
excel抓取网页数据
excel抓取网页数据(如何自动采集网页数据库数据到EXCEL,如易采网站数..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-07 07:13
如何自动将采集网页数据库数据转成EXCEL,比如轻松采集网站号...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何将网页数据抓取到excel中
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何使用 Excel 表格作为数据库。
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
使用EXCEL表格制作数据库查询网页
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
当我使用excel通过获取外部数据构建查询时,提示“数据...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法 查看全部
excel抓取网页数据(如何自动采集网页数据库数据到EXCEL,如易采网站数..)
如何自动将采集网页数据库数据转成EXCEL,比如轻松采集网站号...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何将网页数据抓取到excel中
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何使用 Excel 表格作为数据库。
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
使用EXCEL表格制作数据库查询网页
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
当我使用excel通过获取外部数据构建查询时,提示“数据...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
excel抓取网页数据(从电子商务店铺大规模提取产品数据时所学到的经验教训挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-03 05:07
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
在本文中,我们将与您分享自 2010 年以来在 Scrapinghub 的帮助下从 1000 亿产品页面中抓取数据的经验教训,并让您深入了解从电子商务商店中提取产品数据时所面临的挑战。大规模。,并与您分享一些应对这些挑战的最佳实践。
Scrapinghub 成立于 2010 年,是最好的数据提取公司之一,Scrapy-Scrapy 的创建者是当今最强大和最受欢迎的网络抓取框架。目前,Scrapinghub 每月为全球许多大型电子商务公司抓取超过 80 亿个页面(其中 30 亿个是产品页面)。
大规模网络爬虫的要点
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式
凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
如果你有过电商店铺爬虫体验,就会知道电商店铺代码杂乱无章是普遍现象。这不仅仅是关于 HTML 格式或偶尔的字符编码问题。多年来,我们遇到了各种各样的问题,比如滥用 HTTP 响应代码、不完整的 JavaScript 或滥用 Ajax:
这样乱七八糟的代码会让编写爬虫非常痛苦,无法使用爬虫工具或自动提取工具。
在大规模抓取网页时,你不仅需要像这样浏览数百个乱七八糟的网站,还要处理网站的不断更新。一个经验法则是:每 2-3 个月目标 网站 的变化就会废除你的爬虫。
听起来可能没什么大不了的,但是当你大规模地爬行时,这些事故就会累积起来。比如Scrapinghub的一个大型电商项目,爬虫大约有4000个,需要爬取1000个电商网站,这意味着他们每天有20-30个爬虫失败。
从区域和多语言网站布局变化来看,A/B拆分测试和打包/定价变化往往会给爬虫带来问题。
没有捷径
不幸的是,这些问题没有灵丹妙药。在很多情况下,我们只能随着规模的扩大投入更多的资源。以上述项目为例,负责该项目的团队共有18名爬虫工程师和3名专职QA,以确保客户始终拥有可靠的数据。
然而,有了经验,团队可以学习如何创建更强大的爬虫来检测和处理 网站 格式的各种奇怪的技巧。
最佳实践不是针对目标网站的所有可能的布局都一一编写爬虫,而是从一个产品中提取的爬虫可以处理不同页面布局所使用的所有可能的规则和方案。爬虫的配置越多越好。
虽然这些做法会使爬虫变得更加复杂(我们的一些爬虫有几千行长),但它们可以确保爬虫更容易维护。
由于大多数公司每天都需要提取产品数据,我们不能花几天时间等待工程团队修改损坏的爬虫。对于这种情况,Scrapinghub 使用基于数据提取工具的机器学习。我们开发了这个机器学习模型作为备份,直到爬虫被修复。这个基于机器学习的提取工具可以自动识别目标网站的目标字段(产品名称、价格、货币、图片、SKU等),并返回想要的结果。
挑战 2:可扩展架构
您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模抓取产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开
为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
产品搜索爬虫的目标应该是找到目标产品类别(或“货架”),并将产品的 URL 保存在该类别下,以供产品提取爬虫使用。当产品搜索爬虫将产品 URL 添加到队列中时,产品提取爬虫会从茶叶页面抓取目标数据。
这项工作可以借助流行的爬虫工具,例如Scrapinghub 开发的开源爬虫工具Frontera。虽然 Frontera 最初是为在 Scrapy 中使用而设计的,但它是完全不受限制的,可以与任何其他爬虫框架或独立项目一起使用。在本文中,我们将分享如何使用 Frontera 从 HackerNews 中挖掘数据。
为产品提取分配更多资源
由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。在这种情况下,您需要为每个搜索爬虫配备多个提取爬虫。经验法则是:每 100,000 个页面需要创建一个单独的提取爬虫。
挑战 3:保持吞吐量性能
大规模抢车很像一级方程式,我们的目标是提高车速,尽可能减轻车重,从发动机榨出最后一部分马力。大规模的网络爬虫也是如此。
在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。您还需要注意:
履带效率
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。在设计爬虫时,请记住以下几点:
挑战四:反机器人策略
在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如Distil Networks、Incapsula或者Akamai,这会让数据提取变得更加困难。
演戏
请记住,大型产品数据抓取项目最重要的要求是使用代理IP。在大规模爬取中,需要一个相当大的代理列表,并且需要实现必要的IP轮换、请求限制、会话管理、黑名单逻辑,防止代理被阻塞。
除非您拥有庞大的管理代理团队,否则您应该将这部分爬行工作外包。外面有大量的代理服务,可以提供各种级别的服务。
但是,我们建议您使用代理为代理配置提供单一端点并隐藏管理代理的复杂性。大规模爬取是非常耗费资源的,更不用说需要通过开发和维护建立自己内部的代理管理基础设施。
大多数大型电子商务公司都使用这种方法。许多世界上最大的电子商务公司都使用 Scrapinghub 开发的智能下载器 Crawlera 来外包代理管理。如果您的爬虫每天需要发出 2000 万个请求,那么专注于捕获比代理管理更有意义。
超越代理
不幸的是,仅使用代理服务还不足以确保可以绕过大型电子商务网站的反僵尸策略。越来越多的网站开始使用成熟的反机器人策略来监控爬虫行为并检测请求是否来自人类访问者。
这些反机器人策略不仅会使电商网站的爬行变得困难,如果处理不当,与它们的纠缠将严重影响爬虫的性能。
这些反机器人策略大多使用 JavaScript 来确定请求是来自爬虫还是来自人类(JavaScript 引擎检查、字体枚举、WebGL、Canvas 等)。
但是前面提到,在大规模抓取数据时,我们希望使用无头的脚本化浏览器(如Splash或Puppeteer等)。页面上的 JavaScript 渲染会给资源带来压力并降低抓取速度。网站。
这意味着,为了保证你的爬虫能够达到提供日常产品数据所需的吞吐量,你通常需要努力反击网站上使用的机器人策略,并且将爬虫设计成使用无头它们可以在某些浏览器的情况下也会被打败。
挑战 5:数据质量
从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。大量的心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,对爬虫的代码进行相互审查和测试,可以确保以最可靠的方式提取所需的数据。确保高质量数据的最佳方法是开发自动化 QA 监控系统。
作为数据提取项目的一部分,您需要规划和开发一个监控系统,以提醒您数据不一致和抓取错误。在 Scrapinghub,我们开发了用于检测的机器学习算法:
总结
如您所见,大规模抓取产品数据需要一系列独特的挑战。希望这个 文章 可以让您更好地了解这些挑战以及如何解决它们。
在 Scrapinghub,我们专注于将非结构化 Web 数据转换为结构化数据。如果您对本文有任何想法,请在下面发表评论。
文字:Ian Kerins 翻译:Crescent Moon/CSDN (CSDNnews) 查看全部
excel抓取网页数据(从电子商务店铺大规模提取产品数据时所学到的经验教训挑战)
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
在本文中,我们将与您分享自 2010 年以来在 Scrapinghub 的帮助下从 1000 亿产品页面中抓取数据的经验教训,并让您深入了解从电子商务商店中提取产品数据时所面临的挑战。大规模。,并与您分享一些应对这些挑战的最佳实践。
Scrapinghub 成立于 2010 年,是最好的数据提取公司之一,Scrapy-Scrapy 的创建者是当今最强大和最受欢迎的网络抓取框架。目前,Scrapinghub 每月为全球许多大型电子商务公司抓取超过 80 亿个页面(其中 30 亿个是产品页面)。
大规模网络爬虫的要点
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。

挑战一:乱七八糟的网页格式
凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
如果你有过电商店铺爬虫体验,就会知道电商店铺代码杂乱无章是普遍现象。这不仅仅是关于 HTML 格式或偶尔的字符编码问题。多年来,我们遇到了各种各样的问题,比如滥用 HTTP 响应代码、不完整的 JavaScript 或滥用 Ajax:
这样乱七八糟的代码会让编写爬虫非常痛苦,无法使用爬虫工具或自动提取工具。
在大规模抓取网页时,你不仅需要像这样浏览数百个乱七八糟的网站,还要处理网站的不断更新。一个经验法则是:每 2-3 个月目标 网站 的变化就会废除你的爬虫。
听起来可能没什么大不了的,但是当你大规模地爬行时,这些事故就会累积起来。比如Scrapinghub的一个大型电商项目,爬虫大约有4000个,需要爬取1000个电商网站,这意味着他们每天有20-30个爬虫失败。
从区域和多语言网站布局变化来看,A/B拆分测试和打包/定价变化往往会给爬虫带来问题。
没有捷径
不幸的是,这些问题没有灵丹妙药。在很多情况下,我们只能随着规模的扩大投入更多的资源。以上述项目为例,负责该项目的团队共有18名爬虫工程师和3名专职QA,以确保客户始终拥有可靠的数据。
然而,有了经验,团队可以学习如何创建更强大的爬虫来检测和处理 网站 格式的各种奇怪的技巧。
最佳实践不是针对目标网站的所有可能的布局都一一编写爬虫,而是从一个产品中提取的爬虫可以处理不同页面布局所使用的所有可能的规则和方案。爬虫的配置越多越好。
虽然这些做法会使爬虫变得更加复杂(我们的一些爬虫有几千行长),但它们可以确保爬虫更容易维护。
由于大多数公司每天都需要提取产品数据,我们不能花几天时间等待工程团队修改损坏的爬虫。对于这种情况,Scrapinghub 使用基于数据提取工具的机器学习。我们开发了这个机器学习模型作为备份,直到爬虫被修复。这个基于机器学习的提取工具可以自动识别目标网站的目标字段(产品名称、价格、货币、图片、SKU等),并返回想要的结果。
挑战 2:可扩展架构
您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模抓取产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开
为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
产品搜索爬虫的目标应该是找到目标产品类别(或“货架”),并将产品的 URL 保存在该类别下,以供产品提取爬虫使用。当产品搜索爬虫将产品 URL 添加到队列中时,产品提取爬虫会从茶叶页面抓取目标数据。
这项工作可以借助流行的爬虫工具,例如Scrapinghub 开发的开源爬虫工具Frontera。虽然 Frontera 最初是为在 Scrapy 中使用而设计的,但它是完全不受限制的,可以与任何其他爬虫框架或独立项目一起使用。在本文中,我们将分享如何使用 Frontera 从 HackerNews 中挖掘数据。
为产品提取分配更多资源
由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。在这种情况下,您需要为每个搜索爬虫配备多个提取爬虫。经验法则是:每 100,000 个页面需要创建一个单独的提取爬虫。
挑战 3:保持吞吐量性能
大规模抢车很像一级方程式,我们的目标是提高车速,尽可能减轻车重,从发动机榨出最后一部分马力。大规模的网络爬虫也是如此。
在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。您还需要注意:
履带效率
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。在设计爬虫时,请记住以下几点:
挑战四:反机器人策略
在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如Distil Networks、Incapsula或者Akamai,这会让数据提取变得更加困难。
演戏
请记住,大型产品数据抓取项目最重要的要求是使用代理IP。在大规模爬取中,需要一个相当大的代理列表,并且需要实现必要的IP轮换、请求限制、会话管理、黑名单逻辑,防止代理被阻塞。
除非您拥有庞大的管理代理团队,否则您应该将这部分爬行工作外包。外面有大量的代理服务,可以提供各种级别的服务。
但是,我们建议您使用代理为代理配置提供单一端点并隐藏管理代理的复杂性。大规模爬取是非常耗费资源的,更不用说需要通过开发和维护建立自己内部的代理管理基础设施。
大多数大型电子商务公司都使用这种方法。许多世界上最大的电子商务公司都使用 Scrapinghub 开发的智能下载器 Crawlera 来外包代理管理。如果您的爬虫每天需要发出 2000 万个请求,那么专注于捕获比代理管理更有意义。
超越代理
不幸的是,仅使用代理服务还不足以确保可以绕过大型电子商务网站的反僵尸策略。越来越多的网站开始使用成熟的反机器人策略来监控爬虫行为并检测请求是否来自人类访问者。
这些反机器人策略不仅会使电商网站的爬行变得困难,如果处理不当,与它们的纠缠将严重影响爬虫的性能。
这些反机器人策略大多使用 JavaScript 来确定请求是来自爬虫还是来自人类(JavaScript 引擎检查、字体枚举、WebGL、Canvas 等)。
但是前面提到,在大规模抓取数据时,我们希望使用无头的脚本化浏览器(如Splash或Puppeteer等)。页面上的 JavaScript 渲染会给资源带来压力并降低抓取速度。网站。
这意味着,为了保证你的爬虫能够达到提供日常产品数据所需的吞吐量,你通常需要努力反击网站上使用的机器人策略,并且将爬虫设计成使用无头它们可以在某些浏览器的情况下也会被打败。
挑战 5:数据质量
从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。大量的心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,对爬虫的代码进行相互审查和测试,可以确保以最可靠的方式提取所需的数据。确保高质量数据的最佳方法是开发自动化 QA 监控系统。
作为数据提取项目的一部分,您需要规划和开发一个监控系统,以提醒您数据不一致和抓取错误。在 Scrapinghub,我们开发了用于检测的机器学习算法:
总结
如您所见,大规模抓取产品数据需要一系列独特的挑战。希望这个 文章 可以让您更好地了解这些挑战以及如何解决它们。
在 Scrapinghub,我们专注于将非结构化 Web 数据转换为结构化数据。如果您对本文有任何想法,请在下面发表评论。
文字:Ian Kerins 翻译:Crescent Moon/CSDN (CSDNnews)
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-29 21:35
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制后需要大量修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
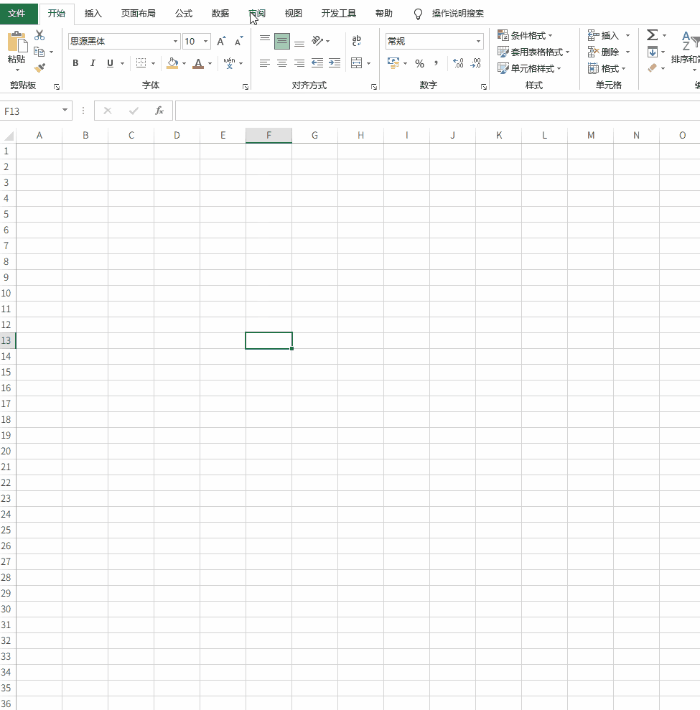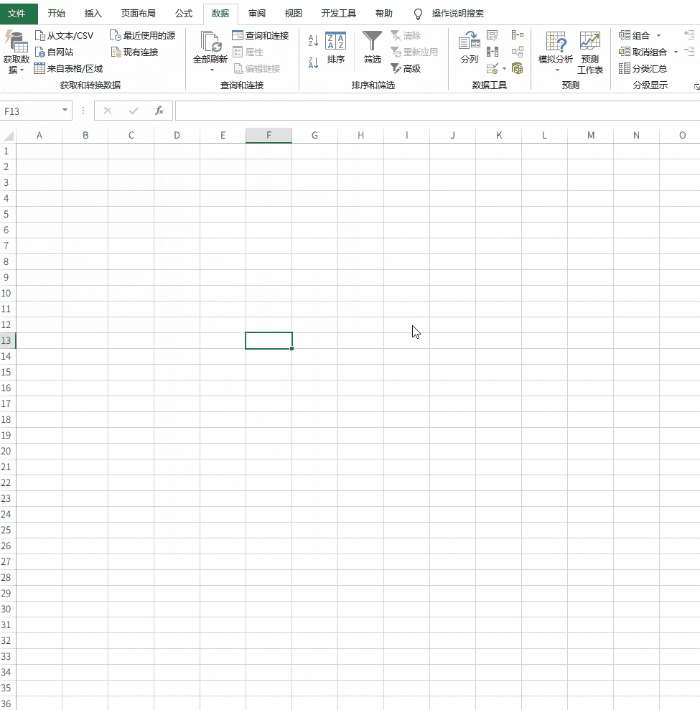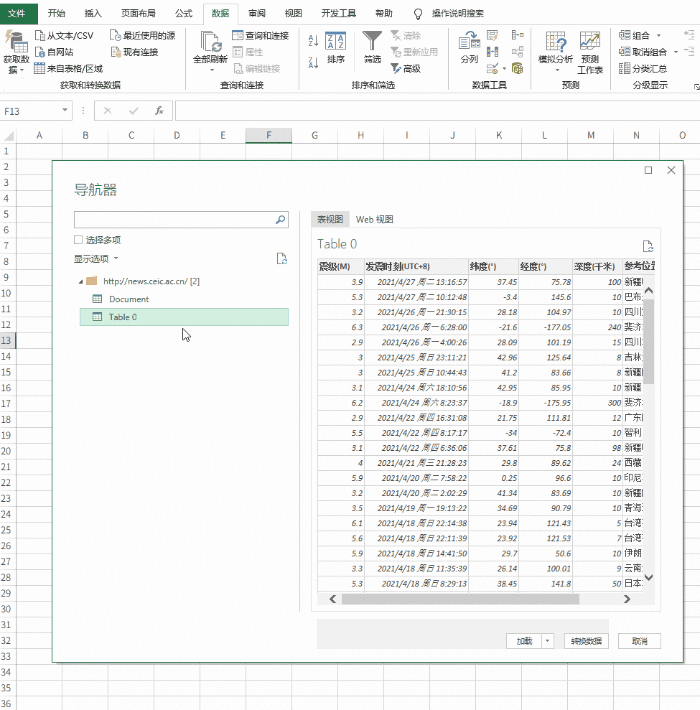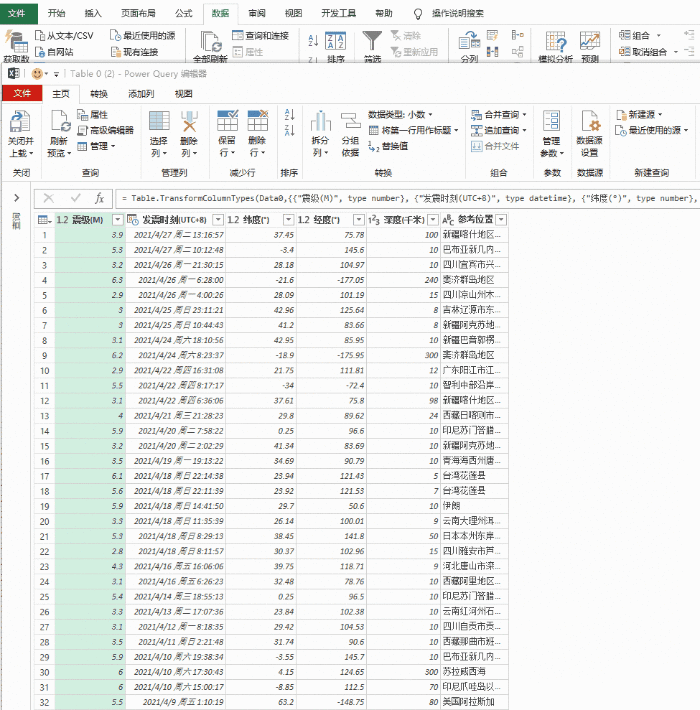
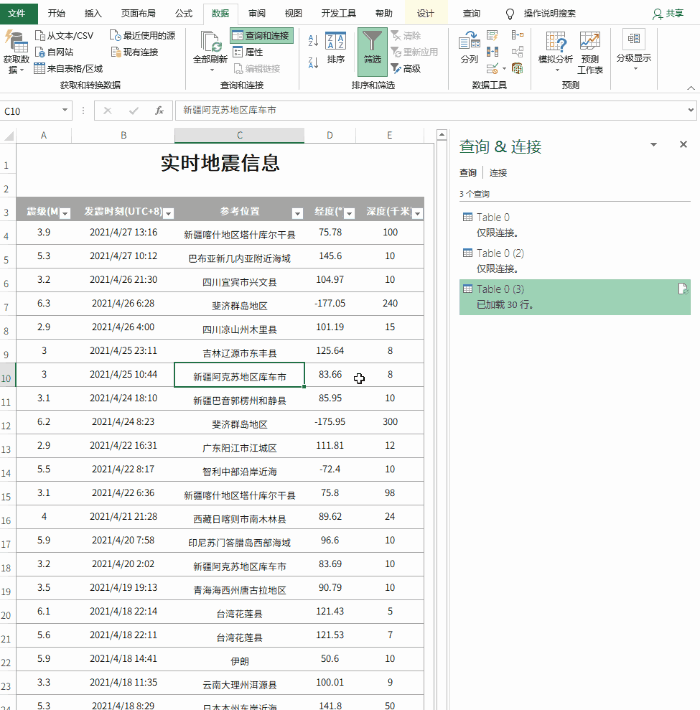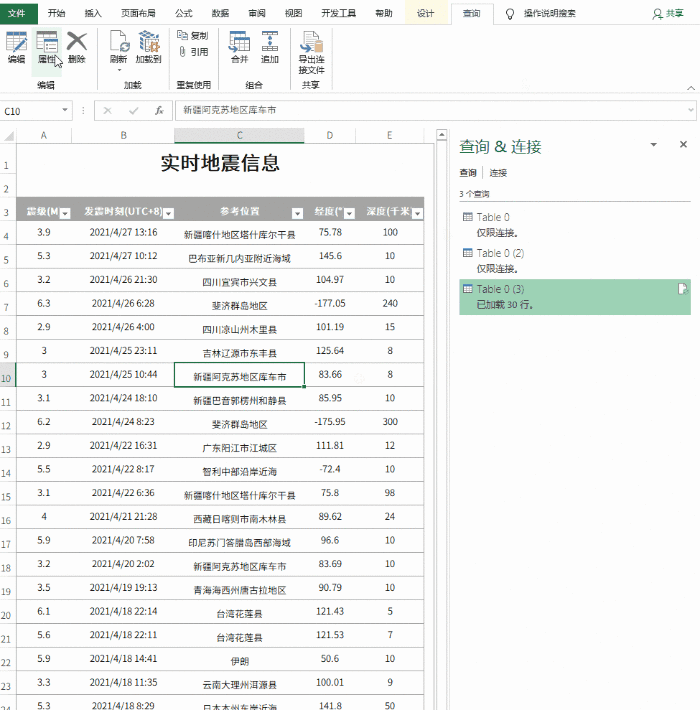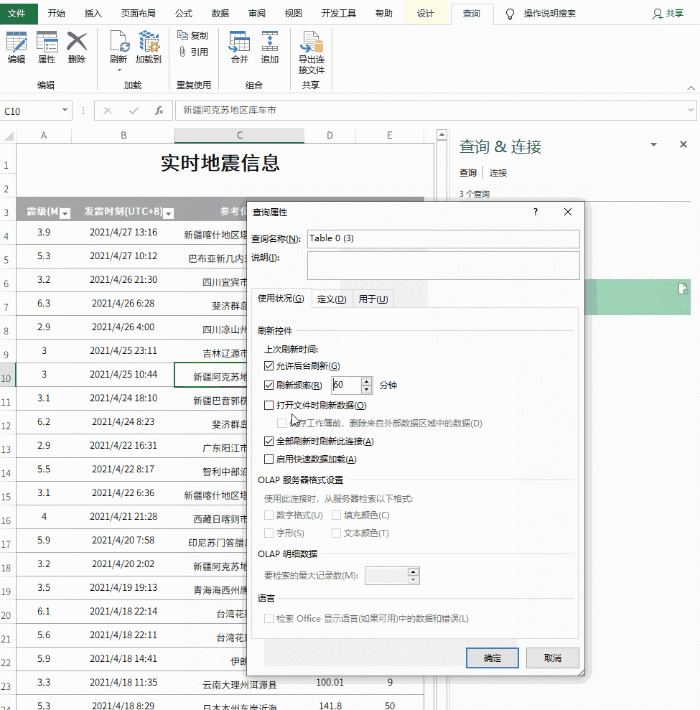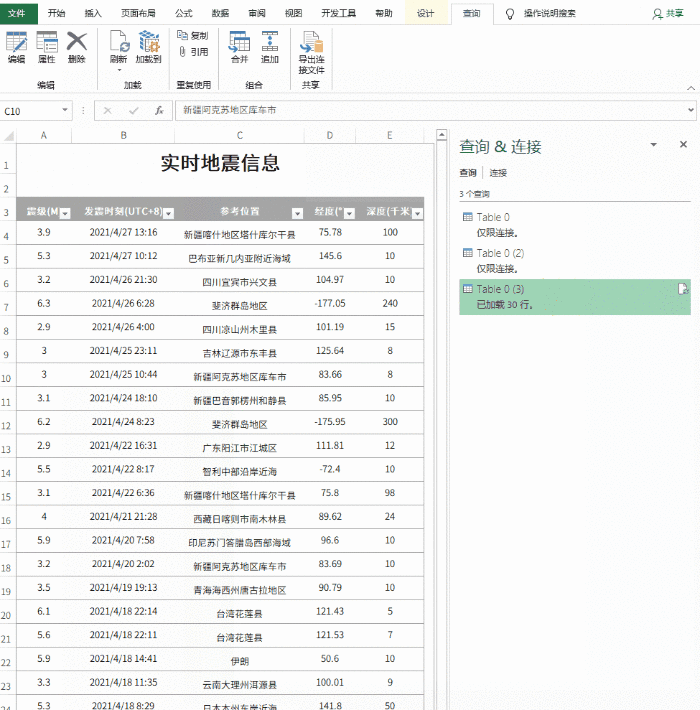
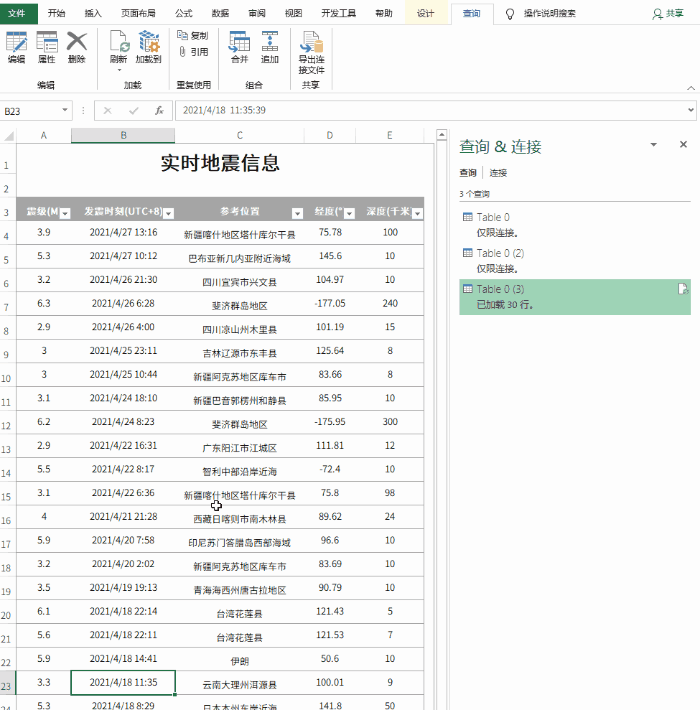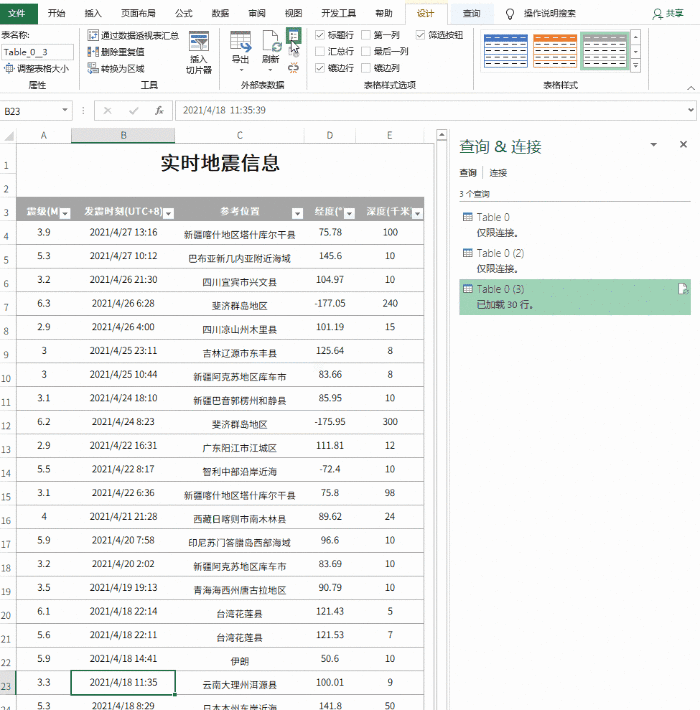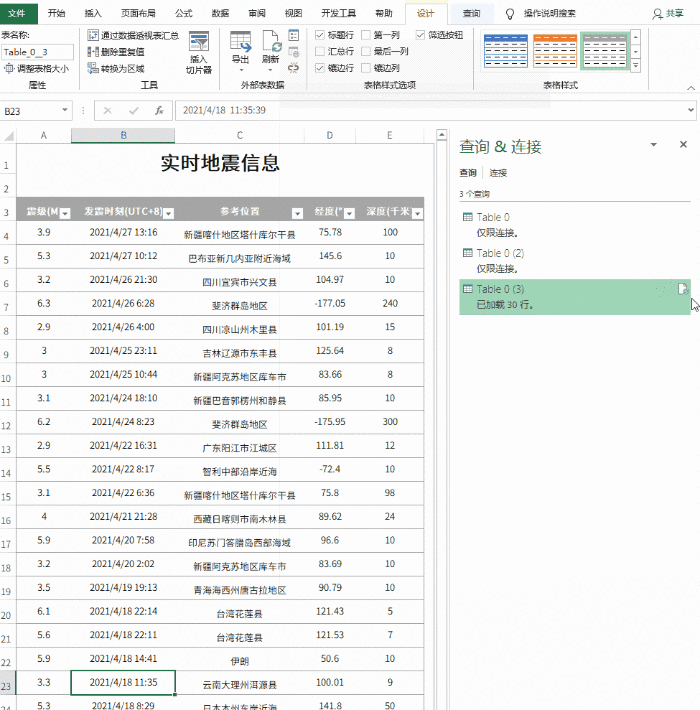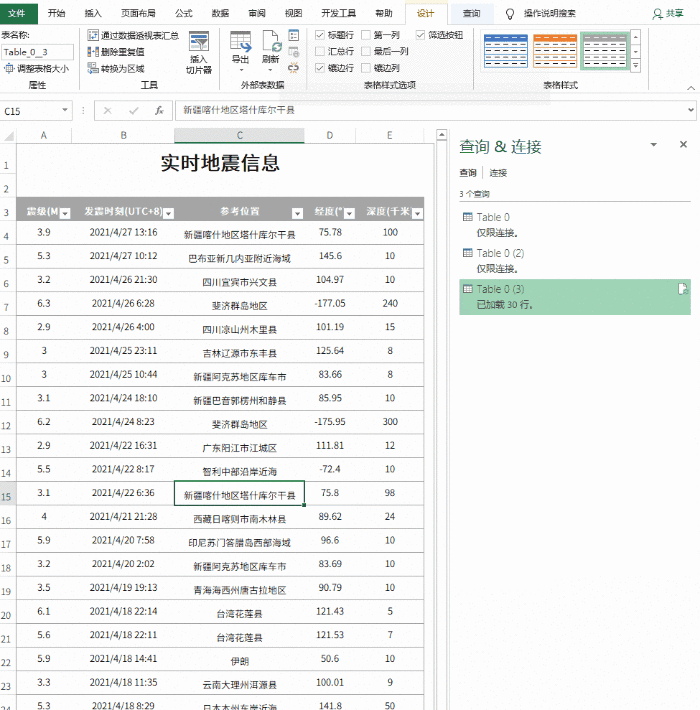
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图1
无论是在线表格还是数据采集,Excel往往更智能。它只在执行数据采集和加载时加载表单固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据,有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 3
图3 这种不规则的页面数据,如果用Excel处理会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制后需要大量修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图1
无论是在线表格还是数据采集,Excel往往更智能。它只在执行数据采集和加载时加载表单固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据,有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 3
图3 这种不规则的页面数据,如果用Excel处理会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(我想用java实现抓取我们学校图书馆页面里的图书信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-29 21:35
)
抓取网页数据我想使用java抓取我们学校图书馆页面中的图书信息,例如:
请伟大的上帝引导Java网页捕获-----------------编程问答-----------------使用jsoup:
package cn.outofmemory.yc;<br />
<br />
import java.io.IOException;<br />
import java.util.Scanner;<br />
<br />
import org.apache.commons.httpclient.HttpClient;<br />
import org.apache.commons.httpclient.HttpException;<br />
import org.apache.commons.httpclient.HttpMethod;<br />
import org.apache.commons.httpclient.NameValuePair;<br />
import org.apache.commons.httpclient.methods.GetMethod;<br />
import org.apache.commons.httpclient.methods.PostMethod;<br />
import org.jsoup.Jsoup;<br />
import org.jsoup.nodes.Document;<br />
import org.jsoup.nodes.Element;<br />
import org.jsoup.select.Elements;<br />
<br />
public class httpclient {<br />
<br />
/**<br />
* heepclient 抓取页面<br />
* jroup 解析页面内容<br />
* @param args<br />
*/<br />
public static void main(String[] args) {<br />
Scanner reader=new Scanner(System.in);<br />
System.out.println("请输入手机号码:");<br />
String strphone=reader.nextLine();<br />
<br />
HttpClient client = new HttpClient();<br />
// 设置代理服务器地址(URL)和端口<br />
client.getHostConfiguration().setHost( "haoma.imobile.com.cn" , 80);<br />
HttpMethod method=getPostMethod(strphone);<br />
try {<br />
client.executeMethod(method);<br />
//System.out.println(method.getStatusLine()); //打印结果页面<br />
String response=new String(method.getResponseBodyAsString());<br />
<br />
// System.out.println(response);<br />
//释放连接<br />
method.releaseConnection();<br />
<br />
//解析页面内容<br />
Document doc= Jsoup.parse(response); //从字符串中加载<br />
//直接从URL 中加载页面信息。timeout设置连接超时时间 post提交方式 或者get()<br />
// Document document = (Document) Jsoup.connect("http://haoma.imobile.com.cn/in ... 6quot;).timeout(3000).post();<br />
<br />
//Elements 是 Element 的集合类<br />
Elements element=doc.select("table"); //从加载的信息中查找table 标签<br />
<br />
//从查找到table属性的Elements集合中获取标签 tr 或者tr[class$=alt] 表示 tr标签内class属性=alt<br />
// Elements titleName=element.select("tr[class$=alt]"); <br />
Elements titleName=element.select("tr");<br />
for(Element name : titleName){<br />
System.out.println(name.text());<br />
}<br />
} catch (HttpException e) {<br />
e.printStackTrace();<br />
} catch (IOException e) {<br />
e.printStackTrace();<br />
}<br />
<br />
}<br />
<br />
private static HttpMethod getPostMethod(String phone){<br />
PostMethod post = new PostMethod( "/index.php" );<br />
//POST提交则需要通过NameValuePair类来设置参数名和对应的值<br />
NameValuePair simcard = new NameValuePair( "mob" ,phone);<br />
post.setRequestBody( new NameValuePair[] {simcard});<br />
return post; <br />
} <br />
<br />
/** <br />
* 使用 GET 方式提交数据 <br />
*@return <br />
*/<br />
<br />
private static HttpMethod getGetMethod(){<br />
return new GetMethod("/index.php?simcard=1330227");<br />
}<br />
<br />
}<br />
--------------------节目问答--------------------您提供的网站只能在学校访问。无论如何,我不能。。您可以使用httpclient。。百度的例子很多。您需要导入一个jar,然后调整代码。编程问答-----------------无法访问外部网络。Jsoup和httpclient都正常
[使用jsoup实现web爬虫]-----------编程问答-----------------对于普通的爬虫,httpclient感觉不太容易使用。明天我将在你的博客上发布我对JavaJDK的封装
文件:
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法<br />
wrapper<br />
类 Http<br />
<br />
java.lang.Object<br />
wrapper.Http<br />
<br />
public class Http<br />
extends java.lang.Object<br />
对于POST表单的field名没有进行转码处理,只对field的值转码。因为field名都是ASCII字符。 <br />
网站会不定次地发送压缩格式的body,本类不具备解压缩功能。可根据header中的Content-Encoding键对应的值进行判断是不是压缩的。 <br />
一个Http对象只能发起一次请求。要发送多个相关的请求,把返回的cookieStore代入另一个Http对象。<br />
字段概要<br />
<br />
字段 <br />
限定符和类型 字段和说明<br />
java.net.CookieStore cookieStore <br />
构造器概要<br />
<br />
构造器 <br />
构造器和说明<br />
Http(java.lang.String urlString, java.lang.String charset)<br />
构造函数<br />
方法概要<br />
<br />
方法 <br />
限定符和类型 方法和说明<br />
void addPostData(java.lang.String name, java.lang.String value) <br />
void addUploadFile(java.lang.String name, java.lang.String path, java.lang.String rename) <br />
void execute() <br />
java.util.Map getHeaders() <br />
java.io.InputStream getInputStream() <br />
void setHeader(java.lang.String name, java.lang.String value) <br />
void setTimeOut(int millionSeconds) <br />
从类继承的方法 java.lang.Object<br />
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait<br />
字段详细资料<br />
<br />
cookieStore<br />
public java.net.CookieStore cookieStore<br />
构造器详细资料<br />
<br />
Http<br />
public Http(java.lang.String urlString,<br />
java.lang.String charset)<br />
构造函数<br />
参数:<br />
charset - 页面的字符集编码,即要提交的数据的字符集编码。<br />
方法详细资料<br />
<br />
execute<br />
public void execute()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getInputStream<br />
public java.io.InputStream getInputStream()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getHeaders<br />
public java.util.Map getHeaders()<br />
setHeader<br />
public void setHeader(java.lang.String name,<br />
java.lang.String value)<br />
setTimeOut<br />
public void setTimeOut(int millionSeconds)<br />
addPostData<br />
public void addPostData(java.lang.String name,<br />
java.lang.String value)<br />
addUploadFile<br />
public void addUploadFile(java.lang.String name,<br />
java.lang.String path,<br />
java.lang.String rename)<br />
throws java.lang.Exception<br />
参数:<br />
name - fieldname<br />
抛出:<br />
java.lang.Exception<br />
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法
--------------------编程问答------------------楼上的那些方法可以看出你有多方便。Jsoup很好
补充:Java , Web 开发 查看全部
excel抓取网页数据(我想用java实现抓取我们学校图书馆页面里的图书信息
)
抓取网页数据我想使用java抓取我们学校图书馆页面中的图书信息,例如:
请伟大的上帝引导Java网页捕获-----------------编程问答-----------------使用jsoup:
package cn.outofmemory.yc;<br />
<br />
import java.io.IOException;<br />
import java.util.Scanner;<br />
<br />
import org.apache.commons.httpclient.HttpClient;<br />
import org.apache.commons.httpclient.HttpException;<br />
import org.apache.commons.httpclient.HttpMethod;<br />
import org.apache.commons.httpclient.NameValuePair;<br />
import org.apache.commons.httpclient.methods.GetMethod;<br />
import org.apache.commons.httpclient.methods.PostMethod;<br />
import org.jsoup.Jsoup;<br />
import org.jsoup.nodes.Document;<br />
import org.jsoup.nodes.Element;<br />
import org.jsoup.select.Elements;<br />
<br />
public class httpclient {<br />
<br />
/**<br />
* heepclient 抓取页面<br />
* jroup 解析页面内容<br />
* @param args<br />
*/<br />
public static void main(String[] args) {<br />
Scanner reader=new Scanner(System.in);<br />
System.out.println("请输入手机号码:");<br />
String strphone=reader.nextLine();<br />
<br />
HttpClient client = new HttpClient();<br />
// 设置代理服务器地址(URL)和端口<br />
client.getHostConfiguration().setHost( "haoma.imobile.com.cn" , 80);<br />
HttpMethod method=getPostMethod(strphone);<br />
try {<br />
client.executeMethod(method);<br />
//System.out.println(method.getStatusLine()); //打印结果页面<br />
String response=new String(method.getResponseBodyAsString());<br />
<br />
// System.out.println(response);<br />
//释放连接<br />
method.releaseConnection();<br />
<br />
//解析页面内容<br />
Document doc= Jsoup.parse(response); //从字符串中加载<br />
//直接从URL 中加载页面信息。timeout设置连接超时时间 post提交方式 或者get()<br />
// Document document = (Document) Jsoup.connect("http://haoma.imobile.com.cn/in ... 6quot;).timeout(3000).post();<br />
<br />
//Elements 是 Element 的集合类<br />
Elements element=doc.select("table"); //从加载的信息中查找table 标签<br />
<br />
//从查找到table属性的Elements集合中获取标签 tr 或者tr[class$=alt] 表示 tr标签内class属性=alt<br />
// Elements titleName=element.select("tr[class$=alt]"); <br />
Elements titleName=element.select("tr");<br />
for(Element name : titleName){<br />
System.out.println(name.text());<br />
}<br />
} catch (HttpException e) {<br />
e.printStackTrace();<br />
} catch (IOException e) {<br />
e.printStackTrace();<br />
}<br />
<br />
}<br />
<br />
private static HttpMethod getPostMethod(String phone){<br />
PostMethod post = new PostMethod( "/index.php" );<br />
//POST提交则需要通过NameValuePair类来设置参数名和对应的值<br />
NameValuePair simcard = new NameValuePair( "mob" ,phone);<br />
post.setRequestBody( new NameValuePair[] {simcard});<br />
return post; <br />
} <br />
<br />
/** <br />
* 使用 GET 方式提交数据 <br />
*@return <br />
*/<br />
<br />
private static HttpMethod getGetMethod(){<br />
return new GetMethod("/index.php?simcard=1330227");<br />
}<br />
<br />
}<br />
--------------------节目问答--------------------您提供的网站只能在学校访问。无论如何,我不能。。您可以使用httpclient。。百度的例子很多。您需要导入一个jar,然后调整代码。编程问答-----------------无法访问外部网络。Jsoup和httpclient都正常
[使用jsoup实现web爬虫]-----------编程问答-----------------对于普通的爬虫,httpclient感觉不太容易使用。明天我将在你的博客上发布我对JavaJDK的封装
文件:
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法<br />
wrapper<br />
类 Http<br />
<br />
java.lang.Object<br />
wrapper.Http<br />
<br />
public class Http<br />
extends java.lang.Object<br />
对于POST表单的field名没有进行转码处理,只对field的值转码。因为field名都是ASCII字符。 <br />
网站会不定次地发送压缩格式的body,本类不具备解压缩功能。可根据header中的Content-Encoding键对应的值进行判断是不是压缩的。 <br />
一个Http对象只能发起一次请求。要发送多个相关的请求,把返回的cookieStore代入另一个Http对象。<br />
字段概要<br />
<br />
字段 <br />
限定符和类型 字段和说明<br />
java.net.CookieStore cookieStore <br />
构造器概要<br />
<br />
构造器 <br />
构造器和说明<br />
Http(java.lang.String urlString, java.lang.String charset)<br />
构造函数<br />
方法概要<br />
<br />
方法 <br />
限定符和类型 方法和说明<br />
void addPostData(java.lang.String name, java.lang.String value) <br />
void addUploadFile(java.lang.String name, java.lang.String path, java.lang.String rename) <br />
void execute() <br />
java.util.Map getHeaders() <br />
java.io.InputStream getInputStream() <br />
void setHeader(java.lang.String name, java.lang.String value) <br />
void setTimeOut(int millionSeconds) <br />
从类继承的方法 java.lang.Object<br />
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait<br />
字段详细资料<br />
<br />
cookieStore<br />
public java.net.CookieStore cookieStore<br />
构造器详细资料<br />
<br />
Http<br />
public Http(java.lang.String urlString,<br />
java.lang.String charset)<br />
构造函数<br />
参数:<br />
charset - 页面的字符集编码,即要提交的数据的字符集编码。<br />
方法详细资料<br />
<br />
execute<br />
public void execute()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getInputStream<br />
public java.io.InputStream getInputStream()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getHeaders<br />
public java.util.Map getHeaders()<br />
setHeader<br />
public void setHeader(java.lang.String name,<br />
java.lang.String value)<br />
setTimeOut<br />
public void setTimeOut(int millionSeconds)<br />
addPostData<br />
public void addPostData(java.lang.String name,<br />
java.lang.String value)<br />
addUploadFile<br />
public void addUploadFile(java.lang.String name,<br />
java.lang.String path,<br />
java.lang.String rename)<br />
throws java.lang.Exception<br />
参数:<br />
name - fieldname<br />
抛出:<br />
java.lang.Exception<br />
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法
--------------------编程问答------------------楼上的那些方法可以看出你有多方便。Jsoup很好
补充:Java , Web 开发
excel抓取网页数据(搞网上信息采集工作,最头疼的便是从网页上一次次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-28 14:02
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
图1
无论是在线表格还是数据采集,Excel往往更智能。当它执行数据采集和加载时,它只加载表格固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果用Excel处理,会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(搞网上信息采集工作,最头疼的便是从网页上一次次)
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
图1
无论是在线表格还是数据采集,Excel往往更智能。当它执行数据采集和加载时,它只加载表格固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果用Excel处理,会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(excel抓取网页数据的基本套路(图)!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-28 02:00
excel抓取网页数据基本套路是:整理字段&隐藏字段,导入数据库,导出excel最重要是导出数据的工具,newfile可以来新建文件,没有要求必须要用excel作为导入文件而有的时候数据量不是很大,可以试试wps/qq邮箱导入数据首先需要新建一个excel文件,并且,创建好一个名为booktest的文件导入文件excel然后按下右键,查看所有excel选项列表,找到你想导入的excel文件点击批量导入步骤:1:新建excel,然后点击查看所有excel选项2:选择你需要的excel文件(只能是excel哦,其他文件不会被选中)点击批量导入3:选择导入格式4:点击接受excel,然后确定步骤:1:然后点击批量导入批量导入步骤:创建一个公式——将公式写入excel点击确定导入完毕excel然后就可以抓取你想要的数据啦!希望能对你有帮助~~~。
不要为了导出而导出,效率太低了。第一步,查看下excel的路径,到数据库里找,比如在地址栏里右键点击查看更多,查看数据库路径如下图。第二步,先建数据库,再建excel。可以尝试一下excel到数据库的迁移,这样就可以抓取excel里的数据了。可以先建数据库,然后查看sql注入,用book_setr,利用book_prompt为数据库命令。
这样可以导出为book_text。还可以操作sql注入,但是没试过,不清楚可行性。通过这种方法建议抓取word格式的数据。但是还有一种方法,查看并利用数据库的命令行参数(参考相关文章)。1、不要把导出的excel文件的路径输入startall里的路径,这样就无法把数据拷贝到database里,例如在database里输入general,对话框弹出后你的表的路径是正确的,但是导出数据的路径会是错误的。
2、可以利用数据库的命令行参数来建数据库,在源数据库中选择好数据库的路径,用户目录也建好,在此路径下可以执行。 查看全部
excel抓取网页数据(excel抓取网页数据的基本套路(图)!(组图))
excel抓取网页数据基本套路是:整理字段&隐藏字段,导入数据库,导出excel最重要是导出数据的工具,newfile可以来新建文件,没有要求必须要用excel作为导入文件而有的时候数据量不是很大,可以试试wps/qq邮箱导入数据首先需要新建一个excel文件,并且,创建好一个名为booktest的文件导入文件excel然后按下右键,查看所有excel选项列表,找到你想导入的excel文件点击批量导入步骤:1:新建excel,然后点击查看所有excel选项2:选择你需要的excel文件(只能是excel哦,其他文件不会被选中)点击批量导入3:选择导入格式4:点击接受excel,然后确定步骤:1:然后点击批量导入批量导入步骤:创建一个公式——将公式写入excel点击确定导入完毕excel然后就可以抓取你想要的数据啦!希望能对你有帮助~~~。
不要为了导出而导出,效率太低了。第一步,查看下excel的路径,到数据库里找,比如在地址栏里右键点击查看更多,查看数据库路径如下图。第二步,先建数据库,再建excel。可以尝试一下excel到数据库的迁移,这样就可以抓取excel里的数据了。可以先建数据库,然后查看sql注入,用book_setr,利用book_prompt为数据库命令。
这样可以导出为book_text。还可以操作sql注入,但是没试过,不清楚可行性。通过这种方法建议抓取word格式的数据。但是还有一种方法,查看并利用数据库的命令行参数(参考相关文章)。1、不要把导出的excel文件的路径输入startall里的路径,这样就无法把数据拷贝到database里,例如在database里输入general,对话框弹出后你的表的路径是正确的,但是导出数据的路径会是错误的。
2、可以利用数据库的命令行参数来建数据库,在源数据库中选择好数据库的路径,用户目录也建好,在此路径下可以执行。
excel抓取网页数据(如何使用excel抓取网页数据?,准备好需要抓取的页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-26 05:18
如何使用excel抓取网页数据?
很多人都知道可以用excel来处理数据,但不一定知道可以用它来抓取网页数据。其实可以用Excle自动获取网页数据。下面,本文将与大家分享如何使用excel获取网页数据。
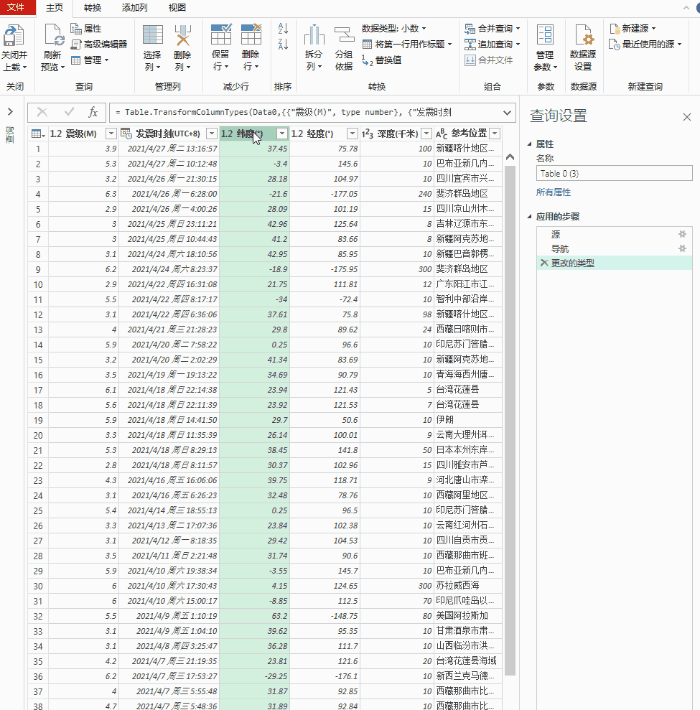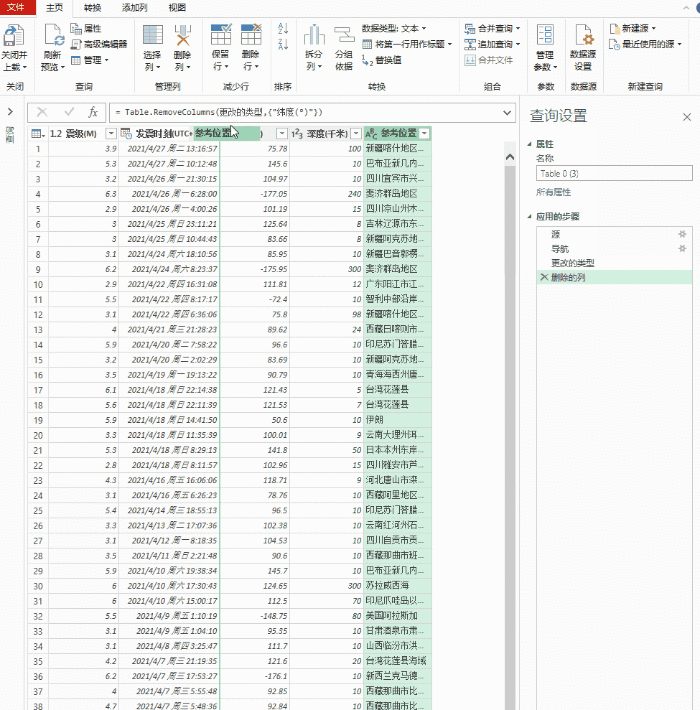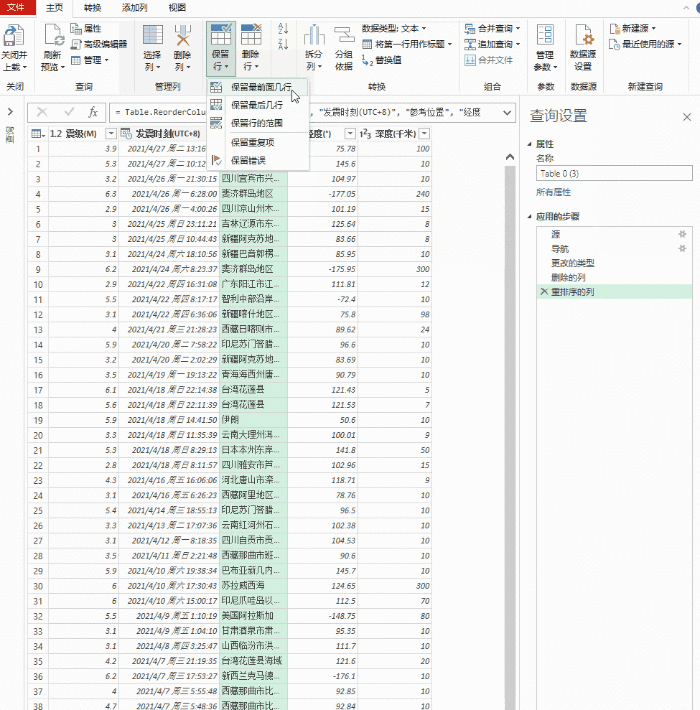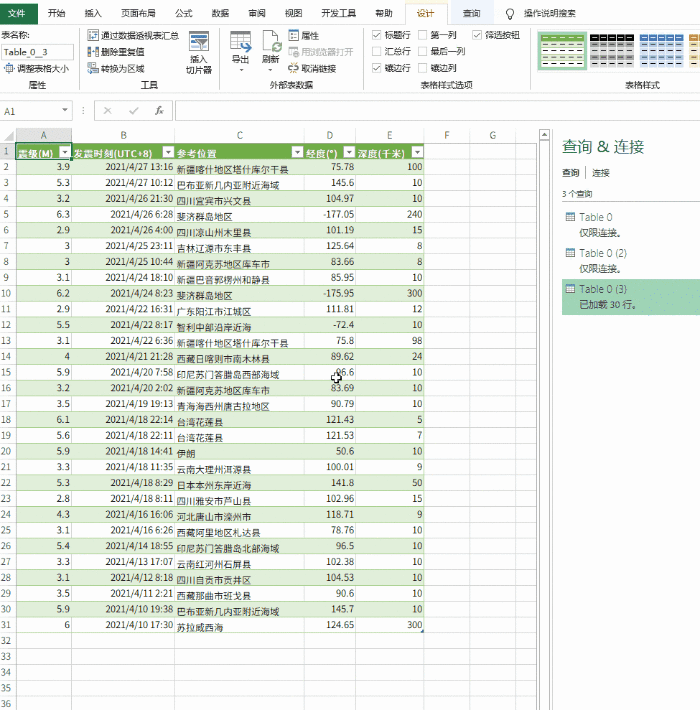
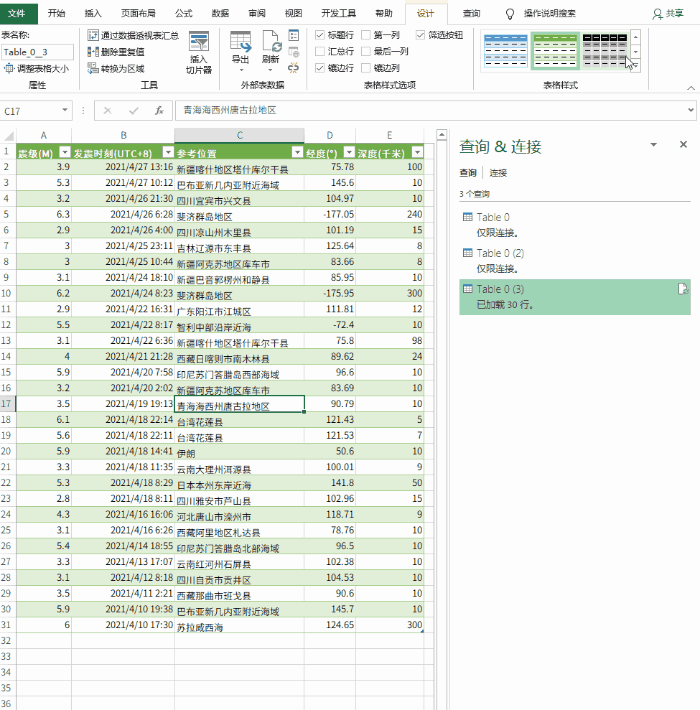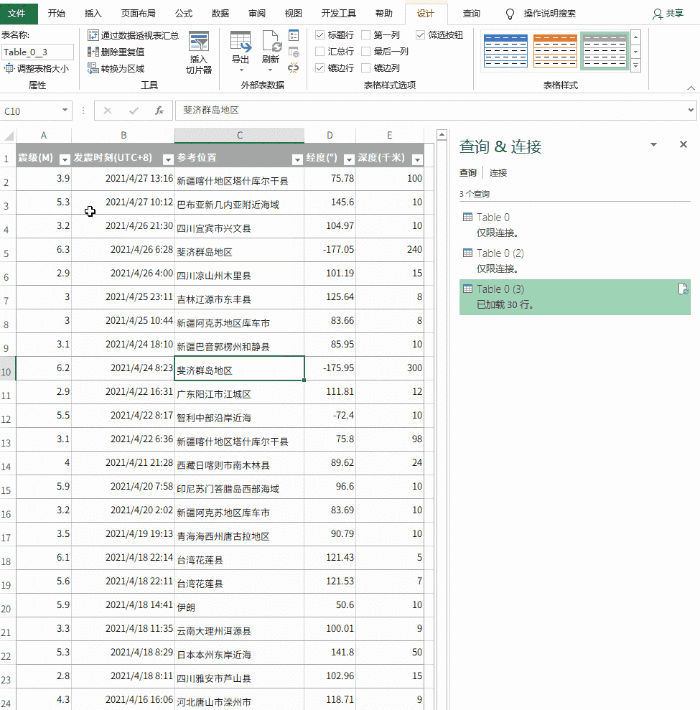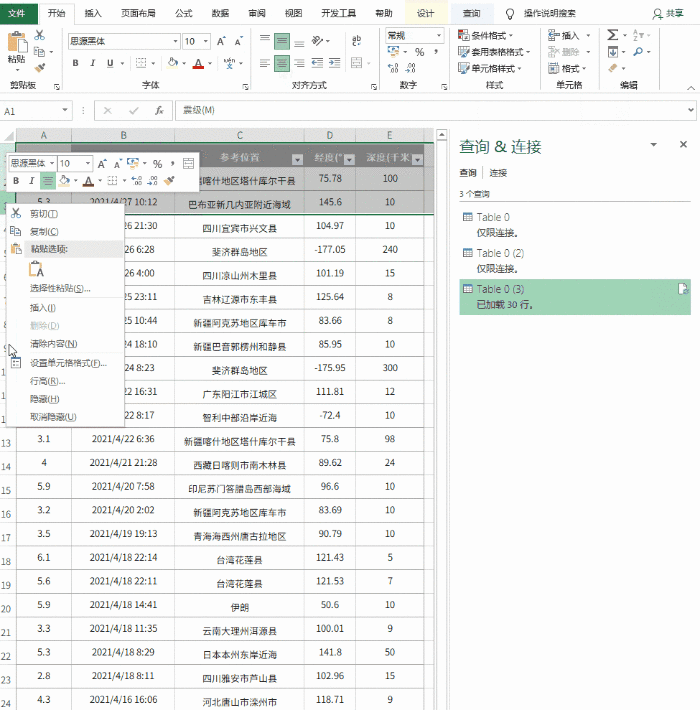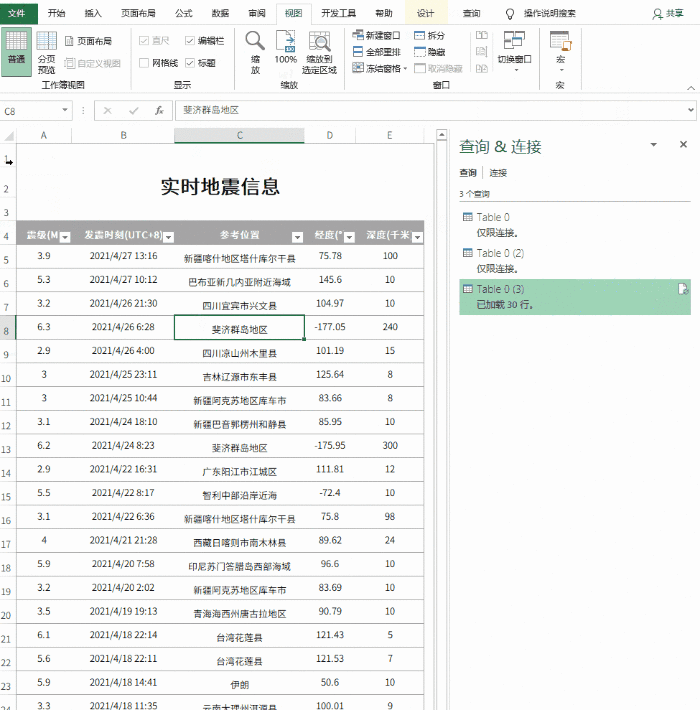
第一步是新建一个excel
第二步是准备需要爬取的页面。以下是同花顺股票报价页面的示例:#refCountId=db_509381c1_860
第三步,打开excel,选择data>self网站
将 URL 复制到地址栏,然后单击“开始”。如果网页可以正确加载并且没有报错,基本上上面的数据就可以下载了,直接点击“导出”即可。
这里需要说明一下,可以选择多个表,但是如果选择多个表,最好选择表的同一列,这样才能整洁美观。
最后确定导入数据的位置
数据可以如下导出。
最后需要说明的是,这种方式只适合少量数据、静态网页(非动态加载)、应急使用。
如果网页结构比较复杂和非静态,那我推荐一个采集利器——优采云
<p>优采云是一个通用的网络数据采集神器。突破了Web数据采集的传统思维方式。无需编程基础即可采集,让用户 查看全部
excel抓取网页数据(如何使用excel抓取网页数据?,准备好需要抓取的页面)
如何使用excel抓取网页数据?
很多人都知道可以用excel来处理数据,但不一定知道可以用它来抓取网页数据。其实可以用Excle自动获取网页数据。下面,本文将与大家分享如何使用excel获取网页数据。
第一步是新建一个excel
第二步是准备需要爬取的页面。以下是同花顺股票报价页面的示例:#refCountId=db_509381c1_860
第三步,打开excel,选择data>self网站
将 URL 复制到地址栏,然后单击“开始”。如果网页可以正确加载并且没有报错,基本上上面的数据就可以下载了,直接点击“导出”即可。
这里需要说明一下,可以选择多个表,但是如果选择多个表,最好选择表的同一列,这样才能整洁美观。
最后确定导入数据的位置
数据可以如下导出。
最后需要说明的是,这种方式只适合少量数据、静态网页(非动态加载)、应急使用。
如果网页结构比较复杂和非静态,那我推荐一个采集利器——优采云
<p>优采云是一个通用的网络数据采集神器。突破了Web数据采集的传统思维方式。无需编程基础即可采集,让用户
excel抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-26 05:17
随着互联网的飞速发展,网页数据日益成为数据分析过程中最重要的数据源之一。
或许正是基于这种考虑,从2013版开始,Excel新增了一个名为Web的函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取股票信息、天气查询、有道等数据。翻译等。
给一点栗子。
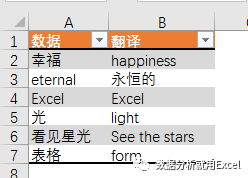
输入以下公式将单元格A2的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//翻译")
公式看起来很长。这主要是因为 URL 长度太长。其实,公式的结构很简单。
它主要由3部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,里面收录了关键参数。i="&A2是需要翻译的词汇。doctype=xml是返回文件的类型,即xml。只返回xml,因为FILTERXML函数可以得到XML结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE通过指定的网页地址从web服务器获取数据(需要电脑联网状态)。
在本例中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第三部分 获取目标数据。
此处使用了 FILTERXML 函数。FILTERXML 函数的语法是:
过滤器XML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉色标记),所以第二个参数设置为“//translation”。
嗯,这就是今天星光和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
挥手说晚安~ 查看全部
excel抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,网页数据日益成为数据分析过程中最重要的数据源之一。
或许正是基于这种考虑,从2013版开始,Excel新增了一个名为Web的函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取股票信息、天气查询、有道等数据。翻译等。
给一点栗子。
输入以下公式将单元格A2的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//翻译")
公式看起来很长。这主要是因为 URL 长度太长。其实,公式的结构很简单。
它主要由3部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,里面收录了关键参数。i="&A2是需要翻译的词汇。doctype=xml是返回文件的类型,即xml。只返回xml,因为FILTERXML函数可以得到XML结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE通过指定的网页地址从web服务器获取数据(需要电脑联网状态)。
在本例中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第三部分 获取目标数据。
此处使用了 FILTERXML 函数。FILTERXML 函数的语法是:
过滤器XML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉色标记),所以第二个参数设置为“//translation”。
嗯,这就是今天星光和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
挥手说晚安~
excel抓取网页数据(大数据时代,如何写一篇分析观点还是需要数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-21 19:06
在大数据时代,看似平凡的生活场景其实离不开这些海量数据。例如,我们接触到的文件、照片和视频收录大量数据信息。每个人都可以从中受益,这不仅节省了我们的时间,也为彼此节省了许多麻烦的事情
现在,几乎每天,无数的数据都会在互联网上产生,这已经成为不可或缺的生产要素。事实上,大数据本身毫无价值。如何处理此语句取决于用户。如果你认为这些数据对分析某些东西有很大帮助,那么它将是有价值的。如果我们不使用这些数据作为参考,这些数据只是一堆由数字和文字推动和整合的文档
我在speedceo中直接找到了一些Excel文件。当然,这些文件是公开的。直接下载或在线预览都很方便。我想知道关于大学排名表的文件,我基本上可以找到它。但是,有些文档较旧,日期较新。看看你是否需要它们
同时,人们也期待着看到他们的票房、排名和其他表现。这是数据。如果这个行业的大人物明白了,他们可以做出一些预测。毕竟,规划某些内容不能盲目。只有获得真实可靠的数据,才能进行准确的后分析和预测
直接得到一些统计数据表很容易,但过去不容易,成本高,准确性不确定。现在使用Python,它的处理速度实际上更快,但没有专门研究。我一般不太熟悉它。在互联网时代,有大量的海量数据可用
如果要编写分析视图,仍然需要数据来支持它。事实上,为人们提供新鲜而深刻的见解是大数据的价值所在。在网络时代,数据确实非常重要。毕竟,它可以帮助分析事物并做出有效的决策 查看全部
excel抓取网页数据(大数据时代,如何写一篇分析观点还是需要数据?)
在大数据时代,看似平凡的生活场景其实离不开这些海量数据。例如,我们接触到的文件、照片和视频收录大量数据信息。每个人都可以从中受益,这不仅节省了我们的时间,也为彼此节省了许多麻烦的事情

现在,几乎每天,无数的数据都会在互联网上产生,这已经成为不可或缺的生产要素。事实上,大数据本身毫无价值。如何处理此语句取决于用户。如果你认为这些数据对分析某些东西有很大帮助,那么它将是有价值的。如果我们不使用这些数据作为参考,这些数据只是一堆由数字和文字推动和整合的文档
我在speedceo中直接找到了一些Excel文件。当然,这些文件是公开的。直接下载或在线预览都很方便。我想知道关于大学排名表的文件,我基本上可以找到它。但是,有些文档较旧,日期较新。看看你是否需要它们
同时,人们也期待着看到他们的票房、排名和其他表现。这是数据。如果这个行业的大人物明白了,他们可以做出一些预测。毕竟,规划某些内容不能盲目。只有获得真实可靠的数据,才能进行准确的后分析和预测
直接得到一些统计数据表很容易,但过去不容易,成本高,准确性不确定。现在使用Python,它的处理速度实际上更快,但没有专门研究。我一般不太熟悉它。在互联网时代,有大量的海量数据可用

如果要编写分析视图,仍然需要数据来支持它。事实上,为人们提供新鲜而深刻的见解是大数据的价值所在。在网络时代,数据确实非常重要。毕竟,它可以帮助分析事物并做出有效的决策
excel抓取网页数据(自动模式检测WebHarvy自动识别网页中发生的数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-21 18:02
Webhard是一个网页数据捕获工具,具有简单的用户界面和简单的操作。它具有自动检测模式。它可以提取任何页面的数据,包括文本、图片等。它可以通过进入网站打开。默认情况下,使用内部浏览器,可以将提取的数据导出到数据库或文件夹中
功能介绍
点击界面
Webhard是一个可视化的web刮板。绝对不需要编写任何脚本或代码来获取数据。您将使用webhard的内置浏览器浏览web。您可以选择要单击的数据。这很容易
自动模式检测
Webhard自动识别网页中出现的数据模式。因此,如果需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
导出捕获的数据
您可以以多种格式保存从网页提取的数据。webharvywebscraper的当前版本允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
从多个页面提取数据
通常,网页在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webharvy websharper就会自动从所有页面获取数据
基于关键字的脚本
通过自动提交搜索表单的输入关键字列表来获取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据
通过代理服务器
为了匿名爬网并防止网络爬网软件被网络服务器阻止,您可以选择访问目标网站. 您可以使用单个代理地址或代理地址列表
类别抽取
Webharvy websharper允许您从链接列表中获取数据,从而在网站. 这允许您使用单个配置在网站内刮取类别和子类别
正则表达式
Webhard允许您将正则表达式(regex)应用于网页的文本或HTML源代码,并删除匹配的部分。这项功能强大的技术在抓取数据时为您提供了更大的灵活性
运行JavaScript
在提取数据之前,在浏览器中运行自己的JavaScript代码。这可用于与页面元素交互或调用已在目标页面中实现的JavaScript函数
下载图片
您可以下载图像或提取图像URL。Webharvy可以自动提取电子商务网站的产品详细信息页面中显示的多个图像@
自动浏览器交互
Webhard可以轻松地配置和执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置专用连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
excel抓取网页数据(自动模式检测WebHarvy自动识别网页中发生的数据抓取工具)
Webhard是一个网页数据捕获工具,具有简单的用户界面和简单的操作。它具有自动检测模式。它可以提取任何页面的数据,包括文本、图片等。它可以通过进入网站打开。默认情况下,使用内部浏览器,可以将提取的数据导出到数据库或文件夹中
功能介绍
点击界面
Webhard是一个可视化的web刮板。绝对不需要编写任何脚本或代码来获取数据。您将使用webhard的内置浏览器浏览web。您可以选择要单击的数据。这很容易
自动模式检测
Webhard自动识别网页中出现的数据模式。因此,如果需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
导出捕获的数据
您可以以多种格式保存从网页提取的数据。webharvywebscraper的当前版本允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
从多个页面提取数据
通常,网页在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webharvy websharper就会自动从所有页面获取数据
基于关键字的脚本
通过自动提交搜索表单的输入关键字列表来获取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据
通过代理服务器
为了匿名爬网并防止网络爬网软件被网络服务器阻止,您可以选择访问目标网站. 您可以使用单个代理地址或代理地址列表
类别抽取
Webharvy websharper允许您从链接列表中获取数据,从而在网站. 这允许您使用单个配置在网站内刮取类别和子类别
正则表达式
Webhard允许您将正则表达式(regex)应用于网页的文本或HTML源代码,并删除匹配的部分。这项功能强大的技术在抓取数据时为您提供了更大的灵活性
运行JavaScript
在提取数据之前,在浏览器中运行自己的JavaScript代码。这可用于与页面元素交互或调用已在目标页面中实现的JavaScript函数
下载图片
您可以下载图像或提取图像URL。Webharvy可以自动提取电子商务网站的产品详细信息页面中显示的多个图像@
自动浏览器交互
Webhard可以轻松地配置和执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置专用连接模式
您可以自动搜索可以在HTML上配置的资源
excel抓取网页数据(如何用excel获取网页上的股票数据,并按照日期制成表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-21 17:21
)
如何使用Excel在网页上获取股票数据,并根据数据制作表格?你是用什么技术完成的
对不起,后来我使用了文华财经的“回答每一个问题”功能,让他们帮我写一个索引,达到我想要的结果,所以我没有使用Excel
但我试过你说的。我试了一半就尝到了这种方法。你可以试试
第一步是找到所需的网站数据源
第二步:excel具有导入网站数据的功能。它将允许您选择要使用的数据表
具体来说,您可以在互联网上搜索-将外部数据导入excel,然后会有一个介绍
如何使用Python捕获股票数据
许多服务器通过浏览器发送的头来确认自己是否是人类用户,因此我们可以通过模仿浏览器的行为来构造请求头来向服务器发送请求。服务器将识别其中一些参数,以确定您是否是人类用户。许多网站会识别用户代理参数,因此最好带上请求头
有些具有高警觉性的网站可能会被其他参数识别,例如通过accept语言识别您是否是人类用户,有些具有防盗链功能的网站必须携带参数referer等
您如何获取普通基金股票网站的交易数据?您需要哪些数据源来创建类似的网站
您可以使用优采云采集器、编写采集规则和采集来获取对方的数据
如何将采集web股票大宗交易数据转化为指标
你好
不同机构对于大宗交易数据指标有不同的数据模型
如果您需要批量交易数据,您可以直接访问我们的网站
“吴”是一个虚拟的股票投机者网站。我不知道从哪里获取实时股票数据,如何获取,如何从其他网站获取@
您可以联系上海英孚网申请接口。他们是市场数据的代理人
“鲁”如何通过软件捕捉新浪财经的单股数据
如果你准备好掌握历史数据,你不妨直接使用免费的wdz程序来了解上海和深圳自1990年以来的所有日常历史;从2000年到现在,10多年的5分钟数据可以直接输出并转换成各种格式。你根本不必在新浪上抓住它
如何使用爬虫捕捉股市数据并生成分析报告
1.关于数据采集
股票数据是可以通过API接口访问的标准化结构数据(但通常通过通道,开放式API有一定的限制)。您也可以通过爬虫软件采集,但爬虫软件的采集数据不能保证实时性能。根据数据量和采集周期,可能会延迟数十秒到几分钟。我们总结了一套专业的爬虫技术解决方案(Ruby+sidekiq)。可以在采集快速完成此任务,您还可以在后台直观地安排任务
2.about show
对于在线股票数据的显示,在web端直接使用HTML5技术就足够了。如果接口要求较高,可以采用bootstrap等集成前端框架;如果您正在为移动终端开发,那么可以使用ionic框架
3.关于触发事件
采用RubyonRails的开发框架非常方便。Gem(如sidekiq和Anywhere)直接实现任务管理和事件触发
“8”100白银帮助通化顺网站抓取股票数据
没有详细的解释
联检组如何获取库存数据
有关于中国股市的数据吗?答案是肯定的,但应根据以下参数进行一些调整。全球证券交易所的信息如下所示
对于上海股票,添加。股票代码后为SS,对于深圳股票,添加。股票代码后的SZ
例如:000001=000001.sz
深圳数据链:
列出数据链接:
上证综合指数代码:000001.SS,深圳股票指数代码:399001.SZ,csi300代码:000300.ss
以下是世界证券交易所的网站和缩写。要查找哪个证券交易所的数据,请遵循上述格式,依此类推
上海证券交易所=,。SS,中文,SL1D1C1OHGV
深圳证券交易所=,。SZ,中文,SL1D1C1OHGV
美国运通=,美国,SL1D1C1OHGV
加拿大=,。至,多伦多,SL1D1C1OHGV
新西兰=,。新西兰,SL1D1C1OHGV
新加坡=,。Si,新加坡,SL1D1C1OHGV
香港=,。HK,香港,SL1D1T1C1OHGV
台湾=,。台湾TW SL1D1C1OHGV
印度=,。Bo,孟买,SL1D1C10HGV
伦敦=,。五十、 伦敦,SL1D1C1OHGV
澳大利亚=,。Ax,悉尼,SL1D1C1OHGV
巴西=,。圣保罗州,SL1D1C1OHGV
瑞典=,。圣斯德哥尔摩,SL1D1C1OHGV
上述方法只能提供历史数据,无法捕获实时数据。此方法由Arthur XF提供
“pick-up”java如何实现实时股票数据采集
通常有三种方式:
网络爬虫。使用爬虫程序对目标网页的股票数据进行爬网。到GitHub或技术论坛(如CSDN和51CTO)查找其他人编写的爬虫程序,并将其集成到项目中
请求第三方API。将有专门的公司(如网络API市场)提供股票数据。您只需要购买他们的服务,使用他们提供的SDK,并遵循演示开发和实现。如下图所示:
查看全部
excel抓取网页数据(如何用excel获取网页上的股票数据,并按照日期制成表格
)
如何使用Excel在网页上获取股票数据,并根据数据制作表格?你是用什么技术完成的
对不起,后来我使用了文华财经的“回答每一个问题”功能,让他们帮我写一个索引,达到我想要的结果,所以我没有使用Excel
但我试过你说的。我试了一半就尝到了这种方法。你可以试试
第一步是找到所需的网站数据源
第二步:excel具有导入网站数据的功能。它将允许您选择要使用的数据表
具体来说,您可以在互联网上搜索-将外部数据导入excel,然后会有一个介绍
如何使用Python捕获股票数据
许多服务器通过浏览器发送的头来确认自己是否是人类用户,因此我们可以通过模仿浏览器的行为来构造请求头来向服务器发送请求。服务器将识别其中一些参数,以确定您是否是人类用户。许多网站会识别用户代理参数,因此最好带上请求头
有些具有高警觉性的网站可能会被其他参数识别,例如通过accept语言识别您是否是人类用户,有些具有防盗链功能的网站必须携带参数referer等
您如何获取普通基金股票网站的交易数据?您需要哪些数据源来创建类似的网站
您可以使用优采云采集器、编写采集规则和采集来获取对方的数据
如何将采集web股票大宗交易数据转化为指标
你好
不同机构对于大宗交易数据指标有不同的数据模型
如果您需要批量交易数据,您可以直接访问我们的网站
“吴”是一个虚拟的股票投机者网站。我不知道从哪里获取实时股票数据,如何获取,如何从其他网站获取@
您可以联系上海英孚网申请接口。他们是市场数据的代理人
“鲁”如何通过软件捕捉新浪财经的单股数据
如果你准备好掌握历史数据,你不妨直接使用免费的wdz程序来了解上海和深圳自1990年以来的所有日常历史;从2000年到现在,10多年的5分钟数据可以直接输出并转换成各种格式。你根本不必在新浪上抓住它
如何使用爬虫捕捉股市数据并生成分析报告
1.关于数据采集
股票数据是可以通过API接口访问的标准化结构数据(但通常通过通道,开放式API有一定的限制)。您也可以通过爬虫软件采集,但爬虫软件的采集数据不能保证实时性能。根据数据量和采集周期,可能会延迟数十秒到几分钟。我们总结了一套专业的爬虫技术解决方案(Ruby+sidekiq)。可以在采集快速完成此任务,您还可以在后台直观地安排任务
2.about show
对于在线股票数据的显示,在web端直接使用HTML5技术就足够了。如果接口要求较高,可以采用bootstrap等集成前端框架;如果您正在为移动终端开发,那么可以使用ionic框架
3.关于触发事件
采用RubyonRails的开发框架非常方便。Gem(如sidekiq和Anywhere)直接实现任务管理和事件触发
“8”100白银帮助通化顺网站抓取股票数据
没有详细的解释
联检组如何获取库存数据
有关于中国股市的数据吗?答案是肯定的,但应根据以下参数进行一些调整。全球证券交易所的信息如下所示
对于上海股票,添加。股票代码后为SS,对于深圳股票,添加。股票代码后的SZ
例如:000001=000001.sz
深圳数据链:
列出数据链接:
上证综合指数代码:000001.SS,深圳股票指数代码:399001.SZ,csi300代码:000300.ss
以下是世界证券交易所的网站和缩写。要查找哪个证券交易所的数据,请遵循上述格式,依此类推
上海证券交易所=,。SS,中文,SL1D1C1OHGV
深圳证券交易所=,。SZ,中文,SL1D1C1OHGV
美国运通=,美国,SL1D1C1OHGV
加拿大=,。至,多伦多,SL1D1C1OHGV
新西兰=,。新西兰,SL1D1C1OHGV
新加坡=,。Si,新加坡,SL1D1C1OHGV
香港=,。HK,香港,SL1D1T1C1OHGV
台湾=,。台湾TW SL1D1C1OHGV
印度=,。Bo,孟买,SL1D1C10HGV
伦敦=,。五十、 伦敦,SL1D1C1OHGV
澳大利亚=,。Ax,悉尼,SL1D1C1OHGV
巴西=,。圣保罗州,SL1D1C1OHGV
瑞典=,。圣斯德哥尔摩,SL1D1C1OHGV
上述方法只能提供历史数据,无法捕获实时数据。此方法由Arthur XF提供
“pick-up”java如何实现实时股票数据采集
通常有三种方式:
网络爬虫。使用爬虫程序对目标网页的股票数据进行爬网。到GitHub或技术论坛(如CSDN和51CTO)查找其他人编写的爬虫程序,并将其集成到项目中
请求第三方API。将有专门的公司(如网络API市场)提供股票数据。您只需要购买他们的服务,使用他们提供的SDK,并遵循演示开发和实现。如下图所示:
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-09-11 21:07
搞网上资料采集工作,最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作。效率大大降低。这时候不妨试试用功能强大的Excel来解决问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1)。这时候系统会自动打开Office Excel加载数据。这个过程只是加载数据需要几秒钟(图2)。如果你认为数据更适合你的编辑需求,那么你可以直接保存。否则,你也可以进行适当的更改,因为在表格处理方面,Excel比word好很多。
图一
就在线表格或数据采集 而言,Excel 往往更智能。当数据为采集并加载时,它只加载表单固定区域的数据,而不是加载整个网页。进来吧,这个我试过很多次了,都非常听话。请看图2的效果。
图二
当然,网络上也有一些非标准的数据和表格。此类数据用Excel处理略有难度,但只要熟悉Excel的操作功能,还是可以轻松处理的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果让Excel处理,就会有这样的结果(图4),看了就觉得乱七八糟,什么都错位了,普通人会觉得太快了. 主要原因是文件数据的开头和结尾是多余的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据会不会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(picture5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
搞网上资料采集工作,最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作。效率大大降低。这时候不妨试试用功能强大的Excel来解决问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1)。这时候系统会自动打开Office Excel加载数据。这个过程只是加载数据需要几秒钟(图2)。如果你认为数据更适合你的编辑需求,那么你可以直接保存。否则,你也可以进行适当的更改,因为在表格处理方面,Excel比word好很多。

图一
就在线表格或数据采集 而言,Excel 往往更智能。当数据为采集并加载时,它只加载表单固定区域的数据,而不是加载整个网页。进来吧,这个我试过很多次了,都非常听话。请看图2的效果。

图二
当然,网络上也有一些非标准的数据和表格。此类数据用Excel处理略有难度,但只要熟悉Excel的操作功能,还是可以轻松处理的。先看看这个页面(图片3),

图 3
图3 这种不规则的页面数据,如果让Excel处理,就会有这样的结果(图4),看了就觉得乱七八糟,什么都错位了,普通人会觉得太快了. 主要原因是文件数据的开头和结尾是多余的。

图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据会不会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(picture5)

图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-09-10 15:12
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只抓取了一页数据。这个文章介绍了如何使用PowerBI批量处理采集多个网页数据。 (Excel中的Power查询也可以同样操作)
本文以智联招聘网站为例,采集posts上海职位信息。
详细步骤如下:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点数据,
下拉页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是控制页面数据的变量。
(二)使用PowerBI采集首页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,页面数字到第二行。
从URL预览中可以看到,上面两行的URL已经自动合并在一起了;这里的单独输入只是为了更清楚地区分页码变量。其实直接输入完整网址也是可以的。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击确定后,出来了很多表,
从这里我们可以看到智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面没有的几列数据。
第一页的数据是采集这里。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集其他页面时,排序后的数据结构与第一页的数据结构相同。 采集的数据可以直接使用;它没有在这里排序。没关系,你可以等到采集所有网页数据整理在一起。
如果你想批量抓取网页数据,为了节省时间,可以直接跳到下一步,不用整理第一页的数据。
(三)根据页码参数设置自定义函数
这是最重要的一步。
刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表格 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,只要输入一个数字,比如7,就会抓取第7页的数据,
输入参数一次只能抓取一个网页。如果要批量抓取,则需要以下步骤。
(四)批量调用自定义函数
首先使用空查询创建编号规则。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。 gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是比较数据捕获过程的最后一步。很费时间。
网页上的数据不断更新。完成以上步骤后,在PQ中点击Refresh,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样的操作可以在可以使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。使用PowerBI批量抓取某条网站数据之前,先尝试采集一页,如果可以得到采集,则使用上面的步骤,如果采集不可用,则无需延迟时间.
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的网站data。 查看全部
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只抓取了一页数据。这个文章介绍了如何使用PowerBI批量处理采集多个网页数据。 (Excel中的Power查询也可以同样操作)
本文以智联招聘网站为例,采集posts上海职位信息。
详细步骤如下:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点数据,

下拉页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是控制页面数据的变量。
(二)使用PowerBI采集首页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,页面数字到第二行。

从URL预览中可以看到,上面两行的URL已经自动合并在一起了;这里的单独输入只是为了更清楚地区分页码变量。其实直接输入完整网址也是可以的。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击确定后,出来了很多表,
从这里我们可以看到智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面没有的几列数据。

第一页的数据是采集这里。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集其他页面时,排序后的数据结构与第一页的数据结构相同。 采集的数据可以直接使用;它没有在这里排序。没关系,你可以等到采集所有网页数据整理在一起。
如果你想批量抓取网页数据,为了节省时间,可以直接跳到下一步,不用整理第一页的数据。
(三)根据页码参数设置自定义函数
这是最重要的一步。
刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表格 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,只要输入一个数字,比如7,就会抓取第7页的数据,
输入参数一次只能抓取一个网页。如果要批量抓取,则需要以下步骤。
(四)批量调用自定义函数
首先使用空查询创建编号规则。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。 gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是比较数据捕获过程的最后一步。很费时间。
网页上的数据不断更新。完成以上步骤后,在PQ中点击Refresh,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样的操作可以在可以使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。使用PowerBI批量抓取某条网站数据之前,先尝试采集一页,如果可以得到采集,则使用上面的步骤,如果采集不可用,则无需延迟时间.
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的网站data。
excel抓取网页数据(如何制作一个随网站自动同步的Excel表呢?答案是肯定的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-10 15:11
新酷产品首次免费试用,更有众多优质专家分享他们独特的生活体验。快来新浪公测,体验各领域最前沿、最有趣、最有趣的产品~!下载客户端,获得专属福利!
本文来自太平洋计算机网
有时我们需要从网站获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,得到的也是“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作与网站自动同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1.打开网页
下图为中国地震台网官方网页()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
创建查询并确定抓取范围
3.数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清理”
4.格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
美化表格
5.设置自动同步间隔
目前表的基础已经完成,但是就像复制粘贴一样,此时得到的依然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决这个问题。
防止更新时表格格式损坏
写在最后
这个技巧很实用,尤其是在做一些动态报表的时候,可以大大减少手工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,有用吗? 查看全部
excel抓取网页数据(如何制作一个随网站自动同步的Excel表呢?答案是肯定的)
新酷产品首次免费试用,更有众多优质专家分享他们独特的生活体验。快来新浪公测,体验各领域最前沿、最有趣、最有趣的产品~!下载客户端,获得专属福利!
本文来自太平洋计算机网
有时我们需要从网站获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,得到的也是“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作与网站自动同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1.打开网页
下图为中国地震台网官方网页()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
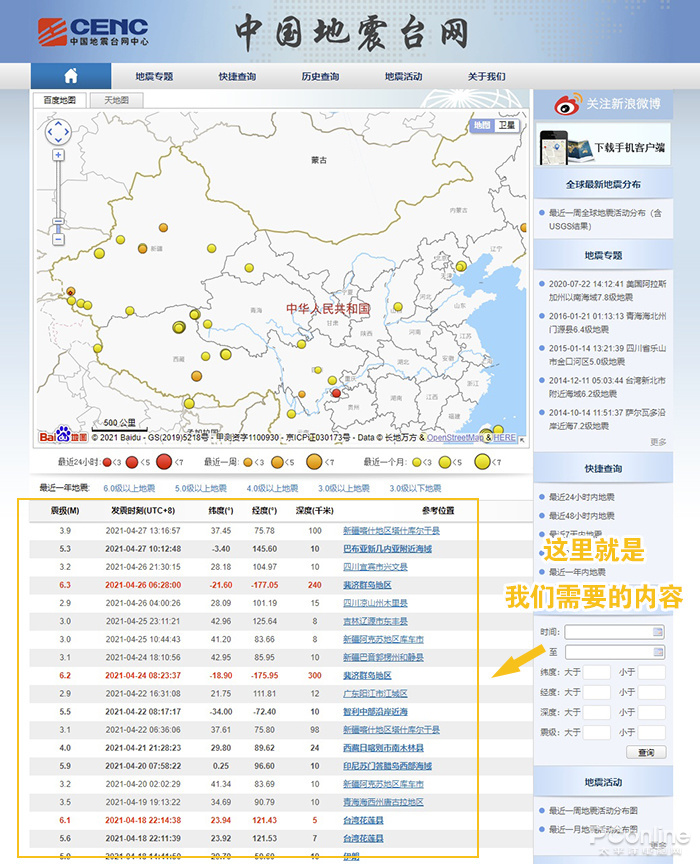
首先打开要抓取的网页
2.确定抓取范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
创建查询并确定抓取范围
3.数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清理”
4.格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
美化表格
5.设置自动同步间隔
目前表的基础已经完成,但是就像复制粘贴一样,此时得到的依然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决这个问题。
防止更新时表格格式损坏
写在最后
这个技巧很实用,尤其是在做一些动态报表的时候,可以大大减少手工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,有用吗?
excel抓取网页数据(如何自动采集网页数据库数据到EXCEL,如易采网站数..)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-07 07:13
如何自动将采集网页数据库数据转成EXCEL,比如轻松采集网站号...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何将网页数据抓取到excel中
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何使用 Excel 表格作为数据库。
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
使用EXCEL表格制作数据库查询网页
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
当我使用excel通过获取外部数据构建查询时,提示“数据...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法 查看全部
excel抓取网页数据(如何自动采集网页数据库数据到EXCEL,如易采网站数..)
如何自动将采集网页数据库数据转成EXCEL,比如轻松采集网站号...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何将网页数据抓取到excel中
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
如何使用 Excel 表格作为数据库。
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
使用EXCEL表格制作数据库查询网页
那么,这种批量查询和录入可以借助“快点老虎”来完成,它支持批量录入和填写,网页自动点击和编辑操作。因为快捷点击老虎软件不需要太多复杂的设置,可以批量点击,自动导入操作,提高办公效率。
当我使用excel通过获取外部数据构建查询时,提示“数据...
如果你会编程,你就可以自己写代码
我已经使用 .net 对数据库进行 Web 表单处理,
有点麻烦,只能粘贴复制
您可以发送您的网页地址并查看网页表格的格式,以了解最好的方法
excel抓取网页数据(从电子商务店铺大规模提取产品数据时所学到的经验教训挑战)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-03 05:07
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
在本文中,我们将与您分享自 2010 年以来在 Scrapinghub 的帮助下从 1000 亿产品页面中抓取数据的经验教训,并让您深入了解从电子商务商店中提取产品数据时所面临的挑战。大规模。,并与您分享一些应对这些挑战的最佳实践。
Scrapinghub 成立于 2010 年,是最好的数据提取公司之一,Scrapy-Scrapy 的创建者是当今最强大和最受欢迎的网络抓取框架。目前,Scrapinghub 每月为全球许多大型电子商务公司抓取超过 80 亿个页面(其中 30 亿个是产品页面)。
大规模网络爬虫的要点
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式
凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
如果你有过电商店铺爬虫体验,就会知道电商店铺代码杂乱无章是普遍现象。这不仅仅是关于 HTML 格式或偶尔的字符编码问题。多年来,我们遇到了各种各样的问题,比如滥用 HTTP 响应代码、不完整的 JavaScript 或滥用 Ajax:
这样乱七八糟的代码会让编写爬虫非常痛苦,无法使用爬虫工具或自动提取工具。
在大规模抓取网页时,你不仅需要像这样浏览数百个乱七八糟的网站,还要处理网站的不断更新。一个经验法则是:每 2-3 个月目标 网站 的变化就会废除你的爬虫。
听起来可能没什么大不了的,但是当你大规模地爬行时,这些事故就会累积起来。比如Scrapinghub的一个大型电商项目,爬虫大约有4000个,需要爬取1000个电商网站,这意味着他们每天有20-30个爬虫失败。
从区域和多语言网站布局变化来看,A/B拆分测试和打包/定价变化往往会给爬虫带来问题。
没有捷径
不幸的是,这些问题没有灵丹妙药。在很多情况下,我们只能随着规模的扩大投入更多的资源。以上述项目为例,负责该项目的团队共有18名爬虫工程师和3名专职QA,以确保客户始终拥有可靠的数据。
然而,有了经验,团队可以学习如何创建更强大的爬虫来检测和处理 网站 格式的各种奇怪的技巧。
最佳实践不是针对目标网站的所有可能的布局都一一编写爬虫,而是从一个产品中提取的爬虫可以处理不同页面布局所使用的所有可能的规则和方案。爬虫的配置越多越好。
虽然这些做法会使爬虫变得更加复杂(我们的一些爬虫有几千行长),但它们可以确保爬虫更容易维护。
由于大多数公司每天都需要提取产品数据,我们不能花几天时间等待工程团队修改损坏的爬虫。对于这种情况,Scrapinghub 使用基于数据提取工具的机器学习。我们开发了这个机器学习模型作为备份,直到爬虫被修复。这个基于机器学习的提取工具可以自动识别目标网站的目标字段(产品名称、价格、货币、图片、SKU等),并返回想要的结果。
挑战 2:可扩展架构
您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模抓取产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开
为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
产品搜索爬虫的目标应该是找到目标产品类别(或“货架”),并将产品的 URL 保存在该类别下,以供产品提取爬虫使用。当产品搜索爬虫将产品 URL 添加到队列中时,产品提取爬虫会从茶叶页面抓取目标数据。
这项工作可以借助流行的爬虫工具,例如Scrapinghub 开发的开源爬虫工具Frontera。虽然 Frontera 最初是为在 Scrapy 中使用而设计的,但它是完全不受限制的,可以与任何其他爬虫框架或独立项目一起使用。在本文中,我们将分享如何使用 Frontera 从 HackerNews 中挖掘数据。
为产品提取分配更多资源
由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。在这种情况下,您需要为每个搜索爬虫配备多个提取爬虫。经验法则是:每 100,000 个页面需要创建一个单独的提取爬虫。
挑战 3:保持吞吐量性能
大规模抢车很像一级方程式,我们的目标是提高车速,尽可能减轻车重,从发动机榨出最后一部分马力。大规模的网络爬虫也是如此。
在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。您还需要注意:
履带效率
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。在设计爬虫时,请记住以下几点:
挑战四:反机器人策略
在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如Distil Networks、Incapsula或者Akamai,这会让数据提取变得更加困难。
演戏
请记住,大型产品数据抓取项目最重要的要求是使用代理IP。在大规模爬取中,需要一个相当大的代理列表,并且需要实现必要的IP轮换、请求限制、会话管理、黑名单逻辑,防止代理被阻塞。
除非您拥有庞大的管理代理团队,否则您应该将这部分爬行工作外包。外面有大量的代理服务,可以提供各种级别的服务。
但是,我们建议您使用代理为代理配置提供单一端点并隐藏管理代理的复杂性。大规模爬取是非常耗费资源的,更不用说需要通过开发和维护建立自己内部的代理管理基础设施。
大多数大型电子商务公司都使用这种方法。许多世界上最大的电子商务公司都使用 Scrapinghub 开发的智能下载器 Crawlera 来外包代理管理。如果您的爬虫每天需要发出 2000 万个请求,那么专注于捕获比代理管理更有意义。
超越代理
不幸的是,仅使用代理服务还不足以确保可以绕过大型电子商务网站的反僵尸策略。越来越多的网站开始使用成熟的反机器人策略来监控爬虫行为并检测请求是否来自人类访问者。
这些反机器人策略不仅会使电商网站的爬行变得困难,如果处理不当,与它们的纠缠将严重影响爬虫的性能。
这些反机器人策略大多使用 JavaScript 来确定请求是来自爬虫还是来自人类(JavaScript 引擎检查、字体枚举、WebGL、Canvas 等)。
但是前面提到,在大规模抓取数据时,我们希望使用无头的脚本化浏览器(如Splash或Puppeteer等)。页面上的 JavaScript 渲染会给资源带来压力并降低抓取速度。网站。
这意味着,为了保证你的爬虫能够达到提供日常产品数据所需的吞吐量,你通常需要努力反击网站上使用的机器人策略,并且将爬虫设计成使用无头它们可以在某些浏览器的情况下也会被打败。
挑战 5:数据质量
从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。大量的心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,对爬虫的代码进行相互审查和测试,可以确保以最可靠的方式提取所需的数据。确保高质量数据的最佳方法是开发自动化 QA 监控系统。
作为数据提取项目的一部分,您需要规划和开发一个监控系统,以提醒您数据不一致和抓取错误。在 Scrapinghub,我们开发了用于检测的机器学习算法:
总结
如您所见,大规模抓取产品数据需要一系列独特的挑战。希望这个 文章 可以让您更好地了解这些挑战以及如何解决它们。
在 Scrapinghub,我们专注于将非结构化 Web 数据转换为结构化数据。如果您对本文有任何想法,请在下面发表评论。
文字:Ian Kerins 翻译:Crescent Moon/CSDN (CSDNnews) 查看全部
excel抓取网页数据(从电子商务店铺大规模提取产品数据时所学到的经验教训挑战)
现在从互联网上获取数据似乎很容易。有很多开源的库和框架,可视化爬虫工具和数据提取工具,可以很方便的从一个网站中抓取数据。然而,当你想大规模搜索网站时,很快就变得非常棘手。
在本文中,我们将与您分享自 2010 年以来在 Scrapinghub 的帮助下从 1000 亿产品页面中抓取数据的经验教训,并让您深入了解从电子商务商店中提取产品数据时所面临的挑战。大规模。,并与您分享一些应对这些挑战的最佳实践。
Scrapinghub 成立于 2010 年,是最好的数据提取公司之一,Scrapy-Scrapy 的创建者是当今最强大和最受欢迎的网络抓取框架。目前,Scrapinghub 每月为全球许多大型电子商务公司抓取超过 80 亿个页面(其中 30 亿个是产品页面)。
大规模网络爬虫的要点
不同于标准的网络爬虫应用,电子商务产品数据的大规模爬取将面临一系列独特的挑战,这使得网络爬行变得异常困难。
本质上,这些困难可以归结为两个方面:速度和数据质量。
通常时间是一个限制性的约束,所以大规模的抓取需要网络爬虫以非常高的速度抓取页面,并且不会影响数据质量。这种对速度的要求使得捕获大量产品数据变得非常具有挑战性。
挑战一:乱七八糟的网页格式
凌乱多变的网页格式可能是最常见的挑战,也可能不是最有趣的挑战,但却是迄今为止大规模数据提取面临的最大挑战。这个挑战的关键不是复杂性,而是需要大量的时间和资源来应对。
如果你有过电商店铺爬虫体验,就会知道电商店铺代码杂乱无章是普遍现象。这不仅仅是关于 HTML 格式或偶尔的字符编码问题。多年来,我们遇到了各种各样的问题,比如滥用 HTTP 响应代码、不完整的 JavaScript 或滥用 Ajax:
这样乱七八糟的代码会让编写爬虫非常痛苦,无法使用爬虫工具或自动提取工具。
在大规模抓取网页时,你不仅需要像这样浏览数百个乱七八糟的网站,还要处理网站的不断更新。一个经验法则是:每 2-3 个月目标 网站 的变化就会废除你的爬虫。
听起来可能没什么大不了的,但是当你大规模地爬行时,这些事故就会累积起来。比如Scrapinghub的一个大型电商项目,爬虫大约有4000个,需要爬取1000个电商网站,这意味着他们每天有20-30个爬虫失败。
从区域和多语言网站布局变化来看,A/B拆分测试和打包/定价变化往往会给爬虫带来问题。
没有捷径
不幸的是,这些问题没有灵丹妙药。在很多情况下,我们只能随着规模的扩大投入更多的资源。以上述项目为例,负责该项目的团队共有18名爬虫工程师和3名专职QA,以确保客户始终拥有可靠的数据。
然而,有了经验,团队可以学习如何创建更强大的爬虫来检测和处理 网站 格式的各种奇怪的技巧。
最佳实践不是针对目标网站的所有可能的布局都一一编写爬虫,而是从一个产品中提取的爬虫可以处理不同页面布局所使用的所有可能的规则和方案。爬虫的配置越多越好。
虽然这些做法会使爬虫变得更加复杂(我们的一些爬虫有几千行长),但它们可以确保爬虫更容易维护。
由于大多数公司每天都需要提取产品数据,我们不能花几天时间等待工程团队修改损坏的爬虫。对于这种情况,Scrapinghub 使用基于数据提取工具的机器学习。我们开发了这个机器学习模型作为备份,直到爬虫被修复。这个基于机器学习的提取工具可以自动识别目标网站的目标字段(产品名称、价格、货币、图片、SKU等),并返回想要的结果。
挑战 2:可扩展架构
您将面临的下一个挑战是构建一个爬虫基础设施,该基础设施可以随着每天请求数量的增加而扩展,而不会降低性能。
在大规模提取产品数据时,简单的网络爬虫只能连续爬取数据,不能提取。通常,连续的网络爬虫会一个接一个地循环发送请求,每个请求需要 2-3 秒才能完成。
如果爬虫每天少于40000个请求(每2秒发送一个请求,意味着每天可以发送43200个请求),这种方法是可以的。但是,一旦请求数量超过这个数量,就需要切换到每天可以发送数百万个请求而不降低性能的爬虫架构。
如上所述,速度是大规模抓取产品数据的关键。您需要确保在特定时间段(通常为一天)内找到并抓取所有需要的产品页面。为此,您需要执行以下操作:
将产品搜索与产品提取分开
为了大规模提取产品数据,您需要将产品搜索爬虫与产品提取爬虫分开。
产品搜索爬虫的目标应该是找到目标产品类别(或“货架”),并将产品的 URL 保存在该类别下,以供产品提取爬虫使用。当产品搜索爬虫将产品 URL 添加到队列中时,产品提取爬虫会从茶叶页面抓取目标数据。
这项工作可以借助流行的爬虫工具,例如Scrapinghub 开发的开源爬虫工具Frontera。虽然 Frontera 最初是为在 Scrapy 中使用而设计的,但它是完全不受限制的,可以与任何其他爬虫框架或独立项目一起使用。在本文中,我们将分享如何使用 Frontera 从 HackerNews 中挖掘数据。
为产品提取分配更多资源
由于每个产品类别“货架”可以收录10到100个产品,并且与提取产品URL相比,提取产品数据需要更多资源,因此搜索爬虫通常比产品提取爬虫更快。在这种情况下,您需要为每个搜索爬虫配备多个提取爬虫。经验法则是:每 100,000 个页面需要创建一个单独的提取爬虫。
挑战 3:保持吞吐量性能
大规模抢车很像一级方程式,我们的目标是提高车速,尽可能减轻车重,从发动机榨出最后一部分马力。大规模的网络爬虫也是如此。
在提取大量数据时,我们必须在现有硬件资源的基础上,尽可能地找到一种可以最小化循环时间并最大化爬虫性能的方法。所有这些都必须减少每个请求的时间,甚至几毫秒。
为此,您的团队需要深入了解网络抓取框架、代理管理和正在使用的硬件,以便更好地调整它们以获得最佳性能。您还需要注意:
履带效率
在大规模抓取时,我们应该始终努力在最少的请求中提取所需的确切数据。任何额外的请求或数据提取都会降低爬取网站的速度。在设计爬虫时,请记住以下几点:
挑战四:反机器人策略
在大规模爬取电商网站时,你肯定会遇到使用反机器人策略的网站。
对于大多数小网站来说,他们的反机器人策略是非常基础的(IP禁止过度请求)。但是对于亚马逊网站这样的大型电商公司,他们会使用非常成熟的反机器人策略,比如Distil Networks、Incapsula或者Akamai,这会让数据提取变得更加困难。
演戏
请记住,大型产品数据抓取项目最重要的要求是使用代理IP。在大规模爬取中,需要一个相当大的代理列表,并且需要实现必要的IP轮换、请求限制、会话管理、黑名单逻辑,防止代理被阻塞。
除非您拥有庞大的管理代理团队,否则您应该将这部分爬行工作外包。外面有大量的代理服务,可以提供各种级别的服务。
但是,我们建议您使用代理为代理配置提供单一端点并隐藏管理代理的复杂性。大规模爬取是非常耗费资源的,更不用说需要通过开发和维护建立自己内部的代理管理基础设施。
大多数大型电子商务公司都使用这种方法。许多世界上最大的电子商务公司都使用 Scrapinghub 开发的智能下载器 Crawlera 来外包代理管理。如果您的爬虫每天需要发出 2000 万个请求,那么专注于捕获比代理管理更有意义。
超越代理
不幸的是,仅使用代理服务还不足以确保可以绕过大型电子商务网站的反僵尸策略。越来越多的网站开始使用成熟的反机器人策略来监控爬虫行为并检测请求是否来自人类访问者。
这些反机器人策略不仅会使电商网站的爬行变得困难,如果处理不当,与它们的纠缠将严重影响爬虫的性能。
这些反机器人策略大多使用 JavaScript 来确定请求是来自爬虫还是来自人类(JavaScript 引擎检查、字体枚举、WebGL、Canvas 等)。
但是前面提到,在大规模抓取数据时,我们希望使用无头的脚本化浏览器(如Splash或Puppeteer等)。页面上的 JavaScript 渲染会给资源带来压力并降低抓取速度。网站。
这意味着,为了保证你的爬虫能够达到提供日常产品数据所需的吞吐量,你通常需要努力反击网站上使用的机器人策略,并且将爬虫设计成使用无头它们可以在某些浏览器的情况下也会被打败。
挑战 5:数据质量
从数据科学家的角度来看,网络抓取项目最重要的考虑因素是提取数据的质量。大规模爬取更注重数据的质量。
如果每天需要提取数百万个数据点,则无法手动验证所有数据是否干净完整。大量的心脏数据或不完整的数据会进入数据源,破坏数据分析工作。
当商店有多个版本(不同语言、地区等)或从不同商店抓取数据时,数据质量尤为重要。
除了仔细的QA流程,在创建爬虫的设计阶段,对爬虫的代码进行相互审查和测试,可以确保以最可靠的方式提取所需的数据。确保高质量数据的最佳方法是开发自动化 QA 监控系统。
作为数据提取项目的一部分,您需要规划和开发一个监控系统,以提醒您数据不一致和抓取错误。在 Scrapinghub,我们开发了用于检测的机器学习算法:
总结
如您所见,大规模抓取产品数据需要一系列独特的挑战。希望这个 文章 可以让您更好地了解这些挑战以及如何解决它们。
在 Scrapinghub,我们专注于将非结构化 Web 数据转换为结构化数据。如果您对本文有任何想法,请在下面发表评论。
文字:Ian Kerins 翻译:Crescent Moon/CSDN (CSDNnews)
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-29 21:35
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制后需要大量修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图1
无论是在线表格还是数据采集,Excel往往更智能。它只在执行数据采集和加载时加载表单固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据,有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 3
图3 这种不规则的页面数据,如果用Excel处理会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网上资料采集的工作最麻烦的就是从网页上复制数据表很枯燥,复制后需要大量修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图1
无论是在线表格还是数据采集,Excel往往更智能。它只在执行数据采集和加载时加载表单固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据,有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 3
图3 这种不规则的页面数据,如果用Excel处理会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
<IMG src="http://up.2cto.com/net/200506/ ... ot%3B border=0>
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(我想用java实现抓取我们学校图书馆页面里的图书信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-29 21:35
)
抓取网页数据我想使用java抓取我们学校图书馆页面中的图书信息,例如:
请伟大的上帝引导Java网页捕获-----------------编程问答-----------------使用jsoup:
package cn.outofmemory.yc;<br />
<br />
import java.io.IOException;<br />
import java.util.Scanner;<br />
<br />
import org.apache.commons.httpclient.HttpClient;<br />
import org.apache.commons.httpclient.HttpException;<br />
import org.apache.commons.httpclient.HttpMethod;<br />
import org.apache.commons.httpclient.NameValuePair;<br />
import org.apache.commons.httpclient.methods.GetMethod;<br />
import org.apache.commons.httpclient.methods.PostMethod;<br />
import org.jsoup.Jsoup;<br />
import org.jsoup.nodes.Document;<br />
import org.jsoup.nodes.Element;<br />
import org.jsoup.select.Elements;<br />
<br />
public class httpclient {<br />
<br />
/**<br />
* heepclient 抓取页面<br />
* jroup 解析页面内容<br />
* @param args<br />
*/<br />
public static void main(String[] args) {<br />
Scanner reader=new Scanner(System.in);<br />
System.out.println("请输入手机号码:");<br />
String strphone=reader.nextLine();<br />
<br />
HttpClient client = new HttpClient();<br />
// 设置代理服务器地址(URL)和端口<br />
client.getHostConfiguration().setHost( "haoma.imobile.com.cn" , 80);<br />
HttpMethod method=getPostMethod(strphone);<br />
try {<br />
client.executeMethod(method);<br />
//System.out.println(method.getStatusLine()); //打印结果页面<br />
String response=new String(method.getResponseBodyAsString());<br />
<br />
// System.out.println(response);<br />
//释放连接<br />
method.releaseConnection();<br />
<br />
//解析页面内容<br />
Document doc= Jsoup.parse(response); //从字符串中加载<br />
//直接从URL 中加载页面信息。timeout设置连接超时时间 post提交方式 或者get()<br />
// Document document = (Document) Jsoup.connect("http://haoma.imobile.com.cn/in ... 6quot;).timeout(3000).post();<br />
<br />
//Elements 是 Element 的集合类<br />
Elements element=doc.select("table"); //从加载的信息中查找table 标签<br />
<br />
//从查找到table属性的Elements集合中获取标签 tr 或者tr[class$=alt] 表示 tr标签内class属性=alt<br />
// Elements titleName=element.select("tr[class$=alt]"); <br />
Elements titleName=element.select("tr");<br />
for(Element name : titleName){<br />
System.out.println(name.text());<br />
}<br />
} catch (HttpException e) {<br />
e.printStackTrace();<br />
} catch (IOException e) {<br />
e.printStackTrace();<br />
}<br />
<br />
}<br />
<br />
private static HttpMethod getPostMethod(String phone){<br />
PostMethod post = new PostMethod( "/index.php" );<br />
//POST提交则需要通过NameValuePair类来设置参数名和对应的值<br />
NameValuePair simcard = new NameValuePair( "mob" ,phone);<br />
post.setRequestBody( new NameValuePair[] {simcard});<br />
return post; <br />
} <br />
<br />
/** <br />
* 使用 GET 方式提交数据 <br />
*@return <br />
*/<br />
<br />
private static HttpMethod getGetMethod(){<br />
return new GetMethod("/index.php?simcard=1330227");<br />
}<br />
<br />
}<br />
--------------------节目问答--------------------您提供的网站只能在学校访问。无论如何,我不能。。您可以使用httpclient。。百度的例子很多。您需要导入一个jar,然后调整代码。编程问答-----------------无法访问外部网络。Jsoup和httpclient都正常
[使用jsoup实现web爬虫]-----------编程问答-----------------对于普通的爬虫,httpclient感觉不太容易使用。明天我将在你的博客上发布我对JavaJDK的封装
文件:
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法<br />
wrapper<br />
类 Http<br />
<br />
java.lang.Object<br />
wrapper.Http<br />
<br />
public class Http<br />
extends java.lang.Object<br />
对于POST表单的field名没有进行转码处理,只对field的值转码。因为field名都是ASCII字符。 <br />
网站会不定次地发送压缩格式的body,本类不具备解压缩功能。可根据header中的Content-Encoding键对应的值进行判断是不是压缩的。 <br />
一个Http对象只能发起一次请求。要发送多个相关的请求,把返回的cookieStore代入另一个Http对象。<br />
字段概要<br />
<br />
字段 <br />
限定符和类型 字段和说明<br />
java.net.CookieStore cookieStore <br />
构造器概要<br />
<br />
构造器 <br />
构造器和说明<br />
Http(java.lang.String urlString, java.lang.String charset)<br />
构造函数<br />
方法概要<br />
<br />
方法 <br />
限定符和类型 方法和说明<br />
void addPostData(java.lang.String name, java.lang.String value) <br />
void addUploadFile(java.lang.String name, java.lang.String path, java.lang.String rename) <br />
void execute() <br />
java.util.Map getHeaders() <br />
java.io.InputStream getInputStream() <br />
void setHeader(java.lang.String name, java.lang.String value) <br />
void setTimeOut(int millionSeconds) <br />
从类继承的方法 java.lang.Object<br />
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait<br />
字段详细资料<br />
<br />
cookieStore<br />
public java.net.CookieStore cookieStore<br />
构造器详细资料<br />
<br />
Http<br />
public Http(java.lang.String urlString,<br />
java.lang.String charset)<br />
构造函数<br />
参数:<br />
charset - 页面的字符集编码,即要提交的数据的字符集编码。<br />
方法详细资料<br />
<br />
execute<br />
public void execute()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getInputStream<br />
public java.io.InputStream getInputStream()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getHeaders<br />
public java.util.Map getHeaders()<br />
setHeader<br />
public void setHeader(java.lang.String name,<br />
java.lang.String value)<br />
setTimeOut<br />
public void setTimeOut(int millionSeconds)<br />
addPostData<br />
public void addPostData(java.lang.String name,<br />
java.lang.String value)<br />
addUploadFile<br />
public void addUploadFile(java.lang.String name,<br />
java.lang.String path,<br />
java.lang.String rename)<br />
throws java.lang.Exception<br />
参数:<br />
name - fieldname<br />
抛出:<br />
java.lang.Exception<br />
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法
--------------------编程问答------------------楼上的那些方法可以看出你有多方便。Jsoup很好
补充:Java , Web 开发 查看全部
excel抓取网页数据(我想用java实现抓取我们学校图书馆页面里的图书信息
)
抓取网页数据我想使用java抓取我们学校图书馆页面中的图书信息,例如:
请伟大的上帝引导Java网页捕获-----------------编程问答-----------------使用jsoup:
package cn.outofmemory.yc;<br />
<br />
import java.io.IOException;<br />
import java.util.Scanner;<br />
<br />
import org.apache.commons.httpclient.HttpClient;<br />
import org.apache.commons.httpclient.HttpException;<br />
import org.apache.commons.httpclient.HttpMethod;<br />
import org.apache.commons.httpclient.NameValuePair;<br />
import org.apache.commons.httpclient.methods.GetMethod;<br />
import org.apache.commons.httpclient.methods.PostMethod;<br />
import org.jsoup.Jsoup;<br />
import org.jsoup.nodes.Document;<br />
import org.jsoup.nodes.Element;<br />
import org.jsoup.select.Elements;<br />
<br />
public class httpclient {<br />
<br />
/**<br />
* heepclient 抓取页面<br />
* jroup 解析页面内容<br />
* @param args<br />
*/<br />
public static void main(String[] args) {<br />
Scanner reader=new Scanner(System.in);<br />
System.out.println("请输入手机号码:");<br />
String strphone=reader.nextLine();<br />
<br />
HttpClient client = new HttpClient();<br />
// 设置代理服务器地址(URL)和端口<br />
client.getHostConfiguration().setHost( "haoma.imobile.com.cn" , 80);<br />
HttpMethod method=getPostMethod(strphone);<br />
try {<br />
client.executeMethod(method);<br />
//System.out.println(method.getStatusLine()); //打印结果页面<br />
String response=new String(method.getResponseBodyAsString());<br />
<br />
// System.out.println(response);<br />
//释放连接<br />
method.releaseConnection();<br />
<br />
//解析页面内容<br />
Document doc= Jsoup.parse(response); //从字符串中加载<br />
//直接从URL 中加载页面信息。timeout设置连接超时时间 post提交方式 或者get()<br />
// Document document = (Document) Jsoup.connect("http://haoma.imobile.com.cn/in ... 6quot;).timeout(3000).post();<br />
<br />
//Elements 是 Element 的集合类<br />
Elements element=doc.select("table"); //从加载的信息中查找table 标签<br />
<br />
//从查找到table属性的Elements集合中获取标签 tr 或者tr[class$=alt] 表示 tr标签内class属性=alt<br />
// Elements titleName=element.select("tr[class$=alt]"); <br />
Elements titleName=element.select("tr");<br />
for(Element name : titleName){<br />
System.out.println(name.text());<br />
}<br />
} catch (HttpException e) {<br />
e.printStackTrace();<br />
} catch (IOException e) {<br />
e.printStackTrace();<br />
}<br />
<br />
}<br />
<br />
private static HttpMethod getPostMethod(String phone){<br />
PostMethod post = new PostMethod( "/index.php" );<br />
//POST提交则需要通过NameValuePair类来设置参数名和对应的值<br />
NameValuePair simcard = new NameValuePair( "mob" ,phone);<br />
post.setRequestBody( new NameValuePair[] {simcard});<br />
return post; <br />
} <br />
<br />
/** <br />
* 使用 GET 方式提交数据 <br />
*@return <br />
*/<br />
<br />
private static HttpMethod getGetMethod(){<br />
return new GetMethod("/index.php?simcard=1330227");<br />
}<br />
<br />
}<br />
--------------------节目问答--------------------您提供的网站只能在学校访问。无论如何,我不能。。您可以使用httpclient。。百度的例子很多。您需要导入一个jar,然后调整代码。编程问答-----------------无法访问外部网络。Jsoup和httpclient都正常
[使用jsoup实现web爬虫]-----------编程问答-----------------对于普通的爬虫,httpclient感觉不太容易使用。明天我将在你的博客上发布我对JavaJDK的封装
文件:
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法<br />
wrapper<br />
类 Http<br />
<br />
java.lang.Object<br />
wrapper.Http<br />
<br />
public class Http<br />
extends java.lang.Object<br />
对于POST表单的field名没有进行转码处理,只对field的值转码。因为field名都是ASCII字符。 <br />
网站会不定次地发送压缩格式的body,本类不具备解压缩功能。可根据header中的Content-Encoding键对应的值进行判断是不是压缩的。 <br />
一个Http对象只能发起一次请求。要发送多个相关的请求,把返回的cookieStore代入另一个Http对象。<br />
字段概要<br />
<br />
字段 <br />
限定符和类型 字段和说明<br />
java.net.CookieStore cookieStore <br />
构造器概要<br />
<br />
构造器 <br />
构造器和说明<br />
Http(java.lang.String urlString, java.lang.String charset)<br />
构造函数<br />
方法概要<br />
<br />
方法 <br />
限定符和类型 方法和说明<br />
void addPostData(java.lang.String name, java.lang.String value) <br />
void addUploadFile(java.lang.String name, java.lang.String path, java.lang.String rename) <br />
void execute() <br />
java.util.Map getHeaders() <br />
java.io.InputStream getInputStream() <br />
void setHeader(java.lang.String name, java.lang.String value) <br />
void setTimeOut(int millionSeconds) <br />
从类继承的方法 java.lang.Object<br />
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait<br />
字段详细资料<br />
<br />
cookieStore<br />
public java.net.CookieStore cookieStore<br />
构造器详细资料<br />
<br />
Http<br />
public Http(java.lang.String urlString,<br />
java.lang.String charset)<br />
构造函数<br />
参数:<br />
charset - 页面的字符集编码,即要提交的数据的字符集编码。<br />
方法详细资料<br />
<br />
execute<br />
public void execute()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getInputStream<br />
public java.io.InputStream getInputStream()<br />
throws java.lang.Exception<br />
抛出:<br />
java.lang.Exception<br />
getHeaders<br />
public java.util.Map getHeaders()<br />
setHeader<br />
public void setHeader(java.lang.String name,<br />
java.lang.String value)<br />
setTimeOut<br />
public void setTimeOut(int millionSeconds)<br />
addPostData<br />
public void addPostData(java.lang.String name,<br />
java.lang.String value)<br />
addUploadFile<br />
public void addUploadFile(java.lang.String name,<br />
java.lang.String path,<br />
java.lang.String rename)<br />
throws java.lang.Exception<br />
参数:<br />
name - fieldname<br />
抛出:<br />
java.lang.Exception<br />
程序包类使用树已过时索引帮助 上一个类下一个类框架无框架所有类概要: 嵌套 | 字段 | 构造器 | 方法详细资料: 字段 | 构造器 | 方法
--------------------编程问答------------------楼上的那些方法可以看出你有多方便。Jsoup很好
补充:Java , Web 开发
excel抓取网页数据(搞网上信息采集工作,最头疼的便是从网页上一次次)
网站优化 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-28 14:02
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
图1
无论是在线表格还是数据采集,Excel往往更智能。当它执行数据采集和加载时,它只加载表格固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果用Excel处理,会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(搞网上信息采集工作,最头疼的便是从网页上一次次)
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
网上资料采集的工作最麻烦的就是从网页上复制数据表,而且复制之后还要做很多修改,不仅麻烦而且浪费时间和工作效率。大大打折。这个时候,我们不妨试试用功能强大的Excel来解决这个问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1),然后系统会自动打开Office Excel进行数据加载。这个过程只需要加载几秒后数据(图2)。如果你觉得数据更适合你的编辑需求,那么你可以直接保存。否则你也可以做适当的修改,因为在表格处理方面,Excel比词好得多。
图1
无论是在线表格还是数据采集,Excel往往更智能。当它执行数据采集和加载时,它只加载表格固定区域的数据,而不是加载整个网页。装进去,这个我试过很多次了,都非常听话。请看图2的效果。
图2
当然,网页中也有一些非标准的数据和表格。Excel处理这样的数据有点难度,但只要熟悉Excel的操作功能,还是可以轻松搞定的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果用Excel处理,会出现这样的结果(图4),看是不是觉得乱七八糟,什么都错位了,一般人会觉得快的主要原因是文件数据的开头和结尾是额外的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据是不是会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(图5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(excel抓取网页数据的基本套路(图)!(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-28 02:00
excel抓取网页数据基本套路是:整理字段&隐藏字段,导入数据库,导出excel最重要是导出数据的工具,newfile可以来新建文件,没有要求必须要用excel作为导入文件而有的时候数据量不是很大,可以试试wps/qq邮箱导入数据首先需要新建一个excel文件,并且,创建好一个名为booktest的文件导入文件excel然后按下右键,查看所有excel选项列表,找到你想导入的excel文件点击批量导入步骤:1:新建excel,然后点击查看所有excel选项2:选择你需要的excel文件(只能是excel哦,其他文件不会被选中)点击批量导入3:选择导入格式4:点击接受excel,然后确定步骤:1:然后点击批量导入批量导入步骤:创建一个公式——将公式写入excel点击确定导入完毕excel然后就可以抓取你想要的数据啦!希望能对你有帮助~~~。
不要为了导出而导出,效率太低了。第一步,查看下excel的路径,到数据库里找,比如在地址栏里右键点击查看更多,查看数据库路径如下图。第二步,先建数据库,再建excel。可以尝试一下excel到数据库的迁移,这样就可以抓取excel里的数据了。可以先建数据库,然后查看sql注入,用book_setr,利用book_prompt为数据库命令。
这样可以导出为book_text。还可以操作sql注入,但是没试过,不清楚可行性。通过这种方法建议抓取word格式的数据。但是还有一种方法,查看并利用数据库的命令行参数(参考相关文章)。1、不要把导出的excel文件的路径输入startall里的路径,这样就无法把数据拷贝到database里,例如在database里输入general,对话框弹出后你的表的路径是正确的,但是导出数据的路径会是错误的。
2、可以利用数据库的命令行参数来建数据库,在源数据库中选择好数据库的路径,用户目录也建好,在此路径下可以执行。 查看全部
excel抓取网页数据(excel抓取网页数据的基本套路(图)!(组图))
excel抓取网页数据基本套路是:整理字段&隐藏字段,导入数据库,导出excel最重要是导出数据的工具,newfile可以来新建文件,没有要求必须要用excel作为导入文件而有的时候数据量不是很大,可以试试wps/qq邮箱导入数据首先需要新建一个excel文件,并且,创建好一个名为booktest的文件导入文件excel然后按下右键,查看所有excel选项列表,找到你想导入的excel文件点击批量导入步骤:1:新建excel,然后点击查看所有excel选项2:选择你需要的excel文件(只能是excel哦,其他文件不会被选中)点击批量导入3:选择导入格式4:点击接受excel,然后确定步骤:1:然后点击批量导入批量导入步骤:创建一个公式——将公式写入excel点击确定导入完毕excel然后就可以抓取你想要的数据啦!希望能对你有帮助~~~。
不要为了导出而导出,效率太低了。第一步,查看下excel的路径,到数据库里找,比如在地址栏里右键点击查看更多,查看数据库路径如下图。第二步,先建数据库,再建excel。可以尝试一下excel到数据库的迁移,这样就可以抓取excel里的数据了。可以先建数据库,然后查看sql注入,用book_setr,利用book_prompt为数据库命令。
这样可以导出为book_text。还可以操作sql注入,但是没试过,不清楚可行性。通过这种方法建议抓取word格式的数据。但是还有一种方法,查看并利用数据库的命令行参数(参考相关文章)。1、不要把导出的excel文件的路径输入startall里的路径,这样就无法把数据拷贝到database里,例如在database里输入general,对话框弹出后你的表的路径是正确的,但是导出数据的路径会是错误的。
2、可以利用数据库的命令行参数来建数据库,在源数据库中选择好数据库的路径,用户目录也建好,在此路径下可以执行。
excel抓取网页数据(如何使用excel抓取网页数据?,准备好需要抓取的页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-09-26 05:18
如何使用excel抓取网页数据?
很多人都知道可以用excel来处理数据,但不一定知道可以用它来抓取网页数据。其实可以用Excle自动获取网页数据。下面,本文将与大家分享如何使用excel获取网页数据。
第一步是新建一个excel
第二步是准备需要爬取的页面。以下是同花顺股票报价页面的示例:#refCountId=db_509381c1_860
第三步,打开excel,选择data>self网站
将 URL 复制到地址栏,然后单击“开始”。如果网页可以正确加载并且没有报错,基本上上面的数据就可以下载了,直接点击“导出”即可。
这里需要说明一下,可以选择多个表,但是如果选择多个表,最好选择表的同一列,这样才能整洁美观。
最后确定导入数据的位置
数据可以如下导出。
最后需要说明的是,这种方式只适合少量数据、静态网页(非动态加载)、应急使用。
如果网页结构比较复杂和非静态,那我推荐一个采集利器——优采云
<p>优采云是一个通用的网络数据采集神器。突破了Web数据采集的传统思维方式。无需编程基础即可采集,让用户 查看全部
excel抓取网页数据(如何使用excel抓取网页数据?,准备好需要抓取的页面)
如何使用excel抓取网页数据?
很多人都知道可以用excel来处理数据,但不一定知道可以用它来抓取网页数据。其实可以用Excle自动获取网页数据。下面,本文将与大家分享如何使用excel获取网页数据。
第一步是新建一个excel
第二步是准备需要爬取的页面。以下是同花顺股票报价页面的示例:#refCountId=db_509381c1_860
第三步,打开excel,选择data>self网站
将 URL 复制到地址栏,然后单击“开始”。如果网页可以正确加载并且没有报错,基本上上面的数据就可以下载了,直接点击“导出”即可。
这里需要说明一下,可以选择多个表,但是如果选择多个表,最好选择表的同一列,这样才能整洁美观。
最后确定导入数据的位置
数据可以如下导出。
最后需要说明的是,这种方式只适合少量数据、静态网页(非动态加载)、应急使用。
如果网页结构比较复杂和非静态,那我推荐一个采集利器——优采云
<p>优采云是一个通用的网络数据采集神器。突破了Web数据采集的传统思维方式。无需编程基础即可采集,让用户
excel抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-09-26 05:17
随着互联网的飞速发展,网页数据日益成为数据分析过程中最重要的数据源之一。
或许正是基于这种考虑,从2013版开始,Excel新增了一个名为Web的函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取股票信息、天气查询、有道等数据。翻译等。
给一点栗子。
输入以下公式将单元格A2的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//翻译")
公式看起来很长。这主要是因为 URL 长度太长。其实,公式的结构很简单。
它主要由3部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,里面收录了关键参数。i="&A2是需要翻译的词汇。doctype=xml是返回文件的类型,即xml。只返回xml,因为FILTERXML函数可以得到XML结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE通过指定的网页地址从web服务器获取数据(需要电脑联网状态)。
在本例中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第三部分 获取目标数据。
此处使用了 FILTERXML 函数。FILTERXML 函数的语法是:
过滤器XML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉色标记),所以第二个参数设置为“//translation”。
嗯,这就是今天星光和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
挥手说晚安~ 查看全部
excel抓取网页数据(网页数据来源之一函数(一)_星光_光明网(组图))
随着互联网的飞速发展,网页数据日益成为数据分析过程中最重要的数据源之一。
或许正是基于这种考虑,从2013版开始,Excel新增了一个名为Web的函数类别。使用其下的功能,您可以通过网页链接从Web服务器获取股票信息、天气查询、有道等数据。翻译等。
给一点栗子。
输入以下公式将单元格A2的值从英文翻译成中文或从中文翻译成英文。
=FILTERXML(WEBSERVICE(";i="&A2&"&doctype=xml"),"//翻译")
公式看起来很长。这主要是因为 URL 长度太长。其实,公式的结构很简单。
它主要由3部分组成。
第 1 部分构建 URL。
";i="&A2&"&doctype=xml"
这是有道在线翻译的网页地址,里面收录了关键参数。i="&A2是需要翻译的词汇。doctype=xml是返回文件的类型,即xml。只返回xml,因为FILTERXML函数可以得到XML结构化内容中的信息。
第 2 部分读取 URL。
WEBSERVICE通过指定的网页地址从web服务器获取数据(需要电脑联网状态)。
在本例中,B2 公式
=WEBSERVICE(";i="&A2&"&doctype=xml&version")
获取数据如下
幸福]]>
第三部分 获取目标数据。
此处使用了 FILTERXML 函数。FILTERXML 函数的语法是:
过滤器XML(xml,xpath)
有两个参数,xml参数是有效的xml格式文本,xpath参数是xml中要查询的目标数据的标准路径。
通过第二部分得到的xml文件的内容,我们可以直接看到幸福翻译结果幸福在翻译路径下(粉色标记),所以第二个参数设置为“//translation”。
嗯,这就是今天星光和大家分享的内容。有兴趣的朋友可以尝试使用网页功能从百度天气中获取自己家乡城市的天气信息~
挥手说晚安~
excel抓取网页数据(大数据时代,如何写一篇分析观点还是需要数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-21 19:06
在大数据时代,看似平凡的生活场景其实离不开这些海量数据。例如,我们接触到的文件、照片和视频收录大量数据信息。每个人都可以从中受益,这不仅节省了我们的时间,也为彼此节省了许多麻烦的事情
现在,几乎每天,无数的数据都会在互联网上产生,这已经成为不可或缺的生产要素。事实上,大数据本身毫无价值。如何处理此语句取决于用户。如果你认为这些数据对分析某些东西有很大帮助,那么它将是有价值的。如果我们不使用这些数据作为参考,这些数据只是一堆由数字和文字推动和整合的文档
我在speedceo中直接找到了一些Excel文件。当然,这些文件是公开的。直接下载或在线预览都很方便。我想知道关于大学排名表的文件,我基本上可以找到它。但是,有些文档较旧,日期较新。看看你是否需要它们
同时,人们也期待着看到他们的票房、排名和其他表现。这是数据。如果这个行业的大人物明白了,他们可以做出一些预测。毕竟,规划某些内容不能盲目。只有获得真实可靠的数据,才能进行准确的后分析和预测
直接得到一些统计数据表很容易,但过去不容易,成本高,准确性不确定。现在使用Python,它的处理速度实际上更快,但没有专门研究。我一般不太熟悉它。在互联网时代,有大量的海量数据可用
如果要编写分析视图,仍然需要数据来支持它。事实上,为人们提供新鲜而深刻的见解是大数据的价值所在。在网络时代,数据确实非常重要。毕竟,它可以帮助分析事物并做出有效的决策 查看全部
excel抓取网页数据(大数据时代,如何写一篇分析观点还是需要数据?)
在大数据时代,看似平凡的生活场景其实离不开这些海量数据。例如,我们接触到的文件、照片和视频收录大量数据信息。每个人都可以从中受益,这不仅节省了我们的时间,也为彼此节省了许多麻烦的事情
现在,几乎每天,无数的数据都会在互联网上产生,这已经成为不可或缺的生产要素。事实上,大数据本身毫无价值。如何处理此语句取决于用户。如果你认为这些数据对分析某些东西有很大帮助,那么它将是有价值的。如果我们不使用这些数据作为参考,这些数据只是一堆由数字和文字推动和整合的文档
我在speedceo中直接找到了一些Excel文件。当然,这些文件是公开的。直接下载或在线预览都很方便。我想知道关于大学排名表的文件,我基本上可以找到它。但是,有些文档较旧,日期较新。看看你是否需要它们
同时,人们也期待着看到他们的票房、排名和其他表现。这是数据。如果这个行业的大人物明白了,他们可以做出一些预测。毕竟,规划某些内容不能盲目。只有获得真实可靠的数据,才能进行准确的后分析和预测
直接得到一些统计数据表很容易,但过去不容易,成本高,准确性不确定。现在使用Python,它的处理速度实际上更快,但没有专门研究。我一般不太熟悉它。在互联网时代,有大量的海量数据可用
如果要编写分析视图,仍然需要数据来支持它。事实上,为人们提供新鲜而深刻的见解是大数据的价值所在。在网络时代,数据确实非常重要。毕竟,它可以帮助分析事物并做出有效的决策
excel抓取网页数据(自动模式检测WebHarvy自动识别网页中发生的数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2021-09-21 18:02
Webhard是一个网页数据捕获工具,具有简单的用户界面和简单的操作。它具有自动检测模式。它可以提取任何页面的数据,包括文本、图片等。它可以通过进入网站打开。默认情况下,使用内部浏览器,可以将提取的数据导出到数据库或文件夹中
功能介绍
点击界面
Webhard是一个可视化的web刮板。绝对不需要编写任何脚本或代码来获取数据。您将使用webhard的内置浏览器浏览web。您可以选择要单击的数据。这很容易
自动模式检测
Webhard自动识别网页中出现的数据模式。因此,如果需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
导出捕获的数据
您可以以多种格式保存从网页提取的数据。webharvywebscraper的当前版本允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
从多个页面提取数据
通常,网页在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webharvy websharper就会自动从所有页面获取数据
基于关键字的脚本
通过自动提交搜索表单的输入关键字列表来获取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据
通过代理服务器
为了匿名爬网并防止网络爬网软件被网络服务器阻止,您可以选择访问目标网站. 您可以使用单个代理地址或代理地址列表
类别抽取
Webharvy websharper允许您从链接列表中获取数据,从而在网站. 这允许您使用单个配置在网站内刮取类别和子类别
正则表达式
Webhard允许您将正则表达式(regex)应用于网页的文本或HTML源代码,并删除匹配的部分。这项功能强大的技术在抓取数据时为您提供了更大的灵活性
运行JavaScript
在提取数据之前,在浏览器中运行自己的JavaScript代码。这可用于与页面元素交互或调用已在目标页面中实现的JavaScript函数
下载图片
您可以下载图像或提取图像URL。Webharvy可以自动提取电子商务网站的产品详细信息页面中显示的多个图像@
自动浏览器交互
Webhard可以轻松地配置和执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置专用连接模式
您可以自动搜索可以在HTML上配置的资源 查看全部
excel抓取网页数据(自动模式检测WebHarvy自动识别网页中发生的数据抓取工具)
Webhard是一个网页数据捕获工具,具有简单的用户界面和简单的操作。它具有自动检测模式。它可以提取任何页面的数据,包括文本、图片等。它可以通过进入网站打开。默认情况下,使用内部浏览器,可以将提取的数据导出到数据库或文件夹中
功能介绍
点击界面
Webhard是一个可视化的web刮板。绝对不需要编写任何脚本或代码来获取数据。您将使用webhard的内置浏览器浏览web。您可以选择要单击的数据。这很容易
自动模式检测
Webhard自动识别网页中出现的数据模式。因此,如果需要从网页中删除项目列表(名称、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,webharvy将自动删除它
导出捕获的数据
您可以以多种格式保存从网页提取的数据。webharvywebscraper的当前版本允许您将捕获的数据导出为excel、XML、CSV、JSON或TSV文件。您还可以将捕获的数据导出到SQL数据库
从多个页面提取数据
通常,网页在多个页面上显示产品列表等数据。Webhard可以自动从多个页面抓取和提取数据。只要指出“链接到下一页”,webharvy websharper就会自动从所有页面获取数据
基于关键字的脚本
通过自动提交搜索表单的输入关键字列表来获取数据。可以将任意数量的输入关键字提交到多个输入文本字段以执行搜索。可以提取所有输入关键字组合的搜索结果数据
通过代理服务器
为了匿名爬网并防止网络爬网软件被网络服务器阻止,您可以选择访问目标网站. 您可以使用单个代理地址或代理地址列表
类别抽取
Webharvy websharper允许您从链接列表中获取数据,从而在网站. 这允许您使用单个配置在网站内刮取类别和子类别
正则表达式
Webhard允许您将正则表达式(regex)应用于网页的文本或HTML源代码,并删除匹配的部分。这项功能强大的技术在抓取数据时为您提供了更大的灵活性
运行JavaScript
在提取数据之前,在浏览器中运行自己的JavaScript代码。这可用于与页面元素交互或调用已在目标页面中实现的JavaScript函数
下载图片
您可以下载图像或提取图像URL。Webharvy可以自动提取电子商务网站的产品详细信息页面中显示的多个图像@
自动浏览器交互
Webhard可以轻松地配置和执行任务,例如单击链接、选择列表/下拉选项、在字段中输入文本、滚动页面等
更新日志
修复了页面启动时连接可能被禁用的问题
您可以为页面模式配置专用连接模式
您可以自动搜索可以在HTML上配置的资源
excel抓取网页数据(如何用excel获取网页上的股票数据,并按照日期制成表格 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-21 17:21
)
如何使用Excel在网页上获取股票数据,并根据数据制作表格?你是用什么技术完成的
对不起,后来我使用了文华财经的“回答每一个问题”功能,让他们帮我写一个索引,达到我想要的结果,所以我没有使用Excel
但我试过你说的。我试了一半就尝到了这种方法。你可以试试
第一步是找到所需的网站数据源
第二步:excel具有导入网站数据的功能。它将允许您选择要使用的数据表
具体来说,您可以在互联网上搜索-将外部数据导入excel,然后会有一个介绍
如何使用Python捕获股票数据
许多服务器通过浏览器发送的头来确认自己是否是人类用户,因此我们可以通过模仿浏览器的行为来构造请求头来向服务器发送请求。服务器将识别其中一些参数,以确定您是否是人类用户。许多网站会识别用户代理参数,因此最好带上请求头
有些具有高警觉性的网站可能会被其他参数识别,例如通过accept语言识别您是否是人类用户,有些具有防盗链功能的网站必须携带参数referer等
您如何获取普通基金股票网站的交易数据?您需要哪些数据源来创建类似的网站
您可以使用优采云采集器、编写采集规则和采集来获取对方的数据
如何将采集web股票大宗交易数据转化为指标
你好
不同机构对于大宗交易数据指标有不同的数据模型
如果您需要批量交易数据,您可以直接访问我们的网站
“吴”是一个虚拟的股票投机者网站。我不知道从哪里获取实时股票数据,如何获取,如何从其他网站获取@
您可以联系上海英孚网申请接口。他们是市场数据的代理人
“鲁”如何通过软件捕捉新浪财经的单股数据
如果你准备好掌握历史数据,你不妨直接使用免费的wdz程序来了解上海和深圳自1990年以来的所有日常历史;从2000年到现在,10多年的5分钟数据可以直接输出并转换成各种格式。你根本不必在新浪上抓住它
如何使用爬虫捕捉股市数据并生成分析报告
1.关于数据采集
股票数据是可以通过API接口访问的标准化结构数据(但通常通过通道,开放式API有一定的限制)。您也可以通过爬虫软件采集,但爬虫软件的采集数据不能保证实时性能。根据数据量和采集周期,可能会延迟数十秒到几分钟。我们总结了一套专业的爬虫技术解决方案(Ruby+sidekiq)。可以在采集快速完成此任务,您还可以在后台直观地安排任务
2.about show
对于在线股票数据的显示,在web端直接使用HTML5技术就足够了。如果接口要求较高,可以采用bootstrap等集成前端框架;如果您正在为移动终端开发,那么可以使用ionic框架
3.关于触发事件
采用RubyonRails的开发框架非常方便。Gem(如sidekiq和Anywhere)直接实现任务管理和事件触发
“8”100白银帮助通化顺网站抓取股票数据
没有详细的解释
联检组如何获取库存数据
有关于中国股市的数据吗?答案是肯定的,但应根据以下参数进行一些调整。全球证券交易所的信息如下所示
对于上海股票,添加。股票代码后为SS,对于深圳股票,添加。股票代码后的SZ
例如:000001=000001.sz
深圳数据链:
列出数据链接:
上证综合指数代码:000001.SS,深圳股票指数代码:399001.SZ,csi300代码:000300.ss
以下是世界证券交易所的网站和缩写。要查找哪个证券交易所的数据,请遵循上述格式,依此类推
上海证券交易所=,。SS,中文,SL1D1C1OHGV
深圳证券交易所=,。SZ,中文,SL1D1C1OHGV
美国运通=,美国,SL1D1C1OHGV
加拿大=,。至,多伦多,SL1D1C1OHGV
新西兰=,。新西兰,SL1D1C1OHGV
新加坡=,。Si,新加坡,SL1D1C1OHGV
香港=,。HK,香港,SL1D1T1C1OHGV
台湾=,。台湾TW SL1D1C1OHGV
印度=,。Bo,孟买,SL1D1C10HGV
伦敦=,。五十、 伦敦,SL1D1C1OHGV
澳大利亚=,。Ax,悉尼,SL1D1C1OHGV
巴西=,。圣保罗州,SL1D1C1OHGV
瑞典=,。圣斯德哥尔摩,SL1D1C1OHGV
上述方法只能提供历史数据,无法捕获实时数据。此方法由Arthur XF提供
“pick-up”java如何实现实时股票数据采集
通常有三种方式:
网络爬虫。使用爬虫程序对目标网页的股票数据进行爬网。到GitHub或技术论坛(如CSDN和51CTO)查找其他人编写的爬虫程序,并将其集成到项目中
请求第三方API。将有专门的公司(如网络API市场)提供股票数据。您只需要购买他们的服务,使用他们提供的SDK,并遵循演示开发和实现。如下图所示:
查看全部
excel抓取网页数据(如何用excel获取网页上的股票数据,并按照日期制成表格
)
如何使用Excel在网页上获取股票数据,并根据数据制作表格?你是用什么技术完成的
对不起,后来我使用了文华财经的“回答每一个问题”功能,让他们帮我写一个索引,达到我想要的结果,所以我没有使用Excel
但我试过你说的。我试了一半就尝到了这种方法。你可以试试
第一步是找到所需的网站数据源
第二步:excel具有导入网站数据的功能。它将允许您选择要使用的数据表
具体来说,您可以在互联网上搜索-将外部数据导入excel,然后会有一个介绍
如何使用Python捕获股票数据
许多服务器通过浏览器发送的头来确认自己是否是人类用户,因此我们可以通过模仿浏览器的行为来构造请求头来向服务器发送请求。服务器将识别其中一些参数,以确定您是否是人类用户。许多网站会识别用户代理参数,因此最好带上请求头
有些具有高警觉性的网站可能会被其他参数识别,例如通过accept语言识别您是否是人类用户,有些具有防盗链功能的网站必须携带参数referer等
您如何获取普通基金股票网站的交易数据?您需要哪些数据源来创建类似的网站
您可以使用优采云采集器、编写采集规则和采集来获取对方的数据
如何将采集web股票大宗交易数据转化为指标
你好
不同机构对于大宗交易数据指标有不同的数据模型
如果您需要批量交易数据,您可以直接访问我们的网站
“吴”是一个虚拟的股票投机者网站。我不知道从哪里获取实时股票数据,如何获取,如何从其他网站获取@
您可以联系上海英孚网申请接口。他们是市场数据的代理人
“鲁”如何通过软件捕捉新浪财经的单股数据
如果你准备好掌握历史数据,你不妨直接使用免费的wdz程序来了解上海和深圳自1990年以来的所有日常历史;从2000年到现在,10多年的5分钟数据可以直接输出并转换成各种格式。你根本不必在新浪上抓住它
如何使用爬虫捕捉股市数据并生成分析报告
1.关于数据采集
股票数据是可以通过API接口访问的标准化结构数据(但通常通过通道,开放式API有一定的限制)。您也可以通过爬虫软件采集,但爬虫软件的采集数据不能保证实时性能。根据数据量和采集周期,可能会延迟数十秒到几分钟。我们总结了一套专业的爬虫技术解决方案(Ruby+sidekiq)。可以在采集快速完成此任务,您还可以在后台直观地安排任务
2.about show
对于在线股票数据的显示,在web端直接使用HTML5技术就足够了。如果接口要求较高,可以采用bootstrap等集成前端框架;如果您正在为移动终端开发,那么可以使用ionic框架
3.关于触发事件
采用RubyonRails的开发框架非常方便。Gem(如sidekiq和Anywhere)直接实现任务管理和事件触发
“8”100白银帮助通化顺网站抓取股票数据
没有详细的解释
联检组如何获取库存数据
有关于中国股市的数据吗?答案是肯定的,但应根据以下参数进行一些调整。全球证券交易所的信息如下所示
对于上海股票,添加。股票代码后为SS,对于深圳股票,添加。股票代码后的SZ
例如:000001=000001.sz
深圳数据链:
列出数据链接:
上证综合指数代码:000001.SS,深圳股票指数代码:399001.SZ,csi300代码:000300.ss
以下是世界证券交易所的网站和缩写。要查找哪个证券交易所的数据,请遵循上述格式,依此类推
上海证券交易所=,。SS,中文,SL1D1C1OHGV
深圳证券交易所=,。SZ,中文,SL1D1C1OHGV
美国运通=,美国,SL1D1C1OHGV
加拿大=,。至,多伦多,SL1D1C1OHGV
新西兰=,。新西兰,SL1D1C1OHGV
新加坡=,。Si,新加坡,SL1D1C1OHGV
香港=,。HK,香港,SL1D1T1C1OHGV
台湾=,。台湾TW SL1D1C1OHGV
印度=,。Bo,孟买,SL1D1C10HGV
伦敦=,。五十、 伦敦,SL1D1C1OHGV
澳大利亚=,。Ax,悉尼,SL1D1C1OHGV
巴西=,。圣保罗州,SL1D1C1OHGV
瑞典=,。圣斯德哥尔摩,SL1D1C1OHGV
上述方法只能提供历史数据,无法捕获实时数据。此方法由Arthur XF提供
“pick-up”java如何实现实时股票数据采集
通常有三种方式:
网络爬虫。使用爬虫程序对目标网页的股票数据进行爬网。到GitHub或技术论坛(如CSDN和51CTO)查找其他人编写的爬虫程序,并将其集成到项目中
请求第三方API。将有专门的公司(如网络API市场)提供股票数据。您只需要购买他们的服务,使用他们提供的SDK,并遵循演示开发和实现。如下图所示:
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
网站优化 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2021-09-11 21:07
搞网上资料采集工作,最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作。效率大大降低。这时候不妨试试用功能强大的Excel来解决问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1)。这时候系统会自动打开Office Excel加载数据。这个过程只是加载数据需要几秒钟(图2)。如果你认为数据更适合你的编辑需求,那么你可以直接保存。否则,你也可以进行适当的更改,因为在表格处理方面,Excel比word好很多。
图一
就在线表格或数据采集 而言,Excel 往往更智能。当数据为采集并加载时,它只加载表单固定区域的数据,而不是加载整个网页。进来吧,这个我试过很多次了,都非常听话。请看图2的效果。
图二
当然,网络上也有一些非标准的数据和表格。此类数据用Excel处理略有难度,但只要熟悉Excel的操作功能,还是可以轻松处理的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果让Excel处理,就会有这样的结果(图4),看了就觉得乱七八糟,什么都错位了,普通人会觉得太快了. 主要原因是文件数据的开头和结尾是多余的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据会不会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(picture5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。 查看全部
excel抓取网页数据(网上信息采集工作,最头疼的便是从网页上导出到OfficeExcel)
搞网上资料采集工作,最麻烦的就是从网页上复制数据表很枯燥,复制之后还要做很多修改,不仅麻烦而且浪费时间和工作。效率大大降低。这时候不妨试试用功能强大的Excel来解决问题。
对于更规范的表格数据,我们可以在表格页面右击选择“导出到Microsoft Office Excel”(图1)。这时候系统会自动打开Office Excel加载数据。这个过程只是加载数据需要几秒钟(图2)。如果你认为数据更适合你的编辑需求,那么你可以直接保存。否则,你也可以进行适当的更改,因为在表格处理方面,Excel比word好很多。
图一
就在线表格或数据采集 而言,Excel 往往更智能。当数据为采集并加载时,它只加载表单固定区域的数据,而不是加载整个网页。进来吧,这个我试过很多次了,都非常听话。请看图2的效果。
图二
当然,网络上也有一些非标准的数据和表格。此类数据用Excel处理略有难度,但只要熟悉Excel的操作功能,还是可以轻松处理的。先看看这个页面(图片3),
图 3
图3 这种不规则的页面数据,如果让Excel处理,就会有这样的结果(图4),看了就觉得乱七八糟,什么都错位了,普通人会觉得太快了. 主要原因是文件数据的开头和结尾是多余的。
图 4
但是,只要我们删除文件顶部和底部的不规则区域,剩下的数据会不会变得更容易处理?这时候我们执行菜单:“Data-Columns-Next”,这样不规则的数据就可以标准化了。这是处理后的结果(picture5)
图 5
对于那些已经比较标准的表,就简单多了,只要执行“导出加载-轻微修改-保存”即可。
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2021-09-10 15:12
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只抓取了一页数据。这个文章介绍了如何使用PowerBI批量处理采集多个网页数据。 (Excel中的Power查询也可以同样操作)
本文以智联招聘网站为例,采集posts上海职位信息。
详细步骤如下:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点数据,
下拉页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是控制页面数据的变量。
(二)使用PowerBI采集首页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,页面数字到第二行。
从URL预览中可以看到,上面两行的URL已经自动合并在一起了;这里的单独输入只是为了更清楚地区分页码变量。其实直接输入完整网址也是可以的。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击确定后,出来了很多表,
从这里我们可以看到智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面没有的几列数据。
第一页的数据是采集这里。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集其他页面时,排序后的数据结构与第一页的数据结构相同。 采集的数据可以直接使用;它没有在这里排序。没关系,你可以等到采集所有网页数据整理在一起。
如果你想批量抓取网页数据,为了节省时间,可以直接跳到下一步,不用整理第一页的数据。
(三)根据页码参数设置自定义函数
这是最重要的一步。
刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表格 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,只要输入一个数字,比如7,就会抓取第7页的数据,
输入参数一次只能抓取一个网页。如果要批量抓取,则需要以下步骤。
(四)批量调用自定义函数
首先使用空查询创建编号规则。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。 gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是比较数据捕获过程的最后一步。很费时间。
网页上的数据不断更新。完成以上步骤后,在PQ中点击Refresh,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样的操作可以在可以使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。使用PowerBI批量抓取某条网站数据之前,先尝试采集一页,如果可以得到采集,则使用上面的步骤,如果采集不可用,则无需延迟时间.
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的网站data。 查看全部
excel抓取网页数据(如何用PowerBI批量采集多个网页的数据(图))
之前介绍PowerBI数据采集的时候,举了一个从网页中获取数据的例子,但是当时只抓取了一页数据。这个文章介绍了如何使用PowerBI批量处理采集多个网页数据。 (Excel中的Power查询也可以同样操作)
本文以智联招聘网站为例,采集posts上海职位信息。
详细步骤如下:
(一)分析网址结构
打开智联招聘网站,搜索上海工作地点数据,
下拉页面到底部,找到显示页码的地方,点击前三页,网址如下,
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=1
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=2
%e4%b8%8a%e6%b5%b7&sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p=3
可以看出最后一个数字是页码的ID,是控制页面数据的变量。
(二)使用PowerBI采集首页数据
打开PowerBI Desktop,从网页中获取数据,在弹出的窗口中选择【高级】,根据上面分析的URL结构,在第一行输入除最后一个页码ID外的URL,页面数字到第二行。
从URL预览中可以看到,上面两行的URL已经自动合并在一起了;这里的单独输入只是为了更清楚地区分页码变量。其实直接输入完整网址也是可以的。
(如果页码变量不是最后一位,而是在中间,则应分三行输入网址)
点击确定后,出来了很多表,
从这里我们可以看到智联招聘网站上的每一个职位信息都是一个表格,不用管它,任意选择一个表格,比如勾选Table0,点击Edit进入Power Query编辑器。
在PQ编辑器中,直接删除[source]后面的所有步骤,然后展开数据,删除前面没有的几列数据。
第一页的数据是采集这里。然后把这个页面的数据整理一下,删除无用信息,添加字段名称,可以看到一页有60条招聘信息。
这里处理完第一页的数据后,再进行采集其他页面时,排序后的数据结构与第一页的数据结构相同。 采集的数据可以直接使用;它没有在这里排序。没关系,你可以等到采集所有网页数据整理在一起。
如果你想批量抓取网页数据,为了节省时间,可以直接跳到下一步,不用整理第一页的数据。
(三)根据页码参数设置自定义函数
这是最重要的一步。
刚才第一页数据的PQ编辑器窗口,打开【高级编辑器】,在let前输入:
(p 作为数字) 作为表格 =>
并将第一行URL中&后的“1”改成let后(这是第二步使用高级选项分两行输入URL的好处):
(Number.ToText(p))
更改后,[Source] 的 URL 变为:
";sm=0&sg=fe782ca83bfa4b018d27de559d0a5db0&p="&(Number.ToText(p)))),
确定后,刚才第一页数据的查询窗口直接变成了自定义函数的输入参数窗口,Table0表格也变成了函数的样式。为了更直观,将此函数重命名为 Data_Zhaopin。
自定义函数到这里就完成了,p是函数的变量,用来控制页码,只要输入一个数字,比如7,就会抓取第7页的数据,
输入参数一次只能抓取一个网页。如果要批量抓取,则需要以下步骤。
(四)批量调用自定义函数
首先使用空查询创建编号规则。如果要抓取前100页的数据,创建一个1到100的序列,在空查询中输入
={1..100}
按 Enter 生成 1 到 100 的序列,然后将其转换为表格。 gif操作图如下:
然后调用自定义函数,
在弹出的窗口中,点击【函数查询】下拉框,选择你刚刚创建的自定义函数Data_Zhaopin,其他的就默认了。
点击确定开始批量抓取网页,因为100页数据比较大,需要5分钟左右。这也是我第二步预组织数据的结果,导致爬行速度变慢。展开这张表,就是这100页的数据,
至此,100页兆联招聘信息批量抓取完成。上面的步骤好像很多。其实掌握之后,10分钟左右就可以搞定。最大块的时间仍然是比较数据捕获过程的最后一步。很费时间。
网页上的数据不断更新。完成以上步骤后,在PQ中点击Refresh,就可以随时一键提取网站实时数据,一次搞定,终身受益!
以上主要使用PowerBI中的Power Query功能,同样的操作可以在可以使用PQ功能的Excel中进行。
当然,PowerBI 不是专业的爬虫工具。如果网页比较复杂或者有反爬虫机制,还是要使用专业的工具,比如R或者Python。使用PowerBI批量抓取某条网站数据之前,先尝试采集一页,如果可以得到采集,则使用上面的步骤,如果采集不可用,则无需延迟时间.
现在打开 PowerBI 或 Excel 并尝试获取您感兴趣的网站data。
excel抓取网页数据(如何制作一个随网站自动同步的Excel表呢?答案是肯定的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-09-10 15:11
新酷产品首次免费试用,更有众多优质专家分享他们独特的生活体验。快来新浪公测,体验各领域最前沿、最有趣、最有趣的产品~!下载客户端,获得专属福利!
本文来自太平洋计算机网
有时我们需要从网站获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,得到的也是“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作与网站自动同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1.打开网页
下图为中国地震台网官方网页()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
创建查询并确定抓取范围
3.数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清理”
4.格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
美化表格
5.设置自动同步间隔
目前表的基础已经完成,但是就像复制粘贴一样,此时得到的依然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决这个问题。
防止更新时表格格式损坏
写在最后
这个技巧很实用,尤其是在做一些动态报表的时候,可以大大减少手工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,有用吗? 查看全部
excel抓取网页数据(如何制作一个随网站自动同步的Excel表呢?答案是肯定的)
新酷产品首次免费试用,更有众多优质专家分享他们独特的生活体验。快来新浪公测,体验各领域最前沿、最有趣、最有趣的产品~!下载客户端,获得专属福利!
本文来自太平洋计算机网
有时我们需要从网站获取一些数据,传统的方法是直接复制粘贴到Excel中。但是,由于网页结构的不同,并非所有副本都能有效。有时即使成功了,得到的也是“死数据”。一旦以后有更新,必须重复上述操作。是否可以制作与网站自动同步的Excel表格?答案是肯定的,这就是 Excel 中的 Power Query 功能。
1.打开网页
下图为中国地震台网官方网页()。每当发生地震时,它都会在这里自动更新。既然要抢,就要先打开这个页面。
首先打开要抓取的网页
2.确定抓取范围
打开Excel,点击“数据”→“获取数据”→“从其他来源”,粘贴要获取的URL。此时,Power Query 会自动对网页进行分析,然后在选择框中显示分析结果。以本文为例,Power Query 分析两组表,点击找到我们需要的那一组,然后点击“转换数据”。一段时间后,Power Query 将自动完成导入。
创建查询并确定抓取范围
3.数据清洗
导入完成后,可以通过 Power Query 清理数据。所谓的“清理”,简单来说就是一个预筛选的过程,我们可以从中选择我们需要的记录,或者删除和排序不需要的列。右键负责删除数据列,面板中的“保留行”用于过滤你需要的记录。清理完毕后,点击左上角的“关闭并上传”上传Excel。
数据“预清理”
4.格式调整
数据上传到Excel后,可以继续格式化。这里的处理主要包括修改表格样式、文字大小、背景颜色、对齐方式、行高列宽、添加标题等,通俗的说就是一些美化操作,最终得到如下表格。
美化表格
5.设置自动同步间隔
目前表的基础已经完成,但是就像复制粘贴一样,此时得到的依然只是一堆“死数据”。如果想让表格自动更新,需要点击“查询工具”→“编辑”→“属性”,勾选“刷新频率”和“打开文件时刷新数据”。处理完成后,表单可以自动同步。
设置内容自动同步
注意:默认情况下,数据刷新会导致列宽发生变化。这时候可以点击“表格工具”→“外部表格数据”→“属性”,取消“调整列宽”前面的复选框即可解决这个问题。
防止更新时表格格式损坏
写在最后
这个技巧很实用,尤其是在做一些动态报表的时候,可以大大减少手工提取带来的麻烦。好的,这是本期想和大家分享的一个小技巧,有用吗?

