
java爬虫抓取动态网页
java爬虫抓取动态网页(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-13 18:07
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫。有需要的小伙伴快来领取吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的可扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。 Teo 线程为每个 URL 执行 URL 处理器链。 URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备,比如延迟和重新处理处理,否决后续操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3)提取链:提取完成后,提取感兴趣的HTML和JavaScript,通常会有新的URL需要爬取。
(4)写链:存储抓取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)Submission chain:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外DNS缓存信息也会更新.
Heritrix 系统框架图
heritrix处理一个url的过程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 使用
1.Visualization 展示页面合集
2.下载页面到本地磁盘离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用 Java 或 Javascript 开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
WebLech 是一个强大的网站下载和镜像免费开源工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特点:
1)开源,免费
2)代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4)可以维护网页之间的链接信息
5) 可配置性强:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络。 URL 优先,以便首先抓取我们感兴趣或对我们重要的网页。可以记录断点时程序的状态,重新启动时可以从上次继续爬行。
四、Arale
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。你可以用它来检查网站错误(内部服务器错误等),网站内外链接检查,分析网站的结构(你可以创建一个网站Map),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。 JSpider的执行格式如下:
jspider [配置名称]
URL中必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。 JSpider的默认配置类型很少,用处不大。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以使用它:
检查您的网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的网站 结构(创建站点地图,...)
下载并修复网站
通过编写JSpider插件实现任何功能。
项目主页:
六、spindle
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
七、Arachnid
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,就可以开发出一个简单的网络蜘蛛,可以在网站上使用每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、JoBo
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
什么是1、snoics-reptile?
纯Java开发,是一个用来抓取网站镜像的工具。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站所有资源都是本地抓取的,包括网页和各类文件,如图片、flash、mp3、zip、rar、exe 等文件。整个网站可以原封不动的转移到硬盘上,保持原来的网站结构准确不变。只需将抓到的网站放到web服务器(如Apache)中即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile?
因为在爬取的过程中经常会出现一些错误的文件,很多由javascript控制的URL没有办法正确解析,snoics-reptile为特殊的URL提供了外部接口和配置文件。 ,可以自由扩展外部提供的接口,通过配置文件注入的方式,基本可以实现对所有网页的正确分析和抓取。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。 Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取能力。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了方便数据的操作和重用,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:net
十二、ItSucks
ItSucks 是 Java 网络爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和Swing GUI操作界面。
特点:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。监听器可以在解析过程中添加,也可以在页面加载前后添加。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。哪里:
shouldVisit是判断当前的URL是否应该被抓取(访问);
visit是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
另外,WebCrawler还有一些其他的方法可以覆盖,其方法的命名规则与Android的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据; onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
许可证 查看全部
java爬虫抓取动态网页(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫。有需要的小伙伴快来领取吧。

一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的可扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。 Teo 线程为每个 URL 执行 URL 处理器链。 URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备,比如延迟和重新处理处理,否决后续操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3)提取链:提取完成后,提取感兴趣的HTML和JavaScript,通常会有新的URL需要爬取。
(4)写链:存储抓取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)Submission chain:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外DNS缓存信息也会更新.

Heritrix 系统框架图

heritrix处理一个url的过程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 使用
1.Visualization 展示页面合集
2.下载页面到本地磁盘离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用 Java 或 Javascript 开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
WebLech 是一个强大的网站下载和镜像免费开源工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特点:
1)开源,免费
2)代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4)可以维护网页之间的链接信息
5) 可配置性强:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络。 URL 优先,以便首先抓取我们感兴趣或对我们重要的网页。可以记录断点时程序的状态,重新启动时可以从上次继续爬行。
四、Arale
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。你可以用它来检查网站错误(内部服务器错误等),网站内外链接检查,分析网站的结构(你可以创建一个网站Map),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。 JSpider的执行格式如下:
jspider [配置名称]
URL中必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。 JSpider的默认配置类型很少,用处不大。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以使用它:
检查您的网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的网站 结构(创建站点地图,...)
下载并修复网站
通过编写JSpider插件实现任何功能。
项目主页:
六、spindle
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
七、Arachnid
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,就可以开发出一个简单的网络蜘蛛,可以在网站上使用每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、JoBo
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
什么是1、snoics-reptile?
纯Java开发,是一个用来抓取网站镜像的工具。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站所有资源都是本地抓取的,包括网页和各类文件,如图片、flash、mp3、zip、rar、exe 等文件。整个网站可以原封不动的转移到硬盘上,保持原来的网站结构准确不变。只需将抓到的网站放到web服务器(如Apache)中即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile?
因为在爬取的过程中经常会出现一些错误的文件,很多由javascript控制的URL没有办法正确解析,snoics-reptile为特殊的URL提供了外部接口和配置文件。 ,可以自由扩展外部提供的接口,通过配置文件注入的方式,基本可以实现对所有网页的正确分析和抓取。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。 Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取能力。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了方便数据的操作和重用,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:net
十二、ItSucks
ItSucks 是 Java 网络爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和Swing GUI操作界面。
特点:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。监听器可以在解析过程中添加,也可以在页面加载前后添加。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。哪里:
shouldVisit是判断当前的URL是否应该被抓取(访问);
visit是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
另外,WebCrawler还有一些其他的方法可以覆盖,其方法的命名规则与Android的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据; onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
许可证
java爬虫抓取动态网页(金融行业需要和技术面等相关信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-13 18:06
前言
在现代社会,有效的信息对于人们来说就像氧气一样不可或缺。互联网使采集有效信息变得更加容易。当您上网时,网络爬虫也会在互联网上穿梭,自动采集互联网上的有用信息。
自动采集和过滤信息的网络爬虫增强了有效信息的流动,使我们能够更有效地获取信息。随着网络上出现的信息越来越多,网络爬虫变得越来越有用。
所有行业都离不开采集和信息的处理。例如,农业需要捕捉天气数据和农产品市场数据,以实现精准农业。机械行业需要抓取零件和图纸信息作为设计参考。制药行业需要获取有关某些疾病治疗的信息。金融业需要捕捉上市公司的基本面和技术面,作为股市涨跌的参考。比如太钢生产圆珠笔,带动其股票“太钢不锈钢”的上涨。此外,金融业还需要捕捉投资者对市场的参与,作为判断市场大势的依据。
每个人都可以利用网络爬虫技术来获得更好的生存策略,避免一些不好的情况,让自己的生活越来越幸福。例如,网络爬虫可以采集二甲双胍等可能抗衰老的药物,让人们过上更健康的生活。
本书的大部分内容来自于搜索引擎、自然语言处理和金融领域的项目开发和教学实践。感谢开源软件的开发者们的无私工作,丰富了本书的内容。
本书从讲解开发网络爬虫所需的Java语法开始,然后介绍爬虫的基本原理。通过对优先队列、广度优先搜索等内容的介绍,引导读者入门,然后根据当前云计算热潮,重点介绍云计算的相关内容及其在爬虫中的应用,以及信息提取、链接分析等内容。接下来介绍爬虫的web数据挖掘等。为了让读者更深入地了解爬虫的实际应用,最后一章是案例分析。本书相关代码可在读者QQ群(294737705))的共享文件中找到。
本书适合需要实现网络爬虫的程序员。对信息检索等相关领域的研究人员也有一定的参考价值。同时,猎兔搜索技术团队开发了专门的培训课程和基于本书的培训课程。商业软件。目前的一些网络爬虫软件还有很多功能有待完善。作者真诚地希望通过本书,将读者带入网络爬虫开发的大门,结识更多的朋友。
感谢早期合著者、合作伙伴、员工、学生和家人的支持。他们为我们提供了良好的工作基础,这是一个持久可用的工作基础。未来,我们希望我们的网络爬虫代码和技术能像植物一样快速成长。
崔志杰、史天英、张继宏、张晋伟、刘宇、何树琴、任彤彤、高丹丹、许有峰、孙宽参与了本书的编写。我想表达我的感激之情。
罗刚
2017 年 2 月 查看全部
java爬虫抓取动态网页(金融行业需要和技术面等相关信息(组图))
前言
在现代社会,有效的信息对于人们来说就像氧气一样不可或缺。互联网使采集有效信息变得更加容易。当您上网时,网络爬虫也会在互联网上穿梭,自动采集互联网上的有用信息。
自动采集和过滤信息的网络爬虫增强了有效信息的流动,使我们能够更有效地获取信息。随着网络上出现的信息越来越多,网络爬虫变得越来越有用。
所有行业都离不开采集和信息的处理。例如,农业需要捕捉天气数据和农产品市场数据,以实现精准农业。机械行业需要抓取零件和图纸信息作为设计参考。制药行业需要获取有关某些疾病治疗的信息。金融业需要捕捉上市公司的基本面和技术面,作为股市涨跌的参考。比如太钢生产圆珠笔,带动其股票“太钢不锈钢”的上涨。此外,金融业还需要捕捉投资者对市场的参与,作为判断市场大势的依据。
每个人都可以利用网络爬虫技术来获得更好的生存策略,避免一些不好的情况,让自己的生活越来越幸福。例如,网络爬虫可以采集二甲双胍等可能抗衰老的药物,让人们过上更健康的生活。
本书的大部分内容来自于搜索引擎、自然语言处理和金融领域的项目开发和教学实践。感谢开源软件的开发者们的无私工作,丰富了本书的内容。
本书从讲解开发网络爬虫所需的Java语法开始,然后介绍爬虫的基本原理。通过对优先队列、广度优先搜索等内容的介绍,引导读者入门,然后根据当前云计算热潮,重点介绍云计算的相关内容及其在爬虫中的应用,以及信息提取、链接分析等内容。接下来介绍爬虫的web数据挖掘等。为了让读者更深入地了解爬虫的实际应用,最后一章是案例分析。本书相关代码可在读者QQ群(294737705))的共享文件中找到。
本书适合需要实现网络爬虫的程序员。对信息检索等相关领域的研究人员也有一定的参考价值。同时,猎兔搜索技术团队开发了专门的培训课程和基于本书的培训课程。商业软件。目前的一些网络爬虫软件还有很多功能有待完善。作者真诚地希望通过本书,将读者带入网络爬虫开发的大门,结识更多的朋友。
感谢早期合著者、合作伙伴、员工、学生和家人的支持。他们为我们提供了良好的工作基础,这是一个持久可用的工作基础。未来,我们希望我们的网络爬虫代码和技术能像植物一样快速成长。
崔志杰、史天英、张继宏、张晋伟、刘宇、何树琴、任彤彤、高丹丹、许有峰、孙宽参与了本书的编写。我想表达我的感激之情。
罗刚
2017 年 2 月
java爬虫抓取动态网页( 本节主要讲述src的基本概念。网页get和动态页面的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-13 18:05
本节主要讲述src的基本概念。网页get和动态页面的区别)
HTML 基础
本节主要介绍HTML的基本概念。要抓取一个网页,首先要对网页有一个基本的了解。网页基础知识可以访问w3c学校学习
1. 页面构成
一个页面通常由css、js和html元素组成,其中css定义页面的样式,js负责渲染动态页面,html元素构成静态页面。常见的html元素包括文本元素、超链接(一般形式a href='#)'、图片(一般形式img src='img.png'); css一般在页面中以div class='demo'的形式来引用; js以javascript标签的形式引用。
常用的查看页面元素的工具是Chrome浏览器的“查看元素”功能。一个典型的页面元素如下:
可以看出页面元素是通过各种标签来组织的。
2.静态和动态页面
Internet 上的第一个网页是静态 html 页面。页面的元素比较简单,展示了一些文字、图片等信息,但是随着js、ajax等技术的发展,网页逐渐变得动态化了。动态页面可以提供更好的用户体验,但增加了抓取的难度。对于动态页面,Chrome下右键“查看网页源代码”和右键“查看元素”看到的页面结构是不同的。 ‘review element’可以获取动态加载的页面。爬取时需要注意静态页面和动态页面的区别。
3. 获取和发布请求
简单的说,一般访问一个网页是get请求,需要向服务器发送数据时使用post请求。在爬虫中使用get请求获取网页信息,向服务器发送数据时使用post请求(如登录和提交)。 查看全部
java爬虫抓取动态网页(
本节主要讲述src的基本概念。网页get和动态页面的区别)
HTML 基础
本节主要介绍HTML的基本概念。要抓取一个网页,首先要对网页有一个基本的了解。网页基础知识可以访问w3c学校学习
1. 页面构成
一个页面通常由css、js和html元素组成,其中css定义页面的样式,js负责渲染动态页面,html元素构成静态页面。常见的html元素包括文本元素、超链接(一般形式a href='#)'、图片(一般形式img src='img.png'); css一般在页面中以div class='demo'的形式来引用; js以javascript标签的形式引用。
常用的查看页面元素的工具是Chrome浏览器的“查看元素”功能。一个典型的页面元素如下:

可以看出页面元素是通过各种标签来组织的。
2.静态和动态页面
Internet 上的第一个网页是静态 html 页面。页面的元素比较简单,展示了一些文字、图片等信息,但是随着js、ajax等技术的发展,网页逐渐变得动态化了。动态页面可以提供更好的用户体验,但增加了抓取的难度。对于动态页面,Chrome下右键“查看网页源代码”和右键“查看元素”看到的页面结构是不同的。 ‘review element’可以获取动态加载的页面。爬取时需要注意静态页面和动态页面的区别。
3. 获取和发布请求
简单的说,一般访问一个网页是get请求,需要向服务器发送数据时使用post请求。在爬虫中使用get请求获取网页信息,向服务器发送数据时使用post请求(如登录和提交)。
java爬虫抓取动态网页(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-13 04:17
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上说HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,还是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据? 查看全部
java爬虫抓取动态网页(java程序中获取后台js完后的完整页面是什么?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上说HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,还是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据?
java爬虫抓取动态网页( Java爬虫爬取网页内容网页内容方法:用apache提供的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-12 04:09
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则爬取网页上的信息,通常是在爬取一些网址之后,再将这些网址放入队列中反复搜索。
2、Java 爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,一直循环直到所有网站网页都被抓取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
3、Java 爬虫方法抓取网页内容:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。可以用代码来用~更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。) 查看全部
java爬虫抓取动态网页(
Java爬虫爬取网页内容网页内容方法:用apache提供的包)

1、网络爬虫
按照一定的规则爬取网页上的信息,通常是在爬取一些网址之后,再将这些网址放入队列中反复搜索。
2、Java 爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,一直循环直到所有网站网页都被抓取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
3、Java 爬虫方法抓取网页内容:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。可以用代码来用~更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。)
java爬虫抓取动态网页(Python可以运用selenium+scrapy来抓取动态网页的信息吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-12 04:08
)
R 语言是一种强大的数据分析工具。还有很多方便的封装例子Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,就需要下载对应版本的浏览器驱动chormedriver。
(下载地址,比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url 查看全部
java爬虫抓取动态网页(Python可以运用selenium+scrapy来抓取动态网页的信息吗
)
R 语言是一种强大的数据分析工具。还有很多方便的封装例子Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,就需要下载对应版本的浏览器驱动chormedriver。
(下载地址,比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url
java爬虫抓取动态网页( 手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-12 04:06
手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
动态网页
相关内容:
【教程】教你使用工具(IE9中的F12)分析模拟登录网站(百度主页)的内部逻辑流程)
【记录】模拟登录google
【教程】如何抓取动态网页内容
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
待办事项:
找一个需要登录的网站,或者需要后续执行js加载的网页内容的例子,然后用抓包工具模拟登录,或者分析数据是如何加载的。
示例:Chrom分析某某大众点评页面获取店铺数据,然后使用PySpider实现代码并下载数据
这次通过一个例子,如何:
期间要注意:需要对各种参数稍作模拟才能得到数据,否则会出现各种错误
要分析的网址:
用Chrome打开后,可以得到数据:
但在 PySpider 中,使用代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-04-15 14:56:12
# Project: DianpingChilrenEnglish
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
import copy
import time
import re
import csv
# import datetime
from datetime import datetime, timedelta
######################################################################
# Const
######################################################################
...
constCityListNamePattern = "cityList_%s_%s.json"
constMainCityFilename = "mainCityWithLevelList.json"
constUserAgentMacChrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
gHost = "http://www.dianping.com"
CategoryLevel1ParentChild = "ch70" # 全部分类->亲子
CategoryLevel2ChildEnglish = "g27762" # 幼儿教育 -> 幼儿外语
######################################################################
# Project Specific Functions
######################################################################
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
"User-Agent": constUserAgentMacChrome,
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/json",
"Origin": "http://www.dianping.com",
# "X-Requested-With": "XMLHttpRequest",
}
}
def on_start(self):
# self.init()
self.realStart()
def realStart(self):
...
# for debug
"""
eachMainCity={'cityAbbrCode': 'SUZ', 'cityAreaCode': '0512', 'cityEnName': 'suzhou', 'cityId': 6, 'cityLevel': 2, 'cityName': '苏州', 'cityOrderId': 4888, 'cityPyName': 'suzhou', 'gLat': 31.297779, 'gLng': 120.585586, 'provinceId': 10, 'currentNodeLevel': 2, 'totalRank': '9', 'cityLevelFloat': 1.5, 'provinceName': '江苏省'}
cityEnName=suzhou
childEnglishEntryUrl=http://www.dianping.com/suzhou/ch70/g27762
"""
childEnglishEntryUrl = "http://www.dianping.com/suzhou/ch70/g27762"
self.crawl(
childEnglishEntryUrl,
callback=self.childEnglishCallback
)
def childEnglishCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
respText = response.text
print("respText=%s" % respText)
#
#
for eachShop in response.doc('ul[class="shop-list"] li[data-shopid]').items():
print("eachShop=%s" % eachShop)
结果返回错误信息:
respText={"customData":{"requestCode":"c9847c945a1440d49460df748b757250","verifyUrl":"https://optimus-mtsi.meituan.c ... ot%3B,"imageUrl":"https://verify.meituan.com/v2/ ... ot%3B,"verifyPageUrl":"https://verify.meituan.com/v2/ ... ot%3B},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}
然后参考Chromet中看到的参数:
对于各种header,试着一一添加,终于找到了:
将 text/html 相关类型添加到接受:
# "Accept": "application/json, text/javascript, */*; q=0.01",
"Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
可以得到数据:
-》 前面提到的逻辑: 找个方法引用Chrome调试看到的所有重要参数:
添加后
,大多数情况下可以得到对应的返回数据。 查看全部
java爬虫抓取动态网页(
手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
动态网页
相关内容:
【教程】教你使用工具(IE9中的F12)分析模拟登录网站(百度主页)的内部逻辑流程)
【记录】模拟登录google
【教程】如何抓取动态网页内容
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
待办事项:
找一个需要登录的网站,或者需要后续执行js加载的网页内容的例子,然后用抓包工具模拟登录,或者分析数据是如何加载的。
示例:Chrom分析某某大众点评页面获取店铺数据,然后使用PySpider实现代码并下载数据
这次通过一个例子,如何:
期间要注意:需要对各种参数稍作模拟才能得到数据,否则会出现各种错误
要分析的网址:
用Chrome打开后,可以得到数据:

但在 PySpider 中,使用代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-04-15 14:56:12
# Project: DianpingChilrenEnglish
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
import copy
import time
import re
import csv
# import datetime
from datetime import datetime, timedelta
######################################################################
# Const
######################################################################
...
constCityListNamePattern = "cityList_%s_%s.json"
constMainCityFilename = "mainCityWithLevelList.json"
constUserAgentMacChrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
gHost = "http://www.dianping.com"
CategoryLevel1ParentChild = "ch70" # 全部分类->亲子
CategoryLevel2ChildEnglish = "g27762" # 幼儿教育 -> 幼儿外语
######################################################################
# Project Specific Functions
######################################################################
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
"User-Agent": constUserAgentMacChrome,
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/json",
"Origin": "http://www.dianping.com",
# "X-Requested-With": "XMLHttpRequest",
}
}
def on_start(self):
# self.init()
self.realStart()
def realStart(self):
...
# for debug
"""
eachMainCity={'cityAbbrCode': 'SUZ', 'cityAreaCode': '0512', 'cityEnName': 'suzhou', 'cityId': 6, 'cityLevel': 2, 'cityName': '苏州', 'cityOrderId': 4888, 'cityPyName': 'suzhou', 'gLat': 31.297779, 'gLng': 120.585586, 'provinceId': 10, 'currentNodeLevel': 2, 'totalRank': '9', 'cityLevelFloat': 1.5, 'provinceName': '江苏省'}
cityEnName=suzhou
childEnglishEntryUrl=http://www.dianping.com/suzhou/ch70/g27762
"""
childEnglishEntryUrl = "http://www.dianping.com/suzhou/ch70/g27762"
self.crawl(
childEnglishEntryUrl,
callback=self.childEnglishCallback
)
def childEnglishCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
respText = response.text
print("respText=%s" % respText)
#
#
for eachShop in response.doc('ul[class="shop-list"] li[data-shopid]').items():
print("eachShop=%s" % eachShop)
结果返回错误信息:
respText={"customData":{"requestCode":"c9847c945a1440d49460df748b757250","verifyUrl":"https://optimus-mtsi.meituan.c ... ot%3B,"imageUrl":"https://verify.meituan.com/v2/ ... ot%3B,"verifyPageUrl":"https://verify.meituan.com/v2/ ... ot%3B},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}

然后参考Chromet中看到的参数:

对于各种header,试着一一添加,终于找到了:
将 text/html 相关类型添加到接受:
# "Accept": "application/json, text/javascript, */*; q=0.01",
"Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
可以得到数据:

-》 前面提到的逻辑: 找个方法引用Chrome调试看到的所有重要参数:
添加后
,大多数情况下可以得到对应的返回数据。
java爬虫抓取动态网页(就是自动爬起来()所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-12 04:06
前言:写这篇文章之前,主要看了几个类似的爬虫写法。有的写在队列中,不是很直观,有的只有一个请求,然后页面解析。不会自动起床。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客网站()的所有链接。
算法简介
该程序在其思想中使用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入到集合中。在下一个循环中被遍历。
在具体实现中使用的是Map,key-value对就是链接以及是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,就说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们就把这个链接放到newMap中继续解析它,等等。这个页面被解析,oldMap中当前页面上的链接的值设置为true,表示已经被遍历了。最后,当整个oldMap没有遍历过的链接遍历完成后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。这次循环没有生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
两个方案的实现
上面的相关思路已经解释的很清楚了,代码中关键的地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn");
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三个最终测试结果
PS:它的实际递归不是很好,因为网站页面多的话,程序运行时间长了内存消耗会很大,但是因为我的博客网站没有很多页面,所以效果还可以 查看全部
java爬虫抓取动态网页(就是自动爬起来()所有链接())
前言:写这篇文章之前,主要看了几个类似的爬虫写法。有的写在队列中,不是很直观,有的只有一个请求,然后页面解析。不会自动起床。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客网站()的所有链接。
算法简介
该程序在其思想中使用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入到集合中。在下一个循环中被遍历。
在具体实现中使用的是Map,key-value对就是链接以及是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,就说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们就把这个链接放到newMap中继续解析它,等等。这个页面被解析,oldMap中当前页面上的链接的值设置为true,表示已经被遍历了。最后,当整个oldMap没有遍历过的链接遍历完成后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。这次循环没有生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
两个方案的实现
上面的相关思路已经解释的很清楚了,代码中关键的地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn";);
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三个最终测试结果
PS:它的实际递归不是很好,因为网站页面多的话,程序运行时间长了内存消耗会很大,但是因为我的博客网站没有很多页面,所以效果还可以
java爬虫抓取动态网页( 2017年11月30日京东手机搜索页面的信息汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-09 16:06
2017年11月30日京东手机搜索页面的信息汇总)
Java爬虫在京东上实现抓取手机搜索页面。 HttpClient+Jsoup
更新时间:2017年11月30日09:42:41 作者:杂兵2号
下面小编给大家分享一个Java爬虫爬取京东上的手机搜索页面。 HttpCliient+Jsoup,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
1、需求和配置
要求:抓取京东手机搜索页面信息,记录每款手机的名称、价格、评论数等,形成数据表,可用于实际分析。
使用Maven项目,log4j记录日志,日志只导出到控制台。
Maven依赖如下(pom.xml)
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.11.2
log4j
log4j
1.2.17
log4j配置(log4j.properties),将INFO及以上级别信息输出到控制台,无需单独设置输出文件。
log4j.rootLogger=INFO, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析及代码
2.1 需求分析
第一步是建立客户端和服务器的连接,通过URL获取网页上的HTML内容。
第二步是解析HTML内容,获取需要的元素。
第三步是将HTML内容输出到本地文本文档,其他数据分析软件可以直接分析。
基于以上分析,建立了四个类,GetHTML(用于获取网站HTML)、ParseHTML(用于解析HTML)、WriteTo(用于输出文档)和Maincontrol(主控)。类说明。为了使代码尽可能简洁,所有异常都直接从方法中抛出,没有使用catch。
2.2Code
2.2.1GetHTML 类
该类收录两个方法:getH(String url)、urlControl(String baseurl, int page),分别用于获取网页的HTML和控制URL。由于本次抓取的网页内容只是京东某类商品的搜索结果,因此无需遍历页面上的所有网址。只需要观察翻页时URL的变化,就可以引入规则了。只暴露了 urlControl 方法,在类中设置了私有日志属性: private static Logger log = Logger.getLogger(getHTML.class);用于日志记录。
getH(String url),获取单个 URL 的 HTML 内容。
urlControl(String baseurl, int page),设置循环访问多个页面的数据。回顾一下元素,我们可以看出京东搜索页面的变化其实是奇数变化。
再次点击后查看URL的变化,可以发现实际变化的是page属性的值。拼接很容易得到下一个网页的地址。
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML 类
这一步需要通过review元素确定需要爬取的标签,然后通过Jsoup中的CSS选择器获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo 类
此类中的方法将解析的内容写入本地文件。只是简单的 IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl 类
主控程序,写基地址和要获取的页数。调用getHTML类中的urlControl方法抓取页面。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search%3 ... ot%3B
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
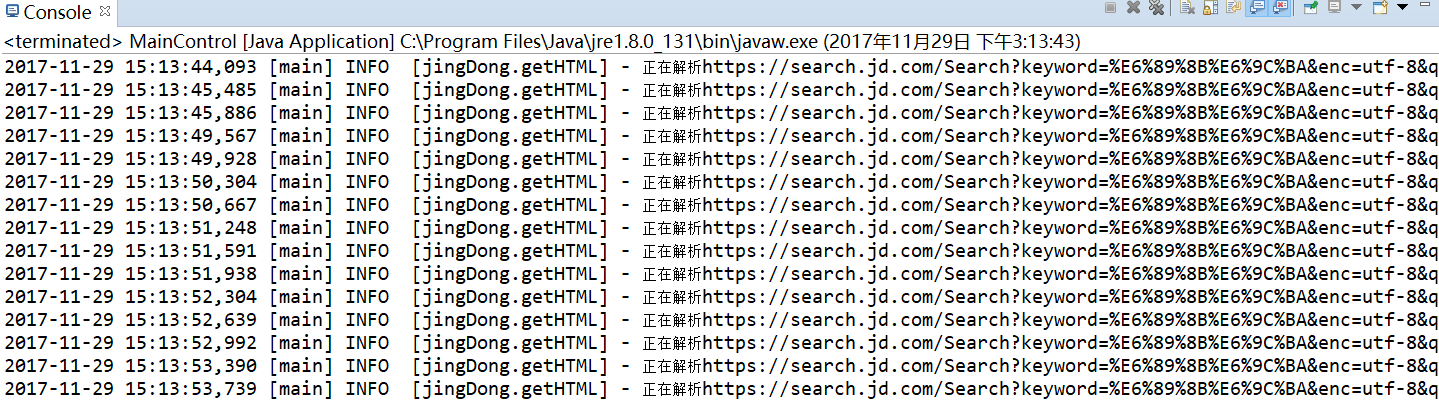
抓取 20 页。
3.1 控制台输出
3.2文档输出
可以直接用Excel打开,分隔符是制表符。列是产品编号、名称、价格和评论数量。
4、小结 查看全部
java爬虫抓取动态网页(
2017年11月30日京东手机搜索页面的信息汇总)
Java爬虫在京东上实现抓取手机搜索页面。 HttpClient+Jsoup
更新时间:2017年11月30日09:42:41 作者:杂兵2号
下面小编给大家分享一个Java爬虫爬取京东上的手机搜索页面。 HttpCliient+Jsoup,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
1、需求和配置
要求:抓取京东手机搜索页面信息,记录每款手机的名称、价格、评论数等,形成数据表,可用于实际分析。

使用Maven项目,log4j记录日志,日志只导出到控制台。
Maven依赖如下(pom.xml)
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.11.2
log4j
log4j
1.2.17
log4j配置(log4j.properties),将INFO及以上级别信息输出到控制台,无需单独设置输出文件。
log4j.rootLogger=INFO, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析及代码
2.1 需求分析
第一步是建立客户端和服务器的连接,通过URL获取网页上的HTML内容。
第二步是解析HTML内容,获取需要的元素。
第三步是将HTML内容输出到本地文本文档,其他数据分析软件可以直接分析。
基于以上分析,建立了四个类,GetHTML(用于获取网站HTML)、ParseHTML(用于解析HTML)、WriteTo(用于输出文档)和Maincontrol(主控)。类说明。为了使代码尽可能简洁,所有异常都直接从方法中抛出,没有使用catch。
2.2Code
2.2.1GetHTML 类
该类收录两个方法:getH(String url)、urlControl(String baseurl, int page),分别用于获取网页的HTML和控制URL。由于本次抓取的网页内容只是京东某类商品的搜索结果,因此无需遍历页面上的所有网址。只需要观察翻页时URL的变化,就可以引入规则了。只暴露了 urlControl 方法,在类中设置了私有日志属性: private static Logger log = Logger.getLogger(getHTML.class);用于日志记录。
getH(String url),获取单个 URL 的 HTML 内容。
urlControl(String baseurl, int page),设置循环访问多个页面的数据。回顾一下元素,我们可以看出京东搜索页面的变化其实是奇数变化。
再次点击后查看URL的变化,可以发现实际变化的是page属性的值。拼接很容易得到下一个网页的地址。
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML 类
这一步需要通过review元素确定需要爬取的标签,然后通过Jsoup中的CSS选择器获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo 类
此类中的方法将解析的内容写入本地文件。只是简单的 IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl 类
主控程序,写基地址和要获取的页数。调用getHTML类中的urlControl方法抓取页面。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search%3 ... ot%3B
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
抓取 20 页。
3.1 控制台输出
3.2文档输出
可以直接用Excel打开,分隔符是制表符。列是产品编号、名称、价格和评论数量。

4、小结
java爬虫抓取动态网页(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-09-13 18:07
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫。有需要的小伙伴快来领取吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的可扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。 Teo 线程为每个 URL 执行 URL 处理器链。 URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备,比如延迟和重新处理处理,否决后续操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3)提取链:提取完成后,提取感兴趣的HTML和JavaScript,通常会有新的URL需要爬取。
(4)写链:存储抓取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)Submission chain:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外DNS缓存信息也会更新.
Heritrix 系统框架图
heritrix处理一个url的过程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 使用
1.Visualization 展示页面合集
2.下载页面到本地磁盘离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用 Java 或 Javascript 开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
WebLech 是一个强大的网站下载和镜像免费开源工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特点:
1)开源,免费
2)代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4)可以维护网页之间的链接信息
5) 可配置性强:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络。 URL 优先,以便首先抓取我们感兴趣或对我们重要的网页。可以记录断点时程序的状态,重新启动时可以从上次继续爬行。
四、Arale
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。你可以用它来检查网站错误(内部服务器错误等),网站内外链接检查,分析网站的结构(你可以创建一个网站Map),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。 JSpider的执行格式如下:
jspider [配置名称]
URL中必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。 JSpider的默认配置类型很少,用处不大。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以使用它:
检查您的网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的网站 结构(创建站点地图,...)
下载并修复网站
通过编写JSpider插件实现任何功能。
项目主页:
六、spindle
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
七、Arachnid
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,就可以开发出一个简单的网络蜘蛛,可以在网站上使用每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、JoBo
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
什么是1、snoics-reptile?
纯Java开发,是一个用来抓取网站镜像的工具。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站所有资源都是本地抓取的,包括网页和各类文件,如图片、flash、mp3、zip、rar、exe 等文件。整个网站可以原封不动的转移到硬盘上,保持原来的网站结构准确不变。只需将抓到的网站放到web服务器(如Apache)中即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile?
因为在爬取的过程中经常会出现一些错误的文件,很多由javascript控制的URL没有办法正确解析,snoics-reptile为特殊的URL提供了外部接口和配置文件。 ,可以自由扩展外部提供的接口,通过配置文件注入的方式,基本可以实现对所有网页的正确分析和抓取。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。 Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取能力。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了方便数据的操作和重用,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:net
十二、ItSucks
ItSucks 是 Java 网络爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和Swing GUI操作界面。
特点:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。监听器可以在解析过程中添加,也可以在页面加载前后添加。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。哪里:
shouldVisit是判断当前的URL是否应该被抓取(访问);
visit是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
另外,WebCrawler还有一些其他的方法可以覆盖,其方法的命名规则与Android的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据; onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
许可证 查看全部
java爬虫抓取动态网页(19款Java开源Web爬虫需要的小伙伴们赶快收藏吧)
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。其他不常用的名称包括蚂蚁、自动索引、模拟器或蠕虫。
今天给大家介绍19款Java开源网络爬虫。有需要的小伙伴快来领取吧。
一、Heritrix
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。其最突出的特点是良好的可扩展性,方便用户实现自己的爬取逻辑。
Heritrix 是一个“档案爬虫”——获取网站内容的完整、准确、深层副本。包括获取图片等非文字内容。抓取并存储相关内容。不拒绝任何内容,不对页面进行任何内容修改。重新抓取不会替换同一 URL 的前一次抓取。爬虫主要通过Web用户界面启动、监控和调整,可以灵活定义获取URL。
Heritrix 是一个多线程爬取的爬虫。主线程将任务分配给 Teo 线程(处理线程),每个 Teo 线程一次处理一个 URL。 Teo 线程为每个 URL 执行 URL 处理器链。 URL 处理器链包括以下五个处理步骤。
(1)预取链:主要是做一些准备,比如延迟和重新处理处理,否决后续操作。
(2)提取链:主要是下载网页,进行DNS转换,填写请求和响应表。
(3)提取链:提取完成后,提取感兴趣的HTML和JavaScript,通常会有新的URL需要爬取。
(4)写链:存储抓取结果,这一步可以直接索引全文。Heritrix提供了ARCWriterProcessor实现,将下载结果保存为ARC格式。
(5)Submission chain:对这个URL相关的操作做最后的处理。检查哪些新提取的URL在爬取范围内,然后将这些URL提交给Frontier。另外DNS缓存信息也会更新.
Heritrix 系统框架图
heritrix处理一个url的过程
二、WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX类包两部分组成。
WebSPHINX 使用
1.Visualization 展示页面合集
2.下载页面到本地磁盘离线浏览
3.将所有页面合并为一个页面进行浏览或打印
4.根据特定规则从页面中提取文本字符串
5.使用 Java 或 Javascript 开发自定义爬虫
详细介绍可见>>>
三、WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
WebLech 是一个强大的网站下载和镜像免费开源工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
这个爬虫很简单,如果你是初学者,如果你想写一个爬虫,可以作为入门参考。所以我选择从这个爬虫开始我的研究。如果你只是做要求不高的应用,也可以试试。如果你想找到一个强大的,不要在 WebLech 上浪费时间。
项目主页:
特点:
1)开源,免费
2)代码纯Java编写,可以在任何支持Java的平台上使用
3)支持多线程下载网页
4)可以维护网页之间的链接信息
5) 可配置性强:可以自定义深度优先或宽度优先的抓取网页,带有URL过滤器,这样就可以根据需要抓取单个Web服务器、单个目录或抓取整个WWW网络。 URL 优先,以便首先抓取我们感兴趣或对我们重要的网页。可以记录断点时程序的状态,重新启动时可以从上次继续爬行。
四、Arale
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
五、JSpider
JSpider:是一个完全可配置和可定制的 Web Spider 引擎。你可以用它来检查网站错误(内部服务器错误等),网站内外链接检查,分析网站的结构(你可以创建一个网站Map),下载整个网站,你也可以写一个JSpider插件来扩展你需要的功能。
Spider 是一个用 Java 实现的 WebSpider。 JSpider的执行格式如下:
jspider [配置名称]
URL中必须加上协议名,如:,否则会报错。如果省略ConfigName,则采用默认配置。
JSpider的行为具体由配置文件配置,比如使用什么插件,结果存储方式等设置在conf\[ConfigName]\目录下。 JSpider的默认配置类型很少,用处不大。但是JSpider非常容易扩展,你可以用它来开发强大的网络爬虫和数据分析工具。为此,您需要深入了解JSpider的原理,然后根据需要开发插件并编写配置文件。
蜘蛛是:
高度可配置和可定制的网络爬虫
在 LGPL 开源许可下开发
100% 纯 Java 实现
您可以使用它:
检查您的网站 错误(内部服务器错误,...)
传出或内部链接检查
分析您的网站 结构(创建站点地图,...)
下载并修复网站
通过编写JSpider插件实现任何功能。
项目主页:
六、spindle
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
七、Arachnid
Arachnid 是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,就可以开发出一个简单的网络蜘蛛,可以在网站上使用每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
项目主页:
八、LARM
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
项目主页:
九、JoBo
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
十、snoics-reptile
什么是1、snoics-reptile?
纯Java开发,是一个用来抓取网站镜像的工具。可以使用配置文件中提供的URL入口获取所有可以通过浏览器GET获取的网站所有资源都是本地抓取的,包括网页和各类文件,如图片、flash、mp3、zip、rar、exe 等文件。整个网站可以原封不动的转移到硬盘上,保持原来的网站结构准确不变。只需将抓到的网站放到web服务器(如Apache)中即可实现完整的网站镜像。
2、既然还有其他类似的软件,为什么还要开发snooics-reptile?
因为在爬取的过程中经常会出现一些错误的文件,很多由javascript控制的URL没有办法正确解析,snoics-reptile为特殊的URL提供了外部接口和配置文件。 ,可以自由扩展外部提供的接口,通过配置文件注入的方式,基本可以实现对所有网页的正确分析和抓取。
项目主页:
十一、Web-Harvest
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以[url=https://www.ucaiyun.com/]采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest主要使用XSLT、XQuery、正则表达式等技术来实现text/xml的操作。
Web-Harvest 是一个用 Java 编写的开源 Web 数据提取工具。它提供了一种从所需页面中提取有用数据的方法。为了实现这个目标,您可能需要使用XSLT、XQuery、正则表达式等相关技术来操作text/xml。 Web-Harvest 主要关注基于 HMLT/XML 的页面内容,目前占大多数。另一方面,它可以通过编写自己的 Java 方法轻松扩展其提取能力。
Web-Harvest 的主要目的是增强现有数据提取技术的应用。它的目标不是创建一种新方法,而是提供一种更好地使用和组合现有方法的方法。它提供了一个处理器集来处理数据和控制流。每个处理器都被看作一个函数,它有参数,执行后返回结果。而且,将处理组合成流水线的形式,从而可以以链式的形式执行。此外,为了方便数据的操作和重用,Web-Harvest 还提供了上下变量来存储声明的变量。
启动web-harvest,可以直接双击jar包运行,但是这种方式不能指定web-harvest java虚拟机的大小。第二种方法是切到cmd下的web-harvest目录,输入命令“java -jar -Xms400m webharvest_all_2.jar”启动,设置java虚拟机大小为400M。
项目主页:net
十二、ItSucks
ItSucks 是 Java 网络爬虫的开源项目。可灵活定制,支持下载模板和正则表达式定义下载规则。提供控制台和Swing GUI操作界面。
特点:
项目主页:
十三、智能简单的网络爬虫
Smart and Simple Web Crawler 是一个网络爬虫框架。集成 Lucene 支持。爬虫可以从单个链接或一组链接开始,提供两种遍历方式:最大迭代和最大深度。您可以设置过滤器来限制爬回的链接。默认提供了三个过滤器 ServerFilter、BeginningPathFilter 和 RegularExpressionFilter。这三个过滤器可以与 AND、OR 和 NOT 组合使用。监听器可以在解析过程中添加,也可以在页面加载前后添加。
十四、Crawler4j
crawler4j 是一个用 Java 实现的开源网络爬虫。提供简单易用的界面,您可以在几分钟内创建一个多线程的网络爬虫。
crawler4j的使用主要分为两步:
实现一个继承自WebCrawler的爬虫类;通过调用 CrawlController 实现的爬虫类。
WebCrawler 是一个抽象类,继承它必须实现两个方法:shouldVisit 和visit。哪里:
shouldVisit是判断当前的URL是否应该被抓取(访问);
visit是抓取URL指向的页面的数据,传入的参数是网页所有数据的封装对象Page。
另外,WebCrawler还有一些其他的方法可以覆盖,其方法的命名规则与Android的命名规则类似。比如getMyLocalData方法可以返回WebCrawler中的数据; onBeforeExit 方法会在 WebCrawler 运行结束前被调用,可以执行一些资源释放等任务。
许可证
java爬虫抓取动态网页(金融行业需要和技术面等相关信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-09-13 18:06
前言
在现代社会,有效的信息对于人们来说就像氧气一样不可或缺。互联网使采集有效信息变得更加容易。当您上网时,网络爬虫也会在互联网上穿梭,自动采集互联网上的有用信息。
自动采集和过滤信息的网络爬虫增强了有效信息的流动,使我们能够更有效地获取信息。随着网络上出现的信息越来越多,网络爬虫变得越来越有用。
所有行业都离不开采集和信息的处理。例如,农业需要捕捉天气数据和农产品市场数据,以实现精准农业。机械行业需要抓取零件和图纸信息作为设计参考。制药行业需要获取有关某些疾病治疗的信息。金融业需要捕捉上市公司的基本面和技术面,作为股市涨跌的参考。比如太钢生产圆珠笔,带动其股票“太钢不锈钢”的上涨。此外,金融业还需要捕捉投资者对市场的参与,作为判断市场大势的依据。
每个人都可以利用网络爬虫技术来获得更好的生存策略,避免一些不好的情况,让自己的生活越来越幸福。例如,网络爬虫可以采集二甲双胍等可能抗衰老的药物,让人们过上更健康的生活。
本书的大部分内容来自于搜索引擎、自然语言处理和金融领域的项目开发和教学实践。感谢开源软件的开发者们的无私工作,丰富了本书的内容。
本书从讲解开发网络爬虫所需的Java语法开始,然后介绍爬虫的基本原理。通过对优先队列、广度优先搜索等内容的介绍,引导读者入门,然后根据当前云计算热潮,重点介绍云计算的相关内容及其在爬虫中的应用,以及信息提取、链接分析等内容。接下来介绍爬虫的web数据挖掘等。为了让读者更深入地了解爬虫的实际应用,最后一章是案例分析。本书相关代码可在读者QQ群(294737705))的共享文件中找到。
本书适合需要实现网络爬虫的程序员。对信息检索等相关领域的研究人员也有一定的参考价值。同时,猎兔搜索技术团队开发了专门的培训课程和基于本书的培训课程。商业软件。目前的一些网络爬虫软件还有很多功能有待完善。作者真诚地希望通过本书,将读者带入网络爬虫开发的大门,结识更多的朋友。
感谢早期合著者、合作伙伴、员工、学生和家人的支持。他们为我们提供了良好的工作基础,这是一个持久可用的工作基础。未来,我们希望我们的网络爬虫代码和技术能像植物一样快速成长。
崔志杰、史天英、张继宏、张晋伟、刘宇、何树琴、任彤彤、高丹丹、许有峰、孙宽参与了本书的编写。我想表达我的感激之情。
罗刚
2017 年 2 月 查看全部
java爬虫抓取动态网页(金融行业需要和技术面等相关信息(组图))
前言
在现代社会,有效的信息对于人们来说就像氧气一样不可或缺。互联网使采集有效信息变得更加容易。当您上网时,网络爬虫也会在互联网上穿梭,自动采集互联网上的有用信息。
自动采集和过滤信息的网络爬虫增强了有效信息的流动,使我们能够更有效地获取信息。随着网络上出现的信息越来越多,网络爬虫变得越来越有用。
所有行业都离不开采集和信息的处理。例如,农业需要捕捉天气数据和农产品市场数据,以实现精准农业。机械行业需要抓取零件和图纸信息作为设计参考。制药行业需要获取有关某些疾病治疗的信息。金融业需要捕捉上市公司的基本面和技术面,作为股市涨跌的参考。比如太钢生产圆珠笔,带动其股票“太钢不锈钢”的上涨。此外,金融业还需要捕捉投资者对市场的参与,作为判断市场大势的依据。
每个人都可以利用网络爬虫技术来获得更好的生存策略,避免一些不好的情况,让自己的生活越来越幸福。例如,网络爬虫可以采集二甲双胍等可能抗衰老的药物,让人们过上更健康的生活。
本书的大部分内容来自于搜索引擎、自然语言处理和金融领域的项目开发和教学实践。感谢开源软件的开发者们的无私工作,丰富了本书的内容。
本书从讲解开发网络爬虫所需的Java语法开始,然后介绍爬虫的基本原理。通过对优先队列、广度优先搜索等内容的介绍,引导读者入门,然后根据当前云计算热潮,重点介绍云计算的相关内容及其在爬虫中的应用,以及信息提取、链接分析等内容。接下来介绍爬虫的web数据挖掘等。为了让读者更深入地了解爬虫的实际应用,最后一章是案例分析。本书相关代码可在读者QQ群(294737705))的共享文件中找到。
本书适合需要实现网络爬虫的程序员。对信息检索等相关领域的研究人员也有一定的参考价值。同时,猎兔搜索技术团队开发了专门的培训课程和基于本书的培训课程。商业软件。目前的一些网络爬虫软件还有很多功能有待完善。作者真诚地希望通过本书,将读者带入网络爬虫开发的大门,结识更多的朋友。
感谢早期合著者、合作伙伴、员工、学生和家人的支持。他们为我们提供了良好的工作基础,这是一个持久可用的工作基础。未来,我们希望我们的网络爬虫代码和技术能像植物一样快速成长。
崔志杰、史天英、张继宏、张晋伟、刘宇、何树琴、任彤彤、高丹丹、许有峰、孙宽参与了本书的编写。我想表达我的感激之情。
罗刚
2017 年 2 月
java爬虫抓取动态网页( 本节主要讲述src的基本概念。网页get和动态页面的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-13 18:05
本节主要讲述src的基本概念。网页get和动态页面的区别)
HTML 基础
本节主要介绍HTML的基本概念。要抓取一个网页,首先要对网页有一个基本的了解。网页基础知识可以访问w3c学校学习
1. 页面构成
一个页面通常由css、js和html元素组成,其中css定义页面的样式,js负责渲染动态页面,html元素构成静态页面。常见的html元素包括文本元素、超链接(一般形式a href='#)'、图片(一般形式img src='img.png'); css一般在页面中以div class='demo'的形式来引用; js以javascript标签的形式引用。
常用的查看页面元素的工具是Chrome浏览器的“查看元素”功能。一个典型的页面元素如下:
可以看出页面元素是通过各种标签来组织的。
2.静态和动态页面
Internet 上的第一个网页是静态 html 页面。页面的元素比较简单,展示了一些文字、图片等信息,但是随着js、ajax等技术的发展,网页逐渐变得动态化了。动态页面可以提供更好的用户体验,但增加了抓取的难度。对于动态页面,Chrome下右键“查看网页源代码”和右键“查看元素”看到的页面结构是不同的。 ‘review element’可以获取动态加载的页面。爬取时需要注意静态页面和动态页面的区别。
3. 获取和发布请求
简单的说,一般访问一个网页是get请求,需要向服务器发送数据时使用post请求。在爬虫中使用get请求获取网页信息,向服务器发送数据时使用post请求(如登录和提交)。 查看全部
java爬虫抓取动态网页(
本节主要讲述src的基本概念。网页get和动态页面的区别)
HTML 基础
本节主要介绍HTML的基本概念。要抓取一个网页,首先要对网页有一个基本的了解。网页基础知识可以访问w3c学校学习
1. 页面构成
一个页面通常由css、js和html元素组成,其中css定义页面的样式,js负责渲染动态页面,html元素构成静态页面。常见的html元素包括文本元素、超链接(一般形式a href='#)'、图片(一般形式img src='img.png'); css一般在页面中以div class='demo'的形式来引用; js以javascript标签的形式引用。
常用的查看页面元素的工具是Chrome浏览器的“查看元素”功能。一个典型的页面元素如下:
可以看出页面元素是通过各种标签来组织的。
2.静态和动态页面
Internet 上的第一个网页是静态 html 页面。页面的元素比较简单,展示了一些文字、图片等信息,但是随着js、ajax等技术的发展,网页逐渐变得动态化了。动态页面可以提供更好的用户体验,但增加了抓取的难度。对于动态页面,Chrome下右键“查看网页源代码”和右键“查看元素”看到的页面结构是不同的。 ‘review element’可以获取动态加载的页面。爬取时需要注意静态页面和动态页面的区别。
3. 获取和发布请求
简单的说,一般访问一个网页是get请求,需要向服务器发送数据时使用post请求。在爬虫中使用get请求获取网页信息,向服务器发送数据时使用post请求(如登录和提交)。
java爬虫抓取动态网页(java程序中获取后台js完后的完整页面是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-09-13 04:17
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上说HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,还是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据? 查看全部
java爬虫抓取动态网页(java程序中获取后台js完后的完整页面是什么?)
很多网站使用js或者jquery来生成数据。后台获取数据后,使用 document.write() 或 ("#id").html="" 写入页面。这时候用浏览器看源码是看不到数据的。
HttpClient 不起作用。看网上说HtmlUnit,说是加载后台js后可以得到完整的页面,但是我按照文章写的,还是不行。一般代码是这样写的:
String url = "http://xinjinqiao.tprtc.com/ad ... 3B%3B
try {
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_10);
//设置webClient的相关参数
webClient.getOptions().setJavaScriptEnabled(true);
webClient.getOptions().setCssEnabled(false);
webClient.setAjaxController(new NicelyResynchronizingAjaxController());
//webClient.getOptions().setTimeout(50000);
webClient.getOptions().setThrowExceptionOnScriptError(false);
//模拟浏览器打开一个目标网址
HtmlPage rootPage = webClient.getPage(url);
System.out.println("为了获取js执行的数据 线程开始沉睡等待");
Thread.sleep(3000);//主要是这个线程的等待 因为js加载也是需要时间的
System.out.println("线程结束沉睡");
String html = rootPage.asText();
System.out.println(html);
} catch (Exception e) {
}
事实上,它根本不起作用。
典型的是这个链接的页面。 java程序中如何获取数据?
java爬虫抓取动态网页( Java爬虫爬取网页内容网页内容方法:用apache提供的包)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-12 04:09
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则爬取网页上的信息,通常是在爬取一些网址之后,再将这些网址放入队列中反复搜索。
2、Java 爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,一直循环直到所有网站网页都被抓取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
3、Java 爬虫方法抓取网页内容:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。可以用代码来用~更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。) 查看全部
java爬虫抓取动态网页(
Java爬虫爬取网页内容网页内容方法:用apache提供的包)
1、网络爬虫
按照一定的规则爬取网页上的信息,通常是在爬取一些网址之后,再将这些网址放入队列中反复搜索。
2、Java 爬虫网页
对于网页的内容,找到网页中的其他链接地址,然后通过这些链接地址找到下一个网页,一直循环直到所有网站网页都被抓取。如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理来抓取互联网上的所有网页。
3、Java 爬虫方法抓取网页内容:使用apache提供的包
// commons-httpclient-3.1.jar
// commons-logging-1.0.4.jar
public static String createhttpClient(String url, String param) {
HttpClient client = new HttpClient();
String response = null ;
String keyword = null ;
PostMethod postMethod = new PostMethod(url);
// try {
// if (param != null)
// keyword = new String(param.getBytes("gb2312"), "ISO-8859-1");
// } catch (UnsupportedEncodingException e1) {
// // TODO Auto-generated catch block
// e1.printStackTrace();
// }
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
// // 将表单的值放入postMethod中
// postMethod.setRequestBody(data);
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
try {
int statusCode = client.executeMethod(postMethod);
response = new String(postMethod.getResponseBodyAsString()
.getBytes( "ISO-8859-1" ), "gb2312" );
//这里要注意下 gb2312要和你抓取网页的编码要一样
String p = response.replaceAll( "//&[a-zA-Z]{1,10};" , "" )
.replaceAll( "]*>" , "" ); //去掉网页中带有html语言的标签
System.out.println(p);
} catch (Exception e) {
e.printStackTrace();
}
return response;
}
在Java爬虫中使用apache提供的包对网页内容进行爬取非常方便。可以用代码来用~更多java学习推荐:java教程。
(推荐操作系统:win7系统,java10版本,DELL G3电脑。)
java爬虫抓取动态网页(Python可以运用selenium+scrapy来抓取动态网页的信息吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-12 04:08
)
R 语言是一种强大的数据分析工具。还有很多方便的封装例子Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,就需要下载对应版本的浏览器驱动chormedriver。
(下载地址,比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url 查看全部
java爬虫抓取动态网页(Python可以运用selenium+scrapy来抓取动态网页的信息吗
)
R 语言是一种强大的数据分析工具。还有很多方便的封装例子Rcurl和rvest,用于数据采集,满足基本需求。 知乎上已经有很多文章来介绍他们的用途了。
但是,当我尝试爬取拉勾网的数据时,发现没有抓取到信息,而且源代码没有对应右键review元素,这让我很困扰。在网上搜索了相关问题,发现这是一个基于AJAX的动态网页,不同于静态网页。
AJAX AJAX 代表“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),指的是一种用于创建交互式 Web 应用程序的 Web 开发技术。
简单来说,网页通过异步传输获取页面信息。以拉勾网为例:
点击右下角下一页后,页面内容发生了变化,但网址没有变化。对爬虫的影响是无法简单地使用Rcurl获取想要的信息。
查找相关资料,了解到Python可以使用selenium+scrapy来抓取动态网页。
Selenium(浏览器自动化测试框架)Selenium 是一种用于 Web 应用程序测试的工具。 Selenium 测试直接在浏览器中运行,就像真实用户操作一样。
无独有偶,作为开源语言,R语言也为类似的操作开发了相应的Rwebdriver包。
本文基于Rwebdriver包抓取拉勾网信息。
前期准备
先下载selenium.3.4。 (下载链接)
要运行selenium,需要java并配置环境变量。 (不明白的请戳传送门)
那么如果你的浏览器和我一样是chorme,就需要下载对应版本的浏览器驱动chormedriver。
(下载地址,比如我是V59,对应的下载就近2.31)
Chromedriver可以放在chorme的安装根目录下,路径也设置为系统路径。
(比如我把chromedriver放在"C:\Program Files (x86)\Google\Chrome\Application\",所以我也把path设置为path)
最后在selenium所在根目录打开cmd,输入“java -jar selenium-server-standalone-3.4.0.jar”启动服务。
(每次开启selenium服务都需要,所以可以写个bat)
当出现“Selenium Server is up and running”时,表示它开始运行了。
R 语言代码部分
需要加载的包
library(RCurl)# 抓取数据
library(XML)# 解析网页
library(stringr)# 字符串处理
library(dplyr)# 调用%>%管道
library(Rwebdriver)# 爬取动态网页
Rwebdriver包需要通过调用devtools从github下载:
devtools::install_github(repo = "Rwebdriver", username = "crubba")
提供主要的浏览器操作功能:
start_session(root = NULL, browser = "firefox",
javascriptEnabled = TRUE, takesScreenshot = TRUE,
handlesAlerts = TRUE, databaseEnabled = TRUE,
cssSelectorsEnabled = TRUE) # 打开浏览器
post.url(url = NULL) # 打开网页
page_refresh() # 刷新网页
page_back() # 网页后退
page_forward() # 网页前进
page_source() # 获得当前页面信息
element_xpath_find() #通过XPATH找到所要部分
element_css_find() #通过CSS找到所要部分
element_click(ID = ID, times = 1, button = "left")# ID为所要点击的地方,times为点击次数,button="left"为左键点击
keys()#输入内容
element_clear()#清除内容
以下为爬行拉钩网示例,可根据需要修改:
<p>start_session(root = 'http://localhost:4444/wd/hub/',browser ="chrome")# 默认端口是4444,我的浏览器是chorme,如果使用火狐改成firefox
list_url
java爬虫抓取动态网页( 手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-12 04:06
手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
动态网页
相关内容:
【教程】教你使用工具(IE9中的F12)分析模拟登录网站(百度主页)的内部逻辑流程)
【记录】模拟登录google
【教程】如何抓取动态网页内容
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
待办事项:
找一个需要登录的网站,或者需要后续执行js加载的网页内容的例子,然后用抓包工具模拟登录,或者分析数据是如何加载的。
示例:Chrom分析某某大众点评页面获取店铺数据,然后使用PySpider实现代码并下载数据
这次通过一个例子,如何:
期间要注意:需要对各种参数稍作模拟才能得到数据,否则会出现各种错误
要分析的网址:
用Chrome打开后,可以得到数据:
但在 PySpider 中,使用代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-04-15 14:56:12
# Project: DianpingChilrenEnglish
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
import copy
import time
import re
import csv
# import datetime
from datetime import datetime, timedelta
######################################################################
# Const
######################################################################
...
constCityListNamePattern = "cityList_%s_%s.json"
constMainCityFilename = "mainCityWithLevelList.json"
constUserAgentMacChrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
gHost = "http://www.dianping.com"
CategoryLevel1ParentChild = "ch70" # 全部分类->亲子
CategoryLevel2ChildEnglish = "g27762" # 幼儿教育 -> 幼儿外语
######################################################################
# Project Specific Functions
######################################################################
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
"User-Agent": constUserAgentMacChrome,
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/json",
"Origin": "http://www.dianping.com",
# "X-Requested-With": "XMLHttpRequest",
}
}
def on_start(self):
# self.init()
self.realStart()
def realStart(self):
...
# for debug
"""
eachMainCity={'cityAbbrCode': 'SUZ', 'cityAreaCode': '0512', 'cityEnName': 'suzhou', 'cityId': 6, 'cityLevel': 2, 'cityName': '苏州', 'cityOrderId': 4888, 'cityPyName': 'suzhou', 'gLat': 31.297779, 'gLng': 120.585586, 'provinceId': 10, 'currentNodeLevel': 2, 'totalRank': '9', 'cityLevelFloat': 1.5, 'provinceName': '江苏省'}
cityEnName=suzhou
childEnglishEntryUrl=http://www.dianping.com/suzhou/ch70/g27762
"""
childEnglishEntryUrl = "http://www.dianping.com/suzhou/ch70/g27762"
self.crawl(
childEnglishEntryUrl,
callback=self.childEnglishCallback
)
def childEnglishCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
respText = response.text
print("respText=%s" % respText)
#
#
for eachShop in response.doc('ul[class="shop-list"] li[data-shopid]').items():
print("eachShop=%s" % eachShop)
结果返回错误信息:
respText={"customData":{"requestCode":"c9847c945a1440d49460df748b757250","verifyUrl":"https://optimus-mtsi.meituan.c ... ot%3B,"imageUrl":"https://verify.meituan.com/v2/ ... ot%3B,"verifyPageUrl":"https://verify.meituan.com/v2/ ... ot%3B},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}
然后参考Chromet中看到的参数:
对于各种header,试着一一添加,终于找到了:
将 text/html 相关类型添加到接受:
# "Accept": "application/json, text/javascript, */*; q=0.01",
"Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
可以得到数据:
-》 前面提到的逻辑: 找个方法引用Chrome调试看到的所有重要参数:
添加后
,大多数情况下可以得到对应的返回数据。 查看全部
java爬虫抓取动态网页(
手把手教你如何利用工具(IE9的F12)去分析模拟登陆google)
动态网页
相关内容:
【教程】教你使用工具(IE9中的F12)分析模拟登录网站(百度主页)的内部逻辑流程)
【记录】模拟登录google
【教程】如何抓取动态网页内容
【教程】以抓取网易博文近期读者信息为例,教你抓取动态网页内容。
待办事项:
找一个需要登录的网站,或者需要后续执行js加载的网页内容的例子,然后用抓包工具模拟登录,或者分析数据是如何加载的。
示例:Chrom分析某某大众点评页面获取店铺数据,然后使用PySpider实现代码并下载数据
这次通过一个例子,如何:
期间要注意:需要对各种参数稍作模拟才能得到数据,否则会出现各种错误
要分析的网址:
用Chrome打开后,可以得到数据:
但在 PySpider 中,使用代码:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2019-04-15 14:56:12
# Project: DianpingChilrenEnglish
from pyspider.libs.base_handler import *
import os
import json
import codecs
import base64
import gzip
import copy
import time
import re
import csv
# import datetime
from datetime import datetime, timedelta
######################################################################
# Const
######################################################################
...
constCityListNamePattern = "cityList_%s_%s.json"
constMainCityFilename = "mainCityWithLevelList.json"
constUserAgentMacChrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
gHost = "http://www.dianping.com"
CategoryLevel1ParentChild = "ch70" # 全部分类->亲子
CategoryLevel2ChildEnglish = "g27762" # 幼儿教育 -> 幼儿外语
######################################################################
# Project Specific Functions
######################################################################
######################################################################
# Main
######################################################################
class Handler(BaseHandler):
crawl_config = {
"connect_timeout": 100,
"timeout": 600,
"retries": 15,
"headers": {
"User-Agent": constUserAgentMacChrome,
"Accept": "application/json, text/javascript, */*; q=0.01",
"Content-Type": "application/json",
"Origin": "http://www.dianping.com",
# "X-Requested-With": "XMLHttpRequest",
}
}
def on_start(self):
# self.init()
self.realStart()
def realStart(self):
...
# for debug
"""
eachMainCity={'cityAbbrCode': 'SUZ', 'cityAreaCode': '0512', 'cityEnName': 'suzhou', 'cityId': 6, 'cityLevel': 2, 'cityName': '苏州', 'cityOrderId': 4888, 'cityPyName': 'suzhou', 'gLat': 31.297779, 'gLng': 120.585586, 'provinceId': 10, 'currentNodeLevel': 2, 'totalRank': '9', 'cityLevelFloat': 1.5, 'provinceName': '江苏省'}
cityEnName=suzhou
childEnglishEntryUrl=http://www.dianping.com/suzhou/ch70/g27762
"""
childEnglishEntryUrl = "http://www.dianping.com/suzhou/ch70/g27762"
self.crawl(
childEnglishEntryUrl,
callback=self.childEnglishCallback
)
def childEnglishCallback(self, response):
respUrl = response.url
print("respUrl=%s" % respUrl)
respText = response.text
print("respText=%s" % respText)
#
#
for eachShop in response.doc('ul[class="shop-list"] li[data-shopid]').items():
print("eachShop=%s" % eachShop)
结果返回错误信息:
respText={"customData":{"requestCode":"c9847c945a1440d49460df748b757250","verifyUrl":"https://optimus-mtsi.meituan.c ... ot%3B,"imageUrl":"https://verify.meituan.com/v2/ ... ot%3B,"verifyPageUrl":"https://verify.meituan.com/v2/ ... ot%3B},"code":406,"msg":"您的网络好像不太给力,请稍后再试"}
然后参考Chromet中看到的参数:
对于各种header,试着一一添加,终于找到了:
将 text/html 相关类型添加到接受:
# "Accept": "application/json, text/javascript, */*; q=0.01",
"Accept": "application/json, text/javascript, text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*; q=0.8,application/signed-exchange;v=b3",
可以得到数据:
-》 前面提到的逻辑: 找个方法引用Chrome调试看到的所有重要参数:
添加后
,大多数情况下可以得到对应的返回数据。
java爬虫抓取动态网页(就是自动爬起来()所有链接())
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-12 04:06
前言:写这篇文章之前,主要看了几个类似的爬虫写法。有的写在队列中,不是很直观,有的只有一个请求,然后页面解析。不会自动起床。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客网站()的所有链接。
算法简介
该程序在其思想中使用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入到集合中。在下一个循环中被遍历。
在具体实现中使用的是Map,key-value对就是链接以及是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,就说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们就把这个链接放到newMap中继续解析它,等等。这个页面被解析,oldMap中当前页面上的链接的值设置为true,表示已经被遍历了。最后,当整个oldMap没有遍历过的链接遍历完成后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。这次循环没有生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
两个方案的实现
上面的相关思路已经解释的很清楚了,代码中关键的地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn");
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三个最终测试结果
PS:它的实际递归不是很好,因为网站页面多的话,程序运行时间长了内存消耗会很大,但是因为我的博客网站没有很多页面,所以效果还可以 查看全部
java爬虫抓取动态网页(就是自动爬起来()所有链接())
前言:写这篇文章之前,主要看了几个类似的爬虫写法。有的写在队列中,不是很直观,有的只有一个请求,然后页面解析。不会自动起床。这也叫爬虫?因此,我根据自己的想法编写了一个简单的爬虫。测试用例是自动抓取我博客网站()的所有链接。
算法简介
该程序在其思想中使用了广度优先算法。它对没有被遍历过的链接一一发起GET请求,然后用正则表达式解析返回的页面,取出没有发现的新链接,加入到集合中。在下一个循环中被遍历。
在具体实现中使用的是Map,key-value对就是链接以及是否遍历。程序中用到了两个Map集合,分别是:oldMap和newMap。初始链接在oldMap中,然后请求oldMap中flag为false的链接,解析页面,使用常规规则检索标签下的链接。如果这个链接不在oldMap和newMap中,就说明这是一个新的链接,如果这个链接是我们需要获取的目标网站的链接,我们就把这个链接放到newMap中继续解析它,等等。这个页面被解析,oldMap中当前页面上的链接的值设置为true,表示已经被遍历了。最后,当整个oldMap没有遍历过的链接遍历完成后,如果发现newMap不为空,说明在这个循环中产生了新的链接。因此,将这些新链接添加到oldMap中并继续递归遍历,反之亦然。这次循环没有生成新链接。如果循环继续,则无法生成新链接。因为任务结束,返回链接集合oldMap
两个方案的实现
上面的相关思路已经解释的很清楚了,代码中关键的地方都有注释,这里就不多说了,代码如下:
package action;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class WebCrawlerDemo {
public static void main(String[] args) {
WebCrawlerDemo webCrawlerDemo = new WebCrawlerDemo();
webCrawlerDemo.myPrint("http://www.zifangsky.cn";);
}
public void myPrint(String baseUrl) {
Map oldMap = new LinkedHashMap(); // 存储链接-是否被遍历
// 键值对
String oldLinkHost = ""; //host
Pattern p = Pattern.compile("(https?://)?[^/\\s]*"); //比如:http://www.zifangsky.cn
Matcher m = p.matcher(baseUrl);
if (m.find()) {
oldLinkHost = m.group();
}
oldMap.put(baseUrl, false);
oldMap = crawlLinks(oldLinkHost, oldMap);
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("链接:" + mapping.getKey());
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法
* 对未遍历过的新链接不断发起GET请求,一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* @param oldLinkHost 域名,如:http://www.zifangsky.cn
* @param oldMap 待遍历的链接集合
*
* @return 返回所有抓取到的链接集合
* */
private Map crawlLinks(String oldLinkHost,
Map oldMap) {
Map newMap = new LinkedHashMap();
String oldLink = "";
for (Map.Entry mapping : oldMap.entrySet()) {
System.out.println("link:" + mapping.getKey() + "--------check:"
+ mapping.getValue());
// 如果没有被遍历过
if (!mapping.getValue()) {
oldLink = mapping.getKey();
// 发起GET请求
try {
URL url = new URL(oldLink);
HttpURLConnection connection = (HttpURLConnection) url
.openConnection();
connection.setRequestMethod("GET");
connection.setConnectTimeout(2000);
connection.setReadTimeout(2000);
if (connection.getResponseCode() == 200) {
InputStream inputStream = connection.getInputStream();
BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, "UTF-8"));
String line = "";
Pattern pattern = Pattern
.compile("(.+)</a>");
Matcher matcher = null;
while ((line = reader.readLine()) != null) {
matcher = pattern.matcher(line);
if (matcher.find()) {
String newLink = matcher.group(1).trim(); // 链接
// String title = matcher.group(3).trim(); //标题
// 判断获取到的链接是否以http开头
if (!newLink.startsWith("http")) {
if (newLink.startsWith("/"))
newLink = oldLinkHost + newLink;
else
newLink = oldLinkHost + "/" + newLink;
}
//去除链接末尾的 /
if(newLink.endsWith("/"))
newLink = newLink.substring(0, newLink.length() - 1);
//去重,并且丢弃其他网站的链接
if (!oldMap.containsKey(newLink)
&& !newMap.containsKey(newLink)
&& newLink.startsWith(oldLinkHost)) {
// System.out.println("temp2: " + newLink);
newMap.put(newLink, false);
}
}
}
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
oldMap.replace(oldLink, false, true);
}
}
//有新链接,继续遍历
if (!newMap.isEmpty()) {
oldMap.putAll(newMap);
oldMap.putAll(crawlLinks(oldLinkHost, oldMap)); //由于Map的特性,不会导致出现重复的键值对
}
return oldMap;
}
}
三个最终测试结果
PS:它的实际递归不是很好,因为网站页面多的话,程序运行时间长了内存消耗会很大,但是因为我的博客网站没有很多页面,所以效果还可以
java爬虫抓取动态网页( 2017年11月30日京东手机搜索页面的信息汇总)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-09 16:06
2017年11月30日京东手机搜索页面的信息汇总)
Java爬虫在京东上实现抓取手机搜索页面。 HttpClient+Jsoup
更新时间:2017年11月30日09:42:41 作者:杂兵2号
下面小编给大家分享一个Java爬虫爬取京东上的手机搜索页面。 HttpCliient+Jsoup,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
1、需求和配置
要求:抓取京东手机搜索页面信息,记录每款手机的名称、价格、评论数等,形成数据表,可用于实际分析。
使用Maven项目,log4j记录日志,日志只导出到控制台。
Maven依赖如下(pom.xml)
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.11.2
log4j
log4j
1.2.17
log4j配置(log4j.properties),将INFO及以上级别信息输出到控制台,无需单独设置输出文件。
log4j.rootLogger=INFO, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析及代码
2.1 需求分析
第一步是建立客户端和服务器的连接,通过URL获取网页上的HTML内容。
第二步是解析HTML内容,获取需要的元素。
第三步是将HTML内容输出到本地文本文档,其他数据分析软件可以直接分析。
基于以上分析,建立了四个类,GetHTML(用于获取网站HTML)、ParseHTML(用于解析HTML)、WriteTo(用于输出文档)和Maincontrol(主控)。类说明。为了使代码尽可能简洁,所有异常都直接从方法中抛出,没有使用catch。
2.2Code
2.2.1GetHTML 类
该类收录两个方法:getH(String url)、urlControl(String baseurl, int page),分别用于获取网页的HTML和控制URL。由于本次抓取的网页内容只是京东某类商品的搜索结果,因此无需遍历页面上的所有网址。只需要观察翻页时URL的变化,就可以引入规则了。只暴露了 urlControl 方法,在类中设置了私有日志属性: private static Logger log = Logger.getLogger(getHTML.class);用于日志记录。
getH(String url),获取单个 URL 的 HTML 内容。
urlControl(String baseurl, int page),设置循环访问多个页面的数据。回顾一下元素,我们可以看出京东搜索页面的变化其实是奇数变化。
再次点击后查看URL的变化,可以发现实际变化的是page属性的值。拼接很容易得到下一个网页的地址。
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML 类
这一步需要通过review元素确定需要爬取的标签,然后通过Jsoup中的CSS选择器获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo 类
此类中的方法将解析的内容写入本地文件。只是简单的 IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl 类
主控程序,写基地址和要获取的页数。调用getHTML类中的urlControl方法抓取页面。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search%3 ... ot%3B
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
抓取 20 页。
3.1 控制台输出
3.2文档输出
可以直接用Excel打开,分隔符是制表符。列是产品编号、名称、价格和评论数量。
4、小结 查看全部
java爬虫抓取动态网页(
2017年11月30日京东手机搜索页面的信息汇总)
Java爬虫在京东上实现抓取手机搜索页面。 HttpClient+Jsoup
更新时间:2017年11月30日09:42:41 作者:杂兵2号
下面小编给大家分享一个Java爬虫爬取京东上的手机搜索页面。 HttpCliient+Jsoup,有很好的参考价值,希望对大家有所帮助。跟着小编一起来看看
1、需求和配置
要求:抓取京东手机搜索页面信息,记录每款手机的名称、价格、评论数等,形成数据表,可用于实际分析。
使用Maven项目,log4j记录日志,日志只导出到控制台。
Maven依赖如下(pom.xml)
org.apache.httpcomponents
httpclient
4.5.3
org.jsoup
jsoup
1.11.2
log4j
log4j
1.2.17
log4j配置(log4j.properties),将INFO及以上级别信息输出到控制台,无需单独设置输出文件。
log4j.rootLogger=INFO, Console
#Console
log4j.appender.Console=org.apache.log4j.ConsoleAppender
log4j.appender.Console.layout=org.apache.log4j.PatternLayout
log4j.appender.Console.layout.ConversionPattern=%d [%t] %-5p [%c] - %m%n
2、需求分析及代码
2.1 需求分析
第一步是建立客户端和服务器的连接,通过URL获取网页上的HTML内容。
第二步是解析HTML内容,获取需要的元素。
第三步是将HTML内容输出到本地文本文档,其他数据分析软件可以直接分析。
基于以上分析,建立了四个类,GetHTML(用于获取网站HTML)、ParseHTML(用于解析HTML)、WriteTo(用于输出文档)和Maincontrol(主控)。类说明。为了使代码尽可能简洁,所有异常都直接从方法中抛出,没有使用catch。
2.2Code
2.2.1GetHTML 类
该类收录两个方法:getH(String url)、urlControl(String baseurl, int page),分别用于获取网页的HTML和控制URL。由于本次抓取的网页内容只是京东某类商品的搜索结果,因此无需遍历页面上的所有网址。只需要观察翻页时URL的变化,就可以引入规则了。只暴露了 urlControl 方法,在类中设置了私有日志属性: private static Logger log = Logger.getLogger(getHTML.class);用于日志记录。
getH(String url),获取单个 URL 的 HTML 内容。
urlControl(String baseurl, int page),设置循环访问多个页面的数据。回顾一下元素,我们可以看出京东搜索页面的变化其实是奇数变化。
再次点击后查看URL的变化,可以发现实际变化的是page属性的值。拼接很容易得到下一个网页的地址。
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=3&s=47&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=5&s=111&click=0
%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=7&s=162&click=0
整体代码:
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.apache.log4j.Logger;
public class getHTML {
//建立日志
private static Logger log = Logger.getLogger(getHTML.class);
private static String getH(String url) throws ClientProtocolException, IOException {
//控制台输出日志,这样每条访问的URL都可以在控制台上看到访问情况
log.info("正在解析" + url);
/*
* 以下内容为HttpClient建立连接的一般用法
* 使用HttpClient建立客户端
* 使用get方法访问指定URL
* 获得应答
* */
CloseableHttpClient client = HttpClients.createDefault();
HttpGet get = new HttpGet(url);
CloseableHttpResponse response = client.execute(get);
/*
* 以下内容为将HTML内容转化为String
* 获得应答体
* 将应答体转为String格式,此处使用了EntityUtils中的toString方法,编码格式设置为"utf-8"
* 完成后关闭客户端与应答
* */
HttpEntity entity = response.getEntity();
String content;
if (entity != null) {
content = EntityUtils.toString(entity, "utf-8");
client.close();
response.close();
return content;
} else
return null;
}
public static void urlControl(String baseurl, int page) throws ClientProtocolException, IOException {
//设置当前页count
int count = 1;
//如果当前页小于想要爬取的页数则执行
while (count < page) {
//实际访问的URL为不变的URL值拼接上URL变化的值
String u = baseurl + (2 * count - 1) + "&click=0";
//此处调用ParseHTML类中的方法对URL中的HTML页面进行处理,后面详细介绍该类
String content = ParseHTML.parse(getH(u)).toString();
//此处调用WriteTo类中的方法对解析出来的内容写入到本地,后面详细介绍该类
WriteTo.writeto(content);
count++;
}
}
}
2.2.2ParseHTML 类
这一步需要通过review元素确定需要爬取的标签,然后通过Jsoup中的CSS选择器获取。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class ParseHTML {
public static StringBuilder parse(String content)
{
//使用Jsoup中的parse方法对已经转换为String的HTML内容进行分析,返回值为Document类
Document doc = Jsoup.parse(content);
//使用选择器select对需要找的元素进行抓取,例如第一个select中选择的是ul标签中class属性等于gl-warp clearfix的内容
Elements ele = doc.select("ul[class = gl-warp clearfix]").select("li[class=gl-item]");
//设置一个容器,用于装各个属性
StringBuilder sb = new StringBuilder();
//通过上一个选择器可以获得整个页面中所有符合要求的元素,也即各款手机,下面则需要对每款手机进行遍历,获取其属性
for (Element e : ele) {
//此处对各个属性的获取参考了网上一篇爬取京东上内容的文章,应该有其他不同的写法
String id = e.attr("data-pid");
String mingzi = e.select("div[class = p-name p-name-type-2]").select("a").select("em").text();
String jiage = e.select("div[class=p-price]").select("strong").select("i").text();
String pinglun = e.select("div[class=p-commit]").select("strong").select("a").text();
//向容器中添加属性
sb.append(id+"\t");
sb.append(mingzi+"\t");
sb.append(jiage+"\t");
sb.append(pinglun+"\t");
sb.append("\r\n");
}
return sb;
}
}
2.2.3WriteTo 类
此类中的方法将解析的内容写入本地文件。只是简单的 IO。
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
public class WriteTo {
// 设置文件存放的位置
private static File f = new File("C:\\jingdong.txt");
public static void writeto(String content) throws IOException {
//使用续写的方式,以免覆盖前面写入的内容
BufferedWriter bw = new BufferedWriter(new FileWriter(f, true));
bw.append(content);
bw.flush();
bw.close();
}
}
2.2.4MainControl 类
主控程序,写基地址和要获取的页数。调用getHTML类中的urlControl方法抓取页面。
import java.io.IOException;
import org.apache.http.client.ClientProtocolException;
public class MainControl {
public static void main(String[] args) throws ClientProtocolException, IOException {
// TODO Auto-generated method stub
String baseurl = "https://search.jd.com/Search%3 ... ot%3B
+ "utf-8&qrst=1&rt=1&stop=1&vt=2&cid2=653&cid3=655&page=";
int page = 5;//设置爬取页数
getHTML.urlControl(baseurl, page);
}
}
3、爬取结果
抓取 20 页。
3.1 控制台输出
3.2文档输出
可以直接用Excel打开,分隔符是制表符。列是产品编号、名称、价格和评论数量。
4、小结

