
自动采集编写
小程序开发(1): 使用scrapy采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 15:21
农历新年后,我一直在业余时间独立开发一个小程序. 主要数据是8000多个视频和10000多个文章,并且每天都会自动更新数据.
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本. 查看全部
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本. 查看全部
农历新年后,我一直在业余时间独立开发一个小程序. 主要数据是8000多个视频和10000多个文章,并且每天都会自动更新数据.
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本.
Python大法之告别脚本小子系列—各类URL采集器编写
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2020-08-04 19:05
本文作者:i春秋签约作家——阿甫哥哥
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
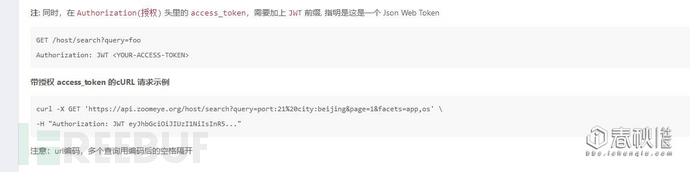
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)
0×05 【彩蛋篇】论坛自动签到脚本 查看全部
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)
0×05 【彩蛋篇】论坛自动签到脚本 查看全部
本文作者:i春秋签约作家——阿甫哥哥
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)

0×05 【彩蛋篇】论坛自动签到脚本
小程序开发(1): 使用scrapy采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 15:21
农历新年后,我一直在业余时间独立开发一个小程序. 主要数据是8000多个视频和10000多个文章,并且每天都会自动更新数据.
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本. 查看全部
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本. 查看全部
农历新年后,我一直在业余时间独立开发一个小程序. 主要数据是8000多个视频和10000多个文章,并且每天都会自动更新数据.
我将整理整个开发过程中遇到的问题和一些细节. 因为内容会更多,所以我将其分为三到四篇文章. 本文是该系列的第一篇文章,内容为python reptile.
本系列文章将大致介绍内容:
数据准备(python scrapy框架)
接口准备(nodejs的hapijs框架)
小型程序开发(小型程序随附的mpvue和组件等)
在线部署(小程序安全性域名以及其他配置和爬网程序/界面在线部署和维护)
数据采集
有很多方法可以获取数据. 这次我们选择了采集器方法. 当然,您可以使用不同的语言和不同的方式编写爬虫. 我以前写过很多爬虫,这次我们选择了python的scrapy库. 关于scrapy,百度百科解释如下:
Scrapy是Python开发的一种快速的高级屏幕抓取和Web抓取框架,用于抓取网站并从页面提取结构化数据. Scrapy用途广泛,可用于数据挖掘,监视和自动化测试.
学习scrapy的最好方法是先阅读文档(Scrapy 1.6文档),然后根据文档中的示例进行编写,您将逐渐熟悉它. 有几个重要的概念必须理解:
物品
官方对items的定义是“The main goal in scraping is to extract structured data from unstructured sources, typically, web pages.”,个人理解为数据结构,也就是要爬取数据的字段,最好能和数据库字段对应,便于入库。
蜘蛛
“Spiders are classes which define how a certain site (or a group of sites) will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from their pages (i.e. scraping items). ”,也就是爬虫比较核心的内容,定义爬虫的方式,一些策略,以及获取那些字段等等。
管道
“蜘蛛抓取了一个项目之后,将其发送到项目管道,该管道通过依次执行的几个组件对其进行处理. ”,管道是我们的采集器在获取数据后将执行的处理操作,例如可以在此处进行操作. 如写入文件或链接到数据库,然后保存到数据库等.
选择器
“When you’re scraping web pages, the most common task you need to perform is to extract data from the HTML source. ”,这部分就是如何解析html,从爬取到的html文件中解析出所需的数据,可以使用BeautifulSoup、lxml、Xpath、CSS等方法。
上面已经解释了几个重要的部分.
准备环境(python3 / scrapy等),我们可以编写一个爬虫项目.
抓取的内容来自此网站.
创建项目
scrapy startproject jqhtml
修改项目
添加采集器
爬行器爬行器
编写管道以修改配置文件
这样我们就顺利地完成了爬虫项目的编写。运行下,发现数据全部存到了数据库中。
部署scrapy爬虫项目
对于scrapy crawler项目的部署,我们可以使用官方scrapyd,并且使用方法相对简单. 在服务器上安装scrapyd并启动它,然后在本地项目中配置部署路径,在本地安装scrapy-client并使用命令deploy可以部署到服务器.
Scrapyd提供了一些api界面来查看项目采集器的状态,并执行或停止采集器.
因此,我们可以轻松调整这些界面来管理抓取工具任务.
注意:
如何将scrapyd部署到服务器上如何将scrapyd设置为系统后台服务和系统启动项
下一个
在下一篇文章中,我们将介绍并使用非常流行的nodejs背景api库-hapijs. 完成applet所需的所有接口的开发,并使用定时任务执行采集器脚本.
Python大法之告别脚本小子系列—各类URL采集器编写
采集交流 • 优采云 发表了文章 • 0 个评论 • 438 次浏览 • 2020-08-04 19:05
本文作者:i春秋签约作家——阿甫哥哥
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)
0×05 【彩蛋篇】论坛自动签到脚本 查看全部
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)
0×05 【彩蛋篇】论坛自动签到脚本 查看全部
本文作者:i春秋签约作家——阿甫哥哥
系列文章专辑:
0×00 前言
URl采集在批量刷洞中也是很重要的
0×01 目录
0×01 前言
0×02 ZoomEyeAPI脚本编写
0×03 ShoDanAPI脚本编写
0×04 简易BaiduURL采集脚本编写
0×05 【彩蛋篇】论坛自动签到脚本
0×02 ZoomEyeAPI脚本编写
ZoomEye是一款对于网络空间的搜索引擎,收录了互联网空间中的设备、网站及其使用的服务或组件等信息。
ZoomEye 拥有两大探测引擎:Xmap 和 Wmap,分别对于网络空间中的设备及网站, 通过 24 小时不间断的侦测、识别,标识出互联网设备及网站所使用的服务及部件。 研究人员可以通过 ZoomEye 方便的了解组件的普及率及漏洞的危害范围等信息。
虽然被称为 “黑客友好” 的搜索引擎,但 ZoomEye 并不会主动对网络设备、网站发起攻击,收录的数据也仅用于安全研究。ZoomEye更像是互联网空间的一张航海图。
ZoomEyeAPI参考手册在这:ZoomEye API 参考手册
先登录,然后获得access_token
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
if __name__ == '__main__':
print Login()
然后,API手册是这样写的,根据这个,咱们先写一个HOST的单页面采集的….
#-*- coding: UTF-8 -*-
import requests
import json
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page=1',
headers = headers)
response = json.loads(r.text)
print response
if __name__ == '__main__':
search()
返回的信息量极大啊,但它只是个JSON数据,SO,我们可以取出IP部分…
for x in response['matches']:
print x['ip']
之后,HOST的单页面采集也就OK了,WEB的也五五开,留着他们自己分析,其实差不多,后文会贴的
接下来,就是用FOR循环….获取多页的IP
#-*- coding: UTF-8 -*-
import requests
import json
def Login():
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search():
headers = {'Authorization': 'JWT ' + Login()}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/host/search?query=tomcat&page='+str(i),
headers = headers)
response = json.loads(r.text)
for x in response['matches']:
print x['ip']
if __name__ == '__main__':
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
search()
这样就取出了你想要的页码的数据,然后就是完善+美观代码了…..
#-*- coding: UTF-8 -*-
import requests
import json
def Login(user,passwd):
data_info = {'username' : user,'password' : passwd}
data_encoded = json.dumps(data_info)
respond = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
try:
r_decoded = json.loads(respond.text)
access_token = r_decoded['access_token']
except KeyError:
return '[-] INFO : USERNAME OR PASSWORD IS WRONG, PLEASE TRY AGAIN'
return access_token
def search(queryType,queryStr,PAGECOUNT,user,passwd):
headers = {'Authorization': 'JWT ' + Login(user,passwd)}
for i in range(1,int(PAGECOUNT)):
r = requests.get(url = 'https://api.zoomeye.org/'+ queryType +'/search?query='+queryStr+'&page=' + str(i),
headers = headers)
response = json.loads(r.text)
try:
if queryType == "host":
for x in response['matches']:
print x['ip']
if queryType == "web":
for x in response['matches']:
print x['ip'][0]
except KeyError:
print "[ERROR] No hosts found"
def main():
print " _____ _____ ____ "
print "|__ /___ ___ _ __ ___ | ____| _ ___/ ___| ___ __ _ _ __"
print " / // _ \ / _ \| '_ ` _ \| _|| | | |/ _ \___ \ / __/ _` | '_ \ "
print " / /| (_) | (_) | | | | | | |__| |_| | __/___) | (_| (_| | | | |"
print "/____\___/ \___/|_| |_| |_|_____\__, |\___|____/ \___\__,_|_| |_|"
print " |___/ "
user = raw_input('[-] PLEASE INPUT YOUR USERNAME:')
passwd = raw_input('[-] PLEASE INPUT YOUR PASSWORD:')
PAGECOUNT = raw_input('[-] PLEASE INPUT YOUR SEARCH_PAGE_COUNT(eg:10):')
queryType = raw_input('[-] PLEASE INPUT YOUR SEARCH_TYPE(eg:web/host):')
queryStr = raw_input('[-] PLEASE INPUT YOUR KEYWORD(eg:tomcat):')
Login(user,passwd)
search(queryType,queryStr,PAGECOUNT,user,passwd)
if __name__ == '__main__':
main()
0×03 ShoDanAPI脚本编写
Shodan是互联网上更可怕的搜索引擎。
CNNMoney的一篇文章写道,虽然现今人们都觉得谷歌是最强劲的搜索引擎,但Shodan才是互联网上更可怕的搜索引擎。
与谷歌不同的是,Shodan不是在网上搜索网址,而是直接处于互联网的背后通道。Shodan可以说是一款“黑暗”谷歌,一刻不停的在寻求着所有跟互联网关联的服务器、摄像头、打印机、路由器等等。每个月Shodan都会在大概5亿个服务器上日夜不停地搜集信息。
Shodan所收集到的信息是非常惊人的。凡是链接至互联网的红绿灯、安全摄像头、家庭自动化设备以及加热系统等等都会被轻易的搜索到。Shodan的使用者曾发现过一个水上公园的控制系统,一个加油站,甚至一个酒店的葡萄酒冷却器。而网站的研究者也曾使用Shodan定位到了核电站的指挥跟控制系统及一个粒子回旋加速器。
Shodan真正值得注意的能力就是能找到几乎所有跟互联网相关联的东西。而Shodan真正的可怕之处就是这些设备几乎都没有安装安全攻击措施,其可以随意进入。
浅安dalao写过,介绍的也更具体…..
地址传送门:基于ShodanApi接口的读取python版
先说基于API查询。。。官方文档:
每次查询要扣除1积分…..,而用shodan库模块不需要….
写个简单的,他和Zoomeye的五五开,就不细写了…
#-*- coding: UTF-8 -*-
import requests
import json
def getip():
API_KEY = *************
url = 'https://api.shodan.io/shodan/host/search?key='+API_KEY+'&query=apache'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
req = requests.get(url=url,headers=headers)
content = json.loads(req.text)
for i in content['matches']:
print i['ip_str']
if __name__ == '__main__':
getip()
接下来,就是基于shodan模块的…直接引用浅安dalao的。。。我没法写….
安装:pip install shodan
#-*- coding: UTF-8 -*-
import shodan
import sys
API_KEY = ‘YOU_API_KEY’ #调用shodan api
FACETS = [
('country',100), # 匹配出前一百位的国家数量,100可自定义
]
FACET_TITLES = {
'country': 'Top 100 Countries',
}
#输入判断
if len(sys.argv) == 1:
print 'Search Method:Input the %s and then the keyword' % sys.argv[0]
sys.exit()
try:
api = shodan.Shodan(API_KEY)
query = ' '.join(sys.argv[1:])
print "You Search is:" + query
result = api.count(query, facets=FACETS) # 使用count比search快
for facet in result['facets']:
print FACET_TITLES[facet]
for key in result['facets'][facet]:
countrie = '%s : %s' % (key['value'], key['count'])
print countrie
with open(u"搜索" + " " + query + " " + u"关键字" +'.txt','a+') as f:
f.write(countrie +"\n")
f.close()
print " "
print "save is coutures.txt"
print "Search is Complete."
except Exception, e:
print 'Error: %s' % e
0×04 简易BaiduURL采集脚本编写
先是爬去单页的URL,举个栗子是爬去阿甫哥哥这个关键字的URL
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=1'
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥')
然后是多页的爬取,比如爬取前20页的
#-*- coding: UTF-8 -*-
import requests
from bs4 import BeautifulSoup as bs
import re
def getfromBaidu(word,pageout):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87'}
for k in range(0,(pageout-1)*10,10):
url = 'https://www.baidu.com.cn/s?wd=' + word + '&pn=' + str(k)
html = requests.get(url=url,headers=headers,timeout=5)
soup = bs(html.content, 'lxml', from_encoding='utf-8')
bqs = soup.find_all(name='a', attrs={'data-click':re.compile(r'.'), 'class':None})
for i in bqs:
r = requests.get(i['href'], headers=headers, timeout=5)
print r.url
if __name__ == '__main__':
getfromBaidu('阿甫哥哥',10)
0×05 【彩蛋篇】论坛自动签到脚本

