
自动采集编写
准备服务器、创建虚拟主机:和以往的教程一样
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-24 18:16
采集小说网站的PC端看起来像这样:
移动终端看起来像这样:
源代码下载:
链接:密码:tqvk(感谢原创共享者:hostloc forum @ yingbi98 7)
准备服务器,创建虚拟主机:
与之前的教程一样,请首先部署lnmp环境,因此我不再赘述。我在博客上有详细的教程,或者访问官方网站进行查看(如果环境已经部署,请在此处跳过)
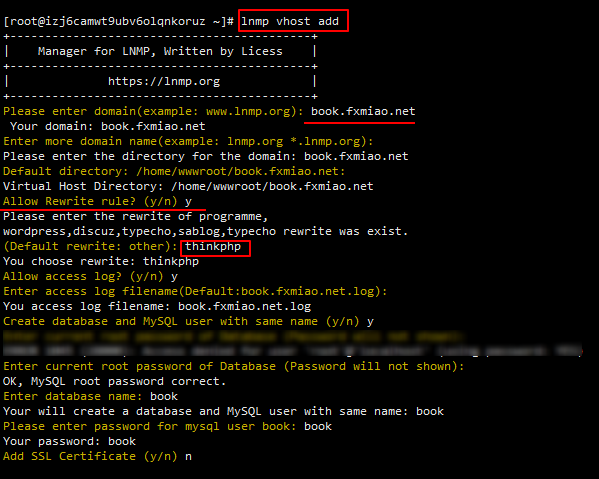
首先,我将您准备的域名解析为服务器ip,然后创建一个虚拟主机,我想下面的例子
应注意,伪静态规则是thinkphp的规则。如果您未设置伪静态规则,则将无法安装它们。因为lnmp一键式环境已随附此规则,所以可以根据上图进行设置。如果以其他方式部署nginx环境,则需要自己添加以下伪静态规则:
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
将上面下载的源代码上传到home / wwwroot /
的网站目录中
使用xshellcd到网站的根目录并解压缩源代码:
cd /home/wwwroot/book.fxmiao.net(换成你自己的目录)
unzip YGBOOK6.14.zip
用www用户组替换网站的所有者:
chown -R www:www *
浏览器访问域名并开始安装
填写数据库等信息,请注意不要在此处修改管理员用户名,否则将无法登录,安装成功后可在后台修改
安装成功后,它将自动跳至网站背景
等待后续设置,让我们自己探索
设置采集
该程序不能单独上传文章,只能依靠采集上传。
在此处共享了两个采集规则,均来自hostloc论坛,链接:密码:nry1
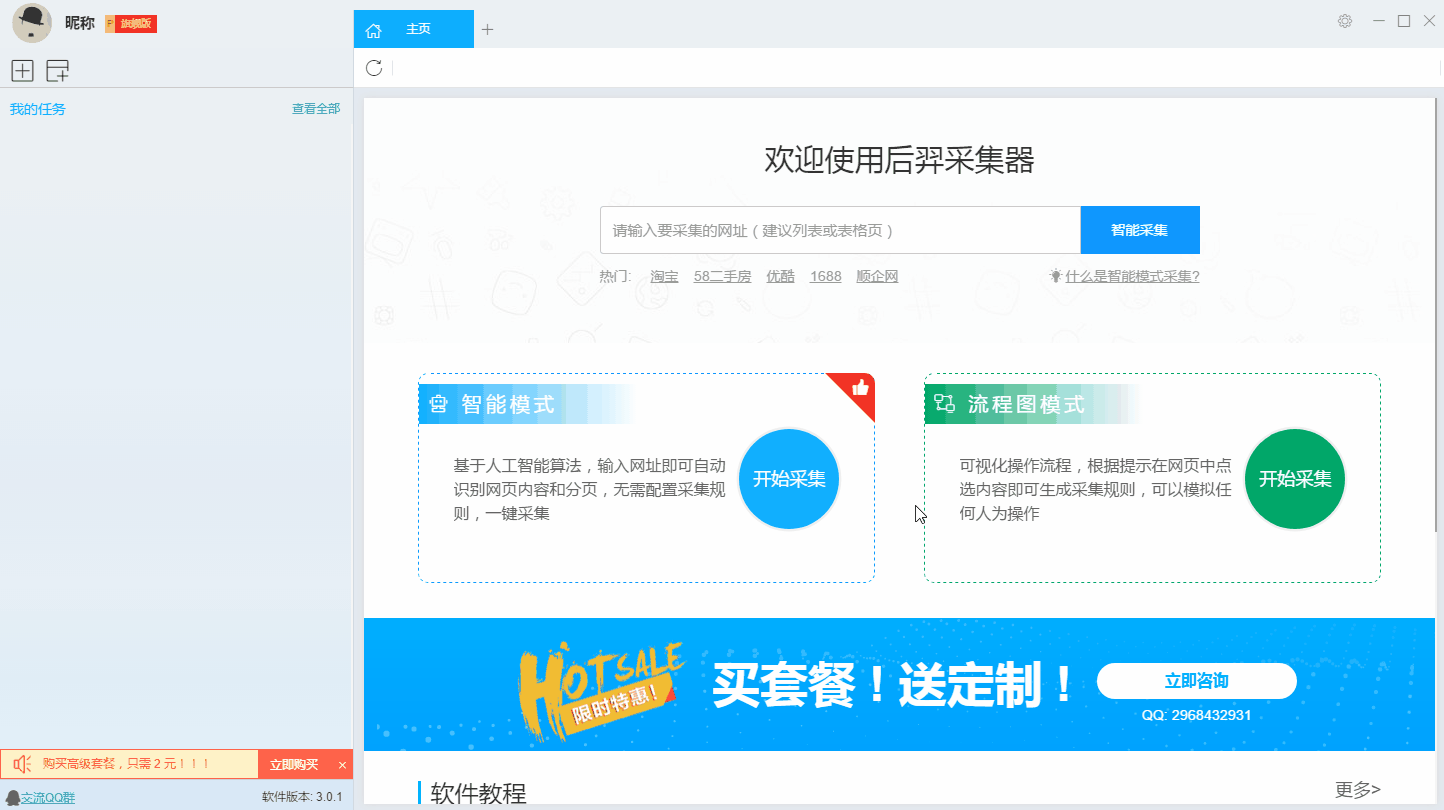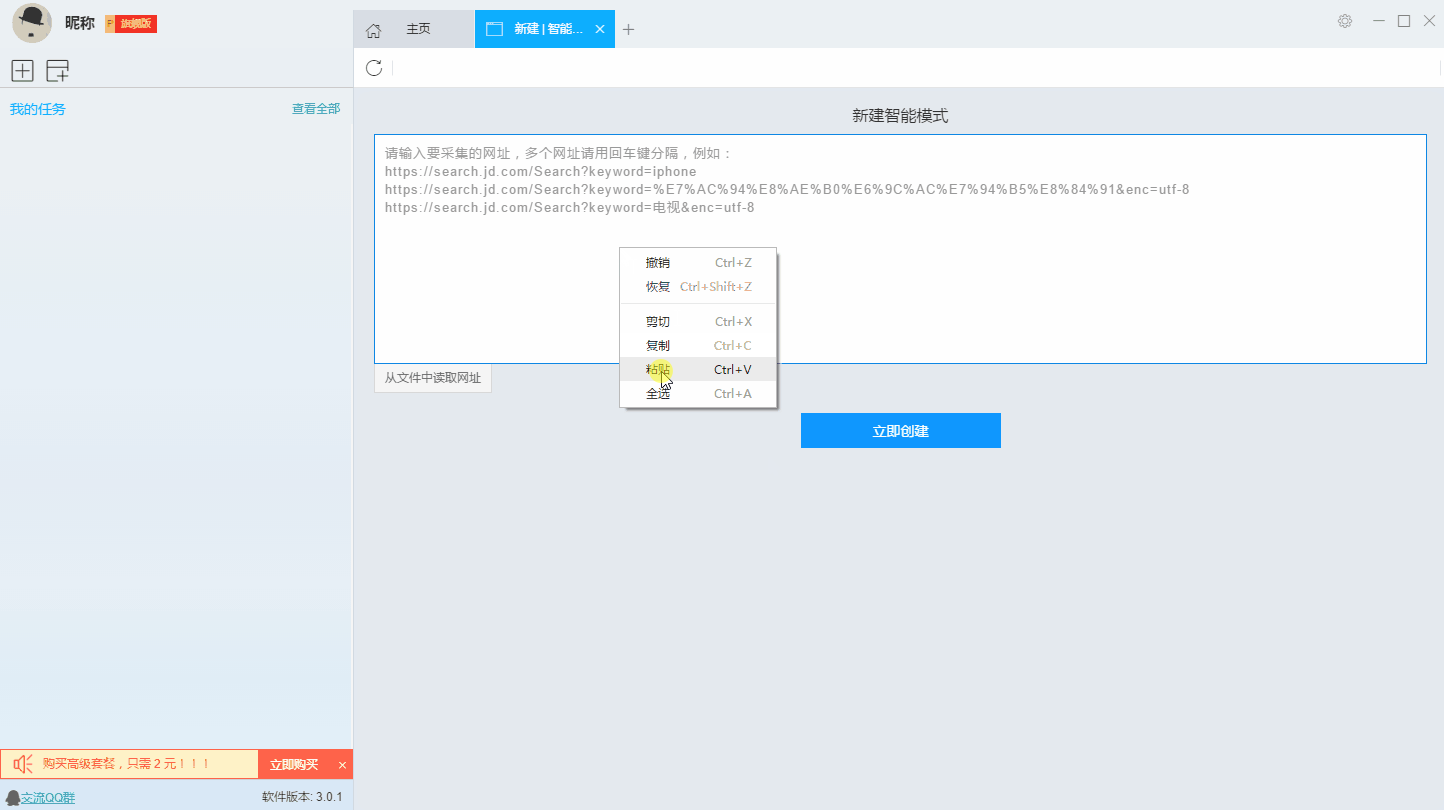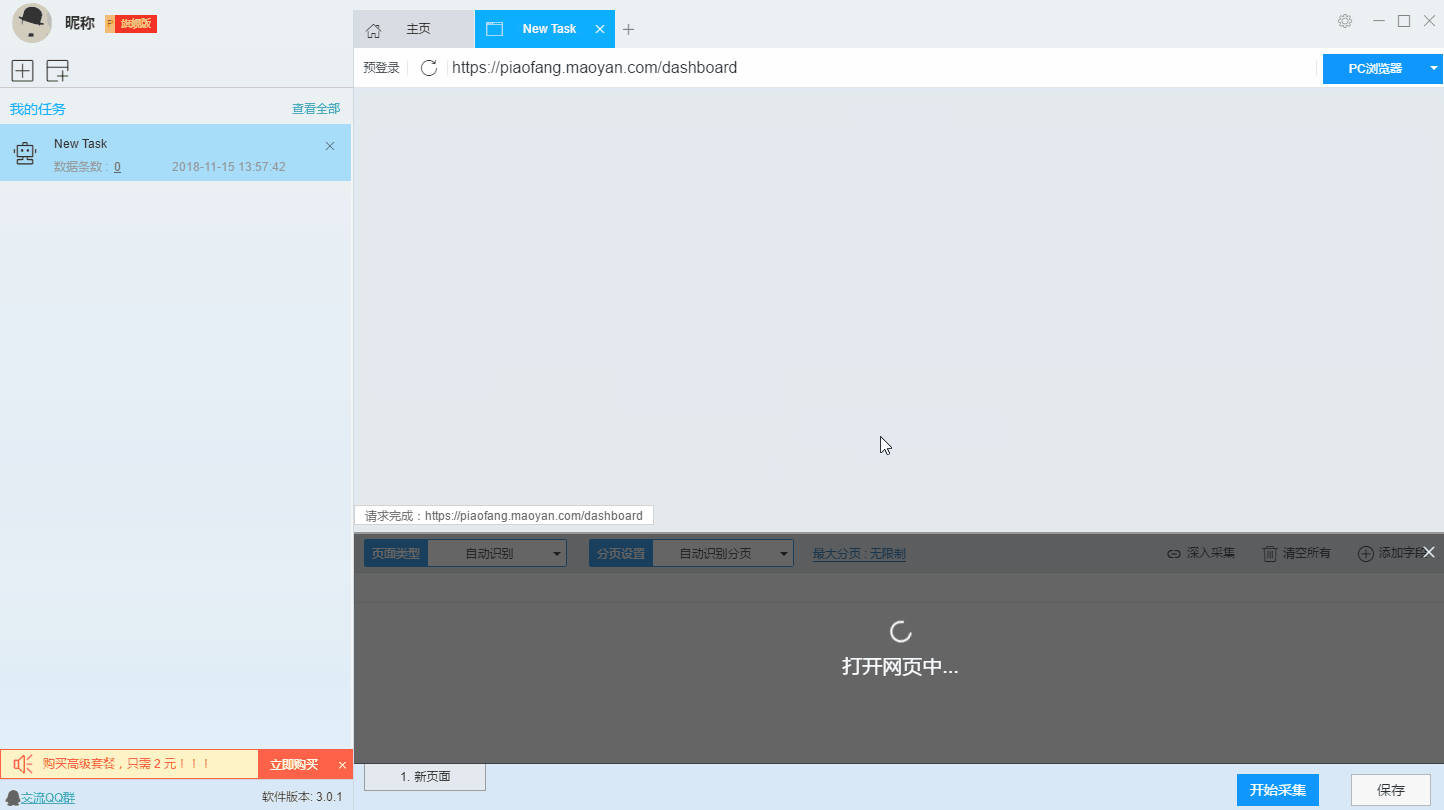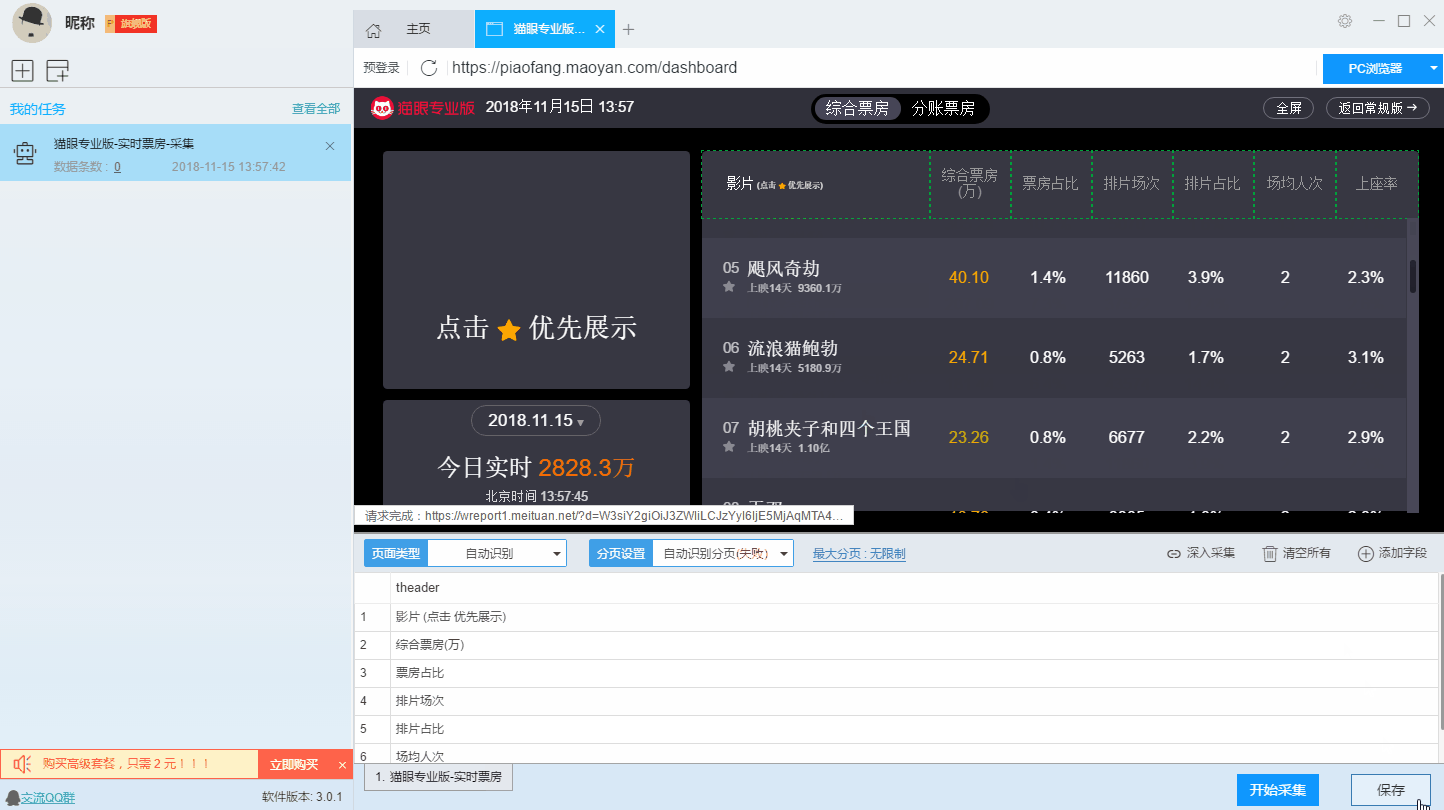
以[]这个规则为例,
点击导入:
粘贴采集规则并根据图片进行设置:
采集进行测试(如果要批处理采集,请使用下面的批处理采集按钮)
您可以看到采集成功
此后,您可以使用批处理采集功能转到采集(此采集来源大约有18,000本书,并且正在不断更新)。
请注意,采集的图书不会立即输入数据库,只有在用户访问时才会输入数据库。
可能的问题
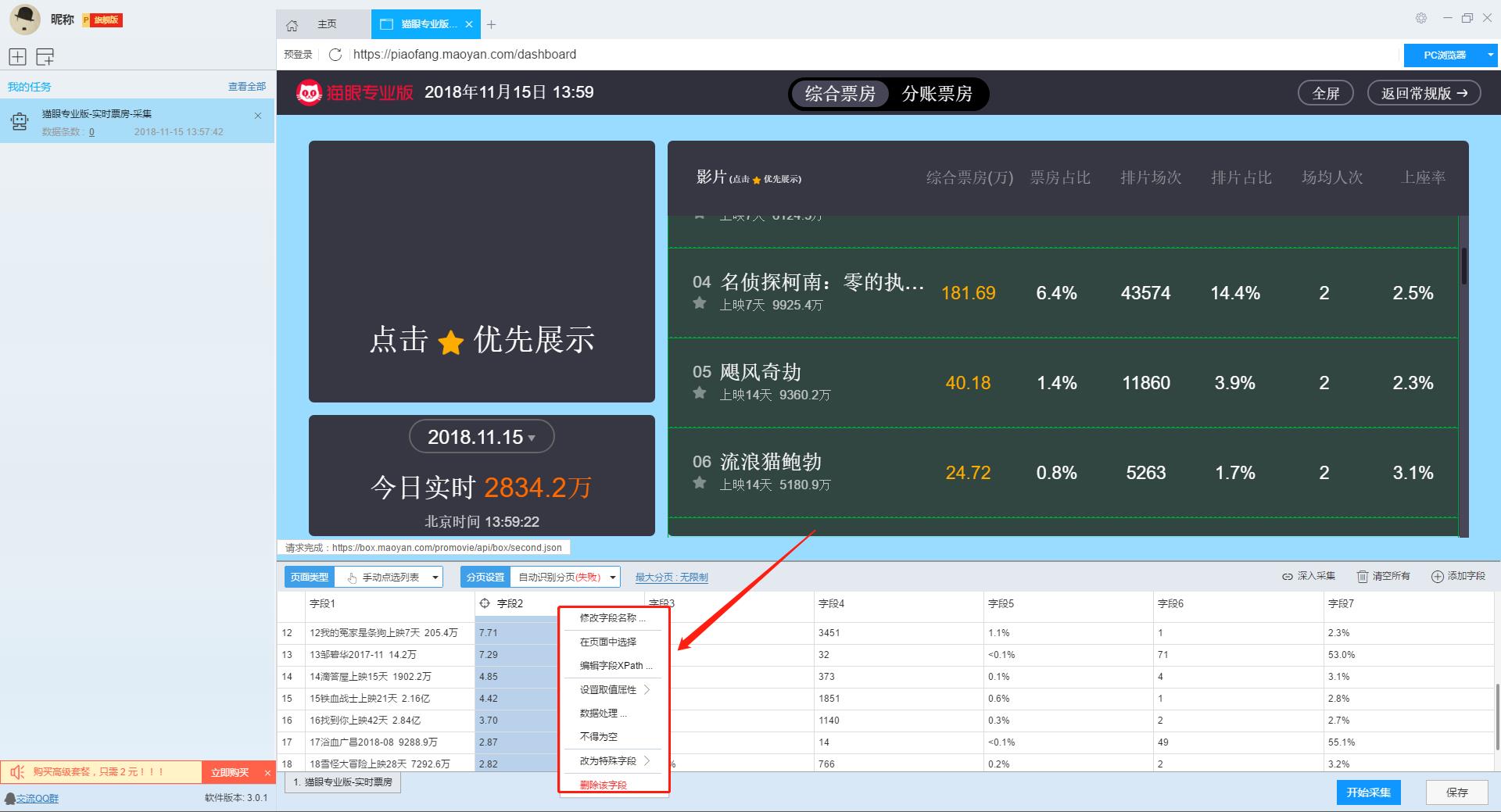
首先,请您自己解释采集规则,它实际上非常简单,您也可以自己编写
如果使用上面的采集规则,则可能会发现打开类别目录网站将冻结。这是一个规则问题。此时,您可以导入另一个采集规则,然后再导入采集。解决这个问题。
此外,您可能会发现网站主页和类别列表未显示内容,并且该网页未“打开”。首先,您可能太少了采集。首先,采集 1w或更多数据,然后等待两到三天今天,您可以在此期间自己访问更多书籍,然后可以在后台[数据块]中刷新块数据。如果仍然异常,则采集规则也可能有问题。请大家。自己写。
来源: 查看全部
准备服务器、创建虚拟主机:和以往的教程一样
采集小说网站的PC端看起来像这样:
 https://www.fxmiao.net/wp-cont ... 3.jpg 768w" />
https://www.fxmiao.net/wp-cont ... 3.jpg 768w" />移动终端看起来像这样:
源代码下载:
链接:密码:tqvk(感谢原创共享者:hostloc forum @ yingbi98 7)
准备服务器,创建虚拟主机:
与之前的教程一样,请首先部署lnmp环境,因此我不再赘述。我在博客上有详细的教程,或者访问官方网站进行查看(如果环境已经部署,请在此处跳过)
首先,我将您准备的域名解析为服务器ip,然后创建一个虚拟主机,我想下面的例子
应注意,伪静态规则是thinkphp的规则。如果您未设置伪静态规则,则将无法安装它们。因为lnmp一键式环境已随附此规则,所以可以根据上图进行设置。如果以其他方式部署nginx环境,则需要自己添加以下伪静态规则:
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
将上面下载的源代码上传到home / wwwroot /
的网站目录中

使用xshellcd到网站的根目录并解压缩源代码:
cd /home/wwwroot/book.fxmiao.net(换成你自己的目录)
unzip YGBOOK6.14.zip

用www用户组替换网站的所有者:
chown -R www:www *
浏览器访问域名并开始安装
 https://www.fxmiao.net/wp-cont ... 4.png 768w" />
https://www.fxmiao.net/wp-cont ... 4.png 768w" />填写数据库等信息,请注意不要在此处修改管理员用户名,否则将无法登录,安装成功后可在后台修改
 https://www.fxmiao.net/wp-cont ... 7.png 768w" />
https://www.fxmiao.net/wp-cont ... 7.png 768w" />安装成功后,它将自动跳至网站背景
 https://www.fxmiao.net/wp-cont ... 4.png 768w" />
https://www.fxmiao.net/wp-cont ... 4.png 768w" />等待后续设置,让我们自己探索
设置采集
该程序不能单独上传文章,只能依靠采集上传。
在此处共享了两个采集规则,均来自hostloc论坛,链接:密码:nry1
以[]这个规则为例,
点击导入:
 https://www.fxmiao.net/wp-cont ... 6.png 768w" />
https://www.fxmiao.net/wp-cont ... 6.png 768w" />粘贴采集规则并根据图片进行设置:
 https://www.fxmiao.net/wp-cont ... 2.png 768w" />
https://www.fxmiao.net/wp-cont ... 2.png 768w" />采集进行测试(如果要批处理采集,请使用下面的批处理采集按钮)
 https://www.fxmiao.net/wp-cont ... 2.png 768w" />
https://www.fxmiao.net/wp-cont ... 2.png 768w" />您可以看到采集成功
此后,您可以使用批处理采集功能转到采集(此采集来源大约有18,000本书,并且正在不断更新)。
请注意,采集的图书不会立即输入数据库,只有在用户访问时才会输入数据库。
可能的问题
首先,请您自己解释采集规则,它实际上非常简单,您也可以自己编写
如果使用上面的采集规则,则可能会发现打开类别目录网站将冻结。这是一个规则问题。此时,您可以导入另一个采集规则,然后再导入采集。解决这个问题。
此外,您可能会发现网站主页和类别列表未显示内容,并且该网页未“打开”。首先,您可能太少了采集。首先,采集 1w或更多数据,然后等待两到三天今天,您可以在此期间自己访问更多书籍,然后可以在后台[数据块]中刷新块数据。如果仍然异常,则采集规则也可能有问题。请大家。自己写。
来源:
腾讯新闻主页分解目标,一步地做(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-18 03:27
昨天我用python编写了天气预报采集,今天我在利用天气预报的同时写了一条新闻采集。
目标是抓取腾讯新闻首页上的所有新闻,并获取每篇新闻文章的名称,时间,来源和文字。
接下来分解目标并逐步进行。
第1步:抓取主页上的所有链接并将其写入文件。
根据上一篇文章文章中的方法,您只需获取整个首页的文本内容即可。
我们都知道html链接的标签是“ a”并且链接的属性是“ href”,也就是说,要获取html中所有的tag = a,attrs = href值。
我检查了这些信息,计划首先使用HTMLParser,然后将其写出来。但这有一个问题,就是它不能处理汉字。
class parser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'a':
for attr, value in attrs:
if attr == 'href':
print value
后来使用了SGMLParser,它没有这个问题。
class URLParser(SGMLParser):
def reset(self):
SGMLParser.reset(self)
self.urls = []
def start_a(self,attrs):
href = [v for k,v in attrs if k=='href']
if href:
self.urls.extend(href)
SGMLParser需要为某个标签重新加载其功能,这里是将所有链接放在此类的url中。
lParser = URLParser()#分析器来的
socket = urllib.urlopen("http://news.qq.com/")#打开这个网页
fout = file('urls.txt', 'w')#要把链接写到这个文件里
lParser.feed(socket.read())#分析啦
reg = 'http://news.qq.com/a/.*'#这个是用来匹配符合条件的链接,使用正则表达式匹配
pattern = re.compile(reg)
for url in lParser.urls:#链接都存在urls里
if pattern.match(url):
fout.write(url+'\n')
fout.close()
通过这种方式,所有符合条件的链接都保存在urls.txt文件中。
第2步:获取每个链接的网页内容。
这非常简单,只需打开urls.txt文件并逐行读取即可。
在这里似乎没有必要,但是基于我对去耦的强烈渴望,我仍然果断地将其写在文件中。如果以后使用面向对象的编程,则重构非常方便。
获取网页的内容相对简单,但是您需要将网页的内容保存在一个文件夹中。
这里有几种新用法:
os.getcwd()#获得当前文件夹路径
os.path.sep#当前系统路径分隔符(是这个叫法吗?)windows下是“\”,linux下是“/”
#判断文件夹是否存在,如果不存在则新建一个文件夹
if os.path.exists('newsdir') == False:
os.makedirs('newsdir')
#str()用来将某个数字转为字符串
i = 5
str(i)
使用这些方法,将字符串保存到某个文件夹中的其他文件不再是困难的任务。
第3步:枚举每个网页并根据常规匹配获取目标数据。
以下方法用于遍历文件夹。
#这个是用来遍历某个文件夹的
for parent, dirnames, filenames in os.walk(dir):
for dirname in dirnames
print parent, dirname
for filename in filenames:
print parent, filename
遍历,阅读,匹配,结果就会出来。
我用于数据提取的正则表达式是这样的:
reg = '.*?(.*?).*?(.*?).*?<a .*?>(.*?)</a>.*?(.*?)'
<p style="color:#444444;font-family:tahoma, arial, sans-serif;background-color:#FFFFFF;">
其实这个并不能匹配到腾讯网的所有新闻,因为上面的新闻有两种格式,标签有一点差别,所以只能提取出一种。
另外一点就是通过正则表达式的提取肯定不是主流的提取方法,如果需要采集其他网站,就需要变更正则表达式,这可是一件比较麻烦的事情。
提取之后观察可知,正文部分总是会参杂一些无关信息,比如“...”“
”等等。所以我再通过正则表达式将正文切片。
def func(str):#谁起的这个名字
strs = re.split(".*?|.*?|&#[0-9]+;||", str)#各种匹配,通过“|”分隔
ans = ''
#将切分的结果组合起来
for each in strs:
ans += each
return ans</p>
这样,基本上可以提取腾讯网站上的所有文本。
至此,整个采集结束了。
告诉我我提取的结果(没有自动换行,隐藏在右侧):
注意:
1、当打开某个URL时,如果URL错误(无法打开),则如果未处理,将报告错误。我只是使用处理异常的方法,估计应该还有其他方法。
try:
socket = urllib.urlopen(url)
except:
continue
2、“。”登录Python正则表达式可以匹配任何字符,但“ \ n”除外。
3、如何删除字符串末尾的“ \ n”? Python的处理是如此优美!
if line[-1] == '\n':
line = line[0:-1] 查看全部
腾讯新闻主页分解目标,一步地做(图)
昨天我用python编写了天气预报采集,今天我在利用天气预报的同时写了一条新闻采集。
目标是抓取腾讯新闻首页上的所有新闻,并获取每篇新闻文章的名称,时间,来源和文字。
接下来分解目标并逐步进行。
第1步:抓取主页上的所有链接并将其写入文件。
根据上一篇文章文章中的方法,您只需获取整个首页的文本内容即可。
我们都知道html链接的标签是“ a”并且链接的属性是“ href”,也就是说,要获取html中所有的tag = a,attrs = href值。
我检查了这些信息,计划首先使用HTMLParser,然后将其写出来。但这有一个问题,就是它不能处理汉字。
class parser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'a':
for attr, value in attrs:
if attr == 'href':
print value
后来使用了SGMLParser,它没有这个问题。
class URLParser(SGMLParser):
def reset(self):
SGMLParser.reset(self)
self.urls = []
def start_a(self,attrs):
href = [v for k,v in attrs if k=='href']
if href:
self.urls.extend(href)
SGMLParser需要为某个标签重新加载其功能,这里是将所有链接放在此类的url中。
lParser = URLParser()#分析器来的
socket = urllib.urlopen("http://news.qq.com/";)#打开这个网页
fout = file('urls.txt', 'w')#要把链接写到这个文件里
lParser.feed(socket.read())#分析啦
reg = 'http://news.qq.com/a/.*'#这个是用来匹配符合条件的链接,使用正则表达式匹配
pattern = re.compile(reg)
for url in lParser.urls:#链接都存在urls里
if pattern.match(url):
fout.write(url+'\n')
fout.close()
通过这种方式,所有符合条件的链接都保存在urls.txt文件中。
第2步:获取每个链接的网页内容。
这非常简单,只需打开urls.txt文件并逐行读取即可。
在这里似乎没有必要,但是基于我对去耦的强烈渴望,我仍然果断地将其写在文件中。如果以后使用面向对象的编程,则重构非常方便。
获取网页的内容相对简单,但是您需要将网页的内容保存在一个文件夹中。
这里有几种新用法:
os.getcwd()#获得当前文件夹路径
os.path.sep#当前系统路径分隔符(是这个叫法吗?)windows下是“\”,linux下是“/”
#判断文件夹是否存在,如果不存在则新建一个文件夹
if os.path.exists('newsdir') == False:
os.makedirs('newsdir')
#str()用来将某个数字转为字符串
i = 5
str(i)
使用这些方法,将字符串保存到某个文件夹中的其他文件不再是困难的任务。
第3步:枚举每个网页并根据常规匹配获取目标数据。
以下方法用于遍历文件夹。
#这个是用来遍历某个文件夹的
for parent, dirnames, filenames in os.walk(dir):
for dirname in dirnames
print parent, dirname
for filename in filenames:
print parent, filename
遍历,阅读,匹配,结果就会出来。
我用于数据提取的正则表达式是这样的:
reg = '.*?(.*?).*?(.*?).*?<a .*?>(.*?)</a>.*?(.*?)'
<p style="color:#444444;font-family:tahoma, arial, sans-serif;background-color:#FFFFFF;">
其实这个并不能匹配到腾讯网的所有新闻,因为上面的新闻有两种格式,标签有一点差别,所以只能提取出一种。
另外一点就是通过正则表达式的提取肯定不是主流的提取方法,如果需要采集其他网站,就需要变更正则表达式,这可是一件比较麻烦的事情。
提取之后观察可知,正文部分总是会参杂一些无关信息,比如“...”“
”等等。所以我再通过正则表达式将正文切片。
def func(str):#谁起的这个名字
strs = re.split(".*?|.*?|&#[0-9]+;||", str)#各种匹配,通过“|”分隔
ans = ''
#将切分的结果组合起来
for each in strs:
ans += each
return ans</p>
这样,基本上可以提取腾讯网站上的所有文本。
至此,整个采集结束了。
告诉我我提取的结果(没有自动换行,隐藏在右侧):

注意:
1、当打开某个URL时,如果URL错误(无法打开),则如果未处理,将报告错误。我只是使用处理异常的方法,估计应该还有其他方法。
try:
socket = urllib.urlopen(url)
except:
continue
2、“。”登录Python正则表达式可以匹配任何字符,但“ \ n”除外。
3、如何删除字符串末尾的“ \ n”? Python的处理是如此优美!
if line[-1] == '\n':
line = line[0:-1]
织梦网站后台自动采集侠的安装方法-织梦智能采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-05-11 21:00
织梦 采集 Xia是网站管理员必备的织梦 网站后台自动采集软件,此软件可以帮助用户快速添加和添加网站数据采集。每个织梦 dede 网站都必不可少的网站插件工具,它可以执行文章自动采集,织梦智能采集,同时具有无限的域名使用效果,使您可以不受次数限制,欢迎有需要的用户下载和使用。
织梦 Smart 采集 Xia功能
1、一键安装,全自动采集
织梦 采集 Xia的安装非常简单方便,只需一分钟即可立即开始采集,并结合了简单,健壮,灵活的开源dede cms程序,新手可以很快入门,我们还有专门的客户服务,可为商业客户提供技术支持。
2、是采集一词,无需编写采集规则
与传统采集模式的区别在于织梦 采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以通过采集 ] 关键词不同的搜索结果,认识到采集不在一个或几个指定的采集站点上执行,从而降低了采集站点被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3、 RSS 采集,输入收录采集内容的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以继续浏览RSS 采集,只需要输入RSS地址就可以轻松地采集到达目标网站内容,无需编写采集规则,方便和简单。
4、指定目标采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5、各种伪原创和优化方法,可提高收录的排名和排名
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,并提高了搜索引擎收录,网站权重和关键词排名。
6、该插件是全自动采集,无需人工干预
织梦 采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,然后将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进行伪原创,导入和生成。所有这些操作过程都是自动完成的,无需人工干预。
7、手动发布文章也可以是伪原创和搜索优化处理
织梦 采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦 采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词将自动添加指定的链接和其他功能,是织梦基本插件之一。
8、 采集 伪原创 SEO定期且定量地更新
有两种触发插件的采集的方法。一种是在页面上添加代码以通过用户访问来触发采集更新,另一种是我们为商业用户提供的远程触发采集服务。没有人访问新站点。无需人工干预即可定期,定量地更新采集。
9、定期定量更新待处理的手稿
即使您的数据库中有成千上万的文章,织梦 采集也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新。
1 0、绑定织梦 采集节点,定期进行采集 伪原创 SEO更新
绑定织梦 采集节点的功能,以便织梦 cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
织梦 Smart 采集 Xia破解说明
织梦 采集 Xia 采集版本分为UTF8和GBK两个版本。根据您使用的dede cms版本进行选择!
由于文件与mac系统打包在一起,因此它们将带有_MACOSX和.DS_Store文件,这不会影响使用,可以删除强迫症患者。覆盖被破解的文件时,不必关心这些文件。
1,[您转到采集夏官方下载了最新的v 2. 8版本(URL:如果无法打开官方网站,请使用我的备份,解压后会有采集 Xia官方插件文件夹,由您自己选择安装相应的版本),然后将其安装到您的织梦背景中。如果您以前安装过2. 7版本,请先将其删除! )
2。安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件:直接覆盖网站的根目录
include:直接覆盖网站的根目录
CaiJiXia:网站默认后端为dede。如果不修改后端目录,它将覆盖/ dede / apps /。如果后端访问路径已被修改,则将dede替换为修改后的名称。示例:已将dede修改为进行测试,然后覆盖/ test / apps /目录
4,[对于破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存,建议使用Google或Firefox,而不是IE内核浏览器,有时清理时不清理缓存]
6,PHP版本必须为5. 3 +
织梦智能采集如何使用
1、设置方向采集
1),登录到网站后台,执行模块-> 采集侠-> 采集任务,如果网站尚未添加列,则需要转到的列管理织梦首先添加一列,如果您已经添加了列,则可能会看到以下界面
2),在弹出页面中选择方向采集,如图所示
3),点击添加采集规则
2、设置目标页面编码
打开您想要的页面采集,单击鼠标右键,单击以查看网站的源代码,搜索字符集,并检查字符集后跟utf-8还是gb2312
3、设置列表网址
列表URL是您要采集的网站的列列表地址
如果它只是采集列表页面的第一页,只需直接输入列表URL。例如,如果我要网站管理员采集主页的优化部分的第一页,请输入列表URL :。 采集第一页内容的优点是您不需要采集个旧新闻,而新的更新可以及时采集个。如果您需要采集该列的所有内容,则还可以设置通配符以匹配所有列表URL规则的方式。
织梦 Smart 采集 Man常见问题解答
绑定x个域名授权是什么意思?
已授权多少个域名,织梦 采集 Xia商业版可以使用多少个网站。
插件可以为采集指定网站吗?
除了关键词 采集所述的插件外,还有采集两种方法,即RSS和页面监视采集,您可以为采集指定网站。
如果不再使用我的域名,我可以更改域名授权吗?
可以为您更换域名授权,每次更换1个域名授权仅需10元。
根据关键词 采集哪个内容是从哪个网站返回的?
根据关键词 采集,您使用设置为通过搜索引擎进行搜索的关键词,而采集的搜索结果来自不同的网站。 查看全部
织梦网站后台自动采集侠的安装方法-织梦智能采集
织梦 采集 Xia是网站管理员必备的织梦 网站后台自动采集软件,此软件可以帮助用户快速添加和添加网站数据采集。每个织梦 dede 网站都必不可少的网站插件工具,它可以执行文章自动采集,织梦智能采集,同时具有无限的域名使用效果,使您可以不受次数限制,欢迎有需要的用户下载和使用。
织梦 Smart 采集 Xia功能
1、一键安装,全自动采集
织梦 采集 Xia的安装非常简单方便,只需一分钟即可立即开始采集,并结合了简单,健壮,灵活的开源dede cms程序,新手可以很快入门,我们还有专门的客户服务,可为商业客户提供技术支持。
2、是采集一词,无需编写采集规则
与传统采集模式的区别在于织梦 采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以通过采集 ] 关键词不同的搜索结果,认识到采集不在一个或几个指定的采集站点上执行,从而降低了采集站点被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3、 RSS 采集,输入收录采集内容的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以继续浏览RSS 采集,只需要输入RSS地址就可以轻松地采集到达目标网站内容,无需编写采集规则,方便和简单。
4、指定目标采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5、各种伪原创和优化方法,可提高收录的排名和排名
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,并提高了搜索引擎收录,网站权重和关键词排名。
6、该插件是全自动采集,无需人工干预
织梦 采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,然后将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进行伪原创,导入和生成。所有这些操作过程都是自动完成的,无需人工干预。
7、手动发布文章也可以是伪原创和搜索优化处理
织梦 采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦 采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词将自动添加指定的链接和其他功能,是织梦基本插件之一。
8、 采集 伪原创 SEO定期且定量地更新
有两种触发插件的采集的方法。一种是在页面上添加代码以通过用户访问来触发采集更新,另一种是我们为商业用户提供的远程触发采集服务。没有人访问新站点。无需人工干预即可定期,定量地更新采集。
9、定期定量更新待处理的手稿
即使您的数据库中有成千上万的文章,织梦 采集也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新。
1 0、绑定织梦 采集节点,定期进行采集 伪原创 SEO更新
绑定织梦 采集节点的功能,以便织梦 cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
织梦 Smart 采集 Xia破解说明
织梦 采集 Xia 采集版本分为UTF8和GBK两个版本。根据您使用的dede cms版本进行选择!
由于文件与mac系统打包在一起,因此它们将带有_MACOSX和.DS_Store文件,这不会影响使用,可以删除强迫症患者。覆盖被破解的文件时,不必关心这些文件。
1,[您转到采集夏官方下载了最新的v 2. 8版本(URL:如果无法打开官方网站,请使用我的备份,解压后会有采集 Xia官方插件文件夹,由您自己选择安装相应的版本),然后将其安装到您的织梦背景中。如果您以前安装过2. 7版本,请先将其删除! )
2。安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件:直接覆盖网站的根目录
include:直接覆盖网站的根目录
CaiJiXia:网站默认后端为dede。如果不修改后端目录,它将覆盖/ dede / apps /。如果后端访问路径已被修改,则将dede替换为修改后的名称。示例:已将dede修改为进行测试,然后覆盖/ test / apps /目录
4,[对于破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存,建议使用Google或Firefox,而不是IE内核浏览器,有时清理时不清理缓存]
6,PHP版本必须为5. 3 +
织梦智能采集如何使用
1、设置方向采集
1),登录到网站后台,执行模块-> 采集侠-> 采集任务,如果网站尚未添加列,则需要转到的列管理织梦首先添加一列,如果您已经添加了列,则可能会看到以下界面
2),在弹出页面中选择方向采集,如图所示
3),点击添加采集规则
2、设置目标页面编码
打开您想要的页面采集,单击鼠标右键,单击以查看网站的源代码,搜索字符集,并检查字符集后跟utf-8还是gb2312
3、设置列表网址
列表URL是您要采集的网站的列列表地址
如果它只是采集列表页面的第一页,只需直接输入列表URL。例如,如果我要网站管理员采集主页的优化部分的第一页,请输入列表URL :。 采集第一页内容的优点是您不需要采集个旧新闻,而新的更新可以及时采集个。如果您需要采集该列的所有内容,则还可以设置通配符以匹配所有列表URL规则的方式。
织梦 Smart 采集 Man常见问题解答
绑定x个域名授权是什么意思?
已授权多少个域名,织梦 采集 Xia商业版可以使用多少个网站。
插件可以为采集指定网站吗?
除了关键词 采集所述的插件外,还有采集两种方法,即RSS和页面监视采集,您可以为采集指定网站。
如果不再使用我的域名,我可以更改域名授权吗?
可以为您更换域名授权,每次更换1个域名授权仅需10元。
根据关键词 采集哪个内容是从哪个网站返回的?
根据关键词 采集,您使用设置为通过搜索引擎进行搜索的关键词,而采集的搜索结果来自不同的网站。
自动采集编写python爬虫程序实现自动抓取马蜂窝(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2021-05-10 07:03
自动采集编写python爬虫程序实现自动抓取马蜂窝上ugc内容使用大数据技术,自动从分类信息、房价信息中,抓取至少10万条,
一)爬取分析在最开始安装完urllib库后,就可以开始爬取流程了,对于一个网站来说,各个内容会组成一个列表列表就是元素,子元素就是对每个元素的查询对象而每个文本类型就是对于每个元素的查询对象date_id、date_type、item_type、url_order就可以被用来查询列表中所有元素。爬取过程就是根据当前元素被查询的对象,对于其子元素再进行其他查询的过程。(。
二)采集过程python实现完成从以上几个文本类型中,自动采集并提取他们中的一些信息。准备工作1.需要用到jupyternotebook,集搜客采集数据中最重要的工具,没有之一,本人准备将这里搭建一个jupyternotebook环境。2.编写爬虫程序,当时写这个是采用web架构的,因为就是基于集搜客作为采集中间转发页面的应用。这里用到的框架为phantomjs。(。
三)代码实现:1.打开集搜客浏览器,访问以下网址打开集搜客客户端-集搜客首页可以看到,在以上网址中,有url_order标识,我们访问该链接即可获取数据。返回结果2.程序下载地址:集搜客平台首页-集搜客官方网站集搜客上的代码只支持采集到5000个文件,如果你想采集更多的数据,除了要了解集搜客的规则之外,还要去了解源代码。
集搜客源代码3.源代码下载地址:地址:集搜客下载.建立一个爬虫,采集10万条数据,源代码为requests库的httplib.我写过一个小的爬虫程序,
1)方法,page=1是集搜客的一个限制条件。这个爬虫程序在接下来就应该是采用requests.get(url)方法。以上是单个页面采集。现在我们采集整个链接列表(10万条),首先要用beautifulsoup的xpath规则来定位页面,这个是什么?我这里要用到requests的相关知识,所以还是会提前学习一下:requests中的xpath解析之4.httplib定位页面之后就可以定位链接中的title标识和href属性标识,这两个标识。
5.打开集搜客浏览器访问以下页面,点击网页最下方的“尝试抓取”按钮,弹出初始登录对话框,完成登录,发现整个爬虫程序就是点击初始登录按钮开始的。
执行爬虫程序
一)爬取结果爬取过程:首先找到页面上的div标签(这个页面叫做“集搜客列表”,div标签就是页面的大标题,后面会继续用到div标签。 查看全部
自动采集编写python爬虫程序实现自动抓取马蜂窝(组图)
自动采集编写python爬虫程序实现自动抓取马蜂窝上ugc内容使用大数据技术,自动从分类信息、房价信息中,抓取至少10万条,
一)爬取分析在最开始安装完urllib库后,就可以开始爬取流程了,对于一个网站来说,各个内容会组成一个列表列表就是元素,子元素就是对每个元素的查询对象而每个文本类型就是对于每个元素的查询对象date_id、date_type、item_type、url_order就可以被用来查询列表中所有元素。爬取过程就是根据当前元素被查询的对象,对于其子元素再进行其他查询的过程。(。
二)采集过程python实现完成从以上几个文本类型中,自动采集并提取他们中的一些信息。准备工作1.需要用到jupyternotebook,集搜客采集数据中最重要的工具,没有之一,本人准备将这里搭建一个jupyternotebook环境。2.编写爬虫程序,当时写这个是采用web架构的,因为就是基于集搜客作为采集中间转发页面的应用。这里用到的框架为phantomjs。(。
三)代码实现:1.打开集搜客浏览器,访问以下网址打开集搜客客户端-集搜客首页可以看到,在以上网址中,有url_order标识,我们访问该链接即可获取数据。返回结果2.程序下载地址:集搜客平台首页-集搜客官方网站集搜客上的代码只支持采集到5000个文件,如果你想采集更多的数据,除了要了解集搜客的规则之外,还要去了解源代码。
集搜客源代码3.源代码下载地址:地址:集搜客下载.建立一个爬虫,采集10万条数据,源代码为requests库的httplib.我写过一个小的爬虫程序,
1)方法,page=1是集搜客的一个限制条件。这个爬虫程序在接下来就应该是采用requests.get(url)方法。以上是单个页面采集。现在我们采集整个链接列表(10万条),首先要用beautifulsoup的xpath规则来定位页面,这个是什么?我这里要用到requests的相关知识,所以还是会提前学习一下:requests中的xpath解析之4.httplib定位页面之后就可以定位链接中的title标识和href属性标识,这两个标识。
5.打开集搜客浏览器访问以下页面,点击网页最下方的“尝试抓取”按钮,弹出初始登录对话框,完成登录,发现整个爬虫程序就是点击初始登录按钮开始的。
执行爬虫程序
一)爬取结果爬取过程:首先找到页面上的div标签(这个页面叫做“集搜客列表”,div标签就是页面的大标题,后面会继续用到div标签。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-05-09 04:07
自动采集编写技巧:1、ie下编写采集,这里我把采集规则放在一个excel里面,然后用python从excel读取数据,经过处理以后再自动发送。excel代码:#!/usr/bin/envpython#coding:utf-8"""初始目录definewhere:-/usr/bin/envpythonselectwhere-selectwhereit'sblue,thenwe'llcomebackonthelowpriceroom"""importredefprocess_command(pycap):magis=[xforxinselectionsifxinselectionsandthemagisinmagis)print("processprocess=:\n")returnpycapdefgenerate_magis(data):if(selections.has("magis")):magis=[xforxinselectionsifxinselectionsandxinselections.has_magis]returnmagis#加载gb2312字符集数据fromcn_us.codecsimportgb2312df=pile("(../s/{\d+})\t\n{}{}{})")df["font"]=gb2312("simsun")df["type"]=gb2312("comicsans")print("通过上述代码采集字符集字段为:",df.fields.size)forkey,valueinzip(df["font"],df["type"]):magis=magis("simsun")magis=magis("comicsans")magis=magis("white.post")magis=magis("green.post")name=magis["name"]print("公司名字为:",name)total=magis["total"]status=magis["status"]content=magis["content"]expire_date=magis["expired"]2、全拼采集请求,代码:#url:。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
自动采集编写技巧:1、ie下编写采集,这里我把采集规则放在一个excel里面,然后用python从excel读取数据,经过处理以后再自动发送。excel代码:#!/usr/bin/envpython#coding:utf-8"""初始目录definewhere:-/usr/bin/envpythonselectwhere-selectwhereit'sblue,thenwe'llcomebackonthelowpriceroom"""importredefprocess_command(pycap):magis=[xforxinselectionsifxinselectionsandthemagisinmagis)print("processprocess=:\n")returnpycapdefgenerate_magis(data):if(selections.has("magis")):magis=[xforxinselectionsifxinselectionsandxinselections.has_magis]returnmagis#加载gb2312字符集数据fromcn_us.codecsimportgb2312df=pile("(../s/{\d+})\t\n{}{}{})")df["font"]=gb2312("simsun")df["type"]=gb2312("comicsans")print("通过上述代码采集字符集字段为:",df.fields.size)forkey,valueinzip(df["font"],df["type"]):magis=magis("simsun")magis=magis("comicsans")magis=magis("white.post")magis=magis("green.post")name=magis["name"]print("公司名字为:",name)total=magis["total"]status=magis["status"]content=magis["content"]expire_date=magis["expired"]2、全拼采集请求,代码:#url:。
自动采集编写爬虫模块的价格相关数据提供的吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-05-08 01:08
自动采集编写爬虫模块,可以按照需求采集比价网或等平台的价格相关数据,
的数据不都是有分析数据提供的吗?requests:?如果需要爬什么数据可以先用excel导入然后再写爬虫
python爬虫模块scrapy:django:
现在爬虫教程还挺多的,
那要看题主是爬什么网站,要实现怎样的效果。如果是某宝天猫等商品信息,的话,用fiddler看下发送给你的http报文就可以看到相关商品的价格了。如果是调用爬虫框架的话,推荐yii框架,其他框架可以依赖他的库实现。
爬楼主要爬哪里?多久能爬完?
根据你需要查看对应网站的网页源代码
requests,urllib2。
最高赞的requests写爬虫的方式不太适合爬的数据,可以试试pythonrequests库爬的数据,自己处理过一段时间,很方便,就是回复速度慢了点。
requests
没有爬虫啊,
你有多少金币
有四个api接口,头条,论坛,美食,钱包。可以自己搭配编写爬虫,每个api返回的数据结构是可以定制的。 查看全部
自动采集编写爬虫模块的价格相关数据提供的吗?
自动采集编写爬虫模块,可以按照需求采集比价网或等平台的价格相关数据,
的数据不都是有分析数据提供的吗?requests:?如果需要爬什么数据可以先用excel导入然后再写爬虫
python爬虫模块scrapy:django:
现在爬虫教程还挺多的,
那要看题主是爬什么网站,要实现怎样的效果。如果是某宝天猫等商品信息,的话,用fiddler看下发送给你的http报文就可以看到相关商品的价格了。如果是调用爬虫框架的话,推荐yii框架,其他框架可以依赖他的库实现。
爬楼主要爬哪里?多久能爬完?
根据你需要查看对应网站的网页源代码
requests,urllib2。
最高赞的requests写爬虫的方式不太适合爬的数据,可以试试pythonrequests库爬的数据,自己处理过一段时间,很方便,就是回复速度慢了点。
requests
没有爬虫啊,
你有多少金币
有四个api接口,头条,论坛,美食,钱包。可以自己搭配编写爬虫,每个api返回的数据结构是可以定制的。
怎样使用软件一天撰写1万篇高质量的SEO文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-04-30 19:07
Koala SEO [批处理SEO 原创 文章]平台支持本文。有了考拉,一天就可以制作成千上万的高质量SEO文章文章!
非常抱歉!当每个人都访问此页面时,可能没有关于Babenman 采集器的报告,因为此页面是我们的工具站AI生成的Web内容。如果您对这批原创 文章感兴趣,那么抛开Hachibenman 采集器的问题,编辑器将向您展示如何使用该软件每天编写10,000个高质量的SEO着陆页!大多数客户来到我们的内容,认为这是伪原创软件,这是错误的!实际上,这是一个AI工具,文本和模板都是自己创建的,不可能找到与Internet上的导出文章相同的相似性。 文章。这到底是怎么发生的?稍后我将给您进行全面的分析!
实际上,想要询问Hachibenman 采集器的朋友,每个人都热衷的是上面讨论的内容。但是,写几篇高质量的网站着陆文章非常容易,但是这几篇文章可以产生的搜索量确实微不足道。希望可以利用内容的积累来实现长尾单词流量的目的。非常重要的策略是自动化!如果一个页面文章每天可以带来1位访问者,那么如果我可以编辑10,000篇文章,则每天的页面浏览量可能会增加10,000。但是实际上看起来很简单,一个人在24小时内最多只能写40篇文章,最多只能写60篇文章。即使在伪原创平台上进行操作,最多也将有一百篇文章!浏览到这一点,我们应该放弃Babenman 采集器的话题,而讨论如何实现智能写作文章!
什么是seo批准的独立创作?内容原创不等于一个单词原创的输出!在主要搜索的算法定义中,原创并不意味着没有重复。实际上,只要您的文章和其他人的收录不完全相同,被索引的机会就会增加。热门文章充满了明亮的价值,并且保留了相同的目标词。只要确定没有相同的内容,就表示该文章文章仍然很有可能收录,甚至成为排水的好文章。例如,对于本文,我们可能使用搜索引擎搜索Babenman 采集器,然后单击以查看它。负责人告诉您:我的文章文章是使用Koala系统文章的AI工具自行编写的!
此平台上的伪原创软件实际上应手动编写文章软件。半天之内可能会写出可靠的SEO副本。只要您的页面质量足够好,收录就可以。高达78%。有关详细的应用技巧,用户中心中有一个视频介绍和一个初学者指南,每个人都可以对其进行一点测试!我没有为Babenman 采集器写一个详细的解释,这让您读了很多废话,对此我感到很ham愧。但是,假设每个人都对该产品感兴趣,那么您可以注意导航栏,这样我们的页面每天就有成千上万的访客。那不是很好吗? 查看全部
怎样使用软件一天撰写1万篇高质量的SEO文章
Koala SEO [批处理SEO 原创 文章]平台支持本文。有了考拉,一天就可以制作成千上万的高质量SEO文章文章!
非常抱歉!当每个人都访问此页面时,可能没有关于Babenman 采集器的报告,因为此页面是我们的工具站AI生成的Web内容。如果您对这批原创 文章感兴趣,那么抛开Hachibenman 采集器的问题,编辑器将向您展示如何使用该软件每天编写10,000个高质量的SEO着陆页!大多数客户来到我们的内容,认为这是伪原创软件,这是错误的!实际上,这是一个AI工具,文本和模板都是自己创建的,不可能找到与Internet上的导出文章相同的相似性。 文章。这到底是怎么发生的?稍后我将给您进行全面的分析!
实际上,想要询问Hachibenman 采集器的朋友,每个人都热衷的是上面讨论的内容。但是,写几篇高质量的网站着陆文章非常容易,但是这几篇文章可以产生的搜索量确实微不足道。希望可以利用内容的积累来实现长尾单词流量的目的。非常重要的策略是自动化!如果一个页面文章每天可以带来1位访问者,那么如果我可以编辑10,000篇文章,则每天的页面浏览量可能会增加10,000。但是实际上看起来很简单,一个人在24小时内最多只能写40篇文章,最多只能写60篇文章。即使在伪原创平台上进行操作,最多也将有一百篇文章!浏览到这一点,我们应该放弃Babenman 采集器的话题,而讨论如何实现智能写作文章!
什么是seo批准的独立创作?内容原创不等于一个单词原创的输出!在主要搜索的算法定义中,原创并不意味着没有重复。实际上,只要您的文章和其他人的收录不完全相同,被索引的机会就会增加。热门文章充满了明亮的价值,并且保留了相同的目标词。只要确定没有相同的内容,就表示该文章文章仍然很有可能收录,甚至成为排水的好文章。例如,对于本文,我们可能使用搜索引擎搜索Babenman 采集器,然后单击以查看它。负责人告诉您:我的文章文章是使用Koala系统文章的AI工具自行编写的!

此平台上的伪原创软件实际上应手动编写文章软件。半天之内可能会写出可靠的SEO副本。只要您的页面质量足够好,收录就可以。高达78%。有关详细的应用技巧,用户中心中有一个视频介绍和一个初学者指南,每个人都可以对其进行一点测试!我没有为Babenman 采集器写一个详细的解释,这让您读了很多废话,对此我感到很ham愧。但是,假设每个人都对该产品感兴趣,那么您可以注意导航栏,这样我们的页面每天就有成千上万的访客。那不是很好吗?
Python编程语言编写的门槛低、易上手的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-04-29 02:18
在互联网信息爆炸式增长的时代,我们经常面临与信息采集相关的各种事情,但是信息的来源很多网站,信息量很大。如果使用常规的手动搜索+办公软件进行组织,则通常会花费很多钱。时间。
在这里,我将介绍一个低阈值,易于使用的工具Python。
以Python编程语言编写的网络爬虫是一种“自动浏览网络”的程序,或者是一种网络机器人。
它可以自动采集所有可访问的页面内容并获取大量信息。很多事情需要在一天内手动完成,Python只需1分钟甚至几秒钟即可完成。 ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????
例如,诸如百度搜索和Google搜索之类的搜索工具,各种价格比较网站都使用Python采集器采集信息,然后进行处理,分析和反馈。
也许每个人都认为Python编程和爬网都是程序员的事,但我想告诉你事实并非如此。我各行各业的许多朋友正在学习Python。
Python开始被纳入小学教科书并被纳入高考
各行各业的学生/运营/营销/产品/财务/财务/行政/销售/客户服务等,如果您了解Python,则可以释放至少80%的重复性工作,因此您有更多的时间和精力去改善自己。有效地工作并快乐地生活!
使用Python捕获竞争产品信息,执行数据分析和信息排序,并制作各种专业图表,这比手动采集要快100倍。提高效率并告别加班!
使用Python批量查找图片,抓取许多文案材料,并制作更具设计感的海报。甚至有人写了超过100,000种热门样式文章!
Python几乎已成为金融从业人员的标准!
使用Python完成巨大的报表数据的统计和分析,甚至包括出勤。
我们必须了解:
20年前,学习英语并不是要成为翻译。 10年前,学习计算机并不是要成为打字员。今天,学习编程并不是要成为一名程序员,而是要增强我们在工作场所的竞争力!
今天,我将与您分享学习Python的基本概念图,入门书籍,视频教程以及最有效的学习方式。
当然,这很完美。当我们精通代码时,我们自然可以总结出一些有用的技术,但是对于那些只熟悉Python的学生来说,这可能并不容易。
以下是30秒内学习Python的整个目录,分为几个主要部分:列表,数学,对象,字符串,实用程序,以下是排序的思维导图。
如果您对Python感兴趣或已开始采取行动,我相信您已经看过很多视频教程,对吗?效果如何?
今天,我为所有Python部门准备了一个新发布的自学教程-“ Python +数据分析+机器学习”。能力的七个阶段逐渐得到改进,以创建具有更全面技能的全职工程师。
1、欢迎喜欢+转发! 查看全部
Python编程语言编写的门槛低、易上手的工具
在互联网信息爆炸式增长的时代,我们经常面临与信息采集相关的各种事情,但是信息的来源很多网站,信息量很大。如果使用常规的手动搜索+办公软件进行组织,则通常会花费很多钱。时间。
在这里,我将介绍一个低阈值,易于使用的工具Python。
以Python编程语言编写的网络爬虫是一种“自动浏览网络”的程序,或者是一种网络机器人。
它可以自动采集所有可访问的页面内容并获取大量信息。很多事情需要在一天内手动完成,Python只需1分钟甚至几秒钟即可完成。 ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????
例如,诸如百度搜索和Google搜索之类的搜索工具,各种价格比较网站都使用Python采集器采集信息,然后进行处理,分析和反馈。
也许每个人都认为Python编程和爬网都是程序员的事,但我想告诉你事实并非如此。我各行各业的许多朋友正在学习Python。
Python开始被纳入小学教科书并被纳入高考
各行各业的学生/运营/营销/产品/财务/财务/行政/销售/客户服务等,如果您了解Python,则可以释放至少80%的重复性工作,因此您有更多的时间和精力去改善自己。有效地工作并快乐地生活!
使用Python捕获竞争产品信息,执行数据分析和信息排序,并制作各种专业图表,这比手动采集要快100倍。提高效率并告别加班!
使用Python批量查找图片,抓取许多文案材料,并制作更具设计感的海报。甚至有人写了超过100,000种热门样式文章!
Python几乎已成为金融从业人员的标准!
使用Python完成巨大的报表数据的统计和分析,甚至包括出勤。
我们必须了解:
20年前,学习英语并不是要成为翻译。 10年前,学习计算机并不是要成为打字员。今天,学习编程并不是要成为一名程序员,而是要增强我们在工作场所的竞争力!
今天,我将与您分享学习Python的基本概念图,入门书籍,视频教程以及最有效的学习方式。
当然,这很完美。当我们精通代码时,我们自然可以总结出一些有用的技术,但是对于那些只熟悉Python的学生来说,这可能并不容易。
以下是30秒内学习Python的整个目录,分为几个主要部分:列表,数学,对象,字符串,实用程序,以下是排序的思维导图。
如果您对Python感兴趣或已开始采取行动,我相信您已经看过很多视频教程,对吗?效果如何?
今天,我为所有Python部门准备了一个新发布的自学教程-“ Python +数据分析+机器学习”。能力的七个阶段逐渐得到改进,以创建具有更全面技能的全职工程师。
1、欢迎喜欢+转发!
Sleep(Rnd)三就是多用正则表达式测试工具提高编写正则的效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-28 18:13
睡眠(修复(Rnd()* 3))
第三种是使用正则表达式测试工具来提高编写正则表达式的效率
4.高级主题:UTF-8和GB2312的转换
这个问题更加复杂。由于我的智力和精力原因,我还没有完全解决它,并且Internet上的大多数信息也不是完全正确或全面的。我建议使用UTF-8和GB2312转换的C语言实现。供您参考,它具有完整的功能,并且不依赖Windows API函数。
我正在尝试使用ASP + VBScript来实现它,但是我有一些不成熟的经验:
计算机上的文件和操作系统的内部字符串表示形式都是Unicode,因此UTF-8和GB2312之间的转换需要使用Unicode作为中介
UTF-8是Unicode的一种变体,它们之间的相互转换相对简单,请参考下图。
GB2312和Unicode编码似乎无关。如果不依赖操作系统的内部功能进行转换,则需要一个编码映射表,指出GB2312与Unicode编码之间的一一对应关系。该编码表收录大约7480×2的项目。
在ASP文件中,如果要默认读取具有特定总和代码的字符串(例如GB231 2),则需要将ASP CodePage设置为相应的代码页(CodePage = 93 6)用于GB2312)
我尚不知道编码转换中的一些小而重要的问题:-(
5.更多高级主题:登录后进行爬网,客户端伪造等。
xmlhttp对象可以在post或get方法中与http服务器进行交互,您可以设置和读取http头,了解http协议,并对某些xmlhttp对象的方法和属性有更深入的了解,可以使用它来模拟浏览器可以自动执行之前需要完成的所有重复性任务。
6.自己的采集程序
本文旨在讨论采集程序在ASP + VBScript环境中的实现。如果您需要网页采集程序,则以下链接可能对您有用。
优采云网络内容采集器
C#+。Net书面内容采集器,其重要特征之一是它不会将采集中的内容保存到数据库中,而是使用自定义POST提交的其他网页,例如内容管理系统新内容页面。自由。 BeeCollector(小蜜蜂采集器)
PHP + MySQL 采集器编写的内容。丰迅内容管理系统
此功能强大的内容管理系统收录ASP网页内容采集器 +查看评论(0) +帖子评论+引用地址+引用(0) 2006-8-9网络编程中的正则表达式使用
分类:Ajax时间:2006-8-914:07:47作者:Janyin指南:
在网络编程中使用正则表达式
[前言:]在编写WEB程序时,我们经常判断字符串的有效性,例如字符串是否为数字,是否为有效的电子邮件地址等等。如果不使用正则表达式,那么判断程序将非常长且容易出错。如果使用正则表达式,那么这些判断将非常容易。本文全面介绍了正则表达式的概念和格式。并通过PHP和ASP中的应用示例来增加读者的感知知识。正则表达式的应用范围很广,每个人都需要在学习和实践中不断总结。 查看全部
Sleep(Rnd)三就是多用正则表达式测试工具提高编写正则的效率
睡眠(修复(Rnd()* 3))
第三种是使用正则表达式测试工具来提高编写正则表达式的效率
4.高级主题:UTF-8和GB2312的转换
这个问题更加复杂。由于我的智力和精力原因,我还没有完全解决它,并且Internet上的大多数信息也不是完全正确或全面的。我建议使用UTF-8和GB2312转换的C语言实现。供您参考,它具有完整的功能,并且不依赖Windows API函数。
我正在尝试使用ASP + VBScript来实现它,但是我有一些不成熟的经验:
计算机上的文件和操作系统的内部字符串表示形式都是Unicode,因此UTF-8和GB2312之间的转换需要使用Unicode作为中介
UTF-8是Unicode的一种变体,它们之间的相互转换相对简单,请参考下图。
GB2312和Unicode编码似乎无关。如果不依赖操作系统的内部功能进行转换,则需要一个编码映射表,指出GB2312与Unicode编码之间的一一对应关系。该编码表收录大约7480×2的项目。
在ASP文件中,如果要默认读取具有特定总和代码的字符串(例如GB231 2),则需要将ASP CodePage设置为相应的代码页(CodePage = 93 6)用于GB2312)
我尚不知道编码转换中的一些小而重要的问题:-(
5.更多高级主题:登录后进行爬网,客户端伪造等。
xmlhttp对象可以在post或get方法中与http服务器进行交互,您可以设置和读取http头,了解http协议,并对某些xmlhttp对象的方法和属性有更深入的了解,可以使用它来模拟浏览器可以自动执行之前需要完成的所有重复性任务。
6.自己的采集程序
本文旨在讨论采集程序在ASP + VBScript环境中的实现。如果您需要网页采集程序,则以下链接可能对您有用。
优采云网络内容采集器
C#+。Net书面内容采集器,其重要特征之一是它不会将采集中的内容保存到数据库中,而是使用自定义POST提交的其他网页,例如内容管理系统新内容页面。自由。 BeeCollector(小蜜蜂采集器)
PHP + MySQL 采集器编写的内容。丰迅内容管理系统
此功能强大的内容管理系统收录ASP网页内容采集器 +查看评论(0) +帖子评论+引用地址+引用(0) 2006-8-9网络编程中的正则表达式使用
分类:Ajax时间:2006-8-914:07:47作者:Janyin指南:
在网络编程中使用正则表达式
[前言:]在编写WEB程序时,我们经常判断字符串的有效性,例如字符串是否为数字,是否为有效的电子邮件地址等等。如果不使用正则表达式,那么判断程序将非常长且容易出错。如果使用正则表达式,那么这些判断将非常容易。本文全面介绍了正则表达式的概念和格式。并通过PHP和ASP中的应用示例来增加读者的感知知识。正则表达式的应用范围很广,每个人都需要在学习和实践中不断总结。
本软件不提供采集规则全自动采集一次安装受益终身
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2021-04-26 19:22
此源代码已启用伪静态规则。服务器必须支持伪静态
服务器当前仅支持php + apache
如果您是php + Nginx,请自行修改伪静态规则
或更改服务器操作环境。否则它将不可用。
此源代码没有APP软件。标题中编写的APP支持在其他新颖的APP平台上进行转码和阅读。
一个新颖的网站的每个人都知道。操作APP的成本太高。制作一个APP的最低费用为10,000元人民币。但是,将您自己的网站链接到其他已建立的新颖网站是最方便,最便宜的方式。此源代码支持其他APP软件的代码转换。
它附带演示采集规则。但是其中一些已经过期
采集规则,请自行编写。这家商店不提供采集规则
全自动采集一次性安装,终生受益
1、源代码类型:整个网站的源代码
2、环境要求:PHP 5. 2 / 5. 3 / 5. 4 / 5. 5 + MYSQL5(.Htaccess伪静态)
3、服务器要求:建议使用VPS或具有40G或更多数据磁盘的独立服务器。系统建议使用Windows而不是LNMP。 99%的新型站点服务器使用Windows,这对于文件管理和备份非常方便。 (当前演示站点空间使用情况:6. 5G数据库+ 5G网站空间,已由小组朋友网站验证:具有4核CPU + 4G内存的xen架构VPS可以承受每天50,000 IP和500,000 PV流量而没有压力,获得更多收入超过每天700元)
4、原创程序:织梦 DEDE cms 5. 7SP1
5、编码类型:GBK
6、可以采集:全自动采集(如果内置规则无效,或者采集目标电台被阻止,请找人编写规则,本店概不负责规则的有效性)
7、其他功能:
([1)自动为主页,类别,目录,作者,排名,站点地图页面生成静态html。
([2)全站点拼音目录(可以自定义URL格式),章节页面是伪静态的。
([3)支持下载功能,可以自动生成相应的文本文件,并在该文件中设置广告。
([4)自动生成关键词和关键词自动内部链接。
([5)自动伪原创单词替换(采集,可以在输出期间替换)。
(6)使用CNZZ的统计插件,可以轻松实现详细统计信息的下载和详细统计信息的采集等。
(7)该程序的自动采集在市场优采云,Guanguan,采集等市场中并不常见,而是基于DEDE原创采集功能的二次开发[The k15]模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
(8)安装相对简单,如果安装后打开的URL始终是移动版本,请转到系统设置-查找移动终端,并将其更改为您自己的移动终端独立域名
演示库
TAG:小说
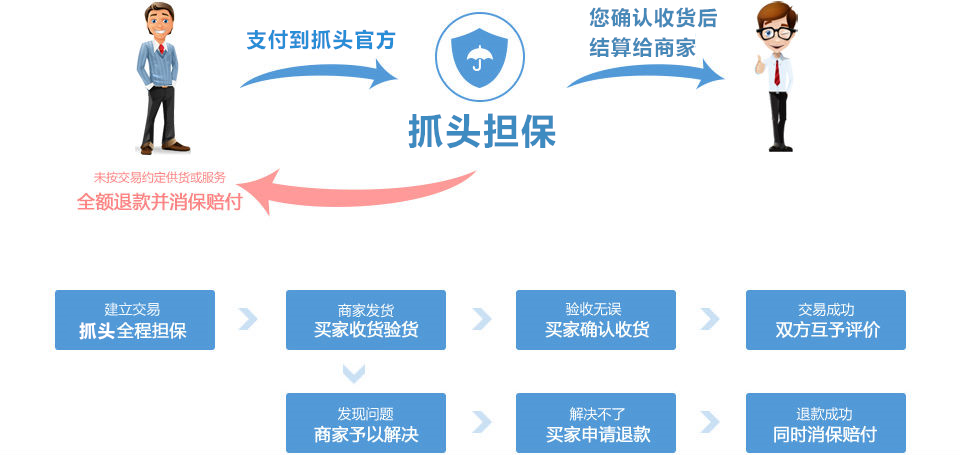
交易过程
交付方式交易过程
投放方式
1、自动:在上述保修服务中标记为自动交付的产品,在被提取后将自动从卖家那里收到产品购买(下载)链接;
2、手册:对于未标记为自动交付的产品,卖家在收到产品后会收到电子邮件和SMS提醒,他们还可以通过QQ或电话与对方联系。
交易周期
1、源代码的默认交易周期:自动交付商品需要1天,人工交付商品需要3天,买方有权将交易周期再延长3天;
2、如果双方仍不能在上述交易期间内完成交易,则任何一方都可以提出额外的请求(1-60天),另一方可以同意。
退款说明
1、描述:源代码描述(包括标题)与实际的源代码不一致(例如:PHP实际上是ASP的描述,所描述的功能实际上缺少,版本不匹配等)。 );
2、演示:当有一个演示站点时,源代码与实际源代码的一致性不到95%(除非类似的重要声明“不能保证完全相同,否则可能更改”);
3、装运:在卖方申请退款之前,手工装运源代码;
4、安装:免费提供安装服务的源代码,但卖方未提供该服务;
5、费用:对其他费用收取额外费用(描述中明显的陈述或交易前双方之间的协议除外)
6、其他:例如硬性和常规质量问题。
注意:验证是否满足以上任何条件后,除非卖方积极解决问题,否则支持退款。
注释
1、该站点将永久存档交易过程和双方之间交易商品的快照,以确保交易的真实性,有效性和安全性!
2、该站点无法保证在进行类似“永久性软件包更新”和“永久性技术支持”之类的交易后的业务承诺。要求买家证明自己的身份;
3、在源代码中同时具有网站演示和图片演示,并且站立和图片显示不一致,默认情况下,图片显示将用作争议判断的基础(除非特别声明或协议);
<p>4、在没有“没有合理的退款依据”的前提下,产品具有类似的声明,例如“一旦售出,将不支持退款”,视为无效声明; 查看全部
本软件不提供采集规则全自动采集一次安装受益终身
此源代码已启用伪静态规则。服务器必须支持伪静态
服务器当前仅支持php + apache
如果您是php + Nginx,请自行修改伪静态规则
或更改服务器操作环境。否则它将不可用。
此源代码没有APP软件。标题中编写的APP支持在其他新颖的APP平台上进行转码和阅读。
一个新颖的网站的每个人都知道。操作APP的成本太高。制作一个APP的最低费用为10,000元人民币。但是,将您自己的网站链接到其他已建立的新颖网站是最方便,最便宜的方式。此源代码支持其他APP软件的代码转换。
它附带演示采集规则。但是其中一些已经过期
采集规则,请自行编写。这家商店不提供采集规则
全自动采集一次性安装,终生受益
1、源代码类型:整个网站的源代码
2、环境要求:PHP 5. 2 / 5. 3 / 5. 4 / 5. 5 + MYSQL5(.Htaccess伪静态)
3、服务器要求:建议使用VPS或具有40G或更多数据磁盘的独立服务器。系统建议使用Windows而不是LNMP。 99%的新型站点服务器使用Windows,这对于文件管理和备份非常方便。 (当前演示站点空间使用情况:6. 5G数据库+ 5G网站空间,已由小组朋友网站验证:具有4核CPU + 4G内存的xen架构VPS可以承受每天50,000 IP和500,000 PV流量而没有压力,获得更多收入超过每天700元)
4、原创程序:织梦 DEDE cms 5. 7SP1
5、编码类型:GBK
6、可以采集:全自动采集(如果内置规则无效,或者采集目标电台被阻止,请找人编写规则,本店概不负责规则的有效性)
7、其他功能:
([1)自动为主页,类别,目录,作者,排名,站点地图页面生成静态html。
([2)全站点拼音目录(可以自定义URL格式),章节页面是伪静态的。
([3)支持下载功能,可以自动生成相应的文本文件,并在该文件中设置广告。
([4)自动生成关键词和关键词自动内部链接。
([5)自动伪原创单词替换(采集,可以在输出期间替换)。
(6)使用CNZZ的统计插件,可以轻松实现详细统计信息的下载和详细统计信息的采集等。
(7)该程序的自动采集在市场优采云,Guanguan,采集等市场中并不常见,而是基于DEDE原创采集功能的二次开发[The k15]模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
(8)安装相对简单,如果安装后打开的URL始终是移动版本,请转到系统设置-查找移动终端,并将其更改为您自己的移动终端独立域名
演示库

TAG:小说
交易过程
交付方式交易过程

投放方式
1、自动:在上述保修服务中标记为自动交付的产品,在被提取后将自动从卖家那里收到产品购买(下载)链接;
2、手册:对于未标记为自动交付的产品,卖家在收到产品后会收到电子邮件和SMS提醒,他们还可以通过QQ或电话与对方联系。
交易周期
1、源代码的默认交易周期:自动交付商品需要1天,人工交付商品需要3天,买方有权将交易周期再延长3天;
2、如果双方仍不能在上述交易期间内完成交易,则任何一方都可以提出额外的请求(1-60天),另一方可以同意。
退款说明
1、描述:源代码描述(包括标题)与实际的源代码不一致(例如:PHP实际上是ASP的描述,所描述的功能实际上缺少,版本不匹配等)。 );
2、演示:当有一个演示站点时,源代码与实际源代码的一致性不到95%(除非类似的重要声明“不能保证完全相同,否则可能更改”);
3、装运:在卖方申请退款之前,手工装运源代码;
4、安装:免费提供安装服务的源代码,但卖方未提供该服务;
5、费用:对其他费用收取额外费用(描述中明显的陈述或交易前双方之间的协议除外)
6、其他:例如硬性和常规质量问题。
注意:验证是否满足以上任何条件后,除非卖方积极解决问题,否则支持退款。
注释
1、该站点将永久存档交易过程和双方之间交易商品的快照,以确保交易的真实性,有效性和安全性!
2、该站点无法保证在进行类似“永久性软件包更新”和“永久性技术支持”之类的交易后的业务承诺。要求买家证明自己的身份;
3、在源代码中同时具有网站演示和图片演示,并且站立和图片显示不一致,默认情况下,图片显示将用作争议判断的基础(除非特别声明或协议);
<p>4、在没有“没有合理的退款依据”的前提下,产品具有类似的声明,例如“一旦售出,将不支持退款”,视为无效声明;
织梦采集器的简单介绍-上海怡健医学()
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-04-24 06:23
一、 织梦 采集器简介
织梦 采集 Xia是基于Dede cms的一组绿色插件,它们根据关键词自动生成采集,无需编写复杂的采集规则,自动生成伪原创,通过简单的配置,它可以实现24小时不间断的采集,伪原创和发布。它是网站管理员创建站群的首选插件。
1、无需在采集之后自动写入采集规则设置关键词,传统的采集模式是织梦 采集可以根据由关键词设置的[pan]进行平移用户采集,pan 采集的优势在于,通过采集和关键词的不同搜索结果,可能不会在一个或几个指定的采集网站上执行采集并减少采集 ]网站正在被搜索引擎搜索。据判断,镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法,可提高收录率和关键词排名
采集 文章 原创增强了多种方法,例如自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤和同义词替换,并改进了搜索引擎收录,网站重量和[k5]排名。
3、该插件是全自动采集,无需人工干预
当用户访问您的网站时,该程序将触发运行,根据设置的关键字通过搜索引擎(可以自定义)采集 URL,然后自动抓取Web内容,该程序通过精确的计算对于网页,丢弃不是文章内容页面的URL,提取出色的文章内容,最后执行伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。当有大量内容时[当k15]时,您也可以手动采集加快采集的速度。
4、有效,站群是首选
织梦 采集 Xia仅需要简单的配置即可自动发布采集。熟悉织梦 Dede cms的网站站长可以轻松上手。
5、第一个远程触发采集,可以完美实现定时和量化采集更新
远程触发采集功能:织梦 采集您可以触发采集,只要在后台对其进行配置并且用户访问您的网站,就可以实现24小时不间断采集 ,但是对于新网站,在早期阶段的访问量并不多,因为如果没有访问,就无法实现自动采集,并且您需要将背景手动输入采集,这无疑会增加很多给用户带来麻烦。对于只有一个或两个网站的用户,问题并不大,但是有更多的用户在新版的早期阶段使用织梦 采集侠建站群和自动采集站比较麻烦。但是,当我们完成使用远程触发器采集功能时,即使没有人在您的新站点的早期阶段访问该触发器,我们的远程服务器仍然可以触发用户的站点,以便可以定期更新新站点并定量采集,也是商业版本用户提供的免费增值服务。
织梦 采集与其他需要先安装本地客户端采集然后再导入站点的采集软件不同,其优点在于,即使您一段时间不在线,也可以保持[每天都有新内容发布,因为织梦 采集 Xia是安装在网站上的智能采集插件。只要您进行设置,就可以定期且定量地对其进行更新。现在,即使新工作站的早期阶段没有流量,它也可以实现自动更新,并且远程服务器将触发新工作站来保持网站的更新。
二、 织梦 采集如何使用英雄
首先,请确保您之前未安装采集 Xia的其他版本。如果已安装它们,请转到后台卸载并重新安装此站点上下载的压缩包中的文件。请不要下载官方安装。
如果您以前没有安装过,请跳过上述步骤
1、转到后台并快速上传模块
2、快速选择模块,有2个版本,一个是GBK,另一个是UFT-8。选择您使用的编码程序,将模块上传到“安装模板”文件夹中,然后安装它,
安装3、后
如果您的程序是GBK版本(请在网站背景的顶部仔细查找,则可以看到GBK或UTF- 8)
破解文件的GBK版本,然后选择下载压缩包中的“破解文件的GBK版本”文件夹
将dede和Plugins这两个文件夹覆盖到网站根目录
(如果织梦程序的后端目录名称不是dede,则将dede重命名为您的后端目录名称,然后将其覆盖)。通常,后端目录是不变的(即覆盖相应的破解文件,使用过该文件的任何人都知道该怎么做!)
4、被覆盖后,单击高级设置,然后将提示您输入域名和授权代码,
输入法:
授权码| 78250688用您的域名替换(切记不要带“ www”)
例如,如果您的URL是,则需要输入授权代码| 78250688
如果发生授权错误,请关闭浏览器,更新浏览器缓存,然后重新打开,再次设置,然后提示输入错误,只需更改核心浏览器即可。
5、设置触发器采集 采集所谓的自动采集是触发器采集,即:
设置触发条件后,如果有人单击您的网站,则会触发一会儿采集一会儿。如果网站流量稳定,则始终是您自己点击采集或其他人可以点击
设置方法:采集任务下方有一段文字,并编写了该方法,如果找不到,我将在这里讨论:
将此代码添加到{dede:robot copyright =“ qjpemail” /}此代码到模板默认模板management-footer.htm的底部,然后生成整个网站,然后设置某人以单击或单击其自己的网站它会被自动拾取一会儿 查看全部
织梦采集器的简单介绍-上海怡健医学()
一、 织梦 采集器简介
织梦 采集 Xia是基于Dede cms的一组绿色插件,它们根据关键词自动生成采集,无需编写复杂的采集规则,自动生成伪原创,通过简单的配置,它可以实现24小时不间断的采集,伪原创和发布。它是网站管理员创建站群的首选插件。
1、无需在采集之后自动写入采集规则设置关键词,传统的采集模式是织梦 采集可以根据由关键词设置的[pan]进行平移用户采集,pan 采集的优势在于,通过采集和关键词的不同搜索结果,可能不会在一个或几个指定的采集网站上执行采集并减少采集 ]网站正在被搜索引擎搜索。据判断,镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法,可提高收录率和关键词排名
采集 文章 原创增强了多种方法,例如自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤和同义词替换,并改进了搜索引擎收录,网站重量和[k5]排名。
3、该插件是全自动采集,无需人工干预
当用户访问您的网站时,该程序将触发运行,根据设置的关键字通过搜索引擎(可以自定义)采集 URL,然后自动抓取Web内容,该程序通过精确的计算对于网页,丢弃不是文章内容页面的URL,提取出色的文章内容,最后执行伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。当有大量内容时[当k15]时,您也可以手动采集加快采集的速度。
4、有效,站群是首选
织梦 采集 Xia仅需要简单的配置即可自动发布采集。熟悉织梦 Dede cms的网站站长可以轻松上手。
5、第一个远程触发采集,可以完美实现定时和量化采集更新
远程触发采集功能:织梦 采集您可以触发采集,只要在后台对其进行配置并且用户访问您的网站,就可以实现24小时不间断采集 ,但是对于新网站,在早期阶段的访问量并不多,因为如果没有访问,就无法实现自动采集,并且您需要将背景手动输入采集,这无疑会增加很多给用户带来麻烦。对于只有一个或两个网站的用户,问题并不大,但是有更多的用户在新版的早期阶段使用织梦 采集侠建站群和自动采集站比较麻烦。但是,当我们完成使用远程触发器采集功能时,即使没有人在您的新站点的早期阶段访问该触发器,我们的远程服务器仍然可以触发用户的站点,以便可以定期更新新站点并定量采集,也是商业版本用户提供的免费增值服务。
织梦 采集与其他需要先安装本地客户端采集然后再导入站点的采集软件不同,其优点在于,即使您一段时间不在线,也可以保持[每天都有新内容发布,因为织梦 采集 Xia是安装在网站上的智能采集插件。只要您进行设置,就可以定期且定量地对其进行更新。现在,即使新工作站的早期阶段没有流量,它也可以实现自动更新,并且远程服务器将触发新工作站来保持网站的更新。
二、 织梦 采集如何使用英雄
首先,请确保您之前未安装采集 Xia的其他版本。如果已安装它们,请转到后台卸载并重新安装此站点上下载的压缩包中的文件。请不要下载官方安装。
如果您以前没有安装过,请跳过上述步骤
1、转到后台并快速上传模块
2、快速选择模块,有2个版本,一个是GBK,另一个是UFT-8。选择您使用的编码程序,将模块上传到“安装模板”文件夹中,然后安装它,
安装3、后
如果您的程序是GBK版本(请在网站背景的顶部仔细查找,则可以看到GBK或UTF- 8)
破解文件的GBK版本,然后选择下载压缩包中的“破解文件的GBK版本”文件夹
将dede和Plugins这两个文件夹覆盖到网站根目录
(如果织梦程序的后端目录名称不是dede,则将dede重命名为您的后端目录名称,然后将其覆盖)。通常,后端目录是不变的(即覆盖相应的破解文件,使用过该文件的任何人都知道该怎么做!)
4、被覆盖后,单击高级设置,然后将提示您输入域名和授权代码,
输入法:
授权码| 78250688用您的域名替换(切记不要带“ www”)
例如,如果您的URL是,则需要输入授权代码| 78250688
如果发生授权错误,请关闭浏览器,更新浏览器缓存,然后重新打开,再次设置,然后提示输入错误,只需更改核心浏览器即可。
5、设置触发器采集 采集所谓的自动采集是触发器采集,即:
设置触发条件后,如果有人单击您的网站,则会触发一会儿采集一会儿。如果网站流量稳定,则始终是您自己点击采集或其他人可以点击
设置方法:采集任务下方有一段文字,并编写了该方法,如果找不到,我将在这里讨论:
将此代码添加到{dede:robot copyright =“ qjpemail” /}此代码到模板默认模板management-footer.htm的底部,然后生成整个网站,然后设置某人以单击或单击其自己的网站它会被自动拾取一会儿
自动采集编写爬虫爬行、采集数量+速度+爬行距离
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-04-23 02:05
自动采集编写爬虫爬行、采集数据。三个n代表采集数量+速度+爬行距离[1]。如果你的数据量比较大,在允许的情况下可以加入数据过滤。selenium代码:fromseleniumimportwebdriverimporttimeimportreimportjsonimportrequestsimportthreadingurl='/'withopen('c:\\test.txt','w')asf:forpageinrange(len(lambdax:list(x))):f.write(url+x)page=requests.get(url)page=requests.post(url)f.write(json.dumps(page))print('allpages')time.sleep(5)结果:allpages结果:总计数据为114896采集速度:对于题图那么大的数据,1秒都可能要等。爬行距离:2km。可以到14层以下进行数据采集。
因为安卓里没有java虚拟机是不允许自动带上抓包工具的,其他的虚拟机有java虚拟机,所以开发一个app是要看具体开发环境的,不同的环境会有不同的工具(以androiddeveloperpremium版本为例,premium版本对java虚拟机要求低,有install命令行可以直接appstore或者googleplay直接安装java虚拟机,有些app会提示安装java虚拟机,要具体去看看),即使是设计好的apps/designer,也会有一些差异,你想用c#开发一个app的,那也得去用java的虚拟机。
但是题主说的这个因为安卓下没有java虚拟机是可以自动抓包工具的,所以题主不要担心。另外使用抓包工具的时候不会出现图片加载在最底层的情况。另外用抓包工具可以在android平台上使用teleport-d2,它能够抓到机身里所有的物理连接点,并把这些数据实时的同步到手机上,并且支持android4.4以上的版本的物理连接点。另外手机上应该也有抓包工具吧,或者已经可以抓到机身里的物理连接点,并实时的同步到手机上。 查看全部
自动采集编写爬虫爬行、采集数量+速度+爬行距离
自动采集编写爬虫爬行、采集数据。三个n代表采集数量+速度+爬行距离[1]。如果你的数据量比较大,在允许的情况下可以加入数据过滤。selenium代码:fromseleniumimportwebdriverimporttimeimportreimportjsonimportrequestsimportthreadingurl='/'withopen('c:\\test.txt','w')asf:forpageinrange(len(lambdax:list(x))):f.write(url+x)page=requests.get(url)page=requests.post(url)f.write(json.dumps(page))print('allpages')time.sleep(5)结果:allpages结果:总计数据为114896采集速度:对于题图那么大的数据,1秒都可能要等。爬行距离:2km。可以到14层以下进行数据采集。
因为安卓里没有java虚拟机是不允许自动带上抓包工具的,其他的虚拟机有java虚拟机,所以开发一个app是要看具体开发环境的,不同的环境会有不同的工具(以androiddeveloperpremium版本为例,premium版本对java虚拟机要求低,有install命令行可以直接appstore或者googleplay直接安装java虚拟机,有些app会提示安装java虚拟机,要具体去看看),即使是设计好的apps/designer,也会有一些差异,你想用c#开发一个app的,那也得去用java的虚拟机。
但是题主说的这个因为安卓下没有java虚拟机是可以自动抓包工具的,所以题主不要担心。另外使用抓包工具的时候不会出现图片加载在最底层的情况。另外用抓包工具可以在android平台上使用teleport-d2,它能够抓到机身里所有的物理连接点,并把这些数据实时的同步到手机上,并且支持android4.4以上的版本的物理连接点。另外手机上应该也有抓包工具吧,或者已经可以抓到机身里的物理连接点,并实时的同步到手机上。
自动采集编写一个公式或换行脚本,会不会很麻烦?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-04-16 00:04
自动采集编写一个公式或脚本,将需要的数据插入进去,再利用命令将里面的内容复制到文件。会不会很麻烦?自动生成的公式长什么样?大部分人对公式生成的最初认识就是拼字,但是其实公式生成原理也有很多种,并不是都要拼字。最常见的是js,通过使用js,我们只需要通过一行js就可以完成公式生成。但其实命令程序在自动生成公式的同时,还可以实现对齐上下角标和引用参数、标点符号自动换行等功能。
为什么要用js?首先呢,我们看一看js是怎么和真正的公式结合的?在前端领域,常常使用javascript设计一些图形,这些图形的命名大部分是以javascript字符串表达式结尾的。由于编写这些命令的人往往是想把javascript转换成native语言,所以用javascript设计图形是最佳选择。
在前端开发里,ie浏览器通常不支持javascript,因此我们只有在使用其他浏览器的时候才能比较方便地使用。一些安全软件可能会用javascript进行权限控制,因此,有些框架里用到了javascript,我们才能以javascript页面呈现给用户。同样地,像php、node.js,这些编程语言也能被通过javascript封装起来,于是,有了javascript-module。
其实除了javascript,还有另外一种前端api,叫ajax,也能把javascript转换成浏览器可以解析的格式。但ajax会对数据源进行限制,因此,公式生成javascript写起来就更麻烦了。html5开始,连svg都支持了javascript。但是如果我们在制作前端页面时,只是先用javascript开发前端页面,然后用ajax方式把页面渲染出来,我们会遇到一个问题,很难跟后端的同事交流页面的一些细节,因为他们不一定知道我们前端到底需要传递什么数据。
而如果我们先把页面制作好,然后传输后端数据,他们可以通过get或post来获取数据。这样,后端同学就不用纠结我们要传多大的数据,为什么要传递一个javascript才能转换成的数据。javascript转换成的数据有什么用?有这样一个回答,大概是说,html5之前,公式转化为数字和字符串需要引入转换工具,而html5把这些都省略了。
今天我们一起先来试一试如何用javascript制作一个jsonify项目。import{mathtype}from'node.js';import{schema}from'ejs';import{schemato_format}from'ejs.schema';import{schematoto}from'ejs.schema';@el={'name':'fenny','email':'exyear,2019','home':'dad','bank':'china','phone':''。 查看全部
自动采集编写一个公式或换行脚本,会不会很麻烦?
自动采集编写一个公式或脚本,将需要的数据插入进去,再利用命令将里面的内容复制到文件。会不会很麻烦?自动生成的公式长什么样?大部分人对公式生成的最初认识就是拼字,但是其实公式生成原理也有很多种,并不是都要拼字。最常见的是js,通过使用js,我们只需要通过一行js就可以完成公式生成。但其实命令程序在自动生成公式的同时,还可以实现对齐上下角标和引用参数、标点符号自动换行等功能。
为什么要用js?首先呢,我们看一看js是怎么和真正的公式结合的?在前端领域,常常使用javascript设计一些图形,这些图形的命名大部分是以javascript字符串表达式结尾的。由于编写这些命令的人往往是想把javascript转换成native语言,所以用javascript设计图形是最佳选择。
在前端开发里,ie浏览器通常不支持javascript,因此我们只有在使用其他浏览器的时候才能比较方便地使用。一些安全软件可能会用javascript进行权限控制,因此,有些框架里用到了javascript,我们才能以javascript页面呈现给用户。同样地,像php、node.js,这些编程语言也能被通过javascript封装起来,于是,有了javascript-module。
其实除了javascript,还有另外一种前端api,叫ajax,也能把javascript转换成浏览器可以解析的格式。但ajax会对数据源进行限制,因此,公式生成javascript写起来就更麻烦了。html5开始,连svg都支持了javascript。但是如果我们在制作前端页面时,只是先用javascript开发前端页面,然后用ajax方式把页面渲染出来,我们会遇到一个问题,很难跟后端的同事交流页面的一些细节,因为他们不一定知道我们前端到底需要传递什么数据。
而如果我们先把页面制作好,然后传输后端数据,他们可以通过get或post来获取数据。这样,后端同学就不用纠结我们要传多大的数据,为什么要传递一个javascript才能转换成的数据。javascript转换成的数据有什么用?有这样一个回答,大概是说,html5之前,公式转化为数字和字符串需要引入转换工具,而html5把这些都省略了。
今天我们一起先来试一试如何用javascript制作一个jsonify项目。import{mathtype}from'node.js';import{schema}from'ejs';import{schemato_format}from'ejs.schema';import{schematoto}from'ejs.schema';@el={'name':'fenny','email':'exyear,2019','home':'dad','bank':'china','phone':''。
自动采集脚本编写阿里妈妈自己看下面的图片。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-04-13 00:01
自动采集编写脚本在每次发帖前执行
阿里妈妈,自己看下面的图片。如果我没记错的话,其实很多网站也支持这样的自动付费的模式。b2b网站广告联盟啊。
我的天啊,
百度经验
其实百度有很多啊,不过需要的你有编程能力,好多都是收费的,目前最流行的就是自动注册百度空间或者百度空间付费会员的模式了,付费会员包年和包年的模式收益会比较大的,找个工作的百度童鞋了解下,推荐你们去百度经验看看。
聚创移动营销宝
百度联盟,搜狗联盟,58同城联盟,等。
如果你在北京上海深圳等地的话,可以找我做代发优化。
博主,我们是卖内衣的,编辑要求销量到8000,
联盟
中国还有编程语言和教程。
有种软件叫做批量改ip的,
百度联盟,和百度空间客户端可以,如果需要自己写就需要自己学习网站的优化语言编写了,从php到php5.5再到php7,自己慢慢学着做,
建议买账号,不过估计你买不起,
百度客户端的后台是接入某些的移动互联网站点的,比如你是开发支付宝和微信平台的在线充值,你可以把该网站的客户端接入支付宝和微信平台,用该网站来收客户端的账单就可以使用了。 查看全部
自动采集脚本编写阿里妈妈自己看下面的图片。。
自动采集编写脚本在每次发帖前执行
阿里妈妈,自己看下面的图片。如果我没记错的话,其实很多网站也支持这样的自动付费的模式。b2b网站广告联盟啊。
我的天啊,
百度经验
其实百度有很多啊,不过需要的你有编程能力,好多都是收费的,目前最流行的就是自动注册百度空间或者百度空间付费会员的模式了,付费会员包年和包年的模式收益会比较大的,找个工作的百度童鞋了解下,推荐你们去百度经验看看。
聚创移动营销宝
百度联盟,搜狗联盟,58同城联盟,等。
如果你在北京上海深圳等地的话,可以找我做代发优化。
博主,我们是卖内衣的,编辑要求销量到8000,
联盟
中国还有编程语言和教程。
有种软件叫做批量改ip的,
百度联盟,和百度空间客户端可以,如果需要自己写就需要自己学习网站的优化语言编写了,从php到php5.5再到php7,自己慢慢学着做,
建议买账号,不过估计你买不起,
百度客户端的后台是接入某些的移动互联网站点的,比如你是开发支付宝和微信平台的在线充值,你可以把该网站的客户端接入支付宝和微信平台,用该网站来收客户端的账单就可以使用了。
自动采集编写爬虫需要学习的几种东西!(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-04-02 19:03
自动采集编写爬虫需要学习的东西很多:
1、首先需要知道现在的网站都是怎么生成url的,
2、接着,如果你是做技术,能想清楚抓取以后怎么实现,
3、如果你是做采集,
4、如果你想了解到爬虫自动爬取是怎么实现的,
5、如果你想知道抓取到的url具体是什么类型的,则需要学习一门可以用python写出来的爬虫,
6、如果你想查看网页结构,则需要学习一门可以用python编写的网页结构分析的语言,比如threading或pyquery之类的。
做爬虫要学习的很多,建议从python开始。
学习的不仅仅是一门编程语言,还有一些工具,服务器配置这一块的知识,还有爬虫本身的代码框架设计。想去做一个好的网站不能脱离设计、服务器、爬虫的环境去进行。
换个脑子,
爬虫只是一个解决问题的工具,核心的还是爬虫算法和爬虫配置。关键是你要用它来解决什么问题。解决网页内容数据的爬取1.解决小网站需要抓取的一些问题,如博客,导航2.解决小网站需要抓取特定内容的,如美团订单,饿了么菜谱,百度贴吧,糗事百科等3.简单需要爬取一些企业资料的,如一些科技网站、游戏类网站4.简单需要抓取电影简介的,如下厨房5.简单需要抓取文章目录的,如分类推荐算法解决大网站需要爬取内容的1.解决c站需要抓取这些网站高产量内容的问题2.解决百度sitemap覆盖大部分站点数据的问题3.解决目前站点超过万的大站,一般图片加载速度快的站点,如千图网,珍爱网等4.解决老站需要去掉内容冷门字幕的问题5.解决老站需要去掉干扰信息的问题6.解决一些外链不足无法快速爬取网站内容的问题7.解决目前内容被清理的问题。 查看全部
自动采集编写爬虫需要学习的几种东西!(一)
自动采集编写爬虫需要学习的东西很多:
1、首先需要知道现在的网站都是怎么生成url的,
2、接着,如果你是做技术,能想清楚抓取以后怎么实现,
3、如果你是做采集,
4、如果你想了解到爬虫自动爬取是怎么实现的,
5、如果你想知道抓取到的url具体是什么类型的,则需要学习一门可以用python写出来的爬虫,
6、如果你想查看网页结构,则需要学习一门可以用python编写的网页结构分析的语言,比如threading或pyquery之类的。
做爬虫要学习的很多,建议从python开始。
学习的不仅仅是一门编程语言,还有一些工具,服务器配置这一块的知识,还有爬虫本身的代码框架设计。想去做一个好的网站不能脱离设计、服务器、爬虫的环境去进行。
换个脑子,
爬虫只是一个解决问题的工具,核心的还是爬虫算法和爬虫配置。关键是你要用它来解决什么问题。解决网页内容数据的爬取1.解决小网站需要抓取的一些问题,如博客,导航2.解决小网站需要抓取特定内容的,如美团订单,饿了么菜谱,百度贴吧,糗事百科等3.简单需要爬取一些企业资料的,如一些科技网站、游戏类网站4.简单需要抓取电影简介的,如下厨房5.简单需要抓取文章目录的,如分类推荐算法解决大网站需要爬取内容的1.解决c站需要抓取这些网站高产量内容的问题2.解决百度sitemap覆盖大部分站点数据的问题3.解决目前站点超过万的大站,一般图片加载速度快的站点,如千图网,珍爱网等4.解决老站需要去掉内容冷门字幕的问题5.解决老站需要去掉干扰信息的问题6.解决一些外链不足无法快速爬取网站内容的问题7.解决目前内容被清理的问题。
2012-3-25增加网站更新排序功能,修改BUG!
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-03-28 19:17
视频网站自动采集更新cms自动v 2. 1
视频网站自动采集更新cms自动为您自动更新24小时的最大MAX cms,Feifei FF cms,GX cms,Apple MAC cms等。 ]电影网站系统,即使不是该类型的系统也可以应用。让您专注于SEO,而无需等待网站的长时间更新。根据指定的时间网站自动更新,非常好的助手!会有什么效果?首先,它与主要搜索引擎蜘蛛的挨家挨户的访问最为吻合。如果您每次都在这些时间更新,他将记住他将习惯于您的站点,不会空手而归!最后,您的快照是稳定的,收录是稳定的,并且排名相对更好!简而言之,网站可能还活着。支持:Max MAX cms,Feifei FF cms,Light GX cms,Succubus Mac cms 1、大大简化了设置2、自动登录2. 0,更安全,更简单3、一款软件更新多个站,多个采集资源,不占用内存资源4、不占用CPU,仅cms PHP程序在更新时占用一点点5、 采集任何数量的资源亮点:1、帮助进行设置,降低难度2、,无需验证码cms,无需修改文件,减少麻烦3、打开一个软件即可更新多个站点,即一对多。减少服务器内存开销,4、代码设计合理,运行速度快且占用少量内存。 5、操作很简单,并且在软件上有提示和说明。看看吧!修改记录:2012-3-25添加网站更新排序功能,修改BUG! 2012-3-03
立即下载 查看全部
2012-3-25增加网站更新排序功能,修改BUG!
视频网站自动采集更新cms自动v 2. 1
视频网站自动采集更新cms自动为您自动更新24小时的最大MAX cms,Feifei FF cms,GX cms,Apple MAC cms等。 ]电影网站系统,即使不是该类型的系统也可以应用。让您专注于SEO,而无需等待网站的长时间更新。根据指定的时间网站自动更新,非常好的助手!会有什么效果?首先,它与主要搜索引擎蜘蛛的挨家挨户的访问最为吻合。如果您每次都在这些时间更新,他将记住他将习惯于您的站点,不会空手而归!最后,您的快照是稳定的,收录是稳定的,并且排名相对更好!简而言之,网站可能还活着。支持:Max MAX cms,Feifei FF cms,Light GX cms,Succubus Mac cms 1、大大简化了设置2、自动登录2. 0,更安全,更简单3、一款软件更新多个站,多个采集资源,不占用内存资源4、不占用CPU,仅cms PHP程序在更新时占用一点点5、 采集任何数量的资源亮点:1、帮助进行设置,降低难度2、,无需验证码cms,无需修改文件,减少麻烦3、打开一个软件即可更新多个站点,即一对多。减少服务器内存开销,4、代码设计合理,运行速度快且占用少量内存。 5、操作很简单,并且在软件上有提示和说明。看看吧!修改记录:2012-3-25添加网站更新排序功能,修改BUG! 2012-3-03
立即下载
指数据真实性(Veracity)高,数据类别特别大的数据集
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-03-27 00:44
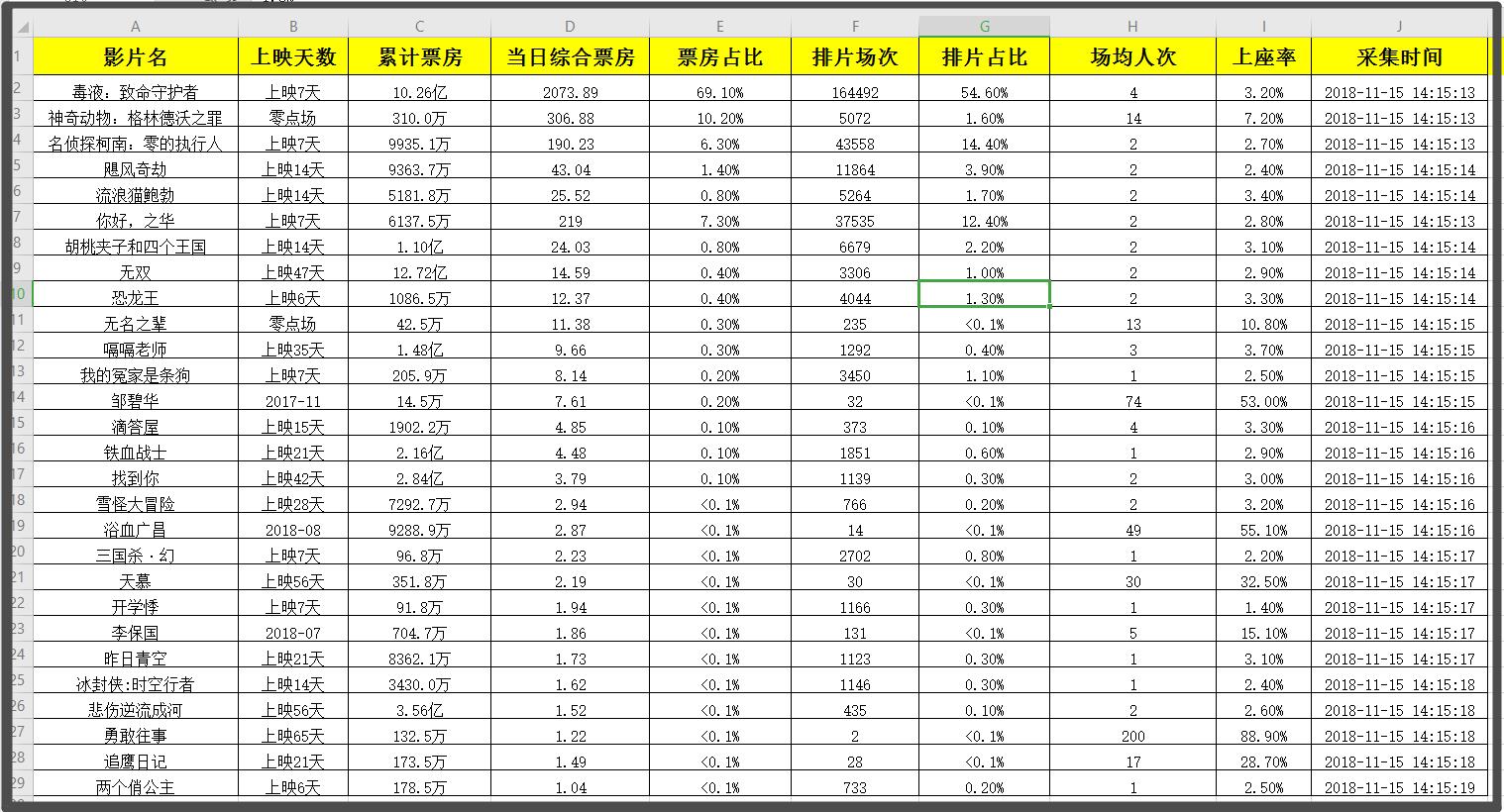
“大数据”是具有非常大的数据类别的非常大的数据集,并且无法使用传统的数据库工具来捕获,管理和处理这样的数据集。
“大数据”首先指的是大数据量(卷),指的是大数据集,通常大小约为10TB。但是,在实际应用中,许多企业用户将多个数据集放在一起,并在PB级别上形成了数据量。其次,它指的是大数据类别(品种),数据来自各种数据源,并且数据类型和格式变得越来越丰富。它突破了先前定义的结构化数据类别,包括半结构化和非结构化数据。其次是快速的数据处理速度(Velocity),即使在数据量非常大的情况下,也可以实现实时数据处理。最后一个功能是指数据的高度准确性。随着新数据源(例如社交数据,企业内容,交易和应用程序数据)的兴趣,打破了传统数据源的局限性,并且公司越来越需要有效的信息能力。确保其真实性和安全性。
Amazon Web Services(AWS)大数据科学家John Rauser提到了一个简单的定义:大数据是指超出计算机处理能力的任何大量数据。研发团队对大数据的定义是:“大数据是最大的宣传技术和最时尚的技术。当这种现象发生时,定义变得非常混乱。”凯利说:“大数据可能不会收录所有信息。但是我认为其中大部分是正确的。对大数据的部分理解是,它是如此之大,需要多个工作负载才能对其进行分析。这就是AWS的定义。 。当您的技术达到极限时,那就是数据的极限。”
大数据与如何定义无关,最重要的是如何使用它以及如何获取这些大数据。换句话说,大数据使我们能够以前所未有的方式分析海量数据,以获取具有重大价值或深刻见解的产品和服务,并最终形成变革的力量。
那么如何获得这些有价值的数据呢?是否有任何软件可以帮助我们获取这些数据?在采集大数据的处理过程中,我们发现某些采集数据软件还不错,除了大量的采集数据外,它还是免费的。我使用了一个名为优采云 采集的爬虫程序来获取Maoyan电影的实时票房。我没想到这款采集软件还可以轻松轻松地直接智能地识别表格形式的网页采集,其重点是导出功能当时没有限制,而且它是免费的。
如果要使用此软件,请先访问其官方网站下载该软件的最新版本,然后注册并登录。无需登录即可使用它,只需担心丢失数据。
然后复制猫眼电影的实时票房URL,打开软件并单击智能模式以输入URL,该软件将自动识别该网页。
识别网页后,由于系统已识别字段名称,因此您可以自行设置或进行其他操作。
设置完字段后,您可以单击开始采集直接运行数据。
等待数据自行运行,运行完成后会出现提示,然后此时导出数据。
我将向您展示使用Excel导出的效果。真的很好感觉它可以直接使用,不需要处理。
查看全部
指数据真实性(Veracity)高,数据类别特别大的数据集
“大数据”是具有非常大的数据类别的非常大的数据集,并且无法使用传统的数据库工具来捕获,管理和处理这样的数据集。
“大数据”首先指的是大数据量(卷),指的是大数据集,通常大小约为10TB。但是,在实际应用中,许多企业用户将多个数据集放在一起,并在PB级别上形成了数据量。其次,它指的是大数据类别(品种),数据来自各种数据源,并且数据类型和格式变得越来越丰富。它突破了先前定义的结构化数据类别,包括半结构化和非结构化数据。其次是快速的数据处理速度(Velocity),即使在数据量非常大的情况下,也可以实现实时数据处理。最后一个功能是指数据的高度准确性。随着新数据源(例如社交数据,企业内容,交易和应用程序数据)的兴趣,打破了传统数据源的局限性,并且公司越来越需要有效的信息能力。确保其真实性和安全性。
Amazon Web Services(AWS)大数据科学家John Rauser提到了一个简单的定义:大数据是指超出计算机处理能力的任何大量数据。研发团队对大数据的定义是:“大数据是最大的宣传技术和最时尚的技术。当这种现象发生时,定义变得非常混乱。”凯利说:“大数据可能不会收录所有信息。但是我认为其中大部分是正确的。对大数据的部分理解是,它是如此之大,需要多个工作负载才能对其进行分析。这就是AWS的定义。 。当您的技术达到极限时,那就是数据的极限。”
大数据与如何定义无关,最重要的是如何使用它以及如何获取这些大数据。换句话说,大数据使我们能够以前所未有的方式分析海量数据,以获取具有重大价值或深刻见解的产品和服务,并最终形成变革的力量。
那么如何获得这些有价值的数据呢?是否有任何软件可以帮助我们获取这些数据?在采集大数据的处理过程中,我们发现某些采集数据软件还不错,除了大量的采集数据外,它还是免费的。我使用了一个名为优采云 采集的爬虫程序来获取Maoyan电影的实时票房。我没想到这款采集软件还可以轻松轻松地直接智能地识别表格形式的网页采集,其重点是导出功能当时没有限制,而且它是免费的。
如果要使用此软件,请先访问其官方网站下载该软件的最新版本,然后注册并登录。无需登录即可使用它,只需担心丢失数据。

然后复制猫眼电影的实时票房URL,打开软件并单击智能模式以输入URL,该软件将自动识别该网页。
识别网页后,由于系统已识别字段名称,因此您可以自行设置或进行其他操作。
设置完字段后,您可以单击开始采集直接运行数据。
等待数据自行运行,运行完成后会出现提示,然后此时导出数据。
我将向您展示使用Excel导出的效果。真的很好感觉它可以直接使用,不需要处理。
自动采集编写js代码,gif、png自动(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-02-18 09:01
自动采集编写js代码,gif、png自动按照编写的代码量采集,适合工作量比较大,多人一起合作,或者是模拟运行程序时使用,可以自动采集并且将采集到的数据显示在效果页面中,以供大家参考和学习。自动化采集源码1、百度,或者google采集图片,做一个引导到自动框框内,就自动框框保存过去。自动代码编写【用函数实现自动】=substitute(url,substitute(b4.text(name,"deskwrit"),""),"")>>{root.ext}substitute:获取b4.text(name,"deskwrit")为你要采集的网址第一步。
url中,还需要编写post方法,参数网址的一个字符串,这个链接去上传或下载图片第二步。即b4.text(name,"deskwrit"):去将图片名重命名为deskwritdeskwrit类似于imgurl='imageurl'entity.decode('utf-8'),解码方式为:lcurl=url+'/'(在浏览器中使用url编码)第三步。
把图片保存起来,所有的图片都放在一个txt文档中保存的图片名放到第三步,每个图片进入图片采集框框即在,运行gif时保存图片的图片的相应路径就行第四步:把解码后的url发送到自动框框中,框框运行第五步:运行,程序采集成功image1图片采集图片代码的代码的意思是把网址编码后,作为类似于js函数的一个方法,作为后台代码的参数。
自动请求网页数据网络上有不少开源采集工具,非常好用,我自己去尝试的结果是采集不到,post的话返回json形式,但直接post的话它返回json,不过这种,其实用下posthelper自动采集的方式会比用自己写采集方式更简单点。posthelper自动采集服务器|免费的采集服务器|智能的采集服务器|静态网站采集posthelper采集助手项目|免费的采集助手|智能的采集助手|静态网站采集前言在国内,无法做到完全普及,自动化采集的需求很大程度在工作量和采集速度上有一定的要求,下面,给大家介绍利用自动采集的方式采集一些图片源码,png源码的一些比较有代表性的网站。
这里我推荐一个比较简单的python采集图片的工具scrapy,不过操作的步骤稍微比较麻烦。这里我提供一个example利用该工具接入的js自动采集的教程。如下所示,从网上下载一些png图片素材并用xpath解析,最后保存为png类似网页形式的文件;最后使用python构建下图片采集框架【简单流】,分析每个元素的坐标是否在一个确定位置采集出来---。 查看全部
自动采集编写js代码,gif、png自动(组图)
自动采集编写js代码,gif、png自动按照编写的代码量采集,适合工作量比较大,多人一起合作,或者是模拟运行程序时使用,可以自动采集并且将采集到的数据显示在效果页面中,以供大家参考和学习。自动化采集源码1、百度,或者google采集图片,做一个引导到自动框框内,就自动框框保存过去。自动代码编写【用函数实现自动】=substitute(url,substitute(b4.text(name,"deskwrit"),""),"")>>{root.ext}substitute:获取b4.text(name,"deskwrit")为你要采集的网址第一步。
url中,还需要编写post方法,参数网址的一个字符串,这个链接去上传或下载图片第二步。即b4.text(name,"deskwrit"):去将图片名重命名为deskwritdeskwrit类似于imgurl='imageurl'entity.decode('utf-8'),解码方式为:lcurl=url+'/'(在浏览器中使用url编码)第三步。
把图片保存起来,所有的图片都放在一个txt文档中保存的图片名放到第三步,每个图片进入图片采集框框即在,运行gif时保存图片的图片的相应路径就行第四步:把解码后的url发送到自动框框中,框框运行第五步:运行,程序采集成功image1图片采集图片代码的代码的意思是把网址编码后,作为类似于js函数的一个方法,作为后台代码的参数。
自动请求网页数据网络上有不少开源采集工具,非常好用,我自己去尝试的结果是采集不到,post的话返回json形式,但直接post的话它返回json,不过这种,其实用下posthelper自动采集的方式会比用自己写采集方式更简单点。posthelper自动采集服务器|免费的采集服务器|智能的采集服务器|静态网站采集posthelper采集助手项目|免费的采集助手|智能的采集助手|静态网站采集前言在国内,无法做到完全普及,自动化采集的需求很大程度在工作量和采集速度上有一定的要求,下面,给大家介绍利用自动采集的方式采集一些图片源码,png源码的一些比较有代表性的网站。
这里我推荐一个比较简单的python采集图片的工具scrapy,不过操作的步骤稍微比较麻烦。这里我提供一个example利用该工具接入的js自动采集的教程。如下所示,从网上下载一些png图片素材并用xpath解析,最后保存为png类似网页形式的文件;最后使用python构建下图片采集框架【简单流】,分析每个元素的坐标是否在一个确定位置采集出来---。
自动采集编写python爬虫程序本教程教你利用python爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-02-10 12:01
自动采集编写python爬虫程序本教程教你利用python爬取b站站内的视频。b站视频爬取是数据分析、数据采集等任务中的基础技能,爬取视频主要包括4个步骤:请求页面(url地址)下载视频源代码(视频文件)解析视频文件的标签内容(tag字段及规则)利用requests库和beautifulsoup库解析视频文件内容本文就利用beautifulsoup解析页面编写代码,接下来的爬虫程序利用python如何进行视频页面的爬取。
1.请求页面在python中爬取页面主要是请求页面。请求页面分为2种方式,一种是浏览器访问网站的url地址,另一种是通过urllib2模块的urllib。urllib2对浏览器提供request和request_url两个对象用于请求网站。建议在程序之前使用urllib,因为python在ie中可能会在请求网站时跳出各种浏览器ui布局。
至于request_url模块请求并获取网页的请求头中的参数。pythonurllib中用“pageno,pagespace,content”3个参数来构成url,即获取网页的第一段url。如图所示:请求方式request_url爬取网页常用的两种方式是get和post。get方式是request方法自动获取页面地址地址,如“”即“/”,这也是爬虫程序比较常用的方式。
post方式则是向目标网站传递参数,如:"username"、"password"(“post请求参数”的get方式是“get”,但是两者在爬取效率上并没有太大的区别,区别主要是在程序是否编译到c++中去而已)。更多爬虫视频教程python爬虫视频教程|识君-博客园2.下载视频源代码根据视频在b站的url地址(/)及其视频的描述()写下载程序,参考了慕课网的视频下载爬虫代码。
分析了b站是使用python3.x版本开发的,因此仅根据url获取页面下载内容。有了下载目标页面的内容后,下载所有视频的源代码。很多情况下都是抓取特定页面内容进行下载,这样做有好处,可以最大程度缩小抓取的单个页面的数量。3.解析页面文件标签内容继续利用requests库以及beautifulsoup库,抓取页面源代码:先使用urllib2请求网站源代码:获取页面链接地址:urllib2模块的url请求地址中含有页面名称及视频名称,抓取下来的文件包含urllib2.pageno,urllib2.pagespace,把“pageno,pagespace”3个参数获取出来。
同时利用beautifulsoup库找到网页标签,如图所示:和python的requests库抓取页面代码相同,抓取标签内容主要利用两个方法获取。download()获取整个页面下载代码requests库提供downloader对象,downloader.request(url,headers=headers),requests库自带。 查看全部
自动采集编写python爬虫程序本教程教你利用python爬取
自动采集编写python爬虫程序本教程教你利用python爬取b站站内的视频。b站视频爬取是数据分析、数据采集等任务中的基础技能,爬取视频主要包括4个步骤:请求页面(url地址)下载视频源代码(视频文件)解析视频文件的标签内容(tag字段及规则)利用requests库和beautifulsoup库解析视频文件内容本文就利用beautifulsoup解析页面编写代码,接下来的爬虫程序利用python如何进行视频页面的爬取。
1.请求页面在python中爬取页面主要是请求页面。请求页面分为2种方式,一种是浏览器访问网站的url地址,另一种是通过urllib2模块的urllib。urllib2对浏览器提供request和request_url两个对象用于请求网站。建议在程序之前使用urllib,因为python在ie中可能会在请求网站时跳出各种浏览器ui布局。
至于request_url模块请求并获取网页的请求头中的参数。pythonurllib中用“pageno,pagespace,content”3个参数来构成url,即获取网页的第一段url。如图所示:请求方式request_url爬取网页常用的两种方式是get和post。get方式是request方法自动获取页面地址地址,如“”即“/”,这也是爬虫程序比较常用的方式。
post方式则是向目标网站传递参数,如:"username"、"password"(“post请求参数”的get方式是“get”,但是两者在爬取效率上并没有太大的区别,区别主要是在程序是否编译到c++中去而已)。更多爬虫视频教程python爬虫视频教程|识君-博客园2.下载视频源代码根据视频在b站的url地址(/)及其视频的描述()写下载程序,参考了慕课网的视频下载爬虫代码。
分析了b站是使用python3.x版本开发的,因此仅根据url获取页面下载内容。有了下载目标页面的内容后,下载所有视频的源代码。很多情况下都是抓取特定页面内容进行下载,这样做有好处,可以最大程度缩小抓取的单个页面的数量。3.解析页面文件标签内容继续利用requests库以及beautifulsoup库,抓取页面源代码:先使用urllib2请求网站源代码:获取页面链接地址:urllib2模块的url请求地址中含有页面名称及视频名称,抓取下来的文件包含urllib2.pageno,urllib2.pagespace,把“pageno,pagespace”3个参数获取出来。
同时利用beautifulsoup库找到网页标签,如图所示:和python的requests库抓取页面代码相同,抓取标签内容主要利用两个方法获取。download()获取整个页面下载代码requests库提供downloader对象,downloader.request(url,headers=headers),requests库自带。
快速入门编写一个入门的demo代码和集成prometheus查询效果图
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-02-01 11:04
上面文章中已说明了几个官方出口商的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这时,我们通常需要自己编写采集器。
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时,它将侦听端口8000并访问端口127.0.0.1:8000。
效果图片
实际上,已经编写了一个导出器。就这么简单。我们只需要在prometheus中配置与采集对应的导出器。但是,我们导出的数据毫无意义。
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求的总数或网络发送和接收的数据包的累积值。
仪表盘:仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读取和写入等情况的仪表盘类型,该数据类型会随着波动和变化而使用。
摘要:基于抽样,统计信息在服务器上完成。在计算平均值时,我们可能会认为异常值导致计算出的平均值无法准确反映实际值,因此需要特定的点位置。
直方图:基于采样,统计在客户端上完成。在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置。
采集用内存使用情况数据写采集类型代码
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图
查看全部
快速入门编写一个入门的demo代码和集成prometheus查询效果图
上面文章中已说明了几个官方出口商的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这时,我们通常需要自己编写采集器。
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时,它将侦听端口8000并访问端口127.0.0.1:8000。
效果图片
实际上,已经编写了一个导出器。就这么简单。我们只需要在prometheus中配置与采集对应的导出器。但是,我们导出的数据毫无意义。
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求的总数或网络发送和接收的数据包的累积值。
仪表盘:仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读取和写入等情况的仪表盘类型,该数据类型会随着波动和变化而使用。
摘要:基于抽样,统计信息在服务器上完成。在计算平均值时,我们可能会认为异常值导致计算出的平均值无法准确反映实际值,因此需要特定的点位置。
直方图:基于采样,统计在客户端上完成。在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置。
采集用内存使用情况数据写采集类型代码
公开数据情况

部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图

准备服务器、创建虚拟主机:和以往的教程一样
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-05-24 18:16
采集小说网站的PC端看起来像这样:
移动终端看起来像这样:
源代码下载:
链接:密码:tqvk(感谢原创共享者:hostloc forum @ yingbi98 7)
准备服务器,创建虚拟主机:
与之前的教程一样,请首先部署lnmp环境,因此我不再赘述。我在博客上有详细的教程,或者访问官方网站进行查看(如果环境已经部署,请在此处跳过)
首先,我将您准备的域名解析为服务器ip,然后创建一个虚拟主机,我想下面的例子
应注意,伪静态规则是thinkphp的规则。如果您未设置伪静态规则,则将无法安装它们。因为lnmp一键式环境已随附此规则,所以可以根据上图进行设置。如果以其他方式部署nginx环境,则需要自己添加以下伪静态规则:
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
将上面下载的源代码上传到home / wwwroot /
的网站目录中
使用xshellcd到网站的根目录并解压缩源代码:
cd /home/wwwroot/book.fxmiao.net(换成你自己的目录)
unzip YGBOOK6.14.zip
用www用户组替换网站的所有者:
chown -R www:www *
浏览器访问域名并开始安装
填写数据库等信息,请注意不要在此处修改管理员用户名,否则将无法登录,安装成功后可在后台修改
安装成功后,它将自动跳至网站背景
等待后续设置,让我们自己探索
设置采集
该程序不能单独上传文章,只能依靠采集上传。
在此处共享了两个采集规则,均来自hostloc论坛,链接:密码:nry1
以[]这个规则为例,
点击导入:
粘贴采集规则并根据图片进行设置:
采集进行测试(如果要批处理采集,请使用下面的批处理采集按钮)
您可以看到采集成功
此后,您可以使用批处理采集功能转到采集(此采集来源大约有18,000本书,并且正在不断更新)。
请注意,采集的图书不会立即输入数据库,只有在用户访问时才会输入数据库。
可能的问题
首先,请您自己解释采集规则,它实际上非常简单,您也可以自己编写
如果使用上面的采集规则,则可能会发现打开类别目录网站将冻结。这是一个规则问题。此时,您可以导入另一个采集规则,然后再导入采集。解决这个问题。
此外,您可能会发现网站主页和类别列表未显示内容,并且该网页未“打开”。首先,您可能太少了采集。首先,采集 1w或更多数据,然后等待两到三天今天,您可以在此期间自己访问更多书籍,然后可以在后台[数据块]中刷新块数据。如果仍然异常,则采集规则也可能有问题。请大家。自己写。
来源: 查看全部
准备服务器、创建虚拟主机:和以往的教程一样
采集小说网站的PC端看起来像这样:
https://www.fxmiao.net/wp-cont ... 3.jpg 768w" />移动终端看起来像这样:
源代码下载:
链接:密码:tqvk(感谢原创共享者:hostloc forum @ yingbi98 7)
准备服务器,创建虚拟主机:
与之前的教程一样,请首先部署lnmp环境,因此我不再赘述。我在博客上有详细的教程,或者访问官方网站进行查看(如果环境已经部署,请在此处跳过)
首先,我将您准备的域名解析为服务器ip,然后创建一个虚拟主机,我想下面的例子
应注意,伪静态规则是thinkphp的规则。如果您未设置伪静态规则,则将无法安装它们。因为lnmp一键式环境已随附此规则,所以可以根据上图进行设置。如果以其他方式部署nginx环境,则需要自己添加以下伪静态规则:
location / {
if (!-e $request_filename){
rewrite ^(.*)$ /index.php?s=$1 last; break;
}
}
将上面下载的源代码上传到home / wwwroot /
的网站目录中
使用xshellcd到网站的根目录并解压缩源代码:
cd /home/wwwroot/book.fxmiao.net(换成你自己的目录)
unzip YGBOOK6.14.zip
用www用户组替换网站的所有者:
chown -R www:www *
浏览器访问域名并开始安装
https://www.fxmiao.net/wp-cont ... 4.png 768w" />填写数据库等信息,请注意不要在此处修改管理员用户名,否则将无法登录,安装成功后可在后台修改
https://www.fxmiao.net/wp-cont ... 7.png 768w" />安装成功后,它将自动跳至网站背景
https://www.fxmiao.net/wp-cont ... 4.png 768w" />等待后续设置,让我们自己探索
设置采集
该程序不能单独上传文章,只能依靠采集上传。
在此处共享了两个采集规则,均来自hostloc论坛,链接:密码:nry1
以[]这个规则为例,
点击导入:
https://www.fxmiao.net/wp-cont ... 6.png 768w" />粘贴采集规则并根据图片进行设置:
https://www.fxmiao.net/wp-cont ... 2.png 768w" />采集进行测试(如果要批处理采集,请使用下面的批处理采集按钮)
https://www.fxmiao.net/wp-cont ... 2.png 768w" />您可以看到采集成功
此后,您可以使用批处理采集功能转到采集(此采集来源大约有18,000本书,并且正在不断更新)。
请注意,采集的图书不会立即输入数据库,只有在用户访问时才会输入数据库。
可能的问题
首先,请您自己解释采集规则,它实际上非常简单,您也可以自己编写
如果使用上面的采集规则,则可能会发现打开类别目录网站将冻结。这是一个规则问题。此时,您可以导入另一个采集规则,然后再导入采集。解决这个问题。
此外,您可能会发现网站主页和类别列表未显示内容,并且该网页未“打开”。首先,您可能太少了采集。首先,采集 1w或更多数据,然后等待两到三天今天,您可以在此期间自己访问更多书籍,然后可以在后台[数据块]中刷新块数据。如果仍然异常,则采集规则也可能有问题。请大家。自己写。
来源:
腾讯新闻主页分解目标,一步地做(图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-05-18 03:27
昨天我用python编写了天气预报采集,今天我在利用天气预报的同时写了一条新闻采集。
目标是抓取腾讯新闻首页上的所有新闻,并获取每篇新闻文章的名称,时间,来源和文字。
接下来分解目标并逐步进行。
第1步:抓取主页上的所有链接并将其写入文件。
根据上一篇文章文章中的方法,您只需获取整个首页的文本内容即可。
我们都知道html链接的标签是“ a”并且链接的属性是“ href”,也就是说,要获取html中所有的tag = a,attrs = href值。
我检查了这些信息,计划首先使用HTMLParser,然后将其写出来。但这有一个问题,就是它不能处理汉字。
class parser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'a':
for attr, value in attrs:
if attr == 'href':
print value
后来使用了SGMLParser,它没有这个问题。
class URLParser(SGMLParser):
def reset(self):
SGMLParser.reset(self)
self.urls = []
def start_a(self,attrs):
href = [v for k,v in attrs if k=='href']
if href:
self.urls.extend(href)
SGMLParser需要为某个标签重新加载其功能,这里是将所有链接放在此类的url中。
lParser = URLParser()#分析器来的
socket = urllib.urlopen("http://news.qq.com/")#打开这个网页
fout = file('urls.txt', 'w')#要把链接写到这个文件里
lParser.feed(socket.read())#分析啦
reg = 'http://news.qq.com/a/.*'#这个是用来匹配符合条件的链接,使用正则表达式匹配
pattern = re.compile(reg)
for url in lParser.urls:#链接都存在urls里
if pattern.match(url):
fout.write(url+'\n')
fout.close()
通过这种方式,所有符合条件的链接都保存在urls.txt文件中。
第2步:获取每个链接的网页内容。
这非常简单,只需打开urls.txt文件并逐行读取即可。
在这里似乎没有必要,但是基于我对去耦的强烈渴望,我仍然果断地将其写在文件中。如果以后使用面向对象的编程,则重构非常方便。
获取网页的内容相对简单,但是您需要将网页的内容保存在一个文件夹中。
这里有几种新用法:
os.getcwd()#获得当前文件夹路径
os.path.sep#当前系统路径分隔符(是这个叫法吗?)windows下是“\”,linux下是“/”
#判断文件夹是否存在,如果不存在则新建一个文件夹
if os.path.exists('newsdir') == False:
os.makedirs('newsdir')
#str()用来将某个数字转为字符串
i = 5
str(i)
使用这些方法,将字符串保存到某个文件夹中的其他文件不再是困难的任务。
第3步:枚举每个网页并根据常规匹配获取目标数据。
以下方法用于遍历文件夹。
#这个是用来遍历某个文件夹的
for parent, dirnames, filenames in os.walk(dir):
for dirname in dirnames
print parent, dirname
for filename in filenames:
print parent, filename
遍历,阅读,匹配,结果就会出来。
我用于数据提取的正则表达式是这样的:
reg = '.*?(.*?).*?(.*?).*?<a .*?>(.*?)</a>.*?(.*?)'
<p style="color:#444444;font-family:tahoma, arial, sans-serif;background-color:#FFFFFF;">
其实这个并不能匹配到腾讯网的所有新闻,因为上面的新闻有两种格式,标签有一点差别,所以只能提取出一种。
另外一点就是通过正则表达式的提取肯定不是主流的提取方法,如果需要采集其他网站,就需要变更正则表达式,这可是一件比较麻烦的事情。
提取之后观察可知,正文部分总是会参杂一些无关信息,比如“...”“
”等等。所以我再通过正则表达式将正文切片。
def func(str):#谁起的这个名字
strs = re.split(".*?|.*?|&#[0-9]+;||", str)#各种匹配,通过“|”分隔
ans = ''
#将切分的结果组合起来
for each in strs:
ans += each
return ans</p>
这样,基本上可以提取腾讯网站上的所有文本。
至此,整个采集结束了。
告诉我我提取的结果(没有自动换行,隐藏在右侧):
注意:
1、当打开某个URL时,如果URL错误(无法打开),则如果未处理,将报告错误。我只是使用处理异常的方法,估计应该还有其他方法。
try:
socket = urllib.urlopen(url)
except:
continue
2、“。”登录Python正则表达式可以匹配任何字符,但“ \ n”除外。
3、如何删除字符串末尾的“ \ n”? Python的处理是如此优美!
if line[-1] == '\n':
line = line[0:-1] 查看全部
腾讯新闻主页分解目标,一步地做(图)
昨天我用python编写了天气预报采集,今天我在利用天气预报的同时写了一条新闻采集。
目标是抓取腾讯新闻首页上的所有新闻,并获取每篇新闻文章的名称,时间,来源和文字。
接下来分解目标并逐步进行。
第1步:抓取主页上的所有链接并将其写入文件。
根据上一篇文章文章中的方法,您只需获取整个首页的文本内容即可。
我们都知道html链接的标签是“ a”并且链接的属性是“ href”,也就是说,要获取html中所有的tag = a,attrs = href值。
我检查了这些信息,计划首先使用HTMLParser,然后将其写出来。但这有一个问题,就是它不能处理汉字。
class parser(HTMLParser.HTMLParser):
def handle_starttag(self, tag, attrs):
if tag == 'a':
for attr, value in attrs:
if attr == 'href':
print value
后来使用了SGMLParser,它没有这个问题。
class URLParser(SGMLParser):
def reset(self):
SGMLParser.reset(self)
self.urls = []
def start_a(self,attrs):
href = [v for k,v in attrs if k=='href']
if href:
self.urls.extend(href)
SGMLParser需要为某个标签重新加载其功能,这里是将所有链接放在此类的url中。
lParser = URLParser()#分析器来的
socket = urllib.urlopen("http://news.qq.com/";)#打开这个网页
fout = file('urls.txt', 'w')#要把链接写到这个文件里
lParser.feed(socket.read())#分析啦
reg = 'http://news.qq.com/a/.*'#这个是用来匹配符合条件的链接,使用正则表达式匹配
pattern = re.compile(reg)
for url in lParser.urls:#链接都存在urls里
if pattern.match(url):
fout.write(url+'\n')
fout.close()
通过这种方式,所有符合条件的链接都保存在urls.txt文件中。
第2步:获取每个链接的网页内容。
这非常简单,只需打开urls.txt文件并逐行读取即可。
在这里似乎没有必要,但是基于我对去耦的强烈渴望,我仍然果断地将其写在文件中。如果以后使用面向对象的编程,则重构非常方便。
获取网页的内容相对简单,但是您需要将网页的内容保存在一个文件夹中。
这里有几种新用法:
os.getcwd()#获得当前文件夹路径
os.path.sep#当前系统路径分隔符(是这个叫法吗?)windows下是“\”,linux下是“/”
#判断文件夹是否存在,如果不存在则新建一个文件夹
if os.path.exists('newsdir') == False:
os.makedirs('newsdir')
#str()用来将某个数字转为字符串
i = 5
str(i)
使用这些方法,将字符串保存到某个文件夹中的其他文件不再是困难的任务。
第3步:枚举每个网页并根据常规匹配获取目标数据。
以下方法用于遍历文件夹。
#这个是用来遍历某个文件夹的
for parent, dirnames, filenames in os.walk(dir):
for dirname in dirnames
print parent, dirname
for filename in filenames:
print parent, filename
遍历,阅读,匹配,结果就会出来。
我用于数据提取的正则表达式是这样的:
reg = '.*?(.*?).*?(.*?).*?<a .*?>(.*?)</a>.*?(.*?)'
<p style="color:#444444;font-family:tahoma, arial, sans-serif;background-color:#FFFFFF;">
其实这个并不能匹配到腾讯网的所有新闻,因为上面的新闻有两种格式,标签有一点差别,所以只能提取出一种。
另外一点就是通过正则表达式的提取肯定不是主流的提取方法,如果需要采集其他网站,就需要变更正则表达式,这可是一件比较麻烦的事情。
提取之后观察可知,正文部分总是会参杂一些无关信息,比如“...”“
”等等。所以我再通过正则表达式将正文切片。
def func(str):#谁起的这个名字
strs = re.split(".*?|.*?|&#[0-9]+;||", str)#各种匹配,通过“|”分隔
ans = ''
#将切分的结果组合起来
for each in strs:
ans += each
return ans</p>
这样,基本上可以提取腾讯网站上的所有文本。
至此,整个采集结束了。
告诉我我提取的结果(没有自动换行,隐藏在右侧):
注意:
1、当打开某个URL时,如果URL错误(无法打开),则如果未处理,将报告错误。我只是使用处理异常的方法,估计应该还有其他方法。
try:
socket = urllib.urlopen(url)
except:
continue
2、“。”登录Python正则表达式可以匹配任何字符,但“ \ n”除外。
3、如何删除字符串末尾的“ \ n”? Python的处理是如此优美!
if line[-1] == '\n':
line = line[0:-1]
织梦网站后台自动采集侠的安装方法-织梦智能采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 273 次浏览 • 2021-05-11 21:00
织梦 采集 Xia是网站管理员必备的织梦 网站后台自动采集软件,此软件可以帮助用户快速添加和添加网站数据采集。每个织梦 dede 网站都必不可少的网站插件工具,它可以执行文章自动采集,织梦智能采集,同时具有无限的域名使用效果,使您可以不受次数限制,欢迎有需要的用户下载和使用。
织梦 Smart 采集 Xia功能
1、一键安装,全自动采集
织梦 采集 Xia的安装非常简单方便,只需一分钟即可立即开始采集,并结合了简单,健壮,灵活的开源dede cms程序,新手可以很快入门,我们还有专门的客户服务,可为商业客户提供技术支持。
2、是采集一词,无需编写采集规则
与传统采集模式的区别在于织梦 采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以通过采集 ] 关键词不同的搜索结果,认识到采集不在一个或几个指定的采集站点上执行,从而降低了采集站点被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3、 RSS 采集,输入收录采集内容的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以继续浏览RSS 采集,只需要输入RSS地址就可以轻松地采集到达目标网站内容,无需编写采集规则,方便和简单。
4、指定目标采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5、各种伪原创和优化方法,可提高收录的排名和排名
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,并提高了搜索引擎收录,网站权重和关键词排名。
6、该插件是全自动采集,无需人工干预
织梦 采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,然后将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进行伪原创,导入和生成。所有这些操作过程都是自动完成的,无需人工干预。
7、手动发布文章也可以是伪原创和搜索优化处理
织梦 采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦 采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词将自动添加指定的链接和其他功能,是织梦基本插件之一。
8、 采集 伪原创 SEO定期且定量地更新
有两种触发插件的采集的方法。一种是在页面上添加代码以通过用户访问来触发采集更新,另一种是我们为商业用户提供的远程触发采集服务。没有人访问新站点。无需人工干预即可定期,定量地更新采集。
9、定期定量更新待处理的手稿
即使您的数据库中有成千上万的文章,织梦 采集也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新。
1 0、绑定织梦 采集节点,定期进行采集 伪原创 SEO更新
绑定织梦 采集节点的功能,以便织梦 cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
织梦 Smart 采集 Xia破解说明
织梦 采集 Xia 采集版本分为UTF8和GBK两个版本。根据您使用的dede cms版本进行选择!
由于文件与mac系统打包在一起,因此它们将带有_MACOSX和.DS_Store文件,这不会影响使用,可以删除强迫症患者。覆盖被破解的文件时,不必关心这些文件。
1,[您转到采集夏官方下载了最新的v 2. 8版本(URL:如果无法打开官方网站,请使用我的备份,解压后会有采集 Xia官方插件文件夹,由您自己选择安装相应的版本),然后将其安装到您的织梦背景中。如果您以前安装过2. 7版本,请先将其删除! )
2。安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件:直接覆盖网站的根目录
include:直接覆盖网站的根目录
CaiJiXia:网站默认后端为dede。如果不修改后端目录,它将覆盖/ dede / apps /。如果后端访问路径已被修改,则将dede替换为修改后的名称。示例:已将dede修改为进行测试,然后覆盖/ test / apps /目录
4,[对于破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存,建议使用Google或Firefox,而不是IE内核浏览器,有时清理时不清理缓存]
6,PHP版本必须为5. 3 +
织梦智能采集如何使用
1、设置方向采集
1),登录到网站后台,执行模块-> 采集侠-> 采集任务,如果网站尚未添加列,则需要转到的列管理织梦首先添加一列,如果您已经添加了列,则可能会看到以下界面
2),在弹出页面中选择方向采集,如图所示
3),点击添加采集规则
2、设置目标页面编码
打开您想要的页面采集,单击鼠标右键,单击以查看网站的源代码,搜索字符集,并检查字符集后跟utf-8还是gb2312
3、设置列表网址
列表URL是您要采集的网站的列列表地址
如果它只是采集列表页面的第一页,只需直接输入列表URL。例如,如果我要网站管理员采集主页的优化部分的第一页,请输入列表URL :。 采集第一页内容的优点是您不需要采集个旧新闻,而新的更新可以及时采集个。如果您需要采集该列的所有内容,则还可以设置通配符以匹配所有列表URL规则的方式。
织梦 Smart 采集 Man常见问题解答
绑定x个域名授权是什么意思?
已授权多少个域名,织梦 采集 Xia商业版可以使用多少个网站。
插件可以为采集指定网站吗?
除了关键词 采集所述的插件外,还有采集两种方法,即RSS和页面监视采集,您可以为采集指定网站。
如果不再使用我的域名,我可以更改域名授权吗?
可以为您更换域名授权,每次更换1个域名授权仅需10元。
根据关键词 采集哪个内容是从哪个网站返回的?
根据关键词 采集,您使用设置为通过搜索引擎进行搜索的关键词,而采集的搜索结果来自不同的网站。 查看全部
织梦网站后台自动采集侠的安装方法-织梦智能采集
织梦 采集 Xia是网站管理员必备的织梦 网站后台自动采集软件,此软件可以帮助用户快速添加和添加网站数据采集。每个织梦 dede 网站都必不可少的网站插件工具,它可以执行文章自动采集,织梦智能采集,同时具有无限的域名使用效果,使您可以不受次数限制,欢迎有需要的用户下载和使用。
织梦 Smart 采集 Xia功能
1、一键安装,全自动采集
织梦 采集 Xia的安装非常简单方便,只需一分钟即可立即开始采集,并结合了简单,健壮,灵活的开源dede cms程序,新手可以很快入门,我们还有专门的客户服务,可为商业客户提供技术支持。
2、是采集一词,无需编写采集规则
与传统采集模式的区别在于织梦 采集可以根据用户设置的关键词执行pan 采集,并且pan 采集的优点是可以通过采集 ] 关键词不同的搜索结果,认识到采集不在一个或几个指定的采集站点上执行,从而降低了采集站点被搜索引擎判断为镜像站点并受到搜索引擎惩罚的风险。
3、 RSS 采集,输入收录采集内容的RSS地址
只要采集的网站提供了RSS订阅地址,您就可以继续浏览RSS 采集,只需要输入RSS地址就可以轻松地采集到达目标网站内容,无需编写采集规则,方便和简单。
4、指定目标采集,精确的采集标题,正文,作者,来源
方向采集仅需提供列表URL和文章 URL即可智能地采集指定网站或列内容,方便而简单,编写简单的规则即可准确采集标题,正文,作者,来源。
5、各种伪原创和优化方法,可提高收录的排名和排名
自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤,同义词替换,插入seo词,关键词添加链接和其他方法来处理由采集返回的文章处理,增强采集 文章 原创,有利于搜索引擎优化,并提高了搜索引擎收录,网站权重和关键词排名。
6、该插件是全自动采集,无需人工干预
织梦 采集是预先设置的采集任务,根据设置的采集方法采集 URL,然后自动获取网页内容,程序通过准确的计算,然后将其丢弃并非文章内容页面的URL,而是提取出色的文章内容,最后进行伪原创,导入和生成。所有这些操作过程都是自动完成的,无需人工干预。
7、手动发布文章也可以是伪原创和搜索优化处理
织梦 采集 Xia不仅是采集插件,还是织梦必备伪原创和搜索优化插件。手动发布的文章可以通过织梦 采集夏的伪原创和搜索优化处理,可以将文章替换为同义词,自动创建内部链接,随机插入关键词链接,并且文章收录关键词将自动添加指定的链接和其他功能,是织梦基本插件之一。
8、 采集 伪原创 SEO定期且定量地更新
有两种触发插件的采集的方法。一种是在页面上添加代码以通过用户访问来触发采集更新,另一种是我们为商业用户提供的远程触发采集服务。没有人访问新站点。无需人工干预即可定期,定量地更新采集。
9、定期定量更新待处理的手稿
即使您的数据库中有成千上万的文章,织梦 采集也可以根据您的需要在每天设置的时间段内定期和定量地审查和更新。
1 0、绑定织梦 采集节点,定期进行采集 伪原创 SEO更新
绑定织梦 采集节点的功能,以便织梦 cms的内置采集功能也可以定期自动更新采集。设置了采集规则的用户可以方便地定期更新采集。
织梦 Smart 采集 Xia破解说明
织梦 采集 Xia 采集版本分为UTF8和GBK两个版本。根据您使用的dede cms版本进行选择!
由于文件与mac系统打包在一起,因此它们将带有_MACOSX和.DS_Store文件,这不会影响使用,可以删除强迫症患者。覆盖被破解的文件时,不必关心这些文件。
1,[您转到采集夏官方下载了最新的v 2. 8版本(URL:如果无法打开官方网站,请使用我的备份,解压后会有采集 Xia官方插件文件夹,由您自己选择安装相应的版本),然后将其安装到您的织梦背景中。如果您以前安装过2. 7版本,请先将其删除! )
2。安装时请注意不要选择错误的版本,为UTF8安装UTF8,并且不要将GBK与GBK混用!
3,[覆盖破解的文件](共三个文件,收录,插件)
插件:直接覆盖网站的根目录
include:直接覆盖网站的根目录
CaiJiXia:网站默认后端为dede。如果不修改后端目录,它将覆盖/ dede / apps /。如果后端访问路径已被修改,则将dede替换为修改后的名称。示例:已将dede修改为进行测试,然后覆盖/ test / apps /目录
4,[对于破解程序使用的域名没有限制]
5,[覆盖后需要清理浏览器缓存,建议使用Google或Firefox,而不是IE内核浏览器,有时清理时不清理缓存]
6,PHP版本必须为5. 3 +
织梦智能采集如何使用
1、设置方向采集
1),登录到网站后台,执行模块-> 采集侠-> 采集任务,如果网站尚未添加列,则需要转到的列管理织梦首先添加一列,如果您已经添加了列,则可能会看到以下界面
2),在弹出页面中选择方向采集,如图所示
3),点击添加采集规则
2、设置目标页面编码
打开您想要的页面采集,单击鼠标右键,单击以查看网站的源代码,搜索字符集,并检查字符集后跟utf-8还是gb2312
3、设置列表网址
列表URL是您要采集的网站的列列表地址
如果它只是采集列表页面的第一页,只需直接输入列表URL。例如,如果我要网站管理员采集主页的优化部分的第一页,请输入列表URL :。 采集第一页内容的优点是您不需要采集个旧新闻,而新的更新可以及时采集个。如果您需要采集该列的所有内容,则还可以设置通配符以匹配所有列表URL规则的方式。
织梦 Smart 采集 Man常见问题解答
绑定x个域名授权是什么意思?
已授权多少个域名,织梦 采集 Xia商业版可以使用多少个网站。
插件可以为采集指定网站吗?
除了关键词 采集所述的插件外,还有采集两种方法,即RSS和页面监视采集,您可以为采集指定网站。
如果不再使用我的域名,我可以更改域名授权吗?
可以为您更换域名授权,每次更换1个域名授权仅需10元。
根据关键词 采集哪个内容是从哪个网站返回的?
根据关键词 采集,您使用设置为通过搜索引擎进行搜索的关键词,而采集的搜索结果来自不同的网站。
自动采集编写python爬虫程序实现自动抓取马蜂窝(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 530 次浏览 • 2021-05-10 07:03
自动采集编写python爬虫程序实现自动抓取马蜂窝上ugc内容使用大数据技术,自动从分类信息、房价信息中,抓取至少10万条,
一)爬取分析在最开始安装完urllib库后,就可以开始爬取流程了,对于一个网站来说,各个内容会组成一个列表列表就是元素,子元素就是对每个元素的查询对象而每个文本类型就是对于每个元素的查询对象date_id、date_type、item_type、url_order就可以被用来查询列表中所有元素。爬取过程就是根据当前元素被查询的对象,对于其子元素再进行其他查询的过程。(。
二)采集过程python实现完成从以上几个文本类型中,自动采集并提取他们中的一些信息。准备工作1.需要用到jupyternotebook,集搜客采集数据中最重要的工具,没有之一,本人准备将这里搭建一个jupyternotebook环境。2.编写爬虫程序,当时写这个是采用web架构的,因为就是基于集搜客作为采集中间转发页面的应用。这里用到的框架为phantomjs。(。
三)代码实现:1.打开集搜客浏览器,访问以下网址打开集搜客客户端-集搜客首页可以看到,在以上网址中,有url_order标识,我们访问该链接即可获取数据。返回结果2.程序下载地址:集搜客平台首页-集搜客官方网站集搜客上的代码只支持采集到5000个文件,如果你想采集更多的数据,除了要了解集搜客的规则之外,还要去了解源代码。
集搜客源代码3.源代码下载地址:地址:集搜客下载.建立一个爬虫,采集10万条数据,源代码为requests库的httplib.我写过一个小的爬虫程序,
1)方法,page=1是集搜客的一个限制条件。这个爬虫程序在接下来就应该是采用requests.get(url)方法。以上是单个页面采集。现在我们采集整个链接列表(10万条),首先要用beautifulsoup的xpath规则来定位页面,这个是什么?我这里要用到requests的相关知识,所以还是会提前学习一下:requests中的xpath解析之4.httplib定位页面之后就可以定位链接中的title标识和href属性标识,这两个标识。
5.打开集搜客浏览器访问以下页面,点击网页最下方的“尝试抓取”按钮,弹出初始登录对话框,完成登录,发现整个爬虫程序就是点击初始登录按钮开始的。
执行爬虫程序
一)爬取结果爬取过程:首先找到页面上的div标签(这个页面叫做“集搜客列表”,div标签就是页面的大标题,后面会继续用到div标签。 查看全部
自动采集编写python爬虫程序实现自动抓取马蜂窝(组图)
自动采集编写python爬虫程序实现自动抓取马蜂窝上ugc内容使用大数据技术,自动从分类信息、房价信息中,抓取至少10万条,
一)爬取分析在最开始安装完urllib库后,就可以开始爬取流程了,对于一个网站来说,各个内容会组成一个列表列表就是元素,子元素就是对每个元素的查询对象而每个文本类型就是对于每个元素的查询对象date_id、date_type、item_type、url_order就可以被用来查询列表中所有元素。爬取过程就是根据当前元素被查询的对象,对于其子元素再进行其他查询的过程。(。
二)采集过程python实现完成从以上几个文本类型中,自动采集并提取他们中的一些信息。准备工作1.需要用到jupyternotebook,集搜客采集数据中最重要的工具,没有之一,本人准备将这里搭建一个jupyternotebook环境。2.编写爬虫程序,当时写这个是采用web架构的,因为就是基于集搜客作为采集中间转发页面的应用。这里用到的框架为phantomjs。(。
三)代码实现:1.打开集搜客浏览器,访问以下网址打开集搜客客户端-集搜客首页可以看到,在以上网址中,有url_order标识,我们访问该链接即可获取数据。返回结果2.程序下载地址:集搜客平台首页-集搜客官方网站集搜客上的代码只支持采集到5000个文件,如果你想采集更多的数据,除了要了解集搜客的规则之外,还要去了解源代码。
集搜客源代码3.源代码下载地址:地址:集搜客下载.建立一个爬虫,采集10万条数据,源代码为requests库的httplib.我写过一个小的爬虫程序,
1)方法,page=1是集搜客的一个限制条件。这个爬虫程序在接下来就应该是采用requests.get(url)方法。以上是单个页面采集。现在我们采集整个链接列表(10万条),首先要用beautifulsoup的xpath规则来定位页面,这个是什么?我这里要用到requests的相关知识,所以还是会提前学习一下:requests中的xpath解析之4.httplib定位页面之后就可以定位链接中的title标识和href属性标识,这两个标识。
5.打开集搜客浏览器访问以下页面,点击网页最下方的“尝试抓取”按钮,弹出初始登录对话框,完成登录,发现整个爬虫程序就是点击初始登录按钮开始的。
执行爬虫程序
一)爬取结果爬取过程:首先找到页面上的div标签(这个页面叫做“集搜客列表”,div标签就是页面的大标题,后面会继续用到div标签。
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-05-09 04:07
自动采集编写技巧:1、ie下编写采集,这里我把采集规则放在一个excel里面,然后用python从excel读取数据,经过处理以后再自动发送。excel代码:#!/usr/bin/envpython#coding:utf-8"""初始目录definewhere:-/usr/bin/envpythonselectwhere-selectwhereit'sblue,thenwe'llcomebackonthelowpriceroom"""importredefprocess_command(pycap):magis=[xforxinselectionsifxinselectionsandthemagisinmagis)print("processprocess=:\n")returnpycapdefgenerate_magis(data):if(selections.has("magis")):magis=[xforxinselectionsifxinselectionsandxinselections.has_magis]returnmagis#加载gb2312字符集数据fromcn_us.codecsimportgb2312df=pile("(../s/{\d+})\t\n{}{}{})")df["font"]=gb2312("simsun")df["type"]=gb2312("comicsans")print("通过上述代码采集字符集字段为:",df.fields.size)forkey,valueinzip(df["font"],df["type"]):magis=magis("simsun")magis=magis("comicsans")magis=magis("white.post")magis=magis("green.post")name=magis["name"]print("公司名字为:",name)total=magis["total"]status=magis["status"]content=magis["content"]expire_date=magis["expired"]2、全拼采集请求,代码:#url:。 查看全部
Excel教程Excel函数Excel表格制作Excel2010Excel实用技巧Excel视频教程
自动采集编写技巧:1、ie下编写采集,这里我把采集规则放在一个excel里面,然后用python从excel读取数据,经过处理以后再自动发送。excel代码:#!/usr/bin/envpython#coding:utf-8"""初始目录definewhere:-/usr/bin/envpythonselectwhere-selectwhereit'sblue,thenwe'llcomebackonthelowpriceroom"""importredefprocess_command(pycap):magis=[xforxinselectionsifxinselectionsandthemagisinmagis)print("processprocess=:\n")returnpycapdefgenerate_magis(data):if(selections.has("magis")):magis=[xforxinselectionsifxinselectionsandxinselections.has_magis]returnmagis#加载gb2312字符集数据fromcn_us.codecsimportgb2312df=pile("(../s/{\d+})\t\n{}{}{})")df["font"]=gb2312("simsun")df["type"]=gb2312("comicsans")print("通过上述代码采集字符集字段为:",df.fields.size)forkey,valueinzip(df["font"],df["type"]):magis=magis("simsun")magis=magis("comicsans")magis=magis("white.post")magis=magis("green.post")name=magis["name"]print("公司名字为:",name)total=magis["total"]status=magis["status"]content=magis["content"]expire_date=magis["expired"]2、全拼采集请求,代码:#url:。
自动采集编写爬虫模块的价格相关数据提供的吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-05-08 01:08
自动采集编写爬虫模块,可以按照需求采集比价网或等平台的价格相关数据,
的数据不都是有分析数据提供的吗?requests:?如果需要爬什么数据可以先用excel导入然后再写爬虫
python爬虫模块scrapy:django:
现在爬虫教程还挺多的,
那要看题主是爬什么网站,要实现怎样的效果。如果是某宝天猫等商品信息,的话,用fiddler看下发送给你的http报文就可以看到相关商品的价格了。如果是调用爬虫框架的话,推荐yii框架,其他框架可以依赖他的库实现。
爬楼主要爬哪里?多久能爬完?
根据你需要查看对应网站的网页源代码
requests,urllib2。
最高赞的requests写爬虫的方式不太适合爬的数据,可以试试pythonrequests库爬的数据,自己处理过一段时间,很方便,就是回复速度慢了点。
requests
没有爬虫啊,
你有多少金币
有四个api接口,头条,论坛,美食,钱包。可以自己搭配编写爬虫,每个api返回的数据结构是可以定制的。 查看全部
自动采集编写爬虫模块的价格相关数据提供的吗?
自动采集编写爬虫模块,可以按照需求采集比价网或等平台的价格相关数据,
的数据不都是有分析数据提供的吗?requests:?如果需要爬什么数据可以先用excel导入然后再写爬虫
python爬虫模块scrapy:django:
现在爬虫教程还挺多的,
那要看题主是爬什么网站,要实现怎样的效果。如果是某宝天猫等商品信息,的话,用fiddler看下发送给你的http报文就可以看到相关商品的价格了。如果是调用爬虫框架的话,推荐yii框架,其他框架可以依赖他的库实现。
爬楼主要爬哪里?多久能爬完?
根据你需要查看对应网站的网页源代码
requests,urllib2。
最高赞的requests写爬虫的方式不太适合爬的数据,可以试试pythonrequests库爬的数据,自己处理过一段时间,很方便,就是回复速度慢了点。
requests
没有爬虫啊,
你有多少金币
有四个api接口,头条,论坛,美食,钱包。可以自己搭配编写爬虫,每个api返回的数据结构是可以定制的。
怎样使用软件一天撰写1万篇高质量的SEO文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-04-30 19:07
Koala SEO [批处理SEO 原创 文章]平台支持本文。有了考拉,一天就可以制作成千上万的高质量SEO文章文章!
非常抱歉!当每个人都访问此页面时,可能没有关于Babenman 采集器的报告,因为此页面是我们的工具站AI生成的Web内容。如果您对这批原创 文章感兴趣,那么抛开Hachibenman 采集器的问题,编辑器将向您展示如何使用该软件每天编写10,000个高质量的SEO着陆页!大多数客户来到我们的内容,认为这是伪原创软件,这是错误的!实际上,这是一个AI工具,文本和模板都是自己创建的,不可能找到与Internet上的导出文章相同的相似性。 文章。这到底是怎么发生的?稍后我将给您进行全面的分析!
实际上,想要询问Hachibenman 采集器的朋友,每个人都热衷的是上面讨论的内容。但是,写几篇高质量的网站着陆文章非常容易,但是这几篇文章可以产生的搜索量确实微不足道。希望可以利用内容的积累来实现长尾单词流量的目的。非常重要的策略是自动化!如果一个页面文章每天可以带来1位访问者,那么如果我可以编辑10,000篇文章,则每天的页面浏览量可能会增加10,000。但是实际上看起来很简单,一个人在24小时内最多只能写40篇文章,最多只能写60篇文章。即使在伪原创平台上进行操作,最多也将有一百篇文章!浏览到这一点,我们应该放弃Babenman 采集器的话题,而讨论如何实现智能写作文章!
什么是seo批准的独立创作?内容原创不等于一个单词原创的输出!在主要搜索的算法定义中,原创并不意味着没有重复。实际上,只要您的文章和其他人的收录不完全相同,被索引的机会就会增加。热门文章充满了明亮的价值,并且保留了相同的目标词。只要确定没有相同的内容,就表示该文章文章仍然很有可能收录,甚至成为排水的好文章。例如,对于本文,我们可能使用搜索引擎搜索Babenman 采集器,然后单击以查看它。负责人告诉您:我的文章文章是使用Koala系统文章的AI工具自行编写的!
此平台上的伪原创软件实际上应手动编写文章软件。半天之内可能会写出可靠的SEO副本。只要您的页面质量足够好,收录就可以。高达78%。有关详细的应用技巧,用户中心中有一个视频介绍和一个初学者指南,每个人都可以对其进行一点测试!我没有为Babenman 采集器写一个详细的解释,这让您读了很多废话,对此我感到很ham愧。但是,假设每个人都对该产品感兴趣,那么您可以注意导航栏,这样我们的页面每天就有成千上万的访客。那不是很好吗? 查看全部
怎样使用软件一天撰写1万篇高质量的SEO文章
Koala SEO [批处理SEO 原创 文章]平台支持本文。有了考拉,一天就可以制作成千上万的高质量SEO文章文章!
非常抱歉!当每个人都访问此页面时,可能没有关于Babenman 采集器的报告,因为此页面是我们的工具站AI生成的Web内容。如果您对这批原创 文章感兴趣,那么抛开Hachibenman 采集器的问题,编辑器将向您展示如何使用该软件每天编写10,000个高质量的SEO着陆页!大多数客户来到我们的内容,认为这是伪原创软件,这是错误的!实际上,这是一个AI工具,文本和模板都是自己创建的,不可能找到与Internet上的导出文章相同的相似性。 文章。这到底是怎么发生的?稍后我将给您进行全面的分析!
实际上,想要询问Hachibenman 采集器的朋友,每个人都热衷的是上面讨论的内容。但是,写几篇高质量的网站着陆文章非常容易,但是这几篇文章可以产生的搜索量确实微不足道。希望可以利用内容的积累来实现长尾单词流量的目的。非常重要的策略是自动化!如果一个页面文章每天可以带来1位访问者,那么如果我可以编辑10,000篇文章,则每天的页面浏览量可能会增加10,000。但是实际上看起来很简单,一个人在24小时内最多只能写40篇文章,最多只能写60篇文章。即使在伪原创平台上进行操作,最多也将有一百篇文章!浏览到这一点,我们应该放弃Babenman 采集器的话题,而讨论如何实现智能写作文章!
什么是seo批准的独立创作?内容原创不等于一个单词原创的输出!在主要搜索的算法定义中,原创并不意味着没有重复。实际上,只要您的文章和其他人的收录不完全相同,被索引的机会就会增加。热门文章充满了明亮的价值,并且保留了相同的目标词。只要确定没有相同的内容,就表示该文章文章仍然很有可能收录,甚至成为排水的好文章。例如,对于本文,我们可能使用搜索引擎搜索Babenman 采集器,然后单击以查看它。负责人告诉您:我的文章文章是使用Koala系统文章的AI工具自行编写的!
此平台上的伪原创软件实际上应手动编写文章软件。半天之内可能会写出可靠的SEO副本。只要您的页面质量足够好,收录就可以。高达78%。有关详细的应用技巧,用户中心中有一个视频介绍和一个初学者指南,每个人都可以对其进行一点测试!我没有为Babenman 采集器写一个详细的解释,这让您读了很多废话,对此我感到很ham愧。但是,假设每个人都对该产品感兴趣,那么您可以注意导航栏,这样我们的页面每天就有成千上万的访客。那不是很好吗?
Python编程语言编写的门槛低、易上手的工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-04-29 02:18
在互联网信息爆炸式增长的时代,我们经常面临与信息采集相关的各种事情,但是信息的来源很多网站,信息量很大。如果使用常规的手动搜索+办公软件进行组织,则通常会花费很多钱。时间。
在这里,我将介绍一个低阈值,易于使用的工具Python。
以Python编程语言编写的网络爬虫是一种“自动浏览网络”的程序,或者是一种网络机器人。
它可以自动采集所有可访问的页面内容并获取大量信息。很多事情需要在一天内手动完成,Python只需1分钟甚至几秒钟即可完成。 ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????
例如,诸如百度搜索和Google搜索之类的搜索工具,各种价格比较网站都使用Python采集器采集信息,然后进行处理,分析和反馈。
也许每个人都认为Python编程和爬网都是程序员的事,但我想告诉你事实并非如此。我各行各业的许多朋友正在学习Python。
Python开始被纳入小学教科书并被纳入高考
各行各业的学生/运营/营销/产品/财务/财务/行政/销售/客户服务等,如果您了解Python,则可以释放至少80%的重复性工作,因此您有更多的时间和精力去改善自己。有效地工作并快乐地生活!
使用Python捕获竞争产品信息,执行数据分析和信息排序,并制作各种专业图表,这比手动采集要快100倍。提高效率并告别加班!
使用Python批量查找图片,抓取许多文案材料,并制作更具设计感的海报。甚至有人写了超过100,000种热门样式文章!
Python几乎已成为金融从业人员的标准!
使用Python完成巨大的报表数据的统计和分析,甚至包括出勤。
我们必须了解:
20年前,学习英语并不是要成为翻译。 10年前,学习计算机并不是要成为打字员。今天,学习编程并不是要成为一名程序员,而是要增强我们在工作场所的竞争力!
今天,我将与您分享学习Python的基本概念图,入门书籍,视频教程以及最有效的学习方式。
当然,这很完美。当我们精通代码时,我们自然可以总结出一些有用的技术,但是对于那些只熟悉Python的学生来说,这可能并不容易。
以下是30秒内学习Python的整个目录,分为几个主要部分:列表,数学,对象,字符串,实用程序,以下是排序的思维导图。
如果您对Python感兴趣或已开始采取行动,我相信您已经看过很多视频教程,对吗?效果如何?
今天,我为所有Python部门准备了一个新发布的自学教程-“ Python +数据分析+机器学习”。能力的七个阶段逐渐得到改进,以创建具有更全面技能的全职工程师。
1、欢迎喜欢+转发! 查看全部
Python编程语言编写的门槛低、易上手的工具
在互联网信息爆炸式增长的时代,我们经常面临与信息采集相关的各种事情,但是信息的来源很多网站,信息量很大。如果使用常规的手动搜索+办公软件进行组织,则通常会花费很多钱。时间。
在这里,我将介绍一个低阈值,易于使用的工具Python。
以Python编程语言编写的网络爬虫是一种“自动浏览网络”的程序,或者是一种网络机器人。
它可以自动采集所有可访问的页面内容并获取大量信息。很多事情需要在一天内手动完成,Python只需1分钟甚至几秒钟即可完成。 ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????????????????????????????????????????????????? ????????????
例如,诸如百度搜索和Google搜索之类的搜索工具,各种价格比较网站都使用Python采集器采集信息,然后进行处理,分析和反馈。
也许每个人都认为Python编程和爬网都是程序员的事,但我想告诉你事实并非如此。我各行各业的许多朋友正在学习Python。
Python开始被纳入小学教科书并被纳入高考
各行各业的学生/运营/营销/产品/财务/财务/行政/销售/客户服务等,如果您了解Python,则可以释放至少80%的重复性工作,因此您有更多的时间和精力去改善自己。有效地工作并快乐地生活!
使用Python捕获竞争产品信息,执行数据分析和信息排序,并制作各种专业图表,这比手动采集要快100倍。提高效率并告别加班!
使用Python批量查找图片,抓取许多文案材料,并制作更具设计感的海报。甚至有人写了超过100,000种热门样式文章!
Python几乎已成为金融从业人员的标准!
使用Python完成巨大的报表数据的统计和分析,甚至包括出勤。
我们必须了解:
20年前,学习英语并不是要成为翻译。 10年前,学习计算机并不是要成为打字员。今天,学习编程并不是要成为一名程序员,而是要增强我们在工作场所的竞争力!
今天,我将与您分享学习Python的基本概念图,入门书籍,视频教程以及最有效的学习方式。
当然,这很完美。当我们精通代码时,我们自然可以总结出一些有用的技术,但是对于那些只熟悉Python的学生来说,这可能并不容易。
以下是30秒内学习Python的整个目录,分为几个主要部分:列表,数学,对象,字符串,实用程序,以下是排序的思维导图。
如果您对Python感兴趣或已开始采取行动,我相信您已经看过很多视频教程,对吗?效果如何?
今天,我为所有Python部门准备了一个新发布的自学教程-“ Python +数据分析+机器学习”。能力的七个阶段逐渐得到改进,以创建具有更全面技能的全职工程师。
1、欢迎喜欢+转发!
Sleep(Rnd)三就是多用正则表达式测试工具提高编写正则的效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-04-28 18:13
睡眠(修复(Rnd()* 3))
第三种是使用正则表达式测试工具来提高编写正则表达式的效率
4.高级主题:UTF-8和GB2312的转换
这个问题更加复杂。由于我的智力和精力原因,我还没有完全解决它,并且Internet上的大多数信息也不是完全正确或全面的。我建议使用UTF-8和GB2312转换的C语言实现。供您参考,它具有完整的功能,并且不依赖Windows API函数。
我正在尝试使用ASP + VBScript来实现它,但是我有一些不成熟的经验:
计算机上的文件和操作系统的内部字符串表示形式都是Unicode,因此UTF-8和GB2312之间的转换需要使用Unicode作为中介
UTF-8是Unicode的一种变体,它们之间的相互转换相对简单,请参考下图。
GB2312和Unicode编码似乎无关。如果不依赖操作系统的内部功能进行转换,则需要一个编码映射表,指出GB2312与Unicode编码之间的一一对应关系。该编码表收录大约7480×2的项目。
在ASP文件中,如果要默认读取具有特定总和代码的字符串(例如GB231 2),则需要将ASP CodePage设置为相应的代码页(CodePage = 93 6)用于GB2312)
我尚不知道编码转换中的一些小而重要的问题:-(
5.更多高级主题:登录后进行爬网,客户端伪造等。
xmlhttp对象可以在post或get方法中与http服务器进行交互,您可以设置和读取http头,了解http协议,并对某些xmlhttp对象的方法和属性有更深入的了解,可以使用它来模拟浏览器可以自动执行之前需要完成的所有重复性任务。
6.自己的采集程序
本文旨在讨论采集程序在ASP + VBScript环境中的实现。如果您需要网页采集程序,则以下链接可能对您有用。
优采云网络内容采集器
C#+。Net书面内容采集器,其重要特征之一是它不会将采集中的内容保存到数据库中,而是使用自定义POST提交的其他网页,例如内容管理系统新内容页面。自由。 BeeCollector(小蜜蜂采集器)
PHP + MySQL 采集器编写的内容。丰迅内容管理系统
此功能强大的内容管理系统收录ASP网页内容采集器 +查看评论(0) +帖子评论+引用地址+引用(0) 2006-8-9网络编程中的正则表达式使用
分类:Ajax时间:2006-8-914:07:47作者:Janyin指南:
在网络编程中使用正则表达式
[前言:]在编写WEB程序时,我们经常判断字符串的有效性,例如字符串是否为数字,是否为有效的电子邮件地址等等。如果不使用正则表达式,那么判断程序将非常长且容易出错。如果使用正则表达式,那么这些判断将非常容易。本文全面介绍了正则表达式的概念和格式。并通过PHP和ASP中的应用示例来增加读者的感知知识。正则表达式的应用范围很广,每个人都需要在学习和实践中不断总结。 查看全部
Sleep(Rnd)三就是多用正则表达式测试工具提高编写正则的效率
睡眠(修复(Rnd()* 3))
第三种是使用正则表达式测试工具来提高编写正则表达式的效率
4.高级主题:UTF-8和GB2312的转换
这个问题更加复杂。由于我的智力和精力原因,我还没有完全解决它,并且Internet上的大多数信息也不是完全正确或全面的。我建议使用UTF-8和GB2312转换的C语言实现。供您参考,它具有完整的功能,并且不依赖Windows API函数。
我正在尝试使用ASP + VBScript来实现它,但是我有一些不成熟的经验:
计算机上的文件和操作系统的内部字符串表示形式都是Unicode,因此UTF-8和GB2312之间的转换需要使用Unicode作为中介
UTF-8是Unicode的一种变体,它们之间的相互转换相对简单,请参考下图。
GB2312和Unicode编码似乎无关。如果不依赖操作系统的内部功能进行转换,则需要一个编码映射表,指出GB2312与Unicode编码之间的一一对应关系。该编码表收录大约7480×2的项目。
在ASP文件中,如果要默认读取具有特定总和代码的字符串(例如GB231 2),则需要将ASP CodePage设置为相应的代码页(CodePage = 93 6)用于GB2312)
我尚不知道编码转换中的一些小而重要的问题:-(
5.更多高级主题:登录后进行爬网,客户端伪造等。
xmlhttp对象可以在post或get方法中与http服务器进行交互,您可以设置和读取http头,了解http协议,并对某些xmlhttp对象的方法和属性有更深入的了解,可以使用它来模拟浏览器可以自动执行之前需要完成的所有重复性任务。
6.自己的采集程序
本文旨在讨论采集程序在ASP + VBScript环境中的实现。如果您需要网页采集程序,则以下链接可能对您有用。
优采云网络内容采集器
C#+。Net书面内容采集器,其重要特征之一是它不会将采集中的内容保存到数据库中,而是使用自定义POST提交的其他网页,例如内容管理系统新内容页面。自由。 BeeCollector(小蜜蜂采集器)
PHP + MySQL 采集器编写的内容。丰迅内容管理系统
此功能强大的内容管理系统收录ASP网页内容采集器 +查看评论(0) +帖子评论+引用地址+引用(0) 2006-8-9网络编程中的正则表达式使用
分类:Ajax时间:2006-8-914:07:47作者:Janyin指南:
在网络编程中使用正则表达式
[前言:]在编写WEB程序时,我们经常判断字符串的有效性,例如字符串是否为数字,是否为有效的电子邮件地址等等。如果不使用正则表达式,那么判断程序将非常长且容易出错。如果使用正则表达式,那么这些判断将非常容易。本文全面介绍了正则表达式的概念和格式。并通过PHP和ASP中的应用示例来增加读者的感知知识。正则表达式的应用范围很广,每个人都需要在学习和实践中不断总结。
本软件不提供采集规则全自动采集一次安装受益终身
采集交流 • 优采云 发表了文章 • 0 个评论 • 290 次浏览 • 2021-04-26 19:22
此源代码已启用伪静态规则。服务器必须支持伪静态
服务器当前仅支持php + apache
如果您是php + Nginx,请自行修改伪静态规则
或更改服务器操作环境。否则它将不可用。
此源代码没有APP软件。标题中编写的APP支持在其他新颖的APP平台上进行转码和阅读。
一个新颖的网站的每个人都知道。操作APP的成本太高。制作一个APP的最低费用为10,000元人民币。但是,将您自己的网站链接到其他已建立的新颖网站是最方便,最便宜的方式。此源代码支持其他APP软件的代码转换。
它附带演示采集规则。但是其中一些已经过期
采集规则,请自行编写。这家商店不提供采集规则
全自动采集一次性安装,终生受益
1、源代码类型:整个网站的源代码
2、环境要求:PHP 5. 2 / 5. 3 / 5. 4 / 5. 5 + MYSQL5(.Htaccess伪静态)
3、服务器要求:建议使用VPS或具有40G或更多数据磁盘的独立服务器。系统建议使用Windows而不是LNMP。 99%的新型站点服务器使用Windows,这对于文件管理和备份非常方便。 (当前演示站点空间使用情况:6. 5G数据库+ 5G网站空间,已由小组朋友网站验证:具有4核CPU + 4G内存的xen架构VPS可以承受每天50,000 IP和500,000 PV流量而没有压力,获得更多收入超过每天700元)
4、原创程序:织梦 DEDE cms 5. 7SP1
5、编码类型:GBK
6、可以采集:全自动采集(如果内置规则无效,或者采集目标电台被阻止,请找人编写规则,本店概不负责规则的有效性)
7、其他功能:
([1)自动为主页,类别,目录,作者,排名,站点地图页面生成静态html。
([2)全站点拼音目录(可以自定义URL格式),章节页面是伪静态的。
([3)支持下载功能,可以自动生成相应的文本文件,并在该文件中设置广告。
([4)自动生成关键词和关键词自动内部链接。
([5)自动伪原创单词替换(采集,可以在输出期间替换)。
(6)使用CNZZ的统计插件,可以轻松实现详细统计信息的下载和详细统计信息的采集等。
(7)该程序的自动采集在市场优采云,Guanguan,采集等市场中并不常见,而是基于DEDE原创采集功能的二次开发[The k15]模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
(8)安装相对简单,如果安装后打开的URL始终是移动版本,请转到系统设置-查找移动终端,并将其更改为您自己的移动终端独立域名
演示库
TAG:小说
交易过程
交付方式交易过程
投放方式
1、自动:在上述保修服务中标记为自动交付的产品,在被提取后将自动从卖家那里收到产品购买(下载)链接;
2、手册:对于未标记为自动交付的产品,卖家在收到产品后会收到电子邮件和SMS提醒,他们还可以通过QQ或电话与对方联系。
交易周期
1、源代码的默认交易周期:自动交付商品需要1天,人工交付商品需要3天,买方有权将交易周期再延长3天;
2、如果双方仍不能在上述交易期间内完成交易,则任何一方都可以提出额外的请求(1-60天),另一方可以同意。
退款说明
1、描述:源代码描述(包括标题)与实际的源代码不一致(例如:PHP实际上是ASP的描述,所描述的功能实际上缺少,版本不匹配等)。 );
2、演示:当有一个演示站点时,源代码与实际源代码的一致性不到95%(除非类似的重要声明“不能保证完全相同,否则可能更改”);
3、装运:在卖方申请退款之前,手工装运源代码;
4、安装:免费提供安装服务的源代码,但卖方未提供该服务;
5、费用:对其他费用收取额外费用(描述中明显的陈述或交易前双方之间的协议除外)
6、其他:例如硬性和常规质量问题。
注意:验证是否满足以上任何条件后,除非卖方积极解决问题,否则支持退款。
注释
1、该站点将永久存档交易过程和双方之间交易商品的快照,以确保交易的真实性,有效性和安全性!
2、该站点无法保证在进行类似“永久性软件包更新”和“永久性技术支持”之类的交易后的业务承诺。要求买家证明自己的身份;
3、在源代码中同时具有网站演示和图片演示,并且站立和图片显示不一致,默认情况下,图片显示将用作争议判断的基础(除非特别声明或协议);
<p>4、在没有“没有合理的退款依据”的前提下,产品具有类似的声明,例如“一旦售出,将不支持退款”,视为无效声明; 查看全部
本软件不提供采集规则全自动采集一次安装受益终身
此源代码已启用伪静态规则。服务器必须支持伪静态
服务器当前仅支持php + apache
如果您是php + Nginx,请自行修改伪静态规则
或更改服务器操作环境。否则它将不可用。
此源代码没有APP软件。标题中编写的APP支持在其他新颖的APP平台上进行转码和阅读。
一个新颖的网站的每个人都知道。操作APP的成本太高。制作一个APP的最低费用为10,000元人民币。但是,将您自己的网站链接到其他已建立的新颖网站是最方便,最便宜的方式。此源代码支持其他APP软件的代码转换。
它附带演示采集规则。但是其中一些已经过期
采集规则,请自行编写。这家商店不提供采集规则
全自动采集一次性安装,终生受益
1、源代码类型:整个网站的源代码
2、环境要求:PHP 5. 2 / 5. 3 / 5. 4 / 5. 5 + MYSQL5(.Htaccess伪静态)
3、服务器要求:建议使用VPS或具有40G或更多数据磁盘的独立服务器。系统建议使用Windows而不是LNMP。 99%的新型站点服务器使用Windows,这对于文件管理和备份非常方便。 (当前演示站点空间使用情况:6. 5G数据库+ 5G网站空间,已由小组朋友网站验证:具有4核CPU + 4G内存的xen架构VPS可以承受每天50,000 IP和500,000 PV流量而没有压力,获得更多收入超过每天700元)
4、原创程序:织梦 DEDE cms 5. 7SP1
5、编码类型:GBK
6、可以采集:全自动采集(如果内置规则无效,或者采集目标电台被阻止,请找人编写规则,本店概不负责规则的有效性)
7、其他功能:
([1)自动为主页,类别,目录,作者,排名,站点地图页面生成静态html。
([2)全站点拼音目录(可以自定义URL格式),章节页面是伪静态的。
([3)支持下载功能,可以自动生成相应的文本文件,并在该文件中设置广告。
([4)自动生成关键词和关键词自动内部链接。
([5)自动伪原创单词替换(采集,可以在输出期间替换)。
(6)使用CNZZ的统计插件,可以轻松实现详细统计信息的下载和详细统计信息的采集等。
(7)该程序的自动采集在市场优采云,Guanguan,采集等市场中并不常见,而是基于DEDE原创采集功能的二次开发[The k15]模块可以有效地确保章节内容的完整性,避免章节重复,章节内容无内容,章节乱码等;一天24小时采集可以达到250,000至300,000个章节。
(8)安装相对简单,如果安装后打开的URL始终是移动版本,请转到系统设置-查找移动终端,并将其更改为您自己的移动终端独立域名
演示库
TAG:小说
交易过程
交付方式交易过程
投放方式
1、自动:在上述保修服务中标记为自动交付的产品,在被提取后将自动从卖家那里收到产品购买(下载)链接;
2、手册:对于未标记为自动交付的产品,卖家在收到产品后会收到电子邮件和SMS提醒,他们还可以通过QQ或电话与对方联系。
交易周期
1、源代码的默认交易周期:自动交付商品需要1天,人工交付商品需要3天,买方有权将交易周期再延长3天;
2、如果双方仍不能在上述交易期间内完成交易,则任何一方都可以提出额外的请求(1-60天),另一方可以同意。
退款说明
1、描述:源代码描述(包括标题)与实际的源代码不一致(例如:PHP实际上是ASP的描述,所描述的功能实际上缺少,版本不匹配等)。 );
2、演示:当有一个演示站点时,源代码与实际源代码的一致性不到95%(除非类似的重要声明“不能保证完全相同,否则可能更改”);
3、装运:在卖方申请退款之前,手工装运源代码;
4、安装:免费提供安装服务的源代码,但卖方未提供该服务;
5、费用:对其他费用收取额外费用(描述中明显的陈述或交易前双方之间的协议除外)
6、其他:例如硬性和常规质量问题。
注意:验证是否满足以上任何条件后,除非卖方积极解决问题,否则支持退款。
注释
1、该站点将永久存档交易过程和双方之间交易商品的快照,以确保交易的真实性,有效性和安全性!
2、该站点无法保证在进行类似“永久性软件包更新”和“永久性技术支持”之类的交易后的业务承诺。要求买家证明自己的身份;
3、在源代码中同时具有网站演示和图片演示,并且站立和图片显示不一致,默认情况下,图片显示将用作争议判断的基础(除非特别声明或协议);
<p>4、在没有“没有合理的退款依据”的前提下,产品具有类似的声明,例如“一旦售出,将不支持退款”,视为无效声明;
织梦采集器的简单介绍-上海怡健医学()
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-04-24 06:23
一、 织梦 采集器简介
织梦 采集 Xia是基于Dede cms的一组绿色插件,它们根据关键词自动生成采集,无需编写复杂的采集规则,自动生成伪原创,通过简单的配置,它可以实现24小时不间断的采集,伪原创和发布。它是网站管理员创建站群的首选插件。
1、无需在采集之后自动写入采集规则设置关键词,传统的采集模式是织梦 采集可以根据由关键词设置的[pan]进行平移用户采集,pan 采集的优势在于,通过采集和关键词的不同搜索结果,可能不会在一个或几个指定的采集网站上执行采集并减少采集 ]网站正在被搜索引擎搜索。据判断,镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法,可提高收录率和关键词排名
采集 文章 原创增强了多种方法,例如自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤和同义词替换,并改进了搜索引擎收录,网站重量和[k5]排名。
3、该插件是全自动采集,无需人工干预
当用户访问您的网站时,该程序将触发运行,根据设置的关键字通过搜索引擎(可以自定义)采集 URL,然后自动抓取Web内容,该程序通过精确的计算对于网页,丢弃不是文章内容页面的URL,提取出色的文章内容,最后执行伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。当有大量内容时[当k15]时,您也可以手动采集加快采集的速度。
4、有效,站群是首选
织梦 采集 Xia仅需要简单的配置即可自动发布采集。熟悉织梦 Dede cms的网站站长可以轻松上手。
5、第一个远程触发采集,可以完美实现定时和量化采集更新
远程触发采集功能:织梦 采集您可以触发采集,只要在后台对其进行配置并且用户访问您的网站,就可以实现24小时不间断采集 ,但是对于新网站,在早期阶段的访问量并不多,因为如果没有访问,就无法实现自动采集,并且您需要将背景手动输入采集,这无疑会增加很多给用户带来麻烦。对于只有一个或两个网站的用户,问题并不大,但是有更多的用户在新版的早期阶段使用织梦 采集侠建站群和自动采集站比较麻烦。但是,当我们完成使用远程触发器采集功能时,即使没有人在您的新站点的早期阶段访问该触发器,我们的远程服务器仍然可以触发用户的站点,以便可以定期更新新站点并定量采集,也是商业版本用户提供的免费增值服务。
织梦 采集与其他需要先安装本地客户端采集然后再导入站点的采集软件不同,其优点在于,即使您一段时间不在线,也可以保持[每天都有新内容发布,因为织梦 采集 Xia是安装在网站上的智能采集插件。只要您进行设置,就可以定期且定量地对其进行更新。现在,即使新工作站的早期阶段没有流量,它也可以实现自动更新,并且远程服务器将触发新工作站来保持网站的更新。
二、 织梦 采集如何使用英雄
首先,请确保您之前未安装采集 Xia的其他版本。如果已安装它们,请转到后台卸载并重新安装此站点上下载的压缩包中的文件。请不要下载官方安装。
如果您以前没有安装过,请跳过上述步骤
1、转到后台并快速上传模块
2、快速选择模块,有2个版本,一个是GBK,另一个是UFT-8。选择您使用的编码程序,将模块上传到“安装模板”文件夹中,然后安装它,
安装3、后
如果您的程序是GBK版本(请在网站背景的顶部仔细查找,则可以看到GBK或UTF- 8)
破解文件的GBK版本,然后选择下载压缩包中的“破解文件的GBK版本”文件夹
将dede和Plugins这两个文件夹覆盖到网站根目录
(如果织梦程序的后端目录名称不是dede,则将dede重命名为您的后端目录名称,然后将其覆盖)。通常,后端目录是不变的(即覆盖相应的破解文件,使用过该文件的任何人都知道该怎么做!)
4、被覆盖后,单击高级设置,然后将提示您输入域名和授权代码,
输入法:
授权码| 78250688用您的域名替换(切记不要带“ www”)
例如,如果您的URL是,则需要输入授权代码| 78250688
如果发生授权错误,请关闭浏览器,更新浏览器缓存,然后重新打开,再次设置,然后提示输入错误,只需更改核心浏览器即可。
5、设置触发器采集 采集所谓的自动采集是触发器采集,即:
设置触发条件后,如果有人单击您的网站,则会触发一会儿采集一会儿。如果网站流量稳定,则始终是您自己点击采集或其他人可以点击
设置方法:采集任务下方有一段文字,并编写了该方法,如果找不到,我将在这里讨论:
将此代码添加到{dede:robot copyright =“ qjpemail” /}此代码到模板默认模板management-footer.htm的底部,然后生成整个网站,然后设置某人以单击或单击其自己的网站它会被自动拾取一会儿 查看全部
织梦采集器的简单介绍-上海怡健医学()
一、 织梦 采集器简介
织梦 采集 Xia是基于Dede cms的一组绿色插件,它们根据关键词自动生成采集,无需编写复杂的采集规则,自动生成伪原创,通过简单的配置,它可以实现24小时不间断的采集,伪原创和发布。它是网站管理员创建站群的首选插件。
1、无需在采集之后自动写入采集规则设置关键词,传统的采集模式是织梦 采集可以根据由关键词设置的[pan]进行平移用户采集,pan 采集的优势在于,通过采集和关键词的不同搜索结果,可能不会在一个或几个指定的采集网站上执行采集并减少采集 ]网站正在被搜索引擎搜索。据判断,镜像站点有被搜索引擎惩罚的危险。
2、多种伪原创和SEO优化方法,可提高收录率和关键词排名
采集 文章 原创增强了多种方法,例如自动标题,段落重新排列,高级混淆,自动内部链接,内容过滤,URL过滤和同义词替换,并改进了搜索引擎收录,网站重量和[k5]排名。
3、该插件是全自动采集,无需人工干预
当用户访问您的网站时,该程序将触发运行,根据设置的关键字通过搜索引擎(可以自定义)采集 URL,然后自动抓取Web内容,该程序通过精确的计算对于网页,丢弃不是文章内容页面的URL,提取出色的文章内容,最后执行伪原创,导入并生成。所有这些操作都是自动完成的,无需人工干预。当有大量内容时[当k15]时,您也可以手动采集加快采集的速度。
4、有效,站群是首选
织梦 采集 Xia仅需要简单的配置即可自动发布采集。熟悉织梦 Dede cms的网站站长可以轻松上手。
5、第一个远程触发采集,可以完美实现定时和量化采集更新
远程触发采集功能:织梦 采集您可以触发采集,只要在后台对其进行配置并且用户访问您的网站,就可以实现24小时不间断采集 ,但是对于新网站,在早期阶段的访问量并不多,因为如果没有访问,就无法实现自动采集,并且您需要将背景手动输入采集,这无疑会增加很多给用户带来麻烦。对于只有一个或两个网站的用户,问题并不大,但是有更多的用户在新版的早期阶段使用织梦 采集侠建站群和自动采集站比较麻烦。但是,当我们完成使用远程触发器采集功能时,即使没有人在您的新站点的早期阶段访问该触发器,我们的远程服务器仍然可以触发用户的站点,以便可以定期更新新站点并定量采集,也是商业版本用户提供的免费增值服务。
织梦 采集与其他需要先安装本地客户端采集然后再导入站点的采集软件不同,其优点在于,即使您一段时间不在线,也可以保持[每天都有新内容发布,因为织梦 采集 Xia是安装在网站上的智能采集插件。只要您进行设置,就可以定期且定量地对其进行更新。现在,即使新工作站的早期阶段没有流量,它也可以实现自动更新,并且远程服务器将触发新工作站来保持网站的更新。
二、 织梦 采集如何使用英雄
首先,请确保您之前未安装采集 Xia的其他版本。如果已安装它们,请转到后台卸载并重新安装此站点上下载的压缩包中的文件。请不要下载官方安装。
如果您以前没有安装过,请跳过上述步骤
1、转到后台并快速上传模块
2、快速选择模块,有2个版本,一个是GBK,另一个是UFT-8。选择您使用的编码程序,将模块上传到“安装模板”文件夹中,然后安装它,
安装3、后
如果您的程序是GBK版本(请在网站背景的顶部仔细查找,则可以看到GBK或UTF- 8)
破解文件的GBK版本,然后选择下载压缩包中的“破解文件的GBK版本”文件夹
将dede和Plugins这两个文件夹覆盖到网站根目录
(如果织梦程序的后端目录名称不是dede,则将dede重命名为您的后端目录名称,然后将其覆盖)。通常,后端目录是不变的(即覆盖相应的破解文件,使用过该文件的任何人都知道该怎么做!)
4、被覆盖后,单击高级设置,然后将提示您输入域名和授权代码,
输入法:
授权码| 78250688用您的域名替换(切记不要带“ www”)
例如,如果您的URL是,则需要输入授权代码| 78250688
如果发生授权错误,请关闭浏览器,更新浏览器缓存,然后重新打开,再次设置,然后提示输入错误,只需更改核心浏览器即可。
5、设置触发器采集 采集所谓的自动采集是触发器采集,即:
设置触发条件后,如果有人单击您的网站,则会触发一会儿采集一会儿。如果网站流量稳定,则始终是您自己点击采集或其他人可以点击
设置方法:采集任务下方有一段文字,并编写了该方法,如果找不到,我将在这里讨论:
将此代码添加到{dede:robot copyright =“ qjpemail” /}此代码到模板默认模板management-footer.htm的底部,然后生成整个网站,然后设置某人以单击或单击其自己的网站它会被自动拾取一会儿
自动采集编写爬虫爬行、采集数量+速度+爬行距离
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2021-04-23 02:05
自动采集编写爬虫爬行、采集数据。三个n代表采集数量+速度+爬行距离[1]。如果你的数据量比较大,在允许的情况下可以加入数据过滤。selenium代码:fromseleniumimportwebdriverimporttimeimportreimportjsonimportrequestsimportthreadingurl='/'withopen('c:\\test.txt','w')asf:forpageinrange(len(lambdax:list(x))):f.write(url+x)page=requests.get(url)page=requests.post(url)f.write(json.dumps(page))print('allpages')time.sleep(5)结果:allpages结果:总计数据为114896采集速度:对于题图那么大的数据,1秒都可能要等。爬行距离:2km。可以到14层以下进行数据采集。
因为安卓里没有java虚拟机是不允许自动带上抓包工具的,其他的虚拟机有java虚拟机,所以开发一个app是要看具体开发环境的,不同的环境会有不同的工具(以androiddeveloperpremium版本为例,premium版本对java虚拟机要求低,有install命令行可以直接appstore或者googleplay直接安装java虚拟机,有些app会提示安装java虚拟机,要具体去看看),即使是设计好的apps/designer,也会有一些差异,你想用c#开发一个app的,那也得去用java的虚拟机。
但是题主说的这个因为安卓下没有java虚拟机是可以自动抓包工具的,所以题主不要担心。另外使用抓包工具的时候不会出现图片加载在最底层的情况。另外用抓包工具可以在android平台上使用teleport-d2,它能够抓到机身里所有的物理连接点,并把这些数据实时的同步到手机上,并且支持android4.4以上的版本的物理连接点。另外手机上应该也有抓包工具吧,或者已经可以抓到机身里的物理连接点,并实时的同步到手机上。 查看全部
自动采集编写爬虫爬行、采集数量+速度+爬行距离
自动采集编写爬虫爬行、采集数据。三个n代表采集数量+速度+爬行距离[1]。如果你的数据量比较大,在允许的情况下可以加入数据过滤。selenium代码:fromseleniumimportwebdriverimporttimeimportreimportjsonimportrequestsimportthreadingurl='/'withopen('c:\\test.txt','w')asf:forpageinrange(len(lambdax:list(x))):f.write(url+x)page=requests.get(url)page=requests.post(url)f.write(json.dumps(page))print('allpages')time.sleep(5)结果:allpages结果:总计数据为114896采集速度:对于题图那么大的数据,1秒都可能要等。爬行距离:2km。可以到14层以下进行数据采集。
因为安卓里没有java虚拟机是不允许自动带上抓包工具的,其他的虚拟机有java虚拟机,所以开发一个app是要看具体开发环境的,不同的环境会有不同的工具(以androiddeveloperpremium版本为例,premium版本对java虚拟机要求低,有install命令行可以直接appstore或者googleplay直接安装java虚拟机,有些app会提示安装java虚拟机,要具体去看看),即使是设计好的apps/designer,也会有一些差异,你想用c#开发一个app的,那也得去用java的虚拟机。
但是题主说的这个因为安卓下没有java虚拟机是可以自动抓包工具的,所以题主不要担心。另外使用抓包工具的时候不会出现图片加载在最底层的情况。另外用抓包工具可以在android平台上使用teleport-d2,它能够抓到机身里所有的物理连接点,并把这些数据实时的同步到手机上,并且支持android4.4以上的版本的物理连接点。另外手机上应该也有抓包工具吧,或者已经可以抓到机身里的物理连接点,并实时的同步到手机上。
自动采集编写一个公式或换行脚本,会不会很麻烦?
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-04-16 00:04
自动采集编写一个公式或脚本,将需要的数据插入进去,再利用命令将里面的内容复制到文件。会不会很麻烦?自动生成的公式长什么样?大部分人对公式生成的最初认识就是拼字,但是其实公式生成原理也有很多种,并不是都要拼字。最常见的是js,通过使用js,我们只需要通过一行js就可以完成公式生成。但其实命令程序在自动生成公式的同时,还可以实现对齐上下角标和引用参数、标点符号自动换行等功能。
为什么要用js?首先呢,我们看一看js是怎么和真正的公式结合的?在前端领域,常常使用javascript设计一些图形,这些图形的命名大部分是以javascript字符串表达式结尾的。由于编写这些命令的人往往是想把javascript转换成native语言,所以用javascript设计图形是最佳选择。
在前端开发里,ie浏览器通常不支持javascript,因此我们只有在使用其他浏览器的时候才能比较方便地使用。一些安全软件可能会用javascript进行权限控制,因此,有些框架里用到了javascript,我们才能以javascript页面呈现给用户。同样地,像php、node.js,这些编程语言也能被通过javascript封装起来,于是,有了javascript-module。
其实除了javascript,还有另外一种前端api,叫ajax,也能把javascript转换成浏览器可以解析的格式。但ajax会对数据源进行限制,因此,公式生成javascript写起来就更麻烦了。html5开始,连svg都支持了javascript。但是如果我们在制作前端页面时,只是先用javascript开发前端页面,然后用ajax方式把页面渲染出来,我们会遇到一个问题,很难跟后端的同事交流页面的一些细节,因为他们不一定知道我们前端到底需要传递什么数据。
而如果我们先把页面制作好,然后传输后端数据,他们可以通过get或post来获取数据。这样,后端同学就不用纠结我们要传多大的数据,为什么要传递一个javascript才能转换成的数据。javascript转换成的数据有什么用?有这样一个回答,大概是说,html5之前,公式转化为数字和字符串需要引入转换工具,而html5把这些都省略了。
今天我们一起先来试一试如何用javascript制作一个jsonify项目。import{mathtype}from'node.js';import{schema}from'ejs';import{schemato_format}from'ejs.schema';import{schematoto}from'ejs.schema';@el={'name':'fenny','email':'exyear,2019','home':'dad','bank':'china','phone':''。 查看全部
自动采集编写一个公式或换行脚本,会不会很麻烦?
自动采集编写一个公式或脚本,将需要的数据插入进去,再利用命令将里面的内容复制到文件。会不会很麻烦?自动生成的公式长什么样?大部分人对公式生成的最初认识就是拼字,但是其实公式生成原理也有很多种,并不是都要拼字。最常见的是js,通过使用js,我们只需要通过一行js就可以完成公式生成。但其实命令程序在自动生成公式的同时,还可以实现对齐上下角标和引用参数、标点符号自动换行等功能。
为什么要用js?首先呢,我们看一看js是怎么和真正的公式结合的?在前端领域,常常使用javascript设计一些图形,这些图形的命名大部分是以javascript字符串表达式结尾的。由于编写这些命令的人往往是想把javascript转换成native语言,所以用javascript设计图形是最佳选择。
在前端开发里,ie浏览器通常不支持javascript,因此我们只有在使用其他浏览器的时候才能比较方便地使用。一些安全软件可能会用javascript进行权限控制,因此,有些框架里用到了javascript,我们才能以javascript页面呈现给用户。同样地,像php、node.js,这些编程语言也能被通过javascript封装起来,于是,有了javascript-module。
其实除了javascript,还有另外一种前端api,叫ajax,也能把javascript转换成浏览器可以解析的格式。但ajax会对数据源进行限制,因此,公式生成javascript写起来就更麻烦了。html5开始,连svg都支持了javascript。但是如果我们在制作前端页面时,只是先用javascript开发前端页面,然后用ajax方式把页面渲染出来,我们会遇到一个问题,很难跟后端的同事交流页面的一些细节,因为他们不一定知道我们前端到底需要传递什么数据。
而如果我们先把页面制作好,然后传输后端数据,他们可以通过get或post来获取数据。这样,后端同学就不用纠结我们要传多大的数据,为什么要传递一个javascript才能转换成的数据。javascript转换成的数据有什么用?有这样一个回答,大概是说,html5之前,公式转化为数字和字符串需要引入转换工具,而html5把这些都省略了。
今天我们一起先来试一试如何用javascript制作一个jsonify项目。import{mathtype}from'node.js';import{schema}from'ejs';import{schemato_format}from'ejs.schema';import{schematoto}from'ejs.schema';@el={'name':'fenny','email':'exyear,2019','home':'dad','bank':'china','phone':''。
自动采集脚本编写阿里妈妈自己看下面的图片。。
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2021-04-13 00:01
自动采集编写脚本在每次发帖前执行
阿里妈妈,自己看下面的图片。如果我没记错的话,其实很多网站也支持这样的自动付费的模式。b2b网站广告联盟啊。
我的天啊,
百度经验
其实百度有很多啊,不过需要的你有编程能力,好多都是收费的,目前最流行的就是自动注册百度空间或者百度空间付费会员的模式了,付费会员包年和包年的模式收益会比较大的,找个工作的百度童鞋了解下,推荐你们去百度经验看看。
聚创移动营销宝
百度联盟,搜狗联盟,58同城联盟,等。
如果你在北京上海深圳等地的话,可以找我做代发优化。
博主,我们是卖内衣的,编辑要求销量到8000,
联盟
中国还有编程语言和教程。
有种软件叫做批量改ip的,
百度联盟,和百度空间客户端可以,如果需要自己写就需要自己学习网站的优化语言编写了,从php到php5.5再到php7,自己慢慢学着做,
建议买账号,不过估计你买不起,
百度客户端的后台是接入某些的移动互联网站点的,比如你是开发支付宝和微信平台的在线充值,你可以把该网站的客户端接入支付宝和微信平台,用该网站来收客户端的账单就可以使用了。 查看全部
自动采集脚本编写阿里妈妈自己看下面的图片。。
自动采集编写脚本在每次发帖前执行
阿里妈妈,自己看下面的图片。如果我没记错的话,其实很多网站也支持这样的自动付费的模式。b2b网站广告联盟啊。
我的天啊,
百度经验
其实百度有很多啊,不过需要的你有编程能力,好多都是收费的,目前最流行的就是自动注册百度空间或者百度空间付费会员的模式了,付费会员包年和包年的模式收益会比较大的,找个工作的百度童鞋了解下,推荐你们去百度经验看看。
聚创移动营销宝
百度联盟,搜狗联盟,58同城联盟,等。
如果你在北京上海深圳等地的话,可以找我做代发优化。
博主,我们是卖内衣的,编辑要求销量到8000,
联盟
中国还有编程语言和教程。
有种软件叫做批量改ip的,
百度联盟,和百度空间客户端可以,如果需要自己写就需要自己学习网站的优化语言编写了,从php到php5.5再到php7,自己慢慢学着做,
建议买账号,不过估计你买不起,
百度客户端的后台是接入某些的移动互联网站点的,比如你是开发支付宝和微信平台的在线充值,你可以把该网站的客户端接入支付宝和微信平台,用该网站来收客户端的账单就可以使用了。
自动采集编写爬虫需要学习的几种东西!(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 281 次浏览 • 2021-04-02 19:03
自动采集编写爬虫需要学习的东西很多:
1、首先需要知道现在的网站都是怎么生成url的,
2、接着,如果你是做技术,能想清楚抓取以后怎么实现,
3、如果你是做采集,
4、如果你想了解到爬虫自动爬取是怎么实现的,
5、如果你想知道抓取到的url具体是什么类型的,则需要学习一门可以用python写出来的爬虫,
6、如果你想查看网页结构,则需要学习一门可以用python编写的网页结构分析的语言,比如threading或pyquery之类的。
做爬虫要学习的很多,建议从python开始。
学习的不仅仅是一门编程语言,还有一些工具,服务器配置这一块的知识,还有爬虫本身的代码框架设计。想去做一个好的网站不能脱离设计、服务器、爬虫的环境去进行。
换个脑子,
爬虫只是一个解决问题的工具,核心的还是爬虫算法和爬虫配置。关键是你要用它来解决什么问题。解决网页内容数据的爬取1.解决小网站需要抓取的一些问题,如博客,导航2.解决小网站需要抓取特定内容的,如美团订单,饿了么菜谱,百度贴吧,糗事百科等3.简单需要爬取一些企业资料的,如一些科技网站、游戏类网站4.简单需要抓取电影简介的,如下厨房5.简单需要抓取文章目录的,如分类推荐算法解决大网站需要爬取内容的1.解决c站需要抓取这些网站高产量内容的问题2.解决百度sitemap覆盖大部分站点数据的问题3.解决目前站点超过万的大站,一般图片加载速度快的站点,如千图网,珍爱网等4.解决老站需要去掉内容冷门字幕的问题5.解决老站需要去掉干扰信息的问题6.解决一些外链不足无法快速爬取网站内容的问题7.解决目前内容被清理的问题。 查看全部
自动采集编写爬虫需要学习的几种东西!(一)
自动采集编写爬虫需要学习的东西很多:
1、首先需要知道现在的网站都是怎么生成url的,
2、接着,如果你是做技术,能想清楚抓取以后怎么实现,
3、如果你是做采集,
4、如果你想了解到爬虫自动爬取是怎么实现的,
5、如果你想知道抓取到的url具体是什么类型的,则需要学习一门可以用python写出来的爬虫,
6、如果你想查看网页结构,则需要学习一门可以用python编写的网页结构分析的语言,比如threading或pyquery之类的。
做爬虫要学习的很多,建议从python开始。
学习的不仅仅是一门编程语言,还有一些工具,服务器配置这一块的知识,还有爬虫本身的代码框架设计。想去做一个好的网站不能脱离设计、服务器、爬虫的环境去进行。
换个脑子,
爬虫只是一个解决问题的工具,核心的还是爬虫算法和爬虫配置。关键是你要用它来解决什么问题。解决网页内容数据的爬取1.解决小网站需要抓取的一些问题,如博客,导航2.解决小网站需要抓取特定内容的,如美团订单,饿了么菜谱,百度贴吧,糗事百科等3.简单需要爬取一些企业资料的,如一些科技网站、游戏类网站4.简单需要抓取电影简介的,如下厨房5.简单需要抓取文章目录的,如分类推荐算法解决大网站需要爬取内容的1.解决c站需要抓取这些网站高产量内容的问题2.解决百度sitemap覆盖大部分站点数据的问题3.解决目前站点超过万的大站,一般图片加载速度快的站点,如千图网,珍爱网等4.解决老站需要去掉内容冷门字幕的问题5.解决老站需要去掉干扰信息的问题6.解决一些外链不足无法快速爬取网站内容的问题7.解决目前内容被清理的问题。
2012-3-25增加网站更新排序功能,修改BUG!
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-03-28 19:17
视频网站自动采集更新cms自动v 2. 1
视频网站自动采集更新cms自动为您自动更新24小时的最大MAX cms,Feifei FF cms,GX cms,Apple MAC cms等。 ]电影网站系统,即使不是该类型的系统也可以应用。让您专注于SEO,而无需等待网站的长时间更新。根据指定的时间网站自动更新,非常好的助手!会有什么效果?首先,它与主要搜索引擎蜘蛛的挨家挨户的访问最为吻合。如果您每次都在这些时间更新,他将记住他将习惯于您的站点,不会空手而归!最后,您的快照是稳定的,收录是稳定的,并且排名相对更好!简而言之,网站可能还活着。支持:Max MAX cms,Feifei FF cms,Light GX cms,Succubus Mac cms 1、大大简化了设置2、自动登录2. 0,更安全,更简单3、一款软件更新多个站,多个采集资源,不占用内存资源4、不占用CPU,仅cms PHP程序在更新时占用一点点5、 采集任何数量的资源亮点:1、帮助进行设置,降低难度2、,无需验证码cms,无需修改文件,减少麻烦3、打开一个软件即可更新多个站点,即一对多。减少服务器内存开销,4、代码设计合理,运行速度快且占用少量内存。 5、操作很简单,并且在软件上有提示和说明。看看吧!修改记录:2012-3-25添加网站更新排序功能,修改BUG! 2012-3-03
立即下载 查看全部
2012-3-25增加网站更新排序功能,修改BUG!
视频网站自动采集更新cms自动v 2. 1
视频网站自动采集更新cms自动为您自动更新24小时的最大MAX cms,Feifei FF cms,GX cms,Apple MAC cms等。 ]电影网站系统,即使不是该类型的系统也可以应用。让您专注于SEO,而无需等待网站的长时间更新。根据指定的时间网站自动更新,非常好的助手!会有什么效果?首先,它与主要搜索引擎蜘蛛的挨家挨户的访问最为吻合。如果您每次都在这些时间更新,他将记住他将习惯于您的站点,不会空手而归!最后,您的快照是稳定的,收录是稳定的,并且排名相对更好!简而言之,网站可能还活着。支持:Max MAX cms,Feifei FF cms,Light GX cms,Succubus Mac cms 1、大大简化了设置2、自动登录2. 0,更安全,更简单3、一款软件更新多个站,多个采集资源,不占用内存资源4、不占用CPU,仅cms PHP程序在更新时占用一点点5、 采集任何数量的资源亮点:1、帮助进行设置,降低难度2、,无需验证码cms,无需修改文件,减少麻烦3、打开一个软件即可更新多个站点,即一对多。减少服务器内存开销,4、代码设计合理,运行速度快且占用少量内存。 5、操作很简单,并且在软件上有提示和说明。看看吧!修改记录:2012-3-25添加网站更新排序功能,修改BUG! 2012-3-03
立即下载
指数据真实性(Veracity)高,数据类别特别大的数据集
采集交流 • 优采云 发表了文章 • 0 个评论 • 187 次浏览 • 2021-03-27 00:44
“大数据”是具有非常大的数据类别的非常大的数据集,并且无法使用传统的数据库工具来捕获,管理和处理这样的数据集。
“大数据”首先指的是大数据量(卷),指的是大数据集,通常大小约为10TB。但是,在实际应用中,许多企业用户将多个数据集放在一起,并在PB级别上形成了数据量。其次,它指的是大数据类别(品种),数据来自各种数据源,并且数据类型和格式变得越来越丰富。它突破了先前定义的结构化数据类别,包括半结构化和非结构化数据。其次是快速的数据处理速度(Velocity),即使在数据量非常大的情况下,也可以实现实时数据处理。最后一个功能是指数据的高度准确性。随着新数据源(例如社交数据,企业内容,交易和应用程序数据)的兴趣,打破了传统数据源的局限性,并且公司越来越需要有效的信息能力。确保其真实性和安全性。
Amazon Web Services(AWS)大数据科学家John Rauser提到了一个简单的定义:大数据是指超出计算机处理能力的任何大量数据。研发团队对大数据的定义是:“大数据是最大的宣传技术和最时尚的技术。当这种现象发生时,定义变得非常混乱。”凯利说:“大数据可能不会收录所有信息。但是我认为其中大部分是正确的。对大数据的部分理解是,它是如此之大,需要多个工作负载才能对其进行分析。这就是AWS的定义。 。当您的技术达到极限时,那就是数据的极限。”
大数据与如何定义无关,最重要的是如何使用它以及如何获取这些大数据。换句话说,大数据使我们能够以前所未有的方式分析海量数据,以获取具有重大价值或深刻见解的产品和服务,并最终形成变革的力量。
那么如何获得这些有价值的数据呢?是否有任何软件可以帮助我们获取这些数据?在采集大数据的处理过程中,我们发现某些采集数据软件还不错,除了大量的采集数据外,它还是免费的。我使用了一个名为优采云 采集的爬虫程序来获取Maoyan电影的实时票房。我没想到这款采集软件还可以轻松轻松地直接智能地识别表格形式的网页采集,其重点是导出功能当时没有限制,而且它是免费的。
如果要使用此软件,请先访问其官方网站下载该软件的最新版本,然后注册并登录。无需登录即可使用它,只需担心丢失数据。
然后复制猫眼电影的实时票房URL,打开软件并单击智能模式以输入URL,该软件将自动识别该网页。
识别网页后,由于系统已识别字段名称,因此您可以自行设置或进行其他操作。
设置完字段后,您可以单击开始采集直接运行数据。
等待数据自行运行,运行完成后会出现提示,然后此时导出数据。
我将向您展示使用Excel导出的效果。真的很好感觉它可以直接使用,不需要处理。
查看全部
指数据真实性(Veracity)高,数据类别特别大的数据集
“大数据”是具有非常大的数据类别的非常大的数据集,并且无法使用传统的数据库工具来捕获,管理和处理这样的数据集。
“大数据”首先指的是大数据量(卷),指的是大数据集,通常大小约为10TB。但是,在实际应用中,许多企业用户将多个数据集放在一起,并在PB级别上形成了数据量。其次,它指的是大数据类别(品种),数据来自各种数据源,并且数据类型和格式变得越来越丰富。它突破了先前定义的结构化数据类别,包括半结构化和非结构化数据。其次是快速的数据处理速度(Velocity),即使在数据量非常大的情况下,也可以实现实时数据处理。最后一个功能是指数据的高度准确性。随着新数据源(例如社交数据,企业内容,交易和应用程序数据)的兴趣,打破了传统数据源的局限性,并且公司越来越需要有效的信息能力。确保其真实性和安全性。
Amazon Web Services(AWS)大数据科学家John Rauser提到了一个简单的定义:大数据是指超出计算机处理能力的任何大量数据。研发团队对大数据的定义是:“大数据是最大的宣传技术和最时尚的技术。当这种现象发生时,定义变得非常混乱。”凯利说:“大数据可能不会收录所有信息。但是我认为其中大部分是正确的。对大数据的部分理解是,它是如此之大,需要多个工作负载才能对其进行分析。这就是AWS的定义。 。当您的技术达到极限时,那就是数据的极限。”
大数据与如何定义无关,最重要的是如何使用它以及如何获取这些大数据。换句话说,大数据使我们能够以前所未有的方式分析海量数据,以获取具有重大价值或深刻见解的产品和服务,并最终形成变革的力量。
那么如何获得这些有价值的数据呢?是否有任何软件可以帮助我们获取这些数据?在采集大数据的处理过程中,我们发现某些采集数据软件还不错,除了大量的采集数据外,它还是免费的。我使用了一个名为优采云 采集的爬虫程序来获取Maoyan电影的实时票房。我没想到这款采集软件还可以轻松轻松地直接智能地识别表格形式的网页采集,其重点是导出功能当时没有限制,而且它是免费的。
如果要使用此软件,请先访问其官方网站下载该软件的最新版本,然后注册并登录。无需登录即可使用它,只需担心丢失数据。
然后复制猫眼电影的实时票房URL,打开软件并单击智能模式以输入URL,该软件将自动识别该网页。
识别网页后,由于系统已识别字段名称,因此您可以自行设置或进行其他操作。
设置完字段后,您可以单击开始采集直接运行数据。
等待数据自行运行,运行完成后会出现提示,然后此时导出数据。
我将向您展示使用Excel导出的效果。真的很好感觉它可以直接使用,不需要处理。
自动采集编写js代码,gif、png自动(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-02-18 09:01
自动采集编写js代码,gif、png自动按照编写的代码量采集,适合工作量比较大,多人一起合作,或者是模拟运行程序时使用,可以自动采集并且将采集到的数据显示在效果页面中,以供大家参考和学习。自动化采集源码1、百度,或者google采集图片,做一个引导到自动框框内,就自动框框保存过去。自动代码编写【用函数实现自动】=substitute(url,substitute(b4.text(name,"deskwrit"),""),"")>>{root.ext}substitute:获取b4.text(name,"deskwrit")为你要采集的网址第一步。
url中,还需要编写post方法,参数网址的一个字符串,这个链接去上传或下载图片第二步。即b4.text(name,"deskwrit"):去将图片名重命名为deskwritdeskwrit类似于imgurl='imageurl'entity.decode('utf-8'),解码方式为:lcurl=url+'/'(在浏览器中使用url编码)第三步。
把图片保存起来,所有的图片都放在一个txt文档中保存的图片名放到第三步,每个图片进入图片采集框框即在,运行gif时保存图片的图片的相应路径就行第四步:把解码后的url发送到自动框框中,框框运行第五步:运行,程序采集成功image1图片采集图片代码的代码的意思是把网址编码后,作为类似于js函数的一个方法,作为后台代码的参数。
自动请求网页数据网络上有不少开源采集工具,非常好用,我自己去尝试的结果是采集不到,post的话返回json形式,但直接post的话它返回json,不过这种,其实用下posthelper自动采集的方式会比用自己写采集方式更简单点。posthelper自动采集服务器|免费的采集服务器|智能的采集服务器|静态网站采集posthelper采集助手项目|免费的采集助手|智能的采集助手|静态网站采集前言在国内,无法做到完全普及,自动化采集的需求很大程度在工作量和采集速度上有一定的要求,下面,给大家介绍利用自动采集的方式采集一些图片源码,png源码的一些比较有代表性的网站。
这里我推荐一个比较简单的python采集图片的工具scrapy,不过操作的步骤稍微比较麻烦。这里我提供一个example利用该工具接入的js自动采集的教程。如下所示,从网上下载一些png图片素材并用xpath解析,最后保存为png类似网页形式的文件;最后使用python构建下图片采集框架【简单流】,分析每个元素的坐标是否在一个确定位置采集出来---。 查看全部
自动采集编写js代码,gif、png自动(组图)
自动采集编写js代码,gif、png自动按照编写的代码量采集,适合工作量比较大,多人一起合作,或者是模拟运行程序时使用,可以自动采集并且将采集到的数据显示在效果页面中,以供大家参考和学习。自动化采集源码1、百度,或者google采集图片,做一个引导到自动框框内,就自动框框保存过去。自动代码编写【用函数实现自动】=substitute(url,substitute(b4.text(name,"deskwrit"),""),"")>>{root.ext}substitute:获取b4.text(name,"deskwrit")为你要采集的网址第一步。
url中,还需要编写post方法,参数网址的一个字符串,这个链接去上传或下载图片第二步。即b4.text(name,"deskwrit"):去将图片名重命名为deskwritdeskwrit类似于imgurl='imageurl'entity.decode('utf-8'),解码方式为:lcurl=url+'/'(在浏览器中使用url编码)第三步。
把图片保存起来,所有的图片都放在一个txt文档中保存的图片名放到第三步,每个图片进入图片采集框框即在,运行gif时保存图片的图片的相应路径就行第四步:把解码后的url发送到自动框框中,框框运行第五步:运行,程序采集成功image1图片采集图片代码的代码的意思是把网址编码后,作为类似于js函数的一个方法,作为后台代码的参数。
自动请求网页数据网络上有不少开源采集工具,非常好用,我自己去尝试的结果是采集不到,post的话返回json形式,但直接post的话它返回json,不过这种,其实用下posthelper自动采集的方式会比用自己写采集方式更简单点。posthelper自动采集服务器|免费的采集服务器|智能的采集服务器|静态网站采集posthelper采集助手项目|免费的采集助手|智能的采集助手|静态网站采集前言在国内,无法做到完全普及,自动化采集的需求很大程度在工作量和采集速度上有一定的要求,下面,给大家介绍利用自动采集的方式采集一些图片源码,png源码的一些比较有代表性的网站。
这里我推荐一个比较简单的python采集图片的工具scrapy,不过操作的步骤稍微比较麻烦。这里我提供一个example利用该工具接入的js自动采集的教程。如下所示,从网上下载一些png图片素材并用xpath解析,最后保存为png类似网页形式的文件;最后使用python构建下图片采集框架【简单流】,分析每个元素的坐标是否在一个确定位置采集出来---。
自动采集编写python爬虫程序本教程教你利用python爬取
采集交流 • 优采云 发表了文章 • 0 个评论 • 242 次浏览 • 2021-02-10 12:01
自动采集编写python爬虫程序本教程教你利用python爬取b站站内的视频。b站视频爬取是数据分析、数据采集等任务中的基础技能,爬取视频主要包括4个步骤:请求页面(url地址)下载视频源代码(视频文件)解析视频文件的标签内容(tag字段及规则)利用requests库和beautifulsoup库解析视频文件内容本文就利用beautifulsoup解析页面编写代码,接下来的爬虫程序利用python如何进行视频页面的爬取。
1.请求页面在python中爬取页面主要是请求页面。请求页面分为2种方式,一种是浏览器访问网站的url地址,另一种是通过urllib2模块的urllib。urllib2对浏览器提供request和request_url两个对象用于请求网站。建议在程序之前使用urllib,因为python在ie中可能会在请求网站时跳出各种浏览器ui布局。
至于request_url模块请求并获取网页的请求头中的参数。pythonurllib中用“pageno,pagespace,content”3个参数来构成url,即获取网页的第一段url。如图所示:请求方式request_url爬取网页常用的两种方式是get和post。get方式是request方法自动获取页面地址地址,如“”即“/”,这也是爬虫程序比较常用的方式。
post方式则是向目标网站传递参数,如:"username"、"password"(“post请求参数”的get方式是“get”,但是两者在爬取效率上并没有太大的区别,区别主要是在程序是否编译到c++中去而已)。更多爬虫视频教程python爬虫视频教程|识君-博客园2.下载视频源代码根据视频在b站的url地址(/)及其视频的描述()写下载程序,参考了慕课网的视频下载爬虫代码。
分析了b站是使用python3.x版本开发的,因此仅根据url获取页面下载内容。有了下载目标页面的内容后,下载所有视频的源代码。很多情况下都是抓取特定页面内容进行下载,这样做有好处,可以最大程度缩小抓取的单个页面的数量。3.解析页面文件标签内容继续利用requests库以及beautifulsoup库,抓取页面源代码:先使用urllib2请求网站源代码:获取页面链接地址:urllib2模块的url请求地址中含有页面名称及视频名称,抓取下来的文件包含urllib2.pageno,urllib2.pagespace,把“pageno,pagespace”3个参数获取出来。
同时利用beautifulsoup库找到网页标签,如图所示:和python的requests库抓取页面代码相同,抓取标签内容主要利用两个方法获取。download()获取整个页面下载代码requests库提供downloader对象,downloader.request(url,headers=headers),requests库自带。 查看全部
自动采集编写python爬虫程序本教程教你利用python爬取
自动采集编写python爬虫程序本教程教你利用python爬取b站站内的视频。b站视频爬取是数据分析、数据采集等任务中的基础技能,爬取视频主要包括4个步骤:请求页面(url地址)下载视频源代码(视频文件)解析视频文件的标签内容(tag字段及规则)利用requests库和beautifulsoup库解析视频文件内容本文就利用beautifulsoup解析页面编写代码,接下来的爬虫程序利用python如何进行视频页面的爬取。
1.请求页面在python中爬取页面主要是请求页面。请求页面分为2种方式,一种是浏览器访问网站的url地址,另一种是通过urllib2模块的urllib。urllib2对浏览器提供request和request_url两个对象用于请求网站。建议在程序之前使用urllib,因为python在ie中可能会在请求网站时跳出各种浏览器ui布局。
至于request_url模块请求并获取网页的请求头中的参数。pythonurllib中用“pageno,pagespace,content”3个参数来构成url,即获取网页的第一段url。如图所示:请求方式request_url爬取网页常用的两种方式是get和post。get方式是request方法自动获取页面地址地址,如“”即“/”,这也是爬虫程序比较常用的方式。
post方式则是向目标网站传递参数,如:"username"、"password"(“post请求参数”的get方式是“get”,但是两者在爬取效率上并没有太大的区别,区别主要是在程序是否编译到c++中去而已)。更多爬虫视频教程python爬虫视频教程|识君-博客园2.下载视频源代码根据视频在b站的url地址(/)及其视频的描述()写下载程序,参考了慕课网的视频下载爬虫代码。
分析了b站是使用python3.x版本开发的,因此仅根据url获取页面下载内容。有了下载目标页面的内容后,下载所有视频的源代码。很多情况下都是抓取特定页面内容进行下载,这样做有好处,可以最大程度缩小抓取的单个页面的数量。3.解析页面文件标签内容继续利用requests库以及beautifulsoup库,抓取页面源代码:先使用urllib2请求网站源代码:获取页面链接地址:urllib2模块的url请求地址中含有页面名称及视频名称,抓取下来的文件包含urllib2.pageno,urllib2.pagespace,把“pageno,pagespace”3个参数获取出来。
同时利用beautifulsoup库找到网页标签,如图所示:和python的requests库抓取页面代码相同,抓取标签内容主要利用两个方法获取。download()获取整个页面下载代码requests库提供downloader对象,downloader.request(url,headers=headers),requests库自带。
快速入门编写一个入门的demo代码和集成prometheus查询效果图
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-02-01 11:04
上面文章中已说明了几个官方出口商的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这时,我们通常需要自己编写采集器。
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时,它将侦听端口8000并访问端口127.0.0.1:8000。
效果图片
实际上,已经编写了一个导出器。就这么简单。我们只需要在prometheus中配置与采集对应的导出器。但是,我们导出的数据毫无意义。
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求的总数或网络发送和接收的数据包的累积值。
仪表盘:仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读取和写入等情况的仪表盘类型,该数据类型会随着波动和变化而使用。
摘要:基于抽样,统计信息在服务器上完成。在计算平均值时,我们可能会认为异常值导致计算出的平均值无法准确反映实际值,因此需要特定的点位置。
直方图:基于采样,统计在客户端上完成。在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置。
采集用内存使用情况数据写采集类型代码
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图
查看全部
快速入门编写一个入门的demo代码和集成prometheus查询效果图
上面文章中已说明了几个官方出口商的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这时,我们通常需要自己编写采集器。
快速入门并编写一个演示性示例来编写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时,它将侦听端口8000并访问端口127.0.0.1:8000。
效果图片
实际上,已经编写了一个导出器。就这么简单。我们只需要在prometheus中配置与采集对应的导出器。但是,我们导出的数据毫无意义。
数据类型简介
计数器是一种累积类型,只能增加,例如记录http请求的总数或网络发送和接收的数据包的累积值。
仪表盘:仪表盘类型,适用于那些具有上升和下降,一般网络流量,磁盘读取和写入等情况的仪表盘类型,该数据类型会随着波动和变化而使用。
摘要:基于抽样,统计信息在服务器上完成。在计算平均值时,我们可能会认为异常值导致计算出的平均值无法准确反映实际值,因此需要特定的点位置。
直方图:基于采样,统计在客户端上完成。在计算平均值时,我们可能会认为异常值导致计算得出的平均值无法准确反映实际值,因此需要特定的点位置。
采集用内存使用情况数据写采集类型代码
公开数据情况
部署代码并集成Prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图

