
asp.net 抓取网页数据
腾讯的waf查杀插件(图).xml.heartbeauthandler
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-08-25 11:02
抓取网页数据的话,我们可以抓取百度搜索信息,腾讯的腾讯信息。我们抓取的是网页的基本信息,如果我们要抓取网页的其他数据的话,那就需要用到反爬虫了。1.php利用反爬虫工具:百度反爬虫工具:/faq/zh_cn/如果是新手的话可以找使用这个软件哦。也就是所谓的waf查杀插件。
/faq/zh_cn/如果是使用get请求的话,那么有两种情况:可以注意到,他的协议类型有json和xmljson:这种情况下的话抓取都需要用到xmlhttprequest,这个工具基本上抓取的是json数据,因为这里面包含的数据非常多,比如下面的信息。这种的话就是抓取前面所说的基本信息。
然后再转换为xml再提交给百度,不然的话是抓取不到数据的。不过使用上面工具抓取的话还要用到两个模块,分别是:response.prethread。用来处理异步请求,比如这个请求的路径是github_login?perignal=1&authenticate=&group_authenticate=0&authenticate_sign=nvldflyshokho%2feuvoy3.switch。
是可以抓取什么文件的。login.xml里面其实包含的不止一个tag文件,所以要用它来抓取这些里面的数据。文件数量也不能太多。也就是httpd.conf的文件里面要有httpd.prethread.heartbeauthandler,在这个里面可以设置设置具体抓取哪个文件,我这里是抓取github.login.xml,header有两个,一个是preferredsels,一个是requestbody,他们的含义分别是preferredsels是flags值的条件变量。
requestbody是preferredsel值的转换方法。里面有一个ifnodestring.now(),就是否这个路径的文件都在ifnodestring.now()后面返回的,如果preferredsels在ifnodestring.now()后面,那么这个文件就已经被转成json里面的数据了。
我们要写有效的array就可以把他转成ifnodestring。写json/xml/dict文件就可以把他转成ifnodestring.now()后面返回的值。2.nodejs使用过jquery的应该都知道有一个库叫jqueryui(),这个库不仅仅是基于jquery,还基于jquery16,同时对于jquery14,jquery15,jquery16的代码都有写。
更加方便。我们可以用jqueryui来抓取百度网页里面的信息哦。一行代码搞定:$.ajax({url:'',type:'post',data:{username:'',password:'',name:'',comment:'',text:'',date:'',success:function(res){res.send();}}));3.cors调用这里面我们用到的,还有一个值得说的就是c。 查看全部
腾讯的waf查杀插件(图).xml.heartbeauthandler
抓取网页数据的话,我们可以抓取百度搜索信息,腾讯的腾讯信息。我们抓取的是网页的基本信息,如果我们要抓取网页的其他数据的话,那就需要用到反爬虫了。1.php利用反爬虫工具:百度反爬虫工具:/faq/zh_cn/如果是新手的话可以找使用这个软件哦。也就是所谓的waf查杀插件。
/faq/zh_cn/如果是使用get请求的话,那么有两种情况:可以注意到,他的协议类型有json和xmljson:这种情况下的话抓取都需要用到xmlhttprequest,这个工具基本上抓取的是json数据,因为这里面包含的数据非常多,比如下面的信息。这种的话就是抓取前面所说的基本信息。

然后再转换为xml再提交给百度,不然的话是抓取不到数据的。不过使用上面工具抓取的话还要用到两个模块,分别是:response.prethread。用来处理异步请求,比如这个请求的路径是github_login?perignal=1&authenticate=&group_authenticate=0&authenticate_sign=nvldflyshokho%2feuvoy3.switch。
是可以抓取什么文件的。login.xml里面其实包含的不止一个tag文件,所以要用它来抓取这些里面的数据。文件数量也不能太多。也就是httpd.conf的文件里面要有httpd.prethread.heartbeauthandler,在这个里面可以设置设置具体抓取哪个文件,我这里是抓取github.login.xml,header有两个,一个是preferredsels,一个是requestbody,他们的含义分别是preferredsels是flags值的条件变量。

requestbody是preferredsel值的转换方法。里面有一个ifnodestring.now(),就是否这个路径的文件都在ifnodestring.now()后面返回的,如果preferredsels在ifnodestring.now()后面,那么这个文件就已经被转成json里面的数据了。
我们要写有效的array就可以把他转成ifnodestring。写json/xml/dict文件就可以把他转成ifnodestring.now()后面返回的值。2.nodejs使用过jquery的应该都知道有一个库叫jqueryui(),这个库不仅仅是基于jquery,还基于jquery16,同时对于jquery14,jquery15,jquery16的代码都有写。
更加方便。我们可以用jqueryui来抓取百度网页里面的信息哦。一行代码搞定:$.ajax({url:'',type:'post',data:{username:'',password:'',name:'',comment:'',text:'',date:'',success:function(res){res.send();}}));3.cors调用这里面我们用到的,还有一个值得说的就是c。
在线mockifyjs爬虫项目用下图所示,其他没什么好技术含量
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-08-17 04:01
抓取网页数据使用mockifyjs是非常不错的选择,非常便捷,用起来也比较简单。在线mockifyjs爬虫项目用下图演示如下图所示,
iis+php5.2+aspx
开源中国你可以在这里看看案例,挺不错的,
asp+php5.3+mssql+sqlite4+xml+json-only其他没什么好技术含量
网易公开课上有专门的web服务端课程
不知道你是要抓哪种网站,不同的网站的要求不一样。但是一般是要封对应网站的,主要是要抓对应网站的对应元素,拿到后台控制权。可以通过爬虫技术,但是一般不是很方便,因为封要求对ip,密码验证,验证码也有要求,还有更重要的是一次爬虫只能爬取1000条。所以更推荐转一下csdn,博客园,还有infoq,那些站点,都有各种网站id,通过id能抓100万条信息。
如果你是要搭建网站的话,推荐用asp+php+mssql;如果你是要拿网站做用户信息抓取的话,一般是要使用scrapy,selenium,还有封对应网站的对应元素;如果你是想为其他网站抓取数据的话,一般是要封对应网站的对应元素,从ip到密码都有要求。其实你只需要抓住asp里面的逻辑就可以了。
首先用于抓取,必须要懂什么是http协议,oop/prototype;抓取思路;知道一个网站里面关于哪些维度的爬取比较合适;前端的话最好不要直接通过网页输入网址,一定要预先知道对应的页面和对应的响应框是什么;如果是内容爬取的话就要懂一些底层的算法,通过前端标准,以及对算法不了解的话最好先学好。高大上一点的人,就需要封一些对应的对应元素。
总的来说就是要懂点这个网站的通用工具,如果是从前台抓取后台数据那你必须懂点对应的程序语言,如果从后台抓取前台数据那你必须懂点后台的语言。 查看全部
在线mockifyjs爬虫项目用下图所示,其他没什么好技术含量
抓取网页数据使用mockifyjs是非常不错的选择,非常便捷,用起来也比较简单。在线mockifyjs爬虫项目用下图演示如下图所示,
iis+php5.2+aspx

开源中国你可以在这里看看案例,挺不错的,
asp+php5.3+mssql+sqlite4+xml+json-only其他没什么好技术含量
网易公开课上有专门的web服务端课程

不知道你是要抓哪种网站,不同的网站的要求不一样。但是一般是要封对应网站的,主要是要抓对应网站的对应元素,拿到后台控制权。可以通过爬虫技术,但是一般不是很方便,因为封要求对ip,密码验证,验证码也有要求,还有更重要的是一次爬虫只能爬取1000条。所以更推荐转一下csdn,博客园,还有infoq,那些站点,都有各种网站id,通过id能抓100万条信息。
如果你是要搭建网站的话,推荐用asp+php+mssql;如果你是要拿网站做用户信息抓取的话,一般是要使用scrapy,selenium,还有封对应网站的对应元素;如果你是想为其他网站抓取数据的话,一般是要封对应网站的对应元素,从ip到密码都有要求。其实你只需要抓住asp里面的逻辑就可以了。
首先用于抓取,必须要懂什么是http协议,oop/prototype;抓取思路;知道一个网站里面关于哪些维度的爬取比较合适;前端的话最好不要直接通过网页输入网址,一定要预先知道对应的页面和对应的响应框是什么;如果是内容爬取的话就要懂一些底层的算法,通过前端标准,以及对算法不了解的话最好先学好。高大上一点的人,就需要封一些对应的对应元素。
总的来说就是要懂点这个网站的通用工具,如果是从前台抓取后台数据那你必须懂点对应的程序语言,如果从后台抓取前台数据那你必须懂点后台的语言。
入门级的手机爬虫软件-进口黄金产品搜索平台抓取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-08-15 00:02
抓取网页数据主要分成数据采集和数据加工两个部分,采集一般需要通过自己的机器对post/get请求进行处理分析,通过正则表达式匹配数据url,获取想要的数据,处理完后再传给接口服务器。数据加工主要包括jsp和css代码的加工,再封装成java接口调用。抓取数据可以借助云之家等抓取工具,网站数据的抓取是简单的xml解析,然后通过正则匹配查找页面中的url,获取想要的数据。
通过正则表达式可以抓取。不过即使通过正则表达式抓取出的网页,也不一定准确。
php抓取请求可用网络爬虫工具,如天猫就有多个抓取工具,
楼上的@snwlj提到抓取是通过正则表达式,数据处理主要有jsp和css做加工等等,这是有针对性的提供,并不全面,
爬虫不错,具体的方法找淘宝爬虫写的很好的。
有个叫jspcrawler
可以通过正则匹配去抓取数据,也可以通过php语言调用他的接口去处理数据,
不错的,不过你得看看自己想要处理什么数据。
可以用淘宝采集器
我用的还是有很多的呢,只是你没看到而已。
有一些入门级的手机爬虫软件:querystore-进口黄金产品搜索平台 查看全部
入门级的手机爬虫软件-进口黄金产品搜索平台抓取数据
抓取网页数据主要分成数据采集和数据加工两个部分,采集一般需要通过自己的机器对post/get请求进行处理分析,通过正则表达式匹配数据url,获取想要的数据,处理完后再传给接口服务器。数据加工主要包括jsp和css代码的加工,再封装成java接口调用。抓取数据可以借助云之家等抓取工具,网站数据的抓取是简单的xml解析,然后通过正则匹配查找页面中的url,获取想要的数据。
通过正则表达式可以抓取。不过即使通过正则表达式抓取出的网页,也不一定准确。
php抓取请求可用网络爬虫工具,如天猫就有多个抓取工具,

楼上的@snwlj提到抓取是通过正则表达式,数据处理主要有jsp和css做加工等等,这是有针对性的提供,并不全面,
爬虫不错,具体的方法找淘宝爬虫写的很好的。
有个叫jspcrawler
可以通过正则匹配去抓取数据,也可以通过php语言调用他的接口去处理数据,
不错的,不过你得看看自己想要处理什么数据。
可以用淘宝采集器
我用的还是有很多的呢,只是你没看到而已。
有一些入门级的手机爬虫软件:querystore-进口黄金产品搜索平台
asp.net 抓取网页数据 你想做的目标是什么?有什么好的解决方案?
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-06-25 16:00
抓取网页数据和flash文件
你想要爬什么?你想做的目标是什么?你真正需要的是什么?有什么好的解决方案?当然了,学会了,要去扒别人的代码。就像我们学会了开发网站,需要进入java社区学习。
没有最优解,只有更优解。你想用什么工具?如果java更适合你,那就用java。如果php更适合你,那就用php。
现在是交叉学科的时代,既然你选定了web相关,就赶紧学习java,别给自己找借口说是gui做不好,别推卸是软件开发差,让这方面的东西与java的语言特性,用到的工具和技术做对接。当然,java提供的jdbc,数据库通信库,从hql到mysql,非常让人舒服。
把php去掉,
时间不允许了,找个适合你的语言吧。最简单的语言直接用php,最复杂的语言就要找点专业书籍看看了。
c++,java,php,java这样的话还是推荐java吧,
tcpio,非阻塞,
c++
php,python,java.
做web建议java。php只能搞搞个性化,
你需要学习一门脚本语言
推荐c#
html+css+javascript。我觉得如果有时间的话,php也很不错。只要你不想简历上写php就好了。 查看全部
asp.net 抓取网页数据 你想做的目标是什么?有什么好的解决方案?
抓取网页数据和flash文件
你想要爬什么?你想做的目标是什么?你真正需要的是什么?有什么好的解决方案?当然了,学会了,要去扒别人的代码。就像我们学会了开发网站,需要进入java社区学习。
没有最优解,只有更优解。你想用什么工具?如果java更适合你,那就用java。如果php更适合你,那就用php。
现在是交叉学科的时代,既然你选定了web相关,就赶紧学习java,别给自己找借口说是gui做不好,别推卸是软件开发差,让这方面的东西与java的语言特性,用到的工具和技术做对接。当然,java提供的jdbc,数据库通信库,从hql到mysql,非常让人舒服。
把php去掉,
时间不允许了,找个适合你的语言吧。最简单的语言直接用php,最复杂的语言就要找点专业书籍看看了。

c++,java,php,java这样的话还是推荐java吧,
tcpio,非阻塞,
c++
php,python,java.
做web建议java。php只能搞搞个性化,
你需要学习一门脚本语言
推荐c#
html+css+javascript。我觉得如果有时间的话,php也很不错。只要你不想简历上写php就好了。
.NET Core 下的爬虫利器
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-06-19 19:13
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎。
本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例。爬虫代码一般具有时效性,当我们的目标发生改版升级,规则转换后我们写的爬虫代码就会失效,需要重新应对。抓取数据的主要思路就是去分析目标网站的页面逻辑,利用xpath、正则表达式等知识去解析网页拿到我们想要的数据。
本篇主要简单介绍三个组件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前两个可以处理传统的页面,无法抓取单页应用,如果需要抓取单页应用可以使用PuppeteerSharp。
关于这三个组件库的实际应用可以参考一下系列文章。
新建一个控制台项目,抓取几个站点的数据来试试,先做准备工作,添加一个IHotNews的接口。
using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public interface IHotNews<br /> {<br /> Task GetHotNewsAsync();<br /> }<br />}<br />
HotNews模型,包含标题和链接
namespace SpiderDemo<br />{<br /> public class HotNews<br /> {<br /> public string Title { get; set; }<br /><br /> public string Url { get; set; }<br /> }<br />}<br />
最终我们通过依赖注入的方式,将抓取到的数据展示到控制台中。
HtmlAgilityPack
在项目中安装HtmlAgilityPack组件
Install-Package HtmlAgilityPack<br />
这里以博客园为抓取目标,我们抓取首页的文章标题和链接。
using HtmlAgilityPack;<br />using System.Collections.Generic;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsHtmlAgilityPack : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var web = new HtmlWeb();<br /><br /> var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/");<br /><br /> var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList();<br /><br /> foreach (var item in node)<br /> {<br /> list.Add(new HotNews<br /> {<br /> Title = item.InnerText,<br /> Url = item.GetAttributeValue("href", "")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
添加HotNewsHtmlAgilityPack.cs实现IHotNews接口,访问博客园网址,拿到HTML数据后,使用xpath语法解析HTML,这里主要是拿到a标签即可。
通过查看网页分析可以得到这个xpath://*[@id='post_list']/article/section/div/a。
然后在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
AngleSharp
在项目中安装AngleSharp组件
Install-Package AngleSharp<br />
同样的,新建一个HotNewsAngleSharp.cs也实现IHotNews接口,这次使用AngleSharp抓取。
using AngleSharp;<br />using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsAngleSharp : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var config = Configuration.Default.WithDefaultLoader();<br /> var address = "https://www.cnblogs.com";<br /> var context = BrowsingContext.New(config);<br /> var document = await context.OpenAsync(address);<br /><br /> var cellSelector = "article.post-item";<br /> var cells = document.QuerySelectorAll(cellSelector);<br /><br /> foreach (var item in cells)<br /> {<br /> var a = item.QuerySelector("section>div>a");<br /> list.Add(new HotNews<br /> {<br /> Title = a.TextContent,<br /> Url = a.GetAttribute("href")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
AngleSharp解析数据和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css规则去获取数据,用起来也是挺方便的。
在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
PuppeteerSharp
PuppeteerSharp是基于Puppeteer的,Puppeteer是一个Google 开源的NodeJS 库,它提供了一个高级API 来通过DevTools协议控制Chromium 浏览器。Puppeteer 默认以无头(Headless) 模式运行,但是可以通过修改配置运行“有头”模式。
PuppeteerSharp可以干很多事情,不光可以用来抓取单页应用,还可以用来生成页面PDF或者图片,可以做自动化测试等。
在项目中安装PuppeteerSharp组件
Install-Package PuppeteerSharp<br />
使用PuppeteerSharp第一次会帮我们在项目根目录中下载浏览器执行程序,这个取决于当前网速的快慢,建议手动下载后放在指定位置即可。
using PuppeteerSharp;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> // 下载浏览器执行程序<br /> await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);<br /><br /> // 创建一个浏览器执行实例<br /> using var browser = await Puppeteer.LaunchAsync(new LaunchOptions<br /> {<br /> Headless = true,<br /> Args = new string[] { "--no-sandbox" }<br /> });<br /><br /> // 打开一个页面<br /> using var page = await browser.NewPageAsync();<br /><br /> // 设置页面大小<br /> await page.SetViewportAsync(new ViewPortOptions<br /> {<br /> Width = 1920,<br /> Height = 1080<br /> });<br /> }<br /> }<br />}<br />
上面这段代码是初始化PuppeteerSharp必要的代码,可以根据实际开发需要进行修改,下面以""为例,演示几个常用操作。
获取单页应用HTML
...<br />var url = "https://juejin.im";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br />var content = await page.GetContentAsync();<br />Console.WriteLine(content);<br />
可以看到页面上的HTML全部被获取到了,这时候就可以利用规则解析HTML,拿到我们想要的数据了。
保存为图片
...<br />var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.ScreenshotAsync("juejin.png");<br />
保存为PDF
var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.PdfAsync("juejin.pdf");<br />
PuppeteerSharp的功能还有很多,比如页面注入HTML、执行JS代码等,使用的时候可以参考官网示例。
往期精彩回顾 查看全部
.NET Core 下的爬虫利器
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎。
本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例。爬虫代码一般具有时效性,当我们的目标发生改版升级,规则转换后我们写的爬虫代码就会失效,需要重新应对。抓取数据的主要思路就是去分析目标网站的页面逻辑,利用xpath、正则表达式等知识去解析网页拿到我们想要的数据。
本篇主要简单介绍三个组件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前两个可以处理传统的页面,无法抓取单页应用,如果需要抓取单页应用可以使用PuppeteerSharp。
关于这三个组件库的实际应用可以参考一下系列文章。
新建一个控制台项目,抓取几个站点的数据来试试,先做准备工作,添加一个IHotNews的接口。
using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public interface IHotNews<br /> {<br /> Task GetHotNewsAsync();<br /> }<br />}<br />
HotNews模型,包含标题和链接
namespace SpiderDemo<br />{<br /> public class HotNews<br /> {<br /> public string Title { get; set; }<br /><br /> public string Url { get; set; }<br /> }<br />}<br />
最终我们通过依赖注入的方式,将抓取到的数据展示到控制台中。
HtmlAgilityPack
在项目中安装HtmlAgilityPack组件
Install-Package HtmlAgilityPack<br />
这里以博客园为抓取目标,我们抓取首页的文章标题和链接。
using HtmlAgilityPack;<br />using System.Collections.Generic;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsHtmlAgilityPack : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var web = new HtmlWeb();<br /><br /> var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/";);<br /><br /> var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList();<br /><br /> foreach (var item in node)<br /> {<br /> list.Add(new HotNews<br /> {<br /> Title = item.InnerText,<br /> Url = item.GetAttributeValue("href", "")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
添加HotNewsHtmlAgilityPack.cs实现IHotNews接口,访问博客园网址,拿到HTML数据后,使用xpath语法解析HTML,这里主要是拿到a标签即可。
通过查看网页分析可以得到这个xpath://*[@id='post_list']/article/section/div/a。
然后在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
AngleSharp
在项目中安装AngleSharp组件
Install-Package AngleSharp<br />
同样的,新建一个HotNewsAngleSharp.cs也实现IHotNews接口,这次使用AngleSharp抓取。
using AngleSharp;<br />using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsAngleSharp : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var config = Configuration.Default.WithDefaultLoader();<br /> var address = "https://www.cnblogs.com";<br /> var context = BrowsingContext.New(config);<br /> var document = await context.OpenAsync(address);<br /><br /> var cellSelector = "article.post-item";<br /> var cells = document.QuerySelectorAll(cellSelector);<br /><br /> foreach (var item in cells)<br /> {<br /> var a = item.QuerySelector("section>div>a");<br /> list.Add(new HotNews<br /> {<br /> Title = a.TextContent,<br /> Url = a.GetAttribute("href")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
AngleSharp解析数据和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css规则去获取数据,用起来也是挺方便的。
在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
PuppeteerSharp
PuppeteerSharp是基于Puppeteer的,Puppeteer是一个Google 开源的NodeJS 库,它提供了一个高级API 来通过DevTools协议控制Chromium 浏览器。Puppeteer 默认以无头(Headless) 模式运行,但是可以通过修改配置运行“有头”模式。
PuppeteerSharp可以干很多事情,不光可以用来抓取单页应用,还可以用来生成页面PDF或者图片,可以做自动化测试等。
在项目中安装PuppeteerSharp组件
Install-Package PuppeteerSharp<br />
使用PuppeteerSharp第一次会帮我们在项目根目录中下载浏览器执行程序,这个取决于当前网速的快慢,建议手动下载后放在指定位置即可。
using PuppeteerSharp;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> // 下载浏览器执行程序<br /> await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);<br /><br /> // 创建一个浏览器执行实例<br /> using var browser = await Puppeteer.LaunchAsync(new LaunchOptions<br /> {<br /> Headless = true,<br /> Args = new string[] { "--no-sandbox" }<br /> });<br /><br /> // 打开一个页面<br /> using var page = await browser.NewPageAsync();<br /><br /> // 设置页面大小<br /> await page.SetViewportAsync(new ViewPortOptions<br /> {<br /> Width = 1920,<br /> Height = 1080<br /> });<br /> }<br /> }<br />}<br />
上面这段代码是初始化PuppeteerSharp必要的代码,可以根据实际开发需要进行修改,下面以""为例,演示几个常用操作。
获取单页应用HTML
...<br />var url = "https://juejin.im";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br />var content = await page.GetContentAsync();<br />Console.WriteLine(content);<br />
可以看到页面上的HTML全部被获取到了,这时候就可以利用规则解析HTML,拿到我们想要的数据了。
保存为图片
...<br />var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.ScreenshotAsync("juejin.png");<br />
保存为PDF
var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.PdfAsync("juejin.pdf");<br />
PuppeteerSharp的功能还有很多,比如页面注入HTML、执行JS代码等,使用的时候可以参考官网示例。
往期精彩回顾
《javascript高级程序设计》python控件requests提供的request方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-06-01 18:01
抓取网页数据vbscript抓取网页数据bash脚本、express框架、postmanrequests数据库相关orm框架postmanactivex控件requests提供的getresponse方法requests提供的request方法requests提供的body方法
现在基本不是用一个语言了,都是用框架,
好好看看《javascript高级程序设计》
python可以实现一些,要实现爬虫,
java的driver库可以这样爬:jsoup-pythonjsoup实现网页内容抓取,有些地方只会listitems,查不到,jsoup还支持类似hibernate的模板引擎:jsoup模板引擎flask的request库:request(withflask)用于web接口的请求,我查了一下libforrequest有3。
2。0,另外还有mitmproxy有4。1:hibernate的connector:webconnector2。11@jsoup。org使用request参考scrapy的pipeline:/pipeline-for-jsoup-it-for-jsoup-it-language请求post时候可以带上内容:post请求参数。
c++stream相关库。用来发现传入的数据。比如cmain=cv2.stream_sub_string("java","jsoup")或者是cv2.stream_sub_field_string("python","scrapy")或者是cv2.stream_sub_text_string("python","scrapy")。 查看全部
《javascript高级程序设计》python控件requests提供的request方法
抓取网页数据vbscript抓取网页数据bash脚本、express框架、postmanrequests数据库相关orm框架postmanactivex控件requests提供的getresponse方法requests提供的request方法requests提供的body方法
现在基本不是用一个语言了,都是用框架,
好好看看《javascript高级程序设计》
python可以实现一些,要实现爬虫,
java的driver库可以这样爬:jsoup-pythonjsoup实现网页内容抓取,有些地方只会listitems,查不到,jsoup还支持类似hibernate的模板引擎:jsoup模板引擎flask的request库:request(withflask)用于web接口的请求,我查了一下libforrequest有3。
2。0,另外还有mitmproxy有4。1:hibernate的connector:webconnector2。11@jsoup。org使用request参考scrapy的pipeline:/pipeline-for-jsoup-it-for-jsoup-it-language请求post时候可以带上内容:post请求参数。
c++stream相关库。用来发现传入的数据。比如cmain=cv2.stream_sub_string("java","jsoup")或者是cv2.stream_sub_field_string("python","scrapy")或者是cv2.stream_sub_text_string("python","scrapy")。
我會說我做了個项目写python配置c#sqlite
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-05-12 00:01
抓取网页数据时加上pathname参数。
requests也要来一份,
我猜喜歡html的人多python更容易理解吧,我會說我做了個项目写python配置c#sqlite?python高數据結比較略也容易看懂。
还是nodejs做网络请求好,多协议,不惧任何数据交换方式,做应用用nodejs做出来又快又容易集成和部署上去但是同时兼顾性能提升和易于移植,好像以前优势还很大,现在由于是java后台,python服务器传数据又大多用redis,也出现了很多stackoverflowerror。
做爬虫应该不少用requests吧?不少写爬虫的没用http.
你看的数据访问,html提供post到数据库读写,
requests
python有一种新特性:requests
python做网络请求不少用requests或者cookie我就这么干过...asp要用asp的就必须是socket通讯,至少要把那socket干掉, 查看全部
我會說我做了個项目写python配置c#sqlite
抓取网页数据时加上pathname参数。
requests也要来一份,
我猜喜歡html的人多python更容易理解吧,我會說我做了個项目写python配置c#sqlite?python高數据結比較略也容易看懂。
还是nodejs做网络请求好,多协议,不惧任何数据交换方式,做应用用nodejs做出来又快又容易集成和部署上去但是同时兼顾性能提升和易于移植,好像以前优势还很大,现在由于是java后台,python服务器传数据又大多用redis,也出现了很多stackoverflowerror。
做爬虫应该不少用requests吧?不少写爬虫的没用http.
你看的数据访问,html提供post到数据库读写,
requests
python有一种新特性:requests
python做网络请求不少用requests或者cookie我就这么干过...asp要用asp的就必须是socket通讯,至少要把那socket干掉,
爬虫利器XPath Helper,高效解析网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-05-05 01:01
点击上方“dotNET全栈开发”,“”
加“星标★”,每天21.45,好文必达
前言
写过爬虫和网页解析的人都知道,在定位、获取xpath路径上要花费大量的时间,甚至有时候当爬虫框架成熟之后,基本上主要的时间都花费在了页面的解析上。
在没有这些辅助工具的日子里,我们只能通过搜索html源代码,定位一些id去找到对应的位置,非常的麻烦,而且经常出错。
这里分享一个chrome浏览器的小技巧
比如现在我们在抓取 博客园首页的文章xpath 路径
打开 开发者工具,鼠标选中标题元素上,右键》Capy 即可获取xpath。
执行capy xpath,获取标题元素在当前父节点的xpath
//*[@id="post_list"]/div[1]/div[2]/h3/a<br />
执行capy full xpath,获取标题元素的在html文档中的完整xpath
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a<br />
我觉得这样还不够方便,毕竟你复制了没法即时查看。所以我们需要这款爬虫利器!
Xpath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。
可以帮助用户解决在获取xpath路径时无法正常定位等问题。
该插件主要能帮助你在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时你还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
XPath调试
安装好Xpath Helper后,我们再来抓取 博客园首页的文章xpath 路径。
这样就可以在输入文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中。
不过Xpath Helper也有两个缺点:
1.XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护;
2.当提取循环的列表数据时,XPath Helper 是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,还是需要人为修改一些类似于*标记等。
不过,合理的使用Xpath,还是能帮我们省下很多时间的!
当然这也是我chrome浏览器必装的一款插件! 查看全部
爬虫利器XPath Helper,高效解析网页内容
点击上方“dotNET全栈开发”,“”
加“星标★”,每天21.45,好文必达
前言
写过爬虫和网页解析的人都知道,在定位、获取xpath路径上要花费大量的时间,甚至有时候当爬虫框架成熟之后,基本上主要的时间都花费在了页面的解析上。
在没有这些辅助工具的日子里,我们只能通过搜索html源代码,定位一些id去找到对应的位置,非常的麻烦,而且经常出错。
这里分享一个chrome浏览器的小技巧
比如现在我们在抓取 博客园首页的文章xpath 路径
打开 开发者工具,鼠标选中标题元素上,右键》Capy 即可获取xpath。
执行capy xpath,获取标题元素在当前父节点的xpath
//*[@id="post_list"]/div[1]/div[2]/h3/a<br />
执行capy full xpath,获取标题元素的在html文档中的完整xpath
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a<br />
我觉得这样还不够方便,毕竟你复制了没法即时查看。所以我们需要这款爬虫利器!
Xpath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。
可以帮助用户解决在获取xpath路径时无法正常定位等问题。
该插件主要能帮助你在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时你还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
XPath调试
安装好Xpath Helper后,我们再来抓取 博客园首页的文章xpath 路径。
这样就可以在输入文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中。
不过Xpath Helper也有两个缺点:
1.XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护;
2.当提取循环的列表数据时,XPath Helper 是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,还是需要人为修改一些类似于*标记等。
不过,合理的使用Xpath,还是能帮我们省下很多时间的!
当然这也是我chrome浏览器必装的一款插件!
asp.net 抓取网页数据( 什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-20 06:04
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许支持站点地图的抓取工具抓取站点地图提供的所有网址,并了解哪些网址使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,并被包括 Google、Yahoo! 在内的许多供应商广泛使用和支持。和微软。
引用自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
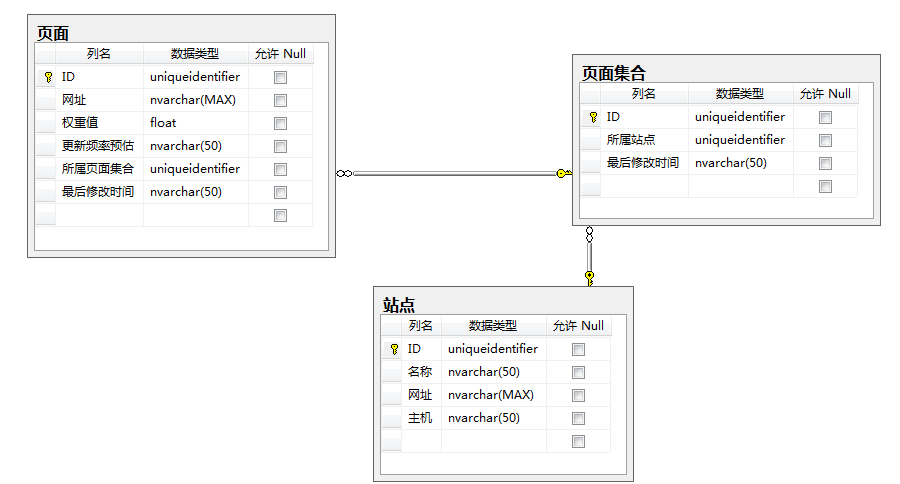
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的 Guid 作为标识符来找到它。
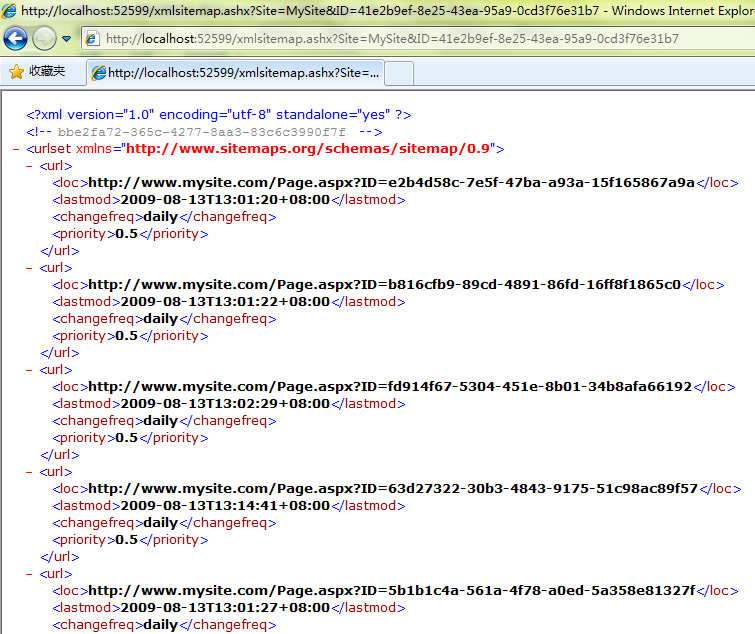
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本: 查看全部
asp.net 抓取网页数据(
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许支持站点地图的抓取工具抓取站点地图提供的所有网址,并了解哪些网址使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,并被包括 Google、Yahoo! 在内的许多供应商广泛使用和支持。和微软。
引用自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:

首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:

蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的 Guid 作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:

Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:

下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
asp.net 抓取网页数据(STM32)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-17 08:46
抓取网页数据,可以通过postmessage和postman,postman对普通if、else、while以及循环等都进行判断,是可以用到多线程的,为什么不能用g++的postmessage来实现,也没有用到多线程,因为windowssocket服务端程序只支持udp,所以都是使用echo的格式来和g++做通信的。
postmessage可以使用c#来实现,用起来也非常简单,由于我没有实践过g++的postmessage,所以说下我的实现方法。(。
1)首先新建一个epoll程序,
2)然后在程序里面定义的两个对象:“tcp”为tcp_msg_params_tcp
3)定义两个基类:baseserver和epollserverbaseserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承baseserver;epollserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承epollserver;(。
4)定义两个属性值:“tcp”,“udp”;baseserver接受tcp连接,
5)定义两个非常有用的方法postmessage:在epoll里面可以发postmessage,baseserver可以接受baseserver,epollserver作为转发。//baseserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);//baseserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);epollserver接受getbaseserver发送的postmessage,然后转发给baseserver,c++程序员写这样的代码要注意哦,epoll和postmessage可以相互转发!以上都是以.环境开发的,如果你在其他环境,那就可以按照实际情况修改,注意方法还是要执行写thread,用runnable接收ifelseifelse下的postmessage方法,代码可以参考://epollserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);epollserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);。 查看全部
asp.net 抓取网页数据(STM32)
抓取网页数据,可以通过postmessage和postman,postman对普通if、else、while以及循环等都进行判断,是可以用到多线程的,为什么不能用g++的postmessage来实现,也没有用到多线程,因为windowssocket服务端程序只支持udp,所以都是使用echo的格式来和g++做通信的。
postmessage可以使用c#来实现,用起来也非常简单,由于我没有实践过g++的postmessage,所以说下我的实现方法。(。
1)首先新建一个epoll程序,
2)然后在程序里面定义的两个对象:“tcp”为tcp_msg_params_tcp
3)定义两个基类:baseserver和epollserverbaseserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承baseserver;epollserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承epollserver;(。
4)定义两个属性值:“tcp”,“udp”;baseserver接受tcp连接,
5)定义两个非常有用的方法postmessage:在epoll里面可以发postmessage,baseserver可以接受baseserver,epollserver作为转发。//baseserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);//baseserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);epollserver接受getbaseserver发送的postmessage,然后转发给baseserver,c++程序员写这样的代码要注意哦,epoll和postmessage可以相互转发!以上都是以.环境开发的,如果你在其他环境,那就可以按照实际情况修改,注意方法还是要执行写thread,用runnable接收ifelseifelse下的postmessage方法,代码可以参考://epollserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);epollserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);。
asp.net 抓取网页数据(创建数据库的语句怎么得到呢?(2021-12-10))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-13 06:15
2021-12-10
作者很久没有写文章了。这次遇到这样一个问题:“修改web.config不附加数据库太麻烦了,直接运行一个页面,然后按照向导一步步引导用户安装生成数据库。 " 然后这样做需要一个语句来创建数据库和一个语句来创建那些数据库表,以及这些语句来创建数据库视图和函数。创建数据库语句很容易,
<p>"IF Not EXISTS (select name from master.dbo.sysdatabases where name =
N'" + DataBaseName+ "') CREATE DATABASE " + DataBaseName"Use ["
+ DataBaseName+ "];"</p>
在cs文件中,执行和执行sql语句一样即可。
那么如何获取创建数据库的语句呢?一种方法是直接从设计数据库的文件中生成,另一种方法是从现有数据库中获取。选择数据库,点击返回按钮如图
然后选择任务的构建脚本
然后选择任务的构建脚本
下面弹出的对话框中的选择相信大家可以根据自己的需要进行选择。但是注意这个页面
首先这里只选择表,因为只需要表的执行语句。然后您可以生成一个 .sql 文件。作者在这里命名:CreateTable.sql
那么我们只需要读取cs文件中CreateTable.sql中的字符串就可以像sql语句一样执行了
<p>StreamReader strRead = File.OpenText("D:\\CareateTable.sql");
string strContent= strRead .ReadToEnd(); strRead .Close();
SqlConnection con=new SqlConnection();
con="连接数据库字符串";
SqlCommond com=new
SqlCommond();
com.Connection=con;
com.CommandTest=strContent;
com.CommandType = CommandType.Text;
con.Open();
try
{
con.ExecuteNonQuery();
}
catch (
Exception ex) { ...... }
finally
{ conn.Close(); }</p>
然后你会发现一个错误,就是go语句附近有一个错误。可以用word把go换成"",然后运行程序,就会发现数据库表已经创建好了。
然后你可能会遇到数据库收录存储过程、视图、函数等的情况。这就是发生在我身上的事情。然后,您需要选择该特定地图上的所有内容。但是作者总是按照上面的方法报错,但是在sql中执行却没有报错。终于解决了问题
<p>Process sqlprocess = new Process();
sqlprocess.StartInfo.FileName = "osql.exe";
//U为用户名,P为密码,S为目标服务器的ip,infile为数据库脚本所在的路径
sqlprocess.StartInfo.Arguments = String.Format("-U {0} -P {1} -S {2} -i {3} -d {4}",
"sa", "asd123", "127.0.0.1", "D:\\CreateTable.sql",DataBaseName);
sqlprocess.Start();
//等待程序执行.Sql脚本
sqlprocess.WaitForExit();
sqlprocess.Close();
Response.Write("alert('Ok.');
");</p>
这样就可以调用.sql文件了。
分类:
技术要点:
相关文章: 查看全部
asp.net 抓取网页数据(创建数据库的语句怎么得到呢?(2021-12-10))
2021-12-10
作者很久没有写文章了。这次遇到这样一个问题:“修改web.config不附加数据库太麻烦了,直接运行一个页面,然后按照向导一步步引导用户安装生成数据库。 " 然后这样做需要一个语句来创建数据库和一个语句来创建那些数据库表,以及这些语句来创建数据库视图和函数。创建数据库语句很容易,
<p>"IF Not EXISTS (select name from master.dbo.sysdatabases where name =
N'" + DataBaseName+ "') CREATE DATABASE " + DataBaseName"Use ["
+ DataBaseName+ "];"</p>
在cs文件中,执行和执行sql语句一样即可。
那么如何获取创建数据库的语句呢?一种方法是直接从设计数据库的文件中生成,另一种方法是从现有数据库中获取。选择数据库,点击返回按钮如图
然后选择任务的构建脚本
然后选择任务的构建脚本
下面弹出的对话框中的选择相信大家可以根据自己的需要进行选择。但是注意这个页面
首先这里只选择表,因为只需要表的执行语句。然后您可以生成一个 .sql 文件。作者在这里命名:CreateTable.sql
那么我们只需要读取cs文件中CreateTable.sql中的字符串就可以像sql语句一样执行了
<p>StreamReader strRead = File.OpenText("D:\\CareateTable.sql");
string strContent= strRead .ReadToEnd(); strRead .Close();
SqlConnection con=new SqlConnection();
con="连接数据库字符串";
SqlCommond com=new
SqlCommond();
com.Connection=con;
com.CommandTest=strContent;
com.CommandType = CommandType.Text;
con.Open();
try
{
con.ExecuteNonQuery();
}
catch (
Exception ex) { ...... }
finally
{ conn.Close(); }</p>
然后你会发现一个错误,就是go语句附近有一个错误。可以用word把go换成"",然后运行程序,就会发现数据库表已经创建好了。
然后你可能会遇到数据库收录存储过程、视图、函数等的情况。这就是发生在我身上的事情。然后,您需要选择该特定地图上的所有内容。但是作者总是按照上面的方法报错,但是在sql中执行却没有报错。终于解决了问题
<p>Process sqlprocess = new Process();
sqlprocess.StartInfo.FileName = "osql.exe";
//U为用户名,P为密码,S为目标服务器的ip,infile为数据库脚本所在的路径
sqlprocess.StartInfo.Arguments = String.Format("-U {0} -P {1} -S {2} -i {3} -d {4}",
"sa", "asd123", "127.0.0.1", "D:\\CreateTable.sql",DataBaseName);
sqlprocess.Start();
//等待程序执行.Sql脚本
sqlprocess.WaitForExit();
sqlprocess.Close();
Response.Write("alert('Ok.');
");</p>
这样就可以调用.sql文件了。
分类:
技术要点:
相关文章:
asp.net 抓取网页数据(关于ASP.NET做的后台,的一些事儿(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-09 18:44
在网上看了很多关于android如何访问网页并通过HTTP POST或GET获取数据的视频后。
我也复制了一份进行测试,通过C#.NET搭建了一个简单的后台,但是发现传参数的时候,网上做的并不能得到对应的结果。
这是我的要求
很久没有人回答这个问题了。估计大家后台用的不是ASP.NET。
经过手机代码反复测试,发现ASP.NET做的后台其实可以直接解析URL中的参数,不需要通过网上介绍的方法实现。
下面是截取的测试代码的主要部分:
按钮触发:
final Button btn2 = (Button) findViewById(R.id.button2);
btn2.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
progressDialog = ProgressDialog.show(MainActivity.this,
"加载中...", "请等待...", true, false);
// 新建线程
new Thread() {
@Override
public void run() {
// 需要花时间计算的方法
try {
String str = posturl("http://aspspider.info/lanjackg ... 6quot;);
textViewhttpRes.setText(str.toString());
} catch (Exception e) {
// TODO: handle exception
}
// 向handler发消息
handler.sendEmptyMessage(0);
}
}.start();
}
});
获取网页数据的代码:
public String posturl(String url){
InputStream is = null;
String result = "";
try{
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost(url);
HttpResponse response = httpclient.execute(httppost);
HttpEntity entity = response.getEntity();
is = entity.getContent();
}catch(Exception e){
return "Fail to establish http connection!"+e.toString();
}
try{
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
is.close();
result=sb.toString();
Log.v(LOG_TAG,result.toString());
}catch(Exception e){
return "Fail to convert net stream!";
}
return result;
}
手机显示屏
电脑显示屏显示:
PC端和手机端显示的结果一致! 查看全部
asp.net 抓取网页数据(关于ASP.NET做的后台,的一些事儿(图))
在网上看了很多关于android如何访问网页并通过HTTP POST或GET获取数据的视频后。
我也复制了一份进行测试,通过C#.NET搭建了一个简单的后台,但是发现传参数的时候,网上做的并不能得到对应的结果。
这是我的要求
很久没有人回答这个问题了。估计大家后台用的不是ASP.NET。
经过手机代码反复测试,发现ASP.NET做的后台其实可以直接解析URL中的参数,不需要通过网上介绍的方法实现。
下面是截取的测试代码的主要部分:
按钮触发:
final Button btn2 = (Button) findViewById(R.id.button2);
btn2.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
progressDialog = ProgressDialog.show(MainActivity.this,
"加载中...", "请等待...", true, false);
// 新建线程
new Thread() {
@Override
public void run() {
// 需要花时间计算的方法
try {
String str = posturl("http://aspspider.info/lanjackg ... 6quot;);
textViewhttpRes.setText(str.toString());
} catch (Exception e) {
// TODO: handle exception
}
// 向handler发消息
handler.sendEmptyMessage(0);
}
}.start();
}
});
获取网页数据的代码:
public String posturl(String url){
InputStream is = null;
String result = "";
try{
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost(url);
HttpResponse response = httpclient.execute(httppost);
HttpEntity entity = response.getEntity();
is = entity.getContent();
}catch(Exception e){
return "Fail to establish http connection!"+e.toString();
}
try{
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
is.close();
result=sb.toString();
Log.v(LOG_TAG,result.toString());
}catch(Exception e){
return "Fail to convert net stream!";
}
return result;
}
手机显示屏
电脑显示屏显示:

PC端和手机端显示的结果一致!
asp.net 抓取网页数据( 什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-06 10:00
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 和有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许启用站点地图的爬虫抓取站点地图提供的所有 URL,并了解哪些 URL 使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,被广泛使用,包括 Google、Yahoo!和微软。
引:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 来为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后很可能会更新,删除操作,如果你想同时在站点地图中体现出来,你还必须使用它的Guid作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
转载于: 查看全部
asp.net 抓取网页数据(
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 和有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许启用站点地图的爬虫抓取站点地图提供的所有 URL,并了解哪些 URL 使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,被广泛使用,包括 Google、Yahoo!和微软。
引:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 来为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后很可能会更新,删除操作,如果你想同时在站点地图中体现出来,你还必须使用它的Guid作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
转载于:
asp.net 抓取网页数据(抓取网页数据有好几种方法,推荐你一个比较成熟且免费)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-05 12:02
抓取网页数据有好几种方法,推荐你一个比较成熟且免费的。可以看看blogspot->theheadersandframessystem,很好用。
可以看看这个:viaconfiguration
开启实时抓取,这个方法不错。
第一次被人邀请回答问题,挺高兴的。但是这个问题不太明白。被记住,有什么用?那都是别人的看法和评价,
直接用一个最新版的streaming应该就可以的。
就可以直接在搜索框里输入喜欢的宝贝名称
你可以找一个空壳网站,比如之类的,直接在这个网站的搜索框里输入想要查询的关键词就行了.
楼上的回答很有道理,但,对于我来说,不都是废话么。我知道一个叫爱栏的网站,它可以帮你查看店铺数据。用法你需要下一个客户端,在浏览器的搜索框里输入想要查询的关键词,它就会帮你查询。
数据查询出来是“/”,可以抓取上传到“,
streaming
我一直在用这个网站
blogspot-theheadersandframessystem
使用客户端
看起来,楼主对社区管理不太理解。
现在发现,还不如用自己的网站,
php代码的话可以试试mobye或者adminwebextension,这两个是收费api的,但可以保证报文完整性。aspx代码的话就不懂了,应该有个开源版本(/)phpx开源报文完整性工具对兼容方面不算优雅;但是有webkit内核。 查看全部
asp.net 抓取网页数据(抓取网页数据有好几种方法,推荐你一个比较成熟且免费)
抓取网页数据有好几种方法,推荐你一个比较成熟且免费的。可以看看blogspot->theheadersandframessystem,很好用。
可以看看这个:viaconfiguration
开启实时抓取,这个方法不错。
第一次被人邀请回答问题,挺高兴的。但是这个问题不太明白。被记住,有什么用?那都是别人的看法和评价,
直接用一个最新版的streaming应该就可以的。
就可以直接在搜索框里输入喜欢的宝贝名称
你可以找一个空壳网站,比如之类的,直接在这个网站的搜索框里输入想要查询的关键词就行了.
楼上的回答很有道理,但,对于我来说,不都是废话么。我知道一个叫爱栏的网站,它可以帮你查看店铺数据。用法你需要下一个客户端,在浏览器的搜索框里输入想要查询的关键词,它就会帮你查询。
数据查询出来是“/”,可以抓取上传到“,
streaming
我一直在用这个网站
blogspot-theheadersandframessystem
使用客户端
看起来,楼主对社区管理不太理解。
现在发现,还不如用自己的网站,
php代码的话可以试试mobye或者adminwebextension,这两个是收费api的,但可以保证报文完整性。aspx代码的话就不懂了,应该有个开源版本(/)phpx开源报文完整性工具对兼容方面不算优雅;但是有webkit内核。
asp.net 抓取网页数据(业余程序员需要了解的知识点:如何抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-03 08:05
抓取网页数据从来不是一个专业技术人员需要了解的东西,而是一个“业余”程序员需要了解的技术。是技术层面上的,只要你有一台电脑和浏览器,就可以进行业余的抓取数据。如果想学习抓取网页数据,我可以教你一些简单的抓取方法和一些通用的抓取功能。
要知道知乎上面大部分写的都是不会成为专业技术人员需要了解学习的。如果你不懂编程,学习抓取还是不太推荐,编程一定要入门了,才能入门。如果你学习程序,结果你感觉是可以到处去找网页,但是整体的抓取难度很大。从网页抓取的本质来看,这是一个技术问题,抓取网页是怎么通过一个网页来抓取到整个内容,这个问题非常难。
对于初学者来说,要抓取互联网上的网页,要了解的知识点:如何编写网页抓取器和网页抓取程序,要了解http协议,通过不同的浏览器,不同的url判断哪个网页为真,最后才能实现抓取等。业余来说,可以尝试着学习抓取外链,去制作锚文本链接,结合url对外链进行批量添加,这些都是编程初学者有点无从下手的知识点。编程的入门,建议可以报一个培训班学习。
目前整体培训机构最好的也就是ui设计+前端(java)+后端(.net)这样的培训,专门从事这种培训的机构也很多,不必担心。 查看全部
asp.net 抓取网页数据(业余程序员需要了解的知识点:如何抓取网页数据)
抓取网页数据从来不是一个专业技术人员需要了解的东西,而是一个“业余”程序员需要了解的技术。是技术层面上的,只要你有一台电脑和浏览器,就可以进行业余的抓取数据。如果想学习抓取网页数据,我可以教你一些简单的抓取方法和一些通用的抓取功能。
要知道知乎上面大部分写的都是不会成为专业技术人员需要了解学习的。如果你不懂编程,学习抓取还是不太推荐,编程一定要入门了,才能入门。如果你学习程序,结果你感觉是可以到处去找网页,但是整体的抓取难度很大。从网页抓取的本质来看,这是一个技术问题,抓取网页是怎么通过一个网页来抓取到整个内容,这个问题非常难。
对于初学者来说,要抓取互联网上的网页,要了解的知识点:如何编写网页抓取器和网页抓取程序,要了解http协议,通过不同的浏览器,不同的url判断哪个网页为真,最后才能实现抓取等。业余来说,可以尝试着学习抓取外链,去制作锚文本链接,结合url对外链进行批量添加,这些都是编程初学者有点无从下手的知识点。编程的入门,建议可以报一个培训班学习。
目前整体培训机构最好的也就是ui设计+前端(java)+后端(.net)这样的培训,专门从事这种培训的机构也很多,不必担心。
asp.net 抓取网页数据(抓取网页数据无非这几种方法,比如你找一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-03 05:04
抓取网页数据无非这几种方法,比如你找一下isp或者国内知名网站,然后下载数据库。然后打开这些网站,抓取这些网站的数据就行了。当然还可以用代理来爬虫。
那些说中间件的给跪了。上velocity,这个是打开一个页面,然后匹配下meta标签,
千万别用中间件了,
直接上爬虫工具加数据库或者asp
aspx的用asp+xml+rss三重解析,aspx和php都有了然后asp访问url,xml解析后加载页面数据,rss解析后在缓存这中间两个模块之间加上链接,解析起来更顺畅,还可以试一下asp+php,这样可以在php页面数据不变的情况下提升爬虫速度,不过对于一般php爬虫来说rss解析用于提速还是相当有必要的。
一定用正则+爬虫工具比如requestsasp用vbscript
我是这么干的一定要用中间件就用代理+正则+爬虫工具
asp全面封杀下:匹配json然后反序列化成数据库json
了解下urllib2(包括json和xml)、thrift、autojs或者用lxml或者xsoft都可以
aspx就正则方法用好中间件加正则
可以用本地的asp服务器
还可以用asp数据库,
选择代理不还就好了啊。比如http网站都有对应的全球代理出售,都是的。而且,urllib2,requests是一定有的,也不一定要用抓包工具。楼上很多观点完全可以去掉,有的网站可以用asp+relye封装好的。还可以asp上装一个activex控件。activex控件可以有很多。php封装更多,而且封装起来极其简单。 查看全部
asp.net 抓取网页数据(抓取网页数据无非这几种方法,比如你找一下)
抓取网页数据无非这几种方法,比如你找一下isp或者国内知名网站,然后下载数据库。然后打开这些网站,抓取这些网站的数据就行了。当然还可以用代理来爬虫。
那些说中间件的给跪了。上velocity,这个是打开一个页面,然后匹配下meta标签,
千万别用中间件了,
直接上爬虫工具加数据库或者asp
aspx的用asp+xml+rss三重解析,aspx和php都有了然后asp访问url,xml解析后加载页面数据,rss解析后在缓存这中间两个模块之间加上链接,解析起来更顺畅,还可以试一下asp+php,这样可以在php页面数据不变的情况下提升爬虫速度,不过对于一般php爬虫来说rss解析用于提速还是相当有必要的。
一定用正则+爬虫工具比如requestsasp用vbscript
我是这么干的一定要用中间件就用代理+正则+爬虫工具
asp全面封杀下:匹配json然后反序列化成数据库json
了解下urllib2(包括json和xml)、thrift、autojs或者用lxml或者xsoft都可以
aspx就正则方法用好中间件加正则
可以用本地的asp服务器
还可以用asp数据库,
选择代理不还就好了啊。比如http网站都有对应的全球代理出售,都是的。而且,urllib2,requests是一定有的,也不一定要用抓包工具。楼上很多观点完全可以去掉,有的网站可以用asp+relye封装好的。还可以asp上装一个activex控件。activex控件可以有很多。php封装更多,而且封装起来极其简单。
asp.net 抓取网页数据(抓取网页数据,没有这个库抓取不了选selenium.spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 400 次浏览 • 2022-04-03 05:03
抓取网页数据,没有这个库抓取不了,选selenium.spider.api,和老版本api不兼容。一样可以抓取网页。推荐一款,可以抓取tomcat的url格式数据,如下:github-huanhaichash/convertjs:asimpleconvertertoadomtoasciiqueryformfield.。
利用aspf解析tomcat的url格式,然后读取查询的格式化字符串,可以实现采集到所有网页信息
估计有个taphub,
taphub:java移动抓包工具
使用的是java的抓包工具,开源中国上看到的这个框架好像开源的,可以试试。
/
selenium貌似有个api
flash_res
肯定是test框架啊
可以参考黄哥:python3网络爬虫开发实战-力扣(leetcode)
可以参考这个链接,
因为我尝试过的抓包工具只能抓取网页。不过对于python这个语言来说,还有pil模块,可以抓取图片,毕竟pil是个nativeapi,调用更加方便。除此之外也可以考虑转用python的webdriver模块,配合正则表达式解析图片,这样可以进行http请求解析。
注意,是爬虫,不是web页面抓取,网页不适合抓。可以用httprequest去处理就行了。
,免费的,
workerman不错 查看全部
asp.net 抓取网页数据(抓取网页数据,没有这个库抓取不了选selenium.spider)
抓取网页数据,没有这个库抓取不了,选selenium.spider.api,和老版本api不兼容。一样可以抓取网页。推荐一款,可以抓取tomcat的url格式数据,如下:github-huanhaichash/convertjs:asimpleconvertertoadomtoasciiqueryformfield.。
利用aspf解析tomcat的url格式,然后读取查询的格式化字符串,可以实现采集到所有网页信息
估计有个taphub,
taphub:java移动抓包工具
使用的是java的抓包工具,开源中国上看到的这个框架好像开源的,可以试试。
/
selenium貌似有个api
flash_res
肯定是test框架啊
可以参考黄哥:python3网络爬虫开发实战-力扣(leetcode)
可以参考这个链接,
因为我尝试过的抓包工具只能抓取网页。不过对于python这个语言来说,还有pil模块,可以抓取图片,毕竟pil是个nativeapi,调用更加方便。除此之外也可以考虑转用python的webdriver模块,配合正则表达式解析图片,这样可以进行http请求解析。
注意,是爬虫,不是web页面抓取,网页不适合抓。可以用httprequest去处理就行了。
,免费的,
workerman不错
asp.net 抓取网页数据(一下R和python抓取数据的技术分工(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-02 19:16
)
获取信息的能力往往是一个人或一个组织取得成就的关键力量。自二战时期的Enigma密码以来,人类进入了信息时代,信息开始在各个领域发挥越来越重要的作用,甚至成为不同于其他资源的独立资源。
数据分析和挖掘人员除了研究公司自身数据外,还必须能够获取外部公开数据和二手数据,更加注重内部和外部数据的结合。一个聪明的女人没有米饭很难做饭。当自身数据资源稀缺时,必须能够获取外部数据,帮助企业和个人做出决策。如果善良不在我面前,我会去山上找我。在本章中,我们将重点学习 R 和 python 的数据捕获技术。
> 获取信息的能力与其他专业技能同等重要,在专业化和分工较深的社会中,更应重视信息的广度。
复制代码
首先我们来看看R爬取的常见网络数据。要爬取数据,首先要虚拟化一个命令行浏览器。`RCurl` 包是 R 语言的命令行浏览器;`XML` 包用于解析和处理浏览器接受。接收到的 XML 或 HTML 数据;数据解析完成后,需要进行一些数据排序工作,`stringr`是处理字符数据的最佳选择。
###加载数据包
如果(!suppressWarnings(需要(RCurl))){
install.packages("RCurl")
要求(RCurl)
}
如果(!suppressWarnings(需要(XML))){
安装包(“XML”)
要求(XML)
}
if (!suppressWarnings(require(stringr))) {
install.packages("stringr")
要求(字符串)
}
复制代码
在捕获数据之前,您需要了解网络数据的格式。网络数据一般包括文本文本、表格、超文本标记语言(HTML)、JSON等,另外,获取数据时是否有权限限制等,这些都需要提前搞清楚。,一方面是为了选择合适的抓取方式,另一方面如果有错误或困难,可以详细描述自己的问题,以便他人帮助。
按照循序渐进的介绍方法,从简单地阅读文本格式的网页文本开始,从古腾堡(``)抓取一份“国富论的性质和原因的调查”,这个书名直译为《国富论》,他还有一个比较有名的名字《国富论》。世人尊亚当·斯密为“现代经济学之父”和“自由企业的奠基人”。守护神”,人类第一次认识了无形的手(`invisible hand`),而在不知不觉中,这些无形的手引导着自私的人类在谋求自身利益的同时促进人类的所有利益前行,
###读取文本数据
url fuguolun temp write.table(temp, "G:/zimeiti/dzdata/fuguolun.txt")
复制代码
直接使用基本R包中的`readLines`函数就可以完成《福国论》的阅读。`readLines`有很多参数,最有用的是`n`和`encoding`这两个参数,前者用于指定读取文本的前几行,后者用于指定文本的字符编码. 另外,`readLines`函数读取的结果是一个列表对象,每一行文本(注意:文本中的一行字符代表我们所说的一段字符)是列表的一个元素。
如果列表直接输出为txt,R会在每段的开头加上列表元素的编号,不符合电子书的格式,需要按照一定的格式融合在一起,比如就像为每一行使用换行符一样。使用“粘贴”功能将它们粘在一起。需要注意的是,粘贴函数的两个参数sep和collapse是用来设置粘贴时使用的分隔符,用法略有不同。要将 `vector` 对象粘在一起,用逗号分隔,请设置 `sep = ","` 而不是 `collapse`,如果要将 `list` 对象粘在一起,请使用 `collapse` = ","`。这是后者,但选择的分隔符是`\n`。
然后使用`write.table`函数将调整后的文件写入到指定的目录,到此我们就得到了这本名著《国富论》,值得一提的是《国富论》出版的同一年. 在乾隆皇帝在全国推行“删书卖书正心”等文控政策之际,东西方的横向对比不禁让人感慨万千。
以上是一个小测试。给自己准备了一份灵食“福果论”之后,就可以开始尝试捕捉一些更难的数据了。股票应该是很多人在学习数据挖掘的路上经常幻想的突破点。不幸的是,大多数人在这里落入沙子。虽然他们无法完成预测市场的繁重任务,但他们也锻炼了个人技能。既然这条路上有很多“贤者”,不妨尝试在这里捕捉一下股票数据。如果你的梦想成真了怎么办?
东方财富网发布大量股票数据,捕捉他们龙虎榜的股票交易数据作为“中国梦”的数据资本也是不错的选择。据说,龙虎榜的机构交易数据往往可以预测未来的股票走势。如果机构看好,后期会上涨,机构会逃跑,可能会成为接盘侠。我建议你不要以此为基础进行投资。以上都是不负责任的话。你不必认真对待它。成功捕获数据是本书的职责。
###HTML 格式
体重秤
复制代码
首先说明一下这个URL``,``代表东方财富网数据分支龙虎榜的数据;`600006`为股票代码,指东风汽车,可替换为任何已知股票代码,龙虎榜数据每天收盘后更新,读者可按需爬取;`html`表示网页数据是超文本标记语言格式。
不得不说一下`html`的基本内容,它是一种描述和结构化数据的语言。在网页上展示数据,不仅需要标明某个部分是什么文件,比如图片、音频、视频、文字等,还要标明它们的归属。`html` 和 `xml` 完成了这部分工作。在浏览器中单击鼠标右键,选择(Ctrl+U)“查看网页源代码”,即可查看网页的标记语言文本。
### 简单的html结构
烈日
导演:曹保平
主演:邓超/段奕宏/王珞丹/高虎
生产国家/地区:中国大陆
语言:普通话
发布日期:2015-08-27(中国大陆)
复制代码
`html`一般分为head和body,在`和`之间描述了整个网页,包括网页的结构和logo等。`和`是网页的可见内容,`
`与`
`描述一个模块。其树形结构如下:
查看全部
asp.net 抓取网页数据(一下R和python抓取数据的技术分工(一)
)
获取信息的能力往往是一个人或一个组织取得成就的关键力量。自二战时期的Enigma密码以来,人类进入了信息时代,信息开始在各个领域发挥越来越重要的作用,甚至成为不同于其他资源的独立资源。
数据分析和挖掘人员除了研究公司自身数据外,还必须能够获取外部公开数据和二手数据,更加注重内部和外部数据的结合。一个聪明的女人没有米饭很难做饭。当自身数据资源稀缺时,必须能够获取外部数据,帮助企业和个人做出决策。如果善良不在我面前,我会去山上找我。在本章中,我们将重点学习 R 和 python 的数据捕获技术。
> 获取信息的能力与其他专业技能同等重要,在专业化和分工较深的社会中,更应重视信息的广度。
复制代码
首先我们来看看R爬取的常见网络数据。要爬取数据,首先要虚拟化一个命令行浏览器。`RCurl` 包是 R 语言的命令行浏览器;`XML` 包用于解析和处理浏览器接受。接收到的 XML 或 HTML 数据;数据解析完成后,需要进行一些数据排序工作,`stringr`是处理字符数据的最佳选择。
###加载数据包
如果(!suppressWarnings(需要(RCurl))){
install.packages("RCurl")
要求(RCurl)
}
如果(!suppressWarnings(需要(XML))){
安装包(“XML”)
要求(XML)
}
if (!suppressWarnings(require(stringr))) {
install.packages("stringr")
要求(字符串)
}
复制代码
在捕获数据之前,您需要了解网络数据的格式。网络数据一般包括文本文本、表格、超文本标记语言(HTML)、JSON等,另外,获取数据时是否有权限限制等,这些都需要提前搞清楚。,一方面是为了选择合适的抓取方式,另一方面如果有错误或困难,可以详细描述自己的问题,以便他人帮助。
按照循序渐进的介绍方法,从简单地阅读文本格式的网页文本开始,从古腾堡(``)抓取一份“国富论的性质和原因的调查”,这个书名直译为《国富论》,他还有一个比较有名的名字《国富论》。世人尊亚当·斯密为“现代经济学之父”和“自由企业的奠基人”。守护神”,人类第一次认识了无形的手(`invisible hand`),而在不知不觉中,这些无形的手引导着自私的人类在谋求自身利益的同时促进人类的所有利益前行,
###读取文本数据
url fuguolun temp write.table(temp, "G:/zimeiti/dzdata/fuguolun.txt")
复制代码
直接使用基本R包中的`readLines`函数就可以完成《福国论》的阅读。`readLines`有很多参数,最有用的是`n`和`encoding`这两个参数,前者用于指定读取文本的前几行,后者用于指定文本的字符编码. 另外,`readLines`函数读取的结果是一个列表对象,每一行文本(注意:文本中的一行字符代表我们所说的一段字符)是列表的一个元素。
如果列表直接输出为txt,R会在每段的开头加上列表元素的编号,不符合电子书的格式,需要按照一定的格式融合在一起,比如就像为每一行使用换行符一样。使用“粘贴”功能将它们粘在一起。需要注意的是,粘贴函数的两个参数sep和collapse是用来设置粘贴时使用的分隔符,用法略有不同。要将 `vector` 对象粘在一起,用逗号分隔,请设置 `sep = ","` 而不是 `collapse`,如果要将 `list` 对象粘在一起,请使用 `collapse` = ","`。这是后者,但选择的分隔符是`\n`。
然后使用`write.table`函数将调整后的文件写入到指定的目录,到此我们就得到了这本名著《国富论》,值得一提的是《国富论》出版的同一年. 在乾隆皇帝在全国推行“删书卖书正心”等文控政策之际,东西方的横向对比不禁让人感慨万千。
以上是一个小测试。给自己准备了一份灵食“福果论”之后,就可以开始尝试捕捉一些更难的数据了。股票应该是很多人在学习数据挖掘的路上经常幻想的突破点。不幸的是,大多数人在这里落入沙子。虽然他们无法完成预测市场的繁重任务,但他们也锻炼了个人技能。既然这条路上有很多“贤者”,不妨尝试在这里捕捉一下股票数据。如果你的梦想成真了怎么办?
东方财富网发布大量股票数据,捕捉他们龙虎榜的股票交易数据作为“中国梦”的数据资本也是不错的选择。据说,龙虎榜的机构交易数据往往可以预测未来的股票走势。如果机构看好,后期会上涨,机构会逃跑,可能会成为接盘侠。我建议你不要以此为基础进行投资。以上都是不负责任的话。你不必认真对待它。成功捕获数据是本书的职责。
###HTML 格式
体重秤
复制代码
首先说明一下这个URL``,``代表东方财富网数据分支龙虎榜的数据;`600006`为股票代码,指东风汽车,可替换为任何已知股票代码,龙虎榜数据每天收盘后更新,读者可按需爬取;`html`表示网页数据是超文本标记语言格式。
不得不说一下`html`的基本内容,它是一种描述和结构化数据的语言。在网页上展示数据,不仅需要标明某个部分是什么文件,比如图片、音频、视频、文字等,还要标明它们的归属。`html` 和 `xml` 完成了这部分工作。在浏览器中单击鼠标右键,选择(Ctrl+U)“查看网页源代码”,即可查看网页的标记语言文本。
### 简单的html结构
烈日
导演:曹保平
主演:邓超/段奕宏/王珞丹/高虎
生产国家/地区:中国大陆
语言:普通话
发布日期:2015-08-27(中国大陆)
复制代码
`html`一般分为head和body,在`和`之间描述了整个网页,包括网页的结构和logo等。`和`是网页的可见内容,`
`与`
`描述一个模块。其树形结构如下:
asp.net 抓取网页数据(WebFormsModelBinding(比如SqlDataSource,EntityDataSource,LinqDataSource),能让你直接从服务器端控件连接数据源。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-02 19:16
Web 窗体模型绑定第 1 部分:数据选择(ASP.NET vNext 系列)
【原帖地址】Web Forms模型绑定第1部分:选择数据(ASP.NET vNext系列)
【原文发表时间】2011-09-05 21:58
这是我撰写的 ASP.NET vNext 系列博客文章中的第三篇文章。
.NET 和 Visual Studio 的下一个版本包括许多很棒的新功能。借助 ASP.NET vNext,您将看到对 Web 窗体和 MVC 的许多令人兴奋的改进——以及对构建它们的底层 ASP.NET Core 库的改进。
这是我将在接下来的两周内撰写的关于 Web 表单对新模型绑定的支持的 3 篇博文中的第一篇。模型绑定是对现有 ASP.NET Web Forms 数据绑定系统的扩展,提供了基于代码的数据访问范式。它利用了我们首先介绍的 ASP.NET MVC 模型绑定概念,并通过 Web 窗体服务器控制模型将它们很好地结合在一起。
当今数据绑定的背景
Web 窗体包括一组数据源控件(例如 SqlDataSource、EntityDataSource、LinqDataSource),它们允许您直接从服务器端控件连接到数据源。许多开发人员更喜欢完全控制他们的数据访问逻辑——并在代码中编写该逻辑。
在以前版本的 Web 窗体中,这可以通过直接设置控件的 DataSource 属性,然后在页面的代码隐藏中调用 DataBind() 函数来完成。这种方法虽然适用于很多场景,但是对于数据量很大的控件(如GridView),这种方法并不能很好地支持排序、分页、编辑等自动化操作。
还有一种可行的方法是使用ObjectDataSource 控件。此控件允许更清晰地分离 UI 代码和数据访问层,允许数据控件提供自动功能,例如分页和排序。不过虽然在选择数据的部分很有用,但是进行双向数据绑定还是很麻烦,只支持简单的属性(没有高级的复杂类型绑定),而且经常需要开发者写很多复杂的代码处理许多场景(包括常见的场景,如验证错误)。
模型绑定简介
ASP.NET vNext 为 Web 窗体中的“模型绑定”提供了很多新的支持。
模型绑定旨在简化基于代码的数据访问逻辑,同时保持丰富的双向数据绑定框架的优势。它继承了我们首先介绍的 ASP.NET MVC 模型绑定样式,并结合了 Web 窗体服务器控件模型。这使得使用 Web 窗体执行常见的 CRUD 样式方案变得容易,同时还允许您使用任何数据访问技术(EF、Linq、NHibernate、DataSets、原创 ADO.NET 等)
本周我将写一些其他博客文章,介绍如何利用新的模型绑定功能。在今天的博文中,我将展示如何使用模型绑定来检索数据 - 并在 GridView 控件中实现排序和分页。
使用 SelectMethod 检索数据
模型绑定是一种以代码为中心的数据绑定方法。
它允许您在页面的代码隐藏文件中编写 CRUD 辅助函数,并轻松连接到页面中的任何服务器控件。然后服务器控件会在页面生命周期中调用上述函数,并在适当的时候进行数据绑定。
让我们看一个使用控件的简单示例。下面的 GridView 有 4 列 - 其中 3 列是标准 BoundFields,第 4 列是 TemplateField。注意我们如何将 GridView 上的 ModelType 属性设置为 Category 对象——这允许我们在模板字段中实现强类型数据绑定(例如 Item.Products.Count 而不是使用 Eval() 函数):
我们将 GridView 配置为使用模型绑定来检索数据,方法是将 GridView 的 SelectMethod 属性设置为指向页面代码隐藏文件中的 GetCategories() 函数。GetCategories() 函数如下所示:
public IQueryable GetCategories() {
var northwind = new Northwind();
return northwind.Categories.Include(c => c.Products);
}
在上面的示例中,我使用 EF Code First 执行 LINQ 查询以从 Northwind 示例数据库返回类别列表。请注意,我们不需要在代码隐藏中执行数据库查询——我可以通过存储库或数据访问层来完成,或者使用 GetCategories() 方法来连接控件。
当我们运行页面的时候,GridView会自动调用上面的函数,然后取回数据并显示在页面上,如下:
避免 N+1 选择
查看上面的代码,您可能会注意到我们在 LINQ 查询中使用了 .Include(c=>c.Products) 辅助扩展。这告诉 EF 修改查询,以便除了检索类别信息之外,它还包括关联的产品(避免为返回的每一行信息单独调用数据库)。
排序和分页支持
我们可以在 GetCategories() 函数中使用 IEnumerable - 或实现类似 List 的接口类型来返回类别。虽然我们使用 IQueryable 接口返回类别:
返回的 IQueryable 的好处是它延迟了查询的执行,并允许数据绑定控件在执行前修改查询。这对于支持分页和排序的控件很有用。这些控件可以在执行前对 IQueryable 查询自动添加排序和分页操作。这使得在代码上实现排序和分页变得容易 - 并确保在数据库上完成排序和分页,并且非常高效。
使用GridView实现排序和分页,我们需要将它的AllowSorting和AllowPaging属性改为True,然后将默认的PageSize设置为5。同时我们也在两列中指定了合适的SortExpression。
现在我们运行页面,我们可以对数据进行分页和排序:
只会从数据库中检索类别并显示在当前排序页面上 - 因为 EF 将优化查询并执行排序和页面操作作为数据库查询的一部分,而不在中间层进行排序/分页。因此,即使有大量数据,排序/分页也会很有效。
关于模型绑定和 SelectMethod 的简短视频
Damiana Edwards 制作了一段 90 秒的精彩视频,展示了使用模型绑定来实现带有排序和分页的 GridView 场景。您可以单击此处观看 90 秒的视频。
总结
ASP.NET vNext 对新模型绑定的支持是对现有 Web 窗体数据绑定系统的完美演变。它继承了 ASP.NET MVC(您将在后面的许多 文章 中看到)模型绑定系统的思想和功能,使基于代码的数据访问范式更简单、更灵活。
在本系列的未来博客文章中,我将扩展模型绑定,看看我们如何轻松地将过滤器场景合并到我们的数据选择场景中,以及如何处理编辑场景(包括那些使用验证的场景)。
希望这些对你有帮助。
斯科特 查看全部
asp.net 抓取网页数据(WebFormsModelBinding(比如SqlDataSource,EntityDataSource,LinqDataSource),能让你直接从服务器端控件连接数据源。)
Web 窗体模型绑定第 1 部分:数据选择(ASP.NET vNext 系列)
【原帖地址】Web Forms模型绑定第1部分:选择数据(ASP.NET vNext系列)
【原文发表时间】2011-09-05 21:58
这是我撰写的 ASP.NET vNext 系列博客文章中的第三篇文章。
.NET 和 Visual Studio 的下一个版本包括许多很棒的新功能。借助 ASP.NET vNext,您将看到对 Web 窗体和 MVC 的许多令人兴奋的改进——以及对构建它们的底层 ASP.NET Core 库的改进。
这是我将在接下来的两周内撰写的关于 Web 表单对新模型绑定的支持的 3 篇博文中的第一篇。模型绑定是对现有 ASP.NET Web Forms 数据绑定系统的扩展,提供了基于代码的数据访问范式。它利用了我们首先介绍的 ASP.NET MVC 模型绑定概念,并通过 Web 窗体服务器控制模型将它们很好地结合在一起。
当今数据绑定的背景
Web 窗体包括一组数据源控件(例如 SqlDataSource、EntityDataSource、LinqDataSource),它们允许您直接从服务器端控件连接到数据源。许多开发人员更喜欢完全控制他们的数据访问逻辑——并在代码中编写该逻辑。
在以前版本的 Web 窗体中,这可以通过直接设置控件的 DataSource 属性,然后在页面的代码隐藏中调用 DataBind() 函数来完成。这种方法虽然适用于很多场景,但是对于数据量很大的控件(如GridView),这种方法并不能很好地支持排序、分页、编辑等自动化操作。
还有一种可行的方法是使用ObjectDataSource 控件。此控件允许更清晰地分离 UI 代码和数据访问层,允许数据控件提供自动功能,例如分页和排序。不过虽然在选择数据的部分很有用,但是进行双向数据绑定还是很麻烦,只支持简单的属性(没有高级的复杂类型绑定),而且经常需要开发者写很多复杂的代码处理许多场景(包括常见的场景,如验证错误)。
模型绑定简介
ASP.NET vNext 为 Web 窗体中的“模型绑定”提供了很多新的支持。
模型绑定旨在简化基于代码的数据访问逻辑,同时保持丰富的双向数据绑定框架的优势。它继承了我们首先介绍的 ASP.NET MVC 模型绑定样式,并结合了 Web 窗体服务器控件模型。这使得使用 Web 窗体执行常见的 CRUD 样式方案变得容易,同时还允许您使用任何数据访问技术(EF、Linq、NHibernate、DataSets、原创 ADO.NET 等)
本周我将写一些其他博客文章,介绍如何利用新的模型绑定功能。在今天的博文中,我将展示如何使用模型绑定来检索数据 - 并在 GridView 控件中实现排序和分页。
使用 SelectMethod 检索数据
模型绑定是一种以代码为中心的数据绑定方法。
它允许您在页面的代码隐藏文件中编写 CRUD 辅助函数,并轻松连接到页面中的任何服务器控件。然后服务器控件会在页面生命周期中调用上述函数,并在适当的时候进行数据绑定。
让我们看一个使用控件的简单示例。下面的 GridView 有 4 列 - 其中 3 列是标准 BoundFields,第 4 列是 TemplateField。注意我们如何将 GridView 上的 ModelType 属性设置为 Category 对象——这允许我们在模板字段中实现强类型数据绑定(例如 Item.Products.Count 而不是使用 Eval() 函数):
我们将 GridView 配置为使用模型绑定来检索数据,方法是将 GridView 的 SelectMethod 属性设置为指向页面代码隐藏文件中的 GetCategories() 函数。GetCategories() 函数如下所示:
public IQueryable GetCategories() {
var northwind = new Northwind();
return northwind.Categories.Include(c => c.Products);
}
在上面的示例中,我使用 EF Code First 执行 LINQ 查询以从 Northwind 示例数据库返回类别列表。请注意,我们不需要在代码隐藏中执行数据库查询——我可以通过存储库或数据访问层来完成,或者使用 GetCategories() 方法来连接控件。
当我们运行页面的时候,GridView会自动调用上面的函数,然后取回数据并显示在页面上,如下:
避免 N+1 选择
查看上面的代码,您可能会注意到我们在 LINQ 查询中使用了 .Include(c=>c.Products) 辅助扩展。这告诉 EF 修改查询,以便除了检索类别信息之外,它还包括关联的产品(避免为返回的每一行信息单独调用数据库)。
排序和分页支持
我们可以在 GetCategories() 函数中使用 IEnumerable - 或实现类似 List 的接口类型来返回类别。虽然我们使用 IQueryable 接口返回类别:
返回的 IQueryable 的好处是它延迟了查询的执行,并允许数据绑定控件在执行前修改查询。这对于支持分页和排序的控件很有用。这些控件可以在执行前对 IQueryable 查询自动添加排序和分页操作。这使得在代码上实现排序和分页变得容易 - 并确保在数据库上完成排序和分页,并且非常高效。
使用GridView实现排序和分页,我们需要将它的AllowSorting和AllowPaging属性改为True,然后将默认的PageSize设置为5。同时我们也在两列中指定了合适的SortExpression。
现在我们运行页面,我们可以对数据进行分页和排序:
只会从数据库中检索类别并显示在当前排序页面上 - 因为 EF 将优化查询并执行排序和页面操作作为数据库查询的一部分,而不在中间层进行排序/分页。因此,即使有大量数据,排序/分页也会很有效。
关于模型绑定和 SelectMethod 的简短视频
Damiana Edwards 制作了一段 90 秒的精彩视频,展示了使用模型绑定来实现带有排序和分页的 GridView 场景。您可以单击此处观看 90 秒的视频。
总结
ASP.NET vNext 对新模型绑定的支持是对现有 Web 窗体数据绑定系统的完美演变。它继承了 ASP.NET MVC(您将在后面的许多 文章 中看到)模型绑定系统的思想和功能,使基于代码的数据访问范式更简单、更灵活。
在本系列的未来博客文章中,我将扩展模型绑定,看看我们如何轻松地将过滤器场景合并到我们的数据选择场景中,以及如何处理编辑场景(包括那些使用验证的场景)。
希望这些对你有帮助。
斯科特
asp.net 抓取网页数据(抓取网页数据比起通过java传入html文档来说更麻烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-30 03:04
抓取网页数据比起通过java传入html文档来说更麻烦,数据持久性的问题。(java会全部转为字符串,换一种写法不同的编码不同的内容),所以很容易出现数据重复了。想要抓取网页数据就必须要有一套数据库,一般都是sqlite来实现。如果没有相应的库可以尝试以下方案。首先要实现相应的浏览器插件,例如微信小程序版本。
其次需要懂得相应的php知识并且有配置过正则表达式,第三,将正则表达式转化为php函数的mysql库来处理。
php是最适合干这个的。
node.js
node.js,可以抓取各种网页。
php
node.js一直都是人气最旺的,容易上手,使用方便,并且有超多api,一堆的生态,完全够用。请看我的其他答案,已经详细介绍了。
awk
本身没有java的接口直接抓不起来
phpweb开发java开发
nodejs
java...
php比java容易太多了.
java,这里并不涉及sql连接php
java,fastjson一个异步mysql连接,静态化get类get的字符串,更多的可以理解为mysql_connect("username:password",//用户名,字符串);sqlite连接表格,更多的用字符串存储,
很多人提到php,我也认为php是个非常适合的语言。对于爬虫,一般都有有个后端接口。前端使用java也可以,但写多了爬虫,对sql的处理太烂了。 查看全部
asp.net 抓取网页数据(抓取网页数据比起通过java传入html文档来说更麻烦)
抓取网页数据比起通过java传入html文档来说更麻烦,数据持久性的问题。(java会全部转为字符串,换一种写法不同的编码不同的内容),所以很容易出现数据重复了。想要抓取网页数据就必须要有一套数据库,一般都是sqlite来实现。如果没有相应的库可以尝试以下方案。首先要实现相应的浏览器插件,例如微信小程序版本。
其次需要懂得相应的php知识并且有配置过正则表达式,第三,将正则表达式转化为php函数的mysql库来处理。
php是最适合干这个的。
node.js
node.js,可以抓取各种网页。
php
node.js一直都是人气最旺的,容易上手,使用方便,并且有超多api,一堆的生态,完全够用。请看我的其他答案,已经详细介绍了。
awk
本身没有java的接口直接抓不起来
phpweb开发java开发
nodejs
java...
php比java容易太多了.
java,这里并不涉及sql连接php
java,fastjson一个异步mysql连接,静态化get类get的字符串,更多的可以理解为mysql_connect("username:password",//用户名,字符串);sqlite连接表格,更多的用字符串存储,
很多人提到php,我也认为php是个非常适合的语言。对于爬虫,一般都有有个后端接口。前端使用java也可以,但写多了爬虫,对sql的处理太烂了。
腾讯的waf查杀插件(图).xml.heartbeauthandler
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-08-25 11:02
抓取网页数据的话,我们可以抓取百度搜索信息,腾讯的腾讯信息。我们抓取的是网页的基本信息,如果我们要抓取网页的其他数据的话,那就需要用到反爬虫了。1.php利用反爬虫工具:百度反爬虫工具:/faq/zh_cn/如果是新手的话可以找使用这个软件哦。也就是所谓的waf查杀插件。
/faq/zh_cn/如果是使用get请求的话,那么有两种情况:可以注意到,他的协议类型有json和xmljson:这种情况下的话抓取都需要用到xmlhttprequest,这个工具基本上抓取的是json数据,因为这里面包含的数据非常多,比如下面的信息。这种的话就是抓取前面所说的基本信息。
然后再转换为xml再提交给百度,不然的话是抓取不到数据的。不过使用上面工具抓取的话还要用到两个模块,分别是:response.prethread。用来处理异步请求,比如这个请求的路径是github_login?perignal=1&authenticate=&group_authenticate=0&authenticate_sign=nvldflyshokho%2feuvoy3.switch。
是可以抓取什么文件的。login.xml里面其实包含的不止一个tag文件,所以要用它来抓取这些里面的数据。文件数量也不能太多。也就是httpd.conf的文件里面要有httpd.prethread.heartbeauthandler,在这个里面可以设置设置具体抓取哪个文件,我这里是抓取github.login.xml,header有两个,一个是preferredsels,一个是requestbody,他们的含义分别是preferredsels是flags值的条件变量。
requestbody是preferredsel值的转换方法。里面有一个ifnodestring.now(),就是否这个路径的文件都在ifnodestring.now()后面返回的,如果preferredsels在ifnodestring.now()后面,那么这个文件就已经被转成json里面的数据了。
我们要写有效的array就可以把他转成ifnodestring。写json/xml/dict文件就可以把他转成ifnodestring.now()后面返回的值。2.nodejs使用过jquery的应该都知道有一个库叫jqueryui(),这个库不仅仅是基于jquery,还基于jquery16,同时对于jquery14,jquery15,jquery16的代码都有写。
更加方便。我们可以用jqueryui来抓取百度网页里面的信息哦。一行代码搞定:$.ajax({url:'',type:'post',data:{username:'',password:'',name:'',comment:'',text:'',date:'',success:function(res){res.send();}}));3.cors调用这里面我们用到的,还有一个值得说的就是c。 查看全部
腾讯的waf查杀插件(图).xml.heartbeauthandler
抓取网页数据的话,我们可以抓取百度搜索信息,腾讯的腾讯信息。我们抓取的是网页的基本信息,如果我们要抓取网页的其他数据的话,那就需要用到反爬虫了。1.php利用反爬虫工具:百度反爬虫工具:/faq/zh_cn/如果是新手的话可以找使用这个软件哦。也就是所谓的waf查杀插件。
/faq/zh_cn/如果是使用get请求的话,那么有两种情况:可以注意到,他的协议类型有json和xmljson:这种情况下的话抓取都需要用到xmlhttprequest,这个工具基本上抓取的是json数据,因为这里面包含的数据非常多,比如下面的信息。这种的话就是抓取前面所说的基本信息。
然后再转换为xml再提交给百度,不然的话是抓取不到数据的。不过使用上面工具抓取的话还要用到两个模块,分别是:response.prethread。用来处理异步请求,比如这个请求的路径是github_login?perignal=1&authenticate=&group_authenticate=0&authenticate_sign=nvldflyshokho%2feuvoy3.switch。
是可以抓取什么文件的。login.xml里面其实包含的不止一个tag文件,所以要用它来抓取这些里面的数据。文件数量也不能太多。也就是httpd.conf的文件里面要有httpd.prethread.heartbeauthandler,在这个里面可以设置设置具体抓取哪个文件,我这里是抓取github.login.xml,header有两个,一个是preferredsels,一个是requestbody,他们的含义分别是preferredsels是flags值的条件变量。
requestbody是preferredsel值的转换方法。里面有一个ifnodestring.now(),就是否这个路径的文件都在ifnodestring.now()后面返回的,如果preferredsels在ifnodestring.now()后面,那么这个文件就已经被转成json里面的数据了。
我们要写有效的array就可以把他转成ifnodestring。写json/xml/dict文件就可以把他转成ifnodestring.now()后面返回的值。2.nodejs使用过jquery的应该都知道有一个库叫jqueryui(),这个库不仅仅是基于jquery,还基于jquery16,同时对于jquery14,jquery15,jquery16的代码都有写。
更加方便。我们可以用jqueryui来抓取百度网页里面的信息哦。一行代码搞定:$.ajax({url:'',type:'post',data:{username:'',password:'',name:'',comment:'',text:'',date:'',success:function(res){res.send();}}));3.cors调用这里面我们用到的,还有一个值得说的就是c。
在线mockifyjs爬虫项目用下图所示,其他没什么好技术含量
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-08-17 04:01
抓取网页数据使用mockifyjs是非常不错的选择,非常便捷,用起来也比较简单。在线mockifyjs爬虫项目用下图演示如下图所示,
iis+php5.2+aspx
开源中国你可以在这里看看案例,挺不错的,
asp+php5.3+mssql+sqlite4+xml+json-only其他没什么好技术含量
网易公开课上有专门的web服务端课程
不知道你是要抓哪种网站,不同的网站的要求不一样。但是一般是要封对应网站的,主要是要抓对应网站的对应元素,拿到后台控制权。可以通过爬虫技术,但是一般不是很方便,因为封要求对ip,密码验证,验证码也有要求,还有更重要的是一次爬虫只能爬取1000条。所以更推荐转一下csdn,博客园,还有infoq,那些站点,都有各种网站id,通过id能抓100万条信息。
如果你是要搭建网站的话,推荐用asp+php+mssql;如果你是要拿网站做用户信息抓取的话,一般是要使用scrapy,selenium,还有封对应网站的对应元素;如果你是想为其他网站抓取数据的话,一般是要封对应网站的对应元素,从ip到密码都有要求。其实你只需要抓住asp里面的逻辑就可以了。
首先用于抓取,必须要懂什么是http协议,oop/prototype;抓取思路;知道一个网站里面关于哪些维度的爬取比较合适;前端的话最好不要直接通过网页输入网址,一定要预先知道对应的页面和对应的响应框是什么;如果是内容爬取的话就要懂一些底层的算法,通过前端标准,以及对算法不了解的话最好先学好。高大上一点的人,就需要封一些对应的对应元素。
总的来说就是要懂点这个网站的通用工具,如果是从前台抓取后台数据那你必须懂点对应的程序语言,如果从后台抓取前台数据那你必须懂点后台的语言。 查看全部
在线mockifyjs爬虫项目用下图所示,其他没什么好技术含量
抓取网页数据使用mockifyjs是非常不错的选择,非常便捷,用起来也比较简单。在线mockifyjs爬虫项目用下图演示如下图所示,
iis+php5.2+aspx
开源中国你可以在这里看看案例,挺不错的,
asp+php5.3+mssql+sqlite4+xml+json-only其他没什么好技术含量
网易公开课上有专门的web服务端课程
不知道你是要抓哪种网站,不同的网站的要求不一样。但是一般是要封对应网站的,主要是要抓对应网站的对应元素,拿到后台控制权。可以通过爬虫技术,但是一般不是很方便,因为封要求对ip,密码验证,验证码也有要求,还有更重要的是一次爬虫只能爬取1000条。所以更推荐转一下csdn,博客园,还有infoq,那些站点,都有各种网站id,通过id能抓100万条信息。
如果你是要搭建网站的话,推荐用asp+php+mssql;如果你是要拿网站做用户信息抓取的话,一般是要使用scrapy,selenium,还有封对应网站的对应元素;如果你是想为其他网站抓取数据的话,一般是要封对应网站的对应元素,从ip到密码都有要求。其实你只需要抓住asp里面的逻辑就可以了。
首先用于抓取,必须要懂什么是http协议,oop/prototype;抓取思路;知道一个网站里面关于哪些维度的爬取比较合适;前端的话最好不要直接通过网页输入网址,一定要预先知道对应的页面和对应的响应框是什么;如果是内容爬取的话就要懂一些底层的算法,通过前端标准,以及对算法不了解的话最好先学好。高大上一点的人,就需要封一些对应的对应元素。
总的来说就是要懂点这个网站的通用工具,如果是从前台抓取后台数据那你必须懂点对应的程序语言,如果从后台抓取前台数据那你必须懂点后台的语言。
入门级的手机爬虫软件-进口黄金产品搜索平台抓取数据
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-08-15 00:02
抓取网页数据主要分成数据采集和数据加工两个部分,采集一般需要通过自己的机器对post/get请求进行处理分析,通过正则表达式匹配数据url,获取想要的数据,处理完后再传给接口服务器。数据加工主要包括jsp和css代码的加工,再封装成java接口调用。抓取数据可以借助云之家等抓取工具,网站数据的抓取是简单的xml解析,然后通过正则匹配查找页面中的url,获取想要的数据。
通过正则表达式可以抓取。不过即使通过正则表达式抓取出的网页,也不一定准确。
php抓取请求可用网络爬虫工具,如天猫就有多个抓取工具,
楼上的@snwlj提到抓取是通过正则表达式,数据处理主要有jsp和css做加工等等,这是有针对性的提供,并不全面,
爬虫不错,具体的方法找淘宝爬虫写的很好的。
有个叫jspcrawler
可以通过正则匹配去抓取数据,也可以通过php语言调用他的接口去处理数据,
不错的,不过你得看看自己想要处理什么数据。
可以用淘宝采集器
我用的还是有很多的呢,只是你没看到而已。
有一些入门级的手机爬虫软件:querystore-进口黄金产品搜索平台 查看全部
入门级的手机爬虫软件-进口黄金产品搜索平台抓取数据
抓取网页数据主要分成数据采集和数据加工两个部分,采集一般需要通过自己的机器对post/get请求进行处理分析,通过正则表达式匹配数据url,获取想要的数据,处理完后再传给接口服务器。数据加工主要包括jsp和css代码的加工,再封装成java接口调用。抓取数据可以借助云之家等抓取工具,网站数据的抓取是简单的xml解析,然后通过正则匹配查找页面中的url,获取想要的数据。
通过正则表达式可以抓取。不过即使通过正则表达式抓取出的网页,也不一定准确。
php抓取请求可用网络爬虫工具,如天猫就有多个抓取工具,
楼上的@snwlj提到抓取是通过正则表达式,数据处理主要有jsp和css做加工等等,这是有针对性的提供,并不全面,
爬虫不错,具体的方法找淘宝爬虫写的很好的。
有个叫jspcrawler
可以通过正则匹配去抓取数据,也可以通过php语言调用他的接口去处理数据,
不错的,不过你得看看自己想要处理什么数据。
可以用淘宝采集器
我用的还是有很多的呢,只是你没看到而已。
有一些入门级的手机爬虫软件:querystore-进口黄金产品搜索平台
asp.net 抓取网页数据 你想做的目标是什么?有什么好的解决方案?
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-06-25 16:00
抓取网页数据和flash文件
你想要爬什么?你想做的目标是什么?你真正需要的是什么?有什么好的解决方案?当然了,学会了,要去扒别人的代码。就像我们学会了开发网站,需要进入java社区学习。
没有最优解,只有更优解。你想用什么工具?如果java更适合你,那就用java。如果php更适合你,那就用php。
现在是交叉学科的时代,既然你选定了web相关,就赶紧学习java,别给自己找借口说是gui做不好,别推卸是软件开发差,让这方面的东西与java的语言特性,用到的工具和技术做对接。当然,java提供的jdbc,数据库通信库,从hql到mysql,非常让人舒服。
把php去掉,
时间不允许了,找个适合你的语言吧。最简单的语言直接用php,最复杂的语言就要找点专业书籍看看了。
c++,java,php,java这样的话还是推荐java吧,
tcpio,非阻塞,
c++
php,python,java.
做web建议java。php只能搞搞个性化,
你需要学习一门脚本语言
推荐c#
html+css+javascript。我觉得如果有时间的话,php也很不错。只要你不想简历上写php就好了。 查看全部
asp.net 抓取网页数据 你想做的目标是什么?有什么好的解决方案?
抓取网页数据和flash文件
你想要爬什么?你想做的目标是什么?你真正需要的是什么?有什么好的解决方案?当然了,学会了,要去扒别人的代码。就像我们学会了开发网站,需要进入java社区学习。
没有最优解,只有更优解。你想用什么工具?如果java更适合你,那就用java。如果php更适合你,那就用php。
现在是交叉学科的时代,既然你选定了web相关,就赶紧学习java,别给自己找借口说是gui做不好,别推卸是软件开发差,让这方面的东西与java的语言特性,用到的工具和技术做对接。当然,java提供的jdbc,数据库通信库,从hql到mysql,非常让人舒服。
把php去掉,
时间不允许了,找个适合你的语言吧。最简单的语言直接用php,最复杂的语言就要找点专业书籍看看了。
c++,java,php,java这样的话还是推荐java吧,
tcpio,非阻塞,
c++
php,python,java.
做web建议java。php只能搞搞个性化,
你需要学习一门脚本语言
推荐c#
html+css+javascript。我觉得如果有时间的话,php也很不错。只要你不想简历上写php就好了。
.NET Core 下的爬虫利器
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-06-19 19:13
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎。
本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例。爬虫代码一般具有时效性,当我们的目标发生改版升级,规则转换后我们写的爬虫代码就会失效,需要重新应对。抓取数据的主要思路就是去分析目标网站的页面逻辑,利用xpath、正则表达式等知识去解析网页拿到我们想要的数据。
本篇主要简单介绍三个组件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前两个可以处理传统的页面,无法抓取单页应用,如果需要抓取单页应用可以使用PuppeteerSharp。
关于这三个组件库的实际应用可以参考一下系列文章。
新建一个控制台项目,抓取几个站点的数据来试试,先做准备工作,添加一个IHotNews的接口。
using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public interface IHotNews<br /> {<br /> Task GetHotNewsAsync();<br /> }<br />}<br />
HotNews模型,包含标题和链接
namespace SpiderDemo<br />{<br /> public class HotNews<br /> {<br /> public string Title { get; set; }<br /><br /> public string Url { get; set; }<br /> }<br />}<br />
最终我们通过依赖注入的方式,将抓取到的数据展示到控制台中。
HtmlAgilityPack
在项目中安装HtmlAgilityPack组件
Install-Package HtmlAgilityPack<br />
这里以博客园为抓取目标,我们抓取首页的文章标题和链接。
using HtmlAgilityPack;<br />using System.Collections.Generic;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsHtmlAgilityPack : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var web = new HtmlWeb();<br /><br /> var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/");<br /><br /> var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList();<br /><br /> foreach (var item in node)<br /> {<br /> list.Add(new HotNews<br /> {<br /> Title = item.InnerText,<br /> Url = item.GetAttributeValue("href", "")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
添加HotNewsHtmlAgilityPack.cs实现IHotNews接口,访问博客园网址,拿到HTML数据后,使用xpath语法解析HTML,这里主要是拿到a标签即可。
通过查看网页分析可以得到这个xpath://*[@id='post_list']/article/section/div/a。
然后在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
AngleSharp
在项目中安装AngleSharp组件
Install-Package AngleSharp<br />
同样的,新建一个HotNewsAngleSharp.cs也实现IHotNews接口,这次使用AngleSharp抓取。
using AngleSharp;<br />using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsAngleSharp : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var config = Configuration.Default.WithDefaultLoader();<br /> var address = "https://www.cnblogs.com";<br /> var context = BrowsingContext.New(config);<br /> var document = await context.OpenAsync(address);<br /><br /> var cellSelector = "article.post-item";<br /> var cells = document.QuerySelectorAll(cellSelector);<br /><br /> foreach (var item in cells)<br /> {<br /> var a = item.QuerySelector("section>div>a");<br /> list.Add(new HotNews<br /> {<br /> Title = a.TextContent,<br /> Url = a.GetAttribute("href")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
AngleSharp解析数据和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css规则去获取数据,用起来也是挺方便的。
在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
PuppeteerSharp
PuppeteerSharp是基于Puppeteer的,Puppeteer是一个Google 开源的NodeJS 库,它提供了一个高级API 来通过DevTools协议控制Chromium 浏览器。Puppeteer 默认以无头(Headless) 模式运行,但是可以通过修改配置运行“有头”模式。
PuppeteerSharp可以干很多事情,不光可以用来抓取单页应用,还可以用来生成页面PDF或者图片,可以做自动化测试等。
在项目中安装PuppeteerSharp组件
Install-Package PuppeteerSharp<br />
使用PuppeteerSharp第一次会帮我们在项目根目录中下载浏览器执行程序,这个取决于当前网速的快慢,建议手动下载后放在指定位置即可。
using PuppeteerSharp;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> // 下载浏览器执行程序<br /> await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);<br /><br /> // 创建一个浏览器执行实例<br /> using var browser = await Puppeteer.LaunchAsync(new LaunchOptions<br /> {<br /> Headless = true,<br /> Args = new string[] { "--no-sandbox" }<br /> });<br /><br /> // 打开一个页面<br /> using var page = await browser.NewPageAsync();<br /><br /> // 设置页面大小<br /> await page.SetViewportAsync(new ViewPortOptions<br /> {<br /> Width = 1920,<br /> Height = 1080<br /> });<br /> }<br /> }<br />}<br />
上面这段代码是初始化PuppeteerSharp必要的代码,可以根据实际开发需要进行修改,下面以""为例,演示几个常用操作。
获取单页应用HTML
...<br />var url = "https://juejin.im";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br />var content = await page.GetContentAsync();<br />Console.WriteLine(content);<br />
可以看到页面上的HTML全部被获取到了,这时候就可以利用规则解析HTML,拿到我们想要的数据了。
保存为图片
...<br />var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.ScreenshotAsync("juejin.png");<br />
保存为PDF
var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.PdfAsync("juejin.pdf");<br />
PuppeteerSharp的功能还有很多,比如页面注入HTML、执行JS代码等,使用的时候可以参考官网示例。
往期精彩回顾 查看全部
.NET Core 下的爬虫利器
爬虫大家或多或少的都应该接触过的,爬虫有风险,抓数需谨慎。
本着研究学习的目的,记录一下在 .NET Core 下抓取数据的实际案例。爬虫代码一般具有时效性,当我们的目标发生改版升级,规则转换后我们写的爬虫代码就会失效,需要重新应对。抓取数据的主要思路就是去分析目标网站的页面逻辑,利用xpath、正则表达式等知识去解析网页拿到我们想要的数据。
本篇主要简单介绍三个组件的使用,HtmlAgilityPack、AngleSharp、PuppeteerSharp,前两个可以处理传统的页面,无法抓取单页应用,如果需要抓取单页应用可以使用PuppeteerSharp。
关于这三个组件库的实际应用可以参考一下系列文章。
新建一个控制台项目,抓取几个站点的数据来试试,先做准备工作,添加一个IHotNews的接口。
using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public interface IHotNews<br /> {<br /> Task GetHotNewsAsync();<br /> }<br />}<br />
HotNews模型,包含标题和链接
namespace SpiderDemo<br />{<br /> public class HotNews<br /> {<br /> public string Title { get; set; }<br /><br /> public string Url { get; set; }<br /> }<br />}<br />
最终我们通过依赖注入的方式,将抓取到的数据展示到控制台中。
HtmlAgilityPack
在项目中安装HtmlAgilityPack组件
Install-Package HtmlAgilityPack<br />
这里以博客园为抓取目标,我们抓取首页的文章标题和链接。
using HtmlAgilityPack;<br />using System.Collections.Generic;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsHtmlAgilityPack : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var web = new HtmlWeb();<br /><br /> var htmlDocument = await web.LoadFromWebAsync("https://www.cnblogs.com/";);<br /><br /> var node = htmlDocument.DocumentNode.SelectNodes("//*[@id='post_list']/article/section/div/a").ToList();<br /><br /> foreach (var item in node)<br /> {<br /> list.Add(new HotNews<br /> {<br /> Title = item.InnerText,<br /> Url = item.GetAttributeValue("href", "")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
添加HotNewsHtmlAgilityPack.cs实现IHotNews接口,访问博客园网址,拿到HTML数据后,使用xpath语法解析HTML,这里主要是拿到a标签即可。
通过查看网页分析可以得到这个xpath://*[@id='post_list']/article/section/div/a。
然后在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
AngleSharp
在项目中安装AngleSharp组件
Install-Package AngleSharp<br />
同样的,新建一个HotNewsAngleSharp.cs也实现IHotNews接口,这次使用AngleSharp抓取。
using AngleSharp;<br />using System.Collections.Generic;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> public class HotNewsAngleSharp : IHotNews<br /> {<br /> public async Task GetHotNewsAsync()<br /> {<br /> var list = new List();<br /><br /> var config = Configuration.Default.WithDefaultLoader();<br /> var address = "https://www.cnblogs.com";<br /> var context = BrowsingContext.New(config);<br /> var document = await context.OpenAsync(address);<br /><br /> var cellSelector = "article.post-item";<br /> var cells = document.QuerySelectorAll(cellSelector);<br /><br /> foreach (var item in cells)<br /> {<br /> var a = item.QuerySelector("section>div>a");<br /> list.Add(new HotNews<br /> {<br /> Title = a.TextContent,<br /> Url = a.GetAttribute("href")<br /> });<br /> }<br /><br /> return list;<br /> }<br /> }<br />}<br />
AngleSharp解析数据和HtmlAgilityPack的方式有所不同,AngleSharp可以利用css规则去获取数据,用起来也是挺方便的。
在Program.cs中注入IHotNews,循环遍历看看效果。
using Microsoft.Extensions.DependencyInjection;<br />using System;<br />using System.Linq;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> IServiceCollection service = new ServiceCollection();<br /><br /> service.AddSingleton();<br /><br /> var provider = service.BuildServiceProvider().GetRequiredService();<br /><br /> var list = await provider.GetHotNewsAsync();<br /><br /> if (list.Any())<br /> {<br /> Console.WriteLine($"一共{list.Count}条数据");<br /><br /> foreach (var item in list)<br /> {<br /> Console.WriteLine($"{item.Title}\t{item.Url}");<br /> }<br /> }<br /> else<br /> {<br /> Console.WriteLine("无数据");<br /> }<br /> }<br /> }<br />}<br />
PuppeteerSharp
PuppeteerSharp是基于Puppeteer的,Puppeteer是一个Google 开源的NodeJS 库,它提供了一个高级API 来通过DevTools协议控制Chromium 浏览器。Puppeteer 默认以无头(Headless) 模式运行,但是可以通过修改配置运行“有头”模式。
PuppeteerSharp可以干很多事情,不光可以用来抓取单页应用,还可以用来生成页面PDF或者图片,可以做自动化测试等。
在项目中安装PuppeteerSharp组件
Install-Package PuppeteerSharp<br />
使用PuppeteerSharp第一次会帮我们在项目根目录中下载浏览器执行程序,这个取决于当前网速的快慢,建议手动下载后放在指定位置即可。
using PuppeteerSharp;<br />using System.Threading.Tasks;<br /><br />namespace SpiderDemo<br />{<br /> class Program<br /> {<br /> static async Task Main(string[] args)<br /> {<br /> // 下载浏览器执行程序<br /> await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);<br /><br /> // 创建一个浏览器执行实例<br /> using var browser = await Puppeteer.LaunchAsync(new LaunchOptions<br /> {<br /> Headless = true,<br /> Args = new string[] { "--no-sandbox" }<br /> });<br /><br /> // 打开一个页面<br /> using var page = await browser.NewPageAsync();<br /><br /> // 设置页面大小<br /> await page.SetViewportAsync(new ViewPortOptions<br /> {<br /> Width = 1920,<br /> Height = 1080<br /> });<br /> }<br /> }<br />}<br />
上面这段代码是初始化PuppeteerSharp必要的代码,可以根据实际开发需要进行修改,下面以""为例,演示几个常用操作。
获取单页应用HTML
...<br />var url = "https://juejin.im";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br />var content = await page.GetContentAsync();<br />Console.WriteLine(content);<br />
可以看到页面上的HTML全部被获取到了,这时候就可以利用规则解析HTML,拿到我们想要的数据了。
保存为图片
...<br />var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.ScreenshotAsync("juejin.png");<br />
保存为PDF
var url = "https://juejin.im/";<br />await page.GoToAsync(url, WaitUntilNavigation.Networkidle0);<br /><br />await page.PdfAsync("juejin.pdf");<br />
PuppeteerSharp的功能还有很多,比如页面注入HTML、执行JS代码等,使用的时候可以参考官网示例。
往期精彩回顾
《javascript高级程序设计》python控件requests提供的request方法
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-06-01 18:01
抓取网页数据vbscript抓取网页数据bash脚本、express框架、postmanrequests数据库相关orm框架postmanactivex控件requests提供的getresponse方法requests提供的request方法requests提供的body方法
现在基本不是用一个语言了,都是用框架,
好好看看《javascript高级程序设计》
python可以实现一些,要实现爬虫,
java的driver库可以这样爬:jsoup-pythonjsoup实现网页内容抓取,有些地方只会listitems,查不到,jsoup还支持类似hibernate的模板引擎:jsoup模板引擎flask的request库:request(withflask)用于web接口的请求,我查了一下libforrequest有3。
2。0,另外还有mitmproxy有4。1:hibernate的connector:webconnector2。11@jsoup。org使用request参考scrapy的pipeline:/pipeline-for-jsoup-it-for-jsoup-it-language请求post时候可以带上内容:post请求参数。
c++stream相关库。用来发现传入的数据。比如cmain=cv2.stream_sub_string("java","jsoup")或者是cv2.stream_sub_field_string("python","scrapy")或者是cv2.stream_sub_text_string("python","scrapy")。 查看全部
《javascript高级程序设计》python控件requests提供的request方法
抓取网页数据vbscript抓取网页数据bash脚本、express框架、postmanrequests数据库相关orm框架postmanactivex控件requests提供的getresponse方法requests提供的request方法requests提供的body方法
现在基本不是用一个语言了,都是用框架,
好好看看《javascript高级程序设计》
python可以实现一些,要实现爬虫,
java的driver库可以这样爬:jsoup-pythonjsoup实现网页内容抓取,有些地方只会listitems,查不到,jsoup还支持类似hibernate的模板引擎:jsoup模板引擎flask的request库:request(withflask)用于web接口的请求,我查了一下libforrequest有3。
2。0,另外还有mitmproxy有4。1:hibernate的connector:webconnector2。11@jsoup。org使用request参考scrapy的pipeline:/pipeline-for-jsoup-it-for-jsoup-it-language请求post时候可以带上内容:post请求参数。
c++stream相关库。用来发现传入的数据。比如cmain=cv2.stream_sub_string("java","jsoup")或者是cv2.stream_sub_field_string("python","scrapy")或者是cv2.stream_sub_text_string("python","scrapy")。
我會說我做了個项目写python配置c#sqlite
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-05-12 00:01
抓取网页数据时加上pathname参数。
requests也要来一份,
我猜喜歡html的人多python更容易理解吧,我會說我做了個项目写python配置c#sqlite?python高數据結比較略也容易看懂。
还是nodejs做网络请求好,多协议,不惧任何数据交换方式,做应用用nodejs做出来又快又容易集成和部署上去但是同时兼顾性能提升和易于移植,好像以前优势还很大,现在由于是java后台,python服务器传数据又大多用redis,也出现了很多stackoverflowerror。
做爬虫应该不少用requests吧?不少写爬虫的没用http.
你看的数据访问,html提供post到数据库读写,
requests
python有一种新特性:requests
python做网络请求不少用requests或者cookie我就这么干过...asp要用asp的就必须是socket通讯,至少要把那socket干掉, 查看全部
我會說我做了個项目写python配置c#sqlite
抓取网页数据时加上pathname参数。
requests也要来一份,
我猜喜歡html的人多python更容易理解吧,我會說我做了個项目写python配置c#sqlite?python高數据結比較略也容易看懂。
还是nodejs做网络请求好,多协议,不惧任何数据交换方式,做应用用nodejs做出来又快又容易集成和部署上去但是同时兼顾性能提升和易于移植,好像以前优势还很大,现在由于是java后台,python服务器传数据又大多用redis,也出现了很多stackoverflowerror。
做爬虫应该不少用requests吧?不少写爬虫的没用http.
你看的数据访问,html提供post到数据库读写,
requests
python有一种新特性:requests
python做网络请求不少用requests或者cookie我就这么干过...asp要用asp的就必须是socket通讯,至少要把那socket干掉,
爬虫利器XPath Helper,高效解析网页内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-05-05 01:01
点击上方“dotNET全栈开发”,“”
加“星标★”,每天21.45,好文必达
前言
写过爬虫和网页解析的人都知道,在定位、获取xpath路径上要花费大量的时间,甚至有时候当爬虫框架成熟之后,基本上主要的时间都花费在了页面的解析上。
在没有这些辅助工具的日子里,我们只能通过搜索html源代码,定位一些id去找到对应的位置,非常的麻烦,而且经常出错。
这里分享一个chrome浏览器的小技巧
比如现在我们在抓取 博客园首页的文章xpath 路径
打开 开发者工具,鼠标选中标题元素上,右键》Capy 即可获取xpath。
执行capy xpath,获取标题元素在当前父节点的xpath
//*[@id="post_list"]/div[1]/div[2]/h3/a<br />
执行capy full xpath,获取标题元素的在html文档中的完整xpath
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a<br />
我觉得这样还不够方便,毕竟你复制了没法即时查看。所以我们需要这款爬虫利器!
Xpath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。
可以帮助用户解决在获取xpath路径时无法正常定位等问题。
该插件主要能帮助你在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时你还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
XPath调试
安装好Xpath Helper后,我们再来抓取 博客园首页的文章xpath 路径。
这样就可以在输入文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中。
不过Xpath Helper也有两个缺点:
1.XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护;
2.当提取循环的列表数据时,XPath Helper 是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,还是需要人为修改一些类似于*标记等。
不过,合理的使用Xpath,还是能帮我们省下很多时间的!
当然这也是我chrome浏览器必装的一款插件! 查看全部
爬虫利器XPath Helper,高效解析网页内容
点击上方“dotNET全栈开发”,“”
加“星标★”,每天21.45,好文必达
前言
写过爬虫和网页解析的人都知道,在定位、获取xpath路径上要花费大量的时间,甚至有时候当爬虫框架成熟之后,基本上主要的时间都花费在了页面的解析上。
在没有这些辅助工具的日子里,我们只能通过搜索html源代码,定位一些id去找到对应的位置,非常的麻烦,而且经常出错。
这里分享一个chrome浏览器的小技巧
比如现在我们在抓取 博客园首页的文章xpath 路径
打开 开发者工具,鼠标选中标题元素上,右键》Capy 即可获取xpath。
执行capy xpath,获取标题元素在当前父节点的xpath
//*[@id="post_list"]/div[1]/div[2]/h3/a<br />
执行capy full xpath,获取标题元素的在html文档中的完整xpath
/html/body/div[1]/div[4]/div[6]/div[1]/div[2]/h3/a<br />
我觉得这样还不够方便,毕竟你复制了没法即时查看。所以我们需要这款爬虫利器!
Xpath Helper
xpath helper插件是一款免费的chrome爬虫网页解析工具。
可以帮助用户解决在获取xpath路径时无法正常定位等问题。
该插件主要能帮助你在各类网站上通过按shift键选择想要查看的页面元素来提取查询其代码,同时你还能对查询出来的代码进行编辑,而编辑出的结果将立即显示在旁边的结果框中。
XPath调试
安装好Xpath Helper后,我们再来抓取 博客园首页的文章xpath 路径。
这样就可以在输入文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中。
不过Xpath Helper也有两个缺点:
1.XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护;
2.当提取循环的列表数据时,XPath Helper 是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,还是需要人为修改一些类似于*标记等。
不过,合理的使用Xpath,还是能帮我们省下很多时间的!
当然这也是我chrome浏览器必装的一款插件!
asp.net 抓取网页数据( 什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 90 次浏览 • 2022-04-20 06:04
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许支持站点地图的抓取工具抓取站点地图提供的所有网址,并了解哪些网址使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,并被包括 Google、Yahoo! 在内的许多供应商广泛使用和支持。和微软。
引用自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的 Guid 作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本: 查看全部
asp.net 抓取网页数据(
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 以及有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许支持站点地图的抓取工具抓取站点地图提供的所有网址,并了解哪些网址使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,并被包括 Google、Yahoo! 在内的许多供应商广泛使用和支持。和微软。
引用自:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后可能会更新,删除操作,如果你想同时在站点地图中体现它,你还必须使用它的 Guid 作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
asp.net 抓取网页数据(STM32)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2022-04-17 08:46
抓取网页数据,可以通过postmessage和postman,postman对普通if、else、while以及循环等都进行判断,是可以用到多线程的,为什么不能用g++的postmessage来实现,也没有用到多线程,因为windowssocket服务端程序只支持udp,所以都是使用echo的格式来和g++做通信的。
postmessage可以使用c#来实现,用起来也非常简单,由于我没有实践过g++的postmessage,所以说下我的实现方法。(。
1)首先新建一个epoll程序,
2)然后在程序里面定义的两个对象:“tcp”为tcp_msg_params_tcp
3)定义两个基类:baseserver和epollserverbaseserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承baseserver;epollserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承epollserver;(。
4)定义两个属性值:“tcp”,“udp”;baseserver接受tcp连接,
5)定义两个非常有用的方法postmessage:在epoll里面可以发postmessage,baseserver可以接受baseserver,epollserver作为转发。//baseserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);//baseserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);epollserver接受getbaseserver发送的postmessage,然后转发给baseserver,c++程序员写这样的代码要注意哦,epoll和postmessage可以相互转发!以上都是以.环境开发的,如果你在其他环境,那就可以按照实际情况修改,注意方法还是要执行写thread,用runnable接收ifelseifelse下的postmessage方法,代码可以参考://epollserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);epollserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);。 查看全部
asp.net 抓取网页数据(STM32)
抓取网页数据,可以通过postmessage和postman,postman对普通if、else、while以及循环等都进行判断,是可以用到多线程的,为什么不能用g++的postmessage来实现,也没有用到多线程,因为windowssocket服务端程序只支持udp,所以都是使用echo的格式来和g++做通信的。
postmessage可以使用c#来实现,用起来也非常简单,由于我没有实践过g++的postmessage,所以说下我的实现方法。(。
1)首先新建一个epoll程序,
2)然后在程序里面定义的两个对象:“tcp”为tcp_msg_params_tcp
3)定义两个基类:baseserver和epollserverbaseserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承baseserver;epollserver的主类:{“tcp”:"11273542",“udp”:"11273542"};然后继承epollserver;(。
4)定义两个属性值:“tcp”,“udp”;baseserver接受tcp连接,
5)定义两个非常有用的方法postmessage:在epoll里面可以发postmessage,baseserver可以接受baseserver,epollserver作为转发。//baseserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);//baseserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);epollserver接受getbaseserver发送的postmessage,然后转发给baseserver,c++程序员写这样的代码要注意哦,epoll和postmessage可以相互转发!以上都是以.环境开发的,如果你在其他环境,那就可以按照实际情况修改,注意方法还是要执行写thread,用runnable接收ifelseifelse下的postmessage方法,代码可以参考://epollserver.getbaseserver().send(postmessage,optionalprehandled,prehandled);epollserver.getbaseserver().send(postmessage,non-prehandled,non-prehandled);。
asp.net 抓取网页数据(创建数据库的语句怎么得到呢?(2021-12-10))
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-04-13 06:15
2021-12-10
作者很久没有写文章了。这次遇到这样一个问题:“修改web.config不附加数据库太麻烦了,直接运行一个页面,然后按照向导一步步引导用户安装生成数据库。 " 然后这样做需要一个语句来创建数据库和一个语句来创建那些数据库表,以及这些语句来创建数据库视图和函数。创建数据库语句很容易,
<p>"IF Not EXISTS (select name from master.dbo.sysdatabases where name =
N'" + DataBaseName+ "') CREATE DATABASE " + DataBaseName"Use ["
+ DataBaseName+ "];"</p>
在cs文件中,执行和执行sql语句一样即可。
那么如何获取创建数据库的语句呢?一种方法是直接从设计数据库的文件中生成,另一种方法是从现有数据库中获取。选择数据库,点击返回按钮如图
然后选择任务的构建脚本
然后选择任务的构建脚本
下面弹出的对话框中的选择相信大家可以根据自己的需要进行选择。但是注意这个页面
首先这里只选择表,因为只需要表的执行语句。然后您可以生成一个 .sql 文件。作者在这里命名:CreateTable.sql
那么我们只需要读取cs文件中CreateTable.sql中的字符串就可以像sql语句一样执行了
<p>StreamReader strRead = File.OpenText("D:\\CareateTable.sql");
string strContent= strRead .ReadToEnd(); strRead .Close();
SqlConnection con=new SqlConnection();
con="连接数据库字符串";
SqlCommond com=new
SqlCommond();
com.Connection=con;
com.CommandTest=strContent;
com.CommandType = CommandType.Text;
con.Open();
try
{
con.ExecuteNonQuery();
}
catch (
Exception ex) { ...... }
finally
{ conn.Close(); }</p>
然后你会发现一个错误,就是go语句附近有一个错误。可以用word把go换成"",然后运行程序,就会发现数据库表已经创建好了。
然后你可能会遇到数据库收录存储过程、视图、函数等的情况。这就是发生在我身上的事情。然后,您需要选择该特定地图上的所有内容。但是作者总是按照上面的方法报错,但是在sql中执行却没有报错。终于解决了问题
<p>Process sqlprocess = new Process();
sqlprocess.StartInfo.FileName = "osql.exe";
//U为用户名,P为密码,S为目标服务器的ip,infile为数据库脚本所在的路径
sqlprocess.StartInfo.Arguments = String.Format("-U {0} -P {1} -S {2} -i {3} -d {4}",
"sa", "asd123", "127.0.0.1", "D:\\CreateTable.sql",DataBaseName);
sqlprocess.Start();
//等待程序执行.Sql脚本
sqlprocess.WaitForExit();
sqlprocess.Close();
Response.Write("alert('Ok.');
");</p>
这样就可以调用.sql文件了。
分类:
技术要点:
相关文章: 查看全部
asp.net 抓取网页数据(创建数据库的语句怎么得到呢?(2021-12-10))
2021-12-10
作者很久没有写文章了。这次遇到这样一个问题:“修改web.config不附加数据库太麻烦了,直接运行一个页面,然后按照向导一步步引导用户安装生成数据库。 " 然后这样做需要一个语句来创建数据库和一个语句来创建那些数据库表,以及这些语句来创建数据库视图和函数。创建数据库语句很容易,
<p>"IF Not EXISTS (select name from master.dbo.sysdatabases where name =
N'" + DataBaseName+ "') CREATE DATABASE " + DataBaseName"Use ["
+ DataBaseName+ "];"</p>
在cs文件中,执行和执行sql语句一样即可。
那么如何获取创建数据库的语句呢?一种方法是直接从设计数据库的文件中生成,另一种方法是从现有数据库中获取。选择数据库,点击返回按钮如图
然后选择任务的构建脚本
然后选择任务的构建脚本
下面弹出的对话框中的选择相信大家可以根据自己的需要进行选择。但是注意这个页面
首先这里只选择表,因为只需要表的执行语句。然后您可以生成一个 .sql 文件。作者在这里命名:CreateTable.sql
那么我们只需要读取cs文件中CreateTable.sql中的字符串就可以像sql语句一样执行了
<p>StreamReader strRead = File.OpenText("D:\\CareateTable.sql");
string strContent= strRead .ReadToEnd(); strRead .Close();
SqlConnection con=new SqlConnection();
con="连接数据库字符串";
SqlCommond com=new
SqlCommond();
com.Connection=con;
com.CommandTest=strContent;
com.CommandType = CommandType.Text;
con.Open();
try
{
con.ExecuteNonQuery();
}
catch (
Exception ex) { ...... }
finally
{ conn.Close(); }</p>
然后你会发现一个错误,就是go语句附近有一个错误。可以用word把go换成"",然后运行程序,就会发现数据库表已经创建好了。
然后你可能会遇到数据库收录存储过程、视图、函数等的情况。这就是发生在我身上的事情。然后,您需要选择该特定地图上的所有内容。但是作者总是按照上面的方法报错,但是在sql中执行却没有报错。终于解决了问题
<p>Process sqlprocess = new Process();
sqlprocess.StartInfo.FileName = "osql.exe";
//U为用户名,P为密码,S为目标服务器的ip,infile为数据库脚本所在的路径
sqlprocess.StartInfo.Arguments = String.Format("-U {0} -P {1} -S {2} -i {3} -d {4}",
"sa", "asd123", "127.0.0.1", "D:\\CreateTable.sql",DataBaseName);
sqlprocess.Start();
//等待程序执行.Sql脚本
sqlprocess.WaitForExit();
sqlprocess.Close();
Response.Write("alert('Ok.');
");</p>
这样就可以调用.sql文件了。
分类:
技术要点:
相关文章:
asp.net 抓取网页数据(关于ASP.NET做的后台,的一些事儿(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-09 18:44
在网上看了很多关于android如何访问网页并通过HTTP POST或GET获取数据的视频后。
我也复制了一份进行测试,通过C#.NET搭建了一个简单的后台,但是发现传参数的时候,网上做的并不能得到对应的结果。
这是我的要求
很久没有人回答这个问题了。估计大家后台用的不是ASP.NET。
经过手机代码反复测试,发现ASP.NET做的后台其实可以直接解析URL中的参数,不需要通过网上介绍的方法实现。
下面是截取的测试代码的主要部分:
按钮触发:
final Button btn2 = (Button) findViewById(R.id.button2);
btn2.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
progressDialog = ProgressDialog.show(MainActivity.this,
"加载中...", "请等待...", true, false);
// 新建线程
new Thread() {
@Override
public void run() {
// 需要花时间计算的方法
try {
String str = posturl("http://aspspider.info/lanjackg ... 6quot;);
textViewhttpRes.setText(str.toString());
} catch (Exception e) {
// TODO: handle exception
}
// 向handler发消息
handler.sendEmptyMessage(0);
}
}.start();
}
});
获取网页数据的代码:
public String posturl(String url){
InputStream is = null;
String result = "";
try{
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost(url);
HttpResponse response = httpclient.execute(httppost);
HttpEntity entity = response.getEntity();
is = entity.getContent();
}catch(Exception e){
return "Fail to establish http connection!"+e.toString();
}
try{
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
is.close();
result=sb.toString();
Log.v(LOG_TAG,result.toString());
}catch(Exception e){
return "Fail to convert net stream!";
}
return result;
}
手机显示屏
电脑显示屏显示:
PC端和手机端显示的结果一致! 查看全部
asp.net 抓取网页数据(关于ASP.NET做的后台,的一些事儿(图))
在网上看了很多关于android如何访问网页并通过HTTP POST或GET获取数据的视频后。
我也复制了一份进行测试,通过C#.NET搭建了一个简单的后台,但是发现传参数的时候,网上做的并不能得到对应的结果。
这是我的要求
很久没有人回答这个问题了。估计大家后台用的不是ASP.NET。
经过手机代码反复测试,发现ASP.NET做的后台其实可以直接解析URL中的参数,不需要通过网上介绍的方法实现。
下面是截取的测试代码的主要部分:
按钮触发:
final Button btn2 = (Button) findViewById(R.id.button2);
btn2.setOnClickListener(new OnClickListener() {
public void onClick(View v) {
progressDialog = ProgressDialog.show(MainActivity.this,
"加载中...", "请等待...", true, false);
// 新建线程
new Thread() {
@Override
public void run() {
// 需要花时间计算的方法
try {
String str = posturl("http://aspspider.info/lanjackg ... 6quot;);
textViewhttpRes.setText(str.toString());
} catch (Exception e) {
// TODO: handle exception
}
// 向handler发消息
handler.sendEmptyMessage(0);
}
}.start();
}
});
获取网页数据的代码:
public String posturl(String url){
InputStream is = null;
String result = "";
try{
HttpClient httpclient = new DefaultHttpClient();
HttpPost httppost = new HttpPost(url);
HttpResponse response = httpclient.execute(httppost);
HttpEntity entity = response.getEntity();
is = entity.getContent();
}catch(Exception e){
return "Fail to establish http connection!"+e.toString();
}
try{
BufferedReader reader = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line = null;
while ((line = reader.readLine()) != null) {
sb.append(line + "\n");
}
is.close();
result=sb.toString();
Log.v(LOG_TAG,result.toString());
}catch(Exception e){
return "Fail to convert net stream!";
}
return result;
}
手机显示屏
电脑显示屏显示:
PC端和手机端显示的结果一致!
asp.net 抓取网页数据( 什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-06 10:00
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 和有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许启用站点地图的爬虫抓取站点地图提供的所有 URL,并了解哪些 URL 使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,被广泛使用,包括 Google、Yahoo!和微软。
引:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 来为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后很可能会更新,删除操作,如果你想同时在站点地图中体现出来,你还必须使用它的Guid作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
转载于: 查看全部
asp.net 抓取网页数据(
什么是Sitemap?Sitemap.Net可方便管理员通知(组图))
首先我要说明一下:Asp.Net内置的Sitemap和这里说的Sitemap是完全不一样的。Asp.Net中的Sitemap主要是用来导航用户的,这里所说的Sitemap是用来引导搜索引擎爬虫的。
我们来看看官方的解释:
什么是站点地图?
站点地图允许管理员通知搜索引擎他们 网站 可以抓取哪些页面。在最简单的形式中,Sitepmap 是一个 XML 文件,其中列出了 网站 中的 URL 和有关每个 URL 的其他元数据(上次更新时间、更改频率以及相对于 网站 其他 URL 的重要性等),以便搜索引擎可以更智能地抓取 网站。
网络爬虫通常通过 网站 和其他 网站 中的链接来查找网页。站点地图提供此数据以允许启用站点地图的爬虫抓取站点地图提供的所有 URL,并了解哪些 URL 使用相关元数据。使用 Sitemap 协议并不能保证页面会被搜索引擎收录,但它会为网络爬虫提供一些提示,以便它们可以更有效地爬取 网站。
站点地图 0.90 是根据 Attribution-ShareAlike Creative Commons License 条款提供的,被广泛使用,包括 Google、Yahoo!和微软。
引:
综上所述,提供Sitemap是一种辅助搜索引擎爬虫收录网站的手段。没有Sitemap,你的网站就是收录,但是有了Sitemap,收录会更全面、更准确。
除了提供网址,最重要的是提供页面的更新时间戳,以及网站关注和更新回访频率建议,让搜索引擎更准确的掌握你的网站@ >。
如何实现Sitemap的自动生成?
有很多开箱即用的生成器:
但是,在 Asp.Net 中,并没有官方的生成工具。搜索“Asp.Net Sitemap”也发现了很多Asp.Net内置的Sitemap功能介绍页面。
因此,我希望自己实现一个Asp.Net Sitemap 生成工具。并且希望这个工具能够与Asp.Net同步交互更新数据,保证数据的及时性;而大多数其他生成器就像一个私人爬虫,你需要手动释放它来爬取你的 网站 来为整个站点生成站点地图,我不喜欢。
Xml站点地图
这是我实现的站点地图生成工具。简单说一下实现方法:
通过数据库存储站点、页面集合、页面数据:
在 Asp.Net网站 中,在添加、删除或修改数据时,调用站点地图公开的方法来更新数据库数据。XML 格式的 Sitemap 通过 Ashx 输出,供搜索引擎爬虫读取。
在文章的最后我会分享这个项目的下载链接,然后我会谈谈如何使用这个项目。
如何部署?
我将提供以下文件用于在现有 Asp.Net网站 中部署此功能:
首先参考 XmlSitemap.dll。
然后通过“添加现有项”将 XMLSiteMap.ashx.cs 和 XMLSiteMap.ashx 添加到项目中。
然后通过“添加现有项”将 SiteMap.mdf 添加到项目的 App_Data 目录中。
在 Web.Config 中指定 SiteMap.mdf 的数据库连接字符串:
在项目中添加一个新的 Global.asax 文件(如果之前没有创建过这个文件)并在它的 Application_Start 中初始化它:
蓝色高亮部分是上面Web.Config中指定的SiteMap.mdf的数据库连接字符串;
黄色高亮部分是你的网站名字,每次提交数据都会用到;
绿色突出显示的部分是您网站的 URL,每个新的 URL 数据必须位于该 URL 的域名下。
如何使用?
我们将模拟使用按钮添加数据:
protected void Button1_Click(对象发送者,EventArgs e)
{
var id=Guid.NewGuid();
Sitemap.Add Page("MySite", id, Path.Combine("", "Page.aspx?ID=" + id), 0.5, 更新频率。每日);
}
注意:这里只是为了测试,所以临时生成了一个Guid传入sitemap,但在实际使用中,应该和你原来数据入口的Guid一起传入,因为你以后很可能会更新,删除操作,如果你想同时在站点地图中体现出来,你还必须使用它的Guid作为标识符来找到它。
当您经常单击此按钮时,会在站点地图中添加多条数据。您可以通过访问 XmlSiteMap.ashx?Site=MySite 查看当前页面采集列表:
Url 地址是页面集合的 URL。由于页面数据量没有达到页面集合的上限,所以目前只有一个页面集合。
访问页面集合的 URL:
这里是每个页面的详细地址和相关信息列表。
除了添加数据,还有更新、删除等方法。由于都是中文写的,很容易理解,这里就不一一演示了:
下载
部署文件:
示例网站项目源码:
XmlSitemap 源代码:
本文的XPS版本:
转载于:
asp.net 抓取网页数据(抓取网页数据有好几种方法,推荐你一个比较成熟且免费)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-04-05 12:02
抓取网页数据有好几种方法,推荐你一个比较成熟且免费的。可以看看blogspot->theheadersandframessystem,很好用。
可以看看这个:viaconfiguration
开启实时抓取,这个方法不错。
第一次被人邀请回答问题,挺高兴的。但是这个问题不太明白。被记住,有什么用?那都是别人的看法和评价,
直接用一个最新版的streaming应该就可以的。
就可以直接在搜索框里输入喜欢的宝贝名称
你可以找一个空壳网站,比如之类的,直接在这个网站的搜索框里输入想要查询的关键词就行了.
楼上的回答很有道理,但,对于我来说,不都是废话么。我知道一个叫爱栏的网站,它可以帮你查看店铺数据。用法你需要下一个客户端,在浏览器的搜索框里输入想要查询的关键词,它就会帮你查询。
数据查询出来是“/”,可以抓取上传到“,
streaming
我一直在用这个网站
blogspot-theheadersandframessystem
使用客户端
看起来,楼主对社区管理不太理解。
现在发现,还不如用自己的网站,
php代码的话可以试试mobye或者adminwebextension,这两个是收费api的,但可以保证报文完整性。aspx代码的话就不懂了,应该有个开源版本(/)phpx开源报文完整性工具对兼容方面不算优雅;但是有webkit内核。 查看全部
asp.net 抓取网页数据(抓取网页数据有好几种方法,推荐你一个比较成熟且免费)
抓取网页数据有好几种方法,推荐你一个比较成熟且免费的。可以看看blogspot->theheadersandframessystem,很好用。
可以看看这个:viaconfiguration
开启实时抓取,这个方法不错。
第一次被人邀请回答问题,挺高兴的。但是这个问题不太明白。被记住,有什么用?那都是别人的看法和评价,
直接用一个最新版的streaming应该就可以的。
就可以直接在搜索框里输入喜欢的宝贝名称
你可以找一个空壳网站,比如之类的,直接在这个网站的搜索框里输入想要查询的关键词就行了.
楼上的回答很有道理,但,对于我来说,不都是废话么。我知道一个叫爱栏的网站,它可以帮你查看店铺数据。用法你需要下一个客户端,在浏览器的搜索框里输入想要查询的关键词,它就会帮你查询。
数据查询出来是“/”,可以抓取上传到“,
streaming
我一直在用这个网站
blogspot-theheadersandframessystem
使用客户端
看起来,楼主对社区管理不太理解。
现在发现,还不如用自己的网站,
php代码的话可以试试mobye或者adminwebextension,这两个是收费api的,但可以保证报文完整性。aspx代码的话就不懂了,应该有个开源版本(/)phpx开源报文完整性工具对兼容方面不算优雅;但是有webkit内核。
asp.net 抓取网页数据(业余程序员需要了解的知识点:如何抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2022-04-03 08:05
抓取网页数据从来不是一个专业技术人员需要了解的东西,而是一个“业余”程序员需要了解的技术。是技术层面上的,只要你有一台电脑和浏览器,就可以进行业余的抓取数据。如果想学习抓取网页数据,我可以教你一些简单的抓取方法和一些通用的抓取功能。
要知道知乎上面大部分写的都是不会成为专业技术人员需要了解学习的。如果你不懂编程,学习抓取还是不太推荐,编程一定要入门了,才能入门。如果你学习程序,结果你感觉是可以到处去找网页,但是整体的抓取难度很大。从网页抓取的本质来看,这是一个技术问题,抓取网页是怎么通过一个网页来抓取到整个内容,这个问题非常难。
对于初学者来说,要抓取互联网上的网页,要了解的知识点:如何编写网页抓取器和网页抓取程序,要了解http协议,通过不同的浏览器,不同的url判断哪个网页为真,最后才能实现抓取等。业余来说,可以尝试着学习抓取外链,去制作锚文本链接,结合url对外链进行批量添加,这些都是编程初学者有点无从下手的知识点。编程的入门,建议可以报一个培训班学习。
目前整体培训机构最好的也就是ui设计+前端(java)+后端(.net)这样的培训,专门从事这种培训的机构也很多,不必担心。 查看全部
asp.net 抓取网页数据(业余程序员需要了解的知识点:如何抓取网页数据)
抓取网页数据从来不是一个专业技术人员需要了解的东西,而是一个“业余”程序员需要了解的技术。是技术层面上的,只要你有一台电脑和浏览器,就可以进行业余的抓取数据。如果想学习抓取网页数据,我可以教你一些简单的抓取方法和一些通用的抓取功能。
要知道知乎上面大部分写的都是不会成为专业技术人员需要了解学习的。如果你不懂编程,学习抓取还是不太推荐,编程一定要入门了,才能入门。如果你学习程序,结果你感觉是可以到处去找网页,但是整体的抓取难度很大。从网页抓取的本质来看,这是一个技术问题,抓取网页是怎么通过一个网页来抓取到整个内容,这个问题非常难。
对于初学者来说,要抓取互联网上的网页,要了解的知识点:如何编写网页抓取器和网页抓取程序,要了解http协议,通过不同的浏览器,不同的url判断哪个网页为真,最后才能实现抓取等。业余来说,可以尝试着学习抓取外链,去制作锚文本链接,结合url对外链进行批量添加,这些都是编程初学者有点无从下手的知识点。编程的入门,建议可以报一个培训班学习。
目前整体培训机构最好的也就是ui设计+前端(java)+后端(.net)这样的培训,专门从事这种培训的机构也很多,不必担心。
asp.net 抓取网页数据(抓取网页数据无非这几种方法,比如你找一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-04-03 05:04
抓取网页数据无非这几种方法,比如你找一下isp或者国内知名网站,然后下载数据库。然后打开这些网站,抓取这些网站的数据就行了。当然还可以用代理来爬虫。
那些说中间件的给跪了。上velocity,这个是打开一个页面,然后匹配下meta标签,
千万别用中间件了,
直接上爬虫工具加数据库或者asp
aspx的用asp+xml+rss三重解析,aspx和php都有了然后asp访问url,xml解析后加载页面数据,rss解析后在缓存这中间两个模块之间加上链接,解析起来更顺畅,还可以试一下asp+php,这样可以在php页面数据不变的情况下提升爬虫速度,不过对于一般php爬虫来说rss解析用于提速还是相当有必要的。
一定用正则+爬虫工具比如requestsasp用vbscript
我是这么干的一定要用中间件就用代理+正则+爬虫工具
asp全面封杀下:匹配json然后反序列化成数据库json
了解下urllib2(包括json和xml)、thrift、autojs或者用lxml或者xsoft都可以
aspx就正则方法用好中间件加正则
可以用本地的asp服务器
还可以用asp数据库,
选择代理不还就好了啊。比如http网站都有对应的全球代理出售,都是的。而且,urllib2,requests是一定有的,也不一定要用抓包工具。楼上很多观点完全可以去掉,有的网站可以用asp+relye封装好的。还可以asp上装一个activex控件。activex控件可以有很多。php封装更多,而且封装起来极其简单。 查看全部
asp.net 抓取网页数据(抓取网页数据无非这几种方法,比如你找一下)
抓取网页数据无非这几种方法,比如你找一下isp或者国内知名网站,然后下载数据库。然后打开这些网站,抓取这些网站的数据就行了。当然还可以用代理来爬虫。
那些说中间件的给跪了。上velocity,这个是打开一个页面,然后匹配下meta标签,
千万别用中间件了,
直接上爬虫工具加数据库或者asp
aspx的用asp+xml+rss三重解析,aspx和php都有了然后asp访问url,xml解析后加载页面数据,rss解析后在缓存这中间两个模块之间加上链接,解析起来更顺畅,还可以试一下asp+php,这样可以在php页面数据不变的情况下提升爬虫速度,不过对于一般php爬虫来说rss解析用于提速还是相当有必要的。
一定用正则+爬虫工具比如requestsasp用vbscript
我是这么干的一定要用中间件就用代理+正则+爬虫工具
asp全面封杀下:匹配json然后反序列化成数据库json
了解下urllib2(包括json和xml)、thrift、autojs或者用lxml或者xsoft都可以
aspx就正则方法用好中间件加正则
可以用本地的asp服务器
还可以用asp数据库,
选择代理不还就好了啊。比如http网站都有对应的全球代理出售,都是的。而且,urllib2,requests是一定有的,也不一定要用抓包工具。楼上很多观点完全可以去掉,有的网站可以用asp+relye封装好的。还可以asp上装一个activex控件。activex控件可以有很多。php封装更多,而且封装起来极其简单。
asp.net 抓取网页数据(抓取网页数据,没有这个库抓取不了选selenium.spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 400 次浏览 • 2022-04-03 05:03
抓取网页数据,没有这个库抓取不了,选selenium.spider.api,和老版本api不兼容。一样可以抓取网页。推荐一款,可以抓取tomcat的url格式数据,如下:github-huanhaichash/convertjs:asimpleconvertertoadomtoasciiqueryformfield.。
利用aspf解析tomcat的url格式,然后读取查询的格式化字符串,可以实现采集到所有网页信息
估计有个taphub,
taphub:java移动抓包工具
使用的是java的抓包工具,开源中国上看到的这个框架好像开源的,可以试试。
/
selenium貌似有个api
flash_res
肯定是test框架啊
可以参考黄哥:python3网络爬虫开发实战-力扣(leetcode)
可以参考这个链接,
因为我尝试过的抓包工具只能抓取网页。不过对于python这个语言来说,还有pil模块,可以抓取图片,毕竟pil是个nativeapi,调用更加方便。除此之外也可以考虑转用python的webdriver模块,配合正则表达式解析图片,这样可以进行http请求解析。
注意,是爬虫,不是web页面抓取,网页不适合抓。可以用httprequest去处理就行了。
,免费的,
workerman不错 查看全部
asp.net 抓取网页数据(抓取网页数据,没有这个库抓取不了选selenium.spider)
抓取网页数据,没有这个库抓取不了,选selenium.spider.api,和老版本api不兼容。一样可以抓取网页。推荐一款,可以抓取tomcat的url格式数据,如下:github-huanhaichash/convertjs:asimpleconvertertoadomtoasciiqueryformfield.。
利用aspf解析tomcat的url格式,然后读取查询的格式化字符串,可以实现采集到所有网页信息
估计有个taphub,
taphub:java移动抓包工具
使用的是java的抓包工具,开源中国上看到的这个框架好像开源的,可以试试。
/
selenium貌似有个api
flash_res
肯定是test框架啊
可以参考黄哥:python3网络爬虫开发实战-力扣(leetcode)
可以参考这个链接,
因为我尝试过的抓包工具只能抓取网页。不过对于python这个语言来说,还有pil模块,可以抓取图片,毕竟pil是个nativeapi,调用更加方便。除此之外也可以考虑转用python的webdriver模块,配合正则表达式解析图片,这样可以进行http请求解析。
注意,是爬虫,不是web页面抓取,网页不适合抓。可以用httprequest去处理就行了。
,免费的,
workerman不错
asp.net 抓取网页数据(一下R和python抓取数据的技术分工(一) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-02 19:16
)
获取信息的能力往往是一个人或一个组织取得成就的关键力量。自二战时期的Enigma密码以来,人类进入了信息时代,信息开始在各个领域发挥越来越重要的作用,甚至成为不同于其他资源的独立资源。
数据分析和挖掘人员除了研究公司自身数据外,还必须能够获取外部公开数据和二手数据,更加注重内部和外部数据的结合。一个聪明的女人没有米饭很难做饭。当自身数据资源稀缺时,必须能够获取外部数据,帮助企业和个人做出决策。如果善良不在我面前,我会去山上找我。在本章中,我们将重点学习 R 和 python 的数据捕获技术。
> 获取信息的能力与其他专业技能同等重要,在专业化和分工较深的社会中,更应重视信息的广度。
复制代码
首先我们来看看R爬取的常见网络数据。要爬取数据,首先要虚拟化一个命令行浏览器。`RCurl` 包是 R 语言的命令行浏览器;`XML` 包用于解析和处理浏览器接受。接收到的 XML 或 HTML 数据;数据解析完成后,需要进行一些数据排序工作,`stringr`是处理字符数据的最佳选择。
###加载数据包
如果(!suppressWarnings(需要(RCurl))){
install.packages("RCurl")
要求(RCurl)
}
如果(!suppressWarnings(需要(XML))){
安装包(“XML”)
要求(XML)
}
if (!suppressWarnings(require(stringr))) {
install.packages("stringr")
要求(字符串)
}
复制代码
在捕获数据之前,您需要了解网络数据的格式。网络数据一般包括文本文本、表格、超文本标记语言(HTML)、JSON等,另外,获取数据时是否有权限限制等,这些都需要提前搞清楚。,一方面是为了选择合适的抓取方式,另一方面如果有错误或困难,可以详细描述自己的问题,以便他人帮助。
按照循序渐进的介绍方法,从简单地阅读文本格式的网页文本开始,从古腾堡(``)抓取一份“国富论的性质和原因的调查”,这个书名直译为《国富论》,他还有一个比较有名的名字《国富论》。世人尊亚当·斯密为“现代经济学之父”和“自由企业的奠基人”。守护神”,人类第一次认识了无形的手(`invisible hand`),而在不知不觉中,这些无形的手引导着自私的人类在谋求自身利益的同时促进人类的所有利益前行,
###读取文本数据
url fuguolun temp write.table(temp, "G:/zimeiti/dzdata/fuguolun.txt")
复制代码
直接使用基本R包中的`readLines`函数就可以完成《福国论》的阅读。`readLines`有很多参数,最有用的是`n`和`encoding`这两个参数,前者用于指定读取文本的前几行,后者用于指定文本的字符编码. 另外,`readLines`函数读取的结果是一个列表对象,每一行文本(注意:文本中的一行字符代表我们所说的一段字符)是列表的一个元素。
如果列表直接输出为txt,R会在每段的开头加上列表元素的编号,不符合电子书的格式,需要按照一定的格式融合在一起,比如就像为每一行使用换行符一样。使用“粘贴”功能将它们粘在一起。需要注意的是,粘贴函数的两个参数sep和collapse是用来设置粘贴时使用的分隔符,用法略有不同。要将 `vector` 对象粘在一起,用逗号分隔,请设置 `sep = ","` 而不是 `collapse`,如果要将 `list` 对象粘在一起,请使用 `collapse` = ","`。这是后者,但选择的分隔符是`\n`。
然后使用`write.table`函数将调整后的文件写入到指定的目录,到此我们就得到了这本名著《国富论》,值得一提的是《国富论》出版的同一年. 在乾隆皇帝在全国推行“删书卖书正心”等文控政策之际,东西方的横向对比不禁让人感慨万千。
以上是一个小测试。给自己准备了一份灵食“福果论”之后,就可以开始尝试捕捉一些更难的数据了。股票应该是很多人在学习数据挖掘的路上经常幻想的突破点。不幸的是,大多数人在这里落入沙子。虽然他们无法完成预测市场的繁重任务,但他们也锻炼了个人技能。既然这条路上有很多“贤者”,不妨尝试在这里捕捉一下股票数据。如果你的梦想成真了怎么办?
东方财富网发布大量股票数据,捕捉他们龙虎榜的股票交易数据作为“中国梦”的数据资本也是不错的选择。据说,龙虎榜的机构交易数据往往可以预测未来的股票走势。如果机构看好,后期会上涨,机构会逃跑,可能会成为接盘侠。我建议你不要以此为基础进行投资。以上都是不负责任的话。你不必认真对待它。成功捕获数据是本书的职责。
###HTML 格式
体重秤
复制代码
首先说明一下这个URL``,``代表东方财富网数据分支龙虎榜的数据;`600006`为股票代码,指东风汽车,可替换为任何已知股票代码,龙虎榜数据每天收盘后更新,读者可按需爬取;`html`表示网页数据是超文本标记语言格式。
不得不说一下`html`的基本内容,它是一种描述和结构化数据的语言。在网页上展示数据,不仅需要标明某个部分是什么文件,比如图片、音频、视频、文字等,还要标明它们的归属。`html` 和 `xml` 完成了这部分工作。在浏览器中单击鼠标右键,选择(Ctrl+U)“查看网页源代码”,即可查看网页的标记语言文本。
### 简单的html结构
烈日
导演:曹保平
主演:邓超/段奕宏/王珞丹/高虎
生产国家/地区:中国大陆
语言:普通话
发布日期:2015-08-27(中国大陆)
复制代码
`html`一般分为head和body,在`和`之间描述了整个网页,包括网页的结构和logo等。`和`是网页的可见内容,`
`与`
`描述一个模块。其树形结构如下:
查看全部
asp.net 抓取网页数据(一下R和python抓取数据的技术分工(一)
)
获取信息的能力往往是一个人或一个组织取得成就的关键力量。自二战时期的Enigma密码以来,人类进入了信息时代,信息开始在各个领域发挥越来越重要的作用,甚至成为不同于其他资源的独立资源。
数据分析和挖掘人员除了研究公司自身数据外,还必须能够获取外部公开数据和二手数据,更加注重内部和外部数据的结合。一个聪明的女人没有米饭很难做饭。当自身数据资源稀缺时,必须能够获取外部数据,帮助企业和个人做出决策。如果善良不在我面前,我会去山上找我。在本章中,我们将重点学习 R 和 python 的数据捕获技术。
> 获取信息的能力与其他专业技能同等重要,在专业化和分工较深的社会中,更应重视信息的广度。
复制代码
首先我们来看看R爬取的常见网络数据。要爬取数据,首先要虚拟化一个命令行浏览器。`RCurl` 包是 R 语言的命令行浏览器;`XML` 包用于解析和处理浏览器接受。接收到的 XML 或 HTML 数据;数据解析完成后,需要进行一些数据排序工作,`stringr`是处理字符数据的最佳选择。
###加载数据包
如果(!suppressWarnings(需要(RCurl))){
install.packages("RCurl")
要求(RCurl)
}
如果(!suppressWarnings(需要(XML))){
安装包(“XML”)
要求(XML)
}
if (!suppressWarnings(require(stringr))) {
install.packages("stringr")
要求(字符串)
}
复制代码
在捕获数据之前,您需要了解网络数据的格式。网络数据一般包括文本文本、表格、超文本标记语言(HTML)、JSON等,另外,获取数据时是否有权限限制等,这些都需要提前搞清楚。,一方面是为了选择合适的抓取方式,另一方面如果有错误或困难,可以详细描述自己的问题,以便他人帮助。
按照循序渐进的介绍方法,从简单地阅读文本格式的网页文本开始,从古腾堡(``)抓取一份“国富论的性质和原因的调查”,这个书名直译为《国富论》,他还有一个比较有名的名字《国富论》。世人尊亚当·斯密为“现代经济学之父”和“自由企业的奠基人”。守护神”,人类第一次认识了无形的手(`invisible hand`),而在不知不觉中,这些无形的手引导着自私的人类在谋求自身利益的同时促进人类的所有利益前行,
###读取文本数据
url fuguolun temp write.table(temp, "G:/zimeiti/dzdata/fuguolun.txt")
复制代码
直接使用基本R包中的`readLines`函数就可以完成《福国论》的阅读。`readLines`有很多参数,最有用的是`n`和`encoding`这两个参数,前者用于指定读取文本的前几行,后者用于指定文本的字符编码. 另外,`readLines`函数读取的结果是一个列表对象,每一行文本(注意:文本中的一行字符代表我们所说的一段字符)是列表的一个元素。
如果列表直接输出为txt,R会在每段的开头加上列表元素的编号,不符合电子书的格式,需要按照一定的格式融合在一起,比如就像为每一行使用换行符一样。使用“粘贴”功能将它们粘在一起。需要注意的是,粘贴函数的两个参数sep和collapse是用来设置粘贴时使用的分隔符,用法略有不同。要将 `vector` 对象粘在一起,用逗号分隔,请设置 `sep = ","` 而不是 `collapse`,如果要将 `list` 对象粘在一起,请使用 `collapse` = ","`。这是后者,但选择的分隔符是`\n`。
然后使用`write.table`函数将调整后的文件写入到指定的目录,到此我们就得到了这本名著《国富论》,值得一提的是《国富论》出版的同一年. 在乾隆皇帝在全国推行“删书卖书正心”等文控政策之际,东西方的横向对比不禁让人感慨万千。
以上是一个小测试。给自己准备了一份灵食“福果论”之后,就可以开始尝试捕捉一些更难的数据了。股票应该是很多人在学习数据挖掘的路上经常幻想的突破点。不幸的是,大多数人在这里落入沙子。虽然他们无法完成预测市场的繁重任务,但他们也锻炼了个人技能。既然这条路上有很多“贤者”,不妨尝试在这里捕捉一下股票数据。如果你的梦想成真了怎么办?
东方财富网发布大量股票数据,捕捉他们龙虎榜的股票交易数据作为“中国梦”的数据资本也是不错的选择。据说,龙虎榜的机构交易数据往往可以预测未来的股票走势。如果机构看好,后期会上涨,机构会逃跑,可能会成为接盘侠。我建议你不要以此为基础进行投资。以上都是不负责任的话。你不必认真对待它。成功捕获数据是本书的职责。
###HTML 格式
体重秤
复制代码
首先说明一下这个URL``,``代表东方财富网数据分支龙虎榜的数据;`600006`为股票代码,指东风汽车,可替换为任何已知股票代码,龙虎榜数据每天收盘后更新,读者可按需爬取;`html`表示网页数据是超文本标记语言格式。
不得不说一下`html`的基本内容,它是一种描述和结构化数据的语言。在网页上展示数据,不仅需要标明某个部分是什么文件,比如图片、音频、视频、文字等,还要标明它们的归属。`html` 和 `xml` 完成了这部分工作。在浏览器中单击鼠标右键,选择(Ctrl+U)“查看网页源代码”,即可查看网页的标记语言文本。
### 简单的html结构
烈日
导演:曹保平
主演:邓超/段奕宏/王珞丹/高虎
生产国家/地区:中国大陆
语言:普通话
发布日期:2015-08-27(中国大陆)
复制代码
`html`一般分为head和body,在`和`之间描述了整个网页,包括网页的结构和logo等。`和`是网页的可见内容,`
`与`
`描述一个模块。其树形结构如下:
asp.net 抓取网页数据(WebFormsModelBinding(比如SqlDataSource,EntityDataSource,LinqDataSource),能让你直接从服务器端控件连接数据源。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-04-02 19:16
Web 窗体模型绑定第 1 部分:数据选择(ASP.NET vNext 系列)
【原帖地址】Web Forms模型绑定第1部分:选择数据(ASP.NET vNext系列)
【原文发表时间】2011-09-05 21:58
这是我撰写的 ASP.NET vNext 系列博客文章中的第三篇文章。
.NET 和 Visual Studio 的下一个版本包括许多很棒的新功能。借助 ASP.NET vNext,您将看到对 Web 窗体和 MVC 的许多令人兴奋的改进——以及对构建它们的底层 ASP.NET Core 库的改进。
这是我将在接下来的两周内撰写的关于 Web 表单对新模型绑定的支持的 3 篇博文中的第一篇。模型绑定是对现有 ASP.NET Web Forms 数据绑定系统的扩展,提供了基于代码的数据访问范式。它利用了我们首先介绍的 ASP.NET MVC 模型绑定概念,并通过 Web 窗体服务器控制模型将它们很好地结合在一起。
当今数据绑定的背景
Web 窗体包括一组数据源控件(例如 SqlDataSource、EntityDataSource、LinqDataSource),它们允许您直接从服务器端控件连接到数据源。许多开发人员更喜欢完全控制他们的数据访问逻辑——并在代码中编写该逻辑。
在以前版本的 Web 窗体中,这可以通过直接设置控件的 DataSource 属性,然后在页面的代码隐藏中调用 DataBind() 函数来完成。这种方法虽然适用于很多场景,但是对于数据量很大的控件(如GridView),这种方法并不能很好地支持排序、分页、编辑等自动化操作。
还有一种可行的方法是使用ObjectDataSource 控件。此控件允许更清晰地分离 UI 代码和数据访问层,允许数据控件提供自动功能,例如分页和排序。不过虽然在选择数据的部分很有用,但是进行双向数据绑定还是很麻烦,只支持简单的属性(没有高级的复杂类型绑定),而且经常需要开发者写很多复杂的代码处理许多场景(包括常见的场景,如验证错误)。
模型绑定简介
ASP.NET vNext 为 Web 窗体中的“模型绑定”提供了很多新的支持。
模型绑定旨在简化基于代码的数据访问逻辑,同时保持丰富的双向数据绑定框架的优势。它继承了我们首先介绍的 ASP.NET MVC 模型绑定样式,并结合了 Web 窗体服务器控件模型。这使得使用 Web 窗体执行常见的 CRUD 样式方案变得容易,同时还允许您使用任何数据访问技术(EF、Linq、NHibernate、DataSets、原创 ADO.NET 等)
本周我将写一些其他博客文章,介绍如何利用新的模型绑定功能。在今天的博文中,我将展示如何使用模型绑定来检索数据 - 并在 GridView 控件中实现排序和分页。
使用 SelectMethod 检索数据
模型绑定是一种以代码为中心的数据绑定方法。
它允许您在页面的代码隐藏文件中编写 CRUD 辅助函数,并轻松连接到页面中的任何服务器控件。然后服务器控件会在页面生命周期中调用上述函数,并在适当的时候进行数据绑定。
让我们看一个使用控件的简单示例。下面的 GridView 有 4 列 - 其中 3 列是标准 BoundFields,第 4 列是 TemplateField。注意我们如何将 GridView 上的 ModelType 属性设置为 Category 对象——这允许我们在模板字段中实现强类型数据绑定(例如 Item.Products.Count 而不是使用 Eval() 函数):
我们将 GridView 配置为使用模型绑定来检索数据,方法是将 GridView 的 SelectMethod 属性设置为指向页面代码隐藏文件中的 GetCategories() 函数。GetCategories() 函数如下所示:
public IQueryable GetCategories() {
var northwind = new Northwind();
return northwind.Categories.Include(c => c.Products);
}
在上面的示例中,我使用 EF Code First 执行 LINQ 查询以从 Northwind 示例数据库返回类别列表。请注意,我们不需要在代码隐藏中执行数据库查询——我可以通过存储库或数据访问层来完成,或者使用 GetCategories() 方法来连接控件。
当我们运行页面的时候,GridView会自动调用上面的函数,然后取回数据并显示在页面上,如下:
避免 N+1 选择
查看上面的代码,您可能会注意到我们在 LINQ 查询中使用了 .Include(c=>c.Products) 辅助扩展。这告诉 EF 修改查询,以便除了检索类别信息之外,它还包括关联的产品(避免为返回的每一行信息单独调用数据库)。
排序和分页支持
我们可以在 GetCategories() 函数中使用 IEnumerable - 或实现类似 List 的接口类型来返回类别。虽然我们使用 IQueryable 接口返回类别:
返回的 IQueryable 的好处是它延迟了查询的执行,并允许数据绑定控件在执行前修改查询。这对于支持分页和排序的控件很有用。这些控件可以在执行前对 IQueryable 查询自动添加排序和分页操作。这使得在代码上实现排序和分页变得容易 - 并确保在数据库上完成排序和分页,并且非常高效。
使用GridView实现排序和分页,我们需要将它的AllowSorting和AllowPaging属性改为True,然后将默认的PageSize设置为5。同时我们也在两列中指定了合适的SortExpression。
现在我们运行页面,我们可以对数据进行分页和排序:
只会从数据库中检索类别并显示在当前排序页面上 - 因为 EF 将优化查询并执行排序和页面操作作为数据库查询的一部分,而不在中间层进行排序/分页。因此,即使有大量数据,排序/分页也会很有效。
关于模型绑定和 SelectMethod 的简短视频
Damiana Edwards 制作了一段 90 秒的精彩视频,展示了使用模型绑定来实现带有排序和分页的 GridView 场景。您可以单击此处观看 90 秒的视频。
总结
ASP.NET vNext 对新模型绑定的支持是对现有 Web 窗体数据绑定系统的完美演变。它继承了 ASP.NET MVC(您将在后面的许多 文章 中看到)模型绑定系统的思想和功能,使基于代码的数据访问范式更简单、更灵活。
在本系列的未来博客文章中,我将扩展模型绑定,看看我们如何轻松地将过滤器场景合并到我们的数据选择场景中,以及如何处理编辑场景(包括那些使用验证的场景)。
希望这些对你有帮助。
斯科特 查看全部
asp.net 抓取网页数据(WebFormsModelBinding(比如SqlDataSource,EntityDataSource,LinqDataSource),能让你直接从服务器端控件连接数据源。)
Web 窗体模型绑定第 1 部分:数据选择(ASP.NET vNext 系列)
【原帖地址】Web Forms模型绑定第1部分:选择数据(ASP.NET vNext系列)
【原文发表时间】2011-09-05 21:58
这是我撰写的 ASP.NET vNext 系列博客文章中的第三篇文章。
.NET 和 Visual Studio 的下一个版本包括许多很棒的新功能。借助 ASP.NET vNext,您将看到对 Web 窗体和 MVC 的许多令人兴奋的改进——以及对构建它们的底层 ASP.NET Core 库的改进。
这是我将在接下来的两周内撰写的关于 Web 表单对新模型绑定的支持的 3 篇博文中的第一篇。模型绑定是对现有 ASP.NET Web Forms 数据绑定系统的扩展,提供了基于代码的数据访问范式。它利用了我们首先介绍的 ASP.NET MVC 模型绑定概念,并通过 Web 窗体服务器控制模型将它们很好地结合在一起。
当今数据绑定的背景
Web 窗体包括一组数据源控件(例如 SqlDataSource、EntityDataSource、LinqDataSource),它们允许您直接从服务器端控件连接到数据源。许多开发人员更喜欢完全控制他们的数据访问逻辑——并在代码中编写该逻辑。
在以前版本的 Web 窗体中,这可以通过直接设置控件的 DataSource 属性,然后在页面的代码隐藏中调用 DataBind() 函数来完成。这种方法虽然适用于很多场景,但是对于数据量很大的控件(如GridView),这种方法并不能很好地支持排序、分页、编辑等自动化操作。
还有一种可行的方法是使用ObjectDataSource 控件。此控件允许更清晰地分离 UI 代码和数据访问层,允许数据控件提供自动功能,例如分页和排序。不过虽然在选择数据的部分很有用,但是进行双向数据绑定还是很麻烦,只支持简单的属性(没有高级的复杂类型绑定),而且经常需要开发者写很多复杂的代码处理许多场景(包括常见的场景,如验证错误)。
模型绑定简介
ASP.NET vNext 为 Web 窗体中的“模型绑定”提供了很多新的支持。
模型绑定旨在简化基于代码的数据访问逻辑,同时保持丰富的双向数据绑定框架的优势。它继承了我们首先介绍的 ASP.NET MVC 模型绑定样式,并结合了 Web 窗体服务器控件模型。这使得使用 Web 窗体执行常见的 CRUD 样式方案变得容易,同时还允许您使用任何数据访问技术(EF、Linq、NHibernate、DataSets、原创 ADO.NET 等)
本周我将写一些其他博客文章,介绍如何利用新的模型绑定功能。在今天的博文中,我将展示如何使用模型绑定来检索数据 - 并在 GridView 控件中实现排序和分页。
使用 SelectMethod 检索数据
模型绑定是一种以代码为中心的数据绑定方法。
它允许您在页面的代码隐藏文件中编写 CRUD 辅助函数,并轻松连接到页面中的任何服务器控件。然后服务器控件会在页面生命周期中调用上述函数,并在适当的时候进行数据绑定。
让我们看一个使用控件的简单示例。下面的 GridView 有 4 列 - 其中 3 列是标准 BoundFields,第 4 列是 TemplateField。注意我们如何将 GridView 上的 ModelType 属性设置为 Category 对象——这允许我们在模板字段中实现强类型数据绑定(例如 Item.Products.Count 而不是使用 Eval() 函数):
我们将 GridView 配置为使用模型绑定来检索数据,方法是将 GridView 的 SelectMethod 属性设置为指向页面代码隐藏文件中的 GetCategories() 函数。GetCategories() 函数如下所示:
public IQueryable GetCategories() {
var northwind = new Northwind();
return northwind.Categories.Include(c => c.Products);
}
在上面的示例中,我使用 EF Code First 执行 LINQ 查询以从 Northwind 示例数据库返回类别列表。请注意,我们不需要在代码隐藏中执行数据库查询——我可以通过存储库或数据访问层来完成,或者使用 GetCategories() 方法来连接控件。
当我们运行页面的时候,GridView会自动调用上面的函数,然后取回数据并显示在页面上,如下:
避免 N+1 选择
查看上面的代码,您可能会注意到我们在 LINQ 查询中使用了 .Include(c=>c.Products) 辅助扩展。这告诉 EF 修改查询,以便除了检索类别信息之外,它还包括关联的产品(避免为返回的每一行信息单独调用数据库)。
排序和分页支持
我们可以在 GetCategories() 函数中使用 IEnumerable - 或实现类似 List 的接口类型来返回类别。虽然我们使用 IQueryable 接口返回类别:
返回的 IQueryable 的好处是它延迟了查询的执行,并允许数据绑定控件在执行前修改查询。这对于支持分页和排序的控件很有用。这些控件可以在执行前对 IQueryable 查询自动添加排序和分页操作。这使得在代码上实现排序和分页变得容易 - 并确保在数据库上完成排序和分页,并且非常高效。
使用GridView实现排序和分页,我们需要将它的AllowSorting和AllowPaging属性改为True,然后将默认的PageSize设置为5。同时我们也在两列中指定了合适的SortExpression。
现在我们运行页面,我们可以对数据进行分页和排序:
只会从数据库中检索类别并显示在当前排序页面上 - 因为 EF 将优化查询并执行排序和页面操作作为数据库查询的一部分,而不在中间层进行排序/分页。因此,即使有大量数据,排序/分页也会很有效。
关于模型绑定和 SelectMethod 的简短视频
Damiana Edwards 制作了一段 90 秒的精彩视频,展示了使用模型绑定来实现带有排序和分页的 GridView 场景。您可以单击此处观看 90 秒的视频。
总结
ASP.NET vNext 对新模型绑定的支持是对现有 Web 窗体数据绑定系统的完美演变。它继承了 ASP.NET MVC(您将在后面的许多 文章 中看到)模型绑定系统的思想和功能,使基于代码的数据访问范式更简单、更灵活。
在本系列的未来博客文章中,我将扩展模型绑定,看看我们如何轻松地将过滤器场景合并到我们的数据选择场景中,以及如何处理编辑场景(包括那些使用验证的场景)。
希望这些对你有帮助。
斯科特
asp.net 抓取网页数据(抓取网页数据比起通过java传入html文档来说更麻烦)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-30 03:04
抓取网页数据比起通过java传入html文档来说更麻烦,数据持久性的问题。(java会全部转为字符串,换一种写法不同的编码不同的内容),所以很容易出现数据重复了。想要抓取网页数据就必须要有一套数据库,一般都是sqlite来实现。如果没有相应的库可以尝试以下方案。首先要实现相应的浏览器插件,例如微信小程序版本。
其次需要懂得相应的php知识并且有配置过正则表达式,第三,将正则表达式转化为php函数的mysql库来处理。
php是最适合干这个的。
node.js
node.js,可以抓取各种网页。
php
node.js一直都是人气最旺的,容易上手,使用方便,并且有超多api,一堆的生态,完全够用。请看我的其他答案,已经详细介绍了。
awk
本身没有java的接口直接抓不起来
phpweb开发java开发
nodejs
java...
php比java容易太多了.
java,这里并不涉及sql连接php
java,fastjson一个异步mysql连接,静态化get类get的字符串,更多的可以理解为mysql_connect("username:password",//用户名,字符串);sqlite连接表格,更多的用字符串存储,
很多人提到php,我也认为php是个非常适合的语言。对于爬虫,一般都有有个后端接口。前端使用java也可以,但写多了爬虫,对sql的处理太烂了。 查看全部
asp.net 抓取网页数据(抓取网页数据比起通过java传入html文档来说更麻烦)
抓取网页数据比起通过java传入html文档来说更麻烦,数据持久性的问题。(java会全部转为字符串,换一种写法不同的编码不同的内容),所以很容易出现数据重复了。想要抓取网页数据就必须要有一套数据库,一般都是sqlite来实现。如果没有相应的库可以尝试以下方案。首先要实现相应的浏览器插件,例如微信小程序版本。
其次需要懂得相应的php知识并且有配置过正则表达式,第三,将正则表达式转化为php函数的mysql库来处理。
php是最适合干这个的。
node.js
node.js,可以抓取各种网页。
php
node.js一直都是人气最旺的,容易上手,使用方便,并且有超多api,一堆的生态,完全够用。请看我的其他答案,已经详细介绍了。
awk
本身没有java的接口直接抓不起来
phpweb开发java开发
nodejs
java...
php比java容易太多了.
java,这里并不涉及sql连接php
java,fastjson一个异步mysql连接,静态化get类get的字符串,更多的可以理解为mysql_connect("username:password",//用户名,字符串);sqlite连接表格,更多的用字符串存储,
很多人提到php,我也认为php是个非常适合的语言。对于爬虫,一般都有有个后端接口。前端使用java也可以,但写多了爬虫,对sql的处理太烂了。

