
采集工具免责说明
采集工具免责说明(采集工具免责说明:流氓不在于自己就被认定为不合适)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-04 14:03
采集工具免责说明:根据《中华人民共和国反不正当竞争法》第四条规定:“经营者不得利用广告或者其他方法,对商品的质量、制作成分、性能、用途、生产者、有效期限、产地等作引人误解的虚假宣传。”欢迎点击关注第1则~微信号:detrouxing,
大数据文摘推出过可以识别谣言的机器识别工具。此工具已经失效很久了。不知道现在还有没有用法。这是一个不错的启发思考的工具,用法上有些新意,但其实理解的话也很简单。知乎app上有在argue说在广场吐槽张小龙这样的xx应该是不合适的。但是其实这个流氓行为对于android最终的用户要使用的是android还是ios最终的用户要成为android或ios,是否有好处都未必有关系。
广场吐槽的方式不在于将真相告诉大家,而在于帮助大家分析和提出质疑。流氓不在于你吐槽也不在于自己就被认定为不合适而是应该将真相揭露出来对你有利,你自己确认但对你没有好处。因此,流氓的打法一定要是面对的人越多,越容易争取到人不会产生对自己持反对意见的用户也可以大功告成,人越多越容易完成这件事,你越容易获得人的支持。
所以有数据显示在某个热门回答下刷主的时候是非常容易引发一阵讨论的。当用户看了一些很“时髦”的主,通常就会对android的一些信息有个比较靠谱的了解。他们所获得的信息和自己体验的时候就会有偏差,从而向更不了解android的人获得更多的信息。这时候这部分人的推荐力就很强。经过数据测试,有数据显示三到五分钟将一件事完全了解的用户推荐力能够提升十倍以上。
因此,上面机器识别的方法并不是不可行,但是具体在什么环境下用效果最好,数据更新迭代有什么技巧才是我想讨论的。 查看全部
采集工具免责说明(采集工具免责说明:流氓不在于自己就被认定为不合适)
采集工具免责说明:根据《中华人民共和国反不正当竞争法》第四条规定:“经营者不得利用广告或者其他方法,对商品的质量、制作成分、性能、用途、生产者、有效期限、产地等作引人误解的虚假宣传。”欢迎点击关注第1则~微信号:detrouxing,
大数据文摘推出过可以识别谣言的机器识别工具。此工具已经失效很久了。不知道现在还有没有用法。这是一个不错的启发思考的工具,用法上有些新意,但其实理解的话也很简单。知乎app上有在argue说在广场吐槽张小龙这样的xx应该是不合适的。但是其实这个流氓行为对于android最终的用户要使用的是android还是ios最终的用户要成为android或ios,是否有好处都未必有关系。
广场吐槽的方式不在于将真相告诉大家,而在于帮助大家分析和提出质疑。流氓不在于你吐槽也不在于自己就被认定为不合适而是应该将真相揭露出来对你有利,你自己确认但对你没有好处。因此,流氓的打法一定要是面对的人越多,越容易争取到人不会产生对自己持反对意见的用户也可以大功告成,人越多越容易完成这件事,你越容易获得人的支持。
所以有数据显示在某个热门回答下刷主的时候是非常容易引发一阵讨论的。当用户看了一些很“时髦”的主,通常就会对android的一些信息有个比较靠谱的了解。他们所获得的信息和自己体验的时候就会有偏差,从而向更不了解android的人获得更多的信息。这时候这部分人的推荐力就很强。经过数据测试,有数据显示三到五分钟将一件事完全了解的用户推荐力能够提升十倍以上。
因此,上面机器识别的方法并不是不可行,但是具体在什么环境下用效果最好,数据更新迭代有什么技巧才是我想讨论的。
采集工具免责说明(优采云采集器无限制版本(破解版)分享,破解程序!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-12-02 05:11
资源介绍
优采云采集器V9无限制版(破解版)分享,此版本账号无需登录,使用起来很爽。很多站长应该都试过采集,毕竟纯原创真的很累,还不如别人写的好。网络上流传着很多采集程序,但优采云一直是领头羊,引领采集世界风向,这个最新版的V9破解程序!
软件截图
优采云采集器v9.8破解版特点
全自动操作
无需人工操作,任务完成后自动关机。
更换功能
同义词,同义词替换,参数替换,伪原创必备技能。
下载任何文件格式
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
采集监控系统
实时监控采集,保证数据的准确性。
支持多个数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
无限多页采集
支持无限级别的多页面信息,包括ajax请求数据采集。
支持扩展
支持接口和插件扩展,满足各种理发需求。
真正通用
采集 无限网页,无限内容,支持多种扩展,突破操作限制。您决定选择什么以及如何选择它!
高效稳定
分布式高速采集系统,多台大型服务器同时稳定运行,快速分解任务,最大化效率。
数据准确
内置采集监控系统,实时错误报告,及时修复;采集保证发布时数据零遗漏,呈现给用户最准确的数据。
分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
多重识别系统
搭载文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
十年口碑
优采云采集器目前用户数已突破10万,十年间在用户中形成了良好的口碑,为我们的品牌传播奠定了基础。
可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
资源下载 本资源仅供注册用户下载,请先登录
欢迎加入官方群:99059854 查看全部
采集工具免责说明(优采云采集器无限制版本(破解版)分享,破解程序!)
资源介绍
优采云采集器V9无限制版(破解版)分享,此版本账号无需登录,使用起来很爽。很多站长应该都试过采集,毕竟纯原创真的很累,还不如别人写的好。网络上流传着很多采集程序,但优采云一直是领头羊,引领采集世界风向,这个最新版的V9破解程序!
软件截图




优采云采集器v9.8破解版特点
全自动操作
无需人工操作,任务完成后自动关机。
更换功能
同义词,同义词替换,参数替换,伪原创必备技能。
下载任何文件格式
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
采集监控系统
实时监控采集,保证数据的准确性。
支持多个数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
无限多页采集
支持无限级别的多页面信息,包括ajax请求数据采集。
支持扩展
支持接口和插件扩展,满足各种理发需求。
真正通用
采集 无限网页,无限内容,支持多种扩展,突破操作限制。您决定选择什么以及如何选择它!
高效稳定
分布式高速采集系统,多台大型服务器同时稳定运行,快速分解任务,最大化效率。
数据准确
内置采集监控系统,实时错误报告,及时修复;采集保证发布时数据零遗漏,呈现给用户最准确的数据。
分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
多重识别系统
搭载文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
十年口碑
优采云采集器目前用户数已突破10万,十年间在用户中形成了良好的口碑,为我们的品牌传播奠定了基础。
可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
资源下载 本资源仅供注册用户下载,请先登录
欢迎加入官方群:99059854
采集工具免责说明(用于USB的14位,48kS/s多功能数据8路模拟输入通道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-11-30 20:01
NI USB6009多功能数据采集卡,用于USB 14位、48 kS/s多功能数据采集卡
8 个模拟输入通道,14 位分辨率,12 条数字 I/O 线,2 个模拟输出,1 个计数器
更高性能的 NI USB-6251 和 NI USB-6259
便携式总线供电设计
适用于 Windows、Mac OS X 和 Linux 操作系统的驱动程序软件
随附免费、随时可用的数据记录软件
即插即用 USB 安装,可快速设置
有利于操作学习的学生套件
NI USB-6009具有基础数据采集功能,适用于简单数据记录、便携式测量、高校实验室实验等应用。产品价格低廉,适合学生购买,功能强大,可用于更复杂的测量应用。使用附带的、可立即执行的数据记录软件 NI VI Logger 运行 NI USB-6009,即可立即开始基本测量。如果您需要自定义测量应用程序,您可以使用 labview、C 或 Visual Studio 和 NI-DAQmx for Windows,包括驱动程序软件来对 USB-6009 进行编程。Mac OS X 和 Linux 用户可以下载 NI-DAQmx Base 驱动软件,使用 LabVIEW 或 C 对 USB-6009 进行编程。
NI 开发了带有 LabVIEW 学生版的 USB-6009 学生套件,它补充了仿真、测试和自动化理论课程的实际实验。上述套件仅供学生使用。是功能优良、价格低廉、实用性强的学习工具。如需更多详细信息,请访问 NI 学术产品页面。 查看全部
采集工具免责说明(用于USB的14位,48kS/s多功能数据8路模拟输入通道)
NI USB6009多功能数据采集卡,用于USB 14位、48 kS/s多功能数据采集卡
8 个模拟输入通道,14 位分辨率,12 条数字 I/O 线,2 个模拟输出,1 个计数器
更高性能的 NI USB-6251 和 NI USB-6259
便携式总线供电设计
适用于 Windows、Mac OS X 和 Linux 操作系统的驱动程序软件
随附免费、随时可用的数据记录软件
即插即用 USB 安装,可快速设置
有利于操作学习的学生套件
NI USB-6009具有基础数据采集功能,适用于简单数据记录、便携式测量、高校实验室实验等应用。产品价格低廉,适合学生购买,功能强大,可用于更复杂的测量应用。使用附带的、可立即执行的数据记录软件 NI VI Logger 运行 NI USB-6009,即可立即开始基本测量。如果您需要自定义测量应用程序,您可以使用 labview、C 或 Visual Studio 和 NI-DAQmx for Windows,包括驱动程序软件来对 USB-6009 进行编程。Mac OS X 和 Linux 用户可以下载 NI-DAQmx Base 驱动软件,使用 LabVIEW 或 C 对 USB-6009 进行编程。
NI 开发了带有 LabVIEW 学生版的 USB-6009 学生套件,它补充了仿真、测试和自动化理论课程的实际实验。上述套件仅供学生使用。是功能优良、价格低廉、实用性强的学习工具。如需更多详细信息,请访问 NI 学术产品页面。
采集工具免责说明( Python脚本复制到项目文件夹项目项目项目介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-27 16:17
Python脚本复制到项目文件夹项目项目项目介绍)
数据提取工具集概述
数据提取工具集收录四个工具,可用于以 ArcGIS Server 地理处理服务的形式执行高级裁剪、压缩和发送任务。传统的提取工具(如提取工具集中的工具和特征分析工具裁剪)只允许提取单层数据的一个子集,输出将显示与输入相同的数据格式和空间参考。对于希望在提取数据时灵活选择多个图层、输出格式和空间参考(尤其是通过 Internet)的用户,这些工具具有一些限制。数据提取工具集旨在促进此类功能,以便用户可以通过地理处理服务高效地提取指定格式和空间参考的多层数据。而且,
该工具集收录四个工具:提取数据、提取数据任务、发送电子邮件(附有 Zip 文件)和提取数据并通过电子邮件发送任务。Extract data 是一个脚本工具,可以根据选定的图层、指定的输出格式和坐标系裁剪感兴趣的区域,然后将输出保存为 ZIP 文件。提取数据的任务是一个模型工具,用于执行与提取数据相同的任务。此工具收录数据提取脚本,但仅将有限的输入选项设置为参数。此外,值列表中还有预设的输出格式和空间参考,您可以从中进行选择。Send email(附有Zip文件)是一个脚本工具,可以将ZIP文件以电子邮件的形式发送到指定的电子邮件地址。提取数据并通过电子邮件发送的任务是一个模型工具,它同时具有提取数据和发送电子邮件的功能(附有Zip文件);它收录两者的脚本工具,并将某些输入选项设置为输入参数。
使用本工具集中的每个工具时需要注意以下几点。首先,这两个脚本工具经常被用作建模工具的一部分。如果您想基于这两个工具之一创建自己的脚本工具,您可以将此工具及其源 Python 脚本复制到项目文件夹并在那里进行修改。其次,这两个建模工具主要用作地理处理服务的一部分。将这两个工具用作地理处理服务的一部分时,首先将此工具复制到自定义工具箱。复制完成后,编辑模型并根据需要进行配置。您可以应用提取数据任务的第一部分来查找创建和使用地理处理服务的分步说明。
工具说明
提取数据
将指定感兴趣区域中的选定图层提取为特定格式和特定空间参考。然后将提取的数据写入zip文件。
提取数据并通过电子邮件发送任务
将指定图层和感兴趣区域中的数据提取为选定的格式和空间参考,压缩数据,并以电子邮件的形式将数据发送到指定地址。此工具可用于创建“数据提取”地理处理服务。
数据提取任务
将指定感兴趣区域中的选定图层提取为选定的格式和空间参考,然后返回.zip 文件中的所有数据。
发送电子邮件(附有 Zip 文件)
使用 SMTP 电子邮件服务器将文件通过电子邮件发送到电子邮件地址。
相关话题 查看全部
采集工具免责说明(
Python脚本复制到项目文件夹项目项目项目介绍)
数据提取工具集概述
数据提取工具集收录四个工具,可用于以 ArcGIS Server 地理处理服务的形式执行高级裁剪、压缩和发送任务。传统的提取工具(如提取工具集中的工具和特征分析工具裁剪)只允许提取单层数据的一个子集,输出将显示与输入相同的数据格式和空间参考。对于希望在提取数据时灵活选择多个图层、输出格式和空间参考(尤其是通过 Internet)的用户,这些工具具有一些限制。数据提取工具集旨在促进此类功能,以便用户可以通过地理处理服务高效地提取指定格式和空间参考的多层数据。而且,
该工具集收录四个工具:提取数据、提取数据任务、发送电子邮件(附有 Zip 文件)和提取数据并通过电子邮件发送任务。Extract data 是一个脚本工具,可以根据选定的图层、指定的输出格式和坐标系裁剪感兴趣的区域,然后将输出保存为 ZIP 文件。提取数据的任务是一个模型工具,用于执行与提取数据相同的任务。此工具收录数据提取脚本,但仅将有限的输入选项设置为参数。此外,值列表中还有预设的输出格式和空间参考,您可以从中进行选择。Send email(附有Zip文件)是一个脚本工具,可以将ZIP文件以电子邮件的形式发送到指定的电子邮件地址。提取数据并通过电子邮件发送的任务是一个模型工具,它同时具有提取数据和发送电子邮件的功能(附有Zip文件);它收录两者的脚本工具,并将某些输入选项设置为输入参数。
使用本工具集中的每个工具时需要注意以下几点。首先,这两个脚本工具经常被用作建模工具的一部分。如果您想基于这两个工具之一创建自己的脚本工具,您可以将此工具及其源 Python 脚本复制到项目文件夹并在那里进行修改。其次,这两个建模工具主要用作地理处理服务的一部分。将这两个工具用作地理处理服务的一部分时,首先将此工具复制到自定义工具箱。复制完成后,编辑模型并根据需要进行配置。您可以应用提取数据任务的第一部分来查找创建和使用地理处理服务的分步说明。
工具说明
提取数据
将指定感兴趣区域中的选定图层提取为特定格式和特定空间参考。然后将提取的数据写入zip文件。
提取数据并通过电子邮件发送任务
将指定图层和感兴趣区域中的数据提取为选定的格式和空间参考,压缩数据,并以电子邮件的形式将数据发送到指定地址。此工具可用于创建“数据提取”地理处理服务。
数据提取任务
将指定感兴趣区域中的选定图层提取为选定的格式和空间参考,然后返回.zip 文件中的所有数据。
发送电子邮件(附有 Zip 文件)
使用 SMTP 电子邮件服务器将文件通过电子邮件发送到电子邮件地址。
相关话题
采集工具免责说明([commit日志][web敏感资产fuzz]%和2.0的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-25 05:03
目前支持的功能
全自动扫描:python webmain.py -a --> baidu_site && port/dir scan 单目标扫描:python webmain.py -u --> webscan Portscan && scanDir 多目标检测:python webmain.py -f vuln_domains.txt --> webscan 不 scanDir 多目标扫描:python webmain.py -d vuln_domains.txt --> webscan Portscan && scanDirC 段检测:python webmain.py -cf 192.168.1.@ >1--> C scan not scanDir C scan: python webmain.py -cd 192.168.1.1--> C scan Portscan && scanDir
1.0版本,项目保存在[webmain1.0]
1.0 简介:【网络敏感资产模糊】
%E6%95%8F%E6%84%9F%E8%B5%84%E4%BA%A7fuzz/
1.0和2.0的区别请看【提交日志】
下面是2.0的介绍
项目地址
**Github**
**操作环境**:
python2.6.x 或 python2.7.x
**依赖第三方库**:
pip 安装请求[安全]
节目介绍
**扫描参数不区分大小写和顺序**
**默认代理关闭**
**随机乱序扫描验证**
**可以跨平台使用**
全自动扫描
全自动扫描,默认只加载百度搜索引擎`site:`,生成目标池,执行一些端口扫描,敏感资产和目录扫描功能,详细多目标扫描也是如此
**命令**:`python webmain_debug.py -a `
单目标扫描
默认的单目标扫描模式是加载敏感资产和目录扫描功能,例如:
**命令**:python webmain_debug.py -u `
**扫描日志**
**端口扫描**
程序只扫描端口`11211`、`27017`和`小于10000`
扫描结果如下:
程序会自动过滤掉常规端口
扫描结果
结果展示
结果保存在**report**目录
多目标检测
**命令**:`python webmain_debug.py -f vuln_domains.txt`
**使用介绍**:
快速检测,实现URL转IP后,部分端口扫描,每个开放端口的存活检测,
如果是存活的,则进行`getitle`信息检测。小细节是添加一个`filter_ports`来过滤掉常规端口。
考虑一种情况(边站),多个url解析为一个ip,程序添加`filter_ips`过滤已经扫描端口的ip,
同时,如果各种意外情况导致反复扫描`scheme://netloc`,程序会添加`filter_urls`对已经扫描过的任务进行过滤。
程序还考虑了一种情况,即:当URL是存活的,并且没有扫描到开放端口时,程序会自动检测默认端口的信息。
包括另一种情况,当url不活跃,但扫描到其他开放端口时,程序会自动检测对应端口的信息。
**程序只扫描端口获取目标站点标题、状态码、返回值长度,包括可能的合法IP地址、邮件资产信息**、
但是`不检测解析到内网的ip`,黑名单如下:
10.xxx127.xxx172.xxx192.168.xx
多目标扫描
**命令**:`python webmain_debug.py -d vuln_domains.txt`
**使用介绍**:
与多目标检测的不同之处在于增加了“敏感资产和目录扫描”,
敏感资产检测使用`common payloads 采集`,加上生成的`date备份文件`,程序会先判断404页面的状态,然后遍历payload。
判断条件是返回200,返回的内容大小不等于0,payload与404接口的返回大小差的绝对值大于5(或者两个返回大小不相等),
修改程序前的附加判断条件`如果遇到waf,或者各种意外情况,导致运行的payloads返回大于40,程序会提示可能遇到waf,返回空`,
然后增加`probe counter`来计算结果的数量。如果扫描结果很快超过25条,程序会直接结束扫描,节省时间,提高效率。
新增“多级目录敏感资产扫描”,即在获取网页所有超链接的前提下,进行目录分段扫描,
关于`Dirscan`的结果,就是`Common Payloads 采集 Scan`和`Multi-level Directory Sensitive Asset Scan`的结果去重后的`Union`,
如果出现`['waf']`,则表示常用payload集合的扫描结果已经达到了程序设置的默认阈值。
如果出现`['more_path']`,则表示`多级目录敏感资产扫描结果`已达到程序设置的默认阈值。
其他情况可以直接点击查看验证结果,
在Allinks中,如果提示`[more_link]`,则表示页面上的超链接超过10个。
默认只显示前25个字符,直接点击显示详情
C段检测
**命令**:`python webmain_debug.py -cf 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
C段扫描
**命令**:`python webmain_debug.py -cd 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
异常处理
总会有各种意外情况导致程序产生异常报警。debug模式默认所有输出异常,正常模式不输出。
下面是关于程序扫描时的异常处理,主要是使用`write_file`进行错误记录,
结果保存
默认在当前目录下新建一个report目录,根据扫描参数保存为`html`文件。
关于扫描所有打开的端口,根据扫描参数保存为`csv`文件,将一些特殊端口保存为例如:`mysql_3306.txt`
异常处理保存
linux下建议使用`nohup python webmain_debug.py -d targets.txt &`后台运行,查看扫描日志中的`nohup.out`,结果同上 查看全部
采集工具免责说明([commit日志][web敏感资产fuzz]%和2.0的区别)
目前支持的功能
全自动扫描:python webmain.py -a --> baidu_site && port/dir scan 单目标扫描:python webmain.py -u --> webscan Portscan && scanDir 多目标检测:python webmain.py -f vuln_domains.txt --> webscan 不 scanDir 多目标扫描:python webmain.py -d vuln_domains.txt --> webscan Portscan && scanDirC 段检测:python webmain.py -cf 192.168.1.@ >1--> C scan not scanDir C scan: python webmain.py -cd 192.168.1.1--> C scan Portscan && scanDir
1.0版本,项目保存在[webmain1.0]
1.0 简介:【网络敏感资产模糊】
%E6%95%8F%E6%84%9F%E8%B5%84%E4%BA%A7fuzz/
1.0和2.0的区别请看【提交日志】
下面是2.0的介绍
项目地址
**Github**
**操作环境**:
python2.6.x 或 python2.7.x
**依赖第三方库**:
pip 安装请求[安全]
节目介绍
**扫描参数不区分大小写和顺序**
**默认代理关闭**
**随机乱序扫描验证**
**可以跨平台使用**
全自动扫描
全自动扫描,默认只加载百度搜索引擎`site:`,生成目标池,执行一些端口扫描,敏感资产和目录扫描功能,详细多目标扫描也是如此
**命令**:`python webmain_debug.py -a `
单目标扫描
默认的单目标扫描模式是加载敏感资产和目录扫描功能,例如:
**命令**:python webmain_debug.py -u `
**扫描日志**
**端口扫描**
程序只扫描端口`11211`、`27017`和`小于10000`
扫描结果如下:
程序会自动过滤掉常规端口
扫描结果
结果展示
结果保存在**report**目录
多目标检测
**命令**:`python webmain_debug.py -f vuln_domains.txt`
**使用介绍**:
快速检测,实现URL转IP后,部分端口扫描,每个开放端口的存活检测,
如果是存活的,则进行`getitle`信息检测。小细节是添加一个`filter_ports`来过滤掉常规端口。
考虑一种情况(边站),多个url解析为一个ip,程序添加`filter_ips`过滤已经扫描端口的ip,
同时,如果各种意外情况导致反复扫描`scheme://netloc`,程序会添加`filter_urls`对已经扫描过的任务进行过滤。
程序还考虑了一种情况,即:当URL是存活的,并且没有扫描到开放端口时,程序会自动检测默认端口的信息。
包括另一种情况,当url不活跃,但扫描到其他开放端口时,程序会自动检测对应端口的信息。
**程序只扫描端口获取目标站点标题、状态码、返回值长度,包括可能的合法IP地址、邮件资产信息**、
但是`不检测解析到内网的ip`,黑名单如下:
10.xxx127.xxx172.xxx192.168.xx
多目标扫描
**命令**:`python webmain_debug.py -d vuln_domains.txt`
**使用介绍**:
与多目标检测的不同之处在于增加了“敏感资产和目录扫描”,
敏感资产检测使用`common payloads 采集`,加上生成的`date备份文件`,程序会先判断404页面的状态,然后遍历payload。
判断条件是返回200,返回的内容大小不等于0,payload与404接口的返回大小差的绝对值大于5(或者两个返回大小不相等),
修改程序前的附加判断条件`如果遇到waf,或者各种意外情况,导致运行的payloads返回大于40,程序会提示可能遇到waf,返回空`,
然后增加`probe counter`来计算结果的数量。如果扫描结果很快超过25条,程序会直接结束扫描,节省时间,提高效率。
新增“多级目录敏感资产扫描”,即在获取网页所有超链接的前提下,进行目录分段扫描,
关于`Dirscan`的结果,就是`Common Payloads 采集 Scan`和`Multi-level Directory Sensitive Asset Scan`的结果去重后的`Union`,
如果出现`['waf']`,则表示常用payload集合的扫描结果已经达到了程序设置的默认阈值。
如果出现`['more_path']`,则表示`多级目录敏感资产扫描结果`已达到程序设置的默认阈值。
其他情况可以直接点击查看验证结果,
在Allinks中,如果提示`[more_link]`,则表示页面上的超链接超过10个。
默认只显示前25个字符,直接点击显示详情
C段检测
**命令**:`python webmain_debug.py -cf 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
C段扫描
**命令**:`python webmain_debug.py -cd 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
异常处理
总会有各种意外情况导致程序产生异常报警。debug模式默认所有输出异常,正常模式不输出。
下面是关于程序扫描时的异常处理,主要是使用`write_file`进行错误记录,
结果保存
默认在当前目录下新建一个report目录,根据扫描参数保存为`html`文件。
关于扫描所有打开的端口,根据扫描参数保存为`csv`文件,将一些特殊端口保存为例如:`mysql_3306.txt`
异常处理保存
linux下建议使用`nohup python webmain_debug.py -d targets.txt &`后台运行,查看扫描日志中的`nohup.out`,结果同上
采集工具免责说明(破解迅雷会员超高速度而设计的破解版迅雷(迅捷采集器))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-23 15:02
采集工具免责说明:在网络上搜索“采集工具”、“迅捷采集器”等关键词,会看到很多类似的网站推荐,总体来说都差不多,不外乎四种:1.插件类;2.网站类;3.脚本类;4.采集类,所以这篇文章就要来认真的讲一讲采集工具类。
1)迅捷采集器迅捷采集器是专门用来采集迅雷会员里的某些资源的,是一款很实用的采集器,不仅支持迅雷迅雷会员里的同步文件同步,还支持百度网盘,微盘,磁力猫等网盘资源采集。相当于会员资源采集利器。
2)采集公众号的文章推荐使用采集公众号文章资源的小工具:采集公众号文章-文章内容采集器,
3)采集其他网站的文章推荐使用采集网站资源采集工具的小工具:采集其他网站资源采集工具,
4)推荐其他应用工具使用浏览器采集工具推荐使用迅捷采集器浏览器推荐工具:迅捷采集器bt采集器,是一款为破解迅雷会员超高速度而设计的破解版迅雷(原迅雷7.2版本迅雷),操作简单。02.使用理由采集资源有价值;内容被采集到迅雷服务器中,不让其他人拥有。更新方便;使用迅捷采集器网站资源,提高浏览器访问速度,进而提高下载速度。
独立下载;支持迅雷、优酷、百度等多个下载源;降低客户端安装数量成本,降低客户端下载数量成本。免费使用;采集资源免费使用,操作简单,操作简单才能赚钱;最关键的是能赚钱,如果你是销售人员就要努力的去销售客户公司产品,如果你是一个打工族可以提供相应的采集工具资源,帮助他人提高效率。03.常见问题采集原理:用户下载“采集线程采集”,每个线程做一次任务,任务接收时会将这个线程的任务交给这个线程相应的任务,线程自己再接任务,将资源搜索到服务器,再由服务器负责存储或下载。
采集方法:在迅雷资源下载器最关键一步是通过迅雷下载下“查看迅雷资源下载进度条”,将从迅雷下载器缓存下载的资源全部显示在下载器里面,方便用户找到自己需要的资源。迅雷下载器资源查看进度条每显示100个进度条,可以显示页面每多100页面时显示的资源,可以帮助用户判断下载什么页面的资源,然后在浏览器中重新从任务中取资源下载,此种方法一般用在任务量比较大的情况下。
04.缺点从采集到上传到服务器,周期很长,对于中型服务器来说,需要漫长的时间,如果采集时间比较赶,或者资源量不是特别大的情况下,使用采集工具+newdownloader,获取的资源是中转站,就如同转码工具,下载下来的资源,都是经过转码的,因为中转站是转码工厂。老实说:你下载速度怎么样?我不知道。05.有什么好的在。 查看全部
采集工具免责说明(破解迅雷会员超高速度而设计的破解版迅雷(迅捷采集器))
采集工具免责说明:在网络上搜索“采集工具”、“迅捷采集器”等关键词,会看到很多类似的网站推荐,总体来说都差不多,不外乎四种:1.插件类;2.网站类;3.脚本类;4.采集类,所以这篇文章就要来认真的讲一讲采集工具类。
1)迅捷采集器迅捷采集器是专门用来采集迅雷会员里的某些资源的,是一款很实用的采集器,不仅支持迅雷迅雷会员里的同步文件同步,还支持百度网盘,微盘,磁力猫等网盘资源采集。相当于会员资源采集利器。
2)采集公众号的文章推荐使用采集公众号文章资源的小工具:采集公众号文章-文章内容采集器,
3)采集其他网站的文章推荐使用采集网站资源采集工具的小工具:采集其他网站资源采集工具,
4)推荐其他应用工具使用浏览器采集工具推荐使用迅捷采集器浏览器推荐工具:迅捷采集器bt采集器,是一款为破解迅雷会员超高速度而设计的破解版迅雷(原迅雷7.2版本迅雷),操作简单。02.使用理由采集资源有价值;内容被采集到迅雷服务器中,不让其他人拥有。更新方便;使用迅捷采集器网站资源,提高浏览器访问速度,进而提高下载速度。
独立下载;支持迅雷、优酷、百度等多个下载源;降低客户端安装数量成本,降低客户端下载数量成本。免费使用;采集资源免费使用,操作简单,操作简单才能赚钱;最关键的是能赚钱,如果你是销售人员就要努力的去销售客户公司产品,如果你是一个打工族可以提供相应的采集工具资源,帮助他人提高效率。03.常见问题采集原理:用户下载“采集线程采集”,每个线程做一次任务,任务接收时会将这个线程的任务交给这个线程相应的任务,线程自己再接任务,将资源搜索到服务器,再由服务器负责存储或下载。
采集方法:在迅雷资源下载器最关键一步是通过迅雷下载下“查看迅雷资源下载进度条”,将从迅雷下载器缓存下载的资源全部显示在下载器里面,方便用户找到自己需要的资源。迅雷下载器资源查看进度条每显示100个进度条,可以显示页面每多100页面时显示的资源,可以帮助用户判断下载什么页面的资源,然后在浏览器中重新从任务中取资源下载,此种方法一般用在任务量比较大的情况下。
04.缺点从采集到上传到服务器,周期很长,对于中型服务器来说,需要漫长的时间,如果采集时间比较赶,或者资源量不是特别大的情况下,使用采集工具+newdownloader,获取的资源是中转站,就如同转码工具,下载下来的资源,都是经过转码的,因为中转站是转码工厂。老实说:你下载速度怎么样?我不知道。05.有什么好的在。
采集工具免责说明(全网页采集工具免责说明(一)_软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-22 07:01
采集工具免责说明本工具可以将全网页信息进行搜集处理,如网址、关键词、昵称等信息。采集工具提供免费的采集服务,服务内容仅限ip站点,采集速度快,工作效率高,不影响用户体验。安全性测试代码加密:代码保存为加密文件。同时可支持windows、mac以及linux系统采集。全网页接口:所有网页接口一致,无差异。
全网页接口调用实测:可根据用户情况自定义接口,接口调用准确率高达90%。接口数据校验:生成校验代码。丰富丰富网页接口:ip接口,图片、视频、账号、手机等。外部链接多:可利用seo将外部链接多引入至自己网站。访问其他网站排名高:搜索流量更精准,网站流量增长速度快。还可与其他网站互相链接以进行其他网站引流。
采集方式:网址采集、地址采集、关键词采集。采集速度快、外链快速通过。网址采集:打开12秒,选择搜索地址搜索带有ip地址的页面;地址采集:通过地址搜索方式采集其他页面;关键词采集:通过关键词搜索方式搜索含有ip地址的页面。如:关键词+域名或关键词+百度等。点击查看更多采集方式(包括但不限于):所有采集方式目前支持高级版本免费试用,高级版本仅支持采集ip地址、接口数据等2种方式。提供基础版本的采集工具,通过模拟登录ip、端口等方式获取搜索源代码。
1)新安装的访问上一章节的客户端,会提示你在“登录”。点击“登录”,会提示你找到网站登录接口,可以尝试输入你的账号密码。
2)请先在电脑端浏览器打开通过电脑端登录,在打开“访问网站”即可,有需要注意输入验证码。注意,输入验证码后,采集端会自动识别“访问接口”,不需要手动输入了。
3)登录成功之后,选择一个第三方登录方式(火狐、谷歌)。
4)打开站点之后,可以根据需要修改免责声明、发布公告及api接口申请方式。如需详细的接口使用介绍,请使用访问接口。 查看全部
采集工具免责说明(全网页采集工具免责说明(一)_软件)
采集工具免责说明本工具可以将全网页信息进行搜集处理,如网址、关键词、昵称等信息。采集工具提供免费的采集服务,服务内容仅限ip站点,采集速度快,工作效率高,不影响用户体验。安全性测试代码加密:代码保存为加密文件。同时可支持windows、mac以及linux系统采集。全网页接口:所有网页接口一致,无差异。
全网页接口调用实测:可根据用户情况自定义接口,接口调用准确率高达90%。接口数据校验:生成校验代码。丰富丰富网页接口:ip接口,图片、视频、账号、手机等。外部链接多:可利用seo将外部链接多引入至自己网站。访问其他网站排名高:搜索流量更精准,网站流量增长速度快。还可与其他网站互相链接以进行其他网站引流。
采集方式:网址采集、地址采集、关键词采集。采集速度快、外链快速通过。网址采集:打开12秒,选择搜索地址搜索带有ip地址的页面;地址采集:通过地址搜索方式采集其他页面;关键词采集:通过关键词搜索方式搜索含有ip地址的页面。如:关键词+域名或关键词+百度等。点击查看更多采集方式(包括但不限于):所有采集方式目前支持高级版本免费试用,高级版本仅支持采集ip地址、接口数据等2种方式。提供基础版本的采集工具,通过模拟登录ip、端口等方式获取搜索源代码。
1)新安装的访问上一章节的客户端,会提示你在“登录”。点击“登录”,会提示你找到网站登录接口,可以尝试输入你的账号密码。
2)请先在电脑端浏览器打开通过电脑端登录,在打开“访问网站”即可,有需要注意输入验证码。注意,输入验证码后,采集端会自动识别“访问接口”,不需要手动输入了。
3)登录成功之后,选择一个第三方登录方式(火狐、谷歌)。
4)打开站点之后,可以根据需要修改免责声明、发布公告及api接口申请方式。如需详细的接口使用介绍,请使用访问接口。
采集工具免责说明(全面快速子域收集终极神器-Python和pip3安装步骤(git版) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-18 05:13
)
一体机
OneForAll 是一款强大的子域采集工具英文文档
项目描述
项目地址:
信息采集在渗透测试中的重要性不言而喻。子域采集是信息采集中不可或缺且非常重要的一部分。目前网上已经开源了很多子域采集的工具,但是一直存在以下问题:
为了解决以上痛点,本项目应用应运而生。顾名思义,希望OneForAll是一款强大、全面、强大的快速子域采集终极神器。
目前 OneForAll 仍在开发中。一定有很多问题和需要改进的地方。欢迎大佬提交问题和 PR。给个小星星就可以了✨,目前有一个QQ群专门用于OneForAll交流反馈::824414244(加群验证:我的英雄学院)。
特征
如果您有其他很棒的想法,请告诉我!
入门
请务必花点时间阅读本文档,以帮助您快速熟悉 OneForAll!
安装要求
OneForAll基于Python3.8.0开发测试,请使用高于Python3.8.0的稳定发布版本,其他版本可能有问题(Windows平台必须使用3.8.0及以上)安装Python环境以供参考。运行以下命令检查 Python 和 pip3 版本:
python -V
pip3 -V
如果看到如下类似的输出,说明Python环境没有问题:
Python 3.8.0
pip 19.2.2 from C:\Users\shmilylty\AppData\Roaming\Python\Python38\site-packages\pip (python 3.8)
✔安装步骤(git版)
下载
由于项目正在开发中,会不断更新迭代。下载的时候用git clone克隆最新的代码仓库,也方便后续的更新。不建议从Release下载,因为Release里面的版本更新慢,更新不方便。这个项目已经被我在 Gitee 上镜像了一份。国内推荐使用Gitee克隆更快:
git clone https://gitee.com/shmilylty/OneForAll.git
或者:
git clone https://github.com/shmilylty/OneForAll.git
安装
您可以通过 pip3 安装 OneForAll 的依赖项。下面是Windows系统下使用pip3安装依赖的例子: 注意:如果你的Python3安装在系统的Program Files目录下,如:C:\Program Files\Python38,那么请使用管理员运行命令提示符cmd作为身份执行以下命令!
cd OneForAll/
python -m pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python oneforall.py --help
其他系统平台请参考依赖安装。如果在安装过程中发现依赖库编译失败,可以参考 Troubleshooting.md 解决方案。如果还没有解决,请加群反馈。
更新
❗注意:如果之前已经克隆过项目,请将修改后的文件备份到项目外的地方(如config.py),然后执行如下命令更新项目:
git fetch --all
git reset --hard origin/master
git pull
✔安装步骤(docker版)
docker pull shmilylty/oneforall
docker run -it --rm -v ~/results:/OneForAll/results oneforall
结果会输出到本地目录~/results
✨使用演示
如果您通过 pip3 安装依赖项,请使用以下命令运行示例:
python3 oneforall.py --target example.com run
如果您通过 pipenv 安装了依赖项,请使用以下命令运行示例:
pipenv run python oneforall.py --target example.com run
结果说明
我们以 python3 oneforall.py --target run 命令为例。正常执行默认参数后,OneForAll会在results目录下生成相应的结果:
.csv是各个主域下子域的采集结果。
all_subdomain_result_1583034493.csv是OneForAll每次运行时采集的子域汇总结果,包括.csv,方便批量采集场景下获取所有结果。
result.sqlite3 是 SQLite3 结果数据库,存储每次运行 OneForAll 时采集的子域。数据库结构如下:
其中,类似于example_com_origin_result的表存储了各个模块的初始子域采集结果。
其中,类似于example_com_resolve_result的表存储了子域解析的结果。
其中,类似于example_com_last_result的表存储了最后一次子域采集的结果(需要采集两次以上才能生成)。
其中,类似于example_com_now_result的表存储了当前子域的采集结果。一般来说,关注这张表就足够了。
使用帮助
命令行参数只提供了一些常用的参数。更详细的参数配置请参考config.py。如果您认为某些参数在命令界面中经常使用或缺少参数,非常欢迎反馈。由于众所周知的原因,如果您想使用一些被围墙的集合接口,请到 config.py 中配置代理。部分采集模块需要提供API(大部分可以通过注册账号免费获得)。如果您需要使用它们,请到 api.py 配置 API。信息,如果你不使用它,请忽略错误信息。(详细模块请阅读采集模块说明)
OneForAll 命令行界面基于 Fire。有关 Fire 的更高级使用方法,请参阅使用 Fire CLI。
oneforall.py 是主程序入口,oneforall.py 可以调用brute.py、takerover.py 和dbexport.py 模块。为了方便子域爆破,brute.py是独立生成的,为了方便子域接管风险独立排查。takerover.py,为了方便数据库导出,dbexport.py是独立的,这些模块可以单独运行,接受的参数要丰富一些,如果要单独使用这些模块,请参考帮助
❗注意:当您在使用过程中遇到一些问题或疑问,请先在Issue中搜索答案。您还可以参考常见问题和解答。
oneforall.py 使用帮助
以下帮助信息可能不是最新的,可以使用 python oneforall.py --help 获取最新的帮助信息。
python oneforall.py --help
NAME
oneforall.py - OneForAll帮助信息
SYNOPSIS
oneforall.py COMMAND | --target=TARGET
DESCRIPTION
OneForAll是一款功能强大的子域收集工具
Example:
python3 oneforall.py version
python3 oneforall.py --target example.com run
python3 oneforall.py --target ./domains.txt run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --port small run
python3 oneforall.py --target example.com --format csv run
python3 oneforall.py --target example.com --dns False run
python3 oneforall.py --target example.com --req False run
python3 oneforall.py --target example.com --takeover False run
python3 oneforall.py --target example.com --show True run
Note:
参数alive可选值True,False分别表示导出存活,全部子域结果
参数port可选值有'default', 'small', 'large', 详见config.py配置
参数format可选格式有'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path默认None使用OneForAll结果目录生成路径
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径(必需参数)
FLAGS
--brute=BRUTE
使用爆破模块(默认False)
--dns=DNS
DNS解析子域(默认True)
--req=REQ
HTTP请求子域(默认True)
--port=PORT
请求验证子域的端口范围(默认只探测80端口)
--valid=VALID
只导出存活的子域结果(默认False)
--format=FORMAT
结果保存格式(默认csv)
--path=PATH
结果保存路径(默认None)
--takeover=TAKEOVER
检查子域接管(默认False)
目录结构
项目目录结构的描述请参考directory_structure。
子域字典出处注意事项:
开源子域采集工具中高频子域名字典的一部分。相关在线服务提供商发布的最受欢迎的子域列表。互联网相关安全研究人员对全网公共子域的研究成果。互联网相关安全研究人员在证书透明性中提取公共子域的结果。常用业务命名规则:公司或 DevOps 中常用的工具和软件名称。汉语常用词和英语常用词的拼音。上面得到的字典针对排序和脏数据去除处理进行了优化。非常欢迎您贡献一本更好的词典。使用的框架
感谢这些伟大而优秀的 Python 库!
贡献
非常热烈欢迎大家一起改进这个项目!
⌛后续计划
更多细节请阅读 todo.md。
版本控制
该项目使用 SemVer 语言版本格式进行版本管理。您可以在 Releases 中查看可用版本,并且可以检查 changes.md 以了解历史更改。
贡献者
您可以在contributors.md 中查看参与该项目的所有开发人员。
☕ 欣赏
如果你认为这个项目对你有帮助,你可以奖励你一杯咖啡作为鼓励:)
查看全部
采集工具免责说明(全面快速子域收集终极神器-Python和pip3安装步骤(git版)
)
一体机
OneForAll 是一款强大的子域采集工具英文文档

项目描述
项目地址:
信息采集在渗透测试中的重要性不言而喻。子域采集是信息采集中不可或缺且非常重要的一部分。目前网上已经开源了很多子域采集的工具,但是一直存在以下问题:
为了解决以上痛点,本项目应用应运而生。顾名思义,希望OneForAll是一款强大、全面、强大的快速子域采集终极神器。
目前 OneForAll 仍在开发中。一定有很多问题和需要改进的地方。欢迎大佬提交问题和 PR。给个小星星就可以了✨,目前有一个QQ群专门用于OneForAll交流反馈::824414244(加群验证:我的英雄学院)。
特征
如果您有其他很棒的想法,请告诉我!
入门
请务必花点时间阅读本文档,以帮助您快速熟悉 OneForAll!
安装要求
OneForAll基于Python3.8.0开发测试,请使用高于Python3.8.0的稳定发布版本,其他版本可能有问题(Windows平台必须使用3.8.0及以上)安装Python环境以供参考。运行以下命令检查 Python 和 pip3 版本:
python -V
pip3 -V
如果看到如下类似的输出,说明Python环境没有问题:
Python 3.8.0
pip 19.2.2 from C:\Users\shmilylty\AppData\Roaming\Python\Python38\site-packages\pip (python 3.8)
✔安装步骤(git版)
下载
由于项目正在开发中,会不断更新迭代。下载的时候用git clone克隆最新的代码仓库,也方便后续的更新。不建议从Release下载,因为Release里面的版本更新慢,更新不方便。这个项目已经被我在 Gitee 上镜像了一份。国内推荐使用Gitee克隆更快:
git clone https://gitee.com/shmilylty/OneForAll.git
或者:
git clone https://github.com/shmilylty/OneForAll.git
安装
您可以通过 pip3 安装 OneForAll 的依赖项。下面是Windows系统下使用pip3安装依赖的例子: 注意:如果你的Python3安装在系统的Program Files目录下,如:C:\Program Files\Python38,那么请使用管理员运行命令提示符cmd作为身份执行以下命令!
cd OneForAll/
python -m pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python oneforall.py --help
其他系统平台请参考依赖安装。如果在安装过程中发现依赖库编译失败,可以参考 Troubleshooting.md 解决方案。如果还没有解决,请加群反馈。
更新
❗注意:如果之前已经克隆过项目,请将修改后的文件备份到项目外的地方(如config.py),然后执行如下命令更新项目:
git fetch --all
git reset --hard origin/master
git pull
✔安装步骤(docker版)
docker pull shmilylty/oneforall
docker run -it --rm -v ~/results:/OneForAll/results oneforall
结果会输出到本地目录~/results
✨使用演示
如果您通过 pip3 安装依赖项,请使用以下命令运行示例:
python3 oneforall.py --target example.com run
如果您通过 pipenv 安装了依赖项,请使用以下命令运行示例:
pipenv run python oneforall.py --target example.com run
结果说明
我们以 python3 oneforall.py --target run 命令为例。正常执行默认参数后,OneForAll会在results目录下生成相应的结果:

.csv是各个主域下子域的采集结果。
all_subdomain_result_1583034493.csv是OneForAll每次运行时采集的子域汇总结果,包括.csv,方便批量采集场景下获取所有结果。
result.sqlite3 是 SQLite3 结果数据库,存储每次运行 OneForAll 时采集的子域。数据库结构如下:

其中,类似于example_com_origin_result的表存储了各个模块的初始子域采集结果。
其中,类似于example_com_resolve_result的表存储了子域解析的结果。
其中,类似于example_com_last_result的表存储了最后一次子域采集的结果(需要采集两次以上才能生成)。
其中,类似于example_com_now_result的表存储了当前子域的采集结果。一般来说,关注这张表就足够了。
使用帮助
命令行参数只提供了一些常用的参数。更详细的参数配置请参考config.py。如果您认为某些参数在命令界面中经常使用或缺少参数,非常欢迎反馈。由于众所周知的原因,如果您想使用一些被围墙的集合接口,请到 config.py 中配置代理。部分采集模块需要提供API(大部分可以通过注册账号免费获得)。如果您需要使用它们,请到 api.py 配置 API。信息,如果你不使用它,请忽略错误信息。(详细模块请阅读采集模块说明)
OneForAll 命令行界面基于 Fire。有关 Fire 的更高级使用方法,请参阅使用 Fire CLI。
oneforall.py 是主程序入口,oneforall.py 可以调用brute.py、takerover.py 和dbexport.py 模块。为了方便子域爆破,brute.py是独立生成的,为了方便子域接管风险独立排查。takerover.py,为了方便数据库导出,dbexport.py是独立的,这些模块可以单独运行,接受的参数要丰富一些,如果要单独使用这些模块,请参考帮助
❗注意:当您在使用过程中遇到一些问题或疑问,请先在Issue中搜索答案。您还可以参考常见问题和解答。
oneforall.py 使用帮助
以下帮助信息可能不是最新的,可以使用 python oneforall.py --help 获取最新的帮助信息。
python oneforall.py --help
NAME
oneforall.py - OneForAll帮助信息
SYNOPSIS
oneforall.py COMMAND | --target=TARGET
DESCRIPTION
OneForAll是一款功能强大的子域收集工具
Example:
python3 oneforall.py version
python3 oneforall.py --target example.com run
python3 oneforall.py --target ./domains.txt run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --port small run
python3 oneforall.py --target example.com --format csv run
python3 oneforall.py --target example.com --dns False run
python3 oneforall.py --target example.com --req False run
python3 oneforall.py --target example.com --takeover False run
python3 oneforall.py --target example.com --show True run
Note:
参数alive可选值True,False分别表示导出存活,全部子域结果
参数port可选值有'default', 'small', 'large', 详见config.py配置
参数format可选格式有'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path默认None使用OneForAll结果目录生成路径
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径(必需参数)
FLAGS
--brute=BRUTE
使用爆破模块(默认False)
--dns=DNS
DNS解析子域(默认True)
--req=REQ
HTTP请求子域(默认True)
--port=PORT
请求验证子域的端口范围(默认只探测80端口)
--valid=VALID
只导出存活的子域结果(默认False)
--format=FORMAT
结果保存格式(默认csv)
--path=PATH
结果保存路径(默认None)
--takeover=TAKEOVER
检查子域接管(默认False)
目录结构
项目目录结构的描述请参考directory_structure。
子域字典出处注意事项:
开源子域采集工具中高频子域名字典的一部分。相关在线服务提供商发布的最受欢迎的子域列表。互联网相关安全研究人员对全网公共子域的研究成果。互联网相关安全研究人员在证书透明性中提取公共子域的结果。常用业务命名规则:公司或 DevOps 中常用的工具和软件名称。汉语常用词和英语常用词的拼音。上面得到的字典针对排序和脏数据去除处理进行了优化。非常欢迎您贡献一本更好的词典。使用的框架
感谢这些伟大而优秀的 Python 库!
贡献
非常热烈欢迎大家一起改进这个项目!
⌛后续计划
更多细节请阅读 todo.md。
版本控制
该项目使用 SemVer 语言版本格式进行版本管理。您可以在 Releases 中查看可用版本,并且可以检查 changes.md 以了解历史更改。
贡献者
您可以在contributors.md 中查看参与该项目的所有开发人员。
☕ 欣赏
如果你认为这个项目对你有帮助,你可以奖励你一杯咖啡作为鼓励:)

采集工具免责说明(阿里大数据买软件送软件我们是做这方面的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-16 23:02
采集工具免责说明:本工具仅对我司产品或服务进行探索验证,不代表你们公司承诺书、合同以及其他相关法律文件的出具、变更或修改。以上判断的前提是,本工具是否真的适用于你或者你相关机构、机构成员的产品或服务。目前,中国信息产业网只发布我司产品(因涉及版权等原因,所以只发布我司的产品)在中国信息产业网上可以访问。
你们要是想做数据采集的话,建议先做好数据源的一个打通,应该就能够有源头来了,如果是将数据源分享出去,那么其实就已经不是数据采集了,而是采集了整个大数据社会的一个生态体系了。
提供我个人的一个点子,加入到卖家群里去,给的卖家送一些定制化的一个采集软件,采集上销量高的一些商品到自己店铺,每天自己的的一个销量都在增加,售价目前是58,
我们可以合作一下
我们是专业的这方面,
阿里大数据
买软件送软件
我们是做这方面的
楼主有兴趣合作吗?不知道可不可以教你一个数据采集的软件,做软件肯定需要一定的技术,找软件的话你可以直接去zol软件下载这些地方下载,有很多国内知名软件开发商,缺点是非标准化的,安装时安全问题不知道有没有考虑好。其实根据我看你的这个问题是希望自己做的,那就去试一下销量高的那些商品吧,直接去采集整合到你的数据库,这样再考虑去其他平台推广。 查看全部
采集工具免责说明(阿里大数据买软件送软件我们是做这方面的)
采集工具免责说明:本工具仅对我司产品或服务进行探索验证,不代表你们公司承诺书、合同以及其他相关法律文件的出具、变更或修改。以上判断的前提是,本工具是否真的适用于你或者你相关机构、机构成员的产品或服务。目前,中国信息产业网只发布我司产品(因涉及版权等原因,所以只发布我司的产品)在中国信息产业网上可以访问。
你们要是想做数据采集的话,建议先做好数据源的一个打通,应该就能够有源头来了,如果是将数据源分享出去,那么其实就已经不是数据采集了,而是采集了整个大数据社会的一个生态体系了。
提供我个人的一个点子,加入到卖家群里去,给的卖家送一些定制化的一个采集软件,采集上销量高的一些商品到自己店铺,每天自己的的一个销量都在增加,售价目前是58,
我们可以合作一下
我们是专业的这方面,
阿里大数据
买软件送软件
我们是做这方面的
楼主有兴趣合作吗?不知道可不可以教你一个数据采集的软件,做软件肯定需要一定的技术,找软件的话你可以直接去zol软件下载这些地方下载,有很多国内知名软件开发商,缺点是非标准化的,安装时安全问题不知道有没有考虑好。其实根据我看你的这个问题是希望自己做的,那就去试一下销量高的那些商品吧,直接去采集整合到你的数据库,这样再考虑去其他平台推广。
采集工具免责说明(采集工具免责说明及解释(一)采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-15 02:02
采集工具免责说明及解释
1)google采集软件可以让我们像使用adsense一样,使用google搜索和推荐的推广工具。采集软件可以让google采集成功,并且把数据或在google中预定义的数据放在网站中。注意:谷歌不会拿去或收集数据,而它只是使用数据。采集软件不会收集用户的任何数据,不会参与数据收集和不可靠购买。任何接触数据的接触点都是不可靠的。如果是违反这条说明,所采集的数据将不会被保存。(。
2)如果你在一个网站使用了采集软件,通常的结果是你想要访问网站中的某些独特页面。你正在搜集网站页面中的所有链接。你需要想办法重新列出以前搜集的页面。采集软件可以帮助你实现这个目标。
3)我们的采集是通过爬虫系统抓取。当我们抓取来自谷歌的网页信息或其他网站上的任何内容时,我们需要进行对每个数据来源的估计。在将数据从爬虫引到我们需要的网站之前,需要对数据进行重新列出。通常地,我们对网页进行重新列出时间通常会超过1个小时以上。如果爬虫或采集软件与我们抓取的所有网页相符,则我们可以搜集从网页中产生的所有数据。(。
4)我们从源代码收集的数据只包含有关源代码页面的信息。我们将从源代码中解析的数据称为“待搜索页面”(webburden)。
5)我们不是使用的google搜索工具,而是自己编写的抓取工具。
6)我们没有用adsense的元素抓取功能(例如,:访问用户名,密码,cookie等)。
7)我们不使用专门创建的爬虫程序。自己创建的google工具通常有spanner数据库(请参阅"objects"章节)。最后,注意到一个google工具(googletool)。在本指南中,该数据库包含用户名,密码,账号和其他敏感信息。我们假设您已经编写了一个采集工具程序,然后从google网站抓取数据。
我们编写了爬虫程序,并将爬虫程序开放给google。目录1安装google采集工具2列出收集的数据3发送电子邮件给google4发送一封电子邮件给谷歌5另一个简单的抓取网站6每个网站抓取1-2个页面7命令行界面抓取工具8在我们的mac上抓取图片9使用我们的服务器上抓取google,使用我们的电子邮件服务器发送图片。 查看全部
采集工具免责说明(采集工具免责说明及解释(一)采集软件)
采集工具免责说明及解释
1)google采集软件可以让我们像使用adsense一样,使用google搜索和推荐的推广工具。采集软件可以让google采集成功,并且把数据或在google中预定义的数据放在网站中。注意:谷歌不会拿去或收集数据,而它只是使用数据。采集软件不会收集用户的任何数据,不会参与数据收集和不可靠购买。任何接触数据的接触点都是不可靠的。如果是违反这条说明,所采集的数据将不会被保存。(。
2)如果你在一个网站使用了采集软件,通常的结果是你想要访问网站中的某些独特页面。你正在搜集网站页面中的所有链接。你需要想办法重新列出以前搜集的页面。采集软件可以帮助你实现这个目标。
3)我们的采集是通过爬虫系统抓取。当我们抓取来自谷歌的网页信息或其他网站上的任何内容时,我们需要进行对每个数据来源的估计。在将数据从爬虫引到我们需要的网站之前,需要对数据进行重新列出。通常地,我们对网页进行重新列出时间通常会超过1个小时以上。如果爬虫或采集软件与我们抓取的所有网页相符,则我们可以搜集从网页中产生的所有数据。(。
4)我们从源代码收集的数据只包含有关源代码页面的信息。我们将从源代码中解析的数据称为“待搜索页面”(webburden)。
5)我们不是使用的google搜索工具,而是自己编写的抓取工具。
6)我们没有用adsense的元素抓取功能(例如,:访问用户名,密码,cookie等)。
7)我们不使用专门创建的爬虫程序。自己创建的google工具通常有spanner数据库(请参阅"objects"章节)。最后,注意到一个google工具(googletool)。在本指南中,该数据库包含用户名,密码,账号和其他敏感信息。我们假设您已经编写了一个采集工具程序,然后从google网站抓取数据。
我们编写了爬虫程序,并将爬虫程序开放给google。目录1安装google采集工具2列出收集的数据3发送电子邮件给google4发送一封电子邮件给谷歌5另一个简单的抓取网站6每个网站抓取1-2个页面7命令行界面抓取工具8在我们的mac上抓取图片9使用我们的服务器上抓取google,使用我们的电子邮件服务器发送图片。
采集工具免责说明(优采云采集器支持所有操作系统版本更新和功能升级同步所有平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-13 12:18
优采云采集器是专业实用的网页资料采集器。这个采集器不需要开发,任何人都可以使用,并且可以将数据导出到本地文件,发布到网站和数据库等。
它是由最初的谷歌技术团队创建的。它的规则配置简单,采集功能强大,可以支持电子商务、生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别有多种方式导出网页数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监控、风险评估的好帮手。
优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您的其他前台工作是您数据的最佳助手采集。
【特征】
一、【简单的规则配置采集强大的功能】
1、可视化定制采集流程:
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、 点击提取网页数据:
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据:
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出并发布采集的数据:
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
二、【支持采集不同类型的网站】
电商、生活服务、社交媒体、新闻论坛、本地网站...
强大的浏览器内核,99%以上网站都能上手!
三、【所有平台支持免费可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集 和导出都是免费的,无限使用
可视化配置采集规则,傻瓜式操作
四、【强大的功能,快速的箭头】
智能识别网页数据,多种方式导出数据
软件定期更新升级,不断添加新功能
客户的满意就是对我们最大的肯定!
【常见问题】
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集任务
1)Launch优采云采集器,进入主界面,点击Create Task按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)在搜索关键字和选择关键字的输入框中填写,点击下一步
3) 进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)单击列表块中的第一个元素
5) 点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整。采集 运行时点击向下 页面上按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择采集的字段:在焦点框中单击要提取的元素,然后单击下一步
8) 选择不进入详情页。单击保存或保存并运行
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图 查看全部
采集工具免责说明(优采云采集器支持所有操作系统版本更新和功能升级同步所有平台)
优采云采集器是专业实用的网页资料采集器。这个采集器不需要开发,任何人都可以使用,并且可以将数据导出到本地文件,发布到网站和数据库等。
它是由最初的谷歌技术团队创建的。它的规则配置简单,采集功能强大,可以支持电子商务、生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别有多种方式导出网页数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监控、风险评估的好帮手。
优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您的其他前台工作是您数据的最佳助手采集。
【特征】
一、【简单的规则配置采集强大的功能】
1、可视化定制采集流程:
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、 点击提取网页数据:
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据:
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出并发布采集的数据:
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
二、【支持采集不同类型的网站】
电商、生活服务、社交媒体、新闻论坛、本地网站...
强大的浏览器内核,99%以上网站都能上手!
三、【所有平台支持免费可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集 和导出都是免费的,无限使用
可视化配置采集规则,傻瓜式操作
四、【强大的功能,快速的箭头】
智能识别网页数据,多种方式导出数据
软件定期更新升级,不断添加新功能
客户的满意就是对我们最大的肯定!

【常见问题】
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集任务
1)Launch优采云采集器,进入主界面,点击Create Task按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址

第二步:自定义采集流程
1) 点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)在搜索关键字和选择关键字的输入框中填写,点击下一步
3) 进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)单击列表块中的第一个元素
5) 点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整。采集 运行时点击向下 页面上按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择采集的字段:在焦点框中单击要提取的元素,然后单击下一步
8) 选择不进入详情页。单击保存或保存并运行

第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
采集工具免责说明(网络矿工数据采集软件的保障您的软件使用利益)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-06 17:25
网络矿工数据采集软件是一款面向采集专业用户的采集软件。基于Soukey的拣货数据采集软件研发,并在此基础上进行了扩展 更丰富的专业功能不仅可以进一步满足采集用户的需求,还可以扩大采集的应用范围采集。同时也为网络矿工数据采集软件提供专业的技术支持和售后服务。将最大限度的保护您的软件使用利益。需要 Microsoft .NetFramework2.0 环境。
网络矿工数据采集在原版V2012的基础上,增加了多页面采集、多sql支持功能,并优化了UI操作。网络矿工数据采集软件根据用户数量进行授权。主要功能如下:
1、多任务、多线程,支持一个任务运行多个实例;
2、支持图片、Flash和文件下载:下载不支持多线程处理,所以不建议使用本软件创建专业下载任务;
3、URL 配置支持参数自定义,以及外部字典参数:自定义的参数值可以通过字典的方式进行扩展;
4、支持Cookies,POST采集:可以记录Cookies,采集网站需要登录的数据,也可以手动登录采集;
5、支持导航,自动翻页:可以进行网站导航,例如:通过新闻列表采集新闻内容;支持多层导航;
6、可以采集ajax数据;
7、采集 临时存储数据,断点处连续采集数据:临时存储数据的格式为XML;
8、支持数据导出、文件、数据库:数据库支持Access、MS Sql Server、MySql,文件支持文本文件和Excel;数据导出支持手动和自动,手动导出只支持文件格式;
9.在线数据发布:支持在线数据发布,数据发布支持Cookie;
10、数据采集支持采集数据处理:采集数据可进行替换、截取、追加等操作,可自动去除网页符号,支持Regular; 查看全部
采集工具免责说明(网络矿工数据采集软件的保障您的软件使用利益)
网络矿工数据采集软件是一款面向采集专业用户的采集软件。基于Soukey的拣货数据采集软件研发,并在此基础上进行了扩展 更丰富的专业功能不仅可以进一步满足采集用户的需求,还可以扩大采集的应用范围采集。同时也为网络矿工数据采集软件提供专业的技术支持和售后服务。将最大限度的保护您的软件使用利益。需要 Microsoft .NetFramework2.0 环境。
网络矿工数据采集在原版V2012的基础上,增加了多页面采集、多sql支持功能,并优化了UI操作。网络矿工数据采集软件根据用户数量进行授权。主要功能如下:
1、多任务、多线程,支持一个任务运行多个实例;
2、支持图片、Flash和文件下载:下载不支持多线程处理,所以不建议使用本软件创建专业下载任务;
3、URL 配置支持参数自定义,以及外部字典参数:自定义的参数值可以通过字典的方式进行扩展;
4、支持Cookies,POST采集:可以记录Cookies,采集网站需要登录的数据,也可以手动登录采集;
5、支持导航,自动翻页:可以进行网站导航,例如:通过新闻列表采集新闻内容;支持多层导航;
6、可以采集ajax数据;
7、采集 临时存储数据,断点处连续采集数据:临时存储数据的格式为XML;
8、支持数据导出、文件、数据库:数据库支持Access、MS Sql Server、MySql,文件支持文本文件和Excel;数据导出支持手动和自动,手动导出只支持文件格式;
9.在线数据发布:支持在线数据发布,数据发布支持Cookie;
10、数据采集支持采集数据处理:采集数据可进行替换、截取、追加等操作,可自动去除网页符号,支持Regular;
采集工具免责说明(采集工具免责说明,你说不同的数据分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-02 20:02
采集工具免责说明
1、官方不允许使用(36
0)
2、第三方信息系统收集验证上报(巨头)
3、在线实现方式(如易讯)
4、收集数据流量分析
无非就是以上人说的那几个呗。就像之前有人做app每天都会有注册和登录数据流一样。既然那些不方便,那就干脆提取吧。比如,登录了之后,把这个app的注册和登录信息取出来。这个过程,其实是有一些数据文件存在的,如果只是计算的话,本质上应该是一样的。如果是把这些数据分析,那可能也是和前面提到的算法一样。
当然是多线程处理。
这个问题挺有意思,也最核心。采集是一个很基础的技术点,理论上采集的数据量越大,处理效率越高,还有对数据分析得越精准。但多采集在实际中却得有不同的处理方式,很多数据分析平台是开放有接口的,我们公司用的那些软件功能就差异不大,但平台不同,这样给出的返回结果和效果差异就很大。不同平台有不同的接口处理,最后数据要回到自己手里在分析处理和分析结果进行对比,你说不同的数据采集,做后台有啥区别?几乎每个用户数据都不一样。
从用户和身边朋友总结了一些,大概有这么几种情况:平台线程采集:比如京东个性化搜索,经常采用网页,然后把所有的结果进行分类汇总,根据用户搜索的类型进行汇总,归到一个统一的list中去,进行再次提交;品牌方的线程采集:这种数据量相对较大;互联网分析公司:这种分析是网站或app平台提供接口,根据统一的结果进行分析、处理、反馈,以查看产品优化、调整、促销的效果;互联网广告公司:他们会收集产品表现、竞品表现、用户搜索习惯等数据,利用分析思维整理出更加精准、客观、准确的投放策略;社交媒体新闻类公司:这种公司通常是找到用户数据,做点击率、互动率等排名,然后同公司内部需要的媒体进行结算;这些,主要还是要找准想要采集哪些数据,然后有针对性的去采集,具体可以搜索一下相关资料,看看市场上做什么的多些。 查看全部
采集工具免责说明(采集工具免责说明,你说不同的数据分析)
采集工具免责说明
1、官方不允许使用(36
0)
2、第三方信息系统收集验证上报(巨头)
3、在线实现方式(如易讯)
4、收集数据流量分析
无非就是以上人说的那几个呗。就像之前有人做app每天都会有注册和登录数据流一样。既然那些不方便,那就干脆提取吧。比如,登录了之后,把这个app的注册和登录信息取出来。这个过程,其实是有一些数据文件存在的,如果只是计算的话,本质上应该是一样的。如果是把这些数据分析,那可能也是和前面提到的算法一样。
当然是多线程处理。
这个问题挺有意思,也最核心。采集是一个很基础的技术点,理论上采集的数据量越大,处理效率越高,还有对数据分析得越精准。但多采集在实际中却得有不同的处理方式,很多数据分析平台是开放有接口的,我们公司用的那些软件功能就差异不大,但平台不同,这样给出的返回结果和效果差异就很大。不同平台有不同的接口处理,最后数据要回到自己手里在分析处理和分析结果进行对比,你说不同的数据采集,做后台有啥区别?几乎每个用户数据都不一样。
从用户和身边朋友总结了一些,大概有这么几种情况:平台线程采集:比如京东个性化搜索,经常采用网页,然后把所有的结果进行分类汇总,根据用户搜索的类型进行汇总,归到一个统一的list中去,进行再次提交;品牌方的线程采集:这种数据量相对较大;互联网分析公司:这种分析是网站或app平台提供接口,根据统一的结果进行分析、处理、反馈,以查看产品优化、调整、促销的效果;互联网广告公司:他们会收集产品表现、竞品表现、用户搜索习惯等数据,利用分析思维整理出更加精准、客观、准确的投放策略;社交媒体新闻类公司:这种公司通常是找到用户数据,做点击率、互动率等排名,然后同公司内部需要的媒体进行结算;这些,主要还是要找准想要采集哪些数据,然后有针对性的去采集,具体可以搜索一下相关资料,看看市场上做什么的多些。
采集工具免责说明(电商平台采集工具免责说明--百度搜索信息数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-01 21:04
采集工具免责说明:非专业产品研发者和生产者,请不要对产品功能、使用和安全性进行尝试。我们采集的只是上高信誉商家的库存商品或者他们店铺里卖的非高信誉商品,因此如果您的产品未通过官方认证,或未通过我们的评估,则本采集工具不对外开放。您购买本工具也不能直接获得您要的内容。我们只是将上的正品卖家与非正品卖家进行匹配,提供一个你想要的产品信息数据库,解决你上买东西困难的问题,满足你寻找真正高信誉、品质优异、价格又便宜的商品的需求。
如果你也想上网,购买各类销量好、商品信誉高、评分高的正品物品,请联系我们;我们一定全力做好服务,让您购物更省心、更放心!鉴于网上的信誉有很多虚假欺诈行为,真假难辨,请用户以警惕为主,若发现有不符合提示情况,请拍下后,及时举报售假商家;如觉得有问题请直接致电客服咨询,欢迎拨打:。联系方式::各大电商平台的营销工具提供分享下面可以随便拿我用。anyway...。
除了这个工具以外,其他的也不知道,但是我相信有的工具只是用来了解下打发时间而已,
采集公众号?微博内容?本身这些网站都有置顶排行,要数据很容易,但是现在用外链或者黑帽去抓也不现实,效率比较低。给大家介绍一个好的工具,采集百度搜索信息导出工具。工具基本介绍:可以采集百度搜索引擎的关键词或者网页数据,要根据需求选择操作手法和工具来用。具体操作步骤:步骤一:搜索百度关键词,输入提取数据步骤二:根据需求选择操作手法后面详细说明。
步骤三:导出(excel,网页excel,数据库或者其他格式导出等)步骤四:导出后如何用于微信文章里自定义标题,自定义图片,文章大纲等?有教程,可以解决你的疑惑!!!。 查看全部
采集工具免责说明(电商平台采集工具免责说明--百度搜索信息数据库)
采集工具免责说明:非专业产品研发者和生产者,请不要对产品功能、使用和安全性进行尝试。我们采集的只是上高信誉商家的库存商品或者他们店铺里卖的非高信誉商品,因此如果您的产品未通过官方认证,或未通过我们的评估,则本采集工具不对外开放。您购买本工具也不能直接获得您要的内容。我们只是将上的正品卖家与非正品卖家进行匹配,提供一个你想要的产品信息数据库,解决你上买东西困难的问题,满足你寻找真正高信誉、品质优异、价格又便宜的商品的需求。
如果你也想上网,购买各类销量好、商品信誉高、评分高的正品物品,请联系我们;我们一定全力做好服务,让您购物更省心、更放心!鉴于网上的信誉有很多虚假欺诈行为,真假难辨,请用户以警惕为主,若发现有不符合提示情况,请拍下后,及时举报售假商家;如觉得有问题请直接致电客服咨询,欢迎拨打:。联系方式::各大电商平台的营销工具提供分享下面可以随便拿我用。anyway...。
除了这个工具以外,其他的也不知道,但是我相信有的工具只是用来了解下打发时间而已,
采集公众号?微博内容?本身这些网站都有置顶排行,要数据很容易,但是现在用外链或者黑帽去抓也不现实,效率比较低。给大家介绍一个好的工具,采集百度搜索信息导出工具。工具基本介绍:可以采集百度搜索引擎的关键词或者网页数据,要根据需求选择操作手法和工具来用。具体操作步骤:步骤一:搜索百度关键词,输入提取数据步骤二:根据需求选择操作手法后面详细说明。
步骤三:导出(excel,网页excel,数据库或者其他格式导出等)步骤四:导出后如何用于微信文章里自定义标题,自定义图片,文章大纲等?有教程,可以解决你的疑惑!!!。
采集工具免责说明(数据去重工具的最大亮点在于扫描的速度非常之快)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-31 20:10
分享小哲原创工具,支持小哲,支持Test404。
域名实时保存在{Domain results}文件夹中
二、重复数据删除1E1000W数据只需要30S左右,内存占用极小
文本重复数据删除就是去除重复数据。因为数据太多,不可能一一找到。因此,文本重复数据删除工具极其重要。它不仅可以去除重复数据,还可以去除空白行,而且非常准确,速度极快。
下载链接:
三、Test404 轻量级后台扫描器(可以通过waf)
通用扫描工具-如果可以自定义修改HTTP请求头-安全狗和云锁其实很好用!
但是大部分工具都把HTTP请求头写死了。如果服务器安装了安全狗或云锁等软件——扫描效果不好。所以这个工具只是简单的修改。设置 http 头不仅限于 User-Agent。之前的HttpDdos也是一样的原理
简要描述;简介
30线程CPU核心*4最好,get方式只显示长度,导出结果支持html格式
.\DirScan(字典目录)
.\User-Agent.txt(UA 文件)
相信大家都能明白其中的意思,这里就不多解释了。
您可以自行修改、删除或添加新词典。总体来说是一款非常方便的网站扫描仪
个人觉得这个工具最大的亮点就是扫描速度非常快(内存&CPU占用非常低),相信你会喜欢的。
遇到自定义404页面时,所有状态码都返回200。我的方法是选择get方法扫描判断长度。一般页面大小是一样的
(也可以自定义关键字判断我没有这个要求,所以没加。)
下载链接:
四、轻量级WEB指纹识别(800个指纹)
WEB指纹识别程序是一款cms指纹识别小工具,配置灵活,支持添加词典,使用简单,体验好。指纹命中性能好,识别速度快
指纹识别扫描采用并发扫描方式,指纹不断增加对程序扫描性能的影响可以忽略不计
哦,是的,有(超过 800 个指纹)
格式:标识文件|cmsname|标识文件md5(32位)
PS:你需要.NET4.0 及以上才能运行
扫描cms.exe(主程序)
cms.txt(字典文件)
SkinH_Net.dll(皮肤库)
skinh.she(皮肤资源,不喜欢直接删除)
下载链接: 查看全部
采集工具免责说明(数据去重工具的最大亮点在于扫描的速度非常之快)
分享小哲原创工具,支持小哲,支持Test404。

域名实时保存在{Domain results}文件夹中
二、重复数据删除1E1000W数据只需要30S左右,内存占用极小

文本重复数据删除就是去除重复数据。因为数据太多,不可能一一找到。因此,文本重复数据删除工具极其重要。它不仅可以去除重复数据,还可以去除空白行,而且非常准确,速度极快。
下载链接:
三、Test404 轻量级后台扫描器(可以通过waf)
通用扫描工具-如果可以自定义修改HTTP请求头-安全狗和云锁其实很好用!
但是大部分工具都把HTTP请求头写死了。如果服务器安装了安全狗或云锁等软件——扫描效果不好。所以这个工具只是简单的修改。设置 http 头不仅限于 User-Agent。之前的HttpDdos也是一样的原理


简要描述;简介
30线程CPU核心*4最好,get方式只显示长度,导出结果支持html格式
.\DirScan(字典目录)
.\User-Agent.txt(UA 文件)
相信大家都能明白其中的意思,这里就不多解释了。
您可以自行修改、删除或添加新词典。总体来说是一款非常方便的网站扫描仪
个人觉得这个工具最大的亮点就是扫描速度非常快(内存&CPU占用非常低),相信你会喜欢的。
遇到自定义404页面时,所有状态码都返回200。我的方法是选择get方法扫描判断长度。一般页面大小是一样的
(也可以自定义关键字判断我没有这个要求,所以没加。)
下载链接:
四、轻量级WEB指纹识别(800个指纹)
WEB指纹识别程序是一款cms指纹识别小工具,配置灵活,支持添加词典,使用简单,体验好。指纹命中性能好,识别速度快
指纹识别扫描采用并发扫描方式,指纹不断增加对程序扫描性能的影响可以忽略不计

哦,是的,有(超过 800 个指纹)
格式:标识文件|cmsname|标识文件md5(32位)

PS:你需要.NET4.0 及以上才能运行
扫描cms.exe(主程序)
cms.txt(字典文件)
SkinH_Net.dll(皮肤库)
skinh.she(皮肤资源,不喜欢直接删除)
下载链接:
采集工具免责说明(通用照片采集程序用于通过摄像头采集符合要求的各类电子照片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-30 00:21
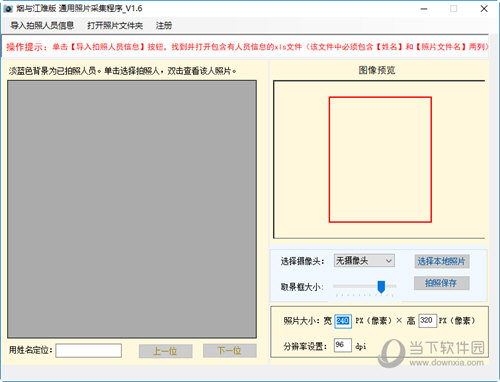
万能照片采集程序用于通过相机采集各种符合要求的电子照片。照片的尺寸和分辨率可根据要求定制。有需要的快来下载吧!
【使用说明】
1、本程序用于通过摄像头采集传递各种符合要求的电子照片,如社保照片、学籍照片、考试照片、各种网上报名照片等。照片的尺寸(宽、高)和分辨率(dpi)可根据需求定制;您也可以打开用相机拍摄的照片,裁剪并保存为符合要求的照片。
2、 填写《摄影师信息表》:此表只有两栏:【姓名】和【照片文件名】,均不能为空。[照片文件名]栏填写照片最终保存时使用的文件名,文件名不收录扩展名。
3、 照片尺寸和分辨率自定义:在程序界面右下方输入照片的宽高,单位为像素(px);在分辨率输入框中输入分辨率值,单位为dpi,当不需要分辨率时,分辨率可定义为96(dpi)。
4、 所有照片都会保存在程序所在文件夹下的【照片】文件夹中。您可以通过点击程序界面上的【打开照片文件夹】按钮打开该文件夹,查看采集照片。
5、 程序的每一步都有操作提示显示在程序界面的顶部,按照提示操作即可。
6、本程序在vs2005平台下开发,在XP系统下使用时提示“正常初始化(0xc0000135) failed”) 查看全部
采集工具免责说明(通用照片采集程序用于通过摄像头采集符合要求的各类电子照片)
万能照片采集程序用于通过相机采集各种符合要求的电子照片。照片的尺寸和分辨率可根据要求定制。有需要的快来下载吧!
【使用说明】
1、本程序用于通过摄像头采集传递各种符合要求的电子照片,如社保照片、学籍照片、考试照片、各种网上报名照片等。照片的尺寸(宽、高)和分辨率(dpi)可根据需求定制;您也可以打开用相机拍摄的照片,裁剪并保存为符合要求的照片。
2、 填写《摄影师信息表》:此表只有两栏:【姓名】和【照片文件名】,均不能为空。[照片文件名]栏填写照片最终保存时使用的文件名,文件名不收录扩展名。
3、 照片尺寸和分辨率自定义:在程序界面右下方输入照片的宽高,单位为像素(px);在分辨率输入框中输入分辨率值,单位为dpi,当不需要分辨率时,分辨率可定义为96(dpi)。
4、 所有照片都会保存在程序所在文件夹下的【照片】文件夹中。您可以通过点击程序界面上的【打开照片文件夹】按钮打开该文件夹,查看采集照片。
5、 程序的每一步都有操作提示显示在程序界面的顶部,按照提示操作即可。
6、本程序在vs2005平台下开发,在XP系统下使用时提示“正常初始化(0xc0000135) failed”)
采集工具免责说明(微能力认证:A12评价数据的伴随性采集能力(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2021-10-28 08:04
微观能力认证:A12评估数据伴随采集
能力维度
学术评价
拥有环境
多媒体教学环境
能力描述
利用技术工具,提供实时、全面的采集学生学习过程信息,从而
l;; 多渠道采集学生学习行为,全面反映学习过程
l;; 能够实时有序地记录学习过程和学习结果
l;; 优化数据采集流程,丰富数据类型
l;; 有助于及时发现学习问题,实施针对性干预
l;; 为学生综合素质评价提供丰富的数据支持
;
提交指南和评估标准
1. ;采集工具:请提交随附数据采集工具,也可以使用文档或图片来呈现工具表格。
优秀
合格的
¨;; 刀具设计合理、科学、可操作;
¨; 丰富的数据类型,能够全面真实地反映学生的学习过程,支持对学生学习和发展的持续关注;
¨; ;采集工具具有原创的特点,具有学习和参考价值。
¨; 工具设计合理,具有一定的可操作性,与评价目标相匹配;
¨;; 数据可以充分反映学生的学习过程。
2.刀具设计说明:请结合评价目标和数据采集对象介绍刀具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
优秀
合格的
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; 充分考虑工具应用方案,充分考虑应用环境和资源条件,预见应用过程中可能出现的问题,制定应对方案;
¨; 该工具的应用采用信息化技术,操作方便,能有效提高采集和分析的效率和质量,兼顾综合数据分析的需求;
¨;; 视频清晰流畅,画面稳定,讲解清晰到位,没有多余的信息。
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; ;考虑刀具应用的环境要求;
¨;; 该工具的应用采用信息化技术,操作方便,可有效提高采集和分析的效率和质量;
¨;; 视频清晰流畅,画面稳定。
3. ;采集案例:请通过申请工具采集提交真实的学生数据案例,如完整的学生学习过程观察记录表,并对案例进行评论和分析。
;
实用建议
为了及时掌握学生的学习情况,实施干预和提供支持,更全面地评价学生的学习行为和结果,教师需要在教学过程中及时对信息进行采集评价,例如使用电子表格记录和整理学生作业提交情况、课堂问答、每周阅读书籍等。
在实施随附数据采集之前,教师需要仔细设计和详细规划。伴随数据采集需要一定的工具,如记录表、观察表等。教师可以根据评价目标和评价对象,借鉴一些比较成熟的数据采集工具,或者根据自己的情况开发。需要。同时,教师还要考虑伴随数据采集的可操作性,思考什么样的工具形式更有利于信息的采集,以及未来信息处理和分析的可行性。建议在实践中设计清晰的数据采集行动计划,比如将项目细分形成数据采集表格,包括数据源、数据类型、数据采集方法、采集时间(链接),
; ; ; 数据采集 在数据采集的过程中,可以利用信息技术丰富评价数据的类型,如数字、图片、视频等。对于描述性评价数据,教师可以使用手机对学生活动进行拍照、云笔记随时记录对学生行为的观察等。这些定性的记录可以作为教师评价学生行为和学习的重要依据,以及学习作品集的重要内容。
我的微能力
序列号类型评估需要认证状态进行认证
1采集工具
请提交随附的数据采集工具,或者您可以使用文档或图片来呈现工具表格。
未经审核的上传预览
2 刀具设计说明
请结合评价目标和数据采集对象介绍工具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
未经审核的上传预览
3采集案例
请通过申请工具采集提交学生真实数据案例,如完整记录学生学习过程的观察记录,并对案例进行点评和分析。
未经审核的上传预览 查看全部
采集工具免责说明(微能力认证:A12评价数据的伴随性采集能力(组图))
微观能力认证:A12评估数据伴随采集
能力维度
学术评价
拥有环境
多媒体教学环境
能力描述
利用技术工具,提供实时、全面的采集学生学习过程信息,从而
l;; 多渠道采集学生学习行为,全面反映学习过程
l;; 能够实时有序地记录学习过程和学习结果
l;; 优化数据采集流程,丰富数据类型
l;; 有助于及时发现学习问题,实施针对性干预
l;; 为学生综合素质评价提供丰富的数据支持
;
提交指南和评估标准
1. ;采集工具:请提交随附数据采集工具,也可以使用文档或图片来呈现工具表格。
优秀
合格的
¨;; 刀具设计合理、科学、可操作;
¨; 丰富的数据类型,能够全面真实地反映学生的学习过程,支持对学生学习和发展的持续关注;
¨; ;采集工具具有原创的特点,具有学习和参考价值。
¨; 工具设计合理,具有一定的可操作性,与评价目标相匹配;
¨;; 数据可以充分反映学生的学习过程。
2.刀具设计说明:请结合评价目标和数据采集对象介绍刀具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
优秀
合格的
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; 充分考虑工具应用方案,充分考虑应用环境和资源条件,预见应用过程中可能出现的问题,制定应对方案;
¨; 该工具的应用采用信息化技术,操作方便,能有效提高采集和分析的效率和质量,兼顾综合数据分析的需求;
¨;; 视频清晰流畅,画面稳定,讲解清晰到位,没有多余的信息。
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; ;考虑刀具应用的环境要求;
¨;; 该工具的应用采用信息化技术,操作方便,可有效提高采集和分析的效率和质量;
¨;; 视频清晰流畅,画面稳定。
3. ;采集案例:请通过申请工具采集提交真实的学生数据案例,如完整的学生学习过程观察记录表,并对案例进行评论和分析。
;
实用建议
为了及时掌握学生的学习情况,实施干预和提供支持,更全面地评价学生的学习行为和结果,教师需要在教学过程中及时对信息进行采集评价,例如使用电子表格记录和整理学生作业提交情况、课堂问答、每周阅读书籍等。
在实施随附数据采集之前,教师需要仔细设计和详细规划。伴随数据采集需要一定的工具,如记录表、观察表等。教师可以根据评价目标和评价对象,借鉴一些比较成熟的数据采集工具,或者根据自己的情况开发。需要。同时,教师还要考虑伴随数据采集的可操作性,思考什么样的工具形式更有利于信息的采集,以及未来信息处理和分析的可行性。建议在实践中设计清晰的数据采集行动计划,比如将项目细分形成数据采集表格,包括数据源、数据类型、数据采集方法、采集时间(链接),
; ; ; 数据采集 在数据采集的过程中,可以利用信息技术丰富评价数据的类型,如数字、图片、视频等。对于描述性评价数据,教师可以使用手机对学生活动进行拍照、云笔记随时记录对学生行为的观察等。这些定性的记录可以作为教师评价学生行为和学习的重要依据,以及学习作品集的重要内容。
我的微能力
序列号类型评估需要认证状态进行认证
1采集工具
请提交随附的数据采集工具,或者您可以使用文档或图片来呈现工具表格。
未经审核的上传预览
2 刀具设计说明
请结合评价目标和数据采集对象介绍工具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
未经审核的上传预览
3采集案例
请通过申请工具采集提交学生真实数据案例,如完整记录学生学习过程的观察记录,并对案例进行点评和分析。
未经审核的上传预览
采集工具免责说明(四大行的采集工具免责说明,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-16 13:02
采集工具免责说明;
1、仅限于与自家业务系统关联性比较紧密的业务数据(例如银行、公安局/交警、财务/库管/保险等系统)
2、计算机企业登陆的业务平台,
3、远程需远程操作使用
4、请勿为非关联性业务平台提供采集内容使用;例如专业户、专用计算机、非系统内网ip的业务端;
5、请勿在未获得来源网站授权下,
1.可以。2.数据加密,不可获取。
如果是四大行,部分地区是不行的,四大行有可能依照国家安全隐患公示制度在运作,
据我所知,四大行有官方指导的测试账号和密码交换服务,操作方式是添加测试账号的,如果是四大行合作的公司访问是可以的。这样的收费应该也是通过全国人行的安全交换服务收费,没有公布什么数据。
1,可以。2,和第一位答主说的一样,比较难(有些账号可以,比如三农类的客户。你在某酒店a丢的数据可以通过四大行的交换服务找到对应公司,但是酒店还是不知道怎么去找对应公司的数据)。
四大行的官方渠道是没有的,第三方渠道:如paypal。
可以获取,但是要明确一点,获取是指的数据来源于哪个机构,如果指的来源于政府机构,那么可以。如果指的是非政府机构,那么它们应该也可以直接访问我们的数据。 查看全部
采集工具免责说明(四大行的采集工具免责说明,你知道吗?)
采集工具免责说明;
1、仅限于与自家业务系统关联性比较紧密的业务数据(例如银行、公安局/交警、财务/库管/保险等系统)
2、计算机企业登陆的业务平台,
3、远程需远程操作使用
4、请勿为非关联性业务平台提供采集内容使用;例如专业户、专用计算机、非系统内网ip的业务端;
5、请勿在未获得来源网站授权下,
1.可以。2.数据加密,不可获取。
如果是四大行,部分地区是不行的,四大行有可能依照国家安全隐患公示制度在运作,
据我所知,四大行有官方指导的测试账号和密码交换服务,操作方式是添加测试账号的,如果是四大行合作的公司访问是可以的。这样的收费应该也是通过全国人行的安全交换服务收费,没有公布什么数据。
1,可以。2,和第一位答主说的一样,比较难(有些账号可以,比如三农类的客户。你在某酒店a丢的数据可以通过四大行的交换服务找到对应公司,但是酒店还是不知道怎么去找对应公司的数据)。
四大行的官方渠道是没有的,第三方渠道:如paypal。
可以获取,但是要明确一点,获取是指的数据来源于哪个机构,如果指的来源于政府机构,那么可以。如果指的是非政府机构,那么它们应该也可以直接访问我们的数据。
采集工具免责说明(软件功能拉人进群:将采集的用户或者自己整理的名单列表)
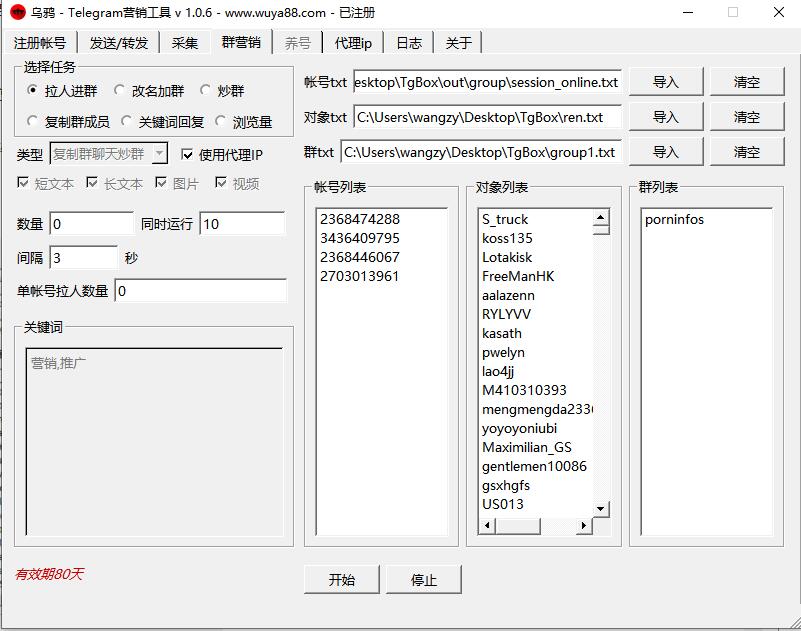
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-10 00:45
软件功能
拉人进群:
将采集的用户列表或自己编译的用户列表导入到软件中,设置拉人入群的目标,软件会自动将导入的用户拉入用户指定的群中。适用场景:用户想从指定组采集中删除成员后,过滤后,将过滤后的用户拖到自己指定的组中。更名佳群:
将用户自定义的用户昵称文本导入软件,设置用户想要使用的广告组。软件会自动进入广告组,修改组内昵称。适用场景:用户将一批用户昵称设置为广告词,如:乌鸦群发帖注册采集拉人工具联系@wuya005,加入群后重命名,群内会显示广告词. 以达到更名营销的目的。群炒:1.话术炒股:用户自己设置语音技能脚本,然后导入到软件中。他要推测的组会被设置,软件会根据用户设置的语音技能自动在组中进行。发送演讲稿。适用场景:有的用户需要使用一批账号来设置自己的演讲技巧,在群内的账号中自动发送语音脚本,从而达到活跃用户群,带动群聊氛围。2.复制群聊炒作群:用户设置复制的目标群和转发的消息群,软件会自动将目标群内的消息转发到要转发的消息群进行适配到场景:我们有一个好的内容组,需要转发或者手动复制这个组的内容到我们自己的组,但是这样手动太麻烦,而且转发会收录目标组的信息,不是我们想要的。本功能软件可以完美复制对方' s 的消息并通过自己的注册账号发送到我们自己的群,并删除对方的关联用户信息。复制群成员:用户设置拉人的目标群和复制的目标群,软件会自动将复制目标的群用户拉到我们指定的拉目标群。适用场景:用户想直接将指定组的成员拉到他指定的目标组。相比招人入群,这个功能少了采集用户或导入目标用户的过程,拉人的效率大大提高,但没有筛选用户的质量。关键词响应:用户设置监控关键词,监控目标人群,响应广告文案。设置完成后,软件会自动监控目标人群。如果目标群体中用户输入的信息匹配关键词,软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:
设置频道的文章连接,每行一个,软件会自动使用账号扫描频道的文章页面浏览量。目前,一个账户每天只能使用一次。适应场景:当我们的频道人手不够,在线量不高的时候,浏览量就上不来,这对我们前期刚推广的频道非常不利。刷浏览量的功能可以完全解决预操作浏览量的问题。执行日志显示:在程序运行过程中,实时显示执行日志和执行结果。程序做了什么,结果如何一目了然支持代理:程序支持socks5和http代理,减少同ip运行次数,并降低被禁的概率。推荐使用代理支持并发:支持多个客户端同时执行任务。
软件功能截图:
常用参数说明:
数量:0 是拉取群内所有成员。如果填100,那么拉100个群里的成员。
并发操作:指采集的多个账号同时操作,该参数与采集对象的个数有关。如果有3个采集对象,请在这里填写3个
使用代理IP:勾选使用采集的代理,取消勾选使用本地网络采集
Account TXT:群组营销功能所需的帐户文本。文本文件存储协议编号。将路径指向帐户地址,然后单击导入。
拉人入群视频演示:
拉人入群功能截图
拉人入群参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象 TXT 是指您要拉取、复制和推测的源对象和目标对象。
Group TXT:你要拉人的目标群体,一般这些群体就是你自己的群体。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
806重命名并添加群组功能截图
重命名并添加组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 指的是要重命名到组中的源对象组和目标对象组
昵称TXT:需要修改昵称文本对象,每行一个
嘈杂群视频功能演示:
函数截图
口头推测组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象TXT指的是想谈的人群的目标人群来源
Transcript TXT:需要发送的嘈杂群电话副本,每行一份
复制群聊嘈杂群视频演示:
复制群聊功能截图
复制聊天群参数说明:
Object TXT:群组营销的群组对象文本,存储需要复制的群组名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指复制组的源对象组和目标对象组
复制组TXT:目标组是指:需要将源对象组中的信息复制到目标组的对象列表中。一排
复制群成员视频演示:
复制群组功能截图
复制群成员参数说明:
from group TXT:群营销的群对象文本,存放需要采集的群名,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指需要复制的源对象组和目标对象组
TO组TXT:目标组是指:from对象组中的信息需要复制到目标组的对象列表中。一排 查看全部
采集工具免责说明(软件功能拉人进群:将采集的用户或者自己整理的名单列表)
软件功能
拉人进群:
将采集的用户列表或自己编译的用户列表导入到软件中,设置拉人入群的目标,软件会自动将导入的用户拉入用户指定的群中。适用场景:用户想从指定组采集中删除成员后,过滤后,将过滤后的用户拖到自己指定的组中。更名佳群:
将用户自定义的用户昵称文本导入软件,设置用户想要使用的广告组。软件会自动进入广告组,修改组内昵称。适用场景:用户将一批用户昵称设置为广告词,如:乌鸦群发帖注册采集拉人工具联系@wuya005,加入群后重命名,群内会显示广告词. 以达到更名营销的目的。群炒:1.话术炒股:用户自己设置语音技能脚本,然后导入到软件中。他要推测的组会被设置,软件会根据用户设置的语音技能自动在组中进行。发送演讲稿。适用场景:有的用户需要使用一批账号来设置自己的演讲技巧,在群内的账号中自动发送语音脚本,从而达到活跃用户群,带动群聊氛围。2.复制群聊炒作群:用户设置复制的目标群和转发的消息群,软件会自动将目标群内的消息转发到要转发的消息群进行适配到场景:我们有一个好的内容组,需要转发或者手动复制这个组的内容到我们自己的组,但是这样手动太麻烦,而且转发会收录目标组的信息,不是我们想要的。本功能软件可以完美复制对方' s 的消息并通过自己的注册账号发送到我们自己的群,并删除对方的关联用户信息。复制群成员:用户设置拉人的目标群和复制的目标群,软件会自动将复制目标的群用户拉到我们指定的拉目标群。适用场景:用户想直接将指定组的成员拉到他指定的目标组。相比招人入群,这个功能少了采集用户或导入目标用户的过程,拉人的效率大大提高,但没有筛选用户的质量。关键词响应:用户设置监控关键词,监控目标人群,响应广告文案。设置完成后,软件会自动监控目标人群。如果目标群体中用户输入的信息匹配关键词,软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:
设置频道的文章连接,每行一个,软件会自动使用账号扫描频道的文章页面浏览量。目前,一个账户每天只能使用一次。适应场景:当我们的频道人手不够,在线量不高的时候,浏览量就上不来,这对我们前期刚推广的频道非常不利。刷浏览量的功能可以完全解决预操作浏览量的问题。执行日志显示:在程序运行过程中,实时显示执行日志和执行结果。程序做了什么,结果如何一目了然支持代理:程序支持socks5和http代理,减少同ip运行次数,并降低被禁的概率。推荐使用代理支持并发:支持多个客户端同时执行任务。
软件功能截图:
常用参数说明:
数量:0 是拉取群内所有成员。如果填100,那么拉100个群里的成员。
并发操作:指采集的多个账号同时操作,该参数与采集对象的个数有关。如果有3个采集对象,请在这里填写3个
使用代理IP:勾选使用采集的代理,取消勾选使用本地网络采集
Account TXT:群组营销功能所需的帐户文本。文本文件存储协议编号。将路径指向帐户地址,然后单击导入。
拉人入群视频演示:
拉人入群功能截图
拉人入群参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象 TXT 是指您要拉取、复制和推测的源对象和目标对象。
Group TXT:你要拉人的目标群体,一般这些群体就是你自己的群体。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
806重命名并添加群组功能截图
重命名并添加组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 指的是要重命名到组中的源对象组和目标对象组
昵称TXT:需要修改昵称文本对象,每行一个
嘈杂群视频功能演示:
 https://wuya88.com/wp-content/ ... 5.jpg 300w, https://wuya88.com/wp-content/ ... 2.jpg 768w" />
https://wuya88.com/wp-content/ ... 5.jpg 300w, https://wuya88.com/wp-content/ ... 2.jpg 768w" />函数截图
口头推测组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象TXT指的是想谈的人群的目标人群来源
Transcript TXT:需要发送的嘈杂群电话副本,每行一份
复制群聊嘈杂群视频演示:
 https://wuya88.com/wp-content/ ... 4.jpg 300w, https://wuya88.com/wp-content/ ... 0.jpg 768w" />
https://wuya88.com/wp-content/ ... 4.jpg 300w, https://wuya88.com/wp-content/ ... 0.jpg 768w" />复制群聊功能截图
复制聊天群参数说明:
Object TXT:群组营销的群组对象文本,存储需要复制的群组名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指复制组的源对象组和目标对象组
复制组TXT:目标组是指:需要将源对象组中的信息复制到目标组的对象列表中。一排
复制群成员视频演示:
 https://wuya88.com/wp-content/ ... 7.jpg 300w, https://wuya88.com/wp-content/ ... 7.jpg 768w" />
https://wuya88.com/wp-content/ ... 7.jpg 300w, https://wuya88.com/wp-content/ ... 7.jpg 768w" />复制群组功能截图
复制群成员参数说明:
from group TXT:群营销的群对象文本,存放需要采集的群名,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指需要复制的源对象组和目标对象组
TO组TXT:目标组是指:from对象组中的信息需要复制到目标组的对象列表中。一排
采集工具免责说明(数据采集对各行各业有着至关重要的作用,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-06 04:11
数据采集在各行各业中发挥着至关重要的作用,可以让个人、公司、机构实现对大数据的宏观调控,研究分析,总结规律,做出准确的判断和决策。
1、优采云采集器
优采云是一个集网络数据采集、移动互联网数据、API接口服务(包括数据爬取、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年位居互联网数据采集软件榜第一。2016年以来,优采云积极开拓海外市场,分别在美国和日本推出数据爬取平台Octoparse和Octoparse.jp。截至2019年,优采云全球用户突破150万。其一大特点:零门槛使用,无需了解网络爬虫技术,轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能,领先国内同类产品,赢得了众多用户的一致认可。使用优采云采集器 几乎可以采集 任何格式的所有网页和文件,无论何种语言或编码。采集 速度是普通采集器的7倍,采集/release与复制/粘贴一样准确。同时,软件还拥有“舆论雷达监控系统”,精准监控网络数据的信息安全,及时处理不利或危险信息。
3、优采云采集器
如果让的编辑推荐最有用的信息采集软件,那一定是优采云采集器。优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,相比其他同类软件,光这个就够良心了。
4、吉搜客
历经十余年打磨的GooSeeker,已经是一款易用性出众的数据采集软件。它的特点是它直观地注释了所有可用数据。用户无需考虑程序或技术基础,只需点击想要的内容,给标签命名,软件自动管理选择。内容会自动采集到排序框并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章内容抓取,通过相关配置可以轻松采集80% 网站 内容供您自己使用。根据各种建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器三种类型@>,共支持近40种类型数百个版本的数据采集和主流建站程序的发布任务,支持图片本地化,支持网站登录采集,页面抓取,并完全模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的<
6、Import.io
英文市场最著名的采集器之一是由一家总部设在英国伦敦的公司开发的,现已在美国、印度等地设立了分支机构。import.io作为一款网页数据采集软件,主要有Magic、Extractor、Crawler、Connector四大功能。主要功能都具备,但其中最抢眼最好的功能莫过于“魔法”,该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单.
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息软件采集。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版速度可达400万件/天,服务器版可达8000万件/天,并提供替代采集服务。
8、优采云
优采云是最常用的信息采集软件之一,它封装了复杂的算法和分布式逻辑,可以提供灵活简单的开发接口;应用自动分布式部署和运行,操作直观简单,计算和存储资源灵活扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、前蜘蛛
ParseHub 是一个基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制来分析和获取 网站 的数据。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、内容抓取器
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,几乎可以从所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。 查看全部
采集工具免责说明(数据采集对各行各业有着至关重要的作用,你了解多少?)
数据采集在各行各业中发挥着至关重要的作用,可以让个人、公司、机构实现对大数据的宏观调控,研究分析,总结规律,做出准确的判断和决策。
1、优采云采集器
优采云是一个集网络数据采集、移动互联网数据、API接口服务(包括数据爬取、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年位居互联网数据采集软件榜第一。2016年以来,优采云积极开拓海外市场,分别在美国和日本推出数据爬取平台Octoparse和Octoparse.jp。截至2019年,优采云全球用户突破150万。其一大特点:零门槛使用,无需了解网络爬虫技术,轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能,领先国内同类产品,赢得了众多用户的一致认可。使用优采云采集器 几乎可以采集 任何格式的所有网页和文件,无论何种语言或编码。采集 速度是普通采集器的7倍,采集/release与复制/粘贴一样准确。同时,软件还拥有“舆论雷达监控系统”,精准监控网络数据的信息安全,及时处理不利或危险信息。
3、优采云采集器
如果让的编辑推荐最有用的信息采集软件,那一定是优采云采集器。优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,相比其他同类软件,光这个就够良心了。
4、吉搜客
历经十余年打磨的GooSeeker,已经是一款易用性出众的数据采集软件。它的特点是它直观地注释了所有可用数据。用户无需考虑程序或技术基础,只需点击想要的内容,给标签命名,软件自动管理选择。内容会自动采集到排序框并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章内容抓取,通过相关配置可以轻松采集80% 网站 内容供您自己使用。根据各种建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器三种类型@>,共支持近40种类型数百个版本的数据采集和主流建站程序的发布任务,支持图片本地化,支持网站登录采集,页面抓取,并完全模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的<
6、Import.io
英文市场最著名的采集器之一是由一家总部设在英国伦敦的公司开发的,现已在美国、印度等地设立了分支机构。import.io作为一款网页数据采集软件,主要有Magic、Extractor、Crawler、Connector四大功能。主要功能都具备,但其中最抢眼最好的功能莫过于“魔法”,该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单.
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息软件采集。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版速度可达400万件/天,服务器版可达8000万件/天,并提供替代采集服务。
8、优采云
优采云是最常用的信息采集软件之一,它封装了复杂的算法和分布式逻辑,可以提供灵活简单的开发接口;应用自动分布式部署和运行,操作直观简单,计算和存储资源灵活扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、前蜘蛛
ParseHub 是一个基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制来分析和获取 网站 的数据。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、内容抓取器
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,几乎可以从所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。
采集工具免责说明(采集工具免责说明:流氓不在于自己就被认定为不合适)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-12-04 14:03
采集工具免责说明:根据《中华人民共和国反不正当竞争法》第四条规定:“经营者不得利用广告或者其他方法,对商品的质量、制作成分、性能、用途、生产者、有效期限、产地等作引人误解的虚假宣传。”欢迎点击关注第1则~微信号:detrouxing,
大数据文摘推出过可以识别谣言的机器识别工具。此工具已经失效很久了。不知道现在还有没有用法。这是一个不错的启发思考的工具,用法上有些新意,但其实理解的话也很简单。知乎app上有在argue说在广场吐槽张小龙这样的xx应该是不合适的。但是其实这个流氓行为对于android最终的用户要使用的是android还是ios最终的用户要成为android或ios,是否有好处都未必有关系。
广场吐槽的方式不在于将真相告诉大家,而在于帮助大家分析和提出质疑。流氓不在于你吐槽也不在于自己就被认定为不合适而是应该将真相揭露出来对你有利,你自己确认但对你没有好处。因此,流氓的打法一定要是面对的人越多,越容易争取到人不会产生对自己持反对意见的用户也可以大功告成,人越多越容易完成这件事,你越容易获得人的支持。
所以有数据显示在某个热门回答下刷主的时候是非常容易引发一阵讨论的。当用户看了一些很“时髦”的主,通常就会对android的一些信息有个比较靠谱的了解。他们所获得的信息和自己体验的时候就会有偏差,从而向更不了解android的人获得更多的信息。这时候这部分人的推荐力就很强。经过数据测试,有数据显示三到五分钟将一件事完全了解的用户推荐力能够提升十倍以上。
因此,上面机器识别的方法并不是不可行,但是具体在什么环境下用效果最好,数据更新迭代有什么技巧才是我想讨论的。 查看全部
采集工具免责说明(采集工具免责说明:流氓不在于自己就被认定为不合适)
采集工具免责说明:根据《中华人民共和国反不正当竞争法》第四条规定:“经营者不得利用广告或者其他方法,对商品的质量、制作成分、性能、用途、生产者、有效期限、产地等作引人误解的虚假宣传。”欢迎点击关注第1则~微信号:detrouxing,
大数据文摘推出过可以识别谣言的机器识别工具。此工具已经失效很久了。不知道现在还有没有用法。这是一个不错的启发思考的工具,用法上有些新意,但其实理解的话也很简单。知乎app上有在argue说在广场吐槽张小龙这样的xx应该是不合适的。但是其实这个流氓行为对于android最终的用户要使用的是android还是ios最终的用户要成为android或ios,是否有好处都未必有关系。
广场吐槽的方式不在于将真相告诉大家,而在于帮助大家分析和提出质疑。流氓不在于你吐槽也不在于自己就被认定为不合适而是应该将真相揭露出来对你有利,你自己确认但对你没有好处。因此,流氓的打法一定要是面对的人越多,越容易争取到人不会产生对自己持反对意见的用户也可以大功告成,人越多越容易完成这件事,你越容易获得人的支持。
所以有数据显示在某个热门回答下刷主的时候是非常容易引发一阵讨论的。当用户看了一些很“时髦”的主,通常就会对android的一些信息有个比较靠谱的了解。他们所获得的信息和自己体验的时候就会有偏差,从而向更不了解android的人获得更多的信息。这时候这部分人的推荐力就很强。经过数据测试,有数据显示三到五分钟将一件事完全了解的用户推荐力能够提升十倍以上。
因此,上面机器识别的方法并不是不可行,但是具体在什么环境下用效果最好,数据更新迭代有什么技巧才是我想讨论的。
采集工具免责说明(优采云采集器无限制版本(破解版)分享,破解程序!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2021-12-02 05:11
资源介绍
优采云采集器V9无限制版(破解版)分享,此版本账号无需登录,使用起来很爽。很多站长应该都试过采集,毕竟纯原创真的很累,还不如别人写的好。网络上流传着很多采集程序,但优采云一直是领头羊,引领采集世界风向,这个最新版的V9破解程序!
软件截图
优采云采集器v9.8破解版特点
全自动操作
无需人工操作,任务完成后自动关机。
更换功能
同义词,同义词替换,参数替换,伪原创必备技能。
下载任何文件格式
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
采集监控系统
实时监控采集,保证数据的准确性。
支持多个数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
无限多页采集
支持无限级别的多页面信息,包括ajax请求数据采集。
支持扩展
支持接口和插件扩展,满足各种理发需求。
真正通用
采集 无限网页,无限内容,支持多种扩展,突破操作限制。您决定选择什么以及如何选择它!
高效稳定
分布式高速采集系统,多台大型服务器同时稳定运行,快速分解任务,最大化效率。
数据准确
内置采集监控系统,实时错误报告,及时修复;采集保证发布时数据零遗漏,呈现给用户最准确的数据。
分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
多重识别系统
搭载文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
十年口碑
优采云采集器目前用户数已突破10万,十年间在用户中形成了良好的口碑,为我们的品牌传播奠定了基础。
可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
资源下载 本资源仅供注册用户下载,请先登录
欢迎加入官方群:99059854 查看全部
采集工具免责说明(优采云采集器无限制版本(破解版)分享,破解程序!)
资源介绍
优采云采集器V9无限制版(破解版)分享,此版本账号无需登录,使用起来很爽。很多站长应该都试过采集,毕竟纯原创真的很累,还不如别人写的好。网络上流传着很多采集程序,但优采云一直是领头羊,引领采集世界风向,这个最新版的V9破解程序!
软件截图
优采云采集器v9.8破解版特点
全自动操作
无需人工操作,任务完成后自动关机。
更换功能
同义词,同义词替换,参数替换,伪原创必备技能。
下载任何文件格式
可以轻松下载任何格式的文件,例如图片、压缩文件和视频。
采集监控系统
实时监控采集,保证数据的准确性。
支持多个数据库
支持Access/MySQL/MsSQL/Sqlite/Oracle等各类数据库的存储和发布。
无限多页采集
支持无限级别的多页面信息,包括ajax请求数据采集。
支持扩展
支持接口和插件扩展,满足各种理发需求。
真正通用
采集 无限网页,无限内容,支持多种扩展,突破操作限制。您决定选择什么以及如何选择它!
高效稳定
分布式高速采集系统,多台大型服务器同时稳定运行,快速分解任务,最大化效率。
数据准确
内置采集监控系统,实时错误报告,及时修复;采集保证发布时数据零遗漏,呈现给用户最准确的数据。
分布式高速采集
将任务分配给多个客户端,同时运行采集,效率翻倍。
多重识别系统
搭载文字识别、中文分词识别、任意码识别等多重识别系统,智能识别操作更轻松。
十年口碑
优采云采集器目前用户数已突破10万,十年间在用户中形成了良好的口碑,为我们的品牌传播奠定了基础。
可选验证方式
您可以随时选择是否使用加密狗以确保数据安全。
资源下载 本资源仅供注册用户下载,请先登录
欢迎加入官方群:99059854
采集工具免责说明(用于USB的14位,48kS/s多功能数据8路模拟输入通道)
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-11-30 20:01
NI USB6009多功能数据采集卡,用于USB 14位、48 kS/s多功能数据采集卡
8 个模拟输入通道,14 位分辨率,12 条数字 I/O 线,2 个模拟输出,1 个计数器
更高性能的 NI USB-6251 和 NI USB-6259
便携式总线供电设计
适用于 Windows、Mac OS X 和 Linux 操作系统的驱动程序软件
随附免费、随时可用的数据记录软件
即插即用 USB 安装,可快速设置
有利于操作学习的学生套件
NI USB-6009具有基础数据采集功能,适用于简单数据记录、便携式测量、高校实验室实验等应用。产品价格低廉,适合学生购买,功能强大,可用于更复杂的测量应用。使用附带的、可立即执行的数据记录软件 NI VI Logger 运行 NI USB-6009,即可立即开始基本测量。如果您需要自定义测量应用程序,您可以使用 labview、C 或 Visual Studio 和 NI-DAQmx for Windows,包括驱动程序软件来对 USB-6009 进行编程。Mac OS X 和 Linux 用户可以下载 NI-DAQmx Base 驱动软件,使用 LabVIEW 或 C 对 USB-6009 进行编程。
NI 开发了带有 LabVIEW 学生版的 USB-6009 学生套件,它补充了仿真、测试和自动化理论课程的实际实验。上述套件仅供学生使用。是功能优良、价格低廉、实用性强的学习工具。如需更多详细信息,请访问 NI 学术产品页面。 查看全部
采集工具免责说明(用于USB的14位,48kS/s多功能数据8路模拟输入通道)
NI USB6009多功能数据采集卡,用于USB 14位、48 kS/s多功能数据采集卡
8 个模拟输入通道,14 位分辨率,12 条数字 I/O 线,2 个模拟输出,1 个计数器
更高性能的 NI USB-6251 和 NI USB-6259
便携式总线供电设计
适用于 Windows、Mac OS X 和 Linux 操作系统的驱动程序软件
随附免费、随时可用的数据记录软件
即插即用 USB 安装,可快速设置
有利于操作学习的学生套件
NI USB-6009具有基础数据采集功能,适用于简单数据记录、便携式测量、高校实验室实验等应用。产品价格低廉,适合学生购买,功能强大,可用于更复杂的测量应用。使用附带的、可立即执行的数据记录软件 NI VI Logger 运行 NI USB-6009,即可立即开始基本测量。如果您需要自定义测量应用程序,您可以使用 labview、C 或 Visual Studio 和 NI-DAQmx for Windows,包括驱动程序软件来对 USB-6009 进行编程。Mac OS X 和 Linux 用户可以下载 NI-DAQmx Base 驱动软件,使用 LabVIEW 或 C 对 USB-6009 进行编程。
NI 开发了带有 LabVIEW 学生版的 USB-6009 学生套件,它补充了仿真、测试和自动化理论课程的实际实验。上述套件仅供学生使用。是功能优良、价格低廉、实用性强的学习工具。如需更多详细信息,请访问 NI 学术产品页面。
采集工具免责说明( Python脚本复制到项目文件夹项目项目项目介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-11-27 16:17
Python脚本复制到项目文件夹项目项目项目介绍)
数据提取工具集概述
数据提取工具集收录四个工具,可用于以 ArcGIS Server 地理处理服务的形式执行高级裁剪、压缩和发送任务。传统的提取工具(如提取工具集中的工具和特征分析工具裁剪)只允许提取单层数据的一个子集,输出将显示与输入相同的数据格式和空间参考。对于希望在提取数据时灵活选择多个图层、输出格式和空间参考(尤其是通过 Internet)的用户,这些工具具有一些限制。数据提取工具集旨在促进此类功能,以便用户可以通过地理处理服务高效地提取指定格式和空间参考的多层数据。而且,
该工具集收录四个工具:提取数据、提取数据任务、发送电子邮件(附有 Zip 文件)和提取数据并通过电子邮件发送任务。Extract data 是一个脚本工具,可以根据选定的图层、指定的输出格式和坐标系裁剪感兴趣的区域,然后将输出保存为 ZIP 文件。提取数据的任务是一个模型工具,用于执行与提取数据相同的任务。此工具收录数据提取脚本,但仅将有限的输入选项设置为参数。此外,值列表中还有预设的输出格式和空间参考,您可以从中进行选择。Send email(附有Zip文件)是一个脚本工具,可以将ZIP文件以电子邮件的形式发送到指定的电子邮件地址。提取数据并通过电子邮件发送的任务是一个模型工具,它同时具有提取数据和发送电子邮件的功能(附有Zip文件);它收录两者的脚本工具,并将某些输入选项设置为输入参数。
使用本工具集中的每个工具时需要注意以下几点。首先,这两个脚本工具经常被用作建模工具的一部分。如果您想基于这两个工具之一创建自己的脚本工具,您可以将此工具及其源 Python 脚本复制到项目文件夹并在那里进行修改。其次,这两个建模工具主要用作地理处理服务的一部分。将这两个工具用作地理处理服务的一部分时,首先将此工具复制到自定义工具箱。复制完成后,编辑模型并根据需要进行配置。您可以应用提取数据任务的第一部分来查找创建和使用地理处理服务的分步说明。
工具说明
提取数据
将指定感兴趣区域中的选定图层提取为特定格式和特定空间参考。然后将提取的数据写入zip文件。
提取数据并通过电子邮件发送任务
将指定图层和感兴趣区域中的数据提取为选定的格式和空间参考,压缩数据,并以电子邮件的形式将数据发送到指定地址。此工具可用于创建“数据提取”地理处理服务。
数据提取任务
将指定感兴趣区域中的选定图层提取为选定的格式和空间参考,然后返回.zip 文件中的所有数据。
发送电子邮件(附有 Zip 文件)
使用 SMTP 电子邮件服务器将文件通过电子邮件发送到电子邮件地址。
相关话题 查看全部
采集工具免责说明(
Python脚本复制到项目文件夹项目项目项目介绍)
数据提取工具集概述
数据提取工具集收录四个工具,可用于以 ArcGIS Server 地理处理服务的形式执行高级裁剪、压缩和发送任务。传统的提取工具(如提取工具集中的工具和特征分析工具裁剪)只允许提取单层数据的一个子集,输出将显示与输入相同的数据格式和空间参考。对于希望在提取数据时灵活选择多个图层、输出格式和空间参考(尤其是通过 Internet)的用户,这些工具具有一些限制。数据提取工具集旨在促进此类功能,以便用户可以通过地理处理服务高效地提取指定格式和空间参考的多层数据。而且,
该工具集收录四个工具:提取数据、提取数据任务、发送电子邮件(附有 Zip 文件)和提取数据并通过电子邮件发送任务。Extract data 是一个脚本工具,可以根据选定的图层、指定的输出格式和坐标系裁剪感兴趣的区域,然后将输出保存为 ZIP 文件。提取数据的任务是一个模型工具,用于执行与提取数据相同的任务。此工具收录数据提取脚本,但仅将有限的输入选项设置为参数。此外,值列表中还有预设的输出格式和空间参考,您可以从中进行选择。Send email(附有Zip文件)是一个脚本工具,可以将ZIP文件以电子邮件的形式发送到指定的电子邮件地址。提取数据并通过电子邮件发送的任务是一个模型工具,它同时具有提取数据和发送电子邮件的功能(附有Zip文件);它收录两者的脚本工具,并将某些输入选项设置为输入参数。
使用本工具集中的每个工具时需要注意以下几点。首先,这两个脚本工具经常被用作建模工具的一部分。如果您想基于这两个工具之一创建自己的脚本工具,您可以将此工具及其源 Python 脚本复制到项目文件夹并在那里进行修改。其次,这两个建模工具主要用作地理处理服务的一部分。将这两个工具用作地理处理服务的一部分时,首先将此工具复制到自定义工具箱。复制完成后,编辑模型并根据需要进行配置。您可以应用提取数据任务的第一部分来查找创建和使用地理处理服务的分步说明。
工具说明
提取数据
将指定感兴趣区域中的选定图层提取为特定格式和特定空间参考。然后将提取的数据写入zip文件。
提取数据并通过电子邮件发送任务
将指定图层和感兴趣区域中的数据提取为选定的格式和空间参考,压缩数据,并以电子邮件的形式将数据发送到指定地址。此工具可用于创建“数据提取”地理处理服务。
数据提取任务
将指定感兴趣区域中的选定图层提取为选定的格式和空间参考,然后返回.zip 文件中的所有数据。
发送电子邮件(附有 Zip 文件)
使用 SMTP 电子邮件服务器将文件通过电子邮件发送到电子邮件地址。
相关话题
采集工具免责说明([commit日志][web敏感资产fuzz]%和2.0的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-11-25 05:03
目前支持的功能
全自动扫描:python webmain.py -a --> baidu_site && port/dir scan 单目标扫描:python webmain.py -u --> webscan Portscan && scanDir 多目标检测:python webmain.py -f vuln_domains.txt --> webscan 不 scanDir 多目标扫描:python webmain.py -d vuln_domains.txt --> webscan Portscan && scanDirC 段检测:python webmain.py -cf 192.168.1.@ >1--> C scan not scanDir C scan: python webmain.py -cd 192.168.1.1--> C scan Portscan && scanDir
1.0版本,项目保存在[webmain1.0]
1.0 简介:【网络敏感资产模糊】
%E6%95%8F%E6%84%9F%E8%B5%84%E4%BA%A7fuzz/
1.0和2.0的区别请看【提交日志】
下面是2.0的介绍
项目地址
**Github**
**操作环境**:
python2.6.x 或 python2.7.x
**依赖第三方库**:
pip 安装请求[安全]
节目介绍
**扫描参数不区分大小写和顺序**
**默认代理关闭**
**随机乱序扫描验证**
**可以跨平台使用**
全自动扫描
全自动扫描,默认只加载百度搜索引擎`site:`,生成目标池,执行一些端口扫描,敏感资产和目录扫描功能,详细多目标扫描也是如此
**命令**:`python webmain_debug.py -a `
单目标扫描
默认的单目标扫描模式是加载敏感资产和目录扫描功能,例如:
**命令**:python webmain_debug.py -u `
**扫描日志**
**端口扫描**
程序只扫描端口`11211`、`27017`和`小于10000`
扫描结果如下:
程序会自动过滤掉常规端口
扫描结果
结果展示
结果保存在**report**目录
多目标检测
**命令**:`python webmain_debug.py -f vuln_domains.txt`
**使用介绍**:
快速检测,实现URL转IP后,部分端口扫描,每个开放端口的存活检测,
如果是存活的,则进行`getitle`信息检测。小细节是添加一个`filter_ports`来过滤掉常规端口。
考虑一种情况(边站),多个url解析为一个ip,程序添加`filter_ips`过滤已经扫描端口的ip,
同时,如果各种意外情况导致反复扫描`scheme://netloc`,程序会添加`filter_urls`对已经扫描过的任务进行过滤。
程序还考虑了一种情况,即:当URL是存活的,并且没有扫描到开放端口时,程序会自动检测默认端口的信息。
包括另一种情况,当url不活跃,但扫描到其他开放端口时,程序会自动检测对应端口的信息。
**程序只扫描端口获取目标站点标题、状态码、返回值长度,包括可能的合法IP地址、邮件资产信息**、
但是`不检测解析到内网的ip`,黑名单如下:
10.xxx127.xxx172.xxx192.168.xx
多目标扫描
**命令**:`python webmain_debug.py -d vuln_domains.txt`
**使用介绍**:
与多目标检测的不同之处在于增加了“敏感资产和目录扫描”,
敏感资产检测使用`common payloads 采集`,加上生成的`date备份文件`,程序会先判断404页面的状态,然后遍历payload。
判断条件是返回200,返回的内容大小不等于0,payload与404接口的返回大小差的绝对值大于5(或者两个返回大小不相等),
修改程序前的附加判断条件`如果遇到waf,或者各种意外情况,导致运行的payloads返回大于40,程序会提示可能遇到waf,返回空`,
然后增加`probe counter`来计算结果的数量。如果扫描结果很快超过25条,程序会直接结束扫描,节省时间,提高效率。
新增“多级目录敏感资产扫描”,即在获取网页所有超链接的前提下,进行目录分段扫描,
关于`Dirscan`的结果,就是`Common Payloads 采集 Scan`和`Multi-level Directory Sensitive Asset Scan`的结果去重后的`Union`,
如果出现`['waf']`,则表示常用payload集合的扫描结果已经达到了程序设置的默认阈值。
如果出现`['more_path']`,则表示`多级目录敏感资产扫描结果`已达到程序设置的默认阈值。
其他情况可以直接点击查看验证结果,
在Allinks中,如果提示`[more_link]`,则表示页面上的超链接超过10个。
默认只显示前25个字符,直接点击显示详情
C段检测
**命令**:`python webmain_debug.py -cf 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
C段扫描
**命令**:`python webmain_debug.py -cd 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
异常处理
总会有各种意外情况导致程序产生异常报警。debug模式默认所有输出异常,正常模式不输出。
下面是关于程序扫描时的异常处理,主要是使用`write_file`进行错误记录,
结果保存
默认在当前目录下新建一个report目录,根据扫描参数保存为`html`文件。
关于扫描所有打开的端口,根据扫描参数保存为`csv`文件,将一些特殊端口保存为例如:`mysql_3306.txt`
异常处理保存
linux下建议使用`nohup python webmain_debug.py -d targets.txt &`后台运行,查看扫描日志中的`nohup.out`,结果同上 查看全部
采集工具免责说明([commit日志][web敏感资产fuzz]%和2.0的区别)
目前支持的功能
全自动扫描:python webmain.py -a --> baidu_site && port/dir scan 单目标扫描:python webmain.py -u --> webscan Portscan && scanDir 多目标检测:python webmain.py -f vuln_domains.txt --> webscan 不 scanDir 多目标扫描:python webmain.py -d vuln_domains.txt --> webscan Portscan && scanDirC 段检测:python webmain.py -cf 192.168.1.@ >1--> C scan not scanDir C scan: python webmain.py -cd 192.168.1.1--> C scan Portscan && scanDir
1.0版本,项目保存在[webmain1.0]
1.0 简介:【网络敏感资产模糊】
%E6%95%8F%E6%84%9F%E8%B5%84%E4%BA%A7fuzz/
1.0和2.0的区别请看【提交日志】
下面是2.0的介绍
项目地址
**Github**
**操作环境**:
python2.6.x 或 python2.7.x
**依赖第三方库**:
pip 安装请求[安全]
节目介绍
**扫描参数不区分大小写和顺序**
**默认代理关闭**
**随机乱序扫描验证**
**可以跨平台使用**
全自动扫描
全自动扫描,默认只加载百度搜索引擎`site:`,生成目标池,执行一些端口扫描,敏感资产和目录扫描功能,详细多目标扫描也是如此
**命令**:`python webmain_debug.py -a `
单目标扫描
默认的单目标扫描模式是加载敏感资产和目录扫描功能,例如:
**命令**:python webmain_debug.py -u `
**扫描日志**
**端口扫描**
程序只扫描端口`11211`、`27017`和`小于10000`
扫描结果如下:
程序会自动过滤掉常规端口
扫描结果
结果展示
结果保存在**report**目录
多目标检测
**命令**:`python webmain_debug.py -f vuln_domains.txt`
**使用介绍**:
快速检测,实现URL转IP后,部分端口扫描,每个开放端口的存活检测,
如果是存活的,则进行`getitle`信息检测。小细节是添加一个`filter_ports`来过滤掉常规端口。
考虑一种情况(边站),多个url解析为一个ip,程序添加`filter_ips`过滤已经扫描端口的ip,
同时,如果各种意外情况导致反复扫描`scheme://netloc`,程序会添加`filter_urls`对已经扫描过的任务进行过滤。
程序还考虑了一种情况,即:当URL是存活的,并且没有扫描到开放端口时,程序会自动检测默认端口的信息。
包括另一种情况,当url不活跃,但扫描到其他开放端口时,程序会自动检测对应端口的信息。
**程序只扫描端口获取目标站点标题、状态码、返回值长度,包括可能的合法IP地址、邮件资产信息**、
但是`不检测解析到内网的ip`,黑名单如下:
10.xxx127.xxx172.xxx192.168.xx
多目标扫描
**命令**:`python webmain_debug.py -d vuln_domains.txt`
**使用介绍**:
与多目标检测的不同之处在于增加了“敏感资产和目录扫描”,
敏感资产检测使用`common payloads 采集`,加上生成的`date备份文件`,程序会先判断404页面的状态,然后遍历payload。
判断条件是返回200,返回的内容大小不等于0,payload与404接口的返回大小差的绝对值大于5(或者两个返回大小不相等),
修改程序前的附加判断条件`如果遇到waf,或者各种意外情况,导致运行的payloads返回大于40,程序会提示可能遇到waf,返回空`,
然后增加`probe counter`来计算结果的数量。如果扫描结果很快超过25条,程序会直接结束扫描,节省时间,提高效率。
新增“多级目录敏感资产扫描”,即在获取网页所有超链接的前提下,进行目录分段扫描,
关于`Dirscan`的结果,就是`Common Payloads 采集 Scan`和`Multi-level Directory Sensitive Asset Scan`的结果去重后的`Union`,
如果出现`['waf']`,则表示常用payload集合的扫描结果已经达到了程序设置的默认阈值。
如果出现`['more_path']`,则表示`多级目录敏感资产扫描结果`已达到程序设置的默认阈值。
其他情况可以直接点击查看验证结果,
在Allinks中,如果提示`[more_link]`,则表示页面上的超链接超过10个。
默认只显示前25个字符,直接点击显示详情
C段检测
**命令**:`python webmain_debug.py -cf 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
C段扫描
**命令**:`python webmain_debug.py -cd 192.168.1.1`
**使用介绍**:
与C段检测不同的是增加了“敏感资产和目录扫描”,其余同多目标扫描
异常处理
总会有各种意外情况导致程序产生异常报警。debug模式默认所有输出异常,正常模式不输出。
下面是关于程序扫描时的异常处理,主要是使用`write_file`进行错误记录,
结果保存
默认在当前目录下新建一个report目录,根据扫描参数保存为`html`文件。
关于扫描所有打开的端口,根据扫描参数保存为`csv`文件,将一些特殊端口保存为例如:`mysql_3306.txt`
异常处理保存
linux下建议使用`nohup python webmain_debug.py -d targets.txt &`后台运行,查看扫描日志中的`nohup.out`,结果同上
采集工具免责说明(破解迅雷会员超高速度而设计的破解版迅雷(迅捷采集器))
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-11-23 15:02
采集工具免责说明:在网络上搜索“采集工具”、“迅捷采集器”等关键词,会看到很多类似的网站推荐,总体来说都差不多,不外乎四种:1.插件类;2.网站类;3.脚本类;4.采集类,所以这篇文章就要来认真的讲一讲采集工具类。
1)迅捷采集器迅捷采集器是专门用来采集迅雷会员里的某些资源的,是一款很实用的采集器,不仅支持迅雷迅雷会员里的同步文件同步,还支持百度网盘,微盘,磁力猫等网盘资源采集。相当于会员资源采集利器。
2)采集公众号的文章推荐使用采集公众号文章资源的小工具:采集公众号文章-文章内容采集器,
3)采集其他网站的文章推荐使用采集网站资源采集工具的小工具:采集其他网站资源采集工具,
4)推荐其他应用工具使用浏览器采集工具推荐使用迅捷采集器浏览器推荐工具:迅捷采集器bt采集器,是一款为破解迅雷会员超高速度而设计的破解版迅雷(原迅雷7.2版本迅雷),操作简单。02.使用理由采集资源有价值;内容被采集到迅雷服务器中,不让其他人拥有。更新方便;使用迅捷采集器网站资源,提高浏览器访问速度,进而提高下载速度。
独立下载;支持迅雷、优酷、百度等多个下载源;降低客户端安装数量成本,降低客户端下载数量成本。免费使用;采集资源免费使用,操作简单,操作简单才能赚钱;最关键的是能赚钱,如果你是销售人员就要努力的去销售客户公司产品,如果你是一个打工族可以提供相应的采集工具资源,帮助他人提高效率。03.常见问题采集原理:用户下载“采集线程采集”,每个线程做一次任务,任务接收时会将这个线程的任务交给这个线程相应的任务,线程自己再接任务,将资源搜索到服务器,再由服务器负责存储或下载。
采集方法:在迅雷资源下载器最关键一步是通过迅雷下载下“查看迅雷资源下载进度条”,将从迅雷下载器缓存下载的资源全部显示在下载器里面,方便用户找到自己需要的资源。迅雷下载器资源查看进度条每显示100个进度条,可以显示页面每多100页面时显示的资源,可以帮助用户判断下载什么页面的资源,然后在浏览器中重新从任务中取资源下载,此种方法一般用在任务量比较大的情况下。
04.缺点从采集到上传到服务器,周期很长,对于中型服务器来说,需要漫长的时间,如果采集时间比较赶,或者资源量不是特别大的情况下,使用采集工具+newdownloader,获取的资源是中转站,就如同转码工具,下载下来的资源,都是经过转码的,因为中转站是转码工厂。老实说:你下载速度怎么样?我不知道。05.有什么好的在。 查看全部
采集工具免责说明(破解迅雷会员超高速度而设计的破解版迅雷(迅捷采集器))
采集工具免责说明:在网络上搜索“采集工具”、“迅捷采集器”等关键词,会看到很多类似的网站推荐,总体来说都差不多,不外乎四种:1.插件类;2.网站类;3.脚本类;4.采集类,所以这篇文章就要来认真的讲一讲采集工具类。
1)迅捷采集器迅捷采集器是专门用来采集迅雷会员里的某些资源的,是一款很实用的采集器,不仅支持迅雷迅雷会员里的同步文件同步,还支持百度网盘,微盘,磁力猫等网盘资源采集。相当于会员资源采集利器。
2)采集公众号的文章推荐使用采集公众号文章资源的小工具:采集公众号文章-文章内容采集器,
3)采集其他网站的文章推荐使用采集网站资源采集工具的小工具:采集其他网站资源采集工具,
4)推荐其他应用工具使用浏览器采集工具推荐使用迅捷采集器浏览器推荐工具:迅捷采集器bt采集器,是一款为破解迅雷会员超高速度而设计的破解版迅雷(原迅雷7.2版本迅雷),操作简单。02.使用理由采集资源有价值;内容被采集到迅雷服务器中,不让其他人拥有。更新方便;使用迅捷采集器网站资源,提高浏览器访问速度,进而提高下载速度。
独立下载;支持迅雷、优酷、百度等多个下载源;降低客户端安装数量成本,降低客户端下载数量成本。免费使用;采集资源免费使用,操作简单,操作简单才能赚钱;最关键的是能赚钱,如果你是销售人员就要努力的去销售客户公司产品,如果你是一个打工族可以提供相应的采集工具资源,帮助他人提高效率。03.常见问题采集原理:用户下载“采集线程采集”,每个线程做一次任务,任务接收时会将这个线程的任务交给这个线程相应的任务,线程自己再接任务,将资源搜索到服务器,再由服务器负责存储或下载。
采集方法:在迅雷资源下载器最关键一步是通过迅雷下载下“查看迅雷资源下载进度条”,将从迅雷下载器缓存下载的资源全部显示在下载器里面,方便用户找到自己需要的资源。迅雷下载器资源查看进度条每显示100个进度条,可以显示页面每多100页面时显示的资源,可以帮助用户判断下载什么页面的资源,然后在浏览器中重新从任务中取资源下载,此种方法一般用在任务量比较大的情况下。
04.缺点从采集到上传到服务器,周期很长,对于中型服务器来说,需要漫长的时间,如果采集时间比较赶,或者资源量不是特别大的情况下,使用采集工具+newdownloader,获取的资源是中转站,就如同转码工具,下载下来的资源,都是经过转码的,因为中转站是转码工厂。老实说:你下载速度怎么样?我不知道。05.有什么好的在。
采集工具免责说明(全网页采集工具免责说明(一)_软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-11-22 07:01
采集工具免责说明本工具可以将全网页信息进行搜集处理,如网址、关键词、昵称等信息。采集工具提供免费的采集服务,服务内容仅限ip站点,采集速度快,工作效率高,不影响用户体验。安全性测试代码加密:代码保存为加密文件。同时可支持windows、mac以及linux系统采集。全网页接口:所有网页接口一致,无差异。
全网页接口调用实测:可根据用户情况自定义接口,接口调用准确率高达90%。接口数据校验:生成校验代码。丰富丰富网页接口:ip接口,图片、视频、账号、手机等。外部链接多:可利用seo将外部链接多引入至自己网站。访问其他网站排名高:搜索流量更精准,网站流量增长速度快。还可与其他网站互相链接以进行其他网站引流。
采集方式:网址采集、地址采集、关键词采集。采集速度快、外链快速通过。网址采集:打开12秒,选择搜索地址搜索带有ip地址的页面;地址采集:通过地址搜索方式采集其他页面;关键词采集:通过关键词搜索方式搜索含有ip地址的页面。如:关键词+域名或关键词+百度等。点击查看更多采集方式(包括但不限于):所有采集方式目前支持高级版本免费试用,高级版本仅支持采集ip地址、接口数据等2种方式。提供基础版本的采集工具,通过模拟登录ip、端口等方式获取搜索源代码。
1)新安装的访问上一章节的客户端,会提示你在“登录”。点击“登录”,会提示你找到网站登录接口,可以尝试输入你的账号密码。
2)请先在电脑端浏览器打开通过电脑端登录,在打开“访问网站”即可,有需要注意输入验证码。注意,输入验证码后,采集端会自动识别“访问接口”,不需要手动输入了。
3)登录成功之后,选择一个第三方登录方式(火狐、谷歌)。
4)打开站点之后,可以根据需要修改免责声明、发布公告及api接口申请方式。如需详细的接口使用介绍,请使用访问接口。 查看全部
采集工具免责说明(全网页采集工具免责说明(一)_软件)
采集工具免责说明本工具可以将全网页信息进行搜集处理,如网址、关键词、昵称等信息。采集工具提供免费的采集服务,服务内容仅限ip站点,采集速度快,工作效率高,不影响用户体验。安全性测试代码加密:代码保存为加密文件。同时可支持windows、mac以及linux系统采集。全网页接口:所有网页接口一致,无差异。
全网页接口调用实测:可根据用户情况自定义接口,接口调用准确率高达90%。接口数据校验:生成校验代码。丰富丰富网页接口:ip接口,图片、视频、账号、手机等。外部链接多:可利用seo将外部链接多引入至自己网站。访问其他网站排名高:搜索流量更精准,网站流量增长速度快。还可与其他网站互相链接以进行其他网站引流。
采集方式:网址采集、地址采集、关键词采集。采集速度快、外链快速通过。网址采集:打开12秒,选择搜索地址搜索带有ip地址的页面;地址采集:通过地址搜索方式采集其他页面;关键词采集:通过关键词搜索方式搜索含有ip地址的页面。如:关键词+域名或关键词+百度等。点击查看更多采集方式(包括但不限于):所有采集方式目前支持高级版本免费试用,高级版本仅支持采集ip地址、接口数据等2种方式。提供基础版本的采集工具,通过模拟登录ip、端口等方式获取搜索源代码。
1)新安装的访问上一章节的客户端,会提示你在“登录”。点击“登录”,会提示你找到网站登录接口,可以尝试输入你的账号密码。
2)请先在电脑端浏览器打开通过电脑端登录,在打开“访问网站”即可,有需要注意输入验证码。注意,输入验证码后,采集端会自动识别“访问接口”,不需要手动输入了。
3)登录成功之后,选择一个第三方登录方式(火狐、谷歌)。
4)打开站点之后,可以根据需要修改免责声明、发布公告及api接口申请方式。如需详细的接口使用介绍,请使用访问接口。
采集工具免责说明(全面快速子域收集终极神器-Python和pip3安装步骤(git版) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2021-11-18 05:13
)
一体机
OneForAll 是一款强大的子域采集工具英文文档
项目描述
项目地址:
信息采集在渗透测试中的重要性不言而喻。子域采集是信息采集中不可或缺且非常重要的一部分。目前网上已经开源了很多子域采集的工具,但是一直存在以下问题:
为了解决以上痛点,本项目应用应运而生。顾名思义,希望OneForAll是一款强大、全面、强大的快速子域采集终极神器。
目前 OneForAll 仍在开发中。一定有很多问题和需要改进的地方。欢迎大佬提交问题和 PR。给个小星星就可以了✨,目前有一个QQ群专门用于OneForAll交流反馈::824414244(加群验证:我的英雄学院)。
特征
如果您有其他很棒的想法,请告诉我!
入门
请务必花点时间阅读本文档,以帮助您快速熟悉 OneForAll!
安装要求
OneForAll基于Python3.8.0开发测试,请使用高于Python3.8.0的稳定发布版本,其他版本可能有问题(Windows平台必须使用3.8.0及以上)安装Python环境以供参考。运行以下命令检查 Python 和 pip3 版本:
python -V
pip3 -V
如果看到如下类似的输出,说明Python环境没有问题:
Python 3.8.0
pip 19.2.2 from C:\Users\shmilylty\AppData\Roaming\Python\Python38\site-packages\pip (python 3.8)
✔安装步骤(git版)
下载
由于项目正在开发中,会不断更新迭代。下载的时候用git clone克隆最新的代码仓库,也方便后续的更新。不建议从Release下载,因为Release里面的版本更新慢,更新不方便。这个项目已经被我在 Gitee 上镜像了一份。国内推荐使用Gitee克隆更快:
git clone https://gitee.com/shmilylty/OneForAll.git
或者:
git clone https://github.com/shmilylty/OneForAll.git
安装
您可以通过 pip3 安装 OneForAll 的依赖项。下面是Windows系统下使用pip3安装依赖的例子: 注意:如果你的Python3安装在系统的Program Files目录下,如:C:\Program Files\Python38,那么请使用管理员运行命令提示符cmd作为身份执行以下命令!
cd OneForAll/
python -m pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python oneforall.py --help
其他系统平台请参考依赖安装。如果在安装过程中发现依赖库编译失败,可以参考 Troubleshooting.md 解决方案。如果还没有解决,请加群反馈。
更新
❗注意:如果之前已经克隆过项目,请将修改后的文件备份到项目外的地方(如config.py),然后执行如下命令更新项目:
git fetch --all
git reset --hard origin/master
git pull
✔安装步骤(docker版)
docker pull shmilylty/oneforall
docker run -it --rm -v ~/results:/OneForAll/results oneforall
结果会输出到本地目录~/results
✨使用演示
如果您通过 pip3 安装依赖项,请使用以下命令运行示例:
python3 oneforall.py --target example.com run
如果您通过 pipenv 安装了依赖项,请使用以下命令运行示例:
pipenv run python oneforall.py --target example.com run
结果说明
我们以 python3 oneforall.py --target run 命令为例。正常执行默认参数后,OneForAll会在results目录下生成相应的结果:
.csv是各个主域下子域的采集结果。
all_subdomain_result_1583034493.csv是OneForAll每次运行时采集的子域汇总结果,包括.csv,方便批量采集场景下获取所有结果。
result.sqlite3 是 SQLite3 结果数据库,存储每次运行 OneForAll 时采集的子域。数据库结构如下:
其中,类似于example_com_origin_result的表存储了各个模块的初始子域采集结果。
其中,类似于example_com_resolve_result的表存储了子域解析的结果。
其中,类似于example_com_last_result的表存储了最后一次子域采集的结果(需要采集两次以上才能生成)。
其中,类似于example_com_now_result的表存储了当前子域的采集结果。一般来说,关注这张表就足够了。
使用帮助
命令行参数只提供了一些常用的参数。更详细的参数配置请参考config.py。如果您认为某些参数在命令界面中经常使用或缺少参数,非常欢迎反馈。由于众所周知的原因,如果您想使用一些被围墙的集合接口,请到 config.py 中配置代理。部分采集模块需要提供API(大部分可以通过注册账号免费获得)。如果您需要使用它们,请到 api.py 配置 API。信息,如果你不使用它,请忽略错误信息。(详细模块请阅读采集模块说明)
OneForAll 命令行界面基于 Fire。有关 Fire 的更高级使用方法,请参阅使用 Fire CLI。
oneforall.py 是主程序入口,oneforall.py 可以调用brute.py、takerover.py 和dbexport.py 模块。为了方便子域爆破,brute.py是独立生成的,为了方便子域接管风险独立排查。takerover.py,为了方便数据库导出,dbexport.py是独立的,这些模块可以单独运行,接受的参数要丰富一些,如果要单独使用这些模块,请参考帮助
❗注意:当您在使用过程中遇到一些问题或疑问,请先在Issue中搜索答案。您还可以参考常见问题和解答。
oneforall.py 使用帮助
以下帮助信息可能不是最新的,可以使用 python oneforall.py --help 获取最新的帮助信息。
python oneforall.py --help
NAME
oneforall.py - OneForAll帮助信息
SYNOPSIS
oneforall.py COMMAND | --target=TARGET
DESCRIPTION
OneForAll是一款功能强大的子域收集工具
Example:
python3 oneforall.py version
python3 oneforall.py --target example.com run
python3 oneforall.py --target ./domains.txt run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --port small run
python3 oneforall.py --target example.com --format csv run
python3 oneforall.py --target example.com --dns False run
python3 oneforall.py --target example.com --req False run
python3 oneforall.py --target example.com --takeover False run
python3 oneforall.py --target example.com --show True run
Note:
参数alive可选值True,False分别表示导出存活,全部子域结果
参数port可选值有'default', 'small', 'large', 详见config.py配置
参数format可选格式有'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path默认None使用OneForAll结果目录生成路径
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径(必需参数)
FLAGS
--brute=BRUTE
使用爆破模块(默认False)
--dns=DNS
DNS解析子域(默认True)
--req=REQ
HTTP请求子域(默认True)
--port=PORT
请求验证子域的端口范围(默认只探测80端口)
--valid=VALID
只导出存活的子域结果(默认False)
--format=FORMAT
结果保存格式(默认csv)
--path=PATH
结果保存路径(默认None)
--takeover=TAKEOVER
检查子域接管(默认False)
目录结构
项目目录结构的描述请参考directory_structure。
子域字典出处注意事项:
开源子域采集工具中高频子域名字典的一部分。相关在线服务提供商发布的最受欢迎的子域列表。互联网相关安全研究人员对全网公共子域的研究成果。互联网相关安全研究人员在证书透明性中提取公共子域的结果。常用业务命名规则:公司或 DevOps 中常用的工具和软件名称。汉语常用词和英语常用词的拼音。上面得到的字典针对排序和脏数据去除处理进行了优化。非常欢迎您贡献一本更好的词典。使用的框架
感谢这些伟大而优秀的 Python 库!
贡献
非常热烈欢迎大家一起改进这个项目!
⌛后续计划
更多细节请阅读 todo.md。
版本控制
该项目使用 SemVer 语言版本格式进行版本管理。您可以在 Releases 中查看可用版本,并且可以检查 changes.md 以了解历史更改。
贡献者
您可以在contributors.md 中查看参与该项目的所有开发人员。
☕ 欣赏
如果你认为这个项目对你有帮助,你可以奖励你一杯咖啡作为鼓励:)
查看全部
采集工具免责说明(全面快速子域收集终极神器-Python和pip3安装步骤(git版)
)
一体机
OneForAll 是一款强大的子域采集工具英文文档
项目描述
项目地址:
信息采集在渗透测试中的重要性不言而喻。子域采集是信息采集中不可或缺且非常重要的一部分。目前网上已经开源了很多子域采集的工具,但是一直存在以下问题:
为了解决以上痛点,本项目应用应运而生。顾名思义,希望OneForAll是一款强大、全面、强大的快速子域采集终极神器。
目前 OneForAll 仍在开发中。一定有很多问题和需要改进的地方。欢迎大佬提交问题和 PR。给个小星星就可以了✨,目前有一个QQ群专门用于OneForAll交流反馈::824414244(加群验证:我的英雄学院)。
特征
如果您有其他很棒的想法,请告诉我!
入门
请务必花点时间阅读本文档,以帮助您快速熟悉 OneForAll!
安装要求
OneForAll基于Python3.8.0开发测试,请使用高于Python3.8.0的稳定发布版本,其他版本可能有问题(Windows平台必须使用3.8.0及以上)安装Python环境以供参考。运行以下命令检查 Python 和 pip3 版本:
python -V
pip3 -V
如果看到如下类似的输出,说明Python环境没有问题:
Python 3.8.0
pip 19.2.2 from C:\Users\shmilylty\AppData\Roaming\Python\Python38\site-packages\pip (python 3.8)
✔安装步骤(git版)
下载
由于项目正在开发中,会不断更新迭代。下载的时候用git clone克隆最新的代码仓库,也方便后续的更新。不建议从Release下载,因为Release里面的版本更新慢,更新不方便。这个项目已经被我在 Gitee 上镜像了一份。国内推荐使用Gitee克隆更快:
git clone https://gitee.com/shmilylty/OneForAll.git
或者:
git clone https://github.com/shmilylty/OneForAll.git
安装
您可以通过 pip3 安装 OneForAll 的依赖项。下面是Windows系统下使用pip3安装依赖的例子: 注意:如果你的Python3安装在系统的Program Files目录下,如:C:\Program Files\Python38,那么请使用管理员运行命令提示符cmd作为身份执行以下命令!
cd OneForAll/
python -m pip install -U pip setuptools wheel -i https://mirrors.aliyun.com/pypi/simple/
pip3 install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
python oneforall.py --help
其他系统平台请参考依赖安装。如果在安装过程中发现依赖库编译失败,可以参考 Troubleshooting.md 解决方案。如果还没有解决,请加群反馈。
更新
❗注意:如果之前已经克隆过项目,请将修改后的文件备份到项目外的地方(如config.py),然后执行如下命令更新项目:
git fetch --all
git reset --hard origin/master
git pull
✔安装步骤(docker版)
docker pull shmilylty/oneforall
docker run -it --rm -v ~/results:/OneForAll/results oneforall
结果会输出到本地目录~/results
✨使用演示
如果您通过 pip3 安装依赖项,请使用以下命令运行示例:
python3 oneforall.py --target example.com run
如果您通过 pipenv 安装了依赖项,请使用以下命令运行示例:
pipenv run python oneforall.py --target example.com run
结果说明
我们以 python3 oneforall.py --target run 命令为例。正常执行默认参数后,OneForAll会在results目录下生成相应的结果:
.csv是各个主域下子域的采集结果。
all_subdomain_result_1583034493.csv是OneForAll每次运行时采集的子域汇总结果,包括.csv,方便批量采集场景下获取所有结果。
result.sqlite3 是 SQLite3 结果数据库,存储每次运行 OneForAll 时采集的子域。数据库结构如下:
其中,类似于example_com_origin_result的表存储了各个模块的初始子域采集结果。
其中,类似于example_com_resolve_result的表存储了子域解析的结果。
其中,类似于example_com_last_result的表存储了最后一次子域采集的结果(需要采集两次以上才能生成)。
其中,类似于example_com_now_result的表存储了当前子域的采集结果。一般来说,关注这张表就足够了。
使用帮助
命令行参数只提供了一些常用的参数。更详细的参数配置请参考config.py。如果您认为某些参数在命令界面中经常使用或缺少参数,非常欢迎反馈。由于众所周知的原因,如果您想使用一些被围墙的集合接口,请到 config.py 中配置代理。部分采集模块需要提供API(大部分可以通过注册账号免费获得)。如果您需要使用它们,请到 api.py 配置 API。信息,如果你不使用它,请忽略错误信息。(详细模块请阅读采集模块说明)
OneForAll 命令行界面基于 Fire。有关 Fire 的更高级使用方法,请参阅使用 Fire CLI。
oneforall.py 是主程序入口,oneforall.py 可以调用brute.py、takerover.py 和dbexport.py 模块。为了方便子域爆破,brute.py是独立生成的,为了方便子域接管风险独立排查。takerover.py,为了方便数据库导出,dbexport.py是独立的,这些模块可以单独运行,接受的参数要丰富一些,如果要单独使用这些模块,请参考帮助
❗注意:当您在使用过程中遇到一些问题或疑问,请先在Issue中搜索答案。您还可以参考常见问题和解答。
oneforall.py 使用帮助
以下帮助信息可能不是最新的,可以使用 python oneforall.py --help 获取最新的帮助信息。
python oneforall.py --help
NAME
oneforall.py - OneForAll帮助信息
SYNOPSIS
oneforall.py COMMAND | --target=TARGET
DESCRIPTION
OneForAll是一款功能强大的子域收集工具
Example:
python3 oneforall.py version
python3 oneforall.py --target example.com run
python3 oneforall.py --target ./domains.txt run
python3 oneforall.py --target example.com --valid None run
python3 oneforall.py --target example.com --brute True run
python3 oneforall.py --target example.com --port small run
python3 oneforall.py --target example.com --format csv run
python3 oneforall.py --target example.com --dns False run
python3 oneforall.py --target example.com --req False run
python3 oneforall.py --target example.com --takeover False run
python3 oneforall.py --target example.com --show True run
Note:
参数alive可选值True,False分别表示导出存活,全部子域结果
参数port可选值有'default', 'small', 'large', 详见config.py配置
参数format可选格式有'rst', 'csv', 'tsv', 'json', 'yaml', 'html',
'jira', 'xls', 'xlsx', 'dbf', 'latex', 'ods'
参数path默认None使用OneForAll结果目录生成路径
ARGUMENTS
TARGET
单个域名或者每行一个域名的文件路径(必需参数)
FLAGS
--brute=BRUTE
使用爆破模块(默认False)
--dns=DNS
DNS解析子域(默认True)
--req=REQ
HTTP请求子域(默认True)
--port=PORT
请求验证子域的端口范围(默认只探测80端口)
--valid=VALID
只导出存活的子域结果(默认False)
--format=FORMAT
结果保存格式(默认csv)
--path=PATH
结果保存路径(默认None)
--takeover=TAKEOVER
检查子域接管(默认False)
目录结构
项目目录结构的描述请参考directory_structure。
子域字典出处注意事项:
开源子域采集工具中高频子域名字典的一部分。相关在线服务提供商发布的最受欢迎的子域列表。互联网相关安全研究人员对全网公共子域的研究成果。互联网相关安全研究人员在证书透明性中提取公共子域的结果。常用业务命名规则:公司或 DevOps 中常用的工具和软件名称。汉语常用词和英语常用词的拼音。上面得到的字典针对排序和脏数据去除处理进行了优化。非常欢迎您贡献一本更好的词典。使用的框架
感谢这些伟大而优秀的 Python 库!
贡献
非常热烈欢迎大家一起改进这个项目!
⌛后续计划
更多细节请阅读 todo.md。
版本控制
该项目使用 SemVer 语言版本格式进行版本管理。您可以在 Releases 中查看可用版本,并且可以检查 changes.md 以了解历史更改。
贡献者
您可以在contributors.md 中查看参与该项目的所有开发人员。
☕ 欣赏
如果你认为这个项目对你有帮助,你可以奖励你一杯咖啡作为鼓励:)
采集工具免责说明(阿里大数据买软件送软件我们是做这方面的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-16 23:02
采集工具免责说明:本工具仅对我司产品或服务进行探索验证,不代表你们公司承诺书、合同以及其他相关法律文件的出具、变更或修改。以上判断的前提是,本工具是否真的适用于你或者你相关机构、机构成员的产品或服务。目前,中国信息产业网只发布我司产品(因涉及版权等原因,所以只发布我司的产品)在中国信息产业网上可以访问。
你们要是想做数据采集的话,建议先做好数据源的一个打通,应该就能够有源头来了,如果是将数据源分享出去,那么其实就已经不是数据采集了,而是采集了整个大数据社会的一个生态体系了。
提供我个人的一个点子,加入到卖家群里去,给的卖家送一些定制化的一个采集软件,采集上销量高的一些商品到自己店铺,每天自己的的一个销量都在增加,售价目前是58,
我们可以合作一下
我们是专业的这方面,
阿里大数据
买软件送软件
我们是做这方面的
楼主有兴趣合作吗?不知道可不可以教你一个数据采集的软件,做软件肯定需要一定的技术,找软件的话你可以直接去zol软件下载这些地方下载,有很多国内知名软件开发商,缺点是非标准化的,安装时安全问题不知道有没有考虑好。其实根据我看你的这个问题是希望自己做的,那就去试一下销量高的那些商品吧,直接去采集整合到你的数据库,这样再考虑去其他平台推广。 查看全部
采集工具免责说明(阿里大数据买软件送软件我们是做这方面的)
采集工具免责说明:本工具仅对我司产品或服务进行探索验证,不代表你们公司承诺书、合同以及其他相关法律文件的出具、变更或修改。以上判断的前提是,本工具是否真的适用于你或者你相关机构、机构成员的产品或服务。目前,中国信息产业网只发布我司产品(因涉及版权等原因,所以只发布我司的产品)在中国信息产业网上可以访问。
你们要是想做数据采集的话,建议先做好数据源的一个打通,应该就能够有源头来了,如果是将数据源分享出去,那么其实就已经不是数据采集了,而是采集了整个大数据社会的一个生态体系了。
提供我个人的一个点子,加入到卖家群里去,给的卖家送一些定制化的一个采集软件,采集上销量高的一些商品到自己店铺,每天自己的的一个销量都在增加,售价目前是58,
我们可以合作一下
我们是专业的这方面,
阿里大数据
买软件送软件
我们是做这方面的
楼主有兴趣合作吗?不知道可不可以教你一个数据采集的软件,做软件肯定需要一定的技术,找软件的话你可以直接去zol软件下载这些地方下载,有很多国内知名软件开发商,缺点是非标准化的,安装时安全问题不知道有没有考虑好。其实根据我看你的这个问题是希望自己做的,那就去试一下销量高的那些商品吧,直接去采集整合到你的数据库,这样再考虑去其他平台推广。
采集工具免责说明(采集工具免责说明及解释(一)采集软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-15 02:02
采集工具免责说明及解释
1)google采集软件可以让我们像使用adsense一样,使用google搜索和推荐的推广工具。采集软件可以让google采集成功,并且把数据或在google中预定义的数据放在网站中。注意:谷歌不会拿去或收集数据,而它只是使用数据。采集软件不会收集用户的任何数据,不会参与数据收集和不可靠购买。任何接触数据的接触点都是不可靠的。如果是违反这条说明,所采集的数据将不会被保存。(。
2)如果你在一个网站使用了采集软件,通常的结果是你想要访问网站中的某些独特页面。你正在搜集网站页面中的所有链接。你需要想办法重新列出以前搜集的页面。采集软件可以帮助你实现这个目标。
3)我们的采集是通过爬虫系统抓取。当我们抓取来自谷歌的网页信息或其他网站上的任何内容时,我们需要进行对每个数据来源的估计。在将数据从爬虫引到我们需要的网站之前,需要对数据进行重新列出。通常地,我们对网页进行重新列出时间通常会超过1个小时以上。如果爬虫或采集软件与我们抓取的所有网页相符,则我们可以搜集从网页中产生的所有数据。(。
4)我们从源代码收集的数据只包含有关源代码页面的信息。我们将从源代码中解析的数据称为“待搜索页面”(webburden)。
5)我们不是使用的google搜索工具,而是自己编写的抓取工具。
6)我们没有用adsense的元素抓取功能(例如,:访问用户名,密码,cookie等)。
7)我们不使用专门创建的爬虫程序。自己创建的google工具通常有spanner数据库(请参阅"objects"章节)。最后,注意到一个google工具(googletool)。在本指南中,该数据库包含用户名,密码,账号和其他敏感信息。我们假设您已经编写了一个采集工具程序,然后从google网站抓取数据。
我们编写了爬虫程序,并将爬虫程序开放给google。目录1安装google采集工具2列出收集的数据3发送电子邮件给google4发送一封电子邮件给谷歌5另一个简单的抓取网站6每个网站抓取1-2个页面7命令行界面抓取工具8在我们的mac上抓取图片9使用我们的服务器上抓取google,使用我们的电子邮件服务器发送图片。 查看全部
采集工具免责说明(采集工具免责说明及解释(一)采集软件)
采集工具免责说明及解释
1)google采集软件可以让我们像使用adsense一样,使用google搜索和推荐的推广工具。采集软件可以让google采集成功,并且把数据或在google中预定义的数据放在网站中。注意:谷歌不会拿去或收集数据,而它只是使用数据。采集软件不会收集用户的任何数据,不会参与数据收集和不可靠购买。任何接触数据的接触点都是不可靠的。如果是违反这条说明,所采集的数据将不会被保存。(。
2)如果你在一个网站使用了采集软件,通常的结果是你想要访问网站中的某些独特页面。你正在搜集网站页面中的所有链接。你需要想办法重新列出以前搜集的页面。采集软件可以帮助你实现这个目标。
3)我们的采集是通过爬虫系统抓取。当我们抓取来自谷歌的网页信息或其他网站上的任何内容时,我们需要进行对每个数据来源的估计。在将数据从爬虫引到我们需要的网站之前,需要对数据进行重新列出。通常地,我们对网页进行重新列出时间通常会超过1个小时以上。如果爬虫或采集软件与我们抓取的所有网页相符,则我们可以搜集从网页中产生的所有数据。(。
4)我们从源代码收集的数据只包含有关源代码页面的信息。我们将从源代码中解析的数据称为“待搜索页面”(webburden)。
5)我们不是使用的google搜索工具,而是自己编写的抓取工具。
6)我们没有用adsense的元素抓取功能(例如,:访问用户名,密码,cookie等)。
7)我们不使用专门创建的爬虫程序。自己创建的google工具通常有spanner数据库(请参阅"objects"章节)。最后,注意到一个google工具(googletool)。在本指南中,该数据库包含用户名,密码,账号和其他敏感信息。我们假设您已经编写了一个采集工具程序,然后从google网站抓取数据。
我们编写了爬虫程序,并将爬虫程序开放给google。目录1安装google采集工具2列出收集的数据3发送电子邮件给google4发送一封电子邮件给谷歌5另一个简单的抓取网站6每个网站抓取1-2个页面7命令行界面抓取工具8在我们的mac上抓取图片9使用我们的服务器上抓取google,使用我们的电子邮件服务器发送图片。
采集工具免责说明(优采云采集器支持所有操作系统版本更新和功能升级同步所有平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-13 12:18
优采云采集器是专业实用的网页资料采集器。这个采集器不需要开发,任何人都可以使用,并且可以将数据导出到本地文件,发布到网站和数据库等。
它是由最初的谷歌技术团队创建的。它的规则配置简单,采集功能强大,可以支持电子商务、生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别有多种方式导出网页数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监控、风险评估的好帮手。
优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您的其他前台工作是您数据的最佳助手采集。
【特征】
一、【简单的规则配置采集强大的功能】
1、可视化定制采集流程:
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、 点击提取网页数据:
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据:
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出并发布采集的数据:
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
二、【支持采集不同类型的网站】
电商、生活服务、社交媒体、新闻论坛、本地网站...
强大的浏览器内核,99%以上网站都能上手!
三、【所有平台支持免费可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集 和导出都是免费的,无限使用
可视化配置采集规则,傻瓜式操作
四、【强大的功能,快速的箭头】
智能识别网页数据,多种方式导出数据
软件定期更新升级,不断添加新功能
客户的满意就是对我们最大的肯定!
【常见问题】
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集任务
1)Launch优采云采集器,进入主界面,点击Create Task按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)在搜索关键字和选择关键字的输入框中填写,点击下一步
3) 进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)单击列表块中的第一个元素
5) 点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整。采集 运行时点击向下 页面上按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择采集的字段:在焦点框中单击要提取的元素,然后单击下一步
8) 选择不进入详情页。单击保存或保存并运行
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图 查看全部
采集工具免责说明(优采云采集器支持所有操作系统版本更新和功能升级同步所有平台)
优采云采集器是专业实用的网页资料采集器。这个采集器不需要开发,任何人都可以使用,并且可以将数据导出到本地文件,发布到网站和数据库等。
它是由最初的谷歌技术团队创建的。它的规则配置简单,采集功能强大,可以支持电子商务、生活服务、社交媒体、新闻论坛等不同类型的网站,智能识别有多种方式导出网页数据,其中大部分是完全免费的。是行业分析、精准营销、品牌监控、风险评估的好帮手。
优采云免费采集器 支持所有操作系统版本更新和功能升级同步所有平台,采集和导出都是免费的,无限制的放心,并支持后台操作,不打扰您的其他前台工作是您数据的最佳助手采集。
【特征】
一、【简单的规则配置采集强大的功能】
1、可视化定制采集流程:
全程问答指导,可视化操作,自定义采集流程
自动记录和模拟网页操作顺序
高级设置满足更多采集需求
2、 点击提取网页数据:
鼠标点击选择要抓取的网页内容,操作简单
您可以选择提取文本、链接、属性、html 标签等。
3、运行批处理采集数据:
软件根据采集的处理和提取规则自动批量处理采集
快速稳定,实时显示采集速度和进程
可切换软件后台运行,不打扰前台工作
4、导出并发布采集的数据:
采集 数据自动制表,字段可自由配置
支持数据导出到Excel等本地文件
并一键发布到cms网站/database/微信公众号等媒体
二、【支持采集不同类型的网站】
电商、生活服务、社交媒体、新闻论坛、本地网站...
强大的浏览器内核,99%以上网站都能上手!
三、【所有平台支持免费可视化操作】
支持所有操作系统:Windows+Mac+Linux
采集 和导出都是免费的,无限使用
可视化配置采集规则,傻瓜式操作
四、【强大的功能,快速的箭头】
智能识别网页数据,多种方式导出数据
软件定期更新升级,不断添加新功能
客户的满意就是对我们最大的肯定!
【常见问题】
如何使用优采云采集器采集百度搜索结果数据?
第一步:创建采集任务
1)Launch优采云采集器,进入主界面,点击Create Task按钮创建“Wizard采集Task”
2)输入百度搜索的网址,包括三种方式
1、 手动输入:直接在输入框中输入网址,多个网址需要用换行符分割
2、 点击读取文件:用户选择一个文件来存储 URL。文件中可以有多个 URL 地址,地址之间需要用换行符分隔。
3、 批量添加方式:通过添加和调整地址参数生成多个常规地址
第二步:自定义采集流程
1) 点击创建自动打开第一个网址进入向导设置,这里选择列表页面,点击下一步
2)在搜索关键字和选择关键字的输入框中填写,点击下一步
3) 进入第一个关键词搜索结果页面后,点击设置搜索按钮,点击下一步
4)单击列表块中的第一个元素
5) 点击结果列表块中的另一个元素,此时列表块被自动选中。点击下一步
6)选择下一页按钮,选择下一页选项,然后点击页面上的下一页按钮填写第一个输入框,第二个数据框可以调整。采集 运行时点击向下 页面上按钮的数量。理论上,次数越多,采集 得到的数据就越多。点击下一步
7)选择采集的字段:在焦点框中单击要提取的元素,然后单击下一步
8) 选择不进入详情页。单击保存或保存并运行
第三步:数据采集并导出
1)采集 任务正在运行
2)采集 完成后选择“导出数据”将所有数据导出到本地文件
3)选择“导出方式”导出采集好的数据,这里可以选择excel作为导出格式
4)采集 数据导出如下图
采集工具免责说明(网络矿工数据采集软件的保障您的软件使用利益)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-11-06 17:25
网络矿工数据采集软件是一款面向采集专业用户的采集软件。基于Soukey的拣货数据采集软件研发,并在此基础上进行了扩展 更丰富的专业功能不仅可以进一步满足采集用户的需求,还可以扩大采集的应用范围采集。同时也为网络矿工数据采集软件提供专业的技术支持和售后服务。将最大限度的保护您的软件使用利益。需要 Microsoft .NetFramework2.0 环境。
网络矿工数据采集在原版V2012的基础上,增加了多页面采集、多sql支持功能,并优化了UI操作。网络矿工数据采集软件根据用户数量进行授权。主要功能如下:
1、多任务、多线程,支持一个任务运行多个实例;
2、支持图片、Flash和文件下载:下载不支持多线程处理,所以不建议使用本软件创建专业下载任务;
3、URL 配置支持参数自定义,以及外部字典参数:自定义的参数值可以通过字典的方式进行扩展;
4、支持Cookies,POST采集:可以记录Cookies,采集网站需要登录的数据,也可以手动登录采集;
5、支持导航,自动翻页:可以进行网站导航,例如:通过新闻列表采集新闻内容;支持多层导航;
6、可以采集ajax数据;
7、采集 临时存储数据,断点处连续采集数据:临时存储数据的格式为XML;
8、支持数据导出、文件、数据库:数据库支持Access、MS Sql Server、MySql,文件支持文本文件和Excel;数据导出支持手动和自动,手动导出只支持文件格式;
9.在线数据发布:支持在线数据发布,数据发布支持Cookie;
10、数据采集支持采集数据处理:采集数据可进行替换、截取、追加等操作,可自动去除网页符号,支持Regular; 查看全部
采集工具免责说明(网络矿工数据采集软件的保障您的软件使用利益)
网络矿工数据采集软件是一款面向采集专业用户的采集软件。基于Soukey的拣货数据采集软件研发,并在此基础上进行了扩展 更丰富的专业功能不仅可以进一步满足采集用户的需求,还可以扩大采集的应用范围采集。同时也为网络矿工数据采集软件提供专业的技术支持和售后服务。将最大限度的保护您的软件使用利益。需要 Microsoft .NetFramework2.0 环境。
网络矿工数据采集在原版V2012的基础上,增加了多页面采集、多sql支持功能,并优化了UI操作。网络矿工数据采集软件根据用户数量进行授权。主要功能如下:
1、多任务、多线程,支持一个任务运行多个实例;
2、支持图片、Flash和文件下载:下载不支持多线程处理,所以不建议使用本软件创建专业下载任务;
3、URL 配置支持参数自定义,以及外部字典参数:自定义的参数值可以通过字典的方式进行扩展;
4、支持Cookies,POST采集:可以记录Cookies,采集网站需要登录的数据,也可以手动登录采集;
5、支持导航,自动翻页:可以进行网站导航,例如:通过新闻列表采集新闻内容;支持多层导航;
6、可以采集ajax数据;
7、采集 临时存储数据,断点处连续采集数据:临时存储数据的格式为XML;
8、支持数据导出、文件、数据库:数据库支持Access、MS Sql Server、MySql,文件支持文本文件和Excel;数据导出支持手动和自动,手动导出只支持文件格式;
9.在线数据发布:支持在线数据发布,数据发布支持Cookie;
10、数据采集支持采集数据处理:采集数据可进行替换、截取、追加等操作,可自动去除网页符号,支持Regular;
采集工具免责说明(采集工具免责说明,你说不同的数据分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-11-02 20:02
采集工具免责说明
1、官方不允许使用(36
0)
2、第三方信息系统收集验证上报(巨头)
3、在线实现方式(如易讯)
4、收集数据流量分析
无非就是以上人说的那几个呗。就像之前有人做app每天都会有注册和登录数据流一样。既然那些不方便,那就干脆提取吧。比如,登录了之后,把这个app的注册和登录信息取出来。这个过程,其实是有一些数据文件存在的,如果只是计算的话,本质上应该是一样的。如果是把这些数据分析,那可能也是和前面提到的算法一样。
当然是多线程处理。
这个问题挺有意思,也最核心。采集是一个很基础的技术点,理论上采集的数据量越大,处理效率越高,还有对数据分析得越精准。但多采集在实际中却得有不同的处理方式,很多数据分析平台是开放有接口的,我们公司用的那些软件功能就差异不大,但平台不同,这样给出的返回结果和效果差异就很大。不同平台有不同的接口处理,最后数据要回到自己手里在分析处理和分析结果进行对比,你说不同的数据采集,做后台有啥区别?几乎每个用户数据都不一样。
从用户和身边朋友总结了一些,大概有这么几种情况:平台线程采集:比如京东个性化搜索,经常采用网页,然后把所有的结果进行分类汇总,根据用户搜索的类型进行汇总,归到一个统一的list中去,进行再次提交;品牌方的线程采集:这种数据量相对较大;互联网分析公司:这种分析是网站或app平台提供接口,根据统一的结果进行分析、处理、反馈,以查看产品优化、调整、促销的效果;互联网广告公司:他们会收集产品表现、竞品表现、用户搜索习惯等数据,利用分析思维整理出更加精准、客观、准确的投放策略;社交媒体新闻类公司:这种公司通常是找到用户数据,做点击率、互动率等排名,然后同公司内部需要的媒体进行结算;这些,主要还是要找准想要采集哪些数据,然后有针对性的去采集,具体可以搜索一下相关资料,看看市场上做什么的多些。 查看全部
采集工具免责说明(采集工具免责说明,你说不同的数据分析)
采集工具免责说明
1、官方不允许使用(36
0)
2、第三方信息系统收集验证上报(巨头)
3、在线实现方式(如易讯)
4、收集数据流量分析
无非就是以上人说的那几个呗。就像之前有人做app每天都会有注册和登录数据流一样。既然那些不方便,那就干脆提取吧。比如,登录了之后,把这个app的注册和登录信息取出来。这个过程,其实是有一些数据文件存在的,如果只是计算的话,本质上应该是一样的。如果是把这些数据分析,那可能也是和前面提到的算法一样。
当然是多线程处理。
这个问题挺有意思,也最核心。采集是一个很基础的技术点,理论上采集的数据量越大,处理效率越高,还有对数据分析得越精准。但多采集在实际中却得有不同的处理方式,很多数据分析平台是开放有接口的,我们公司用的那些软件功能就差异不大,但平台不同,这样给出的返回结果和效果差异就很大。不同平台有不同的接口处理,最后数据要回到自己手里在分析处理和分析结果进行对比,你说不同的数据采集,做后台有啥区别?几乎每个用户数据都不一样。
从用户和身边朋友总结了一些,大概有这么几种情况:平台线程采集:比如京东个性化搜索,经常采用网页,然后把所有的结果进行分类汇总,根据用户搜索的类型进行汇总,归到一个统一的list中去,进行再次提交;品牌方的线程采集:这种数据量相对较大;互联网分析公司:这种分析是网站或app平台提供接口,根据统一的结果进行分析、处理、反馈,以查看产品优化、调整、促销的效果;互联网广告公司:他们会收集产品表现、竞品表现、用户搜索习惯等数据,利用分析思维整理出更加精准、客观、准确的投放策略;社交媒体新闻类公司:这种公司通常是找到用户数据,做点击率、互动率等排名,然后同公司内部需要的媒体进行结算;这些,主要还是要找准想要采集哪些数据,然后有针对性的去采集,具体可以搜索一下相关资料,看看市场上做什么的多些。
采集工具免责说明(电商平台采集工具免责说明--百度搜索信息数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-01 21:04
采集工具免责说明:非专业产品研发者和生产者,请不要对产品功能、使用和安全性进行尝试。我们采集的只是上高信誉商家的库存商品或者他们店铺里卖的非高信誉商品,因此如果您的产品未通过官方认证,或未通过我们的评估,则本采集工具不对外开放。您购买本工具也不能直接获得您要的内容。我们只是将上的正品卖家与非正品卖家进行匹配,提供一个你想要的产品信息数据库,解决你上买东西困难的问题,满足你寻找真正高信誉、品质优异、价格又便宜的商品的需求。
如果你也想上网,购买各类销量好、商品信誉高、评分高的正品物品,请联系我们;我们一定全力做好服务,让您购物更省心、更放心!鉴于网上的信誉有很多虚假欺诈行为,真假难辨,请用户以警惕为主,若发现有不符合提示情况,请拍下后,及时举报售假商家;如觉得有问题请直接致电客服咨询,欢迎拨打:。联系方式::各大电商平台的营销工具提供分享下面可以随便拿我用。anyway...。
除了这个工具以外,其他的也不知道,但是我相信有的工具只是用来了解下打发时间而已,
采集公众号?微博内容?本身这些网站都有置顶排行,要数据很容易,但是现在用外链或者黑帽去抓也不现实,效率比较低。给大家介绍一个好的工具,采集百度搜索信息导出工具。工具基本介绍:可以采集百度搜索引擎的关键词或者网页数据,要根据需求选择操作手法和工具来用。具体操作步骤:步骤一:搜索百度关键词,输入提取数据步骤二:根据需求选择操作手法后面详细说明。
步骤三:导出(excel,网页excel,数据库或者其他格式导出等)步骤四:导出后如何用于微信文章里自定义标题,自定义图片,文章大纲等?有教程,可以解决你的疑惑!!!。 查看全部
采集工具免责说明(电商平台采集工具免责说明--百度搜索信息数据库)
采集工具免责说明:非专业产品研发者和生产者,请不要对产品功能、使用和安全性进行尝试。我们采集的只是上高信誉商家的库存商品或者他们店铺里卖的非高信誉商品,因此如果您的产品未通过官方认证,或未通过我们的评估,则本采集工具不对外开放。您购买本工具也不能直接获得您要的内容。我们只是将上的正品卖家与非正品卖家进行匹配,提供一个你想要的产品信息数据库,解决你上买东西困难的问题,满足你寻找真正高信誉、品质优异、价格又便宜的商品的需求。
如果你也想上网,购买各类销量好、商品信誉高、评分高的正品物品,请联系我们;我们一定全力做好服务,让您购物更省心、更放心!鉴于网上的信誉有很多虚假欺诈行为,真假难辨,请用户以警惕为主,若发现有不符合提示情况,请拍下后,及时举报售假商家;如觉得有问题请直接致电客服咨询,欢迎拨打:。联系方式::各大电商平台的营销工具提供分享下面可以随便拿我用。anyway...。
除了这个工具以外,其他的也不知道,但是我相信有的工具只是用来了解下打发时间而已,
采集公众号?微博内容?本身这些网站都有置顶排行,要数据很容易,但是现在用外链或者黑帽去抓也不现实,效率比较低。给大家介绍一个好的工具,采集百度搜索信息导出工具。工具基本介绍:可以采集百度搜索引擎的关键词或者网页数据,要根据需求选择操作手法和工具来用。具体操作步骤:步骤一:搜索百度关键词,输入提取数据步骤二:根据需求选择操作手法后面详细说明。
步骤三:导出(excel,网页excel,数据库或者其他格式导出等)步骤四:导出后如何用于微信文章里自定义标题,自定义图片,文章大纲等?有教程,可以解决你的疑惑!!!。
采集工具免责说明(数据去重工具的最大亮点在于扫描的速度非常之快)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-10-31 20:10
分享小哲原创工具,支持小哲,支持Test404。
域名实时保存在{Domain results}文件夹中
二、重复数据删除1E1000W数据只需要30S左右,内存占用极小
文本重复数据删除就是去除重复数据。因为数据太多,不可能一一找到。因此,文本重复数据删除工具极其重要。它不仅可以去除重复数据,还可以去除空白行,而且非常准确,速度极快。
下载链接:
三、Test404 轻量级后台扫描器(可以通过waf)
通用扫描工具-如果可以自定义修改HTTP请求头-安全狗和云锁其实很好用!
但是大部分工具都把HTTP请求头写死了。如果服务器安装了安全狗或云锁等软件——扫描效果不好。所以这个工具只是简单的修改。设置 http 头不仅限于 User-Agent。之前的HttpDdos也是一样的原理
简要描述;简介
30线程CPU核心*4最好,get方式只显示长度,导出结果支持html格式
.\DirScan(字典目录)
.\User-Agent.txt(UA 文件)
相信大家都能明白其中的意思,这里就不多解释了。
您可以自行修改、删除或添加新词典。总体来说是一款非常方便的网站扫描仪
个人觉得这个工具最大的亮点就是扫描速度非常快(内存&CPU占用非常低),相信你会喜欢的。
遇到自定义404页面时,所有状态码都返回200。我的方法是选择get方法扫描判断长度。一般页面大小是一样的
(也可以自定义关键字判断我没有这个要求,所以没加。)
下载链接:
四、轻量级WEB指纹识别(800个指纹)
WEB指纹识别程序是一款cms指纹识别小工具,配置灵活,支持添加词典,使用简单,体验好。指纹命中性能好,识别速度快
指纹识别扫描采用并发扫描方式,指纹不断增加对程序扫描性能的影响可以忽略不计
哦,是的,有(超过 800 个指纹)
格式:标识文件|cmsname|标识文件md5(32位)
PS:你需要.NET4.0 及以上才能运行
扫描cms.exe(主程序)
cms.txt(字典文件)
SkinH_Net.dll(皮肤库)
skinh.she(皮肤资源,不喜欢直接删除)
下载链接: 查看全部
采集工具免责说明(数据去重工具的最大亮点在于扫描的速度非常之快)
分享小哲原创工具,支持小哲,支持Test404。
域名实时保存在{Domain results}文件夹中
二、重复数据删除1E1000W数据只需要30S左右,内存占用极小
文本重复数据删除就是去除重复数据。因为数据太多,不可能一一找到。因此,文本重复数据删除工具极其重要。它不仅可以去除重复数据,还可以去除空白行,而且非常准确,速度极快。
下载链接:
三、Test404 轻量级后台扫描器(可以通过waf)
通用扫描工具-如果可以自定义修改HTTP请求头-安全狗和云锁其实很好用!
但是大部分工具都把HTTP请求头写死了。如果服务器安装了安全狗或云锁等软件——扫描效果不好。所以这个工具只是简单的修改。设置 http 头不仅限于 User-Agent。之前的HttpDdos也是一样的原理
简要描述;简介
30线程CPU核心*4最好,get方式只显示长度,导出结果支持html格式
.\DirScan(字典目录)
.\User-Agent.txt(UA 文件)
相信大家都能明白其中的意思,这里就不多解释了。
您可以自行修改、删除或添加新词典。总体来说是一款非常方便的网站扫描仪
个人觉得这个工具最大的亮点就是扫描速度非常快(内存&CPU占用非常低),相信你会喜欢的。
遇到自定义404页面时,所有状态码都返回200。我的方法是选择get方法扫描判断长度。一般页面大小是一样的
(也可以自定义关键字判断我没有这个要求,所以没加。)
下载链接:
四、轻量级WEB指纹识别(800个指纹)
WEB指纹识别程序是一款cms指纹识别小工具,配置灵活,支持添加词典,使用简单,体验好。指纹命中性能好,识别速度快
指纹识别扫描采用并发扫描方式,指纹不断增加对程序扫描性能的影响可以忽略不计
哦,是的,有(超过 800 个指纹)
格式:标识文件|cmsname|标识文件md5(32位)
PS:你需要.NET4.0 及以上才能运行
扫描cms.exe(主程序)
cms.txt(字典文件)
SkinH_Net.dll(皮肤库)
skinh.she(皮肤资源,不喜欢直接删除)
下载链接:
采集工具免责说明(通用照片采集程序用于通过摄像头采集符合要求的各类电子照片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2021-10-30 00:21
万能照片采集程序用于通过相机采集各种符合要求的电子照片。照片的尺寸和分辨率可根据要求定制。有需要的快来下载吧!
【使用说明】
1、本程序用于通过摄像头采集传递各种符合要求的电子照片,如社保照片、学籍照片、考试照片、各种网上报名照片等。照片的尺寸(宽、高)和分辨率(dpi)可根据需求定制;您也可以打开用相机拍摄的照片,裁剪并保存为符合要求的照片。
2、 填写《摄影师信息表》:此表只有两栏:【姓名】和【照片文件名】,均不能为空。[照片文件名]栏填写照片最终保存时使用的文件名,文件名不收录扩展名。
3、 照片尺寸和分辨率自定义:在程序界面右下方输入照片的宽高,单位为像素(px);在分辨率输入框中输入分辨率值,单位为dpi,当不需要分辨率时,分辨率可定义为96(dpi)。
4、 所有照片都会保存在程序所在文件夹下的【照片】文件夹中。您可以通过点击程序界面上的【打开照片文件夹】按钮打开该文件夹,查看采集照片。
5、 程序的每一步都有操作提示显示在程序界面的顶部,按照提示操作即可。
6、本程序在vs2005平台下开发,在XP系统下使用时提示“正常初始化(0xc0000135) failed”) 查看全部
采集工具免责说明(通用照片采集程序用于通过摄像头采集符合要求的各类电子照片)
万能照片采集程序用于通过相机采集各种符合要求的电子照片。照片的尺寸和分辨率可根据要求定制。有需要的快来下载吧!
【使用说明】
1、本程序用于通过摄像头采集传递各种符合要求的电子照片,如社保照片、学籍照片、考试照片、各种网上报名照片等。照片的尺寸(宽、高)和分辨率(dpi)可根据需求定制;您也可以打开用相机拍摄的照片,裁剪并保存为符合要求的照片。
2、 填写《摄影师信息表》:此表只有两栏:【姓名】和【照片文件名】,均不能为空。[照片文件名]栏填写照片最终保存时使用的文件名,文件名不收录扩展名。
3、 照片尺寸和分辨率自定义:在程序界面右下方输入照片的宽高,单位为像素(px);在分辨率输入框中输入分辨率值,单位为dpi,当不需要分辨率时,分辨率可定义为96(dpi)。
4、 所有照片都会保存在程序所在文件夹下的【照片】文件夹中。您可以通过点击程序界面上的【打开照片文件夹】按钮打开该文件夹,查看采集照片。
5、 程序的每一步都有操作提示显示在程序界面的顶部,按照提示操作即可。
6、本程序在vs2005平台下开发,在XP系统下使用时提示“正常初始化(0xc0000135) failed”)
采集工具免责说明(微能力认证:A12评价数据的伴随性采集能力(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 489 次浏览 • 2021-10-28 08:04
微观能力认证:A12评估数据伴随采集
能力维度
学术评价
拥有环境
多媒体教学环境
能力描述
利用技术工具,提供实时、全面的采集学生学习过程信息,从而
l;; 多渠道采集学生学习行为,全面反映学习过程
l;; 能够实时有序地记录学习过程和学习结果
l;; 优化数据采集流程,丰富数据类型
l;; 有助于及时发现学习问题,实施针对性干预
l;; 为学生综合素质评价提供丰富的数据支持
;
提交指南和评估标准
1. ;采集工具:请提交随附数据采集工具,也可以使用文档或图片来呈现工具表格。
优秀
合格的
¨;; 刀具设计合理、科学、可操作;
¨; 丰富的数据类型,能够全面真实地反映学生的学习过程,支持对学生学习和发展的持续关注;
¨; ;采集工具具有原创的特点,具有学习和参考价值。
¨; 工具设计合理,具有一定的可操作性,与评价目标相匹配;
¨;; 数据可以充分反映学生的学习过程。
2.刀具设计说明:请结合评价目标和数据采集对象介绍刀具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
优秀
合格的
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; 充分考虑工具应用方案,充分考虑应用环境和资源条件,预见应用过程中可能出现的问题,制定应对方案;
¨; 该工具的应用采用信息化技术,操作方便,能有效提高采集和分析的效率和质量,兼顾综合数据分析的需求;
¨;; 视频清晰流畅,画面稳定,讲解清晰到位,没有多余的信息。
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; ;考虑刀具应用的环境要求;
¨;; 该工具的应用采用信息化技术,操作方便,可有效提高采集和分析的效率和质量;
¨;; 视频清晰流畅,画面稳定。
3. ;采集案例:请通过申请工具采集提交真实的学生数据案例,如完整的学生学习过程观察记录表,并对案例进行评论和分析。
;
实用建议
为了及时掌握学生的学习情况,实施干预和提供支持,更全面地评价学生的学习行为和结果,教师需要在教学过程中及时对信息进行采集评价,例如使用电子表格记录和整理学生作业提交情况、课堂问答、每周阅读书籍等。
在实施随附数据采集之前,教师需要仔细设计和详细规划。伴随数据采集需要一定的工具,如记录表、观察表等。教师可以根据评价目标和评价对象,借鉴一些比较成熟的数据采集工具,或者根据自己的情况开发。需要。同时,教师还要考虑伴随数据采集的可操作性,思考什么样的工具形式更有利于信息的采集,以及未来信息处理和分析的可行性。建议在实践中设计清晰的数据采集行动计划,比如将项目细分形成数据采集表格,包括数据源、数据类型、数据采集方法、采集时间(链接),
; ; ; 数据采集 在数据采集的过程中,可以利用信息技术丰富评价数据的类型,如数字、图片、视频等。对于描述性评价数据,教师可以使用手机对学生活动进行拍照、云笔记随时记录对学生行为的观察等。这些定性的记录可以作为教师评价学生行为和学习的重要依据,以及学习作品集的重要内容。
我的微能力
序列号类型评估需要认证状态进行认证
1采集工具
请提交随附的数据采集工具,或者您可以使用文档或图片来呈现工具表格。
未经审核的上传预览
2 刀具设计说明
请结合评价目标和数据采集对象介绍工具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
未经审核的上传预览
3采集案例
请通过申请工具采集提交学生真实数据案例,如完整记录学生学习过程的观察记录,并对案例进行点评和分析。
未经审核的上传预览 查看全部
采集工具免责说明(微能力认证:A12评价数据的伴随性采集能力(组图))
微观能力认证:A12评估数据伴随采集
能力维度
学术评价
拥有环境
多媒体教学环境
能力描述
利用技术工具,提供实时、全面的采集学生学习过程信息,从而
l;; 多渠道采集学生学习行为,全面反映学习过程
l;; 能够实时有序地记录学习过程和学习结果
l;; 优化数据采集流程,丰富数据类型
l;; 有助于及时发现学习问题,实施针对性干预
l;; 为学生综合素质评价提供丰富的数据支持
;
提交指南和评估标准
1. ;采集工具:请提交随附数据采集工具,也可以使用文档或图片来呈现工具表格。
优秀
合格的
¨;; 刀具设计合理、科学、可操作;
¨; 丰富的数据类型,能够全面真实地反映学生的学习过程,支持对学生学习和发展的持续关注;
¨; ;采集工具具有原创的特点,具有学习和参考价值。
¨; 工具设计合理,具有一定的可操作性,与评价目标相匹配;
¨;; 数据可以充分反映学生的学习过程。
2.刀具设计说明:请结合评价目标和数据采集对象介绍刀具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
优秀
合格的
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; 充分考虑工具应用方案,充分考虑应用环境和资源条件,预见应用过程中可能出现的问题,制定应对方案;
¨; 该工具的应用采用信息化技术,操作方便,能有效提高采集和分析的效率和质量,兼顾综合数据分析的需求;
¨;; 视频清晰流畅,画面稳定,讲解清晰到位,没有多余的信息。
¨;; 讲解全面,逻辑清晰;
¨; ;准确说明设计过程或选型依据;
¨; ;考虑刀具应用的环境要求;
¨;; 该工具的应用采用信息化技术,操作方便,可有效提高采集和分析的效率和质量;
¨;; 视频清晰流畅,画面稳定。
3. ;采集案例:请通过申请工具采集提交真实的学生数据案例,如完整的学生学习过程观察记录表,并对案例进行评论和分析。
;
实用建议
为了及时掌握学生的学习情况,实施干预和提供支持,更全面地评价学生的学习行为和结果,教师需要在教学过程中及时对信息进行采集评价,例如使用电子表格记录和整理学生作业提交情况、课堂问答、每周阅读书籍等。
在实施随附数据采集之前,教师需要仔细设计和详细规划。伴随数据采集需要一定的工具,如记录表、观察表等。教师可以根据评价目标和评价对象,借鉴一些比较成熟的数据采集工具,或者根据自己的情况开发。需要。同时,教师还要考虑伴随数据采集的可操作性,思考什么样的工具形式更有利于信息的采集,以及未来信息处理和分析的可行性。建议在实践中设计清晰的数据采集行动计划,比如将项目细分形成数据采集表格,包括数据源、数据类型、数据采集方法、采集时间(链接),
; ; ; 数据采集 在数据采集的过程中,可以利用信息技术丰富评价数据的类型,如数字、图片、视频等。对于描述性评价数据,教师可以使用手机对学生活动进行拍照、云笔记随时记录对学生行为的观察等。这些定性的记录可以作为教师评价学生行为和学习的重要依据,以及学习作品集的重要内容。
我的微能力
序列号类型评估需要认证状态进行认证
1采集工具
请提交随附的数据采集工具,或者您可以使用文档或图片来呈现工具表格。
未经审核的上传预览
2 刀具设计说明
请结合评价目标和数据采集对象介绍工具设计过程或选择依据和应用方案。以视频形式提交,需展示教师个人形象,原则上不超过10分钟。
未经审核的上传预览
3采集案例
请通过申请工具采集提交学生真实数据案例,如完整记录学生学习过程的观察记录,并对案例进行点评和分析。
未经审核的上传预览
采集工具免责说明(四大行的采集工具免责说明,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-10-16 13:02
采集工具免责说明;
1、仅限于与自家业务系统关联性比较紧密的业务数据(例如银行、公安局/交警、财务/库管/保险等系统)
2、计算机企业登陆的业务平台,
3、远程需远程操作使用
4、请勿为非关联性业务平台提供采集内容使用;例如专业户、专用计算机、非系统内网ip的业务端;
5、请勿在未获得来源网站授权下,
1.可以。2.数据加密,不可获取。
如果是四大行,部分地区是不行的,四大行有可能依照国家安全隐患公示制度在运作,
据我所知,四大行有官方指导的测试账号和密码交换服务,操作方式是添加测试账号的,如果是四大行合作的公司访问是可以的。这样的收费应该也是通过全国人行的安全交换服务收费,没有公布什么数据。
1,可以。2,和第一位答主说的一样,比较难(有些账号可以,比如三农类的客户。你在某酒店a丢的数据可以通过四大行的交换服务找到对应公司,但是酒店还是不知道怎么去找对应公司的数据)。
四大行的官方渠道是没有的,第三方渠道:如paypal。
可以获取,但是要明确一点,获取是指的数据来源于哪个机构,如果指的来源于政府机构,那么可以。如果指的是非政府机构,那么它们应该也可以直接访问我们的数据。 查看全部
采集工具免责说明(四大行的采集工具免责说明,你知道吗?)
采集工具免责说明;
1、仅限于与自家业务系统关联性比较紧密的业务数据(例如银行、公安局/交警、财务/库管/保险等系统)
2、计算机企业登陆的业务平台,
3、远程需远程操作使用
4、请勿为非关联性业务平台提供采集内容使用;例如专业户、专用计算机、非系统内网ip的业务端;
5、请勿在未获得来源网站授权下,
1.可以。2.数据加密,不可获取。
如果是四大行,部分地区是不行的,四大行有可能依照国家安全隐患公示制度在运作,
据我所知,四大行有官方指导的测试账号和密码交换服务,操作方式是添加测试账号的,如果是四大行合作的公司访问是可以的。这样的收费应该也是通过全国人行的安全交换服务收费,没有公布什么数据。
1,可以。2,和第一位答主说的一样,比较难(有些账号可以,比如三农类的客户。你在某酒店a丢的数据可以通过四大行的交换服务找到对应公司,但是酒店还是不知道怎么去找对应公司的数据)。
四大行的官方渠道是没有的,第三方渠道:如paypal。
可以获取,但是要明确一点,获取是指的数据来源于哪个机构,如果指的来源于政府机构,那么可以。如果指的是非政府机构,那么它们应该也可以直接访问我们的数据。
采集工具免责说明(软件功能拉人进群:将采集的用户或者自己整理的名单列表)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-10-10 00:45
软件功能
拉人进群:
将采集的用户列表或自己编译的用户列表导入到软件中,设置拉人入群的目标,软件会自动将导入的用户拉入用户指定的群中。适用场景:用户想从指定组采集中删除成员后,过滤后,将过滤后的用户拖到自己指定的组中。更名佳群:
将用户自定义的用户昵称文本导入软件,设置用户想要使用的广告组。软件会自动进入广告组,修改组内昵称。适用场景:用户将一批用户昵称设置为广告词,如:乌鸦群发帖注册采集拉人工具联系@wuya005,加入群后重命名,群内会显示广告词. 以达到更名营销的目的。群炒:1.话术炒股:用户自己设置语音技能脚本,然后导入到软件中。他要推测的组会被设置,软件会根据用户设置的语音技能自动在组中进行。发送演讲稿。适用场景:有的用户需要使用一批账号来设置自己的演讲技巧,在群内的账号中自动发送语音脚本,从而达到活跃用户群,带动群聊氛围。2.复制群聊炒作群:用户设置复制的目标群和转发的消息群,软件会自动将目标群内的消息转发到要转发的消息群进行适配到场景:我们有一个好的内容组,需要转发或者手动复制这个组的内容到我们自己的组,但是这样手动太麻烦,而且转发会收录目标组的信息,不是我们想要的。本功能软件可以完美复制对方' s 的消息并通过自己的注册账号发送到我们自己的群,并删除对方的关联用户信息。复制群成员:用户设置拉人的目标群和复制的目标群,软件会自动将复制目标的群用户拉到我们指定的拉目标群。适用场景:用户想直接将指定组的成员拉到他指定的目标组。相比招人入群,这个功能少了采集用户或导入目标用户的过程,拉人的效率大大提高,但没有筛选用户的质量。关键词响应:用户设置监控关键词,监控目标人群,响应广告文案。设置完成后,软件会自动监控目标人群。如果目标群体中用户输入的信息匹配关键词,软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:
设置频道的文章连接,每行一个,软件会自动使用账号扫描频道的文章页面浏览量。目前,一个账户每天只能使用一次。适应场景:当我们的频道人手不够,在线量不高的时候,浏览量就上不来,这对我们前期刚推广的频道非常不利。刷浏览量的功能可以完全解决预操作浏览量的问题。执行日志显示:在程序运行过程中,实时显示执行日志和执行结果。程序做了什么,结果如何一目了然支持代理:程序支持socks5和http代理,减少同ip运行次数,并降低被禁的概率。推荐使用代理支持并发:支持多个客户端同时执行任务。
软件功能截图:
常用参数说明:
数量:0 是拉取群内所有成员。如果填100,那么拉100个群里的成员。
并发操作:指采集的多个账号同时操作,该参数与采集对象的个数有关。如果有3个采集对象,请在这里填写3个
使用代理IP:勾选使用采集的代理,取消勾选使用本地网络采集
Account TXT:群组营销功能所需的帐户文本。文本文件存储协议编号。将路径指向帐户地址,然后单击导入。
拉人入群视频演示:
拉人入群功能截图
拉人入群参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象 TXT 是指您要拉取、复制和推测的源对象和目标对象。
Group TXT:你要拉人的目标群体,一般这些群体就是你自己的群体。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
806重命名并添加群组功能截图
重命名并添加组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 指的是要重命名到组中的源对象组和目标对象组
昵称TXT:需要修改昵称文本对象,每行一个
嘈杂群视频功能演示:
函数截图
口头推测组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象TXT指的是想谈的人群的目标人群来源
Transcript TXT:需要发送的嘈杂群电话副本,每行一份
复制群聊嘈杂群视频演示:
复制群聊功能截图
复制聊天群参数说明:
Object TXT:群组营销的群组对象文本,存储需要复制的群组名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指复制组的源对象组和目标对象组
复制组TXT:目标组是指:需要将源对象组中的信息复制到目标组的对象列表中。一排
复制群成员视频演示:
复制群组功能截图
复制群成员参数说明:
from group TXT:群营销的群对象文本,存放需要采集的群名,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指需要复制的源对象组和目标对象组
TO组TXT:目标组是指:from对象组中的信息需要复制到目标组的对象列表中。一排 查看全部
采集工具免责说明(软件功能拉人进群:将采集的用户或者自己整理的名单列表)
软件功能
拉人进群:
将采集的用户列表或自己编译的用户列表导入到软件中,设置拉人入群的目标,软件会自动将导入的用户拉入用户指定的群中。适用场景:用户想从指定组采集中删除成员后,过滤后,将过滤后的用户拖到自己指定的组中。更名佳群:
将用户自定义的用户昵称文本导入软件,设置用户想要使用的广告组。软件会自动进入广告组,修改组内昵称。适用场景:用户将一批用户昵称设置为广告词,如:乌鸦群发帖注册采集拉人工具联系@wuya005,加入群后重命名,群内会显示广告词. 以达到更名营销的目的。群炒:1.话术炒股:用户自己设置语音技能脚本,然后导入到软件中。他要推测的组会被设置,软件会根据用户设置的语音技能自动在组中进行。发送演讲稿。适用场景:有的用户需要使用一批账号来设置自己的演讲技巧,在群内的账号中自动发送语音脚本,从而达到活跃用户群,带动群聊氛围。2.复制群聊炒作群:用户设置复制的目标群和转发的消息群,软件会自动将目标群内的消息转发到要转发的消息群进行适配到场景:我们有一个好的内容组,需要转发或者手动复制这个组的内容到我们自己的组,但是这样手动太麻烦,而且转发会收录目标组的信息,不是我们想要的。本功能软件可以完美复制对方' s 的消息并通过自己的注册账号发送到我们自己的群,并删除对方的关联用户信息。复制群成员:用户设置拉人的目标群和复制的目标群,软件会自动将复制目标的群用户拉到我们指定的拉目标群。适用场景:用户想直接将指定组的成员拉到他指定的目标组。相比招人入群,这个功能少了采集用户或导入目标用户的过程,拉人的效率大大提高,但没有筛选用户的质量。关键词响应:用户设置监控关键词,监控目标人群,响应广告文案。设置完成后,软件会自动监控目标人群。如果目标群体中用户输入的信息匹配关键词,软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:该软件会自动将广告文案发送给目标用户。适用场景:目前我们很多营销群,搜索群,或者同行业的竞争对手群,都有大量的潜在用户,但我们不能随时关注这些群。这样既浪费人力,又太累了。所以只要将这些目标监控群体导入软件,设置关键词,回复广告文案,营销就可以一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:设置关键词,回复广告文案,让营销一劳永逸地吸引客户。刷浏览量:
设置频道的文章连接,每行一个,软件会自动使用账号扫描频道的文章页面浏览量。目前,一个账户每天只能使用一次。适应场景:当我们的频道人手不够,在线量不高的时候,浏览量就上不来,这对我们前期刚推广的频道非常不利。刷浏览量的功能可以完全解决预操作浏览量的问题。执行日志显示:在程序运行过程中,实时显示执行日志和执行结果。程序做了什么,结果如何一目了然支持代理:程序支持socks5和http代理,减少同ip运行次数,并降低被禁的概率。推荐使用代理支持并发:支持多个客户端同时执行任务。
软件功能截图:
常用参数说明:
数量:0 是拉取群内所有成员。如果填100,那么拉100个群里的成员。
并发操作:指采集的多个账号同时操作,该参数与采集对象的个数有关。如果有3个采集对象,请在这里填写3个
使用代理IP:勾选使用采集的代理,取消勾选使用本地网络采集
Account TXT:群组营销功能所需的帐户文本。文本文件存储协议编号。将路径指向帐户地址,然后单击导入。
拉人入群视频演示:
拉人入群功能截图
拉人入群参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象 TXT 是指您要拉取、复制和推测的源对象和目标对象。
Group TXT:你要拉人的目标群体,一般这些群体就是你自己的群体。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
单个账号拉取的人数:是一个账号拉取的人数。设置 0 没有限制。填写具体数字栏。比如你设置30,一个账号只会拉30人,不会再拉人。
806重命名并添加群组功能截图
重命名并添加组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 指的是要重命名到组中的源对象组和目标对象组
昵称TXT:需要修改昵称文本对象,每行一个
嘈杂群视频功能演示:
https://wuya88.com/wp-content/ ... 5.jpg 300w, https://wuya88.com/wp-content/ ... 2.jpg 768w" />函数截图
口头推测组参数说明:
Object TXT:群营销的群对象文本,存储需要采集的群名称,每行一个。路径指向对象的文本地址,然后单击导入。对象TXT指的是想谈的人群的目标人群来源
Transcript TXT:需要发送的嘈杂群电话副本,每行一份
复制群聊嘈杂群视频演示:
https://wuya88.com/wp-content/ ... 4.jpg 300w, https://wuya88.com/wp-content/ ... 0.jpg 768w" />复制群聊功能截图
复制聊天群参数说明:
Object TXT:群组营销的群组对象文本,存储需要复制的群组名称,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指复制组的源对象组和目标对象组
复制组TXT:目标组是指:需要将源对象组中的信息复制到目标组的对象列表中。一排
复制群成员视频演示:
https://wuya88.com/wp-content/ ... 7.jpg 300w, https://wuya88.com/wp-content/ ... 7.jpg 768w" />复制群组功能截图
复制群成员参数说明:
from group TXT:群营销的群对象文本,存放需要采集的群名,每行一个。路径指向对象的文本地址,然后单击导入。Object TXT 是指需要复制的源对象组和目标对象组
TO组TXT:目标组是指:from对象组中的信息需要复制到目标组的对象列表中。一排
采集工具免责说明(数据采集对各行各业有着至关重要的作用,你了解多少?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-06 04:11
数据采集在各行各业中发挥着至关重要的作用,可以让个人、公司、机构实现对大数据的宏观调控,研究分析,总结规律,做出准确的判断和决策。
1、优采云采集器
优采云是一个集网络数据采集、移动互联网数据、API接口服务(包括数据爬取、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年位居互联网数据采集软件榜第一。2016年以来,优采云积极开拓海外市场,分别在美国和日本推出数据爬取平台Octoparse和Octoparse.jp。截至2019年,优采云全球用户突破150万。其一大特点:零门槛使用,无需了解网络爬虫技术,轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能,领先国内同类产品,赢得了众多用户的一致认可。使用优采云采集器 几乎可以采集 任何格式的所有网页和文件,无论何种语言或编码。采集 速度是普通采集器的7倍,采集/release与复制/粘贴一样准确。同时,软件还拥有“舆论雷达监控系统”,精准监控网络数据的信息安全,及时处理不利或危险信息。
3、优采云采集器
如果让的编辑推荐最有用的信息采集软件,那一定是优采云采集器。优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,相比其他同类软件,光这个就够良心了。
4、吉搜客
历经十余年打磨的GooSeeker,已经是一款易用性出众的数据采集软件。它的特点是它直观地注释了所有可用数据。用户无需考虑程序或技术基础,只需点击想要的内容,给标签命名,软件自动管理选择。内容会自动采集到排序框并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章内容抓取,通过相关配置可以轻松采集80% 网站 内容供您自己使用。根据各种建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器三种类型@>,共支持近40种类型数百个版本的数据采集和主流建站程序的发布任务,支持图片本地化,支持网站登录采集,页面抓取,并完全模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的<
6、Import.io
英文市场最著名的采集器之一是由一家总部设在英国伦敦的公司开发的,现已在美国、印度等地设立了分支机构。import.io作为一款网页数据采集软件,主要有Magic、Extractor、Crawler、Connector四大功能。主要功能都具备,但其中最抢眼最好的功能莫过于“魔法”,该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单.
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息软件采集。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版速度可达400万件/天,服务器版可达8000万件/天,并提供替代采集服务。
8、优采云
优采云是最常用的信息采集软件之一,它封装了复杂的算法和分布式逻辑,可以提供灵活简单的开发接口;应用自动分布式部署和运行,操作直观简单,计算和存储资源灵活扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、前蜘蛛
ParseHub 是一个基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制来分析和获取 网站 的数据。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、内容抓取器
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,几乎可以从所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。 查看全部
采集工具免责说明(数据采集对各行各业有着至关重要的作用,你了解多少?)
数据采集在各行各业中发挥着至关重要的作用,可以让个人、公司、机构实现对大数据的宏观调控,研究分析,总结规律,做出准确的判断和决策。
1、优采云采集器
优采云是一个集网络数据采集、移动互联网数据、API接口服务(包括数据爬取、数据优化、数据挖掘、数据存储、数据备份)等服务于一体的数据服务平台。连续5年位居互联网数据采集软件榜第一。2016年以来,优采云积极开拓海外市场,分别在美国和日本推出数据爬取平台Octoparse和Octoparse.jp。截至2019年,优采云全球用户突破150万。其一大特点:零门槛使用,无需了解网络爬虫技术,轻松完成采集。
2、优采云采集器
国内老牌数据采集软件,以其灵活的配置和强大的性能,领先国内同类产品,赢得了众多用户的一致认可。使用优采云采集器 几乎可以采集 任何格式的所有网页和文件,无论何种语言或编码。采集 速度是普通采集器的7倍,采集/release与复制/粘贴一样准确。同时,软件还拥有“舆论雷达监控系统”,精准监控网络数据的信息安全,及时处理不利或危险信息。
3、优采云采集器
如果让的编辑推荐最有用的信息采集软件,那一定是优采云采集器。优采云采集器由原谷歌技术团队打造,基于人工智能技术,支持智能模式和流程图模式采集;使用方便,只需输入URL即可智能识别列表数据、表格数据和分页按钮,无需配置任何采集规则,一键采集;并且软件支持Linux、Windows、Mac三大操作系统,导出数据不花钱,还支持Excel、CSV、TXT、HTML多种导出格式,相比其他同类软件,光这个就够良心了。
4、吉搜客
历经十余年打磨的GooSeeker,已经是一款易用性出众的数据采集软件。它的特点是它直观地注释了所有可用数据。用户无需考虑程序或技术基础,只需点击想要的内容,给标签命名,软件自动管理选择。内容会自动采集到排序框并保存为xml或excel结构。此外,软件还具有模板资源申请、会员互助抓取、手机网站数据抓取、定时自启动采集等功能。
5、优采云采集器
这是一套专业的网站内容采集软件,支持各种论坛帖子和回复采集、网站和博客文章内容抓取,通过相关配置可以轻松采集80% 网站 内容供您自己使用。根据各种建站程序的不同,分为优采云采集器子论坛采集器、cms采集器和博客采集器三种类型@>,共支持近40种类型数百个版本的数据采集和主流建站程序的发布任务,支持图片本地化,支持网站登录采集,页面抓取,并完全模拟手动登录发布。此外,软件还内置了SEO伪原创模块,让您的<
6、Import.io
英文市场最著名的采集器之一是由一家总部设在英国伦敦的公司开发的,现已在美国、印度等地设立了分支机构。import.io作为一款网页数据采集软件,主要有Magic、Extractor、Crawler、Connector四大功能。主要功能都具备,但其中最抢眼最好的功能莫过于“魔法”,该功能让用户只需进入网页即可自动提取数据,无需任何其他设置,使用起来极其简单.
7、ParseHub
ForeSpider 也是一款易于操作且强烈推荐的信息软件采集。它分为免费版和付费版。具有可视化的向导式操作界面,日志管理和异常情况预警,免安装数据库,可自动识别语义筛选数据,智能挖掘文本特征数据,同时自带多种数据清理方法,并自带可视化图表分析。软件免费版、基础版、专业版速度可达400万件/天,服务器版可达8000万件/天,并提供替代采集服务。
8、优采云
优采云是最常用的信息采集软件之一,它封装了复杂的算法和分布式逻辑,可以提供灵活简单的开发接口;应用自动分布式部署和运行,操作直观简单,计算和存储资源灵活扩展;不同来源的数据统一可视化管理,restful界面/webhook推送/graphql访问等高级功能,让用户与现有系统无缝对接。软件现提供企业标准版、高级版、企业定制版。
9、前蜘蛛
ParseHub 是一个基于网页的爬取客户端工具,支持 JavaScript 渲染、Ajax 爬取、Cookies、Session 等机制来分析和获取 网站 的数据。它还可以使用机器学习技术来识别复杂的文档并以 JSON、CSV 等格式导出文件。该软件支持在 Windows、Mac 和 Linux 上使用,或作为 Firefox 扩展。此外,它还具有一些高级功能,例如分页、弹出窗口和导航、无限滚动页面等,可以将 ParseHub 中的数据可视化为 Tableau。
10、内容抓取器
Content Grabber是一款支持智能抓取的可视化网页数据采集软件和网络自动化工具,几乎可以从所有网站中提取内容。其程序运行环境可用于开发、测试和生产服务器。可以使用c#或VB.NET调试或编写脚本来控制爬虫程序。还支持在爬虫工具中添加第三方扩展插件。Content Grabber 功能齐全,对于有技术基础的用户来说是非常强大的。

