
c httpclient抓取网页
c httpclient抓取网页( 一个Python抓取网页的库:urllib与urllib2有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-15 22:24
一个Python抓取网页的库:urllib与urllib2有什么区别?)
python网络爬虫的初级实现代码,python爬虫
首先,我们来看一个用于抓取网页的 Python 库:urllib 或 urllib2。
那么 urllib 和 urllib2 有什么区别呢?
您可以使用 urllib2 作为 urllib 的扩展。明显的好处就是urllib2.urlopen()可以接受Request对象作为参数,这样就可以控制HTTP Request的头部部分了。
在做HTTP Request的时候应该尽量使用urllib2库,但是urllib2中并没有加入urllib.urlretrieve()函数和urllib.quote等一系列quote和unquote函数,所以有时候辅助需要 urllib。
urllib.open() 这里传入的参数必须遵循一些协议,比如http、ftp、file等。例如:
urllib.open('')
urllib.open('file:D\Python\Hello.py')
现在有一个以 gif 格式下载所有图像的 网站 的示例。那么Python代码如下:
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.*?\.gif)"'
imgre = re.compile(reg)
imgList = re.findall(imgre,html)
print imgList
cnt = 1
for imgurl in imgList:
urllib.urlretrieve(imgurl,'%s.jpg' %cnt)
cnt += 1
if __name__ == '__main__':
html = getHtml('http://www.baidu.com')
getImg(html)
根据上面的方法,我们可以爬取某些网页,然后提取出我们需要的数据。
实际上,我们使用 urllib 模块作为网络爬虫是非常低效的。让我们介绍 Tornado Web Server。
Tornado Web 服务器是一个用 Python 编写的极其轻量级、高度可扩展且非阻塞的 IO Web 服务器软件。著名的 Friendfeed网站 就是使用它构建的。 Tornado 与其他主流 Web 服务器框架(主要是 Python 框架)的不同之处在于它采用了 epoll 非阻塞 IO,响应速度快,可以处理数千个并发连接,尤其适用于实时 Web 服务。
使用 Tornado Web Server 抓取网页会更高效。
从 Tornado 的官方网站,也应该安装 backports.ssl_match_hostname。官网如下:
import tornado.httpclient
def Fetch(url):
http_header = {'User-Agent' : 'Chrome'}
http_request = tornado.httpclient.HTTPRequest(url=url,method='GET',headers=http_header,connect_timeout=200,request_timeout=600)
print 'Hello'
http_client = tornado.httpclient.HTTPClient()
print 'Hello World'
print 'Start downloading data...'
http_response = http_client.fetch(http_request)
print 'Finish downloading data...'
print http_response.code
all_fields = http_response.headers.get_all()
for field in all_fields:
print field
print http_response.body
if __name__ == '__main__':
Fetch('http://www.baidu.com')
urllib2的常用方法:
(1)info()获取网页的Header信息
(2)getcode()获取网页的状态码
(3)geturl() 获取传入的 URL
(4)read() 读取文件内容 查看全部
c httpclient抓取网页(
一个Python抓取网页的库:urllib与urllib2有什么区别?)
python网络爬虫的初级实现代码,python爬虫
首先,我们来看一个用于抓取网页的 Python 库:urllib 或 urllib2。
那么 urllib 和 urllib2 有什么区别呢?
您可以使用 urllib2 作为 urllib 的扩展。明显的好处就是urllib2.urlopen()可以接受Request对象作为参数,这样就可以控制HTTP Request的头部部分了。
在做HTTP Request的时候应该尽量使用urllib2库,但是urllib2中并没有加入urllib.urlretrieve()函数和urllib.quote等一系列quote和unquote函数,所以有时候辅助需要 urllib。
urllib.open() 这里传入的参数必须遵循一些协议,比如http、ftp、file等。例如:
urllib.open('')
urllib.open('file:D\Python\Hello.py')
现在有一个以 gif 格式下载所有图像的 网站 的示例。那么Python代码如下:
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.*?\.gif)"'
imgre = re.compile(reg)
imgList = re.findall(imgre,html)
print imgList
cnt = 1
for imgurl in imgList:
urllib.urlretrieve(imgurl,'%s.jpg' %cnt)
cnt += 1
if __name__ == '__main__':
html = getHtml('http://www.baidu.com')
getImg(html)
根据上面的方法,我们可以爬取某些网页,然后提取出我们需要的数据。
实际上,我们使用 urllib 模块作为网络爬虫是非常低效的。让我们介绍 Tornado Web Server。
Tornado Web 服务器是一个用 Python 编写的极其轻量级、高度可扩展且非阻塞的 IO Web 服务器软件。著名的 Friendfeed网站 就是使用它构建的。 Tornado 与其他主流 Web 服务器框架(主要是 Python 框架)的不同之处在于它采用了 epoll 非阻塞 IO,响应速度快,可以处理数千个并发连接,尤其适用于实时 Web 服务。
使用 Tornado Web Server 抓取网页会更高效。
从 Tornado 的官方网站,也应该安装 backports.ssl_match_hostname。官网如下:
import tornado.httpclient
def Fetch(url):
http_header = {'User-Agent' : 'Chrome'}
http_request = tornado.httpclient.HTTPRequest(url=url,method='GET',headers=http_header,connect_timeout=200,request_timeout=600)
print 'Hello'
http_client = tornado.httpclient.HTTPClient()
print 'Hello World'
print 'Start downloading data...'
http_response = http_client.fetch(http_request)
print 'Finish downloading data...'
print http_response.code
all_fields = http_response.headers.get_all()
for field in all_fields:
print field
print http_response.body
if __name__ == '__main__':
Fetch('http://www.baidu.com')
urllib2的常用方法:
(1)info()获取网页的Header信息
(2)getcode()获取网页的状态码
(3)geturl() 获取传入的 URL
(4)read() 读取文件内容
c httpclient抓取网页(mancurl阅读手册页上传文件路径-curl模拟http提交数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-15 11:17
使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好使用登录页面测试,因为你传值后,curl会抓取数据回来,可以查看是否传值成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。 查看全部
c httpclient抓取网页(mancurl阅读手册页上传文件路径-curl模拟http提交数据)
使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好使用登录页面测试,因为你传值后,curl会抓取数据回来,可以查看是否传值成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。
c httpclient抓取网页(互联网-java使用浏览器内核模拟浏览器操作驱动包下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-11 03:09
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
由于部分网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,此时无法通过httpclient获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。对于Windows和Linux平台,需要分别指定对应的驱动路径。
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。 查看全部
c httpclient抓取网页(互联网-java使用浏览器内核模拟浏览器操作驱动包下载地址)
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
由于部分网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,此时无法通过httpclient获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。

2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。对于Windows和Linux平台,需要分别指定对应的驱动路径。
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。
c httpclient抓取网页(怎么用网络爬虫获取数据基于html标签的内容--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-05 09:11
登录后,如果只是简单的获取数据,只需要写一个过滤器,过滤html标签,找到你想要的。
如果不想自己写,百度htmlunit负责把html转成dom。然后找到对应的html标签。
想偷懒解决一次,百度jsoup jsoup=httpclient+htmlunit 可以直接通过url获取网页的dom。
表示你应该是登录失败或者登录后没有使用cookies。登录浏览器查看返回的响应,然后输出登录后得到的响应的header和response,看看是否与浏览器返回的响应一致。专注于您的 cookie 的价值。
如何使用java实现网络爬虫爬取页面内容-》》以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是jdk自带,速度比较快,缺点是有方法更少,功能更复杂 自己实现往往需要很多代码 第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般是HttpClient + JSOUP配合完成爬取,HttpClient获取页面,JSOUP解析网页并获取数据HttpUnit:相当于没有界面的浏览器,缺点是占用内存大,速度慢,优点是可以执行js,功能强大
java网络爬虫是如何实现对登录后页面的爬取-""" 原理是保存cookie数据,登录后保存cookie,以后每次页面的时候都会在header信息中发送cookie系统根据cookie判断用户有了cookie,就有登录状态,后续的访问都是基于这个cookie对应的用户补充:Java是一种面向对象的编程语言,可以跨平台编写应用软件 Java技术具有优异的通用性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
java网络爬虫如何实现对登录页面的抓取-》》我没做过网络爬虫,但是写了一个程序自动登录猫拍卡3233363533e78988e69d83338。你可以参考一下。需要的包是commons-logging.jar,commons-net-1.4.1.jar,commons-codec-1.3.jar,log4j.jar ……
基于java如何使用网络爬虫获取数据——“”“爬虫的原理其实就是获取网页的内容然后解析,只不过获取网页的方式有很多种,然后解析内容。可以简单的使用httpclient发送get/post请求,得到结果,然后使用截取的字符串和正则表达式来获取想要的内容。或者使用Jsoup/crawler4j等封装好的库来更方便的爬取信息。
java爬虫登录后是如何抓取网页数据的——《》》一般爬虫登录后是不会抓取页面的。如果只是临时抓取一个站点,可以模拟登录,登录后获取cookies,然后请求相关的页面。
java中如何爬取网页数据-》》》1.生成页面后使用jsoup爬取静态信息,很简单,知道jquery的选择器会使用2.获取生成后的页面loading 通过ajax返回刷新的页面,没办法,请从发送的请求中分析xml或json数据,看看哪个爬虫在任何情况下都不可能申请!
java爬虫爬取指定数据-"""如何通过Java代码实现对网页数据的指定爬取,我总结Jsoup.Jar包会用到以下步骤:1、在project.jar包2、获取url指定的url或者文档指定的body3、获取网页中超链接的标题和链接4、获取指定的内容blog文章5、@ 获取网页中超链接的标题和链接结果
java正则如何提取数据?(网络爬虫) - """ 通过 Matcher 写正则配置~...
JAVA爬虫如何爬取动态页面——《》》解析ajax地址,发给自己和地址
java爬虫怎么爬取js动态生成的内容-"""我用jsoup写爬虫,一般会遇到html没有返回的内容,但是浏览器显示了一些内容,就是分析http请求页面的日志。分析页面的JS代码来解决。1、一些页面元素被隐藏->更改选择器解决2、一些数据存储在js/json对象中->拦截对应字符串,分析解决3、通过api接口调用还有一个终极方法->假请求获取数据4、使用无头浏览器如phantomjs或casperjs 查看全部
c httpclient抓取网页(怎么用网络爬虫获取数据基于html标签的内容--)
登录后,如果只是简单的获取数据,只需要写一个过滤器,过滤html标签,找到你想要的。
如果不想自己写,百度htmlunit负责把html转成dom。然后找到对应的html标签。
想偷懒解决一次,百度jsoup jsoup=httpclient+htmlunit 可以直接通过url获取网页的dom。
表示你应该是登录失败或者登录后没有使用cookies。登录浏览器查看返回的响应,然后输出登录后得到的响应的header和response,看看是否与浏览器返回的响应一致。专注于您的 cookie 的价值。
如何使用java实现网络爬虫爬取页面内容-》》以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是jdk自带,速度比较快,缺点是有方法更少,功能更复杂 自己实现往往需要很多代码 第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般是HttpClient + JSOUP配合完成爬取,HttpClient获取页面,JSOUP解析网页并获取数据HttpUnit:相当于没有界面的浏览器,缺点是占用内存大,速度慢,优点是可以执行js,功能强大
java网络爬虫是如何实现对登录后页面的爬取-""" 原理是保存cookie数据,登录后保存cookie,以后每次页面的时候都会在header信息中发送cookie系统根据cookie判断用户有了cookie,就有登录状态,后续的访问都是基于这个cookie对应的用户补充:Java是一种面向对象的编程语言,可以跨平台编写应用软件 Java技术具有优异的通用性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
java网络爬虫如何实现对登录页面的抓取-》》我没做过网络爬虫,但是写了一个程序自动登录猫拍卡3233363533e78988e69d83338。你可以参考一下。需要的包是commons-logging.jar,commons-net-1.4.1.jar,commons-codec-1.3.jar,log4j.jar ……
基于java如何使用网络爬虫获取数据——“”“爬虫的原理其实就是获取网页的内容然后解析,只不过获取网页的方式有很多种,然后解析内容。可以简单的使用httpclient发送get/post请求,得到结果,然后使用截取的字符串和正则表达式来获取想要的内容。或者使用Jsoup/crawler4j等封装好的库来更方便的爬取信息。
java爬虫登录后是如何抓取网页数据的——《》》一般爬虫登录后是不会抓取页面的。如果只是临时抓取一个站点,可以模拟登录,登录后获取cookies,然后请求相关的页面。
java中如何爬取网页数据-》》》1.生成页面后使用jsoup爬取静态信息,很简单,知道jquery的选择器会使用2.获取生成后的页面loading 通过ajax返回刷新的页面,没办法,请从发送的请求中分析xml或json数据,看看哪个爬虫在任何情况下都不可能申请!
java爬虫爬取指定数据-"""如何通过Java代码实现对网页数据的指定爬取,我总结Jsoup.Jar包会用到以下步骤:1、在project.jar包2、获取url指定的url或者文档指定的body3、获取网页中超链接的标题和链接4、获取指定的内容blog文章5、@ 获取网页中超链接的标题和链接结果
java正则如何提取数据?(网络爬虫) - """ 通过 Matcher 写正则配置~...
JAVA爬虫如何爬取动态页面——《》》解析ajax地址,发给自己和地址
java爬虫怎么爬取js动态生成的内容-"""我用jsoup写爬虫,一般会遇到html没有返回的内容,但是浏览器显示了一些内容,就是分析http请求页面的日志。分析页面的JS代码来解决。1、一些页面元素被隐藏->更改选择器解决2、一些数据存储在js/json对象中->拦截对应字符串,分析解决3、通过api接口调用还有一个终极方法->假请求获取数据4、使用无头浏览器如phantomjs或casperjs
c httpclient抓取网页(【】网站管理员的基本操作技巧(二)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-04-05 09:09
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Reset Content) 服务器成功处理请求但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(临时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 中没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。 查看全部
c httpclient抓取网页(【】网站管理员的基本操作技巧(二)——)
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Reset Content) 服务器成功处理请求但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(临时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 中没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。
c httpclient抓取网页(Python语言例子用C#来实现,代码贴在文中方便各位园友学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-29 03:05
最近重读了当年出版的介绍推荐系统的书《集体智能的编程》,在当时似乎引领了潮流,现在已经成为所有互联网公司的必备技术。
这次在阅读的同时,尝试用C#实现书中的一些Python语言示例,有利于自己的理解。代码贴在文中,方便园丁学习。
由于本文与原书可能涉及版权问题,请勿以任何形式被第三方转载,谢谢合作。
第三部分全文搜索引擎的搜索和排名
全文搜索引擎的作用是在大量文档中搜索一系列单词,并根据文档与搜索单词的相关程度对结果进行排名。
搜索引擎的组成
从 Internet 或从固定数量的文档中采集文档。
为采集的文档创建索引。
按查询返回排序的文档。这个过程的关键是文档的排序方法。
建立一个搜索引擎
首先构造一个爬行动物的“外壳”。以下方法逐步完善:
public class Crawler : IDisposable
{
private HttpClient _httpClient;
private IDbConnection _connection;
private static readonly HashSet IgnoreWords
= new HashSet(new [] {"the","of","to","and","a","in","is","it"});
//构造函数,接收数据库名作为参数
public Crawler(string dbname)
{
_httpClient = new HttpClient();
_connection = GetConn(dbname);
}
//辅助函数,用于获取条目Id,且如果条目不存在,就将其加入数据库中
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
return 0;
}
//为每个网页建立索引
public async Task AddtoIndex(string url, HtmlDocument soup)
{
Console.WriteLine($"Indexing {url}");
}
//从一个HTML网页提取文字(不带html标签)
public string GetTextOnly(HtmlDocument soup)
{
return null;
}
//分词
public List SeparateWords(string text)
{
return null;
}
//如果Url已经建立索引,则返回true
public bool IsIndexed(string url)
{
return false;
}
//添加一个关联两个网页的链接
public void AddLinkref(string urlFrom, string urlTo, string linkText)
{
}
//从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
public async Task Crawl(List pages, int depth = 2)
{
throw new NotImplementedException();
}
public async Task GetHtmlDoc(string url)
{
return null;
}
//创建数据库表
public void CreateIndexTables()
{
}
public static string UrlJoin(string urlBase, string urlRel)
{
return null;
}
public IDbConnection GetConn(string dbname)
{
return null;
}
public void Dispose()
{
_connection.Close();
}
}
这还收录一些管理数据库连接的代码,以及索引时要忽略的单词列表。
履带式
对于 C#,抓取网页 HttpClient 是一个很好的选择。
可以使用nuget安装HttpClient,在NuGet管理器中搜索“httpclient”,名为Microsoft.Net.Http的项就是HttpClient库。
爬取网页代码很简单:
var url = "http://xxx.com";
var httpClient = new HttpClient();
var content = await httpClient.GetStringAsync(url);
HttpClient每次释放都会断开Tcp连接,所以为了节省性能,尽量把HttpClient做成单例。
爬取网页后的另一个非常重要的步骤是分析Html的内容。对于 C#,可以使用 Html Agility Pack 库。安装Html Agility Pack也很简单,在Nuget中搜索HtmlAgilityPack,或者直接使用Install-Package HtmlAgilityPack。
我们首先在爬虫类中实现 Crawl 方法。
<p>public async Task Crawl(List pages, int depth = 2)
{
for (int i = 0; i 查看全部
c httpclient抓取网页(Python语言例子用C#来实现,代码贴在文中方便各位园友学习)
最近重读了当年出版的介绍推荐系统的书《集体智能的编程》,在当时似乎引领了潮流,现在已经成为所有互联网公司的必备技术。
这次在阅读的同时,尝试用C#实现书中的一些Python语言示例,有利于自己的理解。代码贴在文中,方便园丁学习。
由于本文与原书可能涉及版权问题,请勿以任何形式被第三方转载,谢谢合作。
第三部分全文搜索引擎的搜索和排名
全文搜索引擎的作用是在大量文档中搜索一系列单词,并根据文档与搜索单词的相关程度对结果进行排名。
搜索引擎的组成
从 Internet 或从固定数量的文档中采集文档。
为采集的文档创建索引。
按查询返回排序的文档。这个过程的关键是文档的排序方法。
建立一个搜索引擎
首先构造一个爬行动物的“外壳”。以下方法逐步完善:
public class Crawler : IDisposable
{
private HttpClient _httpClient;
private IDbConnection _connection;
private static readonly HashSet IgnoreWords
= new HashSet(new [] {"the","of","to","and","a","in","is","it"});
//构造函数,接收数据库名作为参数
public Crawler(string dbname)
{
_httpClient = new HttpClient();
_connection = GetConn(dbname);
}
//辅助函数,用于获取条目Id,且如果条目不存在,就将其加入数据库中
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
return 0;
}
//为每个网页建立索引
public async Task AddtoIndex(string url, HtmlDocument soup)
{
Console.WriteLine($"Indexing {url}");
}
//从一个HTML网页提取文字(不带html标签)
public string GetTextOnly(HtmlDocument soup)
{
return null;
}
//分词
public List SeparateWords(string text)
{
return null;
}
//如果Url已经建立索引,则返回true
public bool IsIndexed(string url)
{
return false;
}
//添加一个关联两个网页的链接
public void AddLinkref(string urlFrom, string urlTo, string linkText)
{
}
//从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
public async Task Crawl(List pages, int depth = 2)
{
throw new NotImplementedException();
}
public async Task GetHtmlDoc(string url)
{
return null;
}
//创建数据库表
public void CreateIndexTables()
{
}
public static string UrlJoin(string urlBase, string urlRel)
{
return null;
}
public IDbConnection GetConn(string dbname)
{
return null;
}
public void Dispose()
{
_connection.Close();
}
}
这还收录一些管理数据库连接的代码,以及索引时要忽略的单词列表。
履带式
对于 C#,抓取网页 HttpClient 是一个很好的选择。
可以使用nuget安装HttpClient,在NuGet管理器中搜索“httpclient”,名为Microsoft.Net.Http的项就是HttpClient库。
爬取网页代码很简单:
var url = "http://xxx.com";
var httpClient = new HttpClient();
var content = await httpClient.GetStringAsync(url);
HttpClient每次释放都会断开Tcp连接,所以为了节省性能,尽量把HttpClient做成单例。
爬取网页后的另一个非常重要的步骤是分析Html的内容。对于 C#,可以使用 Html Agility Pack 库。安装Html Agility Pack也很简单,在Nuget中搜索HtmlAgilityPack,或者直接使用Install-Package HtmlAgilityPack。
我们首先在爬虫类中实现 Crawl 方法。
<p>public async Task Crawl(List pages, int depth = 2)
{
for (int i = 0; i
c httpclient抓取网页(修改heritrix的默认抓取策略()的抓取算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-28 02:11
一种。首先修改heritrix的默认爬取策略
Heritrix默认的抓取策略是HostnameQueueAssignmentPolicy,该策略以hostname为key,所以一个域名下的所有连接都会放在同一个线程中,这样会导致抓取时一般只有一个线程运行(一般我们抓取特定 网站 上的内容)。这种方法可以很大程度上解决广域网中取信息时队列的键值问题。但是,单个 网站 网络抓取存在很大问题。以新浪的新闻页面为例,大部分的URL来自新浪网站内部,所以如果使用HostnameQueueAssignmentPolicy,会造成很长的队列。在 Heritrix 中,当线程从队列中获取 URL 链接时,它总是从队列的头部获取第一个链接。在那之后,从中获取链接的队列将进入阻塞状态,直到链接被处理。之后,它将从阻塞状态中恢复。如果使用HostnameQueueAssignmentPolicy策略来处理抓取一个网站的内容的情况,很有可能只有一个线程在工作,而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。
因此,我们需要改变Heritrix的爬取策略,即改变key的生成方式。我们需要使用这个键有效地将所有 URL 散列到不同的队列中,最终减少所有队列长度的方差。,在这种情况下,可以保证工作线程的最大效率。我们需要继承QueueAssignmentPolicy类,重写getClassKey()方法。getClassKey 方法的参数是一个链接对象,ELF Hash 算法可以通过这个链接对象返回一个值,并将其平均分配到各个队列中。更多线程爬取同域名下的网页,爬取速度会大大提高。
ELFHash算法是对字符串进行哈希运算,巧妙地计算出字符的ASCII码值,可以将字符串在哈希表中分布更均匀。
1、以下是ELFHash算法实现的抓取策略:
package org.archive.crawler.frontier;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.commons.httpclient.URIException;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.net.UURI;
import org.archive.net.UURIFactory;
public class ELFHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
private static final Logger logger = Logger.getLogger(ELFHashQueueAssignmentPolicy.class.getName());
/**
* When neat host-based class-key fails us
*/
private static String DEFAULT_CLASS_KEY = "default...";
private static final String DNS = "dns";
public String getClassKey(CrawlController controller, CandidateURI cauri) {
String scheme = cauri.getUURI().getScheme();
String candidate = null;
try {
if (scheme.equals(DNS)){
if (cauri.getVia() != null) {
// Special handling for DNS: treat as being
// of the same class as the triggering URI.
// When a URI includes a port, this ensures
// the DNS lookup goes atop the host:port
// queue that triggered it, rather than
// some other host queue
UURI viaUuri = UURIFactory.getInstance(cauri.flattenVia());
candidate = viaUuri.getAuthorityMinusUserinfo();
// adopt scheme of triggering URI
scheme = viaUuri.getScheme();
} else {
candidate= cauri.getUURI().getReferencedHost();
}
} else {
// 注释掉原来的
// candidate = cauri.getUURI().getAuthorityMinusUserinfo();
// 使用ELFHash算法
String uri = cauri.getUURI().toString();
long hash = ELFHash(uri);
candidate = Long.toString(hash % 100); // 取模 100,Heritrix默认开100个线程,对应100个不同的URI处理队列
}
if(candidate == null || candidate.length() == 0) {
candidate = DEFAULT_CLASS_KEY;
}
} catch (URIException e) {
logger.log(Level.INFO,
"unable to extract class key; using default", e);
candidate = DEFAULT_CLASS_KEY;
}
if (scheme != null && scheme.equals(UURIFactory.HTTPS)) {
// If https and no port specified, add default https port to
// distinguish https from http server without a port.
if (!candidate.matches(".+:[0-9]+")) {
candidate += UURIFactory.HTTPS_PORT;
}
}
// Ensure classKeys are safe as filenames on NTFS
return candidate.replace(':','#');
}
public long ELFHash(String str) {
long hash = 0;
long x = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash > 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
}
2、在 org.archive.crawler.frontier.AbstractFrontier 类中查找“HostnameQueueAssignmentPolicy”关键字,大约第 293 行,注释掉更改,然后添加我们的 ELFHashQueueAssignmentPolicy,如下(蓝色字体行):
// Read the list of permissible choices from heritrix.properties.
// Its a list of space- or comma-separated values.
String queueStr = System.getProperty(AbstractFrontier.class.getName() +
"." + ATTR_QUEUE_ASSIGNMENT_POLICY,
// HostnameQueueAssignmentPolicy.class.getName() + " " +
ELFHashQueueAssignmentPolicy.class.getName() + " " +
IPQueueAssignmentPolicy.class.getName() + " " +
BucketQueueAssignmentPolicy.class.getName() + " " +
SurtAuthorityQueueAssignmentPolicy.class.getName() + " " +
TopmostAssignedSurtQueueAssignmentPolicy.class.getName());
Pattern p = Pattern.compile("\\s*,\\s*|\\s+");
String [] queues = p.split(queueStr);
3、修改heritrix.properties文件中的配置,在文件中查找“HostnameQueueAssignmentPolicy”关键字,15左右两行9、160,复制后将这两行注释掉,粘贴到下面, 将这两行中的“HostnameQueueAssignmentPolicy”替换为“ELFHashQueueAssignmentPolicy”,如下(蓝色字体):
#org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
# org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.IPQueueAssignmentPolicy \
org.archive.crawler.frontier.BucketQueueAssignmentPolicy \
org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy \
org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.BdbFrontier.level = INFO
下面我们分别使用这两种抓取策略来创建抓取任务并做个对比:
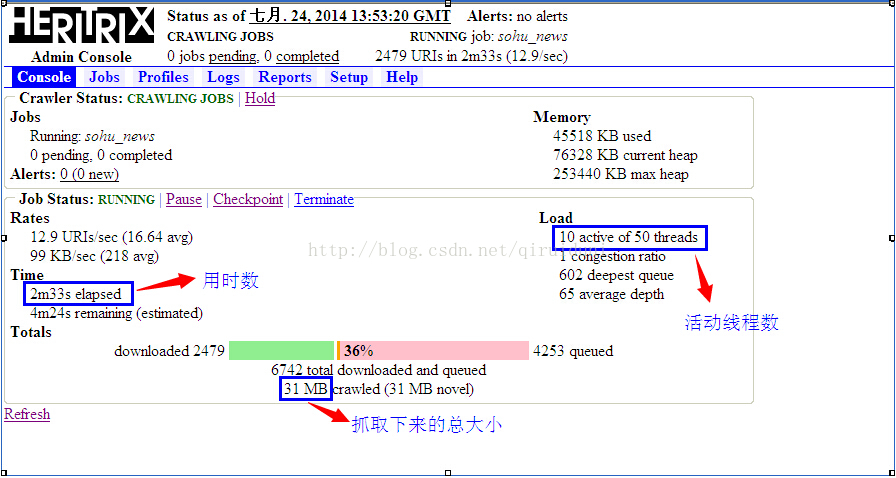
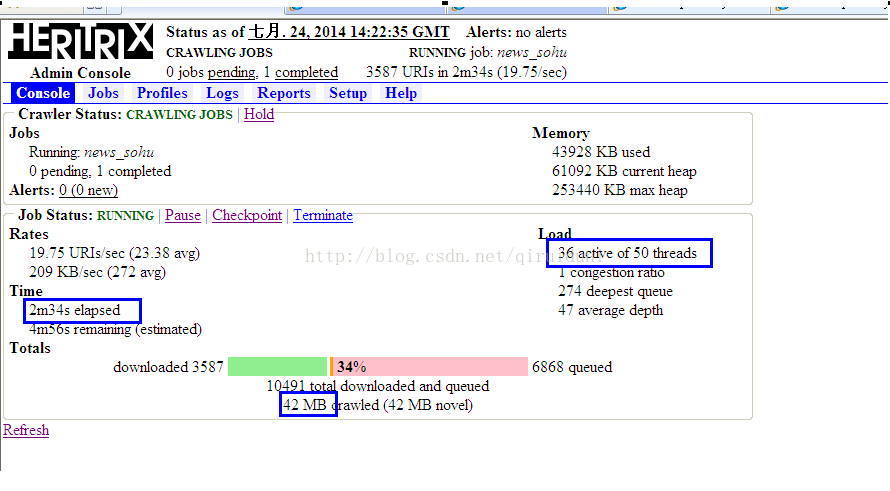
下图是使用 HostnameQueueAssignmentPolicy 抓取策略创建的任务的状态图:
下图是使用 ELFHashQueueAssignmentPolicy 抓取策略创建的任务的状态图:
从上面两张图可以看出,同时在活跃线程数和fetches总大小上,ELFHashQueueAssignmentPolicy远高于HostnameQueueAssignmentPolicy。
注意:当使用 ELFHashQueueAssignmentPolicy 爬取策略时,爬取可能会停止。检查任务的 crawl.log 日志。URL后跟“robots.txt”,如:“”。这是因为Heritrix是一个完整的遵守“robots.txt”协议的网络爬虫,如果一个网站声明了他们不想被机器人访问的部分文件,Heritrix不会爬取那些内容。可以去掉robots.txt的限制,应该不会出现这种现象。
湾。取消rebots.txt的限制。
关于rebots.txt协议的取消,可以参考另一篇文章文章:
C。抓取指定网页内容
Heritrix的Extractors用于解析当前服务器返回的内容,提取页面中的URL,放入提取队列。因为它会爬取网页中的所有链接,但是有些链接不是我们想要的,比如图片链接、pdf文档等,这些链接需要过滤掉,我们可以创建自己的Extractor来爬取特定的网页内容。如下,是一个自定义的抓取搜狐新闻的Extractor:
<p>package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {
super(name, description);
}
public ExtractorSohu(String name) {
super(name, "sohu news extractor");
}
// http://news.sohu.com/20131020/n388534488.shtml
private static final String A_HERF = " 查看全部
c httpclient抓取网页(修改heritrix的默认抓取策略()的抓取算法)
一种。首先修改heritrix的默认爬取策略
Heritrix默认的抓取策略是HostnameQueueAssignmentPolicy,该策略以hostname为key,所以一个域名下的所有连接都会放在同一个线程中,这样会导致抓取时一般只有一个线程运行(一般我们抓取特定 网站 上的内容)。这种方法可以很大程度上解决广域网中取信息时队列的键值问题。但是,单个 网站 网络抓取存在很大问题。以新浪的新闻页面为例,大部分的URL来自新浪网站内部,所以如果使用HostnameQueueAssignmentPolicy,会造成很长的队列。在 Heritrix 中,当线程从队列中获取 URL 链接时,它总是从队列的头部获取第一个链接。在那之后,从中获取链接的队列将进入阻塞状态,直到链接被处理。之后,它将从阻塞状态中恢复。如果使用HostnameQueueAssignmentPolicy策略来处理抓取一个网站的内容的情况,很有可能只有一个线程在工作,而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。
因此,我们需要改变Heritrix的爬取策略,即改变key的生成方式。我们需要使用这个键有效地将所有 URL 散列到不同的队列中,最终减少所有队列长度的方差。,在这种情况下,可以保证工作线程的最大效率。我们需要继承QueueAssignmentPolicy类,重写getClassKey()方法。getClassKey 方法的参数是一个链接对象,ELF Hash 算法可以通过这个链接对象返回一个值,并将其平均分配到各个队列中。更多线程爬取同域名下的网页,爬取速度会大大提高。
ELFHash算法是对字符串进行哈希运算,巧妙地计算出字符的ASCII码值,可以将字符串在哈希表中分布更均匀。
1、以下是ELFHash算法实现的抓取策略:
package org.archive.crawler.frontier;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.commons.httpclient.URIException;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.net.UURI;
import org.archive.net.UURIFactory;
public class ELFHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
private static final Logger logger = Logger.getLogger(ELFHashQueueAssignmentPolicy.class.getName());
/**
* When neat host-based class-key fails us
*/
private static String DEFAULT_CLASS_KEY = "default...";
private static final String DNS = "dns";
public String getClassKey(CrawlController controller, CandidateURI cauri) {
String scheme = cauri.getUURI().getScheme();
String candidate = null;
try {
if (scheme.equals(DNS)){
if (cauri.getVia() != null) {
// Special handling for DNS: treat as being
// of the same class as the triggering URI.
// When a URI includes a port, this ensures
// the DNS lookup goes atop the host:port
// queue that triggered it, rather than
// some other host queue
UURI viaUuri = UURIFactory.getInstance(cauri.flattenVia());
candidate = viaUuri.getAuthorityMinusUserinfo();
// adopt scheme of triggering URI
scheme = viaUuri.getScheme();
} else {
candidate= cauri.getUURI().getReferencedHost();
}
} else {
// 注释掉原来的
// candidate = cauri.getUURI().getAuthorityMinusUserinfo();
// 使用ELFHash算法
String uri = cauri.getUURI().toString();
long hash = ELFHash(uri);
candidate = Long.toString(hash % 100); // 取模 100,Heritrix默认开100个线程,对应100个不同的URI处理队列
}
if(candidate == null || candidate.length() == 0) {
candidate = DEFAULT_CLASS_KEY;
}
} catch (URIException e) {
logger.log(Level.INFO,
"unable to extract class key; using default", e);
candidate = DEFAULT_CLASS_KEY;
}
if (scheme != null && scheme.equals(UURIFactory.HTTPS)) {
// If https and no port specified, add default https port to
// distinguish https from http server without a port.
if (!candidate.matches(".+:[0-9]+")) {
candidate += UURIFactory.HTTPS_PORT;
}
}
// Ensure classKeys are safe as filenames on NTFS
return candidate.replace(':','#');
}
public long ELFHash(String str) {
long hash = 0;
long x = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash > 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
}
2、在 org.archive.crawler.frontier.AbstractFrontier 类中查找“HostnameQueueAssignmentPolicy”关键字,大约第 293 行,注释掉更改,然后添加我们的 ELFHashQueueAssignmentPolicy,如下(蓝色字体行):
// Read the list of permissible choices from heritrix.properties.
// Its a list of space- or comma-separated values.
String queueStr = System.getProperty(AbstractFrontier.class.getName() +
"." + ATTR_QUEUE_ASSIGNMENT_POLICY,
// HostnameQueueAssignmentPolicy.class.getName() + " " +
ELFHashQueueAssignmentPolicy.class.getName() + " " +
IPQueueAssignmentPolicy.class.getName() + " " +
BucketQueueAssignmentPolicy.class.getName() + " " +
SurtAuthorityQueueAssignmentPolicy.class.getName() + " " +
TopmostAssignedSurtQueueAssignmentPolicy.class.getName());
Pattern p = Pattern.compile("\\s*,\\s*|\\s+");
String [] queues = p.split(queueStr);
3、修改heritrix.properties文件中的配置,在文件中查找“HostnameQueueAssignmentPolicy”关键字,15左右两行9、160,复制后将这两行注释掉,粘贴到下面, 将这两行中的“HostnameQueueAssignmentPolicy”替换为“ELFHashQueueAssignmentPolicy”,如下(蓝色字体):
#org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
# org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.IPQueueAssignmentPolicy \
org.archive.crawler.frontier.BucketQueueAssignmentPolicy \
org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy \
org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.BdbFrontier.level = INFO
下面我们分别使用这两种抓取策略来创建抓取任务并做个对比:
下图是使用 HostnameQueueAssignmentPolicy 抓取策略创建的任务的状态图:
下图是使用 ELFHashQueueAssignmentPolicy 抓取策略创建的任务的状态图:
从上面两张图可以看出,同时在活跃线程数和fetches总大小上,ELFHashQueueAssignmentPolicy远高于HostnameQueueAssignmentPolicy。
注意:当使用 ELFHashQueueAssignmentPolicy 爬取策略时,爬取可能会停止。检查任务的 crawl.log 日志。URL后跟“robots.txt”,如:“”。这是因为Heritrix是一个完整的遵守“robots.txt”协议的网络爬虫,如果一个网站声明了他们不想被机器人访问的部分文件,Heritrix不会爬取那些内容。可以去掉robots.txt的限制,应该不会出现这种现象。
湾。取消rebots.txt的限制。
关于rebots.txt协议的取消,可以参考另一篇文章文章:
C。抓取指定网页内容
Heritrix的Extractors用于解析当前服务器返回的内容,提取页面中的URL,放入提取队列。因为它会爬取网页中的所有链接,但是有些链接不是我们想要的,比如图片链接、pdf文档等,这些链接需要过滤掉,我们可以创建自己的Extractor来爬取特定的网页内容。如下,是一个自定义的抓取搜狐新闻的Extractor:
<p>package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {
super(name, description);
}
public ExtractorSohu(String name) {
super(name, "sohu news extractor");
}
// http://news.sohu.com/20131020/n388534488.shtml
private static final String A_HERF = "
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-27 23:01
)
在使用 HttpClient 抓取一些网页时,往往会保留从服务器发回的 cookie 信息,以便发起其他需要这些 cookie 的请求。在大多数情况下,我们使用内置的 cookie 策略,这使得获取这些 cookie 变得容易和直接。
下面一小段代码是访问并获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com");
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,也有一些由 网站 返回的 cookie 不一定完全符合规范。例如,在下面的例子中,从打印的 header 中可以看出,这个 cookie 中的 Expires 属性是时间戳的形式,不符合标准时间。格式化,因此,httpclient对cookies的处理无效,最终无法获取cookie,并发出警告信息:“Invalid 'expires' attribute: 1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用头部数据来重构一个cookie,而且很多人都这样做,但是这种方法并不优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4的“自定义cookie策略”一节中,提到了允许自定义cookie策略。自定义方法是实现CookieSpec接口,通过CookieSpecProvider在httpclient中完成策略实例的初始化和注册。嗯,关键线索就在 CookieSpec 接口,我们来看一下它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中找到了一个parse方法,看注释就知道是这个方法。它将 Set-Cookie 的头部信息解析成一个 Cookie 对象。自然,我们将了解 httplcient 中的默认实现 DefaultCookieSpec。由于篇幅限制,源代码没有贴出来。在默认实现中,DefaultCookieSpec的主要工作就是判断头部中Cookie规范的类型,然后调用具体的实现。像上面这样的 Cookie 最终由 NetscapeDraftSpec 的一个实例解析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE, dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就比较清楚了,我们只需要将cookie中的expires时间转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个CookieSpec类,继承DefaultCookieSpec并重写解析器方法将cookie中的expires转换为正确的时间格式并调用默认解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017] 查看全部
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作
)
在使用 HttpClient 抓取一些网页时,往往会保留从服务器发回的 cookie 信息,以便发起其他需要这些 cookie 的请求。在大多数情况下,我们使用内置的 cookie 策略,这使得获取这些 cookie 变得容易和直接。
下面一小段代码是访问并获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com";);
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,也有一些由 网站 返回的 cookie 不一定完全符合规范。例如,在下面的例子中,从打印的 header 中可以看出,这个 cookie 中的 Expires 属性是时间戳的形式,不符合标准时间。格式化,因此,httpclient对cookies的处理无效,最终无法获取cookie,并发出警告信息:“Invalid 'expires' attribute: 1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用头部数据来重构一个cookie,而且很多人都这样做,但是这种方法并不优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4的“自定义cookie策略”一节中,提到了允许自定义cookie策略。自定义方法是实现CookieSpec接口,通过CookieSpecProvider在httpclient中完成策略实例的初始化和注册。嗯,关键线索就在 CookieSpec 接口,我们来看一下它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中找到了一个parse方法,看注释就知道是这个方法。它将 Set-Cookie 的头部信息解析成一个 Cookie 对象。自然,我们将了解 httplcient 中的默认实现 DefaultCookieSpec。由于篇幅限制,源代码没有贴出来。在默认实现中,DefaultCookieSpec的主要工作就是判断头部中Cookie规范的类型,然后调用具体的实现。像上面这样的 Cookie 最终由 NetscapeDraftSpec 的一个实例解析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE, dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就比较清楚了,我们只需要将cookie中的expires时间转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个CookieSpec类,继承DefaultCookieSpec并重写解析器方法将cookie中的expires转换为正确的时间格式并调用默认解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017]
c httpclient抓取网页(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-27 12:05
爬取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页中图片的抓取功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
好了,今天就到这里了,以后会有更多精彩的python内容分享给大家。 查看全部
c httpclient抓取网页(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
爬取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页中图片的抓取功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
好了,今天就到这里了,以后会有更多精彩的python内容分享给大家。
c httpclient抓取网页(一下Java语言环境中能够用于网页下载或信息提取的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-15 08:19
如果您需要从 Internet 下载特定网页,或者从网页中解析特定信息,那么这个 文章 将帮助您。下面我列出了Java语言环境下可用于网页下载或信息提取的工具。以下工具各有特点。
Web-harvest 是一个开源的 Java 网页信息提取工具。它主要使用XQuery、XPath、正则表达式和javascript等脚本语言从网页中提取字段信息。提取信息的灵活性和准确性主要来自于 XPath 和 XQuery。Web-harvest 提供了一个可以在 JRE 环境中执行的 jar 文件。运行这个文件可以执行一个简单的XML类型的配置文件,就是你定义的网页访问和解析规则。你可以简单的使用执行程序中的xml配置文件,他也可以通过javaapi进行更复杂的开发。它支持使用代理服务器。性能较差,更适合小而简单的程序。
HttpClient是Apache的一个子项目,支持所有http协议,可以管理cookie信息。它的强项在于访问网页,但它不具备解析网页的能力。还有两个比较实用的功能是指定代理服务器,如果你有多个网卡和多个网络,也可以指定网络出口。
Jsoup 是一个非常方便的网页访问和解析工具。它可以用非常简单的代码访问网页,并通过一种叫做css的格式提取网页的信息。非常简单易学,处理效率也很高。另外,它只能用来解析传入的html字符串,所以结合其他工具开发程序非常容易。
SWT下的WebBrowser,首先SWT是Eclipse下的一个图形化开发工具包,其中WebBrowser允许你调用系统中的浏览器,比如IE或者Firefox,相当于把浏览器嵌入到你的java程序中。它最大的优点是可以完全模拟浏览器,所以可以执行以上工具无法执行的javascript和css,让系统浏览器管理你的cookies。当然WebBrowser是异步的,需要监听complete事件来判断页面是否加载并绘制。并在竞技赛事中进行后续处理。它有一个很亮眼的特性就是它可以让你执行你传入的Javascipt。
以上是过去工作中实际使用过的工具。您可以选择自己的优势并一起使用。我希望它会帮助你。 查看全部
c httpclient抓取网页(一下Java语言环境中能够用于网页下载或信息提取的工具)
如果您需要从 Internet 下载特定网页,或者从网页中解析特定信息,那么这个 文章 将帮助您。下面我列出了Java语言环境下可用于网页下载或信息提取的工具。以下工具各有特点。
Web-harvest 是一个开源的 Java 网页信息提取工具。它主要使用XQuery、XPath、正则表达式和javascript等脚本语言从网页中提取字段信息。提取信息的灵活性和准确性主要来自于 XPath 和 XQuery。Web-harvest 提供了一个可以在 JRE 环境中执行的 jar 文件。运行这个文件可以执行一个简单的XML类型的配置文件,就是你定义的网页访问和解析规则。你可以简单的使用执行程序中的xml配置文件,他也可以通过javaapi进行更复杂的开发。它支持使用代理服务器。性能较差,更适合小而简单的程序。
HttpClient是Apache的一个子项目,支持所有http协议,可以管理cookie信息。它的强项在于访问网页,但它不具备解析网页的能力。还有两个比较实用的功能是指定代理服务器,如果你有多个网卡和多个网络,也可以指定网络出口。
Jsoup 是一个非常方便的网页访问和解析工具。它可以用非常简单的代码访问网页,并通过一种叫做css的格式提取网页的信息。非常简单易学,处理效率也很高。另外,它只能用来解析传入的html字符串,所以结合其他工具开发程序非常容易。
SWT下的WebBrowser,首先SWT是Eclipse下的一个图形化开发工具包,其中WebBrowser允许你调用系统中的浏览器,比如IE或者Firefox,相当于把浏览器嵌入到你的java程序中。它最大的优点是可以完全模拟浏览器,所以可以执行以上工具无法执行的javascript和css,让系统浏览器管理你的cookies。当然WebBrowser是异步的,需要监听complete事件来判断页面是否加载并绘制。并在竞技赛事中进行后续处理。它有一个很亮眼的特性就是它可以让你执行你传入的Javascipt。
以上是过去工作中实际使用过的工具。您可以选择自己的优势并一起使用。我希望它会帮助你。
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-13 03:18
)
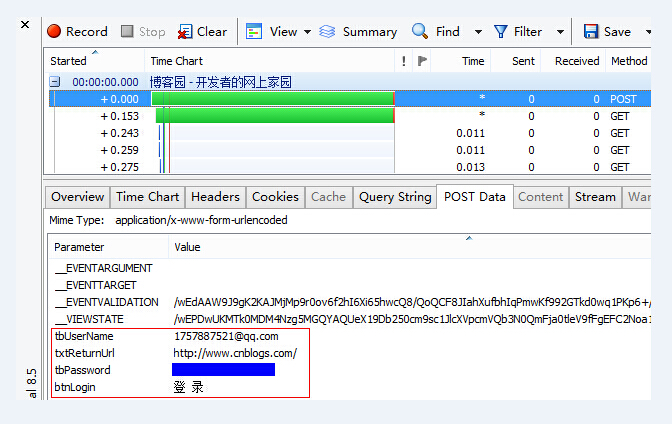
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
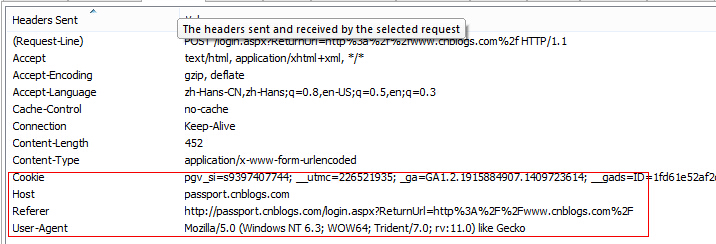
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/");
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 } 查看全部
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦!
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/";);
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 }
c httpclient抓取网页(爬虫环境python3.7+pycharm()机制都没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-23 01:09
)
爬行动物环境
python3.7+pycharm
最近发现了一个网站,首商网,里面有超过一百万的企业信息,但是网站根本没有反爬机制,对喜欢的我们来说是不是太爽了爬虫,直接拿我自己创建了一组代码,用了三个并发,每次20个线程,爬了五六个小时,得到了20万条数据,太棒了!
还是老规矩,代码直接在下面,所有的注释和解释都在代码里,直接运行即可:
for k in range(1, 1651, 50):
# -*- coding: utf-8 -*-
# 本项目是原始的异步爬虫,没有封装为函数
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 先用并发获取每个页面的子链接
########################################################################################################################
pro = 'zhaoshuang:LINA5201314@ 14.215.44.251:28803'
proxies = {'http://': 'http://' + pro,
'httpS://': 'https://' + pro
}
# 加入请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
wzs = []
def parser(url):
print(url)
try:
response = requests.get(url, headers=headers)
soup1 = BeautifulSoup(response.text, "lxml")
# body > div.list_contain > div.left > div.list_li > ul > li:nth-child(1) > table > tbody > tr > td:nth-child(3) > div.title > a
wz = soup1.select('div.title')
for i in wz:
wzs.append(i.contents[0].get("href"))
time.sleep(1)
except:
print('公司正在审核中')
urls = ['http://www.sooshong.com/c-3p{}'.format(num) for num in range(k, k + 50)]
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('子页链接抓取完毕!')
########################################################################################################################
# 使用并发法爬取详细页链接
# 定义函数获取每个网页需要爬取的内容
wzs1 = []
def parser(url):
# 利用正则表达式解析网页
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
except:
print('子页解析失败')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('详细页链接获取完毕!')
"""
# 使用异步法抓取子页面的链接
########################################################################################################################
async def get_html(sess, ur):
try:
proxy_auth = aiohttp.BasicAuth('zhaoshuang', 'LINA5201314')
html = await sess.get(ur,
headers=headers) # , proxy='http://'+'14.116.200.33:28803', proxy_auth=proxy_auth)
r = await html.text()
return r
except:
print("error")
# f = requests.get('http://211775.sooshong.com', headers=headers)
wzs1 = []
# 解析网页
async def parser(respo):
# 利用正则表达式解析网页
try:
# 对响应体进行解析
soup = BeautifulSoup(respo, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
company = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong") # 标题
company = company[0].text
# 匹配电话号码
dianhua = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(3)") # 地址
dianhua = dianhua[0].text.split(":")[1]
# 匹配手机号码
phone = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(4)") # 日租价格
phone = phone[0].text.split(":")[1]
# 匹配传真
chuanzhen = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(5)") # 月租价格
chuanzhen = chuanzhen[0].text.split(":")[1]
# 经营模式
jingying = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(8)") # 面积大小
jingying = jingying[0].text.split(":")[1]
# 公司地址
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)') # 抽取建造年份
address = address[0].text.split(":")[1]
# 公司简介
# introduction = soup.select("#main > div.main > div.intro > div.intros > div.text > p") # 楼层属性
# introduction = introduction[0].text.strip()
data = [company, address, dianhua, phone, chuanzhen, jingying]
print(data)
with open('首富网企业7.csv', 'a+', newline='', encoding='GB2312', errors='ignore') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data, [1])
except:
print("出错!")
async def main(loop):
async with aiohttp.ClientSession() as sess:
tasks = []
for ii in wzs:
ur = ii
try:
tasks.append(loop.create_task(get_html(sess, ur)))
except:
print('error')
# 设置0.1的网络延迟增加爬取效率
await asyncio.sleep(0.1)
finished, unfinised = await asyncio.wait(tasks)
for i1 in finished:
await parser(i1.result())
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
print("花费时间", time.time() - t1)
print('详细页链接抓取完毕!')
"""
########################################################################################################################
# 使用并发法获取详细页的内容
########################################################################################################################
# 定义函数获取每个网页需要爬取的内容
def parser(url):
global data
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, 'lxml')
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
company = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong')
company = company[0].text
name = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(2)')
name = name[0].text
dianhua = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(3)')
dianhua = dianhua[0].text.split(':')[1]
shouji = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(4)')
shouji = shouji[0].text.split(':')[1]
chuanzhen = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(5)')
chuanzhen = chuanzhen[0].text.split(':')[1]
product = soup.select('tr:nth-child(1) > td:nth-child(2)')
product = product[0].text
company_type = soup.select('tr:nth-child(2) > td:nth-child(2) > span')
company_type = company_type[0].text.strip()
legal_person = soup.select('tr:nth-child(3) > td:nth-child(2)')
legal_person = legal_person[0].text
main_address = soup.select('tr:nth-child(5) > td:nth-child(2) > span')
main_address = main_address[0].text
brand = soup.select('tr:nth-child(6) > td:nth-child(2) > span')
brand = brand[0].text
area = soup.select('tr:nth-child(9) > td:nth-child(2) > span')
area = area[0].text
industry = soup.select('tr:nth-child(1) > td:nth-child(4)')
industry = industry[0].text.strip()
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)')
address = address[0].text.split(':')[1]
jingying = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(8)')
jingying = jingying[0].text.split(':')[1]
date = soup.select('tr:nth-child(5) > td:nth-child(4) > span')
date = date[0].text
wangzhi = soup.select('tr:nth-child(12) > td:nth-child(4) > p > span > a')
wangzhi = wangzhi[0].text
data = [company, date, name, legal_person, shouji, dianhua, chuanzhen, company_type, jingying, industry,
product, wangzhi, area, brand, address, main_address] # 将以上数据放入列表中打印在命令框
print(data)
with open('服装1.csv', 'a', newline='', encoding='GB2312') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
except:
with open('服装2.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
print('utf解码成功')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs1]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('全部信息抓取完毕') 查看全部
c httpclient抓取网页(爬虫环境python3.7+pycharm()机制都没有
)
爬行动物环境
python3.7+pycharm
最近发现了一个网站,首商网,里面有超过一百万的企业信息,但是网站根本没有反爬机制,对喜欢的我们来说是不是太爽了爬虫,直接拿我自己创建了一组代码,用了三个并发,每次20个线程,爬了五六个小时,得到了20万条数据,太棒了!
还是老规矩,代码直接在下面,所有的注释和解释都在代码里,直接运行即可:
for k in range(1, 1651, 50):
# -*- coding: utf-8 -*-
# 本项目是原始的异步爬虫,没有封装为函数
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 先用并发获取每个页面的子链接
########################################################################################################################
pro = 'zhaoshuang:LINA5201314@ 14.215.44.251:28803'
proxies = {'http://': 'http://' + pro,
'httpS://': 'https://' + pro
}
# 加入请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
wzs = []
def parser(url):
print(url)
try:
response = requests.get(url, headers=headers)
soup1 = BeautifulSoup(response.text, "lxml")
# body > div.list_contain > div.left > div.list_li > ul > li:nth-child(1) > table > tbody > tr > td:nth-child(3) > div.title > a
wz = soup1.select('div.title')
for i in wz:
wzs.append(i.contents[0].get("href"))
time.sleep(1)
except:
print('公司正在审核中')
urls = ['http://www.sooshong.com/c-3p{}'.format(num) for num in range(k, k + 50)]
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('子页链接抓取完毕!')
########################################################################################################################
# 使用并发法爬取详细页链接
# 定义函数获取每个网页需要爬取的内容
wzs1 = []
def parser(url):
# 利用正则表达式解析网页
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
except:
print('子页解析失败')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('详细页链接获取完毕!')
"""
# 使用异步法抓取子页面的链接
########################################################################################################################
async def get_html(sess, ur):
try:
proxy_auth = aiohttp.BasicAuth('zhaoshuang', 'LINA5201314')
html = await sess.get(ur,
headers=headers) # , proxy='http://'+'14.116.200.33:28803', proxy_auth=proxy_auth)
r = await html.text()
return r
except:
print("error")
# f = requests.get('http://211775.sooshong.com', headers=headers)
wzs1 = []
# 解析网页
async def parser(respo):
# 利用正则表达式解析网页
try:
# 对响应体进行解析
soup = BeautifulSoup(respo, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
company = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong") # 标题
company = company[0].text
# 匹配电话号码
dianhua = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(3)") # 地址
dianhua = dianhua[0].text.split(":")[1]
# 匹配手机号码
phone = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(4)") # 日租价格
phone = phone[0].text.split(":")[1]
# 匹配传真
chuanzhen = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(5)") # 月租价格
chuanzhen = chuanzhen[0].text.split(":")[1]
# 经营模式
jingying = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(8)") # 面积大小
jingying = jingying[0].text.split(":")[1]
# 公司地址
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)') # 抽取建造年份
address = address[0].text.split(":")[1]
# 公司简介
# introduction = soup.select("#main > div.main > div.intro > div.intros > div.text > p") # 楼层属性
# introduction = introduction[0].text.strip()
data = [company, address, dianhua, phone, chuanzhen, jingying]
print(data)
with open('首富网企业7.csv', 'a+', newline='', encoding='GB2312', errors='ignore') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data, [1])
except:
print("出错!")
async def main(loop):
async with aiohttp.ClientSession() as sess:
tasks = []
for ii in wzs:
ur = ii
try:
tasks.append(loop.create_task(get_html(sess, ur)))
except:
print('error')
# 设置0.1的网络延迟增加爬取效率
await asyncio.sleep(0.1)
finished, unfinised = await asyncio.wait(tasks)
for i1 in finished:
await parser(i1.result())
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
print("花费时间", time.time() - t1)
print('详细页链接抓取完毕!')
"""
########################################################################################################################
# 使用并发法获取详细页的内容
########################################################################################################################
# 定义函数获取每个网页需要爬取的内容
def parser(url):
global data
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, 'lxml')
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
company = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong')
company = company[0].text
name = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(2)')
name = name[0].text
dianhua = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(3)')
dianhua = dianhua[0].text.split(':')[1]
shouji = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(4)')
shouji = shouji[0].text.split(':')[1]
chuanzhen = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(5)')
chuanzhen = chuanzhen[0].text.split(':')[1]
product = soup.select('tr:nth-child(1) > td:nth-child(2)')
product = product[0].text
company_type = soup.select('tr:nth-child(2) > td:nth-child(2) > span')
company_type = company_type[0].text.strip()
legal_person = soup.select('tr:nth-child(3) > td:nth-child(2)')
legal_person = legal_person[0].text
main_address = soup.select('tr:nth-child(5) > td:nth-child(2) > span')
main_address = main_address[0].text
brand = soup.select('tr:nth-child(6) > td:nth-child(2) > span')
brand = brand[0].text
area = soup.select('tr:nth-child(9) > td:nth-child(2) > span')
area = area[0].text
industry = soup.select('tr:nth-child(1) > td:nth-child(4)')
industry = industry[0].text.strip()
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)')
address = address[0].text.split(':')[1]
jingying = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(8)')
jingying = jingying[0].text.split(':')[1]
date = soup.select('tr:nth-child(5) > td:nth-child(4) > span')
date = date[0].text
wangzhi = soup.select('tr:nth-child(12) > td:nth-child(4) > p > span > a')
wangzhi = wangzhi[0].text
data = [company, date, name, legal_person, shouji, dianhua, chuanzhen, company_type, jingying, industry,
product, wangzhi, area, brand, address, main_address] # 将以上数据放入列表中打印在命令框
print(data)
with open('服装1.csv', 'a', newline='', encoding='GB2312') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
except:
with open('服装2.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
print('utf解码成功')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs1]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('全部信息抓取完毕')
c httpclient抓取网页(Python爬虫怎么入门,到底要学习哪些内容?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-23 01:08
很多朋友不知道Python爬虫怎么上手,怎么学,学什么。今天给大家介绍一些学习爬虫必须掌握的第三方库。
废话不多说,直接上干货。
请求库
GitHub:
requests 库应该是现在爬虫最流行和最实用的库了,而且非常人性化。在文章之前我也写过一篇关于它的使用的文章,我们来看看Python中的Requests库,大家可以看看。
requests最详细的用法可以参考官方文档:
使用一个小案例:
>>> import requests
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
u'{"type":"User"...'
>>> r.json()
{u'disk_usage': 368627, u'private_gists': 484, ...}
GitHub:
urllib3 是一个非常强大的 http 请求库,提供了一系列操作 URL 的函数。
详细使用方法请参考:
使用一个小案例:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request('GET', 'http://httpbin.org/robots.txt')
>>> r.status
200
>>> r.data
'User-agent: *\nDisallow: /deny\n'
GitHub:
自动化测试工具。调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
对于这个库,不仅可以使用Python,比如JAVA、Python、C#等都可以使用selenium库
有关如何在 Python 语言中使用该库的信息,可以访问并查看官方文档
使用一个小案例:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://seleniumhq.org/')
GitHub:
基于 asyncio 实现的 HTTP 框架。借助 async/await 关键字的异步操作和使用异步库进行数据捕获可以大大提高效率。
这是一个高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用一个小案例:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
解析库
官方文档:
解析html和XML,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的人必备的库。
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
GitHub:
jQuery的Python实现可以使用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
数据存储库
GitHub:
官方文档:
一个用纯 Python 实现的 MySQL 客户端操作库。很实用也很简单。
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
指示:
redis-dump 是一个redis和json转换的工具;redis-dump是基于ruby开发的,需要ruby环境,而新版本的redis-dump需要2.2.2或以上的ruby版本,centos中yum,你只能安装 2.0 版本的 ruby。需要先安装ruby管理工具rvm才能安装更高版本的ruby。 查看全部
c httpclient抓取网页(Python爬虫怎么入门,到底要学习哪些内容?(上))
很多朋友不知道Python爬虫怎么上手,怎么学,学什么。今天给大家介绍一些学习爬虫必须掌握的第三方库。
废话不多说,直接上干货。
请求库
GitHub:
requests 库应该是现在爬虫最流行和最实用的库了,而且非常人性化。在文章之前我也写过一篇关于它的使用的文章,我们来看看Python中的Requests库,大家可以看看。
requests最详细的用法可以参考官方文档:
使用一个小案例:
>>> import requests
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
u'{"type":"User"...'
>>> r.json()
{u'disk_usage': 368627, u'private_gists': 484, ...}
GitHub:
urllib3 是一个非常强大的 http 请求库,提供了一系列操作 URL 的函数。
详细使用方法请参考:
使用一个小案例:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request('GET', 'http://httpbin.org/robots.txt')
>>> r.status
200
>>> r.data
'User-agent: *\nDisallow: /deny\n'
GitHub:
自动化测试工具。调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
对于这个库,不仅可以使用Python,比如JAVA、Python、C#等都可以使用selenium库
有关如何在 Python 语言中使用该库的信息,可以访问并查看官方文档
使用一个小案例:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://seleniumhq.org/')
GitHub:
基于 asyncio 实现的 HTTP 框架。借助 async/await 关键字的异步操作和使用异步库进行数据捕获可以大大提高效率。
这是一个高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用一个小案例:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
解析库
官方文档:
解析html和XML,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的人必备的库。
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
GitHub:
jQuery的Python实现可以使用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
数据存储库
GitHub:
官方文档:
一个用纯 Python 实现的 MySQL 客户端操作库。很实用也很简单。
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
指示:
redis-dump 是一个redis和json转换的工具;redis-dump是基于ruby开发的,需要ruby环境,而新版本的redis-dump需要2.2.2或以上的ruby版本,centos中yum,你只能安装 2.0 版本的 ruby。需要先安装ruby管理工具rvm才能安装更高版本的ruby。
c httpclient抓取网页( 2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-19 15:11
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站,登录后抓取网页信息。
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站并抓取登录后网页信息的实现方法,涉及C#基于session操作登录网页和页面阅读相关操作技巧,小伙伴们有需要的可以参考下
本文示例介绍了C#使用WebClient登录网站并获取登录后网页信息的实现方法。分享给大家参考,详情如下:
C# login网站其实是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求到request,达到模拟登录的效果。
以下 CookieAwareWebClient 实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
对C#相关内容比较感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用方法》总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》和《C#编程线程使用技巧总结》
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
c httpclient抓取网页(
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站,登录后抓取网页信息。
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站并抓取登录后网页信息的实现方法,涉及C#基于session操作登录网页和页面阅读相关操作技巧,小伙伴们有需要的可以参考下
本文示例介绍了C#使用WebClient登录网站并获取登录后网页信息的实现方法。分享给大家参考,详情如下:
C# login网站其实是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求到request,达到模拟登录的效果。
以下 CookieAwareWebClient 实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
对C#相关内容比较感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用方法》总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》和《C#编程线程使用技巧总结》
我希望这篇文章对你的 C# 编程有所帮助。
c httpclient抓取网页(如何用httpclient+jsoup实现抓取网页分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 15:06
和之前的博客一样,在学习用httpclient实现网络爬虫的时候,在网上查了很多资料,但是httpclient的版本是之前的版本3.1或者4.3。我通过学习了解了httpclient4.5。今天给大家分享一下我自己用httpclient+jsoup爬取网页的实现。
httpclient+jsoup 获取网页非常简单。首先可以通过httpclient的get方法获取一个网页的所有内容(如果有什么不懂的可以看我之前关于get方法的解释),然后使用jsoup获取一个网页的所有内容网页。解析内容,获取该网页中的所有链接,然后通过get方法获取这些链接中的网页内容,这样我们就可以获取到一个网页下所有链接的网页内容。例如,如果我们得到一个下面有 50 个链接的网页,我们可以得到 50 个网页。下面是代码,大家感受一下
获取网址
public class GetUrl {
public static List getUrl(String ur) {
//创建默认的httpClient实例
CloseableHttpClient client = HttpClients.createDefault();
//创建list存放已读取过的页面
List urllist = new ArrayList();
//创建get
HttpGet get=new HttpGet(ur);
//设置连接超时
Builder custom = RequestConfig.custom();
RequestConfig config = custom.setConnectTimeout(5000).setConnectionRequestTimeout(1000).setSocketTimeout(5000).build();
get.setConfig(config);
//设置消息头部
get.setHeader("Accept", "Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
try {
//执行get请求
CloseableHttpResponse response = client.execute(get);
//获取响应实体
HttpEntity entity = response.getEntity();
//将响应实体转为String类型
String html = EntityUtils.toString(entity);
//通过jsoup将String转为jsoup可处理的文档类型
Document doc = Jsoup.parse(html);
//找到该页面中所有的a标签
Elements links = doc.getElementsByTag("a");
int i=1;
for (Element element : links) {
//获取到a标签中href属性的内容
String url = element.attr("href");
//对href内容进行判断 来判断该内容是否是url
if(url.startsWith("http://blog.csdn.net/") && !urllist.contains(url)){
GetPage.getPage(url);
System.out.println(url);
urllist.add(url);
i++;
}
}
response.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return urllist;
}
}
根据获取的url生成页面
最后是测试课
public class Test {
public static void main(String[] args) {
List list = GetUrl.getUrl("http://blog.csdn.net/");
System.out.println("所写链接内的所有内容");
int i=1;
for (String url : list) {
GetUrl.getUrl(url);
System.out.println("第"+i+"条链接内容");
i++;
}
}
}
以上就是如何使用httpclient+jsoup爬取网页,希望对大家有所帮助。 查看全部
c httpclient抓取网页(如何用httpclient+jsoup实现抓取网页分享(图))
和之前的博客一样,在学习用httpclient实现网络爬虫的时候,在网上查了很多资料,但是httpclient的版本是之前的版本3.1或者4.3。我通过学习了解了httpclient4.5。今天给大家分享一下我自己用httpclient+jsoup爬取网页的实现。
httpclient+jsoup 获取网页非常简单。首先可以通过httpclient的get方法获取一个网页的所有内容(如果有什么不懂的可以看我之前关于get方法的解释),然后使用jsoup获取一个网页的所有内容网页。解析内容,获取该网页中的所有链接,然后通过get方法获取这些链接中的网页内容,这样我们就可以获取到一个网页下所有链接的网页内容。例如,如果我们得到一个下面有 50 个链接的网页,我们可以得到 50 个网页。下面是代码,大家感受一下
获取网址
public class GetUrl {
public static List getUrl(String ur) {
//创建默认的httpClient实例
CloseableHttpClient client = HttpClients.createDefault();
//创建list存放已读取过的页面
List urllist = new ArrayList();
//创建get
HttpGet get=new HttpGet(ur);
//设置连接超时
Builder custom = RequestConfig.custom();
RequestConfig config = custom.setConnectTimeout(5000).setConnectionRequestTimeout(1000).setSocketTimeout(5000).build();
get.setConfig(config);
//设置消息头部
get.setHeader("Accept", "Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
try {
//执行get请求
CloseableHttpResponse response = client.execute(get);
//获取响应实体
HttpEntity entity = response.getEntity();
//将响应实体转为String类型
String html = EntityUtils.toString(entity);
//通过jsoup将String转为jsoup可处理的文档类型
Document doc = Jsoup.parse(html);
//找到该页面中所有的a标签
Elements links = doc.getElementsByTag("a");
int i=1;
for (Element element : links) {
//获取到a标签中href属性的内容
String url = element.attr("href");
//对href内容进行判断 来判断该内容是否是url
if(url.startsWith("http://blog.csdn.net/";) && !urllist.contains(url)){
GetPage.getPage(url);
System.out.println(url);
urllist.add(url);
i++;
}
}
response.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return urllist;
}
}
根据获取的url生成页面
最后是测试课
public class Test {
public static void main(String[] args) {
List list = GetUrl.getUrl("http://blog.csdn.net/";);
System.out.println("所写链接内的所有内容");
int i=1;
for (String url : list) {
GetUrl.getUrl(url);
System.out.println("第"+i+"条链接内容");
i++;
}
}
}
以上就是如何使用httpclient+jsoup爬取网页,希望对大家有所帮助。
c httpclient抓取网页(这里有新鲜出炉的Java设计模式,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-15 18:09
这里有新鲜出炉的Java设计模式,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。(j2se))一般。
本文章主要介绍Java爬虫Jsoup+httpclient获取动态生成数据的相关信息。有需要的朋友可以参考以下
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细聊过Jsoup,发现这个东西其实是一样的。只要是可以访问的静态资源页面,就可以直接用它来获取你需要的数据。详情跳转到Jsoup爬虫详解,不过很多时候网站为了防止数据被恶意爬取,做了很多掩饰,比如加密、动态加载等。这给我们写的爬虫程序造成了很大的麻烦,那么我们如何突破这个梗,得到我们急需的数据,
下面我们将详细说明如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品价格是通过回调函数获取的然后填充的,所以这就需要我们编写爬虫开发者非常耐心的找到价格的回调接口数据,我们直接访问这个接口就可以直接得到价格。下面是一个演示:
从这个截图可以看出,他传递的只是一个静态资源页面,完全没有价格参数,那么价格是怎么来的,继续找这个界面:
你会发现这个界面里面有很多参数是拼接在一起的,那么我们要做的就是分析一下所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这个你兴奋吗?您实际上可以更改其他一些京东产品ID,以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个Httpclient来模拟请求接口。
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,你直接解析JSON字符串,那么你想要的数据就是GET。
注意
这是对回调请求的数据的重新请求获取。这只是对之前动态获取商品价格的补充。在这种情况下,价格本身不是通过主链接带到页面的,而是在加载过程中由异步请求填充的。有时候数据是带过来的,但是我们用相关的JS处理还是拿不到。这时候,我们就不得不通过其他方式来获取数据了,后面会讲到。 查看全部
c httpclient抓取网页(这里有新鲜出炉的Java设计模式,程序狗速度看过来!)
这里有新鲜出炉的Java设计模式,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。(j2se))一般。
本文章主要介绍Java爬虫Jsoup+httpclient获取动态生成数据的相关信息。有需要的朋友可以参考以下
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细聊过Jsoup,发现这个东西其实是一样的。只要是可以访问的静态资源页面,就可以直接用它来获取你需要的数据。详情跳转到Jsoup爬虫详解,不过很多时候网站为了防止数据被恶意爬取,做了很多掩饰,比如加密、动态加载等。这给我们写的爬虫程序造成了很大的麻烦,那么我们如何突破这个梗,得到我们急需的数据,
下面我们将详细说明如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品价格是通过回调函数获取的然后填充的,所以这就需要我们编写爬虫开发者非常耐心的找到价格的回调接口数据,我们直接访问这个接口就可以直接得到价格。下面是一个演示:

从这个截图可以看出,他传递的只是一个静态资源页面,完全没有价格参数,那么价格是怎么来的,继续找这个界面:


你会发现这个界面里面有很多参数是拼接在一起的,那么我们要做的就是分析一下所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这个你兴奋吗?您实际上可以更改其他一些京东产品ID,以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个Httpclient来模拟请求接口。
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,你直接解析JSON字符串,那么你想要的数据就是GET。
注意
这是对回调请求的数据的重新请求获取。这只是对之前动态获取商品价格的补充。在这种情况下,价格本身不是通过主链接带到页面的,而是在加载过程中由异步请求填充的。有时候数据是带过来的,但是我们用相关的JS处理还是拿不到。这时候,我们就不得不通过其他方式来获取数据了,后面会讲到。
c httpclient抓取网页(分为GET请求、有参请求相同有参数的连接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 15:13
HttpClient是Apache Jakarta Common下的一个子项目,可用于提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,支持最新版本和推荐HTTP 协议。因此,为了爬取网络资源,需要使用Http协议来访问网页。
HttpClient分为不带参数的GET请求、带参数的GET请求、不带参数的POST请求、带参数的POST请求。
无参数GET请求:类似于普通的主页连接,没有任何参数的网页
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
带参数的GET请求:带参数的连接,例如带有搜索和分类功能的网页
HttpGet httpGet = new HttpGet("https://search.jd.com/Search?keyword=Java");
不带参数的POST请求:与带参数的GET请求相同
HttpPost httpPost = new HttpPost("https://www.baidu.com/");
带参数的POST请求:url地址无参数,将参数keys=java放在表单中提交
// 创建HttpGet请求
HttpPost httpPost = new HttpPost("https://search.jd.com/");
// 声明存放参数的List集合
List params = new ArrayList();
params.add(new BasicNameValuePair("keys", "java"));
// 创建表单数据Entity
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "UTF-8");
// 设置表单Entity到httpPost请求对象中
httpPost.setEntity(formEntity);
开始
IDEA环境配置
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加 log4j.properties 资源文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
编写代码
public static void main(String[] args) throws Exception {
// 创建 HttpClient 对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建 HTTPGET 请求
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
// 使用 HttpClient 发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
// 判断响应状态码是否为200(200指OK,,网页请求成功)
if (response.getStatusLine().getStatusCode() == 200) {
// 先把网页保存成String,解析获取字符集,将网页中文内容转换成对应字符集,再转换成统一的字符集utf-8
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
输出结果为网页源代码,可自行演示 查看全部
c httpclient抓取网页(分为GET请求、有参请求相同有参数的连接)
HttpClient是Apache Jakarta Common下的一个子项目,可用于提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,支持最新版本和推荐HTTP 协议。因此,为了爬取网络资源,需要使用Http协议来访问网页。
HttpClient分为不带参数的GET请求、带参数的GET请求、不带参数的POST请求、带参数的POST请求。
无参数GET请求:类似于普通的主页连接,没有任何参数的网页
HttpGet httpGet = new HttpGet("https://www.baidu.com/";);
带参数的GET请求:带参数的连接,例如带有搜索和分类功能的网页
HttpGet httpGet = new HttpGet("https://search.jd.com/Search?keyword=Java";);
不带参数的POST请求:与带参数的GET请求相同
HttpPost httpPost = new HttpPost("https://www.baidu.com/";);
带参数的POST请求:url地址无参数,将参数keys=java放在表单中提交
// 创建HttpGet请求
HttpPost httpPost = new HttpPost("https://search.jd.com/";);
// 声明存放参数的List集合
List params = new ArrayList();
params.add(new BasicNameValuePair("keys", "java"));
// 创建表单数据Entity
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "UTF-8");
// 设置表单Entity到httpPost请求对象中
httpPost.setEntity(formEntity);
开始
IDEA环境配置
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加 log4j.properties 资源文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
编写代码
public static void main(String[] args) throws Exception {
// 创建 HttpClient 对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建 HTTPGET 请求
HttpGet httpGet = new HttpGet("https://www.baidu.com/";);
// 使用 HttpClient 发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
// 判断响应状态码是否为200(200指OK,,网页请求成功)
if (response.getStatusLine().getStatusCode() == 200) {
// 先把网页保存成String,解析获取字符集,将网页中文内容转换成对应字符集,再转换成统一的字符集utf-8
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
输出结果为网页源代码,可自行演示
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 16:06
数据是科学研究活动的重要依据。本系列博客将介绍如何使用 Java 工具获取网络数据。
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫介绍(二) - Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序上网,然后将数据保存在本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般是从网站获取的,比如电商网站商品信息、商品评论、微博信息等。爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫示例。
一、环境准备
这里的环境是指开发环境。本篇博客将使用Java编写爬虫程序。因此,有必要构建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ 想法:
网上有很多JDK的安装和环境变量的配置,就不多说了。IntelliJ IDEA是傻瓜式安装的,基本没有问题。也别说。
二、创建项目
安装好环境后,我们打开 IntelliJ IDEA,然后创建一个 Maven 项目。Group Id 和 Artifact Id 是不是自己写的也没关系。创建后,我们的目录将如下图所示。
好吧,让我们开始编写爬虫。
三、第一个例子
首先假设我们需要爬取数据学习首页网站的博客( )。首先,我们需要使用maven导入HttpClient4.5.3包(这是最新的包,你可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
Java 本身提供了关于网络访问的包,在,然后它还不够强大。于是Apache基金会发布了一个开源的http请求包,即HttpClient,它提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好吧,在使用 pom.xml 下载这个包之后,我们可以开始编写我们的第一个爬虫示例。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog");
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
如上代码所示,爬虫的第一步需要构建一个客户端,即请求者。我们这里使用CloseableHttpClient作为我们的请求者,然后确定以哪种方式请求什么URL,然后使用HttpResponse获取请求的地址。相应的结果。最后,取出HttpEntity并进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。所以我们的第一个爬虫成功下载了门户网站需要的页面内容。 查看全部
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
数据是科学研究活动的重要依据。本系列博客将介绍如何使用 Java 工具获取网络数据。
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫介绍(二) - Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序上网,然后将数据保存在本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般是从网站获取的,比如电商网站商品信息、商品评论、微博信息等。爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫示例。
一、环境准备
这里的环境是指开发环境。本篇博客将使用Java编写爬虫程序。因此,有必要构建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ 想法:
网上有很多JDK的安装和环境变量的配置,就不多说了。IntelliJ IDEA是傻瓜式安装的,基本没有问题。也别说。
二、创建项目
安装好环境后,我们打开 IntelliJ IDEA,然后创建一个 Maven 项目。Group Id 和 Artifact Id 是不是自己写的也没关系。创建后,我们的目录将如下图所示。

好吧,让我们开始编写爬虫。
三、第一个例子
首先假设我们需要爬取数据学习首页网站的博客( )。首先,我们需要使用maven导入HttpClient4.5.3包(这是最新的包,你可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
Java 本身提供了关于网络访问的包,在,然后它还不够强大。于是Apache基金会发布了一个开源的http请求包,即HttpClient,它提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好吧,在使用 pom.xml 下载这个包之后,我们可以开始编写我们的第一个爬虫示例。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog";);
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
如上代码所示,爬虫的第一步需要构建一个客户端,即请求者。我们这里使用CloseableHttpClient作为我们的请求者,然后确定以哪种方式请求什么URL,然后使用HttpResponse获取请求的地址。相应的结果。最后,取出HttpEntity并进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:

很明显,这就是我们需要的URL对应的页面的源码。所以我们的第一个爬虫成功下载了门户网站需要的页面内容。
c httpclient抓取网页(【经济学人手把手教你学英语】控件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-07 16:11
使用 HttpWebRequest 方法非常有效,但是根据我的经验,当页面上的脚本没有实际的 Web 浏览器可以渲染时,就会出现许多问题,例如您遇到的问题。我的经验是,当页面没有要呈现的实际 Web 浏览器,它会导致许多问题,就像您所拥有的一样。
我通过在 Windows 窗体上放置一个实际的 WebBrowser 控件然后将该控件导航到所需的 URL 来解决这个问题。 ,解决了这个问题。当控件(它是一个真正的 Web 浏览器)完成页面呈现后,您可以访问其中的任何内容。例如,如果在隐藏的 DIV 元素中存在被打乱的文本(阻止抓取的常用策略),您无法从页面源中获取它,但在 WebBrowser 控件中您仍然可以获取它,因为在为了显示它必须由客户端脚本解密。例如,如果某些文本在隐藏的 DIV 元素中被打乱(防止抓取的常用策略),它无法从页面源中获取,但在 WebBrowser 控件中,您仍然可以获取该文本,因为为了显示它,它必须已被客户端脚本解密。在WebBrowser控件中“看得到就得到”。
编辑:最简单的实现。编辑:最简单的实现。只需尝试一下,看看缺少的源代码现在是否存在于文档源中。
创建一个窗口窗体。创建一个窗口窗体。添加一个名为 button1. 的按钮 添加一个名为 button1 的按钮。添加一个名为 webBrowser1 的 WebBrowser 控件,取消停靠并调整其大小。添加一个名为 textBox1 的 TextBox 并将其设为多行。然后在表单后面添加这段代码: 然后在表单后面添加这段代码:
private void button1_Click(object sender, EventArgs e) {
string url = "http://google.ca";
webBrowser1.Navigate(url);
}
private void webBrowser1_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e) {
string pageSource = webBrowser1.Document.Body.OuterHtml;
textBox1.Text = pageSource;
}
将上述网址替换为您的网址。运行表单并单击按钮。查看您想要的 HTML 现在是否出现在结果文本框中。如果是,那么您的大部分问题现在都已解决。我对这项技术非常幸运。它应该可以解决延迟呈现的内容的任何问题,因此不会在实际源代码中以未混淆的形式出现。 查看全部
c httpclient抓取网页(【经济学人手把手教你学英语】控件)
使用 HttpWebRequest 方法非常有效,但是根据我的经验,当页面上的脚本没有实际的 Web 浏览器可以渲染时,就会出现许多问题,例如您遇到的问题。我的经验是,当页面没有要呈现的实际 Web 浏览器,它会导致许多问题,就像您所拥有的一样。
我通过在 Windows 窗体上放置一个实际的 WebBrowser 控件然后将该控件导航到所需的 URL 来解决这个问题。 ,解决了这个问题。当控件(它是一个真正的 Web 浏览器)完成页面呈现后,您可以访问其中的任何内容。例如,如果在隐藏的 DIV 元素中存在被打乱的文本(阻止抓取的常用策略),您无法从页面源中获取它,但在 WebBrowser 控件中您仍然可以获取它,因为在为了显示它必须由客户端脚本解密。例如,如果某些文本在隐藏的 DIV 元素中被打乱(防止抓取的常用策略),它无法从页面源中获取,但在 WebBrowser 控件中,您仍然可以获取该文本,因为为了显示它,它必须已被客户端脚本解密。在WebBrowser控件中“看得到就得到”。
编辑:最简单的实现。编辑:最简单的实现。只需尝试一下,看看缺少的源代码现在是否存在于文档源中。
创建一个窗口窗体。创建一个窗口窗体。添加一个名为 button1. 的按钮 添加一个名为 button1 的按钮。添加一个名为 webBrowser1 的 WebBrowser 控件,取消停靠并调整其大小。添加一个名为 textBox1 的 TextBox 并将其设为多行。然后在表单后面添加这段代码: 然后在表单后面添加这段代码:
private void button1_Click(object sender, EventArgs e) {
string url = "http://google.ca";
webBrowser1.Navigate(url);
}
private void webBrowser1_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e) {
string pageSource = webBrowser1.Document.Body.OuterHtml;
textBox1.Text = pageSource;
}
将上述网址替换为您的网址。运行表单并单击按钮。查看您想要的 HTML 现在是否出现在结果文本框中。如果是,那么您的大部分问题现在都已解决。我对这项技术非常幸运。它应该可以解决延迟呈现的内容的任何问题,因此不会在实际源代码中以未混淆的形式出现。
c httpclient抓取网页(GitHub:基于asyncio实现HTTP框架。异步操作借助于/await关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-02 23:04
GitHub:
基于 asyncio 实现的 HTTP 框架。异步操作依赖 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
这是高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用小盒子:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2个解析库
1、美丽的汤
官方文档:
HTML和XML解析,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的必备库。
2、lxml
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
3、pyquery
GitHub:
jQuery的Python实现可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
3 数据存储库
1、pymysql
GitHub:
官方文档:
MySQL 客户端操作库的纯 Python 实现。很实用也很简单。
2、pymongo
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
3、redisdump
使用方法:
redis-dump是一个redis和json转换的工具; redis-dump是基于ruby开发的,需要一个ruby环境,而新版redis-dump需要2.2.2个以上的ruby版本,centos中yum只能安装< @2.0 版本的红宝石。需要先安装ruby的管理工具rvm才能安装更高版本的ruby;
最后,我是一个从事多年开发的老Python程序员。我已经辞职,目前正在做我自己的私人 Python 课程。今年年初,我花了一个月的时间整理了一篇最适合2019年学习的Python学习,干货可以送给每一位喜欢Python的朋友。想要领取的可以关注我的头条号,后台私信我:01,免费领取。 查看全部
c httpclient抓取网页(GitHub:基于asyncio实现HTTP框架。异步操作借助于/await关键字)
GitHub:
基于 asyncio 实现的 HTTP 框架。异步操作依赖 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
这是高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用小盒子:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2个解析库
1、美丽的汤
官方文档:
HTML和XML解析,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的必备库。
2、lxml
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
3、pyquery
GitHub:
jQuery的Python实现可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
3 数据存储库
1、pymysql
GitHub:
官方文档:
MySQL 客户端操作库的纯 Python 实现。很实用也很简单。
2、pymongo
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
3、redisdump
使用方法:
redis-dump是一个redis和json转换的工具; redis-dump是基于ruby开发的,需要一个ruby环境,而新版redis-dump需要2.2.2个以上的ruby版本,centos中yum只能安装< @2.0 版本的红宝石。需要先安装ruby的管理工具rvm才能安装更高版本的ruby;
最后,我是一个从事多年开发的老Python程序员。我已经辞职,目前正在做我自己的私人 Python 课程。今年年初,我花了一个月的时间整理了一篇最适合2019年学习的Python学习,干货可以送给每一位喜欢Python的朋友。想要领取的可以关注我的头条号,后台私信我:01,免费领取。
c httpclient抓取网页( 一个Python抓取网页的库:urllib与urllib2有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-04-15 22:24
一个Python抓取网页的库:urllib与urllib2有什么区别?)
python网络爬虫的初级实现代码,python爬虫
首先,我们来看一个用于抓取网页的 Python 库:urllib 或 urllib2。
那么 urllib 和 urllib2 有什么区别呢?
您可以使用 urllib2 作为 urllib 的扩展。明显的好处就是urllib2.urlopen()可以接受Request对象作为参数,这样就可以控制HTTP Request的头部部分了。
在做HTTP Request的时候应该尽量使用urllib2库,但是urllib2中并没有加入urllib.urlretrieve()函数和urllib.quote等一系列quote和unquote函数,所以有时候辅助需要 urllib。
urllib.open() 这里传入的参数必须遵循一些协议,比如http、ftp、file等。例如:
urllib.open('')
urllib.open('file:D\Python\Hello.py')
现在有一个以 gif 格式下载所有图像的 网站 的示例。那么Python代码如下:
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.*?\.gif)"'
imgre = re.compile(reg)
imgList = re.findall(imgre,html)
print imgList
cnt = 1
for imgurl in imgList:
urllib.urlretrieve(imgurl,'%s.jpg' %cnt)
cnt += 1
if __name__ == '__main__':
html = getHtml('http://www.baidu.com')
getImg(html)
根据上面的方法,我们可以爬取某些网页,然后提取出我们需要的数据。
实际上,我们使用 urllib 模块作为网络爬虫是非常低效的。让我们介绍 Tornado Web Server。
Tornado Web 服务器是一个用 Python 编写的极其轻量级、高度可扩展且非阻塞的 IO Web 服务器软件。著名的 Friendfeed网站 就是使用它构建的。 Tornado 与其他主流 Web 服务器框架(主要是 Python 框架)的不同之处在于它采用了 epoll 非阻塞 IO,响应速度快,可以处理数千个并发连接,尤其适用于实时 Web 服务。
使用 Tornado Web Server 抓取网页会更高效。
从 Tornado 的官方网站,也应该安装 backports.ssl_match_hostname。官网如下:
import tornado.httpclient
def Fetch(url):
http_header = {'User-Agent' : 'Chrome'}
http_request = tornado.httpclient.HTTPRequest(url=url,method='GET',headers=http_header,connect_timeout=200,request_timeout=600)
print 'Hello'
http_client = tornado.httpclient.HTTPClient()
print 'Hello World'
print 'Start downloading data...'
http_response = http_client.fetch(http_request)
print 'Finish downloading data...'
print http_response.code
all_fields = http_response.headers.get_all()
for field in all_fields:
print field
print http_response.body
if __name__ == '__main__':
Fetch('http://www.baidu.com')
urllib2的常用方法:
(1)info()获取网页的Header信息
(2)getcode()获取网页的状态码
(3)geturl() 获取传入的 URL
(4)read() 读取文件内容 查看全部
c httpclient抓取网页(
一个Python抓取网页的库:urllib与urllib2有什么区别?)
python网络爬虫的初级实现代码,python爬虫
首先,我们来看一个用于抓取网页的 Python 库:urllib 或 urllib2。
那么 urllib 和 urllib2 有什么区别呢?
您可以使用 urllib2 作为 urllib 的扩展。明显的好处就是urllib2.urlopen()可以接受Request对象作为参数,这样就可以控制HTTP Request的头部部分了。
在做HTTP Request的时候应该尽量使用urllib2库,但是urllib2中并没有加入urllib.urlretrieve()函数和urllib.quote等一系列quote和unquote函数,所以有时候辅助需要 urllib。
urllib.open() 这里传入的参数必须遵循一些协议,比如http、ftp、file等。例如:
urllib.open('')
urllib.open('file:D\Python\Hello.py')
现在有一个以 gif 格式下载所有图像的 网站 的示例。那么Python代码如下:
import re
import urllib
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
def getImg(html):
reg = r'src="(.*?\.gif)"'
imgre = re.compile(reg)
imgList = re.findall(imgre,html)
print imgList
cnt = 1
for imgurl in imgList:
urllib.urlretrieve(imgurl,'%s.jpg' %cnt)
cnt += 1
if __name__ == '__main__':
html = getHtml('http://www.baidu.com')
getImg(html)
根据上面的方法,我们可以爬取某些网页,然后提取出我们需要的数据。
实际上,我们使用 urllib 模块作为网络爬虫是非常低效的。让我们介绍 Tornado Web Server。
Tornado Web 服务器是一个用 Python 编写的极其轻量级、高度可扩展且非阻塞的 IO Web 服务器软件。著名的 Friendfeed网站 就是使用它构建的。 Tornado 与其他主流 Web 服务器框架(主要是 Python 框架)的不同之处在于它采用了 epoll 非阻塞 IO,响应速度快,可以处理数千个并发连接,尤其适用于实时 Web 服务。
使用 Tornado Web Server 抓取网页会更高效。
从 Tornado 的官方网站,也应该安装 backports.ssl_match_hostname。官网如下:
import tornado.httpclient
def Fetch(url):
http_header = {'User-Agent' : 'Chrome'}
http_request = tornado.httpclient.HTTPRequest(url=url,method='GET',headers=http_header,connect_timeout=200,request_timeout=600)
print 'Hello'
http_client = tornado.httpclient.HTTPClient()
print 'Hello World'
print 'Start downloading data...'
http_response = http_client.fetch(http_request)
print 'Finish downloading data...'
print http_response.code
all_fields = http_response.headers.get_all()
for field in all_fields:
print field
print http_response.body
if __name__ == '__main__':
Fetch('http://www.baidu.com')
urllib2的常用方法:
(1)info()获取网页的Header信息
(2)getcode()获取网页的状态码
(3)geturl() 获取传入的 URL
(4)read() 读取文件内容
c httpclient抓取网页(mancurl阅读手册页上传文件路径-curl模拟http提交数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-04-15 11:17
使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好使用登录页面测试,因为你传值后,curl会抓取数据回来,可以查看是否传值成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。 查看全部
c httpclient抓取网页(mancurl阅读手册页上传文件路径-curl模拟http提交数据)
使用说明
curl命令是一个功能强大的网络工具,可以通过http、ftp等方式下载和上传文件。其实curl远不止上面提到的功能。您可以通过 man curl 阅读手册页以获取更多信息。 wget 是一个类似的工具。
curl 命令是使用 libcurl 库实现的。 libcurl 库通常在 C 程序中用于处理 HTTP 请求。 curlpp 是 libcurl 的 C++ 包。这些东西可以用在web抓取、网络监控等开发中,curl命令可以帮助解决开发过程中遇到的问题。
常用参数
curl命令的参数很多,这里只列出我用过的,尤其是shell脚本中的。
-A:请随意指定您自己为本次访问声明的浏览器信息
-b/--cookie cookie 字符串或文件读取位置,使用 option 将最后一个 cookie 信息附加到 http 请求中。
-c/--cookie-jar 操作完成后将cookies写入该文件
-C/--continue-在断点处继续
-d/--data HTTP POST方法传输数据
-D/--dump-header 将头信息写入该文件
-F/--form 模拟http表单提交数据
-v/--verbose 小写的v参数用于打印更多信息,包括发送的请求信息,在调试脚本时特别有用。
-m/--max-time 指定处理的最大持续时间
-H/--header 指定请求头参数
-s/--slent reduce输出信息,如进度
--connect-timeout 指定尝试连接的最长时间
-x/--代理
指定代理服务器地址和端口,默认端口为1080
-T/--upload-file 指定上传文件路径
-o/--output 指定输出文件名
--retry 指定重试次数
-e/--referer 指定引用地址
-I/--head 只返回header信息,使用HEAD请求
-u/--user 设置服务器用户和密码
-O:根据服务器上的文件名,会自动在本地存在
-r/--range 从 HTTP/1.1 或 FTP 服务器检索字节范围
-T/--upload-file 上传文件
使用示例
1、抓取页面内容到文件中
[root@xi mytest]# curl -o home.html -- 将百度首页的内容抓取到home.html中
[root@xi mytest]#curl -o #2_#1.jpg~{A,B}/[001-201].JPG
因为A/B下的文件名都是001、002...、201,所以下载的文件同名,所以自定义下载的文件名变成这样: 原文:A/00< @1.JPG ---> 下载后:001-A.JPG 原文:B/001.JPG ---> 下载后:001-B.JPG
2、使用-O(大写),后面的url必须特定于某个文件,否则不会被抓到。你也可以使用正则表达式来抓取东西
[root@xi mytest]# curl -O
结果如下:
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 1575 100 1575 0 0 14940 0 --:--:-- --:--:-- --:--:-- 1538k
在当前执行目录中会生成一张bdlogo.gif的图片。
[root@xi mytest]# curl -O[1-10].JPG --下载屏幕1.jpg~screen10.jpg
3、模拟表单信息、模拟登录、保存cookie信息
[root@xi mytest]# curl -c ./cookie_c.txt -F log=aaaa -F pwd=******
4、模拟表单信息、模拟登录、保存表头信息
[root@xi mytest]# curl -D ./cookie_D.txt -F log=aaaa -F pwd=******
由
生成的cookie
-c(小写)与-D中的cookie不同。
5、使用cookie文件
[root@xi mytest]# curl -b ./cookie_c.txt
6、从断点恢复,-C(大写)
[root@xi mytest]# curl -C -O
7、发送数据,最好使用登录页面测试,因为你传值后,curl会抓取数据回来,可以查看是否传值成功
[root@xi mytest]# curl -d log=aaaa
8、显示爬取错误,下面的例子清楚的显示出来。
[root@xi mytest]# curl -f
curl:(22)请求的URL返回错误:404
[root@xi mytest]# curl
404,未找到
9。伪造源地址,有的网站会判断并请求源地址,防止盗链。
[root@xi mytest]# curl -e:///wp-login.php
10、当我们经常用curl做别人的事情的时候,人家会屏蔽你的IP,这个时候我们可以使用代理
[root@xi mytest]# curl -x 24.10.28.84:32779 -o home.html
11,对于较大的东西,我们可以分段下载
[root@xi mytest]# curl -r 0-100 -o img.part1
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 105 0 --:--:-- --:--:-- --:--:-- 0
[root@xi mytest]# curl -r 100-200 -o img.part2
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 101 100 101 0 0 57 0 0:00:01 0:00:01 --:--:-- 0
[root@xi mytest]# curl -r 200- -o img.part3
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
100 104k 100 104k 0 0 52793 0 0:00:02 0:00:02 --:--:-- 88961
[root@xi mytest]# ls |grep part | xargs du -sh
4.0K one.part1
112K 三.part3
4.0K two.part2
使用的时候,cat一下就可以了,cat img.part* >img.jpg
12,不会显示下载进度信息
[root@xi mytest]# curl -s -o aaa.jpg
13、显示下载进度条
[root@xi mytest]# curl -0(使用http1.0协议的请求)
############################################## # ######################### 100.0%
14、通过ftp下载文件
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
[xifj@Xi ~]$ curl -u 用户名:密码 -O
% Total % Received % Xferd 平均速度 时间 时间 时间 当前
Dload 上传总花费的左速度
101 1934 101 1934 0 0 3184 0 --:--:-- --:--:-- --:--:-- 7136
或者使用下面的方法
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
[xifj@Xi ~]$ curl -O ftp://username:password@ip:port/demo/curtain/bbstudy_files/style.css
15、通过ftp上传
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
[xifj@Xi ~]$ curl -T test.sql ftp://username:password@ip:port/demo/curtain/bbstudy_files/
15、模拟浏览器头部
[xifj@Xi ~]$ curl -A "Mozilla/4.0 (兼容; MSIE 6.0; Windows NT 5.0)" -x 12< @3.45.67.89:1080 -o page.html -D cookie0001.txt
16,PUT,GET,POST
比如curl -T localfile~zz/abc.cgi,此时使用的协议是HTTP PUT方式
刚才说到PUT,我自然会想到其他几种方法——GET和POST。
c httpclient抓取网页(互联网-java使用浏览器内核模拟浏览器操作驱动包下载地址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-04-11 03:09
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
由于部分网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,此时无法通过httpclient获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。对于Windows和Linux平台,需要分别指定对应的驱动路径。
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。 查看全部
c httpclient抓取网页(互联网-java使用浏览器内核模拟浏览器操作驱动包下载地址)
互联网提供了大量的数据,有时需要抓取网页上的数据。通过程序采集的数据可实现自动化处理。与手动打开网页查看和处理数据相比,效率显着提高。
由于部分网页的内容是通过ajax方式通过js请求后端数据后在页面上设置的,此时无法通过httpclient获取页面的数据。此时,您可以使用模拟浏览器访问该页面。浏览器下载页面的js后,会解析并执行相关操作。
通过selenium-java,使用浏览器内核模拟浏览器操作,访问网页,解析并执行js,生成完整的页面内容,然后通过接口解析返回的数据。
1. 下载驱动包
下载地址为:CNPM Binaries Mirror
这里使用的是谷歌浏览器,所以下载了对应版本的windows和linux驱动。此外,可以使用诸如 firefox 之类的浏览器内核。
2. 创建maven项目并配置依赖
org.seleniumhq.selenium
selenium-java
3.141.59
3. 配置驱动程序
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/tools/chromedriver_win32/chromedriver.exe");
驱动程序的位置需要在代码中指定。对于Windows和Linux平台,需要分别指定对应的驱动路径。
4. 代码实现
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
public class FindDataDemo {
private void seleniumProcess() {
String uri = "http://tools.2345.com/rili.htm";
// 设置 chromedirver 的存放位置
System.getProperties().setProperty("webdriver.chrome.driver", "D:/sdks/tools/chromedriver_win32/chromedriver.exe");
// 设置浏览器参数
ChromeOptions chromeOptions = new ChromeOptions();
chromeOptions.addArguments("--no-sandbox");//禁用沙箱
chromeOptions.addArguments("--disable-dev-shm-usage");//禁用开发者shm
chromeOptions.addArguments("--headless"); //无头浏览器,这样不会打开浏览器窗口
WebDriver webDriver = new ChromeDriver(chromeOptions);
webDriver.get(uri);
WebElement webElements = webDriver.findElement(By.id("yi"));
System.out.println("webElements = " + webElements);
System.out.println("webElements.getText() = " + webElements.getText());
String pageSource = webDriver.getPageSource();
System.out.println("webElements = " + pageSource);
webDriver.close();
}
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
FindDataDemo findDataDemo = new FindDataDemo();
findDataDemo.seleniumProcess();
long endTime = System.currentTimeMillis();
System.out.println("(endTime - startTime) = " + (endTime - startTime));
}
}
执行测试程序,可以看到获取到页面上的内容。
c httpclient抓取网页(怎么用网络爬虫获取数据基于html标签的内容--)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-05 09:11
登录后,如果只是简单的获取数据,只需要写一个过滤器,过滤html标签,找到你想要的。
如果不想自己写,百度htmlunit负责把html转成dom。然后找到对应的html标签。
想偷懒解决一次,百度jsoup jsoup=httpclient+htmlunit 可以直接通过url获取网页的dom。
表示你应该是登录失败或者登录后没有使用cookies。登录浏览器查看返回的响应,然后输出登录后得到的响应的header和response,看看是否与浏览器返回的响应一致。专注于您的 cookie 的价值。
如何使用java实现网络爬虫爬取页面内容-》》以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是jdk自带,速度比较快,缺点是有方法更少,功能更复杂 自己实现往往需要很多代码 第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般是HttpClient + JSOUP配合完成爬取,HttpClient获取页面,JSOUP解析网页并获取数据HttpUnit:相当于没有界面的浏览器,缺点是占用内存大,速度慢,优点是可以执行js,功能强大
java网络爬虫是如何实现对登录后页面的爬取-""" 原理是保存cookie数据,登录后保存cookie,以后每次页面的时候都会在header信息中发送cookie系统根据cookie判断用户有了cookie,就有登录状态,后续的访问都是基于这个cookie对应的用户补充:Java是一种面向对象的编程语言,可以跨平台编写应用软件 Java技术具有优异的通用性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
java网络爬虫如何实现对登录页面的抓取-》》我没做过网络爬虫,但是写了一个程序自动登录猫拍卡3233363533e78988e69d83338。你可以参考一下。需要的包是commons-logging.jar,commons-net-1.4.1.jar,commons-codec-1.3.jar,log4j.jar ……
基于java如何使用网络爬虫获取数据——“”“爬虫的原理其实就是获取网页的内容然后解析,只不过获取网页的方式有很多种,然后解析内容。可以简单的使用httpclient发送get/post请求,得到结果,然后使用截取的字符串和正则表达式来获取想要的内容。或者使用Jsoup/crawler4j等封装好的库来更方便的爬取信息。
java爬虫登录后是如何抓取网页数据的——《》》一般爬虫登录后是不会抓取页面的。如果只是临时抓取一个站点,可以模拟登录,登录后获取cookies,然后请求相关的页面。
java中如何爬取网页数据-》》》1.生成页面后使用jsoup爬取静态信息,很简单,知道jquery的选择器会使用2.获取生成后的页面loading 通过ajax返回刷新的页面,没办法,请从发送的请求中分析xml或json数据,看看哪个爬虫在任何情况下都不可能申请!
java爬虫爬取指定数据-"""如何通过Java代码实现对网页数据的指定爬取,我总结Jsoup.Jar包会用到以下步骤:1、在project.jar包2、获取url指定的url或者文档指定的body3、获取网页中超链接的标题和链接4、获取指定的内容blog文章5、@ 获取网页中超链接的标题和链接结果
java正则如何提取数据?(网络爬虫) - """ 通过 Matcher 写正则配置~...
JAVA爬虫如何爬取动态页面——《》》解析ajax地址,发给自己和地址
java爬虫怎么爬取js动态生成的内容-"""我用jsoup写爬虫,一般会遇到html没有返回的内容,但是浏览器显示了一些内容,就是分析http请求页面的日志。分析页面的JS代码来解决。1、一些页面元素被隐藏->更改选择器解决2、一些数据存储在js/json对象中->拦截对应字符串,分析解决3、通过api接口调用还有一个终极方法->假请求获取数据4、使用无头浏览器如phantomjs或casperjs 查看全部
c httpclient抓取网页(怎么用网络爬虫获取数据基于html标签的内容--)
登录后,如果只是简单的获取数据,只需要写一个过滤器,过滤html标签,找到你想要的。
如果不想自己写,百度htmlunit负责把html转成dom。然后找到对应的html标签。
想偷懒解决一次,百度jsoup jsoup=httpclient+htmlunit 可以直接通过url获取网页的dom。
表示你应该是登录失败或者登录后没有使用cookies。登录浏览器查看返回的响应,然后输出登录后得到的响应的header和response,看看是否与浏览器返回的响应一致。专注于您的 cookie 的价值。
如何使用java实现网络爬虫爬取页面内容-》》以下工具可以实现java爬虫JDK原生类: HttpURLConnection HttpURLConnection:优点是jdk自带,速度比较快,缺点是有方法更少,功能更复杂 自己实现往往需要很多代码 第三方爬虫工具:JSOUP、HttpClient、HttpUnit 一般是HttpClient + JSOUP配合完成爬取,HttpClient获取页面,JSOUP解析网页并获取数据HttpUnit:相当于没有界面的浏览器,缺点是占用内存大,速度慢,优点是可以执行js,功能强大
java网络爬虫是如何实现对登录后页面的爬取-""" 原理是保存cookie数据,登录后保存cookie,以后每次页面的时候都会在header信息中发送cookie系统根据cookie判断用户有了cookie,就有登录状态,后续的访问都是基于这个cookie对应的用户补充:Java是一种面向对象的编程语言,可以跨平台编写应用软件 Java技术具有优异的通用性,广泛应用于PC、数据中心、游戏机、科学超级计算机、手机和互联网,拥有全球最大的专业开发者社区。
java网络爬虫如何实现对登录页面的抓取-》》我没做过网络爬虫,但是写了一个程序自动登录猫拍卡3233363533e78988e69d83338。你可以参考一下。需要的包是commons-logging.jar,commons-net-1.4.1.jar,commons-codec-1.3.jar,log4j.jar ……
基于java如何使用网络爬虫获取数据——“”“爬虫的原理其实就是获取网页的内容然后解析,只不过获取网页的方式有很多种,然后解析内容。可以简单的使用httpclient发送get/post请求,得到结果,然后使用截取的字符串和正则表达式来获取想要的内容。或者使用Jsoup/crawler4j等封装好的库来更方便的爬取信息。
java爬虫登录后是如何抓取网页数据的——《》》一般爬虫登录后是不会抓取页面的。如果只是临时抓取一个站点,可以模拟登录,登录后获取cookies,然后请求相关的页面。
java中如何爬取网页数据-》》》1.生成页面后使用jsoup爬取静态信息,很简单,知道jquery的选择器会使用2.获取生成后的页面loading 通过ajax返回刷新的页面,没办法,请从发送的请求中分析xml或json数据,看看哪个爬虫在任何情况下都不可能申请!
java爬虫爬取指定数据-"""如何通过Java代码实现对网页数据的指定爬取,我总结Jsoup.Jar包会用到以下步骤:1、在project.jar包2、获取url指定的url或者文档指定的body3、获取网页中超链接的标题和链接4、获取指定的内容blog文章5、@ 获取网页中超链接的标题和链接结果
java正则如何提取数据?(网络爬虫) - """ 通过 Matcher 写正则配置~...
JAVA爬虫如何爬取动态页面——《》》解析ajax地址,发给自己和地址
java爬虫怎么爬取js动态生成的内容-"""我用jsoup写爬虫,一般会遇到html没有返回的内容,但是浏览器显示了一些内容,就是分析http请求页面的日志。分析页面的JS代码来解决。1、一些页面元素被隐藏->更改选择器解决2、一些数据存储在js/json对象中->拦截对应字符串,分析解决3、通过api接口调用还有一个终极方法->假请求获取数据4、使用无头浏览器如phantomjs或casperjs
c httpclient抓取网页(【】网站管理员的基本操作技巧(二)——)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-04-05 09:09
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Reset Content) 服务器成功处理请求但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(临时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 中没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。 查看全部
c httpclient抓取网页(【】网站管理员的基本操作技巧(二)——)
1xx(临时回复)
用于指示需要请求者采取行动才能继续的临时响应的状态代码。
代码说明
100(继续)请求者应继续请求。返回此代码的服务器意味着服务器已收到请求的第一部分,现在正在等待接收其余部分。
101 (Switch Protocol) 请求者已向服务器请求切换协议,服务器已确认并准备切换。
2xx(成功)
用于指示服务器已成功处理请求的状态码。
代码说明
200 (Success) 服务器已成功处理请求。通常,这意味着服务器提供了所请求的网页。如果您的 robots.txt 文件显示此状态,则表明 Googlebot 已成功检索该文件。
201 (created) 请求成功,服务器已创建新资源。
202 (Accepted) 服务器已接受请求但尚未处理。
203(未经授权的信息)服务器成功处理了请求,但返回的信息可能来自其他来源。
204 (No Content) 服务器成功处理请求但没有返回任何内容。
205 (Reset Content) 服务器成功处理请求但没有返回任何内容。与 204 响应不同,此响应要求请求者重置文档视图(例如,清除表单内容以输入新内容)。
206(部分内容)服务器成功处理了部分 GET 请求。
3xx(重定向)
要完成请求,您需要采取进一步的措施。通常,这些状态代码会永远重定向。Google 建议您对每个请求使用少于 5 个重定向。您可以使用 网站管理工具查看 Googlebot 是否在抓取您重定向的网页时遇到问题。诊断下的抓取错误页面列出了 Googlebot 由于重定向错误而无法抓取的网址。
代码说明
300(多选) 服务器可以根据请求执行各种动作。服务器可以根据请求者(用户代理)选择一个动作,或者提供一个动作列表供请求者选择。
301(永久移动)请求的网页已永久移动到新位置。当服务器返回此响应(作为对 GET 或 HEAD 请求的响应)时,它会自动将请求者重定向到新位置。您应该使用此代码通知 Googlebot 页面或 网站 已永久移动到新位置。
302(临时移动)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行未来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
303(查看其他位置)当请求者应针对不同位置发出单独的 GET 请求以检索响应时,服务器会返回此代码。对于除 HEAD 请求之外的所有请求,服务器会自动转到其他位置。
304(未修改)自上次请求以来,请求的页面尚未修改。当服务器返回此响应时,不会返回任何网页内容。
如果自请求者的最后一次请求以来页面没有更改,您应该配置您的服务器以返回此响应(称为 If-Modified-Since HTTP 标头)。节省带宽和开销,因为服务器可以告诉 Googlebot 该页面自上次抓取以来没有更改
.
305 (Use Proxy) 请求者只能使用代理访问所请求的网页。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
307(临时重定向)服务器当前正在响应来自不同位置的网页的请求,但请求者应继续使用原创位置进行将来的请求。此代码类似于响应 GET 和 HEAD 请求的 301 代码,并自动将请求者重定向到不同的位置。但是,由于 Googlebot 将继续抓取旧位置并将其编入索引,因此您不应使用此代码通知 Googlebot 某个页面或 网站 已被移动。
4xx(请求错误)
这些状态码表明请求可能出错,阻止服务器处理请求。
代码说明
400 (Bad Request) 服务器不理解请求的语法。
401(未授权)请求需要身份验证。登录后,服务器可能会向页面返回此响应。
403 (Forbidden) 服务器拒绝了请求。如果当 Googlebot 尝试在您的 网站 上抓取有效页面时出现此状态代码(您可以在 Google 网站Admin Tools 的诊断下的 Web Crawl 页面上看到此状态代码),那么,有可能您的服务器或主机拒绝 Googlebot 访问它。
404(未找到)服务器找不到请求的网页。例如,如果请求是针对服务器上不存在的页面,服务器通常会返回此代码。
如果您的 网站 中没有 robots.txt 文件,并且您在 Google 的 网站 管理工具的“诊断”标签中的 robots.txt 页面上看到此状态,那么这是正确的状态。但是,如果您有 robots.txt 文件并发现此状态,则您的 robots.txt 文件可能命名不正确或位于错误的位置。(该文件应位于顶级域中,并应命名为 robots.txt)。
如果您在 Googlebot 尝试抓取的网址(在诊断标签中的 HTTP 错误页面上)看到此状态,则表示 Googlebot 可能正在跟踪来自另一个页面的死链接(旧链接或输入错误的链接)链接到)。
405 (Method Disabled) 禁用请求中指定的方法。
406(不接受)无法使用请求的内容属性响应请求的网页。
407(需要代理授权)此状态码类似于 401(未授权),但指定请求者应使用代理进行授权。如果服务器返回此响应,则服务器还指示请求者应使用哪个代理。
408(请求超时)服务器等待请求超时。
409(冲突)服务器在完成请求时遇到冲突。服务器必须收录有关在响应中发生的冲突的信息。服务器可能会返回此代码以响应与先前请求冲突的 PUT 请求,以及两个请求之间的差异列表。
410 (Deleted) 如果请求的资源已被永久删除,服务器返回此响应。此代码类似于 404(未找到)代码,但在资源曾经存在但不再存在的情况下,有时会出现而不是 404 代码。如果资源已被永久删除,则应使用 301 代码指定资源的新位置。
411(需要有效长度)服务器将不接受收录无效 Content-Length 标头字段的请求。
412 (Precondition not met) 服务器不满足请求者在请求中设置的前提条件之一。
413 (Request Entity Too Large) 服务器无法处理请求,因为请求实体太大,服务器无法处理。
414 (Request URI Too Long) 请求的 URI(通常是 URL)太长,服务器无法处理。
415 (Unsupported media type) 请求的页面不支持请求的格式。
416(请求范围不符合要求)如果请求是针对页面的无效范围发出的,则服务器返回此状态代码。
417 (Expected value not met) 服务器不满足“Expected”请求头域的要求。
5xx(服务器错误)
这些状态代码表明服务器在尝试处理请求时遇到了内部错误。这些错误可能是服务器本身的错误,而不是请求。
代码说明
500(内部服务器错误)服务器遇到错误,无法完成请求。
501(尚未实现)服务器没有能力完成请求。例如,当服务器无法识别请求方法时,服务器可能会返回此代码。
502 (Bad Gateway) 作为网关或代理的服务器收到来自上游服务器的无效响应。
503(服务不可用)服务器当前不可用(由于过载或停机维护)。通常,这只是一个暂时的状态。
504 (Gateway Timeout) 服务器作为网关或代理,没有及时收到上游服务器的请求。
c httpclient抓取网页(Python语言例子用C#来实现,代码贴在文中方便各位园友学习)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-03-29 03:05
最近重读了当年出版的介绍推荐系统的书《集体智能的编程》,在当时似乎引领了潮流,现在已经成为所有互联网公司的必备技术。
这次在阅读的同时,尝试用C#实现书中的一些Python语言示例,有利于自己的理解。代码贴在文中,方便园丁学习。
由于本文与原书可能涉及版权问题,请勿以任何形式被第三方转载,谢谢合作。
第三部分全文搜索引擎的搜索和排名
全文搜索引擎的作用是在大量文档中搜索一系列单词,并根据文档与搜索单词的相关程度对结果进行排名。
搜索引擎的组成
从 Internet 或从固定数量的文档中采集文档。
为采集的文档创建索引。
按查询返回排序的文档。这个过程的关键是文档的排序方法。
建立一个搜索引擎
首先构造一个爬行动物的“外壳”。以下方法逐步完善:
public class Crawler : IDisposable
{
private HttpClient _httpClient;
private IDbConnection _connection;
private static readonly HashSet IgnoreWords
= new HashSet(new [] {"the","of","to","and","a","in","is","it"});
//构造函数,接收数据库名作为参数
public Crawler(string dbname)
{
_httpClient = new HttpClient();
_connection = GetConn(dbname);
}
//辅助函数,用于获取条目Id,且如果条目不存在,就将其加入数据库中
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
return 0;
}
//为每个网页建立索引
public async Task AddtoIndex(string url, HtmlDocument soup)
{
Console.WriteLine($"Indexing {url}");
}
//从一个HTML网页提取文字(不带html标签)
public string GetTextOnly(HtmlDocument soup)
{
return null;
}
//分词
public List SeparateWords(string text)
{
return null;
}
//如果Url已经建立索引,则返回true
public bool IsIndexed(string url)
{
return false;
}
//添加一个关联两个网页的链接
public void AddLinkref(string urlFrom, string urlTo, string linkText)
{
}
//从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
public async Task Crawl(List pages, int depth = 2)
{
throw new NotImplementedException();
}
public async Task GetHtmlDoc(string url)
{
return null;
}
//创建数据库表
public void CreateIndexTables()
{
}
public static string UrlJoin(string urlBase, string urlRel)
{
return null;
}
public IDbConnection GetConn(string dbname)
{
return null;
}
public void Dispose()
{
_connection.Close();
}
}
这还收录一些管理数据库连接的代码,以及索引时要忽略的单词列表。
履带式
对于 C#,抓取网页 HttpClient 是一个很好的选择。
可以使用nuget安装HttpClient,在NuGet管理器中搜索“httpclient”,名为Microsoft.Net.Http的项就是HttpClient库。
爬取网页代码很简单:
var url = "http://xxx.com";
var httpClient = new HttpClient();
var content = await httpClient.GetStringAsync(url);
HttpClient每次释放都会断开Tcp连接,所以为了节省性能,尽量把HttpClient做成单例。
爬取网页后的另一个非常重要的步骤是分析Html的内容。对于 C#,可以使用 Html Agility Pack 库。安装Html Agility Pack也很简单,在Nuget中搜索HtmlAgilityPack,或者直接使用Install-Package HtmlAgilityPack。
我们首先在爬虫类中实现 Crawl 方法。
<p>public async Task Crawl(List pages, int depth = 2)
{
for (int i = 0; i 查看全部
c httpclient抓取网页(Python语言例子用C#来实现,代码贴在文中方便各位园友学习)
最近重读了当年出版的介绍推荐系统的书《集体智能的编程》,在当时似乎引领了潮流,现在已经成为所有互联网公司的必备技术。
这次在阅读的同时,尝试用C#实现书中的一些Python语言示例,有利于自己的理解。代码贴在文中,方便园丁学习。
由于本文与原书可能涉及版权问题,请勿以任何形式被第三方转载,谢谢合作。
第三部分全文搜索引擎的搜索和排名
全文搜索引擎的作用是在大量文档中搜索一系列单词,并根据文档与搜索单词的相关程度对结果进行排名。
搜索引擎的组成
从 Internet 或从固定数量的文档中采集文档。
为采集的文档创建索引。
按查询返回排序的文档。这个过程的关键是文档的排序方法。
建立一个搜索引擎
首先构造一个爬行动物的“外壳”。以下方法逐步完善:
public class Crawler : IDisposable
{
private HttpClient _httpClient;
private IDbConnection _connection;
private static readonly HashSet IgnoreWords
= new HashSet(new [] {"the","of","to","and","a","in","is","it"});
//构造函数,接收数据库名作为参数
public Crawler(string dbname)
{
_httpClient = new HttpClient();
_connection = GetConn(dbname);
}
//辅助函数,用于获取条目Id,且如果条目不存在,就将其加入数据库中
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
return 0;
}
//为每个网页建立索引
public async Task AddtoIndex(string url, HtmlDocument soup)
{
Console.WriteLine($"Indexing {url}");
}
//从一个HTML网页提取文字(不带html标签)
public string GetTextOnly(HtmlDocument soup)
{
return null;
}
//分词
public List SeparateWords(string text)
{
return null;
}
//如果Url已经建立索引,则返回true
public bool IsIndexed(string url)
{
return false;
}
//添加一个关联两个网页的链接
public void AddLinkref(string urlFrom, string urlTo, string linkText)
{
}
//从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
public async Task Crawl(List pages, int depth = 2)
{
throw new NotImplementedException();
}
public async Task GetHtmlDoc(string url)
{
return null;
}
//创建数据库表
public void CreateIndexTables()
{
}
public static string UrlJoin(string urlBase, string urlRel)
{
return null;
}
public IDbConnection GetConn(string dbname)
{
return null;
}
public void Dispose()
{
_connection.Close();
}
}
这还收录一些管理数据库连接的代码,以及索引时要忽略的单词列表。
履带式
对于 C#,抓取网页 HttpClient 是一个很好的选择。
可以使用nuget安装HttpClient,在NuGet管理器中搜索“httpclient”,名为Microsoft.Net.Http的项就是HttpClient库。
爬取网页代码很简单:
var url = "http://xxx.com";
var httpClient = new HttpClient();
var content = await httpClient.GetStringAsync(url);
HttpClient每次释放都会断开Tcp连接,所以为了节省性能,尽量把HttpClient做成单例。
爬取网页后的另一个非常重要的步骤是分析Html的内容。对于 C#,可以使用 Html Agility Pack 库。安装Html Agility Pack也很简单,在Nuget中搜索HtmlAgilityPack,或者直接使用Install-Package HtmlAgilityPack。
我们首先在爬虫类中实现 Crawl 方法。
<p>public async Task Crawl(List pages, int depth = 2)
{
for (int i = 0; i
c httpclient抓取网页(修改heritrix的默认抓取策略()的抓取算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-03-28 02:11
一种。首先修改heritrix的默认爬取策略
Heritrix默认的抓取策略是HostnameQueueAssignmentPolicy,该策略以hostname为key,所以一个域名下的所有连接都会放在同一个线程中,这样会导致抓取时一般只有一个线程运行(一般我们抓取特定 网站 上的内容)。这种方法可以很大程度上解决广域网中取信息时队列的键值问题。但是,单个 网站 网络抓取存在很大问题。以新浪的新闻页面为例,大部分的URL来自新浪网站内部,所以如果使用HostnameQueueAssignmentPolicy,会造成很长的队列。在 Heritrix 中,当线程从队列中获取 URL 链接时,它总是从队列的头部获取第一个链接。在那之后,从中获取链接的队列将进入阻塞状态,直到链接被处理。之后,它将从阻塞状态中恢复。如果使用HostnameQueueAssignmentPolicy策略来处理抓取一个网站的内容的情况,很有可能只有一个线程在工作,而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。
因此,我们需要改变Heritrix的爬取策略,即改变key的生成方式。我们需要使用这个键有效地将所有 URL 散列到不同的队列中,最终减少所有队列长度的方差。,在这种情况下,可以保证工作线程的最大效率。我们需要继承QueueAssignmentPolicy类,重写getClassKey()方法。getClassKey 方法的参数是一个链接对象,ELF Hash 算法可以通过这个链接对象返回一个值,并将其平均分配到各个队列中。更多线程爬取同域名下的网页,爬取速度会大大提高。
ELFHash算法是对字符串进行哈希运算,巧妙地计算出字符的ASCII码值,可以将字符串在哈希表中分布更均匀。
1、以下是ELFHash算法实现的抓取策略:
package org.archive.crawler.frontier;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.commons.httpclient.URIException;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.net.UURI;
import org.archive.net.UURIFactory;
public class ELFHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
private static final Logger logger = Logger.getLogger(ELFHashQueueAssignmentPolicy.class.getName());
/**
* When neat host-based class-key fails us
*/
private static String DEFAULT_CLASS_KEY = "default...";
private static final String DNS = "dns";
public String getClassKey(CrawlController controller, CandidateURI cauri) {
String scheme = cauri.getUURI().getScheme();
String candidate = null;
try {
if (scheme.equals(DNS)){
if (cauri.getVia() != null) {
// Special handling for DNS: treat as being
// of the same class as the triggering URI.
// When a URI includes a port, this ensures
// the DNS lookup goes atop the host:port
// queue that triggered it, rather than
// some other host queue
UURI viaUuri = UURIFactory.getInstance(cauri.flattenVia());
candidate = viaUuri.getAuthorityMinusUserinfo();
// adopt scheme of triggering URI
scheme = viaUuri.getScheme();
} else {
candidate= cauri.getUURI().getReferencedHost();
}
} else {
// 注释掉原来的
// candidate = cauri.getUURI().getAuthorityMinusUserinfo();
// 使用ELFHash算法
String uri = cauri.getUURI().toString();
long hash = ELFHash(uri);
candidate = Long.toString(hash % 100); // 取模 100,Heritrix默认开100个线程,对应100个不同的URI处理队列
}
if(candidate == null || candidate.length() == 0) {
candidate = DEFAULT_CLASS_KEY;
}
} catch (URIException e) {
logger.log(Level.INFO,
"unable to extract class key; using default", e);
candidate = DEFAULT_CLASS_KEY;
}
if (scheme != null && scheme.equals(UURIFactory.HTTPS)) {
// If https and no port specified, add default https port to
// distinguish https from http server without a port.
if (!candidate.matches(".+:[0-9]+")) {
candidate += UURIFactory.HTTPS_PORT;
}
}
// Ensure classKeys are safe as filenames on NTFS
return candidate.replace(':','#');
}
public long ELFHash(String str) {
long hash = 0;
long x = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash > 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
}
2、在 org.archive.crawler.frontier.AbstractFrontier 类中查找“HostnameQueueAssignmentPolicy”关键字,大约第 293 行,注释掉更改,然后添加我们的 ELFHashQueueAssignmentPolicy,如下(蓝色字体行):
// Read the list of permissible choices from heritrix.properties.
// Its a list of space- or comma-separated values.
String queueStr = System.getProperty(AbstractFrontier.class.getName() +
"." + ATTR_QUEUE_ASSIGNMENT_POLICY,
// HostnameQueueAssignmentPolicy.class.getName() + " " +
ELFHashQueueAssignmentPolicy.class.getName() + " " +
IPQueueAssignmentPolicy.class.getName() + " " +
BucketQueueAssignmentPolicy.class.getName() + " " +
SurtAuthorityQueueAssignmentPolicy.class.getName() + " " +
TopmostAssignedSurtQueueAssignmentPolicy.class.getName());
Pattern p = Pattern.compile("\\s*,\\s*|\\s+");
String [] queues = p.split(queueStr);
3、修改heritrix.properties文件中的配置,在文件中查找“HostnameQueueAssignmentPolicy”关键字,15左右两行9、160,复制后将这两行注释掉,粘贴到下面, 将这两行中的“HostnameQueueAssignmentPolicy”替换为“ELFHashQueueAssignmentPolicy”,如下(蓝色字体):
#org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
# org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.IPQueueAssignmentPolicy \
org.archive.crawler.frontier.BucketQueueAssignmentPolicy \
org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy \
org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.BdbFrontier.level = INFO
下面我们分别使用这两种抓取策略来创建抓取任务并做个对比:
下图是使用 HostnameQueueAssignmentPolicy 抓取策略创建的任务的状态图:
下图是使用 ELFHashQueueAssignmentPolicy 抓取策略创建的任务的状态图:
从上面两张图可以看出,同时在活跃线程数和fetches总大小上,ELFHashQueueAssignmentPolicy远高于HostnameQueueAssignmentPolicy。
注意:当使用 ELFHashQueueAssignmentPolicy 爬取策略时,爬取可能会停止。检查任务的 crawl.log 日志。URL后跟“robots.txt”,如:“”。这是因为Heritrix是一个完整的遵守“robots.txt”协议的网络爬虫,如果一个网站声明了他们不想被机器人访问的部分文件,Heritrix不会爬取那些内容。可以去掉robots.txt的限制,应该不会出现这种现象。
湾。取消rebots.txt的限制。
关于rebots.txt协议的取消,可以参考另一篇文章文章:
C。抓取指定网页内容
Heritrix的Extractors用于解析当前服务器返回的内容,提取页面中的URL,放入提取队列。因为它会爬取网页中的所有链接,但是有些链接不是我们想要的,比如图片链接、pdf文档等,这些链接需要过滤掉,我们可以创建自己的Extractor来爬取特定的网页内容。如下,是一个自定义的抓取搜狐新闻的Extractor:
<p>package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {
super(name, description);
}
public ExtractorSohu(String name) {
super(name, "sohu news extractor");
}
// http://news.sohu.com/20131020/n388534488.shtml
private static final String A_HERF = " 查看全部
c httpclient抓取网页(修改heritrix的默认抓取策略()的抓取算法)
一种。首先修改heritrix的默认爬取策略
Heritrix默认的抓取策略是HostnameQueueAssignmentPolicy,该策略以hostname为key,所以一个域名下的所有连接都会放在同一个线程中,这样会导致抓取时一般只有一个线程运行(一般我们抓取特定 网站 上的内容)。这种方法可以很大程度上解决广域网中取信息时队列的键值问题。但是,单个 网站 网络抓取存在很大问题。以新浪的新闻页面为例,大部分的URL来自新浪网站内部,所以如果使用HostnameQueueAssignmentPolicy,会造成很长的队列。在 Heritrix 中,当线程从队列中获取 URL 链接时,它总是从队列的头部获取第一个链接。在那之后,从中获取链接的队列将进入阻塞状态,直到链接被处理。之后,它将从阻塞状态中恢复。如果使用HostnameQueueAssignmentPolicy策略来处理抓取一个网站的内容的情况,很有可能只有一个线程在工作,而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。而所有其他线程都在等待。这是因为拥有绝大多数 URL 链接的队列将几乎永远被阻塞,因此其他线程根本无法获取 URL,在这种情况下,抓取工作将进入一种类似睡眠的状态。
因此,我们需要改变Heritrix的爬取策略,即改变key的生成方式。我们需要使用这个键有效地将所有 URL 散列到不同的队列中,最终减少所有队列长度的方差。,在这种情况下,可以保证工作线程的最大效率。我们需要继承QueueAssignmentPolicy类,重写getClassKey()方法。getClassKey 方法的参数是一个链接对象,ELF Hash 算法可以通过这个链接对象返回一个值,并将其平均分配到各个队列中。更多线程爬取同域名下的网页,爬取速度会大大提高。
ELFHash算法是对字符串进行哈希运算,巧妙地计算出字符的ASCII码值,可以将字符串在哈希表中分布更均匀。
1、以下是ELFHash算法实现的抓取策略:
package org.archive.crawler.frontier;
import java.util.logging.Level;
import java.util.logging.Logger;
import org.apache.commons.httpclient.URIException;
import org.archive.crawler.datamodel.CandidateURI;
import org.archive.crawler.framework.CrawlController;
import org.archive.net.UURI;
import org.archive.net.UURIFactory;
public class ELFHashQueueAssignmentPolicy extends QueueAssignmentPolicy {
private static final Logger logger = Logger.getLogger(ELFHashQueueAssignmentPolicy.class.getName());
/**
* When neat host-based class-key fails us
*/
private static String DEFAULT_CLASS_KEY = "default...";
private static final String DNS = "dns";
public String getClassKey(CrawlController controller, CandidateURI cauri) {
String scheme = cauri.getUURI().getScheme();
String candidate = null;
try {
if (scheme.equals(DNS)){
if (cauri.getVia() != null) {
// Special handling for DNS: treat as being
// of the same class as the triggering URI.
// When a URI includes a port, this ensures
// the DNS lookup goes atop the host:port
// queue that triggered it, rather than
// some other host queue
UURI viaUuri = UURIFactory.getInstance(cauri.flattenVia());
candidate = viaUuri.getAuthorityMinusUserinfo();
// adopt scheme of triggering URI
scheme = viaUuri.getScheme();
} else {
candidate= cauri.getUURI().getReferencedHost();
}
} else {
// 注释掉原来的
// candidate = cauri.getUURI().getAuthorityMinusUserinfo();
// 使用ELFHash算法
String uri = cauri.getUURI().toString();
long hash = ELFHash(uri);
candidate = Long.toString(hash % 100); // 取模 100,Heritrix默认开100个线程,对应100个不同的URI处理队列
}
if(candidate == null || candidate.length() == 0) {
candidate = DEFAULT_CLASS_KEY;
}
} catch (URIException e) {
logger.log(Level.INFO,
"unable to extract class key; using default", e);
candidate = DEFAULT_CLASS_KEY;
}
if (scheme != null && scheme.equals(UURIFactory.HTTPS)) {
// If https and no port specified, add default https port to
// distinguish https from http server without a port.
if (!candidate.matches(".+:[0-9]+")) {
candidate += UURIFactory.HTTPS_PORT;
}
}
// Ensure classKeys are safe as filenames on NTFS
return candidate.replace(':','#');
}
public long ELFHash(String str) {
long hash = 0;
long x = 0;
for (int i = 0; i < str.length(); i++) {
hash = (hash > 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF);
}
}
2、在 org.archive.crawler.frontier.AbstractFrontier 类中查找“HostnameQueueAssignmentPolicy”关键字,大约第 293 行,注释掉更改,然后添加我们的 ELFHashQueueAssignmentPolicy,如下(蓝色字体行):
// Read the list of permissible choices from heritrix.properties.
// Its a list of space- or comma-separated values.
String queueStr = System.getProperty(AbstractFrontier.class.getName() +
"." + ATTR_QUEUE_ASSIGNMENT_POLICY,
// HostnameQueueAssignmentPolicy.class.getName() + " " +
ELFHashQueueAssignmentPolicy.class.getName() + " " +
IPQueueAssignmentPolicy.class.getName() + " " +
BucketQueueAssignmentPolicy.class.getName() + " " +
SurtAuthorityQueueAssignmentPolicy.class.getName() + " " +
TopmostAssignedSurtQueueAssignmentPolicy.class.getName());
Pattern p = Pattern.compile("\\s*,\\s*|\\s+");
String [] queues = p.split(queueStr);
3、修改heritrix.properties文件中的配置,在文件中查找“HostnameQueueAssignmentPolicy”关键字,15左右两行9、160,复制后将这两行注释掉,粘贴到下面, 将这两行中的“HostnameQueueAssignmentPolicy”替换为“ELFHashQueueAssignmentPolicy”,如下(蓝色字体):
#org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
# org.archive.crawler.frontier.HostnameQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.AbstractFrontier.queue-assignment-policy = org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.ELFHashQueueAssignmentPolicy org.archive.crawler.frontier.IPQueueAssignmentPolicy org.archive.crawler.frontier.BucketQueueAssignmentPolicy org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.IPQueueAssignmentPolicy \
org.archive.crawler.frontier.BucketQueueAssignmentPolicy \
org.archive.crawler.frontier.SurtAuthorityQueueAssignmentPolicy \
org.archive.crawler.frontier.TopmostAssignedSurtQueueAssignmentPolicy
org.archive.crawler.frontier.BdbFrontier.level = INFO
下面我们分别使用这两种抓取策略来创建抓取任务并做个对比:
下图是使用 HostnameQueueAssignmentPolicy 抓取策略创建的任务的状态图:
下图是使用 ELFHashQueueAssignmentPolicy 抓取策略创建的任务的状态图:
从上面两张图可以看出,同时在活跃线程数和fetches总大小上,ELFHashQueueAssignmentPolicy远高于HostnameQueueAssignmentPolicy。
注意:当使用 ELFHashQueueAssignmentPolicy 爬取策略时,爬取可能会停止。检查任务的 crawl.log 日志。URL后跟“robots.txt”,如:“”。这是因为Heritrix是一个完整的遵守“robots.txt”协议的网络爬虫,如果一个网站声明了他们不想被机器人访问的部分文件,Heritrix不会爬取那些内容。可以去掉robots.txt的限制,应该不会出现这种现象。
湾。取消rebots.txt的限制。
关于rebots.txt协议的取消,可以参考另一篇文章文章:
C。抓取指定网页内容
Heritrix的Extractors用于解析当前服务器返回的内容,提取页面中的URL,放入提取队列。因为它会爬取网页中的所有链接,但是有些链接不是我们想要的,比如图片链接、pdf文档等,这些链接需要过滤掉,我们可以创建自己的Extractor来爬取特定的网页内容。如下,是一个自定义的抓取搜狐新闻的Extractor:
<p>package org.archive.crawler.extractor;
import java.io.IOException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.archive.crawler.datamodel.CrawlURI;
import org.archive.io.ReplayCharSequence;
import org.archive.util.HttpRecorder;
public class ExtractorSohu extends Extractor {
private static final long serialVersionUID = -7914995152462902519L;
public ExtractorSohu(String name, String description) {
super(name, description);
}
public ExtractorSohu(String name) {
super(name, "sohu news extractor");
}
// http://news.sohu.com/20131020/n388534488.shtml
private static final String A_HERF = "
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-27 23:01
)
在使用 HttpClient 抓取一些网页时,往往会保留从服务器发回的 cookie 信息,以便发起其他需要这些 cookie 的请求。在大多数情况下,我们使用内置的 cookie 策略,这使得获取这些 cookie 变得容易和直接。
下面一小段代码是访问并获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com");
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,也有一些由 网站 返回的 cookie 不一定完全符合规范。例如,在下面的例子中,从打印的 header 中可以看出,这个 cookie 中的 Expires 属性是时间戳的形式,不符合标准时间。格式化,因此,httpclient对cookies的处理无效,最终无法获取cookie,并发出警告信息:“Invalid 'expires' attribute: 1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用头部数据来重构一个cookie,而且很多人都这样做,但是这种方法并不优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4的“自定义cookie策略”一节中,提到了允许自定义cookie策略。自定义方法是实现CookieSpec接口,通过CookieSpecProvider在httpclient中完成策略实例的初始化和注册。嗯,关键线索就在 CookieSpec 接口,我们来看一下它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中找到了一个parse方法,看注释就知道是这个方法。它将 Set-Cookie 的头部信息解析成一个 Cookie 对象。自然,我们将了解 httplcient 中的默认实现 DefaultCookieSpec。由于篇幅限制,源代码没有贴出来。在默认实现中,DefaultCookieSpec的主要工作就是判断头部中Cookie规范的类型,然后调用具体的实现。像上面这样的 Cookie 最终由 NetscapeDraftSpec 的一个实例解析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE, dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就比较清楚了,我们只需要将cookie中的expires时间转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个CookieSpec类,继承DefaultCookieSpec并重写解析器方法将cookie中的expires转换为正确的时间格式并调用默认解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017] 查看全部
c httpclient抓取网页(一下-Cookie的header信息解析信息的制作
)
在使用 HttpClient 抓取一些网页时,往往会保留从服务器发回的 cookie 信息,以便发起其他需要这些 cookie 的请求。在大多数情况下,我们使用内置的 cookie 策略,这使得获取这些 cookie 变得容易和直接。
下面一小段代码是访问并获取对应的cookie:
@Test
public void getCookie(){
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet get=new HttpGet("http://www.baidu.com";);
HttpClientContext context = HttpClientContext.create();
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
打印结果
>>>>>>headers:
Server: bfe/1.0.8.18
Date: Tue, 12 Sep 2017 06:19:06 GMT
Content-Type: text/html
Last-Modified: Mon, 23 Jan 2017 13:28:24 GMT
Transfer-Encoding: chunked
Connection: Keep-Alive
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Pragma: no-cache
Set-Cookie: BDORZ=27315; max-age=86400; domain=.baidu.com; path=/
>>>>>>cookies:
[version: 0][name: BDORZ][value: 27315][domain: baidu.com][path: /][expiry: null]
但是,也有一些由 网站 返回的 cookie 不一定完全符合规范。例如,在下面的例子中,从打印的 header 中可以看出,这个 cookie 中的 Expires 属性是时间戳的形式,不符合标准时间。格式化,因此,httpclient对cookies的处理无效,最终无法获取cookie,并发出警告信息:“Invalid 'expires' attribute: 1505204523”
警告: Invalid cookie header: "Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly". Invalid 'expires' attribute: 1505204523
>>>>>>headers:
Date: Tue, 12 Sep 2017 06:22:03 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=90236a64-8650-494b332a285dbd886e5981965fc4a93f023d; Expires=1505204523; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
虽然我们可以使用头部数据来重构一个cookie,而且很多人都这样做,但是这种方法并不优雅,那么如何解决这个问题呢?网上相关资料很少,只能从官方文档入手。在官方文档3.4的“自定义cookie策略”一节中,提到了允许自定义cookie策略。自定义方法是实现CookieSpec接口,通过CookieSpecProvider在httpclient中完成策略实例的初始化和注册。嗯,关键线索就在 CookieSpec 接口,我们来看一下它的源码:
public interface CookieSpec {
……
/**
* Parse the {@code "Set-Cookie"} Header into an array of Cookies.
*
* <p>This method will not perform the validation of the resultant
* {@link Cookie}s
*
* @see #validate
*
* @param header the {@code Set-Cookie} received from the server
* @param origin details of the cookie origin
* @return an array of {@code Cookie}s parsed from the header
* @throws MalformedCookieException if an exception occurs during parsing
*/
List parse(Header header, CookieOrigin origin) throws MalformedCookieException;
……
}</p>
在源码中找到了一个parse方法,看注释就知道是这个方法。它将 Set-Cookie 的头部信息解析成一个 Cookie 对象。自然,我们将了解 httplcient 中的默认实现 DefaultCookieSpec。由于篇幅限制,源代码没有贴出来。在默认实现中,DefaultCookieSpec的主要工作就是判断头部中Cookie规范的类型,然后调用具体的实现。像上面这样的 Cookie 最终由 NetscapeDraftSpec 的一个实例解析。在 NetscapeDraftSpec 的源代码中,默认的过期时间格式定义为“EEE, dd-MMM-yy HH:mm:ss z”
public class NetscapeDraftSpec extends CookieSpecBase {
protected static final String EXPIRES_PATTERN = "EEE, dd-MMM-yy HH:mm:ss z";
/** Default constructor */
public NetscapeDraftSpec(final String[] datepatterns) {
super(new BasicPathHandler(),
new NetscapeDomainHandler(),
new BasicSecureHandler(),
new BasicCommentHandler(),
new BasicExpiresHandler(
datepatterns != null ? datepatterns.clone() : new String[]{EXPIRES_PATTERN}));
}
NetscapeDraftSpec(final CommonCookieAttributeHandler... handlers) {
super(handlers);
}
public NetscapeDraftSpec() {
this((String[]) null);
}
……
}
至此,就比较清楚了,我们只需要将cookie中的expires时间转换成正确的格式,然后发送给默认的解析器即可。
解决方案:
自定义一个CookieSpec类,继承DefaultCookieSpec并重写解析器方法将cookie中的expires转换为正确的时间格式并调用默认解析方法
实现如下(网址不公开,已隐藏)
public class TestHttpClient {
String url = sth;
class MyCookieSpec extends DefaultCookieSpec {
@Override
public List parse(Header header, CookieOrigin cookieOrigin) throws MalformedCookieException {
String value = header.getValue();
String prefix = "Expires=";
if (value.contains(prefix)) {
String expires = value.substring(value.indexOf(prefix) + prefix.length());
expires = expires.substring(0, expires.indexOf(";"));
String date = DateUtils.formatDate(new Date(Long.parseLong(expires) * 1000L),"EEE, dd-MMM-yy HH:mm:ss z");
value = value.replaceAll(prefix + "\\d{10};", prefix + date + ";");
}
header = new BasicHeader(header.getName(), value);
return super.parse(header, cookieOrigin);
}
}
@Test
public void getCookie() {
CloseableHttpClient httpClient = HttpClients.createDefault();
Registry cookieSpecProviderRegistry = RegistryBuilder.create()
.register("myCookieSpec", context -> new MyCookieSpec()).build();//注册自定义CookieSpec
HttpClientContext context = HttpClientContext.create();
context.setCookieSpecRegistry(cookieSpecProviderRegistry);
HttpGet get = new HttpGet(url);
get.setConfig(RequestConfig.custom().setCookieSpec("myCookieSpec").build());
try {
CloseableHttpResponse response = httpClient.execute(get, context);
try{
System.out.println(">>>>>>headers:");
Arrays.stream(response.getAllHeaders()).forEach(System.out::println);
System.out.println(">>>>>>cookies:");
context.getCookieStore().getCookies().forEach(System.out::println);
}
finally {
response.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
再次运行,顺利打印出正确的结果,完美!
>>>>>>headers:
Date: Tue, 12 Sep 2017 07:24:10 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: yd_cookie=9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f; Expires=1505208250; Path=/; HttpOnly
Cache-Control: no-cache, no-store
Server: WAF/2.4-12.1
>>>>>>cookies:
[version: 0][name: yd_cookie][value: 9f521fc5-0248-4ab3ee650ca50b1c7abb1cd2526b830e620f][domain: www.sth.com][path: /][expiry: Tue Sep 12 17:24:10 CST 2017]
c httpclient抓取网页(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-27 12:05
爬取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页中图片的抓取功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
好了,今天就到这里了,以后会有更多精彩的python内容分享给大家。 查看全部
c httpclient抓取网页(最基本的抓取网页内容的代码实现:利用urllib模块,来实现一个)
爬取网页内容最基本的代码实现:
#!/usr/bin/env python
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print firstNonBlank(lines),
lines.reverse()
print firstNonBlank(lines),
def download(url='http://www',process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()
使用urllib模块实现网页中图片的抓取功能:
import urllib.request
import socket
import re
import sys
import os
targetDir = r"C:\Users\elqstux\Desktop\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:])
return t
if __name__ == "__main__":
hostname = "http://www.douban.com"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
for link, t in set(re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes))):
print(link)
urllib.request.urlretrieve(link, destFile(link))
import urllib.request
import socket
import re
import sys
import os
targetDir = r"H:\pic"
def destFile(path):
if not os.path.isdir(targetDir):
os.mkdir(targetDir)
pos = path.rindex('/')
t = os.path.join(targetDir, path[pos+1:]) #会以/作为分隔
return t
if __name__ == "__main__":
hostname = "http://www.douban.com/"
req = urllib.request.Request(hostname)
webpage = urllib.request.urlopen(req)
contentBytes = webpage.read()
match = re.findall(r'(http:[^\s]*?(jpg|png|gif))', str(contentBytes) )#r'(http:[^\s]*?(jpg|png|gif))'中包含两层圆括号,故有两个分组,
#上面会返回列表,括号中匹配的内容才会出现在列表中
for picname, picType in match:
print(picname)
print(picType)
'''''
输出:
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g111328-1.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
http://img3.douban.com/icon/g197523-19.jpg
jpg
http://img3.douban.com/pics/blank.gif
gif
...
'''
好了,今天就到这里了,以后会有更多精彩的python内容分享给大家。
c httpclient抓取网页(一下Java语言环境中能够用于网页下载或信息提取的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-15 08:19
如果您需要从 Internet 下载特定网页,或者从网页中解析特定信息,那么这个 文章 将帮助您。下面我列出了Java语言环境下可用于网页下载或信息提取的工具。以下工具各有特点。
Web-harvest 是一个开源的 Java 网页信息提取工具。它主要使用XQuery、XPath、正则表达式和javascript等脚本语言从网页中提取字段信息。提取信息的灵活性和准确性主要来自于 XPath 和 XQuery。Web-harvest 提供了一个可以在 JRE 环境中执行的 jar 文件。运行这个文件可以执行一个简单的XML类型的配置文件,就是你定义的网页访问和解析规则。你可以简单的使用执行程序中的xml配置文件,他也可以通过javaapi进行更复杂的开发。它支持使用代理服务器。性能较差,更适合小而简单的程序。
HttpClient是Apache的一个子项目,支持所有http协议,可以管理cookie信息。它的强项在于访问网页,但它不具备解析网页的能力。还有两个比较实用的功能是指定代理服务器,如果你有多个网卡和多个网络,也可以指定网络出口。
Jsoup 是一个非常方便的网页访问和解析工具。它可以用非常简单的代码访问网页,并通过一种叫做css的格式提取网页的信息。非常简单易学,处理效率也很高。另外,它只能用来解析传入的html字符串,所以结合其他工具开发程序非常容易。
SWT下的WebBrowser,首先SWT是Eclipse下的一个图形化开发工具包,其中WebBrowser允许你调用系统中的浏览器,比如IE或者Firefox,相当于把浏览器嵌入到你的java程序中。它最大的优点是可以完全模拟浏览器,所以可以执行以上工具无法执行的javascript和css,让系统浏览器管理你的cookies。当然WebBrowser是异步的,需要监听complete事件来判断页面是否加载并绘制。并在竞技赛事中进行后续处理。它有一个很亮眼的特性就是它可以让你执行你传入的Javascipt。
以上是过去工作中实际使用过的工具。您可以选择自己的优势并一起使用。我希望它会帮助你。 查看全部
c httpclient抓取网页(一下Java语言环境中能够用于网页下载或信息提取的工具)
如果您需要从 Internet 下载特定网页,或者从网页中解析特定信息,那么这个 文章 将帮助您。下面我列出了Java语言环境下可用于网页下载或信息提取的工具。以下工具各有特点。
Web-harvest 是一个开源的 Java 网页信息提取工具。它主要使用XQuery、XPath、正则表达式和javascript等脚本语言从网页中提取字段信息。提取信息的灵活性和准确性主要来自于 XPath 和 XQuery。Web-harvest 提供了一个可以在 JRE 环境中执行的 jar 文件。运行这个文件可以执行一个简单的XML类型的配置文件,就是你定义的网页访问和解析规则。你可以简单的使用执行程序中的xml配置文件,他也可以通过javaapi进行更复杂的开发。它支持使用代理服务器。性能较差,更适合小而简单的程序。
HttpClient是Apache的一个子项目,支持所有http协议,可以管理cookie信息。它的强项在于访问网页,但它不具备解析网页的能力。还有两个比较实用的功能是指定代理服务器,如果你有多个网卡和多个网络,也可以指定网络出口。
Jsoup 是一个非常方便的网页访问和解析工具。它可以用非常简单的代码访问网页,并通过一种叫做css的格式提取网页的信息。非常简单易学,处理效率也很高。另外,它只能用来解析传入的html字符串,所以结合其他工具开发程序非常容易。
SWT下的WebBrowser,首先SWT是Eclipse下的一个图形化开发工具包,其中WebBrowser允许你调用系统中的浏览器,比如IE或者Firefox,相当于把浏览器嵌入到你的java程序中。它最大的优点是可以完全模拟浏览器,所以可以执行以上工具无法执行的javascript和css,让系统浏览器管理你的cookies。当然WebBrowser是异步的,需要监听complete事件来判断页面是否加载并绘制。并在竞技赛事中进行后续处理。它有一个很亮眼的特性就是它可以让你执行你传入的Javascipt。
以上是过去工作中实际使用过的工具。您可以选择自己的优势并一起使用。我希望它会帮助你。
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-03-13 03:18
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/");
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 } 查看全部
c httpclient抓取网页(【魔兽世界】《守望先锋》登录结果公布啦!
)
登录页面:
登录结果页面: , , ...
登录时需要用户名和密码,属性分别为tbUserName和tbPassword;如图:
登录成功。进入下一页时需要提供cookies,也可以设置UA等属性:
具体代码:
1 package com.arlen.login;
2
3 import org.apache.commons.httpclient.Cookie;
4 import org.apache.commons.httpclient.HttpClient;
5 import org.apache.commons.httpclient.NameValuePair;
6 import org.apache.commons.httpclient.cookie.CookiePolicy;
7 import org.apache.commons.httpclient.methods.GetMethod;
8 import org.apache.commons.httpclient.methods.PostMethod;
9 import org.apache.commons.httpclient.params.HttpMethodParams;
10
11 public class ImitateLogin {
12
13 public static void main(String[] args) {
14 String userName = "username";
15 String password = "password"
16 String loginUrl = "http://passport.cnblogs.com/login.aspx";
17 String dataUrl = "http://home.cnblogs.com/";
18 HttpClientLogin(userName, password, loginUrl, dataUrl);
19 }
20
21 private static void HttpClientLogin(String userName, String password,
22 String loginUrl, String dataUrl) {
23 HttpClient httpClient = new HttpClient();
24 httpClient.getParams().setParameter(
25 HttpMethodParams.HTTP_CONTENT_CHARSET, "utf-8");
26 PostMethod postMethod = new PostMethod(loginUrl);
27
28 NameValuePair[] postData = { new NameValuePair("tbUserName", userName),
29 new NameValuePair("tbPassword", password) };
30 postMethod.setRequestBody(postData);
31
32 try {
33
34 httpClient.getParams().setCookiePolicy(
35 CookiePolicy.BROWSER_COMPATIBILITY);
36 httpClient.executeMethod(postMethod);
37 Cookie[] cookies = httpClient.getState().getCookies();
38 StringBuffer stringBuffer = new StringBuffer();
39 for (Cookie c : cookies) {
40 stringBuffer.append(c.toString() + ";");
41 }
42
43 GetMethod getMethod = new GetMethod(dataUrl);
44 getMethod.setRequestHeader("Cookie", stringBuffer.toString());
45 postMethod.setRequestHeader("Host", "passport.cnblogs.com");
46 postMethod.setRequestHeader("Referer", "http://home.cnblogs.com/";);
47 postMethod.setRequestHeader("User-Agent", "AndroidCnblogs");
48 httpClient.executeMethod(getMethod);
49
50 String result = getMethod.getResponseBodyAsString();
51 System.out.println(result);
52
53 } catch (Exception e) {
54 e.printStackTrace();
55 }
56 }
57
58 }
c httpclient抓取网页(爬虫环境python3.7+pycharm()机制都没有 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-23 01:09
)
爬行动物环境
python3.7+pycharm
最近发现了一个网站,首商网,里面有超过一百万的企业信息,但是网站根本没有反爬机制,对喜欢的我们来说是不是太爽了爬虫,直接拿我自己创建了一组代码,用了三个并发,每次20个线程,爬了五六个小时,得到了20万条数据,太棒了!
还是老规矩,代码直接在下面,所有的注释和解释都在代码里,直接运行即可:
for k in range(1, 1651, 50):
# -*- coding: utf-8 -*-
# 本项目是原始的异步爬虫,没有封装为函数
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 先用并发获取每个页面的子链接
########################################################################################################################
pro = 'zhaoshuang:LINA5201314@ 14.215.44.251:28803'
proxies = {'http://': 'http://' + pro,
'httpS://': 'https://' + pro
}
# 加入请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
wzs = []
def parser(url):
print(url)
try:
response = requests.get(url, headers=headers)
soup1 = BeautifulSoup(response.text, "lxml")
# body > div.list_contain > div.left > div.list_li > ul > li:nth-child(1) > table > tbody > tr > td:nth-child(3) > div.title > a
wz = soup1.select('div.title')
for i in wz:
wzs.append(i.contents[0].get("href"))
time.sleep(1)
except:
print('公司正在审核中')
urls = ['http://www.sooshong.com/c-3p{}'.format(num) for num in range(k, k + 50)]
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('子页链接抓取完毕!')
########################################################################################################################
# 使用并发法爬取详细页链接
# 定义函数获取每个网页需要爬取的内容
wzs1 = []
def parser(url):
# 利用正则表达式解析网页
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
except:
print('子页解析失败')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('详细页链接获取完毕!')
"""
# 使用异步法抓取子页面的链接
########################################################################################################################
async def get_html(sess, ur):
try:
proxy_auth = aiohttp.BasicAuth('zhaoshuang', 'LINA5201314')
html = await sess.get(ur,
headers=headers) # , proxy='http://'+'14.116.200.33:28803', proxy_auth=proxy_auth)
r = await html.text()
return r
except:
print("error")
# f = requests.get('http://211775.sooshong.com', headers=headers)
wzs1 = []
# 解析网页
async def parser(respo):
# 利用正则表达式解析网页
try:
# 对响应体进行解析
soup = BeautifulSoup(respo, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
company = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong") # 标题
company = company[0].text
# 匹配电话号码
dianhua = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(3)") # 地址
dianhua = dianhua[0].text.split(":")[1]
# 匹配手机号码
phone = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(4)") # 日租价格
phone = phone[0].text.split(":")[1]
# 匹配传真
chuanzhen = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(5)") # 月租价格
chuanzhen = chuanzhen[0].text.split(":")[1]
# 经营模式
jingying = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(8)") # 面积大小
jingying = jingying[0].text.split(":")[1]
# 公司地址
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)') # 抽取建造年份
address = address[0].text.split(":")[1]
# 公司简介
# introduction = soup.select("#main > div.main > div.intro > div.intros > div.text > p") # 楼层属性
# introduction = introduction[0].text.strip()
data = [company, address, dianhua, phone, chuanzhen, jingying]
print(data)
with open('首富网企业7.csv', 'a+', newline='', encoding='GB2312', errors='ignore') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data, [1])
except:
print("出错!")
async def main(loop):
async with aiohttp.ClientSession() as sess:
tasks = []
for ii in wzs:
ur = ii
try:
tasks.append(loop.create_task(get_html(sess, ur)))
except:
print('error')
# 设置0.1的网络延迟增加爬取效率
await asyncio.sleep(0.1)
finished, unfinised = await asyncio.wait(tasks)
for i1 in finished:
await parser(i1.result())
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
print("花费时间", time.time() - t1)
print('详细页链接抓取完毕!')
"""
########################################################################################################################
# 使用并发法获取详细页的内容
########################################################################################################################
# 定义函数获取每个网页需要爬取的内容
def parser(url):
global data
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, 'lxml')
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
company = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong')
company = company[0].text
name = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(2)')
name = name[0].text
dianhua = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(3)')
dianhua = dianhua[0].text.split(':')[1]
shouji = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(4)')
shouji = shouji[0].text.split(':')[1]
chuanzhen = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(5)')
chuanzhen = chuanzhen[0].text.split(':')[1]
product = soup.select('tr:nth-child(1) > td:nth-child(2)')
product = product[0].text
company_type = soup.select('tr:nth-child(2) > td:nth-child(2) > span')
company_type = company_type[0].text.strip()
legal_person = soup.select('tr:nth-child(3) > td:nth-child(2)')
legal_person = legal_person[0].text
main_address = soup.select('tr:nth-child(5) > td:nth-child(2) > span')
main_address = main_address[0].text
brand = soup.select('tr:nth-child(6) > td:nth-child(2) > span')
brand = brand[0].text
area = soup.select('tr:nth-child(9) > td:nth-child(2) > span')
area = area[0].text
industry = soup.select('tr:nth-child(1) > td:nth-child(4)')
industry = industry[0].text.strip()
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)')
address = address[0].text.split(':')[1]
jingying = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(8)')
jingying = jingying[0].text.split(':')[1]
date = soup.select('tr:nth-child(5) > td:nth-child(4) > span')
date = date[0].text
wangzhi = soup.select('tr:nth-child(12) > td:nth-child(4) > p > span > a')
wangzhi = wangzhi[0].text
data = [company, date, name, legal_person, shouji, dianhua, chuanzhen, company_type, jingying, industry,
product, wangzhi, area, brand, address, main_address] # 将以上数据放入列表中打印在命令框
print(data)
with open('服装1.csv', 'a', newline='', encoding='GB2312') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
except:
with open('服装2.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
print('utf解码成功')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs1]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('全部信息抓取完毕') 查看全部
c httpclient抓取网页(爬虫环境python3.7+pycharm()机制都没有
)
爬行动物环境
python3.7+pycharm
最近发现了一个网站,首商网,里面有超过一百万的企业信息,但是网站根本没有反爬机制,对喜欢的我们来说是不是太爽了爬虫,直接拿我自己创建了一组代码,用了三个并发,每次20个线程,爬了五六个小时,得到了20万条数据,太棒了!
还是老规矩,代码直接在下面,所有的注释和解释都在代码里,直接运行即可:
for k in range(1, 1651, 50):
# -*- coding: utf-8 -*-
# 本项目是原始的异步爬虫,没有封装为函数
import asyncio
import aiohttp
import time
from bs4 import BeautifulSoup
import csv
import requests
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
# 先用并发获取每个页面的子链接
########################################################################################################################
pro = 'zhaoshuang:LINA5201314@ 14.215.44.251:28803'
proxies = {'http://': 'http://' + pro,
'httpS://': 'https://' + pro
}
# 加入请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit'
'/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
wzs = []
def parser(url):
print(url)
try:
response = requests.get(url, headers=headers)
soup1 = BeautifulSoup(response.text, "lxml")
# body > div.list_contain > div.left > div.list_li > ul > li:nth-child(1) > table > tbody > tr > td:nth-child(3) > div.title > a
wz = soup1.select('div.title')
for i in wz:
wzs.append(i.contents[0].get("href"))
time.sleep(1)
except:
print('公司正在审核中')
urls = ['http://www.sooshong.com/c-3p{}'.format(num) for num in range(k, k + 50)]
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in urls]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('子页链接抓取完毕!')
########################################################################################################################
# 使用并发法爬取详细页链接
# 定义函数获取每个网页需要爬取的内容
wzs1 = []
def parser(url):
# 利用正则表达式解析网页
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
except:
print('子页解析失败')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('详细页链接获取完毕!')
"""
# 使用异步法抓取子页面的链接
########################################################################################################################
async def get_html(sess, ur):
try:
proxy_auth = aiohttp.BasicAuth('zhaoshuang', 'LINA5201314')
html = await sess.get(ur,
headers=headers) # , proxy='http://'+'14.116.200.33:28803', proxy_auth=proxy_auth)
r = await html.text()
return r
except:
print("error")
# f = requests.get('http://211775.sooshong.com', headers=headers)
wzs1 = []
# 解析网页
async def parser(respo):
# 利用正则表达式解析网页
try:
# 对响应体进行解析
soup = BeautifulSoup(respo, "lxml")
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
lianjie = soup.select('#main > div.main > div.intro > div.intros > div.text > p > a')
lianjie = lianjie[0].get('href')
wzs1.append(lianjie)
print(lianjie)
company = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong") # 标题
company = company[0].text
# 匹配电话号码
dianhua = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(3)") # 地址
dianhua = dianhua[0].text.split(":")[1]
# 匹配手机号码
phone = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(4)") # 日租价格
phone = phone[0].text.split(":")[1]
# 匹配传真
chuanzhen = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(5)") # 月租价格
chuanzhen = chuanzhen[0].text.split(":")[1]
# 经营模式
jingying = soup.select("#main > div.aside > div.info > div.info_c > p:nth-child(8)") # 面积大小
jingying = jingying[0].text.split(":")[1]
# 公司地址
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)') # 抽取建造年份
address = address[0].text.split(":")[1]
# 公司简介
# introduction = soup.select("#main > div.main > div.intro > div.intros > div.text > p") # 楼层属性
# introduction = introduction[0].text.strip()
data = [company, address, dianhua, phone, chuanzhen, jingying]
print(data)
with open('首富网企业7.csv', 'a+', newline='', encoding='GB2312', errors='ignore') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data, [1])
except:
print("出错!")
async def main(loop):
async with aiohttp.ClientSession() as sess:
tasks = []
for ii in wzs:
ur = ii
try:
tasks.append(loop.create_task(get_html(sess, ur)))
except:
print('error')
# 设置0.1的网络延迟增加爬取效率
await asyncio.sleep(0.1)
finished, unfinised = await asyncio.wait(tasks)
for i1 in finished:
await parser(i1.result())
if __name__ == '__main__':
t1 = time.time()
loop = asyncio.get_event_loop()
loop.run_until_complete(main(loop))
print("花费时间", time.time() - t1)
print('详细页链接抓取完毕!')
"""
########################################################################################################################
# 使用并发法获取详细页的内容
########################################################################################################################
# 定义函数获取每个网页需要爬取的内容
def parser(url):
global data
try:
res = requests.get(url, headers=headers)
# 对响应体进行解析
soup = BeautifulSoup(res.text, 'lxml')
# 找到页面子链接,进入子页面,对子页面进行抓取
# 用select函数抽取需要的内容,单击需要的内容》检查》copy select
company = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(1) > strong')
company = company[0].text
name = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(2)')
name = name[0].text
dianhua = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(3)')
dianhua = dianhua[0].text.split(':')[1]
shouji = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(4)')
shouji = shouji[0].text.split(':')[1]
chuanzhen = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(5)')
chuanzhen = chuanzhen[0].text.split(':')[1]
product = soup.select('tr:nth-child(1) > td:nth-child(2)')
product = product[0].text
company_type = soup.select('tr:nth-child(2) > td:nth-child(2) > span')
company_type = company_type[0].text.strip()
legal_person = soup.select('tr:nth-child(3) > td:nth-child(2)')
legal_person = legal_person[0].text
main_address = soup.select('tr:nth-child(5) > td:nth-child(2) > span')
main_address = main_address[0].text
brand = soup.select('tr:nth-child(6) > td:nth-child(2) > span')
brand = brand[0].text
area = soup.select('tr:nth-child(9) > td:nth-child(2) > span')
area = area[0].text
industry = soup.select('tr:nth-child(1) > td:nth-child(4)')
industry = industry[0].text.strip()
address = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(9)')
address = address[0].text.split(':')[1]
jingying = soup.select('#main > div.aside > div.info > div.info_c > p:nth-child(8)')
jingying = jingying[0].text.split(':')[1]
date = soup.select('tr:nth-child(5) > td:nth-child(4) > span')
date = date[0].text
wangzhi = soup.select('tr:nth-child(12) > td:nth-child(4) > p > span > a')
wangzhi = wangzhi[0].text
data = [company, date, name, legal_person, shouji, dianhua, chuanzhen, company_type, jingying, industry,
product, wangzhi, area, brand, address, main_address] # 将以上数据放入列表中打印在命令框
print(data)
with open('服装1.csv', 'a', newline='', encoding='GB2312') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
except:
with open('服装2.csv', 'a', newline='', encoding='utf-8-sig') as csvfile:
w1 = csv.writer(csvfile)
w1.writerow(data)
print('utf解码成功')
# 利用并发加速爬取,最大线程为50个,本文章中一共有50个网站,可以加入50个线程
# 建立一个加速器对象,线程数每个网站都不同,太大网站接受不了会造成数据损失
executor = ThreadPoolExecutor(max_workers=10)
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(parser, url) for url in wzs1]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
print('全部信息抓取完毕')
c httpclient抓取网页(Python爬虫怎么入门,到底要学习哪些内容?(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-23 01:08
很多朋友不知道Python爬虫怎么上手,怎么学,学什么。今天给大家介绍一些学习爬虫必须掌握的第三方库。
废话不多说,直接上干货。
请求库
GitHub:
requests 库应该是现在爬虫最流行和最实用的库了,而且非常人性化。在文章之前我也写过一篇关于它的使用的文章,我们来看看Python中的Requests库,大家可以看看。
requests最详细的用法可以参考官方文档:
使用一个小案例:
>>> import requests
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
u'{"type":"User"...'
>>> r.json()
{u'disk_usage': 368627, u'private_gists': 484, ...}
GitHub:
urllib3 是一个非常强大的 http 请求库,提供了一系列操作 URL 的函数。
详细使用方法请参考:
使用一个小案例:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request('GET', 'http://httpbin.org/robots.txt')
>>> r.status
200
>>> r.data
'User-agent: *\nDisallow: /deny\n'
GitHub:
自动化测试工具。调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
对于这个库,不仅可以使用Python,比如JAVA、Python、C#等都可以使用selenium库
有关如何在 Python 语言中使用该库的信息,可以访问并查看官方文档
使用一个小案例:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://seleniumhq.org/')
GitHub:
基于 asyncio 实现的 HTTP 框架。借助 async/await 关键字的异步操作和使用异步库进行数据捕获可以大大提高效率。
这是一个高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用一个小案例:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
解析库
官方文档:
解析html和XML,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的人必备的库。
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
GitHub:
jQuery的Python实现可以使用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
数据存储库
GitHub:
官方文档:
一个用纯 Python 实现的 MySQL 客户端操作库。很实用也很简单。
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
指示:
redis-dump 是一个redis和json转换的工具;redis-dump是基于ruby开发的,需要ruby环境,而新版本的redis-dump需要2.2.2或以上的ruby版本,centos中yum,你只能安装 2.0 版本的 ruby。需要先安装ruby管理工具rvm才能安装更高版本的ruby。 查看全部
c httpclient抓取网页(Python爬虫怎么入门,到底要学习哪些内容?(上))
很多朋友不知道Python爬虫怎么上手,怎么学,学什么。今天给大家介绍一些学习爬虫必须掌握的第三方库。
废话不多说,直接上干货。
请求库
GitHub:
requests 库应该是现在爬虫最流行和最实用的库了,而且非常人性化。在文章之前我也写过一篇关于它的使用的文章,我们来看看Python中的Requests库,大家可以看看。
requests最详细的用法可以参考官方文档:
使用一个小案例:
>>> import requests
>>> r = requests.get('https://api.github.com/user', auth=('user', 'pass'))
>>> r.status_code
200
>>> r.headers['content-type']
'application/json; charset=utf8'
>>> r.encoding
'utf-8'
>>> r.text
u'{"type":"User"...'
>>> r.json()
{u'disk_usage': 368627, u'private_gists': 484, ...}
GitHub:
urllib3 是一个非常强大的 http 请求库,提供了一系列操作 URL 的函数。
详细使用方法请参考:
使用一个小案例:
>>> import urllib3
>>> http = urllib3.PoolManager()
>>> r = http.request('GET', 'http://httpbin.org/robots.txt')
>>> r.status
200
>>> r.data
'User-agent: *\nDisallow: /deny\n'
GitHub:
自动化测试工具。调用浏览器的驱动程序。有了这个库,你可以直接调用浏览器完成某些操作,比如输入验证码。
对于这个库,不仅可以使用Python,比如JAVA、Python、C#等都可以使用selenium库
有关如何在 Python 语言中使用该库的信息,可以访问并查看官方文档
使用一个小案例:
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://seleniumhq.org/')
GitHub:
基于 asyncio 实现的 HTTP 框架。借助 async/await 关键字的异步操作和使用异步库进行数据捕获可以大大提高效率。
这是一个高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用一个小案例:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
解析库
官方文档:
解析html和XML,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的人必备的库。
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
GitHub:
jQuery的Python实现可以使用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
数据存储库
GitHub:
官方文档:
一个用纯 Python 实现的 MySQL 客户端操作库。很实用也很简单。
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
指示:
redis-dump 是一个redis和json转换的工具;redis-dump是基于ruby开发的,需要ruby环境,而新版本的redis-dump需要2.2.2或以上的ruby版本,centos中yum,你只能安装 2.0 版本的 ruby。需要先安装ruby管理工具rvm才能安装更高版本的ruby。
c httpclient抓取网页( 2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-19 15:11
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站,登录后抓取网页信息。
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站并抓取登录后网页信息的实现方法,涉及C#基于session操作登录网页和页面阅读相关操作技巧,小伙伴们有需要的可以参考下
本文示例介绍了C#使用WebClient登录网站并获取登录后网页信息的实现方法。分享给大家参考,详情如下:
C# login网站其实是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求到request,达到模拟登录的效果。
以下 CookieAwareWebClient 实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
对C#相关内容比较感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用方法》总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》和《C#编程线程使用技巧总结》
我希望这篇文章对你的 C# 编程有所帮助。 查看全部
c httpclient抓取网页(
2017年05月13日12:00本文基于会话操作登陆网页及页面读取相关操作技巧,)
C#使用WebClient登录网站,登录后抓取网页信息。
更新时间:2017-05-13 12:00:58 作者:柔城
本文文章主要介绍C#使用WebClient登录网站并抓取登录后网页信息的实现方法,涉及C#基于session操作登录网页和页面阅读相关操作技巧,小伙伴们有需要的可以参考下
本文示例介绍了C#使用WebClient登录网站并获取登录后网页信息的实现方法。分享给大家参考,详情如下:
C# login网站其实是模拟浏览器提交表单,然后记录浏览器响应返回的session cookie值,并用这个session cookie值再次发送请求到request,达到模拟登录的效果。
以下 CookieAwareWebClient 实现在发送请求时携带 cookie。
public class CookieAwareWebClient : WebClient
{
private CookieContainer cookie = new CookieContainer();
protected override WebRequest GetWebRequest(Uri address)
{
WebRequest request = base.GetWebRequest(address);
if (request is HttpWebRequest)
{
(request as HttpWebRequest).CookieContainer = cookie;
}
return request;
}
}
以下是模拟表单提交登录的使用示例:
var client = new CookieAwareWebClient();
client.BaseAddress = @"https://hovertree.net/any/base/url/";
var loginData = new NameValueCollection();
loginData.Add("login", "YourLogin");
loginData.Add("password", "YourPassword");
client.UploadValues("login.php", "POST", loginData);
//Now you are logged in and can request pages
string htmlSource = client.DownloadString("index.php");
对C#相关内容比较感兴趣的读者可以查看本站专题:《C#编码操作技巧总结》、《C#中XML文件操作技巧总结》、《C#常用控件使用教程》、《WinForm控件使用方法》总结》、《C#数据结构与算法教程》、《C#面向对象编程入门教程》和《C#编程线程使用技巧总结》
我希望这篇文章对你的 C# 编程有所帮助。
c httpclient抓取网页(如何用httpclient+jsoup实现抓取网页分享(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-19 15:06
和之前的博客一样,在学习用httpclient实现网络爬虫的时候,在网上查了很多资料,但是httpclient的版本是之前的版本3.1或者4.3。我通过学习了解了httpclient4.5。今天给大家分享一下我自己用httpclient+jsoup爬取网页的实现。
httpclient+jsoup 获取网页非常简单。首先可以通过httpclient的get方法获取一个网页的所有内容(如果有什么不懂的可以看我之前关于get方法的解释),然后使用jsoup获取一个网页的所有内容网页。解析内容,获取该网页中的所有链接,然后通过get方法获取这些链接中的网页内容,这样我们就可以获取到一个网页下所有链接的网页内容。例如,如果我们得到一个下面有 50 个链接的网页,我们可以得到 50 个网页。下面是代码,大家感受一下
获取网址
public class GetUrl {
public static List getUrl(String ur) {
//创建默认的httpClient实例
CloseableHttpClient client = HttpClients.createDefault();
//创建list存放已读取过的页面
List urllist = new ArrayList();
//创建get
HttpGet get=new HttpGet(ur);
//设置连接超时
Builder custom = RequestConfig.custom();
RequestConfig config = custom.setConnectTimeout(5000).setConnectionRequestTimeout(1000).setSocketTimeout(5000).build();
get.setConfig(config);
//设置消息头部
get.setHeader("Accept", "Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
try {
//执行get请求
CloseableHttpResponse response = client.execute(get);
//获取响应实体
HttpEntity entity = response.getEntity();
//将响应实体转为String类型
String html = EntityUtils.toString(entity);
//通过jsoup将String转为jsoup可处理的文档类型
Document doc = Jsoup.parse(html);
//找到该页面中所有的a标签
Elements links = doc.getElementsByTag("a");
int i=1;
for (Element element : links) {
//获取到a标签中href属性的内容
String url = element.attr("href");
//对href内容进行判断 来判断该内容是否是url
if(url.startsWith("http://blog.csdn.net/") && !urllist.contains(url)){
GetPage.getPage(url);
System.out.println(url);
urllist.add(url);
i++;
}
}
response.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return urllist;
}
}
根据获取的url生成页面
最后是测试课
public class Test {
public static void main(String[] args) {
List list = GetUrl.getUrl("http://blog.csdn.net/");
System.out.println("所写链接内的所有内容");
int i=1;
for (String url : list) {
GetUrl.getUrl(url);
System.out.println("第"+i+"条链接内容");
i++;
}
}
}
以上就是如何使用httpclient+jsoup爬取网页,希望对大家有所帮助。 查看全部
c httpclient抓取网页(如何用httpclient+jsoup实现抓取网页分享(图))
和之前的博客一样,在学习用httpclient实现网络爬虫的时候,在网上查了很多资料,但是httpclient的版本是之前的版本3.1或者4.3。我通过学习了解了httpclient4.5。今天给大家分享一下我自己用httpclient+jsoup爬取网页的实现。
httpclient+jsoup 获取网页非常简单。首先可以通过httpclient的get方法获取一个网页的所有内容(如果有什么不懂的可以看我之前关于get方法的解释),然后使用jsoup获取一个网页的所有内容网页。解析内容,获取该网页中的所有链接,然后通过get方法获取这些链接中的网页内容,这样我们就可以获取到一个网页下所有链接的网页内容。例如,如果我们得到一个下面有 50 个链接的网页,我们可以得到 50 个网页。下面是代码,大家感受一下
获取网址
public class GetUrl {
public static List getUrl(String ur) {
//创建默认的httpClient实例
CloseableHttpClient client = HttpClients.createDefault();
//创建list存放已读取过的页面
List urllist = new ArrayList();
//创建get
HttpGet get=new HttpGet(ur);
//设置连接超时
Builder custom = RequestConfig.custom();
RequestConfig config = custom.setConnectTimeout(5000).setConnectionRequestTimeout(1000).setSocketTimeout(5000).build();
get.setConfig(config);
//设置消息头部
get.setHeader("Accept", "Accept text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8");
get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 6.1; rv:6.0.2) Gecko/20100101 Firefox/6.0.2");
try {
//执行get请求
CloseableHttpResponse response = client.execute(get);
//获取响应实体
HttpEntity entity = response.getEntity();
//将响应实体转为String类型
String html = EntityUtils.toString(entity);
//通过jsoup将String转为jsoup可处理的文档类型
Document doc = Jsoup.parse(html);
//找到该页面中所有的a标签
Elements links = doc.getElementsByTag("a");
int i=1;
for (Element element : links) {
//获取到a标签中href属性的内容
String url = element.attr("href");
//对href内容进行判断 来判断该内容是否是url
if(url.startsWith("http://blog.csdn.net/";) && !urllist.contains(url)){
GetPage.getPage(url);
System.out.println(url);
urllist.add(url);
i++;
}
}
response.close();
} catch (IOException e) {
e.printStackTrace();
}finally {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return urllist;
}
}
根据获取的url生成页面
最后是测试课
public class Test {
public static void main(String[] args) {
List list = GetUrl.getUrl("http://blog.csdn.net/";);
System.out.println("所写链接内的所有内容");
int i=1;
for (String url : list) {
GetUrl.getUrl(url);
System.out.println("第"+i+"条链接内容");
i++;
}
}
}
以上就是如何使用httpclient+jsoup爬取网页,希望对大家有所帮助。
c httpclient抓取网页(这里有新鲜出炉的Java设计模式,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-15 18:09
这里有新鲜出炉的Java设计模式,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。(j2se))一般。
本文章主要介绍Java爬虫Jsoup+httpclient获取动态生成数据的相关信息。有需要的朋友可以参考以下
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细聊过Jsoup,发现这个东西其实是一样的。只要是可以访问的静态资源页面,就可以直接用它来获取你需要的数据。详情跳转到Jsoup爬虫详解,不过很多时候网站为了防止数据被恶意爬取,做了很多掩饰,比如加密、动态加载等。这给我们写的爬虫程序造成了很大的麻烦,那么我们如何突破这个梗,得到我们急需的数据,
下面我们将详细说明如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品价格是通过回调函数获取的然后填充的,所以这就需要我们编写爬虫开发者非常耐心的找到价格的回调接口数据,我们直接访问这个接口就可以直接得到价格。下面是一个演示:
从这个截图可以看出,他传递的只是一个静态资源页面,完全没有价格参数,那么价格是怎么来的,继续找这个界面:
你会发现这个界面里面有很多参数是拼接在一起的,那么我们要做的就是分析一下所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这个你兴奋吗?您实际上可以更改其他一些京东产品ID,以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个Httpclient来模拟请求接口。
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,你直接解析JSON字符串,那么你想要的数据就是GET。
注意
这是对回调请求的数据的重新请求获取。这只是对之前动态获取商品价格的补充。在这种情况下,价格本身不是通过主链接带到页面的,而是在加载过程中由异步请求填充的。有时候数据是带过来的,但是我们用相关的JS处理还是拿不到。这时候,我们就不得不通过其他方式来获取数据了,后面会讲到。 查看全部
c httpclient抓取网页(这里有新鲜出炉的Java设计模式,程序狗速度看过来!)
这里有新鲜出炉的Java设计模式,程序狗的速度来了!
Java 编程语言 java 是一种面向对象的编程语言,可以编写跨平台的应用软件。(j2se))一般。
本文章主要介绍Java爬虫Jsoup+httpclient获取动态生成数据的相关信息。有需要的朋友可以参考以下
Java爬虫Jsoup+httpclient获取动态生成的数据
前面我们详细聊过Jsoup,发现这个东西其实是一样的。只要是可以访问的静态资源页面,就可以直接用它来获取你需要的数据。详情跳转到Jsoup爬虫详解,不过很多时候网站为了防止数据被恶意爬取,做了很多掩饰,比如加密、动态加载等。这给我们写的爬虫程序造成了很大的麻烦,那么我们如何突破这个梗,得到我们急需的数据,
下面我们将详细说明如何获取
String startPage="https://item.jd.com/11476104681.html";
Document document = Jsoup.connect(startPage).userAgent
("Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/52.0.2743.116 Safari/537.36").get();
这时候整个页面的数据其实已经获取到了,但是商品价格是通过回调函数获取的然后填充的,所以这就需要我们编写爬虫开发者非常耐心的找到价格的回调接口数据,我们直接访问这个接口就可以直接得到价格。下面是一个演示:
从这个截图可以看出,他传递的只是一个静态资源页面,完全没有价格参数,那么价格是怎么来的,继续找这个界面:
你会发现这个界面里面有很多参数是拼接在一起的,那么我们要做的就是分析一下所有参数是否有用
https://p.3.cn/prices/mgets%3F ... tk%3D
pduid=14930020970791835891856&pdpin=jd_6738608ee8eed&pdbp=0&skuIds=J_11476104681&source=item-pc
可以尝试删除一些参数,发现这个接口需要的参数其实很简单:
https://p.3.cn/prices/mgets%3F ... em-pc
看到这个你兴奋吗?您实际上可以更改其他一些京东产品ID,以获取当前价格和最高价格。我不知道价格是多少。我们需要做的就是编写一个Httpclient来模拟请求接口。
String doGet = HttpUtils.doGet("https://p.3.cn/prices/mgets%3F ... ot%3B, null);
System.out.println(doGet);
结果是这样的:
jQuery9734926([{"id":"J_11476104681","p":"880.00","m":"980.00","op":"980.00"}]);
至于后者,你直接解析JSON字符串,那么你想要的数据就是GET。
注意
这是对回调请求的数据的重新请求获取。这只是对之前动态获取商品价格的补充。在这种情况下,价格本身不是通过主链接带到页面的,而是在加载过程中由异步请求填充的。有时候数据是带过来的,但是我们用相关的JS处理还是拿不到。这时候,我们就不得不通过其他方式来获取数据了,后面会讲到。
c httpclient抓取网页(分为GET请求、有参请求相同有参数的连接)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-13 15:13
HttpClient是Apache Jakarta Common下的一个子项目,可用于提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,支持最新版本和推荐HTTP 协议。因此,为了爬取网络资源,需要使用Http协议来访问网页。
HttpClient分为不带参数的GET请求、带参数的GET请求、不带参数的POST请求、带参数的POST请求。
无参数GET请求:类似于普通的主页连接,没有任何参数的网页
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
带参数的GET请求:带参数的连接,例如带有搜索和分类功能的网页
HttpGet httpGet = new HttpGet("https://search.jd.com/Search?keyword=Java");
不带参数的POST请求:与带参数的GET请求相同
HttpPost httpPost = new HttpPost("https://www.baidu.com/");
带参数的POST请求:url地址无参数,将参数keys=java放在表单中提交
// 创建HttpGet请求
HttpPost httpPost = new HttpPost("https://search.jd.com/");
// 声明存放参数的List集合
List params = new ArrayList();
params.add(new BasicNameValuePair("keys", "java"));
// 创建表单数据Entity
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "UTF-8");
// 设置表单Entity到httpPost请求对象中
httpPost.setEntity(formEntity);
开始
IDEA环境配置
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加 log4j.properties 资源文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
编写代码
public static void main(String[] args) throws Exception {
// 创建 HttpClient 对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建 HTTPGET 请求
HttpGet httpGet = new HttpGet("https://www.baidu.com/");
// 使用 HttpClient 发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
// 判断响应状态码是否为200(200指OK,,网页请求成功)
if (response.getStatusLine().getStatusCode() == 200) {
// 先把网页保存成String,解析获取字符集,将网页中文内容转换成对应字符集,再转换成统一的字符集utf-8
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
输出结果为网页源代码,可自行演示 查看全部
c httpclient抓取网页(分为GET请求、有参请求相同有参数的连接)
HttpClient是Apache Jakarta Common下的一个子项目,可用于提供高效、最新、功能丰富的支持HTTP协议的客户端编程工具包,支持最新版本和推荐HTTP 协议。因此,为了爬取网络资源,需要使用Http协议来访问网页。
HttpClient分为不带参数的GET请求、带参数的GET请求、不带参数的POST请求、带参数的POST请求。
无参数GET请求:类似于普通的主页连接,没有任何参数的网页
HttpGet httpGet = new HttpGet("https://www.baidu.com/";);
带参数的GET请求:带参数的连接,例如带有搜索和分类功能的网页
HttpGet httpGet = new HttpGet("https://search.jd.com/Search?keyword=Java";);
不带参数的POST请求:与带参数的GET请求相同
HttpPost httpPost = new HttpPost("https://www.baidu.com/";);
带参数的POST请求:url地址无参数,将参数keys=java放在表单中提交
// 创建HttpGet请求
HttpPost httpPost = new HttpPost("https://search.jd.com/";);
// 声明存放参数的List集合
List params = new ArrayList();
params.add(new BasicNameValuePair("keys", "java"));
// 创建表单数据Entity
UrlEncodedFormEntity formEntity = new UrlEncodedFormEntity(params, "UTF-8");
// 设置表单Entity到httpPost请求对象中
httpPost.setEntity(formEntity);
开始
IDEA环境配置
org.apache.httpcomponents
httpclient
4.5.3
org.slf4j
slf4j-log4j12
1.7.25
添加 log4j.properties 资源文件
log4j.rootLogger=DEBUG,A1
log4j.logger.cn.itcast = DEBUG
log4j.appender.A1=org.apache.log4j.ConsoleAppender
log4j.appender.A1.layout=org.apache.log4j.PatternLayout
log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
编写代码
public static void main(String[] args) throws Exception {
// 创建 HttpClient 对象
CloseableHttpClient httpClient = HttpClients.createDefault();
// 创建 HTTPGET 请求
HttpGet httpGet = new HttpGet("https://www.baidu.com/";);
// 使用 HttpClient 发起请求
CloseableHttpResponse response = httpClient.execute(httpGet);
// 判断响应状态码是否为200(200指OK,,网页请求成功)
if (response.getStatusLine().getStatusCode() == 200) {
// 先把网页保存成String,解析获取字符集,将网页中文内容转换成对应字符集,再转换成统一的字符集utf-8
String content = EntityUtils.toString(response.getEntity(), "UTF-8");
System.out.println(content);
}
}
输出结果为网页源代码,可自行演示
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-02-09 16:06
数据是科学研究活动的重要依据。本系列博客将介绍如何使用 Java 工具获取网络数据。
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫介绍(二) - Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序上网,然后将数据保存在本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般是从网站获取的,比如电商网站商品信息、商品评论、微博信息等。爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫示例。
一、环境准备
这里的环境是指开发环境。本篇博客将使用Java编写爬虫程序。因此,有必要构建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ 想法:
网上有很多JDK的安装和环境变量的配置,就不多说了。IntelliJ IDEA是傻瓜式安装的,基本没有问题。也别说。
二、创建项目
安装好环境后,我们打开 IntelliJ IDEA,然后创建一个 Maven 项目。Group Id 和 Artifact Id 是不是自己写的也没关系。创建后,我们的目录将如下图所示。
好吧,让我们开始编写爬虫。
三、第一个例子
首先假设我们需要爬取数据学习首页网站的博客( )。首先,我们需要使用maven导入HttpClient4.5.3包(这是最新的包,你可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
Java 本身提供了关于网络访问的包,在,然后它还不够强大。于是Apache基金会发布了一个开源的http请求包,即HttpClient,它提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好吧,在使用 pom.xml 下载这个包之后,我们可以开始编写我们的第一个爬虫示例。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog");
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
如上代码所示,爬虫的第一步需要构建一个客户端,即请求者。我们这里使用CloseableHttpClient作为我们的请求者,然后确定以哪种方式请求什么URL,然后使用HttpResponse获取请求的地址。相应的结果。最后,取出HttpEntity并进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。所以我们的第一个爬虫成功下载了门户网站需要的页面内容。 查看全部
c httpclient抓取网页(博客系列Java爬虫入门简介(二)——HttpClient请求)
数据是科学研究活动的重要依据。本系列博客将介绍如何使用 Java 工具获取网络数据。
博客系列
Java爬虫简介(一)——HttpClient请求(本文)
Java爬虫介绍(二) - Jsoup解析HTML页面
首先说一下爬虫的基本原理。爬虫的基本原理很简单,就是利用程序上网,然后将数据保存在本地。我们都知道,互联网提供的大部分服务都是以网站的形式提供的。我们需要的数据一般是从网站获取的,比如电商网站商品信息、商品评论、微博信息等。爬虫类似于手动复制粘贴我们看到的数据,但是手动获取大量数据显然是不可能的。因此,我们需要工具来帮助获取知识。用程序写爬虫就是用程序写一些网络访问规则,保存我们的目标数据。接下来,让我们从头开始构建一个爬虫示例。
一、环境准备
这里的环境是指开发环境。本篇博客将使用Java编写爬虫程序。因此,有必要构建一个Java编程环境。需要安装的软件包括(注意我的电脑使用的是windows X64程序,请选择对应的JDK版本,使用8.0及以上):
1、JDK 8.0:
2、IntelliJ 想法:
网上有很多JDK的安装和环境变量的配置,就不多说了。IntelliJ IDEA是傻瓜式安装的,基本没有问题。也别说。
二、创建项目
安装好环境后,我们打开 IntelliJ IDEA,然后创建一个 Maven 项目。Group Id 和 Artifact Id 是不是自己写的也没关系。创建后,我们的目录将如下图所示。
好吧,让我们开始编写爬虫。
三、第一个例子
首先假设我们需要爬取数据学习首页网站的博客( )。首先,我们需要使用maven导入HttpClient4.5.3包(这是最新的包,你可以根据需要使用其他版本)。然后,我们在 pom.xml 中添加以下语句:
org.apache.httpcomponents
httpclient
4.5.3
Java 本身提供了关于网络访问的包,在,然后它还不够强大。于是Apache基金会发布了一个开源的http请求包,即HttpClient,它提供了很多网络访问功能。在这里,我们也使用这个包来编写爬虫。好吧,在使用 pom.xml 下载这个包之后,我们可以开始编写我们的第一个爬虫示例。代码如下(注意我们的程序是在test包下构建的,所以需要在这个包下运行):
package test;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
/**
* 第一个爬虫测试
* Created by DuFei on 2017/7/27.
*/
public class FirstTest {
public static void main(String[] args) {
//建立一个新的请求客户端
CloseableHttpClient httpClient = HttpClients.createDefault();
//使用HttpGet方式请求网址
HttpGet httpGet = new HttpGet("http://www.datalearner.com/blog";);
//获取网址的返回结果
CloseableHttpResponse response = null;
try {
response = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
//获取返回结果中的实体
HttpEntity entity = response.getEntity();
//将返回的实体输出
try {
System.out.println(EntityUtils.toString(entity));
EntityUtils.consume(entity);
} catch (IOException e) {
e.printStackTrace();
}
}
}
如上代码所示,爬虫的第一步需要构建一个客户端,即请求者。我们这里使用CloseableHttpClient作为我们的请求者,然后确定以哪种方式请求什么URL,然后使用HttpResponse获取请求的地址。相应的结果。最后,取出HttpEntity并进行转换,得到我们请求的URL对应的内容。上述程序对应的输出如下图所示:
很明显,这就是我们需要的URL对应的页面的源码。所以我们的第一个爬虫成功下载了门户网站需要的页面内容。
c httpclient抓取网页(【经济学人手把手教你学英语】控件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-07 16:11
使用 HttpWebRequest 方法非常有效,但是根据我的经验,当页面上的脚本没有实际的 Web 浏览器可以渲染时,就会出现许多问题,例如您遇到的问题。我的经验是,当页面没有要呈现的实际 Web 浏览器,它会导致许多问题,就像您所拥有的一样。
我通过在 Windows 窗体上放置一个实际的 WebBrowser 控件然后将该控件导航到所需的 URL 来解决这个问题。 ,解决了这个问题。当控件(它是一个真正的 Web 浏览器)完成页面呈现后,您可以访问其中的任何内容。例如,如果在隐藏的 DIV 元素中存在被打乱的文本(阻止抓取的常用策略),您无法从页面源中获取它,但在 WebBrowser 控件中您仍然可以获取它,因为在为了显示它必须由客户端脚本解密。例如,如果某些文本在隐藏的 DIV 元素中被打乱(防止抓取的常用策略),它无法从页面源中获取,但在 WebBrowser 控件中,您仍然可以获取该文本,因为为了显示它,它必须已被客户端脚本解密。在WebBrowser控件中“看得到就得到”。
编辑:最简单的实现。编辑:最简单的实现。只需尝试一下,看看缺少的源代码现在是否存在于文档源中。
创建一个窗口窗体。创建一个窗口窗体。添加一个名为 button1. 的按钮 添加一个名为 button1 的按钮。添加一个名为 webBrowser1 的 WebBrowser 控件,取消停靠并调整其大小。添加一个名为 textBox1 的 TextBox 并将其设为多行。然后在表单后面添加这段代码: 然后在表单后面添加这段代码:
private void button1_Click(object sender, EventArgs e) {
string url = "http://google.ca";
webBrowser1.Navigate(url);
}
private void webBrowser1_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e) {
string pageSource = webBrowser1.Document.Body.OuterHtml;
textBox1.Text = pageSource;
}
将上述网址替换为您的网址。运行表单并单击按钮。查看您想要的 HTML 现在是否出现在结果文本框中。如果是,那么您的大部分问题现在都已解决。我对这项技术非常幸运。它应该可以解决延迟呈现的内容的任何问题,因此不会在实际源代码中以未混淆的形式出现。 查看全部
c httpclient抓取网页(【经济学人手把手教你学英语】控件)
使用 HttpWebRequest 方法非常有效,但是根据我的经验,当页面上的脚本没有实际的 Web 浏览器可以渲染时,就会出现许多问题,例如您遇到的问题。我的经验是,当页面没有要呈现的实际 Web 浏览器,它会导致许多问题,就像您所拥有的一样。
我通过在 Windows 窗体上放置一个实际的 WebBrowser 控件然后将该控件导航到所需的 URL 来解决这个问题。 ,解决了这个问题。当控件(它是一个真正的 Web 浏览器)完成页面呈现后,您可以访问其中的任何内容。例如,如果在隐藏的 DIV 元素中存在被打乱的文本(阻止抓取的常用策略),您无法从页面源中获取它,但在 WebBrowser 控件中您仍然可以获取它,因为在为了显示它必须由客户端脚本解密。例如,如果某些文本在隐藏的 DIV 元素中被打乱(防止抓取的常用策略),它无法从页面源中获取,但在 WebBrowser 控件中,您仍然可以获取该文本,因为为了显示它,它必须已被客户端脚本解密。在WebBrowser控件中“看得到就得到”。
编辑:最简单的实现。编辑:最简单的实现。只需尝试一下,看看缺少的源代码现在是否存在于文档源中。
创建一个窗口窗体。创建一个窗口窗体。添加一个名为 button1. 的按钮 添加一个名为 button1 的按钮。添加一个名为 webBrowser1 的 WebBrowser 控件,取消停靠并调整其大小。添加一个名为 textBox1 的 TextBox 并将其设为多行。然后在表单后面添加这段代码: 然后在表单后面添加这段代码:
private void button1_Click(object sender, EventArgs e) {
string url = "http://google.ca";
webBrowser1.Navigate(url);
}
private void webBrowser1_DocumentCompleted(object sender,
WebBrowserDocumentCompletedEventArgs e) {
string pageSource = webBrowser1.Document.Body.OuterHtml;
textBox1.Text = pageSource;
}
将上述网址替换为您的网址。运行表单并单击按钮。查看您想要的 HTML 现在是否出现在结果文本框中。如果是,那么您的大部分问题现在都已解决。我对这项技术非常幸运。它应该可以解决延迟呈现的内容的任何问题,因此不会在实际源代码中以未混淆的形式出现。
c httpclient抓取网页(GitHub:基于asyncio实现HTTP框架。异步操作借助于/await关键字)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-02 23:04
GitHub:
基于 asyncio 实现的 HTTP 框架。异步操作依赖 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
这是高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用小盒子:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2个解析库
1、美丽的汤
官方文档:
HTML和XML解析,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的必备库。
2、lxml
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
3、pyquery
GitHub:
jQuery的Python实现可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
3 数据存储库
1、pymysql
GitHub:
官方文档:
MySQL 客户端操作库的纯 Python 实现。很实用也很简单。
2、pymongo
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
3、redisdump
使用方法:
redis-dump是一个redis和json转换的工具; redis-dump是基于ruby开发的,需要一个ruby环境,而新版redis-dump需要2.2.2个以上的ruby版本,centos中yum只能安装< @2.0 版本的红宝石。需要先安装ruby的管理工具rvm才能安装更高版本的ruby;
最后,我是一个从事多年开发的老Python程序员。我已经辞职,目前正在做我自己的私人 Python 课程。今年年初,我花了一个月的时间整理了一篇最适合2019年学习的Python学习,干货可以送给每一位喜欢Python的朋友。想要领取的可以关注我的头条号,后台私信我:01,免费领取。 查看全部
c httpclient抓取网页(GitHub:基于asyncio实现HTTP框架。异步操作借助于/await关键字)
GitHub:
基于 asyncio 实现的 HTTP 框架。异步操作依赖 async/await 关键字,使用异步库进行数据抓取,可以大大提高效率。
这是高级爬虫时必须掌握的异步库。关于aiohttp的详细操作可以去官方文档:
使用小盒子:
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch(session, 'http://python.org')
print(html)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
2个解析库
1、美丽的汤
官方文档:
HTML和XML解析,从网页中提取信息,具有强大的API和多种解析方法。我经常使用的一个解析库,对html解析很有用。这也是编写爬虫的必备库。
2、lxml
GitHub:
支持HTML和XML解析,支持XPath解析方式,解析效率很高。
3、pyquery
GitHub:
jQuery的Python实现可以用jQuery语法对HTML文档进行操作和解析,具有很好的易用性和解析速度。
3 数据存储库
1、pymysql
GitHub:
官方文档:
MySQL 客户端操作库的纯 Python 实现。很实用也很简单。
2、pymongo
GitHub:
官方文档:
顾名思义,一个直接连接mongodb数据库进行查询操作的库。
3、redisdump
使用方法:
redis-dump是一个redis和json转换的工具; redis-dump是基于ruby开发的,需要一个ruby环境,而新版redis-dump需要2.2.2个以上的ruby版本,centos中yum只能安装< @2.0 版本的红宝石。需要先安装ruby的管理工具rvm才能安装更高版本的ruby;
最后,我是一个从事多年开发的老Python程序员。我已经辞职,目前正在做我自己的私人 Python 课程。今年年初,我花了一个月的时间整理了一篇最适合2019年学习的Python学习,干货可以送给每一位喜欢Python的朋友。想要领取的可以关注我的头条号,后台私信我:01,免费领取。

