
java爬虫抓取动态网页
java爬虫抓取动态网页(scrapy利器之scrapy+json的安装方法和使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-05 11:21
介绍
Scrapy是爬虫的利器,我就不多说了。
常见的爬虫结合js一般都是用来抓取网页的动态内容,就是通过操作js来获取渲染出来的内容。
现在大部分网站使用ajax+json来获取数据。所以大家都习惯了爬行,第一件事就是抓包,然后找模式抓数据。当然,有时接口加密算法非常复杂,短时间内难以破解。通过js抓取内容相对容易。这时候爬虫结合js可以更直接的达到目的。当然,数据抓取的效率没有直接抓取界面那么快。.
爬虫结合js
目前我知道的结合js的爬虫有以下3种。(如果有什么要补充的,请留言。)
selenium+webdriver(如firefox、chrome等)。这就要求你的系统有相应的浏览器,而且浏览器必须全程打开。说白了,通过浏览器看到的东西都能被抓到。一般在遇到特别复杂的验证码时,这种方法是很有必要的。当然,用浏览器爬取的效率可想而知。
硒+幻影。PhantomJS 是一个 WebKit,它的使用和 webdriver 是一样的,但是它不需要打开浏览器,可以直接在 Linux 服务器上运行,不需要 GUI,非常棒。
飞溅。与上述两种方法相比,具有以下优点。
splash 作为 js 渲染服务,是基于 Twisted 和 QT 开发的轻量级浏览器引擎,提供直接的 http api。快速、轻量的特点,便于进行分布式开发。
Splash和scrapy集成在一起,两者相互兼容,爬取效率更好。
虽然目前只有英文文档,但是已经写得很详细了,仔细阅读可以快速开发。
本文主要介绍第三种爬虫程序的使用。
安装
网上有很多安装,请自行谷歌。
建议按照官网安装方法。但是要注意,因为splash服务需要依赖docker。docker在Ubuntu下的安装方法,需要仔细阅读文档,注意Ubuntu版本。
启动
安装好docker后,官方文档给了docker启动splash容器的命令(docker run -d -p 8050:8050 scrapinghub/splash),但是一定要查阅splash文档了解相关的启动参数。
比如我启动的时候需要指定max-timeout参数。因为我长时间操作js的时候很可能会超过默认的超时时间,以防万一我设置成3600(一小时),但是对于js操作时间不长的同学,注意不要设置max随机-超时。
docker run -d -p 8050:8050 scrapinghub/splash --max-timeout 3600
用
关于scrapy-splash的教程主要来自scrapy-splash github和splash官方文档。另外,给一个我最近写的scrapy-splash代码。代码主要是实现js页面不断切换,然后抓取数据。以下是代码的核心部分。因为splash使用lua脚本来实现js操作,看官方文档和这段代码,基本可以上手splash了。
fly_spider.py
class FlySpider(scrapy.Spider):
name = "FlySpider"
house_pc_index_url='xxxxx'
def __init__(self):
client = MongoClient("mongodb://name:[email protected]:27017/myspace")
db = client.myspace
self.fly = db["fly"]
def start_requests(self):
for x in xrange(0,1):
try:
script = """
function process_one(splash)
splash:runjs("$('#next_title').click()")
splash:wait(1)
local content=splash:evaljs("$('.scrollbar_content').html()")
return content
end
function process_mul(splash,totalPageNum)
local res={}
for i=1,totalPageNum,1 do
res[i]=process_one(splash)
end
return res
end
function main(splash)
splash.resource_timeout = 1800
local tmp=splash:get_cookies()
splash:add_cookie('PHPSESSID', splash.args.cookies['PHPSESSID'],"/", "www.feizhiyi.com")
splash:add_cookie('FEIZHIYI_LOGGED_USER', splash.args.cookies['FEIZHIYI_LOGGED_USER'],"/", "www.feizhiyi.com" )
splash:autoload("http://cdn.bootcss.com/jquery/ ... 6quot;)
assert(splash:go{
splash.args.url,
http_method=splash.args.http_method,
headers=splash.args.headers,
})
assert(splash:wait(splash.args.wait) )
return {res=process_mul(splash,100)}
end
"""
agent = random.choice(agents)
print "------cookie---------"
headers={
"User-Agent":agent,
"Referer":"xxxxxxx",
}
splash_args = {
'wait': 3,
"http_method":"GET",
# "images":0,
"timeout":1800,
"render_all":1,
"headers":headers,
'lua_source': script,
"cookies":cookies,
# "proxy":"http://101.200.153.236:8123",
}
yield SplashRequest(self.house_pc_index_url, self.parse_result, endpoint='execute',args=splash_args,dont_filter=True)
# +"&page="+str(x+1)
except Exception, e:
print e.__doc__
print e.message
pass
如果你想更深入地使用scrapy-splash,请研究splash官方文档。另外,欢迎留言交流学习。 查看全部
java爬虫抓取动态网页(scrapy利器之scrapy+json的安装方法和使用方法)
介绍
Scrapy是爬虫的利器,我就不多说了。
常见的爬虫结合js一般都是用来抓取网页的动态内容,就是通过操作js来获取渲染出来的内容。
现在大部分网站使用ajax+json来获取数据。所以大家都习惯了爬行,第一件事就是抓包,然后找模式抓数据。当然,有时接口加密算法非常复杂,短时间内难以破解。通过js抓取内容相对容易。这时候爬虫结合js可以更直接的达到目的。当然,数据抓取的效率没有直接抓取界面那么快。.
爬虫结合js
目前我知道的结合js的爬虫有以下3种。(如果有什么要补充的,请留言。)
selenium+webdriver(如firefox、chrome等)。这就要求你的系统有相应的浏览器,而且浏览器必须全程打开。说白了,通过浏览器看到的东西都能被抓到。一般在遇到特别复杂的验证码时,这种方法是很有必要的。当然,用浏览器爬取的效率可想而知。
硒+幻影。PhantomJS 是一个 WebKit,它的使用和 webdriver 是一样的,但是它不需要打开浏览器,可以直接在 Linux 服务器上运行,不需要 GUI,非常棒。
飞溅。与上述两种方法相比,具有以下优点。
splash 作为 js 渲染服务,是基于 Twisted 和 QT 开发的轻量级浏览器引擎,提供直接的 http api。快速、轻量的特点,便于进行分布式开发。
Splash和scrapy集成在一起,两者相互兼容,爬取效率更好。
虽然目前只有英文文档,但是已经写得很详细了,仔细阅读可以快速开发。
本文主要介绍第三种爬虫程序的使用。
安装
网上有很多安装,请自行谷歌。
建议按照官网安装方法。但是要注意,因为splash服务需要依赖docker。docker在Ubuntu下的安装方法,需要仔细阅读文档,注意Ubuntu版本。
启动
安装好docker后,官方文档给了docker启动splash容器的命令(docker run -d -p 8050:8050 scrapinghub/splash),但是一定要查阅splash文档了解相关的启动参数。
比如我启动的时候需要指定max-timeout参数。因为我长时间操作js的时候很可能会超过默认的超时时间,以防万一我设置成3600(一小时),但是对于js操作时间不长的同学,注意不要设置max随机-超时。
docker run -d -p 8050:8050 scrapinghub/splash --max-timeout 3600
用
关于scrapy-splash的教程主要来自scrapy-splash github和splash官方文档。另外,给一个我最近写的scrapy-splash代码。代码主要是实现js页面不断切换,然后抓取数据。以下是代码的核心部分。因为splash使用lua脚本来实现js操作,看官方文档和这段代码,基本可以上手splash了。
fly_spider.py
class FlySpider(scrapy.Spider):
name = "FlySpider"
house_pc_index_url='xxxxx'
def __init__(self):
client = MongoClient("mongodb://name:[email protected]:27017/myspace")
db = client.myspace
self.fly = db["fly"]
def start_requests(self):
for x in xrange(0,1):
try:
script = """
function process_one(splash)
splash:runjs("$('#next_title').click()")
splash:wait(1)
local content=splash:evaljs("$('.scrollbar_content').html()")
return content
end
function process_mul(splash,totalPageNum)
local res={}
for i=1,totalPageNum,1 do
res[i]=process_one(splash)
end
return res
end
function main(splash)
splash.resource_timeout = 1800
local tmp=splash:get_cookies()
splash:add_cookie('PHPSESSID', splash.args.cookies['PHPSESSID'],"/", "www.feizhiyi.com")
splash:add_cookie('FEIZHIYI_LOGGED_USER', splash.args.cookies['FEIZHIYI_LOGGED_USER'],"/", "www.feizhiyi.com" )
splash:autoload("http://cdn.bootcss.com/jquery/ ... 6quot;)
assert(splash:go{
splash.args.url,
http_method=splash.args.http_method,
headers=splash.args.headers,
})
assert(splash:wait(splash.args.wait) )
return {res=process_mul(splash,100)}
end
"""
agent = random.choice(agents)
print "------cookie---------"
headers={
"User-Agent":agent,
"Referer":"xxxxxxx",
}
splash_args = {
'wait': 3,
"http_method":"GET",
# "images":0,
"timeout":1800,
"render_all":1,
"headers":headers,
'lua_source': script,
"cookies":cookies,
# "proxy":"http://101.200.153.236:8123",
}
yield SplashRequest(self.house_pc_index_url, self.parse_result, endpoint='execute',args=splash_args,dont_filter=True)
# +"&page="+str(x+1)
except Exception, e:
print e.__doc__
print e.message
pass
如果你想更深入地使用scrapy-splash,请研究splash官方文档。另外,欢迎留言交流学习。
java爬虫抓取动态网页( 全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 00:18
全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
解析动态内容
根据权威机构发布的全球互联网无障碍审计报告,全球约四分之三的网站是通过JavaScript动态生成的,即在浏览器窗口中“查看网页”。在 HTML 代码中找不到“源代码”,这意味着我们用来获取数据的方法无法正常工作。解决这个问题基本上有两种方案,一种是JavaScript逆向工程;另一种是渲染 JavaScript 以获取渲染的内容。
JavaScript 逆向工程
我们以“360图片”网站为例来说明什么是JavaScript逆向工程。其实所谓的 JavaScript 逆向工程就是通过 Ajax 技术找到一个接口来动态获取数据。在浏览器中输入,打开“360图片”的“美女”版块,如下图。
但是当我们在浏览器中使用右键菜单“显示网页源代码”时,我们惊讶地发现页面的HTML代码连接到一个
没有标签,那么我们看到的图片是如何显示的呢?原来所有的图片都是通过JavaScript动态加载的,获取这些图片数据的web API接口可以在浏览器“开发者工具”的“网络”中找到,如下图所示。
那么结论就很简单了。只要找到这些网络API接口,就可以通过这些接口获取数据。当然,在实际开发过程中,我们可能需要分析这些接口的参数以及接口返回的数据,了解每个参数的含义以及返回的JSON数据的格式,这样我们才能在我们的程序中使用这些数据履带。
如何从web API中获取JSON格式的数据,提取出我们需要的内容,在之前的“文件与异常”一文中已经说明,这里不再赘述。
使用硒
虽然很多网站保护了自己的web API接口,增加了获取数据的难度,但只要足够努力,大部分都是可以逆向工程的,但是在实际开发中,我们可以通过浏览器渲染引擎来避免这些繁琐的工作,WebKit 是使用的渲染引擎。
WebKit 的代码始于 1998 年的 KHTML 项目,当时它是 Konqueror 浏览器的渲染引擎。2001 年,苹果从该项目的代码中衍生出 WebKit,并将其应用到 Safari 浏览器中。早期的 Chrome 浏览器也使用了这个内核。在Python中,我们可以通过Qt框架获取WebKit引擎,用它来渲染页面,获取动态内容。此内容请阅读《爬虫技术:动态页面抓取超级指南》一文。
如果你不打算使用上述方法来渲染页面和获取动态内容,其实还有一个选择就是使用自动化测试工具Selenium,它提供了浏览器自动化的API接口,这样你就可以通过操纵浏览器内容获得动态。首先,您可以使用 pip 安装 Selenium。
pip3 install selenium
下面以《阿里V任务》的“直播服务”为例,演示如何使用Selenium获取动态内容和抓拍主播图片。
import requestsfrom bs4 import BeautifulSoupdef main(): resp = requests.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(resp.text, 'lxml') for img_tag in soup.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
运行上面的程序会发现没有输出,因为根本找不到页面的HTML代码
标签。接下来我们使用Selenium获取页面上的动态内容,然后提取锚点图片。
from bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef main(): driver = webdriver.Chrome() driver.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(driver.page_source, 'lxml') for img_tag in soup.body.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果你想控制其他浏览器,可以创建相应的浏览器对象,如Firefox、IE等。 运行上面的程序,如果看到如下所示的错误信息,说明我们还没有添加Chrome浏览器驱动PATH环境变量,我们也没有在程序中指定Chrome浏览器驱动的位置。
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chr ... /home
为了解决以上问题,可以到Selenium官方网站找到浏览器驱动的下载链接,下载需要的驱动。Linux或者macOS下可以使用下面的命令设置PATH环境变量,Windows下配置环境变量也很简单,不明白的可以看懂。
export PATH=$PATH:/Users/Hao/Downloads/Tools/chromedriver/
其中/Users/Hao/Downloads/Tools/chromedriver/是chromedriver所在的路径。 查看全部
java爬虫抓取动态网页(
全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
解析动态内容
根据权威机构发布的全球互联网无障碍审计报告,全球约四分之三的网站是通过JavaScript动态生成的,即在浏览器窗口中“查看网页”。在 HTML 代码中找不到“源代码”,这意味着我们用来获取数据的方法无法正常工作。解决这个问题基本上有两种方案,一种是JavaScript逆向工程;另一种是渲染 JavaScript 以获取渲染的内容。
JavaScript 逆向工程
我们以“360图片”网站为例来说明什么是JavaScript逆向工程。其实所谓的 JavaScript 逆向工程就是通过 Ajax 技术找到一个接口来动态获取数据。在浏览器中输入,打开“360图片”的“美女”版块,如下图。

但是当我们在浏览器中使用右键菜单“显示网页源代码”时,我们惊讶地发现页面的HTML代码连接到一个
没有标签,那么我们看到的图片是如何显示的呢?原来所有的图片都是通过JavaScript动态加载的,获取这些图片数据的web API接口可以在浏览器“开发者工具”的“网络”中找到,如下图所示。
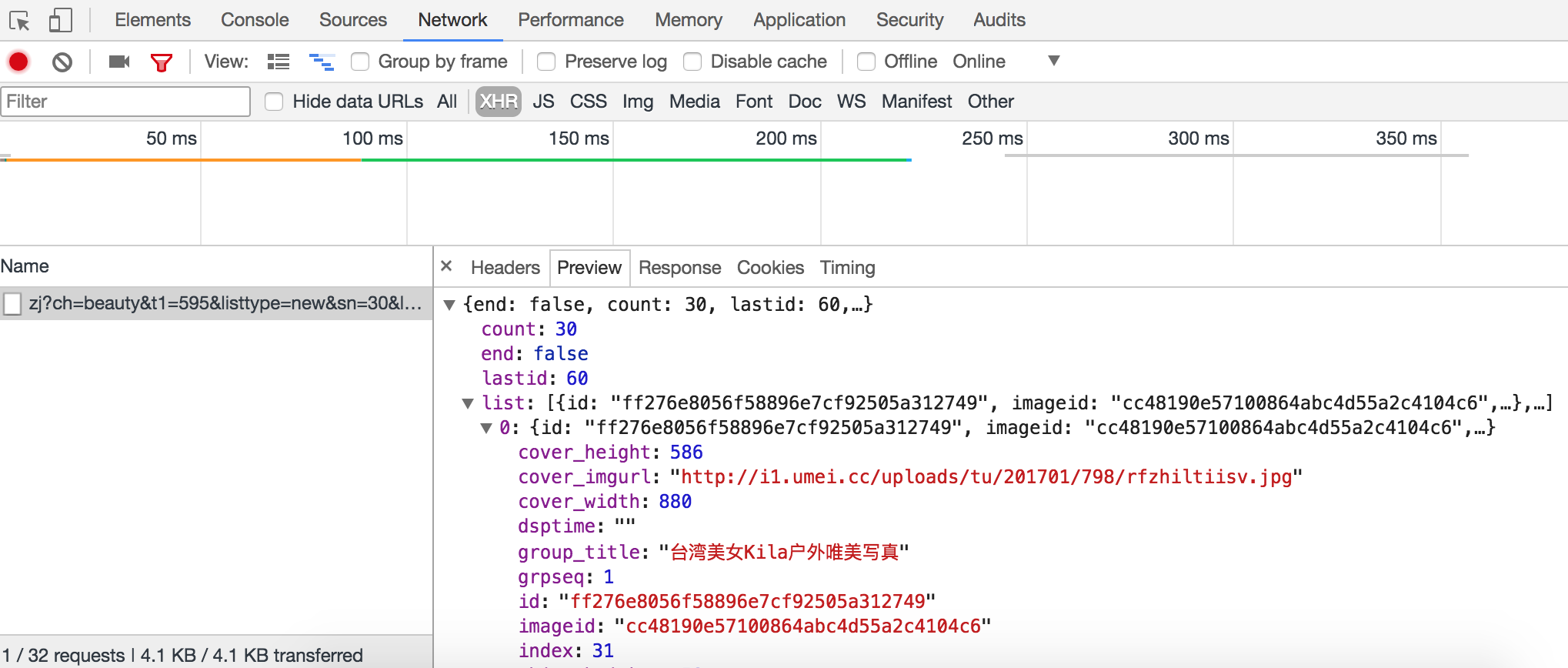
那么结论就很简单了。只要找到这些网络API接口,就可以通过这些接口获取数据。当然,在实际开发过程中,我们可能需要分析这些接口的参数以及接口返回的数据,了解每个参数的含义以及返回的JSON数据的格式,这样我们才能在我们的程序中使用这些数据履带。
如何从web API中获取JSON格式的数据,提取出我们需要的内容,在之前的“文件与异常”一文中已经说明,这里不再赘述。
使用硒
虽然很多网站保护了自己的web API接口,增加了获取数据的难度,但只要足够努力,大部分都是可以逆向工程的,但是在实际开发中,我们可以通过浏览器渲染引擎来避免这些繁琐的工作,WebKit 是使用的渲染引擎。
WebKit 的代码始于 1998 年的 KHTML 项目,当时它是 Konqueror 浏览器的渲染引擎。2001 年,苹果从该项目的代码中衍生出 WebKit,并将其应用到 Safari 浏览器中。早期的 Chrome 浏览器也使用了这个内核。在Python中,我们可以通过Qt框架获取WebKit引擎,用它来渲染页面,获取动态内容。此内容请阅读《爬虫技术:动态页面抓取超级指南》一文。
如果你不打算使用上述方法来渲染页面和获取动态内容,其实还有一个选择就是使用自动化测试工具Selenium,它提供了浏览器自动化的API接口,这样你就可以通过操纵浏览器内容获得动态。首先,您可以使用 pip 安装 Selenium。
pip3 install selenium
下面以《阿里V任务》的“直播服务”为例,演示如何使用Selenium获取动态内容和抓拍主播图片。
import requestsfrom bs4 import BeautifulSoupdef main(): resp = requests.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(resp.text, 'lxml') for img_tag in soup.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
运行上面的程序会发现没有输出,因为根本找不到页面的HTML代码
标签。接下来我们使用Selenium获取页面上的动态内容,然后提取锚点图片。
from bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef main(): driver = webdriver.Chrome() driver.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(driver.page_source, 'lxml') for img_tag in soup.body.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果你想控制其他浏览器,可以创建相应的浏览器对象,如Firefox、IE等。 运行上面的程序,如果看到如下所示的错误信息,说明我们还没有添加Chrome浏览器驱动PATH环境变量,我们也没有在程序中指定Chrome浏览器驱动的位置。
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chr ... /home
为了解决以上问题,可以到Selenium官方网站找到浏览器驱动的下载链接,下载需要的驱动。Linux或者macOS下可以使用下面的命令设置PATH环境变量,Windows下配置环境变量也很简单,不明白的可以看懂。
export PATH=$PATH:/Users/Hao/Downloads/Tools/chromedriver/
其中/Users/Hao/Downloads/Tools/chromedriver/是chromedriver所在的路径。
java爬虫抓取动态网页(谷歌浏览器的检查功能分析(图)为什么呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-04 16:12
目标网址网址:
%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=
使用谷歌浏览器的检查功能分析网站,发现需要抓取的内容在'movie-list-item playable unwatched'类下。
好了,我们按照之前的方式爬一下,看看。
url='https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
res=requests.get(url)
res.encoding= 'utf-8'#该网页是以utf-8的编码形式显示的
soup=BeautifulSoup(res.text, 'html.parser')#使用美丽汤解析网页内容
print(soup)
查看打印结果,发现get信息中没有电影的相关信息。为什么是这样?因为这个页面上的所有电影信息都是动态加载的。
转动鼠标滚轮下拉页面,你会发现加载的内容越来越多,查看显示器,'movie-list-item playable unwatched'类的列数增加了。看来静态的网站 集对动态加载的网站 不起作用,那么如何解决呢?
点击显示器的网络--->XHR。继续向下滑动滚轮,你会发现Name下的文件增加了!
点击文件末尾的start=0&limit=20和start=20&limit=20的文件,对比查看,发现这正是我们要找的信息。
通过对比,我们现在可以大胆猜想,start指的是起始电影序列号,limit是每个请求显示的电影数量,信息以json格式存储。我们再次点击Headers,发现如下:
发现获取的内容是通过GET url获取的:';interval_id=100%3A90&action=&start=0&limit=20'。
好的,现在我们知道如何获取数据了。经过测试,我们其实可以直接start=0 limit=256直接得到所有的top10数据。但是我们还是按照网站的要求,一次拿到20份。代码显示如下:
import requests
import json
#爬取豆瓣电影分类排行榜 - 动作片top10%的电影名、评分和豆瓣链接
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start={}&limit=20'
filminfolist=[]#存放结果
for i in range(0,300,20):
aimurl=url.format(i)
res=requests.get(aimurl)
jd=json.loads(res.text)#改成json格式方便读取数据
for j in jd:
filminfo={}#以字典存储单条数据
filminfo['title']=j['title']
filminfo['score'] = j['score']
filminfo['url'] = j['url']
filminfolist.append(filminfo)
打印filminfolist的结果如下:
{'title':'这个杀手不太冷','score':'9.4','url':''}
{'title':'七武士','score':'9.2','url':''}
{'title':'蝙蝠侠:黑暗骑士','score':'9.1','url':''}
{'title':'指环王3:无敌之王','score':'9.1','url':''}
{'title':'Fight Club','score':'9.0','url':''}
{'title':'指环王2:两塔','score':'9.0','url':''}
{'title':'General title','score':'9.0','url':''}
{'title':'魔戒1:魔戒再现','score':'8.9','url':''}
......
稍微展开一下:
初识DataFrame
使用Data Frame格式将刚才的数据保存到excel中,这是通过使用包pandas实现的。
代码显示如下:
import pandas
df=pandas.DataFrame(filminfolist)
df.to_excel('D:\\douban.xlsx')
总结:对于动态加载的网页,需要多观察监视器,分析实际爬取的页面。美利堂解析html格式,json解析json格式。当然,也可以使用正则表达式进行分析。 查看全部
java爬虫抓取动态网页(谷歌浏览器的检查功能分析(图)为什么呢?)
目标网址网址:
%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=
使用谷歌浏览器的检查功能分析网站,发现需要抓取的内容在'movie-list-item playable unwatched'类下。
好了,我们按照之前的方式爬一下,看看。
url='https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
res=requests.get(url)
res.encoding= 'utf-8'#该网页是以utf-8的编码形式显示的
soup=BeautifulSoup(res.text, 'html.parser')#使用美丽汤解析网页内容
print(soup)
查看打印结果,发现get信息中没有电影的相关信息。为什么是这样?因为这个页面上的所有电影信息都是动态加载的。
转动鼠标滚轮下拉页面,你会发现加载的内容越来越多,查看显示器,'movie-list-item playable unwatched'类的列数增加了。看来静态的网站 集对动态加载的网站 不起作用,那么如何解决呢?
点击显示器的网络--->XHR。继续向下滑动滚轮,你会发现Name下的文件增加了!

点击文件末尾的start=0&limit=20和start=20&limit=20的文件,对比查看,发现这正是我们要找的信息。

通过对比,我们现在可以大胆猜想,start指的是起始电影序列号,limit是每个请求显示的电影数量,信息以json格式存储。我们再次点击Headers,发现如下:

发现获取的内容是通过GET url获取的:';interval_id=100%3A90&action=&start=0&limit=20'。
好的,现在我们知道如何获取数据了。经过测试,我们其实可以直接start=0 limit=256直接得到所有的top10数据。但是我们还是按照网站的要求,一次拿到20份。代码显示如下:
import requests
import json
#爬取豆瓣电影分类排行榜 - 动作片top10%的电影名、评分和豆瓣链接
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start={}&limit=20'
filminfolist=[]#存放结果
for i in range(0,300,20):
aimurl=url.format(i)
res=requests.get(aimurl)
jd=json.loads(res.text)#改成json格式方便读取数据
for j in jd:
filminfo={}#以字典存储单条数据
filminfo['title']=j['title']
filminfo['score'] = j['score']
filminfo['url'] = j['url']
filminfolist.append(filminfo)
打印filminfolist的结果如下:
{'title':'这个杀手不太冷','score':'9.4','url':''}
{'title':'七武士','score':'9.2','url':''}
{'title':'蝙蝠侠:黑暗骑士','score':'9.1','url':''}
{'title':'指环王3:无敌之王','score':'9.1','url':''}
{'title':'Fight Club','score':'9.0','url':''}
{'title':'指环王2:两塔','score':'9.0','url':''}
{'title':'General title','score':'9.0','url':''}
{'title':'魔戒1:魔戒再现','score':'8.9','url':''}
......
稍微展开一下:
初识DataFrame
使用Data Frame格式将刚才的数据保存到excel中,这是通过使用包pandas实现的。
代码显示如下:
import pandas
df=pandas.DataFrame(filminfolist)
df.to_excel('D:\\douban.xlsx')
总结:对于动态加载的网页,需要多观察监视器,分析实际爬取的页面。美利堂解析html格式,json解析json格式。当然,也可以使用正则表达式进行分析。
java爬虫抓取动态网页(PHPHTML数据爬虫的设计思路及应用的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-04 15:11
内容
1. 为什么要爬行?
“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫是如何抓取网页数据的?
首先,您需要了解网页的三个特征:
每个网页都有自己的 URL(统一资源定位器)来定位网页。HTML(超文本标记语言)用于描述页面信息。该网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
爬虫的设计思路:
首先确定需要爬取的网址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一种。如果需要数据保存
湾 如果还有其他网址,继续第二步4. Python爬虫的优点?语言优缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运行效率和性能几乎是最强的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面学习路线:解析服务器对应内容:采集动态HTML,验证码处理Scrapy框架:分布式策略:爬虫、反爬虫、反爬虫的较量:6.爬虫分类6.1 一般爬虫:
1. 定义:搜索引擎的爬虫系统
2. 目标:抓取互联网上的所有网页,放在本地服务器上形成备份,并对这些网页进行相关处理(提取关键词,去除广告),最终为用户提供一个借口可以参观
3. 获取过程:
a) 先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中获取 URL,然后通过 NDS 解析得到主机 IP,然后到这个 IP 对应的服务器下载 HTML 页面,保存到搜索引擎的本地服务器,然后把抓取到的进入抓取队列的 URL
c) 分析网页内容,找出网页中的其他网址链接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取新的网站 URL:
主动提交网址给搜索引擎:在其他网站中设置网站的外链:其他网站上面的友情链接搜索引擎会和DNS服务商合作,可以快速< @收录新网站
5.一般爬虫注意事项
一般的爬虫不是可以爬的东西,它必须遵守规则:
机器人协议:协议会规定一般爬虫爬取网页的权限
我们可以访问不同网页的机器人权限
6.通用爬虫一般流程:
7. 一般爬虫的缺点
只能提供与文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。人类语义检索侧重爬虫的优势
DNS域名解析为IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员针对某个内容编写的爬虫-> 面向主题的爬虫,面向需求的爬虫 查看全部
java爬虫抓取动态网页(PHPHTML数据爬虫的设计思路及应用的优势)
内容
1. 为什么要爬行?
“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫是如何抓取网页数据的?
首先,您需要了解网页的三个特征:
每个网页都有自己的 URL(统一资源定位器)来定位网页。HTML(超文本标记语言)用于描述页面信息。该网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
爬虫的设计思路:
首先确定需要爬取的网址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一种。如果需要数据保存
湾 如果还有其他网址,继续第二步4. Python爬虫的优点?语言优缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运行效率和性能几乎是最强的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面学习路线:解析服务器对应内容:采集动态HTML,验证码处理Scrapy框架:分布式策略:爬虫、反爬虫、反爬虫的较量:6.爬虫分类6.1 一般爬虫:
1. 定义:搜索引擎的爬虫系统
2. 目标:抓取互联网上的所有网页,放在本地服务器上形成备份,并对这些网页进行相关处理(提取关键词,去除广告),最终为用户提供一个借口可以参观
3. 获取过程:
a) 先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中获取 URL,然后通过 NDS 解析得到主机 IP,然后到这个 IP 对应的服务器下载 HTML 页面,保存到搜索引擎的本地服务器,然后把抓取到的进入抓取队列的 URL
c) 分析网页内容,找出网页中的其他网址链接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取新的网站 URL:
主动提交网址给搜索引擎:在其他网站中设置网站的外链:其他网站上面的友情链接搜索引擎会和DNS服务商合作,可以快速< @收录新网站
5.一般爬虫注意事项
一般的爬虫不是可以爬的东西,它必须遵守规则:
机器人协议:协议会规定一般爬虫爬取网页的权限
我们可以访问不同网页的机器人权限
6.通用爬虫一般流程:
7. 一般爬虫的缺点
只能提供与文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。人类语义检索侧重爬虫的优势
DNS域名解析为IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员针对某个内容编写的爬虫-> 面向主题的爬虫,面向需求的爬虫
java爬虫抓取动态网页(所说的问题试试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-02 23:08
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,底层将启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,然后获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是HtmlUnit提供了对执行javascript的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面时总是出错。我还没有找到错误在哪里。分析网上查询的结果,最可能的错误原因是htmlunit在执行某些带参数的请求时,参数的顺序或编码问题会导致请求失败并报错。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064");
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn");
11 list.add("http://www.sohu.com");
12 list.add("http://www.163.com");
13 list.add("http://www.qq.com");
14
15 long start,end;
16
17 for(int i=0;i 查看全部
java爬虫抓取动态网页(所说的问题试试)
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,底层将启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,然后获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是HtmlUnit提供了对执行javascript的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面时总是出错。我还没有找到错误在哪里。分析网上查询的结果,最可能的错误原因是htmlunit在执行某些带参数的请求时,参数的顺序或编码问题会导致请求失败并报错。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064";);
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn";);
11 list.add("http://www.sohu.com";);
12 list.add("http://www.163.com";);
13 list.add("http://www.qq.com";);
14
15 long start,end;
16
17 for(int i=0;i
java爬虫抓取动态网页(java爬虫抓取动态网页还没抓取该怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-01 15:17
java爬虫抓取动态网页时,上方网页已经抓取,但是下方网页还没抓取,该怎么办?首先解释一下下方网页此时的抓取策略,若是使用f12进入开发者选项,选择“打开控制台”,在搜索框输入“element.screenshot”即可找到下方网页提示的代码。在抓取上方动态网页的同时,下方的网页也同时抓取到了。而我们要抓取的是通过上方get方法获取的下方java源码页,该代码如下:图1上方页的源码如图2所示,代码第二行是ajax回调方法,简单来说就是用了上方的get方法提交信息到服务器,服务器返回参数给ajax的代码,然后通过这个返回值去爬取下方代码,根据dom去处理动态页面中有用的数据。
在上方代码中有个重要的逻辑:若上方代码里某条数据内容并没有就返回“error_element.thumbnailfoa()”这个错误页面(或是通过f12打开github开发者工具的时候提示该选项无效,因为这个选项是开发者在向浏览器上传数据的时候,获取到该网页的代码,然后上传的。)那么,通过该代码抓取的该代码页也就不会有下方代码的java返回值,此时下方页就返回空。
大家可以打开下方代码看看效果,图3所示的情况是获取到的所有数据都用“url”关键字加了formdata值,我们没有wxss代码,也就不能通过style来定位formdata值,正确做法为下方代码抓取该代码页同时,将获取到的返回值setinfos添加到本页数据下方。(注意:要定位formdata,由上方源码结果来看,该get方法只传递参数,没有将该参数作为返回值)。
最后总结一下,如果上方代码的动态页数据是通过js注入上传,那么会再次上传数据返回,不然就返回空值。如果上方代码中不再有对外setdata数据,那么原先我们获取到的上方代码页就不会再返回这条数据。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页还没抓取该怎么办?(图))
java爬虫抓取动态网页时,上方网页已经抓取,但是下方网页还没抓取,该怎么办?首先解释一下下方网页此时的抓取策略,若是使用f12进入开发者选项,选择“打开控制台”,在搜索框输入“element.screenshot”即可找到下方网页提示的代码。在抓取上方动态网页的同时,下方的网页也同时抓取到了。而我们要抓取的是通过上方get方法获取的下方java源码页,该代码如下:图1上方页的源码如图2所示,代码第二行是ajax回调方法,简单来说就是用了上方的get方法提交信息到服务器,服务器返回参数给ajax的代码,然后通过这个返回值去爬取下方代码,根据dom去处理动态页面中有用的数据。
在上方代码中有个重要的逻辑:若上方代码里某条数据内容并没有就返回“error_element.thumbnailfoa()”这个错误页面(或是通过f12打开github开发者工具的时候提示该选项无效,因为这个选项是开发者在向浏览器上传数据的时候,获取到该网页的代码,然后上传的。)那么,通过该代码抓取的该代码页也就不会有下方代码的java返回值,此时下方页就返回空。
大家可以打开下方代码看看效果,图3所示的情况是获取到的所有数据都用“url”关键字加了formdata值,我们没有wxss代码,也就不能通过style来定位formdata值,正确做法为下方代码抓取该代码页同时,将获取到的返回值setinfos添加到本页数据下方。(注意:要定位formdata,由上方源码结果来看,该get方法只传递参数,没有将该参数作为返回值)。
最后总结一下,如果上方代码的动态页数据是通过js注入上传,那么会再次上传数据返回,不然就返回空值。如果上方代码中不再有对外setdata数据,那么原先我们获取到的上方代码页就不会再返回这条数据。
java爬虫抓取动态网页(解析解析动态网页的一种方法:仅供参考左边的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-26 23:06
网页是静态的和动态的。一般我们可以通过抓包来找出真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候,我们希望直接得到js加载后的最终网页数据。如果使用java,java是如何抓取动态网页数据的?下面就和精灵代理聊一聊动态网页的爬取方法。
如果只是抓取互联网上的特定数据,比如静态网页,那就再简单不过了,直接使用Jsoup:
Documentdoc=Jsoup.connect(url).timeout(2000).get();
获取文档,然后做你想做的。
但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者是用户滑动浏览触发的js加载数据,这样的网页使用 Jsoup 显然得不到你想要的数据。
后来使用Selenium获取动态网页的数据,就可以成功获取到数据了。打包程序在机器上运行,开始测试,结果不太理想,经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。
一种解析动态网页的方法:
首先是动态网页,既然是动态的,浏览器加载网页后,必须唤醒对服务器的网络请求。如果我拿到网络请求的url,模拟参数,自己发送请求,解析数据也不是更好。
抓包工具:fiddle
打开浏览器,打开目标url,然后就可以看到fiddle打开这个页面的所有网络请求,并一一查看网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。专注于文本格式的请求。然后右键copy->justurl,把url复制到浏览器,看看能得到什么。最后,18行请求是Data接口,可以直接获取数据,而且是json格式!
java如何抓取动态网页数据?上面分享了一种解析动态网页的方法,仅供参考! 查看全部
java爬虫抓取动态网页(解析解析动态网页的一种方法:仅供参考左边的抓取方法)
网页是静态的和动态的。一般我们可以通过抓包来找出真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候,我们希望直接得到js加载后的最终网页数据。如果使用java,java是如何抓取动态网页数据的?下面就和精灵代理聊一聊动态网页的爬取方法。
如果只是抓取互联网上的特定数据,比如静态网页,那就再简单不过了,直接使用Jsoup:
Documentdoc=Jsoup.connect(url).timeout(2000).get();
获取文档,然后做你想做的。
但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者是用户滑动浏览触发的js加载数据,这样的网页使用 Jsoup 显然得不到你想要的数据。
后来使用Selenium获取动态网页的数据,就可以成功获取到数据了。打包程序在机器上运行,开始测试,结果不太理想,经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。
一种解析动态网页的方法:
首先是动态网页,既然是动态的,浏览器加载网页后,必须唤醒对服务器的网络请求。如果我拿到网络请求的url,模拟参数,自己发送请求,解析数据也不是更好。
抓包工具:fiddle
打开浏览器,打开目标url,然后就可以看到fiddle打开这个页面的所有网络请求,并一一查看网络请求:

先看左边的图标,直接跳过图片。显然,我们需要的是数据。专注于文本格式的请求。然后右键copy->justurl,把url复制到浏览器,看看能得到什么。最后,18行请求是Data接口,可以直接获取数据,而且是json格式!
java如何抓取动态网页数据?上面分享了一种解析动态网页的方法,仅供参考!
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-26 23:05
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录Java代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录Java代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
很明显,这是一个带有Java渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('')
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?网页上有很多文件。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。 查看全部
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录Java代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录Java代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
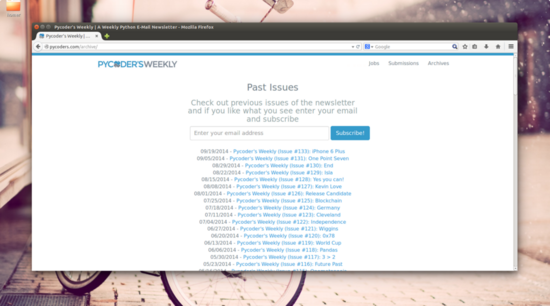
很明显,这是一个带有Java渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('')
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?网页上有很多文件。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
java爬虫抓取动态网页(spider,大数据的兴起,爬虫应用被提升到前所未有高度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-26 14:06
又称蜘蛛,起源于百度和谷歌。但随着近年来大数据的兴起,爬虫应用被提升到了前所未有的高度。就大数据而言,实际上,自有数据或用户生成数据的平台非常有限。只有电商、微博这样的平台才能避免自给自足。许多数据分析和挖掘公司使用网络爬虫来获得不同的结果。元数据采集,最终用于它,构建自己的大数据集成平台。其中,舆情、财经股票分析、广告数据挖掘等都属于这一类。技术层面描述如下。
(1)传统爬虫,如nutch、hetriex等,比较适合抓取简单的页面,即没有复杂请求的页面。但是随着web2.0的兴起,越来越网站 很多动态交互技术,比如ajax,用来提升用户体验,页面需要登录才能访问等,无能为力,或者二次开发的开发成本太高,很多人给使用它们。
(2)定制爬虫,对于一些大数据平台,如微博、电商、大众点评等,页面交互复杂,用户登录后才能访问,往往需要定制开发一些爬虫项目,比如微博专用的微博爬虫、大众点评的自定义爬虫、豆瓣书评的评论爬虫都是典型的自定义爬虫,比传统爬虫难度大,需要相应的定制分析工具和能力,只有扎实的编程功底,优化效率,克服验证码,拒绝服务等反爬措施,才能做出这种高效的爬虫,现在主流还是基于httpclient+jsoup来处理网络下载和页面分析。
(3) 一种新型爬虫,结合一些成熟的第三方工具,如c/c++实现的webkit、htmlunit、phantomjs、casper等工具。共同点是最大限度地模拟人的方式浏览器的操作,用(1)、(2))不容易解决的问题,比如模拟登录、复杂参数的获取、复杂的页面交互等,这些问题往往可以轻松解决通过使用以上工具,其最大的缺点是基于真实浏览器的操作,所以效率比较低,所以往往需要结合httpclient来达到高效实用的目的。 on phantomjs 也证明了这一点,下一步可以结合起来。完成微博爬虫的模拟登录获取cookies,然后使用httpclient+jsoup解决海量数据的抓取,是一个非常不错的微博爬虫方案。
因为它需要的知识相对较多,所以它的待遇比web开发高,增长的速度和速度比web开发高很多。
三、自然语言处理 查看全部
java爬虫抓取动态网页(spider,大数据的兴起,爬虫应用被提升到前所未有高度)
又称蜘蛛,起源于百度和谷歌。但随着近年来大数据的兴起,爬虫应用被提升到了前所未有的高度。就大数据而言,实际上,自有数据或用户生成数据的平台非常有限。只有电商、微博这样的平台才能避免自给自足。许多数据分析和挖掘公司使用网络爬虫来获得不同的结果。元数据采集,最终用于它,构建自己的大数据集成平台。其中,舆情、财经股票分析、广告数据挖掘等都属于这一类。技术层面描述如下。
(1)传统爬虫,如nutch、hetriex等,比较适合抓取简单的页面,即没有复杂请求的页面。但是随着web2.0的兴起,越来越网站 很多动态交互技术,比如ajax,用来提升用户体验,页面需要登录才能访问等,无能为力,或者二次开发的开发成本太高,很多人给使用它们。
(2)定制爬虫,对于一些大数据平台,如微博、电商、大众点评等,页面交互复杂,用户登录后才能访问,往往需要定制开发一些爬虫项目,比如微博专用的微博爬虫、大众点评的自定义爬虫、豆瓣书评的评论爬虫都是典型的自定义爬虫,比传统爬虫难度大,需要相应的定制分析工具和能力,只有扎实的编程功底,优化效率,克服验证码,拒绝服务等反爬措施,才能做出这种高效的爬虫,现在主流还是基于httpclient+jsoup来处理网络下载和页面分析。
(3) 一种新型爬虫,结合一些成熟的第三方工具,如c/c++实现的webkit、htmlunit、phantomjs、casper等工具。共同点是最大限度地模拟人的方式浏览器的操作,用(1)、(2))不容易解决的问题,比如模拟登录、复杂参数的获取、复杂的页面交互等,这些问题往往可以轻松解决通过使用以上工具,其最大的缺点是基于真实浏览器的操作,所以效率比较低,所以往往需要结合httpclient来达到高效实用的目的。 on phantomjs 也证明了这一点,下一步可以结合起来。完成微博爬虫的模拟登录获取cookies,然后使用httpclient+jsoup解决海量数据的抓取,是一个非常不错的微博爬虫方案。
因为它需要的知识相对较多,所以它的待遇比web开发高,增长的速度和速度比web开发高很多。
三、自然语言处理
java爬虫抓取动态网页(Web爬虫的结构(可创建一个网站地图)下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-25 23:07
Heritrix
Heritrix 是一个开源、可扩展的网络爬虫项目。 Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。
WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX包两部分组成。
WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
阿拉蕾
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
J-蜘蛛
J-Spider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站的结构(可以创建一个网站@ > map),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
主轴
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
蛛形纲动物
Arachnid:是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在网站上使用页面上的每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
警报
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
snoics-爬行动物
snoics-reptile 是用纯 Java 开发的。它是一个用于网站 图像捕获的工具。可以使用配置文件中提供的URL入口来转换这个网站所有可以使用的浏览器通过GET获取的资源都是本地抓取的,包括网页和各种类型的文件,比如图片、flash、 mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
下载链接:
snoics-reptile2.0.part1.rar
snoics-reptile2.0.part2.rar
snoics-reptile2.0-doc.rar
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现对 text/xml 的操作 查看全部
java爬虫抓取动态网页(Web爬虫的结构(可创建一个网站地图)下载)
Heritrix
Heritrix 是一个开源、可扩展的网络爬虫项目。 Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。
WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX包两部分组成。
WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
阿拉蕾
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
J-蜘蛛
J-Spider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站的结构(可以创建一个网站@ > map),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
主轴
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
蛛形纲动物
Arachnid:是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在网站上使用页面上的每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
警报
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
snoics-爬行动物
snoics-reptile 是用纯 Java 开发的。它是一个用于网站 图像捕获的工具。可以使用配置文件中提供的URL入口来转换这个网站所有可以使用的浏览器通过GET获取的资源都是本地抓取的,包括网页和各种类型的文件,比如图片、flash、 mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
下载链接:
snoics-reptile2.0.part1.rar
snoics-reptile2.0.part2.rar
snoics-reptile2.0-doc.rar
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现对 text/xml 的操作
java爬虫抓取动态网页(Java爬虫简单的网络爬虫原理是怎样的?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-25 12:12
Java爬虫的简单实现
最近学习搜索,需要了解一下网络爬虫的知识。虽然有很多强大的开源爬虫,为了了解原理,我还是抱着学习的态度写了一个简单的网络爬虫。
先介绍一下各个类的功能:
DownloadPage.java 的作用是下载这个超链接的页面源代码。
FunctionUtils.java的作用是提供不同的静态方法,包括:页面链接正则表达式匹配、获取URL链接元素、判断是否创建文件、获取页面Url并转换为标准Url、拦截网页源文件 目标内容。
HrefOfPage.java 的作用是获取页面源代码的超链接。
UrlDataHanding.java 的作用是集成各种类,实现url获取数据到数据处理类。
UrlQueue.java 未访问的 Url 队列。
VisitedUrlQueue.java 已访问的 URL 队列。
下面介绍每个类的源代码: DownloadPage.java 该类使用HttpClient 组件。FunctionUtils.java的方法是静态方法HrefOfPage.java,是获取页面的超链接UrlDataHanding.java,主要用于从未访问队列获取URL、下载页面、分析URL、保存访问过的URL等操作。实现 Runnable 接口 UrlQueue.java。该类主要用于存储未访问的 URL 队列。VisitedUrlQueue.java 主要用于存储访问过的 URL,使用 HashSet 保存,主要是考虑到每个访问过的 URL 是不同的。HashSet 正好满足这个要求 Test.java 这个类是一个测试类
说明:因为我抓的是oschina,里面的url正则表达式不适合其他网站,需要自己修改。也可以写xml来配置。 查看全部
java爬虫抓取动态网页(Java爬虫简单的网络爬虫原理是怎样的?-八维教育)
Java爬虫的简单实现
最近学习搜索,需要了解一下网络爬虫的知识。虽然有很多强大的开源爬虫,为了了解原理,我还是抱着学习的态度写了一个简单的网络爬虫。
先介绍一下各个类的功能:
DownloadPage.java 的作用是下载这个超链接的页面源代码。
FunctionUtils.java的作用是提供不同的静态方法,包括:页面链接正则表达式匹配、获取URL链接元素、判断是否创建文件、获取页面Url并转换为标准Url、拦截网页源文件 目标内容。
HrefOfPage.java 的作用是获取页面源代码的超链接。
UrlDataHanding.java 的作用是集成各种类,实现url获取数据到数据处理类。
UrlQueue.java 未访问的 Url 队列。
VisitedUrlQueue.java 已访问的 URL 队列。
下面介绍每个类的源代码: DownloadPage.java 该类使用HttpClient 组件。FunctionUtils.java的方法是静态方法HrefOfPage.java,是获取页面的超链接UrlDataHanding.java,主要用于从未访问队列获取URL、下载页面、分析URL、保存访问过的URL等操作。实现 Runnable 接口 UrlQueue.java。该类主要用于存储未访问的 URL 队列。VisitedUrlQueue.java 主要用于存储访问过的 URL,使用 HashSet 保存,主要是考虑到每个访问过的 URL 是不同的。HashSet 正好满足这个要求 Test.java 这个类是一个测试类
说明:因为我抓的是oschina,里面的url正则表达式不适合其他网站,需要自己修改。也可以写xml来配置。
java爬虫抓取动态网页(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-24 05:15
本文文章在链接的基础上爬取目标网站进一步增加难度,在目标页面抓取我们需要的内容并保存到数据库中。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一个文章类似。不同的是,考虑到这个网站的分类列表太多,如果不选择这些标签,会花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接来爬取其他页面,只需使用页面底部的所有类型电影的选项卡即可获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是将获取到的所有电影的下载链接保存在videolinkmap集合中,遍历这个集合将数据保存到mysql
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.bufferedreader;
import java.io.ioexception;
import java.io.inputstream;
import java.io.inputstreamreader;
import java.net.httpurlconnection;
import java.net.malformedurlexception;
import java.net.url;
import java.sql.connection;
import java.sql.preparedstatement;
import java.sql.sqlexception;
import java.util.linkedhashmap;
import java.util.map;
import java.util.regex.matcher;
import java.util.regex.pattern;
public class videolinkgrab {
public static void main(string[] args) {
videolinkgrab videolinkgrab = new videolinkgrab();
videolinkgrab.savedata("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseurl
* 爬虫起点
* @return null
* */
public void savedata(string baseurl) {
map oldmap = new linkedhashmap(); // 存储链接-是否被遍历
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlinkhost = ""; // host
pattern p = pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
matcher m = p.matcher(baseurl);
if (m.find()) {
oldlinkhost = m.group();
}
oldmap.put(baseurl, false);
videolinkmap = crawllinks(oldlinkhost, oldmap);
// 遍历,然后将数据保存在数据库中
try {
connection connection = jdbcdemo.getconnection();
for (map.entry mapping : videolinkmap.entryset()) {
preparedstatement pstatement = connection
.preparestatement("insert into movie(moviename,movielink) values(?,?)");
pstatement.setstring(1, mapping.getkey());
pstatement.setstring(2, mapping.getvalue());
pstatement.executeupdate();
pstatement.close();
// system.out.println(mapping.getkey() + " : " + mapping.getvalue());
}
connection.close();
} catch (sqlexception e) {
e.printstacktrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起get请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videolinkmap
*
* @param oldlinkhost
* 域名,如:http://www.zifangsky.cn
* @param oldmap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private map crawllinks(string oldlinkhost,
map oldmap) {
map newmap = new linkedhashmap(); // 每次循环获取到的新链接
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlink = "";
for (map.entry mapping : oldmap.entryset()) {
// system.out.println("link:" + mapping.getkey() + "--------check:"
// + mapping.getvalue());
// 如果没有被遍历过
if (!mapping.getvalue()) {
oldlink = mapping.getkey();
// 发起get请求
try {
url url = new url(oldlink);
httpurlconnection connection = (httpurlconnection) url
.openconnection();
connection.setrequestmethod("get");
connection.setconnecttimeout(2500);
connection.setreadtimeout(2500);
if (connection.getresponsecode() == 200) {
inputstream inputstream = connection.getinputstream();
bufferedreader reader = new bufferedreader(
new inputstreamreader(inputstream, "utf-8"));
string line = "";
pattern pattern = null;
matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(ismoviepage(oldlink)){
boolean checktitle = false;
string title = "";
while ((line = reader.readline()) != null) {
//取出页面中的视频标题
if(!checktitle){
pattern = pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checktitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = pattern
.compile("(thunder:[^\"]+).*thunder[rr]es[tt]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videolinkmap.put(title,matcher.group(1));
system.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkurl(oldlink)){
while ((line = reader.readline()) != null) {
pattern = pattern
.compile(" 查看全部
java爬虫抓取动态网页(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
本文文章在链接的基础上爬取目标网站进一步增加难度,在目标页面抓取我们需要的内容并保存到数据库中。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一个文章类似。不同的是,考虑到这个网站的分类列表太多,如果不选择这些标签,会花费难以想象的时间。

不需要类别链接和标签链接。不要使用这些链接来爬取其他页面,只需使用页面底部的所有类型电影的选项卡即可获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。

最后一步是将获取到的所有电影的下载链接保存在videolinkmap集合中,遍历这个集合将数据保存到mysql
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.bufferedreader;
import java.io.ioexception;
import java.io.inputstream;
import java.io.inputstreamreader;
import java.net.httpurlconnection;
import java.net.malformedurlexception;
import java.net.url;
import java.sql.connection;
import java.sql.preparedstatement;
import java.sql.sqlexception;
import java.util.linkedhashmap;
import java.util.map;
import java.util.regex.matcher;
import java.util.regex.pattern;
public class videolinkgrab {
public static void main(string[] args) {
videolinkgrab videolinkgrab = new videolinkgrab();
videolinkgrab.savedata("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseurl
* 爬虫起点
* @return null
* */
public void savedata(string baseurl) {
map oldmap = new linkedhashmap(); // 存储链接-是否被遍历
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlinkhost = ""; // host
pattern p = pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
matcher m = p.matcher(baseurl);
if (m.find()) {
oldlinkhost = m.group();
}
oldmap.put(baseurl, false);
videolinkmap = crawllinks(oldlinkhost, oldmap);
// 遍历,然后将数据保存在数据库中
try {
connection connection = jdbcdemo.getconnection();
for (map.entry mapping : videolinkmap.entryset()) {
preparedstatement pstatement = connection
.preparestatement("insert into movie(moviename,movielink) values(?,?)");
pstatement.setstring(1, mapping.getkey());
pstatement.setstring(2, mapping.getvalue());
pstatement.executeupdate();
pstatement.close();
// system.out.println(mapping.getkey() + " : " + mapping.getvalue());
}
connection.close();
} catch (sqlexception e) {
e.printstacktrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起get请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videolinkmap
*
* @param oldlinkhost
* 域名,如:http://www.zifangsky.cn
* @param oldmap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private map crawllinks(string oldlinkhost,
map oldmap) {
map newmap = new linkedhashmap(); // 每次循环获取到的新链接
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlink = "";
for (map.entry mapping : oldmap.entryset()) {
// system.out.println("link:" + mapping.getkey() + "--------check:"
// + mapping.getvalue());
// 如果没有被遍历过
if (!mapping.getvalue()) {
oldlink = mapping.getkey();
// 发起get请求
try {
url url = new url(oldlink);
httpurlconnection connection = (httpurlconnection) url
.openconnection();
connection.setrequestmethod("get");
connection.setconnecttimeout(2500);
connection.setreadtimeout(2500);
if (connection.getresponsecode() == 200) {
inputstream inputstream = connection.getinputstream();
bufferedreader reader = new bufferedreader(
new inputstreamreader(inputstream, "utf-8"));
string line = "";
pattern pattern = null;
matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(ismoviepage(oldlink)){
boolean checktitle = false;
string title = "";
while ((line = reader.readline()) != null) {
//取出页面中的视频标题
if(!checktitle){
pattern = pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checktitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = pattern
.compile("(thunder:[^\"]+).*thunder[rr]es[tt]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videolinkmap.put(title,matcher.group(1));
system.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkurl(oldlink)){
while ((line = reader.readline()) != null) {
pattern = pattern
.compile("
java爬虫抓取动态网页(JAVA有什么优势?代理IP客服小范为您解答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-23 23:21
之前讲过python网络爬虫的优点,今天来详细了解一下JAVA网络爬虫。Python已经是爬虫的代名词之一,远不如Java。很多人不知道Java可以用作网络爬虫。事实上,Java 也可以用作网络爬虫,它可以做得很好。
Java网络爬虫具有良好的扩展性和扩展性,是当前搜索引擎发展的重要组成部分。比如著名的网络爬虫工具Nutch就是用Java开发的。该工具依赖于 Apache Hadoop 数据结构,并提供良好的批处理支持。接下来,一牛云代理IP客服的小粉丝将详细解答JAVA与爬虫工作的关系。
什么是JAVA爬虫
Java是一门面向对象的编程语言,它既吸收了C++语言的各种优点,又摒弃了C++中难以理解的多重继承和指针的概念。因此,Java 语言具有两个特点:功能强大且易于使用。Java语言作为静态面向对象编程语言的代表,很好地实现了面向对象的理论,让程序员能够以优雅的思维进行复杂的编程。Java具有简单、面向对象、分布式、健壮性、安全性、平台独立性和可移植性、多线程、动态等特点。Java 可以编写桌面应用程序、Web 应用程序、分布式系统和嵌入式系统应用程序。
JAVA有什么优势
以下是我自己总结的JAVA相对于其他语言的优势,仅供参考
1:在语言运行效率上,Java比脚本语言python快。在开发效率方面,脚本有着天然的优势。我觉得验证一些简短的逻辑比较方便,因为不需要更改编译器写端口函数。另外python语言有成熟的爬虫框架scrapy,即使自己写,也有成熟的网络库和解析库,开发效率非常高。但是,但是,但是!Python有一个很痛苦的编码问题,因为在设计之初没有充分考虑其他国家的语言,所以很多老库都不支持中文。
2:Java 比 Python 有一个优势,那就是线程。Java中的多线程可以使用多核,而Python中的多线程只能使用单核。
爬虫无非就是发送网络请求、解析数据、持久化数据,但是为了高效快速的抓取对应的数据,这些步骤必须在模块中进行处理(即每个模块都有对应的线程来处理),有的甚至做分布式爬虫。
既然是网络爬虫,在抓取网站信息的时候难免会遇到反爬虫程序。除了使用大量的http代理,比如一牛云代理,还需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookie的存储和设置。
当然,JAVA爬虫和优质的http代理采集可以高效的完成工作。 查看全部
java爬虫抓取动态网页(JAVA有什么优势?代理IP客服小范为您解答)
之前讲过python网络爬虫的优点,今天来详细了解一下JAVA网络爬虫。Python已经是爬虫的代名词之一,远不如Java。很多人不知道Java可以用作网络爬虫。事实上,Java 也可以用作网络爬虫,它可以做得很好。
Java网络爬虫具有良好的扩展性和扩展性,是当前搜索引擎发展的重要组成部分。比如著名的网络爬虫工具Nutch就是用Java开发的。该工具依赖于 Apache Hadoop 数据结构,并提供良好的批处理支持。接下来,一牛云代理IP客服的小粉丝将详细解答JAVA与爬虫工作的关系。
什么是JAVA爬虫
Java是一门面向对象的编程语言,它既吸收了C++语言的各种优点,又摒弃了C++中难以理解的多重继承和指针的概念。因此,Java 语言具有两个特点:功能强大且易于使用。Java语言作为静态面向对象编程语言的代表,很好地实现了面向对象的理论,让程序员能够以优雅的思维进行复杂的编程。Java具有简单、面向对象、分布式、健壮性、安全性、平台独立性和可移植性、多线程、动态等特点。Java 可以编写桌面应用程序、Web 应用程序、分布式系统和嵌入式系统应用程序。
JAVA有什么优势
以下是我自己总结的JAVA相对于其他语言的优势,仅供参考
1:在语言运行效率上,Java比脚本语言python快。在开发效率方面,脚本有着天然的优势。我觉得验证一些简短的逻辑比较方便,因为不需要更改编译器写端口函数。另外python语言有成熟的爬虫框架scrapy,即使自己写,也有成熟的网络库和解析库,开发效率非常高。但是,但是,但是!Python有一个很痛苦的编码问题,因为在设计之初没有充分考虑其他国家的语言,所以很多老库都不支持中文。
2:Java 比 Python 有一个优势,那就是线程。Java中的多线程可以使用多核,而Python中的多线程只能使用单核。
爬虫无非就是发送网络请求、解析数据、持久化数据,但是为了高效快速的抓取对应的数据,这些步骤必须在模块中进行处理(即每个模块都有对应的线程来处理),有的甚至做分布式爬虫。
既然是网络爬虫,在抓取网站信息的时候难免会遇到反爬虫程序。除了使用大量的http代理,比如一牛云代理,还需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookie的存储和设置。
当然,JAVA爬虫和优质的http代理采集可以高效的完成工作。
java爬虫抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-22 13:12
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示 查看全部
java爬虫抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示

SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示
java爬虫抓取动态网页(动态信息爬取的网络爬虫设计思路与优采云采集器类似)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-22 13:09
nlp-spider-dynamic 是一个爬取数据的组件,专门针对自然语言处理系统组件,动态信息爬取的网络爬虫
该爬虫的特点是垂直爬虫,主要针对动态网页信息的爬取。设计思路类似于优采云采集器。
请注意,此爬虫纯粹是为了个人发展兴趣而开发的。如果您有任何问题,欢迎您提交错误。电子邮件地址:
目前正在完善中,部分功能可能存在BUG,敬请期待...
1、说明
动态网站爬取和静态网站爬取最大的区别就是解析JS。
2、新手教程
不同平台的驱动目录(存放selenium需要运行的驱动)请参考本教程,自编译目前只提供windows GhostDriver已经集成在Phantomjs.exe
简单爬取示例 tasks\test_ghost 下的配置文件说明了如何配置爬虫来爬取各种网页。以下是每个文件的说明:
jd_1product.xml 演示如何抓取一个简单商品页上的信息(商品名,动态评论数)
jd_products_comments.xml 演示如何抓取一个商品的评论(内容循环提取)
jd_shop_allproducts.cml 将演示如何循环抓取一个店铺的所有商品(翻页循环抓取)
与其他任务类似,数据存储的名称和方法在配置文件中定义。配置好爬虫后,启动程序爬虫会自动生成需要保存的数据文件。
爬虫执行org.wisdomdata.main.MainCrawler,将配置文件的地址添加到tasksFiles中,启动程序。目前只能支持一个爬虫,未来可能会支持分布式爬虫。3、建筑设计
对于 Selenium,最大的限制之一是多线程并发控制。最好的方法是使用 WebDriver 单例模式。它可以使用 Spring 框架轻松实现。
垂直网络爬虫不仅仅是下载页面,下载页面只是其组件之一。
还需要针对性的页面进行处理,比如:
在页面上点击一个按钮(本质是执行一段JS);
在页面上跳转直接(比如:加载一个新的页面)
碰到特殊情况处理(比如:弹出验证码输入框,提取不到页面内容等等)
页面内容提取(包括链接,以及主题指标数据)
如何保存批量提取的链接?
垂直爬虫得到的链接比较少量。
如何增量爬取数据?
如何解决爬虫被封的问题?
这些过程是抽象的,与编程语言中的三大程序流程结构非常一致:
1、序列2、循环3、条件
通过将这三者结合起来,可以完成任何复杂的程序流程。
一个网站的垂直爬行也可以结合以上三个过程来描述:例如爬取一个网站时:
do for 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
do for 每一个内容页面(循环方式 依次抓取,结束条件)
提取信息(异步提取,同步提取)
done
点击下一页
done
比如更复杂的网站:
do
填写表单,点击提交,指定页面跳转
done
do then
do 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
提取信息
done
do then
点击某个按钮
do
do for 循环内容
提取信息(
if (未提取到信息,或者提取到信息有什么问题)
dosome
endif
done
done
点击按钮
done
done
基于这个逻辑,开发了这个系统。
4、如何组合和设计一个爬虫。爬虫设计是从编程语言具有的三种处理结构中抽象出来的。
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
每次状态转换动作后,都会生成一个新的页面,跳转前需要判断,如:(事务支持,要么全部执行原子动作,要么全部失败)
点击下一页(是否存在点击下一页这个按钮,没有怎么办?)
点击某个按钮加载一段新页面(是否存在需要这个按钮,没有怎么办?)
跳转到一个新的页面(新页面链接是否是有效链接?)
(上面的每个动作都收录一个原子动作,它执行某个按钮点击动作)
以上每个进程都是嵌套的,也就是说可能有循环判断,有循环判断等等。 #### 而相对于爬虫:####上面的每个过程都必须以打开页面为基准。
业务逻辑处理器里面包含转移动作组合
转移动作组里面包含系列内容抽取器
内容抽取器里面可能包含业务逻辑组
4.1 示例:
1) 单独爬取一个网站,需要的组件
顺序执行处理器1(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
)
2) 登录页面抓取
顺序执行处理器2(
登录动作组(无抽取动作)
顺序执行处理器1
)
3) 循环页面抓取
循环执行处理器2(
循环初始化条件
循环执行动作(抽取器)
循环结束条件
)
4) 页面点击抓取
顺序执行处理器3(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
点击页面按钮动作组(
顺序抽取器(多个单元抽取器,去重保存组件)?
)
)
以上四种情况可以组合成更复杂的情况。抽象处理为:
处理器中有动作组。每个操作都有一个提取器组。每个提取器都有一个保存组件和一个原子提取器。5、 项目相关信息。一个可以抓取动态信息的爬虫。爬虫 查看全部
java爬虫抓取动态网页(动态信息爬取的网络爬虫设计思路与优采云采集器类似)
nlp-spider-dynamic 是一个爬取数据的组件,专门针对自然语言处理系统组件,动态信息爬取的网络爬虫
该爬虫的特点是垂直爬虫,主要针对动态网页信息的爬取。设计思路类似于优采云采集器。
请注意,此爬虫纯粹是为了个人发展兴趣而开发的。如果您有任何问题,欢迎您提交错误。电子邮件地址:
目前正在完善中,部分功能可能存在BUG,敬请期待...
1、说明
动态网站爬取和静态网站爬取最大的区别就是解析JS。
2、新手教程
不同平台的驱动目录(存放selenium需要运行的驱动)请参考本教程,自编译目前只提供windows GhostDriver已经集成在Phantomjs.exe
简单爬取示例 tasks\test_ghost 下的配置文件说明了如何配置爬虫来爬取各种网页。以下是每个文件的说明:
jd_1product.xml 演示如何抓取一个简单商品页上的信息(商品名,动态评论数)
jd_products_comments.xml 演示如何抓取一个商品的评论(内容循环提取)
jd_shop_allproducts.cml 将演示如何循环抓取一个店铺的所有商品(翻页循环抓取)
与其他任务类似,数据存储的名称和方法在配置文件中定义。配置好爬虫后,启动程序爬虫会自动生成需要保存的数据文件。
爬虫执行org.wisdomdata.main.MainCrawler,将配置文件的地址添加到tasksFiles中,启动程序。目前只能支持一个爬虫,未来可能会支持分布式爬虫。3、建筑设计
对于 Selenium,最大的限制之一是多线程并发控制。最好的方法是使用 WebDriver 单例模式。它可以使用 Spring 框架轻松实现。
垂直网络爬虫不仅仅是下载页面,下载页面只是其组件之一。
还需要针对性的页面进行处理,比如:
在页面上点击一个按钮(本质是执行一段JS);
在页面上跳转直接(比如:加载一个新的页面)
碰到特殊情况处理(比如:弹出验证码输入框,提取不到页面内容等等)
页面内容提取(包括链接,以及主题指标数据)
如何保存批量提取的链接?
垂直爬虫得到的链接比较少量。
如何增量爬取数据?
如何解决爬虫被封的问题?
这些过程是抽象的,与编程语言中的三大程序流程结构非常一致:
1、序列2、循环3、条件
通过将这三者结合起来,可以完成任何复杂的程序流程。
一个网站的垂直爬行也可以结合以上三个过程来描述:例如爬取一个网站时:
do for 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
do for 每一个内容页面(循环方式 依次抓取,结束条件)
提取信息(异步提取,同步提取)
done
点击下一页
done
比如更复杂的网站:
do
填写表单,点击提交,指定页面跳转
done
do then
do 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
提取信息
done
do then
点击某个按钮
do
do for 循环内容
提取信息(
if (未提取到信息,或者提取到信息有什么问题)
dosome
endif
done
done
点击按钮
done
done
基于这个逻辑,开发了这个系统。
4、如何组合和设计一个爬虫。爬虫设计是从编程语言具有的三种处理结构中抽象出来的。
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
每次状态转换动作后,都会生成一个新的页面,跳转前需要判断,如:(事务支持,要么全部执行原子动作,要么全部失败)
点击下一页(是否存在点击下一页这个按钮,没有怎么办?)
点击某个按钮加载一段新页面(是否存在需要这个按钮,没有怎么办?)
跳转到一个新的页面(新页面链接是否是有效链接?)
(上面的每个动作都收录一个原子动作,它执行某个按钮点击动作)
以上每个进程都是嵌套的,也就是说可能有循环判断,有循环判断等等。 #### 而相对于爬虫:####上面的每个过程都必须以打开页面为基准。
业务逻辑处理器里面包含转移动作组合
转移动作组里面包含系列内容抽取器
内容抽取器里面可能包含业务逻辑组
4.1 示例:
1) 单独爬取一个网站,需要的组件
顺序执行处理器1(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
)
2) 登录页面抓取
顺序执行处理器2(
登录动作组(无抽取动作)
顺序执行处理器1
)
3) 循环页面抓取
循环执行处理器2(
循环初始化条件
循环执行动作(抽取器)
循环结束条件
)
4) 页面点击抓取
顺序执行处理器3(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
点击页面按钮动作组(
顺序抽取器(多个单元抽取器,去重保存组件)?
)
)
以上四种情况可以组合成更复杂的情况。抽象处理为:
处理器中有动作组。每个操作都有一个提取器组。每个提取器都有一个保存组件和一个原子提取器。5、 项目相关信息。一个可以抓取动态信息的爬虫。爬虫
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-21 12:01
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver 驱动程序 = new InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
复制代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面加载完毕!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
复制代码
在java端执行的代码
复制代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
复制代码
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取动态生成的网页
原来的: 查看全部
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver 驱动程序 = new InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
复制代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面加载完毕!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
复制代码
在java端执行的代码
复制代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
复制代码
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取动态生成的网页
原来的:
java爬虫抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-21 10:08
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它将等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
java爬虫抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它将等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-21 10:05
本文将介绍如何使用SeimiCrawler将页面中的信息提取成结构化数据并存入数据库,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍,SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源的ORM框架paoding-jade的使用。由于SeimiCrawler的对象池和依赖管理都是使用spring实现的,所以SeimiCrawler自然支持所有可以和spring集成的ORM框架。
要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
文章链接:[](转载请注明本文出处及链接文章) 查看全部
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
本文将介绍如何使用SeimiCrawler将页面中的信息提取成结构化数据并存入数据库,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍,SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源的ORM框架paoding-jade的使用。由于SeimiCrawler的对象池和依赖管理都是使用spring实现的,所以SeimiCrawler自然支持所有可以和spring集成的ORM框架。
要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
文章链接:[](转载请注明本文出处及链接文章)
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-21 07:22
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL去重采用Bloom filter方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (高大上)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2. 支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5.在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到: 查看全部
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL去重采用Bloom filter方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (高大上)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2. 支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5.在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
java爬虫抓取动态网页(csdn用python3简单入门爬虫()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-21 07:20
最近看了csdn微信推荐的python 3的简单入门爬虫(),想知道能不能用java技术做一个简单的爬虫?
于是这个文章诞生了,我用的是jsoup,相关需求网上可以随便搜,接口文档()也可以搜到。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
可以知道文档的内容,获取数据源的方式有以下三种:
(1) 从一段html代码字符串中获取:Document doc = Jsoup.parse(html);
(2) 从一个url获取:Document doc = Jsoup.connect(url).get();
(3)Get File input = new File("XXX.html"); 或 Document doc = Jsoup.parse(input, "UTF-8", url); 从一个 html 文件
废话不多说,进入正文。
每个页面都有相关的前端内容。这里我们先对相关页面的内容进行分析,然后根据标签分别进行分类获取,然后利用剩下的Java技术对获取到的内容进行处理。
首先,最基本的就是获取页面的所有代码,包括HTML、CSS等内容。这里也以网络盗版小说网站为例进行相关爬虫。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test1 {
//第一个,完整爬虫爬下来内容
public static void get_html(String url){
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
输出如下:
因为consle不能全部截图,所以我截图了,可以从这里看到完整的前端内容。
而我们只需要里面的小说内容,什么风格、剧本等等都不是我们需要的,所以我们先找到小说的正文,根据正文内容进行处理。
我们分析了文本的内容,发现文本的内容全部被一组id为content的div所收录。对于其他内容,我们不需要它。我们只需要id为content的div内容中的数据。那么我们可以直接使用它吗?东西。
在查询jsoup的时候发现确实有获取class、id、tag的相关方法。这些发现可以用来获取我们需要的数据,于是出现了第二个例子。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
System.out.println(tag);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
他的输出如下:
我们发现我们已经得到了最基本的内容,现在我们需要简单地处理相反的内容。这个很简单,转换成string类型,用string相关的方法来处理。
如果我们想导出保存到本地,可以使用java的io来处理和保存相关数据。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
//System.out.println(tag);
String text = tag.text();
//替换里面的空格为换行
String needs = text.replace(" ", "\n");
//得到整个html里面的tittle,方便爬虫下来的txt命名文件名
Elements titlehtml = doc.getElementsByTag("title");
String tittle = titlehtml.text();
//去掉多余的txt文件命名的文字
String head=tittle.substring(0,tittle.length()-7);
File file = new File("D:\\"+head+".txt");
FileWriter fw = new FileWriter(file);
fw.write(needs);
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
以上只是一个简单的小说。如果我们想把整本小说下载到电脑上保存,那怎么处理呢?
我们先来看看整个小说目录的前端内容分析。我们发现每章的内容其实都在一个id为list的div下。根据以上经验,我们使用list来获取。
然后得到之后,我们根据超链接标签a进行遍历。获取数据后,循环打开页面,然后爬虫下载。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test3 {
//第三个,批量选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
//模仿浏览器访问
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
//得到html中id为list下的所有内容
Element ele = doc.getElementById("list");
//得到html中id为list下,同时标签为a的下面数据
Elements tag = ele.getElementsByTag("a");
String taghref, tagtext;
for (int i = 9; i < tag.size(); i++) {
try {
//当前循环时间睡眠为10
Thread.currentThread().sleep(5000);
taghref = tag.get(i).attr("href");
tagtext = tag.get(i).text();
Document docs = Jsoup.connect(taghref)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
Element eles = docs.getElementById("content");
Elements tags = eles.getElementsByTag("div");
String texts = tags.text().replace(" ", "\r\n\r\n");
String tittle = docs.getElementsByTag("title").text();
String head = tittle.substring(0, tittle.length() - 7);
File file = new File("D:\\Desktop\\hanxiang\\" + head + ".txt");
FileWriter fw = new FileWriter(file);
fw.write(texts);
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_78387/";
get_html(url);
}
}
这里有一些解释:
1.先说.userAgent("Mozilla/5.0 (兼容; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC) ").超时(999999999)
.userAgent的意思是模拟自己作为浏览器访问,防止反爬虫网站禁止访问爬虫程序;
.timeout(999999999) 个人理解是延迟访问,也是为了防止反爬虫网站禁止访问爬虫程序;
2.为什么循环从 9 而不是 0 或 1 开始?
因为我们看小说的章节列表,发现前九章是最新的九章,而我们不需要这九章,因为我们可以在后面的循环中捕捉后九章,所以从9开始,或在循环结束时。减去9就可以了,因人而异。
3.为什么要写一个 Thread.currentThread().sleep(5000); 来循环睡眠:
因为你的频繁访问,即使你冒充浏览器,仍然会影响服务器的性能。服务器将拒绝此连接并使线程休眠。在这种情况下,它将模拟一个人浏览小说并在 5 秒内阅读。小说比较一般,可以下载几百本小说。
以上内容就是我们对jsoup前端文字的简单爬虫获取。这里需要注意反爬虫服务器报的5XX和4XX错误。 查看全部
java爬虫抓取动态网页(csdn用python3简单入门爬虫()())
最近看了csdn微信推荐的python 3的简单入门爬虫(),想知道能不能用java技术做一个简单的爬虫?
于是这个文章诞生了,我用的是jsoup,相关需求网上可以随便搜,接口文档()也可以搜到。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
可以知道文档的内容,获取数据源的方式有以下三种:
(1) 从一段html代码字符串中获取:Document doc = Jsoup.parse(html);
(2) 从一个url获取:Document doc = Jsoup.connect(url).get();
(3)Get File input = new File("XXX.html"); 或 Document doc = Jsoup.parse(input, "UTF-8", url); 从一个 html 文件
废话不多说,进入正文。
每个页面都有相关的前端内容。这里我们先对相关页面的内容进行分析,然后根据标签分别进行分类获取,然后利用剩下的Java技术对获取到的内容进行处理。
首先,最基本的就是获取页面的所有代码,包括HTML、CSS等内容。这里也以网络盗版小说网站为例进行相关爬虫。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test1 {
//第一个,完整爬虫爬下来内容
public static void get_html(String url){
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
输出如下:

因为consle不能全部截图,所以我截图了,可以从这里看到完整的前端内容。
而我们只需要里面的小说内容,什么风格、剧本等等都不是我们需要的,所以我们先找到小说的正文,根据正文内容进行处理。

我们分析了文本的内容,发现文本的内容全部被一组id为content的div所收录。对于其他内容,我们不需要它。我们只需要id为content的div内容中的数据。那么我们可以直接使用它吗?东西。
在查询jsoup的时候发现确实有获取class、id、tag的相关方法。这些发现可以用来获取我们需要的数据,于是出现了第二个例子。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
System.out.println(tag);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
他的输出如下:

我们发现我们已经得到了最基本的内容,现在我们需要简单地处理相反的内容。这个很简单,转换成string类型,用string相关的方法来处理。
如果我们想导出保存到本地,可以使用java的io来处理和保存相关数据。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
//System.out.println(tag);
String text = tag.text();
//替换里面的空格为换行
String needs = text.replace(" ", "\n");
//得到整个html里面的tittle,方便爬虫下来的txt命名文件名
Elements titlehtml = doc.getElementsByTag("title");
String tittle = titlehtml.text();
//去掉多余的txt文件命名的文字
String head=tittle.substring(0,tittle.length()-7);
File file = new File("D:\\"+head+".txt");
FileWriter fw = new FileWriter(file);
fw.write(needs);
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
以上只是一个简单的小说。如果我们想把整本小说下载到电脑上保存,那怎么处理呢?
我们先来看看整个小说目录的前端内容分析。我们发现每章的内容其实都在一个id为list的div下。根据以上经验,我们使用list来获取。
然后得到之后,我们根据超链接标签a进行遍历。获取数据后,循环打开页面,然后爬虫下载。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test3 {
//第三个,批量选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
//模仿浏览器访问
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
//得到html中id为list下的所有内容
Element ele = doc.getElementById("list");
//得到html中id为list下,同时标签为a的下面数据
Elements tag = ele.getElementsByTag("a");
String taghref, tagtext;
for (int i = 9; i < tag.size(); i++) {
try {
//当前循环时间睡眠为10
Thread.currentThread().sleep(5000);
taghref = tag.get(i).attr("href");
tagtext = tag.get(i).text();
Document docs = Jsoup.connect(taghref)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
Element eles = docs.getElementById("content");
Elements tags = eles.getElementsByTag("div");
String texts = tags.text().replace(" ", "\r\n\r\n");
String tittle = docs.getElementsByTag("title").text();
String head = tittle.substring(0, tittle.length() - 7);
File file = new File("D:\\Desktop\\hanxiang\\" + head + ".txt");
FileWriter fw = new FileWriter(file);
fw.write(texts);
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_78387/";
get_html(url);
}
}
这里有一些解释:
1.先说.userAgent("Mozilla/5.0 (兼容; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC) ").超时(999999999)
.userAgent的意思是模拟自己作为浏览器访问,防止反爬虫网站禁止访问爬虫程序;
.timeout(999999999) 个人理解是延迟访问,也是为了防止反爬虫网站禁止访问爬虫程序;
2.为什么循环从 9 而不是 0 或 1 开始?
因为我们看小说的章节列表,发现前九章是最新的九章,而我们不需要这九章,因为我们可以在后面的循环中捕捉后九章,所以从9开始,或在循环结束时。减去9就可以了,因人而异。
3.为什么要写一个 Thread.currentThread().sleep(5000); 来循环睡眠:
因为你的频繁访问,即使你冒充浏览器,仍然会影响服务器的性能。服务器将拒绝此连接并使线程休眠。在这种情况下,它将模拟一个人浏览小说并在 5 秒内阅读。小说比较一般,可以下载几百本小说。
以上内容就是我们对jsoup前端文字的简单爬虫获取。这里需要注意反爬虫服务器报的5XX和4XX错误。
java爬虫抓取动态网页(scrapy利器之scrapy+json的安装方法和使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-11-05 11:21
介绍
Scrapy是爬虫的利器,我就不多说了。
常见的爬虫结合js一般都是用来抓取网页的动态内容,就是通过操作js来获取渲染出来的内容。
现在大部分网站使用ajax+json来获取数据。所以大家都习惯了爬行,第一件事就是抓包,然后找模式抓数据。当然,有时接口加密算法非常复杂,短时间内难以破解。通过js抓取内容相对容易。这时候爬虫结合js可以更直接的达到目的。当然,数据抓取的效率没有直接抓取界面那么快。.
爬虫结合js
目前我知道的结合js的爬虫有以下3种。(如果有什么要补充的,请留言。)
selenium+webdriver(如firefox、chrome等)。这就要求你的系统有相应的浏览器,而且浏览器必须全程打开。说白了,通过浏览器看到的东西都能被抓到。一般在遇到特别复杂的验证码时,这种方法是很有必要的。当然,用浏览器爬取的效率可想而知。
硒+幻影。PhantomJS 是一个 WebKit,它的使用和 webdriver 是一样的,但是它不需要打开浏览器,可以直接在 Linux 服务器上运行,不需要 GUI,非常棒。
飞溅。与上述两种方法相比,具有以下优点。
splash 作为 js 渲染服务,是基于 Twisted 和 QT 开发的轻量级浏览器引擎,提供直接的 http api。快速、轻量的特点,便于进行分布式开发。
Splash和scrapy集成在一起,两者相互兼容,爬取效率更好。
虽然目前只有英文文档,但是已经写得很详细了,仔细阅读可以快速开发。
本文主要介绍第三种爬虫程序的使用。
安装
网上有很多安装,请自行谷歌。
建议按照官网安装方法。但是要注意,因为splash服务需要依赖docker。docker在Ubuntu下的安装方法,需要仔细阅读文档,注意Ubuntu版本。
启动
安装好docker后,官方文档给了docker启动splash容器的命令(docker run -d -p 8050:8050 scrapinghub/splash),但是一定要查阅splash文档了解相关的启动参数。
比如我启动的时候需要指定max-timeout参数。因为我长时间操作js的时候很可能会超过默认的超时时间,以防万一我设置成3600(一小时),但是对于js操作时间不长的同学,注意不要设置max随机-超时。
docker run -d -p 8050:8050 scrapinghub/splash --max-timeout 3600
用
关于scrapy-splash的教程主要来自scrapy-splash github和splash官方文档。另外,给一个我最近写的scrapy-splash代码。代码主要是实现js页面不断切换,然后抓取数据。以下是代码的核心部分。因为splash使用lua脚本来实现js操作,看官方文档和这段代码,基本可以上手splash了。
fly_spider.py
class FlySpider(scrapy.Spider):
name = "FlySpider"
house_pc_index_url='xxxxx'
def __init__(self):
client = MongoClient("mongodb://name:[email protected]:27017/myspace")
db = client.myspace
self.fly = db["fly"]
def start_requests(self):
for x in xrange(0,1):
try:
script = """
function process_one(splash)
splash:runjs("$('#next_title').click()")
splash:wait(1)
local content=splash:evaljs("$('.scrollbar_content').html()")
return content
end
function process_mul(splash,totalPageNum)
local res={}
for i=1,totalPageNum,1 do
res[i]=process_one(splash)
end
return res
end
function main(splash)
splash.resource_timeout = 1800
local tmp=splash:get_cookies()
splash:add_cookie('PHPSESSID', splash.args.cookies['PHPSESSID'],"/", "www.feizhiyi.com")
splash:add_cookie('FEIZHIYI_LOGGED_USER', splash.args.cookies['FEIZHIYI_LOGGED_USER'],"/", "www.feizhiyi.com" )
splash:autoload("http://cdn.bootcss.com/jquery/ ... 6quot;)
assert(splash:go{
splash.args.url,
http_method=splash.args.http_method,
headers=splash.args.headers,
})
assert(splash:wait(splash.args.wait) )
return {res=process_mul(splash,100)}
end
"""
agent = random.choice(agents)
print "------cookie---------"
headers={
"User-Agent":agent,
"Referer":"xxxxxxx",
}
splash_args = {
'wait': 3,
"http_method":"GET",
# "images":0,
"timeout":1800,
"render_all":1,
"headers":headers,
'lua_source': script,
"cookies":cookies,
# "proxy":"http://101.200.153.236:8123",
}
yield SplashRequest(self.house_pc_index_url, self.parse_result, endpoint='execute',args=splash_args,dont_filter=True)
# +"&page="+str(x+1)
except Exception, e:
print e.__doc__
print e.message
pass
如果你想更深入地使用scrapy-splash,请研究splash官方文档。另外,欢迎留言交流学习。 查看全部
java爬虫抓取动态网页(scrapy利器之scrapy+json的安装方法和使用方法)
介绍
Scrapy是爬虫的利器,我就不多说了。
常见的爬虫结合js一般都是用来抓取网页的动态内容,就是通过操作js来获取渲染出来的内容。
现在大部分网站使用ajax+json来获取数据。所以大家都习惯了爬行,第一件事就是抓包,然后找模式抓数据。当然,有时接口加密算法非常复杂,短时间内难以破解。通过js抓取内容相对容易。这时候爬虫结合js可以更直接的达到目的。当然,数据抓取的效率没有直接抓取界面那么快。.
爬虫结合js
目前我知道的结合js的爬虫有以下3种。(如果有什么要补充的,请留言。)
selenium+webdriver(如firefox、chrome等)。这就要求你的系统有相应的浏览器,而且浏览器必须全程打开。说白了,通过浏览器看到的东西都能被抓到。一般在遇到特别复杂的验证码时,这种方法是很有必要的。当然,用浏览器爬取的效率可想而知。
硒+幻影。PhantomJS 是一个 WebKit,它的使用和 webdriver 是一样的,但是它不需要打开浏览器,可以直接在 Linux 服务器上运行,不需要 GUI,非常棒。
飞溅。与上述两种方法相比,具有以下优点。
splash 作为 js 渲染服务,是基于 Twisted 和 QT 开发的轻量级浏览器引擎,提供直接的 http api。快速、轻量的特点,便于进行分布式开发。
Splash和scrapy集成在一起,两者相互兼容,爬取效率更好。
虽然目前只有英文文档,但是已经写得很详细了,仔细阅读可以快速开发。
本文主要介绍第三种爬虫程序的使用。
安装
网上有很多安装,请自行谷歌。
建议按照官网安装方法。但是要注意,因为splash服务需要依赖docker。docker在Ubuntu下的安装方法,需要仔细阅读文档,注意Ubuntu版本。
启动
安装好docker后,官方文档给了docker启动splash容器的命令(docker run -d -p 8050:8050 scrapinghub/splash),但是一定要查阅splash文档了解相关的启动参数。
比如我启动的时候需要指定max-timeout参数。因为我长时间操作js的时候很可能会超过默认的超时时间,以防万一我设置成3600(一小时),但是对于js操作时间不长的同学,注意不要设置max随机-超时。
docker run -d -p 8050:8050 scrapinghub/splash --max-timeout 3600
用
关于scrapy-splash的教程主要来自scrapy-splash github和splash官方文档。另外,给一个我最近写的scrapy-splash代码。代码主要是实现js页面不断切换,然后抓取数据。以下是代码的核心部分。因为splash使用lua脚本来实现js操作,看官方文档和这段代码,基本可以上手splash了。
fly_spider.py
class FlySpider(scrapy.Spider):
name = "FlySpider"
house_pc_index_url='xxxxx'
def __init__(self):
client = MongoClient("mongodb://name:[email protected]:27017/myspace")
db = client.myspace
self.fly = db["fly"]
def start_requests(self):
for x in xrange(0,1):
try:
script = """
function process_one(splash)
splash:runjs("$('#next_title').click()")
splash:wait(1)
local content=splash:evaljs("$('.scrollbar_content').html()")
return content
end
function process_mul(splash,totalPageNum)
local res={}
for i=1,totalPageNum,1 do
res[i]=process_one(splash)
end
return res
end
function main(splash)
splash.resource_timeout = 1800
local tmp=splash:get_cookies()
splash:add_cookie('PHPSESSID', splash.args.cookies['PHPSESSID'],"/", "www.feizhiyi.com")
splash:add_cookie('FEIZHIYI_LOGGED_USER', splash.args.cookies['FEIZHIYI_LOGGED_USER'],"/", "www.feizhiyi.com" )
splash:autoload("http://cdn.bootcss.com/jquery/ ... 6quot;)
assert(splash:go{
splash.args.url,
http_method=splash.args.http_method,
headers=splash.args.headers,
})
assert(splash:wait(splash.args.wait) )
return {res=process_mul(splash,100)}
end
"""
agent = random.choice(agents)
print "------cookie---------"
headers={
"User-Agent":agent,
"Referer":"xxxxxxx",
}
splash_args = {
'wait': 3,
"http_method":"GET",
# "images":0,
"timeout":1800,
"render_all":1,
"headers":headers,
'lua_source': script,
"cookies":cookies,
# "proxy":"http://101.200.153.236:8123",
}
yield SplashRequest(self.house_pc_index_url, self.parse_result, endpoint='execute',args=splash_args,dont_filter=True)
# +"&page="+str(x+1)
except Exception, e:
print e.__doc__
print e.message
pass
如果你想更深入地使用scrapy-splash,请研究splash官方文档。另外,欢迎留言交流学习。
java爬虫抓取动态网页( 全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-05 00:18
全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
解析动态内容
根据权威机构发布的全球互联网无障碍审计报告,全球约四分之三的网站是通过JavaScript动态生成的,即在浏览器窗口中“查看网页”。在 HTML 代码中找不到“源代码”,这意味着我们用来获取数据的方法无法正常工作。解决这个问题基本上有两种方案,一种是JavaScript逆向工程;另一种是渲染 JavaScript 以获取渲染的内容。
JavaScript 逆向工程
我们以“360图片”网站为例来说明什么是JavaScript逆向工程。其实所谓的 JavaScript 逆向工程就是通过 Ajax 技术找到一个接口来动态获取数据。在浏览器中输入,打开“360图片”的“美女”版块,如下图。
但是当我们在浏览器中使用右键菜单“显示网页源代码”时,我们惊讶地发现页面的HTML代码连接到一个
没有标签,那么我们看到的图片是如何显示的呢?原来所有的图片都是通过JavaScript动态加载的,获取这些图片数据的web API接口可以在浏览器“开发者工具”的“网络”中找到,如下图所示。
那么结论就很简单了。只要找到这些网络API接口,就可以通过这些接口获取数据。当然,在实际开发过程中,我们可能需要分析这些接口的参数以及接口返回的数据,了解每个参数的含义以及返回的JSON数据的格式,这样我们才能在我们的程序中使用这些数据履带。
如何从web API中获取JSON格式的数据,提取出我们需要的内容,在之前的“文件与异常”一文中已经说明,这里不再赘述。
使用硒
虽然很多网站保护了自己的web API接口,增加了获取数据的难度,但只要足够努力,大部分都是可以逆向工程的,但是在实际开发中,我们可以通过浏览器渲染引擎来避免这些繁琐的工作,WebKit 是使用的渲染引擎。
WebKit 的代码始于 1998 年的 KHTML 项目,当时它是 Konqueror 浏览器的渲染引擎。2001 年,苹果从该项目的代码中衍生出 WebKit,并将其应用到 Safari 浏览器中。早期的 Chrome 浏览器也使用了这个内核。在Python中,我们可以通过Qt框架获取WebKit引擎,用它来渲染页面,获取动态内容。此内容请阅读《爬虫技术:动态页面抓取超级指南》一文。
如果你不打算使用上述方法来渲染页面和获取动态内容,其实还有一个选择就是使用自动化测试工具Selenium,它提供了浏览器自动化的API接口,这样你就可以通过操纵浏览器内容获得动态。首先,您可以使用 pip 安装 Selenium。
pip3 install selenium
下面以《阿里V任务》的“直播服务”为例,演示如何使用Selenium获取动态内容和抓拍主播图片。
import requestsfrom bs4 import BeautifulSoupdef main(): resp = requests.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(resp.text, 'lxml') for img_tag in soup.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
运行上面的程序会发现没有输出,因为根本找不到页面的HTML代码
标签。接下来我们使用Selenium获取页面上的动态内容,然后提取锚点图片。
from bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef main(): driver = webdriver.Chrome() driver.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(driver.page_source, 'lxml') for img_tag in soup.body.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果你想控制其他浏览器,可以创建相应的浏览器对象,如Firefox、IE等。 运行上面的程序,如果看到如下所示的错误信息,说明我们还没有添加Chrome浏览器驱动PATH环境变量,我们也没有在程序中指定Chrome浏览器驱动的位置。
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chr ... /home
为了解决以上问题,可以到Selenium官方网站找到浏览器驱动的下载链接,下载需要的驱动。Linux或者macOS下可以使用下面的命令设置PATH环境变量,Windows下配置环境变量也很简单,不明白的可以看懂。
export PATH=$PATH:/Users/Hao/Downloads/Tools/chromedriver/
其中/Users/Hao/Downloads/Tools/chromedriver/是chromedriver所在的路径。 查看全部
java爬虫抓取动态网页(
全球互联网可访问性审计报告,说明什么是JavaScript逆向工程)
解析动态内容
根据权威机构发布的全球互联网无障碍审计报告,全球约四分之三的网站是通过JavaScript动态生成的,即在浏览器窗口中“查看网页”。在 HTML 代码中找不到“源代码”,这意味着我们用来获取数据的方法无法正常工作。解决这个问题基本上有两种方案,一种是JavaScript逆向工程;另一种是渲染 JavaScript 以获取渲染的内容。
JavaScript 逆向工程
我们以“360图片”网站为例来说明什么是JavaScript逆向工程。其实所谓的 JavaScript 逆向工程就是通过 Ajax 技术找到一个接口来动态获取数据。在浏览器中输入,打开“360图片”的“美女”版块,如下图。
但是当我们在浏览器中使用右键菜单“显示网页源代码”时,我们惊讶地发现页面的HTML代码连接到一个
没有标签,那么我们看到的图片是如何显示的呢?原来所有的图片都是通过JavaScript动态加载的,获取这些图片数据的web API接口可以在浏览器“开发者工具”的“网络”中找到,如下图所示。
那么结论就很简单了。只要找到这些网络API接口,就可以通过这些接口获取数据。当然,在实际开发过程中,我们可能需要分析这些接口的参数以及接口返回的数据,了解每个参数的含义以及返回的JSON数据的格式,这样我们才能在我们的程序中使用这些数据履带。
如何从web API中获取JSON格式的数据,提取出我们需要的内容,在之前的“文件与异常”一文中已经说明,这里不再赘述。
使用硒
虽然很多网站保护了自己的web API接口,增加了获取数据的难度,但只要足够努力,大部分都是可以逆向工程的,但是在实际开发中,我们可以通过浏览器渲染引擎来避免这些繁琐的工作,WebKit 是使用的渲染引擎。
WebKit 的代码始于 1998 年的 KHTML 项目,当时它是 Konqueror 浏览器的渲染引擎。2001 年,苹果从该项目的代码中衍生出 WebKit,并将其应用到 Safari 浏览器中。早期的 Chrome 浏览器也使用了这个内核。在Python中,我们可以通过Qt框架获取WebKit引擎,用它来渲染页面,获取动态内容。此内容请阅读《爬虫技术:动态页面抓取超级指南》一文。
如果你不打算使用上述方法来渲染页面和获取动态内容,其实还有一个选择就是使用自动化测试工具Selenium,它提供了浏览器自动化的API接口,这样你就可以通过操纵浏览器内容获得动态。首先,您可以使用 pip 安装 Selenium。
pip3 install selenium
下面以《阿里V任务》的“直播服务”为例,演示如何使用Selenium获取动态内容和抓拍主播图片。
import requestsfrom bs4 import BeautifulSoupdef main(): resp = requests.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(resp.text, 'lxml') for img_tag in soup.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
运行上面的程序会发现没有输出,因为根本找不到页面的HTML代码
标签。接下来我们使用Selenium获取页面上的动态内容,然后提取锚点图片。
from bs4 import BeautifulSoupfrom selenium import webdriverfrom selenium.webdriver.common.keys import Keysdef main(): driver = webdriver.Chrome() driver.get('https://v.taobao.com/v/content ... %2339;) soup = BeautifulSoup(driver.page_source, 'lxml') for img_tag in soup.body.select('img[src]'): print(img_tag.attrs['src'])if __name__ == '__main__': main()
在上面的程序中,我们使用 Selenium 来控制 Chrome 浏览器。如果你想控制其他浏览器,可以创建相应的浏览器对象,如Firefox、IE等。 运行上面的程序,如果看到如下所示的错误信息,说明我们还没有添加Chrome浏览器驱动PATH环境变量,我们也没有在程序中指定Chrome浏览器驱动的位置。
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chr ... /home
为了解决以上问题,可以到Selenium官方网站找到浏览器驱动的下载链接,下载需要的驱动。Linux或者macOS下可以使用下面的命令设置PATH环境变量,Windows下配置环境变量也很简单,不明白的可以看懂。
export PATH=$PATH:/Users/Hao/Downloads/Tools/chromedriver/
其中/Users/Hao/Downloads/Tools/chromedriver/是chromedriver所在的路径。
java爬虫抓取动态网页(谷歌浏览器的检查功能分析(图)为什么呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-04 16:12
目标网址网址:
%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=
使用谷歌浏览器的检查功能分析网站,发现需要抓取的内容在'movie-list-item playable unwatched'类下。
好了,我们按照之前的方式爬一下,看看。
url='https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
res=requests.get(url)
res.encoding= 'utf-8'#该网页是以utf-8的编码形式显示的
soup=BeautifulSoup(res.text, 'html.parser')#使用美丽汤解析网页内容
print(soup)
查看打印结果,发现get信息中没有电影的相关信息。为什么是这样?因为这个页面上的所有电影信息都是动态加载的。
转动鼠标滚轮下拉页面,你会发现加载的内容越来越多,查看显示器,'movie-list-item playable unwatched'类的列数增加了。看来静态的网站 集对动态加载的网站 不起作用,那么如何解决呢?
点击显示器的网络--->XHR。继续向下滑动滚轮,你会发现Name下的文件增加了!
点击文件末尾的start=0&limit=20和start=20&limit=20的文件,对比查看,发现这正是我们要找的信息。
通过对比,我们现在可以大胆猜想,start指的是起始电影序列号,limit是每个请求显示的电影数量,信息以json格式存储。我们再次点击Headers,发现如下:
发现获取的内容是通过GET url获取的:';interval_id=100%3A90&action=&start=0&limit=20'。
好的,现在我们知道如何获取数据了。经过测试,我们其实可以直接start=0 limit=256直接得到所有的top10数据。但是我们还是按照网站的要求,一次拿到20份。代码显示如下:
import requests
import json
#爬取豆瓣电影分类排行榜 - 动作片top10%的电影名、评分和豆瓣链接
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start={}&limit=20'
filminfolist=[]#存放结果
for i in range(0,300,20):
aimurl=url.format(i)
res=requests.get(aimurl)
jd=json.loads(res.text)#改成json格式方便读取数据
for j in jd:
filminfo={}#以字典存储单条数据
filminfo['title']=j['title']
filminfo['score'] = j['score']
filminfo['url'] = j['url']
filminfolist.append(filminfo)
打印filminfolist的结果如下:
{'title':'这个杀手不太冷','score':'9.4','url':''}
{'title':'七武士','score':'9.2','url':''}
{'title':'蝙蝠侠:黑暗骑士','score':'9.1','url':''}
{'title':'指环王3:无敌之王','score':'9.1','url':''}
{'title':'Fight Club','score':'9.0','url':''}
{'title':'指环王2:两塔','score':'9.0','url':''}
{'title':'General title','score':'9.0','url':''}
{'title':'魔戒1:魔戒再现','score':'8.9','url':''}
......
稍微展开一下:
初识DataFrame
使用Data Frame格式将刚才的数据保存到excel中,这是通过使用包pandas实现的。
代码显示如下:
import pandas
df=pandas.DataFrame(filminfolist)
df.to_excel('D:\\douban.xlsx')
总结:对于动态加载的网页,需要多观察监视器,分析实际爬取的页面。美利堂解析html格式,json解析json格式。当然,也可以使用正则表达式进行分析。 查看全部
java爬虫抓取动态网页(谷歌浏览器的检查功能分析(图)为什么呢?)
目标网址网址:
%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action=
使用谷歌浏览器的检查功能分析网站,发现需要抓取的内容在'movie-list-item playable unwatched'类下。
好了,我们按照之前的方式爬一下,看看。
url='https://movie.douban.com/typerank?type_name=%E5%8A%A8%E4%BD%9C&type=5&interval_id=100:90&action='
res=requests.get(url)
res.encoding= 'utf-8'#该网页是以utf-8的编码形式显示的
soup=BeautifulSoup(res.text, 'html.parser')#使用美丽汤解析网页内容
print(soup)
查看打印结果,发现get信息中没有电影的相关信息。为什么是这样?因为这个页面上的所有电影信息都是动态加载的。
转动鼠标滚轮下拉页面,你会发现加载的内容越来越多,查看显示器,'movie-list-item playable unwatched'类的列数增加了。看来静态的网站 集对动态加载的网站 不起作用,那么如何解决呢?
点击显示器的网络--->XHR。继续向下滑动滚轮,你会发现Name下的文件增加了!
点击文件末尾的start=0&limit=20和start=20&limit=20的文件,对比查看,发现这正是我们要找的信息。
通过对比,我们现在可以大胆猜想,start指的是起始电影序列号,limit是每个请求显示的电影数量,信息以json格式存储。我们再次点击Headers,发现如下:
发现获取的内容是通过GET url获取的:';interval_id=100%3A90&action=&start=0&limit=20'。
好的,现在我们知道如何获取数据了。经过测试,我们其实可以直接start=0 limit=256直接得到所有的top10数据。但是我们还是按照网站的要求,一次拿到20份。代码显示如下:
import requests
import json
#爬取豆瓣电影分类排行榜 - 动作片top10%的电影名、评分和豆瓣链接
url='https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start={}&limit=20'
filminfolist=[]#存放结果
for i in range(0,300,20):
aimurl=url.format(i)
res=requests.get(aimurl)
jd=json.loads(res.text)#改成json格式方便读取数据
for j in jd:
filminfo={}#以字典存储单条数据
filminfo['title']=j['title']
filminfo['score'] = j['score']
filminfo['url'] = j['url']
filminfolist.append(filminfo)
打印filminfolist的结果如下:
{'title':'这个杀手不太冷','score':'9.4','url':''}
{'title':'七武士','score':'9.2','url':''}
{'title':'蝙蝠侠:黑暗骑士','score':'9.1','url':''}
{'title':'指环王3:无敌之王','score':'9.1','url':''}
{'title':'Fight Club','score':'9.0','url':''}
{'title':'指环王2:两塔','score':'9.0','url':''}
{'title':'General title','score':'9.0','url':''}
{'title':'魔戒1:魔戒再现','score':'8.9','url':''}
......
稍微展开一下:
初识DataFrame
使用Data Frame格式将刚才的数据保存到excel中,这是通过使用包pandas实现的。
代码显示如下:
import pandas
df=pandas.DataFrame(filminfolist)
df.to_excel('D:\\douban.xlsx')
总结:对于动态加载的网页,需要多观察监视器,分析实际爬取的页面。美利堂解析html格式,json解析json格式。当然,也可以使用正则表达式进行分析。
java爬虫抓取动态网页(PHPHTML数据爬虫的设计思路及应用的优势)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-04 15:11
内容
1. 为什么要爬行?
“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫是如何抓取网页数据的?
首先,您需要了解网页的三个特征:
每个网页都有自己的 URL(统一资源定位器)来定位网页。HTML(超文本标记语言)用于描述页面信息。该网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
爬虫的设计思路:
首先确定需要爬取的网址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一种。如果需要数据保存
湾 如果还有其他网址,继续第二步4. Python爬虫的优点?语言优缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运行效率和性能几乎是最强的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面学习路线:解析服务器对应内容:采集动态HTML,验证码处理Scrapy框架:分布式策略:爬虫、反爬虫、反爬虫的较量:6.爬虫分类6.1 一般爬虫:
1. 定义:搜索引擎的爬虫系统
2. 目标:抓取互联网上的所有网页,放在本地服务器上形成备份,并对这些网页进行相关处理(提取关键词,去除广告),最终为用户提供一个借口可以参观
3. 获取过程:
a) 先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中获取 URL,然后通过 NDS 解析得到主机 IP,然后到这个 IP 对应的服务器下载 HTML 页面,保存到搜索引擎的本地服务器,然后把抓取到的进入抓取队列的 URL
c) 分析网页内容,找出网页中的其他网址链接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取新的网站 URL:
主动提交网址给搜索引擎:在其他网站中设置网站的外链:其他网站上面的友情链接搜索引擎会和DNS服务商合作,可以快速< @收录新网站
5.一般爬虫注意事项
一般的爬虫不是可以爬的东西,它必须遵守规则:
机器人协议:协议会规定一般爬虫爬取网页的权限
我们可以访问不同网页的机器人权限
6.通用爬虫一般流程:
7. 一般爬虫的缺点
只能提供与文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。人类语义检索侧重爬虫的优势
DNS域名解析为IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员针对某个内容编写的爬虫-> 面向主题的爬虫,面向需求的爬虫 查看全部
java爬虫抓取动态网页(PHPHTML数据爬虫的设计思路及应用的优势)
内容
1. 为什么要爬行?
“大数据时代”,数据获取方式:
从第三方数据平台购买数据爬虫数据2. 什么是爬虫?
抓取网页数据的程序
3. 爬虫是如何抓取网页数据的?
首先,您需要了解网页的三个特征:
每个网页都有自己的 URL(统一资源定位器)来定位网页。HTML(超文本标记语言)用于描述页面信息。该网页使用 HTTP/HTTPS(超文本传输协议)来传输 HTML 数据。
爬虫的设计思路:
首先确定需要爬取的网址,通过HTTP/HTTPS协议获取对应的HTML页面,提取HTML页面中的有用数据:
一种。如果需要数据保存
湾 如果还有其他网址,继续第二步4. Python爬虫的优点?语言优缺点
PHP
世界上最好的语言
对于多线程,异步支持不好,并发处理不够
爪哇
完善的网络爬虫生态系统
Java语言本身繁琐,代码量大,数据重构成本高
C/C++
运行效率和性能几乎是最强的
学习成本高
Python
语法优美,代码简洁,开发效率高,模块多
5.抓取HTML页面学习路线:解析服务器对应内容:采集动态HTML,验证码处理Scrapy框架:分布式策略:爬虫、反爬虫、反爬虫的较量:6.爬虫分类6.1 一般爬虫:
1. 定义:搜索引擎的爬虫系统
2. 目标:抓取互联网上的所有网页,放在本地服务器上形成备份,并对这些网页进行相关处理(提取关键词,去除广告),最终为用户提供一个借口可以参观
3. 获取过程:
a) 先选择一部分已有的URL,将这些URL放入爬取队列
b) 从队列中获取 URL,然后通过 NDS 解析得到主机 IP,然后到这个 IP 对应的服务器下载 HTML 页面,保存到搜索引擎的本地服务器,然后把抓取到的进入抓取队列的 URL
c) 分析网页内容,找出网页中的其他网址链接,继续执行第二步,直到爬取结束
4.搜索引擎如何获取新的网站 URL:
主动提交网址给搜索引擎:在其他网站中设置网站的外链:其他网站上面的友情链接搜索引擎会和DNS服务商合作,可以快速< @收录新网站
5.一般爬虫注意事项
一般的爬虫不是可以爬的东西,它必须遵守规则:
机器人协议:协议会规定一般爬虫爬取网页的权限
我们可以访问不同网页的机器人权限
6.通用爬虫一般流程:
7. 一般爬虫的缺点
只能提供与文本相关的内容(HTML、WORD、PDF)等,不能提供多媒体文件(msic、图片、视频)等二进制文件。人类语义检索侧重爬虫的优势
DNS域名解析为IP:在命令框中输入ping获取服务器的IP
6.2 关注爬虫:
爬虫程序员针对某个内容编写的爬虫-> 面向主题的爬虫,面向需求的爬虫
java爬虫抓取动态网页(所说的问题试试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-11-02 23:08
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,底层将启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,然后获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是HtmlUnit提供了对执行javascript的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面时总是出错。我还没有找到错误在哪里。分析网上查询的结果,最可能的错误原因是htmlunit在执行某些带参数的请求时,参数的顺序或编码问题会导致请求失败并报错。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064");
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn");
11 list.add("http://www.sohu.com");
12 list.add("http://www.163.com");
13 list.add("http://www.qq.com");
14
15 long start,end;
16
17 for(int i=0;i 查看全部
java爬虫抓取动态网页(所说的问题试试)
是的,最后还是用Selenium来实现上一篇我提到的问题。我没有尝试其他任何东西。我只试过火狐引擎。整体效果还是可以接受的。
继续昨天的话题,既然要实现上一篇提到的问题,就需要一个可以执行js代码的框架。我的第一选择是 htmlunit。先简单介绍一下htmlunit。以下段落摘自互联网。
htmlunit 是一个开源的java 页面分析工具。启动 htmlunit 后,底层将启动一个无界面浏览器。用户可以指定浏览器类型:firefox、ie等,如果不指定,默认使用INTERNET_EXPLORER_7:
WebClient webClient = new WebClient(BrowserVersion.FIREFOX_3_6);
通过一个简单的调用:
HtmlPage 页面 = webClient.getPage(url);
可以得到页面的HtmlPage表示,然后通过:
InputStream 是 = targetPage.getWebResponse().getContentAsStream()
可以获取页面的输入流,然后获取页面的源代码,这对于网络爬虫项目非常有用。
当然,你也可以从页面中获取更多的页面元素。
很重要的一点是HtmlUnit提供了对执行javascript的支持:
page.executeJavaScript(javascript)
js执行后返回一个ScriptResult对象,通过该对象可以获取js执行后的页面等信息。默认情况下,内部浏览器执行js后,会做一次页面跳转,跳转到执行js后生成的新页面。如果js执行失败,页面跳转将不会被执行。
最后可以通过获取 page.executeJavaScript(javascript).getNewPage() 来获取执行后的页面。也就是说,这里需要人工执行javascript。显然这不符合我的初衷。另外,也可能是我水平太差了。我在爬新浪新闻页面时总是出错。我还没有找到错误在哪里。分析网上查询的结果,最可能的错误原因是htmlunit在执行某些带参数的请求时,参数的顺序或编码问题会导致请求失败并报错。关键是我运行后没有得到我需要的结果。
然后我寻找了另一种解决方案。这时候我找到了SeleniumWebDriver,这就是我需要的解决方案。
参考资料和例子后,就可以开始使用了。示例代码如下。
<p> 1 File pathToBinary = new File("D:\\Program Files (x86)\\Mozilla Firefox\\firefox.exe");
2 FirefoxBinary ffBinary = new FirefoxBinary(pathToBinary);
3 FirefoxProfile firefoxProfile = new FirefoxProfile();
4 FirefoxDriver driver = new FirefoxDriver(ffBinary,firefoxProfile);
5
6
7 driver.get("http://cq.qq.com/baoliao/detail.htm?294064";);
8
9 ArrayList list = new ArrayList();
10 list.add("http://www.sina.com.cn";);
11 list.add("http://www.sohu.com";);
12 list.add("http://www.163.com";);
13 list.add("http://www.qq.com";);
14
15 long start,end;
16
17 for(int i=0;i
java爬虫抓取动态网页(java爬虫抓取动态网页还没抓取该怎么办?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-01 15:17
java爬虫抓取动态网页时,上方网页已经抓取,但是下方网页还没抓取,该怎么办?首先解释一下下方网页此时的抓取策略,若是使用f12进入开发者选项,选择“打开控制台”,在搜索框输入“element.screenshot”即可找到下方网页提示的代码。在抓取上方动态网页的同时,下方的网页也同时抓取到了。而我们要抓取的是通过上方get方法获取的下方java源码页,该代码如下:图1上方页的源码如图2所示,代码第二行是ajax回调方法,简单来说就是用了上方的get方法提交信息到服务器,服务器返回参数给ajax的代码,然后通过这个返回值去爬取下方代码,根据dom去处理动态页面中有用的数据。
在上方代码中有个重要的逻辑:若上方代码里某条数据内容并没有就返回“error_element.thumbnailfoa()”这个错误页面(或是通过f12打开github开发者工具的时候提示该选项无效,因为这个选项是开发者在向浏览器上传数据的时候,获取到该网页的代码,然后上传的。)那么,通过该代码抓取的该代码页也就不会有下方代码的java返回值,此时下方页就返回空。
大家可以打开下方代码看看效果,图3所示的情况是获取到的所有数据都用“url”关键字加了formdata值,我们没有wxss代码,也就不能通过style来定位formdata值,正确做法为下方代码抓取该代码页同时,将获取到的返回值setinfos添加到本页数据下方。(注意:要定位formdata,由上方源码结果来看,该get方法只传递参数,没有将该参数作为返回值)。
最后总结一下,如果上方代码的动态页数据是通过js注入上传,那么会再次上传数据返回,不然就返回空值。如果上方代码中不再有对外setdata数据,那么原先我们获取到的上方代码页就不会再返回这条数据。 查看全部
java爬虫抓取动态网页(java爬虫抓取动态网页还没抓取该怎么办?(图))
java爬虫抓取动态网页时,上方网页已经抓取,但是下方网页还没抓取,该怎么办?首先解释一下下方网页此时的抓取策略,若是使用f12进入开发者选项,选择“打开控制台”,在搜索框输入“element.screenshot”即可找到下方网页提示的代码。在抓取上方动态网页的同时,下方的网页也同时抓取到了。而我们要抓取的是通过上方get方法获取的下方java源码页,该代码如下:图1上方页的源码如图2所示,代码第二行是ajax回调方法,简单来说就是用了上方的get方法提交信息到服务器,服务器返回参数给ajax的代码,然后通过这个返回值去爬取下方代码,根据dom去处理动态页面中有用的数据。
在上方代码中有个重要的逻辑:若上方代码里某条数据内容并没有就返回“error_element.thumbnailfoa()”这个错误页面(或是通过f12打开github开发者工具的时候提示该选项无效,因为这个选项是开发者在向浏览器上传数据的时候,获取到该网页的代码,然后上传的。)那么,通过该代码抓取的该代码页也就不会有下方代码的java返回值,此时下方页就返回空。
大家可以打开下方代码看看效果,图3所示的情况是获取到的所有数据都用“url”关键字加了formdata值,我们没有wxss代码,也就不能通过style来定位formdata值,正确做法为下方代码抓取该代码页同时,将获取到的返回值setinfos添加到本页数据下方。(注意:要定位formdata,由上方源码结果来看,该get方法只传递参数,没有将该参数作为返回值)。
最后总结一下,如果上方代码的动态页数据是通过js注入上传,那么会再次上传数据返回,不然就返回空值。如果上方代码中不再有对外setdata数据,那么原先我们获取到的上方代码页就不会再返回这条数据。
java爬虫抓取动态网页(解析解析动态网页的一种方法:仅供参考左边的抓取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-26 23:06
网页是静态的和动态的。一般我们可以通过抓包来找出真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候,我们希望直接得到js加载后的最终网页数据。如果使用java,java是如何抓取动态网页数据的?下面就和精灵代理聊一聊动态网页的爬取方法。
如果只是抓取互联网上的特定数据,比如静态网页,那就再简单不过了,直接使用Jsoup:
Documentdoc=Jsoup.connect(url).timeout(2000).get();
获取文档,然后做你想做的。
但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者是用户滑动浏览触发的js加载数据,这样的网页使用 Jsoup 显然得不到你想要的数据。
后来使用Selenium获取动态网页的数据,就可以成功获取到数据了。打包程序在机器上运行,开始测试,结果不太理想,经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。
一种解析动态网页的方法:
首先是动态网页,既然是动态的,浏览器加载网页后,必须唤醒对服务器的网络请求。如果我拿到网络请求的url,模拟参数,自己发送请求,解析数据也不是更好。
抓包工具:fiddle
打开浏览器,打开目标url,然后就可以看到fiddle打开这个页面的所有网络请求,并一一查看网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。专注于文本格式的请求。然后右键copy->justurl,把url复制到浏览器,看看能得到什么。最后,18行请求是Data接口,可以直接获取数据,而且是json格式!
java如何抓取动态网页数据?上面分享了一种解析动态网页的方法,仅供参考! 查看全部
java爬虫抓取动态网页(解析解析动态网页的一种方法:仅供参考左边的抓取方法)
网页是静态的和动态的。一般我们可以通过抓包来找出真正的数据实体是哪个异步请求获取的,但是获取数据的请求链接也可能是其他js生成的。这时候,我们希望直接得到js加载后的最终网页数据。如果使用java,java是如何抓取动态网页数据的?下面就和精灵代理聊一聊动态网页的爬取方法。
如果只是抓取互联网上的特定数据,比如静态网页,那就再简单不过了,直接使用Jsoup:
Documentdoc=Jsoup.connect(url).timeout(2000).get();
获取文档,然后做你想做的。
但是一旦遇到一些动态生成的网站,就不行了,因为数据是在网页加载后执行js代码加载的,或者是用户滑动浏览触发的js加载数据,这样的网页使用 Jsoup 显然得不到你想要的数据。
后来使用Selenium获取动态网页的数据,就可以成功获取到数据了。打包程序在机器上运行,开始测试,结果不太理想,经常出现内存溢出,或者浏览器升级导致驱动和浏览器版本不匹配等一系列问题。
一种解析动态网页的方法:
首先是动态网页,既然是动态的,浏览器加载网页后,必须唤醒对服务器的网络请求。如果我拿到网络请求的url,模拟参数,自己发送请求,解析数据也不是更好。
抓包工具:fiddle
打开浏览器,打开目标url,然后就可以看到fiddle打开这个页面的所有网络请求,并一一查看网络请求:
先看左边的图标,直接跳过图片。显然,我们需要的是数据。专注于文本格式的请求。然后右键copy->justurl,把url复制到浏览器,看看能得到什么。最后,18行请求是Data接口,可以直接获取数据,而且是json格式!
java如何抓取动态网页数据?上面分享了一种解析动态网页的方法,仅供参考!
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-26 23:05
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录Java代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录Java代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
很明显,这是一个带有Java渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('')
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?网页上有很多文件。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。 查看全部
java爬虫抓取动态网页(如何利用Webkit从JS渲染网页中实现浏览器非常有趣)
当我们抓取网页时,我们会使用一定的规则从返回的 HTML 数据中提取有效信息。但是如果网页中收录Java代码,就必须经过渲染处理才能得到原创数据。此时,如果我们仍然使用常规方法从中抓取数据,那么我们将一无所获。浏览器知道如何处理这些代码并显示出来,但是我们的程序应该如何处理这些代码呢?接下来介绍一个简单粗暴的抓取收录Java代码的网页信息的方法。
大多数人使用 lxml 和 BeautifulSoup 两个包来提取数据。在本文中,我不会介绍任何爬虫框架内容,因为我只使用最基础的 lxml 包来处理数据。也许你很好奇我为什么更喜欢 lxml。那是因为 lxml 使用元素遍历来处理数据,而不是像 BeautifulSoup 那样使用正则表达式来提取数据。在这篇文章中,我将介绍一个非常有趣的案例——我突然发现我的文章出现在最近的Pycoders周刊第147期,所以我想爬取Pycoders周刊中所有文件的链接。
很明显,这是一个带有Java渲染的网页。我想抓取网页中的所有文件信息和相应的链接信息。所以我该怎么做?首先,我们无法使用 HTTP 方法获取任何信息。
进口请求
从 lxml 导入 html
# 存储响应
response = requests.get('')
# 从响应体创建 lxml 树
树 = html.fromstring(response.text)
# 在响应中查找所有锚标记
print tree.xpath('//div[@class="campaign"]/a/@href')
当我们运行上面的代码时,我们无法获得任何信息。这怎么可能?网页上有很多文件。接下来我们需要考虑如何解决这个问题?
如何获取内容信息?
接下来,我将介绍如何使用 Web kit 从 JS 渲染网页中获取数据。什么是网络套件?Web kit 可以实现浏览器可以处理的任何内容。对于某些浏览器,Web kit 是底层的网页渲染工具。Web kit 是 QT 库的一部分,所以如果你已经安装了 QT 和 PyQT4 库,那么你可以直接运行它。
您可以使用命令行安装软件库:
须藤 apt-get 安装 python-qt4
现在所有的准备工作已经完成,我们将使用一种全新的方法来提取信息。
解决方案
我们首先通过Web kit发送请求信息,然后等待网页完全加载并赋值给一个变量。接下来,我们使用 lxml 从 HTML 数据中提取有效信息。这个过程需要一段时间,但你会惊讶地发现整个网页都被完全加载了。
导入系统
从 PyQt4.QtGui 导入 *
从 PyQt4.Qtcore 导入 *
从 PyQt4.QtWebKit 导入 *
类渲染(QWebPage):
def __init__(self, url):
self.app = QApplication(sys.argv)
QWebPage.__init__(self)
self.loadFinished.connect(self._loadFinished)
self.mainFrame().load(QUrl(url))
self.app.exec_()
def _loadFinished(self, result):
self.frame = self.mainFrame()
self.app.quit()
Render 类可用于呈现网页。当我们创建一个新的Render类时,它可以加载url中的所有信息并将其存储在一个新的框架中。
java爬虫抓取动态网页(spider,大数据的兴起,爬虫应用被提升到前所未有高度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-26 14:06
又称蜘蛛,起源于百度和谷歌。但随着近年来大数据的兴起,爬虫应用被提升到了前所未有的高度。就大数据而言,实际上,自有数据或用户生成数据的平台非常有限。只有电商、微博这样的平台才能避免自给自足。许多数据分析和挖掘公司使用网络爬虫来获得不同的结果。元数据采集,最终用于它,构建自己的大数据集成平台。其中,舆情、财经股票分析、广告数据挖掘等都属于这一类。技术层面描述如下。
(1)传统爬虫,如nutch、hetriex等,比较适合抓取简单的页面,即没有复杂请求的页面。但是随着web2.0的兴起,越来越网站 很多动态交互技术,比如ajax,用来提升用户体验,页面需要登录才能访问等,无能为力,或者二次开发的开发成本太高,很多人给使用它们。
(2)定制爬虫,对于一些大数据平台,如微博、电商、大众点评等,页面交互复杂,用户登录后才能访问,往往需要定制开发一些爬虫项目,比如微博专用的微博爬虫、大众点评的自定义爬虫、豆瓣书评的评论爬虫都是典型的自定义爬虫,比传统爬虫难度大,需要相应的定制分析工具和能力,只有扎实的编程功底,优化效率,克服验证码,拒绝服务等反爬措施,才能做出这种高效的爬虫,现在主流还是基于httpclient+jsoup来处理网络下载和页面分析。
(3) 一种新型爬虫,结合一些成熟的第三方工具,如c/c++实现的webkit、htmlunit、phantomjs、casper等工具。共同点是最大限度地模拟人的方式浏览器的操作,用(1)、(2))不容易解决的问题,比如模拟登录、复杂参数的获取、复杂的页面交互等,这些问题往往可以轻松解决通过使用以上工具,其最大的缺点是基于真实浏览器的操作,所以效率比较低,所以往往需要结合httpclient来达到高效实用的目的。 on phantomjs 也证明了这一点,下一步可以结合起来。完成微博爬虫的模拟登录获取cookies,然后使用httpclient+jsoup解决海量数据的抓取,是一个非常不错的微博爬虫方案。
因为它需要的知识相对较多,所以它的待遇比web开发高,增长的速度和速度比web开发高很多。
三、自然语言处理 查看全部
java爬虫抓取动态网页(spider,大数据的兴起,爬虫应用被提升到前所未有高度)
又称蜘蛛,起源于百度和谷歌。但随着近年来大数据的兴起,爬虫应用被提升到了前所未有的高度。就大数据而言,实际上,自有数据或用户生成数据的平台非常有限。只有电商、微博这样的平台才能避免自给自足。许多数据分析和挖掘公司使用网络爬虫来获得不同的结果。元数据采集,最终用于它,构建自己的大数据集成平台。其中,舆情、财经股票分析、广告数据挖掘等都属于这一类。技术层面描述如下。
(1)传统爬虫,如nutch、hetriex等,比较适合抓取简单的页面,即没有复杂请求的页面。但是随着web2.0的兴起,越来越网站 很多动态交互技术,比如ajax,用来提升用户体验,页面需要登录才能访问等,无能为力,或者二次开发的开发成本太高,很多人给使用它们。
(2)定制爬虫,对于一些大数据平台,如微博、电商、大众点评等,页面交互复杂,用户登录后才能访问,往往需要定制开发一些爬虫项目,比如微博专用的微博爬虫、大众点评的自定义爬虫、豆瓣书评的评论爬虫都是典型的自定义爬虫,比传统爬虫难度大,需要相应的定制分析工具和能力,只有扎实的编程功底,优化效率,克服验证码,拒绝服务等反爬措施,才能做出这种高效的爬虫,现在主流还是基于httpclient+jsoup来处理网络下载和页面分析。
(3) 一种新型爬虫,结合一些成熟的第三方工具,如c/c++实现的webkit、htmlunit、phantomjs、casper等工具。共同点是最大限度地模拟人的方式浏览器的操作,用(1)、(2))不容易解决的问题,比如模拟登录、复杂参数的获取、复杂的页面交互等,这些问题往往可以轻松解决通过使用以上工具,其最大的缺点是基于真实浏览器的操作,所以效率比较低,所以往往需要结合httpclient来达到高效实用的目的。 on phantomjs 也证明了这一点,下一步可以结合起来。完成微博爬虫的模拟登录获取cookies,然后使用httpclient+jsoup解决海量数据的抓取,是一个非常不错的微博爬虫方案。
因为它需要的知识相对较多,所以它的待遇比web开发高,增长的速度和速度比web开发高很多。
三、自然语言处理
java爬虫抓取动态网页(Web爬虫的结构(可创建一个网站地图)下载)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-25 23:07
Heritrix
Heritrix 是一个开源、可扩展的网络爬虫项目。 Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。
WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX包两部分组成。
WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
阿拉蕾
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
J-蜘蛛
J-Spider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站的结构(可以创建一个网站@ > map),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
主轴
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
蛛形纲动物
Arachnid:是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在网站上使用页面上的每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
警报
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
snoics-爬行动物
snoics-reptile 是用纯 Java 开发的。它是一个用于网站 图像捕获的工具。可以使用配置文件中提供的URL入口来转换这个网站所有可以使用的浏览器通过GET获取的资源都是本地抓取的,包括网页和各种类型的文件,比如图片、flash、 mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
下载链接:
snoics-reptile2.0.part1.rar
snoics-reptile2.0.part2.rar
snoics-reptile2.0-doc.rar
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现对 text/xml 的操作 查看全部
java爬虫抓取动态网页(Web爬虫的结构(可创建一个网站地图)下载)
Heritrix
Heritrix 是一个开源、可扩展的网络爬虫项目。 Heritrix 的设计严格遵循 robots.txt 文件和 META 机器人标签的排除说明。
WebSPHINX
WebSPHINX 是 Java 类包和网络爬虫的交互式开发环境。网络爬虫(也称为机器人或蜘蛛)是可以自动浏览和处理网页的程序。 WebSPHINX由爬虫工作平台和WebSPHINX包两部分组成。
WebLech
WebLech 是一个强大的网站下载和镜像工具。支持根据功能需求下载网站,并尽可能模仿标准网页浏览器的行为。 WebLech 有功能控制台,使用多线程操作。
阿拉蕾
Arale 主要供个人使用,不像其他爬虫那样专注于页面索引。 Arale 可以下载整个网站或网站上的部分资源。 Arale 还可以将动态页面映射到静态页面。
J-蜘蛛
J-Spider:是一个完全可配置和可定制的 Web Spider 引擎。可以用它来检查网站错误(内部服务器错误等),网站内外部链接检查,分析网站的结构(可以创建一个网站@ > map),下载整个网站,也可以写一个JSpider插件扩展你需要的功能。
主轴
spindle 是一个建立在 Lucene 工具包上的 Web 索引/搜索工具。它包括一个用于创建索引的 HTTP 蜘蛛和一个用于搜索这些索引的搜索类。主轴项目提供了一套JSP标签库,让那些基于JSP的站点无需开发任何Java类即可添加搜索功能。
蛛形纲动物
Arachnid:是一个基于 Java 的网络蜘蛛框架。它收录一个简单的 HTML 解析器,可以分析收录 HTML 内容的输入流。通过实现Arachnid子类,可以开发一个简单的Web蜘蛛,可以在网站上使用页面上的每个页面解析完成后,添加几行代码调用。 Arachnid 下载包中收录两个蜘蛛应用程序示例,用于演示如何使用该框架。
警报
LARM 可为 Jakarta Lucene 搜索引擎框架的用户提供纯 Java 搜索解决方案。它收录索引文件、数据库表和用于索引网站的爬虫的方法。
乔博
JoBo 是一个用于下载整个网站的简单工具。它本质上是一个网络蜘蛛。与其他下载工具相比,它的主要优点是能够自动填写表单(如自动登录)和使用cookies来处理会话。 JoBo 也有灵活的下载规则(如:URL、大小、MIME 类型等)来限制下载。
snoics-爬行动物
snoics-reptile 是用纯 Java 开发的。它是一个用于网站 图像捕获的工具。可以使用配置文件中提供的URL入口来转换这个网站所有可以使用的浏览器通过GET获取的资源都是本地抓取的,包括网页和各种类型的文件,比如图片、flash、 mp3、zip、rar、exe等文件。整个网站可以完全转移到硬盘上,保持原有的网站结构准确不变。只需将捕获到的网站放入Web服务器(如Apache)即可实现完整的网站镜像。
下载链接:
snoics-reptile2.0.part1.rar
snoics-reptile2.0.part2.rar
snoics-reptile2.0-doc.rar
网络收获
Web-Harvest 是一个 Java 开源 Web 数据提取工具。它可以采集指定的网页并从这些网页中提取有用的数据。 Web-Harvest 主要使用 XSLT、XQuery、正则表达式等技术来实现对 text/xml 的操作
java爬虫抓取动态网页(Java爬虫简单的网络爬虫原理是怎样的?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-10-25 12:12
Java爬虫的简单实现
最近学习搜索,需要了解一下网络爬虫的知识。虽然有很多强大的开源爬虫,为了了解原理,我还是抱着学习的态度写了一个简单的网络爬虫。
先介绍一下各个类的功能:
DownloadPage.java 的作用是下载这个超链接的页面源代码。
FunctionUtils.java的作用是提供不同的静态方法,包括:页面链接正则表达式匹配、获取URL链接元素、判断是否创建文件、获取页面Url并转换为标准Url、拦截网页源文件 目标内容。
HrefOfPage.java 的作用是获取页面源代码的超链接。
UrlDataHanding.java 的作用是集成各种类,实现url获取数据到数据处理类。
UrlQueue.java 未访问的 Url 队列。
VisitedUrlQueue.java 已访问的 URL 队列。
下面介绍每个类的源代码: DownloadPage.java 该类使用HttpClient 组件。FunctionUtils.java的方法是静态方法HrefOfPage.java,是获取页面的超链接UrlDataHanding.java,主要用于从未访问队列获取URL、下载页面、分析URL、保存访问过的URL等操作。实现 Runnable 接口 UrlQueue.java。该类主要用于存储未访问的 URL 队列。VisitedUrlQueue.java 主要用于存储访问过的 URL,使用 HashSet 保存,主要是考虑到每个访问过的 URL 是不同的。HashSet 正好满足这个要求 Test.java 这个类是一个测试类
说明:因为我抓的是oschina,里面的url正则表达式不适合其他网站,需要自己修改。也可以写xml来配置。 查看全部
java爬虫抓取动态网页(Java爬虫简单的网络爬虫原理是怎样的?-八维教育)
Java爬虫的简单实现
最近学习搜索,需要了解一下网络爬虫的知识。虽然有很多强大的开源爬虫,为了了解原理,我还是抱着学习的态度写了一个简单的网络爬虫。
先介绍一下各个类的功能:
DownloadPage.java 的作用是下载这个超链接的页面源代码。
FunctionUtils.java的作用是提供不同的静态方法,包括:页面链接正则表达式匹配、获取URL链接元素、判断是否创建文件、获取页面Url并转换为标准Url、拦截网页源文件 目标内容。
HrefOfPage.java 的作用是获取页面源代码的超链接。
UrlDataHanding.java 的作用是集成各种类,实现url获取数据到数据处理类。
UrlQueue.java 未访问的 Url 队列。
VisitedUrlQueue.java 已访问的 URL 队列。
下面介绍每个类的源代码: DownloadPage.java 该类使用HttpClient 组件。FunctionUtils.java的方法是静态方法HrefOfPage.java,是获取页面的超链接UrlDataHanding.java,主要用于从未访问队列获取URL、下载页面、分析URL、保存访问过的URL等操作。实现 Runnable 接口 UrlQueue.java。该类主要用于存储未访问的 URL 队列。VisitedUrlQueue.java 主要用于存储访问过的 URL,使用 HashSet 保存,主要是考虑到每个访问过的 URL 是不同的。HashSet 正好满足这个要求 Test.java 这个类是一个测试类
说明:因为我抓的是oschina,里面的url正则表达式不适合其他网站,需要自己修改。也可以写xml来配置。
java爬虫抓取动态网页(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-10-24 05:15
本文文章在链接的基础上爬取目标网站进一步增加难度,在目标页面抓取我们需要的内容并保存到数据库中。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一个文章类似。不同的是,考虑到这个网站的分类列表太多,如果不选择这些标签,会花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接来爬取其他页面,只需使用页面底部的所有类型电影的选项卡即可获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是将获取到的所有电影的下载链接保存在videolinkmap集合中,遍历这个集合将数据保存到mysql
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.bufferedreader;
import java.io.ioexception;
import java.io.inputstream;
import java.io.inputstreamreader;
import java.net.httpurlconnection;
import java.net.malformedurlexception;
import java.net.url;
import java.sql.connection;
import java.sql.preparedstatement;
import java.sql.sqlexception;
import java.util.linkedhashmap;
import java.util.map;
import java.util.regex.matcher;
import java.util.regex.pattern;
public class videolinkgrab {
public static void main(string[] args) {
videolinkgrab videolinkgrab = new videolinkgrab();
videolinkgrab.savedata("http://www.80s.la/movie/list/-2015----p");
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseurl
* 爬虫起点
* @return null
* */
public void savedata(string baseurl) {
map oldmap = new linkedhashmap(); // 存储链接-是否被遍历
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlinkhost = ""; // host
pattern p = pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
matcher m = p.matcher(baseurl);
if (m.find()) {
oldlinkhost = m.group();
}
oldmap.put(baseurl, false);
videolinkmap = crawllinks(oldlinkhost, oldmap);
// 遍历,然后将数据保存在数据库中
try {
connection connection = jdbcdemo.getconnection();
for (map.entry mapping : videolinkmap.entryset()) {
preparedstatement pstatement = connection
.preparestatement("insert into movie(moviename,movielink) values(?,?)");
pstatement.setstring(1, mapping.getkey());
pstatement.setstring(2, mapping.getvalue());
pstatement.executeupdate();
pstatement.close();
// system.out.println(mapping.getkey() + " : " + mapping.getvalue());
}
connection.close();
} catch (sqlexception e) {
e.printstacktrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起get请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videolinkmap
*
* @param oldlinkhost
* 域名,如:http://www.zifangsky.cn
* @param oldmap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private map crawllinks(string oldlinkhost,
map oldmap) {
map newmap = new linkedhashmap(); // 每次循环获取到的新链接
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlink = "";
for (map.entry mapping : oldmap.entryset()) {
// system.out.println("link:" + mapping.getkey() + "--------check:"
// + mapping.getvalue());
// 如果没有被遍历过
if (!mapping.getvalue()) {
oldlink = mapping.getkey();
// 发起get请求
try {
url url = new url(oldlink);
httpurlconnection connection = (httpurlconnection) url
.openconnection();
connection.setrequestmethod("get");
connection.setconnecttimeout(2500);
connection.setreadtimeout(2500);
if (connection.getresponsecode() == 200) {
inputstream inputstream = connection.getinputstream();
bufferedreader reader = new bufferedreader(
new inputstreamreader(inputstream, "utf-8"));
string line = "";
pattern pattern = null;
matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(ismoviepage(oldlink)){
boolean checktitle = false;
string title = "";
while ((line = reader.readline()) != null) {
//取出页面中的视频标题
if(!checktitle){
pattern = pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checktitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = pattern
.compile("(thunder:[^\"]+).*thunder[rr]es[tt]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videolinkmap.put(title,matcher.group(1));
system.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkurl(oldlink)){
while ((line = reader.readline()) != null) {
pattern = pattern
.compile(" 查看全部
java爬虫抓取动态网页(本篇文章抓取目标网站的链接的基础上,进一步提高难度)
本文文章在链接的基础上爬取目标网站进一步增加难度,在目标页面抓取我们需要的内容并保存到数据库中。这里的测试用例使用了我经常使用的电影下载网站()。本来想抓取网站上所有电影的下载链接,后来觉得时间太长,所以改成抓取2015年电影的下载链接。
一原理介绍
其实原理和第一个文章类似。不同的是,考虑到这个网站的分类列表太多,如果不选择这些标签,会花费难以想象的时间。
不需要类别链接和标签链接。不要使用这些链接来爬取其他页面,只需使用页面底部的所有类型电影的选项卡即可获取其他页面上的电影列表。同时,对于电影详情页,只爬取了片名和迅雷下载链接,并没有进行深度爬取。详情页上的一些推荐电影和其他链接不是必需的。
最后一步是将获取到的所有电影的下载链接保存在videolinkmap集合中,遍历这个集合将数据保存到mysql
二代码实现
实现原理上面已经说了,代码中有详细的注释,这里就不多说了,代码如下:
<p>
package action;
import java.io.bufferedreader;
import java.io.ioexception;
import java.io.inputstream;
import java.io.inputstreamreader;
import java.net.httpurlconnection;
import java.net.malformedurlexception;
import java.net.url;
import java.sql.connection;
import java.sql.preparedstatement;
import java.sql.sqlexception;
import java.util.linkedhashmap;
import java.util.map;
import java.util.regex.matcher;
import java.util.regex.pattern;
public class videolinkgrab {
public static void main(string[] args) {
videolinkgrab videolinkgrab = new videolinkgrab();
videolinkgrab.savedata("http://www.80s.la/movie/list/-2015----p";);
}
/**
* 将获取到的数据保存在数据库中
*
* @param baseurl
* 爬虫起点
* @return null
* */
public void savedata(string baseurl) {
map oldmap = new linkedhashmap(); // 存储链接-是否被遍历
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlinkhost = ""; // host
pattern p = pattern.compile("(https?://)?[^/\\s]*"); // 比如:http://www.zifangsky.cn
matcher m = p.matcher(baseurl);
if (m.find()) {
oldlinkhost = m.group();
}
oldmap.put(baseurl, false);
videolinkmap = crawllinks(oldlinkhost, oldmap);
// 遍历,然后将数据保存在数据库中
try {
connection connection = jdbcdemo.getconnection();
for (map.entry mapping : videolinkmap.entryset()) {
preparedstatement pstatement = connection
.preparestatement("insert into movie(moviename,movielink) values(?,?)");
pstatement.setstring(1, mapping.getkey());
pstatement.setstring(2, mapping.getvalue());
pstatement.executeupdate();
pstatement.close();
// system.out.println(mapping.getkey() + " : " + mapping.getvalue());
}
connection.close();
} catch (sqlexception e) {
e.printstacktrace();
}
}
/**
* 抓取一个网站所有可以抓取的网页链接,在思路上使用了广度优先算法 对未遍历过的新链接不断发起get请求, 一直到遍历完整个集合都没能发现新的链接
* 则表示不能发现新的链接了,任务结束
*
* 对一个链接发起请求时,对该网页用正则查找我们所需要的视频链接,找到后存入集合videolinkmap
*
* @param oldlinkhost
* 域名,如:http://www.zifangsky.cn
* @param oldmap
* 待遍历的链接集合
*
* @return 返回所有抓取到的视频下载链接集合
* */
private map crawllinks(string oldlinkhost,
map oldmap) {
map newmap = new linkedhashmap(); // 每次循环获取到的新链接
map videolinkmap = new linkedhashmap(); // 视频下载链接
string oldlink = "";
for (map.entry mapping : oldmap.entryset()) {
// system.out.println("link:" + mapping.getkey() + "--------check:"
// + mapping.getvalue());
// 如果没有被遍历过
if (!mapping.getvalue()) {
oldlink = mapping.getkey();
// 发起get请求
try {
url url = new url(oldlink);
httpurlconnection connection = (httpurlconnection) url
.openconnection();
connection.setrequestmethod("get");
connection.setconnecttimeout(2500);
connection.setreadtimeout(2500);
if (connection.getresponsecode() == 200) {
inputstream inputstream = connection.getinputstream();
bufferedreader reader = new bufferedreader(
new inputstreamreader(inputstream, "utf-8"));
string line = "";
pattern pattern = null;
matcher matcher = null;
//电影详情页面,取出其中的视频下载链接,不继续深入抓取其他页面
if(ismoviepage(oldlink)){
boolean checktitle = false;
string title = "";
while ((line = reader.readline()) != null) {
//取出页面中的视频标题
if(!checktitle){
pattern = pattern.compile("([^\\s]+).*?");
matcher = pattern.matcher(line);
if(matcher.find()){
title = matcher.group(1);
checktitle = true;
continue;
}
}
// 取出页面中的视频下载链接
pattern = pattern
.compile("(thunder:[^\"]+).*thunder[rr]es[tt]itle=\"[^\"]*\"");
matcher = pattern.matcher(line);
if (matcher.find()) {
videolinkmap.put(title,matcher.group(1));
system.out.println("视频名称: "
+ title + " ------ 视频链接:"
+ matcher.group(1));
break; //当前页面已经检测完毕
}
}
}
//电影列表页面
else if(checkurl(oldlink)){
while ((line = reader.readline()) != null) {
pattern = pattern
.compile("
java爬虫抓取动态网页(JAVA有什么优势?代理IP客服小范为您解答)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-23 23:21
之前讲过python网络爬虫的优点,今天来详细了解一下JAVA网络爬虫。Python已经是爬虫的代名词之一,远不如Java。很多人不知道Java可以用作网络爬虫。事实上,Java 也可以用作网络爬虫,它可以做得很好。
Java网络爬虫具有良好的扩展性和扩展性,是当前搜索引擎发展的重要组成部分。比如著名的网络爬虫工具Nutch就是用Java开发的。该工具依赖于 Apache Hadoop 数据结构,并提供良好的批处理支持。接下来,一牛云代理IP客服的小粉丝将详细解答JAVA与爬虫工作的关系。
什么是JAVA爬虫
Java是一门面向对象的编程语言,它既吸收了C++语言的各种优点,又摒弃了C++中难以理解的多重继承和指针的概念。因此,Java 语言具有两个特点:功能强大且易于使用。Java语言作为静态面向对象编程语言的代表,很好地实现了面向对象的理论,让程序员能够以优雅的思维进行复杂的编程。Java具有简单、面向对象、分布式、健壮性、安全性、平台独立性和可移植性、多线程、动态等特点。Java 可以编写桌面应用程序、Web 应用程序、分布式系统和嵌入式系统应用程序。
JAVA有什么优势
以下是我自己总结的JAVA相对于其他语言的优势,仅供参考
1:在语言运行效率上,Java比脚本语言python快。在开发效率方面,脚本有着天然的优势。我觉得验证一些简短的逻辑比较方便,因为不需要更改编译器写端口函数。另外python语言有成熟的爬虫框架scrapy,即使自己写,也有成熟的网络库和解析库,开发效率非常高。但是,但是,但是!Python有一个很痛苦的编码问题,因为在设计之初没有充分考虑其他国家的语言,所以很多老库都不支持中文。
2:Java 比 Python 有一个优势,那就是线程。Java中的多线程可以使用多核,而Python中的多线程只能使用单核。
爬虫无非就是发送网络请求、解析数据、持久化数据,但是为了高效快速的抓取对应的数据,这些步骤必须在模块中进行处理(即每个模块都有对应的线程来处理),有的甚至做分布式爬虫。
既然是网络爬虫,在抓取网站信息的时候难免会遇到反爬虫程序。除了使用大量的http代理,比如一牛云代理,还需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookie的存储和设置。
当然,JAVA爬虫和优质的http代理采集可以高效的完成工作。 查看全部
java爬虫抓取动态网页(JAVA有什么优势?代理IP客服小范为您解答)
之前讲过python网络爬虫的优点,今天来详细了解一下JAVA网络爬虫。Python已经是爬虫的代名词之一,远不如Java。很多人不知道Java可以用作网络爬虫。事实上,Java 也可以用作网络爬虫,它可以做得很好。
Java网络爬虫具有良好的扩展性和扩展性,是当前搜索引擎发展的重要组成部分。比如著名的网络爬虫工具Nutch就是用Java开发的。该工具依赖于 Apache Hadoop 数据结构,并提供良好的批处理支持。接下来,一牛云代理IP客服的小粉丝将详细解答JAVA与爬虫工作的关系。
什么是JAVA爬虫
Java是一门面向对象的编程语言,它既吸收了C++语言的各种优点,又摒弃了C++中难以理解的多重继承和指针的概念。因此,Java 语言具有两个特点:功能强大且易于使用。Java语言作为静态面向对象编程语言的代表,很好地实现了面向对象的理论,让程序员能够以优雅的思维进行复杂的编程。Java具有简单、面向对象、分布式、健壮性、安全性、平台独立性和可移植性、多线程、动态等特点。Java 可以编写桌面应用程序、Web 应用程序、分布式系统和嵌入式系统应用程序。
JAVA有什么优势
以下是我自己总结的JAVA相对于其他语言的优势,仅供参考
1:在语言运行效率上,Java比脚本语言python快。在开发效率方面,脚本有着天然的优势。我觉得验证一些简短的逻辑比较方便,因为不需要更改编译器写端口函数。另外python语言有成熟的爬虫框架scrapy,即使自己写,也有成熟的网络库和解析库,开发效率非常高。但是,但是,但是!Python有一个很痛苦的编码问题,因为在设计之初没有充分考虑其他国家的语言,所以很多老库都不支持中文。
2:Java 比 Python 有一个优势,那就是线程。Java中的多线程可以使用多核,而Python中的多线程只能使用单核。
爬虫无非就是发送网络请求、解析数据、持久化数据,但是为了高效快速的抓取对应的数据,这些步骤必须在模块中进行处理(即每个模块都有对应的线程来处理),有的甚至做分布式爬虫。
既然是网络爬虫,在抓取网站信息的时候难免会遇到反爬虫程序。除了使用大量的http代理,比如一牛云代理,还需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookie的存储和设置。
当然,JAVA爬虫和优质的http代理采集可以高效的完成工作。
java爬虫抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-22 13:12
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示 查看全部
java爬虫抓取动态网页(基于浏览器内核来开发的动态页面渲染处理服务器(组图))
前言
曾几何时,从动态页面中提取信息(ajax、内部js二次渲染等)一直是爬虫开发者的心病。总之,真的没有合适的工具。尤其是在Java中,像htmlunit这样的工具可以算是解析动态页面的神器,但是还不够完善,无法达到浏览器级别的解析效果,遇到稍微复杂一点的页面就不行了。在经历了各种痛苦和仇恨之后,作者决定开发一个动态页面渲染处理服务器,专门用于抓取、监控和测试此类场景。要达到浏览器级别的效果,必须基于浏览器内核进行开发。幸运的是,我们有一个开源的 webkit。幸运的是,我们有 QtWebkit,它对开发人员更加友好。
SeimiAgent 简介
SeimiAgent 是基于 QtWebkit 开发的 webkit 服务,可以在服务器端后台运行。它可以通过SeimiAgent提供的http接口向SeimiAgent发送加载请求(要加载的URL和该页面接受的渲染时间或使用什么代理等参数),通过SeimiAgent加载并渲染动态页面要处理,然后直接将渲染好的页面返回给调用者进行后续处理,所以运行的SeimiAgent服务是语言无关的,任何语言或框架都可以通过SeimiAgent提供标准的http接口来获取服务。SeimiAgent 的加载和渲染环境都是通用浏览器级别的,所以不用担心他处理动态页面的能力。目前,SeimiAgent 只支持返回渲染的 HTML 文档。未来将增加图片快照和PDF支持,以方便更多样化的使用需求。
使用演示
SeimiCrawler 简介
SeimiCrawler 是一个敏捷、独立部署、支持分布式Java 爬虫框架。希望最大限度地降低新手开发高可用低性能爬虫系统的门槛,提高爬虫系统的开发效率。在 SeimiCrawler 的世界里,大部分人只需要关心编写爬行的业务逻辑,剩下的 Seimi 会为你做。在设计上,SeimiCrawler 极大的受到了 Python 的爬虫框架 Scrapy 的启发,同时结合了 Java 语言的特性和 Spring 的特性,希望在国内使用更高效的 XPath 来更方便、更通用地解析 HTML,所以SeimiCrawler默认为HTML解析解析器为JsoupXpath(独立扩展项目,不收录在jsoup中),
集成和部署 SeimiAgent
下载和解压就不显示了,上面的动态图片里也有演示,下载地址可以在SeimiAgent主页上找到。进入SeimiAgent的bin目录,执行:
./SeimiAgent -p 8000
这就是启动SeimiAgent服务,监听8000端口。接下来其实可以用任何语言通过http请求发送加载页面的请求,然后得到渲染结果。当然,我们这里介绍的是SeimiCrawler是如何集成和使用SeimiAgent的。
SeimiCrawler 配置
SeimiCrawler 在 v0.3.0 版本中内置了对 SeimiAgent 的支持。开发者只需要配置SeimiAgent的地址和端口,然后在生成具体的Request时选择是否提交给SeimiAgent,并指定如何提交。让我们直接在评论中解释最后一个完整的例子:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Value;
/**
* 这个例子演示如何使用SeimiAgent进行复杂动态页面信息抓取
* @author 汪浩淼 et.tw@163.com
* @since 2016/4/14.
*/
@Crawler(name = "seimiagent")
public class SeimiAgentDemo extends BaseSeimiCrawler{
/**
* 在resource/config/seimi.properties中配置方便更换,当然也可以自行根据情况使用自己的统一配置中心等服务。这里配置SeimiAgent服务所在地址。
*/
@Value("${seimiAgentHost}")
private String seimiAgentHost;
//SeimiAgent监听的端口好,如上文中的8000
@Value("${seimiAgentPort}")
private int seimiAgentPort;
@Override
public String[] startUrls() {
return new String[]{"https://www.baidu.com"};
}
@Override
public String seimiAgentHost() {
return this.seimiAgentHost;
}
@Override
public int seimiAgentPort() {
return this.seimiAgentPort;
}
@Override
public void start(Response response) {
Request seimiAgentReq = Request.build("https://www.souyidai.com","getTotalTransactions")
.useSeimiAgent()
// 告诉SeimiAgent针对这个请求是否使用cookie,如果没有设置使用当前Crawler关于cookie使用条件作为默认值。
//.setSeimiAgentUseCookie(true)
// 设置全部load完成后给SeimiAgent多少时间用于执行js并渲染页面,单位为毫秒
.setSeimiAgentRenderTime(5000);
push(seimiAgentReq);
}
/**
* 获取搜易贷首页总成交额
* @param response
*/
public void getTotalTransactions(Response response){
JXDocument doc = response.document();
try {
String trans = StringUtils.join(doc.sel("//div[@class='homepage-amount']/div[@class='number font-arial']/div/span/text()"),"");
logger.info("Final Res:{}",trans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
配置文件seimi.properties
seimiAgentHost=127.0.0.1
seimiAgentPort=8000
启动
public class Boot {
public static void main(String[] args){
Seimi s = new Seimi();
s.start("seimiagent");
}
}
SeimiCrawler 启动后,您可以看到您想要的搜一贷交易总额。
完整演示地址
演示
java爬虫抓取动态网页(动态信息爬取的网络爬虫设计思路与优采云采集器类似)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-22 13:09
nlp-spider-dynamic 是一个爬取数据的组件,专门针对自然语言处理系统组件,动态信息爬取的网络爬虫
该爬虫的特点是垂直爬虫,主要针对动态网页信息的爬取。设计思路类似于优采云采集器。
请注意,此爬虫纯粹是为了个人发展兴趣而开发的。如果您有任何问题,欢迎您提交错误。电子邮件地址:
目前正在完善中,部分功能可能存在BUG,敬请期待...
1、说明
动态网站爬取和静态网站爬取最大的区别就是解析JS。
2、新手教程
不同平台的驱动目录(存放selenium需要运行的驱动)请参考本教程,自编译目前只提供windows GhostDriver已经集成在Phantomjs.exe
简单爬取示例 tasks\test_ghost 下的配置文件说明了如何配置爬虫来爬取各种网页。以下是每个文件的说明:
jd_1product.xml 演示如何抓取一个简单商品页上的信息(商品名,动态评论数)
jd_products_comments.xml 演示如何抓取一个商品的评论(内容循环提取)
jd_shop_allproducts.cml 将演示如何循环抓取一个店铺的所有商品(翻页循环抓取)
与其他任务类似,数据存储的名称和方法在配置文件中定义。配置好爬虫后,启动程序爬虫会自动生成需要保存的数据文件。
爬虫执行org.wisdomdata.main.MainCrawler,将配置文件的地址添加到tasksFiles中,启动程序。目前只能支持一个爬虫,未来可能会支持分布式爬虫。3、建筑设计
对于 Selenium,最大的限制之一是多线程并发控制。最好的方法是使用 WebDriver 单例模式。它可以使用 Spring 框架轻松实现。
垂直网络爬虫不仅仅是下载页面,下载页面只是其组件之一。
还需要针对性的页面进行处理,比如:
在页面上点击一个按钮(本质是执行一段JS);
在页面上跳转直接(比如:加载一个新的页面)
碰到特殊情况处理(比如:弹出验证码输入框,提取不到页面内容等等)
页面内容提取(包括链接,以及主题指标数据)
如何保存批量提取的链接?
垂直爬虫得到的链接比较少量。
如何增量爬取数据?
如何解决爬虫被封的问题?
这些过程是抽象的,与编程语言中的三大程序流程结构非常一致:
1、序列2、循环3、条件
通过将这三者结合起来,可以完成任何复杂的程序流程。
一个网站的垂直爬行也可以结合以上三个过程来描述:例如爬取一个网站时:
do for 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
do for 每一个内容页面(循环方式 依次抓取,结束条件)
提取信息(异步提取,同步提取)
done
点击下一页
done
比如更复杂的网站:
do
填写表单,点击提交,指定页面跳转
done
do then
do 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
提取信息
done
do then
点击某个按钮
do
do for 循环内容
提取信息(
if (未提取到信息,或者提取到信息有什么问题)
dosome
endif
done
done
点击按钮
done
done
基于这个逻辑,开发了这个系统。
4、如何组合和设计一个爬虫。爬虫设计是从编程语言具有的三种处理结构中抽象出来的。
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
每次状态转换动作后,都会生成一个新的页面,跳转前需要判断,如:(事务支持,要么全部执行原子动作,要么全部失败)
点击下一页(是否存在点击下一页这个按钮,没有怎么办?)
点击某个按钮加载一段新页面(是否存在需要这个按钮,没有怎么办?)
跳转到一个新的页面(新页面链接是否是有效链接?)
(上面的每个动作都收录一个原子动作,它执行某个按钮点击动作)
以上每个进程都是嵌套的,也就是说可能有循环判断,有循环判断等等。 #### 而相对于爬虫:####上面的每个过程都必须以打开页面为基准。
业务逻辑处理器里面包含转移动作组合
转移动作组里面包含系列内容抽取器
内容抽取器里面可能包含业务逻辑组
4.1 示例:
1) 单独爬取一个网站,需要的组件
顺序执行处理器1(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
)
2) 登录页面抓取
顺序执行处理器2(
登录动作组(无抽取动作)
顺序执行处理器1
)
3) 循环页面抓取
循环执行处理器2(
循环初始化条件
循环执行动作(抽取器)
循环结束条件
)
4) 页面点击抓取
顺序执行处理器3(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
点击页面按钮动作组(
顺序抽取器(多个单元抽取器,去重保存组件)?
)
)
以上四种情况可以组合成更复杂的情况。抽象处理为:
处理器中有动作组。每个操作都有一个提取器组。每个提取器都有一个保存组件和一个原子提取器。5、 项目相关信息。一个可以抓取动态信息的爬虫。爬虫 查看全部
java爬虫抓取动态网页(动态信息爬取的网络爬虫设计思路与优采云采集器类似)
nlp-spider-dynamic 是一个爬取数据的组件,专门针对自然语言处理系统组件,动态信息爬取的网络爬虫
该爬虫的特点是垂直爬虫,主要针对动态网页信息的爬取。设计思路类似于优采云采集器。
请注意,此爬虫纯粹是为了个人发展兴趣而开发的。如果您有任何问题,欢迎您提交错误。电子邮件地址:
目前正在完善中,部分功能可能存在BUG,敬请期待...
1、说明
动态网站爬取和静态网站爬取最大的区别就是解析JS。
2、新手教程
不同平台的驱动目录(存放selenium需要运行的驱动)请参考本教程,自编译目前只提供windows GhostDriver已经集成在Phantomjs.exe
简单爬取示例 tasks\test_ghost 下的配置文件说明了如何配置爬虫来爬取各种网页。以下是每个文件的说明:
jd_1product.xml 演示如何抓取一个简单商品页上的信息(商品名,动态评论数)
jd_products_comments.xml 演示如何抓取一个商品的评论(内容循环提取)
jd_shop_allproducts.cml 将演示如何循环抓取一个店铺的所有商品(翻页循环抓取)
与其他任务类似,数据存储的名称和方法在配置文件中定义。配置好爬虫后,启动程序爬虫会自动生成需要保存的数据文件。
爬虫执行org.wisdomdata.main.MainCrawler,将配置文件的地址添加到tasksFiles中,启动程序。目前只能支持一个爬虫,未来可能会支持分布式爬虫。3、建筑设计
对于 Selenium,最大的限制之一是多线程并发控制。最好的方法是使用 WebDriver 单例模式。它可以使用 Spring 框架轻松实现。
垂直网络爬虫不仅仅是下载页面,下载页面只是其组件之一。
还需要针对性的页面进行处理,比如:
在页面上点击一个按钮(本质是执行一段JS);
在页面上跳转直接(比如:加载一个新的页面)
碰到特殊情况处理(比如:弹出验证码输入框,提取不到页面内容等等)
页面内容提取(包括链接,以及主题指标数据)
如何保存批量提取的链接?
垂直爬虫得到的链接比较少量。
如何增量爬取数据?
如何解决爬虫被封的问题?
这些过程是抽象的,与编程语言中的三大程序流程结构非常一致:
1、序列2、循环3、条件
通过将这三者结合起来,可以完成任何复杂的程序流程。
一个网站的垂直爬行也可以结合以上三个过程来描述:例如爬取一个网站时:
do for 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
do for 每一个内容页面(循环方式 依次抓取,结束条件)
提取信息(异步提取,同步提取)
done
点击下一页
done
比如更复杂的网站:
do
填写表单,点击提交,指定页面跳转
done
do then
do 循环列表页(循环方式 点击下一页,结束条件(指定最大次数等))
提取信息
done
do then
点击某个按钮
do
do for 循环内容
提取信息(
if (未提取到信息,或者提取到信息有什么问题)
dosome
endif
done
done
点击按钮
done
done
基于这个逻辑,开发了这个系统。
4、如何组合和设计一个爬虫。爬虫设计是从编程语言具有的三种处理结构中抽象出来的。
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
判断(需要判断条件,符合就执行,不符合就执行另外的)
循环(需要开始条件,循环间隔,循环结束条件)
顺序(就是一系列执行下去)
每次状态转换动作后,都会生成一个新的页面,跳转前需要判断,如:(事务支持,要么全部执行原子动作,要么全部失败)
点击下一页(是否存在点击下一页这个按钮,没有怎么办?)
点击某个按钮加载一段新页面(是否存在需要这个按钮,没有怎么办?)
跳转到一个新的页面(新页面链接是否是有效链接?)
(上面的每个动作都收录一个原子动作,它执行某个按钮点击动作)
以上每个进程都是嵌套的,也就是说可能有循环判断,有循环判断等等。 #### 而相对于爬虫:####上面的每个过程都必须以打开页面为基准。
业务逻辑处理器里面包含转移动作组合
转移动作组里面包含系列内容抽取器
内容抽取器里面可能包含业务逻辑组
4.1 示例:
1) 单独爬取一个网站,需要的组件
顺序执行处理器1(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
)
2) 登录页面抓取
顺序执行处理器2(
登录动作组(无抽取动作)
顺序执行处理器1
)
3) 循环页面抓取
循环执行处理器2(
循环初始化条件
循环执行动作(抽取器)
循环结束条件
)
4) 页面点击抓取
顺序执行处理器3(
跳转到一个新页面的转移动作(
顺序抽取器(多个单元抽取器,去重保存组件)
)
点击页面按钮动作组(
顺序抽取器(多个单元抽取器,去重保存组件)?
)
)
以上四种情况可以组合成更复杂的情况。抽象处理为:
处理器中有动作组。每个操作都有一个提取器组。每个提取器都有一个保存组件和一个原子提取器。5、 项目相关信息。一个可以抓取动态信息的爬虫。爬虫
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-21 12:01
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver 驱动程序 = new InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
复制代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面加载完毕!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
复制代码
在java端执行的代码
复制代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
复制代码
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取动态生成的网页
原来的: 查看全部
java爬虫抓取动态网页(中国最强搜索引擎--百度上面行走了好长,我要想骂人了)
最近在做一个项目,有一个需求:要从网页中抓取数据,要求是先抓取整个网页的html源代码(用于后续更新)。一开始看到这个简单,然后就稀里糊涂的打了代码(之前用的是Hadoop平台的分布式爬虫框架Nutch,用起来很方便,最后因为速度放弃了,但是生成的统计数据用在后来爬取),很快就成功下载了holder.html和finance.html页面,然后在解析了holder.html页面后,解析了finance.html,然后就郁闷的在这个页面找到了自己需要的东西数据不在 html 源代码中。去浏览器查看源码确实是这样。源代码中确实没有我需要的数据。
在号称中国最强搜索引擎——百度上走了很久,发现大部分人都在用WebDriver和HttpUnit(其实前者已经收录后者)。我很高兴,终于找到了解决办法。. 兴奋地使用WebDriver,我想骂人。
以下是对WebDriver的投诉
WebDriver 是一个测试框架。当初设计的时候,不是用来服务爬虫的,但我想说的是:星盘只是有点短,你不能再进一步吗?为什么网上那么多人推荐WebDriver?我觉得这些人并没有从实际情况出发,甚至有人说WebDriver可以解析完成的页面,返回给想要爬取整个页面(包括动态生成的内容)的人。是的,WebDriver 可以完成这个任务,但是看关于作者写的代码,我想说的是:哥们,你的代码太有限了。解析你写的js代码,js代码简单,当然WebDriver可以毫无压力的完成任务。WebDriver 对动态内容的分析依赖于 js 代码的复杂性和多样性。
什么是复杂度?
先贴一段代码
WebDriver 驱动程序 = newInternetExplorerDriver();
HtmlPage page = driver.get(url);
System.out.println(page.asXml());
这段代码的意思是大家都明白了。上面用到的IE内核,当然是FirefoxDriver、ChromeDriver、HtmlUnitDriver,这些驱动的使用原理都是一样的,先打开浏览器(这个需要时间),然后加载url并完成动态分析,然后通过page. asXml(),可以得到完整的html页面,其中HtmlUnitDriver模拟无界面浏览器,java有引擎rhino执行js,HtmlUnitDriver使用rhino解析js,因为它不会启动有界面的浏览器,所以HtmlUnitDriver的速度比前三个都快。不管是什么Driver,都难免要解析js,这需要时间,而且对于没有使用的内核,js的支持程序也不同。例如,HtmlUnitDriver 对带有滚动的 js 代码的支持很差,并且在执行过程中会报错。(亲身经历)。js代码的复杂含义是不同内核支持的js并不完全一样。这个要根据具体情况来确定。好久没研究js了,就不讲各个核心对js的支持了。
什么是多样性
前面说过,浏览器解析js需要时间。对于只嵌入少量js代码的页面,通过page.asXml()获取完整页面是没有问题的。但是对于嵌入了大量js代码的页面,解析js需要花费大量的时间(对于jvm),那么大部分时候通过page.asXml()获取的页面并不收录动态生成的内容。问题是,为什么说WebDriver可以获取收录动态内容的html页面呢?网上有人说在driver.get(url)之后,当前线程需要等待一段时间才能得到完成的页面,类似于下面的形式
WebDriver 驱动程序 = new InternetExplorerDriver();
HtmlPage 页面 = dirver.get(url);
Thread.sleep(2000);
System.output.println(page.asXml());
我按照这个想法尝试了以下,是的,确实有可能。但问题不就在那里吗?如何确定等待时间?类似于数据挖掘中使用的经验方法来确定阈值?,或者尽可能长。我觉得这些都不是很好的方法,时间成本也比较高。本来以为driver解析js完成后应该可以抓到状态,于是去找,找,但是根本没有这种方法,所以说为什么WebDriver的设计者没有往前走一步,这样我们就可以在程序中获取解析js后驱动的状态。在这种情况下,没有必要使用像Thread.sleep(2000)这样的不确定代码,可惜我找不到它。这真的让我感到难过。字段。FirefoxDriver,ChromeDriver,HtmlUnitDriver 也有同样的问题。可以说使用WebDriver辅助爬取动态生成的网页得到的结果是非常不稳定的。我对此有深刻的理解。使用IEDriver时,同一个页面两次爬取的结果会出现不同,有时甚至IE直接挂掉。你敢在爬虫程序中使用这种东西吗?我不敢。
另外,有人推荐使用HttpUnit。其实WebDirver中的HtmlUnitDriver内部使用的是httpUnit,所以在使用HttpUnit的时候也会遇到同样的问题。我也做过一个实验,确实如此。通过Thread.sleep(2000))等待js解析完成,我觉得不是一个好方法,不确定性太大,尤其是大型爬虫工作。
综上所述,WebDriver 是一个为测试而设计的框架。虽然理论上可以用来辅助爬虫获取动态内容的html页面,但在实际应用中并没有使用,不确定性太大。稳定性太差,速度太慢。让我们让框架发挥最大的作用。不要损害他们的优势。
我的工作还没有完成,所以我需要想办法上网。这次找到了一个稳定且确定性很强的辅助工具——phantomjs。我还没有完全理解这件事。但是已经用它来实现我想要的功能了。在java中,通过runtime.exec(arg)调用phantomjs来获取解析js后的页面。我会发布代码
phantomjs端要执行的代码
复制代码
system = 要求('系统')
address = system.args[1];//接下来会用到命令行的第二个参数
//console.log('加载网页');
var page = require('webpage').create();
var url = 地址;
//console.log(url);
page.open(网址,功能(状态){
//页面加载完毕!
如果(状态!=='成功'){
console.log('无法发布!');
} 别的 {
//这里的打印是将结果以一流的形式输出到java中,java可以通过InputStream获取输出内容
控制台日志(页面内容);
}
幻影.退出();
});
复制代码
在java端执行的代码
复制代码
public void getParseredHtml(){
字符串 url = "";
运行时运行时 = Runtime.getRuntime();
runtime.exec("F:/phantomjs/phantomjs/phantomjs.exe F:/js/parser.js"+url);
InputStream in = runtime.getInputStream();
//以下代码省略,很容易得到InputStream
}
复制代码
这样就可以在java端获取解析后的html页面,而不用像WebDriver中的Thread.sleep()这样不确定的代码来获取可能的代码。有一点需要说明:phantomjs端的js代码一定不能有语法错误,否则如果js代码不同编译,java端一直在等待,不会抛出异常。而且,在使用phantomjs.exe时,java端每次都要开启一个phantomjs进程,耗费大量时间。但至少,结果是稳定的。当然,我最终没有使用phantomjs。我直接下载了数据,但是没有抓取整个页面,主要是速度问题。(其实我不敢用phantomjs,因为我对phantomjs不熟悉,所以谨慎使用)。
我折腾了好几天了。虽然它没有解决我的问题,但我获得了很多知识。后面的工作就是熟悉phantomjs,看看速度能不能提高。如果能打破速度框架,以后我爬网页的时候就得心应手了。同样,它是 Nutch 框架。我很欣赏使用它时的便利性。后期需要研究如何优化Nutch on Hadoop的爬取速度。另外,Nutch原有的功能不会爬行。动态生成的页面内容,不过可以用Nutch和WebDirver的结合,可能爬取的结果比较稳定,哈哈,这些只是想法,不试试怎么知道呢?
如果大家对使用WebDriver辅助爬虫获得的结果的稳定性有什么要说的,欢迎大家,因为我确实没有找到稳定爬虫结果的相关资料。
java抓取动态生成的网页
原来的:
java爬虫抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-21 10:08
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它将等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
java爬虫抓取动态网页(动态网页数据抓取什么是AJAX:异步JavaScript和XML的区别)
什么是 AJAX?
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,在右键->查看网页源代码中仍然看不到通过ajax加载的数据,只能看到使用这个url加载的html代码。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟人类的一些行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: Install Selenium 和 chromedriver: Install Selenium: Selenium 有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作: 获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它将等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-21 10:05
本文将介绍如何使用SeimiCrawler将页面中的信息提取成结构化数据并存入数据库,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍,SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源的ORM框架paoding-jade的使用。由于SeimiCrawler的对象池和依赖管理都是使用spring实现的,所以SeimiCrawler自然支持所有可以和spring集成的ORM框架。
要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
文章链接:[](转载请注明本文出处及链接文章) 查看全部
java爬虫抓取动态网页(本文将介绍如何使用SeimiCrawler将页面中信息提取为结构化数据并存储到数据库中)
本文将介绍如何使用SeimiCrawler将页面中的信息提取成结构化数据并存入数据库,这也是一个非常常见的使用场景。数据抓取将以博客园的博客为例。
建立基础数据结构
为了演示,为了简单起见,只创建一个表来存储博客标题和内容这两个主要信息。表格如下:
CREATE TABLE `blog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(300) DEFAULT NULL,
`content` text,
`update_time` timestamp NOT NULL DEFAULT '0000-00-00 00:00:00' ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
同时创建对应的Bean对象,如下:
package cn.wanghaomiao.model;
import cn.wanghaomiao.seimi.annotation.Xpath;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.builder.ToStringBuilder;
/**
* Xpath语法可以参考 http://jsoupxpath.wanghaomiao.cn/
*/
public class BlogContent {
@Xpath("//h1[@class='postTitle']/a/text()|//a[@id='cb_post_title_url']/text()")
private String title;
//也可以这么写 @Xpath("//div[@id='cnblogs_post_body']//text()")
@Xpath("//div[@id='cnblogs_post_body']/allText()")
private String content;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
if (StringUtils.isNotBlank(content)&&content.length()>100){
//方便查看截断下
this.content = StringUtils.substring(content,0,100)+"...";
}
return ToStringBuilder.reflectionToString(this);
}
}
这里的@Xpath 注释应该侧重于介绍。注释配置了对应字段的 XPath 提取规则。后面会介绍,SeimiCrawler会调用Response.render(Class bean)自动解析并填充对应的字段。对于开发者来说,提取结构化数据最重要的工作就在这里,仅此而已,接下来就是如何串连起来。
实现数据存储
本文演示了人人网早期开源的ORM框架paoding-jade的使用。由于SeimiCrawler的对象池和依赖管理都是使用spring实现的,所以SeimiCrawler自然支持所有可以和spring集成的ORM框架。
要启用 Jade,请添加 pom 依赖项:
net.paoding
paoding-rose-jade
2.0.u01
org.apache.commons
commons-dbcp2
2.1.1
mysql
mysql-connector-java
5.1.37
在resources下添加seimi-jade.xml配置文件:
写DAO,
package cn.wanghaomiao.dao;
import cn.wanghaomiao.model.BlogContent;
import net.paoding.rose.jade.annotation.DAO;
import net.paoding.rose.jade.annotation.ReturnGeneratedKeys;
import net.paoding.rose.jade.annotation.SQL;
@DAO
public interface StoreToDbDAO {
@ReturnGeneratedKeys
@SQL("insert into blog (title,content,update_time) values (:1.title,:1.content,now())")
public int save(BlogContent blog);
}
数据存储完成后,下一步就是我们的爬虫规则类。
履带式
直接地:
package cn.wanghaomiao.crawlers;
import cn.wanghaomiao.dao.StoreToDbDAO;
import cn.wanghaomiao.model.BlogContent;
import cn.wanghaomiao.seimi.annotation.Crawler;
import cn.wanghaomiao.seimi.struct.Request;
import cn.wanghaomiao.seimi.struct.Response;
import cn.wanghaomiao.seimi.def.BaseSeimiCrawler;
import cn.wanghaomiao.xpath.model.JXDocument;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.List;
/**
* 将解析出来的数据直接存储到数据库中
*/
@Crawler(name = "storedb")
public class DatabaseStoreDemo extends BaseSeimiCrawler {
@Autowired
private StoreToDbDAO storeToDbDAO;
@Override
public String[] startUrls() {
return new String[]{"http://www.cnblogs.com/"};
}
@Override
public void start(Response response) {
JXDocument doc = response.document();
try {
List urls = doc.sel("//a[@class='titlelnk']/@href");
logger.info("{}", urls.size());
for (Object s:urls){
push(Request.build(s.toString(),"renderBean"));
}
} catch (Exception e) {
//ignore
}
}
public void renderBean(Response response){
try {
BlogContent blog = response.render(BlogContent.class);
logger.info("bean resolve res={},url={}",blog,response.getUrl());
//使用神器paoding-jade存储到DB
int blogId = storeToDbDAO.save(blog);
logger.info("store sus,blogId = {}",blogId);
} catch (Exception e) {
//ignore
}
}
}
Github上也有完整的demo,可以下载,自己试试,直接点击。
文章链接:[](转载请注明本文出处及链接文章)
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-10-21 07:22
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL去重采用Bloom filter方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (高大上)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2. 支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5.在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到: 查看全部
java爬虫抓取动态网页(Python开发的一个快速、高层次的优点及应用)
(1),Scrapy:
Scrapy 是一个由 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还提供了多种爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本还提供了web2.0爬虫支持。
废料意味着碎片化。这个 Python 爬虫框架叫做 Scrapy。
优势:
1.极其灵活的自定义爬取。
2. 社区人数比较多,文档比较齐全。
3.URL去重采用Bloom filter方案。
4. 可以处理不完整的 HTML,Scrapy 提供了选择器(一个基于 lxml 的更高级的接口),
可以有效处理不完整的 HTML 代码。
缺点:
1.对新生不友好,需要一定的新手期
(2),Pyspider:
pyspider是一个用python实现的强大的网络爬虫系统。可以在浏览器界面实时编写脚本、调度函数和查看爬取结果。后端使用常用的数据库来存储爬取结果。可以定期设置任务和任务优先级。
优势:
1.支持分布式部署。
2.完全可视化,非常人性化:WEB界面编写调试脚本、启停脚本、监控执行状态、查看活动历史、获取结果。
3.简单,五分钟即可上手。脚本规则简单,开发效率高。支持抓取 JavaScript 页面。
总之,Pyspider 非常强大,强大到它更像是一个产品而不是一个框架。
缺点:
1.URL去重使用数据库代替Bloom filter,数亿存储的db io会导致效率急剧下降。
2. 使用中的人性化牺牲了灵活性并降低了定制能力。
(3)Apache Nutch (高大上)
Nutch 是专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。在 Nutch 运行的一组进程中,三分之二是为搜索引擎设计的。
Nutch的框架需要Hadoop运行,Hadoop需要开集群。对于那些想快速上手爬虫的人来说,我很沮丧......
这里列出了一些资源地址,也许以后会学到。
1.Nutch支持分布式爬取,并且有Hadoop支持,可以进行多机分布式爬取、存储和索引。另一个非常吸引人的地方是它提供了一个插件框架,可以方便的扩展各种网页内容分析、各种数据采集、查询、聚类、过滤等功能。因为有了这个框架,Nutch的插件开发非常容易,第三方插件也层出不穷,大大提升了Nutch的功能和口碑。
缺点
1.Nutch的爬虫定制能力比较弱
(4), WebMagic
WebMagic 是一个简单灵活的 Java 爬虫框架。基于WebMagic,您可以快速开发一个高效且易于维护的爬虫。
优势:
1.简单的API,可以快速上手
2.模块化结构,易于扩展
3.提供多线程和分布式支持
缺点:
1.不支持JS页面爬取
(5), WebCollector
WebCollector是一个不需要配置,方便二次开发的JAVA爬虫框架(内核)。它提供了精简的API,只需少量代码即可实现功能强大的爬虫。WebCollector-Hadoop 是WebCollector 的Hadoop 版本,支持分布式爬取。
优势:
1.基于文本密度自动提取网页正文
2. 支持断点重爬
3.支持代理
缺点:
1. 不支持分布式,只支持单机
2.无URL优先调度
3.不是很活跃
(6), Heritrix3
Heritrix 是一个由java开发的开源网络爬虫。用户可以使用它从互联网上获取他们想要的资源。
优势
Heritrix 的爬虫有很多自定义参数
缺点
1.单实例爬虫不能相互配合。
2. 在机器资源有限的情况下,需要复杂的操作。
3. 仅官方支持,仅在 Linux 上测试。
4.每个爬虫独立工作,更新没有任何修改。
5.在发生硬件和系统故障时,恢复能力较差。
6. 花在优化性能上的时间很少。
7.相比Nutch,Heritrix只是一个爬虫工具,没有搜索引擎。如果要对爬取的站点进行排序,则必须实现类似于 Pagerank 的复杂算法。
(7), Crawler4j
Crawler4j 是一个基于 Java 的轻量级独立开源爬虫框架
优势
1.多线程采集
2. 内置Url过滤机制,BerkeleyDB用于URL过滤。
3. 可以扩展支持网页字段的结构化提取,可以作为一个垂直的采集
缺点
1. 不支持动态网页爬取,比如网页的ajax部分
2.不支持分布式采集,可以认为是分布式爬虫的一部分,客户端采集部分
为了让这7个爬虫框架更加直观,我做了一个框架优缺点对比图,如下:
Jsoup(经典·适合静态网友)
这个框架堪称经典,也是我们暑期培训老师讲解的框架。有近乎完整的文档介绍。
和 HtmlUnit 一样,只能获取静态内容。
不过这个框架有一个优势,它有非常强大的网页解析功能。
selenium(多位谷歌高管参与开发)
感觉很棒,但实际上真的很棒。看官网和其他人的介绍,是真正的模拟浏览器。GitHub1.4w+star,你没看错,有几万个。但我只是没有一个好的环境。入门Demo就是不能成功运行,所以放弃了。
cdp4j(方便快捷,但需要依赖谷歌浏览器)
使用先决条件:
安装 Chrome 浏览器,就是这样。
简要介绍:
HtmlUnit的优点是可以轻松抓取静态网民;缺点是只能抓取静态网页。
selenium 的优点是可以爬取渲染出来的网页;缺点是需要配备环境变量等。
两者结合,互相学习,就会有cdp4j。
选择它的原因是真的很方便好用,而且官方文档很详细,Demo程序基本可以运行,类名众所周知。我在学习软件工程的时候,一直在想,我为什么要写文档?我的程序能不能实现这些功能不重要吗?如今,看着如此详细的文件,我留下了激动和遗憾的泪水……
cdp4j 有很多功能:
一种。获取渲染后的网页源码
湾 模拟浏览器点击事件
C。下载网页上可以下载的文件
d. 截取网页截图或转换为 PDF 进行打印
e. 等待
更详细的信息可以在以下三个地址中找到:
java爬虫抓取动态网页(csdn用python3简单入门爬虫()())
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-10-21 07:20
最近看了csdn微信推荐的python 3的简单入门爬虫(),想知道能不能用java技术做一个简单的爬虫?
于是这个文章诞生了,我用的是jsoup,相关需求网上可以随便搜,接口文档()也可以搜到。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
可以知道文档的内容,获取数据源的方式有以下三种:
(1) 从一段html代码字符串中获取:Document doc = Jsoup.parse(html);
(2) 从一个url获取:Document doc = Jsoup.connect(url).get();
(3)Get File input = new File("XXX.html"); 或 Document doc = Jsoup.parse(input, "UTF-8", url); 从一个 html 文件
废话不多说,进入正文。
每个页面都有相关的前端内容。这里我们先对相关页面的内容进行分析,然后根据标签分别进行分类获取,然后利用剩下的Java技术对获取到的内容进行处理。
首先,最基本的就是获取页面的所有代码,包括HTML、CSS等内容。这里也以网络盗版小说网站为例进行相关爬虫。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test1 {
//第一个,完整爬虫爬下来内容
public static void get_html(String url){
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
输出如下:
因为consle不能全部截图,所以我截图了,可以从这里看到完整的前端内容。
而我们只需要里面的小说内容,什么风格、剧本等等都不是我们需要的,所以我们先找到小说的正文,根据正文内容进行处理。
我们分析了文本的内容,发现文本的内容全部被一组id为content的div所收录。对于其他内容,我们不需要它。我们只需要id为content的div内容中的数据。那么我们可以直接使用它吗?东西。
在查询jsoup的时候发现确实有获取class、id、tag的相关方法。这些发现可以用来获取我们需要的数据,于是出现了第二个例子。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
System.out.println(tag);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
他的输出如下:
我们发现我们已经得到了最基本的内容,现在我们需要简单地处理相反的内容。这个很简单,转换成string类型,用string相关的方法来处理。
如果我们想导出保存到本地,可以使用java的io来处理和保存相关数据。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
//System.out.println(tag);
String text = tag.text();
//替换里面的空格为换行
String needs = text.replace(" ", "\n");
//得到整个html里面的tittle,方便爬虫下来的txt命名文件名
Elements titlehtml = doc.getElementsByTag("title");
String tittle = titlehtml.text();
//去掉多余的txt文件命名的文字
String head=tittle.substring(0,tittle.length()-7);
File file = new File("D:\\"+head+".txt");
FileWriter fw = new FileWriter(file);
fw.write(needs);
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
以上只是一个简单的小说。如果我们想把整本小说下载到电脑上保存,那怎么处理呢?
我们先来看看整个小说目录的前端内容分析。我们发现每章的内容其实都在一个id为list的div下。根据以上经验,我们使用list来获取。
然后得到之后,我们根据超链接标签a进行遍历。获取数据后,循环打开页面,然后爬虫下载。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test3 {
//第三个,批量选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
//模仿浏览器访问
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
//得到html中id为list下的所有内容
Element ele = doc.getElementById("list");
//得到html中id为list下,同时标签为a的下面数据
Elements tag = ele.getElementsByTag("a");
String taghref, tagtext;
for (int i = 9; i < tag.size(); i++) {
try {
//当前循环时间睡眠为10
Thread.currentThread().sleep(5000);
taghref = tag.get(i).attr("href");
tagtext = tag.get(i).text();
Document docs = Jsoup.connect(taghref)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
Element eles = docs.getElementById("content");
Elements tags = eles.getElementsByTag("div");
String texts = tags.text().replace(" ", "\r\n\r\n");
String tittle = docs.getElementsByTag("title").text();
String head = tittle.substring(0, tittle.length() - 7);
File file = new File("D:\\Desktop\\hanxiang\\" + head + ".txt");
FileWriter fw = new FileWriter(file);
fw.write(texts);
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_78387/";
get_html(url);
}
}
这里有一些解释:
1.先说.userAgent("Mozilla/5.0 (兼容; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC) ").超时(999999999)
.userAgent的意思是模拟自己作为浏览器访问,防止反爬虫网站禁止访问爬虫程序;
.timeout(999999999) 个人理解是延迟访问,也是为了防止反爬虫网站禁止访问爬虫程序;
2.为什么循环从 9 而不是 0 或 1 开始?
因为我们看小说的章节列表,发现前九章是最新的九章,而我们不需要这九章,因为我们可以在后面的循环中捕捉后九章,所以从9开始,或在循环结束时。减去9就可以了,因人而异。
3.为什么要写一个 Thread.currentThread().sleep(5000); 来循环睡眠:
因为你的频繁访问,即使你冒充浏览器,仍然会影响服务器的性能。服务器将拒绝此连接并使线程休眠。在这种情况下,它将模拟一个人浏览小说并在 5 秒内阅读。小说比较一般,可以下载几百本小说。
以上内容就是我们对jsoup前端文字的简单爬虫获取。这里需要注意反爬虫服务器报的5XX和4XX错误。 查看全部
java爬虫抓取动态网页(csdn用python3简单入门爬虫()())
最近看了csdn微信推荐的python 3的简单入门爬虫(),想知道能不能用java技术做一个简单的爬虫?
于是这个文章诞生了,我用的是jsoup,相关需求网上可以随便搜,接口文档()也可以搜到。
jsoup 是一个 Java HTML 解析器,可以直接解析 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
可以知道文档的内容,获取数据源的方式有以下三种:
(1) 从一段html代码字符串中获取:Document doc = Jsoup.parse(html);
(2) 从一个url获取:Document doc = Jsoup.connect(url).get();
(3)Get File input = new File("XXX.html"); 或 Document doc = Jsoup.parse(input, "UTF-8", url); 从一个 html 文件
废话不多说,进入正文。
每个页面都有相关的前端内容。这里我们先对相关页面的内容进行分析,然后根据标签分别进行分类获取,然后利用剩下的Java技术对获取到的内容进行处理。
首先,最基本的就是获取页面的所有代码,包括HTML、CSS等内容。这里也以网络盗版小说网站为例进行相关爬虫。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
public class Test1 {
//第一个,完整爬虫爬下来内容
public static void get_html(String url){
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
输出如下:
因为consle不能全部截图,所以我截图了,可以从这里看到完整的前端内容。
而我们只需要里面的小说内容,什么风格、剧本等等都不是我们需要的,所以我们先找到小说的正文,根据正文内容进行处理。
我们分析了文本的内容,发现文本的内容全部被一组id为content的div所收录。对于其他内容,我们不需要它。我们只需要id为content的div内容中的数据。那么我们可以直接使用它吗?东西。
在查询jsoup的时候发现确实有获取class、id、tag的相关方法。这些发现可以用来获取我们需要的数据,于是出现了第二个例子。
package pachong;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
System.out.println(tag);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
他的输出如下:
我们发现我们已经得到了最基本的内容,现在我们需要简单地处理相反的内容。这个很简单,转换成string类型,用string相关的方法来处理。
如果我们想导出保存到本地,可以使用java的io来处理和保存相关数据。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test2 {
//第二个,选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
Document doc = Jsoup.connect(url).get();
//得到html中id为content下的所有内容
Element ele = doc.getElementById("content");
//分离出下面的具体内容
Elements tag = ele.getElementsByTag("div");
//System.out.println(tag);
String text = tag.text();
//替换里面的空格为换行
String needs = text.replace(" ", "\n");
//得到整个html里面的tittle,方便爬虫下来的txt命名文件名
Elements titlehtml = doc.getElementsByTag("title");
String tittle = titlehtml.text();
//去掉多余的txt文件命名的文字
String head=tittle.substring(0,tittle.length()-7);
File file = new File("D:\\"+head+".txt");
FileWriter fw = new FileWriter(file);
fw.write(needs);
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_7 ... 3B%3B
get_html(url);
}
}
以上只是一个简单的小说。如果我们想把整本小说下载到电脑上保存,那怎么处理呢?
我们先来看看整个小说目录的前端内容分析。我们发现每章的内容其实都在一个id为list的div下。根据以上经验,我们使用list来获取。
然后得到之后,我们根据超链接标签a进行遍历。获取数据后,循环打开页面,然后爬虫下载。
package pachong;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class Test3 {
//第三个,批量选择内容爬下来并保存到自己电脑
public static void get_html(String url) {
try {
//模仿浏览器访问
Document doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
//得到html中id为list下的所有内容
Element ele = doc.getElementById("list");
//得到html中id为list下,同时标签为a的下面数据
Elements tag = ele.getElementsByTag("a");
String taghref, tagtext;
for (int i = 9; i < tag.size(); i++) {
try {
//当前循环时间睡眠为10
Thread.currentThread().sleep(5000);
taghref = tag.get(i).attr("href");
tagtext = tag.get(i).text();
Document docs = Jsoup.connect(taghref)
.userAgent("Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC)")
.timeout(999999999)
.get();
Element eles = docs.getElementById("content");
Elements tags = eles.getElementsByTag("div");
String texts = tags.text().replace(" ", "\r\n\r\n");
String tittle = docs.getElementsByTag("title").text();
String head = tittle.substring(0, tittle.length() - 7);
File file = new File("D:\\Desktop\\hanxiang\\" + head + ".txt");
FileWriter fw = new FileWriter(file);
fw.write(texts);
fw.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
String url = "http://www.biquge5200.com/78_78387/";
get_html(url);
}
}
这里有一些解释:
1.先说.userAgent("Mozilla/5.0 (兼容; MSIE 9.0; Windows NT 6.1; Trident/5.0; MALC) ").超时(999999999)
.userAgent的意思是模拟自己作为浏览器访问,防止反爬虫网站禁止访问爬虫程序;
.timeout(999999999) 个人理解是延迟访问,也是为了防止反爬虫网站禁止访问爬虫程序;
2.为什么循环从 9 而不是 0 或 1 开始?
因为我们看小说的章节列表,发现前九章是最新的九章,而我们不需要这九章,因为我们可以在后面的循环中捕捉后九章,所以从9开始,或在循环结束时。减去9就可以了,因人而异。
3.为什么要写一个 Thread.currentThread().sleep(5000); 来循环睡眠:
因为你的频繁访问,即使你冒充浏览器,仍然会影响服务器的性能。服务器将拒绝此连接并使线程休眠。在这种情况下,它将模拟一个人浏览小说并在 5 秒内阅读。小说比较一般,可以下载几百本小说。
以上内容就是我们对jsoup前端文字的简单爬虫获取。这里需要注意反爬虫服务器报的5XX和4XX错误。

