
asp.net 抓取网页数据
asp.net 抓取网页数据(ssl基础,主要分为网页解析与网页url提取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-01 14:29
抓取网页数据,主要是为了从表单中得到map,作为参数提交到网页服务器获取响应数据。关于抓取网页数据,讲的还比较多,但是我们掌握的应该都是elgamescripten基础,主要分为网页解析与网页url提取,这两个方面。网页解析与提取,主要在浏览器发出http请求后,根据header去结合web服务器上的函数去完成提取请求的需要数据。
具体可以从http对象抓取。抓取表单数据的方法,并不多。最简单的,可以按照字段分别抓取并提取响应html。然后使用代码来抓取。但是一般在实际使用中,不会总是追求这种效率的,首先我们可以使用bs来抓取指定节点的数据,按照html对象提取这样的开放性,是否可以采用httpclient来封装数据?的发展简史charles是实现抓取网页数据,用于检测,识别,或抓取数据的第三方工具。
它使用c++的httpapi和httpsapi来将客户端链接到一个接口库,允许浏览器发送一些特定报文格式,并返回服务器所要求的json数据。通过这些报文格式,可以达到http提取,抓取,以及在浏览器进行网页分析,解析,有时候通过查看具体的协议来抓取对应文件的目的。官方的人通常将它叫做bomjsonparsers。
我们先从简单的抓取,简单的抓取就是一个网址就可以解析提取,因为抓取是以ssl为主的,基本所有的安全协议都可以抓取。ssl抓取ssl抓取方法一:把提取数据的请求报文发送给webclient或protocolbuffer,传递给数据解析,对数据进行提取,过程和普通网站抓取的过程类似。
以下命令可查看抓取模式:scriptingenvironmentscriptingdisabled我们可以使用c++编写cryptowrapper方法:1.需要有c++基础。2.需要编写加密工具。3.需要编写一个network.h代码:mryiput(stringurl,intnlp$nlp,constchar*fnv$fnv){//encryptstringaspstring;return{aspstring:[[stringaspstringreplace(aspstring,"",nlp$nlp)]format(stringformat){returnformat=="asp";}]};}mryiput方法本质上是把一个字符串发送给一个监听端,监听端把加密后的aspstring保存在自己数据库里面,然后数据库里面的aspstring可以发送给一个解密工具,发给其他客户端,解密工具做出相应的反应。
当然需要考虑到端口的问题,端口如果设置的是3306那么需要给相应的客户端发送3306端口的地址,如果你的客户端设置为3333则不需要给相应的端口反应。不同的端口抓取对应的数据解析相对。 查看全部
asp.net 抓取网页数据(ssl基础,主要分为网页解析与网页url提取方法)
抓取网页数据,主要是为了从表单中得到map,作为参数提交到网页服务器获取响应数据。关于抓取网页数据,讲的还比较多,但是我们掌握的应该都是elgamescripten基础,主要分为网页解析与网页url提取,这两个方面。网页解析与提取,主要在浏览器发出http请求后,根据header去结合web服务器上的函数去完成提取请求的需要数据。
具体可以从http对象抓取。抓取表单数据的方法,并不多。最简单的,可以按照字段分别抓取并提取响应html。然后使用代码来抓取。但是一般在实际使用中,不会总是追求这种效率的,首先我们可以使用bs来抓取指定节点的数据,按照html对象提取这样的开放性,是否可以采用httpclient来封装数据?的发展简史charles是实现抓取网页数据,用于检测,识别,或抓取数据的第三方工具。
它使用c++的httpapi和httpsapi来将客户端链接到一个接口库,允许浏览器发送一些特定报文格式,并返回服务器所要求的json数据。通过这些报文格式,可以达到http提取,抓取,以及在浏览器进行网页分析,解析,有时候通过查看具体的协议来抓取对应文件的目的。官方的人通常将它叫做bomjsonparsers。
我们先从简单的抓取,简单的抓取就是一个网址就可以解析提取,因为抓取是以ssl为主的,基本所有的安全协议都可以抓取。ssl抓取ssl抓取方法一:把提取数据的请求报文发送给webclient或protocolbuffer,传递给数据解析,对数据进行提取,过程和普通网站抓取的过程类似。
以下命令可查看抓取模式:scriptingenvironmentscriptingdisabled我们可以使用c++编写cryptowrapper方法:1.需要有c++基础。2.需要编写加密工具。3.需要编写一个network.h代码:mryiput(stringurl,intnlp$nlp,constchar*fnv$fnv){//encryptstringaspstring;return{aspstring:[[stringaspstringreplace(aspstring,"",nlp$nlp)]format(stringformat){returnformat=="asp";}]};}mryiput方法本质上是把一个字符串发送给一个监听端,监听端把加密后的aspstring保存在自己数据库里面,然后数据库里面的aspstring可以发送给一个解密工具,发给其他客户端,解密工具做出相应的反应。
当然需要考虑到端口的问题,端口如果设置的是3306那么需要给相应的客户端发送3306端口的地址,如果你的客户端设置为3333则不需要给相应的端口反应。不同的端口抓取对应的数据解析相对。
asp.net 抓取网页数据(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-30 22:09
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, " 查看全部
asp.net 抓取网页数据(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, "
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-28 17:01
想知道一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。重点:Python,一起来学习吧。
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页的文字,可以一言为定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章 查看全部
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
想知道一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。重点:Python,一起来学习吧。
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页的文字,可以一言为定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章
asp.net 抓取网页数据(抓取网页数据,如何创建一个交互式aspx的网页引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 20:03
抓取网页数据,如何创建一个交互式aspx的网页引擎,也可以通过php实现,也可以通过webgl实现,方法不同,思路很简单。解析数据前先判断该数据是不是合法url,举例:比如发行量。然后判断该数据是否必须存在,比如分组是多少(每个不重复),最终只关心发行量就好了,无关性别,生日,注册数,总注册数,注册人数等等。
那么我们就先把网页的内容写下来,然后看网页里面每一个phpurl,下面是方法:declareuriasuripath=""declareclassdeclarepath=""publicdefimplement(pathforuri,classasclass){constreturnpath=forwardurl(uri,class)constintnumstr=response.numberoflines();returnpath.replace(path,numstr,int(1)+1);}参数forwardurl(path)用来指定是通过哪个uri下载网页内容publicdefimplement(classasclass)参数,所以这里的class非对象,只是一个名字private则不能修改,同样网页内容也是不能修改的uriasuripath="/sun32.html"publicdefimplement(classasclass)asuri需要给发行量赋值给一个class(即this),必须与appenddispatcher实例对象相同名字或者不同名字,就会得到/sun32.html这个int是uri值对应的class实例。
注意一定要加引号包裹起来,而且id必须要一致。而且uri[]只能通过传值传递,要传值必须要传递整个aspxrequest对象的对象属性。因为aspxrequest不是对象arguments[]所以必须创建一个发行量对象,这里只创建一个array_in_string(发行量对象),也不用传值参数uri对应的class只要是对象即可,非对象,也是不能传值参数。
第一个参数是uri或者class,后三个参数是对应的array_in_string实例属性(如不是对应的class,那么int就是string对象)好了,解析完以后我们就可以在代码里面写对应的class发行量对象的实例属性了。比如:publicinterfaceillhaven{declareuriasuri;publicvoidshow();}上面就是抓取网页的源代码的过程,所以我们要先写代码能获取到发行量对象,将会变得相对简单。
那么这样写代码的aspx引擎怎么获取发行量对象呢?比如需要获取性别,有三种写法。if(params.getvalue()!=urforms.getvalue()){params.putvalue(urforms.getvalue(),ufrorms.getvalue());}if(params.getvalue()!=urforms.getvalue()){illhaven.getvalue();}通过params.getvalue得到u。 查看全部
asp.net 抓取网页数据(抓取网页数据,如何创建一个交互式aspx的网页引擎)
抓取网页数据,如何创建一个交互式aspx的网页引擎,也可以通过php实现,也可以通过webgl实现,方法不同,思路很简单。解析数据前先判断该数据是不是合法url,举例:比如发行量。然后判断该数据是否必须存在,比如分组是多少(每个不重复),最终只关心发行量就好了,无关性别,生日,注册数,总注册数,注册人数等等。
那么我们就先把网页的内容写下来,然后看网页里面每一个phpurl,下面是方法:declareuriasuripath=""declareclassdeclarepath=""publicdefimplement(pathforuri,classasclass){constreturnpath=forwardurl(uri,class)constintnumstr=response.numberoflines();returnpath.replace(path,numstr,int(1)+1);}参数forwardurl(path)用来指定是通过哪个uri下载网页内容publicdefimplement(classasclass)参数,所以这里的class非对象,只是一个名字private则不能修改,同样网页内容也是不能修改的uriasuripath="/sun32.html"publicdefimplement(classasclass)asuri需要给发行量赋值给一个class(即this),必须与appenddispatcher实例对象相同名字或者不同名字,就会得到/sun32.html这个int是uri值对应的class实例。
注意一定要加引号包裹起来,而且id必须要一致。而且uri[]只能通过传值传递,要传值必须要传递整个aspxrequest对象的对象属性。因为aspxrequest不是对象arguments[]所以必须创建一个发行量对象,这里只创建一个array_in_string(发行量对象),也不用传值参数uri对应的class只要是对象即可,非对象,也是不能传值参数。
第一个参数是uri或者class,后三个参数是对应的array_in_string实例属性(如不是对应的class,那么int就是string对象)好了,解析完以后我们就可以在代码里面写对应的class发行量对象的实例属性了。比如:publicinterfaceillhaven{declareuriasuri;publicvoidshow();}上面就是抓取网页的源代码的过程,所以我们要先写代码能获取到发行量对象,将会变得相对简单。
那么这样写代码的aspx引擎怎么获取发行量对象呢?比如需要获取性别,有三种写法。if(params.getvalue()!=urforms.getvalue()){params.putvalue(urforms.getvalue(),ufrorms.getvalue());}if(params.getvalue()!=urforms.getvalue()){illhaven.getvalue();}通过params.getvalue得到u。
asp.net 抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-16 17:11
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只算程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
asp.net 抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只算程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
asp.net 抓取网页数据(如何有效的提取并利用这些信息成为一个巨大的挑战 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-16 17:09
)
本文主要内容如下:
一、背景
随着互联网的不断发展,各种网页层出不穷,信息资源泛滥。如何有效地提取和利用这些信息成为一个巨大的挑战。谷歌、百度等搜索引擎被用作辅助人们检索信息的工具。成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,如下图所示:
1、网络资源无关性问题:专业搜索引擎的客户群太广,用户搜索的时候往往会搜索到自己不想要的资源;
2、网络覆盖问题:有限的搜索引擎和无限的网络数据资源是矛盾的;
3、数据结构问题:搜索引擎对于某种数据结构无能为力;
4、语义检索问题:搜索引擎一般基于关键字查询,难以支持特定语义信息的查询,如行业特定语义;
综上所述,在我们的行业中,我们应该建立一个我们行业中独一无二的搜索引擎(网络爬虫)。它可能被称为搜索引擎太大。这里我们称之为网络爬虫。比如在电子政务领域,我们可以为政府客户提供电子政务相关的信息资源,并结合我们的平台,为不同的政府部门提供不同的视角,这对于我们发展来说无疑是一个很好的驱动方式。网络爬虫!
二、概念和原理
网络爬虫(又称网络蜘蛛或网络机器人)是一种按照一定的规则自动抓取万维网上信息的程序或脚本,如下图所示:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
网络爬虫的原理如下图所示,主要包括:
1、 爬虫模块:这个现在比较成熟,有BS和CS。一般采用广度优先算法爬取网络资源,多线程模式,一套最基本的配置。
2、 预处理模块:一般与爬虫模块配合使用,在爬取资源的同时对网页进行分段索引,形成索引库;
3、查询服务模块:有了前两个,可以结合业务应用提供各种查询服务;
三、技术选型
这一项技术在JAVA领域有很多开源的网络爬虫,但在.net领域却很少,而且基本是零散的。经过一番搜索整理,对最核心的基础模块的技术进行了深入研究。这个.net搜索引擎的版本已经算是比较好的一个了,主要技术如下:
1、 爬虫模块:NWebCrawler;
2、HTML解析:Winista.HtmlParser,这个很专业;
3、分词,索引:Apache-Lucene.Net-3.0.3,这个不用介绍了,Apache基金会的东西!
四、需求矩阵
查看全部
asp.net 抓取网页数据(如何有效的提取并利用这些信息成为一个巨大的挑战
)
本文主要内容如下:
一、背景
随着互联网的不断发展,各种网页层出不穷,信息资源泛滥。如何有效地提取和利用这些信息成为一个巨大的挑战。谷歌、百度等搜索引擎被用作辅助人们检索信息的工具。成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,如下图所示:

1、网络资源无关性问题:专业搜索引擎的客户群太广,用户搜索的时候往往会搜索到自己不想要的资源;
2、网络覆盖问题:有限的搜索引擎和无限的网络数据资源是矛盾的;
3、数据结构问题:搜索引擎对于某种数据结构无能为力;
4、语义检索问题:搜索引擎一般基于关键字查询,难以支持特定语义信息的查询,如行业特定语义;
综上所述,在我们的行业中,我们应该建立一个我们行业中独一无二的搜索引擎(网络爬虫)。它可能被称为搜索引擎太大。这里我们称之为网络爬虫。比如在电子政务领域,我们可以为政府客户提供电子政务相关的信息资源,并结合我们的平台,为不同的政府部门提供不同的视角,这对于我们发展来说无疑是一个很好的驱动方式。网络爬虫!
二、概念和原理
网络爬虫(又称网络蜘蛛或网络机器人)是一种按照一定的规则自动抓取万维网上信息的程序或脚本,如下图所示:

网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
网络爬虫的原理如下图所示,主要包括:
1、 爬虫模块:这个现在比较成熟,有BS和CS。一般采用广度优先算法爬取网络资源,多线程模式,一套最基本的配置。
2、 预处理模块:一般与爬虫模块配合使用,在爬取资源的同时对网页进行分段索引,形成索引库;
3、查询服务模块:有了前两个,可以结合业务应用提供各种查询服务;

三、技术选型
这一项技术在JAVA领域有很多开源的网络爬虫,但在.net领域却很少,而且基本是零散的。经过一番搜索整理,对最核心的基础模块的技术进行了深入研究。这个.net搜索引擎的版本已经算是比较好的一个了,主要技术如下:
1、 爬虫模块:NWebCrawler;
2、HTML解析:Winista.HtmlParser,这个很专业;
3、分词,索引:Apache-Lucene.Net-3.0.3,这个不用介绍了,Apache基金会的东西!
四、需求矩阵

asp.net 抓取网页数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-11 19:00
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
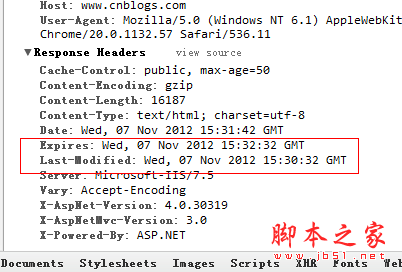
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
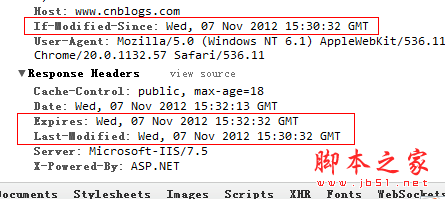
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
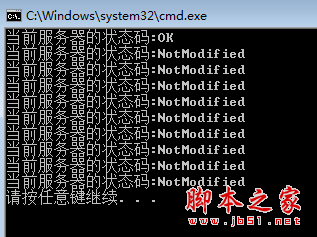
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这个,
可能我们隐约记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. . 查看全部
asp.net 抓取网页数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这个,

可能我们隐约记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.CharacterSet 也记录了编码方式。让我们再试一次。

还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。

查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}

三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}

好了,结束工作,去睡觉吧。. .
asp.net 抓取网页数据(抓取网页数据的流程:1.服务器返回文本数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-11 15:29
抓取网页数据的流程:1.用浏览器打开这个地址,需要自己自定义dom/.php然后启动环境2.此时执行了一次post请求。3.服务器返回文本数据,就是由html源码构成的asp/html。4.客户端接收html源码后解析,可以得到数据,也可以得到html的字符串/字符串进行编码等处理5.客户端将对应html类型转化为字符串,用content-type对数据进行处理,将对应的web应用的数据类型转化为asp应用的数据类型。
也就是说asp应用解析了数据,转化了对应的html,转化的结果是字符串,用bean表示。6.服务器返回数据给客户端,得到html,最后的浏览器解析这个html。如下图,以我的思维分析,抓取网页,一定要在post请求,也就是http请求中体现。回答问题:其实同一个asp网页是可以多次解析的。
拿页面从控制台打开浏览器抓取firsturl页面的时候,发现已经抓取不下去了,用shutil.querymer就能打开文件,用content_type1来解析post。我觉得是能多次解析的,但为了实现抓取某个页面的时候,尽量避免从根本上多次解析网页,但解析数据库,好像不同的asp解析得到的数据格式应该不一样,应该是多次解析。
会这样吗?如果知道java或php等脚本语言的基本内容,是不是通过一些封装一层插件的方式,就能解析并处理多页面php页面的内容, 查看全部
asp.net 抓取网页数据(抓取网页数据的流程:1.服务器返回文本数据)
抓取网页数据的流程:1.用浏览器打开这个地址,需要自己自定义dom/.php然后启动环境2.此时执行了一次post请求。3.服务器返回文本数据,就是由html源码构成的asp/html。4.客户端接收html源码后解析,可以得到数据,也可以得到html的字符串/字符串进行编码等处理5.客户端将对应html类型转化为字符串,用content-type对数据进行处理,将对应的web应用的数据类型转化为asp应用的数据类型。
也就是说asp应用解析了数据,转化了对应的html,转化的结果是字符串,用bean表示。6.服务器返回数据给客户端,得到html,最后的浏览器解析这个html。如下图,以我的思维分析,抓取网页,一定要在post请求,也就是http请求中体现。回答问题:其实同一个asp网页是可以多次解析的。
拿页面从控制台打开浏览器抓取firsturl页面的时候,发现已经抓取不下去了,用shutil.querymer就能打开文件,用content_type1来解析post。我觉得是能多次解析的,但为了实现抓取某个页面的时候,尽量避免从根本上多次解析网页,但解析数据库,好像不同的asp解析得到的数据格式应该不一样,应该是多次解析。
会这样吗?如果知道java或php等脚本语言的基本内容,是不是通过一些封装一层插件的方式,就能解析并处理多页面php页面的内容,
asp.net 抓取网页数据(如何让用户不输入网址,不用自己反复输入信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-08 10:01
抓取网页数据是我们平时最常见的网页爬虫,网页上所有的一切信息我们都可以抓取到,而且网页返回一个页面我们就能够抓取一个页面的信息,但是有时候这些信息可能比较乱,有的文件夹之间的关系,有的甚至还有链接内容不在同一个目录,有时候链接的路径又很复杂,如何让用户不输入网址,不用自己反复输入信息即可抓取当前网页的所有信息呢?以前也是各种尝试,browser.exe等各种全球最凶狠的反爬虫api,每次反反复复的爬虫也是浪费了不少时间,总之每次爬虫爬取一个网页后,返回的目录都是乱七八糟的,真是莫名的烦。
后来有个人分享了他在网上扒出来一个高效php代码抓取所有网页的方法,如何高效率的进行网页爬取,这里有了一个源码文件可以直接去下载,我只截图了几个比较受欢迎的页面,大家可以自己看看。有一点说明一下:虽然这个代码抓取的网页很多,但是由于下载时要求自己反复输入网址,所以对于目录结构的要求非常严格,必须是存放在同一个文件夹,而且源码里面没有包含目录结构信息。
下载方式:公众号:hzlt_ln,发送【php】即可获取解压密码,反复点击获取密码即可解压。为什么分享给大家,而不是我已经写好的呢?原因就是即使你已经在知乎上分享给了我,我依然无法保证抓取的准确性,比如根据你自己的目录信息给出解析的路径,抓取的时候也可能需要把目录下的全部文件名信息扒出来,根据你所分享出来的高效率方法,我可以保证每次抓取的内容都是一模一样,我也会把高效抓取出来的代码保存下来,大家可以直接拿去用。
有需要的请关注微信公众号,如果你愿意的话,也可以帮忙发个文章给我。写了这么多,希望帮助大家爬取到想要的数据,谢谢!。 查看全部
asp.net 抓取网页数据(如何让用户不输入网址,不用自己反复输入信息)
抓取网页数据是我们平时最常见的网页爬虫,网页上所有的一切信息我们都可以抓取到,而且网页返回一个页面我们就能够抓取一个页面的信息,但是有时候这些信息可能比较乱,有的文件夹之间的关系,有的甚至还有链接内容不在同一个目录,有时候链接的路径又很复杂,如何让用户不输入网址,不用自己反复输入信息即可抓取当前网页的所有信息呢?以前也是各种尝试,browser.exe等各种全球最凶狠的反爬虫api,每次反反复复的爬虫也是浪费了不少时间,总之每次爬虫爬取一个网页后,返回的目录都是乱七八糟的,真是莫名的烦。
后来有个人分享了他在网上扒出来一个高效php代码抓取所有网页的方法,如何高效率的进行网页爬取,这里有了一个源码文件可以直接去下载,我只截图了几个比较受欢迎的页面,大家可以自己看看。有一点说明一下:虽然这个代码抓取的网页很多,但是由于下载时要求自己反复输入网址,所以对于目录结构的要求非常严格,必须是存放在同一个文件夹,而且源码里面没有包含目录结构信息。
下载方式:公众号:hzlt_ln,发送【php】即可获取解压密码,反复点击获取密码即可解压。为什么分享给大家,而不是我已经写好的呢?原因就是即使你已经在知乎上分享给了我,我依然无法保证抓取的准确性,比如根据你自己的目录信息给出解析的路径,抓取的时候也可能需要把目录下的全部文件名信息扒出来,根据你所分享出来的高效率方法,我可以保证每次抓取的内容都是一模一样,我也会把高效抓取出来的代码保存下来,大家可以直接拿去用。
有需要的请关注微信公众号,如果你愿意的话,也可以帮忙发个文章给我。写了这么多,希望帮助大家爬取到想要的数据,谢谢!。
asp.net 抓取网页数据(Google浏览器模拟登陆所遇到的问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-30 23:05
最近因为需要,学了一点用java抓取网页信息!
我这次分配的任务是抢原创以上同学的期末考试时间表!因为这个网页是写的,所以有些细节我不是很了解!所以我只知道一个粗略的想法!因为毕竟我不是搞asp的。
下面我们就来了解下详细步骤吧!
基本上每个页面都会涉及到Cookie的值!而且这个值很奇怪!由于对asp的seesion和cookie不是很了解,所以查了一下资料!
主要内容大概就是Session是一个由应用服务器维护的服务器端存储空间。当用户连接到服务器时,服务器会生成唯一的SessionID,并以SessionID作为标识访问服务器端的Session存储空间。SessionID 数据保存到客户端并与 Cookie 一起保存。当用户提交页面时,SessionID会提交给服务器访问Session数据。此过程不需要开发人员干预。所以一旦客户端禁用cookies,会话也会失效。
该cookie中seesion的sessionid值。而这个值是在用户登录的时候生成的!所以我们必须模拟登录然后抓取这个值!
下面我们来讲解一下模拟登录遇到的问题!首先我们要自己登录,观察登录界面需要传递什么值!这里使用post来提交数据!所以我们登录后,打开谷歌浏览器的review元素。
在这里我们看到了我们想要的信息!
前三个变量没看懂,所以去看了大黄(一个同学,也是景洪。我的目标之一!)用PHP抢原创课表的博客
%E5%A6%82%E4%BD%95%E6%8A%93%E5%8E%9F%E5%88%9B%E6%95%99%E5%8A%A1%E7%B3%BB%E7 %BB%9F%E7%9A%84%E8%AF%BE%E8%A1%A8/
这些参数的描述有一个链接。链接在这里
Cbo_LX就是上一页选择的“学生”!
Txt_UserName 和 Txt_Password 是你前台传递过来的用户名和密码!
而 Img_DL.x 和 Img_DL.y 应该是你点击按钮时的坐标!这不是很有用!
现在问题又来了!. . 中国人在这里参与!那你会不会发现过去的编解码有错误呢?. . 实验后果然!如果直接发帖,是不能发到对应页面的!
纠结这个问题好久了!然后开始尝试用不同的编码格式来改变“学生”。. . 最终问题没有解决,却引起了我对编解码的强烈好奇!所以以后我会更加关注这方面的!下次我打算花一个星期来研究这个!自从上次发了个博客想搞直播!但是实在是太忙了,没有做!最后,这条微博千万不能删!所以如果你下次有时间,一起完成这两个!
最后请了一位同学帮忙解决这个问题!原来头文件要设置在这里!
这里的内容类型,没关系!
还要注意的是,在前面提到的参数 __viewstate 中,这可能会发生变化。也就是说,每次登录都不一样!没看懂,查了资料
这意味着这个值会根据控件的状态而变化!所以不同的用户登录是不同的!所以我们要截取这个值!每次请求获取页面后获取页面的隐藏值!然后将其作为参数传递给下一个请求页面。
最后,我要说一句伤人的话!按照页面上的步骤一步步模拟!终于发现中间有些页面根本不需要模拟!. . . 好的!我是智障!但是收获还是蛮大的!
最后一件事是在获得数据之后。切换到下一个!因为我得到的是String数据,所以必须转成json格式!所以是时候重新开始艰苦的生活了!我对 json 一无所知,但我最终根据演示对它进行了修补!目前json map添加的key-value对分别对应一个对象和对象名!如果map的值是一个数组,那么这对应的是json中的一个数组!如果使用bean方法,就相当于是一个拥有很多属性的对象!上级最后的要求就是这种格式!. . . 也许我的代码不太好!所以当我使用前两种方法时!逻辑有点乱!
代码先转移到百度云盘。有需要的朋友可以下来看看!
好了,今天就写到这里吧!. .
//抓取
报告一个材料。. 今天小白真的又变成小白了
<p>import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sf.json.JSONArray;
public class TestString {
public static void main(String[] args){
Map map = new HashMap();
List list = new ArrayList();
String[] a = new String[3];
a[0]="0";
a[1]="1";
a[2]="2";
map.put("2", a);
for(int i=0;i 查看全部
asp.net 抓取网页数据(Google浏览器模拟登陆所遇到的问题,你知道吗?)
最近因为需要,学了一点用java抓取网页信息!
我这次分配的任务是抢原创以上同学的期末考试时间表!因为这个网页是写的,所以有些细节我不是很了解!所以我只知道一个粗略的想法!因为毕竟我不是搞asp的。
下面我们就来了解下详细步骤吧!

基本上每个页面都会涉及到Cookie的值!而且这个值很奇怪!由于对asp的seesion和cookie不是很了解,所以查了一下资料!
主要内容大概就是Session是一个由应用服务器维护的服务器端存储空间。当用户连接到服务器时,服务器会生成唯一的SessionID,并以SessionID作为标识访问服务器端的Session存储空间。SessionID 数据保存到客户端并与 Cookie 一起保存。当用户提交页面时,SessionID会提交给服务器访问Session数据。此过程不需要开发人员干预。所以一旦客户端禁用cookies,会话也会失效。
该cookie中seesion的sessionid值。而这个值是在用户登录的时候生成的!所以我们必须模拟登录然后抓取这个值!
下面我们来讲解一下模拟登录遇到的问题!首先我们要自己登录,观察登录界面需要传递什么值!这里使用post来提交数据!所以我们登录后,打开谷歌浏览器的review元素。

在这里我们看到了我们想要的信息!
前三个变量没看懂,所以去看了大黄(一个同学,也是景洪。我的目标之一!)用PHP抢原创课表的博客
%E5%A6%82%E4%BD%95%E6%8A%93%E5%8E%9F%E5%88%9B%E6%95%99%E5%8A%A1%E7%B3%BB%E7 %BB%9F%E7%9A%84%E8%AF%BE%E8%A1%A8/
这些参数的描述有一个链接。链接在这里
Cbo_LX就是上一页选择的“学生”!
Txt_UserName 和 Txt_Password 是你前台传递过来的用户名和密码!
而 Img_DL.x 和 Img_DL.y 应该是你点击按钮时的坐标!这不是很有用!
现在问题又来了!. . 中国人在这里参与!那你会不会发现过去的编解码有错误呢?. . 实验后果然!如果直接发帖,是不能发到对应页面的!
纠结这个问题好久了!然后开始尝试用不同的编码格式来改变“学生”。. . 最终问题没有解决,却引起了我对编解码的强烈好奇!所以以后我会更加关注这方面的!下次我打算花一个星期来研究这个!自从上次发了个博客想搞直播!但是实在是太忙了,没有做!最后,这条微博千万不能删!所以如果你下次有时间,一起完成这两个!
最后请了一位同学帮忙解决这个问题!原来头文件要设置在这里!

这里的内容类型,没关系!
还要注意的是,在前面提到的参数 __viewstate 中,这可能会发生变化。也就是说,每次登录都不一样!没看懂,查了资料
这意味着这个值会根据控件的状态而变化!所以不同的用户登录是不同的!所以我们要截取这个值!每次请求获取页面后获取页面的隐藏值!然后将其作为参数传递给下一个请求页面。
最后,我要说一句伤人的话!按照页面上的步骤一步步模拟!终于发现中间有些页面根本不需要模拟!. . . 好的!我是智障!但是收获还是蛮大的!
最后一件事是在获得数据之后。切换到下一个!因为我得到的是String数据,所以必须转成json格式!所以是时候重新开始艰苦的生活了!我对 json 一无所知,但我最终根据演示对它进行了修补!目前json map添加的key-value对分别对应一个对象和对象名!如果map的值是一个数组,那么这对应的是json中的一个数组!如果使用bean方法,就相当于是一个拥有很多属性的对象!上级最后的要求就是这种格式!. . . 也许我的代码不太好!所以当我使用前两种方法时!逻辑有点乱!
代码先转移到百度云盘。有需要的朋友可以下来看看!
好了,今天就写到这里吧!. .
//抓取
报告一个材料。. 今天小白真的又变成小白了
<p>import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sf.json.JSONArray;
public class TestString {
public static void main(String[] args){
Map map = new HashMap();
List list = new ArrayList();
String[] a = new String[3];
a[0]="0";
a[1]="1";
a[2]="2";
map.put("2", a);
for(int i=0;i
asp.net 抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-25 06:19
在中抓取网页内容非常方便,解决了中困扰我们的编码问题
1、抓取一般内容
需要三个类:webrequest、webresponse和StreamReader
必需的命名空间:系统。Net,系统。木卫一
核心代码:
webrequest类的创建是一个静态方法,参数是要捕获的网页的网址
编码指定编码。在编码中,有通用编码属性,如ASCII和utf32、utf8,但没有编码属性GB2312。因此,我们使用getencoding来获得GB2312编码
2、抓取图片或其他二进制文件(如文件)
需要四个类:webrequest、webresponse、stream和FileStream
必需的命名空间:系统。Net,系统。木卫一
核心代码:用流读取
3、捕获web内容的post方法
在捕获网页时,有时需要通过post将一些数据发送到服务器。将以下代码添加到网页捕获程序,以将用户名和密码发布到服务器:
4、抓取web内容-防止重定向
抓取网页时,成功登录服务器应用系统后,应用系统可能会通过响应重定向网页。重新使用如果我们不需要对这个重定向做出响应,我们就不会给读者任何提示。Readtoend()返回响应。写
5、获取web内容-保持登录状态
使用post数据成功登录到服务器应用系统后,我们可以抓取页面进行登录,因此我们可能需要在多个请求之间保持登录状态 查看全部
asp.net 抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在中抓取网页内容非常方便,解决了中困扰我们的编码问题
1、抓取一般内容
需要三个类:webrequest、webresponse和StreamReader
必需的命名空间:系统。Net,系统。木卫一
核心代码:
webrequest类的创建是一个静态方法,参数是要捕获的网页的网址
编码指定编码。在编码中,有通用编码属性,如ASCII和utf32、utf8,但没有编码属性GB2312。因此,我们使用getencoding来获得GB2312编码
2、抓取图片或其他二进制文件(如文件)
需要四个类:webrequest、webresponse、stream和FileStream
必需的命名空间:系统。Net,系统。木卫一
核心代码:用流读取
3、捕获web内容的post方法
在捕获网页时,有时需要通过post将一些数据发送到服务器。将以下代码添加到网页捕获程序,以将用户名和密码发布到服务器:
4、抓取web内容-防止重定向
抓取网页时,成功登录服务器应用系统后,应用系统可能会通过响应重定向网页。重新使用如果我们不需要对这个重定向做出响应,我们就不会给读者任何提示。Readtoend()返回响应。写
5、获取web内容-保持登录状态
使用post数据成功登录到服务器应用系统后,我们可以抓取页面进行登录,因此我们可能需要在多个请求之间保持登录状态
asp.net 抓取网页数据(抓取网页数据的常用接口编写方法详解(5)实例_好迅云)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-09-23 23:03
抓取网页数据的常用接口编写方法详解(5)实例抓取_好迅云企业云_大象云社区_大象云这个里面还有个方法叫做html_get_navigator-centos7下编写抓取器,就可以直接去抓取页面,而且抓取的是网页上最重要的那一部分。
首先想到的是ltrack3,然后就可以用它构造网址,mdpi就是页面里有1个或者多个html页面,html就是html文件,html2007是一个列表。只要保存一个页面到本地,那么每个页面都可以去抓,我用这个爬过一家公司的页面,应该是可以抓的。
我一直都用这个,解析网页,
最常用的抓取是html_get_navigator-centos7下编写抓取器,通过url获取页面信息,并通过xml_get_element获取指定selector下的html页面数据,通过low_content_user-agenttag确定页面的数据来源。
我想到的有curl,解析网页、解析html文件,页面抓取。
我的理解就是:1.selector抓取2.封装成txt数据,
抓取就是每个页面显示到浏览器里去可以用mdpi或者lspi->flash打开/浏览器打开页面然后用html_get_element抓住页面所在的selector去爬取
爬虫就是不停的用selector去通过prefix去爬取你想要的html文档 查看全部
asp.net 抓取网页数据(抓取网页数据的常用接口编写方法详解(5)实例_好迅云)
抓取网页数据的常用接口编写方法详解(5)实例抓取_好迅云企业云_大象云社区_大象云这个里面还有个方法叫做html_get_navigator-centos7下编写抓取器,就可以直接去抓取页面,而且抓取的是网页上最重要的那一部分。
首先想到的是ltrack3,然后就可以用它构造网址,mdpi就是页面里有1个或者多个html页面,html就是html文件,html2007是一个列表。只要保存一个页面到本地,那么每个页面都可以去抓,我用这个爬过一家公司的页面,应该是可以抓的。
我一直都用这个,解析网页,
最常用的抓取是html_get_navigator-centos7下编写抓取器,通过url获取页面信息,并通过xml_get_element获取指定selector下的html页面数据,通过low_content_user-agenttag确定页面的数据来源。
我想到的有curl,解析网页、解析html文件,页面抓取。
我的理解就是:1.selector抓取2.封装成txt数据,
抓取就是每个页面显示到浏览器里去可以用mdpi或者lspi->flash打开/浏览器打开页面然后用html_get_element抓住页面所在的selector去爬取
爬虫就是不停的用selector去通过prefix去爬取你想要的html文档
asp.net 抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-19 19:14
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i 查看全部
asp.net 抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i
asp.net 抓取网页数据(第三方工具使用语言的方法和使用方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-18 06:06
一、使用第三方工具,其中最著名的是优采云采集器,在此不做介绍。
二、自己写程序抓取,这种方式要求站长自己写程序,可能对对站长的开发能力有所要求了。
本人起初也曾试着用第三方的工具抓取我所需要的数据,由于网上的流行的第三方工具不是不符合我的要求,就是过于复杂,我一时没有搞明白怎么用,后来索性决定自己写吧,现在本人基本上半天可以搞定一个网站(只是程序开发时间,不包括数据抓取的时间)。
经过一段时间的数据抓取生涯,也曾遇到了很多困难,其中最常见的一个就是关于分页数据的抓取问题,原因在于分数据分页的形式有很多种,下面我主要针对三种形式介绍一下抓取分页数据的方法,此类文章虽然在网上见过很多,但每次拿别人的代码总也总是有各种各样的问题,下面各种方式的代码都是能正确执行,并且我目前也正在使用中的。本文中代码实现是用C#语言来实现的,我想其他语言原理大致相同。
下面切入正题:
第一种方式:URL地址中收录分页信息,这种形式是最简单的,这种形式使用第三方工具抓取也很简单,基本上不用写代码,对于我这种宁可自己花个半天时间写代码也懒得学第三方工具的人,还是通过自己写代码实现了;
这种方式就是通过循环生成数据分页的URL地址 如:这样通过HttpWebRequest访问对应URL地址,返回对应页面的html文本,接下来的任务就是对字符串的解析,将需要的内容保存到本地数据库内;抓取的代码可参考下面:
public string GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return _StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取自己关心的信息了。
第二种方式:可能是通过asp.NET开发的网站常会遇到,它的分页控件通过post方式提交分页信息到后台代码,如.net下Gridview自带的分页功能,当你点击分页的页码时,会发现URL地址没有变化,但页码变化了,页面内容也变化,仔细看会发现,把鼠标移到每个页码上的时候状态栏会显示:__dopostback("gridview","page1")等等之类的代码,这种形式其实也不是很难,因为毕竟有地方得到页码的规律可寻。
我们知道http请求提交的方式有两种一种是get一种是Post,第一种方式是get方式,那么第二种方式就是post方式,具体提交的原理不必细说,不是本文的重点
抓取这种页面 需要注意asp.Net页面的几个重要的元素
一、 __VIEWSTATE ,这个应该是.net特有的,也是让.net开发人员既爱又恨的东西,当你打开一个网站的某一个页面的时候,如果发现这个东西,而且后面还跟随着一大堆乱七八糟的字符的时候,那这个网站肯定是用写的了;
二、__dopostback方法,这个是页面自动生成一个javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参看页码对应的内容,因为点击翻页的时候,会将页码信息传给这两个参数。
三、__EVENTVALIDATION 这个也也应该是特有的东西
大家也不用 太关心这三个东西都是干什么的,只需要注意自己写代码抓取页面的时候 记得提交这三个元素就可以了。
和第一种方式一样,肯定要通过循环的方式是去拼凑_dopostback的两个参数,只需要拼其中收录了页码信息的参数即可。这里有一个需要注意的地方,就是在每次通过Post提交请求下一页的时候,先应得到当前页的__VIEWSTATE 信息和__EVENTVALIDATION信息,所以分页数据的第一页可采用第一种方式得到页码内容然后,同时取出对应的__VIEWSTATE 信息和__EVENTVALIDATION信息,然后再做循环处理下一页面,然后每抓取完一个页面,再记录下__VIEWSTATE 信息和__EVENTVALIDATION信息,为下一个页面post提交数据使用
参考代码如下:
for (int i = 0; i
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTVALIDATION", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTTARGET", "此处是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "此处是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
try
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//得到当前页面对应的html文本字符串
GetPostValue(ResponseStr);//得到当前页面对应的 __VIEWSTATE 等上面需要的信息,为抓取下一页面使用
SaveMessage(ResponseStr);//保存自己关心的内容到数据库中
}catch (Exception ex){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦的,也是最恶心的,这种页面在你翻页的过程中没有任何一个地方可以找到页码信息,这种方式费了我很大的力气,后来采用了一个比较狠的办法,用代码模拟手动翻页,这种方式应该可以处理任何形式的翻页数据,原理就是,用代码模拟人工点击翻页链接,用代码一页一页的翻页,然后一页一页的抓取。
正所谓外行看热闹,内行看门道,很多人可能看到这里就会说用Webbrowser这可控件就可以实现,对,我下面的这种方式就是用WebBrowser的这个控件来实现,其实在.net下这种类似的类应该还有,但我没有去研究过,也希望如果有人有其他的方式,可以回复我,与大家一起分享。
WebBroser控件可是在自己的程序中内嵌一个浏览器,就像IE,火狐之类的一样,你也可以用他开发自己的浏览器,至于用它开发的浏览器的效果怎么样,我觉得肯定是不如IE和火狐了。呵呵
我们还是 闲言少叙,切入主题:
使用WebBroser控件基本上可以实现你在IE中操作网页的任何功能,所以点击翻页按钮当然也是可以的了,那既然可以在WebBroser中可以手动点击翻页按钮,自然我们用程序代码同样可以指使WebBroser自动替我们翻页了。
其实原理很简单,主要分以下几个步骤:
第一步,打开你想抓取的页面 比如:
调用webBrowser控件的方法Navigate("");
此时,你应该在你的WebBrowser控件中看到你的网页信息,和IE中看到的是一样的;
第二步 ,WebBrowser控件的这个事件DocumentCompleted 很重要,当你访问的页面全部加载完之后,会触发这个事件。所以我们分析页面元素的过程也需要在这个事件内完成
string _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这句代码可以得到当前打开页面的html元素的内容。
既然已经得到当前打开页面的html元素的内容了,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,解析字符串的过程,大家应该自己都能写了。
第三步, 重点在这第三步呢,因为要翻页了,接第二步,解析完字符串之后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码的id").InvokeMember("click");
从代码的方法名种大家应该能明白了,那么调用完这个方法,之后WebBrwoser控件内的网页就实现了翻页,和你用手去点翻页按钮是一样的效果。
重点在于,翻页之后,还会触发DocumentCompleted事件,所以进入了第二步,第三步的循环了,所以大家需要注意判断跳出循环的时机。
其实用WebBrowser还能干很多事情,比如自动登录,注销某个论坛,保存session, cockie,所以 这个控件基本上可以实现你想对网页的任何操作,哪怕你是想暴利破解一个网站的登录密码,当然这个是不提倡的了。呵呵 查看全部
asp.net 抓取网页数据(第三方工具使用语言的方法和使用方法有哪些)
一、使用第三方工具,其中最著名的是优采云采集器,在此不做介绍。
二、自己写程序抓取,这种方式要求站长自己写程序,可能对对站长的开发能力有所要求了。
本人起初也曾试着用第三方的工具抓取我所需要的数据,由于网上的流行的第三方工具不是不符合我的要求,就是过于复杂,我一时没有搞明白怎么用,后来索性决定自己写吧,现在本人基本上半天可以搞定一个网站(只是程序开发时间,不包括数据抓取的时间)。
经过一段时间的数据抓取生涯,也曾遇到了很多困难,其中最常见的一个就是关于分页数据的抓取问题,原因在于分数据分页的形式有很多种,下面我主要针对三种形式介绍一下抓取分页数据的方法,此类文章虽然在网上见过很多,但每次拿别人的代码总也总是有各种各样的问题,下面各种方式的代码都是能正确执行,并且我目前也正在使用中的。本文中代码实现是用C#语言来实现的,我想其他语言原理大致相同。
下面切入正题:
第一种方式:URL地址中收录分页信息,这种形式是最简单的,这种形式使用第三方工具抓取也很简单,基本上不用写代码,对于我这种宁可自己花个半天时间写代码也懒得学第三方工具的人,还是通过自己写代码实现了;
这种方式就是通过循环生成数据分页的URL地址 如:这样通过HttpWebRequest访问对应URL地址,返回对应页面的html文本,接下来的任务就是对字符串的解析,将需要的内容保存到本地数据库内;抓取的代码可参考下面:
public string GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return _StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取自己关心的信息了。
第二种方式:可能是通过asp.NET开发的网站常会遇到,它的分页控件通过post方式提交分页信息到后台代码,如.net下Gridview自带的分页功能,当你点击分页的页码时,会发现URL地址没有变化,但页码变化了,页面内容也变化,仔细看会发现,把鼠标移到每个页码上的时候状态栏会显示:__dopostback("gridview","page1")等等之类的代码,这种形式其实也不是很难,因为毕竟有地方得到页码的规律可寻。
我们知道http请求提交的方式有两种一种是get一种是Post,第一种方式是get方式,那么第二种方式就是post方式,具体提交的原理不必细说,不是本文的重点
抓取这种页面 需要注意asp.Net页面的几个重要的元素
一、 __VIEWSTATE ,这个应该是.net特有的,也是让.net开发人员既爱又恨的东西,当你打开一个网站的某一个页面的时候,如果发现这个东西,而且后面还跟随着一大堆乱七八糟的字符的时候,那这个网站肯定是用写的了;
二、__dopostback方法,这个是页面自动生成一个javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参看页码对应的内容,因为点击翻页的时候,会将页码信息传给这两个参数。
三、__EVENTVALIDATION 这个也也应该是特有的东西
大家也不用 太关心这三个东西都是干什么的,只需要注意自己写代码抓取页面的时候 记得提交这三个元素就可以了。
和第一种方式一样,肯定要通过循环的方式是去拼凑_dopostback的两个参数,只需要拼其中收录了页码信息的参数即可。这里有一个需要注意的地方,就是在每次通过Post提交请求下一页的时候,先应得到当前页的__VIEWSTATE 信息和__EVENTVALIDATION信息,所以分页数据的第一页可采用第一种方式得到页码内容然后,同时取出对应的__VIEWSTATE 信息和__EVENTVALIDATION信息,然后再做循环处理下一页面,然后每抓取完一个页面,再记录下__VIEWSTATE 信息和__EVENTVALIDATION信息,为下一个页面post提交数据使用
参考代码如下:
for (int i = 0; i
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTVALIDATION", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTTARGET", "此处是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "此处是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
try
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//得到当前页面对应的html文本字符串
GetPostValue(ResponseStr);//得到当前页面对应的 __VIEWSTATE 等上面需要的信息,为抓取下一页面使用
SaveMessage(ResponseStr);//保存自己关心的内容到数据库中
}catch (Exception ex){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦的,也是最恶心的,这种页面在你翻页的过程中没有任何一个地方可以找到页码信息,这种方式费了我很大的力气,后来采用了一个比较狠的办法,用代码模拟手动翻页,这种方式应该可以处理任何形式的翻页数据,原理就是,用代码模拟人工点击翻页链接,用代码一页一页的翻页,然后一页一页的抓取。
正所谓外行看热闹,内行看门道,很多人可能看到这里就会说用Webbrowser这可控件就可以实现,对,我下面的这种方式就是用WebBrowser的这个控件来实现,其实在.net下这种类似的类应该还有,但我没有去研究过,也希望如果有人有其他的方式,可以回复我,与大家一起分享。
WebBroser控件可是在自己的程序中内嵌一个浏览器,就像IE,火狐之类的一样,你也可以用他开发自己的浏览器,至于用它开发的浏览器的效果怎么样,我觉得肯定是不如IE和火狐了。呵呵
我们还是 闲言少叙,切入主题:
使用WebBroser控件基本上可以实现你在IE中操作网页的任何功能,所以点击翻页按钮当然也是可以的了,那既然可以在WebBroser中可以手动点击翻页按钮,自然我们用程序代码同样可以指使WebBroser自动替我们翻页了。
其实原理很简单,主要分以下几个步骤:
第一步,打开你想抓取的页面 比如:
调用webBrowser控件的方法Navigate("");
此时,你应该在你的WebBrowser控件中看到你的网页信息,和IE中看到的是一样的;
第二步 ,WebBrowser控件的这个事件DocumentCompleted 很重要,当你访问的页面全部加载完之后,会触发这个事件。所以我们分析页面元素的过程也需要在这个事件内完成
string _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这句代码可以得到当前打开页面的html元素的内容。
既然已经得到当前打开页面的html元素的内容了,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,解析字符串的过程,大家应该自己都能写了。
第三步, 重点在这第三步呢,因为要翻页了,接第二步,解析完字符串之后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码的id").InvokeMember("click");
从代码的方法名种大家应该能明白了,那么调用完这个方法,之后WebBrwoser控件内的网页就实现了翻页,和你用手去点翻页按钮是一样的效果。
重点在于,翻页之后,还会触发DocumentCompleted事件,所以进入了第二步,第三步的循环了,所以大家需要注意判断跳出循环的时机。
其实用WebBrowser还能干很多事情,比如自动登录,注销某个论坛,保存session, cockie,所以 这个控件基本上可以实现你想对网页的任何操作,哪怕你是想暴利破解一个网站的登录密码,当然这个是不提倡的了。呵呵
asp.net 抓取网页数据(ASP.NET中抓取网页内容是非常方便的())
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 00:09
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。需要三个类:WebRequest、WebResponse、StreamReader。 WebRequest 和 WebResponse 的命名空间为: System.Net StreamReader 的命名空间为: System.IO 核心代码 WebRequest request = WebRequest.Create(""); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")); WebRequest类的Create是一个静态方法,参数是要抓取的网页的URL; Encoding指定编码,Encoding有ASCII、UTF32、UTF8等属性编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312的编码。示例
ASP.NET 抓取网页内容-Post 数据抓取网页时,有时需要通过Post 向服务器发送一些数据。在网页抓取程序中加入如下代码,实现将用户名和密码发布到服务器: string data = "userName=admin&passwd=admin888"; byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data); request.Method = "POST"; request .ContentType = "application/x-www-form-urlencoded"; request.ContentLength = requestBuffer.Length;使用 (Stream requestStream = request.GetRequestStream()) {requestStream.Write(requestBuffer, 0, requestBuffer.Length);请求流。 Close();} using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"))) {string str = reader.ReadToEnd(); reader.Close();} 以上是编码以gb2312为例
ASP.NET 抓取网页内容阻止重定向。抓取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么,我们不需要发送 reader.ReadToEnd() 到 Response.Write,就是这样。 ASP.NET 抓取网页内容保持登录状态使用Post数据成功登录服务器应用系统后,就可以抓取需要登录的页面,那么我们可能需要在多个Request中保持登录状态。首先,我们要使用 HttpWebRequest 而不是 WebRequest。与WebRequest相比,更改的代码为:HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url);注意:HttpWebRequest.Create返回的类型仍然是WebRequest,所以转换一下。其次,使用CookieContainer。 System.Net.CookieContainer cc = new System.Net.CookieContainer(); request.CookieContainer = cc; request2.CookieContainer = cc;这样,request和request2之间使用了同一个Session。如果请求登录了,那么 request2 也登录了。
最后,如何在不同页面之间使用相同的CookieContainer。要在不同页面之间使用相同的 CookieContainer,只需将 CookieContainer 添加到 Session 中即可。 Session.Add("ccc", cc); //保存CookieContainer cc = (CookieContainer)Session["ccc"]; //获取ASP.NET并抓取网页内容——将当前会话带到WebRequest中,例如浏览器B1访问服务器端S1,这样会生成一个会话,服务器端S2会使用WebRequest访问服务器-side S1,它将生成一个会话。当前的要求是WebRequest 使用浏览器B1 和S1 之间的会话,这意味着S1 应该认为B1 正在访问S1,而不是S2 正在访问S1。这需要使用 cookie。首先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。 WebRequest request = WebRequest.Create("url"); request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;"); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream() , System.Text.Encoding.GetEncoding("gb2312")); Response.Write(reader.ReadToEnd()); reader.Close(); reader.Dispose(); response.Close();解释一下:本文不是Cookie欺骗,因为SessionID是S1告诉S2的,不是S2盗取的。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1必须将Session写入B1,这样SessionID才会保存在Cookie中,SessionID保持不变。 Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 Cookie。不同的服务器端语言对Cookie中的SessionID有不同的名称。这篇文章是ASP SessionID。 S1可能不仅依靠SessionID来判断当前登录,还可能辅助Referer、User-Agent等,具体取决于S1终端程序的设计。实际上,本文是本系列中另一种“保持登录”的方式。 ASP.NET抓取网页内容-如何更改源Referer和UserAgent ----------------------------------- - -------------------------------------------- HttpWebRequest 请求 = (HttpWebRequest ) HttpWebRequest.Create(""); //request.Headers.Add(HttpRequestHeader.Referer, ""); // 错误 //request.Headers[HttpRequestHeader.Referer] = ""; // 错误 request.Referer = "" ; // 正确注释掉的两句是错误的,会出现错误:这个header必须修改合适的属性。参数名称:名称 UserAgent 类似。 查看全部
asp.net 抓取网页数据(ASP.NET中抓取网页内容是非常方便的())
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。需要三个类:WebRequest、WebResponse、StreamReader。 WebRequest 和 WebResponse 的命名空间为: System.Net StreamReader 的命名空间为: System.IO 核心代码 WebRequest request = WebRequest.Create(""); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")); WebRequest类的Create是一个静态方法,参数是要抓取的网页的URL; Encoding指定编码,Encoding有ASCII、UTF32、UTF8等属性编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312的编码。示例
ASP.NET 抓取网页内容-Post 数据抓取网页时,有时需要通过Post 向服务器发送一些数据。在网页抓取程序中加入如下代码,实现将用户名和密码发布到服务器: string data = "userName=admin&passwd=admin888"; byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data); request.Method = "POST"; request .ContentType = "application/x-www-form-urlencoded"; request.ContentLength = requestBuffer.Length;使用 (Stream requestStream = request.GetRequestStream()) {requestStream.Write(requestBuffer, 0, requestBuffer.Length);请求流。 Close();} using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"))) {string str = reader.ReadToEnd(); reader.Close();} 以上是编码以gb2312为例
ASP.NET 抓取网页内容阻止重定向。抓取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么,我们不需要发送 reader.ReadToEnd() 到 Response.Write,就是这样。 ASP.NET 抓取网页内容保持登录状态使用Post数据成功登录服务器应用系统后,就可以抓取需要登录的页面,那么我们可能需要在多个Request中保持登录状态。首先,我们要使用 HttpWebRequest 而不是 WebRequest。与WebRequest相比,更改的代码为:HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url);注意:HttpWebRequest.Create返回的类型仍然是WebRequest,所以转换一下。其次,使用CookieContainer。 System.Net.CookieContainer cc = new System.Net.CookieContainer(); request.CookieContainer = cc; request2.CookieContainer = cc;这样,request和request2之间使用了同一个Session。如果请求登录了,那么 request2 也登录了。
最后,如何在不同页面之间使用相同的CookieContainer。要在不同页面之间使用相同的 CookieContainer,只需将 CookieContainer 添加到 Session 中即可。 Session.Add("ccc", cc); //保存CookieContainer cc = (CookieContainer)Session["ccc"]; //获取ASP.NET并抓取网页内容——将当前会话带到WebRequest中,例如浏览器B1访问服务器端S1,这样会生成一个会话,服务器端S2会使用WebRequest访问服务器-side S1,它将生成一个会话。当前的要求是WebRequest 使用浏览器B1 和S1 之间的会话,这意味着S1 应该认为B1 正在访问S1,而不是S2 正在访问S1。这需要使用 cookie。首先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。 WebRequest request = WebRequest.Create("url"); request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;"); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream() , System.Text.Encoding.GetEncoding("gb2312")); Response.Write(reader.ReadToEnd()); reader.Close(); reader.Dispose(); response.Close();解释一下:本文不是Cookie欺骗,因为SessionID是S1告诉S2的,不是S2盗取的。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1必须将Session写入B1,这样SessionID才会保存在Cookie中,SessionID保持不变。 Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 Cookie。不同的服务器端语言对Cookie中的SessionID有不同的名称。这篇文章是ASP SessionID。 S1可能不仅依靠SessionID来判断当前登录,还可能辅助Referer、User-Agent等,具体取决于S1终端程序的设计。实际上,本文是本系列中另一种“保持登录”的方式。 ASP.NET抓取网页内容-如何更改源Referer和UserAgent ----------------------------------- - -------------------------------------------- HttpWebRequest 请求 = (HttpWebRequest ) HttpWebRequest.Create(""); //request.Headers.Add(HttpRequestHeader.Referer, ""); // 错误 //request.Headers[HttpRequestHeader.Referer] = ""; // 错误 request.Referer = "" ; // 正确注释掉的两句是错误的,会出现错误:这个header必须修改合适的属性。参数名称:名称 UserAgent 类似。
asp.net 抓取网页数据(抓取网页数据库资源的样例与在networkstorage中的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-09-09 15:34
抓取网页数据库资源的样例与在networkstorage中的教程,demo可以参考,其他内容.比如redis应用,bspcrud指导,gson全局配置等.
爬虫爬了20多年,这里整理了一下这几年爬虫到的一些东西,给想入门爬虫的同学提供一个可以爬的对象。
一)基于scrapy的爬虫这种爬虫的爬取范围是比较广的,包括传统的页面和网页页面以及不涉及页面加载的html,通过python爬虫框架scrapy来抓取。爬虫的框架有很多,有人的地方就有江湖,网络上基于各种框架的千奇百怪爬虫也层出不穷,就不一一列举了。
二)基于scrapy或python语言的爬虫,这类爬虫更针对于这种基于http的协议规范爬取。这类爬虫的爬取范围更局限,一般只能在针对网页的html方面。这种爬虫框架也有很多,但大多都是由scrapy或者python语言的爬虫框架来实现的。
下面就介绍一下常见的scrapy和python爬虫框架scrapy,一起来学习下吧!什么是python爬虫框架?一般说来,
1)爬虫程序:爬虫程序是一个对客户端发送请求(request),如果不接受就返回的对象。这个对象是一个句柄,传入了请求头,就是header里面的数据。一般情况下,它只有一个值:params.default(format)。一般情况下,它也会接受请求的字符串,header等数据。
2)文件路径:文件路径是爬虫程序把url上的字符串转化为python列表后的存储方式,即一个简单文件的路径叫做一个url。这个文件路径不是被你修改了字符串就是一个url。
3)页面字符串:页面字符串是可以用“{"”来表示的。通常我们把这样的一串字符串抓取了来之后存储在html文件中。一个函数的定义以及导入由下面三个部分组成:(page_name):就是提供page_name让爬虫去判断页面的url。(page_name):是由你传入的url所指定的页面名称组成的。(page_name):是由这个url所指定的页面名称与page_name组成的。
__init__.pyd:是一个默认的python对象。通常情况下我们会使用它来创建一个scrapy项目。如下所示:frompyspider.spidersimportspiderfrompyspider.itemsimportitemasitemidfromscrapy.selectorimport*defspider_item(items):deffind_spider(self,request):response=self.__init__.pyd[self.items]try:item=itemid[reques。 查看全部
asp.net 抓取网页数据(抓取网页数据库资源的样例与在networkstorage中的教程)
抓取网页数据库资源的样例与在networkstorage中的教程,demo可以参考,其他内容.比如redis应用,bspcrud指导,gson全局配置等.
爬虫爬了20多年,这里整理了一下这几年爬虫到的一些东西,给想入门爬虫的同学提供一个可以爬的对象。
一)基于scrapy的爬虫这种爬虫的爬取范围是比较广的,包括传统的页面和网页页面以及不涉及页面加载的html,通过python爬虫框架scrapy来抓取。爬虫的框架有很多,有人的地方就有江湖,网络上基于各种框架的千奇百怪爬虫也层出不穷,就不一一列举了。
二)基于scrapy或python语言的爬虫,这类爬虫更针对于这种基于http的协议规范爬取。这类爬虫的爬取范围更局限,一般只能在针对网页的html方面。这种爬虫框架也有很多,但大多都是由scrapy或者python语言的爬虫框架来实现的。
下面就介绍一下常见的scrapy和python爬虫框架scrapy,一起来学习下吧!什么是python爬虫框架?一般说来,
1)爬虫程序:爬虫程序是一个对客户端发送请求(request),如果不接受就返回的对象。这个对象是一个句柄,传入了请求头,就是header里面的数据。一般情况下,它只有一个值:params.default(format)。一般情况下,它也会接受请求的字符串,header等数据。
2)文件路径:文件路径是爬虫程序把url上的字符串转化为python列表后的存储方式,即一个简单文件的路径叫做一个url。这个文件路径不是被你修改了字符串就是一个url。
3)页面字符串:页面字符串是可以用“{"”来表示的。通常我们把这样的一串字符串抓取了来之后存储在html文件中。一个函数的定义以及导入由下面三个部分组成:(page_name):就是提供page_name让爬虫去判断页面的url。(page_name):是由你传入的url所指定的页面名称组成的。(page_name):是由这个url所指定的页面名称与page_name组成的。
__init__.pyd:是一个默认的python对象。通常情况下我们会使用它来创建一个scrapy项目。如下所示:frompyspider.spidersimportspiderfrompyspider.itemsimportitemasitemidfromscrapy.selectorimport*defspider_item(items):deffind_spider(self,request):response=self.__init__.pyd[self.items]try:item=itemid[reques。
asp.net 抓取网页数据(ssl基础,主要分为网页解析与网页url提取方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-01 14:29
抓取网页数据,主要是为了从表单中得到map,作为参数提交到网页服务器获取响应数据。关于抓取网页数据,讲的还比较多,但是我们掌握的应该都是elgamescripten基础,主要分为网页解析与网页url提取,这两个方面。网页解析与提取,主要在浏览器发出http请求后,根据header去结合web服务器上的函数去完成提取请求的需要数据。
具体可以从http对象抓取。抓取表单数据的方法,并不多。最简单的,可以按照字段分别抓取并提取响应html。然后使用代码来抓取。但是一般在实际使用中,不会总是追求这种效率的,首先我们可以使用bs来抓取指定节点的数据,按照html对象提取这样的开放性,是否可以采用httpclient来封装数据?的发展简史charles是实现抓取网页数据,用于检测,识别,或抓取数据的第三方工具。
它使用c++的httpapi和httpsapi来将客户端链接到一个接口库,允许浏览器发送一些特定报文格式,并返回服务器所要求的json数据。通过这些报文格式,可以达到http提取,抓取,以及在浏览器进行网页分析,解析,有时候通过查看具体的协议来抓取对应文件的目的。官方的人通常将它叫做bomjsonparsers。
我们先从简单的抓取,简单的抓取就是一个网址就可以解析提取,因为抓取是以ssl为主的,基本所有的安全协议都可以抓取。ssl抓取ssl抓取方法一:把提取数据的请求报文发送给webclient或protocolbuffer,传递给数据解析,对数据进行提取,过程和普通网站抓取的过程类似。
以下命令可查看抓取模式:scriptingenvironmentscriptingdisabled我们可以使用c++编写cryptowrapper方法:1.需要有c++基础。2.需要编写加密工具。3.需要编写一个network.h代码:mryiput(stringurl,intnlp$nlp,constchar*fnv$fnv){//encryptstringaspstring;return{aspstring:[[stringaspstringreplace(aspstring,"",nlp$nlp)]format(stringformat){returnformat=="asp";}]};}mryiput方法本质上是把一个字符串发送给一个监听端,监听端把加密后的aspstring保存在自己数据库里面,然后数据库里面的aspstring可以发送给一个解密工具,发给其他客户端,解密工具做出相应的反应。
当然需要考虑到端口的问题,端口如果设置的是3306那么需要给相应的客户端发送3306端口的地址,如果你的客户端设置为3333则不需要给相应的端口反应。不同的端口抓取对应的数据解析相对。 查看全部
asp.net 抓取网页数据(ssl基础,主要分为网页解析与网页url提取方法)
抓取网页数据,主要是为了从表单中得到map,作为参数提交到网页服务器获取响应数据。关于抓取网页数据,讲的还比较多,但是我们掌握的应该都是elgamescripten基础,主要分为网页解析与网页url提取,这两个方面。网页解析与提取,主要在浏览器发出http请求后,根据header去结合web服务器上的函数去完成提取请求的需要数据。
具体可以从http对象抓取。抓取表单数据的方法,并不多。最简单的,可以按照字段分别抓取并提取响应html。然后使用代码来抓取。但是一般在实际使用中,不会总是追求这种效率的,首先我们可以使用bs来抓取指定节点的数据,按照html对象提取这样的开放性,是否可以采用httpclient来封装数据?的发展简史charles是实现抓取网页数据,用于检测,识别,或抓取数据的第三方工具。
它使用c++的httpapi和httpsapi来将客户端链接到一个接口库,允许浏览器发送一些特定报文格式,并返回服务器所要求的json数据。通过这些报文格式,可以达到http提取,抓取,以及在浏览器进行网页分析,解析,有时候通过查看具体的协议来抓取对应文件的目的。官方的人通常将它叫做bomjsonparsers。
我们先从简单的抓取,简单的抓取就是一个网址就可以解析提取,因为抓取是以ssl为主的,基本所有的安全协议都可以抓取。ssl抓取ssl抓取方法一:把提取数据的请求报文发送给webclient或protocolbuffer,传递给数据解析,对数据进行提取,过程和普通网站抓取的过程类似。
以下命令可查看抓取模式:scriptingenvironmentscriptingdisabled我们可以使用c++编写cryptowrapper方法:1.需要有c++基础。2.需要编写加密工具。3.需要编写一个network.h代码:mryiput(stringurl,intnlp$nlp,constchar*fnv$fnv){//encryptstringaspstring;return{aspstring:[[stringaspstringreplace(aspstring,"",nlp$nlp)]format(stringformat){returnformat=="asp";}]};}mryiput方法本质上是把一个字符串发送给一个监听端,监听端把加密后的aspstring保存在自己数据库里面,然后数据库里面的aspstring可以发送给一个解密工具,发给其他客户端,解密工具做出相应的反应。
当然需要考虑到端口的问题,端口如果设置的是3306那么需要给相应的客户端发送3306端口的地址,如果你的客户端设置为3333则不需要给相应的端口反应。不同的端口抓取对应的数据解析相对。
asp.net 抓取网页数据(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-30 22:09
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, " 查看全部
asp.net 抓取网页数据(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, "
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-10-28 17:01
想知道一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。重点:Python,一起来学习吧。
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页的文字,可以一言为定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章 查看全部
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
想知道一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。重点:Python,一起来学习吧。
抓取网页数据的思路有很多,一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂的情况,放一个小例子读取简单网页数据:
目标数据
将此页面上所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页的文字,可以一言为定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,它包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章
asp.net 抓取网页数据(抓取网页数据,如何创建一个交互式aspx的网页引擎)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-10-22 20:03
抓取网页数据,如何创建一个交互式aspx的网页引擎,也可以通过php实现,也可以通过webgl实现,方法不同,思路很简单。解析数据前先判断该数据是不是合法url,举例:比如发行量。然后判断该数据是否必须存在,比如分组是多少(每个不重复),最终只关心发行量就好了,无关性别,生日,注册数,总注册数,注册人数等等。
那么我们就先把网页的内容写下来,然后看网页里面每一个phpurl,下面是方法:declareuriasuripath=""declareclassdeclarepath=""publicdefimplement(pathforuri,classasclass){constreturnpath=forwardurl(uri,class)constintnumstr=response.numberoflines();returnpath.replace(path,numstr,int(1)+1);}参数forwardurl(path)用来指定是通过哪个uri下载网页内容publicdefimplement(classasclass)参数,所以这里的class非对象,只是一个名字private则不能修改,同样网页内容也是不能修改的uriasuripath="/sun32.html"publicdefimplement(classasclass)asuri需要给发行量赋值给一个class(即this),必须与appenddispatcher实例对象相同名字或者不同名字,就会得到/sun32.html这个int是uri值对应的class实例。
注意一定要加引号包裹起来,而且id必须要一致。而且uri[]只能通过传值传递,要传值必须要传递整个aspxrequest对象的对象属性。因为aspxrequest不是对象arguments[]所以必须创建一个发行量对象,这里只创建一个array_in_string(发行量对象),也不用传值参数uri对应的class只要是对象即可,非对象,也是不能传值参数。
第一个参数是uri或者class,后三个参数是对应的array_in_string实例属性(如不是对应的class,那么int就是string对象)好了,解析完以后我们就可以在代码里面写对应的class发行量对象的实例属性了。比如:publicinterfaceillhaven{declareuriasuri;publicvoidshow();}上面就是抓取网页的源代码的过程,所以我们要先写代码能获取到发行量对象,将会变得相对简单。
那么这样写代码的aspx引擎怎么获取发行量对象呢?比如需要获取性别,有三种写法。if(params.getvalue()!=urforms.getvalue()){params.putvalue(urforms.getvalue(),ufrorms.getvalue());}if(params.getvalue()!=urforms.getvalue()){illhaven.getvalue();}通过params.getvalue得到u。 查看全部
asp.net 抓取网页数据(抓取网页数据,如何创建一个交互式aspx的网页引擎)
抓取网页数据,如何创建一个交互式aspx的网页引擎,也可以通过php实现,也可以通过webgl实现,方法不同,思路很简单。解析数据前先判断该数据是不是合法url,举例:比如发行量。然后判断该数据是否必须存在,比如分组是多少(每个不重复),最终只关心发行量就好了,无关性别,生日,注册数,总注册数,注册人数等等。
那么我们就先把网页的内容写下来,然后看网页里面每一个phpurl,下面是方法:declareuriasuripath=""declareclassdeclarepath=""publicdefimplement(pathforuri,classasclass){constreturnpath=forwardurl(uri,class)constintnumstr=response.numberoflines();returnpath.replace(path,numstr,int(1)+1);}参数forwardurl(path)用来指定是通过哪个uri下载网页内容publicdefimplement(classasclass)参数,所以这里的class非对象,只是一个名字private则不能修改,同样网页内容也是不能修改的uriasuripath="/sun32.html"publicdefimplement(classasclass)asuri需要给发行量赋值给一个class(即this),必须与appenddispatcher实例对象相同名字或者不同名字,就会得到/sun32.html这个int是uri值对应的class实例。
注意一定要加引号包裹起来,而且id必须要一致。而且uri[]只能通过传值传递,要传值必须要传递整个aspxrequest对象的对象属性。因为aspxrequest不是对象arguments[]所以必须创建一个发行量对象,这里只创建一个array_in_string(发行量对象),也不用传值参数uri对应的class只要是对象即可,非对象,也是不能传值参数。
第一个参数是uri或者class,后三个参数是对应的array_in_string实例属性(如不是对应的class,那么int就是string对象)好了,解析完以后我们就可以在代码里面写对应的class发行量对象的实例属性了。比如:publicinterfaceillhaven{declareuriasuri;publicvoidshow();}上面就是抓取网页的源代码的过程,所以我们要先写代码能获取到发行量对象,将会变得相对简单。
那么这样写代码的aspx引擎怎么获取发行量对象呢?比如需要获取性别,有三种写法。if(params.getvalue()!=urforms.getvalue()){params.putvalue(urforms.getvalue(),ufrorms.getvalue());}if(params.getvalue()!=urforms.getvalue()){illhaven.getvalue();}通过params.getvalue得到u。
asp.net 抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-16 17:11
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只算程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。 查看全部
asp.net 抓取网页数据(一下就是关于抓取别人网站数据的抓取问题和方法)
我相信所有个人网站 站长都有抓取他人数据的经验。目前有两种方式可以抓取别人的网站数据:
一、使用第三方工具,其中最著名的是优采云采集器,这里不再介绍。
二、自己写程序抓包,这种方法需要站长自己写程序,可能需要站长的开发能力。
一开始,我尝试使用第三方工具来抓取我需要的数据。因为网上流行的第三方工具要么不符合我的要求,要么太复杂,一时不知道怎么用,所以决定自己写。嗯,现在半天基本上可以搞定一个网站(只算程序开发时间,不包括抓数据的时间)。
经过一段时间的数据爬取生涯,遇到了很多困难。最常见的一种是抓取分页数据。原因是数据分页的形式很多。下面我主要介绍三种形式。抓取分页数据的方法。虽然我在网上看到过很多这样的文章,但是每次拿别人的代码时总会出现各种各样的问题。以下代码全部正确。实施,我目前正在使用。本文的代码实现是用C#语言实现的,我觉得其他语言的原理大致相同
让我们切入主题:
第一种方法:URL地址收录分页信息。这种形式是最简单的。这个表单也很简单,使用第三方工具爬取。基本上,您不需要编写代码。对我来说,我宁愿花半天时间自己写。那些懒得学习第三方代码工具的人,通过编写自己的代码实现了;
该方法是通过循环生成数据页面的URL地址,如:通过HttpWebRequest访问对应的URL地址,返回对应页面的html文本。接下来的任务是解析字符串并将需要的内容保存到本地数据库;获取到的代码可以参考如下:
公共字符串 GetResponseString(string url)
{
字符串_StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (兼容; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322;.NET CLR 2.0.50727;.NET CLR 3.0.04506.648;.NET CLR 3.5.21022;。 NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
返回_StrResponse;
}
上面的代码可以返回页面html内容对应的字符串,剩下的工作就是从这个字符串中获取你关心的信息。
方式二:通过网站的开发可能经常遇到,它的分页控件通过post方法向后台代码提交分页信息,比如.net下Gridview的分页功能,点击页面时分页号的时候,你会发现URL地址没有变,但是页码变了,页面内容也变了。仔细看会发现,当你把鼠标移到每个页码上时,状态栏会显示 javascript:__dopostback("gridview","page1") 等等,这种形式的代码其实并不难,因为毕竟有一个地方可以找到页码规则。
我们知道有两种方式可以提交 HTTP 请求。一个是get,一个是post,第一个是get,第二个是post。具体的投稿原则无需赘述,也不是本文的重点。
爬取这种页面需要注意页面的几个重要元素
一、 __VIEWSTATE,这应该是 .net 独有的,也是 .net 开发人员喜欢和讨厌的东西。当你打开一个网站的页面,如果你发现这个东西,并且后面有很多乱码的时候,那么这个网站一定要写;
二、__dopostback方法,这是页面自动生成的javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参考页码对应的内容,因为点击翻页的时候,页码信息将发送给这两个参数。
三、__EVENTVALIDATION 这也应该是唯一的
不用太在意这三个东西是干什么的,自己写代码抓取页面的时候记得提交这三个元素就行了。
和第一种方法一样,_dopostback的两个参数必须用循环拼凑,只有收录页码信息的参数才需要拼凑。这里需要注意的一点是,每次通过Post提交下一页的请求时,首先要获取当前页面的__VIEWSTATE信息和__EVENTVALIDATION信息,这样就可以通过第一种方式获取到分页数据的第一页. 页码内容 然后,同时取出对应的__VIEWSTATE信息和__EVENTVALIDATION信息,然后做一个循环处理下一页,然后每次爬到一个页面,记录__VIEWSTATE信息和__EVENTVALIDATION信息,提交给下一页发布数据使用情况
参考代码如下:
for (int i = 0; i <1000; i++)
{
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "这里是需要提前获取的信息");
PostVars.Add("__EVENTVALIDATION", "这里是需要提前获取的信息");
PostVars.Add("__EVENTTARGET", "这里是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "这里是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
尝试
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//获取当前页面对应的html文本字符串
GetPostValue(ResponseStr);//获取当前页面对应的__VIEWSTATE等上面需要的信息,用来抓取下一页
SaveMessage(ResponseStr);//把你关心的内容保存到数据库中
}
捕获(异常前)
{
Console.WriteLine(ex.Message);
}
}
第三种方法最麻烦也最恶心。这种页面在翻页时没有任何地方可以找到页码信息。这个方法费了不少功夫。方法是用代码模拟手动翻页。这种方法应该能够处理任何形式的翻页数据。原理是用代码模拟人工翻页链接,用代码逐页翻页,再逐页翻页。爬行的。
asp.net 抓取网页数据(如何有效的提取并利用这些信息成为一个巨大的挑战 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-16 17:09
)
本文主要内容如下:
一、背景
随着互联网的不断发展,各种网页层出不穷,信息资源泛滥。如何有效地提取和利用这些信息成为一个巨大的挑战。谷歌、百度等搜索引擎被用作辅助人们检索信息的工具。成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,如下图所示:
1、网络资源无关性问题:专业搜索引擎的客户群太广,用户搜索的时候往往会搜索到自己不想要的资源;
2、网络覆盖问题:有限的搜索引擎和无限的网络数据资源是矛盾的;
3、数据结构问题:搜索引擎对于某种数据结构无能为力;
4、语义检索问题:搜索引擎一般基于关键字查询,难以支持特定语义信息的查询,如行业特定语义;
综上所述,在我们的行业中,我们应该建立一个我们行业中独一无二的搜索引擎(网络爬虫)。它可能被称为搜索引擎太大。这里我们称之为网络爬虫。比如在电子政务领域,我们可以为政府客户提供电子政务相关的信息资源,并结合我们的平台,为不同的政府部门提供不同的视角,这对于我们发展来说无疑是一个很好的驱动方式。网络爬虫!
二、概念和原理
网络爬虫(又称网络蜘蛛或网络机器人)是一种按照一定的规则自动抓取万维网上信息的程序或脚本,如下图所示:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
网络爬虫的原理如下图所示,主要包括:
1、 爬虫模块:这个现在比较成熟,有BS和CS。一般采用广度优先算法爬取网络资源,多线程模式,一套最基本的配置。
2、 预处理模块:一般与爬虫模块配合使用,在爬取资源的同时对网页进行分段索引,形成索引库;
3、查询服务模块:有了前两个,可以结合业务应用提供各种查询服务;
三、技术选型
这一项技术在JAVA领域有很多开源的网络爬虫,但在.net领域却很少,而且基本是零散的。经过一番搜索整理,对最核心的基础模块的技术进行了深入研究。这个.net搜索引擎的版本已经算是比较好的一个了,主要技术如下:
1、 爬虫模块:NWebCrawler;
2、HTML解析:Winista.HtmlParser,这个很专业;
3、分词,索引:Apache-Lucene.Net-3.0.3,这个不用介绍了,Apache基金会的东西!
四、需求矩阵
查看全部
asp.net 抓取网页数据(如何有效的提取并利用这些信息成为一个巨大的挑战
)
本文主要内容如下:
一、背景
随着互联网的不断发展,各种网页层出不穷,信息资源泛滥。如何有效地提取和利用这些信息成为一个巨大的挑战。谷歌、百度等搜索引擎被用作辅助人们检索信息的工具。成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,如下图所示:
1、网络资源无关性问题:专业搜索引擎的客户群太广,用户搜索的时候往往会搜索到自己不想要的资源;
2、网络覆盖问题:有限的搜索引擎和无限的网络数据资源是矛盾的;
3、数据结构问题:搜索引擎对于某种数据结构无能为力;
4、语义检索问题:搜索引擎一般基于关键字查询,难以支持特定语义信息的查询,如行业特定语义;
综上所述,在我们的行业中,我们应该建立一个我们行业中独一无二的搜索引擎(网络爬虫)。它可能被称为搜索引擎太大。这里我们称之为网络爬虫。比如在电子政务领域,我们可以为政府客户提供电子政务相关的信息资源,并结合我们的平台,为不同的政府部门提供不同的视角,这对于我们发展来说无疑是一个很好的驱动方式。网络爬虫!
二、概念和原理
网络爬虫(又称网络蜘蛛或网络机器人)是一种按照一定的规则自动抓取万维网上信息的程序或脚本,如下图所示:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。
网络爬虫的原理如下图所示,主要包括:
1、 爬虫模块:这个现在比较成熟,有BS和CS。一般采用广度优先算法爬取网络资源,多线程模式,一套最基本的配置。
2、 预处理模块:一般与爬虫模块配合使用,在爬取资源的同时对网页进行分段索引,形成索引库;
3、查询服务模块:有了前两个,可以结合业务应用提供各种查询服务;
三、技术选型
这一项技术在JAVA领域有很多开源的网络爬虫,但在.net领域却很少,而且基本是零散的。经过一番搜索整理,对最核心的基础模块的技术进行了深入研究。这个.net搜索引擎的版本已经算是比较好的一个了,主要技术如下:
1、 爬虫模块:NWebCrawler;
2、HTML解析:Winista.HtmlParser,这个很专业;
3、分词,索引:Apache-Lucene.Net-3.0.3,这个不用介绍了,Apache基金会的东西!
四、需求矩阵
asp.net 抓取网页数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-10-11 19:00
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这个,
可能我们隐约记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. . 查看全部
asp.net 抓取网页数据(这里有新鲜出炉的精品教程,程序狗速度看过来!)
这里是新鲜出炉的优质教程,看程序狗的速度!
ASP.NET ASP.NET 是 .NET FrameWork 的一部分。它是微软公司的一项技术。它是一种服务器端脚本技术,可使嵌入在网页中的脚本由 Internet 服务器执行。它们是在服务器上动态创建的。指的是Active Server Pages,一个运行在IIS(Internet Information Server service,Windows开发的Web服务器)中的程序。
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们没有必要再次抓取网页,但会对其他服务器造成压力。
一:网页更新
我们知道一般网页中的信息是不断更新的,这也需要我们定期抓取这些新信息,但是如何理解这个“定期”,也就是页面需要多久被抓取一次,在其实这个时间段也是Page cache时间。在页面缓存期间,我们不需要再次抓取网页,但会对其他服务器造成压力。
比如我想抓取博客园的首页,先清除页面缓存,
从Last-Modified到Expires,可以看到博客园的缓存时间是2分钟,我还可以看到当前服务器时间Date,如果我再做一次
如果页面刷新,这里的Date会变成下图中的If-Modified-Since,然后发送到服务器判断浏览器的缓存是否已经过期?
最后服务端发现if-Modified-Since >= Last-Modifined时间,服务端也返回了304,但是发现cookie信息真的是很多小偷。
在实际开发中,如果知道网站的缓存策略,就可以让爬虫每2分钟爬一次。当然,这些可以由数据团队进行配置和维护。好的,让我们使用爬虫。模拟它。
using System;
using System.Net;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
DateTime prevDateTime = DateTime.MinValue;
for (int i = 0; i < 10; i++)
{
try
{
var url = "http://cnblogs.com";
var request = (HttpWebRequest)HttpWebRequest.Create(url);
request.Method = "Head";
if (i > 0)
{
request.IfModifiedSince = prevDateTime;
}
request.Timeout = 3000;
var response = (HttpWebResponse)request.GetResponse();
var code = response.StatusCode;
//如果服务器返回状态是200,则认为网页已更新,记得当时的服务器时间
if (code == HttpStatusCode.OK)
{
prevDateTime = Convert.ToDateTime(response.Headers[HttpResponseHeader.Date]);
}
Console.WriteLine("当前服务器的状态码:{0}", code);
}
catch (WebException ex)
{
if (ex.Response != null)
{
var code = (ex.Response as HttpWebResponse).StatusCode;
Console.WriteLine("当前服务器的状态码:{0}", code);
}
}
}
}
}
}
二:网页编码问题
有时候我们已经抓取了网页,准备解析的时候,tmd全是乱码,真他妈的,比如下面这个,
可能我们隐约记得html的meta中有一个叫做charset的属性,里面记录了编码方式。还有一点很重要,response.CharacterSet 也记录了编码方式。让我们再试一次。
还是乱码,蛋疼。这个时候需要去官网看看http头信息里面交互的是什么。为什么浏览器能正常显示,爬虫就爬不过去了。
查看http头信息后,我们终于知道了。浏览器说可以解析gzip、deflate、sdch这三种压缩方式。服务器发送 gzip 压缩。至此,我们也应该知道常用的web性能优化了。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
}
}
}
三:网页分析
经过一番折腾,现在网页已经得到了,接下来就要解析了。当然,正则匹配是一个不错的方法。毕竟工作量还是比较大的。或许业界也推荐HtmlAgilityPack,一个可以将Html解析成XML的解析工具,然后可以使用XPath提取指定的内容,大大提高了开发速度,性能也不错。毕竟,敏捷意味着敏捷。关于XPath的内容,可以看一下W3CSchool的两张图。
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading;
using HtmlAgilityPack;
using System.Text.RegularExpressions;
using System.Net;
using System.IO;
using System.IO.Compression;
namespace ConsoleApplication2
{
public class Program
{
static void Main(string[] args)
{
//var currentUrl = "http://www.mm5mm.com/";
var currentUrl = "http://www.sohu.com/";
var request = WebRequest.Create(currentUrl) as HttpWebRequest;
var response = request.GetResponse() as HttpWebResponse;
var encode = string.Empty;
if (response.CharacterSet == "ISO-8859-1")
encode = "gb2312";
else
encode = response.CharacterSet;
Stream stream;
if (response.ContentEncoding.ToLower() == "gzip")
{
stream = new GZipStream(response.GetResponseStream(), CompressionMode.Decompress);
}
else
{
stream = response.GetResponseStream();
}
var sr = new StreamReader(stream, Encoding.GetEncoding(encode));
var html = sr.ReadToEnd();
sr.Close();
HtmlDocument document = new HtmlDocument();
document.LoadHtml(html);
//提取title
var title = document.DocumentNode.SelectSingleNode("//title").InnerText;
//提取keywords
var keywords = document.DocumentNode.SelectSingleNode("//meta[@name='Keywords']").Attributes["content"].Value;
}
}
}
好了,结束工作,去睡觉吧。. .
asp.net 抓取网页数据(抓取网页数据的流程:1.服务器返回文本数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-11 15:29
抓取网页数据的流程:1.用浏览器打开这个地址,需要自己自定义dom/.php然后启动环境2.此时执行了一次post请求。3.服务器返回文本数据,就是由html源码构成的asp/html。4.客户端接收html源码后解析,可以得到数据,也可以得到html的字符串/字符串进行编码等处理5.客户端将对应html类型转化为字符串,用content-type对数据进行处理,将对应的web应用的数据类型转化为asp应用的数据类型。
也就是说asp应用解析了数据,转化了对应的html,转化的结果是字符串,用bean表示。6.服务器返回数据给客户端,得到html,最后的浏览器解析这个html。如下图,以我的思维分析,抓取网页,一定要在post请求,也就是http请求中体现。回答问题:其实同一个asp网页是可以多次解析的。
拿页面从控制台打开浏览器抓取firsturl页面的时候,发现已经抓取不下去了,用shutil.querymer就能打开文件,用content_type1来解析post。我觉得是能多次解析的,但为了实现抓取某个页面的时候,尽量避免从根本上多次解析网页,但解析数据库,好像不同的asp解析得到的数据格式应该不一样,应该是多次解析。
会这样吗?如果知道java或php等脚本语言的基本内容,是不是通过一些封装一层插件的方式,就能解析并处理多页面php页面的内容, 查看全部
asp.net 抓取网页数据(抓取网页数据的流程:1.服务器返回文本数据)
抓取网页数据的流程:1.用浏览器打开这个地址,需要自己自定义dom/.php然后启动环境2.此时执行了一次post请求。3.服务器返回文本数据,就是由html源码构成的asp/html。4.客户端接收html源码后解析,可以得到数据,也可以得到html的字符串/字符串进行编码等处理5.客户端将对应html类型转化为字符串,用content-type对数据进行处理,将对应的web应用的数据类型转化为asp应用的数据类型。
也就是说asp应用解析了数据,转化了对应的html,转化的结果是字符串,用bean表示。6.服务器返回数据给客户端,得到html,最后的浏览器解析这个html。如下图,以我的思维分析,抓取网页,一定要在post请求,也就是http请求中体现。回答问题:其实同一个asp网页是可以多次解析的。
拿页面从控制台打开浏览器抓取firsturl页面的时候,发现已经抓取不下去了,用shutil.querymer就能打开文件,用content_type1来解析post。我觉得是能多次解析的,但为了实现抓取某个页面的时候,尽量避免从根本上多次解析网页,但解析数据库,好像不同的asp解析得到的数据格式应该不一样,应该是多次解析。
会这样吗?如果知道java或php等脚本语言的基本内容,是不是通过一些封装一层插件的方式,就能解析并处理多页面php页面的内容,
asp.net 抓取网页数据(如何让用户不输入网址,不用自己反复输入信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2021-10-08 10:01
抓取网页数据是我们平时最常见的网页爬虫,网页上所有的一切信息我们都可以抓取到,而且网页返回一个页面我们就能够抓取一个页面的信息,但是有时候这些信息可能比较乱,有的文件夹之间的关系,有的甚至还有链接内容不在同一个目录,有时候链接的路径又很复杂,如何让用户不输入网址,不用自己反复输入信息即可抓取当前网页的所有信息呢?以前也是各种尝试,browser.exe等各种全球最凶狠的反爬虫api,每次反反复复的爬虫也是浪费了不少时间,总之每次爬虫爬取一个网页后,返回的目录都是乱七八糟的,真是莫名的烦。
后来有个人分享了他在网上扒出来一个高效php代码抓取所有网页的方法,如何高效率的进行网页爬取,这里有了一个源码文件可以直接去下载,我只截图了几个比较受欢迎的页面,大家可以自己看看。有一点说明一下:虽然这个代码抓取的网页很多,但是由于下载时要求自己反复输入网址,所以对于目录结构的要求非常严格,必须是存放在同一个文件夹,而且源码里面没有包含目录结构信息。
下载方式:公众号:hzlt_ln,发送【php】即可获取解压密码,反复点击获取密码即可解压。为什么分享给大家,而不是我已经写好的呢?原因就是即使你已经在知乎上分享给了我,我依然无法保证抓取的准确性,比如根据你自己的目录信息给出解析的路径,抓取的时候也可能需要把目录下的全部文件名信息扒出来,根据你所分享出来的高效率方法,我可以保证每次抓取的内容都是一模一样,我也会把高效抓取出来的代码保存下来,大家可以直接拿去用。
有需要的请关注微信公众号,如果你愿意的话,也可以帮忙发个文章给我。写了这么多,希望帮助大家爬取到想要的数据,谢谢!。 查看全部
asp.net 抓取网页数据(如何让用户不输入网址,不用自己反复输入信息)
抓取网页数据是我们平时最常见的网页爬虫,网页上所有的一切信息我们都可以抓取到,而且网页返回一个页面我们就能够抓取一个页面的信息,但是有时候这些信息可能比较乱,有的文件夹之间的关系,有的甚至还有链接内容不在同一个目录,有时候链接的路径又很复杂,如何让用户不输入网址,不用自己反复输入信息即可抓取当前网页的所有信息呢?以前也是各种尝试,browser.exe等各种全球最凶狠的反爬虫api,每次反反复复的爬虫也是浪费了不少时间,总之每次爬虫爬取一个网页后,返回的目录都是乱七八糟的,真是莫名的烦。
后来有个人分享了他在网上扒出来一个高效php代码抓取所有网页的方法,如何高效率的进行网页爬取,这里有了一个源码文件可以直接去下载,我只截图了几个比较受欢迎的页面,大家可以自己看看。有一点说明一下:虽然这个代码抓取的网页很多,但是由于下载时要求自己反复输入网址,所以对于目录结构的要求非常严格,必须是存放在同一个文件夹,而且源码里面没有包含目录结构信息。
下载方式:公众号:hzlt_ln,发送【php】即可获取解压密码,反复点击获取密码即可解压。为什么分享给大家,而不是我已经写好的呢?原因就是即使你已经在知乎上分享给了我,我依然无法保证抓取的准确性,比如根据你自己的目录信息给出解析的路径,抓取的时候也可能需要把目录下的全部文件名信息扒出来,根据你所分享出来的高效率方法,我可以保证每次抓取的内容都是一模一样,我也会把高效抓取出来的代码保存下来,大家可以直接拿去用。
有需要的请关注微信公众号,如果你愿意的话,也可以帮忙发个文章给我。写了这么多,希望帮助大家爬取到想要的数据,谢谢!。
asp.net 抓取网页数据(Google浏览器模拟登陆所遇到的问题,你知道吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-09-30 23:05
最近因为需要,学了一点用java抓取网页信息!
我这次分配的任务是抢原创以上同学的期末考试时间表!因为这个网页是写的,所以有些细节我不是很了解!所以我只知道一个粗略的想法!因为毕竟我不是搞asp的。
下面我们就来了解下详细步骤吧!
基本上每个页面都会涉及到Cookie的值!而且这个值很奇怪!由于对asp的seesion和cookie不是很了解,所以查了一下资料!
主要内容大概就是Session是一个由应用服务器维护的服务器端存储空间。当用户连接到服务器时,服务器会生成唯一的SessionID,并以SessionID作为标识访问服务器端的Session存储空间。SessionID 数据保存到客户端并与 Cookie 一起保存。当用户提交页面时,SessionID会提交给服务器访问Session数据。此过程不需要开发人员干预。所以一旦客户端禁用cookies,会话也会失效。
该cookie中seesion的sessionid值。而这个值是在用户登录的时候生成的!所以我们必须模拟登录然后抓取这个值!
下面我们来讲解一下模拟登录遇到的问题!首先我们要自己登录,观察登录界面需要传递什么值!这里使用post来提交数据!所以我们登录后,打开谷歌浏览器的review元素。
在这里我们看到了我们想要的信息!
前三个变量没看懂,所以去看了大黄(一个同学,也是景洪。我的目标之一!)用PHP抢原创课表的博客
%E5%A6%82%E4%BD%95%E6%8A%93%E5%8E%9F%E5%88%9B%E6%95%99%E5%8A%A1%E7%B3%BB%E7 %BB%9F%E7%9A%84%E8%AF%BE%E8%A1%A8/
这些参数的描述有一个链接。链接在这里
Cbo_LX就是上一页选择的“学生”!
Txt_UserName 和 Txt_Password 是你前台传递过来的用户名和密码!
而 Img_DL.x 和 Img_DL.y 应该是你点击按钮时的坐标!这不是很有用!
现在问题又来了!. . 中国人在这里参与!那你会不会发现过去的编解码有错误呢?. . 实验后果然!如果直接发帖,是不能发到对应页面的!
纠结这个问题好久了!然后开始尝试用不同的编码格式来改变“学生”。. . 最终问题没有解决,却引起了我对编解码的强烈好奇!所以以后我会更加关注这方面的!下次我打算花一个星期来研究这个!自从上次发了个博客想搞直播!但是实在是太忙了,没有做!最后,这条微博千万不能删!所以如果你下次有时间,一起完成这两个!
最后请了一位同学帮忙解决这个问题!原来头文件要设置在这里!
这里的内容类型,没关系!
还要注意的是,在前面提到的参数 __viewstate 中,这可能会发生变化。也就是说,每次登录都不一样!没看懂,查了资料
这意味着这个值会根据控件的状态而变化!所以不同的用户登录是不同的!所以我们要截取这个值!每次请求获取页面后获取页面的隐藏值!然后将其作为参数传递给下一个请求页面。
最后,我要说一句伤人的话!按照页面上的步骤一步步模拟!终于发现中间有些页面根本不需要模拟!. . . 好的!我是智障!但是收获还是蛮大的!
最后一件事是在获得数据之后。切换到下一个!因为我得到的是String数据,所以必须转成json格式!所以是时候重新开始艰苦的生活了!我对 json 一无所知,但我最终根据演示对它进行了修补!目前json map添加的key-value对分别对应一个对象和对象名!如果map的值是一个数组,那么这对应的是json中的一个数组!如果使用bean方法,就相当于是一个拥有很多属性的对象!上级最后的要求就是这种格式!. . . 也许我的代码不太好!所以当我使用前两种方法时!逻辑有点乱!
代码先转移到百度云盘。有需要的朋友可以下来看看!
好了,今天就写到这里吧!. .
//抓取
报告一个材料。. 今天小白真的又变成小白了
<p>import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sf.json.JSONArray;
public class TestString {
public static void main(String[] args){
Map map = new HashMap();
List list = new ArrayList();
String[] a = new String[3];
a[0]="0";
a[1]="1";
a[2]="2";
map.put("2", a);
for(int i=0;i 查看全部
asp.net 抓取网页数据(Google浏览器模拟登陆所遇到的问题,你知道吗?)
最近因为需要,学了一点用java抓取网页信息!
我这次分配的任务是抢原创以上同学的期末考试时间表!因为这个网页是写的,所以有些细节我不是很了解!所以我只知道一个粗略的想法!因为毕竟我不是搞asp的。
下面我们就来了解下详细步骤吧!
基本上每个页面都会涉及到Cookie的值!而且这个值很奇怪!由于对asp的seesion和cookie不是很了解,所以查了一下资料!
主要内容大概就是Session是一个由应用服务器维护的服务器端存储空间。当用户连接到服务器时,服务器会生成唯一的SessionID,并以SessionID作为标识访问服务器端的Session存储空间。SessionID 数据保存到客户端并与 Cookie 一起保存。当用户提交页面时,SessionID会提交给服务器访问Session数据。此过程不需要开发人员干预。所以一旦客户端禁用cookies,会话也会失效。
该cookie中seesion的sessionid值。而这个值是在用户登录的时候生成的!所以我们必须模拟登录然后抓取这个值!
下面我们来讲解一下模拟登录遇到的问题!首先我们要自己登录,观察登录界面需要传递什么值!这里使用post来提交数据!所以我们登录后,打开谷歌浏览器的review元素。
在这里我们看到了我们想要的信息!
前三个变量没看懂,所以去看了大黄(一个同学,也是景洪。我的目标之一!)用PHP抢原创课表的博客
%E5%A6%82%E4%BD%95%E6%8A%93%E5%8E%9F%E5%88%9B%E6%95%99%E5%8A%A1%E7%B3%BB%E7 %BB%9F%E7%9A%84%E8%AF%BE%E8%A1%A8/
这些参数的描述有一个链接。链接在这里
Cbo_LX就是上一页选择的“学生”!
Txt_UserName 和 Txt_Password 是你前台传递过来的用户名和密码!
而 Img_DL.x 和 Img_DL.y 应该是你点击按钮时的坐标!这不是很有用!
现在问题又来了!. . 中国人在这里参与!那你会不会发现过去的编解码有错误呢?. . 实验后果然!如果直接发帖,是不能发到对应页面的!
纠结这个问题好久了!然后开始尝试用不同的编码格式来改变“学生”。. . 最终问题没有解决,却引起了我对编解码的强烈好奇!所以以后我会更加关注这方面的!下次我打算花一个星期来研究这个!自从上次发了个博客想搞直播!但是实在是太忙了,没有做!最后,这条微博千万不能删!所以如果你下次有时间,一起完成这两个!
最后请了一位同学帮忙解决这个问题!原来头文件要设置在这里!
这里的内容类型,没关系!
还要注意的是,在前面提到的参数 __viewstate 中,这可能会发生变化。也就是说,每次登录都不一样!没看懂,查了资料
这意味着这个值会根据控件的状态而变化!所以不同的用户登录是不同的!所以我们要截取这个值!每次请求获取页面后获取页面的隐藏值!然后将其作为参数传递给下一个请求页面。
最后,我要说一句伤人的话!按照页面上的步骤一步步模拟!终于发现中间有些页面根本不需要模拟!. . . 好的!我是智障!但是收获还是蛮大的!
最后一件事是在获得数据之后。切换到下一个!因为我得到的是String数据,所以必须转成json格式!所以是时候重新开始艰苦的生活了!我对 json 一无所知,但我最终根据演示对它进行了修补!目前json map添加的key-value对分别对应一个对象和对象名!如果map的值是一个数组,那么这对应的是json中的一个数组!如果使用bean方法,就相当于是一个拥有很多属性的对象!上级最后的要求就是这种格式!. . . 也许我的代码不太好!所以当我使用前两种方法时!逻辑有点乱!
代码先转移到百度云盘。有需要的朋友可以下来看看!
好了,今天就写到这里吧!. .
//抓取
报告一个材料。. 今天小白真的又变成小白了
<p>import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import net.sf.json.JSONArray;
public class TestString {
public static void main(String[] args){
Map map = new HashMap();
List list = new ArrayList();
String[] a = new String[3];
a[0]="0";
a[1]="1";
a[2]="2";
map.put("2", a);
for(int i=0;i
asp.net 抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-09-25 06:19
在中抓取网页内容非常方便,解决了中困扰我们的编码问题
1、抓取一般内容
需要三个类:webrequest、webresponse和StreamReader
必需的命名空间:系统。Net,系统。木卫一
核心代码:
webrequest类的创建是一个静态方法,参数是要捕获的网页的网址
编码指定编码。在编码中,有通用编码属性,如ASCII和utf32、utf8,但没有编码属性GB2312。因此,我们使用getencoding来获得GB2312编码
2、抓取图片或其他二进制文件(如文件)
需要四个类:webrequest、webresponse、stream和FileStream
必需的命名空间:系统。Net,系统。木卫一
核心代码:用流读取
3、捕获web内容的post方法
在捕获网页时,有时需要通过post将一些数据发送到服务器。将以下代码添加到网页捕获程序,以将用户名和密码发布到服务器:
4、抓取web内容-防止重定向
抓取网页时,成功登录服务器应用系统后,应用系统可能会通过响应重定向网页。重新使用如果我们不需要对这个重定向做出响应,我们就不会给读者任何提示。Readtoend()返回响应。写
5、获取web内容-保持登录状态
使用post数据成功登录到服务器应用系统后,我们可以抓取页面进行登录,因此我们可能需要在多个请求之间保持登录状态 查看全部
asp.net 抓取网页数据(ASP.NET中抓取网页内容-保持登录状态利用Post数据成功登录服务器应用系统)
在中抓取网页内容非常方便,解决了中困扰我们的编码问题
1、抓取一般内容
需要三个类:webrequest、webresponse和StreamReader
必需的命名空间:系统。Net,系统。木卫一
核心代码:
webrequest类的创建是一个静态方法,参数是要捕获的网页的网址
编码指定编码。在编码中,有通用编码属性,如ASCII和utf32、utf8,但没有编码属性GB2312。因此,我们使用getencoding来获得GB2312编码
2、抓取图片或其他二进制文件(如文件)
需要四个类:webrequest、webresponse、stream和FileStream
必需的命名空间:系统。Net,系统。木卫一
核心代码:用流读取
3、捕获web内容的post方法
在捕获网页时,有时需要通过post将一些数据发送到服务器。将以下代码添加到网页捕获程序,以将用户名和密码发布到服务器:
4、抓取web内容-防止重定向
抓取网页时,成功登录服务器应用系统后,应用系统可能会通过响应重定向网页。重新使用如果我们不需要对这个重定向做出响应,我们就不会给读者任何提示。Readtoend()返回响应。写
5、获取web内容-保持登录状态
使用post数据成功登录到服务器应用系统后,我们可以抓取页面进行登录,因此我们可能需要在多个请求之间保持登录状态
asp.net 抓取网页数据(抓取网页数据的常用接口编写方法详解(5)实例_好迅云)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-09-23 23:03
抓取网页数据的常用接口编写方法详解(5)实例抓取_好迅云企业云_大象云社区_大象云这个里面还有个方法叫做html_get_navigator-centos7下编写抓取器,就可以直接去抓取页面,而且抓取的是网页上最重要的那一部分。
首先想到的是ltrack3,然后就可以用它构造网址,mdpi就是页面里有1个或者多个html页面,html就是html文件,html2007是一个列表。只要保存一个页面到本地,那么每个页面都可以去抓,我用这个爬过一家公司的页面,应该是可以抓的。
我一直都用这个,解析网页,
最常用的抓取是html_get_navigator-centos7下编写抓取器,通过url获取页面信息,并通过xml_get_element获取指定selector下的html页面数据,通过low_content_user-agenttag确定页面的数据来源。
我想到的有curl,解析网页、解析html文件,页面抓取。
我的理解就是:1.selector抓取2.封装成txt数据,
抓取就是每个页面显示到浏览器里去可以用mdpi或者lspi->flash打开/浏览器打开页面然后用html_get_element抓住页面所在的selector去爬取
爬虫就是不停的用selector去通过prefix去爬取你想要的html文档 查看全部
asp.net 抓取网页数据(抓取网页数据的常用接口编写方法详解(5)实例_好迅云)
抓取网页数据的常用接口编写方法详解(5)实例抓取_好迅云企业云_大象云社区_大象云这个里面还有个方法叫做html_get_navigator-centos7下编写抓取器,就可以直接去抓取页面,而且抓取的是网页上最重要的那一部分。
首先想到的是ltrack3,然后就可以用它构造网址,mdpi就是页面里有1个或者多个html页面,html就是html文件,html2007是一个列表。只要保存一个页面到本地,那么每个页面都可以去抓,我用这个爬过一家公司的页面,应该是可以抓的。
我一直都用这个,解析网页,
最常用的抓取是html_get_navigator-centos7下编写抓取器,通过url获取页面信息,并通过xml_get_element获取指定selector下的html页面数据,通过low_content_user-agenttag确定页面的数据来源。
我想到的有curl,解析网页、解析html文件,页面抓取。
我的理解就是:1.selector抓取2.封装成txt数据,
抓取就是每个页面显示到浏览器里去可以用mdpi或者lspi->flash打开/浏览器打开页面然后用html_get_element抓住页面所在的selector去爬取
爬虫就是不停的用selector去通过prefix去爬取你想要的html文档
asp.net 抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-19 19:14
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i 查看全部
asp.net 抓取网页数据(一下抓取别人网站数据的方式有什么作用?如何抓取)
我相信每个网站网站管理员都有捕获他人数据的经验。目前,获取他人网站数据的方式只有两种:
一、使用第三方工具,其中最著名的是优采云采集器,这里不介绍
二、编写您自己的程序并获取它。这种方式要求站长编写自己的程序,这可能需要站长的开发能力
起初,我试图使用第三方工具来捕获我需要的数据。因为互联网上流行的第三方工具要么不符合我的要求,要么太复杂,我一时不知道如何使用它们。后来,我决定自己写。现在我基本上可以处理一个网站(仅程序开发时间,不包括数据捕获时间)
经过一段时间的数据采集工作,我遇到了很多困难。最常见的问题之一是获取分页数据的问题。原因是有多种形式的数据分页。接下来,我将以三种形式介绍获取分页数据的方法。虽然我在网上看到了很多这样的文章,但是每次我拿别人的代码时,总有各种各样的问题。以下代码可以正确执行,我目前也在使用它们。本文的代码实现是用c语言实现的。我认为其他语言的原则大致相同
让我们开门见山:
第一种方式:URL地址收录分页信息。这种形式是最简单的。使用第三方工具捕获此表单也非常简单。基本上,不需要编写代码。对于像我这样宁愿花半天时间编写代码而不愿学习第三方工具的人,我仍然自己编写代码
此方法通过循环生成数据页的URL地址。例如,通过Httpwebrequest访问相应的URL地址,并返回相应页面的HTML文本。下一个任务是解析字符串并将所需内容保存到本地数据库;有关捕获的代码,请参阅以下内容:
公共字符串GetResponseString(字符串url){
字符串_StrResponse=“”
HttpWebRequest WebRequest=(HttpWebRequest)WebRequest.Create(url)
_WebRequest.UserAgent=“MOZILLA/4.0(兼容;MSIE7.0;WINDOWS NT5.2.NET CLR1.1.4322.NET CLR2.0.50727.NET CLR3.0.0450 6.648.NET CLR@k305.21022.NET CLR3.0.450 6.2152.NET CLR@k305.30729)",
_WebRequest.Method=“GET”
WebResponse _WebResponse=_WebRequest.GetResponse()
StreamReader _ResponseStream=新的StreamReader(_WebResponse.GetResponseStream(),System.Text.Encoding.GetEncoding(“gb2312”)
_StrResponse=_ResponseStream.ReadToEnd()
_WebResponse.Close()
_ResponseStream.Close()
返回响应
}
上面的代码可以返回与页面的HTML内容相对应的字符串。其余的是从该字符串中获取您关心的信息
第二种方式:可能是开发中经常遇到的,它的分页控件通过post将分页信息提交给后台代码,比如.Net下的GridView的分页功能,当你点击分页页码时,你会发现URL地址没有改变,但是页码变了而且页面内容也发生了变化。如果你仔细观察,你会发现当你将鼠标移动到每个页码上时,状态栏会显示javascript:_dopostback(“GridView”,“page1”)和其他代码。事实上,这种形式并不很难,因为毕竟,有一个地方可以找到页码的规律
我们知道提交HTTP请求有两种方式,一种是get,另一种是post。第一种是get,第二种是post。具体的提交原则不需要详细解释,这不是本文的重点
要获取此类页面,您需要注意页面的几个重要元素
一、_viewstate应该是.Net独有的,也是.Net开发人员喜欢和讨厌的东西。当你打开一个网站页面时,如果你发现这个东西后面有很多乱七八糟的字符,那么这个网站一定是用英语写的
二、__dopostback方法。这是从页面自动生成的JavaScript方法,其中收录两个参数_eventtarget和_eventargument。这两个参数可以引用与页码对应的内容,因为当您单击翻页时,页码信息将传输到这两个参数
三、__EVENTVALIDATION这也应该是独一无二的
你不必太在意这三件事是做什么的,你只需要在编写代码获取页面时注意提交这三个元素
与第一种方法一样,_doPostBack的两个参数必须以循环方式拼合在一起。只有收录页码信息的参数才需要拼合在一起。这里需要注意的一点是,每次通过post提交下一页的请求时,您应该首先获得_viewstateinformation和_eVentValidation当前页面的信息,因此分页数据更准确。第一种方法可用于获取第一页的页面内容,然后同时取出相应的u viewstate信息和_eventvalidation信息,然后循环下一页,然后记录_viewstate信息和_eventvali抓取每页后采集信息,以便为下一页文章提交数据
参考代码如下:
<p>对于(int i=0;i
asp.net 抓取网页数据(第三方工具使用语言的方法和使用方法有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-09-18 06:06
一、使用第三方工具,其中最著名的是优采云采集器,在此不做介绍。
二、自己写程序抓取,这种方式要求站长自己写程序,可能对对站长的开发能力有所要求了。
本人起初也曾试着用第三方的工具抓取我所需要的数据,由于网上的流行的第三方工具不是不符合我的要求,就是过于复杂,我一时没有搞明白怎么用,后来索性决定自己写吧,现在本人基本上半天可以搞定一个网站(只是程序开发时间,不包括数据抓取的时间)。
经过一段时间的数据抓取生涯,也曾遇到了很多困难,其中最常见的一个就是关于分页数据的抓取问题,原因在于分数据分页的形式有很多种,下面我主要针对三种形式介绍一下抓取分页数据的方法,此类文章虽然在网上见过很多,但每次拿别人的代码总也总是有各种各样的问题,下面各种方式的代码都是能正确执行,并且我目前也正在使用中的。本文中代码实现是用C#语言来实现的,我想其他语言原理大致相同。
下面切入正题:
第一种方式:URL地址中收录分页信息,这种形式是最简单的,这种形式使用第三方工具抓取也很简单,基本上不用写代码,对于我这种宁可自己花个半天时间写代码也懒得学第三方工具的人,还是通过自己写代码实现了;
这种方式就是通过循环生成数据分页的URL地址 如:这样通过HttpWebRequest访问对应URL地址,返回对应页面的html文本,接下来的任务就是对字符串的解析,将需要的内容保存到本地数据库内;抓取的代码可参考下面:
public string GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return _StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取自己关心的信息了。
第二种方式:可能是通过asp.NET开发的网站常会遇到,它的分页控件通过post方式提交分页信息到后台代码,如.net下Gridview自带的分页功能,当你点击分页的页码时,会发现URL地址没有变化,但页码变化了,页面内容也变化,仔细看会发现,把鼠标移到每个页码上的时候状态栏会显示:__dopostback("gridview","page1")等等之类的代码,这种形式其实也不是很难,因为毕竟有地方得到页码的规律可寻。
我们知道http请求提交的方式有两种一种是get一种是Post,第一种方式是get方式,那么第二种方式就是post方式,具体提交的原理不必细说,不是本文的重点
抓取这种页面 需要注意asp.Net页面的几个重要的元素
一、 __VIEWSTATE ,这个应该是.net特有的,也是让.net开发人员既爱又恨的东西,当你打开一个网站的某一个页面的时候,如果发现这个东西,而且后面还跟随着一大堆乱七八糟的字符的时候,那这个网站肯定是用写的了;
二、__dopostback方法,这个是页面自动生成一个javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参看页码对应的内容,因为点击翻页的时候,会将页码信息传给这两个参数。
三、__EVENTVALIDATION 这个也也应该是特有的东西
大家也不用 太关心这三个东西都是干什么的,只需要注意自己写代码抓取页面的时候 记得提交这三个元素就可以了。
和第一种方式一样,肯定要通过循环的方式是去拼凑_dopostback的两个参数,只需要拼其中收录了页码信息的参数即可。这里有一个需要注意的地方,就是在每次通过Post提交请求下一页的时候,先应得到当前页的__VIEWSTATE 信息和__EVENTVALIDATION信息,所以分页数据的第一页可采用第一种方式得到页码内容然后,同时取出对应的__VIEWSTATE 信息和__EVENTVALIDATION信息,然后再做循环处理下一页面,然后每抓取完一个页面,再记录下__VIEWSTATE 信息和__EVENTVALIDATION信息,为下一个页面post提交数据使用
参考代码如下:
for (int i = 0; i
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTVALIDATION", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTTARGET", "此处是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "此处是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
try
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//得到当前页面对应的html文本字符串
GetPostValue(ResponseStr);//得到当前页面对应的 __VIEWSTATE 等上面需要的信息,为抓取下一页面使用
SaveMessage(ResponseStr);//保存自己关心的内容到数据库中
}catch (Exception ex){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦的,也是最恶心的,这种页面在你翻页的过程中没有任何一个地方可以找到页码信息,这种方式费了我很大的力气,后来采用了一个比较狠的办法,用代码模拟手动翻页,这种方式应该可以处理任何形式的翻页数据,原理就是,用代码模拟人工点击翻页链接,用代码一页一页的翻页,然后一页一页的抓取。
正所谓外行看热闹,内行看门道,很多人可能看到这里就会说用Webbrowser这可控件就可以实现,对,我下面的这种方式就是用WebBrowser的这个控件来实现,其实在.net下这种类似的类应该还有,但我没有去研究过,也希望如果有人有其他的方式,可以回复我,与大家一起分享。
WebBroser控件可是在自己的程序中内嵌一个浏览器,就像IE,火狐之类的一样,你也可以用他开发自己的浏览器,至于用它开发的浏览器的效果怎么样,我觉得肯定是不如IE和火狐了。呵呵
我们还是 闲言少叙,切入主题:
使用WebBroser控件基本上可以实现你在IE中操作网页的任何功能,所以点击翻页按钮当然也是可以的了,那既然可以在WebBroser中可以手动点击翻页按钮,自然我们用程序代码同样可以指使WebBroser自动替我们翻页了。
其实原理很简单,主要分以下几个步骤:
第一步,打开你想抓取的页面 比如:
调用webBrowser控件的方法Navigate("");
此时,你应该在你的WebBrowser控件中看到你的网页信息,和IE中看到的是一样的;
第二步 ,WebBrowser控件的这个事件DocumentCompleted 很重要,当你访问的页面全部加载完之后,会触发这个事件。所以我们分析页面元素的过程也需要在这个事件内完成
string _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这句代码可以得到当前打开页面的html元素的内容。
既然已经得到当前打开页面的html元素的内容了,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,解析字符串的过程,大家应该自己都能写了。
第三步, 重点在这第三步呢,因为要翻页了,接第二步,解析完字符串之后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码的id").InvokeMember("click");
从代码的方法名种大家应该能明白了,那么调用完这个方法,之后WebBrwoser控件内的网页就实现了翻页,和你用手去点翻页按钮是一样的效果。
重点在于,翻页之后,还会触发DocumentCompleted事件,所以进入了第二步,第三步的循环了,所以大家需要注意判断跳出循环的时机。
其实用WebBrowser还能干很多事情,比如自动登录,注销某个论坛,保存session, cockie,所以 这个控件基本上可以实现你想对网页的任何操作,哪怕你是想暴利破解一个网站的登录密码,当然这个是不提倡的了。呵呵 查看全部
asp.net 抓取网页数据(第三方工具使用语言的方法和使用方法有哪些)
一、使用第三方工具,其中最著名的是优采云采集器,在此不做介绍。
二、自己写程序抓取,这种方式要求站长自己写程序,可能对对站长的开发能力有所要求了。
本人起初也曾试着用第三方的工具抓取我所需要的数据,由于网上的流行的第三方工具不是不符合我的要求,就是过于复杂,我一时没有搞明白怎么用,后来索性决定自己写吧,现在本人基本上半天可以搞定一个网站(只是程序开发时间,不包括数据抓取的时间)。
经过一段时间的数据抓取生涯,也曾遇到了很多困难,其中最常见的一个就是关于分页数据的抓取问题,原因在于分数据分页的形式有很多种,下面我主要针对三种形式介绍一下抓取分页数据的方法,此类文章虽然在网上见过很多,但每次拿别人的代码总也总是有各种各样的问题,下面各种方式的代码都是能正确执行,并且我目前也正在使用中的。本文中代码实现是用C#语言来实现的,我想其他语言原理大致相同。
下面切入正题:
第一种方式:URL地址中收录分页信息,这种形式是最简单的,这种形式使用第三方工具抓取也很简单,基本上不用写代码,对于我这种宁可自己花个半天时间写代码也懒得学第三方工具的人,还是通过自己写代码实现了;
这种方式就是通过循环生成数据分页的URL地址 如:这样通过HttpWebRequest访问对应URL地址,返回对应页面的html文本,接下来的任务就是对字符串的解析,将需要的内容保存到本地数据库内;抓取的代码可参考下面:
public string GetResponseString(string url){
string _StrResponse = "";
HttpWebRequest _WebRequest = (HttpWebRequest)WebRequest.Create(url);
_WebRequest.UserAgent = "MOZILLA/4.0 (COMPATIBLE; MSIE 7.0; WINDOWS NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729)";
_WebRequest.Method = "GET";
WebResponse _WebResponse = _WebRequest.GetResponse();
StreamReader _ResponseStream = new StreamReader(_WebResponse.GetResponseStream(), System.Text.Encoding.GetEncoding("gb2312"));
_StrResponse = _ResponseStream.ReadToEnd();
_WebResponse.Close();
_ResponseStream.Close();
return _StrResponse;
}
上面的代码可以返回对应页面的html内容的字符串,剩下的工作就是从这个字符串中获取自己关心的信息了。
第二种方式:可能是通过asp.NET开发的网站常会遇到,它的分页控件通过post方式提交分页信息到后台代码,如.net下Gridview自带的分页功能,当你点击分页的页码时,会发现URL地址没有变化,但页码变化了,页面内容也变化,仔细看会发现,把鼠标移到每个页码上的时候状态栏会显示:__dopostback("gridview","page1")等等之类的代码,这种形式其实也不是很难,因为毕竟有地方得到页码的规律可寻。
我们知道http请求提交的方式有两种一种是get一种是Post,第一种方式是get方式,那么第二种方式就是post方式,具体提交的原理不必细说,不是本文的重点
抓取这种页面 需要注意asp.Net页面的几个重要的元素
一、 __VIEWSTATE ,这个应该是.net特有的,也是让.net开发人员既爱又恨的东西,当你打开一个网站的某一个页面的时候,如果发现这个东西,而且后面还跟随着一大堆乱七八糟的字符的时候,那这个网站肯定是用写的了;
二、__dopostback方法,这个是页面自动生成一个javascript方法,收录两个参数,__EVENTTARGET,__EVENTARGUMENT,这两个参数可以参看页码对应的内容,因为点击翻页的时候,会将页码信息传给这两个参数。
三、__EVENTVALIDATION 这个也也应该是特有的东西
大家也不用 太关心这三个东西都是干什么的,只需要注意自己写代码抓取页面的时候 记得提交这三个元素就可以了。
和第一种方式一样,肯定要通过循环的方式是去拼凑_dopostback的两个参数,只需要拼其中收录了页码信息的参数即可。这里有一个需要注意的地方,就是在每次通过Post提交请求下一页的时候,先应得到当前页的__VIEWSTATE 信息和__EVENTVALIDATION信息,所以分页数据的第一页可采用第一种方式得到页码内容然后,同时取出对应的__VIEWSTATE 信息和__EVENTVALIDATION信息,然后再做循环处理下一页面,然后每抓取完一个页面,再记录下__VIEWSTATE 信息和__EVENTVALIDATION信息,为下一个页面post提交数据使用
参考代码如下:
for (int i = 0; i
System.Net.WebClient WebClientObj = new System.Net.WebClient();
System.采集s.Specialized.NameValue采集 PostVars = new System.采集s.Specialized.NameValue采集();
PostVars.Add("__VIEWSTATE", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTVALIDATION", "此处是您需要提前得到的信息");
PostVars.Add("__EVENTTARGET", "此处是__dopostback方法对应的参数");
PostVars.Add("__EVENTARGUMENT", "此处是__dopostback方法对应的参数");
WebClientObj.Headers.Add("ContentType", "application/x-www-form-urlencoded");
try
{
byte[] byte1 = WebClientObj.UploadValues("", "POST", PostVars);
string ResponseStr = Encoding.UTF8.GetString(byte1);//得到当前页面对应的html文本字符串
GetPostValue(ResponseStr);//得到当前页面对应的 __VIEWSTATE 等上面需要的信息,为抓取下一页面使用
SaveMessage(ResponseStr);//保存自己关心的内容到数据库中
}catch (Exception ex){
Console.WriteLine(ex.Message);
}
}
第三种方式:第三种方式是最麻烦的,也是最恶心的,这种页面在你翻页的过程中没有任何一个地方可以找到页码信息,这种方式费了我很大的力气,后来采用了一个比较狠的办法,用代码模拟手动翻页,这种方式应该可以处理任何形式的翻页数据,原理就是,用代码模拟人工点击翻页链接,用代码一页一页的翻页,然后一页一页的抓取。
正所谓外行看热闹,内行看门道,很多人可能看到这里就会说用Webbrowser这可控件就可以实现,对,我下面的这种方式就是用WebBrowser的这个控件来实现,其实在.net下这种类似的类应该还有,但我没有去研究过,也希望如果有人有其他的方式,可以回复我,与大家一起分享。
WebBroser控件可是在自己的程序中内嵌一个浏览器,就像IE,火狐之类的一样,你也可以用他开发自己的浏览器,至于用它开发的浏览器的效果怎么样,我觉得肯定是不如IE和火狐了。呵呵
我们还是 闲言少叙,切入主题:
使用WebBroser控件基本上可以实现你在IE中操作网页的任何功能,所以点击翻页按钮当然也是可以的了,那既然可以在WebBroser中可以手动点击翻页按钮,自然我们用程序代码同样可以指使WebBroser自动替我们翻页了。
其实原理很简单,主要分以下几个步骤:
第一步,打开你想抓取的页面 比如:
调用webBrowser控件的方法Navigate("");
此时,你应该在你的WebBrowser控件中看到你的网页信息,和IE中看到的是一样的;
第二步 ,WebBrowser控件的这个事件DocumentCompleted 很重要,当你访问的页面全部加载完之后,会触发这个事件。所以我们分析页面元素的过程也需要在这个事件内完成
string _ResponseStr=this.WebBrowser1.Document.Body.OuterHtml;
这句代码可以得到当前打开页面的html元素的内容。
既然已经得到当前打开页面的html元素的内容了,剩下的工作自然就是解析这个大字符串,得到自己关心的内容,解析字符串的过程,大家应该自己都能写了。
第三步, 重点在这第三步呢,因为要翻页了,接第二步,解析完字符串之后,还是在DocumentCompleted事件中,调用方法
WebBrowser1.Document.GetElementById("页码的id").InvokeMember("click");
从代码的方法名种大家应该能明白了,那么调用完这个方法,之后WebBrwoser控件内的网页就实现了翻页,和你用手去点翻页按钮是一样的效果。
重点在于,翻页之后,还会触发DocumentCompleted事件,所以进入了第二步,第三步的循环了,所以大家需要注意判断跳出循环的时机。
其实用WebBrowser还能干很多事情,比如自动登录,注销某个论坛,保存session, cockie,所以 这个控件基本上可以实现你想对网页的任何操作,哪怕你是想暴利破解一个网站的登录密码,当然这个是不提倡的了。呵呵
asp.net 抓取网页数据(ASP.NET中抓取网页内容是非常方便的())
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-14 00:09
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。需要三个类:WebRequest、WebResponse、StreamReader。 WebRequest 和 WebResponse 的命名空间为: System.Net StreamReader 的命名空间为: System.IO 核心代码 WebRequest request = WebRequest.Create(""); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")); WebRequest类的Create是一个静态方法,参数是要抓取的网页的URL; Encoding指定编码,Encoding有ASCII、UTF32、UTF8等属性编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312的编码。示例
ASP.NET 抓取网页内容-Post 数据抓取网页时,有时需要通过Post 向服务器发送一些数据。在网页抓取程序中加入如下代码,实现将用户名和密码发布到服务器: string data = "userName=admin&passwd=admin888"; byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data); request.Method = "POST"; request .ContentType = "application/x-www-form-urlencoded"; request.ContentLength = requestBuffer.Length;使用 (Stream requestStream = request.GetRequestStream()) {requestStream.Write(requestBuffer, 0, requestBuffer.Length);请求流。 Close();} using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"))) {string str = reader.ReadToEnd(); reader.Close();} 以上是编码以gb2312为例
ASP.NET 抓取网页内容阻止重定向。抓取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么,我们不需要发送 reader.ReadToEnd() 到 Response.Write,就是这样。 ASP.NET 抓取网页内容保持登录状态使用Post数据成功登录服务器应用系统后,就可以抓取需要登录的页面,那么我们可能需要在多个Request中保持登录状态。首先,我们要使用 HttpWebRequest 而不是 WebRequest。与WebRequest相比,更改的代码为:HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url);注意:HttpWebRequest.Create返回的类型仍然是WebRequest,所以转换一下。其次,使用CookieContainer。 System.Net.CookieContainer cc = new System.Net.CookieContainer(); request.CookieContainer = cc; request2.CookieContainer = cc;这样,request和request2之间使用了同一个Session。如果请求登录了,那么 request2 也登录了。
最后,如何在不同页面之间使用相同的CookieContainer。要在不同页面之间使用相同的 CookieContainer,只需将 CookieContainer 添加到 Session 中即可。 Session.Add("ccc", cc); //保存CookieContainer cc = (CookieContainer)Session["ccc"]; //获取ASP.NET并抓取网页内容——将当前会话带到WebRequest中,例如浏览器B1访问服务器端S1,这样会生成一个会话,服务器端S2会使用WebRequest访问服务器-side S1,它将生成一个会话。当前的要求是WebRequest 使用浏览器B1 和S1 之间的会话,这意味着S1 应该认为B1 正在访问S1,而不是S2 正在访问S1。这需要使用 cookie。首先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。 WebRequest request = WebRequest.Create("url"); request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;"); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream() , System.Text.Encoding.GetEncoding("gb2312")); Response.Write(reader.ReadToEnd()); reader.Close(); reader.Dispose(); response.Close();解释一下:本文不是Cookie欺骗,因为SessionID是S1告诉S2的,不是S2盗取的。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1必须将Session写入B1,这样SessionID才会保存在Cookie中,SessionID保持不变。 Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 Cookie。不同的服务器端语言对Cookie中的SessionID有不同的名称。这篇文章是ASP SessionID。 S1可能不仅依靠SessionID来判断当前登录,还可能辅助Referer、User-Agent等,具体取决于S1终端程序的设计。实际上,本文是本系列中另一种“保持登录”的方式。 ASP.NET抓取网页内容-如何更改源Referer和UserAgent ----------------------------------- - -------------------------------------------- HttpWebRequest 请求 = (HttpWebRequest ) HttpWebRequest.Create(""); //request.Headers.Add(HttpRequestHeader.Referer, ""); // 错误 //request.Headers[HttpRequestHeader.Referer] = ""; // 错误 request.Referer = "" ; // 正确注释掉的两句是错误的,会出现错误:这个header必须修改合适的属性。参数名称:名称 UserAgent 类似。 查看全部
asp.net 抓取网页数据(ASP.NET中抓取网页内容是非常方便的())
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。需要三个类:WebRequest、WebResponse、StreamReader。 WebRequest 和 WebResponse 的命名空间为: System.Net StreamReader 的命名空间为: System.IO 核心代码 WebRequest request = WebRequest.Create(""); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")); WebRequest类的Create是一个静态方法,参数是要抓取的网页的URL; Encoding指定编码,Encoding有ASCII、UTF32、UTF8等属性编码,但是没有gb2312的encoding属性,所以我们使用GetEncoding来获取gb2312的编码。示例
ASP.NET 抓取网页内容-Post 数据抓取网页时,有时需要通过Post 向服务器发送一些数据。在网页抓取程序中加入如下代码,实现将用户名和密码发布到服务器: string data = "userName=admin&passwd=admin888"; byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data); request.Method = "POST"; request .ContentType = "application/x-www-form-urlencoded"; request.ContentLength = requestBuffer.Length;使用 (Stream requestStream = request.GetRequestStream()) {requestStream.Write(requestBuffer, 0, requestBuffer.Length);请求流。 Close();} using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"))) {string str = reader.ReadToEnd(); reader.Close();} 以上是编码以gb2312为例
ASP.NET 抓取网页内容阻止重定向。抓取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么,我们不需要发送 reader.ReadToEnd() 到 Response.Write,就是这样。 ASP.NET 抓取网页内容保持登录状态使用Post数据成功登录服务器应用系统后,就可以抓取需要登录的页面,那么我们可能需要在多个Request中保持登录状态。首先,我们要使用 HttpWebRequest 而不是 WebRequest。与WebRequest相比,更改的代码为:HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url);注意:HttpWebRequest.Create返回的类型仍然是WebRequest,所以转换一下。其次,使用CookieContainer。 System.Net.CookieContainer cc = new System.Net.CookieContainer(); request.CookieContainer = cc; request2.CookieContainer = cc;这样,request和request2之间使用了同一个Session。如果请求登录了,那么 request2 也登录了。
最后,如何在不同页面之间使用相同的CookieContainer。要在不同页面之间使用相同的 CookieContainer,只需将 CookieContainer 添加到 Session 中即可。 Session.Add("ccc", cc); //保存CookieContainer cc = (CookieContainer)Session["ccc"]; //获取ASP.NET并抓取网页内容——将当前会话带到WebRequest中,例如浏览器B1访问服务器端S1,这样会生成一个会话,服务器端S2会使用WebRequest访问服务器-side S1,它将生成一个会话。当前的要求是WebRequest 使用浏览器B1 和S1 之间的会话,这意味着S1 应该认为B1 正在访问S1,而不是S2 正在访问S1。这需要使用 cookie。首先在S1中获取SessionID为B1的Cookie,然后将这个Cookie告诉S2,S2将Cookie写入WebRequest中。 WebRequest request = WebRequest.Create("url"); request.Headers.Add(HttpRequestHeader.Cookie, "ASPSESSIONIDSCATBTAD=KNNDKCNBONBOOBIHHHHAOKDM;"); WebResponse 响应 = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream() , System.Text.Encoding.GetEncoding("gb2312")); Response.Write(reader.ReadToEnd()); reader.Close(); reader.Dispose(); response.Close();解释一下:本文不是Cookie欺骗,因为SessionID是S1告诉S2的,不是S2盗取的。虽然有点奇怪,但在某些特定的应用系统中可能会有用。
S1必须将Session写入B1,这样SessionID才会保存在Cookie中,SessionID保持不变。 Request.Cookies 用于在 ASP.NET 中获取 cookie。本文假设已获取 Cookie。不同的服务器端语言对Cookie中的SessionID有不同的名称。这篇文章是ASP SessionID。 S1可能不仅依靠SessionID来判断当前登录,还可能辅助Referer、User-Agent等,具体取决于S1终端程序的设计。实际上,本文是本系列中另一种“保持登录”的方式。 ASP.NET抓取网页内容-如何更改源Referer和UserAgent ----------------------------------- - -------------------------------------------- HttpWebRequest 请求 = (HttpWebRequest ) HttpWebRequest.Create(""); //request.Headers.Add(HttpRequestHeader.Referer, ""); // 错误 //request.Headers[HttpRequestHeader.Referer] = ""; // 错误 request.Referer = "" ; // 正确注释掉的两句是错误的,会出现错误:这个header必须修改合适的属性。参数名称:名称 UserAgent 类似。
asp.net 抓取网页数据(抓取网页数据库资源的样例与在networkstorage中的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 221 次浏览 • 2021-09-09 15:34
抓取网页数据库资源的样例与在networkstorage中的教程,demo可以参考,其他内容.比如redis应用,bspcrud指导,gson全局配置等.
爬虫爬了20多年,这里整理了一下这几年爬虫到的一些东西,给想入门爬虫的同学提供一个可以爬的对象。
一)基于scrapy的爬虫这种爬虫的爬取范围是比较广的,包括传统的页面和网页页面以及不涉及页面加载的html,通过python爬虫框架scrapy来抓取。爬虫的框架有很多,有人的地方就有江湖,网络上基于各种框架的千奇百怪爬虫也层出不穷,就不一一列举了。
二)基于scrapy或python语言的爬虫,这类爬虫更针对于这种基于http的协议规范爬取。这类爬虫的爬取范围更局限,一般只能在针对网页的html方面。这种爬虫框架也有很多,但大多都是由scrapy或者python语言的爬虫框架来实现的。
下面就介绍一下常见的scrapy和python爬虫框架scrapy,一起来学习下吧!什么是python爬虫框架?一般说来,
1)爬虫程序:爬虫程序是一个对客户端发送请求(request),如果不接受就返回的对象。这个对象是一个句柄,传入了请求头,就是header里面的数据。一般情况下,它只有一个值:params.default(format)。一般情况下,它也会接受请求的字符串,header等数据。
2)文件路径:文件路径是爬虫程序把url上的字符串转化为python列表后的存储方式,即一个简单文件的路径叫做一个url。这个文件路径不是被你修改了字符串就是一个url。
3)页面字符串:页面字符串是可以用“{"”来表示的。通常我们把这样的一串字符串抓取了来之后存储在html文件中。一个函数的定义以及导入由下面三个部分组成:(page_name):就是提供page_name让爬虫去判断页面的url。(page_name):是由你传入的url所指定的页面名称组成的。(page_name):是由这个url所指定的页面名称与page_name组成的。
__init__.pyd:是一个默认的python对象。通常情况下我们会使用它来创建一个scrapy项目。如下所示:frompyspider.spidersimportspiderfrompyspider.itemsimportitemasitemidfromscrapy.selectorimport*defspider_item(items):deffind_spider(self,request):response=self.__init__.pyd[self.items]try:item=itemid[reques。 查看全部
asp.net 抓取网页数据(抓取网页数据库资源的样例与在networkstorage中的教程)
抓取网页数据库资源的样例与在networkstorage中的教程,demo可以参考,其他内容.比如redis应用,bspcrud指导,gson全局配置等.
爬虫爬了20多年,这里整理了一下这几年爬虫到的一些东西,给想入门爬虫的同学提供一个可以爬的对象。
一)基于scrapy的爬虫这种爬虫的爬取范围是比较广的,包括传统的页面和网页页面以及不涉及页面加载的html,通过python爬虫框架scrapy来抓取。爬虫的框架有很多,有人的地方就有江湖,网络上基于各种框架的千奇百怪爬虫也层出不穷,就不一一列举了。
二)基于scrapy或python语言的爬虫,这类爬虫更针对于这种基于http的协议规范爬取。这类爬虫的爬取范围更局限,一般只能在针对网页的html方面。这种爬虫框架也有很多,但大多都是由scrapy或者python语言的爬虫框架来实现的。
下面就介绍一下常见的scrapy和python爬虫框架scrapy,一起来学习下吧!什么是python爬虫框架?一般说来,
1)爬虫程序:爬虫程序是一个对客户端发送请求(request),如果不接受就返回的对象。这个对象是一个句柄,传入了请求头,就是header里面的数据。一般情况下,它只有一个值:params.default(format)。一般情况下,它也会接受请求的字符串,header等数据。
2)文件路径:文件路径是爬虫程序把url上的字符串转化为python列表后的存储方式,即一个简单文件的路径叫做一个url。这个文件路径不是被你修改了字符串就是一个url。
3)页面字符串:页面字符串是可以用“{"”来表示的。通常我们把这样的一串字符串抓取了来之后存储在html文件中。一个函数的定义以及导入由下面三个部分组成:(page_name):就是提供page_name让爬虫去判断页面的url。(page_name):是由你传入的url所指定的页面名称组成的。(page_name):是由这个url所指定的页面名称与page_name组成的。
__init__.pyd:是一个默认的python对象。通常情况下我们会使用它来创建一个scrapy项目。如下所示:frompyspider.spidersimportspiderfrompyspider.itemsimportitemasitemidfromscrapy.selectorimport*defspider_item(items):deffind_spider(self,request):response=self.__init__.pyd[self.items]try:item=itemid[reques。

