
c httpclient抓取网页
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-29 08:16
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
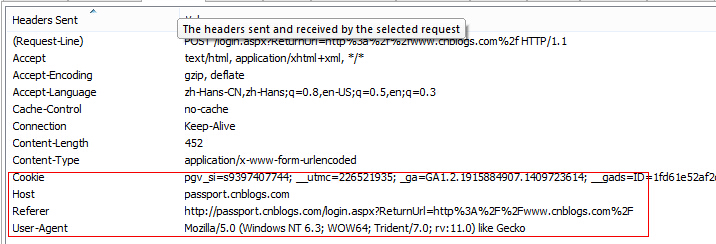
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/");
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 } 查看全部
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦!
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
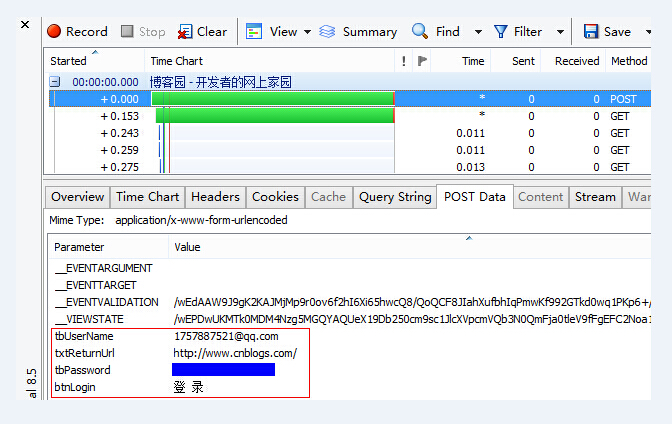
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/";);
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 }
c httpclient抓取网页(模拟网站的登录请求:最简单的方法是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-20 21:01
您应该模拟 网站 的登录过程。最简单的方法是通过一些调试器(例如 Fiddler)检查 网站。
这是 网站 的登录请求:
POST https://members.morningstar.co ... me%3D HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Referer: https://members.morningstar.co ... .aspx ** omitted ** Cookie: cookies=true; TestCookieExist=Exist; fp=001140581745182496; __utma=172984700.91600904.1405817457.1405817457.1405817457.1; __utmb=172984700.8.10.1405817457; __utmz=172984700.1405817457.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=172984700; ASP.NET_SessionId=b5bpepm3pftgoz55to3ql4me email_textbox=test@email.com&pwd_textbox=password&remember=on&email_textbox2=&go_button.x=36&go_button.y=16&__LASTFOCUS=&__EVENTTARGET=&__EVENTARGUMENT=&__VIEWSTATE=omitted&__EVENTVALIDATION=omited
检查时,您会看到一些 cookie 和表单字段,例如“__VIEWSTATE”。您需要该字段的实际值才能登录。您可以使用以下步骤:
发出请求并丢弃“__LASTFOCUS”、“__EVENTTARGET”、“_ _EVENTARGUMENT”、“_ _ _ JSTENT”、“_ _EVVALIDATION”等字段;和饼干。使用上一个中的 CookieContainer 在同一页面上创建一个新的 POST 请求;使用废弃字段、用户名和密码构建帖子字符串。使用 MIME 类型 application/x-www-form-urlencoded。如果成功,则使用 cookie 保持登录状态以获取更多请求。
注意:您可以使用 htmlagilitypack 或 scrapysharp 来报废 html。ScrapySharp 为表单发布表单和浏览 网站 提供了易于使用的工具。
mental is process 是模拟一个人在 网站 上登录,一些登录是使用 AJAX 或传统的 POST 请求完成的,所以,你做的第一件事就是像浏览器一样的请求,在服务器响应中,你会获取 cookie、标头和其他信息,您需要使用这些信息来构建一个新请求,这是一个冗长的请求。
步骤是:
1)像浏览器一样构建请求以向应用程序验证自身。2)检查响应,并保存标头、cookie 或其他有用信息以保持与服务器的会话。3)使用从第二步采集的信息向服务器发出另一个请求。4)检查响应并使用数据分析算法或其他东西来提取数据。
暗示:
你这里没有使用 javascript 引擎,一些 网站 使用 javascript 来显示图形,或者在 DOM 文档中执行一些交互。在这种情况下,您可能需要使用 WebKit lib 包装器。
以上是C#学习教程:使用C#HttpClient登录网站,从另一个页面抓取信息分享的全部内容。如果对你有用,需要进一步了解C#学习教程,希望你多多关注——猴子科技屋() 查看全部
c httpclient抓取网页(模拟网站的登录请求:最简单的方法是什么?)
您应该模拟 网站 的登录过程。最简单的方法是通过一些调试器(例如 Fiddler)检查 网站。
这是 网站 的登录请求:
POST https://members.morningstar.co ... me%3D HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Referer: https://members.morningstar.co ... .aspx ** omitted ** Cookie: cookies=true; TestCookieExist=Exist; fp=001140581745182496; __utma=172984700.91600904.1405817457.1405817457.1405817457.1; __utmb=172984700.8.10.1405817457; __utmz=172984700.1405817457.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=172984700; ASP.NET_SessionId=b5bpepm3pftgoz55to3ql4me email_textbox=test@email.com&pwd_textbox=password&remember=on&email_textbox2=&go_button.x=36&go_button.y=16&__LASTFOCUS=&__EVENTTARGET=&__EVENTARGUMENT=&__VIEWSTATE=omitted&__EVENTVALIDATION=omited
检查时,您会看到一些 cookie 和表单字段,例如“__VIEWSTATE”。您需要该字段的实际值才能登录。您可以使用以下步骤:
发出请求并丢弃“__LASTFOCUS”、“__EVENTTARGET”、“_ _EVENTARGUMENT”、“_ _ _ JSTENT”、“_ _EVVALIDATION”等字段;和饼干。使用上一个中的 CookieContainer 在同一页面上创建一个新的 POST 请求;使用废弃字段、用户名和密码构建帖子字符串。使用 MIME 类型 application/x-www-form-urlencoded。如果成功,则使用 cookie 保持登录状态以获取更多请求。
注意:您可以使用 htmlagilitypack 或 scrapysharp 来报废 html。ScrapySharp 为表单发布表单和浏览 网站 提供了易于使用的工具。
mental is process 是模拟一个人在 网站 上登录,一些登录是使用 AJAX 或传统的 POST 请求完成的,所以,你做的第一件事就是像浏览器一样的请求,在服务器响应中,你会获取 cookie、标头和其他信息,您需要使用这些信息来构建一个新请求,这是一个冗长的请求。
步骤是:
1)像浏览器一样构建请求以向应用程序验证自身。2)检查响应,并保存标头、cookie 或其他有用信息以保持与服务器的会话。3)使用从第二步采集的信息向服务器发出另一个请求。4)检查响应并使用数据分析算法或其他东西来提取数据。
暗示:
你这里没有使用 javascript 引擎,一些 网站 使用 javascript 来显示图形,或者在 DOM 文档中执行一些交互。在这种情况下,您可能需要使用 WebKit lib 包装器。
以上是C#学习教程:使用C#HttpClient登录网站,从另一个页面抓取信息分享的全部内容。如果对你有用,需要进一步了解C#学习教程,希望你多多关注——猴子科技屋()
c httpclient抓取网页( 一个基于JAVA的知乎爬虫,抓取90W+用户信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-18 18:11
一个基于JAVA的知乎爬虫,抓取90W+用户信息
)
Java实现爬取知乎用户基本信息
更新时间:2016-05-24 16:24:45 作者:卧燕无语
本文章主要介绍了一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下
本文示例分享一个基于JAVA的知乎爬虫,抓取知乎用户的基本信息,基于HttpClient4.5,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户在里面)
大概的概念:
1.先模拟登录知乎,登录成功后将cookie序列化到磁盘,以后不需要每次都登录(如果不模拟登录,就是也可以直接从浏览器插入 cookie)。
2.创建两个线程池和一个Storage。用于抓取网页的线程池,负责执行请求请求,返回网页内容,存储在Storage中。另一个是解析网页线程池,负责从Storage中提取和解析网页内容,解析用户数据并存入数据库,解析用户关注人的主页,并将地址请求加入到爬取中网页线程池。继续循环。
3. 关于url去重,我直接把访问过的链接md5存入数据库。每次访问前,检查数据库中是否存在链接。
到目前为止,已经捕获了 100W 用户,访问了 220W+ 链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户基本应该被抓到。
项目地址:
实现代码:
作者:卧颜沉默
链接:https://www.zhihu.com/question ... 43000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
/**
*
* @param httpClient Http客户端
* @param context Http上下文
* @return
*/
public boolean login(CloseableHttpClient httpClient, HttpClientContext context){
String yzm = null;
String loginState = null;
HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin");
HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false);
HttpPost request = new HttpPost("https://www.zhihu.com/login/email");
List formParams = new ArrayList();
yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login");//肉眼识别验证码
formParams.add(new BasicNameValuePair("captcha", yzm));
formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用
formParams.add(new BasicNameValuePair("email", "邮箱"));
formParams.add(new BasicNameValuePair("password", "密码"));
formParams.add(new BasicNameValuePair("remember_me", "true"));
UrlEncodedFormEntity entity = null;
try {
entity = new UrlEncodedFormEntity(formParams, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
request.setEntity(entity);
loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录
JSONObject jo = new JSONObject(loginState);
if(jo.get("r").toString().equals("0")){
System.out.println("登录成功");
getRequest = new HttpGet("https://www.zhihu.com");
HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页
HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录
return true;
}else{
System.out.println("登录失败" + loginState);
return false;
}
}
/**
* 肉眼识别验证码
* @param httpClient Http客户端
* @param context Http上下文
* @param url 验证码地址
* @return
*/
public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){
HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true);
Scanner sc = new Scanner(System.in);
String yzm = sc.nextLine();
return yzm;
}
效果图:
查看全部
c httpclient抓取网页(
一个基于JAVA的知乎爬虫,抓取90W+用户信息
)
Java实现爬取知乎用户基本信息
更新时间:2016-05-24 16:24:45 作者:卧燕无语
本文章主要介绍了一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下
本文示例分享一个基于JAVA的知乎爬虫,抓取知乎用户的基本信息,基于HttpClient4.5,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户在里面)
大概的概念:
1.先模拟登录知乎,登录成功后将cookie序列化到磁盘,以后不需要每次都登录(如果不模拟登录,就是也可以直接从浏览器插入 cookie)。
2.创建两个线程池和一个Storage。用于抓取网页的线程池,负责执行请求请求,返回网页内容,存储在Storage中。另一个是解析网页线程池,负责从Storage中提取和解析网页内容,解析用户数据并存入数据库,解析用户关注人的主页,并将地址请求加入到爬取中网页线程池。继续循环。
3. 关于url去重,我直接把访问过的链接md5存入数据库。每次访问前,检查数据库中是否存在链接。
到目前为止,已经捕获了 100W 用户,访问了 220W+ 链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户基本应该被抓到。
项目地址:
实现代码:
作者:卧颜沉默
链接:https://www.zhihu.com/question ... 43000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
/**
*
* @param httpClient Http客户端
* @param context Http上下文
* @return
*/
public boolean login(CloseableHttpClient httpClient, HttpClientContext context){
String yzm = null;
String loginState = null;
HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin";);
HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false);
HttpPost request = new HttpPost("https://www.zhihu.com/login/email";);
List formParams = new ArrayList();
yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login";);//肉眼识别验证码
formParams.add(new BasicNameValuePair("captcha", yzm));
formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用
formParams.add(new BasicNameValuePair("email", "邮箱"));
formParams.add(new BasicNameValuePair("password", "密码"));
formParams.add(new BasicNameValuePair("remember_me", "true"));
UrlEncodedFormEntity entity = null;
try {
entity = new UrlEncodedFormEntity(formParams, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
request.setEntity(entity);
loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录
JSONObject jo = new JSONObject(loginState);
if(jo.get("r").toString().equals("0")){
System.out.println("登录成功");
getRequest = new HttpGet("https://www.zhihu.com";);
HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页
HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录
return true;
}else{
System.out.println("登录失败" + loginState);
return false;
}
}
/**
* 肉眼识别验证码
* @param httpClient Http客户端
* @param context Http上下文
* @param url 验证码地址
* @return
*/
public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){
HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true);
Scanner sc = new Scanner(System.in);
String yzm = sc.nextLine();
return yzm;
}
效果图:


c httpclient抓取网页(如何实现一下抢票软件的第一步库的相关知识? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-15 23:05
)
最近想了解一下抢票软件的实现流程,于是开始晚上搜集资料。通过对众多数据的综合分析,发现大部分都是通过httpclient连接网络的。所以,作为实现抢票软件的第一步,有必要对httpclient库的相关知识有一个详细的了解。
无论是网络爬虫还是抢票软件,首先需要做的就是能够获取到的网页的代码。只有这样,才能进行后续的搜索和筛选工作。httpclient最基本的连接过程就是通过httpclient执行httpGet或httpPost方法,等到网站返回保存在httpResponse中,从中提取httpEntity获取网页数据。
<p>import java.io.*;
import java.util.regex.*;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHeader;
public class my12306Test {
public static void main(String[] args)throws Exception
{
// TODO Auto-generated method stub
connection();
}
/*
* 此方法用来实现对于网页数据的下载并存储在本地;
* 解决的问题:
* 1、连接网站下载网页前端代码;
* 2、不同网站的代码使用不同的编码方式,需要在读取时使用相应的字符编码格式;
* 3、在读取编码格式时,需要用到从网页的代码中利用正则表达式抓取charest这个编码格式属性的信息;
* */
public static void connection()throws Exception
{
//建立httpclient对象连接
HttpClient client = new DefaultHttpClient();
//使用get方法访问相关网站
HttpGet get =new HttpGet("http://www.taobao.com");
//执行get方法,获取网站响应;
HttpResponse response = client.execute(get);
//得到网站响应实体并读取信息
HttpEntity entity = response.getEntity();
InputStream input = entity.getContent();
//BasicHeader getHeader =(BasicHeader) entity.getContentEncoding();
//显示网站响应头的信息
System.out.println(response.getStatusLine().getStatusCode());
System.out.println("Response content length: " + entity.getContentLength());
System.out.println("content-type:" +entity.getContentType().getValue());
System.out.println("getMehod::"+get.getMethod());//显示请求的方法名
System.out.println("getCountry::"+response.getLocale().getDefault());//getDisplayCountry());
/*
* 1、读取网站代码,输入流信息用于getCharest函数提取字符编码信息
* 2、利用getCharest函数从网站的头或者代码中获取网站字符编码规则
* */
BufferedReader bufrBuf = new BufferedReader(new InputStreamReader(input));
BufferedWriter bufw = new BufferedWriter(new FileWriter("bufJD.html"));
String charest = getChrest(bufrBuf,entity.getContentType().getValue());
//若果得到的是UTF编码,则还需要规范其的名称
if(charest.equals("utf"))
{
System.out.println("out:"+charest);
charest="utf-8";
}
//System.out.println("out::"+charest);
//这个输入流用于读取并用于后面将其存入外部存储中,这里用到了返回的编码信息,已保证中文不会出现乱码的情况。
BufferedReader bufr =new BufferedReader(new InputStreamReader(input,charest));
String buf =null;
while((buf=bufr.readLine())!=null)
{
bufw.write(buf);
bufw.newLine();
//System.out.println(buf);
}
//bufw.close();
//bufr.close();
}
/*
* 在写入12306网站时遇到了一个问题,就是sohu等网站使用的是zh-cn方式进行编码,而12306则采用的是UTF-8作为编码方式,因此必须在写入前将指出其的编码方式。
* 目前的代码使用的还是手动在代码上进行修改,需要专门写一个函数能够自动识别网页的编码方式并返回响应的编码方式;
* */
public static String getChrest(BufferedReader bufr,String Head)throws Exception
{
BufferedWriter bufw = new BufferedWriter(new FileWriter("buf1.html"));
//如果Head代码中拥有字符编码信息,则提取出来,这样就可以提前返回,不用读取后面的entity信息。
/*
* 在head中,只有字符编码信息才有=,因此利用这个规律判断是否有字符编码信息,并且将其分割,取最后一个就是编码规则。
* */
if(Head.contains("="))
{
String[] headString=Head.split("=");
for(int i=0;i 查看全部
c httpclient抓取网页(如何实现一下抢票软件的第一步库的相关知识?
)
最近想了解一下抢票软件的实现流程,于是开始晚上搜集资料。通过对众多数据的综合分析,发现大部分都是通过httpclient连接网络的。所以,作为实现抢票软件的第一步,有必要对httpclient库的相关知识有一个详细的了解。
无论是网络爬虫还是抢票软件,首先需要做的就是能够获取到的网页的代码。只有这样,才能进行后续的搜索和筛选工作。httpclient最基本的连接过程就是通过httpclient执行httpGet或httpPost方法,等到网站返回保存在httpResponse中,从中提取httpEntity获取网页数据。
<p>import java.io.*;
import java.util.regex.*;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHeader;
public class my12306Test {
public static void main(String[] args)throws Exception
{
// TODO Auto-generated method stub
connection();
}
/*
* 此方法用来实现对于网页数据的下载并存储在本地;
* 解决的问题:
* 1、连接网站下载网页前端代码;
* 2、不同网站的代码使用不同的编码方式,需要在读取时使用相应的字符编码格式;
* 3、在读取编码格式时,需要用到从网页的代码中利用正则表达式抓取charest这个编码格式属性的信息;
* */
public static void connection()throws Exception
{
//建立httpclient对象连接
HttpClient client = new DefaultHttpClient();
//使用get方法访问相关网站
HttpGet get =new HttpGet("http://www.taobao.com";);
//执行get方法,获取网站响应;
HttpResponse response = client.execute(get);
//得到网站响应实体并读取信息
HttpEntity entity = response.getEntity();
InputStream input = entity.getContent();
//BasicHeader getHeader =(BasicHeader) entity.getContentEncoding();
//显示网站响应头的信息
System.out.println(response.getStatusLine().getStatusCode());
System.out.println("Response content length: " + entity.getContentLength());
System.out.println("content-type:" +entity.getContentType().getValue());
System.out.println("getMehod::"+get.getMethod());//显示请求的方法名
System.out.println("getCountry::"+response.getLocale().getDefault());//getDisplayCountry());
/*
* 1、读取网站代码,输入流信息用于getCharest函数提取字符编码信息
* 2、利用getCharest函数从网站的头或者代码中获取网站字符编码规则
* */
BufferedReader bufrBuf = new BufferedReader(new InputStreamReader(input));
BufferedWriter bufw = new BufferedWriter(new FileWriter("bufJD.html"));
String charest = getChrest(bufrBuf,entity.getContentType().getValue());
//若果得到的是UTF编码,则还需要规范其的名称
if(charest.equals("utf"))
{
System.out.println("out:"+charest);
charest="utf-8";
}
//System.out.println("out::"+charest);
//这个输入流用于读取并用于后面将其存入外部存储中,这里用到了返回的编码信息,已保证中文不会出现乱码的情况。
BufferedReader bufr =new BufferedReader(new InputStreamReader(input,charest));
String buf =null;
while((buf=bufr.readLine())!=null)
{
bufw.write(buf);
bufw.newLine();
//System.out.println(buf);
}
//bufw.close();
//bufr.close();
}
/*
* 在写入12306网站时遇到了一个问题,就是sohu等网站使用的是zh-cn方式进行编码,而12306则采用的是UTF-8作为编码方式,因此必须在写入前将指出其的编码方式。
* 目前的代码使用的还是手动在代码上进行修改,需要专门写一个函数能够自动识别网页的编码方式并返回响应的编码方式;
* */
public static String getChrest(BufferedReader bufr,String Head)throws Exception
{
BufferedWriter bufw = new BufferedWriter(new FileWriter("buf1.html"));
//如果Head代码中拥有字符编码信息,则提取出来,这样就可以提前返回,不用读取后面的entity信息。
/*
* 在head中,只有字符编码信息才有=,因此利用这个规律判断是否有字符编码信息,并且将其分割,取最后一个就是编码规则。
* */
if(Head.contains("="))
{
String[] headString=Head.split("=");
for(int i=0;i
c httpclient抓取网页(添加头部Cookie进行模拟登录的两种方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 12:22
在网络爬虫中,我们经常需要设置一些头信息,这样我们的网络爬取行为就更像是使用浏览器浏览网页,而我们有时需要正确设置头信息才能得到正确的数据,否则就有了信息可用的页面可能与浏览器显示的页面不同。
设置header也可以模拟登录。我们可以设置cookies来获取登录页面并获取我们需要的数据。
接下来我会讲两种模拟登录的方式。
为模拟登录添加标头 cookie
代码显示如下:
import org.apache.http.Header;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import static java.lang.System.out;
/**
* Created by paranoid on 17-3-26.
*/
public class HttpClientDemo {
public static void main(String[] args){
//创建客户端
CloseableHttpClient closeableHttpClient = HttpClients.createDefault();
//创建请求Get实例
HttpGet httpGet = new HttpGet("https://www.baidu.com");
//设置头部信息进行模拟登录(添加登录后的Cookie)
httpGet.setHeader("Accept", "text/html,application/xhtml+xml," +
"application/xml;q=0.9,image/webp,*/*;q=0.8");
httpGet.setHeader("Accept-Encoding", "gzip, deflate, sdch, br");
httpGet.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
//httpGet.setHeader("Cookie", ".......");
httpGet.setHeader("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36" +
" (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
try {
//客户端执行httpGet方法,返回响应
CloseableHttpResponse closeableHttpResponse = closeableHttpClient.execute(httpGet);
//得到服务响应状态码
if (closeableHttpResponse.getStatusLine().getStatusCode() == 200) {
//打印所有响应头
Header[] headers = closeableHttpResponse.getAllHeaders();
for (Header header : headers) {
out.println(header.getName() + ": " + header.getValue());
}
}
else {
//如果是其他状态码则做其他处理
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
httpClient.close();
}
}
}
只要在上面的代码中添加登录cookie,就可以进行模拟登录。至于为什么添加cookie后可以进行模拟登录,大家可以在百度上搜索一下cookie的机制和作用,相信你就明白了。
以上参数可以在chrome的开发者工具中获取。Cookie是您手动登录后生成的,您也可以获取。设置这些参数后,我们模拟浏览器的行为和模拟登录。
您可以将不添加cookie的结果与添加cookie后的结果进行比较,您会发现模拟登录确实是可以的。
接下来,我们将讨论另一种实现模拟登录的方法,这种方法比较麻烦并且有一定的局限性(验证码),但它是最常用的。选择哪种模拟登录方式,有项目需求的时候就懂了~ 查看全部
c httpclient抓取网页(添加头部Cookie进行模拟登录的两种方法-乐题库)
在网络爬虫中,我们经常需要设置一些头信息,这样我们的网络爬取行为就更像是使用浏览器浏览网页,而我们有时需要正确设置头信息才能得到正确的数据,否则就有了信息可用的页面可能与浏览器显示的页面不同。
设置header也可以模拟登录。我们可以设置cookies来获取登录页面并获取我们需要的数据。
接下来我会讲两种模拟登录的方式。
为模拟登录添加标头 cookie
代码显示如下:
import org.apache.http.Header;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import static java.lang.System.out;
/**
* Created by paranoid on 17-3-26.
*/
public class HttpClientDemo {
public static void main(String[] args){
//创建客户端
CloseableHttpClient closeableHttpClient = HttpClients.createDefault();
//创建请求Get实例
HttpGet httpGet = new HttpGet("https://www.baidu.com";);
//设置头部信息进行模拟登录(添加登录后的Cookie)
httpGet.setHeader("Accept", "text/html,application/xhtml+xml," +
"application/xml;q=0.9,image/webp,*/*;q=0.8");
httpGet.setHeader("Accept-Encoding", "gzip, deflate, sdch, br");
httpGet.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
//httpGet.setHeader("Cookie", ".......");
httpGet.setHeader("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36" +
" (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
try {
//客户端执行httpGet方法,返回响应
CloseableHttpResponse closeableHttpResponse = closeableHttpClient.execute(httpGet);
//得到服务响应状态码
if (closeableHttpResponse.getStatusLine().getStatusCode() == 200) {
//打印所有响应头
Header[] headers = closeableHttpResponse.getAllHeaders();
for (Header header : headers) {
out.println(header.getName() + ": " + header.getValue());
}
}
else {
//如果是其他状态码则做其他处理
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
httpClient.close();
}
}
}
只要在上面的代码中添加登录cookie,就可以进行模拟登录。至于为什么添加cookie后可以进行模拟登录,大家可以在百度上搜索一下cookie的机制和作用,相信你就明白了。
以上参数可以在chrome的开发者工具中获取。Cookie是您手动登录后生成的,您也可以获取。设置这些参数后,我们模拟浏览器的行为和模拟登录。
您可以将不添加cookie的结果与添加cookie后的结果进行比较,您会发现模拟登录确实是可以的。
接下来,我们将讨论另一种实现模拟登录的方法,这种方法比较麻烦并且有一定的局限性(验证码),但它是最常用的。选择哪种模拟登录方式,有项目需求的时候就懂了~
c httpclient抓取网页(.HttpClient模拟登录网页,一直持续记录学习!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-04 20:09
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、使用org.apache.HttpClient模拟登录网页和抓取数据,需要用到HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn");
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
二、运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
查看全部
c httpclient抓取网页(.HttpClient模拟登录网页,一直持续记录学习!!
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、使用org.apache.HttpClient模拟登录网页和抓取数据,需要用到HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn";);
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
二、运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码

c httpclient抓取网页((本文与shell编程无关)的需求分析与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-03 00:16
一、灵感来源
前两天有朋友跟我提过这样的需求,希望从某个网页抓取数据,自动填入本地Excel表格中。当你需要做大量的数据统计时,将简单的任务自动化会显得很方便。这不就是shell编程的目的吗? (本文与shell编程无关,有感就贴)
二、需求分析
首先,对于需求,需要进行粗略的分析和设计(因为只是一个简单的测试demo,所以不需要考虑可行性、可维护性等),主要归结为到以下步骤:
要抓取网页数据,您必须知道网页的网址。这是我们从中抓取数据的入口网页。它需要根据发送的 url 生成响应并返回一个 html 响应页面。判断返回的结果是否是我们需要的。返回的html页面会将解析后的数据打包写入本地磁盘。 三、解决方案
这个例子测试了“Program it”信息的检索。
1、用到的jar包,主要包括
2、演示结构
模型类(存储对象):
package com.crawler.bean;
public class Model {
private String cardTitle;//帖子标题
private String authorName;//作者
private String cardContent;//帖子内容
private String cardDate;//发帖日期
public String getCardTitle() {
return cardTitle;
}
public void setCardTitle(String cardTitle) {
this.cardTitle = cardTitle;
}
public String getAuthorName() {
return authorName;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getCardContent() {
return cardContent;
}
public void setCardContent(String cardContent) {
this.cardContent = cardContent;
}
public String getCardDate() {
return cardDate;
}
public void setCardDate(String cardDate) {
this.cardDate = cardDate;
}
}
UrlToHtml 类(返回 html 响应页面):
package com.crawler.util;
import com.crawler.bean.Model;
import com.crawler.parser.DataParse;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class UrlToHtml {
public List URLParser(String url) throws Exception {
//初始化一个httpclient
HttpClient client = new DefaultHttpClient();
//用来接收解析的数据
List cardDatas = new ArrayList();
//获取响应文件,即html,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
}
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
//如果状态响应码为200,则获取html实体内容或者json文件
if (statusCode == 200) {
//设置字符编码
String entity = EntityUtils.toString(response.getEntity(), "utf-8");
//对响应的html内容进行解析
cardDatas = DataParse.getData(entity);
EntityUtils.consume(response.getEntity());
} else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return cardDatas;
}
}
DataParse 类(解析 html 响应页面):
package com.crawler.parser;
import com.crawler.bean.Model;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
public class DataParse {
public static List getData(String html) throws Exception {
//cardDatas用于存放结果
List cardDatas = new ArrayList();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的内容
Elements elements = doc.select("div[class=content]").select("ul[id=thread_list]").select("div[class=t_con cleafix]");
//遍历
for (Element ele : elements) {
//获取标题
String cardName = ele.select("a").text();
//获取作者
String authorName = ele.select("div[class=threadlist_author pull_right]").select("span").attr("title");
String newAuthorName = authorName.substring(6);
//获取内容
String cardContent = ele.select("div[class=threadlist_text pull_left]").text();
//获取日期
String cardDate = ele.select("div[class=threadlist_author pull_right]").select("span[class=pull-right is_show_create_time]").text();
//写入Model属性中
Model cd = new Model();
cd.setCardTitle(cardName);
cd.setAuthorName(newAuthorName);
cd.setCardContent(cardContent);
cd.setCardDate(cardDate);
cardDatas.add(cd);
}
//返回数据
return cardDatas;
}
}
WriteToLocal 类(写入本地磁盘):
<p>package com.crawler.service;
import com.crawler.bean.Model;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.hssf.util.HSSFColor;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class WriteToLocal {
public void writeToExcel(List cardDatas, int columeCount, String[] titles, String path) {
HSSFWorkbook hssfWorkbook = new HSSFWorkbook();
HSSFSheet sheet = hssfWorkbook.createSheet("我的表格");
//创建标题行
HSSFRow headRow = sheet.createRow(0);
for (int i = 0; i 查看全部
c httpclient抓取网页((本文与shell编程无关)的需求分析与应用)
一、灵感来源
前两天有朋友跟我提过这样的需求,希望从某个网页抓取数据,自动填入本地Excel表格中。当你需要做大量的数据统计时,将简单的任务自动化会显得很方便。这不就是shell编程的目的吗? (本文与shell编程无关,有感就贴)
二、需求分析
首先,对于需求,需要进行粗略的分析和设计(因为只是一个简单的测试demo,所以不需要考虑可行性、可维护性等),主要归结为到以下步骤:
要抓取网页数据,您必须知道网页的网址。这是我们从中抓取数据的入口网页。它需要根据发送的 url 生成响应并返回一个 html 响应页面。判断返回的结果是否是我们需要的。返回的html页面会将解析后的数据打包写入本地磁盘。 三、解决方案
这个例子测试了“Program it”信息的检索。
1、用到的jar包,主要包括
2、演示结构

模型类(存储对象):
package com.crawler.bean;
public class Model {
private String cardTitle;//帖子标题
private String authorName;//作者
private String cardContent;//帖子内容
private String cardDate;//发帖日期
public String getCardTitle() {
return cardTitle;
}
public void setCardTitle(String cardTitle) {
this.cardTitle = cardTitle;
}
public String getAuthorName() {
return authorName;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getCardContent() {
return cardContent;
}
public void setCardContent(String cardContent) {
this.cardContent = cardContent;
}
public String getCardDate() {
return cardDate;
}
public void setCardDate(String cardDate) {
this.cardDate = cardDate;
}
}
UrlToHtml 类(返回 html 响应页面):
package com.crawler.util;
import com.crawler.bean.Model;
import com.crawler.parser.DataParse;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class UrlToHtml {
public List URLParser(String url) throws Exception {
//初始化一个httpclient
HttpClient client = new DefaultHttpClient();
//用来接收解析的数据
List cardDatas = new ArrayList();
//获取响应文件,即html,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
}
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
//如果状态响应码为200,则获取html实体内容或者json文件
if (statusCode == 200) {
//设置字符编码
String entity = EntityUtils.toString(response.getEntity(), "utf-8");
//对响应的html内容进行解析
cardDatas = DataParse.getData(entity);
EntityUtils.consume(response.getEntity());
} else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return cardDatas;
}
}
DataParse 类(解析 html 响应页面):
package com.crawler.parser;
import com.crawler.bean.Model;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
public class DataParse {
public static List getData(String html) throws Exception {
//cardDatas用于存放结果
List cardDatas = new ArrayList();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的内容
Elements elements = doc.select("div[class=content]").select("ul[id=thread_list]").select("div[class=t_con cleafix]");
//遍历
for (Element ele : elements) {
//获取标题
String cardName = ele.select("a").text();
//获取作者
String authorName = ele.select("div[class=threadlist_author pull_right]").select("span").attr("title");
String newAuthorName = authorName.substring(6);
//获取内容
String cardContent = ele.select("div[class=threadlist_text pull_left]").text();
//获取日期
String cardDate = ele.select("div[class=threadlist_author pull_right]").select("span[class=pull-right is_show_create_time]").text();
//写入Model属性中
Model cd = new Model();
cd.setCardTitle(cardName);
cd.setAuthorName(newAuthorName);
cd.setCardContent(cardContent);
cd.setCardDate(cardDate);
cardDatas.add(cd);
}
//返回数据
return cardDatas;
}
}
WriteToLocal 类(写入本地磁盘):
<p>package com.crawler.service;
import com.crawler.bean.Model;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.hssf.util.HSSFColor;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class WriteToLocal {
public void writeToExcel(List cardDatas, int columeCount, String[] titles, String path) {
HSSFWorkbook hssfWorkbook = new HSSFWorkbook();
HSSFSheet sheet = hssfWorkbook.createSheet("我的表格");
//创建标题行
HSSFRow headRow = sheet.createRow(0);
for (int i = 0; i
c httpclient抓取网页(转发其他道友的文章需要发送自己的Cookietruetrue)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-01 02:13
以下是转发其他dao朋友的文章,主要是在使用过程中,需要向目标服务器发送自定义cookie,但是死活发送不了,最后百度的其他道友文章发现如果需要自己发cookies,需要做个设置:
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
道友文章地址:原文如下:
一般有两种方式
第一类handler.UseCookies=true(默认为true),默认会自带cookies,例如
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=600");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xxxx"),
new KeyValuePair("password", "xxxx"),
});
var result = await client.PostAsync("https://www.xxxx.com/cp/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,直接跳转到登录页面。
第二个设置handler.UseCookies = false,需要手动在headers中添加cookies。
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
var message = new HttpRequestMessage(HttpMethod.Get, url);
message.Headers.Add("Cookie", "session_id=7258abbd1544b6c530a9f406d3e600239bd788fb");
var result = await client.SendAsync(message);
result.EnsureSuccessStatusCode();
如果使用场景是:抓取需要登录的网页数据,推荐使用第一种方式,不设置任何cookies,httpclient登录后会在后续请求中自动放置cookies。 查看全部
c httpclient抓取网页(转发其他道友的文章需要发送自己的Cookietruetrue)
以下是转发其他dao朋友的文章,主要是在使用过程中,需要向目标服务器发送自定义cookie,但是死活发送不了,最后百度的其他道友文章发现如果需要自己发cookies,需要做个设置:
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
道友文章地址:原文如下:
一般有两种方式
第一类handler.UseCookies=true(默认为true),默认会自带cookies,例如
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=600");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xxxx"),
new KeyValuePair("password", "xxxx"),
});
var result = await client.PostAsync("https://www.xxxx.com/cp/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,直接跳转到登录页面。
第二个设置handler.UseCookies = false,需要手动在headers中添加cookies。
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
var message = new HttpRequestMessage(HttpMethod.Get, url);
message.Headers.Add("Cookie", "session_id=7258abbd1544b6c530a9f406d3e600239bd788fb");
var result = await client.SendAsync(message);
result.EnsureSuccessStatusCode();
如果使用场景是:抓取需要登录的网页数据,推荐使用第一种方式,不设置任何cookies,httpclient登录后会在后续请求中自动放置cookies。
c httpclient抓取网页(做一些必要的笔记,一来是对自己学习的巩固)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 00:15
我最近研究了 Jsoup 并做了一些必要的笔记。一是巩固所学知识,二是给遇到同样问题的人参考
文章目录
Jsoup 简介
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
Jsoup 从 URL、文件或字符串解析 HTML 的两个主要功能;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
注:jsoup基于MIT协议发布,可放心用于商业项目。
三种常用的获取元素的方法
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
doc.getElementById("nav_top"); // 获取id=nav_top的DOM元素
doc.getElementsByClass("card"); // 根据样式名称来查询DOM元素
doc.getElementsByAttribute("width"); // 根据属性名来查询DOM元素
doc.getElementsByAttributeValue("target", "_blank"); // 根据属性名和属性值来查询DOM元素
doc.select(".columns .column h1 a"); // 通过选择器查找DOM元素
Element e = linkElements.first();
e.text(); // 获取DOM元素文本
e.attr("href"); //获取DOM元素属性值
抓取网页内容的四个示例
以抓取一个博客页面上的所有博客标题和对应的博客链接为例。
网页内容
需要的包
org.apache.httpcomponents
httpclient
4.5.2
org.jsoup
jsoup
1.10.2
完整代码
/**
* @author ys
* @version 2.0
* @date 2020/5/24 11:46
* @decs: 使用选择器语法查找DOM元素
*/
public class Demo4 {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpclient实例
HttpGet httpGet = new HttpGet("https://www.zhjynet.cn/"); // 创建httpGet实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(httpGet); // 执行get请求
HttpEntity entity = response.getEntity(); // 获取返回实体
String content = EntityUtils.toString(entity, "utf-8"); // 获取网页内容
response.close();
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
Elements linkElements = doc.select(".columns .column .card .card-content h1 a"); // 通过选择器查找所有博客的标题
for (Element e : linkElements){
System.out.println("博客标题;"+e.text()); // 获取文本内容
System.out.println("博客链接:"+e.attr("href")); // 获取特定属性值
}
}
}
抓取结果
五点总结 查看全部
c httpclient抓取网页(做一些必要的笔记,一来是对自己学习的巩固)
我最近研究了 Jsoup 并做了一些必要的笔记。一是巩固所学知识,二是给遇到同样问题的人参考
文章目录
Jsoup 简介
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
Jsoup 从 URL、文件或字符串解析 HTML 的两个主要功能;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
注:jsoup基于MIT协议发布,可放心用于商业项目。
三种常用的获取元素的方法
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
doc.getElementById("nav_top"); // 获取id=nav_top的DOM元素
doc.getElementsByClass("card"); // 根据样式名称来查询DOM元素
doc.getElementsByAttribute("width"); // 根据属性名来查询DOM元素
doc.getElementsByAttributeValue("target", "_blank"); // 根据属性名和属性值来查询DOM元素
doc.select(".columns .column h1 a"); // 通过选择器查找DOM元素
Element e = linkElements.first();
e.text(); // 获取DOM元素文本
e.attr("href"); //获取DOM元素属性值
抓取网页内容的四个示例
以抓取一个博客页面上的所有博客标题和对应的博客链接为例。
网页内容

需要的包
org.apache.httpcomponents
httpclient
4.5.2
org.jsoup
jsoup
1.10.2
完整代码
/**
* @author ys
* @version 2.0
* @date 2020/5/24 11:46
* @decs: 使用选择器语法查找DOM元素
*/
public class Demo4 {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpclient实例
HttpGet httpGet = new HttpGet("https://www.zhjynet.cn/";); // 创建httpGet实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(httpGet); // 执行get请求
HttpEntity entity = response.getEntity(); // 获取返回实体
String content = EntityUtils.toString(entity, "utf-8"); // 获取网页内容
response.close();
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
Elements linkElements = doc.select(".columns .column .card .card-content h1 a"); // 通过选择器查找所有博客的标题
for (Element e : linkElements){
System.out.println("博客标题;"+e.text()); // 获取文本内容
System.out.println("博客链接:"+e.attr("href")); // 获取特定属性值
}
}
}
抓取结果

五点总结
c httpclient抓取网页( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-28 00:20
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
用java爬虫Gecco工具抓取新闻的例子
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,爬取网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
c httpclient抓取网页(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
用java爬虫Gecco工具抓取新闻的例子
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,爬取网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 00:20
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
c httpclient抓取网页(2.1.网络爬虫入门2.1.1.环境准备创建工程-crawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-23 23:00
2.1.网络爬虫入门2.1.1. 环境准备
JDK1.8
IntelliJ IDEA
IDEA自带的Maven
2.1.2.环境准备
创建Maven项目itcast-crawler-first并在pom.xml中添加依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.1.3. 加入log4j.properties
log4j.rootLogger=调试,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{
yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.1.4. 写代码
```java
编写最简单的爬虫,抓取传智播客首页:http://www.itcast.cn/
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://www.itcast.cn/");
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
测试结果:可以获取到页面数据
3.1. 网络爬虫简介
大数据时代,信息的采集是一项重要的任务,互联网上的数据是海量的。如果单纯依靠人力资源进行信息采集,不仅效率低下、繁琐,而且采集成本高。提升。如何在互联网上自动高效地获取我们感兴趣的信息并为我们使用是一个重要的问题,爬虫技术就是为了解决这些问题而诞生的。
网络爬虫也叫网络机器人,可以代替人自动采集,组织互联网上的数据和信息。它是一个程序或脚本,按照一定的规则自动抓取万维网上的信息,并可以自动采集所有它可以访问的页面内容获取相关数据。
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
3.2. 为什么要学习网络爬虫
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?只有清楚地知道我们的学习目的,才能更好地学习这些知识。在这里,我总结了学习爬虫的4个常见原因:
可以实现搜索引擎
在我们学会了如何编写爬虫之后,我们就可以使用爬虫自动采集互联网上的信息,返回后采集会存储或处理相应的信息。当我们需要检索某些信息时,只能使用采集 @采集从返回的信息中检索,实现了私有搜索引擎。
大数据时代让我们获得了更多的数据源。
在进行大数据分析或数据挖掘时,需要数据源进行分析。我们可以从一些提供统计数据的网站,或者一些文献或内部资料中获取数据,但是这些获取数据的方法有时难以满足我们的数据需求,而手动从网上找也太费精力了这些数据。此时,我们可以利用爬虫技术自动从互联网上获取我们感兴趣的数据内容,并将这些数据内容抓取回来作为我们的数据源,进而进行更深入的数据分析,获取更多有价值的信息。
可以更好地进行搜索引擎优化(SEO)。
对于很多SEO从业者来说,为了更好的完成工作,他们必须非常清楚搜索引擎的工作原理,同时也需要掌握搜索引擎爬虫的工作原理。
而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,这样你在做搜索引擎优化的时候,知己知彼,百战不殆。
有利于就业。
在就业方面,爬虫工程师方向是不错的选择之一,因为对爬虫工程师的需求越来越大,能胜任这个职位的人越来越少,所以属于比较稀缺的职业方向,并且随着数据时代和人工智能的到来,爬虫技术的应用会越来越广泛,未来会有很好的发展空间。 查看全部
c httpclient抓取网页(2.1.网络爬虫入门2.1.1.环境准备创建工程-crawler)
2.1.网络爬虫入门2.1.1. 环境准备
JDK1.8
IntelliJ IDEA
IDEA自带的Maven
2.1.2.环境准备
创建Maven项目itcast-crawler-first并在pom.xml中添加依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.1.3. 加入log4j.properties
log4j.rootLogger=调试,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{
yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.1.4. 写代码
```java
编写最简单的爬虫,抓取传智播客首页:http://www.itcast.cn/
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://www.itcast.cn/";);
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
测试结果:可以获取到页面数据
3.1. 网络爬虫简介
大数据时代,信息的采集是一项重要的任务,互联网上的数据是海量的。如果单纯依靠人力资源进行信息采集,不仅效率低下、繁琐,而且采集成本高。提升。如何在互联网上自动高效地获取我们感兴趣的信息并为我们使用是一个重要的问题,爬虫技术就是为了解决这些问题而诞生的。
网络爬虫也叫网络机器人,可以代替人自动采集,组织互联网上的数据和信息。它是一个程序或脚本,按照一定的规则自动抓取万维网上的信息,并可以自动采集所有它可以访问的页面内容获取相关数据。
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
3.2. 为什么要学习网络爬虫
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?只有清楚地知道我们的学习目的,才能更好地学习这些知识。在这里,我总结了学习爬虫的4个常见原因:
可以实现搜索引擎
在我们学会了如何编写爬虫之后,我们就可以使用爬虫自动采集互联网上的信息,返回后采集会存储或处理相应的信息。当我们需要检索某些信息时,只能使用采集 @采集从返回的信息中检索,实现了私有搜索引擎。
大数据时代让我们获得了更多的数据源。
在进行大数据分析或数据挖掘时,需要数据源进行分析。我们可以从一些提供统计数据的网站,或者一些文献或内部资料中获取数据,但是这些获取数据的方法有时难以满足我们的数据需求,而手动从网上找也太费精力了这些数据。此时,我们可以利用爬虫技术自动从互联网上获取我们感兴趣的数据内容,并将这些数据内容抓取回来作为我们的数据源,进而进行更深入的数据分析,获取更多有价值的信息。
可以更好地进行搜索引擎优化(SEO)。
对于很多SEO从业者来说,为了更好的完成工作,他们必须非常清楚搜索引擎的工作原理,同时也需要掌握搜索引擎爬虫的工作原理。
而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,这样你在做搜索引擎优化的时候,知己知彼,百战不殆。
有利于就业。
在就业方面,爬虫工程师方向是不错的选择之一,因为对爬虫工程师的需求越来越大,能胜任这个职位的人越来越少,所以属于比较稀缺的职业方向,并且随着数据时代和人工智能的到来,爬虫技术的应用会越来越广泛,未来会有很好的发展空间。
c httpclient抓取网页(案例展示如何使用Jsoup进行解析,案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-20 14:17
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
我只听到山中建筑师的声音:
蜡拍半笼金翡翠,芙蓉微微绣有麝香烟。上联和下联谁来匹配?
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
此代码由Java架构师必看网-架构君整理
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人建议使用 select 方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
此代码由Java架构师必看网-架构君整理
public static void main(String[] args) {
String unsafe = "<p>博客园";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
我猜你会喜欢: 查看全部
c httpclient抓取网页(案例展示如何使用Jsoup进行解析,案例中将获取博客园首页)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。

请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
我只听到山中建筑师的声音:
蜡拍半笼金翡翠,芙蓉微微绣有麝香烟。上联和下联谁来匹配?
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
此代码由Java架构师必看网-架构君整理
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人建议使用 select 方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
此代码由Java架构师必看网-架构君整理
public static void main(String[] args) {
String unsafe = "<p>博客园";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
我猜你会喜欢:
c httpclient抓取网页(Web信息提取、数据挖掘、Crowbar的运行方法以及解析执行方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-19 19:13
在网页信息抽取和数据挖掘的过程中,一个关键的步骤是获取网页的源代码。但是,由于种种原因,网页上我们感兴趣的内容很有可能是在HTML文档加载或使用AJAX异步读取后,通过客户端JavaScript输出的。这样我们就可以直接使用POCO或者HttpClient等库了。这些内容不可用于下载文档。当然,你也可以选择自己来实现对JS代码的分析和执行,但是借助浏览器来完成这些脚本的执行无疑要简单得多,也更可行。
Crowbar 是麻省理工学院 SIMILE 团队编写的工具。它使用Firefox的Gecko引擎在网页上执行脚本,然后在脚本执行一段时间后将DOM重新序列化成HTML代码输出。
Crowbar这个词本身的意思是撬棍,一种用来拔钉子的工具。用在这里也很有意义。使用Crowbar读取难以直接获取的异步输出内容就像用Crowbar拔钉子一样。简单。遗憾的是,Crowbar 似乎在几年前就停止了开发,并没有正式的 Release。也许作者已经找到了更好的方法来完成这个任务,但我还没有找到。
环保要求
XULRunner (v1.8.1 +) XUL 是 Mozilla 使用 XML 来描述用户界面的技术,Firefox 就是基于该技术构建的。有了XULRunner工具,我们就可以轻松的执行我们自己编写的类似于Firefox的用户界面程序。Crowbar就是基于这个环境。配置 XULRunner 可以参考 Mozilla 对 XULRunner 的介绍。根据以上说明,您应该可以轻松运行 Hello World 程序。获取撬棍
Crowbar 没有正式发布的版本。官方下载只给出了Subversion库的地址:
http://simile.mit.edu/repository/crowbar/trunk/
或者你可以在这里下载我的修改版本。运行撬棍
官方文档分别描述了Windows/Linux/MacOSX下的操作方法。这里我简单介绍一下Windows下的方法。运行 cmd.exe 并输入以下命令:Bash
c:\> %XULRUNNER_HOME%\xulrunner.exe --install-app %CROWBAR%\xulappc:\> cd %CROWBAR%\xulappc:\> %XULRUNNER_HOME%\xulrunner.exe application.ini
其中,%XULRUNNER_HOME%为XULRunner的安装目录,%CROWBAR%为Crowbar的文件目录。如果成功,将弹出一个标题为“Crowbar”的窗口。
当 Crowbar 运行时,这个小窗口会显示当前正在读取或已读取的最后一个网页地址。其最终输出作为基于 REST 的 Web 服务提供。程序默认会监听本地10000端口,当用户打开任意浏览器指向127.0.0.1:10000时,浏览器可以调用Crowbar查看结果。当然,我们最终并不想在浏览器中得到结果。当我们使用HttpClient等库进行网页抓取时,只需要将目标地址设置为类似如下即可。
http://127.0.0.1:10000/%3Furl% ... D1000
其中url为URL编码后的目标URL,delay指定DOM加载后网页内容输出的时间。
Crowbar 还提供了几种不同的爬行模式。官方文档似乎不完整。如果你有兴趣,你需要检查源代码。当然,目前使用Crowbar的方法只能完成一些简单的应用,我还没有测试过大规模网络爬虫的性能。修复中文乱码问题
使用Crowbar读取中文网页内容时,会出现乱码,因为Crowbar没有处理过非英文字符集。只需修改其部分源代码即可解决乱码问题。
打开文件%CROWBAR%\xulapp\chrome\crowbar\content\crowbar.js,找到第223行,将整个try代码块的内容改成如下:
try {
var charset = "UTF-8"; // Can be any character encoding name that Mozilla supports
var os = Components.classes["@mozilla.org/intl/converter-output-stream;1"]
.createInstance(Components.interfaces.nsIConverterOutputStream);
os.init(outstream, charset, 0, 0x0000);
os.writeString(response);
os.close();
instream.close();
outstream.close();
}
这样,最终的结果就可以用UTF-8编码输出了。
参考 查看全部
c httpclient抓取网页(Web信息提取、数据挖掘、Crowbar的运行方法以及解析执行方法)
在网页信息抽取和数据挖掘的过程中,一个关键的步骤是获取网页的源代码。但是,由于种种原因,网页上我们感兴趣的内容很有可能是在HTML文档加载或使用AJAX异步读取后,通过客户端JavaScript输出的。这样我们就可以直接使用POCO或者HttpClient等库了。这些内容不可用于下载文档。当然,你也可以选择自己来实现对JS代码的分析和执行,但是借助浏览器来完成这些脚本的执行无疑要简单得多,也更可行。
Crowbar 是麻省理工学院 SIMILE 团队编写的工具。它使用Firefox的Gecko引擎在网页上执行脚本,然后在脚本执行一段时间后将DOM重新序列化成HTML代码输出。
Crowbar这个词本身的意思是撬棍,一种用来拔钉子的工具。用在这里也很有意义。使用Crowbar读取难以直接获取的异步输出内容就像用Crowbar拔钉子一样。简单。遗憾的是,Crowbar 似乎在几年前就停止了开发,并没有正式的 Release。也许作者已经找到了更好的方法来完成这个任务,但我还没有找到。
环保要求
XULRunner (v1.8.1 +) XUL 是 Mozilla 使用 XML 来描述用户界面的技术,Firefox 就是基于该技术构建的。有了XULRunner工具,我们就可以轻松的执行我们自己编写的类似于Firefox的用户界面程序。Crowbar就是基于这个环境。配置 XULRunner 可以参考 Mozilla 对 XULRunner 的介绍。根据以上说明,您应该可以轻松运行 Hello World 程序。获取撬棍
Crowbar 没有正式发布的版本。官方下载只给出了Subversion库的地址:
http://simile.mit.edu/repository/crowbar/trunk/
或者你可以在这里下载我的修改版本。运行撬棍
官方文档分别描述了Windows/Linux/MacOSX下的操作方法。这里我简单介绍一下Windows下的方法。运行 cmd.exe 并输入以下命令:Bash
c:\> %XULRUNNER_HOME%\xulrunner.exe --install-app %CROWBAR%\xulappc:\> cd %CROWBAR%\xulappc:\> %XULRUNNER_HOME%\xulrunner.exe application.ini
其中,%XULRUNNER_HOME%为XULRunner的安装目录,%CROWBAR%为Crowbar的文件目录。如果成功,将弹出一个标题为“Crowbar”的窗口。
当 Crowbar 运行时,这个小窗口会显示当前正在读取或已读取的最后一个网页地址。其最终输出作为基于 REST 的 Web 服务提供。程序默认会监听本地10000端口,当用户打开任意浏览器指向127.0.0.1:10000时,浏览器可以调用Crowbar查看结果。当然,我们最终并不想在浏览器中得到结果。当我们使用HttpClient等库进行网页抓取时,只需要将目标地址设置为类似如下即可。
http://127.0.0.1:10000/%3Furl% ... D1000
其中url为URL编码后的目标URL,delay指定DOM加载后网页内容输出的时间。
Crowbar 还提供了几种不同的爬行模式。官方文档似乎不完整。如果你有兴趣,你需要检查源代码。当然,目前使用Crowbar的方法只能完成一些简单的应用,我还没有测试过大规模网络爬虫的性能。修复中文乱码问题
使用Crowbar读取中文网页内容时,会出现乱码,因为Crowbar没有处理过非英文字符集。只需修改其部分源代码即可解决乱码问题。
打开文件%CROWBAR%\xulapp\chrome\crowbar\content\crowbar.js,找到第223行,将整个try代码块的内容改成如下:
try {
var charset = "UTF-8"; // Can be any character encoding name that Mozilla supports
var os = Components.classes["@mozilla.org/intl/converter-output-stream;1"]
.createInstance(Components.interfaces.nsIConverterOutputStream);
os.init(outstream, charset, 0, 0x0000);
os.writeString(response);
os.close();
instream.close();
outstream.close();
}
这样,最终的结果就可以用UTF-8编码输出了。
参考
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-17 01:20
数据是科学研究活动的重要依据。本系列博客将介绍如何使用Java工具获取网络数据。
博客系列
Java爬虫介绍(一)——HttpClient请求(本文)
Java爬虫介绍(二)——Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序访问互联网,然后将数据保存到本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般都是从网站获取的,比如电商网站的商品信息、商品评论、微博信息等,爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要使用工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫案例。
一、环境准备
这里的环境是指开发环境。本博客将使用Java编写爬虫。因此,有必要搭建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ IDEA:
JDK安装和环境变量配置网上有很多,就不多说了。IntelliJ IDEA是傻瓜式的安装,基本不会有问题。不要说什么。
二、创建项目
环境安装好后,我们打开IntelliJ IDEA,然后创建一个Maven项目。Group Id 和 Artifact Id 自己写也没关系。创建后,我们的目录将如下图所示。
好了,开始写爬虫吧。
三、第一个例子
首先,假设我们需要爬取数据来学习网站第一页的blog()。首先我们需要使用maven导入HttpClient4.5.3包(这是最新的包,可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
1234567
Java本身提供了一个关于网络访问的包,在,然后还不够强大。于是Apache基金会发布了一个开源的http请求包HttpClient,提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好了,在使用 pom.xml 下载这个包之后,我们就可以开始编写我们的第一个爬虫示例了。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog");
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
如上代码所示,爬虫第一步需要搭建一个客户端,即请求者。这里我们使用CloseableHttpClient作为我们的请求者,然后判断以何种方式请求哪个URL,然后使用HttpResponse获取请求的地址即可得到相应的结果。最后取出HttpEntity,进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。这样我们的第一个爬虫就成功下载了网门需要的页面内容。 查看全部
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
数据是科学研究活动的重要依据。本系列博客将介绍如何使用Java工具获取网络数据。
博客系列
Java爬虫介绍(一)——HttpClient请求(本文)
Java爬虫介绍(二)——Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序访问互联网,然后将数据保存到本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般都是从网站获取的,比如电商网站的商品信息、商品评论、微博信息等,爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要使用工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫案例。
一、环境准备
这里的环境是指开发环境。本博客将使用Java编写爬虫。因此,有必要搭建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ IDEA:
JDK安装和环境变量配置网上有很多,就不多说了。IntelliJ IDEA是傻瓜式的安装,基本不会有问题。不要说什么。
二、创建项目
环境安装好后,我们打开IntelliJ IDEA,然后创建一个Maven项目。Group Id 和 Artifact Id 自己写也没关系。创建后,我们的目录将如下图所示。

好了,开始写爬虫吧。
三、第一个例子
首先,假设我们需要爬取数据来学习网站第一页的blog()。首先我们需要使用maven导入HttpClient4.5.3包(这是最新的包,可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
1234567
Java本身提供了一个关于网络访问的包,在,然后还不够强大。于是Apache基金会发布了一个开源的http请求包HttpClient,提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好了,在使用 pom.xml 下载这个包之后,我们就可以开始编写我们的第一个爬虫示例了。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog";);
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
如上代码所示,爬虫第一步需要搭建一个客户端,即请求者。这里我们使用CloseableHttpClient作为我们的请求者,然后判断以何种方式请求哪个URL,然后使用HttpResponse获取请求的地址即可得到相应的结果。最后取出HttpEntity,进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:

很明显,这就是我们需要的URL对应的页面的源码。这样我们的第一个爬虫就成功下载了网门需要的页面内容。
c httpclient抓取网页(某一的事情交给httpclient替你完成(图)HTTP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 00:06
一般情况下,我们使用IE或谷歌浏览器访问WEB服务器来浏览页面查看信息或提交一些数据等。但是,在某些情况下,可能需要通过程序访问这些页面来“窃取”一些来自其他人网页的数据。比如我们想获取某个微信公众号的信息,但是我们自己没有这样的数据,所以只能通过搜狗搜索引擎来完成。我们需要将公众号关键字提交到网页中,并从返回的页面中解析出我们想要的数据。.
JDK包中已经提供了访问HTTP协议的基本功能。如果要访问的对象只是一个简单的页面,JDK提供的HttpURLConnection就可以处理。
但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问。有的需要用户登录后才能使用,有的需要认证,有的通过加密方式传输,比如HTTPS。.
这时候就涉及到COOKIE问题的处理了。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,需要程序登录后访问服务页面。这个过程需要自己处理cookies。使用 .HttpURLConnection 来完成这些功能是多么可怕的事情!
HttpClient 是 Apache Jakarta Common 下的一个子项目,专门用于简化 HTTP 客户端和服务器之间的各种通信编程。通过它,你可以轻松解决原本头疼的问题。例如,您不再关心 HTTP 或 HTTPS 通信方式,告诉它您要使用 HTTPS,然后让 httpclient 为您完成剩下的工作。 查看全部
c httpclient抓取网页(某一的事情交给httpclient替你完成(图)HTTP)
一般情况下,我们使用IE或谷歌浏览器访问WEB服务器来浏览页面查看信息或提交一些数据等。但是,在某些情况下,可能需要通过程序访问这些页面来“窃取”一些来自其他人网页的数据。比如我们想获取某个微信公众号的信息,但是我们自己没有这样的数据,所以只能通过搜狗搜索引擎来完成。我们需要将公众号关键字提交到网页中,并从返回的页面中解析出我们想要的数据。.
JDK包中已经提供了访问HTTP协议的基本功能。如果要访问的对象只是一个简单的页面,JDK提供的HttpURLConnection就可以处理。
但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问。有的需要用户登录后才能使用,有的需要认证,有的通过加密方式传输,比如HTTPS。.
这时候就涉及到COOKIE问题的处理了。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,需要程序登录后访问服务页面。这个过程需要自己处理cookies。使用 .HttpURLConnection 来完成这些功能是多么可怕的事情!
HttpClient 是 Apache Jakarta Common 下的一个子项目,专门用于简化 HTTP 客户端和服务器之间的各种通信编程。通过它,你可以轻松解决原本头疼的问题。例如,您不再关心 HTTP 或 HTTPS 通信方式,告诉它您要使用 HTTPS,然后让 httpclient 为您完成剩下的工作。
c httpclient抓取网页(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-12-07 01:10
微博爬虫,单机几千万日数据&&吐血整理微博爬虫总结介绍
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没解决,所以每天上百万的数据里有水。仅爬取友情就可以达到百万级别的数据。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级。
不过既然坑已经被埋了,就一定要填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经彻底解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能用于复杂爬行!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这一切都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这种需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,必须通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站一页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以举例来说,如果搜索时间段是10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量很大,过滤条件很详细,比如region,其他所有爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是,由于您购买的帐户较小,可能会因操作频繁而被微博瞄准。登录时账号异常,会生成非常恶心的验证码,如下图。
在这种情况下,我建议你放弃治疗,不要考虑破解这个验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不同的,所以必须构建两个账户池,一个是cn站点,一个是com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求之间的延迟会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
总觉得我上面搭建的爬虫已经占了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化。这里推荐Redis-Scrapy。所有爬虫共享一个Redis队列,通过Redis将URL统一分配给爬虫,Redis是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前运行稳定
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。 查看全部
c httpclient抓取网页(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机几千万日数据&&吐血整理微博爬虫总结介绍
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没解决,所以每天上百万的数据里有水。仅爬取友情就可以达到百万级别的数据。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级。
不过既然坑已经被埋了,就一定要填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经彻底解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能用于复杂爬行!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这一切都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这种需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,必须通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
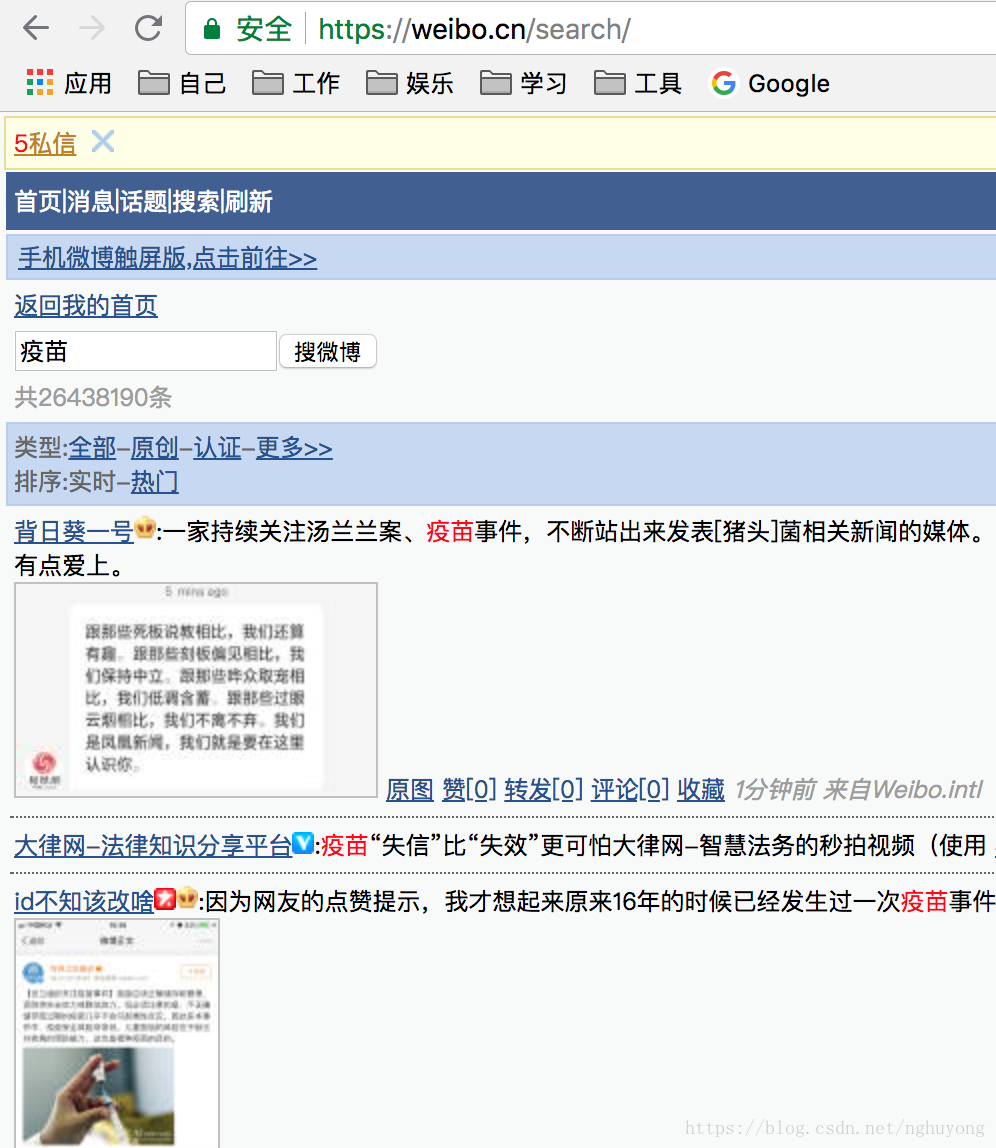
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站一页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以举例来说,如果搜索时间段是10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量很大,过滤条件很详细,比如region,其他所有爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是,由于您购买的帐户较小,可能会因操作频繁而被微博瞄准。登录时账号异常,会生成非常恶心的验证码,如下图。
在这种情况下,我建议你放弃治疗,不要考虑破解这个验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不同的,所以必须构建两个账户池,一个是cn站点,一个是com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求之间的延迟会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
总觉得我上面搭建的爬虫已经占了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化。这里推荐Redis-Scrapy。所有爬虫共享一个Redis队列,通过Redis将URL统一分配给爬虫,Redis是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前运行稳定
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 03:18
HttpClient 是 Apache Jakarta Common 下的一个子项目,可用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 下的一个子项目,可用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
c httpclient抓取网页(环境准备引入maven依赖加入日志配置文件的HTTP协议访问网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-18 16:14
)
文章内容
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。我们一直使用HTTP协议访问互联网上的网页,而网络爬虫需要编写程序,其中访问网页也使用相同的HTTP协议。这里我们使用Java的HTTP协议客户端HttpClient的技术来抓取网页数据。环境准备
引入maven依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加日志配置文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n 查看全部
c httpclient抓取网页(环境准备引入maven依赖加入日志配置文件的HTTP协议访问网页
)
文章内容
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。我们一直使用HTTP协议访问互联网上的网页,而网络爬虫需要编写程序,其中访问网页也使用相同的HTTP协议。这里我们使用Java的HTTP协议客户端HttpClient的技术来抓取网页数据。环境准备
引入maven依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加日志配置文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
c httpclient抓取网页(WebReaper(离线浏览器)一个不错不错的离线)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-18 08:03
WebReaper(离线浏览器)是一款不错的离线浏览器,使用它可以下载整个网站,只需要输入这个网站 URL,方便快捷。没有网络的时候,我们也可以看自己喜欢的网站。WebReaper 是一个网络爬虫或蜘蛛,它的工作方式是通过一个网站,下载网页、图片和对象,并发现它们可以在不连接互联网的情况下在本地查看。作为一个完全浏览的网站,它可以保存在本地,可以连接任何浏览器(如Internet浏览网站 Explorer、Netscape、Opera等),也可以保存到Internet资源管理器缓存,请使用IE的离线模式,看来可以“动手”了网站。要使用 WebReaper,只需输入一个起始 URL 并点击 Go 按钮。该程序将在 URL 处下载页面,解析 HTML,并找到指向其他页面的链接和对象。然后,它会提取这个子链接列表并下载它们。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。 查看全部
c httpclient抓取网页(WebReaper(离线浏览器)一个不错不错的离线)
WebReaper(离线浏览器)是一款不错的离线浏览器,使用它可以下载整个网站,只需要输入这个网站 URL,方便快捷。没有网络的时候,我们也可以看自己喜欢的网站。WebReaper 是一个网络爬虫或蜘蛛,它的工作方式是通过一个网站,下载网页、图片和对象,并发现它们可以在不连接互联网的情况下在本地查看。作为一个完全浏览的网站,它可以保存在本地,可以连接任何浏览器(如Internet浏览网站 Explorer、Netscape、Opera等),也可以保存到Internet资源管理器缓存,请使用IE的离线模式,看来可以“动手”了网站。要使用 WebReaper,只需输入一个起始 URL 并点击 Go 按钮。该程序将在 URL 处下载页面,解析 HTML,并找到指向其他页面的链接和对象。然后,它会提取这个子链接列表并下载它们。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-29 08:16
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/");
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 } 查看全部
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦!
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/";);
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 }
c httpclient抓取网页(模拟网站的登录请求:最简单的方法是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-01-20 21:01
您应该模拟 网站 的登录过程。最简单的方法是通过一些调试器(例如 Fiddler)检查 网站。
这是 网站 的登录请求:
POST https://members.morningstar.co ... me%3D HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Referer: https://members.morningstar.co ... .aspx ** omitted ** Cookie: cookies=true; TestCookieExist=Exist; fp=001140581745182496; __utma=172984700.91600904.1405817457.1405817457.1405817457.1; __utmb=172984700.8.10.1405817457; __utmz=172984700.1405817457.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=172984700; ASP.NET_SessionId=b5bpepm3pftgoz55to3ql4me email_textbox=test@email.com&pwd_textbox=password&remember=on&email_textbox2=&go_button.x=36&go_button.y=16&__LASTFOCUS=&__EVENTTARGET=&__EVENTARGUMENT=&__VIEWSTATE=omitted&__EVENTVALIDATION=omited
检查时,您会看到一些 cookie 和表单字段,例如“__VIEWSTATE”。您需要该字段的实际值才能登录。您可以使用以下步骤:
发出请求并丢弃“__LASTFOCUS”、“__EVENTTARGET”、“_ _EVENTARGUMENT”、“_ _ _ JSTENT”、“_ _EVVALIDATION”等字段;和饼干。使用上一个中的 CookieContainer 在同一页面上创建一个新的 POST 请求;使用废弃字段、用户名和密码构建帖子字符串。使用 MIME 类型 application/x-www-form-urlencoded。如果成功,则使用 cookie 保持登录状态以获取更多请求。
注意:您可以使用 htmlagilitypack 或 scrapysharp 来报废 html。ScrapySharp 为表单发布表单和浏览 网站 提供了易于使用的工具。
mental is process 是模拟一个人在 网站 上登录,一些登录是使用 AJAX 或传统的 POST 请求完成的,所以,你做的第一件事就是像浏览器一样的请求,在服务器响应中,你会获取 cookie、标头和其他信息,您需要使用这些信息来构建一个新请求,这是一个冗长的请求。
步骤是:
1)像浏览器一样构建请求以向应用程序验证自身。2)检查响应,并保存标头、cookie 或其他有用信息以保持与服务器的会话。3)使用从第二步采集的信息向服务器发出另一个请求。4)检查响应并使用数据分析算法或其他东西来提取数据。
暗示:
你这里没有使用 javascript 引擎,一些 网站 使用 javascript 来显示图形,或者在 DOM 文档中执行一些交互。在这种情况下,您可能需要使用 WebKit lib 包装器。
以上是C#学习教程:使用C#HttpClient登录网站,从另一个页面抓取信息分享的全部内容。如果对你有用,需要进一步了解C#学习教程,希望你多多关注——猴子科技屋() 查看全部
c httpclient抓取网页(模拟网站的登录请求:最简单的方法是什么?)
您应该模拟 网站 的登录过程。最简单的方法是通过一些调试器(例如 Fiddler)检查 网站。
这是 网站 的登录请求:
POST https://members.morningstar.co ... me%3D HTTP/1.1 Accept: text/html, application/xhtml+xml, */* Referer: https://members.morningstar.co ... .aspx ** omitted ** Cookie: cookies=true; TestCookieExist=Exist; fp=001140581745182496; __utma=172984700.91600904.1405817457.1405817457.1405817457.1; __utmb=172984700.8.10.1405817457; __utmz=172984700.1405817457.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utmc=172984700; ASP.NET_SessionId=b5bpepm3pftgoz55to3ql4me email_textbox=test@email.com&pwd_textbox=password&remember=on&email_textbox2=&go_button.x=36&go_button.y=16&__LASTFOCUS=&__EVENTTARGET=&__EVENTARGUMENT=&__VIEWSTATE=omitted&__EVENTVALIDATION=omited
检查时,您会看到一些 cookie 和表单字段,例如“__VIEWSTATE”。您需要该字段的实际值才能登录。您可以使用以下步骤:
发出请求并丢弃“__LASTFOCUS”、“__EVENTTARGET”、“_ _EVENTARGUMENT”、“_ _ _ JSTENT”、“_ _EVVALIDATION”等字段;和饼干。使用上一个中的 CookieContainer 在同一页面上创建一个新的 POST 请求;使用废弃字段、用户名和密码构建帖子字符串。使用 MIME 类型 application/x-www-form-urlencoded。如果成功,则使用 cookie 保持登录状态以获取更多请求。
注意:您可以使用 htmlagilitypack 或 scrapysharp 来报废 html。ScrapySharp 为表单发布表单和浏览 网站 提供了易于使用的工具。
mental is process 是模拟一个人在 网站 上登录,一些登录是使用 AJAX 或传统的 POST 请求完成的,所以,你做的第一件事就是像浏览器一样的请求,在服务器响应中,你会获取 cookie、标头和其他信息,您需要使用这些信息来构建一个新请求,这是一个冗长的请求。
步骤是:
1)像浏览器一样构建请求以向应用程序验证自身。2)检查响应,并保存标头、cookie 或其他有用信息以保持与服务器的会话。3)使用从第二步采集的信息向服务器发出另一个请求。4)检查响应并使用数据分析算法或其他东西来提取数据。
暗示:
你这里没有使用 javascript 引擎,一些 网站 使用 javascript 来显示图形,或者在 DOM 文档中执行一些交互。在这种情况下,您可能需要使用 WebKit lib 包装器。
以上是C#学习教程:使用C#HttpClient登录网站,从另一个页面抓取信息分享的全部内容。如果对你有用,需要进一步了解C#学习教程,希望你多多关注——猴子科技屋()
c httpclient抓取网页( 一个基于JAVA的知乎爬虫,抓取90W+用户信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-01-18 18:11
一个基于JAVA的知乎爬虫,抓取90W+用户信息
)
Java实现爬取知乎用户基本信息
更新时间:2016-05-24 16:24:45 作者:卧燕无语
本文章主要介绍了一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下
本文示例分享一个基于JAVA的知乎爬虫,抓取知乎用户的基本信息,基于HttpClient4.5,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户在里面)
大概的概念:
1.先模拟登录知乎,登录成功后将cookie序列化到磁盘,以后不需要每次都登录(如果不模拟登录,就是也可以直接从浏览器插入 cookie)。
2.创建两个线程池和一个Storage。用于抓取网页的线程池,负责执行请求请求,返回网页内容,存储在Storage中。另一个是解析网页线程池,负责从Storage中提取和解析网页内容,解析用户数据并存入数据库,解析用户关注人的主页,并将地址请求加入到爬取中网页线程池。继续循环。
3. 关于url去重,我直接把访问过的链接md5存入数据库。每次访问前,检查数据库中是否存在链接。
到目前为止,已经捕获了 100W 用户,访问了 220W+ 链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户基本应该被抓到。
项目地址:
实现代码:
作者:卧颜沉默
链接:https://www.zhihu.com/question ... 43000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
/**
*
* @param httpClient Http客户端
* @param context Http上下文
* @return
*/
public boolean login(CloseableHttpClient httpClient, HttpClientContext context){
String yzm = null;
String loginState = null;
HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin");
HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false);
HttpPost request = new HttpPost("https://www.zhihu.com/login/email");
List formParams = new ArrayList();
yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login");//肉眼识别验证码
formParams.add(new BasicNameValuePair("captcha", yzm));
formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用
formParams.add(new BasicNameValuePair("email", "邮箱"));
formParams.add(new BasicNameValuePair("password", "密码"));
formParams.add(new BasicNameValuePair("remember_me", "true"));
UrlEncodedFormEntity entity = null;
try {
entity = new UrlEncodedFormEntity(formParams, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
request.setEntity(entity);
loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录
JSONObject jo = new JSONObject(loginState);
if(jo.get("r").toString().equals("0")){
System.out.println("登录成功");
getRequest = new HttpGet("https://www.zhihu.com");
HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页
HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录
return true;
}else{
System.out.println("登录失败" + loginState);
return false;
}
}
/**
* 肉眼识别验证码
* @param httpClient Http客户端
* @param context Http上下文
* @param url 验证码地址
* @return
*/
public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){
HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true);
Scanner sc = new Scanner(System.in);
String yzm = sc.nextLine();
return yzm;
}
效果图:
查看全部
c httpclient抓取网页(
一个基于JAVA的知乎爬虫,抓取90W+用户信息
)
Java实现爬取知乎用户基本信息
更新时间:2016-05-24 16:24:45 作者:卧燕无语
本文章主要介绍了一个基于JAVA的知乎爬虫,用于抓取知乎用户的基本信息。有兴趣的朋友可以参考一下
本文示例分享一个基于JAVA的知乎爬虫,抓取知乎用户的基本信息,基于HttpClient4.5,供大家参考,具体内容如下
细节:
抓取90W+用户信息(基本活跃用户在里面)
大概的概念:
1.先模拟登录知乎,登录成功后将cookie序列化到磁盘,以后不需要每次都登录(如果不模拟登录,就是也可以直接从浏览器插入 cookie)。
2.创建两个线程池和一个Storage。用于抓取网页的线程池,负责执行请求请求,返回网页内容,存储在Storage中。另一个是解析网页线程池,负责从Storage中提取和解析网页内容,解析用户数据并存入数据库,解析用户关注人的主页,并将地址请求加入到爬取中网页线程池。继续循环。
3. 关于url去重,我直接把访问过的链接md5存入数据库。每次访问前,检查数据库中是否存在链接。
到目前为止,已经捕获了 100W 用户,访问了 220W+ 链接。现在爬取的用户是一些不太活跃的用户。比较活跃的用户基本应该被抓到。
项目地址:
实现代码:
作者:卧颜沉默
链接:https://www.zhihu.com/question ... 43000
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
/**
*
* @param httpClient Http客户端
* @param context Http上下文
* @return
*/
public boolean login(CloseableHttpClient httpClient, HttpClientContext context){
String yzm = null;
String loginState = null;
HttpGet getRequest = new HttpGet("https://www.zhihu.com/#signin";);
HttpClientUtil.getWebPage(httpClient,context, getRequest, "utf-8", false);
HttpPost request = new HttpPost("https://www.zhihu.com/login/email";);
List formParams = new ArrayList();
yzm = yzm(httpClient, context,"https://www.zhihu.com/captcha.gif?type=login";);//肉眼识别验证码
formParams.add(new BasicNameValuePair("captcha", yzm));
formParams.add(new BasicNameValuePair("_xsrf", ""));//这个参数可以不用
formParams.add(new BasicNameValuePair("email", "邮箱"));
formParams.add(new BasicNameValuePair("password", "密码"));
formParams.add(new BasicNameValuePair("remember_me", "true"));
UrlEncodedFormEntity entity = null;
try {
entity = new UrlEncodedFormEntity(formParams, "utf-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
request.setEntity(entity);
loginState = HttpClientUtil.getWebPage(httpClient,context, request, "utf-8", false);//登录
JSONObject jo = new JSONObject(loginState);
if(jo.get("r").toString().equals("0")){
System.out.println("登录成功");
getRequest = new HttpGet("https://www.zhihu.com";);
HttpClientUtil.getWebPage(httpClient,context ,getRequest, "utf-8", false);//访问首页
HttpClientUtil.serializeObject(context.getCookieStore(),"resources/zhihucookies");//序列化知乎Cookies,下次登录直接通过该cookies登录
return true;
}else{
System.out.println("登录失败" + loginState);
return false;
}
}
/**
* 肉眼识别验证码
* @param httpClient Http客户端
* @param context Http上下文
* @param url 验证码地址
* @return
*/
public String yzm(CloseableHttpClient httpClient,HttpClientContext context, String url){
HttpClientUtil.downloadFile(httpClient, context, url, "d:/test/", "1.gif",true);
Scanner sc = new Scanner(System.in);
String yzm = sc.nextLine();
return yzm;
}
效果图:
c httpclient抓取网页(如何实现一下抢票软件的第一步库的相关知识? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-15 23:05
)
最近想了解一下抢票软件的实现流程,于是开始晚上搜集资料。通过对众多数据的综合分析,发现大部分都是通过httpclient连接网络的。所以,作为实现抢票软件的第一步,有必要对httpclient库的相关知识有一个详细的了解。
无论是网络爬虫还是抢票软件,首先需要做的就是能够获取到的网页的代码。只有这样,才能进行后续的搜索和筛选工作。httpclient最基本的连接过程就是通过httpclient执行httpGet或httpPost方法,等到网站返回保存在httpResponse中,从中提取httpEntity获取网页数据。
<p>import java.io.*;
import java.util.regex.*;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHeader;
public class my12306Test {
public static void main(String[] args)throws Exception
{
// TODO Auto-generated method stub
connection();
}
/*
* 此方法用来实现对于网页数据的下载并存储在本地;
* 解决的问题:
* 1、连接网站下载网页前端代码;
* 2、不同网站的代码使用不同的编码方式,需要在读取时使用相应的字符编码格式;
* 3、在读取编码格式时,需要用到从网页的代码中利用正则表达式抓取charest这个编码格式属性的信息;
* */
public static void connection()throws Exception
{
//建立httpclient对象连接
HttpClient client = new DefaultHttpClient();
//使用get方法访问相关网站
HttpGet get =new HttpGet("http://www.taobao.com");
//执行get方法,获取网站响应;
HttpResponse response = client.execute(get);
//得到网站响应实体并读取信息
HttpEntity entity = response.getEntity();
InputStream input = entity.getContent();
//BasicHeader getHeader =(BasicHeader) entity.getContentEncoding();
//显示网站响应头的信息
System.out.println(response.getStatusLine().getStatusCode());
System.out.println("Response content length: " + entity.getContentLength());
System.out.println("content-type:" +entity.getContentType().getValue());
System.out.println("getMehod::"+get.getMethod());//显示请求的方法名
System.out.println("getCountry::"+response.getLocale().getDefault());//getDisplayCountry());
/*
* 1、读取网站代码,输入流信息用于getCharest函数提取字符编码信息
* 2、利用getCharest函数从网站的头或者代码中获取网站字符编码规则
* */
BufferedReader bufrBuf = new BufferedReader(new InputStreamReader(input));
BufferedWriter bufw = new BufferedWriter(new FileWriter("bufJD.html"));
String charest = getChrest(bufrBuf,entity.getContentType().getValue());
//若果得到的是UTF编码,则还需要规范其的名称
if(charest.equals("utf"))
{
System.out.println("out:"+charest);
charest="utf-8";
}
//System.out.println("out::"+charest);
//这个输入流用于读取并用于后面将其存入外部存储中,这里用到了返回的编码信息,已保证中文不会出现乱码的情况。
BufferedReader bufr =new BufferedReader(new InputStreamReader(input,charest));
String buf =null;
while((buf=bufr.readLine())!=null)
{
bufw.write(buf);
bufw.newLine();
//System.out.println(buf);
}
//bufw.close();
//bufr.close();
}
/*
* 在写入12306网站时遇到了一个问题,就是sohu等网站使用的是zh-cn方式进行编码,而12306则采用的是UTF-8作为编码方式,因此必须在写入前将指出其的编码方式。
* 目前的代码使用的还是手动在代码上进行修改,需要专门写一个函数能够自动识别网页的编码方式并返回响应的编码方式;
* */
public static String getChrest(BufferedReader bufr,String Head)throws Exception
{
BufferedWriter bufw = new BufferedWriter(new FileWriter("buf1.html"));
//如果Head代码中拥有字符编码信息,则提取出来,这样就可以提前返回,不用读取后面的entity信息。
/*
* 在head中,只有字符编码信息才有=,因此利用这个规律判断是否有字符编码信息,并且将其分割,取最后一个就是编码规则。
* */
if(Head.contains("="))
{
String[] headString=Head.split("=");
for(int i=0;i 查看全部
c httpclient抓取网页(如何实现一下抢票软件的第一步库的相关知识?
)
最近想了解一下抢票软件的实现流程,于是开始晚上搜集资料。通过对众多数据的综合分析,发现大部分都是通过httpclient连接网络的。所以,作为实现抢票软件的第一步,有必要对httpclient库的相关知识有一个详细的了解。
无论是网络爬虫还是抢票软件,首先需要做的就是能够获取到的网页的代码。只有这样,才能进行后续的搜索和筛选工作。httpclient最基本的连接过程就是通过httpclient执行httpGet或httpPost方法,等到网站返回保存在httpResponse中,从中提取httpEntity获取网页数据。
<p>import java.io.*;
import java.util.regex.*;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpUriRequest;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHeader;
public class my12306Test {
public static void main(String[] args)throws Exception
{
// TODO Auto-generated method stub
connection();
}
/*
* 此方法用来实现对于网页数据的下载并存储在本地;
* 解决的问题:
* 1、连接网站下载网页前端代码;
* 2、不同网站的代码使用不同的编码方式,需要在读取时使用相应的字符编码格式;
* 3、在读取编码格式时,需要用到从网页的代码中利用正则表达式抓取charest这个编码格式属性的信息;
* */
public static void connection()throws Exception
{
//建立httpclient对象连接
HttpClient client = new DefaultHttpClient();
//使用get方法访问相关网站
HttpGet get =new HttpGet("http://www.taobao.com";);
//执行get方法,获取网站响应;
HttpResponse response = client.execute(get);
//得到网站响应实体并读取信息
HttpEntity entity = response.getEntity();
InputStream input = entity.getContent();
//BasicHeader getHeader =(BasicHeader) entity.getContentEncoding();
//显示网站响应头的信息
System.out.println(response.getStatusLine().getStatusCode());
System.out.println("Response content length: " + entity.getContentLength());
System.out.println("content-type:" +entity.getContentType().getValue());
System.out.println("getMehod::"+get.getMethod());//显示请求的方法名
System.out.println("getCountry::"+response.getLocale().getDefault());//getDisplayCountry());
/*
* 1、读取网站代码,输入流信息用于getCharest函数提取字符编码信息
* 2、利用getCharest函数从网站的头或者代码中获取网站字符编码规则
* */
BufferedReader bufrBuf = new BufferedReader(new InputStreamReader(input));
BufferedWriter bufw = new BufferedWriter(new FileWriter("bufJD.html"));
String charest = getChrest(bufrBuf,entity.getContentType().getValue());
//若果得到的是UTF编码,则还需要规范其的名称
if(charest.equals("utf"))
{
System.out.println("out:"+charest);
charest="utf-8";
}
//System.out.println("out::"+charest);
//这个输入流用于读取并用于后面将其存入外部存储中,这里用到了返回的编码信息,已保证中文不会出现乱码的情况。
BufferedReader bufr =new BufferedReader(new InputStreamReader(input,charest));
String buf =null;
while((buf=bufr.readLine())!=null)
{
bufw.write(buf);
bufw.newLine();
//System.out.println(buf);
}
//bufw.close();
//bufr.close();
}
/*
* 在写入12306网站时遇到了一个问题,就是sohu等网站使用的是zh-cn方式进行编码,而12306则采用的是UTF-8作为编码方式,因此必须在写入前将指出其的编码方式。
* 目前的代码使用的还是手动在代码上进行修改,需要专门写一个函数能够自动识别网页的编码方式并返回响应的编码方式;
* */
public static String getChrest(BufferedReader bufr,String Head)throws Exception
{
BufferedWriter bufw = new BufferedWriter(new FileWriter("buf1.html"));
//如果Head代码中拥有字符编码信息,则提取出来,这样就可以提前返回,不用读取后面的entity信息。
/*
* 在head中,只有字符编码信息才有=,因此利用这个规律判断是否有字符编码信息,并且将其分割,取最后一个就是编码规则。
* */
if(Head.contains("="))
{
String[] headString=Head.split("=");
for(int i=0;i
c httpclient抓取网页(添加头部Cookie进行模拟登录的两种方法-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-09 12:22
在网络爬虫中,我们经常需要设置一些头信息,这样我们的网络爬取行为就更像是使用浏览器浏览网页,而我们有时需要正确设置头信息才能得到正确的数据,否则就有了信息可用的页面可能与浏览器显示的页面不同。
设置header也可以模拟登录。我们可以设置cookies来获取登录页面并获取我们需要的数据。
接下来我会讲两种模拟登录的方式。
为模拟登录添加标头 cookie
代码显示如下:
import org.apache.http.Header;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import static java.lang.System.out;
/**
* Created by paranoid on 17-3-26.
*/
public class HttpClientDemo {
public static void main(String[] args){
//创建客户端
CloseableHttpClient closeableHttpClient = HttpClients.createDefault();
//创建请求Get实例
HttpGet httpGet = new HttpGet("https://www.baidu.com");
//设置头部信息进行模拟登录(添加登录后的Cookie)
httpGet.setHeader("Accept", "text/html,application/xhtml+xml," +
"application/xml;q=0.9,image/webp,*/*;q=0.8");
httpGet.setHeader("Accept-Encoding", "gzip, deflate, sdch, br");
httpGet.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
//httpGet.setHeader("Cookie", ".......");
httpGet.setHeader("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36" +
" (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
try {
//客户端执行httpGet方法,返回响应
CloseableHttpResponse closeableHttpResponse = closeableHttpClient.execute(httpGet);
//得到服务响应状态码
if (closeableHttpResponse.getStatusLine().getStatusCode() == 200) {
//打印所有响应头
Header[] headers = closeableHttpResponse.getAllHeaders();
for (Header header : headers) {
out.println(header.getName() + ": " + header.getValue());
}
}
else {
//如果是其他状态码则做其他处理
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
httpClient.close();
}
}
}
只要在上面的代码中添加登录cookie,就可以进行模拟登录。至于为什么添加cookie后可以进行模拟登录,大家可以在百度上搜索一下cookie的机制和作用,相信你就明白了。
以上参数可以在chrome的开发者工具中获取。Cookie是您手动登录后生成的,您也可以获取。设置这些参数后,我们模拟浏览器的行为和模拟登录。
您可以将不添加cookie的结果与添加cookie后的结果进行比较,您会发现模拟登录确实是可以的。
接下来,我们将讨论另一种实现模拟登录的方法,这种方法比较麻烦并且有一定的局限性(验证码),但它是最常用的。选择哪种模拟登录方式,有项目需求的时候就懂了~ 查看全部
c httpclient抓取网页(添加头部Cookie进行模拟登录的两种方法-乐题库)
在网络爬虫中,我们经常需要设置一些头信息,这样我们的网络爬取行为就更像是使用浏览器浏览网页,而我们有时需要正确设置头信息才能得到正确的数据,否则就有了信息可用的页面可能与浏览器显示的页面不同。
设置header也可以模拟登录。我们可以设置cookies来获取登录页面并获取我们需要的数据。
接下来我会讲两种模拟登录的方式。
为模拟登录添加标头 cookie
代码显示如下:
import org.apache.http.Header;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import java.io.IOException;
import static java.lang.System.out;
/**
* Created by paranoid on 17-3-26.
*/
public class HttpClientDemo {
public static void main(String[] args){
//创建客户端
CloseableHttpClient closeableHttpClient = HttpClients.createDefault();
//创建请求Get实例
HttpGet httpGet = new HttpGet("https://www.baidu.com";);
//设置头部信息进行模拟登录(添加登录后的Cookie)
httpGet.setHeader("Accept", "text/html,application/xhtml+xml," +
"application/xml;q=0.9,image/webp,*/*;q=0.8");
httpGet.setHeader("Accept-Encoding", "gzip, deflate, sdch, br");
httpGet.setHeader("Accept-Language", "zh-CN,zh;q=0.8");
//httpGet.setHeader("Cookie", ".......");
httpGet.setHeader("User-Agent", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36" +
" (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
try {
//客户端执行httpGet方法,返回响应
CloseableHttpResponse closeableHttpResponse = closeableHttpClient.execute(httpGet);
//得到服务响应状态码
if (closeableHttpResponse.getStatusLine().getStatusCode() == 200) {
//打印所有响应头
Header[] headers = closeableHttpResponse.getAllHeaders();
for (Header header : headers) {
out.println(header.getName() + ": " + header.getValue());
}
}
else {
//如果是其他状态码则做其他处理
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
httpClient.close();
}
}
}
只要在上面的代码中添加登录cookie,就可以进行模拟登录。至于为什么添加cookie后可以进行模拟登录,大家可以在百度上搜索一下cookie的机制和作用,相信你就明白了。
以上参数可以在chrome的开发者工具中获取。Cookie是您手动登录后生成的,您也可以获取。设置这些参数后,我们模拟浏览器的行为和模拟登录。
您可以将不添加cookie的结果与添加cookie后的结果进行比较,您会发现模拟登录确实是可以的。
接下来,我们将讨论另一种实现模拟登录的方法,这种方法比较麻烦并且有一定的局限性(验证码),但它是最常用的。选择哪种模拟登录方式,有项目需求的时候就懂了~
c httpclient抓取网页(.HttpClient模拟登录网页,一直持续记录学习!! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-01-04 20:09
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、使用org.apache.HttpClient模拟登录网页和抓取数据,需要用到HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn");
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
二、运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
查看全部
c httpclient抓取网页(.HttpClient模拟登录网页,一直持续记录学习!!
)
我目前正在学习Android并开发了一个类似于Super Course Schedule和Campus Today的APP。然而,我一直卡在抢课表这一步。遍历了很多数据,还是解决不了。我下定决心要系统信息HttpClient。写一个helloWord,继续记录和学习!
一、使用org.apache.HttpClient模拟登录网页和抓取数据,需要用到HttpClient包
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class HellWord {
//直接模拟
public static void main(String[] a){
//生成一个可关闭的HTTP浏览器(相当于)
CloseableHttpClient httpClient=HttpClients.createDefault();
CloseableHttpResponse response=null;
//创建http Get请求
HttpGet httpGet=new HttpGet("http://hll520.cn";);
try {
response=httpClient.execute(httpGet);//执行
} catch (IOException e) {
e.printStackTrace();
}
//获取网页源码
HttpEntity httpEntity=response.getEntity();//获取网页源码
try {
String h=EntityUtils.toString(httpEntity,"UTF-8");//指定编码避免乱码
System.out.printf(h);
} catch (IOException e) {
//io异常(网络问题)
e.printStackTrace();
}
//关闭HTTp
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
二、运行结果,模拟打开网页,使用getEntity显示网页的HTML源代码
c httpclient抓取网页((本文与shell编程无关)的需求分析与应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2022-01-03 00:16
一、灵感来源
前两天有朋友跟我提过这样的需求,希望从某个网页抓取数据,自动填入本地Excel表格中。当你需要做大量的数据统计时,将简单的任务自动化会显得很方便。这不就是shell编程的目的吗? (本文与shell编程无关,有感就贴)
二、需求分析
首先,对于需求,需要进行粗略的分析和设计(因为只是一个简单的测试demo,所以不需要考虑可行性、可维护性等),主要归结为到以下步骤:
要抓取网页数据,您必须知道网页的网址。这是我们从中抓取数据的入口网页。它需要根据发送的 url 生成响应并返回一个 html 响应页面。判断返回的结果是否是我们需要的。返回的html页面会将解析后的数据打包写入本地磁盘。 三、解决方案
这个例子测试了“Program it”信息的检索。
1、用到的jar包,主要包括
2、演示结构
模型类(存储对象):
package com.crawler.bean;
public class Model {
private String cardTitle;//帖子标题
private String authorName;//作者
private String cardContent;//帖子内容
private String cardDate;//发帖日期
public String getCardTitle() {
return cardTitle;
}
public void setCardTitle(String cardTitle) {
this.cardTitle = cardTitle;
}
public String getAuthorName() {
return authorName;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getCardContent() {
return cardContent;
}
public void setCardContent(String cardContent) {
this.cardContent = cardContent;
}
public String getCardDate() {
return cardDate;
}
public void setCardDate(String cardDate) {
this.cardDate = cardDate;
}
}
UrlToHtml 类(返回 html 响应页面):
package com.crawler.util;
import com.crawler.bean.Model;
import com.crawler.parser.DataParse;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class UrlToHtml {
public List URLParser(String url) throws Exception {
//初始化一个httpclient
HttpClient client = new DefaultHttpClient();
//用来接收解析的数据
List cardDatas = new ArrayList();
//获取响应文件,即html,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
}
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
//如果状态响应码为200,则获取html实体内容或者json文件
if (statusCode == 200) {
//设置字符编码
String entity = EntityUtils.toString(response.getEntity(), "utf-8");
//对响应的html内容进行解析
cardDatas = DataParse.getData(entity);
EntityUtils.consume(response.getEntity());
} else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return cardDatas;
}
}
DataParse 类(解析 html 响应页面):
package com.crawler.parser;
import com.crawler.bean.Model;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
public class DataParse {
public static List getData(String html) throws Exception {
//cardDatas用于存放结果
List cardDatas = new ArrayList();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的内容
Elements elements = doc.select("div[class=content]").select("ul[id=thread_list]").select("div[class=t_con cleafix]");
//遍历
for (Element ele : elements) {
//获取标题
String cardName = ele.select("a").text();
//获取作者
String authorName = ele.select("div[class=threadlist_author pull_right]").select("span").attr("title");
String newAuthorName = authorName.substring(6);
//获取内容
String cardContent = ele.select("div[class=threadlist_text pull_left]").text();
//获取日期
String cardDate = ele.select("div[class=threadlist_author pull_right]").select("span[class=pull-right is_show_create_time]").text();
//写入Model属性中
Model cd = new Model();
cd.setCardTitle(cardName);
cd.setAuthorName(newAuthorName);
cd.setCardContent(cardContent);
cd.setCardDate(cardDate);
cardDatas.add(cd);
}
//返回数据
return cardDatas;
}
}
WriteToLocal 类(写入本地磁盘):
<p>package com.crawler.service;
import com.crawler.bean.Model;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.hssf.util.HSSFColor;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class WriteToLocal {
public void writeToExcel(List cardDatas, int columeCount, String[] titles, String path) {
HSSFWorkbook hssfWorkbook = new HSSFWorkbook();
HSSFSheet sheet = hssfWorkbook.createSheet("我的表格");
//创建标题行
HSSFRow headRow = sheet.createRow(0);
for (int i = 0; i 查看全部
c httpclient抓取网页((本文与shell编程无关)的需求分析与应用)
一、灵感来源
前两天有朋友跟我提过这样的需求,希望从某个网页抓取数据,自动填入本地Excel表格中。当你需要做大量的数据统计时,将简单的任务自动化会显得很方便。这不就是shell编程的目的吗? (本文与shell编程无关,有感就贴)
二、需求分析
首先,对于需求,需要进行粗略的分析和设计(因为只是一个简单的测试demo,所以不需要考虑可行性、可维护性等),主要归结为到以下步骤:
要抓取网页数据,您必须知道网页的网址。这是我们从中抓取数据的入口网页。它需要根据发送的 url 生成响应并返回一个 html 响应页面。判断返回的结果是否是我们需要的。返回的html页面会将解析后的数据打包写入本地磁盘。 三、解决方案
这个例子测试了“Program it”信息的检索。
1、用到的jar包,主要包括
2、演示结构
模型类(存储对象):
package com.crawler.bean;
public class Model {
private String cardTitle;//帖子标题
private String authorName;//作者
private String cardContent;//帖子内容
private String cardDate;//发帖日期
public String getCardTitle() {
return cardTitle;
}
public void setCardTitle(String cardTitle) {
this.cardTitle = cardTitle;
}
public String getAuthorName() {
return authorName;
}
public void setAuthorName(String authorName) {
this.authorName = authorName;
}
public String getCardContent() {
return cardContent;
}
public void setCardContent(String cardContent) {
this.cardContent = cardContent;
}
public String getCardDate() {
return cardDate;
}
public void setCardDate(String cardDate) {
this.cardDate = cardDate;
}
}
UrlToHtml 类(返回 html 响应页面):
package com.crawler.util;
import com.crawler.bean.Model;
import com.crawler.parser.DataParse;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHttpResponse;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class UrlToHtml {
public List URLParser(String url) throws Exception {
//初始化一个httpclient
HttpClient client = new DefaultHttpClient();
//用来接收解析的数据
List cardDatas = new ArrayList();
//获取响应文件,即html,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
}
//获取响应状态码
int statusCode = response.getStatusLine().getStatusCode();
//如果状态响应码为200,则获取html实体内容或者json文件
if (statusCode == 200) {
//设置字符编码
String entity = EntityUtils.toString(response.getEntity(), "utf-8");
//对响应的html内容进行解析
cardDatas = DataParse.getData(entity);
EntityUtils.consume(response.getEntity());
} else {
//否则,消耗掉实体
EntityUtils.consume(response.getEntity());
}
return cardDatas;
}
}
DataParse 类(解析 html 响应页面):
package com.crawler.parser;
import com.crawler.bean.Model;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.util.ArrayList;
import java.util.List;
public class DataParse {
public static List getData(String html) throws Exception {
//cardDatas用于存放结果
List cardDatas = new ArrayList();
//采用Jsoup解析
Document doc = Jsoup.parse(html);
//获取html标签中的内容
Elements elements = doc.select("div[class=content]").select("ul[id=thread_list]").select("div[class=t_con cleafix]");
//遍历
for (Element ele : elements) {
//获取标题
String cardName = ele.select("a").text();
//获取作者
String authorName = ele.select("div[class=threadlist_author pull_right]").select("span").attr("title");
String newAuthorName = authorName.substring(6);
//获取内容
String cardContent = ele.select("div[class=threadlist_text pull_left]").text();
//获取日期
String cardDate = ele.select("div[class=threadlist_author pull_right]").select("span[class=pull-right is_show_create_time]").text();
//写入Model属性中
Model cd = new Model();
cd.setCardTitle(cardName);
cd.setAuthorName(newAuthorName);
cd.setCardContent(cardContent);
cd.setCardDate(cardDate);
cardDatas.add(cd);
}
//返回数据
return cardDatas;
}
}
WriteToLocal 类(写入本地磁盘):
<p>package com.crawler.service;
import com.crawler.bean.Model;
import org.apache.poi.hssf.usermodel.*;
import org.apache.poi.hssf.util.HSSFColor;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.List;
public class WriteToLocal {
public void writeToExcel(List cardDatas, int columeCount, String[] titles, String path) {
HSSFWorkbook hssfWorkbook = new HSSFWorkbook();
HSSFSheet sheet = hssfWorkbook.createSheet("我的表格");
//创建标题行
HSSFRow headRow = sheet.createRow(0);
for (int i = 0; i
c httpclient抓取网页(转发其他道友的文章需要发送自己的Cookietruetrue)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-01-01 02:13
以下是转发其他dao朋友的文章,主要是在使用过程中,需要向目标服务器发送自定义cookie,但是死活发送不了,最后百度的其他道友文章发现如果需要自己发cookies,需要做个设置:
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
道友文章地址:原文如下:
一般有两种方式
第一类handler.UseCookies=true(默认为true),默认会自带cookies,例如
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=600");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xxxx"),
new KeyValuePair("password", "xxxx"),
});
var result = await client.PostAsync("https://www.xxxx.com/cp/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,直接跳转到登录页面。
第二个设置handler.UseCookies = false,需要手动在headers中添加cookies。
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
var message = new HttpRequestMessage(HttpMethod.Get, url);
message.Headers.Add("Cookie", "session_id=7258abbd1544b6c530a9f406d3e600239bd788fb");
var result = await client.SendAsync(message);
result.EnsureSuccessStatusCode();
如果使用场景是:抓取需要登录的网页数据,推荐使用第一种方式,不设置任何cookies,httpclient登录后会在后续请求中自动放置cookies。 查看全部
c httpclient抓取网页(转发其他道友的文章需要发送自己的Cookietruetrue)
以下是转发其他dao朋友的文章,主要是在使用过程中,需要向目标服务器发送自定义cookie,但是死活发送不了,最后百度的其他道友文章发现如果需要自己发cookies,需要做个设置:
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
道友文章地址:原文如下:
一般有两种方式
第一类handler.UseCookies=true(默认为true),默认会自带cookies,例如
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=600");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xxxx"),
new KeyValuePair("password", "xxxx"),
});
var result = await client.PostAsync("https://www.xxxx.com/cp/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,直接跳转到登录页面。
第二个设置handler.UseCookies = false,需要手动在headers中添加cookies。
var handler = new HttpClientHandler() { UseCookies = false};
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
var message = new HttpRequestMessage(HttpMethod.Get, url);
message.Headers.Add("Cookie", "session_id=7258abbd1544b6c530a9f406d3e600239bd788fb");
var result = await client.SendAsync(message);
result.EnsureSuccessStatusCode();
如果使用场景是:抓取需要登录的网页数据,推荐使用第一种方式,不设置任何cookies,httpclient登录后会在后续请求中自动放置cookies。
c httpclient抓取网页(做一些必要的笔记,一来是对自己学习的巩固)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-29 00:15
我最近研究了 Jsoup 并做了一些必要的笔记。一是巩固所学知识,二是给遇到同样问题的人参考
文章目录
Jsoup 简介
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
Jsoup 从 URL、文件或字符串解析 HTML 的两个主要功能;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
注:jsoup基于MIT协议发布,可放心用于商业项目。
三种常用的获取元素的方法
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
doc.getElementById("nav_top"); // 获取id=nav_top的DOM元素
doc.getElementsByClass("card"); // 根据样式名称来查询DOM元素
doc.getElementsByAttribute("width"); // 根据属性名来查询DOM元素
doc.getElementsByAttributeValue("target", "_blank"); // 根据属性名和属性值来查询DOM元素
doc.select(".columns .column h1 a"); // 通过选择器查找DOM元素
Element e = linkElements.first();
e.text(); // 获取DOM元素文本
e.attr("href"); //获取DOM元素属性值
抓取网页内容的四个示例
以抓取一个博客页面上的所有博客标题和对应的博客链接为例。
网页内容
需要的包
org.apache.httpcomponents
httpclient
4.5.2
org.jsoup
jsoup
1.10.2
完整代码
/**
* @author ys
* @version 2.0
* @date 2020/5/24 11:46
* @decs: 使用选择器语法查找DOM元素
*/
public class Demo4 {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpclient实例
HttpGet httpGet = new HttpGet("https://www.zhjynet.cn/"); // 创建httpGet实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(httpGet); // 执行get请求
HttpEntity entity = response.getEntity(); // 获取返回实体
String content = EntityUtils.toString(entity, "utf-8"); // 获取网页内容
response.close();
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
Elements linkElements = doc.select(".columns .column .card .card-content h1 a"); // 通过选择器查找所有博客的标题
for (Element e : linkElements){
System.out.println("博客标题;"+e.text()); // 获取文本内容
System.out.println("博客链接:"+e.attr("href")); // 获取特定属性值
}
}
}
抓取结果
五点总结 查看全部
c httpclient抓取网页(做一些必要的笔记,一来是对自己学习的巩固)
我最近研究了 Jsoup 并做了一些必要的笔记。一是巩固所学知识,二是给遇到同样问题的人参考
文章目录
Jsoup 简介
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的API,可以通过DOM、CSS和类似jQuery的操作方法来检索和操作数据。
Jsoup 从 URL、文件或字符串解析 HTML 的两个主要功能;使用 DOM 或 CSS 选择器来查找和检索数据;操作 HTML 元素、属性和文本;
注:jsoup基于MIT协议发布,可放心用于商业项目。
三种常用的获取元素的方法
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
doc.getElementsByTag("title"); // 获取tag是title的所有DOM元素
doc.getElementById("nav_top"); // 获取id=nav_top的DOM元素
doc.getElementsByClass("card"); // 根据样式名称来查询DOM元素
doc.getElementsByAttribute("width"); // 根据属性名来查询DOM元素
doc.getElementsByAttributeValue("target", "_blank"); // 根据属性名和属性值来查询DOM元素
doc.select(".columns .column h1 a"); // 通过选择器查找DOM元素
Element e = linkElements.first();
e.text(); // 获取DOM元素文本
e.attr("href"); //获取DOM元素属性值
抓取网页内容的四个示例
以抓取一个博客页面上的所有博客标题和对应的博客链接为例。
网页内容
需要的包
org.apache.httpcomponents
httpclient
4.5.2
org.jsoup
jsoup
1.10.2
完整代码
/**
* @author ys
* @version 2.0
* @date 2020/5/24 11:46
* @decs: 使用选择器语法查找DOM元素
*/
public class Demo4 {
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault(); // 创建httpclient实例
HttpGet httpGet = new HttpGet("https://www.zhjynet.cn/";); // 创建httpGet实例
httpGet.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36");
CloseableHttpResponse response = httpClient.execute(httpGet); // 执行get请求
HttpEntity entity = response.getEntity(); // 获取返回实体
String content = EntityUtils.toString(entity, "utf-8"); // 获取网页内容
response.close();
Document doc = Jsoup.parse(content); // 解析网页 得到文档对象
Elements linkElements = doc.select(".columns .column .card .card-content h1 a"); // 通过选择器查找所有博客的标题
for (Element e : linkElements){
System.out.println("博客标题;"+e.text()); // 获取文本内容
System.out.println("博客链接:"+e.attr("href")); // 获取特定属性值
}
}
}
抓取结果
五点总结
c httpclient抓取网页( JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-28 00:20
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
用java爬虫Gecco工具抓取新闻的例子
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,爬取网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripthome。 查看全部
c httpclient抓取网页(
JAVA爬虫Gecco工具抓取新闻实例,具有一定的参考价值工具)
用java爬虫Gecco工具抓取新闻的例子
更新时间:2016年10月28日11:11:19 作者:赵霞客
本文主要介绍JAVA爬虫Gecco工具抓取新闻实例,有一定参考价值,感兴趣的朋友可以参考。
最近看到Gecoo爬虫工具,感觉比较简单好用,所以写了个DEMO来测试一下,爬取网站
,主要抓取新闻的标题和发布时间作为爬取测试对象。通过像 Jquery 选择器一样选择节点来抓取 HTML 节点非常方便。 Gecco代码主要是通过注解来实现URL匹配,看起来更加简洁美观。
添加Maven依赖
com.geccocrawler
gecco
1.0.8
编写抓取列表页面
@Gecco(matchUrl = "http://zj.zjol.com.cn/home.html?pageIndex={pageIndex}&pageSize={pageSize}",pipelines = "zJNewsListPipelines")
public class ZJNewsGeccoList implements HtmlBean {
@Request
private HttpRequest request;
@RequestParameter
private int pageIndex;
@RequestParameter
private int pageSize;
@HtmlField(cssPath = "#content > div > div > div.con_index > div.r.main_mod > div > ul > li > dl > dt > a")
private List newList;
}
@PipelineName("zJNewsListPipelines")
public class ZJNewsListPipelines implements Pipeline {
public void process(ZJNewsGeccoList zjNewsGeccoList) {
HttpRequest request=zjNewsGeccoList.getRequest();
for (HrefBean bean:zjNewsGeccoList.getNewList()){
//进入祥情页面抓取
SchedulerContext.into(request.subRequest("http://zj.zjol.com.cn"+bean.getUrl()));
}
int page=zjNewsGeccoList.getPageIndex()+1;
String nextUrl = "http://zj.zjol.com.cn/home.htm ... 3B%3B
//抓取下一页
SchedulerContext.into(request.subRequest(nextUrl));
}
}
撰写并拍摄吉祥爱情页
@Gecco(matchUrl = "http://zj.zjol.com.cn/news/[code].html" ,pipelines = "zjNewsDetailPipeline")
public class ZJNewsDetail implements HtmlBean {
@Text
@HtmlField(cssPath = "#headline")
private String title ;
@Text
@HtmlField(cssPath = "#content > div > div.news_con > div.news-content > div:nth-child(1) > div > p.go-left.post-time.c-gray")
private String createTime;
}
@PipelineName("zjNewsDetailPipeline")
public class ZJNewsDetailPipeline implements Pipeline {
public void process(ZJNewsDetail zjNewsDetail) {
System.out.println(zjNewsDetail.getTitle()+" "+zjNewsDetail.getCreateTime());
}
}
启动主函数
public class Main {
public static void main(String [] rags){
GeccoEngine.create()
//工程的包路径
.classpath("com.zhaochao.gecco.zj")
//开始抓取的页面地址
.start("http://zj.zjol.com.cn/home.htm ... 6quot;)
//开启几个爬虫线程
.thread(10)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(10)
//使用pc端userAgent
.mobile(false)
//开始运行
.run();
}
}
获取结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持Scripthome。
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-28 00:20
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 的一个子项目,可用于提供支持 HTTP 协议的高效、最新且功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套后,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
c httpclient抓取网页(2.1.网络爬虫入门2.1.1.环境准备创建工程-crawler)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-12-23 23:00
2.1.网络爬虫入门2.1.1. 环境准备
JDK1.8
IntelliJ IDEA
IDEA自带的Maven
2.1.2.环境准备
创建Maven项目itcast-crawler-first并在pom.xml中添加依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.1.3. 加入log4j.properties
log4j.rootLogger=调试,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{
yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.1.4. 写代码
```java
编写最简单的爬虫,抓取传智播客首页:http://www.itcast.cn/
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://www.itcast.cn/");
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
测试结果:可以获取到页面数据
3.1. 网络爬虫简介
大数据时代,信息的采集是一项重要的任务,互联网上的数据是海量的。如果单纯依靠人力资源进行信息采集,不仅效率低下、繁琐,而且采集成本高。提升。如何在互联网上自动高效地获取我们感兴趣的信息并为我们使用是一个重要的问题,爬虫技术就是为了解决这些问题而诞生的。
网络爬虫也叫网络机器人,可以代替人自动采集,组织互联网上的数据和信息。它是一个程序或脚本,按照一定的规则自动抓取万维网上的信息,并可以自动采集所有它可以访问的页面内容获取相关数据。
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
3.2. 为什么要学习网络爬虫
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?只有清楚地知道我们的学习目的,才能更好地学习这些知识。在这里,我总结了学习爬虫的4个常见原因:
可以实现搜索引擎
在我们学会了如何编写爬虫之后,我们就可以使用爬虫自动采集互联网上的信息,返回后采集会存储或处理相应的信息。当我们需要检索某些信息时,只能使用采集 @采集从返回的信息中检索,实现了私有搜索引擎。
大数据时代让我们获得了更多的数据源。
在进行大数据分析或数据挖掘时,需要数据源进行分析。我们可以从一些提供统计数据的网站,或者一些文献或内部资料中获取数据,但是这些获取数据的方法有时难以满足我们的数据需求,而手动从网上找也太费精力了这些数据。此时,我们可以利用爬虫技术自动从互联网上获取我们感兴趣的数据内容,并将这些数据内容抓取回来作为我们的数据源,进而进行更深入的数据分析,获取更多有价值的信息。
可以更好地进行搜索引擎优化(SEO)。
对于很多SEO从业者来说,为了更好的完成工作,他们必须非常清楚搜索引擎的工作原理,同时也需要掌握搜索引擎爬虫的工作原理。
而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,这样你在做搜索引擎优化的时候,知己知彼,百战不殆。
有利于就业。
在就业方面,爬虫工程师方向是不错的选择之一,因为对爬虫工程师的需求越来越大,能胜任这个职位的人越来越少,所以属于比较稀缺的职业方向,并且随着数据时代和人工智能的到来,爬虫技术的应用会越来越广泛,未来会有很好的发展空间。 查看全部
c httpclient抓取网页(2.1.网络爬虫入门2.1.1.环境准备创建工程-crawler)
2.1.网络爬虫入门2.1.1. 环境准备
JDK1.8
IntelliJ IDEA
IDEA自带的Maven
2.1.2.环境准备
创建Maven项目itcast-crawler-first并在pom.xml中添加依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
2.1.3. 加入log4j.properties
log4j.rootLogger=调试,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{
yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
2.1.4. 写代码
```java
编写最简单的爬虫,抓取传智播客首页:http://www.itcast.cn/
public static void main(String[] args) throws Exception {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("http://www.itcast.cn/";);
CloseableHttpResponse response = httpClient.execute(httpGet);
if (response.getStatusLine().getStatusCode() == 200) {
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
测试结果:可以获取到页面数据
3.1. 网络爬虫简介
大数据时代,信息的采集是一项重要的任务,互联网上的数据是海量的。如果单纯依靠人力资源进行信息采集,不仅效率低下、繁琐,而且采集成本高。提升。如何在互联网上自动高效地获取我们感兴趣的信息并为我们使用是一个重要的问题,爬虫技术就是为了解决这些问题而诞生的。
网络爬虫也叫网络机器人,可以代替人自动采集,组织互联网上的数据和信息。它是一个程序或脚本,按照一定的规则自动抓取万维网上的信息,并可以自动采集所有它可以访问的页面内容获取相关数据。
从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的 URL 并将它们放入队列中,直到满足系统的某个停止条件。
3.2. 为什么要学习网络爬虫
我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?只有清楚地知道我们的学习目的,才能更好地学习这些知识。在这里,我总结了学习爬虫的4个常见原因:
可以实现搜索引擎
在我们学会了如何编写爬虫之后,我们就可以使用爬虫自动采集互联网上的信息,返回后采集会存储或处理相应的信息。当我们需要检索某些信息时,只能使用采集 @采集从返回的信息中检索,实现了私有搜索引擎。
大数据时代让我们获得了更多的数据源。
在进行大数据分析或数据挖掘时,需要数据源进行分析。我们可以从一些提供统计数据的网站,或者一些文献或内部资料中获取数据,但是这些获取数据的方法有时难以满足我们的数据需求,而手动从网上找也太费精力了这些数据。此时,我们可以利用爬虫技术自动从互联网上获取我们感兴趣的数据内容,并将这些数据内容抓取回来作为我们的数据源,进而进行更深入的数据分析,获取更多有价值的信息。
可以更好地进行搜索引擎优化(SEO)。
对于很多SEO从业者来说,为了更好的完成工作,他们必须非常清楚搜索引擎的工作原理,同时也需要掌握搜索引擎爬虫的工作原理。
而学习爬虫,可以更深入的了解搜索引擎爬虫的工作原理,这样你在做搜索引擎优化的时候,知己知彼,百战不殆。
有利于就业。
在就业方面,爬虫工程师方向是不错的选择之一,因为对爬虫工程师的需求越来越大,能胜任这个职位的人越来越少,所以属于比较稀缺的职业方向,并且随着数据时代和人工智能的到来,爬虫技术的应用会越来越广泛,未来会有很好的发展空间。
c httpclient抓取网页(案例展示如何使用Jsoup进行解析,案例中将获取博客园首页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-12-20 14:17
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
我只听到山中建筑师的声音:
蜡拍半笼金翡翠,芙蓉微微绣有麝香烟。上联和下联谁来匹配?
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
此代码由Java架构师必看网-架构君整理
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人建议使用 select 方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
此代码由Java架构师必看网-架构君整理
public static void main(String[] args) {
String unsafe = "<p>博客园";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/");
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
我猜你会喜欢: 查看全部
c httpclient抓取网页(案例展示如何使用Jsoup进行解析,案例中将获取博客园首页)
下面的例子展示了如何使用 Jsoup 进行分析。在这种情况下,将获得博客花园首页的标题和第一页的博客列表文章。
请看代码(在前面代码的基础上进行操作,如果不知道如何使用httpclient,请跳转页面阅读):
引入依赖
org.jsoup
jsoup
1.12.1
我只听到山中建筑师的声音:
蜡拍半笼金翡翠,芙蓉微微绣有麝香烟。上联和下联谁来匹配?
实现代码。在实现代码之前,先分析一下html结构。标题不用说了,文章列表呢?浏览器按F12查看页面元素源码,会发现list是一个大div,id="post_list",每篇文章文章都是一个小div,class="post_item"
然后就可以开始代码了,Jsoup的核心代码如下(整体源码会在文章的最后给出):
此代码由Java架构师必看网-架构君整理
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
根据上面的代码,你会发现我通过Jsoup.parse(String html)方法解析httpclient获取到的html内容获取Document,然后文档可以通过两种方式获取它的子元素:像js一样,它可以通过 getElementXXXX 获取。像 jquery 选择器一样传递 select() 方法。无论哪种方式都可以,我个人建议使用 select 方法。对于元素中的属性,比如超链接地址,可以使用 element.attr(String) 方法获取,对于元素的文本内容,可以使用 element.text() 方法获取。
执行代码,查看结果(不得不感慨博客园的园友真是厉害。从上面对首页html结构的分析,到Jsoup分析的代码的执行,还有这么多首页在这一段时间文章)
由于新的文章发布太快,上面的截图和这里的输出有些不同。
三、Jsoup的其他用法
我Jsoup除了可以发挥httpclient小哥的工作成果外,还可以自己动手,自己抓取页面,然后自己分析。上面已经展示了分析技巧,下面展示如何自己抓取页面。其实很简单。不同的是我直接拿到文档,不需要通过Jsoup.parse()方法解析。
除了直接获取在线资源,我还可以分析本地资源:
代码:
public static void main(String[] args) {
try {
Document document = Jsoup.parse(new File("d://1.html"), "utf-8");
System.out.println(document);
} catch (IOException e) {
e.printStackTrace();
}
}
四、Jsoup 另一个值得一提的功能
你一定有过这样的经历。在你页面的文本框中,如果你输入了html元素,保存后页面布局很可能会乱七八糟。如果能过滤一下内容就完美了。
碰巧我可以用 Jsoup 做到这一点。
此代码由Java架构师必看网-架构君整理
public static void main(String[] args) {
String unsafe = "<p>博客园";
System.out.println("unsafe: " + unsafe);
String safe = Jsoup.clean(unsafe, Whitelist.basic());
System.out.println("safe: " + safe);
}</p>
通过 Jsoup.clean 方法,使用白名单进行过滤。结果:
unsafe: <p>博客园
safe:
<a rel="nofollow">博客园</a></p>
五、结论
通过以上,大家都相信我很厉害了。不仅可以解析HttpClient抓取到的html元素,还可以自己抓取页面dom,还可以加载解析本地保存的html文件。
另外,我可以通过白名单过滤字符串,过滤掉一些不安全的字符。
最重要的是,以上所有函数的API调用都比较简单。
============华丽的分割线============
码字不易,点赞再走~~
最后附上案例分析中博客园首页文章列表的完整源码:
package httpclient_learn;
import java.io.IOException;
import org.apache.http.HttpEntity;
import org.apache.http.HttpStatus;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.utils.HttpClientUtils;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class HttpClientTest {
public static void main(String[] args) {
//1.生成httpclient,相当于该打开一个浏览器
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
//2.创建get请求,相当于在浏览器地址栏输入 网址
HttpGet request = new HttpGet("https://www.cnblogs.com/";);
//设置请求头,将爬虫伪装成浏览器
request.setHeader("User-Agent","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36");
// HttpHost proxy = new HttpHost("60.13.42.232", 9999);
// RequestConfig config = RequestConfig.custom().setProxy(proxy).build();
// request.setConfig(config);
try {
//3.执行get请求,相当于在输入地址栏后敲回车键
response = httpClient.execute(request);
//4.判断响应状态为200,进行处理
if(response.getStatusLine().getStatusCode() == HttpStatus.SC_OK) {
//5.获取响应内容
HttpEntity httpEntity = response.getEntity();
String html = EntityUtils.toString(httpEntity, "utf-8");
System.out.println(html);
/**
* 下面是Jsoup展现自我的平台
*/
//6.Jsoup解析html
Document document = Jsoup.parse(html);
//像js一样,通过标签获取title
System.out.println(document.getElementsByTag("title").first());
//像js一样,通过id 获取文章列表元素对象
Element postList = document.getElementById("post_list");
//像js一样,通过class 获取列表下的所有博客
Elements postItems = postList.getElementsByClass("post_item");
//循环处理每篇博客
for (Element postItem : postItems) {
//像jquery选择器一样,获取文章标题元素
Elements titleEle = postItem.select(".post_item_body a[class='titlelnk']");
System.out.println("文章标题:" + titleEle.text());;
System.out.println("文章地址:" + titleEle.attr("href"));
//像jquery选择器一样,获取文章作者元素
Elements footEle = postItem.select(".post_item_foot a[class='lightblue']");
System.out.println("文章作者:" + footEle.text());;
System.out.println("作者主页:" + footEle.attr("href"));
System.out.println("*********************************");
}
} else {
//如果返回状态不是200,比如404(页面不存在)等,根据情况做处理,这里略
System.out.println("返回状态不是200");
System.out.println(EntityUtils.toString(response.getEntity(), "utf-8"));
}
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
//6.关闭
HttpClientUtils.closeQuietly(response);
HttpClientUtils.closeQuietly(httpClient);
}
}
}
查看代码
我猜你会喜欢:
c httpclient抓取网页(Web信息提取、数据挖掘、Crowbar的运行方法以及解析执行方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-19 19:13
在网页信息抽取和数据挖掘的过程中,一个关键的步骤是获取网页的源代码。但是,由于种种原因,网页上我们感兴趣的内容很有可能是在HTML文档加载或使用AJAX异步读取后,通过客户端JavaScript输出的。这样我们就可以直接使用POCO或者HttpClient等库了。这些内容不可用于下载文档。当然,你也可以选择自己来实现对JS代码的分析和执行,但是借助浏览器来完成这些脚本的执行无疑要简单得多,也更可行。
Crowbar 是麻省理工学院 SIMILE 团队编写的工具。它使用Firefox的Gecko引擎在网页上执行脚本,然后在脚本执行一段时间后将DOM重新序列化成HTML代码输出。
Crowbar这个词本身的意思是撬棍,一种用来拔钉子的工具。用在这里也很有意义。使用Crowbar读取难以直接获取的异步输出内容就像用Crowbar拔钉子一样。简单。遗憾的是,Crowbar 似乎在几年前就停止了开发,并没有正式的 Release。也许作者已经找到了更好的方法来完成这个任务,但我还没有找到。
环保要求
XULRunner (v1.8.1 +) XUL 是 Mozilla 使用 XML 来描述用户界面的技术,Firefox 就是基于该技术构建的。有了XULRunner工具,我们就可以轻松的执行我们自己编写的类似于Firefox的用户界面程序。Crowbar就是基于这个环境。配置 XULRunner 可以参考 Mozilla 对 XULRunner 的介绍。根据以上说明,您应该可以轻松运行 Hello World 程序。获取撬棍
Crowbar 没有正式发布的版本。官方下载只给出了Subversion库的地址:
http://simile.mit.edu/repository/crowbar/trunk/
或者你可以在这里下载我的修改版本。运行撬棍
官方文档分别描述了Windows/Linux/MacOSX下的操作方法。这里我简单介绍一下Windows下的方法。运行 cmd.exe 并输入以下命令:Bash
c:\> %XULRUNNER_HOME%\xulrunner.exe --install-app %CROWBAR%\xulappc:\> cd %CROWBAR%\xulappc:\> %XULRUNNER_HOME%\xulrunner.exe application.ini
其中,%XULRUNNER_HOME%为XULRunner的安装目录,%CROWBAR%为Crowbar的文件目录。如果成功,将弹出一个标题为“Crowbar”的窗口。
当 Crowbar 运行时,这个小窗口会显示当前正在读取或已读取的最后一个网页地址。其最终输出作为基于 REST 的 Web 服务提供。程序默认会监听本地10000端口,当用户打开任意浏览器指向127.0.0.1:10000时,浏览器可以调用Crowbar查看结果。当然,我们最终并不想在浏览器中得到结果。当我们使用HttpClient等库进行网页抓取时,只需要将目标地址设置为类似如下即可。
http://127.0.0.1:10000/%3Furl% ... D1000
其中url为URL编码后的目标URL,delay指定DOM加载后网页内容输出的时间。
Crowbar 还提供了几种不同的爬行模式。官方文档似乎不完整。如果你有兴趣,你需要检查源代码。当然,目前使用Crowbar的方法只能完成一些简单的应用,我还没有测试过大规模网络爬虫的性能。修复中文乱码问题
使用Crowbar读取中文网页内容时,会出现乱码,因为Crowbar没有处理过非英文字符集。只需修改其部分源代码即可解决乱码问题。
打开文件%CROWBAR%\xulapp\chrome\crowbar\content\crowbar.js,找到第223行,将整个try代码块的内容改成如下:
try {
var charset = "UTF-8"; // Can be any character encoding name that Mozilla supports
var os = Components.classes["@mozilla.org/intl/converter-output-stream;1"]
.createInstance(Components.interfaces.nsIConverterOutputStream);
os.init(outstream, charset, 0, 0x0000);
os.writeString(response);
os.close();
instream.close();
outstream.close();
}
这样,最终的结果就可以用UTF-8编码输出了。
参考 查看全部
c httpclient抓取网页(Web信息提取、数据挖掘、Crowbar的运行方法以及解析执行方法)
在网页信息抽取和数据挖掘的过程中,一个关键的步骤是获取网页的源代码。但是,由于种种原因,网页上我们感兴趣的内容很有可能是在HTML文档加载或使用AJAX异步读取后,通过客户端JavaScript输出的。这样我们就可以直接使用POCO或者HttpClient等库了。这些内容不可用于下载文档。当然,你也可以选择自己来实现对JS代码的分析和执行,但是借助浏览器来完成这些脚本的执行无疑要简单得多,也更可行。
Crowbar 是麻省理工学院 SIMILE 团队编写的工具。它使用Firefox的Gecko引擎在网页上执行脚本,然后在脚本执行一段时间后将DOM重新序列化成HTML代码输出。
Crowbar这个词本身的意思是撬棍,一种用来拔钉子的工具。用在这里也很有意义。使用Crowbar读取难以直接获取的异步输出内容就像用Crowbar拔钉子一样。简单。遗憾的是,Crowbar 似乎在几年前就停止了开发,并没有正式的 Release。也许作者已经找到了更好的方法来完成这个任务,但我还没有找到。
环保要求
XULRunner (v1.8.1 +) XUL 是 Mozilla 使用 XML 来描述用户界面的技术,Firefox 就是基于该技术构建的。有了XULRunner工具,我们就可以轻松的执行我们自己编写的类似于Firefox的用户界面程序。Crowbar就是基于这个环境。配置 XULRunner 可以参考 Mozilla 对 XULRunner 的介绍。根据以上说明,您应该可以轻松运行 Hello World 程序。获取撬棍
Crowbar 没有正式发布的版本。官方下载只给出了Subversion库的地址:
http://simile.mit.edu/repository/crowbar/trunk/
或者你可以在这里下载我的修改版本。运行撬棍
官方文档分别描述了Windows/Linux/MacOSX下的操作方法。这里我简单介绍一下Windows下的方法。运行 cmd.exe 并输入以下命令:Bash
c:\> %XULRUNNER_HOME%\xulrunner.exe --install-app %CROWBAR%\xulappc:\> cd %CROWBAR%\xulappc:\> %XULRUNNER_HOME%\xulrunner.exe application.ini
其中,%XULRUNNER_HOME%为XULRunner的安装目录,%CROWBAR%为Crowbar的文件目录。如果成功,将弹出一个标题为“Crowbar”的窗口。
当 Crowbar 运行时,这个小窗口会显示当前正在读取或已读取的最后一个网页地址。其最终输出作为基于 REST 的 Web 服务提供。程序默认会监听本地10000端口,当用户打开任意浏览器指向127.0.0.1:10000时,浏览器可以调用Crowbar查看结果。当然,我们最终并不想在浏览器中得到结果。当我们使用HttpClient等库进行网页抓取时,只需要将目标地址设置为类似如下即可。
http://127.0.0.1:10000/%3Furl% ... D1000
其中url为URL编码后的目标URL,delay指定DOM加载后网页内容输出的时间。
Crowbar 还提供了几种不同的爬行模式。官方文档似乎不完整。如果你有兴趣,你需要检查源代码。当然,目前使用Crowbar的方法只能完成一些简单的应用,我还没有测试过大规模网络爬虫的性能。修复中文乱码问题
使用Crowbar读取中文网页内容时,会出现乱码,因为Crowbar没有处理过非英文字符集。只需修改其部分源代码即可解决乱码问题。
打开文件%CROWBAR%\xulapp\chrome\crowbar\content\crowbar.js,找到第223行,将整个try代码块的内容改成如下:
try {
var charset = "UTF-8"; // Can be any character encoding name that Mozilla supports
var os = Components.classes["@mozilla.org/intl/converter-output-stream;1"]
.createInstance(Components.interfaces.nsIConverterOutputStream);
os.init(outstream, charset, 0, 0x0000);
os.writeString(response);
os.close();
instream.close();
outstream.close();
}
这样,最终的结果就可以用UTF-8编码输出了。
参考
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-12-17 01:20
数据是科学研究活动的重要依据。本系列博客将介绍如何使用Java工具获取网络数据。
博客系列
Java爬虫介绍(一)——HttpClient请求(本文)
Java爬虫介绍(二)——Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序访问互联网,然后将数据保存到本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般都是从网站获取的,比如电商网站的商品信息、商品评论、微博信息等,爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要使用工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫案例。
一、环境准备
这里的环境是指开发环境。本博客将使用Java编写爬虫。因此,有必要搭建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ IDEA:
JDK安装和环境变量配置网上有很多,就不多说了。IntelliJ IDEA是傻瓜式的安装,基本不会有问题。不要说什么。
二、创建项目
环境安装好后,我们打开IntelliJ IDEA,然后创建一个Maven项目。Group Id 和 Artifact Id 自己写也没关系。创建后,我们的目录将如下图所示。
好了,开始写爬虫吧。
三、第一个例子
首先,假设我们需要爬取数据来学习网站第一页的blog()。首先我们需要使用maven导入HttpClient4.5.3包(这是最新的包,可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
1234567
Java本身提供了一个关于网络访问的包,在,然后还不够强大。于是Apache基金会发布了一个开源的http请求包HttpClient,提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好了,在使用 pom.xml 下载这个包之后,我们就可以开始编写我们的第一个爬虫示例了。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog");
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
如上代码所示,爬虫第一步需要搭建一个客户端,即请求者。这里我们使用CloseableHttpClient作为我们的请求者,然后判断以何种方式请求哪个URL,然后使用HttpResponse获取请求的地址即可得到相应的结果。最后取出HttpEntity,进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。这样我们的第一个爬虫就成功下载了网门需要的页面内容。 查看全部
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
数据是科学研究活动的重要依据。本系列博客将介绍如何使用Java工具获取网络数据。
博客系列
Java爬虫介绍(一)——HttpClient请求(本文)
Java爬虫介绍(二)——Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序访问互联网,然后将数据保存到本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般都是从网站获取的,比如电商网站的商品信息、商品评论、微博信息等,爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要使用工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫案例。
一、环境准备
这里的环境是指开发环境。本博客将使用Java编写爬虫。因此,有必要搭建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ IDEA:
JDK安装和环境变量配置网上有很多,就不多说了。IntelliJ IDEA是傻瓜式的安装,基本不会有问题。不要说什么。
二、创建项目
环境安装好后,我们打开IntelliJ IDEA,然后创建一个Maven项目。Group Id 和 Artifact Id 自己写也没关系。创建后,我们的目录将如下图所示。
好了,开始写爬虫吧。
三、第一个例子
首先,假设我们需要爬取数据来学习网站第一页的blog()。首先我们需要使用maven导入HttpClient4.5.3包(这是最新的包,可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
1234567
Java本身提供了一个关于网络访问的包,在,然后还不够强大。于是Apache基金会发布了一个开源的http请求包HttpClient,提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好了,在使用 pom.xml 下载这个包之后,我们就可以开始编写我们的第一个爬虫示例了。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog";);
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647
如上代码所示,爬虫第一步需要搭建一个客户端,即请求者。这里我们使用CloseableHttpClient作为我们的请求者,然后判断以何种方式请求哪个URL,然后使用HttpResponse获取请求的地址即可得到相应的结果。最后取出HttpEntity,进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。这样我们的第一个爬虫就成功下载了网门需要的页面内容。
c httpclient抓取网页(某一的事情交给httpclient替你完成(图)HTTP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-12-15 00:06
一般情况下,我们使用IE或谷歌浏览器访问WEB服务器来浏览页面查看信息或提交一些数据等。但是,在某些情况下,可能需要通过程序访问这些页面来“窃取”一些来自其他人网页的数据。比如我们想获取某个微信公众号的信息,但是我们自己没有这样的数据,所以只能通过搜狗搜索引擎来完成。我们需要将公众号关键字提交到网页中,并从返回的页面中解析出我们想要的数据。.
JDK包中已经提供了访问HTTP协议的基本功能。如果要访问的对象只是一个简单的页面,JDK提供的HttpURLConnection就可以处理。
但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问。有的需要用户登录后才能使用,有的需要认证,有的通过加密方式传输,比如HTTPS。.
这时候就涉及到COOKIE问题的处理了。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,需要程序登录后访问服务页面。这个过程需要自己处理cookies。使用 .HttpURLConnection 来完成这些功能是多么可怕的事情!
HttpClient 是 Apache Jakarta Common 下的一个子项目,专门用于简化 HTTP 客户端和服务器之间的各种通信编程。通过它,你可以轻松解决原本头疼的问题。例如,您不再关心 HTTP 或 HTTPS 通信方式,告诉它您要使用 HTTPS,然后让 httpclient 为您完成剩下的工作。 查看全部
c httpclient抓取网页(某一的事情交给httpclient替你完成(图)HTTP)
一般情况下,我们使用IE或谷歌浏览器访问WEB服务器来浏览页面查看信息或提交一些数据等。但是,在某些情况下,可能需要通过程序访问这些页面来“窃取”一些来自其他人网页的数据。比如我们想获取某个微信公众号的信息,但是我们自己没有这样的数据,所以只能通过搜狗搜索引擎来完成。我们需要将公众号关键字提交到网页中,并从返回的页面中解析出我们想要的数据。.
JDK包中已经提供了访问HTTP协议的基本功能。如果要访问的对象只是一个简单的页面,JDK提供的HttpURLConnection就可以处理。
但是,考虑到一些服务授权问题,很多公司提供的页面往往无法通过简单的URL访问。有的需要用户登录后才能使用,有的需要认证,有的通过加密方式传输,比如HTTPS。.
这时候就涉及到COOKIE问题的处理了。我们知道,目前流行的 ASP、JSP 等动态 Web 技术都使用 cookie 来处理会话信息。为了让我们的程序使用他人提供的服务页面,需要程序登录后访问服务页面。这个过程需要自己处理cookies。使用 .HttpURLConnection 来完成这些功能是多么可怕的事情!
HttpClient 是 Apache Jakarta Common 下的一个子项目,专门用于简化 HTTP 客户端和服务器之间的各种通信编程。通过它,你可以轻松解决原本头疼的问题。例如,您不再关心 HTTP 或 HTTPS 通信方式,告诉它您要使用 HTTPS,然后让 httpclient 为您完成剩下的工作。
c httpclient抓取网页(微博爬虫,单机每日千万级的数据ampamp总结(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 249 次浏览 • 2021-12-07 01:10
微博爬虫,单机几千万日数据&&吐血整理微博爬虫总结介绍
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没解决,所以每天上百万的数据里有水。仅爬取友情就可以达到百万级别的数据。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级。
不过既然坑已经被埋了,就一定要填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经彻底解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能用于复杂爬行!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这一切都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这种需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,必须通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站一页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以举例来说,如果搜索时间段是10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量很大,过滤条件很详细,比如region,其他所有爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是,由于您购买的帐户较小,可能会因操作频繁而被微博瞄准。登录时账号异常,会生成非常恶心的验证码,如下图。
在这种情况下,我建议你放弃治疗,不要考虑破解这个验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不同的,所以必须构建两个账户池,一个是cn站点,一个是com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求之间的延迟会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
总觉得我上面搭建的爬虫已经占了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化。这里推荐Redis-Scrapy。所有爬虫共享一个Redis队列,通过Redis将URL统一分配给爬虫,Redis是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前运行稳定
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。 查看全部
c httpclient抓取网页(微博爬虫,单机每日千万级的数据ampamp总结(图))
微博爬虫,单机几千万日数据&&吐血整理微博爬虫总结介绍
之前我发布了一个每天百万数据的博客微博爬虫,并在Github上开源了代码,然后很多人联系我,我也在公众号转载了这个文章。
但是对于微博爬虫,我还是心虚,因为账号池问题还没解决,所以每天上百万的数据里有水。仅爬取友情就可以达到百万级别的数据。如果爬取关键词搜索到的微博,或者一个人的所有微博,都不会达到百万级。
不过既然坑已经被埋了,就一定要填满!所以自从写了那篇文章,我就一直想搭建一个稳定的单机日千万条微博爬虫系统。
值得庆幸的是,这个问题现在已经彻底解决了!也对微博爬虫有了更深入的了解!
微博站点分析
目前共有三个微博站点,分别是
可以看出,这三个站点的复杂度是逐渐增加的。显然,如果能完成最简单的爬行,肯定不会去复杂爬行,但实际上,有些只能用于复杂爬行!
什么任务不能完成?可以说,抓取一个人的所有微博,抓取好友,抓取个人信息,这一切都可以在这个网站上完成。
但是,有一个任务无法完成,那就是高级搜索
微博高级搜索
也许你经常有这种需求。比如最近兴起的疫苗事件,你要抢7月10日到7月20日这段时间,提到疫苗的微博关键词。
这其实是一个非常刚性的需求,必须通过微博的高级搜索来完成。
对于高级搜索界面,三个微博站点的条件是:
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time。请注意,这里的时间以天为单位。
下面具体搜索关键词,疫苗
可以看到一页有10条搜索结果,最多显示100页,也就是1000条结果。
因此,搜索结果最多会返回 1,000 条微博。
本站的时间单位是天,比如搜索时间段是10天,那么最多可以抓取10*1000=10000条数据。
不幸的是,该站点没有高级搜索界面
高级搜索条目:
可以看到这里可以过滤的条件是type、user、time、region。请注意,这里的时间以小时为单位。
本站一页收录20条微博,最多50页,因此单次搜索最多可返回1000条微博数据。
但是这个网站的时间单位是小时,
所以举例来说,如果搜索时间段是10天,那么最多可以抓取10*24*1000=240,000条数据。
总结
所以可能只需要使用高级搜索,而你需要的搜索结果数据量很大,过滤条件很详细,比如region,其他所有爬虫需求都可以通过本站抓取,包括比较粗略的高级搜索
微博爬取经验总结
或者传统的验证码,5位数字和字母的组合
这种验证码可以通过扫码平台解决。具体登录代码请参考这里
但是,由于您购买的帐户较小,可能会因操作频繁而被微博瞄准。登录时账号异常,会生成非常恶心的验证码,如下图。
在这种情况下,我建议你放弃治疗,不要考虑破解这个验证码。所以平时买的小号也不是100%可用的,有些是异常账号!
构建千万级爬虫系统
基于以上分析,如果你想搭建一个千万级别的爬虫系统,你只需要做一件事,搭建一个账户池。
建立账户池的步骤也很简单:
1. 大量购买账号
2. 登录微博并保存cookie
通过这两个步骤,对于每个后续请求,只需从帐户池中随机选择一个帐户。
这两个站点的cookies是不同的,所以必须构建两个账户池,一个是cn站点,一个是com站点。
这时候结合我之前写的项目WeiboSpider就可以轻松达到每天数百万的数据抓取了!
注意这里的实际爬取速度与你的账户池大小和电脑带宽有很大关系。如果账户池不大,请求之间的延迟会稍长一些。如果带宽很小,每个请求都需要时间。更长
我的数据是
账户池中有230个账户,每个请求延迟0. 1秒,一天可以达到2到300万条爬取结果。
冲刺千万
总觉得我上面搭建的爬虫已经占了带宽!
有一次,我启动了一个爬虫程序,发现另外一个爬虫可以达到每天2到300万的爬虫速度。同时,之前的爬虫也以每天2到300万的爬虫速度在运行。
所以,只是因为CPU限制了爬虫的爬取量,而不是网络IO!
所以只需要使用多进程优化。这里推荐Redis-Scrapy。所有爬虫共享一个Redis队列,通过Redis将URL统一分配给爬虫,Redis是一个分布式爬虫系统。
它可以部署在不同的机器上(如果一台机器满是带宽/CPU),或者只是在一台机器上运行多个进程。
就这样,我开了5个进程,不敢再开。毕竟账户池还有200多个。
那么结果是:
一分钟8000条数据,一天1100万+
本爬虫系统目前运行稳定
于是最初的目标就实现了,一个千万级别的微博爬虫系统
总结
至此,可以说微博爬虫的所有问题都彻底解决了!!!
开源代码在这里,需要添加自己的账户池。
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-12-04 03:18
HttpClient 是 Apache Jakarta Common 下的一个子项目,可用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入) 查看全部
c httpclient抓取网页(服务器判定你是ie还是chrome还是firefox?分析的请求地址)
HttpClient 是 Apache Jakarta Common 下的一个子项目,可用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。
3.上一页
首先模拟手机浏览器的UA。就是让我们打开的页面回到移动端的页面效果,那我们该怎么做呢?其实服务器是根据请求头中的UA来判断你是chrome还是firefox的,所以我们来找一个手机浏览器的UA。.
我们可以直接f12或者直接在浏览器中模拟移动端,然后查看请求参数:
User-Agent:Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36
正常没问题:
那么我们如何将这句话反映到程序中呢?
简单,我们拿到get对象后直接设置:
httpGet.setHeader("User-Agent", "Mozilla/5.0
(Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36");
就可以了,然后我们就可以使用jsoup来获取我们想要的元素了。jsoup 的语法与 jq 相同。
我们直接面对页面,右键我们想要的元素,选中review元素,然后用jq选择器选中它。
你可以参考jQuery选择器
4.获得关注者
直接获取我们之前分析的请求地址
https://www.zhihu.com/api/v4/m ... mp%3B
include=data%5B%2A%5D.employments%2Ccover_url%2Callow_message%2Canswer_coun
t%2Carticles_count%2Cfavorite_count%2Cfollower_count%2Cgender%2Cis_followe
d%2Cmessage_thread_token%2Cis_following%2Cbadge%5B%3F%28type%3Dbest_answerer
%29%5D.topics&limit=10&offset=30
但是记得替换用户名,在请求头中添加cookie zc_0的最后一段
那么返回的请求数据就是json
{
"paging": {
"is_end": false,
"next": "https://www.zhihu.com/api/v4/m ... ot%3B,
"previous": "https://www.zhihu.com/api/v4/m ... ot%3B,
"is_start": false,
"totals": 398
},
"data": [
{
"is_followed": true,
"avatar_url_template": "https://pic1.zhimg.com/da8e974dc_{size}.jpg",
"name": "陈晓峰",
"url": "",
"type": "people",
"user_type": "people",
"answer_count": 0,
"url_token": "chen-xiao-feng-84",
"headline": "阿里巴巴,分布式数据库,",
"avatar_url": "https://pic1.zhimg.com/da8e974dc_is.jpg",
"is_following": false,
"is_org": false,
"follower_count": 14,
"badge": [],
"id": "ff02ea0544901a9ddfcb7ba60c73b673",
"articles_count": 0
}
]
}
这个数据包括下一个请求地址,最后一个请求地址,时间是开始,时间是结束,总共有多少粉丝,以及关注者的基本信息,
所以我们可以在一段时间内得到所有的粉丝:
过程:
第一次获取数据,获取is_end字段判断is_end是否为真,根据is_end判断是否继续循环。如果循环,更新 is_end 并更新下一个连接请求
一套,你可以得到一个用户的所有粉丝。
我爱Java(QQ群):170936712(点击加入)
c httpclient抓取网页(环境准备引入maven依赖加入日志配置文件的HTTP协议访问网页 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-18 16:14
)
文章内容
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。我们一直使用HTTP协议访问互联网上的网页,而网络爬虫需要编写程序,其中访问网页也使用相同的HTTP协议。这里我们使用Java的HTTP协议客户端HttpClient的技术来抓取网页数据。环境准备
引入maven依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加日志配置文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n 查看全部
c httpclient抓取网页(环境准备引入maven依赖加入日志配置文件的HTTP协议访问网页
)
文章内容
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。我们一直使用HTTP协议访问互联网上的网页,而网络爬虫需要编写程序,其中访问网页也使用相同的HTTP协议。这里我们使用Java的HTTP协议客户端HttpClient的技术来抓取网页数据。环境准备
引入maven依赖
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加日志配置文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
c httpclient抓取网页(WebReaper(离线浏览器)一个不错不错的离线)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-18 08:03
WebReaper(离线浏览器)是一款不错的离线浏览器,使用它可以下载整个网站,只需要输入这个网站 URL,方便快捷。没有网络的时候,我们也可以看自己喜欢的网站。WebReaper 是一个网络爬虫或蜘蛛,它的工作方式是通过一个网站,下载网页、图片和对象,并发现它们可以在不连接互联网的情况下在本地查看。作为一个完全浏览的网站,它可以保存在本地,可以连接任何浏览器(如Internet浏览网站 Explorer、Netscape、Opera等),也可以保存到Internet资源管理器缓存,请使用IE的离线模式,看来可以“动手”了网站。要使用 WebReaper,只需输入一个起始 URL 并点击 Go 按钮。该程序将在 URL 处下载页面,解析 HTML,并找到指向其他页面的链接和对象。然后,它会提取这个子链接列表并下载它们。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。 查看全部
c httpclient抓取网页(WebReaper(离线浏览器)一个不错不错的离线)
WebReaper(离线浏览器)是一款不错的离线浏览器,使用它可以下载整个网站,只需要输入这个网站 URL,方便快捷。没有网络的时候,我们也可以看自己喜欢的网站。WebReaper 是一个网络爬虫或蜘蛛,它的工作方式是通过一个网站,下载网页、图片和对象,并发现它们可以在不连接互联网的情况下在本地查看。作为一个完全浏览的网站,它可以保存在本地,可以连接任何浏览器(如Internet浏览网站 Explorer、Netscape、Opera等),也可以保存到Internet资源管理器缓存,请使用IE的离线模式,看来可以“动手”了网站。要使用 WebReaper,只需输入一个起始 URL 并点击 Go 按钮。该程序将在 URL 处下载页面,解析 HTML,并找到指向其他页面的链接和对象。然后,它会提取这个子链接列表并下载它们。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。这个过程递归地继续,直到没有更多的联系人来满足 WebReaper 的过滤标准,或者你的硬盘驱动器已满——这从来没有发生过!本地保存的文件将调整 HTML 链接,以便直接从 Internet 读取它们时可以浏览它们。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。下载是完全可配置的自定义分层过滤器,可以构建 12 种不同的过滤器类型以允许目标下载。可以使用过滤器向导制作简单的过滤器,也可以手工制作更复杂的过滤器。

