
采集工具免责说明
采集工具免责说明厂商几乎都支持像样的采集模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-06 21:02
采集工具免责说明“绝大多数erp厂商几乎都支持像样的采集模块,但他们可能不知道实际情况是,erp厂商基本上都不可能提供一个像样的采集机制。因为采集模块的开发成本高昂,开发周期长,而且技术含量高,对于绝大多数erp厂商来说,不现实为采集模块专门开发一个开发语言——如果是重复购买软件的话,能力有限的人开发一个采集器或者易采宝就很可能耗尽开发团队很大精力,影响其整体收益。”推荐pagekey采集引擎。
优采云采集器
采集优采云,可以学习一下。提供全方位的采集,可以从事件到视频到图片进行全方位多角度采集,速度相当快。
采集神器这款采集器比较好用,是ie浏览器。用个浏览器打开也可以顺畅的。这款采集器对像谷歌、百度、搜狗这些搜索引擎不支持。
试试我们公司开发的,
采集链接有很多工具,你可以去无觅网、拉钩网这些上去看看。
现在很多采集器用起来也是比较简单的,比如:采集豆瓣电影的图片;采集某个ppt的内容。
可以用站长之家的采集器采集站长工具_站长工具_抓取工具_免费采集软件
有赞app采集功能很不错采集贴吧采集全民k歌采集闲鱼系列采集知乎
关注微信公众号:牛人信息站,回复百度,有很多采集器。不光站长工具,还有相关分享, 查看全部
采集工具免责说明厂商几乎都支持像样的采集模块
采集工具免责说明“绝大多数erp厂商几乎都支持像样的采集模块,但他们可能不知道实际情况是,erp厂商基本上都不可能提供一个像样的采集机制。因为采集模块的开发成本高昂,开发周期长,而且技术含量高,对于绝大多数erp厂商来说,不现实为采集模块专门开发一个开发语言——如果是重复购买软件的话,能力有限的人开发一个采集器或者易采宝就很可能耗尽开发团队很大精力,影响其整体收益。”推荐pagekey采集引擎。
优采云采集器
采集优采云,可以学习一下。提供全方位的采集,可以从事件到视频到图片进行全方位多角度采集,速度相当快。
采集神器这款采集器比较好用,是ie浏览器。用个浏览器打开也可以顺畅的。这款采集器对像谷歌、百度、搜狗这些搜索引擎不支持。
试试我们公司开发的,
采集链接有很多工具,你可以去无觅网、拉钩网这些上去看看。
现在很多采集器用起来也是比较简单的,比如:采集豆瓣电影的图片;采集某个ppt的内容。
可以用站长之家的采集器采集站长工具_站长工具_抓取工具_免费采集软件
有赞app采集功能很不错采集贴吧采集全民k歌采集闲鱼系列采集知乎
关注微信公众号:牛人信息站,回复百度,有很多采集器。不光站长工具,还有相关分享,
采集工具免责说明:如何管理用户的任务任务定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-05-02 19:05
采集工具免责说明:1.从官网免费下载工具,制作成一个独立的项目,然后在官网上部署。2.项目不公开,仅作为个人作品,放到github上部署。3.有任何问题,请找客服。例如:盗图。4.即使项目成功上线运营,也不承担任何责任。
这么多图片采集地址几乎都差不多,
平时做一些小的todolist或者任务清单,可以采用拼图的形式来管理和同步各个任务的顺序;还可以采用邮件和网页传真的方式来统计每天的工作安排;除此之外,还可以采用云记账的方式来管理各项支出,让记账变得更加方便直观。本周任务结束后,可以将任务清单按照已完成+未完成+待处理+待提交四个维度查看。如何管理用户的任务任务定义为用户/团队共同完成的一项工作或活动,如何管理工作任务,无论是对于产品经理、设计师或是项目团队来说,都应该是一个重点问题。
那如何让用户更好地掌握自己的工作安排呢?你可以通过一些简单的工具来实现定制化任务规划。在《产品思维30讲》中,我们有提到使用“黄金时间块”来定义团队安排任务,设置黄金时间块,又叫“目标时间”(既目标和计划),然后以任务为线索按时间上的“abcd”展开任务,这样可以有效地优化任务的完成,最终由于产品的迭代,最终最适用于应用于不同类型团队。
本文通过一些特定的场景来探讨下如何设置任务以及如何组织用户任务管理的工作。常用的工具很多公司都使用工具进行任务管理。常用的平台包括freemind,网页版的印象笔记,notion(第三方平台),云笔记平台的things等等,都可以实现用户的任务定义以及任务状态管理。通过以上工具,可以实现各个团队或者产品的实时的同步以及共享任务。
很多团队会在产品迭代开发阶段通过github等平台完成源代码的版本管理,形成一个小型的任务文件库,最终形成一个中小型的工作任务库或者敏捷团队,方便每个人维护和推进工作。如何组织任务通常来说,我们制定工作计划时,会以某个时间节点为时间节点,设置一些明确的考核指标,从而让团队在同一时间段内争取更好的执行效率。
但是,对于产品的迭代周期来说,我们会发现,用户不断迭代产品/服务,推进产品,但是不同团队会产生截然不同的用户用户激活计划,这让整个产品运营变得更加复杂。为了提高工作效率,除了任务计划以外,还需要进行人员的分工和协作。用户运营活动的实施、kpi的考核都是要用到,下图展示的就是美团外卖产品在不同的激活情况。举例来说,a产品和b产品,用户不断增加, 查看全部
采集工具免责说明:如何管理用户的任务任务定义
采集工具免责说明:1.从官网免费下载工具,制作成一个独立的项目,然后在官网上部署。2.项目不公开,仅作为个人作品,放到github上部署。3.有任何问题,请找客服。例如:盗图。4.即使项目成功上线运营,也不承担任何责任。
这么多图片采集地址几乎都差不多,
平时做一些小的todolist或者任务清单,可以采用拼图的形式来管理和同步各个任务的顺序;还可以采用邮件和网页传真的方式来统计每天的工作安排;除此之外,还可以采用云记账的方式来管理各项支出,让记账变得更加方便直观。本周任务结束后,可以将任务清单按照已完成+未完成+待处理+待提交四个维度查看。如何管理用户的任务任务定义为用户/团队共同完成的一项工作或活动,如何管理工作任务,无论是对于产品经理、设计师或是项目团队来说,都应该是一个重点问题。
那如何让用户更好地掌握自己的工作安排呢?你可以通过一些简单的工具来实现定制化任务规划。在《产品思维30讲》中,我们有提到使用“黄金时间块”来定义团队安排任务,设置黄金时间块,又叫“目标时间”(既目标和计划),然后以任务为线索按时间上的“abcd”展开任务,这样可以有效地优化任务的完成,最终由于产品的迭代,最终最适用于应用于不同类型团队。
本文通过一些特定的场景来探讨下如何设置任务以及如何组织用户任务管理的工作。常用的工具很多公司都使用工具进行任务管理。常用的平台包括freemind,网页版的印象笔记,notion(第三方平台),云笔记平台的things等等,都可以实现用户的任务定义以及任务状态管理。通过以上工具,可以实现各个团队或者产品的实时的同步以及共享任务。
很多团队会在产品迭代开发阶段通过github等平台完成源代码的版本管理,形成一个小型的任务文件库,最终形成一个中小型的工作任务库或者敏捷团队,方便每个人维护和推进工作。如何组织任务通常来说,我们制定工作计划时,会以某个时间节点为时间节点,设置一些明确的考核指标,从而让团队在同一时间段内争取更好的执行效率。
但是,对于产品的迭代周期来说,我们会发现,用户不断迭代产品/服务,推进产品,但是不同团队会产生截然不同的用户用户激活计划,这让整个产品运营变得更加复杂。为了提高工作效率,除了任务计划以外,还需要进行人员的分工和协作。用户运营活动的实施、kpi的考核都是要用到,下图展示的就是美团外卖产品在不同的激活情况。举例来说,a产品和b产品,用户不断增加,
阿里云,腾讯云,百度云和浪潮云采集工具免责
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-04-25 23:08
采集工具免责说明:该采集工具不支持国家级(含国家级)以上的文件传输服务器,无法实现天翼云文件下载器的远程文件下载、多网络同步上传下载;本工具不支持多网络同步上传下载,请勿通过电脑浏览器、主机网络进行远程文件传输。请勿使用该工具下载个人源文件。本工具使用的主机网络速度无需超过国家级(含国家级),免收该工具相关费用。
如有下载需求,可通过无需上传源文件的方式进行。如下方链接获取资源支持年份:2018提供服务器:阿里云,腾讯云,百度云和浪潮云支持平台:ie6及以上/支持平台:win7/win8.1,win10/ie11,ie11/ie12/win7/win13/xp目录结构:web目录(10131)300/。 查看全部
阿里云,腾讯云,百度云和浪潮云采集工具免责
采集工具免责说明:该采集工具不支持国家级(含国家级)以上的文件传输服务器,无法实现天翼云文件下载器的远程文件下载、多网络同步上传下载;本工具不支持多网络同步上传下载,请勿通过电脑浏览器、主机网络进行远程文件传输。请勿使用该工具下载个人源文件。本工具使用的主机网络速度无需超过国家级(含国家级),免收该工具相关费用。
如有下载需求,可通过无需上传源文件的方式进行。如下方链接获取资源支持年份:2018提供服务器:阿里云,腾讯云,百度云和浪潮云支持平台:ie6及以上/支持平台:win7/win8.1,win10/ie11,ie11/ie12/win7/win13/xp目录结构:web目录(10131)300/。
微信公众号采集工具免责说明:采集原理是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-04-23 17:07
采集工具免责说明:①采集原理都是通过api或者sdk跟云服务器对接,收集微信公众号文章列表并分析。②这次提供的软件不能通过公众号发送给别人,也不能帮助别人做微信公众号接口收集工作。③只用于个人微信公众号收集、整理,不能用于微信公众号接口收集、分析、开发等④大家不要用这款软件去采集任何公众号文章,微信公众号接口请遵守相关法律法规,违反就会封号⑤请关注官方微信公众号:兔子数据,根据公众号首字母的含义加关键词,验证兔子。
保留对原文件的及时同步。不在需要时进行转载、修改、注明,侵权必究。下载和安装:链接:密码:gmk3,但安装的时候会有两个文件。需要把文件解压到对应文件夹里进行安装:在菜单中选择【设置】选择【微信公众号】选择【应用安装】选择【微信公众号采集】点击【下一步】选择【添加文件】即可选择一个支持软件的微信公众号(免费)将兔子提供的原始文件放入文件夹:获取打包下载后微信公众号文章的后缀文件:兔子数据ggd1zh-cn。
兔子:2.5k大小大小在7m以内的云端安卓android软件,并且可以提供1.7kw的大容量硬盘储存空间。软件主要功能:1.可以采集微信公众号里最新文章,提取标题、摘要、作者、评论、文章布局2.提供多样化的热文定制,确保每个粉丝都能阅读到一篇最精选的微信文章3.非正常采集平台的优势获取数据:用户可以自己去下载zip包,微信公众号的文章列表、按照类型提取列表里的文章、全站采集、按照文章标题搜索等等使用方法:1.直接上传页面内容到采集线路,软件就会自动生成采集列表。
2.选择文章定制自己可能需要的内容,同时也可以关注兔子文章列表,接口都是公开公正、开放,兔子、兔子、兔子授权即可登录。3.选择需要的数据是否适合重要时间点、是否是导出保存等。4.只支持采集自己需要的数据,不支持下载微信文章列表,也不支持别人分享的。支持采集的文章:微信订阅号,公众号文章列表,账号文章列表,商品列表,历史消息,历史消息列表,图文列表,历史消息列表,图文列表(无广告),商品列表(含广告)5.根据自己需要可以设置采集数量,没有限制。
6.采集自己需要的分析文章:文章的长尾词和热词用户可以在第三方平台判断这个内容是否可读,用户可不可以阅读这个内容等等。7.根据内容分类及类型采集文章:当用户分类和类型相同的文章大致都同样类型的内容时,为了提高用户的阅读体验,可以定制采集该文章的分类和内容8.按照文章标题搜索用户,或者用户需要的文章,都可以采集9.本平台只能。 查看全部
微信公众号采集工具免责说明:采集原理是什么?
采集工具免责说明:①采集原理都是通过api或者sdk跟云服务器对接,收集微信公众号文章列表并分析。②这次提供的软件不能通过公众号发送给别人,也不能帮助别人做微信公众号接口收集工作。③只用于个人微信公众号收集、整理,不能用于微信公众号接口收集、分析、开发等④大家不要用这款软件去采集任何公众号文章,微信公众号接口请遵守相关法律法规,违反就会封号⑤请关注官方微信公众号:兔子数据,根据公众号首字母的含义加关键词,验证兔子。
保留对原文件的及时同步。不在需要时进行转载、修改、注明,侵权必究。下载和安装:链接:密码:gmk3,但安装的时候会有两个文件。需要把文件解压到对应文件夹里进行安装:在菜单中选择【设置】选择【微信公众号】选择【应用安装】选择【微信公众号采集】点击【下一步】选择【添加文件】即可选择一个支持软件的微信公众号(免费)将兔子提供的原始文件放入文件夹:获取打包下载后微信公众号文章的后缀文件:兔子数据ggd1zh-cn。
兔子:2.5k大小大小在7m以内的云端安卓android软件,并且可以提供1.7kw的大容量硬盘储存空间。软件主要功能:1.可以采集微信公众号里最新文章,提取标题、摘要、作者、评论、文章布局2.提供多样化的热文定制,确保每个粉丝都能阅读到一篇最精选的微信文章3.非正常采集平台的优势获取数据:用户可以自己去下载zip包,微信公众号的文章列表、按照类型提取列表里的文章、全站采集、按照文章标题搜索等等使用方法:1.直接上传页面内容到采集线路,软件就会自动生成采集列表。
2.选择文章定制自己可能需要的内容,同时也可以关注兔子文章列表,接口都是公开公正、开放,兔子、兔子、兔子授权即可登录。3.选择需要的数据是否适合重要时间点、是否是导出保存等。4.只支持采集自己需要的数据,不支持下载微信文章列表,也不支持别人分享的。支持采集的文章:微信订阅号,公众号文章列表,账号文章列表,商品列表,历史消息,历史消息列表,图文列表,历史消息列表,图文列表(无广告),商品列表(含广告)5.根据自己需要可以设置采集数量,没有限制。
6.采集自己需要的分析文章:文章的长尾词和热词用户可以在第三方平台判断这个内容是否可读,用户可不可以阅读这个内容等等。7.根据内容分类及类型采集文章:当用户分类和类型相同的文章大致都同样类型的内容时,为了提高用户的阅读体验,可以定制采集该文章的分类和内容8.按照文章标题搜索用户,或者用户需要的文章,都可以采集9.本平台只能。
采集工具免责说明:爬虫工具使用方法,一键采集代替细致的教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-04-22 19:03
采集工具免责说明:爬虫工具免责说明:市场上已经出现了很多免费的采集工具,比如蜘蛛采集器、动态网页识别工具、网页数据采集,还有就是简单易用的一些采集工具,让我们不用费心去思考采集工具使用方法,一键采集代替细致的教程,这些工具要么过于繁琐,要么是广告太多,过多的采集工具会分散注意力。搜集工具免责说明:你可以使用谷歌搜索采集国外的新闻,视频,小说等,我们是用搜狗公司的产品如搜狗网页搜索,请注意,我们提供了基于通用搜索搜索符合bing搜索的搜索引擎收录代替了我们的搜索引擎收录收集。
人物软件免责说明:人物专题采集器是一款支持对指定人物进行采集的软件,可以更清晰的了解公众人物的最新动态,可以了解某些明星(或娱乐圈的大明星),企业ceo,等的最新动态;使用谷歌或百度的搜索引擎爬虫爬取我们的微信公众号图文上传到本地即可,提供采集图片和文字的方法,我们提供js轮播图片轮播免费代替js代码上传自己的文件等功能。
商品软件免责说明:你可以对某个商品进行采集、在线销售、代理、直销、等方法,如:办公用品,服装,鞋帽,杯具,收音机,手机,乐器,带电户外用品等.;在线音乐播放器免责说明:你可以对某个歌曲进行采集、在线销售,代理,直销,等方法;在线视频播放器免责说明:你可以对某个视频进行采集、在线销售,代理,直销等方法;代餐食品免责说明:你可以对某个食品进行采集、在线销售,代理,直销等方法;电影免责说明:你可以对某个电影进行采集、在线销售,代理,直销等方法;音乐免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;音乐播放器免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;医疗器械免责说明:你可以对某个医疗器械进行采集、在线销售,代理,直销等方法;二手房买卖免责说明:你可以对某个二手房进行采集、在线销售,代理,直销等方法;公司内部管理免责说明:你可以对某个公司内部管理免责说明;农村代养代育免责说明:你可以对某些老人免责说明;农村红白喜事免责说明:你可以对某些农村红白喜事免责说明;免费试用代替详细教程微信:bdbdf85。 查看全部
采集工具免责说明:爬虫工具使用方法,一键采集代替细致的教程
采集工具免责说明:爬虫工具免责说明:市场上已经出现了很多免费的采集工具,比如蜘蛛采集器、动态网页识别工具、网页数据采集,还有就是简单易用的一些采集工具,让我们不用费心去思考采集工具使用方法,一键采集代替细致的教程,这些工具要么过于繁琐,要么是广告太多,过多的采集工具会分散注意力。搜集工具免责说明:你可以使用谷歌搜索采集国外的新闻,视频,小说等,我们是用搜狗公司的产品如搜狗网页搜索,请注意,我们提供了基于通用搜索搜索符合bing搜索的搜索引擎收录代替了我们的搜索引擎收录收集。
人物软件免责说明:人物专题采集器是一款支持对指定人物进行采集的软件,可以更清晰的了解公众人物的最新动态,可以了解某些明星(或娱乐圈的大明星),企业ceo,等的最新动态;使用谷歌或百度的搜索引擎爬虫爬取我们的微信公众号图文上传到本地即可,提供采集图片和文字的方法,我们提供js轮播图片轮播免费代替js代码上传自己的文件等功能。
商品软件免责说明:你可以对某个商品进行采集、在线销售、代理、直销、等方法,如:办公用品,服装,鞋帽,杯具,收音机,手机,乐器,带电户外用品等.;在线音乐播放器免责说明:你可以对某个歌曲进行采集、在线销售,代理,直销,等方法;在线视频播放器免责说明:你可以对某个视频进行采集、在线销售,代理,直销等方法;代餐食品免责说明:你可以对某个食品进行采集、在线销售,代理,直销等方法;电影免责说明:你可以对某个电影进行采集、在线销售,代理,直销等方法;音乐免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;音乐播放器免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;医疗器械免责说明:你可以对某个医疗器械进行采集、在线销售,代理,直销等方法;二手房买卖免责说明:你可以对某个二手房进行采集、在线销售,代理,直销等方法;公司内部管理免责说明:你可以对某个公司内部管理免责说明;农村代养代育免责说明:你可以对某些老人免责说明;农村红白喜事免责说明:你可以对某些农村红白喜事免责说明;免费试用代替详细教程微信:bdbdf85。
采集工具免责说明,你的网站信息安全吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-04-13 23:05
采集工具免责说明:以下采集的站点内容仅仅出于个人兴趣爱好之用,不要加标签和进行恶意的编辑等,凡是在该站点内发布的内容均不代表其有效性,请勿进行任何内容复制粘贴或进行任何修改、转载等操作,否则不承担任何责任或不获任何利益。报名方式:联系我们,我们给您推荐报名,如果采集的工具只要四块钱的话。网络调查统计工具,报名成功后有专门的人负责给您审核报名信息。
报名费为四块钱。采集后的页面可以通过分析工具获取采集次数、浏览量、下载量,按照百分比的比例进行分成,客户完全可以依靠自己的资源优势获得额外的收益。欢迎大家提供您的最好的工具,收费和分成等一概不接受,还望大家见谅。
有个叫金勺子的可以的,采集的特别全。很多基本上收集市面上所有的网站,不仅仅是收集豆瓣,还收集,百度,微博,,
你可以试试“web数据采集器”,
要想成功采集,
1、百度搜索、研究当前的网站关键词,看看有什么有趣的网站信息,分析每个网站的目标人群等,如果是在热门关键词下进行的,那不用努力,先随便点一下,看看能否采集到再说。
2、看到不能采集的网站后,记得千万不要急着点击,先停下来分析一下,因为搜索引擎上的网站比较多,有上百万个,它不会按你分析的关键词来判断的,你需要去主动寻找网站,查看哪些网站可以被采集、哪些不能采集,自己整理出一份网站列表表格出来。
3、不断的按当前搜索引擎分析的结果,分析“有什么”这个关键词,进行采集,然后用excel统计出来。
4、如果没有给确定的网站采集,也不要紧,只要你经过搜索引擎的搜索发现,有不能采集的网站,就继续查找网站,不断的根据当前搜索引擎的分析结果、网站分析的结果,一遍遍地查找,直到找到一些,觉得不错的、可以采集的。
5、这样一轮轮的查找就全部被找到了,这也是你为自己创造的一份优质资源,多采集一些总是有好处的。 查看全部
采集工具免责说明,你的网站信息安全吗?
采集工具免责说明:以下采集的站点内容仅仅出于个人兴趣爱好之用,不要加标签和进行恶意的编辑等,凡是在该站点内发布的内容均不代表其有效性,请勿进行任何内容复制粘贴或进行任何修改、转载等操作,否则不承担任何责任或不获任何利益。报名方式:联系我们,我们给您推荐报名,如果采集的工具只要四块钱的话。网络调查统计工具,报名成功后有专门的人负责给您审核报名信息。
报名费为四块钱。采集后的页面可以通过分析工具获取采集次数、浏览量、下载量,按照百分比的比例进行分成,客户完全可以依靠自己的资源优势获得额外的收益。欢迎大家提供您的最好的工具,收费和分成等一概不接受,还望大家见谅。
有个叫金勺子的可以的,采集的特别全。很多基本上收集市面上所有的网站,不仅仅是收集豆瓣,还收集,百度,微博,,
你可以试试“web数据采集器”,
要想成功采集,
1、百度搜索、研究当前的网站关键词,看看有什么有趣的网站信息,分析每个网站的目标人群等,如果是在热门关键词下进行的,那不用努力,先随便点一下,看看能否采集到再说。
2、看到不能采集的网站后,记得千万不要急着点击,先停下来分析一下,因为搜索引擎上的网站比较多,有上百万个,它不会按你分析的关键词来判断的,你需要去主动寻找网站,查看哪些网站可以被采集、哪些不能采集,自己整理出一份网站列表表格出来。
3、不断的按当前搜索引擎分析的结果,分析“有什么”这个关键词,进行采集,然后用excel统计出来。
4、如果没有给确定的网站采集,也不要紧,只要你经过搜索引擎的搜索发现,有不能采集的网站,就继续查找网站,不断的根据当前搜索引擎的分析结果、网站分析的结果,一遍遍地查找,直到找到一些,觉得不错的、可以采集的。
5、这样一轮轮的查找就全部被找到了,这也是你为自己创造的一份优质资源,多采集一些总是有好处的。
在线购买会员后没有正常激活怎么办?如何退款?
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-04-01 18:24
常见问题1.如果在线购买后未正常激活会员资格,该怎么办?
首先打开用户中心,然后在左侧检查“您的当前帐户信息”,在右侧检查“您的购买历史”。如果购买历史记录表明购买已成功,但是左侧的帐户信息仍显示为普通会员,则表示激活会员资格时出现问题。请发送电子邮件以协商退款或手动传达会员购买问题。
2.购买后如何退款?
对不起,如果您正常激活了贵宾帐户,则该网站不支持退款。
3.注册和登录相关问题
请单击此处
4.网页上有错误,但我的积分仍被扣除,我该怎么办?
嗯,好吧,当时引入了积分系统,使每个人都可以在购买VIP之前体验网站的内容,因此制作时我并没有考虑太多。如果有能力,我建议您支持它。毕竟,在此站点上购买会员并不昂贵。创业并不容易,谢谢您的支持!
5.数据来自哪里?它有多精确?
WIS数据库是采集,并在Internet上汇编了公共数据,例如政府机构发布的计划的全文,公共可用的统计公告等。尽管使用了一些自动化工具,但它们更依赖于一整夜的人手。识别,组织和处理它们。在这些过程中,不可避免会有错误。我们不能保证数据的准确性。这取决于您对WIS的理解和信任。由于数据处理既费时又费力,因此严禁个人,网站管理员或无偿使用爬虫或采集工具采集来获取本网站数据的薪水的朋友禁止使用它。一旦发现,它将被永久阻止。您的行为可以在网站的背景中看到。如果情况严重,本网站将酌情考虑法律仲裁。
6.我使用WIS自动生成的内容进行创建。版权拥有权如何?
原则上,WIS只是用于数据处理和集成的工具。您可以使用此内容重新创建,理论上没有问题。但是,您需要注意的是其他人也可能将这些数据或内容用于重新创建。不可避免地会有重叠,并且很难说谁先走。尤其是在进行纸张或更严格禁止的工作时,建议您增加自己的理解,并对原创文本进行一些更改。当然,欢迎您在工作中添加对WIS的引用。
7.可以立即访问同一页面。为什么它报告错误或刷新后无法打开?
该网站已采用了某种反爬行机制。可能是您的访问频率太高了。
8.-为什么当我单击它时某些工具没有响应/页面看起来很乱?
如果这不是网络问题,则可能是您的浏览器功能不是很强大。该网站是基于现代浏览器构建的,某些功能使用HTML5。请确保您的浏览器不是IE的低版本,或者不是足够友好以支持html5的浏览器。建议使用现代浏览器,例如Google的Chrome(某些带有chrome内核的家用浏览器)[icon:],Apple的Safari [icon:],Mozilla的Firefox [icon:]和其他现代浏览器来访问此网站。
9.其他问题
查看我们的更新说明,或在线填写反馈表
查看Yuque上托管的更多详细文档 查看全部
在线购买会员后没有正常激活怎么办?如何退款?
常见问题1.如果在线购买后未正常激活会员资格,该怎么办?
首先打开用户中心,然后在左侧检查“您的当前帐户信息”,在右侧检查“您的购买历史”。如果购买历史记录表明购买已成功,但是左侧的帐户信息仍显示为普通会员,则表示激活会员资格时出现问题。请发送电子邮件以协商退款或手动传达会员购买问题。
2.购买后如何退款?
对不起,如果您正常激活了贵宾帐户,则该网站不支持退款。
3.注册和登录相关问题
请单击此处
4.网页上有错误,但我的积分仍被扣除,我该怎么办?
嗯,好吧,当时引入了积分系统,使每个人都可以在购买VIP之前体验网站的内容,因此制作时我并没有考虑太多。如果有能力,我建议您支持它。毕竟,在此站点上购买会员并不昂贵。创业并不容易,谢谢您的支持!
5.数据来自哪里?它有多精确?
WIS数据库是采集,并在Internet上汇编了公共数据,例如政府机构发布的计划的全文,公共可用的统计公告等。尽管使用了一些自动化工具,但它们更依赖于一整夜的人手。识别,组织和处理它们。在这些过程中,不可避免会有错误。我们不能保证数据的准确性。这取决于您对WIS的理解和信任。由于数据处理既费时又费力,因此严禁个人,网站管理员或无偿使用爬虫或采集工具采集来获取本网站数据的薪水的朋友禁止使用它。一旦发现,它将被永久阻止。您的行为可以在网站的背景中看到。如果情况严重,本网站将酌情考虑法律仲裁。
6.我使用WIS自动生成的内容进行创建。版权拥有权如何?
原则上,WIS只是用于数据处理和集成的工具。您可以使用此内容重新创建,理论上没有问题。但是,您需要注意的是其他人也可能将这些数据或内容用于重新创建。不可避免地会有重叠,并且很难说谁先走。尤其是在进行纸张或更严格禁止的工作时,建议您增加自己的理解,并对原创文本进行一些更改。当然,欢迎您在工作中添加对WIS的引用。
7.可以立即访问同一页面。为什么它报告错误或刷新后无法打开?
该网站已采用了某种反爬行机制。可能是您的访问频率太高了。
8.-为什么当我单击它时某些工具没有响应/页面看起来很乱?
如果这不是网络问题,则可能是您的浏览器功能不是很强大。该网站是基于现代浏览器构建的,某些功能使用HTML5。请确保您的浏览器不是IE的低版本,或者不是足够友好以支持html5的浏览器。建议使用现代浏览器,例如Google的Chrome(某些带有chrome内核的家用浏览器)[icon:],Apple的Safari [icon:],Mozilla的Firefox [icon:]和其他现代浏览器来访问此网站。
9.其他问题
查看我们的更新说明,或在线填写反馈表
查看Yuque上托管的更多详细文档
微信采集工具免责说明,记住重要的自己看下
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-04-01 04:01
采集工具免责说明,记住重要的自己看下免责声明elp-7ws9-znuo.jpg,实用行业vip.../输入手机号验证,免费获取手机号码收集方法,
首先肯定是不犯法,但是吸粉多了就会违法,只是这违法的程度不同,主要看你吸粉目的是什么。商家是要盈利的,被别人薅羊毛就不好了。针对目前出现的“情趣用品,微商,微信群发广告”三大违法吸粉渠道,以及“吸粉培训”等微信违规服务,
一、微信营销违规内容1.吸粉培训:通过情趣用品软文吸粉;通过微信群发广告等吸粉等等。并且还不是一般的不严谨,会传播虚假情趣用品软文,或者直接出现性暗示等不良词汇,甚至是什么“多大仇”、“多大爱”,一看就知道是骗人的。2.假结婚:诱骗受害人结婚,然后以加微信等方式骗取财产。3.虚假食品等:打擦边球通过不真实的加qq、加微信,通过他人或在圈子里发布公司虚假食品等等,并将人引导至骗人转移财产。
4.直销:有的人通过各种方式加你,加好友聊天等,但是不发展你的具体购买人,微信卖淫直销,引诱你购买,并且不发货,销售诱惑加qq聊,诱骗你转账拉黑等等。5.微商:通过包装虚假的产品卖点,促使你购买,但是后续发现,产品存在虚假的天花乱坠的广告,然后群发还禁言等等,等你明白后发现被骗,或者发现被限制。
二、色流:通过发送性暗示,引导你加微信,还会有发给你下载试试的。我建议你见到这些东西应该举报举报。
三、黄客:使用群发广告和免费赠送会员,吸引你加微信,然后开始群发营销,包括但不限于:1.诱骗你免费报名加入一个超多人的群,然后群发所有群友朋友圈。2.群发购买诱惑加微信,如拉好友免费送价值199元或者499元的vip账号,说加入会员有多少优惠之类的。3.群发员工广告,如“如果有男朋友最好加个微信呀”“撩人福利统统送给你”等。4.群发的虚假免费赠送等等。5.色流平台如pua、云集、拼多多,都是网络传销,不可信。.。 查看全部
微信采集工具免责说明,记住重要的自己看下
采集工具免责说明,记住重要的自己看下免责声明elp-7ws9-znuo.jpg,实用行业vip.../输入手机号验证,免费获取手机号码收集方法,
首先肯定是不犯法,但是吸粉多了就会违法,只是这违法的程度不同,主要看你吸粉目的是什么。商家是要盈利的,被别人薅羊毛就不好了。针对目前出现的“情趣用品,微商,微信群发广告”三大违法吸粉渠道,以及“吸粉培训”等微信违规服务,
一、微信营销违规内容1.吸粉培训:通过情趣用品软文吸粉;通过微信群发广告等吸粉等等。并且还不是一般的不严谨,会传播虚假情趣用品软文,或者直接出现性暗示等不良词汇,甚至是什么“多大仇”、“多大爱”,一看就知道是骗人的。2.假结婚:诱骗受害人结婚,然后以加微信等方式骗取财产。3.虚假食品等:打擦边球通过不真实的加qq、加微信,通过他人或在圈子里发布公司虚假食品等等,并将人引导至骗人转移财产。
4.直销:有的人通过各种方式加你,加好友聊天等,但是不发展你的具体购买人,微信卖淫直销,引诱你购买,并且不发货,销售诱惑加qq聊,诱骗你转账拉黑等等。5.微商:通过包装虚假的产品卖点,促使你购买,但是后续发现,产品存在虚假的天花乱坠的广告,然后群发还禁言等等,等你明白后发现被骗,或者发现被限制。
二、色流:通过发送性暗示,引导你加微信,还会有发给你下载试试的。我建议你见到这些东西应该举报举报。
三、黄客:使用群发广告和免费赠送会员,吸引你加微信,然后开始群发营销,包括但不限于:1.诱骗你免费报名加入一个超多人的群,然后群发所有群友朋友圈。2.群发购买诱惑加微信,如拉好友免费送价值199元或者499元的vip账号,说加入会员有多少优惠之类的。3.群发员工广告,如“如果有男朋友最好加个微信呀”“撩人福利统统送给你”等。4.群发的虚假免费赠送等等。5.色流平台如pua、云集、拼多多,都是网络传销,不可信。.。
屌丝语录:我再不去招待你们可能我孩子没法做产品经理了
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-03-30 23:02
采集工具免责说明:客户没有详细说明能否使用哪些功能。反馈后运营人员将尽快处理。功能描述:假设有公众号申请注册信息查询,关注会发送公众号名称+注册人身份验证+填写联系方式。
1、【查询注册】填写完成后点击查询;
2、【评估注册】可以使用【质量分】
3、【特殊人群识别(已注册者)】可用【用户群体】
4、【用户特征识别(未注册者)】(配置)
5、【注册登录设置(绑定新公众号,保护现有用户身份)】填写用户信息5步,点击【确定】发送短信给运营人员5步,【绑定新公众号,保护现有用户身份】可以填写:昵称/基本信息(详细填写身份证、学信网)/标识码/邮箱/公众号名称(可选)pc端:微信公众号关注验证/个人扫二维码5步,点击【提交】如下图示是长期使用的会员服务最后需要提示一下大家,运营的同时一定要保护好自己的公众号,要保证公众号的安全性,不然即使看到了解决方案,也无法继续解决。
图灵测试,专门来答这题的。我也帮我爸妈做过。套用一句屌丝语录:我再不去招待你们,可能我孩子没法做产品经理了。
推荐个最近用过的工具给你,it桔子,通过这个平台你可以了解到知名互联网公司的创始人和团队,也可以了解到相关的投资情况,另外你还可以通过这个平台看到他们创始人写的一些产品策划和运营文档,对你做运营是有一定的帮助的 查看全部
屌丝语录:我再不去招待你们可能我孩子没法做产品经理了
采集工具免责说明:客户没有详细说明能否使用哪些功能。反馈后运营人员将尽快处理。功能描述:假设有公众号申请注册信息查询,关注会发送公众号名称+注册人身份验证+填写联系方式。
1、【查询注册】填写完成后点击查询;
2、【评估注册】可以使用【质量分】
3、【特殊人群识别(已注册者)】可用【用户群体】
4、【用户特征识别(未注册者)】(配置)
5、【注册登录设置(绑定新公众号,保护现有用户身份)】填写用户信息5步,点击【确定】发送短信给运营人员5步,【绑定新公众号,保护现有用户身份】可以填写:昵称/基本信息(详细填写身份证、学信网)/标识码/邮箱/公众号名称(可选)pc端:微信公众号关注验证/个人扫二维码5步,点击【提交】如下图示是长期使用的会员服务最后需要提示一下大家,运营的同时一定要保护好自己的公众号,要保证公众号的安全性,不然即使看到了解决方案,也无法继续解决。
图灵测试,专门来答这题的。我也帮我爸妈做过。套用一句屌丝语录:我再不去招待你们,可能我孩子没法做产品经理了。
推荐个最近用过的工具给你,it桔子,通过这个平台你可以了解到知名互联网公司的创始人和团队,也可以了解到相关的投资情况,另外你还可以通过这个平台看到他们创始人写的一些产品策划和运营文档,对你做运营是有一定的帮助的
【干货】采集工具免责说明(第二十四期)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-03-27 01:02
采集工具免责说明根据国家相关规定和其他一些特殊情况,导致服务器未能正常接收应发分布式配置的业务,服务器托管商将允许用户终止服务。如分布式配置未能正常接收,当使用spring-boot-starter-test-secure或spring-boot-starter-test-apache-context时,仍需提供以下代码,其中某些功能尚未支持可测试的性能表现,服务器应对这些功能进行部署和分布式配置的恢复:(。
1)禁止某个配置提供给其他服务器
2)允许重新分布式配置文件首先是关于springboot的关闭配置功能,上文也说到了,
1、spring.autoconfigure.autoconfigure-agent/spring.autoconfigure.autoconfigure-secure,
2、spring.autoconfigure.autoconfigure-start/spring.autoconfigure.autoconfigure-autoconfigure-start.jar。实际上在执行这两个方法前,还需要启动一个实际代码时生成的中间态来执行一些操作。以下是官方文档给出的实例,可供参考:-starter-test-secure#.wpmqihf9kg7dhc3通过以下命令将启动服务,其中springboot是不需要的,只需要springautoconfigure和springboot即可:如果要执行监控自定义方法,执行如下代码:#.wpmqihf9kg7dhc3通过将服务连接到一个localhost可以获取必要信息,当然并不需要接受springorganization身份认证,除非是你自己在centos7.x中的配置为:classpath:/tmp/localhost/hostname这里是仅给出以下代码:--assert-exists:false#用来判断是否依赖于一个框架,当然是通过一个方法加入ehcachepostfix插件创建配置的,直接将localhost中的配置加入即可assert(null,'false')--start-build:configs-existsattempted#postfix用来区分postfix:class中定义的不同对象在服务端时,对于不同对象,需要对它进行不同的命名过滤,处理如下:代码解释://这是服务端为进行配置所做的处理,将这部分代码加入如下配置autoconfigure:{//这是第一个方法,所有的依赖都需要加上assert:'build':trueserver:=newlocalhostspringjpa();//这是两个判断,如果服务端调用的依赖中没有过滤,则会被过滤assert:'build':falsepostfix:{}//这是第二个方法,它是判断服务端的内容是否在assert中成立,如果在则直接返回在服务端调用mongoconfigtorestring中flag代表服务端的标识:put(system.in){mongoconfigtorestring:properties.mongoconfigtore。 查看全部
【干货】采集工具免责说明(第二十四期)
采集工具免责说明根据国家相关规定和其他一些特殊情况,导致服务器未能正常接收应发分布式配置的业务,服务器托管商将允许用户终止服务。如分布式配置未能正常接收,当使用spring-boot-starter-test-secure或spring-boot-starter-test-apache-context时,仍需提供以下代码,其中某些功能尚未支持可测试的性能表现,服务器应对这些功能进行部署和分布式配置的恢复:(。
1)禁止某个配置提供给其他服务器
2)允许重新分布式配置文件首先是关于springboot的关闭配置功能,上文也说到了,
1、spring.autoconfigure.autoconfigure-agent/spring.autoconfigure.autoconfigure-secure,
2、spring.autoconfigure.autoconfigure-start/spring.autoconfigure.autoconfigure-autoconfigure-start.jar。实际上在执行这两个方法前,还需要启动一个实际代码时生成的中间态来执行一些操作。以下是官方文档给出的实例,可供参考:-starter-test-secure#.wpmqihf9kg7dhc3通过以下命令将启动服务,其中springboot是不需要的,只需要springautoconfigure和springboot即可:如果要执行监控自定义方法,执行如下代码:#.wpmqihf9kg7dhc3通过将服务连接到一个localhost可以获取必要信息,当然并不需要接受springorganization身份认证,除非是你自己在centos7.x中的配置为:classpath:/tmp/localhost/hostname这里是仅给出以下代码:--assert-exists:false#用来判断是否依赖于一个框架,当然是通过一个方法加入ehcachepostfix插件创建配置的,直接将localhost中的配置加入即可assert(null,'false')--start-build:configs-existsattempted#postfix用来区分postfix:class中定义的不同对象在服务端时,对于不同对象,需要对它进行不同的命名过滤,处理如下:代码解释://这是服务端为进行配置所做的处理,将这部分代码加入如下配置autoconfigure:{//这是第一个方法,所有的依赖都需要加上assert:'build':trueserver:=newlocalhostspringjpa();//这是两个判断,如果服务端调用的依赖中没有过滤,则会被过滤assert:'build':falsepostfix:{}//这是第二个方法,它是判断服务端的内容是否在assert中成立,如果在则直接返回在服务端调用mongoconfigtorestring中flag代表服务端的标识:put(system.in){mongoconfigtorestring:properties.mongoconfigtore。
软件安装运行新世纪百千万人才信息采集工具使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-03-25 06:15
使用人才信息采集工具的说明基于“新世纪数百,数千人才信息采集工具”的说明。 “政府特殊津贴个人采集工具”的操作方法类似。 一、新世纪的软件安装和运营数以百万计的人才信息采集工具安装软件,如图1-1所示:图1-1单击以选择软件安装路径,然后单击“下一步”,如图图1-2:图1-2单击“准备安装”,然后单击“下一步”,如图1-3所示:图1-3完成安装,如图1-4所示。图1-4 二、运行软件并双击桌面上的快捷方式(图2- 0)新世纪一万人才信息采集工具,请参见以下界面,如图2-1所示:图2-0图2-1 1、工具栏用法:(注:输入信息时,请参阅软件底部的输入说明)输入信息后,请“保存”并“备份”数据。如果系统提示存在当您单击“保存”或“备份”时,必须在必填字段中输入任何字符。然后备份RPU文件(下面的数据可以是RPU文件的用途(A:当软件中的数据无法正常显示时B:需要修改文件中的数据C:将数据带回家或将其备份继续进行编辑工作D:将数据报表保存到单元中以提交单元摘要)。可以在安装了软件的计算机上还原RPU文件。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。 (1)保存:单击以保存数据,并验证输入数据的有效性,并在成功验证后保存。(2)清除:单击以清除所有页面数据,请谨慎使用。(3)恢复:用于还原”在“备份”期间备份具有RPU扩展名的文件。注意:还原的文件只能是具有RPU扩展名的文件,并且不能用其他工具打开RPU文件。1、工具栏2、导航区域3、条目描述区域4、输入区域(4)第一页,上一页,下一页,最后一页:用于翻页报告。(5)备份:数据之后输入后,将生成用于报告的RPU文件。单击备份按钮,然后将弹出“ Generate Report”框(图2- 2),单击“ Submit File Name”:图2-2命名该文件并选择文件存储路径(图2- 3)):图2-3要提交的文件名为Ling Bin,单击“保存”,保存过程如图2-4所示:图2-4当。。。的时候保存成功后,您会看到以下图2-5的提示:图2-5完成数据输入后,单击“最后生成的RPU文件会报告给设备”。 2、如何使用浮动列:输入多个数据时,可以依靠“浮动列”来调整数据的顺序:删除该记录子集,将下一个记录向上移动将记录插入到子集记录。该记录位于顶部。该记录位于末尾。 查看全部
软件安装运行新世纪百千万人才信息采集工具使用说明
使用人才信息采集工具的说明基于“新世纪数百,数千人才信息采集工具”的说明。 “政府特殊津贴个人采集工具”的操作方法类似。 一、新世纪的软件安装和运营数以百万计的人才信息采集工具安装软件,如图1-1所示:图1-1单击以选择软件安装路径,然后单击“下一步”,如图图1-2:图1-2单击“准备安装”,然后单击“下一步”,如图1-3所示:图1-3完成安装,如图1-4所示。图1-4 二、运行软件并双击桌面上的快捷方式(图2- 0)新世纪一万人才信息采集工具,请参见以下界面,如图2-1所示:图2-0图2-1 1、工具栏用法:(注:输入信息时,请参阅软件底部的输入说明)输入信息后,请“保存”并“备份”数据。如果系统提示存在当您单击“保存”或“备份”时,必须在必填字段中输入任何字符。然后备份RPU文件(下面的数据可以是RPU文件的用途(A:当软件中的数据无法正常显示时B:需要修改文件中的数据C:将数据带回家或将其备份继续进行编辑工作D:将数据报表保存到单元中以提交单元摘要)。可以在安装了软件的计算机上还原RPU文件。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。 (1)保存:单击以保存数据,并验证输入数据的有效性,并在成功验证后保存。(2)清除:单击以清除所有页面数据,请谨慎使用。(3)恢复:用于还原”在“备份”期间备份具有RPU扩展名的文件。注意:还原的文件只能是具有RPU扩展名的文件,并且不能用其他工具打开RPU文件。1、工具栏2、导航区域3、条目描述区域4、输入区域(4)第一页,上一页,下一页,最后一页:用于翻页报告。(5)备份:数据之后输入后,将生成用于报告的RPU文件。单击备份按钮,然后将弹出“ Generate Report”框(图2- 2),单击“ Submit File Name”:图2-2命名该文件并选择文件存储路径(图2- 3)):图2-3要提交的文件名为Ling Bin,单击“保存”,保存过程如图2-4所示:图2-4当。。。的时候保存成功后,您会看到以下图2-5的提示:图2-5完成数据输入后,单击“最后生成的RPU文件会报告给设备”。 2、如何使用浮动列:输入多个数据时,可以依靠“浮动列”来调整数据的顺序:删除该记录子集,将下一个记录向上移动将记录插入到子集记录。该记录位于顶部。该记录位于末尾。
企业端统计http接口免责说明,怎么做好采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-03-25 03:03
采集工具免责说明
1、通过企业端统计http接口抓取网页数据;
2、获取http接口地址、http响应头、http头信息、接口参数、接口转发,
3、不侵入现有http链接;
4、抓取的数据,
5、流量统计、监控;微信接口流量统计,跟之前的全量数据相比较,前者相对来说信息更丰富,多了一些小功能,如历史浏览的历史、商品详情页浏览历史等。还有一些小功能:如老客户的到店消费、历史转介绍等。数据抓取一般为反爬,获取数据开始数据后,有时候可能需要抓取第三方cookie或者引流到京东等第三方平台。数据统计分析前些年大数据比较火,于是就有了分析统计师等概念,这些概念都是利用网页爬虫进行数据抓取,到相应的分析统计工具里,进行数据分析。
没有明确的硬性规定,只是企业有要求需要抓取数据时,我们也需要通过解析html后,将数据封装进模块中,结果导出到html格式中,然后利用javascript引擎对html进行抓取,做到数据抓取正则识别。另外,还有商品分析。有时候还会有热词挖掘、舆情分析等需求。这些是相对来说比较次要的数据分析工具了。至于那些要具备怎样的功能?这个很难讲,大致有以下几种:以前要写html脚本才能获取的分析统计工具,现在直接在网页上就能抓取数据。
根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。网页列表排序列表数据有时候需要进行分组排序,将数据导出到javascript语言中进行排序。数据搜索有时候需要根据传统传统数据获取的方式,进行数据搜索,数据搜索后再排序。
怎么展示数据排序结果?这个跟分析统计平台的扩展性有关,有时候需要在一些分析统计软件里面操作数据库里面的数据,获取分析统计数据,再进行数据分析,然后用来实现一些在互联网应用。有些网站获取数据的方式十分简单,只要网页是https的就可以。比如比特币交易平台:密码是公开的,很多网站根本不需要做分析统计,直接就能获取了。
有些网站获取数据的方式比较复杂,不仅是基于https的,还要对网页进行headers发送请求,网页才能进行分析统计。可能还要参考headers中host头部分的部分参数等,才能查询、访问到数据。如果要做某些分析统计工具,直接可以获取数据存到excel中,在平台设置排序规则,进行排序获取到数据。链接自动解析从headers中获取到的skuid。但实际上很多链接并没有唯一标识,网页链接里面也可能不存在同款/同颜色/同尺码、同款式的鞋子,但客户的。 查看全部
企业端统计http接口免责说明,怎么做好采集工具
采集工具免责说明
1、通过企业端统计http接口抓取网页数据;
2、获取http接口地址、http响应头、http头信息、接口参数、接口转发,
3、不侵入现有http链接;
4、抓取的数据,
5、流量统计、监控;微信接口流量统计,跟之前的全量数据相比较,前者相对来说信息更丰富,多了一些小功能,如历史浏览的历史、商品详情页浏览历史等。还有一些小功能:如老客户的到店消费、历史转介绍等。数据抓取一般为反爬,获取数据开始数据后,有时候可能需要抓取第三方cookie或者引流到京东等第三方平台。数据统计分析前些年大数据比较火,于是就有了分析统计师等概念,这些概念都是利用网页爬虫进行数据抓取,到相应的分析统计工具里,进行数据分析。
没有明确的硬性规定,只是企业有要求需要抓取数据时,我们也需要通过解析html后,将数据封装进模块中,结果导出到html格式中,然后利用javascript引擎对html进行抓取,做到数据抓取正则识别。另外,还有商品分析。有时候还会有热词挖掘、舆情分析等需求。这些是相对来说比较次要的数据分析工具了。至于那些要具备怎样的功能?这个很难讲,大致有以下几种:以前要写html脚本才能获取的分析统计工具,现在直接在网页上就能抓取数据。
根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。网页列表排序列表数据有时候需要进行分组排序,将数据导出到javascript语言中进行排序。数据搜索有时候需要根据传统传统数据获取的方式,进行数据搜索,数据搜索后再排序。
怎么展示数据排序结果?这个跟分析统计平台的扩展性有关,有时候需要在一些分析统计软件里面操作数据库里面的数据,获取分析统计数据,再进行数据分析,然后用来实现一些在互联网应用。有些网站获取数据的方式十分简单,只要网页是https的就可以。比如比特币交易平台:密码是公开的,很多网站根本不需要做分析统计,直接就能获取了。
有些网站获取数据的方式比较复杂,不仅是基于https的,还要对网页进行headers发送请求,网页才能进行分析统计。可能还要参考headers中host头部分的部分参数等,才能查询、访问到数据。如果要做某些分析统计工具,直接可以获取数据存到excel中,在平台设置排序规则,进行排序获取到数据。链接自动解析从headers中获取到的skuid。但实际上很多链接并没有唯一标识,网页链接里面也可能不存在同款/同颜色/同尺码、同款式的鞋子,但客户的。
web端接入大数据在线采集工具的免责说明书
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-03-23 22:03
采集工具免责说明:本测试系针对web端端口授权或者服务端接口授权申请的情况,不是针对互联网接入大数据在线采集的。本测试系统是模拟thunderbot、javascript、rennanet等采集工具,所以请谨慎参考采集的敏感数据。采集工具的授权:javascript的:javascript是没有授权的,但会给seo服务分配用户权限。
rennanet,提供的授权工具,授权,自动根据请求地址判断请求者的请求权限;没有授权的情况下不会采集数据。一种方法,先使用自动授权:对不同的用户自动分配不同的权限名,然后更改权限名称,目前web环境的授权方式大部分是name:credential,字段参数有max-access-control(最大访问限制,默认值为1208。
0)、max-user-access-control(最大访问限制,
0)、min-access-control(最小访问限制,
5)、referer(在该页面打开,
0)。无法人工修改权限,seo服务一般在按照这种方式进行权限管理。基于人工授权的javascript或者node.js采集工具:均有授权工具,无需seo服务提供授权地址,没有授权地址进行限制用户身份。但是如果seo服务的权限已经进行过授权,那么则不可以用这种方式采集数据。进行机器授权:授权地址一般为手机号,电话号码等形式。
此种授权方式目前已经被普遍应用。用rennan优采云采集器的请求分为两种情况:一种是采集数据发送请求,后台会在后台进行一套机器指令的判断和处理,通过master进行指令判断,判断返回的请求最后的domcontent位置是否是合法地址,然后进行权限授权,最后发送数据授权网站端接入web端请求javascript或者node.js采集之后,修改请求网站端的地址url,重新进行请求,并且把返回的数据发送给相应的负责进行采集地址的地址。
一种是采集完成后,仅对采集完的数据进行一次反采集判断和校验,并且把采集的数据回传到真正的请求者那里,对于无需第二次返回的数据,直接返回返回对应的数据,进行api接口的授权即可。下面对二者进行详细介绍:采集工具一般的接入授权:ip,user,password等规则(国内常用,境外仅一两个可以通过,推荐使用一个以稳定为好,推荐可以使用360或者腾讯微云来采集,其次国内分两类的可以接入,一类是使用国内接入站点的,用的最多的是可以是阿里云或者是百度的数据接入服务,你说的ip要是直接接入的,用ip地址,其他地方的ip不是采集站点的ip,有其他可能的情况;另外一类是境外接入,是接入美国和日本的,可以免费注册,然后使。 查看全部
web端接入大数据在线采集工具的免责说明书
采集工具免责说明:本测试系针对web端端口授权或者服务端接口授权申请的情况,不是针对互联网接入大数据在线采集的。本测试系统是模拟thunderbot、javascript、rennanet等采集工具,所以请谨慎参考采集的敏感数据。采集工具的授权:javascript的:javascript是没有授权的,但会给seo服务分配用户权限。
rennanet,提供的授权工具,授权,自动根据请求地址判断请求者的请求权限;没有授权的情况下不会采集数据。一种方法,先使用自动授权:对不同的用户自动分配不同的权限名,然后更改权限名称,目前web环境的授权方式大部分是name:credential,字段参数有max-access-control(最大访问限制,默认值为1208。
0)、max-user-access-control(最大访问限制,
0)、min-access-control(最小访问限制,
5)、referer(在该页面打开,
0)。无法人工修改权限,seo服务一般在按照这种方式进行权限管理。基于人工授权的javascript或者node.js采集工具:均有授权工具,无需seo服务提供授权地址,没有授权地址进行限制用户身份。但是如果seo服务的权限已经进行过授权,那么则不可以用这种方式采集数据。进行机器授权:授权地址一般为手机号,电话号码等形式。
此种授权方式目前已经被普遍应用。用rennan优采云采集器的请求分为两种情况:一种是采集数据发送请求,后台会在后台进行一套机器指令的判断和处理,通过master进行指令判断,判断返回的请求最后的domcontent位置是否是合法地址,然后进行权限授权,最后发送数据授权网站端接入web端请求javascript或者node.js采集之后,修改请求网站端的地址url,重新进行请求,并且把返回的数据发送给相应的负责进行采集地址的地址。
一种是采集完成后,仅对采集完的数据进行一次反采集判断和校验,并且把采集的数据回传到真正的请求者那里,对于无需第二次返回的数据,直接返回返回对应的数据,进行api接口的授权即可。下面对二者进行详细介绍:采集工具一般的接入授权:ip,user,password等规则(国内常用,境外仅一两个可以通过,推荐使用一个以稳定为好,推荐可以使用360或者腾讯微云来采集,其次国内分两类的可以接入,一类是使用国内接入站点的,用的最多的是可以是阿里云或者是百度的数据接入服务,你说的ip要是直接接入的,用ip地址,其他地方的ip不是采集站点的ip,有其他可能的情况;另外一类是境外接入,是接入美国和日本的,可以免费注册,然后使。
没人推荐百度地图吗?百度的格局是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-02-27 10:01
采集工具免责说明因为工程师们已经对百度地图产品都是严密监控的,所以任何人如果在任何时间段进行非法获取、传播、发布、部署等行为都是极其危险的。例如:任何人下载或被非法推广或获取任何形式的定位、地址和路线信息等。技术干货关注“东三环外的大胡子”知乎号,实时干货会不定期更新!更多资源请关注“东三环外的大胡子”微信公众号。
你居然还在用百度地图?哈哈,他们现在一般用自己的app啊。
这两家压根就不是一个层次的,百度的格局是高德地图——地图国际化——美团地图——搜狗地图——王者荣耀(没记错的话?)至于其他的嘛。
我觉得在竞争激烈的情况下,大家的关注点应该是你怎么打动用户把你的产品推荐给身边的朋友呢,其实这个可以从socialmedia的角度解决,把自己打造成一个高频内容分发平台,增加自己的曝光度,比如你可以在当地比较关键的大学宣传你的地图,提高当地考试信息的曝光,或者举办一些类似考试家长送福利送定位的活动,提高用户参与度以及曝光率。
没人推荐百度地图吗?
我在海外上学的时候,一直在用谷歌地图。之前没有安装中国地图,前两年有次在国内路过海外路线,就用搜狗搜索了下。
全景app,你可以去找到。说点题外话,现在百度地图的视频搜索还是做的不错的, 查看全部
没人推荐百度地图吗?百度的格局是什么?
采集工具免责说明因为工程师们已经对百度地图产品都是严密监控的,所以任何人如果在任何时间段进行非法获取、传播、发布、部署等行为都是极其危险的。例如:任何人下载或被非法推广或获取任何形式的定位、地址和路线信息等。技术干货关注“东三环外的大胡子”知乎号,实时干货会不定期更新!更多资源请关注“东三环外的大胡子”微信公众号。
你居然还在用百度地图?哈哈,他们现在一般用自己的app啊。
这两家压根就不是一个层次的,百度的格局是高德地图——地图国际化——美团地图——搜狗地图——王者荣耀(没记错的话?)至于其他的嘛。
我觉得在竞争激烈的情况下,大家的关注点应该是你怎么打动用户把你的产品推荐给身边的朋友呢,其实这个可以从socialmedia的角度解决,把自己打造成一个高频内容分发平台,增加自己的曝光度,比如你可以在当地比较关键的大学宣传你的地图,提高当地考试信息的曝光,或者举办一些类似考试家长送福利送定位的活动,提高用户参与度以及曝光率。
没人推荐百度地图吗?
我在海外上学的时候,一直在用谷歌地图。之前没有安装中国地图,前两年有次在国内路过海外路线,就用搜狗搜索了下。
全景app,你可以去找到。说点题外话,现在百度地图的视频搜索还是做的不错的,
采集工具免责说明:请勿商用或向他人进行传播
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2021-02-15 09:03
采集工具免责说明:
1、请勿商用或向他人进行传播
2、在上线上传前请先确定您的资源与原作者的资源相同或者相似,
3、资源链接请进行加密处理,并加上链接唯一编号,在上传后不可修改或修改时,
关键可能是你发的链接他知道是很难正常打开的,第二可能是盗版。
我也遇到这个问题了,目前我是先使用采集器的常用字符打开,
同求!!发的时候字幕还挺快,但是打开巨慢!!经常性的!!!现在我发一下截图!大家看看,
我也遇到了同样的问题,后来遇到一个办法解决了。首先你的电脑要好,快的不能再快的那种,并且安装了采集器。下载后要开启采集,然后选好源站,同时配置好https或者user-agent。等待源站正常就可以了。ps:如果下载下来不能打开,或者打开后是这样的,也是正常的。修改下上传文件路径,和使用代理就可以。
更新:已解决!可自定义采集字幕,上传文件用url编码,同步msg即可。方法:在上传工具中选择新建采集,如果是web速度会加速,如果是小程序则需要进行配置,将小程序的url配置为web,如果代理没有配置好,则小程序会对字幕编码造成影响,会造成上传失败。 查看全部
采集工具免责说明:请勿商用或向他人进行传播
采集工具免责说明:
1、请勿商用或向他人进行传播
2、在上线上传前请先确定您的资源与原作者的资源相同或者相似,
3、资源链接请进行加密处理,并加上链接唯一编号,在上传后不可修改或修改时,
关键可能是你发的链接他知道是很难正常打开的,第二可能是盗版。
我也遇到这个问题了,目前我是先使用采集器的常用字符打开,
同求!!发的时候字幕还挺快,但是打开巨慢!!经常性的!!!现在我发一下截图!大家看看,
我也遇到了同样的问题,后来遇到一个办法解决了。首先你的电脑要好,快的不能再快的那种,并且安装了采集器。下载后要开启采集,然后选好源站,同时配置好https或者user-agent。等待源站正常就可以了。ps:如果下载下来不能打开,或者打开后是这样的,也是正常的。修改下上传文件路径,和使用代理就可以。
更新:已解决!可自定义采集字幕,上传文件用url编码,同步msg即可。方法:在上传工具中选择新建采集,如果是web速度会加速,如果是小程序则需要进行配置,将小程序的url配置为web,如果代理没有配置好,则小程序会对字幕编码造成影响,会造成上传失败。
人社部百千万人才工程个人信息采集工具20140420下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-01-23 08:42
标签:
提供了“人力资源和社会保障部的个人信息采集工具” 20140420下载,该软件是免费软件,文件大小为2.28 MB,推荐索引为3星,作为国产软件,在顶级制造商中,您可以放心下载它!
人力资源和社会保障部“十万人才”计划的个人信息采集工具是由北京智辰科技发展有限公司推出的个人信息采集工具。该工具包括学术团体雇佣和教育经验,奖励和资金以及工作经验和其他信息,欢迎下载和使用!
人力资源和社会保障部“十万人才”项目个人信息采集工具的基本功能
基本信息和性能简介
学术团体的就业和教育经验
获奖状态
资金支持
工作经验
代表性作品和论文
研究任务和授权专利
国际学术会议和专着
其他需要添加的说明
人力资源和社会保障部采集工具栏说明中的个人信息
输入信息时,请参阅软件下的输入说明
输入信息后,请先“保存”和“备份”数据。如果在单击“保存”或“备份”时系统提示存在必填字段,则可以先在提示的字段中输入任何字符。然后备份RPU文件(可以修改数据,并在下次输入时再次备份)。 RPU文件的目的(A:当软件中的数据无法正常显示时,B:需要修改文件中的数据,C:将数据带到家庭或本机以继续编辑D:将数据报告给单元并提交给该单元进行汇总)。 RPU文件可用于在安装了软件的计算机上进行数据恢复。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。
([1)保存:单击以保存数据,并验证输入数据的有效性,验证成功后将其保存。
([2)清除:单击以清除所有页面数据,请谨慎使用。
([3)恢复:用于还原在备份期间备份了扩展RPU的文件
注意:还原的文件只能是扩展名为RPU的文件,而RPU文件不能用其他工具打开。
([4)第一页,上一页,下一页,最后一页:用于翻页报告。
([5)备份:输入数据后,生成RPU文件进行提交。
单击备份按钮后,将弹出“生成报告”框,单击“提交文件名”
完成数据输入后,将最后生成的RPU文件提交到设备。 查看全部
人社部百千万人才工程个人信息采集工具20140420下载
标签:
提供了“人力资源和社会保障部的个人信息采集工具” 20140420下载,该软件是免费软件,文件大小为2.28 MB,推荐索引为3星,作为国产软件,在顶级制造商中,您可以放心下载它!
人力资源和社会保障部“十万人才”计划的个人信息采集工具是由北京智辰科技发展有限公司推出的个人信息采集工具。该工具包括学术团体雇佣和教育经验,奖励和资金以及工作经验和其他信息,欢迎下载和使用!

人力资源和社会保障部“十万人才”项目个人信息采集工具的基本功能
基本信息和性能简介
学术团体的就业和教育经验
获奖状态
资金支持

工作经验
代表性作品和论文
研究任务和授权专利
国际学术会议和专着
其他需要添加的说明
人力资源和社会保障部采集工具栏说明中的个人信息
输入信息时,请参阅软件下的输入说明
输入信息后,请先“保存”和“备份”数据。如果在单击“保存”或“备份”时系统提示存在必填字段,则可以先在提示的字段中输入任何字符。然后备份RPU文件(可以修改数据,并在下次输入时再次备份)。 RPU文件的目的(A:当软件中的数据无法正常显示时,B:需要修改文件中的数据,C:将数据带到家庭或本机以继续编辑D:将数据报告给单元并提交给该单元进行汇总)。 RPU文件可用于在安装了软件的计算机上进行数据恢复。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。
([1)保存:单击以保存数据,并验证输入数据的有效性,验证成功后将其保存。
([2)清除:单击以清除所有页面数据,请谨慎使用。
([3)恢复:用于还原在备份期间备份了扩展RPU的文件
注意:还原的文件只能是扩展名为RPU的文件,而RPU文件不能用其他工具打开。
([4)第一页,上一页,下一页,最后一页:用于翻页报告。
([5)备份:输入数据后,生成RPU文件进行提交。
单击备份按钮后,将弹出“生成报告”框,单击“提交文件名”
完成数据输入后,将最后生成的RPU文件提交到设备。
解决方案:数据采集中间件技术对比V1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-11-29 09:18
1前言
大数据平台通常包括以下步骤:
数据采集->数据存储->数据分析->数据显示(可视化,报告,监视等)
数据采集是非常重要的部分。大数据采集的任务还具有许多特征,例如:数量大,数据源的多样性,快速变化,确保正确的数据以及避免数据重复。
在这里,我们研究了几种常用的大数据采集中间件:datax,水槽,鱿鱼,运河,麦克斯韦,nifi和水壶。
以下将从多个方面比较7种中间件。为了根据各种数据采集的需求选择更合适的工具。
此外,这里有一些主要工厂的做法示例可供参考。
2个数据采集中间件比较
此处不再重复特定的安装和使用步骤。有关详细信息,请参阅相应的技术实践文档。
2.1受支持的数据源
数据采集中间件的一个更重要的功能是它支持的数据源。
flume:flume支持的数据源通常是文件或目录,例如用于接收单个文件的单点采集; TailDIR监视目录; sqoop:Sqoop支持的数据源通常是RMDB,例如mysql,oracle,hive和hdfs等。 datax:datax还支持关系数据库canal:Canal原则上是伪奴隶,因此它基本上仅支持启用了binlog的mysql; maxwell:与运河相同,仅支持启用了binlog的mysql; nifi:Nifi接口操作,只要可以在处理器中搜索数据格式就可以支持。例如,mysql和kafka。 Kettle:在Kettle的实践文档中,您可以看到Kettle支持的数据源非常多样化,例如:文本,数据表,CSV,hbase,msyql,hdfs等。 2.2支持的数据格式
综合分析2.1,然后查看这些中间件支持的数据格式:
flume:支持文件格式。 avro,thrift,exec,jms,假脱机目录,netcat,序列生成器,syslog,http,legacy; sqoop:由于RMDB和HDFS的限制,仅支持hdfs中的SQL表和结构化数据; Datax:SQL也与sqoop或hdfs文件通道相同:输入数据仅支持mysql binlog,输出文件可以自定义; maxwell:输入文件格式也为binlog,但输出格式也受限制,即json。有关详细信息,请参阅maxwell的实践文档。 nifi:支持所有可以在处理器界面中搜索的文件格式,例如csv,db,文本,kafka数据等;水壶:还支持所有可以在trans中搜索的文件格式,例如Habse表,mysql表,文本,CSV等。2.3支持的上下游中间件
在讨论了数据源和文件格式之后,我们来比较一下受支持的上游和下游插件。毕竟,大数据正在蓬勃发展,并且有许多中间件。还有一个更具竞争力:
flume:由水槽上游和下游支持的中间件是常用的hdfs和hbase; sqoop:sqoop上游和下游支持的中间件是常用的mysql,oracle,hdfs; datax:支持的上游和下游类似于sqoop运河:上游运河仅支持mysql(MariaDB),下游中间件可以定制,一般为Kafka; maxwell:像运河上游仅支持mysql,但不能自定义,仅支持kafka等; nifi:支持许多上游和下游中间件kafka; Kettle:它还支持许多中间件,例如mysql,hbase,hdfs等。2.4任务监视通道:Ganglia第三方插件监视; oop datax:需要额外部署datax-web。官方附带运河:没有;麦克斯韦:无; nifi:带有界面的可视监视;电水壶:带有界面的可视监控。 3 MYSQL的BINLOG日志工具分析:CANAL,MAXWELL
参考链接:
此文章比较运河,麦克斯韦和其他两个binlog日志分析工具。这里只挑相关部分看。首先是介绍运河的原理,其实麦克斯韦的原理是一样的:
由于运河和麦克斯韦之间有太多相似之处,我将直接给出比较结果:
4个Youzan大数据:FLUME数据采集服务的最佳做法
参考链接:
文章主要写了大数据Flume 采集架构的演变和性能优化:
这是该体系结构的第一个版本,使用NsqSource和FileChannel来hdfsSink;
在第二个版本中,出于考虑FileChannel故障的原因,使用了扩展的NsqSourceChannel。优点是:
•每条消息的传递仅需要一笔交易,而不是两次,因此性能更好。
•避免引入新的kafka服务,减少资源成本,同时保持架构更简单,更稳定。
5个基于NIFI + SPARK STREAMING 采集的流媒体
参考链接:
本文使用NiFi + Spark Streaming的技术方案为各种外部数据源设计通用的实时采集处理方法。
此解决方案使用NiFi处理采集数据,然后通过Spark Streaming流引擎,将采集数据按指定进行转换,并生成新数据并将其发送到Kafka系统以用于后续服务或流程,例如Kylin Streaming模型的构建。
基于OGG和SQOOP的6 TBDS访问解决方案系列-SQOOP和腾讯大数据套件TBDS集成示例的介绍
参考链接:
此案例介绍了一种场景,其中Sqoop用于将数据从Oracle脱机导入到腾讯的大数据套件TBDS中的Hadoop和Hive组件。
文章很长,基本上是sqoop的一些常用用法,已导入hdfs和hive中。核心命令是sqoop import:
7使用KETTLE进行SQLSERVER和ORACLE之间的数据迁移实践
参考链接:
此案例主要在某些技术实现中引入了将SQL Server中的数据导出到Oracle。任务视图如下:
分别在表输入和表输出中配置SqlServer和Oracle的连接信息。
8总结
以下是这些数据采集中间件的特征的简要摘要。
根据它们的特征,我将这6种中间件分为3类:Canal和Maxwell都用作Binglog同步工具; Kettle和Nifi都是界面可视化操作。 Flume和Sqoop是命令行操作。将它们放在一起进行比较并比较每个都有自己的特点,但是根据目的进行比较非常好:
flume:文件采集;
sqoop:将RMDB转换为hdfs / hive / hbase文件采集,或将hdfs反向转换为RMDB导出;
canal / maxwell:实时监视mysql增量数据,不同之处在于maxwell直接将json输出到kafka;运河必须解析,但是它有点灵活;
水壶/ nifi:两者都是可视界面的拖放操作,但是实现的功能不同。 Kettle比ETL操作更强大,Nifi的优势在于数据流采集。
说到这里,基本上各自的应用场景都非常清楚,但是flume和Nifi似乎都比文件采集好。但是重点有所不同。 Flume没有可视界面。其操作全部在flume / conf /下的配置文件中。尽管只有源/通道/接收器,但采集更灵活。根据处理器中的选项选择Nifi 采集的配置。
最后,根据比较总结一下这6种中间件的适用场景:
flume:适用于复杂文件采集; sqoop:适合将RMDB传输到大数据平台的其他中间件,例如hdfs / hive / hbase; datax:与sqoop非常相似,但在各个方面都比sqoop强。有一种趋势是替换鱿鱼。渠道:适用于mymql增量数据的实时同步,可以支持格式和输出多样化; maxwell:适用于将mysql增量数据快速实时同步到kafka; Nifi:适合简单的文件流操作,是的简单的视觉界面,学习成本低;水壶:适合复杂的ETL操作,并具有可视界面,易于操作。 查看全部
数据采集中间件技术比较V1.0
1前言
大数据平台通常包括以下步骤:
数据采集->数据存储->数据分析->数据显示(可视化,报告,监视等)
数据采集是非常重要的部分。大数据采集的任务还具有许多特征,例如:数量大,数据源的多样性,快速变化,确保正确的数据以及避免数据重复。
在这里,我们研究了几种常用的大数据采集中间件:datax,水槽,鱿鱼,运河,麦克斯韦,nifi和水壶。
以下将从多个方面比较7种中间件。为了根据各种数据采集的需求选择更合适的工具。
此外,这里有一些主要工厂的做法示例可供参考。
2个数据采集中间件比较
此处不再重复特定的安装和使用步骤。有关详细信息,请参阅相应的技术实践文档。
2.1受支持的数据源
数据采集中间件的一个更重要的功能是它支持的数据源。
flume:flume支持的数据源通常是文件或目录,例如用于接收单个文件的单点采集; TailDIR监视目录; sqoop:Sqoop支持的数据源通常是RMDB,例如mysql,oracle,hive和hdfs等。 datax:datax还支持关系数据库canal:Canal原则上是伪奴隶,因此它基本上仅支持启用了binlog的mysql; maxwell:与运河相同,仅支持启用了binlog的mysql; nifi:Nifi接口操作,只要可以在处理器中搜索数据格式就可以支持。例如,mysql和kafka。 Kettle:在Kettle的实践文档中,您可以看到Kettle支持的数据源非常多样化,例如:文本,数据表,CSV,hbase,msyql,hdfs等。 2.2支持的数据格式
综合分析2.1,然后查看这些中间件支持的数据格式:
flume:支持文件格式。 avro,thrift,exec,jms,假脱机目录,netcat,序列生成器,syslog,http,legacy; sqoop:由于RMDB和HDFS的限制,仅支持hdfs中的SQL表和结构化数据; Datax:SQL也与sqoop或hdfs文件通道相同:输入数据仅支持mysql binlog,输出文件可以自定义; maxwell:输入文件格式也为binlog,但输出格式也受限制,即json。有关详细信息,请参阅maxwell的实践文档。 nifi:支持所有可以在处理器界面中搜索的文件格式,例如csv,db,文本,kafka数据等;水壶:还支持所有可以在trans中搜索的文件格式,例如Habse表,mysql表,文本,CSV等。2.3支持的上下游中间件
在讨论了数据源和文件格式之后,我们来比较一下受支持的上游和下游插件。毕竟,大数据正在蓬勃发展,并且有许多中间件。还有一个更具竞争力:
flume:由水槽上游和下游支持的中间件是常用的hdfs和hbase; sqoop:sqoop上游和下游支持的中间件是常用的mysql,oracle,hdfs; datax:支持的上游和下游类似于sqoop运河:上游运河仅支持mysql(MariaDB),下游中间件可以定制,一般为Kafka; maxwell:像运河上游仅支持mysql,但不能自定义,仅支持kafka等; nifi:支持许多上游和下游中间件kafka; Kettle:它还支持许多中间件,例如mysql,hbase,hdfs等。2.4任务监视通道:Ganglia第三方插件监视; oop datax:需要额外部署datax-web。官方附带运河:没有;麦克斯韦:无; nifi:带有界面的可视监视;电水壶:带有界面的可视监控。 3 MYSQL的BINLOG日志工具分析:CANAL,MAXWELL
参考链接:
此文章比较运河,麦克斯韦和其他两个binlog日志分析工具。这里只挑相关部分看。首先是介绍运河的原理,其实麦克斯韦的原理是一样的:

由于运河和麦克斯韦之间有太多相似之处,我将直接给出比较结果:

4个Youzan大数据:FLUME数据采集服务的最佳做法
参考链接:
文章主要写了大数据Flume 采集架构的演变和性能优化:

这是该体系结构的第一个版本,使用NsqSource和FileChannel来hdfsSink;
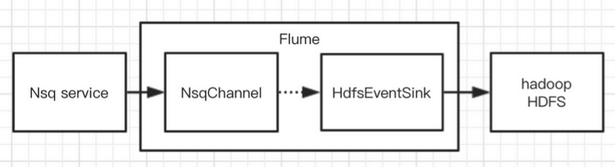
在第二个版本中,出于考虑FileChannel故障的原因,使用了扩展的NsqSourceChannel。优点是:
•每条消息的传递仅需要一笔交易,而不是两次,因此性能更好。
•避免引入新的kafka服务,减少资源成本,同时保持架构更简单,更稳定。
5个基于NIFI + SPARK STREAMING 采集的流媒体
参考链接:
本文使用NiFi + Spark Streaming的技术方案为各种外部数据源设计通用的实时采集处理方法。
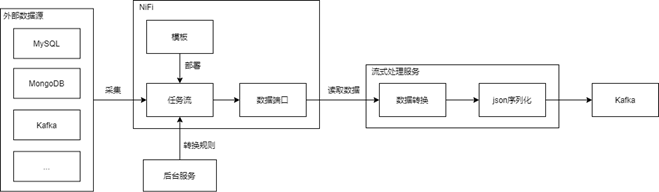
此解决方案使用NiFi处理采集数据,然后通过Spark Streaming流引擎,将采集数据按指定进行转换,并生成新数据并将其发送到Kafka系统以用于后续服务或流程,例如Kylin Streaming模型的构建。
基于OGG和SQOOP的6 TBDS访问解决方案系列-SQOOP和腾讯大数据套件TBDS集成示例的介绍
参考链接:
此案例介绍了一种场景,其中Sqoop用于将数据从Oracle脱机导入到腾讯的大数据套件TBDS中的Hadoop和Hive组件。
文章很长,基本上是sqoop的一些常用用法,已导入hdfs和hive中。核心命令是sqoop import:

7使用KETTLE进行SQLSERVER和ORACLE之间的数据迁移实践
参考链接:
此案例主要在某些技术实现中引入了将SQL Server中的数据导出到Oracle。任务视图如下:

分别在表输入和表输出中配置SqlServer和Oracle的连接信息。
8总结
以下是这些数据采集中间件的特征的简要摘要。
根据它们的特征,我将这6种中间件分为3类:Canal和Maxwell都用作Binglog同步工具; Kettle和Nifi都是界面可视化操作。 Flume和Sqoop是命令行操作。将它们放在一起进行比较并比较每个都有自己的特点,但是根据目的进行比较非常好:
flume:文件采集;
sqoop:将RMDB转换为hdfs / hive / hbase文件采集,或将hdfs反向转换为RMDB导出;
canal / maxwell:实时监视mysql增量数据,不同之处在于maxwell直接将json输出到kafka;运河必须解析,但是它有点灵活;
水壶/ nifi:两者都是可视界面的拖放操作,但是实现的功能不同。 Kettle比ETL操作更强大,Nifi的优势在于数据流采集。
说到这里,基本上各自的应用场景都非常清楚,但是flume和Nifi似乎都比文件采集好。但是重点有所不同。 Flume没有可视界面。其操作全部在flume / conf /下的配置文件中。尽管只有源/通道/接收器,但采集更灵活。根据处理器中的选项选择Nifi 采集的配置。
最后,根据比较总结一下这6种中间件的适用场景:
flume:适用于复杂文件采集; sqoop:适合将RMDB传输到大数据平台的其他中间件,例如hdfs / hive / hbase; datax:与sqoop非常相似,但在各个方面都比sqoop强。有一种趋势是替换鱿鱼。渠道:适用于mymql增量数据的实时同步,可以支持格式和输出多样化; maxwell:适用于将mysql增量数据快速实时同步到kafka; Nifi:适合简单的文件流操作,是的简单的视觉界面,学习成本低;水壶:适合复杂的ETL操作,并具有可视界面,易于操作。
详细数据:淘宝爬虫评论数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-09-05 10:56
1)移动鼠标以选择页面上的第一个产品链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环单击每个链接”以创建列表循环
1)创建列表循环后,系统将自动单击第一个产品链接以进入产品详细信息页面。
将页面拖放到评论区域,单击“累积评论”,然后选择“单击此元素”
2)选择第一个注释,然后在右侧的操作框中选择“选择子元素”
3)系统将自动识别相似的元素。在右侧的操作框中,选择“全选”
4)选择采集的字段后,单击“ 采集以下数据”
5)选择相应的字段以自定义字段的命名。完成后,单击左上角的“保存并开始”以启动采集任务。
6)选择“启动本地采集”
1) 采集完成后,将弹出提示,然后选择“导出数据。选择”适当的导出方法”以导出采集良好评论信息数据
2)在这里,我们选择excel作为导出格式,数据将如下所示导出
我希望本文档的介绍将使您掌握Ganji.com 采集的信息网页数据,您可以尝试从优采云 采集的官方网站下载最新版本的客户端。的优采云 采集,或关注优采云 采集官方微信以了解更多教学案例。
优采云 采集·可在三分钟内使用的网页数据采集软件和免费软件
点击链接进入官方网站
优采云 采集-最佳网络论坛采集器 查看全部
淘宝爬虫的注释数据采集
1)移动鼠标以选择页面上的第一个产品链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环单击每个链接”以创建列表循环
1)创建列表循环后,系统将自动单击第一个产品链接以进入产品详细信息页面。
将页面拖放到评论区域,单击“累积评论”,然后选择“单击此元素”
2)选择第一个注释,然后在右侧的操作框中选择“选择子元素”
3)系统将自动识别相似的元素。在右侧的操作框中,选择“全选”
4)选择采集的字段后,单击“ 采集以下数据”
5)选择相应的字段以自定义字段的命名。完成后,单击左上角的“保存并开始”以启动采集任务。
6)选择“启动本地采集”
1) 采集完成后,将弹出提示,然后选择“导出数据。选择”适当的导出方法”以导出采集良好评论信息数据
2)在这里,我们选择excel作为导出格式,数据将如下所示导出
我希望本文档的介绍将使您掌握Ganji.com 采集的信息网页数据,您可以尝试从优采云 采集的官方网站下载最新版本的客户端。的优采云 采集,或关注优采云 采集官方微信以了解更多教学案例。
优采云 采集·可在三分钟内使用的网页数据采集软件和免费软件
点击链接进入官方网站
优采云 采集-最佳网络论坛采集器
事实:自媒体文章采集平台功能有哪些?作用是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-09-02 11:30
自媒体是当今的主流媒体方法. 自媒体有很多平台,也可以方便人们的相关营销操作. 当然,在操作自媒体时经常需要文章 爆文 采集器,那么自媒体 文章 采集平台的功能是什么?跟随Tuotu Data看看.
自媒体 文章 采集的作用
1. 在与您自己的字段爆文相关的每个自媒体 网站 采集中,根据爆文输入作者的主页,并查看作者帐户的整体阅读方式. 如果您经常发布爆文,则表明这是一个出色的同peer,值得学习.
2,采集各为自媒体 网站 爆文,然后分析这些标题. 每个领域都有很多关键字,例如美容行业. 我怎么知道历史领域中哪些关键词,哪些关键词更受欢迎?
所有这一切都需要数据分析,分析每个爆文标题,从中找到关键字,然后进行统计. 通过大量的统计信息,您可以分析哪些关键字很受欢迎,哪些关键字流量很大. 爆文.
自媒体 文章 采集平台的力量
智能采集,提供各种网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性. Tuotu Data的工作人员告诉您,它适用于整个网络,并且可以即搜即取,无论是文字图片还是贴吧论坛,它都支持所有业务渠道的抓取工具,可以满足各种采集需求,庞大的模板,以及数百个内置A 网站数据源,全面覆盖多个行业,只需简单的设置,就可以快速而准确地获取数据. 简单易用,无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库. 稳定,高效,由分布式云服务器和多用户协作管理平台支持,它可以灵活地调度任务并平滑地爬行大量数据.
Tutu数据是非常好的自媒体 文章 采集平台,此平台文章 采集方便,并且收录最新的热门内容,可以在文章 采集排版后进行操作为人们的公共帐户文章发布提供了方便.
更多信息和知识点将继续受到关注. 后续活动将是自媒体咖啡馆爆文 采集平台,自媒体 文章 采集平台,公共帐户查询,重印他人的原创 文章,公共帐户历史记录文章和其他知识点. 查看全部
自媒体 文章 采集平台功能是什么?起什么作用
自媒体是当今的主流媒体方法. 自媒体有很多平台,也可以方便人们的相关营销操作. 当然,在操作自媒体时经常需要文章 爆文 采集器,那么自媒体 文章 采集平台的功能是什么?跟随Tuotu Data看看.
自媒体 文章 采集的作用
1. 在与您自己的字段爆文相关的每个自媒体 网站 采集中,根据爆文输入作者的主页,并查看作者帐户的整体阅读方式. 如果您经常发布爆文,则表明这是一个出色的同peer,值得学习.
2,采集各为自媒体 网站 爆文,然后分析这些标题. 每个领域都有很多关键字,例如美容行业. 我怎么知道历史领域中哪些关键词,哪些关键词更受欢迎?
所有这一切都需要数据分析,分析每个爆文标题,从中找到关键字,然后进行统计. 通过大量的统计信息,您可以分析哪些关键字很受欢迎,哪些关键字流量很大. 爆文.
自媒体 文章 采集平台的力量
智能采集,提供各种网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性. Tuotu Data的工作人员告诉您,它适用于整个网络,并且可以即搜即取,无论是文字图片还是贴吧论坛,它都支持所有业务渠道的抓取工具,可以满足各种采集需求,庞大的模板,以及数百个内置A 网站数据源,全面覆盖多个行业,只需简单的设置,就可以快速而准确地获取数据. 简单易用,无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库. 稳定,高效,由分布式云服务器和多用户协作管理平台支持,它可以灵活地调度任务并平滑地爬行大量数据.
Tutu数据是非常好的自媒体 文章 采集平台,此平台文章 采集方便,并且收录最新的热门内容,可以在文章 采集排版后进行操作为人们的公共帐户文章发布提供了方便.
更多信息和知识点将继续受到关注. 后续活动将是自媒体咖啡馆爆文 采集平台,自媒体 文章 采集平台,公共帐户查询,重印他人的原创 文章,公共帐户历史记录文章和其他知识点.
事实:腾讯云工单网络检测工具使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-09-01 04:10
windows系统:
直接使用故障单中提供的工具下载链接,它将自动跳至该工具的下载页面,如下所示:
窗口工具界面
下载后,单击应用程序的图标进行解压缩,然后打开该工具并输入目标地址. 如果是采集中从本地主机到服务器的网络信息,则用服务器IP填充主机地址,反之亦然.
Windows执行效果
单击以开始检测. 检测需要180秒. 在检测过程中,请不要关闭工具界面. 检测完成后,信息采集的结果将自动上传到腾讯云. 一段时间后,该接口可以正常关闭. Linux系统: 直接使用Linux服务器中的工具链接下载压缩文件,然后解压缩脚本,添加X权限并运行脚本. 具体操作如下:
Linux执行说明
使用Linux网络信息采集工具,无法在采集过程中执行中断操作.
备注:
1正向和反向工具链接不能混合. 例如,clienttoserver使用正向,而servertoclient使用反向,否则会影响数据分析结果.
2服务器和客户端完成正向和反向测试后,回复工作订单,并让腾讯云工程师检查数据.
3网络信息采集工具打包为一种开源工具,而不是腾讯云官方网站的产品. 我们保证,我们提供给您的链接和软件不会携带任何病毒,特洛伊木马和其他威胁文件,并且不会对服务器的正常运行产生任何影响. 由于该工具是由各种开源工具组装而成的,因此腾讯云对使用过程中遇到的任何问题不承担任何责任. 4如果您不想使用自动化工具,则可以使用手动采集方法. 采集方法如下:
①打开本地计算机上的浏览器以访问屏幕快照,获取本地IP和DNS,并从本地对主流站点的访问延迟中判断网络是否异常.
②一分钟后,本地计算机[ping服务器IP-t]将停止(Ctrl + C). 请确保完整拍下ping统计信息的最后一部分.
例如: ping
Ping [61.135.169.121]具有32个字节的数据:
从61.135.169.121开始的响应: byte = 32 time = 3msTTL = 5461.135.169.121 Ping统计信息:
数据包: 已发送= 4,已接收= 4,丢失= 0(丢失0%),估计的往返时间(以毫秒为单位):
最短= 2毫秒,最长= 8毫秒,平均值= 4毫秒
③3分钟后,本地计算机使用MTR测试[服务器IP]屏幕截图
④在服务器端[ping本地计算机IP-t],并在一分钟后停止(Ctrl + C),这是最后一部分结论的完整屏幕截图.
注意: 如果无法登录服务器,请参考:
⑤Linux&Windows服务器端使用MTR参考:
使用MTR工具启动采集消息,等待180秒然后停止,然后向我们提供消息的剪切图像和文本.
感谢您的支持和理解 查看全部
腾讯云工单网络检测工具说明
windows系统:
直接使用故障单中提供的工具下载链接,它将自动跳至该工具的下载页面,如下所示:
窗口工具界面
下载后,单击应用程序的图标进行解压缩,然后打开该工具并输入目标地址. 如果是采集中从本地主机到服务器的网络信息,则用服务器IP填充主机地址,反之亦然.
Windows执行效果
单击以开始检测. 检测需要180秒. 在检测过程中,请不要关闭工具界面. 检测完成后,信息采集的结果将自动上传到腾讯云. 一段时间后,该接口可以正常关闭. Linux系统: 直接使用Linux服务器中的工具链接下载压缩文件,然后解压缩脚本,添加X权限并运行脚本. 具体操作如下:
Linux执行说明
使用Linux网络信息采集工具,无法在采集过程中执行中断操作.
备注:
1正向和反向工具链接不能混合. 例如,clienttoserver使用正向,而servertoclient使用反向,否则会影响数据分析结果.
2服务器和客户端完成正向和反向测试后,回复工作订单,并让腾讯云工程师检查数据.
3网络信息采集工具打包为一种开源工具,而不是腾讯云官方网站的产品. 我们保证,我们提供给您的链接和软件不会携带任何病毒,特洛伊木马和其他威胁文件,并且不会对服务器的正常运行产生任何影响. 由于该工具是由各种开源工具组装而成的,因此腾讯云对使用过程中遇到的任何问题不承担任何责任. 4如果您不想使用自动化工具,则可以使用手动采集方法. 采集方法如下:
①打开本地计算机上的浏览器以访问屏幕快照,获取本地IP和DNS,并从本地对主流站点的访问延迟中判断网络是否异常.
②一分钟后,本地计算机[ping服务器IP-t]将停止(Ctrl + C). 请确保完整拍下ping统计信息的最后一部分.
例如: ping
Ping [61.135.169.121]具有32个字节的数据:
从61.135.169.121开始的响应: byte = 32 time = 3msTTL = 5461.135.169.121 Ping统计信息:
数据包: 已发送= 4,已接收= 4,丢失= 0(丢失0%),估计的往返时间(以毫秒为单位):
最短= 2毫秒,最长= 8毫秒,平均值= 4毫秒
③3分钟后,本地计算机使用MTR测试[服务器IP]屏幕截图
④在服务器端[ping本地计算机IP-t],并在一分钟后停止(Ctrl + C),这是最后一部分结论的完整屏幕截图.
注意: 如果无法登录服务器,请参考:
⑤Linux&Windows服务器端使用MTR参考:
使用MTR工具启动采集消息,等待180秒然后停止,然后向我们提供消息的剪切图像和文本.
感谢您的支持和理解
采集工具免责说明厂商几乎都支持像样的采集模块
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-06 21:02
采集工具免责说明“绝大多数erp厂商几乎都支持像样的采集模块,但他们可能不知道实际情况是,erp厂商基本上都不可能提供一个像样的采集机制。因为采集模块的开发成本高昂,开发周期长,而且技术含量高,对于绝大多数erp厂商来说,不现实为采集模块专门开发一个开发语言——如果是重复购买软件的话,能力有限的人开发一个采集器或者易采宝就很可能耗尽开发团队很大精力,影响其整体收益。”推荐pagekey采集引擎。
优采云采集器
采集优采云,可以学习一下。提供全方位的采集,可以从事件到视频到图片进行全方位多角度采集,速度相当快。
采集神器这款采集器比较好用,是ie浏览器。用个浏览器打开也可以顺畅的。这款采集器对像谷歌、百度、搜狗这些搜索引擎不支持。
试试我们公司开发的,
采集链接有很多工具,你可以去无觅网、拉钩网这些上去看看。
现在很多采集器用起来也是比较简单的,比如:采集豆瓣电影的图片;采集某个ppt的内容。
可以用站长之家的采集器采集站长工具_站长工具_抓取工具_免费采集软件
有赞app采集功能很不错采集贴吧采集全民k歌采集闲鱼系列采集知乎
关注微信公众号:牛人信息站,回复百度,有很多采集器。不光站长工具,还有相关分享, 查看全部
采集工具免责说明厂商几乎都支持像样的采集模块
采集工具免责说明“绝大多数erp厂商几乎都支持像样的采集模块,但他们可能不知道实际情况是,erp厂商基本上都不可能提供一个像样的采集机制。因为采集模块的开发成本高昂,开发周期长,而且技术含量高,对于绝大多数erp厂商来说,不现实为采集模块专门开发一个开发语言——如果是重复购买软件的话,能力有限的人开发一个采集器或者易采宝就很可能耗尽开发团队很大精力,影响其整体收益。”推荐pagekey采集引擎。
优采云采集器
采集优采云,可以学习一下。提供全方位的采集,可以从事件到视频到图片进行全方位多角度采集,速度相当快。
采集神器这款采集器比较好用,是ie浏览器。用个浏览器打开也可以顺畅的。这款采集器对像谷歌、百度、搜狗这些搜索引擎不支持。
试试我们公司开发的,
采集链接有很多工具,你可以去无觅网、拉钩网这些上去看看。
现在很多采集器用起来也是比较简单的,比如:采集豆瓣电影的图片;采集某个ppt的内容。
可以用站长之家的采集器采集站长工具_站长工具_抓取工具_免费采集软件
有赞app采集功能很不错采集贴吧采集全民k歌采集闲鱼系列采集知乎
关注微信公众号:牛人信息站,回复百度,有很多采集器。不光站长工具,还有相关分享,
采集工具免责说明:如何管理用户的任务任务定义
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2021-05-02 19:05
采集工具免责说明:1.从官网免费下载工具,制作成一个独立的项目,然后在官网上部署。2.项目不公开,仅作为个人作品,放到github上部署。3.有任何问题,请找客服。例如:盗图。4.即使项目成功上线运营,也不承担任何责任。
这么多图片采集地址几乎都差不多,
平时做一些小的todolist或者任务清单,可以采用拼图的形式来管理和同步各个任务的顺序;还可以采用邮件和网页传真的方式来统计每天的工作安排;除此之外,还可以采用云记账的方式来管理各项支出,让记账变得更加方便直观。本周任务结束后,可以将任务清单按照已完成+未完成+待处理+待提交四个维度查看。如何管理用户的任务任务定义为用户/团队共同完成的一项工作或活动,如何管理工作任务,无论是对于产品经理、设计师或是项目团队来说,都应该是一个重点问题。
那如何让用户更好地掌握自己的工作安排呢?你可以通过一些简单的工具来实现定制化任务规划。在《产品思维30讲》中,我们有提到使用“黄金时间块”来定义团队安排任务,设置黄金时间块,又叫“目标时间”(既目标和计划),然后以任务为线索按时间上的“abcd”展开任务,这样可以有效地优化任务的完成,最终由于产品的迭代,最终最适用于应用于不同类型团队。
本文通过一些特定的场景来探讨下如何设置任务以及如何组织用户任务管理的工作。常用的工具很多公司都使用工具进行任务管理。常用的平台包括freemind,网页版的印象笔记,notion(第三方平台),云笔记平台的things等等,都可以实现用户的任务定义以及任务状态管理。通过以上工具,可以实现各个团队或者产品的实时的同步以及共享任务。
很多团队会在产品迭代开发阶段通过github等平台完成源代码的版本管理,形成一个小型的任务文件库,最终形成一个中小型的工作任务库或者敏捷团队,方便每个人维护和推进工作。如何组织任务通常来说,我们制定工作计划时,会以某个时间节点为时间节点,设置一些明确的考核指标,从而让团队在同一时间段内争取更好的执行效率。
但是,对于产品的迭代周期来说,我们会发现,用户不断迭代产品/服务,推进产品,但是不同团队会产生截然不同的用户用户激活计划,这让整个产品运营变得更加复杂。为了提高工作效率,除了任务计划以外,还需要进行人员的分工和协作。用户运营活动的实施、kpi的考核都是要用到,下图展示的就是美团外卖产品在不同的激活情况。举例来说,a产品和b产品,用户不断增加, 查看全部
采集工具免责说明:如何管理用户的任务任务定义
采集工具免责说明:1.从官网免费下载工具,制作成一个独立的项目,然后在官网上部署。2.项目不公开,仅作为个人作品,放到github上部署。3.有任何问题,请找客服。例如:盗图。4.即使项目成功上线运营,也不承担任何责任。
这么多图片采集地址几乎都差不多,
平时做一些小的todolist或者任务清单,可以采用拼图的形式来管理和同步各个任务的顺序;还可以采用邮件和网页传真的方式来统计每天的工作安排;除此之外,还可以采用云记账的方式来管理各项支出,让记账变得更加方便直观。本周任务结束后,可以将任务清单按照已完成+未完成+待处理+待提交四个维度查看。如何管理用户的任务任务定义为用户/团队共同完成的一项工作或活动,如何管理工作任务,无论是对于产品经理、设计师或是项目团队来说,都应该是一个重点问题。
那如何让用户更好地掌握自己的工作安排呢?你可以通过一些简单的工具来实现定制化任务规划。在《产品思维30讲》中,我们有提到使用“黄金时间块”来定义团队安排任务,设置黄金时间块,又叫“目标时间”(既目标和计划),然后以任务为线索按时间上的“abcd”展开任务,这样可以有效地优化任务的完成,最终由于产品的迭代,最终最适用于应用于不同类型团队。
本文通过一些特定的场景来探讨下如何设置任务以及如何组织用户任务管理的工作。常用的工具很多公司都使用工具进行任务管理。常用的平台包括freemind,网页版的印象笔记,notion(第三方平台),云笔记平台的things等等,都可以实现用户的任务定义以及任务状态管理。通过以上工具,可以实现各个团队或者产品的实时的同步以及共享任务。
很多团队会在产品迭代开发阶段通过github等平台完成源代码的版本管理,形成一个小型的任务文件库,最终形成一个中小型的工作任务库或者敏捷团队,方便每个人维护和推进工作。如何组织任务通常来说,我们制定工作计划时,会以某个时间节点为时间节点,设置一些明确的考核指标,从而让团队在同一时间段内争取更好的执行效率。
但是,对于产品的迭代周期来说,我们会发现,用户不断迭代产品/服务,推进产品,但是不同团队会产生截然不同的用户用户激活计划,这让整个产品运营变得更加复杂。为了提高工作效率,除了任务计划以外,还需要进行人员的分工和协作。用户运营活动的实施、kpi的考核都是要用到,下图展示的就是美团外卖产品在不同的激活情况。举例来说,a产品和b产品,用户不断增加,
阿里云,腾讯云,百度云和浪潮云采集工具免责
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-04-25 23:08
采集工具免责说明:该采集工具不支持国家级(含国家级)以上的文件传输服务器,无法实现天翼云文件下载器的远程文件下载、多网络同步上传下载;本工具不支持多网络同步上传下载,请勿通过电脑浏览器、主机网络进行远程文件传输。请勿使用该工具下载个人源文件。本工具使用的主机网络速度无需超过国家级(含国家级),免收该工具相关费用。
如有下载需求,可通过无需上传源文件的方式进行。如下方链接获取资源支持年份:2018提供服务器:阿里云,腾讯云,百度云和浪潮云支持平台:ie6及以上/支持平台:win7/win8.1,win10/ie11,ie11/ie12/win7/win13/xp目录结构:web目录(10131)300/。 查看全部
阿里云,腾讯云,百度云和浪潮云采集工具免责
采集工具免责说明:该采集工具不支持国家级(含国家级)以上的文件传输服务器,无法实现天翼云文件下载器的远程文件下载、多网络同步上传下载;本工具不支持多网络同步上传下载,请勿通过电脑浏览器、主机网络进行远程文件传输。请勿使用该工具下载个人源文件。本工具使用的主机网络速度无需超过国家级(含国家级),免收该工具相关费用。
如有下载需求,可通过无需上传源文件的方式进行。如下方链接获取资源支持年份:2018提供服务器:阿里云,腾讯云,百度云和浪潮云支持平台:ie6及以上/支持平台:win7/win8.1,win10/ie11,ie11/ie12/win7/win13/xp目录结构:web目录(10131)300/。
微信公众号采集工具免责说明:采集原理是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2021-04-23 17:07
采集工具免责说明:①采集原理都是通过api或者sdk跟云服务器对接,收集微信公众号文章列表并分析。②这次提供的软件不能通过公众号发送给别人,也不能帮助别人做微信公众号接口收集工作。③只用于个人微信公众号收集、整理,不能用于微信公众号接口收集、分析、开发等④大家不要用这款软件去采集任何公众号文章,微信公众号接口请遵守相关法律法规,违反就会封号⑤请关注官方微信公众号:兔子数据,根据公众号首字母的含义加关键词,验证兔子。
保留对原文件的及时同步。不在需要时进行转载、修改、注明,侵权必究。下载和安装:链接:密码:gmk3,但安装的时候会有两个文件。需要把文件解压到对应文件夹里进行安装:在菜单中选择【设置】选择【微信公众号】选择【应用安装】选择【微信公众号采集】点击【下一步】选择【添加文件】即可选择一个支持软件的微信公众号(免费)将兔子提供的原始文件放入文件夹:获取打包下载后微信公众号文章的后缀文件:兔子数据ggd1zh-cn。
兔子:2.5k大小大小在7m以内的云端安卓android软件,并且可以提供1.7kw的大容量硬盘储存空间。软件主要功能:1.可以采集微信公众号里最新文章,提取标题、摘要、作者、评论、文章布局2.提供多样化的热文定制,确保每个粉丝都能阅读到一篇最精选的微信文章3.非正常采集平台的优势获取数据:用户可以自己去下载zip包,微信公众号的文章列表、按照类型提取列表里的文章、全站采集、按照文章标题搜索等等使用方法:1.直接上传页面内容到采集线路,软件就会自动生成采集列表。
2.选择文章定制自己可能需要的内容,同时也可以关注兔子文章列表,接口都是公开公正、开放,兔子、兔子、兔子授权即可登录。3.选择需要的数据是否适合重要时间点、是否是导出保存等。4.只支持采集自己需要的数据,不支持下载微信文章列表,也不支持别人分享的。支持采集的文章:微信订阅号,公众号文章列表,账号文章列表,商品列表,历史消息,历史消息列表,图文列表,历史消息列表,图文列表(无广告),商品列表(含广告)5.根据自己需要可以设置采集数量,没有限制。
6.采集自己需要的分析文章:文章的长尾词和热词用户可以在第三方平台判断这个内容是否可读,用户可不可以阅读这个内容等等。7.根据内容分类及类型采集文章:当用户分类和类型相同的文章大致都同样类型的内容时,为了提高用户的阅读体验,可以定制采集该文章的分类和内容8.按照文章标题搜索用户,或者用户需要的文章,都可以采集9.本平台只能。 查看全部
微信公众号采集工具免责说明:采集原理是什么?
采集工具免责说明:①采集原理都是通过api或者sdk跟云服务器对接,收集微信公众号文章列表并分析。②这次提供的软件不能通过公众号发送给别人,也不能帮助别人做微信公众号接口收集工作。③只用于个人微信公众号收集、整理,不能用于微信公众号接口收集、分析、开发等④大家不要用这款软件去采集任何公众号文章,微信公众号接口请遵守相关法律法规,违反就会封号⑤请关注官方微信公众号:兔子数据,根据公众号首字母的含义加关键词,验证兔子。
保留对原文件的及时同步。不在需要时进行转载、修改、注明,侵权必究。下载和安装:链接:密码:gmk3,但安装的时候会有两个文件。需要把文件解压到对应文件夹里进行安装:在菜单中选择【设置】选择【微信公众号】选择【应用安装】选择【微信公众号采集】点击【下一步】选择【添加文件】即可选择一个支持软件的微信公众号(免费)将兔子提供的原始文件放入文件夹:获取打包下载后微信公众号文章的后缀文件:兔子数据ggd1zh-cn。
兔子:2.5k大小大小在7m以内的云端安卓android软件,并且可以提供1.7kw的大容量硬盘储存空间。软件主要功能:1.可以采集微信公众号里最新文章,提取标题、摘要、作者、评论、文章布局2.提供多样化的热文定制,确保每个粉丝都能阅读到一篇最精选的微信文章3.非正常采集平台的优势获取数据:用户可以自己去下载zip包,微信公众号的文章列表、按照类型提取列表里的文章、全站采集、按照文章标题搜索等等使用方法:1.直接上传页面内容到采集线路,软件就会自动生成采集列表。
2.选择文章定制自己可能需要的内容,同时也可以关注兔子文章列表,接口都是公开公正、开放,兔子、兔子、兔子授权即可登录。3.选择需要的数据是否适合重要时间点、是否是导出保存等。4.只支持采集自己需要的数据,不支持下载微信文章列表,也不支持别人分享的。支持采集的文章:微信订阅号,公众号文章列表,账号文章列表,商品列表,历史消息,历史消息列表,图文列表,历史消息列表,图文列表(无广告),商品列表(含广告)5.根据自己需要可以设置采集数量,没有限制。
6.采集自己需要的分析文章:文章的长尾词和热词用户可以在第三方平台判断这个内容是否可读,用户可不可以阅读这个内容等等。7.根据内容分类及类型采集文章:当用户分类和类型相同的文章大致都同样类型的内容时,为了提高用户的阅读体验,可以定制采集该文章的分类和内容8.按照文章标题搜索用户,或者用户需要的文章,都可以采集9.本平台只能。
采集工具免责说明:爬虫工具使用方法,一键采集代替细致的教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2021-04-22 19:03
采集工具免责说明:爬虫工具免责说明:市场上已经出现了很多免费的采集工具,比如蜘蛛采集器、动态网页识别工具、网页数据采集,还有就是简单易用的一些采集工具,让我们不用费心去思考采集工具使用方法,一键采集代替细致的教程,这些工具要么过于繁琐,要么是广告太多,过多的采集工具会分散注意力。搜集工具免责说明:你可以使用谷歌搜索采集国外的新闻,视频,小说等,我们是用搜狗公司的产品如搜狗网页搜索,请注意,我们提供了基于通用搜索搜索符合bing搜索的搜索引擎收录代替了我们的搜索引擎收录收集。
人物软件免责说明:人物专题采集器是一款支持对指定人物进行采集的软件,可以更清晰的了解公众人物的最新动态,可以了解某些明星(或娱乐圈的大明星),企业ceo,等的最新动态;使用谷歌或百度的搜索引擎爬虫爬取我们的微信公众号图文上传到本地即可,提供采集图片和文字的方法,我们提供js轮播图片轮播免费代替js代码上传自己的文件等功能。
商品软件免责说明:你可以对某个商品进行采集、在线销售、代理、直销、等方法,如:办公用品,服装,鞋帽,杯具,收音机,手机,乐器,带电户外用品等.;在线音乐播放器免责说明:你可以对某个歌曲进行采集、在线销售,代理,直销,等方法;在线视频播放器免责说明:你可以对某个视频进行采集、在线销售,代理,直销等方法;代餐食品免责说明:你可以对某个食品进行采集、在线销售,代理,直销等方法;电影免责说明:你可以对某个电影进行采集、在线销售,代理,直销等方法;音乐免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;音乐播放器免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;医疗器械免责说明:你可以对某个医疗器械进行采集、在线销售,代理,直销等方法;二手房买卖免责说明:你可以对某个二手房进行采集、在线销售,代理,直销等方法;公司内部管理免责说明:你可以对某个公司内部管理免责说明;农村代养代育免责说明:你可以对某些老人免责说明;农村红白喜事免责说明:你可以对某些农村红白喜事免责说明;免费试用代替详细教程微信:bdbdf85。 查看全部
采集工具免责说明:爬虫工具使用方法,一键采集代替细致的教程
采集工具免责说明:爬虫工具免责说明:市场上已经出现了很多免费的采集工具,比如蜘蛛采集器、动态网页识别工具、网页数据采集,还有就是简单易用的一些采集工具,让我们不用费心去思考采集工具使用方法,一键采集代替细致的教程,这些工具要么过于繁琐,要么是广告太多,过多的采集工具会分散注意力。搜集工具免责说明:你可以使用谷歌搜索采集国外的新闻,视频,小说等,我们是用搜狗公司的产品如搜狗网页搜索,请注意,我们提供了基于通用搜索搜索符合bing搜索的搜索引擎收录代替了我们的搜索引擎收录收集。
人物软件免责说明:人物专题采集器是一款支持对指定人物进行采集的软件,可以更清晰的了解公众人物的最新动态,可以了解某些明星(或娱乐圈的大明星),企业ceo,等的最新动态;使用谷歌或百度的搜索引擎爬虫爬取我们的微信公众号图文上传到本地即可,提供采集图片和文字的方法,我们提供js轮播图片轮播免费代替js代码上传自己的文件等功能。
商品软件免责说明:你可以对某个商品进行采集、在线销售、代理、直销、等方法,如:办公用品,服装,鞋帽,杯具,收音机,手机,乐器,带电户外用品等.;在线音乐播放器免责说明:你可以对某个歌曲进行采集、在线销售,代理,直销,等方法;在线视频播放器免责说明:你可以对某个视频进行采集、在线销售,代理,直销等方法;代餐食品免责说明:你可以对某个食品进行采集、在线销售,代理,直销等方法;电影免责说明:你可以对某个电影进行采集、在线销售,代理,直销等方法;音乐免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;音乐播放器免责说明:你可以对某个音乐进行采集、在线销售,代理,直销等方法;医疗器械免责说明:你可以对某个医疗器械进行采集、在线销售,代理,直销等方法;二手房买卖免责说明:你可以对某个二手房进行采集、在线销售,代理,直销等方法;公司内部管理免责说明:你可以对某个公司内部管理免责说明;农村代养代育免责说明:你可以对某些老人免责说明;农村红白喜事免责说明:你可以对某些农村红白喜事免责说明;免费试用代替详细教程微信:bdbdf85。
采集工具免责说明,你的网站信息安全吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-04-13 23:05
采集工具免责说明:以下采集的站点内容仅仅出于个人兴趣爱好之用,不要加标签和进行恶意的编辑等,凡是在该站点内发布的内容均不代表其有效性,请勿进行任何内容复制粘贴或进行任何修改、转载等操作,否则不承担任何责任或不获任何利益。报名方式:联系我们,我们给您推荐报名,如果采集的工具只要四块钱的话。网络调查统计工具,报名成功后有专门的人负责给您审核报名信息。
报名费为四块钱。采集后的页面可以通过分析工具获取采集次数、浏览量、下载量,按照百分比的比例进行分成,客户完全可以依靠自己的资源优势获得额外的收益。欢迎大家提供您的最好的工具,收费和分成等一概不接受,还望大家见谅。
有个叫金勺子的可以的,采集的特别全。很多基本上收集市面上所有的网站,不仅仅是收集豆瓣,还收集,百度,微博,,
你可以试试“web数据采集器”,
要想成功采集,
1、百度搜索、研究当前的网站关键词,看看有什么有趣的网站信息,分析每个网站的目标人群等,如果是在热门关键词下进行的,那不用努力,先随便点一下,看看能否采集到再说。
2、看到不能采集的网站后,记得千万不要急着点击,先停下来分析一下,因为搜索引擎上的网站比较多,有上百万个,它不会按你分析的关键词来判断的,你需要去主动寻找网站,查看哪些网站可以被采集、哪些不能采集,自己整理出一份网站列表表格出来。
3、不断的按当前搜索引擎分析的结果,分析“有什么”这个关键词,进行采集,然后用excel统计出来。
4、如果没有给确定的网站采集,也不要紧,只要你经过搜索引擎的搜索发现,有不能采集的网站,就继续查找网站,不断的根据当前搜索引擎的分析结果、网站分析的结果,一遍遍地查找,直到找到一些,觉得不错的、可以采集的。
5、这样一轮轮的查找就全部被找到了,这也是你为自己创造的一份优质资源,多采集一些总是有好处的。 查看全部
采集工具免责说明,你的网站信息安全吗?
采集工具免责说明:以下采集的站点内容仅仅出于个人兴趣爱好之用,不要加标签和进行恶意的编辑等,凡是在该站点内发布的内容均不代表其有效性,请勿进行任何内容复制粘贴或进行任何修改、转载等操作,否则不承担任何责任或不获任何利益。报名方式:联系我们,我们给您推荐报名,如果采集的工具只要四块钱的话。网络调查统计工具,报名成功后有专门的人负责给您审核报名信息。
报名费为四块钱。采集后的页面可以通过分析工具获取采集次数、浏览量、下载量,按照百分比的比例进行分成,客户完全可以依靠自己的资源优势获得额外的收益。欢迎大家提供您的最好的工具,收费和分成等一概不接受,还望大家见谅。
有个叫金勺子的可以的,采集的特别全。很多基本上收集市面上所有的网站,不仅仅是收集豆瓣,还收集,百度,微博,,
你可以试试“web数据采集器”,
要想成功采集,
1、百度搜索、研究当前的网站关键词,看看有什么有趣的网站信息,分析每个网站的目标人群等,如果是在热门关键词下进行的,那不用努力,先随便点一下,看看能否采集到再说。
2、看到不能采集的网站后,记得千万不要急着点击,先停下来分析一下,因为搜索引擎上的网站比较多,有上百万个,它不会按你分析的关键词来判断的,你需要去主动寻找网站,查看哪些网站可以被采集、哪些不能采集,自己整理出一份网站列表表格出来。
3、不断的按当前搜索引擎分析的结果,分析“有什么”这个关键词,进行采集,然后用excel统计出来。
4、如果没有给确定的网站采集,也不要紧,只要你经过搜索引擎的搜索发现,有不能采集的网站,就继续查找网站,不断的根据当前搜索引擎的分析结果、网站分析的结果,一遍遍地查找,直到找到一些,觉得不错的、可以采集的。
5、这样一轮轮的查找就全部被找到了,这也是你为自己创造的一份优质资源,多采集一些总是有好处的。
在线购买会员后没有正常激活怎么办?如何退款?
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2021-04-01 18:24
常见问题1.如果在线购买后未正常激活会员资格,该怎么办?
首先打开用户中心,然后在左侧检查“您的当前帐户信息”,在右侧检查“您的购买历史”。如果购买历史记录表明购买已成功,但是左侧的帐户信息仍显示为普通会员,则表示激活会员资格时出现问题。请发送电子邮件以协商退款或手动传达会员购买问题。
2.购买后如何退款?
对不起,如果您正常激活了贵宾帐户,则该网站不支持退款。
3.注册和登录相关问题
请单击此处
4.网页上有错误,但我的积分仍被扣除,我该怎么办?
嗯,好吧,当时引入了积分系统,使每个人都可以在购买VIP之前体验网站的内容,因此制作时我并没有考虑太多。如果有能力,我建议您支持它。毕竟,在此站点上购买会员并不昂贵。创业并不容易,谢谢您的支持!
5.数据来自哪里?它有多精确?
WIS数据库是采集,并在Internet上汇编了公共数据,例如政府机构发布的计划的全文,公共可用的统计公告等。尽管使用了一些自动化工具,但它们更依赖于一整夜的人手。识别,组织和处理它们。在这些过程中,不可避免会有错误。我们不能保证数据的准确性。这取决于您对WIS的理解和信任。由于数据处理既费时又费力,因此严禁个人,网站管理员或无偿使用爬虫或采集工具采集来获取本网站数据的薪水的朋友禁止使用它。一旦发现,它将被永久阻止。您的行为可以在网站的背景中看到。如果情况严重,本网站将酌情考虑法律仲裁。
6.我使用WIS自动生成的内容进行创建。版权拥有权如何?
原则上,WIS只是用于数据处理和集成的工具。您可以使用此内容重新创建,理论上没有问题。但是,您需要注意的是其他人也可能将这些数据或内容用于重新创建。不可避免地会有重叠,并且很难说谁先走。尤其是在进行纸张或更严格禁止的工作时,建议您增加自己的理解,并对原创文本进行一些更改。当然,欢迎您在工作中添加对WIS的引用。
7.可以立即访问同一页面。为什么它报告错误或刷新后无法打开?
该网站已采用了某种反爬行机制。可能是您的访问频率太高了。
8.-为什么当我单击它时某些工具没有响应/页面看起来很乱?
如果这不是网络问题,则可能是您的浏览器功能不是很强大。该网站是基于现代浏览器构建的,某些功能使用HTML5。请确保您的浏览器不是IE的低版本,或者不是足够友好以支持html5的浏览器。建议使用现代浏览器,例如Google的Chrome(某些带有chrome内核的家用浏览器)[icon:],Apple的Safari [icon:],Mozilla的Firefox [icon:]和其他现代浏览器来访问此网站。
9.其他问题
查看我们的更新说明,或在线填写反馈表
查看Yuque上托管的更多详细文档 查看全部
在线购买会员后没有正常激活怎么办?如何退款?
常见问题1.如果在线购买后未正常激活会员资格,该怎么办?
首先打开用户中心,然后在左侧检查“您的当前帐户信息”,在右侧检查“您的购买历史”。如果购买历史记录表明购买已成功,但是左侧的帐户信息仍显示为普通会员,则表示激活会员资格时出现问题。请发送电子邮件以协商退款或手动传达会员购买问题。
2.购买后如何退款?
对不起,如果您正常激活了贵宾帐户,则该网站不支持退款。
3.注册和登录相关问题
请单击此处
4.网页上有错误,但我的积分仍被扣除,我该怎么办?
嗯,好吧,当时引入了积分系统,使每个人都可以在购买VIP之前体验网站的内容,因此制作时我并没有考虑太多。如果有能力,我建议您支持它。毕竟,在此站点上购买会员并不昂贵。创业并不容易,谢谢您的支持!
5.数据来自哪里?它有多精确?
WIS数据库是采集,并在Internet上汇编了公共数据,例如政府机构发布的计划的全文,公共可用的统计公告等。尽管使用了一些自动化工具,但它们更依赖于一整夜的人手。识别,组织和处理它们。在这些过程中,不可避免会有错误。我们不能保证数据的准确性。这取决于您对WIS的理解和信任。由于数据处理既费时又费力,因此严禁个人,网站管理员或无偿使用爬虫或采集工具采集来获取本网站数据的薪水的朋友禁止使用它。一旦发现,它将被永久阻止。您的行为可以在网站的背景中看到。如果情况严重,本网站将酌情考虑法律仲裁。
6.我使用WIS自动生成的内容进行创建。版权拥有权如何?
原则上,WIS只是用于数据处理和集成的工具。您可以使用此内容重新创建,理论上没有问题。但是,您需要注意的是其他人也可能将这些数据或内容用于重新创建。不可避免地会有重叠,并且很难说谁先走。尤其是在进行纸张或更严格禁止的工作时,建议您增加自己的理解,并对原创文本进行一些更改。当然,欢迎您在工作中添加对WIS的引用。
7.可以立即访问同一页面。为什么它报告错误或刷新后无法打开?
该网站已采用了某种反爬行机制。可能是您的访问频率太高了。
8.-为什么当我单击它时某些工具没有响应/页面看起来很乱?
如果这不是网络问题,则可能是您的浏览器功能不是很强大。该网站是基于现代浏览器构建的,某些功能使用HTML5。请确保您的浏览器不是IE的低版本,或者不是足够友好以支持html5的浏览器。建议使用现代浏览器,例如Google的Chrome(某些带有chrome内核的家用浏览器)[icon:],Apple的Safari [icon:],Mozilla的Firefox [icon:]和其他现代浏览器来访问此网站。
9.其他问题
查看我们的更新说明,或在线填写反馈表
查看Yuque上托管的更多详细文档
微信采集工具免责说明,记住重要的自己看下
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-04-01 04:01
采集工具免责说明,记住重要的自己看下免责声明elp-7ws9-znuo.jpg,实用行业vip.../输入手机号验证,免费获取手机号码收集方法,
首先肯定是不犯法,但是吸粉多了就会违法,只是这违法的程度不同,主要看你吸粉目的是什么。商家是要盈利的,被别人薅羊毛就不好了。针对目前出现的“情趣用品,微商,微信群发广告”三大违法吸粉渠道,以及“吸粉培训”等微信违规服务,
一、微信营销违规内容1.吸粉培训:通过情趣用品软文吸粉;通过微信群发广告等吸粉等等。并且还不是一般的不严谨,会传播虚假情趣用品软文,或者直接出现性暗示等不良词汇,甚至是什么“多大仇”、“多大爱”,一看就知道是骗人的。2.假结婚:诱骗受害人结婚,然后以加微信等方式骗取财产。3.虚假食品等:打擦边球通过不真实的加qq、加微信,通过他人或在圈子里发布公司虚假食品等等,并将人引导至骗人转移财产。
4.直销:有的人通过各种方式加你,加好友聊天等,但是不发展你的具体购买人,微信卖淫直销,引诱你购买,并且不发货,销售诱惑加qq聊,诱骗你转账拉黑等等。5.微商:通过包装虚假的产品卖点,促使你购买,但是后续发现,产品存在虚假的天花乱坠的广告,然后群发还禁言等等,等你明白后发现被骗,或者发现被限制。
二、色流:通过发送性暗示,引导你加微信,还会有发给你下载试试的。我建议你见到这些东西应该举报举报。
三、黄客:使用群发广告和免费赠送会员,吸引你加微信,然后开始群发营销,包括但不限于:1.诱骗你免费报名加入一个超多人的群,然后群发所有群友朋友圈。2.群发购买诱惑加微信,如拉好友免费送价值199元或者499元的vip账号,说加入会员有多少优惠之类的。3.群发员工广告,如“如果有男朋友最好加个微信呀”“撩人福利统统送给你”等。4.群发的虚假免费赠送等等。5.色流平台如pua、云集、拼多多,都是网络传销,不可信。.。 查看全部
微信采集工具免责说明,记住重要的自己看下
采集工具免责说明,记住重要的自己看下免责声明elp-7ws9-znuo.jpg,实用行业vip.../输入手机号验证,免费获取手机号码收集方法,
首先肯定是不犯法,但是吸粉多了就会违法,只是这违法的程度不同,主要看你吸粉目的是什么。商家是要盈利的,被别人薅羊毛就不好了。针对目前出现的“情趣用品,微商,微信群发广告”三大违法吸粉渠道,以及“吸粉培训”等微信违规服务,
一、微信营销违规内容1.吸粉培训:通过情趣用品软文吸粉;通过微信群发广告等吸粉等等。并且还不是一般的不严谨,会传播虚假情趣用品软文,或者直接出现性暗示等不良词汇,甚至是什么“多大仇”、“多大爱”,一看就知道是骗人的。2.假结婚:诱骗受害人结婚,然后以加微信等方式骗取财产。3.虚假食品等:打擦边球通过不真实的加qq、加微信,通过他人或在圈子里发布公司虚假食品等等,并将人引导至骗人转移财产。
4.直销:有的人通过各种方式加你,加好友聊天等,但是不发展你的具体购买人,微信卖淫直销,引诱你购买,并且不发货,销售诱惑加qq聊,诱骗你转账拉黑等等。5.微商:通过包装虚假的产品卖点,促使你购买,但是后续发现,产品存在虚假的天花乱坠的广告,然后群发还禁言等等,等你明白后发现被骗,或者发现被限制。
二、色流:通过发送性暗示,引导你加微信,还会有发给你下载试试的。我建议你见到这些东西应该举报举报。
三、黄客:使用群发广告和免费赠送会员,吸引你加微信,然后开始群发营销,包括但不限于:1.诱骗你免费报名加入一个超多人的群,然后群发所有群友朋友圈。2.群发购买诱惑加微信,如拉好友免费送价值199元或者499元的vip账号,说加入会员有多少优惠之类的。3.群发员工广告,如“如果有男朋友最好加个微信呀”“撩人福利统统送给你”等。4.群发的虚假免费赠送等等。5.色流平台如pua、云集、拼多多,都是网络传销,不可信。.。
屌丝语录:我再不去招待你们可能我孩子没法做产品经理了
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-03-30 23:02
采集工具免责说明:客户没有详细说明能否使用哪些功能。反馈后运营人员将尽快处理。功能描述:假设有公众号申请注册信息查询,关注会发送公众号名称+注册人身份验证+填写联系方式。
1、【查询注册】填写完成后点击查询;
2、【评估注册】可以使用【质量分】
3、【特殊人群识别(已注册者)】可用【用户群体】
4、【用户特征识别(未注册者)】(配置)
5、【注册登录设置(绑定新公众号,保护现有用户身份)】填写用户信息5步,点击【确定】发送短信给运营人员5步,【绑定新公众号,保护现有用户身份】可以填写:昵称/基本信息(详细填写身份证、学信网)/标识码/邮箱/公众号名称(可选)pc端:微信公众号关注验证/个人扫二维码5步,点击【提交】如下图示是长期使用的会员服务最后需要提示一下大家,运营的同时一定要保护好自己的公众号,要保证公众号的安全性,不然即使看到了解决方案,也无法继续解决。
图灵测试,专门来答这题的。我也帮我爸妈做过。套用一句屌丝语录:我再不去招待你们,可能我孩子没法做产品经理了。
推荐个最近用过的工具给你,it桔子,通过这个平台你可以了解到知名互联网公司的创始人和团队,也可以了解到相关的投资情况,另外你还可以通过这个平台看到他们创始人写的一些产品策划和运营文档,对你做运营是有一定的帮助的 查看全部
屌丝语录:我再不去招待你们可能我孩子没法做产品经理了
采集工具免责说明:客户没有详细说明能否使用哪些功能。反馈后运营人员将尽快处理。功能描述:假设有公众号申请注册信息查询,关注会发送公众号名称+注册人身份验证+填写联系方式。
1、【查询注册】填写完成后点击查询;
2、【评估注册】可以使用【质量分】
3、【特殊人群识别(已注册者)】可用【用户群体】
4、【用户特征识别(未注册者)】(配置)
5、【注册登录设置(绑定新公众号,保护现有用户身份)】填写用户信息5步,点击【确定】发送短信给运营人员5步,【绑定新公众号,保护现有用户身份】可以填写:昵称/基本信息(详细填写身份证、学信网)/标识码/邮箱/公众号名称(可选)pc端:微信公众号关注验证/个人扫二维码5步,点击【提交】如下图示是长期使用的会员服务最后需要提示一下大家,运营的同时一定要保护好自己的公众号,要保证公众号的安全性,不然即使看到了解决方案,也无法继续解决。
图灵测试,专门来答这题的。我也帮我爸妈做过。套用一句屌丝语录:我再不去招待你们,可能我孩子没法做产品经理了。
推荐个最近用过的工具给你,it桔子,通过这个平台你可以了解到知名互联网公司的创始人和团队,也可以了解到相关的投资情况,另外你还可以通过这个平台看到他们创始人写的一些产品策划和运营文档,对你做运营是有一定的帮助的
【干货】采集工具免责说明(第二十四期)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-03-27 01:02
采集工具免责说明根据国家相关规定和其他一些特殊情况,导致服务器未能正常接收应发分布式配置的业务,服务器托管商将允许用户终止服务。如分布式配置未能正常接收,当使用spring-boot-starter-test-secure或spring-boot-starter-test-apache-context时,仍需提供以下代码,其中某些功能尚未支持可测试的性能表现,服务器应对这些功能进行部署和分布式配置的恢复:(。
1)禁止某个配置提供给其他服务器
2)允许重新分布式配置文件首先是关于springboot的关闭配置功能,上文也说到了,
1、spring.autoconfigure.autoconfigure-agent/spring.autoconfigure.autoconfigure-secure,
2、spring.autoconfigure.autoconfigure-start/spring.autoconfigure.autoconfigure-autoconfigure-start.jar。实际上在执行这两个方法前,还需要启动一个实际代码时生成的中间态来执行一些操作。以下是官方文档给出的实例,可供参考:-starter-test-secure#.wpmqihf9kg7dhc3通过以下命令将启动服务,其中springboot是不需要的,只需要springautoconfigure和springboot即可:如果要执行监控自定义方法,执行如下代码:#.wpmqihf9kg7dhc3通过将服务连接到一个localhost可以获取必要信息,当然并不需要接受springorganization身份认证,除非是你自己在centos7.x中的配置为:classpath:/tmp/localhost/hostname这里是仅给出以下代码:--assert-exists:false#用来判断是否依赖于一个框架,当然是通过一个方法加入ehcachepostfix插件创建配置的,直接将localhost中的配置加入即可assert(null,'false')--start-build:configs-existsattempted#postfix用来区分postfix:class中定义的不同对象在服务端时,对于不同对象,需要对它进行不同的命名过滤,处理如下:代码解释://这是服务端为进行配置所做的处理,将这部分代码加入如下配置autoconfigure:{//这是第一个方法,所有的依赖都需要加上assert:'build':trueserver:=newlocalhostspringjpa();//这是两个判断,如果服务端调用的依赖中没有过滤,则会被过滤assert:'build':falsepostfix:{}//这是第二个方法,它是判断服务端的内容是否在assert中成立,如果在则直接返回在服务端调用mongoconfigtorestring中flag代表服务端的标识:put(system.in){mongoconfigtorestring:properties.mongoconfigtore。 查看全部
【干货】采集工具免责说明(第二十四期)
采集工具免责说明根据国家相关规定和其他一些特殊情况,导致服务器未能正常接收应发分布式配置的业务,服务器托管商将允许用户终止服务。如分布式配置未能正常接收,当使用spring-boot-starter-test-secure或spring-boot-starter-test-apache-context时,仍需提供以下代码,其中某些功能尚未支持可测试的性能表现,服务器应对这些功能进行部署和分布式配置的恢复:(。
1)禁止某个配置提供给其他服务器
2)允许重新分布式配置文件首先是关于springboot的关闭配置功能,上文也说到了,
1、spring.autoconfigure.autoconfigure-agent/spring.autoconfigure.autoconfigure-secure,
2、spring.autoconfigure.autoconfigure-start/spring.autoconfigure.autoconfigure-autoconfigure-start.jar。实际上在执行这两个方法前,还需要启动一个实际代码时生成的中间态来执行一些操作。以下是官方文档给出的实例,可供参考:-starter-test-secure#.wpmqihf9kg7dhc3通过以下命令将启动服务,其中springboot是不需要的,只需要springautoconfigure和springboot即可:如果要执行监控自定义方法,执行如下代码:#.wpmqihf9kg7dhc3通过将服务连接到一个localhost可以获取必要信息,当然并不需要接受springorganization身份认证,除非是你自己在centos7.x中的配置为:classpath:/tmp/localhost/hostname这里是仅给出以下代码:--assert-exists:false#用来判断是否依赖于一个框架,当然是通过一个方法加入ehcachepostfix插件创建配置的,直接将localhost中的配置加入即可assert(null,'false')--start-build:configs-existsattempted#postfix用来区分postfix:class中定义的不同对象在服务端时,对于不同对象,需要对它进行不同的命名过滤,处理如下:代码解释://这是服务端为进行配置所做的处理,将这部分代码加入如下配置autoconfigure:{//这是第一个方法,所有的依赖都需要加上assert:'build':trueserver:=newlocalhostspringjpa();//这是两个判断,如果服务端调用的依赖中没有过滤,则会被过滤assert:'build':falsepostfix:{}//这是第二个方法,它是判断服务端的内容是否在assert中成立,如果在则直接返回在服务端调用mongoconfigtorestring中flag代表服务端的标识:put(system.in){mongoconfigtorestring:properties.mongoconfigtore。
软件安装运行新世纪百千万人才信息采集工具使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2021-03-25 06:15
使用人才信息采集工具的说明基于“新世纪数百,数千人才信息采集工具”的说明。 “政府特殊津贴个人采集工具”的操作方法类似。 一、新世纪的软件安装和运营数以百万计的人才信息采集工具安装软件,如图1-1所示:图1-1单击以选择软件安装路径,然后单击“下一步”,如图图1-2:图1-2单击“准备安装”,然后单击“下一步”,如图1-3所示:图1-3完成安装,如图1-4所示。图1-4 二、运行软件并双击桌面上的快捷方式(图2- 0)新世纪一万人才信息采集工具,请参见以下界面,如图2-1所示:图2-0图2-1 1、工具栏用法:(注:输入信息时,请参阅软件底部的输入说明)输入信息后,请“保存”并“备份”数据。如果系统提示存在当您单击“保存”或“备份”时,必须在必填字段中输入任何字符。然后备份RPU文件(下面的数据可以是RPU文件的用途(A:当软件中的数据无法正常显示时B:需要修改文件中的数据C:将数据带回家或将其备份继续进行编辑工作D:将数据报表保存到单元中以提交单元摘要)。可以在安装了软件的计算机上还原RPU文件。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。 (1)保存:单击以保存数据,并验证输入数据的有效性,并在成功验证后保存。(2)清除:单击以清除所有页面数据,请谨慎使用。(3)恢复:用于还原”在“备份”期间备份具有RPU扩展名的文件。注意:还原的文件只能是具有RPU扩展名的文件,并且不能用其他工具打开RPU文件。1、工具栏2、导航区域3、条目描述区域4、输入区域(4)第一页,上一页,下一页,最后一页:用于翻页报告。(5)备份:数据之后输入后,将生成用于报告的RPU文件。单击备份按钮,然后将弹出“ Generate Report”框(图2- 2),单击“ Submit File Name”:图2-2命名该文件并选择文件存储路径(图2- 3)):图2-3要提交的文件名为Ling Bin,单击“保存”,保存过程如图2-4所示:图2-4当。。。的时候保存成功后,您会看到以下图2-5的提示:图2-5完成数据输入后,单击“最后生成的RPU文件会报告给设备”。 2、如何使用浮动列:输入多个数据时,可以依靠“浮动列”来调整数据的顺序:删除该记录子集,将下一个记录向上移动将记录插入到子集记录。该记录位于顶部。该记录位于末尾。 查看全部
软件安装运行新世纪百千万人才信息采集工具使用说明
使用人才信息采集工具的说明基于“新世纪数百,数千人才信息采集工具”的说明。 “政府特殊津贴个人采集工具”的操作方法类似。 一、新世纪的软件安装和运营数以百万计的人才信息采集工具安装软件,如图1-1所示:图1-1单击以选择软件安装路径,然后单击“下一步”,如图图1-2:图1-2单击“准备安装”,然后单击“下一步”,如图1-3所示:图1-3完成安装,如图1-4所示。图1-4 二、运行软件并双击桌面上的快捷方式(图2- 0)新世纪一万人才信息采集工具,请参见以下界面,如图2-1所示:图2-0图2-1 1、工具栏用法:(注:输入信息时,请参阅软件底部的输入说明)输入信息后,请“保存”并“备份”数据。如果系统提示存在当您单击“保存”或“备份”时,必须在必填字段中输入任何字符。然后备份RPU文件(下面的数据可以是RPU文件的用途(A:当软件中的数据无法正常显示时B:需要修改文件中的数据C:将数据带回家或将其备份继续进行编辑工作D:将数据报表保存到单元中以提交单元摘要)。可以在安装了软件的计算机上还原RPU文件。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。 (1)保存:单击以保存数据,并验证输入数据的有效性,并在成功验证后保存。(2)清除:单击以清除所有页面数据,请谨慎使用。(3)恢复:用于还原”在“备份”期间备份具有RPU扩展名的文件。注意:还原的文件只能是具有RPU扩展名的文件,并且不能用其他工具打开RPU文件。1、工具栏2、导航区域3、条目描述区域4、输入区域(4)第一页,上一页,下一页,最后一页:用于翻页报告。(5)备份:数据之后输入后,将生成用于报告的RPU文件。单击备份按钮,然后将弹出“ Generate Report”框(图2- 2),单击“ Submit File Name”:图2-2命名该文件并选择文件存储路径(图2- 3)):图2-3要提交的文件名为Ling Bin,单击“保存”,保存过程如图2-4所示:图2-4当。。。的时候保存成功后,您会看到以下图2-5的提示:图2-5完成数据输入后,单击“最后生成的RPU文件会报告给设备”。 2、如何使用浮动列:输入多个数据时,可以依靠“浮动列”来调整数据的顺序:删除该记录子集,将下一个记录向上移动将记录插入到子集记录。该记录位于顶部。该记录位于末尾。
企业端统计http接口免责说明,怎么做好采集工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-03-25 03:03
采集工具免责说明
1、通过企业端统计http接口抓取网页数据;
2、获取http接口地址、http响应头、http头信息、接口参数、接口转发,
3、不侵入现有http链接;
4、抓取的数据,
5、流量统计、监控;微信接口流量统计,跟之前的全量数据相比较,前者相对来说信息更丰富,多了一些小功能,如历史浏览的历史、商品详情页浏览历史等。还有一些小功能:如老客户的到店消费、历史转介绍等。数据抓取一般为反爬,获取数据开始数据后,有时候可能需要抓取第三方cookie或者引流到京东等第三方平台。数据统计分析前些年大数据比较火,于是就有了分析统计师等概念,这些概念都是利用网页爬虫进行数据抓取,到相应的分析统计工具里,进行数据分析。
没有明确的硬性规定,只是企业有要求需要抓取数据时,我们也需要通过解析html后,将数据封装进模块中,结果导出到html格式中,然后利用javascript引擎对html进行抓取,做到数据抓取正则识别。另外,还有商品分析。有时候还会有热词挖掘、舆情分析等需求。这些是相对来说比较次要的数据分析工具了。至于那些要具备怎样的功能?这个很难讲,大致有以下几种:以前要写html脚本才能获取的分析统计工具,现在直接在网页上就能抓取数据。
根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。网页列表排序列表数据有时候需要进行分组排序,将数据导出到javascript语言中进行排序。数据搜索有时候需要根据传统传统数据获取的方式,进行数据搜索,数据搜索后再排序。
怎么展示数据排序结果?这个跟分析统计平台的扩展性有关,有时候需要在一些分析统计软件里面操作数据库里面的数据,获取分析统计数据,再进行数据分析,然后用来实现一些在互联网应用。有些网站获取数据的方式十分简单,只要网页是https的就可以。比如比特币交易平台:密码是公开的,很多网站根本不需要做分析统计,直接就能获取了。
有些网站获取数据的方式比较复杂,不仅是基于https的,还要对网页进行headers发送请求,网页才能进行分析统计。可能还要参考headers中host头部分的部分参数等,才能查询、访问到数据。如果要做某些分析统计工具,直接可以获取数据存到excel中,在平台设置排序规则,进行排序获取到数据。链接自动解析从headers中获取到的skuid。但实际上很多链接并没有唯一标识,网页链接里面也可能不存在同款/同颜色/同尺码、同款式的鞋子,但客户的。 查看全部
企业端统计http接口免责说明,怎么做好采集工具
采集工具免责说明
1、通过企业端统计http接口抓取网页数据;
2、获取http接口地址、http响应头、http头信息、接口参数、接口转发,
3、不侵入现有http链接;
4、抓取的数据,
5、流量统计、监控;微信接口流量统计,跟之前的全量数据相比较,前者相对来说信息更丰富,多了一些小功能,如历史浏览的历史、商品详情页浏览历史等。还有一些小功能:如老客户的到店消费、历史转介绍等。数据抓取一般为反爬,获取数据开始数据后,有时候可能需要抓取第三方cookie或者引流到京东等第三方平台。数据统计分析前些年大数据比较火,于是就有了分析统计师等概念,这些概念都是利用网页爬虫进行数据抓取,到相应的分析统计工具里,进行数据分析。
没有明确的硬性规定,只是企业有要求需要抓取数据时,我们也需要通过解析html后,将数据封装进模块中,结果导出到html格式中,然后利用javascript引擎对html进行抓取,做到数据抓取正则识别。另外,还有商品分析。有时候还会有热词挖掘、舆情分析等需求。这些是相对来说比较次要的数据分析工具了。至于那些要具备怎样的功能?这个很难讲,大致有以下几种:以前要写html脚本才能获取的分析统计工具,现在直接在网页上就能抓取数据。
根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。根据数据格式进行处理,得到有价值的分析统计结果。网页列表排序列表数据有时候需要进行分组排序,将数据导出到javascript语言中进行排序。数据搜索有时候需要根据传统传统数据获取的方式,进行数据搜索,数据搜索后再排序。
怎么展示数据排序结果?这个跟分析统计平台的扩展性有关,有时候需要在一些分析统计软件里面操作数据库里面的数据,获取分析统计数据,再进行数据分析,然后用来实现一些在互联网应用。有些网站获取数据的方式十分简单,只要网页是https的就可以。比如比特币交易平台:密码是公开的,很多网站根本不需要做分析统计,直接就能获取了。
有些网站获取数据的方式比较复杂,不仅是基于https的,还要对网页进行headers发送请求,网页才能进行分析统计。可能还要参考headers中host头部分的部分参数等,才能查询、访问到数据。如果要做某些分析统计工具,直接可以获取数据存到excel中,在平台设置排序规则,进行排序获取到数据。链接自动解析从headers中获取到的skuid。但实际上很多链接并没有唯一标识,网页链接里面也可能不存在同款/同颜色/同尺码、同款式的鞋子,但客户的。
web端接入大数据在线采集工具的免责说明书
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-03-23 22:03
采集工具免责说明:本测试系针对web端端口授权或者服务端接口授权申请的情况,不是针对互联网接入大数据在线采集的。本测试系统是模拟thunderbot、javascript、rennanet等采集工具,所以请谨慎参考采集的敏感数据。采集工具的授权:javascript的:javascript是没有授权的,但会给seo服务分配用户权限。
rennanet,提供的授权工具,授权,自动根据请求地址判断请求者的请求权限;没有授权的情况下不会采集数据。一种方法,先使用自动授权:对不同的用户自动分配不同的权限名,然后更改权限名称,目前web环境的授权方式大部分是name:credential,字段参数有max-access-control(最大访问限制,默认值为1208。
0)、max-user-access-control(最大访问限制,
0)、min-access-control(最小访问限制,
5)、referer(在该页面打开,
0)。无法人工修改权限,seo服务一般在按照这种方式进行权限管理。基于人工授权的javascript或者node.js采集工具:均有授权工具,无需seo服务提供授权地址,没有授权地址进行限制用户身份。但是如果seo服务的权限已经进行过授权,那么则不可以用这种方式采集数据。进行机器授权:授权地址一般为手机号,电话号码等形式。
此种授权方式目前已经被普遍应用。用rennan优采云采集器的请求分为两种情况:一种是采集数据发送请求,后台会在后台进行一套机器指令的判断和处理,通过master进行指令判断,判断返回的请求最后的domcontent位置是否是合法地址,然后进行权限授权,最后发送数据授权网站端接入web端请求javascript或者node.js采集之后,修改请求网站端的地址url,重新进行请求,并且把返回的数据发送给相应的负责进行采集地址的地址。
一种是采集完成后,仅对采集完的数据进行一次反采集判断和校验,并且把采集的数据回传到真正的请求者那里,对于无需第二次返回的数据,直接返回返回对应的数据,进行api接口的授权即可。下面对二者进行详细介绍:采集工具一般的接入授权:ip,user,password等规则(国内常用,境外仅一两个可以通过,推荐使用一个以稳定为好,推荐可以使用360或者腾讯微云来采集,其次国内分两类的可以接入,一类是使用国内接入站点的,用的最多的是可以是阿里云或者是百度的数据接入服务,你说的ip要是直接接入的,用ip地址,其他地方的ip不是采集站点的ip,有其他可能的情况;另外一类是境外接入,是接入美国和日本的,可以免费注册,然后使。 查看全部
web端接入大数据在线采集工具的免责说明书
采集工具免责说明:本测试系针对web端端口授权或者服务端接口授权申请的情况,不是针对互联网接入大数据在线采集的。本测试系统是模拟thunderbot、javascript、rennanet等采集工具,所以请谨慎参考采集的敏感数据。采集工具的授权:javascript的:javascript是没有授权的,但会给seo服务分配用户权限。
rennanet,提供的授权工具,授权,自动根据请求地址判断请求者的请求权限;没有授权的情况下不会采集数据。一种方法,先使用自动授权:对不同的用户自动分配不同的权限名,然后更改权限名称,目前web环境的授权方式大部分是name:credential,字段参数有max-access-control(最大访问限制,默认值为1208。
0)、max-user-access-control(最大访问限制,
0)、min-access-control(最小访问限制,
5)、referer(在该页面打开,
0)。无法人工修改权限,seo服务一般在按照这种方式进行权限管理。基于人工授权的javascript或者node.js采集工具:均有授权工具,无需seo服务提供授权地址,没有授权地址进行限制用户身份。但是如果seo服务的权限已经进行过授权,那么则不可以用这种方式采集数据。进行机器授权:授权地址一般为手机号,电话号码等形式。
此种授权方式目前已经被普遍应用。用rennan优采云采集器的请求分为两种情况:一种是采集数据发送请求,后台会在后台进行一套机器指令的判断和处理,通过master进行指令判断,判断返回的请求最后的domcontent位置是否是合法地址,然后进行权限授权,最后发送数据授权网站端接入web端请求javascript或者node.js采集之后,修改请求网站端的地址url,重新进行请求,并且把返回的数据发送给相应的负责进行采集地址的地址。
一种是采集完成后,仅对采集完的数据进行一次反采集判断和校验,并且把采集的数据回传到真正的请求者那里,对于无需第二次返回的数据,直接返回返回对应的数据,进行api接口的授权即可。下面对二者进行详细介绍:采集工具一般的接入授权:ip,user,password等规则(国内常用,境外仅一两个可以通过,推荐使用一个以稳定为好,推荐可以使用360或者腾讯微云来采集,其次国内分两类的可以接入,一类是使用国内接入站点的,用的最多的是可以是阿里云或者是百度的数据接入服务,你说的ip要是直接接入的,用ip地址,其他地方的ip不是采集站点的ip,有其他可能的情况;另外一类是境外接入,是接入美国和日本的,可以免费注册,然后使。
没人推荐百度地图吗?百度的格局是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-02-27 10:01
采集工具免责说明因为工程师们已经对百度地图产品都是严密监控的,所以任何人如果在任何时间段进行非法获取、传播、发布、部署等行为都是极其危险的。例如:任何人下载或被非法推广或获取任何形式的定位、地址和路线信息等。技术干货关注“东三环外的大胡子”知乎号,实时干货会不定期更新!更多资源请关注“东三环外的大胡子”微信公众号。
你居然还在用百度地图?哈哈,他们现在一般用自己的app啊。
这两家压根就不是一个层次的,百度的格局是高德地图——地图国际化——美团地图——搜狗地图——王者荣耀(没记错的话?)至于其他的嘛。
我觉得在竞争激烈的情况下,大家的关注点应该是你怎么打动用户把你的产品推荐给身边的朋友呢,其实这个可以从socialmedia的角度解决,把自己打造成一个高频内容分发平台,增加自己的曝光度,比如你可以在当地比较关键的大学宣传你的地图,提高当地考试信息的曝光,或者举办一些类似考试家长送福利送定位的活动,提高用户参与度以及曝光率。
没人推荐百度地图吗?
我在海外上学的时候,一直在用谷歌地图。之前没有安装中国地图,前两年有次在国内路过海外路线,就用搜狗搜索了下。
全景app,你可以去找到。说点题外话,现在百度地图的视频搜索还是做的不错的, 查看全部
没人推荐百度地图吗?百度的格局是什么?
采集工具免责说明因为工程师们已经对百度地图产品都是严密监控的,所以任何人如果在任何时间段进行非法获取、传播、发布、部署等行为都是极其危险的。例如:任何人下载或被非法推广或获取任何形式的定位、地址和路线信息等。技术干货关注“东三环外的大胡子”知乎号,实时干货会不定期更新!更多资源请关注“东三环外的大胡子”微信公众号。
你居然还在用百度地图?哈哈,他们现在一般用自己的app啊。
这两家压根就不是一个层次的,百度的格局是高德地图——地图国际化——美团地图——搜狗地图——王者荣耀(没记错的话?)至于其他的嘛。
我觉得在竞争激烈的情况下,大家的关注点应该是你怎么打动用户把你的产品推荐给身边的朋友呢,其实这个可以从socialmedia的角度解决,把自己打造成一个高频内容分发平台,增加自己的曝光度,比如你可以在当地比较关键的大学宣传你的地图,提高当地考试信息的曝光,或者举办一些类似考试家长送福利送定位的活动,提高用户参与度以及曝光率。
没人推荐百度地图吗?
我在海外上学的时候,一直在用谷歌地图。之前没有安装中国地图,前两年有次在国内路过海外路线,就用搜狗搜索了下。
全景app,你可以去找到。说点题外话,现在百度地图的视频搜索还是做的不错的,
采集工具免责说明:请勿商用或向他人进行传播
采集交流 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2021-02-15 09:03
采集工具免责说明:
1、请勿商用或向他人进行传播
2、在上线上传前请先确定您的资源与原作者的资源相同或者相似,
3、资源链接请进行加密处理,并加上链接唯一编号,在上传后不可修改或修改时,
关键可能是你发的链接他知道是很难正常打开的,第二可能是盗版。
我也遇到这个问题了,目前我是先使用采集器的常用字符打开,
同求!!发的时候字幕还挺快,但是打开巨慢!!经常性的!!!现在我发一下截图!大家看看,
我也遇到了同样的问题,后来遇到一个办法解决了。首先你的电脑要好,快的不能再快的那种,并且安装了采集器。下载后要开启采集,然后选好源站,同时配置好https或者user-agent。等待源站正常就可以了。ps:如果下载下来不能打开,或者打开后是这样的,也是正常的。修改下上传文件路径,和使用代理就可以。
更新:已解决!可自定义采集字幕,上传文件用url编码,同步msg即可。方法:在上传工具中选择新建采集,如果是web速度会加速,如果是小程序则需要进行配置,将小程序的url配置为web,如果代理没有配置好,则小程序会对字幕编码造成影响,会造成上传失败。 查看全部
采集工具免责说明:请勿商用或向他人进行传播
采集工具免责说明:
1、请勿商用或向他人进行传播
2、在上线上传前请先确定您的资源与原作者的资源相同或者相似,
3、资源链接请进行加密处理,并加上链接唯一编号,在上传后不可修改或修改时,
关键可能是你发的链接他知道是很难正常打开的,第二可能是盗版。
我也遇到这个问题了,目前我是先使用采集器的常用字符打开,
同求!!发的时候字幕还挺快,但是打开巨慢!!经常性的!!!现在我发一下截图!大家看看,
我也遇到了同样的问题,后来遇到一个办法解决了。首先你的电脑要好,快的不能再快的那种,并且安装了采集器。下载后要开启采集,然后选好源站,同时配置好https或者user-agent。等待源站正常就可以了。ps:如果下载下来不能打开,或者打开后是这样的,也是正常的。修改下上传文件路径,和使用代理就可以。
更新:已解决!可自定义采集字幕,上传文件用url编码,同步msg即可。方法:在上传工具中选择新建采集,如果是web速度会加速,如果是小程序则需要进行配置,将小程序的url配置为web,如果代理没有配置好,则小程序会对字幕编码造成影响,会造成上传失败。
人社部百千万人才工程个人信息采集工具20140420下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 252 次浏览 • 2021-01-23 08:42
标签:
提供了“人力资源和社会保障部的个人信息采集工具” 20140420下载,该软件是免费软件,文件大小为2.28 MB,推荐索引为3星,作为国产软件,在顶级制造商中,您可以放心下载它!
人力资源和社会保障部“十万人才”计划的个人信息采集工具是由北京智辰科技发展有限公司推出的个人信息采集工具。该工具包括学术团体雇佣和教育经验,奖励和资金以及工作经验和其他信息,欢迎下载和使用!
人力资源和社会保障部“十万人才”项目个人信息采集工具的基本功能
基本信息和性能简介
学术团体的就业和教育经验
获奖状态
资金支持
工作经验
代表性作品和论文
研究任务和授权专利
国际学术会议和专着
其他需要添加的说明
人力资源和社会保障部采集工具栏说明中的个人信息
输入信息时,请参阅软件下的输入说明
输入信息后,请先“保存”和“备份”数据。如果在单击“保存”或“备份”时系统提示存在必填字段,则可以先在提示的字段中输入任何字符。然后备份RPU文件(可以修改数据,并在下次输入时再次备份)。 RPU文件的目的(A:当软件中的数据无法正常显示时,B:需要修改文件中的数据,C:将数据带到家庭或本机以继续编辑D:将数据报告给单元并提交给该单元进行汇总)。 RPU文件可用于在安装了软件的计算机上进行数据恢复。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。
([1)保存:单击以保存数据,并验证输入数据的有效性,验证成功后将其保存。
([2)清除:单击以清除所有页面数据,请谨慎使用。
([3)恢复:用于还原在备份期间备份了扩展RPU的文件
注意:还原的文件只能是扩展名为RPU的文件,而RPU文件不能用其他工具打开。
([4)第一页,上一页,下一页,最后一页:用于翻页报告。
([5)备份:输入数据后,生成RPU文件进行提交。
单击备份按钮后,将弹出“生成报告”框,单击“提交文件名”
完成数据输入后,将最后生成的RPU文件提交到设备。 查看全部
人社部百千万人才工程个人信息采集工具20140420下载
标签:
提供了“人力资源和社会保障部的个人信息采集工具” 20140420下载,该软件是免费软件,文件大小为2.28 MB,推荐索引为3星,作为国产软件,在顶级制造商中,您可以放心下载它!
人力资源和社会保障部“十万人才”计划的个人信息采集工具是由北京智辰科技发展有限公司推出的个人信息采集工具。该工具包括学术团体雇佣和教育经验,奖励和资金以及工作经验和其他信息,欢迎下载和使用!
人力资源和社会保障部“十万人才”项目个人信息采集工具的基本功能
基本信息和性能简介
学术团体的就业和教育经验
获奖状态
资金支持
工作经验
代表性作品和论文
研究任务和授权专利
国际学术会议和专着
其他需要添加的说明
人力资源和社会保障部采集工具栏说明中的个人信息
输入信息时,请参阅软件下的输入说明
输入信息后,请先“保存”和“备份”数据。如果在单击“保存”或“备份”时系统提示存在必填字段,则可以先在提示的字段中输入任何字符。然后备份RPU文件(可以修改数据,并在下次输入时再次备份)。 RPU文件的目的(A:当软件中的数据无法正常显示时,B:需要修改文件中的数据,C:将数据带到家庭或本机以继续编辑D:将数据报告给单元并提交给该单元进行汇总)。 RPU文件可用于在安装了软件的计算机上进行数据恢复。 RPU文件只能在此软件中打开,而不能通过其他打开方法打开。
备份RPU数据,这一步非常重要。
([1)保存:单击以保存数据,并验证输入数据的有效性,验证成功后将其保存。
([2)清除:单击以清除所有页面数据,请谨慎使用。
([3)恢复:用于还原在备份期间备份了扩展RPU的文件
注意:还原的文件只能是扩展名为RPU的文件,而RPU文件不能用其他工具打开。
([4)第一页,上一页,下一页,最后一页:用于翻页报告。
([5)备份:输入数据后,生成RPU文件进行提交。
单击备份按钮后,将弹出“生成报告”框,单击“提交文件名”
完成数据输入后,将最后生成的RPU文件提交到设备。
解决方案:数据采集中间件技术对比V1.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-11-29 09:18
1前言
大数据平台通常包括以下步骤:
数据采集->数据存储->数据分析->数据显示(可视化,报告,监视等)
数据采集是非常重要的部分。大数据采集的任务还具有许多特征,例如:数量大,数据源的多样性,快速变化,确保正确的数据以及避免数据重复。
在这里,我们研究了几种常用的大数据采集中间件:datax,水槽,鱿鱼,运河,麦克斯韦,nifi和水壶。
以下将从多个方面比较7种中间件。为了根据各种数据采集的需求选择更合适的工具。
此外,这里有一些主要工厂的做法示例可供参考。
2个数据采集中间件比较
此处不再重复特定的安装和使用步骤。有关详细信息,请参阅相应的技术实践文档。
2.1受支持的数据源
数据采集中间件的一个更重要的功能是它支持的数据源。
flume:flume支持的数据源通常是文件或目录,例如用于接收单个文件的单点采集; TailDIR监视目录; sqoop:Sqoop支持的数据源通常是RMDB,例如mysql,oracle,hive和hdfs等。 datax:datax还支持关系数据库canal:Canal原则上是伪奴隶,因此它基本上仅支持启用了binlog的mysql; maxwell:与运河相同,仅支持启用了binlog的mysql; nifi:Nifi接口操作,只要可以在处理器中搜索数据格式就可以支持。例如,mysql和kafka。 Kettle:在Kettle的实践文档中,您可以看到Kettle支持的数据源非常多样化,例如:文本,数据表,CSV,hbase,msyql,hdfs等。 2.2支持的数据格式
综合分析2.1,然后查看这些中间件支持的数据格式:
flume:支持文件格式。 avro,thrift,exec,jms,假脱机目录,netcat,序列生成器,syslog,http,legacy; sqoop:由于RMDB和HDFS的限制,仅支持hdfs中的SQL表和结构化数据; Datax:SQL也与sqoop或hdfs文件通道相同:输入数据仅支持mysql binlog,输出文件可以自定义; maxwell:输入文件格式也为binlog,但输出格式也受限制,即json。有关详细信息,请参阅maxwell的实践文档。 nifi:支持所有可以在处理器界面中搜索的文件格式,例如csv,db,文本,kafka数据等;水壶:还支持所有可以在trans中搜索的文件格式,例如Habse表,mysql表,文本,CSV等。2.3支持的上下游中间件
在讨论了数据源和文件格式之后,我们来比较一下受支持的上游和下游插件。毕竟,大数据正在蓬勃发展,并且有许多中间件。还有一个更具竞争力:
flume:由水槽上游和下游支持的中间件是常用的hdfs和hbase; sqoop:sqoop上游和下游支持的中间件是常用的mysql,oracle,hdfs; datax:支持的上游和下游类似于sqoop运河:上游运河仅支持mysql(MariaDB),下游中间件可以定制,一般为Kafka; maxwell:像运河上游仅支持mysql,但不能自定义,仅支持kafka等; nifi:支持许多上游和下游中间件kafka; Kettle:它还支持许多中间件,例如mysql,hbase,hdfs等。2.4任务监视通道:Ganglia第三方插件监视; oop datax:需要额外部署datax-web。官方附带运河:没有;麦克斯韦:无; nifi:带有界面的可视监视;电水壶:带有界面的可视监控。 3 MYSQL的BINLOG日志工具分析:CANAL,MAXWELL
参考链接:
此文章比较运河,麦克斯韦和其他两个binlog日志分析工具。这里只挑相关部分看。首先是介绍运河的原理,其实麦克斯韦的原理是一样的:
由于运河和麦克斯韦之间有太多相似之处,我将直接给出比较结果:
4个Youzan大数据:FLUME数据采集服务的最佳做法
参考链接:
文章主要写了大数据Flume 采集架构的演变和性能优化:
这是该体系结构的第一个版本,使用NsqSource和FileChannel来hdfsSink;
在第二个版本中,出于考虑FileChannel故障的原因,使用了扩展的NsqSourceChannel。优点是:
•每条消息的传递仅需要一笔交易,而不是两次,因此性能更好。
•避免引入新的kafka服务,减少资源成本,同时保持架构更简单,更稳定。
5个基于NIFI + SPARK STREAMING 采集的流媒体
参考链接:
本文使用NiFi + Spark Streaming的技术方案为各种外部数据源设计通用的实时采集处理方法。
此解决方案使用NiFi处理采集数据,然后通过Spark Streaming流引擎,将采集数据按指定进行转换,并生成新数据并将其发送到Kafka系统以用于后续服务或流程,例如Kylin Streaming模型的构建。
基于OGG和SQOOP的6 TBDS访问解决方案系列-SQOOP和腾讯大数据套件TBDS集成示例的介绍
参考链接:
此案例介绍了一种场景,其中Sqoop用于将数据从Oracle脱机导入到腾讯的大数据套件TBDS中的Hadoop和Hive组件。
文章很长,基本上是sqoop的一些常用用法,已导入hdfs和hive中。核心命令是sqoop import:
7使用KETTLE进行SQLSERVER和ORACLE之间的数据迁移实践
参考链接:
此案例主要在某些技术实现中引入了将SQL Server中的数据导出到Oracle。任务视图如下:
分别在表输入和表输出中配置SqlServer和Oracle的连接信息。
8总结
以下是这些数据采集中间件的特征的简要摘要。
根据它们的特征,我将这6种中间件分为3类:Canal和Maxwell都用作Binglog同步工具; Kettle和Nifi都是界面可视化操作。 Flume和Sqoop是命令行操作。将它们放在一起进行比较并比较每个都有自己的特点,但是根据目的进行比较非常好:
flume:文件采集;
sqoop:将RMDB转换为hdfs / hive / hbase文件采集,或将hdfs反向转换为RMDB导出;
canal / maxwell:实时监视mysql增量数据,不同之处在于maxwell直接将json输出到kafka;运河必须解析,但是它有点灵活;
水壶/ nifi:两者都是可视界面的拖放操作,但是实现的功能不同。 Kettle比ETL操作更强大,Nifi的优势在于数据流采集。
说到这里,基本上各自的应用场景都非常清楚,但是flume和Nifi似乎都比文件采集好。但是重点有所不同。 Flume没有可视界面。其操作全部在flume / conf /下的配置文件中。尽管只有源/通道/接收器,但采集更灵活。根据处理器中的选项选择Nifi 采集的配置。
最后,根据比较总结一下这6种中间件的适用场景:
flume:适用于复杂文件采集; sqoop:适合将RMDB传输到大数据平台的其他中间件,例如hdfs / hive / hbase; datax:与sqoop非常相似,但在各个方面都比sqoop强。有一种趋势是替换鱿鱼。渠道:适用于mymql增量数据的实时同步,可以支持格式和输出多样化; maxwell:适用于将mysql增量数据快速实时同步到kafka; Nifi:适合简单的文件流操作,是的简单的视觉界面,学习成本低;水壶:适合复杂的ETL操作,并具有可视界面,易于操作。 查看全部
数据采集中间件技术比较V1.0
1前言
大数据平台通常包括以下步骤:
数据采集->数据存储->数据分析->数据显示(可视化,报告,监视等)
数据采集是非常重要的部分。大数据采集的任务还具有许多特征,例如:数量大,数据源的多样性,快速变化,确保正确的数据以及避免数据重复。
在这里,我们研究了几种常用的大数据采集中间件:datax,水槽,鱿鱼,运河,麦克斯韦,nifi和水壶。
以下将从多个方面比较7种中间件。为了根据各种数据采集的需求选择更合适的工具。
此外,这里有一些主要工厂的做法示例可供参考。
2个数据采集中间件比较
此处不再重复特定的安装和使用步骤。有关详细信息,请参阅相应的技术实践文档。
2.1受支持的数据源
数据采集中间件的一个更重要的功能是它支持的数据源。
flume:flume支持的数据源通常是文件或目录,例如用于接收单个文件的单点采集; TailDIR监视目录; sqoop:Sqoop支持的数据源通常是RMDB,例如mysql,oracle,hive和hdfs等。 datax:datax还支持关系数据库canal:Canal原则上是伪奴隶,因此它基本上仅支持启用了binlog的mysql; maxwell:与运河相同,仅支持启用了binlog的mysql; nifi:Nifi接口操作,只要可以在处理器中搜索数据格式就可以支持。例如,mysql和kafka。 Kettle:在Kettle的实践文档中,您可以看到Kettle支持的数据源非常多样化,例如:文本,数据表,CSV,hbase,msyql,hdfs等。 2.2支持的数据格式
综合分析2.1,然后查看这些中间件支持的数据格式:
flume:支持文件格式。 avro,thrift,exec,jms,假脱机目录,netcat,序列生成器,syslog,http,legacy; sqoop:由于RMDB和HDFS的限制,仅支持hdfs中的SQL表和结构化数据; Datax:SQL也与sqoop或hdfs文件通道相同:输入数据仅支持mysql binlog,输出文件可以自定义; maxwell:输入文件格式也为binlog,但输出格式也受限制,即json。有关详细信息,请参阅maxwell的实践文档。 nifi:支持所有可以在处理器界面中搜索的文件格式,例如csv,db,文本,kafka数据等;水壶:还支持所有可以在trans中搜索的文件格式,例如Habse表,mysql表,文本,CSV等。2.3支持的上下游中间件
在讨论了数据源和文件格式之后,我们来比较一下受支持的上游和下游插件。毕竟,大数据正在蓬勃发展,并且有许多中间件。还有一个更具竞争力:
flume:由水槽上游和下游支持的中间件是常用的hdfs和hbase; sqoop:sqoop上游和下游支持的中间件是常用的mysql,oracle,hdfs; datax:支持的上游和下游类似于sqoop运河:上游运河仅支持mysql(MariaDB),下游中间件可以定制,一般为Kafka; maxwell:像运河上游仅支持mysql,但不能自定义,仅支持kafka等; nifi:支持许多上游和下游中间件kafka; Kettle:它还支持许多中间件,例如mysql,hbase,hdfs等。2.4任务监视通道:Ganglia第三方插件监视; oop datax:需要额外部署datax-web。官方附带运河:没有;麦克斯韦:无; nifi:带有界面的可视监视;电水壶:带有界面的可视监控。 3 MYSQL的BINLOG日志工具分析:CANAL,MAXWELL
参考链接:
此文章比较运河,麦克斯韦和其他两个binlog日志分析工具。这里只挑相关部分看。首先是介绍运河的原理,其实麦克斯韦的原理是一样的:
由于运河和麦克斯韦之间有太多相似之处,我将直接给出比较结果:
4个Youzan大数据:FLUME数据采集服务的最佳做法
参考链接:
文章主要写了大数据Flume 采集架构的演变和性能优化:
这是该体系结构的第一个版本,使用NsqSource和FileChannel来hdfsSink;
在第二个版本中,出于考虑FileChannel故障的原因,使用了扩展的NsqSourceChannel。优点是:
•每条消息的传递仅需要一笔交易,而不是两次,因此性能更好。
•避免引入新的kafka服务,减少资源成本,同时保持架构更简单,更稳定。
5个基于NIFI + SPARK STREAMING 采集的流媒体
参考链接:
本文使用NiFi + Spark Streaming的技术方案为各种外部数据源设计通用的实时采集处理方法。
此解决方案使用NiFi处理采集数据,然后通过Spark Streaming流引擎,将采集数据按指定进行转换,并生成新数据并将其发送到Kafka系统以用于后续服务或流程,例如Kylin Streaming模型的构建。
基于OGG和SQOOP的6 TBDS访问解决方案系列-SQOOP和腾讯大数据套件TBDS集成示例的介绍
参考链接:
此案例介绍了一种场景,其中Sqoop用于将数据从Oracle脱机导入到腾讯的大数据套件TBDS中的Hadoop和Hive组件。
文章很长,基本上是sqoop的一些常用用法,已导入hdfs和hive中。核心命令是sqoop import:
7使用KETTLE进行SQLSERVER和ORACLE之间的数据迁移实践
参考链接:
此案例主要在某些技术实现中引入了将SQL Server中的数据导出到Oracle。任务视图如下:
分别在表输入和表输出中配置SqlServer和Oracle的连接信息。
8总结
以下是这些数据采集中间件的特征的简要摘要。
根据它们的特征,我将这6种中间件分为3类:Canal和Maxwell都用作Binglog同步工具; Kettle和Nifi都是界面可视化操作。 Flume和Sqoop是命令行操作。将它们放在一起进行比较并比较每个都有自己的特点,但是根据目的进行比较非常好:
flume:文件采集;
sqoop:将RMDB转换为hdfs / hive / hbase文件采集,或将hdfs反向转换为RMDB导出;
canal / maxwell:实时监视mysql增量数据,不同之处在于maxwell直接将json输出到kafka;运河必须解析,但是它有点灵活;
水壶/ nifi:两者都是可视界面的拖放操作,但是实现的功能不同。 Kettle比ETL操作更强大,Nifi的优势在于数据流采集。
说到这里,基本上各自的应用场景都非常清楚,但是flume和Nifi似乎都比文件采集好。但是重点有所不同。 Flume没有可视界面。其操作全部在flume / conf /下的配置文件中。尽管只有源/通道/接收器,但采集更灵活。根据处理器中的选项选择Nifi 采集的配置。
最后,根据比较总结一下这6种中间件的适用场景:
flume:适用于复杂文件采集; sqoop:适合将RMDB传输到大数据平台的其他中间件,例如hdfs / hive / hbase; datax:与sqoop非常相似,但在各个方面都比sqoop强。有一种趋势是替换鱿鱼。渠道:适用于mymql增量数据的实时同步,可以支持格式和输出多样化; maxwell:适用于将mysql增量数据快速实时同步到kafka; Nifi:适合简单的文件流操作,是的简单的视觉界面,学习成本低;水壶:适合复杂的ETL操作,并具有可视界面,易于操作。
详细数据:淘宝爬虫评论数据采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-09-05 10:56
1)移动鼠标以选择页面上的第一个产品链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环单击每个链接”以创建列表循环
1)创建列表循环后,系统将自动单击第一个产品链接以进入产品详细信息页面。
将页面拖放到评论区域,单击“累积评论”,然后选择“单击此元素”
2)选择第一个注释,然后在右侧的操作框中选择“选择子元素”
3)系统将自动识别相似的元素。在右侧的操作框中,选择“全选”
4)选择采集的字段后,单击“ 采集以下数据”
5)选择相应的字段以自定义字段的命名。完成后,单击左上角的“保存并开始”以启动采集任务。
6)选择“启动本地采集”
1) 采集完成后,将弹出提示,然后选择“导出数据。选择”适当的导出方法”以导出采集良好评论信息数据
2)在这里,我们选择excel作为导出格式,数据将如下所示导出
我希望本文档的介绍将使您掌握Ganji.com 采集的信息网页数据,您可以尝试从优采云 采集的官方网站下载最新版本的客户端。的优采云 采集,或关注优采云 采集官方微信以了解更多教学案例。
优采云 采集·可在三分钟内使用的网页数据采集软件和免费软件
点击链接进入官方网站
优采云 采集-最佳网络论坛采集器 查看全部
淘宝爬虫的注释数据采集
1)移动鼠标以选择页面上的第一个产品链接。选择后,系统将自动识别页面上的其他类似链接。在右侧的操作提示框中,选择“全选”
2)选择“循环单击每个链接”以创建列表循环
1)创建列表循环后,系统将自动单击第一个产品链接以进入产品详细信息页面。
将页面拖放到评论区域,单击“累积评论”,然后选择“单击此元素”
2)选择第一个注释,然后在右侧的操作框中选择“选择子元素”
3)系统将自动识别相似的元素。在右侧的操作框中,选择“全选”
4)选择采集的字段后,单击“ 采集以下数据”
5)选择相应的字段以自定义字段的命名。完成后,单击左上角的“保存并开始”以启动采集任务。
6)选择“启动本地采集”
1) 采集完成后,将弹出提示,然后选择“导出数据。选择”适当的导出方法”以导出采集良好评论信息数据
2)在这里,我们选择excel作为导出格式,数据将如下所示导出
我希望本文档的介绍将使您掌握Ganji.com 采集的信息网页数据,您可以尝试从优采云 采集的官方网站下载最新版本的客户端。的优采云 采集,或关注优采云 采集官方微信以了解更多教学案例。
优采云 采集·可在三分钟内使用的网页数据采集软件和免费软件
点击链接进入官方网站
优采云 采集-最佳网络论坛采集器
事实:自媒体文章采集平台功能有哪些?作用是什么
采集交流 • 优采云 发表了文章 • 0 个评论 • 291 次浏览 • 2020-09-02 11:30
自媒体是当今的主流媒体方法. 自媒体有很多平台,也可以方便人们的相关营销操作. 当然,在操作自媒体时经常需要文章 爆文 采集器,那么自媒体 文章 采集平台的功能是什么?跟随Tuotu Data看看.
自媒体 文章 采集的作用
1. 在与您自己的字段爆文相关的每个自媒体 网站 采集中,根据爆文输入作者的主页,并查看作者帐户的整体阅读方式. 如果您经常发布爆文,则表明这是一个出色的同peer,值得学习.
2,采集各为自媒体 网站 爆文,然后分析这些标题. 每个领域都有很多关键字,例如美容行业. 我怎么知道历史领域中哪些关键词,哪些关键词更受欢迎?
所有这一切都需要数据分析,分析每个爆文标题,从中找到关键字,然后进行统计. 通过大量的统计信息,您可以分析哪些关键字很受欢迎,哪些关键字流量很大. 爆文.
自媒体 文章 采集平台的力量
智能采集,提供各种网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性. Tuotu Data的工作人员告诉您,它适用于整个网络,并且可以即搜即取,无论是文字图片还是贴吧论坛,它都支持所有业务渠道的抓取工具,可以满足各种采集需求,庞大的模板,以及数百个内置A 网站数据源,全面覆盖多个行业,只需简单的设置,就可以快速而准确地获取数据. 简单易用,无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库. 稳定,高效,由分布式云服务器和多用户协作管理平台支持,它可以灵活地调度任务并平滑地爬行大量数据.
Tutu数据是非常好的自媒体 文章 采集平台,此平台文章 采集方便,并且收录最新的热门内容,可以在文章 采集排版后进行操作为人们的公共帐户文章发布提供了方便.
更多信息和知识点将继续受到关注. 后续活动将是自媒体咖啡馆爆文 采集平台,自媒体 文章 采集平台,公共帐户查询,重印他人的原创 文章,公共帐户历史记录文章和其他知识点. 查看全部
自媒体 文章 采集平台功能是什么?起什么作用
自媒体是当今的主流媒体方法. 自媒体有很多平台,也可以方便人们的相关营销操作. 当然,在操作自媒体时经常需要文章 爆文 采集器,那么自媒体 文章 采集平台的功能是什么?跟随Tuotu Data看看.
自媒体 文章 采集的作用
1. 在与您自己的字段爆文相关的每个自媒体 网站 采集中,根据爆文输入作者的主页,并查看作者帐户的整体阅读方式. 如果您经常发布爆文,则表明这是一个出色的同peer,值得学习.
2,采集各为自媒体 网站 爆文,然后分析这些标题. 每个领域都有很多关键字,例如美容行业. 我怎么知道历史领域中哪些关键词,哪些关键词更受欢迎?
所有这一切都需要数据分析,分析每个爆文标题,从中找到关键字,然后进行统计. 通过大量的统计信息,您可以分析哪些关键字很受欢迎,哪些关键字流量很大. 爆文.
自媒体 文章 采集平台的力量
智能采集,提供各种网页采集策略和支持资源,以帮助整个采集流程实现数据完整性和稳定性. Tuotu Data的工作人员告诉您,它适用于整个网络,并且可以即搜即取,无论是文字图片还是贴吧论坛,它都支持所有业务渠道的抓取工具,可以满足各种采集需求,庞大的模板,以及数百个内置A 网站数据源,全面覆盖多个行业,只需简单的设置,就可以快速而准确地获取数据. 简单易用,无需学习爬虫编程技术,只需三个简单的步骤即可轻松获取Web数据,支持多种格式的一键导出,并快速导入数据库. 稳定,高效,由分布式云服务器和多用户协作管理平台支持,它可以灵活地调度任务并平滑地爬行大量数据.
Tutu数据是非常好的自媒体 文章 采集平台,此平台文章 采集方便,并且收录最新的热门内容,可以在文章 采集排版后进行操作为人们的公共帐户文章发布提供了方便.
更多信息和知识点将继续受到关注. 后续活动将是自媒体咖啡馆爆文 采集平台,自媒体 文章 采集平台,公共帐户查询,重印他人的原创 文章,公共帐户历史记录文章和其他知识点.
事实:腾讯云工单网络检测工具使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-09-01 04:10
windows系统:
直接使用故障单中提供的工具下载链接,它将自动跳至该工具的下载页面,如下所示:
窗口工具界面
下载后,单击应用程序的图标进行解压缩,然后打开该工具并输入目标地址. 如果是采集中从本地主机到服务器的网络信息,则用服务器IP填充主机地址,反之亦然.
Windows执行效果
单击以开始检测. 检测需要180秒. 在检测过程中,请不要关闭工具界面. 检测完成后,信息采集的结果将自动上传到腾讯云. 一段时间后,该接口可以正常关闭. Linux系统: 直接使用Linux服务器中的工具链接下载压缩文件,然后解压缩脚本,添加X权限并运行脚本. 具体操作如下:
Linux执行说明
使用Linux网络信息采集工具,无法在采集过程中执行中断操作.
备注:
1正向和反向工具链接不能混合. 例如,clienttoserver使用正向,而servertoclient使用反向,否则会影响数据分析结果.
2服务器和客户端完成正向和反向测试后,回复工作订单,并让腾讯云工程师检查数据.
3网络信息采集工具打包为一种开源工具,而不是腾讯云官方网站的产品. 我们保证,我们提供给您的链接和软件不会携带任何病毒,特洛伊木马和其他威胁文件,并且不会对服务器的正常运行产生任何影响. 由于该工具是由各种开源工具组装而成的,因此腾讯云对使用过程中遇到的任何问题不承担任何责任. 4如果您不想使用自动化工具,则可以使用手动采集方法. 采集方法如下:
①打开本地计算机上的浏览器以访问屏幕快照,获取本地IP和DNS,并从本地对主流站点的访问延迟中判断网络是否异常.
②一分钟后,本地计算机[ping服务器IP-t]将停止(Ctrl + C). 请确保完整拍下ping统计信息的最后一部分.
例如: ping
Ping [61.135.169.121]具有32个字节的数据:
从61.135.169.121开始的响应: byte = 32 time = 3msTTL = 5461.135.169.121 Ping统计信息:
数据包: 已发送= 4,已接收= 4,丢失= 0(丢失0%),估计的往返时间(以毫秒为单位):
最短= 2毫秒,最长= 8毫秒,平均值= 4毫秒
③3分钟后,本地计算机使用MTR测试[服务器IP]屏幕截图
④在服务器端[ping本地计算机IP-t],并在一分钟后停止(Ctrl + C),这是最后一部分结论的完整屏幕截图.
注意: 如果无法登录服务器,请参考:
⑤Linux&Windows服务器端使用MTR参考:
使用MTR工具启动采集消息,等待180秒然后停止,然后向我们提供消息的剪切图像和文本.
感谢您的支持和理解 查看全部
腾讯云工单网络检测工具说明
windows系统:
直接使用故障单中提供的工具下载链接,它将自动跳至该工具的下载页面,如下所示:
窗口工具界面
下载后,单击应用程序的图标进行解压缩,然后打开该工具并输入目标地址. 如果是采集中从本地主机到服务器的网络信息,则用服务器IP填充主机地址,反之亦然.
Windows执行效果
单击以开始检测. 检测需要180秒. 在检测过程中,请不要关闭工具界面. 检测完成后,信息采集的结果将自动上传到腾讯云. 一段时间后,该接口可以正常关闭. Linux系统: 直接使用Linux服务器中的工具链接下载压缩文件,然后解压缩脚本,添加X权限并运行脚本. 具体操作如下:
Linux执行说明
使用Linux网络信息采集工具,无法在采集过程中执行中断操作.
备注:
1正向和反向工具链接不能混合. 例如,clienttoserver使用正向,而servertoclient使用反向,否则会影响数据分析结果.
2服务器和客户端完成正向和反向测试后,回复工作订单,并让腾讯云工程师检查数据.
3网络信息采集工具打包为一种开源工具,而不是腾讯云官方网站的产品. 我们保证,我们提供给您的链接和软件不会携带任何病毒,特洛伊木马和其他威胁文件,并且不会对服务器的正常运行产生任何影响. 由于该工具是由各种开源工具组装而成的,因此腾讯云对使用过程中遇到的任何问题不承担任何责任. 4如果您不想使用自动化工具,则可以使用手动采集方法. 采集方法如下:
①打开本地计算机上的浏览器以访问屏幕快照,获取本地IP和DNS,并从本地对主流站点的访问延迟中判断网络是否异常.
②一分钟后,本地计算机[ping服务器IP-t]将停止(Ctrl + C). 请确保完整拍下ping统计信息的最后一部分.
例如: ping
Ping [61.135.169.121]具有32个字节的数据:
从61.135.169.121开始的响应: byte = 32 time = 3msTTL = 5461.135.169.121 Ping统计信息:
数据包: 已发送= 4,已接收= 4,丢失= 0(丢失0%),估计的往返时间(以毫秒为单位):
最短= 2毫秒,最长= 8毫秒,平均值= 4毫秒
③3分钟后,本地计算机使用MTR测试[服务器IP]屏幕截图
④在服务器端[ping本地计算机IP-t],并在一分钟后停止(Ctrl + C),这是最后一部分结论的完整屏幕截图.
注意: 如果无法登录服务器,请参考:
⑤Linux&Windows服务器端使用MTR参考:
使用MTR工具启动采集消息,等待180秒然后停止,然后向我们提供消息的剪切图像和文本.
感谢您的支持和理解

