
c httpclient抓取网页
c httpclient抓取网页(Jvppeteer本库的灵感来自Puppeteer(Node.js)API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-02 18:36
合作伙伴
这个库的灵感来自Puppeteer(Node.js),其API基本相同。这个库是为了方便使用 Java 来控制 Chrome 或 Chromium
Jvppeteer 通过 DevTools 控制 Chromium 或 Chrome。默认情况下,它以无头模式运行,但也可以通过配置以“无头”模式运行。
你可以在浏览器中手动执行的大部分操作都可以通过 Jvppeteer 来完成!这里有些例子:
入门 以下是使用依赖管理工具(例如 maven 或 gradle)的简要指南。马文
要使用 maven,请将此依赖项添加到 pom.xml 文件中:
io.github.fanyong920
jvppeteer
1.1.3
摇篮
要使用 Gradle,请将 Maven Central Repository 添加到您的存储库列表中:
mavenCentral()
然后,您可以将最新版本添加到您的构建中。
compile "io.github.fanyong920:jvppeteer:1.1.3"
日志记录
该库使用 SLF4J 进行日志记录,并且没有任何默认的日志记录实现。
调试器将日志级别设置为 TRACE。
独立罐
如果你不使用任何依赖管理工具,你可以在这里找到最新的独立 jar。
快速入门1、启动浏览器
//设置基本的启动配置,这里选择了‘有头’模式启动
ArrayList argList = new ArrayList();
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Puppeteer.launch(options);
在这个例子中,我们明确指定了启动路径,程序会根据指定的路径启动相应的浏览器。如果没有明确指定路径,程序会尝试在默认安装路径下启动Chrome浏览器。
2、导航到一个页面
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Browser browser2 = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.taobao.com/about/");
browser.close();
Page page1 = browser2.newPage();
page1.goTo("https://www.taobao.com/about/");
在此示例中,浏览器在导航到特定页面后关闭。这里没有指定启动路径。argList 是放一些额外的命令行启动参数,我会在后面的资源章节中给出相关信息。
3、生成页面的PDF
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
//生成pdf必须在无厘头模式下才能生效
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
PDFOptions pdfOptions = new PDFOptions();
pdfOptions.setPath("test.pdf");
page.pdf(pdfOptions);
page.close();
browser.close();
在本例中,导航到某个页面后,对整个页面进行截图并将其写入为 PDF 文件。注意生成的PDF必须是headless模式才能生效
4、TRACING 性能分析
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(true).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
//开启追踪
page.tracing().start("C:\\Users\\howay\\Desktop\\trace.json");
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
page.tracing().stop();
本例中,页面导航完成后,会生成一个json格式的文件,里面收录了页面性能的具体数据。您可以使用 Chrome 浏览器开发人员工具打开 json 文件并分析性能。
5、 页面截图
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
//设置截图范围
Clip clip = new Clip(1.0,1.56,400,400);
screenshotOptions.setClip(clip);
//设置存放的路径
screenshotOptions.setPath("test.png");
page.screenshot(screenshotOptions);
页面导航完成后,设置截图范围和图片保存路径即可开始截图。
在此处查看更多示例
资源 DevTools ProtocolChrome 命令行启动参数许可
此存储库中的所有内容均已获得 Apache 许可。有关详细信息,请参阅许可证文件 查看全部
c httpclient抓取网页(Jvppeteer本库的灵感来自Puppeteer(Node.js)API)
合作伙伴
这个库的灵感来自Puppeteer(Node.js),其API基本相同。这个库是为了方便使用 Java 来控制 Chrome 或 Chromium
Jvppeteer 通过 DevTools 控制 Chromium 或 Chrome。默认情况下,它以无头模式运行,但也可以通过配置以“无头”模式运行。
你可以在浏览器中手动执行的大部分操作都可以通过 Jvppeteer 来完成!这里有些例子:
入门 以下是使用依赖管理工具(例如 maven 或 gradle)的简要指南。马文
要使用 maven,请将此依赖项添加到 pom.xml 文件中:
io.github.fanyong920
jvppeteer
1.1.3
摇篮
要使用 Gradle,请将 Maven Central Repository 添加到您的存储库列表中:
mavenCentral()
然后,您可以将最新版本添加到您的构建中。
compile "io.github.fanyong920:jvppeteer:1.1.3"
日志记录
该库使用 SLF4J 进行日志记录,并且没有任何默认的日志记录实现。
调试器将日志级别设置为 TRACE。
独立罐
如果你不使用任何依赖管理工具,你可以在这里找到最新的独立 jar。
快速入门1、启动浏览器
//设置基本的启动配置,这里选择了‘有头’模式启动
ArrayList argList = new ArrayList();
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Puppeteer.launch(options);
在这个例子中,我们明确指定了启动路径,程序会根据指定的路径启动相应的浏览器。如果没有明确指定路径,程序会尝试在默认安装路径下启动Chrome浏览器。
2、导航到一个页面
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Browser browser2 = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.taobao.com/about/";);
browser.close();
Page page1 = browser2.newPage();
page1.goTo("https://www.taobao.com/about/";);
在此示例中,浏览器在导航到特定页面后关闭。这里没有指定启动路径。argList 是放一些额外的命令行启动参数,我会在后面的资源章节中给出相关信息。
3、生成页面的PDF
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
//生成pdf必须在无厘头模式下才能生效
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
PDFOptions pdfOptions = new PDFOptions();
pdfOptions.setPath("test.pdf");
page.pdf(pdfOptions);
page.close();
browser.close();
在本例中,导航到某个页面后,对整个页面进行截图并将其写入为 PDF 文件。注意生成的PDF必须是headless模式才能生效
4、TRACING 性能分析
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(true).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
//开启追踪
page.tracing().start("C:\\Users\\howay\\Desktop\\trace.json");
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
page.tracing().stop();
本例中,页面导航完成后,会生成一个json格式的文件,里面收录了页面性能的具体数据。您可以使用 Chrome 浏览器开发人员工具打开 json 文件并分析性能。
5、 页面截图
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
//设置截图范围
Clip clip = new Clip(1.0,1.56,400,400);
screenshotOptions.setClip(clip);
//设置存放的路径
screenshotOptions.setPath("test.png");
page.screenshot(screenshotOptions);
页面导航完成后,设置截图范围和图片保存路径即可开始截图。
在此处查看更多示例
资源 DevTools ProtocolChrome 命令行启动参数许可
此存储库中的所有内容均已获得 Apache 许可。有关详细信息,请参阅许可证文件
c httpclient抓取网页(.net获取网页的源码下载网络图片要下载好 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-30 15:07
)
C# .net 可以使用 HttpWebRequest 来请求网页,如果要获取网页的内容,可以获取网页的源代码。这样,您就可以使用.Net 来实现爬虫和下载网页文件。
获取网页源代码
//请求的URL链接
String URL = "https://baike.baidu.com/item/% ... 3B%3B
//创建HttpWebRequest
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
//定义请求请求Referer
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
//定义浏览器代理
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
//请求网页
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
//判断请求状态
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//打印网页源码
using (StreamReader sr = new StreamReader(myrp.GetResponseStream()))
{
Console.Write(sr.ReadToEnd());
}
Console.ReadKey();
成功获取网页源代码
下载网络图片
下载网络图片只需要对上面的代码做一些简单的改动,把网页改成图片链接,最后写入文件保存即可。
//图片链接
String URL = "https://gss1.bdstatic.com/-vo3 ... 3B%3B
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//保存图片
using (FileStream fs = new FileStream("1.jpg", FileMode.Create))
{
myrp.GetResponseStream().CopyTo(fs);
}
请求完成后,打开项目文件夹,找到下载的图片
查看全部
c httpclient抓取网页(.net获取网页的源码下载网络图片要下载好
)
C# .net 可以使用 HttpWebRequest 来请求网页,如果要获取网页的内容,可以获取网页的源代码。这样,您就可以使用.Net 来实现爬虫和下载网页文件。
获取网页源代码
//请求的URL链接
String URL = "https://baike.baidu.com/item/% ... 3B%3B
//创建HttpWebRequest
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
//定义请求请求Referer
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
//定义浏览器代理
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
//请求网页
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
//判断请求状态
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//打印网页源码
using (StreamReader sr = new StreamReader(myrp.GetResponseStream()))
{
Console.Write(sr.ReadToEnd());
}
Console.ReadKey();
成功获取网页源代码

下载网络图片
下载网络图片只需要对上面的代码做一些简单的改动,把网页改成图片链接,最后写入文件保存即可。
//图片链接
String URL = "https://gss1.bdstatic.com/-vo3 ... 3B%3B
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//保存图片
using (FileStream fs = new FileStream("1.jpg", FileMode.Create))
{
myrp.GetResponseStream().CopyTo(fs);
}
请求完成后,打开项目文件夹,找到下载的图片


c httpclient抓取网页(用UploadValuesPOST数据用UploadData抓取网页用DownloadData或OpenRead抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-26 15:06
我们知道使用WebRequest(HttpWebRequest、FtpWebRequest)和WebResponse(HttpWebResponse、FtpWebResponse)可以实现文件的下载上传、网页抓取,但是使用WebClient更容易一些。
如果我们使用中文,请注意:WebClient 必须指定编码。
使用 DownloadFile 下载网页
这样首页就保存在C盘了。
使用 DownloadString 抓取网页
使用 DownloadData 或 OpenRead 抓取网页
我们将抓取到的网页赋值给变量str,让我们使用。您还可以使用 OpenRead 方法来获取数据流。
使用 UploadFile 上传文件
相比DownloadData和OpenRead,WebClient也有UploadData和OpenWrite方法,不过最常用的方法大概就是上传文件了,也就是uploadFile。
注意UploadFile的第一个参数,这里是ftp,所以加上上传后形成的文件名,也就是说不能是:ftp:///。如果是http,则不存在,直接指定处理哪个文件即可。
使用 UploadValues 发布数据
使用 UploadData 以任何格式上传数据
UploadData就是上传指定的二进制数据,任何格式都可以,可以上传文件,可以上传普通表单数据,也可以上传混合数据,这一切都取决于我们如何构建这个二进制文件。还可以解决UploadFile无法指定文件名的问题。
这种格式请参考:upload file data format,file upload format,但是header部分(Upgrade-Insecure-Requests:1和目标文档示例中的前一行)不要直接放在byte[] , 但由 client.Headers.Add 指定,例如:
指定用户代理 查看全部
c httpclient抓取网页(用UploadValuesPOST数据用UploadData抓取网页用DownloadData或OpenRead抓取)
我们知道使用WebRequest(HttpWebRequest、FtpWebRequest)和WebResponse(HttpWebResponse、FtpWebResponse)可以实现文件的下载上传、网页抓取,但是使用WebClient更容易一些。
如果我们使用中文,请注意:WebClient 必须指定编码。
使用 DownloadFile 下载网页
这样首页就保存在C盘了。
使用 DownloadString 抓取网页
使用 DownloadData 或 OpenRead 抓取网页
我们将抓取到的网页赋值给变量str,让我们使用。您还可以使用 OpenRead 方法来获取数据流。
使用 UploadFile 上传文件
相比DownloadData和OpenRead,WebClient也有UploadData和OpenWrite方法,不过最常用的方法大概就是上传文件了,也就是uploadFile。
注意UploadFile的第一个参数,这里是ftp,所以加上上传后形成的文件名,也就是说不能是:ftp:///。如果是http,则不存在,直接指定处理哪个文件即可。
使用 UploadValues 发布数据
使用 UploadData 以任何格式上传数据
UploadData就是上传指定的二进制数据,任何格式都可以,可以上传文件,可以上传普通表单数据,也可以上传混合数据,这一切都取决于我们如何构建这个二进制文件。还可以解决UploadFile无法指定文件名的问题。
这种格式请参考:upload file data format,file upload format,但是header部分(Upgrade-Insecure-Requests:1和目标文档示例中的前一行)不要直接放在byte[] , 但由 client.Headers.Add 指定,例如:
指定用户代理
c httpclient抓取网页(WEB服务器中的“顽固”“它”就很容易解决了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-25 02:07
一般情况下,我们使用IE或Navigator浏览器访问WEB服务器浏览页面查看信息或提交一些数据等,访问的页面有的只是普通页面,有的需要用户登录后才能使用它们,或者需要身份验证,有些是通过加密方法传输的,例如 HTTPS。我们目前使用的浏览器可以处理这些情况而不会造成问题。但是,您在某些时候可能需要通过程序访问此类页面,例如“窃取”他人网页的某些数据;使用某些网站提供的页面来完成某些功能,比如我们想知道某个手机号码的归属地而我们没有这样的数据,所以只能使用现有的网站 其他公司来完成这个功能。这时候我们需要将手机号提交到网页中,从返回的页面中解析出我们想要的内容。需要的数据来了。如果对方只是一个很简单的页面,那么我们的程序就会很简单,本文就没有必要在这里大张旗鼓地废话了。但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问,必须注册登录后才能使用提供服务的页面。这时候就涉及到cookie的问题了。处理。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,它需要程序登录然后访问服务页面。这个过程需要自己处理cookies。想想当你使用 .HttpURLConnection 来完成这些功能时有多糟糕。什么!而且,这只是我们所谓的顽固网络服务器中非常常见的“固执”!如何通过 HTTP 上传文件?不用头疼,这些问题用“它”就能轻松解决! 查看全部
c httpclient抓取网页(WEB服务器中的“顽固”“它”就很容易解决了)
一般情况下,我们使用IE或Navigator浏览器访问WEB服务器浏览页面查看信息或提交一些数据等,访问的页面有的只是普通页面,有的需要用户登录后才能使用它们,或者需要身份验证,有些是通过加密方法传输的,例如 HTTPS。我们目前使用的浏览器可以处理这些情况而不会造成问题。但是,您在某些时候可能需要通过程序访问此类页面,例如“窃取”他人网页的某些数据;使用某些网站提供的页面来完成某些功能,比如我们想知道某个手机号码的归属地而我们没有这样的数据,所以只能使用现有的网站 其他公司来完成这个功能。这时候我们需要将手机号提交到网页中,从返回的页面中解析出我们想要的内容。需要的数据来了。如果对方只是一个很简单的页面,那么我们的程序就会很简单,本文就没有必要在这里大张旗鼓地废话了。但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问,必须注册登录后才能使用提供服务的页面。这时候就涉及到cookie的问题了。处理。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,它需要程序登录然后访问服务页面。这个过程需要自己处理cookies。想想当你使用 .HttpURLConnection 来完成这些功能时有多糟糕。什么!而且,这只是我们所谓的顽固网络服务器中非常常见的“固执”!如何通过 HTTP 上传文件?不用头疼,这些问题用“它”就能轻松解决!
c httpclient抓取网页(想自己写个客户端,模拟浏览器向服务器(如lighttpd等)上传数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-24 17:04
)
我想编写自己的客户端并模拟浏览器将数据上传到服务器(如lighttpd)。用httprequest获取数据包。以下是发送的数据内容:
引述
POST/upload.php HTTP/1.0
接受:image/gif、image/x-xbitmap、image/jpeg、image/pjpeg、application/vnd.ms-excel、application/msword、application/vnd.ms-powerpoint、*/*
接受语言:en us
接受编码:gzip,deflate
用户代理:Mozilla/4.0
内容长度:180
主持人:19人(k23)16人(k24)(k21)180人)
内容类型:application/x-www-form-urlencoded
-----------------------------7d93a924b05a2
内容配置:表单数据;;filename=“C:\tmp\hello.txt”
内容类型:文本/纯文本
实现时,代码大致如下:
#include
#include
#include
#include
#include
// post a big file
#define Req "POST /upload.php HTTP/1.0\r\n" \
"Accept:image/gif, image/x-xbitmap, image/jpeg, image/pjepg, application/vnd.ms-excel, application/msword, applicationvnd.ms-powerpoint, */*\r\n" \
"Accept-Language:en-us\r\n" \
"Accept-Encoding:gzip, deflate\r\n" \
"User-Agent:Mozilla/4.0\r\n" \
"Host:192.168.1.180\r\n" \
"Content-Type:application/x-www-urlencoded\r\n" \
"-----------------------------7d91a515b05a2\r\n" \
"Content-Disposition:form-data;name=\"upload_file\";filename=\"tmp.gz\"\r\n" \
"Content-Type:application/x-gzip\r\n"
#define DST_IP "192.168.1.180"
#define ReqLen sizeof(Req)
int main()
{
struct sockaddr_in srv;
int sock, nbytes;
char sndbuf[1024] = {0};
char recbuf[1024] = {0};
if((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
fprintf(stderr, "socket() error!\n");
exit(1);
}
srv.sin_family = AF_INET;
srv.sin_addr.s_addr = inet_addr(DST_IP);
srv.sin_port = htons(80);
if((connect(sock, (struct sockaddr *)&srv, sizeof(struct sockaddr))) == -1)
{
printf("connect() error!\n");
exit(1);
}
strncpy(sndbuf, Req, ReqLen);
if(write(sock, sndbuf, ReqLen) == -1)
{
fprintf(stderr, "write() error!\n");
exit(1);
}
// get response
int bytes;
while(1)
{
nbytes = read(sock, recbuf, 1023);
if(nbytes < 0)
break;
recbuf[nbytes] = '\0';
printf(recbuf);
}
close(sock);
return 0;
} 查看全部
c httpclient抓取网页(想自己写个客户端,模拟浏览器向服务器(如lighttpd等)上传数据
)
我想编写自己的客户端并模拟浏览器将数据上传到服务器(如lighttpd)。用httprequest获取数据包。以下是发送的数据内容:
引述
POST/upload.php HTTP/1.0
接受:image/gif、image/x-xbitmap、image/jpeg、image/pjpeg、application/vnd.ms-excel、application/msword、application/vnd.ms-powerpoint、*/*
接受语言:en us
接受编码:gzip,deflate
用户代理:Mozilla/4.0
内容长度:180
主持人:19人(k23)16人(k24)(k21)180人)
内容类型:application/x-www-form-urlencoded
-----------------------------7d93a924b05a2
内容配置:表单数据;;filename=“C:\tmp\hello.txt”
内容类型:文本/纯文本
实现时,代码大致如下:
#include
#include
#include
#include
#include
// post a big file
#define Req "POST /upload.php HTTP/1.0\r\n" \
"Accept:image/gif, image/x-xbitmap, image/jpeg, image/pjepg, application/vnd.ms-excel, application/msword, applicationvnd.ms-powerpoint, */*\r\n" \
"Accept-Language:en-us\r\n" \
"Accept-Encoding:gzip, deflate\r\n" \
"User-Agent:Mozilla/4.0\r\n" \
"Host:192.168.1.180\r\n" \
"Content-Type:application/x-www-urlencoded\r\n" \
"-----------------------------7d91a515b05a2\r\n" \
"Content-Disposition:form-data;name=\"upload_file\";filename=\"tmp.gz\"\r\n" \
"Content-Type:application/x-gzip\r\n"
#define DST_IP "192.168.1.180"
#define ReqLen sizeof(Req)
int main()
{
struct sockaddr_in srv;
int sock, nbytes;
char sndbuf[1024] = {0};
char recbuf[1024] = {0};
if((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
fprintf(stderr, "socket() error!\n");
exit(1);
}
srv.sin_family = AF_INET;
srv.sin_addr.s_addr = inet_addr(DST_IP);
srv.sin_port = htons(80);
if((connect(sock, (struct sockaddr *)&srv, sizeof(struct sockaddr))) == -1)
{
printf("connect() error!\n");
exit(1);
}
strncpy(sndbuf, Req, ReqLen);
if(write(sock, sndbuf, ReqLen) == -1)
{
fprintf(stderr, "write() error!\n");
exit(1);
}
// get response
int bytes;
while(1)
{
nbytes = read(sock, recbuf, 1023);
if(nbytes < 0)
break;
recbuf[nbytes] = '\0';
printf(recbuf);
}
close(sock);
return 0;
}
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 14:03
Httpclient是Apache Jakarta common下的一个子项目。它可以用来提供一个支持HTTP协议的高效、最新和功能丰富的客户端编程工具包,并支持HTTP协议的最新版本和建议
3.起始页
首先,模拟移动浏览器的用户体验。让我们打开页面返回移动终端的页面效果,那么我们应该怎么做?事实上,服务器根据请求头中的UA来确定您是ie、chrome还是Firefox。因此,我们需要为移动浏览器找到UA
我们可以在一定程度上模拟移动终端,也可以在浏览器中直接模拟F12,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
好的,没问题:
我们怎样才能把这句话放到节目里
简单,在获取get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
好的,然后我们可以使用jsoop来获得我们想要的元素。jsoop的语法与JQ相同
让我们直接面对页面,右键单击所需的元素,选择review元素,然后使用JQ的选择器选择它
您可以参考jQuery选择器
4.get followers
直接获取我们前面分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是请记住替换用户名,并将cookie的最后一段添加到请求头ZC_0中
然后,请求的数据作为JSON返回
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这些数据包括下一个请求地址、上一个请求地址、何时开始和何时结束、粉丝总数和追随者的基本信息
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次数据采集是结束字段判断是结束是真的根据是结束确定是否继续循环。如果循环结束,更新将结束以更新下一个连接请求
一次设置,你可以得到一个用户的所有球迷
我爱爪哇(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
Httpclient是Apache Jakarta common下的一个子项目。它可以用来提供一个支持HTTP协议的高效、最新和功能丰富的客户端编程工具包,并支持HTTP协议的最新版本和建议
3.起始页
首先,模拟移动浏览器的用户体验。让我们打开页面返回移动终端的页面效果,那么我们应该怎么做?事实上,服务器根据请求头中的UA来确定您是ie、chrome还是Firefox。因此,我们需要为移动浏览器找到UA
我们可以在一定程度上模拟移动终端,也可以在浏览器中直接模拟F12,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
好的,没问题:
我们怎样才能把这句话放到节目里
简单,在获取get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
好的,然后我们可以使用jsoop来获得我们想要的元素。jsoop的语法与JQ相同
让我们直接面对页面,右键单击所需的元素,选择review元素,然后使用JQ的选择器选择它
您可以参考jQuery选择器
4.get followers
直接获取我们前面分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是请记住替换用户名,并将cookie的最后一段添加到请求头ZC_0中
然后,请求的数据作为JSON返回
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这些数据包括下一个请求地址、上一个请求地址、何时开始和何时结束、粉丝总数和追随者的基本信息
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次数据采集是结束字段判断是结束是真的根据是结束确定是否继续循环。如果循环结束,更新将结束以更新下一个连接请求
一次设置,你可以得到一个用户的所有球迷
我爱爪哇(QQ群):170936712(点击加入)
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-15 13:25
最近,我正在编写一个小爬虫来爬升一些网页数据,以便进行模型训练。在考虑如何抓取网页和分析网页时,我参考了OSC站的一些项目,特别是webmagic的设计机制和原理——如何开发@Huang Yihua编写的Java爬虫。Webmagic是一个垂直爬虫,我想写的是一个通用的爬虫,主要是爬上中文的网站内容。对于HTTP协议和消息处理,没有比httpclient组件更好的选择了。对于HTML代码解析,在比较了Htmlparser和jsoup之后,后者在API使用方面有明显的优势,简单易懂。在确定使用的开源组件之后,我们开始考虑如何捕获和解析这两个基本函数
对于我的爬虫爬行功能,只需根据网页的URL抓取HTML代码,然后解析HTML代码中的链接和链接
标记的文本是OK的,因此解析结果可以用page类表示。这个课程纯粹是一个POJO。如何使用httpclient和jsup直接解析为页面对象
在httpclient4.2在中,提供了responsehandler来处理httpresponse。因此,通过实现此接口,可以将返回的HTML代码解析为所需的页面对象。其主要思想是读取httpresponse中的数据,将其转换为HTML代码,然后使用jsoup对其进行解析
标签和标签。代码如下
公共类PageResponseHandler实现ResponseHandler
{
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在可以直接返回页面对象。编写一个测试类来测试pageresponsehandler。测试此类的函数不需要复杂的代码
公共类页面响应HandlerTest{
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫程序中的爬虫和分析功能运行良好。它也能很好地分析汉语。细心的读者会发现这些代码中没有字符集或字符集转换。稍后我们将讨论httpclient4.2组件中字符集的处理
首先,回顾内容类型在HTTP协议RFC规范中的作用。它指示发送给收件人的HTTP实体内容的媒体类型。对于文本类型httpentity,它通常采用以下形式,指定httpentity的媒体类型以及用于编码的字符集。此外,RFC规范还规定,如果内容类型未指定字符集,则默认情况下使用iso-8859-1字符集对HTTP实体进行编码
一,
内容类型:text/html;字符集=UTF-8
此时,您应该能够猜测httpclient4.2如何正确编码——也就是说,使用内容类型头中收录的字符集作为编码的输入源。有关特定代码,请参见entityutils类第212行开始的代码。Entityutils首先从httpentity对象获取内容类型。如果内容类型的字符集不是空的,它将使用内容类型对象中指定的字符集进行编码。否则,它将使用开发人员指定的字符集进行编码。如果开发人员未指定字符集,则使用默认字符集iso-8859-1进行编码。当然,编码是实现的,或者调用JDK的reader类
ContentType ContentType=ContentType.getOrDefault(实体)
Charset Charset=contentType.getCharset()
if(字符集==null){
charset=defaultCharset
}
if(字符集==null){ 查看全部
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
最近,我正在编写一个小爬虫来爬升一些网页数据,以便进行模型训练。在考虑如何抓取网页和分析网页时,我参考了OSC站的一些项目,特别是webmagic的设计机制和原理——如何开发@Huang Yihua编写的Java爬虫。Webmagic是一个垂直爬虫,我想写的是一个通用的爬虫,主要是爬上中文的网站内容。对于HTTP协议和消息处理,没有比httpclient组件更好的选择了。对于HTML代码解析,在比较了Htmlparser和jsoup之后,后者在API使用方面有明显的优势,简单易懂。在确定使用的开源组件之后,我们开始考虑如何捕获和解析这两个基本函数
对于我的爬虫爬行功能,只需根据网页的URL抓取HTML代码,然后解析HTML代码中的链接和链接
标记的文本是OK的,因此解析结果可以用page类表示。这个课程纯粹是一个POJO。如何使用httpclient和jsup直接解析为页面对象
在httpclient4.2在中,提供了responsehandler来处理httpresponse。因此,通过实现此接口,可以将返回的HTML代码解析为所需的页面对象。其主要思想是读取httpresponse中的数据,将其转换为HTML代码,然后使用jsoup对其进行解析
标签和标签。代码如下
公共类PageResponseHandler实现ResponseHandler
{
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在可以直接返回页面对象。编写一个测试类来测试pageresponsehandler。测试此类的函数不需要复杂的代码
公共类页面响应HandlerTest{
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫程序中的爬虫和分析功能运行良好。它也能很好地分析汉语。细心的读者会发现这些代码中没有字符集或字符集转换。稍后我们将讨论httpclient4.2组件中字符集的处理
首先,回顾内容类型在HTTP协议RFC规范中的作用。它指示发送给收件人的HTTP实体内容的媒体类型。对于文本类型httpentity,它通常采用以下形式,指定httpentity的媒体类型以及用于编码的字符集。此外,RFC规范还规定,如果内容类型未指定字符集,则默认情况下使用iso-8859-1字符集对HTTP实体进行编码
一,
内容类型:text/html;字符集=UTF-8
此时,您应该能够猜测httpclient4.2如何正确编码——也就是说,使用内容类型头中收录的字符集作为编码的输入源。有关特定代码,请参见entityutils类第212行开始的代码。Entityutils首先从httpentity对象获取内容类型。如果内容类型的字符集不是空的,它将使用内容类型对象中指定的字符集进行编码。否则,它将使用开发人员指定的字符集进行编码。如果开发人员未指定字符集,则使用默认字符集iso-8859-1进行编码。当然,编码是实现的,或者调用JDK的reader类
ContentType ContentType=ContentType.getOrDefault(实体)
Charset Charset=contentType.getCharset()
if(字符集==null){
charset=defaultCharset
}
if(字符集==null){
c httpclient抓取网页(【每日一题】模拟客户端(第九期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-15 04:12
获取网页其实就是模拟客户端(PC、手机...)发送请求,获取响应数据文档,解析相应数据的过程。 ---我明白了,如果你有任何错误,请告诉我
一般来说,常用的请求方式有三种:GET、POST、HEAD
GET 请求的数据用作 url 的一部分。对于GET请求,附加数据长度有限,数据安全性低
POST请求,数据作为标准数据传输到服务器,数据长度不限,数据通过加密传输,安全性高
HEAD 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取头部
停止八卦。
通过 GET 请求获取网页
UrlConnection下载网页通过InputStream读取数据,通过FileOutPutStream写入文件
public class DownloadHtml {
/**
* 方法说明:用于下载HTML页面
*@param SrcPath 下载目标页面的URL
*@param filePath 下载得到的HTML页面存放本地目录
*@param fileName 下载页面的名字
*/
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
try{
URL url = new URL(SrcPath);
URLConnection conn = url.openConnection();
//设置超时间为3秒
conn.setConnectTimeout(3*1000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//输出流
InputStream str = conn.getInputStream();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists()){
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}catch (Exception e) {
e.printStackTrace();
}
}
//测试
public static void main(String[] args) {
//下载网页<br /> url是要下载的指定网页,filepath存放文件的目录如d:/resource/html/ ,filename指文件名如"下载的网页.html"
<br />
downloadHtmlByNet(url,filepath,filename);
}
}
HttpClient 是 Apache Jakarta Common 下的一个子项目。提供高效、最新且功能丰富的客户端编程工具包,支持 HTTP 协议
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
DefaultHttpClient httpClient=new DefaultHttpClient();//初始化httpclient
BasicHttpParams httpParams=new BasicHttpParams();//初始化参数<br />
//模拟浏览器访问防止屏蔽程序抓取而返回403错误<br />user_agent="Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 <br /><br />user_agent="Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"
httpParams.setParameter("http.useragent", user_agent);
httpClient.setParams(httpParams);
try {
HttpGet httpGet=new HttpGet(SrcPath);
HttpContext httpContext=new BasicHttpContext();
HttpResponse httpResponse=httpClient.execute(httpGet,httpContext);
HttpEntity entity=httpResponse.getEntity();
if(entity!=null){
writeToFile(entity,filePath,fileName);//将entity内容输出到文件
}
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally {
httpClient.getConnectionManager().shutdown();
}
}
private static void writeToFile(HttpEntity entity, String filepath, String filename) {
//输出流
try{
InputStream str = entity.getContent();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists())
{
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}
catch(Exception e){
e.printStackTrace();
}
}
唉,我以前忘记了,所以了解更多并记住,下次我使用该帖子获取有用的数据。 查看全部
c httpclient抓取网页(【每日一题】模拟客户端(第九期))
获取网页其实就是模拟客户端(PC、手机...)发送请求,获取响应数据文档,解析相应数据的过程。 ---我明白了,如果你有任何错误,请告诉我
一般来说,常用的请求方式有三种:GET、POST、HEAD
GET 请求的数据用作 url 的一部分。对于GET请求,附加数据长度有限,数据安全性低
POST请求,数据作为标准数据传输到服务器,数据长度不限,数据通过加密传输,安全性高
HEAD 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取头部
停止八卦。
通过 GET 请求获取网页
UrlConnection下载网页通过InputStream读取数据,通过FileOutPutStream写入文件
public class DownloadHtml {
/**
* 方法说明:用于下载HTML页面
*@param SrcPath 下载目标页面的URL
*@param filePath 下载得到的HTML页面存放本地目录
*@param fileName 下载页面的名字
*/
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
try{
URL url = new URL(SrcPath);
URLConnection conn = url.openConnection();
//设置超时间为3秒
conn.setConnectTimeout(3*1000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//输出流
InputStream str = conn.getInputStream();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists()){
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}catch (Exception e) {
e.printStackTrace();
}
}
//测试
public static void main(String[] args) {
//下载网页<br /> url是要下载的指定网页,filepath存放文件的目录如d:/resource/html/ ,filename指文件名如"下载的网页.html"
<br />
downloadHtmlByNet(url,filepath,filename);
}
}
HttpClient 是 Apache Jakarta Common 下的一个子项目。提供高效、最新且功能丰富的客户端编程工具包,支持 HTTP 协议
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
DefaultHttpClient httpClient=new DefaultHttpClient();//初始化httpclient
BasicHttpParams httpParams=new BasicHttpParams();//初始化参数<br />
//模拟浏览器访问防止屏蔽程序抓取而返回403错误<br />user_agent="Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 <br /><br />user_agent="Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"
httpParams.setParameter("http.useragent", user_agent);
httpClient.setParams(httpParams);
try {
HttpGet httpGet=new HttpGet(SrcPath);
HttpContext httpContext=new BasicHttpContext();
HttpResponse httpResponse=httpClient.execute(httpGet,httpContext);
HttpEntity entity=httpResponse.getEntity();
if(entity!=null){
writeToFile(entity,filePath,fileName);//将entity内容输出到文件
}
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally {
httpClient.getConnectionManager().shutdown();
}
}
private static void writeToFile(HttpEntity entity, String filepath, String filename) {
//输出流
try{
InputStream str = entity.getContent();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists())
{
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}
catch(Exception e){
e.printStackTrace();
}
}
唉,我以前忘记了,所以了解更多并记住,下次我使用该帖子获取有用的数据。
c httpclient抓取网页( httpClient怎样获取网页中js执行完后的网页源码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-14 22:18
httpClient怎样获取网页中js执行完后的网页源码(图))
网页中httpClient如何获取js执行后的网页源码 httpClient如何获取网页中js执行后的网页源码 源码是静态的,可以全部爬取,但是如果源码代码收录jshttpClient,捕获的源代码不收录js获取的源代码不正确。在网页中执行js后如何获取网页的源代码?比如得到的网页源码可以在论坛上看到解决方案建设计划建设计划实例结构建设计划营销计划计划模板建设组织设计(建设计划)就是调用一个浏览器组件来完成这个东西。 js执行后,取其内容以及如何实现。请大家指导 --- ---最佳解决方案------------------------------------ ------ -------------单独httpclient是做不到的,只能抓取最原创的数据------其他解决办法------- -- ----------------------------------------------------------httpClient抓取到服务端的输出是js执行后的最终结果吗?其他解决方案-------------------------- ---------------------- --------比如我想抓取qq邮箱首页的源码,只获取下面一小段htmlheadmetahttp -equivrefreshcontent0urlcgi-binloginpageheadhtml------其他解决办法------ ------------------------------- -----------我也在找资料获取js分页页面的数据,但是没有其他解决办法------------------------------ ---------------------------- 这是一个单靠httpclient是做不到的引述。只能抓到最原创的数据------其他解决办法---------------------------- ------------------------尝试使用 htmlunit------其他解决方案方案-------------- ---------------------------------
---------单靠httpclient是做不到的。只能捕捉到的是最原创的数据,那我该怎么办?你能给我一些想法吗~~~其他解决方案----------------------------------- ------------- --------最近我用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取,但是如果源代码中收录jshttpClient,则抓取的源代码不收录js获取的源代码是不正确的。如何获取网页中间js执行后的网页源码。例如,获取的网页的源代码是在论坛上看到的。解决办法就是调用一个浏览器组件来完成这件事情。 js执行后,取其内容。能不能交流一下,给点思路~~--------其他解决办法-------------------------------- ------------------------ 主机为什么没有出现?乘法题,口算题,100题,七年级有理数混合运算,100题,计算机一级题库,二元线性方程组单词题真与假刺激问题解决了吗?我也遇到过这样的问题,求教~------其他解决办法-------------------------- ---------------尝试在浏览器中另存为网页----- -其他解决方案----- ---------------------------------- ----------原文请赐教-- ----其他解决方案---------------------------- ---------------- ------------您只能手动保存。太费力了,也不科学。我们要获取的是live值,可以读出js中的内容,目前的情况是请求会来自没有js内容的数据。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题或者谁可以解决这个问题。钱雇人--其他解决办法--------------------其他解决办法--------------------只能是手动保存作为参考。这是非常不科学的。我们要获取的是live值,可以读取js中的内容。现在出现的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以用js做数据?我真的很想知道这个问题或者谁可以解决这个问题。你准备付多少钱?我会给你发一封电子邮件,要钱 geogreno1gmailcom 查看全部
c httpclient抓取网页(
httpClient怎样获取网页中js执行完后的网页源码(图))

网页中httpClient如何获取js执行后的网页源码 httpClient如何获取网页中js执行后的网页源码 源码是静态的,可以全部爬取,但是如果源码代码收录jshttpClient,捕获的源代码不收录js获取的源代码不正确。在网页中执行js后如何获取网页的源代码?比如得到的网页源码可以在论坛上看到解决方案建设计划建设计划实例结构建设计划营销计划计划模板建设组织设计(建设计划)就是调用一个浏览器组件来完成这个东西。 js执行后,取其内容以及如何实现。请大家指导 --- ---最佳解决方案------------------------------------ ------ -------------单独httpclient是做不到的,只能抓取最原创的数据------其他解决办法------- -- ----------------------------------------------------------httpClient抓取到服务端的输出是js执行后的最终结果吗?其他解决方案-------------------------- ---------------------- --------比如我想抓取qq邮箱首页的源码,只获取下面一小段htmlheadmetahttp -equivrefreshcontent0urlcgi-binloginpageheadhtml------其他解决办法------ ------------------------------- -----------我也在找资料获取js分页页面的数据,但是没有其他解决办法------------------------------ ---------------------------- 这是一个单靠httpclient是做不到的引述。只能抓到最原创的数据------其他解决办法---------------------------- ------------------------尝试使用 htmlunit------其他解决方案方案-------------- ---------------------------------

---------单靠httpclient是做不到的。只能捕捉到的是最原创的数据,那我该怎么办?你能给我一些想法吗~~~其他解决方案----------------------------------- ------------- --------最近我用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取,但是如果源代码中收录jshttpClient,则抓取的源代码不收录js获取的源代码是不正确的。如何获取网页中间js执行后的网页源码。例如,获取的网页的源代码是在论坛上看到的。解决办法就是调用一个浏览器组件来完成这件事情。 js执行后,取其内容。能不能交流一下,给点思路~~--------其他解决办法-------------------------------- ------------------------ 主机为什么没有出现?乘法题,口算题,100题,七年级有理数混合运算,100题,计算机一级题库,二元线性方程组单词题真与假刺激问题解决了吗?我也遇到过这样的问题,求教~------其他解决办法-------------------------- ---------------尝试在浏览器中另存为网页----- -其他解决方案----- ---------------------------------- ----------原文请赐教-- ----其他解决方案---------------------------- ---------------- ------------您只能手动保存。太费力了,也不科学。我们要获取的是live值,可以读出js中的内容,目前的情况是请求会来自没有js内容的数据。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题或者谁可以解决这个问题。钱雇人--其他解决办法--------------------其他解决办法--------------------只能是手动保存作为参考。这是非常不科学的。我们要获取的是live值,可以读取js中的内容。现在出现的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以用js做数据?我真的很想知道这个问题或者谁可以解决这个问题。你准备付多少钱?我会给你发一封电子邮件,要钱 geogreno1gmailcom
c httpclient抓取网页(为GET和POST请求添加请求参数和请求头(使用HttpClient) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-14 07:18
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
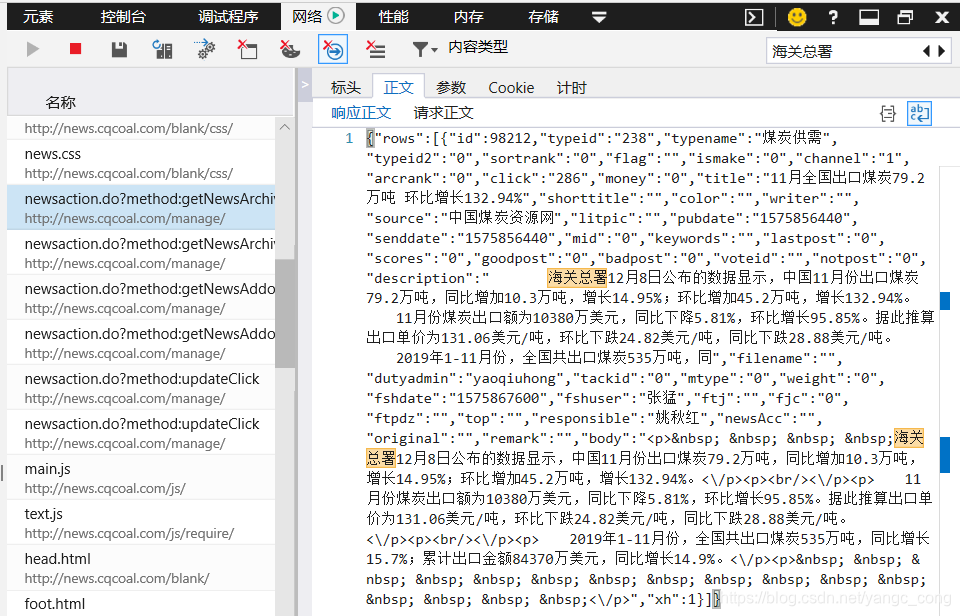
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。 “Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明加载晚了。
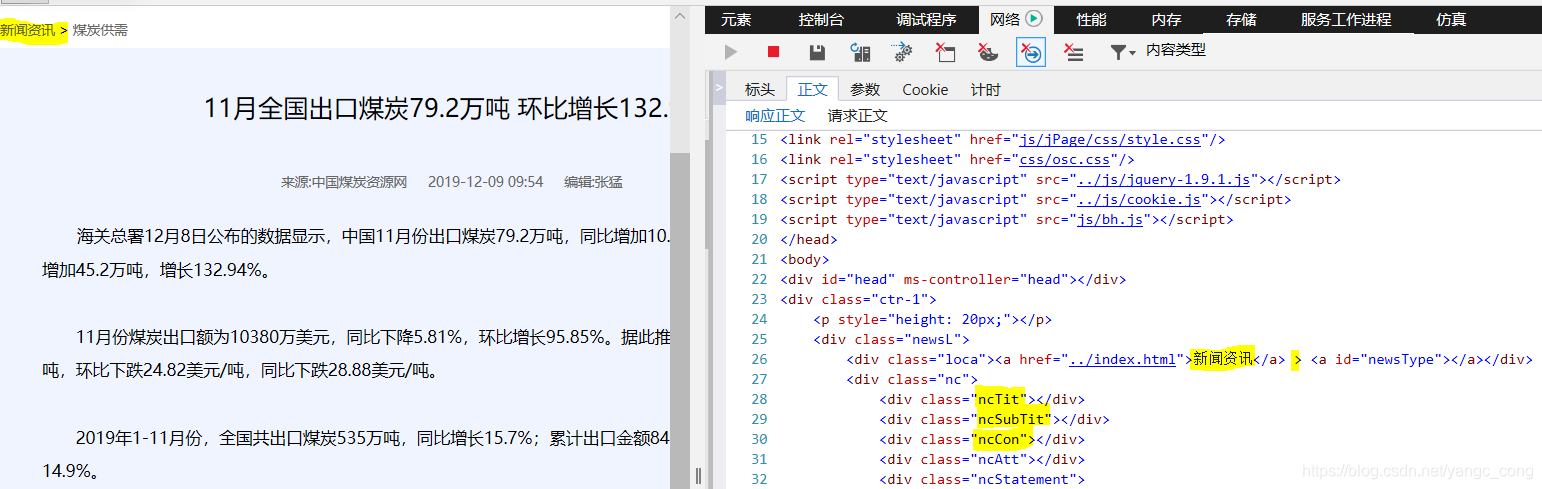
2. 尝试在文中搜索关键字,看看是请求哪些文件来获取数据。例如,在文本中搜索第一个词“海关总署”时,可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
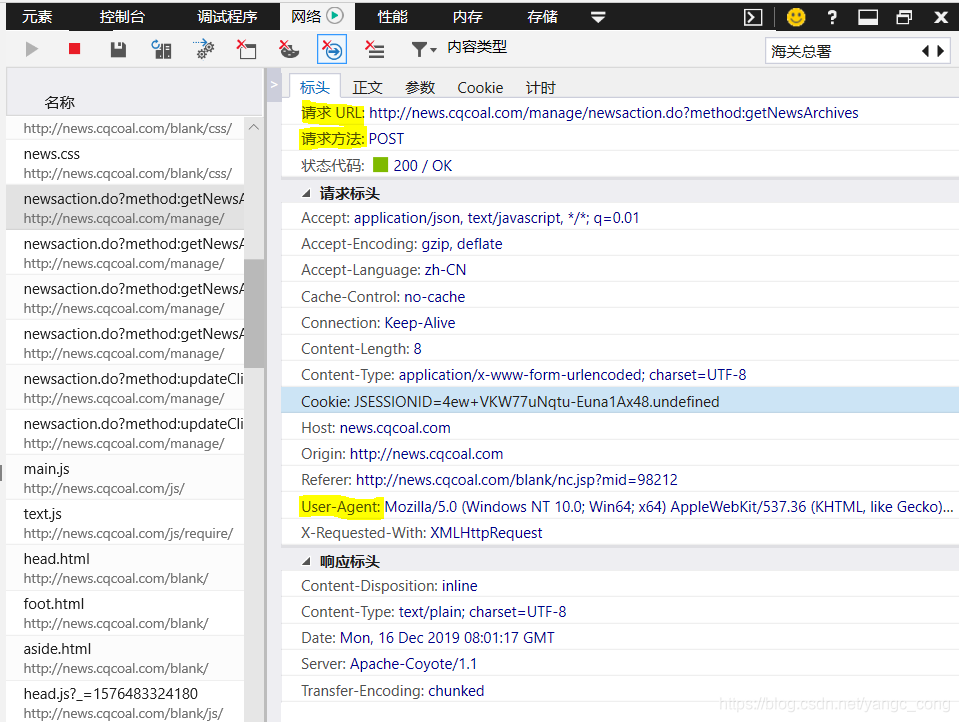
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建一个 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包见下图:
代码如下,我只拿到了文章的正文:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
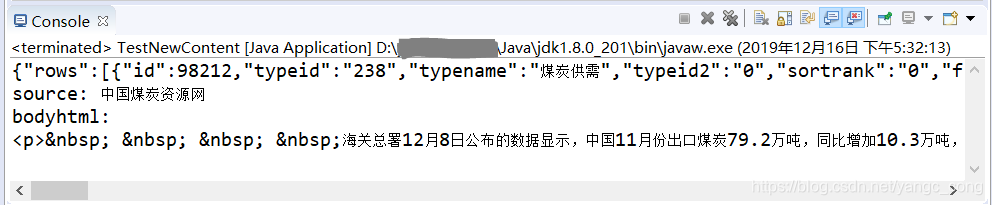
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup 学习总结
1.maven 项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2.Code 部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---标题的值属性。这里只贴出纯文本部分输出结果)
查看全部
c httpclient抓取网页(为GET和POST请求添加请求参数和请求头(使用HttpClient)
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。 “Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明加载晚了。
2. 尝试在文中搜索关键字,看看是请求哪些文件来获取数据。例如,在文本中搜索第一个词“海关总署”时,可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建一个 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包见下图:
代码如下,我只拿到了文章的正文:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup 学习总结
1.maven 项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2.Code 部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---标题的值属性。这里只贴出纯文本部分输出结果)

c httpclient抓取网页(STM32 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-14 04:03
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/");
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com");
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
} 查看全部
c httpclient抓取网页(STM32
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/";);
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com";);
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
c httpclient抓取网页(STM32 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-10 20:03
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/");
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com");
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
} 查看全部
c httpclient抓取网页(STM32
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/";);
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com";);
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
c httpclient抓取网页(做POST登陆程序,用httpclient得到登陆页面的时候出问题了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-08 22:16
我今天在做POST登录程序,使用httpclient获取登录页面时出现问题。页面代码如下:
< !DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> function setCookie(c_name, value, expiredays) { var exdate = new Date(); exdate.setDate(exdate.getDate()+expiredays); document.cookie = c_name + "=" + escape(value) + ((expiredays==null) ? "" : ";expires=" + exdate.toGMTString()) + ";path=/"; } function getHostUri() { var loc = document.location; return loc.toString(); } setCookie('YPF8827340282Jdskjhfiw_928937459182JAX666', '115.173.104.54', 10); setCookie('DOAReferrer', document.referrer, 10); location.href = getHostUri(); < body>< noscript>This site requires JavaScript and Cookies to be enabled. Please change your browser settings or upgrade your browser.
此站点需要启用 JavaScript 和 Cookie。请更改您的浏览器设置或升级您的浏览器。
一开始以为这句话是浏览器能检测到JS是否在运行,然后我的POST登录就不行了,只能考虑用IE插件来模拟登录了。
但是查了资料,有人说,“服务器无法判断你是否开启了JS,如果你判断一个cookie,它应该在首页给你发一个cookie,然后判断其他的是否有cookie页面,所以你必须从 COOKIE 开始,而不是用户代理”
现在放心了。这个解决方案还是很简单的。就是模拟JS,将页面代码中的COOKIE添加到httpclient,然后再次访问登录页面,得到正常代码。
问题终于解决了。它在于第一次捕获数据时返回的数据。根据资料,只要给HttpClient设置cookie,就可以再次捕获了。 查看全部
c httpclient抓取网页(做POST登陆程序,用httpclient得到登陆页面的时候出问题了)
我今天在做POST登录程序,使用httpclient获取登录页面时出现问题。页面代码如下:
< !DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> function setCookie(c_name, value, expiredays) { var exdate = new Date(); exdate.setDate(exdate.getDate()+expiredays); document.cookie = c_name + "=" + escape(value) + ((expiredays==null) ? "" : ";expires=" + exdate.toGMTString()) + ";path=/"; } function getHostUri() { var loc = document.location; return loc.toString(); } setCookie('YPF8827340282Jdskjhfiw_928937459182JAX666', '115.173.104.54', 10); setCookie('DOAReferrer', document.referrer, 10); location.href = getHostUri(); < body>< noscript>This site requires JavaScript and Cookies to be enabled. Please change your browser settings or upgrade your browser.
此站点需要启用 JavaScript 和 Cookie。请更改您的浏览器设置或升级您的浏览器。
一开始以为这句话是浏览器能检测到JS是否在运行,然后我的POST登录就不行了,只能考虑用IE插件来模拟登录了。
但是查了资料,有人说,“服务器无法判断你是否开启了JS,如果你判断一个cookie,它应该在首页给你发一个cookie,然后判断其他的是否有cookie页面,所以你必须从 COOKIE 开始,而不是用户代理”
现在放心了。这个解决方案还是很简单的。就是模拟JS,将页面代码中的COOKIE添加到httpclient,然后再次访问登录页面,得到正常代码。
问题终于解决了。它在于第一次捕获数据时返回的数据。根据资料,只要给HttpClient设置cookie,就可以再次捕获了。
c httpclient抓取网页(GET方法模拟抓取网页使用org.apache.HttpClient )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-08 22:14
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、GET 方法模拟爬取网页
使用org.apache.HttpClient GET方法模拟登录网页并抓取数据,需要使用HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn");
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
二、模拟浏览器UA并返回状态
有些网页会给不同的浏览器提供不同的页面,或者限制机器抓取。这时候就需要设置UA来模拟浏览器登录页面,可以使用getStatusLine返回状态。
1、设置请求头的UA模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
2、返回状态
response.getStatusLine();//获取当前状态
如果只返回状态码(200)
response.getStatusLine().getStatusCode()
3、返回类型
确定链接的目标类型
entity.getContentType().getValue()
三、GET 带参数
使用URIBuilder构造一个URI,并设置参数,多个参数就是多个setParameters
URIBuilder uriBuilder=new URIBuilder("http://baidu.com");
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
使用build()方法转换为URI
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
带参数的完整代码
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URISyntaxException;
//带参数的get
public class HelloWordUA {
public static void main(String[] ars){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient= HttpClients.createDefault();
CloseableHttpResponse response=null;
HttpGet httpGet=null;
try {
URIBuilder uriBuilder=new URIBuilder("http://baidu.com");
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
System.out.println(uriBuilder.build());
//创建http Get请求
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
} catch (URISyntaxException e) {
e.printStackTrace();
}
//设置请求头,UA浏览器型号,模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
try {
response=httpClient.execute(httpGet);//执行
//获取当响应状态
// response.getStatusLine();//获取当前状态
//response.getStatusLine().getStatusCode() 获取当前状态码
System.out.println("Status:"+response.getStatusLine().getStatusCode());
//获取网页源码
HttpEntity entity=response.getEntity();//获取网页实体
//获取目标类型
System.out.println("ContentType:"+entity.getContentType().getValue());
System.out.println(EntityUtils.toString(entity,"UTF-8"));
} catch (IOException e) {
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
c httpclient抓取网页(GET方法模拟抓取网页使用org.apache.HttpClient
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、GET 方法模拟爬取网页
使用org.apache.HttpClient GET方法模拟登录网页并抓取数据,需要使用HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn";);
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码

二、模拟浏览器UA并返回状态
有些网页会给不同的浏览器提供不同的页面,或者限制机器抓取。这时候就需要设置UA来模拟浏览器登录页面,可以使用getStatusLine返回状态。
1、设置请求头的UA模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
2、返回状态
response.getStatusLine();//获取当前状态

如果只返回状态码(200)
response.getStatusLine().getStatusCode()
3、返回类型
确定链接的目标类型
entity.getContentType().getValue()

三、GET 带参数
使用URIBuilder构造一个URI,并设置参数,多个参数就是多个setParameters
URIBuilder uriBuilder=new URIBuilder("http://baidu.com";);
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
使用build()方法转换为URI
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI

带参数的完整代码
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URISyntaxException;
//带参数的get
public class HelloWordUA {
public static void main(String[] ars){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient= HttpClients.createDefault();
CloseableHttpResponse response=null;
HttpGet httpGet=null;
try {
URIBuilder uriBuilder=new URIBuilder("http://baidu.com";);
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
System.out.println(uriBuilder.build());
//创建http Get请求
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
} catch (URISyntaxException e) {
e.printStackTrace();
}
//设置请求头,UA浏览器型号,模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
try {
response=httpClient.execute(httpGet);//执行
//获取当响应状态
// response.getStatusLine();//获取当前状态
//response.getStatusLine().getStatusCode() 获取当前状态码
System.out.println("Status:"+response.getStatusLine().getStatusCode());
//获取网页源码
HttpEntity entity=response.getEntity();//获取网页实体
//获取目标类型
System.out.println("ContentType:"+entity.getContentType().getValue());
System.out.println(EntityUtils.toString(entity,"UTF-8"));
} catch (IOException e) {
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
c httpclient抓取网页(Jvppeteer本库的灵感来自Puppeteer(Node.js)API)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-02 18:36
合作伙伴
这个库的灵感来自Puppeteer(Node.js),其API基本相同。这个库是为了方便使用 Java 来控制 Chrome 或 Chromium
Jvppeteer 通过 DevTools 控制 Chromium 或 Chrome。默认情况下,它以无头模式运行,但也可以通过配置以“无头”模式运行。
你可以在浏览器中手动执行的大部分操作都可以通过 Jvppeteer 来完成!这里有些例子:
入门 以下是使用依赖管理工具(例如 maven 或 gradle)的简要指南。马文
要使用 maven,请将此依赖项添加到 pom.xml 文件中:
io.github.fanyong920
jvppeteer
1.1.3
摇篮
要使用 Gradle,请将 Maven Central Repository 添加到您的存储库列表中:
mavenCentral()
然后,您可以将最新版本添加到您的构建中。
compile "io.github.fanyong920:jvppeteer:1.1.3"
日志记录
该库使用 SLF4J 进行日志记录,并且没有任何默认的日志记录实现。
调试器将日志级别设置为 TRACE。
独立罐
如果你不使用任何依赖管理工具,你可以在这里找到最新的独立 jar。
快速入门1、启动浏览器
//设置基本的启动配置,这里选择了‘有头’模式启动
ArrayList argList = new ArrayList();
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Puppeteer.launch(options);
在这个例子中,我们明确指定了启动路径,程序会根据指定的路径启动相应的浏览器。如果没有明确指定路径,程序会尝试在默认安装路径下启动Chrome浏览器。
2、导航到一个页面
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Browser browser2 = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.taobao.com/about/");
browser.close();
Page page1 = browser2.newPage();
page1.goTo("https://www.taobao.com/about/");
在此示例中,浏览器在导航到特定页面后关闭。这里没有指定启动路径。argList 是放一些额外的命令行启动参数,我会在后面的资源章节中给出相关信息。
3、生成页面的PDF
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
//生成pdf必须在无厘头模式下才能生效
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
PDFOptions pdfOptions = new PDFOptions();
pdfOptions.setPath("test.pdf");
page.pdf(pdfOptions);
page.close();
browser.close();
在本例中,导航到某个页面后,对整个页面进行截图并将其写入为 PDF 文件。注意生成的PDF必须是headless模式才能生效
4、TRACING 性能分析
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(true).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
//开启追踪
page.tracing().start("C:\\Users\\howay\\Desktop\\trace.json");
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
page.tracing().stop();
本例中,页面导航完成后,会生成一个json格式的文件,里面收录了页面性能的具体数据。您可以使用 Chrome 浏览器开发人员工具打开 json 文件并分析性能。
5、 页面截图
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
//设置截图范围
Clip clip = new Clip(1.0,1.56,400,400);
screenshotOptions.setClip(clip);
//设置存放的路径
screenshotOptions.setPath("test.png");
page.screenshot(screenshotOptions);
页面导航完成后,设置截图范围和图片保存路径即可开始截图。
在此处查看更多示例
资源 DevTools ProtocolChrome 命令行启动参数许可
此存储库中的所有内容均已获得 Apache 许可。有关详细信息,请参阅许可证文件 查看全部
c httpclient抓取网页(Jvppeteer本库的灵感来自Puppeteer(Node.js)API)
合作伙伴
这个库的灵感来自Puppeteer(Node.js),其API基本相同。这个库是为了方便使用 Java 来控制 Chrome 或 Chromium
Jvppeteer 通过 DevTools 控制 Chromium 或 Chrome。默认情况下,它以无头模式运行,但也可以通过配置以“无头”模式运行。
你可以在浏览器中手动执行的大部分操作都可以通过 Jvppeteer 来完成!这里有些例子:
入门 以下是使用依赖管理工具(例如 maven 或 gradle)的简要指南。马文
要使用 maven,请将此依赖项添加到 pom.xml 文件中:
io.github.fanyong920
jvppeteer
1.1.3
摇篮
要使用 Gradle,请将 Maven Central Repository 添加到您的存储库列表中:
mavenCentral()
然后,您可以将最新版本添加到您的构建中。
compile "io.github.fanyong920:jvppeteer:1.1.3"
日志记录
该库使用 SLF4J 进行日志记录,并且没有任何默认的日志记录实现。
调试器将日志级别设置为 TRACE。
独立罐
如果你不使用任何依赖管理工具,你可以在这里找到最新的独立 jar。
快速入门1、启动浏览器
//设置基本的启动配置,这里选择了‘有头’模式启动
ArrayList argList = new ArrayList();
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Puppeteer.launch(options);
在这个例子中,我们明确指定了启动路径,程序会根据指定的路径启动相应的浏览器。如果没有明确指定路径,程序会尝试在默认安装路径下启动Chrome浏览器。
2、导航到一个页面
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(false).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Browser browser2 = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.taobao.com/about/";);
browser.close();
Page page1 = browser2.newPage();
page1.goTo("https://www.taobao.com/about/";);
在此示例中,浏览器在导航到特定页面后关闭。这里没有指定启动路径。argList 是放一些额外的命令行启动参数,我会在后面的资源章节中给出相关信息。
3、生成页面的PDF
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
//生成pdf必须在无厘头模式下才能生效
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
PDFOptions pdfOptions = new PDFOptions();
pdfOptions.setPath("test.pdf");
page.pdf(pdfOptions);
page.close();
browser.close();
在本例中,导航到某个页面后,对整个页面进行截图并将其写入为 PDF 文件。注意生成的PDF必须是headless模式才能生效
4、TRACING 性能分析
//自动下载,第一次下载后不会再下载
BrowserFetcher.downloadIfNotExist(null);
ArrayList argList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(argList).withHeadless(true).build();
argList.add("--no-sandbox");
argList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
//开启追踪
page.tracing().start("C:\\Users\\howay\\Desktop\\trace.json");
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
page.tracing().stop();
本例中,页面导航完成后,会生成一个json格式的文件,里面收录了页面性能的具体数据。您可以使用 Chrome 浏览器开发人员工具打开 json 文件并分析性能。
5、 页面截图
BrowserFetcher.downloadIfNotExist(null);
ArrayList arrayList = new ArrayList();
LaunchOptions options = new LaunchOptionsBuilder().withArgs(arrayList).withHeadless(true).build();
arrayList.add("--no-sandbox");
arrayList.add("--disable-setuid-sandbox");
Browser browser = Puppeteer.launch(options);
Page page = browser.newPage();
page.goTo("https://www.baidu.com/%3Ftn%3D ... 6quot;);
ScreenshotOptions screenshotOptions = new ScreenshotOptions();
//设置截图范围
Clip clip = new Clip(1.0,1.56,400,400);
screenshotOptions.setClip(clip);
//设置存放的路径
screenshotOptions.setPath("test.png");
page.screenshot(screenshotOptions);
页面导航完成后,设置截图范围和图片保存路径即可开始截图。
在此处查看更多示例
资源 DevTools ProtocolChrome 命令行启动参数许可
此存储库中的所有内容均已获得 Apache 许可。有关详细信息,请参阅许可证文件
c httpclient抓取网页(.net获取网页的源码下载网络图片要下载好 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-09-30 15:07
)
C# .net 可以使用 HttpWebRequest 来请求网页,如果要获取网页的内容,可以获取网页的源代码。这样,您就可以使用.Net 来实现爬虫和下载网页文件。
获取网页源代码
//请求的URL链接
String URL = "https://baike.baidu.com/item/% ... 3B%3B
//创建HttpWebRequest
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
//定义请求请求Referer
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
//定义浏览器代理
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
//请求网页
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
//判断请求状态
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//打印网页源码
using (StreamReader sr = new StreamReader(myrp.GetResponseStream()))
{
Console.Write(sr.ReadToEnd());
}
Console.ReadKey();
成功获取网页源代码
下载网络图片
下载网络图片只需要对上面的代码做一些简单的改动,把网页改成图片链接,最后写入文件保存即可。
//图片链接
String URL = "https://gss1.bdstatic.com/-vo3 ... 3B%3B
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//保存图片
using (FileStream fs = new FileStream("1.jpg", FileMode.Create))
{
myrp.GetResponseStream().CopyTo(fs);
}
请求完成后,打开项目文件夹,找到下载的图片
查看全部
c httpclient抓取网页(.net获取网页的源码下载网络图片要下载好
)
C# .net 可以使用 HttpWebRequest 来请求网页,如果要获取网页的内容,可以获取网页的源代码。这样,您就可以使用.Net 来实现爬虫和下载网页文件。
获取网页源代码
//请求的URL链接
String URL = "https://baike.baidu.com/item/% ... 3B%3B
//创建HttpWebRequest
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
//定义请求请求Referer
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
//定义浏览器代理
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
//请求网页
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
//判断请求状态
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//打印网页源码
using (StreamReader sr = new StreamReader(myrp.GetResponseStream()))
{
Console.Write(sr.ReadToEnd());
}
Console.ReadKey();
成功获取网页源代码
下载网络图片
下载网络图片只需要对上面的代码做一些简单的改动,把网页改成图片链接,最后写入文件保存即可。
//图片链接
String URL = "https://gss1.bdstatic.com/-vo3 ... 3B%3B
HttpWebRequest myrq = (HttpWebRequest)WebRequest.Create(URL);
myrq.KeepAlive = false;
myrq.Timeout = 30 * 1000; //超时时间
myrq.Method = "Get"; //请求方式
myrq.Accept = "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8";
myrq.Host = "baike.baidu.com"; //来源
myrq.Referer = "https://www.baidu.com/link%3Fu ... 3B%3B
myrq.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36";
HttpWebResponse myrp = (HttpWebResponse)myrq.GetResponse();
if (myrp.StatusCode != HttpStatusCode.OK)
{
return;
}
//保存图片
using (FileStream fs = new FileStream("1.jpg", FileMode.Create))
{
myrp.GetResponseStream().CopyTo(fs);
}
请求完成后,打开项目文件夹,找到下载的图片
c httpclient抓取网页(用UploadValuesPOST数据用UploadData抓取网页用DownloadData或OpenRead抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-26 15:06
我们知道使用WebRequest(HttpWebRequest、FtpWebRequest)和WebResponse(HttpWebResponse、FtpWebResponse)可以实现文件的下载上传、网页抓取,但是使用WebClient更容易一些。
如果我们使用中文,请注意:WebClient 必须指定编码。
使用 DownloadFile 下载网页
这样首页就保存在C盘了。
使用 DownloadString 抓取网页
使用 DownloadData 或 OpenRead 抓取网页
我们将抓取到的网页赋值给变量str,让我们使用。您还可以使用 OpenRead 方法来获取数据流。
使用 UploadFile 上传文件
相比DownloadData和OpenRead,WebClient也有UploadData和OpenWrite方法,不过最常用的方法大概就是上传文件了,也就是uploadFile。
注意UploadFile的第一个参数,这里是ftp,所以加上上传后形成的文件名,也就是说不能是:ftp:///。如果是http,则不存在,直接指定处理哪个文件即可。
使用 UploadValues 发布数据
使用 UploadData 以任何格式上传数据
UploadData就是上传指定的二进制数据,任何格式都可以,可以上传文件,可以上传普通表单数据,也可以上传混合数据,这一切都取决于我们如何构建这个二进制文件。还可以解决UploadFile无法指定文件名的问题。
这种格式请参考:upload file data format,file upload format,但是header部分(Upgrade-Insecure-Requests:1和目标文档示例中的前一行)不要直接放在byte[] , 但由 client.Headers.Add 指定,例如:
指定用户代理 查看全部
c httpclient抓取网页(用UploadValuesPOST数据用UploadData抓取网页用DownloadData或OpenRead抓取)
我们知道使用WebRequest(HttpWebRequest、FtpWebRequest)和WebResponse(HttpWebResponse、FtpWebResponse)可以实现文件的下载上传、网页抓取,但是使用WebClient更容易一些。
如果我们使用中文,请注意:WebClient 必须指定编码。
使用 DownloadFile 下载网页
这样首页就保存在C盘了。
使用 DownloadString 抓取网页
使用 DownloadData 或 OpenRead 抓取网页
我们将抓取到的网页赋值给变量str,让我们使用。您还可以使用 OpenRead 方法来获取数据流。
使用 UploadFile 上传文件
相比DownloadData和OpenRead,WebClient也有UploadData和OpenWrite方法,不过最常用的方法大概就是上传文件了,也就是uploadFile。
注意UploadFile的第一个参数,这里是ftp,所以加上上传后形成的文件名,也就是说不能是:ftp:///。如果是http,则不存在,直接指定处理哪个文件即可。
使用 UploadValues 发布数据
使用 UploadData 以任何格式上传数据
UploadData就是上传指定的二进制数据,任何格式都可以,可以上传文件,可以上传普通表单数据,也可以上传混合数据,这一切都取决于我们如何构建这个二进制文件。还可以解决UploadFile无法指定文件名的问题。
这种格式请参考:upload file data format,file upload format,但是header部分(Upgrade-Insecure-Requests:1和目标文档示例中的前一行)不要直接放在byte[] , 但由 client.Headers.Add 指定,例如:
指定用户代理
c httpclient抓取网页(WEB服务器中的“顽固”“它”就很容易解决了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-09-25 02:07
一般情况下,我们使用IE或Navigator浏览器访问WEB服务器浏览页面查看信息或提交一些数据等,访问的页面有的只是普通页面,有的需要用户登录后才能使用它们,或者需要身份验证,有些是通过加密方法传输的,例如 HTTPS。我们目前使用的浏览器可以处理这些情况而不会造成问题。但是,您在某些时候可能需要通过程序访问此类页面,例如“窃取”他人网页的某些数据;使用某些网站提供的页面来完成某些功能,比如我们想知道某个手机号码的归属地而我们没有这样的数据,所以只能使用现有的网站 其他公司来完成这个功能。这时候我们需要将手机号提交到网页中,从返回的页面中解析出我们想要的内容。需要的数据来了。如果对方只是一个很简单的页面,那么我们的程序就会很简单,本文就没有必要在这里大张旗鼓地废话了。但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问,必须注册登录后才能使用提供服务的页面。这时候就涉及到cookie的问题了。处理。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,它需要程序登录然后访问服务页面。这个过程需要自己处理cookies。想想当你使用 .HttpURLConnection 来完成这些功能时有多糟糕。什么!而且,这只是我们所谓的顽固网络服务器中非常常见的“固执”!如何通过 HTTP 上传文件?不用头疼,这些问题用“它”就能轻松解决! 查看全部
c httpclient抓取网页(WEB服务器中的“顽固”“它”就很容易解决了)
一般情况下,我们使用IE或Navigator浏览器访问WEB服务器浏览页面查看信息或提交一些数据等,访问的页面有的只是普通页面,有的需要用户登录后才能使用它们,或者需要身份验证,有些是通过加密方法传输的,例如 HTTPS。我们目前使用的浏览器可以处理这些情况而不会造成问题。但是,您在某些时候可能需要通过程序访问此类页面,例如“窃取”他人网页的某些数据;使用某些网站提供的页面来完成某些功能,比如我们想知道某个手机号码的归属地而我们没有这样的数据,所以只能使用现有的网站 其他公司来完成这个功能。这时候我们需要将手机号提交到网页中,从返回的页面中解析出我们想要的内容。需要的数据来了。如果对方只是一个很简单的页面,那么我们的程序就会很简单,本文就没有必要在这里大张旗鼓地废话了。但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问,必须注册登录后才能使用提供服务的页面。这时候就涉及到cookie的问题了。处理。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,它需要程序登录然后访问服务页面。这个过程需要自己处理cookies。想想当你使用 .HttpURLConnection 来完成这些功能时有多糟糕。什么!而且,这只是我们所谓的顽固网络服务器中非常常见的“固执”!如何通过 HTTP 上传文件?不用头疼,这些问题用“它”就能轻松解决!
c httpclient抓取网页(想自己写个客户端,模拟浏览器向服务器(如lighttpd等)上传数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-24 17:04
)
我想编写自己的客户端并模拟浏览器将数据上传到服务器(如lighttpd)。用httprequest获取数据包。以下是发送的数据内容:
引述
POST/upload.php HTTP/1.0
接受:image/gif、image/x-xbitmap、image/jpeg、image/pjpeg、application/vnd.ms-excel、application/msword、application/vnd.ms-powerpoint、*/*
接受语言:en us
接受编码:gzip,deflate
用户代理:Mozilla/4.0
内容长度:180
主持人:19人(k23)16人(k24)(k21)180人)
内容类型:application/x-www-form-urlencoded
-----------------------------7d93a924b05a2
内容配置:表单数据;;filename=“C:\tmp\hello.txt”
内容类型:文本/纯文本
实现时,代码大致如下:
#include
#include
#include
#include
#include
// post a big file
#define Req "POST /upload.php HTTP/1.0\r\n" \
"Accept:image/gif, image/x-xbitmap, image/jpeg, image/pjepg, application/vnd.ms-excel, application/msword, applicationvnd.ms-powerpoint, */*\r\n" \
"Accept-Language:en-us\r\n" \
"Accept-Encoding:gzip, deflate\r\n" \
"User-Agent:Mozilla/4.0\r\n" \
"Host:192.168.1.180\r\n" \
"Content-Type:application/x-www-urlencoded\r\n" \
"-----------------------------7d91a515b05a2\r\n" \
"Content-Disposition:form-data;name=\"upload_file\";filename=\"tmp.gz\"\r\n" \
"Content-Type:application/x-gzip\r\n"
#define DST_IP "192.168.1.180"
#define ReqLen sizeof(Req)
int main()
{
struct sockaddr_in srv;
int sock, nbytes;
char sndbuf[1024] = {0};
char recbuf[1024] = {0};
if((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
fprintf(stderr, "socket() error!\n");
exit(1);
}
srv.sin_family = AF_INET;
srv.sin_addr.s_addr = inet_addr(DST_IP);
srv.sin_port = htons(80);
if((connect(sock, (struct sockaddr *)&srv, sizeof(struct sockaddr))) == -1)
{
printf("connect() error!\n");
exit(1);
}
strncpy(sndbuf, Req, ReqLen);
if(write(sock, sndbuf, ReqLen) == -1)
{
fprintf(stderr, "write() error!\n");
exit(1);
}
// get response
int bytes;
while(1)
{
nbytes = read(sock, recbuf, 1023);
if(nbytes < 0)
break;
recbuf[nbytes] = '\0';
printf(recbuf);
}
close(sock);
return 0;
} 查看全部
c httpclient抓取网页(想自己写个客户端,模拟浏览器向服务器(如lighttpd等)上传数据
)
我想编写自己的客户端并模拟浏览器将数据上传到服务器(如lighttpd)。用httprequest获取数据包。以下是发送的数据内容:
引述
POST/upload.php HTTP/1.0
接受:image/gif、image/x-xbitmap、image/jpeg、image/pjpeg、application/vnd.ms-excel、application/msword、application/vnd.ms-powerpoint、*/*
接受语言:en us
接受编码:gzip,deflate
用户代理:Mozilla/4.0
内容长度:180
主持人:19人(k23)16人(k24)(k21)180人)
内容类型:application/x-www-form-urlencoded
-----------------------------7d93a924b05a2
内容配置:表单数据;;filename=“C:\tmp\hello.txt”
内容类型:文本/纯文本
实现时,代码大致如下:
#include
#include
#include
#include
#include
// post a big file
#define Req "POST /upload.php HTTP/1.0\r\n" \
"Accept:image/gif, image/x-xbitmap, image/jpeg, image/pjepg, application/vnd.ms-excel, application/msword, applicationvnd.ms-powerpoint, */*\r\n" \
"Accept-Language:en-us\r\n" \
"Accept-Encoding:gzip, deflate\r\n" \
"User-Agent:Mozilla/4.0\r\n" \
"Host:192.168.1.180\r\n" \
"Content-Type:application/x-www-urlencoded\r\n" \
"-----------------------------7d91a515b05a2\r\n" \
"Content-Disposition:form-data;name=\"upload_file\";filename=\"tmp.gz\"\r\n" \
"Content-Type:application/x-gzip\r\n"
#define DST_IP "192.168.1.180"
#define ReqLen sizeof(Req)
int main()
{
struct sockaddr_in srv;
int sock, nbytes;
char sndbuf[1024] = {0};
char recbuf[1024] = {0};
if((sock = socket(AF_INET, SOCK_STREAM, 0)) == -1)
{
fprintf(stderr, "socket() error!\n");
exit(1);
}
srv.sin_family = AF_INET;
srv.sin_addr.s_addr = inet_addr(DST_IP);
srv.sin_port = htons(80);
if((connect(sock, (struct sockaddr *)&srv, sizeof(struct sockaddr))) == -1)
{
printf("connect() error!\n");
exit(1);
}
strncpy(sndbuf, Req, ReqLen);
if(write(sock, sndbuf, ReqLen) == -1)
{
fprintf(stderr, "write() error!\n");
exit(1);
}
// get response
int bytes;
while(1)
{
nbytes = read(sock, recbuf, 1023);
if(nbytes < 0)
break;
recbuf[nbytes] = '\0';
printf(recbuf);
}
close(sock);
return 0;
}
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-15 14:03
Httpclient是Apache Jakarta common下的一个子项目。它可以用来提供一个支持HTTP协议的高效、最新和功能丰富的客户端编程工具包,并支持HTTP协议的最新版本和建议
3.起始页
首先,模拟移动浏览器的用户体验。让我们打开页面返回移动终端的页面效果,那么我们应该怎么做?事实上,服务器根据请求头中的UA来确定您是ie、chrome还是Firefox。因此,我们需要为移动浏览器找到UA
我们可以在一定程度上模拟移动终端,也可以在浏览器中直接模拟F12,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
好的,没问题:
我们怎样才能把这句话放到节目里
简单,在获取get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
好的,然后我们可以使用jsoop来获得我们想要的元素。jsoop的语法与JQ相同
让我们直接面对页面,右键单击所需的元素,选择review元素,然后使用JQ的选择器选择它
您可以参考jQuery选择器
4.get followers
直接获取我们前面分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是请记住替换用户名,并将cookie的最后一段添加到请求头ZC_0中
然后,请求的数据作为JSON返回
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这些数据包括下一个请求地址、上一个请求地址、何时开始和何时结束、粉丝总数和追随者的基本信息
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次数据采集是结束字段判断是结束是真的根据是结束确定是否继续循环。如果循环结束,更新将结束以更新下一个连接请求
一次设置,你可以得到一个用户的所有球迷
我爱爪哇(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
Httpclient是Apache Jakarta common下的一个子项目。它可以用来提供一个支持HTTP协议的高效、最新和功能丰富的客户端编程工具包,并支持HTTP协议的最新版本和建议
3.起始页
首先,模拟移动浏览器的用户体验。让我们打开页面返回移动终端的页面效果,那么我们应该怎么做?事实上,服务器根据请求头中的UA来确定您是ie、chrome还是Firefox。因此,我们需要为移动浏览器找到UA
我们可以在一定程度上模拟移动终端,也可以在浏览器中直接模拟F12,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
好的,没问题:
我们怎样才能把这句话放到节目里
简单,在获取get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
好的,然后我们可以使用jsoop来获得我们想要的元素。jsoop的语法与JQ相同
让我们直接面对页面,右键单击所需的元素,选择review元素,然后使用JQ的选择器选择它
您可以参考jQuery选择器
4.get followers
直接获取我们前面分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是请记住替换用户名,并将cookie的最后一段添加到请求头ZC_0中
然后,请求的数据作为JSON返回
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这些数据包括下一个请求地址、上一个请求地址、何时开始和何时结束、粉丝总数和追随者的基本信息
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次数据采集是结束字段判断是结束是真的根据是结束确定是否继续循环。如果循环结束,更新将结束以更新下一个连接请求
一次设置,你可以得到一个用户的所有球迷
我爱爪哇(QQ群):170936712(点击加入)
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-09-15 13:25
最近,我正在编写一个小爬虫来爬升一些网页数据,以便进行模型训练。在考虑如何抓取网页和分析网页时,我参考了OSC站的一些项目,特别是webmagic的设计机制和原理——如何开发@Huang Yihua编写的Java爬虫。Webmagic是一个垂直爬虫,我想写的是一个通用的爬虫,主要是爬上中文的网站内容。对于HTTP协议和消息处理,没有比httpclient组件更好的选择了。对于HTML代码解析,在比较了Htmlparser和jsoup之后,后者在API使用方面有明显的优势,简单易懂。在确定使用的开源组件之后,我们开始考虑如何捕获和解析这两个基本函数
对于我的爬虫爬行功能,只需根据网页的URL抓取HTML代码,然后解析HTML代码中的链接和链接
标记的文本是OK的,因此解析结果可以用page类表示。这个课程纯粹是一个POJO。如何使用httpclient和jsup直接解析为页面对象
在httpclient4.2在中,提供了responsehandler来处理httpresponse。因此,通过实现此接口,可以将返回的HTML代码解析为所需的页面对象。其主要思想是读取httpresponse中的数据,将其转换为HTML代码,然后使用jsoup对其进行解析
标签和标签。代码如下
公共类PageResponseHandler实现ResponseHandler
{
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在可以直接返回页面对象。编写一个测试类来测试pageresponsehandler。测试此类的函数不需要复杂的代码
公共类页面响应HandlerTest{
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫程序中的爬虫和分析功能运行良好。它也能很好地分析汉语。细心的读者会发现这些代码中没有字符集或字符集转换。稍后我们将讨论httpclient4.2组件中字符集的处理
首先,回顾内容类型在HTTP协议RFC规范中的作用。它指示发送给收件人的HTTP实体内容的媒体类型。对于文本类型httpentity,它通常采用以下形式,指定httpentity的媒体类型以及用于编码的字符集。此外,RFC规范还规定,如果内容类型未指定字符集,则默认情况下使用iso-8859-1字符集对HTTP实体进行编码
一,
内容类型:text/html;字符集=UTF-8
此时,您应该能够猜测httpclient4.2如何正确编码——也就是说,使用内容类型头中收录的字符集作为编码的输入源。有关特定代码,请参见entityutils类第212行开始的代码。Entityutils首先从httpentity对象获取内容类型。如果内容类型的字符集不是空的,它将使用内容类型对象中指定的字符集进行编码。否则,它将使用开发人员指定的字符集进行编码。如果开发人员未指定字符集,则使用默认字符集iso-8859-1进行编码。当然,编码是实现的,或者调用JDK的reader类
ContentType ContentType=ContentType.getOrDefault(实体)
Charset Charset=contentType.getCharset()
if(字符集==null){
charset=defaultCharset
}
if(字符集==null){ 查看全部
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
最近,我正在编写一个小爬虫来爬升一些网页数据,以便进行模型训练。在考虑如何抓取网页和分析网页时,我参考了OSC站的一些项目,特别是webmagic的设计机制和原理——如何开发@Huang Yihua编写的Java爬虫。Webmagic是一个垂直爬虫,我想写的是一个通用的爬虫,主要是爬上中文的网站内容。对于HTTP协议和消息处理,没有比httpclient组件更好的选择了。对于HTML代码解析,在比较了Htmlparser和jsoup之后,后者在API使用方面有明显的优势,简单易懂。在确定使用的开源组件之后,我们开始考虑如何捕获和解析这两个基本函数
对于我的爬虫爬行功能,只需根据网页的URL抓取HTML代码,然后解析HTML代码中的链接和链接
标记的文本是OK的,因此解析结果可以用page类表示。这个课程纯粹是一个POJO。如何使用httpclient和jsup直接解析为页面对象
在httpclient4.2在中,提供了responsehandler来处理httpresponse。因此,通过实现此接口,可以将返回的HTML代码解析为所需的页面对象。其主要思想是读取httpresponse中的数据,将其转换为HTML代码,然后使用jsoup对其进行解析
标签和标签。代码如下
公共类PageResponseHandler实现ResponseHandler
{
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在可以直接返回页面对象。编写一个测试类来测试pageresponsehandler。测试此类的函数不需要复杂的代码
公共类页面响应HandlerTest{
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫程序中的爬虫和分析功能运行良好。它也能很好地分析汉语。细心的读者会发现这些代码中没有字符集或字符集转换。稍后我们将讨论httpclient4.2组件中字符集的处理
首先,回顾内容类型在HTTP协议RFC规范中的作用。它指示发送给收件人的HTTP实体内容的媒体类型。对于文本类型httpentity,它通常采用以下形式,指定httpentity的媒体类型以及用于编码的字符集。此外,RFC规范还规定,如果内容类型未指定字符集,则默认情况下使用iso-8859-1字符集对HTTP实体进行编码
一,
内容类型:text/html;字符集=UTF-8
此时,您应该能够猜测httpclient4.2如何正确编码——也就是说,使用内容类型头中收录的字符集作为编码的输入源。有关特定代码,请参见entityutils类第212行开始的代码。Entityutils首先从httpentity对象获取内容类型。如果内容类型的字符集不是空的,它将使用内容类型对象中指定的字符集进行编码。否则,它将使用开发人员指定的字符集进行编码。如果开发人员未指定字符集,则使用默认字符集iso-8859-1进行编码。当然,编码是实现的,或者调用JDK的reader类
ContentType ContentType=ContentType.getOrDefault(实体)
Charset Charset=contentType.getCharset()
if(字符集==null){
charset=defaultCharset
}
if(字符集==null){
c httpclient抓取网页(【每日一题】模拟客户端(第九期))
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-09-15 04:12
获取网页其实就是模拟客户端(PC、手机...)发送请求,获取响应数据文档,解析相应数据的过程。 ---我明白了,如果你有任何错误,请告诉我
一般来说,常用的请求方式有三种:GET、POST、HEAD
GET 请求的数据用作 url 的一部分。对于GET请求,附加数据长度有限,数据安全性低
POST请求,数据作为标准数据传输到服务器,数据长度不限,数据通过加密传输,安全性高
HEAD 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取头部
停止八卦。
通过 GET 请求获取网页
UrlConnection下载网页通过InputStream读取数据,通过FileOutPutStream写入文件
public class DownloadHtml {
/**
* 方法说明:用于下载HTML页面
*@param SrcPath 下载目标页面的URL
*@param filePath 下载得到的HTML页面存放本地目录
*@param fileName 下载页面的名字
*/
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
try{
URL url = new URL(SrcPath);
URLConnection conn = url.openConnection();
//设置超时间为3秒
conn.setConnectTimeout(3*1000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//输出流
InputStream str = conn.getInputStream();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists()){
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}catch (Exception e) {
e.printStackTrace();
}
}
//测试
public static void main(String[] args) {
//下载网页<br /> url是要下载的指定网页,filepath存放文件的目录如d:/resource/html/ ,filename指文件名如"下载的网页.html"
<br />
downloadHtmlByNet(url,filepath,filename);
}
}
HttpClient 是 Apache Jakarta Common 下的一个子项目。提供高效、最新且功能丰富的客户端编程工具包,支持 HTTP 协议
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
DefaultHttpClient httpClient=new DefaultHttpClient();//初始化httpclient
BasicHttpParams httpParams=new BasicHttpParams();//初始化参数<br />
//模拟浏览器访问防止屏蔽程序抓取而返回403错误<br />user_agent="Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 <br /><br />user_agent="Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"
httpParams.setParameter("http.useragent", user_agent);
httpClient.setParams(httpParams);
try {
HttpGet httpGet=new HttpGet(SrcPath);
HttpContext httpContext=new BasicHttpContext();
HttpResponse httpResponse=httpClient.execute(httpGet,httpContext);
HttpEntity entity=httpResponse.getEntity();
if(entity!=null){
writeToFile(entity,filePath,fileName);//将entity内容输出到文件
}
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally {
httpClient.getConnectionManager().shutdown();
}
}
private static void writeToFile(HttpEntity entity, String filepath, String filename) {
//输出流
try{
InputStream str = entity.getContent();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists())
{
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}
catch(Exception e){
e.printStackTrace();
}
}
唉,我以前忘记了,所以了解更多并记住,下次我使用该帖子获取有用的数据。 查看全部
c httpclient抓取网页(【每日一题】模拟客户端(第九期))
获取网页其实就是模拟客户端(PC、手机...)发送请求,获取响应数据文档,解析相应数据的过程。 ---我明白了,如果你有任何错误,请告诉我
一般来说,常用的请求方式有三种:GET、POST、HEAD
GET 请求的数据用作 url 的一部分。对于GET请求,附加数据长度有限,数据安全性低
POST请求,数据作为标准数据传输到服务器,数据长度不限,数据通过加密传输,安全性高
HEAD 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取头部
停止八卦。
通过 GET 请求获取网页
UrlConnection下载网页通过InputStream读取数据,通过FileOutPutStream写入文件
public class DownloadHtml {
/**
* 方法说明:用于下载HTML页面
*@param SrcPath 下载目标页面的URL
*@param filePath 下载得到的HTML页面存放本地目录
*@param fileName 下载页面的名字
*/
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
try{
URL url = new URL(SrcPath);
URLConnection conn = url.openConnection();
//设置超时间为3秒
conn.setConnectTimeout(3*1000);
//防止屏蔽程序抓取而返回403错误
conn.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
//输出流
InputStream str = conn.getInputStream();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists()){
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}catch (Exception e) {
e.printStackTrace();
}
}
//测试
public static void main(String[] args) {
//下载网页<br /> url是要下载的指定网页,filepath存放文件的目录如d:/resource/html/ ,filename指文件名如"下载的网页.html"
<br />
downloadHtmlByNet(url,filepath,filename);
}
}
HttpClient 是 Apache Jakarta Common 下的一个子项目。提供高效、最新且功能丰富的客户端编程工具包,支持 HTTP 协议
public static void downloadHtmlByNet(String SrcPath,String filePath,String fileName){
DefaultHttpClient httpClient=new DefaultHttpClient();//初始化httpclient
BasicHttpParams httpParams=new BasicHttpParams();//初始化参数<br />
//模拟浏览器访问防止屏蔽程序抓取而返回403错误<br />user_agent="Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 <br /><br />user_agent="Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)"
httpParams.setParameter("http.useragent", user_agent);
httpClient.setParams(httpParams);
try {
HttpGet httpGet=new HttpGet(SrcPath);
HttpContext httpContext=new BasicHttpContext();
HttpResponse httpResponse=httpClient.execute(httpGet,httpContext);
HttpEntity entity=httpResponse.getEntity();
if(entity!=null){
writeToFile(entity,filePath,fileName);//将entity内容输出到文件
}
} catch (ClientProtocolException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
finally {
httpClient.getConnectionManager().shutdown();
}
}
private static void writeToFile(HttpEntity entity, String filepath, String filename) {
//输出流
try{
InputStream str = entity.getContent();
//控制流的大小为1k
byte[] bs = new byte[1024];
//读取到的长度
int len = 0;
//是否需要创建文件夹
File saveDir = new File(filePath);
if(!saveDir.exists())
{
saveDir.mkdir();
}
File file = new File(saveDir+File.separator+fileName);
//实例输出一个对象
FileOutputStream out = new FileOutputStream(file);
//循环判断,如果读取的个数b为空了,则is.read()方法返回-1,具体请参考InputStream的read();
while ((len = str.read(bs)) != -1) {
//将对象写入到对应的文件中
out.write(bs, 0, len);
}
//刷新流
out.flush();
//关闭流
out.close();
str.close();
System.out.println("下载成功");
}
catch(Exception e){
e.printStackTrace();
}
}
唉,我以前忘记了,所以了解更多并记住,下次我使用该帖子获取有用的数据。
c httpclient抓取网页( httpClient怎样获取网页中js执行完后的网页源码(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-14 22:18
httpClient怎样获取网页中js执行完后的网页源码(图))
网页中httpClient如何获取js执行后的网页源码 httpClient如何获取网页中js执行后的网页源码 源码是静态的,可以全部爬取,但是如果源码代码收录jshttpClient,捕获的源代码不收录js获取的源代码不正确。在网页中执行js后如何获取网页的源代码?比如得到的网页源码可以在论坛上看到解决方案建设计划建设计划实例结构建设计划营销计划计划模板建设组织设计(建设计划)就是调用一个浏览器组件来完成这个东西。 js执行后,取其内容以及如何实现。请大家指导 --- ---最佳解决方案------------------------------------ ------ -------------单独httpclient是做不到的,只能抓取最原创的数据------其他解决办法------- -- ----------------------------------------------------------httpClient抓取到服务端的输出是js执行后的最终结果吗?其他解决方案-------------------------- ---------------------- --------比如我想抓取qq邮箱首页的源码,只获取下面一小段htmlheadmetahttp -equivrefreshcontent0urlcgi-binloginpageheadhtml------其他解决办法------ ------------------------------- -----------我也在找资料获取js分页页面的数据,但是没有其他解决办法------------------------------ ---------------------------- 这是一个单靠httpclient是做不到的引述。只能抓到最原创的数据------其他解决办法---------------------------- ------------------------尝试使用 htmlunit------其他解决方案方案-------------- ---------------------------------
---------单靠httpclient是做不到的。只能捕捉到的是最原创的数据,那我该怎么办?你能给我一些想法吗~~~其他解决方案----------------------------------- ------------- --------最近我用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取,但是如果源代码中收录jshttpClient,则抓取的源代码不收录js获取的源代码是不正确的。如何获取网页中间js执行后的网页源码。例如,获取的网页的源代码是在论坛上看到的。解决办法就是调用一个浏览器组件来完成这件事情。 js执行后,取其内容。能不能交流一下,给点思路~~--------其他解决办法-------------------------------- ------------------------ 主机为什么没有出现?乘法题,口算题,100题,七年级有理数混合运算,100题,计算机一级题库,二元线性方程组单词题真与假刺激问题解决了吗?我也遇到过这样的问题,求教~------其他解决办法-------------------------- ---------------尝试在浏览器中另存为网页----- -其他解决方案----- ---------------------------------- ----------原文请赐教-- ----其他解决方案---------------------------- ---------------- ------------您只能手动保存。太费力了,也不科学。我们要获取的是live值,可以读出js中的内容,目前的情况是请求会来自没有js内容的数据。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题或者谁可以解决这个问题。钱雇人--其他解决办法--------------------其他解决办法--------------------只能是手动保存作为参考。这是非常不科学的。我们要获取的是live值,可以读取js中的内容。现在出现的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以用js做数据?我真的很想知道这个问题或者谁可以解决这个问题。你准备付多少钱?我会给你发一封电子邮件,要钱 geogreno1gmailcom 查看全部
c httpclient抓取网页(
httpClient怎样获取网页中js执行完后的网页源码(图))
网页中httpClient如何获取js执行后的网页源码 httpClient如何获取网页中js执行后的网页源码 源码是静态的,可以全部爬取,但是如果源码代码收录jshttpClient,捕获的源代码不收录js获取的源代码不正确。在网页中执行js后如何获取网页的源代码?比如得到的网页源码可以在论坛上看到解决方案建设计划建设计划实例结构建设计划营销计划计划模板建设组织设计(建设计划)就是调用一个浏览器组件来完成这个东西。 js执行后,取其内容以及如何实现。请大家指导 --- ---最佳解决方案------------------------------------ ------ -------------单独httpclient是做不到的,只能抓取最原创的数据------其他解决办法------- -- ----------------------------------------------------------httpClient抓取到服务端的输出是js执行后的最终结果吗?其他解决方案-------------------------- ---------------------- --------比如我想抓取qq邮箱首页的源码,只获取下面一小段htmlheadmetahttp -equivrefreshcontent0urlcgi-binloginpageheadhtml------其他解决办法------ ------------------------------- -----------我也在找资料获取js分页页面的数据,但是没有其他解决办法------------------------------ ---------------------------- 这是一个单靠httpclient是做不到的引述。只能抓到最原创的数据------其他解决办法---------------------------- ------------------------尝试使用 htmlunit------其他解决方案方案-------------- ---------------------------------
---------单靠httpclient是做不到的。只能捕捉到的是最原创的数据,那我该怎么办?你能给我一些想法吗~~~其他解决方案----------------------------------- ------------- --------最近我用httpClient抓取网页源码的时候,如果源码是静态的,可以全部抓取,但是如果源代码中收录jshttpClient,则抓取的源代码不收录js获取的源代码是不正确的。如何获取网页中间js执行后的网页源码。例如,获取的网页的源代码是在论坛上看到的。解决办法就是调用一个浏览器组件来完成这件事情。 js执行后,取其内容。能不能交流一下,给点思路~~--------其他解决办法-------------------------------- ------------------------ 主机为什么没有出现?乘法题,口算题,100题,七年级有理数混合运算,100题,计算机一级题库,二元线性方程组单词题真与假刺激问题解决了吗?我也遇到过这样的问题,求教~------其他解决办法-------------------------- ---------------尝试在浏览器中另存为网页----- -其他解决方案----- ---------------------------------- ----------原文请赐教-- ----其他解决方案---------------------------- ---------------- ------------您只能手动保存。太费力了,也不科学。我们要获取的是live值,可以读出js中的内容,目前的情况是请求会来自没有js内容的数据。其他数据根本没用。什么方法可以制作js数据?我真的很想知道这个问题或者谁可以解决这个问题。钱雇人--其他解决办法--------------------其他解决办法--------------------只能是手动保存作为参考。这是非常不科学的。我们要获取的是live值,可以读取js中的内容。现在出现的情况是请求的数据不会有js的内容。其他数据根本没用。什么方法可以用js做数据?我真的很想知道这个问题或者谁可以解决这个问题。你准备付多少钱?我会给你发一封电子邮件,要钱 geogreno1gmailcom
c httpclient抓取网页(为GET和POST请求添加请求参数和请求头(使用HttpClient) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-09-14 07:18
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。 “Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明加载晚了。
2. 尝试在文中搜索关键字,看看是请求哪些文件来获取数据。例如,在文本中搜索第一个词“海关总署”时,可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建一个 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包见下图:
代码如下,我只拿到了文章的正文:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup 学习总结
1.maven 项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2.Code 部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---标题的值属性。这里只贴出纯文本部分输出结果)
查看全部
c httpclient抓取网页(为GET和POST请求添加请求参数和请求头(使用HttpClient)
)
缺点是需要手动查找post请求的url和对应的参数。
参考:
1.为GET和POST请求添加请求参数和请求头(使用HttpClient,Java)
2.关于抓取js加载的内容(参考博客流程,比如找到实际的请求url)
以一条新闻为例:
1.使用F12,先在网络文件列表中找到网页,双击弹出详细信息。 “Body”查看了网页内容,发现网页上没有显示该信息对应的信息,说明加载晚了。
2. 尝试在文中搜索关键字,看看是请求哪些文件来获取数据。例如,在文本中搜索第一个词“海关总署”时,可能会发现多个文件,需要判断和选择。
对应的请求体为“id:98212”,即请求参数
3.查看“标题”
主要取决于请求url和请求方式,有时需要设置user-agent。需要使用post方法
4.代码编写
创建一个 Java Maven 项目并添加依赖项:
org.apache.httpcomponents
httpclient
4.5.6
com.google.code.gson
gson
2.2.4
下载的jar包见下图:
代码如下,我只拿到了文章的正文:
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import com.google.gson.Gson;
/**
* http://news.cqcoal.com/blank/nc.jsp?mid=98212
* 该网页的新闻主题是动态生成的,希望获取内容
* @author yangc_cong
*
*/
public class TestNewContent {
/**
* 针对请求的链接,使用post方法获取返回的数据
* @param urlStr String类型
* @return 这里是Map类型
*/
private Map getPageContByHttpCl(String urlStr) {
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpPost post = new HttpPost(urlStr);
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362";
post.setHeader("User-Agent", userAgent);
CloseableHttpResponse response = null;
String result = null;
// 创建请求参数
List list = new LinkedList();
BasicNameValuePair param1 = new BasicNameValuePair("id", "98212");
list.add(param1);
// 使用URL实体转换工具
UrlEncodedFormEntity entityParam = null;
try {
entityParam = new UrlEncodedFormEntity(list, "UTF-8");
post.setEntity(entityParam);
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
try {
response = httpclient.execute(post);
HttpEntity entity = response.getEntity();
result = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
response.close();
httpclient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println(result);
Gson gson = new Gson();
Map map = gson.fromJson(result, Map.class);
return map;
}
private void parse_content(Map map) {
//java.lang.ClassCastException: java.util.ArrayList cannot be cast to java.util.Map
ArrayList arrayList = (ArrayList)(map.get("rows"));
Map innerMap = (Map) arrayList.get(0);
String source = (String) innerMap.get("source");
String bodyhtml = (String) innerMap.get("body");
System.out.println("source: "+source);
System.out.println("bodyhtml:"+'\n'+bodyhtml);
}
public static void main(String[] args) {
TestNewContent test1 = new TestNewContent();
String urlStr = "http://news.cqcoal.com/manage/ ... 3B%3B
Map map = test1.getPageContByHttpCl(urlStr);
test1.parse_content(map);
}
}
运行截图:
补充:使用HtmlUnit抓取网页动态加载的body部分(一个简单的应用)
参考:HtmlUnit+Jsoup 学习总结
1.maven 项目中的配置
net.sourceforge.htmlunit
htmlunit
2.27
下载的jar包如下,有很多,所以建议使用maven进行配置:
2.Code 部分(根据参考博客写的)
import java.io.IOException;
import java.net.MalformedURLException;
import com.gargoylesoftware.htmlunit.BrowserVersion;
import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException;
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
public class HtmlUnitTest {
public static void main(String[] args) {
String url ="http://www.qidian.com";
url = "http://news.cqcoal.com/blank/n ... 3B%3B
// 1创建WebClient
WebClient webClient=new WebClient(BrowserVersion.CHROME);
// 2 启动JS
webClient.getOptions().setJavaScriptEnabled(true);
// 3 禁用Css,可避免自动二次請求CSS进行渲染
webClient.getOptions().setCssEnabled(false);
// 4 启动客戶端重定向
webClient.getOptions().setRedirectEnabled(true);
// 5 js运行错誤時,是否拋出异常
webClient.getOptions().setThrowExceptionOnScriptError(false);
// 6 设置超时
webClient.getOptions().setTimeout(50000); //获取网页
HtmlPage htmlPage = null;
try {
htmlPage = webClient.getPage(url);
} catch (FailingHttpStatusCodeException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (MalformedURLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 等待JS驱动dom完成获得还原后的网页
webClient.waitForBackgroundJavaScript(10000);
// 网页内容
String pageHtml = htmlPage.asXml();
System.out.println(pageHtml);
System.out.println("\n------\n");
//网页内容---纯文本形式
String pageText = htmlPage.asText();
System.out.println(pageText );
//输出网页的title
String title = htmlPage.getTitleText();
System.out.println(title );
//close
webClient.close();
}
}
3.运行结果(代码需要加载js后输出,收录标签的网页内容,纯文本---网页的文本部分,网页的标题---标题的值属性。这里只贴出纯文本部分输出结果)
c httpclient抓取网页(STM32 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-09-14 04:03
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/");
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com");
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
} 查看全部
c httpclient抓取网页(STM32
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/";);
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com";);
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
c httpclient抓取网页(STM32 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-09-10 20:03
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/");
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com");
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
} 查看全部
c httpclient抓取网页(STM32
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com/";);
try {
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
}
// 读取内容
byte[] responseBody = getMethod.getResponseBody();
// 处理内容
String html = new String(responseBody);
System.out.println(html);
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
2、Post 方法
HttpClient httpClient = new HttpClient();
PostMethod postMethod = new PostMethod(UrlPath);
postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
NameValuePair[] postData = new NameValuePair[2];
postData[0] = new NameValuePair("username", "xkey");
postData[1] = new NameValuePair("userpass", "********");
postMethod.setRequestBody(postData);
try {
int statusCode = httpClient.executeMethod(postMethod);
if (statusCode == HttpStatus.SC_OK) {
byte[] responseBody = postMethod.getResponseBody();
String html = new String(responseBody);
System.out.println(html);
}
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
postMethod.releaseConnection();
}
本例传递两个Post参数:username为xkey,userpass为*******,传递给URL UrlPath
如需了解获取gzip网页的信息,请参考
另一种是获取非字符数据,所以可以使用下面的方法
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod("http://www.baidu.com";);
try {
InputStream inputStream = getMethod.getResponseBodyAsStream();
// 这里处理 inputStream
} catch (Exception e) {
System.err.println("页面无法访问");
}finally{
getMethod.releaseConnection();
}
c httpclient抓取网页(做POST登陆程序,用httpclient得到登陆页面的时候出问题了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-08 22:16
我今天在做POST登录程序,使用httpclient获取登录页面时出现问题。页面代码如下:
< !DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> function setCookie(c_name, value, expiredays) { var exdate = new Date(); exdate.setDate(exdate.getDate()+expiredays); document.cookie = c_name + "=" + escape(value) + ((expiredays==null) ? "" : ";expires=" + exdate.toGMTString()) + ";path=/"; } function getHostUri() { var loc = document.location; return loc.toString(); } setCookie('YPF8827340282Jdskjhfiw_928937459182JAX666', '115.173.104.54', 10); setCookie('DOAReferrer', document.referrer, 10); location.href = getHostUri(); < body>< noscript>This site requires JavaScript and Cookies to be enabled. Please change your browser settings or upgrade your browser.
此站点需要启用 JavaScript 和 Cookie。请更改您的浏览器设置或升级您的浏览器。
一开始以为这句话是浏览器能检测到JS是否在运行,然后我的POST登录就不行了,只能考虑用IE插件来模拟登录了。
但是查了资料,有人说,“服务器无法判断你是否开启了JS,如果你判断一个cookie,它应该在首页给你发一个cookie,然后判断其他的是否有cookie页面,所以你必须从 COOKIE 开始,而不是用户代理”
现在放心了。这个解决方案还是很简单的。就是模拟JS,将页面代码中的COOKIE添加到httpclient,然后再次访问登录页面,得到正常代码。
问题终于解决了。它在于第一次捕获数据时返回的数据。根据资料,只要给HttpClient设置cookie,就可以再次捕获了。 查看全部
c httpclient抓取网页(做POST登陆程序,用httpclient得到登陆页面的时候出问题了)
我今天在做POST登录程序,使用httpclient获取登录页面时出现问题。页面代码如下:
< !DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd"> function setCookie(c_name, value, expiredays) { var exdate = new Date(); exdate.setDate(exdate.getDate()+expiredays); document.cookie = c_name + "=" + escape(value) + ((expiredays==null) ? "" : ";expires=" + exdate.toGMTString()) + ";path=/"; } function getHostUri() { var loc = document.location; return loc.toString(); } setCookie('YPF8827340282Jdskjhfiw_928937459182JAX666', '115.173.104.54', 10); setCookie('DOAReferrer', document.referrer, 10); location.href = getHostUri(); < body>< noscript>This site requires JavaScript and Cookies to be enabled. Please change your browser settings or upgrade your browser.
此站点需要启用 JavaScript 和 Cookie。请更改您的浏览器设置或升级您的浏览器。
一开始以为这句话是浏览器能检测到JS是否在运行,然后我的POST登录就不行了,只能考虑用IE插件来模拟登录了。
但是查了资料,有人说,“服务器无法判断你是否开启了JS,如果你判断一个cookie,它应该在首页给你发一个cookie,然后判断其他的是否有cookie页面,所以你必须从 COOKIE 开始,而不是用户代理”
现在放心了。这个解决方案还是很简单的。就是模拟JS,将页面代码中的COOKIE添加到httpclient,然后再次访问登录页面,得到正常代码。
问题终于解决了。它在于第一次捕获数据时返回的数据。根据资料,只要给HttpClient设置cookie,就可以再次捕获了。
c httpclient抓取网页(GET方法模拟抓取网页使用org.apache.HttpClient )
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-08 22:14
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、GET 方法模拟爬取网页
使用org.apache.HttpClient GET方法模拟登录网页并抓取数据,需要使用HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn");
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
二、模拟浏览器UA并返回状态
有些网页会给不同的浏览器提供不同的页面,或者限制机器抓取。这时候就需要设置UA来模拟浏览器登录页面,可以使用getStatusLine返回状态。
1、设置请求头的UA模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
2、返回状态
response.getStatusLine();//获取当前状态
如果只返回状态码(200)
response.getStatusLine().getStatusCode()
3、返回类型
确定链接的目标类型
entity.getContentType().getValue()
三、GET 带参数
使用URIBuilder构造一个URI,并设置参数,多个参数就是多个setParameters
URIBuilder uriBuilder=new URIBuilder("http://baidu.com");
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
使用build()方法转换为URI
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
带参数的完整代码
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URISyntaxException;
//带参数的get
public class HelloWordUA {
public static void main(String[] ars){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient= HttpClients.createDefault();
CloseableHttpResponse response=null;
HttpGet httpGet=null;
try {
URIBuilder uriBuilder=new URIBuilder("http://baidu.com");
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
System.out.println(uriBuilder.build());
//创建http Get请求
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
} catch (URISyntaxException e) {
e.printStackTrace();
}
//设置请求头,UA浏览器型号,模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
try {
response=httpClient.execute(httpGet);//执行
//获取当响应状态
// response.getStatusLine();//获取当前状态
//response.getStatusLine().getStatusCode() 获取当前状态码
System.out.println("Status:"+response.getStatusLine().getStatusCode());
//获取网页源码
HttpEntity entity=response.getEntity();//获取网页实体
//获取目标类型
System.out.println("ContentType:"+entity.getContentType().getValue());
System.out.println(EntityUtils.toString(entity,"UTF-8"));
} catch (IOException e) {
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
} 查看全部
c httpclient抓取网页(GET方法模拟抓取网页使用org.apache.HttpClient
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、GET 方法模拟爬取网页
使用org.apache.HttpClient GET方法模拟登录网页并抓取数据,需要使用HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn";);
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
二、模拟浏览器UA并返回状态
有些网页会给不同的浏览器提供不同的页面,或者限制机器抓取。这时候就需要设置UA来模拟浏览器登录页面,可以使用getStatusLine返回状态。
1、设置请求头的UA模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
2、返回状态
response.getStatusLine();//获取当前状态
如果只返回状态码(200)
response.getStatusLine().getStatusCode()
3、返回类型
确定链接的目标类型
entity.getContentType().getValue()
三、GET 带参数
使用URIBuilder构造一个URI,并设置参数,多个参数就是多个setParameters
URIBuilder uriBuilder=new URIBuilder("http://baidu.com";);
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
使用build()方法转换为URI
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
带参数的完整代码
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.URIBuilder;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.net.URISyntaxException;
//带参数的get
public class HelloWordUA {
public static void main(String[] ars){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient= HttpClients.createDefault();
CloseableHttpResponse response=null;
HttpGet httpGet=null;
try {
URIBuilder uriBuilder=new URIBuilder("http://baidu.com";);
//写入参数 (可以设置多参数)
uriBuilder.setParameter("key","JAVA");
uriBuilder.setParameter("keys","c#");
System.out.println(uriBuilder.build());
//创建http Get请求
httpGet=new HttpGet(uriBuilder.build());//使用builder写入URI
} catch (URISyntaxException e) {
e.printStackTrace();
}
//设置请求头,UA浏览器型号,模拟火狐浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0");
try {
response=httpClient.execute(httpGet);//执行
//获取当响应状态
// response.getStatusLine();//获取当前状态
//response.getStatusLine().getStatusCode() 获取当前状态码
System.out.println("Status:"+response.getStatusLine().getStatusCode());
//获取网页源码
HttpEntity entity=response.getEntity();//获取网页实体
//获取目标类型
System.out.println("ContentType:"+entity.getContentType().getValue());
System.out.println(EntityUtils.toString(entity,"UTF-8"));
} catch (IOException e) {
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}

