内没有响应,可以使用 Requests 设置 timeout 参数来抛出异常。
三:抓取豆瓣百强电影片名示例
先打开网址
然后我们找到每个视频的 HTML 代码:

在这里,我们需要的所有信息都在

在这里,将 lxml 更改为 html.parse:
import requests
from bs4 import BeautifulSoup
def getUrl():
url = "https://www.douban.com/doulist/36513321/"
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
结果如下:

我们这里要爬取的是100个剧名,这里我们只得到了25个,要全部爬取,我们需要分析URL:
发现只有start=""之后的不同,我们可以分析四次,或者用循环来做:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们使用 format() 来格式化字符串(也可以使用 % 来格式化字符串),我们看看结果:

在这里我们看到我们已经成功爬取了我们想要的内容。
java爬虫抓取动态网页(Java爬虫服务器被屏蔽,不要慌,咱们换一台中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-27 04:09
Java爬虫服务器被封了,别慌,换个服务器,我们简单说一下反爬策略和反反爬方法,主要是IP封堵及其对应的方法。之前的文章文章我们讲了爬虫的基础知识。在这篇文章中,我们来谈谈爬虫架构。
在前面的章节中,我们的爬虫程序都是单线程的。我们在调试爬虫程序的时候,单线程爬虫是没有问题的,但是当我们使用单线程爬虫程序去在线环境下的采集网页时,单线程爬虫会不行。暴露了两个致命问题:
线上的环境不能像我们本地的测试一样,不关心采集的效率,只要能正确提取结果即可。在这个时间就是金钱的时代,不可能给你时间慢慢来采集,所以单线程爬虫程序就不行了,我们需要把单线程改成多线程模式来改进采集 效率和提高计算机利用率。想学习交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
多线程爬虫的设计要比单线程的程序复杂得多,但又不同于其他需要在高并发下保证数据安全的业务。被视为一个独立的实体。做多线程爬虫,必须做好两件事:第一点是维护统一的采集 URL,第二点是对URL进行去重。简单说一下这两点。
将 URL 维护为 采集
多线程爬虫不能像单线程一样,每个线程独立维护自己的采集 URL,如果是这样的话,那么每个线程的网页采集都是一样的,你会不是多线程采集,而是要多次采集 一个页面。为此,我们需要将 URL 统一维护为 采集。每个线程从统一的URL维护处接收到采集 URL,完成采集任务。如果在页面上找到新 URL 链接将添加到统一 URL 维护的容器中。这里有几个适合统一 URL 维护的容器:
URL重复数据删除
URL去重也是多线程采集中的一个关键步骤,因为如果我们不去重,那么我们会采集到大量重复的URL,这并不能改善我们的采集 效率,例如在一个分页的新闻列表中,我们可以在 采集 的第一页获取到 2、3、4、5 个页面的链接,并且在采集的第二页会再次得到1、3、4、5个页面链接,采集的URL队列中会有大量列表页面链接@>,会重复采集甚至进入死循环,所以需要进行URL去重。有很多方法可以对 URL 进行重复数据删除。以下是几种常用的URL去重方法:
关于多线程爬虫的两个核心知识点大家都知道。下面我画一个简单的多线程爬虫架构图,如下图所示:
多线程爬虫架构图
以上,我们主要了解了多线程爬虫的架构设计。接下来,我们不妨试试Java多线程爬虫。我们以采集虎扑新闻为例,实战Java多线程爬虫,在Java多线程爬虫中设计的采集URL的维护和URL的去重,由于这里只是演示,所以我们将使用JDK的内置容器来完成它。我们使用 LinkedBlockingQueue 作为 URL 维护容器为 采集,HashSet 作为 URL 到 Heavy 容器。以下是Java多线程爬虫的核心代码。详细代码可以上传到 GitHub。地址在文末:想学习和交流HashMap,nginx,dubbo,Spring MVC,分布式,高性能高可用,
2. public class ThreadCrawler implements Runnable {
3. // 采集的文章数
4. private final AtomicLong pageCount = new AtomicLong(0);
5. // 列表页链接正则表达式
6. public static final String URL_LIST = “https://voice.hupu.com/nba”;
7. protected Logger logger = LoggerFactory.getLogger(getClass());
8. // 待采集的队列
9. LinkedBlockingQueue taskQueue;
10. // 采集过的链接列表
11. HashSet visited;
12. // 线程池
13. CountableThreadPool threadPool;
15. public ThreadCrawler(String url, int threadNum) throws InterruptedException {
16. this.taskQueue = new LinkedBlockingQueue();
17. this.threadPool = new CountableThreadPool(threadNum);
18. this.visited = new HashSet();
19. // 将起始页添加到待采集队列中
20. this.taskQueue.put(url);
21. }
23. @Override
24. public void run() {
25. logger.info(“Spider started!”);
26. while (!Thread.currentThread().isInterrupted()) {
27. // 从队列中获取待采集 URL
28. final String request = taskQueue.poll();
29. // 如果获取 request 为空,并且当前的线程采已经没有线程在运行
30. if (request == null) {
31. if (threadPool.getThreadAlive() == 0) {
32. break;
33. }
34. } else {
35. // 执行采集任务
36. threadPool.execute(new Runnable() {
37. @Override
38. public void run() {
39. try {
40. processRequest(request);
41. } catch (Exception e) {
42. logger.error(“process request “ + request + ” error”, e);
43. } finally {
44. // 采集页面 +1
45. pageCount.incrementAndGet();
46. }
47. }
48. });
49. }
50. }
51. threadPool.shutdown();
52. logger.info(“Spider closed! {} pages downloaded.”, pageCount.get());
53. }
55. protected void processRequest(String url) {
56. // 判断是否为列表页
57. if (url.matches(URL_LIST)) {
58. // 列表页解析出详情页链接添加到待采集URL队列中
59. processTaskQueue(url);
60. } else {
61. // 解析网页
62. processPage(url);
63. }
64. }
66. protected void processTaskQueue(String url) {
67. try {
68. Document doc = Jsoup.connect(url).get();
69. // 详情页链接
70. Elements elements = doc.select(” div.news-list > ul > li > div.list-hd > h4 > a”);
71. elements.stream().forEach((element -> {
72. String request = element.attr(“href”);
73. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
74. if (!visited.contains(request) && !taskQueue.contains(request)) {
75. try {
76. taskQueue.put(request);
77. } catch (InterruptedException e) {
78. e.printStackTrace();
79. }
80. }
81. }));
82. // 列表页链接
83. Elements list_urls = doc.select(“div.voice-paging > a”);
84. list_urls.stream().forEach((element -> {
85. String request = element.absUrl(“href”);
86. // 判断是否符合要提取的列表链接要求
87. if (request.matches(URL_LIST)) {
88. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
89. if (!visited.contains(request) && !taskQueue.contains(request)) {
90. try {
91. taskQueue.put(request);
92. } catch (InterruptedException e) {
93. e.printStackTrace();
94. }
95. }
96. }
97. }));
99. } catch (Exception e) {
100. e.printStackTrace();
101. }
102. }
104. protected void processPage(String url) {
105. try {
106. Document doc = Jsoup.connect(url).get();
107. String title = doc.select(“body > div.hp-wrap > div.voice-main > div.artical-title > h1”).first().ownText();
109. System.out.println(Thread.currentThread().getName() + ” 在 “ + new Date() + ” 采集了虎扑新闻 “ + title);
110. // 将采集完的 url 存入到已经采集的 set 中
111. visited.add(url);
113. } catch (IOException e) {
114. e.printStackTrace();
115. }
116. }
118. public static void main(String[] args) {
120. try {
121. new ThreadCrawler(“https://voice.hupu.com/nba”, 5).run();
122. } catch (InterruptedException e) {
123. e.printStackTrace();
124. }
125. }
126. }
我们用5个线程去采集hupu新闻列表页面看看效果。如果我们运行程序,我们会得到以下结果:
多线程采集结果
从结果可以看出,我们启动了 5 个线程 采集 到 61 个页面,总共耗时 2 秒。可以说效果还是不错的。我们用单线程对比一下,看看差距有多大?我们将线程数设置为1,再次启动程序,得到如下结果:
单线程运行结果
可以看到,单线程采集Hupu 61消息耗时7秒,几乎是多线程的4倍。如果你仔细想想,这只有 61 页。如果有更多的页面,差距会增加。该值越大,多线程爬虫的效率越高。想学交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
分布式爬虫架构
分布式爬虫架构是只有大型采集程序才需要使用的架构。一般可以使用单机多线程来解决业务需求。反正我没有分布式爬虫项目的经验,所以和这个没什么关系。是的,但作为技术人员,我们需要保持技术的热度。虽然我们不需要它,但理解它是可以的。我查了很多资料,得出以下结论:
分布式爬虫架构在思路上和我们的多线程爬虫架构是一样的。我们只需要在多线程的基础上稍加改进,就可以成为一个简单的分布式爬虫架构。由于在分布式爬虫架构中爬虫程序部署在不同的机器上,我们等待的URL采集和已经是采集的URL不能存储在爬虫程序机器的内存中,我们需要存储在某台机器上统一维护,比如存储在Redis或者MongoDB中。每台机器都从这里获取采集链接,而不是从LinkedBlockingQueue等内存队列中获取链接。这样一个简单的分发爬虫架构就出现了。当然会有很多细节,因为我没有分布式架构的经验,也谈不上。如果您有兴趣,欢迎交流。 查看全部
java爬虫抓取动态网页(Java爬虫服务器被屏蔽,不要慌,咱们换一台中)
Java爬虫服务器被封了,别慌,换个服务器,我们简单说一下反爬策略和反反爬方法,主要是IP封堵及其对应的方法。之前的文章文章我们讲了爬虫的基础知识。在这篇文章中,我们来谈谈爬虫架构。

在前面的章节中,我们的爬虫程序都是单线程的。我们在调试爬虫程序的时候,单线程爬虫是没有问题的,但是当我们使用单线程爬虫程序去在线环境下的采集网页时,单线程爬虫会不行。暴露了两个致命问题:
线上的环境不能像我们本地的测试一样,不关心采集的效率,只要能正确提取结果即可。在这个时间就是金钱的时代,不可能给你时间慢慢来采集,所以单线程爬虫程序就不行了,我们需要把单线程改成多线程模式来改进采集 效率和提高计算机利用率。想学习交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
多线程爬虫的设计要比单线程的程序复杂得多,但又不同于其他需要在高并发下保证数据安全的业务。被视为一个独立的实体。做多线程爬虫,必须做好两件事:第一点是维护统一的采集 URL,第二点是对URL进行去重。简单说一下这两点。
将 URL 维护为 采集
多线程爬虫不能像单线程一样,每个线程独立维护自己的采集 URL,如果是这样的话,那么每个线程的网页采集都是一样的,你会不是多线程采集,而是要多次采集 一个页面。为此,我们需要将 URL 统一维护为 采集。每个线程从统一的URL维护处接收到采集 URL,完成采集任务。如果在页面上找到新 URL 链接将添加到统一 URL 维护的容器中。这里有几个适合统一 URL 维护的容器:
URL重复数据删除
URL去重也是多线程采集中的一个关键步骤,因为如果我们不去重,那么我们会采集到大量重复的URL,这并不能改善我们的采集 效率,例如在一个分页的新闻列表中,我们可以在 采集 的第一页获取到 2、3、4、5 个页面的链接,并且在采集的第二页会再次得到1、3、4、5个页面链接,采集的URL队列中会有大量列表页面链接@>,会重复采集甚至进入死循环,所以需要进行URL去重。有很多方法可以对 URL 进行重复数据删除。以下是几种常用的URL去重方法:
关于多线程爬虫的两个核心知识点大家都知道。下面我画一个简单的多线程爬虫架构图,如下图所示:
多线程爬虫架构图
以上,我们主要了解了多线程爬虫的架构设计。接下来,我们不妨试试Java多线程爬虫。我们以采集虎扑新闻为例,实战Java多线程爬虫,在Java多线程爬虫中设计的采集URL的维护和URL的去重,由于这里只是演示,所以我们将使用JDK的内置容器来完成它。我们使用 LinkedBlockingQueue 作为 URL 维护容器为 采集,HashSet 作为 URL 到 Heavy 容器。以下是Java多线程爬虫的核心代码。详细代码可以上传到 GitHub。地址在文末:想学习和交流HashMap,nginx,dubbo,Spring MVC,分布式,高性能高可用,
2. public class ThreadCrawler implements Runnable {
3. // 采集的文章数
4. private final AtomicLong pageCount = new AtomicLong(0);
5. // 列表页链接正则表达式
6. public static final String URL_LIST = “https://voice.hupu.com/nba”;
7. protected Logger logger = LoggerFactory.getLogger(getClass());
8. // 待采集的队列
9. LinkedBlockingQueue taskQueue;
10. // 采集过的链接列表
11. HashSet visited;
12. // 线程池
13. CountableThreadPool threadPool;
15. public ThreadCrawler(String url, int threadNum) throws InterruptedException {
16. this.taskQueue = new LinkedBlockingQueue();
17. this.threadPool = new CountableThreadPool(threadNum);
18. this.visited = new HashSet();
19. // 将起始页添加到待采集队列中
20. this.taskQueue.put(url);
21. }
23. @Override
24. public void run() {
25. logger.info(“Spider started!”);
26. while (!Thread.currentThread().isInterrupted()) {
27. // 从队列中获取待采集 URL
28. final String request = taskQueue.poll();
29. // 如果获取 request 为空,并且当前的线程采已经没有线程在运行
30. if (request == null) {
31. if (threadPool.getThreadAlive() == 0) {
32. break;
33. }
34. } else {
35. // 执行采集任务
36. threadPool.execute(new Runnable() {
37. @Override
38. public void run() {
39. try {
40. processRequest(request);
41. } catch (Exception e) {
42. logger.error(“process request “ + request + ” error”, e);
43. } finally {
44. // 采集页面 +1
45. pageCount.incrementAndGet();
46. }
47. }
48. });
49. }
50. }
51. threadPool.shutdown();
52. logger.info(“Spider closed! {} pages downloaded.”, pageCount.get());
53. }
55. protected void processRequest(String url) {
56. // 判断是否为列表页
57. if (url.matches(URL_LIST)) {
58. // 列表页解析出详情页链接添加到待采集URL队列中
59. processTaskQueue(url);
60. } else {
61. // 解析网页
62. processPage(url);
63. }
64. }
66. protected void processTaskQueue(String url) {
67. try {
68. Document doc = Jsoup.connect(url).get();
69. // 详情页链接
70. Elements elements = doc.select(” div.news-list > ul > li > div.list-hd > h4 > a”);
71. elements.stream().forEach((element -> {
72. String request = element.attr(“href”);
73. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
74. if (!visited.contains(request) && !taskQueue.contains(request)) {
75. try {
76. taskQueue.put(request);
77. } catch (InterruptedException e) {
78. e.printStackTrace();
79. }
80. }
81. }));
82. // 列表页链接
83. Elements list_urls = doc.select(“div.voice-paging > a”);
84. list_urls.stream().forEach((element -> {
85. String request = element.absUrl(“href”);
86. // 判断是否符合要提取的列表链接要求
87. if (request.matches(URL_LIST)) {
88. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
89. if (!visited.contains(request) && !taskQueue.contains(request)) {
90. try {
91. taskQueue.put(request);
92. } catch (InterruptedException e) {
93. e.printStackTrace();
94. }
95. }
96. }
97. }));
99. } catch (Exception e) {
100. e.printStackTrace();
101. }
102. }
104. protected void processPage(String url) {
105. try {
106. Document doc = Jsoup.connect(url).get();
107. String title = doc.select(“body > div.hp-wrap > div.voice-main > div.artical-title > h1”).first().ownText();
109. System.out.println(Thread.currentThread().getName() + ” 在 “ + new Date() + ” 采集了虎扑新闻 “ + title);
110. // 将采集完的 url 存入到已经采集的 set 中
111. visited.add(url);
113. } catch (IOException e) {
114. e.printStackTrace();
115. }
116. }
118. public static void main(String[] args) {
120. try {
121. new ThreadCrawler(“https://voice.hupu.com/nba”, 5).run();
122. } catch (InterruptedException e) {
123. e.printStackTrace();
124. }
125. }
126. }
我们用5个线程去采集hupu新闻列表页面看看效果。如果我们运行程序,我们会得到以下结果:

多线程采集结果
从结果可以看出,我们启动了 5 个线程 采集 到 61 个页面,总共耗时 2 秒。可以说效果还是不错的。我们用单线程对比一下,看看差距有多大?我们将线程数设置为1,再次启动程序,得到如下结果:

单线程运行结果
可以看到,单线程采集Hupu 61消息耗时7秒,几乎是多线程的4倍。如果你仔细想想,这只有 61 页。如果有更多的页面,差距会增加。该值越大,多线程爬虫的效率越高。想学交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
分布式爬虫架构
分布式爬虫架构是只有大型采集程序才需要使用的架构。一般可以使用单机多线程来解决业务需求。反正我没有分布式爬虫项目的经验,所以和这个没什么关系。是的,但作为技术人员,我们需要保持技术的热度。虽然我们不需要它,但理解它是可以的。我查了很多资料,得出以下结论:
分布式爬虫架构在思路上和我们的多线程爬虫架构是一样的。我们只需要在多线程的基础上稍加改进,就可以成为一个简单的分布式爬虫架构。由于在分布式爬虫架构中爬虫程序部署在不同的机器上,我们等待的URL采集和已经是采集的URL不能存储在爬虫程序机器的内存中,我们需要存储在某台机器上统一维护,比如存储在Redis或者MongoDB中。每台机器都从这里获取采集链接,而不是从LinkedBlockingQueue等内存队列中获取链接。这样一个简单的分发爬虫架构就出现了。当然会有很多细节,因为我没有分布式架构的经验,也谈不上。如果您有兴趣,欢迎交流。
java爬虫抓取动态网页(这是移动端微博信息_selenium_sina__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-27 04:05
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热门话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具用于自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但只显示微博或粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content.py 输入: 查看全部
java爬虫抓取动态网页(这是移动端微博信息_selenium_sina__)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热门话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具用于自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但只显示微博或粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content.py 输入:
java爬虫抓取动态网页(WebMagic项目代码分为核心和扩展两部分(webmagic-core))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-26 14:20
一、简介
webmagic是一个爬虫框架,无需配置,方便二次开发。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。
二、概览
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个简化的、模块化的爬虫实现,而扩展部分收录了一些方便实用的功能(比如用注解方式编写爬虫等)。
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,Spider 将它们相互组织起来。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2.1 WebMagic 的四个组成部分
2.2 数据流对象
2.3 控制爬虫的引擎——Spider
Spider 是 WebMagic 内部流程的核心。Downloader、PageProcessor、Scheduler 和 Pipeline 都是 Spider 的属性。这些属性可以自由设置,通过设置该属性可以实现不同的功能。Spider也是WebMagic操作的入口,封装了爬虫创建、启动、停止、多线程等功能。
对于编写爬虫来说,PageProcessor是需要编写的部分,Spider是创建和控制爬虫的入口。
2.4 WebMagic 项目构成
WebMagic 项目代码由几个部分组成,在根目录中由不同的目录名称分隔。它们都是独立的 Maven 项目。
WebMagic 主要包括两个已经被广泛使用和成熟的包:
三、基本爬虫3.1 爬虫流程(参考上面的框架图)
下载器-页面下载
PageProcessor-页面分析和链接提取
Webmagic 的选择器
调度程序-URL 管理
管道 - 离线处理和持久化
3.2 使用 WebMagic 抓取壁纸网站
首先介绍WebMagic的依赖,webmagic-core-{version}.jar和webmagic-extension-{version}.jar。在项目中添加这两个包的依赖即可使用WebMagic。
将依赖jar包引入maven
不使用maven的用户可以去下载最新的jar包。
3.3 爬虫的实现实现PageProcessor接口
爬虫配置
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
编写爬虫代码
<p>package photo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.FileNotFoundException;
import java.io.IOException;
public class GetPhoto implements PageProcessor {
// 设置参数
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
/**
* 主方法启动爬虫
*/
public static void main(String[] args) {
// 这里只爬取第一页的壁纸,如果要爬取其他页数修改for循环参数即可
for (int i = 1; i 查看全部
java爬虫抓取动态网页(WebMagic项目代码分为核心和扩展两部分(webmagic-core))
一、简介
webmagic是一个爬虫框架,无需配置,方便二次开发。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。
二、概览
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个简化的、模块化的爬虫实现,而扩展部分收录了一些方便实用的功能(比如用注解方式编写爬虫等)。
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,Spider 将它们相互组织起来。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
(/Users/guih/Desktop/111.png)])
2.1 WebMagic 的四个组成部分
2.2 数据流对象
2.3 控制爬虫的引擎——Spider
Spider 是 WebMagic 内部流程的核心。Downloader、PageProcessor、Scheduler 和 Pipeline 都是 Spider 的属性。这些属性可以自由设置,通过设置该属性可以实现不同的功能。Spider也是WebMagic操作的入口,封装了爬虫创建、启动、停止、多线程等功能。
对于编写爬虫来说,PageProcessor是需要编写的部分,Spider是创建和控制爬虫的入口。
2.4 WebMagic 项目构成
WebMagic 项目代码由几个部分组成,在根目录中由不同的目录名称分隔。它们都是独立的 Maven 项目。
WebMagic 主要包括两个已经被广泛使用和成熟的包:
三、基本爬虫3.1 爬虫流程(参考上面的框架图)
下载器-页面下载
PageProcessor-页面分析和链接提取
Webmagic 的选择器
调度程序-URL 管理
管道 - 离线处理和持久化
3.2 使用 WebMagic 抓取壁纸网站
首先介绍WebMagic的依赖,webmagic-core-{version}.jar和webmagic-extension-{version}.jar。在项目中添加这两个包的依赖即可使用WebMagic。
将依赖jar包引入maven
不使用maven的用户可以去下载最新的jar包。
3.3 爬虫的实现实现PageProcessor接口
爬虫配置
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
编写爬虫代码
<p>package photo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.FileNotFoundException;
import java.io.IOException;
public class GetPhoto implements PageProcessor {
// 设置参数
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
/**
* 主方法启动爬虫
*/
public static void main(String[] args) {
// 这里只爬取第一页的壁纸,如果要爬取其他页数修改for循环参数即可
for (int i = 1; i
java爬虫抓取动态网页(java爬虫抓取动态网页的教程-java代码和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-26 08:05
java爬虫抓取动态网页的教程。可以爬取专业网站的动态页面,文章和话题页面,如腾讯新闻,百度百科,维基百科等。不用翻墙就可以连接国外的网站。文章单页面可以爬取,而多页面也可以爬取,比如一篇新闻,有完整的首页,发言人,文章详情页,评论页,话题页,文章详情页,评论页等。还可以抓取歌词数据,动态歌词,收藏歌词,特定歌词等歌词。
有兴趣,自己可以尝试实验一下。方法思路:动态网页采集,爬取时需要先生成cookie,当点击某一个url以后,可以获取到cookie,以后再次请求时,直接使用cookie,根据cookie内容可以知道请求的url。再利用java的反射技术,自动的抓取所有抓取过的url请求,抓取完毕,再存储到字典中,等待下次重复抓取时使用。
设置协议代理,当请求时,爬虫会生成一个ip,这个ip代理服务器记录,每次请求时都使用这个ip。每个抓取到的网页,都会存储到一个字典中,等待下次抓取时使用。注意事项1.动态网页,抓取简单,本文采用了经典的动态爬虫技术get,post请求方式2.协议代理设置了,爬虫会生成一个代理ip,为了规避封ip和封端口,动态抓取时网页加密为https,协议代理ip只记录https的网址和端口3.只读协议代理,当使用共享代理端口时,协议代理ip可以改为remote,子代理ip只能为remote请求方式,不能直接使用上面的动态爬虫网页抓取方法。
java代码和注意事项1.整体思路如下动态页面抓取2.操作界面设置:点击右上角文章,可以看到动态页面抓取3.代码代码和注意事项:#!/usr/bin/envpython#coding:utf-8fromhttplibimportparsefromseleniumimportwebdriverhttplib.parse(context='ssl')'''动态抓取动态页面资源.程序详解.'''mask=nonenetwork=['get','post']friend_url='('+network.getcase(url=url)+')'try:friend_url='(/)'exceptexceptionase:e.status='200'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/69.0.3071.142safari/537.36'}#这里的friend_url是自己爬取到的具体页面页面信息,待会使用时需要带上'''[xpath](//div[@class="exterm"]/div/div[2]/div/div/div/a/div/div/div/div/a/span/div/div/div/div/i)'''parsed_c。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页的教程-java代码和注意事项)
java爬虫抓取动态网页的教程。可以爬取专业网站的动态页面,文章和话题页面,如腾讯新闻,百度百科,维基百科等。不用翻墙就可以连接国外的网站。文章单页面可以爬取,而多页面也可以爬取,比如一篇新闻,有完整的首页,发言人,文章详情页,评论页,话题页,文章详情页,评论页等。还可以抓取歌词数据,动态歌词,收藏歌词,特定歌词等歌词。
有兴趣,自己可以尝试实验一下。方法思路:动态网页采集,爬取时需要先生成cookie,当点击某一个url以后,可以获取到cookie,以后再次请求时,直接使用cookie,根据cookie内容可以知道请求的url。再利用java的反射技术,自动的抓取所有抓取过的url请求,抓取完毕,再存储到字典中,等待下次重复抓取时使用。
设置协议代理,当请求时,爬虫会生成一个ip,这个ip代理服务器记录,每次请求时都使用这个ip。每个抓取到的网页,都会存储到一个字典中,等待下次抓取时使用。注意事项1.动态网页,抓取简单,本文采用了经典的动态爬虫技术get,post请求方式2.协议代理设置了,爬虫会生成一个代理ip,为了规避封ip和封端口,动态抓取时网页加密为https,协议代理ip只记录https的网址和端口3.只读协议代理,当使用共享代理端口时,协议代理ip可以改为remote,子代理ip只能为remote请求方式,不能直接使用上面的动态爬虫网页抓取方法。
java代码和注意事项1.整体思路如下动态页面抓取2.操作界面设置:点击右上角文章,可以看到动态页面抓取3.代码代码和注意事项:#!/usr/bin/envpython#coding:utf-8fromhttplibimportparsefromseleniumimportwebdriverhttplib.parse(context='ssl')'''动态抓取动态页面资源.程序详解.'''mask=nonenetwork=['get','post']friend_url='('+network.getcase(url=url)+')'try:friend_url='(/)'exceptexceptionase:e.status='200'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/69.0.3071.142safari/537.36'}#这里的friend_url是自己爬取到的具体页面页面信息,待会使用时需要带上'''[xpath](//div[@class="exterm"]/div/div[2]/div/div/div/a/div/div/div/div/a/span/div/div/div/div/i)'''parsed_c。
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-24 04:10
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与perl、shell等其他动态脚本语言相比,python的urllib包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。 python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
爬取的网页通常需要处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 与 python3.x 非常不同。本文只讨论python的爬虫实现方法3.x.
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,将其存储,并将url补充到URL管理器中。
运行过程
URL管理器基本功能存储方法
1、内存(python 内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
urls(url, is_crawled)
3、缓存(redis)
要爬取的url集合:set
抓取的网址集合:设置
大型互联网公司,由于缓存数据库的高性能,一般将URL存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新百度2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监控数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py.
虽然python报错,但是在fiddler中,我们可以看到请求信息,确实是带参数的。
查了资料,发现以前的Python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 .结果还是报错,但是变成了400错误。
然而,然而。 . 神的转折点出现了! ! !
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法! ! !
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
美人汤
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现警告。根据提示,我们可以在创建BeautifulSoup对象时指定解析器。
5、获取文档中的所有文本
print(soup.get_text())
6、正则匹配
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
书签
Python开发一个简单的爬虫
Python 标准库
美丽的汤4.2.0 文档
为什么python适合写爬虫?
如何学习Python爬虫【简介】?
你需要这些:Python3.x爬虫学习资料整理
如何开始使用 Python 爬虫?
Python3.X爬取网络资源
python 网络请求和“HTTP 错误 504:Fiddler - 接收失败”
如何使用Fiddler抓取自己写的爬虫包?
fiddler抓取python脚本的https包时出错? 查看全部
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与perl、shell等其他动态脚本语言相比,python的urllib包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。 python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
爬取的网页通常需要处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 与 python3.x 非常不同。本文只讨论python的爬虫实现方法3.x.
爬虫架构的组成

URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,将其存储,并将url补充到URL管理器中。
运行过程

URL管理器基本功能存储方法
1、内存(python 内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
urls(url, is_crawled)
3、缓存(redis)
要爬取的url集合:set
抓取的网址集合:设置
大型互联网公司,由于缓存数据库的高性能,一般将URL存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新百度2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监控数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py.

虽然python报错,但是在fiddler中,我们可以看到请求信息,确实是带参数的。

查了资料,发现以前的Python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 .结果还是报错,但是变成了400错误。

然而,然而。 . 神的转折点出现了! ! !
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法! ! !
添加处理器

import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
美人汤
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
说明


基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))

出现警告。根据提示,我们可以在创建BeautifulSoup对象时指定解析器。
5、获取文档中的所有文本
print(soup.get_text())
6、正则匹配
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
书签
Python开发一个简单的爬虫
Python 标准库
美丽的汤4.2.0 文档
为什么python适合写爬虫?
如何学习Python爬虫【简介】?
你需要这些:Python3.x爬虫学习资料整理
如何开始使用 Python 爬虫?
Python3.X爬取网络资源
python 网络请求和“HTTP 错误 504:Fiddler - 接收失败”
如何使用Fiddler抓取自己写的爬虫包?
fiddler抓取python脚本的https包时出错?
java爬虫抓取动态网页(盘点一下数据采集常见的几种网站类型(一)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-24 04:07
)
在学习爬虫之前,我们需要先掌握网站的类型,这样才能根据网站的类型使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件可以采集的网站类型为例,盘点一下数据采集常用类型网站 的类型。
lCommon网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常将 JavaScript 脚本嵌入到 HTML 中来实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,利用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。当浏览一个页面时,我们将页面拉回来,页面链接并没有改变,但是网页中有新的内容。这是通过Ajax获取新数据并呈现流程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。 POST 将表单打包并隐藏在后台并发送给服务器; GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中数据的web内容,即采集post/get请求中的数据。
3.需要 cookie网站
Cookies 是指存储在用户本地终端上的一些网站数据,用于识别用户身份并进行会话跟踪。 Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般用户的帐户信息记录在 cookie 中。爬虫爬取数据时,可以通过cookie模拟登录状态获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要cookie的网站内容。
4.采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供多种OAUTH实现如PHP、Java Script、Java、Ruby等语言开发包,大大节省了程序员的时间,所以OAUTH简单。 Open API等很多互联网服务,谷歌、雅虎、微软等很多大公司都提供了OAUTH认证服务,足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l前端嗅探介绍
前嗅大数据,国内领先的大数据研发专家,多年致力于大数据技术的研发,自主研发了完整的数据集采集,分析,处理、管理和应用。 ,营销大数据产品。千秀致力于打造国内首个深度大数据平台!
查看全部
java爬虫抓取动态网页(盘点一下数据采集常见的几种网站类型(一)(组图)
)
在学习爬虫之前,我们需要先掌握网站的类型,这样才能根据网站的类型使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件可以采集的网站类型为例,盘点一下数据采集常用类型网站 的类型。
lCommon网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常将 JavaScript 脚本嵌入到 HTML 中来实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
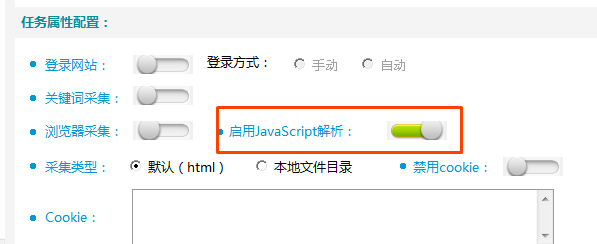
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,利用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。当浏览一个页面时,我们将页面拉回来,页面链接并没有改变,但是网页中有新的内容。这是通过Ajax获取新数据并呈现流程。

ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。 POST 将表单打包并隐藏在后台并发送给服务器; GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。


ForeSpider采集器可以采集post/get请求中数据的web内容,即采集post/get请求中的数据。
3.需要 cookie网站
Cookies 是指存储在用户本地终端上的一些网站数据,用于识别用户身份并进行会话跟踪。 Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
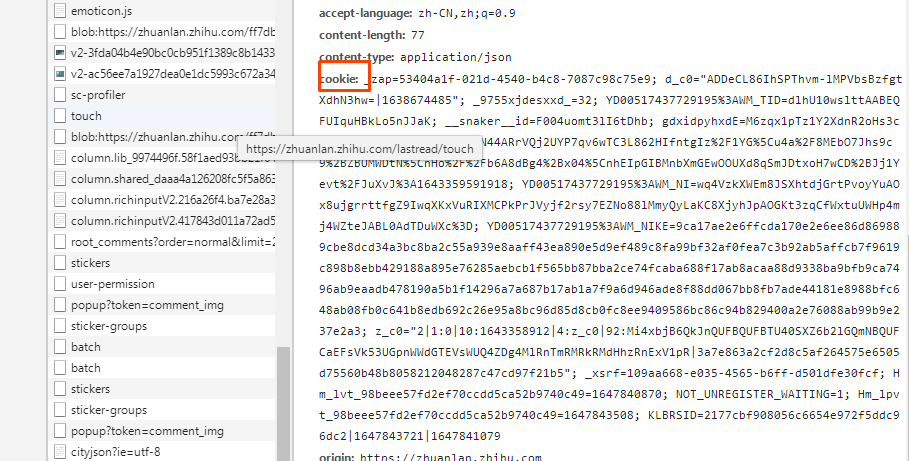
一般用户的帐户信息记录在 cookie 中。爬虫爬取数据时,可以通过cookie模拟登录状态获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要cookie的网站内容。
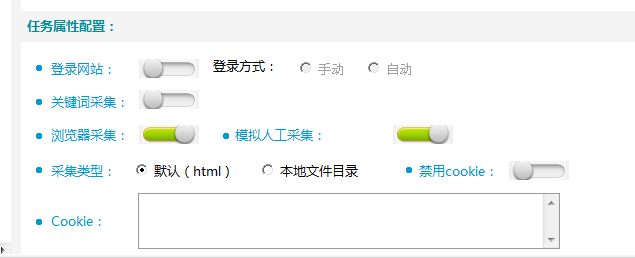
4.采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供多种OAUTH实现如PHP、Java Script、Java、Ruby等语言开发包,大大节省了程序员的时间,所以OAUTH简单。 Open API等很多互联网服务,谷歌、雅虎、微软等很多大公司都提供了OAUTH认证服务,足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。

l前端嗅探介绍
前嗅大数据,国内领先的大数据研发专家,多年致力于大数据技术的研发,自主研发了完整的数据集采集,分析,处理、管理和应用。 ,营销大数据产品。千秀致力于打造国内首个深度大数据平台!

java爬虫抓取动态网页(聚焦网络爬虫又称主题网络数采集的主要功能工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-24 04:05
网络号的主要作用采集
网络数据采集是指通过网络爬虫或网站公共API
从网站获取数据信息
常用网络采集系统网络爬虫工作原理工作流程抓取策略网络爬虫策略中使用的基本概念一般网络爬虫
通用网络爬虫也称为全网络爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
De Bra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,利用空间向量模型计算页面与主题的相关度。通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关度的量化大小。
2)基于链接结构评估的爬取策略
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页。如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。网页的重要性与它所引用的网页同等地传递。
3)基于强化学习的爬取策略
将强化学习引入焦点爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,计算每个链接的重要性,确定链接访问的顺序。
4)基于上下文图的爬取策略
一种通过构建上下文图来了解网页之间相关性的抓取策略。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。访问。
增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。 .
深度网络爬虫
网页按存在方式可分为表层网页和深层网页。表面网页是指可以被传统搜索引擎索引的页面,主要是可以通过超链接到达的静态网页。深度网页是大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
深网爬虫架构由6个基本功能模块组成:
爬虫控制器、解析器、表单分析器、表单处理程序、响应分析器、LVS 控制器和两个爬虫内部数据结构(URL 列表和 LVS 表)。其中,LVS(Label Value Set)代表标签和值集,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
java爬虫抓取动态网页(聚焦网络爬虫又称主题网络数采集的主要功能工作流程)
网络号的主要作用采集
网络数据采集是指通过网络爬虫或网站公共API
从网站获取数据信息
常用网络采集系统网络爬虫工作原理工作流程抓取策略网络爬虫策略中使用的基本概念一般网络爬虫
通用网络爬虫也称为全网络爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
De Bra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,利用空间向量模型计算页面与主题的相关度。通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关度的量化大小。
2)基于链接结构评估的爬取策略
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页。如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。网页的重要性与它所引用的网页同等地传递。
3)基于强化学习的爬取策略
将强化学习引入焦点爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,计算每个链接的重要性,确定链接访问的顺序。
4)基于上下文图的爬取策略
一种通过构建上下文图来了解网页之间相关性的抓取策略。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。访问。
增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。 .
深度网络爬虫
网页按存在方式可分为表层网页和深层网页。表面网页是指可以被传统搜索引擎索引的页面,主要是可以通过超链接到达的静态网页。深度网页是大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
深网爬虫架构由6个基本功能模块组成:
爬虫控制器、解析器、表单分析器、表单处理程序、响应分析器、LVS 控制器和两个爬虫内部数据结构(URL 列表和 LVS 表)。其中,LVS(Label Value Set)代表标签和值集,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-04-14 11:22
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明 基本使用
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。 查看全部
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib 包提供了对 web 文档的更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 和 python3.x 很不一样。本文只讨论python3.x的爬虫实现方法。
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,存储起来,补充url给URL管理器。
运行进程URL管理器基本功能存储方法
1、内存(python内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
网址(网址,is_crawled)
3、缓存(redis)
要爬取的url集合:set
爬取的 url 集合:set
由于缓存数据库的高性能,大型互联网公司一般将 URL 存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器 (urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印出得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新建一个baidu2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监听数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后,无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py。
虽然python报错,但是在fiddler中,我们可以看到请求信息,里面确实携带了参数。
查资料发现以前的python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 . 结果还是报错,但是变成了400错误。
然而,然而,然而。. . 神的转折点出现了!!!
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法!!!
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
Web 解析器 (BeautifulSoup)
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
使用说明 基本使用
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现了警告。根据提示,我们可以在创建 BeautifulSoup 对象时指定解析器。
soup = BeautifulSoup(html_doc,'html.parser')
5、从文档中获取所有文本内容
print(soup.get_text())
6、常规赛
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
java爬虫抓取动态网页(java爬虫抓取动态网页生成web地址的方法和方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-12 21:05
java爬虫抓取动态网页生成web地址本来应该就可以用动态脚本抓取,可以参考百度用java做动态网页抓取web-track-response,复制到浏览器访问即可,不过url貌似不是动态的而是java自己规定的地址,java有反射机制可以自己动态生成url,你需要的是:httpshttp。它可以调用动态抓取到的url,然后把这个url重定向到浏览器内的url里。上面的函数再加上对网页代码的解析也可以获得java自己生成的url,更详细的可以看scrapy..。
有一个应用weburl生成器java开发,可以把前端发给你的url转化为.js生成的地址,方便你抓取生成,具体的可以参考我的文章,
和利用客户端动态生成一个动态地址那种方法一样的
可以看下这个
这个问题我必须要回答,因为我也想过这个问题,因为现在是手机,有些知名网站经常打不开,都是要等到固定时间之后才能打开,但是现在手机浏览器本身就能打开,那么只要是知名网站,一般都会从系统文件和网络获取token然后等时间后就可以打开了。这些都是可以从别人系统下载,
1.使用第三方爬虫工具,比如最简单就是360或者携程等的api接口。2.获取站内链接获取同站其他网站的某些地址,然后用java写个模拟器运行获取的地址。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页生成web地址的方法和方法介绍)
java爬虫抓取动态网页生成web地址本来应该就可以用动态脚本抓取,可以参考百度用java做动态网页抓取web-track-response,复制到浏览器访问即可,不过url貌似不是动态的而是java自己规定的地址,java有反射机制可以自己动态生成url,你需要的是:httpshttp。它可以调用动态抓取到的url,然后把这个url重定向到浏览器内的url里。上面的函数再加上对网页代码的解析也可以获得java自己生成的url,更详细的可以看scrapy..。
有一个应用weburl生成器java开发,可以把前端发给你的url转化为.js生成的地址,方便你抓取生成,具体的可以参考我的文章,
和利用客户端动态生成一个动态地址那种方法一样的
可以看下这个
这个问题我必须要回答,因为我也想过这个问题,因为现在是手机,有些知名网站经常打不开,都是要等到固定时间之后才能打开,但是现在手机浏览器本身就能打开,那么只要是知名网站,一般都会从系统文件和网络获取token然后等时间后就可以打开了。这些都是可以从别人系统下载,
1.使用第三方爬虫工具,比如最简单就是360或者携程等的api接口。2.获取站内链接获取同站其他网站的某些地址,然后用java写个模拟器运行获取的地址。
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-04-12 15:30
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2.社区比较大,文档比较齐全。
3.URL 去重采用布隆过滤器方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider 是一个用 python 实现的强大的网络爬虫系统。可以在浏览器界面编写脚本,调度功能,实时查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.简单,五分钟即可开始。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制的能力。
(3)Apache Nutch)
Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。
Nutch框架需要Hadoop运行,Hadoop需要开集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,也许他们以后会学习。
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展各种网页内容的解析、采集、查询、聚类、过滤各种数据的功能。因为这个框架,Nutch 的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch 的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4),WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的 API 快速上手
2.模块化结构,方便扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5),网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
优势:
1.根据文本密度自动提取网页文本
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.没有URL优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix的爬虫有很多自定义参数
缺点
1.单实例爬虫不能互相配合。
2.在机器资源有限的情况下,需要进行复杂的操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,更新时没有修改。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的站点进行排名,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的 Url 过滤机制使用 BerkeleyDB 进行 url 过滤。
3.可扩展以支持网络字段的结构化提取,可作为垂直方向采集
缺点
1.不支持动态网页抓取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。该文档有一个近乎完整的介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过,这个框架有一个优势,它具有非常强大的网页解析功能。
selenium(谷歌多个大佬参与开发)
感觉很厉害,其实很厉害。看了官网等的介绍,都说是真实的浏览器模拟。GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍性的 Demo 就是无法成功运行,所以我放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器就可以了。
简要介绍:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
将两者融合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也很熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着如此详尽的文件,留下了激动和遗憾的泪水……
cdp4j 有很多特点:
一种。获取渲染后的网页源代码
湾。模拟浏览器点击事件
C。下载可以在网页上下载的文件
d。截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以到以下三个地址去探索发现: 查看全部
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
(1), Scrapy:
Scrapy,一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。还提供了各类爬虫的基类,如BaseSpider、站点地图爬虫等。最新版本提供了对web2.0爬虫的支持。
报废意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2.社区比较大,文档比较齐全。
3.URL 去重采用布隆过滤器方案。
4.可以处理不完整的HTML,Scrapy已经提供了选择器(基于lxml的更高级的接口),
可以有效地处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
Pyspider 是一个用 python 实现的强大的网络爬虫系统。可以在浏览器界面编写脚本,调度功能,实时查看爬取结果。后端使用通用数据库存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本,启动和停止脚本,监控执行状态,查看活动历史,获取结果。
3.简单,五分钟即可开始。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库而不是Bloom过滤器,十亿级存储的db io会导致效率急剧下降。
2.使用的人性化牺牲了灵活性,降低了定制的能力。
(3)Apache Nutch)
Nutch 是为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的三分之二的流程是为搜索引擎设计的。
Nutch框架需要Hadoop运行,Hadoop需要开集群。我不希望快速开始使用爬虫...
这里列出了一些资源地址,也许他们以后会学习。
1.Nutch 支持分布式爬取,拥有Hadoop 支持多机分布式爬取、存储和索引。另一个很吸引人的地方是它提供了一个插件框架,可以很方便的扩展各种网页内容的解析、采集、查询、聚类、过滤各种数据的功能。因为这个框架,Nutch 的插件开发非常容易,第三方插件层出不穷,大大提升了Nutch 的功能和知名度。
缺点
1.Nutch的爬虫定制能力比较弱
(4),WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的 API 快速上手
2.模块化结构,方便扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5),网络采集器
WebCollector是一个无需配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现强大的爬虫。WebCollector-Hadoop 是支持分布式爬取的 WebCollector 的 Hadoop 版本。
优势:
1.根据文本密度自动提取网页文本
2.支持断点重爬
3.支持代理
缺点:
1.不支持分布式,只支持单机
2.没有URL优先级调度
3.不是很活跃
(6), Heritrix3
Heritrix是java开发的开源网络爬虫,用户可以使用它从互联网上爬取想要的资源
优势
Heritrix的爬虫有很多自定义参数
缺点
1.单实例爬虫不能互相配合。
2.在机器资源有限的情况下,需要进行复杂的操作。
3.仅官方支持,仅在 Linux 上测试。
4.每个爬虫单独工作,更新时没有修改。
5.在发生硬件和系统故障时恢复能力很差。
6.优化性能的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,不提供搜索引擎。如果要对爬取的站点进行排名,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2.内置的 Url 过滤机制使用 BerkeleyDB 进行 url 过滤。
3.可扩展以支持网络字段的结构化提取,可作为垂直方向采集
缺点
1.不支持动态网页抓取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,小编做了一个框架优缺点对比图,如下:
Jsoup(经典,适合静态网友)
这个框架很经典,也是我们暑期培训老师讲解的框架。该文档有一个近乎完整的介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过,这个框架有一个优势,它具有非常强大的网页解析功能。
selenium(谷歌多个大佬参与开发)
感觉很厉害,其实很厉害。看了官网等的介绍,都说是真实的浏览器模拟。GitHub1.4w+star,你没看错,上万。但我就是不适应环境。介绍性的 Demo 就是无法成功运行,所以我放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器就可以了。
简要介绍:
HtmlUnit的优点是可以轻松爬取静态网友;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染好的网页;缺点是需要配置环境变量等。
将两者融合,取长补短,就有了cdp4j。
之所以选择它,是因为它真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名也很熟悉。我想我在学习软件工程的时候一直在想,如果我的程序能实现这个功能,为什么还要写文档呢?现在,看着如此详尽的文件,留下了激动和遗憾的泪水……
cdp4j 有很多特点:
一种。获取渲染后的网页源代码
湾。模拟浏览器点击事件
C。下载可以在网页上下载的文件
d。截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以到以下三个地址去探索发现:
java爬虫抓取动态网页(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-04-09 20:32
书接上一本,哈哈,昨天出版了,如何使用Node的cheerio模块来抓取网页信息,那我们就得有自己的用处来获取数据了。
昨天抓了几张超诱人的糕点,今天给大家看,大家都馋了啊哈哈哈~
昨天的爬虫博文,有需要的请点此链接:Node Learning Cheerio Web Crawler
好,我们开始今天的演示,上代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i 查看全部
java爬虫抓取动态网页(Node学习之cheerio网络爬虫好了,啊哈哈哈~昨天的抓取博文)
书接上一本,哈哈,昨天出版了,如何使用Node的cheerio模块来抓取网页信息,那我们就得有自己的用处来获取数据了。
昨天抓了几张超诱人的糕点,今天给大家看,大家都馋了啊哈哈哈~
昨天的爬虫博文,有需要的请点此链接:Node Learning Cheerio Web Crawler
好,我们开始今天的演示,上代码:
<p>var http = require("http");
var cheerio = require("cheerio");
//准备抓取的网站链接
var dataUrl = "http://www.mcake.com/shop/110/ ... 3B%3B
http.get(dataUrl,function(res){
var str = "";
//绑定方法,获取网页数据
res.on("data",function(chunk){
str += chunk;
})
//数据获取完毕
res.on("end",function(){
//调用下方的函数,得到返回值,即是我们想要的img的src
var data = getData(str);
//console.log(data);
----------
//新添加的部分
//用node搭建服务器,将内容展示在页面上
var server = http.createServer(function(req,res){
//定义空的字符串
var html = "";
//循环得到的数据,拼接在html上
for(var i = 0;i
java爬虫抓取动态网页(什么是异步数据加载AJAX的基本概念如何获取异步抓取数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-09 18:19
)
获取异步数据
主要内容:什么是异步数据加载AJAX的基本概念如何使用URL获取异步数据抓取异步数据项目实战:分析某东商城的书评数据,并抓取这些数据关于异步传输AJAX什么是AJAX?
1、异步,请求和下载异步,不占用主线程,即使加载数据缓慢,不会出现页面卡顿
2、传输数据的格式,XML->JSON
AJAX发送请求的基本原理,在网页中实现业务逻辑和页面交互的JavaScript语言,IE7+、FireFox、Chrome、Safari等浏览器都需要使用XMLHttpRequest对象发送请求,IE7以下的浏览器需要使用下面的代码 讲讲Microsoft.XMLHTTP对象 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP") 解析响应,响应主要是指JSON格式的数据。使用 JSON.parse(result) 获取 JavaScript JSON 数据渲染页面 AJAX 服务器请求数据案例 使用 Flask 框架模拟异步加载页面。页面使用模板展示,通过jQuery向服务器发送请求,获取数据后在页面上展示数据。知道异步传输的URI,可以通过请求等网络爬取URL,但是返回的数据格式不是HTML。也不是 XML,而是 JSON。因此,不要使用 XPath 和 CSS 选择器处理,而是使用 json 模块中的加载函数将字符串形式的 JSON 转换为 Python 字典
服务终端:
from flask import Flask,render_template
from flask import make_response
import json
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def data():
data = [
{'id':1,'name':'PyQt5(Python)实战视频课程'},
{'id':2,'name':'Electron实战'},
{'id':3, 'name': '征服C++ 11'},
{'id':4, 'name': '征服Flask'},
]
response = make_response(json.dumps(data))
return response
if __name__ == '__main__':
app.run(host = '0.0.0.0', port='1234')
html页面内容:
<p>
异步加载页面
视频课程
人工智能-机器学习实战视频课程
用C++和Go开发Node.js本地模块
Go Web实战视频教程
Python科学计算与图形渲染库视频教程
function onLoad()
{
$.get("/data", function(result){
data = JSON.parse(result)
for(var i = 0; i 查看全部
java爬虫抓取动态网页(什么是异步数据加载AJAX的基本概念如何获取异步抓取数据
)
获取异步数据
主要内容:什么是异步数据加载AJAX的基本概念如何使用URL获取异步数据抓取异步数据项目实战:分析某东商城的书评数据,并抓取这些数据关于异步传输AJAX什么是AJAX?
1、异步,请求和下载异步,不占用主线程,即使加载数据缓慢,不会出现页面卡顿
2、传输数据的格式,XML->JSON
AJAX发送请求的基本原理,在网页中实现业务逻辑和页面交互的JavaScript语言,IE7+、FireFox、Chrome、Safari等浏览器都需要使用XMLHttpRequest对象发送请求,IE7以下的浏览器需要使用下面的代码 讲讲Microsoft.XMLHTTP对象 xmlhttp = new ActiveXObject("Microsoft.XMLHTTP") 解析响应,响应主要是指JSON格式的数据。使用 JSON.parse(result) 获取 JavaScript JSON 数据渲染页面 AJAX 服务器请求数据案例 使用 Flask 框架模拟异步加载页面。页面使用模板展示,通过jQuery向服务器发送请求,获取数据后在页面上展示数据。知道异步传输的URI,可以通过请求等网络爬取URL,但是返回的数据格式不是HTML。也不是 XML,而是 JSON。因此,不要使用 XPath 和 CSS 选择器处理,而是使用 json 模块中的加载函数将字符串形式的 JSON 转换为 Python 字典
服务终端:
from flask import Flask,render_template
from flask import make_response
import json
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def data():
data = [
{'id':1,'name':'PyQt5(Python)实战视频课程'},
{'id':2,'name':'Electron实战'},
{'id':3, 'name': '征服C++ 11'},
{'id':4, 'name': '征服Flask'},
]
response = make_response(json.dumps(data))
return response
if __name__ == '__main__':
app.run(host = '0.0.0.0', port='1234')
html页面内容:
<p>
异步加载页面
视频课程
人工智能-机器学习实战视频课程
用C++和Go开发Node.js本地模块
Go Web实战视频教程
Python科学计算与图形渲染库视频教程
function onLoad()
{
$.get("/data", function(result){
data = JSON.parse(result)
for(var i = 0; i
java爬虫抓取动态网页(MaterialDesign重构了自己的新闻App,数据来源是个问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-04-08 22:14
一、要求
最近基于Material Design重构了我的新闻应用,数据源是个问题。
有前人分析过知乎日报、凤凰新闻等API,可以根据对应的URL获取新闻的JSON数据。为了锻炼写代码的能力,作者打算爬取新闻页面,获取数据搭建API。
二、渲染
下图为网站的原页面
爬虫获取数据并显示在APP手机上
三、爬虫思路
App的实现过程请参考这些文章文章。本文主要讲解如何爬取数据。
Android下记录App操作生成Gif动态图的全过程:///article/78236.htm
学习Android Material Design(RecyclerView代替ListView):///article/78232.htm
网易新闻模仿Android项目实战的页面(RecyclerView):///article/78230.htm
Jsoup 简介
Jsoup是一个Java开源的HTML解析器,可以直接解析一个URL地址和HTML文本内容。
Jsoup主要有以下功能:
四、爬虫进程
获取获取网页 HTML 的请求
新闻页面Html的DOM树如下:
以下代码使用代码根据指定的url获取get请求返回的html源码。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("新闻服务器返回值不为200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get请求失败");
}
return html;
}
InputStream in = connection.getInputStream();把输入流转成字符串是常见的需求,我们把它抽象出来,写一个工具方法。
五、解析 HTML 得到标题
使用 google 浏览器的 censor 元素找出新闻标题的 html 代码:
关于举办《经典音乐作品欣赏与人文审美》讲座的通知
我们需要从上面的 HTML 中找到 id="article_title" 的部分,使用 getElementById(String id) 方法
String htmlStr = HttpTool.doGet(urlStr);
// 将获取的网页 HTML 源代码转化为 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
六、获取发布日期、信息来源
还可以找到 HTML 代码
2015-05-28
来源:
浏览次数:
477
思路和上面类似,使用getElementById(String id)方法找出id="article_detail"为Element,然后使用getElementsByTag获取span部分。由于有 3 个 ... ,因此返回的是 Elements 而不是 Element。
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
七、分析观看次数
如果打印上面的details.get(2).text(),只会得到 查看全部
java爬虫抓取动态网页(MaterialDesign重构了自己的新闻App,数据来源是个问题)
一、要求
最近基于Material Design重构了我的新闻应用,数据源是个问题。
有前人分析过知乎日报、凤凰新闻等API,可以根据对应的URL获取新闻的JSON数据。为了锻炼写代码的能力,作者打算爬取新闻页面,获取数据搭建API。
二、渲染
下图为网站的原页面
爬虫获取数据并显示在APP手机上
三、爬虫思路
App的实现过程请参考这些文章文章。本文主要讲解如何爬取数据。
Android下记录App操作生成Gif动态图的全过程:///article/78236.htm
学习Android Material Design(RecyclerView代替ListView):///article/78232.htm
网易新闻模仿Android项目实战的页面(RecyclerView):///article/78230.htm
Jsoup 简介
Jsoup是一个Java开源的HTML解析器,可以直接解析一个URL地址和HTML文本内容。
Jsoup主要有以下功能:
四、爬虫进程
获取获取网页 HTML 的请求
新闻页面Html的DOM树如下:
以下代码使用代码根据指定的url获取get请求返回的html源码。
public static String doGet(String urlStr) throws CommonException {
URL url;
String html = "";
try {
url = new URL(urlStr);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(5000);
connection.setDoInput(true);
connection.setDoOutput(true);
if (connection.getResponseCode() == 200) {
InputStream in = connection.getInputStream();
html = StreamTool.inToStringByByte(in);
} else {
throw new CommonException("新闻服务器返回值不为200");
}
} catch (Exception e) {
e.printStackTrace();
throw new CommonException("get请求失败");
}
return html;
}
InputStream in = connection.getInputStream();把输入流转成字符串是常见的需求,我们把它抽象出来,写一个工具方法。
五、解析 HTML 得到标题
使用 google 浏览器的 censor 元素找出新闻标题的 html 代码:
关于举办《经典音乐作品欣赏与人文审美》讲座的通知
我们需要从上面的 HTML 中找到 id="article_title" 的部分,使用 getElementById(String id) 方法
String htmlStr = HttpTool.doGet(urlStr);
// 将获取的网页 HTML 源代码转化为 Document
Document doc = Jsoup.parse(htmlStr);
Element articleEle = doc.getElementById("article");
// 标题
Element titleEle = articleEle.getElementById("article_title");
String titleStr = titleEle.text();
六、获取发布日期、信息来源
还可以找到 HTML 代码
2015-05-28
来源:
浏览次数:
477
思路和上面类似,使用getElementById(String id)方法找出id="article_detail"为Element,然后使用getElementsByTag获取span部分。由于有 3 个 ... ,因此返回的是 Elements 而不是 Element。
// article_detail包括了 2016-01-15 来源: 浏览次数:177
Element detailEle = articleEle.getElementById("article_detail");
Elements details = detailEle.getElementsByTag("span");
// 发布时间
String dateStr = details.get(0).text();
// 新闻来源
String sourceStr = details.get(1).text();
七、分析观看次数
如果打印上面的details.get(2).text(),只会得到
java爬虫抓取动态网页(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 458 次浏览 • 2022-04-08 22:13
本文是关于如何在不使用 selenium 插件模拟浏览器的情况下获取网页上动态加载的数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数被转换成urllib 可以识别的字符串数据。四、初始化请求对象。五、urlopen 这个 Request 对象来获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计确诊、累计死亡等数据。因为这个页面的数据是动态加载的,而不是静态的 html 页面。您需要按照我上面写的步骤来获取数据。关键是获取URL和对应的参数formdata。下面讲讲如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,然后从出现的菜单中选择检查元素。
点击上图中的红色箭头网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右边红色框中的“大小”列。此列表示此 http 请求传输的数据量。一般情况下,动态加载的数据量会大于其他页面元素的传输量。与其他按字节计算的数据相比,数据量很大。当然,有些网页的装饰图片也很大。这需要根据文件类型的栏目进行筛选。
然后点击域名栏对应的行,如下
可以在消息头看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?参数已经写在后面了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url, data = data)
然后 url=""
formdata = {'name': 'disease_h5',
'打回来': '',
'_':当前时间戳
}
名字叫disease_h5,callback是页面回调函数,我们不需要回调动作,所以设置为空,_对应时间戳(Python可以很容易地获取时间戳),因为肺炎患者的数量和时间很接近有关的。
如果都写在如下形式的url中
url='%d'%int(戳*1000)
这样就可以得到疫情数据。有两个选项供您选择。
查找url和参数需要耐心和一定的分析能力,才能正确识别url和参数的含义,并实施正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实是对经验的考验。
有些url很简单,直接返回一个.dat文件,里面有json格式的数据,最友好。有的需要设置大量参数才能获取,而获取的数据是html格式,需要解析才能提取数据。解析部分可以参考我之前写的 查看全部
java爬虫抓取动态网页(不使用selenium插件模拟浏览器如何获得网页上的动态加载数据)
本文是关于如何在不使用 selenium 插件模拟浏览器的情况下获取网页上动态加载的数据。步骤如下: 一、找到正确的URL。二、填写URL对应的参数。三、 参数被转换成urllib 可以识别的字符串数据。四、初始化请求对象。五、urlopen 这个 Request 对象来获取数据。
url='http://www.*****.*****/*********'
formdata = {'year': year,
'month': month,
'day': day
}
data = urllib.urlencode(formdata)
request=urllib2.Request(url,data = data) #如果URL不带参数就是request=urllib2.Request(url)
r = urllib2.urlopen(request)
html=r.read() # html就是你要的数据,可能是html格式,也可能是json,或去他格式
下面的步骤是一样的,关键是如何获取URL和参数。我们以新冠肺炎疫情统计网页为例(#/)。
如果直接抓取浏览器的网址,会看到一个没有数据内容的html,只有标题、列名等,没有累计确诊、累计死亡等数据。因为这个页面的数据是动态加载的,而不是静态的 html 页面。您需要按照我上面写的步骤来获取数据。关键是获取URL和对应的参数formdata。下面讲讲如何用火狐浏览器获取这两个数据。
右键单击肺炎页面,然后从出现的菜单中选择检查元素。
点击上图中的红色箭头网络选项,然后刷新页面。如下,
这里会有很多网络传输记录。观察最右边红色框中的“大小”列。此列表示此 http 请求传输的数据量。一般情况下,动态加载的数据量会大于其他页面元素的传输量。与其他按字节计算的数据相比,数据量很大。当然,有些网页的装饰图片也很大。这需要根据文件类型的栏目进行筛选。
然后点击域名栏对应的行,如下
可以在消息头看到请求的url,这个就是url,点击参数可以看到url对应的参数
你能看到网址的结尾吗?参数已经写在后面了。
如果我们使用带参数的 URL,那么
request=urllib2.Request(url),不带数据参数。
如果你使用 request=urllib2.Request(url, data = data)
然后 url=""
formdata = {'name': 'disease_h5',
'打回来': '',
'_':当前时间戳
}
名字叫disease_h5,callback是页面回调函数,我们不需要回调动作,所以设置为空,_对应时间戳(Python可以很容易地获取时间戳),因为肺炎患者的数量和时间很接近有关的。
如果都写在如下形式的url中
url='%d'%int(戳*1000)
这样就可以得到疫情数据。有两个选项供您选择。
查找url和参数需要耐心和一定的分析能力,才能正确识别url和参数的含义,并实施正确的编程。参数是否可以为空,是否可以硬编码,是否有特殊要求,其实是对经验的考验。
有些url很简单,直接返回一个.dat文件,里面有json格式的数据,最友好。有的需要设置大量参数才能获取,而获取的数据是html格式,需要解析才能提取数据。解析部分可以参考我之前写的
java爬虫抓取动态网页( 我待解决问题爬虫已存入mysql已mysql数据库已成功!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-04-02 22:03
我待解决问题爬虫已存入mysql已mysql数据库已成功!)
图片来自简书App
本文文章使用requests和beautifulsoup进行分析;如果您正在寻找正则表达式和 urllib 案例,建议您学习其他材料。
ps:如果要找案例,可以直接看最后一段代码。如果你和我一样,启动爬虫,从文章开始读罗。
前言:自学爬虫第15天,终于成功爬取了58同城的招聘信息,并保存到mysql数据库中……写下这篇文章,分享给正在自学的各位履带式。数据不全:因为有些网页隐藏了一些信息,爬取到的pos_base_browser和pos_base_apply数据都是空的。这个问题仍在解决中。
启示:学习期间我的心态也不稳定,会有逃避的冲动,但让自己坚持下去的动力是一个接一个地解决问题,升级知识体系。重复找资料、百度、百度翻译的过程15天;我最怕看到代码报错;最常见的错误之一是**超出范围。虽然没有人花很多时间找资料,但在不断的探索中,我也得到了解决问题的办法:少问多想——翻译——百度。
文章 分为四个部分:
一、我的爬虫学习目标
二、爬虫学习升级流程:入门10分
三、学习过程中的坑
四、58城市月嫂招聘信息码
五、我有一个问题要解决
爬虫已经存入mysql数据库
一、我的爬虫学习目标
1、了解html、css、javascript
2、master 请求,beautifulsoup 库
3、 会模仿爬虫案例
二、爬虫学习升级流程:入门10分
1、了解html、css、标签
2、学习requests和beautifulsoup库;会获取请求,通过标签选择对应的文本,通过标签选择属性
3、了解静态加载(翻页请求)、动态加载(Ajax)
4、理解函数循环
5、理解 def main(): 函数,name = "main()": 函数
6、了解打印和返回的区别
7、了解索引页(列表页)、详情页、解析详情页url时索引页返回的字典(用于循环)
8、对于数据库的存储,需要在mysql数据库中创建数据库和字段类型。有关详细信息,请参阅代码的第二部分。
9、推荐使用pycharm
10、半自主解决学习过程中出现的任何问题
三、学习过程中的坑:
知道自己会遇到什么问题和问题的类型,即使学习中有问题,也可以通过百度解决。
学习期间,因为不知道怎么提问(因为听不懂,连提问都不会),走了不少弯路。
eg1:解析索引页的时候,不知道应该返回字典的结果格式,折腾了整整两天,突然发现字典可以遍历,把url存成字典可以请求详细信息页面。
eg2:群主一直建议我把爬取的文件保存到数据库,我也看了相关的视频。在不断删除和定义pymysql函数的过程中,我勇敢地尝试解决错误,终于知道了mysql中新数据库、新表、新表中的字段。
自己做不了的时候就去模仿,模仿的过程有问题的时候去百度。
eg3:requests请求没有找到,beautifulsoup解析静态加载案例。拼凑很多视频,代码
……回想起来,中间有很多困惑,但这毕竟是路,只有亲身经历,才能获得成长。希望这个文章能在你切换到数据分析爬虫时对你有所帮助。
四、58城市月嫂招聘信息码
1、目标网点:
坐月子
2、爬取信息:
索引页公司名称;详情页职位名称、更新时间、浏览人数、应聘人数、工资
列表
详情页面
(PS:其实我也想知道索引页的推广方式和发布地址。学习了15天,还是不知道怎么同时保存索引页和详情页的多个内容时间)
3、爬虫代码
《pycharm代码》
import json
import pymysql
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"}
def get_one_page(url):
try:
respones = requests.get(url, headers=headers)
respones.encoding = 'utf-8'
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求错误')
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
soup = BeautifulSoup(html, 'lxml')
list_li = soup.find_all('ul', id='list_con')[0].find_all('li', class_='job_item clearfix') # 返回一个列表需要用循环
dir = {}
for link in list_li:
list_a = link.find_all('div', class_='job_name clearfix')[0].find_all('a')[0] # 筛选出所有的a标签
address = list_a.find_all('span', class_='address')[0].text
name = list_a.find_all('span', class_='name')[0].text
comp_name = link.find_all('div', class_='comp_name')[0].find_all('a')[0].text
href = list_a['href']
t = list_a['_t']
dir[href] = comp_name
return dir
def get_two_page(url):
try:
respones = requests.get(url, 'lxml')
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求详情页错误')
return None
def parse_two_page(html,comp_name):
comp_name = comp_name
soup = BeautifulSoup(html, 'lxml')
#pos_base = soup.find_all('div',class_ = 'pos_base_statistics')[0]
pos_name = soup.find_all('span',class_ = 'pos_name')[0].text
pos_base_update = soup.find_all('span', class_='pos_base_num pos_base_update')[0].find_all('span')[0].text # 更新日期
pos_base_browser = soup.find_all('span', class_='pos_base_num pos_base_browser')[0].find_all('i', id='totalcount')[0].text # 浏览量
pos_base_apply = soup.find_all('span', class_='pos_base_num pos_base_apply')[0].find_all('span', id='apply_num')[0].text # 申请数
pos_salary = soup.find_all('div', class_='pos_base_info')[0].find_all('span', class_='pos_salary')[0].text # 工资水平
return comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary
def save_to_mysql(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary):
cur = conn.cursor() #用来获得python执行Mysql命令的方法,操作游标。cur = conn.sursor才是真的执行
insert_data = "INSERT INTO 58yuesao(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)" "VALUES(%s,%s,%s,%s,%s,%s)"
val = (comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)
cur.execute(insert_data, val)
conn.commit()
conn=pymysql.connect(host="localhost",user="root", password='18030823940',db='58yuesao',port=3306, charset="utf8")
def main():
urls = ['https://cd.58.com/yuesaoyuying/pn{}/?'.format(i) for i in range(1, 8)]
for url in urls:
html = get_one_page(url)
dir = parse_one_page(html)
for href, comp_name in dir.items():
html = get_two_page(href)
comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary = parse_two_page(html,comp_name)
save_to_mysql(comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary)
if __name__ == '__main__':
main()
《pycharm关联mysql代码》
create database 58yuesao;
use 58yuesao;
create table 58yuesao
(comp_name varchar(40) not null,
pos_name varchar(20) not null,
pos_base_update varchar(15) not null,
pos_base_browser int not null,
pos_base_apply int not null,
pos_salary varchar(20)not null);
ALTER TABLE 58yuesao CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci
图片来自简书App
图片来自简书App
最后,您可以在数据库中看到您爬取的文件。使用count()可以看到一共爬取了239条数据。
五、我有一个问题要解决
1、同时抓取索引页和详情页的多个内容
2、Ajax 异步加载
3、 抓取被后台屏蔽的信息(eg: pos_base_browser, pos_base_apply)
明天继续解决问题,加油! 查看全部
java爬虫抓取动态网页(
我待解决问题爬虫已存入mysql已mysql数据库已成功!)
图片来自简书App
本文文章使用requests和beautifulsoup进行分析;如果您正在寻找正则表达式和 urllib 案例,建议您学习其他材料。
ps:如果要找案例,可以直接看最后一段代码。如果你和我一样,启动爬虫,从文章开始读罗。
前言:自学爬虫第15天,终于成功爬取了58同城的招聘信息,并保存到mysql数据库中……写下这篇文章,分享给正在自学的各位履带式。数据不全:因为有些网页隐藏了一些信息,爬取到的pos_base_browser和pos_base_apply数据都是空的。这个问题仍在解决中。
启示:学习期间我的心态也不稳定,会有逃避的冲动,但让自己坚持下去的动力是一个接一个地解决问题,升级知识体系。重复找资料、百度、百度翻译的过程15天;我最怕看到代码报错;最常见的错误之一是**超出范围。虽然没有人花很多时间找资料,但在不断的探索中,我也得到了解决问题的办法:少问多想——翻译——百度。
文章 分为四个部分:
一、我的爬虫学习目标
二、爬虫学习升级流程:入门10分
三、学习过程中的坑
四、58城市月嫂招聘信息码
五、我有一个问题要解决
爬虫已经存入mysql数据库
一、我的爬虫学习目标
1、了解html、css、javascript
2、master 请求,beautifulsoup 库
3、 会模仿爬虫案例
二、爬虫学习升级流程:入门10分
1、了解html、css、标签
2、学习requests和beautifulsoup库;会获取请求,通过标签选择对应的文本,通过标签选择属性
3、了解静态加载(翻页请求)、动态加载(Ajax)
4、理解函数循环
5、理解 def main(): 函数,name = "main()": 函数
6、了解打印和返回的区别
7、了解索引页(列表页)、详情页、解析详情页url时索引页返回的字典(用于循环)
8、对于数据库的存储,需要在mysql数据库中创建数据库和字段类型。有关详细信息,请参阅代码的第二部分。
9、推荐使用pycharm
10、半自主解决学习过程中出现的任何问题
三、学习过程中的坑:
知道自己会遇到什么问题和问题的类型,即使学习中有问题,也可以通过百度解决。
学习期间,因为不知道怎么提问(因为听不懂,连提问都不会),走了不少弯路。
eg1:解析索引页的时候,不知道应该返回字典的结果格式,折腾了整整两天,突然发现字典可以遍历,把url存成字典可以请求详细信息页面。
eg2:群主一直建议我把爬取的文件保存到数据库,我也看了相关的视频。在不断删除和定义pymysql函数的过程中,我勇敢地尝试解决错误,终于知道了mysql中新数据库、新表、新表中的字段。
自己做不了的时候就去模仿,模仿的过程有问题的时候去百度。
eg3:requests请求没有找到,beautifulsoup解析静态加载案例。拼凑很多视频,代码
……回想起来,中间有很多困惑,但这毕竟是路,只有亲身经历,才能获得成长。希望这个文章能在你切换到数据分析爬虫时对你有所帮助。
四、58城市月嫂招聘信息码
1、目标网点:
坐月子
2、爬取信息:
索引页公司名称;详情页职位名称、更新时间、浏览人数、应聘人数、工资
列表
详情页面
(PS:其实我也想知道索引页的推广方式和发布地址。学习了15天,还是不知道怎么同时保存索引页和详情页的多个内容时间)
3、爬虫代码
《pycharm代码》
import json
import pymysql
import requests
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
headers = {
'user-agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"}
def get_one_page(url):
try:
respones = requests.get(url, headers=headers)
respones.encoding = 'utf-8'
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求错误')
return None
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
soup = BeautifulSoup(html, 'lxml')
list_li = soup.find_all('ul', id='list_con')[0].find_all('li', class_='job_item clearfix') # 返回一个列表需要用循环
dir = {}
for link in list_li:
list_a = link.find_all('div', class_='job_name clearfix')[0].find_all('a')[0] # 筛选出所有的a标签
address = list_a.find_all('span', class_='address')[0].text
name = list_a.find_all('span', class_='name')[0].text
comp_name = link.find_all('div', class_='comp_name')[0].find_all('a')[0].text
href = list_a['href']
t = list_a['_t']
dir[href] = comp_name
return dir
def get_two_page(url):
try:
respones = requests.get(url, 'lxml')
if respones.status_code == 200:
return respones.text
return None
except RequestException:
print('请求详情页错误')
return None
def parse_two_page(html,comp_name):
comp_name = comp_name
soup = BeautifulSoup(html, 'lxml')
#pos_base = soup.find_all('div',class_ = 'pos_base_statistics')[0]
pos_name = soup.find_all('span',class_ = 'pos_name')[0].text
pos_base_update = soup.find_all('span', class_='pos_base_num pos_base_update')[0].find_all('span')[0].text # 更新日期
pos_base_browser = soup.find_all('span', class_='pos_base_num pos_base_browser')[0].find_all('i', id='totalcount')[0].text # 浏览量
pos_base_apply = soup.find_all('span', class_='pos_base_num pos_base_apply')[0].find_all('span', id='apply_num')[0].text # 申请数
pos_salary = soup.find_all('div', class_='pos_base_info')[0].find_all('span', class_='pos_salary')[0].text # 工资水平
return comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary
def save_to_mysql(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary):
cur = conn.cursor() #用来获得python执行Mysql命令的方法,操作游标。cur = conn.sursor才是真的执行
insert_data = "INSERT INTO 58yuesao(comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)" "VALUES(%s,%s,%s,%s,%s,%s)"
val = (comp_name,pos_name, pos_base_update,pos_base_browser, pos_base_apply, pos_salary)
cur.execute(insert_data, val)
conn.commit()
conn=pymysql.connect(host="localhost",user="root", password='18030823940',db='58yuesao',port=3306, charset="utf8")
def main():
urls = ['https://cd.58.com/yuesaoyuying/pn{}/?'.format(i) for i in range(1, 8)]
for url in urls:
html = get_one_page(url)
dir = parse_one_page(html)
for href, comp_name in dir.items():
html = get_two_page(href)
comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary = parse_two_page(html,comp_name)
save_to_mysql(comp_name, pos_name, pos_base_update, pos_base_browser, pos_base_apply, pos_salary)
if __name__ == '__main__':
main()
《pycharm关联mysql代码》
create database 58yuesao;
use 58yuesao;
create table 58yuesao
(comp_name varchar(40) not null,
pos_name varchar(20) not null,
pos_base_update varchar(15) not null,
pos_base_browser int not null,
pos_base_apply int not null,
pos_salary varchar(20)not null);
ALTER TABLE 58yuesao CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci
图片来自简书App
图片来自简书App
最后,您可以在数据库中看到您爬取的文件。使用count()可以看到一共爬取了239条数据。
五、我有一个问题要解决
1、同时抓取索引页和详情页的多个内容
2、Ajax 异步加载
3、 抓取被后台屏蔽的信息(eg: pos_base_browser, pos_base_apply)
明天继续解决问题,加油!
java爬虫抓取动态网页(之前学习j2ee的原理是什么?网络爬虫的搭建原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-04-01 08:20
之前学习j2ee的构建,基本就完成了。
接下来,我要学习爬虫技术。学习一门技术,首先要知道它是如何工作的。
那么网络爬虫的原理是什么?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。
接下来,我将在记录问题和解决方案的同时研究网络爬虫的实现。加油^_^!!
这里我在网上找了一个demo,先给大家演示一下:下面是一个用Java模拟的程序,把新浪页面上的链接提取出来,存到一个文件里:
package testspider;
/**
* Descriptions
*
* @version 2017年3月31日
* @since JDK1.6
*
*/
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/");
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
创建一个java项目,直接把代码放进去。运行后会抓取新浪所有的url,存放在本地的F:/url.txt
只需选择一个要访问的网址,例如
可以获取图片。这只是爬虫的一个简单实现。接下来,我将深入研究它的实现。
网络爬虫:
开发工具:eclipse JDK1.6
网上找的demo没有使用服务器。所以我不再需要服务器了。也没有涉及数据库。将爬取的信息存储在本地目录中。
首先,构建一个java项目。第一个类根据URL获取对应的网页内容。
package webspilder;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
@SuppressWarnings("deprecation")
public class DownloadPage
{
/**
* 根据URL抓取网页内容
*
* @param url
* @return
*/
public static String getContentFormUrl(String url)
{
/* 实例化一个HttpClient客户端 */
@SuppressWarnings({"resource"})
HttpClient client = new DefaultHttpClient();
HttpGet getHttp = new HttpGet(url);
String content = null;
HttpResponse response;
try
{
/*获得信息载体*/
response = client.execute(getHttp);
HttpEntity entity = response.getEntity();
VisitedUrlQueue.addElem(url);
if (entity != null)
{
/* 转化为文本信息 */
content = EntityUtils.toString(entity);
/* 判断是否符合下载网页源代码到本地的条件 */
if (FunctionUtils.isCreateFile(url))
//&& FunctionUtils.isHasGoalContent(content) != -1
{
FunctionUtils.createFile(FunctionUtils
.getGoalContent(content), url);
}
}
} catch (ClientProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
} finally
{
client.getConnectionManager().shutdown();
}
return content;
}
}
第二个类将 URL 与正则表达式匹配,下载文件并将其保存在本地。如果有数据库,可以保存在数据库中。
<p>package webspilder;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FunctionUtils
{
/**
* 匹配超链接的正则表达式
*/
private static String pat = "http://([\\w*\\.]*[\\w*])";
private static Pattern pattern = Pattern.compile(pat);
private static BufferedWriter writer = null;
/**
* 爬虫搜索深度
*/
public static int depth = 0;
/**
* 以"/"来分割URL,获得超链接的元素
*
* @param url
* @return
*/
public static String[] divUrl(String url)
{
return url.split("/");
}
/**
* 判断是否创建文件
*
* @param url
* @return
*/
public static boolean isCreateFile(String url)
{
Matcher matcher = pattern.matcher(url);
return matcher.matches();
}
/**
* 创建对应文件
*
* @param content
* @param urlPath
*/
public static void createFile(String content, String urlPath)
{
/* 分割url */
String[] elems = divUrl(urlPath);
StringBuffer path = new StringBuffer();
File file = null;
for (int i = 1; i < elems.length; i++)
{
if (i != elems.length - 1)
{
path.append(elems[i]);
path.append(File.separator);
file = new File("D:" + File.separator + path.toString());
}
if (i == elems.length - 1)
{
Pattern pattern = Pattern.compile("[\\w*\\.]*[\\w*]");
Matcher matcher = pattern.matcher(elems[i]);
if ((matcher.matches()))
{
if (!file.exists())
{
file.mkdirs();
}
String fileName = elems[i];
file = new File("D:" + File.separator + path.toString()
+ File.separator + fileName + ".html");
System.out.println("文件存储路径为:"+"D:" + File.separator + path.toString()
+ fileName + ".html");
try
{
file.createNewFile();
writer = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file)));
writer.write(content);
writer.flush();
writer.close();
System.out.println("创建文件成功");
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}
}
/**
* 获取页面的超链接并将其转换为正式的A标签
*
* @param href
* @return
*/
public static String getHrefOfInOut(String href)
{
/* 内外部链接最终转化为完整的链接格式 */
String resultHref = null;
/* 判断是否为外部链接 */
if (href.startsWith("http://"))
{
resultHref = href;
} else
{
/* 如果是内部链接,则补充完整的链接地址,其他的格式忽略不处理,如:a href="#" */
if (href.startsWith("/"))
{
resultHref = "http://www.oschina.net" + href;
}
}
return resultHref;
}
/**
* 截取网页网页源文件的目标内容
*
* @param content
* @return
*/
public static String getGoalContent(String content)
{
int sign = content.indexOf(" 查看全部
java爬虫抓取动态网页(之前学习j2ee的原理是什么?网络爬虫的搭建原理)
之前学习j2ee的构建,基本就完成了。
接下来,我要学习爬虫技术。学习一门技术,首先要知道它是如何工作的。
那么网络爬虫的原理是什么?
网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL。
URL,在抓取网页的过程中,不断地从当前页面中提取新的URL,放入队列中,直到满足系统的某个停止条件。
接下来,我将在记录问题和解决方案的同时研究网络爬虫的实现。加油^_^!!
这里我在网上找了一个demo,先给大家演示一下:下面是一个用Java模拟的程序,把新浪页面上的链接提取出来,存到一个文件里:
package testspider;
/**
* Descriptions
*
* @version 2017年3月31日
* @since JDK1.6
*
*/
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebSpider {
public static void main(String[] args) {
URL url = null;
URLConnection urlconn = null;
BufferedReader br = null;
PrintWriter pw = null;
String regex = "http://[\\w+\\.?/?]+\\.[A-Za-z]+";
Pattern p = Pattern.compile(regex);
try {
url = new URL("http://www.sina.com.cn/";);
urlconn = url.openConnection();
pw = new PrintWriter(new FileWriter("f:/url.txt"), true);//这里我们把收集到的链接存储在了E盘底下的一个叫做url的txt文件中
br = new BufferedReader(new InputStreamReader(
urlconn.getInputStream()));
String buf = null;
while ((buf = br.readLine()) != null) {
Matcher buf_m = p.matcher(buf);
while (buf_m.find()) {
pw.println(buf_m.group());
}
}
System.out.println("获取成功!");
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
br.close();
} catch (IOException e) {
e.printStackTrace();
}
pw.close();
}
}
}
创建一个java项目,直接把代码放进去。运行后会抓取新浪所有的url,存放在本地的F:/url.txt
只需选择一个要访问的网址,例如
可以获取图片。这只是爬虫的一个简单实现。接下来,我将深入研究它的实现。
网络爬虫:
开发工具:eclipse JDK1.6
网上找的demo没有使用服务器。所以我不再需要服务器了。也没有涉及数据库。将爬取的信息存储在本地目录中。
首先,构建一个java项目。第一个类根据URL获取对应的网页内容。
package webspilder;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
@SuppressWarnings("deprecation")
public class DownloadPage
{
/**
* 根据URL抓取网页内容
*
* @param url
* @return
*/
public static String getContentFormUrl(String url)
{
/* 实例化一个HttpClient客户端 */
@SuppressWarnings({"resource"})
HttpClient client = new DefaultHttpClient();
HttpGet getHttp = new HttpGet(url);
String content = null;
HttpResponse response;
try
{
/*获得信息载体*/
response = client.execute(getHttp);
HttpEntity entity = response.getEntity();
VisitedUrlQueue.addElem(url);
if (entity != null)
{
/* 转化为文本信息 */
content = EntityUtils.toString(entity);
/* 判断是否符合下载网页源代码到本地的条件 */
if (FunctionUtils.isCreateFile(url))
//&& FunctionUtils.isHasGoalContent(content) != -1
{
FunctionUtils.createFile(FunctionUtils
.getGoalContent(content), url);
}
}
} catch (ClientProtocolException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
} finally
{
client.getConnectionManager().shutdown();
}
return content;
}
}
第二个类将 URL 与正则表达式匹配,下载文件并将其保存在本地。如果有数据库,可以保存在数据库中。
<p>package webspilder;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FunctionUtils
{
/**
* 匹配超链接的正则表达式
*/
private static String pat = "http://([\\w*\\.]*[\\w*])";
private static Pattern pattern = Pattern.compile(pat);
private static BufferedWriter writer = null;
/**
* 爬虫搜索深度
*/
public static int depth = 0;
/**
* 以"/"来分割URL,获得超链接的元素
*
* @param url
* @return
*/
public static String[] divUrl(String url)
{
return url.split("/");
}
/**
* 判断是否创建文件
*
* @param url
* @return
*/
public static boolean isCreateFile(String url)
{
Matcher matcher = pattern.matcher(url);
return matcher.matches();
}
/**
* 创建对应文件
*
* @param content
* @param urlPath
*/
public static void createFile(String content, String urlPath)
{
/* 分割url */
String[] elems = divUrl(urlPath);
StringBuffer path = new StringBuffer();
File file = null;
for (int i = 1; i < elems.length; i++)
{
if (i != elems.length - 1)
{
path.append(elems[i]);
path.append(File.separator);
file = new File("D:" + File.separator + path.toString());
}
if (i == elems.length - 1)
{
Pattern pattern = Pattern.compile("[\\w*\\.]*[\\w*]");
Matcher matcher = pattern.matcher(elems[i]);
if ((matcher.matches()))
{
if (!file.exists())
{
file.mkdirs();
}
String fileName = elems[i];
file = new File("D:" + File.separator + path.toString()
+ File.separator + fileName + ".html");
System.out.println("文件存储路径为:"+"D:" + File.separator + path.toString()
+ fileName + ".html");
try
{
file.createNewFile();
writer = new BufferedWriter(new OutputStreamWriter(
new FileOutputStream(file)));
writer.write(content);
writer.flush();
writer.close();
System.out.println("创建文件成功");
} catch (IOException e)
{
e.printStackTrace();
}
}
}
}
}
/**
* 获取页面的超链接并将其转换为正式的A标签
*
* @param href
* @return
*/
public static String getHrefOfInOut(String href)
{
/* 内外部链接最终转化为完整的链接格式 */
String resultHref = null;
/* 判断是否为外部链接 */
if (href.startsWith("http://";))
{
resultHref = href;
} else
{
/* 如果是内部链接,则补充完整的链接地址,其他的格式忽略不处理,如:a href="#" */
if (href.startsWith("/"))
{
resultHref = "http://www.oschina.net" + href;
}
}
return resultHref;
}
/**
* 截取网页网页源文件的目标内容
*
* @param content
* @return
*/
public static String getGoalContent(String content)
{
int sign = content.indexOf("
java爬虫抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-03-29 09:21
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现网页中动态加载数据爬取的文章文章就介绍到这里了。更多关于Python爬取网页动态数据的信息,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home! 查看全部
java爬虫抓取动态网页(python如何检测网页中是否存在动态加载的数据?(图))
在使用python爬虫技术采集数据信息时,经常会遇到在返回的网页信息中无法抓取到动态加载的可用数据。例如,当在网页中获取产品的价格时,就会出现这种现象。如下所示。本文将实现类似的动态加载数据爬取网页。
1. 那么什么是动态加载的数据呢?
我们通过requests模块爬取的数据不能每次都是可见的,部分数据是通过非浏览器地址栏中的url请求获取的。相反,通过其他请求请求的数据,然后通过其他请求请求的数据是动态加载的数据。(猜测是js代码在我们访问这个页面从其他url获取数据的时候会发送get请求)
2. 如何检测网页中是否有动态加载的数据?
在当前页面打开抓包工具,在地址栏抓到url对应的数据包,在数据包的response选项卡中搜索我们要抓取的数据。如果找到了搜索结果,说明数据不是动态加载的。否则,数据将被动态加载。如图所示:
或者右键要爬取的页面,显示网页的源代码,搜索我们要爬取的数据。如果搜索到结果,说明数据没有动态加载,否则说明数据是动态加载的。如图所示:
3. 如果数据是动态加载的,我们如何捕获动态加载的数据呢?
在实现对动态加载的数据信息的爬取时,首先需要根据动态加载技术在浏览器的网络监控器中选择网络请求的类型,然后通过对预览信息中的关键数据进行一一过滤查询,得到对应请求地址,最后解析信息。具体步骤如下:
在浏览器中,按快捷键F12打开开发者工具,然后选择Network(网络监视器),在网络类型中选择JS,然后按快捷键F5刷新,如下图。
在请求信息列表中,依次点击各个请求信息,然后在对应的Preview(请求结果预览)中查看是否是需要获取的动态加载的数据,如下图所示。
查看动态加载的数据信息后,点击Headers获取当前网络请求地址和所需参数,如下图所示。
根据上述步骤得到的请求地址,发出网络请求,从返回的信息中提取商品价格信息。作者在代码中使用了反序列化。关于json序列化和反序列化,可以点这里学习。代码如下:
import requests
import json
# 获取商品价格的请求地址
url = "https://c0.3.cn/stock?skuId=12464037&cat=1713,3259,3333&venderId=1000077923&area" \
"=4_113_9786_0&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&" \
"pduid=1573698619147398205303&pdpin=jd_635f3b795bb1c&coord=&detailedAdd=&callback=jQuery6495921"
jQuery_id = url.split("=")[-1] + "("
# 头部信息
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发送网络请求
response = requests.get(url, headers=headers)
if response.status_code == 200:
goods_dict = json.loads(response.text.replace(jQuery_id, "")[:-1]) # 反序列化
print(f"当前售价为: {goods_dict['stock']['jdPrice']['op']}")
print(f"定价为: {goods_dict['stock']['jdPrice']['m']}")
print(f"会员价为: {goods_dict['stock']['jdPrice']['tpp']}")
else:
print("请求失败!")
作者在写博文的时候,价格发生了变化,运行结果如下图所示:
注意:爬取动态加载的数据信息时,需要根据不同的网页使用不同的方法提取数据。如果运行源码时出现错误,请按照步骤获取新的请求地址。
至此,这篇关于Python实现网页中动态加载数据爬取的文章文章就介绍到这里了。更多关于Python爬取网页动态数据的信息,请在Scripting Home前搜索文章或继续浏览以下相关文章希望大家以后多多支持Script Home!
java爬虫抓取动态网页(网络爬虫抓取信息的案例分析-一下具体情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-03-28 06:13
对于程序员来说,只有掌握了网络爬虫爬取信息的方法,才能进行更有针对性的防范和限制。让我们通过一个案例来了解具体情况。
爬取网站的思路
先判断是否是动态加载网站
查找 URL 模式
正则表达式或 xpath
定义程序框架,完成并测试代码
多级页面数据抓取
1、爬取一级页面,提取需要的数据+链接,继续跟进
2、 爬取二级页面,提取需要的数据+链接,继续跟进
常见反爬总结
IP限制:网站根据IP地址的访问频率进行反爬,短时间内进行IP访问。
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
Cookies:建立有效的cookie池,每次访问时随机切换
1、适用于网站类型:爬取网站页面时需要登录才能访问,否则无法获取页面的实际响应数据
2、方法一(使用cookies)
1、 先登录一次成功,获取带有登录信息的cookie(处理headers)
2、使用处理后的headers向URL地址发送请求
3、方法二(使用会话会话保留)
1、实例化会话对象
会话=请求。会话()
响应内容前端JS进行处理和反爬
1、html页面中可以匹配内容,程序中匹配结果为空
在响应内容中嵌入js,对页面结构做一些调整,通过打印查看网页源代码,格式化输出查看结构,更改xpath或者常规测试
2、如果数据不可用,考虑更换IE的User-Agent,尝试将数据返回标准
FromExpression数据鉴权(salt,sign)签名和js加密:一般是本地JS加密,找本地JS文件,分析,或者使用execjs模块执行JS
js调整页面结构
js在响应中指定一个新地址:从响应码中找到目标地址,政府行政码
动态生成
动态加载数据,数据不再在网页代码中,而是在后台异步加载的数据包中。
1、F12打开控制台,页面动作抓取网络包
2、 抓取json文件的url地址
控制台中的#XHR:异步加载的数据包
#XHR->QueryString(查询参数) 查看全部
java爬虫抓取动态网页(网络爬虫抓取信息的案例分析-一下具体情况)
对于程序员来说,只有掌握了网络爬虫爬取信息的方法,才能进行更有针对性的防范和限制。让我们通过一个案例来了解具体情况。
爬取网站的思路
先判断是否是动态加载网站
查找 URL 模式
正则表达式或 xpath
定义程序框架,完成并测试代码
多级页面数据抓取
1、爬取一级页面,提取需要的数据+链接,继续跟进
2、 爬取二级页面,提取需要的数据+链接,继续跟进
常见反爬总结
IP限制:网站根据IP地址的访问频率进行反爬,短时间内进行IP访问。
解决方案:
1、构建自己的IP代理池,每次访问随机选择一个代理,并经常更新代理池
2、购买开放代理或私有代理IP
3、降低爬行速度
Cookies:建立有效的cookie池,每次访问时随机切换
1、适用于网站类型:爬取网站页面时需要登录才能访问,否则无法获取页面的实际响应数据
2、方法一(使用cookies)
1、 先登录一次成功,获取带有登录信息的cookie(处理headers)
2、使用处理后的headers向URL地址发送请求
3、方法二(使用会话会话保留)
1、实例化会话对象
会话=请求。会话()
响应内容前端JS进行处理和反爬
1、html页面中可以匹配内容,程序中匹配结果为空
在响应内容中嵌入js,对页面结构做一些调整,通过打印查看网页源代码,格式化输出查看结构,更改xpath或者常规测试
2、如果数据不可用,考虑更换IE的User-Agent,尝试将数据返回标准
FromExpression数据鉴权(salt,sign)签名和js加密:一般是本地JS加密,找本地JS文件,分析,或者使用execjs模块执行JS
js调整页面结构
js在响应中指定一个新地址:从响应码中找到目标地址,政府行政码
动态生成
动态加载数据,数据不再在网页代码中,而是在后台异步加载的数据包中。
1、F12打开控制台,页面动作抓取网络包
2、 抓取json文件的url地址
控制台中的#XHR:异步加载的数据包
#XHR->QueryString(查询参数)
java爬虫抓取动态网页(【悦创】反爬虫是什么首先,我要先跟你探讨)
网站优化 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-03-27 23:25
大家好,我是悦创。
在开始这一系列教程之前,我想和大家讨论一下:什么是反爬虫?
首先,目前还没有明确的反爬虫定义。(整个行业没有明确的定义。)因为各方角色不同,或者使用的编程语言或工具不同,对于反爬虫也有自己的看法。
所以,在我们的系列课程中,我需要大家保持一致的观点:
我们同意限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。
限制包括但不限于:请求限制、拒绝响应、客户端身份验证、文本混淆以及使用动态呈现技术。
这些限制按照起点可以分为主动反爬虫和被动反爬虫。
附言:
主动反爬虫是指为我们(爬虫工程师)特意准备的一些限制。
例如:IP限制、Cookies验证、登录页面验证码或注册页面验证码等。
被动反爬虫是指用户操作某个功能时触发的一种功能机制。
例如:下拉加载、悬停(预览)、以及一些网页数据计算等,这些都是提升用户体验的主要目的,但也造成了爬虫对这些数据获取的限制作用。
本课主要分为4个知识点。
Contents(反爬虫) 网页的基本组成 浏览器组件和功能 HTML DOM 和网页渲染过程 编程语言或工具与浏览器的区别1. 网页的基本组成
这是浏览器打开网页后的截图。从截图中我们可以看到有:导航栏、logo、搜索框、记录号相关信息等,那么这个页面的主要元素就是文字和图片。当然,页面的元素远不止这些,比如优酷、网易或者爱奇艺、搜狗等,网站里面还有音视频。
接下来,我们来看看一个网页的基本结构:
(图片来源-网络)
从左到右:HTML、JavaScript、CSS、媒体资产、其他(以及其他一些)
然后是:图片、视频、音频和字体,这些都是媒体或多媒体资源。(例如:代表图片的标签通常是img标签,然后里面的src指向具体的资源路径
Action: 打开浏览器观察资源加载情况
按着这些次序:
打开浏览器访问:打开浏览器的开发者工具(F12)切换到网络面板
接下来刷新一些网页或者输入:Python搜索
现在,让我们看看究竟加载了什么。
这时候我们会发现,当我们访问百度的网站时,加载的资源有:文档、css文件、图片(png、jpg)、js等。
2. 浏览器组件和函数
我们常用的浏览器有五个组件和三个解释器。这五个组件是:用户界面、浏览器引擎、渲染引擎、数据存储和网络。三个解释器分别是:HTML解释器、JavaScript解释器解释器、CSS解释器。
所以浏览器之所以能够理解 HTML、CSS 和 JavaScript 代码并按照一定的规则进行输入,是这三个解释器的功劳。
在组件方面,用户界面组件的主要功能是显示操作界面。浏览器引擎的主要作用是:负责将用户的操作传递给相应的渲染引擎。渲染引擎的主要作用是调用,**这三个解释器来解释相应文档中的代码。然后根据解释器的结果重新键入页面。**数据存储组件的作用是: **在本地存储一些较小的数据,如Cookies、Storage对象等。 **Web组件:自动加载HTML文档中需要的其他资源。
刚才带大家了解了浏览器的五个组件和三个解释器。我们可以在脑海中填写浏览器的结构图。也就是说,常用的浏览器实际上是由一堆组件组成的工具。
然后每个组件执行自己的职责,例如:渲染组件,渲染引擎,它会调用三个解释器来解释和理解代码中的一些意图。
3. HTML DOM 和网页渲染过程
HTML DOM 是文档对象模型,它是一个平台中立和语言中立的界面。它允许程序动态更新文档内容、文档结构和样式。换句话说:程序可以通过DOM改变页面上显示的内容。HTML文档中的每一个标签对都是一个DOM节点(比如title标签对应一个DOM节点,那么year标签也对应一个DOM节点)看看右上图,HTML我们平时看到的一层一层、一层一层嵌套的标签,其实就是一个父子关系的DOM节点。JavaScript 代码和 CSS 样式可以改变页面上文本或图片的位置、颜色或内容,但需要注意的是,它们改变的只是页面上显示的内容,而不是 HTML 文档本身。他们只是更改浏览器中的 DOM,这一点非常重要。(大家一定要明白)
操作:打开浏览器编辑 HTML
这里我们打开浏览器做一个小实验,这里我们使用W3school的在线编辑器运行HTML代码。
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们可以看一下上面的代码,它们被包裹在成对的 html 标签中。然后 body 标签包裹 HTML 代码,标签对包裹 CSS 样式,标签对包裹 JavaScript 代码。在 HTML 中,这就是注释:被注释注释掉的代码在代码中不起作用。
我们先运行以下代码:
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们来看看运行结果:
我们可以看到右侧的内容显示区显示了HTML文档中定义的内容。
我接下来运行以下代码:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
这时,我们可以看到最后一段文字的颜色发生了变化。
同样,让我们添加 JavaScript 代码来查看:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
first = document.getElementById("first");
first.innerHTML = "我说这是什么就是什么";
我们发现右边内容区的第一行内容变了,那么问题来了:为什么内容区的文字和颜色变了,但是代码中的文字还是body标签中包裹的文字没有发生。任何变化?
左边的代码仍然是:**这是一个段落。**向我们展示的是:我所说的就是它的本来面目。现在想一想,想一想:为什么会这样?
其实这也正是我之前说的:它们其实是 JavaScript 和 CSS 的变化,也就是说浏览器中的 DOM 节点被 CSS 和 JavaScript 变化了,而最终变化的不是 HTML 代码,或者它的文件。内容,变化其实是浏览器中的DOM布局。需要注意的是,这种变化发生在浏览器的显示级别。事实上,HTML 完全没有变化。
上面提到了页面的渲染过程,可以说明我们刚才做的实验的结果。
上图中的步骤将使您更加清晰。
从一开始,用户输入一个 URL(这是在用户界面组件中执行的操作),然后当用户按下 Enter 键时,他进入浏览器引擎的工作流程,然后根据 HTML 文档的内容进行加载。对应的资源(例如:图片、视频、音频、文本等),此时渲染引擎和三大解释器已经开始工作了,否则浏览器不知道需要加载什么样的资源,那么资源代码的加载和代码的解释是同步进行的。最后渲染引擎根据三大解释器的解释结果对DOM进行操作,即重新对页面内容进行排版,并将排版的结果呈现给用户(也就是我们看到的网页内容)。以上是浏览器的工作流程。.
4. 编程语言或工具与浏览器的区别
操作:用浏览器打开指定的URL
这里我们需要打开浏览器并访问一个网站(例如:GitChat)
可以看到,在浏览器访问后,我们得到的是一个比例匀称、布局漂亮的页面。那我们试试代码或者使用工具请求同一个URL,看看得到什么样的结果,打开IDE,也就是Pycharm。
这里我们使用 requests 库向 GitChat 发出网络请求。并打印请求的内容。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author:AI悦创 @DateTime :2020/1/12 13:53 @Function :功能 Development_tool :PyCharm
# code is far away from bugs with the god animal protecting
# I love animals. They taste delicious.
import requests
url = 'https://gitbook.cn/'
html = requests.get(url).text
print(html)
# -------------输出-------------
"C:\Program Files\Python37\python.exe" "D:/daima/pycharm_daima/JavaScript 逆向课程/01-探寻 JavaScript 反爬虫的根本原因/test_1.py"
GitChatMenu首 页专 栏专 题电子书关于我们活动分类前端人工智能架构区块链职场编程语言技术管理大数据移动开发产品与运营测试安全运维>严选
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
})
function changeHomeColumn(num) {
$('#syncColumn').addClass("syncColumn");
$.ajax({
url: "/gitchat/homepage/change/column/" + num,
type: "GET",
contentType: "application/json; charset=utf-8",
success: function (data, status) {
if (status == 'success' && data.code == 0) {
$('#homeColumns').html('');
$('#homeColumns').append(data.data);
$('#changeColumns').attr('onclick', 'changeHomeColumn(' + data.next + '); return false;')
$('#syncColumn').removeClass("syncColumn");
}
}
});
}
Process finished with exit code 0
我们得到的是 HTML 代码,而不是渲染的。
接下来,让我们借助一个工具来操作它,工具:PostMan
这样,我们将在下面得到我们的响应体。可以看到Python代码的结果是一模一样的,没有排版,也没有请求图片等资源。所以,我们所要求的只是 HTML 代码。其实就是 GitChat 的源码。在谷歌浏览器中访问网页后,我们可以右键选择显示网页的源代码,可以看到得到的页面和我们之前得到的代码是一样的。
刚才我们以几种不同的方式访问了我们的 GitChat,并用图表对其进行了解析:
从图中可以看出,我们的浏览器可以获取其他需要的内容,而工具获取的只是HTML。
这其实就是浏览器和其他工具的区别。准确地说,是因为其他工具中没有 JavaScript 解释器。需要注意的是,CSS和JavaScript的情况是一样的,也就是说,反爬虫可以利用其他没有CSS解释器和渲染引擎的工具的特性来实现。实际工作中这样的应用有很多,比如我们经常听到的字体反爬虫、文本偏移反爬虫、文本混淆反爬虫等。 查看全部
java爬虫抓取动态网页(【悦创】反爬虫是什么首先,我要先跟你探讨)
大家好,我是悦创。
在开始这一系列教程之前,我想和大家讨论一下:什么是反爬虫?
首先,目前还没有明确的反爬虫定义。(整个行业没有明确的定义。)因为各方角色不同,或者使用的编程语言或工具不同,对于反爬虫也有自己的看法。
所以,在我们的系列课程中,我需要大家保持一致的观点:
我们同意限制爬虫程序访问服务器资源和获取数据的行为称为反爬虫。
限制包括但不限于:请求限制、拒绝响应、客户端身份验证、文本混淆以及使用动态呈现技术。
这些限制按照起点可以分为主动反爬虫和被动反爬虫。
附言:
主动反爬虫是指为我们(爬虫工程师)特意准备的一些限制。
例如:IP限制、Cookies验证、登录页面验证码或注册页面验证码等。
被动反爬虫是指用户操作某个功能时触发的一种功能机制。
例如:下拉加载、悬停(预览)、以及一些网页数据计算等,这些都是提升用户体验的主要目的,但也造成了爬虫对这些数据获取的限制作用。
本课主要分为4个知识点。
Contents(反爬虫) 网页的基本组成 浏览器组件和功能 HTML DOM 和网页渲染过程 编程语言或工具与浏览器的区别1. 网页的基本组成
这是浏览器打开网页后的截图。从截图中我们可以看到有:导航栏、logo、搜索框、记录号相关信息等,那么这个页面的主要元素就是文字和图片。当然,页面的元素远不止这些,比如优酷、网易或者爱奇艺、搜狗等,网站里面还有音视频。
接下来,我们来看看一个网页的基本结构:
(图片来源-网络)
从左到右:HTML、JavaScript、CSS、媒体资产、其他(以及其他一些)
然后是:图片、视频、音频和字体,这些都是媒体或多媒体资源。(例如:代表图片的标签通常是img标签,然后里面的src指向具体的资源路径
Action: 打开浏览器观察资源加载情况
按着这些次序:
打开浏览器访问:打开浏览器的开发者工具(F12)切换到网络面板
接下来刷新一些网页或者输入:Python搜索
现在,让我们看看究竟加载了什么。
这时候我们会发现,当我们访问百度的网站时,加载的资源有:文档、css文件、图片(png、jpg)、js等。
2. 浏览器组件和函数
我们常用的浏览器有五个组件和三个解释器。这五个组件是:用户界面、浏览器引擎、渲染引擎、数据存储和网络。三个解释器分别是:HTML解释器、JavaScript解释器解释器、CSS解释器。
所以浏览器之所以能够理解 HTML、CSS 和 JavaScript 代码并按照一定的规则进行输入,是这三个解释器的功劳。
在组件方面,用户界面组件的主要功能是显示操作界面。浏览器引擎的主要作用是:负责将用户的操作传递给相应的渲染引擎。渲染引擎的主要作用是调用,**这三个解释器来解释相应文档中的代码。然后根据解释器的结果重新键入页面。**数据存储组件的作用是: **在本地存储一些较小的数据,如Cookies、Storage对象等。 **Web组件:自动加载HTML文档中需要的其他资源。
刚才带大家了解了浏览器的五个组件和三个解释器。我们可以在脑海中填写浏览器的结构图。也就是说,常用的浏览器实际上是由一堆组件组成的工具。
然后每个组件执行自己的职责,例如:渲染组件,渲染引擎,它会调用三个解释器来解释和理解代码中的一些意图。
3. HTML DOM 和网页渲染过程
HTML DOM 是文档对象模型,它是一个平台中立和语言中立的界面。它允许程序动态更新文档内容、文档结构和样式。换句话说:程序可以通过DOM改变页面上显示的内容。HTML文档中的每一个标签对都是一个DOM节点(比如title标签对应一个DOM节点,那么year标签也对应一个DOM节点)看看右上图,HTML我们平时看到的一层一层、一层一层嵌套的标签,其实就是一个父子关系的DOM节点。JavaScript 代码和 CSS 样式可以改变页面上文本或图片的位置、颜色或内容,但需要注意的是,它们改变的只是页面上显示的内容,而不是 HTML 文档本身。他们只是更改浏览器中的 DOM,这一点非常重要。(大家一定要明白)
操作:打开浏览器编辑 HTML
这里我们打开浏览器做一个小实验,这里我们使用W3school的在线编辑器运行HTML代码。
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们可以看一下上面的代码,它们被包裹在成对的 html 标签中。然后 body 标签包裹 HTML 代码,标签对包裹 CSS 样式,标签对包裹 JavaScript 代码。在 HTML 中,这就是注释:被注释注释掉的代码在代码中不起作用。
我们先运行以下代码:
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
我们来看看运行结果:
我们可以看到右侧的内容显示区显示了HTML文档中定义的内容。
我接下来运行以下代码:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
这时,我们可以看到最后一段文字的颜色发生了变化。
同样,让我们添加 JavaScript 代码来查看:
.last{
color:red;
}
这是段落。
这是段落。
这是段落。
段落元素由 p 标签定义
first = document.getElementById("first");
first.innerHTML = "我说这是什么就是什么";
我们发现右边内容区的第一行内容变了,那么问题来了:为什么内容区的文字和颜色变了,但是代码中的文字还是body标签中包裹的文字没有发生。任何变化?
左边的代码仍然是:**这是一个段落。**向我们展示的是:我所说的就是它的本来面目。现在想一想,想一想:为什么会这样?
其实这也正是我之前说的:它们其实是 JavaScript 和 CSS 的变化,也就是说浏览器中的 DOM 节点被 CSS 和 JavaScript 变化了,而最终变化的不是 HTML 代码,或者它的文件。内容,变化其实是浏览器中的DOM布局。需要注意的是,这种变化发生在浏览器的显示级别。事实上,HTML 完全没有变化。
上面提到了页面的渲染过程,可以说明我们刚才做的实验的结果。
上图中的步骤将使您更加清晰。
从一开始,用户输入一个 URL(这是在用户界面组件中执行的操作),然后当用户按下 Enter 键时,他进入浏览器引擎的工作流程,然后根据 HTML 文档的内容进行加载。对应的资源(例如:图片、视频、音频、文本等),此时渲染引擎和三大解释器已经开始工作了,否则浏览器不知道需要加载什么样的资源,那么资源代码的加载和代码的解释是同步进行的。最后渲染引擎根据三大解释器的解释结果对DOM进行操作,即重新对页面内容进行排版,并将排版的结果呈现给用户(也就是我们看到的网页内容)。以上是浏览器的工作流程。.
4. 编程语言或工具与浏览器的区别
操作:用浏览器打开指定的URL
这里我们需要打开浏览器并访问一个网站(例如:GitChat)
可以看到,在浏览器访问后,我们得到的是一个比例匀称、布局漂亮的页面。那我们试试代码或者使用工具请求同一个URL,看看得到什么样的结果,打开IDE,也就是Pycharm。
这里我们使用 requests 库向 GitChat 发出网络请求。并打印请求的内容。
# !/usr/bin/python3
# -*- coding: utf-8 -*-
# @Author:AI悦创 @DateTime :2020/1/12 13:53 @Function :功能 Development_tool :PyCharm
# code is far away from bugs with the god animal protecting
# I love animals. They taste delicious.
import requests
url = 'https://gitbook.cn/'
html = requests.get(url).text
print(html)
# -------------输出-------------
"C:\Program Files\Python37\python.exe" "D:/daima/pycharm_daima/JavaScript 逆向课程/01-探寻 JavaScript 反爬虫的根本原因/test_1.py"
GitChatMenu首 页专 栏专 题电子书关于我们活动分类前端人工智能架构区块链职场编程语言技术管理大数据移动开发产品与运营测试安全运维>严选
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
内容太多省略!
})
function changeHomeColumn(num) {
$('#syncColumn').addClass("syncColumn");
$.ajax({
url: "/gitchat/homepage/change/column/" + num,
type: "GET",
contentType: "application/json; charset=utf-8",
success: function (data, status) {
if (status == 'success' && data.code == 0) {
$('#homeColumns').html('');
$('#homeColumns').append(data.data);
$('#changeColumns').attr('onclick', 'changeHomeColumn(' + data.next + '); return false;')
$('#syncColumn').removeClass("syncColumn");
}
}
});
}
Process finished with exit code 0
我们得到的是 HTML 代码,而不是渲染的。
接下来,让我们借助一个工具来操作它,工具:PostMan
这样,我们将在下面得到我们的响应体。可以看到Python代码的结果是一模一样的,没有排版,也没有请求图片等资源。所以,我们所要求的只是 HTML 代码。其实就是 GitChat 的源码。在谷歌浏览器中访问网页后,我们可以右键选择显示网页的源代码,可以看到得到的页面和我们之前得到的代码是一样的。
刚才我们以几种不同的方式访问了我们的 GitChat,并用图表对其进行了解析:
从图中可以看出,我们的浏览器可以获取其他需要的内容,而工具获取的只是HTML。
这其实就是浏览器和其他工具的区别。准确地说,是因为其他工具中没有 JavaScript 解释器。需要注意的是,CSS和JavaScript的情况是一样的,也就是说,反爬虫可以利用其他没有CSS解释器和渲染引擎的工具的特性来实现。实际工作中这样的应用有很多,比如我们经常听到的字体反爬虫、文本偏移反爬虫、文本混淆反爬虫等。
java爬虫抓取动态网页(2.动态网页:不只有代码写出的网页被称为动态)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-03-27 06:19
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的全网爬取。只要人能看到东西,理论上爬虫就可以获取。不管是静态页面还是动态页面。不管是PC端的页面,还是移动端的APP。爬虫,有多种语言可供选择,python、php、go、java……甚至c。但现在主流是python作为爬虫编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(python3不再使用)、requests。我们先比较一下它们的区别:
urllib和urllib2是python标准库,即如果你已经安装了python,这两个库可以直接使用;requests是第三方库,不是python基金会实现的,但是很强大。
但是 urllib 和 urllib2 都是通过 url 来打开资源的。其中 urllib 只能接受 url,但同样伪装请求的 headers。这样写的爬虫发出的请求会被很多网站直接拦截,伪装不好。嗯,它需要很复杂的修改,在之前的文章中已经介绍过了。
requests 库可以实现 urllib 和 urllib2 的所有功能,并且有它们不具备的优点。在使用过程中,请求更有用。
1:什么是静态网页和动态网页?
1.静态网页:通俗地说,只有 HTML 格式的网页通常被称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python进行爬虫的过程中,有一个强大的Request库可以方便的为我们发送HTTP请求来爬取静态网页。
2.动态网页:不仅HTML代码编写的网页称为动态网页,这些网页一般由CSS、JavaScript代码和HTML代码共同组成。在代码中,这需要复杂的操作。
二:静态网页爬取
1.请求安装和简单操作
(1)安装
在 cmd 或终端中写入
pip install requests
而已。
(2)获取网页内容'
Request 最常用的功能是获取网页的内容。我们首先获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用相应的函数来获取需要的信息。结果如下所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中内置的 JSON 解码器。
2.自定义请求
现在我们可以爬取网页的html代码数据了,但是有时候我们只需要一部分数据,那么就需要设置Requests的参数来获取我们需要的数据,包括传递URL参数、自定义请求头、发送POST 请求、设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。该数据通常后跟一个问号,并作为键值对放置在 URL 中。
在 Request 中,我们可以直接将这些参数保存在字典中,并使用 params 构建到 URL 中。
这是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
让我们看看结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或者请求的请求头与实际网页不一致,可能无法返回正确的结果。请求不会根据自定义的请求头改变自己的行为,只有在最终的请求中,才会传入请求头的信息。
我们可以根据以下方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择inspect(有些浏览器也叫inspect elements),然后选择Network选项:
当我们选择python图片的时候,会发现在左边的资源栏中截取了一个文件,就是图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将自定义请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是400,说明我们的代码有误。这表明我们无法以这种方式抓取图像。关于如何正确抓取图片,我会在下面的文章中告诉你。
3.发送 POST 请求
除了 GET 请求之外,有时还需要发送一些以表单编码的数据。这种情况下,只需要给Request中的data参数传入一个字典,这些数据字典会在发送请求时自动编码成表单。我们在之前的文章爬取有道词典中使用了这个请求。
4.超时
如果在指定时间内没有响应,可以使用 Requests 设置 timeout 参数来抛出异常。
三:抓取豆瓣百强电影片名示例
先打开网址
然后我们找到每个视频的 HTML 代码:
在这里,我们需要的所有信息都在
在这里,将 lxml 更改为 html.parse:
import requests
from bs4 import BeautifulSoup
def getUrl():
url = "https://www.douban.com/doulist/36513321/"
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
结果如下:
我们这里要爬取的是100个剧名,这里我们只得到了25个,要全部爬取,我们需要分析URL:
发现只有start=""之后的不同,我们可以分析四次,或者用循环来做:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们使用 format() 来格式化字符串(也可以使用 % 来格式化字符串),我们看看结果:
在这里我们看到我们已经成功爬取了我们想要的内容。 查看全部
java爬虫抓取动态网页(2.动态网页:不只有代码写出的网页被称为动态)
T小昂仔 11月26日
版本:python3.7
编程软件:sublime
爬取信息是一个很大的需求,从单个页面、某个站点,到搜索引擎(百度、谷歌)的全网爬取。只要人能看到东西,理论上爬虫就可以获取。不管是静态页面还是动态页面。不管是PC端的页面,还是移动端的APP。爬虫,有多种语言可供选择,python、php、go、java……甚至c。但现在主流是python作为爬虫编程语言,因为它好用、高效、省时。
爬取网页信息的python库有很多,urllib、urllib2(python3不再使用)、requests。我们先比较一下它们的区别:
urllib和urllib2是python标准库,即如果你已经安装了python,这两个库可以直接使用;requests是第三方库,不是python基金会实现的,但是很强大。
但是 urllib 和 urllib2 都是通过 url 来打开资源的。其中 urllib 只能接受 url,但同样伪装请求的 headers。这样写的爬虫发出的请求会被很多网站直接拦截,伪装不好。嗯,它需要很复杂的修改,在之前的文章中已经介绍过了。
requests 库可以实现 urllib 和 urllib2 的所有功能,并且有它们不具备的优点。在使用过程中,请求更有用。
1:什么是静态网页和动态网页?
1.静态网页:通俗地说,只有 HTML 格式的网页通常被称为静态网页。这些网页的数据比较容易获取,因为所有的数据都显示在网页的HTML代码中。在用python进行爬虫的过程中,有一个强大的Request库可以方便的为我们发送HTTP请求来爬取静态网页。
2.动态网页:不仅HTML代码编写的网页称为动态网页,这些网页一般由CSS、JavaScript代码和HTML代码共同组成。在代码中,这需要复杂的操作。
二:静态网页爬取
1.请求安装和简单操作
(1)安装
在 cmd 或终端中写入
pip install requests
而已。
(2)获取网页内容'
Request 最常用的功能是获取网页的内容。我们首先获取上一篇博客的内容:
import requests
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139')
print("文本编码为:",rr.encoding)
print("响应状态码为:",rr.status_code)
print("内容字符串为:",rr.text)
这样就返回了一个名为rr的响应对象,我们可以调用相应的函数来获取需要的信息。结果如下所示:
...
以下是一些基本方法:
print(response.status_code) # 打印状态码,200表示请求成功;4xx表示客户端错误;5xx表示服务器错误响应
int(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
您还可以使用 response.json(),它是 Response 中内置的 JSON 解码器。
2.自定义请求
现在我们可以爬取网页的html代码数据了,但是有时候我们只需要一部分数据,那么就需要设置Requests的参数来获取我们需要的数据,包括传递URL参数、自定义请求头、发送POST 请求、设置超时等。
这些操作解释如下:
(1)传递 URL 参数
为了请求特定的数据,我们需要在 URL 的查询字符串中添加一些特定的数据。该数据通常后跟一个问号,并作为键值对放置在 URL 中。
在 Request 中,我们可以直接将这些参数保存在字典中,并使用 params 构建到 URL 中。
这是一个例子:
import requests
key_dict = {'one':'value1','two':'value2'}
rr = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',params = key_dict)
print("URL正确编码为:",rr.url)
print("字符串方式的响应的内容是:",rr.text)
让我们看看结果:
(2) 自定义请求头
请求标头提供有关请求、响应或其他发送实体的信息。如果没有自定义请求头或者请求的请求头与实际网页不一致,可能无法返回正确的结果。请求不会根据自定义的请求头改变自己的行为,只有在最终的请求中,才会传入请求头的信息。
我们可以根据以下方法找到正确的请求头:
打开上一篇博客的内容:
然后我们右键,选择inspect(有些浏览器也叫inspect elements),然后选择Network选项:
当我们选择python图片的时候,会发现在左边的资源栏中截取了一个文件,就是图片文件。我们可以在Header中看到Request Headers的详细信息(其实在之前的博客中已经介绍过了),这里只需要提取请求头的重要部分,即user-agent部分:
然后我们将自定义请求头添加到 requests.get() 函数中:
import requests
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
'Host' : 'https://img-blog.csdn.net/20180716181513532?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0lUeGlhb2FuZ3phaQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70'
}
r = requests.get('https://blog.csdn.net/ITxiaoangzai/article/details/83904139',headers = headers)
print("字符串方式的响应的内容是:",r.text)
print("响应码为:",r.status_code)
结果如下:
这里返回的响应码是400,说明我们的代码有误。这表明我们无法以这种方式抓取图像。关于如何正确抓取图片,我会在下面的文章中告诉你。
3.发送 POST 请求
除了 GET 请求之外,有时还需要发送一些以表单编码的数据。这种情况下,只需要给Request中的data参数传入一个字典,这些数据字典会在发送请求时自动编码成表单。我们在之前的文章爬取有道词典中使用了这个请求。
4.超时
如果在指定时间内没有响应,可以使用 Requests 设置 timeout 参数来抛出异常。
三:抓取豆瓣百强电影片名示例
先打开网址
然后我们找到每个视频的 HTML 代码:
在这里,我们需要的所有信息都在
在这里,将 lxml 更改为 html.parse:
import requests
from bs4 import BeautifulSoup
def getUrl():
url = "https://www.douban.com/doulist/36513321/"
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
结果如下:
我们这里要爬取的是100个剧名,这里我们只得到了25个,要全部爬取,我们需要分析URL:
发现只有start=""之后的不同,我们可以分析四次,或者用循环来做:
import requests
from bs4 import BeautifulSoup
def getUrl():
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5702.400 QQBrowser/10.2.1893.400',
}
for i in range(0,4):
url = "https://www.douban.com/doulist/36513321/?start={}&sort=seq&playable=0&sub_type=".format(i*25)
list = []
r = requests.get(url,headers = headers)
soup = BeautifulSoup(r.text,"html.parser")
thisUrl = soup.find_all('div',class_ = "title")
for each in thisUrl:
everyUrl = each.text.strip()
list.append(everyUrl)
print(list)
print("响应码为:",r.status_code)
def main():
getUrl()
if __name__ == '__main__':
main()
这里我们使用 format() 来格式化字符串(也可以使用 % 来格式化字符串),我们看看结果:
在这里我们看到我们已经成功爬取了我们想要的内容。
java爬虫抓取动态网页(Java爬虫服务器被屏蔽,不要慌,咱们换一台中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-27 04:09
Java爬虫服务器被封了,别慌,换个服务器,我们简单说一下反爬策略和反反爬方法,主要是IP封堵及其对应的方法。之前的文章文章我们讲了爬虫的基础知识。在这篇文章中,我们来谈谈爬虫架构。
在前面的章节中,我们的爬虫程序都是单线程的。我们在调试爬虫程序的时候,单线程爬虫是没有问题的,但是当我们使用单线程爬虫程序去在线环境下的采集网页时,单线程爬虫会不行。暴露了两个致命问题:
线上的环境不能像我们本地的测试一样,不关心采集的效率,只要能正确提取结果即可。在这个时间就是金钱的时代,不可能给你时间慢慢来采集,所以单线程爬虫程序就不行了,我们需要把单线程改成多线程模式来改进采集 效率和提高计算机利用率。想学习交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
多线程爬虫的设计要比单线程的程序复杂得多,但又不同于其他需要在高并发下保证数据安全的业务。被视为一个独立的实体。做多线程爬虫,必须做好两件事:第一点是维护统一的采集 URL,第二点是对URL进行去重。简单说一下这两点。
将 URL 维护为 采集
多线程爬虫不能像单线程一样,每个线程独立维护自己的采集 URL,如果是这样的话,那么每个线程的网页采集都是一样的,你会不是多线程采集,而是要多次采集 一个页面。为此,我们需要将 URL 统一维护为 采集。每个线程从统一的URL维护处接收到采集 URL,完成采集任务。如果在页面上找到新 URL 链接将添加到统一 URL 维护的容器中。这里有几个适合统一 URL 维护的容器:
URL重复数据删除
URL去重也是多线程采集中的一个关键步骤,因为如果我们不去重,那么我们会采集到大量重复的URL,这并不能改善我们的采集 效率,例如在一个分页的新闻列表中,我们可以在 采集 的第一页获取到 2、3、4、5 个页面的链接,并且在采集的第二页会再次得到1、3、4、5个页面链接,采集的URL队列中会有大量列表页面链接@>,会重复采集甚至进入死循环,所以需要进行URL去重。有很多方法可以对 URL 进行重复数据删除。以下是几种常用的URL去重方法:
关于多线程爬虫的两个核心知识点大家都知道。下面我画一个简单的多线程爬虫架构图,如下图所示:
多线程爬虫架构图
以上,我们主要了解了多线程爬虫的架构设计。接下来,我们不妨试试Java多线程爬虫。我们以采集虎扑新闻为例,实战Java多线程爬虫,在Java多线程爬虫中设计的采集URL的维护和URL的去重,由于这里只是演示,所以我们将使用JDK的内置容器来完成它。我们使用 LinkedBlockingQueue 作为 URL 维护容器为 采集,HashSet 作为 URL 到 Heavy 容器。以下是Java多线程爬虫的核心代码。详细代码可以上传到 GitHub。地址在文末:想学习和交流HashMap,nginx,dubbo,Spring MVC,分布式,高性能高可用,
2. public class ThreadCrawler implements Runnable {
3. // 采集的文章数
4. private final AtomicLong pageCount = new AtomicLong(0);
5. // 列表页链接正则表达式
6. public static final String URL_LIST = “https://voice.hupu.com/nba”;
7. protected Logger logger = LoggerFactory.getLogger(getClass());
8. // 待采集的队列
9. LinkedBlockingQueue taskQueue;
10. // 采集过的链接列表
11. HashSet visited;
12. // 线程池
13. CountableThreadPool threadPool;
15. public ThreadCrawler(String url, int threadNum) throws InterruptedException {
16. this.taskQueue = new LinkedBlockingQueue();
17. this.threadPool = new CountableThreadPool(threadNum);
18. this.visited = new HashSet();
19. // 将起始页添加到待采集队列中
20. this.taskQueue.put(url);
21. }
23. @Override
24. public void run() {
25. logger.info(“Spider started!”);
26. while (!Thread.currentThread().isInterrupted()) {
27. // 从队列中获取待采集 URL
28. final String request = taskQueue.poll();
29. // 如果获取 request 为空,并且当前的线程采已经没有线程在运行
30. if (request == null) {
31. if (threadPool.getThreadAlive() == 0) {
32. break;
33. }
34. } else {
35. // 执行采集任务
36. threadPool.execute(new Runnable() {
37. @Override
38. public void run() {
39. try {
40. processRequest(request);
41. } catch (Exception e) {
42. logger.error(“process request “ + request + ” error”, e);
43. } finally {
44. // 采集页面 +1
45. pageCount.incrementAndGet();
46. }
47. }
48. });
49. }
50. }
51. threadPool.shutdown();
52. logger.info(“Spider closed! {} pages downloaded.”, pageCount.get());
53. }
55. protected void processRequest(String url) {
56. // 判断是否为列表页
57. if (url.matches(URL_LIST)) {
58. // 列表页解析出详情页链接添加到待采集URL队列中
59. processTaskQueue(url);
60. } else {
61. // 解析网页
62. processPage(url);
63. }
64. }
66. protected void processTaskQueue(String url) {
67. try {
68. Document doc = Jsoup.connect(url).get();
69. // 详情页链接
70. Elements elements = doc.select(” div.news-list > ul > li > div.list-hd > h4 > a”);
71. elements.stream().forEach((element -> {
72. String request = element.attr(“href”);
73. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
74. if (!visited.contains(request) && !taskQueue.contains(request)) {
75. try {
76. taskQueue.put(request);
77. } catch (InterruptedException e) {
78. e.printStackTrace();
79. }
80. }
81. }));
82. // 列表页链接
83. Elements list_urls = doc.select(“div.voice-paging > a”);
84. list_urls.stream().forEach((element -> {
85. String request = element.absUrl(“href”);
86. // 判断是否符合要提取的列表链接要求
87. if (request.matches(URL_LIST)) {
88. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
89. if (!visited.contains(request) && !taskQueue.contains(request)) {
90. try {
91. taskQueue.put(request);
92. } catch (InterruptedException e) {
93. e.printStackTrace();
94. }
95. }
96. }
97. }));
99. } catch (Exception e) {
100. e.printStackTrace();
101. }
102. }
104. protected void processPage(String url) {
105. try {
106. Document doc = Jsoup.connect(url).get();
107. String title = doc.select(“body > div.hp-wrap > div.voice-main > div.artical-title > h1”).first().ownText();
109. System.out.println(Thread.currentThread().getName() + ” 在 “ + new Date() + ” 采集了虎扑新闻 “ + title);
110. // 将采集完的 url 存入到已经采集的 set 中
111. visited.add(url);
113. } catch (IOException e) {
114. e.printStackTrace();
115. }
116. }
118. public static void main(String[] args) {
120. try {
121. new ThreadCrawler(“https://voice.hupu.com/nba”, 5).run();
122. } catch (InterruptedException e) {
123. e.printStackTrace();
124. }
125. }
126. }
我们用5个线程去采集hupu新闻列表页面看看效果。如果我们运行程序,我们会得到以下结果:
多线程采集结果
从结果可以看出,我们启动了 5 个线程 采集 到 61 个页面,总共耗时 2 秒。可以说效果还是不错的。我们用单线程对比一下,看看差距有多大?我们将线程数设置为1,再次启动程序,得到如下结果:
单线程运行结果
可以看到,单线程采集Hupu 61消息耗时7秒,几乎是多线程的4倍。如果你仔细想想,这只有 61 页。如果有更多的页面,差距会增加。该值越大,多线程爬虫的效率越高。想学交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
分布式爬虫架构
分布式爬虫架构是只有大型采集程序才需要使用的架构。一般可以使用单机多线程来解决业务需求。反正我没有分布式爬虫项目的经验,所以和这个没什么关系。是的,但作为技术人员,我们需要保持技术的热度。虽然我们不需要它,但理解它是可以的。我查了很多资料,得出以下结论:
分布式爬虫架构在思路上和我们的多线程爬虫架构是一样的。我们只需要在多线程的基础上稍加改进,就可以成为一个简单的分布式爬虫架构。由于在分布式爬虫架构中爬虫程序部署在不同的机器上,我们等待的URL采集和已经是采集的URL不能存储在爬虫程序机器的内存中,我们需要存储在某台机器上统一维护,比如存储在Redis或者MongoDB中。每台机器都从这里获取采集链接,而不是从LinkedBlockingQueue等内存队列中获取链接。这样一个简单的分发爬虫架构就出现了。当然会有很多细节,因为我没有分布式架构的经验,也谈不上。如果您有兴趣,欢迎交流。 查看全部
java爬虫抓取动态网页(Java爬虫服务器被屏蔽,不要慌,咱们换一台中)
Java爬虫服务器被封了,别慌,换个服务器,我们简单说一下反爬策略和反反爬方法,主要是IP封堵及其对应的方法。之前的文章文章我们讲了爬虫的基础知识。在这篇文章中,我们来谈谈爬虫架构。
在前面的章节中,我们的爬虫程序都是单线程的。我们在调试爬虫程序的时候,单线程爬虫是没有问题的,但是当我们使用单线程爬虫程序去在线环境下的采集网页时,单线程爬虫会不行。暴露了两个致命问题:
线上的环境不能像我们本地的测试一样,不关心采集的效率,只要能正确提取结果即可。在这个时间就是金钱的时代,不可能给你时间慢慢来采集,所以单线程爬虫程序就不行了,我们需要把单线程改成多线程模式来改进采集 效率和提高计算机利用率。想学习交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
多线程爬虫的设计要比单线程的程序复杂得多,但又不同于其他需要在高并发下保证数据安全的业务。被视为一个独立的实体。做多线程爬虫,必须做好两件事:第一点是维护统一的采集 URL,第二点是对URL进行去重。简单说一下这两点。
将 URL 维护为 采集
多线程爬虫不能像单线程一样,每个线程独立维护自己的采集 URL,如果是这样的话,那么每个线程的网页采集都是一样的,你会不是多线程采集,而是要多次采集 一个页面。为此,我们需要将 URL 统一维护为 采集。每个线程从统一的URL维护处接收到采集 URL,完成采集任务。如果在页面上找到新 URL 链接将添加到统一 URL 维护的容器中。这里有几个适合统一 URL 维护的容器:
URL重复数据删除
URL去重也是多线程采集中的一个关键步骤,因为如果我们不去重,那么我们会采集到大量重复的URL,这并不能改善我们的采集 效率,例如在一个分页的新闻列表中,我们可以在 采集 的第一页获取到 2、3、4、5 个页面的链接,并且在采集的第二页会再次得到1、3、4、5个页面链接,采集的URL队列中会有大量列表页面链接@>,会重复采集甚至进入死循环,所以需要进行URL去重。有很多方法可以对 URL 进行重复数据删除。以下是几种常用的URL去重方法:
关于多线程爬虫的两个核心知识点大家都知道。下面我画一个简单的多线程爬虫架构图,如下图所示:
多线程爬虫架构图
以上,我们主要了解了多线程爬虫的架构设计。接下来,我们不妨试试Java多线程爬虫。我们以采集虎扑新闻为例,实战Java多线程爬虫,在Java多线程爬虫中设计的采集URL的维护和URL的去重,由于这里只是演示,所以我们将使用JDK的内置容器来完成它。我们使用 LinkedBlockingQueue 作为 URL 维护容器为 采集,HashSet 作为 URL 到 Heavy 容器。以下是Java多线程爬虫的核心代码。详细代码可以上传到 GitHub。地址在文末:想学习和交流HashMap,nginx,dubbo,Spring MVC,分布式,高性能高可用,
2. public class ThreadCrawler implements Runnable {
3. // 采集的文章数
4. private final AtomicLong pageCount = new AtomicLong(0);
5. // 列表页链接正则表达式
6. public static final String URL_LIST = “https://voice.hupu.com/nba”;
7. protected Logger logger = LoggerFactory.getLogger(getClass());
8. // 待采集的队列
9. LinkedBlockingQueue taskQueue;
10. // 采集过的链接列表
11. HashSet visited;
12. // 线程池
13. CountableThreadPool threadPool;
15. public ThreadCrawler(String url, int threadNum) throws InterruptedException {
16. this.taskQueue = new LinkedBlockingQueue();
17. this.threadPool = new CountableThreadPool(threadNum);
18. this.visited = new HashSet();
19. // 将起始页添加到待采集队列中
20. this.taskQueue.put(url);
21. }
23. @Override
24. public void run() {
25. logger.info(“Spider started!”);
26. while (!Thread.currentThread().isInterrupted()) {
27. // 从队列中获取待采集 URL
28. final String request = taskQueue.poll();
29. // 如果获取 request 为空,并且当前的线程采已经没有线程在运行
30. if (request == null) {
31. if (threadPool.getThreadAlive() == 0) {
32. break;
33. }
34. } else {
35. // 执行采集任务
36. threadPool.execute(new Runnable() {
37. @Override
38. public void run() {
39. try {
40. processRequest(request);
41. } catch (Exception e) {
42. logger.error(“process request “ + request + ” error”, e);
43. } finally {
44. // 采集页面 +1
45. pageCount.incrementAndGet();
46. }
47. }
48. });
49. }
50. }
51. threadPool.shutdown();
52. logger.info(“Spider closed! {} pages downloaded.”, pageCount.get());
53. }
55. protected void processRequest(String url) {
56. // 判断是否为列表页
57. if (url.matches(URL_LIST)) {
58. // 列表页解析出详情页链接添加到待采集URL队列中
59. processTaskQueue(url);
60. } else {
61. // 解析网页
62. processPage(url);
63. }
64. }
66. protected void processTaskQueue(String url) {
67. try {
68. Document doc = Jsoup.connect(url).get();
69. // 详情页链接
70. Elements elements = doc.select(” div.news-list > ul > li > div.list-hd > h4 > a”);
71. elements.stream().forEach((element -> {
72. String request = element.attr(“href”);
73. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
74. if (!visited.contains(request) && !taskQueue.contains(request)) {
75. try {
76. taskQueue.put(request);
77. } catch (InterruptedException e) {
78. e.printStackTrace();
79. }
80. }
81. }));
82. // 列表页链接
83. Elements list_urls = doc.select(“div.voice-paging > a”);
84. list_urls.stream().forEach((element -> {
85. String request = element.absUrl(“href”);
86. // 判断是否符合要提取的列表链接要求
87. if (request.matches(URL_LIST)) {
88. // 判断该链接是否存在队列或者已采集的 set 中,不存在则添加到队列中
89. if (!visited.contains(request) && !taskQueue.contains(request)) {
90. try {
91. taskQueue.put(request);
92. } catch (InterruptedException e) {
93. e.printStackTrace();
94. }
95. }
96. }
97. }));
99. } catch (Exception e) {
100. e.printStackTrace();
101. }
102. }
104. protected void processPage(String url) {
105. try {
106. Document doc = Jsoup.connect(url).get();
107. String title = doc.select(“body > div.hp-wrap > div.voice-main > div.artical-title > h1”).first().ownText();
109. System.out.println(Thread.currentThread().getName() + ” 在 “ + new Date() + ” 采集了虎扑新闻 “ + title);
110. // 将采集完的 url 存入到已经采集的 set 中
111. visited.add(url);
113. } catch (IOException e) {
114. e.printStackTrace();
115. }
116. }
118. public static void main(String[] args) {
120. try {
121. new ThreadCrawler(“https://voice.hupu.com/nba”, 5).run();
122. } catch (InterruptedException e) {
123. e.printStackTrace();
124. }
125. }
126. }
我们用5个线程去采集hupu新闻列表页面看看效果。如果我们运行程序,我们会得到以下结果:
多线程采集结果
从结果可以看出,我们启动了 5 个线程 采集 到 61 个页面,总共耗时 2 秒。可以说效果还是不错的。我们用单线程对比一下,看看差距有多大?我们将线程数设置为1,再次启动程序,得到如下结果:
单线程运行结果
可以看到,单线程采集Hupu 61消息耗时7秒,几乎是多线程的4倍。如果你仔细想想,这只有 61 页。如果有更多的页面,差距会增加。该值越大,多线程爬虫的效率越高。想学交流HashMap、nginx、dubbo、Spring MVC、分布式、高性能、高可用、MySQL、redis、jvm、多线程、netty、kafka、家微信(佟英文):1253431195 扩展栏目获取资料供学习,无不加工作经验!
分布式爬虫架构
分布式爬虫架构是只有大型采集程序才需要使用的架构。一般可以使用单机多线程来解决业务需求。反正我没有分布式爬虫项目的经验,所以和这个没什么关系。是的,但作为技术人员,我们需要保持技术的热度。虽然我们不需要它,但理解它是可以的。我查了很多资料,得出以下结论:
分布式爬虫架构在思路上和我们的多线程爬虫架构是一样的。我们只需要在多线程的基础上稍加改进,就可以成为一个简单的分布式爬虫架构。由于在分布式爬虫架构中爬虫程序部署在不同的机器上,我们等待的URL采集和已经是采集的URL不能存储在爬虫程序机器的内存中,我们需要存储在某台机器上统一维护,比如存储在Redis或者MongoDB中。每台机器都从这里获取采集链接,而不是从LinkedBlockingQueue等内存队列中获取链接。这样一个简单的分发爬虫架构就出现了。当然会有很多细节,因为我没有分布式架构的经验,也谈不上。如果您有兴趣,欢迎交流。
java爬虫抓取动态网页(这是移动端微博信息_selenium_sina__)
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-03-27 04:05
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热门话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具用于自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但只显示微博或粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content.py 输入: 查看全部
java爬虫抓取动态网页(这是移动端微博信息_selenium_sina__)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热门话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具用于自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但只显示微博或粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content.py 输入:
java爬虫抓取动态网页(WebMagic项目代码分为核心和扩展两部分(webmagic-core))
网站优化 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-03-26 14:20
一、简介
webmagic是一个爬虫框架,无需配置,方便二次开发。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。
二、概览
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个简化的、模块化的爬虫实现,而扩展部分收录了一些方便实用的功能(比如用注解方式编写爬虫等)。
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,Spider 将它们相互组织起来。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2.1 WebMagic 的四个组成部分
2.2 数据流对象
2.3 控制爬虫的引擎——Spider
Spider 是 WebMagic 内部流程的核心。Downloader、PageProcessor、Scheduler 和 Pipeline 都是 Spider 的属性。这些属性可以自由设置,通过设置该属性可以实现不同的功能。Spider也是WebMagic操作的入口,封装了爬虫创建、启动、停止、多线程等功能。
对于编写爬虫来说,PageProcessor是需要编写的部分,Spider是创建和控制爬虫的入口。
2.4 WebMagic 项目构成
WebMagic 项目代码由几个部分组成,在根目录中由不同的目录名称分隔。它们都是独立的 Maven 项目。
WebMagic 主要包括两个已经被广泛使用和成熟的包:
三、基本爬虫3.1 爬虫流程(参考上面的框架图)
下载器-页面下载
PageProcessor-页面分析和链接提取
Webmagic 的选择器
调度程序-URL 管理
管道 - 离线处理和持久化
3.2 使用 WebMagic 抓取壁纸网站
首先介绍WebMagic的依赖,webmagic-core-{version}.jar和webmagic-extension-{version}.jar。在项目中添加这两个包的依赖即可使用WebMagic。
将依赖jar包引入maven
不使用maven的用户可以去下载最新的jar包。
3.3 爬虫的实现实现PageProcessor接口
爬虫配置
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
编写爬虫代码
<p>package photo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.FileNotFoundException;
import java.io.IOException;
public class GetPhoto implements PageProcessor {
// 设置参数
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
/**
* 主方法启动爬虫
*/
public static void main(String[] args) {
// 这里只爬取第一页的壁纸,如果要爬取其他页数修改for循环参数即可
for (int i = 1; i 查看全部
java爬虫抓取动态网页(WebMagic项目代码分为核心和扩展两部分(webmagic-core))
一、简介
webmagic是一个爬虫框架,无需配置,方便二次开发。它提供了简单灵活的API,只需少量代码即可实现爬虫。webmagic采用完全模块化设计,功能覆盖爬虫全生命周期(链接提取、页面下载、内容提取、持久化),支持多线程爬取、分布式爬取,并支持自动重试、自定义UA/等功能饼干。
二、概览
WebMagic 项目代码分为核心和扩展两部分。核心部分(webmagic-core)是一个简化的、模块化的爬虫实现,而扩展部分收录了一些方便实用的功能(比如用注解方式编写爬虫等)。
WebMagic 的结构分为四个组件:Downloader、PageProcessor、Scheduler 和 Pipeline,Spider 将它们相互组织起来。这四个组件分别对应了爬虫生命周期中的下载、处理、管理和持久化的功能。Spider 组织这些组件,以便它们可以相互交互并处理执行。可以认为Spider是一个大容器,也是WebMagic逻辑的核心。
WebMagic的整体架构图如下:
2.1 WebMagic 的四个组成部分
2.2 数据流对象
2.3 控制爬虫的引擎——Spider
Spider 是 WebMagic 内部流程的核心。Downloader、PageProcessor、Scheduler 和 Pipeline 都是 Spider 的属性。这些属性可以自由设置,通过设置该属性可以实现不同的功能。Spider也是WebMagic操作的入口,封装了爬虫创建、启动、停止、多线程等功能。
对于编写爬虫来说,PageProcessor是需要编写的部分,Spider是创建和控制爬虫的入口。
2.4 WebMagic 项目构成
WebMagic 项目代码由几个部分组成,在根目录中由不同的目录名称分隔。它们都是独立的 Maven 项目。
WebMagic 主要包括两个已经被广泛使用和成熟的包:
三、基本爬虫3.1 爬虫流程(参考上面的框架图)
下载器-页面下载
PageProcessor-页面分析和链接提取
Webmagic 的选择器
调度程序-URL 管理
管道 - 离线处理和持久化
3.2 使用 WebMagic 抓取壁纸网站
首先介绍WebMagic的依赖,webmagic-core-{version}.jar和webmagic-extension-{version}.jar。在项目中添加这两个包的依赖即可使用WebMagic。
将依赖jar包引入maven
不使用maven的用户可以去下载最新的jar包。
3.3 爬虫的实现实现PageProcessor接口
爬虫配置
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
编写爬虫代码
<p>package photo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.io.FileNotFoundException;
import java.io.IOException;
public class GetPhoto implements PageProcessor {
// 设置参数
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(3000);
/**
* 主方法启动爬虫
*/
public static void main(String[] args) {
// 这里只爬取第一页的壁纸,如果要爬取其他页数修改for循环参数即可
for (int i = 1; i
java爬虫抓取动态网页(java爬虫抓取动态网页的教程-java代码和注意事项)
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-26 08:05
java爬虫抓取动态网页的教程。可以爬取专业网站的动态页面,文章和话题页面,如腾讯新闻,百度百科,维基百科等。不用翻墙就可以连接国外的网站。文章单页面可以爬取,而多页面也可以爬取,比如一篇新闻,有完整的首页,发言人,文章详情页,评论页,话题页,文章详情页,评论页等。还可以抓取歌词数据,动态歌词,收藏歌词,特定歌词等歌词。
有兴趣,自己可以尝试实验一下。方法思路:动态网页采集,爬取时需要先生成cookie,当点击某一个url以后,可以获取到cookie,以后再次请求时,直接使用cookie,根据cookie内容可以知道请求的url。再利用java的反射技术,自动的抓取所有抓取过的url请求,抓取完毕,再存储到字典中,等待下次重复抓取时使用。
设置协议代理,当请求时,爬虫会生成一个ip,这个ip代理服务器记录,每次请求时都使用这个ip。每个抓取到的网页,都会存储到一个字典中,等待下次抓取时使用。注意事项1.动态网页,抓取简单,本文采用了经典的动态爬虫技术get,post请求方式2.协议代理设置了,爬虫会生成一个代理ip,为了规避封ip和封端口,动态抓取时网页加密为https,协议代理ip只记录https的网址和端口3.只读协议代理,当使用共享代理端口时,协议代理ip可以改为remote,子代理ip只能为remote请求方式,不能直接使用上面的动态爬虫网页抓取方法。
java代码和注意事项1.整体思路如下动态页面抓取2.操作界面设置:点击右上角文章,可以看到动态页面抓取3.代码代码和注意事项:#!/usr/bin/envpython#coding:utf-8fromhttplibimportparsefromseleniumimportwebdriverhttplib.parse(context='ssl')'''动态抓取动态页面资源.程序详解.'''mask=nonenetwork=['get','post']friend_url='('+network.getcase(url=url)+')'try:friend_url='(/)'exceptexceptionase:e.status='200'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/69.0.3071.142safari/537.36'}#这里的friend_url是自己爬取到的具体页面页面信息,待会使用时需要带上'''[xpath](//div[@class="exterm"]/div/div[2]/div/div/div/a/div/div/div/div/a/span/div/div/div/div/i)'''parsed_c。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页的教程-java代码和注意事项)
java爬虫抓取动态网页的教程。可以爬取专业网站的动态页面,文章和话题页面,如腾讯新闻,百度百科,维基百科等。不用翻墙就可以连接国外的网站。文章单页面可以爬取,而多页面也可以爬取,比如一篇新闻,有完整的首页,发言人,文章详情页,评论页,话题页,文章详情页,评论页等。还可以抓取歌词数据,动态歌词,收藏歌词,特定歌词等歌词。
有兴趣,自己可以尝试实验一下。方法思路:动态网页采集,爬取时需要先生成cookie,当点击某一个url以后,可以获取到cookie,以后再次请求时,直接使用cookie,根据cookie内容可以知道请求的url。再利用java的反射技术,自动的抓取所有抓取过的url请求,抓取完毕,再存储到字典中,等待下次重复抓取时使用。
设置协议代理,当请求时,爬虫会生成一个ip,这个ip代理服务器记录,每次请求时都使用这个ip。每个抓取到的网页,都会存储到一个字典中,等待下次抓取时使用。注意事项1.动态网页,抓取简单,本文采用了经典的动态爬虫技术get,post请求方式2.协议代理设置了,爬虫会生成一个代理ip,为了规避封ip和封端口,动态抓取时网页加密为https,协议代理ip只记录https的网址和端口3.只读协议代理,当使用共享代理端口时,协议代理ip可以改为remote,子代理ip只能为remote请求方式,不能直接使用上面的动态爬虫网页抓取方法。
java代码和注意事项1.整体思路如下动态页面抓取2.操作界面设置:点击右上角文章,可以看到动态页面抓取3.代码代码和注意事项:#!/usr/bin/envpython#coding:utf-8fromhttplibimportparsefromseleniumimportwebdriverhttplib.parse(context='ssl')'''动态抓取动态页面资源.程序详解.'''mask=nonenetwork=['get','post']friend_url='('+network.getcase(url=url)+')'try:friend_url='(/)'exceptexceptionase:e.status='200'headers={'user-agent':'mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/69.0.3071.142safari/537.36'}#这里的friend_url是自己爬取到的具体页面页面信息,待会使用时需要带上'''[xpath](//div[@class="exterm"]/div/div[2]/div/div/div/a/div/div/div/div/a/span/div/div/div/div/i)'''parsed_c。
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
网站优化 • 优采云 发表了文章 • 0 个评论 • 287 次浏览 • 2022-03-24 04:10
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与perl、shell等其他动态脚本语言相比,python的urllib包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。 python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
爬取的网页通常需要处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 与 python3.x 非常不同。本文只讨论python的爬虫实现方法3.x.
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,将其存储,并将url补充到URL管理器中。
运行过程
URL管理器基本功能存储方法
1、内存(python 内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
urls(url, is_crawled)
3、缓存(redis)
要爬取的url集合:set
抓取的网址集合:设置
大型互联网公司,由于缓存数据库的高性能,一般将URL存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新百度2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监控数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py.
虽然python报错,但是在fiddler中,我们可以看到请求信息,确实是带参数的。
查了资料,发现以前的Python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 .结果还是报错,但是变成了400错误。
然而,然而。 . 神的转折点出现了! ! !
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法! ! !
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
美人汤
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现警告。根据提示,我们可以在创建BeautifulSoup对象时指定解析器。
5、获取文档中的所有文本
print(soup.get_text())
6、正则匹配
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
书签
Python开发一个简单的爬虫
Python 标准库
美丽的汤4.2.0 文档
为什么python适合写爬虫?
如何学习Python爬虫【简介】?
你需要这些:Python3.x爬虫学习资料整理
如何开始使用 Python 爬虫?
Python3.X爬取网络资源
python 网络请求和“HTTP 错误 504:Fiddler - 接收失败”
如何使用Fiddler抓取自己写的爬虫包?
fiddler抓取python脚本的https包时出错? 查看全部
java爬虫抓取动态网页(Python非常适合用来开发网页爬虫,理由:管理待爬取url)
前言
Python 非常适合开发网络爬虫,原因如下:
1、抓取网页本身的接口
相比其他静态编程语言,如java、c#、c++、python,爬取网页文档的界面更加简洁;与perl、shell等其他动态脚本语言相比,python的urllib包提供了更完善的web文档访问API。 (当然ruby也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当请求的地方,例如模拟用户登录、模拟会话/cookie存储和设置。 python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2、网页抓取后的处理
爬取的网页通常需要处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。
人生苦短,你需要python。
PS:python2.x 与 python3.x 非常不同。本文只讨论python的爬虫实现方法3.x.
爬虫架构的组成
URL管理器:管理待爬取的url集合和已爬取的url集合,并将待爬取的url发送给网页下载器。
网页下载器(urllib):抓取url对应的网页,存储为字符串,发送给网页解析器。
网页解析器(BeautifulSoup):解析出有价值的数据,将其存储,并将url补充到URL管理器中。
运行过程
URL管理器基本功能存储方法
1、内存(python 内存)
要爬取的url集合:set()
抓取的url集合:set()
2、关系型数据库(mysql)
urls(url, is_crawled)
3、缓存(redis)
要爬取的url集合:set
抓取的网址集合:设置
大型互联网公司,由于缓存数据库的高性能,一般将URL存储在缓存数据库中。小公司一般将 URL 存储在内存中,如果要永久存储,请将其存储在关系数据库中。
网页下载器(urllib)
将url对应的网页下载到本地,保存为文件或字符串。
基本方法
新建一个baidu.py,内容如下:
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
buff = response.read()
html = buff.decode("utf8")
print(html)
在命令行执行python baidu.py,打印得到的页面。
构造请求
上面的代码可以修改为:
import urllib.request
request = urllib.request.Request('http://www.baidu.com')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
携带参数
新百度2.py,内容如下:
import urllib.request
import urllib.parse
url = 'http://www.baidu.com'
values = {'name': 'voidking','language': 'Python'}
data = urllib.parse.urlencode(values).encode(encoding='utf-8',errors='ignore')
headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:50.0) Gecko/20100101 Firefox/50.0' }
request = urllib.request.Request(url=url, data=data,headers=headers,method='GET')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
使用 Fiddler 监控数据
我们想看看我们的请求是否真的携带参数,所以我们需要使用fiddler。
打开fiddler后无意中发现上面的代码会报错504,不管是baidu.py还是baidu2.py.
虽然python报错,但是在fiddler中,我们可以看到请求信息,确实是带参数的。
查了资料,发现以前的Python版本不支持代理环境下访问https。但是,最新版本应该支持它。那么,最简单的方法就是更改使用http协议进行爬取的url,例如,将其替换为 .结果还是报错,但是变成了400错误。
然而,然而。 . 神的转折点出现了! ! !
当我将url替换为时,请求成功!没错,只需在 URL 后加一个额外的斜杠 / 即可。同理,改成,请求也成功了!魔法! ! !
添加处理器
import urllib.request
import http.cookiejar
# 创建cookie容器
cj = http.cookiejar.CookieJar()
# 创建opener
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# 给urllib.request安装opener
urllib.request.install_opener(opener)
# 请求
request = urllib.request.Request('http://www.baidu.com/')
response = urllib.request.urlopen(request)
buff = response.read()
html = buff.decode("utf8")
print(html)
print(cj)
美人汤
从网页中提取有价值的数据和新的 url 列表。
解析器选择
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中正则表达式基于模糊匹配,而其他三个基于DOM结构化解析。
BeautifulSoup 安装测试
1、要安装,在命令行执行pip install beautifulsoup4。
2、测试
import bs4
print(bs4)
说明
基本用法
1、创建 BeautifulSoup 对象
import bs4
from bs4 import BeautifulSoup
# 根据html网页字符串创建BeautifulSoup对象
html_doc = """
The Dormouse's story
<p class="title">The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc)
print(soup.prettify())</p>
2、访问节点
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.p)
print(soup.p['class'])
3、指定标签、类或id
print(soup.find_all('a'))
print(soup.find('a'))
print(soup.find(class_='title'))
print(soup.find(id="link3"))
print(soup.find('p',class_='title'))
4、从文档中找到所有标签的链接
for link in soup.find_all('a'):
print(link.get('href'))
出现警告。根据提示,我们可以在创建BeautifulSoup对象时指定解析器。
5、获取文档中的所有文本
print(soup.get_text())
6、正则匹配
link_node = soup.find('a',href=re.compile(r"til"))
print(link_node)
后记
python爬虫的基础知识就够了。接下来,在实战中学习更高级的知识。
书签
Python开发一个简单的爬虫
Python 标准库
美丽的汤4.2.0 文档
为什么python适合写爬虫?
如何学习Python爬虫【简介】?
你需要这些:Python3.x爬虫学习资料整理
如何开始使用 Python 爬虫?
Python3.X爬取网络资源
python 网络请求和“HTTP 错误 504:Fiddler - 接收失败”
如何使用Fiddler抓取自己写的爬虫包?
fiddler抓取python脚本的https包时出错?
java爬虫抓取动态网页(盘点一下数据采集常见的几种网站类型(一)(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-24 04:07
)
在学习爬虫之前,我们需要先掌握网站的类型,这样才能根据网站的类型使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件可以采集的网站类型为例,盘点一下数据采集常用类型网站 的类型。
lCommon网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常将 JavaScript 脚本嵌入到 HTML 中来实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,利用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。当浏览一个页面时,我们将页面拉回来,页面链接并没有改变,但是网页中有新的内容。这是通过Ajax获取新数据并呈现流程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。 POST 将表单打包并隐藏在后台并发送给服务器; GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中数据的web内容,即采集post/get请求中的数据。
3.需要 cookie网站
Cookies 是指存储在用户本地终端上的一些网站数据,用于识别用户身份并进行会话跟踪。 Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般用户的帐户信息记录在 cookie 中。爬虫爬取数据时,可以通过cookie模拟登录状态获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要cookie的网站内容。
4.采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供多种OAUTH实现如PHP、Java Script、Java、Ruby等语言开发包,大大节省了程序员的时间,所以OAUTH简单。 Open API等很多互联网服务,谷歌、雅虎、微软等很多大公司都提供了OAUTH认证服务,足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l前端嗅探介绍
前嗅大数据,国内领先的大数据研发专家,多年致力于大数据技术的研发,自主研发了完整的数据集采集,分析,处理、管理和应用。 ,营销大数据产品。千秀致力于打造国内首个深度大数据平台!
查看全部
java爬虫抓取动态网页(盘点一下数据采集常见的几种网站类型(一)(组图)
)
在学习爬虫之前,我们需要先掌握网站的类型,这样才能根据网站的类型使用适用的方法编写爬虫获取数据。
今天小编就以国内知名的ForeSpider爬虫软件可以采集的网站类型为例,盘点一下数据采集常用类型网站 的类型。
lCommon网站类型
1.js 页面
JavaScript是一种属于网络的脚本语言,广泛用于Web应用程序的开发。常用于为网页添加各种动态功能,为用户提供更流畅、更美观的浏览效果。通常将 JavaScript 脚本嵌入到 HTML 中来实现自己的功能。
ForeSpider数据抓取工具可以自动解析JS,采集根据js页面中的数据,采集页面收录JS数据。
Ajax 是异步 JavaScript 和 XML。它不是一种编程语言,而是一种在不刷新页面和不改变页面链接的情况下,利用 JavaScript 与服务器交换数据并更新部分网页的技术。
我们在浏览网页时,经常会遇到这样的情况。当浏览一个页面时,我们将页面拉回来,页面链接并没有改变,但是网页中有新的内容。这是通过Ajax获取新数据并呈现流程。
ForeSpider数据采集系统支持Ajax技术,可以采集网页中的Ajax内容。
2.发布/获取请求
在 html 语言中,有两种方法可以将表单(您在网页中填写的一些数据)发送到服务器。一种是 POST,另一种是 GET。 POST 将表单打包并隐藏在后台并发送给服务器; GET 包装表单并将其附加到 URL(网站)的后面,然后再发送。
ForeSpider采集器可以采集post/get请求中数据的web内容,即采集post/get请求中的数据。
3.需要 cookie网站
Cookies 是指存储在用户本地终端上的一些网站数据,用于识别用户身份并进行会话跟踪。 Cookie是基于各种互联网服务系统而产生的。它是由网络服务器保存在用户浏览器上的一个小文本文件。它可以收录有关用户的信息,是用户获取、交流和传递信息的主要场所之一。每当用户链接到服务器时,网站都可以访问 cookie 信息。
一般用户的帐户信息记录在 cookie 中。爬虫爬取数据时,可以通过cookie模拟登录状态获取数据。
ForeSpider数据采集分析引擎可以设置cookie来模拟登录,所以采集需要cookie的网站内容。
4.采集需要OAuth认证的网页数据
OAUTH 协议为用户资源的授权提供了一个安全、开放、简单的标准。同时,任何第三方都可以使用OAUTH认证服务,任何服务商都可以实现自己的OAUTH认证服务,所以OAUTH是开放的。
业界提供多种OAUTH实现如PHP、Java Script、Java、Ruby等语言开发包,大大节省了程序员的时间,所以OAUTH简单。 Open API等很多互联网服务,谷歌、雅虎、微软等很多大公司都提供了OAUTH认证服务,足以说明OAUTH标准已经逐渐成为开放资源授权的标准。
ForeSpider爬虫软件支持OAuth认证,可以采集需要OAuth认证的页面中的数据。
l前端嗅探介绍
前嗅大数据,国内领先的大数据研发专家,多年致力于大数据技术的研发,自主研发了完整的数据集采集,分析,处理、管理和应用。 ,营销大数据产品。千秀致力于打造国内首个深度大数据平台!
java爬虫抓取动态网页(聚焦网络爬虫又称主题网络数采集的主要功能工作流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-24 04:05
网络号的主要作用采集
网络数据采集是指通过网络爬虫或网站公共API
从网站获取数据信息
常用网络采集系统网络爬虫工作原理工作流程抓取策略网络爬虫策略中使用的基本概念一般网络爬虫
通用网络爬虫也称为全网络爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
De Bra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,利用空间向量模型计算页面与主题的相关度。通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关度的量化大小。
2)基于链接结构评估的爬取策略
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页。如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。网页的重要性与它所引用的网页同等地传递。
3)基于强化学习的爬取策略
将强化学习引入焦点爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,计算每个链接的重要性,确定链接访问的顺序。
4)基于上下文图的爬取策略
一种通过构建上下文图来了解网页之间相关性的抓取策略。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。访问。
增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。 .
深度网络爬虫
网页按存在方式可分为表层网页和深层网页。表面网页是指可以被传统搜索引擎索引的页面,主要是可以通过超链接到达的静态网页。深度网页是大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
深网爬虫架构由6个基本功能模块组成:
爬虫控制器、解析器、表单分析器、表单处理程序、响应分析器、LVS 控制器和两个爬虫内部数据结构(URL 列表和 LVS 表)。其中,LVS(Label Value Set)代表标签和值集,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
java爬虫抓取动态网页(聚焦网络爬虫又称主题网络数采集的主要功能工作流程)
网络号的主要作用采集
网络数据采集是指通过网络爬虫或网站公共API
从网站获取数据信息
常用网络采集系统网络爬虫工作原理工作流程抓取策略网络爬虫策略中使用的基本概念一般网络爬虫
通用网络爬虫也称为全网络爬虫。爬取对象从一些种子URL延伸到整个网络,主要针对门户网站搜索引擎和大型网络服务商采集数据。
专注于网络爬虫
聚焦网络爬虫,也称为主题网络爬虫,是选择性抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
De Bra 将文本相似度的计算方法引入网络爬虫,提出了 Fish Search 算法。该算法以用户输入的查询词为主题,将收录查询词的页面视为与该主题相关的页面。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,利用空间向量模型计算页面与主题的相关度。通过采用基于连续值计算链接值的方法,我们不仅可以计算出哪些捕获的链接与主题相关,而且可以得到相关度的量化大小。
2)基于链接结构评估的爬取策略
PageRank算法的基本原理是,如果一个网页被多次引用,它可能是一个重要的网页。如果一个网页没有被多次引用,而是被一个重要网页引用,那么它也可能是一个重要网页。网页的重要性与它所引用的网页同等地传递。
3)基于强化学习的爬取策略
将强化学习引入焦点爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,计算每个链接的重要性,确定链接访问的顺序。
4)基于上下文图的爬取策略
一种通过构建上下文图来了解网页之间相关性的抓取策略。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面到相关网页的距离。访问。
增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只爬取新生成或更改的网页的爬虫。可以在一定程度上保证爬取的页面尽可能的新。 .
深度网络爬虫
网页按存在方式可分为表层网页和深层网页。表面网页是指可以被传统搜索引擎索引的页面,主要是可以通过超链接到达的静态网页。深度网页是大部分内容无法通过静态链接获取,隐藏在搜索表单后面,只能通过用户提交一些关键词获取的网页。
深网爬虫架构由6个基本功能模块组成:
爬虫控制器、解析器、表单分析器、表单处理程序、响应分析器、LVS 控制器和两个爬虫内部数据结构(URL 列表和 LVS 表)。其中,LVS(Label Value Set)代表标签和值集,用来表示填写表格的数据源。在爬取过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。

