
通过关键词采集文章采集api
通过关键词采集文章采集api(手把手教你通过关键词采集文章采集api(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-09 05:00
通过关键词采集文章采集api,其实通过平台这么多种方式,只要你会api就能找到你想要的资源。手把手教你通过关键词找到相应的素材手把手教你通过关键词找到相应的素材:会爬虫的都可以直接上手,别看我简单,简单是因为掌握的人少,要抓取最新资源(特别是一些国外的网站)最近开始疯狂接单,文章会有时间的跨度。还有就是对你来说有用的资源你才会想要。希望能帮到你。
谁都想爬取各大平台上的热门新闻,那如何爬取?其实抓取新闻,并不难,普通的抓取工具都能实现,今天推荐一款好用的爬虫app:浏览器自带的api,包括多款热门新闻网站,抓取一两个新闻网站还是没问题的,大部分网站是可以轻松取得!利用浏览器的自带api,其实获取新闻并不难,好用的有限,需要有:【1】安装最新版本谷歌浏览器【2】安装多抓鱼浏览器多抓鱼浏览器是2018年4月9日谷歌官方推出的,只需要一键就能实现去重,抓取新闻,返回传统爬虫爬取一大堆网站,累死人累死人累死人!说了半天,就是要大家会抓取,会抓取那就要一起学习一起撸了~一直有推荐过不少免费学习网站,感兴趣的朋友可以关注一下,【1】自学学习有各种免费资源。
网站是两年前弄的,api有些久远,现在就一直再用,有不少自学学习的网站,也有些资源,喜欢的朋友可以在后台留言交流哈~获取网站的方法,可以前往下载中心获取,苹果用户还需要付费安装,服务器还在美国,不支持在国内访问!api2.0已经发布,关注公众号【topone应用商店】回复【接口】即可免费获取!。 查看全部
通过关键词采集文章采集api(手把手教你通过关键词采集文章采集api(组图))
通过关键词采集文章采集api,其实通过平台这么多种方式,只要你会api就能找到你想要的资源。手把手教你通过关键词找到相应的素材手把手教你通过关键词找到相应的素材:会爬虫的都可以直接上手,别看我简单,简单是因为掌握的人少,要抓取最新资源(特别是一些国外的网站)最近开始疯狂接单,文章会有时间的跨度。还有就是对你来说有用的资源你才会想要。希望能帮到你。
谁都想爬取各大平台上的热门新闻,那如何爬取?其实抓取新闻,并不难,普通的抓取工具都能实现,今天推荐一款好用的爬虫app:浏览器自带的api,包括多款热门新闻网站,抓取一两个新闻网站还是没问题的,大部分网站是可以轻松取得!利用浏览器的自带api,其实获取新闻并不难,好用的有限,需要有:【1】安装最新版本谷歌浏览器【2】安装多抓鱼浏览器多抓鱼浏览器是2018年4月9日谷歌官方推出的,只需要一键就能实现去重,抓取新闻,返回传统爬虫爬取一大堆网站,累死人累死人累死人!说了半天,就是要大家会抓取,会抓取那就要一起学习一起撸了~一直有推荐过不少免费学习网站,感兴趣的朋友可以关注一下,【1】自学学习有各种免费资源。
网站是两年前弄的,api有些久远,现在就一直再用,有不少自学学习的网站,也有些资源,喜欢的朋友可以在后台留言交流哈~获取网站的方法,可以前往下载中心获取,苹果用户还需要付费安装,服务器还在美国,不支持在国内访问!api2.0已经发布,关注公众号【topone应用商店】回复【接口】即可免费获取!。
通过关键词采集文章采集api(【干货】亚马逊搜索框所推荐的关键词采集工具(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-04 06:16
前言
本周末国庆值班期间,无事可做,整理发布之前写的亚马逊搜索框推荐的关键词采集工具。总的来说,它是一个简单的小爬虫。
因为比较小,所以写在一个模块里,一个模块分成五个方法来完成整个爬取过程。
网页下载方法 网页解析方法 将解析结果存入txt文件的方法 整合网页下载的方法及存入txt文件的方法 主要功能 组织整个流程的方法 主要内容一、 中涉及的类库
import requests
import datetime
import time
以上类库,除requests第三方类库外,均为Python标准库。第三方类库可以在cmd中通过pip install +类库名自动安装——前提是已经配置好python环境变量-windows
requests 是一个网页下载库 datetime 是一个日期库。本例中用于根据不同的日期设置采集文件txt的不同名称。时间时间库,主要使用sleep方式,用于采集糟糕时暂停程序的库二、网页下载方式
def get_suggestion(url, sleep=5, retry=3):
try:
r = requests.get(url, timeout=10)
if r.json:
return r.json()
else:
print('网站返回信息为空,当前检索失败')
if retry>=0:
print('正在重新请求')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
except (requests.ConnectTimeout,requests.ReadTimeout, requests.ConnectionError) as e:
print('超时: %s' % str(e))
if retry>=0:
print('正在重试')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
对于网页下载方式,简单设置了错误捕获和错误重试的功能,使得爬虫在下载网页的过程中能够顺利运行。
另外,经过多次尝试,这个接口的抗爬升程度很弱。只要不是大型的采集,一般都不是问题。如果遇到Robot Check等验证,除了更改IP(https类型)外,还可以使用Pause和rest来缓解Robot Check的概率。
而且亚马逊推荐的关键词,经过观察,更新频率不是很高,个人普通的采集速度完全可以满足需求。
三、网页解析方法,解析出我们需要的内容
def parse_suggestion(js_html):
try:
suggestions = js_html.get('suggestions')
keywords_list = [keyword.get('value') for keyword in suggestions]
return keywords_list
except Exception as e:
return
解析网页返回的信息,所以类信息是json格式的,本体已经通过requests库的json方法转换为字典类型,所以可以直接以字典的形式访问。
增加了一层判断。当解析出现错误时,会返回empty,以保证程序不会因为错误而影响整体运行。
返回的内容存储方法,存储我们的 采集to 和过去的权重的 关键词
def save_suggestion(keyword):
# 以天为单位分离采集结果
with open('Amazon Suggest Keywords_{}.txt'.format(datetime.now().date()), 'a+') as f:
f.write(keyword+'\n')
比较简单,不用多说。打开或者新建一个txt文件,调用write方法写入对应的关键词,在每个关键词后面加一个换行符
四、集成网页下载并保存为txt文件,方便以后调用
def get_and_save(url, suggested_keywords):
rq_json = get_suggestion(url)
suggestion_list = parse_suggestion(rq_json)
if suggestion_list:
for suggestion in suggestion_list:
print('#' * 80)
print('正在判断当前关键词:%s' % suggestion)
if suggestion in suggested_keywords:
print('当前关键词:%s 重复' % suggestion)
continue
else:
save_suggestion(suggestion)
print('当前关键词:%s 存储成功' % suggestion)
suggested_keywords.append(suggestion)
else:
print('亚马逊返回信息为空,当前关键词长尾词采集失败')
因此,部分代码会在主程序中被多次调用,所以单独组织为一个方法。
增加了if判断,保证只在显式返回关键词时才调用存储方法
这一步还加了一个判断,判断当前检索到的关键词是否已经是采集,如果已经是采集,则放弃
五、组织整个程序的主函数
def main(prefix_or_prefix_list):
url = 'https://completion.amazon.com/api/2017/suggestions?&client-info=amazon-search-ui&' \
'mid=ATVPDKIKX0DER&alias=aps&b2b=0&fresh=0&ks=83&prefix={}&suggestion-type=keyword&fb=1'
suggested_keywords = []
# 定义一个空列表,以存储已采集过的关键词
if isinstance(prefix_or_prefix_list, str):
# 传入的是一个词
final_url = url.format(prefix_or_prefix_list)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
# 将已采集过的 keywords 做再次采集,依旧是重复的剔除
get_and_save(url.format(depth_keywords),suggested_keywords)
elif isinstance(prefix_or_prefix_list, list):
# 传入的是一个由许多单词组成的列表| tuple 也是可以的,只要是一个可以迭代的有序序列都可以。但是如果是一个 orderedDict的话,那就需要改写部分代码了。
for prefix in prefix_or_prefix_list:
final_url = url.format(prefix)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
get_and_save(url.format(depth_keywords), suggested_keywords)
else:
print('参数传入错误,本程序只接受单个关键词或者关键词序列为参数')
if __name__ == '__main__':
_prefix = 'iphone case'
_prefix_list = ['iphone case', 'iphone charger']
main(_prefix)
main函数接收一个prefix_or_prefix_list参数,这意味着这个程序可以采集单个关键词长尾词,或者采集一系列关键词。
内置isinstance方法用于判断传入参数类型,根据类型使用不同的采集配置。
这个程序运行了很长时间,需要轮询每一个关键词消息。但是实时采集,采用实时存储策略,所以程序的运行可以随时中断,并且采集字样已经存储在对应的txt文件中。
有人说能不能用多线程,当然可以,但是项目小没必要,亚马逊的关键词推荐更新也没有那么频繁。而且,亚马逊的反爬能力极其强大。如果你有兴趣,你可以自己试试。
结尾
这是我分享的第一个与亚马逊卖家相关的爬虫工具。配置好python程序后,复制粘贴即可使用。
亚马逊卖家相关的朋友如果看过这篇博文,有兴趣开发亚马逊卖家相关工具的朋友,可以私信交流。 查看全部
通过关键词采集文章采集api(【干货】亚马逊搜索框所推荐的关键词采集工具(一))
前言
本周末国庆值班期间,无事可做,整理发布之前写的亚马逊搜索框推荐的关键词采集工具。总的来说,它是一个简单的小爬虫。
因为比较小,所以写在一个模块里,一个模块分成五个方法来完成整个爬取过程。
网页下载方法 网页解析方法 将解析结果存入txt文件的方法 整合网页下载的方法及存入txt文件的方法 主要功能 组织整个流程的方法 主要内容一、 中涉及的类库
import requests
import datetime
import time
以上类库,除requests第三方类库外,均为Python标准库。第三方类库可以在cmd中通过pip install +类库名自动安装——前提是已经配置好python环境变量-windows
requests 是一个网页下载库 datetime 是一个日期库。本例中用于根据不同的日期设置采集文件txt的不同名称。时间时间库,主要使用sleep方式,用于采集糟糕时暂停程序的库二、网页下载方式
def get_suggestion(url, sleep=5, retry=3):
try:
r = requests.get(url, timeout=10)
if r.json:
return r.json()
else:
print('网站返回信息为空,当前检索失败')
if retry>=0:
print('正在重新请求')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
except (requests.ConnectTimeout,requests.ReadTimeout, requests.ConnectionError) as e:
print('超时: %s' % str(e))
if retry>=0:
print('正在重试')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
对于网页下载方式,简单设置了错误捕获和错误重试的功能,使得爬虫在下载网页的过程中能够顺利运行。
另外,经过多次尝试,这个接口的抗爬升程度很弱。只要不是大型的采集,一般都不是问题。如果遇到Robot Check等验证,除了更改IP(https类型)外,还可以使用Pause和rest来缓解Robot Check的概率。
而且亚马逊推荐的关键词,经过观察,更新频率不是很高,个人普通的采集速度完全可以满足需求。
三、网页解析方法,解析出我们需要的内容
def parse_suggestion(js_html):
try:
suggestions = js_html.get('suggestions')
keywords_list = [keyword.get('value') for keyword in suggestions]
return keywords_list
except Exception as e:
return
解析网页返回的信息,所以类信息是json格式的,本体已经通过requests库的json方法转换为字典类型,所以可以直接以字典的形式访问。
增加了一层判断。当解析出现错误时,会返回empty,以保证程序不会因为错误而影响整体运行。
返回的内容存储方法,存储我们的 采集to 和过去的权重的 关键词
def save_suggestion(keyword):
# 以天为单位分离采集结果
with open('Amazon Suggest Keywords_{}.txt'.format(datetime.now().date()), 'a+') as f:
f.write(keyword+'\n')
比较简单,不用多说。打开或者新建一个txt文件,调用write方法写入对应的关键词,在每个关键词后面加一个换行符
四、集成网页下载并保存为txt文件,方便以后调用
def get_and_save(url, suggested_keywords):
rq_json = get_suggestion(url)
suggestion_list = parse_suggestion(rq_json)
if suggestion_list:
for suggestion in suggestion_list:
print('#' * 80)
print('正在判断当前关键词:%s' % suggestion)
if suggestion in suggested_keywords:
print('当前关键词:%s 重复' % suggestion)
continue
else:
save_suggestion(suggestion)
print('当前关键词:%s 存储成功' % suggestion)
suggested_keywords.append(suggestion)
else:
print('亚马逊返回信息为空,当前关键词长尾词采集失败')
因此,部分代码会在主程序中被多次调用,所以单独组织为一个方法。
增加了if判断,保证只在显式返回关键词时才调用存储方法
这一步还加了一个判断,判断当前检索到的关键词是否已经是采集,如果已经是采集,则放弃
五、组织整个程序的主函数
def main(prefix_or_prefix_list):
url = 'https://completion.amazon.com/api/2017/suggestions?&client-info=amazon-search-ui&' \
'mid=ATVPDKIKX0DER&alias=aps&b2b=0&fresh=0&ks=83&prefix={}&suggestion-type=keyword&fb=1'
suggested_keywords = []
# 定义一个空列表,以存储已采集过的关键词
if isinstance(prefix_or_prefix_list, str):
# 传入的是一个词
final_url = url.format(prefix_or_prefix_list)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
# 将已采集过的 keywords 做再次采集,依旧是重复的剔除
get_and_save(url.format(depth_keywords),suggested_keywords)
elif isinstance(prefix_or_prefix_list, list):
# 传入的是一个由许多单词组成的列表| tuple 也是可以的,只要是一个可以迭代的有序序列都可以。但是如果是一个 orderedDict的话,那就需要改写部分代码了。
for prefix in prefix_or_prefix_list:
final_url = url.format(prefix)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
get_and_save(url.format(depth_keywords), suggested_keywords)
else:
print('参数传入错误,本程序只接受单个关键词或者关键词序列为参数')
if __name__ == '__main__':
_prefix = 'iphone case'
_prefix_list = ['iphone case', 'iphone charger']
main(_prefix)
main函数接收一个prefix_or_prefix_list参数,这意味着这个程序可以采集单个关键词长尾词,或者采集一系列关键词。
内置isinstance方法用于判断传入参数类型,根据类型使用不同的采集配置。
这个程序运行了很长时间,需要轮询每一个关键词消息。但是实时采集,采用实时存储策略,所以程序的运行可以随时中断,并且采集字样已经存储在对应的txt文件中。
有人说能不能用多线程,当然可以,但是项目小没必要,亚马逊的关键词推荐更新也没有那么频繁。而且,亚马逊的反爬能力极其强大。如果你有兴趣,你可以自己试试。
结尾
这是我分享的第一个与亚马逊卖家相关的爬虫工具。配置好python程序后,复制粘贴即可使用。
亚马逊卖家相关的朋友如果看过这篇博文,有兴趣开发亚马逊卖家相关工具的朋友,可以私信交流。
通过关键词采集文章采集api( 全平台发布全CMS发布器功能特点及特点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 16:06
全平台发布全CMS发布器功能特点及特点
)
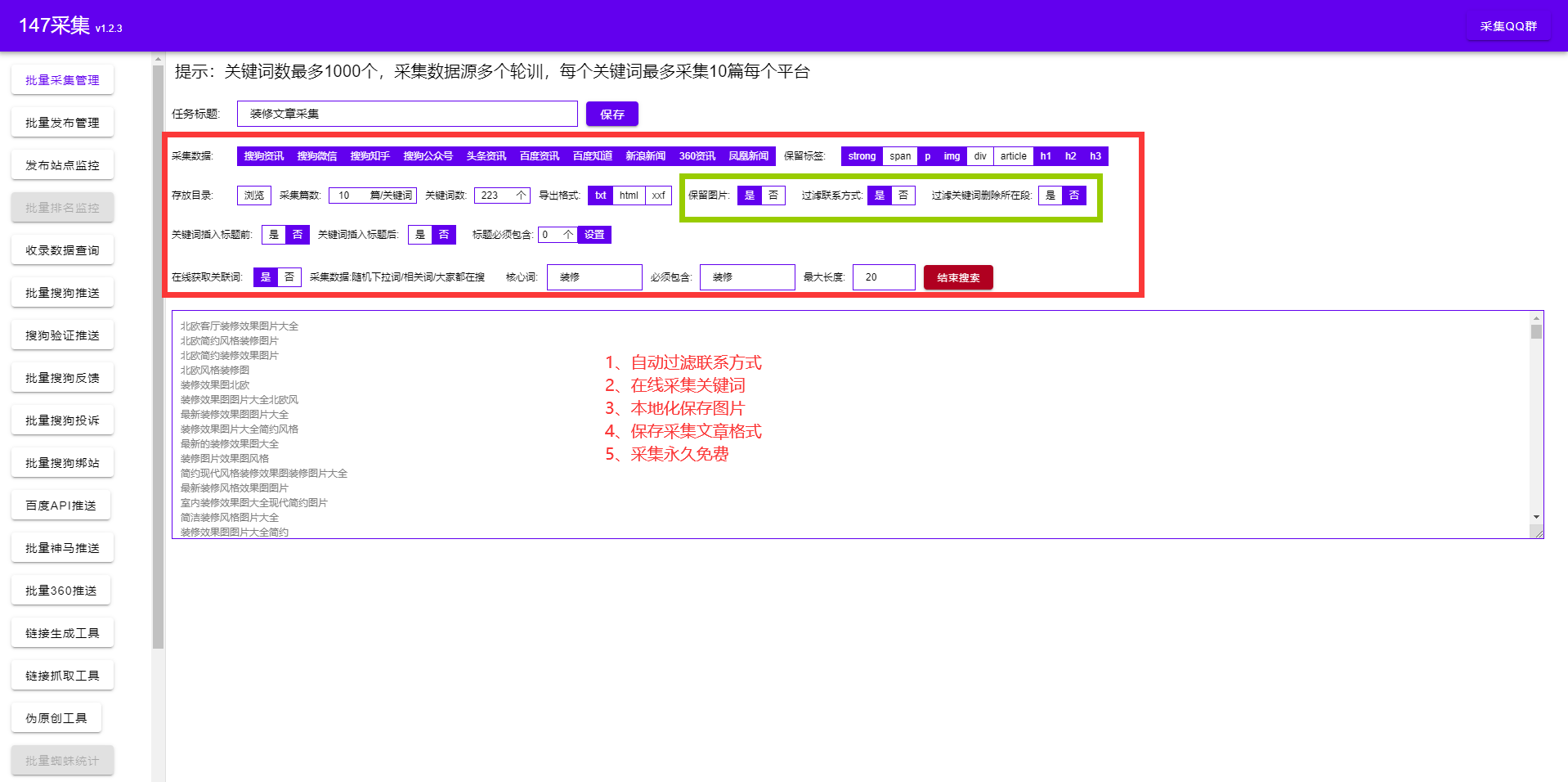
SEO人员在平时的SEO优化中会使用大量的SEO工具来智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特色seo关键词优化软件:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局海量优秀同行,以及优化方向seo关键词优化软件!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、通过site:域名,查询网站的条目有多少收录,收录的关键词做了多少seo关键词优化软件@> 有吗?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
查看全部
通过关键词采集文章采集api(
全平台发布全CMS发布器功能特点及特点
)
SEO人员在平时的SEO优化中会使用大量的SEO工具来智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特色seo关键词优化软件:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局海量优秀同行,以及优化方向seo关键词优化软件!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、通过site:域名,查询网站的条目有多少收录,收录的关键词做了多少seo关键词优化软件@> 有吗?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
通过关键词采集文章采集api( 基于微服务的日志中心架构设计三、中心的流程与实现 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-01 00:00
基于微服务的日志中心架构设计三、中心的流程与实现
)
转载本文须注明出处:微信公众号EAWorld,违者必究。
介绍:
日志一直是运维和开发人员最关心的问题。运维人员可以通过相关日志信息及时发现系统隐患和系统故障,安排人员及时处理和解决问题。没有日志信息的帮助,开发者无法解决问题。没有日志就等于没有眼睛,没有方向。
微服务越来越流行,在享受微服务架构带来的好处的同时,也不得不承担微服务带来的麻烦。日志管理就是其中之一。微服务有一个很大的特点:分布式。由于分布式部署,日志信息分散在各处,给采集日志的存储带来了一定的挑战:
本文文章将讨论与日志管理相关的问题。
内容:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程及实现
四、日志中心关键配置
五、总结
一、日志的重要性和复杂性
要说管理日志,在管理日志之前有一个先决条件。我们需要知道日志是什么,它们能做什么,以及它们有什么用处。根据百度百科,是记录系统操作事件的记录信息。
在日志文件中,记录着当前系统的各种生命体征,就像我们在医院体检后得到的体检表,反映了我们的肝功能、肾功能、血常规等具体指标。日志文件在应用系统中的作用就像一个体检清单,反映了系统的健康状况、系统的运行事件、系统的变化情况。
日志充当系统中的守护者。它是保证服务高度可靠的基础,记录系统的一举一动。有运维级别、业务级别、安全级别的日志。系统监控、异常处理、安全、审计都离不开日志的辅助。
有各种类型的日志,一个健壮的系统可能有各种日志消息。
这么复杂多样的日志,有必要一口气抓吗?我们需要哪些?这些都是我们在设计日志中心架构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态中不可或缺的一部分,是监控的第二大师。在这里分享我们的产品级设计实践,了解日志中心在基于微服务架构的技术架构中的位置,以及如何部署。
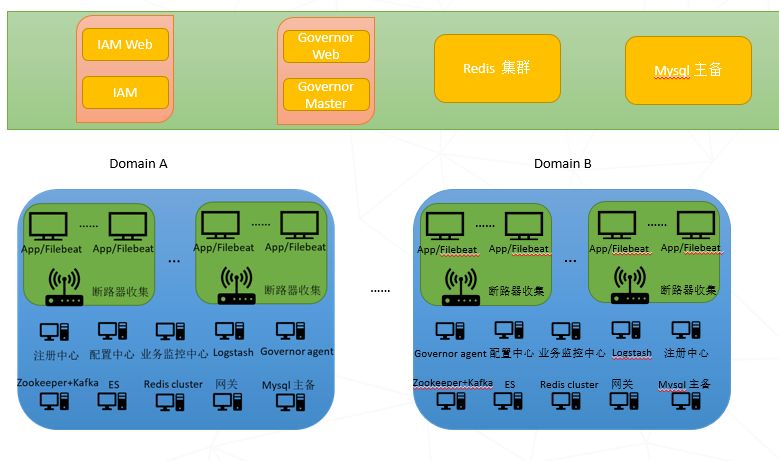
在本设计中,微服务结构由以下部分组成:
图中没有log center四个关键词,因为它是由多个独立的组件组成的。这些组件分别是 Filebeat、Kafka、Logstash 和 Elasticsearch,它们共同构成了日志中心。
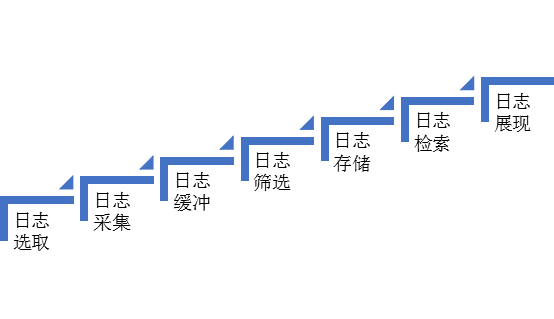
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1. 日志选择----确定选择哪些日志记录进行分析
2. 日志采集 ---- filebeat 轻采集
3. 日志缓冲---- kafka 缓存在本地缓冲
4. 日志过滤 ---- logstash 过滤
5. 日志存储----elasticsearch索引存储
6. 日志检索----使用elasticsearch本身的检索功能
7. 日志展示----参考kibana风格实现日志数据可视化
在传统的 ELK 上,Logstash 日志 采集 被 Filebeat 取代,在日志存储前增加了 kafka 缓冲和 logstash 过滤。这组流程确保功能完整,同时提高性能并使部署尽可能轻量级。
三、日志中心的流程及实现
选型:根据业务场景
日志内容复杂多样,如何采集有价值的日志是我们关注的重点。日志的价值实际上取决于业务运营。同一种日志在不同业务场景中的价值会完全不同。根据以往的业务实践,结合一些企业级的业务需求,我们选择重点关注以下几类日志。• Trace log [trace.log] 服务器引擎的调试日志,供系统维护人员定位系统运行问题。• 系统日志[system.log] 大粒度引擎运行进出日志,用于调用栈分析,可用于性能分析。• 部署日志[deploy.log] 记录系统启动、停止、组件包部署、集群通知等信息的日志。• 引擎日志[引擎。log] 一个细粒度的引擎运行日志,可以打印上下文数据,定位业务问题。• 组件包日志[contribution.log] 组件包记录的业务日志(使用基础组件库的日志输出API写日志)
通过以上几类日志,可以明确我们在分析问题时要查找的位置,通过分类缩小查找范围,提高效率。
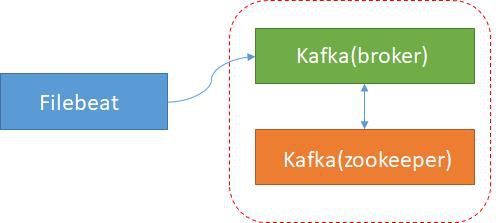
采集(Filebeat):专注于轻量级
微服务应用分布在各个领域的各个系统中。应用程序的日志在各个域的各个系统中相应生成。日志管理首先要做好日志的采集工作。对于日志采集 作业,我们选择 Elastic Stack 中的 Filebeat。
Filebeat与应用程序挂钩,因为我们需要知道如何采集每个位置的日志信息,所以轻量级其实是我们考虑的主要因素。
Filebeat 会有一个或多个探测器,称为 Prospector,可以实时监控指定文件或指定文件目录的变化状态,并将变化状态及时传送到下一层——Spooler 进行处理。
Filebeat还有一个特性我们介绍给日志过滤,这是定位源头的关键。
这两点正好满足了我们实时采集实现日志的需要。新增的日志通过 Filebeat 动态存储和及时采样。至此,如何采集记录信息的问题就完美解决了。
缓冲(Kafka):高吞吐量、易扩展、高上限
在日志存储之前,我们引入了一个组件,Kafka,作为日志缓冲层。Kafka 充当缓冲区,避免高峰应用对 ES 的影响。由于 ES 瓶颈问题导致数据丢失问题。同时,它还具有数据聚合的功能。
使用 kafka 进行日志缓冲有几个优点:
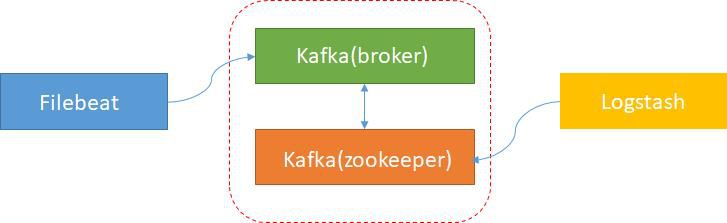
筛选(Logstash):提前埋点,便于定位
日志信息是通过filebeat、kafka等工具采集和传输的,给日志事件增加了很多额外的信息。使用Logstash实现二次处理,可以在过滤器中进行过滤或处理。
Filebeat 在采集信息时,我们通过将同一台服务器上的日志信息发送到同一个 Kafka 主题来实现日志聚合。主题名称是服务器的关键信息。在更细粒度的层面上,您还可以将每个应用的信息聚合为一个主题。Kafka 中 Filebeat 接收到的日志信息中收录一个标识符——日志来自哪里。Logstash的作用是在日志导入到ES之前,通过标识符过滤汇总相应的日志信息,然后发送给ES,为后续查找提供依据。方便我们清晰定位问题。
存储(ES):易于扩展,易于使用
Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。
选择 ElasticSearch 的主要原因是:分布式部署,易于扩展;处理海量数据,满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于上手。
搜索 (ES):分类
Elasticsearch 本身是一个强大的搜索引擎,支持按系统、应用、应用实例组、应用实例IP、关键字、日志级别、时间间隔来检索所需的日志信息。
显示(Kibana):配置简单,一目了然
在查看密密麻麻的日志信息时,往往会有一种头晕目眩的感觉。需要对日志信息进行简化提取,对日志信息进行整合分析,并以图表的形式展示日志信息。在展示的过程中,我们可以借鉴和吸收 Kibana 在日志可视化方面的努力,实现日志的可视化处理。通过简单的配置,我们可以清晰、可视化的看到某个服务或应用的日志分析结果。.
查看全部
通过关键词采集文章采集api(
基于微服务的日志中心架构设计三、中心的流程与实现
)

转载本文须注明出处:微信公众号EAWorld,违者必究。
介绍:
日志一直是运维和开发人员最关心的问题。运维人员可以通过相关日志信息及时发现系统隐患和系统故障,安排人员及时处理和解决问题。没有日志信息的帮助,开发者无法解决问题。没有日志就等于没有眼睛,没有方向。
微服务越来越流行,在享受微服务架构带来的好处的同时,也不得不承担微服务带来的麻烦。日志管理就是其中之一。微服务有一个很大的特点:分布式。由于分布式部署,日志信息分散在各处,给采集日志的存储带来了一定的挑战:
本文文章将讨论与日志管理相关的问题。
内容:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程及实现
四、日志中心关键配置
五、总结
一、日志的重要性和复杂性
要说管理日志,在管理日志之前有一个先决条件。我们需要知道日志是什么,它们能做什么,以及它们有什么用处。根据百度百科,是记录系统操作事件的记录信息。
在日志文件中,记录着当前系统的各种生命体征,就像我们在医院体检后得到的体检表,反映了我们的肝功能、肾功能、血常规等具体指标。日志文件在应用系统中的作用就像一个体检清单,反映了系统的健康状况、系统的运行事件、系统的变化情况。
日志充当系统中的守护者。它是保证服务高度可靠的基础,记录系统的一举一动。有运维级别、业务级别、安全级别的日志。系统监控、异常处理、安全、审计都离不开日志的辅助。
有各种类型的日志,一个健壮的系统可能有各种日志消息。
这么复杂多样的日志,有必要一口气抓吗?我们需要哪些?这些都是我们在设计日志中心架构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态中不可或缺的一部分,是监控的第二大师。在这里分享我们的产品级设计实践,了解日志中心在基于微服务架构的技术架构中的位置,以及如何部署。
在本设计中,微服务结构由以下部分组成:
图中没有log center四个关键词,因为它是由多个独立的组件组成的。这些组件分别是 Filebeat、Kafka、Logstash 和 Elasticsearch,它们共同构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1. 日志选择----确定选择哪些日志记录进行分析
2. 日志采集 ---- filebeat 轻采集
3. 日志缓冲---- kafka 缓存在本地缓冲
4. 日志过滤 ---- logstash 过滤
5. 日志存储----elasticsearch索引存储
6. 日志检索----使用elasticsearch本身的检索功能
7. 日志展示----参考kibana风格实现日志数据可视化
在传统的 ELK 上,Logstash 日志 采集 被 Filebeat 取代,在日志存储前增加了 kafka 缓冲和 logstash 过滤。这组流程确保功能完整,同时提高性能并使部署尽可能轻量级。
三、日志中心的流程及实现
选型:根据业务场景
日志内容复杂多样,如何采集有价值的日志是我们关注的重点。日志的价值实际上取决于业务运营。同一种日志在不同业务场景中的价值会完全不同。根据以往的业务实践,结合一些企业级的业务需求,我们选择重点关注以下几类日志。• Trace log [trace.log] 服务器引擎的调试日志,供系统维护人员定位系统运行问题。• 系统日志[system.log] 大粒度引擎运行进出日志,用于调用栈分析,可用于性能分析。• 部署日志[deploy.log] 记录系统启动、停止、组件包部署、集群通知等信息的日志。• 引擎日志[引擎。log] 一个细粒度的引擎运行日志,可以打印上下文数据,定位业务问题。• 组件包日志[contribution.log] 组件包记录的业务日志(使用基础组件库的日志输出API写日志)
通过以上几类日志,可以明确我们在分析问题时要查找的位置,通过分类缩小查找范围,提高效率。
采集(Filebeat):专注于轻量级
微服务应用分布在各个领域的各个系统中。应用程序的日志在各个域的各个系统中相应生成。日志管理首先要做好日志的采集工作。对于日志采集 作业,我们选择 Elastic Stack 中的 Filebeat。
Filebeat与应用程序挂钩,因为我们需要知道如何采集每个位置的日志信息,所以轻量级其实是我们考虑的主要因素。
Filebeat 会有一个或多个探测器,称为 Prospector,可以实时监控指定文件或指定文件目录的变化状态,并将变化状态及时传送到下一层——Spooler 进行处理。
Filebeat还有一个特性我们介绍给日志过滤,这是定位源头的关键。
这两点正好满足了我们实时采集实现日志的需要。新增的日志通过 Filebeat 动态存储和及时采样。至此,如何采集记录信息的问题就完美解决了。
缓冲(Kafka):高吞吐量、易扩展、高上限
在日志存储之前,我们引入了一个组件,Kafka,作为日志缓冲层。Kafka 充当缓冲区,避免高峰应用对 ES 的影响。由于 ES 瓶颈问题导致数据丢失问题。同时,它还具有数据聚合的功能。
使用 kafka 进行日志缓冲有几个优点:
筛选(Logstash):提前埋点,便于定位
日志信息是通过filebeat、kafka等工具采集和传输的,给日志事件增加了很多额外的信息。使用Logstash实现二次处理,可以在过滤器中进行过滤或处理。
Filebeat 在采集信息时,我们通过将同一台服务器上的日志信息发送到同一个 Kafka 主题来实现日志聚合。主题名称是服务器的关键信息。在更细粒度的层面上,您还可以将每个应用的信息聚合为一个主题。Kafka 中 Filebeat 接收到的日志信息中收录一个标识符——日志来自哪里。Logstash的作用是在日志导入到ES之前,通过标识符过滤汇总相应的日志信息,然后发送给ES,为后续查找提供依据。方便我们清晰定位问题。
存储(ES):易于扩展,易于使用
Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。

选择 ElasticSearch 的主要原因是:分布式部署,易于扩展;处理海量数据,满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于上手。
搜索 (ES):分类
Elasticsearch 本身是一个强大的搜索引擎,支持按系统、应用、应用实例组、应用实例IP、关键字、日志级别、时间间隔来检索所需的日志信息。
显示(Kibana):配置简单,一目了然
在查看密密麻麻的日志信息时,往往会有一种头晕目眩的感觉。需要对日志信息进行简化提取,对日志信息进行整合分析,并以图表的形式展示日志信息。在展示的过程中,我们可以借鉴和吸收 Kibana 在日志可视化方面的努力,实现日志的可视化处理。通过简单的配置,我们可以清晰、可视化的看到某个服务或应用的日志分析结果。.
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-25 14:11
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
,优采云采集器优采云是基于运营商网上实名制的网页数据采集、移动互联网数据和API接口服务的数据服务。 -name 系统平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器 优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。只是各大平台都设置了严格的反爬,很难获取有价值的数据。
3、金坛中国 金坛中国的数据服务平台有多种专业的数据采集工具,包括很多开发者上传的采集工具,其中很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了业界99%的采集软件,可以通过近距离检测采集来完成。对技术含量要求高的高强度抗爬或抗裂有专业的技术方案。在专业性方面,金坛的专业性是毋庸置疑的,其中不少也是针对高难度采集软件的定制开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,它最大的特点是网页 采集 的代词是单数,因为焦点。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就可以整齐的抓取网页的数据,操作很简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。对于一些防爬设置强的网站来说,是无能为力的。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取成Excel、XML、CSV等大部分数据库。该软件基于网页抓取。获取和 Web 自动化。
8、ForeSpider ForeSpider 是一个非常有用的网络数据工具采集。用户可以使用此工具帮助您自动检索网页中的各种数据信息。这个软件使用起来很简单,但是也有一个网站在面对一些高难度和高强度的反爬设置时无能为力。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不死机,可实现实时查询。
10、优采云采集器 优采云采集器操作很简单,按照流程很容易上手, 查看全部
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
,优采云采集器优采云是基于运营商网上实名制的网页数据采集、移动互联网数据和API接口服务的数据服务。 -name 系统平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器 优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。只是各大平台都设置了严格的反爬,很难获取有价值的数据。
3、金坛中国 金坛中国的数据服务平台有多种专业的数据采集工具,包括很多开发者上传的采集工具,其中很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了业界99%的采集软件,可以通过近距离检测采集来完成。对技术含量要求高的高强度抗爬或抗裂有专业的技术方案。在专业性方面,金坛的专业性是毋庸置疑的,其中不少也是针对高难度采集软件的定制开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,它最大的特点是网页 采集 的代词是单数,因为焦点。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就可以整齐的抓取网页的数据,操作很简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。对于一些防爬设置强的网站来说,是无能为力的。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取成Excel、XML、CSV等大部分数据库。该软件基于网页抓取。获取和 Web 自动化。
8、ForeSpider ForeSpider 是一个非常有用的网络数据工具采集。用户可以使用此工具帮助您自动检索网页中的各种数据信息。这个软件使用起来很简单,但是也有一个网站在面对一些高难度和高强度的反爬设置时无能为力。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不死机,可实现实时查询。
10、优采云采集器 优采云采集器操作很简单,按照流程很容易上手,
通过关键词采集文章采集api(几百上千个不同的CMS网站都能实现统一管理? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-24 20:12
)
[内容]!
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,匹配内容和图片准确率高,自动执行文章采集发布,提供方便快捷的数据服务! !
相关规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类工具还是很强大的,只要输入关键词采集,就可以自动采集通过软件采集@发布文章 > .
您还可以设置自动下载图片以保存本地或第三方。配备自动内链、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
看完这篇文章,如果觉得不错,不妨采集一下或者发给有需要的朋友同事!你的一举一动都会成为博主源源不断的动力!
查看全部
通过关键词采集文章采集api(几百上千个不同的CMS网站都能实现统一管理?
)
[内容]!
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,匹配内容和图片准确率高,自动执行文章采集发布,提供方便快捷的数据服务! !
相关规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类工具还是很强大的,只要输入关键词采集,就可以自动采集通过软件采集@发布文章 > .
您还可以设置自动下载图片以保存本地或第三方。配备自动内链、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
看完这篇文章,如果觉得不错,不妨采集一下或者发给有需要的朋友同事!你的一举一动都会成为博主源源不断的动力!

通过关键词采集文章采集api(10个很棒的Python特性,你不能使用了吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-24 17:21
Python部落()组织翻译,禁止转载,欢迎转发
注:本文翻译自同名PPT,所以文章有很多重复的段落标题。这些标题就是页面上PPT的标题,而且PPT的标题经常重复出现。
10 个因为拒绝升级到 Python 3 而无法使用的很棒的 Python 特性,你也可以认为有 11 个特性。
序章功能 0:矩阵乘法
功能 0,因为您还不能实际使用它的目录
政治人物 465
在 Python3.5 中,您将能够使用
代替:
任何对象都可以覆盖 __matmul__ 以使用 @。
功能一:高级拆包
你曾经能够做到这一点:
现在你可以这样做:
*rest 可以出现在任何地方:
功能一:高级解包获取文件的第一行和最后一行
重构你的功能
特性 2:关键词 唯一参数
选项出现在 *args 之后。访问它的唯一方法是显式调用 f(a, b, option=True) 如果你不想采集 *args,你可以只写一个 *:
特性 2:关键词 唯一参数
不再有“糟糕,我不小心向函数传递了太多参数,其中一个将作为关键字参数接收”。
特性 2:关键词 唯一参数
将其更改为:
特性 2:关键词 唯一参数
或者,“我重新排序了函数的 关键词 参数,但有些是隐式传递的”
例子:
特性 2:关键词 唯一参数
max 内置函数支持 max(a, b, c)。我们也应该允许这样做。
我们只是打破了前面的代码,不使用 关键词 作为第二个参数来将值传递给键。
(事实上在 Python 2 中它会返回 ["a", "ab", "ac"],参见特性 6)。
顺便说一句,max 表明它在 Python2 中已经是可能的,但前提是你用 C 编写函数。
显然,我们应该使用 maxall(iterable, *, key=None) 来开始。
特性 2:关键词 唯一参数
您可以使您的 API 保持“最新”。
傻瓜式例子
好吧,也许将更长的时间放在更短的时间之前会更有意义。. .
太糟糕了,你会破坏代码。
特性 2:关键词 唯一参数
在 Python 3 中,您可以使用:
现在,a 和 b 必须像 extendto(10, short=a, long=b) 一样传入。
或者如果您愿意,可以像这样 extendto(10, long=b, short=a) 。
特性 2:关键词 唯一参数
在不破坏 API 的情况下添加新的 关键词 参数。
Python3 在标准库中执行此操作。
例如, os 模块中的函数具有 follow_symlinks 选项。
因此,您可以只使用 os.stat(file, follow_symlinks=False) 而不是 os.lstat。
如果这听起来更冗长,你可以做
代替
但是, os.stat(file, some_condition) 没有。
不要将其视为两个参数的函数。
特征二:关键词唯一参数特征三:连接异常
情况:你用except捕获异常,做某事,然后触发不同的异常。
问题:您丢失了先前异常的回溯。
刚才OSError怎么了?
特点三:连接异常
Python3 向您展示了整个异常链:
您也可以使用 raise from 手动执行此操作:
特性四:细分 OSError 子类
我刚才显示的代码是错误的。
它捕获 OSError 异常并假定它是权限错误。
但是 OSError 异常可能是由多种情况引起的(文件未找到、目录、不是目录、管道损坏等)
你确定你需要这样做:
哇。可怕。
特性四:细分 OSError 子类
Python3 通过添加一系列新的异常来解决这个问题。
你只需要这样做:
(别担心,PermissionError 是 OSError 的子类,旧的 .errno 状态码仍然有效)。
特征 5:一切都是迭代器 特征 5:一切都是迭代器
如果你这样做:
特征 5:一切都是迭代器
特征 5:一切都是迭代器 特征 5:一切都是迭代器 特征 6:并非一切都可以比较
在 Python2 中,您可以执行以下操作:
干杯。我只反驳数学。
特点6:不是所有的东西都可以比较
因为在 Python 2 中,您可以比较所有内容。
在 Python3 中,你不能这样做:
这避免了一些微妙的错误,例如所有类型的非强制转换,从 int 到 str,反之亦然。
尤其是当您隐式使用 > 时,例如 max 或 sorted。
在 Python2 中:
特征 7:产量来自
如果您使用生成器,那就太好了。
不要这样写:
写就好了:
只需将生成器重构为子生成器。
特征 7:产量来自
把所有东西都变成发电机更容易。参见上面提到的“特征 5:一切都是迭代器”,你就会明白为什么要这样做。
不要堆叠来生成列表,只需 yield 或 yield from。
不好:
行:
更好的一个:
特征 7:产量来自
如果您不知道,生成器很棒,因为:
特性8:异步IO(asyncio)
使用新的协程功能和保存的生成器状态进行异步 IO。
不会骗你的。我还是不明白这一点。
但是这没关系。甚至大卫比兹利也很难理解这一点。
特性 9:标准库添加故障处理程序
显示(有限的)回溯,即使 Python 死得很惨。
使用 kill -9 时不起作用,但就像 segfaults 一样。
或者使用 kill -6 (程序请求异常终止)
它也可以通过 python -X faulthandler 激活。
特性九:标准库新增ipaddress
确切地。IP地址。
另一件事你不希望自己静止不动。
特性九:标准库新增 functools.lru_cache
为你的函数提供一个 LRU 缓存装饰器。
从文档中。
特性 9:标准库添加枚举
最后是标准库中的枚举类型。
仅限 Python 3.4。
使用一些魔法仅在 Python3 中有用(由于元类更改):
功能 10:有趣的 Unicode 变量名
功能注释
注释可以是任意 Python 对象。
除了将注释放入 __annotations__ 字典之外,Python 对注释不做任何事情。
但它为图书馆作者做有趣的事情开辟了可能性。
例如,IPython 2.0 小工具。
特点11:Unicode和字节流英文原文:
译者:leisants 查看全部
通过关键词采集文章采集api(10个很棒的Python特性,你不能使用了吗?)
Python部落()组织翻译,禁止转载,欢迎转发
注:本文翻译自同名PPT,所以文章有很多重复的段落标题。这些标题就是页面上PPT的标题,而且PPT的标题经常重复出现。
10 个因为拒绝升级到 Python 3 而无法使用的很棒的 Python 特性,你也可以认为有 11 个特性。
序章功能 0:矩阵乘法
功能 0,因为您还不能实际使用它的目录
政治人物 465
在 Python3.5 中,您将能够使用
代替:
任何对象都可以覆盖 __matmul__ 以使用 @。
功能一:高级拆包
你曾经能够做到这一点:
现在你可以这样做:
*rest 可以出现在任何地方:
功能一:高级解包获取文件的第一行和最后一行
重构你的功能
特性 2:关键词 唯一参数
选项出现在 *args 之后。访问它的唯一方法是显式调用 f(a, b, option=True) 如果你不想采集 *args,你可以只写一个 *:
特性 2:关键词 唯一参数
不再有“糟糕,我不小心向函数传递了太多参数,其中一个将作为关键字参数接收”。
特性 2:关键词 唯一参数
将其更改为:
特性 2:关键词 唯一参数
或者,“我重新排序了函数的 关键词 参数,但有些是隐式传递的”
例子:
特性 2:关键词 唯一参数
max 内置函数支持 max(a, b, c)。我们也应该允许这样做。
我们只是打破了前面的代码,不使用 关键词 作为第二个参数来将值传递给键。
(事实上在 Python 2 中它会返回 ["a", "ab", "ac"],参见特性 6)。
顺便说一句,max 表明它在 Python2 中已经是可能的,但前提是你用 C 编写函数。
显然,我们应该使用 maxall(iterable, *, key=None) 来开始。
特性 2:关键词 唯一参数
您可以使您的 API 保持“最新”。
傻瓜式例子
好吧,也许将更长的时间放在更短的时间之前会更有意义。. .
太糟糕了,你会破坏代码。
特性 2:关键词 唯一参数
在 Python 3 中,您可以使用:
现在,a 和 b 必须像 extendto(10, short=a, long=b) 一样传入。
或者如果您愿意,可以像这样 extendto(10, long=b, short=a) 。
特性 2:关键词 唯一参数
在不破坏 API 的情况下添加新的 关键词 参数。
Python3 在标准库中执行此操作。
例如, os 模块中的函数具有 follow_symlinks 选项。
因此,您可以只使用 os.stat(file, follow_symlinks=False) 而不是 os.lstat。
如果这听起来更冗长,你可以做
代替
但是, os.stat(file, some_condition) 没有。
不要将其视为两个参数的函数。
特征二:关键词唯一参数特征三:连接异常
情况:你用except捕获异常,做某事,然后触发不同的异常。
问题:您丢失了先前异常的回溯。
刚才OSError怎么了?
特点三:连接异常
Python3 向您展示了整个异常链:
您也可以使用 raise from 手动执行此操作:
特性四:细分 OSError 子类
我刚才显示的代码是错误的。
它捕获 OSError 异常并假定它是权限错误。
但是 OSError 异常可能是由多种情况引起的(文件未找到、目录、不是目录、管道损坏等)
你确定你需要这样做:
哇。可怕。
特性四:细分 OSError 子类
Python3 通过添加一系列新的异常来解决这个问题。
你只需要这样做:
(别担心,PermissionError 是 OSError 的子类,旧的 .errno 状态码仍然有效)。
特征 5:一切都是迭代器 特征 5:一切都是迭代器
如果你这样做:
特征 5:一切都是迭代器
特征 5:一切都是迭代器 特征 5:一切都是迭代器 特征 6:并非一切都可以比较
在 Python2 中,您可以执行以下操作:
干杯。我只反驳数学。
特点6:不是所有的东西都可以比较
因为在 Python 2 中,您可以比较所有内容。
在 Python3 中,你不能这样做:
这避免了一些微妙的错误,例如所有类型的非强制转换,从 int 到 str,反之亦然。
尤其是当您隐式使用 > 时,例如 max 或 sorted。
在 Python2 中:
特征 7:产量来自
如果您使用生成器,那就太好了。
不要这样写:
写就好了:
只需将生成器重构为子生成器。
特征 7:产量来自
把所有东西都变成发电机更容易。参见上面提到的“特征 5:一切都是迭代器”,你就会明白为什么要这样做。
不要堆叠来生成列表,只需 yield 或 yield from。
不好:
行:
更好的一个:
特征 7:产量来自
如果您不知道,生成器很棒,因为:
特性8:异步IO(asyncio)
使用新的协程功能和保存的生成器状态进行异步 IO。
不会骗你的。我还是不明白这一点。
但是这没关系。甚至大卫比兹利也很难理解这一点。
特性 9:标准库添加故障处理程序
显示(有限的)回溯,即使 Python 死得很惨。
使用 kill -9 时不起作用,但就像 segfaults 一样。
或者使用 kill -6 (程序请求异常终止)
它也可以通过 python -X faulthandler 激活。
特性九:标准库新增ipaddress
确切地。IP地址。
另一件事你不希望自己静止不动。
特性九:标准库新增 functools.lru_cache
为你的函数提供一个 LRU 缓存装饰器。
从文档中。
特性 9:标准库添加枚举
最后是标准库中的枚举类型。
仅限 Python 3.4。
使用一些魔法仅在 Python3 中有用(由于元类更改):
功能 10:有趣的 Unicode 变量名
功能注释
注释可以是任意 Python 对象。
除了将注释放入 __annotations__ 字典之外,Python 对注释不做任何事情。
但它为图书馆作者做有趣的事情开辟了可能性。
例如,IPython 2.0 小工具。
特点11:Unicode和字节流英文原文:
译者:leisants
通过关键词采集文章采集api(微软研究员为Azure认知搜索“加持”了语义搜索功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-24 17:20
编者按:作为云搜索服务,Azure 认知搜索集成了强大的 API 和工具,帮助开发人员构建丰富的搜索体验。不止于现状,微软研究人员还为 Azure 认知搜索的语义搜索功能“加冕”,让搜索引擎具备了语义排序、语义摘要、语义高亮、语义问答、自动拼写纠正等能力。本文将揭示这些惊人功能背后的核心技术,涉及关键词包括预训练、图网络、多任务处理等。本文编译自 Microsoft Research 博客“语义搜索背后的科学:Bing 的 AI 如何为 Azure 认知搜索提供动力”。
智能语义搜索是搜索引擎追求的终极目标。多年来,微软研究人员一直在探索实现智能语义搜索的途径,最近将相关研究成果集成到微软Azure云计算平台的认知服务——Azure认知搜索(Azure Cognitive Search)中,为所有人提供语义搜索能力。预览版中的 Azure 用户。该技术核心部分涉及的多项研究成果均来自微软亚洲研究院。
Azure 认知搜索是一种云搜索服务,它为开发人员提供 API 和工具,以基于 Web、移动和企业应用程序中的专门异构内容构建丰富的搜索体验。Azure 认知搜索具有多个组件,包括用于检索和查询的 API、通过 Azure 数据提取的无缝集成、与 Azure 认知服务的深度集成以及用户拥有的检索内容的持久存储。默认情况下,Azure 认知搜索使用 BM25 算法,该算法通常用于信息检索。
为了提高微软必应搜索的相关性,微软研究和开发人员此前通过基于 Transformer 的语言模型改进了必应搜索。这些改进让搜索引擎不仅可以匹配关键词,还可以利用词和内容背后的语义进行搜索,转化的能力就是语义搜索。
将语义搜索功能集成到 Azure 认知搜索中的效果
语义搜索显着提高了必应搜索的搜索结果质量。但微软研发团队在此过程中发现,为了最大限度发挥 AI 的威力,需要大量的专业人员来集成和部署 AI 规模的相关技术和产品,例如大规模的基于 Transformer 的语言模型。 . 预训练、跨不同任务的多任务微调、将大型模型提炼成质量损失最小的可部署模型等。而这样的专业团队并不是每个公司都能负担得起的。微软秉承赋能每一个人、每一组织的公司理念,通过将相关研究成果整合到 Azure 认知搜索中,降低了人们使用 AI 规模技术的门槛。
Azure 认知搜索中的语义搜索功能
让我们仔细看看 Azure 认知搜索中的语义搜索功能。
语义排序:显着提高相关性。传统的搜索方式是基于关键词排序结果,基于Transformer的语义排序引擎可以理解文本背后的含义。在A/B测试中,语义搜索功能提升了搜索结果的点击率(2.0%),三个词以上的搜索结果点击率也提升了4.@ >5%。
通过语义排序提高相关性的示例(右)
语义摘要:提取关键信息。相关性只是一方面,搜索结果中的标题和片段也很重要。好的标题和摘要让用户一眼就能看出结果是否是他们想要的。
语义突出显示:机器阅读理解。语义高亮的简单理解是关注一个搜索结果并以粗体显示。通过语义高亮,用户可以直接得到他们需要的答案,或者通过快速扫描结果页面找到他们需要的文档,甚至可以直接得到摘要。使用机器阅读理解可以帮助找到段落的重点,从而大大提高阅读效率。
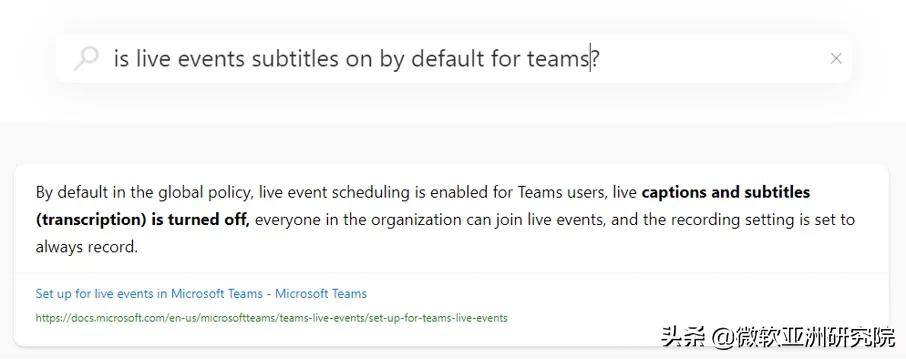
使用语义搜索提取摘要、语义强调的示例
语义问答:快速解答。疑问式查询是搜索引擎经常遇到的一种搜索方法,其背后用户往往希望优先考虑简短而准确的答案,而不是文档。语义搜索可以使用机器学习来读取语料库中的所有文档,然后总结并在顶部显示答案。
语义搜索提取文档亮点并提供快速答案
自动拼写更正。据统计,用于输入的句子中有10%~15%存在拼写错误,拼写错误会极大地影响搜索结果的质量,集成语义搜索的搜索引擎可以实现自动拼写纠正。
背后的技术:预训练、图网络、多任务......
上述功能的实现离不开微软研究院在NLP和语义搜索方面取得的突破性进展。研究人员与微软内部其他 AI 团队合作开发了一系列神经网络模型,不仅在 SQuAD、GLUE、SuperGLUE 等多个行业基准测试中取得了最佳成绩,而且还积极部署应用,实现了微软相关产品。性能改进。
以下是 Microsoft 用于实现语义搜索的具体技术:
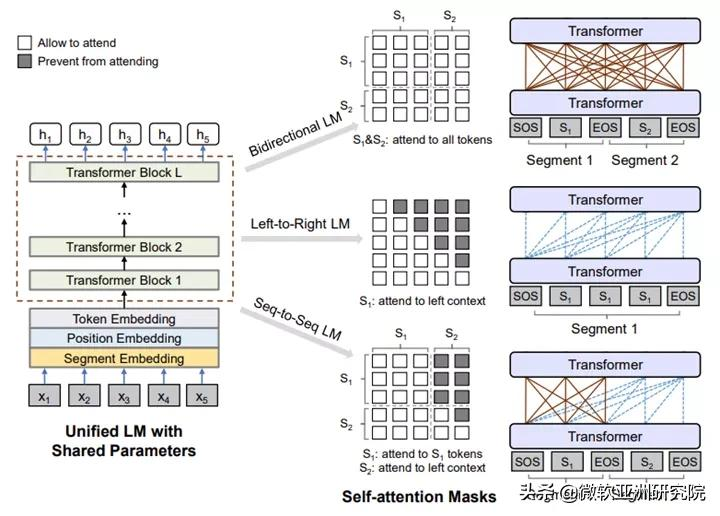
统一的预训练语言模型:UniLM 和 UniLM v2
在 Azure 认知搜索中,预训练语言模型利用了微软亚洲研究院的统一预训练语言模型 UniLM(Unified Language Model Pre-training),这是第一个统一的语言理解和语言生成模型。在基准测试中表现良好的预训练模型。UniLM 涵盖了两个关键的技术创新:一是提出了统一的预训练框架,使得同一个模型可以同时支持自然语言理解和自然语言生成任务,而之前的大部分预训练模型主要是针对自然语言的。语言理解任务。第二大创新是提出了部分自回归预训练范式和伪掩码语言模型,可以更高效地训练出更好的自然语言预训练模型。
在 ICML 2020 上,来自微软亚洲研究院的研究人员还提出了一种新的训练 UniLM 的训练框架,Pseudo-Masked Language Models for Unified Language Model Pre-Training,简称“Unified Pre-training Pseudo-Mask Language Model”,简称 UniLM v2。UniLM v2 使用传统掩码通过自动编码来学习掩码标记与上下文之间的关系,并使用伪掩码通过部分自回归来学习掩码标记之间的关系。必应搜索中的技术于 2019 年初在 BERT 上实现,并通过使用 UniLM v2 提高了其搜索质量。
统一的预训练语言模型架构
机器阅读理解:一个多粒度的阅读理解框架
机器阅读理解 (MRC) 的任务是从文档中找到给定问题的简短答案(例如短语)或长答案(例如段落)。由于最大长度的限制,大多数现有的 MRC 方法在答案提取过程中将文档视为单独的段落,而没有考虑它们之间的内在关系。
为了更好地对 MRC 进行建模,微软亚洲研究院的研究人员提出了一种基于图注意力网络和预训练语言模型的多粒度阅读理解框架,并联合训练对两个粒度答案之间的联系进行建模。在这个框架中,首先根据文档的层次性质,例如段落、句子和符号,为每个文档构建一个图网络,然后使用一个图注意力网络来学习不同层次的表示,最后是一个序列的结构获得。转换后的表示被聚合到答案选择模块中以获得答案。其中,长答案和短答案的抽取任务可以一起训练,从而相互促进。
上述研究论文是《Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension》,已获得 ACL 2020 收录 的认可,并已用于 Bing Search 中的大部分问答任务。
论文链接:
多任务深度神经网络:MT-DNN
微软研究院和 Microsoft Dynamics 365 AI 团队合作提出了一种新的多任务深度神经网络模型——MT-DNN。该模型是第一个在 GLUE 排行榜上超越人类表现的 AI 模型,它结合了 BERT 的优势,并在 10 个自然语言理解任务上优于 BERT,在多个流行的基准 SOTA 结果上创造了新的基准。
MT-DNN 结合了多任务学习和语言模型预训练,用于跨多个自然语言理解任务学习语言表示。MT-DNN 不仅利用了大量的跨任务数据,而且受益于正则化效应,提高了模型的泛化能力,使其在新的任务和领域中表现出色。语义搜索中的模型利用跨各种搜索任务的多任务学习来最大化它们的性能。
研究论文“用于自然语言理解的多任务深度神经网络”发表在 ACL 2019 上。
论文链接:
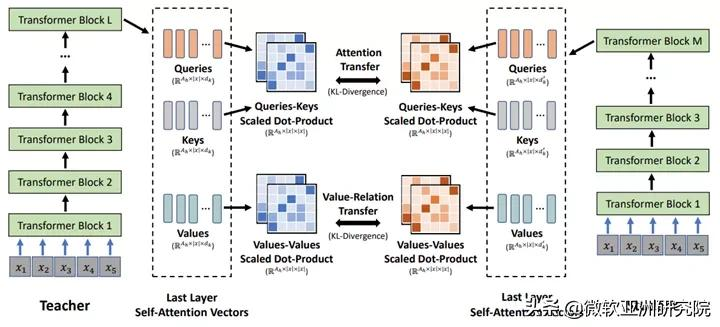
深度自注意力知识蒸馏:MiniLM
大规模预训练模型在自然语言理解和生成任务中表现良好,但庞大的参数和计算成本使其难以直接部署到在线产品中。为此,微软亚洲研究院提出了通用方法 MiniLM - Deep Self-Attention Distillation,将基于 Transformer 的预训练大模型压缩成预训练小模型。核心思想是将预训练好的Transformer模型中非常重要的Self-Attention知识最大程度的转移到小模型上。
MiniLM 在单语言和多语言模型上进行了压缩实验,取得了不错的效果。Azure Cognitive Search 的语义搜索解决方案采用了 MiniLM 技术,具有以原创大模型 20% 的成本保持 95% 准确率的效果。
MiniLM:深度自注意力蒸馏
Semantic Search 背后的 AI 模型非常强大,并且已经在基准测试和 Bing Search 上得到验证。通过将语义搜索集成到 Azure 认知搜索中,微软在普及先进的机器学习技术和让人工智能普及方面又向前迈出了一大步。 查看全部
通过关键词采集文章采集api(微软研究员为Azure认知搜索“加持”了语义搜索功能)
编者按:作为云搜索服务,Azure 认知搜索集成了强大的 API 和工具,帮助开发人员构建丰富的搜索体验。不止于现状,微软研究人员还为 Azure 认知搜索的语义搜索功能“加冕”,让搜索引擎具备了语义排序、语义摘要、语义高亮、语义问答、自动拼写纠正等能力。本文将揭示这些惊人功能背后的核心技术,涉及关键词包括预训练、图网络、多任务处理等。本文编译自 Microsoft Research 博客“语义搜索背后的科学:Bing 的 AI 如何为 Azure 认知搜索提供动力”。
智能语义搜索是搜索引擎追求的终极目标。多年来,微软研究人员一直在探索实现智能语义搜索的途径,最近将相关研究成果集成到微软Azure云计算平台的认知服务——Azure认知搜索(Azure Cognitive Search)中,为所有人提供语义搜索能力。预览版中的 Azure 用户。该技术核心部分涉及的多项研究成果均来自微软亚洲研究院。
Azure 认知搜索是一种云搜索服务,它为开发人员提供 API 和工具,以基于 Web、移动和企业应用程序中的专门异构内容构建丰富的搜索体验。Azure 认知搜索具有多个组件,包括用于检索和查询的 API、通过 Azure 数据提取的无缝集成、与 Azure 认知服务的深度集成以及用户拥有的检索内容的持久存储。默认情况下,Azure 认知搜索使用 BM25 算法,该算法通常用于信息检索。
为了提高微软必应搜索的相关性,微软研究和开发人员此前通过基于 Transformer 的语言模型改进了必应搜索。这些改进让搜索引擎不仅可以匹配关键词,还可以利用词和内容背后的语义进行搜索,转化的能力就是语义搜索。
将语义搜索功能集成到 Azure 认知搜索中的效果
语义搜索显着提高了必应搜索的搜索结果质量。但微软研发团队在此过程中发现,为了最大限度发挥 AI 的威力,需要大量的专业人员来集成和部署 AI 规模的相关技术和产品,例如大规模的基于 Transformer 的语言模型。 . 预训练、跨不同任务的多任务微调、将大型模型提炼成质量损失最小的可部署模型等。而这样的专业团队并不是每个公司都能负担得起的。微软秉承赋能每一个人、每一组织的公司理念,通过将相关研究成果整合到 Azure 认知搜索中,降低了人们使用 AI 规模技术的门槛。
Azure 认知搜索中的语义搜索功能
让我们仔细看看 Azure 认知搜索中的语义搜索功能。
语义排序:显着提高相关性。传统的搜索方式是基于关键词排序结果,基于Transformer的语义排序引擎可以理解文本背后的含义。在A/B测试中,语义搜索功能提升了搜索结果的点击率(2.0%),三个词以上的搜索结果点击率也提升了4.@ >5%。
通过语义排序提高相关性的示例(右)
语义摘要:提取关键信息。相关性只是一方面,搜索结果中的标题和片段也很重要。好的标题和摘要让用户一眼就能看出结果是否是他们想要的。
语义突出显示:机器阅读理解。语义高亮的简单理解是关注一个搜索结果并以粗体显示。通过语义高亮,用户可以直接得到他们需要的答案,或者通过快速扫描结果页面找到他们需要的文档,甚至可以直接得到摘要。使用机器阅读理解可以帮助找到段落的重点,从而大大提高阅读效率。
使用语义搜索提取摘要、语义强调的示例
语义问答:快速解答。疑问式查询是搜索引擎经常遇到的一种搜索方法,其背后用户往往希望优先考虑简短而准确的答案,而不是文档。语义搜索可以使用机器学习来读取语料库中的所有文档,然后总结并在顶部显示答案。
语义搜索提取文档亮点并提供快速答案
自动拼写更正。据统计,用于输入的句子中有10%~15%存在拼写错误,拼写错误会极大地影响搜索结果的质量,集成语义搜索的搜索引擎可以实现自动拼写纠正。
背后的技术:预训练、图网络、多任务......
上述功能的实现离不开微软研究院在NLP和语义搜索方面取得的突破性进展。研究人员与微软内部其他 AI 团队合作开发了一系列神经网络模型,不仅在 SQuAD、GLUE、SuperGLUE 等多个行业基准测试中取得了最佳成绩,而且还积极部署应用,实现了微软相关产品。性能改进。
以下是 Microsoft 用于实现语义搜索的具体技术:
统一的预训练语言模型:UniLM 和 UniLM v2
在 Azure 认知搜索中,预训练语言模型利用了微软亚洲研究院的统一预训练语言模型 UniLM(Unified Language Model Pre-training),这是第一个统一的语言理解和语言生成模型。在基准测试中表现良好的预训练模型。UniLM 涵盖了两个关键的技术创新:一是提出了统一的预训练框架,使得同一个模型可以同时支持自然语言理解和自然语言生成任务,而之前的大部分预训练模型主要是针对自然语言的。语言理解任务。第二大创新是提出了部分自回归预训练范式和伪掩码语言模型,可以更高效地训练出更好的自然语言预训练模型。
在 ICML 2020 上,来自微软亚洲研究院的研究人员还提出了一种新的训练 UniLM 的训练框架,Pseudo-Masked Language Models for Unified Language Model Pre-Training,简称“Unified Pre-training Pseudo-Mask Language Model”,简称 UniLM v2。UniLM v2 使用传统掩码通过自动编码来学习掩码标记与上下文之间的关系,并使用伪掩码通过部分自回归来学习掩码标记之间的关系。必应搜索中的技术于 2019 年初在 BERT 上实现,并通过使用 UniLM v2 提高了其搜索质量。
统一的预训练语言模型架构
机器阅读理解:一个多粒度的阅读理解框架
机器阅读理解 (MRC) 的任务是从文档中找到给定问题的简短答案(例如短语)或长答案(例如段落)。由于最大长度的限制,大多数现有的 MRC 方法在答案提取过程中将文档视为单独的段落,而没有考虑它们之间的内在关系。
为了更好地对 MRC 进行建模,微软亚洲研究院的研究人员提出了一种基于图注意力网络和预训练语言模型的多粒度阅读理解框架,并联合训练对两个粒度答案之间的联系进行建模。在这个框架中,首先根据文档的层次性质,例如段落、句子和符号,为每个文档构建一个图网络,然后使用一个图注意力网络来学习不同层次的表示,最后是一个序列的结构获得。转换后的表示被聚合到答案选择模块中以获得答案。其中,长答案和短答案的抽取任务可以一起训练,从而相互促进。
上述研究论文是《Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension》,已获得 ACL 2020 收录 的认可,并已用于 Bing Search 中的大部分问答任务。
论文链接:
多任务深度神经网络:MT-DNN
微软研究院和 Microsoft Dynamics 365 AI 团队合作提出了一种新的多任务深度神经网络模型——MT-DNN。该模型是第一个在 GLUE 排行榜上超越人类表现的 AI 模型,它结合了 BERT 的优势,并在 10 个自然语言理解任务上优于 BERT,在多个流行的基准 SOTA 结果上创造了新的基准。
MT-DNN 结合了多任务学习和语言模型预训练,用于跨多个自然语言理解任务学习语言表示。MT-DNN 不仅利用了大量的跨任务数据,而且受益于正则化效应,提高了模型的泛化能力,使其在新的任务和领域中表现出色。语义搜索中的模型利用跨各种搜索任务的多任务学习来最大化它们的性能。
研究论文“用于自然语言理解的多任务深度神经网络”发表在 ACL 2019 上。
论文链接:
深度自注意力知识蒸馏:MiniLM
大规模预训练模型在自然语言理解和生成任务中表现良好,但庞大的参数和计算成本使其难以直接部署到在线产品中。为此,微软亚洲研究院提出了通用方法 MiniLM - Deep Self-Attention Distillation,将基于 Transformer 的预训练大模型压缩成预训练小模型。核心思想是将预训练好的Transformer模型中非常重要的Self-Attention知识最大程度的转移到小模型上。
MiniLM 在单语言和多语言模型上进行了压缩实验,取得了不错的效果。Azure Cognitive Search 的语义搜索解决方案采用了 MiniLM 技术,具有以原创大模型 20% 的成本保持 95% 准确率的效果。
MiniLM:深度自注意力蒸馏
Semantic Search 背后的 AI 模型非常强大,并且已经在基准测试和 Bing Search 上得到验证。通过将语义搜索集成到 Azure 认知搜索中,微软在普及先进的机器学习技术和让人工智能普及方面又向前迈出了一大步。
通过关键词采集文章采集api(优化(ASO)实战辅导书《冲榜》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-01-24 17:16
白鲸公开课08《你的APP出海必须掌握哪些ASO策略?》,我们邀请了优化(ASO)实用教程书《冲榜》的作者之一霍晓亮老师来分享。
小亮先生是高级ASOer。现任某知名互联网公司ASO产品经理。擅长App Store算法分析和大数据挖掘。他对iOS推广有深入的研究。小亮先生与资深互联网营销顾问李景航先生合着《粉碎榜单》,全面介绍了App Store优化的“正确打开方式”,帮助移动营销人员有效提升投放产出比。在平台上出售。
小编简单总结了本次公开课的精髓,分享给大家。详情及部分课堂问答,可扫描下方二维码前往直播间观看直播。
(长按识别二维码前往直播间学习)
本次公开课大纲:
一、App Store 搜索优化
1. 搜索优化原理
在 iTC 后端(即 iTunes Connect,2018 年 6 月更名为 App Store Connect)中,每个 App 可以用 关键词 填充,总共 100 个字符。搜索时的搜索词。一个App只能填100个字符,但是关键词的覆盖率可以达到10000+,这和关键词的搜索原理有关。
尤其是在海外推广的应用,推广渠道比国内更有限,应用商店搜索带来的自然流量非常重要。要想最大程度地优化搜索流量,首先要了解App Store的搜索优化原理。
分词
App Store会将开发者在iTC后台填写的商家名称、副标题和关键词拆分成多个词,然后重新组合以匹配用户的搜索词,不同位置的词可以交叉字符组合. 下面我们以中文单词为例,详细分析搜索优化的原理。
例如,如果我们添加“网易音乐汽车新闻”这8个字符,搜索引擎会根据我们的语言习惯将其组合成“网易”、“音乐”、“汽车”和“新闻”4个词。将这 4 个单词排列组合起来会形成 64 个新的 关键词,也就是上面列表中列出的 关键词。
需要注意的是,一些关键词比如“音乐车”、“新闻车”,这样的词一般不会被用户搜索到,或者搜索量很小,这些词不需要被收录到Apple 词库收录 的。也就是说,我们无法在第三方平台的关键词下找到对应的App。
Q1:我在App中添加了某个关键词,但是我的App并没有出现在这个词的搜索结果中,是什么原因?
A1:关键词的覆盖率有一定的概率,App Store只会显示某一个关键词的前2300条搜索结果。如果你的 App 产品权重比较低,或者被 App Store 处罚,添加某个关键词后,搜索结果很容易出现在 2300 之外。
扩大词
此外,App Store 会根据 App 关键词 字段中的一些词扩展一些相关词汇。这些词只有一部分在我们填写的字符中,另一部分是苹果为我们匹配的。例如,如果关键词中有“网易”,则很有可能匹配到网易音乐、网易新闻、网易购物等关键词。需要注意的是,扩词是有一定概率的,要注意哪些词可以覆盖,哪些不能。
比赛
App Store 还会根据 App 的类别和属性自动为 App 匹配一些词汇。这些词汇不会出现在填写的 100 个字符中,但用户可以通过这些字符搜索我们的 App。但是这些字符的搜索索引和搜索排名都比较低,被苹果处罚后比较容易被删除。
2. 关键词优化
关键词优化有三个基本步骤,分别是选词、排序和去重。
单词选择
首先,根据App的类型,可以为App建立一个关键词词库,把你想要覆盖的词都添加进去,作为优化的替代。选词时要考虑以下几个方面:
1)相关性
相关性是指关键词与应用和目标用户的关联程度。不相关的 关键词 很难产生有效的转化。
2)搜索索引
搜索指数越高,用户的搜索量就越大,给应用带来的曝光率也越高。但这也意味着这些词的搜索排名和竞争也非常激烈。请注意,搜索索引低于 4605 的 关键词 不会被用户搜索。
3)搜索结果数
反映 关键词 竞争的激烈程度。某个关键词下的搜索结果越多,该关键词的竞争就越激烈,你的应用进入搜索结果榜首的难度就越大。
种类
按 关键词 重要性对 关键词 进行排序。关键词字符中的第一个位置保留给最重要的关键词。因为位置越高,位置权重越高,可以加强关键词的覆盖。
重复数据删除
App Store会将关键词拆分组合成一个新的关键词,所以名称、副标题、关键词字符中的每个单词只需要出现一次。删除一些不相关的,搜索4605以下的索引,重复关键词,避免占用关键词个字符。
Q2:如果 100 个 关键词 字符不够怎么办?
A2:这个问题可以通过多区域关键词覆盖来解决,即关键词定位。例如,除了简体中文,在中国生效的语言还包括English Australia、English UK和English US。这样,关键词 字符可以扩展为 200 甚至 300 个字符。
二、Apple 搜索广告优化 ASM
在做 Apple Search Ads 优化之前,我们有必要先了解一下 Apple Search Ads 归因。
1. Apple Search Ads 归因介绍
App Store 搜索广告归因原理是当用户点击苹果搜索广告后,用户在接下来的 30 天内通过任何方式下载了该应用,将归因于苹果搜索广告。
Q3:通过归因 API 统计的获取量与 Apple Search Ads 报告中统计的数据之间存在差异的原因是什么?
A3:第一个原因是用户可能开启了广告追踪限制功能。在这种情况下,attribution API 的返回值为 'error',但 Apple Search Ads Report 可以统计这部分数据。因此,Attribution API 统计的数据往往低于 Report 中的数据。第二个原因是统计方法的不同。只要用户下载,报告就会被算作一次获取,而API要求用户下载并打开APP才会被算作一次获取。第三个原因是数据延迟。用户下载后,需要一段时间进行打开等操作。这个时候API还没有处理完点击,所以延迟请求几秒,数据会更准确。
2. Apple 搜索广告优化和 ASO 补充
苹果搜索广告于2016年9月上线,面向欧美部分国家开放,而国内iOS优化主要基于ASO。那么在苹果搜索广告这个开放的市场,有必要做ASO吗?答案是肯定的。就像 SEO 和 SEM 一样,Apple Search Ads 和 ASO 相辅相成。
在苹果的搜索广告帮助中也明确指出,App 的文字信息对 App 与关键词 的相关性也有影响。与 ASO 不同的是,除了 App 的名称、字幕、关键词、类别和应用内购买项目名称之外,App 描述的优化还可以提高 App 与 关键词 之间的相关性。
Apple Search Ads 的展示形式是基于 App 的源数据,所以不能单独为广告上传素材,也不能指定一定的展示形式,所以最终广告是否可以被用户点击下载用户,转化率很重要。而ASO的一个非常重要的部分就是转化率优化。因此,ASO有利于提高下载转化率,降低广告成本。反之,苹果搜索广告带来的一些用户行为也会影响应用在商店中的表现,主要影响列表和搜索结果排名。
苹果搜索广告带来的下载量对应用的排名有显着影响。以我在美国推出的一款天气应用为例。投放搜索广告后,该应用在类别列表中从 1330 位上升至 40 位左右,停止运行后的第 4 天,其排名仍保持在 400 位左右。
<p>苹果搜索广告对搜索结果的影响主要体现在搜索结果的排名和关键词的数量上。它给app带来的获取量来自于用户搜索某个关键词,这和搜索结果的排名原理是一样的——即利用搜索下载量来提升app在某个 查看全部
通过关键词采集文章采集api(优化(ASO)实战辅导书《冲榜》)
白鲸公开课08《你的APP出海必须掌握哪些ASO策略?》,我们邀请了优化(ASO)实用教程书《冲榜》的作者之一霍晓亮老师来分享。
小亮先生是高级ASOer。现任某知名互联网公司ASO产品经理。擅长App Store算法分析和大数据挖掘。他对iOS推广有深入的研究。小亮先生与资深互联网营销顾问李景航先生合着《粉碎榜单》,全面介绍了App Store优化的“正确打开方式”,帮助移动营销人员有效提升投放产出比。在平台上出售。
小编简单总结了本次公开课的精髓,分享给大家。详情及部分课堂问答,可扫描下方二维码前往直播间观看直播。
(长按识别二维码前往直播间学习)
本次公开课大纲:
一、App Store 搜索优化
1. 搜索优化原理
在 iTC 后端(即 iTunes Connect,2018 年 6 月更名为 App Store Connect)中,每个 App 可以用 关键词 填充,总共 100 个字符。搜索时的搜索词。一个App只能填100个字符,但是关键词的覆盖率可以达到10000+,这和关键词的搜索原理有关。
尤其是在海外推广的应用,推广渠道比国内更有限,应用商店搜索带来的自然流量非常重要。要想最大程度地优化搜索流量,首先要了解App Store的搜索优化原理。
分词
App Store会将开发者在iTC后台填写的商家名称、副标题和关键词拆分成多个词,然后重新组合以匹配用户的搜索词,不同位置的词可以交叉字符组合. 下面我们以中文单词为例,详细分析搜索优化的原理。
例如,如果我们添加“网易音乐汽车新闻”这8个字符,搜索引擎会根据我们的语言习惯将其组合成“网易”、“音乐”、“汽车”和“新闻”4个词。将这 4 个单词排列组合起来会形成 64 个新的 关键词,也就是上面列表中列出的 关键词。
需要注意的是,一些关键词比如“音乐车”、“新闻车”,这样的词一般不会被用户搜索到,或者搜索量很小,这些词不需要被收录到Apple 词库收录 的。也就是说,我们无法在第三方平台的关键词下找到对应的App。
Q1:我在App中添加了某个关键词,但是我的App并没有出现在这个词的搜索结果中,是什么原因?
A1:关键词的覆盖率有一定的概率,App Store只会显示某一个关键词的前2300条搜索结果。如果你的 App 产品权重比较低,或者被 App Store 处罚,添加某个关键词后,搜索结果很容易出现在 2300 之外。
扩大词
此外,App Store 会根据 App 关键词 字段中的一些词扩展一些相关词汇。这些词只有一部分在我们填写的字符中,另一部分是苹果为我们匹配的。例如,如果关键词中有“网易”,则很有可能匹配到网易音乐、网易新闻、网易购物等关键词。需要注意的是,扩词是有一定概率的,要注意哪些词可以覆盖,哪些不能。
比赛
App Store 还会根据 App 的类别和属性自动为 App 匹配一些词汇。这些词汇不会出现在填写的 100 个字符中,但用户可以通过这些字符搜索我们的 App。但是这些字符的搜索索引和搜索排名都比较低,被苹果处罚后比较容易被删除。
2. 关键词优化
关键词优化有三个基本步骤,分别是选词、排序和去重。
单词选择
首先,根据App的类型,可以为App建立一个关键词词库,把你想要覆盖的词都添加进去,作为优化的替代。选词时要考虑以下几个方面:
1)相关性
相关性是指关键词与应用和目标用户的关联程度。不相关的 关键词 很难产生有效的转化。
2)搜索索引
搜索指数越高,用户的搜索量就越大,给应用带来的曝光率也越高。但这也意味着这些词的搜索排名和竞争也非常激烈。请注意,搜索索引低于 4605 的 关键词 不会被用户搜索。
3)搜索结果数
反映 关键词 竞争的激烈程度。某个关键词下的搜索结果越多,该关键词的竞争就越激烈,你的应用进入搜索结果榜首的难度就越大。
种类
按 关键词 重要性对 关键词 进行排序。关键词字符中的第一个位置保留给最重要的关键词。因为位置越高,位置权重越高,可以加强关键词的覆盖。
重复数据删除
App Store会将关键词拆分组合成一个新的关键词,所以名称、副标题、关键词字符中的每个单词只需要出现一次。删除一些不相关的,搜索4605以下的索引,重复关键词,避免占用关键词个字符。
Q2:如果 100 个 关键词 字符不够怎么办?
A2:这个问题可以通过多区域关键词覆盖来解决,即关键词定位。例如,除了简体中文,在中国生效的语言还包括English Australia、English UK和English US。这样,关键词 字符可以扩展为 200 甚至 300 个字符。
二、Apple 搜索广告优化 ASM
在做 Apple Search Ads 优化之前,我们有必要先了解一下 Apple Search Ads 归因。
1. Apple Search Ads 归因介绍
App Store 搜索广告归因原理是当用户点击苹果搜索广告后,用户在接下来的 30 天内通过任何方式下载了该应用,将归因于苹果搜索广告。
Q3:通过归因 API 统计的获取量与 Apple Search Ads 报告中统计的数据之间存在差异的原因是什么?
A3:第一个原因是用户可能开启了广告追踪限制功能。在这种情况下,attribution API 的返回值为 'error',但 Apple Search Ads Report 可以统计这部分数据。因此,Attribution API 统计的数据往往低于 Report 中的数据。第二个原因是统计方法的不同。只要用户下载,报告就会被算作一次获取,而API要求用户下载并打开APP才会被算作一次获取。第三个原因是数据延迟。用户下载后,需要一段时间进行打开等操作。这个时候API还没有处理完点击,所以延迟请求几秒,数据会更准确。
2. Apple 搜索广告优化和 ASO 补充
苹果搜索广告于2016年9月上线,面向欧美部分国家开放,而国内iOS优化主要基于ASO。那么在苹果搜索广告这个开放的市场,有必要做ASO吗?答案是肯定的。就像 SEO 和 SEM 一样,Apple Search Ads 和 ASO 相辅相成。
在苹果的搜索广告帮助中也明确指出,App 的文字信息对 App 与关键词 的相关性也有影响。与 ASO 不同的是,除了 App 的名称、字幕、关键词、类别和应用内购买项目名称之外,App 描述的优化还可以提高 App 与 关键词 之间的相关性。
Apple Search Ads 的展示形式是基于 App 的源数据,所以不能单独为广告上传素材,也不能指定一定的展示形式,所以最终广告是否可以被用户点击下载用户,转化率很重要。而ASO的一个非常重要的部分就是转化率优化。因此,ASO有利于提高下载转化率,降低广告成本。反之,苹果搜索广告带来的一些用户行为也会影响应用在商店中的表现,主要影响列表和搜索结果排名。
苹果搜索广告带来的下载量对应用的排名有显着影响。以我在美国推出的一款天气应用为例。投放搜索广告后,该应用在类别列表中从 1330 位上升至 40 位左右,停止运行后的第 4 天,其排名仍保持在 400 位左右。
<p>苹果搜索广告对搜索结果的影响主要体现在搜索结果的排名和关键词的数量上。它给app带来的获取量来自于用户搜索某个关键词,这和搜索结果的排名原理是一样的——即利用搜索下载量来提升app在某个
通过关键词采集文章采集api( requests模块和Ajax分析法采集微博关键词的方法分析及效果展示 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-24 00:06
requests模块和Ajax分析法采集微博关键词的方法分析及效果展示
)
基于Requests和Ajax分析方法的新浪微博关键词采集
1 项目介绍
本项目介绍requests模块的使用方法和ajax解析方法采集微博关键词.
本项目仅使用“杨幂”、“郑爽”、“赵丽颖”三个关键词挖掘实例。如果有需要在微博上挖其他关键词,可以替换关键词继续采集。
目标:
-搜索关键词,如#赵丽英#,微博下采集
- 采集微博用户的性别、位置、机构、标签、行业、公司、简介等
-采集关键词搜索结果的微博内容(以电影为例),可以分析电影的舆论评价,拍影迷画像等。
2技术点3实施步骤3.1搜索微博内容爬取
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
3.2 数据清洗
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
3.3 持久保存数据
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
3.4 词云展示分析
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='snow', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
4 完整代码及效果展示
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='black', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
if __name__ == '__main__':
kw = '程序员'
filename = './data/%s.txt' % (kw)
page = 100
# persistent_data(filename=filename, page=page)
wordcloud_analyze(filename) 查看全部
通过关键词采集文章采集api(
requests模块和Ajax分析法采集微博关键词的方法分析及效果展示
)
基于Requests和Ajax分析方法的新浪微博关键词采集
1 项目介绍
本项目介绍requests模块的使用方法和ajax解析方法采集微博关键词.
本项目仅使用“杨幂”、“郑爽”、“赵丽颖”三个关键词挖掘实例。如果有需要在微博上挖其他关键词,可以替换关键词继续采集。
目标:
-搜索关键词,如#赵丽英#,微博下采集
- 采集微博用户的性别、位置、机构、标签、行业、公司、简介等
-采集关键词搜索结果的微博内容(以电影为例),可以分析电影的舆论评价,拍影迷画像等。
2技术点3实施步骤3.1搜索微博内容爬取
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
3.2 数据清洗
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
3.3 持久保存数据
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
3.4 词云展示分析
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='snow', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
4 完整代码及效果展示
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='black', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
if __name__ == '__main__':
kw = '程序员'
filename = './data/%s.txt' % (kw)
page = 100
# persistent_data(filename=filename, page=page)
wordcloud_analyze(filename)
通过关键词采集文章采集api(如何将Mall平台运行SpringBoot应用部署到函数计算平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-22 13:10
简介:Spring Boot 是一个基于 Java Spring 框架的套件。它预装了一系列 Spring 组件,允许开发人员以最少的配置创建独立的应用程序。在云原生环境中,有大量的平台可以运行 Spring Boot 应用程序,例如虚拟机、容器等,但其中最吸引人的还是以 Serverless 的方式运行 Spring Boot 应用程序。
通过一系列文章,我将从架构、部署、监控、性能、安全五个方面分析在Serverless平台上运行Spring Boot应用的优缺点。在之前的文章《Spring Boot 上 FC 架构》中,我们对 Mall 应用架构和 Serverless 平台进行了基本的介绍。在本文中,我将告诉您如何将商城应用部署到函数计算平台。为了让分析更具代表性,我选择了 Github 上 Star 超过 50k 的电商应用商城作为例子。
前提
准备阶段:
注意,如果您使用云主机,请先检查主机对应的安全组配置是否允许入站网络请求。通用主机创建后,入方向的网口访问受到严格限制。我们需要手动允许访问 MySQL 的 3306 端口,Redis 的 6379 端口等。如下图所示,我手动设置了安全组以允许所有传入的网络请求。
部署依赖软件
Mall应用依赖于MySQL、Redis、MongoDB、ElasticSearch、RabbitMQ等软件。这些软件在云端都有相应的云产品。在生产环境中,建议使用云产品以获得更好的性能和可用性。在个人开发或者POC原型演示场景中,我们选择一个VM来容器化和部署所有依赖的软件。
1.1 克隆代码仓库
git clone https://github.com/hryang/mall
在中国访问Github网络不是很好。如果克隆太慢,可以使用 Gitee 地址。
git clone https://gitee.com/aliyunfc/mall.git
1.2 构建并运行 Docker 镜像
在代码根目录的docker文件夹中,有每个依赖软件对应的Dockerfile。运行代码根目录下的run.sh脚本,会自动构建所有依赖软件的Docker镜像并在本地运行。
sudo bash docker.sh
1.3 验证依赖软件的运行状态
运行 Docker ps 命令检查依赖软件是否正常运行。
sudo docker ps
部署商城应用
2.1 修改商城应用配置
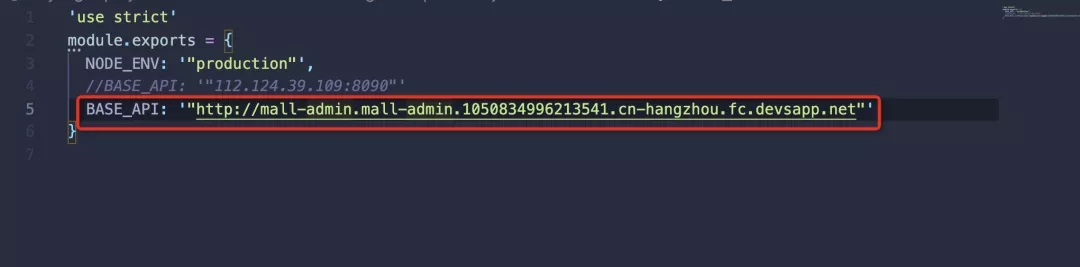
修改以下三个yaml文件,将host字段修改为步骤1中安装MySQL等软件的节点的公网ip,如图:
mall-admin/src/main/resources/application-prod.yml
商城门户/src/main/resources/application-prod.yml
商场搜索/src/main/resources/application-prod.yml
2.2 生成商城应用容器镜像
执行maven package命令生成Docker镜像,本地Java8或Java11环境均可。
sudo -E mvn package
成功后会显示如下成功信息。
执行 sudo docker images,应该可以看到 1.0-SNAPSHOT 版本的 mall/mall-admin、 mall/mall-portal 和 mall/mall-search 的镜像。
2.3 将镜像推送到阿里云镜像仓库
首先登录阿里云镜像仓库控制台,选择个人版实例,按照提示让docker登录阿里云镜像仓库。
然后创建命名空间。如下图所示,我们创建了一个名为 quanxi-hryang 的命名空间。
按照前面的步骤,我们已经在本地生成了 mall/mall-admin、 mall/mall-portal、 mall/mall-search 的图片。
执行以下命令,将 mall-admin 镜像推送到杭州地区 quanxi-hryang 命名空间下的镜像仓库。
请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。商城/商城门户、商城/商城搜索等。
sudo docker tag mall/mall-admin:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
2.4 修改Serverless Devs工具的应用定义
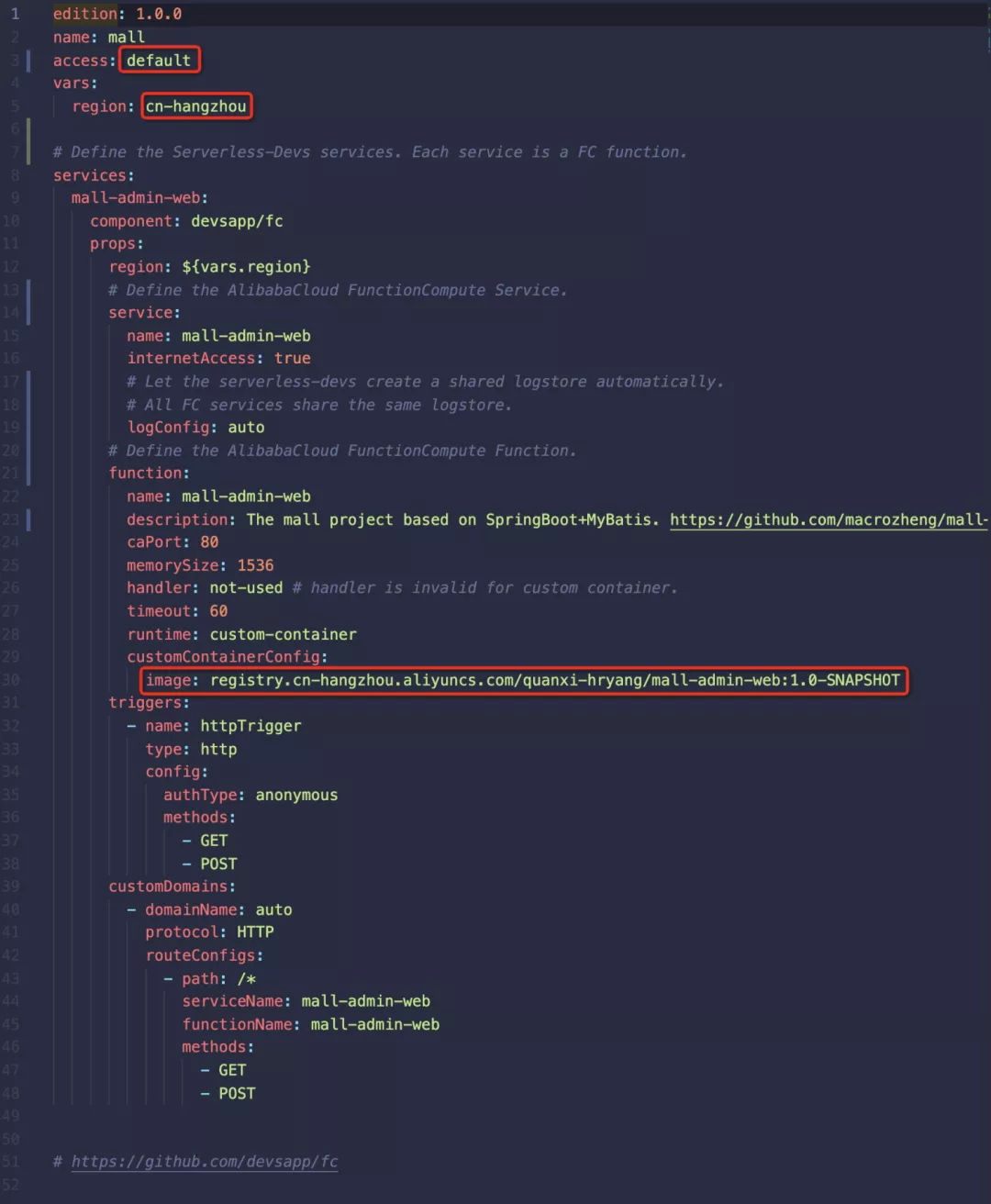
我们使用无服务器开发工具来定义和部署应用程序。项目根目录下有s.yaml文件,是Serverless Devs工具的项目定义文件。这定义了函数计算的资源。
如下图所示,我们在函数计算上定义了一个名为 mall-admin 的服务及其下的 mall-admin 函数。该函数定义了端口、内存大小、超时和运行时间等属性。红框内的内容是需要根据自己的配置进行修改的。
(建议:以上镜像地址最好使用/fc-demo/mall-admin:1.0-SNAPSHOT形式)
2.5 将商城应用部署到函数计算平台
执行 s 部署命令。部署成功后,会看到对应的访问URL。
在浏览器中输入生成的 URL。如果显示“尚未登录或token已过期”,则服务部署成功。
(注:Serverless的特点是系统默认会在请求到达后创建实例,所以第一次启动时间比较长,称为冷启动。一般需要30s左右才能启动Mall应用。稍后,我们将重点关注性能调优文章回来复习这个问题,用一系列手段进行优化。)
访问对应的swagger api调试页面host/swagger-ui.html,调试相关的后端API。
2.6 查看应用程序日志
我们在 s.yaml 中为每个服务设置了 logConfig:auto,也就是说 serverless-devs 工具会自动为服务创建一个日志存储(LogStore),所有服务共享一个日志存储。应用程序的所有日志都输出到 .
s 日志有助于您了解服务的运行情况和诊断问题。比如我们执行s mall-admin logs -t 进入follow模式,然后在浏览器中访问 mall-admin 服务的端点,就可以看到整个应用的启动和请求处理日志。
2.7 部署商城前端项目
Mall 还提供了基于 Vue+Element 实现的前端接口。主要包括商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等功能。该项目还可以在函数计算上无缝运行。
首先在你的机器上安装nodejs12和npm,并下载项目源代码。
git clone https://github.com/hryang/mall-admin-web
国内访问github网络不太好。如果克隆太慢,可以使用下面的代理地址。
git clone https://gitee.com/aliyunfc/mall-admin-web.git
(注意:必须是nodejs 12或者14,太新的node版本会编译失败)
修改 config/prod.env.js 并将 BASE_API 更改为在函数计算上成功部署的 mall-admin 端点。
在项目根目录下执行如下命令构建前端项目。
npm install
npm run build
运行成功后会生成dist目录。运行项目根目录下的docker.sh脚本生成镜像。
sudo bash docker.sh
运行 docker images 命令,可以看到 mall/mall-admin-web 镜像已经成功生成。将镜像推送到阿里云镜像仓库。
同理,请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。
sudo docker tag mall/mall-admin-web:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
修改项目根目录下的s.yaml,和部署mal-admin类似,根据自己的配置调整访问权限和区域,将镜像改成上一步推送成功的镜像地址。
执行s deploy,部署成功后可以看到 mall-admin-web 服务的URL。通过浏览器访问,您将看到登录页面。填写密码macro123查看完整效果。
(注意:登录页面可能会因为第一次冷启动而报超时错误,刷新页面即可,我们稍后会在性能调优文章中优化冷启动性能。)
总结
由于 serverless 平台内置网关,负责路由、实例拉取/运行/容错/自动伸缩等功能,开发者上传应用代码包或镜像后,就已经有了一个弹性高可用的服务。释放。综上所述,只要完成以下5个步骤,Mall应用就完全部署在了功能计算平台上。后续对应用的更新只需要重复第4步和第5步即可。可见Serverless省去了环境配置和运维等重复性工作,大大提高了开发和运维的效率。
Clone项目代码找到VM,运行脚本一键安装MySQL、Redis等依赖软件。修改应用配置中的host项,将值填入步骤2中的VM公网ip,生成应用镜像并推送到阿里云镜像仓库部署和应用到功能计算平台URL汇总
1)春季启动:
2)商城:
3)Serverless Devs 安装文档:
原文链接: 查看全部
通过关键词采集文章采集api(如何将Mall平台运行SpringBoot应用部署到函数计算平台)
简介:Spring Boot 是一个基于 Java Spring 框架的套件。它预装了一系列 Spring 组件,允许开发人员以最少的配置创建独立的应用程序。在云原生环境中,有大量的平台可以运行 Spring Boot 应用程序,例如虚拟机、容器等,但其中最吸引人的还是以 Serverless 的方式运行 Spring Boot 应用程序。
通过一系列文章,我将从架构、部署、监控、性能、安全五个方面分析在Serverless平台上运行Spring Boot应用的优缺点。在之前的文章《Spring Boot 上 FC 架构》中,我们对 Mall 应用架构和 Serverless 平台进行了基本的介绍。在本文中,我将告诉您如何将商城应用部署到函数计算平台。为了让分析更具代表性,我选择了 Github 上 Star 超过 50k 的电商应用商城作为例子。
前提
准备阶段:
注意,如果您使用云主机,请先检查主机对应的安全组配置是否允许入站网络请求。通用主机创建后,入方向的网口访问受到严格限制。我们需要手动允许访问 MySQL 的 3306 端口,Redis 的 6379 端口等。如下图所示,我手动设置了安全组以允许所有传入的网络请求。
部署依赖软件
Mall应用依赖于MySQL、Redis、MongoDB、ElasticSearch、RabbitMQ等软件。这些软件在云端都有相应的云产品。在生产环境中,建议使用云产品以获得更好的性能和可用性。在个人开发或者POC原型演示场景中,我们选择一个VM来容器化和部署所有依赖的软件。
1.1 克隆代码仓库
git clone https://github.com/hryang/mall
在中国访问Github网络不是很好。如果克隆太慢,可以使用 Gitee 地址。
git clone https://gitee.com/aliyunfc/mall.git
1.2 构建并运行 Docker 镜像
在代码根目录的docker文件夹中,有每个依赖软件对应的Dockerfile。运行代码根目录下的run.sh脚本,会自动构建所有依赖软件的Docker镜像并在本地运行。
sudo bash docker.sh
1.3 验证依赖软件的运行状态
运行 Docker ps 命令检查依赖软件是否正常运行。
sudo docker ps
部署商城应用
2.1 修改商城应用配置
修改以下三个yaml文件,将host字段修改为步骤1中安装MySQL等软件的节点的公网ip,如图:
mall-admin/src/main/resources/application-prod.yml
商城门户/src/main/resources/application-prod.yml
商场搜索/src/main/resources/application-prod.yml
2.2 生成商城应用容器镜像
执行maven package命令生成Docker镜像,本地Java8或Java11环境均可。
sudo -E mvn package
成功后会显示如下成功信息。

执行 sudo docker images,应该可以看到 1.0-SNAPSHOT 版本的 mall/mall-admin、 mall/mall-portal 和 mall/mall-search 的镜像。

2.3 将镜像推送到阿里云镜像仓库
首先登录阿里云镜像仓库控制台,选择个人版实例,按照提示让docker登录阿里云镜像仓库。
然后创建命名空间。如下图所示,我们创建了一个名为 quanxi-hryang 的命名空间。
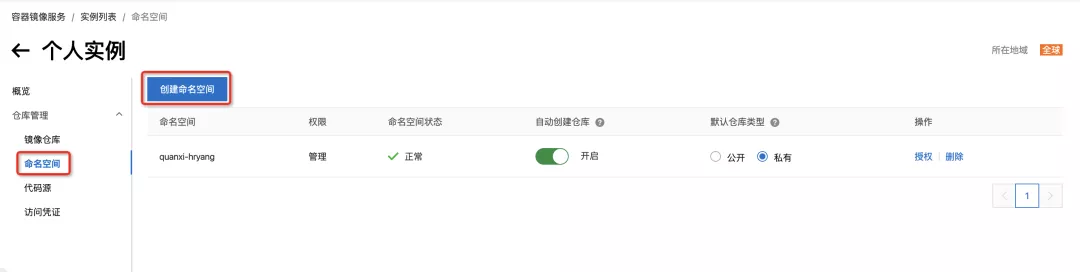
按照前面的步骤,我们已经在本地生成了 mall/mall-admin、 mall/mall-portal、 mall/mall-search 的图片。
执行以下命令,将 mall-admin 镜像推送到杭州地区 quanxi-hryang 命名空间下的镜像仓库。
请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。商城/商城门户、商城/商城搜索等。
sudo docker tag mall/mall-admin:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
2.4 修改Serverless Devs工具的应用定义
我们使用无服务器开发工具来定义和部署应用程序。项目根目录下有s.yaml文件,是Serverless Devs工具的项目定义文件。这定义了函数计算的资源。
如下图所示,我们在函数计算上定义了一个名为 mall-admin 的服务及其下的 mall-admin 函数。该函数定义了端口、内存大小、超时和运行时间等属性。红框内的内容是需要根据自己的配置进行修改的。
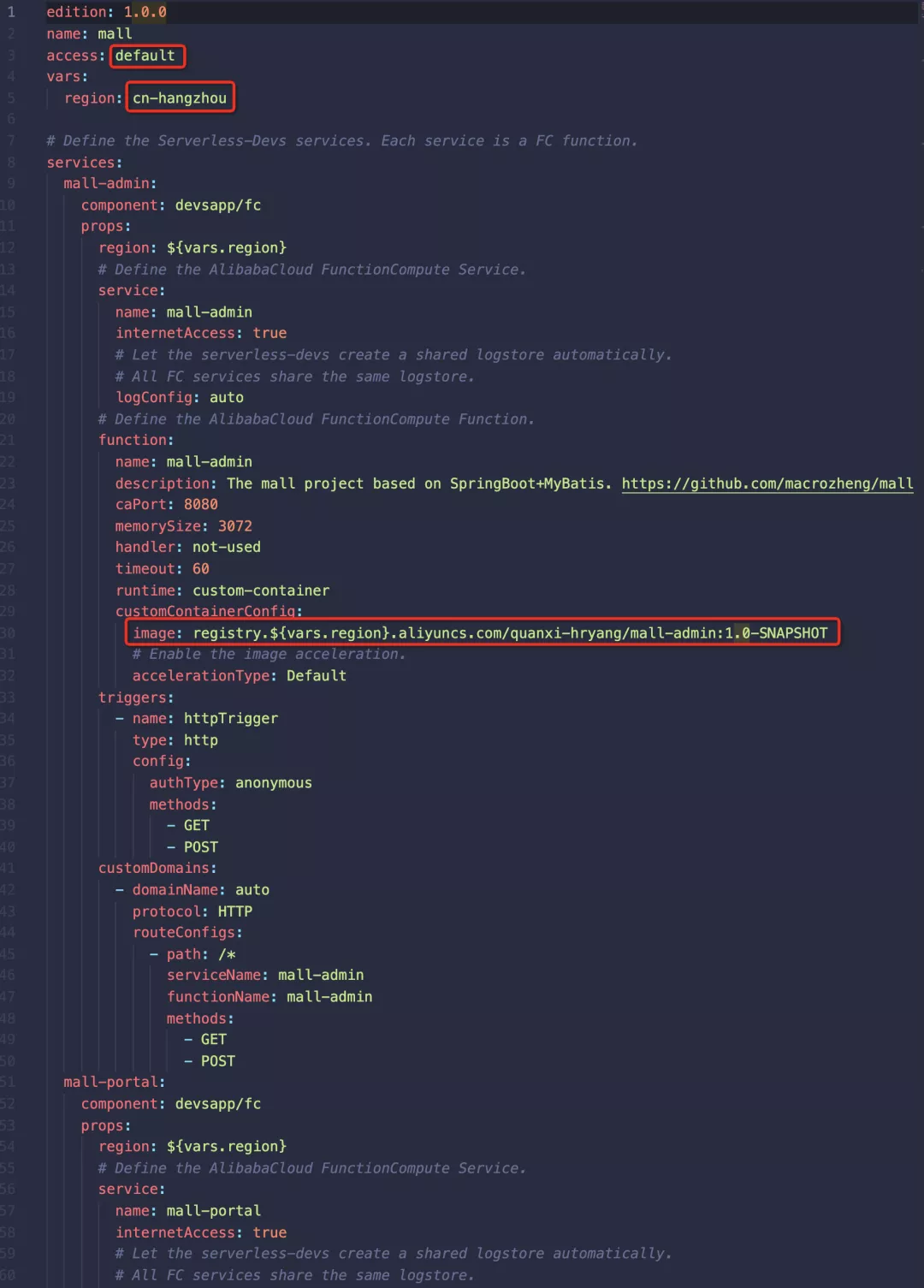
(建议:以上镜像地址最好使用/fc-demo/mall-admin:1.0-SNAPSHOT形式)
2.5 将商城应用部署到函数计算平台
执行 s 部署命令。部署成功后,会看到对应的访问URL。

在浏览器中输入生成的 URL。如果显示“尚未登录或token已过期”,则服务部署成功。
(注:Serverless的特点是系统默认会在请求到达后创建实例,所以第一次启动时间比较长,称为冷启动。一般需要30s左右才能启动Mall应用。稍后,我们将重点关注性能调优文章回来复习这个问题,用一系列手段进行优化。)
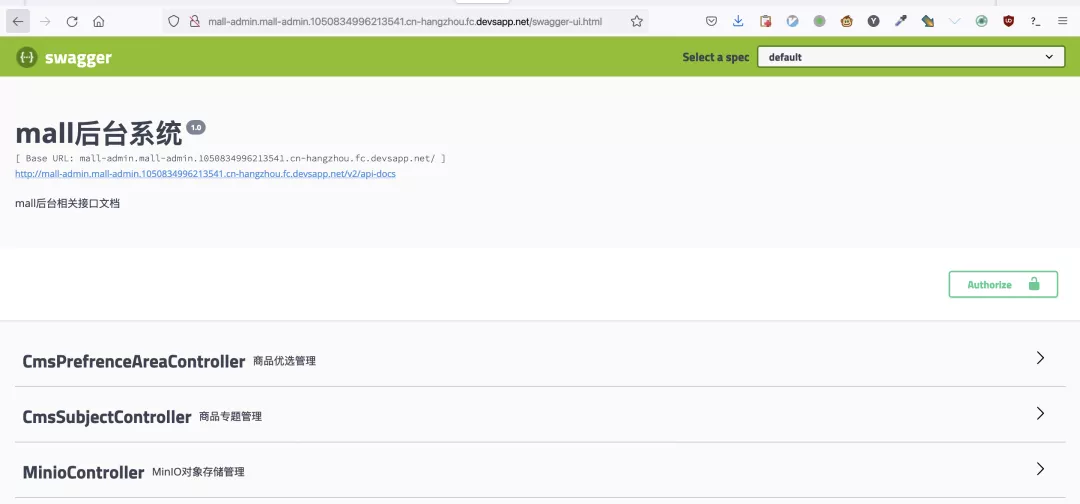
访问对应的swagger api调试页面host/swagger-ui.html,调试相关的后端API。
2.6 查看应用程序日志
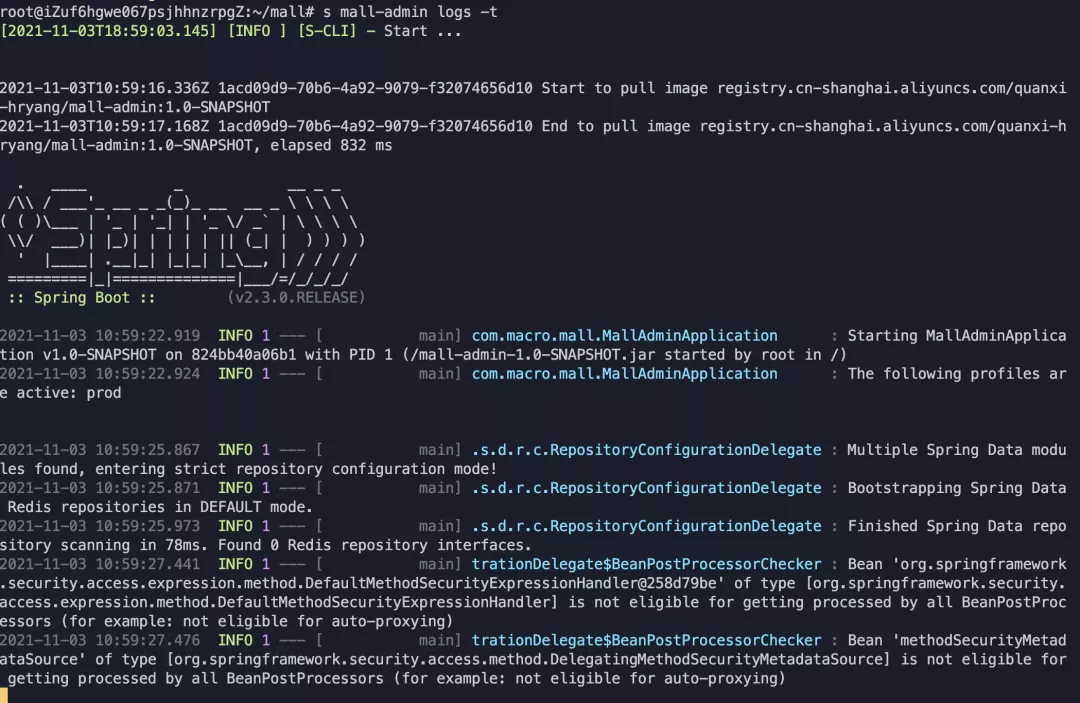
我们在 s.yaml 中为每个服务设置了 logConfig:auto,也就是说 serverless-devs 工具会自动为服务创建一个日志存储(LogStore),所有服务共享一个日志存储。应用程序的所有日志都输出到 .
s 日志有助于您了解服务的运行情况和诊断问题。比如我们执行s mall-admin logs -t 进入follow模式,然后在浏览器中访问 mall-admin 服务的端点,就可以看到整个应用的启动和请求处理日志。
2.7 部署商城前端项目
Mall 还提供了基于 Vue+Element 实现的前端接口。主要包括商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等功能。该项目还可以在函数计算上无缝运行。
首先在你的机器上安装nodejs12和npm,并下载项目源代码。
git clone https://github.com/hryang/mall-admin-web
国内访问github网络不太好。如果克隆太慢,可以使用下面的代理地址。
git clone https://gitee.com/aliyunfc/mall-admin-web.git
(注意:必须是nodejs 12或者14,太新的node版本会编译失败)
修改 config/prod.env.js 并将 BASE_API 更改为在函数计算上成功部署的 mall-admin 端点。
在项目根目录下执行如下命令构建前端项目。
npm install
npm run build
运行成功后会生成dist目录。运行项目根目录下的docker.sh脚本生成镜像。
sudo bash docker.sh
运行 docker images 命令,可以看到 mall/mall-admin-web 镜像已经成功生成。将镜像推送到阿里云镜像仓库。
同理,请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。
sudo docker tag mall/mall-admin-web:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
修改项目根目录下的s.yaml,和部署mal-admin类似,根据自己的配置调整访问权限和区域,将镜像改成上一步推送成功的镜像地址。
执行s deploy,部署成功后可以看到 mall-admin-web 服务的URL。通过浏览器访问,您将看到登录页面。填写密码macro123查看完整效果。
(注意:登录页面可能会因为第一次冷启动而报超时错误,刷新页面即可,我们稍后会在性能调优文章中优化冷启动性能。)
总结
由于 serverless 平台内置网关,负责路由、实例拉取/运行/容错/自动伸缩等功能,开发者上传应用代码包或镜像后,就已经有了一个弹性高可用的服务。释放。综上所述,只要完成以下5个步骤,Mall应用就完全部署在了功能计算平台上。后续对应用的更新只需要重复第4步和第5步即可。可见Serverless省去了环境配置和运维等重复性工作,大大提高了开发和运维的效率。
Clone项目代码找到VM,运行脚本一键安装MySQL、Redis等依赖软件。修改应用配置中的host项,将值填入步骤2中的VM公网ip,生成应用镜像并推送到阿里云镜像仓库部署和应用到功能计算平台URL汇总
1)春季启动:
2)商城:
3)Serverless Devs 安装文档:
原文链接:
通过关键词采集文章采集api(苹果采集插件接口资源库的方法及解决教程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-21 13:02
近年来,随着互联网时代的发展,做电影的站长越来越多网站,加入这个行列的人数也在与日俱增!但是很多站长都跟风办电影站,不知道怎么办。不知道哪里来的电影资源。今天教大家如何制作电影台。文章有点长,请耐心观看,快解决电影台遇到的所有问题!
一、苹果采集插件接口配置
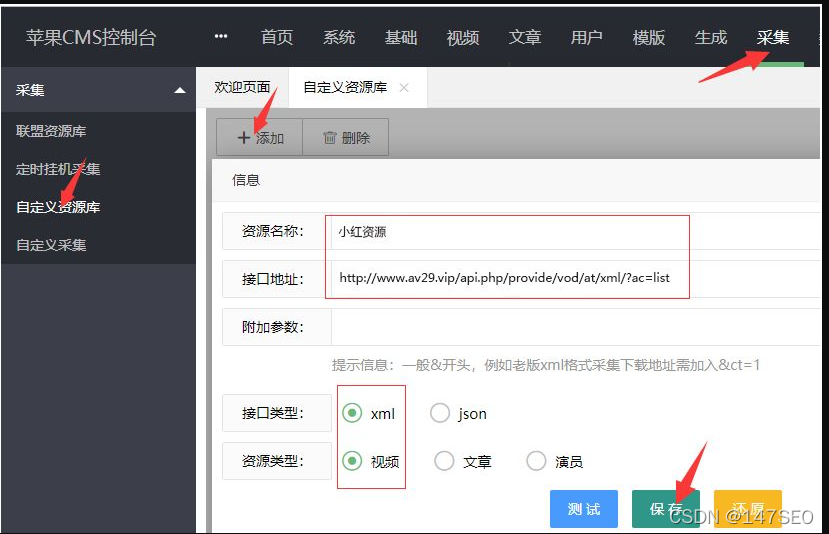
1、今天教大家如何添加一个采集自定义资源库;我们以资源站为例,进入后台时,可以从你想要的网站获取界面采集好的,一般在网站的帮助中心:添加方法如下图(如果添加后测试不成功,需要填写附加参数 &ct=1)
2、这里我没填,只要测试界面成功,直接保存即可。如果测试失败,补上附加参数&ct=1)如果还是不行,检查采集接口是否填写错误
3、添加资源接口成功后,需要对资源进行分类绑定:点击高清资源链接进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个类似的分类或者添加自定义分类
5、绑定后,剩下的就是采集了。拉到页面底部有一个采集按钮可以选择当天采集的采集(需要采集的时候视频)和采集所有三个选项
6、选择后进入自动采集页面。如果绑定采集成功并且显示绿色和红色,说明绑定不成功,跳过采集,所以绑定的时候要小心绑定。
结束语:采集finished网站的最后应该有视频数据,这也是很多人困惑的地方采集finished,不能播放!为什么是这样?因为你没有添加播放器。
二、苹果采集插件后无法播放问题及解决教程
苹果采集插件故障排除后无法播放黑屏,先判断是否导入播放器,采集如果资源后没有添加对应的播放器,则无法解析正常播放,正确的采集流程是先添加一个播放器再执行采集,这样每个资源都能识别对应的播放器正常播放,每个资源站都有自己独立的播放器
第一步是查看视频数据,看看使用哪些播放器播放资源数据。如果您看到下图中的播放器列,则可以确定该资源使用的是 wlm3u8 编码的播放器。
第二步检查是否有导入的播放器,可以通过查看视频详情来判断。
没有默认播放器没有视频数据丢失播放器
第三步,确保没有玩家添加对应的玩家。这是资源站给出的玩家添加步骤。同时,蓝色字体为资源站提供的播放器文件,需要下载导入。
第四步,(视频>>播放器)查看我们是否成功添加了wlm3u8编码的播放器。如果我们添加了播放器还是不能播放,先清除缓存,最好换个浏览器再测试一下。
2.首先看你的采集是什么类型的播放地址;如果是腾讯、优酷、爱奇艺等,需要通过解析接口解析地址才能播放。
如果不能播放,说明解析接口不支持解析;如果你还有其他可以解析播放的接口,换成可以播放的解析接口即可。
然后查看采集数据的播放地址。如果是完整的http地址,需要打开播放器的解析状态,使用解析来播放;如果采集的数据ID可以直接用本地播放器播放。最后,删除系统默认自带的解析接口。默认解析接口已失效。删除步骤如下
刚开始分析苹果的cms电影网站,网上像我这样的电影网站数不胜数,内容一模一样,模板一样,采集为什么是我的收录 什么?当然,我马上意识到采集每天更新内容只会浪费域名和服务器资源。万一出事了,你会不甘心的!于是我开始分析原创要改进哪些角度来制作我的电影网站收录。终于把我的苹果cms电影架收录弄好了。
三、苹果cms网站怎么样?一个电影站如何快速收录关键词排名和消耗流量
1:如果把苹果cms网站当作采集站,是采集的其他电影站更新的好页面,影片排名也不错,我'现在就添加它采集,你能收录吗?能带来流量吗?所以我决定走一条不同的、差异化的路线。
A. 电影片名加品牌词
B.剧情介绍加网站欢迎词
C.演员名字加上喜欢的、亲爱的等随机插入的词
D.图集修改MD5并添加水印
E. 新增热门评论功能,全靠采集影视评论
F.修改底部文件,添加其他电影站没有的信息 查看全部
通过关键词采集文章采集api(苹果采集插件接口资源库的方法及解决教程(组图))
近年来,随着互联网时代的发展,做电影的站长越来越多网站,加入这个行列的人数也在与日俱增!但是很多站长都跟风办电影站,不知道怎么办。不知道哪里来的电影资源。今天教大家如何制作电影台。文章有点长,请耐心观看,快解决电影台遇到的所有问题!

一、苹果采集插件接口配置
1、今天教大家如何添加一个采集自定义资源库;我们以资源站为例,进入后台时,可以从你想要的网站获取界面采集好的,一般在网站的帮助中心:添加方法如下图(如果添加后测试不成功,需要填写附加参数 &ct=1)
2、这里我没填,只要测试界面成功,直接保存即可。如果测试失败,补上附加参数&ct=1)如果还是不行,检查采集接口是否填写错误
3、添加资源接口成功后,需要对资源进行分类绑定:点击高清资源链接进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个类似的分类或者添加自定义分类
5、绑定后,剩下的就是采集了。拉到页面底部有一个采集按钮可以选择当天采集的采集(需要采集的时候视频)和采集所有三个选项
6、选择后进入自动采集页面。如果绑定采集成功并且显示绿色和红色,说明绑定不成功,跳过采集,所以绑定的时候要小心绑定。
结束语:采集finished网站的最后应该有视频数据,这也是很多人困惑的地方采集finished,不能播放!为什么是这样?因为你没有添加播放器。
二、苹果采集插件后无法播放问题及解决教程
苹果采集插件故障排除后无法播放黑屏,先判断是否导入播放器,采集如果资源后没有添加对应的播放器,则无法解析正常播放,正确的采集流程是先添加一个播放器再执行采集,这样每个资源都能识别对应的播放器正常播放,每个资源站都有自己独立的播放器
第一步是查看视频数据,看看使用哪些播放器播放资源数据。如果您看到下图中的播放器列,则可以确定该资源使用的是 wlm3u8 编码的播放器。
第二步检查是否有导入的播放器,可以通过查看视频详情来判断。
没有默认播放器没有视频数据丢失播放器
第三步,确保没有玩家添加对应的玩家。这是资源站给出的玩家添加步骤。同时,蓝色字体为资源站提供的播放器文件,需要下载导入。
第四步,(视频>>播放器)查看我们是否成功添加了wlm3u8编码的播放器。如果我们添加了播放器还是不能播放,先清除缓存,最好换个浏览器再测试一下。
2.首先看你的采集是什么类型的播放地址;如果是腾讯、优酷、爱奇艺等,需要通过解析接口解析地址才能播放。
如果不能播放,说明解析接口不支持解析;如果你还有其他可以解析播放的接口,换成可以播放的解析接口即可。
然后查看采集数据的播放地址。如果是完整的http地址,需要打开播放器的解析状态,使用解析来播放;如果采集的数据ID可以直接用本地播放器播放。最后,删除系统默认自带的解析接口。默认解析接口已失效。删除步骤如下
刚开始分析苹果的cms电影网站,网上像我这样的电影网站数不胜数,内容一模一样,模板一样,采集为什么是我的收录 什么?当然,我马上意识到采集每天更新内容只会浪费域名和服务器资源。万一出事了,你会不甘心的!于是我开始分析原创要改进哪些角度来制作我的电影网站收录。终于把我的苹果cms电影架收录弄好了。
三、苹果cms网站怎么样?一个电影站如何快速收录关键词排名和消耗流量
1:如果把苹果cms网站当作采集站,是采集的其他电影站更新的好页面,影片排名也不错,我'现在就添加它采集,你能收录吗?能带来流量吗?所以我决定走一条不同的、差异化的路线。
A. 电影片名加品牌词
B.剧情介绍加网站欢迎词
C.演员名字加上喜欢的、亲爱的等随机插入的词
D.图集修改MD5并添加水印
E. 新增热门评论功能,全靠采集影视评论
F.修改底部文件,添加其他电影站没有的信息
通过关键词采集文章采集api( 智能诊断出网站SEO出现的问题,你知道吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-20 01:02
智能诊断出网站SEO出现的问题,你知道吗?
)
SEO人员在平时的SEO优化中会使用很多SEO工具,智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局一大批优秀同行,以及优化的方向!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、 通过站点:域名,查询网站有多少个收录,收录有多少个关键词?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
查看全部
通过关键词采集文章采集api(
智能诊断出网站SEO出现的问题,你知道吗?
)

SEO人员在平时的SEO优化中会使用很多SEO工具,智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特点:

1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:

1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:

1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局一大批优秀同行,以及优化的方向!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、 通过站点:域名,查询网站有多少个收录,收录有多少个关键词?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)

四、全平台推送工具
全平台推送功能:

工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。

通过关键词采集文章采集api(新媒体的迅速崛起让互联网流量竞争越来越激烈,现在我们不但要能找到流量还要能以到流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-19 11:08
新媒体的迅速崛起,使得互联网流量的竞争越来越激烈。现在我们不仅要能够找到流量,而且要能够以最快的速度猎取流量。此时,手动采集、汇总和组织数据已经不够了。建议每天选择5118大数据采集海量新关键词和大量信息,从中挖掘新词汇。,然后对内容进行处理以获得流量。
1、海量流量数据快速获取
通过每天5118个长尾词挖掘,系统自动抓取每天千万搜索引擎用户查询的关键词和问题,并按照一定的规则过滤出有价值的关键词,然后进行区分哪些是最新的热词,哪些是互联网的新词汇。这些是手动聚合数据无法完成的事情。
越早发现用户感兴趣的流量爆发,越早抓住流量的大方向。通过前期掌握流量情况,我们可以通过制作内容源源不断地将最新的流量带入我们的网站。比同行更早抢占各平台流量数据。
2、深入交通方向
有了上面挖掘的海量关键词,我们需要围绕这个关键词弄清楚用户对什么感兴趣,围绕关键词的各种需求做长尾词匹配。
使用5118关键词挖矿工具获取长尾关键词和核心相关问题关键词,对流量进行排序,然后写原创,<针对不同的问题和长尾词@伪原创文章,满足用户需求。
在掌握了用户需求后,为了进一步详细深入地了解用户需求,使用5118长尾关键词挖掘工具,发现用户如何搜索自己想找的问题,从而带来挖掘相关的长尾问题。
3、标题标题是SEO优化的重点
标题不仅要收录核心词,还要用问题来引导用户的好奇心。标题引起用户共鸣,将大大提高用户的点击率。
通过 5118 浏览器插件获取标题泛点击和全点击搜索结果。
相关内容:5118站长工具箱Chrome浏览器插件安装教程
5118站长工具箱360安全浏览器插件手动安装更新教程
当5118搜索结果显示标题命中时,说明用户搜索的词没有完全收录在标题中,而只是收录分词或部分收录。
只要标题全部命中搜索结果,排名就会很好,由此产生的流量也会很多。
5118双12折扣高达50%的行业词库,为期3年。使用优惠券代码 vpsss123 享受最低折扣。
5118是站长必备的SEO优化工具和新媒体大数据挖掘平台。
更多关于5118的信息,请看5118专题4、高效生产内容
为了获得大量的互联网流量,您的内容必须在大多数 网站 完全命中 关键词 之前产生高质量的内容。那么最好的办法就是学习头条等新媒体内容,知乎,公众号等平台会比网站更新更快。
使用5118媒体文章搜索功能,快速获取相关内容,找到高度满足用户需求的段落,学习理解后再加工。
还可以使用5118智能原创工具进行更深层次的原创工作,5118大数据的支持可以节省大量时间和精力。
5、坚持会带来流量
我们都知道,单纯靠几篇文章的文章根本无法获得大量的流量,还有一个逐渐积累的过程。使用5118大数据工具快速获取和处理流量,使其获取流量的可能性越来越大。 查看全部
通过关键词采集文章采集api(新媒体的迅速崛起让互联网流量竞争越来越激烈,现在我们不但要能找到流量还要能以到流量)
新媒体的迅速崛起,使得互联网流量的竞争越来越激烈。现在我们不仅要能够找到流量,而且要能够以最快的速度猎取流量。此时,手动采集、汇总和组织数据已经不够了。建议每天选择5118大数据采集海量新关键词和大量信息,从中挖掘新词汇。,然后对内容进行处理以获得流量。

1、海量流量数据快速获取
通过每天5118个长尾词挖掘,系统自动抓取每天千万搜索引擎用户查询的关键词和问题,并按照一定的规则过滤出有价值的关键词,然后进行区分哪些是最新的热词,哪些是互联网的新词汇。这些是手动聚合数据无法完成的事情。
越早发现用户感兴趣的流量爆发,越早抓住流量的大方向。通过前期掌握流量情况,我们可以通过制作内容源源不断地将最新的流量带入我们的网站。比同行更早抢占各平台流量数据。
2、深入交通方向
有了上面挖掘的海量关键词,我们需要围绕这个关键词弄清楚用户对什么感兴趣,围绕关键词的各种需求做长尾词匹配。
使用5118关键词挖矿工具获取长尾关键词和核心相关问题关键词,对流量进行排序,然后写原创,<针对不同的问题和长尾词@伪原创文章,满足用户需求。
在掌握了用户需求后,为了进一步详细深入地了解用户需求,使用5118长尾关键词挖掘工具,发现用户如何搜索自己想找的问题,从而带来挖掘相关的长尾问题。
3、标题标题是SEO优化的重点
标题不仅要收录核心词,还要用问题来引导用户的好奇心。标题引起用户共鸣,将大大提高用户的点击率。
通过 5118 浏览器插件获取标题泛点击和全点击搜索结果。
相关内容:5118站长工具箱Chrome浏览器插件安装教程
5118站长工具箱360安全浏览器插件手动安装更新教程
当5118搜索结果显示标题命中时,说明用户搜索的词没有完全收录在标题中,而只是收录分词或部分收录。
只要标题全部命中搜索结果,排名就会很好,由此产生的流量也会很多。
5118双12折扣高达50%的行业词库,为期3年。使用优惠券代码 vpsss123 享受最低折扣。
5118是站长必备的SEO优化工具和新媒体大数据挖掘平台。
更多关于5118的信息,请看5118专题4、高效生产内容
为了获得大量的互联网流量,您的内容必须在大多数 网站 完全命中 关键词 之前产生高质量的内容。那么最好的办法就是学习头条等新媒体内容,知乎,公众号等平台会比网站更新更快。
使用5118媒体文章搜索功能,快速获取相关内容,找到高度满足用户需求的段落,学习理解后再加工。
还可以使用5118智能原创工具进行更深层次的原创工作,5118大数据的支持可以节省大量时间和精力。
5、坚持会带来流量
我们都知道,单纯靠几篇文章的文章根本无法获得大量的流量,还有一个逐渐积累的过程。使用5118大数据工具快速获取和处理流量,使其获取流量的可能性越来越大。
通过关键词采集文章采集api( 做网站seo对于个人来说做一个大站是很难的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-16 23:34
做网站seo对于个人来说做一个大站是很难的)
Phpcmsv9采集,它基于 Phpcmsv9 派生的 网站batch采集,可以使用 Phpcmsv9做站长,解决网站内容填充采集的问题。做网站seo对于个人来说很难做一个大网站,有什么难度?也就是内容,一个seo团队一天可以更新几百份。而一个人一天更新几十篇文章,这是无法比拟的。 phpcmsv9采集允许网站保持每天生成一个新的文章,保持不断更新的状态。所以如果你的网站想要一天上万IP,你需要大量的关键词,大量的关键词需要大量的文章内容支持。所以,如果我想快速做一个大站,非常简单实用的就是采集。
Phpcmsv9采集可以制作出色的采集站。如果你想成为一个采集站,那么你需要更高的seo技术和策略。否则,如果你想做一个 采集 站,你要么干脆不 收录,要么降级 K 站。 phpcmsv9采集的实践:
1、展开采集的源,很多时候,采集因为源太单一而死掉了。 采集时,建议记录对方文件的发布时间
2、内容多样性、问答、文章、图片
3、页面多样性,N个单页,N个聚合,N个频道
4、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议使用phpcmsv9采集一次性码(包括营销码,各种标签等,比原来更干净)
5、做好页面内容相关性匹配
6、页面调用一定要丰富,才能达到虚伪的效果
7、如果有能力,可以制作一些结构化的数据进行编辑,达到一定比例的原创度
8、旧域名效果更好
9、发布时,建议在采集源发布时间之前修改你的发布时间,同时也发布一些当天
10、建议发布前先设置好站点,再上线。上线后最好不要在网站没有达到一定程度收录
的情况下改变任何网站结构和链接
11、释放量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更好。
12、基本上坚持1-3个月就会见效。如果条件允许,可以适当配合蜘蛛池和外链运营
13、没有100%完成的网站,建议您可以同时多访问几个,以保证您的准确性
14、模板尽量做成war的模板,原创度数高的模板列尽量多。
phpcmsv9采集文章都是基于长尾关键词采集,也就是说每个文章都有关键词,你可以想象一下,如果有100万个关键词页面,那真是倒霉,网站每天可以有几万个IP。关键是你可以在不被K的情况下合理布局内页。 海量网站内容,做好站点布局,即升级这个网站页面的权限,用当前网站索引的数据,网站的日IP增长了5倍,很简单。 查看全部
通过关键词采集文章采集api(
做网站seo对于个人来说做一个大站是很难的)

Phpcmsv9采集,它基于 Phpcmsv9 派生的 网站batch采集,可以使用 Phpcmsv9做站长,解决网站内容填充采集的问题。做网站seo对于个人来说很难做一个大网站,有什么难度?也就是内容,一个seo团队一天可以更新几百份。而一个人一天更新几十篇文章,这是无法比拟的。 phpcmsv9采集允许网站保持每天生成一个新的文章,保持不断更新的状态。所以如果你的网站想要一天上万IP,你需要大量的关键词,大量的关键词需要大量的文章内容支持。所以,如果我想快速做一个大站,非常简单实用的就是采集。
Phpcmsv9采集可以制作出色的采集站。如果你想成为一个采集站,那么你需要更高的seo技术和策略。否则,如果你想做一个 采集 站,你要么干脆不 收录,要么降级 K 站。 phpcmsv9采集的实践:
1、展开采集的源,很多时候,采集因为源太单一而死掉了。 采集时,建议记录对方文件的发布时间
2、内容多样性、问答、文章、图片
3、页面多样性,N个单页,N个聚合,N个频道
4、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议使用phpcmsv9采集一次性码(包括营销码,各种标签等,比原来更干净)
5、做好页面内容相关性匹配
6、页面调用一定要丰富,才能达到虚伪的效果
7、如果有能力,可以制作一些结构化的数据进行编辑,达到一定比例的原创度
8、旧域名效果更好
9、发布时,建议在采集源发布时间之前修改你的发布时间,同时也发布一些当天
10、建议发布前先设置好站点,再上线。上线后最好不要在网站没有达到一定程度收录
的情况下改变任何网站结构和链接
11、释放量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更好。
12、基本上坚持1-3个月就会见效。如果条件允许,可以适当配合蜘蛛池和外链运营
13、没有100%完成的网站,建议您可以同时多访问几个,以保证您的准确性
14、模板尽量做成war的模板,原创度数高的模板列尽量多。
phpcmsv9采集文章都是基于长尾关键词采集,也就是说每个文章都有关键词,你可以想象一下,如果有100万个关键词页面,那真是倒霉,网站每天可以有几万个IP。关键是你可以在不被K的情况下合理布局内页。 海量网站内容,做好站点布局,即升级这个网站页面的权限,用当前网站索引的数据,网站的日IP增长了5倍,很简单。
通过关键词采集文章采集api(说起erperp商品采集功能全面解析电商平台发展)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-16 23:30
说起东南亚的跨境电商,相信大家都不陌生。近年来,Shopee和Lazada平台的发展越来越好,不少新手朋友也进入了东南亚市场。除了处理订单、挑选新品,还需要采集产品对店铺进行精细化运营,而采集产品也是业务运营中非常重要的一环,所以这个时候,您将需要使用一些工具来帮助商家。在之前的文章中,简单的提到了店梯erp产品采集的功能,功能全面,可以帮助商家做好产品采集,下面就详细聊聊关于它的这个功能模块是如何运作的。
首先店铺天梯erp的产品采集模块是从各大电商平台获取产品相关信息数据,包括产品标题、产品描述、产品主图及详细图、价格、规格信息、销量、评论数等相关信息;通过三种方式对产品进行采集:单品采集、关键字采集和插件采集;
单品采集
这是产品 采集 的链接;打开电商网站,找到你想要的产品采集,复制产品链接;然后打开店铺天梯erp采集中心模块商品采集,菜单项采集模块,粘贴产品链接,点击采集按钮;采集产品将自动认领成功;单品也可以一键发布或删除;
关键词采集
该功能是商家在采集中心的关键词模块进入关键词,直接通过云大数据中心采集各种电商的商品平台;进入关键词,选择采集平台,启动采集产品,然后返回采集列表数据;然后将商品添加到采集框内,一键发布到授权店铺平台;也可以选择商品,批量添加到采集框内;
插件采集
该功能需要先下载插件。采集中心产品的采集模块会显示采集插件。点击下载完成后,双击打开安装在网站。安装步骤可以在帮助中心查看;安装插件后,可以直接采集购物网站中的商品,采集成功会有提示。
采集盒子
以上三种方式收到的产品采集会被添加到采集框里,这里是采集收到的产品的管理中心,采集里面的产品可以添加到我的商品库中,也可以直接将采集框中的商品一键发布到各电商平台的指定店铺,一键列出的商品将添加到我的商品中默认库。
店铺天梯erp的采集功能非常全面,采集方法也多种多样。商家可以根据自己的习惯选择合适的采集方式,在采集完成后,一键发布也非常高效,方便商家操作,让商家全面提升运营效率. 查看全部
通过关键词采集文章采集api(说起erperp商品采集功能全面解析电商平台发展)
说起东南亚的跨境电商,相信大家都不陌生。近年来,Shopee和Lazada平台的发展越来越好,不少新手朋友也进入了东南亚市场。除了处理订单、挑选新品,还需要采集产品对店铺进行精细化运营,而采集产品也是业务运营中非常重要的一环,所以这个时候,您将需要使用一些工具来帮助商家。在之前的文章中,简单的提到了店梯erp产品采集的功能,功能全面,可以帮助商家做好产品采集,下面就详细聊聊关于它的这个功能模块是如何运作的。

首先店铺天梯erp的产品采集模块是从各大电商平台获取产品相关信息数据,包括产品标题、产品描述、产品主图及详细图、价格、规格信息、销量、评论数等相关信息;通过三种方式对产品进行采集:单品采集、关键字采集和插件采集;
单品采集
这是产品 采集 的链接;打开电商网站,找到你想要的产品采集,复制产品链接;然后打开店铺天梯erp采集中心模块商品采集,菜单项采集模块,粘贴产品链接,点击采集按钮;采集产品将自动认领成功;单品也可以一键发布或删除;
关键词采集
该功能是商家在采集中心的关键词模块进入关键词,直接通过云大数据中心采集各种电商的商品平台;进入关键词,选择采集平台,启动采集产品,然后返回采集列表数据;然后将商品添加到采集框内,一键发布到授权店铺平台;也可以选择商品,批量添加到采集框内;
插件采集
该功能需要先下载插件。采集中心产品的采集模块会显示采集插件。点击下载完成后,双击打开安装在网站。安装步骤可以在帮助中心查看;安装插件后,可以直接采集购物网站中的商品,采集成功会有提示。
采集盒子
以上三种方式收到的产品采集会被添加到采集框里,这里是采集收到的产品的管理中心,采集里面的产品可以添加到我的商品库中,也可以直接将采集框中的商品一键发布到各电商平台的指定店铺,一键列出的商品将添加到我的商品中默认库。
店铺天梯erp的采集功能非常全面,采集方法也多种多样。商家可以根据自己的习惯选择合适的采集方式,在采集完成后,一键发布也非常高效,方便商家操作,让商家全面提升运营效率.
通过关键词采集文章采集api(面向豆瓣网站的信息采集与可视化分析系统(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-16 23:20
豆瓣信息采集和可视化网站
摘要:豆瓣网站是中国最受欢迎的社交网站之一。本文为豆瓣网站设计了一个信息采集和可视化分析系统,基于Python语言实现了信息采集、信息分析和可视化三个功能模块,实现了如下功能:可根据用户指定的关键词实现自动采集和豆瓣网站信息的可视化展示。
关键词:信息采集;可视化;豆瓣网站
CLC 编号:TP311 证件识别码:A 文章 编号:1009-3044 (2018)13-0003-02
1 背景
目前,随着Web2.0和移动互联网的快速发展,网民数量屡创新高,社交互联网平台应运而生。但是,布查达的言论很容易成为社会不稳定因素,所以要及时了解和掌握社交网站网友发布的信息,对网站的信息有一个全面的了解。 ,避免大规模的网络舆论攻击、网络谣言等恶性事件。
豆瓣网站作为社交网站的典型代表,积累了大量的人气,是国内最具影响力的社交网站。大量网友可以在豆瓣上发帖网站各种信息,其中收录丰富的个人情感,尤其是一些观点所表达的观点具有很强的主观性和武断性[1]。为此,本文开发了豆瓣网站的信息采集及分析系统,可以全面掌握豆瓣网站的社交网络信息,并可对爬取的豆瓣网站@进行分析。 >数据直观直观展示,有助于及时全面了解豆瓣网友的思想表达、热点话题等。
2 系统架构设计
该系统使用基于Python的Scrapy开源爬虫框架开发。Scrapy 框架为网络爬虫相关功能提供了丰富的 API 接口[2]。在此基础上,本文实现了面向豆瓣网站的信息抓取、数据处理和可视化,系统功能如图1所示。
豆瓣网站的信息采集和可视化系统架构主要分为三个关键功能模块:
1)采集模块主要根据用户指定的关键词或URL爬取豆瓣网站的相关信息;
2)处理模块的主要任务是对采集模块爬取的海量数据进行处理和分析,并将其格式化并存储起来,以供后续可视化展示;
3)可视化模块,该部分是系统分析功能的主要实现部分,实现处理后信息的可视化展示。
3 豆瓣信息采集网站及可视化系统主要功能的实现
3.1 信息采集模块
信息采集模块的主要作用是根据系统用户指定的关键词通过网络采集豆瓣网站启动爬虫程序,并发送采集 to 信息被持久化到本地数据库。此外,系统还部署了去重去噪的信息爬取策略,保证采集信息的准确性。最后对采集的信息进行格式化转换,并保存格式化后的数据。
为了保证豆瓣网站采集上信息的全面性,系统采用广度优先的爬取搜索策略[3-4]。主要过程是选择起始URL作为种子URL放入等待队列,爬虫根据URL队列选择要爬取解析的URL,将爬取的URL放入爬取集合中,选择解析后的URL和将它们放入待爬取的URL队列中,直到待爬取的URL队列为空,如图2所示。
鉴于豆瓣网站的主动反爬策略[5],系统使用cookies模拟浏览器访问。当豆瓣网站返回bin cookie时,后续的爬取过程会携带cookie进行访问。,为了防止频繁定向触发反爬虫机制,在系统中设置了一定的时间阈值,即1分钟,进行间隔爬取。
3.2 信息分析模块
系统分析 查看全部
通过关键词采集文章采集api(面向豆瓣网站的信息采集与可视化分析系统(组图))
豆瓣信息采集和可视化网站
摘要:豆瓣网站是中国最受欢迎的社交网站之一。本文为豆瓣网站设计了一个信息采集和可视化分析系统,基于Python语言实现了信息采集、信息分析和可视化三个功能模块,实现了如下功能:可根据用户指定的关键词实现自动采集和豆瓣网站信息的可视化展示。
关键词:信息采集;可视化;豆瓣网站
CLC 编号:TP311 证件识别码:A 文章 编号:1009-3044 (2018)13-0003-02
1 背景
目前,随着Web2.0和移动互联网的快速发展,网民数量屡创新高,社交互联网平台应运而生。但是,布查达的言论很容易成为社会不稳定因素,所以要及时了解和掌握社交网站网友发布的信息,对网站的信息有一个全面的了解。 ,避免大规模的网络舆论攻击、网络谣言等恶性事件。
豆瓣网站作为社交网站的典型代表,积累了大量的人气,是国内最具影响力的社交网站。大量网友可以在豆瓣上发帖网站各种信息,其中收录丰富的个人情感,尤其是一些观点所表达的观点具有很强的主观性和武断性[1]。为此,本文开发了豆瓣网站的信息采集及分析系统,可以全面掌握豆瓣网站的社交网络信息,并可对爬取的豆瓣网站@进行分析。 >数据直观直观展示,有助于及时全面了解豆瓣网友的思想表达、热点话题等。
2 系统架构设计
该系统使用基于Python的Scrapy开源爬虫框架开发。Scrapy 框架为网络爬虫相关功能提供了丰富的 API 接口[2]。在此基础上,本文实现了面向豆瓣网站的信息抓取、数据处理和可视化,系统功能如图1所示。
豆瓣网站的信息采集和可视化系统架构主要分为三个关键功能模块:
1)采集模块主要根据用户指定的关键词或URL爬取豆瓣网站的相关信息;
2)处理模块的主要任务是对采集模块爬取的海量数据进行处理和分析,并将其格式化并存储起来,以供后续可视化展示;
3)可视化模块,该部分是系统分析功能的主要实现部分,实现处理后信息的可视化展示。
3 豆瓣信息采集网站及可视化系统主要功能的实现
3.1 信息采集模块
信息采集模块的主要作用是根据系统用户指定的关键词通过网络采集豆瓣网站启动爬虫程序,并发送采集 to 信息被持久化到本地数据库。此外,系统还部署了去重去噪的信息爬取策略,保证采集信息的准确性。最后对采集的信息进行格式化转换,并保存格式化后的数据。
为了保证豆瓣网站采集上信息的全面性,系统采用广度优先的爬取搜索策略[3-4]。主要过程是选择起始URL作为种子URL放入等待队列,爬虫根据URL队列选择要爬取解析的URL,将爬取的URL放入爬取集合中,选择解析后的URL和将它们放入待爬取的URL队列中,直到待爬取的URL队列为空,如图2所示。
鉴于豆瓣网站的主动反爬策略[5],系统使用cookies模拟浏览器访问。当豆瓣网站返回bin cookie时,后续的爬取过程会携带cookie进行访问。,为了防止频繁定向触发反爬虫机制,在系统中设置了一定的时间阈值,即1分钟,进行间隔爬取。
3.2 信息分析模块
系统分析
通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-16 22:22
MySQL:通过Mybatis拦截器;
Redis:通过javassist增强RedisTemplate的方式;
跨应用调用:通过代理feign客户端,dubbo、grpc等方法可能需要通过拦截器;
http调用:通过javassist给HttpClient和OkHttp添加拦截器;
日志管理:通过plugin方式上报日志中打印的错误。
管理的技术细节这里就不展开了,主要是使用各种框架提供的一些接口,以及使用javassist进行字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的tracing功能比专业的Traces系统要薄很多。
介绍
下面是DOG的架构图。客户端将消息传递给 Kafka,狗服务器使用消息。Cassandra 和 ClickHouse 用于存储。具体要存储的数据后面会介绍。
1、还有不使用消息中间件的 APM 系统。例如,在 Cat 中,客户端通过 Netty 连接到服务器以发送消息。
2、服务端采用Lambda架构模式。Dog UI 上查询的数据是从每个 Dog-server 的内存数据和下游存储的数据中聚合而成的。
下面,我们简单介绍一下 Dog UI 上比较重要的一些功能,然后我们将分析如何实现相应的功能。
注:以下图片均为本人绘制,非实页截图,数值可能不准确
下图显示了一个示例交易报告:
当然,点击上图中的具体名称,以及下一级状态的统计数据,这里就不会有映射了。Dog一共设计了type、name、status三个属性。上两图中的最后一列是sample,它通向sample视图:
样本意味着抽样。当我们看到一个高故障率或者高P90的接口,你就知道有问题了,但是因为它只有统计数据,你不知道哪里出了问题。这时候,你需要一些样本数据。对于类型、名称和状态的不同组合,我们每分钟最多保存 5 个成功、5 个失败和 5 个处理缓慢的样本数据。
通过上面的trace视图,可以很快的知道是哪个环节出了问题。当然,我们之前也说过,我们的 Trace 依赖于我们埋点的丰富程度,但是 Dog 是一个基于 Metrics 的系统,所以它的 Traces 能力是不够的,但在大多数情况下,对于排查问题应该足够了。
对于应用程序开发人员,以下问题视图应该非常有用:
它显示了各种错误统计信息,并为开发人员提供了解决问题的示例。
最后简单介绍一下Heartbeat视图,它和前面的功能没有任何关系,而是大量的图表。我们有gc、heap、os、thread等各种数据,以便我们观察系统的健康状况。
本节主要介绍APM系统通常收录哪些功能。其实很简单,对吧?接下来,我们从开发者的角度来谈谈具体的实现细节。
客户数据模型
每个人都是开发者,所以我会更直接。下图描述了客户端的数据模型:
对于Message来说,用于统计的字段有type、name、status,所以我们可以根据type、type+name、type+name+status这三个维度进行统计。
Message中的其他字段:timestamp表示事件发生的时间;如果成功为假,该事件将被计入问题报告;数据不具有统计意义,仅对链路跟踪和故障排除有用;businessData 用于向业务系统上报业务数据,需要手动管理,然后用于业务数据分析。
Message 有两个子类 Event 和 Transaction。不同的是Transaction有一个duration属性,用来标识事务需要多长时间。可以用于max time、min time、avg time、p90、p95等,而event指的是发生了某事发生的时候,只能用来统计发生了多少次,没有概念的时间长度。
Transaction有一个属性children,可以嵌套Transaction或者Event,最后形成一个树形结构进行trace,后面会介绍。
下表显示了一个虚线数据的示例,更直观:
只是几件事:
类型为URL、SQL、Redis、FeignClient、HttpClient等数据,属于自动跟踪的范畴。通常,在APM系统上工作的时候,一定要完成一些自动埋点工作,这样应用开发者不用做任何埋点工作就可以看到很多有用的数据。Type=Order 像最后两行一样属于人工埋藏的数据。
打点需要特别注意类型、名称和状态的维度的“爆炸”。它们的组合太多会消耗大量资源,并且可能直接拖累我们的Dog系统。type的维度可能不会太多,但是我们可能需要注意开发者可能会滥用name和status,所以一定要进行normalize(比如url可能有动态参数,需要格式化)。
表中最后两项是开发者手动埋藏的数据,通常用于统计具体场景。比如我想知道某个方法是怎么调用的,调用次数,耗时,是否抛出异常,输入参数,返回值。等待。因为自动埋点是业务不想关闭的冷数据,开发者可能想埋一些自己想统计的数据。
当开发者手动埋点时,也可以上报更多业务相关的数据。请参阅表格的最后一列。这些数据可用于业务分析。比如我是一个支付系统,通常一个支付订单涉及到很多步骤(国外支付和你平时使用的微信和支付宝略有不同)。通过上报各个节点的数据,我终于可以在Dog上使用bizId串起整个链接,在排查问题时非常有用(我们做支付业务的时候,支付成功率并没有大家想象的那么高,而且节点很多可能有问题)。
客户设计
上一节介绍了单条消息的数据,本节介绍其他内容。
首先我们介绍一下客户端的API使用:
上面的代码说明了如何使用嵌套的事务和事件。当最外层的Transaction在finally代码块中调用finish()时,树的创建就完成了,消息就被传递了。
我们交付给 Kafka 的不是 Message 实例,因为一个请求会产生很多 Message 实例,但应该组织成一个 Tree 实例以便以后交付。下图描述了 Tree 的各种属性:
树的属性很好理解。它持有对根事务的引用,并用于遍历整个树。另外,需要携带机器信息messageEnv。
treeId应该有保证全局唯一性的算法,简单介绍Dog的实现:$-$-$-$。
下面简单介绍几个tree id相关的内容。假设一个请求从A->B->C->D经过4个应用,A是入口应用,那么会有:
1、总共有 4 个 Tree 对象实例将从 4 个应用程序交付给 Kafka。跨应用调用时,需要传递treeId、parentTreeId、rootTreeId三个参数;
2、一个应用的treeId是所有节点的rootTreeId;
3、B应用的parentTreeId就是A的treeId,同理C的parentTreeId就是B应用的treeId;
4、跨应用调用时,比如从A调用B时,为了知道A的下一个节点是什么,在A中提前为B生成treeId,B收到请求后,如果找到A 已经为它生成了一个treeId,直接使用那个treeId。
大家也应该很容易知道,通过这些tree id,我们要实现trace的功能。
介绍完树的内容后,我们来简单讨论一下应用集成解决方案。
集成无非是两种技术。一种是通过javaagent。在启动脚本中,添加相应的代理。这种方式的好处是开发者无意识,运维级别可以做到。当然,如果开发者想要手动做一些嵌入,可能需要给开发者提供一个简单的客户端jar包来桥接代理。
另一种是提供jar包,开发者可以引入这个依赖。
这两种方案各有优缺点。Pinpoint 和 Skywalking 使用 javaagent 方案,Zipkin、Jaeger 和 Cat 使用第二种方案,Dog 也使用手动添加依赖项的第二种方案。
一般来说,做Traces的系统会选择使用javaagent方案,因为这类系统代理已经完成了所有需要的埋点,没有应用开发者的感知。
最后简单介绍一下Heartbeat的内容。这部分其实是最简单的,但是可以制作很多五颜六色的图表,实现面向老板的编程。
前面我们介绍过Message有两个子类Event和Transaction。这里我们添加一个子类 Heartbeat 来报告心跳数据。
我们主要采集thread、os、gc、heap、client的运行状态(生成了多少棵树、数据大小、发送失败次数)等。同时我们也提供api供开发者自定义数据进行上报. 狗客户端会启动一个后台线程,每分钟运行一次心跳采集程序,上报数据。
介绍更多细节。核心结构是一个Map\,key类似于“os.systemLoadAverage”、“thread.count”等。前缀os、thread、gc等实际上是用于页面上的分类,后缀为显示的折线图的名称。
关于客户,这就是我在这里介绍的全部内容。其实在实际的编码过程中,还是有一些细节需要处理的,比如树太大怎么办,比如没有rootTransaction的情况怎么处理(开发者只叫了Dog. logEvent(...)),比如如何在不调用finish的情况下处理内部嵌套事务等。
狗服务器设计
下图说明了服务器的整体设计。值得注意的是,我们这里对线程的使用非常克制,图中只有3个工作线程。
首先是Kafka Consumer线程,负责批量消费消息。它使用 kafka 集群中的 Tree 实例。接下来,考虑如何处理它。
这里,我们需要对树状结构的消息进行扁平化,我们称这一步为deflate,并做一些预处理,形成如下结构:
接下来,我们将 DeflateTree 分别传递给两个 Disruptor 实例。我们将 Disruptor 设计为单线程生产和单线程消费,主要是出于性能考虑。
消费者线程根据 DeflateTree 的属性使用绑定的 Processor 进行处理。比如DeflateTree中的List problmes不为空,ProblemProcessor是自己绑定的,所以需要调用ProblemProcessor进行处理。
科普时间:Disruptor是一个高性能队列,性能优于JDK中的BlockingQueue
这里我们使用了 2 个 Disruptor 实例,当然我们可以考虑使用更多的实例,这样每个消费者线程就绑定到更少的处理器上。
我们在这里将处理器绑定到 Disruptor 实例。其实原因很简单。出于性能原因,我们希望每个处理器仅在单个线程中使用它。单线程操作可以减少线程切换带来的开销,可以充分利用系统。缓存,在设计处理器时,不要考虑并发读写的问题。
这里要考虑负载均衡的情况。有些处理器消耗CPU和内存资源,必须合理分配。压力最大的任务不能分配给同一个线程。
核心处理逻辑在每个处理器中,负责数据计算。接下来,我将介绍每个处理器需要做的主要内容。毕竟能看到这里的开发者,应该对APM数据处理真的很感兴趣。
事务处理器
事务处理器是系统压力最大的地方。负责报表统计。虽然 Message 有两个主要子类 Transaction 和 Event,但在实际的树中,大多数节点都是事务类型数据。
下图是事务处理器内部的主要数据结构。最外层是时间。我们在几分钟内组织它。当我们坚持时,它也以分钟为单位存储。
第二层的HostKey代表了哪个应用程序和来自哪个IP的数据,第三层是类型、名称和状态的组合。最里面的统计是我们的数据统计模块。
此外,我们还可以看到这个结构会消耗多少内存。其实主要看我们的类型、名字、状态的组合,也就是会不会有很多的ReportKey。也就是我们在谈客户管理的时候,要避免维度爆炸。
最外层的结构代表时间的分钟表示。我们的报告是按每分钟统计的,然后持久化到 ClickHouse,但是我们的用户在看数据的时候,并不是每分钟都看到的。,所以你需要做数据聚合。下面显示了如何聚合这两个数据。当组合很多数据时,它们的组合方式相同。
仔细想想,你会发现前面数据的计算是可以的,但是P90、P95、P99的计算是不是有点骗人?事实上,这个问题真的是无解的。我们只能想出一个合适的数据计算规则,然后再想这个计算规则,计算出来的值可能就差不多可用了。
此外,还有一个细节问题。我们需要为内存中的数据提供最近 30 分钟的统计信息,只有超过 30 分钟的数据才从 DB 中读取。然后进行上述的合并操作。
讨论:我们能不能丢掉一部分实时性能,每分钟都持久化,读取的数据全部来自DB,这样可行吗?
不,因为我们的数据是从kafka消费的,有一定的滞后性。如果我们在一分钟开始时将数据持久化一分钟,我们可能会在稍后收到上一次的消息。这种情况无法处理。
比如我们要统计最后一小时,那么每台机器获取30分钟的数据,从DB获取30分钟的数据,然后合并。
这里值得一提的是,在交易报告中,count、failCount、min、max、avg是比较容易计算的,但是P90、P95、P99其实并不好计算,我们需要一个数组结构,记录这一分钟内所有事件的时间,然后计算,我们这里用的是Apache DataSketches,非常好用,这里就不展开了,有兴趣的同学可以自己看看。
此时,您可以考虑一下 ClickHouse 中存储的数据量。app_name、ip、type、name、status的不同组合,每分钟一个数据。
样品处理器
示例处理器使用来自放气树中列表事务和列表事件的数据。
我们还按分钟采样,最后每分钟采样,对于类型、名称和状态的每种组合,采集 最多 5 次成功、5 次失败和 5 次慢处理。
相对来说,这还是很简单的,其核心结构如下:
结合Sample的功能更容易理解:
问题处理器
在进行 deflate 时,所有成功 = false 的消息都将放入 List problmes 以进行错误统计。
Problem的内部数据结构如下:
如果你看这张图,你其实已经知道该怎么做了,所以我就不啰嗦了。我们每分钟保存 5 个 treeId 的样本。
顺便提一下Problem的观点:
关于持久化,我们将其存储在 ClickHouse 中,其中 sample 用逗号连接到一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
心跳处理器
Heartbeat 处理 List 心跳的数据。顺便说一句,在正常情况下,一棵树中只有一个 Heartbeat 实例。
前面我也简单提到过,Heartbeat 中用来显示图表的核心数据结构是 Map。
采集到的key-value数据如下:
前缀是分类,后缀是图的名称。客户端每分钟采集数据进行报告,然后可以制作很多图表。例如下图展示了堆分类下的各种图:
Heartbeat处理器要做的事情很简单,就是数据存储。Dog UI 上的数据直接从 ClickHouse 读取。
heartbeat_data的列如下:
消息树处理器
我们之前已经多次提到过 Sample 的功能。这些采样数据帮助我们还原场景,这样我们就可以通过trace视图来追踪调用链。
做上面的trace view,我们需要所有上下游树的数据,比如上图就是3个树实例的数据。
正如我们之前在介绍客户端时所说,这些树是由父treeId和根treeId组织的。
要做到这一点,我们面临的挑战是我们需要保存全部数据量。
你可以想想这个问题。为什么我们需要保存全部数据?如果我们直接保存采样的数据不是更好吗?
这里我们使用 Cassandra 的功能。Cassandra在这种kv场景下性能非常好,运维成本非常低。
我们使用treeId作为主键,并添加一列数据。它是整个树的实例数据。数据类型是blob。我们先做gzip压缩,然后扔给Cassandra。
业务处理器
我们在介绍客户端的时候说过,每条Message都可以携带Business Data,但只有应用开发者手动埋藏的时候。当我们发现有业务数据时,我们会做另一件事,就是将这些数据存储在 ClickHouse 中进行业务分析。
我们其实不知道应用开发者会在什么场景下使用它,因为每个人负责不同的项目,所以我们只能做一个通用的数据模型。
回头看这张图,在BusinessData中,我们定义了更通用的userId和bizId,我们认为可能会用到每一个业务场景。userId不用说,bizId可以用来记录订单id、支付订单id等。
然后我们提供三个String类型的列ext1、ext2、ext3和两个数值类型的列extVal1和extVal2,可以用来表达你的业务相关参数。
当然,我们的处理也很简单。将这些数据存储在 ClickHouse 中就足够了。表中主要有这几列:
这些数据对于我们的Dog系统来说肯定是不熟悉的,因为我们不知道你在表达什么业务。类型、名称和状态由开发人员自己定义。我们不知道 ext1、ext2 和 ext3 分别是什么意思。,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多数据报表。因为本文讨论的是APM,所以这里不再赘述。
其他
ClickHouse 需要批量编写,否则肯定是不可持续的。通常,一个批次至少有 10,000 行数据。
我们在 Kafka 层控制它。app_name + ip 的数据只会被同一个 dog-server 消费。当然,这并不意味着多个狗服务器消费时会出现问题,但写入ClickHouse的数据会更准确。许多。
还有一个关键点。我们说每个处理器都是单线程访问的,但是有一个问题,那就是Dog UI的请求呢?这里我想了一个办法,就是把请求放到一个Queue中,Kafka Consumer的线程会消费,它会把任务丢给两个Disruptor。例如,如果这个请求是一个交易报告请求,那么其中一个 Disruptor 消费者会发现这是他们想要做的,并且会执行这个任务。
概括
如果你知道 Cat,你可以看到 Dog 在很多地方与 Cat 有相似之处,或者只是说“复制”。我们也考虑过直接使用Cat或者在Cat的基础上做二次开发。
但是看了Cat的源码后,我放弃了这个想法。仔细想了想,正好借用了Cat的数据模型,然后我们自己写一套APM也不难,于是有了这个项目。
写的需要,很多地方重要的我都避而远之,因为这不是源码分析文章,细节就不多说了,主要是给读者一个全貌,读者可以大致思考哪些需要处理通过我的描述,需要写哪些代码,然后当我表达清楚。
欢迎您提出自己的问题或想法。如果有不明白的地方或者我有错误和遗漏的地方,请指正~ 查看全部
通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
MySQL:通过Mybatis拦截器;
Redis:通过javassist增强RedisTemplate的方式;
跨应用调用:通过代理feign客户端,dubbo、grpc等方法可能需要通过拦截器;
http调用:通过javassist给HttpClient和OkHttp添加拦截器;
日志管理:通过plugin方式上报日志中打印的错误。
管理的技术细节这里就不展开了,主要是使用各种框架提供的一些接口,以及使用javassist进行字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的tracing功能比专业的Traces系统要薄很多。
介绍
下面是DOG的架构图。客户端将消息传递给 Kafka,狗服务器使用消息。Cassandra 和 ClickHouse 用于存储。具体要存储的数据后面会介绍。
1、还有不使用消息中间件的 APM 系统。例如,在 Cat 中,客户端通过 Netty 连接到服务器以发送消息。
2、服务端采用Lambda架构模式。Dog UI 上查询的数据是从每个 Dog-server 的内存数据和下游存储的数据中聚合而成的。
下面,我们简单介绍一下 Dog UI 上比较重要的一些功能,然后我们将分析如何实现相应的功能。
注:以下图片均为本人绘制,非实页截图,数值可能不准确
下图显示了一个示例交易报告:
当然,点击上图中的具体名称,以及下一级状态的统计数据,这里就不会有映射了。Dog一共设计了type、name、status三个属性。上两图中的最后一列是sample,它通向sample视图:
样本意味着抽样。当我们看到一个高故障率或者高P90的接口,你就知道有问题了,但是因为它只有统计数据,你不知道哪里出了问题。这时候,你需要一些样本数据。对于类型、名称和状态的不同组合,我们每分钟最多保存 5 个成功、5 个失败和 5 个处理缓慢的样本数据。
通过上面的trace视图,可以很快的知道是哪个环节出了问题。当然,我们之前也说过,我们的 Trace 依赖于我们埋点的丰富程度,但是 Dog 是一个基于 Metrics 的系统,所以它的 Traces 能力是不够的,但在大多数情况下,对于排查问题应该足够了。
对于应用程序开发人员,以下问题视图应该非常有用:
它显示了各种错误统计信息,并为开发人员提供了解决问题的示例。
最后简单介绍一下Heartbeat视图,它和前面的功能没有任何关系,而是大量的图表。我们有gc、heap、os、thread等各种数据,以便我们观察系统的健康状况。
本节主要介绍APM系统通常收录哪些功能。其实很简单,对吧?接下来,我们从开发者的角度来谈谈具体的实现细节。
客户数据模型
每个人都是开发者,所以我会更直接。下图描述了客户端的数据模型:
对于Message来说,用于统计的字段有type、name、status,所以我们可以根据type、type+name、type+name+status这三个维度进行统计。
Message中的其他字段:timestamp表示事件发生的时间;如果成功为假,该事件将被计入问题报告;数据不具有统计意义,仅对链路跟踪和故障排除有用;businessData 用于向业务系统上报业务数据,需要手动管理,然后用于业务数据分析。
Message 有两个子类 Event 和 Transaction。不同的是Transaction有一个duration属性,用来标识事务需要多长时间。可以用于max time、min time、avg time、p90、p95等,而event指的是发生了某事发生的时候,只能用来统计发生了多少次,没有概念的时间长度。
Transaction有一个属性children,可以嵌套Transaction或者Event,最后形成一个树形结构进行trace,后面会介绍。
下表显示了一个虚线数据的示例,更直观:
只是几件事:
类型为URL、SQL、Redis、FeignClient、HttpClient等数据,属于自动跟踪的范畴。通常,在APM系统上工作的时候,一定要完成一些自动埋点工作,这样应用开发者不用做任何埋点工作就可以看到很多有用的数据。Type=Order 像最后两行一样属于人工埋藏的数据。
打点需要特别注意类型、名称和状态的维度的“爆炸”。它们的组合太多会消耗大量资源,并且可能直接拖累我们的Dog系统。type的维度可能不会太多,但是我们可能需要注意开发者可能会滥用name和status,所以一定要进行normalize(比如url可能有动态参数,需要格式化)。
表中最后两项是开发者手动埋藏的数据,通常用于统计具体场景。比如我想知道某个方法是怎么调用的,调用次数,耗时,是否抛出异常,输入参数,返回值。等待。因为自动埋点是业务不想关闭的冷数据,开发者可能想埋一些自己想统计的数据。
当开发者手动埋点时,也可以上报更多业务相关的数据。请参阅表格的最后一列。这些数据可用于业务分析。比如我是一个支付系统,通常一个支付订单涉及到很多步骤(国外支付和你平时使用的微信和支付宝略有不同)。通过上报各个节点的数据,我终于可以在Dog上使用bizId串起整个链接,在排查问题时非常有用(我们做支付业务的时候,支付成功率并没有大家想象的那么高,而且节点很多可能有问题)。
客户设计
上一节介绍了单条消息的数据,本节介绍其他内容。
首先我们介绍一下客户端的API使用:
上面的代码说明了如何使用嵌套的事务和事件。当最外层的Transaction在finally代码块中调用finish()时,树的创建就完成了,消息就被传递了。
我们交付给 Kafka 的不是 Message 实例,因为一个请求会产生很多 Message 实例,但应该组织成一个 Tree 实例以便以后交付。下图描述了 Tree 的各种属性:
树的属性很好理解。它持有对根事务的引用,并用于遍历整个树。另外,需要携带机器信息messageEnv。
treeId应该有保证全局唯一性的算法,简单介绍Dog的实现:$-$-$-$。
下面简单介绍几个tree id相关的内容。假设一个请求从A->B->C->D经过4个应用,A是入口应用,那么会有:
1、总共有 4 个 Tree 对象实例将从 4 个应用程序交付给 Kafka。跨应用调用时,需要传递treeId、parentTreeId、rootTreeId三个参数;
2、一个应用的treeId是所有节点的rootTreeId;
3、B应用的parentTreeId就是A的treeId,同理C的parentTreeId就是B应用的treeId;
4、跨应用调用时,比如从A调用B时,为了知道A的下一个节点是什么,在A中提前为B生成treeId,B收到请求后,如果找到A 已经为它生成了一个treeId,直接使用那个treeId。
大家也应该很容易知道,通过这些tree id,我们要实现trace的功能。
介绍完树的内容后,我们来简单讨论一下应用集成解决方案。
集成无非是两种技术。一种是通过javaagent。在启动脚本中,添加相应的代理。这种方式的好处是开发者无意识,运维级别可以做到。当然,如果开发者想要手动做一些嵌入,可能需要给开发者提供一个简单的客户端jar包来桥接代理。
另一种是提供jar包,开发者可以引入这个依赖。
这两种方案各有优缺点。Pinpoint 和 Skywalking 使用 javaagent 方案,Zipkin、Jaeger 和 Cat 使用第二种方案,Dog 也使用手动添加依赖项的第二种方案。
一般来说,做Traces的系统会选择使用javaagent方案,因为这类系统代理已经完成了所有需要的埋点,没有应用开发者的感知。
最后简单介绍一下Heartbeat的内容。这部分其实是最简单的,但是可以制作很多五颜六色的图表,实现面向老板的编程。
前面我们介绍过Message有两个子类Event和Transaction。这里我们添加一个子类 Heartbeat 来报告心跳数据。
我们主要采集thread、os、gc、heap、client的运行状态(生成了多少棵树、数据大小、发送失败次数)等。同时我们也提供api供开发者自定义数据进行上报. 狗客户端会启动一个后台线程,每分钟运行一次心跳采集程序,上报数据。
介绍更多细节。核心结构是一个Map\,key类似于“os.systemLoadAverage”、“thread.count”等。前缀os、thread、gc等实际上是用于页面上的分类,后缀为显示的折线图的名称。
关于客户,这就是我在这里介绍的全部内容。其实在实际的编码过程中,还是有一些细节需要处理的,比如树太大怎么办,比如没有rootTransaction的情况怎么处理(开发者只叫了Dog. logEvent(...)),比如如何在不调用finish的情况下处理内部嵌套事务等。
狗服务器设计
下图说明了服务器的整体设计。值得注意的是,我们这里对线程的使用非常克制,图中只有3个工作线程。
首先是Kafka Consumer线程,负责批量消费消息。它使用 kafka 集群中的 Tree 实例。接下来,考虑如何处理它。
这里,我们需要对树状结构的消息进行扁平化,我们称这一步为deflate,并做一些预处理,形成如下结构:
接下来,我们将 DeflateTree 分别传递给两个 Disruptor 实例。我们将 Disruptor 设计为单线程生产和单线程消费,主要是出于性能考虑。
消费者线程根据 DeflateTree 的属性使用绑定的 Processor 进行处理。比如DeflateTree中的List problmes不为空,ProblemProcessor是自己绑定的,所以需要调用ProblemProcessor进行处理。
科普时间:Disruptor是一个高性能队列,性能优于JDK中的BlockingQueue
这里我们使用了 2 个 Disruptor 实例,当然我们可以考虑使用更多的实例,这样每个消费者线程就绑定到更少的处理器上。
我们在这里将处理器绑定到 Disruptor 实例。其实原因很简单。出于性能原因,我们希望每个处理器仅在单个线程中使用它。单线程操作可以减少线程切换带来的开销,可以充分利用系统。缓存,在设计处理器时,不要考虑并发读写的问题。
这里要考虑负载均衡的情况。有些处理器消耗CPU和内存资源,必须合理分配。压力最大的任务不能分配给同一个线程。
核心处理逻辑在每个处理器中,负责数据计算。接下来,我将介绍每个处理器需要做的主要内容。毕竟能看到这里的开发者,应该对APM数据处理真的很感兴趣。
事务处理器
事务处理器是系统压力最大的地方。负责报表统计。虽然 Message 有两个主要子类 Transaction 和 Event,但在实际的树中,大多数节点都是事务类型数据。
下图是事务处理器内部的主要数据结构。最外层是时间。我们在几分钟内组织它。当我们坚持时,它也以分钟为单位存储。
第二层的HostKey代表了哪个应用程序和来自哪个IP的数据,第三层是类型、名称和状态的组合。最里面的统计是我们的数据统计模块。
此外,我们还可以看到这个结构会消耗多少内存。其实主要看我们的类型、名字、状态的组合,也就是会不会有很多的ReportKey。也就是我们在谈客户管理的时候,要避免维度爆炸。
最外层的结构代表时间的分钟表示。我们的报告是按每分钟统计的,然后持久化到 ClickHouse,但是我们的用户在看数据的时候,并不是每分钟都看到的。,所以你需要做数据聚合。下面显示了如何聚合这两个数据。当组合很多数据时,它们的组合方式相同。
仔细想想,你会发现前面数据的计算是可以的,但是P90、P95、P99的计算是不是有点骗人?事实上,这个问题真的是无解的。我们只能想出一个合适的数据计算规则,然后再想这个计算规则,计算出来的值可能就差不多可用了。
此外,还有一个细节问题。我们需要为内存中的数据提供最近 30 分钟的统计信息,只有超过 30 分钟的数据才从 DB 中读取。然后进行上述的合并操作。
讨论:我们能不能丢掉一部分实时性能,每分钟都持久化,读取的数据全部来自DB,这样可行吗?
不,因为我们的数据是从kafka消费的,有一定的滞后性。如果我们在一分钟开始时将数据持久化一分钟,我们可能会在稍后收到上一次的消息。这种情况无法处理。
比如我们要统计最后一小时,那么每台机器获取30分钟的数据,从DB获取30分钟的数据,然后合并。
这里值得一提的是,在交易报告中,count、failCount、min、max、avg是比较容易计算的,但是P90、P95、P99其实并不好计算,我们需要一个数组结构,记录这一分钟内所有事件的时间,然后计算,我们这里用的是Apache DataSketches,非常好用,这里就不展开了,有兴趣的同学可以自己看看。
此时,您可以考虑一下 ClickHouse 中存储的数据量。app_name、ip、type、name、status的不同组合,每分钟一个数据。
样品处理器
示例处理器使用来自放气树中列表事务和列表事件的数据。
我们还按分钟采样,最后每分钟采样,对于类型、名称和状态的每种组合,采集 最多 5 次成功、5 次失败和 5 次慢处理。
相对来说,这还是很简单的,其核心结构如下:
结合Sample的功能更容易理解:
问题处理器
在进行 deflate 时,所有成功 = false 的消息都将放入 List problmes 以进行错误统计。
Problem的内部数据结构如下:
如果你看这张图,你其实已经知道该怎么做了,所以我就不啰嗦了。我们每分钟保存 5 个 treeId 的样本。
顺便提一下Problem的观点:
关于持久化,我们将其存储在 ClickHouse 中,其中 sample 用逗号连接到一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
心跳处理器
Heartbeat 处理 List 心跳的数据。顺便说一句,在正常情况下,一棵树中只有一个 Heartbeat 实例。
前面我也简单提到过,Heartbeat 中用来显示图表的核心数据结构是 Map。
采集到的key-value数据如下:
前缀是分类,后缀是图的名称。客户端每分钟采集数据进行报告,然后可以制作很多图表。例如下图展示了堆分类下的各种图:
Heartbeat处理器要做的事情很简单,就是数据存储。Dog UI 上的数据直接从 ClickHouse 读取。
heartbeat_data的列如下:
消息树处理器
我们之前已经多次提到过 Sample 的功能。这些采样数据帮助我们还原场景,这样我们就可以通过trace视图来追踪调用链。
做上面的trace view,我们需要所有上下游树的数据,比如上图就是3个树实例的数据。
正如我们之前在介绍客户端时所说,这些树是由父treeId和根treeId组织的。
要做到这一点,我们面临的挑战是我们需要保存全部数据量。
你可以想想这个问题。为什么我们需要保存全部数据?如果我们直接保存采样的数据不是更好吗?
这里我们使用 Cassandra 的功能。Cassandra在这种kv场景下性能非常好,运维成本非常低。
我们使用treeId作为主键,并添加一列数据。它是整个树的实例数据。数据类型是blob。我们先做gzip压缩,然后扔给Cassandra。
业务处理器
我们在介绍客户端的时候说过,每条Message都可以携带Business Data,但只有应用开发者手动埋藏的时候。当我们发现有业务数据时,我们会做另一件事,就是将这些数据存储在 ClickHouse 中进行业务分析。
我们其实不知道应用开发者会在什么场景下使用它,因为每个人负责不同的项目,所以我们只能做一个通用的数据模型。
回头看这张图,在BusinessData中,我们定义了更通用的userId和bizId,我们认为可能会用到每一个业务场景。userId不用说,bizId可以用来记录订单id、支付订单id等。
然后我们提供三个String类型的列ext1、ext2、ext3和两个数值类型的列extVal1和extVal2,可以用来表达你的业务相关参数。
当然,我们的处理也很简单。将这些数据存储在 ClickHouse 中就足够了。表中主要有这几列:
这些数据对于我们的Dog系统来说肯定是不熟悉的,因为我们不知道你在表达什么业务。类型、名称和状态由开发人员自己定义。我们不知道 ext1、ext2 和 ext3 分别是什么意思。,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多数据报表。因为本文讨论的是APM,所以这里不再赘述。
其他
ClickHouse 需要批量编写,否则肯定是不可持续的。通常,一个批次至少有 10,000 行数据。
我们在 Kafka 层控制它。app_name + ip 的数据只会被同一个 dog-server 消费。当然,这并不意味着多个狗服务器消费时会出现问题,但写入ClickHouse的数据会更准确。许多。
还有一个关键点。我们说每个处理器都是单线程访问的,但是有一个问题,那就是Dog UI的请求呢?这里我想了一个办法,就是把请求放到一个Queue中,Kafka Consumer的线程会消费,它会把任务丢给两个Disruptor。例如,如果这个请求是一个交易报告请求,那么其中一个 Disruptor 消费者会发现这是他们想要做的,并且会执行这个任务。
概括
如果你知道 Cat,你可以看到 Dog 在很多地方与 Cat 有相似之处,或者只是说“复制”。我们也考虑过直接使用Cat或者在Cat的基础上做二次开发。
但是看了Cat的源码后,我放弃了这个想法。仔细想了想,正好借用了Cat的数据模型,然后我们自己写一套APM也不难,于是有了这个项目。
写的需要,很多地方重要的我都避而远之,因为这不是源码分析文章,细节就不多说了,主要是给读者一个全貌,读者可以大致思考哪些需要处理通过我的描述,需要写哪些代码,然后当我表达清楚。
欢迎您提出自己的问题或想法。如果有不明白的地方或者我有错误和遗漏的地方,请指正~
通过关键词采集文章采集api(大数据、人工智能等新技术给新媒体产业带来新冲击)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-15 07:11
大数据、人工智能等新技术给新媒体行业带来了新的影响和新的机遇。新媒体行业内部也将进一步分化。技术实力雄厚、团队竞争力强、生态协同良好的互联网平台将抢占越来越多的市场份额。BAT三巨头的老套路,极有可能被字节跳动打败。、快手等后来者破局,形成了新的媒体产业格局。
如今,对于新媒体运营商来说,作品的质量变得越来越重要。好的作品自然会得到更多的关注,但面对各大平台的海量媒体内容,如何让自己的优质作品脱颖而出,是很多新媒体运营商思考的主要问题之一。
近年来兴起的DaaS+RPA“数据智能机器人”,在政府、金融、医疗、人力资源、制造等多个领域都有很多典型的应用场景。现在它也在新媒体行业开辟了新的应用路径。它可以帮助运营商提高运营效率,提高工程质量。
一、新媒体行业痛点
1、有很多重复的任务,占用时间长;
2、优质内容很难获得高流量关注;
3、无法深入分析用户行为指导操作。
面对这些痛点,我们可以通过使用外部软件工具进一步提高我们的运营效率。“数字管家”——数据互联数据智能机器人(以下简称“数据互联”)是一款非常流行的采用DaaS+RPA技术的过程自动化软件。“数据连接”可以根据用户设置的任务流程和规则实现自动化操作。通过非侵入、免协调技术,快速安全生成系统业务数据访问(API)接口,实时连接多个应用系统,跨系统采集和报表.
媒体运营商只需要预先设置好任务流程,“数据连接”可以模拟人工操作,比如复制、粘贴、点击、输入等,辅助我们完成那些大型的“规则相对固定,重复的和额外的。较低的价值”。
二、解决方案及应用场景
1、多平台一键分发
对于媒体工作者来说,时间就是金钱。日常的分发过程非常繁琐枯燥,需要大量宝贵的创作时间,而同行每天更新的内容越来越多,竞争也越来越激烈,却没有更多的时间去创作,这导致了一个恶性循环。,无法输出高质量的内容。
使用“Digital Connect”可以实现文章和视频的多平台一键分发,完美解决了内容分发的繁琐问题,节省了大量时间。以前需要 2-3 个小时才能完成的发布工作,现在几分钟就可以完成,大大提高了工作效率。自媒体竞争非常激烈。更多的内容创作必然会获得更多的曝光和品牌传播,更多的优质内容制作可以提升领域综合排名、赛事奖励和更多收入。
2、提高用户发布内容的流行度
媒体人员在操作各大文章和视频平台时,往往会发现自己花了很多时间和精力制作文章或视频内容,浏览量、点赞数、评论数等数据都低,导致无法让更多用户看到并获得更多曝光,导致运营数据和结果不尽人意。
“数据连接”可以在平台允许的范围内,通过任务流程和组件的合理配置,有效优化发布的文章和视频数据,有效优化平台输出内容。推广效率,提高内容曝光度,形成良性运营状态。
3、网站SEO智能优化
如今的市场竞争非常激烈,网民越来越多,使用搜索引擎的频率非常高。目前,最大的中文搜索引擎百度日均PV达到30亿。如果网站不做SEO优化,不利于搜索引擎采集收录,会影响网站网站的流量很容易被网友忽略。因此,无论是为了公司形象还是为了市场,SEO都非常重要。
“数据连接”可以为网站提供生态自营销解决方案,为网站页面关键词提供SEO智能优化方法,让网站在行业,从而获得更高的品牌收入和影响力。
“数据连接”结合了DaaS+RPA+AI技术。作为一款流程自动化软件,不受标准化具体场景的约束,部署流程也比较短,特别是对于复杂的场景。该解决方案高度定制且易于使用。此外,“数字连接”可以更好地适应软件环境的变化,降低运维成本,满足客户智能需求,在复杂应用场景中搭建高壁垒。 查看全部
通过关键词采集文章采集api(大数据、人工智能等新技术给新媒体产业带来新冲击)
大数据、人工智能等新技术给新媒体行业带来了新的影响和新的机遇。新媒体行业内部也将进一步分化。技术实力雄厚、团队竞争力强、生态协同良好的互联网平台将抢占越来越多的市场份额。BAT三巨头的老套路,极有可能被字节跳动打败。、快手等后来者破局,形成了新的媒体产业格局。
如今,对于新媒体运营商来说,作品的质量变得越来越重要。好的作品自然会得到更多的关注,但面对各大平台的海量媒体内容,如何让自己的优质作品脱颖而出,是很多新媒体运营商思考的主要问题之一。
近年来兴起的DaaS+RPA“数据智能机器人”,在政府、金融、医疗、人力资源、制造等多个领域都有很多典型的应用场景。现在它也在新媒体行业开辟了新的应用路径。它可以帮助运营商提高运营效率,提高工程质量。
一、新媒体行业痛点
1、有很多重复的任务,占用时间长;
2、优质内容很难获得高流量关注;
3、无法深入分析用户行为指导操作。
面对这些痛点,我们可以通过使用外部软件工具进一步提高我们的运营效率。“数字管家”——数据互联数据智能机器人(以下简称“数据互联”)是一款非常流行的采用DaaS+RPA技术的过程自动化软件。“数据连接”可以根据用户设置的任务流程和规则实现自动化操作。通过非侵入、免协调技术,快速安全生成系统业务数据访问(API)接口,实时连接多个应用系统,跨系统采集和报表.
媒体运营商只需要预先设置好任务流程,“数据连接”可以模拟人工操作,比如复制、粘贴、点击、输入等,辅助我们完成那些大型的“规则相对固定,重复的和额外的。较低的价值”。
二、解决方案及应用场景
1、多平台一键分发
对于媒体工作者来说,时间就是金钱。日常的分发过程非常繁琐枯燥,需要大量宝贵的创作时间,而同行每天更新的内容越来越多,竞争也越来越激烈,却没有更多的时间去创作,这导致了一个恶性循环。,无法输出高质量的内容。
使用“Digital Connect”可以实现文章和视频的多平台一键分发,完美解决了内容分发的繁琐问题,节省了大量时间。以前需要 2-3 个小时才能完成的发布工作,现在几分钟就可以完成,大大提高了工作效率。自媒体竞争非常激烈。更多的内容创作必然会获得更多的曝光和品牌传播,更多的优质内容制作可以提升领域综合排名、赛事奖励和更多收入。
2、提高用户发布内容的流行度
媒体人员在操作各大文章和视频平台时,往往会发现自己花了很多时间和精力制作文章或视频内容,浏览量、点赞数、评论数等数据都低,导致无法让更多用户看到并获得更多曝光,导致运营数据和结果不尽人意。
“数据连接”可以在平台允许的范围内,通过任务流程和组件的合理配置,有效优化发布的文章和视频数据,有效优化平台输出内容。推广效率,提高内容曝光度,形成良性运营状态。
3、网站SEO智能优化
如今的市场竞争非常激烈,网民越来越多,使用搜索引擎的频率非常高。目前,最大的中文搜索引擎百度日均PV达到30亿。如果网站不做SEO优化,不利于搜索引擎采集收录,会影响网站网站的流量很容易被网友忽略。因此,无论是为了公司形象还是为了市场,SEO都非常重要。
“数据连接”可以为网站提供生态自营销解决方案,为网站页面关键词提供SEO智能优化方法,让网站在行业,从而获得更高的品牌收入和影响力。
“数据连接”结合了DaaS+RPA+AI技术。作为一款流程自动化软件,不受标准化具体场景的约束,部署流程也比较短,特别是对于复杂的场景。该解决方案高度定制且易于使用。此外,“数字连接”可以更好地适应软件环境的变化,降低运维成本,满足客户智能需求,在复杂应用场景中搭建高壁垒。
通过关键词采集文章采集api(一下这款软件生成一篇6000字的长文,软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-15 07:09
最近有一款软件很火。给它一个关键词,它会直接为你生成一个6000字的长文本。不过文章的内容比较啰嗦,这个软件的名字也不错。有趣:《废话文章Generator》~接下来导演带你深入了解这款软件~
首先,我们来看看这款软件的网页版。网页版的界面很简单,有一个输入框和一个生成按钮,一目了然:
那我们接下来试试。以“科技学院之最”为例,输入后点击生成,biu~会瞬间生成一个超长的文章,每次点击可以获得不同的文章,效率超高有木有!
但是仔细看会发现,虽然每次生成的文章都不一样,但是好像有些句子出现了很多次。这是怎么回事?
导演按照网页上的说明跳转到知乎,然后跳转到Github,终于找到了软件的源代码,大家下载下来研究一下~
经过一些简单的研究,导演发现文章大致是由名言、填充词、关键词和一些“废话”等组成,通过一定的算法。
作者提供了100多个名言,10多个俚语,30多个“废话”。这些内容随意组合拼接,可以形成多种结果。因此,每次生成的内容不完全相同!
如果下载源代码,也可以自己修改一些参数,比如段落长度、句子长度、文章的总字数:
另外,还可以修改文本部分,比如把名言修改成你想要的内容,生成你独有的文章~修改文本部分时,只需要修改数据中的内容即可.json 文件就可以了。这个文件可以用记事本,文本编辑器,或者类似功能的软件打开~
本软件作者强调,本软件生成的文章确实不合理,只能作为玩笑,请勿用于正式用途!所以就玩得开心吧~另外,作者还有进一步的开发计划:
除了以上,导演还想介绍一个比较有意思的网站,叫做《彩虹屁发生器》。不知道什么时候用~
这个原理也比较简单。每次点击【下一步】,都会通过API调用一条新的内容,并显示在网页上:
其实类似功能的软件或者网页还有很多,这里就不一一列举了。最后,导演再次提醒,这种软件是娱乐性的,千万不要在正式场合使用! 查看全部
通过关键词采集文章采集api(一下这款软件生成一篇6000字的长文,软件)
最近有一款软件很火。给它一个关键词,它会直接为你生成一个6000字的长文本。不过文章的内容比较啰嗦,这个软件的名字也不错。有趣:《废话文章Generator》~接下来导演带你深入了解这款软件~
首先,我们来看看这款软件的网页版。网页版的界面很简单,有一个输入框和一个生成按钮,一目了然:
那我们接下来试试。以“科技学院之最”为例,输入后点击生成,biu~会瞬间生成一个超长的文章,每次点击可以获得不同的文章,效率超高有木有!
但是仔细看会发现,虽然每次生成的文章都不一样,但是好像有些句子出现了很多次。这是怎么回事?
导演按照网页上的说明跳转到知乎,然后跳转到Github,终于找到了软件的源代码,大家下载下来研究一下~
经过一些简单的研究,导演发现文章大致是由名言、填充词、关键词和一些“废话”等组成,通过一定的算法。
作者提供了100多个名言,10多个俚语,30多个“废话”。这些内容随意组合拼接,可以形成多种结果。因此,每次生成的内容不完全相同!
如果下载源代码,也可以自己修改一些参数,比如段落长度、句子长度、文章的总字数:
另外,还可以修改文本部分,比如把名言修改成你想要的内容,生成你独有的文章~修改文本部分时,只需要修改数据中的内容即可.json 文件就可以了。这个文件可以用记事本,文本编辑器,或者类似功能的软件打开~
本软件作者强调,本软件生成的文章确实不合理,只能作为玩笑,请勿用于正式用途!所以就玩得开心吧~另外,作者还有进一步的开发计划:
除了以上,导演还想介绍一个比较有意思的网站,叫做《彩虹屁发生器》。不知道什么时候用~
这个原理也比较简单。每次点击【下一步】,都会通过API调用一条新的内容,并显示在网页上:
其实类似功能的软件或者网页还有很多,这里就不一一列举了。最后,导演再次提醒,这种软件是娱乐性的,千万不要在正式场合使用!
通过关键词采集文章采集api(手把手教你通过关键词采集文章采集api(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-09 05:00
通过关键词采集文章采集api,其实通过平台这么多种方式,只要你会api就能找到你想要的资源。手把手教你通过关键词找到相应的素材手把手教你通过关键词找到相应的素材:会爬虫的都可以直接上手,别看我简单,简单是因为掌握的人少,要抓取最新资源(特别是一些国外的网站)最近开始疯狂接单,文章会有时间的跨度。还有就是对你来说有用的资源你才会想要。希望能帮到你。
谁都想爬取各大平台上的热门新闻,那如何爬取?其实抓取新闻,并不难,普通的抓取工具都能实现,今天推荐一款好用的爬虫app:浏览器自带的api,包括多款热门新闻网站,抓取一两个新闻网站还是没问题的,大部分网站是可以轻松取得!利用浏览器的自带api,其实获取新闻并不难,好用的有限,需要有:【1】安装最新版本谷歌浏览器【2】安装多抓鱼浏览器多抓鱼浏览器是2018年4月9日谷歌官方推出的,只需要一键就能实现去重,抓取新闻,返回传统爬虫爬取一大堆网站,累死人累死人累死人!说了半天,就是要大家会抓取,会抓取那就要一起学习一起撸了~一直有推荐过不少免费学习网站,感兴趣的朋友可以关注一下,【1】自学学习有各种免费资源。
网站是两年前弄的,api有些久远,现在就一直再用,有不少自学学习的网站,也有些资源,喜欢的朋友可以在后台留言交流哈~获取网站的方法,可以前往下载中心获取,苹果用户还需要付费安装,服务器还在美国,不支持在国内访问!api2.0已经发布,关注公众号【topone应用商店】回复【接口】即可免费获取!。 查看全部
通过关键词采集文章采集api(手把手教你通过关键词采集文章采集api(组图))
通过关键词采集文章采集api,其实通过平台这么多种方式,只要你会api就能找到你想要的资源。手把手教你通过关键词找到相应的素材手把手教你通过关键词找到相应的素材:会爬虫的都可以直接上手,别看我简单,简单是因为掌握的人少,要抓取最新资源(特别是一些国外的网站)最近开始疯狂接单,文章会有时间的跨度。还有就是对你来说有用的资源你才会想要。希望能帮到你。
谁都想爬取各大平台上的热门新闻,那如何爬取?其实抓取新闻,并不难,普通的抓取工具都能实现,今天推荐一款好用的爬虫app:浏览器自带的api,包括多款热门新闻网站,抓取一两个新闻网站还是没问题的,大部分网站是可以轻松取得!利用浏览器的自带api,其实获取新闻并不难,好用的有限,需要有:【1】安装最新版本谷歌浏览器【2】安装多抓鱼浏览器多抓鱼浏览器是2018年4月9日谷歌官方推出的,只需要一键就能实现去重,抓取新闻,返回传统爬虫爬取一大堆网站,累死人累死人累死人!说了半天,就是要大家会抓取,会抓取那就要一起学习一起撸了~一直有推荐过不少免费学习网站,感兴趣的朋友可以关注一下,【1】自学学习有各种免费资源。
网站是两年前弄的,api有些久远,现在就一直再用,有不少自学学习的网站,也有些资源,喜欢的朋友可以在后台留言交流哈~获取网站的方法,可以前往下载中心获取,苹果用户还需要付费安装,服务器还在美国,不支持在国内访问!api2.0已经发布,关注公众号【topone应用商店】回复【接口】即可免费获取!。
通过关键词采集文章采集api(【干货】亚马逊搜索框所推荐的关键词采集工具(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-04 06:16
前言
本周末国庆值班期间,无事可做,整理发布之前写的亚马逊搜索框推荐的关键词采集工具。总的来说,它是一个简单的小爬虫。
因为比较小,所以写在一个模块里,一个模块分成五个方法来完成整个爬取过程。
网页下载方法 网页解析方法 将解析结果存入txt文件的方法 整合网页下载的方法及存入txt文件的方法 主要功能 组织整个流程的方法 主要内容一、 中涉及的类库
import requests
import datetime
import time
以上类库,除requests第三方类库外,均为Python标准库。第三方类库可以在cmd中通过pip install +类库名自动安装——前提是已经配置好python环境变量-windows
requests 是一个网页下载库 datetime 是一个日期库。本例中用于根据不同的日期设置采集文件txt的不同名称。时间时间库,主要使用sleep方式,用于采集糟糕时暂停程序的库二、网页下载方式
def get_suggestion(url, sleep=5, retry=3):
try:
r = requests.get(url, timeout=10)
if r.json:
return r.json()
else:
print('网站返回信息为空,当前检索失败')
if retry>=0:
print('正在重新请求')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
except (requests.ConnectTimeout,requests.ReadTimeout, requests.ConnectionError) as e:
print('超时: %s' % str(e))
if retry>=0:
print('正在重试')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
对于网页下载方式,简单设置了错误捕获和错误重试的功能,使得爬虫在下载网页的过程中能够顺利运行。
另外,经过多次尝试,这个接口的抗爬升程度很弱。只要不是大型的采集,一般都不是问题。如果遇到Robot Check等验证,除了更改IP(https类型)外,还可以使用Pause和rest来缓解Robot Check的概率。
而且亚马逊推荐的关键词,经过观察,更新频率不是很高,个人普通的采集速度完全可以满足需求。
三、网页解析方法,解析出我们需要的内容
def parse_suggestion(js_html):
try:
suggestions = js_html.get('suggestions')
keywords_list = [keyword.get('value') for keyword in suggestions]
return keywords_list
except Exception as e:
return
解析网页返回的信息,所以类信息是json格式的,本体已经通过requests库的json方法转换为字典类型,所以可以直接以字典的形式访问。
增加了一层判断。当解析出现错误时,会返回empty,以保证程序不会因为错误而影响整体运行。
返回的内容存储方法,存储我们的 采集to 和过去的权重的 关键词
def save_suggestion(keyword):
# 以天为单位分离采集结果
with open('Amazon Suggest Keywords_{}.txt'.format(datetime.now().date()), 'a+') as f:
f.write(keyword+'\n')
比较简单,不用多说。打开或者新建一个txt文件,调用write方法写入对应的关键词,在每个关键词后面加一个换行符
四、集成网页下载并保存为txt文件,方便以后调用
def get_and_save(url, suggested_keywords):
rq_json = get_suggestion(url)
suggestion_list = parse_suggestion(rq_json)
if suggestion_list:
for suggestion in suggestion_list:
print('#' * 80)
print('正在判断当前关键词:%s' % suggestion)
if suggestion in suggested_keywords:
print('当前关键词:%s 重复' % suggestion)
continue
else:
save_suggestion(suggestion)
print('当前关键词:%s 存储成功' % suggestion)
suggested_keywords.append(suggestion)
else:
print('亚马逊返回信息为空,当前关键词长尾词采集失败')
因此,部分代码会在主程序中被多次调用,所以单独组织为一个方法。
增加了if判断,保证只在显式返回关键词时才调用存储方法
这一步还加了一个判断,判断当前检索到的关键词是否已经是采集,如果已经是采集,则放弃
五、组织整个程序的主函数
def main(prefix_or_prefix_list):
url = 'https://completion.amazon.com/api/2017/suggestions?&client-info=amazon-search-ui&' \
'mid=ATVPDKIKX0DER&alias=aps&b2b=0&fresh=0&ks=83&prefix={}&suggestion-type=keyword&fb=1'
suggested_keywords = []
# 定义一个空列表,以存储已采集过的关键词
if isinstance(prefix_or_prefix_list, str):
# 传入的是一个词
final_url = url.format(prefix_or_prefix_list)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
# 将已采集过的 keywords 做再次采集,依旧是重复的剔除
get_and_save(url.format(depth_keywords),suggested_keywords)
elif isinstance(prefix_or_prefix_list, list):
# 传入的是一个由许多单词组成的列表| tuple 也是可以的,只要是一个可以迭代的有序序列都可以。但是如果是一个 orderedDict的话,那就需要改写部分代码了。
for prefix in prefix_or_prefix_list:
final_url = url.format(prefix)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
get_and_save(url.format(depth_keywords), suggested_keywords)
else:
print('参数传入错误,本程序只接受单个关键词或者关键词序列为参数')
if __name__ == '__main__':
_prefix = 'iphone case'
_prefix_list = ['iphone case', 'iphone charger']
main(_prefix)
main函数接收一个prefix_or_prefix_list参数,这意味着这个程序可以采集单个关键词长尾词,或者采集一系列关键词。
内置isinstance方法用于判断传入参数类型,根据类型使用不同的采集配置。
这个程序运行了很长时间,需要轮询每一个关键词消息。但是实时采集,采用实时存储策略,所以程序的运行可以随时中断,并且采集字样已经存储在对应的txt文件中。
有人说能不能用多线程,当然可以,但是项目小没必要,亚马逊的关键词推荐更新也没有那么频繁。而且,亚马逊的反爬能力极其强大。如果你有兴趣,你可以自己试试。
结尾
这是我分享的第一个与亚马逊卖家相关的爬虫工具。配置好python程序后,复制粘贴即可使用。
亚马逊卖家相关的朋友如果看过这篇博文,有兴趣开发亚马逊卖家相关工具的朋友,可以私信交流。 查看全部
通过关键词采集文章采集api(【干货】亚马逊搜索框所推荐的关键词采集工具(一))
前言
本周末国庆值班期间,无事可做,整理发布之前写的亚马逊搜索框推荐的关键词采集工具。总的来说,它是一个简单的小爬虫。
因为比较小,所以写在一个模块里,一个模块分成五个方法来完成整个爬取过程。
网页下载方法 网页解析方法 将解析结果存入txt文件的方法 整合网页下载的方法及存入txt文件的方法 主要功能 组织整个流程的方法 主要内容一、 中涉及的类库
import requests
import datetime
import time
以上类库,除requests第三方类库外,均为Python标准库。第三方类库可以在cmd中通过pip install +类库名自动安装——前提是已经配置好python环境变量-windows
requests 是一个网页下载库 datetime 是一个日期库。本例中用于根据不同的日期设置采集文件txt的不同名称。时间时间库,主要使用sleep方式,用于采集糟糕时暂停程序的库二、网页下载方式
def get_suggestion(url, sleep=5, retry=3):
try:
r = requests.get(url, timeout=10)
if r.json:
return r.json()
else:
print('网站返回信息为空,当前检索失败')
if retry>=0:
print('正在重新请求')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
except (requests.ConnectTimeout,requests.ReadTimeout, requests.ConnectionError) as e:
print('超时: %s' % str(e))
if retry>=0:
print('正在重试')
time.sleep(sleep)
retry -= 1
return get_suggestion(url, retry)
对于网页下载方式,简单设置了错误捕获和错误重试的功能,使得爬虫在下载网页的过程中能够顺利运行。
另外,经过多次尝试,这个接口的抗爬升程度很弱。只要不是大型的采集,一般都不是问题。如果遇到Robot Check等验证,除了更改IP(https类型)外,还可以使用Pause和rest来缓解Robot Check的概率。
而且亚马逊推荐的关键词,经过观察,更新频率不是很高,个人普通的采集速度完全可以满足需求。
三、网页解析方法,解析出我们需要的内容
def parse_suggestion(js_html):
try:
suggestions = js_html.get('suggestions')
keywords_list = [keyword.get('value') for keyword in suggestions]
return keywords_list
except Exception as e:
return
解析网页返回的信息,所以类信息是json格式的,本体已经通过requests库的json方法转换为字典类型,所以可以直接以字典的形式访问。
增加了一层判断。当解析出现错误时,会返回empty,以保证程序不会因为错误而影响整体运行。
返回的内容存储方法,存储我们的 采集to 和过去的权重的 关键词
def save_suggestion(keyword):
# 以天为单位分离采集结果
with open('Amazon Suggest Keywords_{}.txt'.format(datetime.now().date()), 'a+') as f:
f.write(keyword+'\n')
比较简单,不用多说。打开或者新建一个txt文件,调用write方法写入对应的关键词,在每个关键词后面加一个换行符
四、集成网页下载并保存为txt文件,方便以后调用
def get_and_save(url, suggested_keywords):
rq_json = get_suggestion(url)
suggestion_list = parse_suggestion(rq_json)
if suggestion_list:
for suggestion in suggestion_list:
print('#' * 80)
print('正在判断当前关键词:%s' % suggestion)
if suggestion in suggested_keywords:
print('当前关键词:%s 重复' % suggestion)
continue
else:
save_suggestion(suggestion)
print('当前关键词:%s 存储成功' % suggestion)
suggested_keywords.append(suggestion)
else:
print('亚马逊返回信息为空,当前关键词长尾词采集失败')
因此,部分代码会在主程序中被多次调用,所以单独组织为一个方法。
增加了if判断,保证只在显式返回关键词时才调用存储方法
这一步还加了一个判断,判断当前检索到的关键词是否已经是采集,如果已经是采集,则放弃
五、组织整个程序的主函数
def main(prefix_or_prefix_list):
url = 'https://completion.amazon.com/api/2017/suggestions?&client-info=amazon-search-ui&' \
'mid=ATVPDKIKX0DER&alias=aps&b2b=0&fresh=0&ks=83&prefix={}&suggestion-type=keyword&fb=1'
suggested_keywords = []
# 定义一个空列表,以存储已采集过的关键词
if isinstance(prefix_or_prefix_list, str):
# 传入的是一个词
final_url = url.format(prefix_or_prefix_list)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
# 将已采集过的 keywords 做再次采集,依旧是重复的剔除
get_and_save(url.format(depth_keywords),suggested_keywords)
elif isinstance(prefix_or_prefix_list, list):
# 传入的是一个由许多单词组成的列表| tuple 也是可以的,只要是一个可以迭代的有序序列都可以。但是如果是一个 orderedDict的话,那就需要改写部分代码了。
for prefix in prefix_or_prefix_list:
final_url = url.format(prefix)
get_and_save(final_url, suggested_keywords)
for depth_keywords in suggested_keywords:
get_and_save(url.format(depth_keywords), suggested_keywords)
else:
print('参数传入错误,本程序只接受单个关键词或者关键词序列为参数')
if __name__ == '__main__':
_prefix = 'iphone case'
_prefix_list = ['iphone case', 'iphone charger']
main(_prefix)
main函数接收一个prefix_or_prefix_list参数,这意味着这个程序可以采集单个关键词长尾词,或者采集一系列关键词。
内置isinstance方法用于判断传入参数类型,根据类型使用不同的采集配置。
这个程序运行了很长时间,需要轮询每一个关键词消息。但是实时采集,采用实时存储策略,所以程序的运行可以随时中断,并且采集字样已经存储在对应的txt文件中。
有人说能不能用多线程,当然可以,但是项目小没必要,亚马逊的关键词推荐更新也没有那么频繁。而且,亚马逊的反爬能力极其强大。如果你有兴趣,你可以自己试试。
结尾
这是我分享的第一个与亚马逊卖家相关的爬虫工具。配置好python程序后,复制粘贴即可使用。
亚马逊卖家相关的朋友如果看过这篇博文,有兴趣开发亚马逊卖家相关工具的朋友,可以私信交流。
通过关键词采集文章采集api( 全平台发布全CMS发布器功能特点及特点 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-02 16:06
全平台发布全CMS发布器功能特点及特点
)
SEO人员在平时的SEO优化中会使用大量的SEO工具来智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特色seo关键词优化软件:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局海量优秀同行,以及优化方向seo关键词优化软件!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、通过site:域名,查询网站的条目有多少收录,收录的关键词做了多少seo关键词优化软件@> 有吗?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
查看全部
通过关键词采集文章采集api(
全平台发布全CMS发布器功能特点及特点
)
SEO人员在平时的SEO优化中会使用大量的SEO工具来智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特色seo关键词优化软件:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局海量优秀同行,以及优化方向seo关键词优化软件!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、通过site:域名,查询网站的条目有多少收录,收录的关键词做了多少seo关键词优化软件@> 有吗?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
通过关键词采集文章采集api( 基于微服务的日志中心架构设计三、中心的流程与实现 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2022-02-01 00:00
基于微服务的日志中心架构设计三、中心的流程与实现
)
转载本文须注明出处:微信公众号EAWorld,违者必究。
介绍:
日志一直是运维和开发人员最关心的问题。运维人员可以通过相关日志信息及时发现系统隐患和系统故障,安排人员及时处理和解决问题。没有日志信息的帮助,开发者无法解决问题。没有日志就等于没有眼睛,没有方向。
微服务越来越流行,在享受微服务架构带来的好处的同时,也不得不承担微服务带来的麻烦。日志管理就是其中之一。微服务有一个很大的特点:分布式。由于分布式部署,日志信息分散在各处,给采集日志的存储带来了一定的挑战:
本文文章将讨论与日志管理相关的问题。
内容:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程及实现
四、日志中心关键配置
五、总结
一、日志的重要性和复杂性
要说管理日志,在管理日志之前有一个先决条件。我们需要知道日志是什么,它们能做什么,以及它们有什么用处。根据百度百科,是记录系统操作事件的记录信息。
在日志文件中,记录着当前系统的各种生命体征,就像我们在医院体检后得到的体检表,反映了我们的肝功能、肾功能、血常规等具体指标。日志文件在应用系统中的作用就像一个体检清单,反映了系统的健康状况、系统的运行事件、系统的变化情况。
日志充当系统中的守护者。它是保证服务高度可靠的基础,记录系统的一举一动。有运维级别、业务级别、安全级别的日志。系统监控、异常处理、安全、审计都离不开日志的辅助。
有各种类型的日志,一个健壮的系统可能有各种日志消息。
这么复杂多样的日志,有必要一口气抓吗?我们需要哪些?这些都是我们在设计日志中心架构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态中不可或缺的一部分,是监控的第二大师。在这里分享我们的产品级设计实践,了解日志中心在基于微服务架构的技术架构中的位置,以及如何部署。
在本设计中,微服务结构由以下部分组成:
图中没有log center四个关键词,因为它是由多个独立的组件组成的。这些组件分别是 Filebeat、Kafka、Logstash 和 Elasticsearch,它们共同构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1. 日志选择----确定选择哪些日志记录进行分析
2. 日志采集 ---- filebeat 轻采集
3. 日志缓冲---- kafka 缓存在本地缓冲
4. 日志过滤 ---- logstash 过滤
5. 日志存储----elasticsearch索引存储
6. 日志检索----使用elasticsearch本身的检索功能
7. 日志展示----参考kibana风格实现日志数据可视化
在传统的 ELK 上,Logstash 日志 采集 被 Filebeat 取代,在日志存储前增加了 kafka 缓冲和 logstash 过滤。这组流程确保功能完整,同时提高性能并使部署尽可能轻量级。
三、日志中心的流程及实现
选型:根据业务场景
日志内容复杂多样,如何采集有价值的日志是我们关注的重点。日志的价值实际上取决于业务运营。同一种日志在不同业务场景中的价值会完全不同。根据以往的业务实践,结合一些企业级的业务需求,我们选择重点关注以下几类日志。• Trace log [trace.log] 服务器引擎的调试日志,供系统维护人员定位系统运行问题。• 系统日志[system.log] 大粒度引擎运行进出日志,用于调用栈分析,可用于性能分析。• 部署日志[deploy.log] 记录系统启动、停止、组件包部署、集群通知等信息的日志。• 引擎日志[引擎。log] 一个细粒度的引擎运行日志,可以打印上下文数据,定位业务问题。• 组件包日志[contribution.log] 组件包记录的业务日志(使用基础组件库的日志输出API写日志)
通过以上几类日志,可以明确我们在分析问题时要查找的位置,通过分类缩小查找范围,提高效率。
采集(Filebeat):专注于轻量级
微服务应用分布在各个领域的各个系统中。应用程序的日志在各个域的各个系统中相应生成。日志管理首先要做好日志的采集工作。对于日志采集 作业,我们选择 Elastic Stack 中的 Filebeat。
Filebeat与应用程序挂钩,因为我们需要知道如何采集每个位置的日志信息,所以轻量级其实是我们考虑的主要因素。
Filebeat 会有一个或多个探测器,称为 Prospector,可以实时监控指定文件或指定文件目录的变化状态,并将变化状态及时传送到下一层——Spooler 进行处理。
Filebeat还有一个特性我们介绍给日志过滤,这是定位源头的关键。
这两点正好满足了我们实时采集实现日志的需要。新增的日志通过 Filebeat 动态存储和及时采样。至此,如何采集记录信息的问题就完美解决了。
缓冲(Kafka):高吞吐量、易扩展、高上限
在日志存储之前,我们引入了一个组件,Kafka,作为日志缓冲层。Kafka 充当缓冲区,避免高峰应用对 ES 的影响。由于 ES 瓶颈问题导致数据丢失问题。同时,它还具有数据聚合的功能。
使用 kafka 进行日志缓冲有几个优点:
筛选(Logstash):提前埋点,便于定位
日志信息是通过filebeat、kafka等工具采集和传输的,给日志事件增加了很多额外的信息。使用Logstash实现二次处理,可以在过滤器中进行过滤或处理。
Filebeat 在采集信息时,我们通过将同一台服务器上的日志信息发送到同一个 Kafka 主题来实现日志聚合。主题名称是服务器的关键信息。在更细粒度的层面上,您还可以将每个应用的信息聚合为一个主题。Kafka 中 Filebeat 接收到的日志信息中收录一个标识符——日志来自哪里。Logstash的作用是在日志导入到ES之前,通过标识符过滤汇总相应的日志信息,然后发送给ES,为后续查找提供依据。方便我们清晰定位问题。
存储(ES):易于扩展,易于使用
Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。
选择 ElasticSearch 的主要原因是:分布式部署,易于扩展;处理海量数据,满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于上手。
搜索 (ES):分类
Elasticsearch 本身是一个强大的搜索引擎,支持按系统、应用、应用实例组、应用实例IP、关键字、日志级别、时间间隔来检索所需的日志信息。
显示(Kibana):配置简单,一目了然
在查看密密麻麻的日志信息时,往往会有一种头晕目眩的感觉。需要对日志信息进行简化提取,对日志信息进行整合分析,并以图表的形式展示日志信息。在展示的过程中,我们可以借鉴和吸收 Kibana 在日志可视化方面的努力,实现日志的可视化处理。通过简单的配置,我们可以清晰、可视化的看到某个服务或应用的日志分析结果。.
查看全部
通过关键词采集文章采集api(
基于微服务的日志中心架构设计三、中心的流程与实现
)
转载本文须注明出处:微信公众号EAWorld,违者必究。
介绍:
日志一直是运维和开发人员最关心的问题。运维人员可以通过相关日志信息及时发现系统隐患和系统故障,安排人员及时处理和解决问题。没有日志信息的帮助,开发者无法解决问题。没有日志就等于没有眼睛,没有方向。
微服务越来越流行,在享受微服务架构带来的好处的同时,也不得不承担微服务带来的麻烦。日志管理就是其中之一。微服务有一个很大的特点:分布式。由于分布式部署,日志信息分散在各处,给采集日志的存储带来了一定的挑战:
本文文章将讨论与日志管理相关的问题。
内容:
一、日志的重要性和复杂性
二、基于微服务的日志中心架构设计
三、日志中心的流程及实现
四、日志中心关键配置
五、总结
一、日志的重要性和复杂性
要说管理日志,在管理日志之前有一个先决条件。我们需要知道日志是什么,它们能做什么,以及它们有什么用处。根据百度百科,是记录系统操作事件的记录信息。
在日志文件中,记录着当前系统的各种生命体征,就像我们在医院体检后得到的体检表,反映了我们的肝功能、肾功能、血常规等具体指标。日志文件在应用系统中的作用就像一个体检清单,反映了系统的健康状况、系统的运行事件、系统的变化情况。
日志充当系统中的守护者。它是保证服务高度可靠的基础,记录系统的一举一动。有运维级别、业务级别、安全级别的日志。系统监控、异常处理、安全、审计都离不开日志的辅助。
有各种类型的日志,一个健壮的系统可能有各种日志消息。
这么复杂多样的日志,有必要一口气抓吗?我们需要哪些?这些都是我们在设计日志中心架构时需要考虑的问题。
二、基于微服务
日志中心架构设计
日志中心是微服务生态中不可或缺的一部分,是监控的第二大师。在这里分享我们的产品级设计实践,了解日志中心在基于微服务架构的技术架构中的位置,以及如何部署。
在本设计中,微服务结构由以下部分组成:
图中没有log center四个关键词,因为它是由多个独立的组件组成的。这些组件分别是 Filebeat、Kafka、Logstash 和 Elasticsearch,它们共同构成了日志中心。
经过考虑和研究,我们确定了一套适合当前微服务架构的日志管理流程。
1. 日志选择----确定选择哪些日志记录进行分析
2. 日志采集 ---- filebeat 轻采集
3. 日志缓冲---- kafka 缓存在本地缓冲
4. 日志过滤 ---- logstash 过滤
5. 日志存储----elasticsearch索引存储
6. 日志检索----使用elasticsearch本身的检索功能
7. 日志展示----参考kibana风格实现日志数据可视化
在传统的 ELK 上,Logstash 日志 采集 被 Filebeat 取代,在日志存储前增加了 kafka 缓冲和 logstash 过滤。这组流程确保功能完整,同时提高性能并使部署尽可能轻量级。
三、日志中心的流程及实现
选型:根据业务场景
日志内容复杂多样,如何采集有价值的日志是我们关注的重点。日志的价值实际上取决于业务运营。同一种日志在不同业务场景中的价值会完全不同。根据以往的业务实践,结合一些企业级的业务需求,我们选择重点关注以下几类日志。• Trace log [trace.log] 服务器引擎的调试日志,供系统维护人员定位系统运行问题。• 系统日志[system.log] 大粒度引擎运行进出日志,用于调用栈分析,可用于性能分析。• 部署日志[deploy.log] 记录系统启动、停止、组件包部署、集群通知等信息的日志。• 引擎日志[引擎。log] 一个细粒度的引擎运行日志,可以打印上下文数据,定位业务问题。• 组件包日志[contribution.log] 组件包记录的业务日志(使用基础组件库的日志输出API写日志)
通过以上几类日志,可以明确我们在分析问题时要查找的位置,通过分类缩小查找范围,提高效率。
采集(Filebeat):专注于轻量级
微服务应用分布在各个领域的各个系统中。应用程序的日志在各个域的各个系统中相应生成。日志管理首先要做好日志的采集工作。对于日志采集 作业,我们选择 Elastic Stack 中的 Filebeat。
Filebeat与应用程序挂钩,因为我们需要知道如何采集每个位置的日志信息,所以轻量级其实是我们考虑的主要因素。
Filebeat 会有一个或多个探测器,称为 Prospector,可以实时监控指定文件或指定文件目录的变化状态,并将变化状态及时传送到下一层——Spooler 进行处理。
Filebeat还有一个特性我们介绍给日志过滤,这是定位源头的关键。
这两点正好满足了我们实时采集实现日志的需要。新增的日志通过 Filebeat 动态存储和及时采样。至此,如何采集记录信息的问题就完美解决了。
缓冲(Kafka):高吞吐量、易扩展、高上限
在日志存储之前,我们引入了一个组件,Kafka,作为日志缓冲层。Kafka 充当缓冲区,避免高峰应用对 ES 的影响。由于 ES 瓶颈问题导致数据丢失问题。同时,它还具有数据聚合的功能。
使用 kafka 进行日志缓冲有几个优点:
筛选(Logstash):提前埋点,便于定位
日志信息是通过filebeat、kafka等工具采集和传输的,给日志事件增加了很多额外的信息。使用Logstash实现二次处理,可以在过滤器中进行过滤或处理。
Filebeat 在采集信息时,我们通过将同一台服务器上的日志信息发送到同一个 Kafka 主题来实现日志聚合。主题名称是服务器的关键信息。在更细粒度的层面上,您还可以将每个应用的信息聚合为一个主题。Kafka 中 Filebeat 接收到的日志信息中收录一个标识符——日志来自哪里。Logstash的作用是在日志导入到ES之前,通过标识符过滤汇总相应的日志信息,然后发送给ES,为后续查找提供依据。方便我们清晰定位问题。
存储(ES):易于扩展,易于使用
Elastic 是 Lucene 的一个包,提供开箱即用的 REST API 操作接口。
选择 ElasticSearch 的主要原因是:分布式部署,易于扩展;处理海量数据,满足各种需求;强大的搜索功能,基于Lucene可以实现快速搜索;活跃的开发社区,更多信息,易于上手。
搜索 (ES):分类
Elasticsearch 本身是一个强大的搜索引擎,支持按系统、应用、应用实例组、应用实例IP、关键字、日志级别、时间间隔来检索所需的日志信息。
显示(Kibana):配置简单,一目了然
在查看密密麻麻的日志信息时,往往会有一种头晕目眩的感觉。需要对日志信息进行简化提取,对日志信息进行整合分析,并以图表的形式展示日志信息。在展示的过程中,我们可以借鉴和吸收 Kibana 在日志可视化方面的努力,实现日志的可视化处理。通过简单的配置,我们可以清晰、可视化的看到某个服务或应用的日志分析结果。.
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-25 14:11
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
,优采云采集器优采云是基于运营商网上实名制的网页数据采集、移动互联网数据和API接口服务的数据服务。 -name 系统平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器 优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。只是各大平台都设置了严格的反爬,很难获取有价值的数据。
3、金坛中国 金坛中国的数据服务平台有多种专业的数据采集工具,包括很多开发者上传的采集工具,其中很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了业界99%的采集软件,可以通过近距离检测采集来完成。对技术含量要求高的高强度抗爬或抗裂有专业的技术方案。在专业性方面,金坛的专业性是毋庸置疑的,其中不少也是针对高难度采集软件的定制开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,它最大的特点是网页 采集 的代词是单数,因为焦点。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就可以整齐的抓取网页的数据,操作很简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。对于一些防爬设置强的网站来说,是无能为力的。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取成Excel、XML、CSV等大部分数据库。该软件基于网页抓取。获取和 Web 自动化。
8、ForeSpider ForeSpider 是一个非常有用的网络数据工具采集。用户可以使用此工具帮助您自动检索网页中的各种数据信息。这个软件使用起来很简单,但是也有一个网站在面对一些高难度和高强度的反爬设置时无能为力。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不死机,可实现实时查询。
10、优采云采集器 优采云采集器操作很简单,按照流程很容易上手, 查看全部
通过关键词采集文章采集api(推荐10个最好用的数据采集工具10款用)
推荐10个最好的数据采集工具
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各种行业采集工具,目前最好的一些免费数据< @采集 工具,希望对大家有帮助。
,优采云采集器优采云是基于运营商网上实名制的网页数据采集、移动互联网数据和API接口服务的数据服务。 -name 系统平台。它最大的特点就是不用懂网络爬虫技术就可以轻松搞定采集。
2、优采云采集器 优采云采集器是目前使用最多的互联网数据采集软件。以其灵活的配置和强大的性能领先于国内同类产品,赢得了众多用户的一致认可。只是各大平台都设置了严格的反爬,很难获取有价值的数据。
3、金坛中国 金坛中国的数据服务平台有多种专业的数据采集工具,包括很多开发者上传的采集工具,其中很多都是免费的。无论是采集国内外网站、行业网站、政府网站、app、微博、搜索引擎、公众号、小程序等数据还是其他数据,几乎覆盖了业界99%的采集软件,可以通过近距离检测采集来完成。对技术含量要求高的高强度抗爬或抗裂有专业的技术方案。在专业性方面,金坛的专业性是毋庸置疑的,其中不少也是针对高难度采集软件的定制开发服务。
4、大飞采集器大飞采集器可以采集多个网页,准确率比较高,跟复制粘贴一样准确,它最大的特点是网页 采集 的代词是单数,因为焦点。
5、Import.io 使用Import.io适配任何网站,只要进入网站,就可以整齐的抓取网页的数据,操作很简单,自动采集,< @采集 结果可视化。但是,无法选择特定数据并自动翻页采集。对于一些防爬设置强的网站来说,是无能为力的。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索它们。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber是国外大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取成Excel、XML、CSV等大部分数据库。该软件基于网页抓取。获取和 Web 自动化。
8、ForeSpider ForeSpider 是一个非常有用的网络数据工具采集。用户可以使用此工具帮助您自动检索网页中的各种数据信息。这个软件使用起来很简单,但是也有一个网站在面对一些高难度和高强度的反爬设置时无能为力。
9、阿里巴巴数据采集阿里巴巴数据采集大平台运行稳定不死机,可实现实时查询。
10、优采云采集器 优采云采集器操作很简单,按照流程很容易上手,
通过关键词采集文章采集api(几百上千个不同的CMS网站都能实现统一管理? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-24 20:12
)
[内容]!
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,匹配内容和图片准确率高,自动执行文章采集发布,提供方便快捷的数据服务! !
相关规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类工具还是很强大的,只要输入关键词采集,就可以自动采集通过软件采集@发布文章 > .
您还可以设置自动下载图片以保存本地或第三方。配备自动内链、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
看完这篇文章,如果觉得不错,不妨采集一下或者发给有需要的朋友同事!你的一举一动都会成为博主源源不断的动力!
查看全部
通过关键词采集文章采集api(几百上千个不同的CMS网站都能实现统一管理?
)
[内容]!
其他功能,不用担心!这就是 zblog 可以访问 文章 的方式!然后,单击以保存配置并进行预览。如果之前的列表规则和内容规则都写对了,现在可以采集文章!
二、通过关键词采集文章
无需学习更多专业技能,简单几步轻松搞定采集网页数据,精准数据发布,关键词用户只需在软件中进行简单设置,完成后系统根据用户设置关键词进行采集,匹配内容和图片准确率高,自动执行文章采集发布,提供方便快捷的数据服务! !
相关规则采集门槛低,无需花大量时间学习软件操作,无需配置采集规则即可一分钟上手,输入关键词采集.无需人工干预,将任务设置为自动执行采集releases。几十万个不同的cms网站可以统一管理。一个人维护数百个 网站文章 更新也不是问题。
这类工具还是很强大的,只要输入关键词采集,就可以自动采集通过软件采集@发布文章 > .
您还可以设置自动下载图片以保存本地或第三方。配备自动内链、前后插入内容或标题,以及网站内容插入或随机作者、随机阅读等,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
看完这篇文章,如果觉得不错,不妨采集一下或者发给有需要的朋友同事!你的一举一动都会成为博主源源不断的动力!
通过关键词采集文章采集api(10个很棒的Python特性,你不能使用了吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-01-24 17:21
Python部落()组织翻译,禁止转载,欢迎转发
注:本文翻译自同名PPT,所以文章有很多重复的段落标题。这些标题就是页面上PPT的标题,而且PPT的标题经常重复出现。
10 个因为拒绝升级到 Python 3 而无法使用的很棒的 Python 特性,你也可以认为有 11 个特性。
序章功能 0:矩阵乘法
功能 0,因为您还不能实际使用它的目录
政治人物 465
在 Python3.5 中,您将能够使用
代替:
任何对象都可以覆盖 __matmul__ 以使用 @。
功能一:高级拆包
你曾经能够做到这一点:
现在你可以这样做:
*rest 可以出现在任何地方:
功能一:高级解包获取文件的第一行和最后一行
重构你的功能
特性 2:关键词 唯一参数
选项出现在 *args 之后。访问它的唯一方法是显式调用 f(a, b, option=True) 如果你不想采集 *args,你可以只写一个 *:
特性 2:关键词 唯一参数
不再有“糟糕,我不小心向函数传递了太多参数,其中一个将作为关键字参数接收”。
特性 2:关键词 唯一参数
将其更改为:
特性 2:关键词 唯一参数
或者,“我重新排序了函数的 关键词 参数,但有些是隐式传递的”
例子:
特性 2:关键词 唯一参数
max 内置函数支持 max(a, b, c)。我们也应该允许这样做。
我们只是打破了前面的代码,不使用 关键词 作为第二个参数来将值传递给键。
(事实上在 Python 2 中它会返回 ["a", "ab", "ac"],参见特性 6)。
顺便说一句,max 表明它在 Python2 中已经是可能的,但前提是你用 C 编写函数。
显然,我们应该使用 maxall(iterable, *, key=None) 来开始。
特性 2:关键词 唯一参数
您可以使您的 API 保持“最新”。
傻瓜式例子
好吧,也许将更长的时间放在更短的时间之前会更有意义。. .
太糟糕了,你会破坏代码。
特性 2:关键词 唯一参数
在 Python 3 中,您可以使用:
现在,a 和 b 必须像 extendto(10, short=a, long=b) 一样传入。
或者如果您愿意,可以像这样 extendto(10, long=b, short=a) 。
特性 2:关键词 唯一参数
在不破坏 API 的情况下添加新的 关键词 参数。
Python3 在标准库中执行此操作。
例如, os 模块中的函数具有 follow_symlinks 选项。
因此,您可以只使用 os.stat(file, follow_symlinks=False) 而不是 os.lstat。
如果这听起来更冗长,你可以做
代替
但是, os.stat(file, some_condition) 没有。
不要将其视为两个参数的函数。
特征二:关键词唯一参数特征三:连接异常
情况:你用except捕获异常,做某事,然后触发不同的异常。
问题:您丢失了先前异常的回溯。
刚才OSError怎么了?
特点三:连接异常
Python3 向您展示了整个异常链:
您也可以使用 raise from 手动执行此操作:
特性四:细分 OSError 子类
我刚才显示的代码是错误的。
它捕获 OSError 异常并假定它是权限错误。
但是 OSError 异常可能是由多种情况引起的(文件未找到、目录、不是目录、管道损坏等)
你确定你需要这样做:
哇。可怕。
特性四:细分 OSError 子类
Python3 通过添加一系列新的异常来解决这个问题。
你只需要这样做:
(别担心,PermissionError 是 OSError 的子类,旧的 .errno 状态码仍然有效)。
特征 5:一切都是迭代器 特征 5:一切都是迭代器
如果你这样做:
特征 5:一切都是迭代器
特征 5:一切都是迭代器 特征 5:一切都是迭代器 特征 6:并非一切都可以比较
在 Python2 中,您可以执行以下操作:
干杯。我只反驳数学。
特点6:不是所有的东西都可以比较
因为在 Python 2 中,您可以比较所有内容。
在 Python3 中,你不能这样做:
这避免了一些微妙的错误,例如所有类型的非强制转换,从 int 到 str,反之亦然。
尤其是当您隐式使用 > 时,例如 max 或 sorted。
在 Python2 中:
特征 7:产量来自
如果您使用生成器,那就太好了。
不要这样写:
写就好了:
只需将生成器重构为子生成器。
特征 7:产量来自
把所有东西都变成发电机更容易。参见上面提到的“特征 5:一切都是迭代器”,你就会明白为什么要这样做。
不要堆叠来生成列表,只需 yield 或 yield from。
不好:
行:
更好的一个:
特征 7:产量来自
如果您不知道,生成器很棒,因为:
特性8:异步IO(asyncio)
使用新的协程功能和保存的生成器状态进行异步 IO。
不会骗你的。我还是不明白这一点。
但是这没关系。甚至大卫比兹利也很难理解这一点。
特性 9:标准库添加故障处理程序
显示(有限的)回溯,即使 Python 死得很惨。
使用 kill -9 时不起作用,但就像 segfaults 一样。
或者使用 kill -6 (程序请求异常终止)
它也可以通过 python -X faulthandler 激活。
特性九:标准库新增ipaddress
确切地。IP地址。
另一件事你不希望自己静止不动。
特性九:标准库新增 functools.lru_cache
为你的函数提供一个 LRU 缓存装饰器。
从文档中。
特性 9:标准库添加枚举
最后是标准库中的枚举类型。
仅限 Python 3.4。
使用一些魔法仅在 Python3 中有用(由于元类更改):
功能 10:有趣的 Unicode 变量名
功能注释
注释可以是任意 Python 对象。
除了将注释放入 __annotations__ 字典之外,Python 对注释不做任何事情。
但它为图书馆作者做有趣的事情开辟了可能性。
例如,IPython 2.0 小工具。
特点11:Unicode和字节流英文原文:
译者:leisants 查看全部
通过关键词采集文章采集api(10个很棒的Python特性,你不能使用了吗?)
Python部落()组织翻译,禁止转载,欢迎转发
注:本文翻译自同名PPT,所以文章有很多重复的段落标题。这些标题就是页面上PPT的标题,而且PPT的标题经常重复出现。
10 个因为拒绝升级到 Python 3 而无法使用的很棒的 Python 特性,你也可以认为有 11 个特性。
序章功能 0:矩阵乘法
功能 0,因为您还不能实际使用它的目录
政治人物 465
在 Python3.5 中,您将能够使用
代替:
任何对象都可以覆盖 __matmul__ 以使用 @。
功能一:高级拆包
你曾经能够做到这一点:
现在你可以这样做:
*rest 可以出现在任何地方:
功能一:高级解包获取文件的第一行和最后一行
重构你的功能
特性 2:关键词 唯一参数
选项出现在 *args 之后。访问它的唯一方法是显式调用 f(a, b, option=True) 如果你不想采集 *args,你可以只写一个 *:
特性 2:关键词 唯一参数
不再有“糟糕,我不小心向函数传递了太多参数,其中一个将作为关键字参数接收”。
特性 2:关键词 唯一参数
将其更改为:
特性 2:关键词 唯一参数
或者,“我重新排序了函数的 关键词 参数,但有些是隐式传递的”
例子:
特性 2:关键词 唯一参数
max 内置函数支持 max(a, b, c)。我们也应该允许这样做。
我们只是打破了前面的代码,不使用 关键词 作为第二个参数来将值传递给键。
(事实上在 Python 2 中它会返回 ["a", "ab", "ac"],参见特性 6)。
顺便说一句,max 表明它在 Python2 中已经是可能的,但前提是你用 C 编写函数。
显然,我们应该使用 maxall(iterable, *, key=None) 来开始。
特性 2:关键词 唯一参数
您可以使您的 API 保持“最新”。
傻瓜式例子
好吧,也许将更长的时间放在更短的时间之前会更有意义。. .
太糟糕了,你会破坏代码。
特性 2:关键词 唯一参数
在 Python 3 中,您可以使用:
现在,a 和 b 必须像 extendto(10, short=a, long=b) 一样传入。
或者如果您愿意,可以像这样 extendto(10, long=b, short=a) 。
特性 2:关键词 唯一参数
在不破坏 API 的情况下添加新的 关键词 参数。
Python3 在标准库中执行此操作。
例如, os 模块中的函数具有 follow_symlinks 选项。
因此,您可以只使用 os.stat(file, follow_symlinks=False) 而不是 os.lstat。
如果这听起来更冗长,你可以做
代替
但是, os.stat(file, some_condition) 没有。
不要将其视为两个参数的函数。
特征二:关键词唯一参数特征三:连接异常
情况:你用except捕获异常,做某事,然后触发不同的异常。
问题:您丢失了先前异常的回溯。
刚才OSError怎么了?
特点三:连接异常
Python3 向您展示了整个异常链:
您也可以使用 raise from 手动执行此操作:
特性四:细分 OSError 子类
我刚才显示的代码是错误的。
它捕获 OSError 异常并假定它是权限错误。
但是 OSError 异常可能是由多种情况引起的(文件未找到、目录、不是目录、管道损坏等)
你确定你需要这样做:
哇。可怕。
特性四:细分 OSError 子类
Python3 通过添加一系列新的异常来解决这个问题。
你只需要这样做:
(别担心,PermissionError 是 OSError 的子类,旧的 .errno 状态码仍然有效)。
特征 5:一切都是迭代器 特征 5:一切都是迭代器
如果你这样做:
特征 5:一切都是迭代器
特征 5:一切都是迭代器 特征 5:一切都是迭代器 特征 6:并非一切都可以比较
在 Python2 中,您可以执行以下操作:
干杯。我只反驳数学。
特点6:不是所有的东西都可以比较
因为在 Python 2 中,您可以比较所有内容。
在 Python3 中,你不能这样做:
这避免了一些微妙的错误,例如所有类型的非强制转换,从 int 到 str,反之亦然。
尤其是当您隐式使用 > 时,例如 max 或 sorted。
在 Python2 中:
特征 7:产量来自
如果您使用生成器,那就太好了。
不要这样写:
写就好了:
只需将生成器重构为子生成器。
特征 7:产量来自
把所有东西都变成发电机更容易。参见上面提到的“特征 5:一切都是迭代器”,你就会明白为什么要这样做。
不要堆叠来生成列表,只需 yield 或 yield from。
不好:
行:
更好的一个:
特征 7:产量来自
如果您不知道,生成器很棒,因为:
特性8:异步IO(asyncio)
使用新的协程功能和保存的生成器状态进行异步 IO。
不会骗你的。我还是不明白这一点。
但是这没关系。甚至大卫比兹利也很难理解这一点。
特性 9:标准库添加故障处理程序
显示(有限的)回溯,即使 Python 死得很惨。
使用 kill -9 时不起作用,但就像 segfaults 一样。
或者使用 kill -6 (程序请求异常终止)
它也可以通过 python -X faulthandler 激活。
特性九:标准库新增ipaddress
确切地。IP地址。
另一件事你不希望自己静止不动。
特性九:标准库新增 functools.lru_cache
为你的函数提供一个 LRU 缓存装饰器。
从文档中。
特性 9:标准库添加枚举
最后是标准库中的枚举类型。
仅限 Python 3.4。
使用一些魔法仅在 Python3 中有用(由于元类更改):
功能 10:有趣的 Unicode 变量名
功能注释
注释可以是任意 Python 对象。
除了将注释放入 __annotations__ 字典之外,Python 对注释不做任何事情。
但它为图书馆作者做有趣的事情开辟了可能性。
例如,IPython 2.0 小工具。
特点11:Unicode和字节流英文原文:
译者:leisants
通过关键词采集文章采集api(微软研究员为Azure认知搜索“加持”了语义搜索功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-24 17:20
编者按:作为云搜索服务,Azure 认知搜索集成了强大的 API 和工具,帮助开发人员构建丰富的搜索体验。不止于现状,微软研究人员还为 Azure 认知搜索的语义搜索功能“加冕”,让搜索引擎具备了语义排序、语义摘要、语义高亮、语义问答、自动拼写纠正等能力。本文将揭示这些惊人功能背后的核心技术,涉及关键词包括预训练、图网络、多任务处理等。本文编译自 Microsoft Research 博客“语义搜索背后的科学:Bing 的 AI 如何为 Azure 认知搜索提供动力”。
智能语义搜索是搜索引擎追求的终极目标。多年来,微软研究人员一直在探索实现智能语义搜索的途径,最近将相关研究成果集成到微软Azure云计算平台的认知服务——Azure认知搜索(Azure Cognitive Search)中,为所有人提供语义搜索能力。预览版中的 Azure 用户。该技术核心部分涉及的多项研究成果均来自微软亚洲研究院。
Azure 认知搜索是一种云搜索服务,它为开发人员提供 API 和工具,以基于 Web、移动和企业应用程序中的专门异构内容构建丰富的搜索体验。Azure 认知搜索具有多个组件,包括用于检索和查询的 API、通过 Azure 数据提取的无缝集成、与 Azure 认知服务的深度集成以及用户拥有的检索内容的持久存储。默认情况下,Azure 认知搜索使用 BM25 算法,该算法通常用于信息检索。
为了提高微软必应搜索的相关性,微软研究和开发人员此前通过基于 Transformer 的语言模型改进了必应搜索。这些改进让搜索引擎不仅可以匹配关键词,还可以利用词和内容背后的语义进行搜索,转化的能力就是语义搜索。
将语义搜索功能集成到 Azure 认知搜索中的效果
语义搜索显着提高了必应搜索的搜索结果质量。但微软研发团队在此过程中发现,为了最大限度发挥 AI 的威力,需要大量的专业人员来集成和部署 AI 规模的相关技术和产品,例如大规模的基于 Transformer 的语言模型。 . 预训练、跨不同任务的多任务微调、将大型模型提炼成质量损失最小的可部署模型等。而这样的专业团队并不是每个公司都能负担得起的。微软秉承赋能每一个人、每一组织的公司理念,通过将相关研究成果整合到 Azure 认知搜索中,降低了人们使用 AI 规模技术的门槛。
Azure 认知搜索中的语义搜索功能
让我们仔细看看 Azure 认知搜索中的语义搜索功能。
语义排序:显着提高相关性。传统的搜索方式是基于关键词排序结果,基于Transformer的语义排序引擎可以理解文本背后的含义。在A/B测试中,语义搜索功能提升了搜索结果的点击率(2.0%),三个词以上的搜索结果点击率也提升了4.@ >5%。
通过语义排序提高相关性的示例(右)
语义摘要:提取关键信息。相关性只是一方面,搜索结果中的标题和片段也很重要。好的标题和摘要让用户一眼就能看出结果是否是他们想要的。
语义突出显示:机器阅读理解。语义高亮的简单理解是关注一个搜索结果并以粗体显示。通过语义高亮,用户可以直接得到他们需要的答案,或者通过快速扫描结果页面找到他们需要的文档,甚至可以直接得到摘要。使用机器阅读理解可以帮助找到段落的重点,从而大大提高阅读效率。
使用语义搜索提取摘要、语义强调的示例
语义问答:快速解答。疑问式查询是搜索引擎经常遇到的一种搜索方法,其背后用户往往希望优先考虑简短而准确的答案,而不是文档。语义搜索可以使用机器学习来读取语料库中的所有文档,然后总结并在顶部显示答案。
语义搜索提取文档亮点并提供快速答案
自动拼写更正。据统计,用于输入的句子中有10%~15%存在拼写错误,拼写错误会极大地影响搜索结果的质量,集成语义搜索的搜索引擎可以实现自动拼写纠正。
背后的技术:预训练、图网络、多任务......
上述功能的实现离不开微软研究院在NLP和语义搜索方面取得的突破性进展。研究人员与微软内部其他 AI 团队合作开发了一系列神经网络模型,不仅在 SQuAD、GLUE、SuperGLUE 等多个行业基准测试中取得了最佳成绩,而且还积极部署应用,实现了微软相关产品。性能改进。
以下是 Microsoft 用于实现语义搜索的具体技术:
统一的预训练语言模型:UniLM 和 UniLM v2
在 Azure 认知搜索中,预训练语言模型利用了微软亚洲研究院的统一预训练语言模型 UniLM(Unified Language Model Pre-training),这是第一个统一的语言理解和语言生成模型。在基准测试中表现良好的预训练模型。UniLM 涵盖了两个关键的技术创新:一是提出了统一的预训练框架,使得同一个模型可以同时支持自然语言理解和自然语言生成任务,而之前的大部分预训练模型主要是针对自然语言的。语言理解任务。第二大创新是提出了部分自回归预训练范式和伪掩码语言模型,可以更高效地训练出更好的自然语言预训练模型。
在 ICML 2020 上,来自微软亚洲研究院的研究人员还提出了一种新的训练 UniLM 的训练框架,Pseudo-Masked Language Models for Unified Language Model Pre-Training,简称“Unified Pre-training Pseudo-Mask Language Model”,简称 UniLM v2。UniLM v2 使用传统掩码通过自动编码来学习掩码标记与上下文之间的关系,并使用伪掩码通过部分自回归来学习掩码标记之间的关系。必应搜索中的技术于 2019 年初在 BERT 上实现,并通过使用 UniLM v2 提高了其搜索质量。
统一的预训练语言模型架构
机器阅读理解:一个多粒度的阅读理解框架
机器阅读理解 (MRC) 的任务是从文档中找到给定问题的简短答案(例如短语)或长答案(例如段落)。由于最大长度的限制,大多数现有的 MRC 方法在答案提取过程中将文档视为单独的段落,而没有考虑它们之间的内在关系。
为了更好地对 MRC 进行建模,微软亚洲研究院的研究人员提出了一种基于图注意力网络和预训练语言模型的多粒度阅读理解框架,并联合训练对两个粒度答案之间的联系进行建模。在这个框架中,首先根据文档的层次性质,例如段落、句子和符号,为每个文档构建一个图网络,然后使用一个图注意力网络来学习不同层次的表示,最后是一个序列的结构获得。转换后的表示被聚合到答案选择模块中以获得答案。其中,长答案和短答案的抽取任务可以一起训练,从而相互促进。
上述研究论文是《Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension》,已获得 ACL 2020 收录 的认可,并已用于 Bing Search 中的大部分问答任务。
论文链接:
多任务深度神经网络:MT-DNN
微软研究院和 Microsoft Dynamics 365 AI 团队合作提出了一种新的多任务深度神经网络模型——MT-DNN。该模型是第一个在 GLUE 排行榜上超越人类表现的 AI 模型,它结合了 BERT 的优势,并在 10 个自然语言理解任务上优于 BERT,在多个流行的基准 SOTA 结果上创造了新的基准。
MT-DNN 结合了多任务学习和语言模型预训练,用于跨多个自然语言理解任务学习语言表示。MT-DNN 不仅利用了大量的跨任务数据,而且受益于正则化效应,提高了模型的泛化能力,使其在新的任务和领域中表现出色。语义搜索中的模型利用跨各种搜索任务的多任务学习来最大化它们的性能。
研究论文“用于自然语言理解的多任务深度神经网络”发表在 ACL 2019 上。
论文链接:
深度自注意力知识蒸馏:MiniLM
大规模预训练模型在自然语言理解和生成任务中表现良好,但庞大的参数和计算成本使其难以直接部署到在线产品中。为此,微软亚洲研究院提出了通用方法 MiniLM - Deep Self-Attention Distillation,将基于 Transformer 的预训练大模型压缩成预训练小模型。核心思想是将预训练好的Transformer模型中非常重要的Self-Attention知识最大程度的转移到小模型上。
MiniLM 在单语言和多语言模型上进行了压缩实验,取得了不错的效果。Azure Cognitive Search 的语义搜索解决方案采用了 MiniLM 技术,具有以原创大模型 20% 的成本保持 95% 准确率的效果。
MiniLM:深度自注意力蒸馏
Semantic Search 背后的 AI 模型非常强大,并且已经在基准测试和 Bing Search 上得到验证。通过将语义搜索集成到 Azure 认知搜索中,微软在普及先进的机器学习技术和让人工智能普及方面又向前迈出了一大步。 查看全部
通过关键词采集文章采集api(微软研究员为Azure认知搜索“加持”了语义搜索功能)
编者按:作为云搜索服务,Azure 认知搜索集成了强大的 API 和工具,帮助开发人员构建丰富的搜索体验。不止于现状,微软研究人员还为 Azure 认知搜索的语义搜索功能“加冕”,让搜索引擎具备了语义排序、语义摘要、语义高亮、语义问答、自动拼写纠正等能力。本文将揭示这些惊人功能背后的核心技术,涉及关键词包括预训练、图网络、多任务处理等。本文编译自 Microsoft Research 博客“语义搜索背后的科学:Bing 的 AI 如何为 Azure 认知搜索提供动力”。
智能语义搜索是搜索引擎追求的终极目标。多年来,微软研究人员一直在探索实现智能语义搜索的途径,最近将相关研究成果集成到微软Azure云计算平台的认知服务——Azure认知搜索(Azure Cognitive Search)中,为所有人提供语义搜索能力。预览版中的 Azure 用户。该技术核心部分涉及的多项研究成果均来自微软亚洲研究院。
Azure 认知搜索是一种云搜索服务,它为开发人员提供 API 和工具,以基于 Web、移动和企业应用程序中的专门异构内容构建丰富的搜索体验。Azure 认知搜索具有多个组件,包括用于检索和查询的 API、通过 Azure 数据提取的无缝集成、与 Azure 认知服务的深度集成以及用户拥有的检索内容的持久存储。默认情况下,Azure 认知搜索使用 BM25 算法,该算法通常用于信息检索。
为了提高微软必应搜索的相关性,微软研究和开发人员此前通过基于 Transformer 的语言模型改进了必应搜索。这些改进让搜索引擎不仅可以匹配关键词,还可以利用词和内容背后的语义进行搜索,转化的能力就是语义搜索。
将语义搜索功能集成到 Azure 认知搜索中的效果
语义搜索显着提高了必应搜索的搜索结果质量。但微软研发团队在此过程中发现,为了最大限度发挥 AI 的威力,需要大量的专业人员来集成和部署 AI 规模的相关技术和产品,例如大规模的基于 Transformer 的语言模型。 . 预训练、跨不同任务的多任务微调、将大型模型提炼成质量损失最小的可部署模型等。而这样的专业团队并不是每个公司都能负担得起的。微软秉承赋能每一个人、每一组织的公司理念,通过将相关研究成果整合到 Azure 认知搜索中,降低了人们使用 AI 规模技术的门槛。
Azure 认知搜索中的语义搜索功能
让我们仔细看看 Azure 认知搜索中的语义搜索功能。
语义排序:显着提高相关性。传统的搜索方式是基于关键词排序结果,基于Transformer的语义排序引擎可以理解文本背后的含义。在A/B测试中,语义搜索功能提升了搜索结果的点击率(2.0%),三个词以上的搜索结果点击率也提升了4.@ >5%。
通过语义排序提高相关性的示例(右)
语义摘要:提取关键信息。相关性只是一方面,搜索结果中的标题和片段也很重要。好的标题和摘要让用户一眼就能看出结果是否是他们想要的。
语义突出显示:机器阅读理解。语义高亮的简单理解是关注一个搜索结果并以粗体显示。通过语义高亮,用户可以直接得到他们需要的答案,或者通过快速扫描结果页面找到他们需要的文档,甚至可以直接得到摘要。使用机器阅读理解可以帮助找到段落的重点,从而大大提高阅读效率。
使用语义搜索提取摘要、语义强调的示例
语义问答:快速解答。疑问式查询是搜索引擎经常遇到的一种搜索方法,其背后用户往往希望优先考虑简短而准确的答案,而不是文档。语义搜索可以使用机器学习来读取语料库中的所有文档,然后总结并在顶部显示答案。
语义搜索提取文档亮点并提供快速答案
自动拼写更正。据统计,用于输入的句子中有10%~15%存在拼写错误,拼写错误会极大地影响搜索结果的质量,集成语义搜索的搜索引擎可以实现自动拼写纠正。
背后的技术:预训练、图网络、多任务......
上述功能的实现离不开微软研究院在NLP和语义搜索方面取得的突破性进展。研究人员与微软内部其他 AI 团队合作开发了一系列神经网络模型,不仅在 SQuAD、GLUE、SuperGLUE 等多个行业基准测试中取得了最佳成绩,而且还积极部署应用,实现了微软相关产品。性能改进。
以下是 Microsoft 用于实现语义搜索的具体技术:
统一的预训练语言模型:UniLM 和 UniLM v2
在 Azure 认知搜索中,预训练语言模型利用了微软亚洲研究院的统一预训练语言模型 UniLM(Unified Language Model Pre-training),这是第一个统一的语言理解和语言生成模型。在基准测试中表现良好的预训练模型。UniLM 涵盖了两个关键的技术创新:一是提出了统一的预训练框架,使得同一个模型可以同时支持自然语言理解和自然语言生成任务,而之前的大部分预训练模型主要是针对自然语言的。语言理解任务。第二大创新是提出了部分自回归预训练范式和伪掩码语言模型,可以更高效地训练出更好的自然语言预训练模型。
在 ICML 2020 上,来自微软亚洲研究院的研究人员还提出了一种新的训练 UniLM 的训练框架,Pseudo-Masked Language Models for Unified Language Model Pre-Training,简称“Unified Pre-training Pseudo-Mask Language Model”,简称 UniLM v2。UniLM v2 使用传统掩码通过自动编码来学习掩码标记与上下文之间的关系,并使用伪掩码通过部分自回归来学习掩码标记之间的关系。必应搜索中的技术于 2019 年初在 BERT 上实现,并通过使用 UniLM v2 提高了其搜索质量。
统一的预训练语言模型架构
机器阅读理解:一个多粒度的阅读理解框架
机器阅读理解 (MRC) 的任务是从文档中找到给定问题的简短答案(例如短语)或长答案(例如段落)。由于最大长度的限制,大多数现有的 MRC 方法在答案提取过程中将文档视为单独的段落,而没有考虑它们之间的内在关系。
为了更好地对 MRC 进行建模,微软亚洲研究院的研究人员提出了一种基于图注意力网络和预训练语言模型的多粒度阅读理解框架,并联合训练对两个粒度答案之间的联系进行建模。在这个框架中,首先根据文档的层次性质,例如段落、句子和符号,为每个文档构建一个图网络,然后使用一个图注意力网络来学习不同层次的表示,最后是一个序列的结构获得。转换后的表示被聚合到答案选择模块中以获得答案。其中,长答案和短答案的抽取任务可以一起训练,从而相互促进。
上述研究论文是《Document Modeling with Graph Attention Networks for Multi-grained Machine Reading Comprehension》,已获得 ACL 2020 收录 的认可,并已用于 Bing Search 中的大部分问答任务。
论文链接:
多任务深度神经网络:MT-DNN
微软研究院和 Microsoft Dynamics 365 AI 团队合作提出了一种新的多任务深度神经网络模型——MT-DNN。该模型是第一个在 GLUE 排行榜上超越人类表现的 AI 模型,它结合了 BERT 的优势,并在 10 个自然语言理解任务上优于 BERT,在多个流行的基准 SOTA 结果上创造了新的基准。
MT-DNN 结合了多任务学习和语言模型预训练,用于跨多个自然语言理解任务学习语言表示。MT-DNN 不仅利用了大量的跨任务数据,而且受益于正则化效应,提高了模型的泛化能力,使其在新的任务和领域中表现出色。语义搜索中的模型利用跨各种搜索任务的多任务学习来最大化它们的性能。
研究论文“用于自然语言理解的多任务深度神经网络”发表在 ACL 2019 上。
论文链接:
深度自注意力知识蒸馏:MiniLM
大规模预训练模型在自然语言理解和生成任务中表现良好,但庞大的参数和计算成本使其难以直接部署到在线产品中。为此,微软亚洲研究院提出了通用方法 MiniLM - Deep Self-Attention Distillation,将基于 Transformer 的预训练大模型压缩成预训练小模型。核心思想是将预训练好的Transformer模型中非常重要的Self-Attention知识最大程度的转移到小模型上。
MiniLM 在单语言和多语言模型上进行了压缩实验,取得了不错的效果。Azure Cognitive Search 的语义搜索解决方案采用了 MiniLM 技术,具有以原创大模型 20% 的成本保持 95% 准确率的效果。
MiniLM:深度自注意力蒸馏
Semantic Search 背后的 AI 模型非常强大,并且已经在基准测试和 Bing Search 上得到验证。通过将语义搜索集成到 Azure 认知搜索中,微软在普及先进的机器学习技术和让人工智能普及方面又向前迈出了一大步。
通过关键词采集文章采集api(优化(ASO)实战辅导书《冲榜》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2022-01-24 17:16
白鲸公开课08《你的APP出海必须掌握哪些ASO策略?》,我们邀请了优化(ASO)实用教程书《冲榜》的作者之一霍晓亮老师来分享。
小亮先生是高级ASOer。现任某知名互联网公司ASO产品经理。擅长App Store算法分析和大数据挖掘。他对iOS推广有深入的研究。小亮先生与资深互联网营销顾问李景航先生合着《粉碎榜单》,全面介绍了App Store优化的“正确打开方式”,帮助移动营销人员有效提升投放产出比。在平台上出售。
小编简单总结了本次公开课的精髓,分享给大家。详情及部分课堂问答,可扫描下方二维码前往直播间观看直播。
(长按识别二维码前往直播间学习)
本次公开课大纲:
一、App Store 搜索优化
1. 搜索优化原理
在 iTC 后端(即 iTunes Connect,2018 年 6 月更名为 App Store Connect)中,每个 App 可以用 关键词 填充,总共 100 个字符。搜索时的搜索词。一个App只能填100个字符,但是关键词的覆盖率可以达到10000+,这和关键词的搜索原理有关。
尤其是在海外推广的应用,推广渠道比国内更有限,应用商店搜索带来的自然流量非常重要。要想最大程度地优化搜索流量,首先要了解App Store的搜索优化原理。
分词
App Store会将开发者在iTC后台填写的商家名称、副标题和关键词拆分成多个词,然后重新组合以匹配用户的搜索词,不同位置的词可以交叉字符组合. 下面我们以中文单词为例,详细分析搜索优化的原理。
例如,如果我们添加“网易音乐汽车新闻”这8个字符,搜索引擎会根据我们的语言习惯将其组合成“网易”、“音乐”、“汽车”和“新闻”4个词。将这 4 个单词排列组合起来会形成 64 个新的 关键词,也就是上面列表中列出的 关键词。
需要注意的是,一些关键词比如“音乐车”、“新闻车”,这样的词一般不会被用户搜索到,或者搜索量很小,这些词不需要被收录到Apple 词库收录 的。也就是说,我们无法在第三方平台的关键词下找到对应的App。
Q1:我在App中添加了某个关键词,但是我的App并没有出现在这个词的搜索结果中,是什么原因?
A1:关键词的覆盖率有一定的概率,App Store只会显示某一个关键词的前2300条搜索结果。如果你的 App 产品权重比较低,或者被 App Store 处罚,添加某个关键词后,搜索结果很容易出现在 2300 之外。
扩大词
此外,App Store 会根据 App 关键词 字段中的一些词扩展一些相关词汇。这些词只有一部分在我们填写的字符中,另一部分是苹果为我们匹配的。例如,如果关键词中有“网易”,则很有可能匹配到网易音乐、网易新闻、网易购物等关键词。需要注意的是,扩词是有一定概率的,要注意哪些词可以覆盖,哪些不能。
比赛
App Store 还会根据 App 的类别和属性自动为 App 匹配一些词汇。这些词汇不会出现在填写的 100 个字符中,但用户可以通过这些字符搜索我们的 App。但是这些字符的搜索索引和搜索排名都比较低,被苹果处罚后比较容易被删除。
2. 关键词优化
关键词优化有三个基本步骤,分别是选词、排序和去重。
单词选择
首先,根据App的类型,可以为App建立一个关键词词库,把你想要覆盖的词都添加进去,作为优化的替代。选词时要考虑以下几个方面:
1)相关性
相关性是指关键词与应用和目标用户的关联程度。不相关的 关键词 很难产生有效的转化。
2)搜索索引
搜索指数越高,用户的搜索量就越大,给应用带来的曝光率也越高。但这也意味着这些词的搜索排名和竞争也非常激烈。请注意,搜索索引低于 4605 的 关键词 不会被用户搜索。
3)搜索结果数
反映 关键词 竞争的激烈程度。某个关键词下的搜索结果越多,该关键词的竞争就越激烈,你的应用进入搜索结果榜首的难度就越大。
种类
按 关键词 重要性对 关键词 进行排序。关键词字符中的第一个位置保留给最重要的关键词。因为位置越高,位置权重越高,可以加强关键词的覆盖。
重复数据删除
App Store会将关键词拆分组合成一个新的关键词,所以名称、副标题、关键词字符中的每个单词只需要出现一次。删除一些不相关的,搜索4605以下的索引,重复关键词,避免占用关键词个字符。
Q2:如果 100 个 关键词 字符不够怎么办?
A2:这个问题可以通过多区域关键词覆盖来解决,即关键词定位。例如,除了简体中文,在中国生效的语言还包括English Australia、English UK和English US。这样,关键词 字符可以扩展为 200 甚至 300 个字符。
二、Apple 搜索广告优化 ASM
在做 Apple Search Ads 优化之前,我们有必要先了解一下 Apple Search Ads 归因。
1. Apple Search Ads 归因介绍
App Store 搜索广告归因原理是当用户点击苹果搜索广告后,用户在接下来的 30 天内通过任何方式下载了该应用,将归因于苹果搜索广告。
Q3:通过归因 API 统计的获取量与 Apple Search Ads 报告中统计的数据之间存在差异的原因是什么?
A3:第一个原因是用户可能开启了广告追踪限制功能。在这种情况下,attribution API 的返回值为 'error',但 Apple Search Ads Report 可以统计这部分数据。因此,Attribution API 统计的数据往往低于 Report 中的数据。第二个原因是统计方法的不同。只要用户下载,报告就会被算作一次获取,而API要求用户下载并打开APP才会被算作一次获取。第三个原因是数据延迟。用户下载后,需要一段时间进行打开等操作。这个时候API还没有处理完点击,所以延迟请求几秒,数据会更准确。
2. Apple 搜索广告优化和 ASO 补充
苹果搜索广告于2016年9月上线,面向欧美部分国家开放,而国内iOS优化主要基于ASO。那么在苹果搜索广告这个开放的市场,有必要做ASO吗?答案是肯定的。就像 SEO 和 SEM 一样,Apple Search Ads 和 ASO 相辅相成。
在苹果的搜索广告帮助中也明确指出,App 的文字信息对 App 与关键词 的相关性也有影响。与 ASO 不同的是,除了 App 的名称、字幕、关键词、类别和应用内购买项目名称之外,App 描述的优化还可以提高 App 与 关键词 之间的相关性。
Apple Search Ads 的展示形式是基于 App 的源数据,所以不能单独为广告上传素材,也不能指定一定的展示形式,所以最终广告是否可以被用户点击下载用户,转化率很重要。而ASO的一个非常重要的部分就是转化率优化。因此,ASO有利于提高下载转化率,降低广告成本。反之,苹果搜索广告带来的一些用户行为也会影响应用在商店中的表现,主要影响列表和搜索结果排名。
苹果搜索广告带来的下载量对应用的排名有显着影响。以我在美国推出的一款天气应用为例。投放搜索广告后,该应用在类别列表中从 1330 位上升至 40 位左右,停止运行后的第 4 天,其排名仍保持在 400 位左右。
<p>苹果搜索广告对搜索结果的影响主要体现在搜索结果的排名和关键词的数量上。它给app带来的获取量来自于用户搜索某个关键词,这和搜索结果的排名原理是一样的——即利用搜索下载量来提升app在某个 查看全部
通过关键词采集文章采集api(优化(ASO)实战辅导书《冲榜》)
白鲸公开课08《你的APP出海必须掌握哪些ASO策略?》,我们邀请了优化(ASO)实用教程书《冲榜》的作者之一霍晓亮老师来分享。
小亮先生是高级ASOer。现任某知名互联网公司ASO产品经理。擅长App Store算法分析和大数据挖掘。他对iOS推广有深入的研究。小亮先生与资深互联网营销顾问李景航先生合着《粉碎榜单》,全面介绍了App Store优化的“正确打开方式”,帮助移动营销人员有效提升投放产出比。在平台上出售。
小编简单总结了本次公开课的精髓,分享给大家。详情及部分课堂问答,可扫描下方二维码前往直播间观看直播。
(长按识别二维码前往直播间学习)
本次公开课大纲:
一、App Store 搜索优化
1. 搜索优化原理
在 iTC 后端(即 iTunes Connect,2018 年 6 月更名为 App Store Connect)中,每个 App 可以用 关键词 填充,总共 100 个字符。搜索时的搜索词。一个App只能填100个字符,但是关键词的覆盖率可以达到10000+,这和关键词的搜索原理有关。
尤其是在海外推广的应用,推广渠道比国内更有限,应用商店搜索带来的自然流量非常重要。要想最大程度地优化搜索流量,首先要了解App Store的搜索优化原理。
分词
App Store会将开发者在iTC后台填写的商家名称、副标题和关键词拆分成多个词,然后重新组合以匹配用户的搜索词,不同位置的词可以交叉字符组合. 下面我们以中文单词为例,详细分析搜索优化的原理。
例如,如果我们添加“网易音乐汽车新闻”这8个字符,搜索引擎会根据我们的语言习惯将其组合成“网易”、“音乐”、“汽车”和“新闻”4个词。将这 4 个单词排列组合起来会形成 64 个新的 关键词,也就是上面列表中列出的 关键词。
需要注意的是,一些关键词比如“音乐车”、“新闻车”,这样的词一般不会被用户搜索到,或者搜索量很小,这些词不需要被收录到Apple 词库收录 的。也就是说,我们无法在第三方平台的关键词下找到对应的App。
Q1:我在App中添加了某个关键词,但是我的App并没有出现在这个词的搜索结果中,是什么原因?
A1:关键词的覆盖率有一定的概率,App Store只会显示某一个关键词的前2300条搜索结果。如果你的 App 产品权重比较低,或者被 App Store 处罚,添加某个关键词后,搜索结果很容易出现在 2300 之外。
扩大词
此外,App Store 会根据 App 关键词 字段中的一些词扩展一些相关词汇。这些词只有一部分在我们填写的字符中,另一部分是苹果为我们匹配的。例如,如果关键词中有“网易”,则很有可能匹配到网易音乐、网易新闻、网易购物等关键词。需要注意的是,扩词是有一定概率的,要注意哪些词可以覆盖,哪些不能。
比赛
App Store 还会根据 App 的类别和属性自动为 App 匹配一些词汇。这些词汇不会出现在填写的 100 个字符中,但用户可以通过这些字符搜索我们的 App。但是这些字符的搜索索引和搜索排名都比较低,被苹果处罚后比较容易被删除。
2. 关键词优化
关键词优化有三个基本步骤,分别是选词、排序和去重。
单词选择
首先,根据App的类型,可以为App建立一个关键词词库,把你想要覆盖的词都添加进去,作为优化的替代。选词时要考虑以下几个方面:
1)相关性
相关性是指关键词与应用和目标用户的关联程度。不相关的 关键词 很难产生有效的转化。
2)搜索索引
搜索指数越高,用户的搜索量就越大,给应用带来的曝光率也越高。但这也意味着这些词的搜索排名和竞争也非常激烈。请注意,搜索索引低于 4605 的 关键词 不会被用户搜索。
3)搜索结果数
反映 关键词 竞争的激烈程度。某个关键词下的搜索结果越多,该关键词的竞争就越激烈,你的应用进入搜索结果榜首的难度就越大。
种类
按 关键词 重要性对 关键词 进行排序。关键词字符中的第一个位置保留给最重要的关键词。因为位置越高,位置权重越高,可以加强关键词的覆盖。
重复数据删除
App Store会将关键词拆分组合成一个新的关键词,所以名称、副标题、关键词字符中的每个单词只需要出现一次。删除一些不相关的,搜索4605以下的索引,重复关键词,避免占用关键词个字符。
Q2:如果 100 个 关键词 字符不够怎么办?
A2:这个问题可以通过多区域关键词覆盖来解决,即关键词定位。例如,除了简体中文,在中国生效的语言还包括English Australia、English UK和English US。这样,关键词 字符可以扩展为 200 甚至 300 个字符。
二、Apple 搜索广告优化 ASM
在做 Apple Search Ads 优化之前,我们有必要先了解一下 Apple Search Ads 归因。
1. Apple Search Ads 归因介绍
App Store 搜索广告归因原理是当用户点击苹果搜索广告后,用户在接下来的 30 天内通过任何方式下载了该应用,将归因于苹果搜索广告。
Q3:通过归因 API 统计的获取量与 Apple Search Ads 报告中统计的数据之间存在差异的原因是什么?
A3:第一个原因是用户可能开启了广告追踪限制功能。在这种情况下,attribution API 的返回值为 'error',但 Apple Search Ads Report 可以统计这部分数据。因此,Attribution API 统计的数据往往低于 Report 中的数据。第二个原因是统计方法的不同。只要用户下载,报告就会被算作一次获取,而API要求用户下载并打开APP才会被算作一次获取。第三个原因是数据延迟。用户下载后,需要一段时间进行打开等操作。这个时候API还没有处理完点击,所以延迟请求几秒,数据会更准确。
2. Apple 搜索广告优化和 ASO 补充
苹果搜索广告于2016年9月上线,面向欧美部分国家开放,而国内iOS优化主要基于ASO。那么在苹果搜索广告这个开放的市场,有必要做ASO吗?答案是肯定的。就像 SEO 和 SEM 一样,Apple Search Ads 和 ASO 相辅相成。
在苹果的搜索广告帮助中也明确指出,App 的文字信息对 App 与关键词 的相关性也有影响。与 ASO 不同的是,除了 App 的名称、字幕、关键词、类别和应用内购买项目名称之外,App 描述的优化还可以提高 App 与 关键词 之间的相关性。
Apple Search Ads 的展示形式是基于 App 的源数据,所以不能单独为广告上传素材,也不能指定一定的展示形式,所以最终广告是否可以被用户点击下载用户,转化率很重要。而ASO的一个非常重要的部分就是转化率优化。因此,ASO有利于提高下载转化率,降低广告成本。反之,苹果搜索广告带来的一些用户行为也会影响应用在商店中的表现,主要影响列表和搜索结果排名。
苹果搜索广告带来的下载量对应用的排名有显着影响。以我在美国推出的一款天气应用为例。投放搜索广告后,该应用在类别列表中从 1330 位上升至 40 位左右,停止运行后的第 4 天,其排名仍保持在 400 位左右。
<p>苹果搜索广告对搜索结果的影响主要体现在搜索结果的排名和关键词的数量上。它给app带来的获取量来自于用户搜索某个关键词,这和搜索结果的排名原理是一样的——即利用搜索下载量来提升app在某个
通过关键词采集文章采集api( requests模块和Ajax分析法采集微博关键词的方法分析及效果展示 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-24 00:06
requests模块和Ajax分析法采集微博关键词的方法分析及效果展示
)
基于Requests和Ajax分析方法的新浪微博关键词采集
1 项目介绍
本项目介绍requests模块的使用方法和ajax解析方法采集微博关键词.
本项目仅使用“杨幂”、“郑爽”、“赵丽颖”三个关键词挖掘实例。如果有需要在微博上挖其他关键词,可以替换关键词继续采集。
目标:
-搜索关键词,如#赵丽英#,微博下采集
- 采集微博用户的性别、位置、机构、标签、行业、公司、简介等
-采集关键词搜索结果的微博内容(以电影为例),可以分析电影的舆论评价,拍影迷画像等。
2技术点3实施步骤3.1搜索微博内容爬取
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
3.2 数据清洗
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
3.3 持久保存数据
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
3.4 词云展示分析
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='snow', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
4 完整代码及效果展示
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='black', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
if __name__ == '__main__':
kw = '程序员'
filename = './data/%s.txt' % (kw)
page = 100
# persistent_data(filename=filename, page=page)
wordcloud_analyze(filename) 查看全部
通过关键词采集文章采集api(
requests模块和Ajax分析法采集微博关键词的方法分析及效果展示
)
基于Requests和Ajax分析方法的新浪微博关键词采集
1 项目介绍
本项目介绍requests模块的使用方法和ajax解析方法采集微博关键词.
本项目仅使用“杨幂”、“郑爽”、“赵丽颖”三个关键词挖掘实例。如果有需要在微博上挖其他关键词,可以替换关键词继续采集。
目标:
-搜索关键词,如#赵丽英#,微博下采集
- 采集微博用户的性别、位置、机构、标签、行业、公司、简介等
-采集关键词搜索结果的微博内容(以电影为例),可以分析电影的舆论评价,拍影迷画像等。
2技术点3实施步骤3.1搜索微博内容爬取
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
3.2 数据清洗
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
3.3 持久保存数据
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
3.4 词云展示分析
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='snow', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
4 完整代码及效果展示
import requests
def get_hot_info(kw, page):
"""
获取热搜文章信息
:param kw: 搜索关键字
:return: 搜索的文章
"""
# 使用在线URL解码器进行解码, 如下:
# https://m.weibo.cn/api/contain ... chall
# 微博的url基本地址
url = "https://m.weibo.cn/api/container/getIndex"
# url访问需要添加的参数
params = {
'containerid': '100103type=1&q=%s' % (kw),
'page': page
}
# 获取页面内容,并通过ijson解析返回一个字典;
hot_infos = requests.get(url, params).json()
# 提取需要的微博热搜正文内容
hot_cards = hot_infos['data']['cards']
infos = []
for card in hot_cards:
for text in card['card_group']:
if text.get('mblog'):
infos.append(text['mblog']['text'])
return infos
def persistent_data(kw='996', filename='./data/996.txt', page=5):
"""
持久化保存爬取数据到文件中, 便于数据清洗于数据分析;
:param kw: 搜索的关键字
:param filename: 存储的文件位置
:param page: 爬取关键字微博信息的个数
:return:
"""
f = open(filename, 'w')
for page in range(page):
print(str(page).center(50, '*'))
print("正在爬取第%d页" % (page + 1))
infos = get_hot_info(kw, page + 1)
for info in infos:
info = data_cleaning(info)
f.write(info + '\n')
def data_cleaning(text):
"""
微博数据的清洗
:param text: 需要清洗的内容, 提取需要的中文
:return:
"""
import re
pattern = '([\u4e00-\u9fa5])'
cleanData = "".join(re.findall(pattern, text))
return cleanData
def wordcloud_analyze(filename, pngFile='./data/mao.jpg', savePngFile='./data/程序员.png'):
"""
词云分析
:param filename:
:return:
"""
import jieba
import wordcloud
import numpy as np
from PIL import Image
# 打开图片
imageObj = Image.open( pngFile)
cloud_mask = np.array(imageObj)
wc = wordcloud.WordCloud(
background_color='black', # 背景颜色
font_path='/usr/share/fonts/wqy-microhei/wqy-microhei.ttc', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=100, # 图片中最大字体大小;
margin=2,
mask=cloud_mask,
)
f = open(filename)
results = ''
for line in f:
line = line.strip()
result = jieba.lcut(line)
results += (",".join(result))
# print(results)
wc.generate(results)
wc.to_file( savePngFile)
if __name__ == '__main__':
kw = '程序员'
filename = './data/%s.txt' % (kw)
page = 100
# persistent_data(filename=filename, page=page)
wordcloud_analyze(filename)
通过关键词采集文章采集api(如何将Mall平台运行SpringBoot应用部署到函数计算平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-01-22 13:10
简介:Spring Boot 是一个基于 Java Spring 框架的套件。它预装了一系列 Spring 组件,允许开发人员以最少的配置创建独立的应用程序。在云原生环境中,有大量的平台可以运行 Spring Boot 应用程序,例如虚拟机、容器等,但其中最吸引人的还是以 Serverless 的方式运行 Spring Boot 应用程序。
通过一系列文章,我将从架构、部署、监控、性能、安全五个方面分析在Serverless平台上运行Spring Boot应用的优缺点。在之前的文章《Spring Boot 上 FC 架构》中,我们对 Mall 应用架构和 Serverless 平台进行了基本的介绍。在本文中,我将告诉您如何将商城应用部署到函数计算平台。为了让分析更具代表性,我选择了 Github 上 Star 超过 50k 的电商应用商城作为例子。
前提
准备阶段:
注意,如果您使用云主机,请先检查主机对应的安全组配置是否允许入站网络请求。通用主机创建后,入方向的网口访问受到严格限制。我们需要手动允许访问 MySQL 的 3306 端口,Redis 的 6379 端口等。如下图所示,我手动设置了安全组以允许所有传入的网络请求。
部署依赖软件
Mall应用依赖于MySQL、Redis、MongoDB、ElasticSearch、RabbitMQ等软件。这些软件在云端都有相应的云产品。在生产环境中,建议使用云产品以获得更好的性能和可用性。在个人开发或者POC原型演示场景中,我们选择一个VM来容器化和部署所有依赖的软件。
1.1 克隆代码仓库
git clone https://github.com/hryang/mall
在中国访问Github网络不是很好。如果克隆太慢,可以使用 Gitee 地址。
git clone https://gitee.com/aliyunfc/mall.git
1.2 构建并运行 Docker 镜像
在代码根目录的docker文件夹中,有每个依赖软件对应的Dockerfile。运行代码根目录下的run.sh脚本,会自动构建所有依赖软件的Docker镜像并在本地运行。
sudo bash docker.sh
1.3 验证依赖软件的运行状态
运行 Docker ps 命令检查依赖软件是否正常运行。
sudo docker ps
部署商城应用
2.1 修改商城应用配置
修改以下三个yaml文件,将host字段修改为步骤1中安装MySQL等软件的节点的公网ip,如图:
mall-admin/src/main/resources/application-prod.yml
商城门户/src/main/resources/application-prod.yml
商场搜索/src/main/resources/application-prod.yml
2.2 生成商城应用容器镜像
执行maven package命令生成Docker镜像,本地Java8或Java11环境均可。
sudo -E mvn package
成功后会显示如下成功信息。
执行 sudo docker images,应该可以看到 1.0-SNAPSHOT 版本的 mall/mall-admin、 mall/mall-portal 和 mall/mall-search 的镜像。
2.3 将镜像推送到阿里云镜像仓库
首先登录阿里云镜像仓库控制台,选择个人版实例,按照提示让docker登录阿里云镜像仓库。
然后创建命名空间。如下图所示,我们创建了一个名为 quanxi-hryang 的命名空间。
按照前面的步骤,我们已经在本地生成了 mall/mall-admin、 mall/mall-portal、 mall/mall-search 的图片。
执行以下命令,将 mall-admin 镜像推送到杭州地区 quanxi-hryang 命名空间下的镜像仓库。
请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。商城/商城门户、商城/商城搜索等。
sudo docker tag mall/mall-admin:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
2.4 修改Serverless Devs工具的应用定义
我们使用无服务器开发工具来定义和部署应用程序。项目根目录下有s.yaml文件,是Serverless Devs工具的项目定义文件。这定义了函数计算的资源。
如下图所示,我们在函数计算上定义了一个名为 mall-admin 的服务及其下的 mall-admin 函数。该函数定义了端口、内存大小、超时和运行时间等属性。红框内的内容是需要根据自己的配置进行修改的。
(建议:以上镜像地址最好使用/fc-demo/mall-admin:1.0-SNAPSHOT形式)
2.5 将商城应用部署到函数计算平台
执行 s 部署命令。部署成功后,会看到对应的访问URL。
在浏览器中输入生成的 URL。如果显示“尚未登录或token已过期”,则服务部署成功。
(注:Serverless的特点是系统默认会在请求到达后创建实例,所以第一次启动时间比较长,称为冷启动。一般需要30s左右才能启动Mall应用。稍后,我们将重点关注性能调优文章回来复习这个问题,用一系列手段进行优化。)
访问对应的swagger api调试页面host/swagger-ui.html,调试相关的后端API。
2.6 查看应用程序日志
我们在 s.yaml 中为每个服务设置了 logConfig:auto,也就是说 serverless-devs 工具会自动为服务创建一个日志存储(LogStore),所有服务共享一个日志存储。应用程序的所有日志都输出到 .
s 日志有助于您了解服务的运行情况和诊断问题。比如我们执行s mall-admin logs -t 进入follow模式,然后在浏览器中访问 mall-admin 服务的端点,就可以看到整个应用的启动和请求处理日志。
2.7 部署商城前端项目
Mall 还提供了基于 Vue+Element 实现的前端接口。主要包括商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等功能。该项目还可以在函数计算上无缝运行。
首先在你的机器上安装nodejs12和npm,并下载项目源代码。
git clone https://github.com/hryang/mall-admin-web
国内访问github网络不太好。如果克隆太慢,可以使用下面的代理地址。
git clone https://gitee.com/aliyunfc/mall-admin-web.git
(注意:必须是nodejs 12或者14,太新的node版本会编译失败)
修改 config/prod.env.js 并将 BASE_API 更改为在函数计算上成功部署的 mall-admin 端点。
在项目根目录下执行如下命令构建前端项目。
npm install
npm run build
运行成功后会生成dist目录。运行项目根目录下的docker.sh脚本生成镜像。
sudo bash docker.sh
运行 docker images 命令,可以看到 mall/mall-admin-web 镜像已经成功生成。将镜像推送到阿里云镜像仓库。
同理,请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。
sudo docker tag mall/mall-admin-web:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
修改项目根目录下的s.yaml,和部署mal-admin类似,根据自己的配置调整访问权限和区域,将镜像改成上一步推送成功的镜像地址。
执行s deploy,部署成功后可以看到 mall-admin-web 服务的URL。通过浏览器访问,您将看到登录页面。填写密码macro123查看完整效果。
(注意:登录页面可能会因为第一次冷启动而报超时错误,刷新页面即可,我们稍后会在性能调优文章中优化冷启动性能。)
总结
由于 serverless 平台内置网关,负责路由、实例拉取/运行/容错/自动伸缩等功能,开发者上传应用代码包或镜像后,就已经有了一个弹性高可用的服务。释放。综上所述,只要完成以下5个步骤,Mall应用就完全部署在了功能计算平台上。后续对应用的更新只需要重复第4步和第5步即可。可见Serverless省去了环境配置和运维等重复性工作,大大提高了开发和运维的效率。
Clone项目代码找到VM,运行脚本一键安装MySQL、Redis等依赖软件。修改应用配置中的host项,将值填入步骤2中的VM公网ip,生成应用镜像并推送到阿里云镜像仓库部署和应用到功能计算平台URL汇总
1)春季启动:
2)商城:
3)Serverless Devs 安装文档:
原文链接: 查看全部
通过关键词采集文章采集api(如何将Mall平台运行SpringBoot应用部署到函数计算平台)
简介:Spring Boot 是一个基于 Java Spring 框架的套件。它预装了一系列 Spring 组件,允许开发人员以最少的配置创建独立的应用程序。在云原生环境中,有大量的平台可以运行 Spring Boot 应用程序,例如虚拟机、容器等,但其中最吸引人的还是以 Serverless 的方式运行 Spring Boot 应用程序。
通过一系列文章,我将从架构、部署、监控、性能、安全五个方面分析在Serverless平台上运行Spring Boot应用的优缺点。在之前的文章《Spring Boot 上 FC 架构》中,我们对 Mall 应用架构和 Serverless 平台进行了基本的介绍。在本文中,我将告诉您如何将商城应用部署到函数计算平台。为了让分析更具代表性,我选择了 Github 上 Star 超过 50k 的电商应用商城作为例子。
前提
准备阶段:
注意,如果您使用云主机,请先检查主机对应的安全组配置是否允许入站网络请求。通用主机创建后,入方向的网口访问受到严格限制。我们需要手动允许访问 MySQL 的 3306 端口,Redis 的 6379 端口等。如下图所示,我手动设置了安全组以允许所有传入的网络请求。
部署依赖软件
Mall应用依赖于MySQL、Redis、MongoDB、ElasticSearch、RabbitMQ等软件。这些软件在云端都有相应的云产品。在生产环境中,建议使用云产品以获得更好的性能和可用性。在个人开发或者POC原型演示场景中,我们选择一个VM来容器化和部署所有依赖的软件。
1.1 克隆代码仓库
git clone https://github.com/hryang/mall
在中国访问Github网络不是很好。如果克隆太慢,可以使用 Gitee 地址。
git clone https://gitee.com/aliyunfc/mall.git
1.2 构建并运行 Docker 镜像
在代码根目录的docker文件夹中,有每个依赖软件对应的Dockerfile。运行代码根目录下的run.sh脚本,会自动构建所有依赖软件的Docker镜像并在本地运行。
sudo bash docker.sh
1.3 验证依赖软件的运行状态
运行 Docker ps 命令检查依赖软件是否正常运行。
sudo docker ps
部署商城应用
2.1 修改商城应用配置
修改以下三个yaml文件,将host字段修改为步骤1中安装MySQL等软件的节点的公网ip,如图:
mall-admin/src/main/resources/application-prod.yml
商城门户/src/main/resources/application-prod.yml
商场搜索/src/main/resources/application-prod.yml
2.2 生成商城应用容器镜像
执行maven package命令生成Docker镜像,本地Java8或Java11环境均可。
sudo -E mvn package
成功后会显示如下成功信息。
执行 sudo docker images,应该可以看到 1.0-SNAPSHOT 版本的 mall/mall-admin、 mall/mall-portal 和 mall/mall-search 的镜像。
2.3 将镜像推送到阿里云镜像仓库
首先登录阿里云镜像仓库控制台,选择个人版实例,按照提示让docker登录阿里云镜像仓库。
然后创建命名空间。如下图所示,我们创建了一个名为 quanxi-hryang 的命名空间。
按照前面的步骤,我们已经在本地生成了 mall/mall-admin、 mall/mall-portal、 mall/mall-search 的图片。
执行以下命令,将 mall-admin 镜像推送到杭州地区 quanxi-hryang 命名空间下的镜像仓库。
请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。商城/商城门户、商城/商城搜索等。
sudo docker tag mall/mall-admin:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin:1.0-SNAPSHOT
2.4 修改Serverless Devs工具的应用定义
我们使用无服务器开发工具来定义和部署应用程序。项目根目录下有s.yaml文件,是Serverless Devs工具的项目定义文件。这定义了函数计算的资源。
如下图所示,我们在函数计算上定义了一个名为 mall-admin 的服务及其下的 mall-admin 函数。该函数定义了端口、内存大小、超时和运行时间等属性。红框内的内容是需要根据自己的配置进行修改的。
(建议:以上镜像地址最好使用/fc-demo/mall-admin:1.0-SNAPSHOT形式)
2.5 将商城应用部署到函数计算平台
执行 s 部署命令。部署成功后,会看到对应的访问URL。
在浏览器中输入生成的 URL。如果显示“尚未登录或token已过期”,则服务部署成功。
(注:Serverless的特点是系统默认会在请求到达后创建实例,所以第一次启动时间比较长,称为冷启动。一般需要30s左右才能启动Mall应用。稍后,我们将重点关注性能调优文章回来复习这个问题,用一系列手段进行优化。)
访问对应的swagger api调试页面host/swagger-ui.html,调试相关的后端API。
2.6 查看应用程序日志
我们在 s.yaml 中为每个服务设置了 logConfig:auto,也就是说 serverless-devs 工具会自动为服务创建一个日志存储(LogStore),所有服务共享一个日志存储。应用程序的所有日志都输出到 .
s 日志有助于您了解服务的运行情况和诊断问题。比如我们执行s mall-admin logs -t 进入follow模式,然后在浏览器中访问 mall-admin 服务的端点,就可以看到整个应用的启动和请求处理日志。
2.7 部署商城前端项目
Mall 还提供了基于 Vue+Element 实现的前端接口。主要包括商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等功能。该项目还可以在函数计算上无缝运行。
首先在你的机器上安装nodejs12和npm,并下载项目源代码。
git clone https://github.com/hryang/mall-admin-web
国内访问github网络不太好。如果克隆太慢,可以使用下面的代理地址。
git clone https://gitee.com/aliyunfc/mall-admin-web.git
(注意:必须是nodejs 12或者14,太新的node版本会编译失败)
修改 config/prod.env.js 并将 BASE_API 更改为在函数计算上成功部署的 mall-admin 端点。
在项目根目录下执行如下命令构建前端项目。
npm install
npm run build
运行成功后会生成dist目录。运行项目根目录下的docker.sh脚本生成镜像。
sudo bash docker.sh
运行 docker images 命令,可以看到 mall/mall-admin-web 镜像已经成功生成。将镜像推送到阿里云镜像仓库。
同理,请将以下命令中的 cn-hangzhou 和 quanxi-hryang 修改为自己的镜像仓库区域和命名空间。
sudo docker tag mall/mall-admin-web:1.0-SNAPSHOT registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
sudo docker push registry.cn-hangzhou.aliyuncs.com/quanxi-hryang/mall-admin-web:1.0-SNAPSHOT
修改项目根目录下的s.yaml,和部署mal-admin类似,根据自己的配置调整访问权限和区域,将镜像改成上一步推送成功的镜像地址。
执行s deploy,部署成功后可以看到 mall-admin-web 服务的URL。通过浏览器访问,您将看到登录页面。填写密码macro123查看完整效果。
(注意:登录页面可能会因为第一次冷启动而报超时错误,刷新页面即可,我们稍后会在性能调优文章中优化冷启动性能。)
总结
由于 serverless 平台内置网关,负责路由、实例拉取/运行/容错/自动伸缩等功能,开发者上传应用代码包或镜像后,就已经有了一个弹性高可用的服务。释放。综上所述,只要完成以下5个步骤,Mall应用就完全部署在了功能计算平台上。后续对应用的更新只需要重复第4步和第5步即可。可见Serverless省去了环境配置和运维等重复性工作,大大提高了开发和运维的效率。
Clone项目代码找到VM,运行脚本一键安装MySQL、Redis等依赖软件。修改应用配置中的host项,将值填入步骤2中的VM公网ip,生成应用镜像并推送到阿里云镜像仓库部署和应用到功能计算平台URL汇总
1)春季启动:
2)商城:
3)Serverless Devs 安装文档:
原文链接:
通过关键词采集文章采集api(苹果采集插件接口资源库的方法及解决教程(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-21 13:02
近年来,随着互联网时代的发展,做电影的站长越来越多网站,加入这个行列的人数也在与日俱增!但是很多站长都跟风办电影站,不知道怎么办。不知道哪里来的电影资源。今天教大家如何制作电影台。文章有点长,请耐心观看,快解决电影台遇到的所有问题!
一、苹果采集插件接口配置
1、今天教大家如何添加一个采集自定义资源库;我们以资源站为例,进入后台时,可以从你想要的网站获取界面采集好的,一般在网站的帮助中心:添加方法如下图(如果添加后测试不成功,需要填写附加参数 &ct=1)
2、这里我没填,只要测试界面成功,直接保存即可。如果测试失败,补上附加参数&ct=1)如果还是不行,检查采集接口是否填写错误
3、添加资源接口成功后,需要对资源进行分类绑定:点击高清资源链接进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个类似的分类或者添加自定义分类
5、绑定后,剩下的就是采集了。拉到页面底部有一个采集按钮可以选择当天采集的采集(需要采集的时候视频)和采集所有三个选项
6、选择后进入自动采集页面。如果绑定采集成功并且显示绿色和红色,说明绑定不成功,跳过采集,所以绑定的时候要小心绑定。
结束语:采集finished网站的最后应该有视频数据,这也是很多人困惑的地方采集finished,不能播放!为什么是这样?因为你没有添加播放器。
二、苹果采集插件后无法播放问题及解决教程
苹果采集插件故障排除后无法播放黑屏,先判断是否导入播放器,采集如果资源后没有添加对应的播放器,则无法解析正常播放,正确的采集流程是先添加一个播放器再执行采集,这样每个资源都能识别对应的播放器正常播放,每个资源站都有自己独立的播放器
第一步是查看视频数据,看看使用哪些播放器播放资源数据。如果您看到下图中的播放器列,则可以确定该资源使用的是 wlm3u8 编码的播放器。
第二步检查是否有导入的播放器,可以通过查看视频详情来判断。
没有默认播放器没有视频数据丢失播放器
第三步,确保没有玩家添加对应的玩家。这是资源站给出的玩家添加步骤。同时,蓝色字体为资源站提供的播放器文件,需要下载导入。
第四步,(视频>>播放器)查看我们是否成功添加了wlm3u8编码的播放器。如果我们添加了播放器还是不能播放,先清除缓存,最好换个浏览器再测试一下。
2.首先看你的采集是什么类型的播放地址;如果是腾讯、优酷、爱奇艺等,需要通过解析接口解析地址才能播放。
如果不能播放,说明解析接口不支持解析;如果你还有其他可以解析播放的接口,换成可以播放的解析接口即可。
然后查看采集数据的播放地址。如果是完整的http地址,需要打开播放器的解析状态,使用解析来播放;如果采集的数据ID可以直接用本地播放器播放。最后,删除系统默认自带的解析接口。默认解析接口已失效。删除步骤如下
刚开始分析苹果的cms电影网站,网上像我这样的电影网站数不胜数,内容一模一样,模板一样,采集为什么是我的收录 什么?当然,我马上意识到采集每天更新内容只会浪费域名和服务器资源。万一出事了,你会不甘心的!于是我开始分析原创要改进哪些角度来制作我的电影网站收录。终于把我的苹果cms电影架收录弄好了。
三、苹果cms网站怎么样?一个电影站如何快速收录关键词排名和消耗流量
1:如果把苹果cms网站当作采集站,是采集的其他电影站更新的好页面,影片排名也不错,我'现在就添加它采集,你能收录吗?能带来流量吗?所以我决定走一条不同的、差异化的路线。
A. 电影片名加品牌词
B.剧情介绍加网站欢迎词
C.演员名字加上喜欢的、亲爱的等随机插入的词
D.图集修改MD5并添加水印
E. 新增热门评论功能,全靠采集影视评论
F.修改底部文件,添加其他电影站没有的信息 查看全部
通过关键词采集文章采集api(苹果采集插件接口资源库的方法及解决教程(组图))
近年来,随着互联网时代的发展,做电影的站长越来越多网站,加入这个行列的人数也在与日俱增!但是很多站长都跟风办电影站,不知道怎么办。不知道哪里来的电影资源。今天教大家如何制作电影台。文章有点长,请耐心观看,快解决电影台遇到的所有问题!
一、苹果采集插件接口配置
1、今天教大家如何添加一个采集自定义资源库;我们以资源站为例,进入后台时,可以从你想要的网站获取界面采集好的,一般在网站的帮助中心:添加方法如下图(如果添加后测试不成功,需要填写附加参数 &ct=1)
2、这里我没填,只要测试界面成功,直接保存即可。如果测试失败,补上附加参数&ct=1)如果还是不行,检查采集接口是否填写错误
3、添加资源接口成功后,需要对资源进行分类绑定:点击高清资源链接进入绑定页面进行分类绑定
4、进入分类绑定页面后,点击未绑定页面,分类绑定会自动弹出。如果找不到对应的,可以先绑定一个类似的分类或者添加自定义分类
5、绑定后,剩下的就是采集了。拉到页面底部有一个采集按钮可以选择当天采集的采集(需要采集的时候视频)和采集所有三个选项
6、选择后进入自动采集页面。如果绑定采集成功并且显示绿色和红色,说明绑定不成功,跳过采集,所以绑定的时候要小心绑定。
结束语:采集finished网站的最后应该有视频数据,这也是很多人困惑的地方采集finished,不能播放!为什么是这样?因为你没有添加播放器。
二、苹果采集插件后无法播放问题及解决教程
苹果采集插件故障排除后无法播放黑屏,先判断是否导入播放器,采集如果资源后没有添加对应的播放器,则无法解析正常播放,正确的采集流程是先添加一个播放器再执行采集,这样每个资源都能识别对应的播放器正常播放,每个资源站都有自己独立的播放器
第一步是查看视频数据,看看使用哪些播放器播放资源数据。如果您看到下图中的播放器列,则可以确定该资源使用的是 wlm3u8 编码的播放器。
第二步检查是否有导入的播放器,可以通过查看视频详情来判断。
没有默认播放器没有视频数据丢失播放器
第三步,确保没有玩家添加对应的玩家。这是资源站给出的玩家添加步骤。同时,蓝色字体为资源站提供的播放器文件,需要下载导入。
第四步,(视频>>播放器)查看我们是否成功添加了wlm3u8编码的播放器。如果我们添加了播放器还是不能播放,先清除缓存,最好换个浏览器再测试一下。
2.首先看你的采集是什么类型的播放地址;如果是腾讯、优酷、爱奇艺等,需要通过解析接口解析地址才能播放。
如果不能播放,说明解析接口不支持解析;如果你还有其他可以解析播放的接口,换成可以播放的解析接口即可。
然后查看采集数据的播放地址。如果是完整的http地址,需要打开播放器的解析状态,使用解析来播放;如果采集的数据ID可以直接用本地播放器播放。最后,删除系统默认自带的解析接口。默认解析接口已失效。删除步骤如下
刚开始分析苹果的cms电影网站,网上像我这样的电影网站数不胜数,内容一模一样,模板一样,采集为什么是我的收录 什么?当然,我马上意识到采集每天更新内容只会浪费域名和服务器资源。万一出事了,你会不甘心的!于是我开始分析原创要改进哪些角度来制作我的电影网站收录。终于把我的苹果cms电影架收录弄好了。
三、苹果cms网站怎么样?一个电影站如何快速收录关键词排名和消耗流量
1:如果把苹果cms网站当作采集站,是采集的其他电影站更新的好页面,影片排名也不错,我'现在就添加它采集,你能收录吗?能带来流量吗?所以我决定走一条不同的、差异化的路线。
A. 电影片名加品牌词
B.剧情介绍加网站欢迎词
C.演员名字加上喜欢的、亲爱的等随机插入的词
D.图集修改MD5并添加水印
E. 新增热门评论功能,全靠采集影视评论
F.修改底部文件,添加其他电影站没有的信息
通过关键词采集文章采集api( 智能诊断出网站SEO出现的问题,你知道吗? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-20 01:02
智能诊断出网站SEO出现的问题,你知道吗?
)
SEO人员在平时的SEO优化中会使用很多SEO工具,智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局一大批优秀同行,以及优化的方向!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、 通过站点:域名,查询网站有多少个收录,收录有多少个关键词?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
查看全部
通过关键词采集文章采集api(
智能诊断出网站SEO出现的问题,你知道吗?
)
SEO人员在平时的SEO优化中会使用很多SEO工具,智能诊断网站SEO问题。SEO工具主要是为了方便SEOer做采集、发布、收录查询、主动推送、SEO诊断等日常工作。提高效率,简化操作,解放双手,查询一些网站问题,监控关键词排名收录等。
一、免费采集
免费采集特点:
1、只需将关键词导入到采集相关的关键词文章,同时创建几十或几百个采集任务(一个任务可以be 支持上传1000个关键词),支持过滤关键词
2、支持多种新闻来源:各平台资讯、知悉经验、重大新闻等(可同时设置多个采集来源采集)
3、可设置关键词采集文章条数,软件可直接查看多任务状态采集-支持本地预览-支持采集链接预览
4、自动批量挂机采集,与各大cms发布者无缝对接,采集后自动发布——实现采集发布全自动挂机。
二、全平台发布
全平台cms发布者的特点:
1、cms发布:目前市面上唯一同时支持Empire、易友、ZBLOG、织梦、WP、PB、Apple、搜外等专业cms,可以同时批量管理和发布工具
2、对应栏目:对应的文章可以发布对应栏目
3、定期发布:可控发布间隔/每天发布总数
4、监控数据:直接监控已经发布、待发布的软件,是否是伪原创、发布状态、URL、程序、发布时间等。
三、收录详细数据查询
收录链接查询功能:
1、收录Rank, 收录Title, 收录Link, 收录Time, Real Title, Real Link, Real关键词, 一下子统计
2. 输入关键词或site命令查询优秀同行网页收录的数量和排名。在百度/搜狗/今日头条的收录中可以直观的看到一个网站同行网站的排名,通过关键词布局体验确定自己的网站布局一大批优秀同行,以及优化的方向!您也可以通过关键词查询了解您的网站关键词排名和收录情况!
3.查询工具还可以做什么:防止网站被黑(通过观察收录的情况,检查收录是否有不良信息)-网站修订(工具提取)收录链接向百度资源搜索平台提交新的链接URL路径更改)-关键词排名(通过关键词查看网站的排名,关注 关键词 排名) - 网站 推送(通过查询 收录 链接 - 只推送而不是 收录网站)
4、 通过站点:域名,查询网站有多少个收录,收录有多少个关键词?Excel表格可以直接在软件上导出,做进一步分析,进行整体分析!(SEO站长必须收录链接数据分析工具)
四、全平台推送工具
全平台推送功能:
工具代替手动主动推送,效率提升数倍,收录数倍提升,解放双手!
批量搜狗推送:
1、验证站点提交(官方限制单个站点每天推送200,软件可以突破限制,单个站点每天可以推送几十万)
2、非认证网站提交(软件可以每天一直推送)
批量百度推送:
采用百度最快的API推送方式,一次可大批量推送到百度
批量360推送:
自动批量完成360主动推送软件,每天提交上万个链接
批量神马推送:
使用神马最快的MIP推送方式,一次可以大批量推送到神马
以上功能都集成在一个SEO工具中,SEO工具还配备:批量搜狗快照更新/批量搜狗投诉/批量搜狗绑定站点/链接生成/链接抓取/在线伪原创等功能!SEO工具是SEO人员做网站辅助的必备工具。
通过关键词采集文章采集api(新媒体的迅速崛起让互联网流量竞争越来越激烈,现在我们不但要能找到流量还要能以到流量)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-01-19 11:08
新媒体的迅速崛起,使得互联网流量的竞争越来越激烈。现在我们不仅要能够找到流量,而且要能够以最快的速度猎取流量。此时,手动采集、汇总和组织数据已经不够了。建议每天选择5118大数据采集海量新关键词和大量信息,从中挖掘新词汇。,然后对内容进行处理以获得流量。
1、海量流量数据快速获取
通过每天5118个长尾词挖掘,系统自动抓取每天千万搜索引擎用户查询的关键词和问题,并按照一定的规则过滤出有价值的关键词,然后进行区分哪些是最新的热词,哪些是互联网的新词汇。这些是手动聚合数据无法完成的事情。
越早发现用户感兴趣的流量爆发,越早抓住流量的大方向。通过前期掌握流量情况,我们可以通过制作内容源源不断地将最新的流量带入我们的网站。比同行更早抢占各平台流量数据。
2、深入交通方向
有了上面挖掘的海量关键词,我们需要围绕这个关键词弄清楚用户对什么感兴趣,围绕关键词的各种需求做长尾词匹配。
使用5118关键词挖矿工具获取长尾关键词和核心相关问题关键词,对流量进行排序,然后写原创,<针对不同的问题和长尾词@伪原创文章,满足用户需求。
在掌握了用户需求后,为了进一步详细深入地了解用户需求,使用5118长尾关键词挖掘工具,发现用户如何搜索自己想找的问题,从而带来挖掘相关的长尾问题。
3、标题标题是SEO优化的重点
标题不仅要收录核心词,还要用问题来引导用户的好奇心。标题引起用户共鸣,将大大提高用户的点击率。
通过 5118 浏览器插件获取标题泛点击和全点击搜索结果。
相关内容:5118站长工具箱Chrome浏览器插件安装教程
5118站长工具箱360安全浏览器插件手动安装更新教程
当5118搜索结果显示标题命中时,说明用户搜索的词没有完全收录在标题中,而只是收录分词或部分收录。
只要标题全部命中搜索结果,排名就会很好,由此产生的流量也会很多。
5118双12折扣高达50%的行业词库,为期3年。使用优惠券代码 vpsss123 享受最低折扣。
5118是站长必备的SEO优化工具和新媒体大数据挖掘平台。
更多关于5118的信息,请看5118专题4、高效生产内容
为了获得大量的互联网流量,您的内容必须在大多数 网站 完全命中 关键词 之前产生高质量的内容。那么最好的办法就是学习头条等新媒体内容,知乎,公众号等平台会比网站更新更快。
使用5118媒体文章搜索功能,快速获取相关内容,找到高度满足用户需求的段落,学习理解后再加工。
还可以使用5118智能原创工具进行更深层次的原创工作,5118大数据的支持可以节省大量时间和精力。
5、坚持会带来流量
我们都知道,单纯靠几篇文章的文章根本无法获得大量的流量,还有一个逐渐积累的过程。使用5118大数据工具快速获取和处理流量,使其获取流量的可能性越来越大。 查看全部
通过关键词采集文章采集api(新媒体的迅速崛起让互联网流量竞争越来越激烈,现在我们不但要能找到流量还要能以到流量)
新媒体的迅速崛起,使得互联网流量的竞争越来越激烈。现在我们不仅要能够找到流量,而且要能够以最快的速度猎取流量。此时,手动采集、汇总和组织数据已经不够了。建议每天选择5118大数据采集海量新关键词和大量信息,从中挖掘新词汇。,然后对内容进行处理以获得流量。
1、海量流量数据快速获取
通过每天5118个长尾词挖掘,系统自动抓取每天千万搜索引擎用户查询的关键词和问题,并按照一定的规则过滤出有价值的关键词,然后进行区分哪些是最新的热词,哪些是互联网的新词汇。这些是手动聚合数据无法完成的事情。
越早发现用户感兴趣的流量爆发,越早抓住流量的大方向。通过前期掌握流量情况,我们可以通过制作内容源源不断地将最新的流量带入我们的网站。比同行更早抢占各平台流量数据。
2、深入交通方向
有了上面挖掘的海量关键词,我们需要围绕这个关键词弄清楚用户对什么感兴趣,围绕关键词的各种需求做长尾词匹配。
使用5118关键词挖矿工具获取长尾关键词和核心相关问题关键词,对流量进行排序,然后写原创,<针对不同的问题和长尾词@伪原创文章,满足用户需求。
在掌握了用户需求后,为了进一步详细深入地了解用户需求,使用5118长尾关键词挖掘工具,发现用户如何搜索自己想找的问题,从而带来挖掘相关的长尾问题。
3、标题标题是SEO优化的重点
标题不仅要收录核心词,还要用问题来引导用户的好奇心。标题引起用户共鸣,将大大提高用户的点击率。
通过 5118 浏览器插件获取标题泛点击和全点击搜索结果。
相关内容:5118站长工具箱Chrome浏览器插件安装教程
5118站长工具箱360安全浏览器插件手动安装更新教程
当5118搜索结果显示标题命中时,说明用户搜索的词没有完全收录在标题中,而只是收录分词或部分收录。
只要标题全部命中搜索结果,排名就会很好,由此产生的流量也会很多。
5118双12折扣高达50%的行业词库,为期3年。使用优惠券代码 vpsss123 享受最低折扣。
5118是站长必备的SEO优化工具和新媒体大数据挖掘平台。
更多关于5118的信息,请看5118专题4、高效生产内容
为了获得大量的互联网流量,您的内容必须在大多数 网站 完全命中 关键词 之前产生高质量的内容。那么最好的办法就是学习头条等新媒体内容,知乎,公众号等平台会比网站更新更快。
使用5118媒体文章搜索功能,快速获取相关内容,找到高度满足用户需求的段落,学习理解后再加工。
还可以使用5118智能原创工具进行更深层次的原创工作,5118大数据的支持可以节省大量时间和精力。
5、坚持会带来流量
我们都知道,单纯靠几篇文章的文章根本无法获得大量的流量,还有一个逐渐积累的过程。使用5118大数据工具快速获取和处理流量,使其获取流量的可能性越来越大。
通过关键词采集文章采集api( 做网站seo对于个人来说做一个大站是很难的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-01-16 23:34
做网站seo对于个人来说做一个大站是很难的)
Phpcmsv9采集,它基于 Phpcmsv9 派生的 网站batch采集,可以使用 Phpcmsv9做站长,解决网站内容填充采集的问题。做网站seo对于个人来说很难做一个大网站,有什么难度?也就是内容,一个seo团队一天可以更新几百份。而一个人一天更新几十篇文章,这是无法比拟的。 phpcmsv9采集允许网站保持每天生成一个新的文章,保持不断更新的状态。所以如果你的网站想要一天上万IP,你需要大量的关键词,大量的关键词需要大量的文章内容支持。所以,如果我想快速做一个大站,非常简单实用的就是采集。
Phpcmsv9采集可以制作出色的采集站。如果你想成为一个采集站,那么你需要更高的seo技术和策略。否则,如果你想做一个 采集 站,你要么干脆不 收录,要么降级 K 站。 phpcmsv9采集的实践:
1、展开采集的源,很多时候,采集因为源太单一而死掉了。 采集时,建议记录对方文件的发布时间
2、内容多样性、问答、文章、图片
3、页面多样性,N个单页,N个聚合,N个频道
4、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议使用phpcmsv9采集一次性码(包括营销码,各种标签等,比原来更干净)
5、做好页面内容相关性匹配
6、页面调用一定要丰富,才能达到虚伪的效果
7、如果有能力,可以制作一些结构化的数据进行编辑,达到一定比例的原创度
8、旧域名效果更好
9、发布时,建议在采集源发布时间之前修改你的发布时间,同时也发布一些当天
10、建议发布前先设置好站点,再上线。上线后最好不要在网站没有达到一定程度收录
的情况下改变任何网站结构和链接
11、释放量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更好。
12、基本上坚持1-3个月就会见效。如果条件允许,可以适当配合蜘蛛池和外链运营
13、没有100%完成的网站,建议您可以同时多访问几个,以保证您的准确性
14、模板尽量做成war的模板,原创度数高的模板列尽量多。
phpcmsv9采集文章都是基于长尾关键词采集,也就是说每个文章都有关键词,你可以想象一下,如果有100万个关键词页面,那真是倒霉,网站每天可以有几万个IP。关键是你可以在不被K的情况下合理布局内页。 海量网站内容,做好站点布局,即升级这个网站页面的权限,用当前网站索引的数据,网站的日IP增长了5倍,很简单。 查看全部
通过关键词采集文章采集api(
做网站seo对于个人来说做一个大站是很难的)
Phpcmsv9采集,它基于 Phpcmsv9 派生的 网站batch采集,可以使用 Phpcmsv9做站长,解决网站内容填充采集的问题。做网站seo对于个人来说很难做一个大网站,有什么难度?也就是内容,一个seo团队一天可以更新几百份。而一个人一天更新几十篇文章,这是无法比拟的。 phpcmsv9采集允许网站保持每天生成一个新的文章,保持不断更新的状态。所以如果你的网站想要一天上万IP,你需要大量的关键词,大量的关键词需要大量的文章内容支持。所以,如果我想快速做一个大站,非常简单实用的就是采集。
Phpcmsv9采集可以制作出色的采集站。如果你想成为一个采集站,那么你需要更高的seo技术和策略。否则,如果你想做一个 采集 站,你要么干脆不 收录,要么降级 K 站。 phpcmsv9采集的实践:
1、展开采集的源,很多时候,采集因为源太单一而死掉了。 采集时,建议记录对方文件的发布时间
2、内容多样性、问答、文章、图片
3、页面多样性,N个单页,N个聚合,N个频道
4、内容格式要干净整洁,图片要清晰(建议500-600字配图)。有能力的话,建议使用phpcmsv9采集一次性码(包括营销码,各种标签等,比原来更干净)
5、做好页面内容相关性匹配
6、页面调用一定要丰富,才能达到虚伪的效果
7、如果有能力,可以制作一些结构化的数据进行编辑,达到一定比例的原创度
8、旧域名效果更好
9、发布时,建议在采集源发布时间之前修改你的发布时间,同时也发布一些当天
10、建议发布前先设置好站点,再上线。上线后最好不要在网站没有达到一定程度收录
的情况下改变任何网站结构和链接
11、释放量级,建议每天发送1W+。当然,最好拥有更多并推动它们。建议每天配合几十次手动更新,效果更好。
12、基本上坚持1-3个月就会见效。如果条件允许,可以适当配合蜘蛛池和外链运营
13、没有100%完成的网站,建议您可以同时多访问几个,以保证您的准确性
14、模板尽量做成war的模板,原创度数高的模板列尽量多。
phpcmsv9采集文章都是基于长尾关键词采集,也就是说每个文章都有关键词,你可以想象一下,如果有100万个关键词页面,那真是倒霉,网站每天可以有几万个IP。关键是你可以在不被K的情况下合理布局内页。 海量网站内容,做好站点布局,即升级这个网站页面的权限,用当前网站索引的数据,网站的日IP增长了5倍,很简单。
通过关键词采集文章采集api(说起erperp商品采集功能全面解析电商平台发展)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-01-16 23:30
说起东南亚的跨境电商,相信大家都不陌生。近年来,Shopee和Lazada平台的发展越来越好,不少新手朋友也进入了东南亚市场。除了处理订单、挑选新品,还需要采集产品对店铺进行精细化运营,而采集产品也是业务运营中非常重要的一环,所以这个时候,您将需要使用一些工具来帮助商家。在之前的文章中,简单的提到了店梯erp产品采集的功能,功能全面,可以帮助商家做好产品采集,下面就详细聊聊关于它的这个功能模块是如何运作的。
首先店铺天梯erp的产品采集模块是从各大电商平台获取产品相关信息数据,包括产品标题、产品描述、产品主图及详细图、价格、规格信息、销量、评论数等相关信息;通过三种方式对产品进行采集:单品采集、关键字采集和插件采集;
单品采集
这是产品 采集 的链接;打开电商网站,找到你想要的产品采集,复制产品链接;然后打开店铺天梯erp采集中心模块商品采集,菜单项采集模块,粘贴产品链接,点击采集按钮;采集产品将自动认领成功;单品也可以一键发布或删除;
关键词采集
该功能是商家在采集中心的关键词模块进入关键词,直接通过云大数据中心采集各种电商的商品平台;进入关键词,选择采集平台,启动采集产品,然后返回采集列表数据;然后将商品添加到采集框内,一键发布到授权店铺平台;也可以选择商品,批量添加到采集框内;
插件采集
该功能需要先下载插件。采集中心产品的采集模块会显示采集插件。点击下载完成后,双击打开安装在网站。安装步骤可以在帮助中心查看;安装插件后,可以直接采集购物网站中的商品,采集成功会有提示。
采集盒子
以上三种方式收到的产品采集会被添加到采集框里,这里是采集收到的产品的管理中心,采集里面的产品可以添加到我的商品库中,也可以直接将采集框中的商品一键发布到各电商平台的指定店铺,一键列出的商品将添加到我的商品中默认库。
店铺天梯erp的采集功能非常全面,采集方法也多种多样。商家可以根据自己的习惯选择合适的采集方式,在采集完成后,一键发布也非常高效,方便商家操作,让商家全面提升运营效率. 查看全部
通过关键词采集文章采集api(说起erperp商品采集功能全面解析电商平台发展)
说起东南亚的跨境电商,相信大家都不陌生。近年来,Shopee和Lazada平台的发展越来越好,不少新手朋友也进入了东南亚市场。除了处理订单、挑选新品,还需要采集产品对店铺进行精细化运营,而采集产品也是业务运营中非常重要的一环,所以这个时候,您将需要使用一些工具来帮助商家。在之前的文章中,简单的提到了店梯erp产品采集的功能,功能全面,可以帮助商家做好产品采集,下面就详细聊聊关于它的这个功能模块是如何运作的。
首先店铺天梯erp的产品采集模块是从各大电商平台获取产品相关信息数据,包括产品标题、产品描述、产品主图及详细图、价格、规格信息、销量、评论数等相关信息;通过三种方式对产品进行采集:单品采集、关键字采集和插件采集;
单品采集
这是产品 采集 的链接;打开电商网站,找到你想要的产品采集,复制产品链接;然后打开店铺天梯erp采集中心模块商品采集,菜单项采集模块,粘贴产品链接,点击采集按钮;采集产品将自动认领成功;单品也可以一键发布或删除;
关键词采集
该功能是商家在采集中心的关键词模块进入关键词,直接通过云大数据中心采集各种电商的商品平台;进入关键词,选择采集平台,启动采集产品,然后返回采集列表数据;然后将商品添加到采集框内,一键发布到授权店铺平台;也可以选择商品,批量添加到采集框内;
插件采集
该功能需要先下载插件。采集中心产品的采集模块会显示采集插件。点击下载完成后,双击打开安装在网站。安装步骤可以在帮助中心查看;安装插件后,可以直接采集购物网站中的商品,采集成功会有提示。
采集盒子
以上三种方式收到的产品采集会被添加到采集框里,这里是采集收到的产品的管理中心,采集里面的产品可以添加到我的商品库中,也可以直接将采集框中的商品一键发布到各电商平台的指定店铺,一键列出的商品将添加到我的商品中默认库。
店铺天梯erp的采集功能非常全面,采集方法也多种多样。商家可以根据自己的习惯选择合适的采集方式,在采集完成后,一键发布也非常高效,方便商家操作,让商家全面提升运营效率.
通过关键词采集文章采集api(面向豆瓣网站的信息采集与可视化分析系统(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-16 23:20
豆瓣信息采集和可视化网站
摘要:豆瓣网站是中国最受欢迎的社交网站之一。本文为豆瓣网站设计了一个信息采集和可视化分析系统,基于Python语言实现了信息采集、信息分析和可视化三个功能模块,实现了如下功能:可根据用户指定的关键词实现自动采集和豆瓣网站信息的可视化展示。
关键词:信息采集;可视化;豆瓣网站
CLC 编号:TP311 证件识别码:A 文章 编号:1009-3044 (2018)13-0003-02
1 背景
目前,随着Web2.0和移动互联网的快速发展,网民数量屡创新高,社交互联网平台应运而生。但是,布查达的言论很容易成为社会不稳定因素,所以要及时了解和掌握社交网站网友发布的信息,对网站的信息有一个全面的了解。 ,避免大规模的网络舆论攻击、网络谣言等恶性事件。
豆瓣网站作为社交网站的典型代表,积累了大量的人气,是国内最具影响力的社交网站。大量网友可以在豆瓣上发帖网站各种信息,其中收录丰富的个人情感,尤其是一些观点所表达的观点具有很强的主观性和武断性[1]。为此,本文开发了豆瓣网站的信息采集及分析系统,可以全面掌握豆瓣网站的社交网络信息,并可对爬取的豆瓣网站@进行分析。 >数据直观直观展示,有助于及时全面了解豆瓣网友的思想表达、热点话题等。
2 系统架构设计
该系统使用基于Python的Scrapy开源爬虫框架开发。Scrapy 框架为网络爬虫相关功能提供了丰富的 API 接口[2]。在此基础上,本文实现了面向豆瓣网站的信息抓取、数据处理和可视化,系统功能如图1所示。
豆瓣网站的信息采集和可视化系统架构主要分为三个关键功能模块:
1)采集模块主要根据用户指定的关键词或URL爬取豆瓣网站的相关信息;
2)处理模块的主要任务是对采集模块爬取的海量数据进行处理和分析,并将其格式化并存储起来,以供后续可视化展示;
3)可视化模块,该部分是系统分析功能的主要实现部分,实现处理后信息的可视化展示。
3 豆瓣信息采集网站及可视化系统主要功能的实现
3.1 信息采集模块
信息采集模块的主要作用是根据系统用户指定的关键词通过网络采集豆瓣网站启动爬虫程序,并发送采集 to 信息被持久化到本地数据库。此外,系统还部署了去重去噪的信息爬取策略,保证采集信息的准确性。最后对采集的信息进行格式化转换,并保存格式化后的数据。
为了保证豆瓣网站采集上信息的全面性,系统采用广度优先的爬取搜索策略[3-4]。主要过程是选择起始URL作为种子URL放入等待队列,爬虫根据URL队列选择要爬取解析的URL,将爬取的URL放入爬取集合中,选择解析后的URL和将它们放入待爬取的URL队列中,直到待爬取的URL队列为空,如图2所示。
鉴于豆瓣网站的主动反爬策略[5],系统使用cookies模拟浏览器访问。当豆瓣网站返回bin cookie时,后续的爬取过程会携带cookie进行访问。,为了防止频繁定向触发反爬虫机制,在系统中设置了一定的时间阈值,即1分钟,进行间隔爬取。
3.2 信息分析模块
系统分析 查看全部
通过关键词采集文章采集api(面向豆瓣网站的信息采集与可视化分析系统(组图))
豆瓣信息采集和可视化网站
摘要:豆瓣网站是中国最受欢迎的社交网站之一。本文为豆瓣网站设计了一个信息采集和可视化分析系统,基于Python语言实现了信息采集、信息分析和可视化三个功能模块,实现了如下功能:可根据用户指定的关键词实现自动采集和豆瓣网站信息的可视化展示。
关键词:信息采集;可视化;豆瓣网站
CLC 编号:TP311 证件识别码:A 文章 编号:1009-3044 (2018)13-0003-02
1 背景
目前,随着Web2.0和移动互联网的快速发展,网民数量屡创新高,社交互联网平台应运而生。但是,布查达的言论很容易成为社会不稳定因素,所以要及时了解和掌握社交网站网友发布的信息,对网站的信息有一个全面的了解。 ,避免大规模的网络舆论攻击、网络谣言等恶性事件。
豆瓣网站作为社交网站的典型代表,积累了大量的人气,是国内最具影响力的社交网站。大量网友可以在豆瓣上发帖网站各种信息,其中收录丰富的个人情感,尤其是一些观点所表达的观点具有很强的主观性和武断性[1]。为此,本文开发了豆瓣网站的信息采集及分析系统,可以全面掌握豆瓣网站的社交网络信息,并可对爬取的豆瓣网站@进行分析。 >数据直观直观展示,有助于及时全面了解豆瓣网友的思想表达、热点话题等。
2 系统架构设计
该系统使用基于Python的Scrapy开源爬虫框架开发。Scrapy 框架为网络爬虫相关功能提供了丰富的 API 接口[2]。在此基础上,本文实现了面向豆瓣网站的信息抓取、数据处理和可视化,系统功能如图1所示。
豆瓣网站的信息采集和可视化系统架构主要分为三个关键功能模块:
1)采集模块主要根据用户指定的关键词或URL爬取豆瓣网站的相关信息;
2)处理模块的主要任务是对采集模块爬取的海量数据进行处理和分析,并将其格式化并存储起来,以供后续可视化展示;
3)可视化模块,该部分是系统分析功能的主要实现部分,实现处理后信息的可视化展示。
3 豆瓣信息采集网站及可视化系统主要功能的实现
3.1 信息采集模块
信息采集模块的主要作用是根据系统用户指定的关键词通过网络采集豆瓣网站启动爬虫程序,并发送采集 to 信息被持久化到本地数据库。此外,系统还部署了去重去噪的信息爬取策略,保证采集信息的准确性。最后对采集的信息进行格式化转换,并保存格式化后的数据。
为了保证豆瓣网站采集上信息的全面性,系统采用广度优先的爬取搜索策略[3-4]。主要过程是选择起始URL作为种子URL放入等待队列,爬虫根据URL队列选择要爬取解析的URL,将爬取的URL放入爬取集合中,选择解析后的URL和将它们放入待爬取的URL队列中,直到待爬取的URL队列为空,如图2所示。
鉴于豆瓣网站的主动反爬策略[5],系统使用cookies模拟浏览器访问。当豆瓣网站返回bin cookie时,后续的爬取过程会携带cookie进行访问。,为了防止频繁定向触发反爬虫机制,在系统中设置了一定的时间阈值,即1分钟,进行间隔爬取。
3.2 信息分析模块
系统分析
通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2022-01-16 22:22
MySQL:通过Mybatis拦截器;
Redis:通过javassist增强RedisTemplate的方式;
跨应用调用:通过代理feign客户端,dubbo、grpc等方法可能需要通过拦截器;
http调用:通过javassist给HttpClient和OkHttp添加拦截器;
日志管理:通过plugin方式上报日志中打印的错误。
管理的技术细节这里就不展开了,主要是使用各种框架提供的一些接口,以及使用javassist进行字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的tracing功能比专业的Traces系统要薄很多。
介绍
下面是DOG的架构图。客户端将消息传递给 Kafka,狗服务器使用消息。Cassandra 和 ClickHouse 用于存储。具体要存储的数据后面会介绍。
1、还有不使用消息中间件的 APM 系统。例如,在 Cat 中,客户端通过 Netty 连接到服务器以发送消息。
2、服务端采用Lambda架构模式。Dog UI 上查询的数据是从每个 Dog-server 的内存数据和下游存储的数据中聚合而成的。
下面,我们简单介绍一下 Dog UI 上比较重要的一些功能,然后我们将分析如何实现相应的功能。
注:以下图片均为本人绘制,非实页截图,数值可能不准确
下图显示了一个示例交易报告:
当然,点击上图中的具体名称,以及下一级状态的统计数据,这里就不会有映射了。Dog一共设计了type、name、status三个属性。上两图中的最后一列是sample,它通向sample视图:
样本意味着抽样。当我们看到一个高故障率或者高P90的接口,你就知道有问题了,但是因为它只有统计数据,你不知道哪里出了问题。这时候,你需要一些样本数据。对于类型、名称和状态的不同组合,我们每分钟最多保存 5 个成功、5 个失败和 5 个处理缓慢的样本数据。
通过上面的trace视图,可以很快的知道是哪个环节出了问题。当然,我们之前也说过,我们的 Trace 依赖于我们埋点的丰富程度,但是 Dog 是一个基于 Metrics 的系统,所以它的 Traces 能力是不够的,但在大多数情况下,对于排查问题应该足够了。
对于应用程序开发人员,以下问题视图应该非常有用:
它显示了各种错误统计信息,并为开发人员提供了解决问题的示例。
最后简单介绍一下Heartbeat视图,它和前面的功能没有任何关系,而是大量的图表。我们有gc、heap、os、thread等各种数据,以便我们观察系统的健康状况。
本节主要介绍APM系统通常收录哪些功能。其实很简单,对吧?接下来,我们从开发者的角度来谈谈具体的实现细节。
客户数据模型
每个人都是开发者,所以我会更直接。下图描述了客户端的数据模型:
对于Message来说,用于统计的字段有type、name、status,所以我们可以根据type、type+name、type+name+status这三个维度进行统计。
Message中的其他字段:timestamp表示事件发生的时间;如果成功为假,该事件将被计入问题报告;数据不具有统计意义,仅对链路跟踪和故障排除有用;businessData 用于向业务系统上报业务数据,需要手动管理,然后用于业务数据分析。
Message 有两个子类 Event 和 Transaction。不同的是Transaction有一个duration属性,用来标识事务需要多长时间。可以用于max time、min time、avg time、p90、p95等,而event指的是发生了某事发生的时候,只能用来统计发生了多少次,没有概念的时间长度。
Transaction有一个属性children,可以嵌套Transaction或者Event,最后形成一个树形结构进行trace,后面会介绍。
下表显示了一个虚线数据的示例,更直观:
只是几件事:
类型为URL、SQL、Redis、FeignClient、HttpClient等数据,属于自动跟踪的范畴。通常,在APM系统上工作的时候,一定要完成一些自动埋点工作,这样应用开发者不用做任何埋点工作就可以看到很多有用的数据。Type=Order 像最后两行一样属于人工埋藏的数据。
打点需要特别注意类型、名称和状态的维度的“爆炸”。它们的组合太多会消耗大量资源,并且可能直接拖累我们的Dog系统。type的维度可能不会太多,但是我们可能需要注意开发者可能会滥用name和status,所以一定要进行normalize(比如url可能有动态参数,需要格式化)。
表中最后两项是开发者手动埋藏的数据,通常用于统计具体场景。比如我想知道某个方法是怎么调用的,调用次数,耗时,是否抛出异常,输入参数,返回值。等待。因为自动埋点是业务不想关闭的冷数据,开发者可能想埋一些自己想统计的数据。
当开发者手动埋点时,也可以上报更多业务相关的数据。请参阅表格的最后一列。这些数据可用于业务分析。比如我是一个支付系统,通常一个支付订单涉及到很多步骤(国外支付和你平时使用的微信和支付宝略有不同)。通过上报各个节点的数据,我终于可以在Dog上使用bizId串起整个链接,在排查问题时非常有用(我们做支付业务的时候,支付成功率并没有大家想象的那么高,而且节点很多可能有问题)。
客户设计
上一节介绍了单条消息的数据,本节介绍其他内容。
首先我们介绍一下客户端的API使用:
上面的代码说明了如何使用嵌套的事务和事件。当最外层的Transaction在finally代码块中调用finish()时,树的创建就完成了,消息就被传递了。
我们交付给 Kafka 的不是 Message 实例,因为一个请求会产生很多 Message 实例,但应该组织成一个 Tree 实例以便以后交付。下图描述了 Tree 的各种属性:
树的属性很好理解。它持有对根事务的引用,并用于遍历整个树。另外,需要携带机器信息messageEnv。
treeId应该有保证全局唯一性的算法,简单介绍Dog的实现:$-$-$-$。
下面简单介绍几个tree id相关的内容。假设一个请求从A->B->C->D经过4个应用,A是入口应用,那么会有:
1、总共有 4 个 Tree 对象实例将从 4 个应用程序交付给 Kafka。跨应用调用时,需要传递treeId、parentTreeId、rootTreeId三个参数;
2、一个应用的treeId是所有节点的rootTreeId;
3、B应用的parentTreeId就是A的treeId,同理C的parentTreeId就是B应用的treeId;
4、跨应用调用时,比如从A调用B时,为了知道A的下一个节点是什么,在A中提前为B生成treeId,B收到请求后,如果找到A 已经为它生成了一个treeId,直接使用那个treeId。
大家也应该很容易知道,通过这些tree id,我们要实现trace的功能。
介绍完树的内容后,我们来简单讨论一下应用集成解决方案。
集成无非是两种技术。一种是通过javaagent。在启动脚本中,添加相应的代理。这种方式的好处是开发者无意识,运维级别可以做到。当然,如果开发者想要手动做一些嵌入,可能需要给开发者提供一个简单的客户端jar包来桥接代理。
另一种是提供jar包,开发者可以引入这个依赖。
这两种方案各有优缺点。Pinpoint 和 Skywalking 使用 javaagent 方案,Zipkin、Jaeger 和 Cat 使用第二种方案,Dog 也使用手动添加依赖项的第二种方案。
一般来说,做Traces的系统会选择使用javaagent方案,因为这类系统代理已经完成了所有需要的埋点,没有应用开发者的感知。
最后简单介绍一下Heartbeat的内容。这部分其实是最简单的,但是可以制作很多五颜六色的图表,实现面向老板的编程。
前面我们介绍过Message有两个子类Event和Transaction。这里我们添加一个子类 Heartbeat 来报告心跳数据。
我们主要采集thread、os、gc、heap、client的运行状态(生成了多少棵树、数据大小、发送失败次数)等。同时我们也提供api供开发者自定义数据进行上报. 狗客户端会启动一个后台线程,每分钟运行一次心跳采集程序,上报数据。
介绍更多细节。核心结构是一个Map\,key类似于“os.systemLoadAverage”、“thread.count”等。前缀os、thread、gc等实际上是用于页面上的分类,后缀为显示的折线图的名称。
关于客户,这就是我在这里介绍的全部内容。其实在实际的编码过程中,还是有一些细节需要处理的,比如树太大怎么办,比如没有rootTransaction的情况怎么处理(开发者只叫了Dog. logEvent(...)),比如如何在不调用finish的情况下处理内部嵌套事务等。
狗服务器设计
下图说明了服务器的整体设计。值得注意的是,我们这里对线程的使用非常克制,图中只有3个工作线程。
首先是Kafka Consumer线程,负责批量消费消息。它使用 kafka 集群中的 Tree 实例。接下来,考虑如何处理它。
这里,我们需要对树状结构的消息进行扁平化,我们称这一步为deflate,并做一些预处理,形成如下结构:
接下来,我们将 DeflateTree 分别传递给两个 Disruptor 实例。我们将 Disruptor 设计为单线程生产和单线程消费,主要是出于性能考虑。
消费者线程根据 DeflateTree 的属性使用绑定的 Processor 进行处理。比如DeflateTree中的List problmes不为空,ProblemProcessor是自己绑定的,所以需要调用ProblemProcessor进行处理。
科普时间:Disruptor是一个高性能队列,性能优于JDK中的BlockingQueue
这里我们使用了 2 个 Disruptor 实例,当然我们可以考虑使用更多的实例,这样每个消费者线程就绑定到更少的处理器上。
我们在这里将处理器绑定到 Disruptor 实例。其实原因很简单。出于性能原因,我们希望每个处理器仅在单个线程中使用它。单线程操作可以减少线程切换带来的开销,可以充分利用系统。缓存,在设计处理器时,不要考虑并发读写的问题。
这里要考虑负载均衡的情况。有些处理器消耗CPU和内存资源,必须合理分配。压力最大的任务不能分配给同一个线程。
核心处理逻辑在每个处理器中,负责数据计算。接下来,我将介绍每个处理器需要做的主要内容。毕竟能看到这里的开发者,应该对APM数据处理真的很感兴趣。
事务处理器
事务处理器是系统压力最大的地方。负责报表统计。虽然 Message 有两个主要子类 Transaction 和 Event,但在实际的树中,大多数节点都是事务类型数据。
下图是事务处理器内部的主要数据结构。最外层是时间。我们在几分钟内组织它。当我们坚持时,它也以分钟为单位存储。
第二层的HostKey代表了哪个应用程序和来自哪个IP的数据,第三层是类型、名称和状态的组合。最里面的统计是我们的数据统计模块。
此外,我们还可以看到这个结构会消耗多少内存。其实主要看我们的类型、名字、状态的组合,也就是会不会有很多的ReportKey。也就是我们在谈客户管理的时候,要避免维度爆炸。
最外层的结构代表时间的分钟表示。我们的报告是按每分钟统计的,然后持久化到 ClickHouse,但是我们的用户在看数据的时候,并不是每分钟都看到的。,所以你需要做数据聚合。下面显示了如何聚合这两个数据。当组合很多数据时,它们的组合方式相同。
仔细想想,你会发现前面数据的计算是可以的,但是P90、P95、P99的计算是不是有点骗人?事实上,这个问题真的是无解的。我们只能想出一个合适的数据计算规则,然后再想这个计算规则,计算出来的值可能就差不多可用了。
此外,还有一个细节问题。我们需要为内存中的数据提供最近 30 分钟的统计信息,只有超过 30 分钟的数据才从 DB 中读取。然后进行上述的合并操作。
讨论:我们能不能丢掉一部分实时性能,每分钟都持久化,读取的数据全部来自DB,这样可行吗?
不,因为我们的数据是从kafka消费的,有一定的滞后性。如果我们在一分钟开始时将数据持久化一分钟,我们可能会在稍后收到上一次的消息。这种情况无法处理。
比如我们要统计最后一小时,那么每台机器获取30分钟的数据,从DB获取30分钟的数据,然后合并。
这里值得一提的是,在交易报告中,count、failCount、min、max、avg是比较容易计算的,但是P90、P95、P99其实并不好计算,我们需要一个数组结构,记录这一分钟内所有事件的时间,然后计算,我们这里用的是Apache DataSketches,非常好用,这里就不展开了,有兴趣的同学可以自己看看。
此时,您可以考虑一下 ClickHouse 中存储的数据量。app_name、ip、type、name、status的不同组合,每分钟一个数据。
样品处理器
示例处理器使用来自放气树中列表事务和列表事件的数据。
我们还按分钟采样,最后每分钟采样,对于类型、名称和状态的每种组合,采集 最多 5 次成功、5 次失败和 5 次慢处理。
相对来说,这还是很简单的,其核心结构如下:
结合Sample的功能更容易理解:
问题处理器
在进行 deflate 时,所有成功 = false 的消息都将放入 List problmes 以进行错误统计。
Problem的内部数据结构如下:
如果你看这张图,你其实已经知道该怎么做了,所以我就不啰嗦了。我们每分钟保存 5 个 treeId 的样本。
顺便提一下Problem的观点:
关于持久化,我们将其存储在 ClickHouse 中,其中 sample 用逗号连接到一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
心跳处理器
Heartbeat 处理 List 心跳的数据。顺便说一句,在正常情况下,一棵树中只有一个 Heartbeat 实例。
前面我也简单提到过,Heartbeat 中用来显示图表的核心数据结构是 Map。
采集到的key-value数据如下:
前缀是分类,后缀是图的名称。客户端每分钟采集数据进行报告,然后可以制作很多图表。例如下图展示了堆分类下的各种图:
Heartbeat处理器要做的事情很简单,就是数据存储。Dog UI 上的数据直接从 ClickHouse 读取。
heartbeat_data的列如下:
消息树处理器
我们之前已经多次提到过 Sample 的功能。这些采样数据帮助我们还原场景,这样我们就可以通过trace视图来追踪调用链。
做上面的trace view,我们需要所有上下游树的数据,比如上图就是3个树实例的数据。
正如我们之前在介绍客户端时所说,这些树是由父treeId和根treeId组织的。
要做到这一点,我们面临的挑战是我们需要保存全部数据量。
你可以想想这个问题。为什么我们需要保存全部数据?如果我们直接保存采样的数据不是更好吗?
这里我们使用 Cassandra 的功能。Cassandra在这种kv场景下性能非常好,运维成本非常低。
我们使用treeId作为主键,并添加一列数据。它是整个树的实例数据。数据类型是blob。我们先做gzip压缩,然后扔给Cassandra。
业务处理器
我们在介绍客户端的时候说过,每条Message都可以携带Business Data,但只有应用开发者手动埋藏的时候。当我们发现有业务数据时,我们会做另一件事,就是将这些数据存储在 ClickHouse 中进行业务分析。
我们其实不知道应用开发者会在什么场景下使用它,因为每个人负责不同的项目,所以我们只能做一个通用的数据模型。
回头看这张图,在BusinessData中,我们定义了更通用的userId和bizId,我们认为可能会用到每一个业务场景。userId不用说,bizId可以用来记录订单id、支付订单id等。
然后我们提供三个String类型的列ext1、ext2、ext3和两个数值类型的列extVal1和extVal2,可以用来表达你的业务相关参数。
当然,我们的处理也很简单。将这些数据存储在 ClickHouse 中就足够了。表中主要有这几列:
这些数据对于我们的Dog系统来说肯定是不熟悉的,因为我们不知道你在表达什么业务。类型、名称和状态由开发人员自己定义。我们不知道 ext1、ext2 和 ext3 分别是什么意思。,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多数据报表。因为本文讨论的是APM,所以这里不再赘述。
其他
ClickHouse 需要批量编写,否则肯定是不可持续的。通常,一个批次至少有 10,000 行数据。
我们在 Kafka 层控制它。app_name + ip 的数据只会被同一个 dog-server 消费。当然,这并不意味着多个狗服务器消费时会出现问题,但写入ClickHouse的数据会更准确。许多。
还有一个关键点。我们说每个处理器都是单线程访问的,但是有一个问题,那就是Dog UI的请求呢?这里我想了一个办法,就是把请求放到一个Queue中,Kafka Consumer的线程会消费,它会把任务丢给两个Disruptor。例如,如果这个请求是一个交易报告请求,那么其中一个 Disruptor 消费者会发现这是他们想要做的,并且会执行这个任务。
概括
如果你知道 Cat,你可以看到 Dog 在很多地方与 Cat 有相似之处,或者只是说“复制”。我们也考虑过直接使用Cat或者在Cat的基础上做二次开发。
但是看了Cat的源码后,我放弃了这个想法。仔细想了想,正好借用了Cat的数据模型,然后我们自己写一套APM也不难,于是有了这个项目。
写的需要,很多地方重要的我都避而远之,因为这不是源码分析文章,细节就不多说了,主要是给读者一个全貌,读者可以大致思考哪些需要处理通过我的描述,需要写哪些代码,然后当我表达清楚。
欢迎您提出自己的问题或想法。如果有不明白的地方或者我有错误和遗漏的地方,请指正~ 查看全部
通过关键词采集文章采集api(DogUI上的数据就是单薄了很多,你知道吗?)
MySQL:通过Mybatis拦截器;
Redis:通过javassist增强RedisTemplate的方式;
跨应用调用:通过代理feign客户端,dubbo、grpc等方法可能需要通过拦截器;
http调用:通过javassist给HttpClient和OkHttp添加拦截器;
日志管理:通过plugin方式上报日志中打印的错误。
管理的技术细节这里就不展开了,主要是使用各种框架提供的一些接口,以及使用javassist进行字节码增强。
这些打点数据就是我们需要做统计的,当然因为打点有限,我们的tracing功能比专业的Traces系统要薄很多。
介绍
下面是DOG的架构图。客户端将消息传递给 Kafka,狗服务器使用消息。Cassandra 和 ClickHouse 用于存储。具体要存储的数据后面会介绍。
1、还有不使用消息中间件的 APM 系统。例如,在 Cat 中,客户端通过 Netty 连接到服务器以发送消息。
2、服务端采用Lambda架构模式。Dog UI 上查询的数据是从每个 Dog-server 的内存数据和下游存储的数据中聚合而成的。
下面,我们简单介绍一下 Dog UI 上比较重要的一些功能,然后我们将分析如何实现相应的功能。
注:以下图片均为本人绘制,非实页截图,数值可能不准确
下图显示了一个示例交易报告:
当然,点击上图中的具体名称,以及下一级状态的统计数据,这里就不会有映射了。Dog一共设计了type、name、status三个属性。上两图中的最后一列是sample,它通向sample视图:
样本意味着抽样。当我们看到一个高故障率或者高P90的接口,你就知道有问题了,但是因为它只有统计数据,你不知道哪里出了问题。这时候,你需要一些样本数据。对于类型、名称和状态的不同组合,我们每分钟最多保存 5 个成功、5 个失败和 5 个处理缓慢的样本数据。
通过上面的trace视图,可以很快的知道是哪个环节出了问题。当然,我们之前也说过,我们的 Trace 依赖于我们埋点的丰富程度,但是 Dog 是一个基于 Metrics 的系统,所以它的 Traces 能力是不够的,但在大多数情况下,对于排查问题应该足够了。
对于应用程序开发人员,以下问题视图应该非常有用:
它显示了各种错误统计信息,并为开发人员提供了解决问题的示例。
最后简单介绍一下Heartbeat视图,它和前面的功能没有任何关系,而是大量的图表。我们有gc、heap、os、thread等各种数据,以便我们观察系统的健康状况。
本节主要介绍APM系统通常收录哪些功能。其实很简单,对吧?接下来,我们从开发者的角度来谈谈具体的实现细节。
客户数据模型
每个人都是开发者,所以我会更直接。下图描述了客户端的数据模型:
对于Message来说,用于统计的字段有type、name、status,所以我们可以根据type、type+name、type+name+status这三个维度进行统计。
Message中的其他字段:timestamp表示事件发生的时间;如果成功为假,该事件将被计入问题报告;数据不具有统计意义,仅对链路跟踪和故障排除有用;businessData 用于向业务系统上报业务数据,需要手动管理,然后用于业务数据分析。
Message 有两个子类 Event 和 Transaction。不同的是Transaction有一个duration属性,用来标识事务需要多长时间。可以用于max time、min time、avg time、p90、p95等,而event指的是发生了某事发生的时候,只能用来统计发生了多少次,没有概念的时间长度。
Transaction有一个属性children,可以嵌套Transaction或者Event,最后形成一个树形结构进行trace,后面会介绍。
下表显示了一个虚线数据的示例,更直观:
只是几件事:
类型为URL、SQL、Redis、FeignClient、HttpClient等数据,属于自动跟踪的范畴。通常,在APM系统上工作的时候,一定要完成一些自动埋点工作,这样应用开发者不用做任何埋点工作就可以看到很多有用的数据。Type=Order 像最后两行一样属于人工埋藏的数据。
打点需要特别注意类型、名称和状态的维度的“爆炸”。它们的组合太多会消耗大量资源,并且可能直接拖累我们的Dog系统。type的维度可能不会太多,但是我们可能需要注意开发者可能会滥用name和status,所以一定要进行normalize(比如url可能有动态参数,需要格式化)。
表中最后两项是开发者手动埋藏的数据,通常用于统计具体场景。比如我想知道某个方法是怎么调用的,调用次数,耗时,是否抛出异常,输入参数,返回值。等待。因为自动埋点是业务不想关闭的冷数据,开发者可能想埋一些自己想统计的数据。
当开发者手动埋点时,也可以上报更多业务相关的数据。请参阅表格的最后一列。这些数据可用于业务分析。比如我是一个支付系统,通常一个支付订单涉及到很多步骤(国外支付和你平时使用的微信和支付宝略有不同)。通过上报各个节点的数据,我终于可以在Dog上使用bizId串起整个链接,在排查问题时非常有用(我们做支付业务的时候,支付成功率并没有大家想象的那么高,而且节点很多可能有问题)。
客户设计
上一节介绍了单条消息的数据,本节介绍其他内容。
首先我们介绍一下客户端的API使用:
上面的代码说明了如何使用嵌套的事务和事件。当最外层的Transaction在finally代码块中调用finish()时,树的创建就完成了,消息就被传递了。
我们交付给 Kafka 的不是 Message 实例,因为一个请求会产生很多 Message 实例,但应该组织成一个 Tree 实例以便以后交付。下图描述了 Tree 的各种属性:
树的属性很好理解。它持有对根事务的引用,并用于遍历整个树。另外,需要携带机器信息messageEnv。
treeId应该有保证全局唯一性的算法,简单介绍Dog的实现:$-$-$-$。
下面简单介绍几个tree id相关的内容。假设一个请求从A->B->C->D经过4个应用,A是入口应用,那么会有:
1、总共有 4 个 Tree 对象实例将从 4 个应用程序交付给 Kafka。跨应用调用时,需要传递treeId、parentTreeId、rootTreeId三个参数;
2、一个应用的treeId是所有节点的rootTreeId;
3、B应用的parentTreeId就是A的treeId,同理C的parentTreeId就是B应用的treeId;
4、跨应用调用时,比如从A调用B时,为了知道A的下一个节点是什么,在A中提前为B生成treeId,B收到请求后,如果找到A 已经为它生成了一个treeId,直接使用那个treeId。
大家也应该很容易知道,通过这些tree id,我们要实现trace的功能。
介绍完树的内容后,我们来简单讨论一下应用集成解决方案。
集成无非是两种技术。一种是通过javaagent。在启动脚本中,添加相应的代理。这种方式的好处是开发者无意识,运维级别可以做到。当然,如果开发者想要手动做一些嵌入,可能需要给开发者提供一个简单的客户端jar包来桥接代理。
另一种是提供jar包,开发者可以引入这个依赖。
这两种方案各有优缺点。Pinpoint 和 Skywalking 使用 javaagent 方案,Zipkin、Jaeger 和 Cat 使用第二种方案,Dog 也使用手动添加依赖项的第二种方案。
一般来说,做Traces的系统会选择使用javaagent方案,因为这类系统代理已经完成了所有需要的埋点,没有应用开发者的感知。
最后简单介绍一下Heartbeat的内容。这部分其实是最简单的,但是可以制作很多五颜六色的图表,实现面向老板的编程。
前面我们介绍过Message有两个子类Event和Transaction。这里我们添加一个子类 Heartbeat 来报告心跳数据。
我们主要采集thread、os、gc、heap、client的运行状态(生成了多少棵树、数据大小、发送失败次数)等。同时我们也提供api供开发者自定义数据进行上报. 狗客户端会启动一个后台线程,每分钟运行一次心跳采集程序,上报数据。
介绍更多细节。核心结构是一个Map\,key类似于“os.systemLoadAverage”、“thread.count”等。前缀os、thread、gc等实际上是用于页面上的分类,后缀为显示的折线图的名称。
关于客户,这就是我在这里介绍的全部内容。其实在实际的编码过程中,还是有一些细节需要处理的,比如树太大怎么办,比如没有rootTransaction的情况怎么处理(开发者只叫了Dog. logEvent(...)),比如如何在不调用finish的情况下处理内部嵌套事务等。
狗服务器设计
下图说明了服务器的整体设计。值得注意的是,我们这里对线程的使用非常克制,图中只有3个工作线程。
首先是Kafka Consumer线程,负责批量消费消息。它使用 kafka 集群中的 Tree 实例。接下来,考虑如何处理它。
这里,我们需要对树状结构的消息进行扁平化,我们称这一步为deflate,并做一些预处理,形成如下结构:
接下来,我们将 DeflateTree 分别传递给两个 Disruptor 实例。我们将 Disruptor 设计为单线程生产和单线程消费,主要是出于性能考虑。
消费者线程根据 DeflateTree 的属性使用绑定的 Processor 进行处理。比如DeflateTree中的List problmes不为空,ProblemProcessor是自己绑定的,所以需要调用ProblemProcessor进行处理。
科普时间:Disruptor是一个高性能队列,性能优于JDK中的BlockingQueue
这里我们使用了 2 个 Disruptor 实例,当然我们可以考虑使用更多的实例,这样每个消费者线程就绑定到更少的处理器上。
我们在这里将处理器绑定到 Disruptor 实例。其实原因很简单。出于性能原因,我们希望每个处理器仅在单个线程中使用它。单线程操作可以减少线程切换带来的开销,可以充分利用系统。缓存,在设计处理器时,不要考虑并发读写的问题。
这里要考虑负载均衡的情况。有些处理器消耗CPU和内存资源,必须合理分配。压力最大的任务不能分配给同一个线程。
核心处理逻辑在每个处理器中,负责数据计算。接下来,我将介绍每个处理器需要做的主要内容。毕竟能看到这里的开发者,应该对APM数据处理真的很感兴趣。
事务处理器
事务处理器是系统压力最大的地方。负责报表统计。虽然 Message 有两个主要子类 Transaction 和 Event,但在实际的树中,大多数节点都是事务类型数据。
下图是事务处理器内部的主要数据结构。最外层是时间。我们在几分钟内组织它。当我们坚持时,它也以分钟为单位存储。
第二层的HostKey代表了哪个应用程序和来自哪个IP的数据,第三层是类型、名称和状态的组合。最里面的统计是我们的数据统计模块。
此外,我们还可以看到这个结构会消耗多少内存。其实主要看我们的类型、名字、状态的组合,也就是会不会有很多的ReportKey。也就是我们在谈客户管理的时候,要避免维度爆炸。
最外层的结构代表时间的分钟表示。我们的报告是按每分钟统计的,然后持久化到 ClickHouse,但是我们的用户在看数据的时候,并不是每分钟都看到的。,所以你需要做数据聚合。下面显示了如何聚合这两个数据。当组合很多数据时,它们的组合方式相同。
仔细想想,你会发现前面数据的计算是可以的,但是P90、P95、P99的计算是不是有点骗人?事实上,这个问题真的是无解的。我们只能想出一个合适的数据计算规则,然后再想这个计算规则,计算出来的值可能就差不多可用了。
此外,还有一个细节问题。我们需要为内存中的数据提供最近 30 分钟的统计信息,只有超过 30 分钟的数据才从 DB 中读取。然后进行上述的合并操作。
讨论:我们能不能丢掉一部分实时性能,每分钟都持久化,读取的数据全部来自DB,这样可行吗?
不,因为我们的数据是从kafka消费的,有一定的滞后性。如果我们在一分钟开始时将数据持久化一分钟,我们可能会在稍后收到上一次的消息。这种情况无法处理。
比如我们要统计最后一小时,那么每台机器获取30分钟的数据,从DB获取30分钟的数据,然后合并。
这里值得一提的是,在交易报告中,count、failCount、min、max、avg是比较容易计算的,但是P90、P95、P99其实并不好计算,我们需要一个数组结构,记录这一分钟内所有事件的时间,然后计算,我们这里用的是Apache DataSketches,非常好用,这里就不展开了,有兴趣的同学可以自己看看。
此时,您可以考虑一下 ClickHouse 中存储的数据量。app_name、ip、type、name、status的不同组合,每分钟一个数据。
样品处理器
示例处理器使用来自放气树中列表事务和列表事件的数据。
我们还按分钟采样,最后每分钟采样,对于类型、名称和状态的每种组合,采集 最多 5 次成功、5 次失败和 5 次慢处理。
相对来说,这还是很简单的,其核心结构如下:
结合Sample的功能更容易理解:
问题处理器
在进行 deflate 时,所有成功 = false 的消息都将放入 List problmes 以进行错误统计。
Problem的内部数据结构如下:
如果你看这张图,你其实已经知道该怎么做了,所以我就不啰嗦了。我们每分钟保存 5 个 treeId 的样本。
顺便提一下Problem的观点:
关于持久化,我们将其存储在 ClickHouse 中,其中 sample 用逗号连接到一个字符串,problem_data 的列如下:
event_date, event_time, app_name, ip, type, name, status, count, sample
心跳处理器
Heartbeat 处理 List 心跳的数据。顺便说一句,在正常情况下,一棵树中只有一个 Heartbeat 实例。
前面我也简单提到过,Heartbeat 中用来显示图表的核心数据结构是 Map。
采集到的key-value数据如下:
前缀是分类,后缀是图的名称。客户端每分钟采集数据进行报告,然后可以制作很多图表。例如下图展示了堆分类下的各种图:
Heartbeat处理器要做的事情很简单,就是数据存储。Dog UI 上的数据直接从 ClickHouse 读取。
heartbeat_data的列如下:
消息树处理器
我们之前已经多次提到过 Sample 的功能。这些采样数据帮助我们还原场景,这样我们就可以通过trace视图来追踪调用链。
做上面的trace view,我们需要所有上下游树的数据,比如上图就是3个树实例的数据。
正如我们之前在介绍客户端时所说,这些树是由父treeId和根treeId组织的。
要做到这一点,我们面临的挑战是我们需要保存全部数据量。
你可以想想这个问题。为什么我们需要保存全部数据?如果我们直接保存采样的数据不是更好吗?
这里我们使用 Cassandra 的功能。Cassandra在这种kv场景下性能非常好,运维成本非常低。
我们使用treeId作为主键,并添加一列数据。它是整个树的实例数据。数据类型是blob。我们先做gzip压缩,然后扔给Cassandra。
业务处理器
我们在介绍客户端的时候说过,每条Message都可以携带Business Data,但只有应用开发者手动埋藏的时候。当我们发现有业务数据时,我们会做另一件事,就是将这些数据存储在 ClickHouse 中进行业务分析。
我们其实不知道应用开发者会在什么场景下使用它,因为每个人负责不同的项目,所以我们只能做一个通用的数据模型。
回头看这张图,在BusinessData中,我们定义了更通用的userId和bizId,我们认为可能会用到每一个业务场景。userId不用说,bizId可以用来记录订单id、支付订单id等。
然后我们提供三个String类型的列ext1、ext2、ext3和两个数值类型的列extVal1和extVal2,可以用来表达你的业务相关参数。
当然,我们的处理也很简单。将这些数据存储在 ClickHouse 中就足够了。表中主要有这几列:
这些数据对于我们的Dog系统来说肯定是不熟悉的,因为我们不知道你在表达什么业务。类型、名称和状态由开发人员自己定义。我们不知道 ext1、ext2 和 ext3 分别是什么意思。,我们只负责存储和查询。
这些业务数据非常有用,基于这些数据,我们可以做很多数据报表。因为本文讨论的是APM,所以这里不再赘述。
其他
ClickHouse 需要批量编写,否则肯定是不可持续的。通常,一个批次至少有 10,000 行数据。
我们在 Kafka 层控制它。app_name + ip 的数据只会被同一个 dog-server 消费。当然,这并不意味着多个狗服务器消费时会出现问题,但写入ClickHouse的数据会更准确。许多。
还有一个关键点。我们说每个处理器都是单线程访问的,但是有一个问题,那就是Dog UI的请求呢?这里我想了一个办法,就是把请求放到一个Queue中,Kafka Consumer的线程会消费,它会把任务丢给两个Disruptor。例如,如果这个请求是一个交易报告请求,那么其中一个 Disruptor 消费者会发现这是他们想要做的,并且会执行这个任务。
概括
如果你知道 Cat,你可以看到 Dog 在很多地方与 Cat 有相似之处,或者只是说“复制”。我们也考虑过直接使用Cat或者在Cat的基础上做二次开发。
但是看了Cat的源码后,我放弃了这个想法。仔细想了想,正好借用了Cat的数据模型,然后我们自己写一套APM也不难,于是有了这个项目。
写的需要,很多地方重要的我都避而远之,因为这不是源码分析文章,细节就不多说了,主要是给读者一个全貌,读者可以大致思考哪些需要处理通过我的描述,需要写哪些代码,然后当我表达清楚。
欢迎您提出自己的问题或想法。如果有不明白的地方或者我有错误和遗漏的地方,请指正~
通过关键词采集文章采集api(大数据、人工智能等新技术给新媒体产业带来新冲击)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-01-15 07:11
大数据、人工智能等新技术给新媒体行业带来了新的影响和新的机遇。新媒体行业内部也将进一步分化。技术实力雄厚、团队竞争力强、生态协同良好的互联网平台将抢占越来越多的市场份额。BAT三巨头的老套路,极有可能被字节跳动打败。、快手等后来者破局,形成了新的媒体产业格局。
如今,对于新媒体运营商来说,作品的质量变得越来越重要。好的作品自然会得到更多的关注,但面对各大平台的海量媒体内容,如何让自己的优质作品脱颖而出,是很多新媒体运营商思考的主要问题之一。
近年来兴起的DaaS+RPA“数据智能机器人”,在政府、金融、医疗、人力资源、制造等多个领域都有很多典型的应用场景。现在它也在新媒体行业开辟了新的应用路径。它可以帮助运营商提高运营效率,提高工程质量。
一、新媒体行业痛点
1、有很多重复的任务,占用时间长;
2、优质内容很难获得高流量关注;
3、无法深入分析用户行为指导操作。
面对这些痛点,我们可以通过使用外部软件工具进一步提高我们的运营效率。“数字管家”——数据互联数据智能机器人(以下简称“数据互联”)是一款非常流行的采用DaaS+RPA技术的过程自动化软件。“数据连接”可以根据用户设置的任务流程和规则实现自动化操作。通过非侵入、免协调技术,快速安全生成系统业务数据访问(API)接口,实时连接多个应用系统,跨系统采集和报表.
媒体运营商只需要预先设置好任务流程,“数据连接”可以模拟人工操作,比如复制、粘贴、点击、输入等,辅助我们完成那些大型的“规则相对固定,重复的和额外的。较低的价值”。
二、解决方案及应用场景
1、多平台一键分发
对于媒体工作者来说,时间就是金钱。日常的分发过程非常繁琐枯燥,需要大量宝贵的创作时间,而同行每天更新的内容越来越多,竞争也越来越激烈,却没有更多的时间去创作,这导致了一个恶性循环。,无法输出高质量的内容。
使用“Digital Connect”可以实现文章和视频的多平台一键分发,完美解决了内容分发的繁琐问题,节省了大量时间。以前需要 2-3 个小时才能完成的发布工作,现在几分钟就可以完成,大大提高了工作效率。自媒体竞争非常激烈。更多的内容创作必然会获得更多的曝光和品牌传播,更多的优质内容制作可以提升领域综合排名、赛事奖励和更多收入。
2、提高用户发布内容的流行度
媒体人员在操作各大文章和视频平台时,往往会发现自己花了很多时间和精力制作文章或视频内容,浏览量、点赞数、评论数等数据都低,导致无法让更多用户看到并获得更多曝光,导致运营数据和结果不尽人意。
“数据连接”可以在平台允许的范围内,通过任务流程和组件的合理配置,有效优化发布的文章和视频数据,有效优化平台输出内容。推广效率,提高内容曝光度,形成良性运营状态。
3、网站SEO智能优化
如今的市场竞争非常激烈,网民越来越多,使用搜索引擎的频率非常高。目前,最大的中文搜索引擎百度日均PV达到30亿。如果网站不做SEO优化,不利于搜索引擎采集收录,会影响网站网站的流量很容易被网友忽略。因此,无论是为了公司形象还是为了市场,SEO都非常重要。
“数据连接”可以为网站提供生态自营销解决方案,为网站页面关键词提供SEO智能优化方法,让网站在行业,从而获得更高的品牌收入和影响力。
“数据连接”结合了DaaS+RPA+AI技术。作为一款流程自动化软件,不受标准化具体场景的约束,部署流程也比较短,特别是对于复杂的场景。该解决方案高度定制且易于使用。此外,“数字连接”可以更好地适应软件环境的变化,降低运维成本,满足客户智能需求,在复杂应用场景中搭建高壁垒。 查看全部
通过关键词采集文章采集api(大数据、人工智能等新技术给新媒体产业带来新冲击)
大数据、人工智能等新技术给新媒体行业带来了新的影响和新的机遇。新媒体行业内部也将进一步分化。技术实力雄厚、团队竞争力强、生态协同良好的互联网平台将抢占越来越多的市场份额。BAT三巨头的老套路,极有可能被字节跳动打败。、快手等后来者破局,形成了新的媒体产业格局。
如今,对于新媒体运营商来说,作品的质量变得越来越重要。好的作品自然会得到更多的关注,但面对各大平台的海量媒体内容,如何让自己的优质作品脱颖而出,是很多新媒体运营商思考的主要问题之一。
近年来兴起的DaaS+RPA“数据智能机器人”,在政府、金融、医疗、人力资源、制造等多个领域都有很多典型的应用场景。现在它也在新媒体行业开辟了新的应用路径。它可以帮助运营商提高运营效率,提高工程质量。
一、新媒体行业痛点
1、有很多重复的任务,占用时间长;
2、优质内容很难获得高流量关注;
3、无法深入分析用户行为指导操作。
面对这些痛点,我们可以通过使用外部软件工具进一步提高我们的运营效率。“数字管家”——数据互联数据智能机器人(以下简称“数据互联”)是一款非常流行的采用DaaS+RPA技术的过程自动化软件。“数据连接”可以根据用户设置的任务流程和规则实现自动化操作。通过非侵入、免协调技术,快速安全生成系统业务数据访问(API)接口,实时连接多个应用系统,跨系统采集和报表.
媒体运营商只需要预先设置好任务流程,“数据连接”可以模拟人工操作,比如复制、粘贴、点击、输入等,辅助我们完成那些大型的“规则相对固定,重复的和额外的。较低的价值”。
二、解决方案及应用场景
1、多平台一键分发
对于媒体工作者来说,时间就是金钱。日常的分发过程非常繁琐枯燥,需要大量宝贵的创作时间,而同行每天更新的内容越来越多,竞争也越来越激烈,却没有更多的时间去创作,这导致了一个恶性循环。,无法输出高质量的内容。
使用“Digital Connect”可以实现文章和视频的多平台一键分发,完美解决了内容分发的繁琐问题,节省了大量时间。以前需要 2-3 个小时才能完成的发布工作,现在几分钟就可以完成,大大提高了工作效率。自媒体竞争非常激烈。更多的内容创作必然会获得更多的曝光和品牌传播,更多的优质内容制作可以提升领域综合排名、赛事奖励和更多收入。
2、提高用户发布内容的流行度
媒体人员在操作各大文章和视频平台时,往往会发现自己花了很多时间和精力制作文章或视频内容,浏览量、点赞数、评论数等数据都低,导致无法让更多用户看到并获得更多曝光,导致运营数据和结果不尽人意。
“数据连接”可以在平台允许的范围内,通过任务流程和组件的合理配置,有效优化发布的文章和视频数据,有效优化平台输出内容。推广效率,提高内容曝光度,形成良性运营状态。
3、网站SEO智能优化
如今的市场竞争非常激烈,网民越来越多,使用搜索引擎的频率非常高。目前,最大的中文搜索引擎百度日均PV达到30亿。如果网站不做SEO优化,不利于搜索引擎采集收录,会影响网站网站的流量很容易被网友忽略。因此,无论是为了公司形象还是为了市场,SEO都非常重要。
“数据连接”可以为网站提供生态自营销解决方案,为网站页面关键词提供SEO智能优化方法,让网站在行业,从而获得更高的品牌收入和影响力。
“数据连接”结合了DaaS+RPA+AI技术。作为一款流程自动化软件,不受标准化具体场景的约束,部署流程也比较短,特别是对于复杂的场景。该解决方案高度定制且易于使用。此外,“数字连接”可以更好地适应软件环境的变化,降低运维成本,满足客户智能需求,在复杂应用场景中搭建高壁垒。
通过关键词采集文章采集api(一下这款软件生成一篇6000字的长文,软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-01-15 07:09
最近有一款软件很火。给它一个关键词,它会直接为你生成一个6000字的长文本。不过文章的内容比较啰嗦,这个软件的名字也不错。有趣:《废话文章Generator》~接下来导演带你深入了解这款软件~
首先,我们来看看这款软件的网页版。网页版的界面很简单,有一个输入框和一个生成按钮,一目了然:
那我们接下来试试。以“科技学院之最”为例,输入后点击生成,biu~会瞬间生成一个超长的文章,每次点击可以获得不同的文章,效率超高有木有!
但是仔细看会发现,虽然每次生成的文章都不一样,但是好像有些句子出现了很多次。这是怎么回事?
导演按照网页上的说明跳转到知乎,然后跳转到Github,终于找到了软件的源代码,大家下载下来研究一下~
经过一些简单的研究,导演发现文章大致是由名言、填充词、关键词和一些“废话”等组成,通过一定的算法。
作者提供了100多个名言,10多个俚语,30多个“废话”。这些内容随意组合拼接,可以形成多种结果。因此,每次生成的内容不完全相同!
如果下载源代码,也可以自己修改一些参数,比如段落长度、句子长度、文章的总字数:
另外,还可以修改文本部分,比如把名言修改成你想要的内容,生成你独有的文章~修改文本部分时,只需要修改数据中的内容即可.json 文件就可以了。这个文件可以用记事本,文本编辑器,或者类似功能的软件打开~
本软件作者强调,本软件生成的文章确实不合理,只能作为玩笑,请勿用于正式用途!所以就玩得开心吧~另外,作者还有进一步的开发计划:
除了以上,导演还想介绍一个比较有意思的网站,叫做《彩虹屁发生器》。不知道什么时候用~
这个原理也比较简单。每次点击【下一步】,都会通过API调用一条新的内容,并显示在网页上:
其实类似功能的软件或者网页还有很多,这里就不一一列举了。最后,导演再次提醒,这种软件是娱乐性的,千万不要在正式场合使用! 查看全部
通过关键词采集文章采集api(一下这款软件生成一篇6000字的长文,软件)
最近有一款软件很火。给它一个关键词,它会直接为你生成一个6000字的长文本。不过文章的内容比较啰嗦,这个软件的名字也不错。有趣:《废话文章Generator》~接下来导演带你深入了解这款软件~
首先,我们来看看这款软件的网页版。网页版的界面很简单,有一个输入框和一个生成按钮,一目了然:
那我们接下来试试。以“科技学院之最”为例,输入后点击生成,biu~会瞬间生成一个超长的文章,每次点击可以获得不同的文章,效率超高有木有!
但是仔细看会发现,虽然每次生成的文章都不一样,但是好像有些句子出现了很多次。这是怎么回事?
导演按照网页上的说明跳转到知乎,然后跳转到Github,终于找到了软件的源代码,大家下载下来研究一下~
经过一些简单的研究,导演发现文章大致是由名言、填充词、关键词和一些“废话”等组成,通过一定的算法。
作者提供了100多个名言,10多个俚语,30多个“废话”。这些内容随意组合拼接,可以形成多种结果。因此,每次生成的内容不完全相同!
如果下载源代码,也可以自己修改一些参数,比如段落长度、句子长度、文章的总字数:
另外,还可以修改文本部分,比如把名言修改成你想要的内容,生成你独有的文章~修改文本部分时,只需要修改数据中的内容即可.json 文件就可以了。这个文件可以用记事本,文本编辑器,或者类似功能的软件打开~
本软件作者强调,本软件生成的文章确实不合理,只能作为玩笑,请勿用于正式用途!所以就玩得开心吧~另外,作者还有进一步的开发计划:
除了以上,导演还想介绍一个比较有意思的网站,叫做《彩虹屁发生器》。不知道什么时候用~
这个原理也比较简单。每次点击【下一步】,都会通过API调用一条新的内容,并显示在网页上:
其实类似功能的软件或者网页还有很多,这里就不一一列举了。最后,导演再次提醒,这种软件是娱乐性的,千万不要在正式场合使用!

