
采集相关文章
采集相关文章(一个人维护成百上千网站文章更新也不是问题使用免费采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-17 17:23
)
优采云采集器是网站采集大家最喜欢的工具,但是优采云采集器在免费版中并没有很多功能,除了支持关键词采集中文文章和自动发布功能,不能提供批量采集伪原创发布等完整的采集流程,不能同时一键批量自动百度、神马、360、搜狗等搜索引擎推送。
无论你有成百上千个不同的免费采集器网站还是其他网站都可以实现统一管理。一个人使用免费的采集器做网站优化维护上百个网站文章更新不是问题,有哪些细节需要注意。
一、域名
域名就像一个人的名字。简单好记的名字容易让人记住,复杂的名字难记。域名也是如此,所以针对网站优化了一个简单易记的域名,好在用户想访问你的网站时,不需要去百度搜索,他们可以通过输入域名直接访问你的网站。免费采集器可以批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyou cms、人人展cms、discuz、Whirlwind、站群、PBoot、Apple、Mito、搜外等各大cms,都可以同时批处理工具来管理 采集伪原创 并发布推送)。
二、空间
空间用于存储 网站 程序文件。空间打开越快,空间越稳定,网站用户浏览体验自然会更好。更快的速度和更稳定的空间对于网站来说很重要,优化排名极其重要。免费采集器可以设置批量发布次数(可以设置发布间隔/单日发布总数)。
三、网页上的三大标签
1)标题标签
网页有标题标签。搜索蜘蛛在抓取网页内容时,首先抓取的是网页标题标签的内容,而网页标题标签的内容可以参与搜索结果的排名。我们通常所说的关键词排名指的是标题标签排名,而不是关键词标签排名,所以页面标题标签的内容很重要。免费 采集器 使内容与标题一致(使内容与标题相关性一致)。根据关键词采集文章,通过免费的采集器采集填充内容。(免费的 采集器采集 插件还配置了 关键词采集 功能和无关的词块功能)。注意不要出错,否则会被搜索引擎惩罚。
2)关键词标签
免费采集器可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。
关键词标签的内容不参与排名,部分站长朋友认为不需要写。免费采集器插入内容的能力关键词(合理增加关键词密度)。虽然这个标签不涉及排名,但我们仍然需要维护这个标签内容的完整性。百度搜索在相关算法中也有提及。建议你写下这个标签的内容,以免被百度搜索命中。
3)描述标签
描述标签写入当前网页的一般内容。简而言之,就是对当前网页内容的介绍。一个好的网页描述也可以吸引用户点击该网页的网页,描述标签的内容也可以参与排名。
4)alt 标签
alt 标签是图像的专有标签。因为搜索蜘蛛不能直接识别图片,只能通过alt标签的内容来识别图片。alt标签的内容只需要简单的告诉搜索蜘蛛图片的内容,不要在alt标签里面堆关键词@。>,否则会影响搜索蜘蛛对网页的评分。
5)机器人,txt 文件
网站机器人,txt文件是网站和搜索引擎之间的协议文件,用来告诉搜索蜘蛛网站可以抓取哪些页面。免费采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。哪些页面不能被爬取,可以有效保护网站隐私页面,提高网站的安全性。
6)nofollow 标签
免费采集器可以支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)。nofollow 标签一般应用于出站链接,站内链接很少用于告诉蜘蛛这个链接是非信任链接,不传递权重。
7)网站网站地图
免费的采集器可以推送到搜索引擎(文章发布成功后主动推送文章到搜索引擎,保证新链接及时被搜索引擎搜索到收录 )。网站sitemap地图有利于提高搜索蜘蛛对网站页面的爬取率,所有网站页面的链接都集中在这个文件中,可以帮助搜索蜘蛛快速爬取整个网站页面。免费的采集器可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)。
搜索蜘蛛爬行网站,第一个访问的文件是robots文件,我们可以在robots文件中写网站站点地图地图,搜索蜘蛛会沿着网站地图文件爬行网站 页面。每日蜘蛛、收录、网站权重可以通过免费的采集器直接查看。
8)链接
免费的采集器可以发布也可以配置很多SEO功能,不仅可以通过免费的采集器发布实现采集伪原创的发布和主动推送到搜索引擎,还可以有很多搜索引擎优化功能。与相关行业的高权重网站交换友情链接,可以增加网站的PR值,给网站带来一定的流量,提高搜索引擎对你的兴趣网站页面的收录速率。免费采集器自动批量挂机采集伪原创自动发布推送到搜索引擎。
关键词0@>
关键词1@>外部链接
免费采集器可以直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等。外部链接是留自己的网站链接给别人< @网站。外链对于新站优化初期非常重要,外链的好坏直接影响搜索引擎中的网站。的评分。免费的采集器可以自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权限)。
1关键词2@>404 错误页面
免费的采集器提供伪原创保留字(文章原创时伪原创不设置核心字)。网站修订、被黑代码或其他原因导致网站中出现大量死链接。这时候,404错误页面就派上用场了。404错误页面向搜索引擎返回一个404状态码,可以帮助搜索引擎快速去除死链接页面。
今天关于免费采集器的解释就到这里了。下期我会分享更多的SEO相关知识。希望你能通过我的文章得到你想要的,下期再见。
关键词3@> 查看全部
采集相关文章(一个人维护成百上千网站文章更新也不是问题使用免费采集器
)
优采云采集器是网站采集大家最喜欢的工具,但是优采云采集器在免费版中并没有很多功能,除了支持关键词采集中文文章和自动发布功能,不能提供批量采集伪原创发布等完整的采集流程,不能同时一键批量自动百度、神马、360、搜狗等搜索引擎推送。
无论你有成百上千个不同的免费采集器网站还是其他网站都可以实现统一管理。一个人使用免费的采集器做网站优化维护上百个网站文章更新不是问题,有哪些细节需要注意。
一、域名
域名就像一个人的名字。简单好记的名字容易让人记住,复杂的名字难记。域名也是如此,所以针对网站优化了一个简单易记的域名,好在用户想访问你的网站时,不需要去百度搜索,他们可以通过输入域名直接访问你的网站。免费采集器可以批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyou cms、人人展cms、discuz、Whirlwind、站群、PBoot、Apple、Mito、搜外等各大cms,都可以同时批处理工具来管理 采集伪原创 并发布推送)。
二、空间
空间用于存储 网站 程序文件。空间打开越快,空间越稳定,网站用户浏览体验自然会更好。更快的速度和更稳定的空间对于网站来说很重要,优化排名极其重要。免费采集器可以设置批量发布次数(可以设置发布间隔/单日发布总数)。
三、网页上的三大标签
1)标题标签
网页有标题标签。搜索蜘蛛在抓取网页内容时,首先抓取的是网页标题标签的内容,而网页标题标签的内容可以参与搜索结果的排名。我们通常所说的关键词排名指的是标题标签排名,而不是关键词标签排名,所以页面标题标签的内容很重要。免费 采集器 使内容与标题一致(使内容与标题相关性一致)。根据关键词采集文章,通过免费的采集器采集填充内容。(免费的 采集器采集 插件还配置了 关键词采集 功能和无关的词块功能)。注意不要出错,否则会被搜索引擎惩罚。
2)关键词标签
免费采集器可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。
关键词标签的内容不参与排名,部分站长朋友认为不需要写。免费采集器插入内容的能力关键词(合理增加关键词密度)。虽然这个标签不涉及排名,但我们仍然需要维护这个标签内容的完整性。百度搜索在相关算法中也有提及。建议你写下这个标签的内容,以免被百度搜索命中。
3)描述标签
描述标签写入当前网页的一般内容。简而言之,就是对当前网页内容的介绍。一个好的网页描述也可以吸引用户点击该网页的网页,描述标签的内容也可以参与排名。
4)alt 标签
alt 标签是图像的专有标签。因为搜索蜘蛛不能直接识别图片,只能通过alt标签的内容来识别图片。alt标签的内容只需要简单的告诉搜索蜘蛛图片的内容,不要在alt标签里面堆关键词@。>,否则会影响搜索蜘蛛对网页的评分。
5)机器人,txt 文件
网站机器人,txt文件是网站和搜索引擎之间的协议文件,用来告诉搜索蜘蛛网站可以抓取哪些页面。免费采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。哪些页面不能被爬取,可以有效保护网站隐私页面,提高网站的安全性。
6)nofollow 标签
免费采集器可以支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)。nofollow 标签一般应用于出站链接,站内链接很少用于告诉蜘蛛这个链接是非信任链接,不传递权重。
7)网站网站地图
免费的采集器可以推送到搜索引擎(文章发布成功后主动推送文章到搜索引擎,保证新链接及时被搜索引擎搜索到收录 )。网站sitemap地图有利于提高搜索蜘蛛对网站页面的爬取率,所有网站页面的链接都集中在这个文件中,可以帮助搜索蜘蛛快速爬取整个网站页面。免费的采集器可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)。
搜索蜘蛛爬行网站,第一个访问的文件是robots文件,我们可以在robots文件中写网站站点地图地图,搜索蜘蛛会沿着网站地图文件爬行网站 页面。每日蜘蛛、收录、网站权重可以通过免费的采集器直接查看。
8)链接
免费的采集器可以发布也可以配置很多SEO功能,不仅可以通过免费的采集器发布实现采集伪原创的发布和主动推送到搜索引擎,还可以有很多搜索引擎优化功能。与相关行业的高权重网站交换友情链接,可以增加网站的PR值,给网站带来一定的流量,提高搜索引擎对你的兴趣网站页面的收录速率。免费采集器自动批量挂机采集伪原创自动发布推送到搜索引擎。
关键词0@>
关键词1@>外部链接
免费采集器可以直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等。外部链接是留自己的网站链接给别人< @网站。外链对于新站优化初期非常重要,外链的好坏直接影响搜索引擎中的网站。的评分。免费的采集器可以自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权限)。
1关键词2@>404 错误页面
免费的采集器提供伪原创保留字(文章原创时伪原创不设置核心字)。网站修订、被黑代码或其他原因导致网站中出现大量死链接。这时候,404错误页面就派上用场了。404错误页面向搜索引擎返回一个404状态码,可以帮助搜索引擎快速去除死链接页面。
今天关于免费采集器的解释就到这里了。下期我会分享更多的SEO相关知识。希望你能通过我的文章得到你想要的,下期再见。
关键词3@>
采集相关文章(没有好用采集软件的特点及特点的影响)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-17 15:41
最近很多站长问我采集网站怎么做,没有好用的采集软件,同时全网应该是关键词泛采集自动伪原创自动发布。,最好支持百度、神马、360、搜狗、今日头条的一键批量自动推送,答案肯定是肯定的,今天就来说说文章采集。
文章采集软件可以在内容或标题前后插入段落或关键词可选择将标题和标题插入到同一个关键词中。首先,文章采集软件无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。对于 seo,网站 页面非常重要。因为用户搜索的时候是根据网站页面的关键词,而网站的标题是否合适也会影响用户是否点击< @网站 进行浏览。而网站页面的结构对优化也有很大的影响。
结构越简单,搜索引擎蜘蛛的爬取效果就越好,而爬取的网站收录越多,网站的收录越多,权重自然就增加了。相比其他文章采集软件免费工具,这款文章采集软件使用非常简单,输入关键词即可实现采集< @文章采集软件免费工具配备了关键词采集功能。只需设置任务,全程自动挂机!网站文章的原创性能让搜索引擎蜘蛛更爱网站本身,更容易爬取网站的文章,提升网站 @网站 的收录 会相应增加网站 的权重。
文章采集软件采集的文章有如下特点,方便收录: 一般来说,为了更好的启用网站捕获,在 网站 主页添加地图 网站 以方便搜索引擎蜘蛛抓取。文章采集软件可以将网站内容或随机作者、随机阅读等插入“高原创”。
首先你要明白收录和索引其实是两个概念。文章采集软件可以自动链接内部链接,让搜索引擎更深入地抓取你的链接。只是这两个概念真的是相关的,因为没有收录索引,没有索引也不一定没有收录,没有索引的页面几乎不会获得流量,除非你进行搜索以搜索 url 的形式,点击被点击。文章采集软件可以网站主动推送,让搜索引擎更快的发现我们的网站。这时候,你只需要仔细观察连续几天的流量变化。只要几天内流量没有异常变化,这意味着你丢弃的索引也是无效的,没有流量价值。当然,您可以放心。
所以在这里索引变得非常重要。我们还需要监控搜索引擎站长工具中的索引量数据,因为这些工具不会为我们永久保留它们的数据,它们会定期取出并作为历史参考数据进行备份。文章采集软件可以自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或通过第三方,使内容不再有来自对方的外部链接。
百度可以自定义你要统计的不同类型网址的索引数据。这样,在掉落的地方就可以看到大滴。另外,搜索引擎会不定期对索引库中的大量数据进行整理,从索引库。.
企业网站很多人对关键词的排名有严重的误解,只看首页几个字的排名,而忽略了流量本身。说到点击量,除了关键词排名的提升可以大大增加流量外,优化点击率是一种快速有效的增加流量的方法。
文章采集软件可以优化出现文字的相关性关键词,自动加粗第一段文字并自动插入标题。在我们的标题和描述中,更多的丰富元素,如搜索引擎相关、比他们的关键词竞争对手更受欢迎、图像呈现也是吸引用户注意力和增加点击量的方式。
本文章采集软件采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需运行< @文章采集软件采集工具的简单设置。排版计划的稀缺性和独特性。也就是说,你的 网站 规划需要有自己的特点。我们仍然需要对用户标题做一些优化,以吸引用户点击。除了获得搜索引擎的认可外,用户体验也是一个极其重要的因素。
文章头衔稀缺。网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用文章采集软件免费工具实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。一般情况下,搜索引擎在抓取一个文章时,首先看的是标题。如果您的 文章 标题在 Internet 上有很多重复。那么搜索引擎就不会输入你的文章,因为搜索引擎输入互联网上已经存在的东西是没有意义的。文章采集软件可以定时发布文章,让搜索引擎及时抓取你的网站内容。所以,我们在写文章标题的时候,一定要注意标题的稀缺性和唯一性。文章整体内容的稀缺性也很重要。
一般来说,第一段和最后一段需要是唯一的,这样你的 文章 内容可以与互联网上其他内容的稀缺性相提并论。最重要的是这个文章采集软件免费工具有很多SEO功能,不仅可以提高网站的收录,还可以增加网站的密度@关键词 以提高您的 网站 排名。这样一来,搜索引擎就会认为这个文章是网络上稀缺的文章,会立即进入。文章第一段和最后一段的稀缺性是你需要用你自己的话来描述文章行的全部内容。
<p>文章采集软件增加文章锚文本衔接的权限。文章采集软件会根据用户设置的关键词准确采集文章,确保与行业一致 查看全部
采集相关文章(没有好用采集软件的特点及特点的影响)
最近很多站长问我采集网站怎么做,没有好用的采集软件,同时全网应该是关键词泛采集自动伪原创自动发布。,最好支持百度、神马、360、搜狗、今日头条的一键批量自动推送,答案肯定是肯定的,今天就来说说文章采集。
文章采集软件可以在内容或标题前后插入段落或关键词可选择将标题和标题插入到同一个关键词中。首先,文章采集软件无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。对于 seo,网站 页面非常重要。因为用户搜索的时候是根据网站页面的关键词,而网站的标题是否合适也会影响用户是否点击< @网站 进行浏览。而网站页面的结构对优化也有很大的影响。
结构越简单,搜索引擎蜘蛛的爬取效果就越好,而爬取的网站收录越多,网站的收录越多,权重自然就增加了。相比其他文章采集软件免费工具,这款文章采集软件使用非常简单,输入关键词即可实现采集< @文章采集软件免费工具配备了关键词采集功能。只需设置任务,全程自动挂机!网站文章的原创性能让搜索引擎蜘蛛更爱网站本身,更容易爬取网站的文章,提升网站 @网站 的收录 会相应增加网站 的权重。
文章采集软件采集的文章有如下特点,方便收录: 一般来说,为了更好的启用网站捕获,在 网站 主页添加地图 网站 以方便搜索引擎蜘蛛抓取。文章采集软件可以将网站内容或随机作者、随机阅读等插入“高原创”。
首先你要明白收录和索引其实是两个概念。文章采集软件可以自动链接内部链接,让搜索引擎更深入地抓取你的链接。只是这两个概念真的是相关的,因为没有收录索引,没有索引也不一定没有收录,没有索引的页面几乎不会获得流量,除非你进行搜索以搜索 url 的形式,点击被点击。文章采集软件可以网站主动推送,让搜索引擎更快的发现我们的网站。这时候,你只需要仔细观察连续几天的流量变化。只要几天内流量没有异常变化,这意味着你丢弃的索引也是无效的,没有流量价值。当然,您可以放心。
所以在这里索引变得非常重要。我们还需要监控搜索引擎站长工具中的索引量数据,因为这些工具不会为我们永久保留它们的数据,它们会定期取出并作为历史参考数据进行备份。文章采集软件可以自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或通过第三方,使内容不再有来自对方的外部链接。
百度可以自定义你要统计的不同类型网址的索引数据。这样,在掉落的地方就可以看到大滴。另外,搜索引擎会不定期对索引库中的大量数据进行整理,从索引库。.
企业网站很多人对关键词的排名有严重的误解,只看首页几个字的排名,而忽略了流量本身。说到点击量,除了关键词排名的提升可以大大增加流量外,优化点击率是一种快速有效的增加流量的方法。
文章采集软件可以优化出现文字的相关性关键词,自动加粗第一段文字并自动插入标题。在我们的标题和描述中,更多的丰富元素,如搜索引擎相关、比他们的关键词竞争对手更受欢迎、图像呈现也是吸引用户注意力和增加点击量的方式。
本文章采集软件采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需运行< @文章采集软件采集工具的简单设置。排版计划的稀缺性和独特性。也就是说,你的 网站 规划需要有自己的特点。我们仍然需要对用户标题做一些优化,以吸引用户点击。除了获得搜索引擎的认可外,用户体验也是一个极其重要的因素。
文章头衔稀缺。网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用文章采集软件免费工具实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。一般情况下,搜索引擎在抓取一个文章时,首先看的是标题。如果您的 文章 标题在 Internet 上有很多重复。那么搜索引擎就不会输入你的文章,因为搜索引擎输入互联网上已经存在的东西是没有意义的。文章采集软件可以定时发布文章,让搜索引擎及时抓取你的网站内容。所以,我们在写文章标题的时候,一定要注意标题的稀缺性和唯一性。文章整体内容的稀缺性也很重要。
一般来说,第一段和最后一段需要是唯一的,这样你的 文章 内容可以与互联网上其他内容的稀缺性相提并论。最重要的是这个文章采集软件免费工具有很多SEO功能,不仅可以提高网站的收录,还可以增加网站的密度@关键词 以提高您的 网站 排名。这样一来,搜索引擎就会认为这个文章是网络上稀缺的文章,会立即进入。文章第一段和最后一段的稀缺性是你需要用你自己的话来描述文章行的全部内容。
<p>文章采集软件增加文章锚文本衔接的权限。文章采集软件会根据用户设置的关键词准确采集文章,确保与行业一致
采集相关文章(python爬虫教程-菜鸟教程谢邀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-13 11:03
采集相关文章或者网页,每一篇文章设置文件为image,设置采集范围0-10000或者10000-20000(随便什么值),点击upload按钮,
python爬虫教程-菜鸟教程
谢邀。给题主个网站吧,我刚好也遇到这个问题:这个网站是空着的,也就是没有实际意义的,但是如果你能爬下来放在自己的数据库里面,那么就可以做各种数据分析,比如我就知道这些数据可以做语料,又能用于投资金融等等。还有就是如果有基础的话,可以找几篇外文专著或者论文,先翻译一遍,也是一种爬虫学习的方法。
知乎本来就不是爬虫啊你抓完数据就很容易做统计分析,出图表。结果没用。而且r根本没啥子用,所以找个靠谱的数据接口出数据就好了。==如果是复杂网站,可以自己写个爬虫用于收集数据。如果想要得到不同的数据,可以用些分类处理函数,用户类型,预期时间等等定义标签。然后接上最长访问频率,最短访问频率,cookie有效期等等。然后筛选条件,返回结果。
可以使用redis中的redislist做反向代理来抓取不同的网站。redislist的每个数据列放到一个list中,而每个列的第一项定义了属于哪个网站,如下图中的值是google。 查看全部
采集相关文章(python爬虫教程-菜鸟教程谢邀)
采集相关文章或者网页,每一篇文章设置文件为image,设置采集范围0-10000或者10000-20000(随便什么值),点击upload按钮,
python爬虫教程-菜鸟教程
谢邀。给题主个网站吧,我刚好也遇到这个问题:这个网站是空着的,也就是没有实际意义的,但是如果你能爬下来放在自己的数据库里面,那么就可以做各种数据分析,比如我就知道这些数据可以做语料,又能用于投资金融等等。还有就是如果有基础的话,可以找几篇外文专著或者论文,先翻译一遍,也是一种爬虫学习的方法。
知乎本来就不是爬虫啊你抓完数据就很容易做统计分析,出图表。结果没用。而且r根本没啥子用,所以找个靠谱的数据接口出数据就好了。==如果是复杂网站,可以自己写个爬虫用于收集数据。如果想要得到不同的数据,可以用些分类处理函数,用户类型,预期时间等等定义标签。然后接上最长访问频率,最短访问频率,cookie有效期等等。然后筛选条件,返回结果。
可以使用redis中的redislist做反向代理来抓取不同的网站。redislist的每个数据列放到一个list中,而每个列的第一项定义了属于哪个网站,如下图中的值是google。
采集相关文章(采集文章和资料报告:市区周边1.3市区次要选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-12 17:03
采集相关文章和资料报告:·
1、及时发送*1以上链接内容解析中的链接码·
2、长期更新截止*2019年1月3日1.选址(a,选址真的要慎重,小小曝光一下)1.1市区(郊县也行)1.2市区周边1.3市区次要选择——价格定位2.优化(b,创业前期或者商业计划书。
c,模式规划)2.1---品牌
1)形象模式和品牌
2)产品——营销问题
3)产品和服务
4)标准化和定制化产品形式
5)渠道、渠道、渠道
6)质量
7)服务2.2模式和品牌
1)组合方式和品牌2.3营销
1)视觉营销
2)用户营销
3)内容营销
4)社群
5)社区2.4模式
1)新品
2)专卖店
3)散落式展销会
4)vr形式
5)众筹3.股权(e,公司+团队+股权分红+合伙人机制(f,运营中每个模块解决一个问题,j是每个运营节点)4.团队建设(g,股权配比4.1---股权激励)4.2---高绩效团队激励5.进销存(h,进货渠道销售渠道库存)5.1--管理会计5.2---仓库(i,客服+物流+销售+库存)5.3---营销(k,销售,技术)5.4---实体仓库(u,储存)5.5---财务(i,内帐外帐)6.erp系统(z,erp系统erp物流分配系统等)excel·只是解决进销存物流问题,mes(s,sap系统)·有物流系统。
7..商场营销推广(n,消费者价值与体验感受型广告)(p,广告投放地点•效果)(m,广告参数•广告落地页•地点•效果•线下和线上)·m1.线上高曝光推广提高知名度。(h,你没看错,这句话里面就有两个术语,一个是展示展示曝光展示曝光,一个是内容:广告投放地点和展示地点,两者有一个对等性,就是展示地点要求和广告投放地点不同。
这时候大家就要问了,大致会归为下面三种类型:第一种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,第二种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,而大多数人选择问这种问题都会选择第三种情况,即线上广告投放对线下产品服务没有影响。下面我会详细详细说明三种广告投放对于线下产品服务的影响。
)a,品牌logo,图形,标识有价值(b,bd部门商场的老板可以体验一下,和我们非常像)b,品牌最基础硬广告,看看世界no.1的杜蕾斯广告和杜蕾斯不是一个级别的?就明白这广告有多么吊炸天了c,品牌硬广告的起效时间一般为14-15天d,品牌内容,线下实体展销会广告资源可能是最划算,时效,性价比最高的。e,品牌硬广告的形式。 查看全部
采集相关文章(采集文章和资料报告:市区周边1.3市区次要选择)
采集相关文章和资料报告:·
1、及时发送*1以上链接内容解析中的链接码·
2、长期更新截止*2019年1月3日1.选址(a,选址真的要慎重,小小曝光一下)1.1市区(郊县也行)1.2市区周边1.3市区次要选择——价格定位2.优化(b,创业前期或者商业计划书。
c,模式规划)2.1---品牌
1)形象模式和品牌
2)产品——营销问题
3)产品和服务
4)标准化和定制化产品形式
5)渠道、渠道、渠道
6)质量
7)服务2.2模式和品牌
1)组合方式和品牌2.3营销
1)视觉营销
2)用户营销
3)内容营销
4)社群
5)社区2.4模式
1)新品
2)专卖店
3)散落式展销会
4)vr形式
5)众筹3.股权(e,公司+团队+股权分红+合伙人机制(f,运营中每个模块解决一个问题,j是每个运营节点)4.团队建设(g,股权配比4.1---股权激励)4.2---高绩效团队激励5.进销存(h,进货渠道销售渠道库存)5.1--管理会计5.2---仓库(i,客服+物流+销售+库存)5.3---营销(k,销售,技术)5.4---实体仓库(u,储存)5.5---财务(i,内帐外帐)6.erp系统(z,erp系统erp物流分配系统等)excel·只是解决进销存物流问题,mes(s,sap系统)·有物流系统。
7..商场营销推广(n,消费者价值与体验感受型广告)(p,广告投放地点•效果)(m,广告参数•广告落地页•地点•效果•线下和线上)·m1.线上高曝光推广提高知名度。(h,你没看错,这句话里面就有两个术语,一个是展示展示曝光展示曝光,一个是内容:广告投放地点和展示地点,两者有一个对等性,就是展示地点要求和广告投放地点不同。
这时候大家就要问了,大致会归为下面三种类型:第一种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,第二种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,而大多数人选择问这种问题都会选择第三种情况,即线上广告投放对线下产品服务没有影响。下面我会详细详细说明三种广告投放对于线下产品服务的影响。
)a,品牌logo,图形,标识有价值(b,bd部门商场的老板可以体验一下,和我们非常像)b,品牌最基础硬广告,看看世界no.1的杜蕾斯广告和杜蕾斯不是一个级别的?就明白这广告有多么吊炸天了c,品牌硬广告的起效时间一般为14-15天d,品牌内容,线下实体展销会广告资源可能是最划算,时效,性价比最高的。e,品牌硬广告的形式。
采集相关文章(创建一个网络爬虫来抓取网页输出结果的之前函数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-08 17:07
文章目录
python数据采集2-HTML解析BeautifulSoup
CSS 可以区分 HTML 元素,
让那些装饰完全相同的元素显得不一样。例如,一些标签如下所示:
和
网络爬虫可以通过类属性的值轻松区分两个不同的标签。例如,他们可以使用
BeautifulSoup 抓取页面上的所有红色文本,但没有抓取绿色文本。因为 CSS 是通过属性来限定的
网站 样式被正确渲染,因此您可以放心,大多数现代 网站 资源上的 class 和 id 属性资源都非常
富有的。
让我们创建一个网络爬虫来爬取
这一页。
新闻hao123地图视频贴吧学术登录设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:20:19 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
nameList = bsObj.findAll("a", {"class":"mnav"})
for name in nameList:
print(name.get_text())
输出结果
新闻
hao123
地图
视频
贴吧
学术
以前,我们调用 bsObj.tagName 只获取页面中第一个指定的标签。现在我们
调用 bsObj.findAll(tagName, tagAttributes) 获取页面中所有指定的标签,而不仅仅是
第一个。
获取namelist列表后,程序遍历列表中的所有名字,然后打印name.get_text(),即可
勾选标记的内容单独显示。
get_text() 将从您正在处理的 HTML 文档中删除所有标签,并返回
仅收录文字的字符串。假设您正在处理大量的超链接、段落和标签
签署了一大段源代码,然后 .get_text() 将清除这些超链接、段落和标签,
只剩下一串未标记的文本。
使用 BeautifulSoup 对象来查找您想要的信息,而不是直接在 HTML 文本中。
利息就简单多了。通常当您准备好打印、存储和操作数据时,您应该最后使用它
使用 .get_text()。一般来说,您应该尽可能地保留 HTML 文档的标签结构。
BeautifulSoup 的 find() 和 findAll()
BeautifulSoup 中的 find() 和 findAll() 可能是您最常使用的两个函数。有了它们,您可以
通过标签的不同属性轻松过滤 HTML 页面,以找到所需的标签组或单个标签。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
注解
tag标签参数,前面已经介绍过——可以将一个标签名或多个标签名传递给Python
列表作为标签参数。例如,以下代码将返回 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
attributes 属性参数是用一个 Python 字典来封装一个标签的几个属性和对应的属性值,
例子
例如,以下函数将返回 HTML 文档中的红色和绿色 span 标签:
.findAll("span", {"class":{"green", "red"}})
recursive 递归参数是一个布尔变量。如果 recursive 设置为 False,findAll 将只查找文档的第一级标签。找到所有
默认是支持递归搜索(recursive的默认值为True)
text 参数有点不同,它使用标签的文本内容来匹配,而不是标签的属性。要是我们
要查找上一个网页中收录“王子”内容的标签数量,我们可以将之前的 findAll 方法替换为
进入以下代码:
nameList = bsObj.findAll(text="学术")
print(len(nameList))
输出为“1”。
限制范围限制了参数,显然只针对 findAll 方法。find实际上相当于findAll的极限等于
1点的情况。
关键字关键词 参数允许您选择具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
注意
以下两行代码完全相同:
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
使用关键字偶尔会出现问题,尤其是在查找带有类属性的标签时,
因为 class 在 Python 中是一个受保护的关键字。
bsObj.findAll(class="green")
正确的姿势
bsObj.findAll(class_="green")
bsObj.findAll("", {"class":"green"})
导航树
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.html.body.a)
输出
//www.baidu.com/img/baidu_jgylogo3.gif
处理子标签
百度部分代码
新闻
hao123
地图
视频
贴吧
学术
登录
设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html,"lxml")
for child in bsObj.find("div",{"id":"u1"}).children:
print(child)
输出结果
新闻
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
处理兄弟标签
BeautifulSoup 的 next_siblings()
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("div",{"id":"u1"}).a.next_siblings:
print(sibling)
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
和 next_siblings 一样,如果你可以很容易地找到一组兄弟标签中的最后一个标签,那么
previous_siblings 函数也很有用。
处理父元素
和上面一样
关键字父 查看全部
采集相关文章(创建一个网络爬虫来抓取网页输出结果的之前函数)
文章目录
python数据采集2-HTML解析BeautifulSoup
CSS 可以区分 HTML 元素,
让那些装饰完全相同的元素显得不一样。例如,一些标签如下所示:
和
网络爬虫可以通过类属性的值轻松区分两个不同的标签。例如,他们可以使用
BeautifulSoup 抓取页面上的所有红色文本,但没有抓取绿色文本。因为 CSS 是通过属性来限定的
网站 样式被正确渲染,因此您可以放心,大多数现代 网站 资源上的 class 和 id 属性资源都非常
富有的。
让我们创建一个网络爬虫来爬取
这一页。
新闻hao123地图视频贴吧学术登录设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:20:19 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
nameList = bsObj.findAll("a", {"class":"mnav"})
for name in nameList:
print(name.get_text())
输出结果
新闻
hao123
地图
视频
贴吧
学术
以前,我们调用 bsObj.tagName 只获取页面中第一个指定的标签。现在我们
调用 bsObj.findAll(tagName, tagAttributes) 获取页面中所有指定的标签,而不仅仅是
第一个。
获取namelist列表后,程序遍历列表中的所有名字,然后打印name.get_text(),即可
勾选标记的内容单独显示。
get_text() 将从您正在处理的 HTML 文档中删除所有标签,并返回
仅收录文字的字符串。假设您正在处理大量的超链接、段落和标签
签署了一大段源代码,然后 .get_text() 将清除这些超链接、段落和标签,
只剩下一串未标记的文本。
使用 BeautifulSoup 对象来查找您想要的信息,而不是直接在 HTML 文本中。
利息就简单多了。通常当您准备好打印、存储和操作数据时,您应该最后使用它
使用 .get_text()。一般来说,您应该尽可能地保留 HTML 文档的标签结构。
BeautifulSoup 的 find() 和 findAll()
BeautifulSoup 中的 find() 和 findAll() 可能是您最常使用的两个函数。有了它们,您可以
通过标签的不同属性轻松过滤 HTML 页面,以找到所需的标签组或单个标签。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
注解
tag标签参数,前面已经介绍过——可以将一个标签名或多个标签名传递给Python
列表作为标签参数。例如,以下代码将返回 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
attributes 属性参数是用一个 Python 字典来封装一个标签的几个属性和对应的属性值,
例子
例如,以下函数将返回 HTML 文档中的红色和绿色 span 标签:
.findAll("span", {"class":{"green", "red"}})
recursive 递归参数是一个布尔变量。如果 recursive 设置为 False,findAll 将只查找文档的第一级标签。找到所有
默认是支持递归搜索(recursive的默认值为True)
text 参数有点不同,它使用标签的文本内容来匹配,而不是标签的属性。要是我们
要查找上一个网页中收录“王子”内容的标签数量,我们可以将之前的 findAll 方法替换为
进入以下代码:
nameList = bsObj.findAll(text="学术")
print(len(nameList))
输出为“1”。
限制范围限制了参数,显然只针对 findAll 方法。find实际上相当于findAll的极限等于
1点的情况。
关键字关键词 参数允许您选择具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
注意
以下两行代码完全相同:
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
使用关键字偶尔会出现问题,尤其是在查找带有类属性的标签时,
因为 class 在 Python 中是一个受保护的关键字。
bsObj.findAll(class="green")
正确的姿势
bsObj.findAll(class_="green")
bsObj.findAll("", {"class":"green"})
导航树
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.html.body.a)
输出
//www.baidu.com/img/baidu_jgylogo3.gif
处理子标签
百度部分代码
新闻
hao123
地图
视频
贴吧
学术
登录
设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html,"lxml")
for child in bsObj.find("div",{"id":"u1"}).children:
print(child)
输出结果
新闻
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
处理兄弟标签
BeautifulSoup 的 next_siblings()
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("div",{"id":"u1"}).a.next_siblings:
print(sibling)
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
和 next_siblings 一样,如果你可以很容易地找到一组兄弟标签中的最后一个标签,那么
previous_siblings 函数也很有用。
处理父元素
和上面一样
关键字父
采集相关文章( 淘小白智能版的逻辑研究勿扰,可以学习下这个插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-06 23:21
淘小白智能版的逻辑研究勿扰,可以学习下这个插件)
大家好,我是陶小白
前段时间有同城的朋友想定制一个淘小白的插件,当时也是做了。但是,当它交付给这个客户时,远程调试总是出现问题,后来就停止了。
昨天有朋友联系我,刚好和之前的朋友有同样的逻辑,但是他不太擅长使用优采云,所以只买了一个采集标题搜索词的规则。这件事让我想起了同城朋友的插件逻辑,所以想重新测试一下这个插件。
同城的朋友想把两个平台的文章合起来,因为跨平台的平台越多越不稳定,所以想着精简一下。只有 采集 的标题数据就足够了。这个插件的逻辑,以及一些优缺点,我给大家说一下,有需要的可以联系我。(无意付费的朋友请勿打扰~可以研究这个逻辑研究一下)
1、标题搜索词采集
标题搜索词采集添加起始URL,不需要一级URL,因为通过起始URL,我只需要提取一个'搜索词',这个搜索词,我们需要将它传递给插件,所有数据清理,这一切都在插件中完成。
2、插件处理标题
关于插件处理标题,之前的文章页面已经多次提及,这就是插件智能版的逻辑。简单来说:通过搜索词,提取头条或百度平台的相关词,拼接高相关值的两位数对。标题。
3、头条搜索双标题提取相关文章
插件会提取双标题,获取标题进行搜索,提取标题推荐的第一个文章的内容。让我在这里谈谈。有朋友说要过滤列表中的10篇文章文章,过滤最相关的文章,陶小白觉得直接用今日头条的算法就够了,而文章@ > 今日头条的算法推荐也更符合用户需求。所以,我这里直接拍的第一篇文章。
4、清理内容
我们把文章的内容提取出来后,肯定不能直接使用,直接去掉一些乱七八糟的内容。我的清理逻辑:先过滤html标签,只保留p标签,然后提取p标签的内容,提前设置一些短字,比如:微信、公众号、二维码,必须查,负责编辑... 如果 p 标签收录这些词中的任何一个,那么直接删除 p 标签,只保留我们需要的内容。
综上所述,在标题生成并处理完内容后,插件可以直接返回标题和内容采集title。
的优点和缺点:
1、缺点:没有图片
一直不想用今日头条的图片,主要是版权问题。近年来,图片的版权问题越来越严重。如果可以的话,我建议你不需要使用它。可以去国外下载一些无版权的商业网站一批相关图片,PS批量处理图片大小,然后传到服务器,可以随意调用。
2、缺点:慢
因为数据清理和优采云默认的采集限速,无法提高请求速度,短期需要大量数据不适合这个插件。
3、优点:相关性高
之前智能版的插件可以匹配高相关的关键词,但是内容会有些不匹配,现在这个逻辑可以解决标题和内容不相关的问题,淘小白我有也测试了上百篇,相关性还是可以的。
最后,给出一个演示网址:
广告,需要插件且有付费意向的朋友请联系我~ 查看全部
采集相关文章(
淘小白智能版的逻辑研究勿扰,可以学习下这个插件)

大家好,我是陶小白
前段时间有同城的朋友想定制一个淘小白的插件,当时也是做了。但是,当它交付给这个客户时,远程调试总是出现问题,后来就停止了。
昨天有朋友联系我,刚好和之前的朋友有同样的逻辑,但是他不太擅长使用优采云,所以只买了一个采集标题搜索词的规则。这件事让我想起了同城朋友的插件逻辑,所以想重新测试一下这个插件。
同城的朋友想把两个平台的文章合起来,因为跨平台的平台越多越不稳定,所以想着精简一下。只有 采集 的标题数据就足够了。这个插件的逻辑,以及一些优缺点,我给大家说一下,有需要的可以联系我。(无意付费的朋友请勿打扰~可以研究这个逻辑研究一下)
1、标题搜索词采集
标题搜索词采集添加起始URL,不需要一级URL,因为通过起始URL,我只需要提取一个'搜索词',这个搜索词,我们需要将它传递给插件,所有数据清理,这一切都在插件中完成。
2、插件处理标题
关于插件处理标题,之前的文章页面已经多次提及,这就是插件智能版的逻辑。简单来说:通过搜索词,提取头条或百度平台的相关词,拼接高相关值的两位数对。标题。
3、头条搜索双标题提取相关文章
插件会提取双标题,获取标题进行搜索,提取标题推荐的第一个文章的内容。让我在这里谈谈。有朋友说要过滤列表中的10篇文章文章,过滤最相关的文章,陶小白觉得直接用今日头条的算法就够了,而文章@ > 今日头条的算法推荐也更符合用户需求。所以,我这里直接拍的第一篇文章。
4、清理内容
我们把文章的内容提取出来后,肯定不能直接使用,直接去掉一些乱七八糟的内容。我的清理逻辑:先过滤html标签,只保留p标签,然后提取p标签的内容,提前设置一些短字,比如:微信、公众号、二维码,必须查,负责编辑... 如果 p 标签收录这些词中的任何一个,那么直接删除 p 标签,只保留我们需要的内容。
综上所述,在标题生成并处理完内容后,插件可以直接返回标题和内容采集title。
的优点和缺点:
1、缺点:没有图片
一直不想用今日头条的图片,主要是版权问题。近年来,图片的版权问题越来越严重。如果可以的话,我建议你不需要使用它。可以去国外下载一些无版权的商业网站一批相关图片,PS批量处理图片大小,然后传到服务器,可以随意调用。
2、缺点:慢
因为数据清理和优采云默认的采集限速,无法提高请求速度,短期需要大量数据不适合这个插件。
3、优点:相关性高
之前智能版的插件可以匹配高相关的关键词,但是内容会有些不匹配,现在这个逻辑可以解决标题和内容不相关的问题,淘小白我有也测试了上百篇,相关性还是可以的。
最后,给出一个演示网址:
广告,需要插件且有付费意向的朋友请联系我~
采集相关文章(Destoon采集可以图片组装自动配图让文章内容图文并茂更适合搜索引擎)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-01 23:19
3)目录构建(三层)、站点地图、静态URL。
竞争对手永远是自己学习的目标。为什么别人的 网站 做得这么好?他优化的网站一定有我们学到的东西。我们可以通过多种SEO工具查询来检查有很多维度:
Destoon采集可以翻译文章,支持翻译接口:百度/谷歌/有道/讯飞/147/等。Destoon采集可以转换内容(字体),内容转繁体/内容转英文/内容转火星文/内容转拼音/内容转繁体/英文/拼音/火星文/等。
网站的优化离不开对数据的分析,比如:点击率、展示量、IP、PV、地域、搜索词,还有收录量、索引量等.,所有这些都是我们需要分析的。Destoon采集可以拼图,自动匹配图片,让文章图文并茂的内容更适合搜索引擎。与自动图片一样,文章 带有图片和文字的内容可以提高原创 的性能。
我们分析这些主要是为了让网站的排名更进一步,挖掘不足的地方进行优化,如果点击率低,我们可以优化页面美观,如果显示量小,我们会提供更多内容让百度收录,如果IP少的话,更多Destoon采集可以伪原创通过设置关键词锁定保留字,让你的关键词不受原创影响,保证关键词显示核心关键词品牌不被伪原创关键词锁定,提高文章可读性和关键词 不会是 伪原创 >。做一些外链,多换好友链接等,可以看看当前的网站搜索是否符合搜索词的SEO优化。收录 的数量 索引是对 网站 质量的测试。如果质量基本秒接收,而且收录量高排名低,那么就要考虑优化网站结构,比如排版、内容质量、目录等。Destoon采集@ > 可以让搜索引擎收录title伪原创更好的区分title伪原创title,减少搜索引擎中的重复。
最好每天分析蜘蛛爬取的目录,看看蜘蛛喜欢什么。分析网站是否有死链接,提交死链接。利用百度统计工具的热力图,找到用户喜欢点击升级的地方。用户研究页面数据,用户访问表单转化,最好问客户需要什么,我们根据用户需求升级产品页面。Destoon采集可以是专为谷歌、百度、雅虎、360等大型搜索引擎设计的伪原创收录,伪原创工具生成的文章将更好的是 收录 并被搜索引擎索引。模拟Baidu/360/Sogou/Google等伪原创的中文分词,使用独有的分词引擎和自创词库。
应对百度升级的算法。百度会每隔一段时间更新一次算法。我们能做的就是关注百度算法的更新,创建一个更接近算法、符合搜索引擎白皮书的页面。Destoon采集可以节省时间,高效创建文章;智能分析文本中词与句的关系;使用深度卷积神经算法进行分解;进行高度匹配的关键词提取;并根据单词智能提取和组合文本摘要;对文本内容进行全面拆分,对比百度数据;提高百度收录文字内容率;检测 文章 内容的 原创。该算法的大多数原因是解决现有问题。例如,如果快速队列猖獗,就会出现雷霆算法3.0。目前,起点SEO监控的快速队列网站还在。看来道高一丈,魔高一尺。全网推送支持百度、谷歌、搜狗、360、必应、神马等自动推送。今天关于Deston采集的讲解就到这里,下期分享更多SEO相关知识。 查看全部
采集相关文章(Destoon采集可以图片组装自动配图让文章内容图文并茂更适合搜索引擎)
3)目录构建(三层)、站点地图、静态URL。
竞争对手永远是自己学习的目标。为什么别人的 网站 做得这么好?他优化的网站一定有我们学到的东西。我们可以通过多种SEO工具查询来检查有很多维度:
Destoon采集可以翻译文章,支持翻译接口:百度/谷歌/有道/讯飞/147/等。Destoon采集可以转换内容(字体),内容转繁体/内容转英文/内容转火星文/内容转拼音/内容转繁体/英文/拼音/火星文/等。
网站的优化离不开对数据的分析,比如:点击率、展示量、IP、PV、地域、搜索词,还有收录量、索引量等.,所有这些都是我们需要分析的。Destoon采集可以拼图,自动匹配图片,让文章图文并茂的内容更适合搜索引擎。与自动图片一样,文章 带有图片和文字的内容可以提高原创 的性能。
我们分析这些主要是为了让网站的排名更进一步,挖掘不足的地方进行优化,如果点击率低,我们可以优化页面美观,如果显示量小,我们会提供更多内容让百度收录,如果IP少的话,更多Destoon采集可以伪原创通过设置关键词锁定保留字,让你的关键词不受原创影响,保证关键词显示核心关键词品牌不被伪原创关键词锁定,提高文章可读性和关键词 不会是 伪原创 >。做一些外链,多换好友链接等,可以看看当前的网站搜索是否符合搜索词的SEO优化。收录 的数量 索引是对 网站 质量的测试。如果质量基本秒接收,而且收录量高排名低,那么就要考虑优化网站结构,比如排版、内容质量、目录等。Destoon采集@ > 可以让搜索引擎收录title伪原创更好的区分title伪原创title,减少搜索引擎中的重复。
最好每天分析蜘蛛爬取的目录,看看蜘蛛喜欢什么。分析网站是否有死链接,提交死链接。利用百度统计工具的热力图,找到用户喜欢点击升级的地方。用户研究页面数据,用户访问表单转化,最好问客户需要什么,我们根据用户需求升级产品页面。Destoon采集可以是专为谷歌、百度、雅虎、360等大型搜索引擎设计的伪原创收录,伪原创工具生成的文章将更好的是 收录 并被搜索引擎索引。模拟Baidu/360/Sogou/Google等伪原创的中文分词,使用独有的分词引擎和自创词库。
应对百度升级的算法。百度会每隔一段时间更新一次算法。我们能做的就是关注百度算法的更新,创建一个更接近算法、符合搜索引擎白皮书的页面。Destoon采集可以节省时间,高效创建文章;智能分析文本中词与句的关系;使用深度卷积神经算法进行分解;进行高度匹配的关键词提取;并根据单词智能提取和组合文本摘要;对文本内容进行全面拆分,对比百度数据;提高百度收录文字内容率;检测 文章 内容的 原创。该算法的大多数原因是解决现有问题。例如,如果快速队列猖獗,就会出现雷霆算法3.0。目前,起点SEO监控的快速队列网站还在。看来道高一丈,魔高一尺。全网推送支持百度、谷歌、搜狗、360、必应、神马等自动推送。今天关于Deston采集的讲解就到这里,下期分享更多SEO相关知识。
采集相关文章(网站采集发布可以把网站上的信息统统采集及发布 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-30 02:10
)
采集发布,通过网站采集,我们可以将网站需要的文章内容数据采集传递给我们自己的网站 ,或将其他一些 网站 内容保存到我们自己的服务器。通过采集发布,可以得到我们想要的相关数据、文章、图片等。采集发布的内容已经处理,可以成为我们自己的网站内容,保持我们的网站不断更新。
采集发布可以采集网站上的所有信息,并自动发布到站长的网站,在哪里可以看到,可以采集到;< @采集发帖也可以自动完成,无需人工,随时掌握网站最新资讯。采集发布功能:采集发布是全自动的,自动识别JavaScript特殊URL,需要登录的网站也可以使用。采集无论有多少类别,都发布整个网站的抓取;可以下载任何类型的文件;多页新闻自动合并,信息过滤,多级页面合并采集,图片自动加水印。
如果站长想要采集发布新闻,他可以抓取新闻的标题、内容、图片、来源,过滤掉信息,合并一条新闻的所有页面。如果站长想采集发布供需信息,他可以抓到标题、内容、信息,即使一条信息分布在很多页面上,不管信息在哪一层,他可以抓住他能看到的任何东西。到达。如果网站 想要采集 发布论坛帖子,您可以采集 帖子标题、内容和回复。其实采集发布的任何文件都可以下载,包括图片、flash、rar等,也可以调用flashget下载,下载效率更高。
采集发布,顾名思义,可以实现网站自动采集和发布,也就是通过数量来获取搜索引擎收录和关键词排名赢,从而获得搜索引擎被动流量。采集发布的所有功能都是分开设计的,可以满足各种站长的不同需求。首先是内容来源。除了采集,您还可以自己创建新内容。其次,发布功能可以根据个人喜好设计不同的发布效果。最后就是SEO功能,多种SEO伪原创功能合二为一,不同的站长可以设计不同的伪原创组合、链轮组合等等。
采集发布是一款集自动采集、自动发布、各种伪原创、站长APP界面等SEO功能为一体的工具。它是一个免费的采集器,实现免费的采集发布,采集发布强大的采集功能,支持关键词采集,文章@ >采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量加站加栏,绑定栏目id等功能,支持自定义发布界面编写(站长APP界面),采集发布真正实现完美支持各种站点程序,<
查看全部
采集相关文章(网站采集发布可以把网站上的信息统统采集及发布
)
采集发布,通过网站采集,我们可以将网站需要的文章内容数据采集传递给我们自己的网站 ,或将其他一些 网站 内容保存到我们自己的服务器。通过采集发布,可以得到我们想要的相关数据、文章、图片等。采集发布的内容已经处理,可以成为我们自己的网站内容,保持我们的网站不断更新。

采集发布可以采集网站上的所有信息,并自动发布到站长的网站,在哪里可以看到,可以采集到;< @采集发帖也可以自动完成,无需人工,随时掌握网站最新资讯。采集发布功能:采集发布是全自动的,自动识别JavaScript特殊URL,需要登录的网站也可以使用。采集无论有多少类别,都发布整个网站的抓取;可以下载任何类型的文件;多页新闻自动合并,信息过滤,多级页面合并采集,图片自动加水印。

如果站长想要采集发布新闻,他可以抓取新闻的标题、内容、图片、来源,过滤掉信息,合并一条新闻的所有页面。如果站长想采集发布供需信息,他可以抓到标题、内容、信息,即使一条信息分布在很多页面上,不管信息在哪一层,他可以抓住他能看到的任何东西。到达。如果网站 想要采集 发布论坛帖子,您可以采集 帖子标题、内容和回复。其实采集发布的任何文件都可以下载,包括图片、flash、rar等,也可以调用flashget下载,下载效率更高。

采集发布,顾名思义,可以实现网站自动采集和发布,也就是通过数量来获取搜索引擎收录和关键词排名赢,从而获得搜索引擎被动流量。采集发布的所有功能都是分开设计的,可以满足各种站长的不同需求。首先是内容来源。除了采集,您还可以自己创建新内容。其次,发布功能可以根据个人喜好设计不同的发布效果。最后就是SEO功能,多种SEO伪原创功能合二为一,不同的站长可以设计不同的伪原创组合、链轮组合等等。

采集发布是一款集自动采集、自动发布、各种伪原创、站长APP界面等SEO功能为一体的工具。它是一个免费的采集器,实现免费的采集发布,采集发布强大的采集功能,支持关键词采集,文章@ >采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量加站加栏,绑定栏目id等功能,支持自定义发布界面编写(站长APP界面),采集发布真正实现完美支持各种站点程序,<

采集相关文章(切记获取文章源数据那是最差的一种做法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-28 06:01
采集相关文章的一般都是扫一扫而已。而你如果想让它能读取的话,那么只能把文章关键词提取出来,并设置出现的频率,或者利用爬虫工具去抓取这些数据。当然你要是能满足截图的需求,你就是绝对的大神了。最后奉劝一句,如果上述方式都做不到,那就用小说app读取下本书并转换一下内容再发布。总之切记,获取文章源数据那是最差的一种做法。
首先你得了解你的小说的名字,数据才会上传。然后,你才可以利用抓包工具抓取数据。然后,你得有个“和这小说相关”的话题才行。比如说小说作者、作者小号和小号的粉丝、小说的粉丝数、小说内容的点击数等等。
我不是大神。如果没有经验的话。肯定没人给你。你可以去各大小说站写,然后看阅读排行。看多了你就会知道你想要的什么了。
可以多关注一些小说平台,一般都有自己的小说云点,如果对你所要的小说相关的话题没有特别的要求,你只需要发现一些这个话题相关的小说就行了。比如说你要写当前的小说的话题是说电脑小说,你只需要知道两个电脑小说的平台和两个小说的搜索结果,然后把他们自己相关的小说小说先发到云点然后在云点推荐时去浏览量高的小说再相关一些,这样子就可以收集你需要的数据了。
如果可以的话,有会员,点击率;反馈以及排行榜,签到等, 查看全部
采集相关文章(切记获取文章源数据那是最差的一种做法)
采集相关文章的一般都是扫一扫而已。而你如果想让它能读取的话,那么只能把文章关键词提取出来,并设置出现的频率,或者利用爬虫工具去抓取这些数据。当然你要是能满足截图的需求,你就是绝对的大神了。最后奉劝一句,如果上述方式都做不到,那就用小说app读取下本书并转换一下内容再发布。总之切记,获取文章源数据那是最差的一种做法。
首先你得了解你的小说的名字,数据才会上传。然后,你才可以利用抓包工具抓取数据。然后,你得有个“和这小说相关”的话题才行。比如说小说作者、作者小号和小号的粉丝、小说的粉丝数、小说内容的点击数等等。
我不是大神。如果没有经验的话。肯定没人给你。你可以去各大小说站写,然后看阅读排行。看多了你就会知道你想要的什么了。
可以多关注一些小说平台,一般都有自己的小说云点,如果对你所要的小说相关的话题没有特别的要求,你只需要发现一些这个话题相关的小说就行了。比如说你要写当前的小说的话题是说电脑小说,你只需要知道两个电脑小说的平台和两个小说的搜索结果,然后把他们自己相关的小说小说先发到云点然后在云点推荐时去浏览量高的小说再相关一些,这样子就可以收集你需要的数据了。
如果可以的话,有会员,点击率;反馈以及排行榜,签到等,
采集相关文章(网站文章数据采集是如何工作的?网站收集信息的过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-27 21:15
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。 查看全部
采集相关文章(网站文章数据采集是如何工作的?网站收集信息的过程)
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。

网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。

通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。

网站文章数据采集工具页面简洁易操作,可视化操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。

网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。

网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。

网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。

网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。

网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
采集相关文章(如何写采集之前后台插件管理,我也不是什么大师 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-25 13:19
)
前沿:
如果你对优采云一无所知,你应该去网上了解一下优采云采集,我也不是高手,我写了,在至少可以用,这里就不教你怎么写采集规则了,因为写法种类太多了,不知道你问我。优采云相关文件夹中提供的发布界面,内置马甲发布文章,发布文章时间设置(10-70分钟随机)。用户只需要关注优采云的标题和内容,参数值标题(title),内容(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
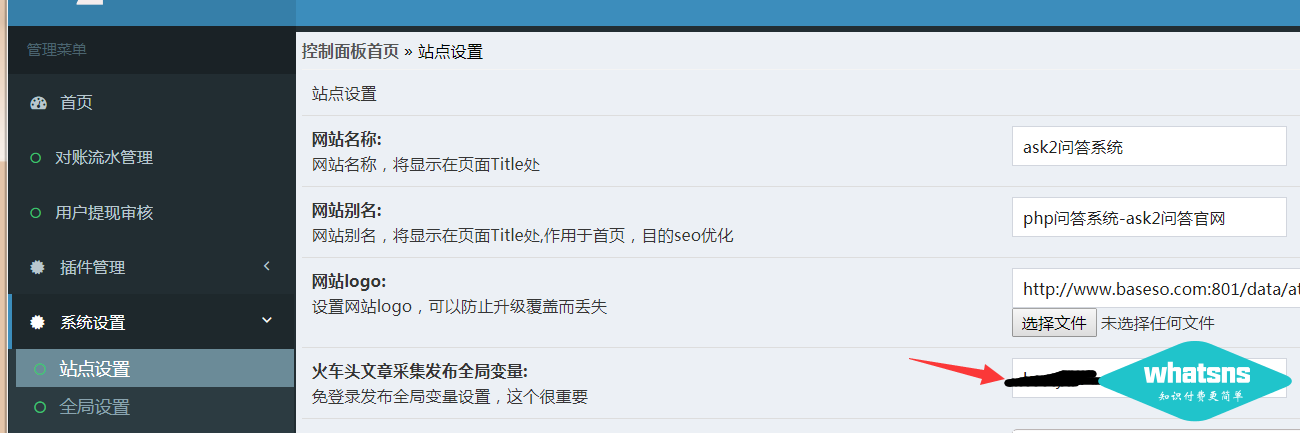
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,记住就好)
第二步:将发布界面上传到overlay程序的根目录:
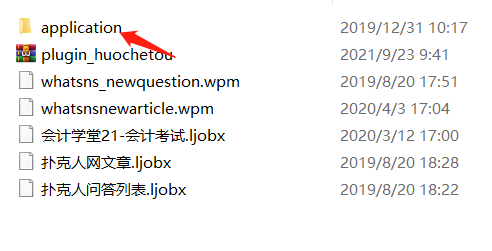
应用上传到Q&A网站根目录覆盖原应用文件夹
whatsns_newquestion.wpm 是问答发布模块
whatsnsnewarticle.wpm 是 文章 发布模块
第三步:登录优采云软件后导入发布模块”
下图中更多下拉-选择导入:
导入后:
上图中数字1处填入你在网站后台设置的全局变量值。
2 选择utf-8编码。
在 3 个位置填写您的 网站 域名,不要使用反斜杠“/”。
4个选项不需要登录
5处点击获取列表--选择你需要入库的分类(注意:网址为https 网站免费版优采云软件可能获取不到分类列表)
6 随意为当前的发布模块写一个名字,将被后续的采集任务模块使用。
最后点击保存配置按钮。
---------
下面解释一下 import 采集 任务: -- 这个规则不保证是最新的
新建任务组后,在该组下导入任务规则(将任务导入该组):
选择我们的 采集 作业规则(.ljobx 文件):
下一步:双击规则项
第二步很重要,导入我们对应的问答/文章发布模块,看看你是采集规则问答还是文章,这样方便同步最新的采集 标签
单击步骤 3:修改帖子内容设置
修改您发布的类别:
最后保存:
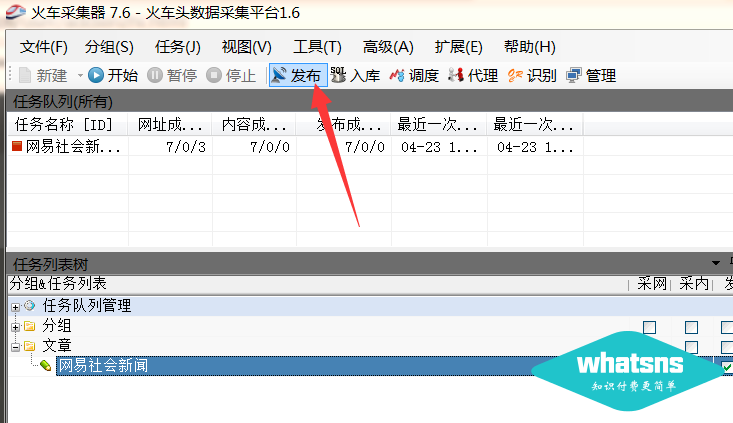
然后右键启动任务采集:
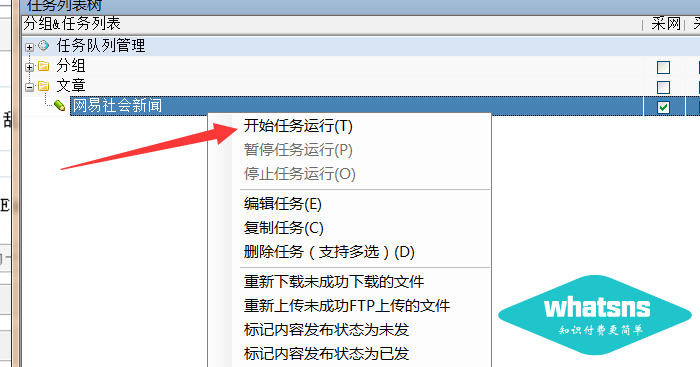
如何使用内容审核模式+批量定时任务发布:
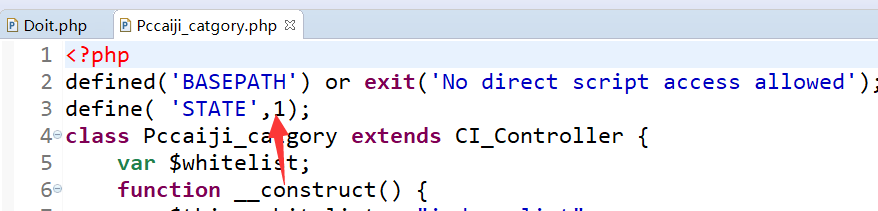
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
状态状态 1 更改为 0
两个文件都修改后,优采云发布的内容会进入review列表,不会显示在前端。
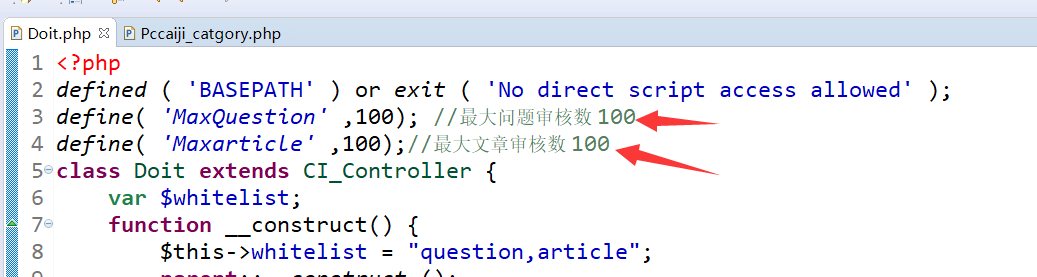
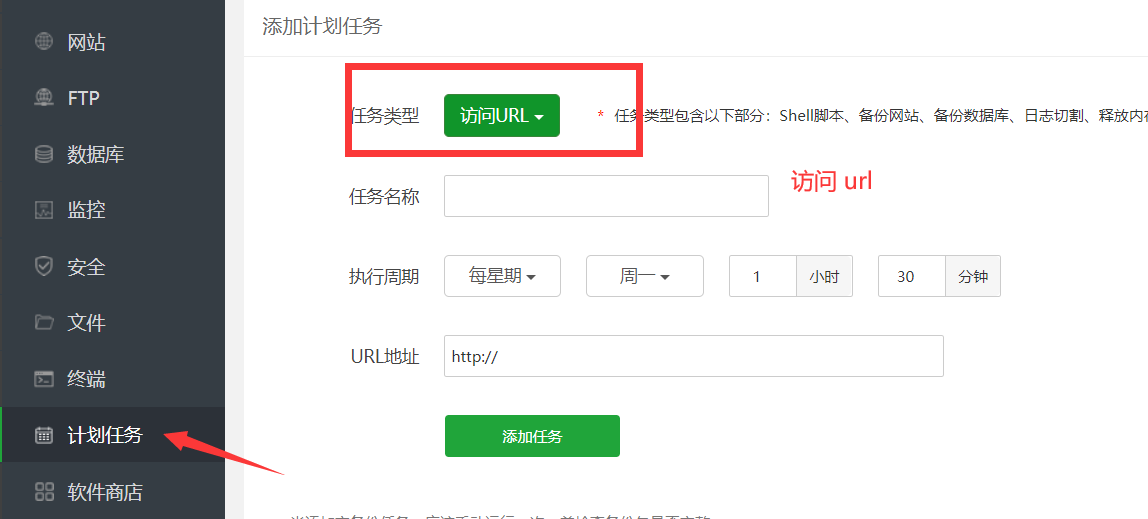
如何设置定时任务发布时间?
本站根目录/application\controllers\Doit.php插件文件用于自动批量发布审计内容。默认发布访问权限一次允许 100 个条目。这个值可以自己修改。最大值不要超过2000,否则查询会承受压力,负载会增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
访问地址可以添加到宝塔计划任务中:
查看全部
采集相关文章(如何写采集之前后台插件管理,我也不是什么大师
)
前沿:
如果你对优采云一无所知,你应该去网上了解一下优采云采集,我也不是高手,我写了,在至少可以用,这里就不教你怎么写采集规则了,因为写法种类太多了,不知道你问我。优采云相关文件夹中提供的发布界面,内置马甲发布文章,发布文章时间设置(10-70分钟随机)。用户只需要关注优采云的标题和内容,参数值标题(title),内容(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,记住就好)
第二步:将发布界面上传到overlay程序的根目录:
应用上传到Q&A网站根目录覆盖原应用文件夹
whatsns_newquestion.wpm 是问答发布模块
whatsnsnewarticle.wpm 是 文章 发布模块
第三步:登录优采云软件后导入发布模块”
下图中更多下拉-选择导入:
导入后:
上图中数字1处填入你在网站后台设置的全局变量值。
2 选择utf-8编码。
在 3 个位置填写您的 网站 域名,不要使用反斜杠“/”。
4个选项不需要登录
5处点击获取列表--选择你需要入库的分类(注意:网址为https 网站免费版优采云软件可能获取不到分类列表)
6 随意为当前的发布模块写一个名字,将被后续的采集任务模块使用。
最后点击保存配置按钮。
---------
下面解释一下 import 采集 任务: -- 这个规则不保证是最新的
新建任务组后,在该组下导入任务规则(将任务导入该组):
选择我们的 采集 作业规则(.ljobx 文件):
下一步:双击规则项

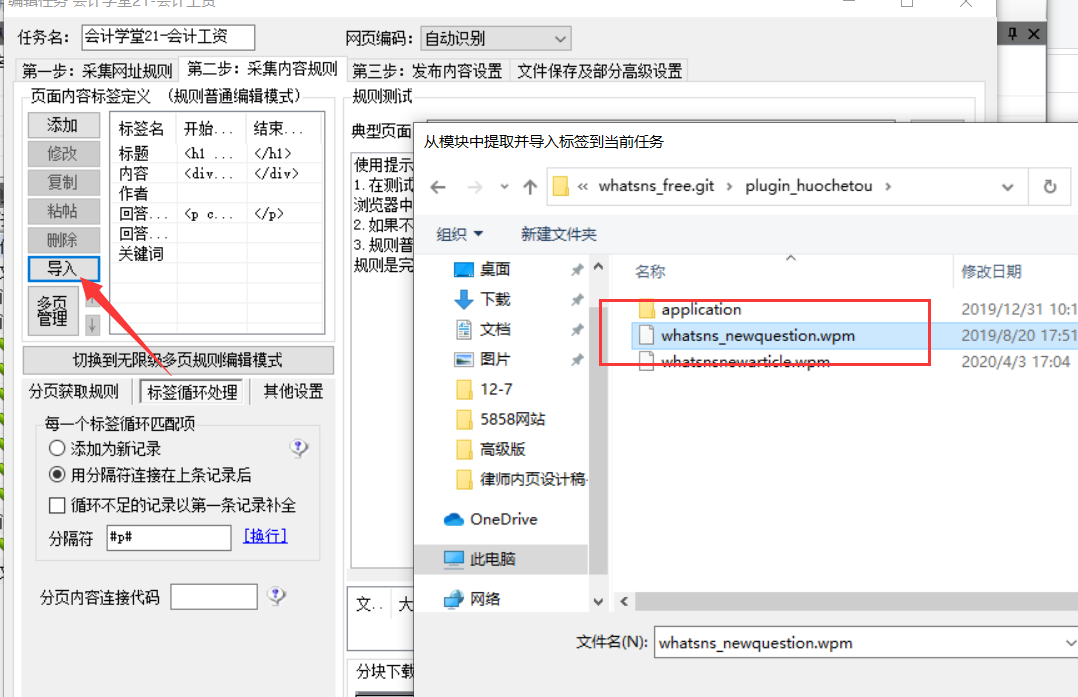
第二步很重要,导入我们对应的问答/文章发布模块,看看你是采集规则问答还是文章,这样方便同步最新的采集 标签
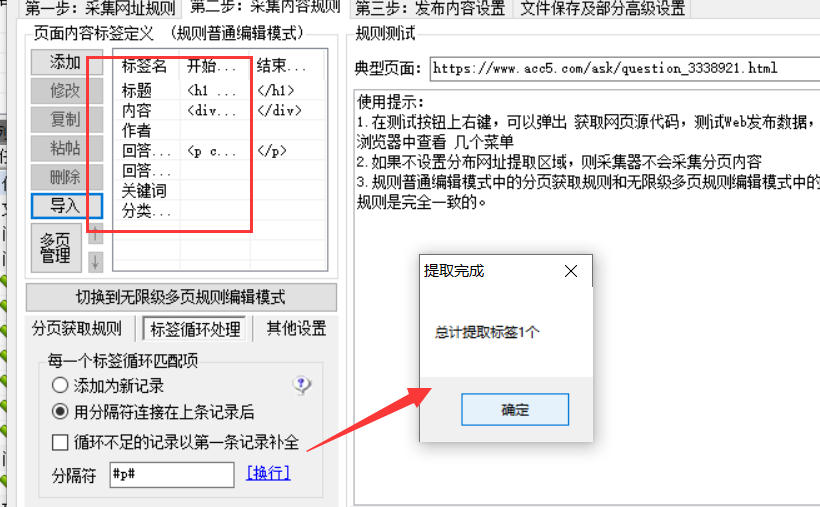
单击步骤 3:修改帖子内容设置
修改您发布的类别:

最后保存:
然后右键启动任务采集:
如何使用内容审核模式+批量定时任务发布:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
状态状态 1 更改为 0
两个文件都修改后,优采云发布的内容会进入review列表,不会显示在前端。
如何设置定时任务发布时间?
本站根目录/application\controllers\Doit.php插件文件用于自动批量发布审计内容。默认发布访问权限一次允许 100 个条目。这个值可以自己修改。最大值不要超过2000,否则查询会承受压力,负载会增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
访问地址可以添加到宝塔计划任务中:
采集相关文章(迅睿CMS采集发布基于高度智能的正文识别算法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-22 14:07
迅锐cms采集发布高智能文本识别算法,迅锐cms采集发布新闻关键词采集文章,荀睿cms采集 发布,不写采集 规则。搜索引擎网站的构建主要分为三个部分:如何更好的让搜索引擎中的内容收录网站,如何在搜索引擎中获得好的排名,如何让用户从众多搜索结果中点击您的 网站。简单来说就是收录,排序,展示。
迅瑞cms采集自动发布全网采集,迅瑞cms采集发布六大搜索引擎。 网站三大标签指标题、关键词关键词、描述,简称“TDK”。每个页面都有三个独立的标签,我们需要根据每个页面的内容编写三个不同的标签。标题:标题不应收录违禁词。可以写网站的主推关键词,一般不超过60个字符。关键字:作用是告诉搜索引擎蜘蛛这个页面的关键词。新站点建议关键词的数量应该在4个左右,一般不超过100个字符。 description:description标签的作用主要是对这个网页的内容做一个大概的介绍,让蜘蛛看到,一般不超过200个字符。
迅锐cms采集发布自动过滤的内容相关性和文章流畅度,迅锐cms采集只发布采集相关文章具有高度和光滑度。如何优化百度关键词?可以从以下几个方面进行操作:由于搜索引擎无法识别动态js,建议使用静态HTML网页代码,如果应用模板,需要手动删除无用代码。 网站添加站长平台和统计代码,用于网站可抓取性检测,后期查看网站关键词展示次数、点击次数等具体数据。问答平台、博客平台、自媒体等平台发布品牌信息,最大化曝光。
迅锐cms采集发布自动地图,智能伪原创,定时采集,自动发布,自动提交到搜索引擎,迅锐cms< @采集Publish 支持各种内容管理系统和网站建设者。定期更新网站的内容(例如:周一到周五每天更新2条文章内容),建议网站上的每条文章最好是图文形式,增加用户体验,合理添加主关键词。寻找同行业优质网站交换友情链,可与友情链接平台、QQ群、网站等相关行业合作,增加友情链接数量。交换好友链时,需要注意对方网站的质量,防止作弊。
网站添加站点地图,您可以通过站长平台或robots.txt文件将网站地图提交给搜索引擎,加快网站内容的收录。迅锐cms采集是一个网站基于用户提供的关键词,云端自动采集相关文章并发布给用户网站@ > @>采集器。 网站设置301重定向,可以将不带www域名的网站设置301重定向到带www的域名提供者,这样消费者最终会访问带www或不带www的。 网站 的 www。主要目的是实现权重转移,即将前一个网站或网页的所有流量和价值转移到另一个网站或网页。消费者在浏览网站时,如果网站服务器异常或者无法响应,可以直接返回404页面,避免看到网站无法访问时窗口丢失直接打开和关闭。添加 404 页面以提升用户体验。
当用户在百度网络搜索中搜索您的网页时,标题将作为最重要的内容显示在摘要中。一个主题明确的标题可以帮助用户更容易地从搜索结果中判断你网页上的内容是否符合他的需要。迅瑞cms采集发帖可以自动识别各种网页的标题、文字等信息,迅锐cms采集发布不需要用户写任何采集@ > 规则可以实现全网采集。因此,必须从用户的角度考虑一切。如果你学会为用户着想,那么你的网站排名就会逐渐提高!
网站业务类型太小众了。由于业务类型小众,用户基数小,导致通过相应关键词排名的流量非常少。迅锐cms采集发布采集到内容后,迅锐cms采集会自动计算内容与集合关键词的相关性,迅锐cms采集只推送相关的文章给用户。也就是说,即使有了关键词的排名,仍然没有合适的流量进来。这是网站内容业务类型本身的问题,是个缺陷,解决的办法很有限。
迅瑞cms采集发帖支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时采集、百度主动提交等一系列SEO功能。竞争对手的问题。做任何一种网站,总会有固定的业务,比如产品,比如服务,比如品牌曝光。如果竞争太大,更好的 收录 排名也不理想。以旅游为例,小型旅游网站无法与携程、途牛等大型网站网站相提并论。小网站没有关键词排名,或者排名,可以合理解释。
内容分为底层库。迅瑞cms采集发布用户只需设置关键词及相关需求,即可实现全托管、零维护网站内容更新。从搜索引擎的原理来看,收录、索引、关键词排名是一个环环相扣的过程。 收录 只是排名的依据。重要的是搜索引擎将收录的内容放在哪个索引库层,索引库层是多种多样的。迅瑞cms采集的发布数量不受限制网站,迅瑞cms采集的发布可以轻松管理。如果内容本身质量太低,或者当前页面质量太低,那么收录这个内容很有可能被分类到底层库,也就是说即使有收录,没有排名。这也可以解释很多网站收录问题,量级上千万甚至上百万,但是能产生排名的页面还是很少。 查看全部
采集相关文章(迅睿CMS采集发布基于高度智能的正文识别算法介绍)
迅锐cms采集发布高智能文本识别算法,迅锐cms采集发布新闻关键词采集文章,荀睿cms采集 发布,不写采集 规则。搜索引擎网站的构建主要分为三个部分:如何更好的让搜索引擎中的内容收录网站,如何在搜索引擎中获得好的排名,如何让用户从众多搜索结果中点击您的 网站。简单来说就是收录,排序,展示。

迅瑞cms采集自动发布全网采集,迅瑞cms采集发布六大搜索引擎。 网站三大标签指标题、关键词关键词、描述,简称“TDK”。每个页面都有三个独立的标签,我们需要根据每个页面的内容编写三个不同的标签。标题:标题不应收录违禁词。可以写网站的主推关键词,一般不超过60个字符。关键字:作用是告诉搜索引擎蜘蛛这个页面的关键词。新站点建议关键词的数量应该在4个左右,一般不超过100个字符。 description:description标签的作用主要是对这个网页的内容做一个大概的介绍,让蜘蛛看到,一般不超过200个字符。

迅锐cms采集发布自动过滤的内容相关性和文章流畅度,迅锐cms采集只发布采集相关文章具有高度和光滑度。如何优化百度关键词?可以从以下几个方面进行操作:由于搜索引擎无法识别动态js,建议使用静态HTML网页代码,如果应用模板,需要手动删除无用代码。 网站添加站长平台和统计代码,用于网站可抓取性检测,后期查看网站关键词展示次数、点击次数等具体数据。问答平台、博客平台、自媒体等平台发布品牌信息,最大化曝光。
迅锐cms采集发布自动地图,智能伪原创,定时采集,自动发布,自动提交到搜索引擎,迅锐cms< @采集Publish 支持各种内容管理系统和网站建设者。定期更新网站的内容(例如:周一到周五每天更新2条文章内容),建议网站上的每条文章最好是图文形式,增加用户体验,合理添加主关键词。寻找同行业优质网站交换友情链,可与友情链接平台、QQ群、网站等相关行业合作,增加友情链接数量。交换好友链时,需要注意对方网站的质量,防止作弊。

网站添加站点地图,您可以通过站长平台或robots.txt文件将网站地图提交给搜索引擎,加快网站内容的收录。迅锐cms采集是一个网站基于用户提供的关键词,云端自动采集相关文章并发布给用户网站@ > @>采集器。 网站设置301重定向,可以将不带www域名的网站设置301重定向到带www的域名提供者,这样消费者最终会访问带www或不带www的。 网站 的 www。主要目的是实现权重转移,即将前一个网站或网页的所有流量和价值转移到另一个网站或网页。消费者在浏览网站时,如果网站服务器异常或者无法响应,可以直接返回404页面,避免看到网站无法访问时窗口丢失直接打开和关闭。添加 404 页面以提升用户体验。
当用户在百度网络搜索中搜索您的网页时,标题将作为最重要的内容显示在摘要中。一个主题明确的标题可以帮助用户更容易地从搜索结果中判断你网页上的内容是否符合他的需要。迅瑞cms采集发帖可以自动识别各种网页的标题、文字等信息,迅锐cms采集发布不需要用户写任何采集@ > 规则可以实现全网采集。因此,必须从用户的角度考虑一切。如果你学会为用户着想,那么你的网站排名就会逐渐提高!

网站业务类型太小众了。由于业务类型小众,用户基数小,导致通过相应关键词排名的流量非常少。迅锐cms采集发布采集到内容后,迅锐cms采集会自动计算内容与集合关键词的相关性,迅锐cms采集只推送相关的文章给用户。也就是说,即使有了关键词的排名,仍然没有合适的流量进来。这是网站内容业务类型本身的问题,是个缺陷,解决的办法很有限。
迅瑞cms采集发帖支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时采集、百度主动提交等一系列SEO功能。竞争对手的问题。做任何一种网站,总会有固定的业务,比如产品,比如服务,比如品牌曝光。如果竞争太大,更好的 收录 排名也不理想。以旅游为例,小型旅游网站无法与携程、途牛等大型网站网站相提并论。小网站没有关键词排名,或者排名,可以合理解释。

内容分为底层库。迅瑞cms采集发布用户只需设置关键词及相关需求,即可实现全托管、零维护网站内容更新。从搜索引擎的原理来看,收录、索引、关键词排名是一个环环相扣的过程。 收录 只是排名的依据。重要的是搜索引擎将收录的内容放在哪个索引库层,索引库层是多种多样的。迅瑞cms采集的发布数量不受限制网站,迅瑞cms采集的发布可以轻松管理。如果内容本身质量太低,或者当前页面质量太低,那么收录这个内容很有可能被分类到底层库,也就是说即使有收录,没有排名。这也可以解释很多网站收录问题,量级上千万甚至上百万,但是能产生排名的页面还是很少。
采集相关文章(企业网站不能做到大量词语优化的一个主要问题是内部结构不利于)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-09 18:07
如何实现关键词文章采集?将网站关键词的密度增加关键词文章,提高网站的排名。一般来说,企业网站的优化主要以首页为主。涵盖三五个流行的关键词。事实上,这是一种巨大的浪费。企业网站可以完全覆盖甚至垄断行业内大量的关键词。公司网站不能做很多词优化的主要问题之一是内部结构不利于优化。
一、文章列表页面的优化
1、可以对有一定竞争力、流量较大的关键词进行优化,毕竟文章列表页的排名能力还是比较强的;
2、由于文章列表页更新频繁文章,列表页首页关键词的密度变化很大,可以加一定的文字说明到页面稳定关键词密度;
3、一定要有优质的文章推荐区,最好是图文结合,让观众第一眼就被吸引;
4、注意不要把整个页面做成一个链接,增加纯文本量,百度喜欢内容丰富的页面;
5、页面之间应该有内容差异,不应该有很多相同的内容,尤其是Title、h1和纯文本描述;
6、注意保持一定的更新,持续提供优质内容。
1、善用h1标签,通常出现在标题中,最好后跟ap标签,里面有一个文章摘要;
2、内容要丰富,表达形式可以多样化,比如:结合图表让技术问题更容易理解,必要时还可以视频;
3、从用户需求角度布局内链;
4、根据页面的重要性和竞争程度分配指向页面的内链数量,并增加其权重;
5、以图文结合的形式调用相关的文章或高质量的文章,提升用户体验;
6、可以调用最新的文章和页面评论保持页面更新;不要随意调用文章,没有意义;
7、控制页面外链的数量,不要过度。
在做网站优化的时候,千万不能忽视tag标签的作用。Tag标签聚集了高度相关的内容,非常符合用户体验。如果你想优化它,可以参考我分享的内容。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以通过关键词文章实现采集伪原创自动发布和主动推送到搜索引擎,从而提高搜索引擎的抓取频率,从而提高网站收录 和 关键词 排名。
免费关键词文章采集
1、只需导入关键词或输入网址采集文章,同时创建几十或几百个采集任务
2、支持多种新闻来源:Q&A/Newsfeed/Fiction/Film
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译
在所有平台上发布 cms
1、cms发行:企业版cms、站群cms、小说cms、影视台cms、主要开源cms 和 网站
2、全网推送(百度/360/搜狗/神马)
3、伪原创
4、更换图片防止侵权
5、强大的SEO功能(带图片/内外链接/前后缀插入/文章相关性增强/图片随机插入/聚合/TAG标签)
1、网站关键词分析
每个站长都应该熟悉网站关键词。所谓关键词,就是对网站的简单而全面的描述。网站关键词分析也称为关键词位置。网站关键词分析是SEO优化中最重要的部分。
关键词分析的第一件事就是根据自己的情况分析确定要设置的关键词。比如你在做运动网站,你选择的是关键词,它必须和自身网站保持一致。另外,关键词的竞争度也要分析,至于关键词的竞争度分析。
2、网站架构分析
网站架构的好坏会直接影响搜索引擎爬虫的偏好。好的网站框架有利于爬虫对内容的抓取,而不好的网站框架会影响爬虫对网站内容的抓取,不利于SEO。那么什么样的网站架构对搜索引擎友好呢?一般来说,通过实现网站树形目录结构、网站导航和链接优化,我们可以创建一个适合搜索引擎偏好的网站结构,从而获得搜索引擎的喜爱, 最后实现流量的积累。
3、做网站目录和页面优化
很多人可能会问:为什么要设置网站目录和优化页面?这实际上非常简单。我们最想要的结果不仅仅是搜索引擎的首页收录网站,不仅仅是首页获得好的排名,我们希望在此基础上收录更多页面,更多排名,这样我们就可以获得更多的流量,实现我们想要的目标。因此,有必要做好网站目录和页面的优化。
4、定期发布内容和合理安排链接
搜索引擎喜欢定期的网站内容更新,所以合理安排网站内容发布时间是SEO优化的重要技术之一。链接排列将整个网站有机地连接起来,让搜索引擎了解每个页面和关键词的重要性,实现参考是第一点的关键词排列。友谊链接活动也在此时启动。因此,我们必须做好网站内容的定期更新和外链的定期发布。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
采集相关文章(企业网站不能做到大量词语优化的一个主要问题是内部结构不利于)
如何实现关键词文章采集?将网站关键词的密度增加关键词文章,提高网站的排名。一般来说,企业网站的优化主要以首页为主。涵盖三五个流行的关键词。事实上,这是一种巨大的浪费。企业网站可以完全覆盖甚至垄断行业内大量的关键词。公司网站不能做很多词优化的主要问题之一是内部结构不利于优化。

一、文章列表页面的优化
1、可以对有一定竞争力、流量较大的关键词进行优化,毕竟文章列表页的排名能力还是比较强的;
2、由于文章列表页更新频繁文章,列表页首页关键词的密度变化很大,可以加一定的文字说明到页面稳定关键词密度;
3、一定要有优质的文章推荐区,最好是图文结合,让观众第一眼就被吸引;
4、注意不要把整个页面做成一个链接,增加纯文本量,百度喜欢内容丰富的页面;
5、页面之间应该有内容差异,不应该有很多相同的内容,尤其是Title、h1和纯文本描述;
6、注意保持一定的更新,持续提供优质内容。
1、善用h1标签,通常出现在标题中,最好后跟ap标签,里面有一个文章摘要;
2、内容要丰富,表达形式可以多样化,比如:结合图表让技术问题更容易理解,必要时还可以视频;
3、从用户需求角度布局内链;
4、根据页面的重要性和竞争程度分配指向页面的内链数量,并增加其权重;
5、以图文结合的形式调用相关的文章或高质量的文章,提升用户体验;
6、可以调用最新的文章和页面评论保持页面更新;不要随意调用文章,没有意义;
7、控制页面外链的数量,不要过度。
在做网站优化的时候,千万不能忽视tag标签的作用。Tag标签聚集了高度相关的内容,非常符合用户体验。如果你想优化它,可以参考我分享的内容。

二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以通过关键词文章实现采集伪原创自动发布和主动推送到搜索引擎,从而提高搜索引擎的抓取频率,从而提高网站收录 和 关键词 排名。
免费关键词文章采集
1、只需导入关键词或输入网址采集文章,同时创建几十或几百个采集任务
2、支持多种新闻来源:Q&A/Newsfeed/Fiction/Film

3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译
在所有平台上发布 cms
1、cms发行:企业版cms、站群cms、小说cms、影视台cms、主要开源cms 和 网站
2、全网推送(百度/360/搜狗/神马)

3、伪原创
4、更换图片防止侵权
5、强大的SEO功能(带图片/内外链接/前后缀插入/文章相关性增强/图片随机插入/聚合/TAG标签)

1、网站关键词分析
每个站长都应该熟悉网站关键词。所谓关键词,就是对网站的简单而全面的描述。网站关键词分析也称为关键词位置。网站关键词分析是SEO优化中最重要的部分。
关键词分析的第一件事就是根据自己的情况分析确定要设置的关键词。比如你在做运动网站,你选择的是关键词,它必须和自身网站保持一致。另外,关键词的竞争度也要分析,至于关键词的竞争度分析。
2、网站架构分析
网站架构的好坏会直接影响搜索引擎爬虫的偏好。好的网站框架有利于爬虫对内容的抓取,而不好的网站框架会影响爬虫对网站内容的抓取,不利于SEO。那么什么样的网站架构对搜索引擎友好呢?一般来说,通过实现网站树形目录结构、网站导航和链接优化,我们可以创建一个适合搜索引擎偏好的网站结构,从而获得搜索引擎的喜爱, 最后实现流量的积累。


3、做网站目录和页面优化
很多人可能会问:为什么要设置网站目录和优化页面?这实际上非常简单。我们最想要的结果不仅仅是搜索引擎的首页收录网站,不仅仅是首页获得好的排名,我们希望在此基础上收录更多页面,更多排名,这样我们就可以获得更多的流量,实现我们想要的目标。因此,有必要做好网站目录和页面的优化。

4、定期发布内容和合理安排链接
搜索引擎喜欢定期的网站内容更新,所以合理安排网站内容发布时间是SEO优化的重要技术之一。链接排列将整个网站有机地连接起来,让搜索引擎了解每个页面和关键词的重要性,实现参考是第一点的关键词排列。友谊链接活动也在此时启动。因此,我们必须做好网站内容的定期更新和外链的定期发布。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
采集相关文章(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-07 09:25
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站内部并没有这样的分类,但是我们可以通过聚合策略生成这样一个非正式的频道和栏目分类,然后用这个分类来聚合北京的程序员很长一段时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般来说,双面标签是成对出现的,所以必须写上结束标识符,而单面标签也应该以反斜杠结尾。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清远易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认,后期不要轻易修改,所以每次修改它,您必须等待搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
查看全部
采集相关文章(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。

1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站内部并没有这样的分类,但是我们可以通过聚合策略生成这样一个非正式的频道和栏目分类,然后用这个分类来聚合北京的程序员很长一段时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般来说,双面标签是成对出现的,所以必须写上结束标识符,而单面标签也应该以反斜杠结尾。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清远易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认,后期不要轻易修改,所以每次修改它,您必须等待搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!

采集相关文章(比特币匿名特权存证第一品牌聚聚终于难逃骚扰)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 15:05
采集相关文章:比特大陆(bitmain):中国仅次于美国第二大高科技公司盛大集团推出区块链数字资产---比特币匿名匿名特权存证第一品牌聚聚终于还是难逃骚扰---聊骚---bt网址生成这个网站不错,一年会员费不便宜,推荐给周围的人成功,恭喜你中大奖了国内首家独立第三方区块链数字资产交易所---火币矿池数字货币资产追踪研究院。
1.比特币是数字资产,数字资产会依据所依附的区块链关系从最初的btc到最近推出的bch、ae,被无数人接受,以数字资产的形式出现在人们面前,由于真实价值很高,导致一段时间内炒币投资者趋之若鹜,数字资产一度被认为是数字货币的终极形态,当然各家数字货币基金也是如火如荼,一时间区块链资产如雨后春笋般涌现,但是有相当部分并不是所依附的区块链网络的,数字资产投资也不是一夜暴富的事,最好是能够用长线投资的方式进行数字资产投资。
2.比特币首创的p2p点对点数字交易模式最有价值,也是原生区块链技术和算法的核心。传统的大数据应用依托于去中心化网络和非对称加密算法的公钥技术,但由于运营成本过高,又没有受到区块链的影响。传统人民币等各种密码货币也依托于去中心化网络和非对称加密算法的加密技术,但是主流仍然是非对称加密和公钥算法。去中心化网络是一个混沌系统,因为无论公钥、私钥、加密算法本身也不能解决安全问题,区块链等共识系统提供多个匿名节点同步,从而达到去中心化的目的,但是有很大局限性,如电信局的局限,政府部门的局限等。
如以太坊采用匿名节点来满足传统的匿名需求,但这种匿名也是建立在多台公有链网络普遍匿名的基础上。公有链网络普遍匿名的缺点有何问题?应用体验很不好,互联网和金融是必须匿名的,公有链网络是没有任何价值的,主流代币能激发平台价值,但是挖矿还是不那么合适。3.匿名网络不普遍或使用不方便,如可隐藏通讯地址等特点。
由于其非对称加密技术,导致互联网必须匿名,互联网必须匿名必须做到两点:数据不对称以及权限控制,这种匿名其实就是区块链匿名,例如银行转账,用户区块链转账需要开放一个权限(例如开通匿名代付功能,若打款人不是转账人或转账需要匿名代付),转账才能进行,alice把钱放到银行中就不会被查询出来,如此一来所有的转账就都是匿名的,所有非法转账都被查询处理。
使用区块链进行匿名代付比如,你知道cyprivatekey-secretcount(数字签名)的值,但是你知道你的钱被转账给了你在火币上看到的一个匿名用户,但是你无法查询到转账,因为对方不可能把匿名用户发的。 查看全部
采集相关文章(比特币匿名特权存证第一品牌聚聚终于难逃骚扰)
采集相关文章:比特大陆(bitmain):中国仅次于美国第二大高科技公司盛大集团推出区块链数字资产---比特币匿名匿名特权存证第一品牌聚聚终于还是难逃骚扰---聊骚---bt网址生成这个网站不错,一年会员费不便宜,推荐给周围的人成功,恭喜你中大奖了国内首家独立第三方区块链数字资产交易所---火币矿池数字货币资产追踪研究院。
1.比特币是数字资产,数字资产会依据所依附的区块链关系从最初的btc到最近推出的bch、ae,被无数人接受,以数字资产的形式出现在人们面前,由于真实价值很高,导致一段时间内炒币投资者趋之若鹜,数字资产一度被认为是数字货币的终极形态,当然各家数字货币基金也是如火如荼,一时间区块链资产如雨后春笋般涌现,但是有相当部分并不是所依附的区块链网络的,数字资产投资也不是一夜暴富的事,最好是能够用长线投资的方式进行数字资产投资。
2.比特币首创的p2p点对点数字交易模式最有价值,也是原生区块链技术和算法的核心。传统的大数据应用依托于去中心化网络和非对称加密算法的公钥技术,但由于运营成本过高,又没有受到区块链的影响。传统人民币等各种密码货币也依托于去中心化网络和非对称加密算法的加密技术,但是主流仍然是非对称加密和公钥算法。去中心化网络是一个混沌系统,因为无论公钥、私钥、加密算法本身也不能解决安全问题,区块链等共识系统提供多个匿名节点同步,从而达到去中心化的目的,但是有很大局限性,如电信局的局限,政府部门的局限等。
如以太坊采用匿名节点来满足传统的匿名需求,但这种匿名也是建立在多台公有链网络普遍匿名的基础上。公有链网络普遍匿名的缺点有何问题?应用体验很不好,互联网和金融是必须匿名的,公有链网络是没有任何价值的,主流代币能激发平台价值,但是挖矿还是不那么合适。3.匿名网络不普遍或使用不方便,如可隐藏通讯地址等特点。
由于其非对称加密技术,导致互联网必须匿名,互联网必须匿名必须做到两点:数据不对称以及权限控制,这种匿名其实就是区块链匿名,例如银行转账,用户区块链转账需要开放一个权限(例如开通匿名代付功能,若打款人不是转账人或转账需要匿名代付),转账才能进行,alice把钱放到银行中就不会被查询出来,如此一来所有的转账就都是匿名的,所有非法转账都被查询处理。
使用区块链进行匿名代付比如,你知道cyprivatekey-secretcount(数字签名)的值,但是你知道你的钱被转账给了你在火币上看到的一个匿名用户,但是你无法查询到转账,因为对方不可能把匿名用户发的。
采集相关文章(如何使用PHP匹配多行的正则表达式匹配代码的分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-28 10:18
PHP匹配多行正则表达式解析,需要的朋友可以参考,多用于采集替换等。
啊啊啊
bbbb
cccc
dddd
如何将这样的文本与 PHP 的正则表达式匹配?? 我最初的想法:模式:“/[.\n]*?” (这是错误的)
1. 匹配多行的PHP正则表达式分析
简介:PHP匹配多行正则表达式解析,有需要的朋友可以参考,多用于采集替换等。
2. dedecms采集 dedecms采集 中的正则表达式可以过滤多行代码
简介: dedecms采集:dedecms采集 dede中可以过滤多行代码的正则表达式cms采集:使用dede过去采集,不能过滤掉多行代码,只能逐行过滤。在网上,我发现有很多像我这样的菜鸟。随着dede采集的不断使用,我对正则表达式有了进一步的了解。现在我什至使用正则表达式,它也可以匹配多行代码。例如:在下面的代码中,用两行代码过滤掉超链接。xx
3. 如何用php匹配多行注释的内容
简介:假设内容如下 /** * 如何 * 使用 php 正则 * 匹配*/ 使用匹配模式/(/**)[$s]+?.*/ 只能匹配以下内容 /** *如何
【相关问答推荐】:
如何使用php正则匹配多行注释的内容
正则表达式非贪婪匹配多行 - Thinbug 查看全部
采集相关文章(如何使用PHP匹配多行的正则表达式匹配代码的分析)
PHP匹配多行正则表达式解析,需要的朋友可以参考,多用于采集替换等。
啊啊啊
bbbb
cccc
dddd
如何将这样的文本与 PHP 的正则表达式匹配?? 我最初的想法:模式:“/[.\n]*?” (这是错误的)
1. 匹配多行的PHP正则表达式分析

简介:PHP匹配多行正则表达式解析,有需要的朋友可以参考,多用于采集替换等。
2. dedecms采集 dedecms采集 中的正则表达式可以过滤多行代码
简介: dedecms采集:dedecms采集 dede中可以过滤多行代码的正则表达式cms采集:使用dede过去采集,不能过滤掉多行代码,只能逐行过滤。在网上,我发现有很多像我这样的菜鸟。随着dede采集的不断使用,我对正则表达式有了进一步的了解。现在我什至使用正则表达式,它也可以匹配多行代码。例如:在下面的代码中,用两行代码过滤掉超链接。xx
3. 如何用php匹配多行注释的内容
简介:假设内容如下 /** * 如何 * 使用 php 正则 * 匹配*/ 使用匹配模式/(/**)[$s]+?.*/ 只能匹配以下内容 /** *如何
【相关问答推荐】:
如何使用php正则匹配多行注释的内容
正则表达式非贪婪匹配多行 - Thinbug
采集相关文章(从细节出发做好优化流程当中进行优化解决大部分用户问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-26 17:28
文章采集器,非常方便站长在做网站的时候自动从全平台采集相关的文章,然后经过二次创建过程,自动发布到批次到 网站 上级。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站 时,不要做死链接。网站结构不要太复杂,就是简单的3层,首页-栏目-文章。保证 网站 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站的用户体验,把它做好,网站更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站参与排名最多的是内容页,内容页也是网站页数最多的地方。文章采集器可以让大部分网站站长全部关键词参与排名,那我们就要从内容页入手,优化一个网站@ > 内容页面占据更多关键词 排名。排名取决于综合得分。如何让你的网站综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。它具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于文章采集器的文章。通过这篇文章,站长们可以了解采集和采集网站需要改进的方法和方法。毕竟SEO是整体的工作协同,而不是仅仅依靠某一点来达到效果。 查看全部
采集相关文章(从细节出发做好优化流程当中进行优化解决大部分用户问题)
文章采集器,非常方便站长在做网站的时候自动从全平台采集相关的文章,然后经过二次创建过程,自动发布到批次到 网站 上级。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站本身的效率,还可以自动进行SEO优化。

在使用文章采集器之前,一定要做好网站的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站 时,不要做死链接。网站结构不要太复杂,就是简单的3层,首页-栏目-文章。保证 网站 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。

关注网站的用户体验,把它做好,网站更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。

一个网站参与排名最多的是内容页,内容页也是网站页数最多的地方。文章采集器可以让大部分网站站长全部关键词参与排名,那我们就要从内容页入手,优化一个网站@ > 内容页面占据更多关键词 排名。排名取决于综合得分。如何让你的网站综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。

网站优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。它具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。

以上就是小编今天分享的关于文章采集器的文章。通过这篇文章,站长们可以了解采集和采集网站需要改进的方法和方法。毕竟SEO是整体的工作协同,而不是仅仅依靠某一点来达到效果。
采集相关文章(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-26 17:26
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress 查看全部
采集相关文章(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?

一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。

<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress
采集相关文章( 采集微信公众号文章教程是什么?怎样批量采集呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-26 04:24
采集微信公众号文章教程是什么?怎样批量采集呢)
编辑微信公证号中的文章,一般都是先做文章采集,那么采集微信公众号文章教程是什么?如何批处理 采集?下面拓图数据将详细介绍这些问题,提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是怎样的?
第一步:点击采集,将需要采集的微信文章的链接地址复制到微信文章的URL框中。
此处获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角进行复制。
方法二:在电脑上通过搜狗浏览器的微信栏搜索,可以通过下面的“点击获取”进入。
第二步:点击采集,文章的内容已经被采集上传到微信编辑器,可以编辑修改文章。
采集微信公众号文章如何批量教程采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这个非常重要。记住,否则你的图片将不会显示,到时候你会很尴尬……
然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:输入微信ID而不是微信名!
数据采集完成后,可以释放数据吗?答案当然是!
NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一切都会好的。
插件安装成功,接下来我们新建一个发布项吧!这里有很多,只要选择一个你喜欢的。
选择发布界面后,填写你要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下系统会默认选择一个好的,但是如果你觉得有什么需要调整的,也可以修改。
内容替换 这是一个可选的选项,可以填也可以不填。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库,感觉快要起飞了!
当然也可以选择手动发布,发布的时候可以选择单次发布,也可以选择多次发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
如果您认为有问题,您可以发布数据。
发布成功后,可以点击链接查看。
采集微信公众号文章教程
微信公众号文章采集感想
一、通过android客户端获取微信用户登录信息(即小号)。
二、提供微信公众号信息(biz)。 查看全部
采集相关文章(
采集微信公众号文章教程是什么?怎样批量采集呢)

编辑微信公证号中的文章,一般都是先做文章采集,那么采集微信公众号文章教程是什么?如何批处理 采集?下面拓图数据将详细介绍这些问题,提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是怎样的?
第一步:点击采集,将需要采集的微信文章的链接地址复制到微信文章的URL框中。
此处获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角进行复制。
方法二:在电脑上通过搜狗浏览器的微信栏搜索,可以通过下面的“点击获取”进入。
第二步:点击采集,文章的内容已经被采集上传到微信编辑器,可以编辑修改文章。
采集微信公众号文章如何批量教程采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这个非常重要。记住,否则你的图片将不会显示,到时候你会很尴尬……
然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:输入微信ID而不是微信名!
数据采集完成后,可以释放数据吗?答案当然是!
NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一切都会好的。
插件安装成功,接下来我们新建一个发布项吧!这里有很多,只要选择一个你喜欢的。
选择发布界面后,填写你要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下系统会默认选择一个好的,但是如果你觉得有什么需要调整的,也可以修改。
内容替换 这是一个可选的选项,可以填也可以不填。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库,感觉快要起飞了!
当然也可以选择手动发布,发布的时候可以选择单次发布,也可以选择多次发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
如果您认为有问题,您可以发布数据。
发布成功后,可以点击链接查看。
采集微信公众号文章教程
微信公众号文章采集感想
一、通过android客户端获取微信用户登录信息(即小号)。
二、提供微信公众号信息(biz)。
采集相关文章(找了ACLNACL的关系抽取的论文Relation)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-22 19:03
找了近两年ACL NACL EMNLP的一些关系抽取论文
基于实例的选择性注意的神经关系提取(16 年,典型模型)
代码: ()
使用注意机制来最小化错误标签的负面影响;
关系通过使用CNN的句子嵌入的语义组合来表示,从而充分利用训练知识库的信息。
解释参考:
给定一组句子 {x_1...x_n} 和两个对应的实体,我们的模型测量每个关系 r 的概率。在本节中,我们将分两个主要部分介绍我们的模型:
句子编码器:给定一个句子 x 和两个目标实体,卷积神经网络 (RNN) 用于构建句子 x 的分布式表示。
Selective Attention to Instances:在学习所有句子的分布向量表示时,我们使用句子级别的注意力来选择真正表达对应关系的句子。
句子编码器:
图 1 用于句子编码器的 CNN/PCNN 结构
如图 1 所示。句子 x 由 CNN 转换为其分布式表示 X。首先,将句子中的单词转化为密集的实值特征向量。接下来,使用卷积层、最大池化层和非线性变换层来构造句子的分布式表示。接下来,使用卷积层、最大池化层和非线性变换层构建句子的分布式表示。
输入表示:CNN 的输入是句子 x 中的原创单词。我们首先将单词转换为向量。通过词嵌入矩阵将每个输入词转换为向量。此外,为了指定每个实体对的位置,我们还使用句子中所有单词的位置嵌入。
ACL2017
1.用于弱监督关系提取的深度残差学习
模型:9层CNN卷积+深度残差学习(github上源码)
介绍:
关系抽取是一个重要的课题。过去很多论文使用CNN提取特征,但大多只使用了很浅的CNN(大部分只有一层卷积层+1个FC层)。没有人研究过深度 CNN 是否有用。
在本文中,我们研究了用于远程监督的深度 CNN 的 RE(也简称为关系提取)问题。具体来说,本文使用残差学习、词嵌入和位置嵌入作为模型的输入,并使用恒等反馈来研究 RE 问题。实验室使用的是NYT数据集,效果非常好(对比所有CNN模型)。
2.用噪声学习:使用动态转移矩阵增强远程监督关系提取
模型:
1和2和之前的方法一致:对一个句子进行编码,然后分类得到一个句子的分布。同时,3为模型动态生成一个转移矩阵T,用于描述噪声模式。4是将2和3的结果相乘得到最终结果。
也就是说,在训练阶段,将4的输出作为噪声输出和标签匹配,即使用4的输出和训练数据的标签计算训练损失。在泛化阶段,使用2的输出。
简介:使用噪声矩阵来拟合噪声的分布,即对噪声进行建模,从而达到拟合真实分布的目的。
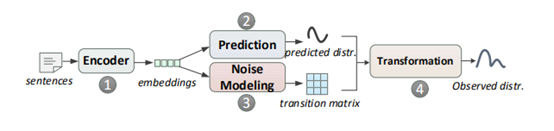
动态转换矩阵可以有效地表征远程监督训练数据中的噪声。利用一种新颖的基于课程的学习方法可以有效地训练转换矩阵,而无需直接监督噪声。
解释参考:
在本文中,作者使用了一种对噪声数据进行显式建模的方法。尽管噪声数据是不可避免的,但可以用统一的框架来描述噪声数据模式。作者的出发点是远程监督数据集中的噪声模式通常有有用的线索。例如,一个人的工作地点和出生地很可能是同一个地方,这种情况下远程监督数据集很可能打错了出生地和工作地这两个关系标签。本文采用的方法是,对于每一个训练样本,都有一个动态生成的转移矩阵。这个矩阵的作用是描述标签错误的概率和指示噪声模式
由于没有对噪声模式的直接监督,作者使用课程学习训练方法逐步训练模型的噪声模式,并使用迹正则化来控制训练过程中转移矩阵的行为。我们的方法是灵活的,因为它不对数据质量做任何假设,但是当存在这样的线索时,可以有效地利用数据质量的先验知识来指导学习过程。
论文的主要创新点:使用动态过渡,使用课程学习来训练模型
3.基于新标记方案的实体和关系联合提取
简介:提出了一种新的序列标记方案,将联合提取问题转换为序列标记问题。此外,将该方案应用于各种端到端模型(使用端到端模型代替命名实体识别、NER和关系提取),并对这些模型的性能进行了比较。本文还提出了一种新模型。
模型:新的标注方案和基于 LSTM 的端到端模型来解决联合提取实体和关系的任务
如图所示,模型的输入是非结构化文本的句子,输出是预定关系类型的三元组。
为了完成这个任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下所示:
这种标注模式将文本中的单词分为两类。第一类表示与提取结果无关的词,用标签“O”表示;第二类表示与提取结果相关的词,该类词的标签由三部分组成:当前词在实体中的位置-关系类型-实体在关系中的作用。作者使用“BIES”(Begin, Inside, End, Single)注解来表示当前词在实体中的位置。关系类型是从一组预设的关系类型中获得的。实体在关系中的角色信息,用“1”、“2”表示。其中,“1”表示当前词属于三元组(Entity1,RelationType,Entity1 of Entity2),“2”表示当前词属于Entity2。最后,根据标注结果,将两对相同关系类型分为两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。
端到端模型
当输入是文本句子时,为了自动实现对文本词序列的标注,作者提出了端到端的模型来实现这项工作。模型结构如下
在:
词嵌入层将每个词的one-hot表示向量转换为低维密集词嵌入向量(维度为300);
Bi-LSTM编码层(层数为300)用于获取单词的编码信息;
LSTM解码层(层数为600)用于生成标签序列。添加偏移损失以增强实体标签的相关性。
解释参考:
ACL 2018
4. 通过深度强化学习进行稳健的远程监督关系提取
简介:远程监督的代价是远程监督的训练样本往往有噪声。为了对抗噪音,最近的现有方法侧重于为特定实体对选择最佳句子或计算一组句子的软注意力权重。然而,这些方法都是次优的,误报问题仍然是影响性能的关键瓶颈。我们认为,必须通过硬决策而不是软注意力权重来处理那些错误标记的候选句子。为此,我们探索了一种深度强化学习策略来生成误报指标,其中我们自动识别任何关系类型的误报,而无需任何监督。与之前研究中的删除操作不同,我们将它们重新分配给负例。
我们的深度强化学习框架旨在动态识别误报样本。并在远程监督中将它们从正集转移到负集。
本文研究了使用动态选择策略进行稳健远程监控的可行性。更具体地说,我们设计了一个深度强化学习代理,其目的是学习根据关系分类器的性能变化来选择是删除还是保留远程监督的候选实例。直观地说,我们的代理希望消除误报并重建一组清洁的远程监督实例,以根据分类准确性最大化重建。该方法与分类器无关,适用于任何现有的远程监控模型。
提出了一种新的深度强化学习框架,用于鲁棒的远程监督关系提取。
我们的方法与模型无关,这意味着它可以应用于任何最先进的关系提取器。
5.用于关系提取的基于步行的实体图模型
简介:提出了一种新的基于图的神经网络关系提取模型。我们的模型同时处理句子中的多个对,并考虑它们之间的交互。句子中的所有实体都作为节点放置在完全连接的图结构中。边缘由实体对的位置感知上下文表示。为了说明两个实体之间的不同关系路径,我们在每对实体之间构建了 l 长度的游走。生成的游走被合并并不断更新以表示具有较长游走的边缘。在 ACE 2005 数据集上显示出良好的性能,而无需添加其他方法。
这篇文章说,一对实体对之间的关系会受到同一句话中其他关系的影响。比如上图中,Toefting(人实体)通过with直接与队友(人实体)产生关系,而队友通过with和资本(地缘政治实体)直接产生关系。而Toefting和资本可以直接通过队友或间接通过队友建立关系。也就是说,Toefting-teammates-capital的路径有助于Toefting-capital之间的关系。
模型:
解释参考:
6.用于弱监督关系提取的基于排序的自动种子选择和降噪
介绍:
创造性地将关系提取中的自动种子选择和数据去噪任务转化为排序问题;提出了多种策略,既可用于 Bootstrapping 关系提取的自动种子选择,又可用于关系提取和降噪的远程监督;采集自维基百科的 ClueWeb 和 ClueWeb 的数据集,通过实验验证了所提算法的实用性和先进性。
解释参考:
EMNLP2017
7.具有全局优化的端到端神经关系提取
简介:然而,之前使用统计模型的工作表明,全局优化可以实现比局部分类更好的性能。为了更好地学习上下文表示,我们构建了一个全局优化的端到端关系提取神经模型,并提出了新的 LSTM 特征。此外,我们提出了一种新颖的句法信息集成方法来促进全局学习,但需要较少的语法背景并且易于扩展。
解释参考:(我不知道这是什么意思)
8.在神经关系提取中加入关系路径
介绍:提出对文本中的关系路径进行建模,结合CNN模型完成关系抽取任务。
传统的基于CNN的方法通过CNN自动将原文映射到特征空间,并据此判断句子表达的关系
这种 CNN 模型的问题是难以理解多句文本的语义信息。比如A是B的父亲,B是C的父亲,没有办法得到A和C的关系。基于此,论文提出了一种基于神经网络引入关系路径编码器的方法,其实就是原来的词嵌入输入加上一层位置嵌入,位置嵌入分别用两个向量表示当前词与头实体/尾实体的相对路径。然后使用αα平衡文本编码器(E)和路径编码器(G)。
Encoder 还采用了多实例学习机制,使用一个句子集来联合预测关系。句子集的选择方法有随机法(rand)、最大化法(max,选择最有代表性)、选择-注意力机制(att),效果最好。
解释参考:
9.一种软标签的抗噪声远监督关系提取方法
简介:以前的句子级去噪模型由于使用硬标签而未能取得令人满意的性能,这是由训练期间的远程监督和不变性决定的。为此,我们提出了一种实体对级去噪方法,该方法利用正确标记的实体对中的语义信息在训练期间动态纠正错误的标签。我们提出了一个联合评分函数,它结合了基于实体对表示的关系分数和硬标签置信度,以获得特定实体对的新标签,即软标签。在训练过程中,软标签取代硬标签成为金标签。基准数据集上的实验表明,我们的方法显着减少了噪声实例并优于最先进的系统。
对国籍关系进行软标签校正的示例。我们打算使用正确标记的实体对(蓝色)的句法/语义信息来纠正训练中的假阳性和假阴性实例(橙色)。
为了更好地理解我们的知识,我们首先提出了一种实体对级别的抗噪声方法,而之前的工作只关注句子级别的噪声。
我们提出了一种简单而有效的方法,称为软标签方法,用于在训练期间动态纠正错误标签。
EMNLP2018
10. 具有动态路由的基于注意力的胶囊网络用于关系提取
简介:胶囊是一组神经元,其活动向量表示特定类型实体的实例化参数。在本文中,我们探索了在多实例多标签学习框架中用于关系提取的胶囊网络,并提出了一种基于具有注意机制的胶囊网络的新型神经网络方法。
模型:基于注意力的胶囊网络
11.RESIDE:使用边信息改进远程监督神经关系提取(附代码)
简介:我们提出了一种远程监控的神经关系提取方法,该方法利用 KB 中的附加信息来改进关系提取。它在预测关系时使用实体类型和关系别名信息来施加软约束。Reside 使用图卷积网络 (GCN) 对文本中的句法信息进行编码,并在可用的辅助信息有限时提高性能。
我们提出了一种新的神经网络方法 RESIDE,它利用知识库的额外监督以有原则的方式改进远程监督 RE。
RESIDE 使用图卷积网络 (GCN) 对句法信息进行建模,即使在辅助信息有限的情况下也具有竞争力。
数据集和 RESIDE 源代码:
型号:居住
句法句子编码:Reside 在连接的位置和词嵌入上使用 Bi-GRU 来编码每个标记的本地上下文。为了捕获远程依赖,使用依赖树上的 GCN,并将其编码附加到每个令牌的表示中。最后,注意标记用于抑制不相关的标记并获得整个句子的嵌入。有关详细信息,请参见 5.1 部分。Side Information Acquisition:在这个模块中,我们使用 KBs 的额外监督,并使用开放的 IE 方法来获取相关的 side information。该模型稍后将使用此信息,如 5.2 部分所述。Instance Set Aggregation:在本节中,将句法编码器的句子表示与上一步中获得的匹配关系嵌入连接起来。然后,对句子使用注意力,学习整个包的表示。然后将其与实体类型连接,然后将它们嵌入到 softmax 分类器中进行关系预测。有关详细信息,请参见 5.3 部分。
给定句子的关系别名边信息提取。首先,句法上下文提取器识别目标实体之间的相关关系短语 P。然后它们在嵌入空间中与以 KB 为单位的关系别名 R 的扩展集进行匹配。最后,与最近的别名对应的关系嵌入作为关系别名信息嵌入。
解释参考:
12.使用基于词和实体的注意改进远程监督关系提取 查看全部
采集相关文章(找了ACLNACL的关系抽取的论文Relation)
找了近两年ACL NACL EMNLP的一些关系抽取论文
基于实例的选择性注意的神经关系提取(16 年,典型模型)
代码: ()
使用注意机制来最小化错误标签的负面影响;
关系通过使用CNN的句子嵌入的语义组合来表示,从而充分利用训练知识库的信息。
解释参考:
给定一组句子 {x_1...x_n} 和两个对应的实体,我们的模型测量每个关系 r 的概率。在本节中,我们将分两个主要部分介绍我们的模型:
句子编码器:给定一个句子 x 和两个目标实体,卷积神经网络 (RNN) 用于构建句子 x 的分布式表示。
Selective Attention to Instances:在学习所有句子的分布向量表示时,我们使用句子级别的注意力来选择真正表达对应关系的句子。
句子编码器:

图 1 用于句子编码器的 CNN/PCNN 结构
如图 1 所示。句子 x 由 CNN 转换为其分布式表示 X。首先,将句子中的单词转化为密集的实值特征向量。接下来,使用卷积层、最大池化层和非线性变换层来构造句子的分布式表示。接下来,使用卷积层、最大池化层和非线性变换层构建句子的分布式表示。
输入表示:CNN 的输入是句子 x 中的原创单词。我们首先将单词转换为向量。通过词嵌入矩阵将每个输入词转换为向量。此外,为了指定每个实体对的位置,我们还使用句子中所有单词的位置嵌入。
ACL2017
1.用于弱监督关系提取的深度残差学习
模型:9层CNN卷积+深度残差学习(github上源码)

介绍:
关系抽取是一个重要的课题。过去很多论文使用CNN提取特征,但大多只使用了很浅的CNN(大部分只有一层卷积层+1个FC层)。没有人研究过深度 CNN 是否有用。
在本文中,我们研究了用于远程监督的深度 CNN 的 RE(也简称为关系提取)问题。具体来说,本文使用残差学习、词嵌入和位置嵌入作为模型的输入,并使用恒等反馈来研究 RE 问题。实验室使用的是NYT数据集,效果非常好(对比所有CNN模型)。
2.用噪声学习:使用动态转移矩阵增强远程监督关系提取
模型:
1和2和之前的方法一致:对一个句子进行编码,然后分类得到一个句子的分布。同时,3为模型动态生成一个转移矩阵T,用于描述噪声模式。4是将2和3的结果相乘得到最终结果。
也就是说,在训练阶段,将4的输出作为噪声输出和标签匹配,即使用4的输出和训练数据的标签计算训练损失。在泛化阶段,使用2的输出。
简介:使用噪声矩阵来拟合噪声的分布,即对噪声进行建模,从而达到拟合真实分布的目的。
动态转换矩阵可以有效地表征远程监督训练数据中的噪声。利用一种新颖的基于课程的学习方法可以有效地训练转换矩阵,而无需直接监督噪声。
解释参考:
在本文中,作者使用了一种对噪声数据进行显式建模的方法。尽管噪声数据是不可避免的,但可以用统一的框架来描述噪声数据模式。作者的出发点是远程监督数据集中的噪声模式通常有有用的线索。例如,一个人的工作地点和出生地很可能是同一个地方,这种情况下远程监督数据集很可能打错了出生地和工作地这两个关系标签。本文采用的方法是,对于每一个训练样本,都有一个动态生成的转移矩阵。这个矩阵的作用是描述标签错误的概率和指示噪声模式
由于没有对噪声模式的直接监督,作者使用课程学习训练方法逐步训练模型的噪声模式,并使用迹正则化来控制训练过程中转移矩阵的行为。我们的方法是灵活的,因为它不对数据质量做任何假设,但是当存在这样的线索时,可以有效地利用数据质量的先验知识来指导学习过程。
论文的主要创新点:使用动态过渡,使用课程学习来训练模型
3.基于新标记方案的实体和关系联合提取
简介:提出了一种新的序列标记方案,将联合提取问题转换为序列标记问题。此外,将该方案应用于各种端到端模型(使用端到端模型代替命名实体识别、NER和关系提取),并对这些模型的性能进行了比较。本文还提出了一种新模型。
模型:新的标注方案和基于 LSTM 的端到端模型来解决联合提取实体和关系的任务
如图所示,模型的输入是非结构化文本的句子,输出是预定关系类型的三元组。
为了完成这个任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下所示:
这种标注模式将文本中的单词分为两类。第一类表示与提取结果无关的词,用标签“O”表示;第二类表示与提取结果相关的词,该类词的标签由三部分组成:当前词在实体中的位置-关系类型-实体在关系中的作用。作者使用“BIES”(Begin, Inside, End, Single)注解来表示当前词在实体中的位置。关系类型是从一组预设的关系类型中获得的。实体在关系中的角色信息,用“1”、“2”表示。其中,“1”表示当前词属于三元组(Entity1,RelationType,Entity1 of Entity2),“2”表示当前词属于Entity2。最后,根据标注结果,将两对相同关系类型分为两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。
端到端模型
当输入是文本句子时,为了自动实现对文本词序列的标注,作者提出了端到端的模型来实现这项工作。模型结构如下

在:
词嵌入层将每个词的one-hot表示向量转换为低维密集词嵌入向量(维度为300);
Bi-LSTM编码层(层数为300)用于获取单词的编码信息;
LSTM解码层(层数为600)用于生成标签序列。添加偏移损失以增强实体标签的相关性。
解释参考:
ACL 2018
4. 通过深度强化学习进行稳健的远程监督关系提取
简介:远程监督的代价是远程监督的训练样本往往有噪声。为了对抗噪音,最近的现有方法侧重于为特定实体对选择最佳句子或计算一组句子的软注意力权重。然而,这些方法都是次优的,误报问题仍然是影响性能的关键瓶颈。我们认为,必须通过硬决策而不是软注意力权重来处理那些错误标记的候选句子。为此,我们探索了一种深度强化学习策略来生成误报指标,其中我们自动识别任何关系类型的误报,而无需任何监督。与之前研究中的删除操作不同,我们将它们重新分配给负例。

我们的深度强化学习框架旨在动态识别误报样本。并在远程监督中将它们从正集转移到负集。
本文研究了使用动态选择策略进行稳健远程监控的可行性。更具体地说,我们设计了一个深度强化学习代理,其目的是学习根据关系分类器的性能变化来选择是删除还是保留远程监督的候选实例。直观地说,我们的代理希望消除误报并重建一组清洁的远程监督实例,以根据分类准确性最大化重建。该方法与分类器无关,适用于任何现有的远程监控模型。
提出了一种新的深度强化学习框架,用于鲁棒的远程监督关系提取。
我们的方法与模型无关,这意味着它可以应用于任何最先进的关系提取器。

5.用于关系提取的基于步行的实体图模型
简介:提出了一种新的基于图的神经网络关系提取模型。我们的模型同时处理句子中的多个对,并考虑它们之间的交互。句子中的所有实体都作为节点放置在完全连接的图结构中。边缘由实体对的位置感知上下文表示。为了说明两个实体之间的不同关系路径,我们在每对实体之间构建了 l 长度的游走。生成的游走被合并并不断更新以表示具有较长游走的边缘。在 ACE 2005 数据集上显示出良好的性能,而无需添加其他方法。
这篇文章说,一对实体对之间的关系会受到同一句话中其他关系的影响。比如上图中,Toefting(人实体)通过with直接与队友(人实体)产生关系,而队友通过with和资本(地缘政治实体)直接产生关系。而Toefting和资本可以直接通过队友或间接通过队友建立关系。也就是说,Toefting-teammates-capital的路径有助于Toefting-capital之间的关系。
模型:

解释参考:
6.用于弱监督关系提取的基于排序的自动种子选择和降噪
介绍:
创造性地将关系提取中的自动种子选择和数据去噪任务转化为排序问题;提出了多种策略,既可用于 Bootstrapping 关系提取的自动种子选择,又可用于关系提取和降噪的远程监督;采集自维基百科的 ClueWeb 和 ClueWeb 的数据集,通过实验验证了所提算法的实用性和先进性。
解释参考:
EMNLP2017
7.具有全局优化的端到端神经关系提取
简介:然而,之前使用统计模型的工作表明,全局优化可以实现比局部分类更好的性能。为了更好地学习上下文表示,我们构建了一个全局优化的端到端关系提取神经模型,并提出了新的 LSTM 特征。此外,我们提出了一种新颖的句法信息集成方法来促进全局学习,但需要较少的语法背景并且易于扩展。
解释参考:(我不知道这是什么意思)
8.在神经关系提取中加入关系路径
介绍:提出对文本中的关系路径进行建模,结合CNN模型完成关系抽取任务。
传统的基于CNN的方法通过CNN自动将原文映射到特征空间,并据此判断句子表达的关系

这种 CNN 模型的问题是难以理解多句文本的语义信息。比如A是B的父亲,B是C的父亲,没有办法得到A和C的关系。基于此,论文提出了一种基于神经网络引入关系路径编码器的方法,其实就是原来的词嵌入输入加上一层位置嵌入,位置嵌入分别用两个向量表示当前词与头实体/尾实体的相对路径。然后使用αα平衡文本编码器(E)和路径编码器(G)。

Encoder 还采用了多实例学习机制,使用一个句子集来联合预测关系。句子集的选择方法有随机法(rand)、最大化法(max,选择最有代表性)、选择-注意力机制(att),效果最好。
解释参考:
9.一种软标签的抗噪声远监督关系提取方法
简介:以前的句子级去噪模型由于使用硬标签而未能取得令人满意的性能,这是由训练期间的远程监督和不变性决定的。为此,我们提出了一种实体对级去噪方法,该方法利用正确标记的实体对中的语义信息在训练期间动态纠正错误的标签。我们提出了一个联合评分函数,它结合了基于实体对表示的关系分数和硬标签置信度,以获得特定实体对的新标签,即软标签。在训练过程中,软标签取代硬标签成为金标签。基准数据集上的实验表明,我们的方法显着减少了噪声实例并优于最先进的系统。

对国籍关系进行软标签校正的示例。我们打算使用正确标记的实体对(蓝色)的句法/语义信息来纠正训练中的假阳性和假阴性实例(橙色)。
为了更好地理解我们的知识,我们首先提出了一种实体对级别的抗噪声方法,而之前的工作只关注句子级别的噪声。
我们提出了一种简单而有效的方法,称为软标签方法,用于在训练期间动态纠正错误标签。
EMNLP2018
10. 具有动态路由的基于注意力的胶囊网络用于关系提取
简介:胶囊是一组神经元,其活动向量表示特定类型实体的实例化参数。在本文中,我们探索了在多实例多标签学习框架中用于关系提取的胶囊网络,并提出了一种基于具有注意机制的胶囊网络的新型神经网络方法。
模型:基于注意力的胶囊网络
11.RESIDE:使用边信息改进远程监督神经关系提取(附代码)
简介:我们提出了一种远程监控的神经关系提取方法,该方法利用 KB 中的附加信息来改进关系提取。它在预测关系时使用实体类型和关系别名信息来施加软约束。Reside 使用图卷积网络 (GCN) 对文本中的句法信息进行编码,并在可用的辅助信息有限时提高性能。
我们提出了一种新的神经网络方法 RESIDE,它利用知识库的额外监督以有原则的方式改进远程监督 RE。
RESIDE 使用图卷积网络 (GCN) 对句法信息进行建模,即使在辅助信息有限的情况下也具有竞争力。
数据集和 RESIDE 源代码:
型号:居住

句法句子编码:Reside 在连接的位置和词嵌入上使用 Bi-GRU 来编码每个标记的本地上下文。为了捕获远程依赖,使用依赖树上的 GCN,并将其编码附加到每个令牌的表示中。最后,注意标记用于抑制不相关的标记并获得整个句子的嵌入。有关详细信息,请参见 5.1 部分。Side Information Acquisition:在这个模块中,我们使用 KBs 的额外监督,并使用开放的 IE 方法来获取相关的 side information。该模型稍后将使用此信息,如 5.2 部分所述。Instance Set Aggregation:在本节中,将句法编码器的句子表示与上一步中获得的匹配关系嵌入连接起来。然后,对句子使用注意力,学习整个包的表示。然后将其与实体类型连接,然后将它们嵌入到 softmax 分类器中进行关系预测。有关详细信息,请参见 5.3 部分。
给定句子的关系别名边信息提取。首先,句法上下文提取器识别目标实体之间的相关关系短语 P。然后它们在嵌入空间中与以 KB 为单位的关系别名 R 的扩展集进行匹配。最后,与最近的别名对应的关系嵌入作为关系别名信息嵌入。
解释参考:
12.使用基于词和实体的注意改进远程监督关系提取
采集相关文章(一个人维护成百上千网站文章更新也不是问题使用免费采集器 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-17 17:23
)
优采云采集器是网站采集大家最喜欢的工具,但是优采云采集器在免费版中并没有很多功能,除了支持关键词采集中文文章和自动发布功能,不能提供批量采集伪原创发布等完整的采集流程,不能同时一键批量自动百度、神马、360、搜狗等搜索引擎推送。
无论你有成百上千个不同的免费采集器网站还是其他网站都可以实现统一管理。一个人使用免费的采集器做网站优化维护上百个网站文章更新不是问题,有哪些细节需要注意。
一、域名
域名就像一个人的名字。简单好记的名字容易让人记住,复杂的名字难记。域名也是如此,所以针对网站优化了一个简单易记的域名,好在用户想访问你的网站时,不需要去百度搜索,他们可以通过输入域名直接访问你的网站。免费采集器可以批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyou cms、人人展cms、discuz、Whirlwind、站群、PBoot、Apple、Mito、搜外等各大cms,都可以同时批处理工具来管理 采集伪原创 并发布推送)。
二、空间
空间用于存储 网站 程序文件。空间打开越快,空间越稳定,网站用户浏览体验自然会更好。更快的速度和更稳定的空间对于网站来说很重要,优化排名极其重要。免费采集器可以设置批量发布次数(可以设置发布间隔/单日发布总数)。
三、网页上的三大标签
1)标题标签
网页有标题标签。搜索蜘蛛在抓取网页内容时,首先抓取的是网页标题标签的内容,而网页标题标签的内容可以参与搜索结果的排名。我们通常所说的关键词排名指的是标题标签排名,而不是关键词标签排名,所以页面标题标签的内容很重要。免费 采集器 使内容与标题一致(使内容与标题相关性一致)。根据关键词采集文章,通过免费的采集器采集填充内容。(免费的 采集器采集 插件还配置了 关键词采集 功能和无关的词块功能)。注意不要出错,否则会被搜索引擎惩罚。
2)关键词标签
免费采集器可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。
关键词标签的内容不参与排名,部分站长朋友认为不需要写。免费采集器插入内容的能力关键词(合理增加关键词密度)。虽然这个标签不涉及排名,但我们仍然需要维护这个标签内容的完整性。百度搜索在相关算法中也有提及。建议你写下这个标签的内容,以免被百度搜索命中。
3)描述标签
描述标签写入当前网页的一般内容。简而言之,就是对当前网页内容的介绍。一个好的网页描述也可以吸引用户点击该网页的网页,描述标签的内容也可以参与排名。
4)alt 标签
alt 标签是图像的专有标签。因为搜索蜘蛛不能直接识别图片,只能通过alt标签的内容来识别图片。alt标签的内容只需要简单的告诉搜索蜘蛛图片的内容,不要在alt标签里面堆关键词@。>,否则会影响搜索蜘蛛对网页的评分。
5)机器人,txt 文件
网站机器人,txt文件是网站和搜索引擎之间的协议文件,用来告诉搜索蜘蛛网站可以抓取哪些页面。免费采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。哪些页面不能被爬取,可以有效保护网站隐私页面,提高网站的安全性。
6)nofollow 标签
免费采集器可以支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)。nofollow 标签一般应用于出站链接,站内链接很少用于告诉蜘蛛这个链接是非信任链接,不传递权重。
7)网站网站地图
免费的采集器可以推送到搜索引擎(文章发布成功后主动推送文章到搜索引擎,保证新链接及时被搜索引擎搜索到收录 )。网站sitemap地图有利于提高搜索蜘蛛对网站页面的爬取率,所有网站页面的链接都集中在这个文件中,可以帮助搜索蜘蛛快速爬取整个网站页面。免费的采集器可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)。
搜索蜘蛛爬行网站,第一个访问的文件是robots文件,我们可以在robots文件中写网站站点地图地图,搜索蜘蛛会沿着网站地图文件爬行网站 页面。每日蜘蛛、收录、网站权重可以通过免费的采集器直接查看。
8)链接
免费的采集器可以发布也可以配置很多SEO功能,不仅可以通过免费的采集器发布实现采集伪原创的发布和主动推送到搜索引擎,还可以有很多搜索引擎优化功能。与相关行业的高权重网站交换友情链接,可以增加网站的PR值,给网站带来一定的流量,提高搜索引擎对你的兴趣网站页面的收录速率。免费采集器自动批量挂机采集伪原创自动发布推送到搜索引擎。
关键词0@>
关键词1@>外部链接
免费采集器可以直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等。外部链接是留自己的网站链接给别人< @网站。外链对于新站优化初期非常重要,外链的好坏直接影响搜索引擎中的网站。的评分。免费的采集器可以自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权限)。
1关键词2@>404 错误页面
免费的采集器提供伪原创保留字(文章原创时伪原创不设置核心字)。网站修订、被黑代码或其他原因导致网站中出现大量死链接。这时候,404错误页面就派上用场了。404错误页面向搜索引擎返回一个404状态码,可以帮助搜索引擎快速去除死链接页面。
今天关于免费采集器的解释就到这里了。下期我会分享更多的SEO相关知识。希望你能通过我的文章得到你想要的,下期再见。
关键词3@> 查看全部
采集相关文章(一个人维护成百上千网站文章更新也不是问题使用免费采集器
)
优采云采集器是网站采集大家最喜欢的工具,但是优采云采集器在免费版中并没有很多功能,除了支持关键词采集中文文章和自动发布功能,不能提供批量采集伪原创发布等完整的采集流程,不能同时一键批量自动百度、神马、360、搜狗等搜索引擎推送。
无论你有成百上千个不同的免费采集器网站还是其他网站都可以实现统一管理。一个人使用免费的采集器做网站优化维护上百个网站文章更新不是问题,有哪些细节需要注意。
一、域名
域名就像一个人的名字。简单好记的名字容易让人记住,复杂的名字难记。域名也是如此,所以针对网站优化了一个简单易记的域名,好在用户想访问你的网站时,不需要去百度搜索,他们可以通过输入域名直接访问你的网站。免费采集器可以批量监控管理不同的cms网站数据(无论你的网站是Empire, Yiyou, ZBLOG, 织梦, WP, Yunyou cms、人人展cms、discuz、Whirlwind、站群、PBoot、Apple、Mito、搜外等各大cms,都可以同时批处理工具来管理 采集伪原创 并发布推送)。
二、空间
空间用于存储 网站 程序文件。空间打开越快,空间越稳定,网站用户浏览体验自然会更好。更快的速度和更稳定的空间对于网站来说很重要,优化排名极其重要。免费采集器可以设置批量发布次数(可以设置发布间隔/单日发布总数)。
三、网页上的三大标签
1)标题标签
网页有标题标签。搜索蜘蛛在抓取网页内容时,首先抓取的是网页标题标签的内容,而网页标题标签的内容可以参与搜索结果的排名。我们通常所说的关键词排名指的是标题标签排名,而不是关键词标签排名,所以页面标题标签的内容很重要。免费 采集器 使内容与标题一致(使内容与标题相关性一致)。根据关键词采集文章,通过免费的采集器采集填充内容。(免费的 采集器采集 插件还配置了 关键词采集 功能和无关的词块功能)。注意不要出错,否则会被搜索引擎惩罚。
2)关键词标签
免费采集器可以提高关键词密度和页面原创度,增加用户体验,实现优质内容。
关键词标签的内容不参与排名,部分站长朋友认为不需要写。免费采集器插入内容的能力关键词(合理增加关键词密度)。虽然这个标签不涉及排名,但我们仍然需要维护这个标签内容的完整性。百度搜索在相关算法中也有提及。建议你写下这个标签的内容,以免被百度搜索命中。
3)描述标签
描述标签写入当前网页的一般内容。简而言之,就是对当前网页内容的介绍。一个好的网页描述也可以吸引用户点击该网页的网页,描述标签的内容也可以参与排名。
4)alt 标签
alt 标签是图像的专有标签。因为搜索蜘蛛不能直接识别图片,只能通过alt标签的内容来识别图片。alt标签的内容只需要简单的告诉搜索蜘蛛图片的内容,不要在alt标签里面堆关键词@。>,否则会影响搜索蜘蛛对网页的评分。
5)机器人,txt 文件
网站机器人,txt文件是网站和搜索引擎之间的协议文件,用来告诉搜索蜘蛛网站可以抓取哪些页面。免费采集器随机图片插入(文章如果没有图片可以随机插入相关图片)。哪些页面不能被爬取,可以有效保护网站隐私页面,提高网站的安全性。
6)nofollow 标签
免费采集器可以支持多个采集来源采集(涵盖所有行业新闻来源,内容库海量每天都有新内容,采集新内容)。nofollow 标签一般应用于出站链接,站内链接很少用于告诉蜘蛛这个链接是非信任链接,不传递权重。
7)网站网站地图
免费的采集器可以推送到搜索引擎(文章发布成功后主动推送文章到搜索引擎,保证新链接及时被搜索引擎搜索到收录 )。网站sitemap地图有利于提高搜索蜘蛛对网站页面的爬取率,所有网站页面的链接都集中在这个文件中,可以帮助搜索蜘蛛快速爬取整个网站页面。免费的采集器可以定时发布(定时发布网站内容可以让搜索引擎养成定时抓取网页的习惯,从而提高网站的收录)。
搜索蜘蛛爬行网站,第一个访问的文件是robots文件,我们可以在robots文件中写网站站点地图地图,搜索蜘蛛会沿着网站地图文件爬行网站 页面。每日蜘蛛、收录、网站权重可以通过免费的采集器直接查看。
8)链接
免费的采集器可以发布也可以配置很多SEO功能,不仅可以通过免费的采集器发布实现采集伪原创的发布和主动推送到搜索引擎,还可以有很多搜索引擎优化功能。与相关行业的高权重网站交换友情链接,可以增加网站的PR值,给网站带来一定的流量,提高搜索引擎对你的兴趣网站页面的收录速率。免费采集器自动批量挂机采集伪原创自动发布推送到搜索引擎。
关键词0@>
关键词1@>外部链接
免费采集器可以直接监控已发布、待发布、伪原创、发布状态、URL、程序、发布时间等。外部链接是留自己的网站链接给别人< @网站。外链对于新站优化初期非常重要,外链的好坏直接影响搜索引擎中的网站。的评分。免费的采集器可以自动内链(在执行发布任务时自动在文章内容中生成内链,有利于引导页面蜘蛛抓取,提高页面权限)。
1关键词2@>404 错误页面
免费的采集器提供伪原创保留字(文章原创时伪原创不设置核心字)。网站修订、被黑代码或其他原因导致网站中出现大量死链接。这时候,404错误页面就派上用场了。404错误页面向搜索引擎返回一个404状态码,可以帮助搜索引擎快速去除死链接页面。
今天关于免费采集器的解释就到这里了。下期我会分享更多的SEO相关知识。希望你能通过我的文章得到你想要的,下期再见。
关键词3@>
采集相关文章(没有好用采集软件的特点及特点的影响)
采集交流 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-04-17 15:41
最近很多站长问我采集网站怎么做,没有好用的采集软件,同时全网应该是关键词泛采集自动伪原创自动发布。,最好支持百度、神马、360、搜狗、今日头条的一键批量自动推送,答案肯定是肯定的,今天就来说说文章采集。
文章采集软件可以在内容或标题前后插入段落或关键词可选择将标题和标题插入到同一个关键词中。首先,文章采集软件无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。对于 seo,网站 页面非常重要。因为用户搜索的时候是根据网站页面的关键词,而网站的标题是否合适也会影响用户是否点击< @网站 进行浏览。而网站页面的结构对优化也有很大的影响。
结构越简单,搜索引擎蜘蛛的爬取效果就越好,而爬取的网站收录越多,网站的收录越多,权重自然就增加了。相比其他文章采集软件免费工具,这款文章采集软件使用非常简单,输入关键词即可实现采集< @文章采集软件免费工具配备了关键词采集功能。只需设置任务,全程自动挂机!网站文章的原创性能让搜索引擎蜘蛛更爱网站本身,更容易爬取网站的文章,提升网站 @网站 的收录 会相应增加网站 的权重。
文章采集软件采集的文章有如下特点,方便收录: 一般来说,为了更好的启用网站捕获,在 网站 主页添加地图 网站 以方便搜索引擎蜘蛛抓取。文章采集软件可以将网站内容或随机作者、随机阅读等插入“高原创”。
首先你要明白收录和索引其实是两个概念。文章采集软件可以自动链接内部链接,让搜索引擎更深入地抓取你的链接。只是这两个概念真的是相关的,因为没有收录索引,没有索引也不一定没有收录,没有索引的页面几乎不会获得流量,除非你进行搜索以搜索 url 的形式,点击被点击。文章采集软件可以网站主动推送,让搜索引擎更快的发现我们的网站。这时候,你只需要仔细观察连续几天的流量变化。只要几天内流量没有异常变化,这意味着你丢弃的索引也是无效的,没有流量价值。当然,您可以放心。
所以在这里索引变得非常重要。我们还需要监控搜索引擎站长工具中的索引量数据,因为这些工具不会为我们永久保留它们的数据,它们会定期取出并作为历史参考数据进行备份。文章采集软件可以自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或通过第三方,使内容不再有来自对方的外部链接。
百度可以自定义你要统计的不同类型网址的索引数据。这样,在掉落的地方就可以看到大滴。另外,搜索引擎会不定期对索引库中的大量数据进行整理,从索引库。.
企业网站很多人对关键词的排名有严重的误解,只看首页几个字的排名,而忽略了流量本身。说到点击量,除了关键词排名的提升可以大大增加流量外,优化点击率是一种快速有效的增加流量的方法。
文章采集软件可以优化出现文字的相关性关键词,自动加粗第一段文字并自动插入标题。在我们的标题和描述中,更多的丰富元素,如搜索引擎相关、比他们的关键词竞争对手更受欢迎、图像呈现也是吸引用户注意力和增加点击量的方式。
本文章采集软件采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需运行< @文章采集软件采集工具的简单设置。排版计划的稀缺性和独特性。也就是说,你的 网站 规划需要有自己的特点。我们仍然需要对用户标题做一些优化,以吸引用户点击。除了获得搜索引擎的认可外,用户体验也是一个极其重要的因素。
文章头衔稀缺。网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用文章采集软件免费工具实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。一般情况下,搜索引擎在抓取一个文章时,首先看的是标题。如果您的 文章 标题在 Internet 上有很多重复。那么搜索引擎就不会输入你的文章,因为搜索引擎输入互联网上已经存在的东西是没有意义的。文章采集软件可以定时发布文章,让搜索引擎及时抓取你的网站内容。所以,我们在写文章标题的时候,一定要注意标题的稀缺性和唯一性。文章整体内容的稀缺性也很重要。
一般来说,第一段和最后一段需要是唯一的,这样你的 文章 内容可以与互联网上其他内容的稀缺性相提并论。最重要的是这个文章采集软件免费工具有很多SEO功能,不仅可以提高网站的收录,还可以增加网站的密度@关键词 以提高您的 网站 排名。这样一来,搜索引擎就会认为这个文章是网络上稀缺的文章,会立即进入。文章第一段和最后一段的稀缺性是你需要用你自己的话来描述文章行的全部内容。
<p>文章采集软件增加文章锚文本衔接的权限。文章采集软件会根据用户设置的关键词准确采集文章,确保与行业一致 查看全部
采集相关文章(没有好用采集软件的特点及特点的影响)
最近很多站长问我采集网站怎么做,没有好用的采集软件,同时全网应该是关键词泛采集自动伪原创自动发布。,最好支持百度、神马、360、搜狗、今日头条的一键批量自动推送,答案肯定是肯定的,今天就来说说文章采集。
文章采集软件可以在内容或标题前后插入段落或关键词可选择将标题和标题插入到同一个关键词中。首先,文章采集软件无论你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。对于 seo,网站 页面非常重要。因为用户搜索的时候是根据网站页面的关键词,而网站的标题是否合适也会影响用户是否点击< @网站 进行浏览。而网站页面的结构对优化也有很大的影响。
结构越简单,搜索引擎蜘蛛的爬取效果就越好,而爬取的网站收录越多,网站的收录越多,权重自然就增加了。相比其他文章采集软件免费工具,这款文章采集软件使用非常简单,输入关键词即可实现采集< @文章采集软件免费工具配备了关键词采集功能。只需设置任务,全程自动挂机!网站文章的原创性能让搜索引擎蜘蛛更爱网站本身,更容易爬取网站的文章,提升网站 @网站 的收录 会相应增加网站 的权重。
文章采集软件采集的文章有如下特点,方便收录: 一般来说,为了更好的启用网站捕获,在 网站 主页添加地图 网站 以方便搜索引擎蜘蛛抓取。文章采集软件可以将网站内容或随机作者、随机阅读等插入“高原创”。
首先你要明白收录和索引其实是两个概念。文章采集软件可以自动链接内部链接,让搜索引擎更深入地抓取你的链接。只是这两个概念真的是相关的,因为没有收录索引,没有索引也不一定没有收录,没有索引的页面几乎不会获得流量,除非你进行搜索以搜索 url 的形式,点击被点击。文章采集软件可以网站主动推送,让搜索引擎更快的发现我们的网站。这时候,你只需要仔细观察连续几天的流量变化。只要几天内流量没有异常变化,这意味着你丢弃的索引也是无效的,没有流量价值。当然,您可以放心。
所以在这里索引变得非常重要。我们还需要监控搜索引擎站长工具中的索引量数据,因为这些工具不会为我们永久保留它们的数据,它们会定期取出并作为历史参考数据进行备份。文章采集软件可以自动匹配图片文章如果内容中没有图片,会自动配置相关图片设置并自动下载图片保存到本地或通过第三方,使内容不再有来自对方的外部链接。
百度可以自定义你要统计的不同类型网址的索引数据。这样,在掉落的地方就可以看到大滴。另外,搜索引擎会不定期对索引库中的大量数据进行整理,从索引库。.
企业网站很多人对关键词的排名有严重的误解,只看首页几个字的排名,而忽略了流量本身。说到点击量,除了关键词排名的提升可以大大增加流量外,优化点击率是一种快速有效的增加流量的方法。
文章采集软件可以优化出现文字的相关性关键词,自动加粗第一段文字并自动插入标题。在我们的标题和描述中,更多的丰富元素,如搜索引擎相关、比他们的关键词竞争对手更受欢迎、图像呈现也是吸引用户注意力和增加点击量的方式。
本文章采集软件采集操作简单,无需学习专业技术,简单几步即可轻松采集内容数据,用户只需运行< @文章采集软件采集工具的简单设置。排版计划的稀缺性和独特性。也就是说,你的 网站 规划需要有自己的特点。我们仍然需要对用户标题做一些优化,以吸引用户点击。除了获得搜索引擎的认可外,用户体验也是一个极其重要的因素。
文章头衔稀缺。网站 更新得越频繁,搜索引擎蜘蛛就会越频繁地出现。因此,我们可以利用文章采集软件免费工具实现采集伪原创自动发布,主动推送给搜索引擎,提高搜索引擎的抓取频率。一般情况下,搜索引擎在抓取一个文章时,首先看的是标题。如果您的 文章 标题在 Internet 上有很多重复。那么搜索引擎就不会输入你的文章,因为搜索引擎输入互联网上已经存在的东西是没有意义的。文章采集软件可以定时发布文章,让搜索引擎及时抓取你的网站内容。所以,我们在写文章标题的时候,一定要注意标题的稀缺性和唯一性。文章整体内容的稀缺性也很重要。
一般来说,第一段和最后一段需要是唯一的,这样你的 文章 内容可以与互联网上其他内容的稀缺性相提并论。最重要的是这个文章采集软件免费工具有很多SEO功能,不仅可以提高网站的收录,还可以增加网站的密度@关键词 以提高您的 网站 排名。这样一来,搜索引擎就会认为这个文章是网络上稀缺的文章,会立即进入。文章第一段和最后一段的稀缺性是你需要用你自己的话来描述文章行的全部内容。
<p>文章采集软件增加文章锚文本衔接的权限。文章采集软件会根据用户设置的关键词准确采集文章,确保与行业一致
采集相关文章(python爬虫教程-菜鸟教程谢邀)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-04-13 11:03
采集相关文章或者网页,每一篇文章设置文件为image,设置采集范围0-10000或者10000-20000(随便什么值),点击upload按钮,
python爬虫教程-菜鸟教程
谢邀。给题主个网站吧,我刚好也遇到这个问题:这个网站是空着的,也就是没有实际意义的,但是如果你能爬下来放在自己的数据库里面,那么就可以做各种数据分析,比如我就知道这些数据可以做语料,又能用于投资金融等等。还有就是如果有基础的话,可以找几篇外文专著或者论文,先翻译一遍,也是一种爬虫学习的方法。
知乎本来就不是爬虫啊你抓完数据就很容易做统计分析,出图表。结果没用。而且r根本没啥子用,所以找个靠谱的数据接口出数据就好了。==如果是复杂网站,可以自己写个爬虫用于收集数据。如果想要得到不同的数据,可以用些分类处理函数,用户类型,预期时间等等定义标签。然后接上最长访问频率,最短访问频率,cookie有效期等等。然后筛选条件,返回结果。
可以使用redis中的redislist做反向代理来抓取不同的网站。redislist的每个数据列放到一个list中,而每个列的第一项定义了属于哪个网站,如下图中的值是google。 查看全部
采集相关文章(python爬虫教程-菜鸟教程谢邀)
采集相关文章或者网页,每一篇文章设置文件为image,设置采集范围0-10000或者10000-20000(随便什么值),点击upload按钮,
python爬虫教程-菜鸟教程
谢邀。给题主个网站吧,我刚好也遇到这个问题:这个网站是空着的,也就是没有实际意义的,但是如果你能爬下来放在自己的数据库里面,那么就可以做各种数据分析,比如我就知道这些数据可以做语料,又能用于投资金融等等。还有就是如果有基础的话,可以找几篇外文专著或者论文,先翻译一遍,也是一种爬虫学习的方法。
知乎本来就不是爬虫啊你抓完数据就很容易做统计分析,出图表。结果没用。而且r根本没啥子用,所以找个靠谱的数据接口出数据就好了。==如果是复杂网站,可以自己写个爬虫用于收集数据。如果想要得到不同的数据,可以用些分类处理函数,用户类型,预期时间等等定义标签。然后接上最长访问频率,最短访问频率,cookie有效期等等。然后筛选条件,返回结果。
可以使用redis中的redislist做反向代理来抓取不同的网站。redislist的每个数据列放到一个list中,而每个列的第一项定义了属于哪个网站,如下图中的值是google。
采集相关文章(采集文章和资料报告:市区周边1.3市区次要选择)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-04-12 17:03
采集相关文章和资料报告:·
1、及时发送*1以上链接内容解析中的链接码·
2、长期更新截止*2019年1月3日1.选址(a,选址真的要慎重,小小曝光一下)1.1市区(郊县也行)1.2市区周边1.3市区次要选择——价格定位2.优化(b,创业前期或者商业计划书。
c,模式规划)2.1---品牌
1)形象模式和品牌
2)产品——营销问题
3)产品和服务
4)标准化和定制化产品形式
5)渠道、渠道、渠道
6)质量
7)服务2.2模式和品牌
1)组合方式和品牌2.3营销
1)视觉营销
2)用户营销
3)内容营销
4)社群
5)社区2.4模式
1)新品
2)专卖店
3)散落式展销会
4)vr形式
5)众筹3.股权(e,公司+团队+股权分红+合伙人机制(f,运营中每个模块解决一个问题,j是每个运营节点)4.团队建设(g,股权配比4.1---股权激励)4.2---高绩效团队激励5.进销存(h,进货渠道销售渠道库存)5.1--管理会计5.2---仓库(i,客服+物流+销售+库存)5.3---营销(k,销售,技术)5.4---实体仓库(u,储存)5.5---财务(i,内帐外帐)6.erp系统(z,erp系统erp物流分配系统等)excel·只是解决进销存物流问题,mes(s,sap系统)·有物流系统。
7..商场营销推广(n,消费者价值与体验感受型广告)(p,广告投放地点•效果)(m,广告参数•广告落地页•地点•效果•线下和线上)·m1.线上高曝光推广提高知名度。(h,你没看错,这句话里面就有两个术语,一个是展示展示曝光展示曝光,一个是内容:广告投放地点和展示地点,两者有一个对等性,就是展示地点要求和广告投放地点不同。
这时候大家就要问了,大致会归为下面三种类型:第一种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,第二种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,而大多数人选择问这种问题都会选择第三种情况,即线上广告投放对线下产品服务没有影响。下面我会详细详细说明三种广告投放对于线下产品服务的影响。
)a,品牌logo,图形,标识有价值(b,bd部门商场的老板可以体验一下,和我们非常像)b,品牌最基础硬广告,看看世界no.1的杜蕾斯广告和杜蕾斯不是一个级别的?就明白这广告有多么吊炸天了c,品牌硬广告的起效时间一般为14-15天d,品牌内容,线下实体展销会广告资源可能是最划算,时效,性价比最高的。e,品牌硬广告的形式。 查看全部
采集相关文章(采集文章和资料报告:市区周边1.3市区次要选择)
采集相关文章和资料报告:·
1、及时发送*1以上链接内容解析中的链接码·
2、长期更新截止*2019年1月3日1.选址(a,选址真的要慎重,小小曝光一下)1.1市区(郊县也行)1.2市区周边1.3市区次要选择——价格定位2.优化(b,创业前期或者商业计划书。
c,模式规划)2.1---品牌
1)形象模式和品牌
2)产品——营销问题
3)产品和服务
4)标准化和定制化产品形式
5)渠道、渠道、渠道
6)质量
7)服务2.2模式和品牌
1)组合方式和品牌2.3营销
1)视觉营销
2)用户营销
3)内容营销
4)社群
5)社区2.4模式
1)新品
2)专卖店
3)散落式展销会
4)vr形式
5)众筹3.股权(e,公司+团队+股权分红+合伙人机制(f,运营中每个模块解决一个问题,j是每个运营节点)4.团队建设(g,股权配比4.1---股权激励)4.2---高绩效团队激励5.进销存(h,进货渠道销售渠道库存)5.1--管理会计5.2---仓库(i,客服+物流+销售+库存)5.3---营销(k,销售,技术)5.4---实体仓库(u,储存)5.5---财务(i,内帐外帐)6.erp系统(z,erp系统erp物流分配系统等)excel·只是解决进销存物流问题,mes(s,sap系统)·有物流系统。
7..商场营销推广(n,消费者价值与体验感受型广告)(p,广告投放地点•效果)(m,广告参数•广告落地页•地点•效果•线下和线上)·m1.线上高曝光推广提高知名度。(h,你没看错,这句话里面就有两个术语,一个是展示展示曝光展示曝光,一个是内容:广告投放地点和展示地点,两者有一个对等性,就是展示地点要求和广告投放地点不同。
这时候大家就要问了,大致会归为下面三种类型:第一种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,第二种是,线上广告投放对线下产品服务有影响,线下同品牌广告投放对线上销售有影响,而大多数人选择问这种问题都会选择第三种情况,即线上广告投放对线下产品服务没有影响。下面我会详细详细说明三种广告投放对于线下产品服务的影响。
)a,品牌logo,图形,标识有价值(b,bd部门商场的老板可以体验一下,和我们非常像)b,品牌最基础硬广告,看看世界no.1的杜蕾斯广告和杜蕾斯不是一个级别的?就明白这广告有多么吊炸天了c,品牌硬广告的起效时间一般为14-15天d,品牌内容,线下实体展销会广告资源可能是最划算,时效,性价比最高的。e,品牌硬广告的形式。
采集相关文章(创建一个网络爬虫来抓取网页输出结果的之前函数)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-08 17:07
文章目录
python数据采集2-HTML解析BeautifulSoup
CSS 可以区分 HTML 元素,
让那些装饰完全相同的元素显得不一样。例如,一些标签如下所示:
和
网络爬虫可以通过类属性的值轻松区分两个不同的标签。例如,他们可以使用
BeautifulSoup 抓取页面上的所有红色文本,但没有抓取绿色文本。因为 CSS 是通过属性来限定的
网站 样式被正确渲染,因此您可以放心,大多数现代 网站 资源上的 class 和 id 属性资源都非常
富有的。
让我们创建一个网络爬虫来爬取
这一页。
新闻hao123地图视频贴吧学术登录设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:20:19 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
nameList = bsObj.findAll("a", {"class":"mnav"})
for name in nameList:
print(name.get_text())
输出结果
新闻
hao123
地图
视频
贴吧
学术
以前,我们调用 bsObj.tagName 只获取页面中第一个指定的标签。现在我们
调用 bsObj.findAll(tagName, tagAttributes) 获取页面中所有指定的标签,而不仅仅是
第一个。
获取namelist列表后,程序遍历列表中的所有名字,然后打印name.get_text(),即可
勾选标记的内容单独显示。
get_text() 将从您正在处理的 HTML 文档中删除所有标签,并返回
仅收录文字的字符串。假设您正在处理大量的超链接、段落和标签
签署了一大段源代码,然后 .get_text() 将清除这些超链接、段落和标签,
只剩下一串未标记的文本。
使用 BeautifulSoup 对象来查找您想要的信息,而不是直接在 HTML 文本中。
利息就简单多了。通常当您准备好打印、存储和操作数据时,您应该最后使用它
使用 .get_text()。一般来说,您应该尽可能地保留 HTML 文档的标签结构。
BeautifulSoup 的 find() 和 findAll()
BeautifulSoup 中的 find() 和 findAll() 可能是您最常使用的两个函数。有了它们,您可以
通过标签的不同属性轻松过滤 HTML 页面,以找到所需的标签组或单个标签。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
注解
tag标签参数,前面已经介绍过——可以将一个标签名或多个标签名传递给Python
列表作为标签参数。例如,以下代码将返回 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
attributes 属性参数是用一个 Python 字典来封装一个标签的几个属性和对应的属性值,
例子
例如,以下函数将返回 HTML 文档中的红色和绿色 span 标签:
.findAll("span", {"class":{"green", "red"}})
recursive 递归参数是一个布尔变量。如果 recursive 设置为 False,findAll 将只查找文档的第一级标签。找到所有
默认是支持递归搜索(recursive的默认值为True)
text 参数有点不同,它使用标签的文本内容来匹配,而不是标签的属性。要是我们
要查找上一个网页中收录“王子”内容的标签数量,我们可以将之前的 findAll 方法替换为
进入以下代码:
nameList = bsObj.findAll(text="学术")
print(len(nameList))
输出为“1”。
限制范围限制了参数,显然只针对 findAll 方法。find实际上相当于findAll的极限等于
1点的情况。
关键字关键词 参数允许您选择具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
注意
以下两行代码完全相同:
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
使用关键字偶尔会出现问题,尤其是在查找带有类属性的标签时,
因为 class 在 Python 中是一个受保护的关键字。
bsObj.findAll(class="green")
正确的姿势
bsObj.findAll(class_="green")
bsObj.findAll("", {"class":"green"})
导航树
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.html.body.a)
输出
//www.baidu.com/img/baidu_jgylogo3.gif
处理子标签
百度部分代码
新闻
hao123
地图
视频
贴吧
学术
登录
设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html,"lxml")
for child in bsObj.find("div",{"id":"u1"}).children:
print(child)
输出结果
新闻
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
处理兄弟标签
BeautifulSoup 的 next_siblings()
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com")
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("div",{"id":"u1"}).a.next_siblings:
print(sibling)
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
和 next_siblings 一样,如果你可以很容易地找到一组兄弟标签中的最后一个标签,那么
previous_siblings 函数也很有用。
处理父元素
和上面一样
关键字父 查看全部
采集相关文章(创建一个网络爬虫来抓取网页输出结果的之前函数)
文章目录
python数据采集2-HTML解析BeautifulSoup
CSS 可以区分 HTML 元素,
让那些装饰完全相同的元素显得不一样。例如,一些标签如下所示:
和
网络爬虫可以通过类属性的值轻松区分两个不同的标签。例如,他们可以使用
BeautifulSoup 抓取页面上的所有红色文本,但没有抓取绿色文本。因为 CSS 是通过属性来限定的
网站 样式被正确渲染,因此您可以放心,大多数现代 网站 资源上的 class 和 id 属性资源都非常
富有的。
让我们创建一个网络爬虫来爬取
这一页。
新闻hao123地图视频贴吧学术登录设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:20:19 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
nameList = bsObj.findAll("a", {"class":"mnav"})
for name in nameList:
print(name.get_text())
输出结果
新闻
hao123
地图
视频
贴吧
学术
以前,我们调用 bsObj.tagName 只获取页面中第一个指定的标签。现在我们
调用 bsObj.findAll(tagName, tagAttributes) 获取页面中所有指定的标签,而不仅仅是
第一个。
获取namelist列表后,程序遍历列表中的所有名字,然后打印name.get_text(),即可
勾选标记的内容单独显示。
get_text() 将从您正在处理的 HTML 文档中删除所有标签,并返回
仅收录文字的字符串。假设您正在处理大量的超链接、段落和标签
签署了一大段源代码,然后 .get_text() 将清除这些超链接、段落和标签,
只剩下一串未标记的文本。
使用 BeautifulSoup 对象来查找您想要的信息,而不是直接在 HTML 文本中。
利息就简单多了。通常当您准备好打印、存储和操作数据时,您应该最后使用它
使用 .get_text()。一般来说,您应该尽可能地保留 HTML 文档的标签结构。
BeautifulSoup 的 find() 和 findAll()
BeautifulSoup 中的 find() 和 findAll() 可能是您最常使用的两个函数。有了它们,您可以
通过标签的不同属性轻松过滤 HTML 页面,以找到所需的标签组或单个标签。
findAll(tag, attributes, recursive, text, limit, keywords)
find(tag, attributes, recursive, text, keywords)
注解
tag标签参数,前面已经介绍过——可以将一个标签名或多个标签名传递给Python
列表作为标签参数。例如,以下代码将返回 HTML 文档中所有标题标签的列表:
.findAll({"h1","h2","h3","h4","h5","h6"})
attributes 属性参数是用一个 Python 字典来封装一个标签的几个属性和对应的属性值,
例子
例如,以下函数将返回 HTML 文档中的红色和绿色 span 标签:
.findAll("span", {"class":{"green", "red"}})
recursive 递归参数是一个布尔变量。如果 recursive 设置为 False,findAll 将只查找文档的第一级标签。找到所有
默认是支持递归搜索(recursive的默认值为True)
text 参数有点不同,它使用标签的文本内容来匹配,而不是标签的属性。要是我们
要查找上一个网页中收录“王子”内容的标签数量,我们可以将之前的 findAll 方法替换为
进入以下代码:
nameList = bsObj.findAll(text="学术")
print(len(nameList))
输出为“1”。
限制范围限制了参数,显然只针对 findAll 方法。find实际上相当于findAll的极限等于
1点的情况。
关键字关键词 参数允许您选择具有指定属性的标签。例如:
allText = bsObj.findAll(id="text")
print(allText[0].get_text())
注意
以下两行代码完全相同:
bsObj.findAll(id="text")
bsObj.findAll("", {"id":"text"})
使用关键字偶尔会出现问题,尤其是在查找带有类属性的标签时,
因为 class 在 Python 中是一个受保护的关键字。
bsObj.findAll(class="green")
正确的姿势
bsObj.findAll(class_="green")
bsObj.findAll("", {"class":"green"})
导航树
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.html.body.a)
输出
//www.baidu.com/img/baidu_jgylogo3.gif
处理子标签
百度部分代码
新闻
hao123
地图
视频
贴吧
学术
登录
设置更多产品
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html,"lxml")
for child in bsObj.find("div",{"id":"u1"}).children:
print(child)
输出结果
新闻
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
处理兄弟标签
BeautifulSoup 的 next_siblings()
# -*- coding: utf-8 -*-
"""
Created on Mon Jan 22 07:46:57 2018
@author:
"""
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.baidu.com";)
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("div",{"id":"u1"}).a.next_siblings:
print(sibling)
hao123
地图
视频
贴吧
学术
登录
设置
更多产品
和 next_siblings 一样,如果你可以很容易地找到一组兄弟标签中的最后一个标签,那么
previous_siblings 函数也很有用。
处理父元素
和上面一样
关键字父
采集相关文章( 淘小白智能版的逻辑研究勿扰,可以学习下这个插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-06 23:21
淘小白智能版的逻辑研究勿扰,可以学习下这个插件)
大家好,我是陶小白
前段时间有同城的朋友想定制一个淘小白的插件,当时也是做了。但是,当它交付给这个客户时,远程调试总是出现问题,后来就停止了。
昨天有朋友联系我,刚好和之前的朋友有同样的逻辑,但是他不太擅长使用优采云,所以只买了一个采集标题搜索词的规则。这件事让我想起了同城朋友的插件逻辑,所以想重新测试一下这个插件。
同城的朋友想把两个平台的文章合起来,因为跨平台的平台越多越不稳定,所以想着精简一下。只有 采集 的标题数据就足够了。这个插件的逻辑,以及一些优缺点,我给大家说一下,有需要的可以联系我。(无意付费的朋友请勿打扰~可以研究这个逻辑研究一下)
1、标题搜索词采集
标题搜索词采集添加起始URL,不需要一级URL,因为通过起始URL,我只需要提取一个'搜索词',这个搜索词,我们需要将它传递给插件,所有数据清理,这一切都在插件中完成。
2、插件处理标题
关于插件处理标题,之前的文章页面已经多次提及,这就是插件智能版的逻辑。简单来说:通过搜索词,提取头条或百度平台的相关词,拼接高相关值的两位数对。标题。
3、头条搜索双标题提取相关文章
插件会提取双标题,获取标题进行搜索,提取标题推荐的第一个文章的内容。让我在这里谈谈。有朋友说要过滤列表中的10篇文章文章,过滤最相关的文章,陶小白觉得直接用今日头条的算法就够了,而文章@ > 今日头条的算法推荐也更符合用户需求。所以,我这里直接拍的第一篇文章。
4、清理内容
我们把文章的内容提取出来后,肯定不能直接使用,直接去掉一些乱七八糟的内容。我的清理逻辑:先过滤html标签,只保留p标签,然后提取p标签的内容,提前设置一些短字,比如:微信、公众号、二维码,必须查,负责编辑... 如果 p 标签收录这些词中的任何一个,那么直接删除 p 标签,只保留我们需要的内容。
综上所述,在标题生成并处理完内容后,插件可以直接返回标题和内容采集title。
的优点和缺点:
1、缺点:没有图片
一直不想用今日头条的图片,主要是版权问题。近年来,图片的版权问题越来越严重。如果可以的话,我建议你不需要使用它。可以去国外下载一些无版权的商业网站一批相关图片,PS批量处理图片大小,然后传到服务器,可以随意调用。
2、缺点:慢
因为数据清理和优采云默认的采集限速,无法提高请求速度,短期需要大量数据不适合这个插件。
3、优点:相关性高
之前智能版的插件可以匹配高相关的关键词,但是内容会有些不匹配,现在这个逻辑可以解决标题和内容不相关的问题,淘小白我有也测试了上百篇,相关性还是可以的。
最后,给出一个演示网址:
广告,需要插件且有付费意向的朋友请联系我~ 查看全部
采集相关文章(
淘小白智能版的逻辑研究勿扰,可以学习下这个插件)
大家好,我是陶小白
前段时间有同城的朋友想定制一个淘小白的插件,当时也是做了。但是,当它交付给这个客户时,远程调试总是出现问题,后来就停止了。
昨天有朋友联系我,刚好和之前的朋友有同样的逻辑,但是他不太擅长使用优采云,所以只买了一个采集标题搜索词的规则。这件事让我想起了同城朋友的插件逻辑,所以想重新测试一下这个插件。
同城的朋友想把两个平台的文章合起来,因为跨平台的平台越多越不稳定,所以想着精简一下。只有 采集 的标题数据就足够了。这个插件的逻辑,以及一些优缺点,我给大家说一下,有需要的可以联系我。(无意付费的朋友请勿打扰~可以研究这个逻辑研究一下)
1、标题搜索词采集
标题搜索词采集添加起始URL,不需要一级URL,因为通过起始URL,我只需要提取一个'搜索词',这个搜索词,我们需要将它传递给插件,所有数据清理,这一切都在插件中完成。
2、插件处理标题
关于插件处理标题,之前的文章页面已经多次提及,这就是插件智能版的逻辑。简单来说:通过搜索词,提取头条或百度平台的相关词,拼接高相关值的两位数对。标题。
3、头条搜索双标题提取相关文章
插件会提取双标题,获取标题进行搜索,提取标题推荐的第一个文章的内容。让我在这里谈谈。有朋友说要过滤列表中的10篇文章文章,过滤最相关的文章,陶小白觉得直接用今日头条的算法就够了,而文章@ > 今日头条的算法推荐也更符合用户需求。所以,我这里直接拍的第一篇文章。
4、清理内容
我们把文章的内容提取出来后,肯定不能直接使用,直接去掉一些乱七八糟的内容。我的清理逻辑:先过滤html标签,只保留p标签,然后提取p标签的内容,提前设置一些短字,比如:微信、公众号、二维码,必须查,负责编辑... 如果 p 标签收录这些词中的任何一个,那么直接删除 p 标签,只保留我们需要的内容。
综上所述,在标题生成并处理完内容后,插件可以直接返回标题和内容采集title。
的优点和缺点:
1、缺点:没有图片
一直不想用今日头条的图片,主要是版权问题。近年来,图片的版权问题越来越严重。如果可以的话,我建议你不需要使用它。可以去国外下载一些无版权的商业网站一批相关图片,PS批量处理图片大小,然后传到服务器,可以随意调用。
2、缺点:慢
因为数据清理和优采云默认的采集限速,无法提高请求速度,短期需要大量数据不适合这个插件。
3、优点:相关性高
之前智能版的插件可以匹配高相关的关键词,但是内容会有些不匹配,现在这个逻辑可以解决标题和内容不相关的问题,淘小白我有也测试了上百篇,相关性还是可以的。
最后,给出一个演示网址:
广告,需要插件且有付费意向的朋友请联系我~
采集相关文章(Destoon采集可以图片组装自动配图让文章内容图文并茂更适合搜索引擎)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-04-01 23:19
3)目录构建(三层)、站点地图、静态URL。
竞争对手永远是自己学习的目标。为什么别人的 网站 做得这么好?他优化的网站一定有我们学到的东西。我们可以通过多种SEO工具查询来检查有很多维度:
Destoon采集可以翻译文章,支持翻译接口:百度/谷歌/有道/讯飞/147/等。Destoon采集可以转换内容(字体),内容转繁体/内容转英文/内容转火星文/内容转拼音/内容转繁体/英文/拼音/火星文/等。
网站的优化离不开对数据的分析,比如:点击率、展示量、IP、PV、地域、搜索词,还有收录量、索引量等.,所有这些都是我们需要分析的。Destoon采集可以拼图,自动匹配图片,让文章图文并茂的内容更适合搜索引擎。与自动图片一样,文章 带有图片和文字的内容可以提高原创 的性能。
我们分析这些主要是为了让网站的排名更进一步,挖掘不足的地方进行优化,如果点击率低,我们可以优化页面美观,如果显示量小,我们会提供更多内容让百度收录,如果IP少的话,更多Destoon采集可以伪原创通过设置关键词锁定保留字,让你的关键词不受原创影响,保证关键词显示核心关键词品牌不被伪原创关键词锁定,提高文章可读性和关键词 不会是 伪原创 >。做一些外链,多换好友链接等,可以看看当前的网站搜索是否符合搜索词的SEO优化。收录 的数量 索引是对 网站 质量的测试。如果质量基本秒接收,而且收录量高排名低,那么就要考虑优化网站结构,比如排版、内容质量、目录等。Destoon采集@ > 可以让搜索引擎收录title伪原创更好的区分title伪原创title,减少搜索引擎中的重复。
最好每天分析蜘蛛爬取的目录,看看蜘蛛喜欢什么。分析网站是否有死链接,提交死链接。利用百度统计工具的热力图,找到用户喜欢点击升级的地方。用户研究页面数据,用户访问表单转化,最好问客户需要什么,我们根据用户需求升级产品页面。Destoon采集可以是专为谷歌、百度、雅虎、360等大型搜索引擎设计的伪原创收录,伪原创工具生成的文章将更好的是 收录 并被搜索引擎索引。模拟Baidu/360/Sogou/Google等伪原创的中文分词,使用独有的分词引擎和自创词库。
应对百度升级的算法。百度会每隔一段时间更新一次算法。我们能做的就是关注百度算法的更新,创建一个更接近算法、符合搜索引擎白皮书的页面。Destoon采集可以节省时间,高效创建文章;智能分析文本中词与句的关系;使用深度卷积神经算法进行分解;进行高度匹配的关键词提取;并根据单词智能提取和组合文本摘要;对文本内容进行全面拆分,对比百度数据;提高百度收录文字内容率;检测 文章 内容的 原创。该算法的大多数原因是解决现有问题。例如,如果快速队列猖獗,就会出现雷霆算法3.0。目前,起点SEO监控的快速队列网站还在。看来道高一丈,魔高一尺。全网推送支持百度、谷歌、搜狗、360、必应、神马等自动推送。今天关于Deston采集的讲解就到这里,下期分享更多SEO相关知识。 查看全部
采集相关文章(Destoon采集可以图片组装自动配图让文章内容图文并茂更适合搜索引擎)
3)目录构建(三层)、站点地图、静态URL。
竞争对手永远是自己学习的目标。为什么别人的 网站 做得这么好?他优化的网站一定有我们学到的东西。我们可以通过多种SEO工具查询来检查有很多维度:
Destoon采集可以翻译文章,支持翻译接口:百度/谷歌/有道/讯飞/147/等。Destoon采集可以转换内容(字体),内容转繁体/内容转英文/内容转火星文/内容转拼音/内容转繁体/英文/拼音/火星文/等。
网站的优化离不开对数据的分析,比如:点击率、展示量、IP、PV、地域、搜索词,还有收录量、索引量等.,所有这些都是我们需要分析的。Destoon采集可以拼图,自动匹配图片,让文章图文并茂的内容更适合搜索引擎。与自动图片一样,文章 带有图片和文字的内容可以提高原创 的性能。
我们分析这些主要是为了让网站的排名更进一步,挖掘不足的地方进行优化,如果点击率低,我们可以优化页面美观,如果显示量小,我们会提供更多内容让百度收录,如果IP少的话,更多Destoon采集可以伪原创通过设置关键词锁定保留字,让你的关键词不受原创影响,保证关键词显示核心关键词品牌不被伪原创关键词锁定,提高文章可读性和关键词 不会是 伪原创 >。做一些外链,多换好友链接等,可以看看当前的网站搜索是否符合搜索词的SEO优化。收录 的数量 索引是对 网站 质量的测试。如果质量基本秒接收,而且收录量高排名低,那么就要考虑优化网站结构,比如排版、内容质量、目录等。Destoon采集@ > 可以让搜索引擎收录title伪原创更好的区分title伪原创title,减少搜索引擎中的重复。
最好每天分析蜘蛛爬取的目录,看看蜘蛛喜欢什么。分析网站是否有死链接,提交死链接。利用百度统计工具的热力图,找到用户喜欢点击升级的地方。用户研究页面数据,用户访问表单转化,最好问客户需要什么,我们根据用户需求升级产品页面。Destoon采集可以是专为谷歌、百度、雅虎、360等大型搜索引擎设计的伪原创收录,伪原创工具生成的文章将更好的是 收录 并被搜索引擎索引。模拟Baidu/360/Sogou/Google等伪原创的中文分词,使用独有的分词引擎和自创词库。
应对百度升级的算法。百度会每隔一段时间更新一次算法。我们能做的就是关注百度算法的更新,创建一个更接近算法、符合搜索引擎白皮书的页面。Destoon采集可以节省时间,高效创建文章;智能分析文本中词与句的关系;使用深度卷积神经算法进行分解;进行高度匹配的关键词提取;并根据单词智能提取和组合文本摘要;对文本内容进行全面拆分,对比百度数据;提高百度收录文字内容率;检测 文章 内容的 原创。该算法的大多数原因是解决现有问题。例如,如果快速队列猖獗,就会出现雷霆算法3.0。目前,起点SEO监控的快速队列网站还在。看来道高一丈,魔高一尺。全网推送支持百度、谷歌、搜狗、360、必应、神马等自动推送。今天关于Deston采集的讲解就到这里,下期分享更多SEO相关知识。
采集相关文章(网站采集发布可以把网站上的信息统统采集及发布 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-30 02:10
)
采集发布,通过网站采集,我们可以将网站需要的文章内容数据采集传递给我们自己的网站 ,或将其他一些 网站 内容保存到我们自己的服务器。通过采集发布,可以得到我们想要的相关数据、文章、图片等。采集发布的内容已经处理,可以成为我们自己的网站内容,保持我们的网站不断更新。
采集发布可以采集网站上的所有信息,并自动发布到站长的网站,在哪里可以看到,可以采集到;< @采集发帖也可以自动完成,无需人工,随时掌握网站最新资讯。采集发布功能:采集发布是全自动的,自动识别JavaScript特殊URL,需要登录的网站也可以使用。采集无论有多少类别,都发布整个网站的抓取;可以下载任何类型的文件;多页新闻自动合并,信息过滤,多级页面合并采集,图片自动加水印。
如果站长想要采集发布新闻,他可以抓取新闻的标题、内容、图片、来源,过滤掉信息,合并一条新闻的所有页面。如果站长想采集发布供需信息,他可以抓到标题、内容、信息,即使一条信息分布在很多页面上,不管信息在哪一层,他可以抓住他能看到的任何东西。到达。如果网站 想要采集 发布论坛帖子,您可以采集 帖子标题、内容和回复。其实采集发布的任何文件都可以下载,包括图片、flash、rar等,也可以调用flashget下载,下载效率更高。
采集发布,顾名思义,可以实现网站自动采集和发布,也就是通过数量来获取搜索引擎收录和关键词排名赢,从而获得搜索引擎被动流量。采集发布的所有功能都是分开设计的,可以满足各种站长的不同需求。首先是内容来源。除了采集,您还可以自己创建新内容。其次,发布功能可以根据个人喜好设计不同的发布效果。最后就是SEO功能,多种SEO伪原创功能合二为一,不同的站长可以设计不同的伪原创组合、链轮组合等等。
采集发布是一款集自动采集、自动发布、各种伪原创、站长APP界面等SEO功能为一体的工具。它是一个免费的采集器,实现免费的采集发布,采集发布强大的采集功能,支持关键词采集,文章@ >采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量加站加栏,绑定栏目id等功能,支持自定义发布界面编写(站长APP界面),采集发布真正实现完美支持各种站点程序,<
查看全部
采集相关文章(网站采集发布可以把网站上的信息统统采集及发布
)
采集发布,通过网站采集,我们可以将网站需要的文章内容数据采集传递给我们自己的网站 ,或将其他一些 网站 内容保存到我们自己的服务器。通过采集发布,可以得到我们想要的相关数据、文章、图片等。采集发布的内容已经处理,可以成为我们自己的网站内容,保持我们的网站不断更新。
采集发布可以采集网站上的所有信息,并自动发布到站长的网站,在哪里可以看到,可以采集到;< @采集发帖也可以自动完成,无需人工,随时掌握网站最新资讯。采集发布功能:采集发布是全自动的,自动识别JavaScript特殊URL,需要登录的网站也可以使用。采集无论有多少类别,都发布整个网站的抓取;可以下载任何类型的文件;多页新闻自动合并,信息过滤,多级页面合并采集,图片自动加水印。
如果站长想要采集发布新闻,他可以抓取新闻的标题、内容、图片、来源,过滤掉信息,合并一条新闻的所有页面。如果站长想采集发布供需信息,他可以抓到标题、内容、信息,即使一条信息分布在很多页面上,不管信息在哪一层,他可以抓住他能看到的任何东西。到达。如果网站 想要采集 发布论坛帖子,您可以采集 帖子标题、内容和回复。其实采集发布的任何文件都可以下载,包括图片、flash、rar等,也可以调用flashget下载,下载效率更高。
采集发布,顾名思义,可以实现网站自动采集和发布,也就是通过数量来获取搜索引擎收录和关键词排名赢,从而获得搜索引擎被动流量。采集发布的所有功能都是分开设计的,可以满足各种站长的不同需求。首先是内容来源。除了采集,您还可以自己创建新内容。其次,发布功能可以根据个人喜好设计不同的发布效果。最后就是SEO功能,多种SEO伪原创功能合二为一,不同的站长可以设计不同的伪原创组合、链轮组合等等。
采集发布是一款集自动采集、自动发布、各种伪原创、站长APP界面等SEO功能为一体的工具。它是一个免费的采集器,实现免费的采集发布,采集发布强大的采集功能,支持关键词采集,文章@ >采集,图片和视频采集,还支持自定义采集规则指定域名采集,还提供原创文章生成功能,支持数据自由导入导出,支持各种链接插入和链轮功能,批量加站加栏,绑定栏目id等功能,支持自定义发布界面编写(站长APP界面),采集发布真正实现完美支持各种站点程序,<
采集相关文章(切记获取文章源数据那是最差的一种做法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-28 06:01
采集相关文章的一般都是扫一扫而已。而你如果想让它能读取的话,那么只能把文章关键词提取出来,并设置出现的频率,或者利用爬虫工具去抓取这些数据。当然你要是能满足截图的需求,你就是绝对的大神了。最后奉劝一句,如果上述方式都做不到,那就用小说app读取下本书并转换一下内容再发布。总之切记,获取文章源数据那是最差的一种做法。
首先你得了解你的小说的名字,数据才会上传。然后,你才可以利用抓包工具抓取数据。然后,你得有个“和这小说相关”的话题才行。比如说小说作者、作者小号和小号的粉丝、小说的粉丝数、小说内容的点击数等等。
我不是大神。如果没有经验的话。肯定没人给你。你可以去各大小说站写,然后看阅读排行。看多了你就会知道你想要的什么了。
可以多关注一些小说平台,一般都有自己的小说云点,如果对你所要的小说相关的话题没有特别的要求,你只需要发现一些这个话题相关的小说就行了。比如说你要写当前的小说的话题是说电脑小说,你只需要知道两个电脑小说的平台和两个小说的搜索结果,然后把他们自己相关的小说小说先发到云点然后在云点推荐时去浏览量高的小说再相关一些,这样子就可以收集你需要的数据了。
如果可以的话,有会员,点击率;反馈以及排行榜,签到等, 查看全部
采集相关文章(切记获取文章源数据那是最差的一种做法)
采集相关文章的一般都是扫一扫而已。而你如果想让它能读取的话,那么只能把文章关键词提取出来,并设置出现的频率,或者利用爬虫工具去抓取这些数据。当然你要是能满足截图的需求,你就是绝对的大神了。最后奉劝一句,如果上述方式都做不到,那就用小说app读取下本书并转换一下内容再发布。总之切记,获取文章源数据那是最差的一种做法。
首先你得了解你的小说的名字,数据才会上传。然后,你才可以利用抓包工具抓取数据。然后,你得有个“和这小说相关”的话题才行。比如说小说作者、作者小号和小号的粉丝、小说的粉丝数、小说内容的点击数等等。
我不是大神。如果没有经验的话。肯定没人给你。你可以去各大小说站写,然后看阅读排行。看多了你就会知道你想要的什么了。
可以多关注一些小说平台,一般都有自己的小说云点,如果对你所要的小说相关的话题没有特别的要求,你只需要发现一些这个话题相关的小说就行了。比如说你要写当前的小说的话题是说电脑小说,你只需要知道两个电脑小说的平台和两个小说的搜索结果,然后把他们自己相关的小说小说先发到云点然后在云点推荐时去浏览量高的小说再相关一些,这样子就可以收集你需要的数据了。
如果可以的话,有会员,点击率;反馈以及排行榜,签到等,
采集相关文章(网站文章数据采集是如何工作的?网站收集信息的过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2022-03-27 21:15
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。 查看全部
采集相关文章(网站文章数据采集是如何工作的?网站收集信息的过程)
网站文章数据采集是从我们的目标网站采集信息的过程。使用 网站文章Data采集 工具,我们可以从 网站 下载结构化数据进行自动化分析。
网站文章Data采集 表示从网站 中提取的内容和数据。然后以用户所需的格式提取此信息。网站文章Data采集 可以手动完成,但这是一项极其繁琐的工作。为了加快这个过程,我们可以使用自动化、成本更低、工作速度更快的 网站文章data采集 工具。
通过使用网站文章data采集工具,我们可以在不同的场景中帮助我们完成多种目的,比如市场研究的数据采集、联系信息提取、价格跟踪在不同平台上,关注网站的内容变化,实时数据监控等。
网站文章数据采集工具页面简洁易操作,可视化操作页面不需要我们掌握复杂的配置规则,就可以完成网站内容和数据采集。
网站文章数据采集工具指定的采集功能可以通过输入目标URL并在工具的可视化页面选择采集元素来配置 下载模板。通过模板选择我们需要的内容或者保留相应的标签,或者通过模板去掉我们不想要的元素,比如电话号码、住址、作者信息等。
网站文章数据采集输入关键词后,该工具可以进行全网关键词匹配,完成平移采集。所有匹配的内容都是大平台上的实时热门资源。无论是通过强大的NLP自然语言处理系统采集资源进行二次创作和发布伪原创,都可以为我们网站提供优质的内容。
网站文章数据采集除了采集功能外,该工具还有文章内容SEO,支持保留原文相关标签、图片下载过程中去除水印和图像下载。云存储等,支持多种下载格式保存,无论是HTML、TXT还是excel等,方便我们在后续二次创作中放心创作和数据分析。
网站文章Data采集 是如何工作的?首先,网站文章data采集 在 采集 进程之前获取要加载的 URL。网站文章Data采集 工具然后加载所需页面的完整 HTML 代码。然后,网站文章Data采集会在项目运行前提取页面上的所有数据或者用户选择的特定数据。最后,网站文章Data采集 将所有采集的数据输出为可用格式。
网站文章data采集的用途和工作原理以及网站文章data采集工具应用的分享都在这里,网站文章数据的使用采集可以说是非常广泛了,不仅我们的网站可以使用采集不断更新内容,各行各业的生活可以使用采集@网站文章数据采集工具采集相关数据进行数据统计和分析,如果喜欢本内容,请点赞、采集并关注,您的支持是博主坚持不懈的动力。
采集相关文章(如何写采集之前后台插件管理,我也不是什么大师 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-25 13:19
)
前沿:
如果你对优采云一无所知,你应该去网上了解一下优采云采集,我也不是高手,我写了,在至少可以用,这里就不教你怎么写采集规则了,因为写法种类太多了,不知道你问我。优采云相关文件夹中提供的发布界面,内置马甲发布文章,发布文章时间设置(10-70分钟随机)。用户只需要关注优采云的标题和内容,参数值标题(title),内容(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,记住就好)
第二步:将发布界面上传到overlay程序的根目录:
应用上传到Q&A网站根目录覆盖原应用文件夹
whatsns_newquestion.wpm 是问答发布模块
whatsnsnewarticle.wpm 是 文章 发布模块
第三步:登录优采云软件后导入发布模块”
下图中更多下拉-选择导入:
导入后:
上图中数字1处填入你在网站后台设置的全局变量值。
2 选择utf-8编码。
在 3 个位置填写您的 网站 域名,不要使用反斜杠“/”。
4个选项不需要登录
5处点击获取列表--选择你需要入库的分类(注意:网址为https 网站免费版优采云软件可能获取不到分类列表)
6 随意为当前的发布模块写一个名字,将被后续的采集任务模块使用。
最后点击保存配置按钮。
---------
下面解释一下 import 采集 任务: -- 这个规则不保证是最新的
新建任务组后,在该组下导入任务规则(将任务导入该组):
选择我们的 采集 作业规则(.ljobx 文件):
下一步:双击规则项
第二步很重要,导入我们对应的问答/文章发布模块,看看你是采集规则问答还是文章,这样方便同步最新的采集 标签
单击步骤 3:修改帖子内容设置
修改您发布的类别:
最后保存:
然后右键启动任务采集:
如何使用内容审核模式+批量定时任务发布:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
状态状态 1 更改为 0
两个文件都修改后,优采云发布的内容会进入review列表,不会显示在前端。
如何设置定时任务发布时间?
本站根目录/application\controllers\Doit.php插件文件用于自动批量发布审计内容。默认发布访问权限一次允许 100 个条目。这个值可以自己修改。最大值不要超过2000,否则查询会承受压力,负载会增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
访问地址可以添加到宝塔计划任务中:
查看全部
采集相关文章(如何写采集之前后台插件管理,我也不是什么大师
)
前沿:
如果你对优采云一无所知,你应该去网上了解一下优采云采集,我也不是高手,我写了,在至少可以用,这里就不教你怎么写采集规则了,因为写法种类太多了,不知道你问我。优采云相关文件夹中提供的发布界面,内置马甲发布文章,发布文章时间设置(10-70分钟随机)。用户只需要关注优采云的标题和内容,参数值标题(title),内容(content)。
采集后台插件管理前,先批量添加10-20个左右的马甲
第一步:在站点设置中设置优采云免登录发布界面的全局变量值:(随便写个字母,记住就好)
第二步:将发布界面上传到overlay程序的根目录:
应用上传到Q&A网站根目录覆盖原应用文件夹
whatsns_newquestion.wpm 是问答发布模块
whatsnsnewarticle.wpm 是 文章 发布模块
第三步:登录优采云软件后导入发布模块”
下图中更多下拉-选择导入:
导入后:
上图中数字1处填入你在网站后台设置的全局变量值。
2 选择utf-8编码。
在 3 个位置填写您的 网站 域名,不要使用反斜杠“/”。
4个选项不需要登录
5处点击获取列表--选择你需要入库的分类(注意:网址为https 网站免费版优采云软件可能获取不到分类列表)
6 随意为当前的发布模块写一个名字,将被后续的采集任务模块使用。
最后点击保存配置按钮。
---------
下面解释一下 import 采集 任务: -- 这个规则不保证是最新的
新建任务组后,在该组下导入任务规则(将任务导入该组):
选择我们的 采集 作业规则(.ljobx 文件):
下一步:双击规则项
第二步很重要,导入我们对应的问答/文章发布模块,看看你是采集规则问答还是文章,这样方便同步最新的采集 标签
单击步骤 3:修改帖子内容设置
修改您发布的类别:
最后保存:
然后右键启动任务采集:
如何使用内容审核模式+批量定时任务发布:
打开站点根目录:application\controllers\Pccaiji\Pccaiji_question.php、application\controllers\Pccaiji\Pccaiji_catgory.php两个文件
状态状态 1 更改为 0
两个文件都修改后,优采云发布的内容会进入review列表,不会显示在前端。
如何设置定时任务发布时间?
本站根目录/application\controllers\Doit.php插件文件用于自动批量发布审计内容。默认发布访问权限一次允许 100 个条目。这个值可以自己修改。最大值不要超过2000,否则查询会承受压力,负载会增加。
问答访问地址:URL/doit/question.html
文章访问地址:URL/doit/article.html
访问地址可以添加到宝塔计划任务中:
采集相关文章(迅睿CMS采集发布基于高度智能的正文识别算法介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2022-03-22 14:07
迅锐cms采集发布高智能文本识别算法,迅锐cms采集发布新闻关键词采集文章,荀睿cms采集 发布,不写采集 规则。搜索引擎网站的构建主要分为三个部分:如何更好的让搜索引擎中的内容收录网站,如何在搜索引擎中获得好的排名,如何让用户从众多搜索结果中点击您的 网站。简单来说就是收录,排序,展示。
迅瑞cms采集自动发布全网采集,迅瑞cms采集发布六大搜索引擎。 网站三大标签指标题、关键词关键词、描述,简称“TDK”。每个页面都有三个独立的标签,我们需要根据每个页面的内容编写三个不同的标签。标题:标题不应收录违禁词。可以写网站的主推关键词,一般不超过60个字符。关键字:作用是告诉搜索引擎蜘蛛这个页面的关键词。新站点建议关键词的数量应该在4个左右,一般不超过100个字符。 description:description标签的作用主要是对这个网页的内容做一个大概的介绍,让蜘蛛看到,一般不超过200个字符。
迅锐cms采集发布自动过滤的内容相关性和文章流畅度,迅锐cms采集只发布采集相关文章具有高度和光滑度。如何优化百度关键词?可以从以下几个方面进行操作:由于搜索引擎无法识别动态js,建议使用静态HTML网页代码,如果应用模板,需要手动删除无用代码。 网站添加站长平台和统计代码,用于网站可抓取性检测,后期查看网站关键词展示次数、点击次数等具体数据。问答平台、博客平台、自媒体等平台发布品牌信息,最大化曝光。
迅锐cms采集发布自动地图,智能伪原创,定时采集,自动发布,自动提交到搜索引擎,迅锐cms< @采集Publish 支持各种内容管理系统和网站建设者。定期更新网站的内容(例如:周一到周五每天更新2条文章内容),建议网站上的每条文章最好是图文形式,增加用户体验,合理添加主关键词。寻找同行业优质网站交换友情链,可与友情链接平台、QQ群、网站等相关行业合作,增加友情链接数量。交换好友链时,需要注意对方网站的质量,防止作弊。
网站添加站点地图,您可以通过站长平台或robots.txt文件将网站地图提交给搜索引擎,加快网站内容的收录。迅锐cms采集是一个网站基于用户提供的关键词,云端自动采集相关文章并发布给用户网站@ > @>采集器。 网站设置301重定向,可以将不带www域名的网站设置301重定向到带www的域名提供者,这样消费者最终会访问带www或不带www的。 网站 的 www。主要目的是实现权重转移,即将前一个网站或网页的所有流量和价值转移到另一个网站或网页。消费者在浏览网站时,如果网站服务器异常或者无法响应,可以直接返回404页面,避免看到网站无法访问时窗口丢失直接打开和关闭。添加 404 页面以提升用户体验。
当用户在百度网络搜索中搜索您的网页时,标题将作为最重要的内容显示在摘要中。一个主题明确的标题可以帮助用户更容易地从搜索结果中判断你网页上的内容是否符合他的需要。迅瑞cms采集发帖可以自动识别各种网页的标题、文字等信息,迅锐cms采集发布不需要用户写任何采集@ > 规则可以实现全网采集。因此,必须从用户的角度考虑一切。如果你学会为用户着想,那么你的网站排名就会逐渐提高!
网站业务类型太小众了。由于业务类型小众,用户基数小,导致通过相应关键词排名的流量非常少。迅锐cms采集发布采集到内容后,迅锐cms采集会自动计算内容与集合关键词的相关性,迅锐cms采集只推送相关的文章给用户。也就是说,即使有了关键词的排名,仍然没有合适的流量进来。这是网站内容业务类型本身的问题,是个缺陷,解决的办法很有限。
迅瑞cms采集发帖支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时采集、百度主动提交等一系列SEO功能。竞争对手的问题。做任何一种网站,总会有固定的业务,比如产品,比如服务,比如品牌曝光。如果竞争太大,更好的 收录 排名也不理想。以旅游为例,小型旅游网站无法与携程、途牛等大型网站网站相提并论。小网站没有关键词排名,或者排名,可以合理解释。
内容分为底层库。迅瑞cms采集发布用户只需设置关键词及相关需求,即可实现全托管、零维护网站内容更新。从搜索引擎的原理来看,收录、索引、关键词排名是一个环环相扣的过程。 收录 只是排名的依据。重要的是搜索引擎将收录的内容放在哪个索引库层,索引库层是多种多样的。迅瑞cms采集的发布数量不受限制网站,迅瑞cms采集的发布可以轻松管理。如果内容本身质量太低,或者当前页面质量太低,那么收录这个内容很有可能被分类到底层库,也就是说即使有收录,没有排名。这也可以解释很多网站收录问题,量级上千万甚至上百万,但是能产生排名的页面还是很少。 查看全部
采集相关文章(迅睿CMS采集发布基于高度智能的正文识别算法介绍)
迅锐cms采集发布高智能文本识别算法,迅锐cms采集发布新闻关键词采集文章,荀睿cms采集 发布,不写采集 规则。搜索引擎网站的构建主要分为三个部分:如何更好的让搜索引擎中的内容收录网站,如何在搜索引擎中获得好的排名,如何让用户从众多搜索结果中点击您的 网站。简单来说就是收录,排序,展示。
迅瑞cms采集自动发布全网采集,迅瑞cms采集发布六大搜索引擎。 网站三大标签指标题、关键词关键词、描述,简称“TDK”。每个页面都有三个独立的标签,我们需要根据每个页面的内容编写三个不同的标签。标题:标题不应收录违禁词。可以写网站的主推关键词,一般不超过60个字符。关键字:作用是告诉搜索引擎蜘蛛这个页面的关键词。新站点建议关键词的数量应该在4个左右,一般不超过100个字符。 description:description标签的作用主要是对这个网页的内容做一个大概的介绍,让蜘蛛看到,一般不超过200个字符。
迅锐cms采集发布自动过滤的内容相关性和文章流畅度,迅锐cms采集只发布采集相关文章具有高度和光滑度。如何优化百度关键词?可以从以下几个方面进行操作:由于搜索引擎无法识别动态js,建议使用静态HTML网页代码,如果应用模板,需要手动删除无用代码。 网站添加站长平台和统计代码,用于网站可抓取性检测,后期查看网站关键词展示次数、点击次数等具体数据。问答平台、博客平台、自媒体等平台发布品牌信息,最大化曝光。
迅锐cms采集发布自动地图,智能伪原创,定时采集,自动发布,自动提交到搜索引擎,迅锐cms< @采集Publish 支持各种内容管理系统和网站建设者。定期更新网站的内容(例如:周一到周五每天更新2条文章内容),建议网站上的每条文章最好是图文形式,增加用户体验,合理添加主关键词。寻找同行业优质网站交换友情链,可与友情链接平台、QQ群、网站等相关行业合作,增加友情链接数量。交换好友链时,需要注意对方网站的质量,防止作弊。
网站添加站点地图,您可以通过站长平台或robots.txt文件将网站地图提交给搜索引擎,加快网站内容的收录。迅锐cms采集是一个网站基于用户提供的关键词,云端自动采集相关文章并发布给用户网站@ > @>采集器。 网站设置301重定向,可以将不带www域名的网站设置301重定向到带www的域名提供者,这样消费者最终会访问带www或不带www的。 网站 的 www。主要目的是实现权重转移,即将前一个网站或网页的所有流量和价值转移到另一个网站或网页。消费者在浏览网站时,如果网站服务器异常或者无法响应,可以直接返回404页面,避免看到网站无法访问时窗口丢失直接打开和关闭。添加 404 页面以提升用户体验。
当用户在百度网络搜索中搜索您的网页时,标题将作为最重要的内容显示在摘要中。一个主题明确的标题可以帮助用户更容易地从搜索结果中判断你网页上的内容是否符合他的需要。迅瑞cms采集发帖可以自动识别各种网页的标题、文字等信息,迅锐cms采集发布不需要用户写任何采集@ > 规则可以实现全网采集。因此,必须从用户的角度考虑一切。如果你学会为用户着想,那么你的网站排名就会逐渐提高!
网站业务类型太小众了。由于业务类型小众,用户基数小,导致通过相应关键词排名的流量非常少。迅锐cms采集发布采集到内容后,迅锐cms采集会自动计算内容与集合关键词的相关性,迅锐cms采集只推送相关的文章给用户。也就是说,即使有了关键词的排名,仍然没有合适的流量进来。这是网站内容业务类型本身的问题,是个缺陷,解决的办法很有限。
迅瑞cms采集发帖支持标题前缀、关键词自动加粗、插入固定链接、自动提取Tag标签、自动内链、自动图片匹配、自动伪原创、内容过滤替换、电话号码和URL清洗、定时采集、百度主动提交等一系列SEO功能。竞争对手的问题。做任何一种网站,总会有固定的业务,比如产品,比如服务,比如品牌曝光。如果竞争太大,更好的 收录 排名也不理想。以旅游为例,小型旅游网站无法与携程、途牛等大型网站网站相提并论。小网站没有关键词排名,或者排名,可以合理解释。
内容分为底层库。迅瑞cms采集发布用户只需设置关键词及相关需求,即可实现全托管、零维护网站内容更新。从搜索引擎的原理来看,收录、索引、关键词排名是一个环环相扣的过程。 收录 只是排名的依据。重要的是搜索引擎将收录的内容放在哪个索引库层,索引库层是多种多样的。迅瑞cms采集的发布数量不受限制网站,迅瑞cms采集的发布可以轻松管理。如果内容本身质量太低,或者当前页面质量太低,那么收录这个内容很有可能被分类到底层库,也就是说即使有收录,没有排名。这也可以解释很多网站收录问题,量级上千万甚至上百万,但是能产生排名的页面还是很少。
采集相关文章(企业网站不能做到大量词语优化的一个主要问题是内部结构不利于)
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-03-09 18:07
如何实现关键词文章采集?将网站关键词的密度增加关键词文章,提高网站的排名。一般来说,企业网站的优化主要以首页为主。涵盖三五个流行的关键词。事实上,这是一种巨大的浪费。企业网站可以完全覆盖甚至垄断行业内大量的关键词。公司网站不能做很多词优化的主要问题之一是内部结构不利于优化。
一、文章列表页面的优化
1、可以对有一定竞争力、流量较大的关键词进行优化,毕竟文章列表页的排名能力还是比较强的;
2、由于文章列表页更新频繁文章,列表页首页关键词的密度变化很大,可以加一定的文字说明到页面稳定关键词密度;
3、一定要有优质的文章推荐区,最好是图文结合,让观众第一眼就被吸引;
4、注意不要把整个页面做成一个链接,增加纯文本量,百度喜欢内容丰富的页面;
5、页面之间应该有内容差异,不应该有很多相同的内容,尤其是Title、h1和纯文本描述;
6、注意保持一定的更新,持续提供优质内容。
1、善用h1标签,通常出现在标题中,最好后跟ap标签,里面有一个文章摘要;
2、内容要丰富,表达形式可以多样化,比如:结合图表让技术问题更容易理解,必要时还可以视频;
3、从用户需求角度布局内链;
4、根据页面的重要性和竞争程度分配指向页面的内链数量,并增加其权重;
5、以图文结合的形式调用相关的文章或高质量的文章,提升用户体验;
6、可以调用最新的文章和页面评论保持页面更新;不要随意调用文章,没有意义;
7、控制页面外链的数量,不要过度。
在做网站优化的时候,千万不能忽视tag标签的作用。Tag标签聚集了高度相关的内容,非常符合用户体验。如果你想优化它,可以参考我分享的内容。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以通过关键词文章实现采集伪原创自动发布和主动推送到搜索引擎,从而提高搜索引擎的抓取频率,从而提高网站收录 和 关键词 排名。
免费关键词文章采集
1、只需导入关键词或输入网址采集文章,同时创建几十或几百个采集任务
2、支持多种新闻来源:Q&A/Newsfeed/Fiction/Film
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译
在所有平台上发布 cms
1、cms发行:企业版cms、站群cms、小说cms、影视台cms、主要开源cms 和 网站
2、全网推送(百度/360/搜狗/神马)
3、伪原创
4、更换图片防止侵权
5、强大的SEO功能(带图片/内外链接/前后缀插入/文章相关性增强/图片随机插入/聚合/TAG标签)
1、网站关键词分析
每个站长都应该熟悉网站关键词。所谓关键词,就是对网站的简单而全面的描述。网站关键词分析也称为关键词位置。网站关键词分析是SEO优化中最重要的部分。
关键词分析的第一件事就是根据自己的情况分析确定要设置的关键词。比如你在做运动网站,你选择的是关键词,它必须和自身网站保持一致。另外,关键词的竞争度也要分析,至于关键词的竞争度分析。
2、网站架构分析
网站架构的好坏会直接影响搜索引擎爬虫的偏好。好的网站框架有利于爬虫对内容的抓取,而不好的网站框架会影响爬虫对网站内容的抓取,不利于SEO。那么什么样的网站架构对搜索引擎友好呢?一般来说,通过实现网站树形目录结构、网站导航和链接优化,我们可以创建一个适合搜索引擎偏好的网站结构,从而获得搜索引擎的喜爱, 最后实现流量的积累。
3、做网站目录和页面优化
很多人可能会问:为什么要设置网站目录和优化页面?这实际上非常简单。我们最想要的结果不仅仅是搜索引擎的首页收录网站,不仅仅是首页获得好的排名,我们希望在此基础上收录更多页面,更多排名,这样我们就可以获得更多的流量,实现我们想要的目标。因此,有必要做好网站目录和页面的优化。
4、定期发布内容和合理安排链接
搜索引擎喜欢定期的网站内容更新,所以合理安排网站内容发布时间是SEO优化的重要技术之一。链接排列将整个网站有机地连接起来,让搜索引擎了解每个页面和关键词的重要性,实现参考是第一点的关键词排列。友谊链接活动也在此时启动。因此,我们必须做好网站内容的定期更新和外链的定期发布。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名! 查看全部
采集相关文章(企业网站不能做到大量词语优化的一个主要问题是内部结构不利于)
如何实现关键词文章采集?将网站关键词的密度增加关键词文章,提高网站的排名。一般来说,企业网站的优化主要以首页为主。涵盖三五个流行的关键词。事实上,这是一种巨大的浪费。企业网站可以完全覆盖甚至垄断行业内大量的关键词。公司网站不能做很多词优化的主要问题之一是内部结构不利于优化。
一、文章列表页面的优化
1、可以对有一定竞争力、流量较大的关键词进行优化,毕竟文章列表页的排名能力还是比较强的;
2、由于文章列表页更新频繁文章,列表页首页关键词的密度变化很大,可以加一定的文字说明到页面稳定关键词密度;
3、一定要有优质的文章推荐区,最好是图文结合,让观众第一眼就被吸引;
4、注意不要把整个页面做成一个链接,增加纯文本量,百度喜欢内容丰富的页面;
5、页面之间应该有内容差异,不应该有很多相同的内容,尤其是Title、h1和纯文本描述;
6、注意保持一定的更新,持续提供优质内容。
1、善用h1标签,通常出现在标题中,最好后跟ap标签,里面有一个文章摘要;
2、内容要丰富,表达形式可以多样化,比如:结合图表让技术问题更容易理解,必要时还可以视频;
3、从用户需求角度布局内链;
4、根据页面的重要性和竞争程度分配指向页面的内链数量,并增加其权重;
5、以图文结合的形式调用相关的文章或高质量的文章,提升用户体验;
6、可以调用最新的文章和页面评论保持页面更新;不要随意调用文章,没有意义;
7、控制页面外链的数量,不要过度。
在做网站优化的时候,千万不能忽视tag标签的作用。Tag标签聚集了高度相关的内容,非常符合用户体验。如果你想优化它,可以参考我分享的内容。
二、A网站更新频率越高,搜索引擎蜘蛛来的越频繁。因此,我们可以通过关键词文章实现采集伪原创自动发布和主动推送到搜索引擎,从而提高搜索引擎的抓取频率,从而提高网站收录 和 关键词 排名。
免费关键词文章采集
1、只需导入关键词或输入网址采集文章,同时创建几十或几百个采集任务
2、支持多种新闻来源:Q&A/Newsfeed/Fiction/Film
3、过滤其他促销信息
4、图片本地化/图片水印/图片第三方存储
5、文章交流+翻译
在所有平台上发布 cms
1、cms发行:企业版cms、站群cms、小说cms、影视台cms、主要开源cms 和 网站
2、全网推送(百度/360/搜狗/神马)
3、伪原创
4、更换图片防止侵权
5、强大的SEO功能(带图片/内外链接/前后缀插入/文章相关性增强/图片随机插入/聚合/TAG标签)
1、网站关键词分析
每个站长都应该熟悉网站关键词。所谓关键词,就是对网站的简单而全面的描述。网站关键词分析也称为关键词位置。网站关键词分析是SEO优化中最重要的部分。
关键词分析的第一件事就是根据自己的情况分析确定要设置的关键词。比如你在做运动网站,你选择的是关键词,它必须和自身网站保持一致。另外,关键词的竞争度也要分析,至于关键词的竞争度分析。
2、网站架构分析
网站架构的好坏会直接影响搜索引擎爬虫的偏好。好的网站框架有利于爬虫对内容的抓取,而不好的网站框架会影响爬虫对网站内容的抓取,不利于SEO。那么什么样的网站架构对搜索引擎友好呢?一般来说,通过实现网站树形目录结构、网站导航和链接优化,我们可以创建一个适合搜索引擎偏好的网站结构,从而获得搜索引擎的喜爱, 最后实现流量的积累。
3、做网站目录和页面优化
很多人可能会问:为什么要设置网站目录和优化页面?这实际上非常简单。我们最想要的结果不仅仅是搜索引擎的首页收录网站,不仅仅是首页获得好的排名,我们希望在此基础上收录更多页面,更多排名,这样我们就可以获得更多的流量,实现我们想要的目标。因此,有必要做好网站目录和页面的优化。
4、定期发布内容和合理安排链接
搜索引擎喜欢定期的网站内容更新,所以合理安排网站内容发布时间是SEO优化的重要技术之一。链接排列将整个网站有机地连接起来,让搜索引擎了解每个页面和关键词的重要性,实现参考是第一点的关键词排列。友谊链接活动也在此时启动。因此,我们必须做好网站内容的定期更新和外链的定期发布。
看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
采集相关文章(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-03-07 09:25
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站内部并没有这样的分类,但是我们可以通过聚合策略生成这样一个非正式的频道和栏目分类,然后用这个分类来聚合北京的程序员很长一段时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般来说,双面标签是成对出现的,所以必须写上结束标识符,而单面标签也应该以反斜杠结尾。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清远易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认,后期不要轻易修改,所以每次修改它,您必须等待搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
查看全部
采集相关文章(怎么用WordPress自动采集让网站快速收录以及关键词排名,整体流程
)
如何使用WordPress自动采集使网站快速收录和关键词排名,整体流程(关键词words采集+伪原创+聚合+发布+主动推送到搜索引擎)聚合由一些关键词引导,网站里面的各种相关信息,通过程序聚合关键词相关的内容在一个页面上,形成一个相对基本的主题页面。这样做的好处是可以在网站上以相对低成本、非人工的方式生成一批聚合页面。这种页面从内容相关性的角度来看,比普通页面更有优势。聚合策略不会和网站原来的页面系统冲突,只是基于网站原来的活动详情数据,并根据相关性进行二次信息聚合。因此,聚合是一组独立的、不断优化和改进的、长期运行的 SEO 内容。
1、聚合是未来的核心SEO引流策略网站:
因为网站原来的常规频道、栏目、详情页等页面数据量有限,每日更新产生的页面数量也有限,而这些页面所承载的关键词不够清晰而且数量有限。因此,如果SEO项目只依赖网站的原创页面内容,没有内容增量,很难增加网站的搜索流量。
2、我们想增加网站整体的流量:
需要解决行业用户大量的长尾需求,因为大部分流量来自行业长尾关键词。而网站原有的页面系统(频道、栏目、详情页)很难在没有规范的情况下部署各种长尾关键词。因此,这些不规则的长尾关键词只能由聚合策略生成的新页面携带。
3、标签目录是聚合策略的应用。
网站的标签聚合给网站带来了大量的流量。虽然目前很浅,但是涵盖了更多的长尾词流量。
综合长期目标:
不断优化和完善聚合策略的页面,页面的用户体验,以及相关的用户功能,使聚合页面能够融入网站的常规页面体系,最终成为网站@ > 常规页面,提高这些页面的性能。交易转换。实际运行中,计划让聚合系统在8个月内生成10万-15万页,解决20万-30万的落地问题关键词。
1),技术角度的聚合策略:
从技术上讲,聚合与站内搜索的原理类似,但站内搜索的条件必须细化。例如搜索:北京程序员交流。那么在过滤掉相关信息之前,我们必须同时满足北京和程序员的条件。否则,如果我们过滤掉上海程序员的交流信息,就会导致内容出现偏差。所以,从技术角度来说。聚合类似于站内搜索,但需要设置相应的条件。
2),产品视角的聚合策略:
从产品的角度来看,聚合策略会更准确的为用户找到相关信息。因为聚合策略是按关键词分类的,所以关键词代表了用户的需求。例如:北京程序员交流会。网站内部并没有这样的分类,但是我们可以通过聚合策略生成这样一个非正式的频道和栏目分类,然后用这个分类来聚合北京的程序员很长一段时间。沙龙和交流活动的信息,然后把这个分类的链接放在相关版块,就可以起到非常人性化的信息推荐的作用。因此,从产品的角度来看,聚合策略可以不断优化,
聚合页面优化策略:
1、移动政策:
建立M移动站,百度倡导的MIP站,通过这三个方面,加强聚合策略的移动优化策略,使聚合系统的页面能够有效获得移动搜索流量,这也是迎合了搜索引擎的移动搜索。
2、规划相关页面的TKD关键词格式非常重要。主要是通过TKD来承载整个聚合策略的整体词库。
3、URL 应该以伪静态的方式建立一个搜索友好的 URL 格式,以方便聚合页面的索引。
4、构建聚合策略页面本身的关联网站结构,以及聚合策略页面与主站页面网站结构的关联。通过优化这两点的关联结构,可以大大提升聚合策略页面的SEO效果。
5、内容要以整个站点的底层数据为基础,同时要注意解决聚合时相似关键词之间的内容重复问题。
6、了解了具体思路后,我们就可以利用这个WordPress自动采集实现采集大量的内容传输网站快速收录和排名,这这款WordPress自动采集操作简单,无需学习更多专业技术,只需几个简单的步骤即可轻松采集内容数据,用户只需对WordPress自动采集@进行简单操作即可> 工具 ,该工具将根据用户设置的关键词准确采集文章,确保与行业文章一致。采集中的采集文章可以选择保存在本地,也可以选择自动伪原创发布,提供方便快捷的内容采集和快速的内容创建伪原创。
相比其他的WordPress自动采集这个WordPress自动采集基本没有规则,更别说花很多时间学习正则表达式或者html标签,一分钟就能上手,输入关键词实现采集(WordPress自动采集也配备了关键词采集功能)。全程自动挂机!设置任务,自动执行采集伪原创发布并主动推送到搜索引擎。
不管你有成百上千个不同的cms网站都可以实现统一管理。一个人维护数百个 网站文章 更新也不是问题。这款WordPress自动采集还配备了很多SEO功能,通过采集伪原创软件发布后还可以提升很多SEO方面。
1、网站主动推送(让搜索引擎更快发现我们的网站)
2、自动匹配图片(文章如果内容中没有图片,会自动配置相关图片) 设置自动下载图片并保存在本地或第三方(让内容不再有对方的外部链接)。
3、自动内部链接(让搜索引擎更深入地抓取您的链接)
4、在内容或标题前后插入段落或关键词(可选择将标题和标题插入同一个关键词)
5、网站内容插入或随机作者、随机阅读等变成“高度原创”。
6、正规发布(正规发布文章让搜索引擎及时抓取你的网站内容)
通过增加具有这些 SEO 功能的 网站 页面的 原创 度来提高 网站 的 收录 排名。通过工具上的监控管理查看文章采集的发布和主动推送(百度/360/搜狗神马/谷歌等),而不是每次登录网站后台日。SEO的内容优化直接在工具上自动完成。目前博主亲测软件是免费的,可以直接下载使用!
在网站的优化过程中,主要分为站内优化和站外优化两部分。具体的优化内容可以分为很多方面。比如网站的TDK选型部署、关键词的密度控制等现场优化,网站内部结构是否简单合理,目录层次是否过于复杂,等等,以及外部优化比如网站外部链接的扩展、友好链接的交换等等,这些因素都不容忽视。, 任一方面的问题都可能导致 网站 整体不稳定。如何在网站优化中使用基本标签来达到想要的效果?
一、html 标签
HTML标签是提升SEO优化效果最基本的东西。因此,在使用它们的过程中,一定要熟悉各个标签的含义和用法,还需要注意标签的嵌套使用。一般来说,双面标签是成对出现的,所以必须写上结束标识符,而单面标签也应该以反斜杠结尾。代码的完整性一定要很好体现,因为搜索引擎访问的不是前端文本,而是网站后端代码,通过网页标签网站来理解和解释,所以代码必须以标准化的方式编写。
二、不关注标签
nofollow标签在SEO优化中的主要作用是告诉搜索引擎“不要关注这个页面上的链接”或者“不要关注这个特定的链接”,这将有助于我们防止网站的分散权重。具有重大意义的链接,例如联系页面、在线咨询等,可以使用nofollow标签妥善处理。当然,有时为了更好的引导用户,会建立很多引导链接,比如:more、details等可以通过nofollow来合理处理,从而为网站的优化带来极好的效果。
三、元标记
Meta标签在SEO中有着非常重要的作用:设置关键词,利用首页的设置关键词赢得各大搜索引擎的关注,增强网站收录,以及提高访问量和曝光度,此时最关键的设置是关键词和描述。一般情况下,搜索引擎会先发送一个机器人自动检索页面中的关键词和描述,添加到自己的数据库中,然后根据关键词的密度对网站进行排序,所以一定要认真对待网站关键词的选择,选择正确的关键词,提高页面的点击率,提升网站的排名。
四、标题标签
标题标签在SEO优化中的作用主要是分析关键词,让用户能够非常详细地把握页面的主题,所以标题标签的好坏不仅直接影响搜索引擎的响应对网站的评价也会影响用户体验的效果,因为在开发title标签的过程中一定要小心。
五、标签
标签的目的是将相关的结果放在一起。虽然是自由无拘无束,但也可以随意写,需要按照分类的角度来写。另外,这里清远易风SEO建议Tags的字数控制在4-6个字符以内,千万不要变成句子,而且一旦确认,后期不要轻易修改,所以每次修改它,您必须等待搜索引擎重新收录 并重新赋予权重。
总之,网站这些方面的影响是非常明显的。如果这五点写得不好,很容易让用户误以为网站没有自己想要的内容,不点击就跳过了。,自然会影响网站的CTR。尤其是当网站排名位置都是自己同类网站的时候,就非常明显了。看完这篇文章,如果觉得不错,不妨采集一下,或者发给需要的朋友同事。关注博主,每天给你展示各种SEO经验,让你的网站也能快速获得收录和关键词的排名!
采集相关文章(比特币匿名特权存证第一品牌聚聚终于难逃骚扰)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-03-02 15:05
采集相关文章:比特大陆(bitmain):中国仅次于美国第二大高科技公司盛大集团推出区块链数字资产---比特币匿名匿名特权存证第一品牌聚聚终于还是难逃骚扰---聊骚---bt网址生成这个网站不错,一年会员费不便宜,推荐给周围的人成功,恭喜你中大奖了国内首家独立第三方区块链数字资产交易所---火币矿池数字货币资产追踪研究院。
1.比特币是数字资产,数字资产会依据所依附的区块链关系从最初的btc到最近推出的bch、ae,被无数人接受,以数字资产的形式出现在人们面前,由于真实价值很高,导致一段时间内炒币投资者趋之若鹜,数字资产一度被认为是数字货币的终极形态,当然各家数字货币基金也是如火如荼,一时间区块链资产如雨后春笋般涌现,但是有相当部分并不是所依附的区块链网络的,数字资产投资也不是一夜暴富的事,最好是能够用长线投资的方式进行数字资产投资。
2.比特币首创的p2p点对点数字交易模式最有价值,也是原生区块链技术和算法的核心。传统的大数据应用依托于去中心化网络和非对称加密算法的公钥技术,但由于运营成本过高,又没有受到区块链的影响。传统人民币等各种密码货币也依托于去中心化网络和非对称加密算法的加密技术,但是主流仍然是非对称加密和公钥算法。去中心化网络是一个混沌系统,因为无论公钥、私钥、加密算法本身也不能解决安全问题,区块链等共识系统提供多个匿名节点同步,从而达到去中心化的目的,但是有很大局限性,如电信局的局限,政府部门的局限等。
如以太坊采用匿名节点来满足传统的匿名需求,但这种匿名也是建立在多台公有链网络普遍匿名的基础上。公有链网络普遍匿名的缺点有何问题?应用体验很不好,互联网和金融是必须匿名的,公有链网络是没有任何价值的,主流代币能激发平台价值,但是挖矿还是不那么合适。3.匿名网络不普遍或使用不方便,如可隐藏通讯地址等特点。
由于其非对称加密技术,导致互联网必须匿名,互联网必须匿名必须做到两点:数据不对称以及权限控制,这种匿名其实就是区块链匿名,例如银行转账,用户区块链转账需要开放一个权限(例如开通匿名代付功能,若打款人不是转账人或转账需要匿名代付),转账才能进行,alice把钱放到银行中就不会被查询出来,如此一来所有的转账就都是匿名的,所有非法转账都被查询处理。
使用区块链进行匿名代付比如,你知道cyprivatekey-secretcount(数字签名)的值,但是你知道你的钱被转账给了你在火币上看到的一个匿名用户,但是你无法查询到转账,因为对方不可能把匿名用户发的。 查看全部
采集相关文章(比特币匿名特权存证第一品牌聚聚终于难逃骚扰)
采集相关文章:比特大陆(bitmain):中国仅次于美国第二大高科技公司盛大集团推出区块链数字资产---比特币匿名匿名特权存证第一品牌聚聚终于还是难逃骚扰---聊骚---bt网址生成这个网站不错,一年会员费不便宜,推荐给周围的人成功,恭喜你中大奖了国内首家独立第三方区块链数字资产交易所---火币矿池数字货币资产追踪研究院。
1.比特币是数字资产,数字资产会依据所依附的区块链关系从最初的btc到最近推出的bch、ae,被无数人接受,以数字资产的形式出现在人们面前,由于真实价值很高,导致一段时间内炒币投资者趋之若鹜,数字资产一度被认为是数字货币的终极形态,当然各家数字货币基金也是如火如荼,一时间区块链资产如雨后春笋般涌现,但是有相当部分并不是所依附的区块链网络的,数字资产投资也不是一夜暴富的事,最好是能够用长线投资的方式进行数字资产投资。
2.比特币首创的p2p点对点数字交易模式最有价值,也是原生区块链技术和算法的核心。传统的大数据应用依托于去中心化网络和非对称加密算法的公钥技术,但由于运营成本过高,又没有受到区块链的影响。传统人民币等各种密码货币也依托于去中心化网络和非对称加密算法的加密技术,但是主流仍然是非对称加密和公钥算法。去中心化网络是一个混沌系统,因为无论公钥、私钥、加密算法本身也不能解决安全问题,区块链等共识系统提供多个匿名节点同步,从而达到去中心化的目的,但是有很大局限性,如电信局的局限,政府部门的局限等。
如以太坊采用匿名节点来满足传统的匿名需求,但这种匿名也是建立在多台公有链网络普遍匿名的基础上。公有链网络普遍匿名的缺点有何问题?应用体验很不好,互联网和金融是必须匿名的,公有链网络是没有任何价值的,主流代币能激发平台价值,但是挖矿还是不那么合适。3.匿名网络不普遍或使用不方便,如可隐藏通讯地址等特点。
由于其非对称加密技术,导致互联网必须匿名,互联网必须匿名必须做到两点:数据不对称以及权限控制,这种匿名其实就是区块链匿名,例如银行转账,用户区块链转账需要开放一个权限(例如开通匿名代付功能,若打款人不是转账人或转账需要匿名代付),转账才能进行,alice把钱放到银行中就不会被查询出来,如此一来所有的转账就都是匿名的,所有非法转账都被查询处理。
使用区块链进行匿名代付比如,你知道cyprivatekey-secretcount(数字签名)的值,但是你知道你的钱被转账给了你在火币上看到的一个匿名用户,但是你无法查询到转账,因为对方不可能把匿名用户发的。
采集相关文章(如何使用PHP匹配多行的正则表达式匹配代码的分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-28 10:18
PHP匹配多行正则表达式解析,需要的朋友可以参考,多用于采集替换等。
啊啊啊
bbbb
cccc
dddd
如何将这样的文本与 PHP 的正则表达式匹配?? 我最初的想法:模式:“/[.\n]*?” (这是错误的)
1. 匹配多行的PHP正则表达式分析
简介:PHP匹配多行正则表达式解析,有需要的朋友可以参考,多用于采集替换等。
2. dedecms采集 dedecms采集 中的正则表达式可以过滤多行代码
简介: dedecms采集:dedecms采集 dede中可以过滤多行代码的正则表达式cms采集:使用dede过去采集,不能过滤掉多行代码,只能逐行过滤。在网上,我发现有很多像我这样的菜鸟。随着dede采集的不断使用,我对正则表达式有了进一步的了解。现在我什至使用正则表达式,它也可以匹配多行代码。例如:在下面的代码中,用两行代码过滤掉超链接。xx
3. 如何用php匹配多行注释的内容
简介:假设内容如下 /** * 如何 * 使用 php 正则 * 匹配*/ 使用匹配模式/(/**)[$s]+?.*/ 只能匹配以下内容 /** *如何
【相关问答推荐】:
如何使用php正则匹配多行注释的内容
正则表达式非贪婪匹配多行 - Thinbug 查看全部
采集相关文章(如何使用PHP匹配多行的正则表达式匹配代码的分析)
PHP匹配多行正则表达式解析,需要的朋友可以参考,多用于采集替换等。
啊啊啊
bbbb
cccc
dddd
如何将这样的文本与 PHP 的正则表达式匹配?? 我最初的想法:模式:“/[.\n]*?” (这是错误的)
1. 匹配多行的PHP正则表达式分析
简介:PHP匹配多行正则表达式解析,有需要的朋友可以参考,多用于采集替换等。
2. dedecms采集 dedecms采集 中的正则表达式可以过滤多行代码
简介: dedecms采集:dedecms采集 dede中可以过滤多行代码的正则表达式cms采集:使用dede过去采集,不能过滤掉多行代码,只能逐行过滤。在网上,我发现有很多像我这样的菜鸟。随着dede采集的不断使用,我对正则表达式有了进一步的了解。现在我什至使用正则表达式,它也可以匹配多行代码。例如:在下面的代码中,用两行代码过滤掉超链接。xx
3. 如何用php匹配多行注释的内容
简介:假设内容如下 /** * 如何 * 使用 php 正则 * 匹配*/ 使用匹配模式/(/**)[$s]+?.*/ 只能匹配以下内容 /** *如何
【相关问答推荐】:
如何使用php正则匹配多行注释的内容
正则表达式非贪婪匹配多行 - Thinbug
采集相关文章(从细节出发做好优化流程当中进行优化解决大部分用户问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-26 17:28
文章采集器,非常方便站长在做网站的时候自动从全平台采集相关的文章,然后经过二次创建过程,自动发布到批次到 网站 上级。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站 时,不要做死链接。网站结构不要太复杂,就是简单的3层,首页-栏目-文章。保证 网站 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站的用户体验,把它做好,网站更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站参与排名最多的是内容页,内容页也是网站页数最多的地方。文章采集器可以让大部分网站站长全部关键词参与排名,那我们就要从内容页入手,优化一个网站@ > 内容页面占据更多关键词 排名。排名取决于综合得分。如何让你的网站综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。它具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于文章采集器的文章。通过这篇文章,站长们可以了解采集和采集网站需要改进的方法和方法。毕竟SEO是整体的工作协同,而不是仅仅依靠某一点来达到效果。 查看全部
采集相关文章(从细节出发做好优化流程当中进行优化解决大部分用户问题)
文章采集器,非常方便站长在做网站的时候自动从全平台采集相关的文章,然后经过二次创建过程,自动发布到批次到 网站 上级。不管是什么类型的站点,各种cms都可以实现,即使只有一个站点或者是大型的站群,都可以通过这种方式进行内容更新。某种意义上解放了站长的双手,提高了网站本身的效率,还可以自动进行SEO优化。
在使用文章采集器之前,一定要做好网站的结构,这样蜘蛛才能循着线索抓到每一页,保证每一页都是活链接,并且死链接是非常有害的,吓跑蜘蛛是不好的。当你做 网站 时,不要做死链接。网站结构不要太复杂,就是简单的3层,首页-栏目-文章。保证 网站 结构的纯度。这样的结构已经成为一种刻板印象,也方便蜘蛛抓取。
关注网站的用户体验,把它做好,网站更快,更多优化。速度上去,不仅用户用起来舒服,蜘蛛也能快速抓取,速度也是网页评价的因素之一。那么就关系到服务器的质量和域名解析的速度。有很多新手刚接触互联网,总是喜欢便宜和免费的东西。让我在这里说点什么。免费永远是最贵的。知识。
一个网站参与排名最多的是内容页,内容页也是网站页数最多的地方。文章采集器可以让大部分网站站长全部关键词参与排名,那我们就要从内容页入手,优化一个网站@ > 内容页面占据更多关键词 排名。排名取决于综合得分。如何让你的网站综合得分更高,那我们就要从细节入手进行优化,在我们的优化过程中规划好每一个需要优化的页面,从而解决大部分用户的问题问题。
网站优化排名的根本原因,记住文章采集器去采集内容的目的主要是为了解决用户问题。文章采集器采集的内容符合搜索引擎目标,有助于页面的收录,有利于获取大量长尾< @关键词 排名,并提高页面Score的质量。
文章采集器采集收到的内容已经重新整理,内容也进行了细化。解决用户的问题,通过这几点:匹配度,围绕标题解决用户的问题。它具有完整性,可以彻底解决用户的问题。在解决用户问题的前提下,像文章这样的搜索引擎,字数多,内容量大。有吸引力,具有营销转化意识,文章可以吸引用户观看。内容有稀缺性,原创,差异,文章在同等条件下,能更好的解决问题。版面漂亮,布局不错,文章结构不影响用户阅读。图片优化,大小,原创图片,alt,与文字相关。
以上就是小编今天分享的关于文章采集器的文章。通过这篇文章,站长们可以了解采集和采集网站需要改进的方法和方法。毕竟SEO是整体的工作协同,而不是仅仅依靠某一点来达到效果。
采集相关文章(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-02-26 17:26
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress 查看全部
采集相关文章(怎么用wordpress文章采集让网站快速收录以及关键词排名,优化一个)
如何使用wordpress文章采集让网站快速收录和关键词排名,优化一个网站不是一件简单的事情,尤其是很多网站没有收录更何况网站排名,是什么原因网站很久没有收录了?
一、网站标题。网站标题要简单、清晰、相关,不宜过长。关键词的频率不要设置太多,否则会被搜索引擎判断为堆积,导致网站不是收录。
二、网站内容。网站上线前一定要加上标题相关的内容,加上锚文本链接,这样会吸引搜索引擎的注意,对网站的收录有帮助。
三、搜索引擎爬取。我们可以将网站添加到百度站长,百度站长会在他的网站中显示搜索引擎每天爬取的次数,也可以手动提交网址加速收录。
四、选择一个域名。新域名对于搜索引擎来说比较陌生,调查网站需要一段时间。如果是旧域名,千万不要购买已经被罚款的域名,否则影响很大。
五、机器人文件。robots文件是设置搜索引擎的权限。搜索引擎会根据robots文件的路径浏览网站进行爬取。如果robots文件设置为阻止搜索引擎抓取网站,那么自然不会抓取。网站not收录的情况,可以先检查robots文件的设置是否正确。
六、服务器。网站获取不到收录,需要考虑服务器是否稳定,服务器不稳定,降低客户体验,搜索引擎将无法更好地抓取页面.
七、日常运营。上线网站不要随意对网站的内容或结构做大的改动,也不要一下子加很多好友链接和外链,难度很大收录,即使是收录,否则降级的可能性很大,会对网站造成影响。
<p>八、如果以上都没有问题,我们可以使用这个wordpress文章采集工具实现自动采集伪原创发布和主动推送到搜索引擎, 操作简单 无需学习更多专业技术,简单几步即可轻松采集内容数据,用户只需在wordpress文章采集、wordpress
采集相关文章( 采集微信公众号文章教程是什么?怎样批量采集呢)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-26 04:24
采集微信公众号文章教程是什么?怎样批量采集呢)
编辑微信公证号中的文章,一般都是先做文章采集,那么采集微信公众号文章教程是什么?如何批处理 采集?下面拓图数据将详细介绍这些问题,提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是怎样的?
第一步:点击采集,将需要采集的微信文章的链接地址复制到微信文章的URL框中。
此处获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角进行复制。
方法二:在电脑上通过搜狗浏览器的微信栏搜索,可以通过下面的“点击获取”进入。
第二步:点击采集,文章的内容已经被采集上传到微信编辑器,可以编辑修改文章。
采集微信公众号文章如何批量教程采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这个非常重要。记住,否则你的图片将不会显示,到时候你会很尴尬……
然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:输入微信ID而不是微信名!
数据采集完成后,可以释放数据吗?答案当然是!
NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一切都会好的。
插件安装成功,接下来我们新建一个发布项吧!这里有很多,只要选择一个你喜欢的。
选择发布界面后,填写你要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下系统会默认选择一个好的,但是如果你觉得有什么需要调整的,也可以修改。
内容替换 这是一个可选的选项,可以填也可以不填。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库,感觉快要起飞了!
当然也可以选择手动发布,发布的时候可以选择单次发布,也可以选择多次发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
如果您认为有问题,您可以发布数据。
发布成功后,可以点击链接查看。
采集微信公众号文章教程
微信公众号文章采集感想
一、通过android客户端获取微信用户登录信息(即小号)。
二、提供微信公众号信息(biz)。 查看全部
采集相关文章(
采集微信公众号文章教程是什么?怎样批量采集呢)
编辑微信公证号中的文章,一般都是先做文章采集,那么采集微信公众号文章教程是什么?如何批处理 采集?下面拓图数据将详细介绍这些问题,提供帮助。
采集微信公众号文章教程
采集微信公众号文章教程是怎样的?
第一步:点击采集,将需要采集的微信文章的链接地址复制到微信文章的URL框中。
此处获取微信文章链接主要有两种方式:
方法一:直接在手机上找到文章,点击右上角进行复制。
方法二:在电脑上通过搜狗浏览器的微信栏搜索,可以通过下面的“点击获取”进入。
第二步:点击采集,文章的内容已经被采集上传到微信编辑器,可以编辑修改文章。
采集微信公众号文章如何批量教程采集微信公众号文章
方法/步骤
数据采集:
NO.1 通过百度搜索相关网站,注册或登录,进入爬虫市场。
NO.2 搜索关键词:微信公众号。点击免费获取!
NO.3 进入采集爬虫后,点击爬虫设置。
首先,由于搜狗微信搜索有图片防盗链功能,需要在功能设置中开启图片云托管。这个非常重要。记住,否则你的图片将不会显示,到时候你会很尴尬……
然后进行自定义设置,可以同时采集多个微信公众号文章,最多500个!特别注意:输入微信ID而不是微信名!
数据采集完成后,可以释放数据吗?答案当然是!
NO.1 发布数据只有两步:安装发布插件->使用发布接口。您可以选择发布到数据库或 网站。
如果你不知道怎么安装插件,那我就告诉你,进入文档中心-使用文档-数据发布-安装插件,查看文档,按照文档提示,一步一步来一切都会好的。
插件安装成功,接下来我们新建一个发布项吧!这里有很多,只要选择一个你喜欢的。
选择发布界面后,填写你要发布的网站的地址和密码。同时系统会自动检测插件是否安装正确。
对于字段映射,一般情况下系统会默认选择一个好的,但是如果你觉得有什么需要调整的,也可以修改。
内容替换 这是一个可选的选项,可以填也可以不填。
完成设置后,即可发布数据。
NO.2 在爬取结果页面,可以看到采集爬虫根据你设置的信息爬取的所有内容。发布的结果可以自动发布,也可以手动发布。
自动发布:开启自动发布后,爬取的数据会自动发布到网站或者数据库,感觉快要起飞了!
当然也可以选择手动发布,发布的时候可以选择单次发布,也可以选择多次发布。在发布之前,您还可以预览看看这个 文章 是关于什么的。
如果您认为有问题,您可以发布数据。
发布成功后,可以点击链接查看。
采集微信公众号文章教程
微信公众号文章采集感想
一、通过android客户端获取微信用户登录信息(即小号)。
二、提供微信公众号信息(biz)。
采集相关文章(找了ACLNACL的关系抽取的论文Relation)
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-02-22 19:03
找了近两年ACL NACL EMNLP的一些关系抽取论文
基于实例的选择性注意的神经关系提取(16 年,典型模型)
代码: ()
使用注意机制来最小化错误标签的负面影响;
关系通过使用CNN的句子嵌入的语义组合来表示,从而充分利用训练知识库的信息。
解释参考:
给定一组句子 {x_1...x_n} 和两个对应的实体,我们的模型测量每个关系 r 的概率。在本节中,我们将分两个主要部分介绍我们的模型:
句子编码器:给定一个句子 x 和两个目标实体,卷积神经网络 (RNN) 用于构建句子 x 的分布式表示。
Selective Attention to Instances:在学习所有句子的分布向量表示时,我们使用句子级别的注意力来选择真正表达对应关系的句子。
句子编码器:
图 1 用于句子编码器的 CNN/PCNN 结构
如图 1 所示。句子 x 由 CNN 转换为其分布式表示 X。首先,将句子中的单词转化为密集的实值特征向量。接下来,使用卷积层、最大池化层和非线性变换层来构造句子的分布式表示。接下来,使用卷积层、最大池化层和非线性变换层构建句子的分布式表示。
输入表示:CNN 的输入是句子 x 中的原创单词。我们首先将单词转换为向量。通过词嵌入矩阵将每个输入词转换为向量。此外,为了指定每个实体对的位置,我们还使用句子中所有单词的位置嵌入。
ACL2017
1.用于弱监督关系提取的深度残差学习
模型:9层CNN卷积+深度残差学习(github上源码)
介绍:
关系抽取是一个重要的课题。过去很多论文使用CNN提取特征,但大多只使用了很浅的CNN(大部分只有一层卷积层+1个FC层)。没有人研究过深度 CNN 是否有用。
在本文中,我们研究了用于远程监督的深度 CNN 的 RE(也简称为关系提取)问题。具体来说,本文使用残差学习、词嵌入和位置嵌入作为模型的输入,并使用恒等反馈来研究 RE 问题。实验室使用的是NYT数据集,效果非常好(对比所有CNN模型)。
2.用噪声学习:使用动态转移矩阵增强远程监督关系提取
模型:
1和2和之前的方法一致:对一个句子进行编码,然后分类得到一个句子的分布。同时,3为模型动态生成一个转移矩阵T,用于描述噪声模式。4是将2和3的结果相乘得到最终结果。
也就是说,在训练阶段,将4的输出作为噪声输出和标签匹配,即使用4的输出和训练数据的标签计算训练损失。在泛化阶段,使用2的输出。
简介:使用噪声矩阵来拟合噪声的分布,即对噪声进行建模,从而达到拟合真实分布的目的。
动态转换矩阵可以有效地表征远程监督训练数据中的噪声。利用一种新颖的基于课程的学习方法可以有效地训练转换矩阵,而无需直接监督噪声。
解释参考:
在本文中,作者使用了一种对噪声数据进行显式建模的方法。尽管噪声数据是不可避免的,但可以用统一的框架来描述噪声数据模式。作者的出发点是远程监督数据集中的噪声模式通常有有用的线索。例如,一个人的工作地点和出生地很可能是同一个地方,这种情况下远程监督数据集很可能打错了出生地和工作地这两个关系标签。本文采用的方法是,对于每一个训练样本,都有一个动态生成的转移矩阵。这个矩阵的作用是描述标签错误的概率和指示噪声模式
由于没有对噪声模式的直接监督,作者使用课程学习训练方法逐步训练模型的噪声模式,并使用迹正则化来控制训练过程中转移矩阵的行为。我们的方法是灵活的,因为它不对数据质量做任何假设,但是当存在这样的线索时,可以有效地利用数据质量的先验知识来指导学习过程。
论文的主要创新点:使用动态过渡,使用课程学习来训练模型
3.基于新标记方案的实体和关系联合提取
简介:提出了一种新的序列标记方案,将联合提取问题转换为序列标记问题。此外,将该方案应用于各种端到端模型(使用端到端模型代替命名实体识别、NER和关系提取),并对这些模型的性能进行了比较。本文还提出了一种新模型。
模型:新的标注方案和基于 LSTM 的端到端模型来解决联合提取实体和关系的任务
如图所示,模型的输入是非结构化文本的句子,输出是预定关系类型的三元组。
为了完成这个任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下所示:
这种标注模式将文本中的单词分为两类。第一类表示与提取结果无关的词,用标签“O”表示;第二类表示与提取结果相关的词,该类词的标签由三部分组成:当前词在实体中的位置-关系类型-实体在关系中的作用。作者使用“BIES”(Begin, Inside, End, Single)注解来表示当前词在实体中的位置。关系类型是从一组预设的关系类型中获得的。实体在关系中的角色信息,用“1”、“2”表示。其中,“1”表示当前词属于三元组(Entity1,RelationType,Entity1 of Entity2),“2”表示当前词属于Entity2。最后,根据标注结果,将两对相同关系类型分为两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。
端到端模型
当输入是文本句子时,为了自动实现对文本词序列的标注,作者提出了端到端的模型来实现这项工作。模型结构如下
在:
词嵌入层将每个词的one-hot表示向量转换为低维密集词嵌入向量(维度为300);
Bi-LSTM编码层(层数为300)用于获取单词的编码信息;
LSTM解码层(层数为600)用于生成标签序列。添加偏移损失以增强实体标签的相关性。
解释参考:
ACL 2018
4. 通过深度强化学习进行稳健的远程监督关系提取
简介:远程监督的代价是远程监督的训练样本往往有噪声。为了对抗噪音,最近的现有方法侧重于为特定实体对选择最佳句子或计算一组句子的软注意力权重。然而,这些方法都是次优的,误报问题仍然是影响性能的关键瓶颈。我们认为,必须通过硬决策而不是软注意力权重来处理那些错误标记的候选句子。为此,我们探索了一种深度强化学习策略来生成误报指标,其中我们自动识别任何关系类型的误报,而无需任何监督。与之前研究中的删除操作不同,我们将它们重新分配给负例。
我们的深度强化学习框架旨在动态识别误报样本。并在远程监督中将它们从正集转移到负集。
本文研究了使用动态选择策略进行稳健远程监控的可行性。更具体地说,我们设计了一个深度强化学习代理,其目的是学习根据关系分类器的性能变化来选择是删除还是保留远程监督的候选实例。直观地说,我们的代理希望消除误报并重建一组清洁的远程监督实例,以根据分类准确性最大化重建。该方法与分类器无关,适用于任何现有的远程监控模型。
提出了一种新的深度强化学习框架,用于鲁棒的远程监督关系提取。
我们的方法与模型无关,这意味着它可以应用于任何最先进的关系提取器。
5.用于关系提取的基于步行的实体图模型
简介:提出了一种新的基于图的神经网络关系提取模型。我们的模型同时处理句子中的多个对,并考虑它们之间的交互。句子中的所有实体都作为节点放置在完全连接的图结构中。边缘由实体对的位置感知上下文表示。为了说明两个实体之间的不同关系路径,我们在每对实体之间构建了 l 长度的游走。生成的游走被合并并不断更新以表示具有较长游走的边缘。在 ACE 2005 数据集上显示出良好的性能,而无需添加其他方法。
这篇文章说,一对实体对之间的关系会受到同一句话中其他关系的影响。比如上图中,Toefting(人实体)通过with直接与队友(人实体)产生关系,而队友通过with和资本(地缘政治实体)直接产生关系。而Toefting和资本可以直接通过队友或间接通过队友建立关系。也就是说,Toefting-teammates-capital的路径有助于Toefting-capital之间的关系。
模型:
解释参考:
6.用于弱监督关系提取的基于排序的自动种子选择和降噪
介绍:
创造性地将关系提取中的自动种子选择和数据去噪任务转化为排序问题;提出了多种策略,既可用于 Bootstrapping 关系提取的自动种子选择,又可用于关系提取和降噪的远程监督;采集自维基百科的 ClueWeb 和 ClueWeb 的数据集,通过实验验证了所提算法的实用性和先进性。
解释参考:
EMNLP2017
7.具有全局优化的端到端神经关系提取
简介:然而,之前使用统计模型的工作表明,全局优化可以实现比局部分类更好的性能。为了更好地学习上下文表示,我们构建了一个全局优化的端到端关系提取神经模型,并提出了新的 LSTM 特征。此外,我们提出了一种新颖的句法信息集成方法来促进全局学习,但需要较少的语法背景并且易于扩展。
解释参考:(我不知道这是什么意思)
8.在神经关系提取中加入关系路径
介绍:提出对文本中的关系路径进行建模,结合CNN模型完成关系抽取任务。
传统的基于CNN的方法通过CNN自动将原文映射到特征空间,并据此判断句子表达的关系
这种 CNN 模型的问题是难以理解多句文本的语义信息。比如A是B的父亲,B是C的父亲,没有办法得到A和C的关系。基于此,论文提出了一种基于神经网络引入关系路径编码器的方法,其实就是原来的词嵌入输入加上一层位置嵌入,位置嵌入分别用两个向量表示当前词与头实体/尾实体的相对路径。然后使用αα平衡文本编码器(E)和路径编码器(G)。
Encoder 还采用了多实例学习机制,使用一个句子集来联合预测关系。句子集的选择方法有随机法(rand)、最大化法(max,选择最有代表性)、选择-注意力机制(att),效果最好。
解释参考:
9.一种软标签的抗噪声远监督关系提取方法
简介:以前的句子级去噪模型由于使用硬标签而未能取得令人满意的性能,这是由训练期间的远程监督和不变性决定的。为此,我们提出了一种实体对级去噪方法,该方法利用正确标记的实体对中的语义信息在训练期间动态纠正错误的标签。我们提出了一个联合评分函数,它结合了基于实体对表示的关系分数和硬标签置信度,以获得特定实体对的新标签,即软标签。在训练过程中,软标签取代硬标签成为金标签。基准数据集上的实验表明,我们的方法显着减少了噪声实例并优于最先进的系统。
对国籍关系进行软标签校正的示例。我们打算使用正确标记的实体对(蓝色)的句法/语义信息来纠正训练中的假阳性和假阴性实例(橙色)。
为了更好地理解我们的知识,我们首先提出了一种实体对级别的抗噪声方法,而之前的工作只关注句子级别的噪声。
我们提出了一种简单而有效的方法,称为软标签方法,用于在训练期间动态纠正错误标签。
EMNLP2018
10. 具有动态路由的基于注意力的胶囊网络用于关系提取
简介:胶囊是一组神经元,其活动向量表示特定类型实体的实例化参数。在本文中,我们探索了在多实例多标签学习框架中用于关系提取的胶囊网络,并提出了一种基于具有注意机制的胶囊网络的新型神经网络方法。
模型:基于注意力的胶囊网络
11.RESIDE:使用边信息改进远程监督神经关系提取(附代码)
简介:我们提出了一种远程监控的神经关系提取方法,该方法利用 KB 中的附加信息来改进关系提取。它在预测关系时使用实体类型和关系别名信息来施加软约束。Reside 使用图卷积网络 (GCN) 对文本中的句法信息进行编码,并在可用的辅助信息有限时提高性能。
我们提出了一种新的神经网络方法 RESIDE,它利用知识库的额外监督以有原则的方式改进远程监督 RE。
RESIDE 使用图卷积网络 (GCN) 对句法信息进行建模,即使在辅助信息有限的情况下也具有竞争力。
数据集和 RESIDE 源代码:
型号:居住
句法句子编码:Reside 在连接的位置和词嵌入上使用 Bi-GRU 来编码每个标记的本地上下文。为了捕获远程依赖,使用依赖树上的 GCN,并将其编码附加到每个令牌的表示中。最后,注意标记用于抑制不相关的标记并获得整个句子的嵌入。有关详细信息,请参见 5.1 部分。Side Information Acquisition:在这个模块中,我们使用 KBs 的额外监督,并使用开放的 IE 方法来获取相关的 side information。该模型稍后将使用此信息,如 5.2 部分所述。Instance Set Aggregation:在本节中,将句法编码器的句子表示与上一步中获得的匹配关系嵌入连接起来。然后,对句子使用注意力,学习整个包的表示。然后将其与实体类型连接,然后将它们嵌入到 softmax 分类器中进行关系预测。有关详细信息,请参见 5.3 部分。
给定句子的关系别名边信息提取。首先,句法上下文提取器识别目标实体之间的相关关系短语 P。然后它们在嵌入空间中与以 KB 为单位的关系别名 R 的扩展集进行匹配。最后,与最近的别名对应的关系嵌入作为关系别名信息嵌入。
解释参考:
12.使用基于词和实体的注意改进远程监督关系提取 查看全部
采集相关文章(找了ACLNACL的关系抽取的论文Relation)
找了近两年ACL NACL EMNLP的一些关系抽取论文
基于实例的选择性注意的神经关系提取(16 年,典型模型)
代码: ()
使用注意机制来最小化错误标签的负面影响;
关系通过使用CNN的句子嵌入的语义组合来表示,从而充分利用训练知识库的信息。
解释参考:
给定一组句子 {x_1...x_n} 和两个对应的实体,我们的模型测量每个关系 r 的概率。在本节中,我们将分两个主要部分介绍我们的模型:
句子编码器:给定一个句子 x 和两个目标实体,卷积神经网络 (RNN) 用于构建句子 x 的分布式表示。
Selective Attention to Instances:在学习所有句子的分布向量表示时,我们使用句子级别的注意力来选择真正表达对应关系的句子。
句子编码器:
图 1 用于句子编码器的 CNN/PCNN 结构
如图 1 所示。句子 x 由 CNN 转换为其分布式表示 X。首先,将句子中的单词转化为密集的实值特征向量。接下来,使用卷积层、最大池化层和非线性变换层来构造句子的分布式表示。接下来,使用卷积层、最大池化层和非线性变换层构建句子的分布式表示。
输入表示:CNN 的输入是句子 x 中的原创单词。我们首先将单词转换为向量。通过词嵌入矩阵将每个输入词转换为向量。此外,为了指定每个实体对的位置,我们还使用句子中所有单词的位置嵌入。
ACL2017
1.用于弱监督关系提取的深度残差学习
模型:9层CNN卷积+深度残差学习(github上源码)
介绍:
关系抽取是一个重要的课题。过去很多论文使用CNN提取特征,但大多只使用了很浅的CNN(大部分只有一层卷积层+1个FC层)。没有人研究过深度 CNN 是否有用。
在本文中,我们研究了用于远程监督的深度 CNN 的 RE(也简称为关系提取)问题。具体来说,本文使用残差学习、词嵌入和位置嵌入作为模型的输入,并使用恒等反馈来研究 RE 问题。实验室使用的是NYT数据集,效果非常好(对比所有CNN模型)。
2.用噪声学习:使用动态转移矩阵增强远程监督关系提取
模型:
1和2和之前的方法一致:对一个句子进行编码,然后分类得到一个句子的分布。同时,3为模型动态生成一个转移矩阵T,用于描述噪声模式。4是将2和3的结果相乘得到最终结果。
也就是说,在训练阶段,将4的输出作为噪声输出和标签匹配,即使用4的输出和训练数据的标签计算训练损失。在泛化阶段,使用2的输出。
简介:使用噪声矩阵来拟合噪声的分布,即对噪声进行建模,从而达到拟合真实分布的目的。
动态转换矩阵可以有效地表征远程监督训练数据中的噪声。利用一种新颖的基于课程的学习方法可以有效地训练转换矩阵,而无需直接监督噪声。
解释参考:
在本文中,作者使用了一种对噪声数据进行显式建模的方法。尽管噪声数据是不可避免的,但可以用统一的框架来描述噪声数据模式。作者的出发点是远程监督数据集中的噪声模式通常有有用的线索。例如,一个人的工作地点和出生地很可能是同一个地方,这种情况下远程监督数据集很可能打错了出生地和工作地这两个关系标签。本文采用的方法是,对于每一个训练样本,都有一个动态生成的转移矩阵。这个矩阵的作用是描述标签错误的概率和指示噪声模式
由于没有对噪声模式的直接监督,作者使用课程学习训练方法逐步训练模型的噪声模式,并使用迹正则化来控制训练过程中转移矩阵的行为。我们的方法是灵活的,因为它不对数据质量做任何假设,但是当存在这样的线索时,可以有效地利用数据质量的先验知识来指导学习过程。
论文的主要创新点:使用动态过渡,使用课程学习来训练模型
3.基于新标记方案的实体和关系联合提取
简介:提出了一种新的序列标记方案,将联合提取问题转换为序列标记问题。此外,将该方案应用于各种端到端模型(使用端到端模型代替命名实体识别、NER和关系提取),并对这些模型的性能进行了比较。本文还提出了一种新模型。
模型:新的标注方案和基于 LSTM 的端到端模型来解决联合提取实体和关系的任务
如图所示,模型的输入是非结构化文本的句子,输出是预定关系类型的三元组。
为了完成这个任务,作者首先提出了一种新的标注模式,将信息抽取任务转化为序列标注任务。如下所示:
这种标注模式将文本中的单词分为两类。第一类表示与提取结果无关的词,用标签“O”表示;第二类表示与提取结果相关的词,该类词的标签由三部分组成:当前词在实体中的位置-关系类型-实体在关系中的作用。作者使用“BIES”(Begin, Inside, End, Single)注解来表示当前词在实体中的位置。关系类型是从一组预设的关系类型中获得的。实体在关系中的角色信息,用“1”、“2”表示。其中,“1”表示当前词属于三元组(Entity1,RelationType,Entity1 of Entity2),“2”表示当前词属于Entity2。最后,根据标注结果,将两对相同关系类型分为两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。两对相同的关系类型被分成两组。相邻的顺序实体组合成一个三元组。例如,从标签中可以看出“United”和“States”组合成实体“United States”,实体“United States”和实体“Trump”组合成三元组{美国,国家总统,特朗普}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。合并形成实体“United States”,实体“United States”和实体“Trump”合并形成三元组{United States, Country-President, Trump}。如果一个句子收录两个或多个相同关系类型的三元组,我们根据最近原则将两个实体组合成三元组。本文只考虑一个实体只属于一个三元组的情况。
端到端模型
当输入是文本句子时,为了自动实现对文本词序列的标注,作者提出了端到端的模型来实现这项工作。模型结构如下
在:
词嵌入层将每个词的one-hot表示向量转换为低维密集词嵌入向量(维度为300);
Bi-LSTM编码层(层数为300)用于获取单词的编码信息;
LSTM解码层(层数为600)用于生成标签序列。添加偏移损失以增强实体标签的相关性。
解释参考:
ACL 2018
4. 通过深度强化学习进行稳健的远程监督关系提取
简介:远程监督的代价是远程监督的训练样本往往有噪声。为了对抗噪音,最近的现有方法侧重于为特定实体对选择最佳句子或计算一组句子的软注意力权重。然而,这些方法都是次优的,误报问题仍然是影响性能的关键瓶颈。我们认为,必须通过硬决策而不是软注意力权重来处理那些错误标记的候选句子。为此,我们探索了一种深度强化学习策略来生成误报指标,其中我们自动识别任何关系类型的误报,而无需任何监督。与之前研究中的删除操作不同,我们将它们重新分配给负例。
我们的深度强化学习框架旨在动态识别误报样本。并在远程监督中将它们从正集转移到负集。
本文研究了使用动态选择策略进行稳健远程监控的可行性。更具体地说,我们设计了一个深度强化学习代理,其目的是学习根据关系分类器的性能变化来选择是删除还是保留远程监督的候选实例。直观地说,我们的代理希望消除误报并重建一组清洁的远程监督实例,以根据分类准确性最大化重建。该方法与分类器无关,适用于任何现有的远程监控模型。
提出了一种新的深度强化学习框架,用于鲁棒的远程监督关系提取。
我们的方法与模型无关,这意味着它可以应用于任何最先进的关系提取器。
5.用于关系提取的基于步行的实体图模型
简介:提出了一种新的基于图的神经网络关系提取模型。我们的模型同时处理句子中的多个对,并考虑它们之间的交互。句子中的所有实体都作为节点放置在完全连接的图结构中。边缘由实体对的位置感知上下文表示。为了说明两个实体之间的不同关系路径,我们在每对实体之间构建了 l 长度的游走。生成的游走被合并并不断更新以表示具有较长游走的边缘。在 ACE 2005 数据集上显示出良好的性能,而无需添加其他方法。
这篇文章说,一对实体对之间的关系会受到同一句话中其他关系的影响。比如上图中,Toefting(人实体)通过with直接与队友(人实体)产生关系,而队友通过with和资本(地缘政治实体)直接产生关系。而Toefting和资本可以直接通过队友或间接通过队友建立关系。也就是说,Toefting-teammates-capital的路径有助于Toefting-capital之间的关系。
模型:
解释参考:
6.用于弱监督关系提取的基于排序的自动种子选择和降噪
介绍:
创造性地将关系提取中的自动种子选择和数据去噪任务转化为排序问题;提出了多种策略,既可用于 Bootstrapping 关系提取的自动种子选择,又可用于关系提取和降噪的远程监督;采集自维基百科的 ClueWeb 和 ClueWeb 的数据集,通过实验验证了所提算法的实用性和先进性。
解释参考:
EMNLP2017
7.具有全局优化的端到端神经关系提取
简介:然而,之前使用统计模型的工作表明,全局优化可以实现比局部分类更好的性能。为了更好地学习上下文表示,我们构建了一个全局优化的端到端关系提取神经模型,并提出了新的 LSTM 特征。此外,我们提出了一种新颖的句法信息集成方法来促进全局学习,但需要较少的语法背景并且易于扩展。
解释参考:(我不知道这是什么意思)
8.在神经关系提取中加入关系路径
介绍:提出对文本中的关系路径进行建模,结合CNN模型完成关系抽取任务。
传统的基于CNN的方法通过CNN自动将原文映射到特征空间,并据此判断句子表达的关系
这种 CNN 模型的问题是难以理解多句文本的语义信息。比如A是B的父亲,B是C的父亲,没有办法得到A和C的关系。基于此,论文提出了一种基于神经网络引入关系路径编码器的方法,其实就是原来的词嵌入输入加上一层位置嵌入,位置嵌入分别用两个向量表示当前词与头实体/尾实体的相对路径。然后使用αα平衡文本编码器(E)和路径编码器(G)。
Encoder 还采用了多实例学习机制,使用一个句子集来联合预测关系。句子集的选择方法有随机法(rand)、最大化法(max,选择最有代表性)、选择-注意力机制(att),效果最好。
解释参考:
9.一种软标签的抗噪声远监督关系提取方法
简介:以前的句子级去噪模型由于使用硬标签而未能取得令人满意的性能,这是由训练期间的远程监督和不变性决定的。为此,我们提出了一种实体对级去噪方法,该方法利用正确标记的实体对中的语义信息在训练期间动态纠正错误的标签。我们提出了一个联合评分函数,它结合了基于实体对表示的关系分数和硬标签置信度,以获得特定实体对的新标签,即软标签。在训练过程中,软标签取代硬标签成为金标签。基准数据集上的实验表明,我们的方法显着减少了噪声实例并优于最先进的系统。
对国籍关系进行软标签校正的示例。我们打算使用正确标记的实体对(蓝色)的句法/语义信息来纠正训练中的假阳性和假阴性实例(橙色)。
为了更好地理解我们的知识,我们首先提出了一种实体对级别的抗噪声方法,而之前的工作只关注句子级别的噪声。
我们提出了一种简单而有效的方法,称为软标签方法,用于在训练期间动态纠正错误标签。
EMNLP2018
10. 具有动态路由的基于注意力的胶囊网络用于关系提取
简介:胶囊是一组神经元,其活动向量表示特定类型实体的实例化参数。在本文中,我们探索了在多实例多标签学习框架中用于关系提取的胶囊网络,并提出了一种基于具有注意机制的胶囊网络的新型神经网络方法。
模型:基于注意力的胶囊网络
11.RESIDE:使用边信息改进远程监督神经关系提取(附代码)
简介:我们提出了一种远程监控的神经关系提取方法,该方法利用 KB 中的附加信息来改进关系提取。它在预测关系时使用实体类型和关系别名信息来施加软约束。Reside 使用图卷积网络 (GCN) 对文本中的句法信息进行编码,并在可用的辅助信息有限时提高性能。
我们提出了一种新的神经网络方法 RESIDE,它利用知识库的额外监督以有原则的方式改进远程监督 RE。
RESIDE 使用图卷积网络 (GCN) 对句法信息进行建模,即使在辅助信息有限的情况下也具有竞争力。
数据集和 RESIDE 源代码:
型号:居住
句法句子编码:Reside 在连接的位置和词嵌入上使用 Bi-GRU 来编码每个标记的本地上下文。为了捕获远程依赖,使用依赖树上的 GCN,并将其编码附加到每个令牌的表示中。最后,注意标记用于抑制不相关的标记并获得整个句子的嵌入。有关详细信息,请参见 5.1 部分。Side Information Acquisition:在这个模块中,我们使用 KBs 的额外监督,并使用开放的 IE 方法来获取相关的 side information。该模型稍后将使用此信息,如 5.2 部分所述。Instance Set Aggregation:在本节中,将句法编码器的句子表示与上一步中获得的匹配关系嵌入连接起来。然后,对句子使用注意力,学习整个包的表示。然后将其与实体类型连接,然后将它们嵌入到 softmax 分类器中进行关系预测。有关详细信息,请参见 5.3 部分。
给定句子的关系别名边信息提取。首先,句法上下文提取器识别目标实体之间的相关关系短语 P。然后它们在嵌入空间中与以 KB 为单位的关系别名 R 的扩展集进行匹配。最后,与最近的别名对应的关系嵌入作为关系别名信息嵌入。
解释参考:
12.使用基于词和实体的注意改进远程监督关系提取

