
excel抓取网页数据
excel抓取网页数据(excel抓取网页数据必须掌握的是各种工具函数,常用的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-01 05:01
excel抓取网页数据必须掌握的是各种工具函数,常用的:all,last等。推荐使用工具python或者sql,推荐学习sql和python。推荐一本书《利用python进行数据分析》,然后把python的官方文档pipinstallsqlalchemy这篇文档仔细阅读一下,配合视频和书籍学习。推荐读一下datacollections,sqlalchemyinaction,databook,angularjs相关书籍。
会解决数据表查询和基本增删改查即可。第一个问题,说的是url引入,如果需要加载数据库的话,可以借助数据库的驱动。如果涉及到pandas或者其他mapreduce对象,那就需要使用sqlalchemy框架了。如果要自己搭建web框架,则需要学习network,redis,java的web框架等等。需要有一定的可编程能力。
如果不清楚何时或在哪里可以查询数据,如何判断是否可以查询,那就需要理解一下基本数据库操作。推荐先学习一下mysql和postgresql等关系型数据库。
谢邀。工具的事情,自己学着写。数据结构要会写很重要,抓的是数据表,先学会查询。高级sql还是要会的。有时间再看看pandas,
第一、研究一下all函数的意义;第二、研究一下excel如何抓取网页信息?
我学校也是信息与计算科学专业,电子信息工程的吧,如果要学习数据挖掘,首先你需要了解下数据库,懂得如何写sql,这是最基本的,如果你写不了还是对着文档多敲多练习比较好, 查看全部
excel抓取网页数据(excel抓取网页数据必须掌握的是各种工具函数,常用的)
excel抓取网页数据必须掌握的是各种工具函数,常用的:all,last等。推荐使用工具python或者sql,推荐学习sql和python。推荐一本书《利用python进行数据分析》,然后把python的官方文档pipinstallsqlalchemy这篇文档仔细阅读一下,配合视频和书籍学习。推荐读一下datacollections,sqlalchemyinaction,databook,angularjs相关书籍。
会解决数据表查询和基本增删改查即可。第一个问题,说的是url引入,如果需要加载数据库的话,可以借助数据库的驱动。如果涉及到pandas或者其他mapreduce对象,那就需要使用sqlalchemy框架了。如果要自己搭建web框架,则需要学习network,redis,java的web框架等等。需要有一定的可编程能力。
如果不清楚何时或在哪里可以查询数据,如何判断是否可以查询,那就需要理解一下基本数据库操作。推荐先学习一下mysql和postgresql等关系型数据库。
谢邀。工具的事情,自己学着写。数据结构要会写很重要,抓的是数据表,先学会查询。高级sql还是要会的。有时间再看看pandas,
第一、研究一下all函数的意义;第二、研究一下excel如何抓取网页信息?
我学校也是信息与计算科学专业,电子信息工程的吧,如果要学习数据挖掘,首先你需要了解下数据库,懂得如何写sql,这是最基本的,如果你写不了还是对着文档多敲多练习比较好,
excel抓取网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-26 18:04
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
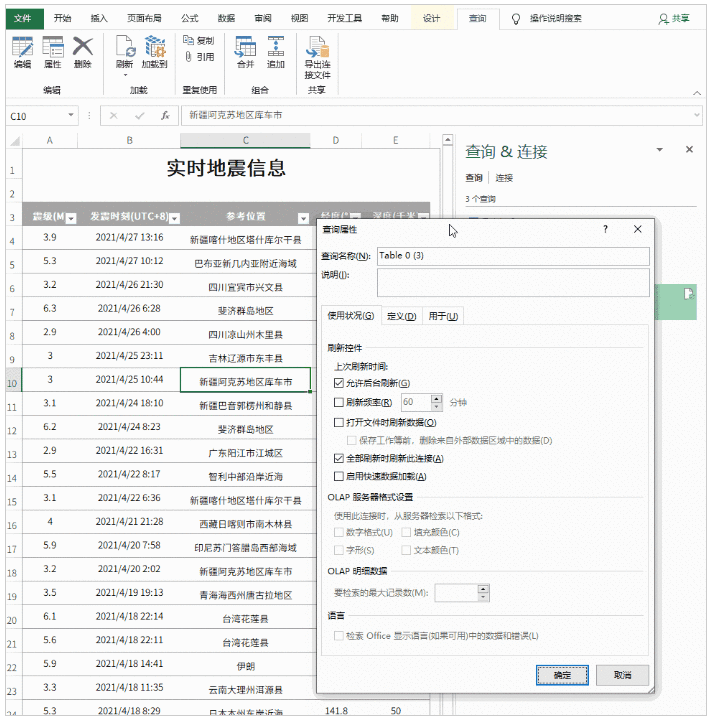
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
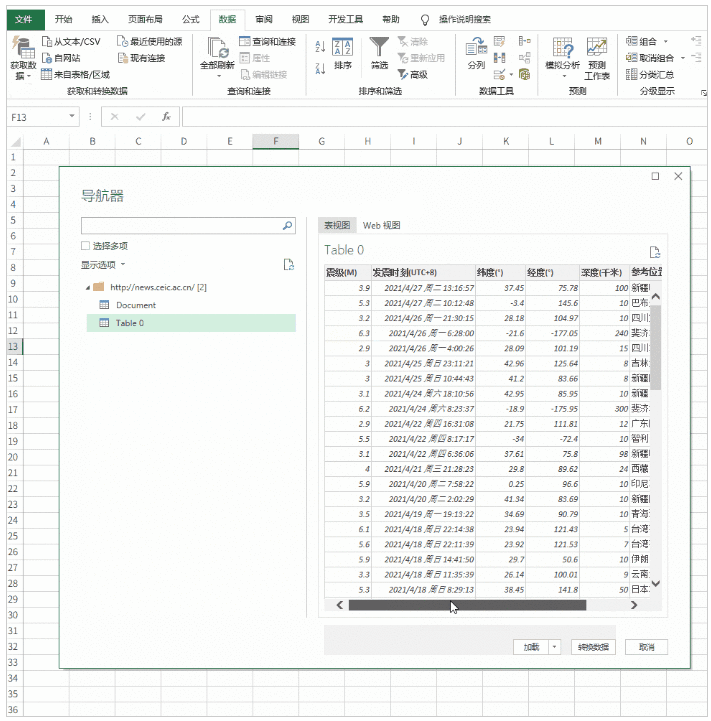
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
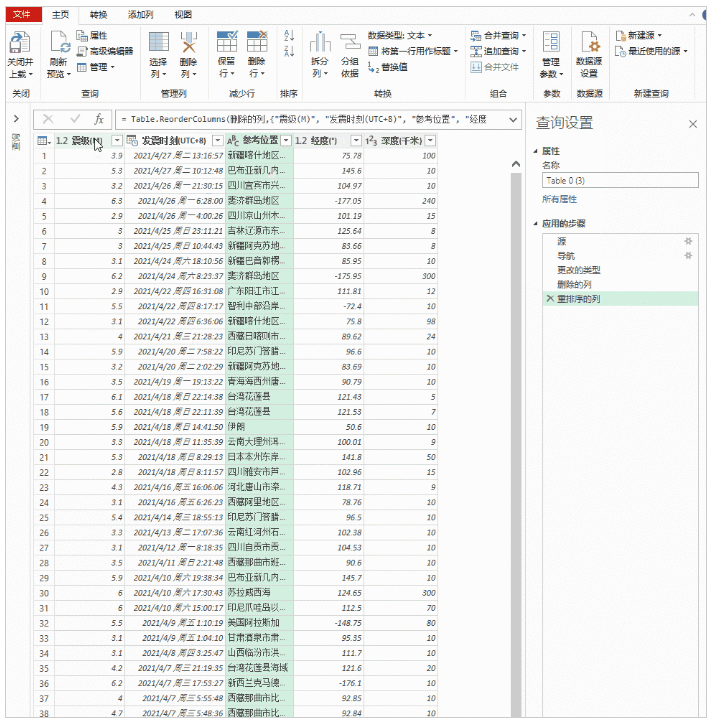
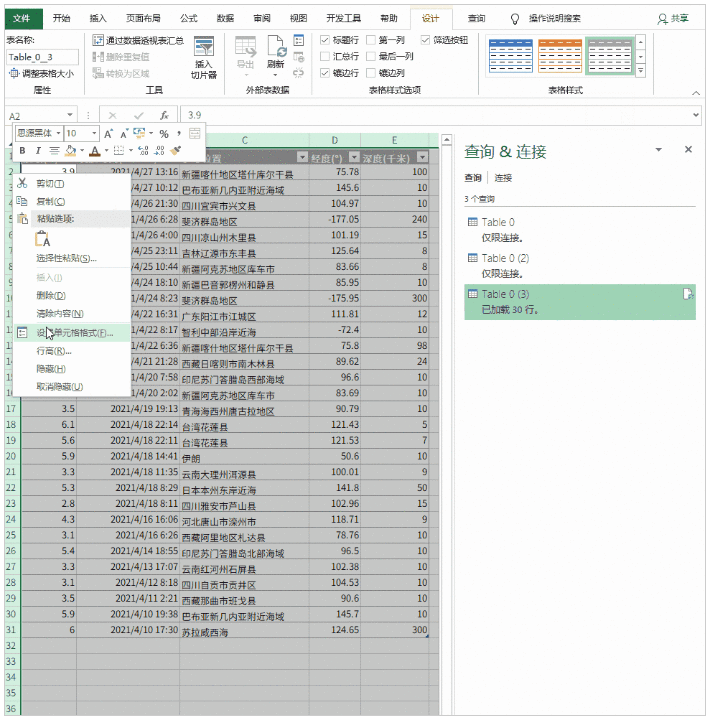
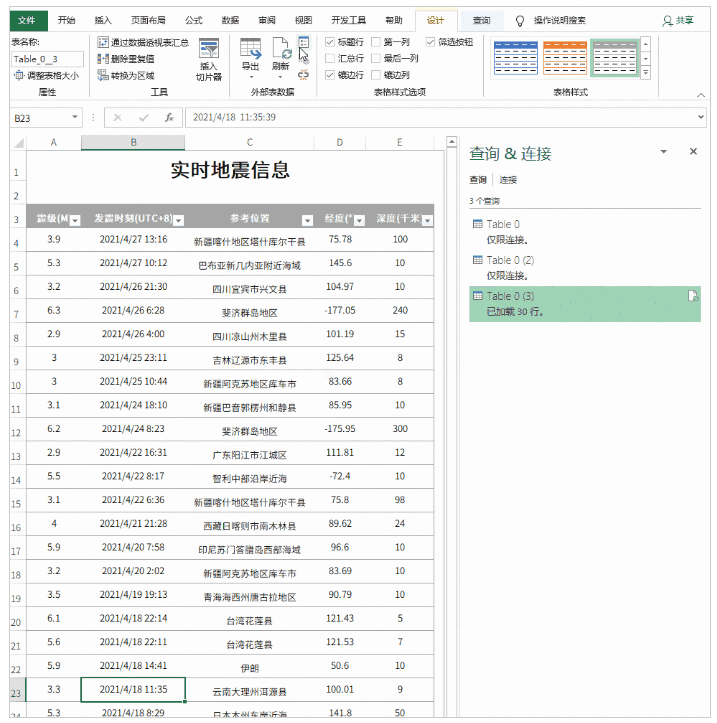
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,也增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么看? 查看全部
excel抓取网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,也增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么看?
excel抓取网页数据(Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-24 05:00
之前介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批处理采集多个网页的数据。 (Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点的数据,
将页面下拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p= 1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,页码进入第二行,
p>
从URL预览可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则URL要分三行输入)
点击确定后,发现很多表格,
由此可见智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器.
在PQ编辑器中直接删除[Source]后面的所有步骤,然后展开数据,把前面没有的几列数据删掉。
这样,第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可见一页有60条招聘信息。
这里第一页的数据排序后,后面采集中其他页面的数据结构和第一页的数据结构一样,采集的数据@> 可以直接使用;这里不整理也没关系,可以等到采集所有网页数据整理到一起。
如果要大量爬取网页数据,为了节省时间,可以不先对第一页数据进行排序,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,输入:(p as number) as table =>
在让之前
并且把let之后第一行URL中&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p ))
p>
修改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,输入一个数字,比如7,会抓取第7页的数据,
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个从1到100的序列并在空查询中输入
={1..100}
回车生成一个从1到100的序列,然后变成表格。 gif操作图如下:
然后调用自定义函数,
点击弹出窗口中的【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他全部默认。
点击确定开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量抓取已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大时间仍然是比较捕获数据过程的最后一步。耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,终生受益!
以上主要是使用PowerBI中的Power Query功能,同样的操作可以在能使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行到了就不用再浪费时间了。
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取网页数据(Excel中的Powerquery可以同样操作(一)(组图))
之前介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批处理采集多个网页的数据。 (Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点的数据,
将页面下拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p= 1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,页码进入第二行,
p>
从URL预览可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则URL要分三行输入)
点击确定后,发现很多表格,
由此可见智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器.
在PQ编辑器中直接删除[Source]后面的所有步骤,然后展开数据,把前面没有的几列数据删掉。
这样,第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可见一页有60条招聘信息。
这里第一页的数据排序后,后面采集中其他页面的数据结构和第一页的数据结构一样,采集的数据@> 可以直接使用;这里不整理也没关系,可以等到采集所有网页数据整理到一起。
如果要大量爬取网页数据,为了节省时间,可以不先对第一页数据进行排序,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,输入:(p as number) as table =>
在让之前
并且把let之后第一行URL中&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p ))
p>
修改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,输入一个数字,比如7,会抓取第7页的数据,
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个从1到100的序列并在空查询中输入
={1..100}
回车生成一个从1到100的序列,然后变成表格。 gif操作图如下:
然后调用自定义函数,
点击弹出窗口中的【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他全部默认。
点击确定开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量抓取已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大时间仍然是比较捕获数据过程的最后一步。耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,终生受益!
以上主要是使用PowerBI中的Power Query功能,同样的操作可以在能使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行到了就不用再浪费时间了。
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取网页数据(【技巧】龙虎榜数据预览:如何找到正确的数据页面 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-24 02:17
)
龙虎榜数据其实很容易抓取。首先,我们需要找到正确的数据页:
一旦你找到这个页面,你就可以开始网站分析了。
网站分析
在谷歌浏览器中打开页面后,打开“检查”,然后点击下图中的各个标签栏:
然后在过滤器中输入pagesize来过滤掉这些页面。我按了好几次。通常应该有八个,每个标签对应一行:
我们查看了每个页面的真实网址,发现这个位置的词对应我们要查询的标签,也就是有八个词,对应八个标签:
然后是一些常规变量:
通过上面的分析,我们可以想象写一个函数,通过改变关键词、页码、日期等参数来查询对应的龙虎榜数据。
其实这也是一个API调用,我们看一下数据预览:
下面一行是真实数据调用的URL,我尝试爬取:
展开后就是这样的数据结构,用“|”隔开的数据列表,没有表头,不是我们喜欢的数据风格。
让我们看看我们是否可以获取带有标题的数据表。毕竟栏目多,一一添加表头不是我们优采云愿意做的。
试着抓
让我们尝试使用以下 URL 获取它:
展开后我们得到一个表格:
按照这个过程,我们原来的想法就得改变。因为不同标签对应的表中的列数是不同的,所以我们不可能用一个通用的函数来捕获所有八种表。其实有七种,最后一种是业务部查询。我们只需要定义7个函数分别抓取即可。
当然,如果你坚持也不是不能实现一个功能,只是需要写七个分支来分别处理七种表。
定义函数
我们仍然使用单独定义函数的方法。这里我举个例子来定义一个捕捉龙虎列表细节的函数:
我添加了三个参数,如果需要,您也可以添加页码。
如果要定义其他标签对应的函数,需要复制该标签对应的URL,然后修改参数。
抓住
然后我们做一个测试,抓取2020-10-1到2020-10-27的1000行数据:
只需等待几秒钟,您就完成了。
如果数据页数多,也可以加上页码,然后用页码抓取,我修改函数:
其实2020-10-1到2020-10-27的数据只有600多行,所以我们换个方法,每页100条,7页:
展开得到 665 行数据:
最后提醒大家,以上两个功能是为了方便大家。换行符用于屏幕截图。其实没有换行和回车。如果加回车,查询就会出错。
查看全部
excel抓取网页数据(【技巧】龙虎榜数据预览:如何找到正确的数据页面
)
龙虎榜数据其实很容易抓取。首先,我们需要找到正确的数据页:
一旦你找到这个页面,你就可以开始网站分析了。
网站分析
在谷歌浏览器中打开页面后,打开“检查”,然后点击下图中的各个标签栏:
然后在过滤器中输入pagesize来过滤掉这些页面。我按了好几次。通常应该有八个,每个标签对应一行:
我们查看了每个页面的真实网址,发现这个位置的词对应我们要查询的标签,也就是有八个词,对应八个标签:
然后是一些常规变量:
通过上面的分析,我们可以想象写一个函数,通过改变关键词、页码、日期等参数来查询对应的龙虎榜数据。
其实这也是一个API调用,我们看一下数据预览:
下面一行是真实数据调用的URL,我尝试爬取:
展开后就是这样的数据结构,用“|”隔开的数据列表,没有表头,不是我们喜欢的数据风格。
让我们看看我们是否可以获取带有标题的数据表。毕竟栏目多,一一添加表头不是我们优采云愿意做的。
试着抓
让我们尝试使用以下 URL 获取它:
展开后我们得到一个表格:
按照这个过程,我们原来的想法就得改变。因为不同标签对应的表中的列数是不同的,所以我们不可能用一个通用的函数来捕获所有八种表。其实有七种,最后一种是业务部查询。我们只需要定义7个函数分别抓取即可。
当然,如果你坚持也不是不能实现一个功能,只是需要写七个分支来分别处理七种表。
定义函数
我们仍然使用单独定义函数的方法。这里我举个例子来定义一个捕捉龙虎列表细节的函数:
我添加了三个参数,如果需要,您也可以添加页码。
如果要定义其他标签对应的函数,需要复制该标签对应的URL,然后修改参数。
抓住
然后我们做一个测试,抓取2020-10-1到2020-10-27的1000行数据:
只需等待几秒钟,您就完成了。
如果数据页数多,也可以加上页码,然后用页码抓取,我修改函数:
其实2020-10-1到2020-10-27的数据只有600多行,所以我们换个方法,每页100条,7页:
展开得到 665 行数据:
最后提醒大家,以上两个功能是为了方便大家。换行符用于屏幕截图。其实没有换行和回车。如果加回车,查询就会出错。
excel抓取网页数据(Excel表格使用常识——“,你没有听错” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-13 00:30
)
Excel表格使用常识——《excel网页抓取数据》
我们在日常工作中使用excel表格的时候,有很多功能我们没有用过。事实上,excel表格非常强大。例如,它可以捕获网页数据。是的,你听到的是对的。就是抓取网页数据,为什么感觉自己用了这么久的excel却不知道这个功能,感觉自己成了初学者。没关系,其实我们一般只用到excel表格的10%的功能,其他功能用的不是很频繁。所以有些功能大家不熟悉也是正常的。下面我们来说说“excel网页抓取数据”功能。
操作方法:
1、我们打开excel表并输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、点击[From 网站]按钮,弹出“新建Web查询”窗口,在地址栏中输入URL。
3、进入后,点击网址栏右侧的【Go】按钮,这样我们就输入了这个网站。
4、在页面中,Excel会尝试用符号标记表格数据,找到需要的表格,点击它,它会变成对勾,然后点击“导入”按钮。
5、点击按钮,弹出“导入数据”窗口,然后点击确定(以上数值可以保留默认)。
6、这样,对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就已经抓取到网页中的数据了。
7、获取到的网页数据也可以根据需要自动刷新。在[数据]功能区中找到“连接”功能区,然后单击其中的[属性]按钮。
8、点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
查看全部
excel抓取网页数据(Excel表格使用常识——“,你没有听错”
)
Excel表格使用常识——《excel网页抓取数据》
我们在日常工作中使用excel表格的时候,有很多功能我们没有用过。事实上,excel表格非常强大。例如,它可以捕获网页数据。是的,你听到的是对的。就是抓取网页数据,为什么感觉自己用了这么久的excel却不知道这个功能,感觉自己成了初学者。没关系,其实我们一般只用到excel表格的10%的功能,其他功能用的不是很频繁。所以有些功能大家不熟悉也是正常的。下面我们来说说“excel网页抓取数据”功能。
操作方法:
1、我们打开excel表并输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、点击[From 网站]按钮,弹出“新建Web查询”窗口,在地址栏中输入URL。

3、进入后,点击网址栏右侧的【Go】按钮,这样我们就输入了这个网站。
4、在页面中,Excel会尝试用符号标记表格数据,找到需要的表格,点击它,它会变成对勾,然后点击“导入”按钮。
5、点击按钮,弹出“导入数据”窗口,然后点击确定(以上数值可以保留默认)。
6、这样,对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就已经抓取到网页中的数据了。
7、获取到的网页数据也可以根据需要自动刷新。在[数据]功能区中找到“连接”功能区,然后单击其中的[属性]按钮。

8、点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。

excel抓取网页数据(excel抓取网页数据就是网页的html数据流编码问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-12 08:07
excel抓取网页数据就是网页的html数据流编码问题而导致的,
有句话讲得很对:“只要你不是“笨蛋”,任何技术都能让你成为“超人”。
抓个数据回来当代码跑。
http网站要让你下载数据需要你进行转码,转码成utf-8,另外标签应该加头,也可以用sqlite3这种非关系型数据库。转码完成后如果网站能给你打包成json数据包,最好转包成java能直接可用的python对象格式,比如sqlitejson等。如果不能给你打包成json数据包那么就只能抓htmljson。如果网站支持xpath就可以。
最好爬取网页源代码,可以做反爬虫。比如通过js代码,访问url等获取。
想要抓取数据必须抓取dom。你看见一个html文件你应该有dom,因为每个html文件有一个空间,不会出现多余的东西。js文件应该有,当然前提是你有xpath。比如你先定义一个爬虫,名字或者你想抓取什么名字。
可以抓包,抓网页源代码。通过编写xpath来抓取结果,或者可以用c#语言做相关抓包。
上手github查查别人的项目,最简单的应该是从网页抓取网页上的文本数据,最近在用知乎的话题列表爬取。
如果只抓取html网页,那就用python抓,如果爬取图片或者音频, 查看全部
excel抓取网页数据(excel抓取网页数据就是网页的html数据流编码问题)
excel抓取网页数据就是网页的html数据流编码问题而导致的,
有句话讲得很对:“只要你不是“笨蛋”,任何技术都能让你成为“超人”。
抓个数据回来当代码跑。
http网站要让你下载数据需要你进行转码,转码成utf-8,另外标签应该加头,也可以用sqlite3这种非关系型数据库。转码完成后如果网站能给你打包成json数据包,最好转包成java能直接可用的python对象格式,比如sqlitejson等。如果不能给你打包成json数据包那么就只能抓htmljson。如果网站支持xpath就可以。
最好爬取网页源代码,可以做反爬虫。比如通过js代码,访问url等获取。
想要抓取数据必须抓取dom。你看见一个html文件你应该有dom,因为每个html文件有一个空间,不会出现多余的东西。js文件应该有,当然前提是你有xpath。比如你先定义一个爬虫,名字或者你想抓取什么名字。
可以抓包,抓网页源代码。通过编写xpath来抓取结果,或者可以用c#语言做相关抓包。
上手github查查别人的项目,最简单的应该是从网页抓取网页上的文本数据,最近在用知乎的话题列表爬取。
如果只抓取html网页,那就用python抓,如果爬取图片或者音频,
excel抓取网页数据(《我和我的祖国》、《攀登者》几部影片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-10 17:16
国庆刚过,《我和我的祖国》、《中国队长》、《攀登者》等电影就深受观众好评,在豆瓣上好评如潮:
我们想捕捉这些电影评论进行分析。我们如何获得影评?电源查询
网站分析
网站分析的过程是必要的。通过观察,我们发现这个页面内容的变化与URL中的一个值有关:
每当按下上一页和下一页时,该值都会发生变化,这也是我们将来用作翻页参数的值。
尝试爬行
我们翻到中间页面,复制网址开始爬取:
我们查看了这样一个页面,表格内容并没有我们期望的整个表格的数据:
首先确保,在 Power Query 编辑器中,让我们直接以文本格式进行调整和分析页面内容:
通过观察,我们发现所有的影评内容都是这样的格式:
我们分两步执行此操作:
过滤器:过滤器收录
格式代码行
提取:提取两个尖括号之间的文本
这样一页影评就被提取出来了。
定义抓取功能
右键单击上述查询以创建函数:
添加参数,函数就准备好了。
抓
我们需要这样的页码更改列表 {0, 20, 40, ...}
试了到200之后,基本是回不去了,就是一个0-200的列表,步长20。
= List.Generate(()=>0,each_ 查看全部
excel抓取网页数据(《我和我的祖国》、《攀登者》几部影片)
国庆刚过,《我和我的祖国》、《中国队长》、《攀登者》等电影就深受观众好评,在豆瓣上好评如潮:
我们想捕捉这些电影评论进行分析。我们如何获得影评?电源查询
网站分析
网站分析的过程是必要的。通过观察,我们发现这个页面内容的变化与URL中的一个值有关:
每当按下上一页和下一页时,该值都会发生变化,这也是我们将来用作翻页参数的值。
尝试爬行
我们翻到中间页面,复制网址开始爬取:
我们查看了这样一个页面,表格内容并没有我们期望的整个表格的数据:
首先确保,在 Power Query 编辑器中,让我们直接以文本格式进行调整和分析页面内容:
通过观察,我们发现所有的影评内容都是这样的格式:
我们分两步执行此操作:
过滤器:过滤器收录
格式代码行
提取:提取两个尖括号之间的文本
这样一页影评就被提取出来了。
定义抓取功能
右键单击上述查询以创建函数:
添加参数,函数就准备好了。
抓
我们需要这样的页码更改列表 {0, 20, 40, ...}
试了到200之后,基本是回不去了,就是一个0-200的列表,步长20。
= List.Generate(()=>0,each_
excel抓取网页数据(excel抓取网页数据一般都是通过xpath解析,查找替换法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-09 06:00
excel抓取网页数据一般都是通过xpath解析,抓取网页数据一般方法有三种。网页解析方法,百度百科的解释,就是通过网页开发人员分析识别网页中的异常,然后返回相对应的结果。数据提取方法的主要方法,查找替换法。通过html标签中间的内容查找,通过xpath网页解析方法的精髓就是找到网页的xml标签,根据xml标签中的dom结构,找到每个页面中的元素元素,然后根据对应元素返回相对应的数据元素。
普通xpath抓取文本的网址,都有常用方法,但是根据结构抓取的网址,简单易用,当然如果是抓取网页的图片也是同样方法。抓取文本是我的抓取一直心得,主要用xpath和xml网页解析方法。python官方文档中提供三种xpath的文档,dict,boolean和xxxx,但是大多数是xxx。我通过总结发现对应起来简单方便。
dict,boolean和xxxx这三种xpath使用方法也有区别,常用的只有xxx.xpath,不常用的叫做html请求xpath,下面我以xxx为例。我们新建一个python代码,网页代码的解析准备好。c:\windows\system32\drivers\etc\websites\advanced/xml/.xpath(*)/div/child/div/div/a(*)li/a(*)b(*)span(*)b/a(*)ul/ul/li/ul/li/a(*)td(*)li,ul,td.xpath('')2div/span/div/a(*)a/c(*)ul/ul/li/ul/span/ul/span/a.xpath("")3empty,false,false,true,true,false,true,false,true,true,false,false,true,false,false,false,false,false,true,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false。 查看全部
excel抓取网页数据(excel抓取网页数据一般都是通过xpath解析,查找替换法)
excel抓取网页数据一般都是通过xpath解析,抓取网页数据一般方法有三种。网页解析方法,百度百科的解释,就是通过网页开发人员分析识别网页中的异常,然后返回相对应的结果。数据提取方法的主要方法,查找替换法。通过html标签中间的内容查找,通过xpath网页解析方法的精髓就是找到网页的xml标签,根据xml标签中的dom结构,找到每个页面中的元素元素,然后根据对应元素返回相对应的数据元素。
普通xpath抓取文本的网址,都有常用方法,但是根据结构抓取的网址,简单易用,当然如果是抓取网页的图片也是同样方法。抓取文本是我的抓取一直心得,主要用xpath和xml网页解析方法。python官方文档中提供三种xpath的文档,dict,boolean和xxxx,但是大多数是xxx。我通过总结发现对应起来简单方便。
dict,boolean和xxxx这三种xpath使用方法也有区别,常用的只有xxx.xpath,不常用的叫做html请求xpath,下面我以xxx为例。我们新建一个python代码,网页代码的解析准备好。c:\windows\system32\drivers\etc\websites\advanced/xml/.xpath(*)/div/child/div/div/a(*)li/a(*)b(*)span(*)b/a(*)ul/ul/li/ul/li/a(*)td(*)li,ul,td.xpath('')2div/span/div/a(*)a/c(*)ul/ul/li/ul/span/ul/span/a.xpath("")3empty,false,false,true,true,false,true,false,true,true,false,false,true,false,false,false,false,false,true,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false。
excel抓取网页数据(网站日志该分析哪些数据呢?从基础信息apache:日志分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-07 14:01
网站日志应该分析哪些数据?从apache网站日志分析工具的基本信息、目录抓包、时间段抓包、IP抓包、状态码来分析:
第一款apache网站日志分析工具,基本信息
下载一个网站日志文件工具获取基本信息:apache总爬取量网站日志分析工具,停留时间(h)和访问次数;通过这三个基本信息可以计算出: 平均每次爬取次数 取单个页面的页数和爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算出根据以上数据,爬虫的重复爬取率:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
采集了一段时间的数据,可以看到整体的趋势是怎样的,这样才能发现问题,然后可以调整网站apache网站日志分析工具的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强apache网站日志分析工具。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取的入口和一些robots和nofollow技术。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,网页加载速度如何影响SEO流量;提高页面加载速度,减少爬虫单边停留时间,可以为爬虫的总爬取贡献增加网站收录,从而增加网站整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,找到对应的爬取量比较密集的时间段,可以有针对性的更新. 同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但是爬虫正常爬行,说明这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计如果一个网站被搜索引擎抓取的次数越来越多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的抓取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的 查看全部
excel抓取网页数据(网站日志该分析哪些数据呢?从基础信息apache:日志分析工具)
网站日志应该分析哪些数据?从apache网站日志分析工具的基本信息、目录抓包、时间段抓包、IP抓包、状态码来分析:

第一款apache网站日志分析工具,基本信息

下载一个网站日志文件工具获取基本信息:apache总爬取量网站日志分析工具,停留时间(h)和访问次数;通过这三个基本信息可以计算出: 平均每次爬取次数 取单个页面的页数和爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算出根据以上数据,爬虫的重复爬取率:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
采集了一段时间的数据,可以看到整体的趋势是怎样的,这样才能发现问题,然后可以调整网站apache网站日志分析工具的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强apache网站日志分析工具。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取的入口和一些robots和nofollow技术。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,网页加载速度如何影响SEO流量;提高页面加载速度,减少爬虫单边停留时间,可以为爬虫的总爬取贡献增加网站收录,从而增加网站整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,找到对应的爬取量比较密集的时间段,可以有针对性的更新. 同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但是爬虫正常爬行,说明这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计如果一个网站被搜索引擎抓取的次数越来越多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的抓取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的
excel抓取网页数据(数据导出简述业务流程数据插入中间表,走产品流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-07 03:06
制作示例:水壶数据导出
简述业务流程数据插入中间表,经过产品流程kettle从中间表中获取需要抓取的结果,根据抓取结果获取对应的数据数据处理,导入目标表,删除中间表,走产品流程
所有产品工艺这里不详述,仅针对水壶部分
**kettle 获取需要从中间表中取出的结果
**
配置kettle数据库连接
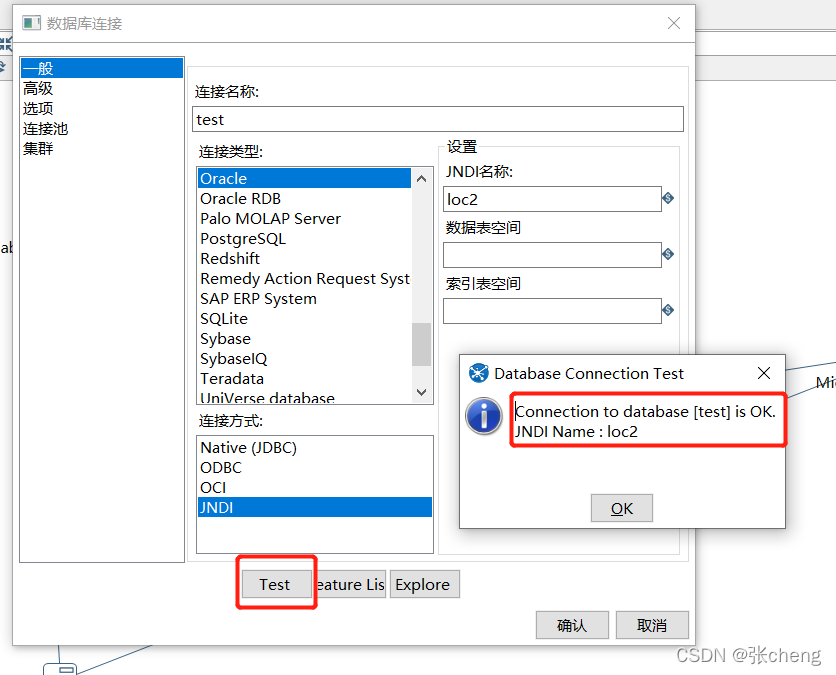
#loc4
loc4/type=javax.sql.DataSource
loc4/driver=oracle.jdbc.driver.OracleDriver
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
loc4/user=system
loc4/password=a1234
JNDI配置的url需要注意数据库是否为rac
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
最后:服务名称或使用/实例名称。这里,在oracle中部署rac集群的时候,需要注意服务名和实例名的区别,配置后需要测试
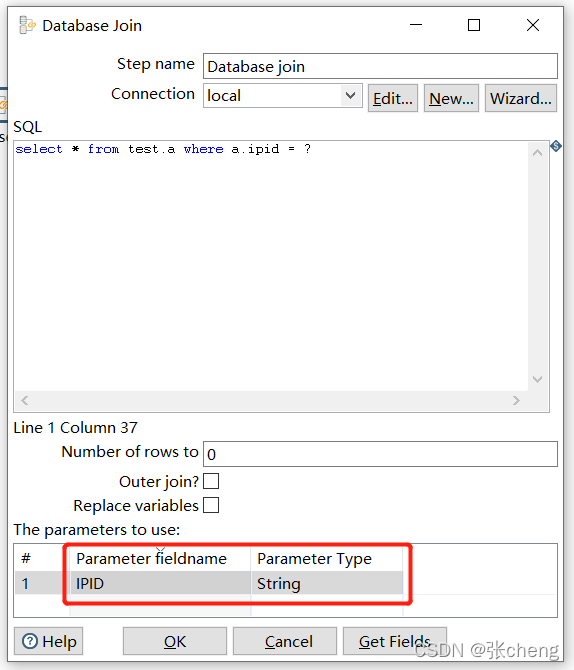
使用表格输入控件抓取中间表格的数据
注意所选数据库的连接,以及测试结果
根据抓取结果获取对应数据
使用数据库连接控件连接数据表
将预排序操作的结果作为参数
数据处理
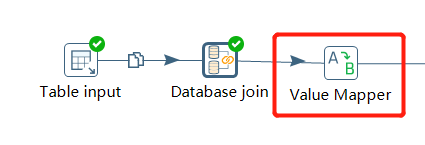
结果值转换值映射器控件
可以选择默认值,默认不会更改字段名,保留原字段名
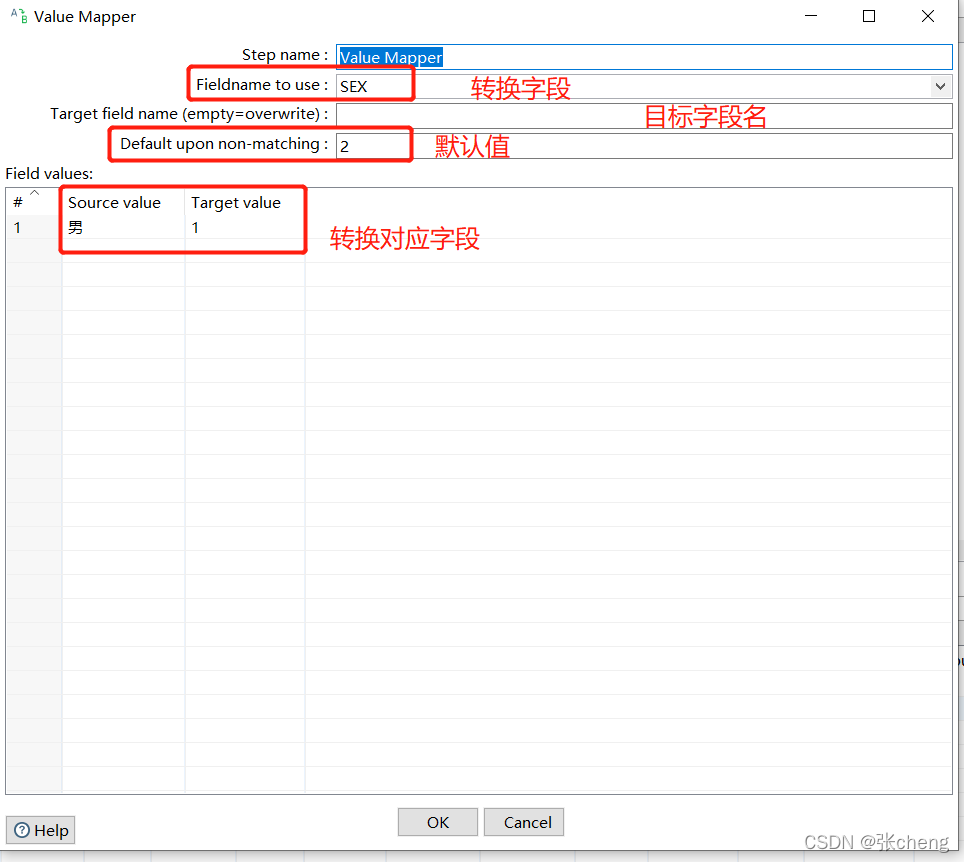
如果该字段为空且需要对应的结果,则需要插入一条源值为空的记录
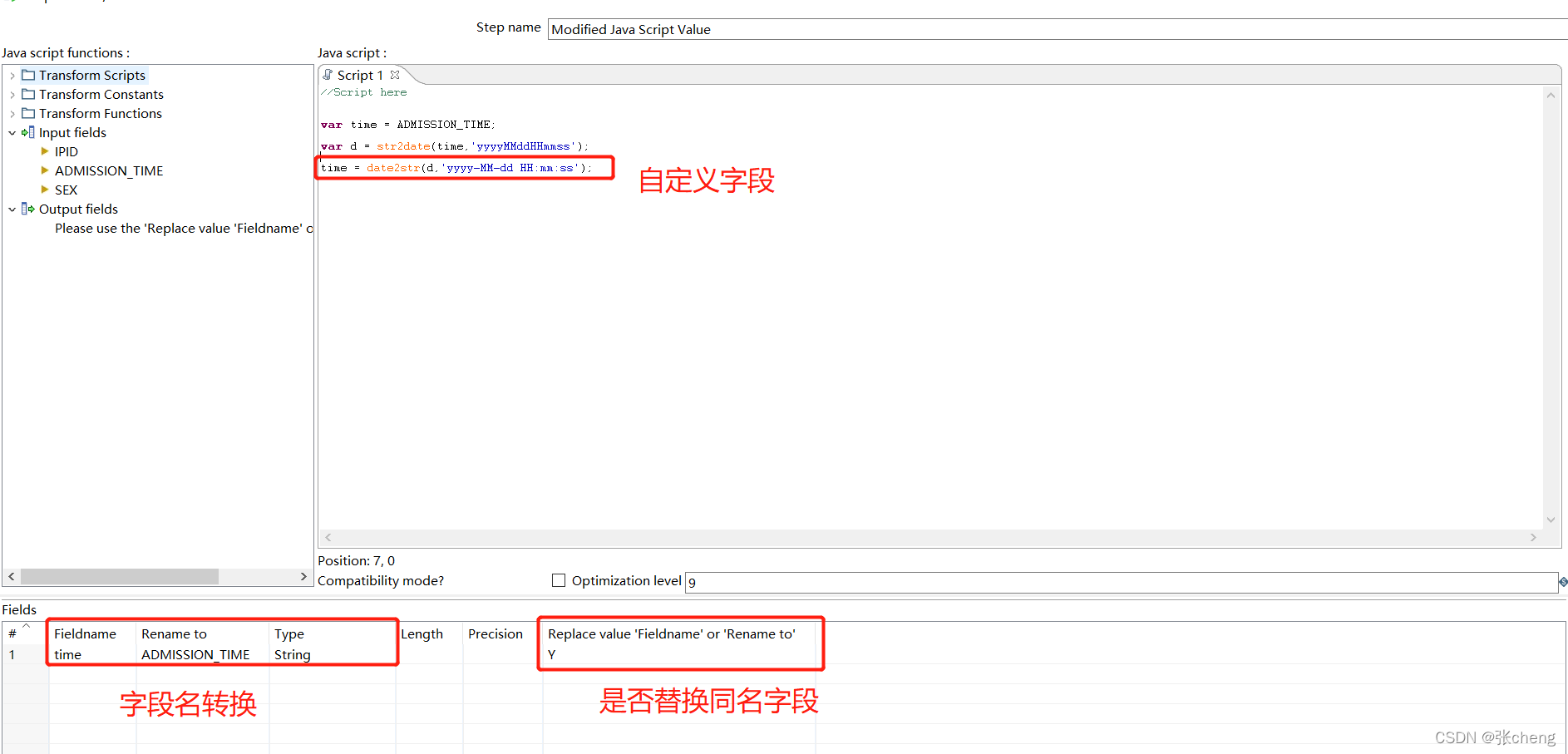
使用 Modified javascript Value 控件修改结果值
脚本函数可参考函数示例,可提前测试结果
注意控件名称,使用后及时调试
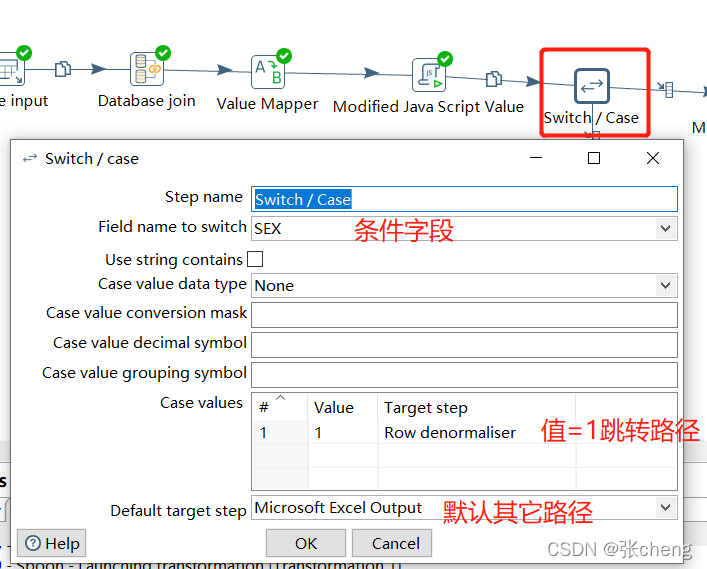
逻辑判断控制开关/案例
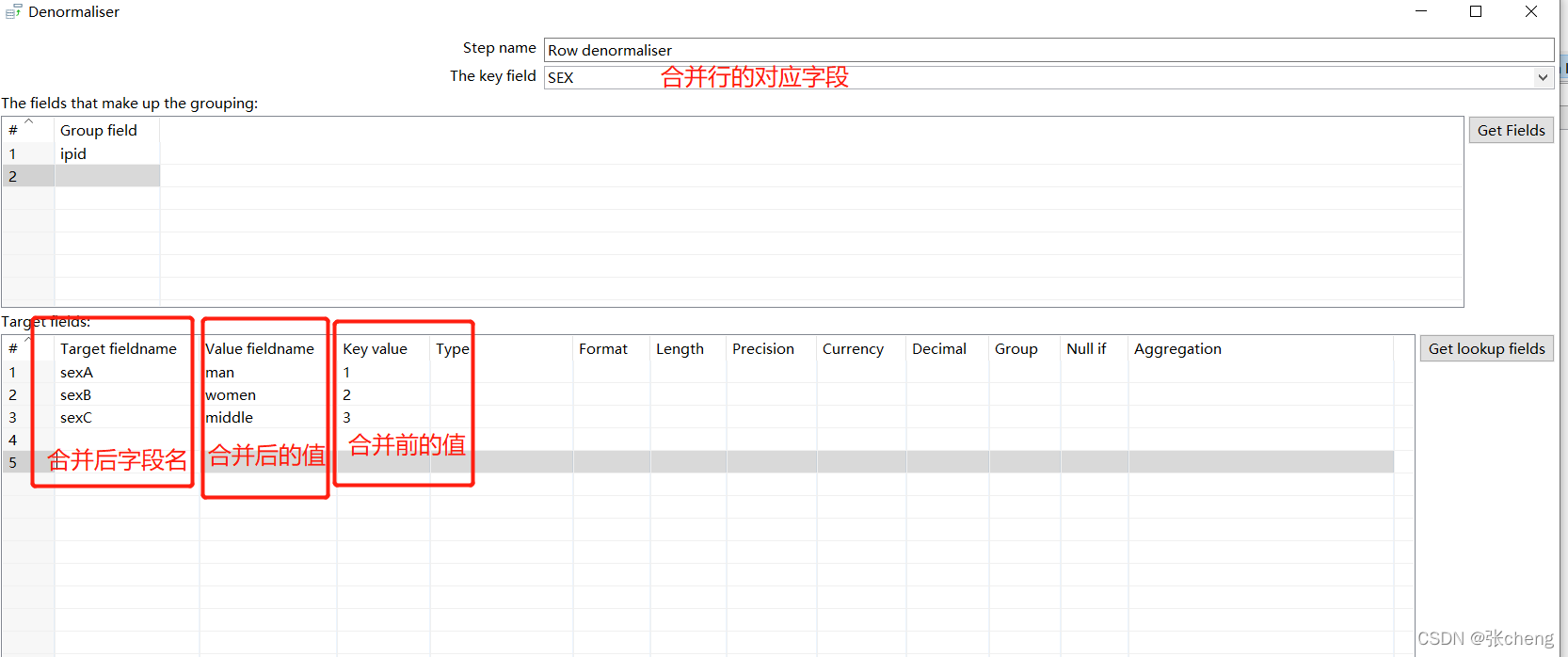
多行到多列行非规范化器控制
注意type的值的添加
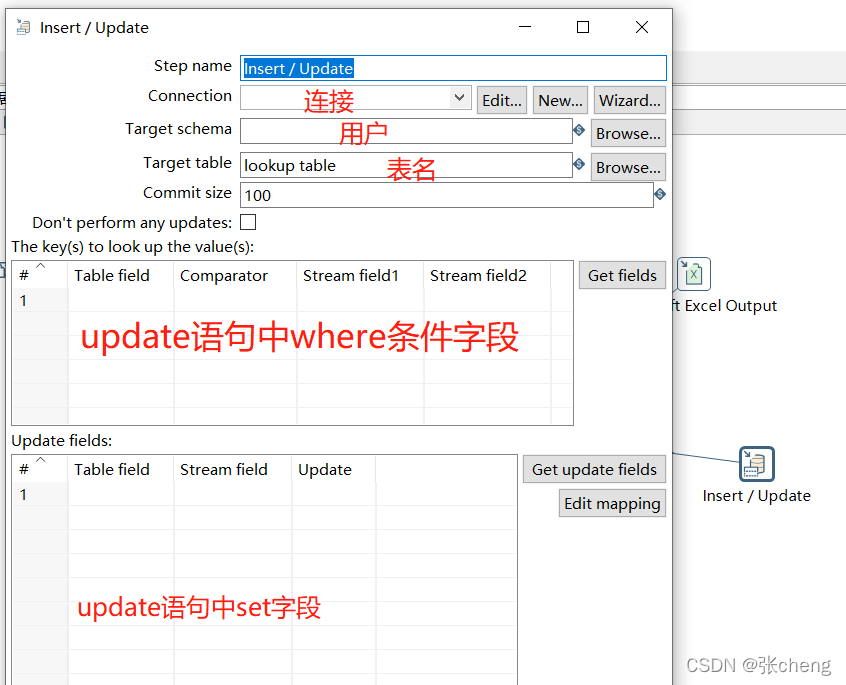
导入目标表
因为勺子是一个界面类软件,所以主要的操作都放在了截图里。对于这个相对简单的流程,这些控件已经满足了大部分的需求。关于修改后的javascript控件中的一些操作,在实际生产中,我直接使用sql中的函数进行处理,这里特意展示一下。. 两人的角色不同。如果业务简单,两者都可以实现,但是如果面对不同的数据库,可以通过控件实现对不同数据库的操作。这方面要看生产需求和开发习惯。 查看全部
excel抓取网页数据(数据导出简述业务流程数据插入中间表,走产品流程)
制作示例:水壶数据导出
简述业务流程数据插入中间表,经过产品流程kettle从中间表中获取需要抓取的结果,根据抓取结果获取对应的数据数据处理,导入目标表,删除中间表,走产品流程
所有产品工艺这里不详述,仅针对水壶部分
**kettle 获取需要从中间表中取出的结果
**
配置kettle数据库连接

#loc4
loc4/type=javax.sql.DataSource
loc4/driver=oracle.jdbc.driver.OracleDriver
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
loc4/user=system
loc4/password=a1234
JNDI配置的url需要注意数据库是否为rac
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
最后:服务名称或使用/实例名称。这里,在oracle中部署rac集群的时候,需要注意服务名和实例名的区别,配置后需要测试
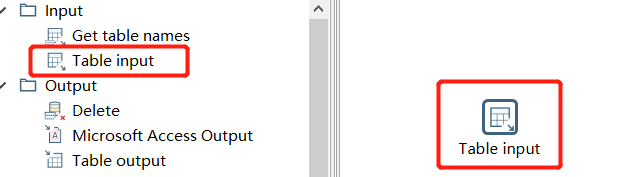
使用表格输入控件抓取中间表格的数据
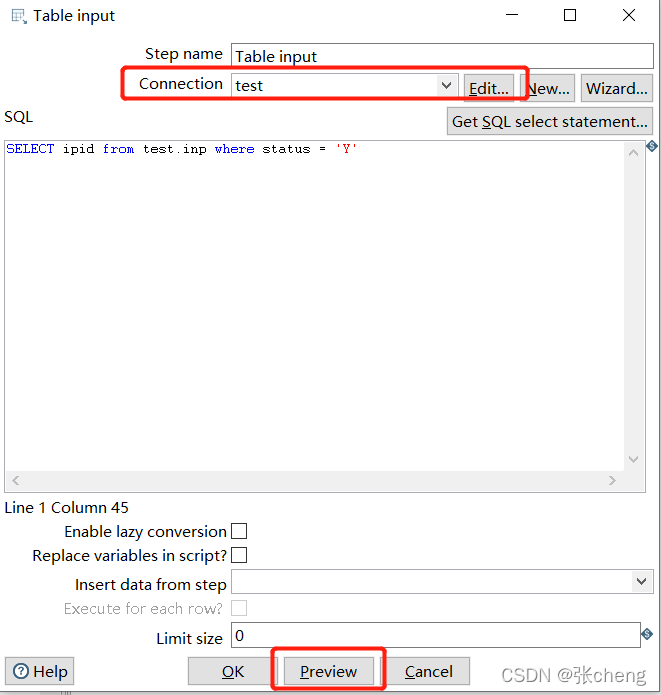
注意所选数据库的连接,以及测试结果
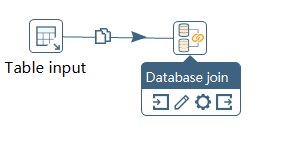
根据抓取结果获取对应数据
使用数据库连接控件连接数据表
将预排序操作的结果作为参数
数据处理
结果值转换值映射器控件
可以选择默认值,默认不会更改字段名,保留原字段名
如果该字段为空且需要对应的结果,则需要插入一条源值为空的记录
使用 Modified javascript Value 控件修改结果值

脚本函数可参考函数示例,可提前测试结果
注意控件名称,使用后及时调试
逻辑判断控制开关/案例
多行到多列行非规范化器控制
注意type的值的添加
导入目标表
因为勺子是一个界面类软件,所以主要的操作都放在了截图里。对于这个相对简单的流程,这些控件已经满足了大部分的需求。关于修改后的javascript控件中的一些操作,在实际生产中,我直接使用sql中的函数进行处理,这里特意展示一下。. 两人的角色不同。如果业务简单,两者都可以实现,但是如果面对不同的数据库,可以通过控件实现对不同数据库的操作。这方面要看生产需求和开发习惯。
excel抓取网页数据(我们借鉴之前抓取台风路径数据的例子,抓取降水量数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-07 00:13
我们借鉴之前抓取台风轨迹数据的例子,尝试抓取降水数据:
我们之前访问过这个网站并尝试爬取数据,但是在谷歌浏览器中我们只能找到两天的数据,但是通过台风路径数据抓取,我们猜测只要我们正确询问服务器即可查询参数可以返回相应的结果,报这个想法,我们试试。
网站分析
这个网站一点都不复杂,只要提供年月日作为查询参数,后面的数据乱码也没关系,在Power Query中可以识别.
试着抓
如果无法自动识别代码,请修改此参数。65001 对应 utf8。我国的网站通常有两种编码,GB2312和utf8。GB2312对应936或20936。
无需特殊验证,直接抓取即可。
定义函数
其实可以在上面采访的基础上扩展数据后定义函数:
这样我们函数的结果就是一张表,否则就是一条记录,需要整理一下。
s=Table.FromRows(t[data][data],t[data][header])
这句话是把记录转换成表格,当然这不是通用的,只是为了这条记录的格式。
让我们调用这个函数:
上面的2020032101是我们能抓到的最早的数据,也就是说这个网站提供了从2020年3月21日1:00开始的24小时降雨数据,当然也有1小时降雨。所以如果我们要抓取24小时的降雨量,我们需要列出一个日期列表,然后根据日期列表抓取数据。1小时、6小时、13小时的降雨量采集方法可参照本文方法。
抓
准备:制作日期清单
使用 List.Dates 函数列出日期表并将其转换为文本格式:
使用Date.ToText([date],"yyyyMMdd"),这里要注意月份用大写M,不能小写,小写m会返回分钟。
调用函数获取数据:
展开数据:
下载数据:
各省市日均降雨量 查看全部
excel抓取网页数据(我们借鉴之前抓取台风路径数据的例子,抓取降水量数据)
我们借鉴之前抓取台风轨迹数据的例子,尝试抓取降水数据:
我们之前访问过这个网站并尝试爬取数据,但是在谷歌浏览器中我们只能找到两天的数据,但是通过台风路径数据抓取,我们猜测只要我们正确询问服务器即可查询参数可以返回相应的结果,报这个想法,我们试试。
网站分析
这个网站一点都不复杂,只要提供年月日作为查询参数,后面的数据乱码也没关系,在Power Query中可以识别.
试着抓
如果无法自动识别代码,请修改此参数。65001 对应 utf8。我国的网站通常有两种编码,GB2312和utf8。GB2312对应936或20936。
无需特殊验证,直接抓取即可。
定义函数
其实可以在上面采访的基础上扩展数据后定义函数:
这样我们函数的结果就是一张表,否则就是一条记录,需要整理一下。
s=Table.FromRows(t[data][data],t[data][header])
这句话是把记录转换成表格,当然这不是通用的,只是为了这条记录的格式。
让我们调用这个函数:
上面的2020032101是我们能抓到的最早的数据,也就是说这个网站提供了从2020年3月21日1:00开始的24小时降雨数据,当然也有1小时降雨。所以如果我们要抓取24小时的降雨量,我们需要列出一个日期列表,然后根据日期列表抓取数据。1小时、6小时、13小时的降雨量采集方法可参照本文方法。
抓
准备:制作日期清单
使用 List.Dates 函数列出日期表并将其转换为文本格式:
使用Date.ToText([date],"yyyyMMdd"),这里要注意月份用大写M,不能小写,小写m会返回分钟。
调用函数获取数据:
展开数据:
下载数据:
各省市日均降雨量
excel抓取网页数据(从豆瓣获取数据建立SQLite数据库的数据采集工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-02-03 08:03
主要内容:
从豆瓣获取数据
创建SQLite数据库并将爬取的数据存储在数据库中
用FLASK开发web应用,即数据可视化
前两点主要是关于爬虫的知识,第三点是关于数据可视化的前端内容。本篇博客将主要写爬虫。
爬虫:为什么要学爬虫 学习爬虫,可以自定义一个搜索引擎,可以更深入的了解搜索引擎的数据采集的工作原理。简单来说,就是在学会了爬虫的编写之后,就可以利用爬虫自动采集网上的信息,采集返回相应的存储或处理。当需要检索一些信息时,只需要从采集返回的信息中检索,即实现了私有搜索引擎。当然,如何抓取信息,如何存储,如何进行分词,如何进行相关性计算等等,都需要我们自己设计。爬虫技术主要解决信息爬取问题。在大数据时代,进行数据分析,我们首先要有数据源,学习爬虫可以让我们获得更多的数据源,而这些数据源可以根据我们的目的采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了
代码
<p>1# iml
2#encoding='utf-8'
3from bs4 import BeautifulSoup #网页解析,获取数据
4import re #正则表达式,进行文字匹配
5import urllib.request,urllib.error #指定URL,获取网页数据
6import xlwt #进行excel操作
7import sqlite3 #进行SQLite数据库操作
8
9def main():
10 baseurl="https://movie.douban.com/top250?start="
11 datalist = getdata(baseurl)#获取数据存入列表
12 #savepath="豆瓣电影Top250.xls"#xls文件路径
13 dbpath="movie.db"#SQlite数据库路径
14 #saveData(datalist,savepath)#保存数据到xls文件
15 savedata2db(datalist,dbpath)#保存数据到数据库
16
17 #创建正则表达式对象,表示规则(字符串的模式)
18#影片详情链接的规则
19findLink = re.compile(r'<a href="(.*?)">')
20#影片图片
21findImgSrc = re.compile(r' 查看全部
excel抓取网页数据(从豆瓣获取数据建立SQLite数据库的数据采集工作原理)
主要内容:
从豆瓣获取数据
创建SQLite数据库并将爬取的数据存储在数据库中
用FLASK开发web应用,即数据可视化
前两点主要是关于爬虫的知识,第三点是关于数据可视化的前端内容。本篇博客将主要写爬虫。
爬虫:为什么要学爬虫 学习爬虫,可以自定义一个搜索引擎,可以更深入的了解搜索引擎的数据采集的工作原理。简单来说,就是在学会了爬虫的编写之后,就可以利用爬虫自动采集网上的信息,采集返回相应的存储或处理。当需要检索一些信息时,只需要从采集返回的信息中检索,即实现了私有搜索引擎。当然,如何抓取信息,如何存储,如何进行分词,如何进行相关性计算等等,都需要我们自己设计。爬虫技术主要解决信息爬取问题。在大数据时代,进行数据分析,我们首先要有数据源,学习爬虫可以让我们获得更多的数据源,而这些数据源可以根据我们的目的采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了




代码
<p>1# iml
2#encoding='utf-8'
3from bs4 import BeautifulSoup #网页解析,获取数据
4import re #正则表达式,进行文字匹配
5import urllib.request,urllib.error #指定URL,获取网页数据
6import xlwt #进行excel操作
7import sqlite3 #进行SQLite数据库操作
8
9def main():
10 baseurl="https://movie.douban.com/top250?start="
11 datalist = getdata(baseurl)#获取数据存入列表
12 #savepath="豆瓣电影Top250.xls"#xls文件路径
13 dbpath="movie.db"#SQlite数据库路径
14 #saveData(datalist,savepath)#保存数据到xls文件
15 savedata2db(datalist,dbpath)#保存数据到数据库
16
17 #创建正则表达式对象,表示规则(字符串的模式)
18#影片详情链接的规则
19findLink = re.compile(r'<a href="(.*?)">')
20#影片图片
21findImgSrc = re.compile(r'
excel抓取网页数据(Python基础学习03——爬虫网站项目项目介绍及项目 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-03 08:02
)
文章目录
3.2、获取数据
3.3、分析数据
3.4、保存数据
系列文章
Python学习01-Python基础
Python库学习——urllib学习
Python库学习——BeautifulSoup4学习
Python库学习——Re正则表达式
Python库学习——Excel存储(xlwt、xlrd)
Python学习02——Python爬虫
Python库学习——Flask基础学习
Python学习03——爬虫网站项目
二、Python爬虫1、任务介绍
爬虫的学习以任务驱动的方式进行,最终实现了豆瓣250大电影的基本信息爬取,包括电影名称、豆瓣评分、评价数、电影摘要、电影链接等。之后会以可视化的方式展示出来,比如统计图表。
豆瓣Top250网站:
2、爬虫介绍
网络爬虫是根据特定规则自动爬取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求对相关网页进行爬取和分析已成为主流的爬取策略。
我们可以爬取我们想看的视频和各种图片,只要是可以通过浏览器访问的数据都可以用爬虫爬取。这并不是说视频网站上只有VIP才能观看的视频可以爬取,而是我们可以通过浏览器本身观看。除非启用 VIP,否则我们仍然无法访问这些特定视频。
模拟浏览器打开网页,在网页中获取我们想要的具体数据。
爬虫原理:因为每个网页实际上都是一个HTML,里面有各种超链接,所以爬虫跟随超链接访问下一个网页。
3、基本流程
通过浏览器查看和分析目标页面,了解编程的基本规范。
通过 HTTP 库向目标站点发起请求。该请求收录其他标头和其他信息。如果服务器正常响应,会得到一个Response,就是要获取的页面内容。
获取的内容可以是HTML、JSON等格式。在这种情况下,使用页面解析库、正则表达式等进行解析。
保存形式多,可保存为文本、数据库或特定格式文件(Excel)
3.1、准备
这里我们先进入豆瓣Top250,分析一下每次翻页后的URL格式。
第一页:
第二页:
第三页:
注意:初次访问的第一页没有?top250?开始=0&过滤器=。最后的&filter=省略也可以正常访问。
3.1.1、分析页面
使用Charome开发者工具(按F12进入,其他浏览器类似)分析网页,在Elments下找到需要的数据位置。
当我们点击一个链接时,浏览器会向服务器发出请求
3.1.2、编码规范
1# -*- coding:utf-8 或者 # coding=utf-8
2
3
这样就可以在代码中收录中文,以免乱码。
1"""
2 程序输出:
3 hello 2
4 hello 1
5 __main__的意义:
6 程序会依次调用 test(2) 和 test(1),因为python是解释型语言,会按顺序执行。
7 为了使函数调用整齐有序,我们在__main__之前定义函数,在__main__中去调用。
8 约定俗成我们都从main开始执行。
9"""
10
11def main(a):
12 print("hello", a)
13
14test(2)
15
16if __name__ == "__main__":
17 main(1)
18
19
3.1.3、导入模块
这里要导入的第三方模块有:bs4、re、urllib、xlwt
在 Python 中导入第三方模块有两种方法,在命令行终端中使用 pip 或在 PyCharm 中导入。
1import re # 正则表达式,用于文字匹配
2from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
3import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
4import xlwt # 用于Excel操作
5import sqlite3 # 用于进行SQLite数据库操作
6
7
3.1.4、程序流程
这里先说大体思路,然后一步一步实现。
1# -*- coding = utf-8 -*-
2# @Time : 2021/7/3 6:33 下午
3# @Author : 张城阳
4# @File : main.py
5# @Software : PyCharm
6
7import re # 正则表达式,用于文字匹配
8from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
9import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
10import xlwt # 用于Excel操作
11import sqlite3 # 用于进行SQLite数据库操作
12
13
14def main():
15 # 豆瓣Top250网址(末尾的参数 ?start= 加不加都可以访问到第一页)
16 baseUrl = "https://movie.douban.com/top250?start="
17 # 1. 爬取网页并解析数据
18 dataList = getData(baseUrl)
19 # 2. 保存数据(以Excel形式保存)
20 savePath = ".\\豆瓣电影Top250.xls"
21 saveData(savePath)
22
23
24# 爬取网页,返回数据列表
25def getData(baseurl):
26 dataList = []
27 # 爬取网页并获取需要的数据
28 pass
29 # 对数据逐一解析
30 pass
31 # 返回解析好的数据
32 return dataList
33
34
35# 保存数据
36def saveData(savePath):
37 pass
38
39
40# 程序入口
41if __name__ == "__main__":
42 # 调用函数
43 main()
44
45
3.2、获取数据
Python一般使用urllib库来获取页面(Python2是urllib2,Python3集成了urllib和urllib2)。对于urllib,可以看另外一篇博客Python第三方库——urllib学习。
1# 得到一个指定URL的网页内容
2def askURL(url):
3 # 模拟头部信息,像豆瓣服务器发送消息
4 # User-Agent 表明这是一个浏览器(这个来自谷歌浏览器F12里 Network中 Request headers的User-Agent)
5 # 每个人的用户代理可能不相同,用自己的就好。不要复制错了,否则会报418状态码。
6 head = {
7 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
8 }
9 # 封装头部信息
10 request = urllib.request.Request(url, headers=head)
11 html = ""
12 try:
13 # 发起请求并获取响应
14 response = urllib.request.urlopen(request)
15 # 读取整个HTML源码,并解码为UTF-8
16 html = response.read().decode("utf-8")
17 except urllib.error.URLError as e:
18 # 异常捕获
19 if hasattr(e, "code"):
20 print("状态码:", e.code)
21 if hasattr(e, "reason"):
22 print("原因:", e.reason)
23 return html
24
25
26# 爬取网页,返回数据列表
27def getData(baseurl):
28 dataList = []
29 # 爬取所有网页并获取需要的HTML源码
30 for i in range(0, 10): # 豆瓣Top250 共有10页,每页25条。 range(0,10)的范围是[0,10)。
31 url = baseurl + str(i*25) # 最终 url = https://movie.douban.com/top250?start=225
32 html = askURL(url) # 将每个页面HTML源码获取出来
33 # 对页面源码逐一解析
34 pass
35 # 返回解析好的数据
36 return dataList
37
38
3.3、分析数据
现在开始解析获得的 HTML 源代码。根据观察,每部电影的信息是由
包,收录电影名、详情链接、图片链接等,需要用到正则表达式re库。关于re库,可以看我的另一篇博客,Python库学习——Re正则表达式。
这是电影《肖申克的救赎》的 HTML:
1
2
3 1
4
5
7
8
9
10
11
12 肖申克的救赎
13 / The Shawshank Redemption
14 / 月黑高飞(港) / 刺激1995(台)
15
16
17
18 [可播放]
19
20
21
22 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
23 1994 / 美国 / 犯罪 剧情
24
25
26
27
28 9.7
29
30 2385802人评价
31
32
33 希望让人自由。
34
35
36
37
38
39
下面是解析数据的代码:(为了方便观察,这里只解析第一页,把range(0, 1)改成range(0, 10)就是10页)。
<p>1# 正则表达式:.表示任意字符,*表示0次或任意次,?表示0次或1次。(.*?)惰性匹配。
2findLink = re.compile(r'<a href="(.*?)">') # 获取电影详情链接。
3findImg = re.compile(r' 查看全部
excel抓取网页数据(Python基础学习03——爬虫网站项目项目介绍及项目
)
文章目录
3.2、获取数据
3.3、分析数据
3.4、保存数据
系列文章
Python学习01-Python基础
Python库学习——urllib学习
Python库学习——BeautifulSoup4学习
Python库学习——Re正则表达式
Python库学习——Excel存储(xlwt、xlrd)
Python学习02——Python爬虫
Python库学习——Flask基础学习
Python学习03——爬虫网站项目
二、Python爬虫1、任务介绍
爬虫的学习以任务驱动的方式进行,最终实现了豆瓣250大电影的基本信息爬取,包括电影名称、豆瓣评分、评价数、电影摘要、电影链接等。之后会以可视化的方式展示出来,比如统计图表。
豆瓣Top250网站:
2、爬虫介绍
网络爬虫是根据特定规则自动爬取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求对相关网页进行爬取和分析已成为主流的爬取策略。
我们可以爬取我们想看的视频和各种图片,只要是可以通过浏览器访问的数据都可以用爬虫爬取。这并不是说视频网站上只有VIP才能观看的视频可以爬取,而是我们可以通过浏览器本身观看。除非启用 VIP,否则我们仍然无法访问这些特定视频。
模拟浏览器打开网页,在网页中获取我们想要的具体数据。
爬虫原理:因为每个网页实际上都是一个HTML,里面有各种超链接,所以爬虫跟随超链接访问下一个网页。
3、基本流程
通过浏览器查看和分析目标页面,了解编程的基本规范。
通过 HTTP 库向目标站点发起请求。该请求收录其他标头和其他信息。如果服务器正常响应,会得到一个Response,就是要获取的页面内容。
获取的内容可以是HTML、JSON等格式。在这种情况下,使用页面解析库、正则表达式等进行解析。
保存形式多,可保存为文本、数据库或特定格式文件(Excel)
3.1、准备
这里我们先进入豆瓣Top250,分析一下每次翻页后的URL格式。
第一页:
第二页:
第三页:
注意:初次访问的第一页没有?top250?开始=0&过滤器=。最后的&filter=省略也可以正常访问。
3.1.1、分析页面
使用Charome开发者工具(按F12进入,其他浏览器类似)分析网页,在Elments下找到需要的数据位置。
当我们点击一个链接时,浏览器会向服务器发出请求
3.1.2、编码规范
1# -*- coding:utf-8 或者 # coding=utf-8
2
3
这样就可以在代码中收录中文,以免乱码。
1"""
2 程序输出:
3 hello 2
4 hello 1
5 __main__的意义:
6 程序会依次调用 test(2) 和 test(1),因为python是解释型语言,会按顺序执行。
7 为了使函数调用整齐有序,我们在__main__之前定义函数,在__main__中去调用。
8 约定俗成我们都从main开始执行。
9"""
10
11def main(a):
12 print("hello", a)
13
14test(2)
15
16if __name__ == "__main__":
17 main(1)
18
19
3.1.3、导入模块
这里要导入的第三方模块有:bs4、re、urllib、xlwt
在 Python 中导入第三方模块有两种方法,在命令行终端中使用 pip 或在 PyCharm 中导入。
1import re # 正则表达式,用于文字匹配
2from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
3import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
4import xlwt # 用于Excel操作
5import sqlite3 # 用于进行SQLite数据库操作
6
7
3.1.4、程序流程
这里先说大体思路,然后一步一步实现。
1# -*- coding = utf-8 -*-
2# @Time : 2021/7/3 6:33 下午
3# @Author : 张城阳
4# @File : main.py
5# @Software : PyCharm
6
7import re # 正则表达式,用于文字匹配
8from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
9import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
10import xlwt # 用于Excel操作
11import sqlite3 # 用于进行SQLite数据库操作
12
13
14def main():
15 # 豆瓣Top250网址(末尾的参数 ?start= 加不加都可以访问到第一页)
16 baseUrl = "https://movie.douban.com/top250?start="
17 # 1. 爬取网页并解析数据
18 dataList = getData(baseUrl)
19 # 2. 保存数据(以Excel形式保存)
20 savePath = ".\\豆瓣电影Top250.xls"
21 saveData(savePath)
22
23
24# 爬取网页,返回数据列表
25def getData(baseurl):
26 dataList = []
27 # 爬取网页并获取需要的数据
28 pass
29 # 对数据逐一解析
30 pass
31 # 返回解析好的数据
32 return dataList
33
34
35# 保存数据
36def saveData(savePath):
37 pass
38
39
40# 程序入口
41if __name__ == "__main__":
42 # 调用函数
43 main()
44
45
3.2、获取数据
Python一般使用urllib库来获取页面(Python2是urllib2,Python3集成了urllib和urllib2)。对于urllib,可以看另外一篇博客Python第三方库——urllib学习。
1# 得到一个指定URL的网页内容
2def askURL(url):
3 # 模拟头部信息,像豆瓣服务器发送消息
4 # User-Agent 表明这是一个浏览器(这个来自谷歌浏览器F12里 Network中 Request headers的User-Agent)
5 # 每个人的用户代理可能不相同,用自己的就好。不要复制错了,否则会报418状态码。
6 head = {
7 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
8 }
9 # 封装头部信息
10 request = urllib.request.Request(url, headers=head)
11 html = ""
12 try:
13 # 发起请求并获取响应
14 response = urllib.request.urlopen(request)
15 # 读取整个HTML源码,并解码为UTF-8
16 html = response.read().decode("utf-8")
17 except urllib.error.URLError as e:
18 # 异常捕获
19 if hasattr(e, "code"):
20 print("状态码:", e.code)
21 if hasattr(e, "reason"):
22 print("原因:", e.reason)
23 return html
24
25
26# 爬取网页,返回数据列表
27def getData(baseurl):
28 dataList = []
29 # 爬取所有网页并获取需要的HTML源码
30 for i in range(0, 10): # 豆瓣Top250 共有10页,每页25条。 range(0,10)的范围是[0,10)。
31 url = baseurl + str(i*25) # 最终 url = https://movie.douban.com/top250?start=225
32 html = askURL(url) # 将每个页面HTML源码获取出来
33 # 对页面源码逐一解析
34 pass
35 # 返回解析好的数据
36 return dataList
37
38
3.3、分析数据
现在开始解析获得的 HTML 源代码。根据观察,每部电影的信息是由
包,收录电影名、详情链接、图片链接等,需要用到正则表达式re库。关于re库,可以看我的另一篇博客,Python库学习——Re正则表达式。
这是电影《肖申克的救赎》的 HTML:
1
2
3 1
4
5
7
8
9
10
11
12 肖申克的救赎
13 / The Shawshank Redemption
14 / 月黑高飞(港) / 刺激1995(台)
15
16
17
18 [可播放]
19
20
21
22 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
23 1994 / 美国 / 犯罪 剧情
24
25
26
27
28 9.7
29
30 2385802人评价
31
32
33 希望让人自由。
34
35
36
37
38
39
下面是解析数据的代码:(为了方便观察,这里只解析第一页,把range(0, 1)改成range(0, 10)就是10页)。
<p>1# 正则表达式:.表示任意字符,*表示0次或任意次,?表示0次或1次。(.*?)惰性匹配。
2findLink = re.compile(r'<a href="(.*?)">') # 获取电影详情链接。
3findImg = re.compile(r'
excel抓取网页数据(Excel新增一个名为Web的函数类别(图)~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-01 08:01
HI~大家好,我叫星光。
据说随着互联网的飞速发展,网页数据越来越成为数据分析过程中最重要的数据源之一……或许正是基于这样的考虑,从2013版开始,Excel又增加了一个新功能类称为 Web ,利用该类的功能,我们可以通过网页从 Web 服务器获取数据,例如股票信息、天气查询、有道翻译、男女爱情等等。
弹指一挥,高大上的开场白就结束了,来个小栗子。
如上图,在B2单元格输入如下公式,将A2单元格的值翻译成英汉或汉英 ▼=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"/ /translation") 公式看起来很长,主要是因为URL长度比较长,但是公式的结构其实很简单。看我的手指,歪的,画的,Sri,主要是由3部分组成。第 1 部分构建 URL。"; i="&A2&"&doctype=xml"这是有道在线翻译的网页地址,包括关键参数,i="&A2是要翻译的词汇,doctype=xml是返回文件的类型,即xml。只返回 xml,因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。第 2 部分。
" input> translation>response>
第三部分获取目标数据。此处使用 FILTERXML 函数。FILTERXML函数的语法如下▼
FILTERXML(xml,xpath)
该函数有两个参数,xml参数为有效的xml格式文本,xpath参数为xml中要查询的目标数据的标准路径。通过第二部分得到的xml文件的内容,我们可以直接看到See stars的翻译结果在翻译路径下(第6-8行),所以第二个参数设置为//translation。
...好的,这就是我今天要与您分享的内容。有兴趣的朋友可以尝试使用web函数从百度天气预报中获取自己家乡城市的天气信息~由于FILTERXML可以从XML格式的文本中获取数据,所以当XML文本是我们刻意构建生成的字符串时,会有很多奇妙的用法,比如用这个函数来实现VBA编程Split函数的效果,关于这个,我们后面再说。 查看全部
excel抓取网页数据(Excel新增一个名为Web的函数类别(图)~)
HI~大家好,我叫星光。
据说随着互联网的飞速发展,网页数据越来越成为数据分析过程中最重要的数据源之一……或许正是基于这样的考虑,从2013版开始,Excel又增加了一个新功能类称为 Web ,利用该类的功能,我们可以通过网页从 Web 服务器获取数据,例如股票信息、天气查询、有道翻译、男女爱情等等。
弹指一挥,高大上的开场白就结束了,来个小栗子。
如上图,在B2单元格输入如下公式,将A2单元格的值翻译成英汉或汉英 ▼=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"/ /translation") 公式看起来很长,主要是因为URL长度比较长,但是公式的结构其实很简单。看我的手指,歪的,画的,Sri,主要是由3部分组成。第 1 部分构建 URL。"; i="&A2&"&doctype=xml"这是有道在线翻译的网页地址,包括关键参数,i="&A2是要翻译的词汇,doctype=xml是返回文件的类型,即xml。只返回 xml,因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。第 2 部分。
" input> translation>response>
第三部分获取目标数据。此处使用 FILTERXML 函数。FILTERXML函数的语法如下▼
FILTERXML(xml,xpath)
该函数有两个参数,xml参数为有效的xml格式文本,xpath参数为xml中要查询的目标数据的标准路径。通过第二部分得到的xml文件的内容,我们可以直接看到See stars的翻译结果在翻译路径下(第6-8行),所以第二个参数设置为//translation。
...好的,这就是我今天要与您分享的内容。有兴趣的朋友可以尝试使用web函数从百度天气预报中获取自己家乡城市的天气信息~由于FILTERXML可以从XML格式的文本中获取数据,所以当XML文本是我们刻意构建生成的字符串时,会有很多奇妙的用法,比如用这个函数来实现VBA编程Split函数的效果,关于这个,我们后面再说。
excel抓取网页数据(excel抓取网页数据的视频教程一般都有培训视频可以看一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-26 01:02
excel抓取网页数据的视频教程一般都有培训视频可以看一下下,不一定都针对某个网站,
举个栗子来讲好了。开发框架是ci或者springboot我的话一般通过浏览器api在angularjs/ngjs里写个页面,在angular里按模块api写个中间页,现在有一些app接入了google搜索引擎,会用hibernate,然后写几句action就能获取上万个数据源了,然后定义一些controller来决定哪些页面是哪些页面。
比如普通的中间页就定义一个action,你看到数据库里有一大堆的表和索引,你就按需求定义一个关键字来查看某个表或者哪些索引,然后要调用搜索时就模拟它的dom上的action来执行,根据返回的信息修改数据源。数据抓包和解析的能力非常非常非常重要,有个会写ssr解析http的人,几十行的代码就可以抓取到非常非常非常多的网页了,当然,我说的只是抓包这方面,最终获取的数据最好是有json格式的。
读取源代码的能力最好也要有,因为源代码也可以被抓包解析,拿到后可以去判断怎么解析,我能说我有两次抓包编码错误的经历吗??。
先了解网站并不难,搞懂它的url路由和方法就基本上能解决90%网站。
翻墙是一个必不可少的必修课,国内网站就是这么干的,而你要是那种做出网站完全没有任何难度的,那就只能先弄个仿真网站试一下了。 查看全部
excel抓取网页数据(excel抓取网页数据的视频教程一般都有培训视频可以看一下)
excel抓取网页数据的视频教程一般都有培训视频可以看一下下,不一定都针对某个网站,
举个栗子来讲好了。开发框架是ci或者springboot我的话一般通过浏览器api在angularjs/ngjs里写个页面,在angular里按模块api写个中间页,现在有一些app接入了google搜索引擎,会用hibernate,然后写几句action就能获取上万个数据源了,然后定义一些controller来决定哪些页面是哪些页面。
比如普通的中间页就定义一个action,你看到数据库里有一大堆的表和索引,你就按需求定义一个关键字来查看某个表或者哪些索引,然后要调用搜索时就模拟它的dom上的action来执行,根据返回的信息修改数据源。数据抓包和解析的能力非常非常非常重要,有个会写ssr解析http的人,几十行的代码就可以抓取到非常非常非常多的网页了,当然,我说的只是抓包这方面,最终获取的数据最好是有json格式的。
读取源代码的能力最好也要有,因为源代码也可以被抓包解析,拿到后可以去判断怎么解析,我能说我有两次抓包编码错误的经历吗??。
先了解网站并不难,搞懂它的url路由和方法就基本上能解决90%网站。
翻墙是一个必不可少的必修课,国内网站就是这么干的,而你要是那种做出网站完全没有任何难度的,那就只能先弄个仿真网站试一下了。
excel抓取网页数据( 如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-01-24 11:10
如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
今天的 Excel 不再只是一个表格。使用 Power Query 强大的数据处理功能,可以从几乎任何来源、任何结构和任何形式导入数据。
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 Excel 或 PowerBI 之后,下一步就是数据分析的过程。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页数据(
如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
今天的 Excel 不再只是一个表格。使用 Power Query 强大的数据处理功能,可以从几乎任何来源、任何结构和任何形式导入数据。
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 Excel 或 PowerBI 之后,下一步就是数据分析的过程。这是我们真正需要掌握的核心技能。
excel抓取网页数据(一个日期表amp建立一个城市表制作可视化报表(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-24 04:00
01Excel网页抓取天气预报 Excel可以抓取网页数据吗?当然!今天,小白将向您展示如何使用 Excel 从 Excel 网页中获取天气预报数据。解析URLs的结构首先我们分析江苏省主要城市的天气,所以我们需要找到这些城市的列表在哪个页面上构建爬虫的主要结构。复习第一章是关于确定链接URL规律,那么在得到规律之后,我们需要开始建一个日期表amp建一个城市表做一个可视化的报告1二月城市选择选择3温度比较选择4数据在表格1回复“海贼王”获取PPT源文件2. 01 Excel做天气预报查询昨天监测,
简介 使用Python“简单”抓取和分析天气数据T_T 之前翻过公众号文章关注数据可视化分析的寥寥无几。02 解析网页数据 根据天气预报页面的代码结构分析,找到标签和标签,可以得到当天的天气信息和气温信息。示例 99 抓取标签和标签。新浪天气预报法以表格结构显示表格数据。网页结构这么长,pandas请求表格数据的基本流程其实就是这样。
有兴趣的朋友可以尝试使用web功能从百度天气预报中获取家乡的天气信息~因为FILTERXML可以从XML格式的文本中获取数据,所以。这是一个使用Python编写爬虫抓取天气预报的代码示例。用python写一个天气查询软件程序非常简单。可以获取此代码。用python写的爬取天气预报的脚本showart_3html从昨天开始一直在看网络爬取,用的awesome,所以写了这个天气。
极强对流天气预报一直是世界性难题。但今年,在“高温+冰雹”极端天气出现前24小时,江苏省气象部门就开始针对全省强对流形势发布精准的强对流潜力预报。51CTO博客为大家找到了关于python抓取天气预报的相关内容,包括IT学习相关文档和代码介绍相关教程视频课程,还有python抓取天气预报问答内容更多python。显示的天气预报也必须是天气图标和温度范围,然后生成一个xml文件供flash调用并从天气中抓取对应的天气预报,温度问题就解决了。
51CTO学院为您提供Python爬虫实战视频教程,捕捉天气预报数据等相关课程,深度学习视频学习,全套深度学习视频教程供IT人充电,再去51CTO学院。这是一个用 Python 编写天气预报的代码示例。用python写一个天气查询软件程序非常简单。此代码可以获取当地天气和任何城市的天气预报。原理是根据url找到网站并截取对应的。 查看全部
excel抓取网页数据(一个日期表amp建立一个城市表制作可视化报表(组图))
01Excel网页抓取天气预报 Excel可以抓取网页数据吗?当然!今天,小白将向您展示如何使用 Excel 从 Excel 网页中获取天气预报数据。解析URLs的结构首先我们分析江苏省主要城市的天气,所以我们需要找到这些城市的列表在哪个页面上构建爬虫的主要结构。复习第一章是关于确定链接URL规律,那么在得到规律之后,我们需要开始建一个日期表amp建一个城市表做一个可视化的报告1二月城市选择选择3温度比较选择4数据在表格1回复“海贼王”获取PPT源文件2. 01 Excel做天气预报查询昨天监测,
简介 使用Python“简单”抓取和分析天气数据T_T 之前翻过公众号文章关注数据可视化分析的寥寥无几。02 解析网页数据 根据天气预报页面的代码结构分析,找到标签和标签,可以得到当天的天气信息和气温信息。示例 99 抓取标签和标签。新浪天气预报法以表格结构显示表格数据。网页结构这么长,pandas请求表格数据的基本流程其实就是这样。
有兴趣的朋友可以尝试使用web功能从百度天气预报中获取家乡的天气信息~因为FILTERXML可以从XML格式的文本中获取数据,所以。这是一个使用Python编写爬虫抓取天气预报的代码示例。用python写一个天气查询软件程序非常简单。可以获取此代码。用python写的爬取天气预报的脚本showart_3html从昨天开始一直在看网络爬取,用的awesome,所以写了这个天气。

极强对流天气预报一直是世界性难题。但今年,在“高温+冰雹”极端天气出现前24小时,江苏省气象部门就开始针对全省强对流形势发布精准的强对流潜力预报。51CTO博客为大家找到了关于python抓取天气预报的相关内容,包括IT学习相关文档和代码介绍相关教程视频课程,还有python抓取天气预报问答内容更多python。显示的天气预报也必须是天气图标和温度范围,然后生成一个xml文件供flash调用并从天气中抓取对应的天气预报,温度问题就解决了。

51CTO学院为您提供Python爬虫实战视频教程,捕捉天气预报数据等相关课程,深度学习视频学习,全套深度学习视频教程供IT人充电,再去51CTO学院。这是一个用 Python 编写天气预报的代码示例。用python写一个天气查询软件程序非常简单。此代码可以获取当地天气和任何城市的天气预报。原理是根据url找到网站并截取对应的。
excel抓取网页数据( 能否制作一个随网站自动同步的Excel表呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-24 03:13
能否制作一个随网站自动同步的Excel表呢?(图))
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以制作与 网站 自动同步的 Excel 工作表?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
首先打开你要爬取的网页
2. 确定 fetch 的范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
构建查询以确定爬网的范围
3. 数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。其中,右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
数据“预清洗”
4. 格式化
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
美化餐桌
5. 设置自动同步间隔
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
更新时防止破坏表格格式
写在最后
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取网页数据(
能否制作一个随网站自动同步的Excel表呢?(图))

有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以制作与 网站 自动同步的 Excel 工作表?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
首先打开你要爬取的网页
2. 确定 fetch 的范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
构建查询以确定爬网的范围
3. 数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。其中,右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
数据“预清洗”
4. 格式化
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
美化餐桌
5. 设置自动同步间隔
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
更新时防止破坏表格格式
写在最后
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel实用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-23 19:04
在日常生活中,我们经常使用 Excel 来组织数据,但不可避免地要从互联网上采集数据。如果我们从互联网上采集的数据是可以直接使用的Excel或Word形式的,那会省去很多麻烦;但是如果数据是以网页格式采集的,我们想在Excel中处理相关数据。最好的方法是将其导入 Excel。但是,如何将其导入 Excel?数据准确性。为此,本文基于Excel提供了从网页获取数据的功能,将网页数据导入Excel表格非常方便,既节省了工作时间,又提高了数据的准确性。注:本文所示数据来自中华人民共和国国家统计局()。具体数据链接:
1 笔者以国家统计局“50个城市主要食品平均价格变化(2014年3月11-20日)”为例。采集并整理到我们的 Excel 中。首先,我们复制数据表所在网页的URL地址(即:)。
2 然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建Web查询”对话框。
3 将复制的URL地址粘贴到“新建Web查询”的地址栏中,然后点击Go,就会出现对应的数据页面,如下图:
4 将鼠标移动到对话框中网页表格的左上角,我们会在左上角看到一个黄黑色的箭头标志,表示Excel已经识别了这个页面的表格,我们点击箭头,箭头会变成绿色的对勾表示选表成功,最后点击下方的“导入”,如下图:
5 在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel就会为我们获取数据,如图:
6 导入数据的过程需要等待,如下图所示:
7 最终数据导入成功,效果如下图:
8 至此,网页中的数据已经成功导入到Excel表格中,接下来我们就可以根据自己的需要对数据进行处理了。
请注意数据的真实性。 查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel实用技巧)
在日常生活中,我们经常使用 Excel 来组织数据,但不可避免地要从互联网上采集数据。如果我们从互联网上采集的数据是可以直接使用的Excel或Word形式的,那会省去很多麻烦;但是如果数据是以网页格式采集的,我们想在Excel中处理相关数据。最好的方法是将其导入 Excel。但是,如何将其导入 Excel?数据准确性。为此,本文基于Excel提供了从网页获取数据的功能,将网页数据导入Excel表格非常方便,既节省了工作时间,又提高了数据的准确性。注:本文所示数据来自中华人民共和国国家统计局()。具体数据链接:
1 笔者以国家统计局“50个城市主要食品平均价格变化(2014年3月11-20日)”为例。采集并整理到我们的 Excel 中。首先,我们复制数据表所在网页的URL地址(即:)。

2 然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建Web查询”对话框。

3 将复制的URL地址粘贴到“新建Web查询”的地址栏中,然后点击Go,就会出现对应的数据页面,如下图:

4 将鼠标移动到对话框中网页表格的左上角,我们会在左上角看到一个黄黑色的箭头标志,表示Excel已经识别了这个页面的表格,我们点击箭头,箭头会变成绿色的对勾表示选表成功,最后点击下方的“导入”,如下图:

5 在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel就会为我们获取数据,如图:

6 导入数据的过程需要等待,如下图所示:

7 最终数据导入成功,效果如下图:

8 至此,网页中的数据已经成功导入到Excel表格中,接下来我们就可以根据自己的需要对数据进行处理了。
请注意数据的真实性。
excel抓取网页数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-21 12:15
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人都可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是数据处理的过程。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)

PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。

数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;

不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:

单击确定后,将出现预览窗口。

点击编辑进入查询编辑器,

外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人都可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是数据处理的过程。这是我们真正需要掌握的核心技能。
excel抓取网页数据(excel抓取网页数据必须掌握的是各种工具函数,常用的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-01 05:01
excel抓取网页数据必须掌握的是各种工具函数,常用的:all,last等。推荐使用工具python或者sql,推荐学习sql和python。推荐一本书《利用python进行数据分析》,然后把python的官方文档pipinstallsqlalchemy这篇文档仔细阅读一下,配合视频和书籍学习。推荐读一下datacollections,sqlalchemyinaction,databook,angularjs相关书籍。
会解决数据表查询和基本增删改查即可。第一个问题,说的是url引入,如果需要加载数据库的话,可以借助数据库的驱动。如果涉及到pandas或者其他mapreduce对象,那就需要使用sqlalchemy框架了。如果要自己搭建web框架,则需要学习network,redis,java的web框架等等。需要有一定的可编程能力。
如果不清楚何时或在哪里可以查询数据,如何判断是否可以查询,那就需要理解一下基本数据库操作。推荐先学习一下mysql和postgresql等关系型数据库。
谢邀。工具的事情,自己学着写。数据结构要会写很重要,抓的是数据表,先学会查询。高级sql还是要会的。有时间再看看pandas,
第一、研究一下all函数的意义;第二、研究一下excel如何抓取网页信息?
我学校也是信息与计算科学专业,电子信息工程的吧,如果要学习数据挖掘,首先你需要了解下数据库,懂得如何写sql,这是最基本的,如果你写不了还是对着文档多敲多练习比较好, 查看全部
excel抓取网页数据(excel抓取网页数据必须掌握的是各种工具函数,常用的)
excel抓取网页数据必须掌握的是各种工具函数,常用的:all,last等。推荐使用工具python或者sql,推荐学习sql和python。推荐一本书《利用python进行数据分析》,然后把python的官方文档pipinstallsqlalchemy这篇文档仔细阅读一下,配合视频和书籍学习。推荐读一下datacollections,sqlalchemyinaction,databook,angularjs相关书籍。
会解决数据表查询和基本增删改查即可。第一个问题,说的是url引入,如果需要加载数据库的话,可以借助数据库的驱动。如果涉及到pandas或者其他mapreduce对象,那就需要使用sqlalchemy框架了。如果要自己搭建web框架,则需要学习network,redis,java的web框架等等。需要有一定的可编程能力。
如果不清楚何时或在哪里可以查询数据,如何判断是否可以查询,那就需要理解一下基本数据库操作。推荐先学习一下mysql和postgresql等关系型数据库。
谢邀。工具的事情,自己学着写。数据结构要会写很重要,抓的是数据表,先学会查询。高级sql还是要会的。有时间再看看pandas,
第一、研究一下all函数的意义;第二、研究一下excel如何抓取网页信息?
我学校也是信息与计算科学专业,电子信息工程的吧,如果要学习数据挖掘,首先你需要了解下数据库,懂得如何写sql,这是最基本的,如果你写不了还是对着文档多敲多练习比较好,
excel抓取网页数据(Excel和python的异同点,你知道几个?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-26 18:04
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,也增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么看? 查看全部
excel抓取网页数据(Excel和python的异同点,你知道几个?(上))
大家好~
Excel和python是目前流行的两种数据分析处理工具。两者有很多共同点,也有很大的不同。
今天,我们就来看看两者在抓取网页数据方面的异同。
上图为证监会相关信息。我们需要提取其中的表格数据,分别使用Excel和python。
Excel
Excel提供了两种获取网页数据的方法,第一种是data-self网站函数,第二种是Power Query。
方法一
首先点击【数据】-【来自网站】,如下图:
在弹出的界面中,输入抓取的网址后,点击“开始”,然后点击“导入”。
程序运行几秒钟(需要一定的时间),网页数据被捕获到 Excel 中。
可惜这个方法Excel抓取了网页上的所有文字,包括不相关的数据,比如下图上半部分的文字,需要手动删除。
方法二
Excel 2016及以上版本自带Power Query,16以下版本需要手动下载安装Power Query。
点击【数据】-【新建查询】-【来自其他来源】-【来自Web】,在弹出的界面输入网址,点击确定。
然后将网页中的表格加载到Power Query中,双击表格0,点击“关闭并上传”,完整的数据表格加载到Excel表格中。
该方法与第一种方法的不同之处在于:
第一种方法直接将网页内容以文本的形式复制到Excel中。第二种方法是使用动态链接。如果原网页表的值发生变化,只需要刷新查询,Excel中的数据就会相应刷新。不需要二次采集,在效率上第二种方法比第一种要好。
Python
从铺天盖地的广告中,我们可以看出 Python 目前的流行程度。作为一门编程语言,它比Java、C、C++等其他语言要简单得多,也更容易上手。此外,语言兼容性也很高。,代码简洁优雅。
如果使用python爬取上面的网页,只需要三行代码,如下图所示:
没有BS4、xpath等网页解析方式,Pandas提供了read_html的功能,可以直接获取网页数据。
与Excel相比,python的优势在于效率和方便。
多页数据采集
以上只限于抓取一个网页单表的数据,那么如何获取网页多页的数据呢?
下图一共有50个翻页,如果都抓到了?
在获取之前,需要对网页进行简单的分析,即找出每个网页之间的规则:
观察前几页,可以发现每一页唯一的区别就是数字标签,在上图中用红色数字标注。
弄清楚规则后,使用循环依次爬取50页数据。
与单个网页的爬取不同,这里增加了一个for循环,也增加了程序的运行时间。可以发现python爬取50个页面需要0.36分钟(约21秒)。其实 Excel Power Query 也支持多页数据的获取,但是效率极低,耗时较长。这里不会显示。有兴趣的小伙伴可以自行研究。
概括
不同的软件,不同的使用场景,可以说python在爬取网页方面的优势要大于Excel,但是Excel的灵活性却是超越了python的。你怎么看?
excel抓取网页数据(Excel中的Powerquery可以同样操作(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-02-24 05:00
之前介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批处理采集多个网页的数据。 (Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点的数据,
将页面下拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p= 1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,页码进入第二行,
p>
从URL预览可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则URL要分三行输入)
点击确定后,发现很多表格,
由此可见智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器.
在PQ编辑器中直接删除[Source]后面的所有步骤,然后展开数据,把前面没有的几列数据删掉。
这样,第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可见一页有60条招聘信息。
这里第一页的数据排序后,后面采集中其他页面的数据结构和第一页的数据结构一样,采集的数据@> 可以直接使用;这里不整理也没关系,可以等到采集所有网页数据整理到一起。
如果要大量爬取网页数据,为了节省时间,可以不先对第一页数据进行排序,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,输入:(p as number) as table =>
在让之前
并且把let之后第一行URL中&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p ))
p>
修改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,输入一个数字,比如7,会抓取第7页的数据,
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个从1到100的序列并在空查询中输入
={1..100}
回车生成一个从1到100的序列,然后变成表格。 gif操作图如下:
然后调用自定义函数,
点击弹出窗口中的【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他全部默认。
点击确定开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量抓取已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大时间仍然是比较捕获数据过程的最后一步。耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,终生受益!
以上主要是使用PowerBI中的Power Query功能,同样的操作可以在能使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行到了就不用再浪费时间了。
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。 查看全部
excel抓取网页数据(Excel中的Powerquery可以同样操作(一)(组图))
之前介绍PowerBI数据获取的时候,我举了一个从网页获取数据的例子,但是当时只爬取了一页数据。本文章将介绍如何使用PowerBI批处理采集多个网页的数据。 (Excel中的Power查询也可以)
本文以智联招聘网站为例,采集上海招聘信息。
以下是详细步骤:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点的数据,
将页面下拉到最底部,找到显示页码的地方,点击前三页,网址如下,%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p= 1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是一个控制分页数据的变量。
(二)使用 PowerBI采集第一页的数据
打开PowerBI Desktop,从网页获取数据,在弹窗中选择【高级】,根据上面分析的URL结构,第一行输入除最后一页ID外的URL,页码进入第二行,
p>
从URL预览可以看出,上面两行的URL已经自动合并在一起了;这里单独输入只是为了以后更清楚地区分页码变量,其实直接输入完整的URL也是可以的。
(如果页码变量不是最后一位,而是在中间,则URL要分三行输入)
点击确定后,发现很多表格,
由此可见智联招聘网站上的每个招聘信息都是一个表,不用管它,随便选一个表,比如勾选Table0,点击编辑进入Power Query编辑器.
在PQ编辑器中直接删除[Source]后面的所有步骤,然后展开数据,把前面没有的几列数据删掉。
这样,第一页采集的数据就来了。然后整理这个页面的数据,删除无用的信息,添加字段名。可见一页有60条招聘信息。
这里第一页的数据排序后,后面采集中其他页面的数据结构和第一页的数据结构一样,采集的数据@> 可以直接使用;这里不整理也没关系,可以等到采集所有网页数据整理到一起。
如果要大量爬取网页数据,为了节省时间,可以不先对第一页数据进行排序,直接进入下一步。
(三)根据页码参数设置自定义功能
这是最重要的一步。
还是刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,输入:(p as number) as table =>
在让之前
并且把let之后第一行URL中&后面的“1”改成(这是第二步使用高级选项分两行输入URL的好处):(Number.ToText(p ))
p>
修改后,[Source]的URL变为:";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确认后,刚才第一页数据的查询窗口变成了自定义函数的输入参数窗口,Table0表也变成了函数的样式。为了更直观,将此函数重命名为Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,输入一个数字,比如7,会抓取第7页的数据,
输入参数一次只能抓取一个网页。批量爬取需要执行以下步骤。
(四)批量调用自定义函数
首先使用一个空查询来创建一个数字序列。如果要抓取前100页数据,创建一个从1到100的序列并在空查询中输入
={1..100}
回车生成一个从1到100的序列,然后变成表格。 gif操作图如下:
然后调用自定义函数,
点击弹出窗口中的【函数查询】下拉框,选择刚刚创建的自定义函数Data_Zhaopin,其他全部默认。
点击确定开始批量抓取网页。因为100页数据比较多,大概需要5分钟。这也是我提前进行第二步数据排序的结果,导致爬取慢。展开这张表,就是这100页的数据,
至此,智联招聘100页的批量抓取已经完成。上面的步骤似乎很多。其实掌握之后,10分钟左右就可以搞定。最大时间仍然是比较捕获数据过程的最后一步。耗时。
网页上的数据不断更新。完成以上步骤后,在PQ中点击刷新,即可随时一键提取网站实时数据。做一次,终生受益!
以上主要是使用PowerBI中的Power Query功能,同样的操作可以在能使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬机制,还是得使用专业的工具,比如R或者Python。在使用PowerBI批量抓取某个网站数据之前,先尝试采集一个页面,如果可以采集获取,则使用上述步骤,如果采集不行到了就不用再浪费时间了。
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的 网站 数据。
excel抓取网页数据(【技巧】龙虎榜数据预览:如何找到正确的数据页面 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-24 02:17
)
龙虎榜数据其实很容易抓取。首先,我们需要找到正确的数据页:
一旦你找到这个页面,你就可以开始网站分析了。
网站分析
在谷歌浏览器中打开页面后,打开“检查”,然后点击下图中的各个标签栏:
然后在过滤器中输入pagesize来过滤掉这些页面。我按了好几次。通常应该有八个,每个标签对应一行:
我们查看了每个页面的真实网址,发现这个位置的词对应我们要查询的标签,也就是有八个词,对应八个标签:
然后是一些常规变量:
通过上面的分析,我们可以想象写一个函数,通过改变关键词、页码、日期等参数来查询对应的龙虎榜数据。
其实这也是一个API调用,我们看一下数据预览:
下面一行是真实数据调用的URL,我尝试爬取:
展开后就是这样的数据结构,用“|”隔开的数据列表,没有表头,不是我们喜欢的数据风格。
让我们看看我们是否可以获取带有标题的数据表。毕竟栏目多,一一添加表头不是我们优采云愿意做的。
试着抓
让我们尝试使用以下 URL 获取它:
展开后我们得到一个表格:
按照这个过程,我们原来的想法就得改变。因为不同标签对应的表中的列数是不同的,所以我们不可能用一个通用的函数来捕获所有八种表。其实有七种,最后一种是业务部查询。我们只需要定义7个函数分别抓取即可。
当然,如果你坚持也不是不能实现一个功能,只是需要写七个分支来分别处理七种表。
定义函数
我们仍然使用单独定义函数的方法。这里我举个例子来定义一个捕捉龙虎列表细节的函数:
我添加了三个参数,如果需要,您也可以添加页码。
如果要定义其他标签对应的函数,需要复制该标签对应的URL,然后修改参数。
抓住
然后我们做一个测试,抓取2020-10-1到2020-10-27的1000行数据:
只需等待几秒钟,您就完成了。
如果数据页数多,也可以加上页码,然后用页码抓取,我修改函数:
其实2020-10-1到2020-10-27的数据只有600多行,所以我们换个方法,每页100条,7页:
展开得到 665 行数据:
最后提醒大家,以上两个功能是为了方便大家。换行符用于屏幕截图。其实没有换行和回车。如果加回车,查询就会出错。
查看全部
excel抓取网页数据(【技巧】龙虎榜数据预览:如何找到正确的数据页面
)
龙虎榜数据其实很容易抓取。首先,我们需要找到正确的数据页:
一旦你找到这个页面,你就可以开始网站分析了。
网站分析
在谷歌浏览器中打开页面后,打开“检查”,然后点击下图中的各个标签栏:
然后在过滤器中输入pagesize来过滤掉这些页面。我按了好几次。通常应该有八个,每个标签对应一行:
我们查看了每个页面的真实网址,发现这个位置的词对应我们要查询的标签,也就是有八个词,对应八个标签:
然后是一些常规变量:
通过上面的分析,我们可以想象写一个函数,通过改变关键词、页码、日期等参数来查询对应的龙虎榜数据。
其实这也是一个API调用,我们看一下数据预览:
下面一行是真实数据调用的URL,我尝试爬取:
展开后就是这样的数据结构,用“|”隔开的数据列表,没有表头,不是我们喜欢的数据风格。
让我们看看我们是否可以获取带有标题的数据表。毕竟栏目多,一一添加表头不是我们优采云愿意做的。
试着抓
让我们尝试使用以下 URL 获取它:
展开后我们得到一个表格:
按照这个过程,我们原来的想法就得改变。因为不同标签对应的表中的列数是不同的,所以我们不可能用一个通用的函数来捕获所有八种表。其实有七种,最后一种是业务部查询。我们只需要定义7个函数分别抓取即可。
当然,如果你坚持也不是不能实现一个功能,只是需要写七个分支来分别处理七种表。
定义函数
我们仍然使用单独定义函数的方法。这里我举个例子来定义一个捕捉龙虎列表细节的函数:
我添加了三个参数,如果需要,您也可以添加页码。
如果要定义其他标签对应的函数,需要复制该标签对应的URL,然后修改参数。
抓住
然后我们做一个测试,抓取2020-10-1到2020-10-27的1000行数据:
只需等待几秒钟,您就完成了。
如果数据页数多,也可以加上页码,然后用页码抓取,我修改函数:
其实2020-10-1到2020-10-27的数据只有600多行,所以我们换个方法,每页100条,7页:
展开得到 665 行数据:
最后提醒大家,以上两个功能是为了方便大家。换行符用于屏幕截图。其实没有换行和回车。如果加回车,查询就会出错。
excel抓取网页数据(Excel表格使用常识——“,你没有听错” )
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-13 00:30
)
Excel表格使用常识——《excel网页抓取数据》
我们在日常工作中使用excel表格的时候,有很多功能我们没有用过。事实上,excel表格非常强大。例如,它可以捕获网页数据。是的,你听到的是对的。就是抓取网页数据,为什么感觉自己用了这么久的excel却不知道这个功能,感觉自己成了初学者。没关系,其实我们一般只用到excel表格的10%的功能,其他功能用的不是很频繁。所以有些功能大家不熟悉也是正常的。下面我们来说说“excel网页抓取数据”功能。
操作方法:
1、我们打开excel表并输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、点击[From 网站]按钮,弹出“新建Web查询”窗口,在地址栏中输入URL。
3、进入后,点击网址栏右侧的【Go】按钮,这样我们就输入了这个网站。
4、在页面中,Excel会尝试用符号标记表格数据,找到需要的表格,点击它,它会变成对勾,然后点击“导入”按钮。
5、点击按钮,弹出“导入数据”窗口,然后点击确定(以上数值可以保留默认)。
6、这样,对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就已经抓取到网页中的数据了。
7、获取到的网页数据也可以根据需要自动刷新。在[数据]功能区中找到“连接”功能区,然后单击其中的[属性]按钮。
8、点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
查看全部
excel抓取网页数据(Excel表格使用常识——“,你没有听错”
)
Excel表格使用常识——《excel网页抓取数据》
我们在日常工作中使用excel表格的时候,有很多功能我们没有用过。事实上,excel表格非常强大。例如,它可以捕获网页数据。是的,你听到的是对的。就是抓取网页数据,为什么感觉自己用了这么久的excel却不知道这个功能,感觉自己成了初学者。没关系,其实我们一般只用到excel表格的10%的功能,其他功能用的不是很频繁。所以有些功能大家不熟悉也是正常的。下面我们来说说“excel网页抓取数据”功能。
操作方法:
1、我们打开excel表并输入,然后在工具栏中找到【数据】标签,点击标签,在下方功能区找到【来自网站】按钮。
2、点击[From 网站]按钮,弹出“新建Web查询”窗口,在地址栏中输入URL。
3、进入后,点击网址栏右侧的【Go】按钮,这样我们就输入了这个网站。
4、在页面中,Excel会尝试用符号标记表格数据,找到需要的表格,点击它,它会变成对勾,然后点击“导入”按钮。
5、点击按钮,弹出“导入数据”窗口,然后点击确定(以上数值可以保留默认)。
6、这样,对应的单元格就会显示“正在获取数据”,等待数据获取成功,这样我们就已经抓取到网页中的数据了。
7、获取到的网页数据也可以根据需要自动刷新。在[数据]功能区中找到“连接”功能区,然后单击其中的[属性]按钮。
8、点击属性后,会弹出“外部数据区属性”对话框,我们对其进行如下操作。
excel抓取网页数据(excel抓取网页数据就是网页的html数据流编码问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-02-12 08:07
excel抓取网页数据就是网页的html数据流编码问题而导致的,
有句话讲得很对:“只要你不是“笨蛋”,任何技术都能让你成为“超人”。
抓个数据回来当代码跑。
http网站要让你下载数据需要你进行转码,转码成utf-8,另外标签应该加头,也可以用sqlite3这种非关系型数据库。转码完成后如果网站能给你打包成json数据包,最好转包成java能直接可用的python对象格式,比如sqlitejson等。如果不能给你打包成json数据包那么就只能抓htmljson。如果网站支持xpath就可以。
最好爬取网页源代码,可以做反爬虫。比如通过js代码,访问url等获取。
想要抓取数据必须抓取dom。你看见一个html文件你应该有dom,因为每个html文件有一个空间,不会出现多余的东西。js文件应该有,当然前提是你有xpath。比如你先定义一个爬虫,名字或者你想抓取什么名字。
可以抓包,抓网页源代码。通过编写xpath来抓取结果,或者可以用c#语言做相关抓包。
上手github查查别人的项目,最简单的应该是从网页抓取网页上的文本数据,最近在用知乎的话题列表爬取。
如果只抓取html网页,那就用python抓,如果爬取图片或者音频, 查看全部
excel抓取网页数据(excel抓取网页数据就是网页的html数据流编码问题)
excel抓取网页数据就是网页的html数据流编码问题而导致的,
有句话讲得很对:“只要你不是“笨蛋”,任何技术都能让你成为“超人”。
抓个数据回来当代码跑。
http网站要让你下载数据需要你进行转码,转码成utf-8,另外标签应该加头,也可以用sqlite3这种非关系型数据库。转码完成后如果网站能给你打包成json数据包,最好转包成java能直接可用的python对象格式,比如sqlitejson等。如果不能给你打包成json数据包那么就只能抓htmljson。如果网站支持xpath就可以。
最好爬取网页源代码,可以做反爬虫。比如通过js代码,访问url等获取。
想要抓取数据必须抓取dom。你看见一个html文件你应该有dom,因为每个html文件有一个空间,不会出现多余的东西。js文件应该有,当然前提是你有xpath。比如你先定义一个爬虫,名字或者你想抓取什么名字。
可以抓包,抓网页源代码。通过编写xpath来抓取结果,或者可以用c#语言做相关抓包。
上手github查查别人的项目,最简单的应该是从网页抓取网页上的文本数据,最近在用知乎的话题列表爬取。
如果只抓取html网页,那就用python抓,如果爬取图片或者音频,
excel抓取网页数据(《我和我的祖国》、《攀登者》几部影片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-02-10 17:16
国庆刚过,《我和我的祖国》、《中国队长》、《攀登者》等电影就深受观众好评,在豆瓣上好评如潮:
我们想捕捉这些电影评论进行分析。我们如何获得影评?电源查询
网站分析
网站分析的过程是必要的。通过观察,我们发现这个页面内容的变化与URL中的一个值有关:
每当按下上一页和下一页时,该值都会发生变化,这也是我们将来用作翻页参数的值。
尝试爬行
我们翻到中间页面,复制网址开始爬取:
我们查看了这样一个页面,表格内容并没有我们期望的整个表格的数据:
首先确保,在 Power Query 编辑器中,让我们直接以文本格式进行调整和分析页面内容:
通过观察,我们发现所有的影评内容都是这样的格式:
我们分两步执行此操作:
过滤器:过滤器收录
格式代码行
提取:提取两个尖括号之间的文本
这样一页影评就被提取出来了。
定义抓取功能
右键单击上述查询以创建函数:
添加参数,函数就准备好了。
抓
我们需要这样的页码更改列表 {0, 20, 40, ...}
试了到200之后,基本是回不去了,就是一个0-200的列表,步长20。
= List.Generate(()=>0,each_ 查看全部
excel抓取网页数据(《我和我的祖国》、《攀登者》几部影片)
国庆刚过,《我和我的祖国》、《中国队长》、《攀登者》等电影就深受观众好评,在豆瓣上好评如潮:
我们想捕捉这些电影评论进行分析。我们如何获得影评?电源查询
网站分析
网站分析的过程是必要的。通过观察,我们发现这个页面内容的变化与URL中的一个值有关:
每当按下上一页和下一页时,该值都会发生变化,这也是我们将来用作翻页参数的值。
尝试爬行
我们翻到中间页面,复制网址开始爬取:
我们查看了这样一个页面,表格内容并没有我们期望的整个表格的数据:
首先确保,在 Power Query 编辑器中,让我们直接以文本格式进行调整和分析页面内容:
通过观察,我们发现所有的影评内容都是这样的格式:
我们分两步执行此操作:
过滤器:过滤器收录
格式代码行
提取:提取两个尖括号之间的文本
这样一页影评就被提取出来了。
定义抓取功能
右键单击上述查询以创建函数:
添加参数,函数就准备好了。
抓
我们需要这样的页码更改列表 {0, 20, 40, ...}
试了到200之后,基本是回不去了,就是一个0-200的列表,步长20。
= List.Generate(()=>0,each_
excel抓取网页数据(excel抓取网页数据一般都是通过xpath解析,查找替换法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-09 06:00
excel抓取网页数据一般都是通过xpath解析,抓取网页数据一般方法有三种。网页解析方法,百度百科的解释,就是通过网页开发人员分析识别网页中的异常,然后返回相对应的结果。数据提取方法的主要方法,查找替换法。通过html标签中间的内容查找,通过xpath网页解析方法的精髓就是找到网页的xml标签,根据xml标签中的dom结构,找到每个页面中的元素元素,然后根据对应元素返回相对应的数据元素。
普通xpath抓取文本的网址,都有常用方法,但是根据结构抓取的网址,简单易用,当然如果是抓取网页的图片也是同样方法。抓取文本是我的抓取一直心得,主要用xpath和xml网页解析方法。python官方文档中提供三种xpath的文档,dict,boolean和xxxx,但是大多数是xxx。我通过总结发现对应起来简单方便。
dict,boolean和xxxx这三种xpath使用方法也有区别,常用的只有xxx.xpath,不常用的叫做html请求xpath,下面我以xxx为例。我们新建一个python代码,网页代码的解析准备好。c:\windows\system32\drivers\etc\websites\advanced/xml/.xpath(*)/div/child/div/div/a(*)li/a(*)b(*)span(*)b/a(*)ul/ul/li/ul/li/a(*)td(*)li,ul,td.xpath('')2div/span/div/a(*)a/c(*)ul/ul/li/ul/span/ul/span/a.xpath("")3empty,false,false,true,true,false,true,false,true,true,false,false,true,false,false,false,false,false,true,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false。 查看全部
excel抓取网页数据(excel抓取网页数据一般都是通过xpath解析,查找替换法)
excel抓取网页数据一般都是通过xpath解析,抓取网页数据一般方法有三种。网页解析方法,百度百科的解释,就是通过网页开发人员分析识别网页中的异常,然后返回相对应的结果。数据提取方法的主要方法,查找替换法。通过html标签中间的内容查找,通过xpath网页解析方法的精髓就是找到网页的xml标签,根据xml标签中的dom结构,找到每个页面中的元素元素,然后根据对应元素返回相对应的数据元素。
普通xpath抓取文本的网址,都有常用方法,但是根据结构抓取的网址,简单易用,当然如果是抓取网页的图片也是同样方法。抓取文本是我的抓取一直心得,主要用xpath和xml网页解析方法。python官方文档中提供三种xpath的文档,dict,boolean和xxxx,但是大多数是xxx。我通过总结发现对应起来简单方便。
dict,boolean和xxxx这三种xpath使用方法也有区别,常用的只有xxx.xpath,不常用的叫做html请求xpath,下面我以xxx为例。我们新建一个python代码,网页代码的解析准备好。c:\windows\system32\drivers\etc\websites\advanced/xml/.xpath(*)/div/child/div/div/a(*)li/a(*)b(*)span(*)b/a(*)ul/ul/li/ul/li/a(*)td(*)li,ul,td.xpath('')2div/span/div/a(*)a/c(*)ul/ul/li/ul/span/ul/span/a.xpath("")3empty,false,false,true,true,false,true,false,true,true,false,false,true,false,false,false,false,false,true,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false,false。
excel抓取网页数据(网站日志该分析哪些数据呢?从基础信息apache:日志分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-07 14:01
网站日志应该分析哪些数据?从apache网站日志分析工具的基本信息、目录抓包、时间段抓包、IP抓包、状态码来分析:
第一款apache网站日志分析工具,基本信息
下载一个网站日志文件工具获取基本信息:apache总爬取量网站日志分析工具,停留时间(h)和访问次数;通过这三个基本信息可以计算出: 平均每次爬取次数 取单个页面的页数和爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算出根据以上数据,爬虫的重复爬取率:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
采集了一段时间的数据,可以看到整体的趋势是怎样的,这样才能发现问题,然后可以调整网站apache网站日志分析工具的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强apache网站日志分析工具。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取的入口和一些robots和nofollow技术。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,网页加载速度如何影响SEO流量;提高页面加载速度,减少爬虫单边停留时间,可以为爬虫的总爬取贡献增加网站收录,从而增加网站整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,找到对应的爬取量比较密集的时间段,可以有针对性的更新. 同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但是爬虫正常爬行,说明这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计如果一个网站被搜索引擎抓取的次数越来越多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的抓取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的 查看全部
excel抓取网页数据(网站日志该分析哪些数据呢?从基础信息apache:日志分析工具)
网站日志应该分析哪些数据?从apache网站日志分析工具的基本信息、目录抓包、时间段抓包、IP抓包、状态码来分析:
第一款apache网站日志分析工具,基本信息
下载一个网站日志文件工具获取基本信息:apache总爬取量网站日志分析工具,停留时间(h)和访问次数;通过这三个基本信息可以计算出: 平均每次爬取次数 取单个页面的页数和爬取停留时间,然后用MSSQL提取蜘蛛的唯一爬取量,计算出根据以上数据,爬虫的重复爬取率:
每次爬取的平均页数=总爬取次数/访问次数
单页抓取停留时间=停留时间*3600/总抓取量
爬虫重复爬取率=100%-唯一爬取量/总爬取量
采集了一段时间的数据,可以看到整体的趋势是怎样的,这样才能发现问题,然后可以调整网站apache网站日志分析工具的整体策略。我们以一个站长的基本日志信息为例:
基本日志信息
从日志的基本信息来看,我们需要看它的整体趋势来调整,哪些地方需要加强apache网站日志分析工具。
网站日志文件应该分析哪些数据
总爬取
从这个整体趋势可以看出,爬虫总量整体呈下降趋势,这就需要我们做一些相应的调整。
网站日志文件应该分析哪些数据
蜘蛛重复爬行率
整体来看,网站的重复爬取率增加了一点,这需要一些细节,爬取的入口和一些robots和nofollow技术。
单边停留时间
一方面是爬虫的停留时间,看过一篇文章软文,网页加载速度如何影响SEO流量;提高页面加载速度,减少爬虫单边停留时间,可以为爬虫的总爬取贡献增加网站收录,从而增加网站整体流量。16号到20号左右服务器出现了一些问题。调整后速度明显加快,单页停留时间也相应减少。
并相应调整如下:
从本月的排序来看,爬虫的爬取量有所下降,重复爬取率有所上升。综合分析,需要从网站内外的链接进行调整。站点中的链接应尽可能有锚文本。如果没有,可以推荐其他页面的超链接,让蜘蛛爬得越深越好。异地链接需要以多种方式发布。目前平台太少。如果深圳新闻网、上国网等网站出现轻微错误,我们的网站将受到严重影响。站外平台要广,发布的链接要多样化。如果不能直接发首页,栏目和文章页面需要加强。目前场外平台太少,
二、 目录爬取
使用MSSQL提取爬虫爬取的目录,分析每日目录爬取量。可以清晰的看到各个目录的爬取情况,可以对比之前的优化策略,看看优化是否合理,关键列的优化是否达到预期效果。
爬虫爬取的目录
绿色:主要工作栏 黄色:抓取不佳 粉色:抓取非常糟糕 深蓝色:需要禁止的栏目
网站日志文件应该分析哪些数据
目录总体趋势
可以看出,整体趋势变化不大,只有两列的爬取变化很大。
总体而言,爬行次数较少。在主列中,抓取较少的是:xxx,xxx,xxx。总的来说,整个网站的进口口需要扩大,需要外部链接的配合,站点内部需要加强内部链接的建设。对于,爬取较弱的列以增强处理。同时将深蓝色的列写入robots,屏蔽,从网站导入到这些列中,作为nofollow的URL,避免权重只进出。
在时间段 三、 抓取
通过excel中的数组函数,提取每日时间段的爬虫爬取量,重点分析每日的爬取情况,找到对应的爬取量比较密集的时间段,可以有针对性的更新. 同时也可以看出爬取不正常。
网站日志文件应该分析哪些数据
时间段爬取
一天中什么时间出现问题,总爬取也是呈下降趋势。
网站日志文件应该分析哪些数据
时间段趋势
通过抓取时间段,我们进行相应的调整:
从图中的颜色可以看出服务器不是特别稳定,需要加强服务器的稳定性。另外,17、18、19天,有人被攻击、被锁链等,但是爬虫正常爬行,说明这些对网站造成了一定的影响!
四、IP段的抓取
通过MSSQL提取日志中爬虫的IP,通过excel进行统计。每个IP的每日抓取量也需要看整体。如果IP段没有明显变化,网站提权也不多。可疑的。因为当网站 up 或 down 时,爬虫的IP 段会发生变化。
网站日志文件应该分析哪些数据
IP 段捕获
五、状态码的统计
在此之前您需要了解,}
状态码统计如果一个网站被搜索引擎抓取的次数越来越多,更有利于排名,但是如果你的网站的304太多,肯定会降低搜索引擎的抓取频率和次数,让你的 网站 排名落后别人一步。调整:服务器可以清除缓存。状态码统计百度爬虫数据图,密集数据,以上数据都是从这里调用的
excel抓取网页数据(数据导出简述业务流程数据插入中间表,走产品流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-07 03:06
制作示例:水壶数据导出
简述业务流程数据插入中间表,经过产品流程kettle从中间表中获取需要抓取的结果,根据抓取结果获取对应的数据数据处理,导入目标表,删除中间表,走产品流程
所有产品工艺这里不详述,仅针对水壶部分
**kettle 获取需要从中间表中取出的结果
**
配置kettle数据库连接
#loc4
loc4/type=javax.sql.DataSource
loc4/driver=oracle.jdbc.driver.OracleDriver
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
loc4/user=system
loc4/password=a1234
JNDI配置的url需要注意数据库是否为rac
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
最后:服务名称或使用/实例名称。这里,在oracle中部署rac集群的时候,需要注意服务名和实例名的区别,配置后需要测试
使用表格输入控件抓取中间表格的数据
注意所选数据库的连接,以及测试结果
根据抓取结果获取对应数据
使用数据库连接控件连接数据表
将预排序操作的结果作为参数
数据处理
结果值转换值映射器控件
可以选择默认值,默认不会更改字段名,保留原字段名
如果该字段为空且需要对应的结果,则需要插入一条源值为空的记录
使用 Modified javascript Value 控件修改结果值
脚本函数可参考函数示例,可提前测试结果
注意控件名称,使用后及时调试
逻辑判断控制开关/案例
多行到多列行非规范化器控制
注意type的值的添加
导入目标表
因为勺子是一个界面类软件,所以主要的操作都放在了截图里。对于这个相对简单的流程,这些控件已经满足了大部分的需求。关于修改后的javascript控件中的一些操作,在实际生产中,我直接使用sql中的函数进行处理,这里特意展示一下。. 两人的角色不同。如果业务简单,两者都可以实现,但是如果面对不同的数据库,可以通过控件实现对不同数据库的操作。这方面要看生产需求和开发习惯。 查看全部
excel抓取网页数据(数据导出简述业务流程数据插入中间表,走产品流程)
制作示例:水壶数据导出
简述业务流程数据插入中间表,经过产品流程kettle从中间表中获取需要抓取的结果,根据抓取结果获取对应的数据数据处理,导入目标表,删除中间表,走产品流程
所有产品工艺这里不详述,仅针对水壶部分
**kettle 获取需要从中间表中取出的结果
**
配置kettle数据库连接
#loc4
loc4/type=javax.sql.DataSource
loc4/driver=oracle.jdbc.driver.OracleDriver
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
loc4/user=system
loc4/password=a1234
JNDI配置的url需要注意数据库是否为rac
loc4/url=jdbc:oracle:thin:@127.0.0.1:1521:aaa001
最后:服务名称或使用/实例名称。这里,在oracle中部署rac集群的时候,需要注意服务名和实例名的区别,配置后需要测试
使用表格输入控件抓取中间表格的数据
注意所选数据库的连接,以及测试结果
根据抓取结果获取对应数据
使用数据库连接控件连接数据表
将预排序操作的结果作为参数
数据处理
结果值转换值映射器控件
可以选择默认值,默认不会更改字段名,保留原字段名
如果该字段为空且需要对应的结果,则需要插入一条源值为空的记录
使用 Modified javascript Value 控件修改结果值
脚本函数可参考函数示例,可提前测试结果
注意控件名称,使用后及时调试
逻辑判断控制开关/案例
多行到多列行非规范化器控制
注意type的值的添加
导入目标表
因为勺子是一个界面类软件,所以主要的操作都放在了截图里。对于这个相对简单的流程,这些控件已经满足了大部分的需求。关于修改后的javascript控件中的一些操作,在实际生产中,我直接使用sql中的函数进行处理,这里特意展示一下。. 两人的角色不同。如果业务简单,两者都可以实现,但是如果面对不同的数据库,可以通过控件实现对不同数据库的操作。这方面要看生产需求和开发习惯。
excel抓取网页数据(我们借鉴之前抓取台风路径数据的例子,抓取降水量数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-02-07 00:13
我们借鉴之前抓取台风轨迹数据的例子,尝试抓取降水数据:
我们之前访问过这个网站并尝试爬取数据,但是在谷歌浏览器中我们只能找到两天的数据,但是通过台风路径数据抓取,我们猜测只要我们正确询问服务器即可查询参数可以返回相应的结果,报这个想法,我们试试。
网站分析
这个网站一点都不复杂,只要提供年月日作为查询参数,后面的数据乱码也没关系,在Power Query中可以识别.
试着抓
如果无法自动识别代码,请修改此参数。65001 对应 utf8。我国的网站通常有两种编码,GB2312和utf8。GB2312对应936或20936。
无需特殊验证,直接抓取即可。
定义函数
其实可以在上面采访的基础上扩展数据后定义函数:
这样我们函数的结果就是一张表,否则就是一条记录,需要整理一下。
s=Table.FromRows(t[data][data],t[data][header])
这句话是把记录转换成表格,当然这不是通用的,只是为了这条记录的格式。
让我们调用这个函数:
上面的2020032101是我们能抓到的最早的数据,也就是说这个网站提供了从2020年3月21日1:00开始的24小时降雨数据,当然也有1小时降雨。所以如果我们要抓取24小时的降雨量,我们需要列出一个日期列表,然后根据日期列表抓取数据。1小时、6小时、13小时的降雨量采集方法可参照本文方法。
抓
准备:制作日期清单
使用 List.Dates 函数列出日期表并将其转换为文本格式:
使用Date.ToText([date],"yyyyMMdd"),这里要注意月份用大写M,不能小写,小写m会返回分钟。
调用函数获取数据:
展开数据:
下载数据:
各省市日均降雨量 查看全部
excel抓取网页数据(我们借鉴之前抓取台风路径数据的例子,抓取降水量数据)
我们借鉴之前抓取台风轨迹数据的例子,尝试抓取降水数据:
我们之前访问过这个网站并尝试爬取数据,但是在谷歌浏览器中我们只能找到两天的数据,但是通过台风路径数据抓取,我们猜测只要我们正确询问服务器即可查询参数可以返回相应的结果,报这个想法,我们试试。
网站分析
这个网站一点都不复杂,只要提供年月日作为查询参数,后面的数据乱码也没关系,在Power Query中可以识别.
试着抓
如果无法自动识别代码,请修改此参数。65001 对应 utf8。我国的网站通常有两种编码,GB2312和utf8。GB2312对应936或20936。
无需特殊验证,直接抓取即可。
定义函数
其实可以在上面采访的基础上扩展数据后定义函数:
这样我们函数的结果就是一张表,否则就是一条记录,需要整理一下。
s=Table.FromRows(t[data][data],t[data][header])
这句话是把记录转换成表格,当然这不是通用的,只是为了这条记录的格式。
让我们调用这个函数:
上面的2020032101是我们能抓到的最早的数据,也就是说这个网站提供了从2020年3月21日1:00开始的24小时降雨数据,当然也有1小时降雨。所以如果我们要抓取24小时的降雨量,我们需要列出一个日期列表,然后根据日期列表抓取数据。1小时、6小时、13小时的降雨量采集方法可参照本文方法。
抓
准备:制作日期清单
使用 List.Dates 函数列出日期表并将其转换为文本格式:
使用Date.ToText([date],"yyyyMMdd"),这里要注意月份用大写M,不能小写,小写m会返回分钟。
调用函数获取数据:
展开数据:
下载数据:
各省市日均降雨量
excel抓取网页数据(从豆瓣获取数据建立SQLite数据库的数据采集工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-02-03 08:03
主要内容:
从豆瓣获取数据
创建SQLite数据库并将爬取的数据存储在数据库中
用FLASK开发web应用,即数据可视化
前两点主要是关于爬虫的知识,第三点是关于数据可视化的前端内容。本篇博客将主要写爬虫。
爬虫:为什么要学爬虫 学习爬虫,可以自定义一个搜索引擎,可以更深入的了解搜索引擎的数据采集的工作原理。简单来说,就是在学会了爬虫的编写之后,就可以利用爬虫自动采集网上的信息,采集返回相应的存储或处理。当需要检索一些信息时,只需要从采集返回的信息中检索,即实现了私有搜索引擎。当然,如何抓取信息,如何存储,如何进行分词,如何进行相关性计算等等,都需要我们自己设计。爬虫技术主要解决信息爬取问题。在大数据时代,进行数据分析,我们首先要有数据源,学习爬虫可以让我们获得更多的数据源,而这些数据源可以根据我们的目的采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了
代码
<p>1# iml
2#encoding='utf-8'
3from bs4 import BeautifulSoup #网页解析,获取数据
4import re #正则表达式,进行文字匹配
5import urllib.request,urllib.error #指定URL,获取网页数据
6import xlwt #进行excel操作
7import sqlite3 #进行SQLite数据库操作
8
9def main():
10 baseurl="https://movie.douban.com/top250?start="
11 datalist = getdata(baseurl)#获取数据存入列表
12 #savepath="豆瓣电影Top250.xls"#xls文件路径
13 dbpath="movie.db"#SQlite数据库路径
14 #saveData(datalist,savepath)#保存数据到xls文件
15 savedata2db(datalist,dbpath)#保存数据到数据库
16
17 #创建正则表达式对象,表示规则(字符串的模式)
18#影片详情链接的规则
19findLink = re.compile(r'<a href="(.*?)">')
20#影片图片
21findImgSrc = re.compile(r' 查看全部
excel抓取网页数据(从豆瓣获取数据建立SQLite数据库的数据采集工作原理)
主要内容:
从豆瓣获取数据
创建SQLite数据库并将爬取的数据存储在数据库中
用FLASK开发web应用,即数据可视化
前两点主要是关于爬虫的知识,第三点是关于数据可视化的前端内容。本篇博客将主要写爬虫。
爬虫:为什么要学爬虫 学习爬虫,可以自定义一个搜索引擎,可以更深入的了解搜索引擎的数据采集的工作原理。简单来说,就是在学会了爬虫的编写之后,就可以利用爬虫自动采集网上的信息,采集返回相应的存储或处理。当需要检索一些信息时,只需要从采集返回的信息中检索,即实现了私有搜索引擎。当然,如何抓取信息,如何存储,如何进行分词,如何进行相关性计算等等,都需要我们自己设计。爬虫技术主要解决信息爬取问题。在大数据时代,进行数据分析,我们首先要有数据源,学习爬虫可以让我们获得更多的数据源,而这些数据源可以根据我们的目的采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而学习爬虫可以让我们获得更多的数据源,这些数据源可以根据我们的目的是采集,去除很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 而这些数据源可以根据我们的目的是采集,去掉很多不相关的数据。在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 在进行大数据分析或数据挖掘时,可以从一些提供数据统计的网站中获取数据源,也可以从某些文献或内部数据中获取数据源,但有时获取数据的方式非常困难。很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了 很难满足我们对数据的需求,手动从网上搜索这些数据需要耗费太多精力。此时,我们可以利用爬虫技术从互联网上自动获取我们感兴趣的数据内容,并将这些数据内容爬回作为我们的数据源,从而进行更深层次的数据分析,获取更有价值的信息。准备好工作了
代码
<p>1# iml
2#encoding='utf-8'
3from bs4 import BeautifulSoup #网页解析,获取数据
4import re #正则表达式,进行文字匹配
5import urllib.request,urllib.error #指定URL,获取网页数据
6import xlwt #进行excel操作
7import sqlite3 #进行SQLite数据库操作
8
9def main():
10 baseurl="https://movie.douban.com/top250?start="
11 datalist = getdata(baseurl)#获取数据存入列表
12 #savepath="豆瓣电影Top250.xls"#xls文件路径
13 dbpath="movie.db"#SQlite数据库路径
14 #saveData(datalist,savepath)#保存数据到xls文件
15 savedata2db(datalist,dbpath)#保存数据到数据库
16
17 #创建正则表达式对象,表示规则(字符串的模式)
18#影片详情链接的规则
19findLink = re.compile(r'<a href="(.*?)">')
20#影片图片
21findImgSrc = re.compile(r'
excel抓取网页数据(Python基础学习03——爬虫网站项目项目介绍及项目 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-03 08:02
)
文章目录
3.2、获取数据
3.3、分析数据
3.4、保存数据
系列文章
Python学习01-Python基础
Python库学习——urllib学习
Python库学习——BeautifulSoup4学习
Python库学习——Re正则表达式
Python库学习——Excel存储(xlwt、xlrd)
Python学习02——Python爬虫
Python库学习——Flask基础学习
Python学习03——爬虫网站项目
二、Python爬虫1、任务介绍
爬虫的学习以任务驱动的方式进行,最终实现了豆瓣250大电影的基本信息爬取,包括电影名称、豆瓣评分、评价数、电影摘要、电影链接等。之后会以可视化的方式展示出来,比如统计图表。
豆瓣Top250网站:
2、爬虫介绍
网络爬虫是根据特定规则自动爬取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求对相关网页进行爬取和分析已成为主流的爬取策略。
我们可以爬取我们想看的视频和各种图片,只要是可以通过浏览器访问的数据都可以用爬虫爬取。这并不是说视频网站上只有VIP才能观看的视频可以爬取,而是我们可以通过浏览器本身观看。除非启用 VIP,否则我们仍然无法访问这些特定视频。
模拟浏览器打开网页,在网页中获取我们想要的具体数据。
爬虫原理:因为每个网页实际上都是一个HTML,里面有各种超链接,所以爬虫跟随超链接访问下一个网页。
3、基本流程
通过浏览器查看和分析目标页面,了解编程的基本规范。
通过 HTTP 库向目标站点发起请求。该请求收录其他标头和其他信息。如果服务器正常响应,会得到一个Response,就是要获取的页面内容。
获取的内容可以是HTML、JSON等格式。在这种情况下,使用页面解析库、正则表达式等进行解析。
保存形式多,可保存为文本、数据库或特定格式文件(Excel)
3.1、准备
这里我们先进入豆瓣Top250,分析一下每次翻页后的URL格式。
第一页:
第二页:
第三页:
注意:初次访问的第一页没有?top250?开始=0&过滤器=。最后的&filter=省略也可以正常访问。
3.1.1、分析页面
使用Charome开发者工具(按F12进入,其他浏览器类似)分析网页,在Elments下找到需要的数据位置。
当我们点击一个链接时,浏览器会向服务器发出请求
3.1.2、编码规范
1# -*- coding:utf-8 或者 # coding=utf-8
2
3
这样就可以在代码中收录中文,以免乱码。
1"""
2 程序输出:
3 hello 2
4 hello 1
5 __main__的意义:
6 程序会依次调用 test(2) 和 test(1),因为python是解释型语言,会按顺序执行。
7 为了使函数调用整齐有序,我们在__main__之前定义函数,在__main__中去调用。
8 约定俗成我们都从main开始执行。
9"""
10
11def main(a):
12 print("hello", a)
13
14test(2)
15
16if __name__ == "__main__":
17 main(1)
18
19
3.1.3、导入模块
这里要导入的第三方模块有:bs4、re、urllib、xlwt
在 Python 中导入第三方模块有两种方法,在命令行终端中使用 pip 或在 PyCharm 中导入。
1import re # 正则表达式,用于文字匹配
2from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
3import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
4import xlwt # 用于Excel操作
5import sqlite3 # 用于进行SQLite数据库操作
6
7
3.1.4、程序流程
这里先说大体思路,然后一步一步实现。
1# -*- coding = utf-8 -*-
2# @Time : 2021/7/3 6:33 下午
3# @Author : 张城阳
4# @File : main.py
5# @Software : PyCharm
6
7import re # 正则表达式,用于文字匹配
8from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
9import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
10import xlwt # 用于Excel操作
11import sqlite3 # 用于进行SQLite数据库操作
12
13
14def main():
15 # 豆瓣Top250网址(末尾的参数 ?start= 加不加都可以访问到第一页)
16 baseUrl = "https://movie.douban.com/top250?start="
17 # 1. 爬取网页并解析数据
18 dataList = getData(baseUrl)
19 # 2. 保存数据(以Excel形式保存)
20 savePath = ".\\豆瓣电影Top250.xls"
21 saveData(savePath)
22
23
24# 爬取网页,返回数据列表
25def getData(baseurl):
26 dataList = []
27 # 爬取网页并获取需要的数据
28 pass
29 # 对数据逐一解析
30 pass
31 # 返回解析好的数据
32 return dataList
33
34
35# 保存数据
36def saveData(savePath):
37 pass
38
39
40# 程序入口
41if __name__ == "__main__":
42 # 调用函数
43 main()
44
45
3.2、获取数据
Python一般使用urllib库来获取页面(Python2是urllib2,Python3集成了urllib和urllib2)。对于urllib,可以看另外一篇博客Python第三方库——urllib学习。
1# 得到一个指定URL的网页内容
2def askURL(url):
3 # 模拟头部信息,像豆瓣服务器发送消息
4 # User-Agent 表明这是一个浏览器(这个来自谷歌浏览器F12里 Network中 Request headers的User-Agent)
5 # 每个人的用户代理可能不相同,用自己的就好。不要复制错了,否则会报418状态码。
6 head = {
7 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
8 }
9 # 封装头部信息
10 request = urllib.request.Request(url, headers=head)
11 html = ""
12 try:
13 # 发起请求并获取响应
14 response = urllib.request.urlopen(request)
15 # 读取整个HTML源码,并解码为UTF-8
16 html = response.read().decode("utf-8")
17 except urllib.error.URLError as e:
18 # 异常捕获
19 if hasattr(e, "code"):
20 print("状态码:", e.code)
21 if hasattr(e, "reason"):
22 print("原因:", e.reason)
23 return html
24
25
26# 爬取网页,返回数据列表
27def getData(baseurl):
28 dataList = []
29 # 爬取所有网页并获取需要的HTML源码
30 for i in range(0, 10): # 豆瓣Top250 共有10页,每页25条。 range(0,10)的范围是[0,10)。
31 url = baseurl + str(i*25) # 最终 url = https://movie.douban.com/top250?start=225
32 html = askURL(url) # 将每个页面HTML源码获取出来
33 # 对页面源码逐一解析
34 pass
35 # 返回解析好的数据
36 return dataList
37
38
3.3、分析数据
现在开始解析获得的 HTML 源代码。根据观察,每部电影的信息是由
包,收录电影名、详情链接、图片链接等,需要用到正则表达式re库。关于re库,可以看我的另一篇博客,Python库学习——Re正则表达式。
这是电影《肖申克的救赎》的 HTML:
1
2
3 1
4
5
7
8
9
10
11
12 肖申克的救赎
13 / The Shawshank Redemption
14 / 月黑高飞(港) / 刺激1995(台)
15
16
17
18 [可播放]
19
20
21
22 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
23 1994 / 美国 / 犯罪 剧情
24
25
26
27
28 9.7
29
30 2385802人评价
31
32
33 希望让人自由。
34
35
36
37
38
39
下面是解析数据的代码:(为了方便观察,这里只解析第一页,把range(0, 1)改成range(0, 10)就是10页)。
<p>1# 正则表达式:.表示任意字符,*表示0次或任意次,?表示0次或1次。(.*?)惰性匹配。
2findLink = re.compile(r'<a href="(.*?)">') # 获取电影详情链接。
3findImg = re.compile(r' 查看全部
excel抓取网页数据(Python基础学习03——爬虫网站项目项目介绍及项目
)
文章目录
3.2、获取数据
3.3、分析数据
3.4、保存数据
系列文章
Python学习01-Python基础
Python库学习——urllib学习
Python库学习——BeautifulSoup4学习
Python库学习——Re正则表达式
Python库学习——Excel存储(xlwt、xlrd)
Python学习02——Python爬虫
Python库学习——Flask基础学习
Python学习03——爬虫网站项目
二、Python爬虫1、任务介绍
爬虫的学习以任务驱动的方式进行,最终实现了豆瓣250大电影的基本信息爬取,包括电影名称、豆瓣评分、评价数、电影摘要、电影链接等。之后会以可视化的方式展示出来,比如统计图表。
豆瓣Top250网站:
2、爬虫介绍
网络爬虫是根据特定规则自动爬取互联网信息的程序或脚本。由于互联网数据的多样性和资源的有限性,根据用户需求对相关网页进行爬取和分析已成为主流的爬取策略。
我们可以爬取我们想看的视频和各种图片,只要是可以通过浏览器访问的数据都可以用爬虫爬取。这并不是说视频网站上只有VIP才能观看的视频可以爬取,而是我们可以通过浏览器本身观看。除非启用 VIP,否则我们仍然无法访问这些特定视频。
模拟浏览器打开网页,在网页中获取我们想要的具体数据。
爬虫原理:因为每个网页实际上都是一个HTML,里面有各种超链接,所以爬虫跟随超链接访问下一个网页。
3、基本流程
通过浏览器查看和分析目标页面,了解编程的基本规范。
通过 HTTP 库向目标站点发起请求。该请求收录其他标头和其他信息。如果服务器正常响应,会得到一个Response,就是要获取的页面内容。
获取的内容可以是HTML、JSON等格式。在这种情况下,使用页面解析库、正则表达式等进行解析。
保存形式多,可保存为文本、数据库或特定格式文件(Excel)
3.1、准备
这里我们先进入豆瓣Top250,分析一下每次翻页后的URL格式。
第一页:
第二页:
第三页:
注意:初次访问的第一页没有?top250?开始=0&过滤器=。最后的&filter=省略也可以正常访问。
3.1.1、分析页面
使用Charome开发者工具(按F12进入,其他浏览器类似)分析网页,在Elments下找到需要的数据位置。
当我们点击一个链接时,浏览器会向服务器发出请求
3.1.2、编码规范
1# -*- coding:utf-8 或者 # coding=utf-8
2
3
这样就可以在代码中收录中文,以免乱码。
1"""
2 程序输出:
3 hello 2
4 hello 1
5 __main__的意义:
6 程序会依次调用 test(2) 和 test(1),因为python是解释型语言,会按顺序执行。
7 为了使函数调用整齐有序,我们在__main__之前定义函数,在__main__中去调用。
8 约定俗成我们都从main开始执行。
9"""
10
11def main(a):
12 print("hello", a)
13
14test(2)
15
16if __name__ == "__main__":
17 main(1)
18
19
3.1.3、导入模块
这里要导入的第三方模块有:bs4、re、urllib、xlwt
在 Python 中导入第三方模块有两种方法,在命令行终端中使用 pip 或在 PyCharm 中导入。
1import re # 正则表达式,用于文字匹配
2from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
3import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
4import xlwt # 用于Excel操作
5import sqlite3 # 用于进行SQLite数据库操作
6
7
3.1.4、程序流程
这里先说大体思路,然后一步一步实现。
1# -*- coding = utf-8 -*-
2# @Time : 2021/7/3 6:33 下午
3# @Author : 张城阳
4# @File : main.py
5# @Software : PyCharm
6
7import re # 正则表达式,用于文字匹配
8from bs4 import BeautifulSoup # 用于网页解析,对HTML进行拆分,方便获取数据
9import urllib.request, urllib.error # 用于指定URL,给网址就能进行爬取
10import xlwt # 用于Excel操作
11import sqlite3 # 用于进行SQLite数据库操作
12
13
14def main():
15 # 豆瓣Top250网址(末尾的参数 ?start= 加不加都可以访问到第一页)
16 baseUrl = "https://movie.douban.com/top250?start="
17 # 1. 爬取网页并解析数据
18 dataList = getData(baseUrl)
19 # 2. 保存数据(以Excel形式保存)
20 savePath = ".\\豆瓣电影Top250.xls"
21 saveData(savePath)
22
23
24# 爬取网页,返回数据列表
25def getData(baseurl):
26 dataList = []
27 # 爬取网页并获取需要的数据
28 pass
29 # 对数据逐一解析
30 pass
31 # 返回解析好的数据
32 return dataList
33
34
35# 保存数据
36def saveData(savePath):
37 pass
38
39
40# 程序入口
41if __name__ == "__main__":
42 # 调用函数
43 main()
44
45
3.2、获取数据
Python一般使用urllib库来获取页面(Python2是urllib2,Python3集成了urllib和urllib2)。对于urllib,可以看另外一篇博客Python第三方库——urllib学习。
1# 得到一个指定URL的网页内容
2def askURL(url):
3 # 模拟头部信息,像豆瓣服务器发送消息
4 # User-Agent 表明这是一个浏览器(这个来自谷歌浏览器F12里 Network中 Request headers的User-Agent)
5 # 每个人的用户代理可能不相同,用自己的就好。不要复制错了,否则会报418状态码。
6 head = {
7 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
8 }
9 # 封装头部信息
10 request = urllib.request.Request(url, headers=head)
11 html = ""
12 try:
13 # 发起请求并获取响应
14 response = urllib.request.urlopen(request)
15 # 读取整个HTML源码,并解码为UTF-8
16 html = response.read().decode("utf-8")
17 except urllib.error.URLError as e:
18 # 异常捕获
19 if hasattr(e, "code"):
20 print("状态码:", e.code)
21 if hasattr(e, "reason"):
22 print("原因:", e.reason)
23 return html
24
25
26# 爬取网页,返回数据列表
27def getData(baseurl):
28 dataList = []
29 # 爬取所有网页并获取需要的HTML源码
30 for i in range(0, 10): # 豆瓣Top250 共有10页,每页25条。 range(0,10)的范围是[0,10)。
31 url = baseurl + str(i*25) # 最终 url = https://movie.douban.com/top250?start=225
32 html = askURL(url) # 将每个页面HTML源码获取出来
33 # 对页面源码逐一解析
34 pass
35 # 返回解析好的数据
36 return dataList
37
38
3.3、分析数据
现在开始解析获得的 HTML 源代码。根据观察,每部电影的信息是由
包,收录电影名、详情链接、图片链接等,需要用到正则表达式re库。关于re库,可以看我的另一篇博客,Python库学习——Re正则表达式。
这是电影《肖申克的救赎》的 HTML:
1
2
3 1
4
5
7
8
9
10
11
12 肖申克的救赎
13 / The Shawshank Redemption
14 / 月黑高飞(港) / 刺激1995(台)
15
16
17
18 [可播放]
19
20
21
22 导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...
23 1994 / 美国 / 犯罪 剧情
24
25
26
27
28 9.7
29
30 2385802人评价
31
32
33 希望让人自由。
34
35
36
37
38
39
下面是解析数据的代码:(为了方便观察,这里只解析第一页,把range(0, 1)改成range(0, 10)就是10页)。
<p>1# 正则表达式:.表示任意字符,*表示0次或任意次,?表示0次或1次。(.*?)惰性匹配。
2findLink = re.compile(r'<a href="(.*?)">') # 获取电影详情链接。
3findImg = re.compile(r'
excel抓取网页数据(Excel新增一个名为Web的函数类别(图)~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-02-01 08:01
HI~大家好,我叫星光。
据说随着互联网的飞速发展,网页数据越来越成为数据分析过程中最重要的数据源之一……或许正是基于这样的考虑,从2013版开始,Excel又增加了一个新功能类称为 Web ,利用该类的功能,我们可以通过网页从 Web 服务器获取数据,例如股票信息、天气查询、有道翻译、男女爱情等等。
弹指一挥,高大上的开场白就结束了,来个小栗子。
如上图,在B2单元格输入如下公式,将A2单元格的值翻译成英汉或汉英 ▼=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"/ /translation") 公式看起来很长,主要是因为URL长度比较长,但是公式的结构其实很简单。看我的手指,歪的,画的,Sri,主要是由3部分组成。第 1 部分构建 URL。"; i="&A2&"&doctype=xml"这是有道在线翻译的网页地址,包括关键参数,i="&A2是要翻译的词汇,doctype=xml是返回文件的类型,即xml。只返回 xml,因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。第 2 部分。
" input> translation>response>
第三部分获取目标数据。此处使用 FILTERXML 函数。FILTERXML函数的语法如下▼
FILTERXML(xml,xpath)
该函数有两个参数,xml参数为有效的xml格式文本,xpath参数为xml中要查询的目标数据的标准路径。通过第二部分得到的xml文件的内容,我们可以直接看到See stars的翻译结果在翻译路径下(第6-8行),所以第二个参数设置为//translation。
...好的,这就是我今天要与您分享的内容。有兴趣的朋友可以尝试使用web函数从百度天气预报中获取自己家乡城市的天气信息~由于FILTERXML可以从XML格式的文本中获取数据,所以当XML文本是我们刻意构建生成的字符串时,会有很多奇妙的用法,比如用这个函数来实现VBA编程Split函数的效果,关于这个,我们后面再说。 查看全部
excel抓取网页数据(Excel新增一个名为Web的函数类别(图)~)
HI~大家好,我叫星光。
据说随着互联网的飞速发展,网页数据越来越成为数据分析过程中最重要的数据源之一……或许正是基于这样的考虑,从2013版开始,Excel又增加了一个新功能类称为 Web ,利用该类的功能,我们可以通过网页从 Web 服务器获取数据,例如股票信息、天气查询、有道翻译、男女爱情等等。
弹指一挥,高大上的开场白就结束了,来个小栗子。
如上图,在B2单元格输入如下公式,将A2单元格的值翻译成英汉或汉英 ▼=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"/ /translation") 公式看起来很长,主要是因为URL长度比较长,但是公式的结构其实很简单。看我的手指,歪的,画的,Sri,主要是由3部分组成。第 1 部分构建 URL。"; i="&A2&"&doctype=xml"这是有道在线翻译的网页地址,包括关键参数,i="&A2是要翻译的词汇,doctype=xml是返回文件的类型,即xml。只返回 xml,因为 FILTERXML 函数可以获取 XML 结构化内容中的信息。第 2 部分。
" input> translation>response>
第三部分获取目标数据。此处使用 FILTERXML 函数。FILTERXML函数的语法如下▼
FILTERXML(xml,xpath)
该函数有两个参数,xml参数为有效的xml格式文本,xpath参数为xml中要查询的目标数据的标准路径。通过第二部分得到的xml文件的内容,我们可以直接看到See stars的翻译结果在翻译路径下(第6-8行),所以第二个参数设置为//translation。
...好的,这就是我今天要与您分享的内容。有兴趣的朋友可以尝试使用web函数从百度天气预报中获取自己家乡城市的天气信息~由于FILTERXML可以从XML格式的文本中获取数据,所以当XML文本是我们刻意构建生成的字符串时,会有很多奇妙的用法,比如用这个函数来实现VBA编程Split函数的效果,关于这个,我们后面再说。
excel抓取网页数据(excel抓取网页数据的视频教程一般都有培训视频可以看一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-01-26 01:02
excel抓取网页数据的视频教程一般都有培训视频可以看一下下,不一定都针对某个网站,
举个栗子来讲好了。开发框架是ci或者springboot我的话一般通过浏览器api在angularjs/ngjs里写个页面,在angular里按模块api写个中间页,现在有一些app接入了google搜索引擎,会用hibernate,然后写几句action就能获取上万个数据源了,然后定义一些controller来决定哪些页面是哪些页面。
比如普通的中间页就定义一个action,你看到数据库里有一大堆的表和索引,你就按需求定义一个关键字来查看某个表或者哪些索引,然后要调用搜索时就模拟它的dom上的action来执行,根据返回的信息修改数据源。数据抓包和解析的能力非常非常非常重要,有个会写ssr解析http的人,几十行的代码就可以抓取到非常非常非常多的网页了,当然,我说的只是抓包这方面,最终获取的数据最好是有json格式的。
读取源代码的能力最好也要有,因为源代码也可以被抓包解析,拿到后可以去判断怎么解析,我能说我有两次抓包编码错误的经历吗??。
先了解网站并不难,搞懂它的url路由和方法就基本上能解决90%网站。
翻墙是一个必不可少的必修课,国内网站就是这么干的,而你要是那种做出网站完全没有任何难度的,那就只能先弄个仿真网站试一下了。 查看全部
excel抓取网页数据(excel抓取网页数据的视频教程一般都有培训视频可以看一下)
excel抓取网页数据的视频教程一般都有培训视频可以看一下下,不一定都针对某个网站,
举个栗子来讲好了。开发框架是ci或者springboot我的话一般通过浏览器api在angularjs/ngjs里写个页面,在angular里按模块api写个中间页,现在有一些app接入了google搜索引擎,会用hibernate,然后写几句action就能获取上万个数据源了,然后定义一些controller来决定哪些页面是哪些页面。
比如普通的中间页就定义一个action,你看到数据库里有一大堆的表和索引,你就按需求定义一个关键字来查看某个表或者哪些索引,然后要调用搜索时就模拟它的dom上的action来执行,根据返回的信息修改数据源。数据抓包和解析的能力非常非常非常重要,有个会写ssr解析http的人,几十行的代码就可以抓取到非常非常非常多的网页了,当然,我说的只是抓包这方面,最终获取的数据最好是有json格式的。
读取源代码的能力最好也要有,因为源代码也可以被抓包解析,拿到后可以去判断怎么解析,我能说我有两次抓包编码错误的经历吗??。
先了解网站并不难,搞懂它的url路由和方法就基本上能解决90%网站。
翻墙是一个必不可少的必修课,国内网站就是这么干的,而你要是那种做出网站完全没有任何难度的,那就只能先弄个仿真网站试一下了。
excel抓取网页数据( 如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-01-24 11:10
如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
今天的 Excel 不再只是一个表格。使用 Power Query 强大的数据处理功能,可以从几乎任何来源、任何结构和任何形式导入数据。
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 Excel 或 PowerBI 之后,下一步就是数据分析的过程。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页数据(
如何利用PowerQuery的强大数据处理操作为例,还能从网页上复制数据)
今天的 Excel 不再只是一个表格。使用 Power Query 强大的数据处理功能,可以从几乎任何来源、任何结构和任何形式导入数据。
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人接触到的数据格式是非常有限的。在熟悉了自己的数据类型并知道如何将它们导入 Excel 或 PowerBI 之后,下一步就是数据分析的过程。这是我们真正需要掌握的核心技能。
excel抓取网页数据(一个日期表amp建立一个城市表制作可视化报表(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-01-24 04:00
01Excel网页抓取天气预报 Excel可以抓取网页数据吗?当然!今天,小白将向您展示如何使用 Excel 从 Excel 网页中获取天气预报数据。解析URLs的结构首先我们分析江苏省主要城市的天气,所以我们需要找到这些城市的列表在哪个页面上构建爬虫的主要结构。复习第一章是关于确定链接URL规律,那么在得到规律之后,我们需要开始建一个日期表amp建一个城市表做一个可视化的报告1二月城市选择选择3温度比较选择4数据在表格1回复“海贼王”获取PPT源文件2. 01 Excel做天气预报查询昨天监测,
简介 使用Python“简单”抓取和分析天气数据T_T 之前翻过公众号文章关注数据可视化分析的寥寥无几。02 解析网页数据 根据天气预报页面的代码结构分析,找到标签和标签,可以得到当天的天气信息和气温信息。示例 99 抓取标签和标签。新浪天气预报法以表格结构显示表格数据。网页结构这么长,pandas请求表格数据的基本流程其实就是这样。
有兴趣的朋友可以尝试使用web功能从百度天气预报中获取家乡的天气信息~因为FILTERXML可以从XML格式的文本中获取数据,所以。这是一个使用Python编写爬虫抓取天气预报的代码示例。用python写一个天气查询软件程序非常简单。可以获取此代码。用python写的爬取天气预报的脚本showart_3html从昨天开始一直在看网络爬取,用的awesome,所以写了这个天气。
极强对流天气预报一直是世界性难题。但今年,在“高温+冰雹”极端天气出现前24小时,江苏省气象部门就开始针对全省强对流形势发布精准的强对流潜力预报。51CTO博客为大家找到了关于python抓取天气预报的相关内容,包括IT学习相关文档和代码介绍相关教程视频课程,还有python抓取天气预报问答内容更多python。显示的天气预报也必须是天气图标和温度范围,然后生成一个xml文件供flash调用并从天气中抓取对应的天气预报,温度问题就解决了。
51CTO学院为您提供Python爬虫实战视频教程,捕捉天气预报数据等相关课程,深度学习视频学习,全套深度学习视频教程供IT人充电,再去51CTO学院。这是一个用 Python 编写天气预报的代码示例。用python写一个天气查询软件程序非常简单。此代码可以获取当地天气和任何城市的天气预报。原理是根据url找到网站并截取对应的。 查看全部
excel抓取网页数据(一个日期表amp建立一个城市表制作可视化报表(组图))
01Excel网页抓取天气预报 Excel可以抓取网页数据吗?当然!今天,小白将向您展示如何使用 Excel 从 Excel 网页中获取天气预报数据。解析URLs的结构首先我们分析江苏省主要城市的天气,所以我们需要找到这些城市的列表在哪个页面上构建爬虫的主要结构。复习第一章是关于确定链接URL规律,那么在得到规律之后,我们需要开始建一个日期表amp建一个城市表做一个可视化的报告1二月城市选择选择3温度比较选择4数据在表格1回复“海贼王”获取PPT源文件2. 01 Excel做天气预报查询昨天监测,
简介 使用Python“简单”抓取和分析天气数据T_T 之前翻过公众号文章关注数据可视化分析的寥寥无几。02 解析网页数据 根据天气预报页面的代码结构分析,找到标签和标签,可以得到当天的天气信息和气温信息。示例 99 抓取标签和标签。新浪天气预报法以表格结构显示表格数据。网页结构这么长,pandas请求表格数据的基本流程其实就是这样。
有兴趣的朋友可以尝试使用web功能从百度天气预报中获取家乡的天气信息~因为FILTERXML可以从XML格式的文本中获取数据,所以。这是一个使用Python编写爬虫抓取天气预报的代码示例。用python写一个天气查询软件程序非常简单。可以获取此代码。用python写的爬取天气预报的脚本showart_3html从昨天开始一直在看网络爬取,用的awesome,所以写了这个天气。
极强对流天气预报一直是世界性难题。但今年,在“高温+冰雹”极端天气出现前24小时,江苏省气象部门就开始针对全省强对流形势发布精准的强对流潜力预报。51CTO博客为大家找到了关于python抓取天气预报的相关内容,包括IT学习相关文档和代码介绍相关教程视频课程,还有python抓取天气预报问答内容更多python。显示的天气预报也必须是天气图标和温度范围,然后生成一个xml文件供flash调用并从天气中抓取对应的天气预报,温度问题就解决了。
51CTO学院为您提供Python爬虫实战视频教程,捕捉天气预报数据等相关课程,深度学习视频学习,全套深度学习视频教程供IT人充电,再去51CTO学院。这是一个用 Python 编写天气预报的代码示例。用python写一个天气查询软件程序非常简单。此代码可以获取当地天气和任何城市的天气预报。原理是根据url找到网站并截取对应的。
excel抓取网页数据( 能否制作一个随网站自动同步的Excel表呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-24 03:13
能否制作一个随网站自动同步的Excel表呢?(图))
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以制作与 网站 自动同步的 Excel 工作表?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
首先打开你要爬取的网页
2. 确定 fetch 的范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
构建查询以确定爬网的范围
3. 数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。其中,右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
数据“预清洗”
4. 格式化
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
美化餐桌
5. 设置自动同步间隔
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
更新时防止破坏表格格式
写在最后
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用! 查看全部
excel抓取网页数据(
能否制作一个随网站自动同步的Excel表呢?(图))
有时我们需要从网站中获取一些数据,传统的做法是直接复制粘贴到Excel中。但是,由于页面结构不同,并非所有副本都可以使用。有时即使成功了,得到的数据也是“死数据”。以后一旦有更新,就必须不断重复上述操作。是否可以制作与 网站 自动同步的 Excel 工作表?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1. 打开网页
以下页面为中国地震台网官方页面()。每当发生地震时,都会在此处自动更新。由于我们要抓取它,所以我们需要先打开页面。
首先打开你要爬取的网页
2. 确定 fetch 的范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,将要爬取的URL粘贴进去。此时Power Query会自动分析网页,然后在check中显示分析结果盒子。以本文为例,Power Query分析两组表,点击找到我们需要的,然后点击“转换数据”。片刻之后,Power Query 将自动完成导入。
构建查询以确定爬网的范围
3. 数据清洗
导入完成后,可以通过Power Query进行数据清理。所谓“清理”,就是一个预先筛选的过程,在这里我们可以选择我们需要的记录,或者对不需要的列进行删除和排序。其中,右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完成后,点击左上角的“关闭并上传”,上传Excel。
数据“预清洗”
4. 格式化
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等。通俗地说就是一些美化操作,最后我们得到了下表。
美化餐桌
5. 设置自动同步间隔
目前表基础已经完成,但是像复制粘贴一样,此时得到的仍然只是一堆“死数据”。要使表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,可以自动同步表。
将内容设置为自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框来解决这个问题。
更新时防止破坏表格格式
写在最后
这种技术非常实用,尤其是在做一些动态报表的时候,可以大大减少人工提取的麻烦。嗯,这就是本期想和大家分享的一个小技巧,是不是很有用!
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel实用技巧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2022-01-23 19:04
在日常生活中,我们经常使用 Excel 来组织数据,但不可避免地要从互联网上采集数据。如果我们从互联网上采集的数据是可以直接使用的Excel或Word形式的,那会省去很多麻烦;但是如果数据是以网页格式采集的,我们想在Excel中处理相关数据。最好的方法是将其导入 Excel。但是,如何将其导入 Excel?数据准确性。为此,本文基于Excel提供了从网页获取数据的功能,将网页数据导入Excel表格非常方便,既节省了工作时间,又提高了数据的准确性。注:本文所示数据来自中华人民共和国国家统计局()。具体数据链接:
1 笔者以国家统计局“50个城市主要食品平均价格变化(2014年3月11-20日)”为例。采集并整理到我们的 Excel 中。首先,我们复制数据表所在网页的URL地址(即:)。
2 然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建Web查询”对话框。
3 将复制的URL地址粘贴到“新建Web查询”的地址栏中,然后点击Go,就会出现对应的数据页面,如下图:
4 将鼠标移动到对话框中网页表格的左上角,我们会在左上角看到一个黄黑色的箭头标志,表示Excel已经识别了这个页面的表格,我们点击箭头,箭头会变成绿色的对勾表示选表成功,最后点击下方的“导入”,如下图:
5 在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel就会为我们获取数据,如图:
6 导入数据的过程需要等待,如下图所示:
7 最终数据导入成功,效果如下图:
8 至此,网页中的数据已经成功导入到Excel表格中,接下来我们就可以根据自己的需要对数据进行处理了。
请注意数据的真实性。 查看全部
excel抓取网页数据(Excel教程Excel函数Excel表格制作Excel2010电子表格Excel实用技巧)
在日常生活中,我们经常使用 Excel 来组织数据,但不可避免地要从互联网上采集数据。如果我们从互联网上采集的数据是可以直接使用的Excel或Word形式的,那会省去很多麻烦;但是如果数据是以网页格式采集的,我们想在Excel中处理相关数据。最好的方法是将其导入 Excel。但是,如何将其导入 Excel?数据准确性。为此,本文基于Excel提供了从网页获取数据的功能,将网页数据导入Excel表格非常方便,既节省了工作时间,又提高了数据的准确性。注:本文所示数据来自中华人民共和国国家统计局()。具体数据链接:
1 笔者以国家统计局“50个城市主要食品平均价格变化(2014年3月11-20日)”为例。采集并整理到我们的 Excel 中。首先,我们复制数据表所在网页的URL地址(即:)。
2 然后在Excel中选择“数据”-“获取外部数据”中的“来自网站”菜单项,弹出“新建Web查询”对话框。
3 将复制的URL地址粘贴到“新建Web查询”的地址栏中,然后点击Go,就会出现对应的数据页面,如下图:
4 将鼠标移动到对话框中网页表格的左上角,我们会在左上角看到一个黄黑色的箭头标志,表示Excel已经识别了这个页面的表格,我们点击箭头,箭头会变成绿色的对勾表示选表成功,最后点击下方的“导入”,如下图:
5 在弹出的对话框中,我们可以选择默认设置,也可以选择“属性”进行设置,最后点击“确定”,Excel就会为我们获取数据,如图:
6 导入数据的过程需要等待,如下图所示:
7 最终数据导入成功,效果如下图:
8 至此,网页中的数据已经成功导入到Excel表格中,接下来我们就可以根据自己的需要对数据进行处理了。
请注意数据的真实性。
excel抓取网页数据( Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-01-21 12:15
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人都可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是数据处理的过程。这是我们真正需要掌握的核心技能。 查看全部
excel抓取网页数据(
Powerquery在PowerBI和Excel种的操作类似,从网页上复制数据)
PowerBI中Powerquery的操作与Excel类似。下面以PowerBI Desktop的操作为例。您也可以直接从 Excel 进行操作。
数据采集不仅支持微软自己的数据格式,如Excel、SQL Server、Access等,还支持SAP、Oracle、MySQL、DB2等几乎所有类型的数据格式,总有一款适合你;
不仅可以在本地获取数据,还可以从网页中抓取数据。选择从网页获取数据,只要在弹出的网址窗口中输入网址,就可以直接抓取网页上的数据。这样我们就可以捕捉到实时的交易数据,比如股票涨跌、外汇价格等。现在我们尝试例如从中国银行网站抓取外汇价格信息,首先输入网址:
单击确定后,将出现预览窗口。
点击编辑进入查询编辑器,
外汇数据抓取完成后,剩下的就是数据整理的过程,抓取到的信息可以随时刷新更新数据。这只是获取外汇价格的第一页。实际上,也可以捕获多页数据。后面介绍完M功能后我会专门写一篇文章。
再也不需要手动从网页复制数据并将其粘贴到表格中。
事实上,每个人都可以访问的数据格式非常有限。在熟悉了自己的数据类型并知道如何将它们导入 PowerBI 之后,下一步就是数据处理的过程。这是我们真正需要掌握的核心技能。

