
c httpclient抓取网页
c httpclient抓取网页(网络爬虫的基本知识如何判断是否空等操做java?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-17 00:08
1、网络爬虫基础知识html
网络爬虫遍历互联网,抓取网络中所有相关的网页,体现了爬虫的概念。爬虫是如何穿越互联网的?互联网可以看成是一张大图,每个页面看成一个节点,页面的链接看成有向边。图的遍历方法分为宽度遍历和深度遍历,但是深度遍历可能会遍历深度过深或者掉进黑洞。因此,大多数爬虫不使用这种形式。另一方面,爬虫在按照宽度优先的方式进行遍历时,会对要遍历的网页给予一定的优先权。这称为具有偏好的遍历。
实际的爬虫从一系列种子连接开始。种子链接是起始节点,种子页面的超链接指向的页面是子节点(中间节点)。对于非html文档,如excel,无法从中提取超链接,将其视为图形的终端节点。在整个遍历过程中,会维护一个visited表,记录哪些节点(连接)被处理过,没有处理的跳过。
使用广度优先搜索策略的主要原因是:
一种。重要的网页通常靠近种子。比如我们打开新闻网站,总是最热的新闻。随着深度冲浪,网页的重要性越来越低。
湾 万维网的实际深度高达17层,但是到某个网页的路径总是很短,宽度优先遍历可以最快找到这个网页
C。宽度优先有利于多爬虫协同抓取。
2、网络爬虫的简单实现
一、定义访问队列,要访问的队列,爬取得到的URL的hash表,包括退出队列,进入队列,判断队列是否为空等,做java
package webspider;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
import java.util.Queue;
public class LinkQueue {
// 已访问的 url 集合
private static Set visitedUrl = new HashSet();
// 待访问的 url 集合
private static Queue unVisitedUrl = new PriorityQueue();
// 得到URL队列
public static Queue getUnVisitedUrl() {
return unVisitedUrl;
}
// 添加到访问过的URL队列中
public static void addVisitedUrl(String url) {
visitedUrl.add(url);
}
// 移除访问过的URL
public static void removeVisitedUrl(String url) {
visitedUrl.remove(url);
}
// 未访问的URL出队列
public static Object unVisitedUrlDeQueue() {
return unVisitedUrl.poll();
}
// 保证每一个 url 只被访问一次
public static void addUnvisitedUrl(String url) {
if (url != null && !url.trim().equals("") && !visitedUrl.contains(url)
&& !unVisitedUrl.contains(url))
unVisitedUrl.add(url);
}
// 得到已经访问的URL数目
public static int getVisitedUrlNum() {
return visitedUrl.size();
}
// 判断未访问的URL队列中是否为空
public static boolean unVisitedUrlsEmpty() {
return unVisitedUrl.isEmpty();
}
}
二、定义DownLoadFile类,根据获取到的url抓取网页内容,下载到本地存储。这里需要引用commons-httpclient.jar、commons-codec.jar、commons-logging.jar。
package webspider;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class DownLoadFile {
/**
* 根据 url 和网页类型生成须要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "."
+ contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private void saveToLocal(byte[] data, String filePath) {
try {
DataOutputStream out = new DataOutputStream(new FileOutputStream(
new File(filePath)));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/* 下载 url 指向的网页 */
public String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 链接超时 5s
httpClient.getHttpConnectionManager().getParams()
.setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "f:\\spider\\"
+ getFileNameByUrl(url,
getMethod.getResponseHeader("Content-Type")
.getValue());
saveToLocal(responseBody, filePath);
} catch (HttpException e) {
// 发生致命的异常,多是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放链接
getMethod.releaseConnection();
}
return filePath;
}
}
三、定义了HtmlParserTool类,用于获取网页中的超链接(包括a标签、frame中的src等),即获取子节点的URL。需要引入htmlparser.jarnode
package webspider;
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class HtmlParserTool {
// 获取一个网站上的连接,filter 用来过滤连接
public static Set extracLinks(String url, LinkFilter filter) {
Set links = new HashSet();
try {
Parser parser = new Parser(url);
//parser.setEncoding("utf-8");
// 过滤 标签的 filter,用来提取 frame 标签里的 src 属性所表示的连接
NodeFilter frameFilter = new NodeFilter() {
public boolean accept(Node node) {
if (node.getText().startsWith("frame src=")) {
return true;
} else {
return false;
}
}
};
// OrFilter 来设置过滤 <a> 标签,和 标签
OrFilter linkFilter = new OrFilter(new NodeClassFilter(
LinkTag.class), frameFilter);
// 获得全部通过过滤的标签
NodeList list = parser.extractAllNodesThatMatch(linkFilter);
for (int i = 0; i < list.size(); i++) {
Node tag = list.elementAt(i);
if (tag instanceof LinkTag)// <a> 标签
{
LinkTag link = (LinkTag) tag;
String linkUrl = link.getLink();// url
if (filter.accept(linkUrl))
links.add(linkUrl);
} else// 标签
{
// 提取 frame 里 src 属性的连接如
String frame = tag.getText();
int start = frame.indexOf("src=");
frame = frame.substring(start);
int end = frame.indexOf(" ");
if (end == -1)
end = frame.indexOf(">");
String frameUrl = frame.substring(5, end - 1);
if (filter.accept(frameUrl))
links.add(frameUrl);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return links;
}
}
四、写一个测试类MyCrawler来测试爬取效果
<p>package webspider;
import java.util.Set;
public class MyCrawler {
/**
* 使用种子初始化 URL 队列
*
* @return
* @param seeds
* 种子URL
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++)
LinkQueue.addUnvisitedUrl(seeds[i]);
}
/**
* 抓取过程
*
* @return
* @param seeds
*/
public void crawling(String[] seeds) { // 定义过滤器,提取以http://www.lietu.com开头的连接
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com"))
return true;
else
return false;
}
};
// 初始化 URL 队列
initCrawlerWithSeeds(seeds);
// 循环条件:待抓取的连接不空且抓取的网页很少于1000
while (!LinkQueue.unVisitedUrlsEmpty()
&& LinkQueue.getVisitedUrlNum() 查看全部
c httpclient抓取网页(网络爬虫的基本知识如何判断是否空等操做java?)
1、网络爬虫基础知识html
网络爬虫遍历互联网,抓取网络中所有相关的网页,体现了爬虫的概念。爬虫是如何穿越互联网的?互联网可以看成是一张大图,每个页面看成一个节点,页面的链接看成有向边。图的遍历方法分为宽度遍历和深度遍历,但是深度遍历可能会遍历深度过深或者掉进黑洞。因此,大多数爬虫不使用这种形式。另一方面,爬虫在按照宽度优先的方式进行遍历时,会对要遍历的网页给予一定的优先权。这称为具有偏好的遍历。
实际的爬虫从一系列种子连接开始。种子链接是起始节点,种子页面的超链接指向的页面是子节点(中间节点)。对于非html文档,如excel,无法从中提取超链接,将其视为图形的终端节点。在整个遍历过程中,会维护一个visited表,记录哪些节点(连接)被处理过,没有处理的跳过。
使用广度优先搜索策略的主要原因是:
一种。重要的网页通常靠近种子。比如我们打开新闻网站,总是最热的新闻。随着深度冲浪,网页的重要性越来越低。
湾 万维网的实际深度高达17层,但是到某个网页的路径总是很短,宽度优先遍历可以最快找到这个网页
C。宽度优先有利于多爬虫协同抓取。
2、网络爬虫的简单实现
一、定义访问队列,要访问的队列,爬取得到的URL的hash表,包括退出队列,进入队列,判断队列是否为空等,做java
package webspider;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
import java.util.Queue;
public class LinkQueue {
// 已访问的 url 集合
private static Set visitedUrl = new HashSet();
// 待访问的 url 集合
private static Queue unVisitedUrl = new PriorityQueue();
// 得到URL队列
public static Queue getUnVisitedUrl() {
return unVisitedUrl;
}
// 添加到访问过的URL队列中
public static void addVisitedUrl(String url) {
visitedUrl.add(url);
}
// 移除访问过的URL
public static void removeVisitedUrl(String url) {
visitedUrl.remove(url);
}
// 未访问的URL出队列
public static Object unVisitedUrlDeQueue() {
return unVisitedUrl.poll();
}
// 保证每一个 url 只被访问一次
public static void addUnvisitedUrl(String url) {
if (url != null && !url.trim().equals("") && !visitedUrl.contains(url)
&& !unVisitedUrl.contains(url))
unVisitedUrl.add(url);
}
// 得到已经访问的URL数目
public static int getVisitedUrlNum() {
return visitedUrl.size();
}
// 判断未访问的URL队列中是否为空
public static boolean unVisitedUrlsEmpty() {
return unVisitedUrl.isEmpty();
}
}
二、定义DownLoadFile类,根据获取到的url抓取网页内容,下载到本地存储。这里需要引用commons-httpclient.jar、commons-codec.jar、commons-logging.jar。
package webspider;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class DownLoadFile {
/**
* 根据 url 和网页类型生成须要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "."
+ contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private void saveToLocal(byte[] data, String filePath) {
try {
DataOutputStream out = new DataOutputStream(new FileOutputStream(
new File(filePath)));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/* 下载 url 指向的网页 */
public String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 链接超时 5s
httpClient.getHttpConnectionManager().getParams()
.setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "f:\\spider\\"
+ getFileNameByUrl(url,
getMethod.getResponseHeader("Content-Type")
.getValue());
saveToLocal(responseBody, filePath);
} catch (HttpException e) {
// 发生致命的异常,多是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放链接
getMethod.releaseConnection();
}
return filePath;
}
}
三、定义了HtmlParserTool类,用于获取网页中的超链接(包括a标签、frame中的src等),即获取子节点的URL。需要引入htmlparser.jarnode
package webspider;
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class HtmlParserTool {
// 获取一个网站上的连接,filter 用来过滤连接
public static Set extracLinks(String url, LinkFilter filter) {
Set links = new HashSet();
try {
Parser parser = new Parser(url);
//parser.setEncoding("utf-8");
// 过滤 标签的 filter,用来提取 frame 标签里的 src 属性所表示的连接
NodeFilter frameFilter = new NodeFilter() {
public boolean accept(Node node) {
if (node.getText().startsWith("frame src=")) {
return true;
} else {
return false;
}
}
};
// OrFilter 来设置过滤 <a> 标签,和 标签
OrFilter linkFilter = new OrFilter(new NodeClassFilter(
LinkTag.class), frameFilter);
// 获得全部通过过滤的标签
NodeList list = parser.extractAllNodesThatMatch(linkFilter);
for (int i = 0; i < list.size(); i++) {
Node tag = list.elementAt(i);
if (tag instanceof LinkTag)// <a> 标签
{
LinkTag link = (LinkTag) tag;
String linkUrl = link.getLink();// url
if (filter.accept(linkUrl))
links.add(linkUrl);
} else// 标签
{
// 提取 frame 里 src 属性的连接如
String frame = tag.getText();
int start = frame.indexOf("src=");
frame = frame.substring(start);
int end = frame.indexOf(" ");
if (end == -1)
end = frame.indexOf(">");
String frameUrl = frame.substring(5, end - 1);
if (filter.accept(frameUrl))
links.add(frameUrl);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return links;
}
}
四、写一个测试类MyCrawler来测试爬取效果
<p>package webspider;
import java.util.Set;
public class MyCrawler {
/**
* 使用种子初始化 URL 队列
*
* @return
* @param seeds
* 种子URL
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++)
LinkQueue.addUnvisitedUrl(seeds[i]);
}
/**
* 抓取过程
*
* @return
* @param seeds
*/
public void crawling(String[] seeds) { // 定义过滤器,提取以http://www.lietu.com开头的连接
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com";))
return true;
else
return false;
}
};
// 初始化 URL 队列
initCrawlerWithSeeds(seeds);
// 循环条件:待抓取的连接不空且抓取的网页很少于1000
while (!LinkQueue.unVisitedUrlsEmpty()
&& LinkQueue.getVisitedUrlNum()
c httpclient抓取网页(先来说下数据抓取系统的大致工作流程.下背景 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-10 01:02
)
公司的数据采集系统已经写了一段时间了,是时候总结一下了。否则,以我的记忆力,过一会我就会忘记。打算写个系列,记录下我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,我们来谈谈数据采集的一般工作流程。
我先说一下背景。该公司正在做企业信用报告服务。整合各个方面的数据,生成企业信用报告。主要数据来源包括:第三方采购(整体采购数据或界面形式);捕获在 Internet 上公开可用的数据。那么就需要一个数据采集平台,以便为采集方便快捷地添加新的数据对象。关于数据采集平台的架构设计,我也是新手,以后会吸取这次的经验教训。本系列从实战开始,然后是第一点:数据抓取的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人觉得这三步是我在努力做的。但是,先听我说。##清除数据采集 需要先分享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张这么努力地加班,还没有完成任务。是不是产品经理没把需求说清楚?但是产品经理也说这个页面都是需要的。问题是:
分析数据的url和相关参数要采集,我先走一遍我想爬取数据的过程,看下面四张图:
提取url和参数
从以上四张图,我们可以确定有以下连接需要处理:-1. 获取验证码connection-2。提交查询-3。查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用 Chrome 的开发者工具进行页面分析。类似的工具有很多,各个浏览器自带的开发者工具基本可以满足需求,也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们已经提取出公司的基本注册信息为采集。我们需要提交三个请求,每个提交方法(POST 或 GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。本文文章不重复代码实现的具体逻辑,因为本文的重点是讲解:抓取网页的工作流程。后期会一一总结代码实现过程中用到的关键技术点和踩过的坑。暂时列出涉及的相关内容:
您也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天一个小笔记,每天进步一点点:
对公众有好处:enilu123
查看全部
c httpclient抓取网页(先来说下数据抓取系统的大致工作流程.下背景
)
公司的数据采集系统已经写了一段时间了,是时候总结一下了。否则,以我的记忆力,过一会我就会忘记。打算写个系列,记录下我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,我们来谈谈数据采集的一般工作流程。
我先说一下背景。该公司正在做企业信用报告服务。整合各个方面的数据,生成企业信用报告。主要数据来源包括:第三方采购(整体采购数据或界面形式);捕获在 Internet 上公开可用的数据。那么就需要一个数据采集平台,以便为采集方便快捷地添加新的数据对象。关于数据采集平台的架构设计,我也是新手,以后会吸取这次的经验教训。本系列从实战开始,然后是第一点:数据抓取的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人觉得这三步是我在努力做的。但是,先听我说。##清除数据采集 需要先分享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张这么努力地加班,还没有完成任务。是不是产品经理没把需求说清楚?但是产品经理也说这个页面都是需要的。问题是:
分析数据的url和相关参数要采集,我先走一遍我想爬取数据的过程,看下面四张图:




提取url和参数
从以上四张图,我们可以确定有以下连接需要处理:-1. 获取验证码connection-2。提交查询-3。查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用 Chrome 的开发者工具进行页面分析。类似的工具有很多,各个浏览器自带的开发者工具基本可以满足需求,也可以使用一些第三方插件:如firebug、httpwatch等。


编写代码实现功能
通过前面的步骤,我们已经提取出公司的基本注册信息为采集。我们需要提交三个请求,每个提交方法(POST 或 GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。本文文章不重复代码实现的具体逻辑,因为本文的重点是讲解:抓取网页的工作流程。后期会一一总结代码实现过程中用到的关键技术点和踩过的坑。暂时列出涉及的相关内容:
您也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天一个小笔记,每天进步一点点:
对公众有好处:enilu123

c httpclient抓取网页(最简单的爬虫,不需要设定代理服务器,怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-05 12:16
)
最简单的爬虫不需要设置代理服务器,不需要设置cookie,不需要设置http连接池,使用httpget方法,只需要获取html代码...
嗯,满足这个要求的爬虫应该就是最基础的爬虫了。当然,这也是复杂爬虫的基础。
使用了httpclient4的相关API。别跟我说网上有很多httpclient3代码兼容性问题,都没有太大区别,但是我们应该选择一个可以使用的新接口!
当然还有很多细节需要注意,比如编码问题(我一般强制UTF-8)
毕业:
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class Easy {
//输入流转为String类型
public static String inputStream2String(InputStream is)throws IOException{
ByteArrayOutputStream baos=new ByteArrayOutputStream();
int i=-1;
while((i=is.read())!=-1){
baos.write(i);
}
return baos.toString();
}
//抓取网页的核心函数
public static void doGrab() throws Exception {
//httpclient可以认为是模拟的浏览器
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//要访问的目标页面url
String targetUrl="http://chriszz.sinaapp.com";
//使用get方式请求页面。复杂一点也可以换成post方式的
HttpGet httpGet = new HttpGet(targetUrl);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
try {
String status=response1.getStatusLine().toString();
//通过状态码来判断访问是否正常。200表示抓取成功
if(!status.equals("HTTP/1.1 200 OK")){
System.out.println("此页面可以正常获取!");
}else{
response1 = httpclient.execute(httpGet);
System.out.println(status);
}
//System.out.println(response1.getStatusLine());
HttpEntity entity1 = response1.getEntity();
// do something useful with the response body
// and ensure it is fully consumed
InputStream input=entity1.getContent();
String rawHtml=inputStream2String(input);
System.out.println(rawHtml);
//有时候会有中文乱码问题,这取决于你的eclipse java工程设定的编码格式、当前java文件的编码格式,以及抓取的网页的编码格式
//比如,你可以用String的getBytes()转换编码
//String html = new String(rawHtml.getBytes("ISO-8859-1"),"UTF-8");//转换后的结果
EntityUtils.consume(entity1);
} finally {
response1.close();//记得要关闭
}
} finally {
httpclient.close();//这个也要关闭哦!
}
}
/*
* 最简单的java爬虫--抓取百度首页
* memo:
* 0.抓取的是百度的首页,对应一个html页面。
* (至于为啥我们访问的是http://www.baidu.com而不是http://www.baidu.com/xxx.html,这个是百度那边设定的,总之我们会访问到那个包含html的页面)
* 1.使用http协议的get方法就可以了(以后复杂了可以用post方法,设定cookie,甚至设定http连接池;或者抓取json格式的数据、抓取图片等,也是类似的)
* 2.通过httpclient的相关包(httpclient4版本)编写,需要下载并添加相应的jar包到build path中
* 3.代码主要参考了httpclient(http://hc.apache.org/)包里面的tutorial的pdf文件。
*/
public static void main(String[] args) throws Exception{
Easy.doGrab();//为了简答这里把doGrab()方法定义为静态方法了所以直接Easy.doGrab()就好了
}
} 查看全部
c httpclient抓取网页(最简单的爬虫,不需要设定代理服务器,怎么办?
)
最简单的爬虫不需要设置代理服务器,不需要设置cookie,不需要设置http连接池,使用httpget方法,只需要获取html代码...
嗯,满足这个要求的爬虫应该就是最基础的爬虫了。当然,这也是复杂爬虫的基础。
使用了httpclient4的相关API。别跟我说网上有很多httpclient3代码兼容性问题,都没有太大区别,但是我们应该选择一个可以使用的新接口!
当然还有很多细节需要注意,比如编码问题(我一般强制UTF-8)
毕业:
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class Easy {
//输入流转为String类型
public static String inputStream2String(InputStream is)throws IOException{
ByteArrayOutputStream baos=new ByteArrayOutputStream();
int i=-1;
while((i=is.read())!=-1){
baos.write(i);
}
return baos.toString();
}
//抓取网页的核心函数
public static void doGrab() throws Exception {
//httpclient可以认为是模拟的浏览器
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//要访问的目标页面url
String targetUrl="http://chriszz.sinaapp.com";
//使用get方式请求页面。复杂一点也可以换成post方式的
HttpGet httpGet = new HttpGet(targetUrl);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
try {
String status=response1.getStatusLine().toString();
//通过状态码来判断访问是否正常。200表示抓取成功
if(!status.equals("HTTP/1.1 200 OK")){
System.out.println("此页面可以正常获取!");
}else{
response1 = httpclient.execute(httpGet);
System.out.println(status);
}
//System.out.println(response1.getStatusLine());
HttpEntity entity1 = response1.getEntity();
// do something useful with the response body
// and ensure it is fully consumed
InputStream input=entity1.getContent();
String rawHtml=inputStream2String(input);
System.out.println(rawHtml);
//有时候会有中文乱码问题,这取决于你的eclipse java工程设定的编码格式、当前java文件的编码格式,以及抓取的网页的编码格式
//比如,你可以用String的getBytes()转换编码
//String html = new String(rawHtml.getBytes("ISO-8859-1"),"UTF-8");//转换后的结果
EntityUtils.consume(entity1);
} finally {
response1.close();//记得要关闭
}
} finally {
httpclient.close();//这个也要关闭哦!
}
}
/*
* 最简单的java爬虫--抓取百度首页
* memo:
* 0.抓取的是百度的首页,对应一个html页面。
* (至于为啥我们访问的是http://www.baidu.com而不是http://www.baidu.com/xxx.html,这个是百度那边设定的,总之我们会访问到那个包含html的页面)
* 1.使用http协议的get方法就可以了(以后复杂了可以用post方法,设定cookie,甚至设定http连接池;或者抓取json格式的数据、抓取图片等,也是类似的)
* 2.通过httpclient的相关包(httpclient4版本)编写,需要下载并添加相应的jar包到build path中
* 3.代码主要参考了httpclient(http://hc.apache.org/)包里面的tutorial的pdf文件。
*/
public static void main(String[] args) throws Exception{
Easy.doGrab();//为了简答这里把doGrab()方法定义为静态方法了所以直接Easy.doGrab()就好了
}
}
c httpclient抓取网页(cookies设置.UseCookies=(默认为true),默认的会自己带上cookies)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-30 09:05
通过设置handler.UseCookies=true(默认为true),默认会自带cookies
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20200101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=900");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xj"),
new KeyValuePair("password", "a"),
});
var result = await client.PostAsync("https://www.xxjj.com/login/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,会跳转到登录页面。
该方法的使用场景:抓取需要登录的网页数据,不设置任何cookies,httpclient登录后会自动将cookies放入后续请求中。
但也要注意,如果你只是直接发起一个请求,它不会传递被发起项目本身的cookie信息,它会带上你请求的cookie网站 查看全部
c httpclient抓取网页(cookies设置.UseCookies=(默认为true),默认的会自己带上cookies)
通过设置handler.UseCookies=true(默认为true),默认会自带cookies
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20200101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=900");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xj"),
new KeyValuePair("password", "a"),
});
var result = await client.PostAsync("https://www.xxjj.com/login/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,会跳转到登录页面。
该方法的使用场景:抓取需要登录的网页数据,不设置任何cookies,httpclient登录后会自动将cookies放入后续请求中。
但也要注意,如果你只是直接发起一个请求,它不会传递被发起项目本身的cookie信息,它会带上你请求的cookie网站
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-30 00:19
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,然后在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
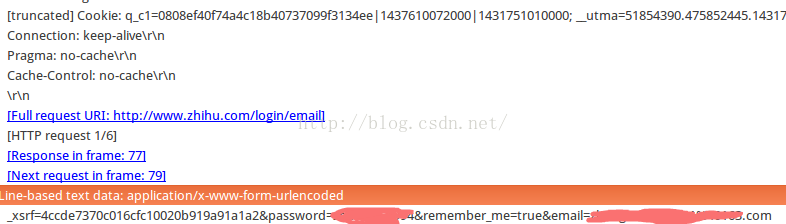
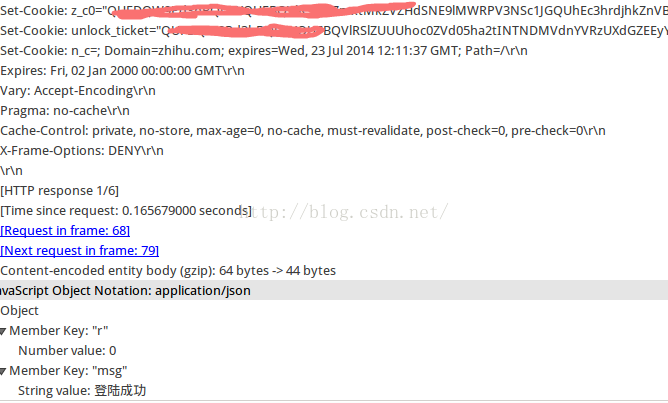
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第4章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,然后在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:


第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第4章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(Android应用程序使用HttpClient即可访问被保护页而了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-29 08:20
例如,Android 应用程序需要向指定页面发送请求,但该页面不是简单的页面。只有当用户已经登录并且登录用户的用户名有效时,才能访问该页面。如果使用HttpURLConnection访问这个受保护的页面,需要处理的细节太复杂了。
其实,在web应用中访问受保护的页面,使用浏览器是非常简单的。用户通过系统提供的登录页面登录系统,浏览器负责维护与服务器的Session。如果用户登录用户名和密码符合要求,您就可以访问受保护的资源。
在 Android 应用中,您可以使用 HttpClient 登录系统。只要应用使用同一个HttpClient发送请求,HttpClient就会自动与服务器保持Session状态。也就是说,程序第一次使用HttpClient登录系统。然后使用 HttpClient 访问受保护的页面。
总结:在Android开发中,虽然HttpClient更好的支持了很多细节控件(比如代理、cookie、认证、压缩、连接池),但是对开发者的要求更高,而且代码写起来也比较复杂,普通开发难度大人员管理好,官方支持越来越少;而 HttpUrlConnection 包裹了大部分工作,屏蔽了不必要的细节,更适合开发者直接调用,官方对它的支持和优化也会越来越好。既然是开发Android应用,自然要遵循Android官方的指导方针,选择HttpUrlConnection。 查看全部
c httpclient抓取网页(Android应用程序使用HttpClient即可访问被保护页而了吗?)
例如,Android 应用程序需要向指定页面发送请求,但该页面不是简单的页面。只有当用户已经登录并且登录用户的用户名有效时,才能访问该页面。如果使用HttpURLConnection访问这个受保护的页面,需要处理的细节太复杂了。
其实,在web应用中访问受保护的页面,使用浏览器是非常简单的。用户通过系统提供的登录页面登录系统,浏览器负责维护与服务器的Session。如果用户登录用户名和密码符合要求,您就可以访问受保护的资源。
在 Android 应用中,您可以使用 HttpClient 登录系统。只要应用使用同一个HttpClient发送请求,HttpClient就会自动与服务器保持Session状态。也就是说,程序第一次使用HttpClient登录系统。然后使用 HttpClient 访问受保护的页面。
总结:在Android开发中,虽然HttpClient更好的支持了很多细节控件(比如代理、cookie、认证、压缩、连接池),但是对开发者的要求更高,而且代码写起来也比较复杂,普通开发难度大人员管理好,官方支持越来越少;而 HttpUrlConnection 包裹了大部分工作,屏蔽了不必要的细节,更适合开发者直接调用,官方对它的支持和优化也会越来越好。既然是开发Android应用,自然要遵循Android官方的指导方针,选择HttpUrlConnection。
c httpclient抓取网页(我正在尝试使用C#和ChromeWebInspector登录并在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-28 07:11
问题
我正在尝试使用 C# 和 Chrome Web Inspector 登录并进入。
我不太了解人们必须用来解释 Web Inspector 中的信息以模拟登录和模拟维护会话并导航到下一页以采集信息的心理过程。
有人可以向我解释或指点我吗?
目前,我只有一些代码来获取主页和登录页面的内容:
公共类Morningstar
{
公共异步静态无效Ru4n()
{
var url =" http://www.morningstar.com/";
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept"," text / html,application / xhtml + xml,application / xml");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Encoding"," gzip,deflate");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" User-Agent"," Mozilla / 5.0(Windows NT 6.2; WOW64; rv:19.0)Gecko / 20100101 Firefox / 19.0");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Charset"," ISO-8859-1");
var response = await httpClient.GetAsync(new Uri(url));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var decompressedStream = new GZipStream(responseStream,CompressionMode.Decompress))
使用(var streamReader = new StreamReader(decompressedStream) ))
{
//Console.WriteLine(streamReader.ReadToEnd());
}
var loginURL =" https://members.morningstar.co ... 3B%3B
response =等待httpClient.GetAsync(new Uri(loginURL));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var streamReader = new StreamReader(responseStream))
{
Console.WriteLine(streamReader.ReadToEnd( ));
}
}
编辑:最后,按照穆罕默德的建议,我使用了以下代码:
ScrapingBrowser浏览器= new ScrapingBrowser();
//如果网站返回的cookie格式无效,则将UseDefaultCookiesParser设置为false
//browser.UseDefaultCookiesParser = false;
网页主页=浏览器。NavigateToPage(新Uri(" https://members.morningstar.co ... ot%3B));
PageWebForm form = homePage.FindFormById(" memberLoginForm");
form [" email_textbox"] =" example@example.com";
form [" pwd_textbox"] ="密码";
form [" go_button.x"] =" 57";
form [" go_button.y"] =" 22";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
解决方案
你应该模拟网站的登录过程。最简单的方法是通过一些调试器(如 Fiddler)检查 网站。
以下是网站的登录请求:
POST https ://members.morningstar.com/memberservice/login.aspx?CustId =& CType =& CName =& RememberMe = true& CookieTime = HTTP / 1.1
接受:text / html,application / xhtml + xml,* / *
推荐人:https://members.morningstar.co ... .aspx
**省略**
Cookie:cookies = true; TestCookieExist =存在; fp = 001140581745182496; __utma = 172984700.91600904.1405817457.1405817457.1405817457.1; __utmb = 172984700.8.10.1405817457; __utmz = 172984700.1405817457.1.1.utmcsr =(直接)| utmccn =(直接)| utmcmd =(无); __utmc = 172984700; ASP.NET_SessionId = b5bpepm3pftgoz55to3ql4me
email_textbox=test@email.com& pwd_textbox = password& remember = on& email_textbox2 =& go_button.x = 36& go_button.y = 16& ____ LAST =& __ EVENTARGUMENT =& __ VIEWSTATE =省略& __ EVENTVALIDATION =省略
您将看到一些 cookie 和表单字段,例如“__VIEWSTATE”。需要输入这个文件的实际值才能登录,可以使用以下步骤:
提出请求并删除“__LASTFOCUS”、“__EVENTTARGET”、“__EVENTARGUMENT”、“__VIEWSTATE”、“__EVENTVALIDATION”;
在同一页面上创建一个新的 POST 请求,使用上一个的 CookieContainer;使用废弃的字段、用户名和密码来构造帖子字符串。使用 MIME 类型应用程序/x-www-form-urlencoded 来发布。
如果成功,请使用 cookie 进行进一步请求以保留记录
注意:您可以使用 htmlagilitypack 或 scrapysharp 丢弃 html。ScrapySharp 提供了易于使用的表单发布和浏览工具网站。 查看全部
c httpclient抓取网页(我正在尝试使用C#和ChromeWebInspector登录并在)
问题
我正在尝试使用 C# 和 Chrome Web Inspector 登录并进入。
我不太了解人们必须用来解释 Web Inspector 中的信息以模拟登录和模拟维护会话并导航到下一页以采集信息的心理过程。
有人可以向我解释或指点我吗?
目前,我只有一些代码来获取主页和登录页面的内容:
公共类Morningstar
{
公共异步静态无效Ru4n()
{
var url =" http://www.morningstar.com/";
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept"," text / html,application / xhtml + xml,application / xml");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Encoding"," gzip,deflate");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" User-Agent"," Mozilla / 5.0(Windows NT 6.2; WOW64; rv:19.0)Gecko / 20100101 Firefox / 19.0");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Charset"," ISO-8859-1");
var response = await httpClient.GetAsync(new Uri(url));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var decompressedStream = new GZipStream(responseStream,CompressionMode.Decompress))
使用(var streamReader = new StreamReader(decompressedStream) ))
{
//Console.WriteLine(streamReader.ReadToEnd());
}
var loginURL =" https://members.morningstar.co ... 3B%3B
response =等待httpClient.GetAsync(new Uri(loginURL));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var streamReader = new StreamReader(responseStream))
{
Console.WriteLine(streamReader.ReadToEnd( ));
}
}
编辑:最后,按照穆罕默德的建议,我使用了以下代码:
ScrapingBrowser浏览器= new ScrapingBrowser();
//如果网站返回的cookie格式无效,则将UseDefaultCookiesParser设置为false
//browser.UseDefaultCookiesParser = false;
网页主页=浏览器。NavigateToPage(新Uri(" https://members.morningstar.co ... ot%3B));
PageWebForm form = homePage.FindFormById(" memberLoginForm");
form [" email_textbox"] =" example@example.com";
form [" pwd_textbox"] ="密码";
form [" go_button.x"] =" 57";
form [" go_button.y"] =" 22";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
解决方案
你应该模拟网站的登录过程。最简单的方法是通过一些调试器(如 Fiddler)检查 网站。
以下是网站的登录请求:
POST https ://members.morningstar.com/memberservice/login.aspx?CustId =& CType =& CName =& RememberMe = true& CookieTime = HTTP / 1.1
接受:text / html,application / xhtml + xml,* / *
推荐人:https://members.morningstar.co ... .aspx
**省略**
Cookie:cookies = true; TestCookieExist =存在; fp = 001140581745182496; __utma = 172984700.91600904.1405817457.1405817457.1405817457.1; __utmb = 172984700.8.10.1405817457; __utmz = 172984700.1405817457.1.1.utmcsr =(直接)| utmccn =(直接)| utmcmd =(无); __utmc = 172984700; ASP.NET_SessionId = b5bpepm3pftgoz55to3ql4me
email_textbox=test@email.com& pwd_textbox = password& remember = on& email_textbox2 =& go_button.x = 36& go_button.y = 16& ____ LAST =& __ EVENTARGUMENT =& __ VIEWSTATE =省略& __ EVENTVALIDATION =省略
您将看到一些 cookie 和表单字段,例如“__VIEWSTATE”。需要输入这个文件的实际值才能登录,可以使用以下步骤:
提出请求并删除“__LASTFOCUS”、“__EVENTTARGET”、“__EVENTARGUMENT”、“__VIEWSTATE”、“__EVENTVALIDATION”;
在同一页面上创建一个新的 POST 请求,使用上一个的 CookieContainer;使用废弃的字段、用户名和密码来构造帖子字符串。使用 MIME 类型应用程序/x-www-form-urlencoded 来发布。
如果成功,请使用 cookie 进行进一步请求以保留记录
注意:您可以使用 htmlagilitypack 或 scrapysharp 丢弃 html。ScrapySharp 提供了易于使用的表单发布和浏览工具网站。
c httpclient抓取网页(mons.httpclient与org.apache.http.client的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 15:10
)
与传统JDK自带的URLConnection相比,HttpClient增加了易用性和灵活性。不仅方便了客户端发送Http请求,也方便了开发者测试接口(基于Http协议),提高了开发效率,也方便了提高代码的健壮性。因此,掌握HttpClient是非常重要的必修内容。掌握了HttpClient之后,相信你会对Http协议有更深入的了解。
mons.httpclient.HttpClient 和 org.apache.http.client.HttpClient 的区别
Commons HttpClient 项目现已结束,不再开发。它已被 ApacheHttpComponents 项目的 HttpClient 和 HttpCore 模块取代,提供更好的性能和更大的灵活性。
一、简介
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。HttpClient 已经在很多项目中使用。例如,Apache Jakarta 上的另外两个著名的开源项目 Cactus 和 HTMLUnit,都使用 HttpClient。
所以这里简单介绍一下如何获取网页的源代码:
Maven 依赖:
org.apache.httpcomponents
httpclient
4.5.2
这里最大的问题是编码问题。如果编码不合适,就会出现中文乱码。
获取代码的方式一般有两种,一种是从响应头中获取,另一种是从网页源代码的meta中获取。
这两种方法应该结合使用。一般的过程是先从响应头中获取。如果响应头不可用,请从 Web 源代码元中获取。如果没有,请设置默认编码。
我的代码如下:
<p>package httpclient.download;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
/**
* httpclient来下载网页源码。
*
* @author 徐金仁
*
*关于网页下载最大的问题是编码的问题
*
*/
public class Download {
public String getHtmlSource(String url){
String htmlSource = null;
String finallyCharset = null;
//使用httpclient下载
//创建一个httpclient的引擎
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建一个httpGet对象,用于发送get请求,如果要发post请求,就创建一个post对象
HttpGet get = new HttpGet(url);
try {
//发送get请求,获取一个响应
CloseableHttpResponse response= httpClient.execute(get);
//获取这次响应的实体,接下来所有的操作都是基于此实体完成,
HttpEntity entity = response.getEntity();
//方法还是两个,先从header里面来查看,如果没有,再从meta里面查看
//这个方法主要是从header里面来获取,如果没有,会返回一个null
finallyCharset = EntityUtils.getContentCharSet(entity);
System.out.println("编码如下:");
System.out.println("charset1 = " + finallyCharset);
byte[] byteArray = null;
if(finallyCharset == null){
//如果header里面没有,则要从meta里面来获取,为了节约网络资源,网页只读取一次,
/*
* 那么,就有几个关系 :url->字符流->子节流->字符串
* 这里可以用子节数组来作为中间的过渡,从字节数组这里获取到编码,再通过正确的编码变为字符串
*/
byteArray = convertInputStreamToByteArray(entity.getContent());
if(byteArray == null){
throw new Exception("字节数组为空");
}
//接下来要从字节数组中获取到meta里面的chatset
finallyCharset = getCharsetFromMeta(byteArray);
System.out.println("charset2 = " + finallyCharset);
if(finallyCharset == null){
//如果没有找到
finallyCharset = "UTF-8"; //则等于默认的
System.out.println("charset3 = " + finallyCharset);
}
//如果找到了就更好
}
System.out.println("charset = " + finallyCharset);
htmlSource = new String(byteArray, finallyCharset);
}catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return htmlSource;
}
/**
* 将一个输入流转化为一个字节数组
* @param content
* @param defaultCharset
* @return
* @throws IOException
*/
public byte[] convertInputStreamToByteArray(InputStream content) throws IOException {
//输入流转化为一个字节数组
byte[] by = new byte[4096];
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int l = -1;
while((l = content.read(by)) > 0){
bos.write(by, 0, l);
}
byte[] s = bos.toByteArray();
return s;
}
/**
* 从字节数组中获取到meta里面的charset的值
* @param byteArray
* @return
* @throws IOException
*/
public String getCharsetFromMeta(byte[] byteArray) throws IOException {
//将字节数组转化为bufferedReader,从中一行行的读取来,再判断
String htmlSource = new String(byteArray);
StringReader in = new StringReader(htmlSource);
BufferedReader reader = new BufferedReader(in);
String line = null;
while((line = reader.readLine()) != null){
line = line.toLowerCase();
if(line.contains(" 查看全部
c httpclient抓取网页(mons.httpclient与org.apache.http.client的区别
)
与传统JDK自带的URLConnection相比,HttpClient增加了易用性和灵活性。不仅方便了客户端发送Http请求,也方便了开发者测试接口(基于Http协议),提高了开发效率,也方便了提高代码的健壮性。因此,掌握HttpClient是非常重要的必修内容。掌握了HttpClient之后,相信你会对Http协议有更深入的了解。
mons.httpclient.HttpClient 和 org.apache.http.client.HttpClient 的区别
Commons HttpClient 项目现已结束,不再开发。它已被 ApacheHttpComponents 项目的 HttpClient 和 HttpCore 模块取代,提供更好的性能和更大的灵活性。
一、简介
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。HttpClient 已经在很多项目中使用。例如,Apache Jakarta 上的另外两个著名的开源项目 Cactus 和 HTMLUnit,都使用 HttpClient。
所以这里简单介绍一下如何获取网页的源代码:
Maven 依赖:
org.apache.httpcomponents
httpclient
4.5.2
这里最大的问题是编码问题。如果编码不合适,就会出现中文乱码。
获取代码的方式一般有两种,一种是从响应头中获取,另一种是从网页源代码的meta中获取。


这两种方法应该结合使用。一般的过程是先从响应头中获取。如果响应头不可用,请从 Web 源代码元中获取。如果没有,请设置默认编码。
我的代码如下:
<p>package httpclient.download;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
/**
* httpclient来下载网页源码。
*
* @author 徐金仁
*
*关于网页下载最大的问题是编码的问题
*
*/
public class Download {
public String getHtmlSource(String url){
String htmlSource = null;
String finallyCharset = null;
//使用httpclient下载
//创建一个httpclient的引擎
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建一个httpGet对象,用于发送get请求,如果要发post请求,就创建一个post对象
HttpGet get = new HttpGet(url);
try {
//发送get请求,获取一个响应
CloseableHttpResponse response= httpClient.execute(get);
//获取这次响应的实体,接下来所有的操作都是基于此实体完成,
HttpEntity entity = response.getEntity();
//方法还是两个,先从header里面来查看,如果没有,再从meta里面查看
//这个方法主要是从header里面来获取,如果没有,会返回一个null
finallyCharset = EntityUtils.getContentCharSet(entity);
System.out.println("编码如下:");
System.out.println("charset1 = " + finallyCharset);
byte[] byteArray = null;
if(finallyCharset == null){
//如果header里面没有,则要从meta里面来获取,为了节约网络资源,网页只读取一次,
/*
* 那么,就有几个关系 :url->字符流->子节流->字符串
* 这里可以用子节数组来作为中间的过渡,从字节数组这里获取到编码,再通过正确的编码变为字符串
*/
byteArray = convertInputStreamToByteArray(entity.getContent());
if(byteArray == null){
throw new Exception("字节数组为空");
}
//接下来要从字节数组中获取到meta里面的chatset
finallyCharset = getCharsetFromMeta(byteArray);
System.out.println("charset2 = " + finallyCharset);
if(finallyCharset == null){
//如果没有找到
finallyCharset = "UTF-8"; //则等于默认的
System.out.println("charset3 = " + finallyCharset);
}
//如果找到了就更好
}
System.out.println("charset = " + finallyCharset);
htmlSource = new String(byteArray, finallyCharset);
}catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return htmlSource;
}
/**
* 将一个输入流转化为一个字节数组
* @param content
* @param defaultCharset
* @return
* @throws IOException
*/
public byte[] convertInputStreamToByteArray(InputStream content) throws IOException {
//输入流转化为一个字节数组
byte[] by = new byte[4096];
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int l = -1;
while((l = content.read(by)) > 0){
bos.write(by, 0, l);
}
byte[] s = bos.toByteArray();
return s;
}
/**
* 从字节数组中获取到meta里面的charset的值
* @param byteArray
* @return
* @throws IOException
*/
public String getCharsetFromMeta(byte[] byteArray) throws IOException {
//将字节数组转化为bufferedReader,从中一行行的读取来,再判断
String htmlSource = new String(byteArray);
StringReader in = new StringReader(htmlSource);
BufferedReader reader = new BufferedReader(in);
String line = null;
while((line = reader.readLine()) != null){
line = line.toLowerCase();
if(line.contains("
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-21 04:02
)
使用HttpClient抓取某些网页时,往往会保留服务器发回的cookie信息,以便发起其他需要这些cookie的请求。在大多数情况下,我们使用内置的 cookie 策略来轻松、直接地获取这些 cookie。
下面一小段代码就是访问和获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com");
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,有一些网站返回的cookies不一定符合规范。比如下面这个例子,从打印的header可以看出,这个cookie中的Expires属性是时间戳的形式,不符合标准时间。因此httpclient处理cookie失败,最终无法获取cookie,并发出警告信息:“Invalid'expires'属性:1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用header数据来重构cookie,其实很多人都是这么做的,但是这种方法不够优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4节自定义cookie策略中,我们谈到了允许自定义的cookie策略。自定义的方法是实现CookieSpec接口,使用CookieSpecProvider在httpclient中完成策略实例的初始化和注册。好吧,关键线索就在于CookieSpec接口,我们来看看它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中,我们找到了一个解析方法。看评论,我们知道就是这个方法。Set-Cookie 的头部信息被解析为 Cookie 对象。自然而然,我们就会了解 httplcient 中 DefaultCookieSpec 的默认实现。限于篇幅,源码就不贴出来了。在默认实现中,DefaultCookieSpec 的主要工作是确定头部中 Cookie 规范的类型,然后调用具体的实现。像上面这样的 cookie 最终交给 NetscapeDraftSpec 的实例进行分析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE,dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就清楚了,我们只需要将Cookie中的expires time转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个 CookieSpec 类,继承 DefaultCookieSpec,重写解析器方法,将 Cookie 中的 expires 转换成正确的时间格式,调用默认的解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017] 查看全部
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作
)
使用HttpClient抓取某些网页时,往往会保留服务器发回的cookie信息,以便发起其他需要这些cookie的请求。在大多数情况下,我们使用内置的 cookie 策略来轻松、直接地获取这些 cookie。
下面一小段代码就是访问和获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com";);
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,有一些网站返回的cookies不一定符合规范。比如下面这个例子,从打印的header可以看出,这个cookie中的Expires属性是时间戳的形式,不符合标准时间。因此httpclient处理cookie失败,最终无法获取cookie,并发出警告信息:“Invalid'expires'属性:1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用header数据来重构cookie,其实很多人都是这么做的,但是这种方法不够优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4节自定义cookie策略中,我们谈到了允许自定义的cookie策略。自定义的方法是实现CookieSpec接口,使用CookieSpecProvider在httpclient中完成策略实例的初始化和注册。好吧,关键线索就在于CookieSpec接口,我们来看看它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中,我们找到了一个解析方法。看评论,我们知道就是这个方法。Set-Cookie 的头部信息被解析为 Cookie 对象。自然而然,我们就会了解 httplcient 中 DefaultCookieSpec 的默认实现。限于篇幅,源码就不贴出来了。在默认实现中,DefaultCookieSpec 的主要工作是确定头部中 Cookie 规范的类型,然后调用具体的实现。像上面这样的 cookie 最终交给 NetscapeDraftSpec 的实例进行分析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE,dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就清楚了,我们只需要将Cookie中的expires time转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个 CookieSpec 类,继承 DefaultCookieSpec,重写解析器方法,将 Cookie 中的 expires 转换成正确的时间格式,调用默认的解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017]
c httpclient抓取网页(() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-20 15:07
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1");
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1");
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
<br /><br />2、Post方式<br /><br /><br /><br /><br />1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) { <br />16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 } <br /><br /><br /><br /><br /><br /><br />相关链接:http://blog.csdn.net/acceptedx ... %3Bbr />
http://www.cnblogs.com/modou/articles/1325569.html
查看全部
c httpclient抓取网页(()
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1";);
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1";);
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
<br /><br />2、Post方式<br /><br /><br /><br /><br />1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) { <br />16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 } <br /><br /><br /><br /><br /><br /><br />相关链接:http://blog.csdn.net/acceptedx ... %3Bbr />
http://www.cnblogs.com/modou/articles/1325569.html
c httpclient抓取网页(() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-20 15:04
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1");
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1");
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
2、Post方式
1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) {
16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 }
相关链接:http://blog.csdn.net/acceptedx ... 30700
http://www.cnblogs.com/modou/articles/1325569.html
查看全部
c httpclient抓取网页(()
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1";);
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1";);
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
2、Post方式
1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) {
16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 }
相关链接:http://blog.csdn.net/acceptedx ... 30700
http://www.cnblogs.com/modou/articles/1325569.html
c httpclient抓取网页(一下和网页采集相关的组件和插件有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-19 06:04
其实很多做Java编程的人都不懂SEO,不知道怎么去百度收录等。当然,不是所有程序员都考虑爬网和网页爬虫,但是他们是专门针对这个人的. ,还是需要了解一下里面的知识,接下来介绍一些爬虫和网页采集相关的组件和插件~
大家在做爬虫、网页采集、通过网页自动写数据的时候基本都接触过这两个组件。网上已经有很多介绍资料了。我想从实际应用开始,从一个角度谈谈我对这两个组件的看法,并将它们记录在博客中,以便我以后阅读。欢迎大家批评指正。
本文主要比较两者的优缺点并介绍应用中的使用技巧,推荐一些入门资料和非常实用的辅助工具,希望对大家有所帮助。
如果您有任何问题或建议,您可以给我留言,共同交流和学习。
我们先来看看这两个组件的区别和优缺点:
单位
HtmlUnit 最初是一个自动化测试工具。它结合使用HttpClient和java自带的网络api来实现。它和HttpClient的区别在于它比HttpClient更“人性化”。
写HtmlUnit代码的时候,好像是在操作浏览器而不是写代码获取页面(getPage)-找到文本框(getElementByID || getElementByName || getElementByXPath等)-输入文本(type, setValue, setText,等)——其他一些类似的操作——找到提交按钮——提交——得到一个新的Page,这样就很像后台有人帮你操作浏览器了,你只要告诉他怎么操作要操作,需要填写哪些值。
一、网页模拟
首先,让我谈谈 HtmlUnit 相对于 HttpClient 最明显的好处之一。HtmlUnit 更好地将网页封装成一个对象。如果非要说HttpClient返回的接口HttpResponse其实存储的是一个对象,那很好,但是HtmlUnit不仅保存了网页对象,更难能可贵的是它还存储了网页的所有基本操作甚至事件. 也就是说,我们可以像在jsp中写js一样操作这个网页,非常方便,比如:你要一个节点的上一个节点,找到所有的按钮,找到“bt-style”的样式为所有元素,先修改一些元素,再转成String,或者我直接拿到这个网页然后操作这个网页,很方便的完成一个提交。这意味着如果你想分析一个网页,那将是非常容易的。比如我附上一段百度新闻高级搜索的代码:
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("http://news.baidu.com/advanced_news.html");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫"f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入"周星驰"
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
String result = nextPage.asXml();
System.out.println(result);
然后就可以将结果结果复制到一个文本中,然后用浏览器打开该文本。是你想要的吗(见图)?这很简单,对吧?为什么感觉简单,因为完全符合我们的操作和浏览,当然最后也是通过HttpClient等一些工具类来实现的,但是封装的非常人性化,很神奇。
Htmlunit可以有效的分析dom标签,可以有效的在页面上运行js,得到一些需要执行js的值。您需要做的就是执行 executeJavaScript() 方法。这些都是HtmlUnit为我们封装的。好吧,我们所要做的就是告诉它需要做什么。
WebClient webclient = new WebClient();
HtmlPage htmlpage = webclient.getPage("you url");
htmlpage.executeJavaScript("the function name you want to execute");
对于使用Java的程序员来说,对象的操作再熟悉不过了,HtmlUnit所做的就是帮助我们把网页封装成一个对象,一个功能丰富的透明对象。
二、自动处理网络响应
HtmlUnit有强大的响应处理机制,我们知道:常见的404是资源未找到,100是继续,300是跳转……当我们使用HttpClient时,它会告诉我们响应结果,当然你可以做自己判断,比如当你发现响应码是302时,会在响应头中找到新地址,自动跳过。当您发现它是 100 时,您将发送另一个请求。如果你使用HttpClient,你可以做这个来做,也可以写的更完整,但是HtmlUnit把这个功能实现的更完整,甚至说还包括页面JS的自动跳转(响应码是200,但是响应页面是一个JS),天涯的登录就是这样的情况,一起来看看吧。
/**
* @author CaiBo
* @date 2014年9月15日 上午9:16:36
* @version $Id$
*
*/
public class TianyaTest {
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("—————————————————————");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("—————————————————————");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null,
new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login");
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp");
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn");
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List paramsList = new ArrayList();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebut,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn"));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "ifugletest2014"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "test123456"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
}
执行上面的Main函数会得到如下结果:
我们看到响应码确实是200,表示成功。其实这个响应相当于302,需要跳转,只不过它的跳转写在js的body部分。
location.href=”http://passport.tianya.cn:80/o ... %25AD……&t=1410746182629&k=8cd4d967491c44c5eab1097e0f30c054&c=6fc7ebf8d782a07bb06624d9c6fbbf3f”;
这是页面跳转 查看全部
c httpclient抓取网页(一下和网页采集相关的组件和插件有什么区别?)
其实很多做Java编程的人都不懂SEO,不知道怎么去百度收录等。当然,不是所有程序员都考虑爬网和网页爬虫,但是他们是专门针对这个人的. ,还是需要了解一下里面的知识,接下来介绍一些爬虫和网页采集相关的组件和插件~
大家在做爬虫、网页采集、通过网页自动写数据的时候基本都接触过这两个组件。网上已经有很多介绍资料了。我想从实际应用开始,从一个角度谈谈我对这两个组件的看法,并将它们记录在博客中,以便我以后阅读。欢迎大家批评指正。
本文主要比较两者的优缺点并介绍应用中的使用技巧,推荐一些入门资料和非常实用的辅助工具,希望对大家有所帮助。
如果您有任何问题或建议,您可以给我留言,共同交流和学习。
我们先来看看这两个组件的区别和优缺点:
单位
HtmlUnit 最初是一个自动化测试工具。它结合使用HttpClient和java自带的网络api来实现。它和HttpClient的区别在于它比HttpClient更“人性化”。
写HtmlUnit代码的时候,好像是在操作浏览器而不是写代码获取页面(getPage)-找到文本框(getElementByID || getElementByName || getElementByXPath等)-输入文本(type, setValue, setText,等)——其他一些类似的操作——找到提交按钮——提交——得到一个新的Page,这样就很像后台有人帮你操作浏览器了,你只要告诉他怎么操作要操作,需要填写哪些值。
一、网页模拟
首先,让我谈谈 HtmlUnit 相对于 HttpClient 最明显的好处之一。HtmlUnit 更好地将网页封装成一个对象。如果非要说HttpClient返回的接口HttpResponse其实存储的是一个对象,那很好,但是HtmlUnit不仅保存了网页对象,更难能可贵的是它还存储了网页的所有基本操作甚至事件. 也就是说,我们可以像在jsp中写js一样操作这个网页,非常方便,比如:你要一个节点的上一个节点,找到所有的按钮,找到“bt-style”的样式为所有元素,先修改一些元素,再转成String,或者我直接拿到这个网页然后操作这个网页,很方便的完成一个提交。这意味着如果你想分析一个网页,那将是非常容易的。比如我附上一段百度新闻高级搜索的代码:
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("http://news.baidu.com/advanced_news.html";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫"f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入"周星驰"
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
String result = nextPage.asXml();
System.out.println(result);
然后就可以将结果结果复制到一个文本中,然后用浏览器打开该文本。是你想要的吗(见图)?这很简单,对吧?为什么感觉简单,因为完全符合我们的操作和浏览,当然最后也是通过HttpClient等一些工具类来实现的,但是封装的非常人性化,很神奇。
Htmlunit可以有效的分析dom标签,可以有效的在页面上运行js,得到一些需要执行js的值。您需要做的就是执行 executeJavaScript() 方法。这些都是HtmlUnit为我们封装的。好吧,我们所要做的就是告诉它需要做什么。
WebClient webclient = new WebClient();
HtmlPage htmlpage = webclient.getPage("you url");
htmlpage.executeJavaScript("the function name you want to execute");
对于使用Java的程序员来说,对象的操作再熟悉不过了,HtmlUnit所做的就是帮助我们把网页封装成一个对象,一个功能丰富的透明对象。
二、自动处理网络响应
HtmlUnit有强大的响应处理机制,我们知道:常见的404是资源未找到,100是继续,300是跳转……当我们使用HttpClient时,它会告诉我们响应结果,当然你可以做自己判断,比如当你发现响应码是302时,会在响应头中找到新地址,自动跳过。当您发现它是 100 时,您将发送另一个请求。如果你使用HttpClient,你可以做这个来做,也可以写的更完整,但是HtmlUnit把这个功能实现的更完整,甚至说还包括页面JS的自动跳转(响应码是200,但是响应页面是一个JS),天涯的登录就是这样的情况,一起来看看吧。
/**
* @author CaiBo
* @date 2014年9月15日 上午9:16:36
* @version $Id$
*
*/
public class TianyaTest {
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("—————————————————————");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("—————————————————————");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null,
new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login";);
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp";);
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn";);
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List paramsList = new ArrayList();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebut,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn";));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "ifugletest2014"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "test123456"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
}
执行上面的Main函数会得到如下结果:
我们看到响应码确实是200,表示成功。其实这个响应相当于302,需要跳转,只不过它的跳转写在js的body部分。
location.href=”http://passport.tianya.cn:80/o ... %25AD……&t=1410746182629&k=8cd4d967491c44c5eab1097e0f30c054&c=6fc7ebf8d782a07bb06624d9c6fbbf3f”;
这是页面跳转
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-18 13:11
最近在写一个小爬虫,准备爬取一些网页数据进行模型训练。在考虑如何爬取和分析网页的时候,参考了OSC站的一些项目,特别是@黄亿华写的webmagic的设计机制和原理——如何开发一个Java爬虫”文章给了很多启发,webmagic是一个垂直爬虫,我想写的是一个更通用的爬虫,主要爬上中文网站内容,对于HTTP协议和消息处理,没有比HttpClient组件更好的选择了,对于HTML代码解析,经过对比HTMLParser和Jsoup后,后者在API的使用上优势明显,简洁易懂,使用的开源组件敲定后,
对于我的爬虫爬取部分功能,只要根据网页的url爬取html代码,然后从html代码中解析出link和link
标签的文字没问题,所以解析的结果可以用一个Page类来表示。这个类纯粹是一个POJO,那么如何使用HttpClient和Jsoup直接解析成一个Page对象呢?
在HttpClient4.2中,提供了ResponseHandler接口来处理HttpResponse。因此,通过实现该接口,可以将返回的 HTML 代码解析为所需的 Page 对象。主要思路是先把HttpResponse中的数据读出,转换成HTML代码,然后用jsoup解析
标签和标签。代码显示如下,
public class PageResponseHandler implements ResponseHandler {
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在您可以直接返回 Page 对象。编写一个测试类来测试这个 PageResponseHandler。测试这个类的功能不需要复杂的代码。
public class PageResponseHandlerTest {
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫中的爬取和分析功能运行良好。对于中文,也可以很好的解析。更细心的读者会发现,这些代码中没有字符集,也没有设置字符集。转换字符集,后面会讨论HttpClient4.2组件中的字符集处理。
首先回顾一下Content-Type在HTTP协议的RFC规范中的作用。它指定发送给接收者的 Http 实体内容的媒体类型。对于文本类型HttpEntity,通常采用如下形式。指定 HttpEntity 的媒体类型。使用哪个字符集用于编码?另外,RFC规范还规定,如果Content-Type没有指定字符集,则默认使用ISO-8859-1字符集对Http实体进行编码
Content-Type: text/html; charset=UTF-8
说了这么多,大家应该都能猜到HttpClient4.2是如何正确编码的----就是使用Content-Type头中收录的字符集作为编码输入源。具体代码可以看EntityUtils类第212行开始的代码。EntityUtils 首先从 HttpEntity 对象获取 Content-Type。如果Content-Type的字符集不为空,则使用Content-Type对象中指定的字符集进行编码,否则使用开发者指定的字符集进行编码。字符集也没有指定,使用默认的字符集iso-8859-1进行编码。当然是实现了编码,还是调用了JDK的Reader类。
ContentType contentType = ContentType.getOrDefault(entity);
Charset charset = contentType.getCharset();
if (charset == null) {
charset = defaultCharset;
}
if (charset == null) {
charset = HTTP.DEF_CONTENT_CHARSET;
}
Reader reader = new InputStreamReader(instream, charset);
CharArrayBuffer buffer = new CharArrayBuffer(i);
char[] tmp = new char[1024];
int l;
while((l = reader.read(tmp)) != -1) {
buffer.append(tmp, 0, l);
}
return buffer.toString();
开放的互联网在创造了繁荣的网站的同时,也为非HTML规范网站提供了一些机会。部分中文网站没有正确设置HTTP请求对应头部的Content-。Type 属性使 HttpClient 使用默认的 iso-8859-1 字符集对 Http 实体进行编码。所以为了防止HttpClient抓取中文网站,可以指定一个默认的GBK字符集。将原来的 PageResponseHandler 转换字符串的代码行修改为
String html = EntityUtils.toString(entity, Charset.forName("gbk"));
至此,爬虫的爬取解析功能已经完成,再也不怕Content-Type头的中文网站设置不正确了。希望这篇文章文章对读者有用。
@仪山湖 查看全部
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
最近在写一个小爬虫,准备爬取一些网页数据进行模型训练。在考虑如何爬取和分析网页的时候,参考了OSC站的一些项目,特别是@黄亿华写的webmagic的设计机制和原理——如何开发一个Java爬虫”文章给了很多启发,webmagic是一个垂直爬虫,我想写的是一个更通用的爬虫,主要爬上中文网站内容,对于HTTP协议和消息处理,没有比HttpClient组件更好的选择了,对于HTML代码解析,经过对比HTMLParser和Jsoup后,后者在API的使用上优势明显,简洁易懂,使用的开源组件敲定后,
对于我的爬虫爬取部分功能,只要根据网页的url爬取html代码,然后从html代码中解析出link和link
标签的文字没问题,所以解析的结果可以用一个Page类来表示。这个类纯粹是一个POJO,那么如何使用HttpClient和Jsoup直接解析成一个Page对象呢?
在HttpClient4.2中,提供了ResponseHandler接口来处理HttpResponse。因此,通过实现该接口,可以将返回的 HTML 代码解析为所需的 Page 对象。主要思路是先把HttpResponse中的数据读出,转换成HTML代码,然后用jsoup解析
标签和标签。代码显示如下,
public class PageResponseHandler implements ResponseHandler {
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在您可以直接返回 Page 对象。编写一个测试类来测试这个 PageResponseHandler。测试这个类的功能不需要复杂的代码。
public class PageResponseHandlerTest {
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫中的爬取和分析功能运行良好。对于中文,也可以很好的解析。更细心的读者会发现,这些代码中没有字符集,也没有设置字符集。转换字符集,后面会讨论HttpClient4.2组件中的字符集处理。
首先回顾一下Content-Type在HTTP协议的RFC规范中的作用。它指定发送给接收者的 Http 实体内容的媒体类型。对于文本类型HttpEntity,通常采用如下形式。指定 HttpEntity 的媒体类型。使用哪个字符集用于编码?另外,RFC规范还规定,如果Content-Type没有指定字符集,则默认使用ISO-8859-1字符集对Http实体进行编码
Content-Type: text/html; charset=UTF-8
说了这么多,大家应该都能猜到HttpClient4.2是如何正确编码的----就是使用Content-Type头中收录的字符集作为编码输入源。具体代码可以看EntityUtils类第212行开始的代码。EntityUtils 首先从 HttpEntity 对象获取 Content-Type。如果Content-Type的字符集不为空,则使用Content-Type对象中指定的字符集进行编码,否则使用开发者指定的字符集进行编码。字符集也没有指定,使用默认的字符集iso-8859-1进行编码。当然是实现了编码,还是调用了JDK的Reader类。
ContentType contentType = ContentType.getOrDefault(entity);
Charset charset = contentType.getCharset();
if (charset == null) {
charset = defaultCharset;
}
if (charset == null) {
charset = HTTP.DEF_CONTENT_CHARSET;
}
Reader reader = new InputStreamReader(instream, charset);
CharArrayBuffer buffer = new CharArrayBuffer(i);
char[] tmp = new char[1024];
int l;
while((l = reader.read(tmp)) != -1) {
buffer.append(tmp, 0, l);
}
return buffer.toString();
开放的互联网在创造了繁荣的网站的同时,也为非HTML规范网站提供了一些机会。部分中文网站没有正确设置HTTP请求对应头部的Content-。Type 属性使 HttpClient 使用默认的 iso-8859-1 字符集对 Http 实体进行编码。所以为了防止HttpClient抓取中文网站,可以指定一个默认的GBK字符集。将原来的 PageResponseHandler 转换字符串的代码行修改为
String html = EntityUtils.toString(entity, Charset.forName("gbk"));
至此,爬虫的爬取解析功能已经完成,再也不怕Content-Type头的中文网站设置不正确了。希望这篇文章文章对读者有用。
@仪山湖
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-17 21:09
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话少说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,可以在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话少说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,可以在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(HtmlUnitJSoup条目使用Java屏幕抓取器应用程序教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-15 11:00
htmlunit 抓取
我最近发表了一篇关于使用 Java 文章 进行屏幕抓取的文章。一些 Twitter 追随者思考为什么我使用 JSoup 而不是流行的、无浏览器的 Web 测试框架 HtmlUnit。我没有具体的原因,所以我决定使用 HtmlUnit 而不是 JSoup 来重现完全相同的屏幕抓取器应用程序教程。
原教程只是从我写的GitHub面试题文章中提取了一些信息。它提取页面标题、作者姓名和页面上所有链接的列表。本教程将做完全相同的事情,只是不同。
HtmlUnit Maven POM 入口
使用 HtmlUnit 的第一步是创建一个基于 Maven 的项目,并将适当的 GAV 添加到 POM 文件的依赖项部分。这是一个完整的 Maven POM 文件示例,其中收录在依赖项中的 HtmlUnit GAV。
4.0.0
com.mcnz.screen.scraper
java-screen-scraper
1.0
net.sourceforge.htmlunit
htmlunit
2.34.1
maven-compiler-plugin
1.8
1.8
HtmlUnit 屏幕截图代码
HtmlUnit 屏幕抓取应用程序创建过程的下一步是使用main 方法生成一个Java 类,然后使用要HtmlUnit 的站点的URL 来抓取创建一个HtmlUnit WebClient 实例。
package com.mcnz.screen.scraper;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.html.*;
public class HtmlUnitScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/ ... 3B%3B
WebClient webClient = new WebClient();
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
}
}
HtmlUnit API
WebClient 类的 getPage (URL) 方法将解析提供的 URL 并返回一个表示网页的 HtmlPage 对象。但是,CSS、JavaScript 和缺少正确配置的 SSL 密钥库可能会导致 getPage(URL) 方法失败。在获取HtmlPage对象之前,最好先通过prototype关闭这三个功能。
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage htmlPage = webClient.getPage(url);
在前面的示例中,我们通过捕获要解析的网页的标题来测试 Java 屏幕抓取功能。要使用 HtmlUnit 屏幕抓取工具执行此操作,我们只需要调用 htmlPage 实例上的 getTitle() 方法:
System.out.println(htmlPage.getTitleText ());
运行 Java 屏幕抓取应用程序
此时您可以编译代码并运行应用程序,它将输出页面标题:
Tough sample GitHub interview questions and answers for job candidates
显示作者姓名的页面片段的 CSS 选择器是 #author> div> a。如果将此 CSS 选择器插入到 querySelector(String) 方法中,它将返回一个 DomNode 实例,该实例可用于检查 CSS 选择的结果。只需请求 domNode asText 返回 文章 作者姓名:
DomNode domNode = htmlPage.querySelector("#author > div > a");
System.out.println(domNode.asText ());
原文章的最后一个重要成就是打印出页面上每个锚链接的文本。要为此目的使用 HtmlUnit Java 屏幕抓取工具,请调用 HtmlPage 实例的 getAnchors 方法。这将返回一个 HtmlAnchor 实例列表。然后,我们可以通过调用 getAttribute 方法遍历列表并输出与链接关联的 URL:
List anchors = htmlPage.getAnchors ();
for (HtmlAnchor anchor : anchors) {
System.out.println(anchor.getAttribut e ("href"));
}
当类运行时,输出如下:
JSoup vs HtmlUnit 作为屏幕抓取工具
那么我如何看待这两种不同的方法呢?好吧,如果我要编写自己的 Java 屏幕抓取工具,我可能会选择 HtmlUnit。API 内置了许多实用方法,例如 HtmlPage 的 getAnchors() 方法,可以更轻松地执行常见任务。API 由其维护者定期更新,许多开发人员已经知道如何使用 API,因为它通常用作 Java Web 应用程序的单元测试框架。最后,HtmlUnit 具有处理 CSS 和 JavaScript 的一些高级功能,允许该技术的各种外围应用。
总的来说,这两个 API 是实现 Java 屏幕抓取工具的绝佳选择。你真的不会错的任何人。
您可以在 GitHub 上找到 HtmlUnit 屏幕抓取应用程序的完整代码。
HTMLUnit 屏幕抓取应用程序
翻译自:
htmlunit 抓取 查看全部
c httpclient抓取网页(HtmlUnitJSoup条目使用Java屏幕抓取器应用程序教程(上))
htmlunit 抓取
我最近发表了一篇关于使用 Java 文章 进行屏幕抓取的文章。一些 Twitter 追随者思考为什么我使用 JSoup 而不是流行的、无浏览器的 Web 测试框架 HtmlUnit。我没有具体的原因,所以我决定使用 HtmlUnit 而不是 JSoup 来重现完全相同的屏幕抓取器应用程序教程。
原教程只是从我写的GitHub面试题文章中提取了一些信息。它提取页面标题、作者姓名和页面上所有链接的列表。本教程将做完全相同的事情,只是不同。
HtmlUnit Maven POM 入口
使用 HtmlUnit 的第一步是创建一个基于 Maven 的项目,并将适当的 GAV 添加到 POM 文件的依赖项部分。这是一个完整的 Maven POM 文件示例,其中收录在依赖项中的 HtmlUnit GAV。
4.0.0
com.mcnz.screen.scraper
java-screen-scraper
1.0
net.sourceforge.htmlunit
htmlunit
2.34.1
maven-compiler-plugin
1.8
1.8
HtmlUnit 屏幕截图代码
HtmlUnit 屏幕抓取应用程序创建过程的下一步是使用main 方法生成一个Java 类,然后使用要HtmlUnit 的站点的URL 来抓取创建一个HtmlUnit WebClient 实例。
package com.mcnz.screen.scraper;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.html.*;
public class HtmlUnitScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/ ... 3B%3B
WebClient webClient = new WebClient();
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
}
}
HtmlUnit API
WebClient 类的 getPage (URL) 方法将解析提供的 URL 并返回一个表示网页的 HtmlPage 对象。但是,CSS、JavaScript 和缺少正确配置的 SSL 密钥库可能会导致 getPage(URL) 方法失败。在获取HtmlPage对象之前,最好先通过prototype关闭这三个功能。
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage htmlPage = webClient.getPage(url);
在前面的示例中,我们通过捕获要解析的网页的标题来测试 Java 屏幕抓取功能。要使用 HtmlUnit 屏幕抓取工具执行此操作,我们只需要调用 htmlPage 实例上的 getTitle() 方法:
System.out.println(htmlPage.getTitleText ());
运行 Java 屏幕抓取应用程序
此时您可以编译代码并运行应用程序,它将输出页面标题:
Tough sample GitHub interview questions and answers for job candidates
显示作者姓名的页面片段的 CSS 选择器是 #author> div> a。如果将此 CSS 选择器插入到 querySelector(String) 方法中,它将返回一个 DomNode 实例,该实例可用于检查 CSS 选择的结果。只需请求 domNode asText 返回 文章 作者姓名:
DomNode domNode = htmlPage.querySelector("#author > div > a");
System.out.println(domNode.asText ());
原文章的最后一个重要成就是打印出页面上每个锚链接的文本。要为此目的使用 HtmlUnit Java 屏幕抓取工具,请调用 HtmlPage 实例的 getAnchors 方法。这将返回一个 HtmlAnchor 实例列表。然后,我们可以通过调用 getAttribute 方法遍历列表并输出与链接关联的 URL:
List anchors = htmlPage.getAnchors ();
for (HtmlAnchor anchor : anchors) {
System.out.println(anchor.getAttribut e ("href"));
}
当类运行时,输出如下:
JSoup vs HtmlUnit 作为屏幕抓取工具
那么我如何看待这两种不同的方法呢?好吧,如果我要编写自己的 Java 屏幕抓取工具,我可能会选择 HtmlUnit。API 内置了许多实用方法,例如 HtmlPage 的 getAnchors() 方法,可以更轻松地执行常见任务。API 由其维护者定期更新,许多开发人员已经知道如何使用 API,因为它通常用作 Java Web 应用程序的单元测试框架。最后,HtmlUnit 具有处理 CSS 和 JavaScript 的一些高级功能,允许该技术的各种外围应用。
总的来说,这两个 API 是实现 Java 屏幕抓取工具的绝佳选择。你真的不会错的任何人。
您可以在 GitHub 上找到 HtmlUnit 屏幕抓取应用程序的完整代码。
HTMLUnit 屏幕抓取应用程序
翻译自:
htmlunit 抓取
c httpclient抓取网页(登录究竟是怎么回事?登录就是向你的浏览器写cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 12:32
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是本地存储的小文件,由服务器发送命令。浏览器在本地读写。
在访问某些站点时,浏览器会检查是否有所浏览站点的cookie信息。如果有,它会在发送访问请求时携带这些内容。服务器可以读取浏览器发送的请求中的cookie信息。. 能够在响应请求时写入cookie信息。cookie 信息收录键值。内容。到期。拥有网站。
说到这里的cookies,差不多就该结束了。那么登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果您在计算机上写入 cookie,那么伪造 cookie 的人将有机会登录该站点。所以服务器会在内存中保留一份相同信息的副本。这个过程称为对话。假设你点击网站上的退出按钮,服务器会清除内存中的cookies。同时,清除浏览器中的登录cookies。
知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。
打开知乎的首页,打开wireshark。开始监控端口。输入用户名和密码,然后单击登录。检查wireshark捕获的数据包。
截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf和密码。记住_我,电子邮件。注意提交的信息中收录cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章是服务器返回的数据。请注意,它具有三个 cookie 设置。并带有指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?首先,发送登录请求时的cookie。以及帖子数据的格式。其次,我们可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(登录究竟是怎么回事?登录就是向你的浏览器写cookie)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是本地存储的小文件,由服务器发送命令。浏览器在本地读写。
在访问某些站点时,浏览器会检查是否有所浏览站点的cookie信息。如果有,它会在发送访问请求时携带这些内容。服务器可以读取浏览器发送的请求中的cookie信息。. 能够在响应请求时写入cookie信息。cookie 信息收录键值。内容。到期。拥有网站。
说到这里的cookies,差不多就该结束了。那么登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果您在计算机上写入 cookie,那么伪造 cookie 的人将有机会登录该站点。所以服务器会在内存中保留一份相同信息的副本。这个过程称为对话。假设你点击网站上的退出按钮,服务器会清除内存中的cookies。同时,清除浏览器中的登录cookies。
知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。
打开知乎的首页,打开wireshark。开始监控端口。输入用户名和密码,然后单击登录。检查wireshark捕获的数据包。
截图如下:


第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf和密码。记住_我,电子邮件。注意提交的信息中收录cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章是服务器返回的数据。请注意,它具有三个 cookie 设置。并带有指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?首先,发送登录请求时的cookie。以及帖子数据的格式。其次,我们可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(某电商商品详细信息的整体架构布局(图)、业务需求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-09 22:05
)
HtmlCleaner&xPath:网页分析软件,解析出需要的相关信息。
MySQL数据库:用于存储爬取到的产品的详细信息。
ZooKeeper:分布式协调工具,用于监控后期各个爬虫的运行状态。
三、业务需求
获取电子商务产品的详细信息,需要的相关字段有:产品ID、产品名称、产品价格和产品详细信息。
四、 整体结构布局
第一个是我们的核心部件爬虫程序。爬虫过程是:从Redis数据仓库中取出URL,使用HttpClient进行下载,下载的页面内容,我们使用HtmlCleaner和xPath进行页面分析,此时我们解析的页面可能是产品列表页面,或者它可能是产品的详细页面。如果是产品列表页面,则需要在页面中解析出产品详情页面的URL,放入Redis数据仓库进行后期分析;如果是产品详细信息页面,请将其存储在我们的 MySQL 数据中。具体架构图如下:
核心程序爬虫写好后,为了加快页面爬取效率,我们需要对爬虫进行改进:一是多线程修改爬虫程序;二是将爬虫部署到多台服务器上,进一步加快爬虫的爬取效率。在实际生产环境中,由于刀片服务器稳定性较差,可能会出现一些问题,例如:爬虫进程挂掉。这些问题可能经常发生,所以我们需要对其进行监控。一旦发现爬虫进程挂掉,立即启动脚本重启爬虫进程,保证我们整个爬虫核心的持续运行。这是我们的分布式协调服务 ZooKeeper 的使用。我们可以再写一个进程监控程序,实时监控爬虫的运行状态。原理是:爬虫启动时,在ZooKeeper服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:
接下来,我们将重点分析爬虫架构的各个部分。
五、Redis 数据库-临时存储要爬取的 URL。
Redis 数据库是一个基于内存的 Key-Value 非关系型数据库。由于其极快的读写速度,受到了人们的热烈追捧(读写速度约为每秒10W)。Redis 数据库用于临时数据存储的选择就是基于此。为了让我们的爬虫优先抓取商品列表页面,我们在Redis中定义了两个队列(利用Redis的list的lpop和rpush模拟),分别是高优先级队列和低优先级队列,我们有更高优先级的商品列表page存放在队列中,商品详情页存放在低优先级队列中。这样我们就可以保证爬虫在抓取数据的时候,会先从高优先级队列中抓取数据,这样爬虫会先抓取产品列表页面。
package cn.mrchor.spider.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
public static String highKey = "jd_high_key";
public static String lowKey = "jd_low_key";
private JedisPool jedisPool = null;
/**
* 构造函数初始化jedis数据库连接池
*/
public JedisUtils() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(100);
jedisPoolConfig.setMaxWaitMillis(10000);
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool("192.168.52.128", 6379);
}
/**
* 获取jedis对象操作jedis数据库
* @return
*/
public Jedis getJedis() {
return this.jedisPool.getResource();
}
/**
* 往list添加数据
*/
public void addUrl(String key, String url) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(key, url);
jedisPool.returnResourceObject(jedis);
}
/**
* 从list中取数据
*/
public String getUrl(String key) {
Jedis jedis = jedisPool.getResource();
String url = jedis.rpop(key);
jedisPool.returnResourceObject(jedis);
return url;
}
} 查看全部
c httpclient抓取网页(某电商商品详细信息的整体架构布局(图)、业务需求
)
HtmlCleaner&xPath:网页分析软件,解析出需要的相关信息。
MySQL数据库:用于存储爬取到的产品的详细信息。
ZooKeeper:分布式协调工具,用于监控后期各个爬虫的运行状态。
三、业务需求
获取电子商务产品的详细信息,需要的相关字段有:产品ID、产品名称、产品价格和产品详细信息。
四、 整体结构布局
第一个是我们的核心部件爬虫程序。爬虫过程是:从Redis数据仓库中取出URL,使用HttpClient进行下载,下载的页面内容,我们使用HtmlCleaner和xPath进行页面分析,此时我们解析的页面可能是产品列表页面,或者它可能是产品的详细页面。如果是产品列表页面,则需要在页面中解析出产品详情页面的URL,放入Redis数据仓库进行后期分析;如果是产品详细信息页面,请将其存储在我们的 MySQL 数据中。具体架构图如下:
核心程序爬虫写好后,为了加快页面爬取效率,我们需要对爬虫进行改进:一是多线程修改爬虫程序;二是将爬虫部署到多台服务器上,进一步加快爬虫的爬取效率。在实际生产环境中,由于刀片服务器稳定性较差,可能会出现一些问题,例如:爬虫进程挂掉。这些问题可能经常发生,所以我们需要对其进行监控。一旦发现爬虫进程挂掉,立即启动脚本重启爬虫进程,保证我们整个爬虫核心的持续运行。这是我们的分布式协调服务 ZooKeeper 的使用。我们可以再写一个进程监控程序,实时监控爬虫的运行状态。原理是:爬虫启动时,在ZooKeeper服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:
接下来,我们将重点分析爬虫架构的各个部分。
五、Redis 数据库-临时存储要爬取的 URL。
Redis 数据库是一个基于内存的 Key-Value 非关系型数据库。由于其极快的读写速度,受到了人们的热烈追捧(读写速度约为每秒10W)。Redis 数据库用于临时数据存储的选择就是基于此。为了让我们的爬虫优先抓取商品列表页面,我们在Redis中定义了两个队列(利用Redis的list的lpop和rpush模拟),分别是高优先级队列和低优先级队列,我们有更高优先级的商品列表page存放在队列中,商品详情页存放在低优先级队列中。这样我们就可以保证爬虫在抓取数据的时候,会先从高优先级队列中抓取数据,这样爬虫会先抓取产品列表页面。
package cn.mrchor.spider.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
public static String highKey = "jd_high_key";
public static String lowKey = "jd_low_key";
private JedisPool jedisPool = null;
/**
* 构造函数初始化jedis数据库连接池
*/
public JedisUtils() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(100);
jedisPoolConfig.setMaxWaitMillis(10000);
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool("192.168.52.128", 6379);
}
/**
* 获取jedis对象操作jedis数据库
* @return
*/
public Jedis getJedis() {
return this.jedisPool.getResource();
}
/**
* 往list添加数据
*/
public void addUrl(String key, String url) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(key, url);
jedisPool.returnResourceObject(jedis);
}
/**
* 从list中取数据
*/
public String getUrl(String key) {
Jedis jedis = jedisPool.getResource();
String url = jedis.rpop(key);
jedisPool.returnResourceObject(jedis);
return url;
}
}
c httpclient抓取网页(广州图书馆处理方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-09 09:49
)
欢迎访问我的个人网站,如果你能在GitHub上给网站的源代码一个star就更好了。
当我建立自己的网站时,我想记录我所有阅读和借阅的书籍。大学也爬了我学校的图书馆记录,但是数据库被删了==只保留了一个。截图。所以你要珍惜阅读的日子,记录你的借阅记录——广州图书馆。现在代码已经放在服务器上可以正常运行了。结果,检查我的网站(关于我)页面。整个代码使用HttpClient,存储在MySql中,定期使用Spring自带的Schedule。以下是爬取过程。
1.页面跳转过程
一般是进入首页,点击进入登录页面,然后输入账号密码。从表面上看,并没有什么特别之处。实际上,在模拟登录时,并不只是向链接发布请求那么简单。获得的响应要么跳回登录页面,要么不受限制地重定向。
其实是做单点登录的,如下图,广州图书馆网址是:,登录网址是:。原理网上很多人讲的很好,可以看看这篇文章SSO单点登录。
2.如何处理
解决方法不难,只要访问模拟的主页获取库会话,python的获取代码如:session.get(""),打印cookie后如下:
[, , ]
整个登录和抓包流程如下:
即:
(1) 用户首先点击广州图书馆首页获取修改后的URL的session,然后点击登录界面,解析html,获取lt(自定义参数,类似验证码),和单点登录服务器会话。
(2)向目标服务器(单点登录服务器)提交post请求,请求参数包括username(用户名)、password(密码)、event(时间,默认为submit)、lt(自定义请求) parameters) 同时服务器要验证的参数:refer(源页面)、host(主机信息)、Content-Type(类型)。
(3)打印响应,搜索自己的名字,如果有就成功,否则会跳回登录页面。
(4)使用cookies访问其他页面,这里实现的是抓取借阅历史,所以访问的页面是:。
这就是基本的模拟登录和检索。之后就是对html的解析,书名的检索,书的索引等,然后封装成JavaBean,再存入数据库。(我没有做繁重的工作,不知道哪种方式更好)
3.代码
3.1 Java中一般使用httpclient来提交http请求。首先是需要导入的httpclient相关包:
org.apache.httpcomponents
httpclient
4.5.3
org.apache.httpcomponents
httpcore
4.4.7
3.2 构建并声明全局变量-上下文管理器,其中上下文为上下文管理器
public class LibraryUtil {
private static CloseableHttpClient httpClient = null;
private static HttpClientContext context = null;
private static CookieStore cookieStore = null;
static {
init();
}
private static void init() {
context = HttpClientContext.create();
cookieStore = new BasicCookieStore();
// 配置超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(12000).setSocketTimeout(6000)
.setConnectionRequestTimeout(6000).build();
// 设置默认跳转以及存储cookie
httpClient = HttpClientBuilder.create()
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.setRedirectStrategy(new DefaultRedirectStrategy()).setDefaultRequestConfig(requestConfig)
.setDefaultCookieStore(cookieStore).build();
}
...
3.3 声明一个get函数,可以自定义header。这里不需要它,但保留它并使其成为通用目的。
public static CloseableHttpResponse get(String url, Header[] header) throws IOException {
HttpGet httpget = new HttpGet(url);
if (header != null && header.length > 0) {
httpget.setHeaders(header);
}
CloseableHttpResponse response = httpClient.execute(httpget, context);//context用于存储上下文
return response;
}
3.4 访问主页获取会话。服务器上的会话是使用 session 存储的。本地浏览器使用 cookie。只要不在本地注销,也可以使用本地cookies来访问,但是为了达到模拟登录的效果,这里就不解释了。
CloseableHttpResponse homeResponse = get("http://www.gzlib.gov.cn/", null);
homeResponse.close();
此时,如果打印cookie,可以看到当前cookie如下:
3.5 访问登录页面,获取单点登录服务器背后的cookie,解析网页,获取自定义参数lt。这里的解析网页使用的是Jsoup,语法类似于python中的BeautifulSoup。
String loginURL = "http://login.gzlib.gov.cn/sso- ... 3B%3B
CloseableHttpResponse loginGetResponse = get(loginURL, null);
String content = toString(loginGetResponse);
String lt = Jsoup.parse(content).select("form").select("input[name=lt]").attr("value");
loginGetResponse.close();
此时,再次检查cookie,多一个():
3.6 声明一个post函数提交post请求,提交的参数默认为
public static CloseableHttpResponse postParam(String url, String parameters, Header[] headers)
throws IOException {
System.out.println(parameters);
HttpPost httpPost = new HttpPost(url);
if (headers != null && headers.length > 0) {
for (Header header : headers) {
httpPost.addHeader(header);
}
}
List nvps = toNameValuePairList(parameters);
httpPost.setEntity(new UrlEncodedFormEntity(nvps, "UTF-8"));
CloseableHttpResponse response = httpClient.execute(httpPost, context);
return response;
}
3.7 登录成功后,如果没有声明returnurl,即登录链接为(),则只显示登录成功的页面:
后端应定义链接重定向服务。如果想在登录成功后得到重定向页面,可以修改服务后的链接,这里会保持原来的状态。此时查看cookie的结果如下:
其中CASTGC的出现表示登录成功,可以使用cookie访问广州图书馆的其他页面。在python中是直接跳转到其他页面,但是在java中使用httpclient的过程中,看到的并不是直接跳转。,但是一个302重定向,打印Header后的结果如下:
仔细研究一下链接,你会发现服务器就相当于给了一张普通的票券,即可以使用该票券访问任何页面,而returnUrl就是返回的页面。这里我们直接访问重定向的url。
Header header = response.getHeaders("Location")[0];
CloseableHttpResponse home = get(header.getValue(), null);
然后打印页面,得到登录后跳转的首页。
3.8 解析 html
获取session后跳回首页,访问借阅历史页面,然后在html中解析结果。在python中使用了BeautifulSoup,简单实用,java中的jsoup也是不错的选择。
String html = getHTML();
Element element = Jsoup.parse(html).select("table.jieyue-table").get(0).select("tbody").get(0);
Elements trs = element.select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
System.out.println(tds.get(1).text());
}
输出结果:
企业IT架构转型之道
大话Java性能优化
深入理解Hadoop
大话Java性能优化
Java EE开发的颠覆者:Spring Boot实战
大型网站技术架构:核心原理与案例分析
Java性能权威指南
Akka入门与实践
高性能网站建设进阶指南:Web开发者性能优化最佳实践:Performance best practices for Web developers
Java EE开发的颠覆者:Spring Boot实战
深入理解Hadoop
大话Java性能优化
点击查看源代码
总结
目前修改后的代码已经集成到个人网站中,每天抓一次,但是还有很多事情没有做(比如分页、去重等)。如果你有兴趣,你可以研究源代码,如果你能帮助改进它。甚至更好。谢谢♪(・ω・)ノ。整个代码接近250行,当然……包括注释,但是使用python后,只有25行=w=,这里是python源代码。同时欢迎大家访问我的个人网站,也欢迎大家给个star。
import urllib.parse
import requests
from bs4 import BeautifulSoup
session = requests.session()
session.get("http://www.gzlib.gov.cn/")
session.headers.update(
{"Referer": "http://www.gzlib.gov.cn/member ... ot%3B,
"origin": "http://login.gzlib.gov.cn",
'Content-Type': 'application/x-www-form-urlencoded',
'host': 'www.gzlib.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
)
baseURL = "http://login.gzlib.gov.cn/sso-server/login"
soup = BeautifulSoup(session.get(baseURL).text, "html.parser")
lt = soup.select("form")[0].find(attrs={'name': 'lt'})['value']
postdict = {"username": "你的身份证",
"password": "密码(默认为身份证后6位)",
"_eventId": "submit",
"lt": lt
}
postdata = urllib.parse.urlencode(postdict)
session.post(baseURL, postdata)
print(session.get("http://www.gzlib.gov.cn/member ... 6quot;).text) 查看全部
c httpclient抓取网页(广州图书馆处理方法
)
欢迎访问我的个人网站,如果你能在GitHub上给网站的源代码一个star就更好了。
当我建立自己的网站时,我想记录我所有阅读和借阅的书籍。大学也爬了我学校的图书馆记录,但是数据库被删了==只保留了一个。截图。所以你要珍惜阅读的日子,记录你的借阅记录——广州图书馆。现在代码已经放在服务器上可以正常运行了。结果,检查我的网站(关于我)页面。整个代码使用HttpClient,存储在MySql中,定期使用Spring自带的Schedule。以下是爬取过程。
1.页面跳转过程
一般是进入首页,点击进入登录页面,然后输入账号密码。从表面上看,并没有什么特别之处。实际上,在模拟登录时,并不只是向链接发布请求那么简单。获得的响应要么跳回登录页面,要么不受限制地重定向。

其实是做单点登录的,如下图,广州图书馆网址是:,登录网址是:。原理网上很多人讲的很好,可以看看这篇文章SSO单点登录。

2.如何处理
解决方法不难,只要访问模拟的主页获取库会话,python的获取代码如:session.get(""),打印cookie后如下:
[, , ]
整个登录和抓包流程如下:
即:
(1) 用户首先点击广州图书馆首页获取修改后的URL的session,然后点击登录界面,解析html,获取lt(自定义参数,类似验证码),和单点登录服务器会话。
(2)向目标服务器(单点登录服务器)提交post请求,请求参数包括username(用户名)、password(密码)、event(时间,默认为submit)、lt(自定义请求) parameters) 同时服务器要验证的参数:refer(源页面)、host(主机信息)、Content-Type(类型)。
(3)打印响应,搜索自己的名字,如果有就成功,否则会跳回登录页面。
(4)使用cookies访问其他页面,这里实现的是抓取借阅历史,所以访问的页面是:。
这就是基本的模拟登录和检索。之后就是对html的解析,书名的检索,书的索引等,然后封装成JavaBean,再存入数据库。(我没有做繁重的工作,不知道哪种方式更好)
3.代码
3.1 Java中一般使用httpclient来提交http请求。首先是需要导入的httpclient相关包:
org.apache.httpcomponents
httpclient
4.5.3
org.apache.httpcomponents
httpcore
4.4.7
3.2 构建并声明全局变量-上下文管理器,其中上下文为上下文管理器
public class LibraryUtil {
private static CloseableHttpClient httpClient = null;
private static HttpClientContext context = null;
private static CookieStore cookieStore = null;
static {
init();
}
private static void init() {
context = HttpClientContext.create();
cookieStore = new BasicCookieStore();
// 配置超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(12000).setSocketTimeout(6000)
.setConnectionRequestTimeout(6000).build();
// 设置默认跳转以及存储cookie
httpClient = HttpClientBuilder.create()
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.setRedirectStrategy(new DefaultRedirectStrategy()).setDefaultRequestConfig(requestConfig)
.setDefaultCookieStore(cookieStore).build();
}
...
3.3 声明一个get函数,可以自定义header。这里不需要它,但保留它并使其成为通用目的。
public static CloseableHttpResponse get(String url, Header[] header) throws IOException {
HttpGet httpget = new HttpGet(url);
if (header != null && header.length > 0) {
httpget.setHeaders(header);
}
CloseableHttpResponse response = httpClient.execute(httpget, context);//context用于存储上下文
return response;
}
3.4 访问主页获取会话。服务器上的会话是使用 session 存储的。本地浏览器使用 cookie。只要不在本地注销,也可以使用本地cookies来访问,但是为了达到模拟登录的效果,这里就不解释了。
CloseableHttpResponse homeResponse = get("http://www.gzlib.gov.cn/", null);
homeResponse.close();
此时,如果打印cookie,可以看到当前cookie如下:
3.5 访问登录页面,获取单点登录服务器背后的cookie,解析网页,获取自定义参数lt。这里的解析网页使用的是Jsoup,语法类似于python中的BeautifulSoup。
String loginURL = "http://login.gzlib.gov.cn/sso- ... 3B%3B
CloseableHttpResponse loginGetResponse = get(loginURL, null);
String content = toString(loginGetResponse);
String lt = Jsoup.parse(content).select("form").select("input[name=lt]").attr("value");
loginGetResponse.close();
此时,再次检查cookie,多一个():
3.6 声明一个post函数提交post请求,提交的参数默认为
public static CloseableHttpResponse postParam(String url, String parameters, Header[] headers)
throws IOException {
System.out.println(parameters);
HttpPost httpPost = new HttpPost(url);
if (headers != null && headers.length > 0) {
for (Header header : headers) {
httpPost.addHeader(header);
}
}
List nvps = toNameValuePairList(parameters);
httpPost.setEntity(new UrlEncodedFormEntity(nvps, "UTF-8"));
CloseableHttpResponse response = httpClient.execute(httpPost, context);
return response;
}
3.7 登录成功后,如果没有声明returnurl,即登录链接为(),则只显示登录成功的页面:

后端应定义链接重定向服务。如果想在登录成功后得到重定向页面,可以修改服务后的链接,这里会保持原来的状态。此时查看cookie的结果如下:
其中CASTGC的出现表示登录成功,可以使用cookie访问广州图书馆的其他页面。在python中是直接跳转到其他页面,但是在java中使用httpclient的过程中,看到的并不是直接跳转。,但是一个302重定向,打印Header后的结果如下:
仔细研究一下链接,你会发现服务器就相当于给了一张普通的票券,即可以使用该票券访问任何页面,而returnUrl就是返回的页面。这里我们直接访问重定向的url。
Header header = response.getHeaders("Location")[0];
CloseableHttpResponse home = get(header.getValue(), null);
然后打印页面,得到登录后跳转的首页。
3.8 解析 html
获取session后跳回首页,访问借阅历史页面,然后在html中解析结果。在python中使用了BeautifulSoup,简单实用,java中的jsoup也是不错的选择。
String html = getHTML();
Element element = Jsoup.parse(html).select("table.jieyue-table").get(0).select("tbody").get(0);
Elements trs = element.select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
System.out.println(tds.get(1).text());
}
输出结果:
企业IT架构转型之道
大话Java性能优化
深入理解Hadoop
大话Java性能优化
Java EE开发的颠覆者:Spring Boot实战
大型网站技术架构:核心原理与案例分析
Java性能权威指南
Akka入门与实践
高性能网站建设进阶指南:Web开发者性能优化最佳实践:Performance best practices for Web developers
Java EE开发的颠覆者:Spring Boot实战
深入理解Hadoop
大话Java性能优化
点击查看源代码
总结
目前修改后的代码已经集成到个人网站中,每天抓一次,但是还有很多事情没有做(比如分页、去重等)。如果你有兴趣,你可以研究源代码,如果你能帮助改进它。甚至更好。谢谢♪(・ω・)ノ。整个代码接近250行,当然……包括注释,但是使用python后,只有25行=w=,这里是python源代码。同时欢迎大家访问我的个人网站,也欢迎大家给个star。
import urllib.parse
import requests
from bs4 import BeautifulSoup
session = requests.session()
session.get("http://www.gzlib.gov.cn/";)
session.headers.update(
{"Referer": "http://www.gzlib.gov.cn/member ... ot%3B,
"origin": "http://login.gzlib.gov.cn",
'Content-Type': 'application/x-www-form-urlencoded',
'host': 'www.gzlib.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
)
baseURL = "http://login.gzlib.gov.cn/sso-server/login"
soup = BeautifulSoup(session.get(baseURL).text, "html.parser")
lt = soup.select("form")[0].find(attrs={'name': 'lt'})['value']
postdict = {"username": "你的身份证",
"password": "密码(默认为身份证后6位)",
"_eventId": "submit",
"lt": lt
}
postdata = urllib.parse.urlencode(postdict)
session.post(baseURL, postdata)
print(session.get("http://www.gzlib.gov.cn/member ... 6quot;).text)
c httpclient抓取网页(java爬取网页源代码解析搜索词的地址采用模拟地址方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-08 02:18
java爬取网页源码解析
java爬取网页源码解析
1. 搜索词的地址采用模拟地址方式(通过分析搜索引擎的参数获得,如百度),然后将搜索词添加到模拟地址中。
2. 函数的输入参数是模拟地址。
String query = URLEncoder.encode("潘珠婷", "UTF-8");
字符串
url=""+query+"&pn="+p*10+"&tn=baiduhome_pg&ie=utf-8"public void MakeQuery(String domain) {
试试{
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod(domain);
//System.out.println
("************************************************ ****************");
//System.out.println(getMethod);
试试{
httpClient.executeMethod(getMethod);
}catch(异常 e){
System.out.println("网络问题");
}
getMethod.getParams()。 setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("方法失败:"
+ getMethod.getStatusLine());
}
byte[] responseBody = getMethod.getResponseBody();
//System.out.println
("************************************************ ****************");
//System.out.println(responseBody);
String response = new String(responseBody, "UTF-8");
//System.out.println
("************************************************ ****************");
//System.out.println(响应);
//Jsoup解析html
文档 doc=Jsoup.parse(response);
//System.out.println
("************************************************ ****************");
//System.out.println(doc);
元素内容=doc.getElementsByClass("f");
for(元素内容:内容){
元素链接 = content.getElementsByTag("a")。第一个(); 查看全部
c httpclient抓取网页(java爬取网页源代码解析搜索词的地址采用模拟地址方法)
java爬取网页源码解析
java爬取网页源码解析
1. 搜索词的地址采用模拟地址方式(通过分析搜索引擎的参数获得,如百度),然后将搜索词添加到模拟地址中。
2. 函数的输入参数是模拟地址。
String query = URLEncoder.encode("潘珠婷", "UTF-8");
字符串
url=""+query+"&pn="+p*10+"&tn=baiduhome_pg&ie=utf-8"public void MakeQuery(String domain) {
试试{
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod(domain);
//System.out.println
("************************************************ ****************");
//System.out.println(getMethod);
试试{
httpClient.executeMethod(getMethod);
}catch(异常 e){
System.out.println("网络问题");
}
getMethod.getParams()。 setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("方法失败:"
+ getMethod.getStatusLine());
}
byte[] responseBody = getMethod.getResponseBody();
//System.out.println
("************************************************ ****************");
//System.out.println(responseBody);
String response = new String(responseBody, "UTF-8");
//System.out.println
("************************************************ ****************");
//System.out.println(响应);
//Jsoup解析html
文档 doc=Jsoup.parse(response);
//System.out.println
("************************************************ ****************");
//System.out.println(doc);
元素内容=doc.getElementsByClass("f");
for(元素内容:内容){
元素链接 = content.getElementsByTag("a")。第一个();
c httpclient抓取网页(如何在java里面模拟ajax获得表格里的数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-06 02:18
现在我想用httpclient获取页面的数据,但是数据是根据Ajax脚本动态获取的。如何在Java中模拟Ajax以获取表中的数据?[网页URL:]
在此页面中,用于获取数据的JS的URL为
,Currency.ashx
通过检测,可以确定发送了post请求。URL如上所述,post参数。现在我想用Java中的httpclient模拟post请求,以获取返回数据。我试过了,但还是失败了。让我们给你一些建议。多谢各位
部分测试代码
---------------------------------------------------------------------------------------------
[align=left]HttpPostHttpPost=newHttpPost(url)
Listparam=newArrayList()
参数add(newBasicNameValuePair(“控制ID”、“CS30SV9SCKlax9FSDS3HYFUCTJR16N5G”)
setHeader(“X-AjaxPro-Method”、“GetDataSource”)
setHeader(“X_请求的_带有”,“XMLHttpRequest”)
setHeader(“Referer”和“)
httpost.setHeader(“用户代理”、“Mozilla/5.0(Windows;U;WindowsNT5.1;nl;rv:1.8.1.13)Gecko/20080311Firefox/2.0.13”)
setHeader(“Accept”,“text/xml,text/javascript,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5”)
httpost.setHeader(“接受语言”,“zh-cn,zh;q=0.5;en-us;q=0.7,en;q=0.3”)
httpost.setHeader(“接受字符集”,“gb2312,utf-8;q=0.7,*;q=0.7;ISO-8859-1,utf-8,GBK,gb2312;q=0.7,*;q=0.7”)
httpost.setEntity(newUrlEncodedFormEntity(param,HTTP.UTF8))
HttpResponseresp=client.execute(httpost)
InputStreamcontent=resp.getEntity().getContent()
[/align] 查看全部
c httpclient抓取网页(如何在java里面模拟ajax获得表格里的数据呢?)
现在我想用httpclient获取页面的数据,但是数据是根据Ajax脚本动态获取的。如何在Java中模拟Ajax以获取表中的数据?[网页URL:]
在此页面中,用于获取数据的JS的URL为
,Currency.ashx
通过检测,可以确定发送了post请求。URL如上所述,post参数。现在我想用Java中的httpclient模拟post请求,以获取返回数据。我试过了,但还是失败了。让我们给你一些建议。多谢各位
部分测试代码
---------------------------------------------------------------------------------------------
[align=left]HttpPostHttpPost=newHttpPost(url)
Listparam=newArrayList()
参数add(newBasicNameValuePair(“控制ID”、“CS30SV9SCKlax9FSDS3HYFUCTJR16N5G”)
setHeader(“X-AjaxPro-Method”、“GetDataSource”)
setHeader(“X_请求的_带有”,“XMLHttpRequest”)
setHeader(“Referer”和“)
httpost.setHeader(“用户代理”、“Mozilla/5.0(Windows;U;WindowsNT5.1;nl;rv:1.8.1.13)Gecko/20080311Firefox/2.0.13”)
setHeader(“Accept”,“text/xml,text/javascript,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5”)
httpost.setHeader(“接受语言”,“zh-cn,zh;q=0.5;en-us;q=0.7,en;q=0.3”)
httpost.setHeader(“接受字符集”,“gb2312,utf-8;q=0.7,*;q=0.7;ISO-8859-1,utf-8,GBK,gb2312;q=0.7,*;q=0.7”)
httpost.setEntity(newUrlEncodedFormEntity(param,HTTP.UTF8))
HttpResponseresp=client.execute(httpost)
InputStreamcontent=resp.getEntity().getContent()
[/align]
c httpclient抓取网页(网络爬虫的基本知识如何判断是否空等操做java?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-17 00:08
1、网络爬虫基础知识html
网络爬虫遍历互联网,抓取网络中所有相关的网页,体现了爬虫的概念。爬虫是如何穿越互联网的?互联网可以看成是一张大图,每个页面看成一个节点,页面的链接看成有向边。图的遍历方法分为宽度遍历和深度遍历,但是深度遍历可能会遍历深度过深或者掉进黑洞。因此,大多数爬虫不使用这种形式。另一方面,爬虫在按照宽度优先的方式进行遍历时,会对要遍历的网页给予一定的优先权。这称为具有偏好的遍历。
实际的爬虫从一系列种子连接开始。种子链接是起始节点,种子页面的超链接指向的页面是子节点(中间节点)。对于非html文档,如excel,无法从中提取超链接,将其视为图形的终端节点。在整个遍历过程中,会维护一个visited表,记录哪些节点(连接)被处理过,没有处理的跳过。
使用广度优先搜索策略的主要原因是:
一种。重要的网页通常靠近种子。比如我们打开新闻网站,总是最热的新闻。随着深度冲浪,网页的重要性越来越低。
湾 万维网的实际深度高达17层,但是到某个网页的路径总是很短,宽度优先遍历可以最快找到这个网页
C。宽度优先有利于多爬虫协同抓取。
2、网络爬虫的简单实现
一、定义访问队列,要访问的队列,爬取得到的URL的hash表,包括退出队列,进入队列,判断队列是否为空等,做java
package webspider;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
import java.util.Queue;
public class LinkQueue {
// 已访问的 url 集合
private static Set visitedUrl = new HashSet();
// 待访问的 url 集合
private static Queue unVisitedUrl = new PriorityQueue();
// 得到URL队列
public static Queue getUnVisitedUrl() {
return unVisitedUrl;
}
// 添加到访问过的URL队列中
public static void addVisitedUrl(String url) {
visitedUrl.add(url);
}
// 移除访问过的URL
public static void removeVisitedUrl(String url) {
visitedUrl.remove(url);
}
// 未访问的URL出队列
public static Object unVisitedUrlDeQueue() {
return unVisitedUrl.poll();
}
// 保证每一个 url 只被访问一次
public static void addUnvisitedUrl(String url) {
if (url != null && !url.trim().equals("") && !visitedUrl.contains(url)
&& !unVisitedUrl.contains(url))
unVisitedUrl.add(url);
}
// 得到已经访问的URL数目
public static int getVisitedUrlNum() {
return visitedUrl.size();
}
// 判断未访问的URL队列中是否为空
public static boolean unVisitedUrlsEmpty() {
return unVisitedUrl.isEmpty();
}
}
二、定义DownLoadFile类,根据获取到的url抓取网页内容,下载到本地存储。这里需要引用commons-httpclient.jar、commons-codec.jar、commons-logging.jar。
package webspider;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class DownLoadFile {
/**
* 根据 url 和网页类型生成须要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "."
+ contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private void saveToLocal(byte[] data, String filePath) {
try {
DataOutputStream out = new DataOutputStream(new FileOutputStream(
new File(filePath)));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/* 下载 url 指向的网页 */
public String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 链接超时 5s
httpClient.getHttpConnectionManager().getParams()
.setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "f:\\spider\\"
+ getFileNameByUrl(url,
getMethod.getResponseHeader("Content-Type")
.getValue());
saveToLocal(responseBody, filePath);
} catch (HttpException e) {
// 发生致命的异常,多是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放链接
getMethod.releaseConnection();
}
return filePath;
}
}
三、定义了HtmlParserTool类,用于获取网页中的超链接(包括a标签、frame中的src等),即获取子节点的URL。需要引入htmlparser.jarnode
package webspider;
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class HtmlParserTool {
// 获取一个网站上的连接,filter 用来过滤连接
public static Set extracLinks(String url, LinkFilter filter) {
Set links = new HashSet();
try {
Parser parser = new Parser(url);
//parser.setEncoding("utf-8");
// 过滤 标签的 filter,用来提取 frame 标签里的 src 属性所表示的连接
NodeFilter frameFilter = new NodeFilter() {
public boolean accept(Node node) {
if (node.getText().startsWith("frame src=")) {
return true;
} else {
return false;
}
}
};
// OrFilter 来设置过滤 <a> 标签,和 标签
OrFilter linkFilter = new OrFilter(new NodeClassFilter(
LinkTag.class), frameFilter);
// 获得全部通过过滤的标签
NodeList list = parser.extractAllNodesThatMatch(linkFilter);
for (int i = 0; i < list.size(); i++) {
Node tag = list.elementAt(i);
if (tag instanceof LinkTag)// <a> 标签
{
LinkTag link = (LinkTag) tag;
String linkUrl = link.getLink();// url
if (filter.accept(linkUrl))
links.add(linkUrl);
} else// 标签
{
// 提取 frame 里 src 属性的连接如
String frame = tag.getText();
int start = frame.indexOf("src=");
frame = frame.substring(start);
int end = frame.indexOf(" ");
if (end == -1)
end = frame.indexOf(">");
String frameUrl = frame.substring(5, end - 1);
if (filter.accept(frameUrl))
links.add(frameUrl);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return links;
}
}
四、写一个测试类MyCrawler来测试爬取效果
<p>package webspider;
import java.util.Set;
public class MyCrawler {
/**
* 使用种子初始化 URL 队列
*
* @return
* @param seeds
* 种子URL
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++)
LinkQueue.addUnvisitedUrl(seeds[i]);
}
/**
* 抓取过程
*
* @return
* @param seeds
*/
public void crawling(String[] seeds) { // 定义过滤器,提取以http://www.lietu.com开头的连接
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com"))
return true;
else
return false;
}
};
// 初始化 URL 队列
initCrawlerWithSeeds(seeds);
// 循环条件:待抓取的连接不空且抓取的网页很少于1000
while (!LinkQueue.unVisitedUrlsEmpty()
&& LinkQueue.getVisitedUrlNum() 查看全部
c httpclient抓取网页(网络爬虫的基本知识如何判断是否空等操做java?)
1、网络爬虫基础知识html
网络爬虫遍历互联网,抓取网络中所有相关的网页,体现了爬虫的概念。爬虫是如何穿越互联网的?互联网可以看成是一张大图,每个页面看成一个节点,页面的链接看成有向边。图的遍历方法分为宽度遍历和深度遍历,但是深度遍历可能会遍历深度过深或者掉进黑洞。因此,大多数爬虫不使用这种形式。另一方面,爬虫在按照宽度优先的方式进行遍历时,会对要遍历的网页给予一定的优先权。这称为具有偏好的遍历。
实际的爬虫从一系列种子连接开始。种子链接是起始节点,种子页面的超链接指向的页面是子节点(中间节点)。对于非html文档,如excel,无法从中提取超链接,将其视为图形的终端节点。在整个遍历过程中,会维护一个visited表,记录哪些节点(连接)被处理过,没有处理的跳过。
使用广度优先搜索策略的主要原因是:
一种。重要的网页通常靠近种子。比如我们打开新闻网站,总是最热的新闻。随着深度冲浪,网页的重要性越来越低。
湾 万维网的实际深度高达17层,但是到某个网页的路径总是很短,宽度优先遍历可以最快找到这个网页
C。宽度优先有利于多爬虫协同抓取。
2、网络爬虫的简单实现
一、定义访问队列,要访问的队列,爬取得到的URL的hash表,包括退出队列,进入队列,判断队列是否为空等,做java
package webspider;
import java.util.HashSet;
import java.util.PriorityQueue;
import java.util.Set;
import java.util.Queue;
public class LinkQueue {
// 已访问的 url 集合
private static Set visitedUrl = new HashSet();
// 待访问的 url 集合
private static Queue unVisitedUrl = new PriorityQueue();
// 得到URL队列
public static Queue getUnVisitedUrl() {
return unVisitedUrl;
}
// 添加到访问过的URL队列中
public static void addVisitedUrl(String url) {
visitedUrl.add(url);
}
// 移除访问过的URL
public static void removeVisitedUrl(String url) {
visitedUrl.remove(url);
}
// 未访问的URL出队列
public static Object unVisitedUrlDeQueue() {
return unVisitedUrl.poll();
}
// 保证每一个 url 只被访问一次
public static void addUnvisitedUrl(String url) {
if (url != null && !url.trim().equals("") && !visitedUrl.contains(url)
&& !unVisitedUrl.contains(url))
unVisitedUrl.add(url);
}
// 得到已经访问的URL数目
public static int getVisitedUrlNum() {
return visitedUrl.size();
}
// 判断未访问的URL队列中是否为空
public static boolean unVisitedUrlsEmpty() {
return unVisitedUrl.isEmpty();
}
}
二、定义DownLoadFile类,根据获取到的url抓取网页内容,下载到本地存储。这里需要引用commons-httpclient.jar、commons-codec.jar、commons-logging.jar。
package webspider;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.httpclient.DefaultHttpMethodRetryHandler;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpException;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.httpclient.params.HttpMethodParams;
public class DownLoadFile {
/**
* 根据 url 和网页类型生成须要保存的网页的文件名 去除掉 url 中非文件名字符
*/
public String getFileNameByUrl(String url, String contentType) {
// remove http://
url = url.substring(7);
// text/html类型
if (contentType.indexOf("html") != -1) {
url = url.replaceAll("[\\?/:*|\"]", "_") + ".html";
return url;
}
// 如application/pdf类型
else {
return url.replaceAll("[\\?/:*|\"]", "_") + "."
+ contentType.substring(contentType.lastIndexOf("/") + 1);
}
}
/**
* 保存网页字节数组到本地文件 filePath 为要保存的文件的相对地址
*/
private void saveToLocal(byte[] data, String filePath) {
try {
DataOutputStream out = new DataOutputStream(new FileOutputStream(
new File(filePath)));
for (int i = 0; i < data.length; i++)
out.write(data[i]);
out.flush();
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
/* 下载 url 指向的网页 */
public String downloadFile(String url) {
String filePath = null;
/* 1.生成 HttpClinet 对象并设置参数 */
HttpClient httpClient = new HttpClient();
// 设置 Http 链接超时 5s
httpClient.getHttpConnectionManager().getParams()
.setConnectionTimeout(5000);
/* 2.生成 GetMethod 对象并设置参数 */
GetMethod getMethod = new GetMethod(url);
// 设置 get 请求超时 5s
getMethod.getParams().setParameter(HttpMethodParams.SO_TIMEOUT, 5000);
// 设置请求重试处理
getMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,
new DefaultHttpMethodRetryHandler());
/* 3.执行 HTTP GET 请求 */
try {
int statusCode = httpClient.executeMethod(getMethod);
// 判断访问的状态码
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "
+ getMethod.getStatusLine());
filePath = null;
}
/* 4.处理 HTTP 响应内容 */
byte[] responseBody = getMethod.getResponseBody();// 读取为字节数组
// 根据网页 url 生成保存时的文件名
filePath = "f:\\spider\\"
+ getFileNameByUrl(url,
getMethod.getResponseHeader("Content-Type")
.getValue());
saveToLocal(responseBody, filePath);
} catch (HttpException e) {
// 发生致命的异常,多是协议不对或者返回的内容有问题
System.out.println("Please check your provided http address!");
e.printStackTrace();
} catch (IOException e) {
// 发生网络异常
e.printStackTrace();
} finally {
// 释放链接
getMethod.releaseConnection();
}
return filePath;
}
}
三、定义了HtmlParserTool类,用于获取网页中的超链接(包括a标签、frame中的src等),即获取子节点的URL。需要引入htmlparser.jarnode
package webspider;
import java.util.HashSet;
import java.util.Set;
import org.htmlparser.Node;
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.filters.OrFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class HtmlParserTool {
// 获取一个网站上的连接,filter 用来过滤连接
public static Set extracLinks(String url, LinkFilter filter) {
Set links = new HashSet();
try {
Parser parser = new Parser(url);
//parser.setEncoding("utf-8");
// 过滤 标签的 filter,用来提取 frame 标签里的 src 属性所表示的连接
NodeFilter frameFilter = new NodeFilter() {
public boolean accept(Node node) {
if (node.getText().startsWith("frame src=")) {
return true;
} else {
return false;
}
}
};
// OrFilter 来设置过滤 <a> 标签,和 标签
OrFilter linkFilter = new OrFilter(new NodeClassFilter(
LinkTag.class), frameFilter);
// 获得全部通过过滤的标签
NodeList list = parser.extractAllNodesThatMatch(linkFilter);
for (int i = 0; i < list.size(); i++) {
Node tag = list.elementAt(i);
if (tag instanceof LinkTag)// <a> 标签
{
LinkTag link = (LinkTag) tag;
String linkUrl = link.getLink();// url
if (filter.accept(linkUrl))
links.add(linkUrl);
} else// 标签
{
// 提取 frame 里 src 属性的连接如
String frame = tag.getText();
int start = frame.indexOf("src=");
frame = frame.substring(start);
int end = frame.indexOf(" ");
if (end == -1)
end = frame.indexOf(">");
String frameUrl = frame.substring(5, end - 1);
if (filter.accept(frameUrl))
links.add(frameUrl);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return links;
}
}
四、写一个测试类MyCrawler来测试爬取效果
<p>package webspider;
import java.util.Set;
public class MyCrawler {
/**
* 使用种子初始化 URL 队列
*
* @return
* @param seeds
* 种子URL
*/
private void initCrawlerWithSeeds(String[] seeds) {
for (int i = 0; i < seeds.length; i++)
LinkQueue.addUnvisitedUrl(seeds[i]);
}
/**
* 抓取过程
*
* @return
* @param seeds
*/
public void crawling(String[] seeds) { // 定义过滤器,提取以http://www.lietu.com开头的连接
LinkFilter filter = new LinkFilter() {
public boolean accept(String url) {
if (url.startsWith("http://www.baidu.com";))
return true;
else
return false;
}
};
// 初始化 URL 队列
initCrawlerWithSeeds(seeds);
// 循环条件:待抓取的连接不空且抓取的网页很少于1000
while (!LinkQueue.unVisitedUrlsEmpty()
&& LinkQueue.getVisitedUrlNum()
c httpclient抓取网页(先来说下数据抓取系统的大致工作流程.下背景 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-10 01:02
)
公司的数据采集系统已经写了一段时间了,是时候总结一下了。否则,以我的记忆力,过一会我就会忘记。打算写个系列,记录下我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,我们来谈谈数据采集的一般工作流程。
我先说一下背景。该公司正在做企业信用报告服务。整合各个方面的数据,生成企业信用报告。主要数据来源包括:第三方采购(整体采购数据或界面形式);捕获在 Internet 上公开可用的数据。那么就需要一个数据采集平台,以便为采集方便快捷地添加新的数据对象。关于数据采集平台的架构设计,我也是新手,以后会吸取这次的经验教训。本系列从实战开始,然后是第一点:数据抓取的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人觉得这三步是我在努力做的。但是,先听我说。##清除数据采集 需要先分享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张这么努力地加班,还没有完成任务。是不是产品经理没把需求说清楚?但是产品经理也说这个页面都是需要的。问题是:
分析数据的url和相关参数要采集,我先走一遍我想爬取数据的过程,看下面四张图:
提取url和参数
从以上四张图,我们可以确定有以下连接需要处理:-1. 获取验证码connection-2。提交查询-3。查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用 Chrome 的开发者工具进行页面分析。类似的工具有很多,各个浏览器自带的开发者工具基本可以满足需求,也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们已经提取出公司的基本注册信息为采集。我们需要提交三个请求,每个提交方法(POST 或 GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。本文文章不重复代码实现的具体逻辑,因为本文的重点是讲解:抓取网页的工作流程。后期会一一总结代码实现过程中用到的关键技术点和踩过的坑。暂时列出涉及的相关内容:
您也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天一个小笔记,每天进步一点点:
对公众有好处:enilu123
查看全部
c httpclient抓取网页(先来说下数据抓取系统的大致工作流程.下背景
)
公司的数据采集系统已经写了一段时间了,是时候总结一下了。否则,以我的记忆力,过一会我就会忘记。打算写个系列,记录下我踩过的所有坑。临时设置一个目录,按照这个系列写:
今天,我们来谈谈数据采集的一般工作流程。
我先说一下背景。该公司正在做企业信用报告服务。整合各个方面的数据,生成企业信用报告。主要数据来源包括:第三方采购(整体采购数据或界面形式);捕获在 Internet 上公开可用的数据。那么就需要一个数据采集平台,以便为采集方便快捷地添加新的数据对象。关于数据采集平台的架构设计,我也是新手,以后会吸取这次的经验教训。本系列从实战开始,然后是第一点:数据抓取的全过程。
我的日常数据采集分为以下几个步骤:
咳咳……先别扔鸡蛋了,我知道有人觉得这三步是我在努力做的。但是,先听我说。##清除数据采集 需要先分享一个场景:
- 产品经理:小张帅哥,我发现这个网站里面的数据对我们非常有用,你给抓取下来吧。
- 小张:好啊,你要抓取那些数据呢
- 产品经理:就这个页面的数据都要,这里的基本信息,这里的股东信息
- 小张:呃,都要是吧,好
- 产品经理:这个做好要多久啊,
- 小张:应该不会太久,这些都是表格数据,好解析
- 产品经理:好的,小张加油哦,做好了请你吃糖哦。
- 然后小张开始写,写了一会儿小张脸上冒汗了:这怎么基本信息和其他信息还不是一个页面。这表格竟然是在后台画好的,通过js请求数据画在页面的,我去,不同省份的企业表面看着一样,其实标签不一样。这要一个一个省份去适配啊啊啊啊啊啊.
- 小张同志开始加班加点,可还是没有按照和产平经理约定的时间完成任务
那么问题来了,为什么小张这么努力地加班,还没有完成任务。是不是产品经理没把需求说清楚?但是产品经理也说这个页面都是需要的。问题是:
分析数据的url和相关参数要采集,我先走一遍我想爬取数据的过程,看下面四张图:
提取url和参数
从以上四张图,我们可以确定有以下连接需要处理:-1. 获取验证码connection-2。提交查询-3。查看基本注册信息页面
那么我们来看看这三个步骤的提交地址和参数。这里我们使用 Chrome 的开发者工具进行页面分析。类似的工具有很多,各个浏览器自带的开发者工具基本可以满足需求,也可以使用一些第三方插件:如firebug、httpwatch等。
编写代码实现功能
通过前面的步骤,我们已经提取出公司的基本注册信息为采集。我们需要提交三个请求,每个提交方法(POST 或 GET),以及提交的参数。下一步就是用代码实现上面的步骤,得到你想要的数据。本文文章不重复代码实现的具体逻辑,因为本文的重点是讲解:抓取网页的工作流程。后期会一一总结代码实现过程中用到的关键技术点和踩过的坑。暂时列出涉及的相关内容:
您也可以到我的个人网站查看
或者,欢迎关注我的微信订阅号,每天一个小笔记,每天进步一点点:
对公众有好处:enilu123
c httpclient抓取网页(最简单的爬虫,不需要设定代理服务器,怎么办? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-05 12:16
)
最简单的爬虫不需要设置代理服务器,不需要设置cookie,不需要设置http连接池,使用httpget方法,只需要获取html代码...
嗯,满足这个要求的爬虫应该就是最基础的爬虫了。当然,这也是复杂爬虫的基础。
使用了httpclient4的相关API。别跟我说网上有很多httpclient3代码兼容性问题,都没有太大区别,但是我们应该选择一个可以使用的新接口!
当然还有很多细节需要注意,比如编码问题(我一般强制UTF-8)
毕业:
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class Easy {
//输入流转为String类型
public static String inputStream2String(InputStream is)throws IOException{
ByteArrayOutputStream baos=new ByteArrayOutputStream();
int i=-1;
while((i=is.read())!=-1){
baos.write(i);
}
return baos.toString();
}
//抓取网页的核心函数
public static void doGrab() throws Exception {
//httpclient可以认为是模拟的浏览器
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//要访问的目标页面url
String targetUrl="http://chriszz.sinaapp.com";
//使用get方式请求页面。复杂一点也可以换成post方式的
HttpGet httpGet = new HttpGet(targetUrl);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
try {
String status=response1.getStatusLine().toString();
//通过状态码来判断访问是否正常。200表示抓取成功
if(!status.equals("HTTP/1.1 200 OK")){
System.out.println("此页面可以正常获取!");
}else{
response1 = httpclient.execute(httpGet);
System.out.println(status);
}
//System.out.println(response1.getStatusLine());
HttpEntity entity1 = response1.getEntity();
// do something useful with the response body
// and ensure it is fully consumed
InputStream input=entity1.getContent();
String rawHtml=inputStream2String(input);
System.out.println(rawHtml);
//有时候会有中文乱码问题,这取决于你的eclipse java工程设定的编码格式、当前java文件的编码格式,以及抓取的网页的编码格式
//比如,你可以用String的getBytes()转换编码
//String html = new String(rawHtml.getBytes("ISO-8859-1"),"UTF-8");//转换后的结果
EntityUtils.consume(entity1);
} finally {
response1.close();//记得要关闭
}
} finally {
httpclient.close();//这个也要关闭哦!
}
}
/*
* 最简单的java爬虫--抓取百度首页
* memo:
* 0.抓取的是百度的首页,对应一个html页面。
* (至于为啥我们访问的是http://www.baidu.com而不是http://www.baidu.com/xxx.html,这个是百度那边设定的,总之我们会访问到那个包含html的页面)
* 1.使用http协议的get方法就可以了(以后复杂了可以用post方法,设定cookie,甚至设定http连接池;或者抓取json格式的数据、抓取图片等,也是类似的)
* 2.通过httpclient的相关包(httpclient4版本)编写,需要下载并添加相应的jar包到build path中
* 3.代码主要参考了httpclient(http://hc.apache.org/)包里面的tutorial的pdf文件。
*/
public static void main(String[] args) throws Exception{
Easy.doGrab();//为了简答这里把doGrab()方法定义为静态方法了所以直接Easy.doGrab()就好了
}
} 查看全部
c httpclient抓取网页(最简单的爬虫,不需要设定代理服务器,怎么办?
)
最简单的爬虫不需要设置代理服务器,不需要设置cookie,不需要设置http连接池,使用httpget方法,只需要获取html代码...
嗯,满足这个要求的爬虫应该就是最基础的爬虫了。当然,这也是复杂爬虫的基础。
使用了httpclient4的相关API。别跟我说网上有很多httpclient3代码兼容性问题,都没有太大区别,但是我们应该选择一个可以使用的新接口!
当然还有很多细节需要注意,比如编码问题(我一般强制UTF-8)
毕业:
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class Easy {
//输入流转为String类型
public static String inputStream2String(InputStream is)throws IOException{
ByteArrayOutputStream baos=new ByteArrayOutputStream();
int i=-1;
while((i=is.read())!=-1){
baos.write(i);
}
return baos.toString();
}
//抓取网页的核心函数
public static void doGrab() throws Exception {
//httpclient可以认为是模拟的浏览器
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
//要访问的目标页面url
String targetUrl="http://chriszz.sinaapp.com";
//使用get方式请求页面。复杂一点也可以换成post方式的
HttpGet httpGet = new HttpGet(targetUrl);
CloseableHttpResponse response1 = httpclient.execute(httpGet);
try {
String status=response1.getStatusLine().toString();
//通过状态码来判断访问是否正常。200表示抓取成功
if(!status.equals("HTTP/1.1 200 OK")){
System.out.println("此页面可以正常获取!");
}else{
response1 = httpclient.execute(httpGet);
System.out.println(status);
}
//System.out.println(response1.getStatusLine());
HttpEntity entity1 = response1.getEntity();
// do something useful with the response body
// and ensure it is fully consumed
InputStream input=entity1.getContent();
String rawHtml=inputStream2String(input);
System.out.println(rawHtml);
//有时候会有中文乱码问题,这取决于你的eclipse java工程设定的编码格式、当前java文件的编码格式,以及抓取的网页的编码格式
//比如,你可以用String的getBytes()转换编码
//String html = new String(rawHtml.getBytes("ISO-8859-1"),"UTF-8");//转换后的结果
EntityUtils.consume(entity1);
} finally {
response1.close();//记得要关闭
}
} finally {
httpclient.close();//这个也要关闭哦!
}
}
/*
* 最简单的java爬虫--抓取百度首页
* memo:
* 0.抓取的是百度的首页,对应一个html页面。
* (至于为啥我们访问的是http://www.baidu.com而不是http://www.baidu.com/xxx.html,这个是百度那边设定的,总之我们会访问到那个包含html的页面)
* 1.使用http协议的get方法就可以了(以后复杂了可以用post方法,设定cookie,甚至设定http连接池;或者抓取json格式的数据、抓取图片等,也是类似的)
* 2.通过httpclient的相关包(httpclient4版本)编写,需要下载并添加相应的jar包到build path中
* 3.代码主要参考了httpclient(http://hc.apache.org/)包里面的tutorial的pdf文件。
*/
public static void main(String[] args) throws Exception{
Easy.doGrab();//为了简答这里把doGrab()方法定义为静态方法了所以直接Easy.doGrab()就好了
}
}
c httpclient抓取网页(cookies设置.UseCookies=(默认为true),默认的会自己带上cookies)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-30 09:05
通过设置handler.UseCookies=true(默认为true),默认会自带cookies
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20200101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=900");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xj"),
new KeyValuePair("password", "a"),
});
var result = await client.PostAsync("https://www.xxjj.com/login/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,会跳转到登录页面。
该方法的使用场景:抓取需要登录的网页数据,不设置任何cookies,httpclient登录后会自动将cookies放入后续请求中。
但也要注意,如果你只是直接发起一个请求,它不会传递被发起项目本身的cookie信息,它会带上你请求的cookie网站 查看全部
c httpclient抓取网页(cookies设置.UseCookies=(默认为true),默认的会自己带上cookies)
通过设置handler.UseCookies=true(默认为true),默认会自带cookies
var handler = new HttpClientHandler() { UseCookies = true };
var client = new HttpClient(handler);// { BaseAddress = baseAddress };
client.DefaultRequestHeaders.Add("user-agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:57.0) Gecko/20200101 Firefox/57.0");
client.DefaultRequestHeaders.Add("Connection", "Keep-Alive");
client.DefaultRequestHeaders.Add("Keep-Alive", "timeout=900");
var content = new FormUrlEncodedContent(new[]
{
new KeyValuePair("email", "xj"),
new KeyValuePair("password", "a"),
});
var result = await client.PostAsync("https://www.xxjj.com/login/login", content);
result.EnsureSuccessStatusCode();
这种情况下,post请求登录成功后,会跳转到另一个页面,cookies也会自动带上。如果handler.UseCookies设置为false,登录后重定向不会自动带cookies,会跳转到登录页面。
该方法的使用场景:抓取需要登录的网页数据,不设置任何cookies,httpclient登录后会自动将cookies放入后续请求中。
但也要注意,如果你只是直接发起一个请求,它不会传递被发起项目本身的cookie信息,它会带上你请求的cookie网站
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-30 00:19
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,然后在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第4章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,然后在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第4章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(Android应用程序使用HttpClient即可访问被保护页而了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-10-29 08:20
例如,Android 应用程序需要向指定页面发送请求,但该页面不是简单的页面。只有当用户已经登录并且登录用户的用户名有效时,才能访问该页面。如果使用HttpURLConnection访问这个受保护的页面,需要处理的细节太复杂了。
其实,在web应用中访问受保护的页面,使用浏览器是非常简单的。用户通过系统提供的登录页面登录系统,浏览器负责维护与服务器的Session。如果用户登录用户名和密码符合要求,您就可以访问受保护的资源。
在 Android 应用中,您可以使用 HttpClient 登录系统。只要应用使用同一个HttpClient发送请求,HttpClient就会自动与服务器保持Session状态。也就是说,程序第一次使用HttpClient登录系统。然后使用 HttpClient 访问受保护的页面。
总结:在Android开发中,虽然HttpClient更好的支持了很多细节控件(比如代理、cookie、认证、压缩、连接池),但是对开发者的要求更高,而且代码写起来也比较复杂,普通开发难度大人员管理好,官方支持越来越少;而 HttpUrlConnection 包裹了大部分工作,屏蔽了不必要的细节,更适合开发者直接调用,官方对它的支持和优化也会越来越好。既然是开发Android应用,自然要遵循Android官方的指导方针,选择HttpUrlConnection。 查看全部
c httpclient抓取网页(Android应用程序使用HttpClient即可访问被保护页而了吗?)
例如,Android 应用程序需要向指定页面发送请求,但该页面不是简单的页面。只有当用户已经登录并且登录用户的用户名有效时,才能访问该页面。如果使用HttpURLConnection访问这个受保护的页面,需要处理的细节太复杂了。
其实,在web应用中访问受保护的页面,使用浏览器是非常简单的。用户通过系统提供的登录页面登录系统,浏览器负责维护与服务器的Session。如果用户登录用户名和密码符合要求,您就可以访问受保护的资源。
在 Android 应用中,您可以使用 HttpClient 登录系统。只要应用使用同一个HttpClient发送请求,HttpClient就会自动与服务器保持Session状态。也就是说,程序第一次使用HttpClient登录系统。然后使用 HttpClient 访问受保护的页面。
总结:在Android开发中,虽然HttpClient更好的支持了很多细节控件(比如代理、cookie、认证、压缩、连接池),但是对开发者的要求更高,而且代码写起来也比较复杂,普通开发难度大人员管理好,官方支持越来越少;而 HttpUrlConnection 包裹了大部分工作,屏蔽了不必要的细节,更适合开发者直接调用,官方对它的支持和优化也会越来越好。既然是开发Android应用,自然要遵循Android官方的指导方针,选择HttpUrlConnection。
c httpclient抓取网页(我正在尝试使用C#和ChromeWebInspector登录并在)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-28 07:11
问题
我正在尝试使用 C# 和 Chrome Web Inspector 登录并进入。
我不太了解人们必须用来解释 Web Inspector 中的信息以模拟登录和模拟维护会话并导航到下一页以采集信息的心理过程。
有人可以向我解释或指点我吗?
目前,我只有一些代码来获取主页和登录页面的内容:
公共类Morningstar
{
公共异步静态无效Ru4n()
{
var url =" http://www.morningstar.com/";
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept"," text / html,application / xhtml + xml,application / xml");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Encoding"," gzip,deflate");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" User-Agent"," Mozilla / 5.0(Windows NT 6.2; WOW64; rv:19.0)Gecko / 20100101 Firefox / 19.0");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Charset"," ISO-8859-1");
var response = await httpClient.GetAsync(new Uri(url));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var decompressedStream = new GZipStream(responseStream,CompressionMode.Decompress))
使用(var streamReader = new StreamReader(decompressedStream) ))
{
//Console.WriteLine(streamReader.ReadToEnd());
}
var loginURL =" https://members.morningstar.co ... 3B%3B
response =等待httpClient.GetAsync(new Uri(loginURL));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var streamReader = new StreamReader(responseStream))
{
Console.WriteLine(streamReader.ReadToEnd( ));
}
}
编辑:最后,按照穆罕默德的建议,我使用了以下代码:
ScrapingBrowser浏览器= new ScrapingBrowser();
//如果网站返回的cookie格式无效,则将UseDefaultCookiesParser设置为false
//browser.UseDefaultCookiesParser = false;
网页主页=浏览器。NavigateToPage(新Uri(" https://members.morningstar.co ... ot%3B));
PageWebForm form = homePage.FindFormById(" memberLoginForm");
form [" email_textbox"] =" example@example.com";
form [" pwd_textbox"] ="密码";
form [" go_button.x"] =" 57";
form [" go_button.y"] =" 22";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
解决方案
你应该模拟网站的登录过程。最简单的方法是通过一些调试器(如 Fiddler)检查 网站。
以下是网站的登录请求:
POST https ://members.morningstar.com/memberservice/login.aspx?CustId =& CType =& CName =& RememberMe = true& CookieTime = HTTP / 1.1
接受:text / html,application / xhtml + xml,* / *
推荐人:https://members.morningstar.co ... .aspx
**省略**
Cookie:cookies = true; TestCookieExist =存在; fp = 001140581745182496; __utma = 172984700.91600904.1405817457.1405817457.1405817457.1; __utmb = 172984700.8.10.1405817457; __utmz = 172984700.1405817457.1.1.utmcsr =(直接)| utmccn =(直接)| utmcmd =(无); __utmc = 172984700; ASP.NET_SessionId = b5bpepm3pftgoz55to3ql4me
email_textbox=test@email.com& pwd_textbox = password& remember = on& email_textbox2 =& go_button.x = 36& go_button.y = 16& ____ LAST =& __ EVENTARGUMENT =& __ VIEWSTATE =省略& __ EVENTVALIDATION =省略
您将看到一些 cookie 和表单字段,例如“__VIEWSTATE”。需要输入这个文件的实际值才能登录,可以使用以下步骤:
提出请求并删除“__LASTFOCUS”、“__EVENTTARGET”、“__EVENTARGUMENT”、“__VIEWSTATE”、“__EVENTVALIDATION”;
在同一页面上创建一个新的 POST 请求,使用上一个的 CookieContainer;使用废弃的字段、用户名和密码来构造帖子字符串。使用 MIME 类型应用程序/x-www-form-urlencoded 来发布。
如果成功,请使用 cookie 进行进一步请求以保留记录
注意:您可以使用 htmlagilitypack 或 scrapysharp 丢弃 html。ScrapySharp 提供了易于使用的表单发布和浏览工具网站。 查看全部
c httpclient抓取网页(我正在尝试使用C#和ChromeWebInspector登录并在)
问题
我正在尝试使用 C# 和 Chrome Web Inspector 登录并进入。
我不太了解人们必须用来解释 Web Inspector 中的信息以模拟登录和模拟维护会话并导航到下一页以采集信息的心理过程。
有人可以向我解释或指点我吗?
目前,我只有一些代码来获取主页和登录页面的内容:
公共类Morningstar
{
公共异步静态无效Ru4n()
{
var url =" http://www.morningstar.com/";
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept"," text / html,application / xhtml + xml,application / xml");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Encoding"," gzip,deflate");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" User-Agent"," Mozilla / 5.0(Windows NT 6.2; WOW64; rv:19.0)Gecko / 20100101 Firefox / 19.0");
httpClient.DefaultRequestHeaders.TryAddWithoutValidation(" Accept-Charset"," ISO-8859-1");
var response = await httpClient.GetAsync(new Uri(url));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var decompressedStream = new GZipStream(responseStream,CompressionMode.Decompress))
使用(var streamReader = new StreamReader(decompressedStream) ))
{
//Console.WriteLine(streamReader.ReadToEnd());
}
var loginURL =" https://members.morningstar.co ... 3B%3B
response =等待httpClient.GetAsync(new Uri(loginURL));
response.EnsureSuccessStatusCode();
使用(var responseStream =等待response.Content.ReadAsStreamAsync())
使用(var streamReader = new StreamReader(responseStream))
{
Console.WriteLine(streamReader.ReadToEnd( ));
}
}
编辑:最后,按照穆罕默德的建议,我使用了以下代码:
ScrapingBrowser浏览器= new ScrapingBrowser();
//如果网站返回的cookie格式无效,则将UseDefaultCookiesParser设置为false
//browser.UseDefaultCookiesParser = false;
网页主页=浏览器。NavigateToPage(新Uri(" https://members.morningstar.co ... ot%3B));
PageWebForm form = homePage.FindFormById(" memberLoginForm");
form [" email_textbox"] =" example@example.com";
form [" pwd_textbox"] ="密码";
form [" go_button.x"] =" 57";
form [" go_button.y"] =" 22";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
解决方案
你应该模拟网站的登录过程。最简单的方法是通过一些调试器(如 Fiddler)检查 网站。
以下是网站的登录请求:
POST https ://members.morningstar.com/memberservice/login.aspx?CustId =& CType =& CName =& RememberMe = true& CookieTime = HTTP / 1.1
接受:text / html,application / xhtml + xml,* / *
推荐人:https://members.morningstar.co ... .aspx
**省略**
Cookie:cookies = true; TestCookieExist =存在; fp = 001140581745182496; __utma = 172984700.91600904.1405817457.1405817457.1405817457.1; __utmb = 172984700.8.10.1405817457; __utmz = 172984700.1405817457.1.1.utmcsr =(直接)| utmccn =(直接)| utmcmd =(无); __utmc = 172984700; ASP.NET_SessionId = b5bpepm3pftgoz55to3ql4me
email_textbox=test@email.com& pwd_textbox = password& remember = on& email_textbox2 =& go_button.x = 36& go_button.y = 16& ____ LAST =& __ EVENTARGUMENT =& __ VIEWSTATE =省略& __ EVENTVALIDATION =省略
您将看到一些 cookie 和表单字段,例如“__VIEWSTATE”。需要输入这个文件的实际值才能登录,可以使用以下步骤:
提出请求并删除“__LASTFOCUS”、“__EVENTTARGET”、“__EVENTARGUMENT”、“__VIEWSTATE”、“__EVENTVALIDATION”;
在同一页面上创建一个新的 POST 请求,使用上一个的 CookieContainer;使用废弃的字段、用户名和密码来构造帖子字符串。使用 MIME 类型应用程序/x-www-form-urlencoded 来发布。
如果成功,请使用 cookie 进行进一步请求以保留记录
注意:您可以使用 htmlagilitypack 或 scrapysharp 丢弃 html。ScrapySharp 提供了易于使用的表单发布和浏览工具网站。
c httpclient抓取网页(mons.httpclient与org.apache.http.client的区别 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 15:10
)
与传统JDK自带的URLConnection相比,HttpClient增加了易用性和灵活性。不仅方便了客户端发送Http请求,也方便了开发者测试接口(基于Http协议),提高了开发效率,也方便了提高代码的健壮性。因此,掌握HttpClient是非常重要的必修内容。掌握了HttpClient之后,相信你会对Http协议有更深入的了解。
mons.httpclient.HttpClient 和 org.apache.http.client.HttpClient 的区别
Commons HttpClient 项目现已结束,不再开发。它已被 ApacheHttpComponents 项目的 HttpClient 和 HttpCore 模块取代,提供更好的性能和更大的灵活性。
一、简介
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。HttpClient 已经在很多项目中使用。例如,Apache Jakarta 上的另外两个著名的开源项目 Cactus 和 HTMLUnit,都使用 HttpClient。
所以这里简单介绍一下如何获取网页的源代码:
Maven 依赖:
org.apache.httpcomponents
httpclient
4.5.2
这里最大的问题是编码问题。如果编码不合适,就会出现中文乱码。
获取代码的方式一般有两种,一种是从响应头中获取,另一种是从网页源代码的meta中获取。
这两种方法应该结合使用。一般的过程是先从响应头中获取。如果响应头不可用,请从 Web 源代码元中获取。如果没有,请设置默认编码。
我的代码如下:
<p>package httpclient.download;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
/**
* httpclient来下载网页源码。
*
* @author 徐金仁
*
*关于网页下载最大的问题是编码的问题
*
*/
public class Download {
public String getHtmlSource(String url){
String htmlSource = null;
String finallyCharset = null;
//使用httpclient下载
//创建一个httpclient的引擎
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建一个httpGet对象,用于发送get请求,如果要发post请求,就创建一个post对象
HttpGet get = new HttpGet(url);
try {
//发送get请求,获取一个响应
CloseableHttpResponse response= httpClient.execute(get);
//获取这次响应的实体,接下来所有的操作都是基于此实体完成,
HttpEntity entity = response.getEntity();
//方法还是两个,先从header里面来查看,如果没有,再从meta里面查看
//这个方法主要是从header里面来获取,如果没有,会返回一个null
finallyCharset = EntityUtils.getContentCharSet(entity);
System.out.println("编码如下:");
System.out.println("charset1 = " + finallyCharset);
byte[] byteArray = null;
if(finallyCharset == null){
//如果header里面没有,则要从meta里面来获取,为了节约网络资源,网页只读取一次,
/*
* 那么,就有几个关系 :url->字符流->子节流->字符串
* 这里可以用子节数组来作为中间的过渡,从字节数组这里获取到编码,再通过正确的编码变为字符串
*/
byteArray = convertInputStreamToByteArray(entity.getContent());
if(byteArray == null){
throw new Exception("字节数组为空");
}
//接下来要从字节数组中获取到meta里面的chatset
finallyCharset = getCharsetFromMeta(byteArray);
System.out.println("charset2 = " + finallyCharset);
if(finallyCharset == null){
//如果没有找到
finallyCharset = "UTF-8"; //则等于默认的
System.out.println("charset3 = " + finallyCharset);
}
//如果找到了就更好
}
System.out.println("charset = " + finallyCharset);
htmlSource = new String(byteArray, finallyCharset);
}catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return htmlSource;
}
/**
* 将一个输入流转化为一个字节数组
* @param content
* @param defaultCharset
* @return
* @throws IOException
*/
public byte[] convertInputStreamToByteArray(InputStream content) throws IOException {
//输入流转化为一个字节数组
byte[] by = new byte[4096];
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int l = -1;
while((l = content.read(by)) > 0){
bos.write(by, 0, l);
}
byte[] s = bos.toByteArray();
return s;
}
/**
* 从字节数组中获取到meta里面的charset的值
* @param byteArray
* @return
* @throws IOException
*/
public String getCharsetFromMeta(byte[] byteArray) throws IOException {
//将字节数组转化为bufferedReader,从中一行行的读取来,再判断
String htmlSource = new String(byteArray);
StringReader in = new StringReader(htmlSource);
BufferedReader reader = new BufferedReader(in);
String line = null;
while((line = reader.readLine()) != null){
line = line.toLowerCase();
if(line.contains(" 查看全部
c httpclient抓取网页(mons.httpclient与org.apache.http.client的区别
)
与传统JDK自带的URLConnection相比,HttpClient增加了易用性和灵活性。不仅方便了客户端发送Http请求,也方便了开发者测试接口(基于Http协议),提高了开发效率,也方便了提高代码的健壮性。因此,掌握HttpClient是非常重要的必修内容。掌握了HttpClient之后,相信你会对Http协议有更深入的了解。
mons.httpclient.HttpClient 和 org.apache.http.client.HttpClient 的区别
Commons HttpClient 项目现已结束,不再开发。它已被 ApacheHttpComponents 项目的 HttpClient 和 HttpCore 模块取代,提供更好的性能和更大的灵活性。
一、简介
HttpClient 是 Apache Jakarta Common 下的一个子项目,用于提供支持 HTTP 协议的高效、最新、功能丰富的客户端编程工具包,它支持 HTTP 协议的最新版本和推荐。HttpClient 已经在很多项目中使用。例如,Apache Jakarta 上的另外两个著名的开源项目 Cactus 和 HTMLUnit,都使用 HttpClient。
所以这里简单介绍一下如何获取网页的源代码:
Maven 依赖:
org.apache.httpcomponents
httpclient
4.5.2
这里最大的问题是编码问题。如果编码不合适,就会出现中文乱码。
获取代码的方式一般有两种,一种是从响应头中获取,另一种是从网页源代码的meta中获取。
这两种方法应该结合使用。一般的过程是先从响应头中获取。如果响应头不可用,请从 Web 源代码元中获取。如果没有,请设置默认编码。
我的代码如下:
<p>package httpclient.download;
import java.io.BufferedReader;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.StringReader;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
/**
* httpclient来下载网页源码。
*
* @author 徐金仁
*
*关于网页下载最大的问题是编码的问题
*
*/
public class Download {
public String getHtmlSource(String url){
String htmlSource = null;
String finallyCharset = null;
//使用httpclient下载
//创建一个httpclient的引擎
CloseableHttpClient httpClient = HttpClients.createDefault();
//创建一个httpGet对象,用于发送get请求,如果要发post请求,就创建一个post对象
HttpGet get = new HttpGet(url);
try {
//发送get请求,获取一个响应
CloseableHttpResponse response= httpClient.execute(get);
//获取这次响应的实体,接下来所有的操作都是基于此实体完成,
HttpEntity entity = response.getEntity();
//方法还是两个,先从header里面来查看,如果没有,再从meta里面查看
//这个方法主要是从header里面来获取,如果没有,会返回一个null
finallyCharset = EntityUtils.getContentCharSet(entity);
System.out.println("编码如下:");
System.out.println("charset1 = " + finallyCharset);
byte[] byteArray = null;
if(finallyCharset == null){
//如果header里面没有,则要从meta里面来获取,为了节约网络资源,网页只读取一次,
/*
* 那么,就有几个关系 :url->字符流->子节流->字符串
* 这里可以用子节数组来作为中间的过渡,从字节数组这里获取到编码,再通过正确的编码变为字符串
*/
byteArray = convertInputStreamToByteArray(entity.getContent());
if(byteArray == null){
throw new Exception("字节数组为空");
}
//接下来要从字节数组中获取到meta里面的chatset
finallyCharset = getCharsetFromMeta(byteArray);
System.out.println("charset2 = " + finallyCharset);
if(finallyCharset == null){
//如果没有找到
finallyCharset = "UTF-8"; //则等于默认的
System.out.println("charset3 = " + finallyCharset);
}
//如果找到了就更好
}
System.out.println("charset = " + finallyCharset);
htmlSource = new String(byteArray, finallyCharset);
}catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return htmlSource;
}
/**
* 将一个输入流转化为一个字节数组
* @param content
* @param defaultCharset
* @return
* @throws IOException
*/
public byte[] convertInputStreamToByteArray(InputStream content) throws IOException {
//输入流转化为一个字节数组
byte[] by = new byte[4096];
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int l = -1;
while((l = content.read(by)) > 0){
bos.write(by, 0, l);
}
byte[] s = bos.toByteArray();
return s;
}
/**
* 从字节数组中获取到meta里面的charset的值
* @param byteArray
* @return
* @throws IOException
*/
public String getCharsetFromMeta(byte[] byteArray) throws IOException {
//将字节数组转化为bufferedReader,从中一行行的读取来,再判断
String htmlSource = new String(byteArray);
StringReader in = new StringReader(htmlSource);
BufferedReader reader = new BufferedReader(in);
String line = null;
while((line = reader.readLine()) != null){
line = line.toLowerCase();
if(line.contains("
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-21 04:02
)
使用HttpClient抓取某些网页时,往往会保留服务器发回的cookie信息,以便发起其他需要这些cookie的请求。在大多数情况下,我们使用内置的 cookie 策略来轻松、直接地获取这些 cookie。
下面一小段代码就是访问和获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com");
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,有一些网站返回的cookies不一定符合规范。比如下面这个例子,从打印的header可以看出,这个cookie中的Expires属性是时间戳的形式,不符合标准时间。因此httpclient处理cookie失败,最终无法获取cookie,并发出警告信息:“Invalid'expires'属性:1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用header数据来重构cookie,其实很多人都是这么做的,但是这种方法不够优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4节自定义cookie策略中,我们谈到了允许自定义的cookie策略。自定义的方法是实现CookieSpec接口,使用CookieSpecProvider在httpclient中完成策略实例的初始化和注册。好吧,关键线索就在于CookieSpec接口,我们来看看它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中,我们找到了一个解析方法。看评论,我们知道就是这个方法。Set-Cookie 的头部信息被解析为 Cookie 对象。自然而然,我们就会了解 httplcient 中 DefaultCookieSpec 的默认实现。限于篇幅,源码就不贴出来了。在默认实现中,DefaultCookieSpec 的主要工作是确定头部中 Cookie 规范的类型,然后调用具体的实现。像上面这样的 cookie 最终交给 NetscapeDraftSpec 的实例进行分析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE,dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就清楚了,我们只需要将Cookie中的expires time转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个 CookieSpec 类,继承 DefaultCookieSpec,重写解析器方法,将 Cookie 中的 expires 转换成正确的时间格式,调用默认的解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017] 查看全部
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作
)
使用HttpClient抓取某些网页时,往往会保留服务器发回的cookie信息,以便发起其他需要这些cookie的请求。在大多数情况下,我们使用内置的 cookie 策略来轻松、直接地获取这些 cookie。
下面一小段代码就是访问和获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com";);
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,有一些网站返回的cookies不一定符合规范。比如下面这个例子,从打印的header可以看出,这个cookie中的Expires属性是时间戳的形式,不符合标准时间。因此httpclient处理cookie失败,最终无法获取cookie,并发出警告信息:“Invalid'expires'属性:1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用header数据来重构cookie,其实很多人都是这么做的,但是这种方法不够优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4节自定义cookie策略中,我们谈到了允许自定义的cookie策略。自定义的方法是实现CookieSpec接口,使用CookieSpecProvider在httpclient中完成策略实例的初始化和注册。好吧,关键线索就在于CookieSpec接口,我们来看看它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中,我们找到了一个解析方法。看评论,我们知道就是这个方法。Set-Cookie 的头部信息被解析为 Cookie 对象。自然而然,我们就会了解 httplcient 中 DefaultCookieSpec 的默认实现。限于篇幅,源码就不贴出来了。在默认实现中,DefaultCookieSpec 的主要工作是确定头部中 Cookie 规范的类型,然后调用具体的实现。像上面这样的 cookie 最终交给 NetscapeDraftSpec 的实例进行分析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE,dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就清楚了,我们只需要将Cookie中的expires time转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个 CookieSpec 类,继承 DefaultCookieSpec,重写解析器方法,将 Cookie 中的 expires 转换成正确的时间格式,调用默认的解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017]
c httpclient抓取网页(() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-20 15:07
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1");
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1");
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
<br /><br />2、Post方式<br /><br /><br /><br /><br />1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) { <br />16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 } <br /><br /><br /><br /><br /><br /><br />相关链接:http://blog.csdn.net/acceptedx ... %3Bbr />
http://www.cnblogs.com/modou/articles/1325569.html
查看全部
c httpclient抓取网页(()
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1";);
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1";);
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
<br /><br />2、Post方式<br /><br /><br /><br /><br />1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) { <br />16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 } <br /><br /><br /><br /><br /><br /><br />相关链接:http://blog.csdn.net/acceptedx ... %3Bbr />
http://www.cnblogs.com/modou/articles/1325569.html
c httpclient抓取网页(() )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-20 15:04
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1");
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1");
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
2、Post方式
1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) {
16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 }
相关链接:http://blog.csdn.net/acceptedx ... 30700
http://www.cnblogs.com/modou/articles/1325569.html
查看全部
c httpclient抓取网页(()
)
1、GET 方法
第一步是创建一个客户端,类似于用浏览器打开一个网页
HttpClient httpClient = new HttpClient();
第二步是创建一个GET方法来获取你需要爬取的网页的网址
GetMethod getMethod = new GetMethod("");
第三步,获取URL的响应状态码,200表示请求成功
int statusCode = httpClient.executeMethod(getMethod);
第四步,获取网页源代码
byte[] responseBody = getMethod.getResponseBody();
主要就是这四个步骤,当然还有很多其他的,比如网页编码的问题
1 public static String spiderHtml() throws Exception {
2 //URL url = new URL("http://top.baidu.com/buzz?b=1";);
3
4 HttpClient client = new HttpClient();
5 GetMethod method = new GetMethod("http://top.baidu.com/buzz?b=1";);
6
7 int statusCode = client.executeMethod(method);
8 if(statusCode != HttpStatus.SC_OK) {
9 System.err.println("Method failed: " + method.getStatusLine());
10 }
11
12 byte[] body = method.getResponseBody();
13 String html = new String(body,"gbk");
2、Post方式
1 HttpClient httpClient = new HttpClient();
2 PostMethod postMethod = new PostMethod(UrlPath);
3 postMethod.getParams().setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
4 NameValuePair[] postData = new NameValuePair[2];
5 postData[0] = new NameValuePair("username", "xkey");
6 postData[1] = new NameValuePair("userpass", "********");
7 postMethod.setRequestBody(postData);
8 try {
9 int statusCode = httpClient.executeMethod(postMethod);
10 if (statusCode == HttpStatus.SC_OK) {
11 byte[] responseBody = postMethod.getResponseBody();
12 String html = new String(responseBody);
13 System.out.println(html);
14 }
15 } catch (Exception e) {
16 System.err.println("页面无法访问");
17 }finally{
18 postMethod.releaseConnection();
19 }
相关链接:http://blog.csdn.net/acceptedx ... 30700
http://www.cnblogs.com/modou/articles/1325569.html
c httpclient抓取网页(一下和网页采集相关的组件和插件有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-10-19 06:04
其实很多做Java编程的人都不懂SEO,不知道怎么去百度收录等。当然,不是所有程序员都考虑爬网和网页爬虫,但是他们是专门针对这个人的. ,还是需要了解一下里面的知识,接下来介绍一些爬虫和网页采集相关的组件和插件~
大家在做爬虫、网页采集、通过网页自动写数据的时候基本都接触过这两个组件。网上已经有很多介绍资料了。我想从实际应用开始,从一个角度谈谈我对这两个组件的看法,并将它们记录在博客中,以便我以后阅读。欢迎大家批评指正。
本文主要比较两者的优缺点并介绍应用中的使用技巧,推荐一些入门资料和非常实用的辅助工具,希望对大家有所帮助。
如果您有任何问题或建议,您可以给我留言,共同交流和学习。
我们先来看看这两个组件的区别和优缺点:
单位
HtmlUnit 最初是一个自动化测试工具。它结合使用HttpClient和java自带的网络api来实现。它和HttpClient的区别在于它比HttpClient更“人性化”。
写HtmlUnit代码的时候,好像是在操作浏览器而不是写代码获取页面(getPage)-找到文本框(getElementByID || getElementByName || getElementByXPath等)-输入文本(type, setValue, setText,等)——其他一些类似的操作——找到提交按钮——提交——得到一个新的Page,这样就很像后台有人帮你操作浏览器了,你只要告诉他怎么操作要操作,需要填写哪些值。
一、网页模拟
首先,让我谈谈 HtmlUnit 相对于 HttpClient 最明显的好处之一。HtmlUnit 更好地将网页封装成一个对象。如果非要说HttpClient返回的接口HttpResponse其实存储的是一个对象,那很好,但是HtmlUnit不仅保存了网页对象,更难能可贵的是它还存储了网页的所有基本操作甚至事件. 也就是说,我们可以像在jsp中写js一样操作这个网页,非常方便,比如:你要一个节点的上一个节点,找到所有的按钮,找到“bt-style”的样式为所有元素,先修改一些元素,再转成String,或者我直接拿到这个网页然后操作这个网页,很方便的完成一个提交。这意味着如果你想分析一个网页,那将是非常容易的。比如我附上一段百度新闻高级搜索的代码:
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("http://news.baidu.com/advanced_news.html");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫"f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入"周星驰"
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
String result = nextPage.asXml();
System.out.println(result);
然后就可以将结果结果复制到一个文本中,然后用浏览器打开该文本。是你想要的吗(见图)?这很简单,对吧?为什么感觉简单,因为完全符合我们的操作和浏览,当然最后也是通过HttpClient等一些工具类来实现的,但是封装的非常人性化,很神奇。
Htmlunit可以有效的分析dom标签,可以有效的在页面上运行js,得到一些需要执行js的值。您需要做的就是执行 executeJavaScript() 方法。这些都是HtmlUnit为我们封装的。好吧,我们所要做的就是告诉它需要做什么。
WebClient webclient = new WebClient();
HtmlPage htmlpage = webclient.getPage("you url");
htmlpage.executeJavaScript("the function name you want to execute");
对于使用Java的程序员来说,对象的操作再熟悉不过了,HtmlUnit所做的就是帮助我们把网页封装成一个对象,一个功能丰富的透明对象。
二、自动处理网络响应
HtmlUnit有强大的响应处理机制,我们知道:常见的404是资源未找到,100是继续,300是跳转……当我们使用HttpClient时,它会告诉我们响应结果,当然你可以做自己判断,比如当你发现响应码是302时,会在响应头中找到新地址,自动跳过。当您发现它是 100 时,您将发送另一个请求。如果你使用HttpClient,你可以做这个来做,也可以写的更完整,但是HtmlUnit把这个功能实现的更完整,甚至说还包括页面JS的自动跳转(响应码是200,但是响应页面是一个JS),天涯的登录就是这样的情况,一起来看看吧。
/**
* @author CaiBo
* @date 2014年9月15日 上午9:16:36
* @version $Id$
*
*/
public class TianyaTest {
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("—————————————————————");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("—————————————————————");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null,
new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login");
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp");
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn");
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List paramsList = new ArrayList();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebut,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn"));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "ifugletest2014"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "test123456"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
}
执行上面的Main函数会得到如下结果:
我们看到响应码确实是200,表示成功。其实这个响应相当于302,需要跳转,只不过它的跳转写在js的body部分。
location.href=”http://passport.tianya.cn:80/o ... %25AD……&t=1410746182629&k=8cd4d967491c44c5eab1097e0f30c054&c=6fc7ebf8d782a07bb06624d9c6fbbf3f”;
这是页面跳转 查看全部
c httpclient抓取网页(一下和网页采集相关的组件和插件有什么区别?)
其实很多做Java编程的人都不懂SEO,不知道怎么去百度收录等。当然,不是所有程序员都考虑爬网和网页爬虫,但是他们是专门针对这个人的. ,还是需要了解一下里面的知识,接下来介绍一些爬虫和网页采集相关的组件和插件~
大家在做爬虫、网页采集、通过网页自动写数据的时候基本都接触过这两个组件。网上已经有很多介绍资料了。我想从实际应用开始,从一个角度谈谈我对这两个组件的看法,并将它们记录在博客中,以便我以后阅读。欢迎大家批评指正。
本文主要比较两者的优缺点并介绍应用中的使用技巧,推荐一些入门资料和非常实用的辅助工具,希望对大家有所帮助。
如果您有任何问题或建议,您可以给我留言,共同交流和学习。
我们先来看看这两个组件的区别和优缺点:
单位
HtmlUnit 最初是一个自动化测试工具。它结合使用HttpClient和java自带的网络api来实现。它和HttpClient的区别在于它比HttpClient更“人性化”。
写HtmlUnit代码的时候,好像是在操作浏览器而不是写代码获取页面(getPage)-找到文本框(getElementByID || getElementByName || getElementByXPath等)-输入文本(type, setValue, setText,等)——其他一些类似的操作——找到提交按钮——提交——得到一个新的Page,这样就很像后台有人帮你操作浏览器了,你只要告诉他怎么操作要操作,需要填写哪些值。
一、网页模拟
首先,让我谈谈 HtmlUnit 相对于 HttpClient 最明显的好处之一。HtmlUnit 更好地将网页封装成一个对象。如果非要说HttpClient返回的接口HttpResponse其实存储的是一个对象,那很好,但是HtmlUnit不仅保存了网页对象,更难能可贵的是它还存储了网页的所有基本操作甚至事件. 也就是说,我们可以像在jsp中写js一样操作这个网页,非常方便,比如:你要一个节点的上一个节点,找到所有的按钮,找到“bt-style”的样式为所有元素,先修改一些元素,再转成String,或者我直接拿到这个网页然后操作这个网页,很方便的完成一个提交。这意味着如果你想分析一个网页,那将是非常容易的。比如我附上一段百度新闻高级搜索的代码:
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("http://news.baidu.com/advanced_news.html";);
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫"f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入"周星驰"
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
String result = nextPage.asXml();
System.out.println(result);
然后就可以将结果结果复制到一个文本中,然后用浏览器打开该文本。是你想要的吗(见图)?这很简单,对吧?为什么感觉简单,因为完全符合我们的操作和浏览,当然最后也是通过HttpClient等一些工具类来实现的,但是封装的非常人性化,很神奇。
Htmlunit可以有效的分析dom标签,可以有效的在页面上运行js,得到一些需要执行js的值。您需要做的就是执行 executeJavaScript() 方法。这些都是HtmlUnit为我们封装的。好吧,我们所要做的就是告诉它需要做什么。
WebClient webclient = new WebClient();
HtmlPage htmlpage = webclient.getPage("you url");
htmlpage.executeJavaScript("the function name you want to execute");
对于使用Java的程序员来说,对象的操作再熟悉不过了,HtmlUnit所做的就是帮助我们把网页封装成一个对象,一个功能丰富的透明对象。
二、自动处理网络响应
HtmlUnit有强大的响应处理机制,我们知道:常见的404是资源未找到,100是继续,300是跳转……当我们使用HttpClient时,它会告诉我们响应结果,当然你可以做自己判断,比如当你发现响应码是302时,会在响应头中找到新地址,自动跳过。当您发现它是 100 时,您将发送另一个请求。如果你使用HttpClient,你可以做这个来做,也可以写的更完整,但是HtmlUnit把这个功能实现的更完整,甚至说还包括页面JS的自动跳转(响应码是200,但是响应页面是一个JS),天涯的登录就是这样的情况,一起来看看吧。
/**
* @author CaiBo
* @date 2014年9月15日 上午9:16:36
* @version $Id$
*
*/
public class TianyaTest {
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("—————————————————————");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("—————————————————————");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null,
new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login";);
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp";);
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn";);
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List paramsList = new ArrayList();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebut,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn";));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "ifugletest2014"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "test123456"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
}
执行上面的Main函数会得到如下结果:
我们看到响应码确实是200,表示成功。其实这个响应相当于302,需要跳转,只不过它的跳转写在js的body部分。
location.href=”http://passport.tianya.cn:80/o ... %25AD……&t=1410746182629&k=8cd4d967491c44c5eab1097e0f30c054&c=6fc7ebf8d782a07bb06624d9c6fbbf3f”;
这是页面跳转
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-18 13:11
最近在写一个小爬虫,准备爬取一些网页数据进行模型训练。在考虑如何爬取和分析网页的时候,参考了OSC站的一些项目,特别是@黄亿华写的webmagic的设计机制和原理——如何开发一个Java爬虫”文章给了很多启发,webmagic是一个垂直爬虫,我想写的是一个更通用的爬虫,主要爬上中文网站内容,对于HTTP协议和消息处理,没有比HttpClient组件更好的选择了,对于HTML代码解析,经过对比HTMLParser和Jsoup后,后者在API的使用上优势明显,简洁易懂,使用的开源组件敲定后,
对于我的爬虫爬取部分功能,只要根据网页的url爬取html代码,然后从html代码中解析出link和link
标签的文字没问题,所以解析的结果可以用一个Page类来表示。这个类纯粹是一个POJO,那么如何使用HttpClient和Jsoup直接解析成一个Page对象呢?
在HttpClient4.2中,提供了ResponseHandler接口来处理HttpResponse。因此,通过实现该接口,可以将返回的 HTML 代码解析为所需的 Page 对象。主要思路是先把HttpResponse中的数据读出,转换成HTML代码,然后用jsoup解析
标签和标签。代码显示如下,
public class PageResponseHandler implements ResponseHandler {
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在您可以直接返回 Page 对象。编写一个测试类来测试这个 PageResponseHandler。测试这个类的功能不需要复杂的代码。
public class PageResponseHandlerTest {
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫中的爬取和分析功能运行良好。对于中文,也可以很好的解析。更细心的读者会发现,这些代码中没有字符集,也没有设置字符集。转换字符集,后面会讨论HttpClient4.2组件中的字符集处理。
首先回顾一下Content-Type在HTTP协议的RFC规范中的作用。它指定发送给接收者的 Http 实体内容的媒体类型。对于文本类型HttpEntity,通常采用如下形式。指定 HttpEntity 的媒体类型。使用哪个字符集用于编码?另外,RFC规范还规定,如果Content-Type没有指定字符集,则默认使用ISO-8859-1字符集对Http实体进行编码
Content-Type: text/html; charset=UTF-8
说了这么多,大家应该都能猜到HttpClient4.2是如何正确编码的----就是使用Content-Type头中收录的字符集作为编码输入源。具体代码可以看EntityUtils类第212行开始的代码。EntityUtils 首先从 HttpEntity 对象获取 Content-Type。如果Content-Type的字符集不为空,则使用Content-Type对象中指定的字符集进行编码,否则使用开发者指定的字符集进行编码。字符集也没有指定,使用默认的字符集iso-8859-1进行编码。当然是实现了编码,还是调用了JDK的Reader类。
ContentType contentType = ContentType.getOrDefault(entity);
Charset charset = contentType.getCharset();
if (charset == null) {
charset = defaultCharset;
}
if (charset == null) {
charset = HTTP.DEF_CONTENT_CHARSET;
}
Reader reader = new InputStreamReader(instream, charset);
CharArrayBuffer buffer = new CharArrayBuffer(i);
char[] tmp = new char[1024];
int l;
while((l = reader.read(tmp)) != -1) {
buffer.append(tmp, 0, l);
}
return buffer.toString();
开放的互联网在创造了繁荣的网站的同时,也为非HTML规范网站提供了一些机会。部分中文网站没有正确设置HTTP请求对应头部的Content-。Type 属性使 HttpClient 使用默认的 iso-8859-1 字符集对 Http 实体进行编码。所以为了防止HttpClient抓取中文网站,可以指定一个默认的GBK字符集。将原来的 PageResponseHandler 转换字符串的代码行修改为
String html = EntityUtils.toString(entity, Charset.forName("gbk"));
至此,爬虫的爬取解析功能已经完成,再也不怕Content-Type头的中文网站设置不正确了。希望这篇文章文章对读者有用。
@仪山湖 查看全部
c httpclient抓取网页(如何开发一个Java爬虫(的设计机制及原理))
最近在写一个小爬虫,准备爬取一些网页数据进行模型训练。在考虑如何爬取和分析网页的时候,参考了OSC站的一些项目,特别是@黄亿华写的webmagic的设计机制和原理——如何开发一个Java爬虫”文章给了很多启发,webmagic是一个垂直爬虫,我想写的是一个更通用的爬虫,主要爬上中文网站内容,对于HTTP协议和消息处理,没有比HttpClient组件更好的选择了,对于HTML代码解析,经过对比HTMLParser和Jsoup后,后者在API的使用上优势明显,简洁易懂,使用的开源组件敲定后,
对于我的爬虫爬取部分功能,只要根据网页的url爬取html代码,然后从html代码中解析出link和link
标签的文字没问题,所以解析的结果可以用一个Page类来表示。这个类纯粹是一个POJO,那么如何使用HttpClient和Jsoup直接解析成一个Page对象呢?
在HttpClient4.2中,提供了ResponseHandler接口来处理HttpResponse。因此,通过实现该接口,可以将返回的 HTML 代码解析为所需的 Page 对象。主要思路是先把HttpResponse中的数据读出,转换成HTML代码,然后用jsoup解析
标签和标签。代码显示如下,
public class PageResponseHandler implements ResponseHandler {
private Page page;
public PageResponseHandler(Page page) {
this.page = page;
}
public void setPage(Page page) {
this.page = page;
}
public Page getPage() {
return page;
}
@Override
public Page handleResponse(HttpResponse response) throws ClientProtocolException, IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
EntityUtils.consume(entity);
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null)
return null;
// 利用HTTPClient自带的EntityUtils把当前HttpResponse中的HttpEntity转化成HTML代码
String html = EntityUtils.toString(entity);
Document document = Jsoup.parse(html);
Elements links = document.getElementsByTag("a");
for (int i = 0; i < links.size(); i++) {
Element link = links.get(i);
page.addAnchor(link.attr("href"), link.text());
}
// parse context of plain text from HTML code,
Elements paragraphs = document.getElementsByTag("p");
StringBuffer plainText = new StringBuffer(html.length() / 2);
for (int i = 0; i < paragraphs.size(); i++) {
Element paragraph = paragraphs.get(i);
plainText.append(paragraph.text()).append("\n");
}
page.setPlainText(plainText.toString());
return page;
}
}
代码不超过40行,非常简单。现在您可以直接返回 Page 对象。编写一个测试类来测试这个 PageResponseHandler。测试这个类的功能不需要复杂的代码。
public class PageResponseHandlerTest {
HttpClient httpclient;
PageResponseHandler pageResponseHandler;
final String url = "http://news.163.com/13/0903/11 ... 3B%3B
Page page = new Page(url);
@Before
public void setUp() throws Exception {
httpclient = new DefaultHttpClient();
HttpGet httpget = new HttpGet(url);
pageResponseHandler = new PageResponseHandler(page);
httpclient.execute(httpget, pageResponseHandler);
}
@After
public void tearDown() throws Exception {
httpclient.getConnectionManager().shutdown();
}
@Test
public void test() {
System.out.println(page.getPlainText());
assertTrue(page.getPlainText().length() > 0);
assertTrue(page.getAnchors().size() > 0);
}
}
到目前为止,该爬虫中的爬取和分析功能运行良好。对于中文,也可以很好的解析。更细心的读者会发现,这些代码中没有字符集,也没有设置字符集。转换字符集,后面会讨论HttpClient4.2组件中的字符集处理。
首先回顾一下Content-Type在HTTP协议的RFC规范中的作用。它指定发送给接收者的 Http 实体内容的媒体类型。对于文本类型HttpEntity,通常采用如下形式。指定 HttpEntity 的媒体类型。使用哪个字符集用于编码?另外,RFC规范还规定,如果Content-Type没有指定字符集,则默认使用ISO-8859-1字符集对Http实体进行编码
Content-Type: text/html; charset=UTF-8
说了这么多,大家应该都能猜到HttpClient4.2是如何正确编码的----就是使用Content-Type头中收录的字符集作为编码输入源。具体代码可以看EntityUtils类第212行开始的代码。EntityUtils 首先从 HttpEntity 对象获取 Content-Type。如果Content-Type的字符集不为空,则使用Content-Type对象中指定的字符集进行编码,否则使用开发者指定的字符集进行编码。字符集也没有指定,使用默认的字符集iso-8859-1进行编码。当然是实现了编码,还是调用了JDK的Reader类。
ContentType contentType = ContentType.getOrDefault(entity);
Charset charset = contentType.getCharset();
if (charset == null) {
charset = defaultCharset;
}
if (charset == null) {
charset = HTTP.DEF_CONTENT_CHARSET;
}
Reader reader = new InputStreamReader(instream, charset);
CharArrayBuffer buffer = new CharArrayBuffer(i);
char[] tmp = new char[1024];
int l;
while((l = reader.read(tmp)) != -1) {
buffer.append(tmp, 0, l);
}
return buffer.toString();
开放的互联网在创造了繁荣的网站的同时,也为非HTML规范网站提供了一些机会。部分中文网站没有正确设置HTTP请求对应头部的Content-。Type 属性使 HttpClient 使用默认的 iso-8859-1 字符集对 Http 实体进行编码。所以为了防止HttpClient抓取中文网站,可以指定一个默认的GBK字符集。将原来的 PageResponseHandler 转换字符串的代码行修改为
String html = EntityUtils.toString(entity, Charset.forName("gbk"));
至此,爬虫的爬取解析功能已经完成,再也不怕Content-Type头的中文网站设置不正确了。希望这篇文章文章对读者有用。
@仪山湖
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-17 21:09
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话少说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,可以在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(java语言下一个支持http协议的登录意义是什么?)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话少说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是存储在本地的小文件。服务器发送命令,浏览器在本地读写。在访问某些网站时,浏览器会检查是否有网站的cookie信息。如果有,在发送访问请求时会携带这些内容,服务器可以读取到浏览器。在请求中发送cookie信息,可以在响应请求时写入cookie信息。Cookie信息包括键值、内容、过期时间、归属网站。
说到cookies,我就快做完了,那登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果你只是在你的电脑上写了一个cookie,别有用心的人伪造cookie也可能有机会登录网站,所以服务器会在内存中保留一份相同的信息,这个过程叫做一个对话。如果点击网站中的注销按钮,服务器会清除内存中的cookies,也会清除浏览器中与登录相关的cookies。知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。打开知乎的首页,打开wireshark,开始监听端口,输入用户名和密码,点击login查看wireshark抓到的数据包。截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf、密码、remember_me、email。注意提交的信息包括cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章的图是服务器返回的数据。请注意,它具有三个 cookie 设置和一条指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?一是发送登录请求时的cookie和post数据格式,二是可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(HtmlUnitJSoup条目使用Java屏幕抓取器应用程序教程(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-15 11:00
htmlunit 抓取
我最近发表了一篇关于使用 Java 文章 进行屏幕抓取的文章。一些 Twitter 追随者思考为什么我使用 JSoup 而不是流行的、无浏览器的 Web 测试框架 HtmlUnit。我没有具体的原因,所以我决定使用 HtmlUnit 而不是 JSoup 来重现完全相同的屏幕抓取器应用程序教程。
原教程只是从我写的GitHub面试题文章中提取了一些信息。它提取页面标题、作者姓名和页面上所有链接的列表。本教程将做完全相同的事情,只是不同。
HtmlUnit Maven POM 入口
使用 HtmlUnit 的第一步是创建一个基于 Maven 的项目,并将适当的 GAV 添加到 POM 文件的依赖项部分。这是一个完整的 Maven POM 文件示例,其中收录在依赖项中的 HtmlUnit GAV。
4.0.0
com.mcnz.screen.scraper
java-screen-scraper
1.0
net.sourceforge.htmlunit
htmlunit
2.34.1
maven-compiler-plugin
1.8
1.8
HtmlUnit 屏幕截图代码
HtmlUnit 屏幕抓取应用程序创建过程的下一步是使用main 方法生成一个Java 类,然后使用要HtmlUnit 的站点的URL 来抓取创建一个HtmlUnit WebClient 实例。
package com.mcnz.screen.scraper;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.html.*;
public class HtmlUnitScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/ ... 3B%3B
WebClient webClient = new WebClient();
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
}
}
HtmlUnit API
WebClient 类的 getPage (URL) 方法将解析提供的 URL 并返回一个表示网页的 HtmlPage 对象。但是,CSS、JavaScript 和缺少正确配置的 SSL 密钥库可能会导致 getPage(URL) 方法失败。在获取HtmlPage对象之前,最好先通过prototype关闭这三个功能。
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage htmlPage = webClient.getPage(url);
在前面的示例中,我们通过捕获要解析的网页的标题来测试 Java 屏幕抓取功能。要使用 HtmlUnit 屏幕抓取工具执行此操作,我们只需要调用 htmlPage 实例上的 getTitle() 方法:
System.out.println(htmlPage.getTitleText ());
运行 Java 屏幕抓取应用程序
此时您可以编译代码并运行应用程序,它将输出页面标题:
Tough sample GitHub interview questions and answers for job candidates
显示作者姓名的页面片段的 CSS 选择器是 #author> div> a。如果将此 CSS 选择器插入到 querySelector(String) 方法中,它将返回一个 DomNode 实例,该实例可用于检查 CSS 选择的结果。只需请求 domNode asText 返回 文章 作者姓名:
DomNode domNode = htmlPage.querySelector("#author > div > a");
System.out.println(domNode.asText ());
原文章的最后一个重要成就是打印出页面上每个锚链接的文本。要为此目的使用 HtmlUnit Java 屏幕抓取工具,请调用 HtmlPage 实例的 getAnchors 方法。这将返回一个 HtmlAnchor 实例列表。然后,我们可以通过调用 getAttribute 方法遍历列表并输出与链接关联的 URL:
List anchors = htmlPage.getAnchors ();
for (HtmlAnchor anchor : anchors) {
System.out.println(anchor.getAttribut e ("href"));
}
当类运行时,输出如下:
JSoup vs HtmlUnit 作为屏幕抓取工具
那么我如何看待这两种不同的方法呢?好吧,如果我要编写自己的 Java 屏幕抓取工具,我可能会选择 HtmlUnit。API 内置了许多实用方法,例如 HtmlPage 的 getAnchors() 方法,可以更轻松地执行常见任务。API 由其维护者定期更新,许多开发人员已经知道如何使用 API,因为它通常用作 Java Web 应用程序的单元测试框架。最后,HtmlUnit 具有处理 CSS 和 JavaScript 的一些高级功能,允许该技术的各种外围应用。
总的来说,这两个 API 是实现 Java 屏幕抓取工具的绝佳选择。你真的不会错的任何人。
您可以在 GitHub 上找到 HtmlUnit 屏幕抓取应用程序的完整代码。
HTMLUnit 屏幕抓取应用程序
翻译自:
htmlunit 抓取 查看全部
c httpclient抓取网页(HtmlUnitJSoup条目使用Java屏幕抓取器应用程序教程(上))
htmlunit 抓取
我最近发表了一篇关于使用 Java 文章 进行屏幕抓取的文章。一些 Twitter 追随者思考为什么我使用 JSoup 而不是流行的、无浏览器的 Web 测试框架 HtmlUnit。我没有具体的原因,所以我决定使用 HtmlUnit 而不是 JSoup 来重现完全相同的屏幕抓取器应用程序教程。
原教程只是从我写的GitHub面试题文章中提取了一些信息。它提取页面标题、作者姓名和页面上所有链接的列表。本教程将做完全相同的事情,只是不同。
HtmlUnit Maven POM 入口
使用 HtmlUnit 的第一步是创建一个基于 Maven 的项目,并将适当的 GAV 添加到 POM 文件的依赖项部分。这是一个完整的 Maven POM 文件示例,其中收录在依赖项中的 HtmlUnit GAV。
4.0.0
com.mcnz.screen.scraper
java-screen-scraper
1.0
net.sourceforge.htmlunit
htmlunit
2.34.1
maven-compiler-plugin
1.8
1.8
HtmlUnit 屏幕截图代码
HtmlUnit 屏幕抓取应用程序创建过程的下一步是使用main 方法生成一个Java 类,然后使用要HtmlUnit 的站点的URL 来抓取创建一个HtmlUnit WebClient 实例。
package com.mcnz.screen.scraper;
import com.gargoylesoftware.htmlunit.*;
import com.gargoylesoftware.htmlunit.html.*;
public class HtmlUnitScraper {
public static void main(String args[]) throws Exception {
String url = "https://www.theserverside.com/ ... 3B%3B
WebClient webClient = new WebClient();
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
}
}
HtmlUnit API
WebClient 类的 getPage (URL) 方法将解析提供的 URL 并返回一个表示网页的 HtmlPage 对象。但是,CSS、JavaScript 和缺少正确配置的 SSL 密钥库可能会导致 getPage(URL) 方法失败。在获取HtmlPage对象之前,最好先通过prototype关闭这三个功能。
webClient.getOptions().setUseInsecureSSL(true);
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage htmlPage = webClient.getPage(url);
在前面的示例中,我们通过捕获要解析的网页的标题来测试 Java 屏幕抓取功能。要使用 HtmlUnit 屏幕抓取工具执行此操作,我们只需要调用 htmlPage 实例上的 getTitle() 方法:
System.out.println(htmlPage.getTitleText ());
运行 Java 屏幕抓取应用程序
此时您可以编译代码并运行应用程序,它将输出页面标题:
Tough sample GitHub interview questions and answers for job candidates
显示作者姓名的页面片段的 CSS 选择器是 #author> div> a。如果将此 CSS 选择器插入到 querySelector(String) 方法中,它将返回一个 DomNode 实例,该实例可用于检查 CSS 选择的结果。只需请求 domNode asText 返回 文章 作者姓名:
DomNode domNode = htmlPage.querySelector("#author > div > a");
System.out.println(domNode.asText ());
原文章的最后一个重要成就是打印出页面上每个锚链接的文本。要为此目的使用 HtmlUnit Java 屏幕抓取工具,请调用 HtmlPage 实例的 getAnchors 方法。这将返回一个 HtmlAnchor 实例列表。然后,我们可以通过调用 getAttribute 方法遍历列表并输出与链接关联的 URL:
List anchors = htmlPage.getAnchors ();
for (HtmlAnchor anchor : anchors) {
System.out.println(anchor.getAttribut e ("href"));
}
当类运行时,输出如下:
JSoup vs HtmlUnit 作为屏幕抓取工具
那么我如何看待这两种不同的方法呢?好吧,如果我要编写自己的 Java 屏幕抓取工具,我可能会选择 HtmlUnit。API 内置了许多实用方法,例如 HtmlPage 的 getAnchors() 方法,可以更轻松地执行常见任务。API 由其维护者定期更新,许多开发人员已经知道如何使用 API,因为它通常用作 Java Web 应用程序的单元测试框架。最后,HtmlUnit 具有处理 CSS 和 JavaScript 的一些高级功能,允许该技术的各种外围应用。
总的来说,这两个 API 是实现 Java 屏幕抓取工具的绝佳选择。你真的不会错的任何人。
您可以在 GitHub 上找到 HtmlUnit 屏幕抓取应用程序的完整代码。
HTMLUnit 屏幕抓取应用程序
翻译自:
htmlunit 抓取
c httpclient抓取网页(登录究竟是怎么回事?登录就是向你的浏览器写cookie)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-12 12:32
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是本地存储的小文件,由服务器发送命令。浏览器在本地读写。
在访问某些站点时,浏览器会检查是否有所浏览站点的cookie信息。如果有,它会在发送访问请求时携带这些内容。服务器可以读取浏览器发送的请求中的cookie信息。. 能够在响应请求时写入cookie信息。cookie 信息收录键值。内容。到期。拥有网站。
说到这里的cookies,差不多就该结束了。那么登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果您在计算机上写入 cookie,那么伪造 cookie 的人将有机会登录该站点。所以服务器会在内存中保留一份相同信息的副本。这个过程称为对话。假设你点击网站上的退出按钮,服务器会清除内存中的cookies。同时,清除浏览器中的登录cookies。
知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。
打开知乎的首页,打开wireshark。开始监控端口。输入用户名和密码,然后单击登录。检查wireshark捕获的数据包。
截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf和密码。记住_我,电子邮件。注意提交的信息中收录cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章是服务器返回的数据。请注意,它具有三个 cookie 设置。并带有指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?首先,发送登录请求时的cookie。以及帖子数据的格式。其次,我们可以获取登录的cookie信息(第四张图)。 查看全部
c httpclient抓取网页(登录究竟是怎么回事?登录就是向你的浏览器写cookie)
介绍
HttpClient是Java语言下支持HTTP协议的客户端编程工具包。它实现了HTTP协议的所有方法,但不支持JS渲染。我们在做一些小工具的时候,可能需要登录一些网站来获取信息,那么HttpClient就是你的好帮手,废话不多说,进入实战。
登录的实际意义
在HTTP泛滥的今天,我们每天都要登录一些网站,那么登录有什么意义呢?首先,我们必须对cookies有一定的了解。Cookie 是本地存储的小文件,由服务器发送命令。浏览器在本地读写。
在访问某些站点时,浏览器会检查是否有所浏览站点的cookie信息。如果有,它会在发送访问请求时携带这些内容。服务器可以读取浏览器发送的请求中的cookie信息。. 能够在响应请求时写入cookie信息。cookie 信息收录键值。内容。到期。拥有网站。
说到这里的cookies,差不多就该结束了。那么登录有什么问题呢?登录意味着服务器将 cookie 写入您的浏览器。如果您在计算机上写入 cookie,那么伪造 cookie 的人将有机会登录该站点。所以服务器会在内存中保留一份相同信息的副本。这个过程称为对话。假设你点击网站上的退出按钮,服务器会清除内存中的cookies。同时,清除浏览器中的登录cookies。
知道了这一点,我们就可以开始了。
二 找到登录密钥cookie
这里我们可以使用wireshark来抓包分析。
打开知乎的首页,打开wireshark。开始监控端口。输入用户名和密码,然后单击登录。检查wireshark捕获的数据包。
截图如下:
第一张图是本地post提交数据。
第二张图是提交的信息,包括_xsrf和密码。记住_我,电子邮件。注意提交的信息中收录cookies,_xsrf可以从知乎的主页获取。
第三张图是服务器返回的信息。请注意,其状态为 200,表示成功。
第四章是服务器返回的数据。请注意,它具有三个 cookie 设置。并带有指示登录是否成功的消息。
通过上面的步骤我们可以知道什么?首先,发送登录请求时的cookie。以及帖子数据的格式。其次,我们可以获取登录的cookie信息(第四张图)。
c httpclient抓取网页(某电商商品详细信息的整体架构布局(图)、业务需求 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-10-09 22:05
)
HtmlCleaner&xPath:网页分析软件,解析出需要的相关信息。
MySQL数据库:用于存储爬取到的产品的详细信息。
ZooKeeper:分布式协调工具,用于监控后期各个爬虫的运行状态。
三、业务需求
获取电子商务产品的详细信息,需要的相关字段有:产品ID、产品名称、产品价格和产品详细信息。
四、 整体结构布局
第一个是我们的核心部件爬虫程序。爬虫过程是:从Redis数据仓库中取出URL,使用HttpClient进行下载,下载的页面内容,我们使用HtmlCleaner和xPath进行页面分析,此时我们解析的页面可能是产品列表页面,或者它可能是产品的详细页面。如果是产品列表页面,则需要在页面中解析出产品详情页面的URL,放入Redis数据仓库进行后期分析;如果是产品详细信息页面,请将其存储在我们的 MySQL 数据中。具体架构图如下:
核心程序爬虫写好后,为了加快页面爬取效率,我们需要对爬虫进行改进:一是多线程修改爬虫程序;二是将爬虫部署到多台服务器上,进一步加快爬虫的爬取效率。在实际生产环境中,由于刀片服务器稳定性较差,可能会出现一些问题,例如:爬虫进程挂掉。这些问题可能经常发生,所以我们需要对其进行监控。一旦发现爬虫进程挂掉,立即启动脚本重启爬虫进程,保证我们整个爬虫核心的持续运行。这是我们的分布式协调服务 ZooKeeper 的使用。我们可以再写一个进程监控程序,实时监控爬虫的运行状态。原理是:爬虫启动时,在ZooKeeper服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:
接下来,我们将重点分析爬虫架构的各个部分。
五、Redis 数据库-临时存储要爬取的 URL。
Redis 数据库是一个基于内存的 Key-Value 非关系型数据库。由于其极快的读写速度,受到了人们的热烈追捧(读写速度约为每秒10W)。Redis 数据库用于临时数据存储的选择就是基于此。为了让我们的爬虫优先抓取商品列表页面,我们在Redis中定义了两个队列(利用Redis的list的lpop和rpush模拟),分别是高优先级队列和低优先级队列,我们有更高优先级的商品列表page存放在队列中,商品详情页存放在低优先级队列中。这样我们就可以保证爬虫在抓取数据的时候,会先从高优先级队列中抓取数据,这样爬虫会先抓取产品列表页面。
package cn.mrchor.spider.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
public static String highKey = "jd_high_key";
public static String lowKey = "jd_low_key";
private JedisPool jedisPool = null;
/**
* 构造函数初始化jedis数据库连接池
*/
public JedisUtils() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(100);
jedisPoolConfig.setMaxWaitMillis(10000);
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool("192.168.52.128", 6379);
}
/**
* 获取jedis对象操作jedis数据库
* @return
*/
public Jedis getJedis() {
return this.jedisPool.getResource();
}
/**
* 往list添加数据
*/
public void addUrl(String key, String url) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(key, url);
jedisPool.returnResourceObject(jedis);
}
/**
* 从list中取数据
*/
public String getUrl(String key) {
Jedis jedis = jedisPool.getResource();
String url = jedis.rpop(key);
jedisPool.returnResourceObject(jedis);
return url;
}
} 查看全部
c httpclient抓取网页(某电商商品详细信息的整体架构布局(图)、业务需求
)
HtmlCleaner&xPath:网页分析软件,解析出需要的相关信息。
MySQL数据库:用于存储爬取到的产品的详细信息。
ZooKeeper:分布式协调工具,用于监控后期各个爬虫的运行状态。
三、业务需求
获取电子商务产品的详细信息,需要的相关字段有:产品ID、产品名称、产品价格和产品详细信息。
四、 整体结构布局
第一个是我们的核心部件爬虫程序。爬虫过程是:从Redis数据仓库中取出URL,使用HttpClient进行下载,下载的页面内容,我们使用HtmlCleaner和xPath进行页面分析,此时我们解析的页面可能是产品列表页面,或者它可能是产品的详细页面。如果是产品列表页面,则需要在页面中解析出产品详情页面的URL,放入Redis数据仓库进行后期分析;如果是产品详细信息页面,请将其存储在我们的 MySQL 数据中。具体架构图如下:
核心程序爬虫写好后,为了加快页面爬取效率,我们需要对爬虫进行改进:一是多线程修改爬虫程序;二是将爬虫部署到多台服务器上,进一步加快爬虫的爬取效率。在实际生产环境中,由于刀片服务器稳定性较差,可能会出现一些问题,例如:爬虫进程挂掉。这些问题可能经常发生,所以我们需要对其进行监控。一旦发现爬虫进程挂掉,立即启动脚本重启爬虫进程,保证我们整个爬虫核心的持续运行。这是我们的分布式协调服务 ZooKeeper 的使用。我们可以再写一个进程监控程序,实时监控爬虫的运行状态。原理是:爬虫启动时,在ZooKeeper服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:它在 ZooKeeper 服务中注册自己的临时目录。监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:监控程序使用ZooKeeper监控爬虫注册的临时目录。ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:ZooKeeper的本质——如果注册临时目录的程序挂了,过一会临时目录就会消失。利用这种性质,我们的监控程序监控爬虫注册的临时目录。一旦发现临时目录消失,服务器就会发生变化。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:服务器将被更改。其上的爬虫进程已经暂停,所以我们需要启动脚本来重启爬虫进程。然后我们将捕获的产品的详细信息存储在我们的分布式 MySQL 数据库中。以下是整个爬虫项目的架构图:
接下来,我们将重点分析爬虫架构的各个部分。
五、Redis 数据库-临时存储要爬取的 URL。
Redis 数据库是一个基于内存的 Key-Value 非关系型数据库。由于其极快的读写速度,受到了人们的热烈追捧(读写速度约为每秒10W)。Redis 数据库用于临时数据存储的选择就是基于此。为了让我们的爬虫优先抓取商品列表页面,我们在Redis中定义了两个队列(利用Redis的list的lpop和rpush模拟),分别是高优先级队列和低优先级队列,我们有更高优先级的商品列表page存放在队列中,商品详情页存放在低优先级队列中。这样我们就可以保证爬虫在抓取数据的时候,会先从高优先级队列中抓取数据,这样爬虫会先抓取产品列表页面。
package cn.mrchor.spider.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
public static String highKey = "jd_high_key";
public static String lowKey = "jd_low_key";
private JedisPool jedisPool = null;
/**
* 构造函数初始化jedis数据库连接池
*/
public JedisUtils() {
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(10);
jedisPoolConfig.setMaxTotal(100);
jedisPoolConfig.setMaxWaitMillis(10000);
jedisPoolConfig.setTestOnBorrow(true);
jedisPool = new JedisPool("192.168.52.128", 6379);
}
/**
* 获取jedis对象操作jedis数据库
* @return
*/
public Jedis getJedis() {
return this.jedisPool.getResource();
}
/**
* 往list添加数据
*/
public void addUrl(String key, String url) {
Jedis jedis = jedisPool.getResource();
jedis.lpush(key, url);
jedisPool.returnResourceObject(jedis);
}
/**
* 从list中取数据
*/
public String getUrl(String key) {
Jedis jedis = jedisPool.getResource();
String url = jedis.rpop(key);
jedisPool.returnResourceObject(jedis);
return url;
}
}
c httpclient抓取网页(广州图书馆处理方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-09 09:49
)
欢迎访问我的个人网站,如果你能在GitHub上给网站的源代码一个star就更好了。
当我建立自己的网站时,我想记录我所有阅读和借阅的书籍。大学也爬了我学校的图书馆记录,但是数据库被删了==只保留了一个。截图。所以你要珍惜阅读的日子,记录你的借阅记录——广州图书馆。现在代码已经放在服务器上可以正常运行了。结果,检查我的网站(关于我)页面。整个代码使用HttpClient,存储在MySql中,定期使用Spring自带的Schedule。以下是爬取过程。
1.页面跳转过程
一般是进入首页,点击进入登录页面,然后输入账号密码。从表面上看,并没有什么特别之处。实际上,在模拟登录时,并不只是向链接发布请求那么简单。获得的响应要么跳回登录页面,要么不受限制地重定向。
其实是做单点登录的,如下图,广州图书馆网址是:,登录网址是:。原理网上很多人讲的很好,可以看看这篇文章SSO单点登录。
2.如何处理
解决方法不难,只要访问模拟的主页获取库会话,python的获取代码如:session.get(""),打印cookie后如下:
[, , ]
整个登录和抓包流程如下:
即:
(1) 用户首先点击广州图书馆首页获取修改后的URL的session,然后点击登录界面,解析html,获取lt(自定义参数,类似验证码),和单点登录服务器会话。
(2)向目标服务器(单点登录服务器)提交post请求,请求参数包括username(用户名)、password(密码)、event(时间,默认为submit)、lt(自定义请求) parameters) 同时服务器要验证的参数:refer(源页面)、host(主机信息)、Content-Type(类型)。
(3)打印响应,搜索自己的名字,如果有就成功,否则会跳回登录页面。
(4)使用cookies访问其他页面,这里实现的是抓取借阅历史,所以访问的页面是:。
这就是基本的模拟登录和检索。之后就是对html的解析,书名的检索,书的索引等,然后封装成JavaBean,再存入数据库。(我没有做繁重的工作,不知道哪种方式更好)
3.代码
3.1 Java中一般使用httpclient来提交http请求。首先是需要导入的httpclient相关包:
org.apache.httpcomponents
httpclient
4.5.3
org.apache.httpcomponents
httpcore
4.4.7
3.2 构建并声明全局变量-上下文管理器,其中上下文为上下文管理器
public class LibraryUtil {
private static CloseableHttpClient httpClient = null;
private static HttpClientContext context = null;
private static CookieStore cookieStore = null;
static {
init();
}
private static void init() {
context = HttpClientContext.create();
cookieStore = new BasicCookieStore();
// 配置超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(12000).setSocketTimeout(6000)
.setConnectionRequestTimeout(6000).build();
// 设置默认跳转以及存储cookie
httpClient = HttpClientBuilder.create()
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.setRedirectStrategy(new DefaultRedirectStrategy()).setDefaultRequestConfig(requestConfig)
.setDefaultCookieStore(cookieStore).build();
}
...
3.3 声明一个get函数,可以自定义header。这里不需要它,但保留它并使其成为通用目的。
public static CloseableHttpResponse get(String url, Header[] header) throws IOException {
HttpGet httpget = new HttpGet(url);
if (header != null && header.length > 0) {
httpget.setHeaders(header);
}
CloseableHttpResponse response = httpClient.execute(httpget, context);//context用于存储上下文
return response;
}
3.4 访问主页获取会话。服务器上的会话是使用 session 存储的。本地浏览器使用 cookie。只要不在本地注销,也可以使用本地cookies来访问,但是为了达到模拟登录的效果,这里就不解释了。
CloseableHttpResponse homeResponse = get("http://www.gzlib.gov.cn/", null);
homeResponse.close();
此时,如果打印cookie,可以看到当前cookie如下:
3.5 访问登录页面,获取单点登录服务器背后的cookie,解析网页,获取自定义参数lt。这里的解析网页使用的是Jsoup,语法类似于python中的BeautifulSoup。
String loginURL = "http://login.gzlib.gov.cn/sso- ... 3B%3B
CloseableHttpResponse loginGetResponse = get(loginURL, null);
String content = toString(loginGetResponse);
String lt = Jsoup.parse(content).select("form").select("input[name=lt]").attr("value");
loginGetResponse.close();
此时,再次检查cookie,多一个():
3.6 声明一个post函数提交post请求,提交的参数默认为
public static CloseableHttpResponse postParam(String url, String parameters, Header[] headers)
throws IOException {
System.out.println(parameters);
HttpPost httpPost = new HttpPost(url);
if (headers != null && headers.length > 0) {
for (Header header : headers) {
httpPost.addHeader(header);
}
}
List nvps = toNameValuePairList(parameters);
httpPost.setEntity(new UrlEncodedFormEntity(nvps, "UTF-8"));
CloseableHttpResponse response = httpClient.execute(httpPost, context);
return response;
}
3.7 登录成功后,如果没有声明returnurl,即登录链接为(),则只显示登录成功的页面:
后端应定义链接重定向服务。如果想在登录成功后得到重定向页面,可以修改服务后的链接,这里会保持原来的状态。此时查看cookie的结果如下:
其中CASTGC的出现表示登录成功,可以使用cookie访问广州图书馆的其他页面。在python中是直接跳转到其他页面,但是在java中使用httpclient的过程中,看到的并不是直接跳转。,但是一个302重定向,打印Header后的结果如下:
仔细研究一下链接,你会发现服务器就相当于给了一张普通的票券,即可以使用该票券访问任何页面,而returnUrl就是返回的页面。这里我们直接访问重定向的url。
Header header = response.getHeaders("Location")[0];
CloseableHttpResponse home = get(header.getValue(), null);
然后打印页面,得到登录后跳转的首页。
3.8 解析 html
获取session后跳回首页,访问借阅历史页面,然后在html中解析结果。在python中使用了BeautifulSoup,简单实用,java中的jsoup也是不错的选择。
String html = getHTML();
Element element = Jsoup.parse(html).select("table.jieyue-table").get(0).select("tbody").get(0);
Elements trs = element.select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
System.out.println(tds.get(1).text());
}
输出结果:
企业IT架构转型之道
大话Java性能优化
深入理解Hadoop
大话Java性能优化
Java EE开发的颠覆者:Spring Boot实战
大型网站技术架构:核心原理与案例分析
Java性能权威指南
Akka入门与实践
高性能网站建设进阶指南:Web开发者性能优化最佳实践:Performance best practices for Web developers
Java EE开发的颠覆者:Spring Boot实战
深入理解Hadoop
大话Java性能优化
点击查看源代码
总结
目前修改后的代码已经集成到个人网站中,每天抓一次,但是还有很多事情没有做(比如分页、去重等)。如果你有兴趣,你可以研究源代码,如果你能帮助改进它。甚至更好。谢谢♪(・ω・)ノ。整个代码接近250行,当然……包括注释,但是使用python后,只有25行=w=,这里是python源代码。同时欢迎大家访问我的个人网站,也欢迎大家给个star。
import urllib.parse
import requests
from bs4 import BeautifulSoup
session = requests.session()
session.get("http://www.gzlib.gov.cn/")
session.headers.update(
{"Referer": "http://www.gzlib.gov.cn/member ... ot%3B,
"origin": "http://login.gzlib.gov.cn",
'Content-Type': 'application/x-www-form-urlencoded',
'host': 'www.gzlib.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
)
baseURL = "http://login.gzlib.gov.cn/sso-server/login"
soup = BeautifulSoup(session.get(baseURL).text, "html.parser")
lt = soup.select("form")[0].find(attrs={'name': 'lt'})['value']
postdict = {"username": "你的身份证",
"password": "密码(默认为身份证后6位)",
"_eventId": "submit",
"lt": lt
}
postdata = urllib.parse.urlencode(postdict)
session.post(baseURL, postdata)
print(session.get("http://www.gzlib.gov.cn/member ... 6quot;).text) 查看全部
c httpclient抓取网页(广州图书馆处理方法
)
欢迎访问我的个人网站,如果你能在GitHub上给网站的源代码一个star就更好了。
当我建立自己的网站时,我想记录我所有阅读和借阅的书籍。大学也爬了我学校的图书馆记录,但是数据库被删了==只保留了一个。截图。所以你要珍惜阅读的日子,记录你的借阅记录——广州图书馆。现在代码已经放在服务器上可以正常运行了。结果,检查我的网站(关于我)页面。整个代码使用HttpClient,存储在MySql中,定期使用Spring自带的Schedule。以下是爬取过程。
1.页面跳转过程
一般是进入首页,点击进入登录页面,然后输入账号密码。从表面上看,并没有什么特别之处。实际上,在模拟登录时,并不只是向链接发布请求那么简单。获得的响应要么跳回登录页面,要么不受限制地重定向。
其实是做单点登录的,如下图,广州图书馆网址是:,登录网址是:。原理网上很多人讲的很好,可以看看这篇文章SSO单点登录。
2.如何处理
解决方法不难,只要访问模拟的主页获取库会话,python的获取代码如:session.get(""),打印cookie后如下:
[, , ]
整个登录和抓包流程如下:
即:
(1) 用户首先点击广州图书馆首页获取修改后的URL的session,然后点击登录界面,解析html,获取lt(自定义参数,类似验证码),和单点登录服务器会话。
(2)向目标服务器(单点登录服务器)提交post请求,请求参数包括username(用户名)、password(密码)、event(时间,默认为submit)、lt(自定义请求) parameters) 同时服务器要验证的参数:refer(源页面)、host(主机信息)、Content-Type(类型)。
(3)打印响应,搜索自己的名字,如果有就成功,否则会跳回登录页面。
(4)使用cookies访问其他页面,这里实现的是抓取借阅历史,所以访问的页面是:。
这就是基本的模拟登录和检索。之后就是对html的解析,书名的检索,书的索引等,然后封装成JavaBean,再存入数据库。(我没有做繁重的工作,不知道哪种方式更好)
3.代码
3.1 Java中一般使用httpclient来提交http请求。首先是需要导入的httpclient相关包:
org.apache.httpcomponents
httpclient
4.5.3
org.apache.httpcomponents
httpcore
4.4.7
3.2 构建并声明全局变量-上下文管理器,其中上下文为上下文管理器
public class LibraryUtil {
private static CloseableHttpClient httpClient = null;
private static HttpClientContext context = null;
private static CookieStore cookieStore = null;
static {
init();
}
private static void init() {
context = HttpClientContext.create();
cookieStore = new BasicCookieStore();
// 配置超时时间
RequestConfig requestConfig = RequestConfig.custom().setConnectTimeout(12000).setSocketTimeout(6000)
.setConnectionRequestTimeout(6000).build();
// 设置默认跳转以及存储cookie
httpClient = HttpClientBuilder.create()
.setKeepAliveStrategy(new DefaultConnectionKeepAliveStrategy())
.setRedirectStrategy(new DefaultRedirectStrategy()).setDefaultRequestConfig(requestConfig)
.setDefaultCookieStore(cookieStore).build();
}
...
3.3 声明一个get函数,可以自定义header。这里不需要它,但保留它并使其成为通用目的。
public static CloseableHttpResponse get(String url, Header[] header) throws IOException {
HttpGet httpget = new HttpGet(url);
if (header != null && header.length > 0) {
httpget.setHeaders(header);
}
CloseableHttpResponse response = httpClient.execute(httpget, context);//context用于存储上下文
return response;
}
3.4 访问主页获取会话。服务器上的会话是使用 session 存储的。本地浏览器使用 cookie。只要不在本地注销,也可以使用本地cookies来访问,但是为了达到模拟登录的效果,这里就不解释了。
CloseableHttpResponse homeResponse = get("http://www.gzlib.gov.cn/", null);
homeResponse.close();
此时,如果打印cookie,可以看到当前cookie如下:
3.5 访问登录页面,获取单点登录服务器背后的cookie,解析网页,获取自定义参数lt。这里的解析网页使用的是Jsoup,语法类似于python中的BeautifulSoup。
String loginURL = "http://login.gzlib.gov.cn/sso- ... 3B%3B
CloseableHttpResponse loginGetResponse = get(loginURL, null);
String content = toString(loginGetResponse);
String lt = Jsoup.parse(content).select("form").select("input[name=lt]").attr("value");
loginGetResponse.close();
此时,再次检查cookie,多一个():
3.6 声明一个post函数提交post请求,提交的参数默认为
public static CloseableHttpResponse postParam(String url, String parameters, Header[] headers)
throws IOException {
System.out.println(parameters);
HttpPost httpPost = new HttpPost(url);
if (headers != null && headers.length > 0) {
for (Header header : headers) {
httpPost.addHeader(header);
}
}
List nvps = toNameValuePairList(parameters);
httpPost.setEntity(new UrlEncodedFormEntity(nvps, "UTF-8"));
CloseableHttpResponse response = httpClient.execute(httpPost, context);
return response;
}
3.7 登录成功后,如果没有声明returnurl,即登录链接为(),则只显示登录成功的页面:
后端应定义链接重定向服务。如果想在登录成功后得到重定向页面,可以修改服务后的链接,这里会保持原来的状态。此时查看cookie的结果如下:
其中CASTGC的出现表示登录成功,可以使用cookie访问广州图书馆的其他页面。在python中是直接跳转到其他页面,但是在java中使用httpclient的过程中,看到的并不是直接跳转。,但是一个302重定向,打印Header后的结果如下:
仔细研究一下链接,你会发现服务器就相当于给了一张普通的票券,即可以使用该票券访问任何页面,而returnUrl就是返回的页面。这里我们直接访问重定向的url。
Header header = response.getHeaders("Location")[0];
CloseableHttpResponse home = get(header.getValue(), null);
然后打印页面,得到登录后跳转的首页。
3.8 解析 html
获取session后跳回首页,访问借阅历史页面,然后在html中解析结果。在python中使用了BeautifulSoup,简单实用,java中的jsoup也是不错的选择。
String html = getHTML();
Element element = Jsoup.parse(html).select("table.jieyue-table").get(0).select("tbody").get(0);
Elements trs = element.select("tr");
for (int i = 0; i < trs.size(); i++) {
Elements tds = trs.get(i).select("td");
System.out.println(tds.get(1).text());
}
输出结果:
企业IT架构转型之道
大话Java性能优化
深入理解Hadoop
大话Java性能优化
Java EE开发的颠覆者:Spring Boot实战
大型网站技术架构:核心原理与案例分析
Java性能权威指南
Akka入门与实践
高性能网站建设进阶指南:Web开发者性能优化最佳实践:Performance best practices for Web developers
Java EE开发的颠覆者:Spring Boot实战
深入理解Hadoop
大话Java性能优化
点击查看源代码
总结
目前修改后的代码已经集成到个人网站中,每天抓一次,但是还有很多事情没有做(比如分页、去重等)。如果你有兴趣,你可以研究源代码,如果你能帮助改进它。甚至更好。谢谢♪(・ω・)ノ。整个代码接近250行,当然……包括注释,但是使用python后,只有25行=w=,这里是python源代码。同时欢迎大家访问我的个人网站,也欢迎大家给个star。
import urllib.parse
import requests
from bs4 import BeautifulSoup
session = requests.session()
session.get("http://www.gzlib.gov.cn/";)
session.headers.update(
{"Referer": "http://www.gzlib.gov.cn/member ... ot%3B,
"origin": "http://login.gzlib.gov.cn",
'Content-Type': 'application/x-www-form-urlencoded',
'host': 'www.gzlib.gov.cn',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
}
)
baseURL = "http://login.gzlib.gov.cn/sso-server/login"
soup = BeautifulSoup(session.get(baseURL).text, "html.parser")
lt = soup.select("form")[0].find(attrs={'name': 'lt'})['value']
postdict = {"username": "你的身份证",
"password": "密码(默认为身份证后6位)",
"_eventId": "submit",
"lt": lt
}
postdata = urllib.parse.urlencode(postdict)
session.post(baseURL, postdata)
print(session.get("http://www.gzlib.gov.cn/member ... 6quot;).text)
c httpclient抓取网页(java爬取网页源代码解析搜索词的地址采用模拟地址方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-08 02:18
java爬取网页源码解析
java爬取网页源码解析
1. 搜索词的地址采用模拟地址方式(通过分析搜索引擎的参数获得,如百度),然后将搜索词添加到模拟地址中。
2. 函数的输入参数是模拟地址。
String query = URLEncoder.encode("潘珠婷", "UTF-8");
字符串
url=""+query+"&pn="+p*10+"&tn=baiduhome_pg&ie=utf-8"public void MakeQuery(String domain) {
试试{
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod(domain);
//System.out.println
("************************************************ ****************");
//System.out.println(getMethod);
试试{
httpClient.executeMethod(getMethod);
}catch(异常 e){
System.out.println("网络问题");
}
getMethod.getParams()。 setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("方法失败:"
+ getMethod.getStatusLine());
}
byte[] responseBody = getMethod.getResponseBody();
//System.out.println
("************************************************ ****************");
//System.out.println(responseBody);
String response = new String(responseBody, "UTF-8");
//System.out.println
("************************************************ ****************");
//System.out.println(响应);
//Jsoup解析html
文档 doc=Jsoup.parse(response);
//System.out.println
("************************************************ ****************");
//System.out.println(doc);
元素内容=doc.getElementsByClass("f");
for(元素内容:内容){
元素链接 = content.getElementsByTag("a")。第一个(); 查看全部
c httpclient抓取网页(java爬取网页源代码解析搜索词的地址采用模拟地址方法)
java爬取网页源码解析
java爬取网页源码解析
1. 搜索词的地址采用模拟地址方式(通过分析搜索引擎的参数获得,如百度),然后将搜索词添加到模拟地址中。
2. 函数的输入参数是模拟地址。
String query = URLEncoder.encode("潘珠婷", "UTF-8");
字符串
url=""+query+"&pn="+p*10+"&tn=baiduhome_pg&ie=utf-8"public void MakeQuery(String domain) {
试试{
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod(domain);
//System.out.println
("************************************************ ****************");
//System.out.println(getMethod);
试试{
httpClient.executeMethod(getMethod);
}catch(异常 e){
System.out.println("网络问题");
}
getMethod.getParams()。 setParameter(HttpMethodParams.RETRY_HANDLER,new DefaultHttpMethodRetryHandler());
int statusCode = httpClient.executeMethod(getMethod);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("方法失败:"
+ getMethod.getStatusLine());
}
byte[] responseBody = getMethod.getResponseBody();
//System.out.println
("************************************************ ****************");
//System.out.println(responseBody);
String response = new String(responseBody, "UTF-8");
//System.out.println
("************************************************ ****************");
//System.out.println(响应);
//Jsoup解析html
文档 doc=Jsoup.parse(response);
//System.out.println
("************************************************ ****************");
//System.out.println(doc);
元素内容=doc.getElementsByClass("f");
for(元素内容:内容){
元素链接 = content.getElementsByTag("a")。第一个();
c httpclient抓取网页(如何在java里面模拟ajax获得表格里的数据呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-10-06 02:18
现在我想用httpclient获取页面的数据,但是数据是根据Ajax脚本动态获取的。如何在Java中模拟Ajax以获取表中的数据?[网页URL:]
在此页面中,用于获取数据的JS的URL为
,Currency.ashx
通过检测,可以确定发送了post请求。URL如上所述,post参数。现在我想用Java中的httpclient模拟post请求,以获取返回数据。我试过了,但还是失败了。让我们给你一些建议。多谢各位
部分测试代码
---------------------------------------------------------------------------------------------
[align=left]HttpPostHttpPost=newHttpPost(url)
Listparam=newArrayList()
参数add(newBasicNameValuePair(“控制ID”、“CS30SV9SCKlax9FSDS3HYFUCTJR16N5G”)
setHeader(“X-AjaxPro-Method”、“GetDataSource”)
setHeader(“X_请求的_带有”,“XMLHttpRequest”)
setHeader(“Referer”和“)
httpost.setHeader(“用户代理”、“Mozilla/5.0(Windows;U;WindowsNT5.1;nl;rv:1.8.1.13)Gecko/20080311Firefox/2.0.13”)
setHeader(“Accept”,“text/xml,text/javascript,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5”)
httpost.setHeader(“接受语言”,“zh-cn,zh;q=0.5;en-us;q=0.7,en;q=0.3”)
httpost.setHeader(“接受字符集”,“gb2312,utf-8;q=0.7,*;q=0.7;ISO-8859-1,utf-8,GBK,gb2312;q=0.7,*;q=0.7”)
httpost.setEntity(newUrlEncodedFormEntity(param,HTTP.UTF8))
HttpResponseresp=client.execute(httpost)
InputStreamcontent=resp.getEntity().getContent()
[/align] 查看全部
c httpclient抓取网页(如何在java里面模拟ajax获得表格里的数据呢?)
现在我想用httpclient获取页面的数据,但是数据是根据Ajax脚本动态获取的。如何在Java中模拟Ajax以获取表中的数据?[网页URL:]
在此页面中,用于获取数据的JS的URL为
,Currency.ashx
通过检测,可以确定发送了post请求。URL如上所述,post参数。现在我想用Java中的httpclient模拟post请求,以获取返回数据。我试过了,但还是失败了。让我们给你一些建议。多谢各位
部分测试代码
---------------------------------------------------------------------------------------------
[align=left]HttpPostHttpPost=newHttpPost(url)
Listparam=newArrayList()
参数add(newBasicNameValuePair(“控制ID”、“CS30SV9SCKlax9FSDS3HYFUCTJR16N5G”)
setHeader(“X-AjaxPro-Method”、“GetDataSource”)
setHeader(“X_请求的_带有”,“XMLHttpRequest”)
setHeader(“Referer”和“)
httpost.setHeader(“用户代理”、“Mozilla/5.0(Windows;U;WindowsNT5.1;nl;rv:1.8.1.13)Gecko/20080311Firefox/2.0.13”)
setHeader(“Accept”,“text/xml,text/javascript,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5”)
httpost.setHeader(“接受语言”,“zh-cn,zh;q=0.5;en-us;q=0.7,en;q=0.3”)
httpost.setHeader(“接受字符集”,“gb2312,utf-8;q=0.7,*;q=0.7;ISO-8859-1,utf-8,GBK,gb2312;q=0.7,*;q=0.7”)
httpost.setEntity(newUrlEncodedFormEntity(param,HTTP.UTF8))
HttpResponseresp=client.execute(httpost)
InputStreamcontent=resp.getEntity().getContent()
[/align]

