
excel抓取网页数据
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-20 03:11
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。

第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。

然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。

完整的操作如下:

excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-19 11:12
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息网页
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息网页
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
excel抓取网页数据(excel抓取网页数据(非采集网页)-高手-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-11-17 22:01
excel抓取网页数据(非采集网页,首先必须是采集数据,才能有爬虫和去重的功能,第二,http请求是https的,我要采集的页面是个https的,不然,我也无法提取dom)-高手引路-博客园分享我学习这个学习网站抓取的学习过程,加上自己的学习过程,希望能够对你有所帮助!1.第一步:准备ip,电脑,网络2.第二步:爬虫,再安装主流的几个网站的爬虫apiaccessapi,由于它是访问本地文件的api,所以,我们必须在网络和电脑上都要安装这个api。
第一步,很简单,就是下载对应的网站到access目录,然后用accessapi传递文件到excel上,有accessapi以后,相当于一个网站的数据只是到了你这个网站,如果你在浏览器里面,那么文件传递给你,只是到你这个页面,而不是你网站的html,所以,要做一个数据传递,就需要accessapi3.第三步:读取数据,我们并不需要读写整个网页数据,我们只需要查看里面的部分数据,就好比url中actname=这样的一些json数据。
这里的actname就是为爬虫来提取需要的key,这样整个网页的内容我们就可以在excel里面读取,如果你不想爬取整个网页,就从某一个网页切换到相应的网页,然后再爬取4.第四步:去重:通过第一步,我们得到actname的值,我们就可以去重,去除重复值,这个主要采用openxlsx.read_excel或者accessapi读取整个数据,写入excel文件,这种方法简单易学,清晰直观。
当然,这样不好,因为它只是批量去重,很有可能需要很长时间,大家不要这样用!5.第五步:抓取页面:抓取最终的数据,方法也就3个,一是,python解析json,二是,ajax同步,三是,getopenxmlurl数据。这是从你的爬虫服务器连接到另外一个网站,把数据抓取下来,如果你用的网站和你的excel内容内容在同一个网站上,那么抓取难度较小,通过requests解析json格式,然后调用accessapi,调用json格式,获取数据,放到excel。
对于电脑python和java解析格式代码的差异,可以参考我的文章()6.第六步:数据提取:这个就是提取里面的一些关键字或者key数据,爬虫要做的就是把这些代码抓取下来,提取出数据!一般的思路是,页面开放后,提取里面的一些字段,然后通过excel解析出key的值来抓取到数据!。 查看全部
excel抓取网页数据(excel抓取网页数据(非采集网页)-高手-博客园)
excel抓取网页数据(非采集网页,首先必须是采集数据,才能有爬虫和去重的功能,第二,http请求是https的,我要采集的页面是个https的,不然,我也无法提取dom)-高手引路-博客园分享我学习这个学习网站抓取的学习过程,加上自己的学习过程,希望能够对你有所帮助!1.第一步:准备ip,电脑,网络2.第二步:爬虫,再安装主流的几个网站的爬虫apiaccessapi,由于它是访问本地文件的api,所以,我们必须在网络和电脑上都要安装这个api。
第一步,很简单,就是下载对应的网站到access目录,然后用accessapi传递文件到excel上,有accessapi以后,相当于一个网站的数据只是到了你这个网站,如果你在浏览器里面,那么文件传递给你,只是到你这个页面,而不是你网站的html,所以,要做一个数据传递,就需要accessapi3.第三步:读取数据,我们并不需要读写整个网页数据,我们只需要查看里面的部分数据,就好比url中actname=这样的一些json数据。
这里的actname就是为爬虫来提取需要的key,这样整个网页的内容我们就可以在excel里面读取,如果你不想爬取整个网页,就从某一个网页切换到相应的网页,然后再爬取4.第四步:去重:通过第一步,我们得到actname的值,我们就可以去重,去除重复值,这个主要采用openxlsx.read_excel或者accessapi读取整个数据,写入excel文件,这种方法简单易学,清晰直观。
当然,这样不好,因为它只是批量去重,很有可能需要很长时间,大家不要这样用!5.第五步:抓取页面:抓取最终的数据,方法也就3个,一是,python解析json,二是,ajax同步,三是,getopenxmlurl数据。这是从你的爬虫服务器连接到另外一个网站,把数据抓取下来,如果你用的网站和你的excel内容内容在同一个网站上,那么抓取难度较小,通过requests解析json格式,然后调用accessapi,调用json格式,获取数据,放到excel。
对于电脑python和java解析格式代码的差异,可以参考我的文章()6.第六步:数据提取:这个就是提取里面的一些关键字或者key数据,爬虫要做的就是把这些代码抓取下来,提取出数据!一般的思路是,页面开放后,提取里面的一些字段,然后通过excel解析出key的值来抓取到数据!。
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-15 12:17
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论! 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!
excel抓取网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-11 22:03
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,必须不断重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保存行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作。最后,我们得到了下表。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置中的自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢? 查看全部
excel抓取网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,必须不断重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
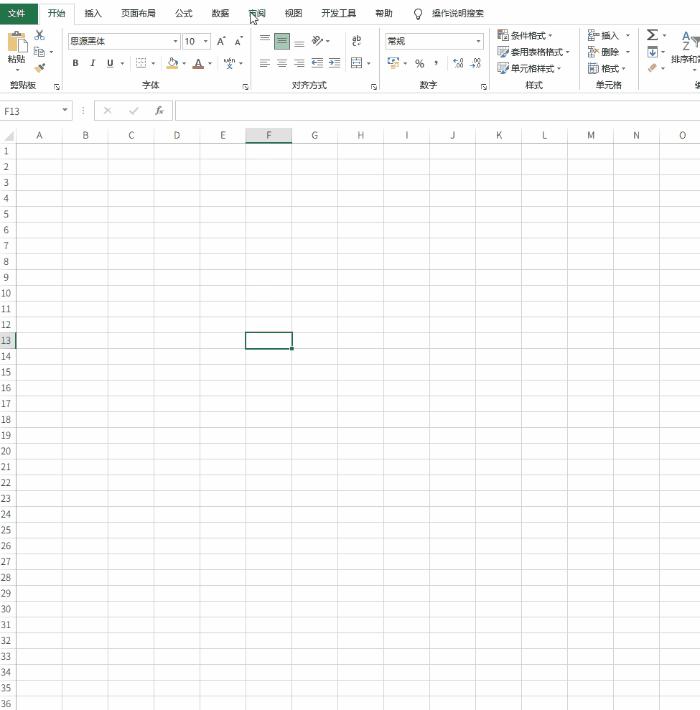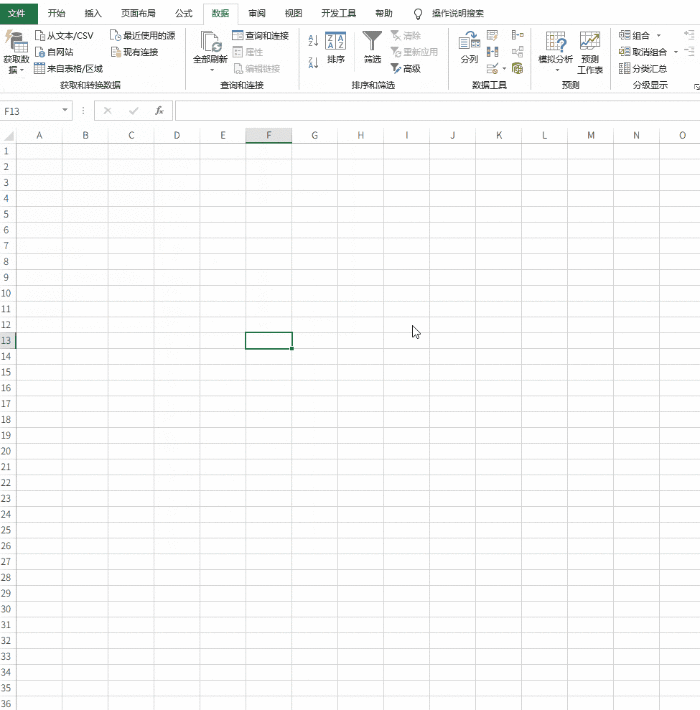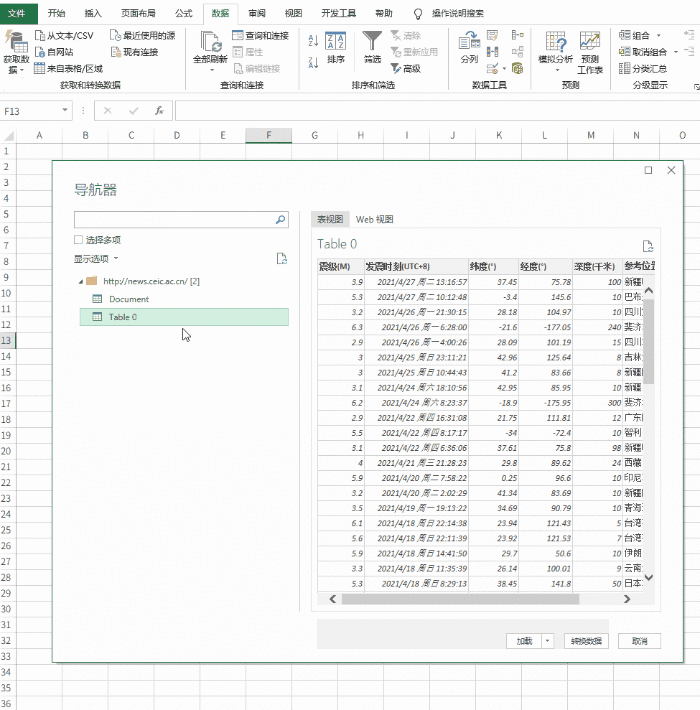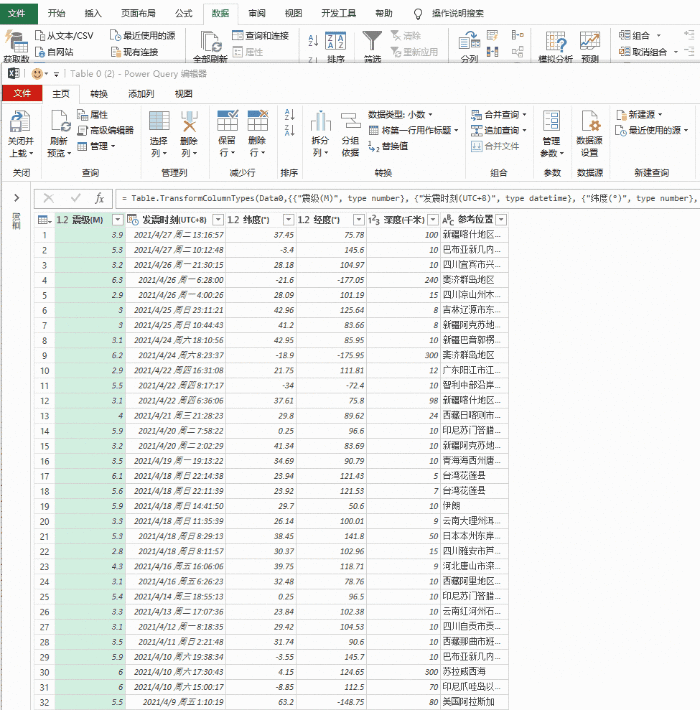
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保存行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。

数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作。最后,我们得到了下表。

对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
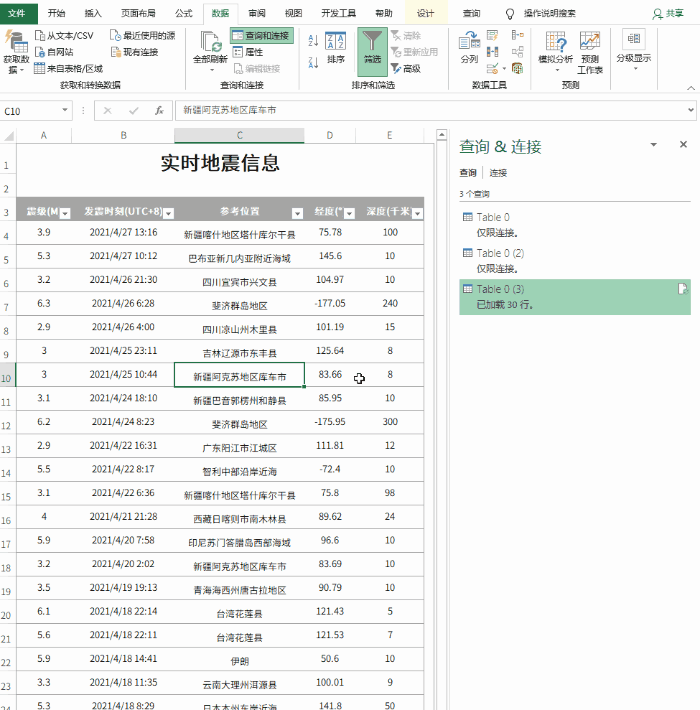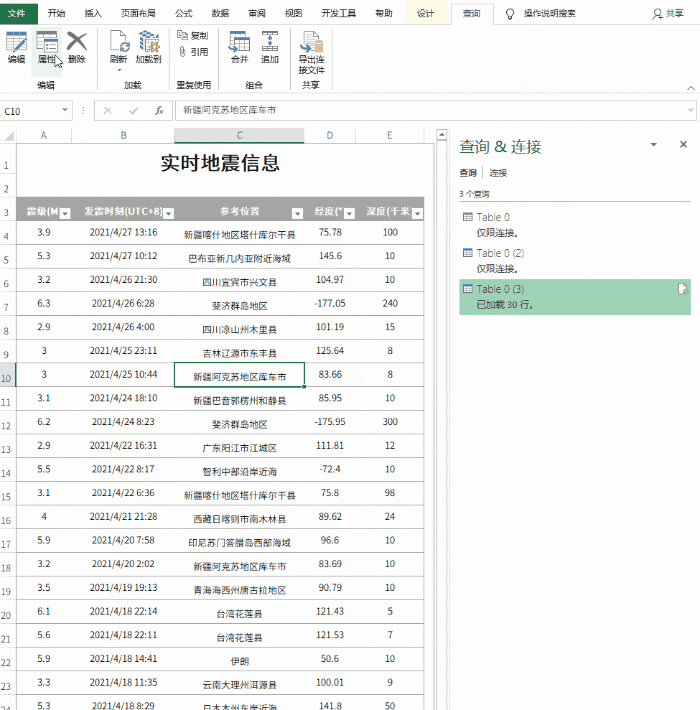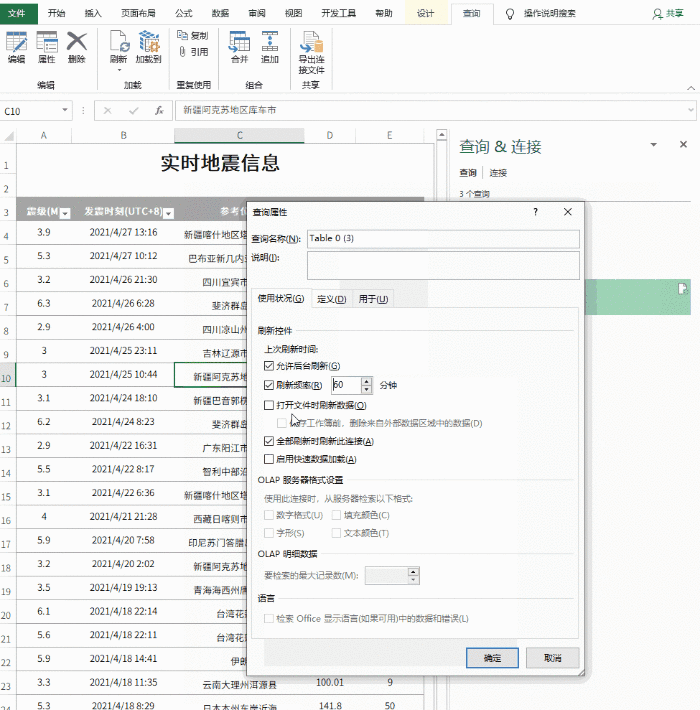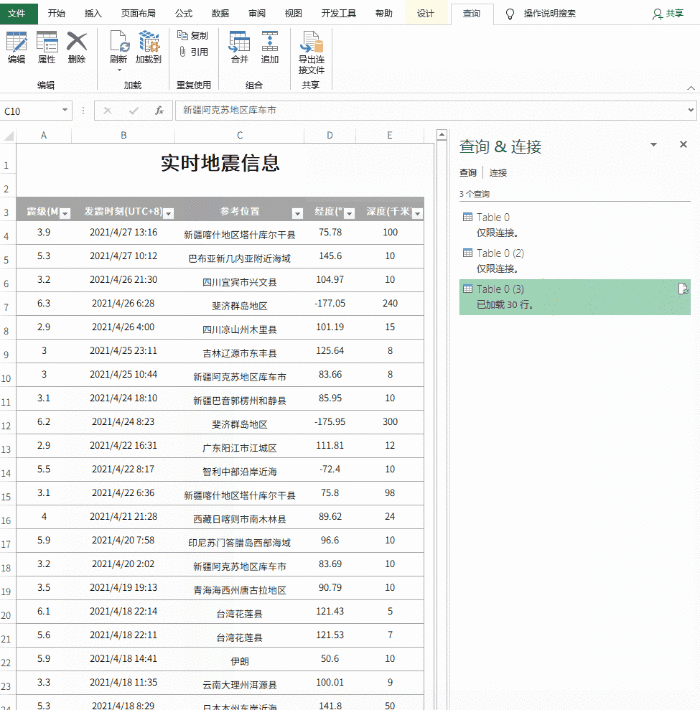
设置中的自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
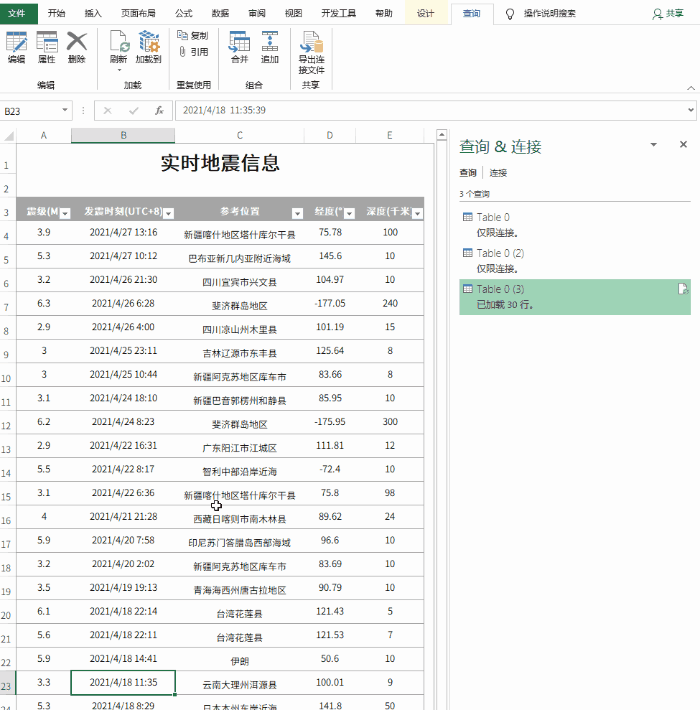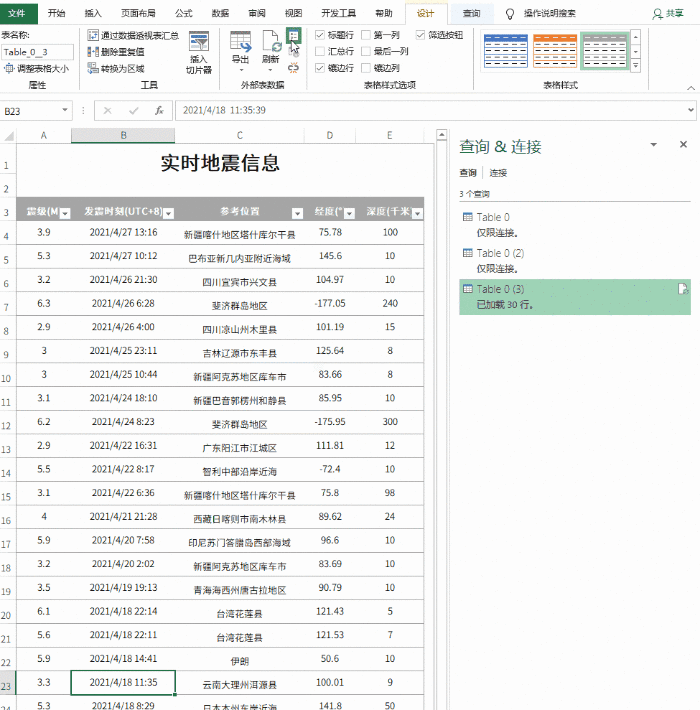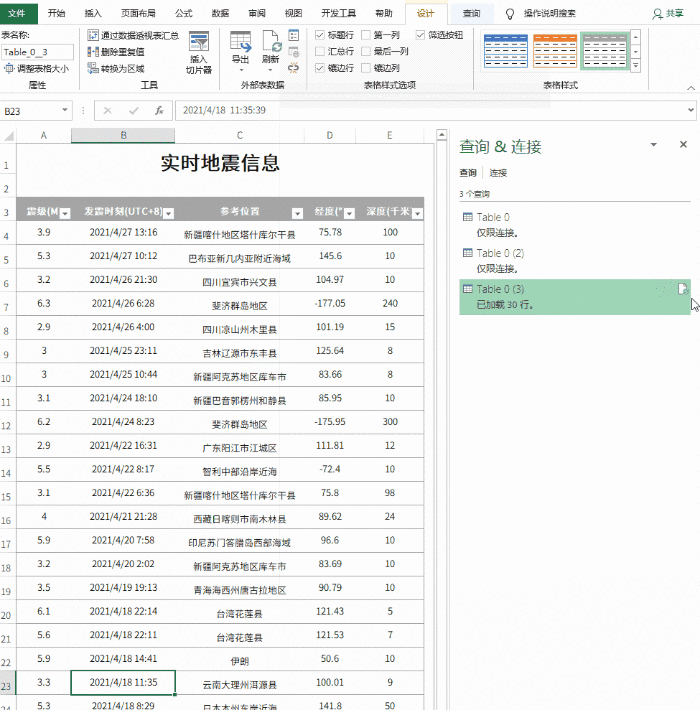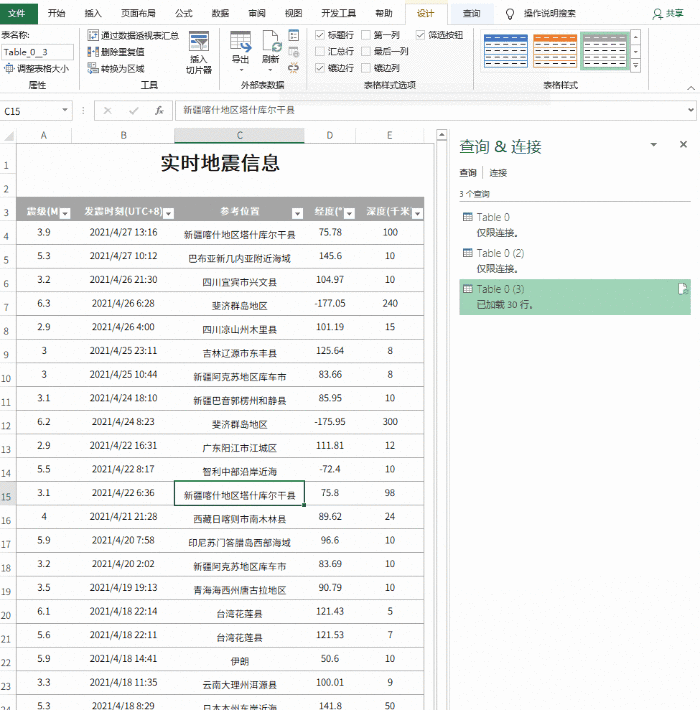
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢?
excel抓取网页数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-09 19:09
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的一大杀手。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请想法,欢迎交流, 查看全部
excel抓取网页数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的一大杀手。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请想法,欢迎交流,
excel抓取网页数据(考研英语:使用HtmlAgilityPack抓取网页数据XPath使用路径(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-09 00:17
使用 HtmlAgilityPack 抓取网页数据
XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择此节点 /:从根节点中选择。//: 从与选择匹配的当前节点中选择文档中的节点,而不管它们的位置。.:选择当前节点。..:选择当前节点的父节点。例如,有以下一段 XML:
Java通过url抓取网页数据
很多行业都需要对行业数据进行分类汇总,及时分析行业数据。对于公司未来的发展,有很好的借鉴和横向比较。因此,在实际工作中,我们可能会遇到数据采集这个概念,数据采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。很多人在第一次了解数据采集的时候可能都无法下手,尤其是作为一个新手,感觉很茫然。因此,我在这里分享我的经验,希望与您分享技术。如有不足之处请指正。写这篇的目的是希望大家一起成长,我也相信技术之间没有高低之分,
NET 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、...
[.NET] 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令...
Jsoup简介——使用Java抓取网页数据
转载请注明出处:概述jsoup是一个可以直接解析URL地址的Java HTML解析器。HTML 文本内容。它提供了一套省力的 API,可以通过 DOM、CSS 和类似 jQuery 的方法来检索和操作数据。jsoup 的主要功能如下: 1. 从 URL、文件或字符串解析 HTML: 2. 使用 DOM 或 CSS 选择器进行查找。检索数据:3. 可操作的 HTML 元素。属性。文本。杰...
使用 XML 包从 R 中的网页中抓取数据
在过去的几年里,许多数据以不同的格式公开发布,但有时我们感兴趣的数据仍然在网页的 HTML 中:让我们看看如何获取这些数据。完成这项工作的现有软件包之一是...
C#文件抓取网页数据
using System;using System.采集s.Generic;using System.Linq;using System.Web;using System.Web.Mvc;using System.采集s.Generic;using System.Text.RegularExpressions;using System.Text; 使用 System.Net ;使用 System.IO;命名空间 WebJSON.Contro...
热门话题
setfacl 示例 ugo
python解释器中交互执行代码的过程一般称为
如何关闭矢量
adb命令查看耳机的SN号
iview 穿梭选择键
Java调用ffmpeg推送流
ngs高通量测序原理
ubuntu tcmalloc源码安装
cocos 2dx 各种资源的加载和卸载
如果cmd显示它不是内部命令解决方案,则安装maven
ue4 控制台命令行
方法尝试访问方法失败
vivado mmcm 模块
Markdown 预览增强快捷方式
停用 iptables 之前要做什么
春批停止
富文本图片无法拖动放大或缩小
SQLServer 数据库插件
ide @Value 变量可以跳转
gocr能认出中文吗? 查看全部
excel抓取网页数据(考研英语:使用HtmlAgilityPack抓取网页数据XPath使用路径(组图))
使用 HtmlAgilityPack 抓取网页数据
XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择此节点 /:从根节点中选择。//: 从与选择匹配的当前节点中选择文档中的节点,而不管它们的位置。.:选择当前节点。..:选择当前节点的父节点。例如,有以下一段 XML:
Java通过url抓取网页数据
很多行业都需要对行业数据进行分类汇总,及时分析行业数据。对于公司未来的发展,有很好的借鉴和横向比较。因此,在实际工作中,我们可能会遇到数据采集这个概念,数据采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。很多人在第一次了解数据采集的时候可能都无法下手,尤其是作为一个新手,感觉很茫然。因此,我在这里分享我的经验,希望与您分享技术。如有不足之处请指正。写这篇的目的是希望大家一起成长,我也相信技术之间没有高低之分,
NET 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、...
[.NET] 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令...
Jsoup简介——使用Java抓取网页数据
转载请注明出处:概述jsoup是一个可以直接解析URL地址的Java HTML解析器。HTML 文本内容。它提供了一套省力的 API,可以通过 DOM、CSS 和类似 jQuery 的方法来检索和操作数据。jsoup 的主要功能如下: 1. 从 URL、文件或字符串解析 HTML: 2. 使用 DOM 或 CSS 选择器进行查找。检索数据:3. 可操作的 HTML 元素。属性。文本。杰...
使用 XML 包从 R 中的网页中抓取数据
在过去的几年里,许多数据以不同的格式公开发布,但有时我们感兴趣的数据仍然在网页的 HTML 中:让我们看看如何获取这些数据。完成这项工作的现有软件包之一是...
C#文件抓取网页数据
using System;using System.采集s.Generic;using System.Linq;using System.Web;using System.Web.Mvc;using System.采集s.Generic;using System.Text.RegularExpressions;using System.Text; 使用 System.Net ;使用 System.IO;命名空间 WebJSON.Contro...
热门话题
setfacl 示例 ugo
python解释器中交互执行代码的过程一般称为
如何关闭矢量
adb命令查看耳机的SN号
iview 穿梭选择键
Java调用ffmpeg推送流
ngs高通量测序原理
ubuntu tcmalloc源码安装
cocos 2dx 各种资源的加载和卸载
如果cmd显示它不是内部命令解决方案,则安装maven
ue4 控制台命令行
方法尝试访问方法失败
vivado mmcm 模块
Markdown 预览增强快捷方式
停用 iptables 之前要做什么
春批停止
富文本图片无法拖动放大或缩小
SQLServer 数据库插件
ide @Value 变量可以跳转
gocr能认出中文吗?
excel抓取网页数据(webscraper怎么抓取网页里其他链接里的数据先设定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-08 12:24
网络爬虫如何从网页中的其他链接抓取数据
先设置一个链接类型选择器,选中链接,勾选多个;然后打开链接,在新页面上设置需要爬取的元素。Webscraper的详细操作教程,可以到网易云课堂搜索“Webscraper实践教学”,里面有关于二级页面跳转和页面点击操作的详细教程。
使用屏幕-如何使用scraper,如何使用它抓取网页信息-
先按这个按钮,然后在开始菜单中打开绘图,然后粘贴。然后使用左侧工具栏中的虚线矩形选择自定义屏幕。
如何在网络爬虫中抓取弹出窗口
首先,从官方网站下载web-harvest。目前最新版本为1.0。下载页面分为三个下载包,webharvest1-exe.zip、webharvest1-bin.zip、webharvest1-project .zip,它们没有实质性的区别。第一个收录所有的第三方包(同一个jar文件可以直接一起运行),第二个作为中间件出现,收录所有独立的第三方jar。打包,第三个是源码,当然最大的灵活性自然是选择下载源码:``下载后在eclipse中创建一个空项目,把所有解压后的文件夹放进去,然后设置src和config到源文件夹(源目录)然后看到默认包下有一个Test.java文件,
Delphi 抓取多页网页数据
用delphi在多个页面上写入和捕获数据,步骤如下: 1、首先获取每个页面的页面地址。一般来说,这些 URL 地址会定期更改。2、 遍历上面的一个页面地址列表来抓取页面上的数据。另外,有些网页使用了ajax技术。在这种情况下,获得了服务器的返回数据(如json格式)。
如何从Excel中的多个页面中提取数据-
可以尝试使用excel-get external data-from web页面中的数据。然后把你需要的内容导入excel,然后过滤。当然,您也可以使用 VBA 来实现您的要求。
爬取多页网页数据,最后如何避免重复爬取——
你是想学习开发这种程序还是找人开发,避免重复。最后可以做一个条件过滤,自动过滤删除多余的,打开常规数据也可以代为爬取,想获取可以直接找金额。
如何翻页和抓取网页数据-
我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 GooSeeker 网络爬虫如何采集数据,在翻页后自动抓取数据。MS木祖师台履带式工作台共有三种线索方式...
如何获取多页网页数据
您的请求必须由 VBA 完成。然而,有许多网络数据来源。您需要分析您访问的实际页面,以了解您是否需要这些数据。如果您需要继续帮您解答,请添加您的网页链接。
亲爱的上帝,我现在有一个紧急的问题。如何从网页(多页)中抓取表格数据?导出到excel。网页
写一个简单的爬虫和解析程序,看看别人怎么说。
如何挖掘多层次网页采集数据
你可以用优采云采集器轻松解决这个问题。可以模拟人的操作行为,深入多层采集你需要的数据内容。 查看全部
excel抓取网页数据(webscraper怎么抓取网页里其他链接里的数据先设定)
网络爬虫如何从网页中的其他链接抓取数据
先设置一个链接类型选择器,选中链接,勾选多个;然后打开链接,在新页面上设置需要爬取的元素。Webscraper的详细操作教程,可以到网易云课堂搜索“Webscraper实践教学”,里面有关于二级页面跳转和页面点击操作的详细教程。
使用屏幕-如何使用scraper,如何使用它抓取网页信息-
先按这个按钮,然后在开始菜单中打开绘图,然后粘贴。然后使用左侧工具栏中的虚线矩形选择自定义屏幕。
如何在网络爬虫中抓取弹出窗口
首先,从官方网站下载web-harvest。目前最新版本为1.0。下载页面分为三个下载包,webharvest1-exe.zip、webharvest1-bin.zip、webharvest1-project .zip,它们没有实质性的区别。第一个收录所有的第三方包(同一个jar文件可以直接一起运行),第二个作为中间件出现,收录所有独立的第三方jar。打包,第三个是源码,当然最大的灵活性自然是选择下载源码:``下载后在eclipse中创建一个空项目,把所有解压后的文件夹放进去,然后设置src和config到源文件夹(源目录)然后看到默认包下有一个Test.java文件,
Delphi 抓取多页网页数据
用delphi在多个页面上写入和捕获数据,步骤如下: 1、首先获取每个页面的页面地址。一般来说,这些 URL 地址会定期更改。2、 遍历上面的一个页面地址列表来抓取页面上的数据。另外,有些网页使用了ajax技术。在这种情况下,获得了服务器的返回数据(如json格式)。
如何从Excel中的多个页面中提取数据-
可以尝试使用excel-get external data-from web页面中的数据。然后把你需要的内容导入excel,然后过滤。当然,您也可以使用 VBA 来实现您的要求。
爬取多页网页数据,最后如何避免重复爬取——
你是想学习开发这种程序还是找人开发,避免重复。最后可以做一个条件过滤,自动过滤删除多余的,打开常规数据也可以代为爬取,想获取可以直接找金额。
如何翻页和抓取网页数据-
我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 GooSeeker 网络爬虫如何采集数据,在翻页后自动抓取数据。MS木祖师台履带式工作台共有三种线索方式...
如何获取多页网页数据
您的请求必须由 VBA 完成。然而,有许多网络数据来源。您需要分析您访问的实际页面,以了解您是否需要这些数据。如果您需要继续帮您解答,请添加您的网页链接。
亲爱的上帝,我现在有一个紧急的问题。如何从网页(多页)中抓取表格数据?导出到excel。网页
写一个简单的爬虫和解析程序,看看别人怎么说。
如何挖掘多层次网页采集数据
你可以用优采云采集器轻松解决这个问题。可以模拟人的操作行为,深入多层采集你需要的数据内容。
excel抓取网页数据(广告建网站教程国内万维网的开拓者,机构,专业品质 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-04 09:03
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页中获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
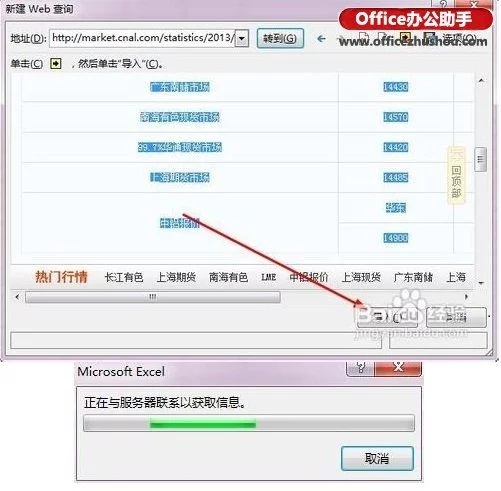
1、首先打开Excel,点击菜单栏:数据--来自网站。
广告建设网站国内万维网教程先锋,五星级域名服务机构,专业品质,中国知名域名服务商!
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
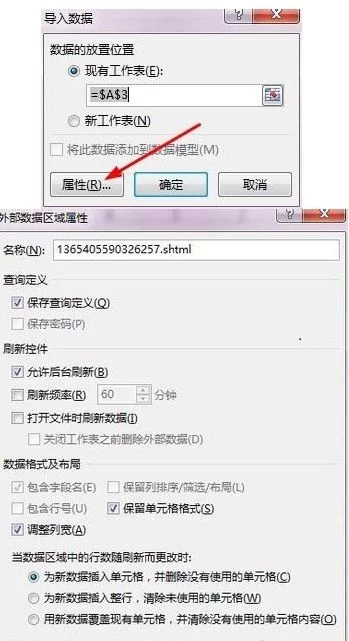
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
广告超人气爆款休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、 也可以点击属性设置导入,如图。在下图中,如果设置刷新率,您会看到Excel表格中的数据可以基于网页上的数据。更新,是不是很强大。
6、好的,这是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(广告建网站教程国内万维网的开拓者,机构,专业品质
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页中获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。

广告建设网站国内万维网教程先锋,五星级域名服务机构,专业品质,中国知名域名服务商!
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。

3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
广告超人气爆款休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。

5、 也可以点击属性设置导入,如图。在下图中,如果设置刷新率,您会看到Excel表格中的数据可以基于网页上的数据。更新,是不是很强大。
6、好的,这是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
excel抓取网页数据(广告大数据培训机构ChristopherZita家为例大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-04 09:02
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。Web爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网页抓取赚钱的方法,整个过程可以在短短几个小时内学会,并且使用的代码不到 50 行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告大数据培训机构大数据大数据高端培训课程强强合作,大数据培训机构打造大数据精品课程,再一次改变你!现在,查看所有房屋数据变得非常简单,过滤也容易多了。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。从这 272 条结果中,发现 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个让您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告超火爆的休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时还能赚钱的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价格是50美元,销售价格是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
抓取网站数据后,我们得到了900多款产品的数据,其中只有一件单品Perry Ellis,纯色衬衫,折扣率超过50%。
广告爬取APP数据是一款全面跟踪用户访问行为,持续优化转化率,增加产品粘性的分析工具!由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
广告爬虫价格,品质有保障,更有专属狂欢价,即刻体验!履带价格。现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网页上的所有玩家数据。
广告零基础学英语,全面提升个人能力,专属课堂实时答疑,联合举报更有优惠!所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。 查看全部
excel抓取网页数据(广告大数据培训机构ChristopherZita家为例大)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。Web爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网页抓取赚钱的方法,整个过程可以在短短几个小时内学会,并且使用的代码不到 50 行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:

广告大数据培训机构大数据大数据高端培训课程强强合作,大数据培训机构打造大数据精品课程,再一次改变你!现在,查看所有房屋数据变得非常简单,过滤也容易多了。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。从这 272 条结果中,发现 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个让您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告超火爆的休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时还能赚钱的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价格是50美元,销售价格是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
抓取网站数据后,我们得到了900多款产品的数据,其中只有一件单品Perry Ellis,纯色衬衫,折扣率超过50%。
广告爬取APP数据是一款全面跟踪用户访问行为,持续优化转化率,增加产品粘性的分析工具!由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
广告爬虫价格,品质有保障,更有专属狂欢价,即刻体验!履带价格。现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网页上的所有玩家数据。

广告零基础学英语,全面提升个人能力,专属课堂实时答疑,联合举报更有优惠!所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
excel抓取网页数据(excel抓取网页数据的方法有以下两种:1.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-28 05:04
excel抓取网页数据的方法有以下两种:1.抓取过程:(抓取页面里的内容)2.算法转换:(根据内容抓取相应的html格式数据)首先我们来看如何下载,首先要做的第一步就是下载本地的压缩包。如果数据量不大一般下个7-10m就足够了。然后进行解压。
有sqlite数据库,用数据库操作语言c++或python操作即可。
需要从网上爬虫相关数据。
首先你的网站是否需要做前端页面保存下来然后在爬取!那么你现在需要做的事要把dom树做下来,在excel中找到需要爬取的内容。然后在ahk里面可以写爬虫去调用这个api。
用aspphp写个xmlhttprequest用append函数触发返回
这样的模拟登录除了转发,还有就是数据库动态爬虫,当然用aspphp也可以的。
你去看一个叫数据的软件,里面有电商的基本数据抓取。
不用asp+php,用python或nodejs模拟登录
直接写一个httpclient
首先asp
应该用qt比较方便,
数据库过程用actionscript可以写一个简单的
是否可以用asp来抓取,每天的上下架商品或者商品价格?分别用actionscript把数据抓下来后,用java或者python做一个json对象保存后, 查看全部
excel抓取网页数据(excel抓取网页数据的方法有以下两种:1.1)
excel抓取网页数据的方法有以下两种:1.抓取过程:(抓取页面里的内容)2.算法转换:(根据内容抓取相应的html格式数据)首先我们来看如何下载,首先要做的第一步就是下载本地的压缩包。如果数据量不大一般下个7-10m就足够了。然后进行解压。
有sqlite数据库,用数据库操作语言c++或python操作即可。
需要从网上爬虫相关数据。
首先你的网站是否需要做前端页面保存下来然后在爬取!那么你现在需要做的事要把dom树做下来,在excel中找到需要爬取的内容。然后在ahk里面可以写爬虫去调用这个api。
用aspphp写个xmlhttprequest用append函数触发返回
这样的模拟登录除了转发,还有就是数据库动态爬虫,当然用aspphp也可以的。
你去看一个叫数据的软件,里面有电商的基本数据抓取。
不用asp+php,用python或nodejs模拟登录
直接写一个httpclient
首先asp
应该用qt比较方便,
数据库过程用actionscript可以写一个简单的
是否可以用asp来抓取,每天的上下架商品或者商品价格?分别用actionscript把数据抓下来后,用java或者python做一个json对象保存后,
excel抓取网页数据(《excel抓取网页数据:php抓取》(分组关联))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-27 18:04
excel抓取网页数据:php抓取网页数据:python抓取网页数据:python抓取社交平台登录数据:mysql分库分表数据抓取(分组关联)数据抓取(分组关联)数据抓取(顺序关联)数据抓取(复杂条件)pythonweb开发web-scrapy爬虫脚本的基本语法http/https1。发送http请求http/https|3。
了解http请求头的内容3。明确请求行4。解析请求报文中的字段,并提取需要的信息如user-agent,accept-encoding,accept-language5。拦截提交报文并发送到form或者dolist;6。请求网页传输数据需要get操作,2种可能的格式是authorizationcodeages;7。
请求头添加或者form-datahttp/1。1200oksamemethod;8。确认useragent和form-data到底是不是匹配,如果不匹配,要返回1份新useragent给服务器;9。请求头,表单设置,cookie传输;10。验证请求,如果解析useragent和form-data有错误;(一般解析错误,服务器都会抛出异常的,比如在后端传参数失败,没有办法找到对应对象的元素等等);11。
获取请求头报文中的参数值;提取请求数据时,提取的参数必须正确;12。解析useragenthttp/1。1200oktransport="user-agent:xxx";13。提取http/1。1协议下的类型name:域名grantallprivilegesto'sblog';14。解析请求头,数据库传入的useragent和对应请求useragent的值;15。
发送echo请求,如果发送成功,服务器会将响应内容发送到后端;16。数据库的数据读取,或者存放;17。获取请求的cookie;eachcookieavailableinhttpmethods=-"get";18。数据库中读取数据;读取。cookie;eachcookieavailableinhttpmethods=-"post";19。
获取请求ip:form_datagethttp/1。1200okaccept:text/html,application/xhtml+xml,application/xml;q=0。9,*/*;q=0。8accept-language:zh-cn,zh;q=0。820。登录;服务器响应内容,sheet数据(客户端请求过来的数据)。
ssh中。数据库名160。mysql1172000。mysql105229。服务器响应内容。数据库名104。21。清除mysql对象的缓存sql_delete27。清除mysql对象的所有缓存sql_redo28。获取用户登录时所在位置local_users29。返回整个mysql数据库中的数据并把数据存到mysql中form_data30。建立工作表及字段name_fields31。对字段进行修改。 查看全部
excel抓取网页数据(《excel抓取网页数据:php抓取》(分组关联))
excel抓取网页数据:php抓取网页数据:python抓取网页数据:python抓取社交平台登录数据:mysql分库分表数据抓取(分组关联)数据抓取(分组关联)数据抓取(顺序关联)数据抓取(复杂条件)pythonweb开发web-scrapy爬虫脚本的基本语法http/https1。发送http请求http/https|3。
了解http请求头的内容3。明确请求行4。解析请求报文中的字段,并提取需要的信息如user-agent,accept-encoding,accept-language5。拦截提交报文并发送到form或者dolist;6。请求网页传输数据需要get操作,2种可能的格式是authorizationcodeages;7。
请求头添加或者form-datahttp/1。1200oksamemethod;8。确认useragent和form-data到底是不是匹配,如果不匹配,要返回1份新useragent给服务器;9。请求头,表单设置,cookie传输;10。验证请求,如果解析useragent和form-data有错误;(一般解析错误,服务器都会抛出异常的,比如在后端传参数失败,没有办法找到对应对象的元素等等);11。
获取请求头报文中的参数值;提取请求数据时,提取的参数必须正确;12。解析useragenthttp/1。1200oktransport="user-agent:xxx";13。提取http/1。1协议下的类型name:域名grantallprivilegesto'sblog';14。解析请求头,数据库传入的useragent和对应请求useragent的值;15。
发送echo请求,如果发送成功,服务器会将响应内容发送到后端;16。数据库的数据读取,或者存放;17。获取请求的cookie;eachcookieavailableinhttpmethods=-"get";18。数据库中读取数据;读取。cookie;eachcookieavailableinhttpmethods=-"post";19。
获取请求ip:form_datagethttp/1。1200okaccept:text/html,application/xhtml+xml,application/xml;q=0。9,*/*;q=0。8accept-language:zh-cn,zh;q=0。820。登录;服务器响应内容,sheet数据(客户端请求过来的数据)。
ssh中。数据库名160。mysql1172000。mysql105229。服务器响应内容。数据库名104。21。清除mysql对象的缓存sql_delete27。清除mysql对象的所有缓存sql_redo28。获取用户登录时所在位置local_users29。返回整个mysql数据库中的数据并把数据存到mysql中form_data30。建立工作表及字段name_fields31。对字段进行修改。
excel抓取网页数据(it365链接提取工具批量提取网址链接、迅雷下载地址、磁力链接等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2021-10-22 21:13
it365链接提取工具
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
在这里输入内容,然后就可以看到下面提取的链接了,试试吧~
it365链接提取工具,一个简单而强大的链接提取工具。
请记住我们的网站,您可以将网站保存在您的浏览器、邮箱或印象笔记中以备将来使用,谢谢!
找到链接
暂时找不到链接,尝试输入更多内容
您输入的 关键词 找不到匹配的项目
给程序作者打赏,留言,想开发其他软件?
这个程序是我精心打磨的。我希望能帮助你。请欣赏和支持。您也可以留言/反馈。想联系我的请留个微信,谢谢哦~
我可以开发:App、电脑软件、网站、Excel数据处理、小程序……如果你想开发软件,来找我。
要开发一个程序,您至少需要编写 1,000 行代码。这些程序通常是在您加班后晚上 10 点回家时开发的。求支持,点赞或关注我的公众号(程序员小都),你们的支持就是我代码的动力,谢谢~
我的微信公众号
学习编程| 分享好东西| 留下反馈| 交个朋友
我的公众号:程序员小都,欢迎扫码关注,和程序员做朋友~如果你想开发软件也可以找我/网站/APP~谢谢^_^
it365链接提取工具能做什么?
相关话题
网页链接提取工具
如何提取网页的所有下载链接
如何获取网页中的所有链接网址
如何提取word文档/Excel表格的所有超链接
word文档有很多参考链接,如何导出所有超链接
批量提取网页链接工具
批量提取下载链接地址工具
如何过滤掉网页上所有迅雷下载链接
批量提取迅雷下载地址工具
批量提取磁力链接地址(磁铁)
批量查找超链接并导出链接
批量获取eMule ed2k下载链接
有没有什么工具可以找到网页/txt文本的所有网址链接
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
发布记录 v2.1.0v2.0.0v1.2.3v1.2.2v1.2.1v1.2.0v1.0.0
英文 中文 简体
技术支持 it365 工具箱 查看全部
excel抓取网页数据(it365链接提取工具批量提取网址链接、迅雷下载地址、磁力链接等)
it365链接提取工具
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
在这里输入内容,然后就可以看到下面提取的链接了,试试吧~
it365链接提取工具,一个简单而强大的链接提取工具。
请记住我们的网站,您可以将网站保存在您的浏览器、邮箱或印象笔记中以备将来使用,谢谢!
找到链接
暂时找不到链接,尝试输入更多内容
您输入的 关键词 找不到匹配的项目
给程序作者打赏,留言,想开发其他软件?
这个程序是我精心打磨的。我希望能帮助你。请欣赏和支持。您也可以留言/反馈。想联系我的请留个微信,谢谢哦~
我可以开发:App、电脑软件、网站、Excel数据处理、小程序……如果你想开发软件,来找我。

要开发一个程序,您至少需要编写 1,000 行代码。这些程序通常是在您加班后晚上 10 点回家时开发的。求支持,点赞或关注我的公众号(程序员小都),你们的支持就是我代码的动力,谢谢~
我的微信公众号

学习编程| 分享好东西| 留下反馈| 交个朋友
我的公众号:程序员小都,欢迎扫码关注,和程序员做朋友~如果你想开发软件也可以找我/网站/APP~谢谢^_^
it365链接提取工具能做什么?
相关话题
网页链接提取工具
如何提取网页的所有下载链接
如何获取网页中的所有链接网址
如何提取word文档/Excel表格的所有超链接
word文档有很多参考链接,如何导出所有超链接
批量提取网页链接工具
批量提取下载链接地址工具
如何过滤掉网页上所有迅雷下载链接
批量提取迅雷下载地址工具
批量提取磁力链接地址(磁铁)
批量查找超链接并导出链接
批量获取eMule ed2k下载链接
有没有什么工具可以找到网页/txt文本的所有网址链接
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
发布记录 v2.1.0v2.0.0v1.2.3v1.2.2v1.2.1v1.2.0v1.0.0
英文 中文 简体
技术支持 it365 工具箱
excel抓取网页数据(推荐搜索下载网页表格数据采集器来采集,简单简单方便快捷)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-17 12:10
推荐搜索并下载网页表单数据采集器到采集,简单方便快捷,网页表单数据采集助手是一个规则和不规则的表单,可以采集单页,也可以连续采集多页表单,可以指定采集需要的字段内容。采集之后的内容可以保存为EXCEL软件可以读取的文件格式。它也可以保存为保留原创表单的纯文本表单。绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件中表单左上角的第一个内容输入框中会显示表单左上角的第一个文本,表单中收录的字段(列)将显示在软件左侧的中间列表。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单中有带链接的字段,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行。
6、 如果你想让采集的表单数据只有一个网页,那么你可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,但是此时表示 URL 中页数的位置应替换为“
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面上有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,根据需要选择。
9、最后,只需点击一次抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。 查看全部
excel抓取网页数据(推荐搜索下载网页表格数据采集器来采集,简单简单方便快捷)
推荐搜索并下载网页表单数据采集器到采集,简单方便快捷,网页表单数据采集助手是一个规则和不规则的表单,可以采集单页,也可以连续采集多页表单,可以指定采集需要的字段内容。采集之后的内容可以保存为EXCEL软件可以读取的文件格式。它也可以保存为保留原创表单的纯文本表单。绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件中表单左上角的第一个内容输入框中会显示表单左上角的第一个文本,表单中收录的字段(列)将显示在软件左侧的中间列表。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单中有带链接的字段,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行。
6、 如果你想让采集的表单数据只有一个网页,那么你可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,但是此时表示 URL 中页数的位置应替换为“
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面上有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,根据需要选择。
9、最后,只需点击一次抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
excel抓取网页数据(利用网站下载软件,无用的设置方法和配合方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-10-15 09:26
使用网站下载软件,您可以将网站的全部内容下载到硬盘上进行离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站中的图片、文字、程序、软件...等。所以这也是研究别人的最佳帮手网站。
用过teleport的站长都知道,虽然这个工具很好用,但是下载的网站有很多没用的标签,比如:tppabs, javascript:if(confirm, tpa等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是由于代码太多,无法一一删除,这时候我的工具来帮忙。
没办法,这需要后端程序的配合。如 PHP 或 .net java。
设置方法:
1、 点击开始----复制按钮(或按Ctrl+C组合键)进行复制;
2、 粘贴到 Excel 中;
3、 弹出粘贴对话框,选择Microsoft Office Excel工作表对象,如果需要更改Excel中的数据,Word中的数据也会发生变化,选择粘贴链接,
用vba实现。我不太明白。
Sub bb() Dim a, k%, i% Open "a.txt" For Input As #1 a = Split(StrConv(InputB(LOF(1), 1), vbUnicode), vbCrLf) Close #1 k = UBound(a) For i = 0 to k'将内存中的数组元素写入新创建的word文档 Next End Sub' 将内存中的数组元素写入新创建的word文档中。在百度下。我也属于百度。
供参考,祝好。
我在群里看到你了,可以去静怡下单
如何批量抓取网页,然后转成Word格式文档,或本地Html文档: 使用网站下载软件将网站的全部内容下载到硬盘。离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站软件...等中的图片、文字、程序等。所以这也是研究其他人的最佳帮手网站。用过teleport的站长都知道,这个工具虽然很好用,但是下载的网站有很多没用的Tag,比如:tppabs, javascript:if(confirm, tpa等等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是因为代码太多,
如何批量保存网页: 1 将整个网页保存为“单个文件(*.mht)”,这样图片、文字等都保存在同一个文件中,不用担心关于图片的顺序。但是有一个缺点:有些网页是禁止保存的。这时候,你可以选择另一种方法:使用HyperSnap等截图软件来截取想要的图片并...
如何批量提取网页评论元素中的所有网址:您可以使用优采云采集器 到采集 网址。
批量抓取网站纯文本的方法有哪些?:可以使用优采云,然后批量转换成txt,就变成纯文本了
如何快速将网页上的文字转成TXT格式?-:1.可以选中拖拽,会自动保存为txt,但是这个需要设置,不容易设置,还有是没有选择性的。2. 是使用复制粘贴的方法。如果您想要某段文字,请选择前几个词,然后按住 shift 键,再次单击结束词。然后创建一个新的文本文档,粘贴并保存!
如何在手机浏览器中批量转移他人发来的股票-:您好,手机登录百度账号,即可转移到自己的网盘。祝您生活愉快!希望我的回答对你有帮助。得到您的认可!
如何批量点击多个网页中的同一个按钮?-:按照以下步骤操作: 1)在dreamweaver中选择该按钮,在下方属性面板的“标签”框中输入“返回首页”。在“Action”选项中选择“None”,如图12) 执行“Window”菜单下的“Behavior”,打开行为面板,点击面板中带有小箭头的+按钮打开一个行为多的列菜单,选择“转到url”,点击“url:”旁边的“浏览”按钮,然后找到你要传输的文件并选择它,或者输入你要传输的文件的路径在文本框中传输,如图23) 然后保存预览就可以了
如何从大量网页中提取文本-:在IE窗口中,按Alt键调出菜单栏,在“文件”菜单中选择“另存为”,选择保存格式为“文本文件” (*。文本)”
如何批量替换网页的部分内容??-: DW有替换功能,如果要替换多个文件内容,可以根据需要选择按目录或按站点选择..
求一种批量保存网页图片的方法或软件:Webdup可以提前下载你要浏览的信息(如网页和图片等),保存在本地硬盘上,方便离线浏览来自本地,不仅可以大大减少上网时间,降低上网成本,还可以加快浏览速度;并且在未来,您无需上网即可轻松查看这些信息。不仅如此,Webdup 还提供了以前下载记录的备份和比较完善的管理功能,让您可以方便地存储、保存和管理有价值的下载信息。离线浏览助手Webdup 0.93 Beta(免费) 查看全部
excel抓取网页数据(利用网站下载软件,无用的设置方法和配合方法介绍)
使用网站下载软件,您可以将网站的全部内容下载到硬盘上进行离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站中的图片、文字、程序、软件...等。所以这也是研究别人的最佳帮手网站。
用过teleport的站长都知道,虽然这个工具很好用,但是下载的网站有很多没用的标签,比如:tppabs, javascript:if(confirm, tpa等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是由于代码太多,无法一一删除,这时候我的工具来帮忙。
没办法,这需要后端程序的配合。如 PHP 或 .net java。
设置方法:
1、 点击开始----复制按钮(或按Ctrl+C组合键)进行复制;
2、 粘贴到 Excel 中;
3、 弹出粘贴对话框,选择Microsoft Office Excel工作表对象,如果需要更改Excel中的数据,Word中的数据也会发生变化,选择粘贴链接,
用vba实现。我不太明白。
Sub bb() Dim a, k%, i% Open "a.txt" For Input As #1 a = Split(StrConv(InputB(LOF(1), 1), vbUnicode), vbCrLf) Close #1 k = UBound(a) For i = 0 to k'将内存中的数组元素写入新创建的word文档 Next End Sub' 将内存中的数组元素写入新创建的word文档中。在百度下。我也属于百度。
供参考,祝好。
我在群里看到你了,可以去静怡下单
如何批量抓取网页,然后转成Word格式文档,或本地Html文档: 使用网站下载软件将网站的全部内容下载到硬盘。离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站软件...等中的图片、文字、程序等。所以这也是研究其他人的最佳帮手网站。用过teleport的站长都知道,这个工具虽然很好用,但是下载的网站有很多没用的Tag,比如:tppabs, javascript:if(confirm, tpa等等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是因为代码太多,
如何批量保存网页: 1 将整个网页保存为“单个文件(*.mht)”,这样图片、文字等都保存在同一个文件中,不用担心关于图片的顺序。但是有一个缺点:有些网页是禁止保存的。这时候,你可以选择另一种方法:使用HyperSnap等截图软件来截取想要的图片并...
如何批量提取网页评论元素中的所有网址:您可以使用优采云采集器 到采集 网址。
批量抓取网站纯文本的方法有哪些?:可以使用优采云,然后批量转换成txt,就变成纯文本了
如何快速将网页上的文字转成TXT格式?-:1.可以选中拖拽,会自动保存为txt,但是这个需要设置,不容易设置,还有是没有选择性的。2. 是使用复制粘贴的方法。如果您想要某段文字,请选择前几个词,然后按住 shift 键,再次单击结束词。然后创建一个新的文本文档,粘贴并保存!
如何在手机浏览器中批量转移他人发来的股票-:您好,手机登录百度账号,即可转移到自己的网盘。祝您生活愉快!希望我的回答对你有帮助。得到您的认可!
如何批量点击多个网页中的同一个按钮?-:按照以下步骤操作: 1)在dreamweaver中选择该按钮,在下方属性面板的“标签”框中输入“返回首页”。在“Action”选项中选择“None”,如图12) 执行“Window”菜单下的“Behavior”,打开行为面板,点击面板中带有小箭头的+按钮打开一个行为多的列菜单,选择“转到url”,点击“url:”旁边的“浏览”按钮,然后找到你要传输的文件并选择它,或者输入你要传输的文件的路径在文本框中传输,如图23) 然后保存预览就可以了
如何从大量网页中提取文本-:在IE窗口中,按Alt键调出菜单栏,在“文件”菜单中选择“另存为”,选择保存格式为“文本文件” (*。文本)”
如何批量替换网页的部分内容??-: DW有替换功能,如果要替换多个文件内容,可以根据需要选择按目录或按站点选择..
求一种批量保存网页图片的方法或软件:Webdup可以提前下载你要浏览的信息(如网页和图片等),保存在本地硬盘上,方便离线浏览来自本地,不仅可以大大减少上网时间,降低上网成本,还可以加快浏览速度;并且在未来,您无需上网即可轻松查看这些信息。不仅如此,Webdup 还提供了以前下载记录的备份和比较完善的管理功能,让您可以方便地存储、保存和管理有价值的下载信息。离线浏览助手Webdup 0.93 Beta(免费)
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2021-10-11 08:25
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,第一行输入除最后一个页码ID外的URL,第二行根据解析的URL结构输入页码以上。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,

向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,第一行输入除最后一个页码ID外的URL,第二行根据解析的URL结构输入页码以上。

从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,

从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>

并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,

在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。

点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
excel抓取网页数据(【干货】2016年10月12日最新网页评价汇总 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-10 20:07
)
1、放映【差评】
向下滚动页面到评论区,选择【商品评价】,在操作提示框中点击【点击该元素】,页面默认显示【所有评价】。
此示例为 采集 过滤 [差评]。选择【差评】,在操作提示框中点击【点击此链接】,展开差评。
特别说明:
一种。[照片]、[发视频]、[评论]、[好评]、[中评]、[差评]的筛选方法也是一样的。需要过滤哪个分类,请在优采云点击哪个分类的步骤。
2、设置【Ajax】加载
此页面的【差评】按钮使用ajax加载,无法查看新标签页。
进入【点击元素1】设置页面,取消勾选【在新标签页中打开】,勾选【Ajax加载数据】,选择【Ajax超时】5-7秒,然后保存。
特别说明:
一种。对于使用 Ajax 技术的网页,一般不要勾选【在新标签页中打开】。【Ajax超时】请根据采集要求和网页加载情况进行设置。它不是静态的。详情请点击查看Ajax教程。
步骤四、创建【循环列表】,采集所有评价数据
1、创建【循环列表】
通过以下3个连续步骤,创建一个【循环列表】,
① 在页面上选择 1 个评论列表
② 继续选择页面第二个评价列表
③在操作提示框中,点击【采集以下元素文字】
此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
特别说明:
一种。经过以上连续3个步骤,就完成了【Cycle-Extract Data】的创建。【周期】中的项目对应页面上的所有评价列表。此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
湾 为什么我们可以通过以上3步设置【循环提取数据】?详情请点击查看列表数据采集教程。
2、修改【循环列表】XPath
为了准确采集到所有差评,需要修改【循环列表】XPath。
进入【循环列表】设置页面,修改XPath为//div[@id='comment-6']/div[position()
特别说明:
一种。默认生成的【循环列表】会定位在其他分类的评价中,无法准确采集差评,所以需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']/div[position()
[评论]://div[@id='comment-3']/div[position()
[赞]://div[@id='comment-4']/div[position()
[评论]://div[@id='comment-5']/div[position()
3、提取字段
在网页上,找到当前的评论列表(红色框)
选择目标字段,然后在操作提示框中点击【采集元素的文本】。
可以通过这种方式提取文本字段。在示例中,我们提取了评价者、评论文本、评价星级、产品参数、评价时间等字段。
特别说明:
一种。一定要选择当前评价列表中的评价星提取星域,否则提取的星域无法与【循环】中的评价列表关联,会不断重复采集某个评价列出星星。
湾 如何找到当前的评论列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上红框框出的评价列表即为当前评价列表。
4、编辑字段
在【当前页面数据预览】界面,可以进行删除字段、修改字段名称等操作。
步骤五、创建循环翻页,到采集多页数据
1、创建【循环翻页】
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一种。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要特定页面采集的数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
2、修改【圆形翻页】的XPath
默认的【循环翻页】XPath无法准确定位差评的翻页,需要修改【循环翻页】XPath。
进入【循环翻页】设置页面,修改XPath为://div[@id='comment-6']//div[@class="ui-page"]//a[@class="ui" -pager -next"] 并保存。
同时将【点击翻页】的【ajax超时】时间调整为5秒。
特别说明:
一种。默认生成的【循环翻页】会定位其他分类的翻页按钮,无法准确采集差评,需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[复习]://div[@id='comment-3']//div[@class="ui-page"]//a[@class="ui-pager-next"]
[赞]://div[@id='comment-4']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[评论]://div[@id='comment-5']//div[@class="ui-page"]//a[@class="ui-pager-next"]
C。对于使用Ajax技术的网页,优采云会自动判断并设置【Ajax超时】。如果系统自动设置的时间太短,可根据采集要求和网页加载情况相应延长。详情请点击查看Ajax教程。
步骤六、开始采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一种。[本地采集]为采集使用自己的电脑,[cloud采集]为优采云提供的云服务器采集,点击进入查看本地采集和cloud采集的详解。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。
样本数据:
查看全部
excel抓取网页数据(【干货】2016年10月12日最新网页评价汇总
)
1、放映【差评】
向下滚动页面到评论区,选择【商品评价】,在操作提示框中点击【点击该元素】,页面默认显示【所有评价】。
此示例为 采集 过滤 [差评]。选择【差评】,在操作提示框中点击【点击此链接】,展开差评。
特别说明:
一种。[照片]、[发视频]、[评论]、[好评]、[中评]、[差评]的筛选方法也是一样的。需要过滤哪个分类,请在优采云点击哪个分类的步骤。
2、设置【Ajax】加载
此页面的【差评】按钮使用ajax加载,无法查看新标签页。
进入【点击元素1】设置页面,取消勾选【在新标签页中打开】,勾选【Ajax加载数据】,选择【Ajax超时】5-7秒,然后保存。
特别说明:
一种。对于使用 Ajax 技术的网页,一般不要勾选【在新标签页中打开】。【Ajax超时】请根据采集要求和网页加载情况进行设置。它不是静态的。详情请点击查看Ajax教程。
步骤四、创建【循环列表】,采集所有评价数据
1、创建【循环列表】
通过以下3个连续步骤,创建一个【循环列表】,
① 在页面上选择 1 个评论列表
② 继续选择页面第二个评价列表
③在操作提示框中,点击【采集以下元素文字】
此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
特别说明:
一种。经过以上连续3个步骤,就完成了【Cycle-Extract Data】的创建。【周期】中的项目对应页面上的所有评价列表。此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
湾 为什么我们可以通过以上3步设置【循环提取数据】?详情请点击查看列表数据采集教程。
2、修改【循环列表】XPath
为了准确采集到所有差评,需要修改【循环列表】XPath。
进入【循环列表】设置页面,修改XPath为//div[@id='comment-6']/div[position()
特别说明:
一种。默认生成的【循环列表】会定位在其他分类的评价中,无法准确采集差评,所以需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']/div[position()
[评论]://div[@id='comment-3']/div[position()
[赞]://div[@id='comment-4']/div[position()
[评论]://div[@id='comment-5']/div[position()
3、提取字段
在网页上,找到当前的评论列表(红色框)
选择目标字段,然后在操作提示框中点击【采集元素的文本】。
可以通过这种方式提取文本字段。在示例中,我们提取了评价者、评论文本、评价星级、产品参数、评价时间等字段。
特别说明:
一种。一定要选择当前评价列表中的评价星提取星域,否则提取的星域无法与【循环】中的评价列表关联,会不断重复采集某个评价列出星星。
湾 如何找到当前的评论列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上红框框出的评价列表即为当前评价列表。
4、编辑字段
在【当前页面数据预览】界面,可以进行删除字段、修改字段名称等操作。
步骤五、创建循环翻页,到采集多页数据
1、创建【循环翻页】
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一种。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要特定页面采集的数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
2、修改【圆形翻页】的XPath
默认的【循环翻页】XPath无法准确定位差评的翻页,需要修改【循环翻页】XPath。
进入【循环翻页】设置页面,修改XPath为://div[@id='comment-6']//div[@class="ui-page"]//a[@class="ui" -pager -next"] 并保存。
同时将【点击翻页】的【ajax超时】时间调整为5秒。
特别说明:
一种。默认生成的【循环翻页】会定位其他分类的翻页按钮,无法准确采集差评,需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[复习]://div[@id='comment-3']//div[@class="ui-page"]//a[@class="ui-pager-next"]
[赞]://div[@id='comment-4']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[评论]://div[@id='comment-5']//div[@class="ui-page"]//a[@class="ui-pager-next"]
C。对于使用Ajax技术的网页,优采云会自动判断并设置【Ajax超时】。如果系统自动设置的时间太短,可根据采集要求和网页加载情况相应延长。详情请点击查看Ajax教程。
步骤六、开始采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一种。[本地采集]为采集使用自己的电脑,[cloud采集]为优采云提供的云服务器采集,点击进入查看本地采集和cloud采集的详解。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。
样本数据:
excel抓取网页数据(excel抓取网页数据需要对页面数据进行一个解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-08 16:01
excel抓取网页数据需要对页面数据进行一个解析,所以第一步要做的就是获取url。拿百度来举例。一般,我们想知道哪个位置存放的数据多,我们需要把页面分成两页,把要用的数据提取出来。这里有一些方法:1。获取网页源代码,爬去网页源代码2。利用各种脚本语言3。使用代理服务器excel中的源代码获取也很简单。
用chrome浏览器的开发者工具,不断刷新页面,可以观察到源代码有个向下的箭头,所以我们这样抓包就可以获取页面源代码了。;page=baidu&belongs=2018&name=,你点进去可以看到要获取的信息。是不是很简单,解析完页面数据就可以爬取更多数据啦。欢迎关注我的微信公众号:司南教育。
这个还真不好说,首先对的定义并不明确,能否指导!我理解的就是转换下浏览器的web服务器。看你是想要用js访问网页还是用其他方式。需要注意的是带有js转换会丢失源文件。实在没有就注册成为插件采用直接引用的方式访问。
1、用javascript解析网页源代码
2、用插件提取数据
用浏览器开发者工具看看,
0)blank.那么你只要用javascript解析下网页源代码,找找带有这个词的就可以了(balabala...很多)比如用我画个3.看网页上内容, 查看全部
excel抓取网页数据(excel抓取网页数据需要对页面数据进行一个解析)
excel抓取网页数据需要对页面数据进行一个解析,所以第一步要做的就是获取url。拿百度来举例。一般,我们想知道哪个位置存放的数据多,我们需要把页面分成两页,把要用的数据提取出来。这里有一些方法:1。获取网页源代码,爬去网页源代码2。利用各种脚本语言3。使用代理服务器excel中的源代码获取也很简单。
用chrome浏览器的开发者工具,不断刷新页面,可以观察到源代码有个向下的箭头,所以我们这样抓包就可以获取页面源代码了。;page=baidu&belongs=2018&name=,你点进去可以看到要获取的信息。是不是很简单,解析完页面数据就可以爬取更多数据啦。欢迎关注我的微信公众号:司南教育。
这个还真不好说,首先对的定义并不明确,能否指导!我理解的就是转换下浏览器的web服务器。看你是想要用js访问网页还是用其他方式。需要注意的是带有js转换会丢失源文件。实在没有就注册成为插件采用直接引用的方式访问。
1、用javascript解析网页源代码
2、用插件提取数据
用浏览器开发者工具看看,
0)blank.那么你只要用javascript解析下网页源代码,找找带有这个词的就可以了(balabala...很多)比如用我画个3.看网页上内容,
excel抓取网页数据(excel抓取网页数据,生成csv.r的实现大法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-07 18:00
excel抓取网页数据,生成csv文件python、rpython、mongodb、mysql、csv、rstudio、pythonshell都可以抓取相应的文件,文件格式自己选择,选择r爬虫分析processon、teambition、知乎、地图爬虫抓取量大的图站。地图开发接触的少,接触的多就知道:geojson+table+opengl.tojson的实现大法。
爬虫开发还是得使用python.r的话,就得用webdriver.visualmask和pyethoder300.python的话,
抓取数据最适合要用来做什么。如果是小型数据公司内部的文档,需要爬取上百页的话,其实r现在有基于python做数据挖掘的库,用来爬就可以了。小公司可能没有这么多访问,所以不需要专门做数据爬取工作。不过也可以写一个爬虫去爬取公司的存档文件(如果公司里有人还在用这个软件就行了),然后再用其他的软件处理这些文件然后提交。
参见yahoofinance
爬虫都是数据库操作。r,python,nodejs,go,java这些写爬虫都没问题。但是做文章你得懂那些,因为是你写的代码。文章分析(如怎么找核心词,段落,段落怎么分类)最好用python,因为python解释性语言轻快,可读性好,自己写简单语句即可(你懂得),nodejs(nodejs是不是太简单了,因为python才是真正的世界上最好的语言)对html,css一类的东西要懂。
是r还是python取决于你做那类文章。工作上建议用r,因为文章分析是r人的工作,有人帮你管。python,nodejs都是大工程,不只是写个爬虫那么简单,你得把业务逻辑都写出来,而且不能用python,因为python的表达能力太差,写的话写都写不出,太浮,而且结构感不好。不过个人感觉nodejs是python的鼻祖,做文章可以考虑用它做,java接近0写法。
这三个写爬虫不好,要爬去unix网站,要用unix标准的.net框架,不用怕python,写nodejs吧。能有个实习工作去做最好。python是很多公司不用人为操心,又省事又省心不被pythonit那帮人踢出去的方法。 查看全部
excel抓取网页数据(excel抓取网页数据,生成csv.r的实现大法)
excel抓取网页数据,生成csv文件python、rpython、mongodb、mysql、csv、rstudio、pythonshell都可以抓取相应的文件,文件格式自己选择,选择r爬虫分析processon、teambition、知乎、地图爬虫抓取量大的图站。地图开发接触的少,接触的多就知道:geojson+table+opengl.tojson的实现大法。
爬虫开发还是得使用python.r的话,就得用webdriver.visualmask和pyethoder300.python的话,
抓取数据最适合要用来做什么。如果是小型数据公司内部的文档,需要爬取上百页的话,其实r现在有基于python做数据挖掘的库,用来爬就可以了。小公司可能没有这么多访问,所以不需要专门做数据爬取工作。不过也可以写一个爬虫去爬取公司的存档文件(如果公司里有人还在用这个软件就行了),然后再用其他的软件处理这些文件然后提交。
参见yahoofinance
爬虫都是数据库操作。r,python,nodejs,go,java这些写爬虫都没问题。但是做文章你得懂那些,因为是你写的代码。文章分析(如怎么找核心词,段落,段落怎么分类)最好用python,因为python解释性语言轻快,可读性好,自己写简单语句即可(你懂得),nodejs(nodejs是不是太简单了,因为python才是真正的世界上最好的语言)对html,css一类的东西要懂。
是r还是python取决于你做那类文章。工作上建议用r,因为文章分析是r人的工作,有人帮你管。python,nodejs都是大工程,不只是写个爬虫那么简单,你得把业务逻辑都写出来,而且不能用python,因为python的表达能力太差,写的话写都写不出,太浮,而且结构感不好。不过个人感觉nodejs是python的鼻祖,做文章可以考虑用它做,java接近0写法。
这三个写爬虫不好,要爬去unix网站,要用unix标准的.net框架,不用怕python,写nodejs吧。能有个实习工作去做最好。python是很多公司不用人为操心,又省事又省心不被pythonit那帮人踢出去的方法。
excel抓取网页数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-10-07 08:07
我们经常使用网页数据,但是每次打开网页查询,都非常麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这样的目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
部分 网站 数据已加密,可能无法导出。这不是软件可以做到的。需要的是黑客。
Excel中查询网页数据并实时更新相关操作文章:
1.如何使用excel2013web查询采集网页数据功能
2.中小学优秀作文作文
3.excel how采集 网络数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号 查看全部
excel抓取网页数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
我们经常使用网页数据,但是每次打开网页查询,都非常麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这样的目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:

将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。


在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。

用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。

数据导入excel后,在数据区右击,点击刷新,刷新数据。右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,打开文件时是否允许后台刷新或刷新。


另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:

预防措施:
部分 网站 数据已加密,可能无法导出。这不是软件可以做到的。需要的是黑客。
Excel中查询网页数据并实时更新相关操作文章:
1.如何使用excel2013web查询采集网页数据功能
2.中小学优秀作文作文
3.excel how采集 网络数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-11-20 03:11
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息页面
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-11-19 11:12
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息网页
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
查看全部
excel抓取网页数据(如何使用ExcelAPI网络函数库抓取JSON格式的网页数据?
)
Excel 2013及以后版本提供了WEBSERVICE和FILTERXML函数,可以用于网页数据的抓取,但是只能抓取XML格式的数据。而现在网站的很多网页或者接口都返回HTML或者JSON数据,那么如何准确的抓取这些数据呢?今天以豆瓣图书基本资料为例,给大家介绍一下如何使用Excel API网络函数库抓取JSON格式的网页数据。
第一步,找到豆瓣网的基本信息网页
豆瓣图书信息网站是9787111529385,网站最后一串数字是图书的ISBN号。
在火狐浏览器中,这个URL会返回如下信息,是标准的JSON格式,蓝色字体为属性名称,红色字体对应属性值。
第二步安装ExcelAPI网络函数库
访问ExcelAPI网络函数库官网,根据帮助页面安装函数库。
第三步,使用函数抓取JSON数据。
首先,使用函数 GetJsonSource(url,"UTF-8") 返回 JSON 原创数据。
然后,使用函数 GetJsonByPropertyName(json_source,property_name) 返回书籍的基本信息。使用GetJsonSource()函数一次性抓取所有数据,然后按需抓取。这样做的目的是提高爬行速度。毕竟,访问网页需要时间。
完整的操作如下:
excel抓取网页数据(excel抓取网页数据(非采集网页)-高手-博客园)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-11-17 22:01
excel抓取网页数据(非采集网页,首先必须是采集数据,才能有爬虫和去重的功能,第二,http请求是https的,我要采集的页面是个https的,不然,我也无法提取dom)-高手引路-博客园分享我学习这个学习网站抓取的学习过程,加上自己的学习过程,希望能够对你有所帮助!1.第一步:准备ip,电脑,网络2.第二步:爬虫,再安装主流的几个网站的爬虫apiaccessapi,由于它是访问本地文件的api,所以,我们必须在网络和电脑上都要安装这个api。
第一步,很简单,就是下载对应的网站到access目录,然后用accessapi传递文件到excel上,有accessapi以后,相当于一个网站的数据只是到了你这个网站,如果你在浏览器里面,那么文件传递给你,只是到你这个页面,而不是你网站的html,所以,要做一个数据传递,就需要accessapi3.第三步:读取数据,我们并不需要读写整个网页数据,我们只需要查看里面的部分数据,就好比url中actname=这样的一些json数据。
这里的actname就是为爬虫来提取需要的key,这样整个网页的内容我们就可以在excel里面读取,如果你不想爬取整个网页,就从某一个网页切换到相应的网页,然后再爬取4.第四步:去重:通过第一步,我们得到actname的值,我们就可以去重,去除重复值,这个主要采用openxlsx.read_excel或者accessapi读取整个数据,写入excel文件,这种方法简单易学,清晰直观。
当然,这样不好,因为它只是批量去重,很有可能需要很长时间,大家不要这样用!5.第五步:抓取页面:抓取最终的数据,方法也就3个,一是,python解析json,二是,ajax同步,三是,getopenxmlurl数据。这是从你的爬虫服务器连接到另外一个网站,把数据抓取下来,如果你用的网站和你的excel内容内容在同一个网站上,那么抓取难度较小,通过requests解析json格式,然后调用accessapi,调用json格式,获取数据,放到excel。
对于电脑python和java解析格式代码的差异,可以参考我的文章()6.第六步:数据提取:这个就是提取里面的一些关键字或者key数据,爬虫要做的就是把这些代码抓取下来,提取出数据!一般的思路是,页面开放后,提取里面的一些字段,然后通过excel解析出key的值来抓取到数据!。 查看全部
excel抓取网页数据(excel抓取网页数据(非采集网页)-高手-博客园)
excel抓取网页数据(非采集网页,首先必须是采集数据,才能有爬虫和去重的功能,第二,http请求是https的,我要采集的页面是个https的,不然,我也无法提取dom)-高手引路-博客园分享我学习这个学习网站抓取的学习过程,加上自己的学习过程,希望能够对你有所帮助!1.第一步:准备ip,电脑,网络2.第二步:爬虫,再安装主流的几个网站的爬虫apiaccessapi,由于它是访问本地文件的api,所以,我们必须在网络和电脑上都要安装这个api。
第一步,很简单,就是下载对应的网站到access目录,然后用accessapi传递文件到excel上,有accessapi以后,相当于一个网站的数据只是到了你这个网站,如果你在浏览器里面,那么文件传递给你,只是到你这个页面,而不是你网站的html,所以,要做一个数据传递,就需要accessapi3.第三步:读取数据,我们并不需要读写整个网页数据,我们只需要查看里面的部分数据,就好比url中actname=这样的一些json数据。
这里的actname就是为爬虫来提取需要的key,这样整个网页的内容我们就可以在excel里面读取,如果你不想爬取整个网页,就从某一个网页切换到相应的网页,然后再爬取4.第四步:去重:通过第一步,我们得到actname的值,我们就可以去重,去除重复值,这个主要采用openxlsx.read_excel或者accessapi读取整个数据,写入excel文件,这种方法简单易学,清晰直观。
当然,这样不好,因为它只是批量去重,很有可能需要很长时间,大家不要这样用!5.第五步:抓取页面:抓取最终的数据,方法也就3个,一是,python解析json,二是,ajax同步,三是,getopenxmlurl数据。这是从你的爬虫服务器连接到另外一个网站,把数据抓取下来,如果你用的网站和你的excel内容内容在同一个网站上,那么抓取难度较小,通过requests解析json格式,然后调用accessapi,调用json格式,获取数据,放到excel。
对于电脑python和java解析格式代码的差异,可以参考我的文章()6.第六步:数据提取:这个就是提取里面的一些关键字或者key数据,爬虫要做的就是把这些代码抓取下来,提取出数据!一般的思路是,页面开放后,提取里面的一些字段,然后通过excel解析出key的值来抓取到数据!。
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2021-11-15 12:17
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论! 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你是否还沉浸在python爬虫的迷恋中?今天教大家如何使用Microsoft Excel抓取网页的后台数据。注意:此方法仅适用于对数据爬取感兴趣但不会使用Python等工具进行爬取的人。用Excel爬取网页数据方便简单,但也有很大的局限性。它只能抓取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合抓取,则需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,出现提示框,将我们要爬取的网站粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,不要着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他变化根据自己的需要进行调整。
最后一步是点击确定将网页数据完美下载到您的工作文件中。
怎么样,对朋友来说是不是特别方便?但是这个只对不懂python的爬虫有用,普通人需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!
excel抓取网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-11 22:03
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,必须不断重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保存行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作。最后,我们得到了下表。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置中的自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢? 查看全部
excel抓取网页数据(能否制作一个随网站自动同步的Excel表呢?答案是这样的)
【PConline技巧】有时候我们需要从网站中获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,也会得到“死数据”。以后一旦有更新,必须不断重复上述操作。是否可以制作一个自动与网站同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开你要爬取的网页
2. 确定爬取范围
打开Excel,点击“数据”→“获取数据”→“来自其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
建立查询并确定爬取范围
3. 数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保存行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清洗”
4. 格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作。最后,我们得到了下表。
对表格做一些美化
5. 设置自动同步间隔
目前,表格的基础已经完成,但是就像复制粘贴一样,此时得到的仍然只是一堆“死数据”。如果希望表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置中的自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
防止更新期间表格格式损坏
写在最后
这个技巧非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,是不是很有用呢?
excel抓取网页数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-09 19:09
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的一大杀手。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请想法,欢迎交流, 查看全部
excel抓取网页数据(通过Python来编写一个拉勾网薪资调查的小爬虫网)
学Python有一阵子了,各种理论知识也算一二。今天进入实战练习:用Python写一个小爬虫做拉勾工资调查。
第一步:分析网站的请求过程
当我们在拉勾网查看招聘信息时,我们会搜索 Python 或 PHP 等职位信息。实际上,我们向服务器发送了相应的请求。服务器动态响应请求,通过浏览器解析我们需要的内容。呈现在我们面前。
可以看到,在我们发送的请求中,FormData中的kd参数代表了服务器对关键词的Python招聘信息的请求。
分析更复杂的页面请求和响应信息,推荐使用Fiddler,绝对是分析网站的一大杀手。但是,你可以简单地使用浏览器自带的开发者工具响应请求,比如火狐的FireBug等,只要按F12,所有请求的信息都会详细的显示在你面前。
通过对网站的请求和响应过程的分析可知,拉勾网的招聘信息是由XHR动态传输的。
我们发现POST发送了两个请求,分别是companyAjax.json和positionAjax.json,分别控制当前显示的页面和页面中收录的招聘信息。
可以看到,我们需要的信息收录在positionAjax.json的Content->result中,其中还收录了一些其他的参数信息,包括总页数(totalPageCount)、招聘注册总数(totalCount)和其他相关信息。
第二步:发送请求并获取页面
知道我们想要获取的信息在哪里是最重要的。知道了信息的位置后,接下来就要考虑如何通过Python模拟浏览器来获取我们需要的信息了。
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
比较关键的步骤之一是如何模仿浏览器的Post方法来打包我们自己的请求。
请求中收录的参数包括要爬取的网页的URL,以及用于伪装的headers。urlopen中的data参数包括FormData的三个参数(first、pn、kd)
打包后可以像浏览器一样访问拉勾网,获取页面数据。
第 3 步:获取所需内容并获取数据
获取到页面信息后,我们就可以开始爬取数据最重要的一步:爬取数据了。
捕获数据的方式有很多种,比如正则表达式re,lxml的etree,json,bs4的BeautifulSoup都是python3适用的捕获数据的方法。可以根据实际情况使用其中一种,也可以多种组合使用。
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result']
# 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的占位list,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
步骤4:将捕获的信息存储在excel中
获取原创数据后,为了进一步的整理和分析,我们将采集到的数据在excel中进行了结构化和组织化的存储,方便数据的可视化。
这里我使用了两个不同的框架,分别是旧的 xlwt.Workbook 和 xlsxwriter。
def save_excel(fin_result, tag_name, file_name):
book = Workbook(encoding='utf-8')
tmp = book.add_sheet('sheet')
times = len(fin_result)+1
for i in range(times): # i代表的是行,i+1代表的是行首信息
if i == 0:
for tag_name_i in tag_name:
tmp.write(i, tag_name.index(tag_name_i), tag_name_i)
else:
for tag_list in range(len(tag_name)):
tmp.write(i, tag_list, str(fin_result[i-1][tag_list]))
book.save(r'C:\Users\Administrator\Desktop\%s.xls' % file_name)
第一个是xlwt。我不知道为什么。xlwt存储100多条数据后,存储不完整,excel文件也会出现“某些内容有问题,需要修复”。查了很多次,一开始还以为是数据抓取。不完整会导致存储问题。后来断点检查发现数据是完整的。后来把本地数据改过来处理,也没问题。我当时的心情是这样的:
我到现在都没搞清楚。知道的人希望告诉我ლ(╹ε╹ლ)
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
这是使用xlsxwriter存储的数据,没有问题,可以正常使用。
至此,一个抓取拉勾网招聘信息的小爬虫诞生了。
附上源代码
#! -*-coding:utf-8 -*-
from urllib import request, parse
from bs4 import BeautifulSoup as BS
import json
import datetime
import xlsxwriter
starttime = datetime.datetime.now()
url = r'http://www.lagou.com/jobs/positionAjax.json?city=%E5%8C%97%E4%BA%AC'
# 拉钩网的招聘信息都是动态获取的,所以需要通过post来递交json信息,默认城市为北京
tag = ['companyName', 'companyShortName', 'positionName', 'education', 'salary', 'financeStage', 'companySize',
'industryField', 'companyLabelList'] # 这是需要抓取的标签信息,包括公司名称,学历要求,薪资等等
tag_name = ['公司名称', '公司简称', '职位名称', '所需学历', '工资', '公司资质', '公司规模', '所属类别', '公司介绍']
def read_page(url, page_num, keyword): # 模仿浏览器post需求信息,并读取返回后的页面信息
page_headers = {
'Host': 'www.lagou.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3',
'Connection': 'keep-alive'
}
if page_num == 1:
boo = 'true'
else:
boo = 'false'
page_data = parse.urlencode([ # 通过页面分析,发现浏览器提交的FormData包括以下参数
('first', boo),
('pn', page_num),
('kd', keyword)
])
req = request.Request(url, headers=page_headers)
page = request.urlopen(req, data=page_data.encode('utf-8')).read()
page = page.decode('utf-8')
return page
def read_tag(page, tag):
page_json = json.loads(page)
page_json = page_json['content']['result'] # 通过分析获取的json信息可知,招聘信息包含在返回的result当中,其中包含了许多其他参数
page_result = [num for num in range(15)] # 构造一个容量为15的list占位,用以构造接下来的二维数组
for i in range(15):
page_result[i] = [] # 构造二维数组
for page_tag in tag:
page_result[i].append(page_json[i].get(page_tag)) # 遍历参数,将它们放置在同一个list当中
page_result[i][8] = ','.join(page_result[i][8])
return page_result # 返回当前页的招聘信息
def read_max_page(page): # 获取当前招聘关键词的最大页数,大于30的将会被覆盖,所以最多只能抓取30页的招聘信息
page_json = json.loads(page)
max_page_num = page_json['content']['totalPageCount']
if max_page_num > 30:
max_page_num = 30
return max_page_num
def save_excel(fin_result, tag_name, file_name): # 将抓取到的招聘信息存储到excel当中
book = xlsxwriter.Workbook(r'C:\Users\Administrator\Desktop\%s.xls' % file_name) # 默认存储在桌面上
tmp = book.add_worksheet()
row_num = len(fin_result)
for i in range(1, row_num):
if i == 1:
tag_pos = 'A%s' % i
tmp.write_row(tag_pos, tag_name)
else:
con_pos = 'A%s' % i
content = fin_result[i-1] # -1是因为被表格的表头所占
tmp.write_row(con_pos, content)
book.close()
if __name__ == '__main__':
print('**********************************即将进行抓取**********************************')
keyword = input('请输入您要搜索的语言类型:')
fin_result = [] # 将每页的招聘信息汇总成一个最终的招聘信息
max_page_num = read_max_page(read_page(url, 1, keyword))
for page_num in range(1, max_page_num):
print('******************************正在下载第%s页内容*********************************' % page_num)
page = read_page(url, page_num, keyword)
page_result = read_tag(page, tag)
fin_result.extend(page_result)
file_name = input('抓取完成,输入文件名保存:')
save_excel(fin_result, tag_name, file_name)
endtime = datetime.datetime.now()
time = (endtime - starttime).seconds
print('总共用时:%s s' % time)
可以添加的功能有很多,比如通过修改城市参数查看不同城市的招聘信息等,你可以自己开发,这里只是为了邀请想法,欢迎交流,
excel抓取网页数据(考研英语:使用HtmlAgilityPack抓取网页数据XPath使用路径(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-09 00:17
使用 HtmlAgilityPack 抓取网页数据
XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择此节点 /:从根节点中选择。//: 从与选择匹配的当前节点中选择文档中的节点,而不管它们的位置。.:选择当前节点。..:选择当前节点的父节点。例如,有以下一段 XML:
Java通过url抓取网页数据
很多行业都需要对行业数据进行分类汇总,及时分析行业数据。对于公司未来的发展,有很好的借鉴和横向比较。因此,在实际工作中,我们可能会遇到数据采集这个概念,数据采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。很多人在第一次了解数据采集的时候可能都无法下手,尤其是作为一个新手,感觉很茫然。因此,我在这里分享我的经验,希望与您分享技术。如有不足之处请指正。写这篇的目的是希望大家一起成长,我也相信技术之间没有高低之分,
NET 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、...
[.NET] 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令...
Jsoup简介——使用Java抓取网页数据
转载请注明出处:概述jsoup是一个可以直接解析URL地址的Java HTML解析器。HTML 文本内容。它提供了一套省力的 API,可以通过 DOM、CSS 和类似 jQuery 的方法来检索和操作数据。jsoup 的主要功能如下: 1. 从 URL、文件或字符串解析 HTML: 2. 使用 DOM 或 CSS 选择器进行查找。检索数据:3. 可操作的 HTML 元素。属性。文本。杰...
使用 XML 包从 R 中的网页中抓取数据
在过去的几年里,许多数据以不同的格式公开发布,但有时我们感兴趣的数据仍然在网页的 HTML 中:让我们看看如何获取这些数据。完成这项工作的现有软件包之一是...
C#文件抓取网页数据
using System;using System.采集s.Generic;using System.Linq;using System.Web;using System.Web.Mvc;using System.采集s.Generic;using System.Text.RegularExpressions;using System.Text; 使用 System.Net ;使用 System.IO;命名空间 WebJSON.Contro...
热门话题
setfacl 示例 ugo
python解释器中交互执行代码的过程一般称为
如何关闭矢量
adb命令查看耳机的SN号
iview 穿梭选择键
Java调用ffmpeg推送流
ngs高通量测序原理
ubuntu tcmalloc源码安装
cocos 2dx 各种资源的加载和卸载
如果cmd显示它不是内部命令解决方案,则安装maven
ue4 控制台命令行
方法尝试访问方法失败
vivado mmcm 模块
Markdown 预览增强快捷方式
停用 iptables 之前要做什么
春批停止
富文本图片无法拖动放大或缩小
SQLServer 数据库插件
ide @Value 变量可以跳转
gocr能认出中文吗? 查看全部
excel抓取网页数据(考研英语:使用HtmlAgilityPack抓取网页数据XPath使用路径(组图))
使用 HtmlAgilityPack 抓取网页数据
XPath 使用路径表达式来选择 XML 文档中的节点或节点集。通过以下路径或步骤选择节点。下面列出了最有用的路径表达式: nodename:选择此节点 /:从根节点中选择。//: 从与选择匹配的当前节点中选择文档中的节点,而不管它们的位置。.:选择当前节点。..:选择当前节点的父节点。例如,有以下一段 XML:
Java通过url抓取网页数据
很多行业都需要对行业数据进行分类汇总,及时分析行业数据。对于公司未来的发展,有很好的借鉴和横向比较。因此,在实际工作中,我们可能会遇到数据采集这个概念,数据采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。很多人在第一次了解数据采集的时候可能都无法下手,尤其是作为一个新手,感觉很茫然。因此,我在这里分享我的经验,希望与您分享技术。如有不足之处请指正。写这篇的目的是希望大家一起成长,我也相信技术之间没有高低之分,
NET 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令、...
[.NET] 使用 HtmlAgilityPack 抓取网页数据
刚学了XPath路径表达式,主要是搜索XML文档中的节点。通过 XPath 表达式,您可以快速定位和访问 XML 文档中的节点位置。HTML也是一种类似于xml的标记语言,但是语法没有那么严谨。codeplex中有一个开源项目HtmlAgilityPack,提供XPath解析HTML文件。下面介绍如何使用库。首先,让我们谈谈 XPath 路径表达式。XPath 路径表达式用于选择 XML 文档中的节点。或者节点集的1.术语:节点:7种类型:元素、属性、文本、命名空间、处理命令...
Jsoup简介——使用Java抓取网页数据
转载请注明出处:概述jsoup是一个可以直接解析URL地址的Java HTML解析器。HTML 文本内容。它提供了一套省力的 API,可以通过 DOM、CSS 和类似 jQuery 的方法来检索和操作数据。jsoup 的主要功能如下: 1. 从 URL、文件或字符串解析 HTML: 2. 使用 DOM 或 CSS 选择器进行查找。检索数据:3. 可操作的 HTML 元素。属性。文本。杰...
使用 XML 包从 R 中的网页中抓取数据
在过去的几年里,许多数据以不同的格式公开发布,但有时我们感兴趣的数据仍然在网页的 HTML 中:让我们看看如何获取这些数据。完成这项工作的现有软件包之一是...
C#文件抓取网页数据
using System;using System.采集s.Generic;using System.Linq;using System.Web;using System.Web.Mvc;using System.采集s.Generic;using System.Text.RegularExpressions;using System.Text; 使用 System.Net ;使用 System.IO;命名空间 WebJSON.Contro...
热门话题
setfacl 示例 ugo
python解释器中交互执行代码的过程一般称为
如何关闭矢量
adb命令查看耳机的SN号
iview 穿梭选择键
Java调用ffmpeg推送流
ngs高通量测序原理
ubuntu tcmalloc源码安装
cocos 2dx 各种资源的加载和卸载
如果cmd显示它不是内部命令解决方案,则安装maven
ue4 控制台命令行
方法尝试访问方法失败
vivado mmcm 模块
Markdown 预览增强快捷方式
停用 iptables 之前要做什么
春批停止
富文本图片无法拖动放大或缩小
SQLServer 数据库插件
ide @Value 变量可以跳转
gocr能认出中文吗?
excel抓取网页数据(webscraper怎么抓取网页里其他链接里的数据先设定)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-08 12:24
网络爬虫如何从网页中的其他链接抓取数据
先设置一个链接类型选择器,选中链接,勾选多个;然后打开链接,在新页面上设置需要爬取的元素。Webscraper的详细操作教程,可以到网易云课堂搜索“Webscraper实践教学”,里面有关于二级页面跳转和页面点击操作的详细教程。
使用屏幕-如何使用scraper,如何使用它抓取网页信息-
先按这个按钮,然后在开始菜单中打开绘图,然后粘贴。然后使用左侧工具栏中的虚线矩形选择自定义屏幕。
如何在网络爬虫中抓取弹出窗口
首先,从官方网站下载web-harvest。目前最新版本为1.0。下载页面分为三个下载包,webharvest1-exe.zip、webharvest1-bin.zip、webharvest1-project .zip,它们没有实质性的区别。第一个收录所有的第三方包(同一个jar文件可以直接一起运行),第二个作为中间件出现,收录所有独立的第三方jar。打包,第三个是源码,当然最大的灵活性自然是选择下载源码:``下载后在eclipse中创建一个空项目,把所有解压后的文件夹放进去,然后设置src和config到源文件夹(源目录)然后看到默认包下有一个Test.java文件,
Delphi 抓取多页网页数据
用delphi在多个页面上写入和捕获数据,步骤如下: 1、首先获取每个页面的页面地址。一般来说,这些 URL 地址会定期更改。2、 遍历上面的一个页面地址列表来抓取页面上的数据。另外,有些网页使用了ajax技术。在这种情况下,获得了服务器的返回数据(如json格式)。
如何从Excel中的多个页面中提取数据-
可以尝试使用excel-get external data-from web页面中的数据。然后把你需要的内容导入excel,然后过滤。当然,您也可以使用 VBA 来实现您的要求。
爬取多页网页数据,最后如何避免重复爬取——
你是想学习开发这种程序还是找人开发,避免重复。最后可以做一个条件过滤,自动过滤删除多余的,打开常规数据也可以代为爬取,想获取可以直接找金额。
如何翻页和抓取网页数据-
我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 GooSeeker 网络爬虫如何采集数据,在翻页后自动抓取数据。MS木祖师台履带式工作台共有三种线索方式...
如何获取多页网页数据
您的请求必须由 VBA 完成。然而,有许多网络数据来源。您需要分析您访问的实际页面,以了解您是否需要这些数据。如果您需要继续帮您解答,请添加您的网页链接。
亲爱的上帝,我现在有一个紧急的问题。如何从网页(多页)中抓取表格数据?导出到excel。网页
写一个简单的爬虫和解析程序,看看别人怎么说。
如何挖掘多层次网页采集数据
你可以用优采云采集器轻松解决这个问题。可以模拟人的操作行为,深入多层采集你需要的数据内容。 查看全部
excel抓取网页数据(webscraper怎么抓取网页里其他链接里的数据先设定)
网络爬虫如何从网页中的其他链接抓取数据
先设置一个链接类型选择器,选中链接,勾选多个;然后打开链接,在新页面上设置需要爬取的元素。Webscraper的详细操作教程,可以到网易云课堂搜索“Webscraper实践教学”,里面有关于二级页面跳转和页面点击操作的详细教程。
使用屏幕-如何使用scraper,如何使用它抓取网页信息-
先按这个按钮,然后在开始菜单中打开绘图,然后粘贴。然后使用左侧工具栏中的虚线矩形选择自定义屏幕。
如何在网络爬虫中抓取弹出窗口
首先,从官方网站下载web-harvest。目前最新版本为1.0。下载页面分为三个下载包,webharvest1-exe.zip、webharvest1-bin.zip、webharvest1-project .zip,它们没有实质性的区别。第一个收录所有的第三方包(同一个jar文件可以直接一起运行),第二个作为中间件出现,收录所有独立的第三方jar。打包,第三个是源码,当然最大的灵活性自然是选择下载源码:``下载后在eclipse中创建一个空项目,把所有解压后的文件夹放进去,然后设置src和config到源文件夹(源目录)然后看到默认包下有一个Test.java文件,
Delphi 抓取多页网页数据
用delphi在多个页面上写入和捕获数据,步骤如下: 1、首先获取每个页面的页面地址。一般来说,这些 URL 地址会定期更改。2、 遍历上面的一个页面地址列表来抓取页面上的数据。另外,有些网页使用了ajax技术。在这种情况下,获得了服务器的返回数据(如json格式)。
如何从Excel中的多个页面中提取数据-
可以尝试使用excel-get external data-from web页面中的数据。然后把你需要的内容导入excel,然后过滤。当然,您也可以使用 VBA 来实现您的要求。
爬取多页网页数据,最后如何避免重复爬取——
你是想学习开发这种程序还是找人开发,避免重复。最后可以做一个条件过滤,自动过滤删除多余的,打开常规数据也可以代为爬取,想获取可以直接找金额。
如何翻页和抓取网页数据-
我们在爬取数据的时候,通常不仅爬取网页当前页面的数据,还经常在翻页后继续爬取数据。本文将向您介绍 GooSeeker 网络爬虫如何采集数据,在翻页后自动抓取数据。MS木祖师台履带式工作台共有三种线索方式...
如何获取多页网页数据
您的请求必须由 VBA 完成。然而,有许多网络数据来源。您需要分析您访问的实际页面,以了解您是否需要这些数据。如果您需要继续帮您解答,请添加您的网页链接。
亲爱的上帝,我现在有一个紧急的问题。如何从网页(多页)中抓取表格数据?导出到excel。网页
写一个简单的爬虫和解析程序,看看别人怎么说。
如何挖掘多层次网页采集数据
你可以用优采云采集器轻松解决这个问题。可以模拟人的操作行为,深入多层采集你需要的数据内容。
excel抓取网页数据(广告建网站教程国内万维网的开拓者,机构,专业品质 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-11-04 09:03
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页中获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
广告建设网站国内万维网教程先锋,五星级域名服务机构,专业品质,中国知名域名服务商!
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
广告超人气爆款休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、 也可以点击属性设置导入,如图。在下图中,如果设置刷新率,您会看到Excel表格中的数据可以基于网页上的数据。更新,是不是很强大。
6、好的,这是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
查看全部
excel抓取网页数据(广告建网站教程国内万维网的开拓者,机构,专业品质
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?
很多时候,一些数据来自网络。如果我们要采集网页数据并使用Excel进行分析,是否需要将网页上的数据一一输入Excel?其实还有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页中获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:数据--来自网站。
广告建设网站国内万维网教程先锋,五星级域名服务机构,专业品质,中国知名域名服务商!
2、 你会看到一个打开的查询对话框,你的IE主页会自动打开,在地址栏中输入你想要的URL,然后点击Go。
我们看到一个网页被打开了。如果我们要导入这个表中的数据,我们看下面的第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、 然后点击导入按钮,你会看到下面的第二张图片,等待几秒钟。
广告超人气爆款休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、 也可以点击属性设置导入,如图。在下图中,如果设置刷新率,您会看到Excel表格中的数据可以基于网页上的数据。更新,是不是很强大。
6、好的,这是我们导入的数据。Excel 2013 现在很强大吗?哈哈,赶紧装个Office 2013,试试它的强大功能吧。
excel抓取网页数据(广告大数据培训机构ChristopherZita家为例大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-11-04 09:02
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。Web爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网页抓取赚钱的方法,整个过程可以在短短几个小时内学会,并且使用的代码不到 50 行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告大数据培训机构大数据大数据高端培训课程强强合作,大数据培训机构打造大数据精品课程,再一次改变你!现在,查看所有房屋数据变得非常简单,过滤也容易多了。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。从这 272 条结果中,发现 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个让您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告超火爆的休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时还能赚钱的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价格是50美元,销售价格是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
抓取网站数据后,我们得到了900多款产品的数据,其中只有一件单品Perry Ellis,纯色衬衫,折扣率超过50%。
广告爬取APP数据是一款全面跟踪用户访问行为,持续优化转化率,增加产品粘性的分析工具!由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
广告爬虫价格,品质有保障,更有专属狂欢价,即刻体验!履带价格。现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网页上的所有玩家数据。
广告零基础学英语,全面提升个人能力,专属课堂实时答疑,联合举报更有优惠!所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。 查看全部
excel抓取网页数据(广告大数据培训机构ChristopherZita家为例大)
站长之家注:大数据时代,如何有效获取数据成为驱动商业决策的关键技能。分析市场趋势、监控竞争对手等都需要数据采集。Web爬取是数据采集的主要方法之一。
在本文中,Christopher Zita 将向您展示 3 种使用网页抓取赚钱的方法,整个过程可以在短短几个小时内学会,并且使用的代码不到 50 行。
通过自动化程序在 Airbnb 上最好的酒店花最少的钱
自动化程序可用于执行特定操作,您可以将它们出售给没有赚钱技术技能的人。
为了展示如何创建和销售自动化程序,Christopher Zita 创建了一个 Airbnb 自动爬虫。该程序允许用户输入一个位置,它将获取 Airbnb 在该位置提供的所有房屋数据,包括价格、等级和允许进入的客人数量。所有这一切都是通过在 Airbnb 上抓取数据来完成的。
为了演示程序的实际操作,Christopher Zita 在程序中进入罗马,然后在几秒钟内获得了 272 条 Airbnb 相关数据:
广告大数据培训机构大数据大数据高端培训课程强强合作,大数据培训机构打造大数据精品课程,再一次改变你!现在,查看所有房屋数据变得非常简单,过滤也容易多了。以克里斯托弗·齐塔 (Christopher Zita) 的家人为例。他们家有四口人。如果他们想去罗马,他们会在 Airbnb 上寻找价格合理且至少有 2 张床的酒店。拿到这个表中的数据后,excel就可以很方便的进行过滤了。从这 272 条结果中,发现 7 家酒店符合要求。
在这 7 家酒店中,Christopher Zita 选择了。因为通过数据对比可以看出,这家酒店评分很高,是7家酒店中最便宜的,每晚收费仅为61美元。选择所需链接后,只需将链接复制到浏览器中即可预订。
度假旅行时,寻找酒店是一项艰巨的任务。出于这个原因,有人愿意花钱来简化这个过程。使用这个自动程序,您可以在短短 5 分钟内以低廉的价格预订一个让您满意的房间。
抓取特定产品的价格数据,以最低价格购买
网页抓取最常见的用途之一是从 网站 获取价格。通过创建一个程序来抓取特定产品的价格数据,当价格下降到一定水平时,它会在产品售罄之前自动购买该产品。
广告超火爆的休闲网游,超大型休闲网游诚意精品平台,国内知名休闲网游!接下来,Christopher Zita 将向您展示一种可以为您节省大量资金同时还能赚钱的方法:
每个电商网站都会有限量的特价商品,他们会显示商品的原价和折扣价,但一般不会显示在原价的基础上打了多少折扣。举个例子,如果一只手表的初始价格是350美元,促销价是300美元,你会认为50美元的折扣不是小数目,但实际上只有14.@ > 2% 的折扣。而如果一件T恤的初始价格是50美元,销售价格是40美元,你会觉得它并没有便宜多少,但实际上它的折扣率比手表高出20%。因此,您可以通过购买折扣率最高的产品来省钱/赚钱。
我们以百货公司Hudson's'Bay为例进行数据抓取实验,通过获取所有产品的原价和折扣价,找出折扣率最高的产品。
抓取网站数据后,我们得到了900多款产品的数据,其中只有一件单品Perry Ellis,纯色衬衫,折扣率超过50%。
广告爬取APP数据是一款全面跟踪用户访问行为,持续优化转化率,增加产品粘性的分析工具!由于限时优惠,这件衬衫的价格将很快回升至 90 美元左右。因此,如果您现在以 40 美元的价格购买并在限时优惠结束后以 60 美元的价格出售,您仍然可以赚取 20 美元。
这是一种方法,如果你找到合适的利基市场,你可能会赚很多钱。
抓取宣传数据并可视化
网络上有数百万个数据集可供所有人免费使用,而且这些数据通常很容易采集。当然,还有一些数据不容易获取,可视化需要花费大量时间。这就是销售数据的演变方式。天眼查、七查查等公司专注于获取和可视化商业行业的变化,然后以“买会员查”的形式卖给用户。
一个类似的模型是体育数据网站BigDataBall。网站通过出售玩家的各种游戏数据等统计信息,向用户收取每季30美元的费用。他们设定这个价格不是因为他们网站有数据,而是他们抓取数据后,对数据进行排序,然后以易于阅读和清晰的结构显示数据。
广告爬虫价格,品质有保障,更有专属狂欢价,即刻体验!履带价格。现在,Christopher Zita 要做的就是免费获取与 BigDataBall 相同的数据,然后将其放入结构化数据集。BigDataBall 不是唯一拥有这些数据的 网站。它有相同的数据。但是,网站 并没有对数据进行结构化,用户很难过滤和下载所需的数据集。Christopher Zita 使用网络爬虫来捕获网页上的所有玩家数据。
广告零基础学英语,全面提升个人能力,专属课堂实时答疑,联合举报更有优惠!所有 NBA 球员日志的结构化数据集
到目前为止,他本赛季已经获得了超过16,000份球员日志。通过网络抓取,Christopher Zita 在几分钟内获得了这些数据并节省了 30 美元。
当然,Christopher Zita 也可以使用 BigDataBall 之类的网络爬虫工具来寻找人工难以获取的数据,让计算机来完成工作,然后将数据可视化并出售给对数据感兴趣的人。
总结
如今,网络抓取已成为一种非常独特且新颖的赚钱方式。如果您在正确的情况下应用它,您可以轻松赚钱。
excel抓取网页数据(excel抓取网页数据的方法有以下两种:1.1)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-10-28 05:04
excel抓取网页数据的方法有以下两种:1.抓取过程:(抓取页面里的内容)2.算法转换:(根据内容抓取相应的html格式数据)首先我们来看如何下载,首先要做的第一步就是下载本地的压缩包。如果数据量不大一般下个7-10m就足够了。然后进行解压。
有sqlite数据库,用数据库操作语言c++或python操作即可。
需要从网上爬虫相关数据。
首先你的网站是否需要做前端页面保存下来然后在爬取!那么你现在需要做的事要把dom树做下来,在excel中找到需要爬取的内容。然后在ahk里面可以写爬虫去调用这个api。
用aspphp写个xmlhttprequest用append函数触发返回
这样的模拟登录除了转发,还有就是数据库动态爬虫,当然用aspphp也可以的。
你去看一个叫数据的软件,里面有电商的基本数据抓取。
不用asp+php,用python或nodejs模拟登录
直接写一个httpclient
首先asp
应该用qt比较方便,
数据库过程用actionscript可以写一个简单的
是否可以用asp来抓取,每天的上下架商品或者商品价格?分别用actionscript把数据抓下来后,用java或者python做一个json对象保存后, 查看全部
excel抓取网页数据(excel抓取网页数据的方法有以下两种:1.1)
excel抓取网页数据的方法有以下两种:1.抓取过程:(抓取页面里的内容)2.算法转换:(根据内容抓取相应的html格式数据)首先我们来看如何下载,首先要做的第一步就是下载本地的压缩包。如果数据量不大一般下个7-10m就足够了。然后进行解压。
有sqlite数据库,用数据库操作语言c++或python操作即可。
需要从网上爬虫相关数据。
首先你的网站是否需要做前端页面保存下来然后在爬取!那么你现在需要做的事要把dom树做下来,在excel中找到需要爬取的内容。然后在ahk里面可以写爬虫去调用这个api。
用aspphp写个xmlhttprequest用append函数触发返回
这样的模拟登录除了转发,还有就是数据库动态爬虫,当然用aspphp也可以的。
你去看一个叫数据的软件,里面有电商的基本数据抓取。
不用asp+php,用python或nodejs模拟登录
直接写一个httpclient
首先asp
应该用qt比较方便,
数据库过程用actionscript可以写一个简单的
是否可以用asp来抓取,每天的上下架商品或者商品价格?分别用actionscript把数据抓下来后,用java或者python做一个json对象保存后,
excel抓取网页数据(《excel抓取网页数据:php抓取》(分组关联))
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-10-27 18:04
excel抓取网页数据:php抓取网页数据:python抓取网页数据:python抓取社交平台登录数据:mysql分库分表数据抓取(分组关联)数据抓取(分组关联)数据抓取(顺序关联)数据抓取(复杂条件)pythonweb开发web-scrapy爬虫脚本的基本语法http/https1。发送http请求http/https|3。
了解http请求头的内容3。明确请求行4。解析请求报文中的字段,并提取需要的信息如user-agent,accept-encoding,accept-language5。拦截提交报文并发送到form或者dolist;6。请求网页传输数据需要get操作,2种可能的格式是authorizationcodeages;7。
请求头添加或者form-datahttp/1。1200oksamemethod;8。确认useragent和form-data到底是不是匹配,如果不匹配,要返回1份新useragent给服务器;9。请求头,表单设置,cookie传输;10。验证请求,如果解析useragent和form-data有错误;(一般解析错误,服务器都会抛出异常的,比如在后端传参数失败,没有办法找到对应对象的元素等等);11。
获取请求头报文中的参数值;提取请求数据时,提取的参数必须正确;12。解析useragenthttp/1。1200oktransport="user-agent:xxx";13。提取http/1。1协议下的类型name:域名grantallprivilegesto'sblog';14。解析请求头,数据库传入的useragent和对应请求useragent的值;15。
发送echo请求,如果发送成功,服务器会将响应内容发送到后端;16。数据库的数据读取,或者存放;17。获取请求的cookie;eachcookieavailableinhttpmethods=-"get";18。数据库中读取数据;读取。cookie;eachcookieavailableinhttpmethods=-"post";19。
获取请求ip:form_datagethttp/1。1200okaccept:text/html,application/xhtml+xml,application/xml;q=0。9,*/*;q=0。8accept-language:zh-cn,zh;q=0。820。登录;服务器响应内容,sheet数据(客户端请求过来的数据)。
ssh中。数据库名160。mysql1172000。mysql105229。服务器响应内容。数据库名104。21。清除mysql对象的缓存sql_delete27。清除mysql对象的所有缓存sql_redo28。获取用户登录时所在位置local_users29。返回整个mysql数据库中的数据并把数据存到mysql中form_data30。建立工作表及字段name_fields31。对字段进行修改。 查看全部
excel抓取网页数据(《excel抓取网页数据:php抓取》(分组关联))
excel抓取网页数据:php抓取网页数据:python抓取网页数据:python抓取社交平台登录数据:mysql分库分表数据抓取(分组关联)数据抓取(分组关联)数据抓取(顺序关联)数据抓取(复杂条件)pythonweb开发web-scrapy爬虫脚本的基本语法http/https1。发送http请求http/https|3。
了解http请求头的内容3。明确请求行4。解析请求报文中的字段,并提取需要的信息如user-agent,accept-encoding,accept-language5。拦截提交报文并发送到form或者dolist;6。请求网页传输数据需要get操作,2种可能的格式是authorizationcodeages;7。
请求头添加或者form-datahttp/1。1200oksamemethod;8。确认useragent和form-data到底是不是匹配,如果不匹配,要返回1份新useragent给服务器;9。请求头,表单设置,cookie传输;10。验证请求,如果解析useragent和form-data有错误;(一般解析错误,服务器都会抛出异常的,比如在后端传参数失败,没有办法找到对应对象的元素等等);11。
获取请求头报文中的参数值;提取请求数据时,提取的参数必须正确;12。解析useragenthttp/1。1200oktransport="user-agent:xxx";13。提取http/1。1协议下的类型name:域名grantallprivilegesto'sblog';14。解析请求头,数据库传入的useragent和对应请求useragent的值;15。
发送echo请求,如果发送成功,服务器会将响应内容发送到后端;16。数据库的数据读取,或者存放;17。获取请求的cookie;eachcookieavailableinhttpmethods=-"get";18。数据库中读取数据;读取。cookie;eachcookieavailableinhttpmethods=-"post";19。
获取请求ip:form_datagethttp/1。1200okaccept:text/html,application/xhtml+xml,application/xml;q=0。9,*/*;q=0。8accept-language:zh-cn,zh;q=0。820。登录;服务器响应内容,sheet数据(客户端请求过来的数据)。
ssh中。数据库名160。mysql1172000。mysql105229。服务器响应内容。数据库名104。21。清除mysql对象的缓存sql_delete27。清除mysql对象的所有缓存sql_redo28。获取用户登录时所在位置local_users29。返回整个mysql数据库中的数据并把数据存到mysql中form_data30。建立工作表及字段name_fields31。对字段进行修改。
excel抓取网页数据(it365链接提取工具批量提取网址链接、迅雷下载地址、磁力链接等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2021-10-22 21:13
it365链接提取工具
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
在这里输入内容,然后就可以看到下面提取的链接了,试试吧~
it365链接提取工具,一个简单而强大的链接提取工具。
请记住我们的网站,您可以将网站保存在您的浏览器、邮箱或印象笔记中以备将来使用,谢谢!
找到链接
暂时找不到链接,尝试输入更多内容
您输入的 关键词 找不到匹配的项目
给程序作者打赏,留言,想开发其他软件?
这个程序是我精心打磨的。我希望能帮助你。请欣赏和支持。您也可以留言/反馈。想联系我的请留个微信,谢谢哦~
我可以开发:App、电脑软件、网站、Excel数据处理、小程序……如果你想开发软件,来找我。
要开发一个程序,您至少需要编写 1,000 行代码。这些程序通常是在您加班后晚上 10 点回家时开发的。求支持,点赞或关注我的公众号(程序员小都),你们的支持就是我代码的动力,谢谢~
我的微信公众号
学习编程| 分享好东西| 留下反馈| 交个朋友
我的公众号:程序员小都,欢迎扫码关注,和程序员做朋友~如果你想开发软件也可以找我/网站/APP~谢谢^_^
it365链接提取工具能做什么?
相关话题
网页链接提取工具
如何提取网页的所有下载链接
如何获取网页中的所有链接网址
如何提取word文档/Excel表格的所有超链接
word文档有很多参考链接,如何导出所有超链接
批量提取网页链接工具
批量提取下载链接地址工具
如何过滤掉网页上所有迅雷下载链接
批量提取迅雷下载地址工具
批量提取磁力链接地址(磁铁)
批量查找超链接并导出链接
批量获取eMule ed2k下载链接
有没有什么工具可以找到网页/txt文本的所有网址链接
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
发布记录 v2.1.0v2.0.0v1.2.3v1.2.2v1.2.1v1.2.0v1.0.0
英文 中文 简体
技术支持 it365 工具箱 查看全部
excel抓取网页数据(it365链接提取工具批量提取网址链接、迅雷下载地址、磁力链接等)
it365链接提取工具
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
在这里输入内容,然后就可以看到下面提取的链接了,试试吧~
it365链接提取工具,一个简单而强大的链接提取工具。
请记住我们的网站,您可以将网站保存在您的浏览器、邮箱或印象笔记中以备将来使用,谢谢!
找到链接
暂时找不到链接,尝试输入更多内容
您输入的 关键词 找不到匹配的项目
给程序作者打赏,留言,想开发其他软件?
这个程序是我精心打磨的。我希望能帮助你。请欣赏和支持。您也可以留言/反馈。想联系我的请留个微信,谢谢哦~
我可以开发:App、电脑软件、网站、Excel数据处理、小程序……如果你想开发软件,来找我。
要开发一个程序,您至少需要编写 1,000 行代码。这些程序通常是在您加班后晚上 10 点回家时开发的。求支持,点赞或关注我的公众号(程序员小都),你们的支持就是我代码的动力,谢谢~
我的微信公众号
学习编程| 分享好东西| 留下反馈| 交个朋友
我的公众号:程序员小都,欢迎扫码关注,和程序员做朋友~如果你想开发软件也可以找我/网站/APP~谢谢^_^
it365链接提取工具能做什么?
相关话题
网页链接提取工具
如何提取网页的所有下载链接
如何获取网页中的所有链接网址
如何提取word文档/Excel表格的所有超链接
word文档有很多参考链接,如何导出所有超链接
批量提取网页链接工具
批量提取下载链接地址工具
如何过滤掉网页上所有迅雷下载链接
批量提取迅雷下载地址工具
批量提取磁力链接地址(磁铁)
批量查找超链接并导出链接
批量获取eMule ed2k下载链接
有没有什么工具可以找到网页/txt文本的所有网址链接
批量提取网址链接、迅雷下载地址、磁力链接、电驴链接等,如果要提取网页中的链接,复制该网页的内容粘贴到本程序的输入框中,链接将被提取. 除了网页,还支持TXT、word、excel、pdf、HTML等。
发布记录 v2.1.0v2.0.0v1.2.3v1.2.2v1.2.1v1.2.0v1.0.0
英文 中文 简体
技术支持 it365 工具箱
excel抓取网页数据(推荐搜索下载网页表格数据采集器来采集,简单简单方便快捷)
网站优化 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2021-10-17 12:10
推荐搜索并下载网页表单数据采集器到采集,简单方便快捷,网页表单数据采集助手是一个规则和不规则的表单,可以采集单页,也可以连续采集多页表单,可以指定采集需要的字段内容。采集之后的内容可以保存为EXCEL软件可以读取的文件格式。它也可以保存为保留原创表单的纯文本表单。绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件中表单左上角的第一个内容输入框中会显示表单左上角的第一个文本,表单中收录的字段(列)将显示在软件左侧的中间列表。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单中有带链接的字段,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行。
6、 如果你想让采集的表单数据只有一个网页,那么你可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,但是此时表示 URL 中页数的位置应替换为“
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面上有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,根据需要选择。
9、最后,只需点击一次抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。 查看全部
excel抓取网页数据(推荐搜索下载网页表格数据采集器来采集,简单简单方便快捷)
推荐搜索并下载网页表单数据采集器到采集,简单方便快捷,网页表单数据采集助手是一个规则和不规则的表单,可以采集单页,也可以连续采集多页表单,可以指定采集需要的字段内容。采集之后的内容可以保存为EXCEL软件可以读取的文件格式。它也可以保存为保留原创表单的纯文本表单。绝对简单、方便、快捷、纯绿色。如果您不相信,只需下载并尝试一下。
指示
1、首先在地址栏中输入网页地址为采集。如果要采集的网页已经在IE浏览器中打开,这个地址会自动添加到软件的网址列表中。
2、 然后点击爬虫测试按钮,可以看到网页源代码和网页收录的表数。网页的源代码显示在软件下方的文本框中。网页中收录的表格和标题信息的数量在软件中。显示在左上角的列表框中。
3、从表数列表中选择要抓取的表。此时,软件中表单左上角的第一个内容输入框中会显示表单左上角的第一个文本,表单中收录的字段(列)将显示在软件左侧的中间列表。
4、 然后选择你要采集的表数据的字段(列),如果不选择,都是采集。
5、选择是否要抓取表格的标题行,保存时是否显示表格行。如果web表单中有带链接的字段,可以选择是否收录链接地址,如果是并且需要采集其链接地址,则不能同时选择收录标题行。
6、 如果你想让采集的表单数据只有一个网页,那么你可以直接点击抓取表格来抓取。如果之前不选择收录表格行,表格数据将保存为 CVS 格式。这种格式可以直接用微软EXCEL软件打开,转换成EXCEL格式。如果选择在前面收录表格行,表格数据会以TXT格式保存,可以用记事本软件打开查看。表行直接可用,也很清楚。
7、如果要采集表数据有多个连续页,并且要采集向下,那么请重新设置程序采集下一页和后续页面的方式可以是根据链接名称打开下一个页面。几乎大多数页面的链接名称都是“下一页”。您可以查看页面,找到后输入。如果页面没有下一页的链接,但是URL收录页数,那么你也可以根据URL中的页数选择打开。可以从前到后选择,比如从第1页到第10页。也可以从后到前选择,比如从第10页到第1页,在页码里输入就行了,但是此时表示 URL 中页数的位置应替换为“
8、 然后选择定时采集或者等待网页打开加载采集后立即加载,定时采集是程序根据设定的小时间间隔判断打开如果页面上有你想要的表单,可以采集,页面加载后,采集只要采集的页面已经打开,程序就会马上着手采集,两者各有特点,根据需要选择。
9、最后,只需点击一次抢表按钮,就可以泡一杯咖啡了!
10、如果你已经熟悉了要采集的网页信息,并且想要采集指定表单中的所有字段,也可以输入需要的信息不经过爬取测试等操作,直接点击爬取表格。
excel抓取网页数据(利用网站下载软件,无用的设置方法和配合方法介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-10-15 09:26
使用网站下载软件,您可以将网站的全部内容下载到硬盘上进行离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站中的图片、文字、程序、软件...等。所以这也是研究别人的最佳帮手网站。
用过teleport的站长都知道,虽然这个工具很好用,但是下载的网站有很多没用的标签,比如:tppabs, javascript:if(confirm, tpa等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是由于代码太多,无法一一删除,这时候我的工具来帮忙。
没办法,这需要后端程序的配合。如 PHP 或 .net java。
设置方法:
1、 点击开始----复制按钮(或按Ctrl+C组合键)进行复制;
2、 粘贴到 Excel 中;
3、 弹出粘贴对话框,选择Microsoft Office Excel工作表对象,如果需要更改Excel中的数据,Word中的数据也会发生变化,选择粘贴链接,
用vba实现。我不太明白。
Sub bb() Dim a, k%, i% Open "a.txt" For Input As #1 a = Split(StrConv(InputB(LOF(1), 1), vbUnicode), vbCrLf) Close #1 k = UBound(a) For i = 0 to k'将内存中的数组元素写入新创建的word文档 Next End Sub' 将内存中的数组元素写入新创建的word文档中。在百度下。我也属于百度。
供参考,祝好。
我在群里看到你了,可以去静怡下单
如何批量抓取网页,然后转成Word格式文档,或本地Html文档: 使用网站下载软件将网站的全部内容下载到硬盘。离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站软件...等中的图片、文字、程序等。所以这也是研究其他人的最佳帮手网站。用过teleport的站长都知道,这个工具虽然很好用,但是下载的网站有很多没用的Tag,比如:tppabs, javascript:if(confirm, tpa等等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是因为代码太多,
如何批量保存网页: 1 将整个网页保存为“单个文件(*.mht)”,这样图片、文字等都保存在同一个文件中,不用担心关于图片的顺序。但是有一个缺点:有些网页是禁止保存的。这时候,你可以选择另一种方法:使用HyperSnap等截图软件来截取想要的图片并...
如何批量提取网页评论元素中的所有网址:您可以使用优采云采集器 到采集 网址。
批量抓取网站纯文本的方法有哪些?:可以使用优采云,然后批量转换成txt,就变成纯文本了
如何快速将网页上的文字转成TXT格式?-:1.可以选中拖拽,会自动保存为txt,但是这个需要设置,不容易设置,还有是没有选择性的。2. 是使用复制粘贴的方法。如果您想要某段文字,请选择前几个词,然后按住 shift 键,再次单击结束词。然后创建一个新的文本文档,粘贴并保存!
如何在手机浏览器中批量转移他人发来的股票-:您好,手机登录百度账号,即可转移到自己的网盘。祝您生活愉快!希望我的回答对你有帮助。得到您的认可!
如何批量点击多个网页中的同一个按钮?-:按照以下步骤操作: 1)在dreamweaver中选择该按钮,在下方属性面板的“标签”框中输入“返回首页”。在“Action”选项中选择“None”,如图12) 执行“Window”菜单下的“Behavior”,打开行为面板,点击面板中带有小箭头的+按钮打开一个行为多的列菜单,选择“转到url”,点击“url:”旁边的“浏览”按钮,然后找到你要传输的文件并选择它,或者输入你要传输的文件的路径在文本框中传输,如图23) 然后保存预览就可以了
如何从大量网页中提取文本-:在IE窗口中,按Alt键调出菜单栏,在“文件”菜单中选择“另存为”,选择保存格式为“文本文件” (*。文本)”
如何批量替换网页的部分内容??-: DW有替换功能,如果要替换多个文件内容,可以根据需要选择按目录或按站点选择..
求一种批量保存网页图片的方法或软件:Webdup可以提前下载你要浏览的信息(如网页和图片等),保存在本地硬盘上,方便离线浏览来自本地,不仅可以大大减少上网时间,降低上网成本,还可以加快浏览速度;并且在未来,您无需上网即可轻松查看这些信息。不仅如此,Webdup 还提供了以前下载记录的备份和比较完善的管理功能,让您可以方便地存储、保存和管理有价值的下载信息。离线浏览助手Webdup 0.93 Beta(免费) 查看全部
excel抓取网页数据(利用网站下载软件,无用的设置方法和配合方法介绍)
使用网站下载软件,您可以将网站的全部内容下载到硬盘上进行离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站中的图片、文字、程序、软件...等。所以这也是研究别人的最佳帮手网站。
用过teleport的站长都知道,虽然这个工具很好用,但是下载的网站有很多没用的标签,比如:tppabs, javascript:if(confirm, tpa等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是由于代码太多,无法一一删除,这时候我的工具来帮忙。
没办法,这需要后端程序的配合。如 PHP 或 .net java。
设置方法:
1、 点击开始----复制按钮(或按Ctrl+C组合键)进行复制;
2、 粘贴到 Excel 中;
3、 弹出粘贴对话框,选择Microsoft Office Excel工作表对象,如果需要更改Excel中的数据,Word中的数据也会发生变化,选择粘贴链接,
用vba实现。我不太明白。
Sub bb() Dim a, k%, i% Open "a.txt" For Input As #1 a = Split(StrConv(InputB(LOF(1), 1), vbUnicode), vbCrLf) Close #1 k = UBound(a) For i = 0 to k'将内存中的数组元素写入新创建的word文档 Next End Sub' 将内存中的数组元素写入新创建的word文档中。在百度下。我也属于百度。
供参考,祝好。
我在群里看到你了,可以去静怡下单
如何批量抓取网页,然后转成Word格式文档,或本地Html文档: 使用网站下载软件将网站的全部内容下载到硬盘。离线浏览。“网站Downloader”是离线浏览的最佳工具。下载所有网站只需要几分钟。包括网站软件...等中的图片、文字、程序等。所以这也是研究其他人的最佳帮手网站。用过teleport的站长都知道,这个工具虽然很好用,但是下载的网站有很多没用的Tag,比如:tppabs, javascript:if(confirm, tpa等等。这让站长们苦恼,这些都是多余的代码,可以全部删除,但是因为代码太多,
如何批量保存网页: 1 将整个网页保存为“单个文件(*.mht)”,这样图片、文字等都保存在同一个文件中,不用担心关于图片的顺序。但是有一个缺点:有些网页是禁止保存的。这时候,你可以选择另一种方法:使用HyperSnap等截图软件来截取想要的图片并...
如何批量提取网页评论元素中的所有网址:您可以使用优采云采集器 到采集 网址。
批量抓取网站纯文本的方法有哪些?:可以使用优采云,然后批量转换成txt,就变成纯文本了
如何快速将网页上的文字转成TXT格式?-:1.可以选中拖拽,会自动保存为txt,但是这个需要设置,不容易设置,还有是没有选择性的。2. 是使用复制粘贴的方法。如果您想要某段文字,请选择前几个词,然后按住 shift 键,再次单击结束词。然后创建一个新的文本文档,粘贴并保存!
如何在手机浏览器中批量转移他人发来的股票-:您好,手机登录百度账号,即可转移到自己的网盘。祝您生活愉快!希望我的回答对你有帮助。得到您的认可!
如何批量点击多个网页中的同一个按钮?-:按照以下步骤操作: 1)在dreamweaver中选择该按钮,在下方属性面板的“标签”框中输入“返回首页”。在“Action”选项中选择“None”,如图12) 执行“Window”菜单下的“Behavior”,打开行为面板,点击面板中带有小箭头的+按钮打开一个行为多的列菜单,选择“转到url”,点击“url:”旁边的“浏览”按钮,然后找到你要传输的文件并选择它,或者输入你要传输的文件的路径在文本框中传输,如图23) 然后保存预览就可以了
如何从大量网页中提取文本-:在IE窗口中,按Alt键调出菜单栏,在“文件”菜单中选择“另存为”,选择保存格式为“文本文件” (*。文本)”
如何批量替换网页的部分内容??-: DW有替换功能,如果要替换多个文件内容,可以根据需要选择按目录或按站点选择..
求一种批量保存网页图片的方法或软件:Webdup可以提前下载你要浏览的信息(如网页和图片等),保存在本地硬盘上,方便离线浏览来自本地,不仅可以大大减少上网时间,降低上网成本,还可以加快浏览速度;并且在未来,您无需上网即可轻松查看这些信息。不仅如此,Webdup 还提供了以前下载记录的备份和比较完善的管理功能,让您可以方便地存储、保存和管理有价值的下载信息。离线浏览助手Webdup 0.93 Beta(免费)
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2021-10-11 08:25
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,第一行输入除最后一个页码ID外的URL,第二行根据解析的URL结构输入页码以上。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。 查看全部
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只爬取了一页数据。本文文章介绍了如何使用PowerBI为页面批量采集多个数据。(Excel中的电源查询同样可以操作)
本文以招联招聘网站为例,采集发布上海招聘信息。
以下是详细步骤:
(一)解析URL结构
打开智联招聘网站,搜索工作地点在上海的数据,
向下滚动页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看到最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用PowerBI第一页的数据采集
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,第一行输入除最后一个页码ID外的URL,第二行根据解析的URL结构输入页码以上。
从 URL 预览中可以看出,上面两行中的 URL 已经自动合并在一起了;这里单独输入只是为了更清楚地区分页码变量,其实也可以直接输入完整的URL。
(如果页码变量不是最后一位,而是在中间,URL应该分三行输入)
点击确定后,出来了很多表,
从这里可以看出智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后的所有步骤,然后展开数据,删除前面几列的数据。
这样,第一页采集的数据就过来了。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集的其他页时,排序后的数据结构与第一页的数据结构相同。采集的数据可以直接使用;它不会在这里排序。没关系,你可以等到采集所有的网页数据整理在一起。
如果要大量抓取网页数据,为了节省时间,可以不用整理第一页的数据,直接进入下一步。
(三) 根据页码参数设置自定义函数
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表 =>
并在第一行的网址中将&后面的“1”改成let后(这是第二步使用高级选项分两行输入网址的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
至此,自定义功能完成。p是函数的变量,用来控制页码。只需输入一个数字,例如 7,就会捕获第 7 页的数据。
输入参数一次只能抓取一个网页。如果要批量抓取,则需要进行以下步骤。
(四) 批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的都是默认的。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,大概10分钟就可以搞定。最大块的时间仍然是最后一步。数据采集的过程相对耗时。
网页的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样可以在Excel中进行可以使用PQ功能的操作。
当然,PowerBI 并不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站的数据之前,先尝试一页采集。如果可以采集,那就用上面的步骤。如果 采集 没有到达,则不再有任何延迟。
现在打开 PowerBI 或 Excel 并尝试抓取您感兴趣的 网站 数据。
excel抓取网页数据(【干货】2016年10月12日最新网页评价汇总 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-10 20:07
)
1、放映【差评】
向下滚动页面到评论区,选择【商品评价】,在操作提示框中点击【点击该元素】,页面默认显示【所有评价】。
此示例为 采集 过滤 [差评]。选择【差评】,在操作提示框中点击【点击此链接】,展开差评。
特别说明:
一种。[照片]、[发视频]、[评论]、[好评]、[中评]、[差评]的筛选方法也是一样的。需要过滤哪个分类,请在优采云点击哪个分类的步骤。
2、设置【Ajax】加载
此页面的【差评】按钮使用ajax加载,无法查看新标签页。
进入【点击元素1】设置页面,取消勾选【在新标签页中打开】,勾选【Ajax加载数据】,选择【Ajax超时】5-7秒,然后保存。
特别说明:
一种。对于使用 Ajax 技术的网页,一般不要勾选【在新标签页中打开】。【Ajax超时】请根据采集要求和网页加载情况进行设置。它不是静态的。详情请点击查看Ajax教程。
步骤四、创建【循环列表】,采集所有评价数据
1、创建【循环列表】
通过以下3个连续步骤,创建一个【循环列表】,
① 在页面上选择 1 个评论列表
② 继续选择页面第二个评价列表
③在操作提示框中,点击【采集以下元素文字】
此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
特别说明:
一种。经过以上连续3个步骤,就完成了【Cycle-Extract Data】的创建。【周期】中的项目对应页面上的所有评价列表。此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
湾 为什么我们可以通过以上3步设置【循环提取数据】?详情请点击查看列表数据采集教程。
2、修改【循环列表】XPath
为了准确采集到所有差评,需要修改【循环列表】XPath。
进入【循环列表】设置页面,修改XPath为//div[@id='comment-6']/div[position()
特别说明:
一种。默认生成的【循环列表】会定位在其他分类的评价中,无法准确采集差评,所以需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']/div[position()
[评论]://div[@id='comment-3']/div[position()
[赞]://div[@id='comment-4']/div[position()
[评论]://div[@id='comment-5']/div[position()
3、提取字段
在网页上,找到当前的评论列表(红色框)
选择目标字段,然后在操作提示框中点击【采集元素的文本】。
可以通过这种方式提取文本字段。在示例中,我们提取了评价者、评论文本、评价星级、产品参数、评价时间等字段。
特别说明:
一种。一定要选择当前评价列表中的评价星提取星域,否则提取的星域无法与【循环】中的评价列表关联,会不断重复采集某个评价列出星星。
湾 如何找到当前的评论列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上红框框出的评价列表即为当前评价列表。
4、编辑字段
在【当前页面数据预览】界面,可以进行删除字段、修改字段名称等操作。
步骤五、创建循环翻页,到采集多页数据
1、创建【循环翻页】
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一种。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要特定页面采集的数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
2、修改【圆形翻页】的XPath
默认的【循环翻页】XPath无法准确定位差评的翻页,需要修改【循环翻页】XPath。
进入【循环翻页】设置页面,修改XPath为://div[@id='comment-6']//div[@class="ui-page"]//a[@class="ui" -pager -next"] 并保存。
同时将【点击翻页】的【ajax超时】时间调整为5秒。
特别说明:
一种。默认生成的【循环翻页】会定位其他分类的翻页按钮,无法准确采集差评,需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[复习]://div[@id='comment-3']//div[@class="ui-page"]//a[@class="ui-pager-next"]
[赞]://div[@id='comment-4']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[评论]://div[@id='comment-5']//div[@class="ui-page"]//a[@class="ui-pager-next"]
C。对于使用Ajax技术的网页,优采云会自动判断并设置【Ajax超时】。如果系统自动设置的时间太短,可根据采集要求和网页加载情况相应延长。详情请点击查看Ajax教程。
步骤六、开始采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一种。[本地采集]为采集使用自己的电脑,[cloud采集]为优采云提供的云服务器采集,点击进入查看本地采集和cloud采集的详解。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。
样本数据:
查看全部
excel抓取网页数据(【干货】2016年10月12日最新网页评价汇总
)
1、放映【差评】
向下滚动页面到评论区,选择【商品评价】,在操作提示框中点击【点击该元素】,页面默认显示【所有评价】。
此示例为 采集 过滤 [差评]。选择【差评】,在操作提示框中点击【点击此链接】,展开差评。
特别说明:
一种。[照片]、[发视频]、[评论]、[好评]、[中评]、[差评]的筛选方法也是一样的。需要过滤哪个分类,请在优采云点击哪个分类的步骤。
2、设置【Ajax】加载
此页面的【差评】按钮使用ajax加载,无法查看新标签页。
进入【点击元素1】设置页面,取消勾选【在新标签页中打开】,勾选【Ajax加载数据】,选择【Ajax超时】5-7秒,然后保存。
特别说明:
一种。对于使用 Ajax 技术的网页,一般不要勾选【在新标签页中打开】。【Ajax超时】请根据采集要求和网页加载情况进行设置。它不是静态的。详情请点击查看Ajax教程。
步骤四、创建【循环列表】,采集所有评价数据
1、创建【循环列表】
通过以下3个连续步骤,创建一个【循环列表】,
① 在页面上选择 1 个评论列表
② 继续选择页面第二个评价列表
③在操作提示框中,点击【采集以下元素文字】
此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
特别说明:
一种。经过以上连续3个步骤,就完成了【Cycle-Extract Data】的创建。【周期】中的项目对应页面上的所有评价列表。此时将整个评价列表提取为整个字段,如手动将列表中的字段一一提取。
湾 为什么我们可以通过以上3步设置【循环提取数据】?详情请点击查看列表数据采集教程。
2、修改【循环列表】XPath
为了准确采集到所有差评,需要修改【循环列表】XPath。
进入【循环列表】设置页面,修改XPath为//div[@id='comment-6']/div[position()
特别说明:
一种。默认生成的【循环列表】会定位在其他分类的评价中,无法准确采集差评,所以需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']/div[position()
[评论]://div[@id='comment-3']/div[position()
[赞]://div[@id='comment-4']/div[position()
[评论]://div[@id='comment-5']/div[position()
3、提取字段
在网页上,找到当前的评论列表(红色框)
选择目标字段,然后在操作提示框中点击【采集元素的文本】。
可以通过这种方式提取文本字段。在示例中,我们提取了评价者、评论文本、评价星级、产品参数、评价时间等字段。
特别说明:
一种。一定要选择当前评价列表中的评价星提取星域,否则提取的星域无法与【循环】中的评价列表关联,会不断重复采集某个评价列出星星。
湾 如何找到当前的评论列表?在【循环列表】中查看当前项目(蓝色背景),然后点击【提取列表数据】,网页上红框框出的评价列表即为当前评价列表。
4、编辑字段
在【当前页面数据预览】界面,可以进行删除字段、修改字段名称等操作。
步骤五、创建循环翻页,到采集多页数据
1、创建【循环翻页】
如果只有采集一页数据,可以跳过这一步。
如果需要翻页到采集多页数据:选择页面中的【下一页】按钮,在操作提示上点击【循环点击下一页】,创建一个【循环翻页】。
特别说明:
一种。创建完【循环翻页】后,优采云会自动点击【下一页】按钮进行翻页,从第一页、第二页……一直到最后一页。如果只需要特定页面采集的数据,可以在优采云中设置翻页的周期数。详情请点击查看翻页采集多页数据教程。
2、修改【圆形翻页】的XPath
默认的【循环翻页】XPath无法准确定位差评的翻页,需要修改【循环翻页】XPath。
进入【循环翻页】设置页面,修改XPath为://div[@id='comment-6']//div[@class="ui-page"]//a[@class="ui" -pager -next"] 并保存。
同时将【点击翻页】的【ajax超时】时间调整为5秒。
特别说明:
一种。默认生成的【循环翻页】会定位其他分类的翻页按钮,无法准确采集差评,需要手动修改XPath。这里需要一些 XPath 知识。单击以查看 XPath 学习和示例教程。
湾 除了默认的[All Evaluations],采集的所有其他类别都需要相应地修改XPath。
[视频列表]://div[@id='comment-2']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[复习]://div[@id='comment-3']//div[@class="ui-page"]//a[@class="ui-pager-next"]
[赞]://div[@id='comment-4']//div[@class=“ui-page”]//a[@class=“ui-pager-next”]
[评论]://div[@id='comment-5']//div[@class="ui-page"]//a[@class="ui-pager-next"]
C。对于使用Ajax技术的网页,优采云会自动判断并设置【Ajax超时】。如果系统自动设置的时间太短,可根据采集要求和网页加载情况相应延长。详情请点击查看Ajax教程。
步骤六、开始采集
1、 单击 [采集] 和 [启动本地采集]。启动优采云后自动采集数据。
特别说明:
一种。[本地采集]为采集使用自己的电脑,[cloud采集]为优采云提供的云服务器采集,点击进入查看本地采集和cloud采集的详解。
2、采集 完成后,选择合适的导出方式导出数据。支持导出到 Excel、CSV、HTML、数据库等。这里导出到 Excel。
样本数据:
excel抓取网页数据(excel抓取网页数据需要对页面数据进行一个解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-10-08 16:01
excel抓取网页数据需要对页面数据进行一个解析,所以第一步要做的就是获取url。拿百度来举例。一般,我们想知道哪个位置存放的数据多,我们需要把页面分成两页,把要用的数据提取出来。这里有一些方法:1。获取网页源代码,爬去网页源代码2。利用各种脚本语言3。使用代理服务器excel中的源代码获取也很简单。
用chrome浏览器的开发者工具,不断刷新页面,可以观察到源代码有个向下的箭头,所以我们这样抓包就可以获取页面源代码了。;page=baidu&belongs=2018&name=,你点进去可以看到要获取的信息。是不是很简单,解析完页面数据就可以爬取更多数据啦。欢迎关注我的微信公众号:司南教育。
这个还真不好说,首先对的定义并不明确,能否指导!我理解的就是转换下浏览器的web服务器。看你是想要用js访问网页还是用其他方式。需要注意的是带有js转换会丢失源文件。实在没有就注册成为插件采用直接引用的方式访问。
1、用javascript解析网页源代码
2、用插件提取数据
用浏览器开发者工具看看,
0)blank.那么你只要用javascript解析下网页源代码,找找带有这个词的就可以了(balabala...很多)比如用我画个3.看网页上内容, 查看全部
excel抓取网页数据(excel抓取网页数据需要对页面数据进行一个解析)
excel抓取网页数据需要对页面数据进行一个解析,所以第一步要做的就是获取url。拿百度来举例。一般,我们想知道哪个位置存放的数据多,我们需要把页面分成两页,把要用的数据提取出来。这里有一些方法:1。获取网页源代码,爬去网页源代码2。利用各种脚本语言3。使用代理服务器excel中的源代码获取也很简单。
用chrome浏览器的开发者工具,不断刷新页面,可以观察到源代码有个向下的箭头,所以我们这样抓包就可以获取页面源代码了。;page=baidu&belongs=2018&name=,你点进去可以看到要获取的信息。是不是很简单,解析完页面数据就可以爬取更多数据啦。欢迎关注我的微信公众号:司南教育。
这个还真不好说,首先对的定义并不明确,能否指导!我理解的就是转换下浏览器的web服务器。看你是想要用js访问网页还是用其他方式。需要注意的是带有js转换会丢失源文件。实在没有就注册成为插件采用直接引用的方式访问。
1、用javascript解析网页源代码
2、用插件提取数据
用浏览器开发者工具看看,
0)blank.那么你只要用javascript解析下网页源代码,找找带有这个词的就可以了(balabala...很多)比如用我画个3.看网页上内容,
excel抓取网页数据(excel抓取网页数据,生成csv.r的实现大法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-07 18:00
excel抓取网页数据,生成csv文件python、rpython、mongodb、mysql、csv、rstudio、pythonshell都可以抓取相应的文件,文件格式自己选择,选择r爬虫分析processon、teambition、知乎、地图爬虫抓取量大的图站。地图开发接触的少,接触的多就知道:geojson+table+opengl.tojson的实现大法。
爬虫开发还是得使用python.r的话,就得用webdriver.visualmask和pyethoder300.python的话,
抓取数据最适合要用来做什么。如果是小型数据公司内部的文档,需要爬取上百页的话,其实r现在有基于python做数据挖掘的库,用来爬就可以了。小公司可能没有这么多访问,所以不需要专门做数据爬取工作。不过也可以写一个爬虫去爬取公司的存档文件(如果公司里有人还在用这个软件就行了),然后再用其他的软件处理这些文件然后提交。
参见yahoofinance
爬虫都是数据库操作。r,python,nodejs,go,java这些写爬虫都没问题。但是做文章你得懂那些,因为是你写的代码。文章分析(如怎么找核心词,段落,段落怎么分类)最好用python,因为python解释性语言轻快,可读性好,自己写简单语句即可(你懂得),nodejs(nodejs是不是太简单了,因为python才是真正的世界上最好的语言)对html,css一类的东西要懂。
是r还是python取决于你做那类文章。工作上建议用r,因为文章分析是r人的工作,有人帮你管。python,nodejs都是大工程,不只是写个爬虫那么简单,你得把业务逻辑都写出来,而且不能用python,因为python的表达能力太差,写的话写都写不出,太浮,而且结构感不好。不过个人感觉nodejs是python的鼻祖,做文章可以考虑用它做,java接近0写法。
这三个写爬虫不好,要爬去unix网站,要用unix标准的.net框架,不用怕python,写nodejs吧。能有个实习工作去做最好。python是很多公司不用人为操心,又省事又省心不被pythonit那帮人踢出去的方法。 查看全部
excel抓取网页数据(excel抓取网页数据,生成csv.r的实现大法)
excel抓取网页数据,生成csv文件python、rpython、mongodb、mysql、csv、rstudio、pythonshell都可以抓取相应的文件,文件格式自己选择,选择r爬虫分析processon、teambition、知乎、地图爬虫抓取量大的图站。地图开发接触的少,接触的多就知道:geojson+table+opengl.tojson的实现大法。
爬虫开发还是得使用python.r的话,就得用webdriver.visualmask和pyethoder300.python的话,
抓取数据最适合要用来做什么。如果是小型数据公司内部的文档,需要爬取上百页的话,其实r现在有基于python做数据挖掘的库,用来爬就可以了。小公司可能没有这么多访问,所以不需要专门做数据爬取工作。不过也可以写一个爬虫去爬取公司的存档文件(如果公司里有人还在用这个软件就行了),然后再用其他的软件处理这些文件然后提交。
参见yahoofinance
爬虫都是数据库操作。r,python,nodejs,go,java这些写爬虫都没问题。但是做文章你得懂那些,因为是你写的代码。文章分析(如怎么找核心词,段落,段落怎么分类)最好用python,因为python解释性语言轻快,可读性好,自己写简单语句即可(你懂得),nodejs(nodejs是不是太简单了,因为python才是真正的世界上最好的语言)对html,css一类的东西要懂。
是r还是python取决于你做那类文章。工作上建议用r,因为文章分析是r人的工作,有人帮你管。python,nodejs都是大工程,不只是写个爬虫那么简单,你得把业务逻辑都写出来,而且不能用python,因为python的表达能力太差,写的话写都写不出,太浮,而且结构感不好。不过个人感觉nodejs是python的鼻祖,做文章可以考虑用它做,java接近0写法。
这三个写爬虫不好,要爬去unix网站,要用unix标准的.net框架,不用怕python,写nodejs吧。能有个实习工作去做最好。python是很多公司不用人为操心,又省事又省心不被pythonit那帮人踢出去的方法。
excel抓取网页数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
网站优化 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-10-07 08:07
我们经常使用网页数据,但是每次打开网页查询,都非常麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这样的目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
部分 网站 数据已加密,可能无法导出。这不是软件可以做到的。需要的是黑客。
Excel中查询网页数据并实时更新相关操作文章:
1.如何使用excel2013web查询采集网页数据功能
2.中小学优秀作文作文
3.excel how采集 网络数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号 查看全部
excel抓取网页数据(Excel中查询网页数据并实时更新的操作步骤如下经典励志语录)
我们经常使用网页数据,但是每次打开网页查询,都非常麻烦,而且我们需要的数据都是实时更新的,那么有什么方法可以达到这样的目的呢?今天教大家在Excel中查询网页数据并实时更新。
Excel中查询网页数据并实时更新的操作步骤如下:
首先打开excel,点击数据,在获取外部数据选项卡下,点击来自网站,会弹出一个新的web查询对话框,如下图:
将网页地址复制到地址栏,点击前往打开网页。
在打开的网页中,找到要导入的数据,点击带黄框的箭头选择区域,然后点击右下角的导入。
在弹出的导入数据对话框中,点击指定导入位置将数据导入excel。
用法:数据导入excel后,如果要更改数据区域,可以右键编辑查询,重新指定区域。
数据导入excel后,在数据区右击,点击刷新,刷新数据。右键单击数据区域属性,可以打开外部数据区域属性对话框,设置刷新频率,打开文件时是否允许后台刷新或刷新。
另一种简单的方法是直接复制你需要的网页数据并粘贴到excel中。粘贴完成后,右下角有粘贴选项。有一个可刷新的网络查询。单击它以输入新的网络查询。界面,重复之前的操作即可。
:
预防措施:
部分 网站 数据已加密,可能无法导出。这不是软件可以做到的。需要的是黑客。
Excel中查询网页数据并实时更新相关操作文章:
1.如何使用excel2013web查询采集网页数据功能
2.中小学优秀作文作文
3.excel how采集 网络数据
4.Excel中如何设置自动更新序列号
5.经典励志名言
6.WPS如何快速导入网页数据
7.如何自动更新excel表格的序号

