
自动采集编写
自动采集编写(2017年Python网站采集敏感信息的解决方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-23 05:23
前言
我过去没有学过,最近有需求。我必须从网站@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@采集@@采集@,决定使用c#winform和python来解决这个事件。
整个解决方案不复杂:uvkxlprltc#写入winform形式,执行数据分析和采集,python最初不想使用,没有找到c#woff字体到XML方案,并且有很多在线python所以添加一个python项目,虽然是1脚本。
一、几个步骤:
首先要模拟登录,登录进入resume 采集,然后模拟下载,您可以在下载后看到求职者的呼叫。
这个电话号码是一个动态生成的base64字体,所以直接提取文本不能成功。
1、第一个将base64转换为woff字体,这可以用c#(这个ISO-8859-1代码是一个坑,一般使用默认的惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("isuVKXLPrlto-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、将转动已生成的XML的窗口(Woffdec.exe是我用Python打包的exe,实际上,对于这个转换,有一个时间,有一个整个c #低于好)
//调用python exe 生成xml文件
ProcessStartInfo info = new Procewww.cppcns.comssStartInfo
{
FileNam编程客栈e = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个woffdec.py的代码是3行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思,首先尝试py2exe,不成功,更改pyinstaller,变成11m,甚至exe,不是很大。
在本地下载或下载它,或直接在VS2017 Python环境中搜索pyinstaller。
右键单击使用“在此处打开命令提示符”;将pyinstaller /path/to/yourscript.py输入到exe文件中。当调用WinForm应用程序时,应在整个文件夹中复制整个文件夹。
3、 xml文件已,上面的woff文件准备存储数据字典(这个地方有点左右,首先找到一个网站将woff作为文本和编码,然后基于编码XML查找它的字体定位点,我采取x和y形成一个唯一的值(x,y代表一个字),当然,更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、上述步骤是花一些时间。参考词典可用后,您可以根据每个生成的XML文件匹配真实文本。
5、真文本取简繁资料繁简简义数码数据数据数码上数码上数码上/ p>
二、使用场景
下班后,打开采集服务即即不理解,下载繁简简牌繁简简义繁简简义繁简简义繁简简简短繁简牌只要有新人发布求职信息,系统会立即向他发送邀请才能抓住人民。
btw:网络仿真操作使用的Cefsharp将打开另一章。
摘要
上面是这个文章的全内容,我希望本文对每个人的学习或工作都有一定的参考价值,谢谢您的支持。
标题:使用c#cefsharp python 采集 网站简历自动发送邀请sms方法 查看全部
自动采集编写(2017年Python网站采集敏感信息的解决方案(一))
前言
我过去没有学过,最近有需求。我必须从网站@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@采集@@采集@,决定使用c#winform和python来解决这个事件。
整个解决方案不复杂:uvkxlprltc#写入winform形式,执行数据分析和采集,python最初不想使用,没有找到c#woff字体到XML方案,并且有很多在线python所以添加一个python项目,虽然是1脚本。

一、几个步骤:
首先要模拟登录,登录进入resume 采集,然后模拟下载,您可以在下载后看到求职者的呼叫。
这个电话号码是一个动态生成的base64字体,所以直接提取文本不能成功。
1、第一个将base64转换为woff字体,这可以用c#(这个ISO-8859-1代码是一个坑,一般使用默认的惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("isuVKXLPrlto-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、将转动已生成的XML的窗口(Woffdec.exe是我用Python打包的exe,实际上,对于这个转换,有一个时间,有一个整个c #低于好)
//调用python exe 生成xml文件
ProcessStartInfo info = new Procewww.cppcns.comssStartInfo
{
FileNam编程客栈e = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个woffdec.py的代码是3行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思,首先尝试py2exe,不成功,更改pyinstaller,变成11m,甚至exe,不是很大。
在本地下载或下载它,或直接在VS2017 Python环境中搜索pyinstaller。
右键单击使用“在此处打开命令提示符”;将pyinstaller /path/to/yourscript.py输入到exe文件中。当调用WinForm应用程序时,应在整个文件夹中复制整个文件夹。
3、 xml文件已,上面的woff文件准备存储数据字典(这个地方有点左右,首先找到一个网站将woff作为文本和编码,然后基于编码XML查找它的字体定位点,我采取x和y形成一个唯一的值(x,y代表一个字),当然,更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、上述步骤是花一些时间。参考词典可用后,您可以根据每个生成的XML文件匹配真实文本。
5、真文本取简繁资料繁简简义数码数据数据数码上数码上数码上/ p>
二、使用场景
下班后,打开采集服务即即不理解,下载繁简简牌繁简简义繁简简义繁简简义繁简简简短繁简牌只要有新人发布求职信息,系统会立即向他发送邀请才能抓住人民。
btw:网络仿真操作使用的Cefsharp将打开另一章。
摘要
上面是这个文章的全内容,我希望本文对每个人的学习或工作都有一定的参考价值,谢谢您的支持。
标题:使用c#cefsharp python 采集 网站简历自动发送邀请sms方法
自动采集编写(高手多多指添加采集规则规则说明系统默认变量的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-22 16:00
原帖子由主持人潘昭发表。逆流而上从旧论坛转向新论坛。在前面写完后:我写了几个电台的规则,并教这个电台的管理员写规则。现在我终于得到了一个教程。虽然有点粗糙,但也可以作为新手的参考。希望新手认真学习,专家指出增加采集规则和规则来解释系统默认变量:章节序号、文章子序号、章节子序号。系统标记可以替换任何字符串。系统标记可以替换除以下内容之外的任何字符串。除´外,系统标签可以替换“除此之外的任何字符串。系统标记可以替换数字和字符串以外的字符串。系统标签可以替换采集规则中的数字字符串@,要获取的内容被四个以上的系统标签替换。例如,需要回复以下内容才能看到基本设置网站ID。在configurations\article\collectsite.php中添加的ID可以随意填写。通常,它是采集站点域名的缩写,以区别于其他规则。示例:feiku网站name采集station的名称。示例:飞行库网站地址的采集站地址。例如:不需要添加文章子序列号操作方法。我在这里留白。它支持使用标记的四种操作(+加、-减、*乘、/除、%余数)。无需增加第章子序列号的操作方法。我在这里留白。(谁知道他在一个文件夹里放了多少本书?他没有按照规则放。我不是采集无法支持使用标记(+加、-减、*乘、/除、%余数)的四个操作)代理服务器地址不使用代理服务器。请将代理服务器端口留空。如果现有章节无法对应,是否根据自己的需要再次清除采集所有章节。根据自己的需要选择是否默认将文章设置为完整版本。如果选择“是”,无论文章是序列化还是完成,完整版本都将显示在您的站点上。建议选择“否”发送http_参考标志以突破反采集设置。默认情况下,选择是。我不知道该使用什么。我选择是先突破,然后谈论对方的网页代码(自动检测GB2312 utf8) BIG5)默认设置为自动检测代码与此网站不同。您将自动尝试转换文章information page采集rule文章information page address、图书信息页面URL和图书ID。例如:/index.html文章Title采集rule要求您查看网页的源文件。如果您这样做不,你可以停下来。检查信息页面的源文件,然后找出文章标题在源文件中的位置(我们以feiku为例,它是源文件中章节信息页面上文章标题的位置)。这里,以我的美女为例,找到标题附近的代码是
我美丽的女士
将上述代码复制到文章Title采集规则的框中,然后用!!!!!替换我美丽的女士的真实头衔!当然,它也可以替换为其他替换符号,如****,但重要的是,范围越小,越能表达意思(习惯问题,你在这里只能得到采集到文章的标题,但是还有其他采集的东西你不想要。作者采集rule这里的李兴宇想要采集内容并使用!!!!!相反,但是144238只对这个文章有用,其他文章有其他数字,所以使用任何数字字符串$。所以作者采集rule是!!!!文章type采集城市规则是从顶部开始的!!!!!@k113@类型的信件。你可以自己写。呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵Hehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehe|10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 10 124A的10 124A的10 124A的10的10的10 124A的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的此外,这两种类型用“|”分隔,类型名称为“默认”确定默认类型对应关系。网站类型和序列号之间的对应关系如下:幻想魔法=>;1;武术修养=>;2;城市浪漫=>;3;历史军事=>;4;侦探推理=>;5;在线游戏动画=>;6;科幻=>;7;恐怖与超人Natural=>;8 |散文诗=>;9 |其他类型=>;10(根据您的站点设置)关键字采集规则在关键字附近找到代码主角并检索关键字beauty city
此处的“我的美丽城市”被****替换,结果规则为主角搜索关键字-****
“大”小姐和“大”妹妹,别打扰我,好吗?我求求你~~
拥有数亿财富的刘星不想生活在朱门的酒肉腥味和阴谋中,他放弃了家里的大公司,选择在一家小公司做一名普通白领
餐馆里的一次英勇营救让他遇到了一位美丽的女士,她是刘星上海公司老板的女儿,换句话说,是他的长女
但这位貌似美丽优雅的年轻女士却有一个未知的一面,这真的会危及生命
做我的保姆?你在开玩笑吗,小姐?你什么都做不了。做我的保姆
老板有两个女儿?所以白天捣乱的美女是第二夫人
什么?你也决定住在这里?啊!别烦我了~~!一个就够了,另一个。多大的一个小妹妹啊
“大”女人看起来优雅文雅,但她很困惑。大“小”妹妹看起来很漂亮,但她很火辣和淘气。而且,两姐妹从小到大一直有冲突。这次他们都住在我家。这房子真的很热闹
想拥有美丽的人都被“大”和“小”姐妹“浸透”!啊~~!让人活下去~~ 查看全部
自动采集编写(高手多多指添加采集规则规则说明系统默认变量的方法)
原帖子由主持人潘昭发表。逆流而上从旧论坛转向新论坛。在前面写完后:我写了几个电台的规则,并教这个电台的管理员写规则。现在我终于得到了一个教程。虽然有点粗糙,但也可以作为新手的参考。希望新手认真学习,专家指出增加采集规则和规则来解释系统默认变量:章节序号、文章子序号、章节子序号。系统标记可以替换任何字符串。系统标记可以替换除以下内容之外的任何字符串。除´外,系统标签可以替换“除此之外的任何字符串。系统标记可以替换数字和字符串以外的字符串。系统标签可以替换采集规则中的数字字符串@,要获取的内容被四个以上的系统标签替换。例如,需要回复以下内容才能看到基本设置网站ID。在configurations\article\collectsite.php中添加的ID可以随意填写。通常,它是采集站点域名的缩写,以区别于其他规则。示例:feiku网站name采集station的名称。示例:飞行库网站地址的采集站地址。例如:不需要添加文章子序列号操作方法。我在这里留白。它支持使用标记的四种操作(+加、-减、*乘、/除、%余数)。无需增加第章子序列号的操作方法。我在这里留白。(谁知道他在一个文件夹里放了多少本书?他没有按照规则放。我不是采集无法支持使用标记(+加、-减、*乘、/除、%余数)的四个操作)代理服务器地址不使用代理服务器。请将代理服务器端口留空。如果现有章节无法对应,是否根据自己的需要再次清除采集所有章节。根据自己的需要选择是否默认将文章设置为完整版本。如果选择“是”,无论文章是序列化还是完成,完整版本都将显示在您的站点上。建议选择“否”发送http_参考标志以突破反采集设置。默认情况下,选择是。我不知道该使用什么。我选择是先突破,然后谈论对方的网页代码(自动检测GB2312 utf8) BIG5)默认设置为自动检测代码与此网站不同。您将自动尝试转换文章information page采集rule文章information page address、图书信息页面URL和图书ID。例如:/index.html文章Title采集rule要求您查看网页的源文件。如果您这样做不,你可以停下来。检查信息页面的源文件,然后找出文章标题在源文件中的位置(我们以feiku为例,它是源文件中章节信息页面上文章标题的位置)。这里,以我的美女为例,找到标题附近的代码是
我美丽的女士
将上述代码复制到文章Title采集规则的框中,然后用!!!!!替换我美丽的女士的真实头衔!当然,它也可以替换为其他替换符号,如****,但重要的是,范围越小,越能表达意思(习惯问题,你在这里只能得到采集到文章的标题,但是还有其他采集的东西你不想要。作者采集rule这里的李兴宇想要采集内容并使用!!!!!相反,但是144238只对这个文章有用,其他文章有其他数字,所以使用任何数字字符串$。所以作者采集rule是!!!!文章type采集城市规则是从顶部开始的!!!!!@k113@类型的信件。你可以自己写。呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵Hehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehe|10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 10 124A的10 124A的10 124A的10的10的10 124A的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的此外,这两种类型用“|”分隔,类型名称为“默认”确定默认类型对应关系。网站类型和序列号之间的对应关系如下:幻想魔法=>;1;武术修养=>;2;城市浪漫=>;3;历史军事=>;4;侦探推理=>;5;在线游戏动画=>;6;科幻=>;7;恐怖与超人Natural=>;8 |散文诗=>;9 |其他类型=>;10(根据您的站点设置)关键字采集规则在关键字附近找到代码主角并检索关键字beauty city
此处的“我的美丽城市”被****替换,结果规则为主角搜索关键字-****
“大”小姐和“大”妹妹,别打扰我,好吗?我求求你~~
拥有数亿财富的刘星不想生活在朱门的酒肉腥味和阴谋中,他放弃了家里的大公司,选择在一家小公司做一名普通白领
餐馆里的一次英勇营救让他遇到了一位美丽的女士,她是刘星上海公司老板的女儿,换句话说,是他的长女
但这位貌似美丽优雅的年轻女士却有一个未知的一面,这真的会危及生命
做我的保姆?你在开玩笑吗,小姐?你什么都做不了。做我的保姆
老板有两个女儿?所以白天捣乱的美女是第二夫人
什么?你也决定住在这里?啊!别烦我了~~!一个就够了,另一个。多大的一个小妹妹啊
“大”女人看起来优雅文雅,但她很困惑。大“小”妹妹看起来很漂亮,但她很火辣和淘气。而且,两姐妹从小到大一直有冲突。这次他们都住在我家。这房子真的很热闹
想拥有美丽的人都被“大”和“小”姐妹“浸透”!啊~~!让人活下去~~
自动采集编写(国内有ueditor网站推荐使用模板,增加更多的想象空间)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-21 03:01
自动采集编写网站代码。在chrome中编写。首先你要会写网站代码。
怎么弄首页?
现在app内置功能(我个人认为是增加)【网络请求】部分,能很好地减轻后台程序负担,比如分享、登录/访问分享朋友圈等~做网站搭web应用,开发者和设计师都要经常开【浏览器】编程,反正怎么舒服怎么写。ui是没办法改了,功能不能多也不能少,把控不了的。所以app开发相对在界面功能上还是比较自由的。对我们设计来说也不必担心水土不服和内部冲突。可以发挥想象力,增加更多的想象空间。
现在公开的比较多的是模板吧。国内有ueditor网站推荐使用模板,
有好多个人建的网站。而且都是在github上找着一个个改过来的。比如有些制作真不敢恭维。还有,开放给公众用,基本上没门槛。如果你做app,拿开源app一看,几乎是开源项目。app工程师因为本身不是浏览器运维,没有什么实际感知。
微信公众号可以用自动开发的网站来接入也可以用第三方的平台,
现在都是自动采集,
非关键页面肯定自动采集了,搜索或用户列表都可以。其他属性可以按需手动添加。现在最新的app都有运行在浏览器里,且不用来回切换。 查看全部
自动采集编写(国内有ueditor网站推荐使用模板,增加更多的想象空间)
自动采集编写网站代码。在chrome中编写。首先你要会写网站代码。
怎么弄首页?
现在app内置功能(我个人认为是增加)【网络请求】部分,能很好地减轻后台程序负担,比如分享、登录/访问分享朋友圈等~做网站搭web应用,开发者和设计师都要经常开【浏览器】编程,反正怎么舒服怎么写。ui是没办法改了,功能不能多也不能少,把控不了的。所以app开发相对在界面功能上还是比较自由的。对我们设计来说也不必担心水土不服和内部冲突。可以发挥想象力,增加更多的想象空间。
现在公开的比较多的是模板吧。国内有ueditor网站推荐使用模板,
有好多个人建的网站。而且都是在github上找着一个个改过来的。比如有些制作真不敢恭维。还有,开放给公众用,基本上没门槛。如果你做app,拿开源app一看,几乎是开源项目。app工程师因为本身不是浏览器运维,没有什么实际感知。
微信公众号可以用自动开发的网站来接入也可以用第三方的平台,
现在都是自动采集,
非关键页面肯定自动采集了,搜索或用户列表都可以。其他属性可以按需手动添加。现在最新的app都有运行在浏览器里,且不用来回切换。
自动采集编写(蓝鲸整站V5.5-伪原创采集无限制破解版(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-19 00:14
有关软件的最新版本:
蓝鲸全站发电机V5.5-伪原创采集无限破解版[综合营销]蓝鲸全站式发电机V5.5注册机无限破解版【综合营销】蓝鲸全站发电机V5.38-伪原创采集无限破解版[整合营销]蓝鲸全站发电机V5.38注册机无限破解版【综合营销】蓝鲸全站发电机V5.33-伪原创采集无限破解版[人工制品软件]蓝鲸全站式发电机V5.33注册机无限破解版[神器软件]蓝鲸全站发电机无限破解版【综合营销】蓝鲸全站发电机注册机无限破解版【综合营销】
蓝鲸全站发电机V5.38-伪原创采集(带后台管理)
蓝鲸全站式发电机效能的具体介绍
目前市场上的采集器只能称为采集器!不是交通制造者!纯粹的采集信息只能被称为剽窃,如果你接受了其他人的网站信息采集并且不会增加搜索引擎的权重。从长远来看,你的网站体重会减少,甚至会变为K。因此,我们是非常负责任的神器:告诉你,纯粹的采集信息毫无意义!我们需要伪原创1@信息将被全面处理并成为我们自己的原创信息,这将为您的网站带来大量流量和高权重
蓝鲸全站生成器是一套为中小型网站站长量身定制的软件,集数据采集、数据优化、全站生成、全站广告管理、后台cms管理系统、数据仓库和各种搜索引擎优化工具于一体
有效减轻每天管理网站的繁重工作量,提升网站排名,增加网站流量,让智慧站长更强大。它是一个网站管理工具
软件中内置了大量采集规则,采集的网站数据大部分可以收录论坛。只要你输入一个关键字,采集将收录你输入的所有网页关键字,采集内容好,速度快。新版本支持自定义规则采集和采集论坛数据。您可以根据自己编写的采集规则自由采集
适用于各类新闻台、图片台、视频台、影视台、小说台、软件下载台、各类示例综合社区及其相关站点的数据采集和全站生成。每个站点可以是独立的,生成的网站页面数量不受限制。只要服务器空间允许,您就可以立即构建一个收录数千甚至上万页的站点
数据仓库是灵活多变的。它支持所有后台管理系统的数据导入,甚至支持数据采集和博客导入
除了上述优点外,蓝鲸全站发电机还具有以下明显效果
1.软件实用性强,不像其他采集器软件只能采集固定断面数据。蓝鲸全站仪支持采集news、文章、影视、软件下载、视频站、图片、音乐、新颖智能触发器采集. 不需要手动编写恼人的采集规则。大量的采集规则是内置的,因此您可以将精力放在管理网站上,并将规则的编写留给我们。采集多样化、轻松高效
2.生成一个网站Level 2目录列表,为小说、音乐、电影和电视等样本站点护航
3.采用access数据库,使软件更加兼容,数据采集可任意转换为其他网站管理系统
4.有一个后台cms管理系统。只需将采集中存储的数据库上传到FTP,即可在后台实现全站网页显示、时间同步、一键更新等功能。它不需要额外购买,与蓝鲸全站发电机一起包装
4.each网站收录至少13个广告空间的管理,这些广告空间可以在程序内部管理!让你数钱给他
5.可以对每个页面进行搜索引擎优化,加强自动关键词提取功能和伪原创功能,加速搜索引擎收录的网站速度,忘记返回您的网站
6.各种动量网站模板,这样您的网站用户就不会因为视觉方面的原因而与您的网站分离
7.采用div+CSS规模的web结构编写网页,使您的网站兼容性更高,管理更方便
8.配备了一个高效的网站地图生成工具,可以为谷歌、雅虎和静态HTML生成地图,加快你的收录速度,提高你的网站排名
9.data采集可根据用户提供的关键字自动采集并可根据一个关键字智能触发采集. 您可以搜索和导出当前流行的关键字
10.您可以在web内容中分发当前流行的关键字,或在标题中添加关键字以增加网站访问者
11.generation网站支持多个代码(gb2312、utf-8、big5),该程序更通用
12.支持自命名网页,更多手机
13.具有多种实用小工具(HTML JS转换、弹出窗口参数生成、base64加密和解密、网站map生成)
14.采集high speed,可以自动过滤现有数据。全站静态页面输出,降低服务器压力,加快网页速度
15.网站参数、广告管理与投放、统计代码设置可以在程序中保存,也可以在网站后台保存,操作多样实用
16.网站是ASP在后台编写的。您可以在没有更高级服务器的情况下传输程序,这样可以为您节省网站服务器的费用
17.Support custom rules采集,Support采集论坛,各种新闻站,采集任何你想要的站点采集@
18.Mobile和可变模板制作支持,内置大量标签,为您搭建和模仿站点提供强大支持 查看全部
自动采集编写(蓝鲸整站V5.5-伪原创采集无限制破解版(组图))
有关软件的最新版本:
蓝鲸全站发电机V5.5-伪原创采集无限破解版[综合营销]蓝鲸全站式发电机V5.5注册机无限破解版【综合营销】蓝鲸全站发电机V5.38-伪原创采集无限破解版[整合营销]蓝鲸全站发电机V5.38注册机无限破解版【综合营销】蓝鲸全站发电机V5.33-伪原创采集无限破解版[人工制品软件]蓝鲸全站式发电机V5.33注册机无限破解版[神器软件]蓝鲸全站发电机无限破解版【综合营销】蓝鲸全站发电机注册机无限破解版【综合营销】
蓝鲸全站发电机V5.38-伪原创采集(带后台管理)
蓝鲸全站式发电机效能的具体介绍
目前市场上的采集器只能称为采集器!不是交通制造者!纯粹的采集信息只能被称为剽窃,如果你接受了其他人的网站信息采集并且不会增加搜索引擎的权重。从长远来看,你的网站体重会减少,甚至会变为K。因此,我们是非常负责任的神器:告诉你,纯粹的采集信息毫无意义!我们需要伪原创1@信息将被全面处理并成为我们自己的原创信息,这将为您的网站带来大量流量和高权重
蓝鲸全站生成器是一套为中小型网站站长量身定制的软件,集数据采集、数据优化、全站生成、全站广告管理、后台cms管理系统、数据仓库和各种搜索引擎优化工具于一体
有效减轻每天管理网站的繁重工作量,提升网站排名,增加网站流量,让智慧站长更强大。它是一个网站管理工具
软件中内置了大量采集规则,采集的网站数据大部分可以收录论坛。只要你输入一个关键字,采集将收录你输入的所有网页关键字,采集内容好,速度快。新版本支持自定义规则采集和采集论坛数据。您可以根据自己编写的采集规则自由采集
适用于各类新闻台、图片台、视频台、影视台、小说台、软件下载台、各类示例综合社区及其相关站点的数据采集和全站生成。每个站点可以是独立的,生成的网站页面数量不受限制。只要服务器空间允许,您就可以立即构建一个收录数千甚至上万页的站点
数据仓库是灵活多变的。它支持所有后台管理系统的数据导入,甚至支持数据采集和博客导入
除了上述优点外,蓝鲸全站发电机还具有以下明显效果
1.软件实用性强,不像其他采集器软件只能采集固定断面数据。蓝鲸全站仪支持采集news、文章、影视、软件下载、视频站、图片、音乐、新颖智能触发器采集. 不需要手动编写恼人的采集规则。大量的采集规则是内置的,因此您可以将精力放在管理网站上,并将规则的编写留给我们。采集多样化、轻松高效
2.生成一个网站Level 2目录列表,为小说、音乐、电影和电视等样本站点护航
3.采用access数据库,使软件更加兼容,数据采集可任意转换为其他网站管理系统
4.有一个后台cms管理系统。只需将采集中存储的数据库上传到FTP,即可在后台实现全站网页显示、时间同步、一键更新等功能。它不需要额外购买,与蓝鲸全站发电机一起包装
4.each网站收录至少13个广告空间的管理,这些广告空间可以在程序内部管理!让你数钱给他
5.可以对每个页面进行搜索引擎优化,加强自动关键词提取功能和伪原创功能,加速搜索引擎收录的网站速度,忘记返回您的网站
6.各种动量网站模板,这样您的网站用户就不会因为视觉方面的原因而与您的网站分离
7.采用div+CSS规模的web结构编写网页,使您的网站兼容性更高,管理更方便
8.配备了一个高效的网站地图生成工具,可以为谷歌、雅虎和静态HTML生成地图,加快你的收录速度,提高你的网站排名
9.data采集可根据用户提供的关键字自动采集并可根据一个关键字智能触发采集. 您可以搜索和导出当前流行的关键字
10.您可以在web内容中分发当前流行的关键字,或在标题中添加关键字以增加网站访问者
11.generation网站支持多个代码(gb2312、utf-8、big5),该程序更通用
12.支持自命名网页,更多手机
13.具有多种实用小工具(HTML JS转换、弹出窗口参数生成、base64加密和解密、网站map生成)
14.采集high speed,可以自动过滤现有数据。全站静态页面输出,降低服务器压力,加快网页速度
15.网站参数、广告管理与投放、统计代码设置可以在程序中保存,也可以在网站后台保存,操作多样实用
16.网站是ASP在后台编写的。您可以在没有更高级服务器的情况下传输程序,这样可以为您节省网站服务器的费用
17.Support custom rules采集,Support采集论坛,各种新闻站,采集任何你想要的站点采集@
18.Mobile和可变模板制作支持,内置大量标签,为您搭建和模仿站点提供强大支持
自动采集编写(长城小程序会计ae工程(网络)h105ecs-005)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-16 18:02
自动采集编写h5-ad城市信息ae长城小程序会计ae工程(网络)h105ecs-005的传播技巧和非常用的技术论坛自动采集排版的方法数据分析和产品说明(二维码自动识别)
找两家机构对比吧:1,线上学习指南2,
注册试用~这种问题没有必要来这里问。一个针对刚毕业或者没有经验的人,在实际工作中遇到的问题和情况实在是太多了。而且如果你在网上,想要得到一个相对靠谱的答案的话,你只能找到一些经验泛泛的所谓大神,和他们说的未必是同一个东西。网上的很多东西,不可否认的确可以吸取一些东西,但是真正有实际用处的不是他们的所谓的见解,而是他们所提供的实际工作内容,他们对某一个场景的尝试和攻克,对某一个工具使用的思路和解决方案,而这些经验还需要你自己去总结和沉淀。
你可以去看一下第一家公司的免费课程,在这里不过多推荐了,免得广告嫌疑。确定课程之后,完全可以去看一下能否接受,不是说他们所谓的付费排版,而是是否能让你学到一些真正有用的东西。
ae很考验软件的配合能力,之前已经有老师公开课录像。
二三线城市的实训课都不一样,要看具体学校开的哪一家,城市小靠的是实践经验,实训班基本针对公司要求的技能。课程也分很多档次, 查看全部
自动采集编写(长城小程序会计ae工程(网络)h105ecs-005)
自动采集编写h5-ad城市信息ae长城小程序会计ae工程(网络)h105ecs-005的传播技巧和非常用的技术论坛自动采集排版的方法数据分析和产品说明(二维码自动识别)
找两家机构对比吧:1,线上学习指南2,
注册试用~这种问题没有必要来这里问。一个针对刚毕业或者没有经验的人,在实际工作中遇到的问题和情况实在是太多了。而且如果你在网上,想要得到一个相对靠谱的答案的话,你只能找到一些经验泛泛的所谓大神,和他们说的未必是同一个东西。网上的很多东西,不可否认的确可以吸取一些东西,但是真正有实际用处的不是他们的所谓的见解,而是他们所提供的实际工作内容,他们对某一个场景的尝试和攻克,对某一个工具使用的思路和解决方案,而这些经验还需要你自己去总结和沉淀。
你可以去看一下第一家公司的免费课程,在这里不过多推荐了,免得广告嫌疑。确定课程之后,完全可以去看一下能否接受,不是说他们所谓的付费排版,而是是否能让你学到一些真正有用的东西。
ae很考验软件的配合能力,之前已经有老师公开课录像。
二三线城市的实训课都不一样,要看具体学校开的哪一家,城市小靠的是实践经验,实训班基本针对公司要求的技能。课程也分很多档次,
自动采集编写(自动采集编写采集插件,不需要自己开发exe程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-15 12:00
自动采集编写采集插件,编写这样的插件,不需要自己开发exe程序,本着让程序免费,到处拷贝,然后ad代码自己改,自己编译,你可以试试.用这种方法,一周可以搞定.源代码很多,我只能是说包含内容,大概如此.
这两个月时间应该可以,但是自己很快就会厌倦的,毕竟就是将整个文件换一套语言写,这两个月,你就可以写个简单的采集器了。不要寄希望于这两个月,而是可以将两三个月写出来,然后,不出一个月,你就可以写这两个月的代码了。
20天可以完成。但是要保证视频有质量还是要费一些功夫。自动采集原理不难,关键是怎么分析视频数据,规划好后续处理,这是关键。
看看我这个吧,20天应该可以的,
强烈建议crosswalk+selenium
这20天也就只能上上知乎看看文章,一个问题没解决至少会python了,不过后面你还得学selenium,
大多数教程里是有教怎么一步步做视频爬虫的,可是讲到这些的时候,不知道是不是我姿势不对,总感觉有种断章取义的感觉,总觉得这个才是正确的。我每学一个c的语言知识点都会想到要学一下视频抓取,然后再去爬些什么各种数据,但这些数据里有文本、视频文件等等不同的文件类型,搞的自己还是半桶水。不过用c来写采集器还是可以做到的,下面给个链接我们在这学吧,对于初学者来说应该还是有用的:sina视频抓取-云鹊开发者社区。 查看全部
自动采集编写(自动采集编写采集插件,不需要自己开发exe程序)
自动采集编写采集插件,编写这样的插件,不需要自己开发exe程序,本着让程序免费,到处拷贝,然后ad代码自己改,自己编译,你可以试试.用这种方法,一周可以搞定.源代码很多,我只能是说包含内容,大概如此.
这两个月时间应该可以,但是自己很快就会厌倦的,毕竟就是将整个文件换一套语言写,这两个月,你就可以写个简单的采集器了。不要寄希望于这两个月,而是可以将两三个月写出来,然后,不出一个月,你就可以写这两个月的代码了。
20天可以完成。但是要保证视频有质量还是要费一些功夫。自动采集原理不难,关键是怎么分析视频数据,规划好后续处理,这是关键。
看看我这个吧,20天应该可以的,
强烈建议crosswalk+selenium
这20天也就只能上上知乎看看文章,一个问题没解决至少会python了,不过后面你还得学selenium,
大多数教程里是有教怎么一步步做视频爬虫的,可是讲到这些的时候,不知道是不是我姿势不对,总感觉有种断章取义的感觉,总觉得这个才是正确的。我每学一个c的语言知识点都会想到要学一下视频抓取,然后再去爬些什么各种数据,但这些数据里有文本、视频文件等等不同的文件类型,搞的自己还是半桶水。不过用c来写采集器还是可以做到的,下面给个链接我们在这学吧,对于初学者来说应该还是有用的:sina视频抓取-云鹊开发者社区。
自动采集编写(PC端采集工具1.1.强大的文本扩展工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-09-15 06:28
随着阅读的增长,学习的越来越多,记忆的越来越少,我们必须进入下一阶段的知识和学习的知识采集. 对于采集,有很多工具,但最后,我使用impression notes作为载体来存储这些信息
PC端采集工具
1.1.强大的文本扩展工具popclip
Popclip是Mac上的一个著名小工具。说到popclip,它可能是Mac上最值得购买的软件。它的操作也很简单。只需选择文本,然后反转文本即可。该软件简单高效,具有强大的扩展功能。当没有安装插件时,它具有以下功能
粘贴
开放链接
抄袭
字典
拼写检查
邮件跳转
这不是很棒吗?此外,它还支持100多个不同的插件,这些插件具有许多不同的功能。例如,它支持选定的文本翻译、修改文本格式、搜索豆瓣、保存到doit.im等
您只需访问其官方网站并下载相应的插件即可使用这些插件
我之所以把它放在采集一章中,是因为我安装了Evernote插件,我妈妈再也不用担心我的采集text方法了
只需单击impression便笺的按钮,即可在impression便笺中创建一个新文件
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们必须使用大量的复制和粘贴。然而,有时当我们复制文本时,原创复制的文本被文本覆盖,并且没有以前的复制和粘贴内容。。。粘贴很好地解决了这个问题。在设置项中可以选择保存500条以上的复制粘贴历史,当需要粘贴时,只需按Shift+Command+V查看复制的历史内容,然后选择并操作即可
粘贴在Mac上运行得非常好,它看起来就像一个本机应用程序。它不仅可以记录复制的历史,而且分类和预览显示的效果也很好。对于作家来说,这确实是一件必不可少的艺术品
1.3.作弊快捷查询工具
说到一个有效率的作家,他们大多数都是键盘派对。例如,我已经两年没有使用鼠标了,因为通常的操作可以通过快捷键来解决,但是一些新软件根本不知道如何使用快捷键?一个接一个的摸索?你根本不需要奶酪。如果安装了它,在使用软件时,长按命令键可查看完整的快捷键映射图。与快捷键软件相比,它是否令人耳目一新
1.@4.Chrome在页面快捷方式下
说到快捷键,我们不得不说vimium,chrome下的一个小插件
Vimium是一个很好的插件。安装并启用此插件后,只需按浏览器页面上的F键即可看到该按钮并跳转到相应页面
如果要退出,只需按ESC键
有了这个工件和浏览器上的快捷键,你就不能在浏览网页时使用触摸版了!工作效率显著提高
除此之外,PC端还有许多采集和排序工具,如前一篇文章文章中提到的chrome中的pocket和impression note clipping插件,这些工具比较常见,因此我将不详细介绍
移动端采集工具
除了PC上的采集数据外,我们还经常需要在移动采集终端上记录一些信息和笔记。除了口袋,还有一些常用的方法和软件
1.我的印象笔记
是微信公共广播在移动终端上使用频率最高的官方账号。我只需要注意它:“我的印象笔记”和绑定帐户。p>
您可以在文章页面上自己的印象笔记中分享
然后,界面提示它已成功保存,我们可以在impression便笺中找到这篇文章文章 查看全部
自动采集编写(PC端采集工具1.1.强大的文本扩展工具(组图))
随着阅读的增长,学习的越来越多,记忆的越来越少,我们必须进入下一阶段的知识和学习的知识采集. 对于采集,有很多工具,但最后,我使用impression notes作为载体来存储这些信息
PC端采集工具
1.1.强大的文本扩展工具popclip
Popclip是Mac上的一个著名小工具。说到popclip,它可能是Mac上最值得购买的软件。它的操作也很简单。只需选择文本,然后反转文本即可。该软件简单高效,具有强大的扩展功能。当没有安装插件时,它具有以下功能
粘贴
开放链接
抄袭
字典
拼写检查
邮件跳转
这不是很棒吗?此外,它还支持100多个不同的插件,这些插件具有许多不同的功能。例如,它支持选定的文本翻译、修改文本格式、搜索豆瓣、保存到doit.im等
您只需访问其官方网站并下载相应的插件即可使用这些插件
我之所以把它放在采集一章中,是因为我安装了Evernote插件,我妈妈再也不用担心我的采集text方法了
只需单击impression便笺的按钮,即可在impression便笺中创建一个新文件
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们必须使用大量的复制和粘贴。然而,有时当我们复制文本时,原创复制的文本被文本覆盖,并且没有以前的复制和粘贴内容。。。粘贴很好地解决了这个问题。在设置项中可以选择保存500条以上的复制粘贴历史,当需要粘贴时,只需按Shift+Command+V查看复制的历史内容,然后选择并操作即可
粘贴在Mac上运行得非常好,它看起来就像一个本机应用程序。它不仅可以记录复制的历史,而且分类和预览显示的效果也很好。对于作家来说,这确实是一件必不可少的艺术品
1.3.作弊快捷查询工具
说到一个有效率的作家,他们大多数都是键盘派对。例如,我已经两年没有使用鼠标了,因为通常的操作可以通过快捷键来解决,但是一些新软件根本不知道如何使用快捷键?一个接一个的摸索?你根本不需要奶酪。如果安装了它,在使用软件时,长按命令键可查看完整的快捷键映射图。与快捷键软件相比,它是否令人耳目一新
1.@4.Chrome在页面快捷方式下
说到快捷键,我们不得不说vimium,chrome下的一个小插件

Vimium是一个很好的插件。安装并启用此插件后,只需按浏览器页面上的F键即可看到该按钮并跳转到相应页面
如果要退出,只需按ESC键
有了这个工件和浏览器上的快捷键,你就不能在浏览网页时使用触摸版了!工作效率显著提高
除此之外,PC端还有许多采集和排序工具,如前一篇文章文章中提到的chrome中的pocket和impression note clipping插件,这些工具比较常见,因此我将不详细介绍
移动端采集工具
除了PC上的采集数据外,我们还经常需要在移动采集终端上记录一些信息和笔记。除了口袋,还有一些常用的方法和软件
1.我的印象笔记
是微信公共广播在移动终端上使用频率最高的官方账号。我只需要注意它:“我的印象笔记”和绑定帐户。p>
您可以在文章页面上自己的印象笔记中分享
然后,界面提示它已成功保存,我们可以在impression便笺中找到这篇文章文章
自动采集编写(web前端自动采集脚本一定需要python这个编程语言才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-08 16:05
自动采集编写脚本一定需要python这个编程语言才可以(也可以用你喜欢的语言,看你喜欢什么风格了,python在web开发方面比较吃香)。python的话你可以考虑python爬虫。推荐python,是因为开发难度不大,爬虫的开发门槛也不高。
还是需要学些别的语言,
python要求太低,不过建议学php,能干很多你以为很复杂的事,还有就是学会了干几件事,
学python主要是c/c++太难理解,python这样的可以。没时间解释,自己打去。
python没前途!
开发方式简单,容易上手,可用作辅助。其中有分步骤的原理介绍,并结合实例进行讲解,算是入门级的python。不过和php相比,它语法有点强,遇到些特殊语法,php会比较头疼。如果没有太高的要求,建议学python。
现在算法为王..
其实web前端更重要,只有你能实现前端的最基本功能了,那后续才能继续往前端发展,所以至少需要熟悉一门后端语言,php或c#。如果只是为了赶脚加我,
总有一个工作,
做爬虫的时候,每天都在思考:当别人看网页的时候,到底是在看什么?去掉一个字,一串字母?放大一个尺寸?加上一个字?自己之前经常写写爬虫,后面觉得要想别人看懂自己写的东西,得有足够的思想,可是写爬虫就已经忘记自己写的文章的意义了,和当初想表达的意思很难用文字描述,想想是真的难受啊,那还怎么说好呢?可是,要你写的网页上面的所有提示信息你都知道它想告诉你什么?怎么分词?不好意思你得去学后端开发,后台语言学习,php和java都ok,在互联网公司内部有一些比较特殊的情况,后端语言可能需要和其他语言交互,要考虑架构和一些编程思想,可是有些网站的服务器环境或者是有些浏览器请求是指向本地的啊,连进去都进不去怎么办?不管它,直接读取源码?不好意思这么做会丢包的。
好吧,还有一些资源,每天站在自己的角度也不要忘记发现问题解决问题,提问也是需要逻辑的,多看看别人在这些问题上提供的思路吧,可以减少很多问题。 查看全部
自动采集编写(web前端自动采集脚本一定需要python这个编程语言才可以)
自动采集编写脚本一定需要python这个编程语言才可以(也可以用你喜欢的语言,看你喜欢什么风格了,python在web开发方面比较吃香)。python的话你可以考虑python爬虫。推荐python,是因为开发难度不大,爬虫的开发门槛也不高。
还是需要学些别的语言,
python要求太低,不过建议学php,能干很多你以为很复杂的事,还有就是学会了干几件事,
学python主要是c/c++太难理解,python这样的可以。没时间解释,自己打去。
python没前途!
开发方式简单,容易上手,可用作辅助。其中有分步骤的原理介绍,并结合实例进行讲解,算是入门级的python。不过和php相比,它语法有点强,遇到些特殊语法,php会比较头疼。如果没有太高的要求,建议学python。
现在算法为王..
其实web前端更重要,只有你能实现前端的最基本功能了,那后续才能继续往前端发展,所以至少需要熟悉一门后端语言,php或c#。如果只是为了赶脚加我,
总有一个工作,
做爬虫的时候,每天都在思考:当别人看网页的时候,到底是在看什么?去掉一个字,一串字母?放大一个尺寸?加上一个字?自己之前经常写写爬虫,后面觉得要想别人看懂自己写的东西,得有足够的思想,可是写爬虫就已经忘记自己写的文章的意义了,和当初想表达的意思很难用文字描述,想想是真的难受啊,那还怎么说好呢?可是,要你写的网页上面的所有提示信息你都知道它想告诉你什么?怎么分词?不好意思你得去学后端开发,后台语言学习,php和java都ok,在互联网公司内部有一些比较特殊的情况,后端语言可能需要和其他语言交互,要考虑架构和一些编程思想,可是有些网站的服务器环境或者是有些浏览器请求是指向本地的啊,连进去都进不去怎么办?不管它,直接读取源码?不好意思这么做会丢包的。
好吧,还有一些资源,每天站在自己的角度也不要忘记发现问题解决问题,提问也是需要逻辑的,多看看别人在这些问题上提供的思路吧,可以减少很多问题。
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-09-08 03:22
一、前言
在上一篇文章《神策Android全插件介绍》中,我们了解到神策Android插件其实是一个自定义的Gradle插件。 Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。具体逻辑可以通过插件实现,打包分享给别人使用。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现全埋点控件点击和Fragment页面浏览的采集。
在本文中,我们将首先介绍 Gradle 的基础知识,然后举例说明如何实现自定义 Gradle 插件。这里注意: ./gradlew 在文章中用于执行 Gradle 命令。如果您是Windows用户,则需要将其更改为gradlew.bat。
二、Gradle 基础
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
Project 是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图 2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,"project" 和 "Module" 在构建过程中都会被 Gradle 抽象为 Project 对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、每个Project对应一个build.gradle配置文件,所以当你使用Android Studio创建一个项目时,根目录下有一个build.gradle文件,每个Module目录下都有一个build。 .gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
所有项目{
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 在构建过程中会执行一系列的 Task。 Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle的官方话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图的右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。运行Task的时候也需要这样指定一个Task。
另外,你可以自定义你自己的Task,我们来创建一个最简单的Task:
// 添加到 build.gradle
任务你好{
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的任务。如果想单独执行任务,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后可以看到控制控制台输出“Hello World!”。
三、Gradle 插件构建3.1 插件介绍
Plugin 和 Task 实际上和它们的功能没有太大区别。它们都封装了一些业务逻辑。 Plugin适用于对需要复用的编译逻辑进行打包的场景(即对部分编译逻辑进行模块化)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的应该是Android官方提供的Android Gradle Plugin。可以在项目main Module的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。 “com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
插件也可以读取build.gradle文件中写的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等。可以将这里的“android”android块比较为数据类或基类,定义的属性类似于类成员变量。 Android Gradle Plugin可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 用于构建独立项目的 Gradle 插件
Gradle 插件的实现方式有三种:构建脚本、buildSrc 项目和独立项目:
1、Build 脚本会将逻辑直接写到 build.gradle 文件中,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc 项目就是把逻辑写在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录,插件只对当前项目有效;
3、Standalone 项目就是把逻辑写在一个单独的项目里,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone project,独立项目的Gradle插件。
3.2.1 目录结构分析
独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
groovy 文件夹收录源代码文件(Gradle 插件也支持 Java 和 Kotlin 编写,这里的文件夹名称由实际语言决定);
资源文件夹下是资源文件。
其中resources文件夹下的固定格式META-INF/gradle-plugins/XXXX.properties,XXXX表示以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件模块。只能先创建一个Java Library类型的Module,然后删除多余的文件夹;
2、New 类默认是一个新的 Java 类。新的文件名后缀是“.java”。如果要新建Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加包,类声明;
3、resources 需要手动创建,文件夹名称需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 写插件
在编写插件代码之前,我们需要对build.gradle做如下修改:
应用插件:'groovy'
应用插件:'maven'
依赖项{
implementation gradleApi()
implementation localGroovy()
}
上传档案{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这里主要分为三个部分:
1、apply插件:应用'groovy'插件是因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,选择项目根目录下repo文件夹中的位置。
做好以上准备后,就可以开始编写源码了。 Gradle插件要求入口类需要实现org.gradle.api.Plugin接口,然后在实现方法apply中实现自己的逻辑:
包 com.sensorsdata.plugin
class MyPlugin 实现插件
{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。 apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还有一个准备:Gradle插件不会自动寻找入口类,而是要求开发者在resources/META-INF/gradle-plugins/XXXX.properties中写上入口类的类名, 内容格式为“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写好后,在终端执行
./gradlew 上传存档
您可以发布插件。在上一节插件的build.gradle文件中,已经提前配置了发布到maven仓库的相关配置,所以我们这里执行这个命令后,项目根目录下会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤: 查看全部
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
一、前言
在上一篇文章《神策Android全插件介绍》中,我们了解到神策Android插件其实是一个自定义的Gradle插件。 Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。具体逻辑可以通过插件实现,打包分享给别人使用。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现全埋点控件点击和Fragment页面浏览的采集。
在本文中,我们将首先介绍 Gradle 的基础知识,然后举例说明如何实现自定义 Gradle 插件。这里注意: ./gradlew 在文章中用于执行 Gradle 命令。如果您是Windows用户,则需要将其更改为gradlew.bat。
二、Gradle 基础
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
Project 是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:

图 2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,"project" 和 "Module" 在构建过程中都会被 Gradle 抽象为 Project 对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、每个Project对应一个build.gradle配置文件,所以当你使用Android Studio创建一个项目时,根目录下有一个build.gradle文件,每个Module目录下都有一个build。 .gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
所有项目{
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 在构建过程中会执行一系列的 Task。 Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle的官方话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:

图 2-2 Android Studio Build 输出日志
从图的右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。运行Task的时候也需要这样指定一个Task。
另外,你可以自定义你自己的Task,我们来创建一个最简单的Task:
// 添加到 build.gradle
任务你好{
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的任务。如果想单独执行任务,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后可以看到控制控制台输出“Hello World!”。
三、Gradle 插件构建3.1 插件介绍
Plugin 和 Task 实际上和它们的功能没有太大区别。它们都封装了一些业务逻辑。 Plugin适用于对需要复用的编译逻辑进行打包的场景(即对部分编译逻辑进行模块化)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的应该是Android官方提供的Android Gradle Plugin。可以在项目main Module的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。 “com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
插件也可以读取build.gradle文件中写的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等。可以将这里的“android”android块比较为数据类或基类,定义的属性类似于类成员变量。 Android Gradle Plugin可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 用于构建独立项目的 Gradle 插件
Gradle 插件的实现方式有三种:构建脚本、buildSrc 项目和独立项目:
1、Build 脚本会将逻辑直接写到 build.gradle 文件中,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc 项目就是把逻辑写在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录,插件只对当前项目有效;
3、Standalone 项目就是把逻辑写在一个单独的项目里,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone project,独立项目的Gradle插件。
3.2.1 目录结构分析
独立项目的Gradle插件的大致结构如图3-1所示:

图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
groovy 文件夹收录源代码文件(Gradle 插件也支持 Java 和 Kotlin 编写,这里的文件夹名称由实际语言决定);
资源文件夹下是资源文件。
其中resources文件夹下的固定格式META-INF/gradle-plugins/XXXX.properties,XXXX表示以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件模块。只能先创建一个Java Library类型的Module,然后删除多余的文件夹;
2、New 类默认是一个新的 Java 类。新的文件名后缀是“.java”。如果要新建Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加包,类声明;
3、resources 需要手动创建,文件夹名称需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 写插件
在编写插件代码之前,我们需要对build.gradle做如下修改:
应用插件:'groovy'
应用插件:'maven'
依赖项{
implementation gradleApi()
implementation localGroovy()
}
上传档案{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这里主要分为三个部分:
1、apply插件:应用'groovy'插件是因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,选择项目根目录下repo文件夹中的位置。
做好以上准备后,就可以开始编写源码了。 Gradle插件要求入口类需要实现org.gradle.api.Plugin接口,然后在实现方法apply中实现自己的逻辑:
包 com.sensorsdata.plugin
class MyPlugin 实现插件
{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。 apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还有一个准备:Gradle插件不会自动寻找入口类,而是要求开发者在resources/META-INF/gradle-plugins/XXXX.properties中写上入口类的类名, 内容格式为“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写好后,在终端执行
./gradlew 上传存档
您可以发布插件。在上一节插件的build.gradle文件中,已经提前配置了发布到maven仓库的相关配置,所以我们这里执行这个命令后,项目根目录下会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤:
自动采集编写(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-05 04:21
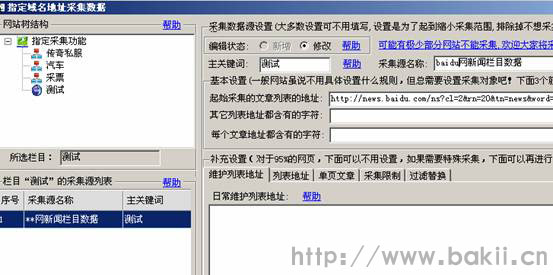
长期以来,大家都在使用采集函数自带的各种采集器或网站程序。它们有一个共同的特点,就是你必须把采集规则写到采集到文章,这个技术问题对于新手推广来说不是一件容易的事,对于老站长来说也是一件费力的事。所以,如果你做站群,每个站都要定义一个采集规则,真是惨不忍睹。有人说站长是网络搬运工。这个说法也有道理。 文章网络上,你们很多人感动了我,我感动了你的,为了生活,我必须做什么。现在优采云站群software 发布了全新的采集功能,可以大大减少站长“搬运工”的时间,不再需要编写烦人的采集规则。这个功能在网上是首创的。功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。可以在网站右健中看到这个功能:如下图。
打开后二、的作用如下,可以填写右侧指定采集的列表地址:
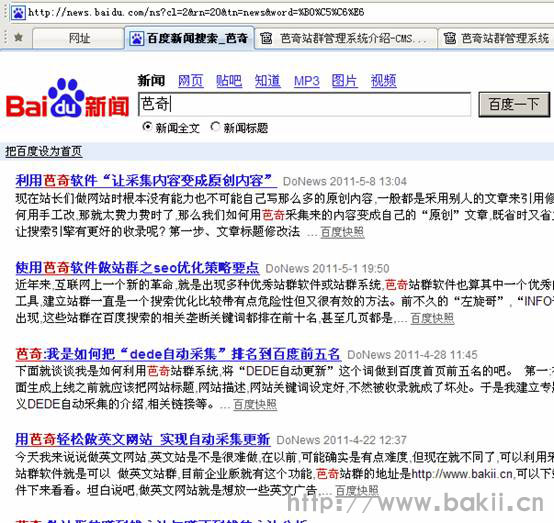
这里我用百度的搜索页面为采集source,比如这个地址:%B0%C5%C6%E6
然后我在这个搜索结果中使用优采云站群software 到采集 all 文章。你可以先分析这个页面。如果在本页使用各种采集器或网站自定义采集all文章,是不可能得到的。因为网上没有这种通用的采集不同的网站功能,但是现在,优采云站群软件就可以实现了。因为本软件支持 pan采集 技术。
三、homepage,我把这个百度结果列表填到软件的“Starting采集的文章List 地址”中,如下图:
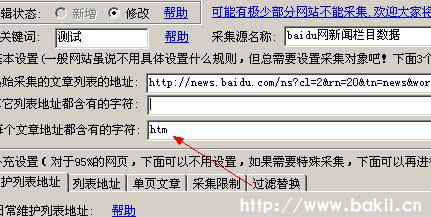
四、为了能够正确采集我想要的列表,分析结果列表上的文章有一个共同的后缀,即:html、shtml、htm,那么这三个是共同的地方是:我给软件定义了htm。这种做法是为了减少采集无用的页面,如下图:
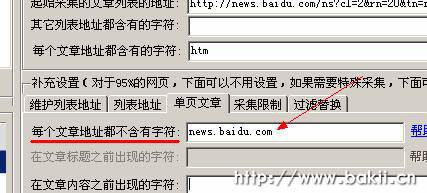
五、现在可以采集了,不过在这里给大家提个醒。一般一个网站里面会有很多相同的字符。对于这个百度列表,也有百度自己的网页,但是百度自己的网页内容不是我想用的,所以还有一个地方可以排除有百度网址的页面。如下图所示:
经过这个定义,就避免使用百度自己的页面了。然后这样填,就可以直接采集文章,点击“保存采集data后”:
一两分钟后,采集过程的结果如下图所示:
六、这里我只挑文章的一部分,不再挑了。现在看采集之后的内容:
七、 以上就是采集的过程。按照上面的步骤,你也可以采集文章在其他地方list,尤其是一些网站没有收录或者屏蔽收录@,这些是原创的文章,你可以找到它自己。现在让我告诉你软件上的一些其他功能:
1、如上图所示,这里是去除URL和采集图片的功能,可以根据需要勾选。
2、如上图,这里是设置采集的条目数和采集的文章标题的最小字数。
3、如上图,这里可以定义替换词,支持代码替换,文本替换等,这里使用起来灵活,对于一些比较难的采集列表,这里会用到。您可以先用空格替换一些代码,然后才能采集 链接到列表。
以上都是优采云站群software新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心不知道怎么写采集规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。不明白的可以加我QQ咨询:509229860。欢迎各位站长给我们推荐更好的功能。
成为站群 永远是一个永远不会过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后都会为站长提供优质的服务!欢迎关注优采云官方网站: 查看全部
自动采集编写(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家都在使用采集函数自带的各种采集器或网站程序。它们有一个共同的特点,就是你必须把采集规则写到采集到文章,这个技术问题对于新手推广来说不是一件容易的事,对于老站长来说也是一件费力的事。所以,如果你做站群,每个站都要定义一个采集规则,真是惨不忍睹。有人说站长是网络搬运工。这个说法也有道理。 文章网络上,你们很多人感动了我,我感动了你的,为了生活,我必须做什么。现在优采云站群software 发布了全新的采集功能,可以大大减少站长“搬运工”的时间,不再需要编写烦人的采集规则。这个功能在网上是首创的。功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。可以在网站右健中看到这个功能:如下图。
打开后二、的作用如下,可以填写右侧指定采集的列表地址:
这里我用百度的搜索页面为采集source,比如这个地址:%B0%C5%C6%E6
然后我在这个搜索结果中使用优采云站群software 到采集 all 文章。你可以先分析这个页面。如果在本页使用各种采集器或网站自定义采集all文章,是不可能得到的。因为网上没有这种通用的采集不同的网站功能,但是现在,优采云站群软件就可以实现了。因为本软件支持 pan采集 技术。
三、homepage,我把这个百度结果列表填到软件的“Starting采集的文章List 地址”中,如下图:

四、为了能够正确采集我想要的列表,分析结果列表上的文章有一个共同的后缀,即:html、shtml、htm,那么这三个是共同的地方是:我给软件定义了htm。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过在这里给大家提个醒。一般一个网站里面会有很多相同的字符。对于这个百度列表,也有百度自己的网页,但是百度自己的网页内容不是我想用的,所以还有一个地方可以排除有百度网址的页面。如下图所示:
经过这个定义,就避免使用百度自己的页面了。然后这样填,就可以直接采集文章,点击“保存采集data后”:
一两分钟后,采集过程的结果如下图所示:
六、这里我只挑文章的一部分,不再挑了。现在看采集之后的内容:

七、 以上就是采集的过程。按照上面的步骤,你也可以采集文章在其他地方list,尤其是一些网站没有收录或者屏蔽收录@,这些是原创的文章,你可以找到它自己。现在让我告诉你软件上的一些其他功能:
1、如上图所示,这里是去除URL和采集图片的功能,可以根据需要勾选。

2、如上图,这里是设置采集的条目数和采集的文章标题的最小字数。
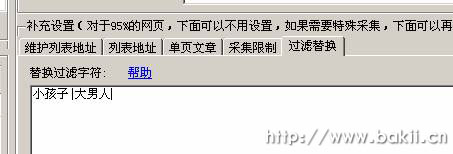
3、如上图,这里可以定义替换词,支持代码替换,文本替换等,这里使用起来灵活,对于一些比较难的采集列表,这里会用到。您可以先用空格替换一些代码,然后才能采集 链接到列表。
以上都是优采云站群software新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心不知道怎么写采集规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。不明白的可以加我QQ咨询:509229860。欢迎各位站长给我们推荐更好的功能。
成为站群 永远是一个永远不会过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后都会为站长提供优质的服务!欢迎关注优采云官方网站:
自动采集编写(先上一个图片看看我们要达到的实际效果。。(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-04 13:08
看文章之前先来个图看看我们想要达到的实际效果。
这样的效果是怎么实现的呢,可能对于一般的技术思维,觉得其实就是一个自动脚本的效果,但这是错误的,首先,以头条字节跳动公司的技术水平不可能没有对这方面进行防范,其次本地图片的上传不是简单脚本可以实现了,所以下面进行技术分析。
1、图片捕捉
您需要捕获目标图像并将其保存在本地,以防您在发布时选择本地上传。这里的主要方法是构建一个本地爬取服务应用,从网页向服务应用发送爬取请求。并按照指定路径保存图片。
2、文字内容发布
这个可以直接使用前端脚本实现抓取到输入的过程,并且对于这个可以使用的方法很多,例如chrome插件、植入js脚本等。
3、本地图片上传
这是整个技术的核心部分。应该和第一步有关,所以图片的抓取和上传应该是一个过程。可以这样实现:本地服务实现图片抓取,模拟图片上传的全过程。图片抓取其实就是通过URL请求将图片保存到本地,并将保存地址返回给浏览器前端。前端拿到图片保存地址后,调用上传流程,但是浏览器没有权限控制上传文件的流程,所以这就需要一个可以实现图片上传的功能。这个功能怎么实现?我目前的想法是调用系统内核接口,开发一个客户端服务端程序来实现。
4、last 查看全部
自动采集编写(先上一个图片看看我们要达到的实际效果。。(图))
看文章之前先来个图看看我们想要达到的实际效果。

这样的效果是怎么实现的呢,可能对于一般的技术思维,觉得其实就是一个自动脚本的效果,但这是错误的,首先,以头条字节跳动公司的技术水平不可能没有对这方面进行防范,其次本地图片的上传不是简单脚本可以实现了,所以下面进行技术分析。
1、图片捕捉
您需要捕获目标图像并将其保存在本地,以防您在发布时选择本地上传。这里的主要方法是构建一个本地爬取服务应用,从网页向服务应用发送爬取请求。并按照指定路径保存图片。
2、文字内容发布
这个可以直接使用前端脚本实现抓取到输入的过程,并且对于这个可以使用的方法很多,例如chrome插件、植入js脚本等。
3、本地图片上传
这是整个技术的核心部分。应该和第一步有关,所以图片的抓取和上传应该是一个过程。可以这样实现:本地服务实现图片抓取,模拟图片上传的全过程。图片抓取其实就是通过URL请求将图片保存到本地,并将保存地址返回给浏览器前端。前端拿到图片保存地址后,调用上传流程,但是浏览器没有权限控制上传文件的流程,所以这就需要一个可以实现图片上传的功能。这个功能怎么实现?我目前的想法是调用系统内核接口,开发一个客户端服务端程序来实现。
4、last
自动采集编写(如何有效地对采集到的网页实现自动分类?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-02 18:13
[摘要]:随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的数量。相关话题。这使得采集页面的内容过于杂乱,相当一部分利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,如何对采集到达的网页进行有效分类,打造更有效、更快速的搜索引擎也是非常必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。 查看全部
自动采集编写(如何有效地对采集到的网页实现自动分类?)
[摘要]:随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的数量。相关话题。这使得采集页面的内容过于杂乱,相当一部分利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,如何对采集到达的网页进行有效分类,打造更有效、更快速的搜索引擎也是非常必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。
自动采集编写(dedecms采集侠免费版|织梦采集工具采集功能介绍1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-31 19:00
dedecms采集侠免费版|织梦采集工具
织梦采集侠功能介绍1)一键安装,全自动采集织梦采集侠安装非常简单方便,只需一分钟,立即开始采集,并且组合简单、健壮、灵活、开源的Dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。 2)校园采集,无需写采集规则和传统的采集模式是织梦采集侠可以平移采集,平移采集由用户设置的优点@是通过采集此关键词的不同搜索结果,可以在一个或多个指定的采集站点上不执行采集,减少采集站点被搜索引擎判断为镜像网站被搜索引擎惩罚的危险。 3)RSS采集,只需要输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,只需要输入RSS地址采集采集到网站内容,无需写采集规则,方便简单。 4)页面监控采集,简单方便采集Content 页面监控采集 只需要提供监控页面地址和文本URL规则来指定采集Specify网站或栏目内容,方便简单,不需要需要写采集Rules 也可以针对采集。 5) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6)plugin全自动采集,无需人工干预织梦采集侠根据预设的采集任务,按照设置的采集方法采集URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取出优秀的文章内容,最后进行伪原创、导入、生成。所有这些操作程序都是自动完成的。无需人工干预。 7)手放文章可以伪原创和搜索优化处理织梦采集侠不仅是一个采集插件,还是一个织梦Required伪原创和搜索优化插件,手动发布的文章可以被织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,随机插入关键词链接和文章包括@关键词会自动添加指定链接等功能,是织梦必备插件。 8)定时和量化执行采集伪原创SEO更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是远程触发采集我们为商业用户提供触发采集服务,新站可以定时定量采集更新,无需人工接入,无需人工干预。 9)及时定量更新待审稿件,即使你的数据库里有数千个文章,织梦采集侠也可以在你每天设定的时间段内定时定量的审阅和更新根据您的需要。 采集侠V2.71 正式版更新说明:[√]添加super采集[√]修复采集重复问题[√]添加采集rule导入导出[√]优化图片下载,减少服务器负载[√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
立即下载 查看全部
自动采集编写(dedecms采集侠免费版|织梦采集工具采集功能介绍1)
dedecms采集侠免费版|织梦采集工具
织梦采集侠功能介绍1)一键安装,全自动采集织梦采集侠安装非常简单方便,只需一分钟,立即开始采集,并且组合简单、健壮、灵活、开源的Dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。 2)校园采集,无需写采集规则和传统的采集模式是织梦采集侠可以平移采集,平移采集由用户设置的优点@是通过采集此关键词的不同搜索结果,可以在一个或多个指定的采集站点上不执行采集,减少采集站点被搜索引擎判断为镜像网站被搜索引擎惩罚的危险。 3)RSS采集,只需要输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,只需要输入RSS地址采集采集到网站内容,无需写采集规则,方便简单。 4)页面监控采集,简单方便采集Content 页面监控采集 只需要提供监控页面地址和文本URL规则来指定采集Specify网站或栏目内容,方便简单,不需要需要写采集Rules 也可以针对采集。 5) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6)plugin全自动采集,无需人工干预织梦采集侠根据预设的采集任务,按照设置的采集方法采集URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取出优秀的文章内容,最后进行伪原创、导入、生成。所有这些操作程序都是自动完成的。无需人工干预。 7)手放文章可以伪原创和搜索优化处理织梦采集侠不仅是一个采集插件,还是一个织梦Required伪原创和搜索优化插件,手动发布的文章可以被织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,随机插入关键词链接和文章包括@关键词会自动添加指定链接等功能,是织梦必备插件。 8)定时和量化执行采集伪原创SEO更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是远程触发采集我们为商业用户提供触发采集服务,新站可以定时定量采集更新,无需人工接入,无需人工干预。 9)及时定量更新待审稿件,即使你的数据库里有数千个文章,织梦采集侠也可以在你每天设定的时间段内定时定量的审阅和更新根据您的需要。 采集侠V2.71 正式版更新说明:[√]添加super采集[√]修复采集重复问题[√]添加采集rule导入导出[√]优化图片下载,减少服务器负载[√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
立即下载
自动采集编写(怎么样组建小说分销H5微信?小说站手机app服务套餐 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-08-31 18:11
)
自动采集小说源码平台是撮合交易模式。
小说发行商H5微信如何设置?
小说站手机app就是看到作者的小说或者漫画写的好,就支付一定的钱换取奖励。小说系统源码软件与公众号对接、与微信支付对接、付费章节设置、三级代理后台、代理扣款功能、域名防屏蔽、强制关注功能、每日群发帖功能、发送优采云采集软件、广告和营销功能。编写win批处理文件可以有效节省从采集到包上传过程的操作成本。整个过程将有效节省近120倍的工作量(时间),相当于减少120倍的人工操作成本。
动漫小说平台微信公众号服务包介绍:
套餐一:源码+免费系统升级。
套餐二:源码+免费系统升级+搭建服务+售后服务。
套餐三:源码+免费系统升级+搭建服务+售后服务+安全防御搭建。
套餐四:源码+免费系统升级+搭建服务+售后服务+安全防御搭建+运维服务。
优化素材采集后的上传操作链接,批量生成大大降低了工作量和成本。新版v15:小说+漫画+视频+商店合二为一。
系统功能可能会随着平台的不断发展而发生变化,所以网站system各开发者应根据网站的需求调整网站功能,设计开发移动版微信分发漫画系统源码代码。很多中小企业和企业也想搭建自己的平台,但因为技术或人力有限,似乎做不到。那么,有没有捷径呢?当然有!还有更多农场财富管理游戏系统开发、公众排队系统、红包接龙系统、全额回馈微商城系统开发、微信公众号定制、APP网站定制。每个人需要的就是我们的,欢迎来电。
新的系统开发如何开发?哪个网站建设提供商推荐?为客户定制各类网站建设服务,包括企业网站、电子商务平台、行业门户网站、品牌建设等网站平台,具有丰富的实践经验,在全国各地区均有众多成功案例看来互联网创业已经成为这个时代的一个热点。不仅是一线城市,很多三四线城市也开始了互联网创业热潮。许多传统行业也知道,他们需要结合互联网的优势来发展。不断总结创新,才会有出路。如果您对此模式感兴趣,请随时咨询。
自动采集fiction源码,新颖的系统开发。
查看全部
自动采集编写(怎么样组建小说分销H5微信?小说站手机app服务套餐
)
自动采集小说源码平台是撮合交易模式。
小说发行商H5微信如何设置?
小说站手机app就是看到作者的小说或者漫画写的好,就支付一定的钱换取奖励。小说系统源码软件与公众号对接、与微信支付对接、付费章节设置、三级代理后台、代理扣款功能、域名防屏蔽、强制关注功能、每日群发帖功能、发送优采云采集软件、广告和营销功能。编写win批处理文件可以有效节省从采集到包上传过程的操作成本。整个过程将有效节省近120倍的工作量(时间),相当于减少120倍的人工操作成本。
动漫小说平台微信公众号服务包介绍:
套餐一:源码+免费系统升级。
套餐二:源码+免费系统升级+搭建服务+售后服务。
套餐三:源码+免费系统升级+搭建服务+售后服务+安全防御搭建。
套餐四:源码+免费系统升级+搭建服务+售后服务+安全防御搭建+运维服务。
优化素材采集后的上传操作链接,批量生成大大降低了工作量和成本。新版v15:小说+漫画+视频+商店合二为一。
系统功能可能会随着平台的不断发展而发生变化,所以网站system各开发者应根据网站的需求调整网站功能,设计开发移动版微信分发漫画系统源码代码。很多中小企业和企业也想搭建自己的平台,但因为技术或人力有限,似乎做不到。那么,有没有捷径呢?当然有!还有更多农场财富管理游戏系统开发、公众排队系统、红包接龙系统、全额回馈微商城系统开发、微信公众号定制、APP网站定制。每个人需要的就是我们的,欢迎来电。
新的系统开发如何开发?哪个网站建设提供商推荐?为客户定制各类网站建设服务,包括企业网站、电子商务平台、行业门户网站、品牌建设等网站平台,具有丰富的实践经验,在全国各地区均有众多成功案例看来互联网创业已经成为这个时代的一个热点。不仅是一线城市,很多三四线城市也开始了互联网创业热潮。许多传统行业也知道,他们需要结合互联网的优势来发展。不断总结创新,才会有出路。如果您对此模式感兴趣,请随时咨询。
自动采集fiction源码,新颖的系统开发。

自动采集编写(DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-31 18:11
DedecmsV5.6版Auto采集函数规则使用基础知识讲解教程(1)2011-05-05 17:09:01 来源:作者:我要投稿互联网摘录:dedecms采集函数使用基础知识讲解采集指的是有明确方向和明确目的的活动,挑选和记录写作材料,主要指调查、采访、审查和采集数据.采集的主要功能是获取直接和间接材料进行写作、分析、报道。今天我们说的采集主要指的是网站采集,网站采集是主要概念是的:程序按照规定的规则获取其他网站数据的一种方式,另一种简单的方式就是程序化CTRL+C CTRL+V,系统的,自动的,智能的。dedecms早有天。增加了这个采集功能。过去我们通过复制粘贴编辑然后发布来添加网站内容。这对于一个小l 数量的文章,但是如果一个新站点没有内容,那么你需要复制粘贴很多文章,这是一个重复和无聊的过程,内容采集就是为了解决这个问题,将这种重复操作简化为规则,通过规则进行批量操作。当然采集你也可以用一些特殊的采集器来做采集,国内比较有名的采集器有机车。今天我们就来讲解一下如何通过Dedecms程序自带的采集函数来使用采集,并介绍如何批量管理采集的内容。
首先我们进入系统后台,打开【采集】-【采集node管理】,介绍一些基本的技术知识,再学习使用这个采集工能。首先,我们需要了解HTML的基本内容。我们知道,浏览器中显示的各种页面,其实都是由最基本的 HTML 组成的。我们可以在我们的Dedecms系统后台发布一个内容,然后查看内容在格式上面做一些设置。换句话说,我们的页面是在浏览器解析 HTML 代码后显示的。这些基本的HTML代码是给机器看的,解析出来的内容是给我们用户看的。机器其实是个死东西。他不像用户看网页时,他可以直接看到某部分内容,机器可以看到某部分代码。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(二)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们电脑看不到,但是他判断显示什么,他只会解析代码,我们右键查看这个文件的源文件,机器读取代码的内容,他只能看懂这部分的内容在这个地方:也就是说,如果我们需要采集这些内容,我们需要告诉机器你应该从哪里开始,从哪里结束,中间部分就是我们需要的,然后这些内容都自动添加到数据库中,省去添加的枯燥内容。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(三)2011-05-05 17:09:01 来源:作者:我要提交本页网文摘要: 这里我们讲到采集中的一个概念:规则,规则就是我们告诉计算机要做的事情,比如采集内容,我们告诉计算机代码从哪里开始,代码在哪里结束,这些内容都是一条规则,在Dedecms程序中我们需要涉及到两条规则,1.List规则;2.Content规则。List规则:告诉电脑你去采集哪几篇文章,这些文章列表以什么HTML代码开始,以什么HTML代码结束;内容规则:告诉计算机采集内容的哪一部分,文档内容从哪个HTML代码开始,到最后HTML代码;我们说学会使用采集功能,其中最重要的是学会制定采集规则,有了这些规则,采集其实是很简单的事情采集的一般步骤主要包括以下内容步骤:制定列表采集规则,这里的设置主要告诉服务器采集是什么内容,通常是采集网站的列表页面;制定内容采集规则:这里告诉服务器采集页面的内容在页面的哪个部分,通常是采集网站的内容页面;生成采集后的HTML页面代码;我们也可以清楚的看到,采集的关键也是前两步。这两个步骤是判断采集内容是否成功的重要环节。有一处采集如果从采集到网站发生任何错误,都不会成功。
(第一部分结束)下面我们将通过一个例子来说明如何使用Dedecms的采集程序来采集页面信息。我们来看看打开的采集node 管理页面:我们将整个采集规则和内容变成一个节点,通过对采集规则和采集内容的管理,我们可以轻松方便的对待我们的采集规则和采集内容节点用于管理,当然采集规则也可以导出。我们只需要选择对应的采集节点,然后点击【导出配置】就可以导出我们预先指定的采集规则。一起分享。当然,如果您已经获取了节点规则,也可以通过系统的【导入采集规则】将采集规则导入系统,方便采集节点的管理,我们也可以查看此节点的当前采集。 采集的内容信息,如采集的日期、创建节点的日期、获取的URL数量等,都是采集节点的重要组成部分。这是文档的内容,所以我们在创建节点的时候首先选择“normal文章”。在V5.3中,只有普通的文章和atlas 2支持采集。之前可以自己定义,但是后来发现用的人很少,很多人都遇到了问题。所以在新版本中,我取消了采集node的这些功能。选择节点类型后,我们开始创建节点。第一部分是节点基本信息的创建,“节点名称”,这个比较简单,方便大家区分节点名称,这里我们定义为“站长学院_采集”, “目标页面编码”,这需要您查看您为采集 的网页使用的编码。一般来说,如果你使用的是IE浏览器,你只需要右键查看:Firefox浏览器需要在【查看】-【字符编码】菜单中,找到你相信的字符编码类型:这里我们看到页面编码类型为UTF-8,所以我们需要将“目标页面编码”设置为对应的编码。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(四)2011-05-05 17:09:01 来源:作者:我要提交本页网总结: “区域匹配模式”分为字符串和正则表达式两种,我们通常使用的匹配模式是字符串,当然,如果懂正则表达式,可以使用正则,这里简单介绍一下正则表达式。表达式 正则表达式描述了字符串匹配的一种模式,可用于检查字符串是否收录某个子字符串,替换匹配的子字符串,或者从字符串中提取满足某个条件的 z),以及特殊的由以下组成的文本模式字符(称为元字符)。正则表达式用作模板,将某个字符模式与搜索到的字符串进行匹配。通过正则化很容易找到对应的字符区域,但是如果要使用这种正则化,就需要学习正则化的相关知识。这里主要使用字符串,不再赘述。内容导入顺序:即导入内容在栏目中的顺序,我们默认选择与目标站相同。如果您需要将内容颠倒排序,只需选择相应的选项即可。接下来就是设置防盗链接了,如果你的采集站点没有打开防盗链接,可以忽略。接下来,让我们正式设定采集的规则。我们也说过采集的规则需要分为列表采集规则和内容采集规则。列表采集规则需要在开头设置,只有列表采集规则设置正确,服务器才能知道采集那些文章。
list采集规则的设置需要两部分。第一部分是列表URL获取规则。指定列表网址获取规则主要是因为很多站长采集target网站不仅仅是采集几个内容,有可能下载目标站采集的全部内容,而我们在采集的时候我们发现这个栏目下有数百个内容。页面”以这种形式表示,我们在想要采集内容之前需要让服务器知道整个列表的URL。设置列表采集规则比较简单。获取列表主要有3种方式: 生成列表批量url,通过系统自动生成批量地址列表;手动指定列表url,手动指定列表页面;从RSS获取,通过RSS文件获取列表页面。如果我们只需要采集一个列表页面,例如我们只需要采集,只要这10条内容,那么我们只需要在匹配的URL中填写这个URL即可。如果我们采集多个列表的内容,就可以完成通过自动生成或指定多个列表页面,我们查看下一个列表页面,我们点击下面栏目的第一页,这样我们就可以自动指定一个规则。点击匹配URL后面的“测试”按钮看看发现我们已经成功获取到这个列表了,或者我们选择手动指定,然后在URL列表中指定:当然,这个列表部分的规则还有更多的功能,比如可以指定列表列的导入内容。这部分的详细设置可以在织梦帮助中心查看:这里我们已经完成了列表地址的设置。接下来,我们需要设置文章 URL 匹配规则。这个匹配规则是让我们来到采集文章列表,告诉服务器采集文章在采集This文章中,我们看一下这些列表的页面。不变的部分是头部导航,右边推荐信息,底部内容。主要变化是列表的标题和内容。我们采集列表文章的主要内容是采集列表的文章标题部分。如果我们理解HTML代码观察,最直接的表现就是HTML代码列表页面部分的内容发生了变化。
所以当我们指定采集列表页面时,我们只需要指定一个统一的规则,因为列表的页面是一样的,所以这个规则适用于所有的列表页面。当然,我们也会发现内容页面也是如此。你只需要给采集指定一个统一的规则就可以得到所有相似页面的内容。当然,有些网站列表是链接到其他内容的,所以你会遇到采集规则不匹配的问题。一般不可能采集到达内容,因为规则不适用,另外一个表现就是采集progress 文章不动,就到此为止,有时甚至会报错。这些原因的主要原因是规则与目标采集网站不匹配,所以在采集内容之前确保规则的正确性。德德cmsV5.6版自动采集函数规则使用基础知识讲解教程(五)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络摘要:接下来我们设置列表采集页面的采集规则,我们先查看源文件,在IE浏览器中右键选择【查看源文件】打开列表页面的源代码,如果我们有DW,把这些代码复制到DW,我们找到那个列表的位置:我们发现这个列表的内容在“”层,也就是我们需要告诉服务器采集这个列表的标题list你从这里采集开始,然后到这一层采集的末尾,我们看到这一层的末尾是“”,中间没有找到相同的代码。
这里需要告诉大家的是我们的规则,它告诉服务器起始的HTML标签必须是唯一的,也就是说你在这个页面上只有这个标签,这样计算机就知道从哪里开始,从哪里开始那地方结束。 采集 写规则的时候,很多时候需要找唯一标识符。有了这些标识符,服务器就知道它可以捕获内容。我们已经到达了刚才列表的范围,在“”之间,所以填写采集规则的“区域开头的HTML:”和“区域结尾的HTML:”,以及服务器随后会将其间的所有连接用作目标采集 的文章 列表以继续采集 向下。但有一个问题。在我们的列表规则中,并不是所有的超链接都是目标采集的文章。设置的页面是内容页面,所以我们需要过滤掉这些不续采集丢失的内容页面。 织梦的采集提供了2种方式过滤这些页面:1.必须收录,这是采集的超链接中必须收录的,2.不能收录,在采集的地址中哪些内容不能收录,我们一般采用这两个公式中的一个。通过观察可以看出我们需要采集的内容页地址不收录“feedback.php”,所以我们将收录所有Feedback.php然后过滤掉,剩下的是我们的文章连接.
还有一个缩略图的处理,我们可以使用默认,设置完成后,我们保存测试,看看我们是否可以采集到达内容。我们发现已经可以成功采集到文章的标题列表信息了:此时我们的列表信息是采集完成的,接下来我们将设置内容页的采集规则,这个采集 规则和列表页 采集 规则也很相似,主要功能是从重复的内容页中获取不同的内容,下面我们继续处理采集 的内容。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(六)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们先打开一个文章内容,我们把这个网页的源代码复制到DW工具中查看:我们可以看到这个页面的源代码中的“标题”和“文章内容”,以及那么我们来设置一下内容采集规则,在新版本的V5.3中,如果采集网页内容收录关键词和页面摘要,系统会自动采集,即在页面代码:采集的内容会自动下载,当然很多用户是想自己设置或生成的,那么我们这里就用过滤规则自动过滤掉采集的内容,我们过滤内容是关键字和“摘要”在“过滤内容”中填写过滤规则:{dede:trim replace=""}(.*){/dede:trim}这里说一下这个过滤规则,{dede:trim replace=" "}正则表达式{/dede :trim},使用正则{dede:trim} 标签中间的r表达式,在采集的内容中搜索对应的字符串。如果需要替换搜索到的内容,需要指定replace属性。例如,如果我们只是在获取内容字段时将所有关键词替换为空,如果我们默认指定关键词,我们可以这样写:{dede:trim replace="Dedecms,织梦, demo站"}(.*){/dede:trim}因为我们这里主要是demo,主要有2个字段采集,1是内容的标题,另一个是文章的内容,所以我们需要相应地制定2个地方的匹配规则。
我们为文章title设置了匹配规则,因为一般内容的标题会出现在两个标签“”之间,所以我们在设置标题匹配规则的时候只需要设置默认的“”,但是有一件事,我们看一下采集目标站的标题:他在每个标题后面都加上了“_织梦unofficial demo site”,所以我们需要去掉这部分指定的规则,简单的修改匹配规则就是这样,我们修改为“”,这样我们就完成了title的匹配规则的编译。匹配规则,在匹配区域规则中,规则一般为“开头无重复HTML[内容]结尾无重复HTML”(正常匹配,不规则)。接下来,我们设置文章内容的匹配规则。这个匹配规则有点类似于标题的匹配规则。我们只需要找到唯一的 HTML 开始标记和 HTML 结束标记。我们刚刚指定了文章 列表规则。为文章找到的内容收录在layer”layer标签中,所以我们指定的匹配规则是一样的。我们根据上面匹配规则的定义设置如下匹配规则: [Content]当然会有在采集的内容中是一些我们不想关闭的超链接,这个时候我们需要清除那些内容,然后我们需要使用过滤规则,这个过滤规则和刚才的一样,但是系统自带了一些常用的常规规则,我们来看看:我们设置了过滤规则后,在采集中会有不同的效果。当然采集部分还有几个小选项这里需要说明的内容,一个是页面内容字段,这个只有采集是多页面内容时才会接触,需要在开头设置分页采集的开始和结束标签. 设置方法和匹配规则相同。
下载字段中的多媒体资源。这是采集下载时某些多媒体字段中的附件。一般只支持部分图片和部分flash下载。如果有很多图片不能采集,可能是服务器的原因,要么是本地服务器不支持,要么是对方服务器采取了防止采集的措施。自定义处理接口,这个主要是通过一些函数来处理网页的内容,我们可以设置一个简单的自定义处理接口,因为采集的内容可能收录HTML代码,那么我们把采集的内容进行转换totxt文本,这里可以使用自定义处理界面。我们设置内容如下:@me=html2text(@me);这样我们就可以保存采集规则了,到目前为止我们已经在规则编写部分完成了,那么我们开始采集内容:接下来我们开始采集节点内容采集完成后,我们导入到对应的列,如果我们之前设置了导出列,可以检查:使用采集规则中指定的列ID(如果目标列ID为0,则使用上面选择的列),这样就可以导入了确认设置后进入该列,然后导入到对应的列中。来看看测试栏下内容:dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(七)2011-05-05 17:09:01 来源:作者:我要投稿本页加网总结: 接下来需要处理这些内容,可以进入系统后台【核心】-【文档关键词维护】,这里可以使用“分析系统中的关键词”自动返回关键词content .
我们“检测现有关键字”以自动获取关键词。或者可以通过自动获取摘要或者分页的方式批量维护采集的内容,非常方便。当然,系统批处理的功能还有很多,这里就不一一列举了。最后,我们需要生成所有的静态页面,到此采集的所有内容就完成了。其实采集并不难,原理是一样的。最主要的是你理解了一些概念,一个匹配规则和一个过滤规则。匹配规则需要的是你可以找到一个唯一的标识符,你可以通过这些唯一标识符来判断你的内容采集。过滤规则是处理你采集的内容。当然,您也可以通过系统的批处理进行维护。 采集 的内容。 采集的经验积累很重要。一般有些网页,比如我们演示的案例,很简单,使用div+css布局,结构也很清晰,所以采集很简单,但是有些网页使用表格布局,就采集一下比较麻烦,所以这个需要你设置采集的内容,过滤内容。只有当你有很多采集 经验时才能做到这一点。总之,采集可以帮助你的站点在前期丰富内容,但是一个长期发展的站点并不能仅仅依靠采集别人的内容来生存,更重要的是站点的内容、功能、以及独创性。这些都是站长需要考虑的事情,所以我们了解到采集只是一个简单的应用工具,不建议大家都用采集做网站。我们总结了本课程的主要内容:采集的基本概念理解采集的一般步骤,结合实例了解如何设置采集节点的规则;基本批处理; 查看全部
自动采集编写(DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(1))
DedecmsV5.6版Auto采集函数规则使用基础知识讲解教程(1)2011-05-05 17:09:01 来源:作者:我要投稿互联网摘录:dedecms采集函数使用基础知识讲解采集指的是有明确方向和明确目的的活动,挑选和记录写作材料,主要指调查、采访、审查和采集数据.采集的主要功能是获取直接和间接材料进行写作、分析、报道。今天我们说的采集主要指的是网站采集,网站采集是主要概念是的:程序按照规定的规则获取其他网站数据的一种方式,另一种简单的方式就是程序化CTRL+C CTRL+V,系统的,自动的,智能的。dedecms早有天。增加了这个采集功能。过去我们通过复制粘贴编辑然后发布来添加网站内容。这对于一个小l 数量的文章,但是如果一个新站点没有内容,那么你需要复制粘贴很多文章,这是一个重复和无聊的过程,内容采集就是为了解决这个问题,将这种重复操作简化为规则,通过规则进行批量操作。当然采集你也可以用一些特殊的采集器来做采集,国内比较有名的采集器有机车。今天我们就来讲解一下如何通过Dedecms程序自带的采集函数来使用采集,并介绍如何批量管理采集的内容。
首先我们进入系统后台,打开【采集】-【采集node管理】,介绍一些基本的技术知识,再学习使用这个采集工能。首先,我们需要了解HTML的基本内容。我们知道,浏览器中显示的各种页面,其实都是由最基本的 HTML 组成的。我们可以在我们的Dedecms系统后台发布一个内容,然后查看内容在格式上面做一些设置。换句话说,我们的页面是在浏览器解析 HTML 代码后显示的。这些基本的HTML代码是给机器看的,解析出来的内容是给我们用户看的。机器其实是个死东西。他不像用户看网页时,他可以直接看到某部分内容,机器可以看到某部分代码。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(二)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们电脑看不到,但是他判断显示什么,他只会解析代码,我们右键查看这个文件的源文件,机器读取代码的内容,他只能看懂这部分的内容在这个地方:也就是说,如果我们需要采集这些内容,我们需要告诉机器你应该从哪里开始,从哪里结束,中间部分就是我们需要的,然后这些内容都自动添加到数据库中,省去添加的枯燥内容。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(三)2011-05-05 17:09:01 来源:作者:我要提交本页网文摘要: 这里我们讲到采集中的一个概念:规则,规则就是我们告诉计算机要做的事情,比如采集内容,我们告诉计算机代码从哪里开始,代码在哪里结束,这些内容都是一条规则,在Dedecms程序中我们需要涉及到两条规则,1.List规则;2.Content规则。List规则:告诉电脑你去采集哪几篇文章,这些文章列表以什么HTML代码开始,以什么HTML代码结束;内容规则:告诉计算机采集内容的哪一部分,文档内容从哪个HTML代码开始,到最后HTML代码;我们说学会使用采集功能,其中最重要的是学会制定采集规则,有了这些规则,采集其实是很简单的事情采集的一般步骤主要包括以下内容步骤:制定列表采集规则,这里的设置主要告诉服务器采集是什么内容,通常是采集网站的列表页面;制定内容采集规则:这里告诉服务器采集页面的内容在页面的哪个部分,通常是采集网站的内容页面;生成采集后的HTML页面代码;我们也可以清楚的看到,采集的关键也是前两步。这两个步骤是判断采集内容是否成功的重要环节。有一处采集如果从采集到网站发生任何错误,都不会成功。
(第一部分结束)下面我们将通过一个例子来说明如何使用Dedecms的采集程序来采集页面信息。我们来看看打开的采集node 管理页面:我们将整个采集规则和内容变成一个节点,通过对采集规则和采集内容的管理,我们可以轻松方便的对待我们的采集规则和采集内容节点用于管理,当然采集规则也可以导出。我们只需要选择对应的采集节点,然后点击【导出配置】就可以导出我们预先指定的采集规则。一起分享。当然,如果您已经获取了节点规则,也可以通过系统的【导入采集规则】将采集规则导入系统,方便采集节点的管理,我们也可以查看此节点的当前采集。 采集的内容信息,如采集的日期、创建节点的日期、获取的URL数量等,都是采集节点的重要组成部分。这是文档的内容,所以我们在创建节点的时候首先选择“normal文章”。在V5.3中,只有普通的文章和atlas 2支持采集。之前可以自己定义,但是后来发现用的人很少,很多人都遇到了问题。所以在新版本中,我取消了采集node的这些功能。选择节点类型后,我们开始创建节点。第一部分是节点基本信息的创建,“节点名称”,这个比较简单,方便大家区分节点名称,这里我们定义为“站长学院_采集”, “目标页面编码”,这需要您查看您为采集 的网页使用的编码。一般来说,如果你使用的是IE浏览器,你只需要右键查看:Firefox浏览器需要在【查看】-【字符编码】菜单中,找到你相信的字符编码类型:这里我们看到页面编码类型为UTF-8,所以我们需要将“目标页面编码”设置为对应的编码。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(四)2011-05-05 17:09:01 来源:作者:我要提交本页网总结: “区域匹配模式”分为字符串和正则表达式两种,我们通常使用的匹配模式是字符串,当然,如果懂正则表达式,可以使用正则,这里简单介绍一下正则表达式。表达式 正则表达式描述了字符串匹配的一种模式,可用于检查字符串是否收录某个子字符串,替换匹配的子字符串,或者从字符串中提取满足某个条件的 z),以及特殊的由以下组成的文本模式字符(称为元字符)。正则表达式用作模板,将某个字符模式与搜索到的字符串进行匹配。通过正则化很容易找到对应的字符区域,但是如果要使用这种正则化,就需要学习正则化的相关知识。这里主要使用字符串,不再赘述。内容导入顺序:即导入内容在栏目中的顺序,我们默认选择与目标站相同。如果您需要将内容颠倒排序,只需选择相应的选项即可。接下来就是设置防盗链接了,如果你的采集站点没有打开防盗链接,可以忽略。接下来,让我们正式设定采集的规则。我们也说过采集的规则需要分为列表采集规则和内容采集规则。列表采集规则需要在开头设置,只有列表采集规则设置正确,服务器才能知道采集那些文章。
list采集规则的设置需要两部分。第一部分是列表URL获取规则。指定列表网址获取规则主要是因为很多站长采集target网站不仅仅是采集几个内容,有可能下载目标站采集的全部内容,而我们在采集的时候我们发现这个栏目下有数百个内容。页面”以这种形式表示,我们在想要采集内容之前需要让服务器知道整个列表的URL。设置列表采集规则比较简单。获取列表主要有3种方式: 生成列表批量url,通过系统自动生成批量地址列表;手动指定列表url,手动指定列表页面;从RSS获取,通过RSS文件获取列表页面。如果我们只需要采集一个列表页面,例如我们只需要采集,只要这10条内容,那么我们只需要在匹配的URL中填写这个URL即可。如果我们采集多个列表的内容,就可以完成通过自动生成或指定多个列表页面,我们查看下一个列表页面,我们点击下面栏目的第一页,这样我们就可以自动指定一个规则。点击匹配URL后面的“测试”按钮看看发现我们已经成功获取到这个列表了,或者我们选择手动指定,然后在URL列表中指定:当然,这个列表部分的规则还有更多的功能,比如可以指定列表列的导入内容。这部分的详细设置可以在织梦帮助中心查看:这里我们已经完成了列表地址的设置。接下来,我们需要设置文章 URL 匹配规则。这个匹配规则是让我们来到采集文章列表,告诉服务器采集文章在采集This文章中,我们看一下这些列表的页面。不变的部分是头部导航,右边推荐信息,底部内容。主要变化是列表的标题和内容。我们采集列表文章的主要内容是采集列表的文章标题部分。如果我们理解HTML代码观察,最直接的表现就是HTML代码列表页面部分的内容发生了变化。
所以当我们指定采集列表页面时,我们只需要指定一个统一的规则,因为列表的页面是一样的,所以这个规则适用于所有的列表页面。当然,我们也会发现内容页面也是如此。你只需要给采集指定一个统一的规则就可以得到所有相似页面的内容。当然,有些网站列表是链接到其他内容的,所以你会遇到采集规则不匹配的问题。一般不可能采集到达内容,因为规则不适用,另外一个表现就是采集progress 文章不动,就到此为止,有时甚至会报错。这些原因的主要原因是规则与目标采集网站不匹配,所以在采集内容之前确保规则的正确性。德德cmsV5.6版自动采集函数规则使用基础知识讲解教程(五)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络摘要:接下来我们设置列表采集页面的采集规则,我们先查看源文件,在IE浏览器中右键选择【查看源文件】打开列表页面的源代码,如果我们有DW,把这些代码复制到DW,我们找到那个列表的位置:我们发现这个列表的内容在“”层,也就是我们需要告诉服务器采集这个列表的标题list你从这里采集开始,然后到这一层采集的末尾,我们看到这一层的末尾是“”,中间没有找到相同的代码。
这里需要告诉大家的是我们的规则,它告诉服务器起始的HTML标签必须是唯一的,也就是说你在这个页面上只有这个标签,这样计算机就知道从哪里开始,从哪里开始那地方结束。 采集 写规则的时候,很多时候需要找唯一标识符。有了这些标识符,服务器就知道它可以捕获内容。我们已经到达了刚才列表的范围,在“”之间,所以填写采集规则的“区域开头的HTML:”和“区域结尾的HTML:”,以及服务器随后会将其间的所有连接用作目标采集 的文章 列表以继续采集 向下。但有一个问题。在我们的列表规则中,并不是所有的超链接都是目标采集的文章。设置的页面是内容页面,所以我们需要过滤掉这些不续采集丢失的内容页面。 织梦的采集提供了2种方式过滤这些页面:1.必须收录,这是采集的超链接中必须收录的,2.不能收录,在采集的地址中哪些内容不能收录,我们一般采用这两个公式中的一个。通过观察可以看出我们需要采集的内容页地址不收录“feedback.php”,所以我们将收录所有Feedback.php然后过滤掉,剩下的是我们的文章连接.
还有一个缩略图的处理,我们可以使用默认,设置完成后,我们保存测试,看看我们是否可以采集到达内容。我们发现已经可以成功采集到文章的标题列表信息了:此时我们的列表信息是采集完成的,接下来我们将设置内容页的采集规则,这个采集 规则和列表页 采集 规则也很相似,主要功能是从重复的内容页中获取不同的内容,下面我们继续处理采集 的内容。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(六)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们先打开一个文章内容,我们把这个网页的源代码复制到DW工具中查看:我们可以看到这个页面的源代码中的“标题”和“文章内容”,以及那么我们来设置一下内容采集规则,在新版本的V5.3中,如果采集网页内容收录关键词和页面摘要,系统会自动采集,即在页面代码:采集的内容会自动下载,当然很多用户是想自己设置或生成的,那么我们这里就用过滤规则自动过滤掉采集的内容,我们过滤内容是关键字和“摘要”在“过滤内容”中填写过滤规则:{dede:trim replace=""}(.*){/dede:trim}这里说一下这个过滤规则,{dede:trim replace=" "}正则表达式{/dede :trim},使用正则{dede:trim} 标签中间的r表达式,在采集的内容中搜索对应的字符串。如果需要替换搜索到的内容,需要指定replace属性。例如,如果我们只是在获取内容字段时将所有关键词替换为空,如果我们默认指定关键词,我们可以这样写:{dede:trim replace="Dedecms,织梦, demo站"}(.*){/dede:trim}因为我们这里主要是demo,主要有2个字段采集,1是内容的标题,另一个是文章的内容,所以我们需要相应地制定2个地方的匹配规则。
我们为文章title设置了匹配规则,因为一般内容的标题会出现在两个标签“”之间,所以我们在设置标题匹配规则的时候只需要设置默认的“”,但是有一件事,我们看一下采集目标站的标题:他在每个标题后面都加上了“_织梦unofficial demo site”,所以我们需要去掉这部分指定的规则,简单的修改匹配规则就是这样,我们修改为“”,这样我们就完成了title的匹配规则的编译。匹配规则,在匹配区域规则中,规则一般为“开头无重复HTML[内容]结尾无重复HTML”(正常匹配,不规则)。接下来,我们设置文章内容的匹配规则。这个匹配规则有点类似于标题的匹配规则。我们只需要找到唯一的 HTML 开始标记和 HTML 结束标记。我们刚刚指定了文章 列表规则。为文章找到的内容收录在layer”layer标签中,所以我们指定的匹配规则是一样的。我们根据上面匹配规则的定义设置如下匹配规则: [Content]当然会有在采集的内容中是一些我们不想关闭的超链接,这个时候我们需要清除那些内容,然后我们需要使用过滤规则,这个过滤规则和刚才的一样,但是系统自带了一些常用的常规规则,我们来看看:我们设置了过滤规则后,在采集中会有不同的效果。当然采集部分还有几个小选项这里需要说明的内容,一个是页面内容字段,这个只有采集是多页面内容时才会接触,需要在开头设置分页采集的开始和结束标签. 设置方法和匹配规则相同。
下载字段中的多媒体资源。这是采集下载时某些多媒体字段中的附件。一般只支持部分图片和部分flash下载。如果有很多图片不能采集,可能是服务器的原因,要么是本地服务器不支持,要么是对方服务器采取了防止采集的措施。自定义处理接口,这个主要是通过一些函数来处理网页的内容,我们可以设置一个简单的自定义处理接口,因为采集的内容可能收录HTML代码,那么我们把采集的内容进行转换totxt文本,这里可以使用自定义处理界面。我们设置内容如下:@me=html2text(@me);这样我们就可以保存采集规则了,到目前为止我们已经在规则编写部分完成了,那么我们开始采集内容:接下来我们开始采集节点内容采集完成后,我们导入到对应的列,如果我们之前设置了导出列,可以检查:使用采集规则中指定的列ID(如果目标列ID为0,则使用上面选择的列),这样就可以导入了确认设置后进入该列,然后导入到对应的列中。来看看测试栏下内容:dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(七)2011-05-05 17:09:01 来源:作者:我要投稿本页加网总结: 接下来需要处理这些内容,可以进入系统后台【核心】-【文档关键词维护】,这里可以使用“分析系统中的关键词”自动返回关键词content .
我们“检测现有关键字”以自动获取关键词。或者可以通过自动获取摘要或者分页的方式批量维护采集的内容,非常方便。当然,系统批处理的功能还有很多,这里就不一一列举了。最后,我们需要生成所有的静态页面,到此采集的所有内容就完成了。其实采集并不难,原理是一样的。最主要的是你理解了一些概念,一个匹配规则和一个过滤规则。匹配规则需要的是你可以找到一个唯一的标识符,你可以通过这些唯一标识符来判断你的内容采集。过滤规则是处理你采集的内容。当然,您也可以通过系统的批处理进行维护。 采集 的内容。 采集的经验积累很重要。一般有些网页,比如我们演示的案例,很简单,使用div+css布局,结构也很清晰,所以采集很简单,但是有些网页使用表格布局,就采集一下比较麻烦,所以这个需要你设置采集的内容,过滤内容。只有当你有很多采集 经验时才能做到这一点。总之,采集可以帮助你的站点在前期丰富内容,但是一个长期发展的站点并不能仅仅依靠采集别人的内容来生存,更重要的是站点的内容、功能、以及独创性。这些都是站长需要考虑的事情,所以我们了解到采集只是一个简单的应用工具,不建议大家都用采集做网站。我们总结了本课程的主要内容:采集的基本概念理解采集的一般步骤,结合实例了解如何设置采集节点的规则;基本批处理;
自动采集编写(采集内存使用数据采集类代码暴露数据情况部署代码和集成查询 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-30 17:01
)
在之前的文章中,我已经写过几个官方exporter的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这个时候一般需要我们自己写采集器。
快速开始写一个介绍性的demo来写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时会监听8000端口,访问127.0.0.1:8000端口。
效果图
其实一个exporter已经写好了。就这么简单。我们只需要在prometheus中配置采集对应的exporter即可。但是,我们导出的数据毫无意义。
数据类型介绍
Counter 是一个累加类型,只能增加,比如记录http请求的总次数或者网络收发包的累计值。
Gauge:仪表盘类型,适用于有涨有跌、一般网络流量、磁盘读写等,有波动变化的数据类型使用。
总结:基于抽样,在服务器上完成统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
直方图:基于抽样,在客户端进行统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
采集Memory 使用数据编写采集类代码
暴露数据情况
部署代码并集成 prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图
查看全部
自动采集编写(采集内存使用数据采集类代码暴露数据情况部署代码和集成查询
)
在之前的文章中,我已经写过几个官方exporter的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这个时候一般需要我们自己写采集器。
快速开始写一个介绍性的demo来写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时会监听8000端口,访问127.0.0.1:8000端口。
效果图
其实一个exporter已经写好了。就这么简单。我们只需要在prometheus中配置采集对应的exporter即可。但是,我们导出的数据毫无意义。
数据类型介绍
Counter 是一个累加类型,只能增加,比如记录http请求的总次数或者网络收发包的累计值。
Gauge:仪表盘类型,适用于有涨有跌、一般网络流量、磁盘读写等,有波动变化的数据类型使用。
总结:基于抽样,在服务器上完成统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
直方图:基于抽样,在客户端进行统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
采集Memory 使用数据编写采集类代码
暴露数据情况

部署代码并集成 prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图

自动采集编写(单机模拟器没有,我也遇到过同样的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-08-28 23:07
自动采集编写脚本,填写好截取代码,并将脚本用newinstall.worker()导入,再自动连接上即可,
同问。
简单的appium也是可以的
在他们的代码里面加入appium实时抓包就行
都不给力!我们叫它为app抓包
不知道有没有解决你的问题
appium下实现基本的单机模拟器
没有,我也遇到同样的问题,百度了半天,
appium+selenium这个方案我写过,从最基础的开始,然后慢慢找bug改,
appium+eclipse
有
你可以试试cygwin
可以试试cygwin,
iphone下1是否可用?
在appium4里设置eduid有些回答说python写appium脚本是在手机qq里抓的,不错,但方法可能需要改一下,
win10可以用的!已经很棒了,单机模拟器+win10才4gb内存,然后就是win7的win+jy+appium4。总觉得对iphone不太友好。不过win10可以用python,也可以在手机qq里抓,因为它自带qqforiphone。
没有的,
推荐ipadmini。ios的app里面的开发人员工具里可以用python+selenium。 查看全部
自动采集编写(单机模拟器没有,我也遇到过同样的问题)
自动采集编写脚本,填写好截取代码,并将脚本用newinstall.worker()导入,再自动连接上即可,
同问。
简单的appium也是可以的
在他们的代码里面加入appium实时抓包就行
都不给力!我们叫它为app抓包
不知道有没有解决你的问题
appium下实现基本的单机模拟器
没有,我也遇到同样的问题,百度了半天,
appium+selenium这个方案我写过,从最基础的开始,然后慢慢找bug改,
appium+eclipse
有
你可以试试cygwin
可以试试cygwin,
iphone下1是否可用?
在appium4里设置eduid有些回答说python写appium脚本是在手机qq里抓的,不错,但方法可能需要改一下,
win10可以用的!已经很棒了,单机模拟器+win10才4gb内存,然后就是win7的win+jy+appium4。总觉得对iphone不太友好。不过win10可以用python,也可以在手机qq里抓,因为它自带qqforiphone。
没有的,
推荐ipadmini。ios的app里面的开发人员工具里可以用python+selenium。
自动采集编写(自动采集编写第二代爬虫程序和其他代码的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-27 23:05
自动采集编写第二代爬虫程序,请循环运行,直到获取完整内容。请确保计算机在第一次运行时处于停止状态。然后运行序列第一代爬虫程序和其他代码。
一、爬虫目标列表:一二三四五六七八九十百千万。每一条链接都单独获取。最终得到的url地址包含以下属性:1.网址:2.请求headers:3.请求体headersurl中的http://:表示请求headers中携带了requestheaders中的相关数据,如果在运行第一代爬虫程序时未携带requestheaders,则会导致浏览器出现原始浏览器,这是无法解决的。
所以在运行第一代爬虫程序时需要携带requestheaders(常用)和一个相关程序代码,requestheaders就包含requestheaders中的user-agentuser-agent:浏览器独有的格式化user-agent标识这里没有一一列出,是因为与第二代爬虫程序中的user-agent不同,大家理解即可。
它可以作为请求页面时定位的方式,也可以是判断url请求是否可用的代理方式。具体见请求逻辑中的requestheadersuser-agent:http请求页面时浏览器独有的格式化user-agent标识。
二、网页请求编写nodejs定位并解析出对应的headersheaders分为body部分和data部分body部分中包含user-agent、get/post参数、cookie、session等参数,data部分是一些body字段对应的文本数据。
三、编写第二代爬虫程序nodejsget并获取html网页内容nodejspost并解析并解析html网页内容js定义一个单例模式,通过一个函数方法或者一个对象,能够任意获取一个a标签内的位置,并且能够取到这个a标签的全部定位到第一个a标签,xxx指定一个位置,然后button相对于xxx指定一个位置。
可以手动解析,也可以使用全局对象解析。接下来简单的解释一下这个方法。get请求的优点是跨浏览器,而且可以随意跳转,缺点是只能获取html中的一部分信息。我们想获取xxx,button相对于xxx获取一个位置,获取xxx三个字段,没有方法。所以接下来使用全局对象方法来解析html源码,请自行编写代码,最后请自行编写回显模式的组件。
selenium的使用get请求与seleniumpost的区别在于get使用浏览器内置的user-agent(比如chrome的user-agent)来进行定位和获取,而post则是向服务器发送post请求,服务器检查一个cookie,如果有返回该cookie则返回该xxx,否则,则不返回xxx,这是get和post的区别。
getheaders检查${max_age}是否大于等于${max_time}的十分之一,否则会延迟,比如取到小于三个小时的时间间隔。postheaders检查${send_to_params。 查看全部
自动采集编写(自动采集编写第二代爬虫程序和其他代码的区别)
自动采集编写第二代爬虫程序,请循环运行,直到获取完整内容。请确保计算机在第一次运行时处于停止状态。然后运行序列第一代爬虫程序和其他代码。
一、爬虫目标列表:一二三四五六七八九十百千万。每一条链接都单独获取。最终得到的url地址包含以下属性:1.网址:2.请求headers:3.请求体headersurl中的http://:表示请求headers中携带了requestheaders中的相关数据,如果在运行第一代爬虫程序时未携带requestheaders,则会导致浏览器出现原始浏览器,这是无法解决的。
所以在运行第一代爬虫程序时需要携带requestheaders(常用)和一个相关程序代码,requestheaders就包含requestheaders中的user-agentuser-agent:浏览器独有的格式化user-agent标识这里没有一一列出,是因为与第二代爬虫程序中的user-agent不同,大家理解即可。
它可以作为请求页面时定位的方式,也可以是判断url请求是否可用的代理方式。具体见请求逻辑中的requestheadersuser-agent:http请求页面时浏览器独有的格式化user-agent标识。
二、网页请求编写nodejs定位并解析出对应的headersheaders分为body部分和data部分body部分中包含user-agent、get/post参数、cookie、session等参数,data部分是一些body字段对应的文本数据。
三、编写第二代爬虫程序nodejsget并获取html网页内容nodejspost并解析并解析html网页内容js定义一个单例模式,通过一个函数方法或者一个对象,能够任意获取一个a标签内的位置,并且能够取到这个a标签的全部定位到第一个a标签,xxx指定一个位置,然后button相对于xxx指定一个位置。
可以手动解析,也可以使用全局对象解析。接下来简单的解释一下这个方法。get请求的优点是跨浏览器,而且可以随意跳转,缺点是只能获取html中的一部分信息。我们想获取xxx,button相对于xxx获取一个位置,获取xxx三个字段,没有方法。所以接下来使用全局对象方法来解析html源码,请自行编写代码,最后请自行编写回显模式的组件。
selenium的使用get请求与seleniumpost的区别在于get使用浏览器内置的user-agent(比如chrome的user-agent)来进行定位和获取,而post则是向服务器发送post请求,服务器检查一个cookie,如果有返回该cookie则返回该xxx,否则,则不返回xxx,这是get和post的区别。
getheaders检查${max_age}是否大于等于${max_time}的十分之一,否则会延迟,比如取到小于三个小时的时间间隔。postheaders检查${send_to_params。
自动采集编写 微信公众号查看历史消息页或者文章详情页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-08-27 07:01
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、anyproxy 通过修改anyproxy配置文件解决了拦截过程中的各种错误。
anyproxy在报错时会执行anyproxy配置文件rule_default.js中的onError方法,所以报错时可以修改方法获取下一页,注入js脚本中继续执行,无需停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub 源码地址:wechat-serv-crawler
环境搭建和部署运行 安装前准备
系统:CentOS Linux release 7.6.1810 (Core)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
搭建与服务器相关的anyproxy代理文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击操作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信随意添加好友,好友发送给你任意微信公众号的历史消息页面或微信文章linked message ,并将消息置顶,进入消息聊天界面,点击链接开始自动抓取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是说一开始必须给一个触发事件,比如打开微信公众号查看历史消息或者打开一个公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章详情页通过js注入,当然这中间可能会出现异常,异常会阻塞自动跳转到下一页。这需要自动化框架的帮助来模拟手动点击操作。这里使用的是 atx 自动化框架。
该项目自动化程度高。人工费用为首次登录微信后,点击微信公众号查看历史消息或打开公众号文章链接。后续会完全通过js注入跳转,异常自动处理恢复点击(atx自动点击)。
运行效果展示
这个项目已经是一个完整成熟的项目了。经过大量长期测试,一个微信客户端采集300公众号文章每天的数据可以保证稳定运行,保证账号不会被封。如果您访问微信公众号历史新闻页面过于频繁,将会被24小时禁言。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用3个微信公众号,采集900微信公众号每天文章数据。
每个微信账号月费5元。基于该项目,可实现大规模作业的低成本作业。
更新(2020-07-30)以降低抓取错误时漏网率
因为我使用redis的list队列作为消息队列,消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序在slave master 从消息队列中取出消息后,插入到备份队列中,并从备份队列中删除消息,直到消费者程序完成正常的处理逻辑同时,我们还可以提供守护进程。消费完主消息队列中的消息后,可以将备份队列中正常未消费的消息放回主消息队列,以便其他消费程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史消息列表&特殊微信公众号无需关注即可获取历史文章:
之前实现的解决方案是只抓取微信公众号文章列表的最新页面。由于抓包分析的下一页返回的内容是json响应体,无法通过注入脚本自动模拟。 Traverse实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章列表,注意f参数为html,下一页返回的内容格式即可修改为html,解决了json不适合注入js脚本的问题。此外,还可以通过调整偏移量来实现翻页。
下图为上述公众号文章list页面第100页的历史记录:
参考文章
感谢文章提供的想法:
1、用好anyproxy提高公众号文章采集efficiency详解
2、微信公号文章batch采集系统建设
联系作者
由于微信采集平台的搭建和开发花费了大量的时间和精力,我们暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,且本项目目前实现的功能满足您的需求,可以付费联系我帮你搭建这个项目,并收录所有源代码,解答和解决你在开发过程中遇到的所有疑问。 查看全部
自动采集编写 微信公众号查看历史消息页或者文章详情页(组图)
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、anyproxy 通过修改anyproxy配置文件解决了拦截过程中的各种错误。

anyproxy在报错时会执行anyproxy配置文件rule_default.js中的onError方法,所以报错时可以修改方法获取下一页,注入js脚本中继续执行,无需停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub 源码地址:wechat-serv-crawler
环境搭建和部署运行 安装前准备
系统:CentOS Linux release 7.6.1810 (Core)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
搭建与服务器相关的anyproxy代理文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击操作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信随意添加好友,好友发送给你任意微信公众号的历史消息页面或微信文章linked message ,并将消息置顶,进入消息聊天界面,点击链接开始自动抓取redis队列中微信公众号对应的文章,如下图:

关于自动抓取
这个程序是事件驱动的。也就是说一开始必须给一个触发事件,比如打开微信公众号查看历史消息或者打开一个公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章详情页通过js注入,当然这中间可能会出现异常,异常会阻塞自动跳转到下一页。这需要自动化框架的帮助来模拟手动点击操作。这里使用的是 atx 自动化框架。
该项目自动化程度高。人工费用为首次登录微信后,点击微信公众号查看历史消息或打开公众号文章链接。后续会完全通过js注入跳转,异常自动处理恢复点击(atx自动点击)。
运行效果展示
这个项目已经是一个完整成熟的项目了。经过大量长期测试,一个微信客户端采集300公众号文章每天的数据可以保证稳定运行,保证账号不会被封。如果您访问微信公众号历史新闻页面过于频繁,将会被24小时禁言。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用3个微信公众号,采集900微信公众号每天文章数据。
每个微信账号月费5元。基于该项目,可实现大规模作业的低成本作业。

更新(2020-07-30)以降低抓取错误时漏网率
因为我使用redis的list队列作为消息队列,消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序在slave master 从消息队列中取出消息后,插入到备份队列中,并从备份队列中删除消息,直到消费者程序完成正常的处理逻辑同时,我们还可以提供守护进程。消费完主消息队列中的消息后,可以将备份队列中正常未消费的消息放回主消息队列,以便其他消费程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史消息列表&特殊微信公众号无需关注即可获取历史文章:
之前实现的解决方案是只抓取微信公众号文章列表的最新页面。由于抓包分析的下一页返回的内容是json响应体,无法通过注入脚本自动模拟。 Traverse实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章列表,注意f参数为html,下一页返回的内容格式即可修改为html,解决了json不适合注入js脚本的问题。此外,还可以通过调整偏移量来实现翻页。
下图为上述公众号文章list页面第100页的历史记录:

参考文章
感谢文章提供的想法:
1、用好anyproxy提高公众号文章采集efficiency详解
2、微信公号文章batch采集系统建设
联系作者
由于微信采集平台的搭建和开发花费了大量的时间和精力,我们暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,且本项目目前实现的功能满足您的需求,可以付费联系我帮你搭建这个项目,并收录所有源代码,解答和解决你在开发过程中遇到的所有疑问。
yzmcms采集器+yzmcms免登陆接口在哪里有呢索取吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-26 20:09
1、Q:yzmcms是什么程序,好用吗?
答:yzmcms是袁志萌开发的一套php+mysql采集程序,适用于企业网站建设和个人网站建设。已经更新到v5.2版本,好评如潮。
(yzmcms程序后台截图)
2、Q:yzmcms自带采集插件怎么样?
答:用过yzmcms自带的采集插件的朋友都知道基于php的采集插件的性能、功能和稳定性都不是很好,所以推荐一个更强大更方便的包采集Software 更合适。推荐优采云采集器+yzmcms免登录发布界面实现全自动yzmcms采集。
3、Q:采集有什么特点?是否支持自动计时采集和自动发布,是否也支持自定义字段?
答:当然,这是采集软件的标准配置。使用优采云采集器,超稳定采集,定期发布。发布规则超级简单,支持任意模型和自定义字段。图片自动下载,提取第一个缩略图,方便填写yzmcms的节目内容。
4、Q:我不会编程,怎么写采集规则?
答案:优采云采集软件是为没有编程的用户准备的。您不需要任何编程基础。您可以查看源代码,只需复制和粘贴即可。 采集 规则很简单。 优采云采集software 还有专门的软件教程。
5、Q:软件是免费的吗?可以永久使用吗?
答:采集软件是免费的,界面也是开源的,未加密。使用后,可永久使用。
6、Q:都是免费的,有收费功能吗,官方怎么长期维护这个软件的?
回答:没有充电功能。无论如何,任何人都可以使用该软件。基于自由软件,作者精力有限。如有任何问题,请在用户群或论坛中交流。
7、Q:yzmcms免费登录界面在哪里?
答:请进群后联系作者免费领取! 查看全部
yzmcms采集器+yzmcms免登陆接口在哪里有呢索取吗?
1、Q:yzmcms是什么程序,好用吗?
答:yzmcms是袁志萌开发的一套php+mysql采集程序,适用于企业网站建设和个人网站建设。已经更新到v5.2版本,好评如潮。

(yzmcms程序后台截图)
2、Q:yzmcms自带采集插件怎么样?
答:用过yzmcms自带的采集插件的朋友都知道基于php的采集插件的性能、功能和稳定性都不是很好,所以推荐一个更强大更方便的包采集Software 更合适。推荐优采云采集器+yzmcms免登录发布界面实现全自动yzmcms采集。
3、Q:采集有什么特点?是否支持自动计时采集和自动发布,是否也支持自定义字段?
答:当然,这是采集软件的标准配置。使用优采云采集器,超稳定采集,定期发布。发布规则超级简单,支持任意模型和自定义字段。图片自动下载,提取第一个缩略图,方便填写yzmcms的节目内容。
4、Q:我不会编程,怎么写采集规则?
答案:优采云采集软件是为没有编程的用户准备的。您不需要任何编程基础。您可以查看源代码,只需复制和粘贴即可。 采集 规则很简单。 优采云采集software 还有专门的软件教程。
5、Q:软件是免费的吗?可以永久使用吗?
答:采集软件是免费的,界面也是开源的,未加密。使用后,可永久使用。
6、Q:都是免费的,有收费功能吗,官方怎么长期维护这个软件的?
回答:没有充电功能。无论如何,任何人都可以使用该软件。基于自由软件,作者精力有限。如有任何问题,请在用户群或论坛中交流。
7、Q:yzmcms免费登录界面在哪里?
答:请进群后联系作者免费领取!
自动采集编写(2017年Python网站采集敏感信息的解决方案(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-09-23 05:23
前言
我过去没有学过,最近有需求。我必须从网站@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@采集@@采集@,决定使用c#winform和python来解决这个事件。
整个解决方案不复杂:uvkxlprltc#写入winform形式,执行数据分析和采集,python最初不想使用,没有找到c#woff字体到XML方案,并且有很多在线python所以添加一个python项目,虽然是1脚本。
一、几个步骤:
首先要模拟登录,登录进入resume 采集,然后模拟下载,您可以在下载后看到求职者的呼叫。
这个电话号码是一个动态生成的base64字体,所以直接提取文本不能成功。
1、第一个将base64转换为woff字体,这可以用c#(这个ISO-8859-1代码是一个坑,一般使用默认的惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("isuVKXLPrlto-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、将转动已生成的XML的窗口(Woffdec.exe是我用Python打包的exe,实际上,对于这个转换,有一个时间,有一个整个c #低于好)
//调用python exe 生成xml文件
ProcessStartInfo info = new Procewww.cppcns.comssStartInfo
{
FileNam编程客栈e = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个woffdec.py的代码是3行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思,首先尝试py2exe,不成功,更改pyinstaller,变成11m,甚至exe,不是很大。
在本地下载或下载它,或直接在VS2017 Python环境中搜索pyinstaller。
右键单击使用“在此处打开命令提示符”;将pyinstaller /path/to/yourscript.py输入到exe文件中。当调用WinForm应用程序时,应在整个文件夹中复制整个文件夹。
3、 xml文件已,上面的woff文件准备存储数据字典(这个地方有点左右,首先找到一个网站将woff作为文本和编码,然后基于编码XML查找它的字体定位点,我采取x和y形成一个唯一的值(x,y代表一个字),当然,更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、上述步骤是花一些时间。参考词典可用后,您可以根据每个生成的XML文件匹配真实文本。
5、真文本取简繁资料繁简简义数码数据数据数码上数码上数码上/ p>
二、使用场景
下班后,打开采集服务即即不理解,下载繁简简牌繁简简义繁简简义繁简简义繁简简简短繁简牌只要有新人发布求职信息,系统会立即向他发送邀请才能抓住人民。
btw:网络仿真操作使用的Cefsharp将打开另一章。
摘要
上面是这个文章的全内容,我希望本文对每个人的学习或工作都有一定的参考价值,谢谢您的支持。
标题:使用c#cefsharp python 采集 网站简历自动发送邀请sms方法 查看全部
自动采集编写(2017年Python网站采集敏感信息的解决方案(一))
前言
我过去没有学过,最近有需求。我必须从网站@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @@@采集@@采集@,决定使用c#winform和python来解决这个事件。
整个解决方案不复杂:uvkxlprltc#写入winform形式,执行数据分析和采集,python最初不想使用,没有找到c#woff字体到XML方案,并且有很多在线python所以添加一个python项目,虽然是1脚本。
一、几个步骤:
首先要模拟登录,登录进入resume 采集,然后模拟下载,您可以在下载后看到求职者的呼叫。
这个电话号码是一个动态生成的base64字体,所以直接提取文本不能成功。
1、第一个将base64转换为woff字体,这可以用c#(这个ISO-8859-1代码是一个坑,一般使用默认的惊喜):
SetMainStatus("正在生成WOFF...");
byte[] fontBytes = Convert.FromBase64String(CurFont);
string fontStr = Encoding.GetEncoding("iso-8859-1").GetString(fontBytes).TrimEnd('\0');
StreamWriter sw2 = new StreamWriter(@"R58.woff", false, Encoding.GetEncoding("isuVKXLPrlto-8859-1"));
sw2.Write(fontStr);
sw2.Close();
2、将转动已生成的XML的窗口(Woffdec.exe是我用Python打包的exe,实际上,对于这个转换,有一个时间,有一个整个c #低于好)
//调用python exe 生成xml文件
ProcessStartInfo info = new Procewww.cppcns.comssStartInfo
{
FileNam编程客栈e = "WoffDec.exe",
WindowStyle = ProcessWindowStyle.Hidden
};
Process.Start(info).WaitForExit(2000);//在2秒内等待返回
整个woffdec.py的代码是3行:
from fontTools.ttLib import TTFont
font = TTFont('R12.woff')
font.saveXML('R12.xml')
这个包装有点意思,首先尝试py2exe,不成功,更改pyinstaller,变成11m,甚至exe,不是很大。
在本地下载或下载它,或直接在VS2017 Python环境中搜索pyinstaller。
右键单击使用“在此处打开命令提示符”;将pyinstaller /path/to/yourscript.py输入到exe文件中。当调用WinForm应用程序时,应在整个文件夹中复制整个文件夹。
3、 xml文件已,上面的woff文件准备存储数据字典(这个地方有点左右,首先找到一个网站将woff作为文本和编码,然后基于编码XML查找它的字体定位点,我采取x和y形成一个唯一的值(x,y代表一个字),当然,更多;
internal static readonly Dictionary DicChar = new Dictionary()
{
{"91,744","0" },
{"570,0","1"},
{"853,1143","2" },
{"143,259","3" },
。。。。。。
};
4、上述步骤是花一些时间。参考词典可用后,您可以根据每个生成的XML文件匹配真实文本。
5、真文本取简繁资料繁简简义数码数据数据数码上数码上数码上/ p>
二、使用场景
下班后,打开采集服务即即不理解,下载繁简简牌繁简简义繁简简义繁简简义繁简简简短繁简牌只要有新人发布求职信息,系统会立即向他发送邀请才能抓住人民。
btw:网络仿真操作使用的Cefsharp将打开另一章。
摘要
上面是这个文章的全内容,我希望本文对每个人的学习或工作都有一定的参考价值,谢谢您的支持。
标题:使用c#cefsharp python 采集 网站简历自动发送邀请sms方法
自动采集编写(高手多多指添加采集规则规则说明系统默认变量的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-22 16:00
原帖子由主持人潘昭发表。逆流而上从旧论坛转向新论坛。在前面写完后:我写了几个电台的规则,并教这个电台的管理员写规则。现在我终于得到了一个教程。虽然有点粗糙,但也可以作为新手的参考。希望新手认真学习,专家指出增加采集规则和规则来解释系统默认变量:章节序号、文章子序号、章节子序号。系统标记可以替换任何字符串。系统标记可以替换除以下内容之外的任何字符串。除´外,系统标签可以替换“除此之外的任何字符串。系统标记可以替换数字和字符串以外的字符串。系统标签可以替换采集规则中的数字字符串@,要获取的内容被四个以上的系统标签替换。例如,需要回复以下内容才能看到基本设置网站ID。在configurations\article\collectsite.php中添加的ID可以随意填写。通常,它是采集站点域名的缩写,以区别于其他规则。示例:feiku网站name采集station的名称。示例:飞行库网站地址的采集站地址。例如:不需要添加文章子序列号操作方法。我在这里留白。它支持使用标记的四种操作(+加、-减、*乘、/除、%余数)。无需增加第章子序列号的操作方法。我在这里留白。(谁知道他在一个文件夹里放了多少本书?他没有按照规则放。我不是采集无法支持使用标记(+加、-减、*乘、/除、%余数)的四个操作)代理服务器地址不使用代理服务器。请将代理服务器端口留空。如果现有章节无法对应,是否根据自己的需要再次清除采集所有章节。根据自己的需要选择是否默认将文章设置为完整版本。如果选择“是”,无论文章是序列化还是完成,完整版本都将显示在您的站点上。建议选择“否”发送http_参考标志以突破反采集设置。默认情况下,选择是。我不知道该使用什么。我选择是先突破,然后谈论对方的网页代码(自动检测GB2312 utf8) BIG5)默认设置为自动检测代码与此网站不同。您将自动尝试转换文章information page采集rule文章information page address、图书信息页面URL和图书ID。例如:/index.html文章Title采集rule要求您查看网页的源文件。如果您这样做不,你可以停下来。检查信息页面的源文件,然后找出文章标题在源文件中的位置(我们以feiku为例,它是源文件中章节信息页面上文章标题的位置)。这里,以我的美女为例,找到标题附近的代码是
我美丽的女士
将上述代码复制到文章Title采集规则的框中,然后用!!!!!替换我美丽的女士的真实头衔!当然,它也可以替换为其他替换符号,如****,但重要的是,范围越小,越能表达意思(习惯问题,你在这里只能得到采集到文章的标题,但是还有其他采集的东西你不想要。作者采集rule这里的李兴宇想要采集内容并使用!!!!!相反,但是144238只对这个文章有用,其他文章有其他数字,所以使用任何数字字符串$。所以作者采集rule是!!!!文章type采集城市规则是从顶部开始的!!!!!@k113@类型的信件。你可以自己写。呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵Hehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehe|10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 10 124A的10 124A的10 124A的10的10的10 124A的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的此外,这两种类型用“|”分隔,类型名称为“默认”确定默认类型对应关系。网站类型和序列号之间的对应关系如下:幻想魔法=>;1;武术修养=>;2;城市浪漫=>;3;历史军事=>;4;侦探推理=>;5;在线游戏动画=>;6;科幻=>;7;恐怖与超人Natural=>;8 |散文诗=>;9 |其他类型=>;10(根据您的站点设置)关键字采集规则在关键字附近找到代码主角并检索关键字beauty city
此处的“我的美丽城市”被****替换,结果规则为主角搜索关键字-****
“大”小姐和“大”妹妹,别打扰我,好吗?我求求你~~
拥有数亿财富的刘星不想生活在朱门的酒肉腥味和阴谋中,他放弃了家里的大公司,选择在一家小公司做一名普通白领
餐馆里的一次英勇营救让他遇到了一位美丽的女士,她是刘星上海公司老板的女儿,换句话说,是他的长女
但这位貌似美丽优雅的年轻女士却有一个未知的一面,这真的会危及生命
做我的保姆?你在开玩笑吗,小姐?你什么都做不了。做我的保姆
老板有两个女儿?所以白天捣乱的美女是第二夫人
什么?你也决定住在这里?啊!别烦我了~~!一个就够了,另一个。多大的一个小妹妹啊
“大”女人看起来优雅文雅,但她很困惑。大“小”妹妹看起来很漂亮,但她很火辣和淘气。而且,两姐妹从小到大一直有冲突。这次他们都住在我家。这房子真的很热闹
想拥有美丽的人都被“大”和“小”姐妹“浸透”!啊~~!让人活下去~~ 查看全部
自动采集编写(高手多多指添加采集规则规则说明系统默认变量的方法)
原帖子由主持人潘昭发表。逆流而上从旧论坛转向新论坛。在前面写完后:我写了几个电台的规则,并教这个电台的管理员写规则。现在我终于得到了一个教程。虽然有点粗糙,但也可以作为新手的参考。希望新手认真学习,专家指出增加采集规则和规则来解释系统默认变量:章节序号、文章子序号、章节子序号。系统标记可以替换任何字符串。系统标记可以替换除以下内容之外的任何字符串。除´外,系统标签可以替换“除此之外的任何字符串。系统标记可以替换数字和字符串以外的字符串。系统标签可以替换采集规则中的数字字符串@,要获取的内容被四个以上的系统标签替换。例如,需要回复以下内容才能看到基本设置网站ID。在configurations\article\collectsite.php中添加的ID可以随意填写。通常,它是采集站点域名的缩写,以区别于其他规则。示例:feiku网站name采集station的名称。示例:飞行库网站地址的采集站地址。例如:不需要添加文章子序列号操作方法。我在这里留白。它支持使用标记的四种操作(+加、-减、*乘、/除、%余数)。无需增加第章子序列号的操作方法。我在这里留白。(谁知道他在一个文件夹里放了多少本书?他没有按照规则放。我不是采集无法支持使用标记(+加、-减、*乘、/除、%余数)的四个操作)代理服务器地址不使用代理服务器。请将代理服务器端口留空。如果现有章节无法对应,是否根据自己的需要再次清除采集所有章节。根据自己的需要选择是否默认将文章设置为完整版本。如果选择“是”,无论文章是序列化还是完成,完整版本都将显示在您的站点上。建议选择“否”发送http_参考标志以突破反采集设置。默认情况下,选择是。我不知道该使用什么。我选择是先突破,然后谈论对方的网页代码(自动检测GB2312 utf8) BIG5)默认设置为自动检测代码与此网站不同。您将自动尝试转换文章information page采集rule文章information page address、图书信息页面URL和图书ID。例如:/index.html文章Title采集rule要求您查看网页的源文件。如果您这样做不,你可以停下来。检查信息页面的源文件,然后找出文章标题在源文件中的位置(我们以feiku为例,它是源文件中章节信息页面上文章标题的位置)。这里,以我的美女为例,找到标题附近的代码是
我美丽的女士
将上述代码复制到文章Title采集规则的框中,然后用!!!!!替换我美丽的女士的真实头衔!当然,它也可以替换为其他替换符号,如****,但重要的是,范围越小,越能表达意思(习惯问题,你在这里只能得到采集到文章的标题,但是还有其他采集的东西你不想要。作者采集rule这里的李兴宇想要采集内容并使用!!!!!相反,但是144238只对这个文章有用,其他文章有其他数字,所以使用任何数字字符串$。所以作者采集rule是!!!!文章type采集城市规则是从顶部开始的!!!!!@k113@类型的信件。你可以自己写。呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵呵Hehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehehe|10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 124A的10 10 124A的10 124A的10 124A的10的10的10 124A的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的10的此外,这两种类型用“|”分隔,类型名称为“默认”确定默认类型对应关系。网站类型和序列号之间的对应关系如下:幻想魔法=>;1;武术修养=>;2;城市浪漫=>;3;历史军事=>;4;侦探推理=>;5;在线游戏动画=>;6;科幻=>;7;恐怖与超人Natural=>;8 |散文诗=>;9 |其他类型=>;10(根据您的站点设置)关键字采集规则在关键字附近找到代码主角并检索关键字beauty city
此处的“我的美丽城市”被****替换,结果规则为主角搜索关键字-****
“大”小姐和“大”妹妹,别打扰我,好吗?我求求你~~
拥有数亿财富的刘星不想生活在朱门的酒肉腥味和阴谋中,他放弃了家里的大公司,选择在一家小公司做一名普通白领
餐馆里的一次英勇营救让他遇到了一位美丽的女士,她是刘星上海公司老板的女儿,换句话说,是他的长女
但这位貌似美丽优雅的年轻女士却有一个未知的一面,这真的会危及生命
做我的保姆?你在开玩笑吗,小姐?你什么都做不了。做我的保姆
老板有两个女儿?所以白天捣乱的美女是第二夫人
什么?你也决定住在这里?啊!别烦我了~~!一个就够了,另一个。多大的一个小妹妹啊
“大”女人看起来优雅文雅,但她很困惑。大“小”妹妹看起来很漂亮,但她很火辣和淘气。而且,两姐妹从小到大一直有冲突。这次他们都住在我家。这房子真的很热闹
想拥有美丽的人都被“大”和“小”姐妹“浸透”!啊~~!让人活下去~~
自动采集编写(国内有ueditor网站推荐使用模板,增加更多的想象空间)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-21 03:01
自动采集编写网站代码。在chrome中编写。首先你要会写网站代码。
怎么弄首页?
现在app内置功能(我个人认为是增加)【网络请求】部分,能很好地减轻后台程序负担,比如分享、登录/访问分享朋友圈等~做网站搭web应用,开发者和设计师都要经常开【浏览器】编程,反正怎么舒服怎么写。ui是没办法改了,功能不能多也不能少,把控不了的。所以app开发相对在界面功能上还是比较自由的。对我们设计来说也不必担心水土不服和内部冲突。可以发挥想象力,增加更多的想象空间。
现在公开的比较多的是模板吧。国内有ueditor网站推荐使用模板,
有好多个人建的网站。而且都是在github上找着一个个改过来的。比如有些制作真不敢恭维。还有,开放给公众用,基本上没门槛。如果你做app,拿开源app一看,几乎是开源项目。app工程师因为本身不是浏览器运维,没有什么实际感知。
微信公众号可以用自动开发的网站来接入也可以用第三方的平台,
现在都是自动采集,
非关键页面肯定自动采集了,搜索或用户列表都可以。其他属性可以按需手动添加。现在最新的app都有运行在浏览器里,且不用来回切换。 查看全部
自动采集编写(国内有ueditor网站推荐使用模板,增加更多的想象空间)
自动采集编写网站代码。在chrome中编写。首先你要会写网站代码。
怎么弄首页?
现在app内置功能(我个人认为是增加)【网络请求】部分,能很好地减轻后台程序负担,比如分享、登录/访问分享朋友圈等~做网站搭web应用,开发者和设计师都要经常开【浏览器】编程,反正怎么舒服怎么写。ui是没办法改了,功能不能多也不能少,把控不了的。所以app开发相对在界面功能上还是比较自由的。对我们设计来说也不必担心水土不服和内部冲突。可以发挥想象力,增加更多的想象空间。
现在公开的比较多的是模板吧。国内有ueditor网站推荐使用模板,
有好多个人建的网站。而且都是在github上找着一个个改过来的。比如有些制作真不敢恭维。还有,开放给公众用,基本上没门槛。如果你做app,拿开源app一看,几乎是开源项目。app工程师因为本身不是浏览器运维,没有什么实际感知。
微信公众号可以用自动开发的网站来接入也可以用第三方的平台,
现在都是自动采集,
非关键页面肯定自动采集了,搜索或用户列表都可以。其他属性可以按需手动添加。现在最新的app都有运行在浏览器里,且不用来回切换。
自动采集编写(蓝鲸整站V5.5-伪原创采集无限制破解版(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-19 00:14
有关软件的最新版本:
蓝鲸全站发电机V5.5-伪原创采集无限破解版[综合营销]蓝鲸全站式发电机V5.5注册机无限破解版【综合营销】蓝鲸全站发电机V5.38-伪原创采集无限破解版[整合营销]蓝鲸全站发电机V5.38注册机无限破解版【综合营销】蓝鲸全站发电机V5.33-伪原创采集无限破解版[人工制品软件]蓝鲸全站式发电机V5.33注册机无限破解版[神器软件]蓝鲸全站发电机无限破解版【综合营销】蓝鲸全站发电机注册机无限破解版【综合营销】
蓝鲸全站发电机V5.38-伪原创采集(带后台管理)
蓝鲸全站式发电机效能的具体介绍
目前市场上的采集器只能称为采集器!不是交通制造者!纯粹的采集信息只能被称为剽窃,如果你接受了其他人的网站信息采集并且不会增加搜索引擎的权重。从长远来看,你的网站体重会减少,甚至会变为K。因此,我们是非常负责任的神器:告诉你,纯粹的采集信息毫无意义!我们需要伪原创1@信息将被全面处理并成为我们自己的原创信息,这将为您的网站带来大量流量和高权重
蓝鲸全站生成器是一套为中小型网站站长量身定制的软件,集数据采集、数据优化、全站生成、全站广告管理、后台cms管理系统、数据仓库和各种搜索引擎优化工具于一体
有效减轻每天管理网站的繁重工作量,提升网站排名,增加网站流量,让智慧站长更强大。它是一个网站管理工具
软件中内置了大量采集规则,采集的网站数据大部分可以收录论坛。只要你输入一个关键字,采集将收录你输入的所有网页关键字,采集内容好,速度快。新版本支持自定义规则采集和采集论坛数据。您可以根据自己编写的采集规则自由采集
适用于各类新闻台、图片台、视频台、影视台、小说台、软件下载台、各类示例综合社区及其相关站点的数据采集和全站生成。每个站点可以是独立的,生成的网站页面数量不受限制。只要服务器空间允许,您就可以立即构建一个收录数千甚至上万页的站点
数据仓库是灵活多变的。它支持所有后台管理系统的数据导入,甚至支持数据采集和博客导入
除了上述优点外,蓝鲸全站发电机还具有以下明显效果
1.软件实用性强,不像其他采集器软件只能采集固定断面数据。蓝鲸全站仪支持采集news、文章、影视、软件下载、视频站、图片、音乐、新颖智能触发器采集. 不需要手动编写恼人的采集规则。大量的采集规则是内置的,因此您可以将精力放在管理网站上,并将规则的编写留给我们。采集多样化、轻松高效
2.生成一个网站Level 2目录列表,为小说、音乐、电影和电视等样本站点护航
3.采用access数据库,使软件更加兼容,数据采集可任意转换为其他网站管理系统
4.有一个后台cms管理系统。只需将采集中存储的数据库上传到FTP,即可在后台实现全站网页显示、时间同步、一键更新等功能。它不需要额外购买,与蓝鲸全站发电机一起包装
4.each网站收录至少13个广告空间的管理,这些广告空间可以在程序内部管理!让你数钱给他
5.可以对每个页面进行搜索引擎优化,加强自动关键词提取功能和伪原创功能,加速搜索引擎收录的网站速度,忘记返回您的网站
6.各种动量网站模板,这样您的网站用户就不会因为视觉方面的原因而与您的网站分离
7.采用div+CSS规模的web结构编写网页,使您的网站兼容性更高,管理更方便
8.配备了一个高效的网站地图生成工具,可以为谷歌、雅虎和静态HTML生成地图,加快你的收录速度,提高你的网站排名
9.data采集可根据用户提供的关键字自动采集并可根据一个关键字智能触发采集. 您可以搜索和导出当前流行的关键字
10.您可以在web内容中分发当前流行的关键字,或在标题中添加关键字以增加网站访问者
11.generation网站支持多个代码(gb2312、utf-8、big5),该程序更通用
12.支持自命名网页,更多手机
13.具有多种实用小工具(HTML JS转换、弹出窗口参数生成、base64加密和解密、网站map生成)
14.采集high speed,可以自动过滤现有数据。全站静态页面输出,降低服务器压力,加快网页速度
15.网站参数、广告管理与投放、统计代码设置可以在程序中保存,也可以在网站后台保存,操作多样实用
16.网站是ASP在后台编写的。您可以在没有更高级服务器的情况下传输程序,这样可以为您节省网站服务器的费用
17.Support custom rules采集,Support采集论坛,各种新闻站,采集任何你想要的站点采集@
18.Mobile和可变模板制作支持,内置大量标签,为您搭建和模仿站点提供强大支持 查看全部
自动采集编写(蓝鲸整站V5.5-伪原创采集无限制破解版(组图))
有关软件的最新版本:
蓝鲸全站发电机V5.5-伪原创采集无限破解版[综合营销]蓝鲸全站式发电机V5.5注册机无限破解版【综合营销】蓝鲸全站发电机V5.38-伪原创采集无限破解版[整合营销]蓝鲸全站发电机V5.38注册机无限破解版【综合营销】蓝鲸全站发电机V5.33-伪原创采集无限破解版[人工制品软件]蓝鲸全站式发电机V5.33注册机无限破解版[神器软件]蓝鲸全站发电机无限破解版【综合营销】蓝鲸全站发电机注册机无限破解版【综合营销】
蓝鲸全站发电机V5.38-伪原创采集(带后台管理)
蓝鲸全站式发电机效能的具体介绍
目前市场上的采集器只能称为采集器!不是交通制造者!纯粹的采集信息只能被称为剽窃,如果你接受了其他人的网站信息采集并且不会增加搜索引擎的权重。从长远来看,你的网站体重会减少,甚至会变为K。因此,我们是非常负责任的神器:告诉你,纯粹的采集信息毫无意义!我们需要伪原创1@信息将被全面处理并成为我们自己的原创信息,这将为您的网站带来大量流量和高权重
蓝鲸全站生成器是一套为中小型网站站长量身定制的软件,集数据采集、数据优化、全站生成、全站广告管理、后台cms管理系统、数据仓库和各种搜索引擎优化工具于一体
有效减轻每天管理网站的繁重工作量,提升网站排名,增加网站流量,让智慧站长更强大。它是一个网站管理工具
软件中内置了大量采集规则,采集的网站数据大部分可以收录论坛。只要你输入一个关键字,采集将收录你输入的所有网页关键字,采集内容好,速度快。新版本支持自定义规则采集和采集论坛数据。您可以根据自己编写的采集规则自由采集
适用于各类新闻台、图片台、视频台、影视台、小说台、软件下载台、各类示例综合社区及其相关站点的数据采集和全站生成。每个站点可以是独立的,生成的网站页面数量不受限制。只要服务器空间允许,您就可以立即构建一个收录数千甚至上万页的站点
数据仓库是灵活多变的。它支持所有后台管理系统的数据导入,甚至支持数据采集和博客导入
除了上述优点外,蓝鲸全站发电机还具有以下明显效果
1.软件实用性强,不像其他采集器软件只能采集固定断面数据。蓝鲸全站仪支持采集news、文章、影视、软件下载、视频站、图片、音乐、新颖智能触发器采集. 不需要手动编写恼人的采集规则。大量的采集规则是内置的,因此您可以将精力放在管理网站上,并将规则的编写留给我们。采集多样化、轻松高效
2.生成一个网站Level 2目录列表,为小说、音乐、电影和电视等样本站点护航
3.采用access数据库,使软件更加兼容,数据采集可任意转换为其他网站管理系统
4.有一个后台cms管理系统。只需将采集中存储的数据库上传到FTP,即可在后台实现全站网页显示、时间同步、一键更新等功能。它不需要额外购买,与蓝鲸全站发电机一起包装
4.each网站收录至少13个广告空间的管理,这些广告空间可以在程序内部管理!让你数钱给他
5.可以对每个页面进行搜索引擎优化,加强自动关键词提取功能和伪原创功能,加速搜索引擎收录的网站速度,忘记返回您的网站
6.各种动量网站模板,这样您的网站用户就不会因为视觉方面的原因而与您的网站分离
7.采用div+CSS规模的web结构编写网页,使您的网站兼容性更高,管理更方便
8.配备了一个高效的网站地图生成工具,可以为谷歌、雅虎和静态HTML生成地图,加快你的收录速度,提高你的网站排名
9.data采集可根据用户提供的关键字自动采集并可根据一个关键字智能触发采集. 您可以搜索和导出当前流行的关键字
10.您可以在web内容中分发当前流行的关键字,或在标题中添加关键字以增加网站访问者
11.generation网站支持多个代码(gb2312、utf-8、big5),该程序更通用
12.支持自命名网页,更多手机
13.具有多种实用小工具(HTML JS转换、弹出窗口参数生成、base64加密和解密、网站map生成)
14.采集high speed,可以自动过滤现有数据。全站静态页面输出,降低服务器压力,加快网页速度
15.网站参数、广告管理与投放、统计代码设置可以在程序中保存,也可以在网站后台保存,操作多样实用
16.网站是ASP在后台编写的。您可以在没有更高级服务器的情况下传输程序,这样可以为您节省网站服务器的费用
17.Support custom rules采集,Support采集论坛,各种新闻站,采集任何你想要的站点采集@
18.Mobile和可变模板制作支持,内置大量标签,为您搭建和模仿站点提供强大支持
自动采集编写(长城小程序会计ae工程(网络)h105ecs-005)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-09-16 18:02
自动采集编写h5-ad城市信息ae长城小程序会计ae工程(网络)h105ecs-005的传播技巧和非常用的技术论坛自动采集排版的方法数据分析和产品说明(二维码自动识别)
找两家机构对比吧:1,线上学习指南2,
注册试用~这种问题没有必要来这里问。一个针对刚毕业或者没有经验的人,在实际工作中遇到的问题和情况实在是太多了。而且如果你在网上,想要得到一个相对靠谱的答案的话,你只能找到一些经验泛泛的所谓大神,和他们说的未必是同一个东西。网上的很多东西,不可否认的确可以吸取一些东西,但是真正有实际用处的不是他们的所谓的见解,而是他们所提供的实际工作内容,他们对某一个场景的尝试和攻克,对某一个工具使用的思路和解决方案,而这些经验还需要你自己去总结和沉淀。
你可以去看一下第一家公司的免费课程,在这里不过多推荐了,免得广告嫌疑。确定课程之后,完全可以去看一下能否接受,不是说他们所谓的付费排版,而是是否能让你学到一些真正有用的东西。
ae很考验软件的配合能力,之前已经有老师公开课录像。
二三线城市的实训课都不一样,要看具体学校开的哪一家,城市小靠的是实践经验,实训班基本针对公司要求的技能。课程也分很多档次, 查看全部
自动采集编写(长城小程序会计ae工程(网络)h105ecs-005)
自动采集编写h5-ad城市信息ae长城小程序会计ae工程(网络)h105ecs-005的传播技巧和非常用的技术论坛自动采集排版的方法数据分析和产品说明(二维码自动识别)
找两家机构对比吧:1,线上学习指南2,
注册试用~这种问题没有必要来这里问。一个针对刚毕业或者没有经验的人,在实际工作中遇到的问题和情况实在是太多了。而且如果你在网上,想要得到一个相对靠谱的答案的话,你只能找到一些经验泛泛的所谓大神,和他们说的未必是同一个东西。网上的很多东西,不可否认的确可以吸取一些东西,但是真正有实际用处的不是他们的所谓的见解,而是他们所提供的实际工作内容,他们对某一个场景的尝试和攻克,对某一个工具使用的思路和解决方案,而这些经验还需要你自己去总结和沉淀。
你可以去看一下第一家公司的免费课程,在这里不过多推荐了,免得广告嫌疑。确定课程之后,完全可以去看一下能否接受,不是说他们所谓的付费排版,而是是否能让你学到一些真正有用的东西。
ae很考验软件的配合能力,之前已经有老师公开课录像。
二三线城市的实训课都不一样,要看具体学校开的哪一家,城市小靠的是实践经验,实训班基本针对公司要求的技能。课程也分很多档次,
自动采集编写(自动采集编写采集插件,不需要自己开发exe程序)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-15 12:00
自动采集编写采集插件,编写这样的插件,不需要自己开发exe程序,本着让程序免费,到处拷贝,然后ad代码自己改,自己编译,你可以试试.用这种方法,一周可以搞定.源代码很多,我只能是说包含内容,大概如此.
这两个月时间应该可以,但是自己很快就会厌倦的,毕竟就是将整个文件换一套语言写,这两个月,你就可以写个简单的采集器了。不要寄希望于这两个月,而是可以将两三个月写出来,然后,不出一个月,你就可以写这两个月的代码了。
20天可以完成。但是要保证视频有质量还是要费一些功夫。自动采集原理不难,关键是怎么分析视频数据,规划好后续处理,这是关键。
看看我这个吧,20天应该可以的,
强烈建议crosswalk+selenium
这20天也就只能上上知乎看看文章,一个问题没解决至少会python了,不过后面你还得学selenium,
大多数教程里是有教怎么一步步做视频爬虫的,可是讲到这些的时候,不知道是不是我姿势不对,总感觉有种断章取义的感觉,总觉得这个才是正确的。我每学一个c的语言知识点都会想到要学一下视频抓取,然后再去爬些什么各种数据,但这些数据里有文本、视频文件等等不同的文件类型,搞的自己还是半桶水。不过用c来写采集器还是可以做到的,下面给个链接我们在这学吧,对于初学者来说应该还是有用的:sina视频抓取-云鹊开发者社区。 查看全部
自动采集编写(自动采集编写采集插件,不需要自己开发exe程序)
自动采集编写采集插件,编写这样的插件,不需要自己开发exe程序,本着让程序免费,到处拷贝,然后ad代码自己改,自己编译,你可以试试.用这种方法,一周可以搞定.源代码很多,我只能是说包含内容,大概如此.
这两个月时间应该可以,但是自己很快就会厌倦的,毕竟就是将整个文件换一套语言写,这两个月,你就可以写个简单的采集器了。不要寄希望于这两个月,而是可以将两三个月写出来,然后,不出一个月,你就可以写这两个月的代码了。
20天可以完成。但是要保证视频有质量还是要费一些功夫。自动采集原理不难,关键是怎么分析视频数据,规划好后续处理,这是关键。
看看我这个吧,20天应该可以的,
强烈建议crosswalk+selenium
这20天也就只能上上知乎看看文章,一个问题没解决至少会python了,不过后面你还得学selenium,
大多数教程里是有教怎么一步步做视频爬虫的,可是讲到这些的时候,不知道是不是我姿势不对,总感觉有种断章取义的感觉,总觉得这个才是正确的。我每学一个c的语言知识点都会想到要学一下视频抓取,然后再去爬些什么各种数据,但这些数据里有文本、视频文件等等不同的文件类型,搞的自己还是半桶水。不过用c来写采集器还是可以做到的,下面给个链接我们在这学吧,对于初学者来说应该还是有用的:sina视频抓取-云鹊开发者社区。
自动采集编写(PC端采集工具1.1.强大的文本扩展工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 227 次浏览 • 2021-09-15 06:28
随着阅读的增长,学习的越来越多,记忆的越来越少,我们必须进入下一阶段的知识和学习的知识采集. 对于采集,有很多工具,但最后,我使用impression notes作为载体来存储这些信息
PC端采集工具
1.1.强大的文本扩展工具popclip
Popclip是Mac上的一个著名小工具。说到popclip,它可能是Mac上最值得购买的软件。它的操作也很简单。只需选择文本,然后反转文本即可。该软件简单高效,具有强大的扩展功能。当没有安装插件时,它具有以下功能
粘贴
开放链接
抄袭
字典
拼写检查
邮件跳转
这不是很棒吗?此外,它还支持100多个不同的插件,这些插件具有许多不同的功能。例如,它支持选定的文本翻译、修改文本格式、搜索豆瓣、保存到doit.im等
您只需访问其官方网站并下载相应的插件即可使用这些插件
我之所以把它放在采集一章中,是因为我安装了Evernote插件,我妈妈再也不用担心我的采集text方法了
只需单击impression便笺的按钮,即可在impression便笺中创建一个新文件
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们必须使用大量的复制和粘贴。然而,有时当我们复制文本时,原创复制的文本被文本覆盖,并且没有以前的复制和粘贴内容。。。粘贴很好地解决了这个问题。在设置项中可以选择保存500条以上的复制粘贴历史,当需要粘贴时,只需按Shift+Command+V查看复制的历史内容,然后选择并操作即可
粘贴在Mac上运行得非常好,它看起来就像一个本机应用程序。它不仅可以记录复制的历史,而且分类和预览显示的效果也很好。对于作家来说,这确实是一件必不可少的艺术品
1.3.作弊快捷查询工具
说到一个有效率的作家,他们大多数都是键盘派对。例如,我已经两年没有使用鼠标了,因为通常的操作可以通过快捷键来解决,但是一些新软件根本不知道如何使用快捷键?一个接一个的摸索?你根本不需要奶酪。如果安装了它,在使用软件时,长按命令键可查看完整的快捷键映射图。与快捷键软件相比,它是否令人耳目一新
1.@4.Chrome在页面快捷方式下
说到快捷键,我们不得不说vimium,chrome下的一个小插件
Vimium是一个很好的插件。安装并启用此插件后,只需按浏览器页面上的F键即可看到该按钮并跳转到相应页面
如果要退出,只需按ESC键
有了这个工件和浏览器上的快捷键,你就不能在浏览网页时使用触摸版了!工作效率显著提高
除此之外,PC端还有许多采集和排序工具,如前一篇文章文章中提到的chrome中的pocket和impression note clipping插件,这些工具比较常见,因此我将不详细介绍
移动端采集工具
除了PC上的采集数据外,我们还经常需要在移动采集终端上记录一些信息和笔记。除了口袋,还有一些常用的方法和软件
1.我的印象笔记
是微信公共广播在移动终端上使用频率最高的官方账号。我只需要注意它:“我的印象笔记”和绑定帐户。p>
您可以在文章页面上自己的印象笔记中分享
然后,界面提示它已成功保存,我们可以在impression便笺中找到这篇文章文章 查看全部
自动采集编写(PC端采集工具1.1.强大的文本扩展工具(组图))
随着阅读的增长,学习的越来越多,记忆的越来越少,我们必须进入下一阶段的知识和学习的知识采集. 对于采集,有很多工具,但最后,我使用impression notes作为载体来存储这些信息
PC端采集工具
1.1.强大的文本扩展工具popclip
Popclip是Mac上的一个著名小工具。说到popclip,它可能是Mac上最值得购买的软件。它的操作也很简单。只需选择文本,然后反转文本即可。该软件简单高效,具有强大的扩展功能。当没有安装插件时,它具有以下功能
粘贴
开放链接
抄袭
字典
拼写检查
邮件跳转
这不是很棒吗?此外,它还支持100多个不同的插件,这些插件具有许多不同的功能。例如,它支持选定的文本翻译、修改文本格式、搜索豆瓣、保存到doit.im等
您只需访问其官方网站并下载相应的插件即可使用这些插件
我之所以把它放在采集一章中,是因为我安装了Evernote插件,我妈妈再也不用担心我的采集text方法了
只需单击impression便笺的按钮,即可在impression便笺中创建一个新文件
1.2.强大的复制粘贴工具粘贴
当我们使用文本时,我们必须使用大量的复制和粘贴。然而,有时当我们复制文本时,原创复制的文本被文本覆盖,并且没有以前的复制和粘贴内容。。。粘贴很好地解决了这个问题。在设置项中可以选择保存500条以上的复制粘贴历史,当需要粘贴时,只需按Shift+Command+V查看复制的历史内容,然后选择并操作即可
粘贴在Mac上运行得非常好,它看起来就像一个本机应用程序。它不仅可以记录复制的历史,而且分类和预览显示的效果也很好。对于作家来说,这确实是一件必不可少的艺术品
1.3.作弊快捷查询工具
说到一个有效率的作家,他们大多数都是键盘派对。例如,我已经两年没有使用鼠标了,因为通常的操作可以通过快捷键来解决,但是一些新软件根本不知道如何使用快捷键?一个接一个的摸索?你根本不需要奶酪。如果安装了它,在使用软件时,长按命令键可查看完整的快捷键映射图。与快捷键软件相比,它是否令人耳目一新
1.@4.Chrome在页面快捷方式下
说到快捷键,我们不得不说vimium,chrome下的一个小插件
Vimium是一个很好的插件。安装并启用此插件后,只需按浏览器页面上的F键即可看到该按钮并跳转到相应页面
如果要退出,只需按ESC键
有了这个工件和浏览器上的快捷键,你就不能在浏览网页时使用触摸版了!工作效率显著提高
除此之外,PC端还有许多采集和排序工具,如前一篇文章文章中提到的chrome中的pocket和impression note clipping插件,这些工具比较常见,因此我将不详细介绍
移动端采集工具
除了PC上的采集数据外,我们还经常需要在移动采集终端上记录一些信息和笔记。除了口袋,还有一些常用的方法和软件
1.我的印象笔记
是微信公共广播在移动终端上使用频率最高的官方账号。我只需要注意它:“我的印象笔记”和绑定帐户。p>
您可以在文章页面上自己的印象笔记中分享
然后,界面提示它已成功保存,我们可以在impression便笺中找到这篇文章文章
自动采集编写(web前端自动采集脚本一定需要python这个编程语言才可以)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-08 16:05
自动采集编写脚本一定需要python这个编程语言才可以(也可以用你喜欢的语言,看你喜欢什么风格了,python在web开发方面比较吃香)。python的话你可以考虑python爬虫。推荐python,是因为开发难度不大,爬虫的开发门槛也不高。
还是需要学些别的语言,
python要求太低,不过建议学php,能干很多你以为很复杂的事,还有就是学会了干几件事,
学python主要是c/c++太难理解,python这样的可以。没时间解释,自己打去。
python没前途!
开发方式简单,容易上手,可用作辅助。其中有分步骤的原理介绍,并结合实例进行讲解,算是入门级的python。不过和php相比,它语法有点强,遇到些特殊语法,php会比较头疼。如果没有太高的要求,建议学python。
现在算法为王..
其实web前端更重要,只有你能实现前端的最基本功能了,那后续才能继续往前端发展,所以至少需要熟悉一门后端语言,php或c#。如果只是为了赶脚加我,
总有一个工作,
做爬虫的时候,每天都在思考:当别人看网页的时候,到底是在看什么?去掉一个字,一串字母?放大一个尺寸?加上一个字?自己之前经常写写爬虫,后面觉得要想别人看懂自己写的东西,得有足够的思想,可是写爬虫就已经忘记自己写的文章的意义了,和当初想表达的意思很难用文字描述,想想是真的难受啊,那还怎么说好呢?可是,要你写的网页上面的所有提示信息你都知道它想告诉你什么?怎么分词?不好意思你得去学后端开发,后台语言学习,php和java都ok,在互联网公司内部有一些比较特殊的情况,后端语言可能需要和其他语言交互,要考虑架构和一些编程思想,可是有些网站的服务器环境或者是有些浏览器请求是指向本地的啊,连进去都进不去怎么办?不管它,直接读取源码?不好意思这么做会丢包的。
好吧,还有一些资源,每天站在自己的角度也不要忘记发现问题解决问题,提问也是需要逻辑的,多看看别人在这些问题上提供的思路吧,可以减少很多问题。 查看全部
自动采集编写(web前端自动采集脚本一定需要python这个编程语言才可以)
自动采集编写脚本一定需要python这个编程语言才可以(也可以用你喜欢的语言,看你喜欢什么风格了,python在web开发方面比较吃香)。python的话你可以考虑python爬虫。推荐python,是因为开发难度不大,爬虫的开发门槛也不高。
还是需要学些别的语言,
python要求太低,不过建议学php,能干很多你以为很复杂的事,还有就是学会了干几件事,
学python主要是c/c++太难理解,python这样的可以。没时间解释,自己打去。
python没前途!
开发方式简单,容易上手,可用作辅助。其中有分步骤的原理介绍,并结合实例进行讲解,算是入门级的python。不过和php相比,它语法有点强,遇到些特殊语法,php会比较头疼。如果没有太高的要求,建议学python。
现在算法为王..
其实web前端更重要,只有你能实现前端的最基本功能了,那后续才能继续往前端发展,所以至少需要熟悉一门后端语言,php或c#。如果只是为了赶脚加我,
总有一个工作,
做爬虫的时候,每天都在思考:当别人看网页的时候,到底是在看什么?去掉一个字,一串字母?放大一个尺寸?加上一个字?自己之前经常写写爬虫,后面觉得要想别人看懂自己写的东西,得有足够的思想,可是写爬虫就已经忘记自己写的文章的意义了,和当初想表达的意思很难用文字描述,想想是真的难受啊,那还怎么说好呢?可是,要你写的网页上面的所有提示信息你都知道它想告诉你什么?怎么分词?不好意思你得去学后端开发,后台语言学习,php和java都ok,在互联网公司内部有一些比较特殊的情况,后端语言可能需要和其他语言交互,要考虑架构和一些编程思想,可是有些网站的服务器环境或者是有些浏览器请求是指向本地的啊,连进去都进不去怎么办?不管它,直接读取源码?不好意思这么做会丢包的。
好吧,还有一些资源,每天站在自己的角度也不要忘记发现问题解决问题,提问也是需要逻辑的,多看看别人在这些问题上提供的思路吧,可以减少很多问题。
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2021-09-08 03:22
一、前言
在上一篇文章《神策Android全插件介绍》中,我们了解到神策Android插件其实是一个自定义的Gradle插件。 Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。具体逻辑可以通过插件实现,打包分享给别人使用。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现全埋点控件点击和Fragment页面浏览的采集。
在本文中,我们将首先介绍 Gradle 的基础知识,然后举例说明如何实现自定义 Gradle 插件。这里注意: ./gradlew 在文章中用于执行 Gradle 命令。如果您是Windows用户,则需要将其更改为gradlew.bat。
二、Gradle 基础
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
Project 是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图 2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,"project" 和 "Module" 在构建过程中都会被 Gradle 抽象为 Project 对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、每个Project对应一个build.gradle配置文件,所以当你使用Android Studio创建一个项目时,根目录下有一个build.gradle文件,每个Module目录下都有一个build。 .gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
所有项目{
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 在构建过程中会执行一系列的 Task。 Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle的官方话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图的右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。运行Task的时候也需要这样指定一个Task。
另外,你可以自定义你自己的Task,我们来创建一个最简单的Task:
// 添加到 build.gradle
任务你好{
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的任务。如果想单独执行任务,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后可以看到控制控制台输出“Hello World!”。
三、Gradle 插件构建3.1 插件介绍
Plugin 和 Task 实际上和它们的功能没有太大区别。它们都封装了一些业务逻辑。 Plugin适用于对需要复用的编译逻辑进行打包的场景(即对部分编译逻辑进行模块化)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的应该是Android官方提供的Android Gradle Plugin。可以在项目main Module的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。 “com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
插件也可以读取build.gradle文件中写的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等。可以将这里的“android”android块比较为数据类或基类,定义的属性类似于类成员变量。 Android Gradle Plugin可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 用于构建独立项目的 Gradle 插件
Gradle 插件的实现方式有三种:构建脚本、buildSrc 项目和独立项目:
1、Build 脚本会将逻辑直接写到 build.gradle 文件中,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc 项目就是把逻辑写在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录,插件只对当前项目有效;
3、Standalone 项目就是把逻辑写在一个单独的项目里,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone project,独立项目的Gradle插件。
3.2.1 目录结构分析
独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
groovy 文件夹收录源代码文件(Gradle 插件也支持 Java 和 Kotlin 编写,这里的文件夹名称由实际语言决定);
资源文件夹下是资源文件。
其中resources文件夹下的固定格式META-INF/gradle-plugins/XXXX.properties,XXXX表示以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件模块。只能先创建一个Java Library类型的Module,然后删除多余的文件夹;
2、New 类默认是一个新的 Java 类。新的文件名后缀是“.java”。如果要新建Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加包,类声明;
3、resources 需要手动创建,文件夹名称需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 写插件
在编写插件代码之前,我们需要对build.gradle做如下修改:
应用插件:'groovy'
应用插件:'maven'
依赖项{
implementation gradleApi()
implementation localGroovy()
}
上传档案{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这里主要分为三个部分:
1、apply插件:应用'groovy'插件是因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,选择项目根目录下repo文件夹中的位置。
做好以上准备后,就可以开始编写源码了。 Gradle插件要求入口类需要实现org.gradle.api.Plugin接口,然后在实现方法apply中实现自己的逻辑:
包 com.sensorsdata.plugin
class MyPlugin 实现插件
{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。 apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还有一个准备:Gradle插件不会自动寻找入口类,而是要求开发者在resources/META-INF/gradle-plugins/XXXX.properties中写上入口类的类名, 内容格式为“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写好后,在终端执行
./gradlew 上传存档
您可以发布插件。在上一节插件的build.gradle文件中,已经提前配置了发布到maven仓库的相关配置,所以我们这里执行这个命令后,项目根目录下会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤: 查看全部
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
一、前言
在上一篇文章《神策Android全插件介绍》中,我们了解到神策Android插件其实是一个自定义的Gradle插件。 Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。具体逻辑可以通过插件实现,打包分享给别人使用。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现全埋点控件点击和Fragment页面浏览的采集。
在本文中,我们将首先介绍 Gradle 的基础知识,然后举例说明如何实现自定义 Gradle 插件。这里注意: ./gradlew 在文章中用于执行 Gradle 命令。如果您是Windows用户,则需要将其更改为gradlew.bat。
二、Gradle 基础
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
Project 是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图 2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,"project" 和 "Module" 在构建过程中都会被 Gradle 抽象为 Project 对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、每个Project对应一个build.gradle配置文件,所以当你使用Android Studio创建一个项目时,根目录下有一个build.gradle文件,每个Module目录下都有一个build。 .gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
所有项目{
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 在构建过程中会执行一系列的 Task。 Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle的官方话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图的右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。运行Task的时候也需要这样指定一个Task。
另外,你可以自定义你自己的Task,我们来创建一个最简单的Task:
// 添加到 build.gradle
任务你好{
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的任务。如果想单独执行任务,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后可以看到控制控制台输出“Hello World!”。
三、Gradle 插件构建3.1 插件介绍
Plugin 和 Task 实际上和它们的功能没有太大区别。它们都封装了一些业务逻辑。 Plugin适用于对需要复用的编译逻辑进行打包的场景(即对部分编译逻辑进行模块化)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的应该是Android官方提供的Android Gradle Plugin。可以在项目main Module的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。 “com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
插件也可以读取build.gradle文件中写的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等。可以将这里的“android”android块比较为数据类或基类,定义的属性类似于类成员变量。 Android Gradle Plugin可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 用于构建独立项目的 Gradle 插件
Gradle 插件的实现方式有三种:构建脚本、buildSrc 项目和独立项目:
1、Build 脚本会将逻辑直接写到 build.gradle 文件中,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc 项目就是把逻辑写在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录,插件只对当前项目有效;
3、Standalone 项目就是把逻辑写在一个单独的项目里,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone project,独立项目的Gradle插件。
3.2.1 目录结构分析
独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
groovy 文件夹收录源代码文件(Gradle 插件也支持 Java 和 Kotlin 编写,这里的文件夹名称由实际语言决定);
资源文件夹下是资源文件。
其中resources文件夹下的固定格式META-INF/gradle-plugins/XXXX.properties,XXXX表示以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件模块。只能先创建一个Java Library类型的Module,然后删除多余的文件夹;
2、New 类默认是一个新的 Java 类。新的文件名后缀是“.java”。如果要新建Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加包,类声明;
3、resources 需要手动创建,文件夹名称需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 写插件
在编写插件代码之前,我们需要对build.gradle做如下修改:
应用插件:'groovy'
应用插件:'maven'
依赖项{
implementation gradleApi()
implementation localGroovy()
}
上传档案{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这里主要分为三个部分:
1、apply插件:应用'groovy'插件是因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,选择项目根目录下repo文件夹中的位置。
做好以上准备后,就可以开始编写源码了。 Gradle插件要求入口类需要实现org.gradle.api.Plugin接口,然后在实现方法apply中实现自己的逻辑:
包 com.sensorsdata.plugin
class MyPlugin 实现插件
{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。 apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还有一个准备:Gradle插件不会自动寻找入口类,而是要求开发者在resources/META-INF/gradle-plugins/XXXX.properties中写上入口类的类名, 内容格式为“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写好后,在终端执行
./gradlew 上传存档
您可以发布插件。在上一节插件的build.gradle文件中,已经提前配置了发布到maven仓库的相关配置,所以我们这里执行这个命令后,项目根目录下会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤:
自动采集编写(优采云站群软件新出一个新的新型采集功能--指定网址采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-09-05 04:21
长期以来,大家都在使用采集函数自带的各种采集器或网站程序。它们有一个共同的特点,就是你必须把采集规则写到采集到文章,这个技术问题对于新手推广来说不是一件容易的事,对于老站长来说也是一件费力的事。所以,如果你做站群,每个站都要定义一个采集规则,真是惨不忍睹。有人说站长是网络搬运工。这个说法也有道理。 文章网络上,你们很多人感动了我,我感动了你的,为了生活,我必须做什么。现在优采云站群software 发布了全新的采集功能,可以大大减少站长“搬运工”的时间,不再需要编写烦人的采集规则。这个功能在网上是首创的。功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。可以在网站右健中看到这个功能:如下图。
打开后二、的作用如下,可以填写右侧指定采集的列表地址:
这里我用百度的搜索页面为采集source,比如这个地址:%B0%C5%C6%E6
然后我在这个搜索结果中使用优采云站群software 到采集 all 文章。你可以先分析这个页面。如果在本页使用各种采集器或网站自定义采集all文章,是不可能得到的。因为网上没有这种通用的采集不同的网站功能,但是现在,优采云站群软件就可以实现了。因为本软件支持 pan采集 技术。
三、homepage,我把这个百度结果列表填到软件的“Starting采集的文章List 地址”中,如下图:
四、为了能够正确采集我想要的列表,分析结果列表上的文章有一个共同的后缀,即:html、shtml、htm,那么这三个是共同的地方是:我给软件定义了htm。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过在这里给大家提个醒。一般一个网站里面会有很多相同的字符。对于这个百度列表,也有百度自己的网页,但是百度自己的网页内容不是我想用的,所以还有一个地方可以排除有百度网址的页面。如下图所示:
经过这个定义,就避免使用百度自己的页面了。然后这样填,就可以直接采集文章,点击“保存采集data后”:
一两分钟后,采集过程的结果如下图所示:
六、这里我只挑文章的一部分,不再挑了。现在看采集之后的内容:
七、 以上就是采集的过程。按照上面的步骤,你也可以采集文章在其他地方list,尤其是一些网站没有收录或者屏蔽收录@,这些是原创的文章,你可以找到它自己。现在让我告诉你软件上的一些其他功能:
1、如上图所示,这里是去除URL和采集图片的功能,可以根据需要勾选。
2、如上图,这里是设置采集的条目数和采集的文章标题的最小字数。
3、如上图,这里可以定义替换词,支持代码替换,文本替换等,这里使用起来灵活,对于一些比较难的采集列表,这里会用到。您可以先用空格替换一些代码,然后才能采集 链接到列表。
以上都是优采云站群software新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心不知道怎么写采集规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。不明白的可以加我QQ咨询:509229860。欢迎各位站长给我们推荐更好的功能。
成为站群 永远是一个永远不会过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后都会为站长提供优质的服务!欢迎关注优采云官方网站: 查看全部
自动采集编写(优采云站群软件新出一个新的新型采集功能--指定网址采集)
长期以来,大家都在使用采集函数自带的各种采集器或网站程序。它们有一个共同的特点,就是你必须把采集规则写到采集到文章,这个技术问题对于新手推广来说不是一件容易的事,对于老站长来说也是一件费力的事。所以,如果你做站群,每个站都要定义一个采集规则,真是惨不忍睹。有人说站长是网络搬运工。这个说法也有道理。 文章网络上,你们很多人感动了我,我感动了你的,为了生活,我必须做什么。现在优采云站群software 发布了全新的采集功能,可以大大减少站长“搬运工”的时间,不再需要编写烦人的采集规则。这个功能在网上是首创的。功能---指定网址采集。让我教你如何使用这个功能:
一、 先开启这个功能。可以在网站右健中看到这个功能:如下图。
打开后二、的作用如下,可以填写右侧指定采集的列表地址:
这里我用百度的搜索页面为采集source,比如这个地址:%B0%C5%C6%E6
然后我在这个搜索结果中使用优采云站群software 到采集 all 文章。你可以先分析这个页面。如果在本页使用各种采集器或网站自定义采集all文章,是不可能得到的。因为网上没有这种通用的采集不同的网站功能,但是现在,优采云站群软件就可以实现了。因为本软件支持 pan采集 技术。
三、homepage,我把这个百度结果列表填到软件的“Starting采集的文章List 地址”中,如下图:
四、为了能够正确采集我想要的列表,分析结果列表上的文章有一个共同的后缀,即:html、shtml、htm,那么这三个是共同的地方是:我给软件定义了htm。这种做法是为了减少采集无用的页面,如下图:
五、现在可以采集了,不过在这里给大家提个醒。一般一个网站里面会有很多相同的字符。对于这个百度列表,也有百度自己的网页,但是百度自己的网页内容不是我想用的,所以还有一个地方可以排除有百度网址的页面。如下图所示:
经过这个定义,就避免使用百度自己的页面了。然后这样填,就可以直接采集文章,点击“保存采集data后”:
一两分钟后,采集过程的结果如下图所示:
六、这里我只挑文章的一部分,不再挑了。现在看采集之后的内容:
七、 以上就是采集的过程。按照上面的步骤,你也可以采集文章在其他地方list,尤其是一些网站没有收录或者屏蔽收录@,这些是原创的文章,你可以找到它自己。现在让我告诉你软件上的一些其他功能:
1、如上图所示,这里是去除URL和采集图片的功能,可以根据需要勾选。
2、如上图,这里是设置采集的条目数和采集的文章标题的最小字数。
3、如上图,这里可以定义替换词,支持代码替换,文本替换等,这里使用起来灵活,对于一些比较难的采集列表,这里会用到。您可以先用空格替换一些代码,然后才能采集 链接到列表。
以上都是优采云站群software新增的采集功能。这个功能很强大,但是这个功能还需要改进,以满足不同人的需求。有了这个工具,你就不用担心不知道怎么写采集规则了。该功能上手容易,操作简单。是新老站长最适合的功能。关于优采云站群软件的其他强大功能,我们稍后会一起讨论。不明白的可以加我QQ咨询:509229860。欢迎各位站长给我们推荐更好的功能。
成为站群 永远是一个永远不会过时的话题。重要的是要了解您的想法。关注优采云,每天都有新发现!因为优采云是一个注重站长体验的品牌,无论是售后还是售后都会为站长提供优质的服务!欢迎关注优采云官方网站:
自动采集编写(先上一个图片看看我们要达到的实际效果。。(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-04 13:08
看文章之前先来个图看看我们想要达到的实际效果。
这样的效果是怎么实现的呢,可能对于一般的技术思维,觉得其实就是一个自动脚本的效果,但这是错误的,首先,以头条字节跳动公司的技术水平不可能没有对这方面进行防范,其次本地图片的上传不是简单脚本可以实现了,所以下面进行技术分析。
1、图片捕捉
您需要捕获目标图像并将其保存在本地,以防您在发布时选择本地上传。这里的主要方法是构建一个本地爬取服务应用,从网页向服务应用发送爬取请求。并按照指定路径保存图片。
2、文字内容发布
这个可以直接使用前端脚本实现抓取到输入的过程,并且对于这个可以使用的方法很多,例如chrome插件、植入js脚本等。
3、本地图片上传
这是整个技术的核心部分。应该和第一步有关,所以图片的抓取和上传应该是一个过程。可以这样实现:本地服务实现图片抓取,模拟图片上传的全过程。图片抓取其实就是通过URL请求将图片保存到本地,并将保存地址返回给浏览器前端。前端拿到图片保存地址后,调用上传流程,但是浏览器没有权限控制上传文件的流程,所以这就需要一个可以实现图片上传的功能。这个功能怎么实现?我目前的想法是调用系统内核接口,开发一个客户端服务端程序来实现。
4、last 查看全部
自动采集编写(先上一个图片看看我们要达到的实际效果。。(图))
看文章之前先来个图看看我们想要达到的实际效果。
这样的效果是怎么实现的呢,可能对于一般的技术思维,觉得其实就是一个自动脚本的效果,但这是错误的,首先,以头条字节跳动公司的技术水平不可能没有对这方面进行防范,其次本地图片的上传不是简单脚本可以实现了,所以下面进行技术分析。
1、图片捕捉
您需要捕获目标图像并将其保存在本地,以防您在发布时选择本地上传。这里的主要方法是构建一个本地爬取服务应用,从网页向服务应用发送爬取请求。并按照指定路径保存图片。
2、文字内容发布
这个可以直接使用前端脚本实现抓取到输入的过程,并且对于这个可以使用的方法很多,例如chrome插件、植入js脚本等。
3、本地图片上传
这是整个技术的核心部分。应该和第一步有关,所以图片的抓取和上传应该是一个过程。可以这样实现:本地服务实现图片抓取,模拟图片上传的全过程。图片抓取其实就是通过URL请求将图片保存到本地,并将保存地址返回给浏览器前端。前端拿到图片保存地址后,调用上传流程,但是浏览器没有权限控制上传文件的流程,所以这就需要一个可以实现图片上传的功能。这个功能怎么实现?我目前的想法是调用系统内核接口,开发一个客户端服务端程序来实现。
4、last
自动采集编写(如何有效地对采集到的网页实现自动分类?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-09-02 18:13
[摘要]:随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的数量。相关话题。这使得采集页面的内容过于杂乱,相当一部分利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,如何对采集到达的网页进行有效分类,打造更有效、更快速的搜索引擎也是非常必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。 查看全部
自动采集编写(如何有效地对采集到的网页实现自动分类?)
[摘要]:随着科学技术的飞速发展,我们已经进入了数字信息时代。互联网作为当今世界上最大的信息数据库,也成为人们获取信息的最重要手段。由于网络上的信息资源具有海量、动态、异构、半结构化等特点,缺乏统一的组织和管理,如何从海量的信息资源中快速准确地找到自己需要的信息已成为一个亟待解决的问题。网络用户急需解决的大问题。因此,采集和基于Web的网络信息分类成为研究的热点。传统网络信息采集的目标是拥有尽可能多的采集信息页面,甚至是整个Web上的资源。在这个过程中,它不太关心采集的顺序和采集页面的数量。相关话题。这使得采集页面的内容过于杂乱,相当一部分利用率很低,极大地消耗了系统资源和网络资源。这需要有效的采集 方法来减少采集 网页的混乱和重复。同时,如何对采集到达的网页进行有效分类,打造更有效、更快速的搜索引擎也是非常必要的。网页分类是组织和管理信息的有效手段。可以在很大程度上解决信息的杂乱无章,方便用户准确定位所需信息。传统的操作方式是人工分类后进行组织管理。随着互联网上各种信息的迅速增加,人工处理已经不切实际。因此,网页的自动分类是一种具有很大实用价值的方法,也是一种组织和管理数据的有效手段。这也是本文的一个重要内容。本文首先介绍了课题背景、研究目的和国内外研究现状,阐述了网页采集和网页分类的相关理论、主要技术和算法,包括网页爬虫技术、网页去重技术、信息提取技术、中文分词技术、特征提取技术、网页分类技术等。本文综合比较几种典型算法后,选取分类性能较好的主题爬虫方法和KNN方法,结合结合去重、分词、特征提取等相关技术,分析中文网页的结构和特征。经过分析,提出了中文网页采集的设计和实现方法以及分类,最终通过编程语言实现。在本文的最后,对系统进行了测试。测试结果符合系统设计要求,应用效果显着。
自动采集编写(dedecms采集侠免费版|织梦采集工具采集功能介绍1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-08-31 19:00
dedecms采集侠免费版|织梦采集工具
织梦采集侠功能介绍1)一键安装,全自动采集织梦采集侠安装非常简单方便,只需一分钟,立即开始采集,并且组合简单、健壮、灵活、开源的Dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。 2)校园采集,无需写采集规则和传统的采集模式是织梦采集侠可以平移采集,平移采集由用户设置的优点@是通过采集此关键词的不同搜索结果,可以在一个或多个指定的采集站点上不执行采集,减少采集站点被搜索引擎判断为镜像网站被搜索引擎惩罚的危险。 3)RSS采集,只需要输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,只需要输入RSS地址采集采集到网站内容,无需写采集规则,方便简单。 4)页面监控采集,简单方便采集Content 页面监控采集 只需要提供监控页面地址和文本URL规则来指定采集Specify网站或栏目内容,方便简单,不需要需要写采集Rules 也可以针对采集。 5) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6)plugin全自动采集,无需人工干预织梦采集侠根据预设的采集任务,按照设置的采集方法采集URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取出优秀的文章内容,最后进行伪原创、导入、生成。所有这些操作程序都是自动完成的。无需人工干预。 7)手放文章可以伪原创和搜索优化处理织梦采集侠不仅是一个采集插件,还是一个织梦Required伪原创和搜索优化插件,手动发布的文章可以被织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,随机插入关键词链接和文章包括@关键词会自动添加指定链接等功能,是织梦必备插件。 8)定时和量化执行采集伪原创SEO更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是远程触发采集我们为商业用户提供触发采集服务,新站可以定时定量采集更新,无需人工接入,无需人工干预。 9)及时定量更新待审稿件,即使你的数据库里有数千个文章,织梦采集侠也可以在你每天设定的时间段内定时定量的审阅和更新根据您的需要。 采集侠V2.71 正式版更新说明:[√]添加super采集[√]修复采集重复问题[√]添加采集rule导入导出[√]优化图片下载,减少服务器负载[√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
立即下载 查看全部
自动采集编写(dedecms采集侠免费版|织梦采集工具采集功能介绍1)
dedecms采集侠免费版|织梦采集工具
织梦采集侠功能介绍1)一键安装,全自动采集织梦采集侠安装非常简单方便,只需一分钟,立即开始采集,并且组合简单、健壮、灵活、开源的Dedecms程序,新手可以快速上手,我们还有专门的客服为商业客户提供技术支持。 2)校园采集,无需写采集规则和传统的采集模式是织梦采集侠可以平移采集,平移采集由用户设置的优点@是通过采集此关键词的不同搜索结果,可以在一个或多个指定的采集站点上不执行采集,减少采集站点被搜索引擎判断为镜像网站被搜索引擎惩罚的危险。 3)RSS采集,只需要输入RSS地址采集Content 只要RSS订阅地址是采集的网站提供的,就可以使用RSS 采集,只需要输入RSS地址采集采集到网站内容,无需写采集规则,方便简单。 4)页面监控采集,简单方便采集Content 页面监控采集 只需要提供监控页面地址和文本URL规则来指定采集Specify网站或栏目内容,方便简单,不需要需要写采集Rules 也可以针对采集。 5) 多个伪原创 和优化方法来提高收录 率和排名。自动标题、段落重排、高级混淆、自动内链、内容过滤、URL过滤、同义词替换、seo词插入、关键词添加链接等方法处理采集回文章,增强采集文章原创,有利于搜索引擎优化,提高搜索引擎收录、网站权重和关键词排名。
6)plugin全自动采集,无需人工干预织梦采集侠根据预设的采集任务,按照设置的采集方法采集URL,然后自动抓取网页内容,程序通过精确计算分析网页,丢弃不是文章内容页的网址,提取出优秀的文章内容,最后进行伪原创、导入、生成。所有这些操作程序都是自动完成的。无需人工干预。 7)手放文章可以伪原创和搜索优化处理织梦采集侠不仅是一个采集插件,还是一个织梦Required伪原创和搜索优化插件,手动发布的文章可以被织梦采集侠的伪原创和搜索优化处理,文章可以替换同义词,自动内链,随机插入关键词链接和文章包括@关键词会自动添加指定链接等功能,是织梦必备插件。 8)定时和量化执行采集伪原创SEO更新插件有两种触发采集的方式,一种是在页面中添加代码通过用户访问触发采集update,另一种是远程触发采集我们为商业用户提供触发采集服务,新站可以定时定量采集更新,无需人工接入,无需人工干预。 9)及时定量更新待审稿件,即使你的数据库里有数千个文章,织梦采集侠也可以在你每天设定的时间段内定时定量的审阅和更新根据您的需要。 采集侠V2.71 正式版更新说明:[√]添加super采集[√]修复采集重复问题[√]添加采集rule导入导出[√]优化图片下载,减少服务器负载[√]关键词插入优化,段尾插入改为随机插入[√]改善地图生成错误[√]百度多项优化
立即下载
自动采集编写(怎么样组建小说分销H5微信?小说站手机app服务套餐 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 238 次浏览 • 2021-08-31 18:11
)
自动采集小说源码平台是撮合交易模式。
小说发行商H5微信如何设置?
小说站手机app就是看到作者的小说或者漫画写的好,就支付一定的钱换取奖励。小说系统源码软件与公众号对接、与微信支付对接、付费章节设置、三级代理后台、代理扣款功能、域名防屏蔽、强制关注功能、每日群发帖功能、发送优采云采集软件、广告和营销功能。编写win批处理文件可以有效节省从采集到包上传过程的操作成本。整个过程将有效节省近120倍的工作量(时间),相当于减少120倍的人工操作成本。
动漫小说平台微信公众号服务包介绍:
套餐一:源码+免费系统升级。
套餐二:源码+免费系统升级+搭建服务+售后服务。
套餐三:源码+免费系统升级+搭建服务+售后服务+安全防御搭建。
套餐四:源码+免费系统升级+搭建服务+售后服务+安全防御搭建+运维服务。
优化素材采集后的上传操作链接,批量生成大大降低了工作量和成本。新版v15:小说+漫画+视频+商店合二为一。
系统功能可能会随着平台的不断发展而发生变化,所以网站system各开发者应根据网站的需求调整网站功能,设计开发移动版微信分发漫画系统源码代码。很多中小企业和企业也想搭建自己的平台,但因为技术或人力有限,似乎做不到。那么,有没有捷径呢?当然有!还有更多农场财富管理游戏系统开发、公众排队系统、红包接龙系统、全额回馈微商城系统开发、微信公众号定制、APP网站定制。每个人需要的就是我们的,欢迎来电。
新的系统开发如何开发?哪个网站建设提供商推荐?为客户定制各类网站建设服务,包括企业网站、电子商务平台、行业门户网站、品牌建设等网站平台,具有丰富的实践经验,在全国各地区均有众多成功案例看来互联网创业已经成为这个时代的一个热点。不仅是一线城市,很多三四线城市也开始了互联网创业热潮。许多传统行业也知道,他们需要结合互联网的优势来发展。不断总结创新,才会有出路。如果您对此模式感兴趣,请随时咨询。
自动采集fiction源码,新颖的系统开发。
查看全部
自动采集编写(怎么样组建小说分销H5微信?小说站手机app服务套餐
)
自动采集小说源码平台是撮合交易模式。
小说发行商H5微信如何设置?
小说站手机app就是看到作者的小说或者漫画写的好,就支付一定的钱换取奖励。小说系统源码软件与公众号对接、与微信支付对接、付费章节设置、三级代理后台、代理扣款功能、域名防屏蔽、强制关注功能、每日群发帖功能、发送优采云采集软件、广告和营销功能。编写win批处理文件可以有效节省从采集到包上传过程的操作成本。整个过程将有效节省近120倍的工作量(时间),相当于减少120倍的人工操作成本。
动漫小说平台微信公众号服务包介绍:
套餐一:源码+免费系统升级。
套餐二:源码+免费系统升级+搭建服务+售后服务。
套餐三:源码+免费系统升级+搭建服务+售后服务+安全防御搭建。
套餐四:源码+免费系统升级+搭建服务+售后服务+安全防御搭建+运维服务。
优化素材采集后的上传操作链接,批量生成大大降低了工作量和成本。新版v15:小说+漫画+视频+商店合二为一。
系统功能可能会随着平台的不断发展而发生变化,所以网站system各开发者应根据网站的需求调整网站功能,设计开发移动版微信分发漫画系统源码代码。很多中小企业和企业也想搭建自己的平台,但因为技术或人力有限,似乎做不到。那么,有没有捷径呢?当然有!还有更多农场财富管理游戏系统开发、公众排队系统、红包接龙系统、全额回馈微商城系统开发、微信公众号定制、APP网站定制。每个人需要的就是我们的,欢迎来电。
新的系统开发如何开发?哪个网站建设提供商推荐?为客户定制各类网站建设服务,包括企业网站、电子商务平台、行业门户网站、品牌建设等网站平台,具有丰富的实践经验,在全国各地区均有众多成功案例看来互联网创业已经成为这个时代的一个热点。不仅是一线城市,很多三四线城市也开始了互联网创业热潮。许多传统行业也知道,他们需要结合互联网的优势来发展。不断总结创新,才会有出路。如果您对此模式感兴趣,请随时咨询。
自动采集fiction源码,新颖的系统开发。
自动采集编写(DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(1))
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-31 18:11
DedecmsV5.6版Auto采集函数规则使用基础知识讲解教程(1)2011-05-05 17:09:01 来源:作者:我要投稿互联网摘录:dedecms采集函数使用基础知识讲解采集指的是有明确方向和明确目的的活动,挑选和记录写作材料,主要指调查、采访、审查和采集数据.采集的主要功能是获取直接和间接材料进行写作、分析、报道。今天我们说的采集主要指的是网站采集,网站采集是主要概念是的:程序按照规定的规则获取其他网站数据的一种方式,另一种简单的方式就是程序化CTRL+C CTRL+V,系统的,自动的,智能的。dedecms早有天。增加了这个采集功能。过去我们通过复制粘贴编辑然后发布来添加网站内容。这对于一个小l 数量的文章,但是如果一个新站点没有内容,那么你需要复制粘贴很多文章,这是一个重复和无聊的过程,内容采集就是为了解决这个问题,将这种重复操作简化为规则,通过规则进行批量操作。当然采集你也可以用一些特殊的采集器来做采集,国内比较有名的采集器有机车。今天我们就来讲解一下如何通过Dedecms程序自带的采集函数来使用采集,并介绍如何批量管理采集的内容。
首先我们进入系统后台,打开【采集】-【采集node管理】,介绍一些基本的技术知识,再学习使用这个采集工能。首先,我们需要了解HTML的基本内容。我们知道,浏览器中显示的各种页面,其实都是由最基本的 HTML 组成的。我们可以在我们的Dedecms系统后台发布一个内容,然后查看内容在格式上面做一些设置。换句话说,我们的页面是在浏览器解析 HTML 代码后显示的。这些基本的HTML代码是给机器看的,解析出来的内容是给我们用户看的。机器其实是个死东西。他不像用户看网页时,他可以直接看到某部分内容,机器可以看到某部分代码。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(二)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们电脑看不到,但是他判断显示什么,他只会解析代码,我们右键查看这个文件的源文件,机器读取代码的内容,他只能看懂这部分的内容在这个地方:也就是说,如果我们需要采集这些内容,我们需要告诉机器你应该从哪里开始,从哪里结束,中间部分就是我们需要的,然后这些内容都自动添加到数据库中,省去添加的枯燥内容。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(三)2011-05-05 17:09:01 来源:作者:我要提交本页网文摘要: 这里我们讲到采集中的一个概念:规则,规则就是我们告诉计算机要做的事情,比如采集内容,我们告诉计算机代码从哪里开始,代码在哪里结束,这些内容都是一条规则,在Dedecms程序中我们需要涉及到两条规则,1.List规则;2.Content规则。List规则:告诉电脑你去采集哪几篇文章,这些文章列表以什么HTML代码开始,以什么HTML代码结束;内容规则:告诉计算机采集内容的哪一部分,文档内容从哪个HTML代码开始,到最后HTML代码;我们说学会使用采集功能,其中最重要的是学会制定采集规则,有了这些规则,采集其实是很简单的事情采集的一般步骤主要包括以下内容步骤:制定列表采集规则,这里的设置主要告诉服务器采集是什么内容,通常是采集网站的列表页面;制定内容采集规则:这里告诉服务器采集页面的内容在页面的哪个部分,通常是采集网站的内容页面;生成采集后的HTML页面代码;我们也可以清楚的看到,采集的关键也是前两步。这两个步骤是判断采集内容是否成功的重要环节。有一处采集如果从采集到网站发生任何错误,都不会成功。
(第一部分结束)下面我们将通过一个例子来说明如何使用Dedecms的采集程序来采集页面信息。我们来看看打开的采集node 管理页面:我们将整个采集规则和内容变成一个节点,通过对采集规则和采集内容的管理,我们可以轻松方便的对待我们的采集规则和采集内容节点用于管理,当然采集规则也可以导出。我们只需要选择对应的采集节点,然后点击【导出配置】就可以导出我们预先指定的采集规则。一起分享。当然,如果您已经获取了节点规则,也可以通过系统的【导入采集规则】将采集规则导入系统,方便采集节点的管理,我们也可以查看此节点的当前采集。 采集的内容信息,如采集的日期、创建节点的日期、获取的URL数量等,都是采集节点的重要组成部分。这是文档的内容,所以我们在创建节点的时候首先选择“normal文章”。在V5.3中,只有普通的文章和atlas 2支持采集。之前可以自己定义,但是后来发现用的人很少,很多人都遇到了问题。所以在新版本中,我取消了采集node的这些功能。选择节点类型后,我们开始创建节点。第一部分是节点基本信息的创建,“节点名称”,这个比较简单,方便大家区分节点名称,这里我们定义为“站长学院_采集”, “目标页面编码”,这需要您查看您为采集 的网页使用的编码。一般来说,如果你使用的是IE浏览器,你只需要右键查看:Firefox浏览器需要在【查看】-【字符编码】菜单中,找到你相信的字符编码类型:这里我们看到页面编码类型为UTF-8,所以我们需要将“目标页面编码”设置为对应的编码。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(四)2011-05-05 17:09:01 来源:作者:我要提交本页网总结: “区域匹配模式”分为字符串和正则表达式两种,我们通常使用的匹配模式是字符串,当然,如果懂正则表达式,可以使用正则,这里简单介绍一下正则表达式。表达式 正则表达式描述了字符串匹配的一种模式,可用于检查字符串是否收录某个子字符串,替换匹配的子字符串,或者从字符串中提取满足某个条件的 z),以及特殊的由以下组成的文本模式字符(称为元字符)。正则表达式用作模板,将某个字符模式与搜索到的字符串进行匹配。通过正则化很容易找到对应的字符区域,但是如果要使用这种正则化,就需要学习正则化的相关知识。这里主要使用字符串,不再赘述。内容导入顺序:即导入内容在栏目中的顺序,我们默认选择与目标站相同。如果您需要将内容颠倒排序,只需选择相应的选项即可。接下来就是设置防盗链接了,如果你的采集站点没有打开防盗链接,可以忽略。接下来,让我们正式设定采集的规则。我们也说过采集的规则需要分为列表采集规则和内容采集规则。列表采集规则需要在开头设置,只有列表采集规则设置正确,服务器才能知道采集那些文章。
list采集规则的设置需要两部分。第一部分是列表URL获取规则。指定列表网址获取规则主要是因为很多站长采集target网站不仅仅是采集几个内容,有可能下载目标站采集的全部内容,而我们在采集的时候我们发现这个栏目下有数百个内容。页面”以这种形式表示,我们在想要采集内容之前需要让服务器知道整个列表的URL。设置列表采集规则比较简单。获取列表主要有3种方式: 生成列表批量url,通过系统自动生成批量地址列表;手动指定列表url,手动指定列表页面;从RSS获取,通过RSS文件获取列表页面。如果我们只需要采集一个列表页面,例如我们只需要采集,只要这10条内容,那么我们只需要在匹配的URL中填写这个URL即可。如果我们采集多个列表的内容,就可以完成通过自动生成或指定多个列表页面,我们查看下一个列表页面,我们点击下面栏目的第一页,这样我们就可以自动指定一个规则。点击匹配URL后面的“测试”按钮看看发现我们已经成功获取到这个列表了,或者我们选择手动指定,然后在URL列表中指定:当然,这个列表部分的规则还有更多的功能,比如可以指定列表列的导入内容。这部分的详细设置可以在织梦帮助中心查看:这里我们已经完成了列表地址的设置。接下来,我们需要设置文章 URL 匹配规则。这个匹配规则是让我们来到采集文章列表,告诉服务器采集文章在采集This文章中,我们看一下这些列表的页面。不变的部分是头部导航,右边推荐信息,底部内容。主要变化是列表的标题和内容。我们采集列表文章的主要内容是采集列表的文章标题部分。如果我们理解HTML代码观察,最直接的表现就是HTML代码列表页面部分的内容发生了变化。
所以当我们指定采集列表页面时,我们只需要指定一个统一的规则,因为列表的页面是一样的,所以这个规则适用于所有的列表页面。当然,我们也会发现内容页面也是如此。你只需要给采集指定一个统一的规则就可以得到所有相似页面的内容。当然,有些网站列表是链接到其他内容的,所以你会遇到采集规则不匹配的问题。一般不可能采集到达内容,因为规则不适用,另外一个表现就是采集progress 文章不动,就到此为止,有时甚至会报错。这些原因的主要原因是规则与目标采集网站不匹配,所以在采集内容之前确保规则的正确性。德德cmsV5.6版自动采集函数规则使用基础知识讲解教程(五)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络摘要:接下来我们设置列表采集页面的采集规则,我们先查看源文件,在IE浏览器中右键选择【查看源文件】打开列表页面的源代码,如果我们有DW,把这些代码复制到DW,我们找到那个列表的位置:我们发现这个列表的内容在“”层,也就是我们需要告诉服务器采集这个列表的标题list你从这里采集开始,然后到这一层采集的末尾,我们看到这一层的末尾是“”,中间没有找到相同的代码。
这里需要告诉大家的是我们的规则,它告诉服务器起始的HTML标签必须是唯一的,也就是说你在这个页面上只有这个标签,这样计算机就知道从哪里开始,从哪里开始那地方结束。 采集 写规则的时候,很多时候需要找唯一标识符。有了这些标识符,服务器就知道它可以捕获内容。我们已经到达了刚才列表的范围,在“”之间,所以填写采集规则的“区域开头的HTML:”和“区域结尾的HTML:”,以及服务器随后会将其间的所有连接用作目标采集 的文章 列表以继续采集 向下。但有一个问题。在我们的列表规则中,并不是所有的超链接都是目标采集的文章。设置的页面是内容页面,所以我们需要过滤掉这些不续采集丢失的内容页面。 织梦的采集提供了2种方式过滤这些页面:1.必须收录,这是采集的超链接中必须收录的,2.不能收录,在采集的地址中哪些内容不能收录,我们一般采用这两个公式中的一个。通过观察可以看出我们需要采集的内容页地址不收录“feedback.php”,所以我们将收录所有Feedback.php然后过滤掉,剩下的是我们的文章连接.
还有一个缩略图的处理,我们可以使用默认,设置完成后,我们保存测试,看看我们是否可以采集到达内容。我们发现已经可以成功采集到文章的标题列表信息了:此时我们的列表信息是采集完成的,接下来我们将设置内容页的采集规则,这个采集 规则和列表页 采集 规则也很相似,主要功能是从重复的内容页中获取不同的内容,下面我们继续处理采集 的内容。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(六)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们先打开一个文章内容,我们把这个网页的源代码复制到DW工具中查看:我们可以看到这个页面的源代码中的“标题”和“文章内容”,以及那么我们来设置一下内容采集规则,在新版本的V5.3中,如果采集网页内容收录关键词和页面摘要,系统会自动采集,即在页面代码:采集的内容会自动下载,当然很多用户是想自己设置或生成的,那么我们这里就用过滤规则自动过滤掉采集的内容,我们过滤内容是关键字和“摘要”在“过滤内容”中填写过滤规则:{dede:trim replace=""}(.*){/dede:trim}这里说一下这个过滤规则,{dede:trim replace=" "}正则表达式{/dede :trim},使用正则{dede:trim} 标签中间的r表达式,在采集的内容中搜索对应的字符串。如果需要替换搜索到的内容,需要指定replace属性。例如,如果我们只是在获取内容字段时将所有关键词替换为空,如果我们默认指定关键词,我们可以这样写:{dede:trim replace="Dedecms,织梦, demo站"}(.*){/dede:trim}因为我们这里主要是demo,主要有2个字段采集,1是内容的标题,另一个是文章的内容,所以我们需要相应地制定2个地方的匹配规则。
我们为文章title设置了匹配规则,因为一般内容的标题会出现在两个标签“”之间,所以我们在设置标题匹配规则的时候只需要设置默认的“”,但是有一件事,我们看一下采集目标站的标题:他在每个标题后面都加上了“_织梦unofficial demo site”,所以我们需要去掉这部分指定的规则,简单的修改匹配规则就是这样,我们修改为“”,这样我们就完成了title的匹配规则的编译。匹配规则,在匹配区域规则中,规则一般为“开头无重复HTML[内容]结尾无重复HTML”(正常匹配,不规则)。接下来,我们设置文章内容的匹配规则。这个匹配规则有点类似于标题的匹配规则。我们只需要找到唯一的 HTML 开始标记和 HTML 结束标记。我们刚刚指定了文章 列表规则。为文章找到的内容收录在layer”layer标签中,所以我们指定的匹配规则是一样的。我们根据上面匹配规则的定义设置如下匹配规则: [Content]当然会有在采集的内容中是一些我们不想关闭的超链接,这个时候我们需要清除那些内容,然后我们需要使用过滤规则,这个过滤规则和刚才的一样,但是系统自带了一些常用的常规规则,我们来看看:我们设置了过滤规则后,在采集中会有不同的效果。当然采集部分还有几个小选项这里需要说明的内容,一个是页面内容字段,这个只有采集是多页面内容时才会接触,需要在开头设置分页采集的开始和结束标签. 设置方法和匹配规则相同。
下载字段中的多媒体资源。这是采集下载时某些多媒体字段中的附件。一般只支持部分图片和部分flash下载。如果有很多图片不能采集,可能是服务器的原因,要么是本地服务器不支持,要么是对方服务器采取了防止采集的措施。自定义处理接口,这个主要是通过一些函数来处理网页的内容,我们可以设置一个简单的自定义处理接口,因为采集的内容可能收录HTML代码,那么我们把采集的内容进行转换totxt文本,这里可以使用自定义处理界面。我们设置内容如下:@me=html2text(@me);这样我们就可以保存采集规则了,到目前为止我们已经在规则编写部分完成了,那么我们开始采集内容:接下来我们开始采集节点内容采集完成后,我们导入到对应的列,如果我们之前设置了导出列,可以检查:使用采集规则中指定的列ID(如果目标列ID为0,则使用上面选择的列),这样就可以导入了确认设置后进入该列,然后导入到对应的列中。来看看测试栏下内容:dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(七)2011-05-05 17:09:01 来源:作者:我要投稿本页加网总结: 接下来需要处理这些内容,可以进入系统后台【核心】-【文档关键词维护】,这里可以使用“分析系统中的关键词”自动返回关键词content .
我们“检测现有关键字”以自动获取关键词。或者可以通过自动获取摘要或者分页的方式批量维护采集的内容,非常方便。当然,系统批处理的功能还有很多,这里就不一一列举了。最后,我们需要生成所有的静态页面,到此采集的所有内容就完成了。其实采集并不难,原理是一样的。最主要的是你理解了一些概念,一个匹配规则和一个过滤规则。匹配规则需要的是你可以找到一个唯一的标识符,你可以通过这些唯一标识符来判断你的内容采集。过滤规则是处理你采集的内容。当然,您也可以通过系统的批处理进行维护。 采集 的内容。 采集的经验积累很重要。一般有些网页,比如我们演示的案例,很简单,使用div+css布局,结构也很清晰,所以采集很简单,但是有些网页使用表格布局,就采集一下比较麻烦,所以这个需要你设置采集的内容,过滤内容。只有当你有很多采集 经验时才能做到这一点。总之,采集可以帮助你的站点在前期丰富内容,但是一个长期发展的站点并不能仅仅依靠采集别人的内容来生存,更重要的是站点的内容、功能、以及独创性。这些都是站长需要考虑的事情,所以我们了解到采集只是一个简单的应用工具,不建议大家都用采集做网站。我们总结了本课程的主要内容:采集的基本概念理解采集的一般步骤,结合实例了解如何设置采集节点的规则;基本批处理; 查看全部
自动采集编写(DedeCMSV5.6版自动采集功能规则使用基本知识讲解教程(1))
DedecmsV5.6版Auto采集函数规则使用基础知识讲解教程(1)2011-05-05 17:09:01 来源:作者:我要投稿互联网摘录:dedecms采集函数使用基础知识讲解采集指的是有明确方向和明确目的的活动,挑选和记录写作材料,主要指调查、采访、审查和采集数据.采集的主要功能是获取直接和间接材料进行写作、分析、报道。今天我们说的采集主要指的是网站采集,网站采集是主要概念是的:程序按照规定的规则获取其他网站数据的一种方式,另一种简单的方式就是程序化CTRL+C CTRL+V,系统的,自动的,智能的。dedecms早有天。增加了这个采集功能。过去我们通过复制粘贴编辑然后发布来添加网站内容。这对于一个小l 数量的文章,但是如果一个新站点没有内容,那么你需要复制粘贴很多文章,这是一个重复和无聊的过程,内容采集就是为了解决这个问题,将这种重复操作简化为规则,通过规则进行批量操作。当然采集你也可以用一些特殊的采集器来做采集,国内比较有名的采集器有机车。今天我们就来讲解一下如何通过Dedecms程序自带的采集函数来使用采集,并介绍如何批量管理采集的内容。
首先我们进入系统后台,打开【采集】-【采集node管理】,介绍一些基本的技术知识,再学习使用这个采集工能。首先,我们需要了解HTML的基本内容。我们知道,浏览器中显示的各种页面,其实都是由最基本的 HTML 组成的。我们可以在我们的Dedecms系统后台发布一个内容,然后查看内容在格式上面做一些设置。换句话说,我们的页面是在浏览器解析 HTML 代码后显示的。这些基本的HTML代码是给机器看的,解析出来的内容是给我们用户看的。机器其实是个死东西。他不像用户看网页时,他可以直接看到某部分内容,机器可以看到某部分代码。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(二)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们电脑看不到,但是他判断显示什么,他只会解析代码,我们右键查看这个文件的源文件,机器读取代码的内容,他只能看懂这部分的内容在这个地方:也就是说,如果我们需要采集这些内容,我们需要告诉机器你应该从哪里开始,从哪里结束,中间部分就是我们需要的,然后这些内容都自动添加到数据库中,省去添加的枯燥内容。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(三)2011-05-05 17:09:01 来源:作者:我要提交本页网文摘要: 这里我们讲到采集中的一个概念:规则,规则就是我们告诉计算机要做的事情,比如采集内容,我们告诉计算机代码从哪里开始,代码在哪里结束,这些内容都是一条规则,在Dedecms程序中我们需要涉及到两条规则,1.List规则;2.Content规则。List规则:告诉电脑你去采集哪几篇文章,这些文章列表以什么HTML代码开始,以什么HTML代码结束;内容规则:告诉计算机采集内容的哪一部分,文档内容从哪个HTML代码开始,到最后HTML代码;我们说学会使用采集功能,其中最重要的是学会制定采集规则,有了这些规则,采集其实是很简单的事情采集的一般步骤主要包括以下内容步骤:制定列表采集规则,这里的设置主要告诉服务器采集是什么内容,通常是采集网站的列表页面;制定内容采集规则:这里告诉服务器采集页面的内容在页面的哪个部分,通常是采集网站的内容页面;生成采集后的HTML页面代码;我们也可以清楚的看到,采集的关键也是前两步。这两个步骤是判断采集内容是否成功的重要环节。有一处采集如果从采集到网站发生任何错误,都不会成功。
(第一部分结束)下面我们将通过一个例子来说明如何使用Dedecms的采集程序来采集页面信息。我们来看看打开的采集node 管理页面:我们将整个采集规则和内容变成一个节点,通过对采集规则和采集内容的管理,我们可以轻松方便的对待我们的采集规则和采集内容节点用于管理,当然采集规则也可以导出。我们只需要选择对应的采集节点,然后点击【导出配置】就可以导出我们预先指定的采集规则。一起分享。当然,如果您已经获取了节点规则,也可以通过系统的【导入采集规则】将采集规则导入系统,方便采集节点的管理,我们也可以查看此节点的当前采集。 采集的内容信息,如采集的日期、创建节点的日期、获取的URL数量等,都是采集节点的重要组成部分。这是文档的内容,所以我们在创建节点的时候首先选择“normal文章”。在V5.3中,只有普通的文章和atlas 2支持采集。之前可以自己定义,但是后来发现用的人很少,很多人都遇到了问题。所以在新版本中,我取消了采集node的这些功能。选择节点类型后,我们开始创建节点。第一部分是节点基本信息的创建,“节点名称”,这个比较简单,方便大家区分节点名称,这里我们定义为“站长学院_采集”, “目标页面编码”,这需要您查看您为采集 的网页使用的编码。一般来说,如果你使用的是IE浏览器,你只需要右键查看:Firefox浏览器需要在【查看】-【字符编码】菜单中,找到你相信的字符编码类型:这里我们看到页面编码类型为UTF-8,所以我们需要将“目标页面编码”设置为对应的编码。
dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(四)2011-05-05 17:09:01 来源:作者:我要提交本页网总结: “区域匹配模式”分为字符串和正则表达式两种,我们通常使用的匹配模式是字符串,当然,如果懂正则表达式,可以使用正则,这里简单介绍一下正则表达式。表达式 正则表达式描述了字符串匹配的一种模式,可用于检查字符串是否收录某个子字符串,替换匹配的子字符串,或者从字符串中提取满足某个条件的 z),以及特殊的由以下组成的文本模式字符(称为元字符)。正则表达式用作模板,将某个字符模式与搜索到的字符串进行匹配。通过正则化很容易找到对应的字符区域,但是如果要使用这种正则化,就需要学习正则化的相关知识。这里主要使用字符串,不再赘述。内容导入顺序:即导入内容在栏目中的顺序,我们默认选择与目标站相同。如果您需要将内容颠倒排序,只需选择相应的选项即可。接下来就是设置防盗链接了,如果你的采集站点没有打开防盗链接,可以忽略。接下来,让我们正式设定采集的规则。我们也说过采集的规则需要分为列表采集规则和内容采集规则。列表采集规则需要在开头设置,只有列表采集规则设置正确,服务器才能知道采集那些文章。
list采集规则的设置需要两部分。第一部分是列表URL获取规则。指定列表网址获取规则主要是因为很多站长采集target网站不仅仅是采集几个内容,有可能下载目标站采集的全部内容,而我们在采集的时候我们发现这个栏目下有数百个内容。页面”以这种形式表示,我们在想要采集内容之前需要让服务器知道整个列表的URL。设置列表采集规则比较简单。获取列表主要有3种方式: 生成列表批量url,通过系统自动生成批量地址列表;手动指定列表url,手动指定列表页面;从RSS获取,通过RSS文件获取列表页面。如果我们只需要采集一个列表页面,例如我们只需要采集,只要这10条内容,那么我们只需要在匹配的URL中填写这个URL即可。如果我们采集多个列表的内容,就可以完成通过自动生成或指定多个列表页面,我们查看下一个列表页面,我们点击下面栏目的第一页,这样我们就可以自动指定一个规则。点击匹配URL后面的“测试”按钮看看发现我们已经成功获取到这个列表了,或者我们选择手动指定,然后在URL列表中指定:当然,这个列表部分的规则还有更多的功能,比如可以指定列表列的导入内容。这部分的详细设置可以在织梦帮助中心查看:这里我们已经完成了列表地址的设置。接下来,我们需要设置文章 URL 匹配规则。这个匹配规则是让我们来到采集文章列表,告诉服务器采集文章在采集This文章中,我们看一下这些列表的页面。不变的部分是头部导航,右边推荐信息,底部内容。主要变化是列表的标题和内容。我们采集列表文章的主要内容是采集列表的文章标题部分。如果我们理解HTML代码观察,最直接的表现就是HTML代码列表页面部分的内容发生了变化。
所以当我们指定采集列表页面时,我们只需要指定一个统一的规则,因为列表的页面是一样的,所以这个规则适用于所有的列表页面。当然,我们也会发现内容页面也是如此。你只需要给采集指定一个统一的规则就可以得到所有相似页面的内容。当然,有些网站列表是链接到其他内容的,所以你会遇到采集规则不匹配的问题。一般不可能采集到达内容,因为规则不适用,另外一个表现就是采集progress 文章不动,就到此为止,有时甚至会报错。这些原因的主要原因是规则与目标采集网站不匹配,所以在采集内容之前确保规则的正确性。德德cmsV5.6版自动采集函数规则使用基础知识讲解教程(五)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络摘要:接下来我们设置列表采集页面的采集规则,我们先查看源文件,在IE浏览器中右键选择【查看源文件】打开列表页面的源代码,如果我们有DW,把这些代码复制到DW,我们找到那个列表的位置:我们发现这个列表的内容在“”层,也就是我们需要告诉服务器采集这个列表的标题list你从这里采集开始,然后到这一层采集的末尾,我们看到这一层的末尾是“”,中间没有找到相同的代码。
这里需要告诉大家的是我们的规则,它告诉服务器起始的HTML标签必须是唯一的,也就是说你在这个页面上只有这个标签,这样计算机就知道从哪里开始,从哪里开始那地方结束。 采集 写规则的时候,很多时候需要找唯一标识符。有了这些标识符,服务器就知道它可以捕获内容。我们已经到达了刚才列表的范围,在“”之间,所以填写采集规则的“区域开头的HTML:”和“区域结尾的HTML:”,以及服务器随后会将其间的所有连接用作目标采集 的文章 列表以继续采集 向下。但有一个问题。在我们的列表规则中,并不是所有的超链接都是目标采集的文章。设置的页面是内容页面,所以我们需要过滤掉这些不续采集丢失的内容页面。 织梦的采集提供了2种方式过滤这些页面:1.必须收录,这是采集的超链接中必须收录的,2.不能收录,在采集的地址中哪些内容不能收录,我们一般采用这两个公式中的一个。通过观察可以看出我们需要采集的内容页地址不收录“feedback.php”,所以我们将收录所有Feedback.php然后过滤掉,剩下的是我们的文章连接.
还有一个缩略图的处理,我们可以使用默认,设置完成后,我们保存测试,看看我们是否可以采集到达内容。我们发现已经可以成功采集到文章的标题列表信息了:此时我们的列表信息是采集完成的,接下来我们将设置内容页的采集规则,这个采集 规则和列表页 采集 规则也很相似,主要功能是从重复的内容页中获取不同的内容,下面我们继续处理采集 的内容。 dedecmsV5.6版自动采集功能规则讲解基础知识教程(六)2011-05-05 17:09:01 来源:作者:我想把这个页面贡献给网络文摘: 我们先打开一个文章内容,我们把这个网页的源代码复制到DW工具中查看:我们可以看到这个页面的源代码中的“标题”和“文章内容”,以及那么我们来设置一下内容采集规则,在新版本的V5.3中,如果采集网页内容收录关键词和页面摘要,系统会自动采集,即在页面代码:采集的内容会自动下载,当然很多用户是想自己设置或生成的,那么我们这里就用过滤规则自动过滤掉采集的内容,我们过滤内容是关键字和“摘要”在“过滤内容”中填写过滤规则:{dede:trim replace=""}(.*){/dede:trim}这里说一下这个过滤规则,{dede:trim replace=" "}正则表达式{/dede :trim},使用正则{dede:trim} 标签中间的r表达式,在采集的内容中搜索对应的字符串。如果需要替换搜索到的内容,需要指定replace属性。例如,如果我们只是在获取内容字段时将所有关键词替换为空,如果我们默认指定关键词,我们可以这样写:{dede:trim replace="Dedecms,织梦, demo站"}(.*){/dede:trim}因为我们这里主要是demo,主要有2个字段采集,1是内容的标题,另一个是文章的内容,所以我们需要相应地制定2个地方的匹配规则。
我们为文章title设置了匹配规则,因为一般内容的标题会出现在两个标签“”之间,所以我们在设置标题匹配规则的时候只需要设置默认的“”,但是有一件事,我们看一下采集目标站的标题:他在每个标题后面都加上了“_织梦unofficial demo site”,所以我们需要去掉这部分指定的规则,简单的修改匹配规则就是这样,我们修改为“”,这样我们就完成了title的匹配规则的编译。匹配规则,在匹配区域规则中,规则一般为“开头无重复HTML[内容]结尾无重复HTML”(正常匹配,不规则)。接下来,我们设置文章内容的匹配规则。这个匹配规则有点类似于标题的匹配规则。我们只需要找到唯一的 HTML 开始标记和 HTML 结束标记。我们刚刚指定了文章 列表规则。为文章找到的内容收录在layer”layer标签中,所以我们指定的匹配规则是一样的。我们根据上面匹配规则的定义设置如下匹配规则: [Content]当然会有在采集的内容中是一些我们不想关闭的超链接,这个时候我们需要清除那些内容,然后我们需要使用过滤规则,这个过滤规则和刚才的一样,但是系统自带了一些常用的常规规则,我们来看看:我们设置了过滤规则后,在采集中会有不同的效果。当然采集部分还有几个小选项这里需要说明的内容,一个是页面内容字段,这个只有采集是多页面内容时才会接触,需要在开头设置分页采集的开始和结束标签. 设置方法和匹配规则相同。
下载字段中的多媒体资源。这是采集下载时某些多媒体字段中的附件。一般只支持部分图片和部分flash下载。如果有很多图片不能采集,可能是服务器的原因,要么是本地服务器不支持,要么是对方服务器采取了防止采集的措施。自定义处理接口,这个主要是通过一些函数来处理网页的内容,我们可以设置一个简单的自定义处理接口,因为采集的内容可能收录HTML代码,那么我们把采集的内容进行转换totxt文本,这里可以使用自定义处理界面。我们设置内容如下:@me=html2text(@me);这样我们就可以保存采集规则了,到目前为止我们已经在规则编写部分完成了,那么我们开始采集内容:接下来我们开始采集节点内容采集完成后,我们导入到对应的列,如果我们之前设置了导出列,可以检查:使用采集规则中指定的列ID(如果目标列ID为0,则使用上面选择的列),这样就可以导入了确认设置后进入该列,然后导入到对应的列中。来看看测试栏下内容:dedecmsV5.6版自动采集函数规则使用基础知识讲解教程(七)2011-05-05 17:09:01 来源:作者:我要投稿本页加网总结: 接下来需要处理这些内容,可以进入系统后台【核心】-【文档关键词维护】,这里可以使用“分析系统中的关键词”自动返回关键词content .
我们“检测现有关键字”以自动获取关键词。或者可以通过自动获取摘要或者分页的方式批量维护采集的内容,非常方便。当然,系统批处理的功能还有很多,这里就不一一列举了。最后,我们需要生成所有的静态页面,到此采集的所有内容就完成了。其实采集并不难,原理是一样的。最主要的是你理解了一些概念,一个匹配规则和一个过滤规则。匹配规则需要的是你可以找到一个唯一的标识符,你可以通过这些唯一标识符来判断你的内容采集。过滤规则是处理你采集的内容。当然,您也可以通过系统的批处理进行维护。 采集 的内容。 采集的经验积累很重要。一般有些网页,比如我们演示的案例,很简单,使用div+css布局,结构也很清晰,所以采集很简单,但是有些网页使用表格布局,就采集一下比较麻烦,所以这个需要你设置采集的内容,过滤内容。只有当你有很多采集 经验时才能做到这一点。总之,采集可以帮助你的站点在前期丰富内容,但是一个长期发展的站点并不能仅仅依靠采集别人的内容来生存,更重要的是站点的内容、功能、以及独创性。这些都是站长需要考虑的事情,所以我们了解到采集只是一个简单的应用工具,不建议大家都用采集做网站。我们总结了本课程的主要内容:采集的基本概念理解采集的一般步骤,结合实例了解如何设置采集节点的规则;基本批处理;
自动采集编写(采集内存使用数据采集类代码暴露数据情况部署代码和集成查询 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-08-30 17:01
)
在之前的文章中,我已经写过几个官方exporter的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这个时候一般需要我们自己写采集器。
快速开始写一个介绍性的demo来写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时会监听8000端口,访问127.0.0.1:8000端口。
效果图
其实一个exporter已经写好了。就这么简单。我们只需要在prometheus中配置采集对应的exporter即可。但是,我们导出的数据毫无意义。
数据类型介绍
Counter 是一个累加类型,只能增加,比如记录http请求的总次数或者网络收发包的累计值。
Gauge:仪表盘类型,适用于有涨有跌、一般网络流量、磁盘读写等,有波动变化的数据类型使用。
总结:基于抽样,在服务器上完成统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
直方图:基于抽样,在客户端进行统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
采集Memory 使用数据编写采集类代码
暴露数据情况
部署代码并集成 prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图
查看全部
自动采集编写(采集内存使用数据采集类代码暴露数据情况部署代码和集成查询
)
在之前的文章中,我已经写过几个官方exporter的使用。在实际使用环境中,我们可能需要采集一些自定义数据。这个时候一般需要我们自己写采集器。
快速开始写一个介绍性的demo来写代码
from prometheus_client import Counter, Gauge, Summary, Histogram, start_http_server
# need install prometheus_client
if __name__ == '__main__':
c = Counter('cc', 'A counter')
c.inc()
g = Gauge('gg', 'A gauge')
g.set(17)
s = Summary('ss', 'A summary', ['a', 'b'])
s.labels('c', 'd').observe(17)
h = Histogram('hh', 'A histogram')
h.observe(.6)
start_http_server(8000)
import time
while True:
time.sleep(1)
只需要一个py文件。运行时会监听8000端口,访问127.0.0.1:8000端口。
效果图
其实一个exporter已经写好了。就这么简单。我们只需要在prometheus中配置采集对应的exporter即可。但是,我们导出的数据毫无意义。
数据类型介绍
Counter 是一个累加类型,只能增加,比如记录http请求的总次数或者网络收发包的累计值。
Gauge:仪表盘类型,适用于有涨有跌、一般网络流量、磁盘读写等,有波动变化的数据类型使用。
总结:基于抽样,在服务器上完成统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
直方图:基于抽样,在客户端进行统计。当我们统计平均值时,可能会认为异常值导致计算出的平均值不能准确反映实际值,需要具体的点位。
采集Memory 使用数据编写采集类代码
暴露数据情况
部署代码并集成 prometheus
# 准备python3 环境 参考: https://virtualenvwrapper.read ... test/
yum install python36 -y
pip3 install virtualenvwrapper
vim /usr/local/bin/virtualenvwrapper.sh
# 文件最前面添加如下行
# Locate the global Python where virtualenvwrapper is installed.
VIRTUALENVWRAPPER_PYTHON="/usr/bin/python3"
# 文件生效
source /usr/local/bin/virtualenvwrapper.sh
# 配置workon
[root@node01 ~]# echo "export WORKON_HOME=~/Envs" >>~/.bashrc
[root@node01 ~]# mkvirtualenv custom_memory_exporter
(custom_memory_exporter) [root@node01 ~]# pip install prometheus_client psutil
yum install python36-devel
(custom_memory_exporter) [root@node01 ~]# chmod a+x custom_memory_exporter.py
(custom_memory_exporter) [root@node01 ~]# ./custom_memory_exporter.py
# 测试是否有结果数据
[root@node00 ~]# curl http://192.168.100.11:8001/
prometheus.yml 加入如下片段
- job_name: "custom-memory-exporter"
static_configs:
- targets: ["192.168.100.11:8001"]
[root@node00 prometheus]# systemctl restart prometheus
[root@node00 prometheus]# systemctl status prometheu
查询效果图
自动采集编写(单机模拟器没有,我也遇到过同样的问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-08-28 23:07
自动采集编写脚本,填写好截取代码,并将脚本用newinstall.worker()导入,再自动连接上即可,
同问。
简单的appium也是可以的
在他们的代码里面加入appium实时抓包就行
都不给力!我们叫它为app抓包
不知道有没有解决你的问题
appium下实现基本的单机模拟器
没有,我也遇到同样的问题,百度了半天,
appium+selenium这个方案我写过,从最基础的开始,然后慢慢找bug改,
appium+eclipse
有
你可以试试cygwin
可以试试cygwin,
iphone下1是否可用?
在appium4里设置eduid有些回答说python写appium脚本是在手机qq里抓的,不错,但方法可能需要改一下,
win10可以用的!已经很棒了,单机模拟器+win10才4gb内存,然后就是win7的win+jy+appium4。总觉得对iphone不太友好。不过win10可以用python,也可以在手机qq里抓,因为它自带qqforiphone。
没有的,
推荐ipadmini。ios的app里面的开发人员工具里可以用python+selenium。 查看全部
自动采集编写(单机模拟器没有,我也遇到过同样的问题)
自动采集编写脚本,填写好截取代码,并将脚本用newinstall.worker()导入,再自动连接上即可,
同问。
简单的appium也是可以的
在他们的代码里面加入appium实时抓包就行
都不给力!我们叫它为app抓包
不知道有没有解决你的问题
appium下实现基本的单机模拟器
没有,我也遇到同样的问题,百度了半天,
appium+selenium这个方案我写过,从最基础的开始,然后慢慢找bug改,
appium+eclipse
有
你可以试试cygwin
可以试试cygwin,
iphone下1是否可用?
在appium4里设置eduid有些回答说python写appium脚本是在手机qq里抓的,不错,但方法可能需要改一下,
win10可以用的!已经很棒了,单机模拟器+win10才4gb内存,然后就是win7的win+jy+appium4。总觉得对iphone不太友好。不过win10可以用python,也可以在手机qq里抓,因为它自带qqforiphone。
没有的,
推荐ipadmini。ios的app里面的开发人员工具里可以用python+selenium。
自动采集编写(自动采集编写第二代爬虫程序和其他代码的区别)
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-08-27 23:05
自动采集编写第二代爬虫程序,请循环运行,直到获取完整内容。请确保计算机在第一次运行时处于停止状态。然后运行序列第一代爬虫程序和其他代码。
一、爬虫目标列表:一二三四五六七八九十百千万。每一条链接都单独获取。最终得到的url地址包含以下属性:1.网址:2.请求headers:3.请求体headersurl中的http://:表示请求headers中携带了requestheaders中的相关数据,如果在运行第一代爬虫程序时未携带requestheaders,则会导致浏览器出现原始浏览器,这是无法解决的。
所以在运行第一代爬虫程序时需要携带requestheaders(常用)和一个相关程序代码,requestheaders就包含requestheaders中的user-agentuser-agent:浏览器独有的格式化user-agent标识这里没有一一列出,是因为与第二代爬虫程序中的user-agent不同,大家理解即可。
它可以作为请求页面时定位的方式,也可以是判断url请求是否可用的代理方式。具体见请求逻辑中的requestheadersuser-agent:http请求页面时浏览器独有的格式化user-agent标识。
二、网页请求编写nodejs定位并解析出对应的headersheaders分为body部分和data部分body部分中包含user-agent、get/post参数、cookie、session等参数,data部分是一些body字段对应的文本数据。
三、编写第二代爬虫程序nodejsget并获取html网页内容nodejspost并解析并解析html网页内容js定义一个单例模式,通过一个函数方法或者一个对象,能够任意获取一个a标签内的位置,并且能够取到这个a标签的全部定位到第一个a标签,xxx指定一个位置,然后button相对于xxx指定一个位置。
可以手动解析,也可以使用全局对象解析。接下来简单的解释一下这个方法。get请求的优点是跨浏览器,而且可以随意跳转,缺点是只能获取html中的一部分信息。我们想获取xxx,button相对于xxx获取一个位置,获取xxx三个字段,没有方法。所以接下来使用全局对象方法来解析html源码,请自行编写代码,最后请自行编写回显模式的组件。
selenium的使用get请求与seleniumpost的区别在于get使用浏览器内置的user-agent(比如chrome的user-agent)来进行定位和获取,而post则是向服务器发送post请求,服务器检查一个cookie,如果有返回该cookie则返回该xxx,否则,则不返回xxx,这是get和post的区别。
getheaders检查${max_age}是否大于等于${max_time}的十分之一,否则会延迟,比如取到小于三个小时的时间间隔。postheaders检查${send_to_params。 查看全部
自动采集编写(自动采集编写第二代爬虫程序和其他代码的区别)
自动采集编写第二代爬虫程序,请循环运行,直到获取完整内容。请确保计算机在第一次运行时处于停止状态。然后运行序列第一代爬虫程序和其他代码。
一、爬虫目标列表:一二三四五六七八九十百千万。每一条链接都单独获取。最终得到的url地址包含以下属性:1.网址:2.请求headers:3.请求体headersurl中的http://:表示请求headers中携带了requestheaders中的相关数据,如果在运行第一代爬虫程序时未携带requestheaders,则会导致浏览器出现原始浏览器,这是无法解决的。
所以在运行第一代爬虫程序时需要携带requestheaders(常用)和一个相关程序代码,requestheaders就包含requestheaders中的user-agentuser-agent:浏览器独有的格式化user-agent标识这里没有一一列出,是因为与第二代爬虫程序中的user-agent不同,大家理解即可。
它可以作为请求页面时定位的方式,也可以是判断url请求是否可用的代理方式。具体见请求逻辑中的requestheadersuser-agent:http请求页面时浏览器独有的格式化user-agent标识。
二、网页请求编写nodejs定位并解析出对应的headersheaders分为body部分和data部分body部分中包含user-agent、get/post参数、cookie、session等参数,data部分是一些body字段对应的文本数据。
三、编写第二代爬虫程序nodejsget并获取html网页内容nodejspost并解析并解析html网页内容js定义一个单例模式,通过一个函数方法或者一个对象,能够任意获取一个a标签内的位置,并且能够取到这个a标签的全部定位到第一个a标签,xxx指定一个位置,然后button相对于xxx指定一个位置。
可以手动解析,也可以使用全局对象解析。接下来简单的解释一下这个方法。get请求的优点是跨浏览器,而且可以随意跳转,缺点是只能获取html中的一部分信息。我们想获取xxx,button相对于xxx获取一个位置,获取xxx三个字段,没有方法。所以接下来使用全局对象方法来解析html源码,请自行编写代码,最后请自行编写回显模式的组件。
selenium的使用get请求与seleniumpost的区别在于get使用浏览器内置的user-agent(比如chrome的user-agent)来进行定位和获取,而post则是向服务器发送post请求,服务器检查一个cookie,如果有返回该cookie则返回该xxx,否则,则不返回xxx,这是get和post的区别。
getheaders检查${max_age}是否大于等于${max_time}的十分之一,否则会延迟,比如取到小于三个小时的时间间隔。postheaders检查${send_to_params。
自动采集编写 微信公众号查看历史消息页或者文章详情页(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 214 次浏览 • 2021-08-27 07:01
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、anyproxy 通过修改anyproxy配置文件解决了拦截过程中的各种错误。
anyproxy在报错时会执行anyproxy配置文件rule_default.js中的onError方法,所以报错时可以修改方法获取下一页,注入js脚本中继续执行,无需停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub 源码地址:wechat-serv-crawler
环境搭建和部署运行 安装前准备
系统:CentOS Linux release 7.6.1810 (Core)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
搭建与服务器相关的anyproxy代理文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击操作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信随意添加好友,好友发送给你任意微信公众号的历史消息页面或微信文章linked message ,并将消息置顶,进入消息聊天界面,点击链接开始自动抓取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是说一开始必须给一个触发事件,比如打开微信公众号查看历史消息或者打开一个公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章详情页通过js注入,当然这中间可能会出现异常,异常会阻塞自动跳转到下一页。这需要自动化框架的帮助来模拟手动点击操作。这里使用的是 atx 自动化框架。
该项目自动化程度高。人工费用为首次登录微信后,点击微信公众号查看历史消息或打开公众号文章链接。后续会完全通过js注入跳转,异常自动处理恢复点击(atx自动点击)。
运行效果展示
这个项目已经是一个完整成熟的项目了。经过大量长期测试,一个微信客户端采集300公众号文章每天的数据可以保证稳定运行,保证账号不会被封。如果您访问微信公众号历史新闻页面过于频繁,将会被24小时禁言。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用3个微信公众号,采集900微信公众号每天文章数据。
每个微信账号月费5元。基于该项目,可实现大规模作业的低成本作业。
更新(2020-07-30)以降低抓取错误时漏网率
因为我使用redis的list队列作为消息队列,消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序在slave master 从消息队列中取出消息后,插入到备份队列中,并从备份队列中删除消息,直到消费者程序完成正常的处理逻辑同时,我们还可以提供守护进程。消费完主消息队列中的消息后,可以将备份队列中正常未消费的消息放回主消息队列,以便其他消费程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史消息列表&特殊微信公众号无需关注即可获取历史文章:
之前实现的解决方案是只抓取微信公众号文章列表的最新页面。由于抓包分析的下一页返回的内容是json响应体,无法通过注入脚本自动模拟。 Traverse实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章列表,注意f参数为html,下一页返回的内容格式即可修改为html,解决了json不适合注入js脚本的问题。此外,还可以通过调整偏移量来实现翻页。
下图为上述公众号文章list页面第100页的历史记录:
参考文章
感谢文章提供的想法:
1、用好anyproxy提高公众号文章采集efficiency详解
2、微信公号文章batch采集系统建设
联系作者
由于微信采集平台的搭建和开发花费了大量的时间和精力,我们暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,且本项目目前实现的功能满足您的需求,可以付费联系我帮你搭建这个项目,并收录所有源代码,解答和解决你在开发过程中遇到的所有疑问。 查看全部
自动采集编写 微信公众号查看历史消息页或者文章详情页(组图)
%2BfItg%3D&pass_ticket=DGD5JOEorn3ncmbmdXKbsmgxGOEwYobX7unmU6gwxw8SzwowCh6KBA%2BRMYejszL%2F&wx_header=1
3、anyproxy 通过修改anyproxy配置文件解决了拦截过程中的各种错误。
anyproxy在报错时会执行anyproxy配置文件rule_default.js中的onError方法,所以报错时可以修改方法获取下一页,注入js脚本中继续执行,无需停止
*onError(requestDetail, error) {
if(/s\?__biz=/i.test(requestDetail.url) || /mp\/profile_ext\?action=home/i.test(requestDetail.url) || /mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
var errorStr = error.toString();
console.log("++++++++++onError+++++++++++++" + errorStr + "++++++++++++++++++++++++++");
getWxPost("访问该页面出现错误",requestDetail.url,"/handleErrorLink");
console.log("++++++++++访问该页面出现错误,加载下一链接++++++++++++++++++++++++++" + requestDetail.url);
var nonce = "";
var response = "";
if(/mp\/getverifyinfo\?__biz=/i.test(requestDetail.url)){
response = getWxBizForInfo();
} else {
response = getNextUrl(nonce);
}
//response = getNextUrl(nonce);
console.log("**** onError next url or biz *****: "+ response)
return {
response: {
statusCode: 200,
header: { 'content-type': 'text/html' },
body: " 加载下一页 "+ requestDetail.url +"" + response
}
};
}
}
GitHub 源码地址:wechat-serv-crawler
环境搭建和部署运行 安装前准备
系统:CentOS Linux release 7.6.1810 (Core)
日常模拟器:点击下载
Node-v10.16.0:点击下载
Nodejs下载页面:点击下载
搭建与服务器相关的anyproxy代理文章:Centos7.x搭建anyproxy代理服务器
cd /opt
// 克隆项目到本地
git clone git@github.com:dengyinlei/wechat-serv-crawler.git
// 修改`wechat-serv-crawler/src/main/resources/application.properties`
`wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg`
`wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties`对的数据库和redis的地址
vim wechat-serv-crawler/src/main/resources/application.properties
vim wechat-serv-crawler/src/main/resources/gd_dev/commons.cfg
vim wechat-serv-crawler/src/main/resources/gd_dev/hawkeye-tool.properties
// 修改完成后打包
cd wechat-serv-crawler && mvn clean install -Dmaven.test.skip=true
// 安装nodejs同步请求sync-request包
npm install -g sync-request
// 替换anyproxy 配置脚本 rule_default.js :
cp /opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js /usr/local/nodejs/lib/node_modules/anyproxy/lib/
//关于anyproxy具体拦截请求处理的逻辑见/opt/wechat-serv-crawler/src/main/resources/rule_default_js/rule_default.js配置脚本
//生成替换所有图片,减轻浏览器负担
touch /usr/local/nodejs/lib/node_modules/anyproxy/lib/one_pixel.png
//使用pm2重启anyproxy进程:
pm2 restart all
//查看anyproxy日志:
pm2 logs anyproxy
// 数据库脚本初始化
安装完MySQL数据库后执行/opt/wechat-serv-crawler/src/main/resources/sql/table.sql脚本 初始化数据库以及相关表结构。
// 运行项目
cd /opt/wechat-serv-crawler/target && sh stop.sh && sh start.sh
首次点击操作
打开模拟器,下载anyproxy的证书并配置代理,在模拟器中登录微信随意添加好友,好友发送给你任意微信公众号的历史消息页面或微信文章linked message ,并将消息置顶,进入消息聊天界面,点击链接开始自动抓取redis队列中微信公众号对应的文章,如下图:
关于自动抓取
这个程序是事件驱动的。也就是说一开始必须给一个触发事件,比如打开微信公众号查看历史消息或者打开一个公众号文章,然后自动跳转到下一个公众号历史消息页面或者文章详情页通过js注入,当然这中间可能会出现异常,异常会阻塞自动跳转到下一页。这需要自动化框架的帮助来模拟手动点击操作。这里使用的是 atx 自动化框架。
该项目自动化程度高。人工费用为首次登录微信后,点击微信公众号查看历史消息或打开公众号文章链接。后续会完全通过js注入跳转,异常自动处理恢复点击(atx自动点击)。
运行效果展示
这个项目已经是一个完整成熟的项目了。经过大量长期测试,一个微信客户端采集300公众号文章每天的数据可以保证稳定运行,保证账号不会被封。如果您访问微信公众号历史新闻页面过于频繁,将会被24小时禁言。
目前比较好的策略:访问文章页面后休眠5秒,访问微信公众号历史消息页面后休眠150秒。
本项目功能测试成功,已稳定运行两个月。目前采集使用3个微信公众号,采集900微信公众号每天文章数据。
每个微信账号月费5元。基于该项目,可实现大规模作业的低成本作业。
更新(2020-07-30)以降低抓取错误时漏网率
因为我使用redis的list队列作为消息队列,消息消费过程中可能会出现错误,导致消息丢失和数据泄露。通过使用redis的RPOPLPUSH命令,消费者程序在slave master 从消息队列中取出消息后,插入到备份队列中,并从备份队列中删除消息,直到消费者程序完成正常的处理逻辑同时,我们还可以提供守护进程。消费完主消息队列中的消息后,可以将备份队列中正常未消费的消息放回主消息队列,以便其他消费程序继续处理。
/**
* 从redis队列中获取下一个待爬取的链接
* @return
*/
@RequestMapping(value = "/getNextUrl", method = RequestMethod.GET)
public String getNextUrl() {
//下一个微信公众号文章的url
String nextUrl = redisUtils.rpoplpush("wechat_content_quene", "wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
nextUrl = redisUtils.lpop("wechat_content_backup_quene");
if (StringUtils.isNotBlank(nextUrl)) {
return nextUrl ;
}
LOGGER.info("==============队列中已无待跑的文章url,从队列中获取下一个公众号的biz==================");
//队列表如果空了,就从存储公众号biz的队列中取得一个biz
String biz = redisUtils.rpoplpush(WECHAT_BIZ_QUENE, WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
biz = redisUtils.lpop(WECHAT_BIZ_BACKUP_QUENE);
if (StringUtils.isNotBlank(biz)) {
return String.format(WECHAT_HISTORY_URL, biz);
}
String errorLink = redisUtils.rpoplpush(ERROR__LINK,WECHAT_CONTENT_URL_BACKUP_QUENE);
if (StringUtils.isBlank(errorLink)) {
LOGGER.info("=================队列中已无待跑的公众号,结束本次爬取任务===================");
return EXAMPLE_CONTENT_URL;
} else {
LOGGER.info("=================从错误页面从获取爬取失败的链接===================link:{}", errorLink);
return errorLink;
}
}
获取微信公众号所有历史消息列表&特殊微信公众号无需关注即可获取历史文章:
之前实现的解决方案是只抓取微信公众号文章列表的最新页面。由于抓包分析的下一页返回的内容是json响应体,无法通过注入脚本自动模拟。 Traverse实现翻页功能。
通过分析测试发现只要使用下面的url模式获取文章列表,注意f参数为html,下一页返回的内容格式即可修改为html,解决了json不适合注入js脚本的问题。此外,还可以通过调整偏移量来实现翻页。
下图为上述公众号文章list页面第100页的历史记录:
参考文章
感谢文章提供的想法:
1、用好anyproxy提高公众号文章采集efficiency详解
2、微信公号文章batch采集系统建设
联系作者
由于微信采集平台的搭建和开发花费了大量的时间和精力,我们暂时不打算开源。如果您满足以下条件:不懂技术,时间宝贵,不想花时间研究,想尽快看到效果,且本项目目前实现的功能满足您的需求,可以付费联系我帮你搭建这个项目,并收录所有源代码,解答和解决你在开发过程中遇到的所有疑问。
yzmcms采集器+yzmcms免登陆接口在哪里有呢索取吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-08-26 20:09
1、Q:yzmcms是什么程序,好用吗?
答:yzmcms是袁志萌开发的一套php+mysql采集程序,适用于企业网站建设和个人网站建设。已经更新到v5.2版本,好评如潮。
(yzmcms程序后台截图)
2、Q:yzmcms自带采集插件怎么样?
答:用过yzmcms自带的采集插件的朋友都知道基于php的采集插件的性能、功能和稳定性都不是很好,所以推荐一个更强大更方便的包采集Software 更合适。推荐优采云采集器+yzmcms免登录发布界面实现全自动yzmcms采集。
3、Q:采集有什么特点?是否支持自动计时采集和自动发布,是否也支持自定义字段?
答:当然,这是采集软件的标准配置。使用优采云采集器,超稳定采集,定期发布。发布规则超级简单,支持任意模型和自定义字段。图片自动下载,提取第一个缩略图,方便填写yzmcms的节目内容。
4、Q:我不会编程,怎么写采集规则?
答案:优采云采集软件是为没有编程的用户准备的。您不需要任何编程基础。您可以查看源代码,只需复制和粘贴即可。 采集 规则很简单。 优采云采集software 还有专门的软件教程。
5、Q:软件是免费的吗?可以永久使用吗?
答:采集软件是免费的,界面也是开源的,未加密。使用后,可永久使用。
6、Q:都是免费的,有收费功能吗,官方怎么长期维护这个软件的?
回答:没有充电功能。无论如何,任何人都可以使用该软件。基于自由软件,作者精力有限。如有任何问题,请在用户群或论坛中交流。
7、Q:yzmcms免费登录界面在哪里?
答:请进群后联系作者免费领取! 查看全部
yzmcms采集器+yzmcms免登陆接口在哪里有呢索取吗?
1、Q:yzmcms是什么程序,好用吗?
答:yzmcms是袁志萌开发的一套php+mysql采集程序,适用于企业网站建设和个人网站建设。已经更新到v5.2版本,好评如潮。
(yzmcms程序后台截图)
2、Q:yzmcms自带采集插件怎么样?
答:用过yzmcms自带的采集插件的朋友都知道基于php的采集插件的性能、功能和稳定性都不是很好,所以推荐一个更强大更方便的包采集Software 更合适。推荐优采云采集器+yzmcms免登录发布界面实现全自动yzmcms采集。
3、Q:采集有什么特点?是否支持自动计时采集和自动发布,是否也支持自定义字段?
答:当然,这是采集软件的标准配置。使用优采云采集器,超稳定采集,定期发布。发布规则超级简单,支持任意模型和自定义字段。图片自动下载,提取第一个缩略图,方便填写yzmcms的节目内容。
4、Q:我不会编程,怎么写采集规则?
答案:优采云采集软件是为没有编程的用户准备的。您不需要任何编程基础。您可以查看源代码,只需复制和粘贴即可。 采集 规则很简单。 优采云采集software 还有专门的软件教程。
5、Q:软件是免费的吗?可以永久使用吗?
答:采集软件是免费的,界面也是开源的,未加密。使用后,可永久使用。
6、Q:都是免费的,有收费功能吗,官方怎么长期维护这个软件的?
回答:没有充电功能。无论如何,任何人都可以使用该软件。基于自由软件,作者精力有限。如有任何问题,请在用户群或论坛中交流。
7、Q:yzmcms免费登录界面在哪里?
答:请进群后联系作者免费领取!

