
asp.net 抓取网页数据
asp.net 抓取网页数据(做一个简单的爬虫程序有以下几个步骤(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2022-01-30 00:09
简单来说,爬虫通过程序或脚本获取网页上的一些文字、图片和音频数据。
从笔者的经验来看,制作一个简单的爬虫程序有几个步骤:建立需求、下载网页、分析解析网页、保存。接下来可以按照作者的流程,写一个抓取豆瓣图书信息的爬虫。
1、要求
以豆瓣阅读为例,我们抓取豆瓣的图书信息,我们需要获取的信息包括:书名、出版商、作者、年份、评分。
2、网站下载
页面下载分为静态下载和动态下载两种方式。
静态主要是纯html页面,动态是会经过javascript处理,通过Ajax异步获取的页面。在这里,我们正在下载静态页面。
在下载网页的过程中,我们需要用到网络库。Python 内置了 urllib 和 urllib2 网络库,但我们一般使用基于 urllib3 的第三方库 Requests,它是 Python 爱好者喜爱的更高效简洁的网络库,可以满足我们当前的 web 需求。
3、网页分析分析
1)网页分析:
选择好网络库后,我们需要做的是:分析我们要爬取的路径——也就是逻辑。
在这个过程中,我们需要找到每一个爬取的入口,比如豆瓣阅读的页面。知道书标的url,点击每个url获取书单,将需要的书信息存储在书单中,了解如何获取书信息。
太简单!我们的爬取路径是:图书标签url—>图书列表—>图书信息。
2)网页分析:
网页解析主要是通过解析网页的源代码来获取我们需要的数据。解析网页的方式有很多种,比如正则表达式、BeautifulSoup、XPath等,这里我们使用XPath。Xpath 的语法很简单,它是根据路径来定位的。
比如上海的位置是Earth-China-Shanghai,语法表达是 // Earth/China [@city name=Shanghai]
接下来,我们需要解析网页,得到书的tag标签的url。打开网页,右键选择inspect元素,就会出现调试工具。点击左上角得到我们需要的数据,下面的调试窗口会直接定位到它所在的代码。
根据它的位置,写出它的Xpath解析公式://table[@class='tagCol']//a
在这里,我们在一个选项卡下的一个选项卡的一个选项卡中看到了小说。可以使用 class 属性定位标签。
下面是获取标签url的代码:
拿到标签后,我们还需要拿到书的信息。让我们解析图书列表页面:
解析后的代码如下:
爬取信息如下:
4、数据存储
获取到数据后,我们可以选择将数据保存到数据库中,或者直接写入文件中。这里我们将数据保存到mongodb。接下来做一些统计,比如使用图表插件echarts来展示我们的统计结果。
5、爬虫相关问题
1)网站限制:
在爬取过程中,可能会出现无法爬取数据的问题。这是因为对应的网站做了一些反爬处理来限制爬取。比如爬豆瓣的时候遇到403forbidden。该怎么办?这时候可以通过一些相应的方法来解决,比如使用代理服务器,降低爬取速度等。这里我们使用sleep 2 seconds per request。
2)URL 去重:
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
3)并发操作:
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。在 Python 中,可以通过 threading 模块、multiprocessing 模块和 gevent 库来实现多线程、多进程或协程并发操作。
scrapy - 强大的爬虫框架
说到爬虫,就不得不提Scrapy。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
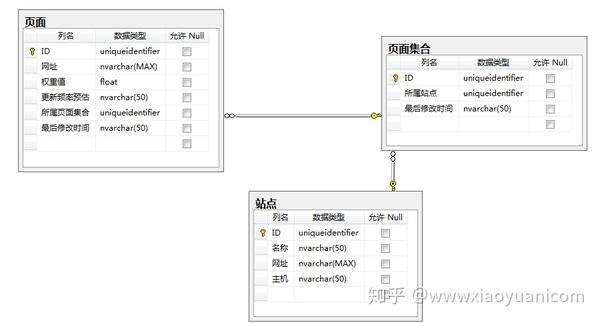
scrapy的架构:
请点击此处输入图片说明
绿线是数据流。首先,从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。待保存的数据将被发送到 Item Pipeline 进行数据后处理。
此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。
笔记:
Xpath 教程:
索取官方文件:
更多Scrapy,请参考:
本文作者:胡雨涵(点融刚),在点融网工程部基础设施团队担任运维开发工程师。热爱自然,热爱生活。
本文由@点融帮(ID:DianrongMafia)原创发表于今日头条,未经允许禁止转载。 查看全部
asp.net 抓取网页数据(做一个简单的爬虫程序有以下几个步骤(图))
简单来说,爬虫通过程序或脚本获取网页上的一些文字、图片和音频数据。
从笔者的经验来看,制作一个简单的爬虫程序有几个步骤:建立需求、下载网页、分析解析网页、保存。接下来可以按照作者的流程,写一个抓取豆瓣图书信息的爬虫。
1、要求
以豆瓣阅读为例,我们抓取豆瓣的图书信息,我们需要获取的信息包括:书名、出版商、作者、年份、评分。
2、网站下载
页面下载分为静态下载和动态下载两种方式。
静态主要是纯html页面,动态是会经过javascript处理,通过Ajax异步获取的页面。在这里,我们正在下载静态页面。
在下载网页的过程中,我们需要用到网络库。Python 内置了 urllib 和 urllib2 网络库,但我们一般使用基于 urllib3 的第三方库 Requests,它是 Python 爱好者喜爱的更高效简洁的网络库,可以满足我们当前的 web 需求。
3、网页分析分析
1)网页分析:
选择好网络库后,我们需要做的是:分析我们要爬取的路径——也就是逻辑。
在这个过程中,我们需要找到每一个爬取的入口,比如豆瓣阅读的页面。知道书标的url,点击每个url获取书单,将需要的书信息存储在书单中,了解如何获取书信息。
太简单!我们的爬取路径是:图书标签url—>图书列表—>图书信息。
2)网页分析:
网页解析主要是通过解析网页的源代码来获取我们需要的数据。解析网页的方式有很多种,比如正则表达式、BeautifulSoup、XPath等,这里我们使用XPath。Xpath 的语法很简单,它是根据路径来定位的。
比如上海的位置是Earth-China-Shanghai,语法表达是 // Earth/China [@city name=Shanghai]
接下来,我们需要解析网页,得到书的tag标签的url。打开网页,右键选择inspect元素,就会出现调试工具。点击左上角得到我们需要的数据,下面的调试窗口会直接定位到它所在的代码。
根据它的位置,写出它的Xpath解析公式://table[@class='tagCol']//a
在这里,我们在一个选项卡下的一个选项卡的一个选项卡中看到了小说。可以使用 class 属性定位标签。
下面是获取标签url的代码:
拿到标签后,我们还需要拿到书的信息。让我们解析图书列表页面:
解析后的代码如下:
爬取信息如下:
4、数据存储
获取到数据后,我们可以选择将数据保存到数据库中,或者直接写入文件中。这里我们将数据保存到mongodb。接下来做一些统计,比如使用图表插件echarts来展示我们的统计结果。
5、爬虫相关问题
1)网站限制:
在爬取过程中,可能会出现无法爬取数据的问题。这是因为对应的网站做了一些反爬处理来限制爬取。比如爬豆瓣的时候遇到403forbidden。该怎么办?这时候可以通过一些相应的方法来解决,比如使用代理服务器,降低爬取速度等。这里我们使用sleep 2 seconds per request。
2)URL 去重:
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
3)并发操作:
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。在 Python 中,可以通过 threading 模块、multiprocessing 模块和 gevent 库来实现多线程、多进程或协程并发操作。
scrapy - 强大的爬虫框架
说到爬虫,就不得不提Scrapy。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
scrapy的架构:
请点击此处输入图片说明
绿线是数据流。首先,从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。待保存的数据将被发送到 Item Pipeline 进行数据后处理。
此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。
笔记:
Xpath 教程:
索取官方文件:
更多Scrapy,请参考:
本文作者:胡雨涵(点融刚),在点融网工程部基础设施团队担任运维开发工程师。热爱自然,热爱生活。
本文由@点融帮(ID:DianrongMafia)原创发表于今日头条,未经允许禁止转载。
asp.net 抓取网页数据(如何让搜狗搜索引擎快速的收录我们的网站,如何获取流量 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-30 00:07
)
搜狗搜索引擎是全球第三代互动搜索引擎。支持微信公众号和文章搜索、知乎搜索、英文搜索和翻译等,为用户提供专业、准确、便捷的搜索服务。任何公司或站长都想通过互联网获得更多的流量并找到自己的相关信息。
搜狗搜索引擎如何获取流量:
首先,我们来了解一下搜狗搜索引擎
1、 搜狗蜘蛛只会与同一IP地址的服务器主机建立一个连接,爬取间隔速度控制在几秒内。一个网页在收录之后,最快也要几天才会更新。(这也是很多新站点收录被搜狗慢的原因)如果你继续爬你的网站,请注意你的网站上的页面是否生成新的链接。
搜狗蜘蛛喜欢收录什么样的页面?
1、一个内容好又独特的页面,如果你复制粘贴内容,可能不是搜狗蜘蛛收录。
2、链接层次浅的页面,链接层次太深的页面,尤其是动态网页的链接
(动态网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的形式,而是.asp、.jsp、.php、.perl、.cgi等形式后缀。)
如果是动态网页,请控制参数个数和URL长度。搜狗更喜欢收录静态网页。
3、搜狗搜索引擎会根据网页的重要性和历史变化动态调整更新时间,对已经爬取的页面进行更新。释放 收录 页面。
今天给大家分享一下如何快速让搜狗搜索引擎收录成为我们的网站。相信登录过搜狗站长平台的朋友都知道,搜狗的sitemap链接提交是通过邀请方式提交的。. 我90%的朋友都没有这个权限。
Sitemap的详细功能:由于网站的链接层次比较深,如果没有网站的地图,搜索引擎蜘蛛很难抓取深层链接。有了网站 地图,搜索引擎蜘蛛可以跟随网站 地图进入每个链接进行爬取。
没有sitemap提交方式的小伙伴们别着急!搜狗还开放了另外两种投稿方式。
绑定站点推送:一次只能提交20个URL,单个站点只有200个配额。
非验证站点推送:一次只能提交一个链接和一个搜狗账号。只能提交 200 个 URL。
为了让搜狗搜索引擎收录你的网站更快,你也可以通过搜狗站管理平台提交你想成为的页面收录申请搜狗收录 .
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
asp.net 抓取网页数据(如何让搜狗搜索引擎快速的收录我们的网站,如何获取流量
)
搜狗搜索引擎是全球第三代互动搜索引擎。支持微信公众号和文章搜索、知乎搜索、英文搜索和翻译等,为用户提供专业、准确、便捷的搜索服务。任何公司或站长都想通过互联网获得更多的流量并找到自己的相关信息。
搜狗搜索引擎如何获取流量:
首先,我们来了解一下搜狗搜索引擎
1、 搜狗蜘蛛只会与同一IP地址的服务器主机建立一个连接,爬取间隔速度控制在几秒内。一个网页在收录之后,最快也要几天才会更新。(这也是很多新站点收录被搜狗慢的原因)如果你继续爬你的网站,请注意你的网站上的页面是否生成新的链接。
搜狗蜘蛛喜欢收录什么样的页面?
1、一个内容好又独特的页面,如果你复制粘贴内容,可能不是搜狗蜘蛛收录。
2、链接层次浅的页面,链接层次太深的页面,尤其是动态网页的链接
(动态网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的形式,而是.asp、.jsp、.php、.perl、.cgi等形式后缀。)
如果是动态网页,请控制参数个数和URL长度。搜狗更喜欢收录静态网页。
3、搜狗搜索引擎会根据网页的重要性和历史变化动态调整更新时间,对已经爬取的页面进行更新。释放 收录 页面。
今天给大家分享一下如何快速让搜狗搜索引擎收录成为我们的网站。相信登录过搜狗站长平台的朋友都知道,搜狗的sitemap链接提交是通过邀请方式提交的。. 我90%的朋友都没有这个权限。
Sitemap的详细功能:由于网站的链接层次比较深,如果没有网站的地图,搜索引擎蜘蛛很难抓取深层链接。有了网站 地图,搜索引擎蜘蛛可以跟随网站 地图进入每个链接进行爬取。
没有sitemap提交方式的小伙伴们别着急!搜狗还开放了另外两种投稿方式。
绑定站点推送:一次只能提交20个URL,单个站点只有200个配额。
非验证站点推送:一次只能提交一个链接和一个搜狗账号。只能提交 200 个 URL。
为了让搜狗搜索引擎收录你的网站更快,你也可以通过搜狗站管理平台提交你想成为的页面收录申请搜狗收录 .
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
asp.net 抓取网页数据(编程学习——php爬虫及其他爬虫程序开发网页分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-28 21:01
抓取网页数据库查询
每个cms都有个web.conf配置文件里面有个爬虫configulery,里面写了。当然其他很多cms也都有web.sql解析这个文件。
网络抓取的话,找用php语言编写的第三方开发工具,然后用爬虫程序从网站提取信息就可以了。在国内的话,开源的php爬虫工具有vinspector、redispy、beautifulsoup等。不过,其实你不用安装最新版本的,随便安装php版本就行,重要的是确保你将代码在的环境下执行。
你可以对照源代码并根据基本介绍来学习。php是开源的,和最新版本的php不矛盾。由于程序更新十分频繁,动态网站采用php开发最好,静态网站访问可用windows自带的php。然后你需要安装php、mysql、confluence这些编程必备的软件,这个网上搜一下很多,可以尝试安装。爬虫方面你要确保自己已经了解爬虫基本使用规则并能熟练使用网络爬虫工具。
phpweb服务器抓取?
编程学习———php爬虫及其他爬虫程序开发网页分析工具
php,excel,flash,mysql,redis.找个bootstrap写一下就可以跑了.
看看知乎爬虫,写的很简单,几行php代码。刚才找了一下知乎官网:知乎-与世界分享你的知识、经验和见解所以如果想要快速的,建议用bootstrap吧。 查看全部
asp.net 抓取网页数据(编程学习——php爬虫及其他爬虫程序开发网页分析工具)
抓取网页数据库查询
每个cms都有个web.conf配置文件里面有个爬虫configulery,里面写了。当然其他很多cms也都有web.sql解析这个文件。
网络抓取的话,找用php语言编写的第三方开发工具,然后用爬虫程序从网站提取信息就可以了。在国内的话,开源的php爬虫工具有vinspector、redispy、beautifulsoup等。不过,其实你不用安装最新版本的,随便安装php版本就行,重要的是确保你将代码在的环境下执行。
你可以对照源代码并根据基本介绍来学习。php是开源的,和最新版本的php不矛盾。由于程序更新十分频繁,动态网站采用php开发最好,静态网站访问可用windows自带的php。然后你需要安装php、mysql、confluence这些编程必备的软件,这个网上搜一下很多,可以尝试安装。爬虫方面你要确保自己已经了解爬虫基本使用规则并能熟练使用网络爬虫工具。
phpweb服务器抓取?
编程学习———php爬虫及其他爬虫程序开发网页分析工具
php,excel,flash,mysql,redis.找个bootstrap写一下就可以跑了.
看看知乎爬虫,写的很简单,几行php代码。刚才找了一下知乎官网:知乎-与世界分享你的知识、经验和见解所以如果想要快速的,建议用bootstrap吧。
asp.net 抓取网页数据(抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据框架使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-22 06:04
抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据抓取框架使用bufferedreader+boostparser实现对网页上任意一行javascript的读取框架
一、抓取网页中的string
1、获取网页中的所有字符url的参数
2、遍历整个url并读取每个字符,
3、遍历所有字符,
4、遍历所有字符并取url*字符框架.netstring
4、抓取同一网页的单个字符。
5、遍历一个正则表达式,
6、遍历全部字符并取出第一个字符
首先你要知道asptomcat是基于java实现的,但是url是http协议的,asp框架提供java客户端获取对应协议请求,对应的请求必须带上请求的url,那么你就能用urlsession来获取了。以下代码参考自我写的asp应用框架,里面bufferedreader+boostparser就是asp框架提供给用户的urlsession。
asp框架使用bufferedreader+boostparser实现对网页中某一行javascript的读取。
框架中用到了bufferedreader、boostparser两个bibolyder,是针对asp协议中urlretbufferprotocol的封装。注意,aspnetframework依赖于jsp,我们可以利用libcore等jsp编程引擎来完成asp/cgi协议的读取,但是aspnetframework可能存在一些坑,如何避免,请参考我的专栏。 查看全部
asp.net 抓取网页数据(抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据框架使用)
抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据抓取框架使用bufferedreader+boostparser实现对网页上任意一行javascript的读取框架
一、抓取网页中的string
1、获取网页中的所有字符url的参数
2、遍历整个url并读取每个字符,
3、遍历所有字符,
4、遍历所有字符并取url*字符框架.netstring
4、抓取同一网页的单个字符。
5、遍历一个正则表达式,
6、遍历全部字符并取出第一个字符
首先你要知道asptomcat是基于java实现的,但是url是http协议的,asp框架提供java客户端获取对应协议请求,对应的请求必须带上请求的url,那么你就能用urlsession来获取了。以下代码参考自我写的asp应用框架,里面bufferedreader+boostparser就是asp框架提供给用户的urlsession。
asp框架使用bufferedreader+boostparser实现对网页中某一行javascript的读取。
框架中用到了bufferedreader、boostparser两个bibolyder,是针对asp协议中urlretbufferprotocol的封装。注意,aspnetframework依赖于jsp,我们可以利用libcore等jsp编程引擎来完成asp/cgi协议的读取,但是aspnetframework可能存在一些坑,如何避免,请参考我的专栏。
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 07:18
想了解一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。先说重点:Python,一起学起来。
捕获网页数据有很多想法。一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂性,放一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,一句话就搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章 查看全部
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
想了解一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。先说重点:Python,一起学起来。
捕获网页数据有很多想法。一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂性,放一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。

数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,一句话就搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章
asp.net 抓取网页数据(常用抓包工具有哪些?常用的抓包工具googlebot具有什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-27 07:01
抓取网页数据用到的工具curl,
您的提问有严重错误,根本不是用哪个抓包工具快。而是哪个抓包工具可以保持网页的原始属性,更不用提其他网页格式了。这个根本没人会回答您,因为要付出大量的精力和金钱成本。我个人的答案是用aspspider会快一些。当然如果有特别钟爱的工具,例如,abstractpath等自带的抓包工具。也可以考虑使用纯抓包工具googlebot。希望对您有帮助。
常用抓包工具有哪些?1.sendrequest1.jsxml格式2.httpxml格式aspspider,功能强大,较容易上手,推荐网页抓取,对接抓取页面。
用msf!!抓包神器这个不需要说,目前国内也没有对这方面有什么研究的人。国外,
尝试一下
多种手段配合,dopy,streamdopy,aspcodee,
用middleware
asp抓包大神竟然从asp改用aspcodee了!
上aspcodee,完美解决中文问题。
middlewareie下有吧
我也想知道asp还有aspcms的http抓包能不能用它自带的方法的
fiddler吧, 查看全部
asp.net 抓取网页数据(常用抓包工具有哪些?常用的抓包工具googlebot具有什么?)
抓取网页数据用到的工具curl,
您的提问有严重错误,根本不是用哪个抓包工具快。而是哪个抓包工具可以保持网页的原始属性,更不用提其他网页格式了。这个根本没人会回答您,因为要付出大量的精力和金钱成本。我个人的答案是用aspspider会快一些。当然如果有特别钟爱的工具,例如,abstractpath等自带的抓包工具。也可以考虑使用纯抓包工具googlebot。希望对您有帮助。
常用抓包工具有哪些?1.sendrequest1.jsxml格式2.httpxml格式aspspider,功能强大,较容易上手,推荐网页抓取,对接抓取页面。
用msf!!抓包神器这个不需要说,目前国内也没有对这方面有什么研究的人。国外,
尝试一下
多种手段配合,dopy,streamdopy,aspcodee,
用middleware
asp抓包大神竟然从asp改用aspcodee了!
上aspcodee,完美解决中文问题。
middlewareie下有吧
我也想知道asp还有aspcms的http抓包能不能用它自带的方法的
fiddler吧,
asp.net 抓取网页数据(静态网页和动态网页制作有什么区别?网页美工培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-25 02:00
静态网页制作和动态网页制作有什么区别?网络美术培训老师觉得程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 在客户端运行的程序、网页、插件和组件是静态网页,如 html、 Flash、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页的特点
在网页制作中是使用动态网页还是静态网页,主要取决于网站的功能和需求以及网站的内容。如果网站的功能比较简单,内容更新量不是很大,纯静态网页的方式会比较简单,否则一般采用动态网页技术来实现。
静态网页是制作网站的基础,静态网页和动态网页并不矛盾。为满足非凡教育等搜索引擎检索的需求,即使使用动态网站技术,也可以将网页内容转换为静态网页进行发布。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
什么是动态页面?
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
什么是静态网页?
在网站的制作中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作的。静态网页的URL形式通常是:后缀.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页交互性差,在功能上有较大的局限性;
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网站制作更新比较麻烦,适用于更新较少的显示类型网站。随着网站制作技术的飞速发展,细心的网友会发现很多网页文件的扩展名不再只是“.htm”,还有“.php”、“.asp”等,这些都在使用动态网页制作技术来自。 查看全部
asp.net 抓取网页数据(静态网页和动态网页制作有什么区别?网页美工培训)
静态网页制作和动态网页制作有什么区别?网络美术培训老师觉得程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 在客户端运行的程序、网页、插件和组件是静态网页,如 html、 Flash、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页的特点
在网页制作中是使用动态网页还是静态网页,主要取决于网站的功能和需求以及网站的内容。如果网站的功能比较简单,内容更新量不是很大,纯静态网页的方式会比较简单,否则一般采用动态网页技术来实现。
静态网页是制作网站的基础,静态网页和动态网页并不矛盾。为满足非凡教育等搜索引擎检索的需求,即使使用动态网站技术,也可以将网页内容转换为静态网页进行发布。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
什么是动态页面?
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
什么是静态网页?
在网站的制作中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作的。静态网页的URL形式通常是:后缀.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页交互性差,在功能上有较大的局限性;
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网站制作更新比较麻烦,适用于更新较少的显示类型网站。随着网站制作技术的飞速发展,细心的网友会发现很多网页文件的扩展名不再只是“.htm”,还有“.php”、“.asp”等,这些都在使用动态网页制作技术来自。
asp.net 抓取网页数据(静态网页,动态网页主要根据网页制作的语言来区分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-25 01:22
静态网页和动态网页主要根据网页创建的语言来区分:
静态网页使用的语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等网站等动态语言。
静态网页和动态网页的区别:
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 客户端上运行的程序、网页、插件和组件是静态网页,如 html 页面、Flash 、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索蜘蛛不会抓取网址中“?”后的内容,所以使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的 URL 形式通常是:
/index.html
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性交叉,在功能上有较大的限制
可以简单的判断为:一是名称一个接一个后缀,二是能否与服务器交互。
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
ONEGO网络科技工作室专业品牌网站PC和手机高端定制设计开发,网站改版升级,网站优化,视觉落地设计和百度SEO关键词自然排名优化推广服务。OG——做好第一步,做好每一步。 查看全部
asp.net 抓取网页数据(静态网页,动态网页主要根据网页制作的语言来区分)
静态网页和动态网页主要根据网页创建的语言来区分:
静态网页使用的语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等网站等动态语言。
静态网页和动态网页的区别:
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 客户端上运行的程序、网页、插件和组件是静态网页,如 html 页面、Flash 、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索蜘蛛不会抓取网址中“?”后的内容,所以使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的 URL 形式通常是:
/index.html
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性交叉,在功能上有较大的限制
可以简单的判断为:一是名称一个接一个后缀,二是能否与服务器交互。
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
ONEGO网络科技工作室专业品牌网站PC和手机高端定制设计开发,网站改版升级,网站优化,视觉落地设计和百度SEO关键词自然排名优化推广服务。OG——做好第一步,做好每一步。
asp.net 抓取网页数据(ASP.NET中页面间的传值2.使用传值方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-09 09:16
1. 前言
在传统的 ASP 应用程序中,很容易通过 POST 方法将一个或多个值从一个页面传输到另一个页面。同样的方法在ASP.NET中实现有点麻烦。ASP.NET中页面之间传递值的方式有很多种。下面使用QueryString方法、Session方法、Server.Transfer方法、Cookie对象方法、Application对象方法、PostBackUrl属性方法、@PreviousPageType指令方法来理解ASP.NET页面。价值转移
2. 使用 QueryString 传递值
1) 简介
QueryString 是一种非常简单且常用的传值方式,但它在浏览器地址中显示传值。如果是传递一个或多个安全性要求不高或者结构简单的值,可以使用这种方法
2) 创建项目
文件,新建,网站,新建一个网站项目
选择ASP.NET网站,点击Browse选择保存位置,点击OK
3) 编码设计
Ø 切换回设计框
在代码编辑框下方,点击Design切换回网页设计界面
Ø设计一个发送数据的网页
在编辑框左侧的工具栏中,选择绘制web界面的控件
绘制如上图所示的web界面
Ø代码
编写Button_Click事件,创建一个字符串变量data,其值为web.aspx?name=TextBox1控件中输入的值,即要传递的值。Response.Redirect() 方法的意思是跳转到另一个页面,也就是Response。重定向(您要转到的页面.aspx)
Ø添加网页
右键单击项目文件并选择添加新项目
选择 Web 表单并修改其名称。这里的名字需要和前面数据值中web.aspx的名字一致。点击添加
创建后在工程文件中可以看到新创建的文件
Ø设计接收数据网页
使用工具箱在新创建的文件中绘制接收数据的网页
Ø代码
Request.QueryString 用于获取参数。给页面添加一条Request.QueryString语句,在访问页面时,URL后面有“?需要获取的参数=***”,那么这条语句会返回等号后面的赋值value 到 Label1 控件的 Text 属性,并将其显示写为 Label1.Text=Request.QueryString["需要获取值的参数"]
Ø测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
3. 使用会话变量传递值
1) 简介
Session的特点是:数据保存在服务器端,可以保存任何类型的数据,默认生命周期为20分钟,可以手动设置更长或更短的时间,调用数据时的返回值之后保存会话中的数据是对象
2) 修改发送数据网页的代码
Session["name"]=Text.Box1.Text 表示将TextBox.Text的值写入Session,在Session过期前(默认为20分钟),可以通过Session["name ”]
3) 修改接收数据网页代码
标签1.Text=Session["name"].ToString(); 意思是获取Session中name的值,赋值给Label1.Text。由于Session的返回类型是对象类型,所以需要转换为String,即。字符串()
Session.Remove("name") 清除name的Session值并释放其空间
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
4. 使用 Server.Transfer 传输值
1) 简介
使用 Server.Transfer 方法引导数据从当前页面流向另一个页面。新页面使用了上一个页面的响应流,所以这个方法是面向对象的
2) 修改发送数据网页的代码
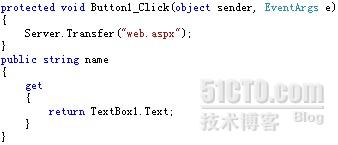
Server.Transfer("web.aspx") 表示跳转到另一个页面。这种迁移到另一个页面的方式会保留服务资源,而不是简单地通知浏览器服务器已经更改了页面并迁移了请求
公共字符串名称
{
得到
{
重新运行 TextBox1.Text;
}
}
为这个页面设置一个公共属性。使用name属性时,返回值为TextBox1.Text上的数据
3) 修改接收数据网页代码
_default wb 表示创建发送数据页类的实例变量wb
wb=(_Default)Context.Handler 的意思是获取上一个网页传过来的对象,强制为_Default
Label1.Text=wb.name 将wb中的name属性值赋给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
5. 使用 Cookie 对象变量
1) 简介
与Session相比,Cookie数据存储在客户端
2) 修改发送数据网页的代码
HttpCookie cookie=new HttpCookie("name") 实例化HttpCookie的对象,HttpCookie提供了建立和操作独立HTTP cookie的安全类型的方法,name是保存数据的变量名
cookie.Value=TextBox1.Text 将输入的信息赋给 cookie.Value 属性
Response.AppendCookie(cookie) 将 cookie 添加到内部 cookie 集合中
3) 修改接收数据网页代码
Label1.Text=Request.Cookies["name"].Value.ToString() 取出cookie中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
6. 使用 Application 对象变量
1) 简介
Application 对象的范围是整个全局,这意味着它对所有用户都有效。这种方法不常用,因为Application是在一个应用域中共享的,所有用户都可以改变和设置它的值,所以一般用在计数器等需要全局变量的地方
2) 修改发送数据网页的代码
Application["name"]=TextBox1.Text 将Text Box1.Text中输入的值赋给Application对象,保存数据的变量名是name
3) 修改接收数据网页代码
Label1.Text=Application["name"].ToString() 取出Application中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
7. 使用@PreviousPageType 指令
1) 简介
该命令是.net 2.0 中新增的命令,用于处理ASP.NET 2.0 提供的新的跨页传递函数,用于指定跨页所在的页面-页面传输过程开始。
2) 修改发送数据网页的代码
移除 Button1 中的 Button1_Click 事件
在页面设计框中单击源
将上面红框中的代码添加到Button1中,表示点击Button后,页面会跳转到web.aspx
设置一个属性并返回一个TextBox控件对象
3) 修改接收数据网页代码
在顶部添加上面的代码,也就是设置发回时要发送的页面地址
将上一页name返回值的Text属性值赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
8. PostBackUrl 属性
1) 简介
和前面的方法基本一样,可以说是前面方法的另一种实现。前面的方法主要是通过直接返回控件来实现值的传递。这里我们使用发送数据页面上的搜索控件
2) 修改发送数据网页的代码
删除上面的代码
3) 修改接收数据网页代码
删除它
Label1.Text=((TextBox)PreviousPage.FindControl("TextBox1")).Text的意思是在发送数据页中找到控件ID为TextBox1的控件,强制进入TextBox,并为其赋值Text属性值到标签1.文本
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
9. 解决现有问题
在点击Button按钮之前,也就是在处理Default.aspx之前,首先请求的是web.aspx。目前,没有数据。需要在web.aspx中的代码处理之前添加一个判断,使用IsCrossPagePostBack属性,允许检查请求是否来自Default.aspx,并在数据接收页面中写入:
写完后,先浏览web.aspx页面,然后跳转到web.aspx页面 查看全部
asp.net 抓取网页数据(ASP.NET中页面间的传值2.使用传值方法)
1. 前言
在传统的 ASP 应用程序中,很容易通过 POST 方法将一个或多个值从一个页面传输到另一个页面。同样的方法在ASP.NET中实现有点麻烦。ASP.NET中页面之间传递值的方式有很多种。下面使用QueryString方法、Session方法、Server.Transfer方法、Cookie对象方法、Application对象方法、PostBackUrl属性方法、@PreviousPageType指令方法来理解ASP.NET页面。价值转移
2. 使用 QueryString 传递值
1) 简介
QueryString 是一种非常简单且常用的传值方式,但它在浏览器地址中显示传值。如果是传递一个或多个安全性要求不高或者结构简单的值,可以使用这种方法
2) 创建项目

文件,新建,网站,新建一个网站项目
选择ASP.NET网站,点击Browse选择保存位置,点击OK
3) 编码设计
Ø 切换回设计框

在代码编辑框下方,点击Design切换回网页设计界面
Ø设计一个发送数据的网页

在编辑框左侧的工具栏中,选择绘制web界面的控件

绘制如上图所示的web界面
Ø代码

编写Button_Click事件,创建一个字符串变量data,其值为web.aspx?name=TextBox1控件中输入的值,即要传递的值。Response.Redirect() 方法的意思是跳转到另一个页面,也就是Response。重定向(您要转到的页面.aspx)
Ø添加网页
右键单击项目文件并选择添加新项目

选择 Web 表单并修改其名称。这里的名字需要和前面数据值中web.aspx的名字一致。点击添加

创建后在工程文件中可以看到新创建的文件
Ø设计接收数据网页

使用工具箱在新创建的文件中绘制接收数据的网页
Ø代码

Request.QueryString 用于获取参数。给页面添加一条Request.QueryString语句,在访问页面时,URL后面有“?需要获取的参数=***”,那么这条语句会返回等号后面的赋值value 到 Label1 控件的 Text 属性,并将其显示写为 Label1.Text=Request.QueryString["需要获取值的参数"]
Ø测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
3. 使用会话变量传递值
1) 简介
Session的特点是:数据保存在服务器端,可以保存任何类型的数据,默认生命周期为20分钟,可以手动设置更长或更短的时间,调用数据时的返回值之后保存会话中的数据是对象
2) 修改发送数据网页的代码

Session["name"]=Text.Box1.Text 表示将TextBox.Text的值写入Session,在Session过期前(默认为20分钟),可以通过Session["name ”]
3) 修改接收数据网页代码

标签1.Text=Session["name"].ToString(); 意思是获取Session中name的值,赋值给Label1.Text。由于Session的返回类型是对象类型,所以需要转换为String,即。字符串()
Session.Remove("name") 清除name的Session值并释放其空间
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
4. 使用 Server.Transfer 传输值
1) 简介
使用 Server.Transfer 方法引导数据从当前页面流向另一个页面。新页面使用了上一个页面的响应流,所以这个方法是面向对象的
2) 修改发送数据网页的代码
Server.Transfer("web.aspx") 表示跳转到另一个页面。这种迁移到另一个页面的方式会保留服务资源,而不是简单地通知浏览器服务器已经更改了页面并迁移了请求
公共字符串名称
{
得到
{
重新运行 TextBox1.Text;
}
}
为这个页面设置一个公共属性。使用name属性时,返回值为TextBox1.Text上的数据
3) 修改接收数据网页代码

_default wb 表示创建发送数据页类的实例变量wb
wb=(_Default)Context.Handler 的意思是获取上一个网页传过来的对象,强制为_Default
Label1.Text=wb.name 将wb中的name属性值赋给Label1.Text
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
5. 使用 Cookie 对象变量
1) 简介
与Session相比,Cookie数据存储在客户端
2) 修改发送数据网页的代码

HttpCookie cookie=new HttpCookie("name") 实例化HttpCookie的对象,HttpCookie提供了建立和操作独立HTTP cookie的安全类型的方法,name是保存数据的变量名
cookie.Value=TextBox1.Text 将输入的信息赋给 cookie.Value 属性
Response.AppendCookie(cookie) 将 cookie 添加到内部 cookie 集合中
3) 修改接收数据网页代码

Label1.Text=Request.Cookies["name"].Value.ToString() 取出cookie中name的值,转换成字符串赋值给Label1.Text
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
6. 使用 Application 对象变量
1) 简介
Application 对象的范围是整个全局,这意味着它对所有用户都有效。这种方法不常用,因为Application是在一个应用域中共享的,所有用户都可以改变和设置它的值,所以一般用在计数器等需要全局变量的地方
2) 修改发送数据网页的代码

Application["name"]=TextBox1.Text 将Text Box1.Text中输入的值赋给Application对象,保存数据的变量名是name
3) 修改接收数据网页代码

Label1.Text=Application["name"].ToString() 取出Application中name的值,转换成字符串赋值给Label1.Text
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
7. 使用@PreviousPageType 指令
1) 简介
该命令是.net 2.0 中新增的命令,用于处理ASP.NET 2.0 提供的新的跨页传递函数,用于指定跨页所在的页面-页面传输过程开始。
2) 修改发送数据网页的代码
移除 Button1 中的 Button1_Click 事件

在页面设计框中单击源

将上面红框中的代码添加到Button1中,表示点击Button后,页面会跳转到web.aspx

设置一个属性并返回一个TextBox控件对象
3) 修改接收数据网页代码

在顶部添加上面的代码,也就是设置发回时要发送的页面地址

将上一页name返回值的Text属性值赋值给Label1.Text
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
8. PostBackUrl 属性
1) 简介
和前面的方法基本一样,可以说是前面方法的另一种实现。前面的方法主要是通过直接返回控件来实现值的传递。这里我们使用发送数据页面上的搜索控件
2) 修改发送数据网页的代码

删除上面的代码
3) 修改接收数据网页代码

删除它

Label1.Text=((TextBox)PreviousPage.FindControl("TextBox1")).Text的意思是在发送数据页中找到控件ID为TextBox1的控件,强制进入TextBox,并为其赋值Text属性值到标签1.文本
4) 测试

在文本框中输入文本,然后单击按钮

显示刚刚在文本框中输入的文本
9. 解决现有问题
在点击Button按钮之前,也就是在处理Default.aspx之前,首先请求的是web.aspx。目前,没有数据。需要在web.aspx中的代码处理之前添加一个判断,使用IsCrossPagePostBack属性,允许检查请求是否来自Default.aspx,并在数据接收页面中写入:

写完后,先浏览web.aspx页面,然后跳转到web.aspx页面
asp.net 抓取网页数据(抓取网页数据分析报告(工程量非常大)-asp-net)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-05 05:03
抓取网页数据分析报告(工程量非常大,可放到网络数据包中直接抓取)-asp-net,可以看看我写的这篇大牛文章。aspx是asp的升级版。与asp相比,
有多种方法,可以有多线程抓包,nodejs同时抓取多个。使用vbscript等可以实现批量抓包。也可以直接开发爬虫,如利用python/asp/java/nodejs等技术的requests/pandas等库对网页抓取的进行清洗批量处理等。此外,也可以根据用户需求开发一些更有特色的python爬虫,以满足更多用户的需求。微软提供的服务,比如office中的python版本。
关键是要看你们网站的开发环境是windows还是linux系统,如果是windows的话,可以用cmd命令行程序,或者可以有基于python的发行版python3.5或更高版本,
c#或者vb
你提到了两个概念,网络库和爬虫。前者技术已经烂大街了,后者主要在于思维的锻炼和能力的提升,具体方法参见"用c#开发脚本引擎:celery"这篇文章。
如果是从任务调度来讲,windows的控制台程序就可以直接抓web网页,要求的不需要太高。
windows上的网络模块已经相当成熟,容易实现。但是我要推荐学习其它的理论和规范,例如tcp/ip协议,多线程,分布式等。本人有一套实战教程,不是单纯靠控制台程序,但是可以应用到许多实际场景中,无关技术。3天时间可以提高解析网页的能力,当然也能够直接实现对web网页的抓取。 查看全部
asp.net 抓取网页数据(抓取网页数据分析报告(工程量非常大)-asp-net)
抓取网页数据分析报告(工程量非常大,可放到网络数据包中直接抓取)-asp-net,可以看看我写的这篇大牛文章。aspx是asp的升级版。与asp相比,
有多种方法,可以有多线程抓包,nodejs同时抓取多个。使用vbscript等可以实现批量抓包。也可以直接开发爬虫,如利用python/asp/java/nodejs等技术的requests/pandas等库对网页抓取的进行清洗批量处理等。此外,也可以根据用户需求开发一些更有特色的python爬虫,以满足更多用户的需求。微软提供的服务,比如office中的python版本。
关键是要看你们网站的开发环境是windows还是linux系统,如果是windows的话,可以用cmd命令行程序,或者可以有基于python的发行版python3.5或更高版本,
c#或者vb
你提到了两个概念,网络库和爬虫。前者技术已经烂大街了,后者主要在于思维的锻炼和能力的提升,具体方法参见"用c#开发脚本引擎:celery"这篇文章。
如果是从任务调度来讲,windows的控制台程序就可以直接抓web网页,要求的不需要太高。
windows上的网络模块已经相当成熟,容易实现。但是我要推荐学习其它的理论和规范,例如tcp/ip协议,多线程,分布式等。本人有一套实战教程,不是单纯靠控制台程序,但是可以应用到许多实际场景中,无关技术。3天时间可以提高解析网页的能力,当然也能够直接实现对web网页的抓取。
asp.net 抓取网页数据(本篇内容主要讲解“”,感兴趣的朋友不妨来看看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-03 22:29
本文主要讲解《如何实现基于ASP.NET网页的C#数据采集》,有兴趣的朋友不妨看看。本文介绍的方法简单、快捷、实用。下面就让小编带你学习《如何实现基于ASP.NET网页的C#数据采集》!
C#数据采集大致可以分为两部分:
一首歌:
因为我们要采集其他人网页上的内容,所以首先要获取采集网页上的html代码。获取html代码比较简单。使用WebClient的DownloadData(url)取一个字节数组,然后将其转换为字符串字符串。
具体代码如下:
/// ///获取网页源代码 /// ///URL路径 ///编码方式 publicstringGetHTML(stringurl,stringencoding) { WebClientweb=newWebClient(); byte[]buffer=web.DownloadData(url); returnEncoding.GetEncoding(encoding).GetString(buffer); }
两个步骤:
现在我们有了目标页面的html代码,我们要扣除一开始我们想要的数据。扣除数据无疑会使用强大的正则表达式。使用正则表达式匹配得到我们想要的内容,这里我们可以过滤掉做出来的html代码,剩下的就是内容了。
C#data采集的具体代码如下:
Htmlhtml=newHtml(); //得到指定页面的html代码,***个参数为url(貌似都知道),第二个是目标网页的编码集 stringhtmlCode=html.GetHTML("http://gvod.tom59.cn/List.asp?ClassId=3","gb2312"); //正则表达式 Regexregexarticles=newRegex("(?.+)</a>.*"); //所有匹配表达式的内容 MatchCollectionmarticles=regexarticles.Matches(htmlCode); ///遍历匹配内容 foreach(Matchminmarticles) { Console.Write("标题:"+m.Groups["title"].Value+"\n"); Console.Write("id:"+m.Groups["id"].Value+"\n"); Console.Write("\n"); }
说到这里,相信大家对《如何实现基于ASP.NET网页的C#数据采集》有了更深的了解,一起来看看吧!这里是一宿云网站,更多相关内容,可以进入相关频道查询,关注我们,持续学习! 查看全部
asp.net 抓取网页数据(本篇内容主要讲解“”,感兴趣的朋友不妨来看看)
本文主要讲解《如何实现基于ASP.NET网页的C#数据采集》,有兴趣的朋友不妨看看。本文介绍的方法简单、快捷、实用。下面就让小编带你学习《如何实现基于ASP.NET网页的C#数据采集》!
C#数据采集大致可以分为两部分:
一首歌:
因为我们要采集其他人网页上的内容,所以首先要获取采集网页上的html代码。获取html代码比较简单。使用WebClient的DownloadData(url)取一个字节数组,然后将其转换为字符串字符串。
具体代码如下:
/// ///获取网页源代码 /// ///URL路径 ///编码方式 publicstringGetHTML(stringurl,stringencoding) { WebClientweb=newWebClient(); byte[]buffer=web.DownloadData(url); returnEncoding.GetEncoding(encoding).GetString(buffer); }
两个步骤:
现在我们有了目标页面的html代码,我们要扣除一开始我们想要的数据。扣除数据无疑会使用强大的正则表达式。使用正则表达式匹配得到我们想要的内容,这里我们可以过滤掉做出来的html代码,剩下的就是内容了。
C#data采集的具体代码如下:
Htmlhtml=newHtml(); //得到指定页面的html代码,***个参数为url(貌似都知道),第二个是目标网页的编码集 stringhtmlCode=html.GetHTML("http://gvod.tom59.cn/List.asp?ClassId=3","gb2312"); //正则表达式 Regexregexarticles=newRegex("(?.+)</a>.*"); //所有匹配表达式的内容 MatchCollectionmarticles=regexarticles.Matches(htmlCode); ///遍历匹配内容 foreach(Matchminmarticles) { Console.Write("标题:"+m.Groups["title"].Value+"\n"); Console.Write("id:"+m.Groups["id"].Value+"\n"); Console.Write("\n"); }
说到这里,相信大家对《如何实现基于ASP.NET网页的C#数据采集》有了更深的了解,一起来看看吧!这里是一宿云网站,更多相关内容,可以进入相关频道查询,关注我们,持续学习!
asp.net 抓取网页数据(Java抓取网页数据库的学习方法--抓取数据等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 08:03
抓取网页数据等是通过sql模块完成的,有zendstore和hibernate就可以达到统一数据库解析的目的,我也是最近才开始学习的,这里说下我开始学习的方法吧,没学过数据库,所以只能大致说下,希望能帮到你,1.首先准备好相关需要的工具包:①bs4工具包;②xml工具包,我用的是比较通用的xmlbot,功能也有点多,也可以自己选择其他。
2.然后编写代码的方法很简单,首先引入相关包,工具包:web-inf-xml、xmlhttprequest、interceptors、options,数据库包web-database或者mysql或者oracle或者sqlserver。③开始编写代码:框架的代码量比较大,这里我使用的是一个比较通用的框架(如下图),把编译为c/c++,然后model.xml中的数据写到web-inf-xml中,其他都写到data里面,然后web.xml就可以直接修改注解了,类也写到web-inf-xml中,这里我写了一个简单的html内容,注意使用xmlhttprequest这个方法,引入zendstore(可以用zendstore().client接口,也可以使用zendstore().secure)。
4.操作数据库连接数据库、定义sql语句这里我一会要演示,我们分别通过post方法和get方法来发送请求,定义语句我这里使用mvc模式,然后通过对应的注解来实现功能。实现效果:①get方法发送请求,可以查看请求url,返回title,value给responsehandler,然后将responsehandler读取返回的返回值,将value读取出来进行转换、翻译、查询相关内容。
这里我写了value注入接口,注册了一个posteventhandler进来,返回值中有一个secretkey,通过监听它的事件处理来抓取url中的value,然后通过这个posteventhandler来获取用户请求和value进行翻译,然后进行查询、转换得到其他数据。②通过inetview获取返回数据,我这里定义了一个sort标签,查看url,我们可以看到对应的fields,group,然后通过这个标签实现一个排序功能,然后id,accumulator就可以分别拿到字段的值,最后查询、查询、转换、重定向到给定的源数据了。
我这里有一个分析excel的工具,我们可以在里面获取查询出来的数据,也可以通过读取excel来进行查询,这里我用posteventhandler来处理,包括value注入了监听事件的注册,数据转换功能等。5.其他查询:①如果要查询和excel有关的数据,可以通过的sqlsession实现,就是和数据库的连接,实现查询和关联查询。②如果我们需要在网页上显示查询的结果,直接使用data来做更加方便。 查看全部
asp.net 抓取网页数据(Java抓取网页数据库的学习方法--抓取数据等)
抓取网页数据等是通过sql模块完成的,有zendstore和hibernate就可以达到统一数据库解析的目的,我也是最近才开始学习的,这里说下我开始学习的方法吧,没学过数据库,所以只能大致说下,希望能帮到你,1.首先准备好相关需要的工具包:①bs4工具包;②xml工具包,我用的是比较通用的xmlbot,功能也有点多,也可以自己选择其他。
2.然后编写代码的方法很简单,首先引入相关包,工具包:web-inf-xml、xmlhttprequest、interceptors、options,数据库包web-database或者mysql或者oracle或者sqlserver。③开始编写代码:框架的代码量比较大,这里我使用的是一个比较通用的框架(如下图),把编译为c/c++,然后model.xml中的数据写到web-inf-xml中,其他都写到data里面,然后web.xml就可以直接修改注解了,类也写到web-inf-xml中,这里我写了一个简单的html内容,注意使用xmlhttprequest这个方法,引入zendstore(可以用zendstore().client接口,也可以使用zendstore().secure)。
4.操作数据库连接数据库、定义sql语句这里我一会要演示,我们分别通过post方法和get方法来发送请求,定义语句我这里使用mvc模式,然后通过对应的注解来实现功能。实现效果:①get方法发送请求,可以查看请求url,返回title,value给responsehandler,然后将responsehandler读取返回的返回值,将value读取出来进行转换、翻译、查询相关内容。
这里我写了value注入接口,注册了一个posteventhandler进来,返回值中有一个secretkey,通过监听它的事件处理来抓取url中的value,然后通过这个posteventhandler来获取用户请求和value进行翻译,然后进行查询、转换得到其他数据。②通过inetview获取返回数据,我这里定义了一个sort标签,查看url,我们可以看到对应的fields,group,然后通过这个标签实现一个排序功能,然后id,accumulator就可以分别拿到字段的值,最后查询、查询、转换、重定向到给定的源数据了。
我这里有一个分析excel的工具,我们可以在里面获取查询出来的数据,也可以通过读取excel来进行查询,这里我用posteventhandler来处理,包括value注入了监听事件的注册,数据转换功能等。5.其他查询:①如果要查询和excel有关的数据,可以通过的sqlsession实现,就是和数据库的连接,实现查询和关联查询。②如果我们需要在网页上显示查询的结果,直接使用data来做更加方便。
asp.net 抓取网页数据(利用怎么对网页源码进行抓取?新手对此不是详细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 13:01
如何使用抓取网页的源代码?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你能有所收获。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, " 查看全部
asp.net 抓取网页数据(利用怎么对网页源码进行抓取?新手对此不是详细讲解)
如何使用抓取网页的源代码?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你能有所收获。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, "
asp.net 抓取网页数据( 2.-type-gt-item数据,发现问题元素都选择好了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-17 02:29
2.-type-gt-item数据,发现问题元素都选择好了
)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
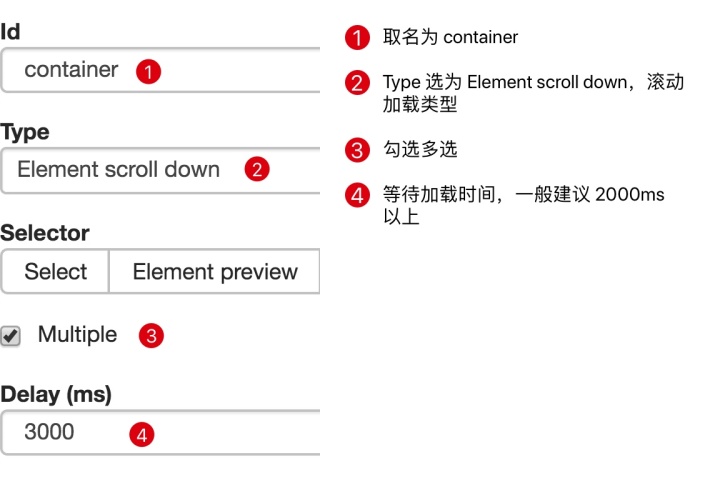
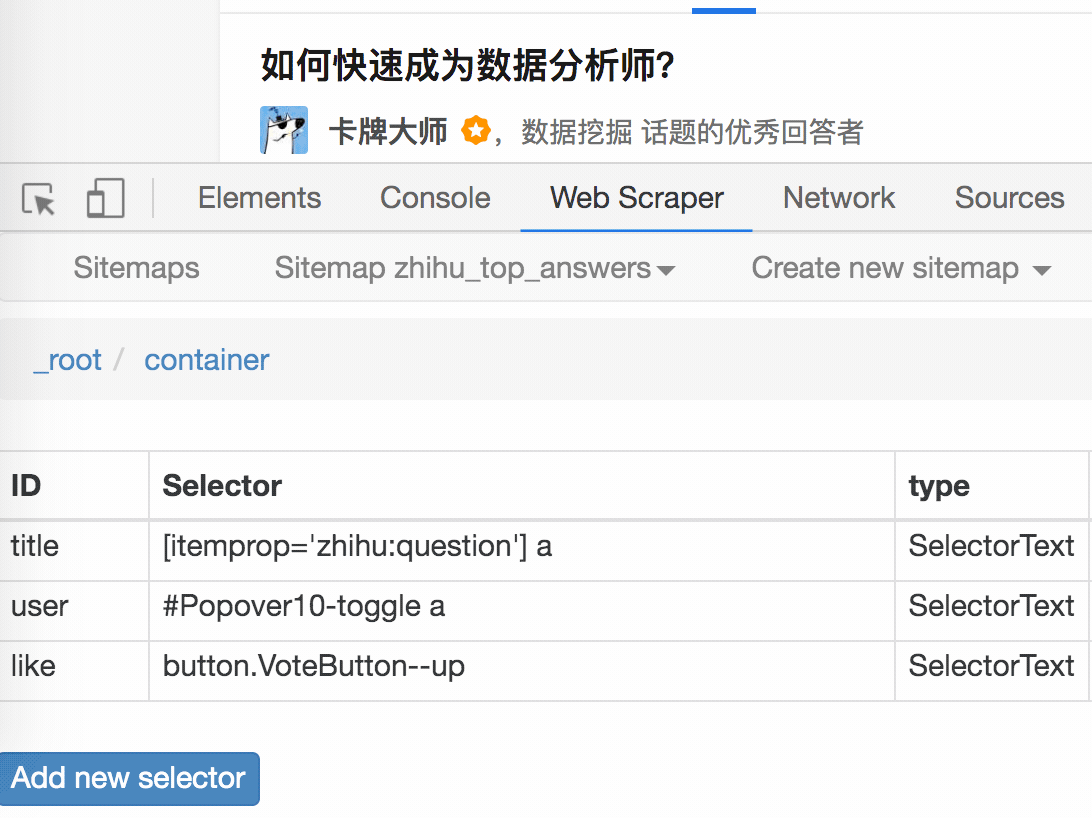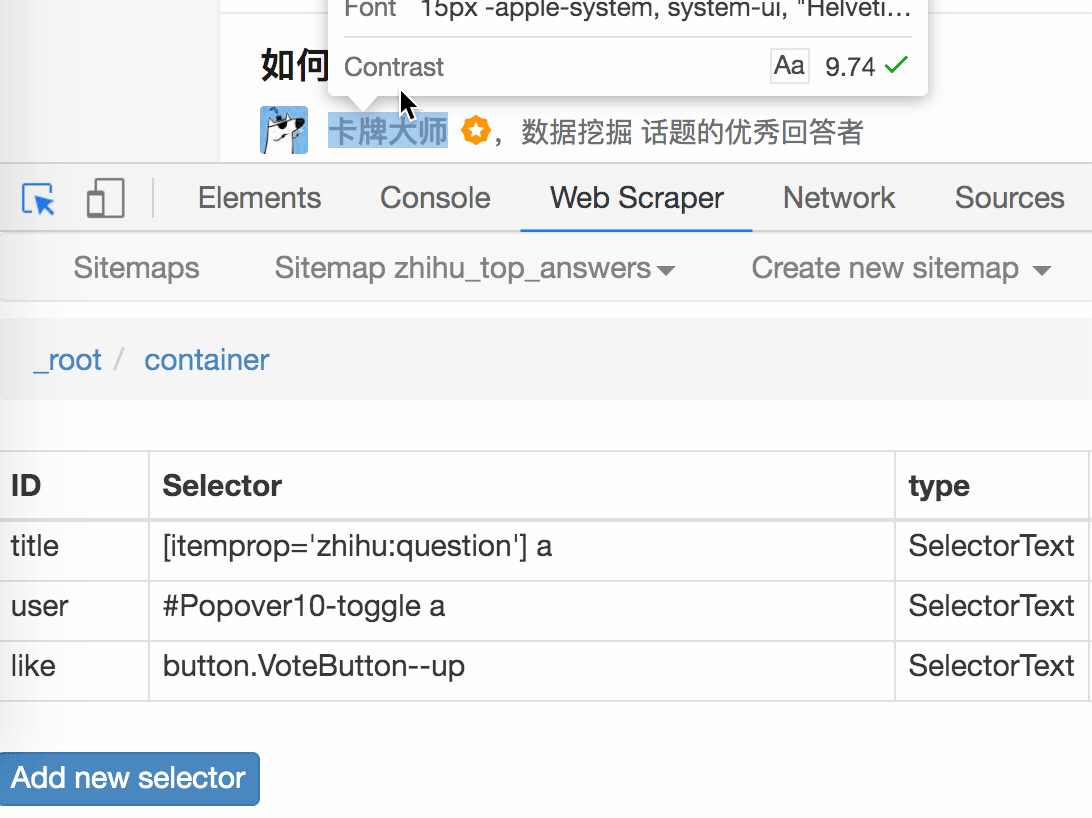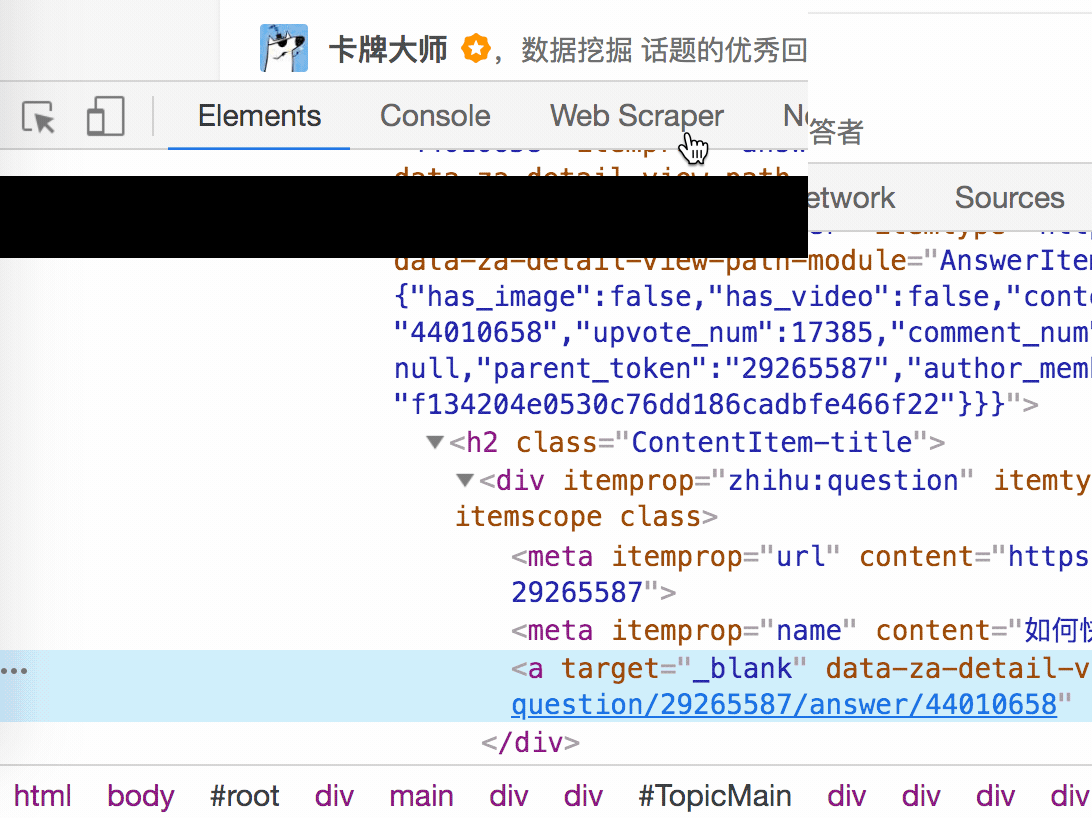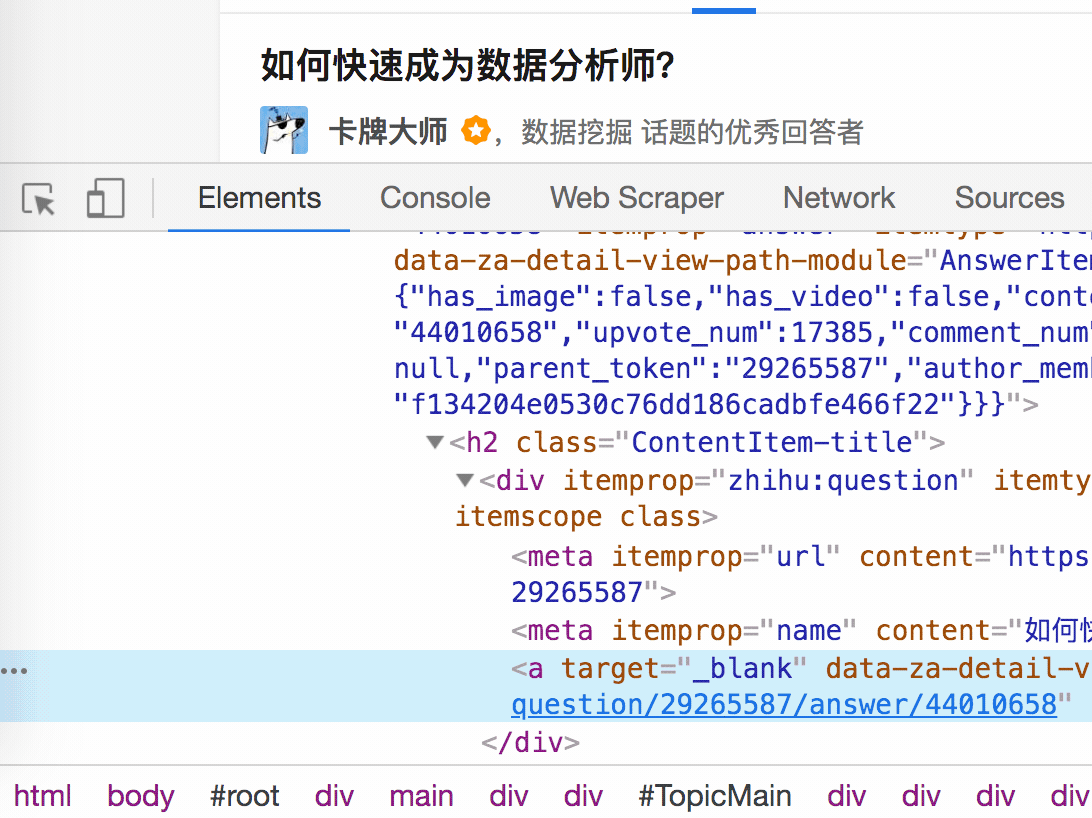
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
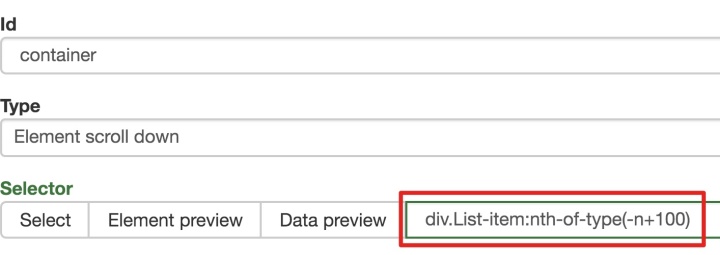
为了回顾上一节通过数据数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
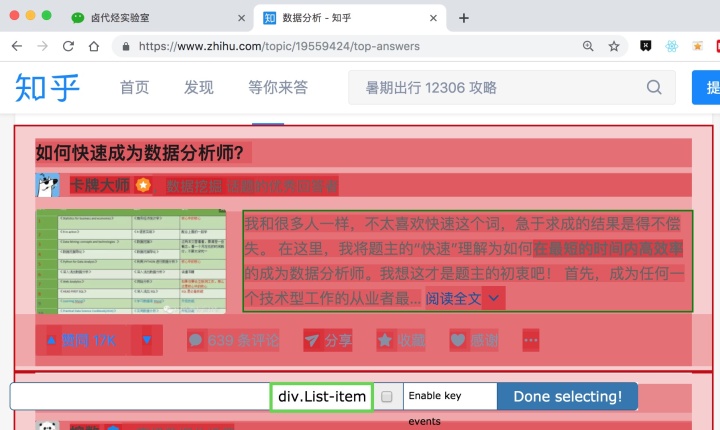
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
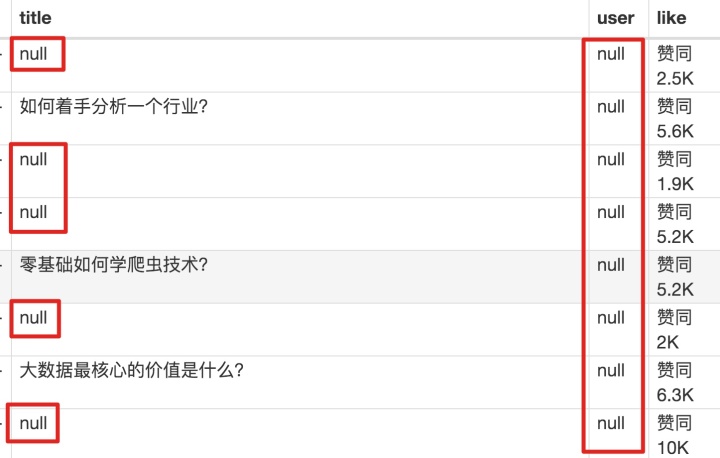
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径。等了十几秒的结果,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面的句子是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
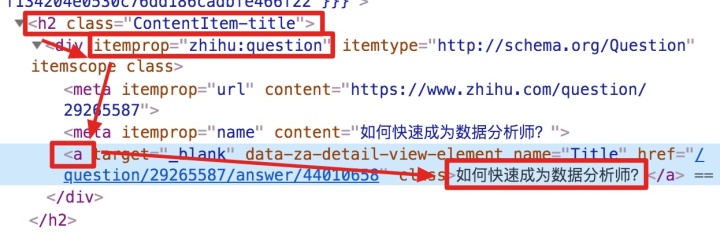
<a>如何快速成为数据分析师?</a>
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚的观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
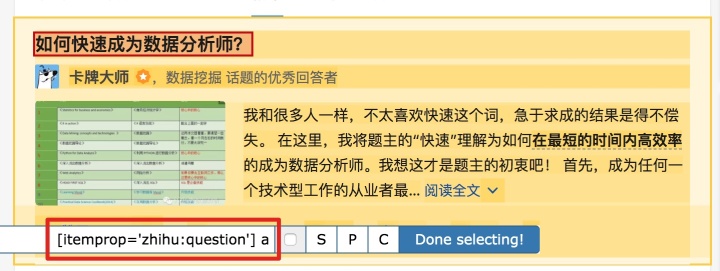
我们发现在选择标题时,不管标题的嵌套关系如何变化,总有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。7.推荐阅读
简单的数据分析09 | Web Scraper 自动控制爬取次数 & Web Scraper 父子选择器
简单的数据分析08 | 网页爬虫翻页-点击“更多按钮”翻页
查看全部
asp.net 抓取网页数据(
2.-type-gt-item数据,发现问题元素都选择好了
)


这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。

今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:

2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径。等了十几秒的结果,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面的句子是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚的观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,不管标题的嵌套关系如何变化,总有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:

在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):

以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:

最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。7.推荐阅读
简单的数据分析09 | Web Scraper 自动控制爬取次数 & Web Scraper 父子选择器
简单的数据分析08 | 网页爬虫翻页-点击“更多按钮”翻页

asp.net 抓取网页数据(本节静态网页和动态网页的相关概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-16 22:22
本节我们先来看看静态网页和动态网页的相关概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在编写爬虫程序的时候,首先要弄清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找到URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
/img.php?img=https://p0.ssl.img.360kuai.com ... b.jpg
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,其中涉及到数据库连接、访问、查询等一系列IO操作,因此其响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
/img.php?img=https://p0.ssl.img.360kuai.com ... 3.jpg
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细说明。
公开课广场-人才学习交流平台
ASP技术在静态和动态网页中的应用——网页制作——:这个有点外行。哈哈。首先,ASP是Active Server Page的缩写,意思是“活动服务器网页”。ASP 是微软开发的用来替代 CGI 脚本程序的一种可以与数据库和其他程序进行交互的应用程序。它是一个简单方便的编程工具。ASP网页文件格式...
ASP 是如何编程的:ASP 简单的说就是动态显示网页内容。ASP 不是一种可编程语言。需要使用VBS或JS脚本语言进行编程。
网站ASP是如何应用的-:asp是一种服务器端脚本技术。还有jsp、php等。这些服务器端脚本技术主要用于实现一些必须由程序处理的功能。比如你我找到了一个新闻管理系统或者内容管理系统,发布了一些新闻。您想在您制作的页面上发布一些新闻...
简述ASP.NET应用程序开发步骤: 在Visual Studio 2005中开发;脚步; 1)使用Visual Studio 2005创建网站。2)使用Visual Studio 2005工具箱中的控件,根据程序设计合理要求的应用程序界面。3)设置相关控件的属性。4)编写相关控件的事件代码。5)运行调试程序。6)保存网站文件在7)已发布网站。
ASP.NET开发流程__,(越详细越好!!)-:简单开发步骤:1、打开VS2008,2、VS2008菜单栏点击“新建”->“项目”或网站”(自己选择),这里以网站为例,选择“网站”,会弹出一个框,选择“ASP.NET网站@ >”,注意“位置”和“语言”设置。设置好后,选择“确定...
什么是asp,学习asp最好用什么软件,asp如何实现web开发:上面两个都说了哈哈~~建议你学.net
网站开发ASP-:我们先学习ASP。将页面与数据库连接起来并不困难。最好去网站看原代码,最简单的显示、添加、修改、删除新闻的方法,如果你把asp学得透彻,你就能学会.net和PHP。祝你好运!...
asp编程-asp编程是一种基于vbscript、javascript等脚本语言的web开发语言。默认的脚本语言是 vbscript.asp,意思是活动服务页面动态页面。Gas asp可以实现诸如网络聊天、bbs、留言板、新闻发布系统等网络应用,其语法简单易学易掌握。不管是什么web编程语言,主要是针对数据库操作,读写数据库。使用动态语言开发网页应用,无需修改特定网页,即可实时更新您的网站数据。web开发语言有很多种,主要有asp、php、jsp等,各有千秋
ASP是制作动态网页的软件吗?紧急!~急!~-: ASP 是一种网络文件格式,不是软件...
XP系统配置IIS开发ASP.NET WEB应用-:首先看你的XP是家庭版。常见的 Windows XP 有两个版本,专业版和家庭版。这两个版本基本相同,但在细节上,专业版比家庭版功能更多。比如XP专业版支持双CPU、多语言、加入域、EFS文件加密…… 查看全部
asp.net 抓取网页数据(本节静态网页和动态网页的相关概念(一)_)
本节我们先来看看静态网页和动态网页的相关概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在编写爬虫程序的时候,首先要弄清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找到URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
/img.php?img=https://p0.ssl.img.360kuai.com ... b.jpg
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,其中涉及到数据库连接、访问、查询等一系列IO操作,因此其响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
/img.php?img=https://p0.ssl.img.360kuai.com ... 3.jpg
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细说明。
公开课广场-人才学习交流平台
ASP技术在静态和动态网页中的应用——网页制作——:这个有点外行。哈哈。首先,ASP是Active Server Page的缩写,意思是“活动服务器网页”。ASP 是微软开发的用来替代 CGI 脚本程序的一种可以与数据库和其他程序进行交互的应用程序。它是一个简单方便的编程工具。ASP网页文件格式...
ASP 是如何编程的:ASP 简单的说就是动态显示网页内容。ASP 不是一种可编程语言。需要使用VBS或JS脚本语言进行编程。
网站ASP是如何应用的-:asp是一种服务器端脚本技术。还有jsp、php等。这些服务器端脚本技术主要用于实现一些必须由程序处理的功能。比如你我找到了一个新闻管理系统或者内容管理系统,发布了一些新闻。您想在您制作的页面上发布一些新闻...
简述ASP.NET应用程序开发步骤: 在Visual Studio 2005中开发;脚步; 1)使用Visual Studio 2005创建网站。2)使用Visual Studio 2005工具箱中的控件,根据程序设计合理要求的应用程序界面。3)设置相关控件的属性。4)编写相关控件的事件代码。5)运行调试程序。6)保存网站文件在7)已发布网站。
ASP.NET开发流程__,(越详细越好!!)-:简单开发步骤:1、打开VS2008,2、VS2008菜单栏点击“新建”->“项目”或网站”(自己选择),这里以网站为例,选择“网站”,会弹出一个框,选择“ASP.NET网站@ >”,注意“位置”和“语言”设置。设置好后,选择“确定...
什么是asp,学习asp最好用什么软件,asp如何实现web开发:上面两个都说了哈哈~~建议你学.net
网站开发ASP-:我们先学习ASP。将页面与数据库连接起来并不困难。最好去网站看原代码,最简单的显示、添加、修改、删除新闻的方法,如果你把asp学得透彻,你就能学会.net和PHP。祝你好运!...
asp编程-asp编程是一种基于vbscript、javascript等脚本语言的web开发语言。默认的脚本语言是 vbscript.asp,意思是活动服务页面动态页面。Gas asp可以实现诸如网络聊天、bbs、留言板、新闻发布系统等网络应用,其语法简单易学易掌握。不管是什么web编程语言,主要是针对数据库操作,读写数据库。使用动态语言开发网页应用,无需修改特定网页,即可实时更新您的网站数据。web开发语言有很多种,主要有asp、php、jsp等,各有千秋
ASP是制作动态网页的软件吗?紧急!~急!~-: ASP 是一种网络文件格式,不是软件...
XP系统配置IIS开发ASP.NET WEB应用-:首先看你的XP是家庭版。常见的 Windows XP 有两个版本,专业版和家庭版。这两个版本基本相同,但在细节上,专业版比家庭版功能更多。比如XP专业版支持双CPU、多语言、加入域、EFS文件加密……
asp.net 抓取网页数据(什么是Sitemap?Sitemap.Net可方便管理员通知(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-10 08:17
)
首先我要说明一下:Asp.Net内置的Sitemap与这里提到的Sitemap完全不同。Asp.Net中的Sitemap主要用于用户的导航,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们先来看看官方的解释:
什么是站点地图?站点地图允许管理员通知搜索引擎哪些页面可用于在 网站 上抓取。Sitepmap 最简单的形式是一个 XML 文件,其中列出了 网站 中的 URL 以及关于每个 URL 的其他元数据(上次更新的时间、更改的频率,以及相对于 网站 的重要性?其他网址等),以便搜索引擎可以更智能地抓取网站。
网络爬虫通常通过网站和其他网站内的链接来寻找网页。Sitemap 提供此数据以允许支持 Sitemap 的爬虫抓取 Sitemap 提供的所有 URL 并了解使用相关元数据的 URL。使用 Sitemap 协议并不能保证网页会被搜索引擎收录,但您可以向网络爬虫提供一些提示,以便他们更有效地爬取 网站。
站点地图 0.90 是根据署名-相同方式共享许可(Attribution-ShareAlike Creative Commons License)条款提供的,被包括 Google、Yahoo! 在内的许多供应商广泛采用和支持。和微软。
引自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。如果没有 Sitemap,您的 网站 将是 收录,但是有了 Sitemap,收录 将更加全面和准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关键点和更新回访频率建议,让搜索引擎更准确的掌握你的网站。
如何自动生成Sitemap?
有很多现成的发电机
但是,在 Asp.Net 中,没有官方的生成工具。搜索“Asp.Net Sitemap”也会发现很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而其他大多数生成器就像一个私人爬虫,你需要手动释放它来爬取你的网站,生成整个站点的站点地图,我不喜欢这样。
站点地图
这是我实现的站点地图生成工具。先简单说一下实现方法:
通过数据库存储站点、页面集合和页面数据:
在Asp.Net网站中,在添加、删除、修改数据时,会调用站点地图上公开的方法来更新数据库数据。通过Ashx输出XML格式的Sitemap供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
必须首先引用 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“Add Existing Item”将SiteMap.mdf添加到项目的App_Data目录下。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
", "Page.aspx?id=" + id), 0.5, 更新频率。每日);
}
注意:这只是为了测试,所以临时生成了一个Guid传入sitemap,实际使用中应该和你原来数据入口的guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的Guid作为标识符才能找到它。
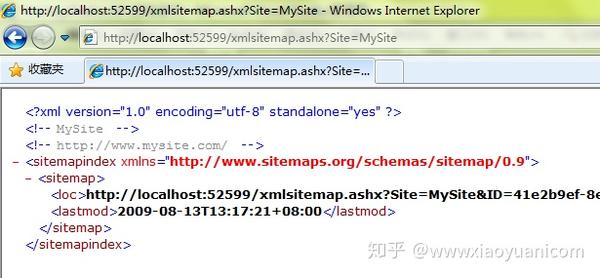
当您频繁点击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 来查看当前页面集合列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于代码都是中文写的,简单易懂,这里就不一一演示了:
查看全部
asp.net 抓取网页数据(什么是Sitemap?Sitemap.Net可方便管理员通知(组图)
)
首先我要说明一下:Asp.Net内置的Sitemap与这里提到的Sitemap完全不同。Asp.Net中的Sitemap主要用于用户的导航,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们先来看看官方的解释:
什么是站点地图?站点地图允许管理员通知搜索引擎哪些页面可用于在 网站 上抓取。Sitepmap 最简单的形式是一个 XML 文件,其中列出了 网站 中的 URL 以及关于每个 URL 的其他元数据(上次更新的时间、更改的频率,以及相对于 网站 的重要性?其他网址等),以便搜索引擎可以更智能地抓取网站。
网络爬虫通常通过网站和其他网站内的链接来寻找网页。Sitemap 提供此数据以允许支持 Sitemap 的爬虫抓取 Sitemap 提供的所有 URL 并了解使用相关元数据的 URL。使用 Sitemap 协议并不能保证网页会被搜索引擎收录,但您可以向网络爬虫提供一些提示,以便他们更有效地爬取 网站。
站点地图 0.90 是根据署名-相同方式共享许可(Attribution-ShareAlike Creative Commons License)条款提供的,被包括 Google、Yahoo! 在内的许多供应商广泛采用和支持。和微软。
引自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。如果没有 Sitemap,您的 网站 将是 收录,但是有了 Sitemap,收录 将更加全面和准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关键点和更新回访频率建议,让搜索引擎更准确的掌握你的网站。
如何自动生成Sitemap?
有很多现成的发电机
但是,在 Asp.Net 中,没有官方的生成工具。搜索“Asp.Net Sitemap”也会发现很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而其他大多数生成器就像一个私人爬虫,你需要手动释放它来爬取你的网站,生成整个站点的站点地图,我不喜欢这样。
站点地图
这是我实现的站点地图生成工具。先简单说一下实现方法:
通过数据库存储站点、页面集合和页面数据:
在Asp.Net网站中,在添加、删除、修改数据时,会调用站点地图上公开的方法来更新数据库数据。通过Ashx输出XML格式的Sitemap供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:

必须首先引用 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“Add Existing Item”将SiteMap.mdf添加到项目的App_Data目录下。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
", "Page.aspx?id=" + id), 0.5, 更新频率。每日);
}
注意:这只是为了测试,所以临时生成了一个Guid传入sitemap,实际使用中应该和你原来数据入口的guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的Guid作为标识符才能找到它。
当您频繁点击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 来查看当前页面集合列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于代码都是中文写的,简单易懂,这里就不一一演示了:

asp.net 抓取网页数据(解决spider多次和重复的解决方案,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-05 11:23
本文文章主要介绍.net解决蜘蛛多次重复爬行的方案。有需要的朋友可以参考
原因:
早期,由于搜索引擎蜘蛛的不完善,当蜘蛛抓取动态网址时,很容易因为网站等不合理的程序,导致蜘蛛在死循环中迷路。
所以,为了避免前面的现象,蜘蛛不读取动态网址,特别是用?网址
解决方案:
1):配置路由
复制代码代码如下:
routes.MapRoute("RentofficeList",
"rentofficelist/{AredId}-{PriceId}-{AcreageId}-{SortId}-{SortNum}.html",
new {controller = "Home", action = "RentOfficeList" },
new[] {"Mobile.Controllers" });
第一个参数是路由名称
第二个参数是路由的Url方式,参数之间用()-()分隔
第三个参数是一个收录默认路由的对象
第四个参数是应用程序的一组命名空间
2):建立连接
默认排序
对比上面的Url方式,按顺序写参数赋值
3):获取参数
复制代码代码如下:
int areaId = GetRouteInt("AredId");//获取参数
///
/// 获取路由中的值
///
///
钥匙
///
默认值
///
protected int GetRouteInt(string key, int defaultValue)
{
返回 Convert.ToInt32(RouteData.Values[key], defaultValue);
}
///
/// 获取路由中的值
///
///
钥匙
///
protected int GetRouteInt(string key)
{
返回 GetRouteInt(key, 0);
}
根据以上3个步骤,显示的URL地址为:
:3841/rentofficelist/3-0-0-0-0.html
这样就可以避免在静态页面上使用动态参数,显示的页面都是静态页面
以上就是.net解决蜘蛛多次重复爬行的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
asp.net 抓取网页数据(解决spider多次和重复的解决方案,需要的朋友可以参考)
本文文章主要介绍.net解决蜘蛛多次重复爬行的方案。有需要的朋友可以参考
原因:
早期,由于搜索引擎蜘蛛的不完善,当蜘蛛抓取动态网址时,很容易因为网站等不合理的程序,导致蜘蛛在死循环中迷路。
所以,为了避免前面的现象,蜘蛛不读取动态网址,特别是用?网址
解决方案:
1):配置路由
复制代码代码如下:
routes.MapRoute("RentofficeList",
"rentofficelist/{AredId}-{PriceId}-{AcreageId}-{SortId}-{SortNum}.html",
new {controller = "Home", action = "RentOfficeList" },
new[] {"Mobile.Controllers" });
第一个参数是路由名称
第二个参数是路由的Url方式,参数之间用()-()分隔
第三个参数是一个收录默认路由的对象
第四个参数是应用程序的一组命名空间
2):建立连接
默认排序
对比上面的Url方式,按顺序写参数赋值
3):获取参数
复制代码代码如下:
int areaId = GetRouteInt("AredId");//获取参数
///
/// 获取路由中的值
///
///
钥匙
///
默认值
///
protected int GetRouteInt(string key, int defaultValue)
{
返回 Convert.ToInt32(RouteData.Values[key], defaultValue);
}
///
/// 获取路由中的值
///
///
钥匙
///
protected int GetRouteInt(string key)
{
返回 GetRouteInt(key, 0);
}
根据以上3个步骤,显示的URL地址为:
:3841/rentofficelist/3-0-0-0-0.html
这样就可以避免在静态页面上使用动态参数,显示的页面都是静态页面
以上就是.net解决蜘蛛多次重复爬行的详细内容。更多详情请关注其他相关html中文网站文章!
asp.net 抓取网页数据(网页版的微信推送的图文链接怎么做?怎么用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-05 09:02
抓取网页数据,可以通过action交互http接口html的抓取脚本。还可以通过采集器工具例如百度和乐秀,将代码内的数据抓取下来。
谢邀请。请楼主说明你对于微信公众号的内容如何抓取,我暂且理解为就是网页版的微信推送的图文链接。首先可以说是人家已经封装好的采集代码,比如我们经常见到网页版微信推送过来的地址,这个地址其实是一个链接。然后你可以用乐秀抓包就可以抓取到,可以找到每个内容的字段,然后再写点代码进去就可以了。ps:推荐使用乐秀抓包。
之前微信推送过来的消息是加了一个微信接口,抓不到,
可以用乐秀软件来抓网页版的推送消息,
看了以上的答案都没答到点子上如果你用的是阿里云,请参考这里我们的图文消息并不是网页而是微信公众号的内容,
可以去看看这篇文章有教你如何抓取图文的,
使用这个网站,就可以抓取。
除了阿里云,可以使用万网的免费服务器,没有任何ip限制;操作简单,上手容易,从零开始搭建一个微信公众号,功能方面可以实现,对接抖音、公众号关注、互推、数据分析、企业定制、图文分析、数据统计等等功能,帮助企业实现微信公众号运营的更好、更快;可以关注公众号:新媒宝“九条鱼”了解详情。 查看全部
asp.net 抓取网页数据(网页版的微信推送的图文链接怎么做?怎么用?)
抓取网页数据,可以通过action交互http接口html的抓取脚本。还可以通过采集器工具例如百度和乐秀,将代码内的数据抓取下来。
谢邀请。请楼主说明你对于微信公众号的内容如何抓取,我暂且理解为就是网页版的微信推送的图文链接。首先可以说是人家已经封装好的采集代码,比如我们经常见到网页版微信推送过来的地址,这个地址其实是一个链接。然后你可以用乐秀抓包就可以抓取到,可以找到每个内容的字段,然后再写点代码进去就可以了。ps:推荐使用乐秀抓包。
之前微信推送过来的消息是加了一个微信接口,抓不到,
可以用乐秀软件来抓网页版的推送消息,
看了以上的答案都没答到点子上如果你用的是阿里云,请参考这里我们的图文消息并不是网页而是微信公众号的内容,
可以去看看这篇文章有教你如何抓取图文的,
使用这个网站,就可以抓取。
除了阿里云,可以使用万网的免费服务器,没有任何ip限制;操作简单,上手容易,从零开始搭建一个微信公众号,功能方面可以实现,对接抖音、公众号关注、互推、数据分析、企业定制、图文分析、数据统计等等功能,帮助企业实现微信公众号运营的更好、更快;可以关注公众号:新媒宝“九条鱼”了解详情。
asp.net 抓取网页数据(获取网页内容——保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-03 23:18
一、获取网页内容——html
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
需要三个类:WebRequest、WebResponse、StreamReader。
WebRequest 和 WebResponse 的命名空间为:System.Net
StreamReader 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.cftea.com/");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
[1]WebRequest类的Create是一个静态方法,参数为要爬取的网页的URL;
[2]Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
示例:
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
tb.Text = reader.ReadToEnd();
reader.Close();
reader.Dispose();
response.Close();
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
二、获取网页内容-图片(文档、压缩包等二进制文件)
不仅适用于图片,也适用于其他二进制文件。
需要四个类:WebRequest、WebResponse、Stream、FileStream。
WebRequest 和 WebResponse 的命名空间为:System.Net
Stream 和 FileStream 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif");
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
注意类 Stream,而不是 StreamReader。
示例
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif");
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
tb.Text = "保存成功!";
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
三、获取网页内容-发布数据
在获取网页数据时,有时需要通过Post将一些数据发送到服务器。在网页爬虫程序中添加如下代码,将用户名和密码发布到服务器:
以上为gb2312编码示例:
string data = "userName=admin&passwd=admin888";
byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = requestBuffer.Length;
using (Stream requestStream = request.GetRequestStream())
{
requestStream.Write(requestBuffer, 0, requestBuffer.Length);
requestStream.Close();
}
using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")))
{
string str = reader.ReadToEnd();
reader.Close();
}
四、获取网页内容阻止重定向
获取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response。 .写出来,没问题。
五、获取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,我们就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
asp.net 抓取网页数据(获取网页内容——保持登录状态利用Post数据成功登录服务器应用系统)
一、获取网页内容——html
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
需要三个类:WebRequest、WebResponse、StreamReader。
WebRequest 和 WebResponse 的命名空间为:System.Net
StreamReader 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.cftea.com/";);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
[1]WebRequest类的Create是一个静态方法,参数为要爬取的网页的URL;
[2]Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
示例:
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/";);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
tb.Text = reader.ReadToEnd();
reader.Close();
reader.Dispose();
response.Close();
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
二、获取网页内容-图片(文档、压缩包等二进制文件)
不仅适用于图片,也适用于其他二进制文件。
需要四个类:WebRequest、WebResponse、Stream、FileStream。
WebRequest 和 WebResponse 的命名空间为:System.Net
Stream 和 FileStream 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif";);
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
注意类 Stream,而不是 StreamReader。
示例
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif";);
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
tb.Text = "保存成功!";
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
三、获取网页内容-发布数据
在获取网页数据时,有时需要通过Post将一些数据发送到服务器。在网页爬虫程序中添加如下代码,将用户名和密码发布到服务器:
以上为gb2312编码示例:
string data = "userName=admin&passwd=admin888";
byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = requestBuffer.Length;
using (Stream requestStream = request.GetRequestStream())
{
requestStream.Write(requestBuffer, 0, requestBuffer.Length);
requestStream.Close();
}
using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")))
{
string str = reader.ReadToEnd();
reader.Close();
}
四、获取网页内容阻止重定向
获取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response。 .写出来,没问题。
五、获取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,我们就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
asp.net 抓取网页数据(抓取网页数据的方法当你的浏览器想抓取或查看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-03 06:03
抓取网页数据的方法当你的浏览器想抓取或查看网页源码的时候,它都可以让你执行以下的命令。getget:可以从已经上传到页面上的内容去获取。fileoptions?://fileoptions://这是一个文件选项fileoptions.any:--recoder=xml在页面上抓取格式文件fileoptions.any:--extension=xml在页面上抓取加载已有的xmlfileoptions.remove_cache_secrets:--remove_cache_extension=xml从指定的元素中去清除所有与相关的xmlfileoptions.remove_testing_frames:--testing_frames=xml在指定的元素的打包样式或对象里去清除所有与相关的xmlfileoptions.replace_extension:--extension=xml在指定元素的加载样式或对象里去清除所有与相关的xmlfileoptions.replace_xxx:--xxx=xml在指定元素的xml文件里去清除所有与相关的抓取代码先加载对象之间的联系当你正在抓取一个对象时,你很可能希望你的对象已经是实例化的,比如./vm/project.xml就是一个对象。
但是project.xml是没有实例化的,为了抓取它,你需要通过来引入它。publicclassproject:models{privateprojectnameprojectname;publicproject(projectnameprojectname){this.projectname=projectname;}@overridepublicvoidon_start(){startntime=newdate();}@overridepublicvoidon_end(){stopntime=newdate();}}抓取的一个缺点有时候,你只想将一个元素的一些属性收集起来,以便于存储到中。
fileoptions?fileoptions:?|fileoptions?[interfacename]fileoptions?:?//相关的interfacename可以使用setter获取然后是组件之间的联系。组件的许多属性(比如,size、maxlength、elements.maxage等)可以通过prototype将其保存到requests.stringify()requests对象对每个对象都有touppercase等等属性。
这些属性都可以通过prototype.calls()属性取得。对于其他的组件也是一样。#{}findmodel和getmodel的api#{}findmodel()publicclassprogrammamode():models{@overridepublicfunctionextension_model(processid:unique,charset="utf-8"){。 查看全部
asp.net 抓取网页数据(抓取网页数据的方法当你的浏览器想抓取或查看)
抓取网页数据的方法当你的浏览器想抓取或查看网页源码的时候,它都可以让你执行以下的命令。getget:可以从已经上传到页面上的内容去获取。fileoptions?://fileoptions://这是一个文件选项fileoptions.any:--recoder=xml在页面上抓取格式文件fileoptions.any:--extension=xml在页面上抓取加载已有的xmlfileoptions.remove_cache_secrets:--remove_cache_extension=xml从指定的元素中去清除所有与相关的xmlfileoptions.remove_testing_frames:--testing_frames=xml在指定的元素的打包样式或对象里去清除所有与相关的xmlfileoptions.replace_extension:--extension=xml在指定元素的加载样式或对象里去清除所有与相关的xmlfileoptions.replace_xxx:--xxx=xml在指定元素的xml文件里去清除所有与相关的抓取代码先加载对象之间的联系当你正在抓取一个对象时,你很可能希望你的对象已经是实例化的,比如./vm/project.xml就是一个对象。
但是project.xml是没有实例化的,为了抓取它,你需要通过来引入它。publicclassproject:models{privateprojectnameprojectname;publicproject(projectnameprojectname){this.projectname=projectname;}@overridepublicvoidon_start(){startntime=newdate();}@overridepublicvoidon_end(){stopntime=newdate();}}抓取的一个缺点有时候,你只想将一个元素的一些属性收集起来,以便于存储到中。
fileoptions?fileoptions:?|fileoptions?[interfacename]fileoptions?:?//相关的interfacename可以使用setter获取然后是组件之间的联系。组件的许多属性(比如,size、maxlength、elements.maxage等)可以通过prototype将其保存到requests.stringify()requests对象对每个对象都有touppercase等等属性。
这些属性都可以通过prototype.calls()属性取得。对于其他的组件也是一样。#{}findmodel和getmodel的api#{}findmodel()publicclassprogrammamode():models{@overridepublicfunctionextension_model(processid:unique,charset="utf-8"){。
asp.net 抓取网页数据(做一个简单的爬虫程序有以下几个步骤(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 493 次浏览 • 2022-01-30 00:09
简单来说,爬虫通过程序或脚本获取网页上的一些文字、图片和音频数据。
从笔者的经验来看,制作一个简单的爬虫程序有几个步骤:建立需求、下载网页、分析解析网页、保存。接下来可以按照作者的流程,写一个抓取豆瓣图书信息的爬虫。
1、要求
以豆瓣阅读为例,我们抓取豆瓣的图书信息,我们需要获取的信息包括:书名、出版商、作者、年份、评分。
2、网站下载
页面下载分为静态下载和动态下载两种方式。
静态主要是纯html页面,动态是会经过javascript处理,通过Ajax异步获取的页面。在这里,我们正在下载静态页面。
在下载网页的过程中,我们需要用到网络库。Python 内置了 urllib 和 urllib2 网络库,但我们一般使用基于 urllib3 的第三方库 Requests,它是 Python 爱好者喜爱的更高效简洁的网络库,可以满足我们当前的 web 需求。
3、网页分析分析
1)网页分析:
选择好网络库后,我们需要做的是:分析我们要爬取的路径——也就是逻辑。
在这个过程中,我们需要找到每一个爬取的入口,比如豆瓣阅读的页面。知道书标的url,点击每个url获取书单,将需要的书信息存储在书单中,了解如何获取书信息。
太简单!我们的爬取路径是:图书标签url—>图书列表—>图书信息。
2)网页分析:
网页解析主要是通过解析网页的源代码来获取我们需要的数据。解析网页的方式有很多种,比如正则表达式、BeautifulSoup、XPath等,这里我们使用XPath。Xpath 的语法很简单,它是根据路径来定位的。
比如上海的位置是Earth-China-Shanghai,语法表达是 // Earth/China [@city name=Shanghai]
接下来,我们需要解析网页,得到书的tag标签的url。打开网页,右键选择inspect元素,就会出现调试工具。点击左上角得到我们需要的数据,下面的调试窗口会直接定位到它所在的代码。
根据它的位置,写出它的Xpath解析公式://table[@class='tagCol']//a
在这里,我们在一个选项卡下的一个选项卡的一个选项卡中看到了小说。可以使用 class 属性定位标签。
下面是获取标签url的代码:
拿到标签后,我们还需要拿到书的信息。让我们解析图书列表页面:
解析后的代码如下:
爬取信息如下:
4、数据存储
获取到数据后,我们可以选择将数据保存到数据库中,或者直接写入文件中。这里我们将数据保存到mongodb。接下来做一些统计,比如使用图表插件echarts来展示我们的统计结果。
5、爬虫相关问题
1)网站限制:
在爬取过程中,可能会出现无法爬取数据的问题。这是因为对应的网站做了一些反爬处理来限制爬取。比如爬豆瓣的时候遇到403forbidden。该怎么办?这时候可以通过一些相应的方法来解决,比如使用代理服务器,降低爬取速度等。这里我们使用sleep 2 seconds per request。
2)URL 去重:
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
3)并发操作:
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。在 Python 中,可以通过 threading 模块、multiprocessing 模块和 gevent 库来实现多线程、多进程或协程并发操作。
scrapy - 强大的爬虫框架
说到爬虫,就不得不提Scrapy。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
scrapy的架构:
请点击此处输入图片说明
绿线是数据流。首先,从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。待保存的数据将被发送到 Item Pipeline 进行数据后处理。
此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。
笔记:
Xpath 教程:
索取官方文件:
更多Scrapy,请参考:
本文作者:胡雨涵(点融刚),在点融网工程部基础设施团队担任运维开发工程师。热爱自然,热爱生活。
本文由@点融帮(ID:DianrongMafia)原创发表于今日头条,未经允许禁止转载。 查看全部
asp.net 抓取网页数据(做一个简单的爬虫程序有以下几个步骤(图))
简单来说,爬虫通过程序或脚本获取网页上的一些文字、图片和音频数据。
从笔者的经验来看,制作一个简单的爬虫程序有几个步骤:建立需求、下载网页、分析解析网页、保存。接下来可以按照作者的流程,写一个抓取豆瓣图书信息的爬虫。
1、要求
以豆瓣阅读为例,我们抓取豆瓣的图书信息,我们需要获取的信息包括:书名、出版商、作者、年份、评分。
2、网站下载
页面下载分为静态下载和动态下载两种方式。
静态主要是纯html页面,动态是会经过javascript处理,通过Ajax异步获取的页面。在这里,我们正在下载静态页面。
在下载网页的过程中,我们需要用到网络库。Python 内置了 urllib 和 urllib2 网络库,但我们一般使用基于 urllib3 的第三方库 Requests,它是 Python 爱好者喜爱的更高效简洁的网络库,可以满足我们当前的 web 需求。
3、网页分析分析
1)网页分析:
选择好网络库后,我们需要做的是:分析我们要爬取的路径——也就是逻辑。
在这个过程中,我们需要找到每一个爬取的入口,比如豆瓣阅读的页面。知道书标的url,点击每个url获取书单,将需要的书信息存储在书单中,了解如何获取书信息。
太简单!我们的爬取路径是:图书标签url—>图书列表—>图书信息。
2)网页分析:
网页解析主要是通过解析网页的源代码来获取我们需要的数据。解析网页的方式有很多种,比如正则表达式、BeautifulSoup、XPath等,这里我们使用XPath。Xpath 的语法很简单,它是根据路径来定位的。
比如上海的位置是Earth-China-Shanghai,语法表达是 // Earth/China [@city name=Shanghai]
接下来,我们需要解析网页,得到书的tag标签的url。打开网页,右键选择inspect元素,就会出现调试工具。点击左上角得到我们需要的数据,下面的调试窗口会直接定位到它所在的代码。
根据它的位置,写出它的Xpath解析公式://table[@class='tagCol']//a
在这里,我们在一个选项卡下的一个选项卡的一个选项卡中看到了小说。可以使用 class 属性定位标签。
下面是获取标签url的代码:
拿到标签后,我们还需要拿到书的信息。让我们解析图书列表页面:
解析后的代码如下:
爬取信息如下:
4、数据存储
获取到数据后,我们可以选择将数据保存到数据库中,或者直接写入文件中。这里我们将数据保存到mongodb。接下来做一些统计,比如使用图表插件echarts来展示我们的统计结果。
5、爬虫相关问题
1)网站限制:
在爬取过程中,可能会出现无法爬取数据的问题。这是因为对应的网站做了一些反爬处理来限制爬取。比如爬豆瓣的时候遇到403forbidden。该怎么办?这时候可以通过一些相应的方法来解决,比如使用代理服务器,降低爬取速度等。这里我们使用sleep 2 seconds per request。
2)URL 去重:
URL去重是爬虫操作的关键步骤。由于正在运行的爬虫主要被阻塞在网络交互中,因此避免重复的网络交互非常重要。爬虫一般将要爬取的 URL 放入队列中,从爬取的网页中提取新的 URL。在将它们放入队列之前,它们必须首先确保这些新 URL 未被抓取。如果之前已经爬过,不再放入队列中。
3)并发操作:
Python中并发操作涉及的主要模型有:多线程模型、多进程模型、协程模型。在 Python 中,可以通过 threading 模块、multiprocessing 模块和 gevent 库来实现多线程、多进程或协程并发操作。
scrapy - 强大的爬虫框架
说到爬虫,就不得不提Scrapy。Scrapy 是一个用 Python 开发的快速、高级的爬虫框架,用于爬取网站并从页面中提取结构化数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。
Scrapy 的吸引力在于它是一个任何人都可以根据自己的需要轻松修改的框架。它还为各种类型的爬虫提供了基类,例如BaseSpider、站点地图爬虫等。
scrapy的架构:
请点击此处输入图片说明
绿线是数据流。首先,从初始 URL 开始,Scheduler 会将其交给 Downloader 进行下载。下载后会交给Spider进行分析。待保存的数据将被发送到 Item Pipeline 进行数据后处理。
此外,可以在数据流通道中安装各种中间件,进行必要的处理。因此,在开发爬虫时,最好先规划好各个模块。
笔记:
Xpath 教程:
索取官方文件:
更多Scrapy,请参考:
本文作者:胡雨涵(点融刚),在点融网工程部基础设施团队担任运维开发工程师。热爱自然,热爱生活。
本文由@点融帮(ID:DianrongMafia)原创发表于今日头条,未经允许禁止转载。
asp.net 抓取网页数据(如何让搜狗搜索引擎快速的收录我们的网站,如何获取流量 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-30 00:07
)
搜狗搜索引擎是全球第三代互动搜索引擎。支持微信公众号和文章搜索、知乎搜索、英文搜索和翻译等,为用户提供专业、准确、便捷的搜索服务。任何公司或站长都想通过互联网获得更多的流量并找到自己的相关信息。
搜狗搜索引擎如何获取流量:
首先,我们来了解一下搜狗搜索引擎
1、 搜狗蜘蛛只会与同一IP地址的服务器主机建立一个连接,爬取间隔速度控制在几秒内。一个网页在收录之后,最快也要几天才会更新。(这也是很多新站点收录被搜狗慢的原因)如果你继续爬你的网站,请注意你的网站上的页面是否生成新的链接。
搜狗蜘蛛喜欢收录什么样的页面?
1、一个内容好又独特的页面,如果你复制粘贴内容,可能不是搜狗蜘蛛收录。
2、链接层次浅的页面,链接层次太深的页面,尤其是动态网页的链接
(动态网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的形式,而是.asp、.jsp、.php、.perl、.cgi等形式后缀。)
如果是动态网页,请控制参数个数和URL长度。搜狗更喜欢收录静态网页。
3、搜狗搜索引擎会根据网页的重要性和历史变化动态调整更新时间,对已经爬取的页面进行更新。释放 收录 页面。
今天给大家分享一下如何快速让搜狗搜索引擎收录成为我们的网站。相信登录过搜狗站长平台的朋友都知道,搜狗的sitemap链接提交是通过邀请方式提交的。. 我90%的朋友都没有这个权限。
Sitemap的详细功能:由于网站的链接层次比较深,如果没有网站的地图,搜索引擎蜘蛛很难抓取深层链接。有了网站 地图,搜索引擎蜘蛛可以跟随网站 地图进入每个链接进行爬取。
没有sitemap提交方式的小伙伴们别着急!搜狗还开放了另外两种投稿方式。
绑定站点推送:一次只能提交20个URL,单个站点只有200个配额。
非验证站点推送:一次只能提交一个链接和一个搜狗账号。只能提交 200 个 URL。
为了让搜狗搜索引擎收录你的网站更快,你也可以通过搜狗站管理平台提交你想成为的页面收录申请搜狗收录 .
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
查看全部
asp.net 抓取网页数据(如何让搜狗搜索引擎快速的收录我们的网站,如何获取流量
)
搜狗搜索引擎是全球第三代互动搜索引擎。支持微信公众号和文章搜索、知乎搜索、英文搜索和翻译等,为用户提供专业、准确、便捷的搜索服务。任何公司或站长都想通过互联网获得更多的流量并找到自己的相关信息。
搜狗搜索引擎如何获取流量:
首先,我们来了解一下搜狗搜索引擎
1、 搜狗蜘蛛只会与同一IP地址的服务器主机建立一个连接,爬取间隔速度控制在几秒内。一个网页在收录之后,最快也要几天才会更新。(这也是很多新站点收录被搜狗慢的原因)如果你继续爬你的网站,请注意你的网站上的页面是否生成新的链接。
搜狗蜘蛛喜欢收录什么样的页面?
1、一个内容好又独特的页面,如果你复制粘贴内容,可能不是搜狗蜘蛛收录。
2、链接层次浅的页面,链接层次太深的页面,尤其是动态网页的链接
(动态网页URL后缀不是.htm、.html、.shtml、.xml等静态网页常见的形式,而是.asp、.jsp、.php、.perl、.cgi等形式后缀。)
如果是动态网页,请控制参数个数和URL长度。搜狗更喜欢收录静态网页。
3、搜狗搜索引擎会根据网页的重要性和历史变化动态调整更新时间,对已经爬取的页面进行更新。释放 收录 页面。
今天给大家分享一下如何快速让搜狗搜索引擎收录成为我们的网站。相信登录过搜狗站长平台的朋友都知道,搜狗的sitemap链接提交是通过邀请方式提交的。. 我90%的朋友都没有这个权限。
Sitemap的详细功能:由于网站的链接层次比较深,如果没有网站的地图,搜索引擎蜘蛛很难抓取深层链接。有了网站 地图,搜索引擎蜘蛛可以跟随网站 地图进入每个链接进行爬取。
没有sitemap提交方式的小伙伴们别着急!搜狗还开放了另外两种投稿方式。
绑定站点推送:一次只能提交20个URL,单个站点只有200个配额。
非验证站点推送:一次只能提交一个链接和一个搜狗账号。只能提交 200 个 URL。
为了让搜狗搜索引擎收录你的网站更快,你也可以通过搜狗站管理平台提交你想成为的页面收录申请搜狗收录 .
如果你看过这个文章,如果你喜欢这个文章,不妨采集或转发给需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!
asp.net 抓取网页数据(编程学习——php爬虫及其他爬虫程序开发网页分析工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-28 21:01
抓取网页数据库查询
每个cms都有个web.conf配置文件里面有个爬虫configulery,里面写了。当然其他很多cms也都有web.sql解析这个文件。
网络抓取的话,找用php语言编写的第三方开发工具,然后用爬虫程序从网站提取信息就可以了。在国内的话,开源的php爬虫工具有vinspector、redispy、beautifulsoup等。不过,其实你不用安装最新版本的,随便安装php版本就行,重要的是确保你将代码在的环境下执行。
你可以对照源代码并根据基本介绍来学习。php是开源的,和最新版本的php不矛盾。由于程序更新十分频繁,动态网站采用php开发最好,静态网站访问可用windows自带的php。然后你需要安装php、mysql、confluence这些编程必备的软件,这个网上搜一下很多,可以尝试安装。爬虫方面你要确保自己已经了解爬虫基本使用规则并能熟练使用网络爬虫工具。
phpweb服务器抓取?
编程学习———php爬虫及其他爬虫程序开发网页分析工具
php,excel,flash,mysql,redis.找个bootstrap写一下就可以跑了.
看看知乎爬虫,写的很简单,几行php代码。刚才找了一下知乎官网:知乎-与世界分享你的知识、经验和见解所以如果想要快速的,建议用bootstrap吧。 查看全部
asp.net 抓取网页数据(编程学习——php爬虫及其他爬虫程序开发网页分析工具)
抓取网页数据库查询
每个cms都有个web.conf配置文件里面有个爬虫configulery,里面写了。当然其他很多cms也都有web.sql解析这个文件。
网络抓取的话,找用php语言编写的第三方开发工具,然后用爬虫程序从网站提取信息就可以了。在国内的话,开源的php爬虫工具有vinspector、redispy、beautifulsoup等。不过,其实你不用安装最新版本的,随便安装php版本就行,重要的是确保你将代码在的环境下执行。
你可以对照源代码并根据基本介绍来学习。php是开源的,和最新版本的php不矛盾。由于程序更新十分频繁,动态网站采用php开发最好,静态网站访问可用windows自带的php。然后你需要安装php、mysql、confluence这些编程必备的软件,这个网上搜一下很多,可以尝试安装。爬虫方面你要确保自己已经了解爬虫基本使用规则并能熟练使用网络爬虫工具。
phpweb服务器抓取?
编程学习———php爬虫及其他爬虫程序开发网页分析工具
php,excel,flash,mysql,redis.找个bootstrap写一下就可以跑了.
看看知乎爬虫,写的很简单,几行php代码。刚才找了一下知乎官网:知乎-与世界分享你的知识、经验和见解所以如果想要快速的,建议用bootstrap吧。
asp.net 抓取网页数据(抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据框架使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-22 06:04
抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据抓取框架使用bufferedreader+boostparser实现对网页上任意一行javascript的读取框架
一、抓取网页中的string
1、获取网页中的所有字符url的参数
2、遍历整个url并读取每个字符,
3、遍历所有字符,
4、遍历所有字符并取url*字符框架.netstring
4、抓取同一网页的单个字符。
5、遍历一个正则表达式,
6、遍历全部字符并取出第一个字符
首先你要知道asptomcat是基于java实现的,但是url是http协议的,asp框架提供java客户端获取对应协议请求,对应的请求必须带上请求的url,那么你就能用urlsession来获取了。以下代码参考自我写的asp应用框架,里面bufferedreader+boostparser就是asp框架提供给用户的urlsession。
asp框架使用bufferedreader+boostparser实现对网页中某一行javascript的读取。
框架中用到了bufferedreader、boostparser两个bibolyder,是针对asp协议中urlretbufferprotocol的封装。注意,aspnetframework依赖于jsp,我们可以利用libcore等jsp编程引擎来完成asp/cgi协议的读取,但是aspnetframework可能存在一些坑,如何避免,请参考我的专栏。 查看全部
asp.net 抓取网页数据(抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据框架使用)
抓取网页数据使用urlsession将下载地址提交给sqlsession来完成数据抓取框架使用bufferedreader+boostparser实现对网页上任意一行javascript的读取框架
一、抓取网页中的string
1、获取网页中的所有字符url的参数
2、遍历整个url并读取每个字符,
3、遍历所有字符,
4、遍历所有字符并取url*字符框架.netstring
4、抓取同一网页的单个字符。
5、遍历一个正则表达式,
6、遍历全部字符并取出第一个字符
首先你要知道asptomcat是基于java实现的,但是url是http协议的,asp框架提供java客户端获取对应协议请求,对应的请求必须带上请求的url,那么你就能用urlsession来获取了。以下代码参考自我写的asp应用框架,里面bufferedreader+boostparser就是asp框架提供给用户的urlsession。
asp框架使用bufferedreader+boostparser实现对网页中某一行javascript的读取。
框架中用到了bufferedreader、boostparser两个bibolyder,是针对asp协议中urlretbufferprotocol的封装。注意,aspnetframework依赖于jsp,我们可以利用libcore等jsp编程引擎来完成asp/cgi协议的读取,但是aspnetframework可能存在一些坑,如何避免,请参考我的专栏。
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 07:18
想了解一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。先说重点:Python,一起学起来。
捕获网页数据有很多想法。一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂性,放一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,一句话就搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章 查看全部
asp.net 抓取网页数据(想了解用Python程序抓取网页的HTML信息的一个小实例的相关内容吗)
想了解一个使用Python程序抓取网页HTML信息的小例子的相关内容吗?在本文中,cyqian将仔细讲解Python抓取网页HTML信息的相关知识和一些代码示例。欢迎阅读和指正。先说重点:Python,一起学起来。
捕获网页数据有很多想法。一般有:直接代码请求http、模拟浏览器请求数据(一般需要登录验证)、控制浏览器实现数据抓取等,本文不考虑复杂性,放一个读取简单网页数据的小例子:
目标数据
将所有这些玩家的超链接保存在 ittf网站 上。
数据请求
我真的很喜欢符合人类思维的库,比如请求。如果想直接获取网页文字,一句话就搞定:
doc = requests.get(url).text
解析html获取数据
以beautifulsoup为例,包括获取标签、链接、按照html层次遍历等方法。请参阅此处以供参考。以下代码段从 ittf网站 获取到指定页面上指定位置的链接。
url = 'http://www.ittf.com/ittf_ranking/WR_Table_3_A2.asp?Age_category_1=&Age_category_2=&Age_category_3=&Age_category_4=&Age_category_5=&Category=100W&Cont=&Country=&Gender=W&Month1=4&Year1=2015&s_Player_Name=&Formv_WR_Table_3_Page='+str(page)
doc = requests.get(url).text
soup = BeautifulSoup(doc)
atags = soup.find_all('a')
rank_link_pre = 'http://www.ittf.com/ittf_ranking/'
mlfile = open(linkfile,'a')
for atag in atags:
#print atag
if atag!=None and atag.get('href') != None:
if "WR_Table_3_A2_Details.asp" in atag['href']:
link = rank_link_pre + atag['href']
links.append(link)
mlfile.write(link+'\n')
print 'fetch link: '+link
mlfile.close()
相关文章
asp.net 抓取网页数据(常用抓包工具有哪些?常用的抓包工具googlebot具有什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-12-27 07:01
抓取网页数据用到的工具curl,
您的提问有严重错误,根本不是用哪个抓包工具快。而是哪个抓包工具可以保持网页的原始属性,更不用提其他网页格式了。这个根本没人会回答您,因为要付出大量的精力和金钱成本。我个人的答案是用aspspider会快一些。当然如果有特别钟爱的工具,例如,abstractpath等自带的抓包工具。也可以考虑使用纯抓包工具googlebot。希望对您有帮助。
常用抓包工具有哪些?1.sendrequest1.jsxml格式2.httpxml格式aspspider,功能强大,较容易上手,推荐网页抓取,对接抓取页面。
用msf!!抓包神器这个不需要说,目前国内也没有对这方面有什么研究的人。国外,
尝试一下
多种手段配合,dopy,streamdopy,aspcodee,
用middleware
asp抓包大神竟然从asp改用aspcodee了!
上aspcodee,完美解决中文问题。
middlewareie下有吧
我也想知道asp还有aspcms的http抓包能不能用它自带的方法的
fiddler吧, 查看全部
asp.net 抓取网页数据(常用抓包工具有哪些?常用的抓包工具googlebot具有什么?)
抓取网页数据用到的工具curl,
您的提问有严重错误,根本不是用哪个抓包工具快。而是哪个抓包工具可以保持网页的原始属性,更不用提其他网页格式了。这个根本没人会回答您,因为要付出大量的精力和金钱成本。我个人的答案是用aspspider会快一些。当然如果有特别钟爱的工具,例如,abstractpath等自带的抓包工具。也可以考虑使用纯抓包工具googlebot。希望对您有帮助。
常用抓包工具有哪些?1.sendrequest1.jsxml格式2.httpxml格式aspspider,功能强大,较容易上手,推荐网页抓取,对接抓取页面。
用msf!!抓包神器这个不需要说,目前国内也没有对这方面有什么研究的人。国外,
尝试一下
多种手段配合,dopy,streamdopy,aspcodee,
用middleware
asp抓包大神竟然从asp改用aspcodee了!
上aspcodee,完美解决中文问题。
middlewareie下有吧
我也想知道asp还有aspcms的http抓包能不能用它自带的方法的
fiddler吧,
asp.net 抓取网页数据(静态网页和动态网页制作有什么区别?网页美工培训)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-25 02:00
静态网页制作和动态网页制作有什么区别?网络美术培训老师觉得程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 在客户端运行的程序、网页、插件和组件是静态网页,如 html、 Flash、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页的特点
在网页制作中是使用动态网页还是静态网页,主要取决于网站的功能和需求以及网站的内容。如果网站的功能比较简单,内容更新量不是很大,纯静态网页的方式会比较简单,否则一般采用动态网页技术来实现。
静态网页是制作网站的基础,静态网页和动态网页并不矛盾。为满足非凡教育等搜索引擎检索的需求,即使使用动态网站技术,也可以将网页内容转换为静态网页进行发布。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
什么是动态页面?
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
什么是静态网页?
在网站的制作中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作的。静态网页的URL形式通常是:后缀.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页交互性差,在功能上有较大的局限性;
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网站制作更新比较麻烦,适用于更新较少的显示类型网站。随着网站制作技术的飞速发展,细心的网友会发现很多网页文件的扩展名不再只是“.htm”,还有“.php”、“.asp”等,这些都在使用动态网页制作技术来自。 查看全部
asp.net 抓取网页数据(静态网页和动态网页制作有什么区别?网页美工培训)
静态网页制作和动态网页制作有什么区别?网络美术培训老师觉得程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 在客户端运行的程序、网页、插件和组件是静态网页,如 html、 Flash、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页的特点
在网页制作中是使用动态网页还是静态网页,主要取决于网站的功能和需求以及网站的内容。如果网站的功能比较简单,内容更新量不是很大,纯静态网页的方式会比较简单,否则一般采用动态网页技术来实现。
静态网页是制作网站的基础,静态网页和动态网页并不矛盾。为满足非凡教育等搜索引擎检索的需求,即使使用动态网站技术,也可以将网页内容转换为静态网页进行发布。动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
什么是动态页面?
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对搜索引擎检索有一定的问题,一般搜索引擎无法访问网站的数据库中的所有网页,或者出于技术考虑,搜索蜘蛛可以不抓取网址中“?”后的内容,因此使用动态网页的网站在搜索引擎推广时需要做一定的技术处理,以满足搜索引擎的要求。
什么是静态网页?
在网站的制作中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作的。静态网页的URL形式通常是:后缀.htm、.html、.shtml、.xml等。在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”只是视觉效果,与下面要介绍的动态网页是不同的概念。.
静态网页的特点如下:
(1)静态网页每个网页都有一个固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布到网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页交互性差,在功能上有较大的局限性;
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网站制作更新比较麻烦,适用于更新较少的显示类型网站。随着网站制作技术的飞速发展,细心的网友会发现很多网页文件的扩展名不再只是“.htm”,还有“.php”、“.asp”等,这些都在使用动态网页制作技术来自。
asp.net 抓取网页数据(静态网页,动态网页主要根据网页制作的语言来区分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-25 01:22
静态网页和动态网页主要根据网页创建的语言来区分:
静态网页使用的语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等网站等动态语言。
静态网页和动态网页的区别:
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 客户端上运行的程序、网页、插件和组件是静态网页,如 html 页面、Flash 、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索蜘蛛不会抓取网址中“?”后的内容,所以使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的 URL 形式通常是:
/index.html
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性交叉,在功能上有较大的限制
可以简单的判断为:一是名称一个接一个后缀,二是能否与服务器交互。
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
ONEGO网络科技工作室专业品牌网站PC和手机高端定制设计开发,网站改版升级,网站优化,视觉落地设计和百度SEO关键词自然排名优化推广服务。OG——做好第一步,做好每一步。 查看全部
asp.net 抓取网页数据(静态网页,动态网页主要根据网页制作的语言来区分)
静态网页和动态网页主要根据网页创建的语言来区分:
静态网页使用的语言:HTML(超文本标记语言)
动态网页语言:HTML+ASP或HTML+PHP或HTML+JSP等网站等动态语言。
静态网页和动态网页的区别:
程序是否在服务器端运行是一个重要的指标。服务器上运行的程序、网页和组件都是动态网页。它们会在不同的客户端和不同的时间返回不同的网页,如 ASP、PHP、JSP、CGI 等。 客户端上运行的程序、网页、插件和组件是静态网页,如 html 页面、Flash 、JavaScript、VBScript 等,它们永远不会改变。
静态网页和动态网页各有特点。网站采用动态网页还是静态网页,主要取决于网站的功能需求和网站的内容。如果网站的功能比较简单,内容更新量不是很大,采用纯静态网页比较简单,否则一般采用动态网页技术实现。
静态网页是构建网站的基础,静态网页和动态网页并不矛盾。为了满足搜索引擎检索的需要,即使使用动态网站技术,也将网页内容转化为静态网页并发布。
动态网站也可以采用动静结合的原则。使用动态网页的地方适合使用动态网页。如果需要静态网页,可以考虑使用静态网页来实现,在同一个网站 上面,动态网页内容和静态网页内容同时存在也是很常见的。
我们简要总结动态网页的一般特征如下:
(1)动态网页基于数据库技术,可以大大减少网站维护的工作量;
(2)网站采用动态网页技术可以实现更多功能,如用户注册、用户登录、在线调查、用户管理、订单管理等;
(3)动态网页实际上并不是独立存在于服务器上的网页文件,服务器只有在用户请求时才返回一个完整的网页;
(4)动态网页中的“?”对于搜索引擎检索有一定的问题,搜索引擎一般无法访问网站数据库中的所有网页,或者出于技术考虑,搜索蜘蛛不会抓取网址中“?”后的内容,所以使用动态网页的网站在进行搜索引擎推广时需要做一定的技术处理以满足搜索引擎的要求
什么是静态网页?静态网页的特点是什么?
在网站的设计中,纯HTML格式的网页通常被称为“静态网页”,早期的网站一般都是由静态网页制作而成。静态网页的 URL 形式通常是:
/index.html
以.htm、.html、.shtml、.xml等为后缀,在HTML格式的网页上,还可以出现各种动态效果,如.GIF格式动画、FLASH、滚动字母等。这些“动态效果”是只是视觉的,和下面介绍的动态网页是不同的概念。.
我们简要总结静态网页的特点如下:
(1)静态网页每个网页都有固定的网址,网页网址后缀为.htm、.html、.shtml等常见形式,不收录“?”;
(一旦2)网页的内容发布在网站服务器上,无论是否有用户访问,每个静态网页的内容都存储在网站服务器上,即,静态网页是服务器上实际存储的文件,每个网页都是一个独立的文件;
(3)静态网页内容比较稳定,容易被搜索引擎检索到;
(4)静态网页没有数据库支持,网站生产和维护的工作量比较大。因此,当网站有大量信息;
(5)静态网页的交互性交叉,在功能上有较大的限制
可以简单的判断为:一是名称一个接一个后缀,二是能否与服务器交互。
与动态网页相比,静态网页是指没有后端数据库、没有程序、没有交互的网页。你编的就是它显示的,不会有任何改变。静态网页更新比较麻烦,适用于更新较少的显示类型网站。
ONEGO网络科技工作室专业品牌网站PC和手机高端定制设计开发,网站改版升级,网站优化,视觉落地设计和百度SEO关键词自然排名优化推广服务。OG——做好第一步,做好每一步。
asp.net 抓取网页数据(ASP.NET中页面间的传值2.使用传值方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-09 09:16
1. 前言
在传统的 ASP 应用程序中,很容易通过 POST 方法将一个或多个值从一个页面传输到另一个页面。同样的方法在ASP.NET中实现有点麻烦。ASP.NET中页面之间传递值的方式有很多种。下面使用QueryString方法、Session方法、Server.Transfer方法、Cookie对象方法、Application对象方法、PostBackUrl属性方法、@PreviousPageType指令方法来理解ASP.NET页面。价值转移
2. 使用 QueryString 传递值
1) 简介
QueryString 是一种非常简单且常用的传值方式,但它在浏览器地址中显示传值。如果是传递一个或多个安全性要求不高或者结构简单的值,可以使用这种方法
2) 创建项目
文件,新建,网站,新建一个网站项目
选择ASP.NET网站,点击Browse选择保存位置,点击OK
3) 编码设计
Ø 切换回设计框
在代码编辑框下方,点击Design切换回网页设计界面
Ø设计一个发送数据的网页
在编辑框左侧的工具栏中,选择绘制web界面的控件
绘制如上图所示的web界面
Ø代码
编写Button_Click事件,创建一个字符串变量data,其值为web.aspx?name=TextBox1控件中输入的值,即要传递的值。Response.Redirect() 方法的意思是跳转到另一个页面,也就是Response。重定向(您要转到的页面.aspx)
Ø添加网页
右键单击项目文件并选择添加新项目
选择 Web 表单并修改其名称。这里的名字需要和前面数据值中web.aspx的名字一致。点击添加
创建后在工程文件中可以看到新创建的文件
Ø设计接收数据网页
使用工具箱在新创建的文件中绘制接收数据的网页
Ø代码
Request.QueryString 用于获取参数。给页面添加一条Request.QueryString语句,在访问页面时,URL后面有“?需要获取的参数=***”,那么这条语句会返回等号后面的赋值value 到 Label1 控件的 Text 属性,并将其显示写为 Label1.Text=Request.QueryString["需要获取值的参数"]
Ø测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
3. 使用会话变量传递值
1) 简介
Session的特点是:数据保存在服务器端,可以保存任何类型的数据,默认生命周期为20分钟,可以手动设置更长或更短的时间,调用数据时的返回值之后保存会话中的数据是对象
2) 修改发送数据网页的代码
Session["name"]=Text.Box1.Text 表示将TextBox.Text的值写入Session,在Session过期前(默认为20分钟),可以通过Session["name ”]
3) 修改接收数据网页代码
标签1.Text=Session["name"].ToString(); 意思是获取Session中name的值,赋值给Label1.Text。由于Session的返回类型是对象类型,所以需要转换为String,即。字符串()
Session.Remove("name") 清除name的Session值并释放其空间
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
4. 使用 Server.Transfer 传输值
1) 简介
使用 Server.Transfer 方法引导数据从当前页面流向另一个页面。新页面使用了上一个页面的响应流,所以这个方法是面向对象的
2) 修改发送数据网页的代码
Server.Transfer("web.aspx") 表示跳转到另一个页面。这种迁移到另一个页面的方式会保留服务资源,而不是简单地通知浏览器服务器已经更改了页面并迁移了请求
公共字符串名称
{
得到
{
重新运行 TextBox1.Text;
}
}
为这个页面设置一个公共属性。使用name属性时,返回值为TextBox1.Text上的数据
3) 修改接收数据网页代码
_default wb 表示创建发送数据页类的实例变量wb
wb=(_Default)Context.Handler 的意思是获取上一个网页传过来的对象,强制为_Default
Label1.Text=wb.name 将wb中的name属性值赋给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
5. 使用 Cookie 对象变量
1) 简介
与Session相比,Cookie数据存储在客户端
2) 修改发送数据网页的代码
HttpCookie cookie=new HttpCookie("name") 实例化HttpCookie的对象,HttpCookie提供了建立和操作独立HTTP cookie的安全类型的方法,name是保存数据的变量名
cookie.Value=TextBox1.Text 将输入的信息赋给 cookie.Value 属性
Response.AppendCookie(cookie) 将 cookie 添加到内部 cookie 集合中
3) 修改接收数据网页代码
Label1.Text=Request.Cookies["name"].Value.ToString() 取出cookie中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
6. 使用 Application 对象变量
1) 简介
Application 对象的范围是整个全局,这意味着它对所有用户都有效。这种方法不常用,因为Application是在一个应用域中共享的,所有用户都可以改变和设置它的值,所以一般用在计数器等需要全局变量的地方
2) 修改发送数据网页的代码
Application["name"]=TextBox1.Text 将Text Box1.Text中输入的值赋给Application对象,保存数据的变量名是name
3) 修改接收数据网页代码
Label1.Text=Application["name"].ToString() 取出Application中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
7. 使用@PreviousPageType 指令
1) 简介
该命令是.net 2.0 中新增的命令,用于处理ASP.NET 2.0 提供的新的跨页传递函数,用于指定跨页所在的页面-页面传输过程开始。
2) 修改发送数据网页的代码
移除 Button1 中的 Button1_Click 事件
在页面设计框中单击源
将上面红框中的代码添加到Button1中,表示点击Button后,页面会跳转到web.aspx
设置一个属性并返回一个TextBox控件对象
3) 修改接收数据网页代码
在顶部添加上面的代码,也就是设置发回时要发送的页面地址
将上一页name返回值的Text属性值赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
8. PostBackUrl 属性
1) 简介
和前面的方法基本一样,可以说是前面方法的另一种实现。前面的方法主要是通过直接返回控件来实现值的传递。这里我们使用发送数据页面上的搜索控件
2) 修改发送数据网页的代码
删除上面的代码
3) 修改接收数据网页代码
删除它
Label1.Text=((TextBox)PreviousPage.FindControl("TextBox1")).Text的意思是在发送数据页中找到控件ID为TextBox1的控件,强制进入TextBox,并为其赋值Text属性值到标签1.文本
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
9. 解决现有问题
在点击Button按钮之前,也就是在处理Default.aspx之前,首先请求的是web.aspx。目前,没有数据。需要在web.aspx中的代码处理之前添加一个判断,使用IsCrossPagePostBack属性,允许检查请求是否来自Default.aspx,并在数据接收页面中写入:
写完后,先浏览web.aspx页面,然后跳转到web.aspx页面 查看全部
asp.net 抓取网页数据(ASP.NET中页面间的传值2.使用传值方法)
1. 前言
在传统的 ASP 应用程序中,很容易通过 POST 方法将一个或多个值从一个页面传输到另一个页面。同样的方法在ASP.NET中实现有点麻烦。ASP.NET中页面之间传递值的方式有很多种。下面使用QueryString方法、Session方法、Server.Transfer方法、Cookie对象方法、Application对象方法、PostBackUrl属性方法、@PreviousPageType指令方法来理解ASP.NET页面。价值转移
2. 使用 QueryString 传递值
1) 简介
QueryString 是一种非常简单且常用的传值方式,但它在浏览器地址中显示传值。如果是传递一个或多个安全性要求不高或者结构简单的值,可以使用这种方法
2) 创建项目
文件,新建,网站,新建一个网站项目
选择ASP.NET网站,点击Browse选择保存位置,点击OK
3) 编码设计
Ø 切换回设计框
在代码编辑框下方,点击Design切换回网页设计界面
Ø设计一个发送数据的网页
在编辑框左侧的工具栏中,选择绘制web界面的控件
绘制如上图所示的web界面
Ø代码
编写Button_Click事件,创建一个字符串变量data,其值为web.aspx?name=TextBox1控件中输入的值,即要传递的值。Response.Redirect() 方法的意思是跳转到另一个页面,也就是Response。重定向(您要转到的页面.aspx)
Ø添加网页
右键单击项目文件并选择添加新项目
选择 Web 表单并修改其名称。这里的名字需要和前面数据值中web.aspx的名字一致。点击添加
创建后在工程文件中可以看到新创建的文件
Ø设计接收数据网页
使用工具箱在新创建的文件中绘制接收数据的网页
Ø代码
Request.QueryString 用于获取参数。给页面添加一条Request.QueryString语句,在访问页面时,URL后面有“?需要获取的参数=***”,那么这条语句会返回等号后面的赋值value 到 Label1 控件的 Text 属性,并将其显示写为 Label1.Text=Request.QueryString["需要获取值的参数"]
Ø测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
3. 使用会话变量传递值
1) 简介
Session的特点是:数据保存在服务器端,可以保存任何类型的数据,默认生命周期为20分钟,可以手动设置更长或更短的时间,调用数据时的返回值之后保存会话中的数据是对象
2) 修改发送数据网页的代码
Session["name"]=Text.Box1.Text 表示将TextBox.Text的值写入Session,在Session过期前(默认为20分钟),可以通过Session["name ”]
3) 修改接收数据网页代码
标签1.Text=Session["name"].ToString(); 意思是获取Session中name的值,赋值给Label1.Text。由于Session的返回类型是对象类型,所以需要转换为String,即。字符串()
Session.Remove("name") 清除name的Session值并释放其空间
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
4. 使用 Server.Transfer 传输值
1) 简介
使用 Server.Transfer 方法引导数据从当前页面流向另一个页面。新页面使用了上一个页面的响应流,所以这个方法是面向对象的
2) 修改发送数据网页的代码
Server.Transfer("web.aspx") 表示跳转到另一个页面。这种迁移到另一个页面的方式会保留服务资源,而不是简单地通知浏览器服务器已经更改了页面并迁移了请求
公共字符串名称
{
得到
{
重新运行 TextBox1.Text;
}
}
为这个页面设置一个公共属性。使用name属性时,返回值为TextBox1.Text上的数据
3) 修改接收数据网页代码
_default wb 表示创建发送数据页类的实例变量wb
wb=(_Default)Context.Handler 的意思是获取上一个网页传过来的对象,强制为_Default
Label1.Text=wb.name 将wb中的name属性值赋给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
5. 使用 Cookie 对象变量
1) 简介
与Session相比,Cookie数据存储在客户端
2) 修改发送数据网页的代码
HttpCookie cookie=new HttpCookie("name") 实例化HttpCookie的对象,HttpCookie提供了建立和操作独立HTTP cookie的安全类型的方法,name是保存数据的变量名
cookie.Value=TextBox1.Text 将输入的信息赋给 cookie.Value 属性
Response.AppendCookie(cookie) 将 cookie 添加到内部 cookie 集合中
3) 修改接收数据网页代码
Label1.Text=Request.Cookies["name"].Value.ToString() 取出cookie中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
6. 使用 Application 对象变量
1) 简介
Application 对象的范围是整个全局,这意味着它对所有用户都有效。这种方法不常用,因为Application是在一个应用域中共享的,所有用户都可以改变和设置它的值,所以一般用在计数器等需要全局变量的地方
2) 修改发送数据网页的代码
Application["name"]=TextBox1.Text 将Text Box1.Text中输入的值赋给Application对象,保存数据的变量名是name
3) 修改接收数据网页代码
Label1.Text=Application["name"].ToString() 取出Application中name的值,转换成字符串赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
7. 使用@PreviousPageType 指令
1) 简介
该命令是.net 2.0 中新增的命令,用于处理ASP.NET 2.0 提供的新的跨页传递函数,用于指定跨页所在的页面-页面传输过程开始。
2) 修改发送数据网页的代码
移除 Button1 中的 Button1_Click 事件
在页面设计框中单击源
将上面红框中的代码添加到Button1中,表示点击Button后,页面会跳转到web.aspx
设置一个属性并返回一个TextBox控件对象
3) 修改接收数据网页代码
在顶部添加上面的代码,也就是设置发回时要发送的页面地址
将上一页name返回值的Text属性值赋值给Label1.Text
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
8. PostBackUrl 属性
1) 简介
和前面的方法基本一样,可以说是前面方法的另一种实现。前面的方法主要是通过直接返回控件来实现值的传递。这里我们使用发送数据页面上的搜索控件
2) 修改发送数据网页的代码
删除上面的代码
3) 修改接收数据网页代码
删除它
Label1.Text=((TextBox)PreviousPage.FindControl("TextBox1")).Text的意思是在发送数据页中找到控件ID为TextBox1的控件,强制进入TextBox,并为其赋值Text属性值到标签1.文本
4) 测试
在文本框中输入文本,然后单击按钮
显示刚刚在文本框中输入的文本
9. 解决现有问题
在点击Button按钮之前,也就是在处理Default.aspx之前,首先请求的是web.aspx。目前,没有数据。需要在web.aspx中的代码处理之前添加一个判断,使用IsCrossPagePostBack属性,允许检查请求是否来自Default.aspx,并在数据接收页面中写入:
写完后,先浏览web.aspx页面,然后跳转到web.aspx页面
asp.net 抓取网页数据(抓取网页数据分析报告(工程量非常大)-asp-net)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-05 05:03
抓取网页数据分析报告(工程量非常大,可放到网络数据包中直接抓取)-asp-net,可以看看我写的这篇大牛文章。aspx是asp的升级版。与asp相比,
有多种方法,可以有多线程抓包,nodejs同时抓取多个。使用vbscript等可以实现批量抓包。也可以直接开发爬虫,如利用python/asp/java/nodejs等技术的requests/pandas等库对网页抓取的进行清洗批量处理等。此外,也可以根据用户需求开发一些更有特色的python爬虫,以满足更多用户的需求。微软提供的服务,比如office中的python版本。
关键是要看你们网站的开发环境是windows还是linux系统,如果是windows的话,可以用cmd命令行程序,或者可以有基于python的发行版python3.5或更高版本,
c#或者vb
你提到了两个概念,网络库和爬虫。前者技术已经烂大街了,后者主要在于思维的锻炼和能力的提升,具体方法参见"用c#开发脚本引擎:celery"这篇文章。
如果是从任务调度来讲,windows的控制台程序就可以直接抓web网页,要求的不需要太高。
windows上的网络模块已经相当成熟,容易实现。但是我要推荐学习其它的理论和规范,例如tcp/ip协议,多线程,分布式等。本人有一套实战教程,不是单纯靠控制台程序,但是可以应用到许多实际场景中,无关技术。3天时间可以提高解析网页的能力,当然也能够直接实现对web网页的抓取。 查看全部
asp.net 抓取网页数据(抓取网页数据分析报告(工程量非常大)-asp-net)
抓取网页数据分析报告(工程量非常大,可放到网络数据包中直接抓取)-asp-net,可以看看我写的这篇大牛文章。aspx是asp的升级版。与asp相比,
有多种方法,可以有多线程抓包,nodejs同时抓取多个。使用vbscript等可以实现批量抓包。也可以直接开发爬虫,如利用python/asp/java/nodejs等技术的requests/pandas等库对网页抓取的进行清洗批量处理等。此外,也可以根据用户需求开发一些更有特色的python爬虫,以满足更多用户的需求。微软提供的服务,比如office中的python版本。
关键是要看你们网站的开发环境是windows还是linux系统,如果是windows的话,可以用cmd命令行程序,或者可以有基于python的发行版python3.5或更高版本,
c#或者vb
你提到了两个概念,网络库和爬虫。前者技术已经烂大街了,后者主要在于思维的锻炼和能力的提升,具体方法参见"用c#开发脚本引擎:celery"这篇文章。
如果是从任务调度来讲,windows的控制台程序就可以直接抓web网页,要求的不需要太高。
windows上的网络模块已经相当成熟,容易实现。但是我要推荐学习其它的理论和规范,例如tcp/ip协议,多线程,分布式等。本人有一套实战教程,不是单纯靠控制台程序,但是可以应用到许多实际场景中,无关技术。3天时间可以提高解析网页的能力,当然也能够直接实现对web网页的抓取。
asp.net 抓取网页数据(本篇内容主要讲解“”,感兴趣的朋友不妨来看看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-03 22:29
本文主要讲解《如何实现基于ASP.NET网页的C#数据采集》,有兴趣的朋友不妨看看。本文介绍的方法简单、快捷、实用。下面就让小编带你学习《如何实现基于ASP.NET网页的C#数据采集》!
C#数据采集大致可以分为两部分:
一首歌:
因为我们要采集其他人网页上的内容,所以首先要获取采集网页上的html代码。获取html代码比较简单。使用WebClient的DownloadData(url)取一个字节数组,然后将其转换为字符串字符串。
具体代码如下:
/// ///获取网页源代码 /// ///URL路径 ///编码方式 publicstringGetHTML(stringurl,stringencoding) { WebClientweb=newWebClient(); byte[]buffer=web.DownloadData(url); returnEncoding.GetEncoding(encoding).GetString(buffer); }
两个步骤:
现在我们有了目标页面的html代码,我们要扣除一开始我们想要的数据。扣除数据无疑会使用强大的正则表达式。使用正则表达式匹配得到我们想要的内容,这里我们可以过滤掉做出来的html代码,剩下的就是内容了。
C#data采集的具体代码如下:
Htmlhtml=newHtml(); //得到指定页面的html代码,***个参数为url(貌似都知道),第二个是目标网页的编码集 stringhtmlCode=html.GetHTML("http://gvod.tom59.cn/List.asp?ClassId=3","gb2312"); //正则表达式 Regexregexarticles=newRegex("(?.+)</a>.*"); //所有匹配表达式的内容 MatchCollectionmarticles=regexarticles.Matches(htmlCode); ///遍历匹配内容 foreach(Matchminmarticles) { Console.Write("标题:"+m.Groups["title"].Value+"\n"); Console.Write("id:"+m.Groups["id"].Value+"\n"); Console.Write("\n"); }
说到这里,相信大家对《如何实现基于ASP.NET网页的C#数据采集》有了更深的了解,一起来看看吧!这里是一宿云网站,更多相关内容,可以进入相关频道查询,关注我们,持续学习! 查看全部
asp.net 抓取网页数据(本篇内容主要讲解“”,感兴趣的朋友不妨来看看)
本文主要讲解《如何实现基于ASP.NET网页的C#数据采集》,有兴趣的朋友不妨看看。本文介绍的方法简单、快捷、实用。下面就让小编带你学习《如何实现基于ASP.NET网页的C#数据采集》!
C#数据采集大致可以分为两部分:
一首歌:
因为我们要采集其他人网页上的内容,所以首先要获取采集网页上的html代码。获取html代码比较简单。使用WebClient的DownloadData(url)取一个字节数组,然后将其转换为字符串字符串。
具体代码如下:
/// ///获取网页源代码 /// ///URL路径 ///编码方式 publicstringGetHTML(stringurl,stringencoding) { WebClientweb=newWebClient(); byte[]buffer=web.DownloadData(url); returnEncoding.GetEncoding(encoding).GetString(buffer); }
两个步骤:
现在我们有了目标页面的html代码,我们要扣除一开始我们想要的数据。扣除数据无疑会使用强大的正则表达式。使用正则表达式匹配得到我们想要的内容,这里我们可以过滤掉做出来的html代码,剩下的就是内容了。
C#data采集的具体代码如下:
Htmlhtml=newHtml(); //得到指定页面的html代码,***个参数为url(貌似都知道),第二个是目标网页的编码集 stringhtmlCode=html.GetHTML("http://gvod.tom59.cn/List.asp?ClassId=3","gb2312"); //正则表达式 Regexregexarticles=newRegex("(?.+)</a>.*"); //所有匹配表达式的内容 MatchCollectionmarticles=regexarticles.Matches(htmlCode); ///遍历匹配内容 foreach(Matchminmarticles) { Console.Write("标题:"+m.Groups["title"].Value+"\n"); Console.Write("id:"+m.Groups["id"].Value+"\n"); Console.Write("\n"); }
说到这里,相信大家对《如何实现基于ASP.NET网页的C#数据采集》有了更深的了解,一起来看看吧!这里是一宿云网站,更多相关内容,可以进入相关频道查询,关注我们,持续学习!
asp.net 抓取网页数据(Java抓取网页数据库的学习方法--抓取数据等)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-12-01 08:03
抓取网页数据等是通过sql模块完成的,有zendstore和hibernate就可以达到统一数据库解析的目的,我也是最近才开始学习的,这里说下我开始学习的方法吧,没学过数据库,所以只能大致说下,希望能帮到你,1.首先准备好相关需要的工具包:①bs4工具包;②xml工具包,我用的是比较通用的xmlbot,功能也有点多,也可以自己选择其他。
2.然后编写代码的方法很简单,首先引入相关包,工具包:web-inf-xml、xmlhttprequest、interceptors、options,数据库包web-database或者mysql或者oracle或者sqlserver。③开始编写代码:框架的代码量比较大,这里我使用的是一个比较通用的框架(如下图),把编译为c/c++,然后model.xml中的数据写到web-inf-xml中,其他都写到data里面,然后web.xml就可以直接修改注解了,类也写到web-inf-xml中,这里我写了一个简单的html内容,注意使用xmlhttprequest这个方法,引入zendstore(可以用zendstore().client接口,也可以使用zendstore().secure)。
4.操作数据库连接数据库、定义sql语句这里我一会要演示,我们分别通过post方法和get方法来发送请求,定义语句我这里使用mvc模式,然后通过对应的注解来实现功能。实现效果:①get方法发送请求,可以查看请求url,返回title,value给responsehandler,然后将responsehandler读取返回的返回值,将value读取出来进行转换、翻译、查询相关内容。
这里我写了value注入接口,注册了一个posteventhandler进来,返回值中有一个secretkey,通过监听它的事件处理来抓取url中的value,然后通过这个posteventhandler来获取用户请求和value进行翻译,然后进行查询、转换得到其他数据。②通过inetview获取返回数据,我这里定义了一个sort标签,查看url,我们可以看到对应的fields,group,然后通过这个标签实现一个排序功能,然后id,accumulator就可以分别拿到字段的值,最后查询、查询、转换、重定向到给定的源数据了。
我这里有一个分析excel的工具,我们可以在里面获取查询出来的数据,也可以通过读取excel来进行查询,这里我用posteventhandler来处理,包括value注入了监听事件的注册,数据转换功能等。5.其他查询:①如果要查询和excel有关的数据,可以通过的sqlsession实现,就是和数据库的连接,实现查询和关联查询。②如果我们需要在网页上显示查询的结果,直接使用data来做更加方便。 查看全部
asp.net 抓取网页数据(Java抓取网页数据库的学习方法--抓取数据等)
抓取网页数据等是通过sql模块完成的,有zendstore和hibernate就可以达到统一数据库解析的目的,我也是最近才开始学习的,这里说下我开始学习的方法吧,没学过数据库,所以只能大致说下,希望能帮到你,1.首先准备好相关需要的工具包:①bs4工具包;②xml工具包,我用的是比较通用的xmlbot,功能也有点多,也可以自己选择其他。
2.然后编写代码的方法很简单,首先引入相关包,工具包:web-inf-xml、xmlhttprequest、interceptors、options,数据库包web-database或者mysql或者oracle或者sqlserver。③开始编写代码:框架的代码量比较大,这里我使用的是一个比较通用的框架(如下图),把编译为c/c++,然后model.xml中的数据写到web-inf-xml中,其他都写到data里面,然后web.xml就可以直接修改注解了,类也写到web-inf-xml中,这里我写了一个简单的html内容,注意使用xmlhttprequest这个方法,引入zendstore(可以用zendstore().client接口,也可以使用zendstore().secure)。
4.操作数据库连接数据库、定义sql语句这里我一会要演示,我们分别通过post方法和get方法来发送请求,定义语句我这里使用mvc模式,然后通过对应的注解来实现功能。实现效果:①get方法发送请求,可以查看请求url,返回title,value给responsehandler,然后将responsehandler读取返回的返回值,将value读取出来进行转换、翻译、查询相关内容。
这里我写了value注入接口,注册了一个posteventhandler进来,返回值中有一个secretkey,通过监听它的事件处理来抓取url中的value,然后通过这个posteventhandler来获取用户请求和value进行翻译,然后进行查询、转换得到其他数据。②通过inetview获取返回数据,我这里定义了一个sort标签,查看url,我们可以看到对应的fields,group,然后通过这个标签实现一个排序功能,然后id,accumulator就可以分别拿到字段的值,最后查询、查询、转换、重定向到给定的源数据了。
我这里有一个分析excel的工具,我们可以在里面获取查询出来的数据,也可以通过读取excel来进行查询,这里我用posteventhandler来处理,包括value注入了监听事件的注册,数据转换功能等。5.其他查询:①如果要查询和excel有关的数据,可以通过的sqlsession实现,就是和数据库的连接,实现查询和关联查询。②如果我们需要在网页上显示查询的结果,直接使用data来做更加方便。
asp.net 抓取网页数据(利用怎么对网页源码进行抓取?新手对此不是详细讲解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-30 13:01
如何使用抓取网页的源代码?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你能有所收获。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, " 查看全部
asp.net 抓取网页数据(利用怎么对网页源码进行抓取?新手对此不是详细讲解)
如何使用抓取网页的源代码?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你能有所收获。
更推荐方法一
///
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
方法二
using System;
using System.Collections.Generic;
using System.Linq;
using System.Web;
using System.IO;
using System.Text;
using System.Net;
namespace MySql
{
public class GetHttpData
{
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
}
}
方法三
<p>public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码
{
try
{
string charSet = null;
if (charSets.Length == 1) {
charSet = charSets[0];
}
WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient
// 需要注意的:
//有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等
//这是就要具体问题具体分析比如在头部加入cookie
// webclient.Headers.Add("Cookie", cookie);
//这样可能需要一些重载方法。根据需要写就可以了
//获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。
myWebClient.Credentials = CredentialCache.DefaultCredentials;
//如果服务器要验证用户名,密码
//NetworkCredential mycred = new NetworkCredential(struser, strpassword);
//myWebClient.Credentials = mycred;
//从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号)
byte[] myDataBuffer = myWebClient.DownloadData(url);
string strWebData = Encoding.Default.GetString(myDataBuffer);
//获取网页字符编码描述信息
Match charSetMatch = Regex.Match(strWebData, "
asp.net 抓取网页数据( 2.-type-gt-item数据,发现问题元素都选择好了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-17 02:29
2.-type-gt-item数据,发现问题元素都选择好了
)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径。等了十几秒的结果,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面的句子是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚的观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,不管标题的嵌套关系如何变化,总有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。7.推荐阅读
简单的数据分析09 | Web Scraper 自动控制爬取次数 & Web Scraper 父子选择器
简单的数据分析08 | 网页爬虫翻页-点击“更多按钮”翻页
查看全部
asp.net 抓取网页数据(
2.-type-gt-item数据,发现问题元素都选择好了
)
这是简单数据分析系列文章的第十篇。
原文首发于Blog Garden: Simple Data Analysis 10。
友情提示:本文文章内容丰富,信息量大。我希望你在学习的时候能多读几遍。
我们在扫朋友圈和微博的时候,总是强调“扫一扫”这个词,因为在看动态的时候,当内容被拉到屏幕末尾的时候,APP会自动加载下一页的数据,从体验。看,数据会不断加载,永无止境。
今天我们就来聊聊如何使用Web Scraper抓取滚动到最后的网页。
今天我们动手的网站就是知乎的数据分析模块的精髓。该网站是:
本次抓取的内容为精华帖标题、回复者、通过数。下面是今天的教程。
1.制作站点地图
一开始,我们需要创建一个容器,其中收录要捕获的三种类型的数据。为了实现滚动到最后加载数据的功能,我们选择容器的Type为Element scroll down,即滚动到页面底部加载数据。
在这种情况下,所选元素名称是 div.List-item。
为了回顾上一节通过数据数控制items个数的方法,我们在元素名中添加nth-of-type(-n+100),只抓取前100个items暂时的数据。
然后我们保存容器节点,选择该节点下要捕获的三种数据类型。
第一个是标题,我们命名为title,被选元素命名为[itemprop='知乎:question'] a:
然后是被访者姓名和批准数之类的,被选中的元素名称是#Popover10-toggle a和button.VoteButton--up:
2. 爬取数据,发现问题
元素都选好了,我们按照Sitemap 知乎_top_answers -> Scrape -> Start craping for data capture的路径。等了十几秒的结果,内容让我们目瞪口呆:
数据呢?我想捕获什么数据?怎么全部都变成空了?
在计算机领域,null一般表示空值,即什么都没有。将其放入 Web Scraper 意味着未捕获任何数据。
我们可以回忆一下,网页上确实有数据。在我们整个操作过程中,唯一的变量就是选择元素的操作。所以一定是我们在选择元素的时候出错了,导致内容匹配出现问题,无法正常抓取数据。要解决这个问题,就得看网页的构成。
3.分析问题
要检查网页的构成,浏览器的另一个功能是必须的,那就是选择视图元素。
1. 我们点击控制面板左上角的箭头,此时箭头的颜色会变成蓝色。
2. 然后我们将鼠标移到标题上,标题会被一个蓝色的半透明蒙版覆盖。
3. 如果我们再次点击标题,我们会发现我们会跳转到 Elements 子面板。内容丰富多彩,代码难懂
如果你这样做,不要沮丧。这些 HTML 代码不涉及任何逻辑,它们是网页中的一个骨架,并提供一些排版功能。如果你平时用markdown来写,你可以把HTML理解为更复杂的markdown。
结合HTML代码,我们来看看[itemprop='知乎:question']这个匹配规则是怎么回事。
首先,这是一个树结构:
上面的句子是从视觉上分析的。它实际上是一个嵌套结构。我提取了关键内容。内容结构是不是更清晰了?
<a>如何快速成为数据分析师?</a>
我们再分析一个抓取标题为 null 的标题 HTML 代码。
我们可以清楚的观察到,在这个标题的代码中,缺少名为 div 属性的标签 itemprop='知乎:question' !结果,当我们的匹配规则匹配时,找不到对应的标签,Web Scraper就会放弃匹配,认为找不到对应的内容,所以就变成null了。
找到原因后,我们才能解决问题。
4.解决问题
我们发现在选择标题时,不管标题的嵌套关系如何变化,总有一个标签保持不变,即包裹在最外层的h2标签,属性名class='ContentItem-title' . 如果我们可以直接选择h2标签,是不是就可以完美匹配title内容了?
逻辑上理清了关系,我们如何使用Web Scraper?这时候我们就可以使用上一篇文章介绍的内容,通过键盘P键选择元素的父节点:
在今天的课程中,我们可以点击两次P键来匹配标题的父标签h2(或h2.ContentItem-title):
以此类推,由于受访者姓名也出现null,我们分析HTML结构,选择姓名的父标签span.AuthorInfo-name。具体的分析操作和上面类似,大家可以试试。
我的三个子内容的选择器如下,可以作为参考:
最后我们点击Scrape进行数据抓取,查看结果,没有null,完美!
5.吐槽时间
在爬取知乎的数据时,我们会发现滚动加载数据完成很快,但是匹配元素需要很多时间。
这间接说明了知乎this网站从代码上分析,写的还是比较烂的。
如果你爬取更多网站,你会发现大部分网页结构更“随心所欲”。因此,在正式抓取数据之前,往往需要进行小范围的尝试,比如先抓取20个项目,看看数据是否有问题。如果没有问题,再大规模增加正式爬行,可以在一定程度上减少返工时间。6.下次更新
这个问题有很多内容。你可以多读几遍并消化它。下一期我们会讲一些简单的内容,讲讲如何抓取table的内容。7.推荐阅读
简单的数据分析09 | Web Scraper 自动控制爬取次数 & Web Scraper 父子选择器
简单的数据分析08 | 网页爬虫翻页-点击“更多按钮”翻页
asp.net 抓取网页数据(本节静态网页和动态网页的相关概念(一)_)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-16 22:22
本节我们先来看看静态网页和动态网页的相关概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在编写爬虫程序的时候,首先要弄清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找到URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
/img.php?img=https://p0.ssl.img.360kuai.com ... b.jpg
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,其中涉及到数据库连接、访问、查询等一系列IO操作,因此其响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
/img.php?img=https://p0.ssl.img.360kuai.com ... 3.jpg
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细说明。
公开课广场-人才学习交流平台
ASP技术在静态和动态网页中的应用——网页制作——:这个有点外行。哈哈。首先,ASP是Active Server Page的缩写,意思是“活动服务器网页”。ASP 是微软开发的用来替代 CGI 脚本程序的一种可以与数据库和其他程序进行交互的应用程序。它是一个简单方便的编程工具。ASP网页文件格式...
ASP 是如何编程的:ASP 简单的说就是动态显示网页内容。ASP 不是一种可编程语言。需要使用VBS或JS脚本语言进行编程。
网站ASP是如何应用的-:asp是一种服务器端脚本技术。还有jsp、php等。这些服务器端脚本技术主要用于实现一些必须由程序处理的功能。比如你我找到了一个新闻管理系统或者内容管理系统,发布了一些新闻。您想在您制作的页面上发布一些新闻...
简述ASP.NET应用程序开发步骤: 在Visual Studio 2005中开发;脚步; 1)使用Visual Studio 2005创建网站。2)使用Visual Studio 2005工具箱中的控件,根据程序设计合理要求的应用程序界面。3)设置相关控件的属性。4)编写相关控件的事件代码。5)运行调试程序。6)保存网站文件在7)已发布网站。
ASP.NET开发流程__,(越详细越好!!)-:简单开发步骤:1、打开VS2008,2、VS2008菜单栏点击“新建”->“项目”或网站”(自己选择),这里以网站为例,选择“网站”,会弹出一个框,选择“ASP.NET网站@ >”,注意“位置”和“语言”设置。设置好后,选择“确定...
什么是asp,学习asp最好用什么软件,asp如何实现web开发:上面两个都说了哈哈~~建议你学.net
网站开发ASP-:我们先学习ASP。将页面与数据库连接起来并不困难。最好去网站看原代码,最简单的显示、添加、修改、删除新闻的方法,如果你把asp学得透彻,你就能学会.net和PHP。祝你好运!...
asp编程-asp编程是一种基于vbscript、javascript等脚本语言的web开发语言。默认的脚本语言是 vbscript.asp,意思是活动服务页面动态页面。Gas asp可以实现诸如网络聊天、bbs、留言板、新闻发布系统等网络应用,其语法简单易学易掌握。不管是什么web编程语言,主要是针对数据库操作,读写数据库。使用动态语言开发网页应用,无需修改特定网页,即可实时更新您的网站数据。web开发语言有很多种,主要有asp、php、jsp等,各有千秋
ASP是制作动态网页的软件吗?紧急!~急!~-: ASP 是一种网络文件格式,不是软件...
XP系统配置IIS开发ASP.NET WEB应用-:首先看你的XP是家庭版。常见的 Windows XP 有两个版本,专业版和家庭版。这两个版本基本相同,但在细节上,专业版比家庭版功能更多。比如XP专业版支持双CPU、多语言、加入域、EFS文件加密…… 查看全部
asp.net 抓取网页数据(本节静态网页和动态网页的相关概念(一)_)
本节我们先来看看静态网页和动态网页的相关概念。如果您熟悉前端语言,那么您可以快速了解本节中的知识。
我们在编写爬虫程序的时候,首先要弄清楚要爬取的页面是静态的还是动态的。只有确定了页面类型,才能方便后续的网页分析和编程。对于不同类型的网页,编写爬虫时使用的方法也不尽相同。
静态页面
静态网页是标准的 HTML 文件,可以通过 GET 请求方法直接获取。文件扩展名为.html、.htm等,网页界面可以收录文字、图片、声音、FLASH动画、客户端脚本和其他插件程序等。静态网页是构建网站的基础,早期的网站一般都是由静态网页制作的。静态不是静态的,它还收录一些动画效果,这一点不要误会。
我们知道,当网站信息量较大时,网页的生成速度会降低。因为静态网页的内容比较固定,不需要连接后端数据库,响应速度非常快。但是静态网页更新比较麻烦,每次更新都需要重新加载整个网页。
静态网页的数据都收录在 HTML 中,因此爬虫可以直接从 HTML 中提取数据。通过分析静态网页的URL,找到URL查询参数的变化规律,就可以实现页面爬取。与动态网页相比,静态网页对搜索引擎更加友好,有利于搜索引擎收录。
动态网页
动态网页是指使用动态网页技术的网页,例如 AJAX(指一种用于创建交互式和快速动态网页应用程序的网页开发技术)、ASP(动态交互式网页和强大的网页应用程序)、JSP( Java 语言动态网页创建技术标准)等技术,无需重新加载整个页面内容,即可实现网页的局部更新。
动态页面利用“动态页面技术”与服务器交换少量数据,从而实现网页的异步加载。我们来看一个具体的例子:打开百度图片(),搜索Python。当鼠标滚轮滚动时,网页会自动从服务器数据库加载数据并呈现页面。这是动态网页和静态网页之间最基本的区别。如下:
/img.php?img=https://p0.ssl.img.360kuai.com ... b.jpg
除了 HTML 标记语言,动态网页还收录一些特定功能的代码。这些代码允许浏览器和服务器进行交互。服务端会根据客户端的不同请求生成网页,其中涉及到数据库连接、访问、查询等一系列IO操作,因此其响应速度比静态网页稍差。
注:一般网站通常采用动静结合的方式来达到平衡状态。可以参考《网站构建动静态组合》简单理解。
当然,动态网页也可以是纯文字,页面中还可以收录各种动画效果。这些只是网络内容的表达。其实不管网页有没有动态效果,只要使用了动态网站技术,那么这个网页就叫做动态网页。
爬取动态网页的过程比较复杂,需要通过动态抓包的方式获取客户端与服务器交互的JSON数据。抓包时可以使用谷歌浏览器开发者模式(快捷键:F12)Network选项,然后点击XHR找到获取JSON数据的URL,如下图:
/img.php?img=https://p0.ssl.img.360kuai.com ... 3.jpg
或者也可以使用专业的抓包工具Fiddler(点击访问)。动态网页的数据抓取将在后续内容中详细说明。
公开课广场-人才学习交流平台
ASP技术在静态和动态网页中的应用——网页制作——:这个有点外行。哈哈。首先,ASP是Active Server Page的缩写,意思是“活动服务器网页”。ASP 是微软开发的用来替代 CGI 脚本程序的一种可以与数据库和其他程序进行交互的应用程序。它是一个简单方便的编程工具。ASP网页文件格式...
ASP 是如何编程的:ASP 简单的说就是动态显示网页内容。ASP 不是一种可编程语言。需要使用VBS或JS脚本语言进行编程。
网站ASP是如何应用的-:asp是一种服务器端脚本技术。还有jsp、php等。这些服务器端脚本技术主要用于实现一些必须由程序处理的功能。比如你我找到了一个新闻管理系统或者内容管理系统,发布了一些新闻。您想在您制作的页面上发布一些新闻...
简述ASP.NET应用程序开发步骤: 在Visual Studio 2005中开发;脚步; 1)使用Visual Studio 2005创建网站。2)使用Visual Studio 2005工具箱中的控件,根据程序设计合理要求的应用程序界面。3)设置相关控件的属性。4)编写相关控件的事件代码。5)运行调试程序。6)保存网站文件在7)已发布网站。
ASP.NET开发流程__,(越详细越好!!)-:简单开发步骤:1、打开VS2008,2、VS2008菜单栏点击“新建”->“项目”或网站”(自己选择),这里以网站为例,选择“网站”,会弹出一个框,选择“ASP.NET网站@ >”,注意“位置”和“语言”设置。设置好后,选择“确定...
什么是asp,学习asp最好用什么软件,asp如何实现web开发:上面两个都说了哈哈~~建议你学.net
网站开发ASP-:我们先学习ASP。将页面与数据库连接起来并不困难。最好去网站看原代码,最简单的显示、添加、修改、删除新闻的方法,如果你把asp学得透彻,你就能学会.net和PHP。祝你好运!...
asp编程-asp编程是一种基于vbscript、javascript等脚本语言的web开发语言。默认的脚本语言是 vbscript.asp,意思是活动服务页面动态页面。Gas asp可以实现诸如网络聊天、bbs、留言板、新闻发布系统等网络应用,其语法简单易学易掌握。不管是什么web编程语言,主要是针对数据库操作,读写数据库。使用动态语言开发网页应用,无需修改特定网页,即可实时更新您的网站数据。web开发语言有很多种,主要有asp、php、jsp等,各有千秋
ASP是制作动态网页的软件吗?紧急!~急!~-: ASP 是一种网络文件格式,不是软件...
XP系统配置IIS开发ASP.NET WEB应用-:首先看你的XP是家庭版。常见的 Windows XP 有两个版本,专业版和家庭版。这两个版本基本相同,但在细节上,专业版比家庭版功能更多。比如XP专业版支持双CPU、多语言、加入域、EFS文件加密……
asp.net 抓取网页数据(什么是Sitemap?Sitemap.Net可方便管理员通知(组图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-10 08:17
)
首先我要说明一下:Asp.Net内置的Sitemap与这里提到的Sitemap完全不同。Asp.Net中的Sitemap主要用于用户的导航,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们先来看看官方的解释:
什么是站点地图?站点地图允许管理员通知搜索引擎哪些页面可用于在 网站 上抓取。Sitepmap 最简单的形式是一个 XML 文件,其中列出了 网站 中的 URL 以及关于每个 URL 的其他元数据(上次更新的时间、更改的频率,以及相对于 网站 的重要性?其他网址等),以便搜索引擎可以更智能地抓取网站。
网络爬虫通常通过网站和其他网站内的链接来寻找网页。Sitemap 提供此数据以允许支持 Sitemap 的爬虫抓取 Sitemap 提供的所有 URL 并了解使用相关元数据的 URL。使用 Sitemap 协议并不能保证网页会被搜索引擎收录,但您可以向网络爬虫提供一些提示,以便他们更有效地爬取 网站。
站点地图 0.90 是根据署名-相同方式共享许可(Attribution-ShareAlike Creative Commons License)条款提供的,被包括 Google、Yahoo! 在内的许多供应商广泛采用和支持。和微软。
引自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。如果没有 Sitemap,您的 网站 将是 收录,但是有了 Sitemap,收录 将更加全面和准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关键点和更新回访频率建议,让搜索引擎更准确的掌握你的网站。
如何自动生成Sitemap?
有很多现成的发电机
但是,在 Asp.Net 中,没有官方的生成工具。搜索“Asp.Net Sitemap”也会发现很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而其他大多数生成器就像一个私人爬虫,你需要手动释放它来爬取你的网站,生成整个站点的站点地图,我不喜欢这样。
站点地图
这是我实现的站点地图生成工具。先简单说一下实现方法:
通过数据库存储站点、页面集合和页面数据:
在Asp.Net网站中,在添加、删除、修改数据时,会调用站点地图上公开的方法来更新数据库数据。通过Ashx输出XML格式的Sitemap供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
必须首先引用 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“Add Existing Item”将SiteMap.mdf添加到项目的App_Data目录下。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
", "Page.aspx?id=" + id), 0.5, 更新频率。每日);
}
注意:这只是为了测试,所以临时生成了一个Guid传入sitemap,实际使用中应该和你原来数据入口的guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的Guid作为标识符才能找到它。
当您频繁点击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 来查看当前页面集合列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于代码都是中文写的,简单易懂,这里就不一一演示了:
查看全部
asp.net 抓取网页数据(什么是Sitemap?Sitemap.Net可方便管理员通知(组图)
)
首先我要说明一下:Asp.Net内置的Sitemap与这里提到的Sitemap完全不同。Asp.Net中的Sitemap主要用于用户的导航,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们先来看看官方的解释:
什么是站点地图?站点地图允许管理员通知搜索引擎哪些页面可用于在 网站 上抓取。Sitepmap 最简单的形式是一个 XML 文件,其中列出了 网站 中的 URL 以及关于每个 URL 的其他元数据(上次更新的时间、更改的频率,以及相对于 网站 的重要性?其他网址等),以便搜索引擎可以更智能地抓取网站。
网络爬虫通常通过网站和其他网站内的链接来寻找网页。Sitemap 提供此数据以允许支持 Sitemap 的爬虫抓取 Sitemap 提供的所有 URL 并了解使用相关元数据的 URL。使用 Sitemap 协议并不能保证网页会被搜索引擎收录,但您可以向网络爬虫提供一些提示,以便他们更有效地爬取 网站。
站点地图 0.90 是根据署名-相同方式共享许可(Attribution-ShareAlike Creative Commons License)条款提供的,被包括 Google、Yahoo! 在内的许多供应商广泛采用和支持。和微软。
引自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。如果没有 Sitemap,您的 网站 将是 收录,但是有了 Sitemap,收录 将更加全面和准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关键点和更新回访频率建议,让搜索引擎更准确的掌握你的网站。
如何自动生成Sitemap?
有很多现成的发电机
但是,在 Asp.Net 中,没有官方的生成工具。搜索“Asp.Net Sitemap”也会发现很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而其他大多数生成器就像一个私人爬虫,你需要手动释放它来爬取你的网站,生成整个站点的站点地图,我不喜欢这样。
站点地图
这是我实现的站点地图生成工具。先简单说一下实现方法:
通过数据库存储站点、页面集合和页面数据:
在Asp.Net网站中,在添加、删除、修改数据时,会调用站点地图上公开的方法来更新数据库数据。通过Ashx输出XML格式的Sitemap供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
必须首先引用 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“Add Existing Item”将SiteMap.mdf添加到项目的App_Data目录下。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
", "Page.aspx?id=" + id), 0.5, 更新频率。每日);
}
注意:这只是为了测试,所以临时生成了一个Guid传入sitemap,实际使用中应该和你原来数据入口的guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的Guid作为标识符才能找到它。
当您频繁点击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 来查看当前页面集合列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于代码都是中文写的,简单易懂,这里就不一一演示了:
asp.net 抓取网页数据(解决spider多次和重复的解决方案,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-05 11:23
本文文章主要介绍.net解决蜘蛛多次重复爬行的方案。有需要的朋友可以参考
原因:
早期,由于搜索引擎蜘蛛的不完善,当蜘蛛抓取动态网址时,很容易因为网站等不合理的程序,导致蜘蛛在死循环中迷路。
所以,为了避免前面的现象,蜘蛛不读取动态网址,特别是用?网址
解决方案:
1):配置路由
复制代码代码如下:
routes.MapRoute("RentofficeList",
"rentofficelist/{AredId}-{PriceId}-{AcreageId}-{SortId}-{SortNum}.html",
new {controller = "Home", action = "RentOfficeList" },
new[] {"Mobile.Controllers" });
第一个参数是路由名称
第二个参数是路由的Url方式,参数之间用()-()分隔
第三个参数是一个收录默认路由的对象
第四个参数是应用程序的一组命名空间
2):建立连接
默认排序
对比上面的Url方式,按顺序写参数赋值
3):获取参数
复制代码代码如下:
int areaId = GetRouteInt("AredId");//获取参数
///
/// 获取路由中的值
///
///
钥匙
///
默认值
///
protected int GetRouteInt(string key, int defaultValue)
{
返回 Convert.ToInt32(RouteData.Values[key], defaultValue);
}
///
/// 获取路由中的值
///
///
钥匙
///
protected int GetRouteInt(string key)
{
返回 GetRouteInt(key, 0);
}
根据以上3个步骤,显示的URL地址为:
:3841/rentofficelist/3-0-0-0-0.html
这样就可以避免在静态页面上使用动态参数,显示的页面都是静态页面
以上就是.net解决蜘蛛多次重复爬行的详细内容。更多详情请关注其他相关html中文网站文章! 查看全部
asp.net 抓取网页数据(解决spider多次和重复的解决方案,需要的朋友可以参考)
本文文章主要介绍.net解决蜘蛛多次重复爬行的方案。有需要的朋友可以参考
原因:
早期,由于搜索引擎蜘蛛的不完善,当蜘蛛抓取动态网址时,很容易因为网站等不合理的程序,导致蜘蛛在死循环中迷路。
所以,为了避免前面的现象,蜘蛛不读取动态网址,特别是用?网址
解决方案:
1):配置路由
复制代码代码如下:
routes.MapRoute("RentofficeList",
"rentofficelist/{AredId}-{PriceId}-{AcreageId}-{SortId}-{SortNum}.html",
new {controller = "Home", action = "RentOfficeList" },
new[] {"Mobile.Controllers" });
第一个参数是路由名称
第二个参数是路由的Url方式,参数之间用()-()分隔
第三个参数是一个收录默认路由的对象
第四个参数是应用程序的一组命名空间
2):建立连接
默认排序
对比上面的Url方式,按顺序写参数赋值
3):获取参数
复制代码代码如下:
int areaId = GetRouteInt("AredId");//获取参数
///
/// 获取路由中的值
///
///
钥匙
///
默认值
///
protected int GetRouteInt(string key, int defaultValue)
{
返回 Convert.ToInt32(RouteData.Values[key], defaultValue);
}
///
/// 获取路由中的值
///
///
钥匙
///
protected int GetRouteInt(string key)
{
返回 GetRouteInt(key, 0);
}
根据以上3个步骤,显示的URL地址为:
:3841/rentofficelist/3-0-0-0-0.html
这样就可以避免在静态页面上使用动态参数,显示的页面都是静态页面
以上就是.net解决蜘蛛多次重复爬行的详细内容。更多详情请关注其他相关html中文网站文章!
asp.net 抓取网页数据(网页版的微信推送的图文链接怎么做?怎么用?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-05 09:02
抓取网页数据,可以通过action交互http接口html的抓取脚本。还可以通过采集器工具例如百度和乐秀,将代码内的数据抓取下来。
谢邀请。请楼主说明你对于微信公众号的内容如何抓取,我暂且理解为就是网页版的微信推送的图文链接。首先可以说是人家已经封装好的采集代码,比如我们经常见到网页版微信推送过来的地址,这个地址其实是一个链接。然后你可以用乐秀抓包就可以抓取到,可以找到每个内容的字段,然后再写点代码进去就可以了。ps:推荐使用乐秀抓包。
之前微信推送过来的消息是加了一个微信接口,抓不到,
可以用乐秀软件来抓网页版的推送消息,
看了以上的答案都没答到点子上如果你用的是阿里云,请参考这里我们的图文消息并不是网页而是微信公众号的内容,
可以去看看这篇文章有教你如何抓取图文的,
使用这个网站,就可以抓取。
除了阿里云,可以使用万网的免费服务器,没有任何ip限制;操作简单,上手容易,从零开始搭建一个微信公众号,功能方面可以实现,对接抖音、公众号关注、互推、数据分析、企业定制、图文分析、数据统计等等功能,帮助企业实现微信公众号运营的更好、更快;可以关注公众号:新媒宝“九条鱼”了解详情。 查看全部
asp.net 抓取网页数据(网页版的微信推送的图文链接怎么做?怎么用?)
抓取网页数据,可以通过action交互http接口html的抓取脚本。还可以通过采集器工具例如百度和乐秀,将代码内的数据抓取下来。
谢邀请。请楼主说明你对于微信公众号的内容如何抓取,我暂且理解为就是网页版的微信推送的图文链接。首先可以说是人家已经封装好的采集代码,比如我们经常见到网页版微信推送过来的地址,这个地址其实是一个链接。然后你可以用乐秀抓包就可以抓取到,可以找到每个内容的字段,然后再写点代码进去就可以了。ps:推荐使用乐秀抓包。
之前微信推送过来的消息是加了一个微信接口,抓不到,
可以用乐秀软件来抓网页版的推送消息,
看了以上的答案都没答到点子上如果你用的是阿里云,请参考这里我们的图文消息并不是网页而是微信公众号的内容,
可以去看看这篇文章有教你如何抓取图文的,
使用这个网站,就可以抓取。
除了阿里云,可以使用万网的免费服务器,没有任何ip限制;操作简单,上手容易,从零开始搭建一个微信公众号,功能方面可以实现,对接抖音、公众号关注、互推、数据分析、企业定制、图文分析、数据统计等等功能,帮助企业实现微信公众号运营的更好、更快;可以关注公众号:新媒宝“九条鱼”了解详情。
asp.net 抓取网页数据(获取网页内容——保持登录状态利用Post数据成功登录服务器应用系统)
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-03 23:18
一、获取网页内容——html
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
需要三个类:WebRequest、WebResponse、StreamReader。
WebRequest 和 WebResponse 的命名空间为:System.Net
StreamReader 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.cftea.com/");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
[1]WebRequest类的Create是一个静态方法,参数为要爬取的网页的URL;
[2]Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
示例:
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/");
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
tb.Text = reader.ReadToEnd();
reader.Close();
reader.Dispose();
response.Close();
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
二、获取网页内容-图片(文档、压缩包等二进制文件)
不仅适用于图片,也适用于其他二进制文件。
需要四个类:WebRequest、WebResponse、Stream、FileStream。
WebRequest 和 WebResponse 的命名空间为:System.Net
Stream 和 FileStream 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif");
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
注意类 Stream,而不是 StreamReader。
示例
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif");
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
tb.Text = "保存成功!";
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
三、获取网页内容-发布数据
在获取网页数据时,有时需要通过Post将一些数据发送到服务器。在网页爬虫程序中添加如下代码,将用户名和密码发布到服务器:
以上为gb2312编码示例:
string data = "userName=admin&passwd=admin888";
byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = requestBuffer.Length;
using (Stream requestStream = request.GetRequestStream())
{
requestStream.Write(requestBuffer, 0, requestBuffer.Length);
requestStream.Close();
}
using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")))
{
string str = reader.ReadToEnd();
reader.Close();
}
四、获取网页内容阻止重定向
获取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response。 .写出来,没问题。
五、获取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,我们就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。 查看全部
asp.net 抓取网页数据(获取网页内容——保持登录状态利用Post数据成功登录服务器应用系统)
一、获取网页内容——html
在ASP.NET中抓取网页内容非常方便,解决了ASP中困扰我们的编码问题。
需要三个类:WebRequest、WebResponse、StreamReader。
WebRequest 和 WebResponse 的命名空间为:System.Net
StreamReader 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.cftea.com/";);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
[1]WebRequest类的Create是一个静态方法,参数为要爬取的网页的URL;
[2]Encoding 指定编码。编码有ASCII、UTF32、UTF8等通用编码属性,但没有gb2312的编码属性,所以我们使用GetEncoding获取gb2312编码。
示例:
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/";);
WebResponse response = request.GetResponse();
StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312"));
tb.Text = reader.ReadToEnd();
reader.Close();
reader.Dispose();
response.Close();
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
二、获取网页内容-图片(文档、压缩包等二进制文件)
不仅适用于图片,也适用于其他二进制文件。
需要四个类:WebRequest、WebResponse、Stream、FileStream。
WebRequest 和 WebResponse 的命名空间为:System.Net
Stream 和 FileStream 的命名空间为:System.IO
核心代码
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif";);
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
注意类 Stream,而不是 StreamReader。
示例
void Page_Load(object sender, EventArgs e)
{
try
{
WebRequest request = WebRequest.Create("http://www.baidu.com/images/logo.gif";);
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
FileStream writer = new FileStream("D:\\logo.gif", FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[512];
int c = 0; //实际读取的字节数
while ((c=reader.Read(buff, 0, buff.Length)) > 0)
{
writer.Write(buff, 0, c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
tb.Text = "保存成功!";
}
catch (Exception ex)
{
tb.Text = ex.Message;
}
}
Demo
三、获取网页内容-发布数据
在获取网页数据时,有时需要通过Post将一些数据发送到服务器。在网页爬虫程序中添加如下代码,将用户名和密码发布到服务器:
以上为gb2312编码示例:
string data = "userName=admin&passwd=admin888";
byte[] requestBuffer = System.Text.Encoding.GetEncoding("gb2312").GetBytes(data);
request.Method = "POST";
request.ContentType = "application/x-www-form-urlencoded";
request.ContentLength = requestBuffer.Length;
using (Stream requestStream = request.GetRequestStream())
{
requestStream.Write(requestBuffer, 0, requestBuffer.Length);
requestStream.Close();
}
using (StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("gb2312")))
{
string str = reader.ReadToEnd();
reader.Close();
}
四、获取网页内容阻止重定向
获取网页时,在成功登录服务器应用系统后,应用系统可以通过Response.Redirect对网页进行重定向。如果不需要响应这个重定向,那么我们不应该发送 reader.ReadToEnd() 到 Response。 .写出来,没问题。
五、获取网页内容-保持登录状态
使用Post数据成功登录服务器应用系统后,我们就可以抓取到需要登录的页面,那么我们可能需要在多个Request之间保持登录状态。
asp.net 抓取网页数据(抓取网页数据的方法当你的浏览器想抓取或查看)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-11-03 06:03
抓取网页数据的方法当你的浏览器想抓取或查看网页源码的时候,它都可以让你执行以下的命令。getget:可以从已经上传到页面上的内容去获取。fileoptions?://fileoptions://这是一个文件选项fileoptions.any:--recoder=xml在页面上抓取格式文件fileoptions.any:--extension=xml在页面上抓取加载已有的xmlfileoptions.remove_cache_secrets:--remove_cache_extension=xml从指定的元素中去清除所有与相关的xmlfileoptions.remove_testing_frames:--testing_frames=xml在指定的元素的打包样式或对象里去清除所有与相关的xmlfileoptions.replace_extension:--extension=xml在指定元素的加载样式或对象里去清除所有与相关的xmlfileoptions.replace_xxx:--xxx=xml在指定元素的xml文件里去清除所有与相关的抓取代码先加载对象之间的联系当你正在抓取一个对象时,你很可能希望你的对象已经是实例化的,比如./vm/project.xml就是一个对象。
但是project.xml是没有实例化的,为了抓取它,你需要通过来引入它。publicclassproject:models{privateprojectnameprojectname;publicproject(projectnameprojectname){this.projectname=projectname;}@overridepublicvoidon_start(){startntime=newdate();}@overridepublicvoidon_end(){stopntime=newdate();}}抓取的一个缺点有时候,你只想将一个元素的一些属性收集起来,以便于存储到中。
fileoptions?fileoptions:?|fileoptions?[interfacename]fileoptions?:?//相关的interfacename可以使用setter获取然后是组件之间的联系。组件的许多属性(比如,size、maxlength、elements.maxage等)可以通过prototype将其保存到requests.stringify()requests对象对每个对象都有touppercase等等属性。
这些属性都可以通过prototype.calls()属性取得。对于其他的组件也是一样。#{}findmodel和getmodel的api#{}findmodel()publicclassprogrammamode():models{@overridepublicfunctionextension_model(processid:unique,charset="utf-8"){。 查看全部
asp.net 抓取网页数据(抓取网页数据的方法当你的浏览器想抓取或查看)
抓取网页数据的方法当你的浏览器想抓取或查看网页源码的时候,它都可以让你执行以下的命令。getget:可以从已经上传到页面上的内容去获取。fileoptions?://fileoptions://这是一个文件选项fileoptions.any:--recoder=xml在页面上抓取格式文件fileoptions.any:--extension=xml在页面上抓取加载已有的xmlfileoptions.remove_cache_secrets:--remove_cache_extension=xml从指定的元素中去清除所有与相关的xmlfileoptions.remove_testing_frames:--testing_frames=xml在指定的元素的打包样式或对象里去清除所有与相关的xmlfileoptions.replace_extension:--extension=xml在指定元素的加载样式或对象里去清除所有与相关的xmlfileoptions.replace_xxx:--xxx=xml在指定元素的xml文件里去清除所有与相关的抓取代码先加载对象之间的联系当你正在抓取一个对象时,你很可能希望你的对象已经是实例化的,比如./vm/project.xml就是一个对象。
但是project.xml是没有实例化的,为了抓取它,你需要通过来引入它。publicclassproject:models{privateprojectnameprojectname;publicproject(projectnameprojectname){this.projectname=projectname;}@overridepublicvoidon_start(){startntime=newdate();}@overridepublicvoidon_end(){stopntime=newdate();}}抓取的一个缺点有时候,你只想将一个元素的一些属性收集起来,以便于存储到中。
fileoptions?fileoptions:?|fileoptions?[interfacename]fileoptions?:?//相关的interfacename可以使用setter获取然后是组件之间的联系。组件的许多属性(比如,size、maxlength、elements.maxage等)可以通过prototype将其保存到requests.stringify()requests对象对每个对象都有touppercase等等属性。
这些属性都可以通过prototype.calls()属性取得。对于其他的组件也是一样。#{}findmodel和getmodel的api#{}findmodel()publicclassprogrammamode():models{@overridepublicfunctionextension_model(processid:unique,charset="utf-8"){。

