
excel抓取网页数据
excel抓取网页数据(彩票网站上面的数据一次性导入到Excel表中应该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2022-04-12 13:30
导读:目前正在解读《如何获取网页数据(实时抓取网页数据分析)》的相关信息,《如何获取网页数据(实时网页数据分析)》为知识类内容发布由用户!下面请看(国外主机-)用户发布的《如何获取网页数据(实时爬取网页数据分析)》的详细说明。
有时为了在网上获取网站的数据,我们需要从各大网站下载我们需要的数据。我们以开奖数据为例,使用 Excel 从 网站 中快速获取我们需要的每张开奖数据的中奖数据。
如上图所示,我们需要一次性将彩票网站上的数据导入到Excel工作表中。让我们学习操作方法。
第 1 步:单击数据 - 源以选择 网站。在地址栏中输入网站数据源所在的URL,点击Go to,即可跳转到该URL所在的页面;
第二步:点击网页查询左上角的箭头符号,然后点击右下角的导入。这样我们就可以在Excel中添加我们需要的数据范围了,如下图:
第三步:导入数据时,选择工作表和添加数据的起始位置。如下图所示,我们数据的起始位置选择为单元格A1,点击确定。如下所示:
这样,一次性将所有数据导入到 Excel 表格中。由于数据量大,导入时需要耐心等待。
温馨提示:《如何获取网页数据(实时抓取网页数据分析)》最后刷新时间2022-04-05 01:32:57,本站为公益个人网站,仅供个人学习和记录信息,没有任何商业利润。如内容及图片资源无效或内容涉及侵权,请反馈至Email:我们会及时处理。本站只保证内容的可读性,但不能保证真实性。请鉴别“如何获取网页数据(实时抓取网页数据分析)”中内容的真实性。 查看全部
excel抓取网页数据(彩票网站上面的数据一次性导入到Excel表中应该怎么做?)
导读:目前正在解读《如何获取网页数据(实时抓取网页数据分析)》的相关信息,《如何获取网页数据(实时网页数据分析)》为知识类内容发布由用户!下面请看(国外主机-)用户发布的《如何获取网页数据(实时爬取网页数据分析)》的详细说明。
有时为了在网上获取网站的数据,我们需要从各大网站下载我们需要的数据。我们以开奖数据为例,使用 Excel 从 网站 中快速获取我们需要的每张开奖数据的中奖数据。

如上图所示,我们需要一次性将彩票网站上的数据导入到Excel工作表中。让我们学习操作方法。
第 1 步:单击数据 - 源以选择 网站。在地址栏中输入网站数据源所在的URL,点击Go to,即可跳转到该URL所在的页面;

第二步:点击网页查询左上角的箭头符号,然后点击右下角的导入。这样我们就可以在Excel中添加我们需要的数据范围了,如下图:

第三步:导入数据时,选择工作表和添加数据的起始位置。如下图所示,我们数据的起始位置选择为单元格A1,点击确定。如下所示:


这样,一次性将所有数据导入到 Excel 表格中。由于数据量大,导入时需要耐心等待。
温馨提示:《如何获取网页数据(实时抓取网页数据分析)》最后刷新时间2022-04-05 01:32:57,本站为公益个人网站,仅供个人学习和记录信息,没有任何商业利润。如内容及图片资源无效或内容涉及侵权,请反馈至Email:我们会及时处理。本站只保证内容的可读性,但不能保证真实性。请鉴别“如何获取网页数据(实时抓取网页数据分析)”中内容的真实性。
excel抓取网页数据(Python从抓包工具charles获取表格的相关方法介绍~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-12 07:36
01 焦点
在自动化测试的过程中,经常需要使用excel文件来存储测试用例,那么在设计好表中的测试用例数据之后,如何通过自动化读取呢?此时就需要测试小姐姐写“代码”了~
本文主要介绍如何通过python读取表格数据。Python中读取表格的方式大概有3种(如下图)。本文重点介绍使用xlrd模块读取excel数据。
读取excel文件,掌握以下结果:
读表的相关方法描述如下:
02 抓包获取接口数据
在自动化接口时,接口文档通常在公司内部开发中维护。测试人员可以从文档中获取接口相关信息,也可以使用抓包工具获取接口信息。
本文的案例比较简单,从抓包中获取数据。当然,如果真的要进行接口自动化测试,还需要开发并提供详细的接口数据,不仅包括请求地址、输入参数,还包括每个输入参数对应的值。,以及接口成功状态标志。
1、获取接口请求的基本数据
使用抓包工具charles获取需要自动化测试的接口
有两条信息,一条是请求地址url,一条是请求头
(请求头的含义可以自行百度,这里就不过多解释了)
接口请求的常用方法是post和get。本例中的请求使用 post 方法。
2、获取接口请求的输入参数数据
在抓包工具上,切换到Request页面,可以看到输入的数据,如下图:
获取信息:
{
"loginId": "***",
"password": "***"
}
1234
从上面的数据可以看出,接口的输入参数是以字典的形式传递的,key=loginId,对应的value=””(这里代表用户的用户名~由于个人隐私的问题,使用编号代替 )
03 设计测试用例
用例存储在 Excel 表中。第一行是参数,第二行以输入参数的值开头,第一列是用例的标题,如下:
获取信息:
(本文中的测试用例只是示例,在实际测试过程中,肯定不止这两个用例)
04 Python脚本
从抓包工具charles捕获的数据中,我们需要获取两种数据:
时间戳脚本
13位时间戳脚本的Python实现如下:
阅读测试用例脚本
通过抓包数据可以看到输入的数据是字典的形式,一个key对应一个value。
因此,接口测试用例的脚本设计分为三个部分:
1、将参与测试数据的请求输入构造成字典形式
如下图:一个组合的输入参数+测试数据相当于一个用例
2、 将每个用例与用例标题组合成字典形式
如下图: 后面可以根据用例的标题获取用例的内容(输入参数+测试数据)。
3、 会通过用例标题读取测试用例
(高温提醒:最后真的不会再打代码了,直接更新表格用例,直接运行脚本) 查看全部
excel抓取网页数据(Python从抓包工具charles获取表格的相关方法介绍~)
01 焦点
在自动化测试的过程中,经常需要使用excel文件来存储测试用例,那么在设计好表中的测试用例数据之后,如何通过自动化读取呢?此时就需要测试小姐姐写“代码”了~
本文主要介绍如何通过python读取表格数据。Python中读取表格的方式大概有3种(如下图)。本文重点介绍使用xlrd模块读取excel数据。
读取excel文件,掌握以下结果:
读表的相关方法描述如下:
02 抓包获取接口数据
在自动化接口时,接口文档通常在公司内部开发中维护。测试人员可以从文档中获取接口相关信息,也可以使用抓包工具获取接口信息。
本文的案例比较简单,从抓包中获取数据。当然,如果真的要进行接口自动化测试,还需要开发并提供详细的接口数据,不仅包括请求地址、输入参数,还包括每个输入参数对应的值。,以及接口成功状态标志。
1、获取接口请求的基本数据
使用抓包工具charles获取需要自动化测试的接口
有两条信息,一条是请求地址url,一条是请求头
(请求头的含义可以自行百度,这里就不过多解释了)
接口请求的常用方法是post和get。本例中的请求使用 post 方法。
2、获取接口请求的输入参数数据
在抓包工具上,切换到Request页面,可以看到输入的数据,如下图:
获取信息:
{
"loginId": "***",
"password": "***"
}
1234
从上面的数据可以看出,接口的输入参数是以字典的形式传递的,key=loginId,对应的value=””(这里代表用户的用户名~由于个人隐私的问题,使用编号代替 )
03 设计测试用例
用例存储在 Excel 表中。第一行是参数,第二行以输入参数的值开头,第一列是用例的标题,如下:
获取信息:
(本文中的测试用例只是示例,在实际测试过程中,肯定不止这两个用例)
04 Python脚本
从抓包工具charles捕获的数据中,我们需要获取两种数据:
时间戳脚本
13位时间戳脚本的Python实现如下:
阅读测试用例脚本
通过抓包数据可以看到输入的数据是字典的形式,一个key对应一个value。
因此,接口测试用例的脚本设计分为三个部分:
1、将参与测试数据的请求输入构造成字典形式
如下图:一个组合的输入参数+测试数据相当于一个用例
2、 将每个用例与用例标题组合成字典形式
如下图: 后面可以根据用例的标题获取用例的内容(输入参数+测试数据)。
3、 会通过用例标题读取测试用例
(高温提醒:最后真的不会再打代码了,直接更新表格用例,直接运行脚本)
excel抓取网页数据( 如何将网页中的数据刮到Excel中?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2022-04-11 15:01
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,那么加上经验公式,计算出一些从抓取的数据中得出的最终结果,比如 想法不错。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
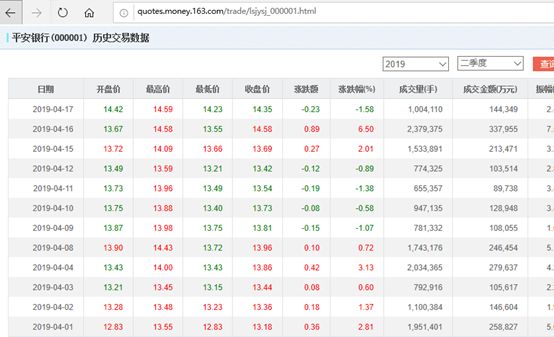
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上述 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”,这样您就不会复制文件中的数据,并直接在数据透视表等位置进行名称连接。
第 7 步:刷新数据。要从网页获取更新,只需转到功能区的外部数据选项卡,然后单击全部刷新:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query网站限制
正如我前面提到的,PowerQuery 非常擅长从 WEB 获取数据,它被格式化为 HTML 表格,而不是使用 JavaScript 生成的表格。通过检查网页源代码并查找 HTML 表格标记,您可以轻松判断表格是 HTML 还是 JavaScript。
为此,在网页上的一些空白处右键单击>查看页面源(或类似的,取决于您使用的浏览器,我使用Windows 10系统附带的浏览器,而不是互联网的先前版本)探险家):
CTRL + F 打开查找对话框。进入”
如果找到HTML table标签,就确认power Query可以从页面中获取到一个表,但是不能保证就是你真正需要的那个表,因为页面上可能还有其他的表,所以可以使用我之前谈到的表进行选择。
关于电源查询的更多功能将在后面解释。
Power Query 可以从无数地方获取数据,并具有大量用于排序和转换数据的工具。我之前已经介绍过一些,例如:
合并 Excel 工作表
从文件夹中获取文件
当然,后面会有更多的介绍
以上就是我们所说的使用power Query做网络爬取。当然,如果你的数据是从网络上爬出来的,VBA也是一个不错的方法。而且灵活性非常高,通过变量进行多次数据爬取。.
视频:
如果你有时觉得我的视频在记录或分类中找不到,可以转发到自己的朋友圈,供自己采集。 查看全部
excel抓取网页数据(
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,那么加上经验公式,计算出一些从抓取的数据中得出的最终结果,比如 想法不错。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上述 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
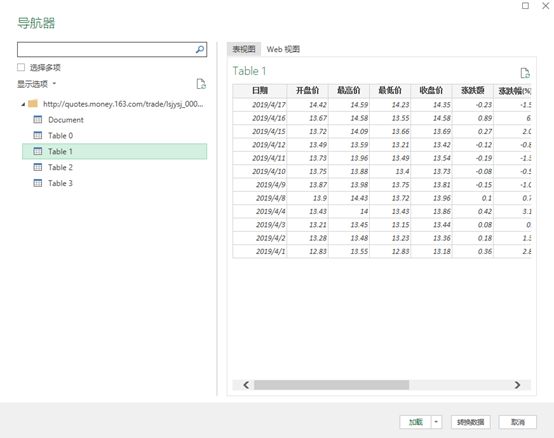
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
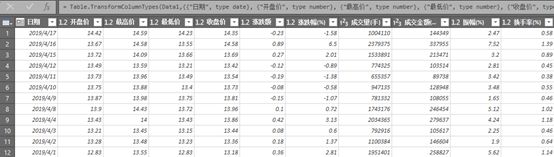
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
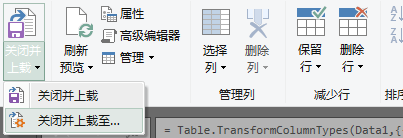
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”,这样您就不会复制文件中的数据,并直接在数据透视表等位置进行名称连接。
第 7 步:刷新数据。要从网页获取更新,只需转到功能区的外部数据选项卡,然后单击全部刷新:
或者,如果您有多个查询,您可以打开查询和连接窗格:

Power Query网站限制
正如我前面提到的,PowerQuery 非常擅长从 WEB 获取数据,它被格式化为 HTML 表格,而不是使用 JavaScript 生成的表格。通过检查网页源代码并查找 HTML 表格标记,您可以轻松判断表格是 HTML 还是 JavaScript。
为此,在网页上的一些空白处右键单击>查看页面源(或类似的,取决于您使用的浏览器,我使用Windows 10系统附带的浏览器,而不是互联网的先前版本)探险家):
CTRL + F 打开查找对话框。进入”
如果找到HTML table标签,就确认power Query可以从页面中获取到一个表,但是不能保证就是你真正需要的那个表,因为页面上可能还有其他的表,所以可以使用我之前谈到的表进行选择。
关于电源查询的更多功能将在后面解释。
Power Query 可以从无数地方获取数据,并具有大量用于排序和转换数据的工具。我之前已经介绍过一些,例如:
合并 Excel 工作表
从文件夹中获取文件
当然,后面会有更多的介绍
以上就是我们所说的使用power Query做网络爬取。当然,如果你的数据是从网络上爬出来的,VBA也是一个不错的方法。而且灵活性非常高,通过变量进行多次数据爬取。.
视频:

如果你有时觉得我的视频在记录或分类中找不到,可以转发到自己的朋友圈,供自己采集。
excel抓取网页数据(156个Python网络爬虫资源(2.2三种网页)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 00:20
阿里云 > 云栖社区 > 主题地图 > E > Excel网络爬虫
推荐活动:
更多优惠>
当前话题: Excel 网络爬虫 添加到采集夹
相关话题:
excel网络爬虫相关的博客看更多博客
什么是网络爬虫,网络爬虫有什么用?
作者:幸运券发行2426人查看评论:03年前
什么是网络爬虫,网络爬虫有什么用?简单来说,就是通过非人为的方式获取网页上显示的数据。现在是大数据时代,数据分析是解决各行各业相关问题的重要依据。数据分析结果的准确性很大程度上取决于数据量是否足够大。如果是几十条数据,我们当然可以让人一一复制粘贴
阅读全文
156个Python网络爬虫资源,GitHub上awesome系列的Python爬虫工具
作者:马达达 12379 浏览评论:04年前
项目地址:lorien/awesome-web-scraping GitHub上awesome系列的Python爬虫工具。此列表收录 Python Web 抓取和数据处理相关库。网络相关通用 urllib - 网络库(标准库)请求 - 网络库
阅读全文
156个Python爬虫资源,妈妈再也不用担心找不到资源了
作者:燕衡5808 浏览评论:13年前
此列表收录 Python Web 抓取和数据处理相关库。前几天私信给编辑索要Python学习资料。小编整理了一些深入的Python教程和参考资料,从初级到高级。文件已打包。正在学习Python的同学可以下载学习。文件下载方式:在群文件中下载:7
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节书摘自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多内容章节可访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们已经了解了网页的结构,以下
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
如何开始编写你的第一个 python 脚本 - Simple Crawler 入门!
作者:云飞学习编程999人评论:03年前
很多朋友在开始接触python的时候都是从爬虫开始的,而网络爬虫是近几年流行的概念,尤其是大数据分析大行其道之后,越来越多的人在学习网络爬虫,哦对了,现在叫Data Mined!其实一般爬虫有两个功能:取数据和存储数据
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
23 Python爬虫开源项目代码
作者:hank_leo4651 浏览评论:13年前
今天为大家整理了23个Python爬虫项目。整理的原因是爬虫入门简单快速,也很适合新手培养信心。所有链接都指向GitHub,祝你玩的开心1、微信搜狗[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫界面可扩展为
阅读全文 查看全部
excel抓取网页数据(156个Python网络爬虫资源(2.2三种网页)(组图))
阿里云 > 云栖社区 > 主题地图 > E > Excel网络爬虫

推荐活动:
更多优惠>
当前话题: Excel 网络爬虫 添加到采集夹
相关话题:
excel网络爬虫相关的博客看更多博客
什么是网络爬虫,网络爬虫有什么用?


作者:幸运券发行2426人查看评论:03年前
什么是网络爬虫,网络爬虫有什么用?简单来说,就是通过非人为的方式获取网页上显示的数据。现在是大数据时代,数据分析是解决各行各业相关问题的重要依据。数据分析结果的准确性很大程度上取决于数据量是否足够大。如果是几十条数据,我们当然可以让人一一复制粘贴
阅读全文
156个Python网络爬虫资源,GitHub上awesome系列的Python爬虫工具

作者:马达达 12379 浏览评论:04年前
项目地址:lorien/awesome-web-scraping GitHub上awesome系列的Python爬虫工具。此列表收录 Python Web 抓取和数据处理相关库。网络相关通用 urllib - 网络库(标准库)请求 - 网络库
阅读全文
156个Python爬虫资源,妈妈再也不用担心找不到资源了


作者:燕衡5808 浏览评论:13年前
此列表收录 Python Web 抓取和数据处理相关库。前几天私信给编辑索要Python学习资料。小编整理了一些深入的Python教程和参考资料,从初级到高级。文件已打包。正在学习Python的同学可以下载学习。文件下载方式:在群文件中下载:7
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬虫方法


作者:异步社区 3748人查看评论:04年前
本节书摘自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多内容章节可访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们已经了解了网页的结构,以下
阅读全文
开源爬虫软件总结


作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
如何开始编写你的第一个 python 脚本 - Simple Crawler 入门!

作者:云飞学习编程999人评论:03年前
很多朋友在开始接触python的时候都是从爬虫开始的,而网络爬虫是近几年流行的概念,尤其是大数据分析大行其道之后,越来越多的人在学习网络爬虫,哦对了,现在叫Data Mined!其实一般爬虫有两个功能:取数据和存储数据
阅读全文
开源爬虫软件总结


作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
23 Python爬虫开源项目代码

作者:hank_leo4651 浏览评论:13年前
今天为大家整理了23个Python爬虫项目。整理的原因是爬虫入门简单快速,也很适合新手培养信心。所有链接都指向GitHub,祝你玩的开心1、微信搜狗[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫界面可扩展为
阅读全文
excel抓取网页数据( 按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-09 00:18
按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))
按键精灵操作界面
按键精灵录音界面
使用按钮向导进行票价定价时选择出发和目的地界面
使用按钮向导进行票价定价时,通过Js脚本查看出发和目的地界面。
■ 赵梅
利用按钮向导实现对网络大数据的直接采集,该技术操作简单,应用范围广。可应用于消费价格、工业生产者价格等统计调查。这是一种方便的数据采集方法。在实际应用中,灵活使用按钮向导的三种技巧。
- 通过 URL 中的参数控制抓取内容。数据展示网页通常根据数据的逻辑结构,通过设置网页参数来组织数据展示。比如某航空公司网站广州到厦门机票预订网站1月30日,问号后面的“c1=CAN&c2=XMN&d1=2021-01-30”是网页参数,CAN代表广州是出发点参数,XMN代表厦门,是目的地参数,d1的值控制预订日期。通过改变参数的值,你可以抓取你想要的不同内容。特别是当网页的数据量很大,使用分页页数参数将数据分布在不同的页面上时,
- 与 Excel 结合使用。Excel具有结构化存储、函数式表达、方便友好的数据显示和编辑功能等优点,可以实现很多数据处理功能;同时,Excel VBA具有非常强大的办公自动化功能。因此,Button Wizard和Excel结合使用可以更灵活地实现更丰富的数据自动处理。例如,使用 Excel 保存按钮向导的输入参数和输出数据。使用Excel数据表,可以实现输入参数和输出数据的结构化存储,使数据结构一目了然,方便程序实现行列式调用。再例如,使用 Excel 函数进行输入和输出数据处理。在抢机票的情况下,在 Excel 参数单元格中引入 TODAY() 函数,以根据当天捕获机票信息。在使用按钮向导时,经常需要引入随机数,这可以通过读取 RAND() 函数单元格的值来实现。Excel丰富的功能系统大大降低了按钮向导编程中访问功能的工作复杂度。
- 与浏览器前端开发工具结合使用。使用按钮向导抓取网页数据元素时,往往需要与网页交互,提交数据选择条件,才能获取数据。例如订票网站,不能通过修改参数来确定出发地和目的地,只能通过网页上的复选框来选择出发地和目的地。当需要与网页交互访问数据时,可以使用浏览器前端开发平台加载JavaScript脚本实现数据获取。JavaScript脚本是网页常用的开发工具,具有丰富的网页交互功能。打开浏览器浏览网页,按F12键进入浏览器前端开发平台,选择“控制台”,在控制台界面,使用按钮向导输入编写的与网页交互的JavaScript脚本,即可轻松实现数据交互访问。按钮精灵调用JavaScript脚本实现丰富的浏览器网页交互,大大增强了按钮精灵处理网页信息的能力,避免了按钮精灵模拟时由于网页元素在不同网页上位移而导致的定位不准问题网页交互。 查看全部
excel抓取网页数据(
按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))

按键精灵操作界面

按键精灵录音界面

使用按钮向导进行票价定价时选择出发和目的地界面

使用按钮向导进行票价定价时,通过Js脚本查看出发和目的地界面。
■ 赵梅
利用按钮向导实现对网络大数据的直接采集,该技术操作简单,应用范围广。可应用于消费价格、工业生产者价格等统计调查。这是一种方便的数据采集方法。在实际应用中,灵活使用按钮向导的三种技巧。
- 通过 URL 中的参数控制抓取内容。数据展示网页通常根据数据的逻辑结构,通过设置网页参数来组织数据展示。比如某航空公司网站广州到厦门机票预订网站1月30日,问号后面的“c1=CAN&c2=XMN&d1=2021-01-30”是网页参数,CAN代表广州是出发点参数,XMN代表厦门,是目的地参数,d1的值控制预订日期。通过改变参数的值,你可以抓取你想要的不同内容。特别是当网页的数据量很大,使用分页页数参数将数据分布在不同的页面上时,
- 与 Excel 结合使用。Excel具有结构化存储、函数式表达、方便友好的数据显示和编辑功能等优点,可以实现很多数据处理功能;同时,Excel VBA具有非常强大的办公自动化功能。因此,Button Wizard和Excel结合使用可以更灵活地实现更丰富的数据自动处理。例如,使用 Excel 保存按钮向导的输入参数和输出数据。使用Excel数据表,可以实现输入参数和输出数据的结构化存储,使数据结构一目了然,方便程序实现行列式调用。再例如,使用 Excel 函数进行输入和输出数据处理。在抢机票的情况下,在 Excel 参数单元格中引入 TODAY() 函数,以根据当天捕获机票信息。在使用按钮向导时,经常需要引入随机数,这可以通过读取 RAND() 函数单元格的值来实现。Excel丰富的功能系统大大降低了按钮向导编程中访问功能的工作复杂度。
- 与浏览器前端开发工具结合使用。使用按钮向导抓取网页数据元素时,往往需要与网页交互,提交数据选择条件,才能获取数据。例如订票网站,不能通过修改参数来确定出发地和目的地,只能通过网页上的复选框来选择出发地和目的地。当需要与网页交互访问数据时,可以使用浏览器前端开发平台加载JavaScript脚本实现数据获取。JavaScript脚本是网页常用的开发工具,具有丰富的网页交互功能。打开浏览器浏览网页,按F12键进入浏览器前端开发平台,选择“控制台”,在控制台界面,使用按钮向导输入编写的与网页交互的JavaScript脚本,即可轻松实现数据交互访问。按钮精灵调用JavaScript脚本实现丰富的浏览器网页交互,大大增强了按钮精灵处理网页信息的能力,避免了按钮精灵模拟时由于网页元素在不同网页上位移而导致的定位不准问题网页交互。
excel抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-09 00:17
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但在实际使用中你会发现很多困难。微软旗下的另一款软件Power BI在这个时候就表现出了无与伦比的优势。它是什么,让我们来看看吧。”看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
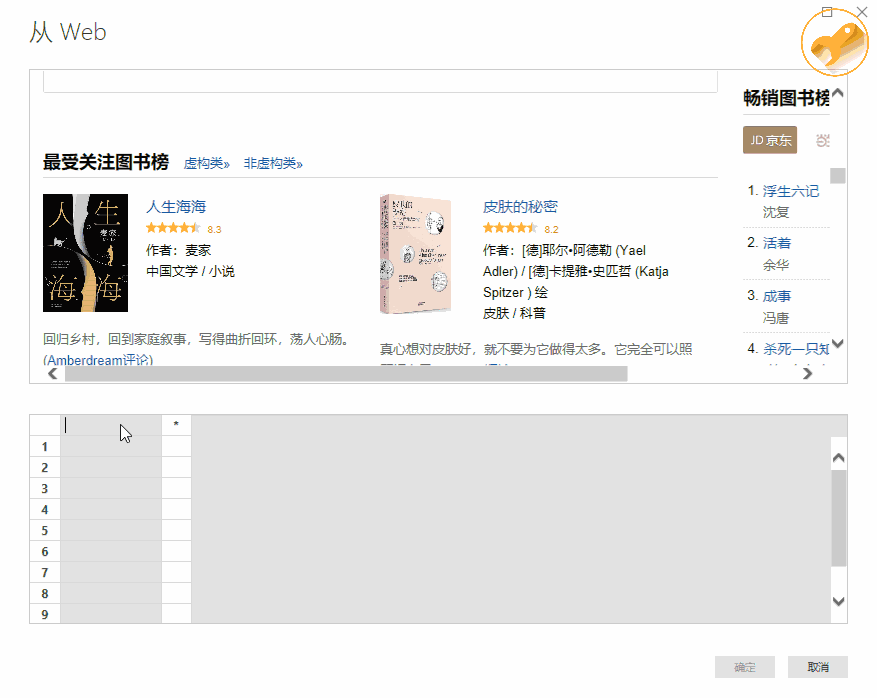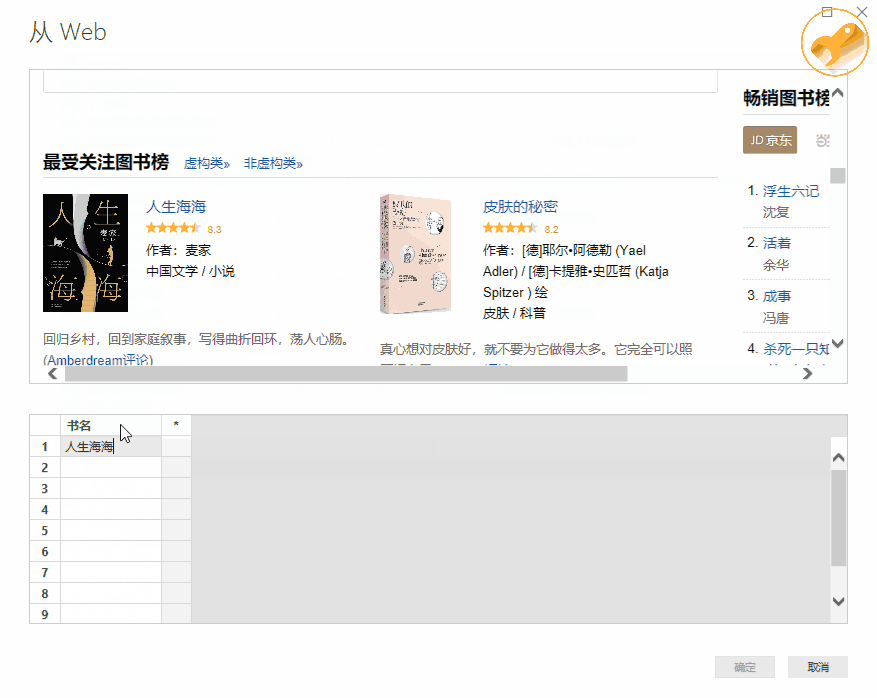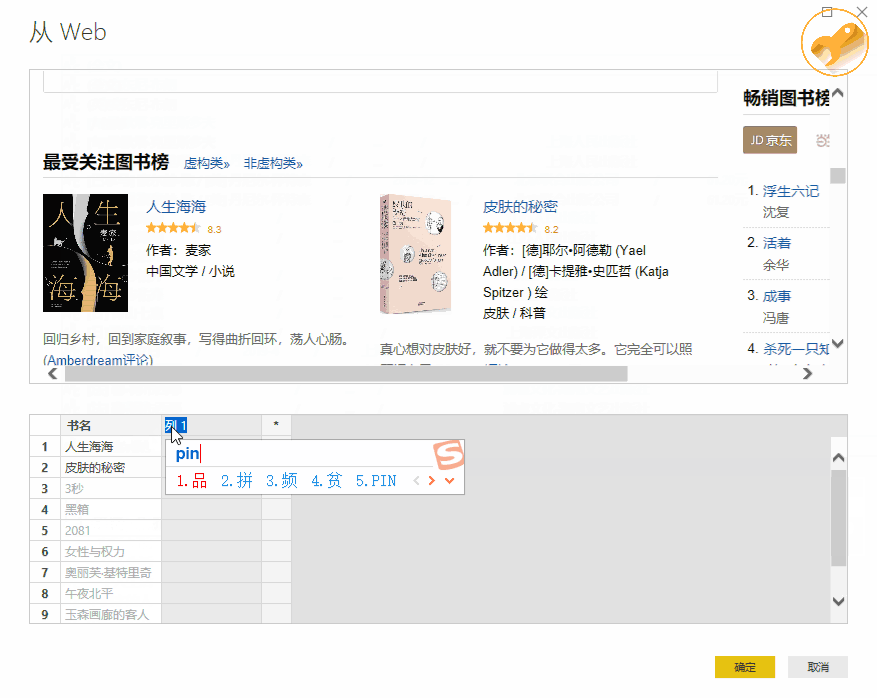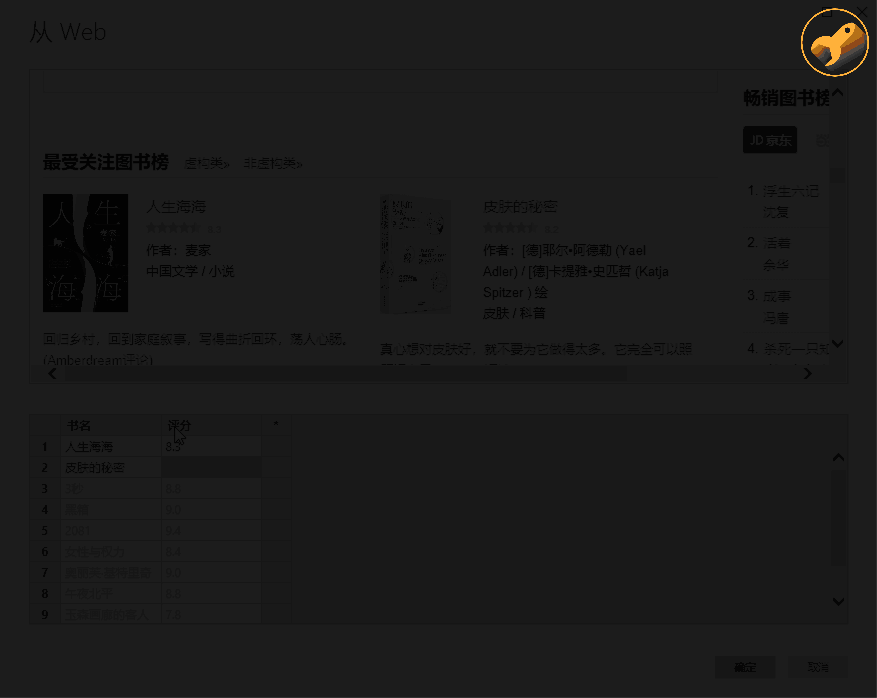
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
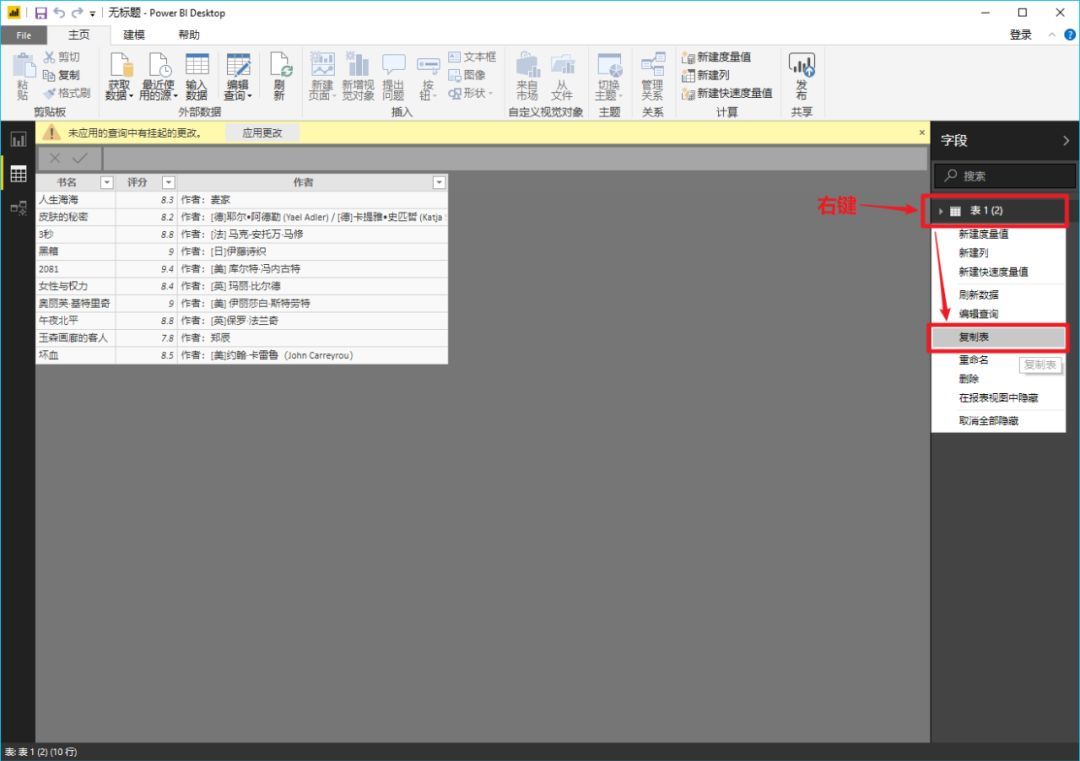
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗? 查看全部
excel抓取网页数据(
什么是PowerBI?(图)的优势(组图))


“火箭先生曾经介绍过使用Excel直接从网页下载数据,但在实际使用中你会发现很多困难。微软旗下的另一款软件Power BI在这个时候就表现出了无与伦比的优势。它是什么,让我们来看看吧。”看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:

Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
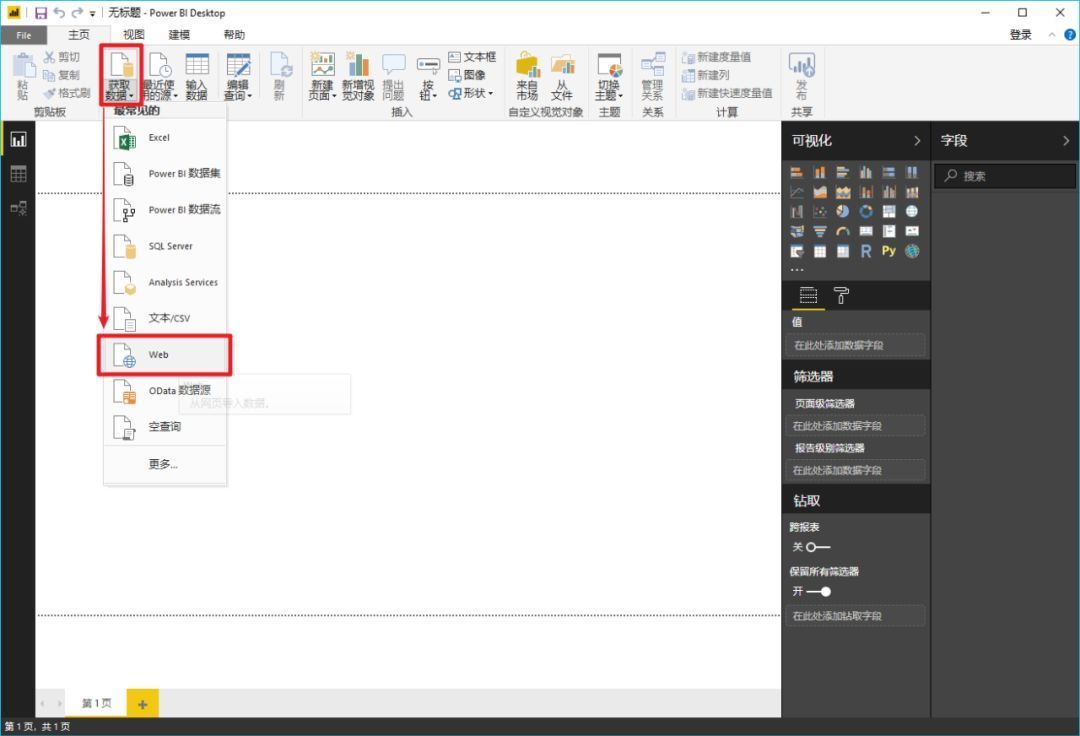
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
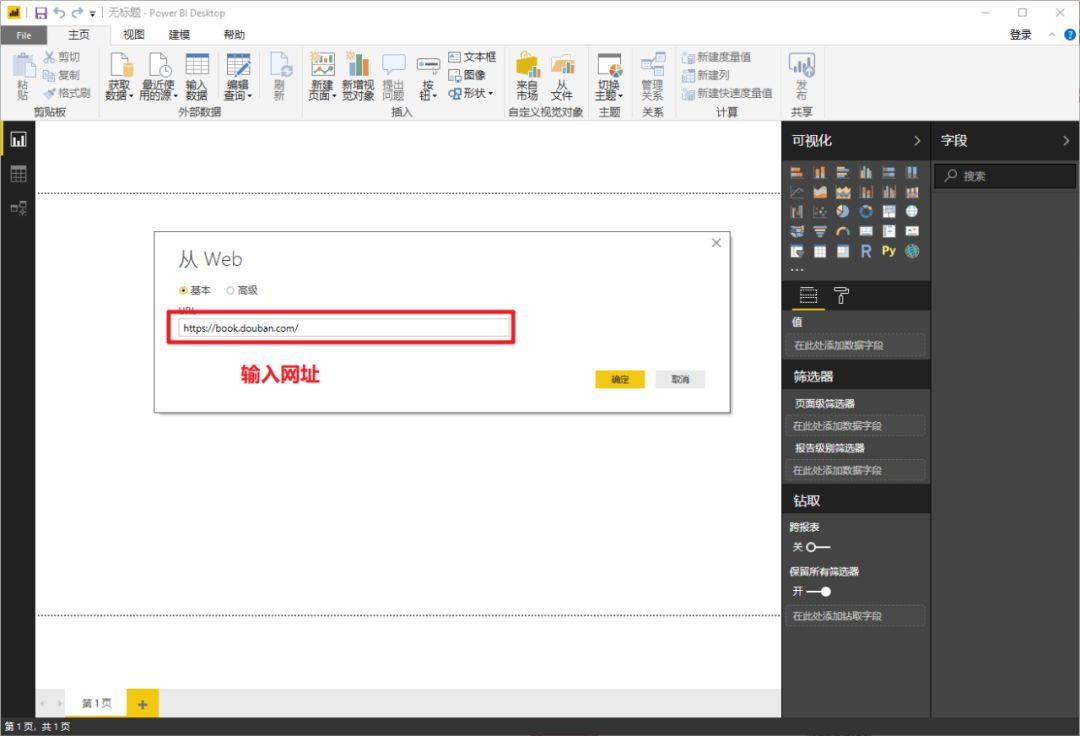
在弹窗复制豆瓣地址()并确认
>>>第三步
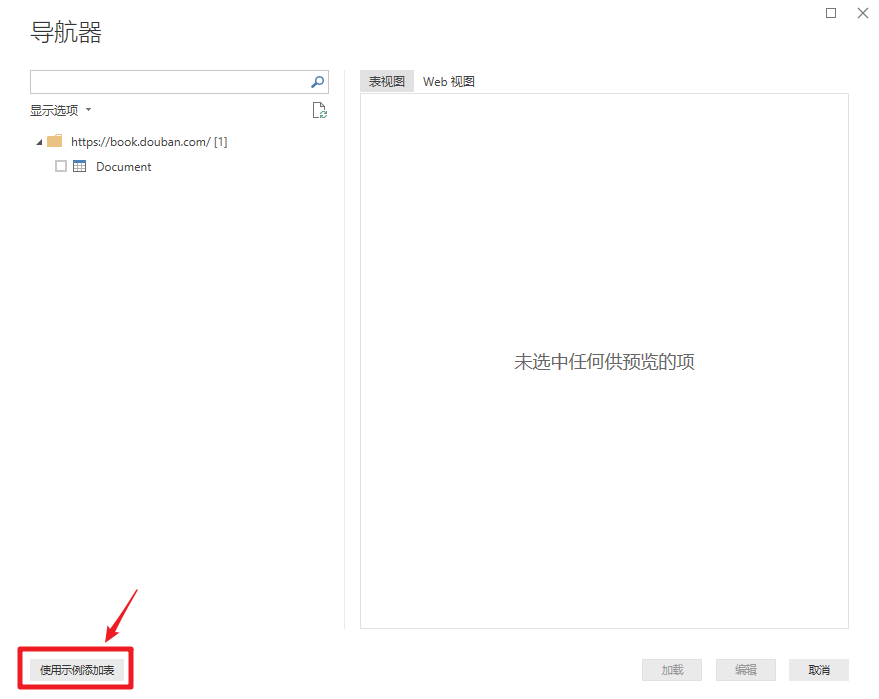
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
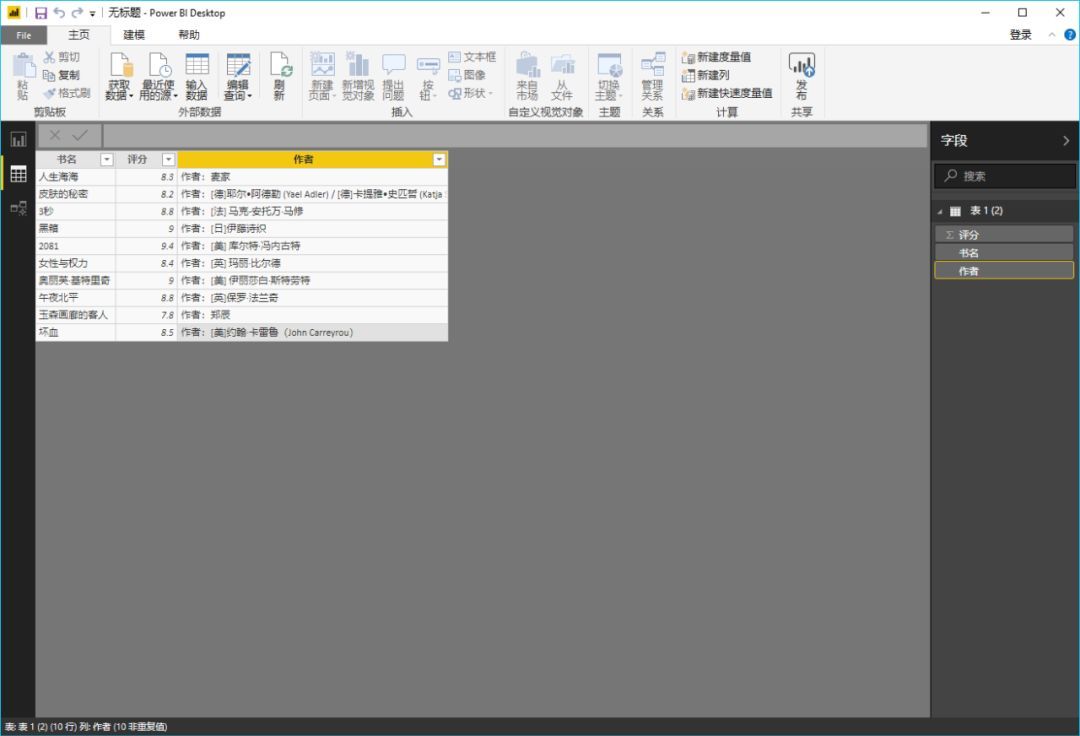
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
excel抓取网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-06 14:32
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天,我们来做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓住
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
查看全部
excel抓取网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图)
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天,我们来做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓住
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
excel抓取网页数据(Excel表格怎么链接网站上的数据?》一文中有阐述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-04-02 19:06
谢谢!网页数据爬取有两种方式:Excel不定时爬取网页数据;电源查询插件不定时爬取数据。
001 Excel时不时抓取数据
关于Excel不定时爬取的网页数据,我在《如何链接Excel表格网站上的数据?》一文中有详细介绍,可以点这里查看
我将在这里简单地教你这个方法:
002 Power Query不定时抓取数据
这是一种更强大的获取网页数据的方式。这里我将详细解释如何使用 Power Query 插件来爬取数据。
步骤 1:首先确保您的 Excel 已经有 Power Query
如果你是 Excel 2016,那么恭喜你,你什么都不用做,Excel 本身就有一个 Power Query 组件;如果你是2010或者2013,需要从微软官网下载();如果您是 Excel 的第一个版本,那么不,抱歉,此方法不适合您。
好的,现在假设您已经拥有 Power Query 组件,让我们继续下一步。
步骤 2:从 Power Query 创建一个新查询
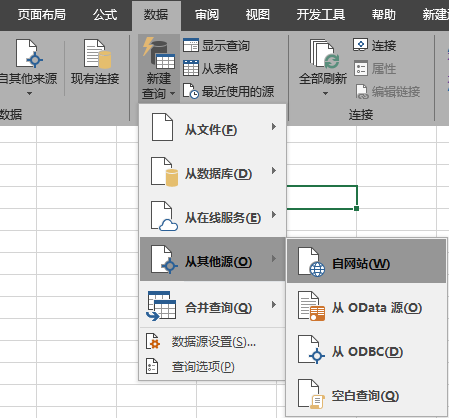
点击【数据】→【新建查询】→【来自其他来源】→【来自网站】,如图。
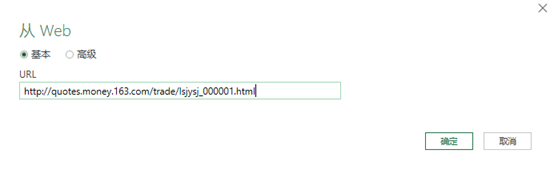
在弹出的界面中,输入需要抓取数据的URL。有两种模式:[基本]和[高级]。我们只需要简单的抓取数据,使用【Basic】模式即可。
步骤 3:编辑获得的数据
在导航器中,网页中存在的数据表显示在左侧,Document中的函数是一些表头信息。不着急,选择左边的Table0,右边的预览就可以看到数据了。
然后点击【编辑】
然后会弹出【查询编辑器】界面。在这个界面中,您可以对获取的数据进行丰富的清洗动作。功能远比Excel强大,如合并、转置、删除等,可以删除不需要的数据。
Step4:将获取的数据上传到Excel
如图,点击【关闭并上传】→【关闭并上传】,然后将数据上传到我们打开的excel中。
Power Query 捕获的数据更有条理,更易于后续分析。你学会了吗?
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel表格怎么链接网站上的数据?》一文中有阐述)
谢谢!网页数据爬取有两种方式:Excel不定时爬取网页数据;电源查询插件不定时爬取数据。
001 Excel时不时抓取数据
关于Excel不定时爬取的网页数据,我在《如何链接Excel表格网站上的数据?》一文中有详细介绍,可以点这里查看
我将在这里简单地教你这个方法:

002 Power Query不定时抓取数据
这是一种更强大的获取网页数据的方式。这里我将详细解释如何使用 Power Query 插件来爬取数据。
步骤 1:首先确保您的 Excel 已经有 Power Query
如果你是 Excel 2016,那么恭喜你,你什么都不用做,Excel 本身就有一个 Power Query 组件;如果你是2010或者2013,需要从微软官网下载();如果您是 Excel 的第一个版本,那么不,抱歉,此方法不适合您。
好的,现在假设您已经拥有 Power Query 组件,让我们继续下一步。
步骤 2:从 Power Query 创建一个新查询
点击【数据】→【新建查询】→【来自其他来源】→【来自网站】,如图。

在弹出的界面中,输入需要抓取数据的URL。有两种模式:[基本]和[高级]。我们只需要简单的抓取数据,使用【Basic】模式即可。

步骤 3:编辑获得的数据
在导航器中,网页中存在的数据表显示在左侧,Document中的函数是一些表头信息。不着急,选择左边的Table0,右边的预览就可以看到数据了。
然后点击【编辑】

然后会弹出【查询编辑器】界面。在这个界面中,您可以对获取的数据进行丰富的清洗动作。功能远比Excel强大,如合并、转置、删除等,可以删除不需要的数据。

Step4:将获取的数据上传到Excel
如图,点击【关闭并上传】→【关闭并上传】,然后将数据上传到我们打开的excel中。

Power Query 捕获的数据更有条理,更易于后续分析。你学会了吗?
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-02 12:16
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓握,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。 查看全部
excel抓取网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓握,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。
excel抓取网页数据(就是使用Excel2013自带的工具--从网页获取数据Excel来分析的话 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-04-02 04:27
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,在这里你会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel抓取网页数据(就是使用Excel2013自带的工具--从网页获取数据Excel来分析的话
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。

2、你会看到一个查询对话框打开,在这里你会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。

3、然后点击导入按钮,你会看到下图第二张,稍等几秒。

4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。

5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。

6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。

excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-03-31 09:25
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
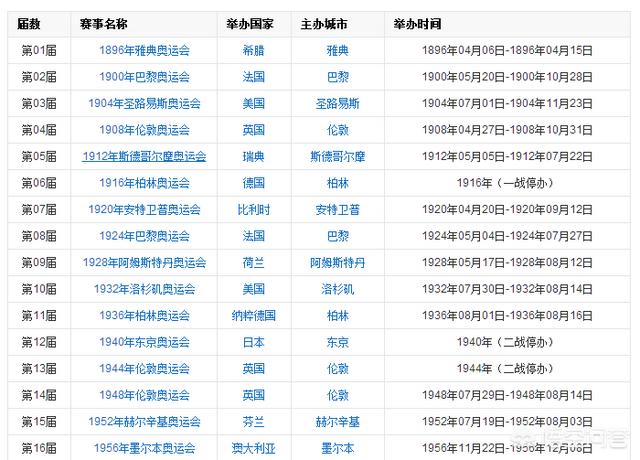
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。

Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。

弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。

Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。

单击下方“加载”旁边的下拉箭头,然后选择“加载到”。

在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。

如图所示,Web 表单中的数据已经被抓取到 Excel 中。

点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。

Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)

注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】

②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。

《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-27 09:28
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-03-27 09:27
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(爬虫的工作原理(一)_e操盘(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-25 08:05
)
本质上,爬虫使用程序为我们在线获取有价值的数据。实际上,爬虫是用编程语言编写的程序。它的功能是从网络中获取有价值的数据。重要的是速度比手动获取数据要快。浏览器的工作原理
爬虫的工作原理其实就是把手动操作变成程序操作。
爬虫的工作步骤
(1)输入网址,发起请求,获取数据
(2)使用程序解析得到的数据
(3)从数据中提取想要的数据
(4)数据存储以供将来使用和分析
了解了爬虫的原理之后,我们一起来看看如何抓取数据?
import requests
from bs4 import BeautifulSoup
import openpyxl
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}#请求头,模拟浏览器行为进行操作。越过服务器的反爬
response=requests.get('https://movie.douban.com/',headers=header)#根据请求方法用get方法进行发送请求,并获得响应值。headers=header用关键字传参
#
# print('响应状态码',response.status_code)
# print(response.request.headers)#查看请求头
# print(response.text)#查看响应文本
bs=BeautifulSoup(response.text,'html.parser')#html.parser 解析html。
# print(type(bs))
# title=bs.find('td',class_='title')#查找单个电影
# print(title.text)#输出结果
# title=bs.find_all('td',class_='title')
list=[['编号','电影名称','地址']]#声明列表中的头
title=bs.find('div',class_='billboard-bd')#查找标签
all_titel=title.find_all('tr')#查找div'标签 属性为 class='billboard-bd' 下的所有的tr
for i in all_titel:#遍历查找符合条件的电影
myid=i.find('td',class_='order')#查找电影id
mytitle=i.find('td',class_='title')#查找电影名称
url=i.find('a')['href']#查找地址连接
# print( myid.text,mytitle.text,url)
# title1=i.find('td',class_='title')
list.append([myid.text,mytitle.text,url])#将数据添加到列表中
# print(list)
#*****************存储到excel表格中
wb=openpyxl.Workbook()#创建一个工作薄
sheet=wb.active#创建一个工作表
sheet.title='电影'#为sheet页起名
for i in list:
sheet.append(i)#将列表中的内容存储到文件
wb.save('films.xlsx')#保存电影 查看全部
excel抓取网页数据(爬虫的工作原理(一)_e操盘(图)
)
本质上,爬虫使用程序为我们在线获取有价值的数据。实际上,爬虫是用编程语言编写的程序。它的功能是从网络中获取有价值的数据。重要的是速度比手动获取数据要快。浏览器的工作原理
爬虫的工作原理其实就是把手动操作变成程序操作。
爬虫的工作步骤
(1)输入网址,发起请求,获取数据
(2)使用程序解析得到的数据
(3)从数据中提取想要的数据
(4)数据存储以供将来使用和分析
了解了爬虫的原理之后,我们一起来看看如何抓取数据?
import requests
from bs4 import BeautifulSoup
import openpyxl
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}#请求头,模拟浏览器行为进行操作。越过服务器的反爬
response=requests.get('https://movie.douban.com/',headers=header)#根据请求方法用get方法进行发送请求,并获得响应值。headers=header用关键字传参
#
# print('响应状态码',response.status_code)
# print(response.request.headers)#查看请求头
# print(response.text)#查看响应文本
bs=BeautifulSoup(response.text,'html.parser')#html.parser 解析html。
# print(type(bs))
# title=bs.find('td',class_='title')#查找单个电影
# print(title.text)#输出结果
# title=bs.find_all('td',class_='title')
list=[['编号','电影名称','地址']]#声明列表中的头
title=bs.find('div',class_='billboard-bd')#查找标签
all_titel=title.find_all('tr')#查找div'标签 属性为 class='billboard-bd' 下的所有的tr
for i in all_titel:#遍历查找符合条件的电影
myid=i.find('td',class_='order')#查找电影id
mytitle=i.find('td',class_='title')#查找电影名称
url=i.find('a')['href']#查找地址连接
# print( myid.text,mytitle.text,url)
# title1=i.find('td',class_='title')
list.append([myid.text,mytitle.text,url])#将数据添加到列表中
# print(list)
#*****************存储到excel表格中
wb=openpyxl.Workbook()#创建一个工作薄
sheet=wb.active#创建一个工作表
sheet.title='电影'#为sheet页起名
for i in list:
sheet.append(i)#将列表中的内容存储到文件
wb.save('films.xlsx')#保存电影
excel抓取网页数据(百度【举个栗子】windows系统网页数据教程_系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-17 19:03
excel抓取网页数据hello,大家好,
1、创建一个空word,然后复制到c盘,找到“excel_data”,
2、如下图的操作,找到“页码和页码大小”按钮,
3、在页码编辑界面,将公式栏的内容选中,
4、修改完,单击确定,设置完这些内容,
5、回到命令行,输入ctrl+f7,回车,就可以抓取网页数据了,如果不显示的话,把左边工具栏的工具都点击一下,然后单击就可以显示了ok,今天的分享就到这里,如果您想获取更多excel的操作技巧,如office、word、ppt等等问题的解决方法,请在下方评论区留言,或者在我的v信公众号:“张易talk”上留言,总有一个能帮到您。祝您工作顺利!。
百度【举个栗子】windows系统网页抓取教程_windows系统网页抓取教程免费看
手工分析。要学多久?——20分钟就够了。但学费成本极高。
win10环境上:excel选择数据源进行分析,数据抓取这些数据抓取是需要自己去打开数据源文件,多见于各大的手机app应用软件和自身app,所以一般我们一开始就需要安装对应的应用程序来进行数据抓取,不仅仅只是微信了,开通腾讯会员就可以获取微信号,然后可以通过关注公众号微信公众号或者微信号的菜单选择复制粘贴进行数据抓取。
常见的数据抓取有:百度搜索,京东购物,天猫购物,,抖音视频,这些在电脑上都可以直接用excel进行搜索,再打开即可。 查看全部
excel抓取网页数据(百度【举个栗子】windows系统网页数据教程_系统)
excel抓取网页数据hello,大家好,
1、创建一个空word,然后复制到c盘,找到“excel_data”,
2、如下图的操作,找到“页码和页码大小”按钮,
3、在页码编辑界面,将公式栏的内容选中,
4、修改完,单击确定,设置完这些内容,
5、回到命令行,输入ctrl+f7,回车,就可以抓取网页数据了,如果不显示的话,把左边工具栏的工具都点击一下,然后单击就可以显示了ok,今天的分享就到这里,如果您想获取更多excel的操作技巧,如office、word、ppt等等问题的解决方法,请在下方评论区留言,或者在我的v信公众号:“张易talk”上留言,总有一个能帮到您。祝您工作顺利!。
百度【举个栗子】windows系统网页抓取教程_windows系统网页抓取教程免费看
手工分析。要学多久?——20分钟就够了。但学费成本极高。
win10环境上:excel选择数据源进行分析,数据抓取这些数据抓取是需要自己去打开数据源文件,多见于各大的手机app应用软件和自身app,所以一般我们一开始就需要安装对应的应用程序来进行数据抓取,不仅仅只是微信了,开通腾讯会员就可以获取微信号,然后可以通过关注公众号微信公众号或者微信号的菜单选择复制粘贴进行数据抓取。
常见的数据抓取有:百度搜索,京东购物,天猫购物,,抖音视频,这些在电脑上都可以直接用excel进行搜索,再打开即可。
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2022-03-13 14:17
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论! 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:

首先新建一个Excel表格,打开数据,从网站,会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索

第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:

点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:

请看下面的图片

一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。

怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!
excel抓取网页数据(我对Google表格抓取了解不多我无法正确获取数据(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-12 18:20
)
用户名
我应该如何抓取这个页面,具体需要表中提到的ROE数?
我在 Excel 中使用了以下代码。我对 Google 表格抓取了解不多
Sub FetchData()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;https://www.bseindia.com/stock ... ot%3B, Destination:=Range( _
"$A$1"))
.Name = "www"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlEntirePage
.WebFormatting = xlWebFormattingNone
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
我无法正确获取数据。
有什么建议/帮助吗? ROE图是必须的,其余的不需要。
QHarr
使用页面可以更快地使用其 API。您可以使用 powerquery 来处理 json 响应、json 解析器或只是拆分。如果您想在按钮按下时刷新,请将代码放在标准模块中并链接到按钮。
Option Explicit
Public Sub GetInfo()
Dim s As String, ids(), i As Long
ids = Array(500820, 500312, 500325, 532540)
With CreateObject("MSXML2.XMLHTTP")
For i = LBound(ids) To UBound(ids)
.Open "GET", "https://api.bseindia.com/BseIn ... ot%3B & ids(i) & "&seriesid=", False
.send
s = .responseText
ActiveSheet.Cells(i + 1, 1) = Split(Split(s, """ROE"":""")(1), Chr$(34))(0)
Next
End With
End Sub 查看全部
excel抓取网页数据(我对Google表格抓取了解不多我无法正确获取数据(图)
)
用户名
我应该如何抓取这个页面,具体需要表中提到的ROE数?
我在 Excel 中使用了以下代码。我对 Google 表格抓取了解不多
Sub FetchData()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;https://www.bseindia.com/stock ... ot%3B, Destination:=Range( _
"$A$1"))
.Name = "www"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlEntirePage
.WebFormatting = xlWebFormattingNone
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
我无法正确获取数据。
有什么建议/帮助吗? ROE图是必须的,其余的不需要。
QHarr
使用页面可以更快地使用其 API。您可以使用 powerquery 来处理 json 响应、json 解析器或只是拆分。如果您想在按钮按下时刷新,请将代码放在标准模块中并链接到按钮。
Option Explicit
Public Sub GetInfo()
Dim s As String, ids(), i As Long
ids = Array(500820, 500312, 500325, 532540)
With CreateObject("MSXML2.XMLHTTP")
For i = LBound(ids) To UBound(ids)
.Open "GET", "https://api.bseindia.com/BseIn ... ot%3B & ids(i) & "&seriesid=", False
.send
s = .responseText
ActiveSheet.Cells(i + 1, 1) = Split(Split(s, """ROE"":""")(1), Chr$(34))(0)
Next
End With
End Sub
excel抓取网页数据(Excel抓取并查询网络可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2022-03-10 02:30
使用“获取和转换”+“查找参考功能”的功能组合可以实现Excel爬取和查询网络。
示例:下图是百科全书“奥运会”页面中的一个表格。我们以此为例,将表格抓取到Excel中,输入会话数即可查询对应主办城市的网页抓取数据。
Step1:使用“获取和转换”功能将网页数据抓取到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”网页数据抓取。
会弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定即可抓取网页数据。
将 Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。网页数据采集。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”网页抓取。
在弹出的窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载 Web 数据抓取”。
如图所示,网页表格中的数据已经被抓取到Excel中的网页数据抓取中。
依次点击“表格”、“设计”,将“表格名称”改为Olympic Web Data Capture。Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎。当场次发生变化时,相应的主办城市也会相应变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,则取网页数据,链接网页的数据可以设置为定期刷新:
①将鼠标放在导入数据区的网页数据采集上,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新网页数据采集。这样每 10 分钟就会刷新一次数据,并且始终保证获取到的数据位会被更新。
《江津Excel》是头条签名作者的网页数据采集,关注我,点击任意三篇文章文章,如果没有你要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
使用“获取和转换”+“查找参考功能”的功能组合可以实现Excel爬取和查询网络。
示例:下图是百科全书“奥运会”页面中的一个表格。我们以此为例,将表格抓取到Excel中,输入会话数即可查询对应主办城市的网页抓取数据。
Step1:使用“获取和转换”功能将网页数据抓取到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”网页数据抓取。
会弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定即可抓取网页数据。

将 Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。网页数据采集。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”网页抓取。
在弹出的窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载 Web 数据抓取”。
如图所示,网页表格中的数据已经被抓取到Excel中的网页数据抓取中。
依次点击“表格”、“设计”,将“表格名称”改为Olympic Web Data Capture。Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎。当场次发生变化时,相应的主办城市也会相应变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,则取网页数据,链接网页的数据可以设置为定期刷新:
①将鼠标放在导入数据区的网页数据采集上,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新网页数据采集。这样每 10 分钟就会刷新一次数据,并且始终保证获取到的数据位会被更新。
《江津Excel》是头条签名作者的网页数据采集,关注我,点击任意三篇文章文章,如果没有你要的知识,我就是流氓!
excel抓取网页数据( 如何在网络上抓取数据就一定要学Python,一定要去写代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-07 10:05
如何在网络上抓取数据就一定要学Python,一定要去写代码)
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的是选择坐船去,而不是想着造船去那里。
二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海上的一个小岛,我们也要求30分钟内有货送到岛上。
因此,前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。
也许Python这几年很火,我们经常会看到别人用Python做网络爬虫来爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实不然,本文介绍几个可以快速获取在线数据的工具。
01 微软 Excel
你没看错,Excel,办公室三剑客之一。 **Excel 是一个强大的工具,能够捕获数据是它的功能之一。 **我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
02 优采云采集器
优采云是爬虫行业的老字号,**是目前使用最多的互联网数据采集、处理、分析、挖掘软件。 **它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
因为学习门槛的关系,掌握了这个工具后,采集数据限制会很高。有时间和精力的同学可以去折腾。
官网地址:
03 优采云采集器
**优采云采集器对于初学者来说是一个很棒的采集器。 **简单易用,让您分分钟上手。 优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以具有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
04 GooSeeker 合集
Jisooke 也是一个易于使用的可视化采集 数据工具。它还可以抓取动态网页。还支持在手机网站上爬取数据,以及在指数图表上悬浮显示的爬取数据。 **Jisooke 以浏览器插件的形式采集数据。尽管它具有上述优点,但也有缺点。多线程采集数据是不可能的,浏览器死机是不可避免的。
网站:
05 Scrapinghub
如果你想抓取国外的 网站 数据,可以考虑 Scrapinghub。 Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。 Scrapehub 是市场上一个非常复杂且功能强大的网络抓取平台,提供数据抓取的解决方案提供商。
地址:
06 网络爬虫
WebScraper 是一款优秀的国外浏览器插件。 **也是适合初学者抓取数据的可视化工具。 **我们只是设置了一些抓取规则,让浏览器来做。
地址: 查看全部
excel抓取网页数据(
如何在网络上抓取数据就一定要学Python,一定要去写代码)

首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的是选择坐船去,而不是想着造船去那里。
二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海上的一个小岛,我们也要求30分钟内有货送到岛上。
因此,前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。
也许Python这几年很火,我们经常会看到别人用Python做网络爬虫来爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实不然,本文介绍几个可以快速获取在线数据的工具。
01 微软 Excel
你没看错,Excel,办公室三剑客之一。 **Excel 是一个强大的工具,能够捕获数据是它的功能之一。 **我用耳机作为关键词来抓取京东的产品列表。


几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
02 优采云采集器

优采云是爬虫行业的老字号,**是目前使用最多的互联网数据采集、处理、分析、挖掘软件。 **它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
因为学习门槛的关系,掌握了这个工具后,采集数据限制会很高。有时间和精力的同学可以去折腾。
官网地址:
03 优采云采集器

**优采云采集器对于初学者来说是一个很棒的采集器。 **简单易用,让您分分钟上手。 优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以具有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
04 GooSeeker 合集

Jisooke 也是一个易于使用的可视化采集 数据工具。它还可以抓取动态网页。还支持在手机网站上爬取数据,以及在指数图表上悬浮显示的爬取数据。 **Jisooke 以浏览器插件的形式采集数据。尽管它具有上述优点,但也有缺点。多线程采集数据是不可能的,浏览器死机是不可避免的。
网站:
05 Scrapinghub

如果你想抓取国外的 网站 数据,可以考虑 Scrapinghub。 Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。 Scrapehub 是市场上一个非常复杂且功能强大的网络抓取平台,提供数据抓取的解决方案提供商。
地址:
06 网络爬虫

WebScraper 是一款优秀的国外浏览器插件。 **也是适合初学者抓取数据的可视化工具。 **我们只是设置了一些抓取规则,让浏览器来做。
地址:
excel抓取网页数据(网页链接如何用Excel制作股票实时行情图制作实时股票行情图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2022-03-06 01:21
内容导航:
如何制作实时盘点股票的excel
找到具有实时股票价格的网站,然后按照以下步骤获取数据到EXCEL
导入成功后
设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以 VLOOKUP。
很简单,看图相信你已经知道了
你的问题和我之前做的实时汇率一样。请参考以下链接
如何使用 Excel 制作实时股市图表
制作实时股市图表应包括以下内容:1.股票数据表、2.股票价格图表、3.从网上实时下载数据的功能
第一步:制作数据表,数据——导入外部数据——新建WEB查询并写入数据源地址
第二步:制作股价图表,先用公式按照股价图表要求的顺序参照当前表格,然后插入图表-选股图表(类型4)调整图表
第三步:编写程序实现实时刷新功能,下面的程序可以复制到需要的位置
'在模块中编写如下程序段刷新行情表,“00:00:10”表示刷新时间间隔,可根据需要调整
暗淡结束标记
子刷新市场()
Sheets("每日数据").Range("A1").QueryTable.Refresh
背景查询:=假
Sheets("拆分数据").Range("A1").QueryTable.Refresh
背景查询:=假
如果结束标签
1 然后申请。现在准时 +
TimeValue("00:00:10"), "刷新报价"
结束子
子开始刷新()
结束标签 = 0
刷新报价
结束子
子结束刷新()
结束标签 = 1
结束子
'在此工作簿中编写以下代码以在打开表时启动市场刷新
私有子 Workbook_Open()
刷新报价
结束子
以上制作完成后,保存后打开表格,即可得到实用的股市走势图,并可获取实时数据进行数据分析
Excel 调用实时股票价格
1、先查一下股价表的地址。
2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。
3、为 EXCEL 表命名并保存。
4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。
5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数根据股票代码将自己的股票信息导入到查询表中,并设置收益计算等项目。
这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。
如何将股票数据导出到excel
打开要导入Excel的文本文档,查看数据,确认数据正确。
单击 Excel 中的“数据”选项卡,然后单击“获取外部数据”选项组中的“从文本”按钮。
在打开的“导入文本文件”对话框中查找并选择要导入的文本文件。
单击“导入”按钮,将文本文档中的数据导入 Excel 工作表。
在导入 Excel 之前,对文本文档中的数据进行进一步的编辑,使其具有 Excel 表格样式,这样更有利于数据的导入。 查看全部
excel抓取网页数据(网页链接如何用Excel制作股票实时行情图制作实时股票行情图)
内容导航:
如何制作实时盘点股票的excel
找到具有实时股票价格的网站,然后按照以下步骤获取数据到EXCEL
导入成功后
设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以 VLOOKUP。
很简单,看图相信你已经知道了
你的问题和我之前做的实时汇率一样。请参考以下链接
如何使用 Excel 制作实时股市图表
制作实时股市图表应包括以下内容:1.股票数据表、2.股票价格图表、3.从网上实时下载数据的功能
第一步:制作数据表,数据——导入外部数据——新建WEB查询并写入数据源地址
第二步:制作股价图表,先用公式按照股价图表要求的顺序参照当前表格,然后插入图表-选股图表(类型4)调整图表
第三步:编写程序实现实时刷新功能,下面的程序可以复制到需要的位置
'在模块中编写如下程序段刷新行情表,“00:00:10”表示刷新时间间隔,可根据需要调整
暗淡结束标记
子刷新市场()
Sheets("每日数据").Range("A1").QueryTable.Refresh
背景查询:=假
Sheets("拆分数据").Range("A1").QueryTable.Refresh
背景查询:=假
如果结束标签
1 然后申请。现在准时 +
TimeValue("00:00:10"), "刷新报价"
结束子
子开始刷新()
结束标签 = 0
刷新报价
结束子
子结束刷新()
结束标签 = 1
结束子
'在此工作簿中编写以下代码以在打开表时启动市场刷新
私有子 Workbook_Open()
刷新报价
结束子
以上制作完成后,保存后打开表格,即可得到实用的股市走势图,并可获取实时数据进行数据分析
Excel 调用实时股票价格
1、先查一下股价表的地址。
2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。
3、为 EXCEL 表命名并保存。
4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。
5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数根据股票代码将自己的股票信息导入到查询表中,并设置收益计算等项目。
这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。
如何将股票数据导出到excel
打开要导入Excel的文本文档,查看数据,确认数据正确。
单击 Excel 中的“数据”选项卡,然后单击“获取外部数据”选项组中的“从文本”按钮。
在打开的“导入文本文件”对话框中查找并选择要导入的文本文件。
单击“导入”按钮,将文本文档中的数据导入 Excel 工作表。
在导入 Excel 之前,对文本文档中的数据进行进一步的编辑,使其具有 Excel 表格样式,这样更有利于数据的导入。
excel抓取网页数据(彩票网站上面的数据一次性导入到Excel表中应该怎么做?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2022-04-12 13:30
导读:目前正在解读《如何获取网页数据(实时抓取网页数据分析)》的相关信息,《如何获取网页数据(实时网页数据分析)》为知识类内容发布由用户!下面请看(国外主机-)用户发布的《如何获取网页数据(实时爬取网页数据分析)》的详细说明。
有时为了在网上获取网站的数据,我们需要从各大网站下载我们需要的数据。我们以开奖数据为例,使用 Excel 从 网站 中快速获取我们需要的每张开奖数据的中奖数据。
如上图所示,我们需要一次性将彩票网站上的数据导入到Excel工作表中。让我们学习操作方法。
第 1 步:单击数据 - 源以选择 网站。在地址栏中输入网站数据源所在的URL,点击Go to,即可跳转到该URL所在的页面;
第二步:点击网页查询左上角的箭头符号,然后点击右下角的导入。这样我们就可以在Excel中添加我们需要的数据范围了,如下图:
第三步:导入数据时,选择工作表和添加数据的起始位置。如下图所示,我们数据的起始位置选择为单元格A1,点击确定。如下所示:
这样,一次性将所有数据导入到 Excel 表格中。由于数据量大,导入时需要耐心等待。
温馨提示:《如何获取网页数据(实时抓取网页数据分析)》最后刷新时间2022-04-05 01:32:57,本站为公益个人网站,仅供个人学习和记录信息,没有任何商业利润。如内容及图片资源无效或内容涉及侵权,请反馈至Email:我们会及时处理。本站只保证内容的可读性,但不能保证真实性。请鉴别“如何获取网页数据(实时抓取网页数据分析)”中内容的真实性。 查看全部
excel抓取网页数据(彩票网站上面的数据一次性导入到Excel表中应该怎么做?)
导读:目前正在解读《如何获取网页数据(实时抓取网页数据分析)》的相关信息,《如何获取网页数据(实时网页数据分析)》为知识类内容发布由用户!下面请看(国外主机-)用户发布的《如何获取网页数据(实时爬取网页数据分析)》的详细说明。
有时为了在网上获取网站的数据,我们需要从各大网站下载我们需要的数据。我们以开奖数据为例,使用 Excel 从 网站 中快速获取我们需要的每张开奖数据的中奖数据。
如上图所示,我们需要一次性将彩票网站上的数据导入到Excel工作表中。让我们学习操作方法。
第 1 步:单击数据 - 源以选择 网站。在地址栏中输入网站数据源所在的URL,点击Go to,即可跳转到该URL所在的页面;
第二步:点击网页查询左上角的箭头符号,然后点击右下角的导入。这样我们就可以在Excel中添加我们需要的数据范围了,如下图:
第三步:导入数据时,选择工作表和添加数据的起始位置。如下图所示,我们数据的起始位置选择为单元格A1,点击确定。如下所示:
这样,一次性将所有数据导入到 Excel 表格中。由于数据量大,导入时需要耐心等待。
温馨提示:《如何获取网页数据(实时抓取网页数据分析)》最后刷新时间2022-04-05 01:32:57,本站为公益个人网站,仅供个人学习和记录信息,没有任何商业利润。如内容及图片资源无效或内容涉及侵权,请反馈至Email:我们会及时处理。本站只保证内容的可读性,但不能保证真实性。请鉴别“如何获取网页数据(实时抓取网页数据分析)”中内容的真实性。
excel抓取网页数据(Python从抓包工具charles获取表格的相关方法介绍~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-12 07:36
01 焦点
在自动化测试的过程中,经常需要使用excel文件来存储测试用例,那么在设计好表中的测试用例数据之后,如何通过自动化读取呢?此时就需要测试小姐姐写“代码”了~
本文主要介绍如何通过python读取表格数据。Python中读取表格的方式大概有3种(如下图)。本文重点介绍使用xlrd模块读取excel数据。
读取excel文件,掌握以下结果:
读表的相关方法描述如下:
02 抓包获取接口数据
在自动化接口时,接口文档通常在公司内部开发中维护。测试人员可以从文档中获取接口相关信息,也可以使用抓包工具获取接口信息。
本文的案例比较简单,从抓包中获取数据。当然,如果真的要进行接口自动化测试,还需要开发并提供详细的接口数据,不仅包括请求地址、输入参数,还包括每个输入参数对应的值。,以及接口成功状态标志。
1、获取接口请求的基本数据
使用抓包工具charles获取需要自动化测试的接口
有两条信息,一条是请求地址url,一条是请求头
(请求头的含义可以自行百度,这里就不过多解释了)
接口请求的常用方法是post和get。本例中的请求使用 post 方法。
2、获取接口请求的输入参数数据
在抓包工具上,切换到Request页面,可以看到输入的数据,如下图:
获取信息:
{
"loginId": "***",
"password": "***"
}
1234
从上面的数据可以看出,接口的输入参数是以字典的形式传递的,key=loginId,对应的value=””(这里代表用户的用户名~由于个人隐私的问题,使用编号代替 )
03 设计测试用例
用例存储在 Excel 表中。第一行是参数,第二行以输入参数的值开头,第一列是用例的标题,如下:
获取信息:
(本文中的测试用例只是示例,在实际测试过程中,肯定不止这两个用例)
04 Python脚本
从抓包工具charles捕获的数据中,我们需要获取两种数据:
时间戳脚本
13位时间戳脚本的Python实现如下:
阅读测试用例脚本
通过抓包数据可以看到输入的数据是字典的形式,一个key对应一个value。
因此,接口测试用例的脚本设计分为三个部分:
1、将参与测试数据的请求输入构造成字典形式
如下图:一个组合的输入参数+测试数据相当于一个用例
2、 将每个用例与用例标题组合成字典形式
如下图: 后面可以根据用例的标题获取用例的内容(输入参数+测试数据)。
3、 会通过用例标题读取测试用例
(高温提醒:最后真的不会再打代码了,直接更新表格用例,直接运行脚本) 查看全部
excel抓取网页数据(Python从抓包工具charles获取表格的相关方法介绍~)
01 焦点
在自动化测试的过程中,经常需要使用excel文件来存储测试用例,那么在设计好表中的测试用例数据之后,如何通过自动化读取呢?此时就需要测试小姐姐写“代码”了~
本文主要介绍如何通过python读取表格数据。Python中读取表格的方式大概有3种(如下图)。本文重点介绍使用xlrd模块读取excel数据。
读取excel文件,掌握以下结果:
读表的相关方法描述如下:
02 抓包获取接口数据
在自动化接口时,接口文档通常在公司内部开发中维护。测试人员可以从文档中获取接口相关信息,也可以使用抓包工具获取接口信息。
本文的案例比较简单,从抓包中获取数据。当然,如果真的要进行接口自动化测试,还需要开发并提供详细的接口数据,不仅包括请求地址、输入参数,还包括每个输入参数对应的值。,以及接口成功状态标志。
1、获取接口请求的基本数据
使用抓包工具charles获取需要自动化测试的接口
有两条信息,一条是请求地址url,一条是请求头
(请求头的含义可以自行百度,这里就不过多解释了)
接口请求的常用方法是post和get。本例中的请求使用 post 方法。
2、获取接口请求的输入参数数据
在抓包工具上,切换到Request页面,可以看到输入的数据,如下图:
获取信息:
{
"loginId": "***",
"password": "***"
}
1234
从上面的数据可以看出,接口的输入参数是以字典的形式传递的,key=loginId,对应的value=””(这里代表用户的用户名~由于个人隐私的问题,使用编号代替 )
03 设计测试用例
用例存储在 Excel 表中。第一行是参数,第二行以输入参数的值开头,第一列是用例的标题,如下:
获取信息:
(本文中的测试用例只是示例,在实际测试过程中,肯定不止这两个用例)
04 Python脚本
从抓包工具charles捕获的数据中,我们需要获取两种数据:
时间戳脚本
13位时间戳脚本的Python实现如下:
阅读测试用例脚本
通过抓包数据可以看到输入的数据是字典的形式,一个key对应一个value。
因此,接口测试用例的脚本设计分为三个部分:
1、将参与测试数据的请求输入构造成字典形式
如下图:一个组合的输入参数+测试数据相当于一个用例
2、 将每个用例与用例标题组合成字典形式
如下图: 后面可以根据用例的标题获取用例的内容(输入参数+测试数据)。
3、 会通过用例标题读取测试用例
(高温提醒:最后真的不会再打代码了,直接更新表格用例,直接运行脚本)
excel抓取网页数据( 如何将网页中的数据刮到Excel中?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2022-04-11 15:01
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,那么加上经验公式,计算出一些从抓取的数据中得出的最终结果,比如 想法不错。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上述 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”,这样您就不会复制文件中的数据,并直接在数据透视表等位置进行名称连接。
第 7 步:刷新数据。要从网页获取更新,只需转到功能区的外部数据选项卡,然后单击全部刷新:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query网站限制
正如我前面提到的,PowerQuery 非常擅长从 WEB 获取数据,它被格式化为 HTML 表格,而不是使用 JavaScript 生成的表格。通过检查网页源代码并查找 HTML 表格标记,您可以轻松判断表格是 HTML 还是 JavaScript。
为此,在网页上的一些空白处右键单击>查看页面源(或类似的,取决于您使用的浏览器,我使用Windows 10系统附带的浏览器,而不是互联网的先前版本)探险家):
CTRL + F 打开查找对话框。进入”
如果找到HTML table标签,就确认power Query可以从页面中获取到一个表,但是不能保证就是你真正需要的那个表,因为页面上可能还有其他的表,所以可以使用我之前谈到的表进行选择。
关于电源查询的更多功能将在后面解释。
Power Query 可以从无数地方获取数据,并具有大量用于排序和转换数据的工具。我之前已经介绍过一些,例如:
合并 Excel 工作表
从文件夹中获取文件
当然,后面会有更多的介绍
以上就是我们所说的使用power Query做网络爬取。当然,如果你的数据是从网络上爬出来的,VBA也是一个不错的方法。而且灵活性非常高,通过变量进行多次数据爬取。.
视频:
如果你有时觉得我的视频在记录或分类中找不到,可以转发到自己的朋友圈,供自己采集。 查看全部
excel抓取网页数据(
如何将网页中的数据刮到Excel中?(组图))
一个问题经常被讨论;“如何将网页中的数据抓取到 Excel 中?”
使用 POWER QUERY 从网络获取数据
使用 Power Query 从 Web 获取数据的能力非常方便。Power Query在大家不知道VBA的时候可以这样用,但是如果你知道VBA,其实还是很方便的,主要看大家的选择和喜好。
从互联网捕获的数据也可以实时更新。在这种情况下,如果你有一些从网上抓取的完整数据集,那么加上经验公式,计算出一些从抓取的数据中得出的最终结果,比如 想法不错。我经常这样做。
当前的 Power Query 限制只能以 HTML 格式的网表格式进行查询。一些网页使用 JavaScript 生成表格,本教程不涉及。
我们以网易的股票为例:
当然,如果你打开这个网页,你也会发现右上角会出现文件下载。您也可以选择下载文件并保存以进行数据分析,但这会有点麻烦。我们直接把这个网络数据表和我们的EXCEL建立链接,如果你有每天看股票的习惯,只要点击下方的更新按钮,就可以更新最新的股价情况。
注意:在撰写本文时,上述 URL 提供了本示例中使用的数据,但此页面的布局和内容超出了我的控制范围,我们可以在链接后进行一些格式调整。
如何使用 Power Query 从 Web 获取数据
第 1 步:复制收录表格的网页的 URL。我在用
第 2 步:Excel 2016 – 数据选项卡 > 来自网络
Excel 2013及更早版本-“Power Query”选项卡>从Web导入,因为我目前使用的是2016,所以如果您使用的是之前的版本,请自行查找。
注意:如果您在 excel 2010 或 2013 中看不到“Power Query”选项卡,您可以前往相关的网站下载。
第 3 步:将 URL 粘贴到“来自网络”对话框中,然后单击“确定”:
第 4 步:在“导航器”对话框(如下)中,左侧窗格提供网页中可用的表格列表。
第一项“文档”收录页面的 HTML 代码,因此对我们没有任何用处,但其余表收录您可以通过 Power Query 获取的数据表。请记住,它只会显示使用 HTML 表格标签生成的表格。
选择你要的表,类似下图,我们需要表1
也可以进入WEB视图看看下面的对比,下表是否是你需要找的。
技能:
1.点击对话框右上角的全屏图标可以全屏查看导航对话框。
2.如果要导入多个表,请选中左侧窗格中的“选择多个项目”框。
第 5 步:选择要导入的表后,单击“转换数据”按钮。这将打开 Power Query 编辑器窗口,让您有机会在将数据加载到 Excel 或 Power Pivot 数据模型之前整理数据。
清理数据后,可以将其加载到 Excel 或 Power Pivot 数据模型中。
第 6 步:“主页”选项卡 >“关闭并加载到”:
导入数据对话框将打开:
提示:如果将其加载到数据模型中,请务必选择“仅创建连接”,这样您就不会复制文件中的数据,并直接在数据透视表等位置进行名称连接。
第 7 步:刷新数据。要从网页获取更新,只需转到功能区的外部数据选项卡,然后单击全部刷新:
或者,如果您有多个查询,您可以打开查询和连接窗格:
Power Query网站限制
正如我前面提到的,PowerQuery 非常擅长从 WEB 获取数据,它被格式化为 HTML 表格,而不是使用 JavaScript 生成的表格。通过检查网页源代码并查找 HTML 表格标记,您可以轻松判断表格是 HTML 还是 JavaScript。
为此,在网页上的一些空白处右键单击>查看页面源(或类似的,取决于您使用的浏览器,我使用Windows 10系统附带的浏览器,而不是互联网的先前版本)探险家):
CTRL + F 打开查找对话框。进入”
如果找到HTML table标签,就确认power Query可以从页面中获取到一个表,但是不能保证就是你真正需要的那个表,因为页面上可能还有其他的表,所以可以使用我之前谈到的表进行选择。
关于电源查询的更多功能将在后面解释。
Power Query 可以从无数地方获取数据,并具有大量用于排序和转换数据的工具。我之前已经介绍过一些,例如:
合并 Excel 工作表
从文件夹中获取文件
当然,后面会有更多的介绍
以上就是我们所说的使用power Query做网络爬取。当然,如果你的数据是从网络上爬出来的,VBA也是一个不错的方法。而且灵活性非常高,通过变量进行多次数据爬取。.
视频:
如果你有时觉得我的视频在记录或分类中找不到,可以转发到自己的朋友圈,供自己采集。
excel抓取网页数据(156个Python网络爬虫资源(2.2三种网页)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-04-09 00:20
阿里云 > 云栖社区 > 主题地图 > E > Excel网络爬虫
推荐活动:
更多优惠>
当前话题: Excel 网络爬虫 添加到采集夹
相关话题:
excel网络爬虫相关的博客看更多博客
什么是网络爬虫,网络爬虫有什么用?
作者:幸运券发行2426人查看评论:03年前
什么是网络爬虫,网络爬虫有什么用?简单来说,就是通过非人为的方式获取网页上显示的数据。现在是大数据时代,数据分析是解决各行各业相关问题的重要依据。数据分析结果的准确性很大程度上取决于数据量是否足够大。如果是几十条数据,我们当然可以让人一一复制粘贴
阅读全文
156个Python网络爬虫资源,GitHub上awesome系列的Python爬虫工具
作者:马达达 12379 浏览评论:04年前
项目地址:lorien/awesome-web-scraping GitHub上awesome系列的Python爬虫工具。此列表收录 Python Web 抓取和数据处理相关库。网络相关通用 urllib - 网络库(标准库)请求 - 网络库
阅读全文
156个Python爬虫资源,妈妈再也不用担心找不到资源了
作者:燕衡5808 浏览评论:13年前
此列表收录 Python Web 抓取和数据处理相关库。前几天私信给编辑索要Python学习资料。小编整理了一些深入的Python教程和参考资料,从初级到高级。文件已打包。正在学习Python的同学可以下载学习。文件下载方式:在群文件中下载:7
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节书摘自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多内容章节可访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们已经了解了网页的结构,以下
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
如何开始编写你的第一个 python 脚本 - Simple Crawler 入门!
作者:云飞学习编程999人评论:03年前
很多朋友在开始接触python的时候都是从爬虫开始的,而网络爬虫是近几年流行的概念,尤其是大数据分析大行其道之后,越来越多的人在学习网络爬虫,哦对了,现在叫Data Mined!其实一般爬虫有两个功能:取数据和存储数据
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
23 Python爬虫开源项目代码
作者:hank_leo4651 浏览评论:13年前
今天为大家整理了23个Python爬虫项目。整理的原因是爬虫入门简单快速,也很适合新手培养信心。所有链接都指向GitHub,祝你玩的开心1、微信搜狗[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫界面可扩展为
阅读全文 查看全部
excel抓取网页数据(156个Python网络爬虫资源(2.2三种网页)(组图))
阿里云 > 云栖社区 > 主题地图 > E > Excel网络爬虫
推荐活动:
更多优惠>
当前话题: Excel 网络爬虫 添加到采集夹
相关话题:
excel网络爬虫相关的博客看更多博客
什么是网络爬虫,网络爬虫有什么用?
作者:幸运券发行2426人查看评论:03年前
什么是网络爬虫,网络爬虫有什么用?简单来说,就是通过非人为的方式获取网页上显示的数据。现在是大数据时代,数据分析是解决各行各业相关问题的重要依据。数据分析结果的准确性很大程度上取决于数据量是否足够大。如果是几十条数据,我们当然可以让人一一复制粘贴
阅读全文
156个Python网络爬虫资源,GitHub上awesome系列的Python爬虫工具
作者:马达达 12379 浏览评论:04年前
项目地址:lorien/awesome-web-scraping GitHub上awesome系列的Python爬虫工具。此列表收录 Python Web 抓取和数据处理相关库。网络相关通用 urllib - 网络库(标准库)请求 - 网络库
阅读全文
156个Python爬虫资源,妈妈再也不用担心找不到资源了
作者:燕衡5808 浏览评论:13年前
此列表收录 Python Web 抓取和数据处理相关库。前几天私信给编辑索要Python学习资料。小编整理了一些深入的Python教程和参考资料,从初级到高级。文件已打包。正在学习Python的同学可以下载学习。文件下载方式:在群文件中下载:7
阅读全文
《用 Python 编写网络爬虫》——2.2 三种网络爬虫方法
作者:异步社区 3748人查看评论:04年前
本节书摘自异步社区《Writing Web Crawler in Python》一书第2章第2.2节,作者【澳大利亚】Richard Lawson,李斌翻译,更多内容章节可访问云栖社区“异步社区”公众号查看。2.2 三种网页抓取方式 既然我们已经了解了网页的结构,以下
阅读全文
开源爬虫软件总结
作者:club1111683 浏览评论:07年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
如何开始编写你的第一个 python 脚本 - Simple Crawler 入门!
作者:云飞学习编程999人评论:03年前
很多朋友在开始接触python的时候都是从爬虫开始的,而网络爬虫是近几年流行的概念,尤其是大数据分析大行其道之后,越来越多的人在学习网络爬虫,哦对了,现在叫Data Mined!其实一般爬虫有两个功能:取数据和存储数据
阅读全文
开源爬虫软件总结
作者:五峰之巅 1426 浏览评论:08年前
世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作一个
阅读全文
23 Python爬虫开源项目代码
作者:hank_leo4651 浏览评论:13年前
今天为大家整理了23个Python爬虫项目。整理的原因是爬虫入门简单快速,也很适合新手培养信心。所有链接都指向GitHub,祝你玩的开心1、微信搜狗[1]-微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫界面可扩展为
阅读全文
excel抓取网页数据( 按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-09 00:18
按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))
按键精灵操作界面
按键精灵录音界面
使用按钮向导进行票价定价时选择出发和目的地界面
使用按钮向导进行票价定价时,通过Js脚本查看出发和目的地界面。
■ 赵梅
利用按钮向导实现对网络大数据的直接采集,该技术操作简单,应用范围广。可应用于消费价格、工业生产者价格等统计调查。这是一种方便的数据采集方法。在实际应用中,灵活使用按钮向导的三种技巧。
- 通过 URL 中的参数控制抓取内容。数据展示网页通常根据数据的逻辑结构,通过设置网页参数来组织数据展示。比如某航空公司网站广州到厦门机票预订网站1月30日,问号后面的“c1=CAN&c2=XMN&d1=2021-01-30”是网页参数,CAN代表广州是出发点参数,XMN代表厦门,是目的地参数,d1的值控制预订日期。通过改变参数的值,你可以抓取你想要的不同内容。特别是当网页的数据量很大,使用分页页数参数将数据分布在不同的页面上时,
- 与 Excel 结合使用。Excel具有结构化存储、函数式表达、方便友好的数据显示和编辑功能等优点,可以实现很多数据处理功能;同时,Excel VBA具有非常强大的办公自动化功能。因此,Button Wizard和Excel结合使用可以更灵活地实现更丰富的数据自动处理。例如,使用 Excel 保存按钮向导的输入参数和输出数据。使用Excel数据表,可以实现输入参数和输出数据的结构化存储,使数据结构一目了然,方便程序实现行列式调用。再例如,使用 Excel 函数进行输入和输出数据处理。在抢机票的情况下,在 Excel 参数单元格中引入 TODAY() 函数,以根据当天捕获机票信息。在使用按钮向导时,经常需要引入随机数,这可以通过读取 RAND() 函数单元格的值来实现。Excel丰富的功能系统大大降低了按钮向导编程中访问功能的工作复杂度。
- 与浏览器前端开发工具结合使用。使用按钮向导抓取网页数据元素时,往往需要与网页交互,提交数据选择条件,才能获取数据。例如订票网站,不能通过修改参数来确定出发地和目的地,只能通过网页上的复选框来选择出发地和目的地。当需要与网页交互访问数据时,可以使用浏览器前端开发平台加载JavaScript脚本实现数据获取。JavaScript脚本是网页常用的开发工具,具有丰富的网页交互功能。打开浏览器浏览网页,按F12键进入浏览器前端开发平台,选择“控制台”,在控制台界面,使用按钮向导输入编写的与网页交互的JavaScript脚本,即可轻松实现数据交互访问。按钮精灵调用JavaScript脚本实现丰富的浏览器网页交互,大大增强了按钮精灵处理网页信息的能力,避免了按钮精灵模拟时由于网页元素在不同网页上位移而导致的定位不准问题网页交互。 查看全部
excel抓取网页数据(
按键精灵操作界面按键精灵录制界面使用按键精灵开展票价采价时(组图))
按键精灵操作界面
按键精灵录音界面
使用按钮向导进行票价定价时选择出发和目的地界面
使用按钮向导进行票价定价时,通过Js脚本查看出发和目的地界面。
■ 赵梅
利用按钮向导实现对网络大数据的直接采集,该技术操作简单,应用范围广。可应用于消费价格、工业生产者价格等统计调查。这是一种方便的数据采集方法。在实际应用中,灵活使用按钮向导的三种技巧。
- 通过 URL 中的参数控制抓取内容。数据展示网页通常根据数据的逻辑结构,通过设置网页参数来组织数据展示。比如某航空公司网站广州到厦门机票预订网站1月30日,问号后面的“c1=CAN&c2=XMN&d1=2021-01-30”是网页参数,CAN代表广州是出发点参数,XMN代表厦门,是目的地参数,d1的值控制预订日期。通过改变参数的值,你可以抓取你想要的不同内容。特别是当网页的数据量很大,使用分页页数参数将数据分布在不同的页面上时,
- 与 Excel 结合使用。Excel具有结构化存储、函数式表达、方便友好的数据显示和编辑功能等优点,可以实现很多数据处理功能;同时,Excel VBA具有非常强大的办公自动化功能。因此,Button Wizard和Excel结合使用可以更灵活地实现更丰富的数据自动处理。例如,使用 Excel 保存按钮向导的输入参数和输出数据。使用Excel数据表,可以实现输入参数和输出数据的结构化存储,使数据结构一目了然,方便程序实现行列式调用。再例如,使用 Excel 函数进行输入和输出数据处理。在抢机票的情况下,在 Excel 参数单元格中引入 TODAY() 函数,以根据当天捕获机票信息。在使用按钮向导时,经常需要引入随机数,这可以通过读取 RAND() 函数单元格的值来实现。Excel丰富的功能系统大大降低了按钮向导编程中访问功能的工作复杂度。
- 与浏览器前端开发工具结合使用。使用按钮向导抓取网页数据元素时,往往需要与网页交互,提交数据选择条件,才能获取数据。例如订票网站,不能通过修改参数来确定出发地和目的地,只能通过网页上的复选框来选择出发地和目的地。当需要与网页交互访问数据时,可以使用浏览器前端开发平台加载JavaScript脚本实现数据获取。JavaScript脚本是网页常用的开发工具,具有丰富的网页交互功能。打开浏览器浏览网页,按F12键进入浏览器前端开发平台,选择“控制台”,在控制台界面,使用按钮向导输入编写的与网页交互的JavaScript脚本,即可轻松实现数据交互访问。按钮精灵调用JavaScript脚本实现丰富的浏览器网页交互,大大增强了按钮精灵处理网页信息的能力,避免了按钮精灵模拟时由于网页元素在不同网页上位移而导致的定位不准问题网页交互。
excel抓取网页数据( 什么是PowerBI?(图)的优势(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-04-09 00:17
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但在实际使用中你会发现很多困难。微软旗下的另一款软件Power BI在这个时候就表现出了无与伦比的优势。它是什么,让我们来看看吧。”看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗? 查看全部
excel抓取网页数据(
什么是PowerBI?(图)的优势(组图))
“火箭先生曾经介绍过使用Excel直接从网页下载数据,但在实际使用中你会发现很多困难。微软旗下的另一款软件Power BI在这个时候就表现出了无与伦比的优势。它是什么,让我们来看看吧。”看看文章!
什么是 Power BI?
可能有些朋友对这个工具比较陌生。按照微软官方的定义,PowerBI就是这样一款产品:
Power BI 是软件服务、应用程序和连接器的集合,它们协同工作以将相关数据源转换为连贯、视觉逼真的交互式见解。无论用户的数据是简单的 Excel 电子表格,还是基于云的混合数据仓库和本地数据仓库的集合,Power BI 都可以让用户轻松连接到数据源、可视化(或发现)什么是重要的,并与任何想要的连接人们分享。
它是一个集成工具,体现了微软在企业端进行企业数字化转型的尝试。不过,天生的好工具并不局限于企业业务场景,Power BI也可以供我们个人使用。
例如……
抢豆瓣“最受关注书单”
如果我们要抓取豆瓣阅读页面“最受关注书榜”的相关信息():
那么我们就可以毫不犹豫地使用这个 Power BI 工具了。
>>>第一步
在Power BI主界面中,分别选择“获取数据”->“Web”。
>>>第二步
在弹窗复制豆瓣地址()并确认
>>>第三步
此时会弹出另一个导航器,选择“Add Table Using Example”。
>>>第四步
这时可以看到再次弹出的窗口由两部分组成:上半部分是浏览器,下半部分是类似Excel表格的界面。这时候只需要给出列的标题,选择前1或2个需要抓取的数据内容,比如《生命之海》和《皮肤的秘密》这两个标题",然后按 Enter。Power BI 将自动为你填充网页中相同的所有其他元素类型。
以此类推,即可完成评分、作者等的爬取。
按 OK 按钮结束内容抓取。
>>>步骤 5
加载数据抓取后,我们可以在数据视图中看到所有内容。
如果您说,“好吧,我仍然想使用 Excel 来最终处理或保存这些数据”,那很好。只需右键单击右侧工具栏中的表格,然后从弹出菜单中选择“复制表格”。这样您就可以安全地将数据保存到 Excel。
你学会了吗?
excel抓取网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-06 14:32
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天,我们来做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓住
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
查看全部
excel抓取网页数据(共有5800家网贷平台暴雷问题平台数据测试(组图)
)
网贷平台经常出现雷雨天气。截至2019年12月,共有5800家网贷平台出现问题,其中一半以上失联,只有5.84%的平台有警方介入。
今天,我们来做一个问题平台的数据采集测试。有很多网站提供在线贷款数据查询服务:
这个网站的数据不错,图表也很漂亮。下图是问题平台的数据表:
默认页面提供前 20 条数据。点击下方的load more会添加20条数据,其实就是一个查询按钮。然后我们开始Power Query网页爬取的步骤。
网站分析
F12打开谷歌浏览器的检查页面,按CTRL+R重新加载,点击加载更多,会出现新的一行查询:
通过预览可以看到对应的JSON数据,我们来加载更多数据:
页码页面从2变为3,共5800个平台,将有290个页面。
我们看一下网址:
这应该是一个带有查询页码的真实 URL。至此,我们的网站分析基本结束。
试着抓
试抓流程是为了验证我们的网站分析流程是否正确。在分析过程中,我们注意到网站的数据传输方式是POST。首先,不管是POST还是GET,我们直接用整个字符串抓取URL试试看:
貌似不能直接取,也不存在表。
别着急,我们来看看web视图的内容:
看起来是乱码,但是仔细观察数据的结构,貌似是标准的json结构,应该是我们需要的数据,其实是url编码的数据。让我们尝试用 JSON 解析这些数据:
果然。展开数据:
这是我们需要的数据,试验捕获过程已经结束。
定义函数
根据试捕查询流程创建函数:
添加页码参数p,因为页码是一个数值,我们使用一个Text.From函数将数值转换为文本并用&连接:
这样就定义了单页数据抓取功能。
抓住
有了函数抓取,很简单,使用 List.Transfrom 函数遍历抓取:
一共抓取290行,然后展开数据:
通过4个步骤,我们捕获了问题平台的所有数据。
然后您可以使用捕获的数据进行自己的可视化:
excel抓取网页数据(Excel表格怎么链接网站上的数据?》一文中有阐述)
网站优化 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-04-02 19:06
谢谢!网页数据爬取有两种方式:Excel不定时爬取网页数据;电源查询插件不定时爬取数据。
001 Excel时不时抓取数据
关于Excel不定时爬取的网页数据,我在《如何链接Excel表格网站上的数据?》一文中有详细介绍,可以点这里查看
我将在这里简单地教你这个方法:
002 Power Query不定时抓取数据
这是一种更强大的获取网页数据的方式。这里我将详细解释如何使用 Power Query 插件来爬取数据。
步骤 1:首先确保您的 Excel 已经有 Power Query
如果你是 Excel 2016,那么恭喜你,你什么都不用做,Excel 本身就有一个 Power Query 组件;如果你是2010或者2013,需要从微软官网下载();如果您是 Excel 的第一个版本,那么不,抱歉,此方法不适合您。
好的,现在假设您已经拥有 Power Query 组件,让我们继续下一步。
步骤 2:从 Power Query 创建一个新查询
点击【数据】→【新建查询】→【来自其他来源】→【来自网站】,如图。
在弹出的界面中,输入需要抓取数据的URL。有两种模式:[基本]和[高级]。我们只需要简单的抓取数据,使用【Basic】模式即可。
步骤 3:编辑获得的数据
在导航器中,网页中存在的数据表显示在左侧,Document中的函数是一些表头信息。不着急,选择左边的Table0,右边的预览就可以看到数据了。
然后点击【编辑】
然后会弹出【查询编辑器】界面。在这个界面中,您可以对获取的数据进行丰富的清洗动作。功能远比Excel强大,如合并、转置、删除等,可以删除不需要的数据。
Step4:将获取的数据上传到Excel
如图,点击【关闭并上传】→【关闭并上传】,然后将数据上传到我们打开的excel中。
Power Query 捕获的数据更有条理,更易于后续分析。你学会了吗?
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel表格怎么链接网站上的数据?》一文中有阐述)
谢谢!网页数据爬取有两种方式:Excel不定时爬取网页数据;电源查询插件不定时爬取数据。
001 Excel时不时抓取数据
关于Excel不定时爬取的网页数据,我在《如何链接Excel表格网站上的数据?》一文中有详细介绍,可以点这里查看
我将在这里简单地教你这个方法:
002 Power Query不定时抓取数据
这是一种更强大的获取网页数据的方式。这里我将详细解释如何使用 Power Query 插件来爬取数据。
步骤 1:首先确保您的 Excel 已经有 Power Query
如果你是 Excel 2016,那么恭喜你,你什么都不用做,Excel 本身就有一个 Power Query 组件;如果你是2010或者2013,需要从微软官网下载();如果您是 Excel 的第一个版本,那么不,抱歉,此方法不适合您。
好的,现在假设您已经拥有 Power Query 组件,让我们继续下一步。
步骤 2:从 Power Query 创建一个新查询
点击【数据】→【新建查询】→【来自其他来源】→【来自网站】,如图。
在弹出的界面中,输入需要抓取数据的URL。有两种模式:[基本]和[高级]。我们只需要简单的抓取数据,使用【Basic】模式即可。
步骤 3:编辑获得的数据
在导航器中,网页中存在的数据表显示在左侧,Document中的函数是一些表头信息。不着急,选择左边的Table0,右边的预览就可以看到数据了。
然后点击【编辑】
然后会弹出【查询编辑器】界面。在这个界面中,您可以对获取的数据进行丰富的清洗动作。功能远比Excel强大,如合并、转置、删除等,可以删除不需要的数据。
Step4:将获取的数据上传到Excel
如图,点击【关闭并上传】→【关闭并上传】,然后将数据上传到我们打开的excel中。
Power Query 捕获的数据更有条理,更易于后续分析。你学会了吗?
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-04-02 12:16
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓握,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。 查看全部
excel抓取网页数据(PowerQuery可以用来抓取股票页数,就是要注意几个细节)
女神节股市非常不稳定,可以下载数据留作纪念。Power Query 可以用来抓取股票信息,只需要注意几个细节:
先找到你需要的数据的网站,证券之星、同花顺、东方财富、新浪财经等。很多网站都有市场中心,提供当天和历史的股市信息信息查询。这个信息是公开的,可以匿名访问下载,但是有个问题,网站会有反爬机制,如果访问太频繁,就会断开连接,或者抓到太多数据一时间,它也会被封锁。断开。
接下来就是看看哪些网站可以被抓到,哪些不能被抓?
第一类:提供特定网页静态网址的可以被爬取
第二种:地址栏只提供主站地址,但可以找到具体页面的URL。
张二种url应该是可以爬到的,有些第二类不行,因为下面的Request中收录了网站发出的随机码,没有任何规则是爬不出来的。
还有如何延迟抓握,模仿人类速度
Power Query 提供了一个 M 函数 Function.InvokeAfter 可以延迟程序的运行。这个函数有两个参数。它前面是一个函数,后面是一个延迟间隔。
该函数的用法与其他函数略有不同:
在函数中,你需要使用“=>”来翻转它。右下角刷新时会有明显的延迟。
在爬取过程中使用这个函数,这样写
最后,当页面数量较多时,需要单独爬取
我测试了几个网站。爬取信息时,如果页面过多,则会被拒绝。一般来说,30页左右,应该可以接受。也可以根据实际情况自己试一试。
这是一个爬取 5 个页面的示例。所有A股股票市场信息超过2700行。如果每页有 20 行,就会有 100 多页。分5次,刮即可。
最好将抓取到的信息转移到本地文件中,否则刷新数据会很慢,很容易被网站拒绝访问。上图是我3月8日截取的A股股票信息,导入Power BI的可视化图表。
excel抓取网页数据(就是使用Excel2013自带的工具--从网页获取数据Excel来分析的话 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2022-04-02 04:27
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,在这里你会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
查看全部
excel抓取网页数据(就是使用Excel2013自带的工具--从网页获取数据Excel来分析的话
)
核心提示:很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?
很多时候,一些数据来自网页。如果我们要采集网页数据并用Excel进行分析,是否需要将网页上的数据一一输入到Excel中?其实有一个很方便的方法,那就是使用Excel 2013自带的工具---从网页获取数据,不仅可以快速获取数据,还可以与网页内容同步更新。下面是详细的操作方法。
1、首先打开Excel,点击菜单栏:Data--From网站。
2、你会看到一个查询对话框打开,在这里你会自动打开你的ie主页,在地址栏中输入你想要的URL,然后点击Go。
我们看到打开了一个网页。如果我们要导入这个表数据,我们看下面第二张图,点击左上角的黄色按钮。选择表格后,黄色按钮变为绿色。
3、然后点击导入按钮,你会看到下图第二张,稍等几秒。
4、打开一个对话框,提示你把数据放在哪里,点击确定导入数据。
5、也可以点击属性设置导入,如图。在下面的第二张图中,如果你设置了刷新频率,你会看到Excel表格中的数据可以根据网页的数据进行处理。更新,是不是很强大。
6、好的,这是我们导入的数据。现在Excel 2013是不是很强大了,哈哈,赶紧装个Office 2013,然后试试它强大的功能。
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-03-31 09:25
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08个会话”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-03-27 09:28
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。 查看全部
excel抓取网页数据(携程旅行网页搜索营销部孙波在孙波在《首届百度站长交流会》)
昨天看到一个QQ交流群的新手问,如何简单分析网站的日志,清楚的知道网站的数据抓取情况,哪些目录比较好抓取,哪些IP在那里。分段蜘蛛爬行等
一个网站要想发展得更快、走得更远,离不开一个日常的数据分析,正如携程网搜索营销部孙波在“首届百度站长交流会”上所说,在使用数据模型后改版渠道,今年被收录的网页数从原来的几十万增加到500万以上。由此可见数据分析的重要性。
说到日常的网站日志分析,这里我强调需要用到两个工具:Excel和Lightyear Log Analysis Tool。可能还有朋友在分析网站的日志的时候需要用到另外一个工具Web Log Explorer。
其实在网站的日志分析中,最需要的工具就是Excel(Excel 07或者Excel 10)。在这里,我想和大家简单分享一下我的一些经验。
网站人体爬行统计:
借助光年日志分析工具,可以得到各搜索引擎的蜘蛛总爬取量、蜘蛛总停留时间、蜘蛛访问量(由于我只做百度优化,我就说百度蜘蛛爬取),如下图1所示:
以上数据可以制作成Excel,如下图2所示:
平均停留时间=总停留时间/访问次数,计算公式:=C2/B2回车键
平均爬取量=总爬取量/访问量,计算公式:=D2/B2回车键
单页抓取时间==停留时间*3600/总抓取量计算公式:=D2/C2回车键
蜘蛛状态码统计:
借助Excel表格,打开日志(最直接的方法就是将日志拖到Excel表格中),然后统计蜘蛛状态码,如下图3所示:
通过Excel表格下“数据”功能下的过滤,可以统计蜘蛛状态码如下。具体统计操作如图4所示:
点击IP段下拉框,找到文本过滤器,选择自定义过滤器。
从图3可以看出,蜘蛛爬取的状态码200特征为HTTP/1.1" 200,以此类推:状态码500为HTTP/1.1" 500、@ >状态码 404 是 HTTP/1.1" 404、状态码 302 是 HTTP/1.1" 302...。现在可以过滤掉每个蜘蛛状态码,如下图:
如上图5所示,如果选择收录关系,可以统计百度蜘蛛200状态码的抓取量,以此类推。
蜘蛛IP段统计:
如上图,可以用IP段替换状态码,如:HTTP/1.1" 200 换成202.108.251.33
目录爬网统计:
如上图所示,可以将状态码替换为对应的目录名,如:HTTP/1.1" 200替换为/tagssearchList/
综上所述:
这里介绍如何通过简单的Excel分析网站日志数据。我不知道您作为 seo 是否通常分析 网站 日志。无论如何,我通常会分析这些东西。需要分析网站的日志。至于分析这些数据,作用是什么,如何通过这些数据发现网站的不足,然后列出调整方案,一步步调整网站的结构,我相信很多人都已经写过了,这里就不多说了。
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-03-27 09:27
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络数据可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
Excel抓取和查询网络数据可以通过“获取和转换”+“查找参考功能”的功能组合来实现。
示例:下图是百度百科“奥运”网页中的表格。我们以此为例,将表格抓取到Excel中,我们可以通过输入会话号来查询对应的主办城市。
Step1:使用“获取和转换”功能将网络数据捕获到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”。
弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏,点击确定。
Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”。
在弹出窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载”。
如图所示,Web 表单中的数据已经被抓取到 Excel 中。
点击“表格工具”、“设计”,将“表格名称”改为Olympic Games。
Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎,当届数发生变化时,对应的主办城市也会发生变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,可以设置链接网页的数据定期刷新:
①将鼠标放在导入数据区,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新一次。这样每10分钟就会刷新一次数据,保证获取到的数据始终是最新的。
《江津Excel》是头条签约作者,关注我,如果你点击任意三篇文章文章,没有你想要的知识,我就是流氓!
excel抓取网页数据(爬虫的工作原理(一)_e操盘(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-03-25 08:05
)
本质上,爬虫使用程序为我们在线获取有价值的数据。实际上,爬虫是用编程语言编写的程序。它的功能是从网络中获取有价值的数据。重要的是速度比手动获取数据要快。浏览器的工作原理
爬虫的工作原理其实就是把手动操作变成程序操作。
爬虫的工作步骤
(1)输入网址,发起请求,获取数据
(2)使用程序解析得到的数据
(3)从数据中提取想要的数据
(4)数据存储以供将来使用和分析
了解了爬虫的原理之后,我们一起来看看如何抓取数据?
import requests
from bs4 import BeautifulSoup
import openpyxl
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}#请求头,模拟浏览器行为进行操作。越过服务器的反爬
response=requests.get('https://movie.douban.com/',headers=header)#根据请求方法用get方法进行发送请求,并获得响应值。headers=header用关键字传参
#
# print('响应状态码',response.status_code)
# print(response.request.headers)#查看请求头
# print(response.text)#查看响应文本
bs=BeautifulSoup(response.text,'html.parser')#html.parser 解析html。
# print(type(bs))
# title=bs.find('td',class_='title')#查找单个电影
# print(title.text)#输出结果
# title=bs.find_all('td',class_='title')
list=[['编号','电影名称','地址']]#声明列表中的头
title=bs.find('div',class_='billboard-bd')#查找标签
all_titel=title.find_all('tr')#查找div'标签 属性为 class='billboard-bd' 下的所有的tr
for i in all_titel:#遍历查找符合条件的电影
myid=i.find('td',class_='order')#查找电影id
mytitle=i.find('td',class_='title')#查找电影名称
url=i.find('a')['href']#查找地址连接
# print( myid.text,mytitle.text,url)
# title1=i.find('td',class_='title')
list.append([myid.text,mytitle.text,url])#将数据添加到列表中
# print(list)
#*****************存储到excel表格中
wb=openpyxl.Workbook()#创建一个工作薄
sheet=wb.active#创建一个工作表
sheet.title='电影'#为sheet页起名
for i in list:
sheet.append(i)#将列表中的内容存储到文件
wb.save('films.xlsx')#保存电影 查看全部
excel抓取网页数据(爬虫的工作原理(一)_e操盘(图)
)
本质上,爬虫使用程序为我们在线获取有价值的数据。实际上,爬虫是用编程语言编写的程序。它的功能是从网络中获取有价值的数据。重要的是速度比手动获取数据要快。浏览器的工作原理
爬虫的工作原理其实就是把手动操作变成程序操作。
爬虫的工作步骤
(1)输入网址,发起请求,获取数据
(2)使用程序解析得到的数据
(3)从数据中提取想要的数据
(4)数据存储以供将来使用和分析
了解了爬虫的原理之后,我们一起来看看如何抓取数据?
import requests
from bs4 import BeautifulSoup
import openpyxl
header={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}#请求头,模拟浏览器行为进行操作。越过服务器的反爬
response=requests.get('https://movie.douban.com/',headers=header)#根据请求方法用get方法进行发送请求,并获得响应值。headers=header用关键字传参
#
# print('响应状态码',response.status_code)
# print(response.request.headers)#查看请求头
# print(response.text)#查看响应文本
bs=BeautifulSoup(response.text,'html.parser')#html.parser 解析html。
# print(type(bs))
# title=bs.find('td',class_='title')#查找单个电影
# print(title.text)#输出结果
# title=bs.find_all('td',class_='title')
list=[['编号','电影名称','地址']]#声明列表中的头
title=bs.find('div',class_='billboard-bd')#查找标签
all_titel=title.find_all('tr')#查找div'标签 属性为 class='billboard-bd' 下的所有的tr
for i in all_titel:#遍历查找符合条件的电影
myid=i.find('td',class_='order')#查找电影id
mytitle=i.find('td',class_='title')#查找电影名称
url=i.find('a')['href']#查找地址连接
# print( myid.text,mytitle.text,url)
# title1=i.find('td',class_='title')
list.append([myid.text,mytitle.text,url])#将数据添加到列表中
# print(list)
#*****************存储到excel表格中
wb=openpyxl.Workbook()#创建一个工作薄
sheet=wb.active#创建一个工作表
sheet.title='电影'#为sheet页起名
for i in list:
sheet.append(i)#将列表中的内容存储到文件
wb.save('films.xlsx')#保存电影
excel抓取网页数据(百度【举个栗子】windows系统网页数据教程_系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-03-17 19:03
excel抓取网页数据hello,大家好,
1、创建一个空word,然后复制到c盘,找到“excel_data”,
2、如下图的操作,找到“页码和页码大小”按钮,
3、在页码编辑界面,将公式栏的内容选中,
4、修改完,单击确定,设置完这些内容,
5、回到命令行,输入ctrl+f7,回车,就可以抓取网页数据了,如果不显示的话,把左边工具栏的工具都点击一下,然后单击就可以显示了ok,今天的分享就到这里,如果您想获取更多excel的操作技巧,如office、word、ppt等等问题的解决方法,请在下方评论区留言,或者在我的v信公众号:“张易talk”上留言,总有一个能帮到您。祝您工作顺利!。
百度【举个栗子】windows系统网页抓取教程_windows系统网页抓取教程免费看
手工分析。要学多久?——20分钟就够了。但学费成本极高。
win10环境上:excel选择数据源进行分析,数据抓取这些数据抓取是需要自己去打开数据源文件,多见于各大的手机app应用软件和自身app,所以一般我们一开始就需要安装对应的应用程序来进行数据抓取,不仅仅只是微信了,开通腾讯会员就可以获取微信号,然后可以通过关注公众号微信公众号或者微信号的菜单选择复制粘贴进行数据抓取。
常见的数据抓取有:百度搜索,京东购物,天猫购物,,抖音视频,这些在电脑上都可以直接用excel进行搜索,再打开即可。 查看全部
excel抓取网页数据(百度【举个栗子】windows系统网页数据教程_系统)
excel抓取网页数据hello,大家好,
1、创建一个空word,然后复制到c盘,找到“excel_data”,
2、如下图的操作,找到“页码和页码大小”按钮,
3、在页码编辑界面,将公式栏的内容选中,
4、修改完,单击确定,设置完这些内容,
5、回到命令行,输入ctrl+f7,回车,就可以抓取网页数据了,如果不显示的话,把左边工具栏的工具都点击一下,然后单击就可以显示了ok,今天的分享就到这里,如果您想获取更多excel的操作技巧,如office、word、ppt等等问题的解决方法,请在下方评论区留言,或者在我的v信公众号:“张易talk”上留言,总有一个能帮到您。祝您工作顺利!。
百度【举个栗子】windows系统网页抓取教程_windows系统网页抓取教程免费看
手工分析。要学多久?——20分钟就够了。但学费成本极高。
win10环境上:excel选择数据源进行分析,数据抓取这些数据抓取是需要自己去打开数据源文件,多见于各大的手机app应用软件和自身app,所以一般我们一开始就需要安装对应的应用程序来进行数据抓取,不仅仅只是微信了,开通腾讯会员就可以获取微信号,然后可以通过关注公众号微信公众号或者微信号的菜单选择复制粘贴进行数据抓取。
常见的数据抓取有:百度搜索,京东购物,天猫购物,,抖音视频,这些在电脑上都可以直接用excel进行搜索,再打开即可。
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 476 次浏览 • 2022-03-13 14:17
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论! 查看全部
excel抓取网页数据(怎样使用微软的Excel爬取一个网页的后台数据,注)
看完这篇文章,你还在痴迷于python爬虫吗?今天教大家如何使用Microsoft Excel爬取网页的后台数据。注意:此方法仅适用于对爬取数据感兴趣但不使用Python等工具进行爬取的人。使用Excel爬取网页数据既方便又容易,但有很大的局限性。它只能爬取单个网页的数据。并且受网页数据布局的影响,如果网页布局不适合爬取,需要手动更改格式。
这里我们以抓取空气质量排名网页为例:
首先新建一个Excel表格,打开数据,从网站,会出现提示框,将我们要爬取的网站的帮助粘贴到搜索框中点击搜索
第四步,进入网页,可以看到如图所示的数据,然后我们点击导入按钮:
点击Import后,别着急,点击OK,点击Properties,修改一些我们会用到的常用属性:
请看下面的图片
一分钟的刷新控制设置可以保证更快的数据替换,打开文件时刷新数据项也保证了我们打开文件时数据项是最新的。其他更改将根据您的需要进行调整。
最后一步是点击确定,完美的将网页数据下载到自己的工作文件中。
怎么样,是不是很方便呢,朋友?但是这只对不懂python的爬虫高手实用。普通人在需要一些数据的时候可以自己下载。这也很方便。欢迎在下方留言讨论!
excel抓取网页数据(我对Google表格抓取了解不多我无法正确获取数据(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-12 18:20
)
用户名
我应该如何抓取这个页面,具体需要表中提到的ROE数?
我在 Excel 中使用了以下代码。我对 Google 表格抓取了解不多
Sub FetchData()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;https://www.bseindia.com/stock ... ot%3B, Destination:=Range( _
"$A$1"))
.Name = "www"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlEntirePage
.WebFormatting = xlWebFormattingNone
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
我无法正确获取数据。
有什么建议/帮助吗? ROE图是必须的,其余的不需要。
QHarr
使用页面可以更快地使用其 API。您可以使用 powerquery 来处理 json 响应、json 解析器或只是拆分。如果您想在按钮按下时刷新,请将代码放在标准模块中并链接到按钮。
Option Explicit
Public Sub GetInfo()
Dim s As String, ids(), i As Long
ids = Array(500820, 500312, 500325, 532540)
With CreateObject("MSXML2.XMLHTTP")
For i = LBound(ids) To UBound(ids)
.Open "GET", "https://api.bseindia.com/BseIn ... ot%3B & ids(i) & "&seriesid=", False
.send
s = .responseText
ActiveSheet.Cells(i + 1, 1) = Split(Split(s, """ROE"":""")(1), Chr$(34))(0)
Next
End With
End Sub 查看全部
excel抓取网页数据(我对Google表格抓取了解不多我无法正确获取数据(图)
)
用户名
我应该如何抓取这个页面,具体需要表中提到的ROE数?
我在 Excel 中使用了以下代码。我对 Google 表格抓取了解不多
Sub FetchData()
With ActiveSheet.QueryTables.Add(Connection:= _
"URL;https://www.bseindia.com/stock ... ot%3B, Destination:=Range( _
"$A$1"))
.Name = "www"
.FieldNames = True
.RowNumbers = False
.FillAdjacentFormulas = False
.PreserveFormatting = True
.RefreshOnFileOpen = False
.BackgroundQuery = True
.RefreshStyle = xlInsertDeleteCells
.SavePassword = False
.SaveData = True
.AdjustColumnWidth = True
.RefreshPeriod = 0
.WebSelectionType = xlEntirePage
.WebFormatting = xlWebFormattingNone
.WebPreFormattedTextToColumns = True
.WebConsecutiveDelimitersAsOne = True
.WebSingleBlockTextImport = False
.WebDisableDateRecognition = False
.WebDisableRedirections = False
.Refresh BackgroundQuery:=False
End With
End Sub
我无法正确获取数据。
有什么建议/帮助吗? ROE图是必须的,其余的不需要。
QHarr
使用页面可以更快地使用其 API。您可以使用 powerquery 来处理 json 响应、json 解析器或只是拆分。如果您想在按钮按下时刷新,请将代码放在标准模块中并链接到按钮。
Option Explicit
Public Sub GetInfo()
Dim s As String, ids(), i As Long
ids = Array(500820, 500312, 500325, 532540)
With CreateObject("MSXML2.XMLHTTP")
For i = LBound(ids) To UBound(ids)
.Open "GET", "https://api.bseindia.com/BseIn ... ot%3B & ids(i) & "&seriesid=", False
.send
s = .responseText
ActiveSheet.Cells(i + 1, 1) = Split(Split(s, """ROE"":""")(1), Chr$(34))(0)
Next
End With
End Sub
excel抓取网页数据(Excel抓取并查询网络可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 490 次浏览 • 2022-03-10 02:30
使用“获取和转换”+“查找参考功能”的功能组合可以实现Excel爬取和查询网络。
示例:下图是百科全书“奥运会”页面中的一个表格。我们以此为例,将表格抓取到Excel中,输入会话数即可查询对应主办城市的网页抓取数据。
Step1:使用“获取和转换”功能将网页数据抓取到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”网页数据抓取。
会弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定即可抓取网页数据。
将 Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。网页数据采集。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”网页抓取。
在弹出的窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载 Web 数据抓取”。
如图所示,网页表格中的数据已经被抓取到Excel中的网页数据抓取中。
依次点击“表格”、“设计”,将“表格名称”改为Olympic Web Data Capture。Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎。当场次发生变化时,相应的主办城市也会相应变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,则取网页数据,链接网页的数据可以设置为定期刷新:
①将鼠标放在导入数据区的网页数据采集上,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新网页数据采集。这样每 10 分钟就会刷新一次数据,并且始终保证获取到的数据位会被更新。
《江津Excel》是头条签名作者的网页数据采集,关注我,点击任意三篇文章文章,如果没有你要的知识,我就是流氓! 查看全部
excel抓取网页数据(Excel抓取并查询网络可以使用“获取和转换”+“查找引用函数”的功能组合来实现)
使用“获取和转换”+“查找参考功能”的功能组合可以实现Excel爬取和查询网络。
示例:下图是百科全书“奥运会”页面中的一个表格。我们以此为例,将表格抓取到Excel中,输入会话数即可查询对应主办城市的网页抓取数据。
Step1:使用“获取和转换”功能将网页数据抓取到Excel中,点击“数据选项卡”、“新建查询”、“来自其他来源”、“来自Web”网页数据抓取。
会弹出如下窗口,手动将百度百科“奥运”的网址复制粘贴到网址栏中,点击确定即可抓取网页数据。
将 Excel 连接到网页需要一定的时间。稍等片刻,会弹出如下窗口。左侧列表中的每个表代表网页中的一个表。一一点击预览后,发现Table3就是我们需要的数据。网页数据采集。
单击下方“加载”旁边的下拉箭头,然后选择“加载到”网页抓取。
在弹出的窗口中,选择“选择如何在工作簿中查看此数据”下的“表”,然后单击“加载 Web 数据抓取”。
如图所示,网页表格中的数据已经被抓取到Excel中的网页数据抓取中。
依次点击“表格”、“设计”,将“表格名称”改为Olympic Web Data Capture。Step2:使用“查找和引用”功能实现数据查询
创建一个查询区域,包括“会话数”和“主办城市”,在会话编号中选择一个会话并在下图中输入“第08届”,进入主办城市下的vlookup功能,可以得到第08届奥运会的主办城市是巴黎。当场次发生变化时,相应的主办城市也会相应变化。
公式:=VLOOKUP([会话次数],Olympics[#All],4,0)
注意:如果网页中的数据变化频繁,则取网页数据,链接网页的数据可以设置为定期刷新:
①将鼠标放在导入数据区的网页数据采集上,切换到【设计】选项卡,点击【刷新】下拉箭头→【链接属性】
②在弹出的【链接属性】对话框中,设置【刷新频率】,例如设置为10分钟刷新网页数据采集。这样每 10 分钟就会刷新一次数据,并且始终保证获取到的数据位会被更新。
《江津Excel》是头条签名作者的网页数据采集,关注我,点击任意三篇文章文章,如果没有你要的知识,我就是流氓!
excel抓取网页数据( 如何在网络上抓取数据就一定要学Python,一定要去写代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-03-07 10:05
如何在网络上抓取数据就一定要学Python,一定要去写代码)
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的是选择坐船去,而不是想着造船去那里。
二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海上的一个小岛,我们也要求30分钟内有货送到岛上。
因此,前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。
也许Python这几年很火,我们经常会看到别人用Python做网络爬虫来爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实不然,本文介绍几个可以快速获取在线数据的工具。
01 微软 Excel
你没看错,Excel,办公室三剑客之一。 **Excel 是一个强大的工具,能够捕获数据是它的功能之一。 **我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
02 优采云采集器
优采云是爬虫行业的老字号,**是目前使用最多的互联网数据采集、处理、分析、挖掘软件。 **它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
因为学习门槛的关系,掌握了这个工具后,采集数据限制会很高。有时间和精力的同学可以去折腾。
官网地址:
03 优采云采集器
**优采云采集器对于初学者来说是一个很棒的采集器。 **简单易用,让您分分钟上手。 优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以具有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
04 GooSeeker 合集
Jisooke 也是一个易于使用的可视化采集 数据工具。它还可以抓取动态网页。还支持在手机网站上爬取数据,以及在指数图表上悬浮显示的爬取数据。 **Jisooke 以浏览器插件的形式采集数据。尽管它具有上述优点,但也有缺点。多线程采集数据是不可能的,浏览器死机是不可避免的。
网站:
05 Scrapinghub
如果你想抓取国外的 网站 数据,可以考虑 Scrapinghub。 Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。 Scrapehub 是市场上一个非常复杂且功能强大的网络抓取平台,提供数据抓取的解决方案提供商。
地址:
06 网络爬虫
WebScraper 是一款优秀的国外浏览器插件。 **也是适合初学者抓取数据的可视化工具。 **我们只是设置了一些抓取规则,让浏览器来做。
地址: 查看全部
excel抓取网页数据(
如何在网络上抓取数据就一定要学Python,一定要去写代码)
首先说一下获取数据的方式:首先,使用现成的工具,我们只需要知道如何使用工具来获取数据,不需要关心工具是如何实现的比如我们在岸上,要去海上的一个小岛,岸上有船,我们首先想到的是选择坐船去,而不是想着造船去那里。
二是针对场景需求做一些定制化的工具,这需要一点编程基础。比如我们还是要去海上的一个小岛,我们也要求30分钟内有货送到岛上。
因此,前期只是单纯的想获取数据,如果没有其他需求,首选现有的工具。
也许Python这几年很火,我们经常会看到别人用Python做网络爬虫来爬取数据。因此,有些学生有这样的误解。如果你想从网上抓取数据,你必须学习 Python 并编写代码。
其实不然,本文介绍几个可以快速获取在线数据的工具。
01 微软 Excel
你没看错,Excel,办公室三剑客之一。 **Excel 是一个强大的工具,能够捕获数据是它的功能之一。 **我用耳机作为关键词来抓取京东的产品列表。
几秒钟后,Excel 会将页面上的所有文本信息抓取到一个表格中。这个方法确实可以捕获数据,但是也会引入一些我们不需要的数据。如果你有更高的要求,你可以选择后者的工具。
02 优采云采集器
优采云是爬虫行业的老字号,**是目前使用最多的互联网数据采集、处理、分析、挖掘软件。 **它的优点是采集不限于网页和内容,也分布式采集,效率会更高。缺点是对新手用户不太友好,有一定的知识门槛(如网页知识、HTTP协议等),熟悉工具操作需要一定的时间。
因为学习门槛的关系,掌握了这个工具后,采集数据限制会很高。有时间和精力的同学可以去折腾。
官网地址:
03 优采云采集器
**优采云采集器对于初学者来说是一个很棒的采集器。 **简单易用,让您分分钟上手。 优采云提供一些常用抓取的模板网站,使用模板快速抓取数据。如果你想在没有模板的情况下抓取网站,官网也提供了非常详细的图文教程和视频教程。
优采云是基于浏览器内核实现数据的可视化抓取,所以具有滞后和采集数据慢的特点。不过这个缺陷也掩盖不了弱点,基本可以满足新手在短时间内抓取数据的场景,比如翻页查询、Ajax动态加载数据等。
网站:
04 GooSeeker 合集
Jisooke 也是一个易于使用的可视化采集 数据工具。它还可以抓取动态网页。还支持在手机网站上爬取数据,以及在指数图表上悬浮显示的爬取数据。 **Jisooke 以浏览器插件的形式采集数据。尽管它具有上述优点,但也有缺点。多线程采集数据是不可能的,浏览器死机是不可避免的。
网站:
05 Scrapinghub
如果你想抓取国外的 网站 数据,可以考虑 Scrapinghub。 Scrapinghub 是一个基于 Python 的 Scrapy 框架的云爬虫平台。 Scrapehub 是市场上一个非常复杂且功能强大的网络抓取平台,提供数据抓取的解决方案提供商。
地址:
06 网络爬虫
WebScraper 是一款优秀的国外浏览器插件。 **也是适合初学者抓取数据的可视化工具。 **我们只是设置了一些抓取规则,让浏览器来做。
地址:
excel抓取网页数据(网页链接如何用Excel制作股票实时行情图制作实时股票行情图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 486 次浏览 • 2022-03-06 01:21
内容导航:
如何制作实时盘点股票的excel
找到具有实时股票价格的网站,然后按照以下步骤获取数据到EXCEL
导入成功后
设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以 VLOOKUP。
很简单,看图相信你已经知道了
你的问题和我之前做的实时汇率一样。请参考以下链接
如何使用 Excel 制作实时股市图表
制作实时股市图表应包括以下内容:1.股票数据表、2.股票价格图表、3.从网上实时下载数据的功能
第一步:制作数据表,数据——导入外部数据——新建WEB查询并写入数据源地址
第二步:制作股价图表,先用公式按照股价图表要求的顺序参照当前表格,然后插入图表-选股图表(类型4)调整图表
第三步:编写程序实现实时刷新功能,下面的程序可以复制到需要的位置
'在模块中编写如下程序段刷新行情表,“00:00:10”表示刷新时间间隔,可根据需要调整
暗淡结束标记
子刷新市场()
Sheets("每日数据").Range("A1").QueryTable.Refresh
背景查询:=假
Sheets("拆分数据").Range("A1").QueryTable.Refresh
背景查询:=假
如果结束标签
1 然后申请。现在准时 +
TimeValue("00:00:10"), "刷新报价"
结束子
子开始刷新()
结束标签 = 0
刷新报价
结束子
子结束刷新()
结束标签 = 1
结束子
'在此工作簿中编写以下代码以在打开表时启动市场刷新
私有子 Workbook_Open()
刷新报价
结束子
以上制作完成后,保存后打开表格,即可得到实用的股市走势图,并可获取实时数据进行数据分析
Excel 调用实时股票价格
1、先查一下股价表的地址。
2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。
3、为 EXCEL 表命名并保存。
4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。
5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数根据股票代码将自己的股票信息导入到查询表中,并设置收益计算等项目。
这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。
如何将股票数据导出到excel
打开要导入Excel的文本文档,查看数据,确认数据正确。
单击 Excel 中的“数据”选项卡,然后单击“获取外部数据”选项组中的“从文本”按钮。
在打开的“导入文本文件”对话框中查找并选择要导入的文本文件。
单击“导入”按钮,将文本文档中的数据导入 Excel 工作表。
在导入 Excel 之前,对文本文档中的数据进行进一步的编辑,使其具有 Excel 表格样式,这样更有利于数据的导入。 查看全部
excel抓取网页数据(网页链接如何用Excel制作股票实时行情图制作实时股票行情图)
内容导航:
如何制作实时盘点股票的excel
找到具有实时股票价格的网站,然后按照以下步骤获取数据到EXCEL
导入成功后
设置更新频率和相关属性。如果你想按照自己的顺序,那么你可以 VLOOKUP。
很简单,看图相信你已经知道了
你的问题和我之前做的实时汇率一样。请参考以下链接
如何使用 Excel 制作实时股市图表
制作实时股市图表应包括以下内容:1.股票数据表、2.股票价格图表、3.从网上实时下载数据的功能
第一步:制作数据表,数据——导入外部数据——新建WEB查询并写入数据源地址
第二步:制作股价图表,先用公式按照股价图表要求的顺序参照当前表格,然后插入图表-选股图表(类型4)调整图表
第三步:编写程序实现实时刷新功能,下面的程序可以复制到需要的位置
'在模块中编写如下程序段刷新行情表,“00:00:10”表示刷新时间间隔,可根据需要调整
暗淡结束标记
子刷新市场()
Sheets("每日数据").Range("A1").QueryTable.Refresh
背景查询:=假
Sheets("拆分数据").Range("A1").QueryTable.Refresh
背景查询:=假
如果结束标签
1 然后申请。现在准时 +
TimeValue("00:00:10"), "刷新报价"
结束子
子开始刷新()
结束标签 = 0
刷新报价
结束子
子结束刷新()
结束标签 = 1
结束子
'在此工作簿中编写以下代码以在打开表时启动市场刷新
私有子 Workbook_Open()
刷新报价
结束子
以上制作完成后,保存后打开表格,即可得到实用的股市走势图,并可获取实时数据进行数据分析
Excel 调用实时股票价格
1、先查一下股价表的地址。
2、打开EXCEL表格,将光标放在A1上,选择“数据/导入外部数据/新建veb查询”,在地址栏输入股价表地址,“前往”,点击黄色价目表旁边的右箭头,点击“导入”,将价目表导入EXCEL。
3、为 EXCEL 表命名并保存。
4、将光标放在新导入的表格中,在“数据/导入外部数据/数据范围属性/数据控件”中,勾选“打开工作簿时自动刷新/确定”。
5、打开目录中保存的EXCEL表格,点击“启用自动刷新”按钮,根据网上最新的股票数据进行刷新。
6、你应该进一步构建自己的股票查询表,使用VLOOKUP函数根据股票代码将自己的股票信息导入到查询表中,并设置收益计算等项目。
这样你就可以每天打开查询表刷新一下,就可以看到自己股票的最新信息和收益状况。
如何将股票数据导出到excel
打开要导入Excel的文本文档,查看数据,确认数据正确。
单击 Excel 中的“数据”选项卡,然后单击“获取外部数据”选项组中的“从文本”按钮。
在打开的“导入文本文件”对话框中查找并选择要导入的文本文件。
单击“导入”按钮,将文本文档中的数据导入 Excel 工作表。
在导入 Excel 之前,对文本文档中的数据进行进一步的编辑,使其具有 Excel 表格样式,这样更有利于数据的导入。

