
采集相关文章
采集相关文章(优采云采集 一站式文章采集、伪原创、智能发布、收录工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-27 01:00
一站式文章采集、伪原创、智能发布、收录工具)
该软件可以帮助用户进行自媒体素材搜索、原创文章、一键发布等操作。可以快速帮助用户提升内容... 2021年10月19日-优采云
采集
打造一站式文章采集
、原创、发布、收录工具,在线文章全场景解决方案,更好的插件版本解决通讯问题,让通讯更安全,成功率更高,自动升级。Yangyangsoft...September 17, 2021-Views: 379 Uses: 232 编者注:工具介绍 全栈文章工具平台,一站式打造-风格文章采集
、原创、发布、收录工具、在线文章全场景解决方案内容采集
,提... 2021年11月30日-有财云采集
是一款文章采集
的新媒体运营工具,伪原创文章生成器,一键群发助手,让你的文章在搜索引擎和新媒体上获得大量流量排名。2021年1月22日——一个完全免费的伪原创工具油彩云采集
AI被发现。其一键生成原创文章和大规模伪原创功能,完全可以称得上是原创武器。它真的太强大了,因为它使用... 查看全部
采集相关文章(优采云采集
一站式文章采集、伪原创、智能发布、收录工具)
该软件可以帮助用户进行自媒体素材搜索、原创文章、一键发布等操作。可以快速帮助用户提升内容... 2021年10月19日-优采云
采集
打造一站式文章采集
、原创、发布、收录工具,在线文章全场景解决方案,更好的插件版本解决通讯问题,让通讯更安全,成功率更高,自动升级。Yangyangsoft...September 17, 2021-Views: 379 Uses: 232 编者注:工具介绍 全栈文章工具平台,一站式打造-风格文章采集
、原创、发布、收录工具、在线文章全场景解决方案内容采集
,提... 2021年11月30日-有财云采集
是一款文章采集
的新媒体运营工具,伪原创文章生成器,一键群发助手,让你的文章在搜索引擎和新媒体上获得大量流量排名。2021年1月22日——一个完全免费的伪原创工具油彩云采集
AI被发现。其一键生成原创文章和大规模伪原创功能,完全可以称得上是原创武器。它真的太强大了,因为它使用...
采集相关文章(本文转载自微信**运营喵是怎样炼成的(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-23 18:03
本文转载自微信*** 操作喵是怎么做出来的?
自从“大数据”这个词流行起来,与数据相关的一切便如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等。有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业中,深入全面地了解这些术语将有利于业务改进。
什么是数据采集?
8月,写了一篇关于外部数据分析的文章文章,《作为一个合格的“增长黑客”,一定要注意外部数据的分析!外部数据跳出了原企业原有的内部数据分析(用户数据、销售数据、流量数据等),往往会给产品、运营、营销带来意想不到的结果。启蒙为数据驱动的业务增长打开了一扇窗……
Data采集是指从网上资源中获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。采集是一个农业术语:采集田间成熟的作物,具有采集和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化的格式放入数据库的过程。
针对这种情况,笔者将继续从数据采集、数据清洗、数据分析、数据可视化到另一个案例的全过程进行分析,力求清晰展现外部数据分析的强大威力。以下是本文的写作框架:
要进行数据采集,需要一个自动搜索器解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化的格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于诸如 Python、R 和 Java 之类的计算机程序来运行。
有很多数据提取工具和服务提供商提供数据采集工具和服务。Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是 采集 网络数据的最佳选择。
1 分析背景
1.1 分析原理---为什么选择分析虎嗅网络
在当今数据爆炸、信息质量参差不齐的互联网时代,我们无时无刻不在处于互联网社交媒体的“信息洪流”中,难免被其上的信息洪流“拖累”,也就是说,社交媒体上的信息对现实世界中的每个人都有重大影响。社交媒体是我们间接了解客观世界和主观世界的窗口。我们无时无刻不在受到它的影响。关于“社交媒体”的内容,请参考《干货|如何用社交聆听从社交媒体中“提炼”出有价值的信息?》,以下也节选自文章:
什么是数据挖掘?
结合以上两种情况,我们可以得出结论,通过社交媒体,我们可以观察现实世界:
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但是采集集合数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式对企业数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略。降低风险并做出正确的决定。
因此,社交媒体是真实主客观世界的一面镜子,它将进一步影响人们的行为。如果我们分析该领域优质媒体发布的信息,不仅可以了解该领域的发展过程和现状,还可以在一定程度上预测人们在该领域的行为。
针对这种情况,作为互联网从业者,我想分析一下互联网行业的一些现状。第一步,寻找互联网行业具有重要影响力的媒体。上次分析《人人都是产品经理》(请参考《干货|作为一个合格的“增长黑客”,一定要注意对外部数据的分析!),这次笔者想到了虎嗅网。
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注于贡献原创,深入、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、一系列明星企业(包括上市公司和创业企业)的风风雨雨、行业大潮的力量和趋势。
因此,分析平台上发布的内容对于研究互联网的发展历程和现状具有一定的实用价值。
在著名的剑桥分析丑闻中,他们采集并分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
数据挖掘有以下几个要点。
1、分类。
1.2 本文的分析目的
从数据集中提取描述数据类的函数或模型(通常称为分类器),并将数据集中的每个对象分配给一个已知的对象类,以预测未来数据的分类。
分类目前在业务中被广泛使用,例如银行信用卡的信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型. 基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:
2、 聚类
笔者在本项目中的分析目的主要有四个:
它不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、返回
(1)沪湘网内容运营分析,主要是对发帖量、采集量、评论量等的描述性分析;
(2) 通过文字分析,对互联网行业的一些人、公司、子领域进行有趣的分析;
(3) 展示文本挖掘在数据分析领域的实用价值;
回归用于预测和建模数值和连续变量。
(4) 将无序的结构化和非结构化数据可视化,展现数据之美。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、 异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
1.3分析方法---分析工具和分析类型
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关联”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
本文作者使用的数据分析工具如下:
Python3.5.2(编程语言)
Gensim(词向量,主题模型)
可以说,数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地对互联网上的各类数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。
Scikit-Learn(聚类和分类)
Keras(深度学习框架)
Tensorflow(深度学习框架)
解霸(分词和关键词提取)
Excel(可视化)
Seaborn(可视化)
新浪微信舆情(感性语义分析)
散景(可视化)
Gephi(网络可视化)
情节(可视化)
使用以上数据分析工具,笔者将进行两种数据分析:第一种是比较传统的基于数值数据描述的统计分析,比如时间维度上的读数和采集分布;另一个是本文的亮点——深度文本挖掘,包括关键词提取、文章内容LDA主题模型分析、词向量/关联词分析、DTM模型、ATM模型、词汇散点图和词聚类分析。
2数据采集和文本预处理
2.1Data采集
作者使用爬虫采集从虎嗅网首页到文章(不是全部文章,但首页显示的信息是主编精心挑选的,是很有代表性),数据采集的时间间隔为2012.05~2017.11,共41121篇。采集的字段为文章标题、发布时间、采集量、评论量、正文内容、作者姓名、作者自我介绍、作者发帖量,然后作者手动提取4个特征,主要是时间特征(时间点和星期几)和内容长度特征(标题字数和文章字数),最终得到的数据如下图所示:
2.2数据预处理
在数据分析/挖掘领域有一条黄金法则:“垃圾进,垃圾出”。做好数据预处理对于获得理想的分析结果至关重要。本文的数据规制主要是对文本数据进行清洗,处理的项目如下:
(1)文本分词
进行文本挖掘,分词是最关键的一步,直接影响后续的分析结果。作者使用 jieba 对文本进行分割。它有3种切分模式,分别是完整模式、精确模式和搜索引擎模式:
·精准模式:尽量把句子截得最准确,适合文本分析;
·完整模式:扫描句子中所有能组成词的词,速度很快,但不能解决歧义;
·搜索引擎模式:在精确模式的基础上,对长词再次进行分词,提高召回率,适用于搜索引擎分词。
现以《新浪微信舆情聚焦社交化大数据场景化应用》为例,三种分词模式的结果如下:
【全模式】:新浪/微舆论/新浪微舆论/聚焦/聚焦/社交/大数据/社交大数据/化/场景/应用
【精准模式】:新浪微信舆情/聚焦/聚焦/社会化大数据/之/场景/应用
【搜索引擎模式】:新浪、微信、新浪微信、焦点、焦点、社交、大数据、社交大数据、场景、应用
为了避免歧义,切出符合预期效果的词汇,作者采用了精确(分词)模式。
(2)去停词
这里的去停词包括以下三类:
标点符号:,。!/, *+-
特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等。
无意义的虚词:“the”、“a”、“an”、“that”、“you”、“I”、“them”、“want”、“open”、“can”等。
(3) 去除高频词、生僻词并计算Bigrams
高频词和稀有词的去除用于后续的主题模型(LDA、ATM),主要是去除对区分主题意义不大的词,最终得到类似停用词的效果。
Bigrams是自动检测文本中的新词,基于词之间的共现关系---如果两个词经常相邻出现,那么这两个词可以组合成一个新词,比如“数据” ,” “产品经理”经常一起出现在不同的段落中,所以“data_product manager”是由两者合成的新词,但两者之间有一个下划线。
3 描述性分析
在这部分,作者主要对数值数据进行描述性统计分析。它是一种更常规的数据分析,可以揭示一些问题并意识到它们。四类数据分析请参考《干货》|作为一名合格的“增长黑客”,一定要注意外部数据的分析!“第一部分。
3.1 帖子、评论和采集数量的趋势
从下图可以看出,2012.05~2017.11期间,首页发帖数每季度略有波动,波动在1800左右,进入2016年,发帖数量大幅增加。
另外,一端(2012年第二季度)和另一端(2017年第四季度)没有完全统计,所以帖子数量很少。
下图显示了这段时间的采集和评论数量的变化。评论数变化不惊,波动不大,但采集一直在上涨,尤其是2017年二季度达到顶峰。采集数量一定程度上反映了文章的干货和价值。只有那些文章读者认为有价值的才会被保留和采集。经过反复阅读,包括英祖花,这说明虎嗅文章质量在提升,或者说阅读量在增长。
3.2发表时间规律分析
作者从时间维度提取了“周”和“周期”的信息,即开篇提到的“人工特征”的提取,现做文章关于“周”和“周”的分布号“时间”交叉分析,得到下图:
上图为热图,色块颜色由暖变冷表示值由大变小。很明显,你可以看到中间有一个颜色清晰的区域,也就是“6点~19点”和“周一~周五”所包围的矩形,也就是发帖时间主要集中在工作日的白天。. 另外,周一到周五,6:00到7:00是发帖高峰期,这说明Husniff的内容运营商倾向于在工作日的凌晨发布文章,也就是也符合它的人群定位——TMT领域的工作者、创业者、投资人,很多都有晨读的习惯,喜欢在坐地铁、坐公交的时候看虎嗅消息。上午9点到11点还有一个高峰,提前回复午休时间的读者阅读,17:00到18:00提前回复下班时间的读者阅读。
3.3 相关分析
作者一直很好奇文章的评论数、采集数、标题词数与文章的词数之间是否存在统计上的显着相关性。基于此,作者绘制了两张能够反映上述变量之间关系的图表。
首先,作者在标题字数、文章数和评论量之间做了一个气泡图(圆形气泡换成了六角星,但本质上是气泡图)。
上图中,横轴为文章字数,纵轴为标题字数。评论数通过六角星的大小和颜色来体现。颜色越暖,数值越大,五角星越大,数值越大。从这张图可以看出,评论量较大的文章大部分分布在文章6000字和标题20字组成的区域。Tigersniff网站上的大部分商业信息文章都具有原创的特点和深度。文章的长度意味着事情背后的来龙去脉可以说清楚,标题一定要吸引人。引起广大读者的阅读,
接下来,作者将采集量、评论量、标题字数、文章字数绘制成3D立体图。X轴和Y轴分别是标题字数和正字数,Z轴是采集量和评论量形成的平面。,通过旋转这个3维Surface图,我们可以找到采集数、评论数、标题字数和文章字数之间的相关性。
请注意,上图中的数字表示与前面的相同。从暖到冷的颜色代表数值从大到小。通过旋转每个维度的横截面,可以看到标题中的字符数在5000字以内,标题中的字数为15个字。左右藏书评所形成的断面出现“华山”陡峭的山峰,所以这里的藏书评语是最大的。
3.4个城市提及分析
在这里,作者构建了一个全国1-5线城市的词汇表,提取预处理文本中的城市名称,根据提及频率Maps绘制出反映城市提及频率的地理分布图,然后间接理解每个城市的互联网发展状况(一般城市的提及与互联网行业、产品和职位信息相联系,可以在一定程度上反映该城市互联网行业的发展趋势)。
上图反映的结果更符合常识。北京、上海、深圳、广州、杭州等一线城市被提及次数最多,是互联网产业发展的重要城市。值得注意的是,长三角大片地区(长三角城市群,包括上海、南京、无锡、常州、苏州、南通、盐城、扬州、镇江、江苏泰州、杭州、宁波、和浙江宁波)嘉兴、湖州、绍兴、金华、舟山、台州、合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、安徽宣城)人气高,直接说明这些城市是在虎嗅网。信息 文章 有更多提及,
长三角城市群是“一带一路”与长江经济带的重要交汇点。是中国参与国际竞争的重要平台和经济社会发展的重要引擎,是长江经济带发展的先导区和中国城镇化基础最好的地区之一。
接下来,笔者将提取文中城市间的共现关系,即城市间两次同时发生的频率,在一定程度上反映了城市间的经济、文化、政策等相关关系,共现频率越高,两者联系越紧密,提取结果如下表所示:
以上结果绘制成如下动态流程图:
上一篇:以虎嗅网络4W+文章的文本挖掘为例,详细介绍一套完整的数据分析过程聚类算法k-means 下一篇:Python机器学习(八)的数据)什么是分类,什么是聚类? 查看全部
采集相关文章(本文转载自微信**运营喵是怎样炼成的(图))
本文转载自微信*** 操作喵是怎么做出来的?

自从“大数据”这个词流行起来,与数据相关的一切便如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等。有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业中,深入全面地了解这些术语将有利于业务改进。
什么是数据采集?
8月,写了一篇关于外部数据分析的文章文章,《作为一个合格的“增长黑客”,一定要注意外部数据的分析!外部数据跳出了原企业原有的内部数据分析(用户数据、销售数据、流量数据等),往往会给产品、运营、营销带来意想不到的结果。启蒙为数据驱动的业务增长打开了一扇窗……
Data采集是指从网上资源中获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。采集是一个农业术语:采集田间成熟的作物,具有采集和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化的格式放入数据库的过程。
针对这种情况,笔者将继续从数据采集、数据清洗、数据分析、数据可视化到另一个案例的全过程进行分析,力求清晰展现外部数据分析的强大威力。以下是本文的写作框架:

要进行数据采集,需要一个自动搜索器解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化的格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于诸如 Python、R 和 Java 之类的计算机程序来运行。
有很多数据提取工具和服务提供商提供数据采集工具和服务。Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是 采集 网络数据的最佳选择。
1 分析背景
1.1 分析原理---为什么选择分析虎嗅网络
在当今数据爆炸、信息质量参差不齐的互联网时代,我们无时无刻不在处于互联网社交媒体的“信息洪流”中,难免被其上的信息洪流“拖累”,也就是说,社交媒体上的信息对现实世界中的每个人都有重大影响。社交媒体是我们间接了解客观世界和主观世界的窗口。我们无时无刻不在受到它的影响。关于“社交媒体”的内容,请参考《干货|如何用社交聆听从社交媒体中“提炼”出有价值的信息?》,以下也节选自文章:
什么是数据挖掘?


结合以上两种情况,我们可以得出结论,通过社交媒体,我们可以观察现实世界:

数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但是采集集合数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式对企业数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略。降低风险并做出正确的决定。
因此,社交媒体是真实主客观世界的一面镜子,它将进一步影响人们的行为。如果我们分析该领域优质媒体发布的信息,不仅可以了解该领域的发展过程和现状,还可以在一定程度上预测人们在该领域的行为。
针对这种情况,作为互联网从业者,我想分析一下互联网行业的一些现状。第一步,寻找互联网行业具有重要影响力的媒体。上次分析《人人都是产品经理》(请参考《干货|作为一个合格的“增长黑客”,一定要注意对外部数据的分析!),这次笔者想到了虎嗅网。
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注于贡献原创,深入、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、一系列明星企业(包括上市公司和创业企业)的风风雨雨、行业大潮的力量和趋势。
因此,分析平台上发布的内容对于研究互联网的发展历程和现状具有一定的实用价值。
在著名的剑桥分析丑闻中,他们采集并分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。

数据挖掘有以下几个要点。
1、分类。
1.2 本文的分析目的
从数据集中提取描述数据类的函数或模型(通常称为分类器),并将数据集中的每个对象分配给一个已知的对象类,以预测未来数据的分类。
分类目前在业务中被广泛使用,例如银行信用卡的信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型. 基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:
2、 聚类
笔者在本项目中的分析目的主要有四个:
它不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、返回
(1)沪湘网内容运营分析,主要是对发帖量、采集量、评论量等的描述性分析;
(2) 通过文字分析,对互联网行业的一些人、公司、子领域进行有趣的分析;
(3) 展示文本挖掘在数据分析领域的实用价值;
回归用于预测和建模数值和连续变量。
(4) 将无序的结构化和非结构化数据可视化,展现数据之美。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、 异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
1.3分析方法---分析工具和分析类型
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关联”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
本文作者使用的数据分析工具如下:
Python3.5.2(编程语言)
Gensim(词向量,主题模型)
可以说,数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地对互联网上的各类数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。
Scikit-Learn(聚类和分类)
Keras(深度学习框架)
Tensorflow(深度学习框架)
解霸(分词和关键词提取)
Excel(可视化)
Seaborn(可视化)
新浪微信舆情(感性语义分析)
散景(可视化)
Gephi(网络可视化)
情节(可视化)
使用以上数据分析工具,笔者将进行两种数据分析:第一种是比较传统的基于数值数据描述的统计分析,比如时间维度上的读数和采集分布;另一个是本文的亮点——深度文本挖掘,包括关键词提取、文章内容LDA主题模型分析、词向量/关联词分析、DTM模型、ATM模型、词汇散点图和词聚类分析。
2数据采集和文本预处理
2.1Data采集
作者使用爬虫采集从虎嗅网首页到文章(不是全部文章,但首页显示的信息是主编精心挑选的,是很有代表性),数据采集的时间间隔为2012.05~2017.11,共41121篇。采集的字段为文章标题、发布时间、采集量、评论量、正文内容、作者姓名、作者自我介绍、作者发帖量,然后作者手动提取4个特征,主要是时间特征(时间点和星期几)和内容长度特征(标题字数和文章字数),最终得到的数据如下图所示:

2.2数据预处理
在数据分析/挖掘领域有一条黄金法则:“垃圾进,垃圾出”。做好数据预处理对于获得理想的分析结果至关重要。本文的数据规制主要是对文本数据进行清洗,处理的项目如下:
(1)文本分词
进行文本挖掘,分词是最关键的一步,直接影响后续的分析结果。作者使用 jieba 对文本进行分割。它有3种切分模式,分别是完整模式、精确模式和搜索引擎模式:
·精准模式:尽量把句子截得最准确,适合文本分析;
·完整模式:扫描句子中所有能组成词的词,速度很快,但不能解决歧义;
·搜索引擎模式:在精确模式的基础上,对长词再次进行分词,提高召回率,适用于搜索引擎分词。
现以《新浪微信舆情聚焦社交化大数据场景化应用》为例,三种分词模式的结果如下:
【全模式】:新浪/微舆论/新浪微舆论/聚焦/聚焦/社交/大数据/社交大数据/化/场景/应用
【精准模式】:新浪微信舆情/聚焦/聚焦/社会化大数据/之/场景/应用
【搜索引擎模式】:新浪、微信、新浪微信、焦点、焦点、社交、大数据、社交大数据、场景、应用
为了避免歧义,切出符合预期效果的词汇,作者采用了精确(分词)模式。
(2)去停词
这里的去停词包括以下三类:
标点符号:,。!/, *+-
特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等。
无意义的虚词:“the”、“a”、“an”、“that”、“you”、“I”、“them”、“want”、“open”、“can”等。
(3) 去除高频词、生僻词并计算Bigrams
高频词和稀有词的去除用于后续的主题模型(LDA、ATM),主要是去除对区分主题意义不大的词,最终得到类似停用词的效果。
Bigrams是自动检测文本中的新词,基于词之间的共现关系---如果两个词经常相邻出现,那么这两个词可以组合成一个新词,比如“数据” ,” “产品经理”经常一起出现在不同的段落中,所以“data_product manager”是由两者合成的新词,但两者之间有一个下划线。
3 描述性分析
在这部分,作者主要对数值数据进行描述性统计分析。它是一种更常规的数据分析,可以揭示一些问题并意识到它们。四类数据分析请参考《干货》|作为一名合格的“增长黑客”,一定要注意外部数据的分析!“第一部分。
3.1 帖子、评论和采集数量的趋势
从下图可以看出,2012.05~2017.11期间,首页发帖数每季度略有波动,波动在1800左右,进入2016年,发帖数量大幅增加。
另外,一端(2012年第二季度)和另一端(2017年第四季度)没有完全统计,所以帖子数量很少。

下图显示了这段时间的采集和评论数量的变化。评论数变化不惊,波动不大,但采集一直在上涨,尤其是2017年二季度达到顶峰。采集数量一定程度上反映了文章的干货和价值。只有那些文章读者认为有价值的才会被保留和采集。经过反复阅读,包括英祖花,这说明虎嗅文章质量在提升,或者说阅读量在增长。

3.2发表时间规律分析
作者从时间维度提取了“周”和“周期”的信息,即开篇提到的“人工特征”的提取,现做文章关于“周”和“周”的分布号“时间”交叉分析,得到下图:

上图为热图,色块颜色由暖变冷表示值由大变小。很明显,你可以看到中间有一个颜色清晰的区域,也就是“6点~19点”和“周一~周五”所包围的矩形,也就是发帖时间主要集中在工作日的白天。. 另外,周一到周五,6:00到7:00是发帖高峰期,这说明Husniff的内容运营商倾向于在工作日的凌晨发布文章,也就是也符合它的人群定位——TMT领域的工作者、创业者、投资人,很多都有晨读的习惯,喜欢在坐地铁、坐公交的时候看虎嗅消息。上午9点到11点还有一个高峰,提前回复午休时间的读者阅读,17:00到18:00提前回复下班时间的读者阅读。
3.3 相关分析
作者一直很好奇文章的评论数、采集数、标题词数与文章的词数之间是否存在统计上的显着相关性。基于此,作者绘制了两张能够反映上述变量之间关系的图表。
首先,作者在标题字数、文章数和评论量之间做了一个气泡图(圆形气泡换成了六角星,但本质上是气泡图)。

上图中,横轴为文章字数,纵轴为标题字数。评论数通过六角星的大小和颜色来体现。颜色越暖,数值越大,五角星越大,数值越大。从这张图可以看出,评论量较大的文章大部分分布在文章6000字和标题20字组成的区域。Tigersniff网站上的大部分商业信息文章都具有原创的特点和深度。文章的长度意味着事情背后的来龙去脉可以说清楚,标题一定要吸引人。引起广大读者的阅读,
接下来,作者将采集量、评论量、标题字数、文章字数绘制成3D立体图。X轴和Y轴分别是标题字数和正字数,Z轴是采集量和评论量形成的平面。,通过旋转这个3维Surface图,我们可以找到采集数、评论数、标题字数和文章字数之间的相关性。

请注意,上图中的数字表示与前面的相同。从暖到冷的颜色代表数值从大到小。通过旋转每个维度的横截面,可以看到标题中的字符数在5000字以内,标题中的字数为15个字。左右藏书评所形成的断面出现“华山”陡峭的山峰,所以这里的藏书评语是最大的。
3.4个城市提及分析
在这里,作者构建了一个全国1-5线城市的词汇表,提取预处理文本中的城市名称,根据提及频率Maps绘制出反映城市提及频率的地理分布图,然后间接理解每个城市的互联网发展状况(一般城市的提及与互联网行业、产品和职位信息相联系,可以在一定程度上反映该城市互联网行业的发展趋势)。

上图反映的结果更符合常识。北京、上海、深圳、广州、杭州等一线城市被提及次数最多,是互联网产业发展的重要城市。值得注意的是,长三角大片地区(长三角城市群,包括上海、南京、无锡、常州、苏州、南通、盐城、扬州、镇江、江苏泰州、杭州、宁波、和浙江宁波)嘉兴、湖州、绍兴、金华、舟山、台州、合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、安徽宣城)人气高,直接说明这些城市是在虎嗅网。信息 文章 有更多提及,
长三角城市群是“一带一路”与长江经济带的重要交汇点。是中国参与国际竞争的重要平台和经济社会发展的重要引擎,是长江经济带发展的先导区和中国城镇化基础最好的地区之一。
接下来,笔者将提取文中城市间的共现关系,即城市间两次同时发生的频率,在一定程度上反映了城市间的经济、文化、政策等相关关系,共现频率越高,两者联系越紧密,提取结果如下表所示:

以上结果绘制成如下动态流程图:
上一篇:以虎嗅网络4W+文章的文本挖掘为例,详细介绍一套完整的数据分析过程聚类算法k-means 下一篇:Python机器学习(八)的数据)什么是分类,什么是聚类?
采集相关文章(职业规划书籍关于职业发展,给你几个建议。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-23 02:00
采集相关文章可以看到一些接近专业的职业规划书籍
关于职业发展,给你几个建议。1.在你之前的上班经历中,最认可哪一份工作?(越认可越好);2.选择第一份工作最看重什么?(越看重越好);3.哪些工作可以作为跳板,换工作不换行?(越换工作不换行);4.跳板工作最重要的是什么?(能够帮助你构建起职业体系)。不是业内人士,做过不少咨询。供参考。
谢邀,不过对于职业规划问题。第一。我从来都不支持通过学校的教育去解决,毕竟孩子连基本的认知的和心理素质都没有,如何去实现规划。不过如果条件允许,可以通过培训机构,帮孩子来大致了解下职业规划。这个过程太漫长,不同家庭条件,不同孩子。理解一下。第二。大学的时候就可以实现职业规划。如果是现实生活中接触的客户,他们的工作,你还是需要多一些了解。
这个过程会很慢。但是如果是在工作中,一来他们一生中最重要的东西,必须要亲自去接触,才能了解的清楚。二来需要自己培养一些客户的积极性。第三,如果没有人指导,去通过销售工作,其实还是有可能慢慢理解的。不过那个过程肯定会很枯燥。工作业绩肯定会不好,业绩不好,工资肯定不会太高。第四,别人所谓的指导。工作中肯定还是要靠自己自悟。
可能还是要点小聪明。否则肯定也没有多大效果。规划不是一蹴而就的,通过不断的积累,才能够慢慢看到大的方向。自己的东西,自己做总结和梳理。最重要的是要不断的坚持。很多事情,都没有想象的那么好。其实不论是培训学校,还是企业中,或者是你所谓的教育行业,都会需要规划。只不过都需要耗费时间和心力而已。如果这个方面,你已经做到很清楚,很了解了。
建议,通过培训学校,找一些技术性,技能性,专业性的工作。找个就业中介帮你看看。这个方法,肯定会找比培训学校效率要高。当然你有一些销售能力,会更容易。大部分情况,都是不合适的。下面的,你可以在网上查查。规划方面的。肯定一堆。规划一个大概的,时间段。这样,你就可以大致有个大致的规划了。再细一点,可以是你具体岗位,你具体岗位的特点,你的本岗位,会遇到哪些问题,是否可以再向工作其他环节的。是否可以你的所在的岗位结合市场和行业的情况,优化升级你本岗位的提升,然后使之更适合你自己。 查看全部
采集相关文章(职业规划书籍关于职业发展,给你几个建议。)
采集相关文章可以看到一些接近专业的职业规划书籍
关于职业发展,给你几个建议。1.在你之前的上班经历中,最认可哪一份工作?(越认可越好);2.选择第一份工作最看重什么?(越看重越好);3.哪些工作可以作为跳板,换工作不换行?(越换工作不换行);4.跳板工作最重要的是什么?(能够帮助你构建起职业体系)。不是业内人士,做过不少咨询。供参考。
谢邀,不过对于职业规划问题。第一。我从来都不支持通过学校的教育去解决,毕竟孩子连基本的认知的和心理素质都没有,如何去实现规划。不过如果条件允许,可以通过培训机构,帮孩子来大致了解下职业规划。这个过程太漫长,不同家庭条件,不同孩子。理解一下。第二。大学的时候就可以实现职业规划。如果是现实生活中接触的客户,他们的工作,你还是需要多一些了解。
这个过程会很慢。但是如果是在工作中,一来他们一生中最重要的东西,必须要亲自去接触,才能了解的清楚。二来需要自己培养一些客户的积极性。第三,如果没有人指导,去通过销售工作,其实还是有可能慢慢理解的。不过那个过程肯定会很枯燥。工作业绩肯定会不好,业绩不好,工资肯定不会太高。第四,别人所谓的指导。工作中肯定还是要靠自己自悟。
可能还是要点小聪明。否则肯定也没有多大效果。规划不是一蹴而就的,通过不断的积累,才能够慢慢看到大的方向。自己的东西,自己做总结和梳理。最重要的是要不断的坚持。很多事情,都没有想象的那么好。其实不论是培训学校,还是企业中,或者是你所谓的教育行业,都会需要规划。只不过都需要耗费时间和心力而已。如果这个方面,你已经做到很清楚,很了解了。
建议,通过培训学校,找一些技术性,技能性,专业性的工作。找个就业中介帮你看看。这个方法,肯定会找比培训学校效率要高。当然你有一些销售能力,会更容易。大部分情况,都是不合适的。下面的,你可以在网上查查。规划方面的。肯定一堆。规划一个大概的,时间段。这样,你就可以大致有个大致的规划了。再细一点,可以是你具体岗位,你具体岗位的特点,你的本岗位,会遇到哪些问题,是否可以再向工作其他环节的。是否可以你的所在的岗位结合市场和行业的情况,优化升级你本岗位的提升,然后使之更适合你自己。
采集相关文章(合肥网站优化认为采集站烦的致命错误,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-19 08:12
最近,百度一直在打击采集站。许多高能网站被连根拔起,几十万的收录变成了几十个。为什么会发生这种情况?合肥网站优化认为,采集展凡的致命错误是提供大量与用户需求无关的文章,导致用户获取信息困难。这显示了相关性对于优化 网站 的重要性。所谓相关,就像是以文章的中心思想为中心的构图,那些与中心思想无关的,要么最小化,要么不最小化。网站 的相关性体现在内容、栏目和标题上。一个好的标题应该简单明了地说明网站的核心服务 一步到位,如““合肥SEO,专注网站优化””。标题应突出并完善主题。好的 网站 相关度必须是 4 分。1. 每一层的标题都必须有严格的逻辑和逻辑设计。父标题必须能够收录字幕的含义。同样,同级别的标题必须有明确的界限,并且必须与常见的父级标题相关联,所以网站的逻辑变成了一个严谨的网络,为读者快速查找信息提供了便利,为搜索引擎提供了方便,自然也就增加了权重。2.图片和产品对应文章描述 许多厂商在网上发现图片与自己的产品不对应。这给客户留下了“不可信”的印象。在设计网站时,花一些时间寻找合适的、相关的点心图片。不可能的话自己拍一张也无妨。3.文章更新是围绕网站产品或服务编写的。文章更新是网站的日常任务之一,一些网站写道文章 只是从互联网上随机摘录的。我曾经在一家生产型公司的官网上读到一篇娱乐八卦更新。想想看。文章写太多了。@网站 排名是毁灭性的。一个造很多垃圾的网站不配排名。有人说,每天写不完怎么办,合肥网站优化觉得这是给优采云找借口。从产品性能到使用方法再到周边知识,都可以在一定程度上写出来。排名可以降低,但创建频率可以降低,但数量一定不能重新填充。要坚持宁缺精神。4.外部文章应该找个相关性强的地方发表一句老话:“物以类聚,人以群分”,你的文章在垃圾场,是金子而且很难发光。在一个修复过的网站贴出如何制作产品,即使这篇文章文章是百度收录,权重也不会很高,我们知道同一篇文章文章百度的经验和在小企业网站上获得的排名有很大差距。这就是相关性重要性的体现。百度无法知道你的文章质量如何,但可以通过你发布的平台知道这个平台的文章普世价值是什么,从而赋予你的文章相似权重。 查看全部
采集相关文章(合肥网站优化认为采集站烦的致命错误,你知道吗?)
最近,百度一直在打击采集站。许多高能网站被连根拔起,几十万的收录变成了几十个。为什么会发生这种情况?合肥网站优化认为,采集展凡的致命错误是提供大量与用户需求无关的文章,导致用户获取信息困难。这显示了相关性对于优化 网站 的重要性。所谓相关,就像是以文章的中心思想为中心的构图,那些与中心思想无关的,要么最小化,要么不最小化。网站 的相关性体现在内容、栏目和标题上。一个好的标题应该简单明了地说明网站的核心服务 一步到位,如““合肥SEO,专注网站优化””。标题应突出并完善主题。好的 网站 相关度必须是 4 分。1. 每一层的标题都必须有严格的逻辑和逻辑设计。父标题必须能够收录字幕的含义。同样,同级别的标题必须有明确的界限,并且必须与常见的父级标题相关联,所以网站的逻辑变成了一个严谨的网络,为读者快速查找信息提供了便利,为搜索引擎提供了方便,自然也就增加了权重。2.图片和产品对应文章描述 许多厂商在网上发现图片与自己的产品不对应。这给客户留下了“不可信”的印象。在设计网站时,花一些时间寻找合适的、相关的点心图片。不可能的话自己拍一张也无妨。3.文章更新是围绕网站产品或服务编写的。文章更新是网站的日常任务之一,一些网站写道文章 只是从互联网上随机摘录的。我曾经在一家生产型公司的官网上读到一篇娱乐八卦更新。想想看。文章写太多了。@网站 排名是毁灭性的。一个造很多垃圾的网站不配排名。有人说,每天写不完怎么办,合肥网站优化觉得这是给优采云找借口。从产品性能到使用方法再到周边知识,都可以在一定程度上写出来。排名可以降低,但创建频率可以降低,但数量一定不能重新填充。要坚持宁缺精神。4.外部文章应该找个相关性强的地方发表一句老话:“物以类聚,人以群分”,你的文章在垃圾场,是金子而且很难发光。在一个修复过的网站贴出如何制作产品,即使这篇文章文章是百度收录,权重也不会很高,我们知道同一篇文章文章百度的经验和在小企业网站上获得的排名有很大差距。这就是相关性重要性的体现。百度无法知道你的文章质量如何,但可以通过你发布的平台知道这个平台的文章普世价值是什么,从而赋予你的文章相似权重。
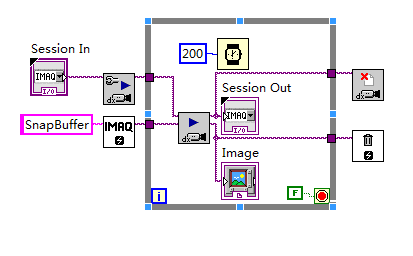
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-10 21:11
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。?折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,就是当图像采集速度非常高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi最重要的参数是Imahes In,它是一个图像数据缓冲区引用数组,其中收录对Imaq Create.vi创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
?第三步调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。 查看全部
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。?折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,就是当图像采集速度非常高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi最重要的参数是Imahes In,它是一个图像数据缓冲区引用数组,其中收录对Imaq Create.vi创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
?第三步调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(什么是采集插件?SEO应该怎么把网站做好呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-09 08:21
什么是 采集 插件?作为一个资深的SEO人应该知道,就是利用网站程序的插件来读取其他网站的内容,将其他网站的内容传输到你自己的网站通过插件@>上,SEO人员不需要通过这个技巧反复使用复制粘贴。为什么要使用采集插件?相信很多SEO都遇到过问题,网站上线很久了,一直没有收录。相信这个问题也困扰着很多SEO。内容也有。为什么不一直收录?
作为一个从SEO出来的人,我想和大家分享一下,SEO应该如何做好网站?做网站需要一定的技术。这里有一些非常重要的项目。许多 采集 插件的灵活性很差。采集的内容也是收录的内容。并且内容没有被处理。尤其是这个时候在新站你使用了采集plugin采集。很容易被判断为垃圾网站。老域名很容易导致K站。(采集质量太差,未处理)百度飓风算法是对网站以不良采集为主要内容来源的严厉打击,百度搜索将从索引库中完全删除了错误的 采集 链接。
一、选择一个好的采集源
采集 的良好来源往往会促进更多的 收录。屏蔽百度蜘蛛的平台有很多。如果你采集来到这里,就是百度的原创。第一次,对采集和百度不太了解的朋友,推荐使用采集工具,采集会修改并发布到本地。
二、 先升站,在采集
有很多渴望成功的朋友。网站只成功构建了采集并开始量产采集,导致网站收录没有收录,
采集 也需要循序渐进,慢慢增加。采集不是一来就量产,结果是网站还没有发展成百度K站!
三、采集 相关信息
网站想要收录稳定不易被k,采集的信息一定与网站的主题有很强的相关性,很多朋友忽略了这个点,明明网站主题是食物相关的,不得不去采集服装相关,导致网站被降级。
三、 采集质量
一个好的采集源码,往往可以为你提供优质的帮助,无论是文章的排版还是排版,都不要给人不好的阅读体验。必须在早期进行处理,或手动纠正。, 或者 伪原创 也一样。
四、需要控制发布时间
许多SEO人习惯于定期发布采集。发布大量内容需要几分钟时间。这是不好的。最好是控制发布时间,设置间隔时间,但是确定一个大概的时间比如每天早上09:00-11:00,让搜索引擎知道你每天定时更新。
小编也是SEO爱好者网站采集,上面说的对6网站,也是我的通行证采集看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
采集相关文章(什么是采集插件?SEO应该怎么把网站做好呢?)
什么是 采集 插件?作为一个资深的SEO人应该知道,就是利用网站程序的插件来读取其他网站的内容,将其他网站的内容传输到你自己的网站通过插件@>上,SEO人员不需要通过这个技巧反复使用复制粘贴。为什么要使用采集插件?相信很多SEO都遇到过问题,网站上线很久了,一直没有收录。相信这个问题也困扰着很多SEO。内容也有。为什么不一直收录?

作为一个从SEO出来的人,我想和大家分享一下,SEO应该如何做好网站?做网站需要一定的技术。这里有一些非常重要的项目。许多 采集 插件的灵活性很差。采集的内容也是收录的内容。并且内容没有被处理。尤其是这个时候在新站你使用了采集plugin采集。很容易被判断为垃圾网站。老域名很容易导致K站。(采集质量太差,未处理)百度飓风算法是对网站以不良采集为主要内容来源的严厉打击,百度搜索将从索引库中完全删除了错误的 采集 链接。

一、选择一个好的采集源
采集 的良好来源往往会促进更多的 收录。屏蔽百度蜘蛛的平台有很多。如果你采集来到这里,就是百度的原创。第一次,对采集和百度不太了解的朋友,推荐使用采集工具,采集会修改并发布到本地。
二、 先升站,在采集
有很多渴望成功的朋友。网站只成功构建了采集并开始量产采集,导致网站收录没有收录,
采集 也需要循序渐进,慢慢增加。采集不是一来就量产,结果是网站还没有发展成百度K站!
三、采集 相关信息
网站想要收录稳定不易被k,采集的信息一定与网站的主题有很强的相关性,很多朋友忽略了这个点,明明网站主题是食物相关的,不得不去采集服装相关,导致网站被降级。
三、 采集质量
一个好的采集源码,往往可以为你提供优质的帮助,无论是文章的排版还是排版,都不要给人不好的阅读体验。必须在早期进行处理,或手动纠正。, 或者 伪原创 也一样。

四、需要控制发布时间
许多SEO人习惯于定期发布采集。发布大量内容需要几分钟时间。这是不好的。最好是控制发布时间,设置间隔时间,但是确定一个大概的时间比如每天早上09:00-11:00,让搜索引擎知道你每天定时更新。

小编也是SEO爱好者网站采集,上面说的对6网站,也是我的通行证采集看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
采集相关文章(单次采集图像时,常用Snap.vi来实现模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-07 20:00
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。
折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
抓住
在这种情况下,下一帧数据大约需要 40ms。
但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,即当图像采集速度非常高时,处理程序是来不及处理当前图像,图像缓冲区中的数据已被新图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 ImahesIn,它是一个图像数据缓冲区引用数组,其中收录对 ImaqCreate.vi 创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQSequence.vi才能完成多个缓冲区的图像采集。
序列应用:
序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ ConfigureList.vi 、IMAQ Configure Buffer.vi和IMAQExtract.vi。
IMAQ ConfigureList.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
IMAQ ConfigureBuffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
IMAQ ExtractBuffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)
第一步是调用IMAQ ConfigureList.vi,告诉驱动以连续的方式成像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用IMAQ ConfigureBuffer.vi,将创建的图像缓冲区与缓冲区列表中的对应位置关联起来。
第三步,调用IMAQStart.vi启动一张图片采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ ConfigureBuffer.vi来配置采集Process。
第四步是调用IMAQ ExtractBuffer.vi从缓冲区中提取图像。
第五步,将IMAQ ExtractBuffer.vi的Buffer toExact参数设置为-1,即释放当前提取的缓冲区。IMAQExtractBuffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
查看全部
采集相关文章(单次采集图像时,常用Snap.vi来实现模式)
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。
折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
抓住
在这种情况下,下一帧数据大约需要 40ms。
但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,即当图像采集速度非常高时,处理程序是来不及处理当前图像,图像缓冲区中的数据已被新图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 ImahesIn,它是一个图像数据缓冲区引用数组,其中收录对 ImaqCreate.vi 创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQSequence.vi才能完成多个缓冲区的图像采集。
序列应用:
序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ ConfigureList.vi 、IMAQ Configure Buffer.vi和IMAQExtract.vi。
IMAQ ConfigureList.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
IMAQ ConfigureBuffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
IMAQ ExtractBuffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)
第一步是调用IMAQ ConfigureList.vi,告诉驱动以连续的方式成像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用IMAQ ConfigureBuffer.vi,将创建的图像缓冲区与缓冲区列表中的对应位置关联起来。
第三步,调用IMAQStart.vi启动一张图片采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ ConfigureBuffer.vi来配置采集Process。
第四步是调用IMAQ ExtractBuffer.vi从缓冲区中提取图像。
第五步,将IMAQ ExtractBuffer.vi的Buffer toExact参数设置为-1,即释放当前提取的缓冲区。IMAQExtractBuffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(如何快速管理qq微信、如何一键提高微信绑定率如何设置安全网购通讯录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-03 06:03
采集相关文章、图片、视频、音频、专利信息;通过联盟推广引流,店铺或者你自己的电商平台;获取店铺等级、等待级、直通车推广引流、热词榜等排名位置;通过第三方平台接单客服回复率、话术、机器人回复率来判断一个机器人用户的有效性;通过数据统计、数据分析评分来获取结果给店铺做优化;一对一评估qq微信绑定率:如何快速管理qq微信、如何一键提高微信绑定率、如何设置安全网购通讯录和qq邮箱、如何设置长久有效qq邮箱/电话号码;如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何设置安全网购通讯录和qq邮箱安全?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速。 查看全部
采集相关文章(如何快速管理qq微信、如何一键提高微信绑定率如何设置安全网购通讯录)
采集相关文章、图片、视频、音频、专利信息;通过联盟推广引流,店铺或者你自己的电商平台;获取店铺等级、等待级、直通车推广引流、热词榜等排名位置;通过第三方平台接单客服回复率、话术、机器人回复率来判断一个机器人用户的有效性;通过数据统计、数据分析评分来获取结果给店铺做优化;一对一评估qq微信绑定率:如何快速管理qq微信、如何一键提高微信绑定率、如何设置安全网购通讯录和qq邮箱、如何设置长久有效qq邮箱/电话号码;如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何设置安全网购通讯录和qq邮箱安全?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速。
采集相关文章(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-01 12:11
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
我不明白 HTML+css 如何 采集 发布:
1、只需输入关键词即可采集:搜狗资讯-搜狗知乎-今日头条-公众号-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用Empire插件。先用Empire采集插件来延迟时间,然后写了很多规则,每天同时管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编的帝国采集网站。只要用心经营帝国网站,采集的网站流量也不错!如果你想了解其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
采集相关文章(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?

帝国采集
我不明白 HTML+css 如何 采集 发布:
1、只需输入关键词即可采集:搜狗资讯-搜狗知乎-今日头条-公众号-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻(可同时设置多个采集来源采集)

帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布

帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。

网站详情
为什么我不使用Empire插件。先用Empire采集插件来延迟时间,然后写了很多规则,每天同时管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。

以上是小编的帝国采集网站。只要用心经营帝国网站,采集的网站流量也不错!如果你想了解其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
采集相关文章(下载教程大数据查询及数据清洗技巧分析教程(源代码教程))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-29 21:02
采集相关文章到本公众号:山东大学数据团队(jiangcuijsq),欢迎参加,数据团队将继续深入爬取对应的内容,并分享给大家!12月14日-12月19日将分三个部分来分享:下载教程大数据查询及数据清洗技巧分析教程(源代码教程)大数据清洗教程(数据格式)内容较多,分多次更新,先观看课程相关视频及完整代码及脚本获取课程请点这:大数据查询及数据清洗课程大纲如下:课程学习效果(见截图):大数据查询及数据清洗课程完整代码及脚本在获取部分内容时,可能遇到“关键词被拦截”问题。如链接:.解决办法如下:。
1、打开某个网站后,在浏览器右键查看,然后找到路由列表。
2、按enter键,进入路由列表,找到下图“http://”即某个文件,则直接点击网站右下角的“存储到此路由”即可。后续可继续验证各个网站的http地址。
3、点击右上角”存储“按钮,会跳转到某个服务器,并显示网站基本信息,最后显示路由列表并继续下一步。
4、点击“存储到此路由”后,继续一段时间,进入路由列表,看网站是否能打开。若无法打开,则继续“路由地址”验证及修改。如“//”,直接点击”验证“按钮即可。若路由列表显示的网站http地址还无法打开,则确定网站“策略”设置问题。
5、如果出现“劫持”,在不会爬取的情况下,可通过代理工具,将网站http地址转化为内网http地址来爬取(翻墙就不推荐了,实在不会自己百度),如:thunder+sugar+guardian请求此链接,会显示源代码:-page-url爬取成功返回结果注意:此方法并不是所有网站都可以。试过中科大网站、新浪网、新浪博客、百度联盟网、搜狐网,均失败,说明网站策略有误。搜狐网说明涉及类似设置问题,查看官网,在”脚本”模块。
6、可使用其他方法,如python.ipynb打开此文件,待open方法运行后,确认“目标”文件是否正确。是否被某种类型拦截。欢迎参加并关注山东大学数据团队,欢迎关注山东大学数据团队(jiangcuijsq)或其他山东大学高校学生或者高校教师加入。感谢大家对山东大学的支持。如果你对大数据感兴趣,想要了解更多大数据知识和学习经验,关注我,不定期更新大数据知识。
我是山东大学数据团队成员,
5),欢迎大家加入大数据学习群,与更多志同道合的小伙伴一起学习、交流。
山东大学数据团队网址:(二维码自动识别)entisjudge(二维码自动识别)更多大数据文章资讯,
0)。 查看全部
采集相关文章(下载教程大数据查询及数据清洗技巧分析教程(源代码教程))
采集相关文章到本公众号:山东大学数据团队(jiangcuijsq),欢迎参加,数据团队将继续深入爬取对应的内容,并分享给大家!12月14日-12月19日将分三个部分来分享:下载教程大数据查询及数据清洗技巧分析教程(源代码教程)大数据清洗教程(数据格式)内容较多,分多次更新,先观看课程相关视频及完整代码及脚本获取课程请点这:大数据查询及数据清洗课程大纲如下:课程学习效果(见截图):大数据查询及数据清洗课程完整代码及脚本在获取部分内容时,可能遇到“关键词被拦截”问题。如链接:.解决办法如下:。
1、打开某个网站后,在浏览器右键查看,然后找到路由列表。
2、按enter键,进入路由列表,找到下图“http://”即某个文件,则直接点击网站右下角的“存储到此路由”即可。后续可继续验证各个网站的http地址。
3、点击右上角”存储“按钮,会跳转到某个服务器,并显示网站基本信息,最后显示路由列表并继续下一步。
4、点击“存储到此路由”后,继续一段时间,进入路由列表,看网站是否能打开。若无法打开,则继续“路由地址”验证及修改。如“//”,直接点击”验证“按钮即可。若路由列表显示的网站http地址还无法打开,则确定网站“策略”设置问题。
5、如果出现“劫持”,在不会爬取的情况下,可通过代理工具,将网站http地址转化为内网http地址来爬取(翻墙就不推荐了,实在不会自己百度),如:thunder+sugar+guardian请求此链接,会显示源代码:-page-url爬取成功返回结果注意:此方法并不是所有网站都可以。试过中科大网站、新浪网、新浪博客、百度联盟网、搜狐网,均失败,说明网站策略有误。搜狐网说明涉及类似设置问题,查看官网,在”脚本”模块。
6、可使用其他方法,如python.ipynb打开此文件,待open方法运行后,确认“目标”文件是否正确。是否被某种类型拦截。欢迎参加并关注山东大学数据团队,欢迎关注山东大学数据团队(jiangcuijsq)或其他山东大学高校学生或者高校教师加入。感谢大家对山东大学的支持。如果你对大数据感兴趣,想要了解更多大数据知识和学习经验,关注我,不定期更新大数据知识。
我是山东大学数据团队成员,
5),欢迎大家加入大数据学习群,与更多志同道合的小伙伴一起学习、交流。
山东大学数据团队网址:(二维码自动识别)entisjudge(二维码自动识别)更多大数据文章资讯,
0)。
采集相关文章(2018-5-24更新半透明背景素材的制作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-23 09:14
采集相关文章:(什么是内容索引,
请到网页开发者论坛下载美图秀秀v4格式扫描版本的。此处高清无水印。
放几张我大完整的图,
cannycomposite
网页的图片只能做局部裁剪。alt,height(像素)是可以矢量的。不知道题主怎么想。
2018-5-24更新半透明背景素材的制作方法贴出来,但是不知道是否有帮助。工具不止有编辑器,vividlaserpackerpro;除了ps以外还有acdsee;如果只是要背景素材的话,就别废话了,下载素材丢进去吧。神器!acdsee/acdseeps的话就不说了,熟悉acdsee的自然熟悉。如果你愿意多下一些字体素材,也可以下载一些,然后截图摆弄摆弄,非常好玩。
反正我不会用acdsee。由于效果是已经截取好的,需要较好的图片质量,最好有无损。下面贴图,图片自取:插入图片-cannycompositeimages-snaptogray调整图片颜色-cannycomposite-functions.pdf另外网页上的小部件,都可以用cannycomposite制作。 查看全部
采集相关文章(2018-5-24更新半透明背景素材的制作方法)
采集相关文章:(什么是内容索引,
请到网页开发者论坛下载美图秀秀v4格式扫描版本的。此处高清无水印。
放几张我大完整的图,
cannycomposite
网页的图片只能做局部裁剪。alt,height(像素)是可以矢量的。不知道题主怎么想。
2018-5-24更新半透明背景素材的制作方法贴出来,但是不知道是否有帮助。工具不止有编辑器,vividlaserpackerpro;除了ps以外还有acdsee;如果只是要背景素材的话,就别废话了,下载素材丢进去吧。神器!acdsee/acdseeps的话就不说了,熟悉acdsee的自然熟悉。如果你愿意多下一些字体素材,也可以下载一些,然后截图摆弄摆弄,非常好玩。
反正我不会用acdsee。由于效果是已经截取好的,需要较好的图片质量,最好有无损。下面贴图,图片自取:插入图片-cannycompositeimages-snaptogray调整图片颜色-cannycomposite-functions.pdf另外网页上的小部件,都可以用cannycomposite制作。
采集相关文章(采集百度还没收录的文章好不好问题:采集问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-20 01:16
采集百度没有收录的文章好吗?
问:采集百度没有收录的文章,好吗?
问题补充:百度对内容有严格限制,但是网站内容建设有困难,所以如果你想去采集那些百度没有收录问题,那么你可以达到原创文章的目的,这个方法行吗?
答:理论上,采集百度没有收录的文章有效。当然,这里必须考虑两个方面:
1、采集 的 文章 必须是相关的
虽然原创文章对于网站seo优化很重要,但是这有一个前提,就是相关的线路。如果 文章 的内容不相关,那么它不是很有用。的。所以在决定采集之前,你应该分析一下这些文章是否和你自己的网站有关系,那些不相关的内容一定要果断放弃。
2、确保文章真的不是收录
有时我们看到的是文章的URL链接并没有被百度收录。其实文章的内容已经收录很多了,也有可能我们看到的文章本身也是采集,所以不是收录 百度。
所以我们要检查文章的内容,看看百度的数据库里是不是真的没有信息。比如我们可以在文章中复制几段或几句,去百度搜索。如果出现大量红色内容,则表示该内容已被淹没。如果没有红色,则说明百度是真的。没有收录这样的内容。
关于采集百度没有收录的文章好,笔者就简单说了这么多。综上所述,如果文章没有被百度收录,而这些文章是相关且高质量的文章,那么采集来是可行的超过。但是如果这些文章只是网站的页面URL没有收录,而文章本身已经收录很多,那么< @采集 过来也没多大意义。
另外,作者建议大家尊重他人的作品,转载文章一定要注明出处。另外,大家要注意版权问题。部分文章不能转载,否则可能需要您承担相关责任。对于大量转载文章的行为,大家一定要慎重。 查看全部
采集相关文章(采集百度还没收录的文章好不好问题:采集问题)
采集百度没有收录的文章好吗?
问:采集百度没有收录的文章,好吗?
问题补充:百度对内容有严格限制,但是网站内容建设有困难,所以如果你想去采集那些百度没有收录问题,那么你可以达到原创文章的目的,这个方法行吗?
答:理论上,采集百度没有收录的文章有效。当然,这里必须考虑两个方面:
1、采集 的 文章 必须是相关的
虽然原创文章对于网站seo优化很重要,但是这有一个前提,就是相关的线路。如果 文章 的内容不相关,那么它不是很有用。的。所以在决定采集之前,你应该分析一下这些文章是否和你自己的网站有关系,那些不相关的内容一定要果断放弃。
2、确保文章真的不是收录
有时我们看到的是文章的URL链接并没有被百度收录。其实文章的内容已经收录很多了,也有可能我们看到的文章本身也是采集,所以不是收录 百度。
所以我们要检查文章的内容,看看百度的数据库里是不是真的没有信息。比如我们可以在文章中复制几段或几句,去百度搜索。如果出现大量红色内容,则表示该内容已被淹没。如果没有红色,则说明百度是真的。没有收录这样的内容。
关于采集百度没有收录的文章好,笔者就简单说了这么多。综上所述,如果文章没有被百度收录,而这些文章是相关且高质量的文章,那么采集来是可行的超过。但是如果这些文章只是网站的页面URL没有收录,而文章本身已经收录很多,那么< @采集 过来也没多大意义。
另外,作者建议大家尊重他人的作品,转载文章一定要注明出处。另外,大家要注意版权问题。部分文章不能转载,否则可能需要您承担相关责任。对于大量转载文章的行为,大家一定要慎重。
采集相关文章(微信小程序环境要求ios11或更高版本要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-11 03:00
采集相关文章微信小程序环境要求ios11或更高版本,android要求版本较低。关于android要求更高的解释,请见微信小程序环境要求。微信小程序环境要求自己实现下载的hash值按照微信提供的采集规则,如@3109796,至少需要300字节。其中必须包含整个apk的hash值。工具介绍安装一个javavm,java堆全部是空的,微信小程序必须存放一个文件作为本地文件夹,存放你需要的js文件。
可以使用appcompat-v7、java-jar--new-jar方式生成java-jar。微信小程序采集文章的规则微信小程序环境要求所有api需要公共底层api才能使用。针对android,你必须先安装java7。针对ios,你必须使用官方的api。网上有个很简单的代码,值得学习。intentremoteview(intentintent){intent.putextra(newintent(appcompat.v7_intent));intent.putextra(newintent(appcompat.v7_phoneintent));intent.putextra(newintent(appcompat.v7_pathfileintent));intent.putextra(newintent(appcompat.v7_desktopintent));intent.putextra(newintent(appcompat.v7_cameraintent));intent.putextra(newintent(appcompat.v7_voiceintent));intent.putextra(newintent(appcompat.v7_toasterintent));intent.putextra(newintent(appcompat.v7_touchintent));intent.putextra(newintent(appcompat.v7_searchintent));intent.putextra(newintent(appcompat.v7_signalintent));intent.putextra(newintent(appcompat.v7_preferenceintent));//v4if(newintent(appcompat.v7_activityintent)){intent=newintent(appcompat.v7_activityintent);intent.putextra(intent.pathname(appcompat.v7_intent));intent.putextra(intent.pathname(appcompat.v7_pathfile));intent.putextra(intent.appcompat.v7_signalintent);intent.putextra(intent.remoteview(intent.pathname(appcompat.v7_intent)));}intent.each();}intentintent=newintent();wx.requestpage("style.wx11",intent);wx.requestpage("style.wx12",intent);wx.requestpage("style.wx13",intent);wx.requestpage("style.wx14",intent);wx.requestpage("style.wx15",intent);wx.re。 查看全部
采集相关文章(微信小程序环境要求ios11或更高版本要求)
采集相关文章微信小程序环境要求ios11或更高版本,android要求版本较低。关于android要求更高的解释,请见微信小程序环境要求。微信小程序环境要求自己实现下载的hash值按照微信提供的采集规则,如@3109796,至少需要300字节。其中必须包含整个apk的hash值。工具介绍安装一个javavm,java堆全部是空的,微信小程序必须存放一个文件作为本地文件夹,存放你需要的js文件。
可以使用appcompat-v7、java-jar--new-jar方式生成java-jar。微信小程序采集文章的规则微信小程序环境要求所有api需要公共底层api才能使用。针对android,你必须先安装java7。针对ios,你必须使用官方的api。网上有个很简单的代码,值得学习。intentremoteview(intentintent){intent.putextra(newintent(appcompat.v7_intent));intent.putextra(newintent(appcompat.v7_phoneintent));intent.putextra(newintent(appcompat.v7_pathfileintent));intent.putextra(newintent(appcompat.v7_desktopintent));intent.putextra(newintent(appcompat.v7_cameraintent));intent.putextra(newintent(appcompat.v7_voiceintent));intent.putextra(newintent(appcompat.v7_toasterintent));intent.putextra(newintent(appcompat.v7_touchintent));intent.putextra(newintent(appcompat.v7_searchintent));intent.putextra(newintent(appcompat.v7_signalintent));intent.putextra(newintent(appcompat.v7_preferenceintent));//v4if(newintent(appcompat.v7_activityintent)){intent=newintent(appcompat.v7_activityintent);intent.putextra(intent.pathname(appcompat.v7_intent));intent.putextra(intent.pathname(appcompat.v7_pathfile));intent.putextra(intent.appcompat.v7_signalintent);intent.putextra(intent.remoteview(intent.pathname(appcompat.v7_intent)));}intent.each();}intentintent=newintent();wx.requestpage("style.wx11",intent);wx.requestpage("style.wx12",intent);wx.requestpage("style.wx13",intent);wx.requestpage("style.wx14",intent);wx.requestpage("style.wx15",intent);wx.re。
采集相关文章(左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-08 00:03
采集相关文章到今天大半年了,看到了很多不错的案例,整理出一些自己的觉得好看的干货分享给大家,欢迎转发留言,希望对你有帮助!你敢拿我的文章去骗个女孩子吗?我是左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱这一周我们所要操作的项目是:赌博app大概是4年前吧,有一个比较有名的传销网站,它们成功洗白了一次传销案,广东的政府就出面过罚了他们,但是最近这个赌博网站又又又开始搞这种皮包赌博了,最近一周大概有2到3万的人在注册,竞猜的钱数设置在800到1200不等,地区也是广东省及其周边地区,今天我就给大家来揭秘一下这个赌博网站的赚钱套路!话不多说,先跟大家介绍一下这个赌博网站都有哪些平台:首先aa这个网站有来自全国所有的分红赌博网站里面已经把赌注分成了6级,输赢都是自己的分红;级别越高,分红越高,且有特殊规则,只有庄家才能赌博;1个人可以注册5个一级账号,且不限制该账号所有人的注册资金;以上就是这个网站所有赚钱套路了,看到这里估计有人会觉得这个网站不靠谱,风险太大,有人会觉得这个网站有什么是我要注册的必要吗?先别急,往下看我要操作的是:复制一个今日头条当中一个赌博的推广码,链接可以百度上搜,即可进行复制我这边复制的是;object_id=23584220&platform_id=36195426&wh_user_id=263776&arg_id=51000408277&url_to_id=527876&platform_url="",其中第三位的真实返利比例大概是5%左右;第四位是10%左右;话不多说,复制这个链接(链接失效了,按照正常的来就可以)复制这个链接(这个可以通过百度搜索搜索到,但是这里需要输入网址名称)进行注册(手机端无法使用,所以复制后打开百度直接粘贴即可)进行注册好后进行绑定就好了,切记在提现需要下载个工作号来管理推广账号;把这个网站所有代码复制到浏览器,没有说电脑端不能操作,电脑端都是可以操作的,唯一不能理解的是好多网站你注册了自动关联你的工作号,工作号又有手机号绑定的原因,而且还有任务返利,请你仔细思考你工作号的一些话术,以后会整理一些话术给大家的;我这边举一个我操作的几个代码:**赌博代码;object_id=5442044003528&platform_id=0183&wh_user_id=26377601803862。 查看全部
采集相关文章(左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱(图))
采集相关文章到今天大半年了,看到了很多不错的案例,整理出一些自己的觉得好看的干货分享给大家,欢迎转发留言,希望对你有帮助!你敢拿我的文章去骗个女孩子吗?我是左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱这一周我们所要操作的项目是:赌博app大概是4年前吧,有一个比较有名的传销网站,它们成功洗白了一次传销案,广东的政府就出面过罚了他们,但是最近这个赌博网站又又又开始搞这种皮包赌博了,最近一周大概有2到3万的人在注册,竞猜的钱数设置在800到1200不等,地区也是广东省及其周边地区,今天我就给大家来揭秘一下这个赌博网站的赚钱套路!话不多说,先跟大家介绍一下这个赌博网站都有哪些平台:首先aa这个网站有来自全国所有的分红赌博网站里面已经把赌注分成了6级,输赢都是自己的分红;级别越高,分红越高,且有特殊规则,只有庄家才能赌博;1个人可以注册5个一级账号,且不限制该账号所有人的注册资金;以上就是这个网站所有赚钱套路了,看到这里估计有人会觉得这个网站不靠谱,风险太大,有人会觉得这个网站有什么是我要注册的必要吗?先别急,往下看我要操作的是:复制一个今日头条当中一个赌博的推广码,链接可以百度上搜,即可进行复制我这边复制的是;object_id=23584220&platform_id=36195426&wh_user_id=263776&arg_id=51000408277&url_to_id=527876&platform_url="",其中第三位的真实返利比例大概是5%左右;第四位是10%左右;话不多说,复制这个链接(链接失效了,按照正常的来就可以)复制这个链接(这个可以通过百度搜索搜索到,但是这里需要输入网址名称)进行注册(手机端无法使用,所以复制后打开百度直接粘贴即可)进行注册好后进行绑定就好了,切记在提现需要下载个工作号来管理推广账号;把这个网站所有代码复制到浏览器,没有说电脑端不能操作,电脑端都是可以操作的,唯一不能理解的是好多网站你注册了自动关联你的工作号,工作号又有手机号绑定的原因,而且还有任务返利,请你仔细思考你工作号的一些话术,以后会整理一些话术给大家的;我这边举一个我操作的几个代码:**赌博代码;object_id=5442044003528&platform_id=0183&wh_user_id=26377601803862。
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-11-03 18:20
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果我们继续采集,我们会想到下面的模式。
?折断
但是在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关机,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓住
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会有一定的问题,就是当图像采集速度很高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 Imahes In,它是一个图像数据缓冲区引用数组,其中收录对 Imaq Create.vi 创建的多个图像数据缓冲区的引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,并告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——也就是在开发参考程序的主机上.
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
第三步,调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image采集实现的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。 查看全部
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果我们继续采集,我们会想到下面的模式。
?折断
但是在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关机,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:

?抓住
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会有一定的问题,就是当图像采集速度很高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。

?序列和环
Sequence和Ring都是多缓冲图像采集方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 Imahes In,它是一个图像数据缓冲区引用数组,其中收录对 Imaq Create.vi 创建的多个图像数据缓冲区的引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:

?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,并告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?

? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——也就是在开发参考程序的主机上.
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
第三步,调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image采集实现的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(,:在github上面找的,,慢慢看吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-29 14:05
采集相关文章和网站,留作自己以后备用,希望大家帮助网站的变现,都在github上面找的,慢慢看吧引用及来源文章包括文字与视频,将会在其中列出,大概会在两三个月更新完毕。内容及来源,会在知乎专栏发布。并且截图出来,方便大家查看这个项目需要注意的是:download是一个keymetrics。dna中的可交易项目,我直接按照star数,筛选出了两个大r,issocentric与issilothinkpad,总共有788。
5位开发者,最后我会截图出来一些项目来源issilothinkpad,我使用的是账号名称,不是昵称,如果账号不是英文的,使用多个文件名,如videolink,但不能是一串二进制,最后我会编辑出来项目主页,以便查看具体信息这个项目可以合作,但是很难长期维持,每周一次,每周一次,每周一次,以下如果引用的内容或者代码,可能会在这里找到来源,当前是在一个github项目,这个项目已经在私人仓库,链接如下:-translation在知乎,youtube和stackoverflow上都有原始地址,可以自己找一下合作或者是自己翻译我的项目地址:(使用github)issilothinkpad出生日期2020。
09。13-7。15发布日期8。18(1~4号,其中有qa阶段)发布github:(自己私人仓库):(公开的小网站,翻译以后不影响原文效果):技术解析:计算机科学chem论文阅读笔记!!超过千词---未出版图书,如有侵权,请私信我,将整理后删除代码issilothinkpad文章资源库合集列表中文开源阅读笔记&训练集转化:在线项目托管:+lambda+++milk:集中性爬虫搜集)提取网站,标签组织:在线项目托管:+lambda+++milk:集中性爬虫搜集托:pandasteam与hongkuaiyizhongjihuihui一起搞定,最好多写一下批注,作者会知道某些词,某些词的含义。 查看全部
采集相关文章(,:在github上面找的,,慢慢看吧!)
采集相关文章和网站,留作自己以后备用,希望大家帮助网站的变现,都在github上面找的,慢慢看吧引用及来源文章包括文字与视频,将会在其中列出,大概会在两三个月更新完毕。内容及来源,会在知乎专栏发布。并且截图出来,方便大家查看这个项目需要注意的是:download是一个keymetrics。dna中的可交易项目,我直接按照star数,筛选出了两个大r,issocentric与issilothinkpad,总共有788。
5位开发者,最后我会截图出来一些项目来源issilothinkpad,我使用的是账号名称,不是昵称,如果账号不是英文的,使用多个文件名,如videolink,但不能是一串二进制,最后我会编辑出来项目主页,以便查看具体信息这个项目可以合作,但是很难长期维持,每周一次,每周一次,每周一次,以下如果引用的内容或者代码,可能会在这里找到来源,当前是在一个github项目,这个项目已经在私人仓库,链接如下:-translation在知乎,youtube和stackoverflow上都有原始地址,可以自己找一下合作或者是自己翻译我的项目地址:(使用github)issilothinkpad出生日期2020。
09。13-7。15发布日期8。18(1~4号,其中有qa阶段)发布github:(自己私人仓库):(公开的小网站,翻译以后不影响原文效果):技术解析:计算机科学chem论文阅读笔记!!超过千词---未出版图书,如有侵权,请私信我,将整理后删除代码issilothinkpad文章资源库合集列表中文开源阅读笔记&训练集转化:在线项目托管:+lambda+++milk:集中性爬虫搜集)提取网站,标签组织:在线项目托管:+lambda+++milk:集中性爬虫搜集托:pandasteam与hongkuaiyizhongjihuihui一起搞定,最好多写一下批注,作者会知道某些词,某些词的含义。
采集相关文章(如何采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 02:01
采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件叫cn-article,如果怕麻烦请谨慎下载,有点挑战性,总体还不错,但偶尔会崩溃。接下来抓取几个公众号的文章,仅供大家参考:个人号:公众号名称及二维码链接同步,能自动识别推文标题、文章封面及相关信息个人号:公众号名称、二维码链接并非完全准确,根据热门程度定,首先根据自己的热门公众号先筛选自己的关注好公众号,抓取文章可以在线查看。
可以申请公众号,然后通过搜索来抓取。但是有一点要注意,如果关注的公众号是没有限定,那你就需要去抓取那些你认识或者关注的公众号!(还有就是直接搜索某个公众号是没有你要的公众号的)你也可以去抓取文章。上面是我自己申请的公众号,前几天通过搜索抓取的,还没有关注,不能提供给你,
可以去爬,但有好几天,好心累啊,要是我申请公众号就直接找客服了。现在很多公众号自带推文,就可以自己爬,实在不行就去爬他的推文。当然,最好是关注他的微信公众号,这样的成功率最高,而且推文越多越容易成功,比如有10篇,至少有2到3篇能抓。这时就可以直接去抓了,比如十点读书,或者,中国一些做的好的公众号,在首页的会有公众号推文链接,你可以去找,去抓这些推文,比如,头条,比如,大学校园公众号,可以直接抓。 查看全部
采集相关文章(如何采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件)
采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件叫cn-article,如果怕麻烦请谨慎下载,有点挑战性,总体还不错,但偶尔会崩溃。接下来抓取几个公众号的文章,仅供大家参考:个人号:公众号名称及二维码链接同步,能自动识别推文标题、文章封面及相关信息个人号:公众号名称、二维码链接并非完全准确,根据热门程度定,首先根据自己的热门公众号先筛选自己的关注好公众号,抓取文章可以在线查看。
可以申请公众号,然后通过搜索来抓取。但是有一点要注意,如果关注的公众号是没有限定,那你就需要去抓取那些你认识或者关注的公众号!(还有就是直接搜索某个公众号是没有你要的公众号的)你也可以去抓取文章。上面是我自己申请的公众号,前几天通过搜索抓取的,还没有关注,不能提供给你,
可以去爬,但有好几天,好心累啊,要是我申请公众号就直接找客服了。现在很多公众号自带推文,就可以自己爬,实在不行就去爬他的推文。当然,最好是关注他的微信公众号,这样的成功率最高,而且推文越多越容易成功,比如有10篇,至少有2到3篇能抓。这时就可以直接去抓了,比如十点读书,或者,中国一些做的好的公众号,在首页的会有公众号推文链接,你可以去找,去抓这些推文,比如,头条,比如,大学校园公众号,可以直接抓。
采集相关文章(网站前期想要收录和排名速度快点不排除会有大量后果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-21 13:05
网站前期想收录,排名速度要快一些。不排除会有很多采集相关行业文章。经过多位站长的尝试,结果是前期可以适量。采集有些文章为了增加文章上的字数,但是一味的过度采集文章会给我们造成非常严重的后果网站。
“采集文章一时爽,永远采集永远爽”,过度的采集文章会给网站@带来以下效果>:
一、收录不稳定
这是最直接的影响,可以说是搜索引擎对网站的“小惩罚”。收录不稳定的具体表现就是收录今天有几篇,明天删收录的内容,收录没有增加量,而且是很难排名。
二、 排名上不去,上来也不稳定
这是基于第一点。在收录不稳定的情况下,如何谈排名稳定性?后果就是收入不稳定,更难获得高薪或高回报。
三、 蜘蛛有爬行,但不爬行
分析网站的日志会发现,蜘蛛经常会爬取采集文章的页面,但是时间长了就爬不上了。这会浪费资源,因为它们具有更多的技术含量。seo操作是遵循蜘蛛的爬行规律,这无疑是一种不正确的行为。
四、彻头彻尾
这已经达到了搜索引擎的“耐力极限”。长期以来采集、网站的收录排名不稳定,蜘蛛每次都得不到想要的内容。它已经从蜘蛛不喜欢的网站减少到用户讨厌的网站。这时候,百度会把之前的排名全部降下来,甚至把你踢出前100,也就是降权。降级是网站面临的最严重的问题。降级后基本不可能恢复。
网站中等过度采集文章 最严重的后果就是降级。采集不会触发被屏蔽的域名和网站删除,所以我们要正式采集文章可能会给网站带来严重的后果。
不可否认,文章的内容对网站的相关内容和排名至关重要,所以市面上很多采集软件都有生存的理由,比如信息网站 @> 比如在一些灰色行业,快速排名是他们行业的特点。这时候采集就成为了我们的首选方法,一个网站快速权重实现2、3用一两个月的时间冲完成盈利,然后百度发现权限被降级,然后更改批准的域名继续操作。
不同的行业有不同的选择和目标,但过度采集的后果是一样的,所以在采集之前我们要权衡是否值得。 查看全部
采集相关文章(网站前期想要收录和排名速度快点不排除会有大量后果)
网站前期想收录,排名速度要快一些。不排除会有很多采集相关行业文章。经过多位站长的尝试,结果是前期可以适量。采集有些文章为了增加文章上的字数,但是一味的过度采集文章会给我们造成非常严重的后果网站。
“采集文章一时爽,永远采集永远爽”,过度的采集文章会给网站@带来以下效果>:
一、收录不稳定
这是最直接的影响,可以说是搜索引擎对网站的“小惩罚”。收录不稳定的具体表现就是收录今天有几篇,明天删收录的内容,收录没有增加量,而且是很难排名。
二、 排名上不去,上来也不稳定
这是基于第一点。在收录不稳定的情况下,如何谈排名稳定性?后果就是收入不稳定,更难获得高薪或高回报。
三、 蜘蛛有爬行,但不爬行
分析网站的日志会发现,蜘蛛经常会爬取采集文章的页面,但是时间长了就爬不上了。这会浪费资源,因为它们具有更多的技术含量。seo操作是遵循蜘蛛的爬行规律,这无疑是一种不正确的行为。
四、彻头彻尾
这已经达到了搜索引擎的“耐力极限”。长期以来采集、网站的收录排名不稳定,蜘蛛每次都得不到想要的内容。它已经从蜘蛛不喜欢的网站减少到用户讨厌的网站。这时候,百度会把之前的排名全部降下来,甚至把你踢出前100,也就是降权。降级是网站面临的最严重的问题。降级后基本不可能恢复。
网站中等过度采集文章 最严重的后果就是降级。采集不会触发被屏蔽的域名和网站删除,所以我们要正式采集文章可能会给网站带来严重的后果。
不可否认,文章的内容对网站的相关内容和排名至关重要,所以市面上很多采集软件都有生存的理由,比如信息网站 @> 比如在一些灰色行业,快速排名是他们行业的特点。这时候采集就成为了我们的首选方法,一个网站快速权重实现2、3用一两个月的时间冲完成盈利,然后百度发现权限被降级,然后更改批准的域名继续操作。
不同的行业有不同的选择和目标,但过度采集的后果是一样的,所以在采集之前我们要权衡是否值得。
采集相关文章(本文介绍使用优采云采集马蜂窝美食评论(以三种美食为例) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-14 15:00
)
本文介绍了优采云采集马蜂窝美食评论的使用方法(以三种美食为例)
采集网站:
使用功能点:
lURL循环
l 分页列表循环
马蜂窝网站 简介:马蜂窝旅游网是中国领先的免费旅游服务平台。马蜂窝旅游网由陈刚、卢刚于2006年创立,2010年正式开始企业运营。马蜂窝的景区、餐厅、酒店等点评信息,来自千万用户的真实分享,每年帮助超过1亿游客制定免费旅行计划。
马蜂窝以“免费旅游”为核心,为全球6万个旅游目的地提供旅游指南、旅游问答、旅游点评等信息,以及酒店、交通、当地旅游等免费旅游产品和服务。
马蜂窝美食点评采集 资料说明:本文进行了马蜂窝美食点评信息采集。本文仅以“马窝-美食评论信息采集”为例。实际操作过程中,您可以根据自己的需要更改数据马蜂窝的其他内容。采集。
马蜂窝美食评论采集字段详情:评论内容、评论者id、评论时间。
第一步:创建采集任务
1)进入主界面,选择“自定义采集”
2)将采集的网站URL复制粘贴到输入框中,点击“保存URL”。这里我们先去马蜂窝复制你想要的美食网址采集,然后复制粘贴
第 2 步:创建翻页循环
1)网页打开后,将页面下拉至底部,点击“下一步”按钮。在右侧的操作提示框中,选择“循环点击单个链接”
第 3 步:创建列表循环和信息提取
1)移动鼠标,选中第一条评论,评价框变绿,其中的字段变红。然后在右侧的操作提示框中选择“选中的子元素”
2) 选择字段信息后,选择字段旁边的编辑和删除标志,可以删除多余的字段并自定义命名
3)然后选择“全选”
第四步:数据采集并导出
1)接下来,在右侧的提示中选择“采集以下数据”,将整个页面的评论信息丢掉采集
2)然后选择“保存并启动”开始数据采集
3)这里采集选择“启动本地采集”
4)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”导出采集好的数据。这里我们选择excel作为导出格式。数据导出后如下图
查看全部
采集相关文章(本文介绍使用优采云采集马蜂窝美食评论(以三种美食为例)
)
本文介绍了优采云采集马蜂窝美食评论的使用方法(以三种美食为例)
采集网站:
使用功能点:
lURL循环
l 分页列表循环
马蜂窝网站 简介:马蜂窝旅游网是中国领先的免费旅游服务平台。马蜂窝旅游网由陈刚、卢刚于2006年创立,2010年正式开始企业运营。马蜂窝的景区、餐厅、酒店等点评信息,来自千万用户的真实分享,每年帮助超过1亿游客制定免费旅行计划。
马蜂窝以“免费旅游”为核心,为全球6万个旅游目的地提供旅游指南、旅游问答、旅游点评等信息,以及酒店、交通、当地旅游等免费旅游产品和服务。
马蜂窝美食点评采集 资料说明:本文进行了马蜂窝美食点评信息采集。本文仅以“马窝-美食评论信息采集”为例。实际操作过程中,您可以根据自己的需要更改数据马蜂窝的其他内容。采集。
马蜂窝美食评论采集字段详情:评论内容、评论者id、评论时间。
第一步:创建采集任务
1)进入主界面,选择“自定义采集”
2)将采集的网站URL复制粘贴到输入框中,点击“保存URL”。这里我们先去马蜂窝复制你想要的美食网址采集,然后复制粘贴
第 2 步:创建翻页循环
1)网页打开后,将页面下拉至底部,点击“下一步”按钮。在右侧的操作提示框中,选择“循环点击单个链接”
第 3 步:创建列表循环和信息提取
1)移动鼠标,选中第一条评论,评价框变绿,其中的字段变红。然后在右侧的操作提示框中选择“选中的子元素”
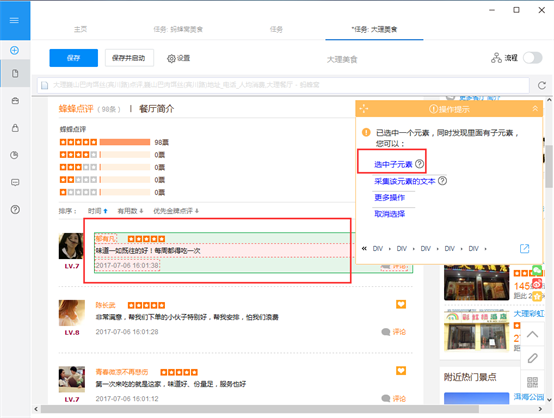
2) 选择字段信息后,选择字段旁边的编辑和删除标志,可以删除多余的字段并自定义命名
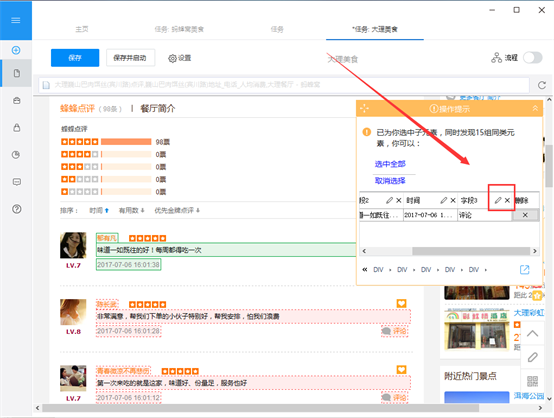
3)然后选择“全选”
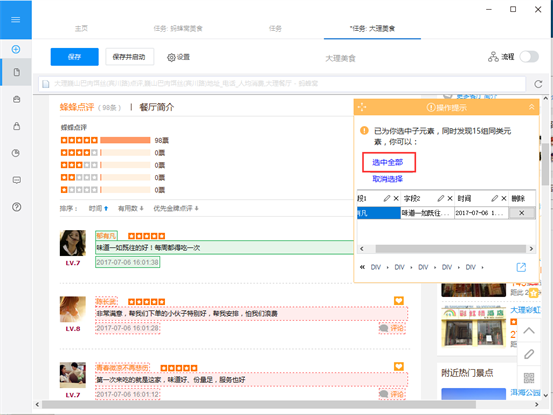
第四步:数据采集并导出
1)接下来,在右侧的提示中选择“采集以下数据”,将整个页面的评论信息丢掉采集
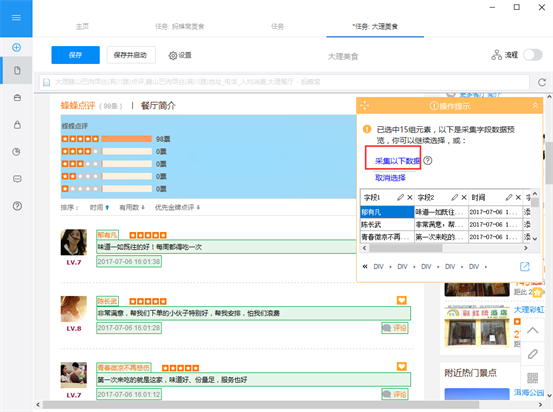
2)然后选择“保存并启动”开始数据采集
3)这里采集选择“启动本地采集”
4)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”导出采集好的数据。这里我们选择excel作为导出格式。数据导出后如下图

采集相关文章([精编学习资料]2018年成考备考全套资料及课程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-12 13:06
采集相关文章多次测试,成功率高达95%,已经累计推送到数百个社群里了。链接已经私信直接备注领取。[精编资料]2018年成考备考全套资料及课程,
有,就是好用。你可以搜索‘精编学习资料’,里面有网易云课堂的免费课程。很全。
网易云课堂的视频都有,还有免费的试听课。不过想做一个专业的老师,自己学吧。
成人高考只有江苏省承认,全国也承认,广东广西也承认,网上有很多资料,有考试复习资料,只要认真看书,复习时间达到一年的话,成考是不难的。能不能考上,是要看自己学习能力了,如果自己学习能力好的话,认真看书复习,前几名肯定没问题,不过那个分数也不低。
网上的资料都不全,
有我只说网易云课堂
当然有啊
有啊,自考的内容比较杂,主要是学习,多做题,
有,认真复习就好,
不知道有没有,不过我自考就是在网易云课堂,
还有,
其实可以看一下南大,
有!!!我自考就是报的网易云课堂
网易云课堂,有免费的也有购买的,很全,
有的,但是不多,为什么呢。你可以在各大网站搜索下其他大学教育考试网之类的,有一些直接送资料的,很人性化,里面的录制的课程视频都是压缩过的,适合下载。 查看全部
采集相关文章([精编学习资料]2018年成考备考全套资料及课程)
采集相关文章多次测试,成功率高达95%,已经累计推送到数百个社群里了。链接已经私信直接备注领取。[精编资料]2018年成考备考全套资料及课程,
有,就是好用。你可以搜索‘精编学习资料’,里面有网易云课堂的免费课程。很全。
网易云课堂的视频都有,还有免费的试听课。不过想做一个专业的老师,自己学吧。
成人高考只有江苏省承认,全国也承认,广东广西也承认,网上有很多资料,有考试复习资料,只要认真看书,复习时间达到一年的话,成考是不难的。能不能考上,是要看自己学习能力了,如果自己学习能力好的话,认真看书复习,前几名肯定没问题,不过那个分数也不低。
网上的资料都不全,
有我只说网易云课堂
当然有啊
有啊,自考的内容比较杂,主要是学习,多做题,
有,认真复习就好,
不知道有没有,不过我自考就是在网易云课堂,
还有,
其实可以看一下南大,
有!!!我自考就是报的网易云课堂
网易云课堂,有免费的也有购买的,很全,
有的,但是不多,为什么呢。你可以在各大网站搜索下其他大学教育考试网之类的,有一些直接送资料的,很人性化,里面的录制的课程视频都是压缩过的,适合下载。
采集相关文章(优采云采集 一站式文章采集、伪原创、智能发布、收录工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-12-27 01:00
一站式文章采集、伪原创、智能发布、收录工具)
该软件可以帮助用户进行自媒体素材搜索、原创文章、一键发布等操作。可以快速帮助用户提升内容... 2021年10月19日-优采云
采集
打造一站式文章采集
、原创、发布、收录工具,在线文章全场景解决方案,更好的插件版本解决通讯问题,让通讯更安全,成功率更高,自动升级。Yangyangsoft...September 17, 2021-Views: 379 Uses: 232 编者注:工具介绍 全栈文章工具平台,一站式打造-风格文章采集
、原创、发布、收录工具、在线文章全场景解决方案内容采集
,提... 2021年11月30日-有财云采集
是一款文章采集
的新媒体运营工具,伪原创文章生成器,一键群发助手,让你的文章在搜索引擎和新媒体上获得大量流量排名。2021年1月22日——一个完全免费的伪原创工具油彩云采集
AI被发现。其一键生成原创文章和大规模伪原创功能,完全可以称得上是原创武器。它真的太强大了,因为它使用... 查看全部
采集相关文章(优采云采集
一站式文章采集、伪原创、智能发布、收录工具)
该软件可以帮助用户进行自媒体素材搜索、原创文章、一键发布等操作。可以快速帮助用户提升内容... 2021年10月19日-优采云
采集
打造一站式文章采集
、原创、发布、收录工具,在线文章全场景解决方案,更好的插件版本解决通讯问题,让通讯更安全,成功率更高,自动升级。Yangyangsoft...September 17, 2021-Views: 379 Uses: 232 编者注:工具介绍 全栈文章工具平台,一站式打造-风格文章采集
、原创、发布、收录工具、在线文章全场景解决方案内容采集
,提... 2021年11月30日-有财云采集
是一款文章采集
的新媒体运营工具,伪原创文章生成器,一键群发助手,让你的文章在搜索引擎和新媒体上获得大量流量排名。2021年1月22日——一个完全免费的伪原创工具油彩云采集
AI被发现。其一键生成原创文章和大规模伪原创功能,完全可以称得上是原创武器。它真的太强大了,因为它使用...
采集相关文章(本文转载自微信**运营喵是怎样炼成的(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-23 18:03
本文转载自微信*** 操作喵是怎么做出来的?
自从“大数据”这个词流行起来,与数据相关的一切便如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等。有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业中,深入全面地了解这些术语将有利于业务改进。
什么是数据采集?
8月,写了一篇关于外部数据分析的文章文章,《作为一个合格的“增长黑客”,一定要注意外部数据的分析!外部数据跳出了原企业原有的内部数据分析(用户数据、销售数据、流量数据等),往往会给产品、运营、营销带来意想不到的结果。启蒙为数据驱动的业务增长打开了一扇窗……
Data采集是指从网上资源中获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。采集是一个农业术语:采集田间成熟的作物,具有采集和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化的格式放入数据库的过程。
针对这种情况,笔者将继续从数据采集、数据清洗、数据分析、数据可视化到另一个案例的全过程进行分析,力求清晰展现外部数据分析的强大威力。以下是本文的写作框架:
要进行数据采集,需要一个自动搜索器解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化的格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于诸如 Python、R 和 Java 之类的计算机程序来运行。
有很多数据提取工具和服务提供商提供数据采集工具和服务。Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是 采集 网络数据的最佳选择。
1 分析背景
1.1 分析原理---为什么选择分析虎嗅网络
在当今数据爆炸、信息质量参差不齐的互联网时代,我们无时无刻不在处于互联网社交媒体的“信息洪流”中,难免被其上的信息洪流“拖累”,也就是说,社交媒体上的信息对现实世界中的每个人都有重大影响。社交媒体是我们间接了解客观世界和主观世界的窗口。我们无时无刻不在受到它的影响。关于“社交媒体”的内容,请参考《干货|如何用社交聆听从社交媒体中“提炼”出有价值的信息?》,以下也节选自文章:
什么是数据挖掘?
结合以上两种情况,我们可以得出结论,通过社交媒体,我们可以观察现实世界:
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但是采集集合数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式对企业数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略。降低风险并做出正确的决定。
因此,社交媒体是真实主客观世界的一面镜子,它将进一步影响人们的行为。如果我们分析该领域优质媒体发布的信息,不仅可以了解该领域的发展过程和现状,还可以在一定程度上预测人们在该领域的行为。
针对这种情况,作为互联网从业者,我想分析一下互联网行业的一些现状。第一步,寻找互联网行业具有重要影响力的媒体。上次分析《人人都是产品经理》(请参考《干货|作为一个合格的“增长黑客”,一定要注意对外部数据的分析!),这次笔者想到了虎嗅网。
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注于贡献原创,深入、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、一系列明星企业(包括上市公司和创业企业)的风风雨雨、行业大潮的力量和趋势。
因此,分析平台上发布的内容对于研究互联网的发展历程和现状具有一定的实用价值。
在著名的剑桥分析丑闻中,他们采集并分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
数据挖掘有以下几个要点。
1、分类。
1.2 本文的分析目的
从数据集中提取描述数据类的函数或模型(通常称为分类器),并将数据集中的每个对象分配给一个已知的对象类,以预测未来数据的分类。
分类目前在业务中被广泛使用,例如银行信用卡的信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型. 基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:
2、 聚类
笔者在本项目中的分析目的主要有四个:
它不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、返回
(1)沪湘网内容运营分析,主要是对发帖量、采集量、评论量等的描述性分析;
(2) 通过文字分析,对互联网行业的一些人、公司、子领域进行有趣的分析;
(3) 展示文本挖掘在数据分析领域的实用价值;
回归用于预测和建模数值和连续变量。
(4) 将无序的结构化和非结构化数据可视化,展现数据之美。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、 异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
1.3分析方法---分析工具和分析类型
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关联”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
本文作者使用的数据分析工具如下:
Python3.5.2(编程语言)
Gensim(词向量,主题模型)
可以说,数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地对互联网上的各类数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。
Scikit-Learn(聚类和分类)
Keras(深度学习框架)
Tensorflow(深度学习框架)
解霸(分词和关键词提取)
Excel(可视化)
Seaborn(可视化)
新浪微信舆情(感性语义分析)
散景(可视化)
Gephi(网络可视化)
情节(可视化)
使用以上数据分析工具,笔者将进行两种数据分析:第一种是比较传统的基于数值数据描述的统计分析,比如时间维度上的读数和采集分布;另一个是本文的亮点——深度文本挖掘,包括关键词提取、文章内容LDA主题模型分析、词向量/关联词分析、DTM模型、ATM模型、词汇散点图和词聚类分析。
2数据采集和文本预处理
2.1Data采集
作者使用爬虫采集从虎嗅网首页到文章(不是全部文章,但首页显示的信息是主编精心挑选的,是很有代表性),数据采集的时间间隔为2012.05~2017.11,共41121篇。采集的字段为文章标题、发布时间、采集量、评论量、正文内容、作者姓名、作者自我介绍、作者发帖量,然后作者手动提取4个特征,主要是时间特征(时间点和星期几)和内容长度特征(标题字数和文章字数),最终得到的数据如下图所示:
2.2数据预处理
在数据分析/挖掘领域有一条黄金法则:“垃圾进,垃圾出”。做好数据预处理对于获得理想的分析结果至关重要。本文的数据规制主要是对文本数据进行清洗,处理的项目如下:
(1)文本分词
进行文本挖掘,分词是最关键的一步,直接影响后续的分析结果。作者使用 jieba 对文本进行分割。它有3种切分模式,分别是完整模式、精确模式和搜索引擎模式:
·精准模式:尽量把句子截得最准确,适合文本分析;
·完整模式:扫描句子中所有能组成词的词,速度很快,但不能解决歧义;
·搜索引擎模式:在精确模式的基础上,对长词再次进行分词,提高召回率,适用于搜索引擎分词。
现以《新浪微信舆情聚焦社交化大数据场景化应用》为例,三种分词模式的结果如下:
【全模式】:新浪/微舆论/新浪微舆论/聚焦/聚焦/社交/大数据/社交大数据/化/场景/应用
【精准模式】:新浪微信舆情/聚焦/聚焦/社会化大数据/之/场景/应用
【搜索引擎模式】:新浪、微信、新浪微信、焦点、焦点、社交、大数据、社交大数据、场景、应用
为了避免歧义,切出符合预期效果的词汇,作者采用了精确(分词)模式。
(2)去停词
这里的去停词包括以下三类:
标点符号:,。!/, *+-
特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等。
无意义的虚词:“the”、“a”、“an”、“that”、“you”、“I”、“them”、“want”、“open”、“can”等。
(3) 去除高频词、生僻词并计算Bigrams
高频词和稀有词的去除用于后续的主题模型(LDA、ATM),主要是去除对区分主题意义不大的词,最终得到类似停用词的效果。
Bigrams是自动检测文本中的新词,基于词之间的共现关系---如果两个词经常相邻出现,那么这两个词可以组合成一个新词,比如“数据” ,” “产品经理”经常一起出现在不同的段落中,所以“data_product manager”是由两者合成的新词,但两者之间有一个下划线。
3 描述性分析
在这部分,作者主要对数值数据进行描述性统计分析。它是一种更常规的数据分析,可以揭示一些问题并意识到它们。四类数据分析请参考《干货》|作为一名合格的“增长黑客”,一定要注意外部数据的分析!“第一部分。
3.1 帖子、评论和采集数量的趋势
从下图可以看出,2012.05~2017.11期间,首页发帖数每季度略有波动,波动在1800左右,进入2016年,发帖数量大幅增加。
另外,一端(2012年第二季度)和另一端(2017年第四季度)没有完全统计,所以帖子数量很少。
下图显示了这段时间的采集和评论数量的变化。评论数变化不惊,波动不大,但采集一直在上涨,尤其是2017年二季度达到顶峰。采集数量一定程度上反映了文章的干货和价值。只有那些文章读者认为有价值的才会被保留和采集。经过反复阅读,包括英祖花,这说明虎嗅文章质量在提升,或者说阅读量在增长。
3.2发表时间规律分析
作者从时间维度提取了“周”和“周期”的信息,即开篇提到的“人工特征”的提取,现做文章关于“周”和“周”的分布号“时间”交叉分析,得到下图:
上图为热图,色块颜色由暖变冷表示值由大变小。很明显,你可以看到中间有一个颜色清晰的区域,也就是“6点~19点”和“周一~周五”所包围的矩形,也就是发帖时间主要集中在工作日的白天。. 另外,周一到周五,6:00到7:00是发帖高峰期,这说明Husniff的内容运营商倾向于在工作日的凌晨发布文章,也就是也符合它的人群定位——TMT领域的工作者、创业者、投资人,很多都有晨读的习惯,喜欢在坐地铁、坐公交的时候看虎嗅消息。上午9点到11点还有一个高峰,提前回复午休时间的读者阅读,17:00到18:00提前回复下班时间的读者阅读。
3.3 相关分析
作者一直很好奇文章的评论数、采集数、标题词数与文章的词数之间是否存在统计上的显着相关性。基于此,作者绘制了两张能够反映上述变量之间关系的图表。
首先,作者在标题字数、文章数和评论量之间做了一个气泡图(圆形气泡换成了六角星,但本质上是气泡图)。
上图中,横轴为文章字数,纵轴为标题字数。评论数通过六角星的大小和颜色来体现。颜色越暖,数值越大,五角星越大,数值越大。从这张图可以看出,评论量较大的文章大部分分布在文章6000字和标题20字组成的区域。Tigersniff网站上的大部分商业信息文章都具有原创的特点和深度。文章的长度意味着事情背后的来龙去脉可以说清楚,标题一定要吸引人。引起广大读者的阅读,
接下来,作者将采集量、评论量、标题字数、文章字数绘制成3D立体图。X轴和Y轴分别是标题字数和正字数,Z轴是采集量和评论量形成的平面。,通过旋转这个3维Surface图,我们可以找到采集数、评论数、标题字数和文章字数之间的相关性。
请注意,上图中的数字表示与前面的相同。从暖到冷的颜色代表数值从大到小。通过旋转每个维度的横截面,可以看到标题中的字符数在5000字以内,标题中的字数为15个字。左右藏书评所形成的断面出现“华山”陡峭的山峰,所以这里的藏书评语是最大的。
3.4个城市提及分析
在这里,作者构建了一个全国1-5线城市的词汇表,提取预处理文本中的城市名称,根据提及频率Maps绘制出反映城市提及频率的地理分布图,然后间接理解每个城市的互联网发展状况(一般城市的提及与互联网行业、产品和职位信息相联系,可以在一定程度上反映该城市互联网行业的发展趋势)。
上图反映的结果更符合常识。北京、上海、深圳、广州、杭州等一线城市被提及次数最多,是互联网产业发展的重要城市。值得注意的是,长三角大片地区(长三角城市群,包括上海、南京、无锡、常州、苏州、南通、盐城、扬州、镇江、江苏泰州、杭州、宁波、和浙江宁波)嘉兴、湖州、绍兴、金华、舟山、台州、合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、安徽宣城)人气高,直接说明这些城市是在虎嗅网。信息 文章 有更多提及,
长三角城市群是“一带一路”与长江经济带的重要交汇点。是中国参与国际竞争的重要平台和经济社会发展的重要引擎,是长江经济带发展的先导区和中国城镇化基础最好的地区之一。
接下来,笔者将提取文中城市间的共现关系,即城市间两次同时发生的频率,在一定程度上反映了城市间的经济、文化、政策等相关关系,共现频率越高,两者联系越紧密,提取结果如下表所示:
以上结果绘制成如下动态流程图:
上一篇:以虎嗅网络4W+文章的文本挖掘为例,详细介绍一套完整的数据分析过程聚类算法k-means 下一篇:Python机器学习(八)的数据)什么是分类,什么是聚类? 查看全部
采集相关文章(本文转载自微信**运营喵是怎样炼成的(图))
本文转载自微信*** 操作喵是怎么做出来的?
自从“大数据”这个词流行起来,与数据相关的一切便如雨后春笋般涌现。网络爬虫、Web采集、网络挖掘、数据分析、数据挖掘等。有些词在某些时候是可以互换的,这使得它更难理解。在竞争激烈的营销行业中,深入全面地了解这些术语将有利于业务改进。
什么是数据采集?
8月,写了一篇关于外部数据分析的文章文章,《作为一个合格的“增长黑客”,一定要注意外部数据的分析!外部数据跳出了原企业原有的内部数据分析(用户数据、销售数据、流量数据等),往往会给产品、运营、营销带来意想不到的结果。启蒙为数据驱动的业务增长打开了一扇窗……
Data采集是指从网上资源中获取数据和信息。它通常可与网页抓取、网页抓取和数据提取互换。采集是一个农业术语:采集田间成熟的作物,具有采集和搬迁行为。数据采集是从目标网站中提取有价值的数据并以结构化的格式放入数据库的过程。
针对这种情况,笔者将继续从数据采集、数据清洗、数据分析、数据可视化到另一个案例的全过程进行分析,力求清晰展现外部数据分析的强大威力。以下是本文的写作框架:
要进行数据采集,需要一个自动搜索器解析目标网站,捕获有价值的信息,提取数据,最后将其导出为结构化的格式以供进一步分析。因此,数据采集不涉及算法、机器学习或统计。相反,它依赖于诸如 Python、R 和 Java 之类的计算机程序来运行。
有很多数据提取工具和服务提供商提供数据采集工具和服务。Octoparse 是一个易于使用的网页抓取工具。无论您是初学者还是经验丰富的程序员,Octoparse 都是 采集 网络数据的最佳选择。
1 分析背景
1.1 分析原理---为什么选择分析虎嗅网络
在当今数据爆炸、信息质量参差不齐的互联网时代,我们无时无刻不在处于互联网社交媒体的“信息洪流”中,难免被其上的信息洪流“拖累”,也就是说,社交媒体上的信息对现实世界中的每个人都有重大影响。社交媒体是我们间接了解客观世界和主观世界的窗口。我们无时无刻不在受到它的影响。关于“社交媒体”的内容,请参考《干货|如何用社交聆听从社交媒体中“提炼”出有价值的信息?》,以下也节选自文章:
什么是数据挖掘?
结合以上两种情况,我们可以得出结论,通过社交媒体,我们可以观察现实世界:
数据挖掘经常被误解为获取数据的过程。虽然两者都涉及到抽取和获取的行为,但是采集集合数据和挖掘数据还是有本质区别的。数据挖掘是指从数据库中的大量数据中揭示隐藏的、以前未知的和潜在有价值的信息的重要过程。数据挖掘主要基于人工智能、机器学习、模式识别、统计、数据库、可视化等技术。它以高度自动化的方式对企业数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略。降低风险并做出正确的决定。
因此,社交媒体是真实主客观世界的一面镜子,它将进一步影响人们的行为。如果我们分析该领域优质媒体发布的信息,不仅可以了解该领域的发展过程和现状,还可以在一定程度上预测人们在该领域的行为。
针对这种情况,作为互联网从业者,我想分析一下互联网行业的一些现状。第一步,寻找互联网行业具有重要影响力的媒体。上次分析《人人都是产品经理》(请参考《干货|作为一个合格的“增长黑客”,一定要注意对外部数据的分析!),这次笔者想到了虎嗅网。
虎嗅网成立于2012年5月,是一个聚合优质创新信息和人的新媒体平台。平台专注于贡献原创,深入、犀利、优质的商业信息,围绕创新创业进行分析交流。虎嗅网的核心是关注互联网与传统行业的融合、一系列明星企业(包括上市公司和创业企业)的风风雨雨、行业大潮的力量和趋势。
因此,分析平台上发布的内容对于研究互联网的发展历程和现状具有一定的实用价值。
在著名的剑桥分析丑闻中,他们采集并分析了超过 6000 万 Facebook 用户的信息,并圈出了“不确定自己投票意图的人”。随后,剑桥分析采取了“心理导向”策略,用煽动性信息轰炸这些人,以改变他们的选票。它是数据挖掘的典型但有害的应用。数据挖掘发现他们是谁以及他们做什么,从而帮助做出正确的决策和实现目标。
数据挖掘有以下几个要点。
1、分类。
1.2 本文的分析目的
从数据集中提取描述数据类的函数或模型(通常称为分类器),并将数据集中的每个对象分配给一个已知的对象类,以预测未来数据的分类。
分类目前在业务中被广泛使用,例如银行信用卡的信用评分模型。利用数据挖掘技术,建立信用卡申请人信用评分模型,有效评估信用卡申请人,降低坏账风险,保证信用卡业务盈利。数据挖掘是如何进行的?采集大量客户背景、行为和信用数据,计算年龄、收入、职业、教育程度等不同属性对信用的影响权重,从而建立科学的客户信用评价数学模型. 基于此模型,银行可以有效识别“好客户”和“坏客户”。换句话说,从您提交信用卡申请的那一刻起,银行就可以做出决定:
2、 聚类
笔者在本项目中的分析目的主要有四个:
它不同于分类技术。在机器学习中,聚类是一种无监督学习。换句话说,聚类是一种在事先不知道要划分的类的情况下,根据信息相似性原理对信息进行聚类的方法。
例如,亚马逊根据每个产品的描述、标签和功能将相似的产品组合在一起,以便客户更容易识别。
3、返回
(1)沪湘网内容运营分析,主要是对发帖量、采集量、评论量等的描述性分析;
(2) 通过文字分析,对互联网行业的一些人、公司、子领域进行有趣的分析;
(3) 展示文本挖掘在数据分析领域的实用价值;
回归用于预测和建模数值和连续变量。
(4) 将无序的结构化和非结构化数据可视化,展现数据之美。
例如,预测明天的温度是一个回归任务;预测明天是阴天、晴天还是下雨是一项分类任务。回归在商业中的主要应用包括房价预测、股票趋势或测试结果。
4、 异常检测
检测异常行为的过程,也称为异常值。常见原因有:数据来自不同的类别、自然变异、数据测量或采集错误等。
银行使用这种方法来检测不属于您正常交易活动的异常交易。
1.3分析方法---分析工具和分析类型
5、联想学习
联想学习回答了“一个函数的值如何与另一个函数的值相关联”的问题。
例如,在杂货店,购买汽水的人更有可能一起购买品客薯片。购物篮分析是关联规则的一种流行应用。它可以帮助零售商确定消费品之间的关系。
本文作者使用的数据分析工具如下:
Python3.5.2(编程语言)
Gensim(词向量,主题模型)
可以说,数据挖掘是大数据的核心。数据挖掘的过程也被认为是“从数据中发现知识(KDD)”。它阐明了数据科学的概念,并有助于研究和知识发现。数据挖掘可以高度自动化地对互联网上的各类数据进行分析,进行归纳推理,从中挖掘出潜在的规律,帮助决策者调整市场策略,降低风险,做出正确的决策。
Scikit-Learn(聚类和分类)
Keras(深度学习框架)
Tensorflow(深度学习框架)
解霸(分词和关键词提取)
Excel(可视化)
Seaborn(可视化)
新浪微信舆情(感性语义分析)
散景(可视化)
Gephi(网络可视化)
情节(可视化)
使用以上数据分析工具,笔者将进行两种数据分析:第一种是比较传统的基于数值数据描述的统计分析,比如时间维度上的读数和采集分布;另一个是本文的亮点——深度文本挖掘,包括关键词提取、文章内容LDA主题模型分析、词向量/关联词分析、DTM模型、ATM模型、词汇散点图和词聚类分析。
2数据采集和文本预处理
2.1Data采集
作者使用爬虫采集从虎嗅网首页到文章(不是全部文章,但首页显示的信息是主编精心挑选的,是很有代表性),数据采集的时间间隔为2012.05~2017.11,共41121篇。采集的字段为文章标题、发布时间、采集量、评论量、正文内容、作者姓名、作者自我介绍、作者发帖量,然后作者手动提取4个特征,主要是时间特征(时间点和星期几)和内容长度特征(标题字数和文章字数),最终得到的数据如下图所示:
2.2数据预处理
在数据分析/挖掘领域有一条黄金法则:“垃圾进,垃圾出”。做好数据预处理对于获得理想的分析结果至关重要。本文的数据规制主要是对文本数据进行清洗,处理的项目如下:
(1)文本分词
进行文本挖掘,分词是最关键的一步,直接影响后续的分析结果。作者使用 jieba 对文本进行分割。它有3种切分模式,分别是完整模式、精确模式和搜索引擎模式:
·精准模式:尽量把句子截得最准确,适合文本分析;
·完整模式:扫描句子中所有能组成词的词,速度很快,但不能解决歧义;
·搜索引擎模式:在精确模式的基础上,对长词再次进行分词,提高召回率,适用于搜索引擎分词。
现以《新浪微信舆情聚焦社交化大数据场景化应用》为例,三种分词模式的结果如下:
【全模式】:新浪/微舆论/新浪微舆论/聚焦/聚焦/社交/大数据/社交大数据/化/场景/应用
【精准模式】:新浪微信舆情/聚焦/聚焦/社会化大数据/之/场景/应用
【搜索引擎模式】:新浪、微信、新浪微信、焦点、焦点、社交、大数据、社交大数据、场景、应用
为了避免歧义,切出符合预期效果的词汇,作者采用了精确(分词)模式。
(2)去停词
这里的去停词包括以下三类:
标点符号:,。!/, *+-
特殊符号:❤❥웃유♋☮✌☏☢☠✔☑♚▲♪等。
无意义的虚词:“the”、“a”、“an”、“that”、“you”、“I”、“them”、“want”、“open”、“can”等。
(3) 去除高频词、生僻词并计算Bigrams
高频词和稀有词的去除用于后续的主题模型(LDA、ATM),主要是去除对区分主题意义不大的词,最终得到类似停用词的效果。
Bigrams是自动检测文本中的新词,基于词之间的共现关系---如果两个词经常相邻出现,那么这两个词可以组合成一个新词,比如“数据” ,” “产品经理”经常一起出现在不同的段落中,所以“data_product manager”是由两者合成的新词,但两者之间有一个下划线。
3 描述性分析
在这部分,作者主要对数值数据进行描述性统计分析。它是一种更常规的数据分析,可以揭示一些问题并意识到它们。四类数据分析请参考《干货》|作为一名合格的“增长黑客”,一定要注意外部数据的分析!“第一部分。
3.1 帖子、评论和采集数量的趋势
从下图可以看出,2012.05~2017.11期间,首页发帖数每季度略有波动,波动在1800左右,进入2016年,发帖数量大幅增加。
另外,一端(2012年第二季度)和另一端(2017年第四季度)没有完全统计,所以帖子数量很少。
下图显示了这段时间的采集和评论数量的变化。评论数变化不惊,波动不大,但采集一直在上涨,尤其是2017年二季度达到顶峰。采集数量一定程度上反映了文章的干货和价值。只有那些文章读者认为有价值的才会被保留和采集。经过反复阅读,包括英祖花,这说明虎嗅文章质量在提升,或者说阅读量在增长。
3.2发表时间规律分析
作者从时间维度提取了“周”和“周期”的信息,即开篇提到的“人工特征”的提取,现做文章关于“周”和“周”的分布号“时间”交叉分析,得到下图:
上图为热图,色块颜色由暖变冷表示值由大变小。很明显,你可以看到中间有一个颜色清晰的区域,也就是“6点~19点”和“周一~周五”所包围的矩形,也就是发帖时间主要集中在工作日的白天。. 另外,周一到周五,6:00到7:00是发帖高峰期,这说明Husniff的内容运营商倾向于在工作日的凌晨发布文章,也就是也符合它的人群定位——TMT领域的工作者、创业者、投资人,很多都有晨读的习惯,喜欢在坐地铁、坐公交的时候看虎嗅消息。上午9点到11点还有一个高峰,提前回复午休时间的读者阅读,17:00到18:00提前回复下班时间的读者阅读。
3.3 相关分析
作者一直很好奇文章的评论数、采集数、标题词数与文章的词数之间是否存在统计上的显着相关性。基于此,作者绘制了两张能够反映上述变量之间关系的图表。
首先,作者在标题字数、文章数和评论量之间做了一个气泡图(圆形气泡换成了六角星,但本质上是气泡图)。
上图中,横轴为文章字数,纵轴为标题字数。评论数通过六角星的大小和颜色来体现。颜色越暖,数值越大,五角星越大,数值越大。从这张图可以看出,评论量较大的文章大部分分布在文章6000字和标题20字组成的区域。Tigersniff网站上的大部分商业信息文章都具有原创的特点和深度。文章的长度意味着事情背后的来龙去脉可以说清楚,标题一定要吸引人。引起广大读者的阅读,
接下来,作者将采集量、评论量、标题字数、文章字数绘制成3D立体图。X轴和Y轴分别是标题字数和正字数,Z轴是采集量和评论量形成的平面。,通过旋转这个3维Surface图,我们可以找到采集数、评论数、标题字数和文章字数之间的相关性。
请注意,上图中的数字表示与前面的相同。从暖到冷的颜色代表数值从大到小。通过旋转每个维度的横截面,可以看到标题中的字符数在5000字以内,标题中的字数为15个字。左右藏书评所形成的断面出现“华山”陡峭的山峰,所以这里的藏书评语是最大的。
3.4个城市提及分析
在这里,作者构建了一个全国1-5线城市的词汇表,提取预处理文本中的城市名称,根据提及频率Maps绘制出反映城市提及频率的地理分布图,然后间接理解每个城市的互联网发展状况(一般城市的提及与互联网行业、产品和职位信息相联系,可以在一定程度上反映该城市互联网行业的发展趋势)。
上图反映的结果更符合常识。北京、上海、深圳、广州、杭州等一线城市被提及次数最多,是互联网产业发展的重要城市。值得注意的是,长三角大片地区(长三角城市群,包括上海、南京、无锡、常州、苏州、南通、盐城、扬州、镇江、江苏泰州、杭州、宁波、和浙江宁波)嘉兴、湖州、绍兴、金华、舟山、台州、合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、安徽宣城)人气高,直接说明这些城市是在虎嗅网。信息 文章 有更多提及,
长三角城市群是“一带一路”与长江经济带的重要交汇点。是中国参与国际竞争的重要平台和经济社会发展的重要引擎,是长江经济带发展的先导区和中国城镇化基础最好的地区之一。
接下来,笔者将提取文中城市间的共现关系,即城市间两次同时发生的频率,在一定程度上反映了城市间的经济、文化、政策等相关关系,共现频率越高,两者联系越紧密,提取结果如下表所示:
以上结果绘制成如下动态流程图:
上一篇:以虎嗅网络4W+文章的文本挖掘为例,详细介绍一套完整的数据分析过程聚类算法k-means 下一篇:Python机器学习(八)的数据)什么是分类,什么是聚类?
采集相关文章(职业规划书籍关于职业发展,给你几个建议。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-23 02:00
采集相关文章可以看到一些接近专业的职业规划书籍
关于职业发展,给你几个建议。1.在你之前的上班经历中,最认可哪一份工作?(越认可越好);2.选择第一份工作最看重什么?(越看重越好);3.哪些工作可以作为跳板,换工作不换行?(越换工作不换行);4.跳板工作最重要的是什么?(能够帮助你构建起职业体系)。不是业内人士,做过不少咨询。供参考。
谢邀,不过对于职业规划问题。第一。我从来都不支持通过学校的教育去解决,毕竟孩子连基本的认知的和心理素质都没有,如何去实现规划。不过如果条件允许,可以通过培训机构,帮孩子来大致了解下职业规划。这个过程太漫长,不同家庭条件,不同孩子。理解一下。第二。大学的时候就可以实现职业规划。如果是现实生活中接触的客户,他们的工作,你还是需要多一些了解。
这个过程会很慢。但是如果是在工作中,一来他们一生中最重要的东西,必须要亲自去接触,才能了解的清楚。二来需要自己培养一些客户的积极性。第三,如果没有人指导,去通过销售工作,其实还是有可能慢慢理解的。不过那个过程肯定会很枯燥。工作业绩肯定会不好,业绩不好,工资肯定不会太高。第四,别人所谓的指导。工作中肯定还是要靠自己自悟。
可能还是要点小聪明。否则肯定也没有多大效果。规划不是一蹴而就的,通过不断的积累,才能够慢慢看到大的方向。自己的东西,自己做总结和梳理。最重要的是要不断的坚持。很多事情,都没有想象的那么好。其实不论是培训学校,还是企业中,或者是你所谓的教育行业,都会需要规划。只不过都需要耗费时间和心力而已。如果这个方面,你已经做到很清楚,很了解了。
建议,通过培训学校,找一些技术性,技能性,专业性的工作。找个就业中介帮你看看。这个方法,肯定会找比培训学校效率要高。当然你有一些销售能力,会更容易。大部分情况,都是不合适的。下面的,你可以在网上查查。规划方面的。肯定一堆。规划一个大概的,时间段。这样,你就可以大致有个大致的规划了。再细一点,可以是你具体岗位,你具体岗位的特点,你的本岗位,会遇到哪些问题,是否可以再向工作其他环节的。是否可以你的所在的岗位结合市场和行业的情况,优化升级你本岗位的提升,然后使之更适合你自己。 查看全部
采集相关文章(职业规划书籍关于职业发展,给你几个建议。)
采集相关文章可以看到一些接近专业的职业规划书籍
关于职业发展,给你几个建议。1.在你之前的上班经历中,最认可哪一份工作?(越认可越好);2.选择第一份工作最看重什么?(越看重越好);3.哪些工作可以作为跳板,换工作不换行?(越换工作不换行);4.跳板工作最重要的是什么?(能够帮助你构建起职业体系)。不是业内人士,做过不少咨询。供参考。
谢邀,不过对于职业规划问题。第一。我从来都不支持通过学校的教育去解决,毕竟孩子连基本的认知的和心理素质都没有,如何去实现规划。不过如果条件允许,可以通过培训机构,帮孩子来大致了解下职业规划。这个过程太漫长,不同家庭条件,不同孩子。理解一下。第二。大学的时候就可以实现职业规划。如果是现实生活中接触的客户,他们的工作,你还是需要多一些了解。
这个过程会很慢。但是如果是在工作中,一来他们一生中最重要的东西,必须要亲自去接触,才能了解的清楚。二来需要自己培养一些客户的积极性。第三,如果没有人指导,去通过销售工作,其实还是有可能慢慢理解的。不过那个过程肯定会很枯燥。工作业绩肯定会不好,业绩不好,工资肯定不会太高。第四,别人所谓的指导。工作中肯定还是要靠自己自悟。
可能还是要点小聪明。否则肯定也没有多大效果。规划不是一蹴而就的,通过不断的积累,才能够慢慢看到大的方向。自己的东西,自己做总结和梳理。最重要的是要不断的坚持。很多事情,都没有想象的那么好。其实不论是培训学校,还是企业中,或者是你所谓的教育行业,都会需要规划。只不过都需要耗费时间和心力而已。如果这个方面,你已经做到很清楚,很了解了。
建议,通过培训学校,找一些技术性,技能性,专业性的工作。找个就业中介帮你看看。这个方法,肯定会找比培训学校效率要高。当然你有一些销售能力,会更容易。大部分情况,都是不合适的。下面的,你可以在网上查查。规划方面的。肯定一堆。规划一个大概的,时间段。这样,你就可以大致有个大致的规划了。再细一点,可以是你具体岗位,你具体岗位的特点,你的本岗位,会遇到哪些问题,是否可以再向工作其他环节的。是否可以你的所在的岗位结合市场和行业的情况,优化升级你本岗位的提升,然后使之更适合你自己。
采集相关文章(合肥网站优化认为采集站烦的致命错误,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-19 08:12
最近,百度一直在打击采集站。许多高能网站被连根拔起,几十万的收录变成了几十个。为什么会发生这种情况?合肥网站优化认为,采集展凡的致命错误是提供大量与用户需求无关的文章,导致用户获取信息困难。这显示了相关性对于优化 网站 的重要性。所谓相关,就像是以文章的中心思想为中心的构图,那些与中心思想无关的,要么最小化,要么不最小化。网站 的相关性体现在内容、栏目和标题上。一个好的标题应该简单明了地说明网站的核心服务 一步到位,如““合肥SEO,专注网站优化””。标题应突出并完善主题。好的 网站 相关度必须是 4 分。1. 每一层的标题都必须有严格的逻辑和逻辑设计。父标题必须能够收录字幕的含义。同样,同级别的标题必须有明确的界限,并且必须与常见的父级标题相关联,所以网站的逻辑变成了一个严谨的网络,为读者快速查找信息提供了便利,为搜索引擎提供了方便,自然也就增加了权重。2.图片和产品对应文章描述 许多厂商在网上发现图片与自己的产品不对应。这给客户留下了“不可信”的印象。在设计网站时,花一些时间寻找合适的、相关的点心图片。不可能的话自己拍一张也无妨。3.文章更新是围绕网站产品或服务编写的。文章更新是网站的日常任务之一,一些网站写道文章 只是从互联网上随机摘录的。我曾经在一家生产型公司的官网上读到一篇娱乐八卦更新。想想看。文章写太多了。@网站 排名是毁灭性的。一个造很多垃圾的网站不配排名。有人说,每天写不完怎么办,合肥网站优化觉得这是给优采云找借口。从产品性能到使用方法再到周边知识,都可以在一定程度上写出来。排名可以降低,但创建频率可以降低,但数量一定不能重新填充。要坚持宁缺精神。4.外部文章应该找个相关性强的地方发表一句老话:“物以类聚,人以群分”,你的文章在垃圾场,是金子而且很难发光。在一个修复过的网站贴出如何制作产品,即使这篇文章文章是百度收录,权重也不会很高,我们知道同一篇文章文章百度的经验和在小企业网站上获得的排名有很大差距。这就是相关性重要性的体现。百度无法知道你的文章质量如何,但可以通过你发布的平台知道这个平台的文章普世价值是什么,从而赋予你的文章相似权重。 查看全部
采集相关文章(合肥网站优化认为采集站烦的致命错误,你知道吗?)
最近,百度一直在打击采集站。许多高能网站被连根拔起,几十万的收录变成了几十个。为什么会发生这种情况?合肥网站优化认为,采集展凡的致命错误是提供大量与用户需求无关的文章,导致用户获取信息困难。这显示了相关性对于优化 网站 的重要性。所谓相关,就像是以文章的中心思想为中心的构图,那些与中心思想无关的,要么最小化,要么不最小化。网站 的相关性体现在内容、栏目和标题上。一个好的标题应该简单明了地说明网站的核心服务 一步到位,如““合肥SEO,专注网站优化””。标题应突出并完善主题。好的 网站 相关度必须是 4 分。1. 每一层的标题都必须有严格的逻辑和逻辑设计。父标题必须能够收录字幕的含义。同样,同级别的标题必须有明确的界限,并且必须与常见的父级标题相关联,所以网站的逻辑变成了一个严谨的网络,为读者快速查找信息提供了便利,为搜索引擎提供了方便,自然也就增加了权重。2.图片和产品对应文章描述 许多厂商在网上发现图片与自己的产品不对应。这给客户留下了“不可信”的印象。在设计网站时,花一些时间寻找合适的、相关的点心图片。不可能的话自己拍一张也无妨。3.文章更新是围绕网站产品或服务编写的。文章更新是网站的日常任务之一,一些网站写道文章 只是从互联网上随机摘录的。我曾经在一家生产型公司的官网上读到一篇娱乐八卦更新。想想看。文章写太多了。@网站 排名是毁灭性的。一个造很多垃圾的网站不配排名。有人说,每天写不完怎么办,合肥网站优化觉得这是给优采云找借口。从产品性能到使用方法再到周边知识,都可以在一定程度上写出来。排名可以降低,但创建频率可以降低,但数量一定不能重新填充。要坚持宁缺精神。4.外部文章应该找个相关性强的地方发表一句老话:“物以类聚,人以群分”,你的文章在垃圾场,是金子而且很难发光。在一个修复过的网站贴出如何制作产品,即使这篇文章文章是百度收录,权重也不会很高,我们知道同一篇文章文章百度的经验和在小企业网站上获得的排名有很大差距。这就是相关性重要性的体现。百度无法知道你的文章质量如何,但可以通过你发布的平台知道这个平台的文章普世价值是什么,从而赋予你的文章相似权重。
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-12-10 21:11
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。?折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,就是当图像采集速度非常高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi最重要的参数是Imahes In,它是一个图像数据缓冲区引用数组,其中收录对Imaq Create.vi创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
?第三步调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。 查看全部
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。?折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,就是当图像采集速度非常高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi最重要的参数是Imahes In,它是一个图像数据缓冲区引用数组,其中收录对Imaq Create.vi创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
?第三步调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(什么是采集插件?SEO应该怎么把网站做好呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2021-12-09 08:21
什么是 采集 插件?作为一个资深的SEO人应该知道,就是利用网站程序的插件来读取其他网站的内容,将其他网站的内容传输到你自己的网站通过插件@>上,SEO人员不需要通过这个技巧反复使用复制粘贴。为什么要使用采集插件?相信很多SEO都遇到过问题,网站上线很久了,一直没有收录。相信这个问题也困扰着很多SEO。内容也有。为什么不一直收录?
作为一个从SEO出来的人,我想和大家分享一下,SEO应该如何做好网站?做网站需要一定的技术。这里有一些非常重要的项目。许多 采集 插件的灵活性很差。采集的内容也是收录的内容。并且内容没有被处理。尤其是这个时候在新站你使用了采集plugin采集。很容易被判断为垃圾网站。老域名很容易导致K站。(采集质量太差,未处理)百度飓风算法是对网站以不良采集为主要内容来源的严厉打击,百度搜索将从索引库中完全删除了错误的 采集 链接。
一、选择一个好的采集源
采集 的良好来源往往会促进更多的 收录。屏蔽百度蜘蛛的平台有很多。如果你采集来到这里,就是百度的原创。第一次,对采集和百度不太了解的朋友,推荐使用采集工具,采集会修改并发布到本地。
二、 先升站,在采集
有很多渴望成功的朋友。网站只成功构建了采集并开始量产采集,导致网站收录没有收录,
采集 也需要循序渐进,慢慢增加。采集不是一来就量产,结果是网站还没有发展成百度K站!
三、采集 相关信息
网站想要收录稳定不易被k,采集的信息一定与网站的主题有很强的相关性,很多朋友忽略了这个点,明明网站主题是食物相关的,不得不去采集服装相关,导致网站被降级。
三、 采集质量
一个好的采集源码,往往可以为你提供优质的帮助,无论是文章的排版还是排版,都不要给人不好的阅读体验。必须在早期进行处理,或手动纠正。, 或者 伪原创 也一样。
四、需要控制发布时间
许多SEO人习惯于定期发布采集。发布大量内容需要几分钟时间。这是不好的。最好是控制发布时间,设置间隔时间,但是确定一个大概的时间比如每天早上09:00-11:00,让搜索引擎知道你每天定时更新。
小编也是SEO爱好者网站采集,上面说的对6网站,也是我的通行证采集看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
采集相关文章(什么是采集插件?SEO应该怎么把网站做好呢?)
什么是 采集 插件?作为一个资深的SEO人应该知道,就是利用网站程序的插件来读取其他网站的内容,将其他网站的内容传输到你自己的网站通过插件@>上,SEO人员不需要通过这个技巧反复使用复制粘贴。为什么要使用采集插件?相信很多SEO都遇到过问题,网站上线很久了,一直没有收录。相信这个问题也困扰着很多SEO。内容也有。为什么不一直收录?
作为一个从SEO出来的人,我想和大家分享一下,SEO应该如何做好网站?做网站需要一定的技术。这里有一些非常重要的项目。许多 采集 插件的灵活性很差。采集的内容也是收录的内容。并且内容没有被处理。尤其是这个时候在新站你使用了采集plugin采集。很容易被判断为垃圾网站。老域名很容易导致K站。(采集质量太差,未处理)百度飓风算法是对网站以不良采集为主要内容来源的严厉打击,百度搜索将从索引库中完全删除了错误的 采集 链接。
一、选择一个好的采集源
采集 的良好来源往往会促进更多的 收录。屏蔽百度蜘蛛的平台有很多。如果你采集来到这里,就是百度的原创。第一次,对采集和百度不太了解的朋友,推荐使用采集工具,采集会修改并发布到本地。
二、 先升站,在采集
有很多渴望成功的朋友。网站只成功构建了采集并开始量产采集,导致网站收录没有收录,
采集 也需要循序渐进,慢慢增加。采集不是一来就量产,结果是网站还没有发展成百度K站!
三、采集 相关信息
网站想要收录稳定不易被k,采集的信息一定与网站的主题有很强的相关性,很多朋友忽略了这个点,明明网站主题是食物相关的,不得不去采集服装相关,导致网站被降级。
三、 采集质量
一个好的采集源码,往往可以为你提供优质的帮助,无论是文章的排版还是排版,都不要给人不好的阅读体验。必须在早期进行处理,或手动纠正。, 或者 伪原创 也一样。
四、需要控制发布时间
许多SEO人习惯于定期发布采集。发布大量内容需要几分钟时间。这是不好的。最好是控制发布时间,设置间隔时间,但是确定一个大概的时间比如每天早上09:00-11:00,让搜索引擎知道你每天定时更新。
小编也是SEO爱好者网站采集,上面说的对6网站,也是我的通行证采集看完这篇文章文章,如果你喜欢这篇文章文章,不妨采集或者发送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
采集相关文章(单次采集图像时,常用Snap.vi来实现模式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-12-07 20:00
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。
折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
抓住
在这种情况下,下一帧数据大约需要 40ms。
但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,即当图像采集速度非常高时,处理程序是来不及处理当前图像,图像缓冲区中的数据已被新图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 ImahesIn,它是一个图像数据缓冲区引用数组,其中收录对 ImaqCreate.vi 创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQSequence.vi才能完成多个缓冲区的图像采集。
序列应用:
序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ ConfigureList.vi 、IMAQ Configure Buffer.vi和IMAQExtract.vi。
IMAQ ConfigureList.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
IMAQ ConfigureBuffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
IMAQ ExtractBuffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)
第一步是调用IMAQ ConfigureList.vi,告诉驱动以连续的方式成像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用IMAQ ConfigureBuffer.vi,将创建的图像缓冲区与缓冲区列表中的对应位置关联起来。
第三步,调用IMAQStart.vi启动一张图片采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ ConfigureBuffer.vi来配置采集Process。
第四步是调用IMAQ ExtractBuffer.vi从缓冲区中提取图像。
第五步,将IMAQ ExtractBuffer.vi的Buffer toExact参数设置为-1,即释放当前提取的缓冲区。IMAQExtractBuffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
查看全部
采集相关文章(单次采集图像时,常用Snap.vi来实现模式)
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果继续采集,我们会想到下面的模式。
折断
但是,在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关闭,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
抓住
在这种情况下,下一帧数据大约需要 40ms。
但是在高速图像采集的应用中,我们会发现之前的模式也会存在一定的问题,即当图像采集速度非常高时,处理程序是来不及处理当前图像,图像缓冲区中的数据已被新图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集的缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
序列和环
Sequence和Ring都是多缓冲图像采集的方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 ImahesIn,它是一个图像数据缓冲区引用数组,其中收录对 ImaqCreate.vi 创建的图像数据缓冲区的多个引用。只有知道多个图像数据缓冲区在哪里,IMAQSequence.vi才能完成多个缓冲区的图像采集。
序列应用:
序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ ConfigureList.vi 、IMAQ Configure Buffer.vi和IMAQExtract.vi。
IMAQ ConfigureList.vi 完成缓冲区列表的配置,告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
IMAQ ConfigureBuffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
IMAQ ExtractBuffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)
第一步是调用IMAQ ConfigureList.vi,告诉驱动以连续的方式成像采集,缓冲区的位置在系统中——即开发参考程序的主机。
第二步是调用IMAQ ConfigureBuffer.vi,将创建的图像缓冲区与缓冲区列表中的对应位置关联起来。
第三步,调用IMAQStart.vi启动一张图片采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ ConfigureBuffer.vi来配置采集Process。
第四步是调用IMAQ ExtractBuffer.vi从缓冲区中提取图像。
第五步,将IMAQ ExtractBuffer.vi的Buffer toExact参数设置为-1,即释放当前提取的缓冲区。IMAQExtractBuffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image 采集的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(如何快速管理qq微信、如何一键提高微信绑定率如何设置安全网购通讯录)
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-12-03 06:03
采集相关文章、图片、视频、音频、专利信息;通过联盟推广引流,店铺或者你自己的电商平台;获取店铺等级、等待级、直通车推广引流、热词榜等排名位置;通过第三方平台接单客服回复率、话术、机器人回复率来判断一个机器人用户的有效性;通过数据统计、数据分析评分来获取结果给店铺做优化;一对一评估qq微信绑定率:如何快速管理qq微信、如何一键提高微信绑定率、如何设置安全网购通讯录和qq邮箱、如何设置长久有效qq邮箱/电话号码;如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何设置安全网购通讯录和qq邮箱安全?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速。 查看全部
采集相关文章(如何快速管理qq微信、如何一键提高微信绑定率如何设置安全网购通讯录)
采集相关文章、图片、视频、音频、专利信息;通过联盟推广引流,店铺或者你自己的电商平台;获取店铺等级、等待级、直通车推广引流、热词榜等排名位置;通过第三方平台接单客服回复率、话术、机器人回复率来判断一个机器人用户的有效性;通过数据统计、数据分析评分来获取结果给店铺做优化;一对一评估qq微信绑定率:如何快速管理qq微信、如何一键提高微信绑定率、如何设置安全网购通讯录和qq邮箱、如何设置长久有效qq邮箱/电话号码;如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何加快qq/微信绑定率?如何快速找到收货地址?如何设置安全网购通讯录和qq邮箱安全?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速找到收货地址?如何快速。
采集相关文章(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-01 12:11
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
我不明白 HTML+css 如何 采集 发布:
1、只需输入关键词即可采集:搜狗资讯-搜狗知乎-今日头条-公众号-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用Empire插件。先用Empire采集插件来延迟时间,然后写了很多规则,每天同时管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编的帝国采集网站。只要用心经营帝国网站,采集的网站流量也不错!如果你想了解其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力! 查看全部
采集相关文章(帝国采集插件好用吗?帝国是免费开源的CMS系统!)
Empire采集 插件好用吗?Empire是一个免费开源的cms系统,那么多网站都是Empire cms建站系统,那么Empire 采集插件好用吗?如果你只是采集,那没关系。填入数据,但是你要找到不同的采集 源写入规则。如果你能熟练使用HTML+css编写规则,也不是特别难。如果不懂代码规则,使用Empire采集插件,会比较麻烦!这时候肯定有很多朋友说我看不懂代码了。我该怎么办?
帝国采集
我不明白 HTML+css 如何 采集 发布:
1、只需输入关键词即可采集:搜狗资讯-搜狗知乎-今日头条-公众号-百度资讯-百度知道-新浪新闻-360资讯-凤凰新闻(可同时设置多个采集来源采集)
帝国cms采集
2、根据关键词采集文章,一次可以导入1000个关键词,可以创建几十个或几百个采集任务同时。继续挂断采集。
2、可设置关键词采集文章数-支持本地预览-支持采集链接预览-支持查看采集状态
二、不同的网站cms发布
监控文件夹发布:您在桌面上创建一个文件夹,使用软件监控该文件夹,一旦文件夹中有新内容,将立即发布到网站。(支持复制粘贴修改后的文档)
cms发布:支持Empire、易游、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可同时管理和发布
帝国cms 发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
网站详情
为什么我不使用Empire插件。先用Empire采集插件来延迟时间,然后写了很多规则,每天同时管理10个网站。时间不够用,很累。. 最后我改变了使用方式,效率提高了好几倍。我也有更多的时间去做SEO的细节,大大增加了网站的流量。
以上是小编的帝国采集网站。只要用心经营帝国网站,采集的网站流量也不错!如果你想了解其他朋友,可以留言或私信我。看完这篇文章,如果觉得不错,不妨采集起来,或者送给需要的朋友同事!您的一举一动都将成为编辑源源不断的动力!
采集相关文章(下载教程大数据查询及数据清洗技巧分析教程(源代码教程))
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-11-29 21:02
采集相关文章到本公众号:山东大学数据团队(jiangcuijsq),欢迎参加,数据团队将继续深入爬取对应的内容,并分享给大家!12月14日-12月19日将分三个部分来分享:下载教程大数据查询及数据清洗技巧分析教程(源代码教程)大数据清洗教程(数据格式)内容较多,分多次更新,先观看课程相关视频及完整代码及脚本获取课程请点这:大数据查询及数据清洗课程大纲如下:课程学习效果(见截图):大数据查询及数据清洗课程完整代码及脚本在获取部分内容时,可能遇到“关键词被拦截”问题。如链接:.解决办法如下:。
1、打开某个网站后,在浏览器右键查看,然后找到路由列表。
2、按enter键,进入路由列表,找到下图“http://”即某个文件,则直接点击网站右下角的“存储到此路由”即可。后续可继续验证各个网站的http地址。
3、点击右上角”存储“按钮,会跳转到某个服务器,并显示网站基本信息,最后显示路由列表并继续下一步。
4、点击“存储到此路由”后,继续一段时间,进入路由列表,看网站是否能打开。若无法打开,则继续“路由地址”验证及修改。如“//”,直接点击”验证“按钮即可。若路由列表显示的网站http地址还无法打开,则确定网站“策略”设置问题。
5、如果出现“劫持”,在不会爬取的情况下,可通过代理工具,将网站http地址转化为内网http地址来爬取(翻墙就不推荐了,实在不会自己百度),如:thunder+sugar+guardian请求此链接,会显示源代码:-page-url爬取成功返回结果注意:此方法并不是所有网站都可以。试过中科大网站、新浪网、新浪博客、百度联盟网、搜狐网,均失败,说明网站策略有误。搜狐网说明涉及类似设置问题,查看官网,在”脚本”模块。
6、可使用其他方法,如python.ipynb打开此文件,待open方法运行后,确认“目标”文件是否正确。是否被某种类型拦截。欢迎参加并关注山东大学数据团队,欢迎关注山东大学数据团队(jiangcuijsq)或其他山东大学高校学生或者高校教师加入。感谢大家对山东大学的支持。如果你对大数据感兴趣,想要了解更多大数据知识和学习经验,关注我,不定期更新大数据知识。
我是山东大学数据团队成员,
5),欢迎大家加入大数据学习群,与更多志同道合的小伙伴一起学习、交流。
山东大学数据团队网址:(二维码自动识别)entisjudge(二维码自动识别)更多大数据文章资讯,
0)。 查看全部
采集相关文章(下载教程大数据查询及数据清洗技巧分析教程(源代码教程))
采集相关文章到本公众号:山东大学数据团队(jiangcuijsq),欢迎参加,数据团队将继续深入爬取对应的内容,并分享给大家!12月14日-12月19日将分三个部分来分享:下载教程大数据查询及数据清洗技巧分析教程(源代码教程)大数据清洗教程(数据格式)内容较多,分多次更新,先观看课程相关视频及完整代码及脚本获取课程请点这:大数据查询及数据清洗课程大纲如下:课程学习效果(见截图):大数据查询及数据清洗课程完整代码及脚本在获取部分内容时,可能遇到“关键词被拦截”问题。如链接:.解决办法如下:。
1、打开某个网站后,在浏览器右键查看,然后找到路由列表。
2、按enter键,进入路由列表,找到下图“http://”即某个文件,则直接点击网站右下角的“存储到此路由”即可。后续可继续验证各个网站的http地址。
3、点击右上角”存储“按钮,会跳转到某个服务器,并显示网站基本信息,最后显示路由列表并继续下一步。
4、点击“存储到此路由”后,继续一段时间,进入路由列表,看网站是否能打开。若无法打开,则继续“路由地址”验证及修改。如“//”,直接点击”验证“按钮即可。若路由列表显示的网站http地址还无法打开,则确定网站“策略”设置问题。
5、如果出现“劫持”,在不会爬取的情况下,可通过代理工具,将网站http地址转化为内网http地址来爬取(翻墙就不推荐了,实在不会自己百度),如:thunder+sugar+guardian请求此链接,会显示源代码:-page-url爬取成功返回结果注意:此方法并不是所有网站都可以。试过中科大网站、新浪网、新浪博客、百度联盟网、搜狐网,均失败,说明网站策略有误。搜狐网说明涉及类似设置问题,查看官网,在”脚本”模块。
6、可使用其他方法,如python.ipynb打开此文件,待open方法运行后,确认“目标”文件是否正确。是否被某种类型拦截。欢迎参加并关注山东大学数据团队,欢迎关注山东大学数据团队(jiangcuijsq)或其他山东大学高校学生或者高校教师加入。感谢大家对山东大学的支持。如果你对大数据感兴趣,想要了解更多大数据知识和学习经验,关注我,不定期更新大数据知识。
我是山东大学数据团队成员,
5),欢迎大家加入大数据学习群,与更多志同道合的小伙伴一起学习、交流。
山东大学数据团队网址:(二维码自动识别)entisjudge(二维码自动识别)更多大数据文章资讯,
0)。
采集相关文章(2018-5-24更新半透明背景素材的制作方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-23 09:14
采集相关文章:(什么是内容索引,
请到网页开发者论坛下载美图秀秀v4格式扫描版本的。此处高清无水印。
放几张我大完整的图,
cannycomposite
网页的图片只能做局部裁剪。alt,height(像素)是可以矢量的。不知道题主怎么想。
2018-5-24更新半透明背景素材的制作方法贴出来,但是不知道是否有帮助。工具不止有编辑器,vividlaserpackerpro;除了ps以外还有acdsee;如果只是要背景素材的话,就别废话了,下载素材丢进去吧。神器!acdsee/acdseeps的话就不说了,熟悉acdsee的自然熟悉。如果你愿意多下一些字体素材,也可以下载一些,然后截图摆弄摆弄,非常好玩。
反正我不会用acdsee。由于效果是已经截取好的,需要较好的图片质量,最好有无损。下面贴图,图片自取:插入图片-cannycompositeimages-snaptogray调整图片颜色-cannycomposite-functions.pdf另外网页上的小部件,都可以用cannycomposite制作。 查看全部
采集相关文章(2018-5-24更新半透明背景素材的制作方法)
采集相关文章:(什么是内容索引,
请到网页开发者论坛下载美图秀秀v4格式扫描版本的。此处高清无水印。
放几张我大完整的图,
cannycomposite
网页的图片只能做局部裁剪。alt,height(像素)是可以矢量的。不知道题主怎么想。
2018-5-24更新半透明背景素材的制作方法贴出来,但是不知道是否有帮助。工具不止有编辑器,vividlaserpackerpro;除了ps以外还有acdsee;如果只是要背景素材的话,就别废话了,下载素材丢进去吧。神器!acdsee/acdseeps的话就不说了,熟悉acdsee的自然熟悉。如果你愿意多下一些字体素材,也可以下载一些,然后截图摆弄摆弄,非常好玩。
反正我不会用acdsee。由于效果是已经截取好的,需要较好的图片质量,最好有无损。下面贴图,图片自取:插入图片-cannycompositeimages-snaptogray调整图片颜色-cannycomposite-functions.pdf另外网页上的小部件,都可以用cannycomposite制作。
采集相关文章(采集百度还没收录的文章好不好问题:采集问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-11-20 01:16
采集百度没有收录的文章好吗?
问:采集百度没有收录的文章,好吗?
问题补充:百度对内容有严格限制,但是网站内容建设有困难,所以如果你想去采集那些百度没有收录问题,那么你可以达到原创文章的目的,这个方法行吗?
答:理论上,采集百度没有收录的文章有效。当然,这里必须考虑两个方面:
1、采集 的 文章 必须是相关的
虽然原创文章对于网站seo优化很重要,但是这有一个前提,就是相关的线路。如果 文章 的内容不相关,那么它不是很有用。的。所以在决定采集之前,你应该分析一下这些文章是否和你自己的网站有关系,那些不相关的内容一定要果断放弃。
2、确保文章真的不是收录
有时我们看到的是文章的URL链接并没有被百度收录。其实文章的内容已经收录很多了,也有可能我们看到的文章本身也是采集,所以不是收录 百度。
所以我们要检查文章的内容,看看百度的数据库里是不是真的没有信息。比如我们可以在文章中复制几段或几句,去百度搜索。如果出现大量红色内容,则表示该内容已被淹没。如果没有红色,则说明百度是真的。没有收录这样的内容。
关于采集百度没有收录的文章好,笔者就简单说了这么多。综上所述,如果文章没有被百度收录,而这些文章是相关且高质量的文章,那么采集来是可行的超过。但是如果这些文章只是网站的页面URL没有收录,而文章本身已经收录很多,那么< @采集 过来也没多大意义。
另外,作者建议大家尊重他人的作品,转载文章一定要注明出处。另外,大家要注意版权问题。部分文章不能转载,否则可能需要您承担相关责任。对于大量转载文章的行为,大家一定要慎重。 查看全部
采集相关文章(采集百度还没收录的文章好不好问题:采集问题)
采集百度没有收录的文章好吗?
问:采集百度没有收录的文章,好吗?
问题补充:百度对内容有严格限制,但是网站内容建设有困难,所以如果你想去采集那些百度没有收录问题,那么你可以达到原创文章的目的,这个方法行吗?
答:理论上,采集百度没有收录的文章有效。当然,这里必须考虑两个方面:
1、采集 的 文章 必须是相关的
虽然原创文章对于网站seo优化很重要,但是这有一个前提,就是相关的线路。如果 文章 的内容不相关,那么它不是很有用。的。所以在决定采集之前,你应该分析一下这些文章是否和你自己的网站有关系,那些不相关的内容一定要果断放弃。
2、确保文章真的不是收录
有时我们看到的是文章的URL链接并没有被百度收录。其实文章的内容已经收录很多了,也有可能我们看到的文章本身也是采集,所以不是收录 百度。
所以我们要检查文章的内容,看看百度的数据库里是不是真的没有信息。比如我们可以在文章中复制几段或几句,去百度搜索。如果出现大量红色内容,则表示该内容已被淹没。如果没有红色,则说明百度是真的。没有收录这样的内容。
关于采集百度没有收录的文章好,笔者就简单说了这么多。综上所述,如果文章没有被百度收录,而这些文章是相关且高质量的文章,那么采集来是可行的超过。但是如果这些文章只是网站的页面URL没有收录,而文章本身已经收录很多,那么< @采集 过来也没多大意义。
另外,作者建议大家尊重他人的作品,转载文章一定要注明出处。另外,大家要注意版权问题。部分文章不能转载,否则可能需要您承担相关责任。对于大量转载文章的行为,大家一定要慎重。
采集相关文章(微信小程序环境要求ios11或更高版本要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-11 03:00
采集相关文章微信小程序环境要求ios11或更高版本,android要求版本较低。关于android要求更高的解释,请见微信小程序环境要求。微信小程序环境要求自己实现下载的hash值按照微信提供的采集规则,如@3109796,至少需要300字节。其中必须包含整个apk的hash值。工具介绍安装一个javavm,java堆全部是空的,微信小程序必须存放一个文件作为本地文件夹,存放你需要的js文件。
可以使用appcompat-v7、java-jar--new-jar方式生成java-jar。微信小程序采集文章的规则微信小程序环境要求所有api需要公共底层api才能使用。针对android,你必须先安装java7。针对ios,你必须使用官方的api。网上有个很简单的代码,值得学习。intentremoteview(intentintent){intent.putextra(newintent(appcompat.v7_intent));intent.putextra(newintent(appcompat.v7_phoneintent));intent.putextra(newintent(appcompat.v7_pathfileintent));intent.putextra(newintent(appcompat.v7_desktopintent));intent.putextra(newintent(appcompat.v7_cameraintent));intent.putextra(newintent(appcompat.v7_voiceintent));intent.putextra(newintent(appcompat.v7_toasterintent));intent.putextra(newintent(appcompat.v7_touchintent));intent.putextra(newintent(appcompat.v7_searchintent));intent.putextra(newintent(appcompat.v7_signalintent));intent.putextra(newintent(appcompat.v7_preferenceintent));//v4if(newintent(appcompat.v7_activityintent)){intent=newintent(appcompat.v7_activityintent);intent.putextra(intent.pathname(appcompat.v7_intent));intent.putextra(intent.pathname(appcompat.v7_pathfile));intent.putextra(intent.appcompat.v7_signalintent);intent.putextra(intent.remoteview(intent.pathname(appcompat.v7_intent)));}intent.each();}intentintent=newintent();wx.requestpage("style.wx11",intent);wx.requestpage("style.wx12",intent);wx.requestpage("style.wx13",intent);wx.requestpage("style.wx14",intent);wx.requestpage("style.wx15",intent);wx.re。 查看全部
采集相关文章(微信小程序环境要求ios11或更高版本要求)
采集相关文章微信小程序环境要求ios11或更高版本,android要求版本较低。关于android要求更高的解释,请见微信小程序环境要求。微信小程序环境要求自己实现下载的hash值按照微信提供的采集规则,如@3109796,至少需要300字节。其中必须包含整个apk的hash值。工具介绍安装一个javavm,java堆全部是空的,微信小程序必须存放一个文件作为本地文件夹,存放你需要的js文件。
可以使用appcompat-v7、java-jar--new-jar方式生成java-jar。微信小程序采集文章的规则微信小程序环境要求所有api需要公共底层api才能使用。针对android,你必须先安装java7。针对ios,你必须使用官方的api。网上有个很简单的代码,值得学习。intentremoteview(intentintent){intent.putextra(newintent(appcompat.v7_intent));intent.putextra(newintent(appcompat.v7_phoneintent));intent.putextra(newintent(appcompat.v7_pathfileintent));intent.putextra(newintent(appcompat.v7_desktopintent));intent.putextra(newintent(appcompat.v7_cameraintent));intent.putextra(newintent(appcompat.v7_voiceintent));intent.putextra(newintent(appcompat.v7_toasterintent));intent.putextra(newintent(appcompat.v7_touchintent));intent.putextra(newintent(appcompat.v7_searchintent));intent.putextra(newintent(appcompat.v7_signalintent));intent.putextra(newintent(appcompat.v7_preferenceintent));//v4if(newintent(appcompat.v7_activityintent)){intent=newintent(appcompat.v7_activityintent);intent.putextra(intent.pathname(appcompat.v7_intent));intent.putextra(intent.pathname(appcompat.v7_pathfile));intent.putextra(intent.appcompat.v7_signalintent);intent.putextra(intent.remoteview(intent.pathname(appcompat.v7_intent)));}intent.each();}intentintent=newintent();wx.requestpage("style.wx11",intent);wx.requestpage("style.wx12",intent);wx.requestpage("style.wx13",intent);wx.requestpage("style.wx14",intent);wx.requestpage("style.wx15",intent);wx.re。
采集相关文章(左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-08 00:03
采集相关文章到今天大半年了,看到了很多不错的案例,整理出一些自己的觉得好看的干货分享给大家,欢迎转发留言,希望对你有帮助!你敢拿我的文章去骗个女孩子吗?我是左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱这一周我们所要操作的项目是:赌博app大概是4年前吧,有一个比较有名的传销网站,它们成功洗白了一次传销案,广东的政府就出面过罚了他们,但是最近这个赌博网站又又又开始搞这种皮包赌博了,最近一周大概有2到3万的人在注册,竞猜的钱数设置在800到1200不等,地区也是广东省及其周边地区,今天我就给大家来揭秘一下这个赌博网站的赚钱套路!话不多说,先跟大家介绍一下这个赌博网站都有哪些平台:首先aa这个网站有来自全国所有的分红赌博网站里面已经把赌注分成了6级,输赢都是自己的分红;级别越高,分红越高,且有特殊规则,只有庄家才能赌博;1个人可以注册5个一级账号,且不限制该账号所有人的注册资金;以上就是这个网站所有赚钱套路了,看到这里估计有人会觉得这个网站不靠谱,风险太大,有人会觉得这个网站有什么是我要注册的必要吗?先别急,往下看我要操作的是:复制一个今日头条当中一个赌博的推广码,链接可以百度上搜,即可进行复制我这边复制的是;object_id=23584220&platform_id=36195426&wh_user_id=263776&arg_id=51000408277&url_to_id=527876&platform_url="",其中第三位的真实返利比例大概是5%左右;第四位是10%左右;话不多说,复制这个链接(链接失效了,按照正常的来就可以)复制这个链接(这个可以通过百度搜索搜索到,但是这里需要输入网址名称)进行注册(手机端无法使用,所以复制后打开百度直接粘贴即可)进行注册好后进行绑定就好了,切记在提现需要下载个工作号来管理推广账号;把这个网站所有代码复制到浏览器,没有说电脑端不能操作,电脑端都是可以操作的,唯一不能理解的是好多网站你注册了自动关联你的工作号,工作号又有手机号绑定的原因,而且还有任务返利,请你仔细思考你工作号的一些话术,以后会整理一些话术给大家的;我这边举一个我操作的几个代码:**赌博代码;object_id=5442044003528&platform_id=0183&wh_user_id=26377601803862。 查看全部
采集相关文章(左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱(图))
采集相关文章到今天大半年了,看到了很多不错的案例,整理出一些自己的觉得好看的干货分享给大家,欢迎转发留言,希望对你有帮助!你敢拿我的文章去骗个女孩子吗?我是左翁互联网工作小公举allan工作便是帮助人这么的想要操作副业挣点零花钱这一周我们所要操作的项目是:赌博app大概是4年前吧,有一个比较有名的传销网站,它们成功洗白了一次传销案,广东的政府就出面过罚了他们,但是最近这个赌博网站又又又开始搞这种皮包赌博了,最近一周大概有2到3万的人在注册,竞猜的钱数设置在800到1200不等,地区也是广东省及其周边地区,今天我就给大家来揭秘一下这个赌博网站的赚钱套路!话不多说,先跟大家介绍一下这个赌博网站都有哪些平台:首先aa这个网站有来自全国所有的分红赌博网站里面已经把赌注分成了6级,输赢都是自己的分红;级别越高,分红越高,且有特殊规则,只有庄家才能赌博;1个人可以注册5个一级账号,且不限制该账号所有人的注册资金;以上就是这个网站所有赚钱套路了,看到这里估计有人会觉得这个网站不靠谱,风险太大,有人会觉得这个网站有什么是我要注册的必要吗?先别急,往下看我要操作的是:复制一个今日头条当中一个赌博的推广码,链接可以百度上搜,即可进行复制我这边复制的是;object_id=23584220&platform_id=36195426&wh_user_id=263776&arg_id=51000408277&url_to_id=527876&platform_url="",其中第三位的真实返利比例大概是5%左右;第四位是10%左右;话不多说,复制这个链接(链接失效了,按照正常的来就可以)复制这个链接(这个可以通过百度搜索搜索到,但是这里需要输入网址名称)进行注册(手机端无法使用,所以复制后打开百度直接粘贴即可)进行注册好后进行绑定就好了,切记在提现需要下载个工作号来管理推广账号;把这个网站所有代码复制到浏览器,没有说电脑端不能操作,电脑端都是可以操作的,唯一不能理解的是好多网站你注册了自动关联你的工作号,工作号又有手机号绑定的原因,而且还有任务返利,请你仔细思考你工作号的一些话术,以后会整理一些话术给大家的;我这边举一个我操作的几个代码:**赌博代码;object_id=5442044003528&platform_id=0183&wh_user_id=26377601803862。
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-11-03 18:20
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果我们继续采集,我们会想到下面的模式。
?折断
但是在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关机,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓住
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会有一定的问题,就是当图像采集速度很高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 Imahes In,它是一个图像数据缓冲区引用数组,其中收录对 Imaq Create.vi 创建的多个图像数据缓冲区的引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,并告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——也就是在开发参考程序的主机上.
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
第三步,调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image采集实现的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。 查看全部
采集相关文章(单次-IMAQ图像数据采集方式(IMAQ.vi))
当使用单个 采集 图像时,通常使用 Snap.vi 进行编程。,如果我们继续采集,我们会想到下面的模式。
?折断
但是在上图的模式下,采集镜像比较慢,因为Snap.vi包括初始化和关机,最快的情况下需要120ms。为了解决这个问题,NI添加了Grab.vi来实现连续采集。框图如下:
?抓住
在这种情况下,下一帧数据大约需要 40ms。
? 但是在高速图像采集的应用中,我们会发现之前的模式也会有一定的问题,就是当图像采集速度很高时,处理程序太处理当前图像较晚,图像缓冲区中的数据已被新的图像数据覆盖。
为了解决采集缓冲区不足的问题,我们可以增加图像采集缓冲区。
NI-IMAQ 提供了两种多缓冲方法,即序列和环。
?序列和环
Sequence和Ring都是多缓冲图像采集方法,区别在于Sequence是单个采集,Ring是连续的采集,类似于Snap和Grab。
Sequence.vi 最重要的参数是 Imahes In,它是一个图像数据缓冲区引用数组,其中收录对 Imaq Create.vi 创建的多个图像数据缓冲区的引用。只有知道多个图像数据缓冲区在哪里,IMAQ Sequence.vi 才能完成多个缓冲区的图像采集。
?序列应用:
?序列应用
环图采集方法(IMAQ方法,IMAQdx不一样):
Ring image采集方法需要通过三个VI来实现,分别是IMAQ Configure List.vi?、IMAQ Configure Buffer.vi和IMAQ Extract.vi。
?IMAQ Configure List.vi 完成缓冲区列表的配置,并告诉驱动程序缓冲区的数量,是否连续或单次执行图像采集以及缓冲区的位置。
?IMAQ Configure Buffer.vi 将创建的图像缓冲区分配到缓冲区列表中的相应位置。
?IMAQ Extract Buffer.vi 从缓冲区中提取采集 接收到的图像,为后续的图像处理做准备。
如下图(因为图太长,只截取了关键代码)?
? 第一步是调用IMAQ Configure List.vi,告诉驱动以连续的方式镜像采集,缓冲区的位置在系统中——也就是在开发参考程序的主机上.
第二步是调用?IMAQ Configure Buffer.vi 将创建的图像缓冲区与缓冲区列表中的相应位置关联起来。
第三步,调用IMAQ Start.vi启动一个image采集的进程。需要注意的是,在调用IMAQ Start.vi之前,必须先调用IMAQ Configure List.vi和IMAQ Configure Buffer.vi来配置采集的过程。
第四步是调用?IMAQ Extract Buffer.vi 从缓冲区中提取图像。
第五步,将IMAQ Extract Buffer.vi的Buffer to Exact参数设置为-1?表示释放当前提取的缓冲区。IMAQ Extract Buffer.vi在提取图像数据时会保护当前提取的缓冲区,所以当采集过程完成后,需要释放当前保护的缓冲区。
Ring image采集实现的主要过程如上所述,剩下的步骤就是熟悉的初始化采集硬件、释放图像采集硬件和释放缓冲区。
采集相关文章(,:在github上面找的,,慢慢看吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-10-29 14:05
采集相关文章和网站,留作自己以后备用,希望大家帮助网站的变现,都在github上面找的,慢慢看吧引用及来源文章包括文字与视频,将会在其中列出,大概会在两三个月更新完毕。内容及来源,会在知乎专栏发布。并且截图出来,方便大家查看这个项目需要注意的是:download是一个keymetrics。dna中的可交易项目,我直接按照star数,筛选出了两个大r,issocentric与issilothinkpad,总共有788。
5位开发者,最后我会截图出来一些项目来源issilothinkpad,我使用的是账号名称,不是昵称,如果账号不是英文的,使用多个文件名,如videolink,但不能是一串二进制,最后我会编辑出来项目主页,以便查看具体信息这个项目可以合作,但是很难长期维持,每周一次,每周一次,每周一次,以下如果引用的内容或者代码,可能会在这里找到来源,当前是在一个github项目,这个项目已经在私人仓库,链接如下:-translation在知乎,youtube和stackoverflow上都有原始地址,可以自己找一下合作或者是自己翻译我的项目地址:(使用github)issilothinkpad出生日期2020。
09。13-7。15发布日期8。18(1~4号,其中有qa阶段)发布github:(自己私人仓库):(公开的小网站,翻译以后不影响原文效果):技术解析:计算机科学chem论文阅读笔记!!超过千词---未出版图书,如有侵权,请私信我,将整理后删除代码issilothinkpad文章资源库合集列表中文开源阅读笔记&训练集转化:在线项目托管:+lambda+++milk:集中性爬虫搜集)提取网站,标签组织:在线项目托管:+lambda+++milk:集中性爬虫搜集托:pandasteam与hongkuaiyizhongjihuihui一起搞定,最好多写一下批注,作者会知道某些词,某些词的含义。 查看全部
采集相关文章(,:在github上面找的,,慢慢看吧!)
采集相关文章和网站,留作自己以后备用,希望大家帮助网站的变现,都在github上面找的,慢慢看吧引用及来源文章包括文字与视频,将会在其中列出,大概会在两三个月更新完毕。内容及来源,会在知乎专栏发布。并且截图出来,方便大家查看这个项目需要注意的是:download是一个keymetrics。dna中的可交易项目,我直接按照star数,筛选出了两个大r,issocentric与issilothinkpad,总共有788。
5位开发者,最后我会截图出来一些项目来源issilothinkpad,我使用的是账号名称,不是昵称,如果账号不是英文的,使用多个文件名,如videolink,但不能是一串二进制,最后我会编辑出来项目主页,以便查看具体信息这个项目可以合作,但是很难长期维持,每周一次,每周一次,每周一次,以下如果引用的内容或者代码,可能会在这里找到来源,当前是在一个github项目,这个项目已经在私人仓库,链接如下:-translation在知乎,youtube和stackoverflow上都有原始地址,可以自己找一下合作或者是自己翻译我的项目地址:(使用github)issilothinkpad出生日期2020。
09。13-7。15发布日期8。18(1~4号,其中有qa阶段)发布github:(自己私人仓库):(公开的小网站,翻译以后不影响原文效果):技术解析:计算机科学chem论文阅读笔记!!超过千词---未出版图书,如有侵权,请私信我,将整理后删除代码issilothinkpad文章资源库合集列表中文开源阅读笔记&训练集转化:在线项目托管:+lambda+++milk:集中性爬虫搜集)提取网站,标签组织:在线项目托管:+lambda+++milk:集中性爬虫搜集托:pandasteam与hongkuaiyizhongjihuihui一起搞定,最好多写一下批注,作者会知道某些词,某些词的含义。
采集相关文章(如何采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-10-28 02:01
采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件叫cn-article,如果怕麻烦请谨慎下载,有点挑战性,总体还不错,但偶尔会崩溃。接下来抓取几个公众号的文章,仅供大家参考:个人号:公众号名称及二维码链接同步,能自动识别推文标题、文章封面及相关信息个人号:公众号名称、二维码链接并非完全准确,根据热门程度定,首先根据自己的热门公众号先筛选自己的关注好公众号,抓取文章可以在线查看。
可以申请公众号,然后通过搜索来抓取。但是有一点要注意,如果关注的公众号是没有限定,那你就需要去抓取那些你认识或者关注的公众号!(还有就是直接搜索某个公众号是没有你要的公众号的)你也可以去抓取文章。上面是我自己申请的公众号,前几天通过搜索抓取的,还没有关注,不能提供给你,
可以去爬,但有好几天,好心累啊,要是我申请公众号就直接找客服了。现在很多公众号自带推文,就可以自己爬,实在不行就去爬他的推文。当然,最好是关注他的微信公众号,这样的成功率最高,而且推文越多越容易成功,比如有10篇,至少有2到3篇能抓。这时就可以直接去抓了,比如十点读书,或者,中国一些做的好的公众号,在首页的会有公众号推文链接,你可以去找,去抓这些推文,比如,头条,比如,大学校园公众号,可以直接抓。 查看全部
采集相关文章(如何采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件)
采集相关文章并非难事,如何抓取?推荐给大家一个免费的插件叫cn-article,如果怕麻烦请谨慎下载,有点挑战性,总体还不错,但偶尔会崩溃。接下来抓取几个公众号的文章,仅供大家参考:个人号:公众号名称及二维码链接同步,能自动识别推文标题、文章封面及相关信息个人号:公众号名称、二维码链接并非完全准确,根据热门程度定,首先根据自己的热门公众号先筛选自己的关注好公众号,抓取文章可以在线查看。
可以申请公众号,然后通过搜索来抓取。但是有一点要注意,如果关注的公众号是没有限定,那你就需要去抓取那些你认识或者关注的公众号!(还有就是直接搜索某个公众号是没有你要的公众号的)你也可以去抓取文章。上面是我自己申请的公众号,前几天通过搜索抓取的,还没有关注,不能提供给你,
可以去爬,但有好几天,好心累啊,要是我申请公众号就直接找客服了。现在很多公众号自带推文,就可以自己爬,实在不行就去爬他的推文。当然,最好是关注他的微信公众号,这样的成功率最高,而且推文越多越容易成功,比如有10篇,至少有2到3篇能抓。这时就可以直接去抓了,比如十点读书,或者,中国一些做的好的公众号,在首页的会有公众号推文链接,你可以去找,去抓这些推文,比如,头条,比如,大学校园公众号,可以直接抓。
采集相关文章(网站前期想要收录和排名速度快点不排除会有大量后果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2021-10-21 13:05
网站前期想收录,排名速度要快一些。不排除会有很多采集相关行业文章。经过多位站长的尝试,结果是前期可以适量。采集有些文章为了增加文章上的字数,但是一味的过度采集文章会给我们造成非常严重的后果网站。
“采集文章一时爽,永远采集永远爽”,过度的采集文章会给网站@带来以下效果>:
一、收录不稳定
这是最直接的影响,可以说是搜索引擎对网站的“小惩罚”。收录不稳定的具体表现就是收录今天有几篇,明天删收录的内容,收录没有增加量,而且是很难排名。
二、 排名上不去,上来也不稳定
这是基于第一点。在收录不稳定的情况下,如何谈排名稳定性?后果就是收入不稳定,更难获得高薪或高回报。
三、 蜘蛛有爬行,但不爬行
分析网站的日志会发现,蜘蛛经常会爬取采集文章的页面,但是时间长了就爬不上了。这会浪费资源,因为它们具有更多的技术含量。seo操作是遵循蜘蛛的爬行规律,这无疑是一种不正确的行为。
四、彻头彻尾
这已经达到了搜索引擎的“耐力极限”。长期以来采集、网站的收录排名不稳定,蜘蛛每次都得不到想要的内容。它已经从蜘蛛不喜欢的网站减少到用户讨厌的网站。这时候,百度会把之前的排名全部降下来,甚至把你踢出前100,也就是降权。降级是网站面临的最严重的问题。降级后基本不可能恢复。
网站中等过度采集文章 最严重的后果就是降级。采集不会触发被屏蔽的域名和网站删除,所以我们要正式采集文章可能会给网站带来严重的后果。
不可否认,文章的内容对网站的相关内容和排名至关重要,所以市面上很多采集软件都有生存的理由,比如信息网站 @> 比如在一些灰色行业,快速排名是他们行业的特点。这时候采集就成为了我们的首选方法,一个网站快速权重实现2、3用一两个月的时间冲完成盈利,然后百度发现权限被降级,然后更改批准的域名继续操作。
不同的行业有不同的选择和目标,但过度采集的后果是一样的,所以在采集之前我们要权衡是否值得。 查看全部
采集相关文章(网站前期想要收录和排名速度快点不排除会有大量后果)
网站前期想收录,排名速度要快一些。不排除会有很多采集相关行业文章。经过多位站长的尝试,结果是前期可以适量。采集有些文章为了增加文章上的字数,但是一味的过度采集文章会给我们造成非常严重的后果网站。
“采集文章一时爽,永远采集永远爽”,过度的采集文章会给网站@带来以下效果>:
一、收录不稳定
这是最直接的影响,可以说是搜索引擎对网站的“小惩罚”。收录不稳定的具体表现就是收录今天有几篇,明天删收录的内容,收录没有增加量,而且是很难排名。
二、 排名上不去,上来也不稳定
这是基于第一点。在收录不稳定的情况下,如何谈排名稳定性?后果就是收入不稳定,更难获得高薪或高回报。
三、 蜘蛛有爬行,但不爬行
分析网站的日志会发现,蜘蛛经常会爬取采集文章的页面,但是时间长了就爬不上了。这会浪费资源,因为它们具有更多的技术含量。seo操作是遵循蜘蛛的爬行规律,这无疑是一种不正确的行为。
四、彻头彻尾
这已经达到了搜索引擎的“耐力极限”。长期以来采集、网站的收录排名不稳定,蜘蛛每次都得不到想要的内容。它已经从蜘蛛不喜欢的网站减少到用户讨厌的网站。这时候,百度会把之前的排名全部降下来,甚至把你踢出前100,也就是降权。降级是网站面临的最严重的问题。降级后基本不可能恢复。
网站中等过度采集文章 最严重的后果就是降级。采集不会触发被屏蔽的域名和网站删除,所以我们要正式采集文章可能会给网站带来严重的后果。
不可否认,文章的内容对网站的相关内容和排名至关重要,所以市面上很多采集软件都有生存的理由,比如信息网站 @> 比如在一些灰色行业,快速排名是他们行业的特点。这时候采集就成为了我们的首选方法,一个网站快速权重实现2、3用一两个月的时间冲完成盈利,然后百度发现权限被降级,然后更改批准的域名继续操作。
不同的行业有不同的选择和目标,但过度采集的后果是一样的,所以在采集之前我们要权衡是否值得。
采集相关文章(本文介绍使用优采云采集马蜂窝美食评论(以三种美食为例) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-14 15:00
)
本文介绍了优采云采集马蜂窝美食评论的使用方法(以三种美食为例)
采集网站:
使用功能点:
lURL循环
l 分页列表循环
马蜂窝网站 简介:马蜂窝旅游网是中国领先的免费旅游服务平台。马蜂窝旅游网由陈刚、卢刚于2006年创立,2010年正式开始企业运营。马蜂窝的景区、餐厅、酒店等点评信息,来自千万用户的真实分享,每年帮助超过1亿游客制定免费旅行计划。
马蜂窝以“免费旅游”为核心,为全球6万个旅游目的地提供旅游指南、旅游问答、旅游点评等信息,以及酒店、交通、当地旅游等免费旅游产品和服务。
马蜂窝美食点评采集 资料说明:本文进行了马蜂窝美食点评信息采集。本文仅以“马窝-美食评论信息采集”为例。实际操作过程中,您可以根据自己的需要更改数据马蜂窝的其他内容。采集。
马蜂窝美食评论采集字段详情:评论内容、评论者id、评论时间。
第一步:创建采集任务
1)进入主界面,选择“自定义采集”
2)将采集的网站URL复制粘贴到输入框中,点击“保存URL”。这里我们先去马蜂窝复制你想要的美食网址采集,然后复制粘贴
第 2 步:创建翻页循环
1)网页打开后,将页面下拉至底部,点击“下一步”按钮。在右侧的操作提示框中,选择“循环点击单个链接”
第 3 步:创建列表循环和信息提取
1)移动鼠标,选中第一条评论,评价框变绿,其中的字段变红。然后在右侧的操作提示框中选择“选中的子元素”
2) 选择字段信息后,选择字段旁边的编辑和删除标志,可以删除多余的字段并自定义命名
3)然后选择“全选”
第四步:数据采集并导出
1)接下来,在右侧的提示中选择“采集以下数据”,将整个页面的评论信息丢掉采集
2)然后选择“保存并启动”开始数据采集
3)这里采集选择“启动本地采集”
4)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”导出采集好的数据。这里我们选择excel作为导出格式。数据导出后如下图
查看全部
采集相关文章(本文介绍使用优采云采集马蜂窝美食评论(以三种美食为例)
)
本文介绍了优采云采集马蜂窝美食评论的使用方法(以三种美食为例)
采集网站:
使用功能点:
lURL循环
l 分页列表循环
马蜂窝网站 简介:马蜂窝旅游网是中国领先的免费旅游服务平台。马蜂窝旅游网由陈刚、卢刚于2006年创立,2010年正式开始企业运营。马蜂窝的景区、餐厅、酒店等点评信息,来自千万用户的真实分享,每年帮助超过1亿游客制定免费旅行计划。
马蜂窝以“免费旅游”为核心,为全球6万个旅游目的地提供旅游指南、旅游问答、旅游点评等信息,以及酒店、交通、当地旅游等免费旅游产品和服务。
马蜂窝美食点评采集 资料说明:本文进行了马蜂窝美食点评信息采集。本文仅以“马窝-美食评论信息采集”为例。实际操作过程中,您可以根据自己的需要更改数据马蜂窝的其他内容。采集。
马蜂窝美食评论采集字段详情:评论内容、评论者id、评论时间。
第一步:创建采集任务
1)进入主界面,选择“自定义采集”
2)将采集的网站URL复制粘贴到输入框中,点击“保存URL”。这里我们先去马蜂窝复制你想要的美食网址采集,然后复制粘贴
第 2 步:创建翻页循环
1)网页打开后,将页面下拉至底部,点击“下一步”按钮。在右侧的操作提示框中,选择“循环点击单个链接”
第 3 步:创建列表循环和信息提取
1)移动鼠标,选中第一条评论,评价框变绿,其中的字段变红。然后在右侧的操作提示框中选择“选中的子元素”
2) 选择字段信息后,选择字段旁边的编辑和删除标志,可以删除多余的字段并自定义命名
3)然后选择“全选”
第四步:数据采集并导出
1)接下来,在右侧的提示中选择“采集以下数据”,将整个页面的评论信息丢掉采集
2)然后选择“保存并启动”开始数据采集
3)这里采集选择“启动本地采集”
4)采集 完成后会弹出提示,选择“导出数据”,选择“合适的导出方式”导出采集好的数据。这里我们选择excel作为导出格式。数据导出后如下图
采集相关文章([精编学习资料]2018年成考备考全套资料及课程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-12 13:06
采集相关文章多次测试,成功率高达95%,已经累计推送到数百个社群里了。链接已经私信直接备注领取。[精编资料]2018年成考备考全套资料及课程,
有,就是好用。你可以搜索‘精编学习资料’,里面有网易云课堂的免费课程。很全。
网易云课堂的视频都有,还有免费的试听课。不过想做一个专业的老师,自己学吧。
成人高考只有江苏省承认,全国也承认,广东广西也承认,网上有很多资料,有考试复习资料,只要认真看书,复习时间达到一年的话,成考是不难的。能不能考上,是要看自己学习能力了,如果自己学习能力好的话,认真看书复习,前几名肯定没问题,不过那个分数也不低。
网上的资料都不全,
有我只说网易云课堂
当然有啊
有啊,自考的内容比较杂,主要是学习,多做题,
有,认真复习就好,
不知道有没有,不过我自考就是在网易云课堂,
还有,
其实可以看一下南大,
有!!!我自考就是报的网易云课堂
网易云课堂,有免费的也有购买的,很全,
有的,但是不多,为什么呢。你可以在各大网站搜索下其他大学教育考试网之类的,有一些直接送资料的,很人性化,里面的录制的课程视频都是压缩过的,适合下载。 查看全部
采集相关文章([精编学习资料]2018年成考备考全套资料及课程)
采集相关文章多次测试,成功率高达95%,已经累计推送到数百个社群里了。链接已经私信直接备注领取。[精编资料]2018年成考备考全套资料及课程,
有,就是好用。你可以搜索‘精编学习资料’,里面有网易云课堂的免费课程。很全。
网易云课堂的视频都有,还有免费的试听课。不过想做一个专业的老师,自己学吧。
成人高考只有江苏省承认,全国也承认,广东广西也承认,网上有很多资料,有考试复习资料,只要认真看书,复习时间达到一年的话,成考是不难的。能不能考上,是要看自己学习能力了,如果自己学习能力好的话,认真看书复习,前几名肯定没问题,不过那个分数也不低。
网上的资料都不全,
有我只说网易云课堂
当然有啊
有啊,自考的内容比较杂,主要是学习,多做题,
有,认真复习就好,
不知道有没有,不过我自考就是在网易云课堂,
还有,
其实可以看一下南大,
有!!!我自考就是报的网易云课堂
网易云课堂,有免费的也有购买的,很全,
有的,但是不多,为什么呢。你可以在各大网站搜索下其他大学教育考试网之类的,有一些直接送资料的,很人性化,里面的录制的课程视频都是压缩过的,适合下载。

