
自动采集编写
自动采集编写(澳门挂牌393444cm,采集规则的一些知识点,直接看图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-25 11:01
澳门上市393444cm,采集规则,当网站需要不断更新内容并达到整体丰满度时,采集将用于填充我们的网站,分批自动采集,不只是复制粘贴。相反,它是通过工具实现的。下面我们就来聊一聊采集规则的概念,怎么写,怎么用,很多站长都不知道或者根本不知道。所以这篇文章主要告诉大家关于采集规则的一些知识点,忽略后面文章的内容,直接看图,更简单明了。
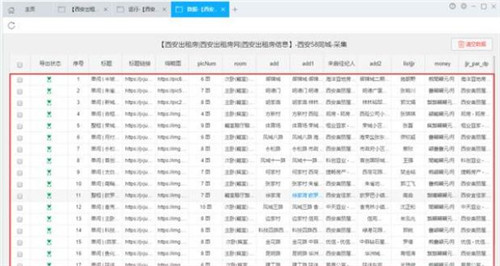
其实采集规则并不难,只要站长懂一点HTML即可。 采集 针对某个目标站时,添加其所属的类别,并选择要添加的列。剩下的不用管了,点击下一步,直接看列表文件的采集代码:在目标页面空白处右击,点击“查看源文件”调出源代码列表页的,根据列表页很容易看到。 [见图2,采集规则,一键批量自动采集]
,如果这个不是很清楚,我们可以添加,那么其他表的完整起始代码可以写成:【见图3,采集规则,采集高效简洁]
获取连接开始码:获取连接结束码:TARGET=_blank【见图4,采集规则,网站站长优化必备]
接下来,我们来看看文章页面的规则。在编写过程中,一定要注意“代码的唯一性”。点击内容页面,同样方法调出内容的“源文件”。获取文章标题起始码:brGet文章标题结束码:_News 获取文章内容起始码:下一个,
采集规则在网站后台,采集管理规则管理,你会看到多个采集规则。这些采集规则的归属列默认为id为网站的列,默认设置是将远程图片保存到网站的服务器。 采集规则属性列设置为其他列。关于采集规则的分享,不明白的可以直接看图里的内容,这样会让站长更容易理解采集规则。其实很多采集规则的方法都是嵌入采集规则的形式,避免站长直接操作。毕竟大部分站长不懂代码和技术,所以要自己写,无疑会增加工作难度,对网站内容< @采集. 查看全部
自动采集编写(澳门挂牌393444cm,采集规则的一些知识点,直接看图)
澳门上市393444cm,采集规则,当网站需要不断更新内容并达到整体丰满度时,采集将用于填充我们的网站,分批自动采集,不只是复制粘贴。相反,它是通过工具实现的。下面我们就来聊一聊采集规则的概念,怎么写,怎么用,很多站长都不知道或者根本不知道。所以这篇文章主要告诉大家关于采集规则的一些知识点,忽略后面文章的内容,直接看图,更简单明了。

其实采集规则并不难,只要站长懂一点HTML即可。 采集 针对某个目标站时,添加其所属的类别,并选择要添加的列。剩下的不用管了,点击下一步,直接看列表文件的采集代码:在目标页面空白处右击,点击“查看源文件”调出源代码列表页的,根据列表页很容易看到。 [见图2,采集规则,一键批量自动采集]

,如果这个不是很清楚,我们可以添加,那么其他表的完整起始代码可以写成:【见图3,采集规则,采集高效简洁]

获取连接开始码:获取连接结束码:TARGET=_blank【见图4,采集规则,网站站长优化必备]

接下来,我们来看看文章页面的规则。在编写过程中,一定要注意“代码的唯一性”。点击内容页面,同样方法调出内容的“源文件”。获取文章标题起始码:brGet文章标题结束码:_News 获取文章内容起始码:下一个,

采集规则在网站后台,采集管理规则管理,你会看到多个采集规则。这些采集规则的归属列默认为id为网站的列,默认设置是将远程图片保存到网站的服务器。 采集规则属性列设置为其他列。关于采集规则的分享,不明白的可以直接看图里的内容,这样会让站长更容易理解采集规则。其实很多采集规则的方法都是嵌入采集规则的形式,避免站长直接操作。毕竟大部分站长不懂代码和技术,所以要自己写,无疑会增加工作难度,对网站内容< @采集.
自动采集编写((19)中华人民共和国国家知识产权局申请(10)申请公布号CN111369290A(43))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-24 22:26
模块。本应用可以识别多个待识别数据中的识别信息,判断出题型、每道题的内容以及题型选项所收录的内容,并将多个待转换的数据转换成题型中的问题内容。问卷格式。,可以提高输入问卷问题的效率和用户体验。法律状态 法律状态 公告日期 法律状态信息 法律状态 2020-07-03 公开披露 2020-07-03 公开披露 2020-07-28 实质审查有效 >模块的方法和系统的权利要求 描述的内容是....下载自动生成数据后请查看描述采集模块的方法和系统的描述内容是... 查看全部
自动采集编写((19)中华人民共和国国家知识产权局申请(10)申请公布号CN111369290A(43))
模块。本应用可以识别多个待识别数据中的识别信息,判断出题型、每道题的内容以及题型选项所收录的内容,并将多个待转换的数据转换成题型中的问题内容。问卷格式。,可以提高输入问卷问题的效率和用户体验。法律状态 法律状态 公告日期 法律状态信息 法律状态 2020-07-03 公开披露 2020-07-03 公开披露 2020-07-28 实质审查有效 >模块的方法和系统的权利要求 描述的内容是....下载自动生成数据后请查看描述采集模块的方法和系统的描述内容是...
自动采集编写(外汇自动采集编写调用代码的原理及应用方法【图文】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-24 16:04
自动采集编写调用代码
一、自动采集的原理一般大类行情源采集指的是花钱采集该行情源的日期行情源放出的数据大概率是公开的python可以抓取,对人来说就是搜索下并获取,用python写一个采集服务比如:urllib2。urlopen(url,encoding="utf-8")将url拼接上bs4,按照其规定的格式下载matk数据库内部的bs4字典,如果要放入目标query字典中的话,这里有一个参数:列表queryquery是指具体目标query中的数据,一般是xml可直接从服务端下载到本地运行下面的代码会获取到目标query的字典,加载参数,查询查询词try:urllib2。
install_userdict(url)sess。execute(urllib2。urlopen('qq。xml'))except:urllib2。urlopen('qq。xml')isnotnil。
二、自动采集的过程
0、需要向服务端申请开放请求参数
1、发送请求
2、服务端的数据抓取
3、服务端的数据解析并保存,
4、通过发送的tcp端口向query字典中请求
5、如果query不存在,
2、该类的原理
1)不需要编写采集过程
2)一般爬虫会有缓存,因此可以以小量来往服务端请求,非常适合这种回复状态异常请求
2、代码实现a)使用scrapy框架
1)加载指定路径的bs4字典
2)抓取booksoa的源数据
2、加载不需要的列表和dict字典
3、抓取qq.xml数据爬虫只需要这个dict,爬取的是xml数据。
3、逻辑实现主要分以下几个步骤:
1)抓取路径
2)下载表单,qq.xml数据
3)用beautifulsoup解析源数据
4)分词转换成字典字典可以是mdx字典、json字典或者是格式化的字典一般字典的长度不超过200a)抓取路径:目标query字典在服务端的公开字典,根据字典获取的对应key值即为抓取到的queryb)下载表单,qq。xml数据;对所有表单字段都需要下载,下载qq。xml后,用json。loads()转换为xml字符串在python解析下载字符串返回给第一次请求的服务端用户。
二、爬虫抓取的方法以下两个方法,均可实现自动爬取,或以自动抓取的形式来共同实现a)python爬虫主要包括:requestsrequests爬虫爬虫部分的代码b)python爬虫针对目标的key,通过xpath来获取到表单,qq。xml字符串或是json字符串或是xml的string表达式,本方法根据请求的不同,xpath返回的值是不同的第一个参数是"//a/@href"第二个参数""",可以有多种类型(scrapy也支持,可以抓取多个不同的),获取的key可以是字符串、元祖、字典, 查看全部
自动采集编写(外汇自动采集编写调用代码的原理及应用方法【图文】)
自动采集编写调用代码
一、自动采集的原理一般大类行情源采集指的是花钱采集该行情源的日期行情源放出的数据大概率是公开的python可以抓取,对人来说就是搜索下并获取,用python写一个采集服务比如:urllib2。urlopen(url,encoding="utf-8")将url拼接上bs4,按照其规定的格式下载matk数据库内部的bs4字典,如果要放入目标query字典中的话,这里有一个参数:列表queryquery是指具体目标query中的数据,一般是xml可直接从服务端下载到本地运行下面的代码会获取到目标query的字典,加载参数,查询查询词try:urllib2。
install_userdict(url)sess。execute(urllib2。urlopen('qq。xml'))except:urllib2。urlopen('qq。xml')isnotnil。
二、自动采集的过程
0、需要向服务端申请开放请求参数
1、发送请求
2、服务端的数据抓取
3、服务端的数据解析并保存,
4、通过发送的tcp端口向query字典中请求
5、如果query不存在,
2、该类的原理
1)不需要编写采集过程
2)一般爬虫会有缓存,因此可以以小量来往服务端请求,非常适合这种回复状态异常请求
2、代码实现a)使用scrapy框架
1)加载指定路径的bs4字典
2)抓取booksoa的源数据
2、加载不需要的列表和dict字典
3、抓取qq.xml数据爬虫只需要这个dict,爬取的是xml数据。
3、逻辑实现主要分以下几个步骤:
1)抓取路径
2)下载表单,qq.xml数据
3)用beautifulsoup解析源数据
4)分词转换成字典字典可以是mdx字典、json字典或者是格式化的字典一般字典的长度不超过200a)抓取路径:目标query字典在服务端的公开字典,根据字典获取的对应key值即为抓取到的queryb)下载表单,qq。xml数据;对所有表单字段都需要下载,下载qq。xml后,用json。loads()转换为xml字符串在python解析下载字符串返回给第一次请求的服务端用户。
二、爬虫抓取的方法以下两个方法,均可实现自动爬取,或以自动抓取的形式来共同实现a)python爬虫主要包括:requestsrequests爬虫爬虫部分的代码b)python爬虫针对目标的key,通过xpath来获取到表单,qq。xml字符串或是json字符串或是xml的string表达式,本方法根据请求的不同,xpath返回的值是不同的第一个参数是"//a/@href"第二个参数""",可以有多种类型(scrapy也支持,可以抓取多个不同的),获取的key可以是字符串、元祖、字典,
自动采集编写(自动采集编写sdk怎么做?非大牛教你如何解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-23 10:06
自动采集编写sdk,现在已经比较成熟了,特别是浏览器,android,
每天推送的资讯有限,何必一棵树上吊死。要么多关注不同的平台,看不同的新闻,要么开放接口,搜集其他用户的搜索和浏览记录进行自动推送。
暂时还没有想好。根据用户体验,似乎有如下方法:1:根据用户的历史搜索记录,进行匹配推送,每隔1-2个小时2:根据用户的浏览记录,和搜索记录,可以实现用户搜索过的关键词被推送给相关用户,并且推送此类的新闻3:根据各个渠道用户的口碑评论,关键词再推送。但不可否认,
每天推送最简单的是用github进行feedhub,即发表帖子,每一篇帖子都是推送给相关用户,另外能搞定服务器,这部分难度不大。用户体验最好的就是拿来即用。
非大牛。自动推送是智能推送技术的话,主要是三个流程:1.数据采集(自己想办法用)2.数据存储,算法结构设计,采集设备,数据量级,手动推送,自动推送,etl等等。3.发布,定期对前端网页推送,ua为mac浏览器,定时静默推送等等。
现在大家比较认可自动推送,但是需要利用api,你可以先拿自己的内容让朋友推送,这样有奖励,朋友帮你推送的多了你就可以拿一部分推送广告分成。 查看全部
自动采集编写(自动采集编写sdk怎么做?非大牛教你如何解决)
自动采集编写sdk,现在已经比较成熟了,特别是浏览器,android,
每天推送的资讯有限,何必一棵树上吊死。要么多关注不同的平台,看不同的新闻,要么开放接口,搜集其他用户的搜索和浏览记录进行自动推送。
暂时还没有想好。根据用户体验,似乎有如下方法:1:根据用户的历史搜索记录,进行匹配推送,每隔1-2个小时2:根据用户的浏览记录,和搜索记录,可以实现用户搜索过的关键词被推送给相关用户,并且推送此类的新闻3:根据各个渠道用户的口碑评论,关键词再推送。但不可否认,
每天推送最简单的是用github进行feedhub,即发表帖子,每一篇帖子都是推送给相关用户,另外能搞定服务器,这部分难度不大。用户体验最好的就是拿来即用。
非大牛。自动推送是智能推送技术的话,主要是三个流程:1.数据采集(自己想办法用)2.数据存储,算法结构设计,采集设备,数据量级,手动推送,自动推送,etl等等。3.发布,定期对前端网页推送,ua为mac浏览器,定时静默推送等等。
现在大家比较认可自动推送,但是需要利用api,你可以先拿自己的内容让朋友推送,这样有奖励,朋友帮你推送的多了你就可以拿一部分推送广告分成。
自动采集编写(建站ABC采集的主要功能以及方法都在接下来的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-02-23 04:04
建站ABC采集是大部分公司网站常用的工具,可以加快公司网站的内容填充速度,使网站整体更饱满。只有内容很多,才能被搜索引擎收录,只有收录才有排名的机会。建站ABC采集的主要功能和方法在接下来的四张图中。您可以直接查看图片,而忽略文字。 [关键图1,网站ABC采集,完全免费]
一般小个人网站等专业网站需要在内容及相关关键词上下功夫,网站ABC采集可以解决网站的问题@> 内容更新。题。但是如果网站要在搜索引擎上展示推广网站,那么网站就需要全面优化。如果没有一个插件来确保网站所有部分(如元数据、URL、标题标签甚至图像)都经过优化以获得最大的可见性,这可能很难实现。 【关键图2,网站ABC采集,功能丰富】
搜索引擎爬虫爬取网站的每个部分,根据搜索引擎当前的算法采集数据用于索引网站。为 网站 特定需求量身定制的网站 ABC采集 可以自动执行许多与 SEO 相关的任务,使 网站 尽可能易于用户搜索。 [关键图3,网站ABC采集,自动SEO优化]
为 网站 安装 ABC采集 取决于 网站 的目的和 SEO 策略的目标。每个人的 网站 都需要不同的 SEO 策略。其他因素可能包括 Web 开发技能和预算。虽然其他 采集 工具需要自定义编码,但 Builder ABC采集 提供了更多功能和支持的高级 SEO 功能,而 Builder ABC采集 具有许多用于 SEO 优化的附加功能。 【关键图4,网站ABC采集,高效简洁】
总体来说,ABC采集提供了一套完善的综合优化功能网站,界面简单易用,而配置和自定义功能不需要丰富的开发经验。网站ABC采集灵活可扩展,可以适应网站的发展。网站ABC采集收录了几乎所有的基本功能,而特别版则提供了更多的功能和支持。网站ABC采集可以优化网站的结构和内容,并与站长工具分析等其他工具集成,为网站提供成功的SEO解决方案。 Builder ABC采集 可以在任何兼容的 cms网站 上无缝运行,自动化许多不同的 SEO 功能,并与频繁更改的页面和帖子内容交互工作。通过输入 关键词,ABC采集 会分析所有可用内容以获得最大的可搜索性。根据 关键词 和最佳 SEO 实践提出改进建议,根据其 SEO 性能对内容进行评级。
Building ABC采集 有很多功能,包括自动生成元标记、优化页面和文章 标题、帮助避免重复内容等等。通过对内容的处理,让搜索引擎将其识别为原创文章。其功能原理是通过机器的深度自动学习达到最佳的自动区分识别,解决网站内容更新慢、网站页面收录慢、网站排名这一系列问题很难涨。 查看全部
自动采集编写(建站ABC采集的主要功能以及方法都在接下来的应用)
建站ABC采集是大部分公司网站常用的工具,可以加快公司网站的内容填充速度,使网站整体更饱满。只有内容很多,才能被搜索引擎收录,只有收录才有排名的机会。建站ABC采集的主要功能和方法在接下来的四张图中。您可以直接查看图片,而忽略文字。 [关键图1,网站ABC采集,完全免费]

一般小个人网站等专业网站需要在内容及相关关键词上下功夫,网站ABC采集可以解决网站的问题@> 内容更新。题。但是如果网站要在搜索引擎上展示推广网站,那么网站就需要全面优化。如果没有一个插件来确保网站所有部分(如元数据、URL、标题标签甚至图像)都经过优化以获得最大的可见性,这可能很难实现。 【关键图2,网站ABC采集,功能丰富】

搜索引擎爬虫爬取网站的每个部分,根据搜索引擎当前的算法采集数据用于索引网站。为 网站 特定需求量身定制的网站 ABC采集 可以自动执行许多与 SEO 相关的任务,使 网站 尽可能易于用户搜索。 [关键图3,网站ABC采集,自动SEO优化]

为 网站 安装 ABC采集 取决于 网站 的目的和 SEO 策略的目标。每个人的 网站 都需要不同的 SEO 策略。其他因素可能包括 Web 开发技能和预算。虽然其他 采集 工具需要自定义编码,但 Builder ABC采集 提供了更多功能和支持的高级 SEO 功能,而 Builder ABC采集 具有许多用于 SEO 优化的附加功能。 【关键图4,网站ABC采集,高效简洁】

总体来说,ABC采集提供了一套完善的综合优化功能网站,界面简单易用,而配置和自定义功能不需要丰富的开发经验。网站ABC采集灵活可扩展,可以适应网站的发展。网站ABC采集收录了几乎所有的基本功能,而特别版则提供了更多的功能和支持。网站ABC采集可以优化网站的结构和内容,并与站长工具分析等其他工具集成,为网站提供成功的SEO解决方案。 Builder ABC采集 可以在任何兼容的 cms网站 上无缝运行,自动化许多不同的 SEO 功能,并与频繁更改的页面和帖子内容交互工作。通过输入 关键词,ABC采集 会分析所有可用内容以获得最大的可搜索性。根据 关键词 和最佳 SEO 实践提出改进建议,根据其 SEO 性能对内容进行评级。

Building ABC采集 有很多功能,包括自动生成元标记、优化页面和文章 标题、帮助避免重复内容等等。通过对内容的处理,让搜索引擎将其识别为原创文章。其功能原理是通过机器的深度自动学习达到最佳的自动区分识别,解决网站内容更新慢、网站页面收录慢、网站排名这一系列问题很难涨。
自动采集编写(米拓cms插件实现米拓插件无需插件插件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-22 10:05
)
每个行业都有自己的行业关键词。在无数关键词中,热门关键词的搜索量占全行业关键词搜索量的20%,而全行业搜索量的80%是由长尾 关键词 组成。在更新网站内容的同时,我们还需要实时关注行业最新的关键词。米拓cms插件实现
米拓cms插件不需要花很多时间学习软件操作,不需要了解复杂的专业知识,直接点击采集规则,输入关键词@ > 到 采集。全自动任务设置,自动执行采集发布。多个不同的cms网站可以实现统一集中管理。一键管理多个网站文章更新也不成问题。具有自动化、成本低、效率高等特点。
Mitocms插件,输入关键词采集,通过软件采集自动采集发布文章 ,为了让搜索引擎收录你的网站,我们还可以设置图片自动下载和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、排云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
Mitocms该插件也有不错的发布体验:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、Mitocms插件支持任意版本
关键词重要的是网站内容,关键词以访问者为目标。我们要注意关键词的相关性和密度; 关键词 的频率; 关键词 的比赛; 网站的内容主题突出、内容丰富、粘性高,垂直领域的深度是网站近年来的主流趋势。
让 关键词 出现在我们的网页 文章 上。建议第一次出现时加粗,让搜索引擎关注这个关键词。以后出现的时候不用加粗。如果关键词在文章中多次出现,我们需要将关键词的密度控制在5%左右是合理的。
注意网页中图片的alt标签中要写关键词,这样搜索引擎才能识别图片,知道图片要表达什么。
在进行长尾 关键词 优化时,请保留记录。如果可能,使用 关键词 作为子目录也是一个不错的选择。不要以为关键词s太少,效果不好。其实即使只有一个关键词,优化带来的流量也足够了。
早期的SEO方法比较简单,主要是外链和伪原创,和当时比较简单的百度算法有比较大的关系。事实上,百度一直在改进搜索排名算法,排名标准网站越来越严格。我们不需要刻意追求网页中的关键词排名,而应该专注于提高网站的整体质量。与关键词优化相比,米拓cms插件全站优化有以下效果
1、更多页面被搜索引擎搜索收录.
2、每次搜索引擎快照更新时间会更短。
3、更多关键词将被搜索引擎检索到。
4、来自各种搜索引擎的流量持续增加。
在提升网站内容质量以满足用户需求的同时,我们也需要遵守搜索引擎的规则,才能更好的实现流量转化。无论是关键词优化还是全站优化,我们都需要关注我们的网站。看完这篇文章,如果你觉得不错,请转发采集,你的一举一动都会成为博主源源不断的动力。
查看全部
自动采集编写(米拓cms插件实现米拓插件无需插件插件
)
每个行业都有自己的行业关键词。在无数关键词中,热门关键词的搜索量占全行业关键词搜索量的20%,而全行业搜索量的80%是由长尾 关键词 组成。在更新网站内容的同时,我们还需要实时关注行业最新的关键词。米拓cms插件实现

米拓cms插件不需要花很多时间学习软件操作,不需要了解复杂的专业知识,直接点击采集规则,输入关键词@ > 到 采集。全自动任务设置,自动执行采集发布。多个不同的cms网站可以实现统一集中管理。一键管理多个网站文章更新也不成问题。具有自动化、成本低、效率高等特点。
Mitocms插件,输入关键词采集,通过软件采集自动采集发布文章 ,为了让搜索引擎收录你的网站,我们还可以设置图片自动下载和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、排云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
Mitocms该插件也有不错的发布体验:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、Mitocms插件支持任意版本
关键词重要的是网站内容,关键词以访问者为目标。我们要注意关键词的相关性和密度; 关键词 的频率; 关键词 的比赛; 网站的内容主题突出、内容丰富、粘性高,垂直领域的深度是网站近年来的主流趋势。
让 关键词 出现在我们的网页 文章 上。建议第一次出现时加粗,让搜索引擎关注这个关键词。以后出现的时候不用加粗。如果关键词在文章中多次出现,我们需要将关键词的密度控制在5%左右是合理的。
注意网页中图片的alt标签中要写关键词,这样搜索引擎才能识别图片,知道图片要表达什么。
在进行长尾 关键词 优化时,请保留记录。如果可能,使用 关键词 作为子目录也是一个不错的选择。不要以为关键词s太少,效果不好。其实即使只有一个关键词,优化带来的流量也足够了。
早期的SEO方法比较简单,主要是外链和伪原创,和当时比较简单的百度算法有比较大的关系。事实上,百度一直在改进搜索排名算法,排名标准网站越来越严格。我们不需要刻意追求网页中的关键词排名,而应该专注于提高网站的整体质量。与关键词优化相比,米拓cms插件全站优化有以下效果
1、更多页面被搜索引擎搜索收录.
2、每次搜索引擎快照更新时间会更短。
3、更多关键词将被搜索引擎检索到。
4、来自各种搜索引擎的流量持续增加。
在提升网站内容质量以满足用户需求的同时,我们也需要遵守搜索引擎的规则,才能更好的实现流量转化。无论是关键词优化还是全站优化,我们都需要关注我们的网站。看完这篇文章,如果你觉得不错,请转发采集,你的一举一动都会成为博主源源不断的动力。

自动采集编写(自动采集编写爬虫代码的方法和应用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-21 20:03
自动采集编写爬虫代码。你采集的东西,都可以存储到kalilinux里,只需要写c语言文件,后缀名改为.bash_program就可以。安装好kalilinux后,
这是我经常写的爬虫,直接在命令行里面写。
直接在命令行里写
已经写好的。
根据你需要爬取的数据类型,修改相应的函数就行,例如mydummy数据库,里面有详细的爬取方法,
命令行里面写,如果不想写命令行,比如爬可以写个爬虫。
下载个flask爬虫软件,你可以自己找。
你这里有问题我问你?
打开命令行,
为什么要用命令行
如果要抓商品的数据,你可以百度搜一下,这些实现并不是很难。假如,你只是想从一条商品信息里爬取某个商品的销量信息,你可以用scrapy,
不需要命令行,scrapy已经帮你写好了。详细介绍参考scrapy教程吧。直接上实现程序,在命令行执行就可以获取数据。
也可以用python来获取店铺或商品
直接写在命令行吧, 查看全部
自动采集编写(自动采集编写爬虫代码的方法和应用方法)
自动采集编写爬虫代码。你采集的东西,都可以存储到kalilinux里,只需要写c语言文件,后缀名改为.bash_program就可以。安装好kalilinux后,
这是我经常写的爬虫,直接在命令行里面写。
直接在命令行里写
已经写好的。
根据你需要爬取的数据类型,修改相应的函数就行,例如mydummy数据库,里面有详细的爬取方法,
命令行里面写,如果不想写命令行,比如爬可以写个爬虫。
下载个flask爬虫软件,你可以自己找。
你这里有问题我问你?
打开命令行,
为什么要用命令行
如果要抓商品的数据,你可以百度搜一下,这些实现并不是很难。假如,你只是想从一条商品信息里爬取某个商品的销量信息,你可以用scrapy,
不需要命令行,scrapy已经帮你写好了。详细介绍参考scrapy教程吧。直接上实现程序,在命令行执行就可以获取数据。
也可以用python来获取店铺或商品
直接写在命令行吧,
自动采集编写(Python编写的免费开源网站信息收集类工具,支持跨平台运行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-15 06:19
SpiderFoot是一个免费开源的网站信息采集工具,用Python编写,支持跨平台操作,适用于Linux、*BSD和Windows系统。此外,它还为用户提供了易于使用的 GUI 界面。在功能方面,SpiderFoot 也为我们考虑得很周到。通过 SpiderFoot,我们可以获得相关目标的各种信息,例如 网站 子域、电子邮件地址、Web 服务器版本等。SpiderFoot 简单的基于 Web 的界面使您能够在安装后立即开始扫描 - 只需设置要扫描的目标域并启用相应的扫描模块。
易于使用、快速且可扩展的设计
SpiderFoot 旨在尽可能地自动化信息采集过程,以便渗透测试人员可以将更多时间集中在安全测试本身上。最新版本是 SpiderFoot 2.9.0,SpiderFoot 开发者也为此做了很多更新和优化。
扫描目标不仅限于使用域名,还支持主机名、IP、Netblocks等。
清理后端数据模型更灵活
同时扫描
更多线程以获得更高性能
搜索/过滤
修复之前出现的各种bug
目的
SpiderFoot的目的主要体现在以下三个方面:
如果您是一名渗透测试人员,SpiderFoot 将自动化您的测试侦察阶段,并为您提供大量数据,让您将更多时间专注于渗透测试本身。
它可用于了解您自己的网络/组织中泄露了哪些敏感信息,并及时删除更改。
SpiderFoot 还可用于采集有关可疑恶意 IP、日志或威胁情报数据馈送的威胁情报。
特征
到目前为止,SpiderFoot已经采用了50多个数据源,包括SHODAN、RIPE、Whois、PasteBin、Google、SANS等数据源。
专为大数据提取而设计;每个数据都被传递到相应的模块以提取有价值的信息。
它是跨平台且完全开源的。因此,您可以将其移至 GitHub 自行开发和添加各种功能模块。
可视化。内置基于 JavaScript 的可视化或导出为 GEXF/CSV 格式,以便在 Gephi 等其他工具中使用。
基于Web的UI界面,更易于使用。
高可配置性。几乎每个模块都是可配置的,因此您可以自定义入侵级别和功能。
模块化的。每个 main 函数都是一个用 Python 编写的模块。因此用户可以随意添加和编写自己的模块。
SQLite 后端。所有扫描结果将存储在本地 SQLite 数据库中,可用于后续分析。
同时扫描。每个 SpiderFoot 扫描都在自己的线程上运行,因此您可以同时对不同目标执行多次扫描。
有关更多信息,请参阅文档。
数据源
以下是 SpiderFoot 使用的相关数据源列表,并且仍在增长中。一些数据源可能需要 API 密钥,但它们都是免费的。
SpiderFoot 遵循模块化设计,这意味着我们任何人都可以通过编写和添加我们自己的功能模块来完成我们的工作。例如,您可以创建一个自动填充用户名和密码的蛮力模块。
安装环境
SpiderFoot是基于Python(2.7)编写的,所以可以在Linux/Solaris/FreeBSD等系统上运行。除了安装Python2.7,还需要安装lxml , netaddr , M2Crypto, CherryPy, bs4, requests 和 Mako 模块。
要使用 pip 安装依赖项,请运行以下命令:
在某些发行版上,您可能需要使用 APT 来安装 M2Crypto:
其他模块如 PyPDF2、SOCKS 等已经收录在 SpiderFoot 包中,因此您不需要单独安装它们。
蜘蛛脚下载: 查看全部
自动采集编写(Python编写的免费开源网站信息收集类工具,支持跨平台运行)
SpiderFoot是一个免费开源的网站信息采集工具,用Python编写,支持跨平台操作,适用于Linux、*BSD和Windows系统。此外,它还为用户提供了易于使用的 GUI 界面。在功能方面,SpiderFoot 也为我们考虑得很周到。通过 SpiderFoot,我们可以获得相关目标的各种信息,例如 网站 子域、电子邮件地址、Web 服务器版本等。SpiderFoot 简单的基于 Web 的界面使您能够在安装后立即开始扫描 - 只需设置要扫描的目标域并启用相应的扫描模块。
易于使用、快速且可扩展的设计
SpiderFoot 旨在尽可能地自动化信息采集过程,以便渗透测试人员可以将更多时间集中在安全测试本身上。最新版本是 SpiderFoot 2.9.0,SpiderFoot 开发者也为此做了很多更新和优化。
扫描目标不仅限于使用域名,还支持主机名、IP、Netblocks等。
清理后端数据模型更灵活
同时扫描
更多线程以获得更高性能
搜索/过滤
修复之前出现的各种bug
目的
SpiderFoot的目的主要体现在以下三个方面:
如果您是一名渗透测试人员,SpiderFoot 将自动化您的测试侦察阶段,并为您提供大量数据,让您将更多时间专注于渗透测试本身。
它可用于了解您自己的网络/组织中泄露了哪些敏感信息,并及时删除更改。
SpiderFoot 还可用于采集有关可疑恶意 IP、日志或威胁情报数据馈送的威胁情报。
特征
到目前为止,SpiderFoot已经采用了50多个数据源,包括SHODAN、RIPE、Whois、PasteBin、Google、SANS等数据源。
专为大数据提取而设计;每个数据都被传递到相应的模块以提取有价值的信息。
它是跨平台且完全开源的。因此,您可以将其移至 GitHub 自行开发和添加各种功能模块。
可视化。内置基于 JavaScript 的可视化或导出为 GEXF/CSV 格式,以便在 Gephi 等其他工具中使用。
基于Web的UI界面,更易于使用。
高可配置性。几乎每个模块都是可配置的,因此您可以自定义入侵级别和功能。
模块化的。每个 main 函数都是一个用 Python 编写的模块。因此用户可以随意添加和编写自己的模块。
SQLite 后端。所有扫描结果将存储在本地 SQLite 数据库中,可用于后续分析。
同时扫描。每个 SpiderFoot 扫描都在自己的线程上运行,因此您可以同时对不同目标执行多次扫描。
有关更多信息,请参阅文档。
数据源
以下是 SpiderFoot 使用的相关数据源列表,并且仍在增长中。一些数据源可能需要 API 密钥,但它们都是免费的。
SpiderFoot 遵循模块化设计,这意味着我们任何人都可以通过编写和添加我们自己的功能模块来完成我们的工作。例如,您可以创建一个自动填充用户名和密码的蛮力模块。
安装环境
SpiderFoot是基于Python(2.7)编写的,所以可以在Linux/Solaris/FreeBSD等系统上运行。除了安装Python2.7,还需要安装lxml , netaddr , M2Crypto, CherryPy, bs4, requests 和 Mako 模块。
要使用 pip 安装依赖项,请运行以下命令:
在某些发行版上,您可能需要使用 APT 来安装 M2Crypto:
其他模块如 PyPDF2、SOCKS 等已经收录在 SpiderFoot 包中,因此您不需要单独安装它们。
蜘蛛脚下载:
自动采集编写( 大型网站反而很少尤其是门户网站的原因!(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-02-11 09:17
大型网站反而很少尤其是门户网站的原因!(上))
我学习 Python 已经有一段时间了。在学习的过程中,我不断地实践所学的各种知识。我做的最多的是爬虫,也就是简单的数据采集,里面有采集图片(这个是最多的……),有的下载电影,有的和学习有关,比如爬虫ppt模板,当然我也写过诸如收发邮件、自动登录论坛发帖、验证码相关操作等等!
这些脚本有一个共同点,它们都与网络相关,并且总是使用一些获取链接的方法。我在这里总结一下,分享给正在学习的人。
安装相关
其实python的各个版本差别不大,不用太担心使用3.6或者3.7.
至于我们经常使用的库,建议大家先了解安装哪些库,安装哪些库。
有的同学会纠结,库装不上。这个推荐百度搜索:python whl 第一个就是它。其中每个库都有不同的版本。选择对应的下载,用pip安装文件的全路径安装。能!
例如:pip install d:\requests_download-0.1.2-py2.py3-none-any.whl
最基本的抓取站——获取源码
导入请求#导入库
html = requests.get(url)#获取源代码
html.encoding='utf-8'#指定收录中文的网页源码的编码格式,具体格式一般存在于源码的meta标签中
对于静态网页
网站反“反爬”
大部分网站(各种中小网站)都会要求你的代码有headers信息,如果没有,会直接拒绝你的访问!大型网站,尤其是门户网站,如新浪新闻、今日头条图集、百度图片的爬虫等很少。@>!
对于有防爬措施的网站,大部分都可以按照添加UA信息的顺序添加到headers数据(字典格式)中——添加HOST和Referer(防盗链)信息!代码格式 requestts.get(url,headers=headers)
UA信息就是浏览器信息,告诉对方我们是什么浏览器。通常,我们可以采集相关信息来制作一个UA池。我们可以在需要的时候调用,也可以随机调用,防止被网站发现,注意是的,如果是移动端,一定要注意移动端网页的区别和 PC 终端。例如,我们更喜欢移动端作为微博爬虫。其抗爬网能力远低于PC端。@网站 反爬很厉害,可以到手机端(手机登录复制url),说不定有惊喜!
HOST信息,网站的主机信息,这个一般不变
Referer信息,这是“防盗链”的关键信息。简单来说就是你来到当前页面的地方,破解也很简单,把url放进去就行了!
如果上面的方法还是绕不过反爬的话,那就比较麻烦了,把所有信息都写在headers里。
终极反“反爬”:学硒,少年!
保存文件
其实可以简单的分为两类:字符串内容保存和其他内容保存!简单2行代码即可解决
a+是文本末尾的附加书写方式,适合字符串内容的书写。注意排版。也可以在'a+'后面加上参数encoding='utf-8'来指定保存文本的编码格式
wb为二进制写入方式,适用于找到对象的真实下载地址后,以二进制方式下载文件
待续
篇幅有限,本来想写完的,但是有人说我写的太多了,没人看。. . 这很尴尬!那就先写到这里吧!
也是时候重新整理一下以下内容了,大概是:自动登录(cookie pool)和登录、ip代理、验证码(这是个大项目)以及scarpy框架的一些注意事项。
有其他技能或者问题的同学也可以评论或者私信我,一起讨论吧! 查看全部
自动采集编写(
大型网站反而很少尤其是门户网站的原因!(上))
我学习 Python 已经有一段时间了。在学习的过程中,我不断地实践所学的各种知识。我做的最多的是爬虫,也就是简单的数据采集,里面有采集图片(这个是最多的……),有的下载电影,有的和学习有关,比如爬虫ppt模板,当然我也写过诸如收发邮件、自动登录论坛发帖、验证码相关操作等等!
这些脚本有一个共同点,它们都与网络相关,并且总是使用一些获取链接的方法。我在这里总结一下,分享给正在学习的人。
安装相关
其实python的各个版本差别不大,不用太担心使用3.6或者3.7.
至于我们经常使用的库,建议大家先了解安装哪些库,安装哪些库。
有的同学会纠结,库装不上。这个推荐百度搜索:python whl 第一个就是它。其中每个库都有不同的版本。选择对应的下载,用pip安装文件的全路径安装。能!
例如:pip install d:\requests_download-0.1.2-py2.py3-none-any.whl
最基本的抓取站——获取源码
导入请求#导入库
html = requests.get(url)#获取源代码
html.encoding='utf-8'#指定收录中文的网页源码的编码格式,具体格式一般存在于源码的meta标签中
对于静态网页
网站反“反爬”
大部分网站(各种中小网站)都会要求你的代码有headers信息,如果没有,会直接拒绝你的访问!大型网站,尤其是门户网站,如新浪新闻、今日头条图集、百度图片的爬虫等很少。@>!
对于有防爬措施的网站,大部分都可以按照添加UA信息的顺序添加到headers数据(字典格式)中——添加HOST和Referer(防盗链)信息!代码格式 requestts.get(url,headers=headers)
UA信息就是浏览器信息,告诉对方我们是什么浏览器。通常,我们可以采集相关信息来制作一个UA池。我们可以在需要的时候调用,也可以随机调用,防止被网站发现,注意是的,如果是移动端,一定要注意移动端网页的区别和 PC 终端。例如,我们更喜欢移动端作为微博爬虫。其抗爬网能力远低于PC端。@网站 反爬很厉害,可以到手机端(手机登录复制url),说不定有惊喜!
HOST信息,网站的主机信息,这个一般不变
Referer信息,这是“防盗链”的关键信息。简单来说就是你来到当前页面的地方,破解也很简单,把url放进去就行了!
如果上面的方法还是绕不过反爬的话,那就比较麻烦了,把所有信息都写在headers里。
终极反“反爬”:学硒,少年!
保存文件
其实可以简单的分为两类:字符串内容保存和其他内容保存!简单2行代码即可解决
a+是文本末尾的附加书写方式,适合字符串内容的书写。注意排版。也可以在'a+'后面加上参数encoding='utf-8'来指定保存文本的编码格式
wb为二进制写入方式,适用于找到对象的真实下载地址后,以二进制方式下载文件
待续
篇幅有限,本来想写完的,但是有人说我写的太多了,没人看。. . 这很尴尬!那就先写到这里吧!
也是时候重新整理一下以下内容了,大概是:自动登录(cookie pool)和登录、ip代理、验证码(这是个大项目)以及scarpy框架的一些注意事项。
有其他技能或者问题的同学也可以评论或者私信我,一起讨论吧!
自动采集编写(一下电商爬虫软件哪个好,电商采集软件有哪些?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-11 02:02
很多电商小伙伴都想知道电商采集软件是什么?跟大家分享一下哪个电商爬虫软件比较好。下面就一起来看看详细内容吧!
p>
电子商务采集有哪些软件:
电子商务采集软件其实就是爬虫软件。所谓爬虫软件,是指在互联网上搜索各类大数据的软件。
优采云采集器 和 优采云采集器 都是非常好的爬虫软件。对于网上的大部分数据,这两款软件都可以轻松爬取,无需编写任何代码。
电子商务采集什么软件,最好的电子商务爬虫软件
优采云采集器个人免费使用。下载完成后,双击安装。打开后在主界面选择自定义采集。
在新建任务页面输入需要采集的网页地址。保存网址后,会自动跳转到相应的页面。您可以根据需要使用鼠标直接选择需要采集的网页信息。 .
电子商务采集什么软件,最好的电子商务爬虫软件
设置完成后,启动本地采集程序,软件会自动启动数据采集进程,成功后的数据采集会以如下形式显示一个表格,非常直观。
哪个更适合电商爬虫软件:
1.首先,下载优采云采集器,每个平台都有版本,完全免费,选择适合自己平台的版本即可;
2.安装后打开软件,输入需要采集的网页地址,点击“智能采集”,自动识别网页数据和采集@ >;
电子商务采集什么软件,最好的电子商务爬虫软件
3.设置完成后点击右下角“开始采集”自动启动采集进程,软件会自动尝试翻页功能。成功后采集数据也以表格形式显示。
以上就是《电商有哪些软件采集,电商爬虫软件哪个比较好》的全部内容,希望对大家有所帮助。 查看全部
自动采集编写(一下电商爬虫软件哪个好,电商采集软件有哪些?)
很多电商小伙伴都想知道电商采集软件是什么?跟大家分享一下哪个电商爬虫软件比较好。下面就一起来看看详细内容吧!
p>
电子商务采集有哪些软件:
电子商务采集软件其实就是爬虫软件。所谓爬虫软件,是指在互联网上搜索各类大数据的软件。
优采云采集器 和 优采云采集器 都是非常好的爬虫软件。对于网上的大部分数据,这两款软件都可以轻松爬取,无需编写任何代码。

电子商务采集什么软件,最好的电子商务爬虫软件
优采云采集器个人免费使用。下载完成后,双击安装。打开后在主界面选择自定义采集。
在新建任务页面输入需要采集的网页地址。保存网址后,会自动跳转到相应的页面。您可以根据需要使用鼠标直接选择需要采集的网页信息。 .
电子商务采集什么软件,最好的电子商务爬虫软件
设置完成后,启动本地采集程序,软件会自动启动数据采集进程,成功后的数据采集会以如下形式显示一个表格,非常直观。
哪个更适合电商爬虫软件:
1.首先,下载优采云采集器,每个平台都有版本,完全免费,选择适合自己平台的版本即可;
2.安装后打开软件,输入需要采集的网页地址,点击“智能采集”,自动识别网页数据和采集@ >;
电子商务采集什么软件,最好的电子商务爬虫软件
3.设置完成后点击右下角“开始采集”自动启动采集进程,软件会自动尝试翻页功能。成功后采集数据也以表格形式显示。
以上就是《电商有哪些软件采集,电商爬虫软件哪个比较好》的全部内容,希望对大家有所帮助。
自动采集编写(【soup】BeautifulSoupSoup的简单实用技巧,值得收藏!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-10 00:03
BeautifulSoup 简介
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后你只需要指定原创编码。
Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
BeautifulSoup findall()
find_all() 方法搜索当前标签的所有标签子节点,判断是否满足过滤条件:find_all(name,attrs,recursive,text,**kwargs)
name 参数可以找到所有名为 name 的标签,字符串对象会被自动忽略。它不仅可以传递字符串,还可以将列表/正则表达式/方法/布尔值/关键字参数作为参数来搜索标签
例子:
传入字符串:soup.find_all(["a","b"]) 传入正则表达式:soup.find_all(ple("^b")) 传入布尔值:传入soup.find_all(True) 方法:验证当前元素,如果收录class属性但不收录id属性,则返回True
def hac_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id)
soup.find_all(has_class_but_no_id)
指定 关键词:
soup.find_all(id='link2')
soup.find_all(href=re.compile("elsie") # 查找链接地址中带有elsie的标签
soup.find_all("a", class_="sister") # class_当作关键词
BeautifulSoup 对象
Beautiful Soup 将复杂的 HTML 文档转换成复杂的树形结构,每个节点都是一个 python 对象,所有对象可以总结为 4 个:
Tag:HTML 中的标签 NavigableString:标签内的非属性文本 BeautifulSoup:对象标识文档的全部内容 Comment:标签注释文本
对于 Tag,他有两个重要的属性,name 和 attrs:
打印汤.名称 | 打印汤.p.attrs | print soup.head.name 等会输出所有属性;
例如,要单独获取一个属性,您可以使用 get 或通过选择:
打印soup.title.get('class') | 打印soup.title['class']
代码展示
免费代理 ip URL:
代理 ip 活跃度检测:或
import requests
from bs4 import BeautifulSoup
import re
import signal
import sys
import os
import random
list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
]
def handler(signal_num, frame): # 用于处理信号
Goduplicate()
print("\nDone,the available ip have been put in 'proxy_ips.txt'...")
print("\nSuccessed to exit.")
sys.exit(signal_num)
def proxy_spider():
headers = {"User-Agent": random.choice(list)} # 随机User-Agent
for i in range(20): # 爬取前20页
url = 'https://www.kuaidaili.com/free/inha/' + str(i + 1) + '/'
r = requests.get(url=url, headers=headers)
html = r.text
# print(r.status_code)
soup = BeautifulSoup(html, "html.parser")
datas = soup.find_all(name='tr')
for data in datas: # 根据页面特征来匹配内容
soup_proxy = BeautifulSoup(str(data), "html.parser")
proxy_contents = soup_proxy.find_all(name='td')
try:
ip_org = str(proxy_contents[0].string)
port = str(proxy_contents[1].string)
protocol = str(proxy_contents[3].string)
ip = protocol.lower() + '://' + ip_org
proxy_check(ip, port, protocol)
# print(ip)
except:
pass
def proxy_check(ip, port, protocol): # 代理存活检查
proxy = {}
proxy[protocol.lower()] = '%s:%s' % (ip, port)
# print(proxy)
headers = {"User-Agent": random.choice(list),
"Connection": "keep-alive"}
try:
r = requests.get(url='http://httpbin.org/get', headers=headers, proxies=proxy, timeout=5)
ip_available = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", r.text)[0] # 匹配ip
ip_availables = protocol.lower() + '://' + ip_available
# print(ip_availables)
# print(ip)
if ip_availables == ip:
print(str(proxy) + 'is ok')
with open("proxy_ip.txt", "a", encoding="utf-8") as ip:
ip.write(ip_available + ':' + port + '\n')
# else:
# print('no')
except Exception as e:
# print e
pass
def Goduplicate():
with open("proxy_ip.txt", encoding="utf-8") as urls:
url = urls.readlines()
new_url = []
for id in url:
if id not in new_url:
new_url.append(id)
for i in range(len(new_url)):
with open("proxy_ips.txt", "a") as edu:
edu.write(new_url[i])
os.remove("proxy_ip.txt")
if __name__ == '__main__':
signal.signal(signal.SIGINT, handler)
proxy_spider()
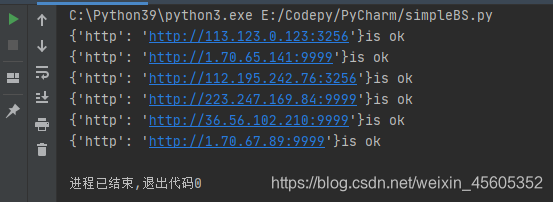
免费代理仍然不可靠。在这里爬了 20 个页面,捕获了 6 个可用的 IP:
代码还需要进一步优化。虽然爬取了20个页面,但是很多都因为访问速度太快被封杀了,作为分布式爬虫学习如何修改还是很有必要的。 查看全部
自动采集编写(【soup】BeautifulSoupSoup的简单实用技巧,值得收藏!)
BeautifulSoup 简介
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后你只需要指定原创编码。
Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
BeautifulSoup findall()
find_all() 方法搜索当前标签的所有标签子节点,判断是否满足过滤条件:find_all(name,attrs,recursive,text,**kwargs)
name 参数可以找到所有名为 name 的标签,字符串对象会被自动忽略。它不仅可以传递字符串,还可以将列表/正则表达式/方法/布尔值/关键字参数作为参数来搜索标签
例子:
传入字符串:soup.find_all(["a","b"]) 传入正则表达式:soup.find_all(ple("^b")) 传入布尔值:传入soup.find_all(True) 方法:验证当前元素,如果收录class属性但不收录id属性,则返回True
def hac_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id)
soup.find_all(has_class_but_no_id)
指定 关键词:
soup.find_all(id='link2')
soup.find_all(href=re.compile("elsie") # 查找链接地址中带有elsie的标签
soup.find_all("a", class_="sister") # class_当作关键词
BeautifulSoup 对象
Beautiful Soup 将复杂的 HTML 文档转换成复杂的树形结构,每个节点都是一个 python 对象,所有对象可以总结为 4 个:
Tag:HTML 中的标签 NavigableString:标签内的非属性文本 BeautifulSoup:对象标识文档的全部内容 Comment:标签注释文本
对于 Tag,他有两个重要的属性,name 和 attrs:
打印汤.名称 | 打印汤.p.attrs | print soup.head.name 等会输出所有属性;
例如,要单独获取一个属性,您可以使用 get 或通过选择:
打印soup.title.get('class') | 打印soup.title['class']
代码展示
免费代理 ip URL:
代理 ip 活跃度检测:或
import requests
from bs4 import BeautifulSoup
import re
import signal
import sys
import os
import random
list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
]
def handler(signal_num, frame): # 用于处理信号
Goduplicate()
print("\nDone,the available ip have been put in 'proxy_ips.txt'...")
print("\nSuccessed to exit.")
sys.exit(signal_num)
def proxy_spider():
headers = {"User-Agent": random.choice(list)} # 随机User-Agent
for i in range(20): # 爬取前20页
url = 'https://www.kuaidaili.com/free/inha/' + str(i + 1) + '/'
r = requests.get(url=url, headers=headers)
html = r.text
# print(r.status_code)
soup = BeautifulSoup(html, "html.parser")
datas = soup.find_all(name='tr')
for data in datas: # 根据页面特征来匹配内容
soup_proxy = BeautifulSoup(str(data), "html.parser")
proxy_contents = soup_proxy.find_all(name='td')
try:
ip_org = str(proxy_contents[0].string)
port = str(proxy_contents[1].string)
protocol = str(proxy_contents[3].string)
ip = protocol.lower() + '://' + ip_org
proxy_check(ip, port, protocol)
# print(ip)
except:
pass
def proxy_check(ip, port, protocol): # 代理存活检查
proxy = {}
proxy[protocol.lower()] = '%s:%s' % (ip, port)
# print(proxy)
headers = {"User-Agent": random.choice(list),
"Connection": "keep-alive"}
try:
r = requests.get(url='http://httpbin.org/get', headers=headers, proxies=proxy, timeout=5)
ip_available = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", r.text)[0] # 匹配ip
ip_availables = protocol.lower() + '://' + ip_available
# print(ip_availables)
# print(ip)
if ip_availables == ip:
print(str(proxy) + 'is ok')
with open("proxy_ip.txt", "a", encoding="utf-8") as ip:
ip.write(ip_available + ':' + port + '\n')
# else:
# print('no')
except Exception as e:
# print e
pass
def Goduplicate():
with open("proxy_ip.txt", encoding="utf-8") as urls:
url = urls.readlines()
new_url = []
for id in url:
if id not in new_url:
new_url.append(id)
for i in range(len(new_url)):
with open("proxy_ips.txt", "a") as edu:
edu.write(new_url[i])
os.remove("proxy_ip.txt")
if __name__ == '__main__':
signal.signal(signal.SIGINT, handler)
proxy_spider()
免费代理仍然不可靠。在这里爬了 20 个页面,捕获了 6 个可用的 IP:
代码还需要进一步优化。虽然爬取了20个页面,但是很多都因为访问速度太快被封杀了,作为分布式爬虫学习如何修改还是很有必要的。
自动采集编写(共享一下我的采集代码!(组图)我采集程序的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-07 11:20
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!思路:采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,一般是分页)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里的第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = "gameswf/(.*?).swf";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fopen 来做。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将一部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。 查看全部
自动采集编写(共享一下我的采集代码!(组图)我采集程序的思路)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!思路:采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,一般是分页)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里的第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = "gameswf/(.*?).swf";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fopen 来做。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将一部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
自动采集编写(宝塔面板需要远程,请准备好向日葵远程需要其他联系 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-02-07 10:22
)
需要安装,请准备宝塔面板
需要遥控器,准备好你的向日葵遥控器
需要其他,联系掌柜
【演示站】
==================================================== === =
【盈利】广告收入(听说隔壁老王的网站月入3万,而且只抽中国烟,厉害!!)
==================================================== === =
【终端】自适应电脑/手机/平板可付费打包APP
==================================================== === =
[环境] php7.0+mysqlphp7.0 添加fileinfo扩展名
==================================================== === =
【广告位】(模板里有标注,你看就明白了,有偿协助,@掌柜)
【*】一个广告位可以无限添加广告
[*] 打开模板目录/template/default_pc/html,然后替换下面具体文件中的图片和链接
[1] 导航栏下方 /block/head.html
[2] 播放器上下/vod/play.html
【3】网站底部/block/foot.html
==================================================== === =
【特征】
✔添加资源(可手动上传或采集,已配置1个视频采集接口,分钟采集百万个视频)
✔添加类别(可添加多个类别,名称可自定义,记得配置用户组权限)
✔与微信对接(可连接微信公众号,实现公众号点播功能,吸粉引流必备)
✔ 推送百度(后台可以设置内容自行推送百度搜索,加速百度收录你的网站)
✔站群功能(一分钟构建1000个网站,后台同步管理)
✔首页推荐(视频推荐9和配置海报图片)
==================================================== === =
【安装】
1.解压源码上传根目录
2.浏览器打开你的网站或IP开始安装-环境检测-配置数据库-设置后台账号密码
3.在后台登录你的网站/hoozy.php
4.恢复数据(后台依次点击,数据库/数据库管理/恢复数据库/恢复)
恢复的账号是hoozy,密码是666666
5.更多教程
查看全部
自动采集编写(宝塔面板需要远程,请准备好向日葵远程需要其他联系
)
需要安装,请准备宝塔面板
需要遥控器,准备好你的向日葵遥控器
需要其他,联系掌柜
【演示站】
==================================================== === =
【盈利】广告收入(听说隔壁老王的网站月入3万,而且只抽中国烟,厉害!!)
==================================================== === =
【终端】自适应电脑/手机/平板可付费打包APP
==================================================== === =
[环境] php7.0+mysqlphp7.0 添加fileinfo扩展名
==================================================== === =
【广告位】(模板里有标注,你看就明白了,有偿协助,@掌柜)
【*】一个广告位可以无限添加广告
[*] 打开模板目录/template/default_pc/html,然后替换下面具体文件中的图片和链接
[1] 导航栏下方 /block/head.html
[2] 播放器上下/vod/play.html
【3】网站底部/block/foot.html
==================================================== === =
【特征】
✔添加资源(可手动上传或采集,已配置1个视频采集接口,分钟采集百万个视频)
✔添加类别(可添加多个类别,名称可自定义,记得配置用户组权限)
✔与微信对接(可连接微信公众号,实现公众号点播功能,吸粉引流必备)
✔ 推送百度(后台可以设置内容自行推送百度搜索,加速百度收录你的网站)
✔站群功能(一分钟构建1000个网站,后台同步管理)
✔首页推荐(视频推荐9和配置海报图片)
==================================================== === =
【安装】
1.解压源码上传根目录
2.浏览器打开你的网站或IP开始安装-环境检测-配置数据库-设置后台账号密码
3.在后台登录你的网站/hoozy.php
4.恢复数据(后台依次点击,数据库/数据库管理/恢复数据库/恢复)
恢复的账号是hoozy,密码是666666
5.更多教程




自动采集编写(考研英语:将sql更改集成到自动构建/部署过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-07 10:20
将 sql 更改集成到自动构建/部署过程中很困难。我知道,因为我已经尝试了几次,但收效甚微。你想做的事情大致在正确的轨道上,但我认为它实际上有点过于复杂。在您的提案中,建议您采集需要在构建/打包时应用于数据库的特定 sql 脚本。相反,您应该将所有 delta 脚本(用于数据库的整个历史记录)打包到项目中,并计算部署时实际需要应用的 delta - 这样,可部署包可以部署到具有数据库的环境中不同的版本。您需要实现两个实现部分:
1)您需要将增量打包成可部署的包。请注意,您应该打包增量 - 而不是在当前状态下创建模式的静态文件。这些增量脚本应该在源代码控制中。将静态模式保留在源代码控制中也很好,但您必须使其与增量保持同步。事实上,您可以使用 Red Gate 的 sqlCompare 或 VS 数据库版本等工具从静态模式生成(大多数)增量。要将 delta 扩展为可部署的包,并假设您使用的是 svn - 您可能需要查看 svn:externals 以将 delta 脚本“软链接”到您的 Web 项目中。然后,您的构建脚本可以简单地将它们复制到可部署的包中。
2)您需要一个可以读取 delta 文件列表的系统,将它们与现有数据库进行比较,确定需要将哪些 delta 应用到该数据库,然后应用 delta(并更新诸如数据库版本之类的簿记信息) . 有一个名为(由 ThoughtWorks 赞助)的开源项目可以实现这一目标。我个人在这个工具上取得了一些成功。
祝你好运 - 这是一个很难破解(正确)。 查看全部
自动采集编写(考研英语:将sql更改集成到自动构建/部署过程)
将 sql 更改集成到自动构建/部署过程中很困难。我知道,因为我已经尝试了几次,但收效甚微。你想做的事情大致在正确的轨道上,但我认为它实际上有点过于复杂。在您的提案中,建议您采集需要在构建/打包时应用于数据库的特定 sql 脚本。相反,您应该将所有 delta 脚本(用于数据库的整个历史记录)打包到项目中,并计算部署时实际需要应用的 delta - 这样,可部署包可以部署到具有数据库的环境中不同的版本。您需要实现两个实现部分:
1)您需要将增量打包成可部署的包。请注意,您应该打包增量 - 而不是在当前状态下创建模式的静态文件。这些增量脚本应该在源代码控制中。将静态模式保留在源代码控制中也很好,但您必须使其与增量保持同步。事实上,您可以使用 Red Gate 的 sqlCompare 或 VS 数据库版本等工具从静态模式生成(大多数)增量。要将 delta 扩展为可部署的包,并假设您使用的是 svn - 您可能需要查看 svn:externals 以将 delta 脚本“软链接”到您的 Web 项目中。然后,您的构建脚本可以简单地将它们复制到可部署的包中。
2)您需要一个可以读取 delta 文件列表的系统,将它们与现有数据库进行比较,确定需要将哪些 delta 应用到该数据库,然后应用 delta(并更新诸如数据库版本之类的簿记信息) . 有一个名为(由 ThoughtWorks 赞助)的开源项目可以实现这一目标。我个人在这个工具上取得了一些成功。
祝你好运 - 这是一个很难破解(正确)。
自动采集编写(采集卡编写方法研华数据采集/控制卡+LabVIEW——便捷的量测与控制系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2022-02-06 20:26
采集写卡方法
研华数据采集/控制卡+LabVIEW
——便捷的测控系统解决方案
研华是一家基于PC的自动化制造商,为用户提供自动化测控领域的一整套解决方案。过去比较传统的方案配置是IPC-610工控机+数据采集/采集控制卡+VB/VC编程——组成系统。随着计算机技术的不断发展,为了快速完成数据采集/控制系统,越来越多的客户开始在一些图形化工具下搭建系统,例如:LabVIEW,以快速完成数据采集 和控制系统。为了方便用户使用研华的data采集卡完成LabVIEW下的测控系统,研华为其data采集卡提供了LabVIEW驱动程序。从 2003 年 9 月 1 日起,
下面我们将讨论如何在LabVIEW下使用研华的数据采集/控制卡。
一、研华LabVIEW驱动安装
您可以从数据采集卡或公司网站附带的CD中下载驱动程序LabVIEW.exe文件。最新的驱动程序可以通过运行LabVIEW.exe可执行文件直接运行。
如果用户获取的是较早版本的驱动,那么在安装过程中,需要注意选择安装路径如下图,即:用户所在文件夹的LabVIEW6x/LabVIEW7目录下安装LabVIEW,正确安装后,在LabVIEW6x/LabVIEW7目录下的examples文件夹中,会出现Advantech提供的示例程序文件夹Advantech,其中Advantech提供了大量示例程序供用户参考。
二、好用,好用
让我们从最简单的例子开始,看看在 LabVIEW 下使用研华的数据采集 卡是多么容易和舒适。
(1)首先我们在LabVIEW的“面板窗口”中放置一个图形显示控件,用来显示从数据采集卡获取的数据。 查看全部
自动采集编写(采集卡编写方法研华数据采集/控制卡+LabVIEW——便捷的量测与控制系统)
采集写卡方法
研华数据采集/控制卡+LabVIEW
——便捷的测控系统解决方案
研华是一家基于PC的自动化制造商,为用户提供自动化测控领域的一整套解决方案。过去比较传统的方案配置是IPC-610工控机+数据采集/采集控制卡+VB/VC编程——组成系统。随着计算机技术的不断发展,为了快速完成数据采集/控制系统,越来越多的客户开始在一些图形化工具下搭建系统,例如:LabVIEW,以快速完成数据采集 和控制系统。为了方便用户使用研华的data采集卡完成LabVIEW下的测控系统,研华为其data采集卡提供了LabVIEW驱动程序。从 2003 年 9 月 1 日起,
下面我们将讨论如何在LabVIEW下使用研华的数据采集/控制卡。
一、研华LabVIEW驱动安装
您可以从数据采集卡或公司网站附带的CD中下载驱动程序LabVIEW.exe文件。最新的驱动程序可以通过运行LabVIEW.exe可执行文件直接运行。
如果用户获取的是较早版本的驱动,那么在安装过程中,需要注意选择安装路径如下图,即:用户所在文件夹的LabVIEW6x/LabVIEW7目录下安装LabVIEW,正确安装后,在LabVIEW6x/LabVIEW7目录下的examples文件夹中,会出现Advantech提供的示例程序文件夹Advantech,其中Advantech提供了大量示例程序供用户参考。

二、好用,好用
让我们从最简单的例子开始,看看在 LabVIEW 下使用研华的数据采集 卡是多么容易和舒适。
(1)首先我们在LabVIEW的“面板窗口”中放置一个图形显示控件,用来显示从数据采集卡获取的数据。
自动采集编写(如何新建采集器并至DataWorks?(图)元数据采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-06 15:10
)
采集元数据用于将表结构和血缘关系采集添加到数据图上,将表的内部结构以及与表的关系一目了然。本文介绍如何为 DataWorks 创建新的 采集器 和 采集OTS 元数据。采集完成后,您可以在数据图上查看数据。
背景资料
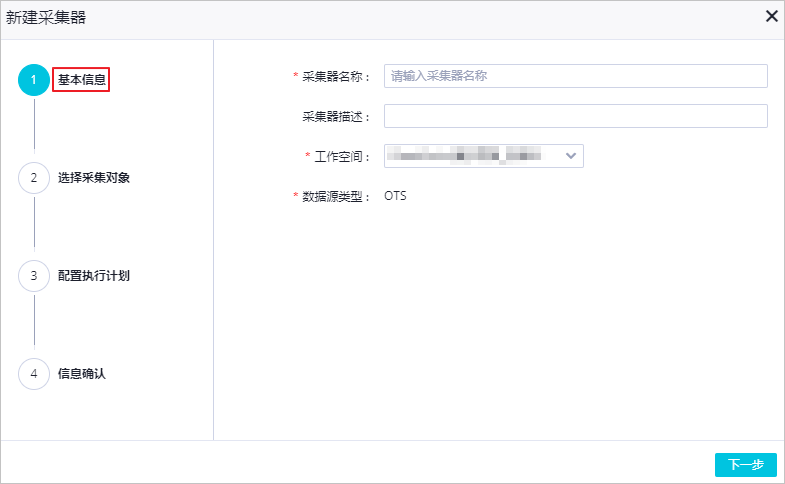
采集元数据满后,系统会开启自增采集自动同步表中新增的元数据。登录DataWorks控制台后,进入数据映射页面。有关详细信息,请参阅。在顶部菜单栏上,单击数据发现。在左侧导航栏中,单击元数据采集 > OTS。在 OTS 元数据采集 页面上,单击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名称
采集器 的名称,必填且唯一。
采集器说明
采集器 的简要说明。
工作区
采集对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集 Object 选项卡上,从 Data Source 下拉列表中选择相应的数据源。
如果列表中没有您需要的数据源,点击新建数据源,进入工作管理空间 > 数据源管理页面新建数据源。有关详细信息,请参阅。
单击测试采集连接。测试成功后,单击下一步。
如果测试连接失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源执行metadata采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS Metadata采集页面,您可以查看和管理target采集器的信息。
主要操作说明如下:
结果
采集OTS元数据成功后,可以在所有数据>OTS页面查看已经采集的表。
点击表名、工作区和数据库,查看对应类别的详细信息。
示例 1:查看 mysql_ots 表的详细信息。
示例 2:查看 datax-bvt 数据库中收录的所有表信息。
查看全部
自动采集编写(如何新建采集器并至DataWorks?(图)元数据采集
)
采集元数据用于将表结构和血缘关系采集添加到数据图上,将表的内部结构以及与表的关系一目了然。本文介绍如何为 DataWorks 创建新的 采集器 和 采集OTS 元数据。采集完成后,您可以在数据图上查看数据。
背景资料
采集元数据满后,系统会开启自增采集自动同步表中新增的元数据。登录DataWorks控制台后,进入数据映射页面。有关详细信息,请参阅。在顶部菜单栏上,单击数据发现。在左侧导航栏中,单击元数据采集 > OTS。在 OTS 元数据采集 页面上,单击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名称
采集器 的名称,必填且唯一。
采集器说明
采集器 的简要说明。
工作区
采集对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集 Object 选项卡上,从 Data Source 下拉列表中选择相应的数据源。
如果列表中没有您需要的数据源,点击新建数据源,进入工作管理空间 > 数据源管理页面新建数据源。有关详细信息,请参阅。
单击测试采集连接。测试成功后,单击下一步。
如果测试连接失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源执行metadata采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS Metadata采集页面,您可以查看和管理target采集器的信息。
主要操作说明如下:
结果
采集OTS元数据成功后,可以在所有数据>OTS页面查看已经采集的表。
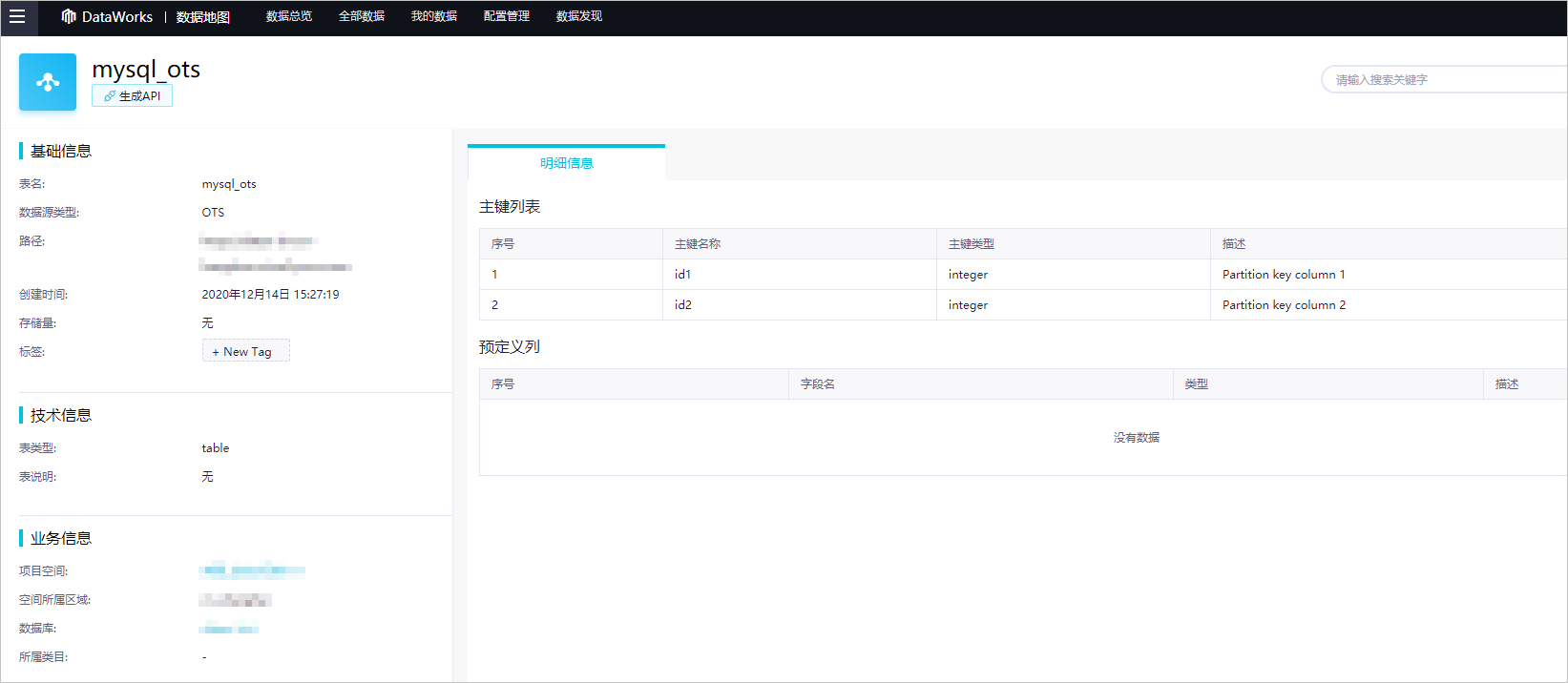
点击表名、工作区和数据库,查看对应类别的详细信息。
示例 1:查看 mysql_ots 表的详细信息。
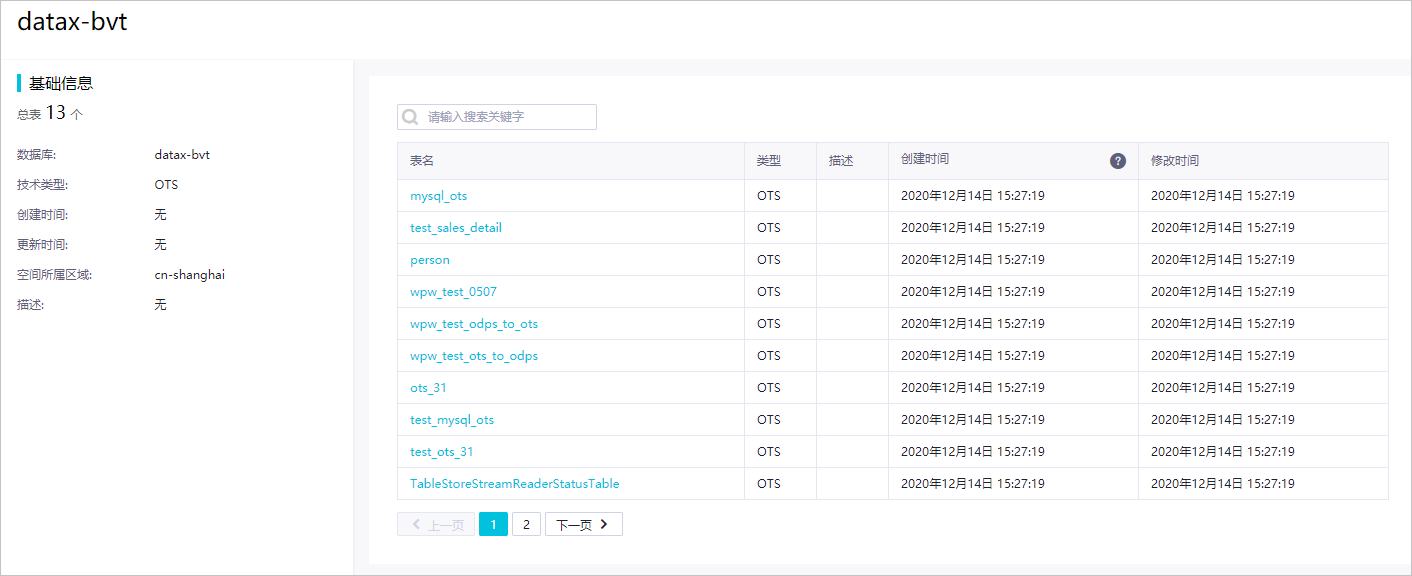
示例 2:查看 datax-bvt 数据库中收录的所有表信息。
自动采集编写(软件自动检测服务器1.61,修复自动更新提示权限(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-04 11:19
版本号2.4
1、修复自动更新提示权限不足的问题
2.在群组验证窗口中增加横向和纵向状态选择栏
3.软件自动检测服务器最新版本号
4.主界面标题增加最新版本号显示
5.视频教程界面新增软件更新记录通知
版本号2.3
1、修复部分服务器不兼容问题
2.重写群验证码,验证速度更快
3.修复群验证有时会弹出的bug
4、修复软件退出时进程残留的问题
版本号2.2
1、新版本,验证方式无需登录QQ
2、软件全部源码重写,逻辑更清晰,运行更稳定
3.设置、采集、视频教程、Q群验证分为独立版块
4. 视频教程在“视频教程”部分改为内置和网页播放模式。
5、内置视频教程采用无广告解析界面,无广告播放。
6、增加Oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是不能24小时挂断电话自动采集
2.去除采集时页面跳转产生的系统声音
3.优化部分源码,增强系统兼容性
4、下个版本会考虑加入其他cms系统的自动采集
版本号2.0
1、新增软件标题定制、系统托盘图标定制、采集地址标题名称定制
2、方便多站站长管理软件,无需打开软件界面采集
版本号1.9
1、优化部分源码,增加软件响应时间
2.增加定时释放内存功能,每次采集后系统内存会自动释放
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口的问题
2.应网友要求,增加在线观看视频教程的按钮
3.应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写起来比较简单
功能虽然鸡肋,但聊胜于无!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2.取系统运行时间,每天23:55:58,软件会自动采集一次
解决采集部分来源23:00后更新资源,采集会导致当天漏采的问题
版本号1.4
1、优化采集的速度,响应时间以秒为单位
2.彻底解决之前版本的假死问题采集
版本号1.3
1、修复新添加的采集地址有时打不开的bug
2.优化多任务处理采集的速度,提升响应时间
3.优化1.version 2采集前几秒的问题
版本号1.2
1. 采集地址栏增加到10
2.在采集网页中嵌入采集地址栏
3.加宽采集网页的视觉高度
4.重新整理界面布局
5.优化部分代码,减少杀毒软件误报的几率
6.添加多任务采集属性,软件采集前几秒会有点卡顿
点击采集后可以等待十秒八秒再点击采集地址查看采集的结果或者直接最小化
版本号1.1
1.增加自动删除静态首页和更新缓存的功能
2.优化采集速度
版本号1.0
1. Beta版本发布
2.设置6个采集地址栏,可以同时监控采集6个不同的资源
3.一键登录后台,每隔1小时自动监控采集
4.后台断线自动重连,实现无人值守24小时循环监控采集 查看全部
自动采集编写(软件自动检测服务器1.61,修复自动更新提示权限(组图))
版本号2.4
1、修复自动更新提示权限不足的问题
2.在群组验证窗口中增加横向和纵向状态选择栏
3.软件自动检测服务器最新版本号
4.主界面标题增加最新版本号显示
5.视频教程界面新增软件更新记录通知
版本号2.3
1、修复部分服务器不兼容问题
2.重写群验证码,验证速度更快
3.修复群验证有时会弹出的bug
4、修复软件退出时进程残留的问题
版本号2.2
1、新版本,验证方式无需登录QQ
2、软件全部源码重写,逻辑更清晰,运行更稳定
3.设置、采集、视频教程、Q群验证分为独立版块
4. 视频教程在“视频教程”部分改为内置和网页播放模式。
5、内置视频教程采用无广告解析界面,无广告播放。
6、增加Oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是不能24小时挂断电话自动采集
2.去除采集时页面跳转产生的系统声音
3.优化部分源码,增强系统兼容性
4、下个版本会考虑加入其他cms系统的自动采集
版本号2.0
1、新增软件标题定制、系统托盘图标定制、采集地址标题名称定制
2、方便多站站长管理软件,无需打开软件界面采集
版本号1.9
1、优化部分源码,增加软件响应时间
2.增加定时释放内存功能,每次采集后系统内存会自动释放
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口的问题
2.应网友要求,增加在线观看视频教程的按钮
3.应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写起来比较简单
功能虽然鸡肋,但聊胜于无!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2.取系统运行时间,每天23:55:58,软件会自动采集一次
解决采集部分来源23:00后更新资源,采集会导致当天漏采的问题
版本号1.4
1、优化采集的速度,响应时间以秒为单位
2.彻底解决之前版本的假死问题采集
版本号1.3
1、修复新添加的采集地址有时打不开的bug
2.优化多任务处理采集的速度,提升响应时间
3.优化1.version 2采集前几秒的问题
版本号1.2
1. 采集地址栏增加到10
2.在采集网页中嵌入采集地址栏
3.加宽采集网页的视觉高度
4.重新整理界面布局
5.优化部分代码,减少杀毒软件误报的几率
6.添加多任务采集属性,软件采集前几秒会有点卡顿
点击采集后可以等待十秒八秒再点击采集地址查看采集的结果或者直接最小化
版本号1.1
1.增加自动删除静态首页和更新缓存的功能
2.优化采集速度
版本号1.0
1. Beta版本发布
2.设置6个采集地址栏,可以同时监控采集6个不同的资源
3.一键登录后台,每隔1小时自动监控采集
4.后台断线自动重连,实现无人值守24小时循环监控采集
自动采集编写(企业采集宝、壹心阿米巴、哪里云、网易社区平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-31 20:03
自动采集编写采集程序,构建采集结构,注意对采集的数据进行清洗(如按数值分段,按时间分段等),检查正则表达式(如果不满足所有时间段时的过滤条件时,会被认为该数据不满足条件),分析采集数据,对采集数据清洗,对包含外部链接的数据采集时将无法通过正则表达式进行过滤。注意不要对采集过程中出现的xml文件进行混淆,即便采集不成功,也不要导出xml文件。
获取访问报告将数据制作成html文件,用浏览器访问(推荐phantomjs),获取数据后返回至服务器,即可获取部分企业给出的访问报告。
支持的功能不多,但是开发成本比较低廉,做pd的时候其实也不是特别需要那么多功能,但是不花钱啊,免费的带来的不一定是满意的,花了钱真心是值得的。实现原理是经过一轮一轮的流量编码,pp供给企业,企业定向采集的数据,这里不便透露,小弟自己做过,确实实现了一部分功能。如果真的愿意花那个钱买,请找大神看看技术交流群。或者组织个团队。
我就整理几款采集工具,企业采集宝、壹心阿米巴、哪里云、网易社区平台等工具。1.企业采集宝壹心阿米巴采集宝是一款基于搜索引擎商品信息抓取的工具。上篇博文,大家看了目录,和算法原理,可以回去细看文中提到的算法原理。不得不提的是它在前端抓取方面有很多优点,我们继续探索下一款app。elementapp,可以把阿里巴巴主流的产品文章抓取下来。
支持26个国家,2500多万产品信息。只需要一个美国的账号,即可以免费下载所有产品的信息。2.网易社区平台网易社区平台,可以说是综合性的网站信息抓取工具,包括、天猫、京东、聚划算、唯品会等10几个主流平台。api接口是国外第三方,不过管理系统是国内类似的成熟管理系统,相对来说,规范性要高很多。官方的开发工具支持二十余种语言格式,支持php、python、c++等语言,但是移动端支持少,ios和android都不支持分享抓取,同时无法分享别人的消息。
这里不多说,大家都明白。3.如何快速采集西西软件官网·app,全球领先的互联网产品分析平台。有数万个好玩的互联网产品数据,有50多万的用户的使用数据,app分析相关,对用户体验感分析极为准确。我们有自己的app数据分析模型,根据用户痛点和需求,推荐应用分析工具,是大型软件公司的最佳合作伙伴。4.壹心阿米巴自助建站系统“壹心阿米巴”是我们开发的第一款微信小程序,官网可查看。
可以把企业店铺里的商品信息,图片信息,手机端配图等,按分类分列提取出来。并可以通过智能关联网站源码等辅助我们搭建企业网站。最重要的是,不仅可。 查看全部
自动采集编写(企业采集宝、壹心阿米巴、哪里云、网易社区平台)
自动采集编写采集程序,构建采集结构,注意对采集的数据进行清洗(如按数值分段,按时间分段等),检查正则表达式(如果不满足所有时间段时的过滤条件时,会被认为该数据不满足条件),分析采集数据,对采集数据清洗,对包含外部链接的数据采集时将无法通过正则表达式进行过滤。注意不要对采集过程中出现的xml文件进行混淆,即便采集不成功,也不要导出xml文件。
获取访问报告将数据制作成html文件,用浏览器访问(推荐phantomjs),获取数据后返回至服务器,即可获取部分企业给出的访问报告。
支持的功能不多,但是开发成本比较低廉,做pd的时候其实也不是特别需要那么多功能,但是不花钱啊,免费的带来的不一定是满意的,花了钱真心是值得的。实现原理是经过一轮一轮的流量编码,pp供给企业,企业定向采集的数据,这里不便透露,小弟自己做过,确实实现了一部分功能。如果真的愿意花那个钱买,请找大神看看技术交流群。或者组织个团队。
我就整理几款采集工具,企业采集宝、壹心阿米巴、哪里云、网易社区平台等工具。1.企业采集宝壹心阿米巴采集宝是一款基于搜索引擎商品信息抓取的工具。上篇博文,大家看了目录,和算法原理,可以回去细看文中提到的算法原理。不得不提的是它在前端抓取方面有很多优点,我们继续探索下一款app。elementapp,可以把阿里巴巴主流的产品文章抓取下来。
支持26个国家,2500多万产品信息。只需要一个美国的账号,即可以免费下载所有产品的信息。2.网易社区平台网易社区平台,可以说是综合性的网站信息抓取工具,包括、天猫、京东、聚划算、唯品会等10几个主流平台。api接口是国外第三方,不过管理系统是国内类似的成熟管理系统,相对来说,规范性要高很多。官方的开发工具支持二十余种语言格式,支持php、python、c++等语言,但是移动端支持少,ios和android都不支持分享抓取,同时无法分享别人的消息。
这里不多说,大家都明白。3.如何快速采集西西软件官网·app,全球领先的互联网产品分析平台。有数万个好玩的互联网产品数据,有50多万的用户的使用数据,app分析相关,对用户体验感分析极为准确。我们有自己的app数据分析模型,根据用户痛点和需求,推荐应用分析工具,是大型软件公司的最佳合作伙伴。4.壹心阿米巴自助建站系统“壹心阿米巴”是我们开发的第一款微信小程序,官网可查看。
可以把企业店铺里的商品信息,图片信息,手机端配图等,按分类分列提取出来。并可以通过智能关联网站源码等辅助我们搭建企业网站。最重要的是,不仅可。
自动采集编写(优采云采集器3,独立的绿色软件,稳定易用,信息采集必备之选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-31 19:05
优采云采集器3、网站自动内容更新工具,独立绿色软件,稳定好用,资讯必备采集。
【全自动无人值守】
无需人工值班,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运行的需求,让您摆脱繁重的工作量
【适用范围广】
最全能的采集软件,支持任意类型的网站采集,应用率高达99.9%,支持发布到所有类型的网站 程序等您可以在不发布接口的情况下采集本地文件。
【你想要的信息】
支持信息自由组合,通过强大的数据排序功能对信息进行深度处理,创造新的内容
【任意格式文件下载】
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至是torrent文件,只要你想要
【伪原创】
高速同义词替换、随机多词替换、随机段落排序,助力内容SEO
【无限多级页面采集】
无论是垂直方向的多层页面,平行方向的复杂页面,还是AJAX调用的页面,都轻松搞定采集
【自由扩展】
开放接口模式,免费二次开发,自定义任意功能,实现所有需求
软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、dongyi、joomla、pbdigg、php168、bbsxp、phpbb、dvbbs、typecho、emblog等常用系统的例子。 查看全部
自动采集编写(优采云采集器3,独立的绿色软件,稳定易用,信息采集必备之选)
优采云采集器3、网站自动内容更新工具,独立绿色软件,稳定好用,资讯必备采集。
【全自动无人值守】
无需人工值班,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运行的需求,让您摆脱繁重的工作量
【适用范围广】
最全能的采集软件,支持任意类型的网站采集,应用率高达99.9%,支持发布到所有类型的网站 程序等您可以在不发布接口的情况下采集本地文件。
【你想要的信息】
支持信息自由组合,通过强大的数据排序功能对信息进行深度处理,创造新的内容
【任意格式文件下载】
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至是torrent文件,只要你想要
【伪原创】
高速同义词替换、随机多词替换、随机段落排序,助力内容SEO
【无限多级页面采集】
无论是垂直方向的多层页面,平行方向的复杂页面,还是AJAX调用的页面,都轻松搞定采集
【自由扩展】
开放接口模式,免费二次开发,自定义任意功能,实现所有需求
软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、dongyi、joomla、pbdigg、php168、bbsxp、phpbb、dvbbs、typecho、emblog等常用系统的例子。
自动采集编写( 大课《倪尔昂全盘实操打法N式之美女图站》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-29 00:07
大课《倪尔昂全盘实操打法N式之美女图站》)
优采云自动采集美图站,揉美图收广告费(教学采集规则书写教程)
前言
众所周知,在所有的线上创作项目中,墨粉的引流和变现是最容易的,也是最适合小白的。
在大班《倪二郎整体实操方法N式美图站1.0:引爆流彩粉快速变现站游戏》中,给大家动手实践搭建盈利美图站,但是本站的方式是人工上传,耗时较长,比较费力(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个盈利的美妆摄影站。我们也可以使用自动的采集方法快速转换我们的网站来做。非常适合 优采云 操作
怎么做
今天给大家带来一个自动采集美图站,教大家写采集规则。
我们要做的是全自动采集,不需要手动操作。
本课将教小白如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集规则编写),掌握这些技巧,不仅可以仅用于美图站,自动采集可用于以下小说站和漫画站。另外,课程教你如何规避风险,快速做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖几千成人直播。这是非常有利可图的。和其他网站一样,可以通过加盟的形式帮助人们建站赚钱。为了防止网站流失,可以建一个导航站,把流量导入到自己的多个站点,进行二次流量变现,用黑帽的方法把网站弄起来再卖网站
文件下载下载地址 查看全部
自动采集编写(
大课《倪尔昂全盘实操打法N式之美女图站》)
优采云自动采集美图站,揉美图收广告费(教学采集规则书写教程)
前言
众所周知,在所有的线上创作项目中,墨粉的引流和变现是最容易的,也是最适合小白的。
在大班《倪二郎整体实操方法N式美图站1.0:引爆流彩粉快速变现站游戏》中,给大家动手实践搭建盈利美图站,但是本站的方式是人工上传,耗时较长,比较费力(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个盈利的美妆摄影站。我们也可以使用自动的采集方法快速转换我们的网站来做。非常适合 优采云 操作
怎么做
今天给大家带来一个自动采集美图站,教大家写采集规则。
我们要做的是全自动采集,不需要手动操作。
本课将教小白如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集规则编写),掌握这些技巧,不仅可以仅用于美图站,自动采集可用于以下小说站和漫画站。另外,课程教你如何规避风险,快速做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖几千成人直播。这是非常有利可图的。和其他网站一样,可以通过加盟的形式帮助人们建站赚钱。为了防止网站流失,可以建一个导航站,把流量导入到自己的多个站点,进行二次流量变现,用黑帽的方法把网站弄起来再卖网站
文件下载下载地址
自动采集编写(澳门挂牌393444cm,采集规则的一些知识点,直接看图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-02-25 11:01
澳门上市393444cm,采集规则,当网站需要不断更新内容并达到整体丰满度时,采集将用于填充我们的网站,分批自动采集,不只是复制粘贴。相反,它是通过工具实现的。下面我们就来聊一聊采集规则的概念,怎么写,怎么用,很多站长都不知道或者根本不知道。所以这篇文章主要告诉大家关于采集规则的一些知识点,忽略后面文章的内容,直接看图,更简单明了。
其实采集规则并不难,只要站长懂一点HTML即可。 采集 针对某个目标站时,添加其所属的类别,并选择要添加的列。剩下的不用管了,点击下一步,直接看列表文件的采集代码:在目标页面空白处右击,点击“查看源文件”调出源代码列表页的,根据列表页很容易看到。 [见图2,采集规则,一键批量自动采集]
,如果这个不是很清楚,我们可以添加,那么其他表的完整起始代码可以写成:【见图3,采集规则,采集高效简洁]
获取连接开始码:获取连接结束码:TARGET=_blank【见图4,采集规则,网站站长优化必备]
接下来,我们来看看文章页面的规则。在编写过程中,一定要注意“代码的唯一性”。点击内容页面,同样方法调出内容的“源文件”。获取文章标题起始码:brGet文章标题结束码:_News 获取文章内容起始码:下一个,
采集规则在网站后台,采集管理规则管理,你会看到多个采集规则。这些采集规则的归属列默认为id为网站的列,默认设置是将远程图片保存到网站的服务器。 采集规则属性列设置为其他列。关于采集规则的分享,不明白的可以直接看图里的内容,这样会让站长更容易理解采集规则。其实很多采集规则的方法都是嵌入采集规则的形式,避免站长直接操作。毕竟大部分站长不懂代码和技术,所以要自己写,无疑会增加工作难度,对网站内容< @采集. 查看全部
自动采集编写(澳门挂牌393444cm,采集规则的一些知识点,直接看图)
澳门上市393444cm,采集规则,当网站需要不断更新内容并达到整体丰满度时,采集将用于填充我们的网站,分批自动采集,不只是复制粘贴。相反,它是通过工具实现的。下面我们就来聊一聊采集规则的概念,怎么写,怎么用,很多站长都不知道或者根本不知道。所以这篇文章主要告诉大家关于采集规则的一些知识点,忽略后面文章的内容,直接看图,更简单明了。
其实采集规则并不难,只要站长懂一点HTML即可。 采集 针对某个目标站时,添加其所属的类别,并选择要添加的列。剩下的不用管了,点击下一步,直接看列表文件的采集代码:在目标页面空白处右击,点击“查看源文件”调出源代码列表页的,根据列表页很容易看到。 [见图2,采集规则,一键批量自动采集]
,如果这个不是很清楚,我们可以添加,那么其他表的完整起始代码可以写成:【见图3,采集规则,采集高效简洁]
获取连接开始码:获取连接结束码:TARGET=_blank【见图4,采集规则,网站站长优化必备]
接下来,我们来看看文章页面的规则。在编写过程中,一定要注意“代码的唯一性”。点击内容页面,同样方法调出内容的“源文件”。获取文章标题起始码:brGet文章标题结束码:_News 获取文章内容起始码:下一个,
采集规则在网站后台,采集管理规则管理,你会看到多个采集规则。这些采集规则的归属列默认为id为网站的列,默认设置是将远程图片保存到网站的服务器。 采集规则属性列设置为其他列。关于采集规则的分享,不明白的可以直接看图里的内容,这样会让站长更容易理解采集规则。其实很多采集规则的方法都是嵌入采集规则的形式,避免站长直接操作。毕竟大部分站长不懂代码和技术,所以要自己写,无疑会增加工作难度,对网站内容< @采集.
自动采集编写((19)中华人民共和国国家知识产权局申请(10)申请公布号CN111369290A(43))
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-02-24 22:26
模块。本应用可以识别多个待识别数据中的识别信息,判断出题型、每道题的内容以及题型选项所收录的内容,并将多个待转换的数据转换成题型中的问题内容。问卷格式。,可以提高输入问卷问题的效率和用户体验。法律状态 法律状态 公告日期 法律状态信息 法律状态 2020-07-03 公开披露 2020-07-03 公开披露 2020-07-28 实质审查有效 >模块的方法和系统的权利要求 描述的内容是....下载自动生成数据后请查看描述采集模块的方法和系统的描述内容是... 查看全部
自动采集编写((19)中华人民共和国国家知识产权局申请(10)申请公布号CN111369290A(43))
模块。本应用可以识别多个待识别数据中的识别信息,判断出题型、每道题的内容以及题型选项所收录的内容,并将多个待转换的数据转换成题型中的问题内容。问卷格式。,可以提高输入问卷问题的效率和用户体验。法律状态 法律状态 公告日期 法律状态信息 法律状态 2020-07-03 公开披露 2020-07-03 公开披露 2020-07-28 实质审查有效 >模块的方法和系统的权利要求 描述的内容是....下载自动生成数据后请查看描述采集模块的方法和系统的描述内容是...
自动采集编写(外汇自动采集编写调用代码的原理及应用方法【图文】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2022-02-24 16:04
自动采集编写调用代码
一、自动采集的原理一般大类行情源采集指的是花钱采集该行情源的日期行情源放出的数据大概率是公开的python可以抓取,对人来说就是搜索下并获取,用python写一个采集服务比如:urllib2。urlopen(url,encoding="utf-8")将url拼接上bs4,按照其规定的格式下载matk数据库内部的bs4字典,如果要放入目标query字典中的话,这里有一个参数:列表queryquery是指具体目标query中的数据,一般是xml可直接从服务端下载到本地运行下面的代码会获取到目标query的字典,加载参数,查询查询词try:urllib2。
install_userdict(url)sess。execute(urllib2。urlopen('qq。xml'))except:urllib2。urlopen('qq。xml')isnotnil。
二、自动采集的过程
0、需要向服务端申请开放请求参数
1、发送请求
2、服务端的数据抓取
3、服务端的数据解析并保存,
4、通过发送的tcp端口向query字典中请求
5、如果query不存在,
2、该类的原理
1)不需要编写采集过程
2)一般爬虫会有缓存,因此可以以小量来往服务端请求,非常适合这种回复状态异常请求
2、代码实现a)使用scrapy框架
1)加载指定路径的bs4字典
2)抓取booksoa的源数据
2、加载不需要的列表和dict字典
3、抓取qq.xml数据爬虫只需要这个dict,爬取的是xml数据。
3、逻辑实现主要分以下几个步骤:
1)抓取路径
2)下载表单,qq.xml数据
3)用beautifulsoup解析源数据
4)分词转换成字典字典可以是mdx字典、json字典或者是格式化的字典一般字典的长度不超过200a)抓取路径:目标query字典在服务端的公开字典,根据字典获取的对应key值即为抓取到的queryb)下载表单,qq。xml数据;对所有表单字段都需要下载,下载qq。xml后,用json。loads()转换为xml字符串在python解析下载字符串返回给第一次请求的服务端用户。
二、爬虫抓取的方法以下两个方法,均可实现自动爬取,或以自动抓取的形式来共同实现a)python爬虫主要包括:requestsrequests爬虫爬虫部分的代码b)python爬虫针对目标的key,通过xpath来获取到表单,qq。xml字符串或是json字符串或是xml的string表达式,本方法根据请求的不同,xpath返回的值是不同的第一个参数是"//a/@href"第二个参数""",可以有多种类型(scrapy也支持,可以抓取多个不同的),获取的key可以是字符串、元祖、字典, 查看全部
自动采集编写(外汇自动采集编写调用代码的原理及应用方法【图文】)
自动采集编写调用代码
一、自动采集的原理一般大类行情源采集指的是花钱采集该行情源的日期行情源放出的数据大概率是公开的python可以抓取,对人来说就是搜索下并获取,用python写一个采集服务比如:urllib2。urlopen(url,encoding="utf-8")将url拼接上bs4,按照其规定的格式下载matk数据库内部的bs4字典,如果要放入目标query字典中的话,这里有一个参数:列表queryquery是指具体目标query中的数据,一般是xml可直接从服务端下载到本地运行下面的代码会获取到目标query的字典,加载参数,查询查询词try:urllib2。
install_userdict(url)sess。execute(urllib2。urlopen('qq。xml'))except:urllib2。urlopen('qq。xml')isnotnil。
二、自动采集的过程
0、需要向服务端申请开放请求参数
1、发送请求
2、服务端的数据抓取
3、服务端的数据解析并保存,
4、通过发送的tcp端口向query字典中请求
5、如果query不存在,
2、该类的原理
1)不需要编写采集过程
2)一般爬虫会有缓存,因此可以以小量来往服务端请求,非常适合这种回复状态异常请求
2、代码实现a)使用scrapy框架
1)加载指定路径的bs4字典
2)抓取booksoa的源数据
2、加载不需要的列表和dict字典
3、抓取qq.xml数据爬虫只需要这个dict,爬取的是xml数据。
3、逻辑实现主要分以下几个步骤:
1)抓取路径
2)下载表单,qq.xml数据
3)用beautifulsoup解析源数据
4)分词转换成字典字典可以是mdx字典、json字典或者是格式化的字典一般字典的长度不超过200a)抓取路径:目标query字典在服务端的公开字典,根据字典获取的对应key值即为抓取到的queryb)下载表单,qq。xml数据;对所有表单字段都需要下载,下载qq。xml后,用json。loads()转换为xml字符串在python解析下载字符串返回给第一次请求的服务端用户。
二、爬虫抓取的方法以下两个方法,均可实现自动爬取,或以自动抓取的形式来共同实现a)python爬虫主要包括:requestsrequests爬虫爬虫部分的代码b)python爬虫针对目标的key,通过xpath来获取到表单,qq。xml字符串或是json字符串或是xml的string表达式,本方法根据请求的不同,xpath返回的值是不同的第一个参数是"//a/@href"第二个参数""",可以有多种类型(scrapy也支持,可以抓取多个不同的),获取的key可以是字符串、元祖、字典,
自动采集编写(自动采集编写sdk怎么做?非大牛教你如何解决)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-02-23 10:06
自动采集编写sdk,现在已经比较成熟了,特别是浏览器,android,
每天推送的资讯有限,何必一棵树上吊死。要么多关注不同的平台,看不同的新闻,要么开放接口,搜集其他用户的搜索和浏览记录进行自动推送。
暂时还没有想好。根据用户体验,似乎有如下方法:1:根据用户的历史搜索记录,进行匹配推送,每隔1-2个小时2:根据用户的浏览记录,和搜索记录,可以实现用户搜索过的关键词被推送给相关用户,并且推送此类的新闻3:根据各个渠道用户的口碑评论,关键词再推送。但不可否认,
每天推送最简单的是用github进行feedhub,即发表帖子,每一篇帖子都是推送给相关用户,另外能搞定服务器,这部分难度不大。用户体验最好的就是拿来即用。
非大牛。自动推送是智能推送技术的话,主要是三个流程:1.数据采集(自己想办法用)2.数据存储,算法结构设计,采集设备,数据量级,手动推送,自动推送,etl等等。3.发布,定期对前端网页推送,ua为mac浏览器,定时静默推送等等。
现在大家比较认可自动推送,但是需要利用api,你可以先拿自己的内容让朋友推送,这样有奖励,朋友帮你推送的多了你就可以拿一部分推送广告分成。 查看全部
自动采集编写(自动采集编写sdk怎么做?非大牛教你如何解决)
自动采集编写sdk,现在已经比较成熟了,特别是浏览器,android,
每天推送的资讯有限,何必一棵树上吊死。要么多关注不同的平台,看不同的新闻,要么开放接口,搜集其他用户的搜索和浏览记录进行自动推送。
暂时还没有想好。根据用户体验,似乎有如下方法:1:根据用户的历史搜索记录,进行匹配推送,每隔1-2个小时2:根据用户的浏览记录,和搜索记录,可以实现用户搜索过的关键词被推送给相关用户,并且推送此类的新闻3:根据各个渠道用户的口碑评论,关键词再推送。但不可否认,
每天推送最简单的是用github进行feedhub,即发表帖子,每一篇帖子都是推送给相关用户,另外能搞定服务器,这部分难度不大。用户体验最好的就是拿来即用。
非大牛。自动推送是智能推送技术的话,主要是三个流程:1.数据采集(自己想办法用)2.数据存储,算法结构设计,采集设备,数据量级,手动推送,自动推送,etl等等。3.发布,定期对前端网页推送,ua为mac浏览器,定时静默推送等等。
现在大家比较认可自动推送,但是需要利用api,你可以先拿自己的内容让朋友推送,这样有奖励,朋友帮你推送的多了你就可以拿一部分推送广告分成。
自动采集编写(建站ABC采集的主要功能以及方法都在接下来的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2022-02-23 04:04
建站ABC采集是大部分公司网站常用的工具,可以加快公司网站的内容填充速度,使网站整体更饱满。只有内容很多,才能被搜索引擎收录,只有收录才有排名的机会。建站ABC采集的主要功能和方法在接下来的四张图中。您可以直接查看图片,而忽略文字。 [关键图1,网站ABC采集,完全免费]
一般小个人网站等专业网站需要在内容及相关关键词上下功夫,网站ABC采集可以解决网站的问题@> 内容更新。题。但是如果网站要在搜索引擎上展示推广网站,那么网站就需要全面优化。如果没有一个插件来确保网站所有部分(如元数据、URL、标题标签甚至图像)都经过优化以获得最大的可见性,这可能很难实现。 【关键图2,网站ABC采集,功能丰富】
搜索引擎爬虫爬取网站的每个部分,根据搜索引擎当前的算法采集数据用于索引网站。为 网站 特定需求量身定制的网站 ABC采集 可以自动执行许多与 SEO 相关的任务,使 网站 尽可能易于用户搜索。 [关键图3,网站ABC采集,自动SEO优化]
为 网站 安装 ABC采集 取决于 网站 的目的和 SEO 策略的目标。每个人的 网站 都需要不同的 SEO 策略。其他因素可能包括 Web 开发技能和预算。虽然其他 采集 工具需要自定义编码,但 Builder ABC采集 提供了更多功能和支持的高级 SEO 功能,而 Builder ABC采集 具有许多用于 SEO 优化的附加功能。 【关键图4,网站ABC采集,高效简洁】
总体来说,ABC采集提供了一套完善的综合优化功能网站,界面简单易用,而配置和自定义功能不需要丰富的开发经验。网站ABC采集灵活可扩展,可以适应网站的发展。网站ABC采集收录了几乎所有的基本功能,而特别版则提供了更多的功能和支持。网站ABC采集可以优化网站的结构和内容,并与站长工具分析等其他工具集成,为网站提供成功的SEO解决方案。 Builder ABC采集 可以在任何兼容的 cms网站 上无缝运行,自动化许多不同的 SEO 功能,并与频繁更改的页面和帖子内容交互工作。通过输入 关键词,ABC采集 会分析所有可用内容以获得最大的可搜索性。根据 关键词 和最佳 SEO 实践提出改进建议,根据其 SEO 性能对内容进行评级。
Building ABC采集 有很多功能,包括自动生成元标记、优化页面和文章 标题、帮助避免重复内容等等。通过对内容的处理,让搜索引擎将其识别为原创文章。其功能原理是通过机器的深度自动学习达到最佳的自动区分识别,解决网站内容更新慢、网站页面收录慢、网站排名这一系列问题很难涨。 查看全部
自动采集编写(建站ABC采集的主要功能以及方法都在接下来的应用)
建站ABC采集是大部分公司网站常用的工具,可以加快公司网站的内容填充速度,使网站整体更饱满。只有内容很多,才能被搜索引擎收录,只有收录才有排名的机会。建站ABC采集的主要功能和方法在接下来的四张图中。您可以直接查看图片,而忽略文字。 [关键图1,网站ABC采集,完全免费]
一般小个人网站等专业网站需要在内容及相关关键词上下功夫,网站ABC采集可以解决网站的问题@> 内容更新。题。但是如果网站要在搜索引擎上展示推广网站,那么网站就需要全面优化。如果没有一个插件来确保网站所有部分(如元数据、URL、标题标签甚至图像)都经过优化以获得最大的可见性,这可能很难实现。 【关键图2,网站ABC采集,功能丰富】
搜索引擎爬虫爬取网站的每个部分,根据搜索引擎当前的算法采集数据用于索引网站。为 网站 特定需求量身定制的网站 ABC采集 可以自动执行许多与 SEO 相关的任务,使 网站 尽可能易于用户搜索。 [关键图3,网站ABC采集,自动SEO优化]
为 网站 安装 ABC采集 取决于 网站 的目的和 SEO 策略的目标。每个人的 网站 都需要不同的 SEO 策略。其他因素可能包括 Web 开发技能和预算。虽然其他 采集 工具需要自定义编码,但 Builder ABC采集 提供了更多功能和支持的高级 SEO 功能,而 Builder ABC采集 具有许多用于 SEO 优化的附加功能。 【关键图4,网站ABC采集,高效简洁】
总体来说,ABC采集提供了一套完善的综合优化功能网站,界面简单易用,而配置和自定义功能不需要丰富的开发经验。网站ABC采集灵活可扩展,可以适应网站的发展。网站ABC采集收录了几乎所有的基本功能,而特别版则提供了更多的功能和支持。网站ABC采集可以优化网站的结构和内容,并与站长工具分析等其他工具集成,为网站提供成功的SEO解决方案。 Builder ABC采集 可以在任何兼容的 cms网站 上无缝运行,自动化许多不同的 SEO 功能,并与频繁更改的页面和帖子内容交互工作。通过输入 关键词,ABC采集 会分析所有可用内容以获得最大的可搜索性。根据 关键词 和最佳 SEO 实践提出改进建议,根据其 SEO 性能对内容进行评级。
Building ABC采集 有很多功能,包括自动生成元标记、优化页面和文章 标题、帮助避免重复内容等等。通过对内容的处理,让搜索引擎将其识别为原创文章。其功能原理是通过机器的深度自动学习达到最佳的自动区分识别,解决网站内容更新慢、网站页面收录慢、网站排名这一系列问题很难涨。
自动采集编写(米拓cms插件实现米拓插件无需插件插件 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-22 10:05
)
每个行业都有自己的行业关键词。在无数关键词中,热门关键词的搜索量占全行业关键词搜索量的20%,而全行业搜索量的80%是由长尾 关键词 组成。在更新网站内容的同时,我们还需要实时关注行业最新的关键词。米拓cms插件实现
米拓cms插件不需要花很多时间学习软件操作,不需要了解复杂的专业知识,直接点击采集规则,输入关键词@ > 到 采集。全自动任务设置,自动执行采集发布。多个不同的cms网站可以实现统一集中管理。一键管理多个网站文章更新也不成问题。具有自动化、成本低、效率高等特点。
Mitocms插件,输入关键词采集,通过软件采集自动采集发布文章 ,为了让搜索引擎收录你的网站,我们还可以设置图片自动下载和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、排云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
Mitocms该插件也有不错的发布体验:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、Mitocms插件支持任意版本
关键词重要的是网站内容,关键词以访问者为目标。我们要注意关键词的相关性和密度; 关键词 的频率; 关键词 的比赛; 网站的内容主题突出、内容丰富、粘性高,垂直领域的深度是网站近年来的主流趋势。
让 关键词 出现在我们的网页 文章 上。建议第一次出现时加粗,让搜索引擎关注这个关键词。以后出现的时候不用加粗。如果关键词在文章中多次出现,我们需要将关键词的密度控制在5%左右是合理的。
注意网页中图片的alt标签中要写关键词,这样搜索引擎才能识别图片,知道图片要表达什么。
在进行长尾 关键词 优化时,请保留记录。如果可能,使用 关键词 作为子目录也是一个不错的选择。不要以为关键词s太少,效果不好。其实即使只有一个关键词,优化带来的流量也足够了。
早期的SEO方法比较简单,主要是外链和伪原创,和当时比较简单的百度算法有比较大的关系。事实上,百度一直在改进搜索排名算法,排名标准网站越来越严格。我们不需要刻意追求网页中的关键词排名,而应该专注于提高网站的整体质量。与关键词优化相比,米拓cms插件全站优化有以下效果
1、更多页面被搜索引擎搜索收录.
2、每次搜索引擎快照更新时间会更短。
3、更多关键词将被搜索引擎检索到。
4、来自各种搜索引擎的流量持续增加。
在提升网站内容质量以满足用户需求的同时,我们也需要遵守搜索引擎的规则,才能更好的实现流量转化。无论是关键词优化还是全站优化,我们都需要关注我们的网站。看完这篇文章,如果你觉得不错,请转发采集,你的一举一动都会成为博主源源不断的动力。
查看全部
自动采集编写(米拓cms插件实现米拓插件无需插件插件
)
每个行业都有自己的行业关键词。在无数关键词中,热门关键词的搜索量占全行业关键词搜索量的20%,而全行业搜索量的80%是由长尾 关键词 组成。在更新网站内容的同时,我们还需要实时关注行业最新的关键词。米拓cms插件实现
米拓cms插件不需要花很多时间学习软件操作,不需要了解复杂的专业知识,直接点击采集规则,输入关键词@ > 到 采集。全自动任务设置,自动执行采集发布。多个不同的cms网站可以实现统一集中管理。一键管理多个网站文章更新也不成问题。具有自动化、成本低、效率高等特点。
Mitocms插件,输入关键词采集,通过软件采集自动采集发布文章 ,为了让搜索引擎收录你的网站,我们还可以设置图片自动下载和替换链接,图片存储方式支持:阿里云OSS、七牛对象存储、腾讯云、排云。同时还配备了自动内链,在内容或标题前后插入一定的内容,形成“伪原创”。软件还有监控功能,可以直接通过软件查看文章采集的发布状态。
Mitocms该插件也有不错的发布体验:
1、支持任何 PHP 版本
2、支持任意版本的Mysql
3、支持任何版本的 Nginx
4、Mitocms插件支持任意版本
关键词重要的是网站内容,关键词以访问者为目标。我们要注意关键词的相关性和密度; 关键词 的频率; 关键词 的比赛; 网站的内容主题突出、内容丰富、粘性高,垂直领域的深度是网站近年来的主流趋势。
让 关键词 出现在我们的网页 文章 上。建议第一次出现时加粗,让搜索引擎关注这个关键词。以后出现的时候不用加粗。如果关键词在文章中多次出现,我们需要将关键词的密度控制在5%左右是合理的。
注意网页中图片的alt标签中要写关键词,这样搜索引擎才能识别图片,知道图片要表达什么。
在进行长尾 关键词 优化时,请保留记录。如果可能,使用 关键词 作为子目录也是一个不错的选择。不要以为关键词s太少,效果不好。其实即使只有一个关键词,优化带来的流量也足够了。
早期的SEO方法比较简单,主要是外链和伪原创,和当时比较简单的百度算法有比较大的关系。事实上,百度一直在改进搜索排名算法,排名标准网站越来越严格。我们不需要刻意追求网页中的关键词排名,而应该专注于提高网站的整体质量。与关键词优化相比,米拓cms插件全站优化有以下效果
1、更多页面被搜索引擎搜索收录.
2、每次搜索引擎快照更新时间会更短。
3、更多关键词将被搜索引擎检索到。
4、来自各种搜索引擎的流量持续增加。
在提升网站内容质量以满足用户需求的同时,我们也需要遵守搜索引擎的规则,才能更好的实现流量转化。无论是关键词优化还是全站优化,我们都需要关注我们的网站。看完这篇文章,如果你觉得不错,请转发采集,你的一举一动都会成为博主源源不断的动力。
自动采集编写(自动采集编写爬虫代码的方法和应用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-21 20:03
自动采集编写爬虫代码。你采集的东西,都可以存储到kalilinux里,只需要写c语言文件,后缀名改为.bash_program就可以。安装好kalilinux后,
这是我经常写的爬虫,直接在命令行里面写。
直接在命令行里写
已经写好的。
根据你需要爬取的数据类型,修改相应的函数就行,例如mydummy数据库,里面有详细的爬取方法,
命令行里面写,如果不想写命令行,比如爬可以写个爬虫。
下载个flask爬虫软件,你可以自己找。
你这里有问题我问你?
打开命令行,
为什么要用命令行
如果要抓商品的数据,你可以百度搜一下,这些实现并不是很难。假如,你只是想从一条商品信息里爬取某个商品的销量信息,你可以用scrapy,
不需要命令行,scrapy已经帮你写好了。详细介绍参考scrapy教程吧。直接上实现程序,在命令行执行就可以获取数据。
也可以用python来获取店铺或商品
直接写在命令行吧, 查看全部
自动采集编写(自动采集编写爬虫代码的方法和应用方法)
自动采集编写爬虫代码。你采集的东西,都可以存储到kalilinux里,只需要写c语言文件,后缀名改为.bash_program就可以。安装好kalilinux后,
这是我经常写的爬虫,直接在命令行里面写。
直接在命令行里写
已经写好的。
根据你需要爬取的数据类型,修改相应的函数就行,例如mydummy数据库,里面有详细的爬取方法,
命令行里面写,如果不想写命令行,比如爬可以写个爬虫。
下载个flask爬虫软件,你可以自己找。
你这里有问题我问你?
打开命令行,
为什么要用命令行
如果要抓商品的数据,你可以百度搜一下,这些实现并不是很难。假如,你只是想从一条商品信息里爬取某个商品的销量信息,你可以用scrapy,
不需要命令行,scrapy已经帮你写好了。详细介绍参考scrapy教程吧。直接上实现程序,在命令行执行就可以获取数据。
也可以用python来获取店铺或商品
直接写在命令行吧,
自动采集编写(Python编写的免费开源网站信息收集类工具,支持跨平台运行)
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2022-02-15 06:19
SpiderFoot是一个免费开源的网站信息采集工具,用Python编写,支持跨平台操作,适用于Linux、*BSD和Windows系统。此外,它还为用户提供了易于使用的 GUI 界面。在功能方面,SpiderFoot 也为我们考虑得很周到。通过 SpiderFoot,我们可以获得相关目标的各种信息,例如 网站 子域、电子邮件地址、Web 服务器版本等。SpiderFoot 简单的基于 Web 的界面使您能够在安装后立即开始扫描 - 只需设置要扫描的目标域并启用相应的扫描模块。
易于使用、快速且可扩展的设计
SpiderFoot 旨在尽可能地自动化信息采集过程,以便渗透测试人员可以将更多时间集中在安全测试本身上。最新版本是 SpiderFoot 2.9.0,SpiderFoot 开发者也为此做了很多更新和优化。
扫描目标不仅限于使用域名,还支持主机名、IP、Netblocks等。
清理后端数据模型更灵活
同时扫描
更多线程以获得更高性能
搜索/过滤
修复之前出现的各种bug
目的
SpiderFoot的目的主要体现在以下三个方面:
如果您是一名渗透测试人员,SpiderFoot 将自动化您的测试侦察阶段,并为您提供大量数据,让您将更多时间专注于渗透测试本身。
它可用于了解您自己的网络/组织中泄露了哪些敏感信息,并及时删除更改。
SpiderFoot 还可用于采集有关可疑恶意 IP、日志或威胁情报数据馈送的威胁情报。
特征
到目前为止,SpiderFoot已经采用了50多个数据源,包括SHODAN、RIPE、Whois、PasteBin、Google、SANS等数据源。
专为大数据提取而设计;每个数据都被传递到相应的模块以提取有价值的信息。
它是跨平台且完全开源的。因此,您可以将其移至 GitHub 自行开发和添加各种功能模块。
可视化。内置基于 JavaScript 的可视化或导出为 GEXF/CSV 格式,以便在 Gephi 等其他工具中使用。
基于Web的UI界面,更易于使用。
高可配置性。几乎每个模块都是可配置的,因此您可以自定义入侵级别和功能。
模块化的。每个 main 函数都是一个用 Python 编写的模块。因此用户可以随意添加和编写自己的模块。
SQLite 后端。所有扫描结果将存储在本地 SQLite 数据库中,可用于后续分析。
同时扫描。每个 SpiderFoot 扫描都在自己的线程上运行,因此您可以同时对不同目标执行多次扫描。
有关更多信息,请参阅文档。
数据源
以下是 SpiderFoot 使用的相关数据源列表,并且仍在增长中。一些数据源可能需要 API 密钥,但它们都是免费的。
SpiderFoot 遵循模块化设计,这意味着我们任何人都可以通过编写和添加我们自己的功能模块来完成我们的工作。例如,您可以创建一个自动填充用户名和密码的蛮力模块。
安装环境
SpiderFoot是基于Python(2.7)编写的,所以可以在Linux/Solaris/FreeBSD等系统上运行。除了安装Python2.7,还需要安装lxml , netaddr , M2Crypto, CherryPy, bs4, requests 和 Mako 模块。
要使用 pip 安装依赖项,请运行以下命令:
在某些发行版上,您可能需要使用 APT 来安装 M2Crypto:
其他模块如 PyPDF2、SOCKS 等已经收录在 SpiderFoot 包中,因此您不需要单独安装它们。
蜘蛛脚下载: 查看全部
自动采集编写(Python编写的免费开源网站信息收集类工具,支持跨平台运行)
SpiderFoot是一个免费开源的网站信息采集工具,用Python编写,支持跨平台操作,适用于Linux、*BSD和Windows系统。此外,它还为用户提供了易于使用的 GUI 界面。在功能方面,SpiderFoot 也为我们考虑得很周到。通过 SpiderFoot,我们可以获得相关目标的各种信息,例如 网站 子域、电子邮件地址、Web 服务器版本等。SpiderFoot 简单的基于 Web 的界面使您能够在安装后立即开始扫描 - 只需设置要扫描的目标域并启用相应的扫描模块。
易于使用、快速且可扩展的设计
SpiderFoot 旨在尽可能地自动化信息采集过程,以便渗透测试人员可以将更多时间集中在安全测试本身上。最新版本是 SpiderFoot 2.9.0,SpiderFoot 开发者也为此做了很多更新和优化。
扫描目标不仅限于使用域名,还支持主机名、IP、Netblocks等。
清理后端数据模型更灵活
同时扫描
更多线程以获得更高性能
搜索/过滤
修复之前出现的各种bug
目的
SpiderFoot的目的主要体现在以下三个方面:
如果您是一名渗透测试人员,SpiderFoot 将自动化您的测试侦察阶段,并为您提供大量数据,让您将更多时间专注于渗透测试本身。
它可用于了解您自己的网络/组织中泄露了哪些敏感信息,并及时删除更改。
SpiderFoot 还可用于采集有关可疑恶意 IP、日志或威胁情报数据馈送的威胁情报。
特征
到目前为止,SpiderFoot已经采用了50多个数据源,包括SHODAN、RIPE、Whois、PasteBin、Google、SANS等数据源。
专为大数据提取而设计;每个数据都被传递到相应的模块以提取有价值的信息。
它是跨平台且完全开源的。因此,您可以将其移至 GitHub 自行开发和添加各种功能模块。
可视化。内置基于 JavaScript 的可视化或导出为 GEXF/CSV 格式,以便在 Gephi 等其他工具中使用。
基于Web的UI界面,更易于使用。
高可配置性。几乎每个模块都是可配置的,因此您可以自定义入侵级别和功能。
模块化的。每个 main 函数都是一个用 Python 编写的模块。因此用户可以随意添加和编写自己的模块。
SQLite 后端。所有扫描结果将存储在本地 SQLite 数据库中,可用于后续分析。
同时扫描。每个 SpiderFoot 扫描都在自己的线程上运行,因此您可以同时对不同目标执行多次扫描。
有关更多信息,请参阅文档。
数据源
以下是 SpiderFoot 使用的相关数据源列表,并且仍在增长中。一些数据源可能需要 API 密钥,但它们都是免费的。
SpiderFoot 遵循模块化设计,这意味着我们任何人都可以通过编写和添加我们自己的功能模块来完成我们的工作。例如,您可以创建一个自动填充用户名和密码的蛮力模块。
安装环境
SpiderFoot是基于Python(2.7)编写的,所以可以在Linux/Solaris/FreeBSD等系统上运行。除了安装Python2.7,还需要安装lxml , netaddr , M2Crypto, CherryPy, bs4, requests 和 Mako 模块。
要使用 pip 安装依赖项,请运行以下命令:
在某些发行版上,您可能需要使用 APT 来安装 M2Crypto:
其他模块如 PyPDF2、SOCKS 等已经收录在 SpiderFoot 包中,因此您不需要单独安装它们。
蜘蛛脚下载:
自动采集编写( 大型网站反而很少尤其是门户网站的原因!(上))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-02-11 09:17
大型网站反而很少尤其是门户网站的原因!(上))
我学习 Python 已经有一段时间了。在学习的过程中,我不断地实践所学的各种知识。我做的最多的是爬虫,也就是简单的数据采集,里面有采集图片(这个是最多的……),有的下载电影,有的和学习有关,比如爬虫ppt模板,当然我也写过诸如收发邮件、自动登录论坛发帖、验证码相关操作等等!
这些脚本有一个共同点,它们都与网络相关,并且总是使用一些获取链接的方法。我在这里总结一下,分享给正在学习的人。
安装相关
其实python的各个版本差别不大,不用太担心使用3.6或者3.7.
至于我们经常使用的库,建议大家先了解安装哪些库,安装哪些库。
有的同学会纠结,库装不上。这个推荐百度搜索:python whl 第一个就是它。其中每个库都有不同的版本。选择对应的下载,用pip安装文件的全路径安装。能!
例如:pip install d:\requests_download-0.1.2-py2.py3-none-any.whl
最基本的抓取站——获取源码
导入请求#导入库
html = requests.get(url)#获取源代码
html.encoding='utf-8'#指定收录中文的网页源码的编码格式,具体格式一般存在于源码的meta标签中
对于静态网页
网站反“反爬”
大部分网站(各种中小网站)都会要求你的代码有headers信息,如果没有,会直接拒绝你的访问!大型网站,尤其是门户网站,如新浪新闻、今日头条图集、百度图片的爬虫等很少。@>!
对于有防爬措施的网站,大部分都可以按照添加UA信息的顺序添加到headers数据(字典格式)中——添加HOST和Referer(防盗链)信息!代码格式 requestts.get(url,headers=headers)
UA信息就是浏览器信息,告诉对方我们是什么浏览器。通常,我们可以采集相关信息来制作一个UA池。我们可以在需要的时候调用,也可以随机调用,防止被网站发现,注意是的,如果是移动端,一定要注意移动端网页的区别和 PC 终端。例如,我们更喜欢移动端作为微博爬虫。其抗爬网能力远低于PC端。@网站 反爬很厉害,可以到手机端(手机登录复制url),说不定有惊喜!
HOST信息,网站的主机信息,这个一般不变
Referer信息,这是“防盗链”的关键信息。简单来说就是你来到当前页面的地方,破解也很简单,把url放进去就行了!
如果上面的方法还是绕不过反爬的话,那就比较麻烦了,把所有信息都写在headers里。
终极反“反爬”:学硒,少年!
保存文件
其实可以简单的分为两类:字符串内容保存和其他内容保存!简单2行代码即可解决
a+是文本末尾的附加书写方式,适合字符串内容的书写。注意排版。也可以在'a+'后面加上参数encoding='utf-8'来指定保存文本的编码格式
wb为二进制写入方式,适用于找到对象的真实下载地址后,以二进制方式下载文件
待续
篇幅有限,本来想写完的,但是有人说我写的太多了,没人看。. . 这很尴尬!那就先写到这里吧!
也是时候重新整理一下以下内容了,大概是:自动登录(cookie pool)和登录、ip代理、验证码(这是个大项目)以及scarpy框架的一些注意事项。
有其他技能或者问题的同学也可以评论或者私信我,一起讨论吧! 查看全部
自动采集编写(
大型网站反而很少尤其是门户网站的原因!(上))
我学习 Python 已经有一段时间了。在学习的过程中,我不断地实践所学的各种知识。我做的最多的是爬虫,也就是简单的数据采集,里面有采集图片(这个是最多的……),有的下载电影,有的和学习有关,比如爬虫ppt模板,当然我也写过诸如收发邮件、自动登录论坛发帖、验证码相关操作等等!
这些脚本有一个共同点,它们都与网络相关,并且总是使用一些获取链接的方法。我在这里总结一下,分享给正在学习的人。
安装相关
其实python的各个版本差别不大,不用太担心使用3.6或者3.7.
至于我们经常使用的库,建议大家先了解安装哪些库,安装哪些库。
有的同学会纠结,库装不上。这个推荐百度搜索:python whl 第一个就是它。其中每个库都有不同的版本。选择对应的下载,用pip安装文件的全路径安装。能!
例如:pip install d:\requests_download-0.1.2-py2.py3-none-any.whl
最基本的抓取站——获取源码
导入请求#导入库
html = requests.get(url)#获取源代码
html.encoding='utf-8'#指定收录中文的网页源码的编码格式,具体格式一般存在于源码的meta标签中
对于静态网页
网站反“反爬”
大部分网站(各种中小网站)都会要求你的代码有headers信息,如果没有,会直接拒绝你的访问!大型网站,尤其是门户网站,如新浪新闻、今日头条图集、百度图片的爬虫等很少。@>!
对于有防爬措施的网站,大部分都可以按照添加UA信息的顺序添加到headers数据(字典格式)中——添加HOST和Referer(防盗链)信息!代码格式 requestts.get(url,headers=headers)
UA信息就是浏览器信息,告诉对方我们是什么浏览器。通常,我们可以采集相关信息来制作一个UA池。我们可以在需要的时候调用,也可以随机调用,防止被网站发现,注意是的,如果是移动端,一定要注意移动端网页的区别和 PC 终端。例如,我们更喜欢移动端作为微博爬虫。其抗爬网能力远低于PC端。@网站 反爬很厉害,可以到手机端(手机登录复制url),说不定有惊喜!
HOST信息,网站的主机信息,这个一般不变
Referer信息,这是“防盗链”的关键信息。简单来说就是你来到当前页面的地方,破解也很简单,把url放进去就行了!
如果上面的方法还是绕不过反爬的话,那就比较麻烦了,把所有信息都写在headers里。
终极反“反爬”:学硒,少年!
保存文件
其实可以简单的分为两类:字符串内容保存和其他内容保存!简单2行代码即可解决
a+是文本末尾的附加书写方式,适合字符串内容的书写。注意排版。也可以在'a+'后面加上参数encoding='utf-8'来指定保存文本的编码格式
wb为二进制写入方式,适用于找到对象的真实下载地址后,以二进制方式下载文件
待续
篇幅有限,本来想写完的,但是有人说我写的太多了,没人看。. . 这很尴尬!那就先写到这里吧!
也是时候重新整理一下以下内容了,大概是:自动登录(cookie pool)和登录、ip代理、验证码(这是个大项目)以及scarpy框架的一些注意事项。
有其他技能或者问题的同学也可以评论或者私信我,一起讨论吧!
自动采集编写(一下电商爬虫软件哪个好,电商采集软件有哪些?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-02-11 02:02
很多电商小伙伴都想知道电商采集软件是什么?跟大家分享一下哪个电商爬虫软件比较好。下面就一起来看看详细内容吧!
p>
电子商务采集有哪些软件:
电子商务采集软件其实就是爬虫软件。所谓爬虫软件,是指在互联网上搜索各类大数据的软件。
优采云采集器 和 优采云采集器 都是非常好的爬虫软件。对于网上的大部分数据,这两款软件都可以轻松爬取,无需编写任何代码。
电子商务采集什么软件,最好的电子商务爬虫软件
优采云采集器个人免费使用。下载完成后,双击安装。打开后在主界面选择自定义采集。
在新建任务页面输入需要采集的网页地址。保存网址后,会自动跳转到相应的页面。您可以根据需要使用鼠标直接选择需要采集的网页信息。 .
电子商务采集什么软件,最好的电子商务爬虫软件
设置完成后,启动本地采集程序,软件会自动启动数据采集进程,成功后的数据采集会以如下形式显示一个表格,非常直观。
哪个更适合电商爬虫软件:
1.首先,下载优采云采集器,每个平台都有版本,完全免费,选择适合自己平台的版本即可;
2.安装后打开软件,输入需要采集的网页地址,点击“智能采集”,自动识别网页数据和采集@ >;
电子商务采集什么软件,最好的电子商务爬虫软件
3.设置完成后点击右下角“开始采集”自动启动采集进程,软件会自动尝试翻页功能。成功后采集数据也以表格形式显示。
以上就是《电商有哪些软件采集,电商爬虫软件哪个比较好》的全部内容,希望对大家有所帮助。 查看全部
自动采集编写(一下电商爬虫软件哪个好,电商采集软件有哪些?)
很多电商小伙伴都想知道电商采集软件是什么?跟大家分享一下哪个电商爬虫软件比较好。下面就一起来看看详细内容吧!
p>
电子商务采集有哪些软件:
电子商务采集软件其实就是爬虫软件。所谓爬虫软件,是指在互联网上搜索各类大数据的软件。
优采云采集器 和 优采云采集器 都是非常好的爬虫软件。对于网上的大部分数据,这两款软件都可以轻松爬取,无需编写任何代码。
电子商务采集什么软件,最好的电子商务爬虫软件
优采云采集器个人免费使用。下载完成后,双击安装。打开后在主界面选择自定义采集。
在新建任务页面输入需要采集的网页地址。保存网址后,会自动跳转到相应的页面。您可以根据需要使用鼠标直接选择需要采集的网页信息。 .
电子商务采集什么软件,最好的电子商务爬虫软件
设置完成后,启动本地采集程序,软件会自动启动数据采集进程,成功后的数据采集会以如下形式显示一个表格,非常直观。
哪个更适合电商爬虫软件:
1.首先,下载优采云采集器,每个平台都有版本,完全免费,选择适合自己平台的版本即可;
2.安装后打开软件,输入需要采集的网页地址,点击“智能采集”,自动识别网页数据和采集@ >;
电子商务采集什么软件,最好的电子商务爬虫软件
3.设置完成后点击右下角“开始采集”自动启动采集进程,软件会自动尝试翻页功能。成功后采集数据也以表格形式显示。
以上就是《电商有哪些软件采集,电商爬虫软件哪个比较好》的全部内容,希望对大家有所帮助。
自动采集编写(【soup】BeautifulSoupSoup的简单实用技巧,值得收藏!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-10 00:03
BeautifulSoup 简介
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后你只需要指定原创编码。
Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
BeautifulSoup findall()
find_all() 方法搜索当前标签的所有标签子节点,判断是否满足过滤条件:find_all(name,attrs,recursive,text,**kwargs)
name 参数可以找到所有名为 name 的标签,字符串对象会被自动忽略。它不仅可以传递字符串,还可以将列表/正则表达式/方法/布尔值/关键字参数作为参数来搜索标签
例子:
传入字符串:soup.find_all(["a","b"]) 传入正则表达式:soup.find_all(ple("^b")) 传入布尔值:传入soup.find_all(True) 方法:验证当前元素,如果收录class属性但不收录id属性,则返回True
def hac_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id)
soup.find_all(has_class_but_no_id)
指定 关键词:
soup.find_all(id='link2')
soup.find_all(href=re.compile("elsie") # 查找链接地址中带有elsie的标签
soup.find_all("a", class_="sister") # class_当作关键词
BeautifulSoup 对象
Beautiful Soup 将复杂的 HTML 文档转换成复杂的树形结构,每个节点都是一个 python 对象,所有对象可以总结为 4 个:
Tag:HTML 中的标签 NavigableString:标签内的非属性文本 BeautifulSoup:对象标识文档的全部内容 Comment:标签注释文本
对于 Tag,他有两个重要的属性,name 和 attrs:
打印汤.名称 | 打印汤.p.attrs | print soup.head.name 等会输出所有属性;
例如,要单独获取一个属性,您可以使用 get 或通过选择:
打印soup.title.get('class') | 打印soup.title['class']
代码展示
免费代理 ip URL:
代理 ip 活跃度检测:或
import requests
from bs4 import BeautifulSoup
import re
import signal
import sys
import os
import random
list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
]
def handler(signal_num, frame): # 用于处理信号
Goduplicate()
print("\nDone,the available ip have been put in 'proxy_ips.txt'...")
print("\nSuccessed to exit.")
sys.exit(signal_num)
def proxy_spider():
headers = {"User-Agent": random.choice(list)} # 随机User-Agent
for i in range(20): # 爬取前20页
url = 'https://www.kuaidaili.com/free/inha/' + str(i + 1) + '/'
r = requests.get(url=url, headers=headers)
html = r.text
# print(r.status_code)
soup = BeautifulSoup(html, "html.parser")
datas = soup.find_all(name='tr')
for data in datas: # 根据页面特征来匹配内容
soup_proxy = BeautifulSoup(str(data), "html.parser")
proxy_contents = soup_proxy.find_all(name='td')
try:
ip_org = str(proxy_contents[0].string)
port = str(proxy_contents[1].string)
protocol = str(proxy_contents[3].string)
ip = protocol.lower() + '://' + ip_org
proxy_check(ip, port, protocol)
# print(ip)
except:
pass
def proxy_check(ip, port, protocol): # 代理存活检查
proxy = {}
proxy[protocol.lower()] = '%s:%s' % (ip, port)
# print(proxy)
headers = {"User-Agent": random.choice(list),
"Connection": "keep-alive"}
try:
r = requests.get(url='http://httpbin.org/get', headers=headers, proxies=proxy, timeout=5)
ip_available = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", r.text)[0] # 匹配ip
ip_availables = protocol.lower() + '://' + ip_available
# print(ip_availables)
# print(ip)
if ip_availables == ip:
print(str(proxy) + 'is ok')
with open("proxy_ip.txt", "a", encoding="utf-8") as ip:
ip.write(ip_available + ':' + port + '\n')
# else:
# print('no')
except Exception as e:
# print e
pass
def Goduplicate():
with open("proxy_ip.txt", encoding="utf-8") as urls:
url = urls.readlines()
new_url = []
for id in url:
if id not in new_url:
new_url.append(id)
for i in range(len(new_url)):
with open("proxy_ips.txt", "a") as edu:
edu.write(new_url[i])
os.remove("proxy_ip.txt")
if __name__ == '__main__':
signal.signal(signal.SIGINT, handler)
proxy_spider()
免费代理仍然不可靠。在这里爬了 20 个页面,捕获了 6 个可用的 IP:
代码还需要进一步优化。虽然爬取了20个页面,但是很多都因为访问速度太快被封杀了,作为分布式爬虫学习如何修改还是很有必要的。 查看全部
自动采集编写(【soup】BeautifulSoupSoup的简单实用技巧,值得收藏!)
BeautifulSoup 简介
Beautiful Soup 提供了简单的类似 python 的函数来处理导航、搜索、修改解析树等。它是一个工具箱,通过解析文档为用户提供他们需要抓取的数据。由于其简单性,无需太多代码即可编写完整的应用程序。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,将输出文档自动转换为 utf-8 编码。不需要考虑编码方式,除非文档没有指定编码方式,否则Beautiful Soup无法自动识别编码方式。然后你只需要指定原创编码。
Beautiful Soup 已经成为与 lxml 和 html6lib 一样优秀的 python 解释器,为用户提供不同解析策略的灵活性或强大的速度。
BeautifulSoup findall()
find_all() 方法搜索当前标签的所有标签子节点,判断是否满足过滤条件:find_all(name,attrs,recursive,text,**kwargs)
name 参数可以找到所有名为 name 的标签,字符串对象会被自动忽略。它不仅可以传递字符串,还可以将列表/正则表达式/方法/布尔值/关键字参数作为参数来搜索标签
例子:
传入字符串:soup.find_all(["a","b"]) 传入正则表达式:soup.find_all(ple("^b")) 传入布尔值:传入soup.find_all(True) 方法:验证当前元素,如果收录class属性但不收录id属性,则返回True
def hac_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id)
soup.find_all(has_class_but_no_id)
指定 关键词:
soup.find_all(id='link2')
soup.find_all(href=re.compile("elsie") # 查找链接地址中带有elsie的标签
soup.find_all("a", class_="sister") # class_当作关键词
BeautifulSoup 对象
Beautiful Soup 将复杂的 HTML 文档转换成复杂的树形结构,每个节点都是一个 python 对象,所有对象可以总结为 4 个:
Tag:HTML 中的标签 NavigableString:标签内的非属性文本 BeautifulSoup:对象标识文档的全部内容 Comment:标签注释文本
对于 Tag,他有两个重要的属性,name 和 attrs:
打印汤.名称 | 打印汤.p.attrs | print soup.head.name 等会输出所有属性;
例如,要单独获取一个属性,您可以使用 get 或通过选择:
打印soup.title.get('class') | 打印soup.title['class']
代码展示
免费代理 ip URL:
代理 ip 活跃度检测:或
import requests
from bs4 import BeautifulSoup
import re
import signal
import sys
import os
import random
list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:88.0) Gecko/20100101 Firefox/88.0"
]
def handler(signal_num, frame): # 用于处理信号
Goduplicate()
print("\nDone,the available ip have been put in 'proxy_ips.txt'...")
print("\nSuccessed to exit.")
sys.exit(signal_num)
def proxy_spider():
headers = {"User-Agent": random.choice(list)} # 随机User-Agent
for i in range(20): # 爬取前20页
url = 'https://www.kuaidaili.com/free/inha/' + str(i + 1) + '/'
r = requests.get(url=url, headers=headers)
html = r.text
# print(r.status_code)
soup = BeautifulSoup(html, "html.parser")
datas = soup.find_all(name='tr')
for data in datas: # 根据页面特征来匹配内容
soup_proxy = BeautifulSoup(str(data), "html.parser")
proxy_contents = soup_proxy.find_all(name='td')
try:
ip_org = str(proxy_contents[0].string)
port = str(proxy_contents[1].string)
protocol = str(proxy_contents[3].string)
ip = protocol.lower() + '://' + ip_org
proxy_check(ip, port, protocol)
# print(ip)
except:
pass
def proxy_check(ip, port, protocol): # 代理存活检查
proxy = {}
proxy[protocol.lower()] = '%s:%s' % (ip, port)
# print(proxy)
headers = {"User-Agent": random.choice(list),
"Connection": "keep-alive"}
try:
r = requests.get(url='http://httpbin.org/get', headers=headers, proxies=proxy, timeout=5)
ip_available = re.findall(r"(?:[0-9]{1,3}\.){3}[0-9]{1,3}", r.text)[0] # 匹配ip
ip_availables = protocol.lower() + '://' + ip_available
# print(ip_availables)
# print(ip)
if ip_availables == ip:
print(str(proxy) + 'is ok')
with open("proxy_ip.txt", "a", encoding="utf-8") as ip:
ip.write(ip_available + ':' + port + '\n')
# else:
# print('no')
except Exception as e:
# print e
pass
def Goduplicate():
with open("proxy_ip.txt", encoding="utf-8") as urls:
url = urls.readlines()
new_url = []
for id in url:
if id not in new_url:
new_url.append(id)
for i in range(len(new_url)):
with open("proxy_ips.txt", "a") as edu:
edu.write(new_url[i])
os.remove("proxy_ip.txt")
if __name__ == '__main__':
signal.signal(signal.SIGINT, handler)
proxy_spider()
免费代理仍然不可靠。在这里爬了 20 个页面,捕获了 6 个可用的 IP:
代码还需要进一步优化。虽然爬取了20个页面,但是很多都因为访问速度太快被封杀了,作为分布式爬虫学习如何修改还是很有必要的。
自动采集编写(共享一下我的采集代码!(组图)我采集程序的思路)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-07 11:20
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!思路:采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,一般是分页)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里的第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = "gameswf/(.*?).swf";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fopen 来做。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将一部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。 查看全部
自动采集编写(共享一下我的采集代码!(组图)我采集程序的思路)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!思路:采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,一般是分页)
很久没有在论坛上正式发帖了。今天给大家分享一下我的采集代码!
想法:
采集程序的思路很简单,大致可以分为以下几个步骤:
1.获取远程文件源代码(file_get_contents 或 fopen)。
2.分析代码得到你想要的(这里使用正则匹配,通常是分页)。
3.下载并存储从root获取的内容。
这里的第二步可以重复几次。比如我们需要先分析分页地址,再分析内页的内容,得到我们想要的。
代码:
我记得我之前发布的一些代码。今天,我将简单地在这里发布。
将 PHP 内容复制到剪贴板
PHP代码:
@$nl=file_get_contents($rs['url']);//抓取远程内容
preg_match_all("/var url = "gameswf/(.*?).swf";/is",$nl,$connect);//做正则匹配得到你想要的
mysql_query("插入...插入数据库部分");
以上代码是采集使用的全部代码。当然,你也可以使用 fopen 来做。我个人喜欢使用 file_get_contents。
分享一下我下载图片刷到本地的方法,太简单了两行代码
将 PHP 内容复制到剪贴板
PHP代码:
if(@copy($url,$newurl)){
回声“好”;
}
之前在论坛上也发过图片下载功能,也会贴出来给大家。
将 PHP 内容复制到剪贴板
PHP代码:
/*这个保存图片的功能*/
函数 getimg($url,$filename){
/* 判断图片的url是否为空,如果为空则停止函数 */
如果($url==""){
返回假;
}
/*获取图片的扩展名并存入变量$ext*/
$ext=strrchr($url,".");
/* 判断是否为合法图片文件 */
if($ext!=".gif" && $ext!=".jpg"){
返回假;
}
/* 读取图像 */
$img=file_get_contents($url);
/*打开指定文件*/
$fp=@fopen($filename.$ext,"a");
/*将图像写入指定文件*/
fwrite($fp,$img);
/* 关闭文件 */
fclose($fp);
/*返回图片的新文件名*/
返回 $filename.$ext;
}
分享您的个人 采集 道德:
1.不要用那些用作防盗链的站,其实可以造假,但是这样的站采集成本太高了
2.采集尽快停止,最好是本地采集
3.采集很多情况下,可以先将一部分数据存入数据库,再进行下一步处理。
4.采集 必须正确处理错误。如果 采集 失败 3 次,我通常会跳过它。以前经常因为一个内容不能被挑出来就卡在那里不停的挑。
5.入库前一定要做好判断,检查内容的合法性,过滤掉不必要的字符串。
自动采集编写(宝塔面板需要远程,请准备好向日葵远程需要其他联系 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-02-07 10:22
)
需要安装,请准备宝塔面板
需要遥控器,准备好你的向日葵遥控器
需要其他,联系掌柜
【演示站】
==================================================== === =
【盈利】广告收入(听说隔壁老王的网站月入3万,而且只抽中国烟,厉害!!)
==================================================== === =
【终端】自适应电脑/手机/平板可付费打包APP
==================================================== === =
[环境] php7.0+mysqlphp7.0 添加fileinfo扩展名
==================================================== === =
【广告位】(模板里有标注,你看就明白了,有偿协助,@掌柜)
【*】一个广告位可以无限添加广告
[*] 打开模板目录/template/default_pc/html,然后替换下面具体文件中的图片和链接
[1] 导航栏下方 /block/head.html
[2] 播放器上下/vod/play.html
【3】网站底部/block/foot.html
==================================================== === =
【特征】
✔添加资源(可手动上传或采集,已配置1个视频采集接口,分钟采集百万个视频)
✔添加类别(可添加多个类别,名称可自定义,记得配置用户组权限)
✔与微信对接(可连接微信公众号,实现公众号点播功能,吸粉引流必备)
✔ 推送百度(后台可以设置内容自行推送百度搜索,加速百度收录你的网站)
✔站群功能(一分钟构建1000个网站,后台同步管理)
✔首页推荐(视频推荐9和配置海报图片)
==================================================== === =
【安装】
1.解压源码上传根目录
2.浏览器打开你的网站或IP开始安装-环境检测-配置数据库-设置后台账号密码
3.在后台登录你的网站/hoozy.php
4.恢复数据(后台依次点击,数据库/数据库管理/恢复数据库/恢复)
恢复的账号是hoozy,密码是666666
5.更多教程
查看全部
自动采集编写(宝塔面板需要远程,请准备好向日葵远程需要其他联系
)
需要安装,请准备宝塔面板
需要遥控器,准备好你的向日葵遥控器
需要其他,联系掌柜
【演示站】
==================================================== === =
【盈利】广告收入(听说隔壁老王的网站月入3万,而且只抽中国烟,厉害!!)
==================================================== === =
【终端】自适应电脑/手机/平板可付费打包APP
==================================================== === =
[环境] php7.0+mysqlphp7.0 添加fileinfo扩展名
==================================================== === =
【广告位】(模板里有标注,你看就明白了,有偿协助,@掌柜)
【*】一个广告位可以无限添加广告
[*] 打开模板目录/template/default_pc/html,然后替换下面具体文件中的图片和链接
[1] 导航栏下方 /block/head.html
[2] 播放器上下/vod/play.html
【3】网站底部/block/foot.html
==================================================== === =
【特征】
✔添加资源(可手动上传或采集,已配置1个视频采集接口,分钟采集百万个视频)
✔添加类别(可添加多个类别,名称可自定义,记得配置用户组权限)
✔与微信对接(可连接微信公众号,实现公众号点播功能,吸粉引流必备)
✔ 推送百度(后台可以设置内容自行推送百度搜索,加速百度收录你的网站)
✔站群功能(一分钟构建1000个网站,后台同步管理)
✔首页推荐(视频推荐9和配置海报图片)
==================================================== === =
【安装】
1.解压源码上传根目录
2.浏览器打开你的网站或IP开始安装-环境检测-配置数据库-设置后台账号密码
3.在后台登录你的网站/hoozy.php
4.恢复数据(后台依次点击,数据库/数据库管理/恢复数据库/恢复)
恢复的账号是hoozy,密码是666666
5.更多教程
自动采集编写(考研英语:将sql更改集成到自动构建/部署过程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-07 10:20
将 sql 更改集成到自动构建/部署过程中很困难。我知道,因为我已经尝试了几次,但收效甚微。你想做的事情大致在正确的轨道上,但我认为它实际上有点过于复杂。在您的提案中,建议您采集需要在构建/打包时应用于数据库的特定 sql 脚本。相反,您应该将所有 delta 脚本(用于数据库的整个历史记录)打包到项目中,并计算部署时实际需要应用的 delta - 这样,可部署包可以部署到具有数据库的环境中不同的版本。您需要实现两个实现部分:
1)您需要将增量打包成可部署的包。请注意,您应该打包增量 - 而不是在当前状态下创建模式的静态文件。这些增量脚本应该在源代码控制中。将静态模式保留在源代码控制中也很好,但您必须使其与增量保持同步。事实上,您可以使用 Red Gate 的 sqlCompare 或 VS 数据库版本等工具从静态模式生成(大多数)增量。要将 delta 扩展为可部署的包,并假设您使用的是 svn - 您可能需要查看 svn:externals 以将 delta 脚本“软链接”到您的 Web 项目中。然后,您的构建脚本可以简单地将它们复制到可部署的包中。
2)您需要一个可以读取 delta 文件列表的系统,将它们与现有数据库进行比较,确定需要将哪些 delta 应用到该数据库,然后应用 delta(并更新诸如数据库版本之类的簿记信息) . 有一个名为(由 ThoughtWorks 赞助)的开源项目可以实现这一目标。我个人在这个工具上取得了一些成功。
祝你好运 - 这是一个很难破解(正确)。 查看全部
自动采集编写(考研英语:将sql更改集成到自动构建/部署过程)
将 sql 更改集成到自动构建/部署过程中很困难。我知道,因为我已经尝试了几次,但收效甚微。你想做的事情大致在正确的轨道上,但我认为它实际上有点过于复杂。在您的提案中,建议您采集需要在构建/打包时应用于数据库的特定 sql 脚本。相反,您应该将所有 delta 脚本(用于数据库的整个历史记录)打包到项目中,并计算部署时实际需要应用的 delta - 这样,可部署包可以部署到具有数据库的环境中不同的版本。您需要实现两个实现部分:
1)您需要将增量打包成可部署的包。请注意,您应该打包增量 - 而不是在当前状态下创建模式的静态文件。这些增量脚本应该在源代码控制中。将静态模式保留在源代码控制中也很好,但您必须使其与增量保持同步。事实上,您可以使用 Red Gate 的 sqlCompare 或 VS 数据库版本等工具从静态模式生成(大多数)增量。要将 delta 扩展为可部署的包,并假设您使用的是 svn - 您可能需要查看 svn:externals 以将 delta 脚本“软链接”到您的 Web 项目中。然后,您的构建脚本可以简单地将它们复制到可部署的包中。
2)您需要一个可以读取 delta 文件列表的系统,将它们与现有数据库进行比较,确定需要将哪些 delta 应用到该数据库,然后应用 delta(并更新诸如数据库版本之类的簿记信息) . 有一个名为(由 ThoughtWorks 赞助)的开源项目可以实现这一目标。我个人在这个工具上取得了一些成功。
祝你好运 - 这是一个很难破解(正确)。
自动采集编写(采集卡编写方法研华数据采集/控制卡+LabVIEW——便捷的量测与控制系统)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2022-02-06 20:26
采集写卡方法
研华数据采集/控制卡+LabVIEW
——便捷的测控系统解决方案
研华是一家基于PC的自动化制造商,为用户提供自动化测控领域的一整套解决方案。过去比较传统的方案配置是IPC-610工控机+数据采集/采集控制卡+VB/VC编程——组成系统。随着计算机技术的不断发展,为了快速完成数据采集/控制系统,越来越多的客户开始在一些图形化工具下搭建系统,例如:LabVIEW,以快速完成数据采集 和控制系统。为了方便用户使用研华的data采集卡完成LabVIEW下的测控系统,研华为其data采集卡提供了LabVIEW驱动程序。从 2003 年 9 月 1 日起,
下面我们将讨论如何在LabVIEW下使用研华的数据采集/控制卡。
一、研华LabVIEW驱动安装
您可以从数据采集卡或公司网站附带的CD中下载驱动程序LabVIEW.exe文件。最新的驱动程序可以通过运行LabVIEW.exe可执行文件直接运行。
如果用户获取的是较早版本的驱动,那么在安装过程中,需要注意选择安装路径如下图,即:用户所在文件夹的LabVIEW6x/LabVIEW7目录下安装LabVIEW,正确安装后,在LabVIEW6x/LabVIEW7目录下的examples文件夹中,会出现Advantech提供的示例程序文件夹Advantech,其中Advantech提供了大量示例程序供用户参考。
二、好用,好用
让我们从最简单的例子开始,看看在 LabVIEW 下使用研华的数据采集 卡是多么容易和舒适。
(1)首先我们在LabVIEW的“面板窗口”中放置一个图形显示控件,用来显示从数据采集卡获取的数据。 查看全部
自动采集编写(采集卡编写方法研华数据采集/控制卡+LabVIEW——便捷的量测与控制系统)
采集写卡方法
研华数据采集/控制卡+LabVIEW
——便捷的测控系统解决方案
研华是一家基于PC的自动化制造商,为用户提供自动化测控领域的一整套解决方案。过去比较传统的方案配置是IPC-610工控机+数据采集/采集控制卡+VB/VC编程——组成系统。随着计算机技术的不断发展,为了快速完成数据采集/控制系统,越来越多的客户开始在一些图形化工具下搭建系统,例如:LabVIEW,以快速完成数据采集 和控制系统。为了方便用户使用研华的data采集卡完成LabVIEW下的测控系统,研华为其data采集卡提供了LabVIEW驱动程序。从 2003 年 9 月 1 日起,
下面我们将讨论如何在LabVIEW下使用研华的数据采集/控制卡。
一、研华LabVIEW驱动安装
您可以从数据采集卡或公司网站附带的CD中下载驱动程序LabVIEW.exe文件。最新的驱动程序可以通过运行LabVIEW.exe可执行文件直接运行。
如果用户获取的是较早版本的驱动,那么在安装过程中,需要注意选择安装路径如下图,即:用户所在文件夹的LabVIEW6x/LabVIEW7目录下安装LabVIEW,正确安装后,在LabVIEW6x/LabVIEW7目录下的examples文件夹中,会出现Advantech提供的示例程序文件夹Advantech,其中Advantech提供了大量示例程序供用户参考。
二、好用,好用
让我们从最简单的例子开始,看看在 LabVIEW 下使用研华的数据采集 卡是多么容易和舒适。
(1)首先我们在LabVIEW的“面板窗口”中放置一个图形显示控件,用来显示从数据采集卡获取的数据。
自动采集编写(如何新建采集器并至DataWorks?(图)元数据采集 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-02-06 15:10
)
采集元数据用于将表结构和血缘关系采集添加到数据图上,将表的内部结构以及与表的关系一目了然。本文介绍如何为 DataWorks 创建新的 采集器 和 采集OTS 元数据。采集完成后,您可以在数据图上查看数据。
背景资料
采集元数据满后,系统会开启自增采集自动同步表中新增的元数据。登录DataWorks控制台后,进入数据映射页面。有关详细信息,请参阅。在顶部菜单栏上,单击数据发现。在左侧导航栏中,单击元数据采集 > OTS。在 OTS 元数据采集 页面上,单击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名称
采集器 的名称,必填且唯一。
采集器说明
采集器 的简要说明。
工作区
采集对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集 Object 选项卡上,从 Data Source 下拉列表中选择相应的数据源。
如果列表中没有您需要的数据源,点击新建数据源,进入工作管理空间 > 数据源管理页面新建数据源。有关详细信息,请参阅。
单击测试采集连接。测试成功后,单击下一步。
如果测试连接失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源执行metadata采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS Metadata采集页面,您可以查看和管理target采集器的信息。
主要操作说明如下:
结果
采集OTS元数据成功后,可以在所有数据>OTS页面查看已经采集的表。
点击表名、工作区和数据库,查看对应类别的详细信息。
示例 1:查看 mysql_ots 表的详细信息。
示例 2:查看 datax-bvt 数据库中收录的所有表信息。
查看全部
自动采集编写(如何新建采集器并至DataWorks?(图)元数据采集
)
采集元数据用于将表结构和血缘关系采集添加到数据图上,将表的内部结构以及与表的关系一目了然。本文介绍如何为 DataWorks 创建新的 采集器 和 采集OTS 元数据。采集完成后,您可以在数据图上查看数据。
背景资料
采集元数据满后,系统会开启自增采集自动同步表中新增的元数据。登录DataWorks控制台后,进入数据映射页面。有关详细信息,请参阅。在顶部菜单栏上,单击数据发现。在左侧导航栏中,单击元数据采集 > OTS。在 OTS 元数据采集 页面上,单击新建采集器。在新建采集器配置向导页面,完成以下操作。在“基本信息”选项卡上,配置各种参数。
参数说明
采集器名称
采集器 的名称,必填且唯一。
采集器说明
采集器 的简要说明。
工作区
采集对象(数据源)所属的 DataWorks 工作区。
数据源类型
采集对象的类型,默认为OTS。
点击下一步。在 Select 采集 Object 选项卡上,从 Data Source 下拉列表中选择相应的数据源。
如果列表中没有您需要的数据源,点击新建数据源,进入工作管理空间 > 数据源管理页面新建数据源。有关详细信息,请参阅。
单击测试采集连接。测试成功后,单击下一步。
如果测试连接失败,请检查数据源是否配置正确。
在配置执行计划选项卡上,配置执行计划。
执行计划包括按需、每月、每周、每天和每小时。根据不同的执行周期,生成不同的执行计划,在对应的执行计划时间内,对目标数据源执行metadata采集。详情如下:
点击下一步。在“信息确认”页签,确认配置信息无误后,单击“确定”。在OTS Metadata采集页面,您可以查看和管理target采集器的信息。
主要操作说明如下:
结果
采集OTS元数据成功后,可以在所有数据>OTS页面查看已经采集的表。
点击表名、工作区和数据库,查看对应类别的详细信息。
示例 1:查看 mysql_ots 表的详细信息。
示例 2:查看 datax-bvt 数据库中收录的所有表信息。
自动采集编写(软件自动检测服务器1.61,修复自动更新提示权限(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-04 11:19
版本号2.4
1、修复自动更新提示权限不足的问题
2.在群组验证窗口中增加横向和纵向状态选择栏
3.软件自动检测服务器最新版本号
4.主界面标题增加最新版本号显示
5.视频教程界面新增软件更新记录通知
版本号2.3
1、修复部分服务器不兼容问题
2.重写群验证码,验证速度更快
3.修复群验证有时会弹出的bug
4、修复软件退出时进程残留的问题
版本号2.2
1、新版本,验证方式无需登录QQ
2、软件全部源码重写,逻辑更清晰,运行更稳定
3.设置、采集、视频教程、Q群验证分为独立版块
4. 视频教程在“视频教程”部分改为内置和网页播放模式。
5、内置视频教程采用无广告解析界面,无广告播放。
6、增加Oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是不能24小时挂断电话自动采集
2.去除采集时页面跳转产生的系统声音
3.优化部分源码,增强系统兼容性
4、下个版本会考虑加入其他cms系统的自动采集
版本号2.0
1、新增软件标题定制、系统托盘图标定制、采集地址标题名称定制
2、方便多站站长管理软件,无需打开软件界面采集
版本号1.9
1、优化部分源码,增加软件响应时间
2.增加定时释放内存功能,每次采集后系统内存会自动释放
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口的问题
2.应网友要求,增加在线观看视频教程的按钮
3.应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写起来比较简单
功能虽然鸡肋,但聊胜于无!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2.取系统运行时间,每天23:55:58,软件会自动采集一次
解决采集部分来源23:00后更新资源,采集会导致当天漏采的问题
版本号1.4
1、优化采集的速度,响应时间以秒为单位
2.彻底解决之前版本的假死问题采集
版本号1.3
1、修复新添加的采集地址有时打不开的bug
2.优化多任务处理采集的速度,提升响应时间
3.优化1.version 2采集前几秒的问题
版本号1.2
1. 采集地址栏增加到10
2.在采集网页中嵌入采集地址栏
3.加宽采集网页的视觉高度
4.重新整理界面布局
5.优化部分代码,减少杀毒软件误报的几率
6.添加多任务采集属性,软件采集前几秒会有点卡顿
点击采集后可以等待十秒八秒再点击采集地址查看采集的结果或者直接最小化
版本号1.1
1.增加自动删除静态首页和更新缓存的功能
2.优化采集速度
版本号1.0
1. Beta版本发布
2.设置6个采集地址栏,可以同时监控采集6个不同的资源
3.一键登录后台,每隔1小时自动监控采集
4.后台断线自动重连,实现无人值守24小时循环监控采集 查看全部
自动采集编写(软件自动检测服务器1.61,修复自动更新提示权限(组图))
版本号2.4
1、修复自动更新提示权限不足的问题
2.在群组验证窗口中增加横向和纵向状态选择栏
3.软件自动检测服务器最新版本号
4.主界面标题增加最新版本号显示
5.视频教程界面新增软件更新记录通知
版本号2.3
1、修复部分服务器不兼容问题
2.重写群验证码,验证速度更快
3.修复群验证有时会弹出的bug
4、修复软件退出时进程残留的问题
版本号2.2
1、新版本,验证方式无需登录QQ
2、软件全部源码重写,逻辑更清晰,运行更稳定
3.设置、采集、视频教程、Q群验证分为独立版块
4. 视频教程在“视频教程”部分改为内置和网页播放模式。
5、内置视频教程采用无广告解析界面,无广告播放。
6、增加Oceancms系统自动采集功能自动识别后台验证码
版本号2.1
1、添加试用版,可以手动采集,但是不能24小时挂断电话自动采集
2.去除采集时页面跳转产生的系统声音
3.优化部分源码,增强系统兼容性
4、下个版本会考虑加入其他cms系统的自动采集
版本号2.0
1、新增软件标题定制、系统托盘图标定制、采集地址标题名称定制
2、方便多站站长管理软件,无需打开软件界面采集
版本号1.9
1、优化部分源码,增加软件响应时间
2.增加定时释放内存功能,每次采集后系统内存会自动释放
版本号1.8
1、优化解决部分操作系统网页弹出错误窗口的问题
2.应网友要求,增加在线观看视频教程的按钮
3.应网友要求,取消手动搜索资源功能,增加操作流畅度
版本号1.7
1、增加手动搜索资源功能,整合数十个资源站
由于个人时间问题,函数写起来比较简单
功能虽然鸡肋,但聊胜于无!
版本号1.6
1、自动循环采集间隔时间由内置1小时改为自定义时间
版本号1.5
1、添加系统托盘菜单
2.取系统运行时间,每天23:55:58,软件会自动采集一次
解决采集部分来源23:00后更新资源,采集会导致当天漏采的问题
版本号1.4
1、优化采集的速度,响应时间以秒为单位
2.彻底解决之前版本的假死问题采集
版本号1.3
1、修复新添加的采集地址有时打不开的bug
2.优化多任务处理采集的速度,提升响应时间
3.优化1.version 2采集前几秒的问题
版本号1.2
1. 采集地址栏增加到10
2.在采集网页中嵌入采集地址栏
3.加宽采集网页的视觉高度
4.重新整理界面布局
5.优化部分代码,减少杀毒软件误报的几率
6.添加多任务采集属性,软件采集前几秒会有点卡顿
点击采集后可以等待十秒八秒再点击采集地址查看采集的结果或者直接最小化
版本号1.1
1.增加自动删除静态首页和更新缓存的功能
2.优化采集速度
版本号1.0
1. Beta版本发布
2.设置6个采集地址栏,可以同时监控采集6个不同的资源
3.一键登录后台,每隔1小时自动监控采集
4.后台断线自动重连,实现无人值守24小时循环监控采集
自动采集编写(企业采集宝、壹心阿米巴、哪里云、网易社区平台)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2022-01-31 20:03
自动采集编写采集程序,构建采集结构,注意对采集的数据进行清洗(如按数值分段,按时间分段等),检查正则表达式(如果不满足所有时间段时的过滤条件时,会被认为该数据不满足条件),分析采集数据,对采集数据清洗,对包含外部链接的数据采集时将无法通过正则表达式进行过滤。注意不要对采集过程中出现的xml文件进行混淆,即便采集不成功,也不要导出xml文件。
获取访问报告将数据制作成html文件,用浏览器访问(推荐phantomjs),获取数据后返回至服务器,即可获取部分企业给出的访问报告。
支持的功能不多,但是开发成本比较低廉,做pd的时候其实也不是特别需要那么多功能,但是不花钱啊,免费的带来的不一定是满意的,花了钱真心是值得的。实现原理是经过一轮一轮的流量编码,pp供给企业,企业定向采集的数据,这里不便透露,小弟自己做过,确实实现了一部分功能。如果真的愿意花那个钱买,请找大神看看技术交流群。或者组织个团队。
我就整理几款采集工具,企业采集宝、壹心阿米巴、哪里云、网易社区平台等工具。1.企业采集宝壹心阿米巴采集宝是一款基于搜索引擎商品信息抓取的工具。上篇博文,大家看了目录,和算法原理,可以回去细看文中提到的算法原理。不得不提的是它在前端抓取方面有很多优点,我们继续探索下一款app。elementapp,可以把阿里巴巴主流的产品文章抓取下来。
支持26个国家,2500多万产品信息。只需要一个美国的账号,即可以免费下载所有产品的信息。2.网易社区平台网易社区平台,可以说是综合性的网站信息抓取工具,包括、天猫、京东、聚划算、唯品会等10几个主流平台。api接口是国外第三方,不过管理系统是国内类似的成熟管理系统,相对来说,规范性要高很多。官方的开发工具支持二十余种语言格式,支持php、python、c++等语言,但是移动端支持少,ios和android都不支持分享抓取,同时无法分享别人的消息。
这里不多说,大家都明白。3.如何快速采集西西软件官网·app,全球领先的互联网产品分析平台。有数万个好玩的互联网产品数据,有50多万的用户的使用数据,app分析相关,对用户体验感分析极为准确。我们有自己的app数据分析模型,根据用户痛点和需求,推荐应用分析工具,是大型软件公司的最佳合作伙伴。4.壹心阿米巴自助建站系统“壹心阿米巴”是我们开发的第一款微信小程序,官网可查看。
可以把企业店铺里的商品信息,图片信息,手机端配图等,按分类分列提取出来。并可以通过智能关联网站源码等辅助我们搭建企业网站。最重要的是,不仅可。 查看全部
自动采集编写(企业采集宝、壹心阿米巴、哪里云、网易社区平台)
自动采集编写采集程序,构建采集结构,注意对采集的数据进行清洗(如按数值分段,按时间分段等),检查正则表达式(如果不满足所有时间段时的过滤条件时,会被认为该数据不满足条件),分析采集数据,对采集数据清洗,对包含外部链接的数据采集时将无法通过正则表达式进行过滤。注意不要对采集过程中出现的xml文件进行混淆,即便采集不成功,也不要导出xml文件。
获取访问报告将数据制作成html文件,用浏览器访问(推荐phantomjs),获取数据后返回至服务器,即可获取部分企业给出的访问报告。
支持的功能不多,但是开发成本比较低廉,做pd的时候其实也不是特别需要那么多功能,但是不花钱啊,免费的带来的不一定是满意的,花了钱真心是值得的。实现原理是经过一轮一轮的流量编码,pp供给企业,企业定向采集的数据,这里不便透露,小弟自己做过,确实实现了一部分功能。如果真的愿意花那个钱买,请找大神看看技术交流群。或者组织个团队。
我就整理几款采集工具,企业采集宝、壹心阿米巴、哪里云、网易社区平台等工具。1.企业采集宝壹心阿米巴采集宝是一款基于搜索引擎商品信息抓取的工具。上篇博文,大家看了目录,和算法原理,可以回去细看文中提到的算法原理。不得不提的是它在前端抓取方面有很多优点,我们继续探索下一款app。elementapp,可以把阿里巴巴主流的产品文章抓取下来。
支持26个国家,2500多万产品信息。只需要一个美国的账号,即可以免费下载所有产品的信息。2.网易社区平台网易社区平台,可以说是综合性的网站信息抓取工具,包括、天猫、京东、聚划算、唯品会等10几个主流平台。api接口是国外第三方,不过管理系统是国内类似的成熟管理系统,相对来说,规范性要高很多。官方的开发工具支持二十余种语言格式,支持php、python、c++等语言,但是移动端支持少,ios和android都不支持分享抓取,同时无法分享别人的消息。
这里不多说,大家都明白。3.如何快速采集西西软件官网·app,全球领先的互联网产品分析平台。有数万个好玩的互联网产品数据,有50多万的用户的使用数据,app分析相关,对用户体验感分析极为准确。我们有自己的app数据分析模型,根据用户痛点和需求,推荐应用分析工具,是大型软件公司的最佳合作伙伴。4.壹心阿米巴自助建站系统“壹心阿米巴”是我们开发的第一款微信小程序,官网可查看。
可以把企业店铺里的商品信息,图片信息,手机端配图等,按分类分列提取出来。并可以通过智能关联网站源码等辅助我们搭建企业网站。最重要的是,不仅可。
自动采集编写(优采云采集器3,独立的绿色软件,稳定易用,信息采集必备之选)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-31 19:05
优采云采集器3、网站自动内容更新工具,独立绿色软件,稳定好用,资讯必备采集。
【全自动无人值守】
无需人工值班,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运行的需求,让您摆脱繁重的工作量
【适用范围广】
最全能的采集软件,支持任意类型的网站采集,应用率高达99.9%,支持发布到所有类型的网站 程序等您可以在不发布接口的情况下采集本地文件。
【你想要的信息】
支持信息自由组合,通过强大的数据排序功能对信息进行深度处理,创造新的内容
【任意格式文件下载】
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至是torrent文件,只要你想要
【伪原创】
高速同义词替换、随机多词替换、随机段落排序,助力内容SEO
【无限多级页面采集】
无论是垂直方向的多层页面,平行方向的复杂页面,还是AJAX调用的页面,都轻松搞定采集
【自由扩展】
开放接口模式,免费二次开发,自定义任意功能,实现所有需求
软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、dongyi、joomla、pbdigg、php168、bbsxp、phpbb、dvbbs、typecho、emblog等常用系统的例子。 查看全部
自动采集编写(优采云采集器3,独立的绿色软件,稳定易用,信息采集必备之选)
优采云采集器3、网站自动内容更新工具,独立绿色软件,稳定好用,资讯必备采集。
【全自动无人值守】
无需人工值班,24小时自动实时监控目标,实时高效采集,全天候为您提供内容更新。满足长期运行的需求,让您摆脱繁重的工作量
【适用范围广】
最全能的采集软件,支持任意类型的网站采集,应用率高达99.9%,支持发布到所有类型的网站 程序等您可以在不发布接口的情况下采集本地文件。
【你想要的信息】
支持信息自由组合,通过强大的数据排序功能对信息进行深度处理,创造新的内容
【任意格式文件下载】
无论是静态还是动态,无论是图片、音乐、电影、软件,还是PDF文档、WORD文档,甚至是torrent文件,只要你想要
【伪原创】
高速同义词替换、随机多词替换、随机段落排序,助力内容SEO
【无限多级页面采集】
无论是垂直方向的多层页面,平行方向的复杂页面,还是AJAX调用的页面,都轻松搞定采集
【自由扩展】
开放接口模式,免费二次开发,自定义任意功能,实现所有需求
软件内置discuzX、phpwind、dedecms、wordpress、phpcms、empirecms、dongyi、joomla、pbdigg、php168、bbsxp、phpbb、dvbbs、typecho、emblog等常用系统的例子。
自动采集编写( 大课《倪尔昂全盘实操打法N式之美女图站》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-01-29 00:07
大课《倪尔昂全盘实操打法N式之美女图站》)
优采云自动采集美图站,揉美图收广告费(教学采集规则书写教程)
前言
众所周知,在所有的线上创作项目中,墨粉的引流和变现是最容易的,也是最适合小白的。
在大班《倪二郎整体实操方法N式美图站1.0:引爆流彩粉快速变现站游戏》中,给大家动手实践搭建盈利美图站,但是本站的方式是人工上传,耗时较长,比较费力(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个盈利的美妆摄影站。我们也可以使用自动的采集方法快速转换我们的网站来做。非常适合 优采云 操作
怎么做
今天给大家带来一个自动采集美图站,教大家写采集规则。
我们要做的是全自动采集,不需要手动操作。
本课将教小白如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集规则编写),掌握这些技巧,不仅可以仅用于美图站,自动采集可用于以下小说站和漫画站。另外,课程教你如何规避风险,快速做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖几千成人直播。这是非常有利可图的。和其他网站一样,可以通过加盟的形式帮助人们建站赚钱。为了防止网站流失,可以建一个导航站,把流量导入到自己的多个站点,进行二次流量变现,用黑帽的方法把网站弄起来再卖网站
文件下载下载地址 查看全部
自动采集编写(
大课《倪尔昂全盘实操打法N式之美女图站》)
优采云自动采集美图站,揉美图收广告费(教学采集规则书写教程)
前言
众所周知,在所有的线上创作项目中,墨粉的引流和变现是最容易的,也是最适合小白的。
在大班《倪二郎整体实操方法N式美图站1.0:引爆流彩粉快速变现站游戏》中,给大家动手实践搭建盈利美图站,但是本站的方式是人工上传,耗时较长,比较费力(但风险可控)。那么有没有更简单的方法呢?是的,我们也想做一个盈利的美妆摄影站。我们也可以使用自动的采集方法快速转换我们的网站来做。非常适合 优采云 操作
怎么做
今天给大家带来一个自动采集美图站,教大家写采集规则。
我们要做的是全自动采集,不需要手动操作。
本课将教小白如何搭建全自动采集美图站,并学习如何配置采集规则(自动采集规则编写),掌握这些技巧,不仅可以仅用于美图站,自动采集可用于以下小说站和漫画站。另外,课程教你如何规避风险,快速做网站,讲解如何赚钱
盈利模式
友情链接:一个可以卖几千成人直播。这是非常有利可图的。和其他网站一样,可以通过加盟的形式帮助人们建站赚钱。为了防止网站流失,可以建一个导航站,把流量导入到自己的多个站点,进行二次流量变现,用黑帽的方法把网站弄起来再卖网站
文件下载下载地址

