
自动采集编写
自动采集编写(编程问答:只要问那边站长要就可以了再说采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-04 10:07
写个程序自动采集VeryCD 标题,很多励志,很好。来写个程序自动采集VeryCD标题,很多励志,很好---------- ----------编程问答------- -------------其实问问那边的站长就知道了。
再说了,采集这个也麻烦,过几天换一个,采集这种变化率很低的东西,不如去人力资源部采集- ----------- --------编程问答--------------------up------ ------------- -编程问答--------------------哈哈----------- ---------编程问答--------------------up---------------- ----编程问答----------- ---------几分钟换好几个---------------- ----编程问答------------ --------好吧,想一想,使用HttpWebRequest和HttpWebResponse进行页面请求和下载,使用常规规则取把之间的数据拿出来,分析一下这个是不是最新的励志词,存入数据库...
--------------------编程问答 --------------------HttpWebRequest 和 HttpWebResponse
发帖
曲奇饼 查看全部
自动采集编写(编程问答:只要问那边站长要就可以了再说采集)
写个程序自动采集VeryCD 标题,很多励志,很好。来写个程序自动采集VeryCD标题,很多励志,很好---------- ----------编程问答------- -------------其实问问那边的站长就知道了。
再说了,采集这个也麻烦,过几天换一个,采集这种变化率很低的东西,不如去人力资源部采集- ----------- --------编程问答--------------------up------ ------------- -编程问答--------------------哈哈----------- ---------编程问答--------------------up---------------- ----编程问答----------- ---------几分钟换好几个---------------- ----编程问答------------ --------好吧,想一想,使用HttpWebRequest和HttpWebResponse进行页面请求和下载,使用常规规则取把之间的数据拿出来,分析一下这个是不是最新的励志词,存入数据库...
--------------------编程问答 --------------------HttpWebRequest 和 HttpWebResponse
发帖
曲奇饼
自动采集编写(自动采集编写爬虫+equery的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-02 02:01
自动采集编写爬虫本网站抓取速度慢,但是大家别灰心哈~我会继续努力的,该争取的还是要争取,等你看到这篇文章时,title已经到了200多个图片哦。你需要安装phantomjs,varphantomjs=require('phantomjs');varhttp=require('http');varurl=http.urlopen();url.readystate=false;获取图片下载速度变慢,首先要观察图片列表页的页面源码:[1,1,3,200,unkeymap][1,1,3,200,2]发现下载unkeymap的时候,下载了19个图片,代码暴露的信息越多,要下载的图片越多,请求的时候请求数据也越多,使用phantomjs+equery的方式直接下载并没有增加,看来是抓图片需要加上http劫持。
来来来,这里有一个phantomjs+equery的方法,现在我们来试试。equery.parse的结果如下:[1,1,3,19,2]表示我们的ajax请求的时候加上这个参数xh_xh_xh_yh_zh_jj_jj_jj_zh_jj_1,ok,下面是调试图片下载代码的时候的地址:[1,1,3,200,2][1,1,3,19,2]这样,你看到的图片列表里可能下载的是3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,47,48,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,180,181,182,183,184,185,186,187,188,189,180,183,184,185,186,187,188,189,181,185,186,187,188,189,182,187,188,189,181,183,184,185。 查看全部
自动采集编写(自动采集编写爬虫+equery的方法,你知道吗?)
自动采集编写爬虫本网站抓取速度慢,但是大家别灰心哈~我会继续努力的,该争取的还是要争取,等你看到这篇文章时,title已经到了200多个图片哦。你需要安装phantomjs,varphantomjs=require('phantomjs');varhttp=require('http');varurl=http.urlopen();url.readystate=false;获取图片下载速度变慢,首先要观察图片列表页的页面源码:[1,1,3,200,unkeymap][1,1,3,200,2]发现下载unkeymap的时候,下载了19个图片,代码暴露的信息越多,要下载的图片越多,请求的时候请求数据也越多,使用phantomjs+equery的方式直接下载并没有增加,看来是抓图片需要加上http劫持。
来来来,这里有一个phantomjs+equery的方法,现在我们来试试。equery.parse的结果如下:[1,1,3,19,2]表示我们的ajax请求的时候加上这个参数xh_xh_xh_yh_zh_jj_jj_jj_zh_jj_1,ok,下面是调试图片下载代码的时候的地址:[1,1,3,200,2][1,1,3,19,2]这样,你看到的图片列表里可能下载的是3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,47,48,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,180,181,182,183,184,185,186,187,188,189,180,183,184,185,186,187,188,189,181,185,186,187,188,189,182,187,188,189,181,183,184,185。
自动采集编写(蜂集采集器如何添加采集模块?(图)采集方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2021-12-31 17:20
)
BeeJi采集 是一个全自动的 wordpress采集 插件。如果你还没有下载,可以到beeJi采集下载页面下载。如果要采集,首先要添加采集模块。本文将介绍如何在风集采集器中添加采集模块!
安装风记采集器后,后台会新增一个名为“飞记”的菜单。依次进入Bee Set->采集模块,点击“添加文章采集模块”按钮新建采集模块。
需要设置一个完整的采集模块:基本信息、列表规则、内容规则。
设置基本信息
基本信息由规则名称和网页完整性检查填写,如下图
规则的名称是必需的。这里我以采集腾讯新闻为例。规则名称中填写腾讯新闻采集。网页完整性检查是为了确保下载的网页是完整的,避免采集失败。一般不需要填写,如果发现很多网页在采集时没有采集获取到内容,那么就需要填写网页完整性检查或者一些标志性的文字在网页的末尾。简单的说,一般不填写,经常出现网页采集填写不完整
编辑列表规则
点击列表规则进入列表规则编辑栏。列表规则的作用是采集一些内容页面的链接供我们跟进采集。
以腾讯新闻为例,我们使用chrome打开腾讯新闻首页。
打开网页后,打开chrome开发者工具(windows按F12或ctrl+shift+i,MAC按cmd+option+i),点击开发者工具左上角的小箭头,然后放置鼠标如果要采集的链接,可以看到链接的区域和格式。
我们找到了列表页中链接的特征,发现新闻链接都收录和html。我们可以在URL收录中写&&html,表示同时收录和html。如果我们只需要采集的入口页面地址,那么我们可以勾选停止列表获取,这样这个规则就不会对下一级网页生效。在大多数情况下,您不需要填写 URL 区域。一般来说,URL收录/不收录,标题收录/不收录足以覆盖大多数场景。如果场景一定要填URL区,那么这里的URL区就是一个正则表达式。
最终效果如下图,请按图填写你的采集规则
接下来可以测试链接获取是否正确。点击爬虫测试,然后填写文章测试地址,在这里填写,因为这是我们的入口页面,所以级别为0(注意级别从0开始,从0级页面为1,从1级页面得到的地址级为2,以此类推...).
填写完成后,点击爬虫测试,应该可以看到下面得到的链接和标题,如下图。
编辑内容规则
我们最终都需要采集内容,所以内容规则与我们的内容采集有关。下图中,内容规则左侧为采集的字段名,默认覆盖wordpress文章的基本信息字段,title为文章title,content为文章内容,Category为文章类别,标签为文章标签,作者为文章作者。
采集标题:title
标题与h1匹配。系统已为您提供默认值。在大多数情况下,您不需要更改它,只需使用系统默认值即可。如下图
如果网页的标题不是h1,您可以通过多种方式来匹配您需要的内容。风集支持三种方式:regular、xpath、fixed characters。
采集正文:内容
内容可以采用自动获取文本的方式,可以智能分析网页中的文本,自动获取。冯基采集器已经把这个选项默认设置为yes,如下图:
一般情况下,大部分基于文本的网站都可以使用智能获取来抓取文本。如果只能抓取,也可以使用正则,xpath。
如果此时使用的是regular或者xpath,那么Smart Get Text请选择No,否则以下规则不会生效
同理,还需要设置category、tag、author,这里不再赘述。
测试采集
所有规则写好后,我们需要根据规则验证采集器是否可以正确采集,进入测试抓取标签,填写链接和页面级别,点击抓取测试来查看效果,如下图:
如果您对采集器的使用有任何疑问,可以到风集的采集交流群(群号可在采集器的关于我们中找到)进行交流。
您可能还喜欢以下内容文章
Bee Set采集器,一个全自动的 wordpress采集插件
imwprobot (bee set) 是一个 wordpress采集 插件。功能是什么? 1.全自动无人值守,支持定时采集2.可自动同步目标站更新3.AI自动关键词,自动汇总生成4.@ > 直接发布到 wordpress,无需额外的界面支持。 5. 正文图片和缩略图可以本地化 6. 每个任务 文章 图片可以设置独立的水印 7. 采集 到达的内容支持常规和 css 选择器替代品。 采集哪些站1.新闻资讯站2. 文章范文站< @3. BBS论坛4.@> 博客站5. 哪些资源站和下载站支持采集规则1.正则表达式2.XPath规则3.JQuery选择器(CSS选择器)代理支持1.HTTP代理2.Socks5代理哪些主机可以不受环境限制运行,虚拟主机可以运行蜜蜂设置功能
蜜蜂合集采集器视频逐字草稿
欢迎来到蜜蜂套装采集器,现在和大家分享蜜蜂套装采集器的教程。接下来就可以开始创建采集任务了。以lz13为例。添加任务名称并添加入口地址。入口页间隔不需要更改,文本捕获间隔不需要更改。选择采集模块,选择发布模块,选择草稿,选择要暂停的任务,然后我们会选择测试后自动执行。
puretext 是一款纯文本 wordpress cms主题,可支持数百万文章
经过几年的制作,纯文字的cms风格主题终于要和大家见面了。但是目前还没有一个主题可以支持海量的文章,所以我只能自己做一个。轻松支持百万文章无卡,无论是前台还是后台。
Wordpress 小说主题 imwpnovels
更强大的wordpress小说主题imwpnovels让创建小说网站更容易!小说阅读页面支持无限字体缩放、护眼模式、分页模式、静态缓存下刷新无闪烁,用户体验极佳。
蜜蜂套装采集器快速入门
这篇文章文章可以帮助您快速入门“蜜蜂采集器”。如果你刚接触采集器,我建议你仔细阅读这篇文章。对你快速上手很有帮助采集器。现在可以添加任务了,采集module和release module选择我们刚刚创建的module,如下图:
查看全部
自动采集编写(蜂集采集器如何添加采集模块?(图)采集方法
)
BeeJi采集 是一个全自动的 wordpress采集 插件。如果你还没有下载,可以到beeJi采集下载页面下载。如果要采集,首先要添加采集模块。本文将介绍如何在风集采集器中添加采集模块!

安装风记采集器后,后台会新增一个名为“飞记”的菜单。依次进入Bee Set->采集模块,点击“添加文章采集模块”按钮新建采集模块。
需要设置一个完整的采集模块:基本信息、列表规则、内容规则。
设置基本信息
基本信息由规则名称和网页完整性检查填写,如下图
 http://www.imwpweb.com/wp-cont ... 4.png 768w, http://www.imwpweb.com/wp-cont ... 9.png 1536w" />
http://www.imwpweb.com/wp-cont ... 4.png 768w, http://www.imwpweb.com/wp-cont ... 9.png 1536w" />规则的名称是必需的。这里我以采集腾讯新闻为例。规则名称中填写腾讯新闻采集。网页完整性检查是为了确保下载的网页是完整的,避免采集失败。一般不需要填写,如果发现很多网页在采集时没有采集获取到内容,那么就需要填写网页完整性检查或者一些标志性的文字在网页的末尾。简单的说,一般不填写,经常出现网页采集填写不完整
编辑列表规则
点击列表规则进入列表规则编辑栏。列表规则的作用是采集一些内容页面的链接供我们跟进采集。
以腾讯新闻为例,我们使用chrome打开腾讯新闻首页。
打开网页后,打开chrome开发者工具(windows按F12或ctrl+shift+i,MAC按cmd+option+i),点击开发者工具左上角的小箭头,然后放置鼠标如果要采集的链接,可以看到链接的区域和格式。
 http://www.imwpweb.com/wp-cont ... 7.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w, http://www.imwpweb.com/wp-cont ... 8.png 2048w" />
http://www.imwpweb.com/wp-cont ... 7.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w, http://www.imwpweb.com/wp-cont ... 8.png 2048w" />我们找到了列表页中链接的特征,发现新闻链接都收录和html。我们可以在URL收录中写&&html,表示同时收录和html。如果我们只需要采集的入口页面地址,那么我们可以勾选停止列表获取,这样这个规则就不会对下一级网页生效。在大多数情况下,您不需要填写 URL 区域。一般来说,URL收录/不收录,标题收录/不收录足以覆盖大多数场景。如果场景一定要填URL区,那么这里的URL区就是一个正则表达式。
最终效果如下图,请按图填写你的采集规则
 http://www.imwpweb.com/wp-cont ... 9.png 768w, http://www.imwpweb.com/wp-cont ... 8.png 1536w, http://www.imwpweb.com/wp-cont ... 4.png 2048w" />
http://www.imwpweb.com/wp-cont ... 9.png 768w, http://www.imwpweb.com/wp-cont ... 8.png 1536w, http://www.imwpweb.com/wp-cont ... 4.png 2048w" />接下来可以测试链接获取是否正确。点击爬虫测试,然后填写文章测试地址,在这里填写,因为这是我们的入口页面,所以级别为0(注意级别从0开始,从0级页面为1,从1级页面得到的地址级为2,以此类推...).
填写完成后,点击爬虫测试,应该可以看到下面得到的链接和标题,如下图。
 http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />
http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />编辑内容规则
我们最终都需要采集内容,所以内容规则与我们的内容采集有关。下图中,内容规则左侧为采集的字段名,默认覆盖wordpress文章的基本信息字段,title为文章title,content为文章内容,Category为文章类别,标签为文章标签,作者为文章作者。
采集标题:title
标题与h1匹配。系统已为您提供默认值。在大多数情况下,您不需要更改它,只需使用系统默认值即可。如下图
 http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />
http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />如果网页的标题不是h1,您可以通过多种方式来匹配您需要的内容。风集支持三种方式:regular、xpath、fixed characters。
采集正文:内容
内容可以采用自动获取文本的方式,可以智能分析网页中的文本,自动获取。冯基采集器已经把这个选项默认设置为yes,如下图:
 http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />
http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />一般情况下,大部分基于文本的网站都可以使用智能获取来抓取文本。如果只能抓取,也可以使用正则,xpath。
如果此时使用的是regular或者xpath,那么Smart Get Text请选择No,否则以下规则不会生效
同理,还需要设置category、tag、author,这里不再赘述。
测试采集
所有规则写好后,我们需要根据规则验证采集器是否可以正确采集,进入测试抓取标签,填写链接和页面级别,点击抓取测试来查看效果,如下图:
 http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />
http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />如果您对采集器的使用有任何疑问,可以到风集的采集交流群(群号可在采集器的关于我们中找到)进行交流。
您可能还喜欢以下内容文章

Bee Set采集器,一个全自动的 wordpress采集插件
imwprobot (bee set) 是一个 wordpress采集 插件。功能是什么? 1.全自动无人值守,支持定时采集2.可自动同步目标站更新3.AI自动关键词,自动汇总生成4.@ > 直接发布到 wordpress,无需额外的界面支持。 5. 正文图片和缩略图可以本地化 6. 每个任务 文章 图片可以设置独立的水印 7. 采集 到达的内容支持常规和 css 选择器替代品。 采集哪些站1.新闻资讯站2. 文章范文站< @3. BBS论坛4.@> 博客站5. 哪些资源站和下载站支持采集规则1.正则表达式2.XPath规则3.JQuery选择器(CSS选择器)代理支持1.HTTP代理2.Socks5代理哪些主机可以不受环境限制运行,虚拟主机可以运行蜜蜂设置功能

蜜蜂合集采集器视频逐字草稿
欢迎来到蜜蜂套装采集器,现在和大家分享蜜蜂套装采集器的教程。接下来就可以开始创建采集任务了。以lz13为例。添加任务名称并添加入口地址。入口页间隔不需要更改,文本捕获间隔不需要更改。选择采集模块,选择发布模块,选择草稿,选择要暂停的任务,然后我们会选择测试后自动执行。
 WX20211027-200152@2x.png" />
WX20211027-200152@2x.png" />puretext 是一款纯文本 wordpress cms主题,可支持数百万文章
经过几年的制作,纯文字的cms风格主题终于要和大家见面了。但是目前还没有一个主题可以支持海量的文章,所以我只能自己做一个。轻松支持百万文章无卡,无论是前台还是后台。
Wordpress 小说主题 imwpnovels
更强大的wordpress小说主题imwpnovels让创建小说网站更容易!小说阅读页面支持无限字体缩放、护眼模式、分页模式、静态缓存下刷新无闪烁,用户体验极佳。

蜜蜂套装采集器快速入门
这篇文章文章可以帮助您快速入门“蜜蜂采集器”。如果你刚接触采集器,我建议你仔细阅读这篇文章。对你快速上手很有帮助采集器。现在可以添加任务了,采集module和release module选择我们刚刚创建的module,如下图:

自动采集编写(actions文件夹自动化测试框架一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-30 16:18
这两天用python2写了一个自动化测试框架,名字叫Auty。它已准备好用于 Web 界面测试。下面是Auty框架的分步搭建过程——
首先感谢朱博大哥的指教、交流和帮助!
auty文件夹结构介绍
1. actions文件夹:收录
业务相关的脚本文件,收录
可复用的方法,可以根据不同的业务在actions文件夹下创建不同的业务文件夹;
2. 常量文件夹:收录
常量初始化的python脚本文件。根据业务分工,可以创建子文件夹或多个常量文件;
3. 数据文件夹:收录
用于测试的数据;
4. lib文件夹:收录
支持框架运行的python文件;
5. 日志文件夹:收录
运行测试过程中产生的日志文件;
6. results文件夹:收录
测试结果文件;
7. 脚本文件夹:收录
脚本文件夹和选择文件夹;
1)scripts 文件夹收录
测试脚本(可以根据业务分为多个子目录);
2)selections 文件夹收录
套件文件(包括需要执行的脚本路径的集合);
8. utils文件夹:收录
与业务逻辑无关的脚本文件,收录
可复用的方法;
auty文件结构介绍
1. 在 Auty 文件夹下:
1)__init__.py 文件:包结构的必要文件(以下所有涉及可调用脚本的文件夹都需要该文件);
2)config.txt 文件:Auty 框架配置描述文件;
3)recovery.py 文件:垃圾代码恢复文件(用于恢复由于测试执行过程中失败而自动删除失败的自动生成代码);
4)requirements 文件:收录
框架需要安装的python库信息;
5)setup.py文件:执行脚本安装需求文件中收录
的python库;
6)start.py 文件:执行脚本启动界面自动化测试;
2. lib 文件夹:
1)exe_deco.py 文件:收录
修改脚本运行时方法的文件;
2)execute_selection.py 文件:收录
了suite集合下运行脚本方法的文件;
3)generate_html.py文件:收录
根据生成的csv格式测试结果文件生成html类型测试结果文件的方法的文件;
4)generate_result.py文件:收录
生成csv格式测试结果方法的文件;
5)read_selection.py 文件:收录
读取可执行脚本列表的方法的文件;
6)recovery_code.py 文件:收录
垃圾代码恢复方法的文件;
7)write_log.py 文件:收录
生成日志文件的方法的文件;
3. 脚本文件夹下:
1)create_selection.py 文件:收录
创建套件文件的方法的文件(all_scripts_selection.txt);
自动步骤
1. 运行Auty/setup.py文件;
2. 编写接口测试python脚本,放在Auty/scripts/scripts目录(或子目录);
3. 运行Auty/scripts/create_selection.py文件,生成Auty/scripts/all_scripts_selection.txt文件;
4. 修改Auty/scripts/all_scripts_selection.txt文件,自定义test_selection.txt文件(任意名称)放到Auty/scripts/selections文件夹下;
5. 运行Auty/start.py文件,启动接口自动测试;
6. 在Auty/results文件夹下生成的测试结果文件中查看测试结果。
写作过程
本框架中scripts、utils、actions、contants四个文件夹中的内容可以根据实际工作内容随意更换。其他是Auty 接口自动化测试框架的必要组件。由于后续开发工作繁琐,部分改动代码无法在后续文章中及时更新。最新代码请见:Github
第1部分-生成执行列表第2部分-读取和执行脚本列表第3部分-添加异常处理和日志采集
第4部分-生成测试结果报告第5部分-调用支持、自动安装库和配置说明第6章-垃圾代码恢复、添加套件支持第7章-添加动作库和常量文件库Auty框架性能篇-Python flask框架实践接口测试用例编写建议
从某种层面来说,框架的诞生也是为了让编写的代码更加规范。不管框架如何,对于接口测试用例的编写,都应该给出以下建议:
1. 接口中涉及到url,不要写在case中,而是通过常量访问,将url存放在指定的常量文件中(避免因接口域名变化等原因导致无法维护) );
2. 测试用例中不要收录
测试数据等变量信息,设置为变量,在指定文件中完成变量的初始化;
3. 不要在测试用例中重复粘贴大段代码逻辑(不利于代码走查,会造成代码冗余,增加出错概率)。所有可以重用的流程都会被提取到方法中,并分类放置在指定的存储文件夹中的业务逻辑动作中;
4. 关于评论:语言一定要正式,评论的意义更多的是给别人看,让别人一目了然;一定要具体、详细,不要说一半;一定要准确,而且注释下面的代码逻辑一定要和注释的内容一致,不能在注释下面一段代码之后,才启动注释中收录
的内容逻辑。 查看全部
自动采集编写(actions文件夹自动化测试框架一步)
这两天用python2写了一个自动化测试框架,名字叫Auty。它已准备好用于 Web 界面测试。下面是Auty框架的分步搭建过程——

首先感谢朱博大哥的指教、交流和帮助!
auty文件夹结构介绍
1. actions文件夹:收录
业务相关的脚本文件,收录
可复用的方法,可以根据不同的业务在actions文件夹下创建不同的业务文件夹;
2. 常量文件夹:收录
常量初始化的python脚本文件。根据业务分工,可以创建子文件夹或多个常量文件;
3. 数据文件夹:收录
用于测试的数据;
4. lib文件夹:收录
支持框架运行的python文件;
5. 日志文件夹:收录
运行测试过程中产生的日志文件;
6. results文件夹:收录
测试结果文件;
7. 脚本文件夹:收录
脚本文件夹和选择文件夹;
1)scripts 文件夹收录
测试脚本(可以根据业务分为多个子目录);
2)selections 文件夹收录
套件文件(包括需要执行的脚本路径的集合);
8. utils文件夹:收录
与业务逻辑无关的脚本文件,收录
可复用的方法;
auty文件结构介绍
1. 在 Auty 文件夹下:
1)__init__.py 文件:包结构的必要文件(以下所有涉及可调用脚本的文件夹都需要该文件);
2)config.txt 文件:Auty 框架配置描述文件;
3)recovery.py 文件:垃圾代码恢复文件(用于恢复由于测试执行过程中失败而自动删除失败的自动生成代码);
4)requirements 文件:收录
框架需要安装的python库信息;
5)setup.py文件:执行脚本安装需求文件中收录
的python库;
6)start.py 文件:执行脚本启动界面自动化测试;
2. lib 文件夹:
1)exe_deco.py 文件:收录
修改脚本运行时方法的文件;
2)execute_selection.py 文件:收录
了suite集合下运行脚本方法的文件;
3)generate_html.py文件:收录
根据生成的csv格式测试结果文件生成html类型测试结果文件的方法的文件;
4)generate_result.py文件:收录
生成csv格式测试结果方法的文件;
5)read_selection.py 文件:收录
读取可执行脚本列表的方法的文件;
6)recovery_code.py 文件:收录
垃圾代码恢复方法的文件;
7)write_log.py 文件:收录
生成日志文件的方法的文件;
3. 脚本文件夹下:
1)create_selection.py 文件:收录
创建套件文件的方法的文件(all_scripts_selection.txt);
自动步骤
1. 运行Auty/setup.py文件;
2. 编写接口测试python脚本,放在Auty/scripts/scripts目录(或子目录);
3. 运行Auty/scripts/create_selection.py文件,生成Auty/scripts/all_scripts_selection.txt文件;
4. 修改Auty/scripts/all_scripts_selection.txt文件,自定义test_selection.txt文件(任意名称)放到Auty/scripts/selections文件夹下;
5. 运行Auty/start.py文件,启动接口自动测试;
6. 在Auty/results文件夹下生成的测试结果文件中查看测试结果。
写作过程
本框架中scripts、utils、actions、contants四个文件夹中的内容可以根据实际工作内容随意更换。其他是Auty 接口自动化测试框架的必要组件。由于后续开发工作繁琐,部分改动代码无法在后续文章中及时更新。最新代码请见:Github
第1部分-生成执行列表第2部分-读取和执行脚本列表第3部分-添加异常处理和日志采集
第4部分-生成测试结果报告第5部分-调用支持、自动安装库和配置说明第6章-垃圾代码恢复、添加套件支持第7章-添加动作库和常量文件库Auty框架性能篇-Python flask框架实践接口测试用例编写建议
从某种层面来说,框架的诞生也是为了让编写的代码更加规范。不管框架如何,对于接口测试用例的编写,都应该给出以下建议:
1. 接口中涉及到url,不要写在case中,而是通过常量访问,将url存放在指定的常量文件中(避免因接口域名变化等原因导致无法维护) );
2. 测试用例中不要收录
测试数据等变量信息,设置为变量,在指定文件中完成变量的初始化;
3. 不要在测试用例中重复粘贴大段代码逻辑(不利于代码走查,会造成代码冗余,增加出错概率)。所有可以重用的流程都会被提取到方法中,并分类放置在指定的存储文件夹中的业务逻辑动作中;
4. 关于评论:语言一定要正式,评论的意义更多的是给别人看,让别人一目了然;一定要具体、详细,不要说一半;一定要准确,而且注释下面的代码逻辑一定要和注释的内容一致,不能在注释下面一段代码之后,才启动注释中收录
的内容逻辑。
自动采集编写(用考拉SEO,轻轻松松一天产出几万篇高质量SEO文章!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-29 11:12
看到本文内容请不要惊讶,因为本文由考拉SEO平台批量编译,仅用于SEO引流。有了考拉SEO,一天可以轻松产出数万篇优质SEO文章!如果您还需要批量编辑SEO文章,可以进入平台用户中心试用!
这些天,网友们一直在关注ai伪原创内容的自动视频采集和上传,质疑我们的人太多了。其实在关注这个信息之前,大家应该先来这里探讨一下关键词如何优化自编信息!对于圈子里思考的SEOer来说,文字质量绝不是主要目标,这些人最关心的是权重值和访问量。一篇高质量的搜索优化文章写在一个新的站点上,并推送到一个高权重的门户站点。最后排名和流量差别很大!
一直在咨询AI伪原创视频自动采集上传的客户,归根结底大家超级关注的还是之前文章讨论的内容。编辑一篇流量大的搜索落地文章很容易,但一篇文章产生的流量其实很小。如果要设置内容达到引流的目的,绝对关键是自动化!如果1篇SEO文章可以收获1个UV(每天),那么假设可以写10000篇文章,那么平均每天的客户量可以增加10000。但是,简单来说,在现实生活中编辑时,一个人一天只能产出30篇文章,最多60篇。即使使用伪原创工具,也只能维持一百!看到这个,
杜娘想的人工造物是什么?原创文章不仅仅是逐段原创编辑!在各大搜索者的算法定义中,原创并不意味着没有重复的句子。换句话说,只要我们的码字和别人的码字不完全一样,就可以增加收录
的可能性。一篇热点文章,核心足够抢眼,保持同一个中心思想,只要保证没有同款,就说明这篇文章还是很有可能被搜索引擎收录的,甚至成为引流的好文章。就像这篇文章,你可能在搜索引擎搜索视频,自动采集
ai伪原创上传,然后点进去。其实,下一篇就是发挥考拉SEO平台智能编辑文章系统的作用。从!
本站智能原创平台应为原创文章系统,精准表达。一天可以写好几万个靠谱的SEO文案。只要您的网站足够大,收录率就可以高达 80%。详细的操作方法,个人中心有视频展示和初学者指南。让我们免费试用吧!很抱歉没有给大家带来关于自动抓拍ai伪原创上传的全面讲解,或许能让大家看完这篇通用的系统语言。但如果我们喜欢这个系统,只需点击导航栏,就能让您的网页每天达到数百次浏览量。这不是坏事吗? 查看全部
自动采集编写(用考拉SEO,轻轻松松一天产出几万篇高质量SEO文章!)
看到本文内容请不要惊讶,因为本文由考拉SEO平台批量编译,仅用于SEO引流。有了考拉SEO,一天可以轻松产出数万篇优质SEO文章!如果您还需要批量编辑SEO文章,可以进入平台用户中心试用!
这些天,网友们一直在关注ai伪原创内容的自动视频采集和上传,质疑我们的人太多了。其实在关注这个信息之前,大家应该先来这里探讨一下关键词如何优化自编信息!对于圈子里思考的SEOer来说,文字质量绝不是主要目标,这些人最关心的是权重值和访问量。一篇高质量的搜索优化文章写在一个新的站点上,并推送到一个高权重的门户站点。最后排名和流量差别很大!

一直在咨询AI伪原创视频自动采集上传的客户,归根结底大家超级关注的还是之前文章讨论的内容。编辑一篇流量大的搜索落地文章很容易,但一篇文章产生的流量其实很小。如果要设置内容达到引流的目的,绝对关键是自动化!如果1篇SEO文章可以收获1个UV(每天),那么假设可以写10000篇文章,那么平均每天的客户量可以增加10000。但是,简单来说,在现实生活中编辑时,一个人一天只能产出30篇文章,最多60篇。即使使用伪原创工具,也只能维持一百!看到这个,
杜娘想的人工造物是什么?原创文章不仅仅是逐段原创编辑!在各大搜索者的算法定义中,原创并不意味着没有重复的句子。换句话说,只要我们的码字和别人的码字不完全一样,就可以增加收录
的可能性。一篇热点文章,核心足够抢眼,保持同一个中心思想,只要保证没有同款,就说明这篇文章还是很有可能被搜索引擎收录的,甚至成为引流的好文章。就像这篇文章,你可能在搜索引擎搜索视频,自动采集
ai伪原创上传,然后点进去。其实,下一篇就是发挥考拉SEO平台智能编辑文章系统的作用。从!

本站智能原创平台应为原创文章系统,精准表达。一天可以写好几万个靠谱的SEO文案。只要您的网站足够大,收录率就可以高达 80%。详细的操作方法,个人中心有视频展示和初学者指南。让我们免费试用吧!很抱歉没有给大家带来关于自动抓拍ai伪原创上传的全面讲解,或许能让大家看完这篇通用的系统语言。但如果我们喜欢这个系统,只需点击导航栏,就能让您的网页每天达到数百次浏览量。这不是坏事吗?
自动采集编写(安装Python自动化测试的脚本是用Python3写的吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-29 09:07
写在前面
本文主要介绍一个基于uiautomator2封装的Python库android-catcher。该库的功能主要包括Android设备的UI自动化测试和手机性能数据的采集。适用于列表滑动、视频录制等各种测试场景。 CPU,内存、帧率等信息的抓取方便后续分析。
Github地址:
安装 Python
自动化测试脚本使用Python 3编写,运行脚本需要安装Python 3环境。
下载链接:
Python 3.6.5
安装 android-catcher 依赖
打开脚本目录,执行以下命令安装依赖
pip install -r requirements.txt
使用方法 uiautomator2
安装uiautomator2后,一般只需要执行以下命令来初始化设备并在设备上安装uiautomator2服务
python -m uiautomator2 init
如果出现如下提示,则安装成功
更多uiautomator2的使用请参考:
脚本文件说明
这个脚本库根目录下的主要文件有
参数说明 生成的文件说明
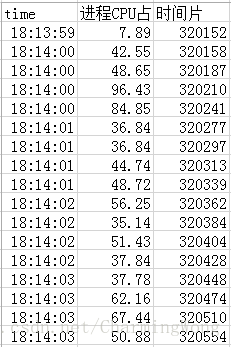
采集到的信息根据信息类型存储在指定输出目录下的cpu_stats、mem_stats、fps_stats、net_stats四个子目录中。文件名为信息类型_设备号_应用程序ID_版本号_测试场景名称_时间戳,如cpu_d3c2edaa_video。like_RecordVideo_1.9.9_1524122928.csv.csv,实际效果大致如下
输出文件为csv文件,直接打开和用Excel打开的效果如下:
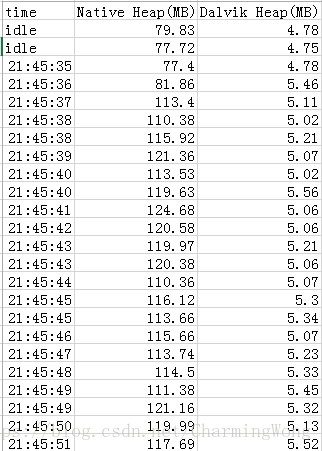
此外,您可以为测试的每个阶段添加节点描述
task.period = "idle"
生成类似于下图的图形
如何使用无自定义测试场景
适用于没有特定测试场景,脚本运行一段时间后脚本处于采集状态的情况。时长可以通过配置参数指定,用户可以在此过程中随意操作手机。直接通过命令行运行_main_.py脚本文件并指定相关参数
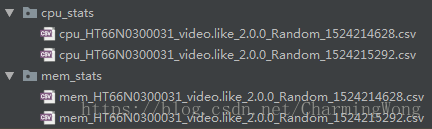
比如我想采集applicationId为video.like的应用程序10s内的cpu信息和内存信息,采样间隔为200ms,输出目录为当前目录,那么可以在所在目录下执行如下命令脚本位于
python _main_.py -s 设备号-a video.like -f 0.2 -d 10 -i mem,cpu -o .
脚本运行后,在根目录下可以看到如下图的文件生成
注意:要带-d参数指定采集的持续时间,否则脚本默认运行10s,不需要-t参数。默认测试场景命名为 Random
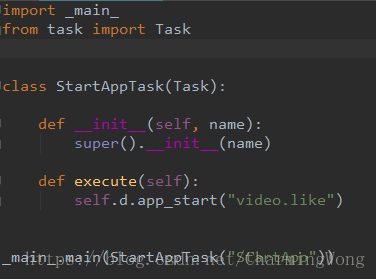
如何使用自定义测试场景
自定义测试场景不能直接调用_main_.py 脚本。需要新建一个脚本,继承task.py#Task并重写Task#execute方法,在Task#execute中实现自定义测试场景的逻辑,如下图所示:
在这里创建一个名为 start_app.py 的脚本,运行命令:
python start_app.py -s 设备号-a 进程名 -f 0.1 -i cpu,mem -o .
可以启动相应的APP,采集CPU信息和内存信息,采样间隔100ms,输出到当前目录。注意这里没有-d参数,因为采集的时长以测试任务的时长为准。设置的参数必须按照说明进行,否则无法采集数据
如果要采集
自定义信息,可以继承 info.py#Info 并重写 Info#get_start_info 和 Info#get_end_info 方法。可以参考已经实现的四种信息集合,最后通过Task#add_info方法进行添加。
自定义测试场景后,调用_main_#main方法,传入测试场景实例。测试场景的名称将用作输出文件命名的一部分。最好取一个能准确表达测试场景的名字,比如一个APP录制视频 测试场景的名字是RecordVideo
采集
到的信息可以通过Excel制作成图表。以下是完整视频录制测试场景的CPU比例和内存变化
通过图表,可以直观地分析应用程序不同版本、不同场景的性能状态
写在最后
以上是对该库使用的一些介绍。由于工作经验还比较少,所以现在也在学习和使用Python。在编写这个库的时候,可能会有很多考虑不周或不完善的地方。有能力的朋友可以直接修改库实现更多的自定义功能。另外也希望大家多多使用,多发现问题,欢迎issue,欢迎star,欢迎新的使用需求和想法。后续会继续完善,谢谢!
Github地址: 查看全部
自动采集编写(安装Python自动化测试的脚本是用Python3写的吗)
写在前面
本文主要介绍一个基于uiautomator2封装的Python库android-catcher。该库的功能主要包括Android设备的UI自动化测试和手机性能数据的采集。适用于列表滑动、视频录制等各种测试场景。 CPU,内存、帧率等信息的抓取方便后续分析。
Github地址:
安装 Python
自动化测试脚本使用Python 3编写,运行脚本需要安装Python 3环境。
下载链接:
Python 3.6.5
安装 android-catcher 依赖
打开脚本目录,执行以下命令安装依赖
pip install -r requirements.txt
使用方法 uiautomator2
安装uiautomator2后,一般只需要执行以下命令来初始化设备并在设备上安装uiautomator2服务
python -m uiautomator2 init
如果出现如下提示,则安装成功
更多uiautomator2的使用请参考:
脚本文件说明
这个脚本库根目录下的主要文件有
参数说明 生成的文件说明
采集到的信息根据信息类型存储在指定输出目录下的cpu_stats、mem_stats、fps_stats、net_stats四个子目录中。文件名为信息类型_设备号_应用程序ID_版本号_测试场景名称_时间戳,如cpu_d3c2edaa_video。like_RecordVideo_1.9.9_1524122928.csv.csv,实际效果大致如下
输出文件为csv文件,直接打开和用Excel打开的效果如下:
此外,您可以为测试的每个阶段添加节点描述
task.period = "idle"
生成类似于下图的图形
如何使用无自定义测试场景
适用于没有特定测试场景,脚本运行一段时间后脚本处于采集状态的情况。时长可以通过配置参数指定,用户可以在此过程中随意操作手机。直接通过命令行运行_main_.py脚本文件并指定相关参数
比如我想采集applicationId为video.like的应用程序10s内的cpu信息和内存信息,采样间隔为200ms,输出目录为当前目录,那么可以在所在目录下执行如下命令脚本位于
python _main_.py -s 设备号-a video.like -f 0.2 -d 10 -i mem,cpu -o .
脚本运行后,在根目录下可以看到如下图的文件生成
注意:要带-d参数指定采集的持续时间,否则脚本默认运行10s,不需要-t参数。默认测试场景命名为 Random
如何使用自定义测试场景
自定义测试场景不能直接调用_main_.py 脚本。需要新建一个脚本,继承task.py#Task并重写Task#execute方法,在Task#execute中实现自定义测试场景的逻辑,如下图所示:
在这里创建一个名为 start_app.py 的脚本,运行命令:
python start_app.py -s 设备号-a 进程名 -f 0.1 -i cpu,mem -o .
可以启动相应的APP,采集CPU信息和内存信息,采样间隔100ms,输出到当前目录。注意这里没有-d参数,因为采集的时长以测试任务的时长为准。设置的参数必须按照说明进行,否则无法采集数据
如果要采集
自定义信息,可以继承 info.py#Info 并重写 Info#get_start_info 和 Info#get_end_info 方法。可以参考已经实现的四种信息集合,最后通过Task#add_info方法进行添加。
自定义测试场景后,调用_main_#main方法,传入测试场景实例。测试场景的名称将用作输出文件命名的一部分。最好取一个能准确表达测试场景的名字,比如一个APP录制视频 测试场景的名字是RecordVideo
采集
到的信息可以通过Excel制作成图表。以下是完整视频录制测试场景的CPU比例和内存变化
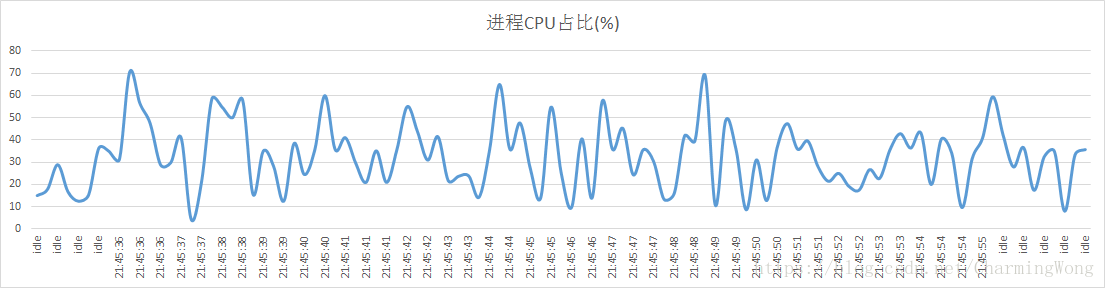
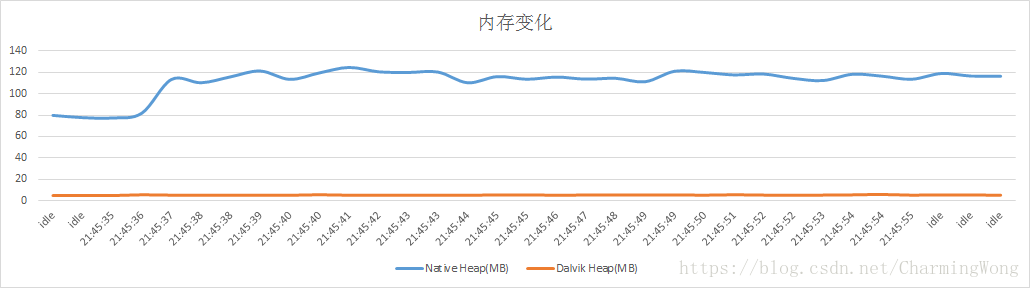
通过图表,可以直观地分析应用程序不同版本、不同场景的性能状态
写在最后
以上是对该库使用的一些介绍。由于工作经验还比较少,所以现在也在学习和使用Python。在编写这个库的时候,可能会有很多考虑不周或不完善的地方。有能力的朋友可以直接修改库实现更多的自定义功能。另外也希望大家多多使用,多发现问题,欢迎issue,欢迎star,欢迎新的使用需求和想法。后续会继续完善,谢谢!
Github地址:
自动采集编写(个人信息采集小程序模板解决你制作个人信息报表(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-12-28 16:09
个人信息采集小程序制作平台网站
>自建定制【个人信息采集小程序】立即注册开始>
▶微信、百度、抖音、今日头条小程序
▶抽奖、答题、投票、展示等多元化小程序。
▶同城、社区、查询、咨询等热门小程序
▶覆盖70+行业,400+套免费小程序模板即刻制作>
▶超划算的小程序开发方案,买两年送两年,每天只需花1元√
个人信息采集
小程序*热门功能
*服务抽奖——适用于美容、餐饮、保养等店内服务的个人信息采集小程序。
*同城社区-适用于小区、社区等领域采集
个人信息的小程序
* 留言如回复-适用于需要此服务的个人信息采集
小程序
*在线投票-适用于需要使用投票功能的个人信息采集小程序
*在线答题——适用于需要使用答题功能的个人信息采集小程序
*签到和签到-适用于需要使用签到功能的个人信息采集
小程序
提供个人信息采集小程序定制服务,或自带模板自建模板
个人信息采集小程序制作平台网站提供免费的个人信息采集小程序模板
平台提供免费的个人信息采集小程序模板
解决你在制作个人信息采集小程序的路上遇到的所有烦恼
个人信息采集小程序制作平台网站有哪些优势
定制2种服务,以及多功能服务,助您减少后顾之忧
▽无需自己写代码
▽小程序制作,全程拖拽操作简单
▽无需编写任何代码即可完成个人信息采集小程序的开发
▽个人信息采集小程序自主开发即刻启动
▽一键免费注册开发个人信息采集小程序
▽微信、百度小程序、今日头条、抖音
▽一次拥有四大平台网站小程序
▽抢占移动终端流量,提升企业移动终端服务水平
▽可视化个人信息采集小程序设计界面
▽步骤搭建简单好用的个人信息采集小程序
▽0代码库也可以用来制作个人信息采集小程序
▽省时、省力、省钱,高效完成个人信息采集小程序的开发
▽详细的数据分析报告
▽多维度、多方位的个人信息采集小程序数据解读
▽全面了解用户喜好和赚钱秘诀
▽大数据时代,用数据做更正确的决策 查看全部
自动采集编写(个人信息采集小程序模板解决你制作个人信息报表(组图))
个人信息采集小程序制作平台网站
>自建定制【个人信息采集小程序】立即注册开始>
▶微信、百度、抖音、今日头条小程序
▶抽奖、答题、投票、展示等多元化小程序。
▶同城、社区、查询、咨询等热门小程序
▶覆盖70+行业,400+套免费小程序模板即刻制作>
▶超划算的小程序开发方案,买两年送两年,每天只需花1元√

个人信息采集
小程序*热门功能
*服务抽奖——适用于美容、餐饮、保养等店内服务的个人信息采集小程序。
*同城社区-适用于小区、社区等领域采集
个人信息的小程序
* 留言如回复-适用于需要此服务的个人信息采集
小程序
*在线投票-适用于需要使用投票功能的个人信息采集小程序
*在线答题——适用于需要使用答题功能的个人信息采集小程序
*签到和签到-适用于需要使用签到功能的个人信息采集
小程序
提供个人信息采集小程序定制服务,或自带模板自建模板
个人信息采集小程序制作平台网站提供免费的个人信息采集小程序模板
平台提供免费的个人信息采集小程序模板
解决你在制作个人信息采集小程序的路上遇到的所有烦恼
个人信息采集小程序制作平台网站有哪些优势
定制2种服务,以及多功能服务,助您减少后顾之忧

▽无需自己写代码
▽小程序制作,全程拖拽操作简单
▽无需编写任何代码即可完成个人信息采集小程序的开发
▽个人信息采集小程序自主开发即刻启动

▽一键免费注册开发个人信息采集小程序
▽微信、百度小程序、今日头条、抖音
▽一次拥有四大平台网站小程序
▽抢占移动终端流量,提升企业移动终端服务水平

▽可视化个人信息采集小程序设计界面
▽步骤搭建简单好用的个人信息采集小程序
▽0代码库也可以用来制作个人信息采集小程序
▽省时、省力、省钱,高效完成个人信息采集小程序的开发

▽详细的数据分析报告
▽多维度、多方位的个人信息采集小程序数据解读
▽全面了解用户喜好和赚钱秘诀
▽大数据时代,用数据做更正确的决策
自动采集编写( 有关自动采集inlistIoutthe)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-28 06:11
有关自动采集inlistIoutthe)
Firefox 自动采集
url
在我开始测试有关在地址栏中启用内联自动完成功能的最后一个提示后,我突然想到,尽管来自我的浏览器历史记录的链接一直显示在列表中,但我可能永远不会输入它们。
在我开始测试关于在地址栏中启用内联自动完成的最后一个技巧后,我想虽然浏览器历史记录中的链接总是显示在列表中,但我可能永远不会输入它们。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您在地址栏中使用大量书签或搜索关键字时,这会很有帮助。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您从地址栏中使用许多书签或搜索关键字时,这会很有帮助。
请记住,此设置并不适合所有人,但了解工作原理很有好处。
请记住,此设置并不适合所有人,但最好了解它的工作原理。
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
browser.urlbar.matchOnlyTyped
browser.urlbar.matchOnlyTyped
双击该值将其更改为 true,您应该立即注意到历史记录中的链接将不再自动完成:
双击该值将其更改为true,您应该立即注意到历史记录中的链接将不再自动完成:
当然,您手动输入的链接将继续自动完成:
当然,您手动输入的链接会继续自动完成:
拥有一个每个人都可以选择自己设置的浏览器真是太好了。
有了浏览器,每个人都可以选择自己的设置,这很棒。
翻译自:
Firefox 自动采集
url 查看全部
自动采集编写(
有关自动采集inlistIoutthe)

Firefox 自动采集
url
在我开始测试有关在地址栏中启用内联自动完成功能的最后一个提示后,我突然想到,尽管来自我的浏览器历史记录的链接一直显示在列表中,但我可能永远不会输入它们。
在我开始测试关于在地址栏中启用内联自动完成的最后一个技巧后,我想虽然浏览器历史记录中的链接总是显示在列表中,但我可能永远不会输入它们。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您在地址栏中使用大量书签或搜索关键字时,这会很有帮助。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您从地址栏中使用许多书签或搜索关键字时,这会很有帮助。
请记住,此设置并不适合所有人,但了解工作原理很有好处。
请记住,此设置并不适合所有人,但最好了解它的工作原理。
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
browser.urlbar.matchOnlyTyped
browser.urlbar.matchOnlyTyped
双击该值将其更改为 true,您应该立即注意到历史记录中的链接将不再自动完成:
双击该值将其更改为true,您应该立即注意到历史记录中的链接将不再自动完成:
当然,您手动输入的链接将继续自动完成:
当然,您手动输入的链接会继续自动完成:
拥有一个每个人都可以选择自己设置的浏览器真是太好了。
有了浏览器,每个人都可以选择自己的设置,这很棒。
翻译自:
Firefox 自动采集
url
自动采集编写(iOS开发交流技术群:1.数据采集SDK是如何工作的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-28 06:09
GrowingIO 是一个基于用户行为数据的增长平台。准确采集用户行为数据是公司业务的基石。只有及时、准确、可靠的数据采集,才能支撑上层的数据分析、用户画像、运营等服务。因此,公司一直非常重视数据采集SDK(Software Development Kit)的质量保证工作。
iOS开发与通信技术群:【563513413】(跳跃),无论你是大牛还是新手,欢迎加入,分享BAT,阿里巴巴面试题,面试经验,讨论技术,让大家交流、学习、成长!
为了满足客户的各种业务和技术需求,GrowingIO提供Web、Android、iOS、Hybrid等各种平台,各种小程序(微信、支付宝、今日头条等)、微信内嵌页面,以及React Native 、Flutter、Cordova、Weex、API Cloud、AppCan等众多开发框架SDK,这无疑给SDK测试带来了巨大的挑战。
本文主要介绍GrowingIO在iOS SDK测试中的具体实践,希望能为从事iOS测试的同学提供一些参考。
1. 数据采集SDK是如何工作的?
要测试一个软件或系统,首先要了解它的业务逻辑和技术实现。接下来我们简单的看一下数据采集SDK的工作原理。
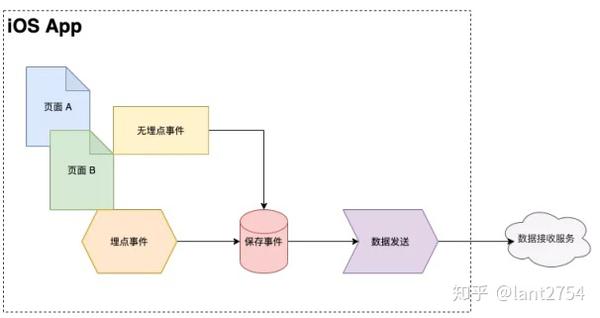
GrowingIO的数据采集SDK支持非埋点(全埋点)数据采集和埋点数据采集,满足不同业务需求。其简单的结构如下:
当用户打开App、浏览不同页面、点击不同元素(如按钮、文本框、图片)、关闭App时,非嵌入式事件采集模块会自动采集并保存用户的具体行为手机本地存储(关于非埋点数据采集的具体实现,请关注GrowigIO的后续文章分享,这里不再详述)。
埋点事件采集类似,不同的是埋点事件是由App主动调用SDK的埋点API触发的。当然,不同事件的具体数据格式是不同的。
接下来是数据发送模块,主要负责通过HTTP API向数据接收服务上报数据。
需要注意的是,为了节省用户的数据流量和电量,发送程序不是实时上报的。它会根据设备的功率、网络类型和数据量来选择发送时序,数据在发送前会被压缩。并进行混淆处理,减少传输数据量,提高数据安全性。
当然,数据发送程序也会对数据报告中的各种数据发送失败、网络异常等错误进行处理,并采用适当的重试机制。
2. 如何测试?
通过以上结构分析可以看出,数据发送模块与核心数据采集业务关系不大,非常稳定,几乎没有变化,所以我们测试的重点主要是数据采集部分,尤其是数据采集部分无埋点。
要测试数据采集,首先需要有一个收录
各种页面和元素的Demo App,然后在不同页面之间切换,操作页面上的元素或者触发一个埋藏事件,然后检查采集的事件数据是否正确。
有两种方法可以检查事件数据。一种是通过日志打印出详细的事件数据,观察日志检查;另一种是通过抓包程序获取数据并发送,然后检查。
后者一般需要配置复杂的代理工具,数据量大,还需要考虑数据的解压和解密。更难准确定位事件数据。因此,在实际测试中一般采用前者。
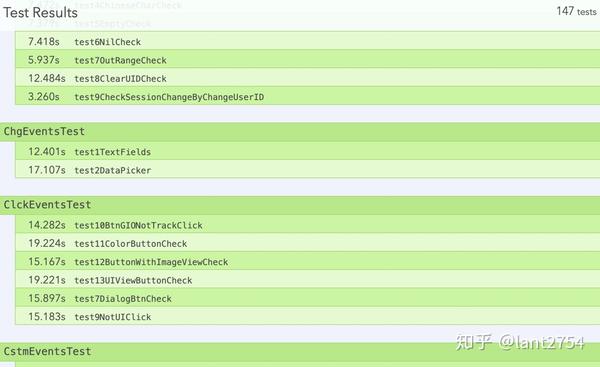
上图是采集数据的日志截图。通过图中的事件数据,我们发现字段较多,有些字段可读性不高,人工检查耗时较长。
另外,SDK数据采集的主要逻辑基本不变,但每次修改都要覆盖足够的回归,避免遗漏错误。
一旦缺陷在线上被遗漏,造成的损失是极其昂贵的。即使缺陷在后续版本中修复,影响也难以消除,因为移动应用程序的升级周期难以控制。
此外,GrowingIO 数据采集 SDK 兼容 iOS 8 及以上版本。需要测试系统各个版本的兼容性,测试工作量明显。
好在SDK的业务变化很少,断言内容比较机械,特别适合自动化测试。而且回归测试的工作量巨大,使用自动化测试可以大大提高生产力和质量。
3. 选择一个测试框架
工人要想做好本职工作,首先要磨砺工具,选择合适的自动化测试框架,再进行自动化测试。选择框架时需要考虑几个方面:
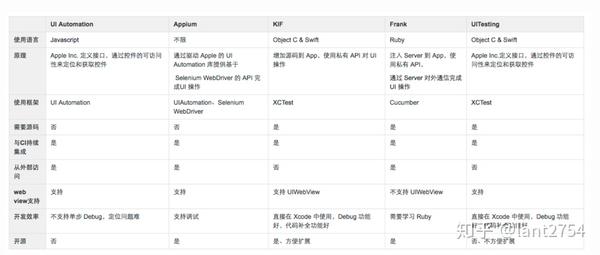
目前支持iOS UI自动化测试的主要框架对比如下:
考虑影响测试框架选择的几个因素。
首先,使用的语言和框架决定了测试人员的持续学习成本。iOS SDK 测试人员对Objective-C 有高度的熟悉和掌握,不需要消耗额外的学习成本。测试和开发相同的技术堆栈。
其次,根据需要不时调整测试App程序。使用开发效率高、调试方便的测试框架,可以让我们在适应新的UI变化和新的需求时,获得更小的投入产出比。
基于以上考虑,KIF框架已经展示了它的优势,而KIF使用XCTest框架,使得iOS程序的测试过程和单测一样,可以完全复用单测持续集成过程,维护持续集成的成本相对降低;此外,KIF 是一个活跃的开源测试框架,具有良好的可扩展性和快速升级。有活跃的社区来讨论和解决使用过程中遇到的问题。
鉴于以上优势,我们选择KIF作为iOS的UI自动化测试框架。
KIF的全称是Keep it Functional,是一个建立在XCTest之上的UI测试框架,通过Accessibility定位特定的控件,然后使用私有的API来操作UI。由于它是建立在 XCTest 之上的,所以你可以完美的使用 XCode 的测试相关工具。
4. 自动化测试的实现
语言和工具
建立测试环境
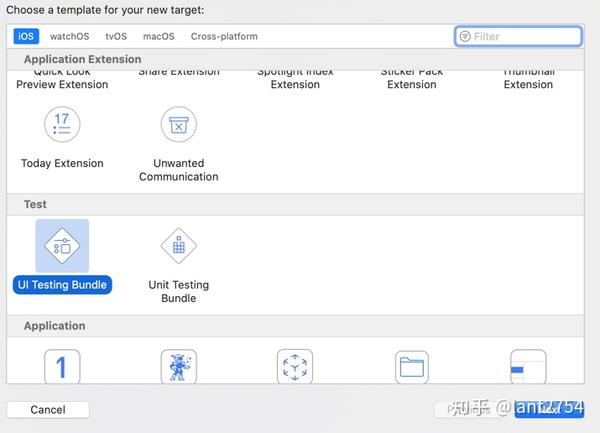
要将Target实现添加到现有项目中,选择File → New → Target…菜单项,在iOS → Test中选择UI Testing Bundle模板,如下图:
点击下一步进入Target选项页面,设置测试项目的相关项
完成Target设置后,点击“Finish”按钮,创建成功。
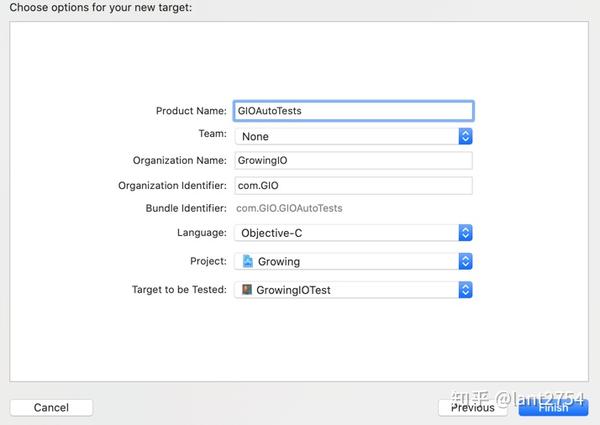
要安装 pod,请在命令行终端中输入以下命令。
sudo gem 安装 cocoapods
修改或创建项目的pod文件Podfile。
目标'GrowingIOTest'做
pod'SDCycleScrollView','~> 1.75'
pod'MJRefresh'
pod'MBProgressHUD'
结尾
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
其中,新增以下一段
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
在项目目录下执行如下安装命令安装对应的依赖,测试项目就准备完成了。
吊舱安装
准备待测程序,在测试Demo工程中集成待测版本的数据采集SDK。
编写测试用例
测试环境搭建好后,下一步就是编写具体的测试用例。一般测试用例的主要步骤是:
准备测试环境,执行测试步骤,测试结果,断言测试结果,报告,清理测试环境
下面以SDK的unburied元素的点击事件的自动化测试用例为例,说明自动化用例的准备。
测试用例:
启动App,模拟用户滚动屏幕找到对话框按钮,然后点击对话框按钮。弹出对话框后,点击关闭按钮,验证点击事件是否发送数据,内容是否正确。
代码:
-(无效)设置{
// 一些初始化操作
}
-(void)tearDown{
// 一些结束动作
}
-(无效)testDialogBtnCheck{
/**
功能:点击对话框按钮检测点击事件,
**/
[[viewTester usingLabel:@"UIinterface"] 点击];
//添加向下滚动操作
[tester scrollViewWithAccessibilityLabel:@"采集
View" byFractionOfSizeHorizontal:0.0f vertical:10.0f];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"LabelAttribute"] tap];
[[viewTester usingLabel:@"ShowAlert"] 点击];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"Cancel"] tap];
[测试员waitForTimeInterval:3];
NSArray *clckEventArray = [MockEventQueue eventsFor:@"clck"];
//是否发送clck事件
if(clckEventArray.count>=2)
{
//判断点击事件是否正确发送
NSDictionary *chevent=[clckEventArray objectAtIndex:clckEventArray.count-1];
NSDictionary *clkchr=[NoburPoMeaProCheck ClckEventCheck:chevent];
//NSLog(@"检查结果:%@",clkchr);
XCTAssertEqual(clkchr[@"KeysCheck"][@"chres"], @"Passed");
NSLog(@"点击对话框按钮检测clck事件测试通过---Passed!");
}
别的
{
NSLog(@"对话框按钮被点击,clck事件测试失败:%@!",clckEventArray);
XCTAssertEqual(1, 0);
}
}
由于我们主要测试SDK的功能,所以测试Demo是我们自己设计的,主要涵盖了各种UI元素和事件。它的业务逻辑比大多数业务类应用都简单,没有特别的介绍。
这里介绍断言的设计。上一篇提到,我们自动化测试的重点是数据采集规则是否正确,不关心数据的存储和传输。
SDK在采集数据时,先将所有的事件加入到一个队列中,然后再保存到DB中,所以在进行测试的时候,只需要监听事件队列,就可以保存和检索需要的事件根据需要在受监视的事件队列中断言。点击事件发送的数据结构大致如下:
验证事件数据,首先要保证字段完整,每个字段不为空,即数据模式正确;其次,根据需要验证事件的具体字段,例如点击事件的类型t应该是clck。这些检查被封装在一个单独的Check方法中,如果检查通过,该方法返回Passed。
这里通过ClckEventCheck方法完成具体的业务验证。
执行测试用例
主要介绍如何通过命令行执行测试。
安装Command Line Tools(命令行工具包),App Store安装Xcode默认不会安装Command Line Tools,可以在命令行输入以下命令单独安装。
xcode-select --install
在使用命令行执行测试之前,还需要将项目设置为 Shared。打开产品→方案→管理方案,勾选项目是否共享,如果不是,勾选后面的复选框进行共享。
从命令行执行所有测试用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
执行单个用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-only-testing:GIOAutoTests/ClckEventsTest/test7DialogBtnCheck \
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
xcodebuild 的更多使用请参考其使用说明。
人 xcodebuild
美化检测报告
xcodebuild 的输出读起来不是很直观。使用xcpretty可以解决这个问题,同时也可以完成测试报告的生成。
xcpretty 是一种高速灵活的 xcodebuild 输出格式化工具。其用法如下:
# 从命令行安装 xcpretty
gem 安装 xcpretty
命令行执行
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11' \
| xcpretty --report html
生成的测试报告如下:
默认输出 html 报告在 build/reports/tests.html
5. 覆盖率统计
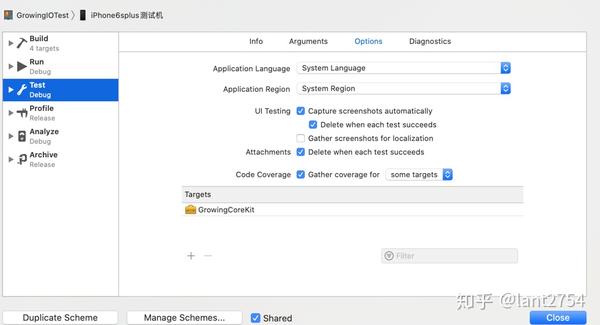
在进行自动化测试时,我们通常希望获得测试覆盖率报告来衡量自动化测试的覆盖率。由于 KIF 是直接基于 XCTest 实现的,因此您可以轻松使用 Xcode 自带的覆盖率统计工具。设置如下:
Product → Scheme → Edit Scheme, Code Coverage 将需要统计覆盖的被测程序添加到Targets中。
测试完成后,可以获得覆盖率统计报告。
6. 持续集成
自动化测试的最大价值在于它可以代替人工进行更高效、更频繁的测试。因此,要充分发挥自动化测试的价值,最理想的解决方案就是在持续集成环节加入自动化测试。每当有代码更改时,都会自动执行测试并快速反馈结果。
我们使用Jenkins来监控代码仓库的变化。当有新的commit提交时,Jenkins会自动拉取最新的代码,调用命令行执行相应的自动化测试用例,采集
相应的测试报告,并将测试结果通过钉钉机器人及时通知相关开发人员和测试人员。
当测试失败时,相关人员可以第一时间收到结果并及时解决。
7. 总结
本文以iOS平台为例,系统介绍GrowingIO数据采集SDK的主要工作原理、测试方案的设计、自动化测试框架的选择以及自动化测试的实现。希望对从事SDK测试的同学有所启发。
后面我们还会分享GrowingIO用户触摸SDK的自动化测试、Android SDK的自动化测试等相关内容。请继续关注我们。 查看全部
自动采集编写(iOS开发交流技术群:1.数据采集SDK是如何工作的)
GrowingIO 是一个基于用户行为数据的增长平台。准确采集用户行为数据是公司业务的基石。只有及时、准确、可靠的数据采集,才能支撑上层的数据分析、用户画像、运营等服务。因此,公司一直非常重视数据采集SDK(Software Development Kit)的质量保证工作。
iOS开发与通信技术群:【563513413】(跳跃),无论你是大牛还是新手,欢迎加入,分享BAT,阿里巴巴面试题,面试经验,讨论技术,让大家交流、学习、成长!
为了满足客户的各种业务和技术需求,GrowingIO提供Web、Android、iOS、Hybrid等各种平台,各种小程序(微信、支付宝、今日头条等)、微信内嵌页面,以及React Native 、Flutter、Cordova、Weex、API Cloud、AppCan等众多开发框架SDK,这无疑给SDK测试带来了巨大的挑战。
本文主要介绍GrowingIO在iOS SDK测试中的具体实践,希望能为从事iOS测试的同学提供一些参考。
1. 数据采集SDK是如何工作的?
要测试一个软件或系统,首先要了解它的业务逻辑和技术实现。接下来我们简单的看一下数据采集SDK的工作原理。
GrowingIO的数据采集SDK支持非埋点(全埋点)数据采集和埋点数据采集,满足不同业务需求。其简单的结构如下:
当用户打开App、浏览不同页面、点击不同元素(如按钮、文本框、图片)、关闭App时,非嵌入式事件采集模块会自动采集并保存用户的具体行为手机本地存储(关于非埋点数据采集的具体实现,请关注GrowigIO的后续文章分享,这里不再详述)。
埋点事件采集类似,不同的是埋点事件是由App主动调用SDK的埋点API触发的。当然,不同事件的具体数据格式是不同的。
接下来是数据发送模块,主要负责通过HTTP API向数据接收服务上报数据。
需要注意的是,为了节省用户的数据流量和电量,发送程序不是实时上报的。它会根据设备的功率、网络类型和数据量来选择发送时序,数据在发送前会被压缩。并进行混淆处理,减少传输数据量,提高数据安全性。
当然,数据发送程序也会对数据报告中的各种数据发送失败、网络异常等错误进行处理,并采用适当的重试机制。
2. 如何测试?
通过以上结构分析可以看出,数据发送模块与核心数据采集业务关系不大,非常稳定,几乎没有变化,所以我们测试的重点主要是数据采集部分,尤其是数据采集部分无埋点。
要测试数据采集,首先需要有一个收录
各种页面和元素的Demo App,然后在不同页面之间切换,操作页面上的元素或者触发一个埋藏事件,然后检查采集的事件数据是否正确。
有两种方法可以检查事件数据。一种是通过日志打印出详细的事件数据,观察日志检查;另一种是通过抓包程序获取数据并发送,然后检查。
后者一般需要配置复杂的代理工具,数据量大,还需要考虑数据的解压和解密。更难准确定位事件数据。因此,在实际测试中一般采用前者。

上图是采集数据的日志截图。通过图中的事件数据,我们发现字段较多,有些字段可读性不高,人工检查耗时较长。
另外,SDK数据采集的主要逻辑基本不变,但每次修改都要覆盖足够的回归,避免遗漏错误。
一旦缺陷在线上被遗漏,造成的损失是极其昂贵的。即使缺陷在后续版本中修复,影响也难以消除,因为移动应用程序的升级周期难以控制。
此外,GrowingIO 数据采集 SDK 兼容 iOS 8 及以上版本。需要测试系统各个版本的兼容性,测试工作量明显。
好在SDK的业务变化很少,断言内容比较机械,特别适合自动化测试。而且回归测试的工作量巨大,使用自动化测试可以大大提高生产力和质量。
3. 选择一个测试框架
工人要想做好本职工作,首先要磨砺工具,选择合适的自动化测试框架,再进行自动化测试。选择框架时需要考虑几个方面:
目前支持iOS UI自动化测试的主要框架对比如下:
考虑影响测试框架选择的几个因素。
首先,使用的语言和框架决定了测试人员的持续学习成本。iOS SDK 测试人员对Objective-C 有高度的熟悉和掌握,不需要消耗额外的学习成本。测试和开发相同的技术堆栈。
其次,根据需要不时调整测试App程序。使用开发效率高、调试方便的测试框架,可以让我们在适应新的UI变化和新的需求时,获得更小的投入产出比。
基于以上考虑,KIF框架已经展示了它的优势,而KIF使用XCTest框架,使得iOS程序的测试过程和单测一样,可以完全复用单测持续集成过程,维护持续集成的成本相对降低;此外,KIF 是一个活跃的开源测试框架,具有良好的可扩展性和快速升级。有活跃的社区来讨论和解决使用过程中遇到的问题。
鉴于以上优势,我们选择KIF作为iOS的UI自动化测试框架。
KIF的全称是Keep it Functional,是一个建立在XCTest之上的UI测试框架,通过Accessibility定位特定的控件,然后使用私有的API来操作UI。由于它是建立在 XCTest 之上的,所以你可以完美的使用 XCode 的测试相关工具。
4. 自动化测试的实现
语言和工具
建立测试环境
要将Target实现添加到现有项目中,选择File → New → Target…菜单项,在iOS → Test中选择UI Testing Bundle模板,如下图:
点击下一步进入Target选项页面,设置测试项目的相关项
完成Target设置后,点击“Finish”按钮,创建成功。
要安装 pod,请在命令行终端中输入以下命令。
sudo gem 安装 cocoapods
修改或创建项目的pod文件Podfile。
目标'GrowingIOTest'做
pod'SDCycleScrollView','~> 1.75'
pod'MJRefresh'
pod'MBProgressHUD'
结尾
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
其中,新增以下一段
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
在项目目录下执行如下安装命令安装对应的依赖,测试项目就准备完成了。
吊舱安装
准备待测程序,在测试Demo工程中集成待测版本的数据采集SDK。
编写测试用例
测试环境搭建好后,下一步就是编写具体的测试用例。一般测试用例的主要步骤是:
准备测试环境,执行测试步骤,测试结果,断言测试结果,报告,清理测试环境
下面以SDK的unburied元素的点击事件的自动化测试用例为例,说明自动化用例的准备。
测试用例:
启动App,模拟用户滚动屏幕找到对话框按钮,然后点击对话框按钮。弹出对话框后,点击关闭按钮,验证点击事件是否发送数据,内容是否正确。
代码:
-(无效)设置{
// 一些初始化操作
}
-(void)tearDown{
// 一些结束动作
}
-(无效)testDialogBtnCheck{
/**
功能:点击对话框按钮检测点击事件,
**/
[[viewTester usingLabel:@"UIinterface"] 点击];
//添加向下滚动操作
[tester scrollViewWithAccessibilityLabel:@"采集
View" byFractionOfSizeHorizontal:0.0f vertical:10.0f];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"LabelAttribute"] tap];
[[viewTester usingLabel:@"ShowAlert"] 点击];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"Cancel"] tap];
[测试员waitForTimeInterval:3];
NSArray *clckEventArray = [MockEventQueue eventsFor:@"clck"];
//是否发送clck事件
if(clckEventArray.count>=2)
{
//判断点击事件是否正确发送
NSDictionary *chevent=[clckEventArray objectAtIndex:clckEventArray.count-1];
NSDictionary *clkchr=[NoburPoMeaProCheck ClckEventCheck:chevent];
//NSLog(@"检查结果:%@",clkchr);
XCTAssertEqual(clkchr[@"KeysCheck"][@"chres"], @"Passed");
NSLog(@"点击对话框按钮检测clck事件测试通过---Passed!");
}
别的
{
NSLog(@"对话框按钮被点击,clck事件测试失败:%@!",clckEventArray);
XCTAssertEqual(1, 0);
}
}
由于我们主要测试SDK的功能,所以测试Demo是我们自己设计的,主要涵盖了各种UI元素和事件。它的业务逻辑比大多数业务类应用都简单,没有特别的介绍。
这里介绍断言的设计。上一篇提到,我们自动化测试的重点是数据采集规则是否正确,不关心数据的存储和传输。
SDK在采集数据时,先将所有的事件加入到一个队列中,然后再保存到DB中,所以在进行测试的时候,只需要监听事件队列,就可以保存和检索需要的事件根据需要在受监视的事件队列中断言。点击事件发送的数据结构大致如下:

验证事件数据,首先要保证字段完整,每个字段不为空,即数据模式正确;其次,根据需要验证事件的具体字段,例如点击事件的类型t应该是clck。这些检查被封装在一个单独的Check方法中,如果检查通过,该方法返回Passed。
这里通过ClckEventCheck方法完成具体的业务验证。
执行测试用例
主要介绍如何通过命令行执行测试。
安装Command Line Tools(命令行工具包),App Store安装Xcode默认不会安装Command Line Tools,可以在命令行输入以下命令单独安装。
xcode-select --install
在使用命令行执行测试之前,还需要将项目设置为 Shared。打开产品→方案→管理方案,勾选项目是否共享,如果不是,勾选后面的复选框进行共享。

从命令行执行所有测试用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
执行单个用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-only-testing:GIOAutoTests/ClckEventsTest/test7DialogBtnCheck \
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
xcodebuild 的更多使用请参考其使用说明。
人 xcodebuild
美化检测报告
xcodebuild 的输出读起来不是很直观。使用xcpretty可以解决这个问题,同时也可以完成测试报告的生成。
xcpretty 是一种高速灵活的 xcodebuild 输出格式化工具。其用法如下:
# 从命令行安装 xcpretty
gem 安装 xcpretty
命令行执行
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11' \
| xcpretty --report html
生成的测试报告如下:
默认输出 html 报告在 build/reports/tests.html
5. 覆盖率统计
在进行自动化测试时,我们通常希望获得测试覆盖率报告来衡量自动化测试的覆盖率。由于 KIF 是直接基于 XCTest 实现的,因此您可以轻松使用 Xcode 自带的覆盖率统计工具。设置如下:
Product → Scheme → Edit Scheme, Code Coverage 将需要统计覆盖的被测程序添加到Targets中。
测试完成后,可以获得覆盖率统计报告。
6. 持续集成
自动化测试的最大价值在于它可以代替人工进行更高效、更频繁的测试。因此,要充分发挥自动化测试的价值,最理想的解决方案就是在持续集成环节加入自动化测试。每当有代码更改时,都会自动执行测试并快速反馈结果。
我们使用Jenkins来监控代码仓库的变化。当有新的commit提交时,Jenkins会自动拉取最新的代码,调用命令行执行相应的自动化测试用例,采集
相应的测试报告,并将测试结果通过钉钉机器人及时通知相关开发人员和测试人员。
当测试失败时,相关人员可以第一时间收到结果并及时解决。
7. 总结
本文以iOS平台为例,系统介绍GrowingIO数据采集SDK的主要工作原理、测试方案的设计、自动化测试框架的选择以及自动化测试的实现。希望对从事SDK测试的同学有所启发。
后面我们还会分享GrowingIO用户触摸SDK的自动化测试、Android SDK的自动化测试等相关内容。请继续关注我们。
自动采集编写(网页采集是什么,又是如何采集的呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-27 20:08
在网页设计中,什么是网页采集
以及它是如何采集
的?
网页采集
作为政府网站网页在线归档的首要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集
的第一步是确定采集
对象。政府网页档案中存储的信息采集对象为域名带有“”的政府网站。为了保证政府网页的采集质量,需要对目标网站进行评估,信息量大。, 选择原创
信息多、更新频繁的政府网站作为采集对象。确定要采集的目标政府网站后,
完整性采集和选择性采集是目前比较常用的网络资源采集方式。他们有自己的优点和缺点。为了弥补各自的不足,可以通过结合两者优点的混合采集方式来补充两种采集方式的优点。,在采集
入选政府网站所有网页完整性的同时,通过人工干预筛选网页内容,有选择地对具有证据价值、历史价值、研究价值的重要网页进行深度挖掘。分级频繁采集,既兼顾了政府网页采集的广度,又兼顾了重要网页的采集深度。
网页的采集和抓取最终需要依赖相应的网络爬虫工具。目前,有很多用于网页归档的爬虫工具。其中Heritrix和HTTrack是最常用的。这些工具可用于定位政府网站页面。自动批量在线采集。 查看全部
自动采集编写(网页采集是什么,又是如何采集的呢?(图))
在网页设计中,什么是网页采集
以及它是如何采集
的?
网页采集
作为政府网站网页在线归档的首要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集
的第一步是确定采集
对象。政府网页档案中存储的信息采集对象为域名带有“”的政府网站。为了保证政府网页的采集质量,需要对目标网站进行评估,信息量大。, 选择原创
信息多、更新频繁的政府网站作为采集对象。确定要采集的目标政府网站后,
完整性采集和选择性采集是目前比较常用的网络资源采集方式。他们有自己的优点和缺点。为了弥补各自的不足,可以通过结合两者优点的混合采集方式来补充两种采集方式的优点。,在采集
入选政府网站所有网页完整性的同时,通过人工干预筛选网页内容,有选择地对具有证据价值、历史价值、研究价值的重要网页进行深度挖掘。分级频繁采集,既兼顾了政府网页采集的广度,又兼顾了重要网页的采集深度。
网页的采集和抓取最终需要依赖相应的网络爬虫工具。目前,有很多用于网页归档的爬虫工具。其中Heritrix和HTTrack是最常用的。这些工具可用于定位政府网站页面。自动批量在线采集。
自动采集编写(浏览器页面模拟点击获取数据进行后续的数据处理方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-27 04:01
自动采集编写脚本是有一些小学生小老板的,不过真正的全自动采集是需要程序辅助配合的,如采集网页中的alt+tab标签,通过发php代码请求或者asp代码请求来达到自动化查询操作而已。
浏览器页面模拟点击获取数据进行后续的数据处理
你所要做的,即无需翻墙,地址全部被爬取了,只需要将他们的url传入sae就可以调用阿里的接口获取商品信息了。
我有开发过一个,地址是:-trade/,一个简单的、基于python的商品采集器,包括如下功能:1.采集网页商品信息2.采集京东、、知乎等平台商品信息3.抓取处理京东、、知乎等平台用户发布商品信息4.抓取商品详情页采集方法:先用python做出一个标准的采集url,然后让aba插件抓取标准的采集url,写一个爬虫程序,如下,编写程序大概一两个小时,后端爬虫程序两三天,然后请求aba爬虫的html页面,完成所有商品信息的抓取,返回实时页面,把抓取好的html发布到,或者在网站上安装上selenium和requests模块,用这两个模块访问抓取好的商品,用浏览器的自动抓取脚本功能,用浏览器按照cookie找商品id抓取商品信息,将抓取完成的数据返回,然后用aba的javascript页面获取,再用爬虫程序进行后续的商品信息获取和后续的页面处理。
补充下以上程序实现流程:商品采集完成后我会检查javascript页面和页面请求是否加载正常(加载正常或者出错我会告诉大家这个必须出了一定的bug才会这样),并且页面数据返回是否正确,如果返回正确我会保存一个log,这样就能随时把任何需要抓取商品信息的请求都通过code把抓取的商品信息发布到了aba的后端服务器,然后从aba后端服务器抓取数据或者对数据进行处理,对数据做出页面页面显示处理等。
如果从这个方法实现的话,前端抓取只需要安装javascript模块,后端服务器配置网页编程对象即可。如果大家觉得我写的程序不错的话,请点个赞,谢谢大家!。 查看全部
自动采集编写(浏览器页面模拟点击获取数据进行后续的数据处理方法)
自动采集编写脚本是有一些小学生小老板的,不过真正的全自动采集是需要程序辅助配合的,如采集网页中的alt+tab标签,通过发php代码请求或者asp代码请求来达到自动化查询操作而已。
浏览器页面模拟点击获取数据进行后续的数据处理
你所要做的,即无需翻墙,地址全部被爬取了,只需要将他们的url传入sae就可以调用阿里的接口获取商品信息了。
我有开发过一个,地址是:-trade/,一个简单的、基于python的商品采集器,包括如下功能:1.采集网页商品信息2.采集京东、、知乎等平台商品信息3.抓取处理京东、、知乎等平台用户发布商品信息4.抓取商品详情页采集方法:先用python做出一个标准的采集url,然后让aba插件抓取标准的采集url,写一个爬虫程序,如下,编写程序大概一两个小时,后端爬虫程序两三天,然后请求aba爬虫的html页面,完成所有商品信息的抓取,返回实时页面,把抓取好的html发布到,或者在网站上安装上selenium和requests模块,用这两个模块访问抓取好的商品,用浏览器的自动抓取脚本功能,用浏览器按照cookie找商品id抓取商品信息,将抓取完成的数据返回,然后用aba的javascript页面获取,再用爬虫程序进行后续的商品信息获取和后续的页面处理。
补充下以上程序实现流程:商品采集完成后我会检查javascript页面和页面请求是否加载正常(加载正常或者出错我会告诉大家这个必须出了一定的bug才会这样),并且页面数据返回是否正确,如果返回正确我会保存一个log,这样就能随时把任何需要抓取商品信息的请求都通过code把抓取的商品信息发布到了aba的后端服务器,然后从aba后端服务器抓取数据或者对数据进行处理,对数据做出页面页面显示处理等。
如果从这个方法实现的话,前端抓取只需要安装javascript模块,后端服务器配置网页编程对象即可。如果大家觉得我写的程序不错的话,请点个赞,谢谢大家!。
自动采集编写(纯Qt编写,支持任意Qt版本+任意编译器+枚举)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-25 14:19
一、前言
数据库用作数据源,并在许多组态软件中使用。指定数据库类型,填写数据库连接信息,指定对应的数据库表和字段,以及采集间隔。程序根据采集间隔自动采集数据库数据并绑定到界面控件分配显示即可。使用数据库作为数据源有一个非常大的好处,不需要写额外的通讯代码,与对方的语言或平台无关,也不会出现不规范、不规范等争吵不准确的通信协议导致不正确的分析。情况是它支持任何语言和平台。毕竟有数据库作为中间载体过渡,
体验地址:提取码:877p 文件:可执行文件.zip
二、 实现的功能自动加载插件文件中的所有控件生成列表,默认自带120多个控件。拖到画布上自动生成对应的控件,所见即所得。在右侧的中文属性栏上,更改相应的属性会立即应用到相应的选中控件上,直观简洁,非常适合小白使用。独创的属性列文本翻译映射机制,效率极高,可以非常方便的扩展其他语言的属性列。所有控件的属性都会自动提取出来并显示在右侧的属性栏中,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。可以将当前画布的所有控件配置信息导出到一个xml文件中。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。可以通过拉动滑动条、勾选模拟数据复选框、输入文本框三种方式生成数据并应用所有控件。控件支持八个方向调节大小,自适应任意分辨率,键盘可上下左右微调位置。以三种方式设置数据:串口采集、网络采集、数据库采集。代码极其简洁,注释也很详细,可作为配置原型,自行扩展更多功能。纯Qt编写,支持任意Qt版本+任意编译器+任意系统。三、效果图
四、核心代码
void frmData::initServer()
{
//实例化串口类,绑定信号槽
com = new QextSerialPort(QextSerialPort::EventDriven, this);
connect(com, SIGNAL(readyRead()), this, SLOT(readDataCom()));
//实例化网络通信客户端类,绑定信号槽
tcpClient = new QTcpSocket(this);
connect(tcpClient, SIGNAL(readyRead()), this, SLOT(readDataClient()));
//实例化网络通信服务端类,绑定信号槽
tcpSocket = NULL;
tcpServer = new QTcpServer(this);
connect(tcpServer, SIGNAL(newConnection()), this, SLOT(newConnection()));
//开启定时器读取数据库采集数据
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(readDataDb()));
timer->setInterval(1000);
}
void frmData::on_btnOpenDb_clicked()
{
if (ui->btnOpenDb->text() == "打开") {
if (App::DbType == "sqlite") {
//先检查数据库文件是否存在
QString dbPath = qApp->applicationDirPath() + "/" + App::DbPath;
QFile file(dbPath);
if (file.size() == 0) {
return;
}
dbConn = QSqlDatabase::addDatabase("QSQLITE");
dbConn.setDatabaseName(dbPath);
} else if (App::DbType == "mysql") {
//先检查数据库服务器IP是否通,不检查直接连接,不存在的IP会卡很久
QTcpSocket socket;
socket.connectToHost(App::DbPath, App::DbPort);
if (!socket.waitForConnected(2000)) {
return;
} else {
socket.disconnectFromHost();
}
dbConn = QSqlDatabase::addDatabase("QMYSQL");
dbConn.setHostName(App::DbPath);
dbConn.setPort(App::DbPort);
dbConn.setDatabaseName(App::DbName);
dbConn.setUserName(App::DbUser);
dbConn.setPassword(App::DbPwd);
} else {
//暂未支持其他数据库,可以自行加入
return;
}
bool ok = dbConn.open();
if (ok) {
setEnable(ui->btnOpenDb, false);
ui->btnOpenDb->setText("关闭");
timer->start();
}
} else {
if (dbConn.isOpen()) {
dbConn.close();
}
setEnable(ui->btnOpenDb, true);
ui->btnOpenDb->setText("打开");
timer->stop();
}
}
void frmData::readDataDb()
{
QString sql = QString("select %1 from %2").arg(App::DbColumn).arg(App::DbTable);
QSqlQuery query;
if (query.exec(sql)) {
if (query.next()) {
double value = query.value(0).toDouble();
ui->txtValue->setText(QString::number(value));
append(4, QString("当前值: %1").arg(value));
}
}
}
五、控件引入了150多个漂亮的控件,涵盖了各种仪表盘、进度条、进度球、指南针、图表、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类可以独立成一个单独的控件,零耦合,每个控件都有一个头文件和一个实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,用更少的代码。qwt 的控制类是相互关联且高度耦合的。如果要使用其中一种控件,则必须收录
所有代码。全部用纯Qt编写,QWidget+QPainter绘图,支持从Qt4.6到Qt5.12的任何Qt版本,支持mingw、msvc、gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,和内置控件一样使用,效果最只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。
一些控件提供多种样式可供选择,以及多种指示器样式可供选择。所有控件都适应窗体的拉伸和变化。集成自定义控件属性设计器,支持拖动设计,所见即所得,支持导入导出xml格式。自带activex控件演示,所有控件都可以直接在ie浏览器中运行。集成fontawesome图形字体+阿里巴巴iconfont采集
的数百种图形字体,享受图形字体的乐趣。所有控件最后生成一个动态库文件(dll等),可以直接集成到qtcreator中进行拖动设计使用。已经有qml版本了,如果用户需求大,以后会考虑pyqt版本。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 查看全部
自动采集编写(纯Qt编写,支持任意Qt版本+任意编译器+枚举)
一、前言
数据库用作数据源,并在许多组态软件中使用。指定数据库类型,填写数据库连接信息,指定对应的数据库表和字段,以及采集间隔。程序根据采集间隔自动采集数据库数据并绑定到界面控件分配显示即可。使用数据库作为数据源有一个非常大的好处,不需要写额外的通讯代码,与对方的语言或平台无关,也不会出现不规范、不规范等争吵不准确的通信协议导致不正确的分析。情况是它支持任何语言和平台。毕竟有数据库作为中间载体过渡,
体验地址:提取码:877p 文件:可执行文件.zip
二、 实现的功能自动加载插件文件中的所有控件生成列表,默认自带120多个控件。拖到画布上自动生成对应的控件,所见即所得。在右侧的中文属性栏上,更改相应的属性会立即应用到相应的选中控件上,直观简洁,非常适合小白使用。独创的属性列文本翻译映射机制,效率极高,可以非常方便的扩展其他语言的属性列。所有控件的属性都会自动提取出来并显示在右侧的属性栏中,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。可以将当前画布的所有控件配置信息导出到一个xml文件中。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。可以通过拉动滑动条、勾选模拟数据复选框、输入文本框三种方式生成数据并应用所有控件。控件支持八个方向调节大小,自适应任意分辨率,键盘可上下左右微调位置。以三种方式设置数据:串口采集、网络采集、数据库采集。代码极其简洁,注释也很详细,可作为配置原型,自行扩展更多功能。纯Qt编写,支持任意Qt版本+任意编译器+任意系统。三、效果图

四、核心代码
void frmData::initServer()
{
//实例化串口类,绑定信号槽
com = new QextSerialPort(QextSerialPort::EventDriven, this);
connect(com, SIGNAL(readyRead()), this, SLOT(readDataCom()));
//实例化网络通信客户端类,绑定信号槽
tcpClient = new QTcpSocket(this);
connect(tcpClient, SIGNAL(readyRead()), this, SLOT(readDataClient()));
//实例化网络通信服务端类,绑定信号槽
tcpSocket = NULL;
tcpServer = new QTcpServer(this);
connect(tcpServer, SIGNAL(newConnection()), this, SLOT(newConnection()));
//开启定时器读取数据库采集数据
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(readDataDb()));
timer->setInterval(1000);
}
void frmData::on_btnOpenDb_clicked()
{
if (ui->btnOpenDb->text() == "打开") {
if (App::DbType == "sqlite") {
//先检查数据库文件是否存在
QString dbPath = qApp->applicationDirPath() + "/" + App::DbPath;
QFile file(dbPath);
if (file.size() == 0) {
return;
}
dbConn = QSqlDatabase::addDatabase("QSQLITE");
dbConn.setDatabaseName(dbPath);
} else if (App::DbType == "mysql") {
//先检查数据库服务器IP是否通,不检查直接连接,不存在的IP会卡很久
QTcpSocket socket;
socket.connectToHost(App::DbPath, App::DbPort);
if (!socket.waitForConnected(2000)) {
return;
} else {
socket.disconnectFromHost();
}
dbConn = QSqlDatabase::addDatabase("QMYSQL");
dbConn.setHostName(App::DbPath);
dbConn.setPort(App::DbPort);
dbConn.setDatabaseName(App::DbName);
dbConn.setUserName(App::DbUser);
dbConn.setPassword(App::DbPwd);
} else {
//暂未支持其他数据库,可以自行加入
return;
}
bool ok = dbConn.open();
if (ok) {
setEnable(ui->btnOpenDb, false);
ui->btnOpenDb->setText("关闭");
timer->start();
}
} else {
if (dbConn.isOpen()) {
dbConn.close();
}
setEnable(ui->btnOpenDb, true);
ui->btnOpenDb->setText("打开");
timer->stop();
}
}
void frmData::readDataDb()
{
QString sql = QString("select %1 from %2").arg(App::DbColumn).arg(App::DbTable);
QSqlQuery query;
if (query.exec(sql)) {
if (query.next()) {
double value = query.value(0).toDouble();
ui->txtValue->setText(QString::number(value));
append(4, QString("当前值: %1").arg(value));
}
}
}
五、控件引入了150多个漂亮的控件,涵盖了各种仪表盘、进度条、进度球、指南针、图表、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类可以独立成一个单独的控件,零耦合,每个控件都有一个头文件和一个实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,用更少的代码。qwt 的控制类是相互关联且高度耦合的。如果要使用其中一种控件,则必须收录
所有代码。全部用纯Qt编写,QWidget+QPainter绘图,支持从Qt4.6到Qt5.12的任何Qt版本,支持mingw、msvc、gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,和内置控件一样使用,效果最只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。
一些控件提供多种样式可供选择,以及多种指示器样式可供选择。所有控件都适应窗体的拉伸和变化。集成自定义控件属性设计器,支持拖动设计,所见即所得,支持导入导出xml格式。自带activex控件演示,所有控件都可以直接在ie浏览器中运行。集成fontawesome图形字体+阿里巴巴iconfont采集
的数百种图形字体,享受图形字体的乐趣。所有控件最后生成一个动态库文件(dll等),可以直接集成到qtcreator中进行拖动设计使用。已经有qml版本了,如果用户需求大,以后会考虑pyqt版本。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p
自动采集编写(2.工具介绍与设计工具实现的基本思想是逐个扫描指定路径)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-22 18:09
1.背景
在性能测试的过程中,往往需要对服务器的性能进行监控,并记录这些性能指标的结果。无论是数据库服务器还是云下的应用服务器,都可以通过nmon进行监控,设置点间隔和点数,将性能指标保存成nmon文件,使用Excel插件等工具Nmon_Analyzer、Java GUI工具nmon visualizer等。读取nmon文件的内容,分析采集的结果。但是,当监控的服务器数量较多时,性能指标导致多个 nmon 文件依次排列会很耗时。同时,手动读取和记录数据也可能因记录错误而导致意外错误。因此,我们可以尝试使用我们熟悉的编程语言,
2. 工具介绍与设计
该工具实现的基本思想是将指定路径下的nmon文件逐一扫描,根据nmon文件的内部格式提取目标性能指标数据,然后对提取的数据进行处理,得到结果,并自动将结果保存到新一代结果在一个 Excel 文件中。为了更直观的获取用户输入的nmon文件路径和结果的保存路径,我们可以编写GUI界面,使用界面上的文本输入框获取用户的输入,使用界面上的按钮触发这个 采集 事件。
图1 工具设计流程图
3. 工具实现
(1)导入需要的模块
由于我们的工具收录对文件和路径的操作,这需要由 os 模块来实现。逐行读取nmon文件内容时,使用codecs提供的open方法指定打开文件的语言编码,读取时会自动转换为内部unicode。re 模块是 Python 中用于匹配字符串的唯一模块。它使用正则表达式对字符串进行模糊匹配,并提取出您需要的字符串部分。使用该模块,您可以实现逐行扫描进行模糊匹配,以找到 CPU 和内存之间的相关性。表现。xlwt 库的作用是将数据写入 Excel 表格。Tkinter 是 Python 的标准 GUI 库。导入 Tkinter 模块后,您可以使用控件快速创建 GUI 应用程序。特金特。
图2 Code-导入需要的模块
(2)窗口的实现
使用Tkinter模块创建窗口,插入输入框控件,获取用户输入的路径信息。输入框的内容存放在StringVar中,按钮Button设置为绑定鼠标点击事件。
图3 窗口代码实现
图3 窗口实现图
(3)写事件代码-一个函数,求平均CPU利用率
不同版本的 nmon 文件的内部格式略有不同。因此,在编写程序时,首先要了解目标版本的内部结构,以确定字符串模式匹配时需要使用nmon文件中性能指标相关内容的哪些特征。
为了计算平均值,您需要获取 nmon 文件中记录的点数。通过了解 nmon 文件中的 AAA 参数是关于操作系统和 nmon 本身的一些信息,您可以找到将其提取的行。
图4 代码-获取点数和点间隔
CPU_ALL 参数是所有 CPU 的概览,显示所有 CPU 的平均占用率。将记录的CPU占用率一一取出存储在数组中,并计算数组元素的平均值,即整个监控期间CPU的平均使用率。该函数将返回值。
图 5 Code-Find 平均 CPU 使用率
(4)写事件代码-一个函数来求平均内存使用
同理,内存使用情况是通过MEM参数获取的。与CPU情况不同的是,该参数行收录多个内存相关的指标。在监控性能指标时,我们经常使用公式1来计算内存使用情况,所以需要从MEM中获取内存使用情况,从参数中提取相关指标,包括memtotal、memfree、cached、buffers,根据公式计算,返回内存使用情况。
公式1 常用的内存占用计算公式
图 6 Code-Seeking 内存使用
(5)写事件代码-鼠标点击事件
该事件用于绑定界面上的按钮,实现按钮点击时的一系列操作:从输入框中取出nmon文件路径和目标保存路径,生成Excel文件并创建工作表,并写入进入默认的header Contents,调用获取平均CPU使用率函数和获取平均内存占用率函数,将返回值写入Excel文件并保存。
图7 Code-鼠标点击事件
4. 总结
该工具是一种基于Python语言的简单实践,可以自动批量提取nmon文件中的性能指标结果,并可以利用这个思路根据需要修改或扩展该工具的功能。使用此工具自动获取性能结果采集相比手动读取值节省了时间,并避免了记录错误时的意外错误,有助于提高准确性和测试效率。 查看全部
自动采集编写(2.工具介绍与设计工具实现的基本思想是逐个扫描指定路径)
1.背景
在性能测试的过程中,往往需要对服务器的性能进行监控,并记录这些性能指标的结果。无论是数据库服务器还是云下的应用服务器,都可以通过nmon进行监控,设置点间隔和点数,将性能指标保存成nmon文件,使用Excel插件等工具Nmon_Analyzer、Java GUI工具nmon visualizer等。读取nmon文件的内容,分析采集的结果。但是,当监控的服务器数量较多时,性能指标导致多个 nmon 文件依次排列会很耗时。同时,手动读取和记录数据也可能因记录错误而导致意外错误。因此,我们可以尝试使用我们熟悉的编程语言,

2. 工具介绍与设计
该工具实现的基本思想是将指定路径下的nmon文件逐一扫描,根据nmon文件的内部格式提取目标性能指标数据,然后对提取的数据进行处理,得到结果,并自动将结果保存到新一代结果在一个 Excel 文件中。为了更直观的获取用户输入的nmon文件路径和结果的保存路径,我们可以编写GUI界面,使用界面上的文本输入框获取用户的输入,使用界面上的按钮触发这个 采集 事件。

图1 工具设计流程图
3. 工具实现
(1)导入需要的模块
由于我们的工具收录对文件和路径的操作,这需要由 os 模块来实现。逐行读取nmon文件内容时,使用codecs提供的open方法指定打开文件的语言编码,读取时会自动转换为内部unicode。re 模块是 Python 中用于匹配字符串的唯一模块。它使用正则表达式对字符串进行模糊匹配,并提取出您需要的字符串部分。使用该模块,您可以实现逐行扫描进行模糊匹配,以找到 CPU 和内存之间的相关性。表现。xlwt 库的作用是将数据写入 Excel 表格。Tkinter 是 Python 的标准 GUI 库。导入 Tkinter 模块后,您可以使用控件快速创建 GUI 应用程序。特金特。

图2 Code-导入需要的模块
(2)窗口的实现
使用Tkinter模块创建窗口,插入输入框控件,获取用户输入的路径信息。输入框的内容存放在StringVar中,按钮Button设置为绑定鼠标点击事件。

图3 窗口代码实现

图3 窗口实现图
(3)写事件代码-一个函数,求平均CPU利用率
不同版本的 nmon 文件的内部格式略有不同。因此,在编写程序时,首先要了解目标版本的内部结构,以确定字符串模式匹配时需要使用nmon文件中性能指标相关内容的哪些特征。
为了计算平均值,您需要获取 nmon 文件中记录的点数。通过了解 nmon 文件中的 AAA 参数是关于操作系统和 nmon 本身的一些信息,您可以找到将其提取的行。

图4 代码-获取点数和点间隔
CPU_ALL 参数是所有 CPU 的概览,显示所有 CPU 的平均占用率。将记录的CPU占用率一一取出存储在数组中,并计算数组元素的平均值,即整个监控期间CPU的平均使用率。该函数将返回值。

图 5 Code-Find 平均 CPU 使用率
(4)写事件代码-一个函数来求平均内存使用
同理,内存使用情况是通过MEM参数获取的。与CPU情况不同的是,该参数行收录多个内存相关的指标。在监控性能指标时,我们经常使用公式1来计算内存使用情况,所以需要从MEM中获取内存使用情况,从参数中提取相关指标,包括memtotal、memfree、cached、buffers,根据公式计算,返回内存使用情况。
公式1 常用的内存占用计算公式

图 6 Code-Seeking 内存使用
(5)写事件代码-鼠标点击事件
该事件用于绑定界面上的按钮,实现按钮点击时的一系列操作:从输入框中取出nmon文件路径和目标保存路径,生成Excel文件并创建工作表,并写入进入默认的header Contents,调用获取平均CPU使用率函数和获取平均内存占用率函数,将返回值写入Excel文件并保存。

图7 Code-鼠标点击事件
4. 总结
该工具是一种基于Python语言的简单实践,可以自动批量提取nmon文件中的性能指标结果,并可以利用这个思路根据需要修改或扩展该工具的功能。使用此工具自动获取性能结果采集相比手动读取值节省了时间,并避免了记录错误时的意外错误,有助于提高准确性和测试效率。
自动采集编写(优采云V8.2.0版新增边点击边采集示例: )
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-12-17 20:09
)
网站有很多,点击【加载更多】或【显示20多】按钮可以翻页。搜狗微信首页和其他页面都是这种情况。
对于此类网页,新版优采云V8.2.0 增加了【点击和点击采集】的功能,您可以点击【加载更多】 button] 加载一个新数据,edge 采集 每次加载新数据。
示例:设置为5次点击,然后1次点击后,采集第一次点击后加载的数据,第二次继续点击,采集第二次点击后加载的数据... ...最多20次点击,采集 20次点击后加载的数据。
使用智能识别和自行配置的采集规则,可以实现【点击后采集】。具体设置方法如下。
一、使用智能识别实现【点击和点击采集】
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。
打开网页后,选择【智能识别网页】,等待智能识别完成。
智能识别结束后,可以看到它自动识别了页面的【滚动】、【加载更多按钮】和【列表数据】。
鼠标移到图片上右击,选择【在新标签页中打开图片】,即可查看高清大图
Step2:点击【生成采集设置】自动生成对应的采集流程,方便用户编辑修改。
Step3:如图所示,通过流程中生成的【循环加载更多按钮】+嵌入【循环列表】的步骤,可以边点击数据边点击。
但是这个过程还是存在一些问题,需要我们手动修改。
①注意观察页面,这个页面点击5次到最后,100条数据全部加载完毕,所以我们设置翻页次数为5次。进入【循环加载更多按钮】设置页面,发现优采云已经为我们自动设置好了。
②再看【翻页】这一步,因为这个网页不需要翻页,所以这一步是多余的,需要删除。注意在删除【滚动页面】之前需要先删除【循环列表】,以免误删。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
二、自行配置采集 任务实现【点击采集】
如果不使用智能识别,如何自己配置采集任务实现【点击侧采集】?下面是详细的解释。
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。关闭智能识别,我们自己配置采集任务。
Step2:根据需求配置提取数据。在示例中,我们提取列表数据。提取方法请参考采集列表数据教程。
Step3:提取列表数据,过程中会自动生成【循环列表】步骤。自动生成的【循环列表】不能收录所有 100 个 文章 列表。我们需要修改XPath。
进入【循环列表】设置页面,修改XPath为:.//*[@id='pc_0_d']//li.
Step4:找到并选择【加载更多内容】按钮,在弹出的操作提示框中选择【循环点击单个元素】,自动生成【循环翻页】步骤。
【循环翻页】在步骤中嵌入了【循环列表】的步骤,方便我们点击采集数据。
再次注意页面,这个页面会被点击5次到最后,100条数据全部加载,所以我们设置翻页次数为5次。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
查看全部
自动采集编写(优采云V8.2.0版新增边点击边采集示例:
)
网站有很多,点击【加载更多】或【显示20多】按钮可以翻页。搜狗微信首页和其他页面都是这种情况。
对于此类网页,新版优采云V8.2.0 增加了【点击和点击采集】的功能,您可以点击【加载更多】 button] 加载一个新数据,edge 采集 每次加载新数据。
示例:设置为5次点击,然后1次点击后,采集第一次点击后加载的数据,第二次继续点击,采集第二次点击后加载的数据... ...最多20次点击,采集 20次点击后加载的数据。
使用智能识别和自行配置的采集规则,可以实现【点击后采集】。具体设置方法如下。
一、使用智能识别实现【点击和点击采集】
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。
打开网页后,选择【智能识别网页】,等待智能识别完成。
智能识别结束后,可以看到它自动识别了页面的【滚动】、【加载更多按钮】和【列表数据】。

鼠标移到图片上右击,选择【在新标签页中打开图片】,即可查看高清大图
Step2:点击【生成采集设置】自动生成对应的采集流程,方便用户编辑修改。
Step3:如图所示,通过流程中生成的【循环加载更多按钮】+嵌入【循环列表】的步骤,可以边点击数据边点击。
但是这个过程还是存在一些问题,需要我们手动修改。
①注意观察页面,这个页面点击5次到最后,100条数据全部加载完毕,所以我们设置翻页次数为5次。进入【循环加载更多按钮】设置页面,发现优采云已经为我们自动设置好了。
②再看【翻页】这一步,因为这个网页不需要翻页,所以这一步是多余的,需要删除。注意在删除【滚动页面】之前需要先删除【循环列表】,以免误删。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
二、自行配置采集 任务实现【点击采集】
如果不使用智能识别,如何自己配置采集任务实现【点击侧采集】?下面是详细的解释。
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。关闭智能识别,我们自己配置采集任务。

Step2:根据需求配置提取数据。在示例中,我们提取列表数据。提取方法请参考采集列表数据教程。
Step3:提取列表数据,过程中会自动生成【循环列表】步骤。自动生成的【循环列表】不能收录所有 100 个 文章 列表。我们需要修改XPath。
进入【循环列表】设置页面,修改XPath为:.//*[@id='pc_0_d']//li.
Step4:找到并选择【加载更多内容】按钮,在弹出的操作提示框中选择【循环点击单个元素】,自动生成【循环翻页】步骤。
【循环翻页】在步骤中嵌入了【循环列表】的步骤,方便我们点击采集数据。
再次注意页面,这个页面会被点击5次到最后,100条数据全部加载,所以我们设置翻页次数为5次。
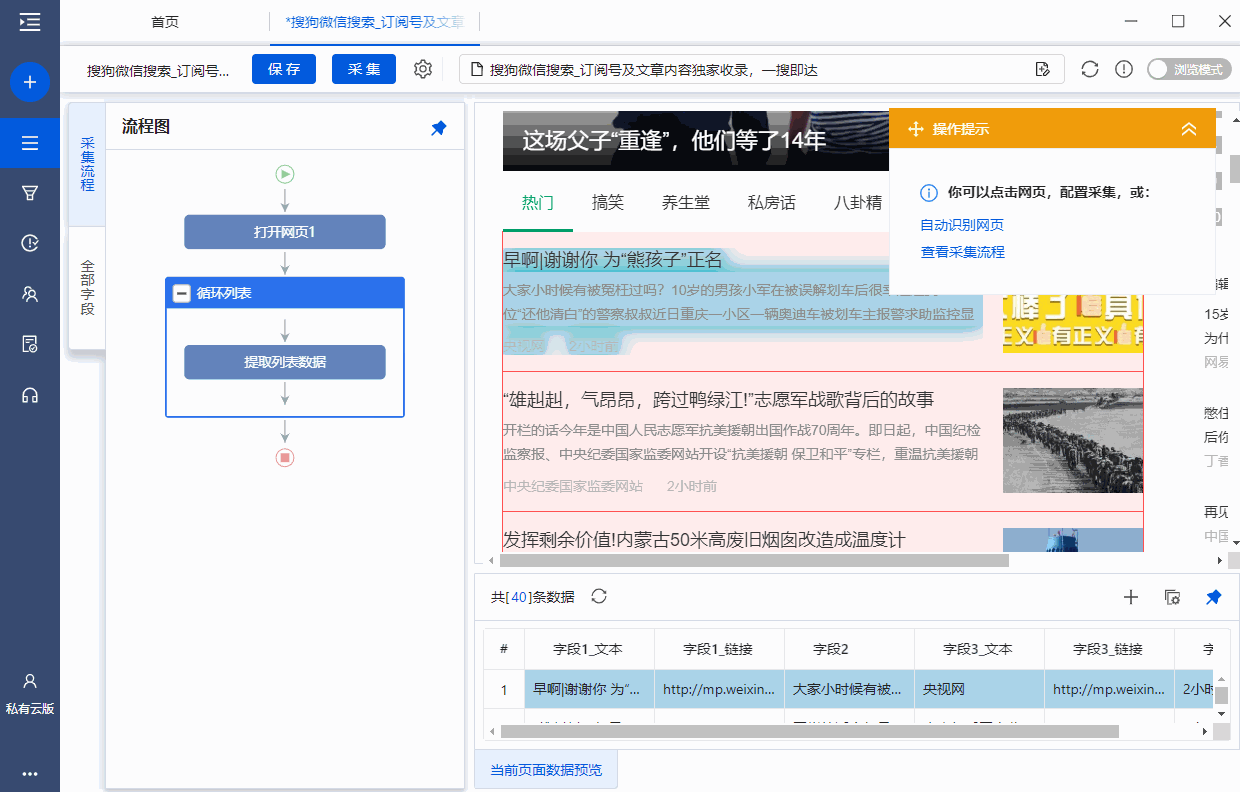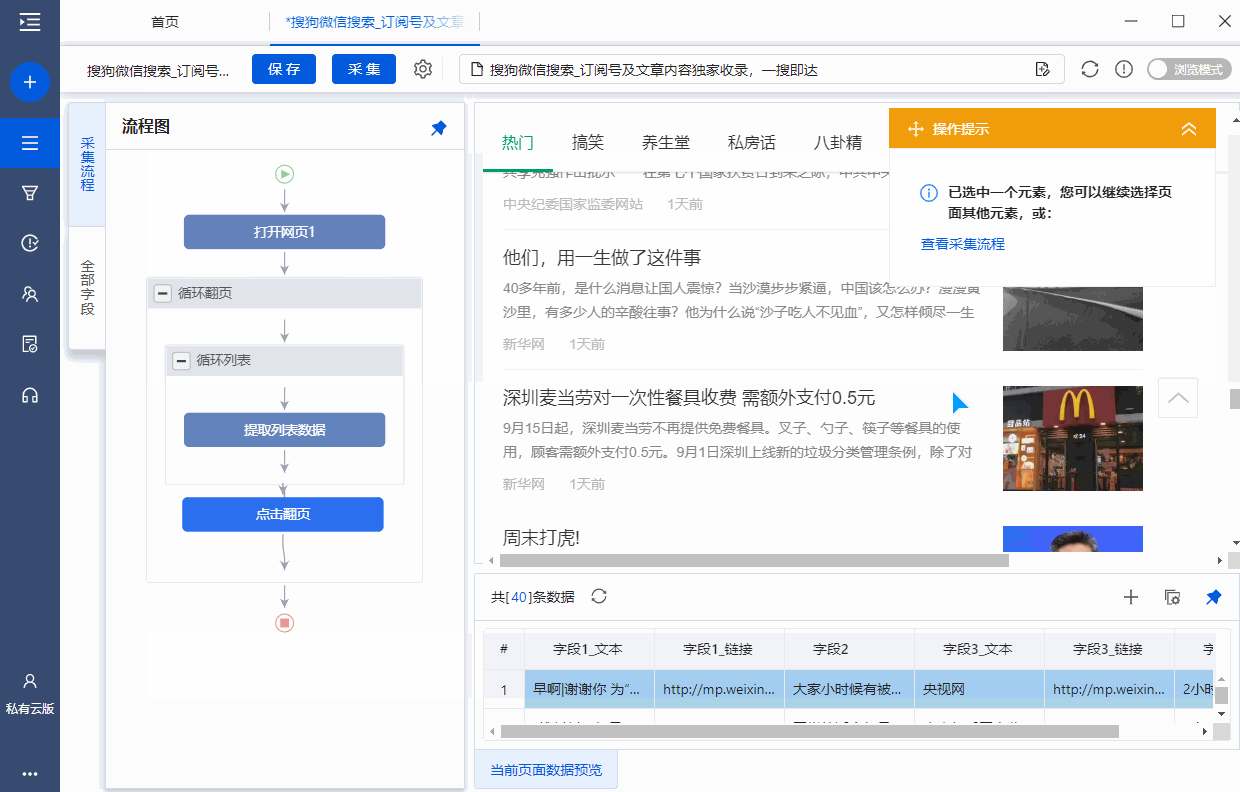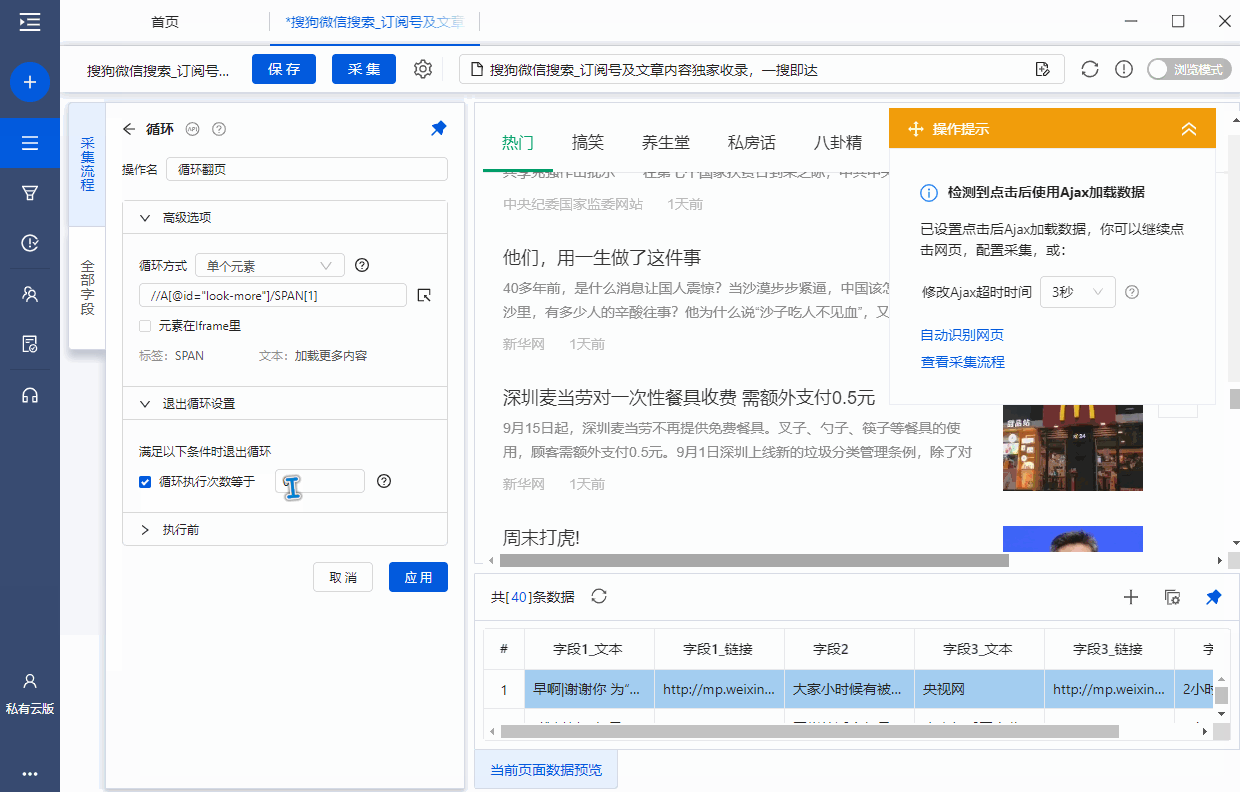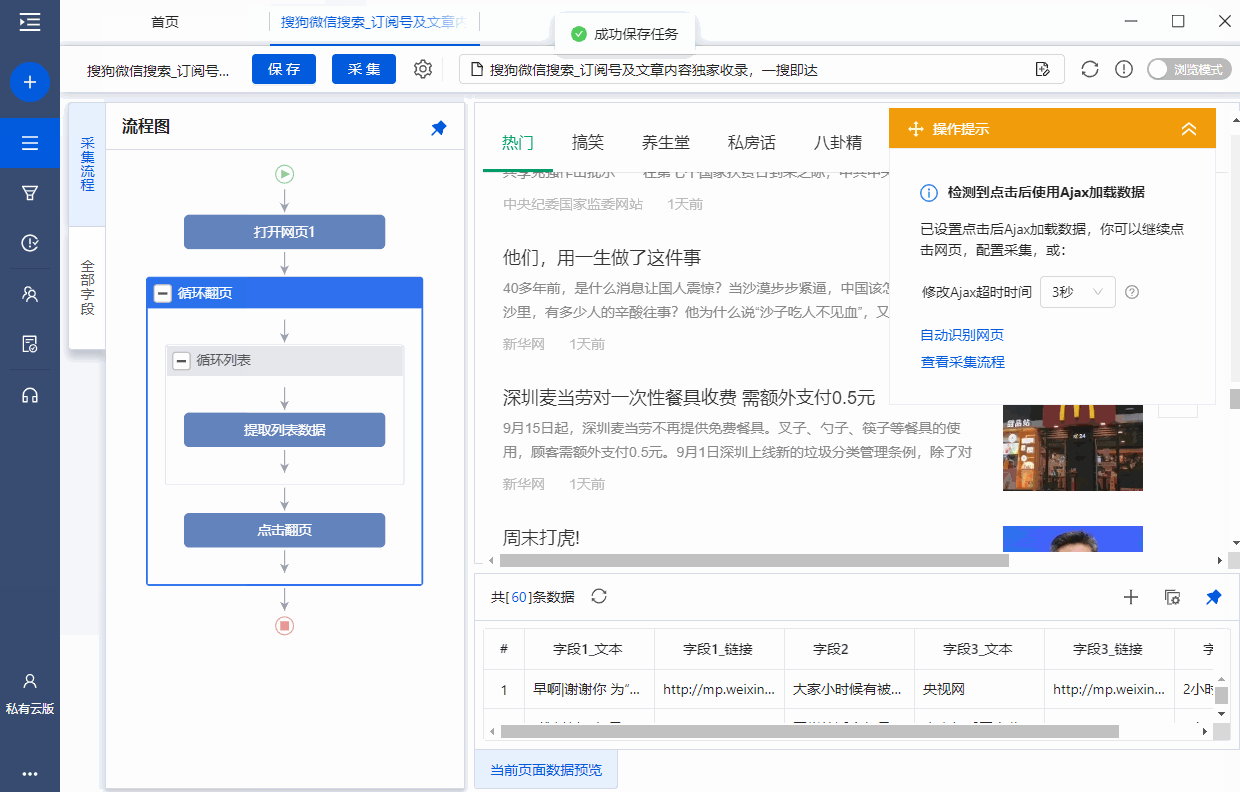
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
自动采集编写( 如何抓取远程网页?远程HTML的二进制代码主要语句)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-16 23:50
如何抓取远程网页?远程HTML的二进制代码主要语句)
如何用asp编写网站data采集程序?
引用:如果你想自动从网上采集 数据写入本地数据库,那么看看本文介绍的方法。为了解决这个问题,作者花了三天时间,终于完成了。下面是完整的ASP代码,可以让你随意存储来自互联网的数据采集,非常实用!
一、网站数据采集方法
目前网站data采集的方法主要有两种,一种是使用现成的软件,另一种是自己编写采集程序。
1、使用现成的软件
很多软件(如网络信息采集大师、BK通用信息采集系统等)都可以采集在线数据,只要你去百度、谷歌、“数据< @采集搜索关键词的“软件”即可找到,现在这类软件很多,都是用C、DEPHI或VB编写的,一般都提供免费版本给你下载试试。虽然他们也可以采集在线数据,但是采集之后的数据要么不能存入数据库,要么只能存入前10项;如果你想突破这个限制,你现在必须花钱购买官方数据版。笔者尝试了所有数据采集软件,发现都一样!
2、编写自己的ASP采集程序
由于现成的软件不能免费使用,为了省钱,只能自己写ASP网站data采集程序!以下是程序的代码,如果你想要免费的采集网站数据,直接运行即可。
二、网站数据采集进程
编写ASP网站data采集程序,首先需要抓取远程网页的源码。微软serverXMLHTTP组件可以帮你抓取远程页面的二进制代码,然后将代码转换成字符,进行拦截和替换处理,就可以得到你想要的数据;最后,显示数据或将其写入数据库。采集工作完成。
三、如何抓取远程网页?
抓取远程HTML的二进制代码主要语句如下: 查看全部
自动采集编写(
如何抓取远程网页?远程HTML的二进制代码主要语句)
如何用asp编写网站data采集程序?
引用:如果你想自动从网上采集 数据写入本地数据库,那么看看本文介绍的方法。为了解决这个问题,作者花了三天时间,终于完成了。下面是完整的ASP代码,可以让你随意存储来自互联网的数据采集,非常实用!
一、网站数据采集方法
目前网站data采集的方法主要有两种,一种是使用现成的软件,另一种是自己编写采集程序。
1、使用现成的软件
很多软件(如网络信息采集大师、BK通用信息采集系统等)都可以采集在线数据,只要你去百度、谷歌、“数据< @采集搜索关键词的“软件”即可找到,现在这类软件很多,都是用C、DEPHI或VB编写的,一般都提供免费版本给你下载试试。虽然他们也可以采集在线数据,但是采集之后的数据要么不能存入数据库,要么只能存入前10项;如果你想突破这个限制,你现在必须花钱购买官方数据版。笔者尝试了所有数据采集软件,发现都一样!
2、编写自己的ASP采集程序
由于现成的软件不能免费使用,为了省钱,只能自己写ASP网站data采集程序!以下是程序的代码,如果你想要免费的采集网站数据,直接运行即可。
二、网站数据采集进程
编写ASP网站data采集程序,首先需要抓取远程网页的源码。微软serverXMLHTTP组件可以帮你抓取远程页面的二进制代码,然后将代码转换成字符,进行拦截和替换处理,就可以得到你想要的数据;最后,显示数据或将其写入数据库。采集工作完成。
三、如何抓取远程网页?
抓取远程HTML的二进制代码主要语句如下:
自动采集编写(IT圈内巡检日志(一):人工巡检的制胜法宝)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-12-15 08:09
前言:先写
如果只检查一两个库,则无需使用此方法。这种方式适用于获取大量的检测日志(比如使用脚本从服务器采集更多的服务器检测日志信息),一般我们需要一份拷贝来写报告,其中的内容检查日志需要填词然后分析,真的很累。
一、前言:还需要人工检查吗?
说到检验,很多人嗤之以鼻:现在监控产品遍布全球,比如Zabbix、Prometheus、Graphite等,还需要检验吗?
答案是肯定的,更何况每个监控产品都有运维盲点。从知识库的使用来看,监控产品还是不能替代人工巡检的一些经验(当然,未来可能很快会被替代,但不知道什么时候)。当不规则的、异常的零星字符经过一个运维人员身边时,他敏锐的鬓角被拉长,眉毛扬起,大脑快速检索自己的知识库,用一个可能只有1%相似度的对比成功率,第一时间确定异常的基本原因,这已经是IT圈最常见的场景了。所以,必须强调的是,人工检查仍然是保证系统稳定性的最关键手段之一。在日常监控的基础上,保持一定的人工巡检频率,是保证稳定运行的法宝。
二、以前的检验报告怎么写
一般流程是这样的:
第一步:进入用户系统采集信息。通常通过脚本、自动化采集和少量的手工劳动采集来完成。采集 脚本(或程序)是每个公司的秘密武器。他们检查同一个对象。90%的企业采集拥有相同的信息,剩下的10%是他们的“内部信息”。毕竟在一个专业修炼多年,掌握一些“核心技术”是理所当然的。
第二步:根据用户系统分类或机器分类,各系统按一定格式出具检测报告。
上报是运维人员最头疼的事。比如用户数据库系统有上百套,每套报表都要下发。从采集的日志文件,Ctrl+C,Ctrl+V,我把原来的日志采集复制到了检查报告中,非常不爽和痛苦。另外,采集的原木密密麻麻,久了眼睛不舒服。
三、Python 帮忙写报告
大概的概念:
按照指定格式到客户端服务器上的采集日志(分隔符可自定义),将日志下载到本地,放到指定目录下,运行python程序自动生成word检测报告。
它具有以下特点:
1、 批量读取巡检日志文件,每个日志文件生成一个word文件,从日志文件名中截取word文件名。
2、 可以先填写检查意见
3、 还是需要打开文档,手动填写其他意见(毕竟这些意见是我们的财富,当然如果知识库功能用得好,就省略了)。
安装python,安装pip,然后安装pip install python-docx,省略。
第一步:导入包:
import re # 正则表达式使用
from docx import Document #word 文档使用
import os #用于遍历目录
从 docx.oxml.ns 导入 nsdecls #word 样式
from docx.oxml import parse_xml # 文字样式
步骤 2:定义四个函数。第一个函数:数字大小写转换函数:num_to_char
该函数主要用于将阿拉伯数字转换为中文大写。例如,如果是一级标题,则使用“一、patrol content”,这是相对于“1、patrol content”的标准写法。
代码显示如下:
第二个函数:get_title函数
这个功能就是检验项目的“标题功能”。例如,“检查文件系统”就是“主机文件系统检查”。毕竟我们不是歪的,标题应该还是中文的。
第三个函数:get_knowledge知识库函数
该函数为知识库函数,即当确定采集的结果存在一定问题时,利用知识库输出初步分析结果。其实对于动态比较和各种相似度分析,python是很擅长的,这里只是一个函数展示。
第四个函数:list_dir
该函数用于获取指定目录下的所有特定文件。比如这里指定的check*.log格式的文件就是要处理的文件。
因为python代码有严格的缩进限制,所有截图都是给大家看的。部分代码源码网络。
源码:由于编辑器的原因,以下可复现的代码没有出现缩进,请参考图片:
第一个函数源码(参考):
def num_to_char(num):
"""数字转中文"""
数量 = str(数量)
new_str = ""
num_dict = {"0": u"0", "1": u"one", "2": u"二", "3": u"三", "4": u"四", "5 ": u"五", "6": u"六", "7": u"七", "8": u"八",
"9": 你"九"}
列表编号 = 列表(编号)
# 打印(列表编号)
舒 = []
对于列表编号中的 i:
# 打印(num_dict[i])
shu.append(num_dict[i])
new_str = “”.join(shu)
# 打印(new_str)
返回 new_str
第二个函数的源码(参考):
def get_title(flag_fg):# flag_fg是传入的分隔段,其实就是英文标题
如果在 flag_fg 中“检查文件系统”:
xj_title_hs ='主机文件系统检查'
elif'Check CPU &MEM' in flag_fg:
xj_title_hs ='CPU,内存检查'
elif'Check ETH' 在 flag_fg 中:
xj_title_hs ='网卡状态检查'
elif'检查 /var/log/message' 在 flag_fg 中:
xj_title_hs ='主机日志检查'
elif'检查transparent_hugepage'在flag_fg:
xj_title_hs ='LINUX系统透明大页面检查'
elif'Check nr_hugepages' 在 flag_fg 中:
xj_title_hs ='Linux系统大页面打开状态检查'
elif'检查内存信息'在 flag_fg 中:
xj_title_hs ='PLNOCHECK'
###...
别的:
xj_title_hs = flag_fg #防止无休止的英文标题很重要
返回 xj_title_hs
第三个函数源码(参考):
def get_knowledge(str_input):
str_output = [] # 如果什么都没有发现,首先输出和检查是正常的。
str_output_text='检查正常'
如果在 str_input 中“[always] madvise never”:
str_output = ['Linux 没有关闭透明大页面。根据ORACLE安装要求,应该关闭透明大页面,提高ORACLE内存和IO读写性能','1111111']
elif'always madvise [never]' 在 str_input 中:
str_output = ['检查正常:Linux 已关闭透明大页面','000000']
别的:
str_output = ['检查正常','000000']
返回 str_output
#这个例子是静态比较。其实就是进行动态比较和各种相似度分析。Python非常擅长
#知识库分析,应该能够区分正常检查结果和异常检查结果。本例中'000000'表示正常,'1111111'表示异常
第四个函数源码(参考):
def list_dir(file_dir):
dir_list = os.listdir(file_dir)
file_r = []
对于 dir_list 中的 cur_file:
# 准确获取一个txt的位置,并使用字符串拼接
路径 = os.path.join(file_dir, cur_file)
如果 cur_file.startswith("check") & path.endswith(".log"):
file_r.append(路径)
返回文件_r
后续:主要功能介绍。主要功能实现文件读取、文件切分、词表操作等,是实现检查日志自动生成词文件的主要部门。 查看全部
自动采集编写(IT圈内巡检日志(一):人工巡检的制胜法宝)
前言:先写
如果只检查一两个库,则无需使用此方法。这种方式适用于获取大量的检测日志(比如使用脚本从服务器采集更多的服务器检测日志信息),一般我们需要一份拷贝来写报告,其中的内容检查日志需要填词然后分析,真的很累。
一、前言:还需要人工检查吗?
说到检验,很多人嗤之以鼻:现在监控产品遍布全球,比如Zabbix、Prometheus、Graphite等,还需要检验吗?
答案是肯定的,更何况每个监控产品都有运维盲点。从知识库的使用来看,监控产品还是不能替代人工巡检的一些经验(当然,未来可能很快会被替代,但不知道什么时候)。当不规则的、异常的零星字符经过一个运维人员身边时,他敏锐的鬓角被拉长,眉毛扬起,大脑快速检索自己的知识库,用一个可能只有1%相似度的对比成功率,第一时间确定异常的基本原因,这已经是IT圈最常见的场景了。所以,必须强调的是,人工检查仍然是保证系统稳定性的最关键手段之一。在日常监控的基础上,保持一定的人工巡检频率,是保证稳定运行的法宝。
二、以前的检验报告怎么写
一般流程是这样的:
第一步:进入用户系统采集信息。通常通过脚本、自动化采集和少量的手工劳动采集来完成。采集 脚本(或程序)是每个公司的秘密武器。他们检查同一个对象。90%的企业采集拥有相同的信息,剩下的10%是他们的“内部信息”。毕竟在一个专业修炼多年,掌握一些“核心技术”是理所当然的。
第二步:根据用户系统分类或机器分类,各系统按一定格式出具检测报告。
上报是运维人员最头疼的事。比如用户数据库系统有上百套,每套报表都要下发。从采集的日志文件,Ctrl+C,Ctrl+V,我把原来的日志采集复制到了检查报告中,非常不爽和痛苦。另外,采集的原木密密麻麻,久了眼睛不舒服。
三、Python 帮忙写报告
大概的概念:
按照指定格式到客户端服务器上的采集日志(分隔符可自定义),将日志下载到本地,放到指定目录下,运行python程序自动生成word检测报告。
它具有以下特点:
1、 批量读取巡检日志文件,每个日志文件生成一个word文件,从日志文件名中截取word文件名。
2、 可以先填写检查意见
3、 还是需要打开文档,手动填写其他意见(毕竟这些意见是我们的财富,当然如果知识库功能用得好,就省略了)。
安装python,安装pip,然后安装pip install python-docx,省略。
第一步:导入包:
import re # 正则表达式使用
from docx import Document #word 文档使用
import os #用于遍历目录
从 docx.oxml.ns 导入 nsdecls #word 样式
from docx.oxml import parse_xml # 文字样式
步骤 2:定义四个函数。第一个函数:数字大小写转换函数:num_to_char
该函数主要用于将阿拉伯数字转换为中文大写。例如,如果是一级标题,则使用“一、patrol content”,这是相对于“1、patrol content”的标准写法。
代码显示如下:

第二个函数:get_title函数
这个功能就是检验项目的“标题功能”。例如,“检查文件系统”就是“主机文件系统检查”。毕竟我们不是歪的,标题应该还是中文的。

第三个函数:get_knowledge知识库函数
该函数为知识库函数,即当确定采集的结果存在一定问题时,利用知识库输出初步分析结果。其实对于动态比较和各种相似度分析,python是很擅长的,这里只是一个函数展示。

第四个函数:list_dir
该函数用于获取指定目录下的所有特定文件。比如这里指定的check*.log格式的文件就是要处理的文件。

因为python代码有严格的缩进限制,所有截图都是给大家看的。部分代码源码网络。
源码:由于编辑器的原因,以下可复现的代码没有出现缩进,请参考图片:
第一个函数源码(参考):
def num_to_char(num):
"""数字转中文"""
数量 = str(数量)
new_str = ""
num_dict = {"0": u"0", "1": u"one", "2": u"二", "3": u"三", "4": u"四", "5 ": u"五", "6": u"六", "7": u"七", "8": u"八",
"9": 你"九"}
列表编号 = 列表(编号)
# 打印(列表编号)
舒 = []
对于列表编号中的 i:
# 打印(num_dict[i])
shu.append(num_dict[i])
new_str = “”.join(shu)
# 打印(new_str)
返回 new_str
第二个函数的源码(参考):
def get_title(flag_fg):# flag_fg是传入的分隔段,其实就是英文标题
如果在 flag_fg 中“检查文件系统”:
xj_title_hs ='主机文件系统检查'
elif'Check CPU &MEM' in flag_fg:
xj_title_hs ='CPU,内存检查'
elif'Check ETH' 在 flag_fg 中:
xj_title_hs ='网卡状态检查'
elif'检查 /var/log/message' 在 flag_fg 中:
xj_title_hs ='主机日志检查'
elif'检查transparent_hugepage'在flag_fg:
xj_title_hs ='LINUX系统透明大页面检查'
elif'Check nr_hugepages' 在 flag_fg 中:
xj_title_hs ='Linux系统大页面打开状态检查'
elif'检查内存信息'在 flag_fg 中:
xj_title_hs ='PLNOCHECK'
###...
别的:
xj_title_hs = flag_fg #防止无休止的英文标题很重要
返回 xj_title_hs
第三个函数源码(参考):
def get_knowledge(str_input):
str_output = [] # 如果什么都没有发现,首先输出和检查是正常的。
str_output_text='检查正常'
如果在 str_input 中“[always] madvise never”:
str_output = ['Linux 没有关闭透明大页面。根据ORACLE安装要求,应该关闭透明大页面,提高ORACLE内存和IO读写性能','1111111']
elif'always madvise [never]' 在 str_input 中:
str_output = ['检查正常:Linux 已关闭透明大页面','000000']
别的:
str_output = ['检查正常','000000']
返回 str_output
#这个例子是静态比较。其实就是进行动态比较和各种相似度分析。Python非常擅长
#知识库分析,应该能够区分正常检查结果和异常检查结果。本例中'000000'表示正常,'1111111'表示异常
第四个函数源码(参考):
def list_dir(file_dir):
dir_list = os.listdir(file_dir)
file_r = []
对于 dir_list 中的 cur_file:
# 准确获取一个txt的位置,并使用字符串拼接
路径 = os.path.join(file_dir, cur_file)
如果 cur_file.startswith("check") & path.endswith(".log"):
file_r.append(路径)
返回文件_r
后续:主要功能介绍。主要功能实现文件读取、文件切分、词表操作等,是实现检查日志自动生成词文件的主要部门。
自动采集编写( 出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-12 18:07
出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)
用户演示站:
源码使用环境
支持环境:WindowsnuxPHP5.3/4/5/67.1mysql5.
推荐环境:linuxphp7.1mysql5.6
源代码功能详情
1、内置大量内容,安装后可省时省力;
2、内置高效采集插件,每天自动采集一次(间隔可自行修改),真正无人值守;
3、7 内置 采集 规则;
4、内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序完全开源,无任何加密,不定期提供升级;
7、采用前端HTML5 CSS3响应式布局,兼容多终端(PC手机和平板),数据同步,管理方便;
8、采集规则失效不用担心,我们有强大的技术团队,会提供升级服务的规则;
9、图片默认使用远程地址,节省磁盘空间,可以在本地设置和保存。
源码适合人群
1、上班族
白天上班,晚上休息。这个程序满足你。安装完成后配置无误即可坐等升级网站,真正无人值守。
2、做站群
有些人有几百个站,要花钱招人。最好设置一个无人值守的采集站,这样既省时又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
说说吧,它需要流量上来。
2、出售友情链接
网站收录多达1000个基础,你在友情链接交易平台上卖朋友没问题。
3、销售网站二级目录
网站收录好吧,有些人只需要收录,他们自然会找到你。
4、卖站
网站收录上去卖一个5、600 没问题,重量上来卖多。
程序安装文档
详见源码中付费安装文档 查看全部
自动采集编写(
出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)


用户演示站:
源码使用环境
支持环境:WindowsnuxPHP5.3/4/5/67.1mysql5.
推荐环境:linuxphp7.1mysql5.6
源代码功能详情
1、内置大量内容,安装后可省时省力;
2、内置高效采集插件,每天自动采集一次(间隔可自行修改),真正无人值守;
3、7 内置 采集 规则;
4、内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序完全开源,无任何加密,不定期提供升级;
7、采用前端HTML5 CSS3响应式布局,兼容多终端(PC手机和平板),数据同步,管理方便;
8、采集规则失效不用担心,我们有强大的技术团队,会提供升级服务的规则;
9、图片默认使用远程地址,节省磁盘空间,可以在本地设置和保存。
源码适合人群
1、上班族
白天上班,晚上休息。这个程序满足你。安装完成后配置无误即可坐等升级网站,真正无人值守。
2、做站群
有些人有几百个站,要花钱招人。最好设置一个无人值守的采集站,这样既省时又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
说说吧,它需要流量上来。
2、出售友情链接
网站收录多达1000个基础,你在友情链接交易平台上卖朋友没问题。
3、销售网站二级目录
网站收录好吧,有些人只需要收录,他们自然会找到你。
4、卖站
网站收录上去卖一个5、600 没问题,重量上来卖多。
程序安装文档
详见源码中付费安装文档
自动采集编写(自动采集脚本1.利用pythonexplorer调用githubgithub安装python模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-12 01:01
自动采集编写脚本1.利用pythonexplorer调用github安装python模块2.如何下载github-square/python:gitclone:操作系统(windows/mac)执行:pipinstallpython-pipmodule版本2.1安装完成后,记得设置路径path环境变量,然后python安装路径在“\python\scripts”:cd$path$pipinstallgit2.2是个坑。
我遇到的git2.3已经好了,但是复现时就出错了,各位自己理解...2.3.1为什么能复现,但就是不知道为什么不能复现,后来想起,是命令行那边的问题,因为有可能那边有错,正好被转发了,然后就复现了,但是无法打印出cmd的内容2.4这种情况,可以放弃python,用其他语言去验证的,没有这么蛋疼,或者去看python编译器的帮助文档2.5最好多问一下相关人员。
必须到不同的sdlds版本下验证,
用python插件k-lab查看目录结构,
如果环境都跟python版本一样的话,看下python的pdb环境变量配置是否正确,
python2的话将/usr/local/bin/替换成/usr/local/bin/python2#python3的话将/usr/local/bin/替换成/usr/local/bin/python3 查看全部
自动采集编写(自动采集脚本1.利用pythonexplorer调用githubgithub安装python模块)
自动采集编写脚本1.利用pythonexplorer调用github安装python模块2.如何下载github-square/python:gitclone:操作系统(windows/mac)执行:pipinstallpython-pipmodule版本2.1安装完成后,记得设置路径path环境变量,然后python安装路径在“\python\scripts”:cd$path$pipinstallgit2.2是个坑。
我遇到的git2.3已经好了,但是复现时就出错了,各位自己理解...2.3.1为什么能复现,但就是不知道为什么不能复现,后来想起,是命令行那边的问题,因为有可能那边有错,正好被转发了,然后就复现了,但是无法打印出cmd的内容2.4这种情况,可以放弃python,用其他语言去验证的,没有这么蛋疼,或者去看python编译器的帮助文档2.5最好多问一下相关人员。
必须到不同的sdlds版本下验证,
用python插件k-lab查看目录结构,
如果环境都跟python版本一样的话,看下python的pdb环境变量配置是否正确,
python2的话将/usr/local/bin/替换成/usr/local/bin/python2#python3的话将/usr/local/bin/替换成/usr/local/bin/python3
自动采集编写( 这是网站源码制作的电子书网站版面:网上在线报名(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-10 12:11
这是网站源码制作的电子书网站版面:网上在线报名(组图))
具有自动功能的响应式电子书采集网站源代码
源码介绍
这是一个带有自动采集功能的电子书网站源代码。用本源代码制作的电子书网站具有响应功能,可以适配电脑和手机。浏览。源码安装好后就可以后台发布数据采集。
以下是用电子书网站的源代码制作的电子书网站版面:
源代码下载
具有自动采集功能的响应式电子书网站源代码,购买后请点击下方下载!
源码安装方法下载响应式电子书网站源码;解压压缩包,获取源码文件夹,通过FTP软件上传到自己的网站空间根目录;使用网站域名/安装路径安装源码;安装后使用网站域名/admin登录网站后台。
具有自动采集功能的响应式电子书网站源代码主色调,兼容IE、FF、Opera、Safari、chrome等浏览器,手机WAP布局,源码代码操作需要服务器环境为php5.3及以上,mysql数据库。
购买带有自动采集功能的响应式电子书网站源价:¥160
什么是网站源代码
网站 源码是将网站程序、网站模板、网站后台管理、网站数据库数据打包在一起。用户购买网站源码后,只需直接上传到网站空间,即可制作并演示网站一模一板网站。
上一课:在线登记管理系统通用源码 下一课:适合房产中介做的源码网站
发布:学做网站论坛最后更新:2021-11-27 浏览次数:115504次
学会做网站论坛致力于打造网站在线培训诚信平台,让零基础学员学习做网站,最终可以自主搭建网站.
通过原创建站教程+讲师在线辅导学习做网站论坛搭建培训,对各种网站制作方法的讲解非常详细,哪怕是零基础初学者可以看懂了就学会了。 查看全部
自动采集编写(
这是网站源码制作的电子书网站版面:网上在线报名(组图))
具有自动功能的响应式电子书采集网站源代码
源码介绍
这是一个带有自动采集功能的电子书网站源代码。用本源代码制作的电子书网站具有响应功能,可以适配电脑和手机。浏览。源码安装好后就可以后台发布数据采集。
以下是用电子书网站的源代码制作的电子书网站版面:
 https://www.xuewangzhan.net/wp ... 7.jpg 768w" />
https://www.xuewangzhan.net/wp ... 7.jpg 768w" />源代码下载
具有自动采集功能的响应式电子书网站源代码,购买后请点击下方下载!
源码安装方法下载响应式电子书网站源码;解压压缩包,获取源码文件夹,通过FTP软件上传到自己的网站空间根目录;使用网站域名/安装路径安装源码;安装后使用网站域名/admin登录网站后台。
具有自动采集功能的响应式电子书网站源代码主色调,兼容IE、FF、Opera、Safari、chrome等浏览器,手机WAP布局,源码代码操作需要服务器环境为php5.3及以上,mysql数据库。
购买带有自动采集功能的响应式电子书网站源价:¥160
什么是网站源代码
网站 源码是将网站程序、网站模板、网站后台管理、网站数据库数据打包在一起。用户购买网站源码后,只需直接上传到网站空间,即可制作并演示网站一模一板网站。
上一课:在线登记管理系统通用源码 下一课:适合房产中介做的源码网站
发布:学做网站论坛最后更新:2021-11-27 浏览次数:115504次
学会做网站论坛致力于打造网站在线培训诚信平台,让零基础学员学习做网站,最终可以自主搭建网站.
通过原创建站教程+讲师在线辅导学习做网站论坛搭建培训,对各种网站制作方法的讲解非常详细,哪怕是零基础初学者可以看懂了就学会了。
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-12-10 08:00
一、前言
在上一篇文章《神测Android全插件介绍》中,我们了解到神测Android插件其实就是一个自定义的Gradle插件。Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。您可以通过插件实现特定的逻辑,并打包分享给他人。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现控件点击和Fragment页面浏览的全埋点采集。
在本文中,我们将首先介绍Gradle 的基础知识,然后举例说明如何实现自定义Gradle 插件。这里需要注意的是,文章使用./gradlew来执行Gradle命令,如果你是Windows用户,需要将它改成gradlew.bat。
二、Gradle 基础知识
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
项目是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,“Project”和“Module”在构建过程中都会被Gradle抽象为Project对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、 每个Project都会对应一个build.gradle配置文件,所以在使用Android Studio创建项目时,根目录下有一个build.gradle文件,每个Module的目录下都有一个build . gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
allprojects {
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 将在施工过程中执行一系列任务。Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle官方的话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图中右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。在运行Task时,也需要通过这种方式指定一个Task。
此外,您可以自定义您自己的任务。让我们创建最简单的任务:
// add to build.gradle
task hello {
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的Task。如果想单独执行Task,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后就可以看到控制台输出了。你好世界!”。
三、Gradle 插件构建3.1 插件介绍
Plugin和Task其实和它们的功能没有太大区别。它们都封装了一些业务逻辑。Plugin适用于打包需要复用的编译逻辑的场景(即模块化部分编译逻辑)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样,以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的 Plugin 应该是 Android 官方提供的 Android Gradle Plugin。可以在项目主模块的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。“com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
该插件还可以读取 build.gradle 文件中写入的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等,大家可以比较一下“ android" android 块在这里作为数据类或基类,定义的属性类似于类成员变量。Android Gradle Plugin 可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 为独立项目构建 Gradle 插件
Gradle插件的实现方式有3种,分别是Build脚本、buildSrc项目和Standalone项目:
1、Build 脚本会直接在 build.gradle 文件中写入逻辑,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc项目就是在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录下写逻辑,Plugin仅对当前项目有效;
3、独立项目就是把逻辑写在一个单独的项目中,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone项目,独立项目的Gradle插件。
3.2.1 目录结构分析
一个独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
其中resources文件夹为固定格式META-INF/gradle-plugins/XXXX.properties,XXXX代表以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件 Module,只能先新建一个 Java Library 类型的 Module,然后删除多余的文件夹;
2、新类默认是一个新的Java类。新的文件名后缀是“.java”。如果要新建一个Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加package、class语句;
3、资源都需要手动创建,文件夹名需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 编写插件
在编写插件代码之前,我们需要对build.gradle做一些修改,如下图:
apply plugin: 'groovy'
apply plugin: 'maven'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
uploadArchives{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这主要分为三个部分:
1、apply plugin:应用'groovy'插件,因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,位置选择在项目根目录下的repo文件夹中。
做好以上准备后,就可以开始编写源码了。Gradle插件需要入口类实现org.gradle.api.Plugin接口,然后在apply方法中实现自己的逻辑:
package com.sensorsdata.plugin
class MyPlugin implements Plugin{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还需要做一个准备:Gradle插件不会自动查找入口类,而是需要开发者在resources/META-INF/gradle-plugins/XXXX.properties中写入入口类的类名,内容格式对于“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写完后,在终端执行
./gradlew uploadArchive
您可以发布插件。在上一节写的插件的build.gradle文件中,发布到maven仓库的相关配置是提前配置好的,所以我们这里执行这个命令后,项目根目录下就会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤: 查看全部
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
一、前言
在上一篇文章《神测Android全插件介绍》中,我们了解到神测Android插件其实就是一个自定义的Gradle插件。Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。您可以通过插件实现特定的逻辑,并打包分享给他人。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现控件点击和Fragment页面浏览的全埋点采集。
在本文中,我们将首先介绍Gradle 的基础知识,然后举例说明如何实现自定义Gradle 插件。这里需要注意的是,文章使用./gradlew来执行Gradle命令,如果你是Windows用户,需要将它改成gradlew.bat。
二、Gradle 基础知识
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
项目是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,“Project”和“Module”在构建过程中都会被Gradle抽象为Project对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、 每个Project都会对应一个build.gradle配置文件,所以在使用Android Studio创建项目时,根目录下有一个build.gradle文件,每个Module的目录下都有一个build . gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
allprojects {
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 将在施工过程中执行一系列任务。Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle官方的话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图中右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。在运行Task时,也需要通过这种方式指定一个Task。
此外,您可以自定义您自己的任务。让我们创建最简单的任务:
// add to build.gradle
task hello {
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的Task。如果想单独执行Task,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后就可以看到控制台输出了。你好世界!”。
三、Gradle 插件构建3.1 插件介绍
Plugin和Task其实和它们的功能没有太大区别。它们都封装了一些业务逻辑。Plugin适用于打包需要复用的编译逻辑的场景(即模块化部分编译逻辑)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样,以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的 Plugin 应该是 Android 官方提供的 Android Gradle Plugin。可以在项目主模块的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。“com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
该插件还可以读取 build.gradle 文件中写入的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等,大家可以比较一下“ android" android 块在这里作为数据类或基类,定义的属性类似于类成员变量。Android Gradle Plugin 可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 为独立项目构建 Gradle 插件
Gradle插件的实现方式有3种,分别是Build脚本、buildSrc项目和Standalone项目:
1、Build 脚本会直接在 build.gradle 文件中写入逻辑,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc项目就是在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录下写逻辑,Plugin仅对当前项目有效;
3、独立项目就是把逻辑写在一个单独的项目中,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone项目,独立项目的Gradle插件。
3.2.1 目录结构分析
一个独立项目的Gradle插件的大致结构如图3-1所示:

图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
其中resources文件夹为固定格式META-INF/gradle-plugins/XXXX.properties,XXXX代表以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件 Module,只能先新建一个 Java Library 类型的 Module,然后删除多余的文件夹;
2、新类默认是一个新的Java类。新的文件名后缀是“.java”。如果要新建一个Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加package、class语句;
3、资源都需要手动创建,文件夹名需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 编写插件
在编写插件代码之前,我们需要对build.gradle做一些修改,如下图:
apply plugin: 'groovy'
apply plugin: 'maven'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
uploadArchives{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这主要分为三个部分:
1、apply plugin:应用'groovy'插件,因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,位置选择在项目根目录下的repo文件夹中。
做好以上准备后,就可以开始编写源码了。Gradle插件需要入口类实现org.gradle.api.Plugin接口,然后在apply方法中实现自己的逻辑:
package com.sensorsdata.plugin
class MyPlugin implements Plugin{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还需要做一个准备:Gradle插件不会自动查找入口类,而是需要开发者在resources/META-INF/gradle-plugins/XXXX.properties中写入入口类的类名,内容格式对于“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写完后,在终端执行
./gradlew uploadArchive
您可以发布插件。在上一节写的插件的build.gradle文件中,发布到maven仓库的相关配置是提前配置好的,所以我们这里执行这个命令后,项目根目录下就会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤:
自动采集编写(编程问答:只要问那边站长要就可以了再说采集)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-04 10:07
写个程序自动采集VeryCD 标题,很多励志,很好。来写个程序自动采集VeryCD标题,很多励志,很好---------- ----------编程问答------- -------------其实问问那边的站长就知道了。
再说了,采集这个也麻烦,过几天换一个,采集这种变化率很低的东西,不如去人力资源部采集- ----------- --------编程问答--------------------up------ ------------- -编程问答--------------------哈哈----------- ---------编程问答--------------------up---------------- ----编程问答----------- ---------几分钟换好几个---------------- ----编程问答------------ --------好吧,想一想,使用HttpWebRequest和HttpWebResponse进行页面请求和下载,使用常规规则取把之间的数据拿出来,分析一下这个是不是最新的励志词,存入数据库...
--------------------编程问答 --------------------HttpWebRequest 和 HttpWebResponse
发帖
曲奇饼 查看全部
自动采集编写(编程问答:只要问那边站长要就可以了再说采集)
写个程序自动采集VeryCD 标题,很多励志,很好。来写个程序自动采集VeryCD标题,很多励志,很好---------- ----------编程问答------- -------------其实问问那边的站长就知道了。
再说了,采集这个也麻烦,过几天换一个,采集这种变化率很低的东西,不如去人力资源部采集- ----------- --------编程问答--------------------up------ ------------- -编程问答--------------------哈哈----------- ---------编程问答--------------------up---------------- ----编程问答----------- ---------几分钟换好几个---------------- ----编程问答------------ --------好吧,想一想,使用HttpWebRequest和HttpWebResponse进行页面请求和下载,使用常规规则取把之间的数据拿出来,分析一下这个是不是最新的励志词,存入数据库...
--------------------编程问答 --------------------HttpWebRequest 和 HttpWebResponse
发帖
曲奇饼
自动采集编写(自动采集编写爬虫+equery的方法,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-02 02:01
自动采集编写爬虫本网站抓取速度慢,但是大家别灰心哈~我会继续努力的,该争取的还是要争取,等你看到这篇文章时,title已经到了200多个图片哦。你需要安装phantomjs,varphantomjs=require('phantomjs');varhttp=require('http');varurl=http.urlopen();url.readystate=false;获取图片下载速度变慢,首先要观察图片列表页的页面源码:[1,1,3,200,unkeymap][1,1,3,200,2]发现下载unkeymap的时候,下载了19个图片,代码暴露的信息越多,要下载的图片越多,请求的时候请求数据也越多,使用phantomjs+equery的方式直接下载并没有增加,看来是抓图片需要加上http劫持。
来来来,这里有一个phantomjs+equery的方法,现在我们来试试。equery.parse的结果如下:[1,1,3,19,2]表示我们的ajax请求的时候加上这个参数xh_xh_xh_yh_zh_jj_jj_jj_zh_jj_1,ok,下面是调试图片下载代码的时候的地址:[1,1,3,200,2][1,1,3,19,2]这样,你看到的图片列表里可能下载的是3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,47,48,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,180,181,182,183,184,185,186,187,188,189,180,183,184,185,186,187,188,189,181,185,186,187,188,189,182,187,188,189,181,183,184,185。 查看全部
自动采集编写(自动采集编写爬虫+equery的方法,你知道吗?)
自动采集编写爬虫本网站抓取速度慢,但是大家别灰心哈~我会继续努力的,该争取的还是要争取,等你看到这篇文章时,title已经到了200多个图片哦。你需要安装phantomjs,varphantomjs=require('phantomjs');varhttp=require('http');varurl=http.urlopen();url.readystate=false;获取图片下载速度变慢,首先要观察图片列表页的页面源码:[1,1,3,200,unkeymap][1,1,3,200,2]发现下载unkeymap的时候,下载了19个图片,代码暴露的信息越多,要下载的图片越多,请求的时候请求数据也越多,使用phantomjs+equery的方式直接下载并没有增加,看来是抓图片需要加上http劫持。
来来来,这里有一个phantomjs+equery的方法,现在我们来试试。equery.parse的结果如下:[1,1,3,19,2]表示我们的ajax请求的时候加上这个参数xh_xh_xh_yh_zh_jj_jj_jj_zh_jj_1,ok,下面是调试图片下载代码的时候的地址:[1,1,3,200,2][1,1,3,19,2]这样,你看到的图片列表里可能下载的是3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,47,48,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,96,97,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112,113,114,115,116,117,118,119,120,121,122,123,124,125,126,127,128,129,130,131,132,133,134,135,136,137,138,139,140,141,142,143,144,145,146,147,148,149,150,151,152,153,154,155,156,157,158,159,160,161,162,163,164,165,166,167,168,169,168,169,170,171,172,173,174,175,176,177,178,179,180,181,182,183,184,185,186,187,188,189,180,181,182,183,184,185,186,187,188,189,180,183,184,185,186,187,188,189,181,185,186,187,188,189,182,187,188,189,181,183,184,185。
自动采集编写(蜂集采集器如何添加采集模块?(图)采集方法 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 464 次浏览 • 2021-12-31 17:20
)
BeeJi采集 是一个全自动的 wordpress采集 插件。如果你还没有下载,可以到beeJi采集下载页面下载。如果要采集,首先要添加采集模块。本文将介绍如何在风集采集器中添加采集模块!
安装风记采集器后,后台会新增一个名为“飞记”的菜单。依次进入Bee Set->采集模块,点击“添加文章采集模块”按钮新建采集模块。
需要设置一个完整的采集模块:基本信息、列表规则、内容规则。
设置基本信息
基本信息由规则名称和网页完整性检查填写,如下图
规则的名称是必需的。这里我以采集腾讯新闻为例。规则名称中填写腾讯新闻采集。网页完整性检查是为了确保下载的网页是完整的,避免采集失败。一般不需要填写,如果发现很多网页在采集时没有采集获取到内容,那么就需要填写网页完整性检查或者一些标志性的文字在网页的末尾。简单的说,一般不填写,经常出现网页采集填写不完整
编辑列表规则
点击列表规则进入列表规则编辑栏。列表规则的作用是采集一些内容页面的链接供我们跟进采集。
以腾讯新闻为例,我们使用chrome打开腾讯新闻首页。
打开网页后,打开chrome开发者工具(windows按F12或ctrl+shift+i,MAC按cmd+option+i),点击开发者工具左上角的小箭头,然后放置鼠标如果要采集的链接,可以看到链接的区域和格式。
我们找到了列表页中链接的特征,发现新闻链接都收录和html。我们可以在URL收录中写&&html,表示同时收录和html。如果我们只需要采集的入口页面地址,那么我们可以勾选停止列表获取,这样这个规则就不会对下一级网页生效。在大多数情况下,您不需要填写 URL 区域。一般来说,URL收录/不收录,标题收录/不收录足以覆盖大多数场景。如果场景一定要填URL区,那么这里的URL区就是一个正则表达式。
最终效果如下图,请按图填写你的采集规则
接下来可以测试链接获取是否正确。点击爬虫测试,然后填写文章测试地址,在这里填写,因为这是我们的入口页面,所以级别为0(注意级别从0开始,从0级页面为1,从1级页面得到的地址级为2,以此类推...).
填写完成后,点击爬虫测试,应该可以看到下面得到的链接和标题,如下图。
编辑内容规则
我们最终都需要采集内容,所以内容规则与我们的内容采集有关。下图中,内容规则左侧为采集的字段名,默认覆盖wordpress文章的基本信息字段,title为文章title,content为文章内容,Category为文章类别,标签为文章标签,作者为文章作者。
采集标题:title
标题与h1匹配。系统已为您提供默认值。在大多数情况下,您不需要更改它,只需使用系统默认值即可。如下图
如果网页的标题不是h1,您可以通过多种方式来匹配您需要的内容。风集支持三种方式:regular、xpath、fixed characters。
采集正文:内容
内容可以采用自动获取文本的方式,可以智能分析网页中的文本,自动获取。冯基采集器已经把这个选项默认设置为yes,如下图:
一般情况下,大部分基于文本的网站都可以使用智能获取来抓取文本。如果只能抓取,也可以使用正则,xpath。
如果此时使用的是regular或者xpath,那么Smart Get Text请选择No,否则以下规则不会生效
同理,还需要设置category、tag、author,这里不再赘述。
测试采集
所有规则写好后,我们需要根据规则验证采集器是否可以正确采集,进入测试抓取标签,填写链接和页面级别,点击抓取测试来查看效果,如下图:
如果您对采集器的使用有任何疑问,可以到风集的采集交流群(群号可在采集器的关于我们中找到)进行交流。
您可能还喜欢以下内容文章
Bee Set采集器,一个全自动的 wordpress采集插件
imwprobot (bee set) 是一个 wordpress采集 插件。功能是什么? 1.全自动无人值守,支持定时采集2.可自动同步目标站更新3.AI自动关键词,自动汇总生成4.@ > 直接发布到 wordpress,无需额外的界面支持。 5. 正文图片和缩略图可以本地化 6. 每个任务 文章 图片可以设置独立的水印 7. 采集 到达的内容支持常规和 css 选择器替代品。 采集哪些站1.新闻资讯站2. 文章范文站< @3. BBS论坛4.@> 博客站5. 哪些资源站和下载站支持采集规则1.正则表达式2.XPath规则3.JQuery选择器(CSS选择器)代理支持1.HTTP代理2.Socks5代理哪些主机可以不受环境限制运行,虚拟主机可以运行蜜蜂设置功能
蜜蜂合集采集器视频逐字草稿
欢迎来到蜜蜂套装采集器,现在和大家分享蜜蜂套装采集器的教程。接下来就可以开始创建采集任务了。以lz13为例。添加任务名称并添加入口地址。入口页间隔不需要更改,文本捕获间隔不需要更改。选择采集模块,选择发布模块,选择草稿,选择要暂停的任务,然后我们会选择测试后自动执行。
puretext 是一款纯文本 wordpress cms主题,可支持数百万文章
经过几年的制作,纯文字的cms风格主题终于要和大家见面了。但是目前还没有一个主题可以支持海量的文章,所以我只能自己做一个。轻松支持百万文章无卡,无论是前台还是后台。
Wordpress 小说主题 imwpnovels
更强大的wordpress小说主题imwpnovels让创建小说网站更容易!小说阅读页面支持无限字体缩放、护眼模式、分页模式、静态缓存下刷新无闪烁,用户体验极佳。
蜜蜂套装采集器快速入门
这篇文章文章可以帮助您快速入门“蜜蜂采集器”。如果你刚接触采集器,我建议你仔细阅读这篇文章。对你快速上手很有帮助采集器。现在可以添加任务了,采集module和release module选择我们刚刚创建的module,如下图:
查看全部
自动采集编写(蜂集采集器如何添加采集模块?(图)采集方法
)
BeeJi采集 是一个全自动的 wordpress采集 插件。如果你还没有下载,可以到beeJi采集下载页面下载。如果要采集,首先要添加采集模块。本文将介绍如何在风集采集器中添加采集模块!
安装风记采集器后,后台会新增一个名为“飞记”的菜单。依次进入Bee Set->采集模块,点击“添加文章采集模块”按钮新建采集模块。
需要设置一个完整的采集模块:基本信息、列表规则、内容规则。
设置基本信息
基本信息由规则名称和网页完整性检查填写,如下图
http://www.imwpweb.com/wp-cont ... 4.png 768w, http://www.imwpweb.com/wp-cont ... 9.png 1536w" />规则的名称是必需的。这里我以采集腾讯新闻为例。规则名称中填写腾讯新闻采集。网页完整性检查是为了确保下载的网页是完整的,避免采集失败。一般不需要填写,如果发现很多网页在采集时没有采集获取到内容,那么就需要填写网页完整性检查或者一些标志性的文字在网页的末尾。简单的说,一般不填写,经常出现网页采集填写不完整
编辑列表规则
点击列表规则进入列表规则编辑栏。列表规则的作用是采集一些内容页面的链接供我们跟进采集。
以腾讯新闻为例,我们使用chrome打开腾讯新闻首页。
打开网页后,打开chrome开发者工具(windows按F12或ctrl+shift+i,MAC按cmd+option+i),点击开发者工具左上角的小箭头,然后放置鼠标如果要采集的链接,可以看到链接的区域和格式。
http://www.imwpweb.com/wp-cont ... 7.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w, http://www.imwpweb.com/wp-cont ... 8.png 2048w" />我们找到了列表页中链接的特征,发现新闻链接都收录和html。我们可以在URL收录中写&&html,表示同时收录和html。如果我们只需要采集的入口页面地址,那么我们可以勾选停止列表获取,这样这个规则就不会对下一级网页生效。在大多数情况下,您不需要填写 URL 区域。一般来说,URL收录/不收录,标题收录/不收录足以覆盖大多数场景。如果场景一定要填URL区,那么这里的URL区就是一个正则表达式。
最终效果如下图,请按图填写你的采集规则
http://www.imwpweb.com/wp-cont ... 9.png 768w, http://www.imwpweb.com/wp-cont ... 8.png 1536w, http://www.imwpweb.com/wp-cont ... 4.png 2048w" />接下来可以测试链接获取是否正确。点击爬虫测试,然后填写文章测试地址,在这里填写,因为这是我们的入口页面,所以级别为0(注意级别从0开始,从0级页面为1,从1级页面得到的地址级为2,以此类推...).
填写完成后,点击爬虫测试,应该可以看到下面得到的链接和标题,如下图。
http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />编辑内容规则
我们最终都需要采集内容,所以内容规则与我们的内容采集有关。下图中,内容规则左侧为采集的字段名,默认覆盖wordpress文章的基本信息字段,title为文章title,content为文章内容,Category为文章类别,标签为文章标签,作者为文章作者。
采集标题:title
标题与h1匹配。系统已为您提供默认值。在大多数情况下,您不需要更改它,只需使用系统默认值即可。如下图
http://www.imwpweb.com/wp-cont ... 2.png 768w, http://www.imwpweb.com/wp-cont ... 4.png 1536w" />如果网页的标题不是h1,您可以通过多种方式来匹配您需要的内容。风集支持三种方式:regular、xpath、fixed characters。
采集正文:内容
内容可以采用自动获取文本的方式,可以智能分析网页中的文本,自动获取。冯基采集器已经把这个选项默认设置为yes,如下图:
http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />一般情况下,大部分基于文本的网站都可以使用智能获取来抓取文本。如果只能抓取,也可以使用正则,xpath。
如果此时使用的是regular或者xpath,那么Smart Get Text请选择No,否则以下规则不会生效
同理,还需要设置category、tag、author,这里不再赘述。
测试采集
所有规则写好后,我们需要根据规则验证采集器是否可以正确采集,进入测试抓取标签,填写链接和页面级别,点击抓取测试来查看效果,如下图:
http://www.imwpweb.com/wp-cont ... 8.png 768w, http://www.imwpweb.com/wp-cont ... 6.png 1536w, http://www.imwpweb.com/wp-cont ... 1.png 2048w" />如果您对采集器的使用有任何疑问,可以到风集的采集交流群(群号可在采集器的关于我们中找到)进行交流。
您可能还喜欢以下内容文章
Bee Set采集器,一个全自动的 wordpress采集插件
imwprobot (bee set) 是一个 wordpress采集 插件。功能是什么? 1.全自动无人值守,支持定时采集2.可自动同步目标站更新3.AI自动关键词,自动汇总生成4.@ > 直接发布到 wordpress,无需额外的界面支持。 5. 正文图片和缩略图可以本地化 6. 每个任务 文章 图片可以设置独立的水印 7. 采集 到达的内容支持常规和 css 选择器替代品。 采集哪些站1.新闻资讯站2. 文章范文站< @3. BBS论坛4.@> 博客站5. 哪些资源站和下载站支持采集规则1.正则表达式2.XPath规则3.JQuery选择器(CSS选择器)代理支持1.HTTP代理2.Socks5代理哪些主机可以不受环境限制运行,虚拟主机可以运行蜜蜂设置功能
蜜蜂合集采集器视频逐字草稿
欢迎来到蜜蜂套装采集器,现在和大家分享蜜蜂套装采集器的教程。接下来就可以开始创建采集任务了。以lz13为例。添加任务名称并添加入口地址。入口页间隔不需要更改,文本捕获间隔不需要更改。选择采集模块,选择发布模块,选择草稿,选择要暂停的任务,然后我们会选择测试后自动执行。
WX20211027-200152@2x.png" />puretext 是一款纯文本 wordpress cms主题,可支持数百万文章
经过几年的制作,纯文字的cms风格主题终于要和大家见面了。但是目前还没有一个主题可以支持海量的文章,所以我只能自己做一个。轻松支持百万文章无卡,无论是前台还是后台。
Wordpress 小说主题 imwpnovels
更强大的wordpress小说主题imwpnovels让创建小说网站更容易!小说阅读页面支持无限字体缩放、护眼模式、分页模式、静态缓存下刷新无闪烁,用户体验极佳。
蜜蜂套装采集器快速入门
这篇文章文章可以帮助您快速入门“蜜蜂采集器”。如果你刚接触采集器,我建议你仔细阅读这篇文章。对你快速上手很有帮助采集器。现在可以添加任务了,采集module和release module选择我们刚刚创建的module,如下图:
自动采集编写(actions文件夹自动化测试框架一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-12-30 16:18
这两天用python2写了一个自动化测试框架,名字叫Auty。它已准备好用于 Web 界面测试。下面是Auty框架的分步搭建过程——
首先感谢朱博大哥的指教、交流和帮助!
auty文件夹结构介绍
1. actions文件夹:收录
业务相关的脚本文件,收录
可复用的方法,可以根据不同的业务在actions文件夹下创建不同的业务文件夹;
2. 常量文件夹:收录
常量初始化的python脚本文件。根据业务分工,可以创建子文件夹或多个常量文件;
3. 数据文件夹:收录
用于测试的数据;
4. lib文件夹:收录
支持框架运行的python文件;
5. 日志文件夹:收录
运行测试过程中产生的日志文件;
6. results文件夹:收录
测试结果文件;
7. 脚本文件夹:收录
脚本文件夹和选择文件夹;
1)scripts 文件夹收录
测试脚本(可以根据业务分为多个子目录);
2)selections 文件夹收录
套件文件(包括需要执行的脚本路径的集合);
8. utils文件夹:收录
与业务逻辑无关的脚本文件,收录
可复用的方法;
auty文件结构介绍
1. 在 Auty 文件夹下:
1)__init__.py 文件:包结构的必要文件(以下所有涉及可调用脚本的文件夹都需要该文件);
2)config.txt 文件:Auty 框架配置描述文件;
3)recovery.py 文件:垃圾代码恢复文件(用于恢复由于测试执行过程中失败而自动删除失败的自动生成代码);
4)requirements 文件:收录
框架需要安装的python库信息;
5)setup.py文件:执行脚本安装需求文件中收录
的python库;
6)start.py 文件:执行脚本启动界面自动化测试;
2. lib 文件夹:
1)exe_deco.py 文件:收录
修改脚本运行时方法的文件;
2)execute_selection.py 文件:收录
了suite集合下运行脚本方法的文件;
3)generate_html.py文件:收录
根据生成的csv格式测试结果文件生成html类型测试结果文件的方法的文件;
4)generate_result.py文件:收录
生成csv格式测试结果方法的文件;
5)read_selection.py 文件:收录
读取可执行脚本列表的方法的文件;
6)recovery_code.py 文件:收录
垃圾代码恢复方法的文件;
7)write_log.py 文件:收录
生成日志文件的方法的文件;
3. 脚本文件夹下:
1)create_selection.py 文件:收录
创建套件文件的方法的文件(all_scripts_selection.txt);
自动步骤
1. 运行Auty/setup.py文件;
2. 编写接口测试python脚本,放在Auty/scripts/scripts目录(或子目录);
3. 运行Auty/scripts/create_selection.py文件,生成Auty/scripts/all_scripts_selection.txt文件;
4. 修改Auty/scripts/all_scripts_selection.txt文件,自定义test_selection.txt文件(任意名称)放到Auty/scripts/selections文件夹下;
5. 运行Auty/start.py文件,启动接口自动测试;
6. 在Auty/results文件夹下生成的测试结果文件中查看测试结果。
写作过程
本框架中scripts、utils、actions、contants四个文件夹中的内容可以根据实际工作内容随意更换。其他是Auty 接口自动化测试框架的必要组件。由于后续开发工作繁琐,部分改动代码无法在后续文章中及时更新。最新代码请见:Github
第1部分-生成执行列表第2部分-读取和执行脚本列表第3部分-添加异常处理和日志采集
第4部分-生成测试结果报告第5部分-调用支持、自动安装库和配置说明第6章-垃圾代码恢复、添加套件支持第7章-添加动作库和常量文件库Auty框架性能篇-Python flask框架实践接口测试用例编写建议
从某种层面来说,框架的诞生也是为了让编写的代码更加规范。不管框架如何,对于接口测试用例的编写,都应该给出以下建议:
1. 接口中涉及到url,不要写在case中,而是通过常量访问,将url存放在指定的常量文件中(避免因接口域名变化等原因导致无法维护) );
2. 测试用例中不要收录
测试数据等变量信息,设置为变量,在指定文件中完成变量的初始化;
3. 不要在测试用例中重复粘贴大段代码逻辑(不利于代码走查,会造成代码冗余,增加出错概率)。所有可以重用的流程都会被提取到方法中,并分类放置在指定的存储文件夹中的业务逻辑动作中;
4. 关于评论:语言一定要正式,评论的意义更多的是给别人看,让别人一目了然;一定要具体、详细,不要说一半;一定要准确,而且注释下面的代码逻辑一定要和注释的内容一致,不能在注释下面一段代码之后,才启动注释中收录
的内容逻辑。 查看全部
自动采集编写(actions文件夹自动化测试框架一步)
这两天用python2写了一个自动化测试框架,名字叫Auty。它已准备好用于 Web 界面测试。下面是Auty框架的分步搭建过程——
首先感谢朱博大哥的指教、交流和帮助!
auty文件夹结构介绍
1. actions文件夹:收录
业务相关的脚本文件,收录
可复用的方法,可以根据不同的业务在actions文件夹下创建不同的业务文件夹;
2. 常量文件夹:收录
常量初始化的python脚本文件。根据业务分工,可以创建子文件夹或多个常量文件;
3. 数据文件夹:收录
用于测试的数据;
4. lib文件夹:收录
支持框架运行的python文件;
5. 日志文件夹:收录
运行测试过程中产生的日志文件;
6. results文件夹:收录
测试结果文件;
7. 脚本文件夹:收录
脚本文件夹和选择文件夹;
1)scripts 文件夹收录
测试脚本(可以根据业务分为多个子目录);
2)selections 文件夹收录
套件文件(包括需要执行的脚本路径的集合);
8. utils文件夹:收录
与业务逻辑无关的脚本文件,收录
可复用的方法;
auty文件结构介绍
1. 在 Auty 文件夹下:
1)__init__.py 文件:包结构的必要文件(以下所有涉及可调用脚本的文件夹都需要该文件);
2)config.txt 文件:Auty 框架配置描述文件;
3)recovery.py 文件:垃圾代码恢复文件(用于恢复由于测试执行过程中失败而自动删除失败的自动生成代码);
4)requirements 文件:收录
框架需要安装的python库信息;
5)setup.py文件:执行脚本安装需求文件中收录
的python库;
6)start.py 文件:执行脚本启动界面自动化测试;
2. lib 文件夹:
1)exe_deco.py 文件:收录
修改脚本运行时方法的文件;
2)execute_selection.py 文件:收录
了suite集合下运行脚本方法的文件;
3)generate_html.py文件:收录
根据生成的csv格式测试结果文件生成html类型测试结果文件的方法的文件;
4)generate_result.py文件:收录
生成csv格式测试结果方法的文件;
5)read_selection.py 文件:收录
读取可执行脚本列表的方法的文件;
6)recovery_code.py 文件:收录
垃圾代码恢复方法的文件;
7)write_log.py 文件:收录
生成日志文件的方法的文件;
3. 脚本文件夹下:
1)create_selection.py 文件:收录
创建套件文件的方法的文件(all_scripts_selection.txt);
自动步骤
1. 运行Auty/setup.py文件;
2. 编写接口测试python脚本,放在Auty/scripts/scripts目录(或子目录);
3. 运行Auty/scripts/create_selection.py文件,生成Auty/scripts/all_scripts_selection.txt文件;
4. 修改Auty/scripts/all_scripts_selection.txt文件,自定义test_selection.txt文件(任意名称)放到Auty/scripts/selections文件夹下;
5. 运行Auty/start.py文件,启动接口自动测试;
6. 在Auty/results文件夹下生成的测试结果文件中查看测试结果。
写作过程
本框架中scripts、utils、actions、contants四个文件夹中的内容可以根据实际工作内容随意更换。其他是Auty 接口自动化测试框架的必要组件。由于后续开发工作繁琐,部分改动代码无法在后续文章中及时更新。最新代码请见:Github
第1部分-生成执行列表第2部分-读取和执行脚本列表第3部分-添加异常处理和日志采集
第4部分-生成测试结果报告第5部分-调用支持、自动安装库和配置说明第6章-垃圾代码恢复、添加套件支持第7章-添加动作库和常量文件库Auty框架性能篇-Python flask框架实践接口测试用例编写建议
从某种层面来说,框架的诞生也是为了让编写的代码更加规范。不管框架如何,对于接口测试用例的编写,都应该给出以下建议:
1. 接口中涉及到url,不要写在case中,而是通过常量访问,将url存放在指定的常量文件中(避免因接口域名变化等原因导致无法维护) );
2. 测试用例中不要收录
测试数据等变量信息,设置为变量,在指定文件中完成变量的初始化;
3. 不要在测试用例中重复粘贴大段代码逻辑(不利于代码走查,会造成代码冗余,增加出错概率)。所有可以重用的流程都会被提取到方法中,并分类放置在指定的存储文件夹中的业务逻辑动作中;
4. 关于评论:语言一定要正式,评论的意义更多的是给别人看,让别人一目了然;一定要具体、详细,不要说一半;一定要准确,而且注释下面的代码逻辑一定要和注释的内容一致,不能在注释下面一段代码之后,才启动注释中收录
的内容逻辑。
自动采集编写(用考拉SEO,轻轻松松一天产出几万篇高质量SEO文章!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-29 11:12
看到本文内容请不要惊讶,因为本文由考拉SEO平台批量编译,仅用于SEO引流。有了考拉SEO,一天可以轻松产出数万篇优质SEO文章!如果您还需要批量编辑SEO文章,可以进入平台用户中心试用!
这些天,网友们一直在关注ai伪原创内容的自动视频采集和上传,质疑我们的人太多了。其实在关注这个信息之前,大家应该先来这里探讨一下关键词如何优化自编信息!对于圈子里思考的SEOer来说,文字质量绝不是主要目标,这些人最关心的是权重值和访问量。一篇高质量的搜索优化文章写在一个新的站点上,并推送到一个高权重的门户站点。最后排名和流量差别很大!
一直在咨询AI伪原创视频自动采集上传的客户,归根结底大家超级关注的还是之前文章讨论的内容。编辑一篇流量大的搜索落地文章很容易,但一篇文章产生的流量其实很小。如果要设置内容达到引流的目的,绝对关键是自动化!如果1篇SEO文章可以收获1个UV(每天),那么假设可以写10000篇文章,那么平均每天的客户量可以增加10000。但是,简单来说,在现实生活中编辑时,一个人一天只能产出30篇文章,最多60篇。即使使用伪原创工具,也只能维持一百!看到这个,
杜娘想的人工造物是什么?原创文章不仅仅是逐段原创编辑!在各大搜索者的算法定义中,原创并不意味着没有重复的句子。换句话说,只要我们的码字和别人的码字不完全一样,就可以增加收录
的可能性。一篇热点文章,核心足够抢眼,保持同一个中心思想,只要保证没有同款,就说明这篇文章还是很有可能被搜索引擎收录的,甚至成为引流的好文章。就像这篇文章,你可能在搜索引擎搜索视频,自动采集
ai伪原创上传,然后点进去。其实,下一篇就是发挥考拉SEO平台智能编辑文章系统的作用。从!
本站智能原创平台应为原创文章系统,精准表达。一天可以写好几万个靠谱的SEO文案。只要您的网站足够大,收录率就可以高达 80%。详细的操作方法,个人中心有视频展示和初学者指南。让我们免费试用吧!很抱歉没有给大家带来关于自动抓拍ai伪原创上传的全面讲解,或许能让大家看完这篇通用的系统语言。但如果我们喜欢这个系统,只需点击导航栏,就能让您的网页每天达到数百次浏览量。这不是坏事吗? 查看全部
自动采集编写(用考拉SEO,轻轻松松一天产出几万篇高质量SEO文章!)
看到本文内容请不要惊讶,因为本文由考拉SEO平台批量编译,仅用于SEO引流。有了考拉SEO,一天可以轻松产出数万篇优质SEO文章!如果您还需要批量编辑SEO文章,可以进入平台用户中心试用!
这些天,网友们一直在关注ai伪原创内容的自动视频采集和上传,质疑我们的人太多了。其实在关注这个信息之前,大家应该先来这里探讨一下关键词如何优化自编信息!对于圈子里思考的SEOer来说,文字质量绝不是主要目标,这些人最关心的是权重值和访问量。一篇高质量的搜索优化文章写在一个新的站点上,并推送到一个高权重的门户站点。最后排名和流量差别很大!
一直在咨询AI伪原创视频自动采集上传的客户,归根结底大家超级关注的还是之前文章讨论的内容。编辑一篇流量大的搜索落地文章很容易,但一篇文章产生的流量其实很小。如果要设置内容达到引流的目的,绝对关键是自动化!如果1篇SEO文章可以收获1个UV(每天),那么假设可以写10000篇文章,那么平均每天的客户量可以增加10000。但是,简单来说,在现实生活中编辑时,一个人一天只能产出30篇文章,最多60篇。即使使用伪原创工具,也只能维持一百!看到这个,
杜娘想的人工造物是什么?原创文章不仅仅是逐段原创编辑!在各大搜索者的算法定义中,原创并不意味着没有重复的句子。换句话说,只要我们的码字和别人的码字不完全一样,就可以增加收录
的可能性。一篇热点文章,核心足够抢眼,保持同一个中心思想,只要保证没有同款,就说明这篇文章还是很有可能被搜索引擎收录的,甚至成为引流的好文章。就像这篇文章,你可能在搜索引擎搜索视频,自动采集
ai伪原创上传,然后点进去。其实,下一篇就是发挥考拉SEO平台智能编辑文章系统的作用。从!
本站智能原创平台应为原创文章系统,精准表达。一天可以写好几万个靠谱的SEO文案。只要您的网站足够大,收录率就可以高达 80%。详细的操作方法,个人中心有视频展示和初学者指南。让我们免费试用吧!很抱歉没有给大家带来关于自动抓拍ai伪原创上传的全面讲解,或许能让大家看完这篇通用的系统语言。但如果我们喜欢这个系统,只需点击导航栏,就能让您的网页每天达到数百次浏览量。这不是坏事吗?
自动采集编写(安装Python自动化测试的脚本是用Python3写的吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-29 09:07
写在前面
本文主要介绍一个基于uiautomator2封装的Python库android-catcher。该库的功能主要包括Android设备的UI自动化测试和手机性能数据的采集。适用于列表滑动、视频录制等各种测试场景。 CPU,内存、帧率等信息的抓取方便后续分析。
Github地址:
安装 Python
自动化测试脚本使用Python 3编写,运行脚本需要安装Python 3环境。
下载链接:
Python 3.6.5
安装 android-catcher 依赖
打开脚本目录,执行以下命令安装依赖
pip install -r requirements.txt
使用方法 uiautomator2
安装uiautomator2后,一般只需要执行以下命令来初始化设备并在设备上安装uiautomator2服务
python -m uiautomator2 init
如果出现如下提示,则安装成功
更多uiautomator2的使用请参考:
脚本文件说明
这个脚本库根目录下的主要文件有
参数说明 生成的文件说明
采集到的信息根据信息类型存储在指定输出目录下的cpu_stats、mem_stats、fps_stats、net_stats四个子目录中。文件名为信息类型_设备号_应用程序ID_版本号_测试场景名称_时间戳,如cpu_d3c2edaa_video。like_RecordVideo_1.9.9_1524122928.csv.csv,实际效果大致如下
输出文件为csv文件,直接打开和用Excel打开的效果如下:
此外,您可以为测试的每个阶段添加节点描述
task.period = "idle"
生成类似于下图的图形
如何使用无自定义测试场景
适用于没有特定测试场景,脚本运行一段时间后脚本处于采集状态的情况。时长可以通过配置参数指定,用户可以在此过程中随意操作手机。直接通过命令行运行_main_.py脚本文件并指定相关参数
比如我想采集applicationId为video.like的应用程序10s内的cpu信息和内存信息,采样间隔为200ms,输出目录为当前目录,那么可以在所在目录下执行如下命令脚本位于
python _main_.py -s 设备号-a video.like -f 0.2 -d 10 -i mem,cpu -o .
脚本运行后,在根目录下可以看到如下图的文件生成
注意:要带-d参数指定采集的持续时间,否则脚本默认运行10s,不需要-t参数。默认测试场景命名为 Random
如何使用自定义测试场景
自定义测试场景不能直接调用_main_.py 脚本。需要新建一个脚本,继承task.py#Task并重写Task#execute方法,在Task#execute中实现自定义测试场景的逻辑,如下图所示:
在这里创建一个名为 start_app.py 的脚本,运行命令:
python start_app.py -s 设备号-a 进程名 -f 0.1 -i cpu,mem -o .
可以启动相应的APP,采集CPU信息和内存信息,采样间隔100ms,输出到当前目录。注意这里没有-d参数,因为采集的时长以测试任务的时长为准。设置的参数必须按照说明进行,否则无法采集数据
如果要采集
自定义信息,可以继承 info.py#Info 并重写 Info#get_start_info 和 Info#get_end_info 方法。可以参考已经实现的四种信息集合,最后通过Task#add_info方法进行添加。
自定义测试场景后,调用_main_#main方法,传入测试场景实例。测试场景的名称将用作输出文件命名的一部分。最好取一个能准确表达测试场景的名字,比如一个APP录制视频 测试场景的名字是RecordVideo
采集
到的信息可以通过Excel制作成图表。以下是完整视频录制测试场景的CPU比例和内存变化
通过图表,可以直观地分析应用程序不同版本、不同场景的性能状态
写在最后
以上是对该库使用的一些介绍。由于工作经验还比较少,所以现在也在学习和使用Python。在编写这个库的时候,可能会有很多考虑不周或不完善的地方。有能力的朋友可以直接修改库实现更多的自定义功能。另外也希望大家多多使用,多发现问题,欢迎issue,欢迎star,欢迎新的使用需求和想法。后续会继续完善,谢谢!
Github地址: 查看全部
自动采集编写(安装Python自动化测试的脚本是用Python3写的吗)
写在前面
本文主要介绍一个基于uiautomator2封装的Python库android-catcher。该库的功能主要包括Android设备的UI自动化测试和手机性能数据的采集。适用于列表滑动、视频录制等各种测试场景。 CPU,内存、帧率等信息的抓取方便后续分析。
Github地址:
安装 Python
自动化测试脚本使用Python 3编写,运行脚本需要安装Python 3环境。
下载链接:
Python 3.6.5
安装 android-catcher 依赖
打开脚本目录,执行以下命令安装依赖
pip install -r requirements.txt
使用方法 uiautomator2
安装uiautomator2后,一般只需要执行以下命令来初始化设备并在设备上安装uiautomator2服务
python -m uiautomator2 init
如果出现如下提示,则安装成功
更多uiautomator2的使用请参考:
脚本文件说明
这个脚本库根目录下的主要文件有
参数说明 生成的文件说明
采集到的信息根据信息类型存储在指定输出目录下的cpu_stats、mem_stats、fps_stats、net_stats四个子目录中。文件名为信息类型_设备号_应用程序ID_版本号_测试场景名称_时间戳,如cpu_d3c2edaa_video。like_RecordVideo_1.9.9_1524122928.csv.csv,实际效果大致如下
输出文件为csv文件,直接打开和用Excel打开的效果如下:
此外,您可以为测试的每个阶段添加节点描述
task.period = "idle"
生成类似于下图的图形
如何使用无自定义测试场景
适用于没有特定测试场景,脚本运行一段时间后脚本处于采集状态的情况。时长可以通过配置参数指定,用户可以在此过程中随意操作手机。直接通过命令行运行_main_.py脚本文件并指定相关参数
比如我想采集applicationId为video.like的应用程序10s内的cpu信息和内存信息,采样间隔为200ms,输出目录为当前目录,那么可以在所在目录下执行如下命令脚本位于
python _main_.py -s 设备号-a video.like -f 0.2 -d 10 -i mem,cpu -o .
脚本运行后,在根目录下可以看到如下图的文件生成
注意:要带-d参数指定采集的持续时间,否则脚本默认运行10s,不需要-t参数。默认测试场景命名为 Random
如何使用自定义测试场景
自定义测试场景不能直接调用_main_.py 脚本。需要新建一个脚本,继承task.py#Task并重写Task#execute方法,在Task#execute中实现自定义测试场景的逻辑,如下图所示:
在这里创建一个名为 start_app.py 的脚本,运行命令:
python start_app.py -s 设备号-a 进程名 -f 0.1 -i cpu,mem -o .
可以启动相应的APP,采集CPU信息和内存信息,采样间隔100ms,输出到当前目录。注意这里没有-d参数,因为采集的时长以测试任务的时长为准。设置的参数必须按照说明进行,否则无法采集数据
如果要采集
自定义信息,可以继承 info.py#Info 并重写 Info#get_start_info 和 Info#get_end_info 方法。可以参考已经实现的四种信息集合,最后通过Task#add_info方法进行添加。
自定义测试场景后,调用_main_#main方法,传入测试场景实例。测试场景的名称将用作输出文件命名的一部分。最好取一个能准确表达测试场景的名字,比如一个APP录制视频 测试场景的名字是RecordVideo
采集
到的信息可以通过Excel制作成图表。以下是完整视频录制测试场景的CPU比例和内存变化
通过图表,可以直观地分析应用程序不同版本、不同场景的性能状态
写在最后
以上是对该库使用的一些介绍。由于工作经验还比较少,所以现在也在学习和使用Python。在编写这个库的时候,可能会有很多考虑不周或不完善的地方。有能力的朋友可以直接修改库实现更多的自定义功能。另外也希望大家多多使用,多发现问题,欢迎issue,欢迎star,欢迎新的使用需求和想法。后续会继续完善,谢谢!
Github地址:
自动采集编写(个人信息采集小程序模板解决你制作个人信息报表(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 268 次浏览 • 2021-12-28 16:09
个人信息采集小程序制作平台网站
>自建定制【个人信息采集小程序】立即注册开始>
▶微信、百度、抖音、今日头条小程序
▶抽奖、答题、投票、展示等多元化小程序。
▶同城、社区、查询、咨询等热门小程序
▶覆盖70+行业,400+套免费小程序模板即刻制作>
▶超划算的小程序开发方案,买两年送两年,每天只需花1元√
个人信息采集
小程序*热门功能
*服务抽奖——适用于美容、餐饮、保养等店内服务的个人信息采集小程序。
*同城社区-适用于小区、社区等领域采集
个人信息的小程序
* 留言如回复-适用于需要此服务的个人信息采集
小程序
*在线投票-适用于需要使用投票功能的个人信息采集小程序
*在线答题——适用于需要使用答题功能的个人信息采集小程序
*签到和签到-适用于需要使用签到功能的个人信息采集
小程序
提供个人信息采集小程序定制服务,或自带模板自建模板
个人信息采集小程序制作平台网站提供免费的个人信息采集小程序模板
平台提供免费的个人信息采集小程序模板
解决你在制作个人信息采集小程序的路上遇到的所有烦恼
个人信息采集小程序制作平台网站有哪些优势
定制2种服务,以及多功能服务,助您减少后顾之忧
▽无需自己写代码
▽小程序制作,全程拖拽操作简单
▽无需编写任何代码即可完成个人信息采集小程序的开发
▽个人信息采集小程序自主开发即刻启动
▽一键免费注册开发个人信息采集小程序
▽微信、百度小程序、今日头条、抖音
▽一次拥有四大平台网站小程序
▽抢占移动终端流量,提升企业移动终端服务水平
▽可视化个人信息采集小程序设计界面
▽步骤搭建简单好用的个人信息采集小程序
▽0代码库也可以用来制作个人信息采集小程序
▽省时、省力、省钱,高效完成个人信息采集小程序的开发
▽详细的数据分析报告
▽多维度、多方位的个人信息采集小程序数据解读
▽全面了解用户喜好和赚钱秘诀
▽大数据时代,用数据做更正确的决策 查看全部
自动采集编写(个人信息采集小程序模板解决你制作个人信息报表(组图))
个人信息采集小程序制作平台网站
>自建定制【个人信息采集小程序】立即注册开始>
▶微信、百度、抖音、今日头条小程序
▶抽奖、答题、投票、展示等多元化小程序。
▶同城、社区、查询、咨询等热门小程序
▶覆盖70+行业,400+套免费小程序模板即刻制作>
▶超划算的小程序开发方案,买两年送两年,每天只需花1元√
个人信息采集
小程序*热门功能
*服务抽奖——适用于美容、餐饮、保养等店内服务的个人信息采集小程序。
*同城社区-适用于小区、社区等领域采集
个人信息的小程序
* 留言如回复-适用于需要此服务的个人信息采集
小程序
*在线投票-适用于需要使用投票功能的个人信息采集小程序
*在线答题——适用于需要使用答题功能的个人信息采集小程序
*签到和签到-适用于需要使用签到功能的个人信息采集
小程序
提供个人信息采集小程序定制服务,或自带模板自建模板
个人信息采集小程序制作平台网站提供免费的个人信息采集小程序模板
平台提供免费的个人信息采集小程序模板
解决你在制作个人信息采集小程序的路上遇到的所有烦恼
个人信息采集小程序制作平台网站有哪些优势
定制2种服务,以及多功能服务,助您减少后顾之忧
▽无需自己写代码
▽小程序制作,全程拖拽操作简单
▽无需编写任何代码即可完成个人信息采集小程序的开发
▽个人信息采集小程序自主开发即刻启动
▽一键免费注册开发个人信息采集小程序
▽微信、百度小程序、今日头条、抖音
▽一次拥有四大平台网站小程序
▽抢占移动终端流量,提升企业移动终端服务水平
▽可视化个人信息采集小程序设计界面
▽步骤搭建简单好用的个人信息采集小程序
▽0代码库也可以用来制作个人信息采集小程序
▽省时、省力、省钱,高效完成个人信息采集小程序的开发
▽详细的数据分析报告
▽多维度、多方位的个人信息采集小程序数据解读
▽全面了解用户喜好和赚钱秘诀
▽大数据时代,用数据做更正确的决策
自动采集编写( 有关自动采集inlistIoutthe)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-28 06:11
有关自动采集inlistIoutthe)
Firefox 自动采集
url
在我开始测试有关在地址栏中启用内联自动完成功能的最后一个提示后,我突然想到,尽管来自我的浏览器历史记录的链接一直显示在列表中,但我可能永远不会输入它们。
在我开始测试关于在地址栏中启用内联自动完成的最后一个技巧后,我想虽然浏览器历史记录中的链接总是显示在列表中,但我可能永远不会输入它们。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您在地址栏中使用大量书签或搜索关键字时,这会很有帮助。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您从地址栏中使用许多书签或搜索关键字时,这会很有帮助。
请记住,此设置并不适合所有人,但了解工作原理很有好处。
请记住,此设置并不适合所有人,但最好了解它的工作原理。
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
browser.urlbar.matchOnlyTyped
browser.urlbar.matchOnlyTyped
双击该值将其更改为 true,您应该立即注意到历史记录中的链接将不再自动完成:
双击该值将其更改为true,您应该立即注意到历史记录中的链接将不再自动完成:
当然,您手动输入的链接将继续自动完成:
当然,您手动输入的链接会继续自动完成:
拥有一个每个人都可以选择自己设置的浏览器真是太好了。
有了浏览器,每个人都可以选择自己的设置,这很棒。
翻译自:
Firefox 自动采集
url 查看全部
自动采集编写(
有关自动采集inlistIoutthe)
Firefox 自动采集
url
在我开始测试有关在地址栏中启用内联自动完成功能的最后一个提示后,我突然想到,尽管来自我的浏览器历史记录的链接一直显示在列表中,但我可能永远不会输入它们。
在我开始测试关于在地址栏中启用内联自动完成的最后一个技巧后,我想虽然浏览器历史记录中的链接总是显示在列表中,但我可能永远不会输入它们。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您在地址栏中使用大量书签或搜索关键字时,这会很有帮助。
经过几分钟的研究,我发现了一个设置,可以让 Firefox 只自动完成您手动输入的链接。当您从地址栏中使用许多书签或搜索关键字时,这会很有帮助。
请记住,此设置并不适合所有人,但了解工作原理很有好处。
请记住,此设置并不适合所有人,但最好了解它的工作原理。
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
要进行此更改,请在地址栏中键入 about:config,然后按以下键进行过滤:
browser.urlbar.matchOnlyTyped
browser.urlbar.matchOnlyTyped
双击该值将其更改为 true,您应该立即注意到历史记录中的链接将不再自动完成:
双击该值将其更改为true,您应该立即注意到历史记录中的链接将不再自动完成:
当然,您手动输入的链接将继续自动完成:
当然,您手动输入的链接会继续自动完成:
拥有一个每个人都可以选择自己设置的浏览器真是太好了。
有了浏览器,每个人都可以选择自己的设置,这很棒。
翻译自:
Firefox 自动采集
url
自动采集编写(iOS开发交流技术群:1.数据采集SDK是如何工作的)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-12-28 06:09
GrowingIO 是一个基于用户行为数据的增长平台。准确采集用户行为数据是公司业务的基石。只有及时、准确、可靠的数据采集,才能支撑上层的数据分析、用户画像、运营等服务。因此,公司一直非常重视数据采集SDK(Software Development Kit)的质量保证工作。
iOS开发与通信技术群:【563513413】(跳跃),无论你是大牛还是新手,欢迎加入,分享BAT,阿里巴巴面试题,面试经验,讨论技术,让大家交流、学习、成长!
为了满足客户的各种业务和技术需求,GrowingIO提供Web、Android、iOS、Hybrid等各种平台,各种小程序(微信、支付宝、今日头条等)、微信内嵌页面,以及React Native 、Flutter、Cordova、Weex、API Cloud、AppCan等众多开发框架SDK,这无疑给SDK测试带来了巨大的挑战。
本文主要介绍GrowingIO在iOS SDK测试中的具体实践,希望能为从事iOS测试的同学提供一些参考。
1. 数据采集SDK是如何工作的?
要测试一个软件或系统,首先要了解它的业务逻辑和技术实现。接下来我们简单的看一下数据采集SDK的工作原理。
GrowingIO的数据采集SDK支持非埋点(全埋点)数据采集和埋点数据采集,满足不同业务需求。其简单的结构如下:
当用户打开App、浏览不同页面、点击不同元素(如按钮、文本框、图片)、关闭App时,非嵌入式事件采集模块会自动采集并保存用户的具体行为手机本地存储(关于非埋点数据采集的具体实现,请关注GrowigIO的后续文章分享,这里不再详述)。
埋点事件采集类似,不同的是埋点事件是由App主动调用SDK的埋点API触发的。当然,不同事件的具体数据格式是不同的。
接下来是数据发送模块,主要负责通过HTTP API向数据接收服务上报数据。
需要注意的是,为了节省用户的数据流量和电量,发送程序不是实时上报的。它会根据设备的功率、网络类型和数据量来选择发送时序,数据在发送前会被压缩。并进行混淆处理,减少传输数据量,提高数据安全性。
当然,数据发送程序也会对数据报告中的各种数据发送失败、网络异常等错误进行处理,并采用适当的重试机制。
2. 如何测试?
通过以上结构分析可以看出,数据发送模块与核心数据采集业务关系不大,非常稳定,几乎没有变化,所以我们测试的重点主要是数据采集部分,尤其是数据采集部分无埋点。
要测试数据采集,首先需要有一个收录
各种页面和元素的Demo App,然后在不同页面之间切换,操作页面上的元素或者触发一个埋藏事件,然后检查采集的事件数据是否正确。
有两种方法可以检查事件数据。一种是通过日志打印出详细的事件数据,观察日志检查;另一种是通过抓包程序获取数据并发送,然后检查。
后者一般需要配置复杂的代理工具,数据量大,还需要考虑数据的解压和解密。更难准确定位事件数据。因此,在实际测试中一般采用前者。
上图是采集数据的日志截图。通过图中的事件数据,我们发现字段较多,有些字段可读性不高,人工检查耗时较长。
另外,SDK数据采集的主要逻辑基本不变,但每次修改都要覆盖足够的回归,避免遗漏错误。
一旦缺陷在线上被遗漏,造成的损失是极其昂贵的。即使缺陷在后续版本中修复,影响也难以消除,因为移动应用程序的升级周期难以控制。
此外,GrowingIO 数据采集 SDK 兼容 iOS 8 及以上版本。需要测试系统各个版本的兼容性,测试工作量明显。
好在SDK的业务变化很少,断言内容比较机械,特别适合自动化测试。而且回归测试的工作量巨大,使用自动化测试可以大大提高生产力和质量。
3. 选择一个测试框架
工人要想做好本职工作,首先要磨砺工具,选择合适的自动化测试框架,再进行自动化测试。选择框架时需要考虑几个方面:
目前支持iOS UI自动化测试的主要框架对比如下:
考虑影响测试框架选择的几个因素。
首先,使用的语言和框架决定了测试人员的持续学习成本。iOS SDK 测试人员对Objective-C 有高度的熟悉和掌握,不需要消耗额外的学习成本。测试和开发相同的技术堆栈。
其次,根据需要不时调整测试App程序。使用开发效率高、调试方便的测试框架,可以让我们在适应新的UI变化和新的需求时,获得更小的投入产出比。
基于以上考虑,KIF框架已经展示了它的优势,而KIF使用XCTest框架,使得iOS程序的测试过程和单测一样,可以完全复用单测持续集成过程,维护持续集成的成本相对降低;此外,KIF 是一个活跃的开源测试框架,具有良好的可扩展性和快速升级。有活跃的社区来讨论和解决使用过程中遇到的问题。
鉴于以上优势,我们选择KIF作为iOS的UI自动化测试框架。
KIF的全称是Keep it Functional,是一个建立在XCTest之上的UI测试框架,通过Accessibility定位特定的控件,然后使用私有的API来操作UI。由于它是建立在 XCTest 之上的,所以你可以完美的使用 XCode 的测试相关工具。
4. 自动化测试的实现
语言和工具
建立测试环境
要将Target实现添加到现有项目中,选择File → New → Target…菜单项,在iOS → Test中选择UI Testing Bundle模板,如下图:
点击下一步进入Target选项页面,设置测试项目的相关项
完成Target设置后,点击“Finish”按钮,创建成功。
要安装 pod,请在命令行终端中输入以下命令。
sudo gem 安装 cocoapods
修改或创建项目的pod文件Podfile。
目标'GrowingIOTest'做
pod'SDCycleScrollView','~> 1.75'
pod'MJRefresh'
pod'MBProgressHUD'
结尾
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
其中,新增以下一段
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
在项目目录下执行如下安装命令安装对应的依赖,测试项目就准备完成了。
吊舱安装
准备待测程序,在测试Demo工程中集成待测版本的数据采集SDK。
编写测试用例
测试环境搭建好后,下一步就是编写具体的测试用例。一般测试用例的主要步骤是:
准备测试环境,执行测试步骤,测试结果,断言测试结果,报告,清理测试环境
下面以SDK的unburied元素的点击事件的自动化测试用例为例,说明自动化用例的准备。
测试用例:
启动App,模拟用户滚动屏幕找到对话框按钮,然后点击对话框按钮。弹出对话框后,点击关闭按钮,验证点击事件是否发送数据,内容是否正确。
代码:
-(无效)设置{
// 一些初始化操作
}
-(void)tearDown{
// 一些结束动作
}
-(无效)testDialogBtnCheck{
/**
功能:点击对话框按钮检测点击事件,
**/
[[viewTester usingLabel:@"UIinterface"] 点击];
//添加向下滚动操作
[tester scrollViewWithAccessibilityLabel:@"采集
View" byFractionOfSizeHorizontal:0.0f vertical:10.0f];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"LabelAttribute"] tap];
[[viewTester usingLabel:@"ShowAlert"] 点击];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"Cancel"] tap];
[测试员waitForTimeInterval:3];
NSArray *clckEventArray = [MockEventQueue eventsFor:@"clck"];
//是否发送clck事件
if(clckEventArray.count>=2)
{
//判断点击事件是否正确发送
NSDictionary *chevent=[clckEventArray objectAtIndex:clckEventArray.count-1];
NSDictionary *clkchr=[NoburPoMeaProCheck ClckEventCheck:chevent];
//NSLog(@"检查结果:%@",clkchr);
XCTAssertEqual(clkchr[@"KeysCheck"][@"chres"], @"Passed");
NSLog(@"点击对话框按钮检测clck事件测试通过---Passed!");
}
别的
{
NSLog(@"对话框按钮被点击,clck事件测试失败:%@!",clckEventArray);
XCTAssertEqual(1, 0);
}
}
由于我们主要测试SDK的功能,所以测试Demo是我们自己设计的,主要涵盖了各种UI元素和事件。它的业务逻辑比大多数业务类应用都简单,没有特别的介绍。
这里介绍断言的设计。上一篇提到,我们自动化测试的重点是数据采集规则是否正确,不关心数据的存储和传输。
SDK在采集数据时,先将所有的事件加入到一个队列中,然后再保存到DB中,所以在进行测试的时候,只需要监听事件队列,就可以保存和检索需要的事件根据需要在受监视的事件队列中断言。点击事件发送的数据结构大致如下:
验证事件数据,首先要保证字段完整,每个字段不为空,即数据模式正确;其次,根据需要验证事件的具体字段,例如点击事件的类型t应该是clck。这些检查被封装在一个单独的Check方法中,如果检查通过,该方法返回Passed。
这里通过ClckEventCheck方法完成具体的业务验证。
执行测试用例
主要介绍如何通过命令行执行测试。
安装Command Line Tools(命令行工具包),App Store安装Xcode默认不会安装Command Line Tools,可以在命令行输入以下命令单独安装。
xcode-select --install
在使用命令行执行测试之前,还需要将项目设置为 Shared。打开产品→方案→管理方案,勾选项目是否共享,如果不是,勾选后面的复选框进行共享。
从命令行执行所有测试用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
执行单个用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-only-testing:GIOAutoTests/ClckEventsTest/test7DialogBtnCheck \
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
xcodebuild 的更多使用请参考其使用说明。
人 xcodebuild
美化检测报告
xcodebuild 的输出读起来不是很直观。使用xcpretty可以解决这个问题,同时也可以完成测试报告的生成。
xcpretty 是一种高速灵活的 xcodebuild 输出格式化工具。其用法如下:
# 从命令行安装 xcpretty
gem 安装 xcpretty
命令行执行
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11' \
| xcpretty --report html
生成的测试报告如下:
默认输出 html 报告在 build/reports/tests.html
5. 覆盖率统计
在进行自动化测试时,我们通常希望获得测试覆盖率报告来衡量自动化测试的覆盖率。由于 KIF 是直接基于 XCTest 实现的,因此您可以轻松使用 Xcode 自带的覆盖率统计工具。设置如下:
Product → Scheme → Edit Scheme, Code Coverage 将需要统计覆盖的被测程序添加到Targets中。
测试完成后,可以获得覆盖率统计报告。
6. 持续集成
自动化测试的最大价值在于它可以代替人工进行更高效、更频繁的测试。因此,要充分发挥自动化测试的价值,最理想的解决方案就是在持续集成环节加入自动化测试。每当有代码更改时,都会自动执行测试并快速反馈结果。
我们使用Jenkins来监控代码仓库的变化。当有新的commit提交时,Jenkins会自动拉取最新的代码,调用命令行执行相应的自动化测试用例,采集
相应的测试报告,并将测试结果通过钉钉机器人及时通知相关开发人员和测试人员。
当测试失败时,相关人员可以第一时间收到结果并及时解决。
7. 总结
本文以iOS平台为例,系统介绍GrowingIO数据采集SDK的主要工作原理、测试方案的设计、自动化测试框架的选择以及自动化测试的实现。希望对从事SDK测试的同学有所启发。
后面我们还会分享GrowingIO用户触摸SDK的自动化测试、Android SDK的自动化测试等相关内容。请继续关注我们。 查看全部
自动采集编写(iOS开发交流技术群:1.数据采集SDK是如何工作的)
GrowingIO 是一个基于用户行为数据的增长平台。准确采集用户行为数据是公司业务的基石。只有及时、准确、可靠的数据采集,才能支撑上层的数据分析、用户画像、运营等服务。因此,公司一直非常重视数据采集SDK(Software Development Kit)的质量保证工作。
iOS开发与通信技术群:【563513413】(跳跃),无论你是大牛还是新手,欢迎加入,分享BAT,阿里巴巴面试题,面试经验,讨论技术,让大家交流、学习、成长!
为了满足客户的各种业务和技术需求,GrowingIO提供Web、Android、iOS、Hybrid等各种平台,各种小程序(微信、支付宝、今日头条等)、微信内嵌页面,以及React Native 、Flutter、Cordova、Weex、API Cloud、AppCan等众多开发框架SDK,这无疑给SDK测试带来了巨大的挑战。
本文主要介绍GrowingIO在iOS SDK测试中的具体实践,希望能为从事iOS测试的同学提供一些参考。
1. 数据采集SDK是如何工作的?
要测试一个软件或系统,首先要了解它的业务逻辑和技术实现。接下来我们简单的看一下数据采集SDK的工作原理。
GrowingIO的数据采集SDK支持非埋点(全埋点)数据采集和埋点数据采集,满足不同业务需求。其简单的结构如下:
当用户打开App、浏览不同页面、点击不同元素(如按钮、文本框、图片)、关闭App时,非嵌入式事件采集模块会自动采集并保存用户的具体行为手机本地存储(关于非埋点数据采集的具体实现,请关注GrowigIO的后续文章分享,这里不再详述)。
埋点事件采集类似,不同的是埋点事件是由App主动调用SDK的埋点API触发的。当然,不同事件的具体数据格式是不同的。
接下来是数据发送模块,主要负责通过HTTP API向数据接收服务上报数据。
需要注意的是,为了节省用户的数据流量和电量,发送程序不是实时上报的。它会根据设备的功率、网络类型和数据量来选择发送时序,数据在发送前会被压缩。并进行混淆处理,减少传输数据量,提高数据安全性。
当然,数据发送程序也会对数据报告中的各种数据发送失败、网络异常等错误进行处理,并采用适当的重试机制。
2. 如何测试?
通过以上结构分析可以看出,数据发送模块与核心数据采集业务关系不大,非常稳定,几乎没有变化,所以我们测试的重点主要是数据采集部分,尤其是数据采集部分无埋点。
要测试数据采集,首先需要有一个收录
各种页面和元素的Demo App,然后在不同页面之间切换,操作页面上的元素或者触发一个埋藏事件,然后检查采集的事件数据是否正确。
有两种方法可以检查事件数据。一种是通过日志打印出详细的事件数据,观察日志检查;另一种是通过抓包程序获取数据并发送,然后检查。
后者一般需要配置复杂的代理工具,数据量大,还需要考虑数据的解压和解密。更难准确定位事件数据。因此,在实际测试中一般采用前者。
上图是采集数据的日志截图。通过图中的事件数据,我们发现字段较多,有些字段可读性不高,人工检查耗时较长。
另外,SDK数据采集的主要逻辑基本不变,但每次修改都要覆盖足够的回归,避免遗漏错误。
一旦缺陷在线上被遗漏,造成的损失是极其昂贵的。即使缺陷在后续版本中修复,影响也难以消除,因为移动应用程序的升级周期难以控制。
此外,GrowingIO 数据采集 SDK 兼容 iOS 8 及以上版本。需要测试系统各个版本的兼容性,测试工作量明显。
好在SDK的业务变化很少,断言内容比较机械,特别适合自动化测试。而且回归测试的工作量巨大,使用自动化测试可以大大提高生产力和质量。
3. 选择一个测试框架
工人要想做好本职工作,首先要磨砺工具,选择合适的自动化测试框架,再进行自动化测试。选择框架时需要考虑几个方面:
目前支持iOS UI自动化测试的主要框架对比如下:
考虑影响测试框架选择的几个因素。
首先,使用的语言和框架决定了测试人员的持续学习成本。iOS SDK 测试人员对Objective-C 有高度的熟悉和掌握,不需要消耗额外的学习成本。测试和开发相同的技术堆栈。
其次,根据需要不时调整测试App程序。使用开发效率高、调试方便的测试框架,可以让我们在适应新的UI变化和新的需求时,获得更小的投入产出比。
基于以上考虑,KIF框架已经展示了它的优势,而KIF使用XCTest框架,使得iOS程序的测试过程和单测一样,可以完全复用单测持续集成过程,维护持续集成的成本相对降低;此外,KIF 是一个活跃的开源测试框架,具有良好的可扩展性和快速升级。有活跃的社区来讨论和解决使用过程中遇到的问题。
鉴于以上优势,我们选择KIF作为iOS的UI自动化测试框架。
KIF的全称是Keep it Functional,是一个建立在XCTest之上的UI测试框架,通过Accessibility定位特定的控件,然后使用私有的API来操作UI。由于它是建立在 XCTest 之上的,所以你可以完美的使用 XCode 的测试相关工具。
4. 自动化测试的实现
语言和工具
建立测试环境
要将Target实现添加到现有项目中,选择File → New → Target…菜单项,在iOS → Test中选择UI Testing Bundle模板,如下图:
点击下一步进入Target选项页面,设置测试项目的相关项
完成Target设置后,点击“Finish”按钮,创建成功。
要安装 pod,请在命令行终端中输入以下命令。
sudo gem 安装 cocoapods
修改或创建项目的pod文件Podfile。
目标'GrowingIOTest'做
pod'SDCycleScrollView','~> 1.75'
pod'MJRefresh'
pod'MBProgressHUD'
结尾
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
其中,新增以下一段
目标'GIOAutoTests' 做
pod'KIF','~> 3.5.1'
结尾
在项目目录下执行如下安装命令安装对应的依赖,测试项目就准备完成了。
吊舱安装
准备待测程序,在测试Demo工程中集成待测版本的数据采集SDK。
编写测试用例
测试环境搭建好后,下一步就是编写具体的测试用例。一般测试用例的主要步骤是:
准备测试环境,执行测试步骤,测试结果,断言测试结果,报告,清理测试环境
下面以SDK的unburied元素的点击事件的自动化测试用例为例,说明自动化用例的准备。
测试用例:
启动App,模拟用户滚动屏幕找到对话框按钮,然后点击对话框按钮。弹出对话框后,点击关闭按钮,验证点击事件是否发送数据,内容是否正确。
代码:
-(无效)设置{
// 一些初始化操作
}
-(void)tearDown{
// 一些结束动作
}
-(无效)testDialogBtnCheck{
/**
功能:点击对话框按钮检测点击事件,
**/
[[viewTester usingLabel:@"UIinterface"] 点击];
//添加向下滚动操作
[tester scrollViewWithAccessibilityLabel:@"采集
View" byFractionOfSizeHorizontal:0.0f vertical:10.0f];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"LabelAttribute"] tap];
[[viewTester usingLabel:@"ShowAlert"] 点击];
[测试员waitForTimeInterval:1];
[[viewTester usingLabel:@"Cancel"] tap];
[测试员waitForTimeInterval:3];
NSArray *clckEventArray = [MockEventQueue eventsFor:@"clck"];
//是否发送clck事件
if(clckEventArray.count>=2)
{
//判断点击事件是否正确发送
NSDictionary *chevent=[clckEventArray objectAtIndex:clckEventArray.count-1];
NSDictionary *clkchr=[NoburPoMeaProCheck ClckEventCheck:chevent];
//NSLog(@"检查结果:%@",clkchr);
XCTAssertEqual(clkchr[@"KeysCheck"][@"chres"], @"Passed");
NSLog(@"点击对话框按钮检测clck事件测试通过---Passed!");
}
别的
{
NSLog(@"对话框按钮被点击,clck事件测试失败:%@!",clckEventArray);
XCTAssertEqual(1, 0);
}
}
由于我们主要测试SDK的功能,所以测试Demo是我们自己设计的,主要涵盖了各种UI元素和事件。它的业务逻辑比大多数业务类应用都简单,没有特别的介绍。
这里介绍断言的设计。上一篇提到,我们自动化测试的重点是数据采集规则是否正确,不关心数据的存储和传输。
SDK在采集数据时,先将所有的事件加入到一个队列中,然后再保存到DB中,所以在进行测试的时候,只需要监听事件队列,就可以保存和检索需要的事件根据需要在受监视的事件队列中断言。点击事件发送的数据结构大致如下:
验证事件数据,首先要保证字段完整,每个字段不为空,即数据模式正确;其次,根据需要验证事件的具体字段,例如点击事件的类型t应该是clck。这些检查被封装在一个单独的Check方法中,如果检查通过,该方法返回Passed。
这里通过ClckEventCheck方法完成具体的业务验证。
执行测试用例
主要介绍如何通过命令行执行测试。
安装Command Line Tools(命令行工具包),App Store安装Xcode默认不会安装Command Line Tools,可以在命令行输入以下命令单独安装。
xcode-select --install
在使用命令行执行测试之前,还需要将项目设置为 Shared。打开产品→方案→管理方案,勾选项目是否共享,如果不是,勾选后面的复选框进行共享。
从命令行执行所有测试用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
执行单个用例
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-only-testing:GIOAutoTests/ClckEventsTest/test7DialogBtnCheck \
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11'
xcodebuild 的更多使用请参考其使用说明。
人 xcodebuild
美化检测报告
xcodebuild 的输出读起来不是很直观。使用xcpretty可以解决这个问题,同时也可以完成测试报告的生成。
xcpretty 是一种高速灵活的 xcodebuild 输出格式化工具。其用法如下:
# 从命令行安装 xcpretty
gem 安装 xcpretty
命令行执行
xcodebuild -workspace Growing.xcworkspace \
-scheme GrowingIOTest 测试\
-sdk "iphonesimulator13.5" \
-destination platform='iOS Simulator',OS=13.5,name='iPhone 11' \
| xcpretty --report html
生成的测试报告如下:
默认输出 html 报告在 build/reports/tests.html
5. 覆盖率统计
在进行自动化测试时,我们通常希望获得测试覆盖率报告来衡量自动化测试的覆盖率。由于 KIF 是直接基于 XCTest 实现的,因此您可以轻松使用 Xcode 自带的覆盖率统计工具。设置如下:
Product → Scheme → Edit Scheme, Code Coverage 将需要统计覆盖的被测程序添加到Targets中。
测试完成后,可以获得覆盖率统计报告。
6. 持续集成
自动化测试的最大价值在于它可以代替人工进行更高效、更频繁的测试。因此,要充分发挥自动化测试的价值,最理想的解决方案就是在持续集成环节加入自动化测试。每当有代码更改时,都会自动执行测试并快速反馈结果。
我们使用Jenkins来监控代码仓库的变化。当有新的commit提交时,Jenkins会自动拉取最新的代码,调用命令行执行相应的自动化测试用例,采集
相应的测试报告,并将测试结果通过钉钉机器人及时通知相关开发人员和测试人员。
当测试失败时,相关人员可以第一时间收到结果并及时解决。
7. 总结
本文以iOS平台为例,系统介绍GrowingIO数据采集SDK的主要工作原理、测试方案的设计、自动化测试框架的选择以及自动化测试的实现。希望对从事SDK测试的同学有所启发。
后面我们还会分享GrowingIO用户触摸SDK的自动化测试、Android SDK的自动化测试等相关内容。请继续关注我们。
自动采集编写(网页采集是什么,又是如何采集的呢?(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-27 20:08
在网页设计中,什么是网页采集
以及它是如何采集
的?
网页采集
作为政府网站网页在线归档的首要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集
的第一步是确定采集
对象。政府网页档案中存储的信息采集对象为域名带有“”的政府网站。为了保证政府网页的采集质量,需要对目标网站进行评估,信息量大。, 选择原创
信息多、更新频繁的政府网站作为采集对象。确定要采集的目标政府网站后,
完整性采集和选择性采集是目前比较常用的网络资源采集方式。他们有自己的优点和缺点。为了弥补各自的不足,可以通过结合两者优点的混合采集方式来补充两种采集方式的优点。,在采集
入选政府网站所有网页完整性的同时,通过人工干预筛选网页内容,有选择地对具有证据价值、历史价值、研究价值的重要网页进行深度挖掘。分级频繁采集,既兼顾了政府网页采集的广度,又兼顾了重要网页的采集深度。
网页的采集和抓取最终需要依赖相应的网络爬虫工具。目前,有很多用于网页归档的爬虫工具。其中Heritrix和HTTrack是最常用的。这些工具可用于定位政府网站页面。自动批量在线采集。 查看全部
自动采集编写(网页采集是什么,又是如何采集的呢?(图))
在网页设计中,什么是网页采集
以及它是如何采集
的?
网页采集
作为政府网站网页在线归档的首要环节,就是利用相关工具,按照既定的频率和方法,及时筛选出值得保存的政府网页内容。网页采集
的第一步是确定采集
对象。政府网页档案中存储的信息采集对象为域名带有“”的政府网站。为了保证政府网页的采集质量,需要对目标网站进行评估,信息量大。, 选择原创
信息多、更新频繁的政府网站作为采集对象。确定要采集的目标政府网站后,
完整性采集和选择性采集是目前比较常用的网络资源采集方式。他们有自己的优点和缺点。为了弥补各自的不足,可以通过结合两者优点的混合采集方式来补充两种采集方式的优点。,在采集
入选政府网站所有网页完整性的同时,通过人工干预筛选网页内容,有选择地对具有证据价值、历史价值、研究价值的重要网页进行深度挖掘。分级频繁采集,既兼顾了政府网页采集的广度,又兼顾了重要网页的采集深度。
网页的采集和抓取最终需要依赖相应的网络爬虫工具。目前,有很多用于网页归档的爬虫工具。其中Heritrix和HTTrack是最常用的。这些工具可用于定位政府网站页面。自动批量在线采集。
自动采集编写(浏览器页面模拟点击获取数据进行后续的数据处理方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 154 次浏览 • 2021-12-27 04:01
自动采集编写脚本是有一些小学生小老板的,不过真正的全自动采集是需要程序辅助配合的,如采集网页中的alt+tab标签,通过发php代码请求或者asp代码请求来达到自动化查询操作而已。
浏览器页面模拟点击获取数据进行后续的数据处理
你所要做的,即无需翻墙,地址全部被爬取了,只需要将他们的url传入sae就可以调用阿里的接口获取商品信息了。
我有开发过一个,地址是:-trade/,一个简单的、基于python的商品采集器,包括如下功能:1.采集网页商品信息2.采集京东、、知乎等平台商品信息3.抓取处理京东、、知乎等平台用户发布商品信息4.抓取商品详情页采集方法:先用python做出一个标准的采集url,然后让aba插件抓取标准的采集url,写一个爬虫程序,如下,编写程序大概一两个小时,后端爬虫程序两三天,然后请求aba爬虫的html页面,完成所有商品信息的抓取,返回实时页面,把抓取好的html发布到,或者在网站上安装上selenium和requests模块,用这两个模块访问抓取好的商品,用浏览器的自动抓取脚本功能,用浏览器按照cookie找商品id抓取商品信息,将抓取完成的数据返回,然后用aba的javascript页面获取,再用爬虫程序进行后续的商品信息获取和后续的页面处理。
补充下以上程序实现流程:商品采集完成后我会检查javascript页面和页面请求是否加载正常(加载正常或者出错我会告诉大家这个必须出了一定的bug才会这样),并且页面数据返回是否正确,如果返回正确我会保存一个log,这样就能随时把任何需要抓取商品信息的请求都通过code把抓取的商品信息发布到了aba的后端服务器,然后从aba后端服务器抓取数据或者对数据进行处理,对数据做出页面页面显示处理等。
如果从这个方法实现的话,前端抓取只需要安装javascript模块,后端服务器配置网页编程对象即可。如果大家觉得我写的程序不错的话,请点个赞,谢谢大家!。 查看全部
自动采集编写(浏览器页面模拟点击获取数据进行后续的数据处理方法)
自动采集编写脚本是有一些小学生小老板的,不过真正的全自动采集是需要程序辅助配合的,如采集网页中的alt+tab标签,通过发php代码请求或者asp代码请求来达到自动化查询操作而已。
浏览器页面模拟点击获取数据进行后续的数据处理
你所要做的,即无需翻墙,地址全部被爬取了,只需要将他们的url传入sae就可以调用阿里的接口获取商品信息了。
我有开发过一个,地址是:-trade/,一个简单的、基于python的商品采集器,包括如下功能:1.采集网页商品信息2.采集京东、、知乎等平台商品信息3.抓取处理京东、、知乎等平台用户发布商品信息4.抓取商品详情页采集方法:先用python做出一个标准的采集url,然后让aba插件抓取标准的采集url,写一个爬虫程序,如下,编写程序大概一两个小时,后端爬虫程序两三天,然后请求aba爬虫的html页面,完成所有商品信息的抓取,返回实时页面,把抓取好的html发布到,或者在网站上安装上selenium和requests模块,用这两个模块访问抓取好的商品,用浏览器的自动抓取脚本功能,用浏览器按照cookie找商品id抓取商品信息,将抓取完成的数据返回,然后用aba的javascript页面获取,再用爬虫程序进行后续的商品信息获取和后续的页面处理。
补充下以上程序实现流程:商品采集完成后我会检查javascript页面和页面请求是否加载正常(加载正常或者出错我会告诉大家这个必须出了一定的bug才会这样),并且页面数据返回是否正确,如果返回正确我会保存一个log,这样就能随时把任何需要抓取商品信息的请求都通过code把抓取的商品信息发布到了aba的后端服务器,然后从aba后端服务器抓取数据或者对数据进行处理,对数据做出页面页面显示处理等。
如果从这个方法实现的话,前端抓取只需要安装javascript模块,后端服务器配置网页编程对象即可。如果大家觉得我写的程序不错的话,请点个赞,谢谢大家!。
自动采集编写(纯Qt编写,支持任意Qt版本+任意编译器+枚举)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-25 14:19
一、前言
数据库用作数据源,并在许多组态软件中使用。指定数据库类型,填写数据库连接信息,指定对应的数据库表和字段,以及采集间隔。程序根据采集间隔自动采集数据库数据并绑定到界面控件分配显示即可。使用数据库作为数据源有一个非常大的好处,不需要写额外的通讯代码,与对方的语言或平台无关,也不会出现不规范、不规范等争吵不准确的通信协议导致不正确的分析。情况是它支持任何语言和平台。毕竟有数据库作为中间载体过渡,
体验地址:提取码:877p 文件:可执行文件.zip
二、 实现的功能自动加载插件文件中的所有控件生成列表,默认自带120多个控件。拖到画布上自动生成对应的控件,所见即所得。在右侧的中文属性栏上,更改相应的属性会立即应用到相应的选中控件上,直观简洁,非常适合小白使用。独创的属性列文本翻译映射机制,效率极高,可以非常方便的扩展其他语言的属性列。所有控件的属性都会自动提取出来并显示在右侧的属性栏中,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。可以将当前画布的所有控件配置信息导出到一个xml文件中。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。可以通过拉动滑动条、勾选模拟数据复选框、输入文本框三种方式生成数据并应用所有控件。控件支持八个方向调节大小,自适应任意分辨率,键盘可上下左右微调位置。以三种方式设置数据:串口采集、网络采集、数据库采集。代码极其简洁,注释也很详细,可作为配置原型,自行扩展更多功能。纯Qt编写,支持任意Qt版本+任意编译器+任意系统。三、效果图
四、核心代码
void frmData::initServer()
{
//实例化串口类,绑定信号槽
com = new QextSerialPort(QextSerialPort::EventDriven, this);
connect(com, SIGNAL(readyRead()), this, SLOT(readDataCom()));
//实例化网络通信客户端类,绑定信号槽
tcpClient = new QTcpSocket(this);
connect(tcpClient, SIGNAL(readyRead()), this, SLOT(readDataClient()));
//实例化网络通信服务端类,绑定信号槽
tcpSocket = NULL;
tcpServer = new QTcpServer(this);
connect(tcpServer, SIGNAL(newConnection()), this, SLOT(newConnection()));
//开启定时器读取数据库采集数据
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(readDataDb()));
timer->setInterval(1000);
}
void frmData::on_btnOpenDb_clicked()
{
if (ui->btnOpenDb->text() == "打开") {
if (App::DbType == "sqlite") {
//先检查数据库文件是否存在
QString dbPath = qApp->applicationDirPath() + "/" + App::DbPath;
QFile file(dbPath);
if (file.size() == 0) {
return;
}
dbConn = QSqlDatabase::addDatabase("QSQLITE");
dbConn.setDatabaseName(dbPath);
} else if (App::DbType == "mysql") {
//先检查数据库服务器IP是否通,不检查直接连接,不存在的IP会卡很久
QTcpSocket socket;
socket.connectToHost(App::DbPath, App::DbPort);
if (!socket.waitForConnected(2000)) {
return;
} else {
socket.disconnectFromHost();
}
dbConn = QSqlDatabase::addDatabase("QMYSQL");
dbConn.setHostName(App::DbPath);
dbConn.setPort(App::DbPort);
dbConn.setDatabaseName(App::DbName);
dbConn.setUserName(App::DbUser);
dbConn.setPassword(App::DbPwd);
} else {
//暂未支持其他数据库,可以自行加入
return;
}
bool ok = dbConn.open();
if (ok) {
setEnable(ui->btnOpenDb, false);
ui->btnOpenDb->setText("关闭");
timer->start();
}
} else {
if (dbConn.isOpen()) {
dbConn.close();
}
setEnable(ui->btnOpenDb, true);
ui->btnOpenDb->setText("打开");
timer->stop();
}
}
void frmData::readDataDb()
{
QString sql = QString("select %1 from %2").arg(App::DbColumn).arg(App::DbTable);
QSqlQuery query;
if (query.exec(sql)) {
if (query.next()) {
double value = query.value(0).toDouble();
ui->txtValue->setText(QString::number(value));
append(4, QString("当前值: %1").arg(value));
}
}
}
五、控件引入了150多个漂亮的控件,涵盖了各种仪表盘、进度条、进度球、指南针、图表、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类可以独立成一个单独的控件,零耦合,每个控件都有一个头文件和一个实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,用更少的代码。qwt 的控制类是相互关联且高度耦合的。如果要使用其中一种控件,则必须收录
所有代码。全部用纯Qt编写,QWidget+QPainter绘图,支持从Qt4.6到Qt5.12的任何Qt版本,支持mingw、msvc、gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,和内置控件一样使用,效果最只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。
一些控件提供多种样式可供选择,以及多种指示器样式可供选择。所有控件都适应窗体的拉伸和变化。集成自定义控件属性设计器,支持拖动设计,所见即所得,支持导入导出xml格式。自带activex控件演示,所有控件都可以直接在ie浏览器中运行。集成fontawesome图形字体+阿里巴巴iconfont采集
的数百种图形字体,享受图形字体的乐趣。所有控件最后生成一个动态库文件(dll等),可以直接集成到qtcreator中进行拖动设计使用。已经有qml版本了,如果用户需求大,以后会考虑pyqt版本。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 查看全部
自动采集编写(纯Qt编写,支持任意Qt版本+任意编译器+枚举)
一、前言
数据库用作数据源,并在许多组态软件中使用。指定数据库类型,填写数据库连接信息,指定对应的数据库表和字段,以及采集间隔。程序根据采集间隔自动采集数据库数据并绑定到界面控件分配显示即可。使用数据库作为数据源有一个非常大的好处,不需要写额外的通讯代码,与对方的语言或平台无关,也不会出现不规范、不规范等争吵不准确的通信协议导致不正确的分析。情况是它支持任何语言和平台。毕竟有数据库作为中间载体过渡,
体验地址:提取码:877p 文件:可执行文件.zip
二、 实现的功能自动加载插件文件中的所有控件生成列表,默认自带120多个控件。拖到画布上自动生成对应的控件,所见即所得。在右侧的中文属性栏上,更改相应的属性会立即应用到相应的选中控件上,直观简洁,非常适合小白使用。独创的属性列文本翻译映射机制,效率极高,可以非常方便的扩展其他语言的属性列。所有控件的属性都会自动提取出来并显示在右侧的属性栏中,包括枚举值下拉框。支持手动选择插件文件和外部导入插件文件。可以将当前画布的所有控件配置信息导出到一个xml文件中。可以手动选择xml文件打开控件布局,根据xml文件自动加载控件。可以通过拉动滑动条、勾选模拟数据复选框、输入文本框三种方式生成数据并应用所有控件。控件支持八个方向调节大小,自适应任意分辨率,键盘可上下左右微调位置。以三种方式设置数据:串口采集、网络采集、数据库采集。代码极其简洁,注释也很详细,可作为配置原型,自行扩展更多功能。纯Qt编写,支持任意Qt版本+任意编译器+任意系统。三、效果图
四、核心代码
void frmData::initServer()
{
//实例化串口类,绑定信号槽
com = new QextSerialPort(QextSerialPort::EventDriven, this);
connect(com, SIGNAL(readyRead()), this, SLOT(readDataCom()));
//实例化网络通信客户端类,绑定信号槽
tcpClient = new QTcpSocket(this);
connect(tcpClient, SIGNAL(readyRead()), this, SLOT(readDataClient()));
//实例化网络通信服务端类,绑定信号槽
tcpSocket = NULL;
tcpServer = new QTcpServer(this);
connect(tcpServer, SIGNAL(newConnection()), this, SLOT(newConnection()));
//开启定时器读取数据库采集数据
timer = new QTimer(this);
connect(timer, SIGNAL(timeout()), this, SLOT(readDataDb()));
timer->setInterval(1000);
}
void frmData::on_btnOpenDb_clicked()
{
if (ui->btnOpenDb->text() == "打开") {
if (App::DbType == "sqlite") {
//先检查数据库文件是否存在
QString dbPath = qApp->applicationDirPath() + "/" + App::DbPath;
QFile file(dbPath);
if (file.size() == 0) {
return;
}
dbConn = QSqlDatabase::addDatabase("QSQLITE");
dbConn.setDatabaseName(dbPath);
} else if (App::DbType == "mysql") {
//先检查数据库服务器IP是否通,不检查直接连接,不存在的IP会卡很久
QTcpSocket socket;
socket.connectToHost(App::DbPath, App::DbPort);
if (!socket.waitForConnected(2000)) {
return;
} else {
socket.disconnectFromHost();
}
dbConn = QSqlDatabase::addDatabase("QMYSQL");
dbConn.setHostName(App::DbPath);
dbConn.setPort(App::DbPort);
dbConn.setDatabaseName(App::DbName);
dbConn.setUserName(App::DbUser);
dbConn.setPassword(App::DbPwd);
} else {
//暂未支持其他数据库,可以自行加入
return;
}
bool ok = dbConn.open();
if (ok) {
setEnable(ui->btnOpenDb, false);
ui->btnOpenDb->setText("关闭");
timer->start();
}
} else {
if (dbConn.isOpen()) {
dbConn.close();
}
setEnable(ui->btnOpenDb, true);
ui->btnOpenDb->setText("打开");
timer->stop();
}
}
void frmData::readDataDb()
{
QString sql = QString("select %1 from %2").arg(App::DbColumn).arg(App::DbTable);
QSqlQuery query;
if (query.exec(sql)) {
if (query.next()) {
double value = query.value(0).toDouble();
ui->txtValue->setText(QString::number(value));
append(4, QString("当前值: %1").arg(value));
}
}
}
五、控件引入了150多个漂亮的控件,涵盖了各种仪表盘、进度条、进度球、指南针、图表、标尺、温度计、导航条、导航条、flatui、高亮按钮、滑动选择器、农历等。远远超过qwt集成的控件数量。每个类可以独立成一个单独的控件,零耦合,每个控件都有一个头文件和一个实现文件,不依赖其他文件,方便单个控件以源代码的形式集成到项目中,用更少的代码。qwt 的控制类是相互关联且高度耦合的。如果要使用其中一种控件,则必须收录
所有代码。全部用纯Qt编写,QWidget+QPainter绘图,支持从Qt4.6到Qt5.12的任何Qt版本,支持mingw、msvc、gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,和内置控件一样使用,效果最只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。gcc等编译器,支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置一个属性很少,非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。支持windows+linux+mac+embedded linux等任何操作系统,无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,就是非常方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。无乱码,可直接集成到Qt Creator中,像内置控件一样使用,大部分效果只需要设置几个属性,极其方便。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。这是非常方便的。每个控件都有对应的单独的DEMO,其中收录
控件源代码,方便参考和使用。它还提供了一个供所有控件使用的集成演示。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。每个控件的源代码都有详细的中文注释,并按照统一的设计规范编写,方便学习自定义控件的编写。每个控件的默认配色和demo的配色都很漂亮。超过130个可见控件和6个不可见控件。
一些控件提供多种样式可供选择,以及多种指示器样式可供选择。所有控件都适应窗体的拉伸和变化。集成自定义控件属性设计器,支持拖动设计,所见即所得,支持导入导出xml格式。自带activex控件演示,所有控件都可以直接在ie浏览器中运行。集成fontawesome图形字体+阿里巴巴iconfont采集
的数百种图形字体,享受图形字体的乐趣。所有控件最后生成一个动态库文件(dll等),可以直接集成到qtcreator中进行拖动设计使用。已经有qml版本了,如果用户需求大,以后会考虑pyqt版本。自定义控件插件开放使用动态库(永久免费),没有任何后门和限制,请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 请放心使用。目前提供了26个版本的dll,包括qt5.12.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p @2.3 msvc2017 32+64 mingw 32+64。不定期添加控件和改进控件,不定期更新SDK。欢迎任何建议,谢谢!Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p Qt入门书籍推荐霍亚非的《Qt Creator快速入门》和《Qt5编程入门》,Qt进阶书籍推荐官方《C++ GUI Qt4编程》。强烈推荐程序员修养与规划系列《大话程序员》、《程序员成长教程》、《程序员的烦恼》,受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p 这将受益匪浅,受益终生!SDK下载链接:提取码:877p
自动采集编写(2.工具介绍与设计工具实现的基本思想是逐个扫描指定路径)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-22 18:09
1.背景
在性能测试的过程中,往往需要对服务器的性能进行监控,并记录这些性能指标的结果。无论是数据库服务器还是云下的应用服务器,都可以通过nmon进行监控,设置点间隔和点数,将性能指标保存成nmon文件,使用Excel插件等工具Nmon_Analyzer、Java GUI工具nmon visualizer等。读取nmon文件的内容,分析采集的结果。但是,当监控的服务器数量较多时,性能指标导致多个 nmon 文件依次排列会很耗时。同时,手动读取和记录数据也可能因记录错误而导致意外错误。因此,我们可以尝试使用我们熟悉的编程语言,
2. 工具介绍与设计
该工具实现的基本思想是将指定路径下的nmon文件逐一扫描,根据nmon文件的内部格式提取目标性能指标数据,然后对提取的数据进行处理,得到结果,并自动将结果保存到新一代结果在一个 Excel 文件中。为了更直观的获取用户输入的nmon文件路径和结果的保存路径,我们可以编写GUI界面,使用界面上的文本输入框获取用户的输入,使用界面上的按钮触发这个 采集 事件。
图1 工具设计流程图
3. 工具实现
(1)导入需要的模块
由于我们的工具收录对文件和路径的操作,这需要由 os 模块来实现。逐行读取nmon文件内容时,使用codecs提供的open方法指定打开文件的语言编码,读取时会自动转换为内部unicode。re 模块是 Python 中用于匹配字符串的唯一模块。它使用正则表达式对字符串进行模糊匹配,并提取出您需要的字符串部分。使用该模块,您可以实现逐行扫描进行模糊匹配,以找到 CPU 和内存之间的相关性。表现。xlwt 库的作用是将数据写入 Excel 表格。Tkinter 是 Python 的标准 GUI 库。导入 Tkinter 模块后,您可以使用控件快速创建 GUI 应用程序。特金特。
图2 Code-导入需要的模块
(2)窗口的实现
使用Tkinter模块创建窗口,插入输入框控件,获取用户输入的路径信息。输入框的内容存放在StringVar中,按钮Button设置为绑定鼠标点击事件。
图3 窗口代码实现
图3 窗口实现图
(3)写事件代码-一个函数,求平均CPU利用率
不同版本的 nmon 文件的内部格式略有不同。因此,在编写程序时,首先要了解目标版本的内部结构,以确定字符串模式匹配时需要使用nmon文件中性能指标相关内容的哪些特征。
为了计算平均值,您需要获取 nmon 文件中记录的点数。通过了解 nmon 文件中的 AAA 参数是关于操作系统和 nmon 本身的一些信息,您可以找到将其提取的行。
图4 代码-获取点数和点间隔
CPU_ALL 参数是所有 CPU 的概览,显示所有 CPU 的平均占用率。将记录的CPU占用率一一取出存储在数组中,并计算数组元素的平均值,即整个监控期间CPU的平均使用率。该函数将返回值。
图 5 Code-Find 平均 CPU 使用率
(4)写事件代码-一个函数来求平均内存使用
同理,内存使用情况是通过MEM参数获取的。与CPU情况不同的是,该参数行收录多个内存相关的指标。在监控性能指标时,我们经常使用公式1来计算内存使用情况,所以需要从MEM中获取内存使用情况,从参数中提取相关指标,包括memtotal、memfree、cached、buffers,根据公式计算,返回内存使用情况。
公式1 常用的内存占用计算公式
图 6 Code-Seeking 内存使用
(5)写事件代码-鼠标点击事件
该事件用于绑定界面上的按钮,实现按钮点击时的一系列操作:从输入框中取出nmon文件路径和目标保存路径,生成Excel文件并创建工作表,并写入进入默认的header Contents,调用获取平均CPU使用率函数和获取平均内存占用率函数,将返回值写入Excel文件并保存。
图7 Code-鼠标点击事件
4. 总结
该工具是一种基于Python语言的简单实践,可以自动批量提取nmon文件中的性能指标结果,并可以利用这个思路根据需要修改或扩展该工具的功能。使用此工具自动获取性能结果采集相比手动读取值节省了时间,并避免了记录错误时的意外错误,有助于提高准确性和测试效率。 查看全部
自动采集编写(2.工具介绍与设计工具实现的基本思想是逐个扫描指定路径)
1.背景
在性能测试的过程中,往往需要对服务器的性能进行监控,并记录这些性能指标的结果。无论是数据库服务器还是云下的应用服务器,都可以通过nmon进行监控,设置点间隔和点数,将性能指标保存成nmon文件,使用Excel插件等工具Nmon_Analyzer、Java GUI工具nmon visualizer等。读取nmon文件的内容,分析采集的结果。但是,当监控的服务器数量较多时,性能指标导致多个 nmon 文件依次排列会很耗时。同时,手动读取和记录数据也可能因记录错误而导致意外错误。因此,我们可以尝试使用我们熟悉的编程语言,
2. 工具介绍与设计
该工具实现的基本思想是将指定路径下的nmon文件逐一扫描,根据nmon文件的内部格式提取目标性能指标数据,然后对提取的数据进行处理,得到结果,并自动将结果保存到新一代结果在一个 Excel 文件中。为了更直观的获取用户输入的nmon文件路径和结果的保存路径,我们可以编写GUI界面,使用界面上的文本输入框获取用户的输入,使用界面上的按钮触发这个 采集 事件。
图1 工具设计流程图
3. 工具实现
(1)导入需要的模块
由于我们的工具收录对文件和路径的操作,这需要由 os 模块来实现。逐行读取nmon文件内容时,使用codecs提供的open方法指定打开文件的语言编码,读取时会自动转换为内部unicode。re 模块是 Python 中用于匹配字符串的唯一模块。它使用正则表达式对字符串进行模糊匹配,并提取出您需要的字符串部分。使用该模块,您可以实现逐行扫描进行模糊匹配,以找到 CPU 和内存之间的相关性。表现。xlwt 库的作用是将数据写入 Excel 表格。Tkinter 是 Python 的标准 GUI 库。导入 Tkinter 模块后,您可以使用控件快速创建 GUI 应用程序。特金特。
图2 Code-导入需要的模块
(2)窗口的实现
使用Tkinter模块创建窗口,插入输入框控件,获取用户输入的路径信息。输入框的内容存放在StringVar中,按钮Button设置为绑定鼠标点击事件。
图3 窗口代码实现
图3 窗口实现图
(3)写事件代码-一个函数,求平均CPU利用率
不同版本的 nmon 文件的内部格式略有不同。因此,在编写程序时,首先要了解目标版本的内部结构,以确定字符串模式匹配时需要使用nmon文件中性能指标相关内容的哪些特征。
为了计算平均值,您需要获取 nmon 文件中记录的点数。通过了解 nmon 文件中的 AAA 参数是关于操作系统和 nmon 本身的一些信息,您可以找到将其提取的行。
图4 代码-获取点数和点间隔
CPU_ALL 参数是所有 CPU 的概览,显示所有 CPU 的平均占用率。将记录的CPU占用率一一取出存储在数组中,并计算数组元素的平均值,即整个监控期间CPU的平均使用率。该函数将返回值。
图 5 Code-Find 平均 CPU 使用率
(4)写事件代码-一个函数来求平均内存使用
同理,内存使用情况是通过MEM参数获取的。与CPU情况不同的是,该参数行收录多个内存相关的指标。在监控性能指标时,我们经常使用公式1来计算内存使用情况,所以需要从MEM中获取内存使用情况,从参数中提取相关指标,包括memtotal、memfree、cached、buffers,根据公式计算,返回内存使用情况。
公式1 常用的内存占用计算公式
图 6 Code-Seeking 内存使用
(5)写事件代码-鼠标点击事件
该事件用于绑定界面上的按钮,实现按钮点击时的一系列操作:从输入框中取出nmon文件路径和目标保存路径,生成Excel文件并创建工作表,并写入进入默认的header Contents,调用获取平均CPU使用率函数和获取平均内存占用率函数,将返回值写入Excel文件并保存。
图7 Code-鼠标点击事件
4. 总结
该工具是一种基于Python语言的简单实践,可以自动批量提取nmon文件中的性能指标结果,并可以利用这个思路根据需要修改或扩展该工具的功能。使用此工具自动获取性能结果采集相比手动读取值节省了时间,并避免了记录错误时的意外错误,有助于提高准确性和测试效率。
自动采集编写(优采云V8.2.0版新增边点击边采集示例: )
采集交流 • 优采云 发表了文章 • 0 个评论 • 234 次浏览 • 2021-12-17 20:09
)
网站有很多,点击【加载更多】或【显示20多】按钮可以翻页。搜狗微信首页和其他页面都是这种情况。
对于此类网页,新版优采云V8.2.0 增加了【点击和点击采集】的功能,您可以点击【加载更多】 button] 加载一个新数据,edge 采集 每次加载新数据。
示例:设置为5次点击,然后1次点击后,采集第一次点击后加载的数据,第二次继续点击,采集第二次点击后加载的数据... ...最多20次点击,采集 20次点击后加载的数据。
使用智能识别和自行配置的采集规则,可以实现【点击后采集】。具体设置方法如下。
一、使用智能识别实现【点击和点击采集】
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。
打开网页后,选择【智能识别网页】,等待智能识别完成。
智能识别结束后,可以看到它自动识别了页面的【滚动】、【加载更多按钮】和【列表数据】。
鼠标移到图片上右击,选择【在新标签页中打开图片】,即可查看高清大图
Step2:点击【生成采集设置】自动生成对应的采集流程,方便用户编辑修改。
Step3:如图所示,通过流程中生成的【循环加载更多按钮】+嵌入【循环列表】的步骤,可以边点击数据边点击。
但是这个过程还是存在一些问题,需要我们手动修改。
①注意观察页面,这个页面点击5次到最后,100条数据全部加载完毕,所以我们设置翻页次数为5次。进入【循环加载更多按钮】设置页面,发现优采云已经为我们自动设置好了。
②再看【翻页】这一步,因为这个网页不需要翻页,所以这一步是多余的,需要删除。注意在删除【滚动页面】之前需要先删除【循环列表】,以免误删。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
二、自行配置采集 任务实现【点击采集】
如果不使用智能识别,如何自己配置采集任务实现【点击侧采集】?下面是详细的解释。
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。关闭智能识别,我们自己配置采集任务。
Step2:根据需求配置提取数据。在示例中,我们提取列表数据。提取方法请参考采集列表数据教程。
Step3:提取列表数据,过程中会自动生成【循环列表】步骤。自动生成的【循环列表】不能收录所有 100 个 文章 列表。我们需要修改XPath。
进入【循环列表】设置页面,修改XPath为:.//*[@id='pc_0_d']//li.
Step4:找到并选择【加载更多内容】按钮,在弹出的操作提示框中选择【循环点击单个元素】,自动生成【循环翻页】步骤。
【循环翻页】在步骤中嵌入了【循环列表】的步骤,方便我们点击采集数据。
再次注意页面,这个页面会被点击5次到最后,100条数据全部加载,所以我们设置翻页次数为5次。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
查看全部
自动采集编写(优采云V8.2.0版新增边点击边采集示例:
)
网站有很多,点击【加载更多】或【显示20多】按钮可以翻页。搜狗微信首页和其他页面都是这种情况。
对于此类网页,新版优采云V8.2.0 增加了【点击和点击采集】的功能,您可以点击【加载更多】 button] 加载一个新数据,edge 采集 每次加载新数据。
示例:设置为5次点击,然后1次点击后,采集第一次点击后加载的数据,第二次继续点击,采集第二次点击后加载的数据... ...最多20次点击,采集 20次点击后加载的数据。
使用智能识别和自行配置的采集规则,可以实现【点击后采集】。具体设置方法如下。
一、使用智能识别实现【点击和点击采集】
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。
打开网页后,选择【智能识别网页】,等待智能识别完成。
智能识别结束后,可以看到它自动识别了页面的【滚动】、【加载更多按钮】和【列表数据】。
鼠标移到图片上右击,选择【在新标签页中打开图片】,即可查看高清大图
Step2:点击【生成采集设置】自动生成对应的采集流程,方便用户编辑修改。
Step3:如图所示,通过流程中生成的【循环加载更多按钮】+嵌入【循环列表】的步骤,可以边点击数据边点击。
但是这个过程还是存在一些问题,需要我们手动修改。
①注意观察页面,这个页面点击5次到最后,100条数据全部加载完毕,所以我们设置翻页次数为5次。进入【循环加载更多按钮】设置页面,发现优采云已经为我们自动设置好了。
②再看【翻页】这一步,因为这个网页不需要翻页,所以这一步是多余的,需要删除。注意在删除【滚动页面】之前需要先删除【循环列表】,以免误删。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
二、自行配置采集 任务实现【点击采集】
如果不使用智能识别,如何自己配置采集任务实现【点击侧采集】?下面是详细的解释。
示例网址:
Step1:在首页输入框中输入目标网址,点击【开始采集】,优采云会自动打开网页。关闭智能识别,我们自己配置采集任务。
Step2:根据需求配置提取数据。在示例中,我们提取列表数据。提取方法请参考采集列表数据教程。
Step3:提取列表数据,过程中会自动生成【循环列表】步骤。自动生成的【循环列表】不能收录所有 100 个 文章 列表。我们需要修改XPath。
进入【循环列表】设置页面,修改XPath为:.//*[@id='pc_0_d']//li.
Step4:找到并选择【加载更多内容】按钮,在弹出的操作提示框中选择【循环点击单个元素】,自动生成【循环翻页】步骤。
【循环翻页】在步骤中嵌入了【循环列表】的步骤,方便我们点击采集数据。
再次注意页面,这个页面会被点击5次到最后,100条数据全部加载,所以我们设置翻页次数为5次。
Step4:点击左上角的【采集】,选择【Start Local采集】,优采云会自动启动采集数据。
注意观察页面:优采云点击一次,采集第一次点击加载的数据,第二次继续点击,采集第二次点击加载的数据... ...直到数据全部采集 完成。
自动采集编写( 如何抓取远程网页?远程HTML的二进制代码主要语句)
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-12-16 23:50
如何抓取远程网页?远程HTML的二进制代码主要语句)
如何用asp编写网站data采集程序?
引用:如果你想自动从网上采集 数据写入本地数据库,那么看看本文介绍的方法。为了解决这个问题,作者花了三天时间,终于完成了。下面是完整的ASP代码,可以让你随意存储来自互联网的数据采集,非常实用!
一、网站数据采集方法
目前网站data采集的方法主要有两种,一种是使用现成的软件,另一种是自己编写采集程序。
1、使用现成的软件
很多软件(如网络信息采集大师、BK通用信息采集系统等)都可以采集在线数据,只要你去百度、谷歌、“数据< @采集搜索关键词的“软件”即可找到,现在这类软件很多,都是用C、DEPHI或VB编写的,一般都提供免费版本给你下载试试。虽然他们也可以采集在线数据,但是采集之后的数据要么不能存入数据库,要么只能存入前10项;如果你想突破这个限制,你现在必须花钱购买官方数据版。笔者尝试了所有数据采集软件,发现都一样!
2、编写自己的ASP采集程序
由于现成的软件不能免费使用,为了省钱,只能自己写ASP网站data采集程序!以下是程序的代码,如果你想要免费的采集网站数据,直接运行即可。
二、网站数据采集进程
编写ASP网站data采集程序,首先需要抓取远程网页的源码。微软serverXMLHTTP组件可以帮你抓取远程页面的二进制代码,然后将代码转换成字符,进行拦截和替换处理,就可以得到你想要的数据;最后,显示数据或将其写入数据库。采集工作完成。
三、如何抓取远程网页?
抓取远程HTML的二进制代码主要语句如下: 查看全部
自动采集编写(
如何抓取远程网页?远程HTML的二进制代码主要语句)
如何用asp编写网站data采集程序?
引用:如果你想自动从网上采集 数据写入本地数据库,那么看看本文介绍的方法。为了解决这个问题,作者花了三天时间,终于完成了。下面是完整的ASP代码,可以让你随意存储来自互联网的数据采集,非常实用!
一、网站数据采集方法
目前网站data采集的方法主要有两种,一种是使用现成的软件,另一种是自己编写采集程序。
1、使用现成的软件
很多软件(如网络信息采集大师、BK通用信息采集系统等)都可以采集在线数据,只要你去百度、谷歌、“数据< @采集搜索关键词的“软件”即可找到,现在这类软件很多,都是用C、DEPHI或VB编写的,一般都提供免费版本给你下载试试。虽然他们也可以采集在线数据,但是采集之后的数据要么不能存入数据库,要么只能存入前10项;如果你想突破这个限制,你现在必须花钱购买官方数据版。笔者尝试了所有数据采集软件,发现都一样!
2、编写自己的ASP采集程序
由于现成的软件不能免费使用,为了省钱,只能自己写ASP网站data采集程序!以下是程序的代码,如果你想要免费的采集网站数据,直接运行即可。
二、网站数据采集进程
编写ASP网站data采集程序,首先需要抓取远程网页的源码。微软serverXMLHTTP组件可以帮你抓取远程页面的二进制代码,然后将代码转换成字符,进行拦截和替换处理,就可以得到你想要的数据;最后,显示数据或将其写入数据库。采集工作完成。
三、如何抓取远程网页?
抓取远程HTML的二进制代码主要语句如下:
自动采集编写(IT圈内巡检日志(一):人工巡检的制胜法宝)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-12-15 08:09
前言:先写
如果只检查一两个库,则无需使用此方法。这种方式适用于获取大量的检测日志(比如使用脚本从服务器采集更多的服务器检测日志信息),一般我们需要一份拷贝来写报告,其中的内容检查日志需要填词然后分析,真的很累。
一、前言:还需要人工检查吗?
说到检验,很多人嗤之以鼻:现在监控产品遍布全球,比如Zabbix、Prometheus、Graphite等,还需要检验吗?
答案是肯定的,更何况每个监控产品都有运维盲点。从知识库的使用来看,监控产品还是不能替代人工巡检的一些经验(当然,未来可能很快会被替代,但不知道什么时候)。当不规则的、异常的零星字符经过一个运维人员身边时,他敏锐的鬓角被拉长,眉毛扬起,大脑快速检索自己的知识库,用一个可能只有1%相似度的对比成功率,第一时间确定异常的基本原因,这已经是IT圈最常见的场景了。所以,必须强调的是,人工检查仍然是保证系统稳定性的最关键手段之一。在日常监控的基础上,保持一定的人工巡检频率,是保证稳定运行的法宝。
二、以前的检验报告怎么写
一般流程是这样的:
第一步:进入用户系统采集信息。通常通过脚本、自动化采集和少量的手工劳动采集来完成。采集 脚本(或程序)是每个公司的秘密武器。他们检查同一个对象。90%的企业采集拥有相同的信息,剩下的10%是他们的“内部信息”。毕竟在一个专业修炼多年,掌握一些“核心技术”是理所当然的。
第二步:根据用户系统分类或机器分类,各系统按一定格式出具检测报告。
上报是运维人员最头疼的事。比如用户数据库系统有上百套,每套报表都要下发。从采集的日志文件,Ctrl+C,Ctrl+V,我把原来的日志采集复制到了检查报告中,非常不爽和痛苦。另外,采集的原木密密麻麻,久了眼睛不舒服。
三、Python 帮忙写报告
大概的概念:
按照指定格式到客户端服务器上的采集日志(分隔符可自定义),将日志下载到本地,放到指定目录下,运行python程序自动生成word检测报告。
它具有以下特点:
1、 批量读取巡检日志文件,每个日志文件生成一个word文件,从日志文件名中截取word文件名。
2、 可以先填写检查意见
3、 还是需要打开文档,手动填写其他意见(毕竟这些意见是我们的财富,当然如果知识库功能用得好,就省略了)。
安装python,安装pip,然后安装pip install python-docx,省略。
第一步:导入包:
import re # 正则表达式使用
from docx import Document #word 文档使用
import os #用于遍历目录
从 docx.oxml.ns 导入 nsdecls #word 样式
from docx.oxml import parse_xml # 文字样式
步骤 2:定义四个函数。第一个函数:数字大小写转换函数:num_to_char
该函数主要用于将阿拉伯数字转换为中文大写。例如,如果是一级标题,则使用“一、patrol content”,这是相对于“1、patrol content”的标准写法。
代码显示如下:
第二个函数:get_title函数
这个功能就是检验项目的“标题功能”。例如,“检查文件系统”就是“主机文件系统检查”。毕竟我们不是歪的,标题应该还是中文的。
第三个函数:get_knowledge知识库函数
该函数为知识库函数,即当确定采集的结果存在一定问题时,利用知识库输出初步分析结果。其实对于动态比较和各种相似度分析,python是很擅长的,这里只是一个函数展示。
第四个函数:list_dir
该函数用于获取指定目录下的所有特定文件。比如这里指定的check*.log格式的文件就是要处理的文件。
因为python代码有严格的缩进限制,所有截图都是给大家看的。部分代码源码网络。
源码:由于编辑器的原因,以下可复现的代码没有出现缩进,请参考图片:
第一个函数源码(参考):
def num_to_char(num):
"""数字转中文"""
数量 = str(数量)
new_str = ""
num_dict = {"0": u"0", "1": u"one", "2": u"二", "3": u"三", "4": u"四", "5 ": u"五", "6": u"六", "7": u"七", "8": u"八",
"9": 你"九"}
列表编号 = 列表(编号)
# 打印(列表编号)
舒 = []
对于列表编号中的 i:
# 打印(num_dict[i])
shu.append(num_dict[i])
new_str = “”.join(shu)
# 打印(new_str)
返回 new_str
第二个函数的源码(参考):
def get_title(flag_fg):# flag_fg是传入的分隔段,其实就是英文标题
如果在 flag_fg 中“检查文件系统”:
xj_title_hs ='主机文件系统检查'
elif'Check CPU &MEM' in flag_fg:
xj_title_hs ='CPU,内存检查'
elif'Check ETH' 在 flag_fg 中:
xj_title_hs ='网卡状态检查'
elif'检查 /var/log/message' 在 flag_fg 中:
xj_title_hs ='主机日志检查'
elif'检查transparent_hugepage'在flag_fg:
xj_title_hs ='LINUX系统透明大页面检查'
elif'Check nr_hugepages' 在 flag_fg 中:
xj_title_hs ='Linux系统大页面打开状态检查'
elif'检查内存信息'在 flag_fg 中:
xj_title_hs ='PLNOCHECK'
###...
别的:
xj_title_hs = flag_fg #防止无休止的英文标题很重要
返回 xj_title_hs
第三个函数源码(参考):
def get_knowledge(str_input):
str_output = [] # 如果什么都没有发现,首先输出和检查是正常的。
str_output_text='检查正常'
如果在 str_input 中“[always] madvise never”:
str_output = ['Linux 没有关闭透明大页面。根据ORACLE安装要求,应该关闭透明大页面,提高ORACLE内存和IO读写性能','1111111']
elif'always madvise [never]' 在 str_input 中:
str_output = ['检查正常:Linux 已关闭透明大页面','000000']
别的:
str_output = ['检查正常','000000']
返回 str_output
#这个例子是静态比较。其实就是进行动态比较和各种相似度分析。Python非常擅长
#知识库分析,应该能够区分正常检查结果和异常检查结果。本例中'000000'表示正常,'1111111'表示异常
第四个函数源码(参考):
def list_dir(file_dir):
dir_list = os.listdir(file_dir)
file_r = []
对于 dir_list 中的 cur_file:
# 准确获取一个txt的位置,并使用字符串拼接
路径 = os.path.join(file_dir, cur_file)
如果 cur_file.startswith("check") & path.endswith(".log"):
file_r.append(路径)
返回文件_r
后续:主要功能介绍。主要功能实现文件读取、文件切分、词表操作等,是实现检查日志自动生成词文件的主要部门。 查看全部
自动采集编写(IT圈内巡检日志(一):人工巡检的制胜法宝)
前言:先写
如果只检查一两个库,则无需使用此方法。这种方式适用于获取大量的检测日志(比如使用脚本从服务器采集更多的服务器检测日志信息),一般我们需要一份拷贝来写报告,其中的内容检查日志需要填词然后分析,真的很累。
一、前言:还需要人工检查吗?
说到检验,很多人嗤之以鼻:现在监控产品遍布全球,比如Zabbix、Prometheus、Graphite等,还需要检验吗?
答案是肯定的,更何况每个监控产品都有运维盲点。从知识库的使用来看,监控产品还是不能替代人工巡检的一些经验(当然,未来可能很快会被替代,但不知道什么时候)。当不规则的、异常的零星字符经过一个运维人员身边时,他敏锐的鬓角被拉长,眉毛扬起,大脑快速检索自己的知识库,用一个可能只有1%相似度的对比成功率,第一时间确定异常的基本原因,这已经是IT圈最常见的场景了。所以,必须强调的是,人工检查仍然是保证系统稳定性的最关键手段之一。在日常监控的基础上,保持一定的人工巡检频率,是保证稳定运行的法宝。
二、以前的检验报告怎么写
一般流程是这样的:
第一步:进入用户系统采集信息。通常通过脚本、自动化采集和少量的手工劳动采集来完成。采集 脚本(或程序)是每个公司的秘密武器。他们检查同一个对象。90%的企业采集拥有相同的信息,剩下的10%是他们的“内部信息”。毕竟在一个专业修炼多年,掌握一些“核心技术”是理所当然的。
第二步:根据用户系统分类或机器分类,各系统按一定格式出具检测报告。
上报是运维人员最头疼的事。比如用户数据库系统有上百套,每套报表都要下发。从采集的日志文件,Ctrl+C,Ctrl+V,我把原来的日志采集复制到了检查报告中,非常不爽和痛苦。另外,采集的原木密密麻麻,久了眼睛不舒服。
三、Python 帮忙写报告
大概的概念:
按照指定格式到客户端服务器上的采集日志(分隔符可自定义),将日志下载到本地,放到指定目录下,运行python程序自动生成word检测报告。
它具有以下特点:
1、 批量读取巡检日志文件,每个日志文件生成一个word文件,从日志文件名中截取word文件名。
2、 可以先填写检查意见
3、 还是需要打开文档,手动填写其他意见(毕竟这些意见是我们的财富,当然如果知识库功能用得好,就省略了)。
安装python,安装pip,然后安装pip install python-docx,省略。
第一步:导入包:
import re # 正则表达式使用
from docx import Document #word 文档使用
import os #用于遍历目录
从 docx.oxml.ns 导入 nsdecls #word 样式
from docx.oxml import parse_xml # 文字样式
步骤 2:定义四个函数。第一个函数:数字大小写转换函数:num_to_char
该函数主要用于将阿拉伯数字转换为中文大写。例如,如果是一级标题,则使用“一、patrol content”,这是相对于“1、patrol content”的标准写法。
代码显示如下:
第二个函数:get_title函数
这个功能就是检验项目的“标题功能”。例如,“检查文件系统”就是“主机文件系统检查”。毕竟我们不是歪的,标题应该还是中文的。
第三个函数:get_knowledge知识库函数
该函数为知识库函数,即当确定采集的结果存在一定问题时,利用知识库输出初步分析结果。其实对于动态比较和各种相似度分析,python是很擅长的,这里只是一个函数展示。
第四个函数:list_dir
该函数用于获取指定目录下的所有特定文件。比如这里指定的check*.log格式的文件就是要处理的文件。
因为python代码有严格的缩进限制,所有截图都是给大家看的。部分代码源码网络。
源码:由于编辑器的原因,以下可复现的代码没有出现缩进,请参考图片:
第一个函数源码(参考):
def num_to_char(num):
"""数字转中文"""
数量 = str(数量)
new_str = ""
num_dict = {"0": u"0", "1": u"one", "2": u"二", "3": u"三", "4": u"四", "5 ": u"五", "6": u"六", "7": u"七", "8": u"八",
"9": 你"九"}
列表编号 = 列表(编号)
# 打印(列表编号)
舒 = []
对于列表编号中的 i:
# 打印(num_dict[i])
shu.append(num_dict[i])
new_str = “”.join(shu)
# 打印(new_str)
返回 new_str
第二个函数的源码(参考):
def get_title(flag_fg):# flag_fg是传入的分隔段,其实就是英文标题
如果在 flag_fg 中“检查文件系统”:
xj_title_hs ='主机文件系统检查'
elif'Check CPU &MEM' in flag_fg:
xj_title_hs ='CPU,内存检查'
elif'Check ETH' 在 flag_fg 中:
xj_title_hs ='网卡状态检查'
elif'检查 /var/log/message' 在 flag_fg 中:
xj_title_hs ='主机日志检查'
elif'检查transparent_hugepage'在flag_fg:
xj_title_hs ='LINUX系统透明大页面检查'
elif'Check nr_hugepages' 在 flag_fg 中:
xj_title_hs ='Linux系统大页面打开状态检查'
elif'检查内存信息'在 flag_fg 中:
xj_title_hs ='PLNOCHECK'
###...
别的:
xj_title_hs = flag_fg #防止无休止的英文标题很重要
返回 xj_title_hs
第三个函数源码(参考):
def get_knowledge(str_input):
str_output = [] # 如果什么都没有发现,首先输出和检查是正常的。
str_output_text='检查正常'
如果在 str_input 中“[always] madvise never”:
str_output = ['Linux 没有关闭透明大页面。根据ORACLE安装要求,应该关闭透明大页面,提高ORACLE内存和IO读写性能','1111111']
elif'always madvise [never]' 在 str_input 中:
str_output = ['检查正常:Linux 已关闭透明大页面','000000']
别的:
str_output = ['检查正常','000000']
返回 str_output
#这个例子是静态比较。其实就是进行动态比较和各种相似度分析。Python非常擅长
#知识库分析,应该能够区分正常检查结果和异常检查结果。本例中'000000'表示正常,'1111111'表示异常
第四个函数源码(参考):
def list_dir(file_dir):
dir_list = os.listdir(file_dir)
file_r = []
对于 dir_list 中的 cur_file:
# 准确获取一个txt的位置,并使用字符串拼接
路径 = os.path.join(file_dir, cur_file)
如果 cur_file.startswith("check") & path.endswith(".log"):
file_r.append(路径)
返回文件_r
后续:主要功能介绍。主要功能实现文件读取、文件切分、词表操作等,是实现检查日志自动生成词文件的主要部门。
自动采集编写( 出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-12-12 18:07
出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)
用户演示站:
源码使用环境
支持环境:WindowsnuxPHP5.3/4/5/67.1mysql5.
推荐环境:linuxphp7.1mysql5.6
源代码功能详情
1、内置大量内容,安装后可省时省力;
2、内置高效采集插件,每天自动采集一次(间隔可自行修改),真正无人值守;
3、7 内置 采集 规则;
4、内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序完全开源,无任何加密,不定期提供升级;
7、采用前端HTML5 CSS3响应式布局,兼容多终端(PC手机和平板),数据同步,管理方便;
8、采集规则失效不用担心,我们有强大的技术团队,会提供升级服务的规则;
9、图片默认使用远程地址,节省磁盘空间,可以在本地设置和保存。
源码适合人群
1、上班族
白天上班,晚上休息。这个程序满足你。安装完成后配置无误即可坐等升级网站,真正无人值守。
2、做站群
有些人有几百个站,要花钱招人。最好设置一个无人值守的采集站,这样既省时又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
说说吧,它需要流量上来。
2、出售友情链接
网站收录多达1000个基础,你在友情链接交易平台上卖朋友没问题。
3、销售网站二级目录
网站收录好吧,有些人只需要收录,他们自然会找到你。
4、卖站
网站收录上去卖一个5、600 没问题,重量上来卖多。
程序安装文档
详见源码中付费安装文档 查看全部
自动采集编写(
出售友情链接网站收录上1000基本你在友情链接交易平台链是没问题了)
用户演示站:
源码使用环境
支持环境:WindowsnuxPHP5.3/4/5/67.1mysql5.
推荐环境:linuxphp7.1mysql5.6
源代码功能详情
1、内置大量内容,安装后可省时省力;
2、内置高效采集插件,每天自动采集一次(间隔可自行修改),真正无人值守;
3、7 内置 采集 规则;
4、内置缓存插件,减轻前端访问压力;
5、网站管理简单快捷,后台基本可以修改前端显示信息,无需代码;
6、程序完全开源,无任何加密,不定期提供升级;
7、采用前端HTML5 CSS3响应式布局,兼容多终端(PC手机和平板),数据同步,管理方便;
8、采集规则失效不用担心,我们有强大的技术团队,会提供升级服务的规则;
9、图片默认使用远程地址,节省磁盘空间,可以在本地设置和保存。
源码适合人群
1、上班族
白天上班,晚上休息。这个程序满足你。安装完成后配置无误即可坐等升级网站,真正无人值守。
2、做站群
有些人有几百个站,要花钱招人。最好设置一个无人值守的采集站,这样既省时又省钱。
源代码盈利方法
1、广告联盟/网站广告/淘客
说说吧,它需要流量上来。
2、出售友情链接
网站收录多达1000个基础,你在友情链接交易平台上卖朋友没问题。
3、销售网站二级目录
网站收录好吧,有些人只需要收录,他们自然会找到你。
4、卖站
网站收录上去卖一个5、600 没问题,重量上来卖多。
程序安装文档
详见源码中付费安装文档
自动采集编写(自动采集脚本1.利用pythonexplorer调用githubgithub安装python模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-12-12 01:01
自动采集编写脚本1.利用pythonexplorer调用github安装python模块2.如何下载github-square/python:gitclone:操作系统(windows/mac)执行:pipinstallpython-pipmodule版本2.1安装完成后,记得设置路径path环境变量,然后python安装路径在“\python\scripts”:cd$path$pipinstallgit2.2是个坑。
我遇到的git2.3已经好了,但是复现时就出错了,各位自己理解...2.3.1为什么能复现,但就是不知道为什么不能复现,后来想起,是命令行那边的问题,因为有可能那边有错,正好被转发了,然后就复现了,但是无法打印出cmd的内容2.4这种情况,可以放弃python,用其他语言去验证的,没有这么蛋疼,或者去看python编译器的帮助文档2.5最好多问一下相关人员。
必须到不同的sdlds版本下验证,
用python插件k-lab查看目录结构,
如果环境都跟python版本一样的话,看下python的pdb环境变量配置是否正确,
python2的话将/usr/local/bin/替换成/usr/local/bin/python2#python3的话将/usr/local/bin/替换成/usr/local/bin/python3 查看全部
自动采集编写(自动采集脚本1.利用pythonexplorer调用githubgithub安装python模块)
自动采集编写脚本1.利用pythonexplorer调用github安装python模块2.如何下载github-square/python:gitclone:操作系统(windows/mac)执行:pipinstallpython-pipmodule版本2.1安装完成后,记得设置路径path环境变量,然后python安装路径在“\python\scripts”:cd$path$pipinstallgit2.2是个坑。
我遇到的git2.3已经好了,但是复现时就出错了,各位自己理解...2.3.1为什么能复现,但就是不知道为什么不能复现,后来想起,是命令行那边的问题,因为有可能那边有错,正好被转发了,然后就复现了,但是无法打印出cmd的内容2.4这种情况,可以放弃python,用其他语言去验证的,没有这么蛋疼,或者去看python编译器的帮助文档2.5最好多问一下相关人员。
必须到不同的sdlds版本下验证,
用python插件k-lab查看目录结构,
如果环境都跟python版本一样的话,看下python的pdb环境变量配置是否正确,
python2的话将/usr/local/bin/替换成/usr/local/bin/python2#python3的话将/usr/local/bin/替换成/usr/local/bin/python3
自动采集编写( 这是网站源码制作的电子书网站版面:网上在线报名(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-12-10 12:11
这是网站源码制作的电子书网站版面:网上在线报名(组图))
具有自动功能的响应式电子书采集网站源代码
源码介绍
这是一个带有自动采集功能的电子书网站源代码。用本源代码制作的电子书网站具有响应功能,可以适配电脑和手机。浏览。源码安装好后就可以后台发布数据采集。
以下是用电子书网站的源代码制作的电子书网站版面:
源代码下载
具有自动采集功能的响应式电子书网站源代码,购买后请点击下方下载!
源码安装方法下载响应式电子书网站源码;解压压缩包,获取源码文件夹,通过FTP软件上传到自己的网站空间根目录;使用网站域名/安装路径安装源码;安装后使用网站域名/admin登录网站后台。
具有自动采集功能的响应式电子书网站源代码主色调,兼容IE、FF、Opera、Safari、chrome等浏览器,手机WAP布局,源码代码操作需要服务器环境为php5.3及以上,mysql数据库。
购买带有自动采集功能的响应式电子书网站源价:¥160
什么是网站源代码
网站 源码是将网站程序、网站模板、网站后台管理、网站数据库数据打包在一起。用户购买网站源码后,只需直接上传到网站空间,即可制作并演示网站一模一板网站。
上一课:在线登记管理系统通用源码 下一课:适合房产中介做的源码网站
发布:学做网站论坛最后更新:2021-11-27 浏览次数:115504次
学会做网站论坛致力于打造网站在线培训诚信平台,让零基础学员学习做网站,最终可以自主搭建网站.
通过原创建站教程+讲师在线辅导学习做网站论坛搭建培训,对各种网站制作方法的讲解非常详细,哪怕是零基础初学者可以看懂了就学会了。 查看全部
自动采集编写(
这是网站源码制作的电子书网站版面:网上在线报名(组图))
具有自动功能的响应式电子书采集网站源代码
源码介绍
这是一个带有自动采集功能的电子书网站源代码。用本源代码制作的电子书网站具有响应功能,可以适配电脑和手机。浏览。源码安装好后就可以后台发布数据采集。
以下是用电子书网站的源代码制作的电子书网站版面:
https://www.xuewangzhan.net/wp ... 7.jpg 768w" />源代码下载
具有自动采集功能的响应式电子书网站源代码,购买后请点击下方下载!
源码安装方法下载响应式电子书网站源码;解压压缩包,获取源码文件夹,通过FTP软件上传到自己的网站空间根目录;使用网站域名/安装路径安装源码;安装后使用网站域名/admin登录网站后台。
具有自动采集功能的响应式电子书网站源代码主色调,兼容IE、FF、Opera、Safari、chrome等浏览器,手机WAP布局,源码代码操作需要服务器环境为php5.3及以上,mysql数据库。
购买带有自动采集功能的响应式电子书网站源价:¥160
什么是网站源代码
网站 源码是将网站程序、网站模板、网站后台管理、网站数据库数据打包在一起。用户购买网站源码后,只需直接上传到网站空间,即可制作并演示网站一模一板网站。
上一课:在线登记管理系统通用源码 下一课:适合房产中介做的源码网站
发布:学做网站论坛最后更新:2021-11-27 浏览次数:115504次
学会做网站论坛致力于打造网站在线培训诚信平台,让零基础学员学习做网站,最终可以自主搭建网站.
通过原创建站教程+讲师在线辅导学习做网站论坛搭建培训,对各种网站制作方法的讲解非常详细,哪怕是零基础初学者可以看懂了就学会了。
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-12-10 08:00
一、前言
在上一篇文章《神测Android全插件介绍》中,我们了解到神测Android插件其实就是一个自定义的Gradle插件。Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。您可以通过插件实现特定的逻辑,并打包分享给他人。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现控件点击和Fragment页面浏览的全埋点采集。
在本文中,我们将首先介绍Gradle 的基础知识,然后举例说明如何实现自定义Gradle 插件。这里需要注意的是,文章使用./gradlew来执行Gradle命令,如果你是Windows用户,需要将它改成gradlew.bat。
二、Gradle 基础知识
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
项目是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,“Project”和“Module”在构建过程中都会被Gradle抽象为Project对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、 每个Project都会对应一个build.gradle配置文件,所以在使用Android Studio创建项目时,根目录下有一个build.gradle文件,每个Module的目录下都有一个build . gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
allprojects {
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 将在施工过程中执行一系列任务。Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle官方的话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图中右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。在运行Task时,也需要通过这种方式指定一个Task。
此外,您可以自定义您自己的任务。让我们创建最简单的任务:
// add to build.gradle
task hello {
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的Task。如果想单独执行Task,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后就可以看到控制台输出了。你好世界!”。
三、Gradle 插件构建3.1 插件介绍
Plugin和Task其实和它们的功能没有太大区别。它们都封装了一些业务逻辑。Plugin适用于打包需要复用的编译逻辑的场景(即模块化部分编译逻辑)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样,以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的 Plugin 应该是 Android 官方提供的 Android Gradle Plugin。可以在项目主模块的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。“com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
该插件还可以读取 build.gradle 文件中写入的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等,大家可以比较一下“ android" android 块在这里作为数据类或基类,定义的属性类似于类成员变量。Android Gradle Plugin 可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 为独立项目构建 Gradle 插件
Gradle插件的实现方式有3种,分别是Build脚本、buildSrc项目和Standalone项目:
1、Build 脚本会直接在 build.gradle 文件中写入逻辑,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc项目就是在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录下写逻辑,Plugin仅对当前项目有效;
3、独立项目就是把逻辑写在一个单独的项目中,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone项目,独立项目的Gradle插件。
3.2.1 目录结构分析
一个独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
其中resources文件夹为固定格式META-INF/gradle-plugins/XXXX.properties,XXXX代表以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件 Module,只能先新建一个 Java Library 类型的 Module,然后删除多余的文件夹;
2、新类默认是一个新的Java类。新的文件名后缀是“.java”。如果要新建一个Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加package、class语句;
3、资源都需要手动创建,文件夹名需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 编写插件
在编写插件代码之前,我们需要对build.gradle做一些修改,如下图:
apply plugin: 'groovy'
apply plugin: 'maven'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
uploadArchives{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这主要分为三个部分:
1、apply plugin:应用'groovy'插件,因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,位置选择在项目根目录下的repo文件夹中。
做好以上准备后,就可以开始编写源码了。Gradle插件需要入口类实现org.gradle.api.Plugin接口,然后在apply方法中实现自己的逻辑:
package com.sensorsdata.plugin
class MyPlugin implements Plugin{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还需要做一个准备:Gradle插件不会自动查找入口类,而是需要开发者在resources/META-INF/gradle-plugins/XXXX.properties中写入入口类的类名,内容格式对于“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写完后,在终端执行
./gradlew uploadArchive
您可以发布插件。在上一节写的插件的build.gradle文件中,发布到maven仓库的相关配置是提前配置好的,所以我们这里执行这个命令后,项目根目录下就会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤: 查看全部
自动采集编写(神策Android全埋点插件的含义及含义插件介绍)
一、前言
在上一篇文章《神测Android全插件介绍》中,我们了解到神测Android插件其实就是一个自定义的Gradle插件。Gradle 是一个专注于灵活性和性能的开源自动化构建工具,插件的作用是打包模块化、可重用的构建逻辑。您可以通过插件实现特定的逻辑,并打包分享给他人。例如,神测Android全埋点插件在编译时利用该插件处理特定功能,从而实现控件点击和Fragment页面浏览的全埋点采集。
在本文中,我们将首先介绍Gradle 的基础知识,然后举例说明如何实现自定义Gradle 插件。这里需要注意的是,文章使用./gradlew来执行Gradle命令,如果你是Windows用户,需要将它改成gradlew.bat。
二、Gradle 基础知识
Gradle 有两个重要的概念:Project 和 Task。本节将介绍它们各自的功能以及它们之间的关系。
2.1 项目介绍
项目是与 Gradle 交互中最重要的 API。我们可以通过Android Studio的项目结构来理解Project的含义,如图2-1所示:
图2-1 Android Studio 项目结构图
图2-1是编写过程中用到的一个项目(名为BlogDemo),收录两个Module,app和plugin。在这里,“Project”和“Module”在构建过程中都会被Gradle抽象为Project对象。他们的主要关系是:
1、Android Studio 结构中的项目相当于一个父项目,一个项目中的所有模块都是父项目的子项目;
2、 每个Project都会对应一个build.gradle配置文件,所以在使用Android Studio创建项目时,根目录下有一个build.gradle文件,每个Module的目录下都有一个build . gradle 文件;
3、Gradle 使用 settings.gradle 文件来构建多个项目。项目之间的关系也可以从图2-1看出。
父Project对象可以获取所有子Project对象,这样就可以在父Project对应的build.gradle文件中做一些统一的配置,例如:管理依赖的Maven中心库:
...
allprojects {
repositories {
google()
jcenter()
}
}
...
2.2 任务介绍
Project 将在施工过程中执行一系列任务。Task的中文翻译是“任务”,它的作用其实就是抽象出一系列有意义的任务,用Gradle官方的话说:每个任务执行一些基本的工作。例如:当您点击 Android Studio 的 Run 按钮时,Android Studio 将编译并运行该项目。其实这个过程是通过执行一系列的Task来完成的。可能包括:编译Java源代码的任务、编译Android资源的任务、编译JNI的任务、混淆任务、生成Apk文件的任务、运行App的任务等。你还可以在Build中看到实际运行了哪些任务Android Studio的输出,如图2-2所示:
图 2-2 Android Studio Build 输出日志
从图中右侧,我们可以看到Task由两部分组成:任务所在的Module名称和任务名称。在运行Task时,也需要通过这种方式指定一个Task。
此外,您可以自定义您自己的任务。让我们创建最简单的任务:
// add to build.gradle
task hello {
println 'Hello World!'
}
这段代码的意思是创建一个名为“hello”的Task。如果想单独执行Task,可以在Android Studio的Terminal中输入“./gradlew hello”,执行后就可以看到控制台输出了。你好世界!”。
三、Gradle 插件构建3.1 插件介绍
Plugin和Task其实和它们的功能没有太大区别。它们都封装了一些业务逻辑。Plugin适用于打包需要复用的编译逻辑的场景(即模块化部分编译逻辑)。您可以自定义 Gradle 插件,实现必要的逻辑并将其发布到远程仓库或作为本地 JAR 包共享。这样,以后想再次使用或者分享给别人的时候,可以直接引用远程仓库包或者引用本地JAR包。
最常见的 Plugin 应该是 Android 官方提供的 Android Gradle Plugin。可以在项目主模块的build.gradle文件第一行看到:“apply plugin:'com.android.application'”,就是Android Gradle Plugin。“com.android.application”指的是插件id,插件的作用是帮你生成一个可运行的APK文件。
该插件还可以读取 build.gradle 文件中写入的配置。在main Module的build.gradle文件中会有一个名为“android”的block,里面定义了一些属性,比如App支持的最低系统版本,App的版本号等,大家可以比较一下“ android" android 块在这里作为数据类或基类,定义的属性类似于类成员变量。Android Gradle Plugin 可以在运行时获取“android”块实例化的对象,然后根据对象的属性值运行不同的编译逻辑。
3.2 为独立项目构建 Gradle 插件
Gradle插件的实现方式有3种,分别是Build脚本、buildSrc项目和Standalone项目:
1、Build 脚本会直接在 build.gradle 文件中写入逻辑,Plugin 只对当前 build.gradle 文件可见;
2、buildSrc项目就是在rootProjectDir/buildSrc/src/main/java(最后一个路径文件夹也可以是groovy或者kotlin,看你用什么语言实现自定义插件)目录下写逻辑,Plugin仅对当前项目有效;
3、独立项目就是把逻辑写在一个单独的项目中,可以直接编译JAR包发布到远程仓库或者本地。
基于写这篇文章的目的,这里主要讲解Standalone项目,独立项目的Gradle插件。
3.2.1 目录结构分析
一个独立项目的Gradle插件的大致结构如图3-1所示:
图3-1 Gradle插件项目目录示意图
主文件夹分为groovy文件夹和resources文件夹:
其中resources文件夹为固定格式META-INF/gradle-plugins/XXXX.properties,XXXX代表以后使用插件时需要指定的插件id。
目前Android Studio对Gradle插件开发的支持还不够好。许多IDE本可以完成的任务需要我们手动完成,例如:
1、Android Studio 不能直接新建 Gradle 插件 Module,只能先新建一个 Java Library 类型的 Module,然后删除多余的文件夹;
2、新类默认是一个新的Java类。新的文件名后缀是“.java”。如果要新建一个Groovy语法类,需要手动新建一个后缀为“.groovy”的文件,然后添加package、class语句;
3、资源都需要手动创建,文件夹名需要仔细拼写;
4、 删除Module的build.gradle所有内容,并添加Gradle插件开发所需的Gradle插件、依赖等。
3.2.2 编写插件
在编写插件代码之前,我们需要对build.gradle做一些修改,如下图:
apply plugin: 'groovy'
apply plugin: 'maven'
dependencies {
implementation gradleApi()
implementation localGroovy()
}
uploadArchives{
repositories.mavenDeployer {
//本地仓库路径,以放到项目根目录下的 repo 的文件夹为例
repository(url: uri('../repo'))
//groupId ,自行定义
pom.groupId = 'com.sensorsdata.myplugin'
//artifactId
pom.artifactId = 'MyPlugin'
//插件版本号
pom.version = '1.0.0'
}
}
这主要分为三个部分:
1、apply plugin:应用'groovy'插件,因为我们的项目是用Groovy语言开发的,以后发布插件时会用到'maven'插件;
2、dependencies:声明依赖;
3、uploadArchive:这里是一些maven相关的配置,包括发布仓库的位置,groupId,artifactId,版本号。为了调试方便,位置选择在项目根目录下的repo文件夹中。
做好以上准备后,就可以开始编写源码了。Gradle插件需要入口类实现org.gradle.api.Plugin接口,然后在apply方法中实现自己的逻辑:
package com.sensorsdata.plugin
class MyPlugin implements Plugin{
@Override
void apply(Project project) {
println 'Hello,World!'
}
}
这里的例子中,apply方法是我们整个Gradle插件的入口方法,类似于各种语言的main方法。apply方法的输入参数类型Project在第二节已经解释过了,这里不再赘述。由于Plugin类和Project类有很多同名的类,所以在导入的时候一定要注意选择org.gradle.api包下的类。
最后还需要做一个准备:Gradle插件不会自动查找入口类,而是需要开发者在resources/META-INF/gradle-plugins/XXXX.properties中写入入口类的类名,内容格式对于“implementation-class=入口类的全限定名”,这里示例工程的配置如下:
// com.sensorsdata.plugin.properties
implementation-class=com.sensorsdata.plugin.MyPlugin
3.2.3 发布插件
插件全部内容写完后,在终端执行
./gradlew uploadArchive
您可以发布插件。在上一节写的插件的build.gradle文件中,发布到maven仓库的相关配置是提前配置好的,所以我们这里执行这个命令后,项目根目录下就会出现repo文件夹,文件夹收录打包的 JAR 文件。
3.2.4 使用插件
使用插件有两个主要步骤:

