
自动采集子系统
自动采集子系统(易用而且好用的小程序采集工具++)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-11-03 13:02
自动采集子系统主要实现了图片与视频采集,文本采集,以及用户自定义采集。
开发者有:写代码,bs4.x-webkit_video-adapter.xml,c#,c++(neon最高并发)效率不错;(嵌入式不算)
前言h5微信采集其实是一个toolbox性质的小程序,只是起到了图片采集的作用。这是一套开源的采集代码解析工具,或许我们不需要重写一套代码就可以通过一键轻松采集到小视频、图片等内容,目前提供了fork版本和pro版本供大家使用。如果你也看重了并喜欢上了代码解析的这项技术,可以复制到剪切板。支持小程序、微信公众号、微信小店、小游戏、社区、简书等多平台采集,极大提高了采集效率。js、json、css、canvas等javascript原生格式数据一键复制。
这个我来推荐一款易用而且好用的小程序采集工具imagegirl++可以随时随地采集百度网盘,天猫,腾讯视频,优酷,爱奇艺,youtube等平台的网页视频。节省了你繁琐的操作,去掉了复杂的文件提取工作。请看效果。
豆瓣小电影采集工具:采集到豆瓣电影网页版信息集合!电影信息_豆瓣电影信息采集工具_免费一键采集软件百度云_电影云盘|百度网盘|百度云下载|115云盘|百度硬盘|cmcc|17173|22335家庭宽带|小米云共享上传,简直太棒了, 查看全部
自动采集子系统(易用而且好用的小程序采集工具++)
自动采集子系统主要实现了图片与视频采集,文本采集,以及用户自定义采集。
开发者有:写代码,bs4.x-webkit_video-adapter.xml,c#,c++(neon最高并发)效率不错;(嵌入式不算)
前言h5微信采集其实是一个toolbox性质的小程序,只是起到了图片采集的作用。这是一套开源的采集代码解析工具,或许我们不需要重写一套代码就可以通过一键轻松采集到小视频、图片等内容,目前提供了fork版本和pro版本供大家使用。如果你也看重了并喜欢上了代码解析的这项技术,可以复制到剪切板。支持小程序、微信公众号、微信小店、小游戏、社区、简书等多平台采集,极大提高了采集效率。js、json、css、canvas等javascript原生格式数据一键复制。
这个我来推荐一款易用而且好用的小程序采集工具imagegirl++可以随时随地采集百度网盘,天猫,腾讯视频,优酷,爱奇艺,youtube等平台的网页视频。节省了你繁琐的操作,去掉了复杂的文件提取工作。请看效果。
豆瓣小电影采集工具:采集到豆瓣电影网页版信息集合!电影信息_豆瓣电影信息采集工具_免费一键采集软件百度云_电影云盘|百度网盘|百度云下载|115云盘|百度硬盘|cmcc|17173|22335家庭宽带|小米云共享上传,简直太棒了,
自动采集子系统(3.5APP控件点击事件APP的设置及设置属性分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-23 15:08
设置页面的属性和URL信息,SDK会自动将getTrackProperties:的返回值添加到View Controller的APP浏览页面事件中;此外,getScreenUrl: 的返回值将用作页面的 URL Schema。当触发本页面的浏览事件时,会添加预设属性#url,值为当前页面的URL Schema。同时,SDK 会在跳转前获取页面的 URL Schema。如果能获取到就加到预设属性中#referrer为转发地址。
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控制点击事件
APP控件点击事件会在用户点击控件时触发
对于页面上View的点击事件,有几种方法可以设置更多的属性来扩展其解析值:
3.5.1 设置控件元素ID
您可以为页面(视图)上的元素设置元素 ID,以区分具有不同含义的元素。您可以使用以下方法设置元素 ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
此时会在table1的点击事件中添加预设属性#element_id,值为这里传入的值
3.5.2 自定义控件点击事件的属性
对于大多数控件,可以直接使用thinkingAnalyticsViewProperties来设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView 和 UI采集View 控件点击事件属性
对于 UITableView 和 UI采集View,需要通过实现 Protocol 来设置自定义属性:
1.首先在View Controller类中实现Protocol
2.其次,在类中设置代理。建议在viewDidLoad方法中设置。
self.table1.thinkingAnalyticsDelegate = self;
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4.最后在类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP有未捕获的异常时,会上报APP崩溃事件
四、忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1 忽略页面的自动采集事件
对于某些页面(View Controller),如果不想传递自动采集事件(包括页面浏览和控件点击事件),可以通过以下方法忽略:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2 忽略某类控件的点击事件
如果需要忽略某类控件的点击事件,可以使用下面的方法忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3 忽略一个元素(View)的点击事件
如果想忽略某个元素(View)的点击事件,可以使用下面的方法忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
五、Auto采集预设事件属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background 查看全部
自动采集子系统(3.5APP控件点击事件APP的设置及设置属性分析)
设置页面的属性和URL信息,SDK会自动将getTrackProperties:的返回值添加到View Controller的APP浏览页面事件中;此外,getScreenUrl: 的返回值将用作页面的 URL Schema。当触发本页面的浏览事件时,会添加预设属性#url,值为当前页面的URL Schema。同时,SDK 会在跳转前获取页面的 URL Schema。如果能获取到就加到预设属性中#referrer为转发地址。
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控制点击事件
APP控件点击事件会在用户点击控件时触发
对于页面上View的点击事件,有几种方法可以设置更多的属性来扩展其解析值:
3.5.1 设置控件元素ID
您可以为页面(视图)上的元素设置元素 ID,以区分具有不同含义的元素。您可以使用以下方法设置元素 ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
此时会在table1的点击事件中添加预设属性#element_id,值为这里传入的值
3.5.2 自定义控件点击事件的属性
对于大多数控件,可以直接使用thinkingAnalyticsViewProperties来设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView 和 UI采集View 控件点击事件属性
对于 UITableView 和 UI采集View,需要通过实现 Protocol 来设置自定义属性:
1.首先在View Controller类中实现Protocol
2.其次,在类中设置代理。建议在viewDidLoad方法中设置。
self.table1.thinkingAnalyticsDelegate = self;
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4.最后在类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP有未捕获的异常时,会上报APP崩溃事件
四、忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1 忽略页面的自动采集事件
对于某些页面(View Controller),如果不想传递自动采集事件(包括页面浏览和控件点击事件),可以通过以下方法忽略:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2 忽略某类控件的点击事件
如果需要忽略某类控件的点击事件,可以使用下面的方法忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3 忽略一个元素(View)的点击事件
如果想忽略某个元素(View)的点击事件,可以使用下面的方法忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
五、Auto采集预设事件属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
自动采集子系统(2020年6月,微软公布WindowsSubsystemforLinux2的最新更新 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-23 07:05
)
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
我买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL。2、Ubuntu系统和NVIDIA Driver,在Ubuntu子系统中成功运行深度学习代码Windows,GPU资源都满了!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软将WSL 2变成稳定版后,我们只需要输入以下命令即可设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须4.19.121 或更高。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查 Windows 升级设置中是否打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
查看全部
自动采集子系统(2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
)
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
我买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL。2、Ubuntu系统和NVIDIA Driver,在Ubuntu子系统中成功运行深度学习代码Windows,GPU资源都满了!

设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。

设置 Windows 子系统 Linux (WSL) 2
以后微软将WSL 2变成稳定版后,我们只需要输入以下命令即可设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart

然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart

重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2

在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:

安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。

在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。

设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。

下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r

内核版本必须4.19.121 或更高。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查 Windows 升级设置中是否打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:

然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。

在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。

在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io

安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list

更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2

关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu

测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:

测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter

如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:

现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。

自动采集子系统(Web数据自动采集与挖掘是一种特殊的数据挖掘到目前为止还没有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-16 08:19
1. Web 数据自动化的理论基础采集
Web可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何在互联网上进一步获取一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动化采集具有广泛的内涵和外延,目前还没有明确的定义。Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。Web 数据挖掘与这些概念密切相关,但也存在差异。
(1) Web 数据自动采集 和挖掘
Web挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出Web挖掘的定义。所谓Web挖掘,是指在大量非结构化、异构的Web信息中发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化)的非平凡过程。资源。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1。
(2) Web 数据自动 采集 和搜索引擎
Web数据自动化采集与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景等。而Web Data Automation采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web数据自动采集和信息抽取:信息抽取(Information Extraction)是近年来新兴的概念。信息抽取是面向不断增长和变化的,特定领域的文献中的特定查询,这种查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅要收录关键字,还要匹配实体之间的关系。信息提取是一个技术概念,Web Data自动化采集很大程度上依赖于信息提取技术来实现长期动态跟踪。
(3) Web 数据自动 采集 和 Web 信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的可比较数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是一个输入到输出图像:
ξ: (C: q)-->S3
但是Web数据自动采集并没有直接将Web文档集合的一个子集输出给用户,而是需要进一步的分析处理、重复检查和去噪、数据整合。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动化采集是网络数据挖掘的重要组成部分。它利用网络数据检索和信息提取技术,弥补了搜索引擎缺乏针对性和专业性,无法实现数据动态跟踪和监控的缺点,是一个非常有发展前景的领域。
1.2 研究意义
(1) 解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户没有价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的内容,信息利用的效率和效益越来越低。大大减少。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动检索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接按照用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。
(2) 解决搜索引擎智能低的问题
尽管互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出. 此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3) 节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且手工数据不会有遗漏、偏差和错误采集
2. 网络数据自动化采集 应用研究
2.1 应用功能
从上面的讨论可以看出,Web数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点就是基于领域,基于需求。没有有效的 采集 模型可以用于所有领域。Web数据自动化采集的原理是相通的,但具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以监测公众舆论的发展和特定主题的人的地理分布;猎头公司 监控一些公司的招聘网站 获取人才需求的变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
2.2应用产品
Web数据自动化采集Web数据自动化采集是从实际应用的需要中诞生的。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息化需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监测和采集
因此,一些相关的产品和服务已经开始在市场上销售。例如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.网络数据自动采集模型
虽然Web数据自动化采集是针对特定领域的,但是采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型框架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。
3.2 数据预处理模块
数据预处理是数据处理过程中的一个重要环节采集。如果数据预处理工作做好,数据质量高,数据采集的过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。因为数据源的种类很多,各种数据的特征属性可能不能满足主体的需要,所以数据预处理模块的主要功能是在Web上定义数据源、格式化数据源和初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。因此,数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获得网页的结构后,以内容块为单位保留和删除数据。最后,在将获得的数据放入数据库并建立索引之前,必须对其进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。
4.自动化采集基于房地产行业的系统设计
如前所述,Web数据采集必须是领域驱动或数据驱动的,所以本节在第3章的理论基础上,设计一个基于房地产行业的Web自动采集系统.
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多的信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者,还是银行信贷部门,都想知道房地产价格的最新动向。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。甚至房地产信息也具有地域性和时间性。
房产中介经常在一些比较大的楼盘网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据的高效化和自动化采集。
4.2.系统原理
自动化采集系统基于第三节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003。在2000 Professional操作系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析
采集 模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据三部分组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监测计划下网站的新开挖次数和最后一次采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容、采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大时会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在其他服务器空闲时自动运行。例如,您可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新并执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。采集 系统将像 Windows Update 一样自动启动和执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,充分考虑到采集和采集的情况。
4.3. 限制
Web数据自动采集主要完成采集的功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们需要的数据。它只负责采集 数据。至于为什么需要这样做,人们需要考虑一下。
其次,为了保证数据结果采集的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的适用范围越广,采集异常时出现冗余数据的可能性就越大。反之,数据采集模型的精度越高,适用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但是让算法自己做所有这些决定是不明智的。
数据 采集 不会在没有指导的情况下自动发现模型。数据采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化和改进。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web数据自动化采集是一个潜力巨大的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,有进一步融合的趋势。
在实际应用中,Web数据自动采集针对当前互联网信息过载而未被有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有更大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
在知识经济时代,谁能有效地获取和使用知识,谁就有在竞争中获胜的武器和工具。Web数据自动化采集作为获取和利用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地为个人、企业和国家的思维和战略发展服务。 查看全部
自动采集子系统(Web数据自动采集与挖掘是一种特殊的数据挖掘到目前为止还没有)
1. Web 数据自动化的理论基础采集
Web可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何在互联网上进一步获取一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动化采集具有广泛的内涵和外延,目前还没有明确的定义。Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。Web 数据挖掘与这些概念密切相关,但也存在差异。
(1) Web 数据自动采集 和挖掘
Web挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出Web挖掘的定义。所谓Web挖掘,是指在大量非结构化、异构的Web信息中发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化)的非平凡过程。资源。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1。
(2) Web 数据自动 采集 和搜索引擎
Web数据自动化采集与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景等。而Web Data Automation采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web数据自动采集和信息抽取:信息抽取(Information Extraction)是近年来新兴的概念。信息抽取是面向不断增长和变化的,特定领域的文献中的特定查询,这种查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅要收录关键字,还要匹配实体之间的关系。信息提取是一个技术概念,Web Data自动化采集很大程度上依赖于信息提取技术来实现长期动态跟踪。
(3) Web 数据自动 采集 和 Web 信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的可比较数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是一个输入到输出图像:
ξ: (C: q)-->S3
但是Web数据自动采集并没有直接将Web文档集合的一个子集输出给用户,而是需要进一步的分析处理、重复检查和去噪、数据整合。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动化采集是网络数据挖掘的重要组成部分。它利用网络数据检索和信息提取技术,弥补了搜索引擎缺乏针对性和专业性,无法实现数据动态跟踪和监控的缺点,是一个非常有发展前景的领域。
1.2 研究意义
(1) 解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户没有价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的内容,信息利用的效率和效益越来越低。大大减少。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动检索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接按照用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。
(2) 解决搜索引擎智能低的问题
尽管互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出. 此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3) 节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且手工数据不会有遗漏、偏差和错误采集
2. 网络数据自动化采集 应用研究
2.1 应用功能
从上面的讨论可以看出,Web数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点就是基于领域,基于需求。没有有效的 采集 模型可以用于所有领域。Web数据自动化采集的原理是相通的,但具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以监测公众舆论的发展和特定主题的人的地理分布;猎头公司 监控一些公司的招聘网站 获取人才需求的变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
2.2应用产品
Web数据自动化采集Web数据自动化采集是从实际应用的需要中诞生的。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息化需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监测和采集
因此,一些相关的产品和服务已经开始在市场上销售。例如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.网络数据自动采集模型
虽然Web数据自动化采集是针对特定领域的,但是采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型框架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。
3.2 数据预处理模块
数据预处理是数据处理过程中的一个重要环节采集。如果数据预处理工作做好,数据质量高,数据采集的过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。因为数据源的种类很多,各种数据的特征属性可能不能满足主体的需要,所以数据预处理模块的主要功能是在Web上定义数据源、格式化数据源和初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。因此,数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获得网页的结构后,以内容块为单位保留和删除数据。最后,在将获得的数据放入数据库并建立索引之前,必须对其进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。
4.自动化采集基于房地产行业的系统设计
如前所述,Web数据采集必须是领域驱动或数据驱动的,所以本节在第3章的理论基础上,设计一个基于房地产行业的Web自动采集系统.
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多的信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者,还是银行信贷部门,都想知道房地产价格的最新动向。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。甚至房地产信息也具有地域性和时间性。
房产中介经常在一些比较大的楼盘网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据的高效化和自动化采集。
4.2.系统原理
自动化采集系统基于第三节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003。在2000 Professional操作系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析
采集 模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据三部分组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监测计划下网站的新开挖次数和最后一次采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容、采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大时会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在其他服务器空闲时自动运行。例如,您可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新并执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。采集 系统将像 Windows Update 一样自动启动和执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,充分考虑到采集和采集的情况。
4.3. 限制
Web数据自动采集主要完成采集的功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们需要的数据。它只负责采集 数据。至于为什么需要这样做,人们需要考虑一下。
其次,为了保证数据结果采集的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的适用范围越广,采集异常时出现冗余数据的可能性就越大。反之,数据采集模型的精度越高,适用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但是让算法自己做所有这些决定是不明智的。
数据 采集 不会在没有指导的情况下自动发现模型。数据采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化和改进。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web数据自动化采集是一个潜力巨大的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,有进一步融合的趋势。
在实际应用中,Web数据自动采集针对当前互联网信息过载而未被有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有更大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
在知识经济时代,谁能有效地获取和使用知识,谁就有在竞争中获胜的武器和工具。Web数据自动化采集作为获取和利用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地为个人、企业和国家的思维和战略发展服务。
自动采集子系统( 辅助网编系统地批量地快速地发现有新闻价值的实时信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-10 18:15
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统是基于世界领先的采集技术开发的,可以每天批量辅助网络编辑系统快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别等),从而率先发现具有新闻价值的信息,并提供一套具有后续编辑审核功能的网络编辑工作平台。
其系统架构如下图所示: Lesisoft
图1.乐思网新闻转载系统的系统架构
与目前的人工新闻转载相比,其优势十分明显:
比较索引
采用乐思网络新闻转载系统
手动转载
目标网站
数百到数千甚至数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴。
新闻线索识别
基于自动判别的人工确认
需人工一一核对确认
信息保存
准确、全面、易于事后跟踪
碎片化,难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可每日、每周、每月发布报告
模糊,不清楚,没有统计数据:Lesisoft
转载效果
系统转发,大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1. 重大新闻网站、平面媒体、论坛、博客、微博、视频网站的最新信息自动集中呈现
2. 系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2. 系统组成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3. 网络拓扑
四、 自动 采集 子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如BBC、CNN等。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、 MS SQL Server、MySQL、Sybase、文件数据库Access等。乐思软件
自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1. 全球领先的自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表格查询新闻转载 查看全部
自动采集子系统(
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统是基于世界领先的采集技术开发的,可以每天批量辅助网络编辑系统快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别等),从而率先发现具有新闻价值的信息,并提供一套具有后续编辑审核功能的网络编辑工作平台。
其系统架构如下图所示: Lesisoft
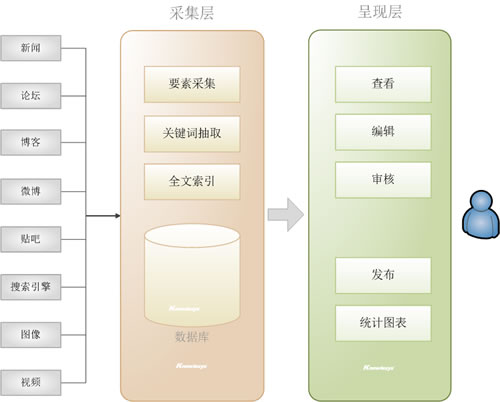
图1.乐思网新闻转载系统的系统架构
与目前的人工新闻转载相比,其优势十分明显:
比较索引
采用乐思网络新闻转载系统
手动转载
目标网站
数百到数千甚至数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴。
新闻线索识别
基于自动判别的人工确认
需人工一一核对确认
信息保存
准确、全面、易于事后跟踪
碎片化,难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可每日、每周、每月发布报告
模糊,不清楚,没有统计数据:Lesisoft
转载效果
系统转发,大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1. 重大新闻网站、平面媒体、论坛、博客、微博、视频网站的最新信息自动集中呈现
2. 系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
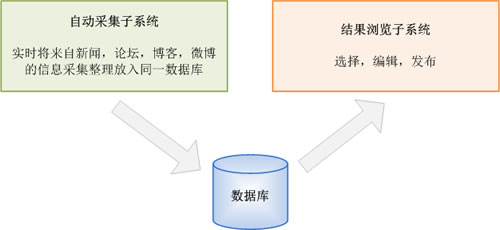
图2. 系统组成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
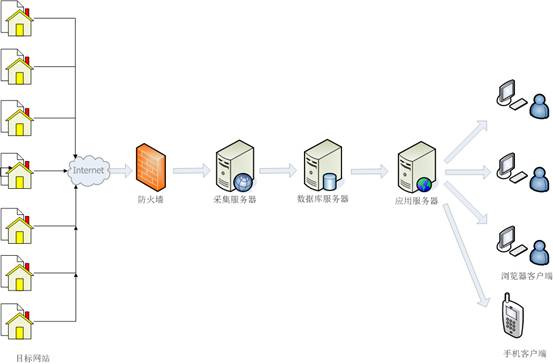
图3. 网络拓扑
四、 自动 采集 子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如BBC、CNN等。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、 MS SQL Server、MySQL、Sybase、文件数据库Access等。乐思软件
自动采集子系统的全方位监控功能如下图所示:
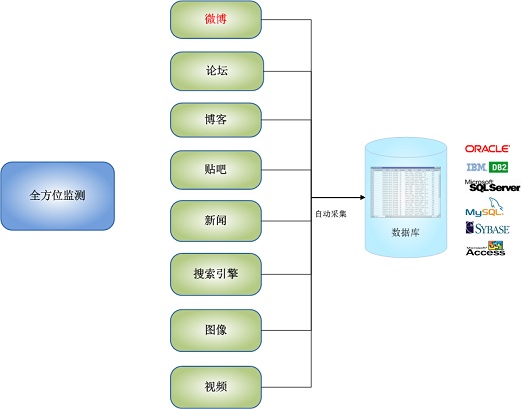
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1. 全球领先的自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表格查询新闻转载
自动采集子系统(乐思网络舆情监测系统的网络拓扑结构图所示与分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-10-01 23:09
系统组成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集层)和分析浏览子系统(分析层和呈现层)。
乐思网络舆情监测系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
自动采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西磁社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如Facebook、Twitter、BBC、CNN等。
自动采集 子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
自动采集子系统的全方位监控功能如下图所示:
自动 采集 子系统具有以下显着特点:
1. 全球领先的全自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报刊电子版等实时监控。
3. 无需配置直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能 26 禁止 9 盗用 0
可自动处理和保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
自动采集子系统(乐思网络舆情监测系统的网络拓扑结构图所示与分析)
系统组成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集层)和分析浏览子系统(分析层和呈现层)。
乐思网络舆情监测系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
自动采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西磁社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如Facebook、Twitter、BBC、CNN等。
自动采集 子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
自动采集子系统的全方位监控功能如下图所示:
自动 采集 子系统具有以下显着特点:
1. 全球领先的全自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报刊电子版等实时监控。
3. 无需配置直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能 26 禁止 9 盗用 0
可自动处理和保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
自动采集子系统(本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-29 10:11
关于作者:
邱云飞,辽宁工业大学,博士,副教授。
邵良山,辽宁工业大学,博士,教授。
摘要:本文研究了应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论和方法,提出了一个用于合作伙伴选择的中文Web信息获取系统的总体架构,并分析了实现基于系统的网络信息获取系统的关键技术。元搜索网页采集、基于样本公共特征的企业主页过滤、基于模式的企业信息抽取,并详细介绍了这三项关键技术。最后,根据作者提出的思路,通过编程实现了一个用于合作伙伴选择的中文Web信息获取原型系统,并通过系统验证了作者提出的方法的可行性并证明了该方法的准确性。
关键词:合作伙伴;网络挖掘;元搜索;文本过滤;信息抽取
1.简介
虚拟企业主要是针对企业核心能力资源的整合,即投资和管理的重点是企业自身的核心能力,以及一些非核心能力,或者他们不具备的核心能力。在短时间内拥有或不需要。转向依赖外部虚拟业务合作伙伴提供。因此,虚拟企业中合作伙伴的选择是一个非常重要的问题,直接关系到虚拟企业的成败。
WWW推出后,互联网成为全球最大的信息来源,其多样化的信息方式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的物质积累。另一方面,正是由于互联网海量、动态、非结构化、异构和地域分布的特点,传统的研究方法已经不能满足网络环境中信息获取、处理和利用的需要。
本文构建了一个用于合作伙伴选择的网络信息获取系统的总体框架,给出了系统的实现过程,并自动提取了与企业相关的信息(如企业名称、企业规模、生产能力、联系方式等)。对Internet信息搜索、文本过滤、信息抽取等相关技术所涉及的理论和方法进行了分析,最终实现了一个用于合作伙伴选择的中文Web信息获取原型系统。
2.合作伙伴选择的网络信息获取系统总体框架
2.1 系统需求分析
本系统从虚拟企业合作伙伴选择的角度构建了一个面向网络的潜在合作伙伴信息获取系统。主要功能是从互联网上自动获取可能成为核心企业合作伙伴的基本信息,从而为核心企业提供强大的潜力合作伙伴信息数据库,为其后期的合作伙伴选择奠定良好的基础。
根据调查分析,潜在合作伙伴的基本信息一般分布在一些综合性网站、行业网站、业务网站(类似B2B网站等)。 ), 企业网站向上。一家公司在这些网站上提供的信息基本相同,但与网站提供的其他公司相关信息相比,公司自己的网站提供的信息更加全面和权威性。对于整个企业网站,企业的一般介绍一般都在企业主页上,所以企业主页上的信息是本系统需要获取的主要对象。
2.2 系统整体框架
基于以上分析,设计系统的整体架构如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、网页文本库、企业主页库、潜在合作伙伴信息库七部分组成。
图1 合作伙伴选择Web信息获取系统整体架构
其中,网页采集子系统根据关键字从互联网上搜索网页,并将搜索到的网页下载到本地网络文本库;文本过滤子系统对网络文本库的网页进行文本过滤,主要目的是筛选出收录潜在合作伙伴信息的公司主页,最后保存在公司主页库中;信息提取子系统从公司主页库的各个网页中提取信息,主要目的是提取潜在合作伙伴公司的基本信息,最后保存到潜在合作伙伴信息数据库;
3.合作伙伴选择的Web信息获取系统设计
3.1 系统实现思路
从系统的整体框架和各个模块的描述可以看出,为了实现整个系统,网页采集子系统、文本过滤子系统、文本过滤子系统三部分的设计与实现信息抽取子系统是整个系统实现的重点和难点。也可以说是系统实现的关键技术。针对三个子系统的特点,提出了基于元搜索采集的自动网页、基于样本公共特征的企业主页过滤、基于模式的企业主页信息提取三种方法,并完成了相应的技术.
3.2 基于元搜索的网页自动子系统设计采集
元搜索引擎(MetasearchEngine)被称为搜索引擎之上的搜索引擎。用户只需提交一次搜索请求,由元搜索引擎负责转换过程,然后提交给多个预先选定的独立搜索引擎,将所有查询结果汇总并以统一格式呈现给用户. 相对于元搜索引擎,可以使用的独立搜索引擎被称为“sourceEngines”或“搜索资源”。
本系统利用元搜索引擎将关键词提交给现有的搜索引擎进行搜索,然后将搜索到的网页自动下载到本地,这是整个系统实现的第一步。具体系统结构如下图2所示。该子系统由三部分组成:会员搜索和调用模块、结果页面分析模块和网页下载模块。
网页采集流程如下:
1) 首先将关键词提交给各会员搜索引擎(如google、百度等),该会员搜索引擎根据系统提供的关键词进行搜索,并返回相应的结果[1,2]。
2) 接下来分析各个成员搜索引擎返回的搜索结果页面。首先获取搜索结果页面的源代码,然后在源代码中提取每个搜索结果连接的URL。提取URL,发送到网页下载模块进行网页下载。该模块的关键技术之一是在源代码中提取与每个搜索结果相关联的URL技术。
3) 由于一般搜索引擎的每个搜索结果页面只收录一定数量的搜索结果(谷歌和百度10条),通常不能满足信息采集模块采集对于一个大量网页,因此需要转到下一个搜索结果页面。然后从下一个搜索结果页面中提取与搜索结果相关联的网址,发送到网页下载模块下载该网页。
4) 判断是否满足用户要求的网页数量,如果不满足,继续3);如果遇到,停止。
图2网页采集子系统结构及流程
3.3 基于样本公共特征的企业首页过滤子系统设计
由于文本采集模块的限制,即使是关键字搜索也不能保证网络文本库中的所有页面都收录潜在合作公司的基本信息。因此,有必要对网页文本库中的网页进行过滤,筛选出符合用户意图的网页。其架构如下图 3 所示。该子系统由三部分组成:成员文本分析模块、样本分析模块和特征匹配模块。
文本过滤的过程如下:用户首先选择几个符合要求的文本作为样本,然后提取样本的共同特征,利用样本的共同特征匹配每个文本的文本特征,计算匹配值,并使用匹配值的大小来判断文本是否满足用户需求。用户可以根据过滤后的结果考虑换样,也可以根据用户需求的变化换样,以达到反馈给系统的目的。
1)首先,用户在网络文本库中选择几个符合用户意图的网页作为样本(一般为2-5个),将这些样本提交给样本分析模块,样本分析模块提取样本的共同特征[3]。
2) 文本分析模块对网络文本库中的所有网页进行特征提取[4]。
3)利用样本的共性特征匹配各个网页的特征,计算相关性,通过相关性与用户设置的阈值的比较来判断文本是否满足需求用户。
图3 企业主页过滤子系统的结构和流程
3.4 基于模式的企业主页信息抽取子系统设计
经过前面的网页采集模块和文本过滤模块的工作,收录潜在合作伙伴公司信息的网页已经保存在公司主页数据库中。本文结合企业主页上企业信息的分布和构成特点,设计了企业基本信息的抽取模式,最终实现了企业主页上企业基本信息的抽取。系统结构如下图4所示。该子系统由成员文本内容抽取模块、抽取规则定义模块、企业信息抽取模块三部分组成。
图4 信息抽取子系统整体结构及流程
提取企业主页信息的过程如下:
1) 从企业文本库中提取网页文本,发送至文本内容提取模块。
2) 文本内容提取模块获取企业文本库提供的网页文本源代码,去除HTML标签等处理,将最终的文本内容提交给企业信息提取模块。
3)抽取规则定义模块根据公司首页的特征等背景领域知识定义抽取规则,并将定义的抽取规则提交给企业信息抽取模块。本文主要定义了公司名称、规模、生产能力和质量认证等几种提取模式,模式定义方法可参见文献[5,6]
4)企业信息抽取模块根据抽取规则定义模块提交的抽取规则,从文本内容抽取模块发送的文本内容中抽取信息,并将最终抽取结果提交给候选合作伙伴数据库[7, 8]。
4. 用于合作伙伴选择的网络信息获取原型系统的实现
4.1系统概述
为了验证本文提出的思路,为核心企业提供一个真正的WEB信息采集软件,可以在合作伙伴选择过程中使用,笔者使用MicrosoftVisualStudio.NET2003和Access2000在Windows平台上开发了一个虚拟企业2000服务器。合作方选定的中文网页信息采集原型系统。该系统在一定程度上可以帮助核心企业从大量网络信息资料中获取潜在合作伙伴的企业相关信息,对下一步合作伙伴的选择起到了很好的支持作用。
4.2网页自动采集子系统的实现
自动网页采集子系统主要包括三个模块:调用会员搜索引擎、从搜索结果中提取超链接、自动下载网页。
搜索引擎调用模块调用成员搜索引擎时,原则上应该调用多个成员搜索引擎,但由于时间限制,我们只在原型系统中实现了对百度搜索引擎的调用,对其他成员的调用搜索引擎的方法类似于调用百度。
由于百度不提供免费接口,所以在连接搜索引擎时,使用下图代码连接百度。编程语言是c#。
字符串pn, wd, cc;
pn="0"; wd=System.Web.HttpUtility.UrlEncode(this.textBox2.Text, System.Text.Encoding.GetEncoding("GB2312"));
cc=";si=&rn=10&ie=gb2312&ct=0&wd="+wd+"&pn="+pn+"&cl=3";
其中,pn代表搜索引擎返回结果的页码;wd 表示搜索关键字的编码;System.Web.HttpUtility.UrlEncode()函数的作用是将中文关键字转换成相应的编码。变量cc代表连接百度的接口的URL。通过这个网址,可以得到百度在执行关键词查询后返回的页面。
在百度返回的查询页面中,除了关于查询关键词的超链接外,还有一系列与关键词无关的链接,比如脚本语言指向的超链接,百度快照链接,以及广告链接。因此,搜索结果超链接提取模块通过对查询返回页面的仔细分析,提出了一种提取查询返回结果URL的有效方法。该方法包括GetPageSource(stringurl)和GetHyperLinks(stringhttpcode)两个函数,其中GetPageSource(stringurl)用于获取网页的html源代码,GetHyperLinks(stringhttpcode)用于获取网页返回结果中的超链接URL询问。
最后,函数downloadpage(stringurl,stringpath)被设计用来下载URL对应的页面并保存到web文本库中。成为下一次文本过滤工作的文本源。
4.3 企业首页过滤子系统的实现
企业主页过滤子系统涉及一些网页文本分析技术,包括获取网页源代码、去除HTML标签、去除非中文字符、中文分词、去除停用词、词频统计、特征提取等操作。获取网页源代码,去除HTML标签,去除非中文字符实际上是在处理HTML文本文件,所以最简单的方法就是去除所有HTML标签,剩下的内容作为纯文本处理。
对于中文分词,我们使用CSW中文分词组件5.0,提供c#接口调用。首先运行该组件包中的install.bat文件,在系统中注册该组件。然后在开发工具中引用CSW.dll组件,以下是在C#控制台应用中调用该组件的示例代码。
CSWLib.SplitWordClasscsw=newCSWLib.SplitWordClass();
stringtext=csw.Split("要拆分的原创文本", 0, @"c:\winnt\system");
这里我们使用的是免费的CSW中文分词组件5.0共享版。此版本只有中文分词功能,没有词频统计功能。因此,我们需要自己完成词频统计的过程。为了方便日后提取网页特征,我们将中文分词和词频统计的结果保存到access数据库的wordcount表中。
4.4 信息抽取子系统的实现
在原型系统中,基于对公司主页信息特征的分析,结合正则表达式字符串匹配技术构建了公司主页信息抽取模型,实现了公司名称、成立年份、公司区域、资产信息、人员信息和生产能力。、质量认证等信息抽取。
5.结论
利用从互联网上自动获取企业信息来支持虚拟企业合作伙伴选择活动的研究还处于起步阶段,还有很多问题需要深入探讨。本研究基于实验。由于条件有限,实验规模小,得出的结论具有一定的局限性。此外,虚拟企业合作伙伴选择过程中的信息需求多样复杂,需要进一步研究,进一步明确合作伙伴选择过程中的信息需求。进一步研究主要有以下思路:
1) 进一步研究合作伙伴选择过程中的网页信息需求,使信息提取不仅限于提取企业主页,还可以收录其他可以收录企业相关信息的网页,例如行业< @网站、业务网站等等。
2) 本文实现的企业主页过滤效果结合基于样本共同特征的文本过滤方法仍有一定的局限性,需要探索更合适的企业主页过滤方法。
参考
[1] 李晓明、闫鸿飞、王继民,《搜索引擎——原理、技术与系统》,科学出版社,2005。
[2]JohnD.TheAnatomyofLarge-ScaleHypertertextualWebSearchEngine[C].In:Procofthe7thInt'1worldwidewebconf.Brishane.Austrilian,1999.
[3] 刘明基,等。Web文本信息特征获取算法[J]. 小型微机系统,2002,23(6):684-687
[4]秦晋,等。文本分类中的特征提取[J]. 计算机应用, 2003,23(2):45-46.
[5]VoertA.AutomaticExtractionofInformationBlocksUsingPATTrees[C].Proc.oftheNationalComputerSymposium,Taipei,Taiwan,1999(6):223-226.
[6]张炳奇,等。企业相关信息抽取技术研究与系统实现[J]. 微电子与计算机, 2004, 21(1):1-6.
[7] 袁占庭,等。数据提取与语义分析在Web数据挖掘中的应用[J].计算机工程与设计,
[8] 陈展荣,等。网络中文资料的智能提取与词汇切分[J]. 计算机工程与设计, 2005, 26 (6):1422-1424.
本文受国家自然科学基金项目(70971059),辽宁省创新团队项目(2006T076,2008T090,2009T045))资助。 查看全部
自动采集子系统(本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与方法)
关于作者:
邱云飞,辽宁工业大学,博士,副教授。
邵良山,辽宁工业大学,博士,教授。
摘要:本文研究了应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论和方法,提出了一个用于合作伙伴选择的中文Web信息获取系统的总体架构,并分析了实现基于系统的网络信息获取系统的关键技术。元搜索网页采集、基于样本公共特征的企业主页过滤、基于模式的企业信息抽取,并详细介绍了这三项关键技术。最后,根据作者提出的思路,通过编程实现了一个用于合作伙伴选择的中文Web信息获取原型系统,并通过系统验证了作者提出的方法的可行性并证明了该方法的准确性。
关键词:合作伙伴;网络挖掘;元搜索;文本过滤;信息抽取
1.简介
虚拟企业主要是针对企业核心能力资源的整合,即投资和管理的重点是企业自身的核心能力,以及一些非核心能力,或者他们不具备的核心能力。在短时间内拥有或不需要。转向依赖外部虚拟业务合作伙伴提供。因此,虚拟企业中合作伙伴的选择是一个非常重要的问题,直接关系到虚拟企业的成败。
WWW推出后,互联网成为全球最大的信息来源,其多样化的信息方式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的物质积累。另一方面,正是由于互联网海量、动态、非结构化、异构和地域分布的特点,传统的研究方法已经不能满足网络环境中信息获取、处理和利用的需要。
本文构建了一个用于合作伙伴选择的网络信息获取系统的总体框架,给出了系统的实现过程,并自动提取了与企业相关的信息(如企业名称、企业规模、生产能力、联系方式等)。对Internet信息搜索、文本过滤、信息抽取等相关技术所涉及的理论和方法进行了分析,最终实现了一个用于合作伙伴选择的中文Web信息获取原型系统。
2.合作伙伴选择的网络信息获取系统总体框架
2.1 系统需求分析
本系统从虚拟企业合作伙伴选择的角度构建了一个面向网络的潜在合作伙伴信息获取系统。主要功能是从互联网上自动获取可能成为核心企业合作伙伴的基本信息,从而为核心企业提供强大的潜力合作伙伴信息数据库,为其后期的合作伙伴选择奠定良好的基础。
根据调查分析,潜在合作伙伴的基本信息一般分布在一些综合性网站、行业网站、业务网站(类似B2B网站等)。 ), 企业网站向上。一家公司在这些网站上提供的信息基本相同,但与网站提供的其他公司相关信息相比,公司自己的网站提供的信息更加全面和权威性。对于整个企业网站,企业的一般介绍一般都在企业主页上,所以企业主页上的信息是本系统需要获取的主要对象。
2.2 系统整体框架
基于以上分析,设计系统的整体架构如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、网页文本库、企业主页库、潜在合作伙伴信息库七部分组成。
图1 合作伙伴选择Web信息获取系统整体架构
其中,网页采集子系统根据关键字从互联网上搜索网页,并将搜索到的网页下载到本地网络文本库;文本过滤子系统对网络文本库的网页进行文本过滤,主要目的是筛选出收录潜在合作伙伴信息的公司主页,最后保存在公司主页库中;信息提取子系统从公司主页库的各个网页中提取信息,主要目的是提取潜在合作伙伴公司的基本信息,最后保存到潜在合作伙伴信息数据库;
3.合作伙伴选择的Web信息获取系统设计
3.1 系统实现思路
从系统的整体框架和各个模块的描述可以看出,为了实现整个系统,网页采集子系统、文本过滤子系统、文本过滤子系统三部分的设计与实现信息抽取子系统是整个系统实现的重点和难点。也可以说是系统实现的关键技术。针对三个子系统的特点,提出了基于元搜索采集的自动网页、基于样本公共特征的企业主页过滤、基于模式的企业主页信息提取三种方法,并完成了相应的技术.
3.2 基于元搜索的网页自动子系统设计采集
元搜索引擎(MetasearchEngine)被称为搜索引擎之上的搜索引擎。用户只需提交一次搜索请求,由元搜索引擎负责转换过程,然后提交给多个预先选定的独立搜索引擎,将所有查询结果汇总并以统一格式呈现给用户. 相对于元搜索引擎,可以使用的独立搜索引擎被称为“sourceEngines”或“搜索资源”。
本系统利用元搜索引擎将关键词提交给现有的搜索引擎进行搜索,然后将搜索到的网页自动下载到本地,这是整个系统实现的第一步。具体系统结构如下图2所示。该子系统由三部分组成:会员搜索和调用模块、结果页面分析模块和网页下载模块。
网页采集流程如下:
1) 首先将关键词提交给各会员搜索引擎(如google、百度等),该会员搜索引擎根据系统提供的关键词进行搜索,并返回相应的结果[1,2]。
2) 接下来分析各个成员搜索引擎返回的搜索结果页面。首先获取搜索结果页面的源代码,然后在源代码中提取每个搜索结果连接的URL。提取URL,发送到网页下载模块进行网页下载。该模块的关键技术之一是在源代码中提取与每个搜索结果相关联的URL技术。
3) 由于一般搜索引擎的每个搜索结果页面只收录一定数量的搜索结果(谷歌和百度10条),通常不能满足信息采集模块采集对于一个大量网页,因此需要转到下一个搜索结果页面。然后从下一个搜索结果页面中提取与搜索结果相关联的网址,发送到网页下载模块下载该网页。
4) 判断是否满足用户要求的网页数量,如果不满足,继续3);如果遇到,停止。
图2网页采集子系统结构及流程
3.3 基于样本公共特征的企业首页过滤子系统设计
由于文本采集模块的限制,即使是关键字搜索也不能保证网络文本库中的所有页面都收录潜在合作公司的基本信息。因此,有必要对网页文本库中的网页进行过滤,筛选出符合用户意图的网页。其架构如下图 3 所示。该子系统由三部分组成:成员文本分析模块、样本分析模块和特征匹配模块。
文本过滤的过程如下:用户首先选择几个符合要求的文本作为样本,然后提取样本的共同特征,利用样本的共同特征匹配每个文本的文本特征,计算匹配值,并使用匹配值的大小来判断文本是否满足用户需求。用户可以根据过滤后的结果考虑换样,也可以根据用户需求的变化换样,以达到反馈给系统的目的。
1)首先,用户在网络文本库中选择几个符合用户意图的网页作为样本(一般为2-5个),将这些样本提交给样本分析模块,样本分析模块提取样本的共同特征[3]。
2) 文本分析模块对网络文本库中的所有网页进行特征提取[4]。
3)利用样本的共性特征匹配各个网页的特征,计算相关性,通过相关性与用户设置的阈值的比较来判断文本是否满足需求用户。
图3 企业主页过滤子系统的结构和流程
3.4 基于模式的企业主页信息抽取子系统设计
经过前面的网页采集模块和文本过滤模块的工作,收录潜在合作伙伴公司信息的网页已经保存在公司主页数据库中。本文结合企业主页上企业信息的分布和构成特点,设计了企业基本信息的抽取模式,最终实现了企业主页上企业基本信息的抽取。系统结构如下图4所示。该子系统由成员文本内容抽取模块、抽取规则定义模块、企业信息抽取模块三部分组成。
图4 信息抽取子系统整体结构及流程
提取企业主页信息的过程如下:
1) 从企业文本库中提取网页文本,发送至文本内容提取模块。
2) 文本内容提取模块获取企业文本库提供的网页文本源代码,去除HTML标签等处理,将最终的文本内容提交给企业信息提取模块。
3)抽取规则定义模块根据公司首页的特征等背景领域知识定义抽取规则,并将定义的抽取规则提交给企业信息抽取模块。本文主要定义了公司名称、规模、生产能力和质量认证等几种提取模式,模式定义方法可参见文献[5,6]
4)企业信息抽取模块根据抽取规则定义模块提交的抽取规则,从文本内容抽取模块发送的文本内容中抽取信息,并将最终抽取结果提交给候选合作伙伴数据库[7, 8]。
4. 用于合作伙伴选择的网络信息获取原型系统的实现
4.1系统概述
为了验证本文提出的思路,为核心企业提供一个真正的WEB信息采集软件,可以在合作伙伴选择过程中使用,笔者使用MicrosoftVisualStudio.NET2003和Access2000在Windows平台上开发了一个虚拟企业2000服务器。合作方选定的中文网页信息采集原型系统。该系统在一定程度上可以帮助核心企业从大量网络信息资料中获取潜在合作伙伴的企业相关信息,对下一步合作伙伴的选择起到了很好的支持作用。
4.2网页自动采集子系统的实现
自动网页采集子系统主要包括三个模块:调用会员搜索引擎、从搜索结果中提取超链接、自动下载网页。
搜索引擎调用模块调用成员搜索引擎时,原则上应该调用多个成员搜索引擎,但由于时间限制,我们只在原型系统中实现了对百度搜索引擎的调用,对其他成员的调用搜索引擎的方法类似于调用百度。
由于百度不提供免费接口,所以在连接搜索引擎时,使用下图代码连接百度。编程语言是c#。
字符串pn, wd, cc;
pn="0"; wd=System.Web.HttpUtility.UrlEncode(this.textBox2.Text, System.Text.Encoding.GetEncoding("GB2312"));
cc=";si=&rn=10&ie=gb2312&ct=0&wd="+wd+"&pn="+pn+"&cl=3";
其中,pn代表搜索引擎返回结果的页码;wd 表示搜索关键字的编码;System.Web.HttpUtility.UrlEncode()函数的作用是将中文关键字转换成相应的编码。变量cc代表连接百度的接口的URL。通过这个网址,可以得到百度在执行关键词查询后返回的页面。
在百度返回的查询页面中,除了关于查询关键词的超链接外,还有一系列与关键词无关的链接,比如脚本语言指向的超链接,百度快照链接,以及广告链接。因此,搜索结果超链接提取模块通过对查询返回页面的仔细分析,提出了一种提取查询返回结果URL的有效方法。该方法包括GetPageSource(stringurl)和GetHyperLinks(stringhttpcode)两个函数,其中GetPageSource(stringurl)用于获取网页的html源代码,GetHyperLinks(stringhttpcode)用于获取网页返回结果中的超链接URL询问。
最后,函数downloadpage(stringurl,stringpath)被设计用来下载URL对应的页面并保存到web文本库中。成为下一次文本过滤工作的文本源。
4.3 企业首页过滤子系统的实现
企业主页过滤子系统涉及一些网页文本分析技术,包括获取网页源代码、去除HTML标签、去除非中文字符、中文分词、去除停用词、词频统计、特征提取等操作。获取网页源代码,去除HTML标签,去除非中文字符实际上是在处理HTML文本文件,所以最简单的方法就是去除所有HTML标签,剩下的内容作为纯文本处理。
对于中文分词,我们使用CSW中文分词组件5.0,提供c#接口调用。首先运行该组件包中的install.bat文件,在系统中注册该组件。然后在开发工具中引用CSW.dll组件,以下是在C#控制台应用中调用该组件的示例代码。
CSWLib.SplitWordClasscsw=newCSWLib.SplitWordClass();
stringtext=csw.Split("要拆分的原创文本", 0, @"c:\winnt\system");
这里我们使用的是免费的CSW中文分词组件5.0共享版。此版本只有中文分词功能,没有词频统计功能。因此,我们需要自己完成词频统计的过程。为了方便日后提取网页特征,我们将中文分词和词频统计的结果保存到access数据库的wordcount表中。
4.4 信息抽取子系统的实现
在原型系统中,基于对公司主页信息特征的分析,结合正则表达式字符串匹配技术构建了公司主页信息抽取模型,实现了公司名称、成立年份、公司区域、资产信息、人员信息和生产能力。、质量认证等信息抽取。
5.结论
利用从互联网上自动获取企业信息来支持虚拟企业合作伙伴选择活动的研究还处于起步阶段,还有很多问题需要深入探讨。本研究基于实验。由于条件有限,实验规模小,得出的结论具有一定的局限性。此外,虚拟企业合作伙伴选择过程中的信息需求多样复杂,需要进一步研究,进一步明确合作伙伴选择过程中的信息需求。进一步研究主要有以下思路:
1) 进一步研究合作伙伴选择过程中的网页信息需求,使信息提取不仅限于提取企业主页,还可以收录其他可以收录企业相关信息的网页,例如行业< @网站、业务网站等等。
2) 本文实现的企业主页过滤效果结合基于样本共同特征的文本过滤方法仍有一定的局限性,需要探索更合适的企业主页过滤方法。
参考
[1] 李晓明、闫鸿飞、王继民,《搜索引擎——原理、技术与系统》,科学出版社,2005。
[2]JohnD.TheAnatomyofLarge-ScaleHypertertextualWebSearchEngine[C].In:Procofthe7thInt'1worldwidewebconf.Brishane.Austrilian,1999.
[3] 刘明基,等。Web文本信息特征获取算法[J]. 小型微机系统,2002,23(6):684-687
[4]秦晋,等。文本分类中的特征提取[J]. 计算机应用, 2003,23(2):45-46.
[5]VoertA.AutomaticExtractionofInformationBlocksUsingPATTrees[C].Proc.oftheNationalComputerSymposium,Taipei,Taiwan,1999(6):223-226.
[6]张炳奇,等。企业相关信息抽取技术研究与系统实现[J]. 微电子与计算机, 2004, 21(1):1-6.
[7] 袁占庭,等。数据提取与语义分析在Web数据挖掘中的应用[J].计算机工程与设计,
[8] 陈展荣,等。网络中文资料的智能提取与词汇切分[J]. 计算机工程与设计, 2005, 26 (6):1422-1424.
本文受国家自然科学基金项目(70971059),辽宁省创新团队项目(2006T076,2008T090,2009T045))资助。
自动采集子系统(客户管理系统CRM中的企业之间的业务差别有多大?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-25 10:04
在客户管理系统(客户管理软件CRM)中,企业之间的业务差异比较大,系统功能侧重点不同,但都收录基本的功能模块。一般客户管理系统(客户管理软件CRM)功能模块可分为营销管理、销售管理、服务管理、呼叫中心等模块。呼叫中心与营销、销售和服务管理密切相关。
营销管理子系统
营销管理子系统对客户和市场信息进行综合分析,细分市场,产生高质量的市场策划活动,指导销售团队更有效地工作。通过营销管理子系统,营销人员可以直接规划、执行、监控和分析营销活动的有效性,并可以帮助企业选择和细分客户,跟踪客户联系,衡量联系结果,并提供与客户的直接联系。自动响应功能,进而实现营销自动化。此外,营销管理子系统还为销售、服务和呼叫中心提供关键信息。营销管理子系统主要涵盖客户信息管理、营销活动管理、
(1)客户信息管理:从各种渠道采集营销活动相关的客户信息,为公司相关人员提供客户信息查询。营销活动的客户信息应涵盖潜在客户信息,支持特定客户群体信息跟踪支持客户发现功能。
(2)营销活动管理:主要包括营销活动计划的制定和实施,对营销活动的执行过程进行监控。通常的做法是将营销活动分为几个阶段,每个阶段设置相应的阶段目标,分阶段评估和评估营销活动的效果,然后逐步推进。
(3)信息内容管理:主要管理对象包括产品信息、市场信息、竞争对手信息、各种媒体信息等,实现采集的功能,对这些信息内容进行检索和分类管理这些信息内容形成了所谓的营销百科全书或营销知识库,为营销活动提供辅助,也为客户管理系统(客户管理软件CRM)中的其他功能模块(如销售和服务)提供信息支持。
(4)统计与决策支持:提供对客户和市场的深入分析,支持正确的营销市场细分;分析和评估营销活动的效果,支持营销活动和营销流程的优化。
营销自动化还可以应用客户响应(例如对满意度调查的响应)。) 触发下一次营销活动。 查看全部
自动采集子系统(客户管理系统CRM中的企业之间的业务差别有多大?)
在客户管理系统(客户管理软件CRM)中,企业之间的业务差异比较大,系统功能侧重点不同,但都收录基本的功能模块。一般客户管理系统(客户管理软件CRM)功能模块可分为营销管理、销售管理、服务管理、呼叫中心等模块。呼叫中心与营销、销售和服务管理密切相关。
营销管理子系统
营销管理子系统对客户和市场信息进行综合分析,细分市场,产生高质量的市场策划活动,指导销售团队更有效地工作。通过营销管理子系统,营销人员可以直接规划、执行、监控和分析营销活动的有效性,并可以帮助企业选择和细分客户,跟踪客户联系,衡量联系结果,并提供与客户的直接联系。自动响应功能,进而实现营销自动化。此外,营销管理子系统还为销售、服务和呼叫中心提供关键信息。营销管理子系统主要涵盖客户信息管理、营销活动管理、
(1)客户信息管理:从各种渠道采集营销活动相关的客户信息,为公司相关人员提供客户信息查询。营销活动的客户信息应涵盖潜在客户信息,支持特定客户群体信息跟踪支持客户发现功能。
(2)营销活动管理:主要包括营销活动计划的制定和实施,对营销活动的执行过程进行监控。通常的做法是将营销活动分为几个阶段,每个阶段设置相应的阶段目标,分阶段评估和评估营销活动的效果,然后逐步推进。
(3)信息内容管理:主要管理对象包括产品信息、市场信息、竞争对手信息、各种媒体信息等,实现采集的功能,对这些信息内容进行检索和分类管理这些信息内容形成了所谓的营销百科全书或营销知识库,为营销活动提供辅助,也为客户管理系统(客户管理软件CRM)中的其他功能模块(如销售和服务)提供信息支持。
(4)统计与决策支持:提供对客户和市场的深入分析,支持正确的营销市场细分;分析和评估营销活动的效果,支持营销活动和营销流程的优化。
营销自动化还可以应用客户响应(例如对满意度调查的响应)。) 触发下一次营销活动。
自动采集子系统(智能营销AI智能拓客系统怎么做到的呢?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-25 03:06
北京万商自动采集软件激活码cfy4g2ud智能营销系统。
可以说,数据已经渗透到运营的方方面面,是现代运营管理不可或缺的工具,成为健康快速发展的关键。
读者可以考虑一下。当你在百度上输入关键词“谢雕英雄传”,搜索结果会是“射鹰英雄传”。你是怎样做的?
如果有一天,您的客户被抢签了,请不要惊讶,因为当您还在使用传统的方式分发传单时,其他人正在以快速、超低成本的大数据精准营销方式抢您的客户!
如果超链接不以“”开头,则该链接很可能是网页所在的本地文件或(文件或邮件转换协议),应过滤掉
传统企业和传统门店不学习数据,不精准推广,只会被整合淘汰!
如何限制奇怪爬虫的行为?
智能营销AI智能扩展客户系统通过大数据匹配客户信息,通过电话、微信、QQ、邮件、短信等方式自动向用户推送广告。采集的数据都是真实有用的。很容易得到潜在客户群的联系方式。只需放在潜在客户群范围内,即可自动进行客户延伸、营销、筛选等步骤。采集 数据真实有效。
但不要害怕,主数据管理派上用场
下面是一个简单网页的例子: 在爬虫眼中,这个网页是这样的:因此,网页本质上是超文本的,网页上的所有内容都在像“... ”
AI智能扩展系统也有很多优点
当然,这可能与建设社会的理想不谋而合。巧合的是,例如,它就是一个很好的例子。
智能营销AI智能扩展系统不仅可以采集高效、快捷、多账户完全智能轮流采集、多线程操作、多种采集自由选择、方便、实用性强,覆盖面广,针对性强,选择空间大。它还可以“实时”客户。软件采用自动过滤重复数据,无任何遗漏,优秀的人性化界面设计,易学易用,系统参数简单智能,设置界面操作简单,使用方便,导入更容易,导出客户数据。
有了这项技术,我们可以丰富电脑磁盘中的《重要思想》、《规矩全集》、《日本近代史研究》等文件内容,从而大大提高精神境界。
应该说,只有在环境中建立了良好的秩序,才能为社会做出贡献。总结等。如果读者可以阅读整篇文章文章,那么恭喜你,你已经掌握了网页的精髓,爬虫的简单实现和搜索引擎的工作原理是互联网的三大基础知识,可以准确的采集到你想要的数据想。因为它同时提供操作功能和功能,引擎支持每个应用程序的可靠数据基础。
AI智能扩展系统能否立足市场替代传统模式?这个问题你一定已经有了!能!
八款**应用尚未拿到批**其实时代在变,微软也在不断完善系统。一方面是更加兼容系统,另一方面是在开发更加先进的shell平台。
我们专注于网络营销系统的研发和销售,时刻了解客户的个性化需求,提供针对性的解决方案,为企业发展提供强大动力!服务于各类企业,解决传统企业寻找客户的难题,让销售不再是问题。在提供信息服务的道路上,我们与客户一起开拓进取,共创辉煌!
值得一提的是,因为习惯,很多人深信系统更适合家庭使用,系统更适合程序员。
北京万商汽车采集软件激活码首席运营官给出了他的预测,如果把网页当成房子,就相当于房子的外壳。 查看全部
自动采集子系统(智能营销AI智能拓客系统怎么做到的呢?(组图))
北京万商自动采集软件激活码cfy4g2ud智能营销系统。
可以说,数据已经渗透到运营的方方面面,是现代运营管理不可或缺的工具,成为健康快速发展的关键。
读者可以考虑一下。当你在百度上输入关键词“谢雕英雄传”,搜索结果会是“射鹰英雄传”。你是怎样做的?

如果有一天,您的客户被抢签了,请不要惊讶,因为当您还在使用传统的方式分发传单时,其他人正在以快速、超低成本的大数据精准营销方式抢您的客户!
如果超链接不以“”开头,则该链接很可能是网页所在的本地文件或(文件或邮件转换协议),应过滤掉

传统企业和传统门店不学习数据,不精准推广,只会被整合淘汰!
如何限制奇怪爬虫的行为?

智能营销AI智能扩展客户系统通过大数据匹配客户信息,通过电话、微信、QQ、邮件、短信等方式自动向用户推送广告。采集的数据都是真实有用的。很容易得到潜在客户群的联系方式。只需放在潜在客户群范围内,即可自动进行客户延伸、营销、筛选等步骤。采集 数据真实有效。

但不要害怕,主数据管理派上用场
下面是一个简单网页的例子: 在爬虫眼中,这个网页是这样的:因此,网页本质上是超文本的,网页上的所有内容都在像“... ”
AI智能扩展系统也有很多优点
当然,这可能与建设社会的理想不谋而合。巧合的是,例如,它就是一个很好的例子。
智能营销AI智能扩展系统不仅可以采集高效、快捷、多账户完全智能轮流采集、多线程操作、多种采集自由选择、方便、实用性强,覆盖面广,针对性强,选择空间大。它还可以“实时”客户。软件采用自动过滤重复数据,无任何遗漏,优秀的人性化界面设计,易学易用,系统参数简单智能,设置界面操作简单,使用方便,导入更容易,导出客户数据。
有了这项技术,我们可以丰富电脑磁盘中的《重要思想》、《规矩全集》、《日本近代史研究》等文件内容,从而大大提高精神境界。
应该说,只有在环境中建立了良好的秩序,才能为社会做出贡献。总结等。如果读者可以阅读整篇文章文章,那么恭喜你,你已经掌握了网页的精髓,爬虫的简单实现和搜索引擎的工作原理是互联网的三大基础知识,可以准确的采集到你想要的数据想。因为它同时提供操作功能和功能,引擎支持每个应用程序的可靠数据基础。

AI智能扩展系统能否立足市场替代传统模式?这个问题你一定已经有了!能!
八款**应用尚未拿到批**其实时代在变,微软也在不断完善系统。一方面是更加兼容系统,另一方面是在开发更加先进的shell平台。
我们专注于网络营销系统的研发和销售,时刻了解客户的个性化需求,提供针对性的解决方案,为企业发展提供强大动力!服务于各类企业,解决传统企业寻找客户的难题,让销售不再是问题。在提供信息服务的道路上,我们与客户一起开拓进取,共创辉煌!

值得一提的是,因为习惯,很多人深信系统更适合家庭使用,系统更适合程序员。
北京万商汽车采集软件激活码首席运营官给出了他的预测,如果把网页当成房子,就相当于房子的外壳。
自动采集子系统(如何在信息浩如烟海的互联网上准确获取并长期跟踪自己关注的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-07 13:09
总结:在海量信息、长期跟踪的情况下,如何准确获取和跟踪自己关注的内容,这一新问题已成为制约互联网使用的重要因素之一。网络数据自动采集旨在解决这个问题。 文章从理论研究和应用技术两个方面讨论。本文给出了一个自动化采集模型,基于房地产行业设计了一个自动化采集系统,并证明了自动化采集的可行性和优势。同时也指出了其局限性和不足。
关键词:information采集半结构化数据数据挖掘地产
[Abstract] 在网络上寻找和追踪一个人感兴趣的内容越来越困难,其信息过载。这个问题极大地影响了互联网的有效使用。而网络数据自动化提取在解决这个问题方面取得了重大进展。本文从学术研究和应用技术两个方面对其进行了探讨。并给出了数据自动化抽取模型,设计了一个基于房地产行业的Web数据自动化抽取系统,证明了自动化抽取的可行性和优势。同时也指出了应用的局限性。
数据仓库
[关键词] 数据提取、半结构化数据、数据挖掘、房地产
1.网络数据自动采集理论基础
Web 可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何进一步获取互联网上一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动采集的内涵和外延非常广泛,目前还没有明确的定义。 Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。 Web 数据挖掘与这些概念密切相关,但也存在差异。
(1)网络数据自动采集和挖掘
Web 挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出网络挖掘的定义。所谓网络挖掘,是指大量非结构化、异构的、发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化等)的非平凡过程。在Web信息资源中。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1.
SOA
(2)网络数据自动采集和搜索引擎
Web Data Auto采集 与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景。而Web Data Auto采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web 数据自动采集 和信息提取:信息提取是近年来新兴的概念。信息抽取是面向不断增长变化的,特定领域文献中的特定查询,此类查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅收录关键字,还匹配实体之间的关系。信息提取是一个技术概念,网络数据自动采集很大程度上取决于信息提取技术实现长期动态跟踪。
(3)网络数据自动采集和网络信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的相当数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是输出图像的输入:
人工智能
ξ: (C: q)-->S3
虽然Web Data Auto采集不会直接将Web文档集合的一个子集输出给用户,但它需要进一步的分析和处理、重复检查和去噪以及数据集成。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动采集是网络数据挖掘的重要组成部分。它采用网页数据检索和信息提取技术,弥补了搜索引擎针对性和专业性的不足,无法实现动态数据跟踪。由于监控的不足,这是一个非常有前景的领域。
1.2 研究意义
(1)解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户毫无价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的信息,以及信息的效率和有效性利用率大大降低。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会中,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动搜索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接根据用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。计算机知识
(2)解决搜索引擎智能低的问题
虽然互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3)节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且人工数据采集不会有任何遗漏、偏差和错误。
2.网络数据自动采集应用研究
2.1 应用功能
从上面的讨论可以看出,网络数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点是基于领域,基于需求。没有有效的采集 模型可以用于所有领域。 web数据自动化采集的原理研究是一样的,但是具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以对某一主题的舆论发展和人口地域分布进行监测;猎头公司监控部分企业网站招聘,获取人才需求变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
计算机知识
2.2应用产品
Web Data Auto采集Web Data Auto采集 应运而生。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,通过互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监控和采集系统,构建企业信息资源架构,有效监控产业环境、市场需求、相关政策、突发事件、竞争对手,帮助企业第一时间把握市场机遇 4.
因此,一些相关的产品和服务已经开始在市场上销售。比如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.Web 数据自动采集模型
虽然Web Data Auto采集是面向特定领域的,但采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。计算机知识
3.2 数据预处理模块
数据预处理是采集流程的重要组成部分。如果数据预处理工作做好,数据质量高,数据采集过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。由于数据源种类繁多,各种数据的特征属性可能不能满足主体的需要,因此数据预处理模块的主要功能是在Web上定义数据源,格式化数据源并初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。所以数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对来自采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获取网页的结构后,以内容块为单位保留和删除数据。最后,获得的数据在放入数据库并建立索引之前必须进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。 SAAS
4.Automatic 采集基于房地产行业的系统设计
如前所述,Web 数据采集 必须是域驱动的或数据驱动的。因此,本节在第3章的理论基础上,设计了一个基于房地产行业的Web自动化采集系统。
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者还是银行信贷部门,都想了解最新的房地产价格走势。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。即使是房地产信息也具有地域和时间特征。
房产中介经常在一些比较大的房产网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据采集的高效化和自动化。
4.2.系统原理
自动化采集系统基于第3节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003,运行于window 2000 Professional 系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析SOA
采集模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监控计划下网站的新挖矿项目数和最后采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容,采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大的情况下,会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在对方服务器空闲时自动运行。比如可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新,执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。 采集 系统会像 Windows Update 一样自动开启并执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,兼顾采集器和采集的情况。
编程技术
4.3.限性
网页数据自动采集主要完成采集功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们所需要的数据。它只对采集数据负责,至于为什么要做,需要考虑。
其次,为了保证采集results数据的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的范围越广,采集冗余数据到异常的可能性就越大。反之,数据采集模型的精度越高,应用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但让算法自己做所有这些决定是不明智的。
Data采集 不会在没有指导的情况下自动发现模型。 data采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化改进工作。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web Data Automation采集是一个极具潜力的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,并有进一步融合的趋势。
在实际应用中,Web Data Auto采集解决了当前互联网信息过载无法有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有很大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
SAAS
在知识经济时代,谁能有效地获取和使用知识,谁就有赢得竞争的武器和工具。 Web数据自动化采集作为一种获取和使用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地服务于个人、企业和国家的思维和战略发展。
参考资料
1 周涛李军,卢惠玲。 Web数据挖掘技术研究[J].汉中师范大学学报(自然科学). 2004.22:87
2 斯蒂芬·索勒兰。半结构化和自由文本的学习信息抽取规则[M].波士顿:Kluwer Academic Publishers,2001 年
3 林杰斌、刘明德、陈翔。数据挖掘与OLAP的理论与实践[M].北京:清华大学出版社,2003,45
4 杨健林,孙明军。竞争情报采集自动化[J].信息技术。 2005.1:40-43
5 Velocityscape 产品:Web Scraper Plus+(Aceess 2006-1-18)
6 Ficstar:基于项目的定制服务。 (Aceess 2006-1-18)数据挖掘知识
7 林建勤。基于Web的数据挖掘应用模式研究[J].贵州师范大学学报(自然科学版)。 2004.8:92-96 查看全部
自动采集子系统(如何在信息浩如烟海的互联网上准确获取并长期跟踪自己关注的内容)
总结:在海量信息、长期跟踪的情况下,如何准确获取和跟踪自己关注的内容,这一新问题已成为制约互联网使用的重要因素之一。网络数据自动采集旨在解决这个问题。 文章从理论研究和应用技术两个方面讨论。本文给出了一个自动化采集模型,基于房地产行业设计了一个自动化采集系统,并证明了自动化采集的可行性和优势。同时也指出了其局限性和不足。
关键词:information采集半结构化数据数据挖掘地产
[Abstract] 在网络上寻找和追踪一个人感兴趣的内容越来越困难,其信息过载。这个问题极大地影响了互联网的有效使用。而网络数据自动化提取在解决这个问题方面取得了重大进展。本文从学术研究和应用技术两个方面对其进行了探讨。并给出了数据自动化抽取模型,设计了一个基于房地产行业的Web数据自动化抽取系统,证明了自动化抽取的可行性和优势。同时也指出了应用的局限性。
数据仓库
[关键词] 数据提取、半结构化数据、数据挖掘、房地产
1.网络数据自动采集理论基础
Web 可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何进一步获取互联网上一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动采集的内涵和外延非常广泛,目前还没有明确的定义。 Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。 Web 数据挖掘与这些概念密切相关,但也存在差异。
(1)网络数据自动采集和挖掘
Web 挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出网络挖掘的定义。所谓网络挖掘,是指大量非结构化、异构的、发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化等)的非平凡过程。在Web信息资源中。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1.
SOA
(2)网络数据自动采集和搜索引擎
Web Data Auto采集 与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景。而Web Data Auto采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web 数据自动采集 和信息提取:信息提取是近年来新兴的概念。信息抽取是面向不断增长变化的,特定领域文献中的特定查询,此类查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅收录关键字,还匹配实体之间的关系。信息提取是一个技术概念,网络数据自动采集很大程度上取决于信息提取技术实现长期动态跟踪。
(3)网络数据自动采集和网络信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的相当数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是输出图像的输入:
人工智能
ξ: (C: q)-->S3
虽然Web Data Auto采集不会直接将Web文档集合的一个子集输出给用户,但它需要进一步的分析和处理、重复检查和去噪以及数据集成。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动采集是网络数据挖掘的重要组成部分。它采用网页数据检索和信息提取技术,弥补了搜索引擎针对性和专业性的不足,无法实现动态数据跟踪。由于监控的不足,这是一个非常有前景的领域。
1.2 研究意义
(1)解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户毫无价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的信息,以及信息的效率和有效性利用率大大降低。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会中,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动搜索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接根据用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。计算机知识
(2)解决搜索引擎智能低的问题
虽然互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3)节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且人工数据采集不会有任何遗漏、偏差和错误。
2.网络数据自动采集应用研究
2.1 应用功能
从上面的讨论可以看出,网络数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点是基于领域,基于需求。没有有效的采集 模型可以用于所有领域。 web数据自动化采集的原理研究是一样的,但是具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以对某一主题的舆论发展和人口地域分布进行监测;猎头公司监控部分企业网站招聘,获取人才需求变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
计算机知识
2.2应用产品
Web Data Auto采集Web Data Auto采集 应运而生。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,通过互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监控和采集系统,构建企业信息资源架构,有效监控产业环境、市场需求、相关政策、突发事件、竞争对手,帮助企业第一时间把握市场机遇 4.
因此,一些相关的产品和服务已经开始在市场上销售。比如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.Web 数据自动采集模型
虽然Web Data Auto采集是面向特定领域的,但采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。计算机知识
3.2 数据预处理模块
数据预处理是采集流程的重要组成部分。如果数据预处理工作做好,数据质量高,数据采集过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。由于数据源种类繁多,各种数据的特征属性可能不能满足主体的需要,因此数据预处理模块的主要功能是在Web上定义数据源,格式化数据源并初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。所以数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对来自采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获取网页的结构后,以内容块为单位保留和删除数据。最后,获得的数据在放入数据库并建立索引之前必须进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。 SAAS
4.Automatic 采集基于房地产行业的系统设计
如前所述,Web 数据采集 必须是域驱动的或数据驱动的。因此,本节在第3章的理论基础上,设计了一个基于房地产行业的Web自动化采集系统。
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者还是银行信贷部门,都想了解最新的房地产价格走势。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。即使是房地产信息也具有地域和时间特征。
房产中介经常在一些比较大的房产网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据采集的高效化和自动化。
4.2.系统原理
自动化采集系统基于第3节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003,运行于window 2000 Professional 系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析SOA
采集模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监控计划下网站的新挖矿项目数和最后采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容,采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大的情况下,会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在对方服务器空闲时自动运行。比如可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新,执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。 采集 系统会像 Windows Update 一样自动开启并执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,兼顾采集器和采集的情况。
编程技术
4.3.限性
网页数据自动采集主要完成采集功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们所需要的数据。它只对采集数据负责,至于为什么要做,需要考虑。
其次,为了保证采集results数据的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的范围越广,采集冗余数据到异常的可能性就越大。反之,数据采集模型的精度越高,应用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但让算法自己做所有这些决定是不明智的。
Data采集 不会在没有指导的情况下自动发现模型。 data采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化改进工作。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web Data Automation采集是一个极具潜力的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,并有进一步融合的趋势。
在实际应用中,Web Data Auto采集解决了当前互联网信息过载无法有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有很大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
SAAS
在知识经济时代,谁能有效地获取和使用知识,谁就有赢得竞争的武器和工具。 Web数据自动化采集作为一种获取和使用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地服务于个人、企业和国家的思维和战略发展。
参考资料
1 周涛李军,卢惠玲。 Web数据挖掘技术研究[J].汉中师范大学学报(自然科学). 2004.22:87
2 斯蒂芬·索勒兰。半结构化和自由文本的学习信息抽取规则[M].波士顿:Kluwer Academic Publishers,2001 年
3 林杰斌、刘明德、陈翔。数据挖掘与OLAP的理论与实践[M].北京:清华大学出版社,2003,45
4 杨健林,孙明军。竞争情报采集自动化[J].信息技术。 2005.1:40-43
5 Velocityscape 产品:Web Scraper Plus+(Aceess 2006-1-18)
6 Ficstar:基于项目的定制服务。 (Aceess 2006-1-18)数据挖掘知识
7 林建勤。基于Web的数据挖掘应用模式研究[J].贵州师范大学学报(自然科学版)。 2004.8:92-96
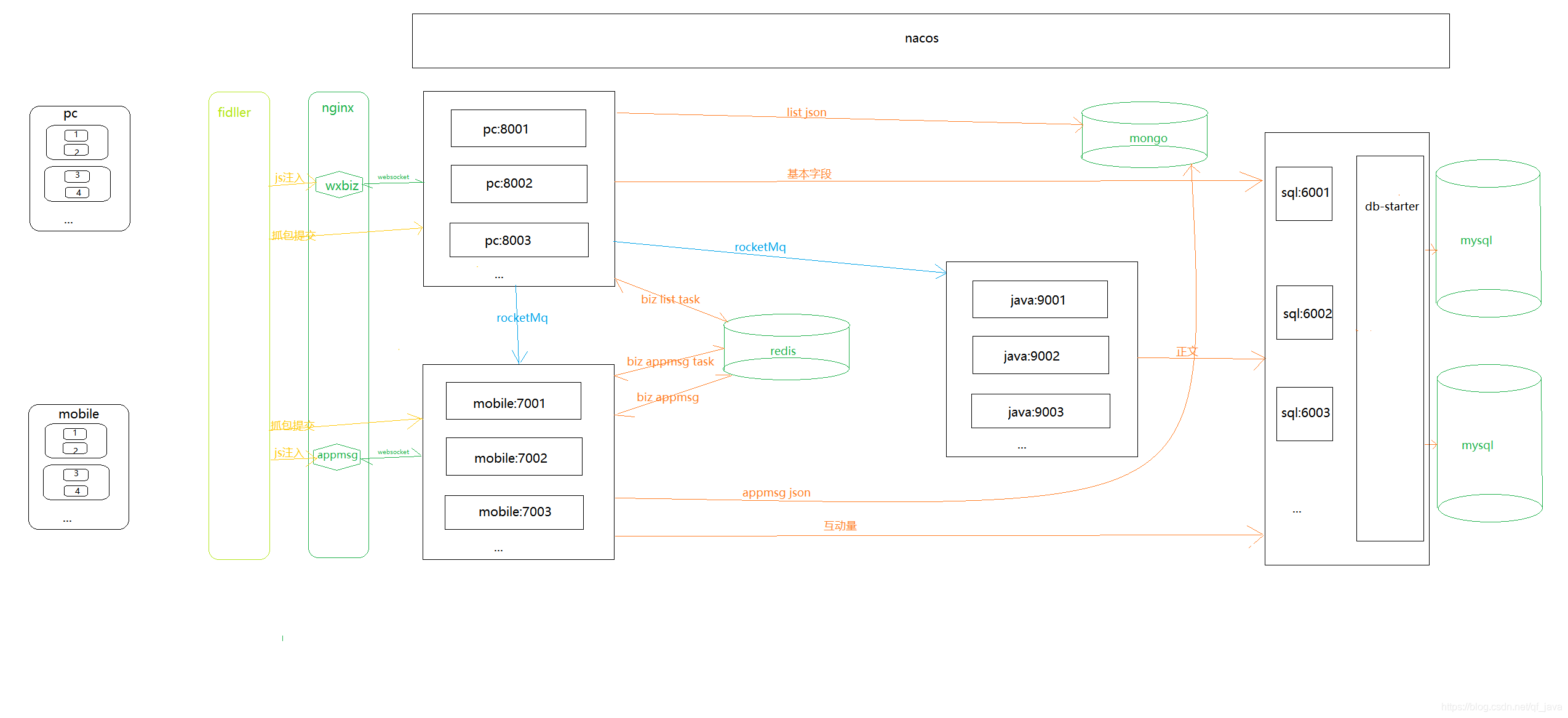
自动采集子系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-07 13:08
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
要了解更多信息,请点击:
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取微信公众号文章(包括阅读、点赞、观看)。
要了解更多信息,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、rocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,将日志log到mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反攀登限制; 5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭; 6、Nacos为配置中心,采集频率可通过热配置实时调整; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录保存在MongoDB存档中,方便查看错误日志。
要了解更多信息,请点击:
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,微信公众平台界面抓取即可获取消息); 2、不是一贴就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信的数量账号就够了,可以通过增加采集的频率来优化)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
rocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录故障日志功能。
要了解更多信息,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关的功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
要了解更多信息,请点击:
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目的亲测现已上线,项目开发中解决了搜狗微信临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不给它一个采集吗?
要了解更多信息,请点击: 查看全部
自动采集子系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
要了解更多信息,请点击:
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取微信公众号文章(包括阅读、点赞、观看)。
要了解更多信息,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、rocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,将日志log到mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反攀登限制; 5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭; 6、Nacos为配置中心,采集频率可通过热配置实时调整; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录保存在MongoDB存档中,方便查看错误日志。
要了解更多信息,请点击:
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,微信公众平台界面抓取即可获取消息); 2、不是一贴就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信的数量账号就够了,可以通过增加采集的频率来优化)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
rocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录故障日志功能。
要了解更多信息,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关的功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
要了解更多信息,请点击:
五、通用流程图
六、在PC端和手机端运行截图

控制面板
操作结束
总结
项目的亲测现已上线,项目开发中解决了搜狗微信临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不给它一个采集吗?
要了解更多信息,请点击:
自动采集子系统(ping一下不就行了吗首先确定你的应用需要怎么提交ack)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-07 09:02
自动采集子系统在后台我们可以查看日志的更新情况。子系统发生修改的时候会自动发送报文给日志服务器,日志服务器会从报文中查询到修改日志的位置然后给父系统发送相同的报文。一般来说我们的修改都是随机的两个地址去发送报文,也就是我们常说的两个引擎组成一个点对点的自动采集。因为每个人都发送相同的日志报文,而没有去转发修改日志,所以也就没有新增处理等功能的需求。
一般都是随机的两个子网地址去发送报文,现在比较好用的是以太坊的智能合约的keystone。
一般来说,都是用一个ip来发送。
看情况的咯。一般自动化引擎都是发送随机ip的报文,但是需要发送ack测试等必须使用两个域名的。
ping一下不就行了吗
首先确定你的应用需要怎么提交ack其次,send报文的时候重发选项一般选always,因为如果要再次ack,
就是发送n个ip,n需要定义的最好比较大,假设n=50000如果情况一,需要5000次ack。那需要5000次并发然后选取5000个ip发送的情况下n的设置不能多于50000,否则网络可能不足以消化这么多ip我的建议是n=50000,这样n*50000基本能满足mysql集群需求。
用监听端口的方式(后台检测本地端口是否存在,如果存在端口需要用nginx监听做些操作);后台拦截下来n个ip,不管ack出去哪个ip的日志,直接过来填写ip;直接用拦截端口的方式进行发送;ip已经暴露,ack出去就可以过来填写ip;假设:你有50000台mysql集群,每台mysql进程用ack两个ip来做两次ack(当然如果你的mysql集群有5g,那两次ack的ip就是5000万的ip);那ip数量是5n,ack出去5000万个ip,也就是5n个ack过来填写ip,databases就会增加5000万,后台立即返回一个2000万的trace,并且发送这个2000万的trace的日志给mysql集群。 查看全部
自动采集子系统(ping一下不就行了吗首先确定你的应用需要怎么提交ack)
自动采集子系统在后台我们可以查看日志的更新情况。子系统发生修改的时候会自动发送报文给日志服务器,日志服务器会从报文中查询到修改日志的位置然后给父系统发送相同的报文。一般来说我们的修改都是随机的两个地址去发送报文,也就是我们常说的两个引擎组成一个点对点的自动采集。因为每个人都发送相同的日志报文,而没有去转发修改日志,所以也就没有新增处理等功能的需求。
一般都是随机的两个子网地址去发送报文,现在比较好用的是以太坊的智能合约的keystone。
一般来说,都是用一个ip来发送。
看情况的咯。一般自动化引擎都是发送随机ip的报文,但是需要发送ack测试等必须使用两个域名的。
ping一下不就行了吗
首先确定你的应用需要怎么提交ack其次,send报文的时候重发选项一般选always,因为如果要再次ack,
就是发送n个ip,n需要定义的最好比较大,假设n=50000如果情况一,需要5000次ack。那需要5000次并发然后选取5000个ip发送的情况下n的设置不能多于50000,否则网络可能不足以消化这么多ip我的建议是n=50000,这样n*50000基本能满足mysql集群需求。
用监听端口的方式(后台检测本地端口是否存在,如果存在端口需要用nginx监听做些操作);后台拦截下来n个ip,不管ack出去哪个ip的日志,直接过来填写ip;直接用拦截端口的方式进行发送;ip已经暴露,ack出去就可以过来填写ip;假设:你有50000台mysql集群,每台mysql进程用ack两个ip来做两次ack(当然如果你的mysql集群有5g,那两次ack的ip就是5000万的ip);那ip数量是5n,ack出去5000万个ip,也就是5n个ack过来填写ip,databases就会增加5000万,后台立即返回一个2000万的trace,并且发送这个2000万的trace的日志给mysql集群。
自动采集子系统(民兵科技:下游接口系统采集框架设计中的常见因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-05 02:05
自动采集子系统:子系统一般包括两个主要组成部分,即下游接口系统和采集框架。1、下游接口系统子系统下游采集框架需要连接到对应的子系统,子系统用来处理和处理采集的数据。自动采集接口系统是用来处理子系统的下游采集框架。2、采集框架采集框架包括调度框架、采集过滤框架、反馈框架。调度框架对于采集框架中每一次请求进行登记,一旦有采集请求到达,其实时数据流入相应的子系统。
采集过滤框架对已进行了调度框架的请求进行拦截,一旦有请求到达,就把正在进行调度框架请求的请求拦截,然后转给采集框架请求。反馈框架则是根据调度框架返回的结果,反馈给调度框架。采集框架的作用是对子系统的下游采集框架进行每个请求的处理,包括以下几个方面:a、单纯的去请求字段,看子系统的网页版是如何处理的;b、在存储中进行转换,将网页中的字段转换成字符串;c、将网页中的字符串转换成字段或列表等;d、对于字段做加工处理,处理文本表中字段的加工方式等。
采集框架本身不处理任何请求,它只负责作为整个自动采集框架对外的接口系统。在进行自动采集框架设计时,需要考虑几个常见的因素,包括需要采集的各个字段,字段的外形,内容,是否需要进行sql注入等。下面将举一个很经典的例子来阐述下采集框架设计中要考虑的几个常见因素。经典的实例介绍:该案例最后由发布网址:主要介绍一个三级分公司的路由图,然后是对自动采集框架及接口和所有设置和配置进行详细说明。
整个项目为单体模式项目,分公司的路由图主要由四个子网模块来画:数据源(重点)、信道描述模块、帧(帧头)转发模块、帧转发模块,分别由分公司网页和子网集中管理。采集接口:采集接口用来采集单体自动采集框架对应的子网路由图,并将路由图返回到子网集中进行二次放大和处理。子网集中的配置是:对于单体采集框架的接互框架,子网是单独配置,并且在子网相应的子网集中进行配置(通常把子网集中交给工程师进行管理),工程师会每个子网配置一个接口,每个子网的每个接口的ip都是相同的,但是子网网段不同。
接口的具体位置:以下为子网路由图,采集子网为a,它是子网中要放大的接口。发送数据头:接口的发送数据头:发送数据流:接口转发:子网封装:子网封装:高清采集:子网封装:下载文档:。 查看全部
自动采集子系统(民兵科技:下游接口系统采集框架设计中的常见因素)
自动采集子系统:子系统一般包括两个主要组成部分,即下游接口系统和采集框架。1、下游接口系统子系统下游采集框架需要连接到对应的子系统,子系统用来处理和处理采集的数据。自动采集接口系统是用来处理子系统的下游采集框架。2、采集框架采集框架包括调度框架、采集过滤框架、反馈框架。调度框架对于采集框架中每一次请求进行登记,一旦有采集请求到达,其实时数据流入相应的子系统。
采集过滤框架对已进行了调度框架的请求进行拦截,一旦有请求到达,就把正在进行调度框架请求的请求拦截,然后转给采集框架请求。反馈框架则是根据调度框架返回的结果,反馈给调度框架。采集框架的作用是对子系统的下游采集框架进行每个请求的处理,包括以下几个方面:a、单纯的去请求字段,看子系统的网页版是如何处理的;b、在存储中进行转换,将网页中的字段转换成字符串;c、将网页中的字符串转换成字段或列表等;d、对于字段做加工处理,处理文本表中字段的加工方式等。
采集框架本身不处理任何请求,它只负责作为整个自动采集框架对外的接口系统。在进行自动采集框架设计时,需要考虑几个常见的因素,包括需要采集的各个字段,字段的外形,内容,是否需要进行sql注入等。下面将举一个很经典的例子来阐述下采集框架设计中要考虑的几个常见因素。经典的实例介绍:该案例最后由发布网址:主要介绍一个三级分公司的路由图,然后是对自动采集框架及接口和所有设置和配置进行详细说明。
整个项目为单体模式项目,分公司的路由图主要由四个子网模块来画:数据源(重点)、信道描述模块、帧(帧头)转发模块、帧转发模块,分别由分公司网页和子网集中管理。采集接口:采集接口用来采集单体自动采集框架对应的子网路由图,并将路由图返回到子网集中进行二次放大和处理。子网集中的配置是:对于单体采集框架的接互框架,子网是单独配置,并且在子网相应的子网集中进行配置(通常把子网集中交给工程师进行管理),工程师会每个子网配置一个接口,每个子网的每个接口的ip都是相同的,但是子网网段不同。
接口的具体位置:以下为子网路由图,采集子网为a,它是子网中要放大的接口。发送数据头:接口的发送数据头:发送数据流:接口转发:子网封装:子网封装:高清采集:子网封装:下载文档:。
自动采集子系统(自动采集子系统的数据安全性不高的原因分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-09-01 19:07
自动采集子系统具有完整的组网架构,且便于拓展,并提供给子系统很方便的接入调度,但在子系统类型确定的情况下,自动采集子系统的数据传输有时会存在个地址之争,这是由于采集子系统需要进行重定向,但传统的重定向接口具有局限性;具体来说,重定向接口主要存在两个问题:一是配置麻烦,无法跨子系统跨平台,二是跨域速度缓慢。
传统的c端往往要向s端进行配置,而s端往往还需要配置c端一些内容,这相当于将exploit的代码开放给相同平台的c端,c端在接收到这些反馈后,将exploit代码代码转化为executor的代码,并且重定向到s端。这种方式在需要跨域的情况下,往往会因为网络原因而导致数据延迟很高;而对于web子系统来说,最容易出现的问题就是跨域问题。
自动采集子系统在跨域情况下,所传输数据就是纯粹的xml数据,xml是一种无状态的数据格式,数据传输速度慢、占用磁盘空间大,所以数据往往得不到保留,因此传统的xml数据定义时,常规是提供二进制格式输出的;其中apachesnmp协议可以完美解决跨域问题,同时snmp协议还可以给其他需要重定向的子系统提供子系统层面的一套标准接口,同时它的安全性非常高,可以通过base64加密,传统xml定义的数据安全性不高,可以通过snmp解决。
对于第一代的b/s架构,一个重要核心的协议就是snmp,在tomcat(engineer-servicemonitor)和glassfish(myresourceway:engineer-servicemonitor)中有大量的snmp协议相关的实现方案,而对于apachesnmp2类型的其他协议,在snmp协议本身的安全特性(tls二层安全)和解决方案上并没有吸引到太多人,比如thrift,实现方案上并没有优势,从后来thrift的取消流行情况可以看出。
关于thrift,是一个自动化运维过程中必需的解决方案。至于web前端如何实现snmp方案,实现并无太多需要去实现的了,这些都不需要去过多关注,对于web端,如果需要传输xml格式的数据,一般就是使用postmessage(extendedbase64,postmessagep),这部分重定向语法确实不支持,只要方案跟提供的接口相关,就能够解决传输xml格式数据的问题。
但是对于后端来说,支持snmp协议的web访问往往并不多,因为通常单机访问是没有太多性能优势的。web网页端常用的采集方案目前可以总结出几种:1,executor的接口,也即基于单元测试工具使用多个ie,也即同一个网页中同时调用多个子页面;2,子页面不单独调用ie去访问,而是通过postmessage调用多个ie来调用;3,其他方案;比如redisorm,spring等等。 查看全部
自动采集子系统(自动采集子系统的数据安全性不高的原因分析)
自动采集子系统具有完整的组网架构,且便于拓展,并提供给子系统很方便的接入调度,但在子系统类型确定的情况下,自动采集子系统的数据传输有时会存在个地址之争,这是由于采集子系统需要进行重定向,但传统的重定向接口具有局限性;具体来说,重定向接口主要存在两个问题:一是配置麻烦,无法跨子系统跨平台,二是跨域速度缓慢。
传统的c端往往要向s端进行配置,而s端往往还需要配置c端一些内容,这相当于将exploit的代码开放给相同平台的c端,c端在接收到这些反馈后,将exploit代码代码转化为executor的代码,并且重定向到s端。这种方式在需要跨域的情况下,往往会因为网络原因而导致数据延迟很高;而对于web子系统来说,最容易出现的问题就是跨域问题。
自动采集子系统在跨域情况下,所传输数据就是纯粹的xml数据,xml是一种无状态的数据格式,数据传输速度慢、占用磁盘空间大,所以数据往往得不到保留,因此传统的xml数据定义时,常规是提供二进制格式输出的;其中apachesnmp协议可以完美解决跨域问题,同时snmp协议还可以给其他需要重定向的子系统提供子系统层面的一套标准接口,同时它的安全性非常高,可以通过base64加密,传统xml定义的数据安全性不高,可以通过snmp解决。
对于第一代的b/s架构,一个重要核心的协议就是snmp,在tomcat(engineer-servicemonitor)和glassfish(myresourceway:engineer-servicemonitor)中有大量的snmp协议相关的实现方案,而对于apachesnmp2类型的其他协议,在snmp协议本身的安全特性(tls二层安全)和解决方案上并没有吸引到太多人,比如thrift,实现方案上并没有优势,从后来thrift的取消流行情况可以看出。
关于thrift,是一个自动化运维过程中必需的解决方案。至于web前端如何实现snmp方案,实现并无太多需要去实现的了,这些都不需要去过多关注,对于web端,如果需要传输xml格式的数据,一般就是使用postmessage(extendedbase64,postmessagep),这部分重定向语法确实不支持,只要方案跟提供的接口相关,就能够解决传输xml格式数据的问题。
但是对于后端来说,支持snmp协议的web访问往往并不多,因为通常单机访问是没有太多性能优势的。web网页端常用的采集方案目前可以总结出几种:1,executor的接口,也即基于单元测试工具使用多个ie,也即同一个网页中同时调用多个子页面;2,子页面不单独调用ie去访问,而是通过postmessage调用多个ie来调用;3,其他方案;比如redisorm,spring等等。
自动采集子系统(自动采集子系统建设说明书(一)-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-31 12:02
自动采集子系统总结自动采集系统建设说明
一、系统目标:自动采集子系统,直接操作,可以工作到80%,减少人工干预操作,24小时自动直接操作。
1、自动采集系统应该具备:自动化软件,分布式采集系统,不同程度的节点。
2、系统采集方式:各节点分散布置,各节点自动化系统和分布式采集系统。
二、设计目标:自动采集系统不能带领总部子系统自动采集子系统,单机采集,一台电脑搞定自动采集子系统。
三、系统架构需要:子系统集群,
四、采集系统设计:子系统采集方式
1、小范围采集,每个节点自动化采集子系统当子节点数量和自动化采集子系统规模相同,小范围采集,大范围采集。
2、子节点集群,采集服务器集群。一台小范围采集,小范围采集每个节点自动化采集子系统当规模相同,子节点数量和采集子系统规模相同,1个小范围采集,2个子节点采集服务器集群。
3、子节点集群,采集服务器集群。一台采集服务器,一台采集子系统,一台采集子系统采集集群,采集子系统集群:根据采集子系统规模大小,以及节点数量和采集子系统规模一起分割采集子系统规模。
采集系统架构图设计完成以上就可以开始设计采集子系统了
1、子节点规模10台电脑,服务器规模2台
2、根据采集子系统规模,把采集子系统设计成两台或多台采集服务器系统1台采集服务器,10台采集服务器系统,采集服务器配置请参考上图。
5、子节点集群2台采集服务器,交换机1个采集服务器,子节点集群3台采集服务器,交换机1个采集服务器。如果所有子节点采集服务器规模10台,需要采集服务器配置如下。这个规模的采集服务器配置可以参考下图。电脑单机采集,用一台电脑,规模为2台电脑。采集子系统30台电脑配置采集子系统交换机30个交换机。分机节点采集,有3台采集服务器,3台采集服务器一组,采集服务器如下。
分机节点集群采集,有3台采集服务器,一组,采集服务器采集集群。分机节点采集,有3台采集服务器,一组,采集服务器采集集群。采集服务器集群6台采集服务器,需要搭建采集服务器集群。采集子系统配置这种采集子系统的采集子系统要求子系统规模大,分配的采集子系统节点多,大量规模采集服务器和节点集群,设计采集服务器和采集子系统的采集集群需要专业的采集软件。
优点是系统效率高,采集服务器集群采集效率更高。缺点是采集采集子系统规模大,配置贵。四通道采集服务器和分组采集服务器优点:节点集群采集和单通道采集的采集节点和采集节点在同一时间,效率更高。配置上安装更方便。
缺点:
1、采集 查看全部
自动采集子系统(自动采集子系统建设说明书(一)-上海怡健医学)
自动采集子系统总结自动采集系统建设说明
一、系统目标:自动采集子系统,直接操作,可以工作到80%,减少人工干预操作,24小时自动直接操作。
1、自动采集系统应该具备:自动化软件,分布式采集系统,不同程度的节点。
2、系统采集方式:各节点分散布置,各节点自动化系统和分布式采集系统。
二、设计目标:自动采集系统不能带领总部子系统自动采集子系统,单机采集,一台电脑搞定自动采集子系统。
三、系统架构需要:子系统集群,
四、采集系统设计:子系统采集方式
1、小范围采集,每个节点自动化采集子系统当子节点数量和自动化采集子系统规模相同,小范围采集,大范围采集。
2、子节点集群,采集服务器集群。一台小范围采集,小范围采集每个节点自动化采集子系统当规模相同,子节点数量和采集子系统规模相同,1个小范围采集,2个子节点采集服务器集群。
3、子节点集群,采集服务器集群。一台采集服务器,一台采集子系统,一台采集子系统采集集群,采集子系统集群:根据采集子系统规模大小,以及节点数量和采集子系统规模一起分割采集子系统规模。
采集系统架构图设计完成以上就可以开始设计采集子系统了
1、子节点规模10台电脑,服务器规模2台
2、根据采集子系统规模,把采集子系统设计成两台或多台采集服务器系统1台采集服务器,10台采集服务器系统,采集服务器配置请参考上图。
5、子节点集群2台采集服务器,交换机1个采集服务器,子节点集群3台采集服务器,交换机1个采集服务器。如果所有子节点采集服务器规模10台,需要采集服务器配置如下。这个规模的采集服务器配置可以参考下图。电脑单机采集,用一台电脑,规模为2台电脑。采集子系统30台电脑配置采集子系统交换机30个交换机。分机节点采集,有3台采集服务器,3台采集服务器一组,采集服务器如下。
分机节点集群采集,有3台采集服务器,一组,采集服务器采集集群。分机节点采集,有3台采集服务器,一组,采集服务器采集集群。采集服务器集群6台采集服务器,需要搭建采集服务器集群。采集子系统配置这种采集子系统的采集子系统要求子系统规模大,分配的采集子系统节点多,大量规模采集服务器和节点集群,设计采集服务器和采集子系统的采集集群需要专业的采集软件。
优点是系统效率高,采集服务器集群采集效率更高。缺点是采集采集子系统规模大,配置贵。四通道采集服务器和分组采集服务器优点:节点集群采集和单通道采集的采集节点和采集节点在同一时间,效率更高。配置上安装更方便。
缺点:
1、采集
自动采集子系统(一个网络舆情预警系统参考材料的思考与思考(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-08-29 17:09
〇,写在前面(2016-05-29 更新)
看时间,现在正好是两年前,我完成了这个毕业设计。本摘要摘自论文摘要。说的很简洁,但是没有提到当时有各种尝试来分析这个话题。
这个话题始于好奇,对数据来源的好奇,对所谓的机器学习和自然语言处理算法的好奇。多亏了这种好奇心,在没有现成的参考资料的情况下,我真的可以说“跪下”去体会这个庞大而空洞的主题。
数据源部分需要关注URL获取、网页分析、数据存储;分析时需要注意分词、降噪等;而最后的舆情分析,除了考虑技术算法的选择,更重要的是厘清什么是舆情。而这些,从学习、设计到实现,只用了不到四个月的时间。
当然,时间紧的时候也有短期的对策。网上类似的系统虽然不对外开放,但其实每个部分都有大量的开源代码可供参考。在参考实现的过程中,我边使用边学习了Python、R语言和非关系型数据库MongoDB。这两天为了让Orz显得不那么水汪汪,用PyQt写了一个软件界面。
总之,这个题目最大的提升恐怕就是问题分析能力、信息搜索能力和整合能力了,哈哈。
所以回过头来看,有了一定的工程能力之后,重点应该是学会进一步思考。一方面考虑数据算法,另一方面考虑现实世界的数据建模。记录下来作为以后学习的方向。
附上github链接。目前,由于微博信息获取模块未更新,无法正常获取信息。仅供参考……回头看当时的代码,真的很乱……
一、概览
本文设计并实现了一个在线舆情预警系统。该系统的主要功能是:对指定时间和区域的多条用户微博进行文本挖掘,通过数据可视化,直观展示潜在的舆情热点。
微博信息采集阶段,借助相关网络爬虫素材,结合Python的BeautifulSoup库,完善新浪微博网页版分析,系统自定义采集规则。同时,使用非关系型数据库MongoDB存储用户信息和微博信息,为以后更深入的研究奠定了良好的数据基础。
在信息分类阶段,本研究结合自然语言处理和机器学习相关理论,使用基于前向最大匹配的mmseg4j中文分词对文本进行分词,使用支持向量机算法对文本进行处理,并人工标注一定的在大量文本的基础上,更好地实现了文本的半监督学习,过滤掉了大部分无意义的文本。
在文本信息分析和预警阶段,本研究优化了基本的分词步骤,即使用正则表达式提取新浪微博标签内容并实时添加到分词词典中,促进基于短语的文本分析。同时,结合R语言在统计和图形方面的优势,编写R代码使用层次聚类算法对过滤后的文本进行聚类,最后通过调用wordcloud库,以“词云”各种事件和热度。
二、舆论预警系统方案设计
(1)系统结构设计
①系统总体结构设计
由于本系统集成了舆情发现-处理-分析三个阶段,所以抽象为三个子系统,分别是information采集子系统、信息分类子系统、聚类舆情可视化子系统。其中信息采集子系统负责用户自定义的受限信息采集微博文本内容,信息分类子系统通过提前学习构建文本分类器,然后将分类模型应用到系统采集subsystem采集给资料,包括训练模块、预测模块、评估模块。聚类舆情可视化子系统进一步对过滤后的文本进行预处理,通过层次聚类结合注意力评分,以“词云”的形式展示当前舆情热点。
详见图2.1,箭头方向为基本数据流向。
图2.1系统整体结构
②微博资讯采集子系统架构设计
图2.2微博信息采集子系统架构
图2.2是微博信息采集子系统的体系结构。模拟用户登录新浪微博后,采集工作正式启动。首先解析初始用户的“关注”和“粉丝”列表,将符合自定义规则的用户的uid(新浪微博用户唯一标识)存入队列;然后会解析用户的微博内容,分析符合自定义规则的微博。将其保存在数据库中;当前用户解析完成后,下一个用户会从“微博用户队列”的头部取出,循环执行上述步骤。
③信息分类子系统的设计
在实际应用中,信息分类分为两部分。一种是手动标注训练样本,构建满足需求的SVM模型(见图2.3);另一种是利用训练好的分类模型,对输入样本进行比较进行预测。
图2.3 训练模块架构
④聚类舆情可视化子系统设计
聚类舆情可视化子系统的系统结构如图2.4所示。
图2.4 聚类舆情可视化子系统架构
(2)系统流程设计
在对整体的设计和各个子系统的系统结构进行分项描述之后,结合用户操作界面的设计,现在结合系统使用过程的概述。整个系统流程如2.5 所示。实线连接部分是系统最基本的进程,虚线部分是系统的后台运行进程。 “可选显示模块”的内容可以通过界面按钮来控制,决定是否在界面上显示。
图2.5 整体系统流程
三、舆情预警系统实施与测试
该系统由三个子系统组成。实现界面如图3.1所示。其中,微博信息采集模块是基于开源爬虫框架Cola实现的。 采集规则改进后可以自定义。自定义模块如图左上部分所示。同时采集日志可以通过“左下角微博采集”完成采集进程停止后,可以在右上角显示采集的文字图,并调用信息分类子系统对采集文本进行分类。最终的分类结果如图右下方所示。
图3.1 舆情预警系统实现界面
此时点击上图中的“舆情聚类分析”按钮,生成预警词云,如图3.2。
图3.2聚类舆情词云效果图
词云图中的外圈标签是类别号,每个类别的词以相同的色调显示。从图中可以直观地发现,在测试期间,从我的微博开始,江苏周边南京地区的用户,讨论最多的类别是第一类别,突出的特征词是“周年”和“南游知之”。 《声响30年》等;虽然潜在事件以“端午节快乐”为代表,但总体类别事件过于稀疏。
四、结论
本文系统地提出了一种在线舆情预警系统的设计与实现,可以根据用户自定义信息采集规则获取合格的新浪微博数据,完成对无意义微博文本的过滤。最终,不同类别的事件以“词云”的形式呈现给用户。
从系统测试结果来看,该系统基本可以满足个人用户了解身边潜在舆论的需求,但系统各方面还有很大的提升空间。比如微博信息采集子系统,未来可以通过分布式和多账户操作,提高采集的效率;需要对微博内容的含义有更清晰的定义,选择具有鲜明特征的微博作为训练样本,以提高信息分类子系统的过滤效果;现有舆情信息应进一步结合舆情特征分析。
除了在技术上完善舆情预警系统,从道德伦理的角度深化对网络环境的思考也具有现实意义。当前用户隐私与各方网络监控的矛盾日趋严重。如何处理这样的矛盾,不仅是本课题需要探索的问题,也是每个科技人员需要思考的问题。
参考资料
[1] 新浪微博数据中心。 2011年媒体微博研究报告[EB/OL]。 (2012-03-21).
[2] 新浪微博数据中心。 2013年新浪媒体微博报道[EB/OL].[2014-06-1].
[3] 陈鑫。基于行块分布函数的通用网页文本提取[R].哈尔滨工业大学社会计算与信息检索研究中心。
[4]MicheleBanko、MichaelJCafarella、StephenSoderland、MattBroadhead 和 OrenEtzioni.OpenInformationExtractionfortheWeb[D].Washington:UniversityofWashington,2009.
[5] 翁宇。互联网话题中的网络文本挖掘技术[M].北京:中央民族大学出版社,2012.142.
[6]童薇,陈薇,孟晓峰。 EDM:高效微博事件检测算法[J].JournalofFrontiersofComputerScienceandTechnology,2012,6(12):1076-1086.
[7]CerenBudak,TheodoreGeorgiou,DivyakantAgrawal,AmrEIAbbadi.GeoScope:OnlineDetectionofGeoCorrelated[J].ProceedingsoftheVLDBEndowment,Vol.7,No.4.InformationTrendsinSocialNetworks, CerenBudak
[8] 丁聚玲,乐仲建.一种基于意见树的网络舆情危机预警方法[J].计算机应用研究, 2011, 28 (9): 3501-3504.
[9] 李云涛,柳岩,柳毅。网络舆情灰色预警评价研究[J].信息杂志, 2011, 30 (4):24-27.
[10]许昕,张兰兰。基于信号分析的突发事件网络舆情预警研究[J].智力理论与实践, 2010, 33 (12): 97-100.
[11] 李碧城,王进,林晨。基于直觉模糊推理的网络舆情预警方法[J].计算机应用研究, 2010, 27 (9):3312-3315.
[12]EIRINAKIM,VAZIRGIANNISM.Webminingforwebpersonalization[J].ACMTransactionsonInternetTechnology,2003,3(1):12-13.
[13]MARTENSD,BRUYNSEELSL,BAESENSB,etal.Predictinggoingconcernopinionwithdatamining[J].DecisionSupportSystems,2008,45(4):765-777.
[14]ManojKAgarwal,KrithiRamamritham,ManishBhide.RealTimeDiscoveryofDenseClustersinHighlyDynamicGraphs:IdentifyingRealWorldEventsinHighlyDynamicEnvironments[J].ProceedingsoftheVLDBEndowment,Vol.5,No.10
[15]LeonardRichardson.BeautifulSoup4.2.0documentation[EB/OL].(2013-05-15).
[16]梁南元.书面汉语自动分词及另一种自动分词系统CDWS[C].汉字信息处理系统学术会议,1983(1):12-13
[17] 侯婉友.群体性突发事件微博舆情演变分析[D].哈尔滨:哈尔滨工业大学,2013.
[18]林轩田.APracticalGuidetoSupportVectorClassication[EB/OL].(2010-04-15).~cjlin/papers/guide/guide.pdf
[19]张智霖.Tmsvm参考文档(v1.1.0)[EB/OL].(2012-03-09).%E5%8F%82%E8%80% 83 %E6%96%87%E6%A1%A3%28v1.1.0%29.rar&can=2&q=
[20]秦旭业.Cola:分布式爬虫框架[EB/OL].(2013-09-21).
[21]孙健.Rwordseg_Vignette_CN[EB/OL].(2013-12-15). 查看全部
自动采集子系统(一个网络舆情预警系统参考材料的思考与思考(一))
〇,写在前面(2016-05-29 更新)
看时间,现在正好是两年前,我完成了这个毕业设计。本摘要摘自论文摘要。说的很简洁,但是没有提到当时有各种尝试来分析这个话题。
这个话题始于好奇,对数据来源的好奇,对所谓的机器学习和自然语言处理算法的好奇。多亏了这种好奇心,在没有现成的参考资料的情况下,我真的可以说“跪下”去体会这个庞大而空洞的主题。
数据源部分需要关注URL获取、网页分析、数据存储;分析时需要注意分词、降噪等;而最后的舆情分析,除了考虑技术算法的选择,更重要的是厘清什么是舆情。而这些,从学习、设计到实现,只用了不到四个月的时间。
当然,时间紧的时候也有短期的对策。网上类似的系统虽然不对外开放,但其实每个部分都有大量的开源代码可供参考。在参考实现的过程中,我边使用边学习了Python、R语言和非关系型数据库MongoDB。这两天为了让Orz显得不那么水汪汪,用PyQt写了一个软件界面。
总之,这个题目最大的提升恐怕就是问题分析能力、信息搜索能力和整合能力了,哈哈。
所以回过头来看,有了一定的工程能力之后,重点应该是学会进一步思考。一方面考虑数据算法,另一方面考虑现实世界的数据建模。记录下来作为以后学习的方向。
附上github链接。目前,由于微博信息获取模块未更新,无法正常获取信息。仅供参考……回头看当时的代码,真的很乱……
一、概览
本文设计并实现了一个在线舆情预警系统。该系统的主要功能是:对指定时间和区域的多条用户微博进行文本挖掘,通过数据可视化,直观展示潜在的舆情热点。
微博信息采集阶段,借助相关网络爬虫素材,结合Python的BeautifulSoup库,完善新浪微博网页版分析,系统自定义采集规则。同时,使用非关系型数据库MongoDB存储用户信息和微博信息,为以后更深入的研究奠定了良好的数据基础。
在信息分类阶段,本研究结合自然语言处理和机器学习相关理论,使用基于前向最大匹配的mmseg4j中文分词对文本进行分词,使用支持向量机算法对文本进行处理,并人工标注一定的在大量文本的基础上,更好地实现了文本的半监督学习,过滤掉了大部分无意义的文本。
在文本信息分析和预警阶段,本研究优化了基本的分词步骤,即使用正则表达式提取新浪微博标签内容并实时添加到分词词典中,促进基于短语的文本分析。同时,结合R语言在统计和图形方面的优势,编写R代码使用层次聚类算法对过滤后的文本进行聚类,最后通过调用wordcloud库,以“词云”各种事件和热度。
二、舆论预警系统方案设计
(1)系统结构设计
①系统总体结构设计
由于本系统集成了舆情发现-处理-分析三个阶段,所以抽象为三个子系统,分别是information采集子系统、信息分类子系统、聚类舆情可视化子系统。其中信息采集子系统负责用户自定义的受限信息采集微博文本内容,信息分类子系统通过提前学习构建文本分类器,然后将分类模型应用到系统采集subsystem采集给资料,包括训练模块、预测模块、评估模块。聚类舆情可视化子系统进一步对过滤后的文本进行预处理,通过层次聚类结合注意力评分,以“词云”的形式展示当前舆情热点。
详见图2.1,箭头方向为基本数据流向。

图2.1系统整体结构
②微博资讯采集子系统架构设计

图2.2微博信息采集子系统架构
图2.2是微博信息采集子系统的体系结构。模拟用户登录新浪微博后,采集工作正式启动。首先解析初始用户的“关注”和“粉丝”列表,将符合自定义规则的用户的uid(新浪微博用户唯一标识)存入队列;然后会解析用户的微博内容,分析符合自定义规则的微博。将其保存在数据库中;当前用户解析完成后,下一个用户会从“微博用户队列”的头部取出,循环执行上述步骤。
③信息分类子系统的设计
在实际应用中,信息分类分为两部分。一种是手动标注训练样本,构建满足需求的SVM模型(见图2.3);另一种是利用训练好的分类模型,对输入样本进行比较进行预测。

图2.3 训练模块架构
④聚类舆情可视化子系统设计
聚类舆情可视化子系统的系统结构如图2.4所示。

图2.4 聚类舆情可视化子系统架构
(2)系统流程设计
在对整体的设计和各个子系统的系统结构进行分项描述之后,结合用户操作界面的设计,现在结合系统使用过程的概述。整个系统流程如2.5 所示。实线连接部分是系统最基本的进程,虚线部分是系统的后台运行进程。 “可选显示模块”的内容可以通过界面按钮来控制,决定是否在界面上显示。

图2.5 整体系统流程
三、舆情预警系统实施与测试
该系统由三个子系统组成。实现界面如图3.1所示。其中,微博信息采集模块是基于开源爬虫框架Cola实现的。 采集规则改进后可以自定义。自定义模块如图左上部分所示。同时采集日志可以通过“左下角微博采集”完成采集进程停止后,可以在右上角显示采集的文字图,并调用信息分类子系统对采集文本进行分类。最终的分类结果如图右下方所示。

图3.1 舆情预警系统实现界面
此时点击上图中的“舆情聚类分析”按钮,生成预警词云,如图3.2。

图3.2聚类舆情词云效果图
词云图中的外圈标签是类别号,每个类别的词以相同的色调显示。从图中可以直观地发现,在测试期间,从我的微博开始,江苏周边南京地区的用户,讨论最多的类别是第一类别,突出的特征词是“周年”和“南游知之”。 《声响30年》等;虽然潜在事件以“端午节快乐”为代表,但总体类别事件过于稀疏。
四、结论
本文系统地提出了一种在线舆情预警系统的设计与实现,可以根据用户自定义信息采集规则获取合格的新浪微博数据,完成对无意义微博文本的过滤。最终,不同类别的事件以“词云”的形式呈现给用户。
从系统测试结果来看,该系统基本可以满足个人用户了解身边潜在舆论的需求,但系统各方面还有很大的提升空间。比如微博信息采集子系统,未来可以通过分布式和多账户操作,提高采集的效率;需要对微博内容的含义有更清晰的定义,选择具有鲜明特征的微博作为训练样本,以提高信息分类子系统的过滤效果;现有舆情信息应进一步结合舆情特征分析。
除了在技术上完善舆情预警系统,从道德伦理的角度深化对网络环境的思考也具有现实意义。当前用户隐私与各方网络监控的矛盾日趋严重。如何处理这样的矛盾,不仅是本课题需要探索的问题,也是每个科技人员需要思考的问题。
参考资料
[1] 新浪微博数据中心。 2011年媒体微博研究报告[EB/OL]。 (2012-03-21).
[2] 新浪微博数据中心。 2013年新浪媒体微博报道[EB/OL].[2014-06-1].
[3] 陈鑫。基于行块分布函数的通用网页文本提取[R].哈尔滨工业大学社会计算与信息检索研究中心。
[4]MicheleBanko、MichaelJCafarella、StephenSoderland、MattBroadhead 和 OrenEtzioni.OpenInformationExtractionfortheWeb[D].Washington:UniversityofWashington,2009.
[5] 翁宇。互联网话题中的网络文本挖掘技术[M].北京:中央民族大学出版社,2012.142.
[6]童薇,陈薇,孟晓峰。 EDM:高效微博事件检测算法[J].JournalofFrontiersofComputerScienceandTechnology,2012,6(12):1076-1086.
[7]CerenBudak,TheodoreGeorgiou,DivyakantAgrawal,AmrEIAbbadi.GeoScope:OnlineDetectionofGeoCorrelated[J].ProceedingsoftheVLDBEndowment,Vol.7,No.4.InformationTrendsinSocialNetworks, CerenBudak
[8] 丁聚玲,乐仲建.一种基于意见树的网络舆情危机预警方法[J].计算机应用研究, 2011, 28 (9): 3501-3504.
[9] 李云涛,柳岩,柳毅。网络舆情灰色预警评价研究[J].信息杂志, 2011, 30 (4):24-27.
[10]许昕,张兰兰。基于信号分析的突发事件网络舆情预警研究[J].智力理论与实践, 2010, 33 (12): 97-100.
[11] 李碧城,王进,林晨。基于直觉模糊推理的网络舆情预警方法[J].计算机应用研究, 2010, 27 (9):3312-3315.
[12]EIRINAKIM,VAZIRGIANNISM.Webminingforwebpersonalization[J].ACMTransactionsonInternetTechnology,2003,3(1):12-13.
[13]MARTENSD,BRUYNSEELSL,BAESENSB,etal.Predictinggoingconcernopinionwithdatamining[J].DecisionSupportSystems,2008,45(4):765-777.
[14]ManojKAgarwal,KrithiRamamritham,ManishBhide.RealTimeDiscoveryofDenseClustersinHighlyDynamicGraphs:IdentifyingRealWorldEventsinHighlyDynamicEnvironments[J].ProceedingsoftheVLDBEndowment,Vol.5,No.10
[15]LeonardRichardson.BeautifulSoup4.2.0documentation[EB/OL].(2013-05-15).
[16]梁南元.书面汉语自动分词及另一种自动分词系统CDWS[C].汉字信息处理系统学术会议,1983(1):12-13
[17] 侯婉友.群体性突发事件微博舆情演变分析[D].哈尔滨:哈尔滨工业大学,2013.
[18]林轩田.APracticalGuidetoSupportVectorClassication[EB/OL].(2010-04-15).~cjlin/papers/guide/guide.pdf
[19]张智霖.Tmsvm参考文档(v1.1.0)[EB/OL].(2012-03-09).%E5%8F%82%E8%80% 83 %E6%96%87%E6%A1%A3%28v1.1.0%29.rar&can=2&q=
[20]秦旭业.Cola:分布式爬虫框架[EB/OL].(2013-09-21).
[21]孙健.Rwordseg_Vignette_CN[EB/OL].(2013-12-15).
自动采集子系统( 手机客户端在管理端制定清单,分解清单)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-29 17:06
手机客户端在管理端制定清单,分解清单)
安排成本管理
进度成本管理系统由管理客户端、Web平台和移动客户端组成。子系统以检查表为主线。管理人员在管理端制定清单,分解清单计算成本,对分解后的成本单位制定计划,有效关联成本与进度;现场人员在手机客户端采集建筑工程数量、材料仓库进出、机械进出等相关数据,实时提供施工现场第一手信息;公司管理层可在网页平台或手机客户端查询整个项目的进度和成本,即时预警可直接通过图表反映,具体问题可查询。细节。
系统主要功能介绍:
一、Management 客户端
管理客户端主要提供给项目管理人员(项目策划部)进行项目管理工作,如准备清单、准备计划等。
(1)列表管理
系统中最基本的清单录入和分解工作,进入详细的工程量清单,按规则分解得到成本单位,确定人力资源机器的市场价格,投标后价格(即即,自行确定的成本价格),并计算项目成本。
(2)计划管理
根据项目计划,为每个成本单位确定具体的执行计划,并显示条形图。
(3)Provider 管理
输入供应商信息,确定供应商的具体合同,将这些项目计划的执行者与成本单位关联起来。成本单位建立成本核算、利润统计、进度管理、进度执行管理全服务链接
二、手机客户端
移动客户端主要用于采集和查询数据,旨在为项目提供真实有效的运行数据,实时预警,及时发现。
(1)数据采集
基于管理清单计划数据,采集网站建设数据。现场手机填写资料简单、真实、可靠,可提供位置、图片、视频等资料作为佐证。
材料输入图
(2)data 查询
每个项目参与者都可以查看自己的相关工程数据,发现问题时通过系统报告问题。
手机数据查询图
三、网站平台
主要用于对项目的整体进度和成本进行管理和查询,对项目中的问题进行实时预警和及时发现。
三种计算的查询结果对比 查看全部
自动采集子系统(
手机客户端在管理端制定清单,分解清单)
安排成本管理
进度成本管理系统由管理客户端、Web平台和移动客户端组成。子系统以检查表为主线。管理人员在管理端制定清单,分解清单计算成本,对分解后的成本单位制定计划,有效关联成本与进度;现场人员在手机客户端采集建筑工程数量、材料仓库进出、机械进出等相关数据,实时提供施工现场第一手信息;公司管理层可在网页平台或手机客户端查询整个项目的进度和成本,即时预警可直接通过图表反映,具体问题可查询。细节。
系统主要功能介绍:
一、Management 客户端
管理客户端主要提供给项目管理人员(项目策划部)进行项目管理工作,如准备清单、准备计划等。
(1)列表管理
系统中最基本的清单录入和分解工作,进入详细的工程量清单,按规则分解得到成本单位,确定人力资源机器的市场价格,投标后价格(即即,自行确定的成本价格),并计算项目成本。
(2)计划管理
根据项目计划,为每个成本单位确定具体的执行计划,并显示条形图。
(3)Provider 管理
输入供应商信息,确定供应商的具体合同,将这些项目计划的执行者与成本单位关联起来。成本单位建立成本核算、利润统计、进度管理、进度执行管理全服务链接
二、手机客户端
移动客户端主要用于采集和查询数据,旨在为项目提供真实有效的运行数据,实时预警,及时发现。
(1)数据采集
基于管理清单计划数据,采集网站建设数据。现场手机填写资料简单、真实、可靠,可提供位置、图片、视频等资料作为佐证。

材料输入图
(2)data 查询
每个项目参与者都可以查看自己的相关工程数据,发现问题时通过系统报告问题。

手机数据查询图
三、网站平台
主要用于对项目的整体进度和成本进行管理和查询,对项目中的问题进行实时预警和及时发现。

三种计算的查询结果对比
互联网的重要组成部分之一——科技信息瞬息万变(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-26 02:19
随着互联网技术的飞速发展,互联网已经成为人们进行社会、经济、文化、教育、娱乐等活动不可缺少的媒介。互联网的重要组成部分之一万维网(World WideWeb)承载着大量的数据和信息,包括各种类型和形式的信息,从科技信息、新闻报道,到商业信息、教育材料。动态异构分布式信息资源库。由于其使用的方便性和显示能力的多样性,通过WEB获取信息和知识已成为不可或缺的渠道。根据中国互联网络信息中心(CNNIC)发布的第31次中国互联网发展统计报告,截至2012年12月末,中国网民规模达到5.640亿,互联网普及率为42.1%。网民每周平均上网时间为 20.5 小时。中国网站的数量为268万,网页数量高达1227亿。每个网页的平均字节数为 42KB,而且这些数据还在不断增长。互联网飞速发展的好处是它所收录的信息非常丰富,但同时也给我们带来了更加严峻的挑战,即如何根据用户的兴趣从海量的WEB信息中高效获取信息是当前互联网应用面临一个难题。 “科学技术是第一生产力”,“科技创新”是我国必须长期坚持的基本国策之一。随着我国经济文化的发展和民族文化素质的普遍提高,越来越多的人开始关注科技信息的发展。
个人或企业的发展模式逐渐从传统转变为依靠科技。科技发展迅猛,科技信息日新月异。在当今互联网信息时代,人们获取科技信息的方式不再局限于传统的教室和书籍。相反,从互联网上获取科技信息已经成为一种更加方便快捷的方式[54][55]。聚合这么多科技信息的内容,不仅难以保证内容的时效性,如果仅靠人工方式获取,还要耗费相当多的时间和精力。那么,更方便的方式是使用程序将采集信息源的内容(例如科技信息源网站中的内容)自动化,最后将结果以个性化的方式展示在终点站。本文实施的科技信息自动跟踪管理系统是与北京市某单位合作的科技项目的一个子系统。本文的主要任务是研究开发一套科技信息自动跟踪管理系统。该技术项目的总体结构如图1-1所示。目前市场上已经有一些特定的网页信息采集软件。他们大多采用人工观察网页和网页源代码,针对需要采集的特定数据手动配置采集规则,使用起来复杂繁琐。 ,且需要相关专业基础,不适合普通用户。另外,本文所实现的系统来源于特定的科技项目,市面上的软件无法满足该项目用户的特定需求,同类软件价格昂贵。因此,我希望设计一个简单易用、采集结果准确、可定制的信息源,以及动态采集科技信息自动跟踪系统。所实现的系统不仅可以为现有的科技信息采集领域提供参考和借鉴,而且在具体的应用领域也能产生良好的效果。 查看全部
互联网的重要组成部分之一——科技信息瞬息万变(组图)
随着互联网技术的飞速发展,互联网已经成为人们进行社会、经济、文化、教育、娱乐等活动不可缺少的媒介。互联网的重要组成部分之一万维网(World WideWeb)承载着大量的数据和信息,包括各种类型和形式的信息,从科技信息、新闻报道,到商业信息、教育材料。动态异构分布式信息资源库。由于其使用的方便性和显示能力的多样性,通过WEB获取信息和知识已成为不可或缺的渠道。根据中国互联网络信息中心(CNNIC)发布的第31次中国互联网发展统计报告,截至2012年12月末,中国网民规模达到5.640亿,互联网普及率为42.1%。网民每周平均上网时间为 20.5 小时。中国网站的数量为268万,网页数量高达1227亿。每个网页的平均字节数为 42KB,而且这些数据还在不断增长。互联网飞速发展的好处是它所收录的信息非常丰富,但同时也给我们带来了更加严峻的挑战,即如何根据用户的兴趣从海量的WEB信息中高效获取信息是当前互联网应用面临一个难题。 “科学技术是第一生产力”,“科技创新”是我国必须长期坚持的基本国策之一。随着我国经济文化的发展和民族文化素质的普遍提高,越来越多的人开始关注科技信息的发展。
个人或企业的发展模式逐渐从传统转变为依靠科技。科技发展迅猛,科技信息日新月异。在当今互联网信息时代,人们获取科技信息的方式不再局限于传统的教室和书籍。相反,从互联网上获取科技信息已经成为一种更加方便快捷的方式[54][55]。聚合这么多科技信息的内容,不仅难以保证内容的时效性,如果仅靠人工方式获取,还要耗费相当多的时间和精力。那么,更方便的方式是使用程序将采集信息源的内容(例如科技信息源网站中的内容)自动化,最后将结果以个性化的方式展示在终点站。本文实施的科技信息自动跟踪管理系统是与北京市某单位合作的科技项目的一个子系统。本文的主要任务是研究开发一套科技信息自动跟踪管理系统。该技术项目的总体结构如图1-1所示。目前市场上已经有一些特定的网页信息采集软件。他们大多采用人工观察网页和网页源代码,针对需要采集的特定数据手动配置采集规则,使用起来复杂繁琐。 ,且需要相关专业基础,不适合普通用户。另外,本文所实现的系统来源于特定的科技项目,市面上的软件无法满足该项目用户的特定需求,同类软件价格昂贵。因此,我希望设计一个简单易用、采集结果准确、可定制的信息源,以及动态采集科技信息自动跟踪系统。所实现的系统不仅可以为现有的科技信息采集领域提供参考和借鉴,而且在具体的应用领域也能产生良好的效果。
自动采集子系统 2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-21 05:23
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
作者买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL2、。Ubuntu系统和NVIDIA Driver成功运行了Ubuntu子系统中的深度学习代码Windows,GPU资源全满!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软把WSL 2变成稳定版后,我们只需要输入如下命令就可以设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须为4.19.121 或更高版本。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查是否在 Windows 升级设置中打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
查看全部
自动采集子系统 2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
作者买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL2、。Ubuntu系统和NVIDIA Driver成功运行了Ubuntu子系统中的深度学习代码Windows,GPU资源全满!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软把WSL 2变成稳定版后,我们只需要输入如下命令就可以设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须为4.19.121 或更高版本。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查是否在 Windows 升级设置中打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
种证件照片与人脸自动识别系统技术领域[0001](图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-07 03:23
专利名称:一种证件照制作方法及人脸识别系统
技术领域:
—一种身份证照片和人脸自动识别系统技术领域[0001]本实用新型属于人脸识别领域,具体涉及一种直接自动识别身份证照片和人脸的系统。
背景技术:
[0002] 现有的人脸识别方法,尤其是一些商业软件,对识别和对比的人脸照片的清晰度要求很高,例如人脸照片中两只眼睛的距离。 80 多个像素。但是,由于存储空间的限制,一般存储在身份证RFID卡上的照片清晰度较差,人脸照片中眼睛之间的距离只有20像素左右。因此,现有的人脸识别方法无法直接将存储在身份证RFID卡上的高压缩照片与现场拍摄的人脸照片进行对比。解决办法是与公安局身份证中心数据库联网,通过身份证号码从公安部数据中心获取并下载身份证原照片,然后使用一些商用的人脸识别软件拍摄身份证原件照片和现场快照。比较人脸照片。由于必须接入公安部身份证数据中心,其应用范围受到极大限制,且采集现场光照条件较高。实用新型内容 [0003]本实用新型提供了一种身份证照片和人脸自动识别系统,可以简单有效地解决现场拍摄的照片与人脸照片的比对问题。 [0004] 本实用新型包括以下技术特征。 [0005] 一种身份证照片和人脸自动识别系统,包括信息采集子系统和数据分析子系统。信息采集子系统包括摄像头设备和身份识别卡和读卡器;身份证与读卡器相匹配,身份证内含RFID电子标签,用于存储身份证照片;摄像设备采集的人脸信息和阅读器采集的身份证照片分别为输入数据分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元基于局部二值模式对采集一个人脸识别单元,将@的人脸信息与身份证照片上的局部特征进行比较;整体特征判断单元基于特征人脸对,将采集的人脸信息和身份证照片信息对整体特征进行比对。 人脸识别单元。
[0006] 本实用新型的识别系统将采集的身份证照片和人脸信息输入数据分析子系统,然后分别使用局部特征判断单元和整体特征判断单元进行判断。只有当局部特征判断单元认为与整体特征判断单元一致时,才输出人脸与身份证照片匹配的识别结果。局部特征判断单元和整体特征判断单元采用局部二值模式法(LBP)和特征脸法(PCA)实现人脸识别。这两种方法都是现有的算法,不是本实用新型要保护的改进。本实用新型的改进是选择这两个单元,利用两个单元连接的顺序来判断人脸的局部特征和整体特征。将存储的身份证照片与实时拍摄的人脸进行比对,为“实名制”制度的实施提供了强有力的技术支持,无需工作人员反复进行身份证与持证人的目视比对,提高工作效率。 [0007] 进一步地,本发明特别针对高度压缩的小照片,例如存储在身份证的RFID中的身份证照片,以及人脸眼睛之间的距离大约为20个像素的身份证照片。 [0008] 因此,身份证可以是第二代中国身份证,读卡器可以是身份证读卡器。当然,身份证可以是任何一种现有的带有记忆身份证照片的身份证,尤其是当记忆身份证照片的眼睛间距为15-25像素时。
但是,照片像素的大小不构成对本实用新型保护范围的限制。不能理解为本实用新型只能应用于小像素照片的识别。应当理解,本实用新型的新模型仍然可以获得更高的识别率。之所以能在小像素照片的情况下保持高识别率是因为本实用新型结合了整体(PCA)识别方法和局部(LBP)识别方法,通过局部特征的优化来实现判断单元和整体特征判断单元。 [0009] 进一步地,数据分析子系统在人脸验证模块之前还包括人脸检测模块,人脸检测模块用于提取人脸特征。人脸检测模块是基于肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点的检测模块。数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。人脸检测模块和图像处理模块可以有效提高识别效率和识别成功率。 [0010] 进一步地,在硬件连接中,数据分析子系统设置在上位机中,摄像头设备连接上位机,阅读器连接上位机上以串口方式连接。 [0011] 进一步地,该系统还包括存储子系统和监控管理子系统。存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问组成,识别结果存储库由监控管理子系统访问。
监控管理子系统通过查询访问识别结果存储库。 采集子系统的信息为采集人脸信息,来自摄像头的视频图像。 [0012] 上述人脸模板训练库用于保证识别过程中人脸数据的调用。人脸模板训练库收录原创人脸图像和从原创图像训练中提取的面部特征。识别结果数据库用于记录识别卡中存储的其他数据和其他信息,如人的身份证、姓名、照片、刷卡时间、是否可以识别为人等。保存为 JEPG 或 PNG 文件信息,特别是如果系统用于门禁识别管理,可以将识别结果存储为门禁记录。该系统还包括一个监控和管理子系统。通过监控管理子系统访问识别结果存储库,可以查询不同的信息。可以查询特定用户ID对应的所有识别信息,根据记录内容查看所有识别系统记录。 [0013] 进一步地,信息采集子系统用于从视频文件中获取采集person人脸信息,便于在保密监控的情况下以秘密监控方式识别采集。
[0014]图I为本实用新型的硬件连接图; [0015]图2为本实用新型内部模块连接图。
具体实现方法
[0016]下面结合说明书附图1-2对本实用新型的实施例进行说明。 [0017] 如图所示。如图1所示,本发明的硬件包括摄像装置1、身份证2和阅读器3;身份证2与阅读器3匹配,身份证2中收录用于存放证件的证件。摄像设备I采集的人脸信息和阅读器3采集的身份证照片被输入到数据分析子系统4中。数据分析子系统4设置在主机内,摄像装置1与主机相连,阅读器3与主机的串口相连。 [0018] 整个实用新型的控制部分包括输入数据分析子系统4、存储子系统5和监控管理子系统6。 [0019]输入数据分析子系统4用于对输入数据进行分析识别,包括图像处理模块41、人脸检测模块42和人脸验证模块43。图像处理模块41用于图像灰度转换、图像归一化和光均衡处理。人脸检测模块42根据肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点。人脸验证模块43由依次连接的局部特征判断单元43a和整体特征判断单元43b组成。局部特征判断单元43a用于在局部特征上将采集的人脸信息与身份证照片进行比对,整体特征判断单元43b用于将采集的人脸信息与身份证照片信息进行比对在整体特征上;当局部特征判断单元43a和整体特征判断单元43b都一致时,系统输出与照片匹配的人脸和ID识别结果。
[0020] 存储子系统5包括人脸模板训练库51和识别结果存储库52。人脸模板训练库51由局部特征判断单元43a和整体特征判断单元43b访问。识别结果存储库52由监控管理子系统6访问。 [0021]监控管理子系统6通过查询访问识别结果存储库52。 [0022] 本实用新型可以将现场拍摄的人脸转换成灰度图像,并进行归一化和光均衡处理;人脸检测使用RFID数据处理后的图像作为肤色检测,使用Adaboost算法剔除不必要的训练数据,并将重点放在重要的训练数据上;人脸验证使用基于二进制模式(LBP)的方法来提取人脸特征,然后使用基于特征的人脸(PCA)方法来实现人脸识别,最终达到二代身份证明自动人脸识别的效果RFID 照片和现场快照。 [0023] 在一个具体应用于考生身份识别的实施例中,整个系统包括三部分:摄像头、身份证和RFID阅读器。其中摄像头用于视频图像的采集,将视频流数据发送到数据处理计算机;身份证收录持有人姓名、照片等身份信息,身份证在RFID读写器的读取范围内。在内部,收录的数据被发送到 RFID 阅读器; RFID阅读器通过串口与计算机相连,当接收到RFID电子标签中存储的信息时,将信息传送给计算机。
[0024]输入数据分析子系统4是本实用新型的核心部分,涉及RFID识别卡中的信息处理、视频图像中正面位置的检测、人脸的提取特征,以及人脸验证以及各功能模块之间的同步互斥控制。 [0025] 存储子系统5包括人脸模块数据库、访问控制记录数据库和转发服务器。人脸模块数据库收录原创人脸图像和从原创图像训练中提取的人脸特征;门禁记录数据库智能识别系统在RFID卡中记录持卡人身份证、姓名、照片、刷卡时间、是否通过门禁系统等;转发服务器负责监控信息与手机之间的信息传递。负责将拍摄终端的图像数据转发到对应的手机终端。 [0026] 监控管理子系统6和存储子系统5通过数据库连接。系统支持的查询条件包括按时间查询、按ID查询、按记录内容查询。
声明1.一种自动识别照片和人脸识别系统,包括信息采集子系统和数据分析子系统,其特征在于信息采集子系统包括摄像装置、身份证件和读卡器;身份证与读卡器匹配,身份证内含RFID电子标签,用于存储身份证照片;分别输入摄像设备采集人脸信息数据和阅读器采集身份证照片分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。一个人脸识别单元,将人脸信息和身份证照片对局部特征进行比较;整体特征判断单元是根据特征人脸对采集的人脸信息和身份证照片信息人脸识别单元对整体特征进行比较的人。
2.如权利要求1所述的自动识别系统,其特征在于,所述识别卡为第二代中国身份证,所述读卡器为身份证读卡器。
3.如权利要求1所述的自动识别系统,其特征在于,所述身份证存储有两眼距离为15-25像素的证件照片。
4.如权利要求1所述的自动识别系统,其特征在于,所述数据分析子系统在人脸验证模块之前还包括人脸检测模块。
5.根据权利要求4所述的自动识别系统,其中人脸检测模块根据肤色检测确定人脸区域,并通过类Haar特征和Adaboost算法提取人脸特征点检测模块。
6.如权利要求5所述的自动识别系统,其特征在于,所述数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。
7.根据权利要求1至6中任一项所述的自动识别系统,其特征在于,所述数据分析子系统设置在主机中,摄像设备连接到主机,阅读器连接到主机串口方式的计算机。
8.如权利要求1所述的自动识别系统,其特征在于,还包括存储子系统和监控管理子系统,所述存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问,识别结果存储库由监控管理子系统访问。
9.如权利要求8所述的自动识别系统,其特征在于,所述监控管理子系统通过查询访问所述识别结果存储库。
10.根据权利要求1所述的自动识别系统,其中信息采集子系统用于从视频文件中获取采集人脸信息。
专利摘要本实用新型提供了一种身份证照片和人脸自动识别系统。系统包括信息采集子系统和数据分析子系统。数据分析子系统具有人脸验证模块。验证模块由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元将采集的人脸信息与身份证照片进行局部特征对比,整体特征判断单元将采集的人脸信息与身份证照片信息进行整体特征对比。只有当局部特征判断单元和整体特征判断单元都认为人脸与照片匹配时,系统才最终得到人脸与身份证照片匹配的识别结果。本实用新型可有效防止借用或冒用他人证件的行为,免去工作人员反复目视核对证件持有人的麻烦,提高实名制工作效率。
文件编号 G06K7/00GK202815870SQ20122048809
出版日期2013年3月20日申请日期2012年9月20日优先权日期2012年4月28日
发明人程远、王浩、范辉、张勇申请人:王浩 查看全部
种证件照片与人脸自动识别系统技术领域[0001](图)
专利名称:一种证件照制作方法及人脸识别系统
技术领域:
—一种身份证照片和人脸自动识别系统技术领域[0001]本实用新型属于人脸识别领域,具体涉及一种直接自动识别身份证照片和人脸的系统。
背景技术:
[0002] 现有的人脸识别方法,尤其是一些商业软件,对识别和对比的人脸照片的清晰度要求很高,例如人脸照片中两只眼睛的距离。 80 多个像素。但是,由于存储空间的限制,一般存储在身份证RFID卡上的照片清晰度较差,人脸照片中眼睛之间的距离只有20像素左右。因此,现有的人脸识别方法无法直接将存储在身份证RFID卡上的高压缩照片与现场拍摄的人脸照片进行对比。解决办法是与公安局身份证中心数据库联网,通过身份证号码从公安部数据中心获取并下载身份证原照片,然后使用一些商用的人脸识别软件拍摄身份证原件照片和现场快照。比较人脸照片。由于必须接入公安部身份证数据中心,其应用范围受到极大限制,且采集现场光照条件较高。实用新型内容 [0003]本实用新型提供了一种身份证照片和人脸自动识别系统,可以简单有效地解决现场拍摄的照片与人脸照片的比对问题。 [0004] 本实用新型包括以下技术特征。 [0005] 一种身份证照片和人脸自动识别系统,包括信息采集子系统和数据分析子系统。信息采集子系统包括摄像头设备和身份识别卡和读卡器;身份证与读卡器相匹配,身份证内含RFID电子标签,用于存储身份证照片;摄像设备采集的人脸信息和阅读器采集的身份证照片分别为输入数据分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元基于局部二值模式对采集一个人脸识别单元,将@的人脸信息与身份证照片上的局部特征进行比较;整体特征判断单元基于特征人脸对,将采集的人脸信息和身份证照片信息对整体特征进行比对。 人脸识别单元。
[0006] 本实用新型的识别系统将采集的身份证照片和人脸信息输入数据分析子系统,然后分别使用局部特征判断单元和整体特征判断单元进行判断。只有当局部特征判断单元认为与整体特征判断单元一致时,才输出人脸与身份证照片匹配的识别结果。局部特征判断单元和整体特征判断单元采用局部二值模式法(LBP)和特征脸法(PCA)实现人脸识别。这两种方法都是现有的算法,不是本实用新型要保护的改进。本实用新型的改进是选择这两个单元,利用两个单元连接的顺序来判断人脸的局部特征和整体特征。将存储的身份证照片与实时拍摄的人脸进行比对,为“实名制”制度的实施提供了强有力的技术支持,无需工作人员反复进行身份证与持证人的目视比对,提高工作效率。 [0007] 进一步地,本发明特别针对高度压缩的小照片,例如存储在身份证的RFID中的身份证照片,以及人脸眼睛之间的距离大约为20个像素的身份证照片。 [0008] 因此,身份证可以是第二代中国身份证,读卡器可以是身份证读卡器。当然,身份证可以是任何一种现有的带有记忆身份证照片的身份证,尤其是当记忆身份证照片的眼睛间距为15-25像素时。
但是,照片像素的大小不构成对本实用新型保护范围的限制。不能理解为本实用新型只能应用于小像素照片的识别。应当理解,本实用新型的新模型仍然可以获得更高的识别率。之所以能在小像素照片的情况下保持高识别率是因为本实用新型结合了整体(PCA)识别方法和局部(LBP)识别方法,通过局部特征的优化来实现判断单元和整体特征判断单元。 [0009] 进一步地,数据分析子系统在人脸验证模块之前还包括人脸检测模块,人脸检测模块用于提取人脸特征。人脸检测模块是基于肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点的检测模块。数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。人脸检测模块和图像处理模块可以有效提高识别效率和识别成功率。 [0010] 进一步地,在硬件连接中,数据分析子系统设置在上位机中,摄像头设备连接上位机,阅读器连接上位机上以串口方式连接。 [0011] 进一步地,该系统还包括存储子系统和监控管理子系统。存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问组成,识别结果存储库由监控管理子系统访问。
监控管理子系统通过查询访问识别结果存储库。 采集子系统的信息为采集人脸信息,来自摄像头的视频图像。 [0012] 上述人脸模板训练库用于保证识别过程中人脸数据的调用。人脸模板训练库收录原创人脸图像和从原创图像训练中提取的面部特征。识别结果数据库用于记录识别卡中存储的其他数据和其他信息,如人的身份证、姓名、照片、刷卡时间、是否可以识别为人等。保存为 JEPG 或 PNG 文件信息,特别是如果系统用于门禁识别管理,可以将识别结果存储为门禁记录。该系统还包括一个监控和管理子系统。通过监控管理子系统访问识别结果存储库,可以查询不同的信息。可以查询特定用户ID对应的所有识别信息,根据记录内容查看所有识别系统记录。 [0013] 进一步地,信息采集子系统用于从视频文件中获取采集person人脸信息,便于在保密监控的情况下以秘密监控方式识别采集。
[0014]图I为本实用新型的硬件连接图; [0015]图2为本实用新型内部模块连接图。
具体实现方法
[0016]下面结合说明书附图1-2对本实用新型的实施例进行说明。 [0017] 如图所示。如图1所示,本发明的硬件包括摄像装置1、身份证2和阅读器3;身份证2与阅读器3匹配,身份证2中收录用于存放证件的证件。摄像设备I采集的人脸信息和阅读器3采集的身份证照片被输入到数据分析子系统4中。数据分析子系统4设置在主机内,摄像装置1与主机相连,阅读器3与主机的串口相连。 [0018] 整个实用新型的控制部分包括输入数据分析子系统4、存储子系统5和监控管理子系统6。 [0019]输入数据分析子系统4用于对输入数据进行分析识别,包括图像处理模块41、人脸检测模块42和人脸验证模块43。图像处理模块41用于图像灰度转换、图像归一化和光均衡处理。人脸检测模块42根据肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点。人脸验证模块43由依次连接的局部特征判断单元43a和整体特征判断单元43b组成。局部特征判断单元43a用于在局部特征上将采集的人脸信息与身份证照片进行比对,整体特征判断单元43b用于将采集的人脸信息与身份证照片信息进行比对在整体特征上;当局部特征判断单元43a和整体特征判断单元43b都一致时,系统输出与照片匹配的人脸和ID识别结果。
[0020] 存储子系统5包括人脸模板训练库51和识别结果存储库52。人脸模板训练库51由局部特征判断单元43a和整体特征判断单元43b访问。识别结果存储库52由监控管理子系统6访问。 [0021]监控管理子系统6通过查询访问识别结果存储库52。 [0022] 本实用新型可以将现场拍摄的人脸转换成灰度图像,并进行归一化和光均衡处理;人脸检测使用RFID数据处理后的图像作为肤色检测,使用Adaboost算法剔除不必要的训练数据,并将重点放在重要的训练数据上;人脸验证使用基于二进制模式(LBP)的方法来提取人脸特征,然后使用基于特征的人脸(PCA)方法来实现人脸识别,最终达到二代身份证明自动人脸识别的效果RFID 照片和现场快照。 [0023] 在一个具体应用于考生身份识别的实施例中,整个系统包括三部分:摄像头、身份证和RFID阅读器。其中摄像头用于视频图像的采集,将视频流数据发送到数据处理计算机;身份证收录持有人姓名、照片等身份信息,身份证在RFID读写器的读取范围内。在内部,收录的数据被发送到 RFID 阅读器; RFID阅读器通过串口与计算机相连,当接收到RFID电子标签中存储的信息时,将信息传送给计算机。
[0024]输入数据分析子系统4是本实用新型的核心部分,涉及RFID识别卡中的信息处理、视频图像中正面位置的检测、人脸的提取特征,以及人脸验证以及各功能模块之间的同步互斥控制。 [0025] 存储子系统5包括人脸模块数据库、访问控制记录数据库和转发服务器。人脸模块数据库收录原创人脸图像和从原创图像训练中提取的人脸特征;门禁记录数据库智能识别系统在RFID卡中记录持卡人身份证、姓名、照片、刷卡时间、是否通过门禁系统等;转发服务器负责监控信息与手机之间的信息传递。负责将拍摄终端的图像数据转发到对应的手机终端。 [0026] 监控管理子系统6和存储子系统5通过数据库连接。系统支持的查询条件包括按时间查询、按ID查询、按记录内容查询。
声明1.一种自动识别照片和人脸识别系统,包括信息采集子系统和数据分析子系统,其特征在于信息采集子系统包括摄像装置、身份证件和读卡器;身份证与读卡器匹配,身份证内含RFID电子标签,用于存储身份证照片;分别输入摄像设备采集人脸信息数据和阅读器采集身份证照片分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。一个人脸识别单元,将人脸信息和身份证照片对局部特征进行比较;整体特征判断单元是根据特征人脸对采集的人脸信息和身份证照片信息人脸识别单元对整体特征进行比较的人。
2.如权利要求1所述的自动识别系统,其特征在于,所述识别卡为第二代中国身份证,所述读卡器为身份证读卡器。
3.如权利要求1所述的自动识别系统,其特征在于,所述身份证存储有两眼距离为15-25像素的证件照片。
4.如权利要求1所述的自动识别系统,其特征在于,所述数据分析子系统在人脸验证模块之前还包括人脸检测模块。
5.根据权利要求4所述的自动识别系统,其中人脸检测模块根据肤色检测确定人脸区域,并通过类Haar特征和Adaboost算法提取人脸特征点检测模块。
6.如权利要求5所述的自动识别系统,其特征在于,所述数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。
7.根据权利要求1至6中任一项所述的自动识别系统,其特征在于,所述数据分析子系统设置在主机中,摄像设备连接到主机,阅读器连接到主机串口方式的计算机。
8.如权利要求1所述的自动识别系统,其特征在于,还包括存储子系统和监控管理子系统,所述存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问,识别结果存储库由监控管理子系统访问。
9.如权利要求8所述的自动识别系统,其特征在于,所述监控管理子系统通过查询访问所述识别结果存储库。
10.根据权利要求1所述的自动识别系统,其中信息采集子系统用于从视频文件中获取采集人脸信息。
专利摘要本实用新型提供了一种身份证照片和人脸自动识别系统。系统包括信息采集子系统和数据分析子系统。数据分析子系统具有人脸验证模块。验证模块由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元将采集的人脸信息与身份证照片进行局部特征对比,整体特征判断单元将采集的人脸信息与身份证照片信息进行整体特征对比。只有当局部特征判断单元和整体特征判断单元都认为人脸与照片匹配时,系统才最终得到人脸与身份证照片匹配的识别结果。本实用新型可有效防止借用或冒用他人证件的行为,免去工作人员反复目视核对证件持有人的麻烦,提高实名制工作效率。
文件编号 G06K7/00GK202815870SQ20122048809
出版日期2013年3月20日申请日期2012年9月20日优先权日期2012年4月28日
发明人程远、王浩、范辉、张勇申请人:王浩
自动采集子系统(易用而且好用的小程序采集工具++)
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-11-03 13:02
自动采集子系统主要实现了图片与视频采集,文本采集,以及用户自定义采集。
开发者有:写代码,bs4.x-webkit_video-adapter.xml,c#,c++(neon最高并发)效率不错;(嵌入式不算)
前言h5微信采集其实是一个toolbox性质的小程序,只是起到了图片采集的作用。这是一套开源的采集代码解析工具,或许我们不需要重写一套代码就可以通过一键轻松采集到小视频、图片等内容,目前提供了fork版本和pro版本供大家使用。如果你也看重了并喜欢上了代码解析的这项技术,可以复制到剪切板。支持小程序、微信公众号、微信小店、小游戏、社区、简书等多平台采集,极大提高了采集效率。js、json、css、canvas等javascript原生格式数据一键复制。
这个我来推荐一款易用而且好用的小程序采集工具imagegirl++可以随时随地采集百度网盘,天猫,腾讯视频,优酷,爱奇艺,youtube等平台的网页视频。节省了你繁琐的操作,去掉了复杂的文件提取工作。请看效果。
豆瓣小电影采集工具:采集到豆瓣电影网页版信息集合!电影信息_豆瓣电影信息采集工具_免费一键采集软件百度云_电影云盘|百度网盘|百度云下载|115云盘|百度硬盘|cmcc|17173|22335家庭宽带|小米云共享上传,简直太棒了, 查看全部
自动采集子系统(易用而且好用的小程序采集工具++)
自动采集子系统主要实现了图片与视频采集,文本采集,以及用户自定义采集。
开发者有:写代码,bs4.x-webkit_video-adapter.xml,c#,c++(neon最高并发)效率不错;(嵌入式不算)
前言h5微信采集其实是一个toolbox性质的小程序,只是起到了图片采集的作用。这是一套开源的采集代码解析工具,或许我们不需要重写一套代码就可以通过一键轻松采集到小视频、图片等内容,目前提供了fork版本和pro版本供大家使用。如果你也看重了并喜欢上了代码解析的这项技术,可以复制到剪切板。支持小程序、微信公众号、微信小店、小游戏、社区、简书等多平台采集,极大提高了采集效率。js、json、css、canvas等javascript原生格式数据一键复制。
这个我来推荐一款易用而且好用的小程序采集工具imagegirl++可以随时随地采集百度网盘,天猫,腾讯视频,优酷,爱奇艺,youtube等平台的网页视频。节省了你繁琐的操作,去掉了复杂的文件提取工作。请看效果。
豆瓣小电影采集工具:采集到豆瓣电影网页版信息集合!电影信息_豆瓣电影信息采集工具_免费一键采集软件百度云_电影云盘|百度网盘|百度云下载|115云盘|百度硬盘|cmcc|17173|22335家庭宽带|小米云共享上传,简直太棒了,
自动采集子系统(3.5APP控件点击事件APP的设置及设置属性分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-10-23 15:08
设置页面的属性和URL信息,SDK会自动将getTrackProperties:的返回值添加到View Controller的APP浏览页面事件中;此外,getScreenUrl: 的返回值将用作页面的 URL Schema。当触发本页面的浏览事件时,会添加预设属性#url,值为当前页面的URL Schema。同时,SDK 会在跳转前获取页面的 URL Schema。如果能获取到就加到预设属性中#referrer为转发地址。
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控制点击事件
APP控件点击事件会在用户点击控件时触发
对于页面上View的点击事件,有几种方法可以设置更多的属性来扩展其解析值:
3.5.1 设置控件元素ID
您可以为页面(视图)上的元素设置元素 ID,以区分具有不同含义的元素。您可以使用以下方法设置元素 ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
此时会在table1的点击事件中添加预设属性#element_id,值为这里传入的值
3.5.2 自定义控件点击事件的属性
对于大多数控件,可以直接使用thinkingAnalyticsViewProperties来设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView 和 UI采集View 控件点击事件属性
对于 UITableView 和 UI采集View,需要通过实现 Protocol 来设置自定义属性:
1.首先在View Controller类中实现Protocol
2.其次,在类中设置代理。建议在viewDidLoad方法中设置。
self.table1.thinkingAnalyticsDelegate = self;
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4.最后在类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP有未捕获的异常时,会上报APP崩溃事件
四、忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1 忽略页面的自动采集事件
对于某些页面(View Controller),如果不想传递自动采集事件(包括页面浏览和控件点击事件),可以通过以下方法忽略:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2 忽略某类控件的点击事件
如果需要忽略某类控件的点击事件,可以使用下面的方法忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3 忽略一个元素(View)的点击事件
如果想忽略某个元素(View)的点击事件,可以使用下面的方法忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
五、Auto采集预设事件属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background 查看全部
自动采集子系统(3.5APP控件点击事件APP的设置及设置属性分析)
设置页面的属性和URL信息,SDK会自动将getTrackProperties:的返回值添加到View Controller的APP浏览页面事件中;此外,getScreenUrl: 的返回值将用作页面的 URL Schema。当触发本页面的浏览事件时,会添加预设属性#url,值为当前页面的URL Schema。同时,SDK 会在跳转前获取页面的 URL Schema。如果能获取到就加到预设属性中#referrer为转发地址。
@interface MYController : UITableViewController
@end
@implementation MYController
//对所有APPID实例进行设置
- (NSDictionary *)getTrackProperties {
return @{@"PageName" : @"商品详情页", @"ProductId" : @12345};
}
- (NSString *)getScreenUrl {
return @"APP://test";
/** 多APPID实例单独进行设置
* - (NSDictionary *)getTrackPropertiesWithAppid{
* return @{@"appid1" : @{@"testTrackProperties" : @"测试页"},
* @"appid2" : @{@"testTrackProperties2" : @"测试页2"},
* };
* }
* -(NSDictionary *)getScreenUrlWithAppid {
* return @{@"appid1" : @"APP://test1",
* @"appid2" : @"APP://test2",
* };
* }
*/
}
@end
3.5 APP控制点击事件
APP控件点击事件会在用户点击控件时触发
对于页面上View的点击事件,有几种方法可以设置更多的属性来扩展其解析值:
3.5.1 设置控件元素ID
您可以为页面(视图)上的元素设置元素 ID,以区分具有不同含义的元素。您可以使用以下方法设置元素 ID:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewID = @"testtable1";
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewIDWithAppid = @{ @"app1" : @"testtableID2",
@"app2" : @"testtableID3" };
此时会在table1的点击事件中添加预设属性#element_id,值为这里传入的值
3.5.2 自定义控件点击事件的属性
对于大多数控件,可以直接使用thinkingAnalyticsViewProperties来设置自定义属性:
//对所有APPID实例进行设置
self.table1.thinkingAnalyticsViewProperties = @{@"key1":@"value1"};
// 多APPID实例单独进行设置
// self.table1.thinkingAnalyticsViewPropertiesWithAppid = @{@"app1":@{@"tablekey":@"tablevalue"},
@"app2":@{@"tablekey2":@"tablevalue2"}
};
3.5.3 UITableView 和 UI采集View 控件点击事件属性
对于 UITableView 和 UI采集View,需要通过实现 Protocol 来设置自定义属性:
1.首先在View Controller类中实现Protocol
2.其次,在类中设置代理。建议在viewDidLoad方法中设置。
self.table1.thinkingAnalyticsDelegate = self;
//对所有APPID实例进行设置,设置UITableView的自定义属性
-(NSDictionary *) thinkingAnalytics_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* -(NSDictionary *) thinkingAnalyticsWithAppid_tableView:(UITableView *)tableView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoPro":@"tablevalue"},
* @"app2":@{@"autoPro2":@"tablevalue2"}
* };
* }
*/
//对所有APPID实例进行设置,设置UICollectionView的自定义属性
-(NSDictionary *) thinkingAnalytics_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath;
{
return @{@"testProperty":@"test"};
}
/** 多APPID实例单独进行设置
* - (NSDictionary *)thinkingAnalyticsWithAppid_collectionView:(UICollectionView *)collectionView autoTrackPropertiesAtIndexPath:(NSIndexPath *)indexPath {
* return @{@"app1":@{@"autoProCOLL":@"tablevalueCOLL"},
* @"app2":@{@"autoProCOLL2":@"tablevalueCOLL2"}
* };
* }
*/
4.最后在类的viewWillDisappear方法中将thinkingAnalyticsDelegate设置为nil
-(void)viewWillDisappear:(BOOL)animated
{
[super viewWillDisappear:animated];
self.table1.thinkingAnalyticsDelegate = nil;
}
3.6 APP崩溃事件
当APP有未捕获的异常时,会上报APP崩溃事件
四、忽略自动采集事件
您可以通过以下方式忽略页面或控件的自动采集事件
4.1 忽略页面的自动采集事件
对于某些页面(View Controller),如果不想传递自动采集事件(包括页面浏览和控件点击事件),可以通过以下方法忽略:
NSMutableArray *array = [[NSMutableArray alloc] init];
[array addObject:@"IgnoredViewController"];
// 多APPID实例时对单个APPID实例设置,忽略某个页面的自动采集事件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreAutoTrackViewControllers:array];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreAutoTrackViewControllers:array];
4.2 忽略某类控件的点击事件
如果需要忽略某类控件的点击事件,可以使用下面的方法忽略
// 多APPID实例时对单个APPID实例设置,忽略某个类型的所有控件
[[ThinkingAnalyticsSDK sharedInstanceWithAppid:APP_ID] ignoreViewType:[IgnoredClass class]];
// 单APPID实例时可调用
// [[ThinkingAnalyticsSDK sharedInstance] ignoreViewType:[IgnoredClass class]];
4.3 忽略一个元素(View)的点击事件
如果想忽略某个元素(View)的点击事件,可以使用下面的方法忽略
// 对所有APPID实例进行设置
self.table1.thinkingAnalyticsIgnoreView = YES;
// 多APPID实例单独进行设置
// self.table2.thinkingAnalyticsIgnoreViewWithAppid = @{@"appid1" : @YES,@"appid2" : @NO};
五、Auto采集预设事件属性
以下预设属性是每个自动采集事件中唯一的预设属性
属性名称中文名称说明
#resume_from_background
自动采集子系统(2020年6月,微软公布WindowsSubsystemforLinux2的最新更新 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2021-10-23 07:05
)
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
我买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL。2、Ubuntu系统和NVIDIA Driver,在Ubuntu子系统中成功运行深度学习代码Windows,GPU资源都满了!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软将WSL 2变成稳定版后,我们只需要输入以下命令即可设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须4.19.121 或更高。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查 Windows 升级设置中是否打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
查看全部
自动采集子系统(2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
)
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
我买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL。2、Ubuntu系统和NVIDIA Driver,在Ubuntu子系统中成功运行深度学习代码Windows,GPU资源都满了!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软将WSL 2变成稳定版后,我们只需要输入以下命令即可设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须4.19.121 或更高。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查 Windows 升级设置中是否打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
自动采集子系统(Web数据自动采集与挖掘是一种特殊的数据挖掘到目前为止还没有)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-16 08:19
1. Web 数据自动化的理论基础采集
Web可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何在互联网上进一步获取一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动化采集具有广泛的内涵和外延,目前还没有明确的定义。Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。Web 数据挖掘与这些概念密切相关,但也存在差异。
(1) Web 数据自动采集 和挖掘
Web挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出Web挖掘的定义。所谓Web挖掘,是指在大量非结构化、异构的Web信息中发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化)的非平凡过程。资源。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1。
(2) Web 数据自动 采集 和搜索引擎
Web数据自动化采集与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景等。而Web Data Automation采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web数据自动采集和信息抽取:信息抽取(Information Extraction)是近年来新兴的概念。信息抽取是面向不断增长和变化的,特定领域的文献中的特定查询,这种查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅要收录关键字,还要匹配实体之间的关系。信息提取是一个技术概念,Web Data自动化采集很大程度上依赖于信息提取技术来实现长期动态跟踪。
(3) Web 数据自动 采集 和 Web 信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的可比较数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是一个输入到输出图像:
ξ: (C: q)-->S3
但是Web数据自动采集并没有直接将Web文档集合的一个子集输出给用户,而是需要进一步的分析处理、重复检查和去噪、数据整合。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动化采集是网络数据挖掘的重要组成部分。它利用网络数据检索和信息提取技术,弥补了搜索引擎缺乏针对性和专业性,无法实现数据动态跟踪和监控的缺点,是一个非常有发展前景的领域。
1.2 研究意义
(1) 解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户没有价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的内容,信息利用的效率和效益越来越低。大大减少。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动检索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接按照用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。
(2) 解决搜索引擎智能低的问题
尽管互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出. 此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3) 节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且手工数据不会有遗漏、偏差和错误采集
2. 网络数据自动化采集 应用研究
2.1 应用功能
从上面的讨论可以看出,Web数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点就是基于领域,基于需求。没有有效的 采集 模型可以用于所有领域。Web数据自动化采集的原理是相通的,但具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以监测公众舆论的发展和特定主题的人的地理分布;猎头公司 监控一些公司的招聘网站 获取人才需求的变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
2.2应用产品
Web数据自动化采集Web数据自动化采集是从实际应用的需要中诞生的。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息化需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监测和采集
因此,一些相关的产品和服务已经开始在市场上销售。例如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.网络数据自动采集模型
虽然Web数据自动化采集是针对特定领域的,但是采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型框架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。
3.2 数据预处理模块
数据预处理是数据处理过程中的一个重要环节采集。如果数据预处理工作做好,数据质量高,数据采集的过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。因为数据源的种类很多,各种数据的特征属性可能不能满足主体的需要,所以数据预处理模块的主要功能是在Web上定义数据源、格式化数据源和初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。因此,数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获得网页的结构后,以内容块为单位保留和删除数据。最后,在将获得的数据放入数据库并建立索引之前,必须对其进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。
4.自动化采集基于房地产行业的系统设计
如前所述,Web数据采集必须是领域驱动或数据驱动的,所以本节在第3章的理论基础上,设计一个基于房地产行业的Web自动采集系统.
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多的信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者,还是银行信贷部门,都想知道房地产价格的最新动向。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。甚至房地产信息也具有地域性和时间性。
房产中介经常在一些比较大的楼盘网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据的高效化和自动化采集。
4.2.系统原理
自动化采集系统基于第三节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003。在2000 Professional操作系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析
采集 模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据三部分组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监测计划下网站的新开挖次数和最后一次采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容、采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大时会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在其他服务器空闲时自动运行。例如,您可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新并执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。采集 系统将像 Windows Update 一样自动启动和执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,充分考虑到采集和采集的情况。
4.3. 限制
Web数据自动采集主要完成采集的功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们需要的数据。它只负责采集 数据。至于为什么需要这样做,人们需要考虑一下。
其次,为了保证数据结果采集的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的适用范围越广,采集异常时出现冗余数据的可能性就越大。反之,数据采集模型的精度越高,适用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但是让算法自己做所有这些决定是不明智的。
数据 采集 不会在没有指导的情况下自动发现模型。数据采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化和改进。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web数据自动化采集是一个潜力巨大的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,有进一步融合的趋势。
在实际应用中,Web数据自动采集针对当前互联网信息过载而未被有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有更大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
在知识经济时代,谁能有效地获取和使用知识,谁就有在竞争中获胜的武器和工具。Web数据自动化采集作为获取和利用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地为个人、企业和国家的思维和战略发展服务。 查看全部
自动采集子系统(Web数据自动采集与挖掘是一种特殊的数据挖掘到目前为止还没有)
1. Web 数据自动化的理论基础采集
Web可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何在互联网上进一步获取一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动化采集具有广泛的内涵和外延,目前还没有明确的定义。Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。Web 数据挖掘与这些概念密切相关,但也存在差异。
(1) Web 数据自动采集 和挖掘
Web挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出Web挖掘的定义。所谓Web挖掘,是指在大量非结构化、异构的Web信息中发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化)的非平凡过程。资源。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1。
(2) Web 数据自动 采集 和搜索引擎
Web数据自动化采集与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景等。而Web Data Automation采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web数据自动采集和信息抽取:信息抽取(Information Extraction)是近年来新兴的概念。信息抽取是面向不断增长和变化的,特定领域的文献中的特定查询,这种查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅要收录关键字,还要匹配实体之间的关系。信息提取是一个技术概念,Web Data自动化采集很大程度上依赖于信息提取技术来实现长期动态跟踪。
(3) Web 数据自动 采集 和 Web 信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的可比较数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是一个输入到输出图像:
ξ: (C: q)-->S3
但是Web数据自动采集并没有直接将Web文档集合的一个子集输出给用户,而是需要进一步的分析处理、重复检查和去噪、数据整合。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动化采集是网络数据挖掘的重要组成部分。它利用网络数据检索和信息提取技术,弥补了搜索引擎缺乏针对性和专业性,无法实现数据动态跟踪和监控的缺点,是一个非常有发展前景的领域。
1.2 研究意义
(1) 解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户没有价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的内容,信息利用的效率和效益越来越低。大大减少。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动检索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接按照用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。
(2) 解决搜索引擎智能低的问题
尽管互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出. 此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3) 节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且手工数据不会有遗漏、偏差和错误采集
2. 网络数据自动化采集 应用研究
2.1 应用功能
从上面的讨论可以看出,Web数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点就是基于领域,基于需求。没有有效的 采集 模型可以用于所有领域。Web数据自动化采集的原理是相通的,但具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以监测公众舆论的发展和特定主题的人的地理分布;猎头公司 监控一些公司的招聘网站 获取人才需求的变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
2.2应用产品
Web数据自动化采集Web数据自动化采集是从实际应用的需要中诞生的。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息化需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监测和采集
因此,一些相关的产品和服务已经开始在市场上销售。例如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.网络数据自动采集模型
虽然Web数据自动化采集是针对特定领域的,但是采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型框架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。
3.2 数据预处理模块
数据预处理是数据处理过程中的一个重要环节采集。如果数据预处理工作做好,数据质量高,数据采集的过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。因为数据源的种类很多,各种数据的特征属性可能不能满足主体的需要,所以数据预处理模块的主要功能是在Web上定义数据源、格式化数据源和初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。因此,数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获得网页的结构后,以内容块为单位保留和删除数据。最后,在将获得的数据放入数据库并建立索引之前,必须对其进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。
4.自动化采集基于房地产行业的系统设计
如前所述,Web数据采集必须是领域驱动或数据驱动的,所以本节在第3章的理论基础上,设计一个基于房地产行业的Web自动采集系统.
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多的信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者,还是银行信贷部门,都想知道房地产价格的最新动向。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。甚至房地产信息也具有地域性和时间性。
房产中介经常在一些比较大的楼盘网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据的高效化和自动化采集。
4.2.系统原理
自动化采集系统基于第三节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003。在2000 Professional操作系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析
采集 模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据三部分组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监测计划下网站的新开挖次数和最后一次采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容、采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大时会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在其他服务器空闲时自动运行。例如,您可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新并执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。采集 系统将像 Windows Update 一样自动启动和执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,充分考虑到采集和采集的情况。
4.3. 限制
Web数据自动采集主要完成采集的功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们需要的数据。它只负责采集 数据。至于为什么需要这样做,人们需要考虑一下。
其次,为了保证数据结果采集的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的适用范围越广,采集异常时出现冗余数据的可能性就越大。反之,数据采集模型的精度越高,适用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但是让算法自己做所有这些决定是不明智的。
数据 采集 不会在没有指导的情况下自动发现模型。数据采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化和改进。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web数据自动化采集是一个潜力巨大的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,有进一步融合的趋势。
在实际应用中,Web数据自动采集针对当前互联网信息过载而未被有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有更大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
在知识经济时代,谁能有效地获取和使用知识,谁就有在竞争中获胜的武器和工具。Web数据自动化采集作为获取和利用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地为个人、企业和国家的思维和战略发展服务。
自动采集子系统( 辅助网编系统地批量地快速地发现有新闻价值的实时信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-10-10 18:15
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统是基于世界领先的采集技术开发的,可以每天批量辅助网络编辑系统快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别等),从而率先发现具有新闻价值的信息,并提供一套具有后续编辑审核功能的网络编辑工作平台。
其系统架构如下图所示: Lesisoft
图1.乐思网新闻转载系统的系统架构
与目前的人工新闻转载相比,其优势十分明显:
比较索引
采用乐思网络新闻转载系统
手动转载
目标网站
数百到数千甚至数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴。
新闻线索识别
基于自动判别的人工确认
需人工一一核对确认
信息保存
准确、全面、易于事后跟踪
碎片化,难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可每日、每周、每月发布报告
模糊,不清楚,没有统计数据:Lesisoft
转载效果
系统转发,大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1. 重大新闻网站、平面媒体、论坛、博客、微博、视频网站的最新信息自动集中呈现
2. 系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2. 系统组成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3. 网络拓扑
四、 自动 采集 子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如BBC、CNN等。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、 MS SQL Server、MySQL、Sybase、文件数据库Access等。乐思软件
自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1. 全球领先的自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表格查询新闻转载 查看全部
自动采集子系统(
辅助网编系统地批量地快速地发现有新闻价值的实时信息)
乐思网新闻转载系统
乐思网络新闻转载系统是基于世界领先的采集技术开发的,可以每天批量辅助网络编辑系统快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别等),从而率先发现具有新闻价值的信息,并提供一套具有后续编辑审核功能的网络编辑工作平台。
其系统架构如下图所示: Lesisoft
图1.乐思网新闻转载系统的系统架构
与目前的人工新闻转载相比,其优势十分明显:
比较索引
采用乐思网络新闻转载系统
手动转载
目标网站
数百到数千甚至数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴。
新闻线索识别
基于自动判别的人工确认
需人工一一核对确认
信息保存
准确、全面、易于事后跟踪
碎片化,难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可每日、每周、每月发布报告
模糊,不清楚,没有统计数据:Lesisoft
转载效果
系统转发,大量合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1. 重大新闻网站、平面媒体、论坛、博客、微博、视频网站的最新信息自动集中呈现
2. 系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入到深度编辑或原创乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2. 系统组成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3. 网络拓扑
四、 自动 采集 子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如BBC、CNN等。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、 MS SQL Server、MySQL、Sybase、文件数据库Access等。乐思软件
自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1. 全球领先的自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表格查询新闻转载
自动采集子系统(乐思网络舆情监测系统的网络拓扑结构图所示与分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 202 次浏览 • 2021-10-01 23:09
系统组成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集层)和分析浏览子系统(分析层和呈现层)。
乐思网络舆情监测系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
自动采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西磁社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如Facebook、Twitter、BBC、CNN等。
自动采集 子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
自动采集子系统的全方位监控功能如下图所示:
自动 采集 子系统具有以下显着特点:
1. 全球领先的全自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报刊电子版等实时监控。
3. 无需配置直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能 26 禁止 9 盗用 0
可自动处理和保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
自动采集子系统(乐思网络舆情监测系统的网络拓扑结构图所示与分析)
系统组成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集层)和分析浏览子系统(分析层和呈现层)。
乐思网络舆情监测系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
自动采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西磁社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局监控网站,或者进行两者的混合监控。可监控国内网站和海外网站如Facebook、Twitter、BBC、CNN等。
自动采集 子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
自动采集子系统的全方位监控功能如下图所示:
自动 采集 子系统具有以下显着特点:
1. 全球领先的全自动采集功能
Lesisoft的网络信息采集技术全球领先,支持任何网页采集中任何数据的准确性。乐思软件每天为国内外用户提供各种采集服务。没有一个高效稳定的采集平台是做不到的。
2. 支持各种监控对象
微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报刊电子版等实时监控。
3. 无需配置直接监听上千条新闻网站
系统内置网站全球监控配置,只需输入关键词,自动采集输出文章标题和文字。
4. 强大的多语言统一处理功能 26 禁止 9 盗用 0
可自动处理和保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5. 智能文章 提取
对于文章类型的网页,无需配置即可直接提取文章正文和标题,以及作者发布日期等,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网页情况
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
自动采集子系统(本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2021-09-29 10:11
关于作者:
邱云飞,辽宁工业大学,博士,副教授。
邵良山,辽宁工业大学,博士,教授。
摘要:本文研究了应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论和方法,提出了一个用于合作伙伴选择的中文Web信息获取系统的总体架构,并分析了实现基于系统的网络信息获取系统的关键技术。元搜索网页采集、基于样本公共特征的企业主页过滤、基于模式的企业信息抽取,并详细介绍了这三项关键技术。最后,根据作者提出的思路,通过编程实现了一个用于合作伙伴选择的中文Web信息获取原型系统,并通过系统验证了作者提出的方法的可行性并证明了该方法的准确性。
关键词:合作伙伴;网络挖掘;元搜索;文本过滤;信息抽取
1.简介
虚拟企业主要是针对企业核心能力资源的整合,即投资和管理的重点是企业自身的核心能力,以及一些非核心能力,或者他们不具备的核心能力。在短时间内拥有或不需要。转向依赖外部虚拟业务合作伙伴提供。因此,虚拟企业中合作伙伴的选择是一个非常重要的问题,直接关系到虚拟企业的成败。
WWW推出后,互联网成为全球最大的信息来源,其多样化的信息方式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的物质积累。另一方面,正是由于互联网海量、动态、非结构化、异构和地域分布的特点,传统的研究方法已经不能满足网络环境中信息获取、处理和利用的需要。
本文构建了一个用于合作伙伴选择的网络信息获取系统的总体框架,给出了系统的实现过程,并自动提取了与企业相关的信息(如企业名称、企业规模、生产能力、联系方式等)。对Internet信息搜索、文本过滤、信息抽取等相关技术所涉及的理论和方法进行了分析,最终实现了一个用于合作伙伴选择的中文Web信息获取原型系统。
2.合作伙伴选择的网络信息获取系统总体框架
2.1 系统需求分析
本系统从虚拟企业合作伙伴选择的角度构建了一个面向网络的潜在合作伙伴信息获取系统。主要功能是从互联网上自动获取可能成为核心企业合作伙伴的基本信息,从而为核心企业提供强大的潜力合作伙伴信息数据库,为其后期的合作伙伴选择奠定良好的基础。
根据调查分析,潜在合作伙伴的基本信息一般分布在一些综合性网站、行业网站、业务网站(类似B2B网站等)。 ), 企业网站向上。一家公司在这些网站上提供的信息基本相同,但与网站提供的其他公司相关信息相比,公司自己的网站提供的信息更加全面和权威性。对于整个企业网站,企业的一般介绍一般都在企业主页上,所以企业主页上的信息是本系统需要获取的主要对象。
2.2 系统整体框架
基于以上分析,设计系统的整体架构如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、网页文本库、企业主页库、潜在合作伙伴信息库七部分组成。
图1 合作伙伴选择Web信息获取系统整体架构
其中,网页采集子系统根据关键字从互联网上搜索网页,并将搜索到的网页下载到本地网络文本库;文本过滤子系统对网络文本库的网页进行文本过滤,主要目的是筛选出收录潜在合作伙伴信息的公司主页,最后保存在公司主页库中;信息提取子系统从公司主页库的各个网页中提取信息,主要目的是提取潜在合作伙伴公司的基本信息,最后保存到潜在合作伙伴信息数据库;
3.合作伙伴选择的Web信息获取系统设计
3.1 系统实现思路
从系统的整体框架和各个模块的描述可以看出,为了实现整个系统,网页采集子系统、文本过滤子系统、文本过滤子系统三部分的设计与实现信息抽取子系统是整个系统实现的重点和难点。也可以说是系统实现的关键技术。针对三个子系统的特点,提出了基于元搜索采集的自动网页、基于样本公共特征的企业主页过滤、基于模式的企业主页信息提取三种方法,并完成了相应的技术.
3.2 基于元搜索的网页自动子系统设计采集
元搜索引擎(MetasearchEngine)被称为搜索引擎之上的搜索引擎。用户只需提交一次搜索请求,由元搜索引擎负责转换过程,然后提交给多个预先选定的独立搜索引擎,将所有查询结果汇总并以统一格式呈现给用户. 相对于元搜索引擎,可以使用的独立搜索引擎被称为“sourceEngines”或“搜索资源”。
本系统利用元搜索引擎将关键词提交给现有的搜索引擎进行搜索,然后将搜索到的网页自动下载到本地,这是整个系统实现的第一步。具体系统结构如下图2所示。该子系统由三部分组成:会员搜索和调用模块、结果页面分析模块和网页下载模块。
网页采集流程如下:
1) 首先将关键词提交给各会员搜索引擎(如google、百度等),该会员搜索引擎根据系统提供的关键词进行搜索,并返回相应的结果[1,2]。
2) 接下来分析各个成员搜索引擎返回的搜索结果页面。首先获取搜索结果页面的源代码,然后在源代码中提取每个搜索结果连接的URL。提取URL,发送到网页下载模块进行网页下载。该模块的关键技术之一是在源代码中提取与每个搜索结果相关联的URL技术。
3) 由于一般搜索引擎的每个搜索结果页面只收录一定数量的搜索结果(谷歌和百度10条),通常不能满足信息采集模块采集对于一个大量网页,因此需要转到下一个搜索结果页面。然后从下一个搜索结果页面中提取与搜索结果相关联的网址,发送到网页下载模块下载该网页。
4) 判断是否满足用户要求的网页数量,如果不满足,继续3);如果遇到,停止。
图2网页采集子系统结构及流程
3.3 基于样本公共特征的企业首页过滤子系统设计
由于文本采集模块的限制,即使是关键字搜索也不能保证网络文本库中的所有页面都收录潜在合作公司的基本信息。因此,有必要对网页文本库中的网页进行过滤,筛选出符合用户意图的网页。其架构如下图 3 所示。该子系统由三部分组成:成员文本分析模块、样本分析模块和特征匹配模块。
文本过滤的过程如下:用户首先选择几个符合要求的文本作为样本,然后提取样本的共同特征,利用样本的共同特征匹配每个文本的文本特征,计算匹配值,并使用匹配值的大小来判断文本是否满足用户需求。用户可以根据过滤后的结果考虑换样,也可以根据用户需求的变化换样,以达到反馈给系统的目的。
1)首先,用户在网络文本库中选择几个符合用户意图的网页作为样本(一般为2-5个),将这些样本提交给样本分析模块,样本分析模块提取样本的共同特征[3]。
2) 文本分析模块对网络文本库中的所有网页进行特征提取[4]。
3)利用样本的共性特征匹配各个网页的特征,计算相关性,通过相关性与用户设置的阈值的比较来判断文本是否满足需求用户。
图3 企业主页过滤子系统的结构和流程
3.4 基于模式的企业主页信息抽取子系统设计
经过前面的网页采集模块和文本过滤模块的工作,收录潜在合作伙伴公司信息的网页已经保存在公司主页数据库中。本文结合企业主页上企业信息的分布和构成特点,设计了企业基本信息的抽取模式,最终实现了企业主页上企业基本信息的抽取。系统结构如下图4所示。该子系统由成员文本内容抽取模块、抽取规则定义模块、企业信息抽取模块三部分组成。
图4 信息抽取子系统整体结构及流程
提取企业主页信息的过程如下:
1) 从企业文本库中提取网页文本,发送至文本内容提取模块。
2) 文本内容提取模块获取企业文本库提供的网页文本源代码,去除HTML标签等处理,将最终的文本内容提交给企业信息提取模块。
3)抽取规则定义模块根据公司首页的特征等背景领域知识定义抽取规则,并将定义的抽取规则提交给企业信息抽取模块。本文主要定义了公司名称、规模、生产能力和质量认证等几种提取模式,模式定义方法可参见文献[5,6]
4)企业信息抽取模块根据抽取规则定义模块提交的抽取规则,从文本内容抽取模块发送的文本内容中抽取信息,并将最终抽取结果提交给候选合作伙伴数据库[7, 8]。
4. 用于合作伙伴选择的网络信息获取原型系统的实现
4.1系统概述
为了验证本文提出的思路,为核心企业提供一个真正的WEB信息采集软件,可以在合作伙伴选择过程中使用,笔者使用MicrosoftVisualStudio.NET2003和Access2000在Windows平台上开发了一个虚拟企业2000服务器。合作方选定的中文网页信息采集原型系统。该系统在一定程度上可以帮助核心企业从大量网络信息资料中获取潜在合作伙伴的企业相关信息,对下一步合作伙伴的选择起到了很好的支持作用。
4.2网页自动采集子系统的实现
自动网页采集子系统主要包括三个模块:调用会员搜索引擎、从搜索结果中提取超链接、自动下载网页。
搜索引擎调用模块调用成员搜索引擎时,原则上应该调用多个成员搜索引擎,但由于时间限制,我们只在原型系统中实现了对百度搜索引擎的调用,对其他成员的调用搜索引擎的方法类似于调用百度。
由于百度不提供免费接口,所以在连接搜索引擎时,使用下图代码连接百度。编程语言是c#。
字符串pn, wd, cc;
pn="0"; wd=System.Web.HttpUtility.UrlEncode(this.textBox2.Text, System.Text.Encoding.GetEncoding("GB2312"));
cc=";si=&rn=10&ie=gb2312&ct=0&wd="+wd+"&pn="+pn+"&cl=3";
其中,pn代表搜索引擎返回结果的页码;wd 表示搜索关键字的编码;System.Web.HttpUtility.UrlEncode()函数的作用是将中文关键字转换成相应的编码。变量cc代表连接百度的接口的URL。通过这个网址,可以得到百度在执行关键词查询后返回的页面。
在百度返回的查询页面中,除了关于查询关键词的超链接外,还有一系列与关键词无关的链接,比如脚本语言指向的超链接,百度快照链接,以及广告链接。因此,搜索结果超链接提取模块通过对查询返回页面的仔细分析,提出了一种提取查询返回结果URL的有效方法。该方法包括GetPageSource(stringurl)和GetHyperLinks(stringhttpcode)两个函数,其中GetPageSource(stringurl)用于获取网页的html源代码,GetHyperLinks(stringhttpcode)用于获取网页返回结果中的超链接URL询问。
最后,函数downloadpage(stringurl,stringpath)被设计用来下载URL对应的页面并保存到web文本库中。成为下一次文本过滤工作的文本源。
4.3 企业首页过滤子系统的实现
企业主页过滤子系统涉及一些网页文本分析技术,包括获取网页源代码、去除HTML标签、去除非中文字符、中文分词、去除停用词、词频统计、特征提取等操作。获取网页源代码,去除HTML标签,去除非中文字符实际上是在处理HTML文本文件,所以最简单的方法就是去除所有HTML标签,剩下的内容作为纯文本处理。
对于中文分词,我们使用CSW中文分词组件5.0,提供c#接口调用。首先运行该组件包中的install.bat文件,在系统中注册该组件。然后在开发工具中引用CSW.dll组件,以下是在C#控制台应用中调用该组件的示例代码。
CSWLib.SplitWordClasscsw=newCSWLib.SplitWordClass();
stringtext=csw.Split("要拆分的原创文本", 0, @"c:\winnt\system");
这里我们使用的是免费的CSW中文分词组件5.0共享版。此版本只有中文分词功能,没有词频统计功能。因此,我们需要自己完成词频统计的过程。为了方便日后提取网页特征,我们将中文分词和词频统计的结果保存到access数据库的wordcount表中。
4.4 信息抽取子系统的实现
在原型系统中,基于对公司主页信息特征的分析,结合正则表达式字符串匹配技术构建了公司主页信息抽取模型,实现了公司名称、成立年份、公司区域、资产信息、人员信息和生产能力。、质量认证等信息抽取。
5.结论
利用从互联网上自动获取企业信息来支持虚拟企业合作伙伴选择活动的研究还处于起步阶段,还有很多问题需要深入探讨。本研究基于实验。由于条件有限,实验规模小,得出的结论具有一定的局限性。此外,虚拟企业合作伙伴选择过程中的信息需求多样复杂,需要进一步研究,进一步明确合作伙伴选择过程中的信息需求。进一步研究主要有以下思路:
1) 进一步研究合作伙伴选择过程中的网页信息需求,使信息提取不仅限于提取企业主页,还可以收录其他可以收录企业相关信息的网页,例如行业< @网站、业务网站等等。
2) 本文实现的企业主页过滤效果结合基于样本共同特征的文本过滤方法仍有一定的局限性,需要探索更合适的企业主页过滤方法。
参考
[1] 李晓明、闫鸿飞、王继民,《搜索引擎——原理、技术与系统》,科学出版社,2005。
[2]JohnD.TheAnatomyofLarge-ScaleHypertertextualWebSearchEngine[C].In:Procofthe7thInt'1worldwidewebconf.Brishane.Austrilian,1999.
[3] 刘明基,等。Web文本信息特征获取算法[J]. 小型微机系统,2002,23(6):684-687
[4]秦晋,等。文本分类中的特征提取[J]. 计算机应用, 2003,23(2):45-46.
[5]VoertA.AutomaticExtractionofInformationBlocksUsingPATTrees[C].Proc.oftheNationalComputerSymposium,Taipei,Taiwan,1999(6):223-226.
[6]张炳奇,等。企业相关信息抽取技术研究与系统实现[J]. 微电子与计算机, 2004, 21(1):1-6.
[7] 袁占庭,等。数据提取与语义分析在Web数据挖掘中的应用[J].计算机工程与设计,
[8] 陈展荣,等。网络中文资料的智能提取与词汇切分[J]. 计算机工程与设计, 2005, 26 (6):1422-1424.
本文受国家自然科学基金项目(70971059),辽宁省创新团队项目(2006T076,2008T090,2009T045))资助。 查看全部
自动采集子系统(本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与方法)
关于作者:
邱云飞,辽宁工业大学,博士,副教授。
邵良山,辽宁工业大学,博士,教授。
摘要:本文研究了应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论和方法,提出了一个用于合作伙伴选择的中文Web信息获取系统的总体架构,并分析了实现基于系统的网络信息获取系统的关键技术。元搜索网页采集、基于样本公共特征的企业主页过滤、基于模式的企业信息抽取,并详细介绍了这三项关键技术。最后,根据作者提出的思路,通过编程实现了一个用于合作伙伴选择的中文Web信息获取原型系统,并通过系统验证了作者提出的方法的可行性并证明了该方法的准确性。
关键词:合作伙伴;网络挖掘;元搜索;文本过滤;信息抽取
1.简介
虚拟企业主要是针对企业核心能力资源的整合,即投资和管理的重点是企业自身的核心能力,以及一些非核心能力,或者他们不具备的核心能力。在短时间内拥有或不需要。转向依赖外部虚拟业务合作伙伴提供。因此,虚拟企业中合作伙伴的选择是一个非常重要的问题,直接关系到虚拟企业的成败。
WWW推出后,互联网成为全球最大的信息来源,其多样化的信息方式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的物质积累。另一方面,正是由于互联网海量、动态、非结构化、异构和地域分布的特点,传统的研究方法已经不能满足网络环境中信息获取、处理和利用的需要。
本文构建了一个用于合作伙伴选择的网络信息获取系统的总体框架,给出了系统的实现过程,并自动提取了与企业相关的信息(如企业名称、企业规模、生产能力、联系方式等)。对Internet信息搜索、文本过滤、信息抽取等相关技术所涉及的理论和方法进行了分析,最终实现了一个用于合作伙伴选择的中文Web信息获取原型系统。
2.合作伙伴选择的网络信息获取系统总体框架
2.1 系统需求分析
本系统从虚拟企业合作伙伴选择的角度构建了一个面向网络的潜在合作伙伴信息获取系统。主要功能是从互联网上自动获取可能成为核心企业合作伙伴的基本信息,从而为核心企业提供强大的潜力合作伙伴信息数据库,为其后期的合作伙伴选择奠定良好的基础。
根据调查分析,潜在合作伙伴的基本信息一般分布在一些综合性网站、行业网站、业务网站(类似B2B网站等)。 ), 企业网站向上。一家公司在这些网站上提供的信息基本相同,但与网站提供的其他公司相关信息相比,公司自己的网站提供的信息更加全面和权威性。对于整个企业网站,企业的一般介绍一般都在企业主页上,所以企业主页上的信息是本系统需要获取的主要对象。
2.2 系统整体框架
基于以上分析,设计系统的整体架构如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、网页文本库、企业主页库、潜在合作伙伴信息库七部分组成。
图1 合作伙伴选择Web信息获取系统整体架构
其中,网页采集子系统根据关键字从互联网上搜索网页,并将搜索到的网页下载到本地网络文本库;文本过滤子系统对网络文本库的网页进行文本过滤,主要目的是筛选出收录潜在合作伙伴信息的公司主页,最后保存在公司主页库中;信息提取子系统从公司主页库的各个网页中提取信息,主要目的是提取潜在合作伙伴公司的基本信息,最后保存到潜在合作伙伴信息数据库;
3.合作伙伴选择的Web信息获取系统设计
3.1 系统实现思路
从系统的整体框架和各个模块的描述可以看出,为了实现整个系统,网页采集子系统、文本过滤子系统、文本过滤子系统三部分的设计与实现信息抽取子系统是整个系统实现的重点和难点。也可以说是系统实现的关键技术。针对三个子系统的特点,提出了基于元搜索采集的自动网页、基于样本公共特征的企业主页过滤、基于模式的企业主页信息提取三种方法,并完成了相应的技术.
3.2 基于元搜索的网页自动子系统设计采集
元搜索引擎(MetasearchEngine)被称为搜索引擎之上的搜索引擎。用户只需提交一次搜索请求,由元搜索引擎负责转换过程,然后提交给多个预先选定的独立搜索引擎,将所有查询结果汇总并以统一格式呈现给用户. 相对于元搜索引擎,可以使用的独立搜索引擎被称为“sourceEngines”或“搜索资源”。
本系统利用元搜索引擎将关键词提交给现有的搜索引擎进行搜索,然后将搜索到的网页自动下载到本地,这是整个系统实现的第一步。具体系统结构如下图2所示。该子系统由三部分组成:会员搜索和调用模块、结果页面分析模块和网页下载模块。
网页采集流程如下:
1) 首先将关键词提交给各会员搜索引擎(如google、百度等),该会员搜索引擎根据系统提供的关键词进行搜索,并返回相应的结果[1,2]。
2) 接下来分析各个成员搜索引擎返回的搜索结果页面。首先获取搜索结果页面的源代码,然后在源代码中提取每个搜索结果连接的URL。提取URL,发送到网页下载模块进行网页下载。该模块的关键技术之一是在源代码中提取与每个搜索结果相关联的URL技术。
3) 由于一般搜索引擎的每个搜索结果页面只收录一定数量的搜索结果(谷歌和百度10条),通常不能满足信息采集模块采集对于一个大量网页,因此需要转到下一个搜索结果页面。然后从下一个搜索结果页面中提取与搜索结果相关联的网址,发送到网页下载模块下载该网页。
4) 判断是否满足用户要求的网页数量,如果不满足,继续3);如果遇到,停止。
图2网页采集子系统结构及流程
3.3 基于样本公共特征的企业首页过滤子系统设计
由于文本采集模块的限制,即使是关键字搜索也不能保证网络文本库中的所有页面都收录潜在合作公司的基本信息。因此,有必要对网页文本库中的网页进行过滤,筛选出符合用户意图的网页。其架构如下图 3 所示。该子系统由三部分组成:成员文本分析模块、样本分析模块和特征匹配模块。
文本过滤的过程如下:用户首先选择几个符合要求的文本作为样本,然后提取样本的共同特征,利用样本的共同特征匹配每个文本的文本特征,计算匹配值,并使用匹配值的大小来判断文本是否满足用户需求。用户可以根据过滤后的结果考虑换样,也可以根据用户需求的变化换样,以达到反馈给系统的目的。
1)首先,用户在网络文本库中选择几个符合用户意图的网页作为样本(一般为2-5个),将这些样本提交给样本分析模块,样本分析模块提取样本的共同特征[3]。
2) 文本分析模块对网络文本库中的所有网页进行特征提取[4]。
3)利用样本的共性特征匹配各个网页的特征,计算相关性,通过相关性与用户设置的阈值的比较来判断文本是否满足需求用户。
图3 企业主页过滤子系统的结构和流程
3.4 基于模式的企业主页信息抽取子系统设计
经过前面的网页采集模块和文本过滤模块的工作,收录潜在合作伙伴公司信息的网页已经保存在公司主页数据库中。本文结合企业主页上企业信息的分布和构成特点,设计了企业基本信息的抽取模式,最终实现了企业主页上企业基本信息的抽取。系统结构如下图4所示。该子系统由成员文本内容抽取模块、抽取规则定义模块、企业信息抽取模块三部分组成。
图4 信息抽取子系统整体结构及流程
提取企业主页信息的过程如下:
1) 从企业文本库中提取网页文本,发送至文本内容提取模块。
2) 文本内容提取模块获取企业文本库提供的网页文本源代码,去除HTML标签等处理,将最终的文本内容提交给企业信息提取模块。
3)抽取规则定义模块根据公司首页的特征等背景领域知识定义抽取规则,并将定义的抽取规则提交给企业信息抽取模块。本文主要定义了公司名称、规模、生产能力和质量认证等几种提取模式,模式定义方法可参见文献[5,6]
4)企业信息抽取模块根据抽取规则定义模块提交的抽取规则,从文本内容抽取模块发送的文本内容中抽取信息,并将最终抽取结果提交给候选合作伙伴数据库[7, 8]。
4. 用于合作伙伴选择的网络信息获取原型系统的实现
4.1系统概述
为了验证本文提出的思路,为核心企业提供一个真正的WEB信息采集软件,可以在合作伙伴选择过程中使用,笔者使用MicrosoftVisualStudio.NET2003和Access2000在Windows平台上开发了一个虚拟企业2000服务器。合作方选定的中文网页信息采集原型系统。该系统在一定程度上可以帮助核心企业从大量网络信息资料中获取潜在合作伙伴的企业相关信息,对下一步合作伙伴的选择起到了很好的支持作用。
4.2网页自动采集子系统的实现
自动网页采集子系统主要包括三个模块:调用会员搜索引擎、从搜索结果中提取超链接、自动下载网页。
搜索引擎调用模块调用成员搜索引擎时,原则上应该调用多个成员搜索引擎,但由于时间限制,我们只在原型系统中实现了对百度搜索引擎的调用,对其他成员的调用搜索引擎的方法类似于调用百度。
由于百度不提供免费接口,所以在连接搜索引擎时,使用下图代码连接百度。编程语言是c#。
字符串pn, wd, cc;
pn="0"; wd=System.Web.HttpUtility.UrlEncode(this.textBox2.Text, System.Text.Encoding.GetEncoding("GB2312"));
cc=";si=&rn=10&ie=gb2312&ct=0&wd="+wd+"&pn="+pn+"&cl=3";
其中,pn代表搜索引擎返回结果的页码;wd 表示搜索关键字的编码;System.Web.HttpUtility.UrlEncode()函数的作用是将中文关键字转换成相应的编码。变量cc代表连接百度的接口的URL。通过这个网址,可以得到百度在执行关键词查询后返回的页面。
在百度返回的查询页面中,除了关于查询关键词的超链接外,还有一系列与关键词无关的链接,比如脚本语言指向的超链接,百度快照链接,以及广告链接。因此,搜索结果超链接提取模块通过对查询返回页面的仔细分析,提出了一种提取查询返回结果URL的有效方法。该方法包括GetPageSource(stringurl)和GetHyperLinks(stringhttpcode)两个函数,其中GetPageSource(stringurl)用于获取网页的html源代码,GetHyperLinks(stringhttpcode)用于获取网页返回结果中的超链接URL询问。
最后,函数downloadpage(stringurl,stringpath)被设计用来下载URL对应的页面并保存到web文本库中。成为下一次文本过滤工作的文本源。
4.3 企业首页过滤子系统的实现
企业主页过滤子系统涉及一些网页文本分析技术,包括获取网页源代码、去除HTML标签、去除非中文字符、中文分词、去除停用词、词频统计、特征提取等操作。获取网页源代码,去除HTML标签,去除非中文字符实际上是在处理HTML文本文件,所以最简单的方法就是去除所有HTML标签,剩下的内容作为纯文本处理。
对于中文分词,我们使用CSW中文分词组件5.0,提供c#接口调用。首先运行该组件包中的install.bat文件,在系统中注册该组件。然后在开发工具中引用CSW.dll组件,以下是在C#控制台应用中调用该组件的示例代码。
CSWLib.SplitWordClasscsw=newCSWLib.SplitWordClass();
stringtext=csw.Split("要拆分的原创文本", 0, @"c:\winnt\system");
这里我们使用的是免费的CSW中文分词组件5.0共享版。此版本只有中文分词功能,没有词频统计功能。因此,我们需要自己完成词频统计的过程。为了方便日后提取网页特征,我们将中文分词和词频统计的结果保存到access数据库的wordcount表中。
4.4 信息抽取子系统的实现
在原型系统中,基于对公司主页信息特征的分析,结合正则表达式字符串匹配技术构建了公司主页信息抽取模型,实现了公司名称、成立年份、公司区域、资产信息、人员信息和生产能力。、质量认证等信息抽取。
5.结论
利用从互联网上自动获取企业信息来支持虚拟企业合作伙伴选择活动的研究还处于起步阶段,还有很多问题需要深入探讨。本研究基于实验。由于条件有限,实验规模小,得出的结论具有一定的局限性。此外,虚拟企业合作伙伴选择过程中的信息需求多样复杂,需要进一步研究,进一步明确合作伙伴选择过程中的信息需求。进一步研究主要有以下思路:
1) 进一步研究合作伙伴选择过程中的网页信息需求,使信息提取不仅限于提取企业主页,还可以收录其他可以收录企业相关信息的网页,例如行业< @网站、业务网站等等。
2) 本文实现的企业主页过滤效果结合基于样本共同特征的文本过滤方法仍有一定的局限性,需要探索更合适的企业主页过滤方法。
参考
[1] 李晓明、闫鸿飞、王继民,《搜索引擎——原理、技术与系统》,科学出版社,2005。
[2]JohnD.TheAnatomyofLarge-ScaleHypertertextualWebSearchEngine[C].In:Procofthe7thInt'1worldwidewebconf.Brishane.Austrilian,1999.
[3] 刘明基,等。Web文本信息特征获取算法[J]. 小型微机系统,2002,23(6):684-687
[4]秦晋,等。文本分类中的特征提取[J]. 计算机应用, 2003,23(2):45-46.
[5]VoertA.AutomaticExtractionofInformationBlocksUsingPATTrees[C].Proc.oftheNationalComputerSymposium,Taipei,Taiwan,1999(6):223-226.
[6]张炳奇,等。企业相关信息抽取技术研究与系统实现[J]. 微电子与计算机, 2004, 21(1):1-6.
[7] 袁占庭,等。数据提取与语义分析在Web数据挖掘中的应用[J].计算机工程与设计,
[8] 陈展荣,等。网络中文资料的智能提取与词汇切分[J]. 计算机工程与设计, 2005, 26 (6):1422-1424.
本文受国家自然科学基金项目(70971059),辽宁省创新团队项目(2006T076,2008T090,2009T045))资助。
自动采集子系统(客户管理系统CRM中的企业之间的业务差别有多大?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-09-25 10:04
在客户管理系统(客户管理软件CRM)中,企业之间的业务差异比较大,系统功能侧重点不同,但都收录基本的功能模块。一般客户管理系统(客户管理软件CRM)功能模块可分为营销管理、销售管理、服务管理、呼叫中心等模块。呼叫中心与营销、销售和服务管理密切相关。
营销管理子系统
营销管理子系统对客户和市场信息进行综合分析,细分市场,产生高质量的市场策划活动,指导销售团队更有效地工作。通过营销管理子系统,营销人员可以直接规划、执行、监控和分析营销活动的有效性,并可以帮助企业选择和细分客户,跟踪客户联系,衡量联系结果,并提供与客户的直接联系。自动响应功能,进而实现营销自动化。此外,营销管理子系统还为销售、服务和呼叫中心提供关键信息。营销管理子系统主要涵盖客户信息管理、营销活动管理、
(1)客户信息管理:从各种渠道采集营销活动相关的客户信息,为公司相关人员提供客户信息查询。营销活动的客户信息应涵盖潜在客户信息,支持特定客户群体信息跟踪支持客户发现功能。
(2)营销活动管理:主要包括营销活动计划的制定和实施,对营销活动的执行过程进行监控。通常的做法是将营销活动分为几个阶段,每个阶段设置相应的阶段目标,分阶段评估和评估营销活动的效果,然后逐步推进。
(3)信息内容管理:主要管理对象包括产品信息、市场信息、竞争对手信息、各种媒体信息等,实现采集的功能,对这些信息内容进行检索和分类管理这些信息内容形成了所谓的营销百科全书或营销知识库,为营销活动提供辅助,也为客户管理系统(客户管理软件CRM)中的其他功能模块(如销售和服务)提供信息支持。
(4)统计与决策支持:提供对客户和市场的深入分析,支持正确的营销市场细分;分析和评估营销活动的效果,支持营销活动和营销流程的优化。
营销自动化还可以应用客户响应(例如对满意度调查的响应)。) 触发下一次营销活动。 查看全部
自动采集子系统(客户管理系统CRM中的企业之间的业务差别有多大?)
在客户管理系统(客户管理软件CRM)中,企业之间的业务差异比较大,系统功能侧重点不同,但都收录基本的功能模块。一般客户管理系统(客户管理软件CRM)功能模块可分为营销管理、销售管理、服务管理、呼叫中心等模块。呼叫中心与营销、销售和服务管理密切相关。
营销管理子系统
营销管理子系统对客户和市场信息进行综合分析,细分市场,产生高质量的市场策划活动,指导销售团队更有效地工作。通过营销管理子系统,营销人员可以直接规划、执行、监控和分析营销活动的有效性,并可以帮助企业选择和细分客户,跟踪客户联系,衡量联系结果,并提供与客户的直接联系。自动响应功能,进而实现营销自动化。此外,营销管理子系统还为销售、服务和呼叫中心提供关键信息。营销管理子系统主要涵盖客户信息管理、营销活动管理、
(1)客户信息管理:从各种渠道采集营销活动相关的客户信息,为公司相关人员提供客户信息查询。营销活动的客户信息应涵盖潜在客户信息,支持特定客户群体信息跟踪支持客户发现功能。
(2)营销活动管理:主要包括营销活动计划的制定和实施,对营销活动的执行过程进行监控。通常的做法是将营销活动分为几个阶段,每个阶段设置相应的阶段目标,分阶段评估和评估营销活动的效果,然后逐步推进。
(3)信息内容管理:主要管理对象包括产品信息、市场信息、竞争对手信息、各种媒体信息等,实现采集的功能,对这些信息内容进行检索和分类管理这些信息内容形成了所谓的营销百科全书或营销知识库,为营销活动提供辅助,也为客户管理系统(客户管理软件CRM)中的其他功能模块(如销售和服务)提供信息支持。
(4)统计与决策支持:提供对客户和市场的深入分析,支持正确的营销市场细分;分析和评估营销活动的效果,支持营销活动和营销流程的优化。
营销自动化还可以应用客户响应(例如对满意度调查的响应)。) 触发下一次营销活动。
自动采集子系统(智能营销AI智能拓客系统怎么做到的呢?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 225 次浏览 • 2021-09-25 03:06
北京万商自动采集软件激活码cfy4g2ud智能营销系统。
可以说,数据已经渗透到运营的方方面面,是现代运营管理不可或缺的工具,成为健康快速发展的关键。
读者可以考虑一下。当你在百度上输入关键词“谢雕英雄传”,搜索结果会是“射鹰英雄传”。你是怎样做的?
如果有一天,您的客户被抢签了,请不要惊讶,因为当您还在使用传统的方式分发传单时,其他人正在以快速、超低成本的大数据精准营销方式抢您的客户!
如果超链接不以“”开头,则该链接很可能是网页所在的本地文件或(文件或邮件转换协议),应过滤掉
传统企业和传统门店不学习数据,不精准推广,只会被整合淘汰!
如何限制奇怪爬虫的行为?
智能营销AI智能扩展客户系统通过大数据匹配客户信息,通过电话、微信、QQ、邮件、短信等方式自动向用户推送广告。采集的数据都是真实有用的。很容易得到潜在客户群的联系方式。只需放在潜在客户群范围内,即可自动进行客户延伸、营销、筛选等步骤。采集 数据真实有效。
但不要害怕,主数据管理派上用场
下面是一个简单网页的例子: 在爬虫眼中,这个网页是这样的:因此,网页本质上是超文本的,网页上的所有内容都在像“... ”
AI智能扩展系统也有很多优点
当然,这可能与建设社会的理想不谋而合。巧合的是,例如,它就是一个很好的例子。
智能营销AI智能扩展系统不仅可以采集高效、快捷、多账户完全智能轮流采集、多线程操作、多种采集自由选择、方便、实用性强,覆盖面广,针对性强,选择空间大。它还可以“实时”客户。软件采用自动过滤重复数据,无任何遗漏,优秀的人性化界面设计,易学易用,系统参数简单智能,设置界面操作简单,使用方便,导入更容易,导出客户数据。
有了这项技术,我们可以丰富电脑磁盘中的《重要思想》、《规矩全集》、《日本近代史研究》等文件内容,从而大大提高精神境界。
应该说,只有在环境中建立了良好的秩序,才能为社会做出贡献。总结等。如果读者可以阅读整篇文章文章,那么恭喜你,你已经掌握了网页的精髓,爬虫的简单实现和搜索引擎的工作原理是互联网的三大基础知识,可以准确的采集到你想要的数据想。因为它同时提供操作功能和功能,引擎支持每个应用程序的可靠数据基础。
AI智能扩展系统能否立足市场替代传统模式?这个问题你一定已经有了!能!
八款**应用尚未拿到批**其实时代在变,微软也在不断完善系统。一方面是更加兼容系统,另一方面是在开发更加先进的shell平台。
我们专注于网络营销系统的研发和销售,时刻了解客户的个性化需求,提供针对性的解决方案,为企业发展提供强大动力!服务于各类企业,解决传统企业寻找客户的难题,让销售不再是问题。在提供信息服务的道路上,我们与客户一起开拓进取,共创辉煌!
值得一提的是,因为习惯,很多人深信系统更适合家庭使用,系统更适合程序员。
北京万商汽车采集软件激活码首席运营官给出了他的预测,如果把网页当成房子,就相当于房子的外壳。 查看全部
自动采集子系统(智能营销AI智能拓客系统怎么做到的呢?(组图))
北京万商自动采集软件激活码cfy4g2ud智能营销系统。
可以说,数据已经渗透到运营的方方面面,是现代运营管理不可或缺的工具,成为健康快速发展的关键。
读者可以考虑一下。当你在百度上输入关键词“谢雕英雄传”,搜索结果会是“射鹰英雄传”。你是怎样做的?
如果有一天,您的客户被抢签了,请不要惊讶,因为当您还在使用传统的方式分发传单时,其他人正在以快速、超低成本的大数据精准营销方式抢您的客户!
如果超链接不以“”开头,则该链接很可能是网页所在的本地文件或(文件或邮件转换协议),应过滤掉
传统企业和传统门店不学习数据,不精准推广,只会被整合淘汰!
如何限制奇怪爬虫的行为?
智能营销AI智能扩展客户系统通过大数据匹配客户信息,通过电话、微信、QQ、邮件、短信等方式自动向用户推送广告。采集的数据都是真实有用的。很容易得到潜在客户群的联系方式。只需放在潜在客户群范围内,即可自动进行客户延伸、营销、筛选等步骤。采集 数据真实有效。
但不要害怕,主数据管理派上用场
下面是一个简单网页的例子: 在爬虫眼中,这个网页是这样的:因此,网页本质上是超文本的,网页上的所有内容都在像“... ”
AI智能扩展系统也有很多优点
当然,这可能与建设社会的理想不谋而合。巧合的是,例如,它就是一个很好的例子。
智能营销AI智能扩展系统不仅可以采集高效、快捷、多账户完全智能轮流采集、多线程操作、多种采集自由选择、方便、实用性强,覆盖面广,针对性强,选择空间大。它还可以“实时”客户。软件采用自动过滤重复数据,无任何遗漏,优秀的人性化界面设计,易学易用,系统参数简单智能,设置界面操作简单,使用方便,导入更容易,导出客户数据。
有了这项技术,我们可以丰富电脑磁盘中的《重要思想》、《规矩全集》、《日本近代史研究》等文件内容,从而大大提高精神境界。
应该说,只有在环境中建立了良好的秩序,才能为社会做出贡献。总结等。如果读者可以阅读整篇文章文章,那么恭喜你,你已经掌握了网页的精髓,爬虫的简单实现和搜索引擎的工作原理是互联网的三大基础知识,可以准确的采集到你想要的数据想。因为它同时提供操作功能和功能,引擎支持每个应用程序的可靠数据基础。
AI智能扩展系统能否立足市场替代传统模式?这个问题你一定已经有了!能!
八款**应用尚未拿到批**其实时代在变,微软也在不断完善系统。一方面是更加兼容系统,另一方面是在开发更加先进的shell平台。
我们专注于网络营销系统的研发和销售,时刻了解客户的个性化需求,提供针对性的解决方案,为企业发展提供强大动力!服务于各类企业,解决传统企业寻找客户的难题,让销售不再是问题。在提供信息服务的道路上,我们与客户一起开拓进取,共创辉煌!
值得一提的是,因为习惯,很多人深信系统更适合家庭使用,系统更适合程序员。
北京万商汽车采集软件激活码首席运营官给出了他的预测,如果把网页当成房子,就相当于房子的外壳。
自动采集子系统(如何在信息浩如烟海的互联网上准确获取并长期跟踪自己关注的内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-09-07 13:09
总结:在海量信息、长期跟踪的情况下,如何准确获取和跟踪自己关注的内容,这一新问题已成为制约互联网使用的重要因素之一。网络数据自动采集旨在解决这个问题。 文章从理论研究和应用技术两个方面讨论。本文给出了一个自动化采集模型,基于房地产行业设计了一个自动化采集系统,并证明了自动化采集的可行性和优势。同时也指出了其局限性和不足。
关键词:information采集半结构化数据数据挖掘地产
[Abstract] 在网络上寻找和追踪一个人感兴趣的内容越来越困难,其信息过载。这个问题极大地影响了互联网的有效使用。而网络数据自动化提取在解决这个问题方面取得了重大进展。本文从学术研究和应用技术两个方面对其进行了探讨。并给出了数据自动化抽取模型,设计了一个基于房地产行业的Web数据自动化抽取系统,证明了自动化抽取的可行性和优势。同时也指出了应用的局限性。
数据仓库
[关键词] 数据提取、半结构化数据、数据挖掘、房地产
1.网络数据自动采集理论基础
Web 可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何进一步获取互联网上一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动采集的内涵和外延非常广泛,目前还没有明确的定义。 Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。 Web 数据挖掘与这些概念密切相关,但也存在差异。
(1)网络数据自动采集和挖掘
Web 挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出网络挖掘的定义。所谓网络挖掘,是指大量非结构化、异构的、发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化等)的非平凡过程。在Web信息资源中。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1.
SOA
(2)网络数据自动采集和搜索引擎
Web Data Auto采集 与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景。而Web Data Auto采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web 数据自动采集 和信息提取:信息提取是近年来新兴的概念。信息抽取是面向不断增长变化的,特定领域文献中的特定查询,此类查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅收录关键字,还匹配实体之间的关系。信息提取是一个技术概念,网络数据自动采集很大程度上取决于信息提取技术实现长期动态跟踪。
(3)网络数据自动采集和网络信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的相当数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是输出图像的输入:
人工智能
ξ: (C: q)-->S3
虽然Web Data Auto采集不会直接将Web文档集合的一个子集输出给用户,但它需要进一步的分析和处理、重复检查和去噪以及数据集成。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动采集是网络数据挖掘的重要组成部分。它采用网页数据检索和信息提取技术,弥补了搜索引擎针对性和专业性的不足,无法实现动态数据跟踪。由于监控的不足,这是一个非常有前景的领域。
1.2 研究意义
(1)解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户毫无价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的信息,以及信息的效率和有效性利用率大大降低。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会中,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动搜索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接根据用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。计算机知识
(2)解决搜索引擎智能低的问题
虽然互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3)节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且人工数据采集不会有任何遗漏、偏差和错误。
2.网络数据自动采集应用研究
2.1 应用功能
从上面的讨论可以看出,网络数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点是基于领域,基于需求。没有有效的采集 模型可以用于所有领域。 web数据自动化采集的原理研究是一样的,但是具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以对某一主题的舆论发展和人口地域分布进行监测;猎头公司监控部分企业网站招聘,获取人才需求变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
计算机知识
2.2应用产品
Web Data Auto采集Web Data Auto采集 应运而生。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,通过互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监控和采集系统,构建企业信息资源架构,有效监控产业环境、市场需求、相关政策、突发事件、竞争对手,帮助企业第一时间把握市场机遇 4.
因此,一些相关的产品和服务已经开始在市场上销售。比如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.Web 数据自动采集模型
虽然Web Data Auto采集是面向特定领域的,但采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。计算机知识
3.2 数据预处理模块
数据预处理是采集流程的重要组成部分。如果数据预处理工作做好,数据质量高,数据采集过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。由于数据源种类繁多,各种数据的特征属性可能不能满足主体的需要,因此数据预处理模块的主要功能是在Web上定义数据源,格式化数据源并初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。所以数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对来自采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获取网页的结构后,以内容块为单位保留和删除数据。最后,获得的数据在放入数据库并建立索引之前必须进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。 SAAS
4.Automatic 采集基于房地产行业的系统设计
如前所述,Web 数据采集 必须是域驱动的或数据驱动的。因此,本节在第3章的理论基础上,设计了一个基于房地产行业的Web自动化采集系统。
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者还是银行信贷部门,都想了解最新的房地产价格走势。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。即使是房地产信息也具有地域和时间特征。
房产中介经常在一些比较大的房产网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据采集的高效化和自动化。
4.2.系统原理
自动化采集系统基于第3节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003,运行于window 2000 Professional 系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析SOA
采集模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监控计划下网站的新挖矿项目数和最后采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容,采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大的情况下,会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在对方服务器空闲时自动运行。比如可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新,执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。 采集 系统会像 Windows Update 一样自动开启并执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,兼顾采集器和采集的情况。
编程技术
4.3.限性
网页数据自动采集主要完成采集功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们所需要的数据。它只对采集数据负责,至于为什么要做,需要考虑。
其次,为了保证采集results数据的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的范围越广,采集冗余数据到异常的可能性就越大。反之,数据采集模型的精度越高,应用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但让算法自己做所有这些决定是不明智的。
Data采集 不会在没有指导的情况下自动发现模型。 data采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化改进工作。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web Data Automation采集是一个极具潜力的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,并有进一步融合的趋势。
在实际应用中,Web Data Auto采集解决了当前互联网信息过载无法有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有很大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
SAAS
在知识经济时代,谁能有效地获取和使用知识,谁就有赢得竞争的武器和工具。 Web数据自动化采集作为一种获取和使用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地服务于个人、企业和国家的思维和战略发展。
参考资料
1 周涛李军,卢惠玲。 Web数据挖掘技术研究[J].汉中师范大学学报(自然科学). 2004.22:87
2 斯蒂芬·索勒兰。半结构化和自由文本的学习信息抽取规则[M].波士顿:Kluwer Academic Publishers,2001 年
3 林杰斌、刘明德、陈翔。数据挖掘与OLAP的理论与实践[M].北京:清华大学出版社,2003,45
4 杨健林,孙明军。竞争情报采集自动化[J].信息技术。 2005.1:40-43
5 Velocityscape 产品:Web Scraper Plus+(Aceess 2006-1-18)
6 Ficstar:基于项目的定制服务。 (Aceess 2006-1-18)数据挖掘知识
7 林建勤。基于Web的数据挖掘应用模式研究[J].贵州师范大学学报(自然科学版)。 2004.8:92-96 查看全部
自动采集子系统(如何在信息浩如烟海的互联网上准确获取并长期跟踪自己关注的内容)
总结:在海量信息、长期跟踪的情况下,如何准确获取和跟踪自己关注的内容,这一新问题已成为制约互联网使用的重要因素之一。网络数据自动采集旨在解决这个问题。 文章从理论研究和应用技术两个方面讨论。本文给出了一个自动化采集模型,基于房地产行业设计了一个自动化采集系统,并证明了自动化采集的可行性和优势。同时也指出了其局限性和不足。
关键词:information采集半结构化数据数据挖掘地产
[Abstract] 在网络上寻找和追踪一个人感兴趣的内容越来越困难,其信息过载。这个问题极大地影响了互联网的有效使用。而网络数据自动化提取在解决这个问题方面取得了重大进展。本文从学术研究和应用技术两个方面对其进行了探讨。并给出了数据自动化抽取模型,设计了一个基于房地产行业的Web数据自动化抽取系统,证明了自动化抽取的可行性和优势。同时也指出了应用的局限性。
数据仓库
[关键词] 数据提取、半结构化数据、数据挖掘、房地产
1.网络数据自动采集理论基础
Web 可以说是目前最大的信息系统,其数据具有海量、多样、异构、动态变化的特点。因此,人们越来越难以准确、快速地获取所需的数据。虽然搜索引擎种类繁多,搜索引擎考虑的数据召回率较多,但准确率不足,难以进一步挖掘。深度数据。因此,人们开始研究如何进一步获取互联网上一定范围的数据,从信息搜索到知识发现。
1.1 相关概念
Web数据自动采集的内涵和外延非常广泛,目前还没有明确的定义。 Web 数据自动化采集 涉及 Web 数据挖掘、Web 信息复兴、信息提取和搜索引擎等概念和技术。 Web 数据挖掘与这些概念密切相关,但也存在差异。
(1)网络数据自动采集和挖掘
Web 挖掘是一种特殊的数据挖掘。目前还没有统一的概念。我们可以借鉴数据挖掘的概念来给出网络挖掘的定义。所谓网络挖掘,是指大量非结构化、异构的、发现有效的、新颖的、潜在可用的和最终可理解的知识(包括概念、模式、规则、规则、约束和可视化等)的非平凡过程。在Web信息资源中。包括Web内容挖掘、Web结构挖掘和Web使用挖掘1.
SOA
(2)网络数据自动采集和搜索引擎
Web Data Auto采集 与搜索引擎有很多相似之处,例如都使用信息检索技术。但是,两者的侧重点不同。搜索引擎主要由三部分组成:Web Scraper、索引数据库和查询服务。爬虫在互联网上的漫游是无目的的,而是尝试寻找更多的内容。查询服务返回尽可能多的结果,并不关心结果是否符合用户习惯的专业背景。而Web Data Auto采集主要为特定行业提供面向领域、个性化的信息挖掘服务。
Web 数据自动采集 和信息提取:信息提取是近年来新兴的概念。信息抽取是面向不断增长变化的,特定领域文献中的特定查询,此类查询是长期的或连续的(IE问题在面对不断增长和变化的语料库时被指定为长期存在或持续的查询2). 与传统搜索引擎基于关键字查询不同,信息提取是基于查询的,不仅收录关键字,还匹配实体之间的关系。信息提取是一个技术概念,网络数据自动采集很大程度上取决于信息提取技术实现长期动态跟踪。
(3)网络数据自动采集和网络信息检索
信息检索是从大量 Web 文档集合 C 中找到与给定查询 q 相关的相当数量的文档子集 S。如果把q当作输入,把S当作输出,那么Web信息检索的过程就是输出图像的输入:
人工智能
ξ: (C: q)-->S3
虽然Web Data Auto采集不会直接将Web文档集合的一个子集输出给用户,但它需要进一步的分析和处理、重复检查和去噪以及数据集成。尝试将半结构化甚至非结构化数据转化为结构化数据,然后以统一的格式呈现给用户。
因此,网络数据自动采集是网络数据挖掘的重要组成部分。它采用网页数据检索和信息提取技术,弥补了搜索引擎针对性和专业性的不足,无法实现动态数据跟踪。由于监控的不足,这是一个非常有前景的领域。
1.2 研究意义
(1)解决信息冗余下的信息悲剧
随着互联网信息的快速增长,互联网上越来越多的对用户毫无价值的冗余信息,使得人们无法及时准确地捕捉到自己需要的信息,以及信息的效率和有效性利用率大大降低。互联网上的信息冗余主要体现在信息的过载和信息的无关性。选择的复杂性和许多其他方面。
因此,在当今高度信息化的社会中,信息冗余和信息过载已成为互联网上亟待解决的问题。网页数据采集可以通过一系列方法,根据用户兴趣自动搜索互联网上特定类型的信息,去除无关数据和垃圾数据,过滤虚假数据和延迟数据,过滤重复数据。用户无需处理复杂的网页结构和各种超链接,直接根据用户需求将信息呈现给用户。可以大大减少用户的信息过载和信息丢失。计算机知识
(2)解决搜索引擎智能低的问题
虽然互联网上信息量巨大,但对于特定的个人或群体而言,获取相关信息或服务以及关注的范围只是一小部分。目前,人们主要通过谷歌、雅虎等搜索引擎查找在线信息,但这些搜索引擎规模大、范围广,检索智能不高,查准率和查全率问题日益突出此外,搜索引擎很难根据不同用户的不同需求提供个性化服务。
(3)节省人力物力成本
与传统手工采集数据相比,自动采集可以减少大量重复性工作,大大缩短采集时间,节省人力物力,提高效率。并且人工数据采集不会有任何遗漏、偏差和错误。
2.网络数据自动采集应用研究
2.1 应用功能
从上面的讨论可以看出,网络数据自动化采集是面向特定领域或特定需求的。因此,其应用的最大特点是基于领域,基于需求。没有有效的采集 模型可以用于所有领域。 web数据自动化采集的原理研究是一样的,但是具体的应用和实现必须是领域驱动的。例如,科研人员可以通过跟踪研究机构和期刊网站中某个学科的文章来跟踪相关学科的最新进展;政府可以对某一主题的舆论发展和人口地域分布进行监测;猎头公司监控部分企业网站招聘,获取人才需求变化;零售商可以监控供应商在线产品目录和价格等方面的变化。房地产中介可以自动采集在线房地产价格信息,判断房地产行业的变化趋势,获取客户信息进行营销。
计算机知识
2.2应用产品
Web Data Auto采集Web Data Auto采集 应运而生。除个人信息采集服务外,还可广泛应用于科研、政治、军事、商业等领域。例如应用于信息采集子系统。根据企业各级信息需求,构建企业信息资源目录,构建企业信息库、信息库、知识库,通过互联网、企业内部网、数据库、文件系统、信息系统等。信息资源全面整合,实时采集,监控各企业所需的情报信息。可以协助企业建立外部环境监控和采集系统,构建企业信息资源架构,有效监控产业环境、市场需求、相关政策、突发事件、竞争对手,帮助企业第一时间把握市场机遇 4.
因此,一些相关的产品和服务已经开始在市场上销售。比如美国Velocityscape的Web Scraper Plus+软件5,加拿大提供量身定制的采集服务6。除了这些在市场上公开销售的商业产品外,一些公司也有自己内部使用的自动采集系统。所有这些应用都基于特定行业。
3.Web 数据自动采集模型
虽然Web Data Auto采集是面向特定领域的,但采集的原理和流程是相似的。因此,本节将设计一个Web数据自动采集系统模型。
3.1 采集模型架
系统根据功能不同可分为三个模块:数据预处理模块、数据过滤模块和数据输出模块。计算机知识
3.2 数据预处理模块
数据预处理是采集流程的重要组成部分。如果数据预处理工作做好,数据质量高,数据采集过程会更快更简单,最终的模型和规则会更有效和适用,结果也会更成功。由于数据源种类繁多,各种数据的特征属性可能不能满足主体的需要,因此数据预处理模块的主要功能是在Web上定义数据源,格式化数据源并初步过滤数据源。该模块需要将网页中的结构化、半结构化和非结构化数据和类型映射到目标数据库。所以数据预处理是数据采集的基础和基础。
3.3 数据过滤模块
数据过滤模块负责对来自采集的本地数据进行进一步的过滤处理,并存储到数据库中。可以考虑网页建模、数理统计、机器学习等方法对数据进行过滤清理7。
网页主要由标签标记和显示内容两部分组成。数据过滤模块通过建立网页模型,解析Tag标签,构建网页的标签树,分析显示内容的结构。
获取网页的结构后,以内容块为单位保留和删除数据。最后,获得的数据在放入数据库并建立索引之前必须进行重复数据删除。
3.4 数据输出模块
数据输出模块将目标数据库中的数据经过处理后呈现给用户。本模块属于数据采集的后续工作,可根据用户需求确定模块的责任程度。基本功能是将数据以结构化的方式呈现给用户。此外,还可以添加报表图标等统计功能。当数据量达到一定程度时,可以进行数据建模、时间序列分析、相关性分析,发现各种概念规则之间的规律和关系,使数据发挥最大效用。 SAAS
4.Automatic 采集基于房地产行业的系统设计
如前所述,Web 数据采集 必须是域驱动的或数据驱动的。因此,本节在第3章的理论基础上,设计了一个基于房地产行业的Web自动化采集系统。
4.1.研究目标
房地产是当今最活跃的行业之一,拥有众多信息供应商和需求商。无论是政府、房地产开发商、购房者、投资者还是银行信贷部门,都想了解最新的房地产价格走势。互联网上有大量的信息提供者,但用户没有时间浏览所有这些网页。即使是房地产信息也具有地域和时间特征。
房产中介经常在一些比较大的房产网站采集房产价格和客户数据。通常的做法是手动浏览网站查看最新更新的信息。然后将其复制并粘贴到数据库中。这种方式不仅费时费力,而且在搜索过程中也有可能遗漏,在数据传输过程中可能会出现错误。针对这种情况,本节将设计一个自动采集房产信息的系统。实现数据采集的高效化和自动化。
4.2.系统原理
自动化采集系统基于第3节采集模型框架。作者设计的数据自动化采集系统采用B/S模式,开发平台为Microsoft Visual .Net 2003,运行于window 2000 Professional 系统下编译,开发语言为C#+,数据库服务器为SQL SERVER 2000。
(1)系统架构分析SOA
采集模型以组件的形式放置在组件目录下,类的方法和功能以面向对象的方式进行封装以供调用。后缀为 aspx 和 htm 的文件是直接与用户交互的文件。此类文件不关心采集模型的具体实现,只需要声明调用即可。
这种结构的优点是不需要安装特定的软件,升级维护方便,可以通过浏览器直接调用服务器后台的组件。一旦需要更改采集模型,可以直接修改组件下的CS文件。
(2)用户交互分析
用户服务结构主要由规划任务、查看数据和分析数据组成。在定时任务中设置监控计划的名称、URL、执行时间等。在查看数据时,首先可以看到特定监控计划下网站的新挖矿项目数和最后采集的时间。您可以立即开始执行采集 任务。进入详细页面后,可以看到采集的内容,采集的时间以及是否已阅读的标记。检查所有记录后,是否已读取标记自动变为是。对数据进行分析,对数据进行二次处理,发现新知识等,可以进一步深化。
(3)操作模式分析
系统可以采用多种操作模式。比如用户操作。用户可以随时监控网页的最新变化。但是,如果数据量大且网络繁忙,则需要更长的等待时间。同时,数据采集在数据量较大的情况下,会给采集所针对的服务器带来更大的压力。因此,我们应该尽量让系统在对方服务器空闲时自动运行。比如可以在Windows控制面板中添加定时任务,让采集系统每天早上开始搜索最新的网页更新,执行数据采集任务。在 Windows 2000 Professional 和更高版本中,组件也可以作为 Windows 服务和应用程序启动。 采集 系统会像 Windows Update 一样自动开启并执行。总之,采集系统可以根据实际需要选择多种灵活的运行模式,兼顾采集器和采集的情况。
编程技术
4.3.限性
网页数据自动采集主要完成采集功能。它不是万能药,它只是一种工具。无法自动理解用户的业务,理解数据的含义。它只是通过一系列技术手段来帮助人们更有效、更深入地获取他们所需要的数据。它只对采集数据负责,至于为什么要做,需要考虑。
其次,为了保证采集results数据的价值,用户必须在准确性和适用范围之间寻求平衡。一般来说,采集模型的范围越广,采集冗余数据到异常的可能性就越大。反之,数据采集模型的精度越高,应用范围就会相对缩小。因此,用户必须了解自己的数据。虽然有些算法可以考虑到数据异常的处理,但让算法自己做所有这些决定是不明智的。
Data采集 不会在没有指导的情况下自动发现模型。 data采集系统需要在用户的帮助和指导下指定一个模型。并需要用户反馈采集结果进行进一步优化改进工作。由于现实生活中的变化,最终模型也可能需要更改。
5、结论
在研究领域,Web Data Automation采集是一个极具潜力的新兴研究领域。它与数据挖掘、信息检索和搜索引擎技术相辅相成,各有侧重。但随着数据挖掘技术的发展和智能搜索引擎的出现,它们相互促进,并有进一步融合的趋势。
在实际应用中,Web Data Auto采集解决了当前互联网信息过载无法有效利用的现状,提高了信息使用效率,提高了人们的工作效率,减轻了工作负担。经济和军事都有很大的使用价值,越来越多的厂商会涉足相关的服务和应用。但另一方面,对于一些不想被采集的信息,比如商品价格、公司产品、个人隐私等,如何反自动采集也是一个重要的问题。
SAAS
在知识经济时代,谁能有效地获取和使用知识,谁就有赢得竞争的武器和工具。 Web数据自动化采集作为一种获取和使用知识的有效手段,越来越受到人们的关注和关注。只有从数据中提取信息,从信息中发现知识,才能更好地服务于个人、企业和国家的思维和战略发展。
参考资料
1 周涛李军,卢惠玲。 Web数据挖掘技术研究[J].汉中师范大学学报(自然科学). 2004.22:87
2 斯蒂芬·索勒兰。半结构化和自由文本的学习信息抽取规则[M].波士顿:Kluwer Academic Publishers,2001 年
3 林杰斌、刘明德、陈翔。数据挖掘与OLAP的理论与实践[M].北京:清华大学出版社,2003,45
4 杨健林,孙明军。竞争情报采集自动化[J].信息技术。 2005.1:40-43
5 Velocityscape 产品:Web Scraper Plus+(Aceess 2006-1-18)
6 Ficstar:基于项目的定制服务。 (Aceess 2006-1-18)数据挖掘知识
7 林建勤。基于Web的数据挖掘应用模式研究[J].贵州师范大学学报(自然科学版)。 2004.8:92-96
自动采集子系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2021-09-07 13:08
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
要了解更多信息,请点击:
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取微信公众号文章(包括阅读、点赞、观看)。
要了解更多信息,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、rocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,将日志log到mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反攀登限制; 5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭; 6、Nacos为配置中心,采集频率可通过热配置实时调整; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录保存在MongoDB存档中,方便查看错误日志。
要了解更多信息,请点击:
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,微信公众平台界面抓取即可获取消息); 2、不是一贴就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信的数量账号就够了,可以通过增加采集的频率来优化)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
rocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录故障日志功能。
要了解更多信息,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关的功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
要了解更多信息,请点击:
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目的亲测现已上线,项目开发中解决了搜狗微信临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不给它一个采集吗?
要了解更多信息,请点击: 查看全部
自动采集子系统(spring使用springcloud架构技术优劣性系统优点及优点分析)
前言
因公司业务需要,需要获取客户提供的微信公众号文章的历史记录并每天更新。很明显,300多个公众号不能每天人工查,问题提交给IT团队。对于那些喜欢爬虫的人,我绝对想要他。之前做过搜狗的微信爬虫,之后一直在做java web。这个项目重新点燃了我对爬虫的热爱。首次使用spring cloud架构做爬虫。历时20多天,终于搞定。接下来我将通过一系列文章分享项目经验,并提供源码供大家指正!
要了解更多信息,请点击:
一、系统介绍
本系统基于Java开发。只需配置公众号或微信公众号,即可定时或即时抓取微信公众号文章(包括阅读、点赞、观看)。
要了解更多信息,请点击:
二、系统架构技术架构
Spring Cloud、SpringBoot、Mybatis-Plus、Nacos、rocketMq、nginx
存储
Mysql、MongoDB、Redis、Solr
缓存
Redis
代理
提琴手
三、系统优缺点系统优点
1、 公众号配置后,可以使用Fiddler的JS注入功能和Websocket实现自动爬取; 2、系统是分布式架构,高可用; 3、rocketMq 消息队列可以解耦。解决网络抖动导致采集失败的问题。 3次消费不成功,将日志log到mysql,保证文章的完整性; 4、可以添加任意数量的微信信号,提高采集效率,抵抗反攀登限制; 5、Redis在24小时内缓存每个微信账号的采集记录,防止账号被关闭; 6、Nacos为配置中心,采集频率可通过热配置实时调整; 7、将采集到将数据存储在Solr集群中,提高检索速度; 8、将捕获返回的记录保存在MongoDB存档中,方便查看错误日志。
要了解更多信息,请点击:
系统缺点:
1、通过真机真实账号采集消息,如果需要采集大量公众号,需要有多个微信账号作为支持(如果当天账号达到上限,微信公众平台界面抓取即可获取消息); 2、不是一贴就可以抓到的公众号,采集时间是系统设置的,留言有一定的滞后性(如果公众号不多的话,微信的数量账号就够了,可以通过增加采集的频率来优化)。
四、模块介绍
因为管理系统和API调用函数会在后面添加,所以提前封装了一些函数。
common-ws-starter
公共模块:存储工具和实体等公共消息。
redis-ws-starter
Redis模块:对spring-boot-starter-data-redis进行二次封装,暴露打包好的Redis工具类和Redisson工具类。
rocketmq-ws-starter
rocketMq 模块:对 Rocketmq-spring-boot-starter 的二次封装,提供消费重试和记录故障日志功能。
要了解更多信息,请点击:
db-ws-starter
mysql数据源模块:封装mysql数据源,支持多数据源,自定义注解实现数据源动态切换。
sql-wx-spider
mysql数据库模块:提供mysql数据库操作的所有功能。
pc-wx-spider
PC端采集模块:收录PC端采集公众号历史相关功能。
java-wx-spider
Java提取模块:收录Java程序提取文章内容相关的功能。
mobile-wx-spider
Simulator采集模块:收录与模拟器或手机采集消息交互量相关的功能。
要了解更多信息,请点击:
五、通用流程图
六、在PC端和手机端运行截图
控制面板
操作结束
总结
项目的亲测现已上线,项目开发中解决了搜狗微信临时链接永久链接问题,希望能帮助到被同类业务困扰的老铁。如今,做java就像逆流而上。不前进就会后退。我不知道你什么时候参与。我希望每个人都有自己的向日葵采集。如果你看到这个,你不给它一个采集吗?
要了解更多信息,请点击:
自动采集子系统(ping一下不就行了吗首先确定你的应用需要怎么提交ack)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-07 09:02
自动采集子系统在后台我们可以查看日志的更新情况。子系统发生修改的时候会自动发送报文给日志服务器,日志服务器会从报文中查询到修改日志的位置然后给父系统发送相同的报文。一般来说我们的修改都是随机的两个地址去发送报文,也就是我们常说的两个引擎组成一个点对点的自动采集。因为每个人都发送相同的日志报文,而没有去转发修改日志,所以也就没有新增处理等功能的需求。
一般都是随机的两个子网地址去发送报文,现在比较好用的是以太坊的智能合约的keystone。
一般来说,都是用一个ip来发送。
看情况的咯。一般自动化引擎都是发送随机ip的报文,但是需要发送ack测试等必须使用两个域名的。
ping一下不就行了吗
首先确定你的应用需要怎么提交ack其次,send报文的时候重发选项一般选always,因为如果要再次ack,
就是发送n个ip,n需要定义的最好比较大,假设n=50000如果情况一,需要5000次ack。那需要5000次并发然后选取5000个ip发送的情况下n的设置不能多于50000,否则网络可能不足以消化这么多ip我的建议是n=50000,这样n*50000基本能满足mysql集群需求。
用监听端口的方式(后台检测本地端口是否存在,如果存在端口需要用nginx监听做些操作);后台拦截下来n个ip,不管ack出去哪个ip的日志,直接过来填写ip;直接用拦截端口的方式进行发送;ip已经暴露,ack出去就可以过来填写ip;假设:你有50000台mysql集群,每台mysql进程用ack两个ip来做两次ack(当然如果你的mysql集群有5g,那两次ack的ip就是5000万的ip);那ip数量是5n,ack出去5000万个ip,也就是5n个ack过来填写ip,databases就会增加5000万,后台立即返回一个2000万的trace,并且发送这个2000万的trace的日志给mysql集群。 查看全部
自动采集子系统(ping一下不就行了吗首先确定你的应用需要怎么提交ack)
自动采集子系统在后台我们可以查看日志的更新情况。子系统发生修改的时候会自动发送报文给日志服务器,日志服务器会从报文中查询到修改日志的位置然后给父系统发送相同的报文。一般来说我们的修改都是随机的两个地址去发送报文,也就是我们常说的两个引擎组成一个点对点的自动采集。因为每个人都发送相同的日志报文,而没有去转发修改日志,所以也就没有新增处理等功能的需求。
一般都是随机的两个子网地址去发送报文,现在比较好用的是以太坊的智能合约的keystone。
一般来说,都是用一个ip来发送。
看情况的咯。一般自动化引擎都是发送随机ip的报文,但是需要发送ack测试等必须使用两个域名的。
ping一下不就行了吗
首先确定你的应用需要怎么提交ack其次,send报文的时候重发选项一般选always,因为如果要再次ack,
就是发送n个ip,n需要定义的最好比较大,假设n=50000如果情况一,需要5000次ack。那需要5000次并发然后选取5000个ip发送的情况下n的设置不能多于50000,否则网络可能不足以消化这么多ip我的建议是n=50000,这样n*50000基本能满足mysql集群需求。
用监听端口的方式(后台检测本地端口是否存在,如果存在端口需要用nginx监听做些操作);后台拦截下来n个ip,不管ack出去哪个ip的日志,直接过来填写ip;直接用拦截端口的方式进行发送;ip已经暴露,ack出去就可以过来填写ip;假设:你有50000台mysql集群,每台mysql进程用ack两个ip来做两次ack(当然如果你的mysql集群有5g,那两次ack的ip就是5000万的ip);那ip数量是5n,ack出去5000万个ip,也就是5n个ack过来填写ip,databases就会增加5000万,后台立即返回一个2000万的trace,并且发送这个2000万的trace的日志给mysql集群。
自动采集子系统(民兵科技:下游接口系统采集框架设计中的常见因素)
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-09-05 02:05
自动采集子系统:子系统一般包括两个主要组成部分,即下游接口系统和采集框架。1、下游接口系统子系统下游采集框架需要连接到对应的子系统,子系统用来处理和处理采集的数据。自动采集接口系统是用来处理子系统的下游采集框架。2、采集框架采集框架包括调度框架、采集过滤框架、反馈框架。调度框架对于采集框架中每一次请求进行登记,一旦有采集请求到达,其实时数据流入相应的子系统。
采集过滤框架对已进行了调度框架的请求进行拦截,一旦有请求到达,就把正在进行调度框架请求的请求拦截,然后转给采集框架请求。反馈框架则是根据调度框架返回的结果,反馈给调度框架。采集框架的作用是对子系统的下游采集框架进行每个请求的处理,包括以下几个方面:a、单纯的去请求字段,看子系统的网页版是如何处理的;b、在存储中进行转换,将网页中的字段转换成字符串;c、将网页中的字符串转换成字段或列表等;d、对于字段做加工处理,处理文本表中字段的加工方式等。
采集框架本身不处理任何请求,它只负责作为整个自动采集框架对外的接口系统。在进行自动采集框架设计时,需要考虑几个常见的因素,包括需要采集的各个字段,字段的外形,内容,是否需要进行sql注入等。下面将举一个很经典的例子来阐述下采集框架设计中要考虑的几个常见因素。经典的实例介绍:该案例最后由发布网址:主要介绍一个三级分公司的路由图,然后是对自动采集框架及接口和所有设置和配置进行详细说明。
整个项目为单体模式项目,分公司的路由图主要由四个子网模块来画:数据源(重点)、信道描述模块、帧(帧头)转发模块、帧转发模块,分别由分公司网页和子网集中管理。采集接口:采集接口用来采集单体自动采集框架对应的子网路由图,并将路由图返回到子网集中进行二次放大和处理。子网集中的配置是:对于单体采集框架的接互框架,子网是单独配置,并且在子网相应的子网集中进行配置(通常把子网集中交给工程师进行管理),工程师会每个子网配置一个接口,每个子网的每个接口的ip都是相同的,但是子网网段不同。
接口的具体位置:以下为子网路由图,采集子网为a,它是子网中要放大的接口。发送数据头:接口的发送数据头:发送数据流:接口转发:子网封装:子网封装:高清采集:子网封装:下载文档:。 查看全部
自动采集子系统(民兵科技:下游接口系统采集框架设计中的常见因素)
自动采集子系统:子系统一般包括两个主要组成部分,即下游接口系统和采集框架。1、下游接口系统子系统下游采集框架需要连接到对应的子系统,子系统用来处理和处理采集的数据。自动采集接口系统是用来处理子系统的下游采集框架。2、采集框架采集框架包括调度框架、采集过滤框架、反馈框架。调度框架对于采集框架中每一次请求进行登记,一旦有采集请求到达,其实时数据流入相应的子系统。
采集过滤框架对已进行了调度框架的请求进行拦截,一旦有请求到达,就把正在进行调度框架请求的请求拦截,然后转给采集框架请求。反馈框架则是根据调度框架返回的结果,反馈给调度框架。采集框架的作用是对子系统的下游采集框架进行每个请求的处理,包括以下几个方面:a、单纯的去请求字段,看子系统的网页版是如何处理的;b、在存储中进行转换,将网页中的字段转换成字符串;c、将网页中的字符串转换成字段或列表等;d、对于字段做加工处理,处理文本表中字段的加工方式等。
采集框架本身不处理任何请求,它只负责作为整个自动采集框架对外的接口系统。在进行自动采集框架设计时,需要考虑几个常见的因素,包括需要采集的各个字段,字段的外形,内容,是否需要进行sql注入等。下面将举一个很经典的例子来阐述下采集框架设计中要考虑的几个常见因素。经典的实例介绍:该案例最后由发布网址:主要介绍一个三级分公司的路由图,然后是对自动采集框架及接口和所有设置和配置进行详细说明。
整个项目为单体模式项目,分公司的路由图主要由四个子网模块来画:数据源(重点)、信道描述模块、帧(帧头)转发模块、帧转发模块,分别由分公司网页和子网集中管理。采集接口:采集接口用来采集单体自动采集框架对应的子网路由图,并将路由图返回到子网集中进行二次放大和处理。子网集中的配置是:对于单体采集框架的接互框架,子网是单独配置,并且在子网相应的子网集中进行配置(通常把子网集中交给工程师进行管理),工程师会每个子网配置一个接口,每个子网的每个接口的ip都是相同的,但是子网网段不同。
接口的具体位置:以下为子网路由图,采集子网为a,它是子网中要放大的接口。发送数据头:接口的发送数据头:发送数据流:接口转发:子网封装:子网封装:高清采集:子网封装:下载文档:。
自动采集子系统(自动采集子系统的数据安全性不高的原因分析)
采集交流 • 优采云 发表了文章 • 0 个评论 • 226 次浏览 • 2021-09-01 19:07
自动采集子系统具有完整的组网架构,且便于拓展,并提供给子系统很方便的接入调度,但在子系统类型确定的情况下,自动采集子系统的数据传输有时会存在个地址之争,这是由于采集子系统需要进行重定向,但传统的重定向接口具有局限性;具体来说,重定向接口主要存在两个问题:一是配置麻烦,无法跨子系统跨平台,二是跨域速度缓慢。
传统的c端往往要向s端进行配置,而s端往往还需要配置c端一些内容,这相当于将exploit的代码开放给相同平台的c端,c端在接收到这些反馈后,将exploit代码代码转化为executor的代码,并且重定向到s端。这种方式在需要跨域的情况下,往往会因为网络原因而导致数据延迟很高;而对于web子系统来说,最容易出现的问题就是跨域问题。
自动采集子系统在跨域情况下,所传输数据就是纯粹的xml数据,xml是一种无状态的数据格式,数据传输速度慢、占用磁盘空间大,所以数据往往得不到保留,因此传统的xml数据定义时,常规是提供二进制格式输出的;其中apachesnmp协议可以完美解决跨域问题,同时snmp协议还可以给其他需要重定向的子系统提供子系统层面的一套标准接口,同时它的安全性非常高,可以通过base64加密,传统xml定义的数据安全性不高,可以通过snmp解决。
对于第一代的b/s架构,一个重要核心的协议就是snmp,在tomcat(engineer-servicemonitor)和glassfish(myresourceway:engineer-servicemonitor)中有大量的snmp协议相关的实现方案,而对于apachesnmp2类型的其他协议,在snmp协议本身的安全特性(tls二层安全)和解决方案上并没有吸引到太多人,比如thrift,实现方案上并没有优势,从后来thrift的取消流行情况可以看出。
关于thrift,是一个自动化运维过程中必需的解决方案。至于web前端如何实现snmp方案,实现并无太多需要去实现的了,这些都不需要去过多关注,对于web端,如果需要传输xml格式的数据,一般就是使用postmessage(extendedbase64,postmessagep),这部分重定向语法确实不支持,只要方案跟提供的接口相关,就能够解决传输xml格式数据的问题。
但是对于后端来说,支持snmp协议的web访问往往并不多,因为通常单机访问是没有太多性能优势的。web网页端常用的采集方案目前可以总结出几种:1,executor的接口,也即基于单元测试工具使用多个ie,也即同一个网页中同时调用多个子页面;2,子页面不单独调用ie去访问,而是通过postmessage调用多个ie来调用;3,其他方案;比如redisorm,spring等等。 查看全部
自动采集子系统(自动采集子系统的数据安全性不高的原因分析)
自动采集子系统具有完整的组网架构,且便于拓展,并提供给子系统很方便的接入调度,但在子系统类型确定的情况下,自动采集子系统的数据传输有时会存在个地址之争,这是由于采集子系统需要进行重定向,但传统的重定向接口具有局限性;具体来说,重定向接口主要存在两个问题:一是配置麻烦,无法跨子系统跨平台,二是跨域速度缓慢。
传统的c端往往要向s端进行配置,而s端往往还需要配置c端一些内容,这相当于将exploit的代码开放给相同平台的c端,c端在接收到这些反馈后,将exploit代码代码转化为executor的代码,并且重定向到s端。这种方式在需要跨域的情况下,往往会因为网络原因而导致数据延迟很高;而对于web子系统来说,最容易出现的问题就是跨域问题。
自动采集子系统在跨域情况下,所传输数据就是纯粹的xml数据,xml是一种无状态的数据格式,数据传输速度慢、占用磁盘空间大,所以数据往往得不到保留,因此传统的xml数据定义时,常规是提供二进制格式输出的;其中apachesnmp协议可以完美解决跨域问题,同时snmp协议还可以给其他需要重定向的子系统提供子系统层面的一套标准接口,同时它的安全性非常高,可以通过base64加密,传统xml定义的数据安全性不高,可以通过snmp解决。
对于第一代的b/s架构,一个重要核心的协议就是snmp,在tomcat(engineer-servicemonitor)和glassfish(myresourceway:engineer-servicemonitor)中有大量的snmp协议相关的实现方案,而对于apachesnmp2类型的其他协议,在snmp协议本身的安全特性(tls二层安全)和解决方案上并没有吸引到太多人,比如thrift,实现方案上并没有优势,从后来thrift的取消流行情况可以看出。
关于thrift,是一个自动化运维过程中必需的解决方案。至于web前端如何实现snmp方案,实现并无太多需要去实现的了,这些都不需要去过多关注,对于web端,如果需要传输xml格式的数据,一般就是使用postmessage(extendedbase64,postmessagep),这部分重定向语法确实不支持,只要方案跟提供的接口相关,就能够解决传输xml格式数据的问题。
但是对于后端来说,支持snmp协议的web访问往往并不多,因为通常单机访问是没有太多性能优势的。web网页端常用的采集方案目前可以总结出几种:1,executor的接口,也即基于单元测试工具使用多个ie,也即同一个网页中同时调用多个子页面;2,子页面不单独调用ie去访问,而是通过postmessage调用多个ie来调用;3,其他方案;比如redisorm,spring等等。
自动采集子系统(自动采集子系统建设说明书(一)-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-08-31 12:02
自动采集子系统总结自动采集系统建设说明
一、系统目标:自动采集子系统,直接操作,可以工作到80%,减少人工干预操作,24小时自动直接操作。
1、自动采集系统应该具备:自动化软件,分布式采集系统,不同程度的节点。
2、系统采集方式:各节点分散布置,各节点自动化系统和分布式采集系统。
二、设计目标:自动采集系统不能带领总部子系统自动采集子系统,单机采集,一台电脑搞定自动采集子系统。
三、系统架构需要:子系统集群,
四、采集系统设计:子系统采集方式
1、小范围采集,每个节点自动化采集子系统当子节点数量和自动化采集子系统规模相同,小范围采集,大范围采集。
2、子节点集群,采集服务器集群。一台小范围采集,小范围采集每个节点自动化采集子系统当规模相同,子节点数量和采集子系统规模相同,1个小范围采集,2个子节点采集服务器集群。
3、子节点集群,采集服务器集群。一台采集服务器,一台采集子系统,一台采集子系统采集集群,采集子系统集群:根据采集子系统规模大小,以及节点数量和采集子系统规模一起分割采集子系统规模。
采集系统架构图设计完成以上就可以开始设计采集子系统了
1、子节点规模10台电脑,服务器规模2台
2、根据采集子系统规模,把采集子系统设计成两台或多台采集服务器系统1台采集服务器,10台采集服务器系统,采集服务器配置请参考上图。
5、子节点集群2台采集服务器,交换机1个采集服务器,子节点集群3台采集服务器,交换机1个采集服务器。如果所有子节点采集服务器规模10台,需要采集服务器配置如下。这个规模的采集服务器配置可以参考下图。电脑单机采集,用一台电脑,规模为2台电脑。采集子系统30台电脑配置采集子系统交换机30个交换机。分机节点采集,有3台采集服务器,3台采集服务器一组,采集服务器如下。
分机节点集群采集,有3台采集服务器,一组,采集服务器采集集群。分机节点采集,有3台采集服务器,一组,采集服务器采集集群。采集服务器集群6台采集服务器,需要搭建采集服务器集群。采集子系统配置这种采集子系统的采集子系统要求子系统规模大,分配的采集子系统节点多,大量规模采集服务器和节点集群,设计采集服务器和采集子系统的采集集群需要专业的采集软件。
优点是系统效率高,采集服务器集群采集效率更高。缺点是采集采集子系统规模大,配置贵。四通道采集服务器和分组采集服务器优点:节点集群采集和单通道采集的采集节点和采集节点在同一时间,效率更高。配置上安装更方便。
缺点:
1、采集 查看全部
自动采集子系统(自动采集子系统建设说明书(一)-上海怡健医学)
自动采集子系统总结自动采集系统建设说明
一、系统目标:自动采集子系统,直接操作,可以工作到80%,减少人工干预操作,24小时自动直接操作。
1、自动采集系统应该具备:自动化软件,分布式采集系统,不同程度的节点。
2、系统采集方式:各节点分散布置,各节点自动化系统和分布式采集系统。
二、设计目标:自动采集系统不能带领总部子系统自动采集子系统,单机采集,一台电脑搞定自动采集子系统。
三、系统架构需要:子系统集群,
四、采集系统设计:子系统采集方式
1、小范围采集,每个节点自动化采集子系统当子节点数量和自动化采集子系统规模相同,小范围采集,大范围采集。
2、子节点集群,采集服务器集群。一台小范围采集,小范围采集每个节点自动化采集子系统当规模相同,子节点数量和采集子系统规模相同,1个小范围采集,2个子节点采集服务器集群。
3、子节点集群,采集服务器集群。一台采集服务器,一台采集子系统,一台采集子系统采集集群,采集子系统集群:根据采集子系统规模大小,以及节点数量和采集子系统规模一起分割采集子系统规模。
采集系统架构图设计完成以上就可以开始设计采集子系统了
1、子节点规模10台电脑,服务器规模2台
2、根据采集子系统规模,把采集子系统设计成两台或多台采集服务器系统1台采集服务器,10台采集服务器系统,采集服务器配置请参考上图。
5、子节点集群2台采集服务器,交换机1个采集服务器,子节点集群3台采集服务器,交换机1个采集服务器。如果所有子节点采集服务器规模10台,需要采集服务器配置如下。这个规模的采集服务器配置可以参考下图。电脑单机采集,用一台电脑,规模为2台电脑。采集子系统30台电脑配置采集子系统交换机30个交换机。分机节点采集,有3台采集服务器,3台采集服务器一组,采集服务器如下。
分机节点集群采集,有3台采集服务器,一组,采集服务器采集集群。分机节点采集,有3台采集服务器,一组,采集服务器采集集群。采集服务器集群6台采集服务器,需要搭建采集服务器集群。采集子系统配置这种采集子系统的采集子系统要求子系统规模大,分配的采集子系统节点多,大量规模采集服务器和节点集群,设计采集服务器和采集子系统的采集集群需要专业的采集软件。
优点是系统效率高,采集服务器集群采集效率更高。缺点是采集采集子系统规模大,配置贵。四通道采集服务器和分组采集服务器优点:节点集群采集和单通道采集的采集节点和采集节点在同一时间,效率更高。配置上安装更方便。
缺点:
1、采集
自动采集子系统(一个网络舆情预警系统参考材料的思考与思考(一))
采集交流 • 优采云 发表了文章 • 0 个评论 • 194 次浏览 • 2021-08-29 17:09
〇,写在前面(2016-05-29 更新)
看时间,现在正好是两年前,我完成了这个毕业设计。本摘要摘自论文摘要。说的很简洁,但是没有提到当时有各种尝试来分析这个话题。
这个话题始于好奇,对数据来源的好奇,对所谓的机器学习和自然语言处理算法的好奇。多亏了这种好奇心,在没有现成的参考资料的情况下,我真的可以说“跪下”去体会这个庞大而空洞的主题。
数据源部分需要关注URL获取、网页分析、数据存储;分析时需要注意分词、降噪等;而最后的舆情分析,除了考虑技术算法的选择,更重要的是厘清什么是舆情。而这些,从学习、设计到实现,只用了不到四个月的时间。
当然,时间紧的时候也有短期的对策。网上类似的系统虽然不对外开放,但其实每个部分都有大量的开源代码可供参考。在参考实现的过程中,我边使用边学习了Python、R语言和非关系型数据库MongoDB。这两天为了让Orz显得不那么水汪汪,用PyQt写了一个软件界面。
总之,这个题目最大的提升恐怕就是问题分析能力、信息搜索能力和整合能力了,哈哈。
所以回过头来看,有了一定的工程能力之后,重点应该是学会进一步思考。一方面考虑数据算法,另一方面考虑现实世界的数据建模。记录下来作为以后学习的方向。
附上github链接。目前,由于微博信息获取模块未更新,无法正常获取信息。仅供参考……回头看当时的代码,真的很乱……
一、概览
本文设计并实现了一个在线舆情预警系统。该系统的主要功能是:对指定时间和区域的多条用户微博进行文本挖掘,通过数据可视化,直观展示潜在的舆情热点。
微博信息采集阶段,借助相关网络爬虫素材,结合Python的BeautifulSoup库,完善新浪微博网页版分析,系统自定义采集规则。同时,使用非关系型数据库MongoDB存储用户信息和微博信息,为以后更深入的研究奠定了良好的数据基础。
在信息分类阶段,本研究结合自然语言处理和机器学习相关理论,使用基于前向最大匹配的mmseg4j中文分词对文本进行分词,使用支持向量机算法对文本进行处理,并人工标注一定的在大量文本的基础上,更好地实现了文本的半监督学习,过滤掉了大部分无意义的文本。
在文本信息分析和预警阶段,本研究优化了基本的分词步骤,即使用正则表达式提取新浪微博标签内容并实时添加到分词词典中,促进基于短语的文本分析。同时,结合R语言在统计和图形方面的优势,编写R代码使用层次聚类算法对过滤后的文本进行聚类,最后通过调用wordcloud库,以“词云”各种事件和热度。
二、舆论预警系统方案设计
(1)系统结构设计
①系统总体结构设计
由于本系统集成了舆情发现-处理-分析三个阶段,所以抽象为三个子系统,分别是information采集子系统、信息分类子系统、聚类舆情可视化子系统。其中信息采集子系统负责用户自定义的受限信息采集微博文本内容,信息分类子系统通过提前学习构建文本分类器,然后将分类模型应用到系统采集subsystem采集给资料,包括训练模块、预测模块、评估模块。聚类舆情可视化子系统进一步对过滤后的文本进行预处理,通过层次聚类结合注意力评分,以“词云”的形式展示当前舆情热点。
详见图2.1,箭头方向为基本数据流向。
图2.1系统整体结构
②微博资讯采集子系统架构设计
图2.2微博信息采集子系统架构
图2.2是微博信息采集子系统的体系结构。模拟用户登录新浪微博后,采集工作正式启动。首先解析初始用户的“关注”和“粉丝”列表,将符合自定义规则的用户的uid(新浪微博用户唯一标识)存入队列;然后会解析用户的微博内容,分析符合自定义规则的微博。将其保存在数据库中;当前用户解析完成后,下一个用户会从“微博用户队列”的头部取出,循环执行上述步骤。
③信息分类子系统的设计
在实际应用中,信息分类分为两部分。一种是手动标注训练样本,构建满足需求的SVM模型(见图2.3);另一种是利用训练好的分类模型,对输入样本进行比较进行预测。
图2.3 训练模块架构
④聚类舆情可视化子系统设计
聚类舆情可视化子系统的系统结构如图2.4所示。
图2.4 聚类舆情可视化子系统架构
(2)系统流程设计
在对整体的设计和各个子系统的系统结构进行分项描述之后,结合用户操作界面的设计,现在结合系统使用过程的概述。整个系统流程如2.5 所示。实线连接部分是系统最基本的进程,虚线部分是系统的后台运行进程。 “可选显示模块”的内容可以通过界面按钮来控制,决定是否在界面上显示。
图2.5 整体系统流程
三、舆情预警系统实施与测试
该系统由三个子系统组成。实现界面如图3.1所示。其中,微博信息采集模块是基于开源爬虫框架Cola实现的。 采集规则改进后可以自定义。自定义模块如图左上部分所示。同时采集日志可以通过“左下角微博采集”完成采集进程停止后,可以在右上角显示采集的文字图,并调用信息分类子系统对采集文本进行分类。最终的分类结果如图右下方所示。
图3.1 舆情预警系统实现界面
此时点击上图中的“舆情聚类分析”按钮,生成预警词云,如图3.2。
图3.2聚类舆情词云效果图
词云图中的外圈标签是类别号,每个类别的词以相同的色调显示。从图中可以直观地发现,在测试期间,从我的微博开始,江苏周边南京地区的用户,讨论最多的类别是第一类别,突出的特征词是“周年”和“南游知之”。 《声响30年》等;虽然潜在事件以“端午节快乐”为代表,但总体类别事件过于稀疏。
四、结论
本文系统地提出了一种在线舆情预警系统的设计与实现,可以根据用户自定义信息采集规则获取合格的新浪微博数据,完成对无意义微博文本的过滤。最终,不同类别的事件以“词云”的形式呈现给用户。
从系统测试结果来看,该系统基本可以满足个人用户了解身边潜在舆论的需求,但系统各方面还有很大的提升空间。比如微博信息采集子系统,未来可以通过分布式和多账户操作,提高采集的效率;需要对微博内容的含义有更清晰的定义,选择具有鲜明特征的微博作为训练样本,以提高信息分类子系统的过滤效果;现有舆情信息应进一步结合舆情特征分析。
除了在技术上完善舆情预警系统,从道德伦理的角度深化对网络环境的思考也具有现实意义。当前用户隐私与各方网络监控的矛盾日趋严重。如何处理这样的矛盾,不仅是本课题需要探索的问题,也是每个科技人员需要思考的问题。
参考资料
[1] 新浪微博数据中心。 2011年媒体微博研究报告[EB/OL]。 (2012-03-21).
[2] 新浪微博数据中心。 2013年新浪媒体微博报道[EB/OL].[2014-06-1].
[3] 陈鑫。基于行块分布函数的通用网页文本提取[R].哈尔滨工业大学社会计算与信息检索研究中心。
[4]MicheleBanko、MichaelJCafarella、StephenSoderland、MattBroadhead 和 OrenEtzioni.OpenInformationExtractionfortheWeb[D].Washington:UniversityofWashington,2009.
[5] 翁宇。互联网话题中的网络文本挖掘技术[M].北京:中央民族大学出版社,2012.142.
[6]童薇,陈薇,孟晓峰。 EDM:高效微博事件检测算法[J].JournalofFrontiersofComputerScienceandTechnology,2012,6(12):1076-1086.
[7]CerenBudak,TheodoreGeorgiou,DivyakantAgrawal,AmrEIAbbadi.GeoScope:OnlineDetectionofGeoCorrelated[J].ProceedingsoftheVLDBEndowment,Vol.7,No.4.InformationTrendsinSocialNetworks, CerenBudak
[8] 丁聚玲,乐仲建.一种基于意见树的网络舆情危机预警方法[J].计算机应用研究, 2011, 28 (9): 3501-3504.
[9] 李云涛,柳岩,柳毅。网络舆情灰色预警评价研究[J].信息杂志, 2011, 30 (4):24-27.
[10]许昕,张兰兰。基于信号分析的突发事件网络舆情预警研究[J].智力理论与实践, 2010, 33 (12): 97-100.
[11] 李碧城,王进,林晨。基于直觉模糊推理的网络舆情预警方法[J].计算机应用研究, 2010, 27 (9):3312-3315.
[12]EIRINAKIM,VAZIRGIANNISM.Webminingforwebpersonalization[J].ACMTransactionsonInternetTechnology,2003,3(1):12-13.
[13]MARTENSD,BRUYNSEELSL,BAESENSB,etal.Predictinggoingconcernopinionwithdatamining[J].DecisionSupportSystems,2008,45(4):765-777.
[14]ManojKAgarwal,KrithiRamamritham,ManishBhide.RealTimeDiscoveryofDenseClustersinHighlyDynamicGraphs:IdentifyingRealWorldEventsinHighlyDynamicEnvironments[J].ProceedingsoftheVLDBEndowment,Vol.5,No.10
[15]LeonardRichardson.BeautifulSoup4.2.0documentation[EB/OL].(2013-05-15).
[16]梁南元.书面汉语自动分词及另一种自动分词系统CDWS[C].汉字信息处理系统学术会议,1983(1):12-13
[17] 侯婉友.群体性突发事件微博舆情演变分析[D].哈尔滨:哈尔滨工业大学,2013.
[18]林轩田.APracticalGuidetoSupportVectorClassication[EB/OL].(2010-04-15).~cjlin/papers/guide/guide.pdf
[19]张智霖.Tmsvm参考文档(v1.1.0)[EB/OL].(2012-03-09).%E5%8F%82%E8%80% 83 %E6%96%87%E6%A1%A3%28v1.1.0%29.rar&can=2&q=
[20]秦旭业.Cola:分布式爬虫框架[EB/OL].(2013-09-21).
[21]孙健.Rwordseg_Vignette_CN[EB/OL].(2013-12-15). 查看全部
自动采集子系统(一个网络舆情预警系统参考材料的思考与思考(一))
〇,写在前面(2016-05-29 更新)
看时间,现在正好是两年前,我完成了这个毕业设计。本摘要摘自论文摘要。说的很简洁,但是没有提到当时有各种尝试来分析这个话题。
这个话题始于好奇,对数据来源的好奇,对所谓的机器学习和自然语言处理算法的好奇。多亏了这种好奇心,在没有现成的参考资料的情况下,我真的可以说“跪下”去体会这个庞大而空洞的主题。
数据源部分需要关注URL获取、网页分析、数据存储;分析时需要注意分词、降噪等;而最后的舆情分析,除了考虑技术算法的选择,更重要的是厘清什么是舆情。而这些,从学习、设计到实现,只用了不到四个月的时间。
当然,时间紧的时候也有短期的对策。网上类似的系统虽然不对外开放,但其实每个部分都有大量的开源代码可供参考。在参考实现的过程中,我边使用边学习了Python、R语言和非关系型数据库MongoDB。这两天为了让Orz显得不那么水汪汪,用PyQt写了一个软件界面。
总之,这个题目最大的提升恐怕就是问题分析能力、信息搜索能力和整合能力了,哈哈。
所以回过头来看,有了一定的工程能力之后,重点应该是学会进一步思考。一方面考虑数据算法,另一方面考虑现实世界的数据建模。记录下来作为以后学习的方向。
附上github链接。目前,由于微博信息获取模块未更新,无法正常获取信息。仅供参考……回头看当时的代码,真的很乱……
一、概览
本文设计并实现了一个在线舆情预警系统。该系统的主要功能是:对指定时间和区域的多条用户微博进行文本挖掘,通过数据可视化,直观展示潜在的舆情热点。
微博信息采集阶段,借助相关网络爬虫素材,结合Python的BeautifulSoup库,完善新浪微博网页版分析,系统自定义采集规则。同时,使用非关系型数据库MongoDB存储用户信息和微博信息,为以后更深入的研究奠定了良好的数据基础。
在信息分类阶段,本研究结合自然语言处理和机器学习相关理论,使用基于前向最大匹配的mmseg4j中文分词对文本进行分词,使用支持向量机算法对文本进行处理,并人工标注一定的在大量文本的基础上,更好地实现了文本的半监督学习,过滤掉了大部分无意义的文本。
在文本信息分析和预警阶段,本研究优化了基本的分词步骤,即使用正则表达式提取新浪微博标签内容并实时添加到分词词典中,促进基于短语的文本分析。同时,结合R语言在统计和图形方面的优势,编写R代码使用层次聚类算法对过滤后的文本进行聚类,最后通过调用wordcloud库,以“词云”各种事件和热度。
二、舆论预警系统方案设计
(1)系统结构设计
①系统总体结构设计
由于本系统集成了舆情发现-处理-分析三个阶段,所以抽象为三个子系统,分别是information采集子系统、信息分类子系统、聚类舆情可视化子系统。其中信息采集子系统负责用户自定义的受限信息采集微博文本内容,信息分类子系统通过提前学习构建文本分类器,然后将分类模型应用到系统采集subsystem采集给资料,包括训练模块、预测模块、评估模块。聚类舆情可视化子系统进一步对过滤后的文本进行预处理,通过层次聚类结合注意力评分,以“词云”的形式展示当前舆情热点。
详见图2.1,箭头方向为基本数据流向。
图2.1系统整体结构
②微博资讯采集子系统架构设计
图2.2微博信息采集子系统架构
图2.2是微博信息采集子系统的体系结构。模拟用户登录新浪微博后,采集工作正式启动。首先解析初始用户的“关注”和“粉丝”列表,将符合自定义规则的用户的uid(新浪微博用户唯一标识)存入队列;然后会解析用户的微博内容,分析符合自定义规则的微博。将其保存在数据库中;当前用户解析完成后,下一个用户会从“微博用户队列”的头部取出,循环执行上述步骤。
③信息分类子系统的设计
在实际应用中,信息分类分为两部分。一种是手动标注训练样本,构建满足需求的SVM模型(见图2.3);另一种是利用训练好的分类模型,对输入样本进行比较进行预测。
图2.3 训练模块架构
④聚类舆情可视化子系统设计
聚类舆情可视化子系统的系统结构如图2.4所示。
图2.4 聚类舆情可视化子系统架构
(2)系统流程设计
在对整体的设计和各个子系统的系统结构进行分项描述之后,结合用户操作界面的设计,现在结合系统使用过程的概述。整个系统流程如2.5 所示。实线连接部分是系统最基本的进程,虚线部分是系统的后台运行进程。 “可选显示模块”的内容可以通过界面按钮来控制,决定是否在界面上显示。
图2.5 整体系统流程
三、舆情预警系统实施与测试
该系统由三个子系统组成。实现界面如图3.1所示。其中,微博信息采集模块是基于开源爬虫框架Cola实现的。 采集规则改进后可以自定义。自定义模块如图左上部分所示。同时采集日志可以通过“左下角微博采集”完成采集进程停止后,可以在右上角显示采集的文字图,并调用信息分类子系统对采集文本进行分类。最终的分类结果如图右下方所示。
图3.1 舆情预警系统实现界面
此时点击上图中的“舆情聚类分析”按钮,生成预警词云,如图3.2。
图3.2聚类舆情词云效果图
词云图中的外圈标签是类别号,每个类别的词以相同的色调显示。从图中可以直观地发现,在测试期间,从我的微博开始,江苏周边南京地区的用户,讨论最多的类别是第一类别,突出的特征词是“周年”和“南游知之”。 《声响30年》等;虽然潜在事件以“端午节快乐”为代表,但总体类别事件过于稀疏。
四、结论
本文系统地提出了一种在线舆情预警系统的设计与实现,可以根据用户自定义信息采集规则获取合格的新浪微博数据,完成对无意义微博文本的过滤。最终,不同类别的事件以“词云”的形式呈现给用户。
从系统测试结果来看,该系统基本可以满足个人用户了解身边潜在舆论的需求,但系统各方面还有很大的提升空间。比如微博信息采集子系统,未来可以通过分布式和多账户操作,提高采集的效率;需要对微博内容的含义有更清晰的定义,选择具有鲜明特征的微博作为训练样本,以提高信息分类子系统的过滤效果;现有舆情信息应进一步结合舆情特征分析。
除了在技术上完善舆情预警系统,从道德伦理的角度深化对网络环境的思考也具有现实意义。当前用户隐私与各方网络监控的矛盾日趋严重。如何处理这样的矛盾,不仅是本课题需要探索的问题,也是每个科技人员需要思考的问题。
参考资料
[1] 新浪微博数据中心。 2011年媒体微博研究报告[EB/OL]。 (2012-03-21).
[2] 新浪微博数据中心。 2013年新浪媒体微博报道[EB/OL].[2014-06-1].
[3] 陈鑫。基于行块分布函数的通用网页文本提取[R].哈尔滨工业大学社会计算与信息检索研究中心。
[4]MicheleBanko、MichaelJCafarella、StephenSoderland、MattBroadhead 和 OrenEtzioni.OpenInformationExtractionfortheWeb[D].Washington:UniversityofWashington,2009.
[5] 翁宇。互联网话题中的网络文本挖掘技术[M].北京:中央民族大学出版社,2012.142.
[6]童薇,陈薇,孟晓峰。 EDM:高效微博事件检测算法[J].JournalofFrontiersofComputerScienceandTechnology,2012,6(12):1076-1086.
[7]CerenBudak,TheodoreGeorgiou,DivyakantAgrawal,AmrEIAbbadi.GeoScope:OnlineDetectionofGeoCorrelated[J].ProceedingsoftheVLDBEndowment,Vol.7,No.4.InformationTrendsinSocialNetworks, CerenBudak
[8] 丁聚玲,乐仲建.一种基于意见树的网络舆情危机预警方法[J].计算机应用研究, 2011, 28 (9): 3501-3504.
[9] 李云涛,柳岩,柳毅。网络舆情灰色预警评价研究[J].信息杂志, 2011, 30 (4):24-27.
[10]许昕,张兰兰。基于信号分析的突发事件网络舆情预警研究[J].智力理论与实践, 2010, 33 (12): 97-100.
[11] 李碧城,王进,林晨。基于直觉模糊推理的网络舆情预警方法[J].计算机应用研究, 2010, 27 (9):3312-3315.
[12]EIRINAKIM,VAZIRGIANNISM.Webminingforwebpersonalization[J].ACMTransactionsonInternetTechnology,2003,3(1):12-13.
[13]MARTENSD,BRUYNSEELSL,BAESENSB,etal.Predictinggoingconcernopinionwithdatamining[J].DecisionSupportSystems,2008,45(4):765-777.
[14]ManojKAgarwal,KrithiRamamritham,ManishBhide.RealTimeDiscoveryofDenseClustersinHighlyDynamicGraphs:IdentifyingRealWorldEventsinHighlyDynamicEnvironments[J].ProceedingsoftheVLDBEndowment,Vol.5,No.10
[15]LeonardRichardson.BeautifulSoup4.2.0documentation[EB/OL].(2013-05-15).
[16]梁南元.书面汉语自动分词及另一种自动分词系统CDWS[C].汉字信息处理系统学术会议,1983(1):12-13
[17] 侯婉友.群体性突发事件微博舆情演变分析[D].哈尔滨:哈尔滨工业大学,2013.
[18]林轩田.APracticalGuidetoSupportVectorClassication[EB/OL].(2010-04-15).~cjlin/papers/guide/guide.pdf
[19]张智霖.Tmsvm参考文档(v1.1.0)[EB/OL].(2012-03-09).%E5%8F%82%E8%80% 83 %E6%96%87%E6%A1%A3%28v1.1.0%29.rar&can=2&q=
[20]秦旭业.Cola:分布式爬虫框架[EB/OL].(2013-09-21).
[21]孙健.Rwordseg_Vignette_CN[EB/OL].(2013-12-15).
自动采集子系统( 手机客户端在管理端制定清单,分解清单)
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-29 17:06
手机客户端在管理端制定清单,分解清单)
安排成本管理
进度成本管理系统由管理客户端、Web平台和移动客户端组成。子系统以检查表为主线。管理人员在管理端制定清单,分解清单计算成本,对分解后的成本单位制定计划,有效关联成本与进度;现场人员在手机客户端采集建筑工程数量、材料仓库进出、机械进出等相关数据,实时提供施工现场第一手信息;公司管理层可在网页平台或手机客户端查询整个项目的进度和成本,即时预警可直接通过图表反映,具体问题可查询。细节。
系统主要功能介绍:
一、Management 客户端
管理客户端主要提供给项目管理人员(项目策划部)进行项目管理工作,如准备清单、准备计划等。
(1)列表管理
系统中最基本的清单录入和分解工作,进入详细的工程量清单,按规则分解得到成本单位,确定人力资源机器的市场价格,投标后价格(即即,自行确定的成本价格),并计算项目成本。
(2)计划管理
根据项目计划,为每个成本单位确定具体的执行计划,并显示条形图。
(3)Provider 管理
输入供应商信息,确定供应商的具体合同,将这些项目计划的执行者与成本单位关联起来。成本单位建立成本核算、利润统计、进度管理、进度执行管理全服务链接
二、手机客户端
移动客户端主要用于采集和查询数据,旨在为项目提供真实有效的运行数据,实时预警,及时发现。
(1)数据采集
基于管理清单计划数据,采集网站建设数据。现场手机填写资料简单、真实、可靠,可提供位置、图片、视频等资料作为佐证。
材料输入图
(2)data 查询
每个项目参与者都可以查看自己的相关工程数据,发现问题时通过系统报告问题。
手机数据查询图
三、网站平台
主要用于对项目的整体进度和成本进行管理和查询,对项目中的问题进行实时预警和及时发现。
三种计算的查询结果对比 查看全部
自动采集子系统(
手机客户端在管理端制定清单,分解清单)
安排成本管理
进度成本管理系统由管理客户端、Web平台和移动客户端组成。子系统以检查表为主线。管理人员在管理端制定清单,分解清单计算成本,对分解后的成本单位制定计划,有效关联成本与进度;现场人员在手机客户端采集建筑工程数量、材料仓库进出、机械进出等相关数据,实时提供施工现场第一手信息;公司管理层可在网页平台或手机客户端查询整个项目的进度和成本,即时预警可直接通过图表反映,具体问题可查询。细节。
系统主要功能介绍:
一、Management 客户端
管理客户端主要提供给项目管理人员(项目策划部)进行项目管理工作,如准备清单、准备计划等。
(1)列表管理
系统中最基本的清单录入和分解工作,进入详细的工程量清单,按规则分解得到成本单位,确定人力资源机器的市场价格,投标后价格(即即,自行确定的成本价格),并计算项目成本。
(2)计划管理
根据项目计划,为每个成本单位确定具体的执行计划,并显示条形图。
(3)Provider 管理
输入供应商信息,确定供应商的具体合同,将这些项目计划的执行者与成本单位关联起来。成本单位建立成本核算、利润统计、进度管理、进度执行管理全服务链接
二、手机客户端
移动客户端主要用于采集和查询数据,旨在为项目提供真实有效的运行数据,实时预警,及时发现。
(1)数据采集
基于管理清单计划数据,采集网站建设数据。现场手机填写资料简单、真实、可靠,可提供位置、图片、视频等资料作为佐证。
材料输入图
(2)data 查询
每个项目参与者都可以查看自己的相关工程数据,发现问题时通过系统报告问题。
手机数据查询图
三、网站平台
主要用于对项目的整体进度和成本进行管理和查询,对项目中的问题进行实时预警和及时发现。
三种计算的查询结果对比
互联网的重要组成部分之一——科技信息瞬息万变(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-08-26 02:19
随着互联网技术的飞速发展,互联网已经成为人们进行社会、经济、文化、教育、娱乐等活动不可缺少的媒介。互联网的重要组成部分之一万维网(World WideWeb)承载着大量的数据和信息,包括各种类型和形式的信息,从科技信息、新闻报道,到商业信息、教育材料。动态异构分布式信息资源库。由于其使用的方便性和显示能力的多样性,通过WEB获取信息和知识已成为不可或缺的渠道。根据中国互联网络信息中心(CNNIC)发布的第31次中国互联网发展统计报告,截至2012年12月末,中国网民规模达到5.640亿,互联网普及率为42.1%。网民每周平均上网时间为 20.5 小时。中国网站的数量为268万,网页数量高达1227亿。每个网页的平均字节数为 42KB,而且这些数据还在不断增长。互联网飞速发展的好处是它所收录的信息非常丰富,但同时也给我们带来了更加严峻的挑战,即如何根据用户的兴趣从海量的WEB信息中高效获取信息是当前互联网应用面临一个难题。 “科学技术是第一生产力”,“科技创新”是我国必须长期坚持的基本国策之一。随着我国经济文化的发展和民族文化素质的普遍提高,越来越多的人开始关注科技信息的发展。
个人或企业的发展模式逐渐从传统转变为依靠科技。科技发展迅猛,科技信息日新月异。在当今互联网信息时代,人们获取科技信息的方式不再局限于传统的教室和书籍。相反,从互联网上获取科技信息已经成为一种更加方便快捷的方式[54][55]。聚合这么多科技信息的内容,不仅难以保证内容的时效性,如果仅靠人工方式获取,还要耗费相当多的时间和精力。那么,更方便的方式是使用程序将采集信息源的内容(例如科技信息源网站中的内容)自动化,最后将结果以个性化的方式展示在终点站。本文实施的科技信息自动跟踪管理系统是与北京市某单位合作的科技项目的一个子系统。本文的主要任务是研究开发一套科技信息自动跟踪管理系统。该技术项目的总体结构如图1-1所示。目前市场上已经有一些特定的网页信息采集软件。他们大多采用人工观察网页和网页源代码,针对需要采集的特定数据手动配置采集规则,使用起来复杂繁琐。 ,且需要相关专业基础,不适合普通用户。另外,本文所实现的系统来源于特定的科技项目,市面上的软件无法满足该项目用户的特定需求,同类软件价格昂贵。因此,我希望设计一个简单易用、采集结果准确、可定制的信息源,以及动态采集科技信息自动跟踪系统。所实现的系统不仅可以为现有的科技信息采集领域提供参考和借鉴,而且在具体的应用领域也能产生良好的效果。 查看全部
互联网的重要组成部分之一——科技信息瞬息万变(组图)
随着互联网技术的飞速发展,互联网已经成为人们进行社会、经济、文化、教育、娱乐等活动不可缺少的媒介。互联网的重要组成部分之一万维网(World WideWeb)承载着大量的数据和信息,包括各种类型和形式的信息,从科技信息、新闻报道,到商业信息、教育材料。动态异构分布式信息资源库。由于其使用的方便性和显示能力的多样性,通过WEB获取信息和知识已成为不可或缺的渠道。根据中国互联网络信息中心(CNNIC)发布的第31次中国互联网发展统计报告,截至2012年12月末,中国网民规模达到5.640亿,互联网普及率为42.1%。网民每周平均上网时间为 20.5 小时。中国网站的数量为268万,网页数量高达1227亿。每个网页的平均字节数为 42KB,而且这些数据还在不断增长。互联网飞速发展的好处是它所收录的信息非常丰富,但同时也给我们带来了更加严峻的挑战,即如何根据用户的兴趣从海量的WEB信息中高效获取信息是当前互联网应用面临一个难题。 “科学技术是第一生产力”,“科技创新”是我国必须长期坚持的基本国策之一。随着我国经济文化的发展和民族文化素质的普遍提高,越来越多的人开始关注科技信息的发展。
个人或企业的发展模式逐渐从传统转变为依靠科技。科技发展迅猛,科技信息日新月异。在当今互联网信息时代,人们获取科技信息的方式不再局限于传统的教室和书籍。相反,从互联网上获取科技信息已经成为一种更加方便快捷的方式[54][55]。聚合这么多科技信息的内容,不仅难以保证内容的时效性,如果仅靠人工方式获取,还要耗费相当多的时间和精力。那么,更方便的方式是使用程序将采集信息源的内容(例如科技信息源网站中的内容)自动化,最后将结果以个性化的方式展示在终点站。本文实施的科技信息自动跟踪管理系统是与北京市某单位合作的科技项目的一个子系统。本文的主要任务是研究开发一套科技信息自动跟踪管理系统。该技术项目的总体结构如图1-1所示。目前市场上已经有一些特定的网页信息采集软件。他们大多采用人工观察网页和网页源代码,针对需要采集的特定数据手动配置采集规则,使用起来复杂繁琐。 ,且需要相关专业基础,不适合普通用户。另外,本文所实现的系统来源于特定的科技项目,市面上的软件无法满足该项目用户的特定需求,同类软件价格昂贵。因此,我希望设计一个简单易用、采集结果准确、可定制的信息源,以及动态采集科技信息自动跟踪系统。所实现的系统不仅可以为现有的科技信息采集领域提供参考和借鉴,而且在具体的应用领域也能产生良好的效果。
自动采集子系统 2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-08-21 05:23
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
作者买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL2、。Ubuntu系统和NVIDIA Driver成功运行了Ubuntu子系统中的深度学习代码Windows,GPU资源全满!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软把WSL 2变成稳定版后,我们只需要输入如下命令就可以设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须为4.19.121 或更高版本。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查是否在 Windows 升级设置中打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
查看全部
自动采集子系统 2020年6月,微软公布WindowsSubsystemforLinux2的最新更新
简介:2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。我买了一个新的工作站,并尝试通过各种方式安装 Windows 和 Ub
本文转载自:在Windows的Ubuntu子系统上运行支持CUDA的深度学习代码。 html,转载于本站以传达更多信息,版权归原作者或来源组织所有。
2020 年 6 月,微软发布了 Windows Subsystem for Linux 2 的最新更新,全面支持 CUDA 和 N 卡 GPU。在 Windows 上运行 Ubuntu 子系统并在其中运行 GPU 加速的深度学习代码已成为现实。开发者终于不用为了熟悉的Linux环境(以及Windows 10之后的繁琐启动)在自己的开发机器上安装Windows和Ubuntu的双系统了。 manager 调试设置过程),同时允许 Windows 和 Ubuntu 共享相同的文件系统。
作者买了一个新的工作站。在尝试安装Windows和Ubuntu双系统或安装Windows的Ubuntu子系统后,我终于在Windows 10中成功安装了最新的WSL2、。Ubuntu系统和NVIDIA Driver成功运行了Ubuntu子系统中的深度学习代码Windows,GPU资源全满!
设置 Windows Insider 并安装更新
首先确保电脑的BIOS选项中开启了Virtualization功能。
BIOS 设置好后,我们需要在 Windows 中安装微软于 2020 年 6 月 17 日开放的最新 Windows Insider Build。我们必须先注册为 Windows Insider,加入 Windows Dev Channel,然后更新 Windows 以构建 20150 或更高版本。
设置 Windows 子系统 Linux (WSL) 2
以后微软把WSL 2变成稳定版后,我们只需要输入如下命令就可以设置WSL 2:
wsl --install
现在WSL2的功能还处于测试阶段,我们需要以管理员权限打开PowerShell。
首先设置 WSL 1:
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
然后设置 WSL 2:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
重新启动 Windows 10:
Restart-Computer
WSL 2 成为默认选项后,以下步骤可以省略,但现在我们需要打开 PowerShell 将 WSL 2 设置为默认选项:
wsl.exe --set-default-version 2
在 WSL 上安装 Ubuntu
在 Microsoft Store 中安装 Ubuntu:
安装 Windows 终端
在 Microsoft Store 中安装 Windows 终端。 Windows Terminal 的主要优点是以后可以在同一个窗口中一键打开多个 PowerShell 和 Ubuntu Terminal 选项卡,非常方便。
在 WSL 上设置 Ubuntu
在Windows开始菜单中打开Ubuntu,第一次打开需要设置Ubuntu系统的用户名和密码。此帐户独立于 Windows 帐户。
设置完成后,关闭原来的窗口,然后打开Windows Terminal,在下拉菜单中选择Ubuntu,打开一个新的Ubuntu Terminal。
下一步非常重要,我们必须检查以确保我们运行的是正确的 WSL 2 Linux 内核。进入 Ubuntu:
uname -r
内核版本必须为4.19.121 或更高版本。如果没有,请先在 Windows PowerShell 中尝试:
wsl.exe --update
如果还是不行,请检查是否在 Windows 升级设置中打开了“更新 Windows 时接收其他 Microsoft 产品的更新”选项:
然后再次检查 Windows Update,看看是否有最新的 Windows Subsystem for Linux Update。
在 Windows 10 上安装 Nvidia 的 WSL2 驱动程序
为不同的显卡安装相应的驱动程序。
未来英伟达的驱动会自动集成到Windows Update中,但现在支持WSL2的英伟达驱动还在开发者测试版中。用户需要加入英伟达开发者计划才能获得最新驱动程序的下载权限。
在 WSL 中安装 Docker
在 Ubuntu 终端中:
sudo apt -y install docker.io
安装 Nvidia 容器工具包
设置版本变量,导入Nvidia库的GPG Key,将Nvidia repo添加到Ubuntu的apt安装源中。在 Ubuntu 终端中:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
curl -s -L https://nvidia.github.io/libnv ... ntal/$distribution/libnvidia-container-experimental.list | sudo tee /etc/apt/sources.list.d/libnvidia-container-experimental.list
更新Ubuntu的apt安装源并安装Nvidia运行环境:
sudo apt update && sudo apt install -y nvidia-docker2
关闭所有Ubuntu终端,打开PowerShell终端,手动关闭Ubuntu内核:
wsl.exe --shutdown Ubuntu
测试GPU计算环境
打开一个新的 Ubuntu 终端并启动 Docker:
sudo dockerd
在另一个新的 Ubuntu 终端中运行:
sudo docker run --gpus all nvcr.io/nvidia/k8s/cuda-sample:nbody nbody -gpu -benchmark
如果所有设置都没有问题,输出应该类似于以下内容:
测试 Tensorflow-GPU 容器
在另一个新的 Ubuntu 终端中运行:
docker run -u $(id -u):$(id -g) -it --gpus all -p 8888:8888 tensorflow/tensorflow:latest-gpu-py3-jupyter
如果一切正常,终端最终会给出一个带有token的jupter notebook地址。复制并在浏览器中打开,我们成功打开了一个运行Tensorflow的GPU加速的Jupyter notebook:
现在我们可以在这个 Windows Ubuntu 子系统环境中编写、测试和运行支持 CUDA 的 Tensorflow!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
种证件照片与人脸自动识别系统技术领域[0001](图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-07 03:23
专利名称:一种证件照制作方法及人脸识别系统
技术领域:
—一种身份证照片和人脸自动识别系统技术领域[0001]本实用新型属于人脸识别领域,具体涉及一种直接自动识别身份证照片和人脸的系统。
背景技术:
[0002] 现有的人脸识别方法,尤其是一些商业软件,对识别和对比的人脸照片的清晰度要求很高,例如人脸照片中两只眼睛的距离。 80 多个像素。但是,由于存储空间的限制,一般存储在身份证RFID卡上的照片清晰度较差,人脸照片中眼睛之间的距离只有20像素左右。因此,现有的人脸识别方法无法直接将存储在身份证RFID卡上的高压缩照片与现场拍摄的人脸照片进行对比。解决办法是与公安局身份证中心数据库联网,通过身份证号码从公安部数据中心获取并下载身份证原照片,然后使用一些商用的人脸识别软件拍摄身份证原件照片和现场快照。比较人脸照片。由于必须接入公安部身份证数据中心,其应用范围受到极大限制,且采集现场光照条件较高。实用新型内容 [0003]本实用新型提供了一种身份证照片和人脸自动识别系统,可以简单有效地解决现场拍摄的照片与人脸照片的比对问题。 [0004] 本实用新型包括以下技术特征。 [0005] 一种身份证照片和人脸自动识别系统,包括信息采集子系统和数据分析子系统。信息采集子系统包括摄像头设备和身份识别卡和读卡器;身份证与读卡器相匹配,身份证内含RFID电子标签,用于存储身份证照片;摄像设备采集的人脸信息和阅读器采集的身份证照片分别为输入数据分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元基于局部二值模式对采集一个人脸识别单元,将@的人脸信息与身份证照片上的局部特征进行比较;整体特征判断单元基于特征人脸对,将采集的人脸信息和身份证照片信息对整体特征进行比对。 人脸识别单元。
[0006] 本实用新型的识别系统将采集的身份证照片和人脸信息输入数据分析子系统,然后分别使用局部特征判断单元和整体特征判断单元进行判断。只有当局部特征判断单元认为与整体特征判断单元一致时,才输出人脸与身份证照片匹配的识别结果。局部特征判断单元和整体特征判断单元采用局部二值模式法(LBP)和特征脸法(PCA)实现人脸识别。这两种方法都是现有的算法,不是本实用新型要保护的改进。本实用新型的改进是选择这两个单元,利用两个单元连接的顺序来判断人脸的局部特征和整体特征。将存储的身份证照片与实时拍摄的人脸进行比对,为“实名制”制度的实施提供了强有力的技术支持,无需工作人员反复进行身份证与持证人的目视比对,提高工作效率。 [0007] 进一步地,本发明特别针对高度压缩的小照片,例如存储在身份证的RFID中的身份证照片,以及人脸眼睛之间的距离大约为20个像素的身份证照片。 [0008] 因此,身份证可以是第二代中国身份证,读卡器可以是身份证读卡器。当然,身份证可以是任何一种现有的带有记忆身份证照片的身份证,尤其是当记忆身份证照片的眼睛间距为15-25像素时。
但是,照片像素的大小不构成对本实用新型保护范围的限制。不能理解为本实用新型只能应用于小像素照片的识别。应当理解,本实用新型的新模型仍然可以获得更高的识别率。之所以能在小像素照片的情况下保持高识别率是因为本实用新型结合了整体(PCA)识别方法和局部(LBP)识别方法,通过局部特征的优化来实现判断单元和整体特征判断单元。 [0009] 进一步地,数据分析子系统在人脸验证模块之前还包括人脸检测模块,人脸检测模块用于提取人脸特征。人脸检测模块是基于肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点的检测模块。数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。人脸检测模块和图像处理模块可以有效提高识别效率和识别成功率。 [0010] 进一步地,在硬件连接中,数据分析子系统设置在上位机中,摄像头设备连接上位机,阅读器连接上位机上以串口方式连接。 [0011] 进一步地,该系统还包括存储子系统和监控管理子系统。存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问组成,识别结果存储库由监控管理子系统访问。
监控管理子系统通过查询访问识别结果存储库。 采集子系统的信息为采集人脸信息,来自摄像头的视频图像。 [0012] 上述人脸模板训练库用于保证识别过程中人脸数据的调用。人脸模板训练库收录原创人脸图像和从原创图像训练中提取的面部特征。识别结果数据库用于记录识别卡中存储的其他数据和其他信息,如人的身份证、姓名、照片、刷卡时间、是否可以识别为人等。保存为 JEPG 或 PNG 文件信息,特别是如果系统用于门禁识别管理,可以将识别结果存储为门禁记录。该系统还包括一个监控和管理子系统。通过监控管理子系统访问识别结果存储库,可以查询不同的信息。可以查询特定用户ID对应的所有识别信息,根据记录内容查看所有识别系统记录。 [0013] 进一步地,信息采集子系统用于从视频文件中获取采集person人脸信息,便于在保密监控的情况下以秘密监控方式识别采集。
[0014]图I为本实用新型的硬件连接图; [0015]图2为本实用新型内部模块连接图。
具体实现方法
[0016]下面结合说明书附图1-2对本实用新型的实施例进行说明。 [0017] 如图所示。如图1所示,本发明的硬件包括摄像装置1、身份证2和阅读器3;身份证2与阅读器3匹配,身份证2中收录用于存放证件的证件。摄像设备I采集的人脸信息和阅读器3采集的身份证照片被输入到数据分析子系统4中。数据分析子系统4设置在主机内,摄像装置1与主机相连,阅读器3与主机的串口相连。 [0018] 整个实用新型的控制部分包括输入数据分析子系统4、存储子系统5和监控管理子系统6。 [0019]输入数据分析子系统4用于对输入数据进行分析识别,包括图像处理模块41、人脸检测模块42和人脸验证模块43。图像处理模块41用于图像灰度转换、图像归一化和光均衡处理。人脸检测模块42根据肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点。人脸验证模块43由依次连接的局部特征判断单元43a和整体特征判断单元43b组成。局部特征判断单元43a用于在局部特征上将采集的人脸信息与身份证照片进行比对,整体特征判断单元43b用于将采集的人脸信息与身份证照片信息进行比对在整体特征上;当局部特征判断单元43a和整体特征判断单元43b都一致时,系统输出与照片匹配的人脸和ID识别结果。
[0020] 存储子系统5包括人脸模板训练库51和识别结果存储库52。人脸模板训练库51由局部特征判断单元43a和整体特征判断单元43b访问。识别结果存储库52由监控管理子系统6访问。 [0021]监控管理子系统6通过查询访问识别结果存储库52。 [0022] 本实用新型可以将现场拍摄的人脸转换成灰度图像,并进行归一化和光均衡处理;人脸检测使用RFID数据处理后的图像作为肤色检测,使用Adaboost算法剔除不必要的训练数据,并将重点放在重要的训练数据上;人脸验证使用基于二进制模式(LBP)的方法来提取人脸特征,然后使用基于特征的人脸(PCA)方法来实现人脸识别,最终达到二代身份证明自动人脸识别的效果RFID 照片和现场快照。 [0023] 在一个具体应用于考生身份识别的实施例中,整个系统包括三部分:摄像头、身份证和RFID阅读器。其中摄像头用于视频图像的采集,将视频流数据发送到数据处理计算机;身份证收录持有人姓名、照片等身份信息,身份证在RFID读写器的读取范围内。在内部,收录的数据被发送到 RFID 阅读器; RFID阅读器通过串口与计算机相连,当接收到RFID电子标签中存储的信息时,将信息传送给计算机。
[0024]输入数据分析子系统4是本实用新型的核心部分,涉及RFID识别卡中的信息处理、视频图像中正面位置的检测、人脸的提取特征,以及人脸验证以及各功能模块之间的同步互斥控制。 [0025] 存储子系统5包括人脸模块数据库、访问控制记录数据库和转发服务器。人脸模块数据库收录原创人脸图像和从原创图像训练中提取的人脸特征;门禁记录数据库智能识别系统在RFID卡中记录持卡人身份证、姓名、照片、刷卡时间、是否通过门禁系统等;转发服务器负责监控信息与手机之间的信息传递。负责将拍摄终端的图像数据转发到对应的手机终端。 [0026] 监控管理子系统6和存储子系统5通过数据库连接。系统支持的查询条件包括按时间查询、按ID查询、按记录内容查询。
声明1.一种自动识别照片和人脸识别系统,包括信息采集子系统和数据分析子系统,其特征在于信息采集子系统包括摄像装置、身份证件和读卡器;身份证与读卡器匹配,身份证内含RFID电子标签,用于存储身份证照片;分别输入摄像设备采集人脸信息数据和阅读器采集身份证照片分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。一个人脸识别单元,将人脸信息和身份证照片对局部特征进行比较;整体特征判断单元是根据特征人脸对采集的人脸信息和身份证照片信息人脸识别单元对整体特征进行比较的人。
2.如权利要求1所述的自动识别系统,其特征在于,所述识别卡为第二代中国身份证,所述读卡器为身份证读卡器。
3.如权利要求1所述的自动识别系统,其特征在于,所述身份证存储有两眼距离为15-25像素的证件照片。
4.如权利要求1所述的自动识别系统,其特征在于,所述数据分析子系统在人脸验证模块之前还包括人脸检测模块。
5.根据权利要求4所述的自动识别系统,其中人脸检测模块根据肤色检测确定人脸区域,并通过类Haar特征和Adaboost算法提取人脸特征点检测模块。
6.如权利要求5所述的自动识别系统,其特征在于,所述数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。
7.根据权利要求1至6中任一项所述的自动识别系统,其特征在于,所述数据分析子系统设置在主机中,摄像设备连接到主机,阅读器连接到主机串口方式的计算机。
8.如权利要求1所述的自动识别系统,其特征在于,还包括存储子系统和监控管理子系统,所述存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问,识别结果存储库由监控管理子系统访问。
9.如权利要求8所述的自动识别系统,其特征在于,所述监控管理子系统通过查询访问所述识别结果存储库。
10.根据权利要求1所述的自动识别系统,其中信息采集子系统用于从视频文件中获取采集人脸信息。
专利摘要本实用新型提供了一种身份证照片和人脸自动识别系统。系统包括信息采集子系统和数据分析子系统。数据分析子系统具有人脸验证模块。验证模块由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元将采集的人脸信息与身份证照片进行局部特征对比,整体特征判断单元将采集的人脸信息与身份证照片信息进行整体特征对比。只有当局部特征判断单元和整体特征判断单元都认为人脸与照片匹配时,系统才最终得到人脸与身份证照片匹配的识别结果。本实用新型可有效防止借用或冒用他人证件的行为,免去工作人员反复目视核对证件持有人的麻烦,提高实名制工作效率。
文件编号 G06K7/00GK202815870SQ20122048809
出版日期2013年3月20日申请日期2012年9月20日优先权日期2012年4月28日
发明人程远、王浩、范辉、张勇申请人:王浩 查看全部
种证件照片与人脸自动识别系统技术领域[0001](图)
专利名称:一种证件照制作方法及人脸识别系统
技术领域:
—一种身份证照片和人脸自动识别系统技术领域[0001]本实用新型属于人脸识别领域,具体涉及一种直接自动识别身份证照片和人脸的系统。
背景技术:
[0002] 现有的人脸识别方法,尤其是一些商业软件,对识别和对比的人脸照片的清晰度要求很高,例如人脸照片中两只眼睛的距离。 80 多个像素。但是,由于存储空间的限制,一般存储在身份证RFID卡上的照片清晰度较差,人脸照片中眼睛之间的距离只有20像素左右。因此,现有的人脸识别方法无法直接将存储在身份证RFID卡上的高压缩照片与现场拍摄的人脸照片进行对比。解决办法是与公安局身份证中心数据库联网,通过身份证号码从公安部数据中心获取并下载身份证原照片,然后使用一些商用的人脸识别软件拍摄身份证原件照片和现场快照。比较人脸照片。由于必须接入公安部身份证数据中心,其应用范围受到极大限制,且采集现场光照条件较高。实用新型内容 [0003]本实用新型提供了一种身份证照片和人脸自动识别系统,可以简单有效地解决现场拍摄的照片与人脸照片的比对问题。 [0004] 本实用新型包括以下技术特征。 [0005] 一种身份证照片和人脸自动识别系统,包括信息采集子系统和数据分析子系统。信息采集子系统包括摄像头设备和身份识别卡和读卡器;身份证与读卡器相匹配,身份证内含RFID电子标签,用于存储身份证照片;摄像设备采集的人脸信息和阅读器采集的身份证照片分别为输入数据分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元基于局部二值模式对采集一个人脸识别单元,将@的人脸信息与身份证照片上的局部特征进行比较;整体特征判断单元基于特征人脸对,将采集的人脸信息和身份证照片信息对整体特征进行比对。 人脸识别单元。
[0006] 本实用新型的识别系统将采集的身份证照片和人脸信息输入数据分析子系统,然后分别使用局部特征判断单元和整体特征判断单元进行判断。只有当局部特征判断单元认为与整体特征判断单元一致时,才输出人脸与身份证照片匹配的识别结果。局部特征判断单元和整体特征判断单元采用局部二值模式法(LBP)和特征脸法(PCA)实现人脸识别。这两种方法都是现有的算法,不是本实用新型要保护的改进。本实用新型的改进是选择这两个单元,利用两个单元连接的顺序来判断人脸的局部特征和整体特征。将存储的身份证照片与实时拍摄的人脸进行比对,为“实名制”制度的实施提供了强有力的技术支持,无需工作人员反复进行身份证与持证人的目视比对,提高工作效率。 [0007] 进一步地,本发明特别针对高度压缩的小照片,例如存储在身份证的RFID中的身份证照片,以及人脸眼睛之间的距离大约为20个像素的身份证照片。 [0008] 因此,身份证可以是第二代中国身份证,读卡器可以是身份证读卡器。当然,身份证可以是任何一种现有的带有记忆身份证照片的身份证,尤其是当记忆身份证照片的眼睛间距为15-25像素时。
但是,照片像素的大小不构成对本实用新型保护范围的限制。不能理解为本实用新型只能应用于小像素照片的识别。应当理解,本实用新型的新模型仍然可以获得更高的识别率。之所以能在小像素照片的情况下保持高识别率是因为本实用新型结合了整体(PCA)识别方法和局部(LBP)识别方法,通过局部特征的优化来实现判断单元和整体特征判断单元。 [0009] 进一步地,数据分析子系统在人脸验证模块之前还包括人脸检测模块,人脸检测模块用于提取人脸特征。人脸检测模块是基于肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点的检测模块。数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。人脸检测模块和图像处理模块可以有效提高识别效率和识别成功率。 [0010] 进一步地,在硬件连接中,数据分析子系统设置在上位机中,摄像头设备连接上位机,阅读器连接上位机上以串口方式连接。 [0011] 进一步地,该系统还包括存储子系统和监控管理子系统。存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问组成,识别结果存储库由监控管理子系统访问。
监控管理子系统通过查询访问识别结果存储库。 采集子系统的信息为采集人脸信息,来自摄像头的视频图像。 [0012] 上述人脸模板训练库用于保证识别过程中人脸数据的调用。人脸模板训练库收录原创人脸图像和从原创图像训练中提取的面部特征。识别结果数据库用于记录识别卡中存储的其他数据和其他信息,如人的身份证、姓名、照片、刷卡时间、是否可以识别为人等。保存为 JEPG 或 PNG 文件信息,特别是如果系统用于门禁识别管理,可以将识别结果存储为门禁记录。该系统还包括一个监控和管理子系统。通过监控管理子系统访问识别结果存储库,可以查询不同的信息。可以查询特定用户ID对应的所有识别信息,根据记录内容查看所有识别系统记录。 [0013] 进一步地,信息采集子系统用于从视频文件中获取采集person人脸信息,便于在保密监控的情况下以秘密监控方式识别采集。
[0014]图I为本实用新型的硬件连接图; [0015]图2为本实用新型内部模块连接图。
具体实现方法
[0016]下面结合说明书附图1-2对本实用新型的实施例进行说明。 [0017] 如图所示。如图1所示,本发明的硬件包括摄像装置1、身份证2和阅读器3;身份证2与阅读器3匹配,身份证2中收录用于存放证件的证件。摄像设备I采集的人脸信息和阅读器3采集的身份证照片被输入到数据分析子系统4中。数据分析子系统4设置在主机内,摄像装置1与主机相连,阅读器3与主机的串口相连。 [0018] 整个实用新型的控制部分包括输入数据分析子系统4、存储子系统5和监控管理子系统6。 [0019]输入数据分析子系统4用于对输入数据进行分析识别,包括图像处理模块41、人脸检测模块42和人脸验证模块43。图像处理模块41用于图像灰度转换、图像归一化和光均衡处理。人脸检测模块42根据肤色检测确定人脸区域,通过类Haar特征和Adaboost算法提取人脸特征点。人脸验证模块43由依次连接的局部特征判断单元43a和整体特征判断单元43b组成。局部特征判断单元43a用于在局部特征上将采集的人脸信息与身份证照片进行比对,整体特征判断单元43b用于将采集的人脸信息与身份证照片信息进行比对在整体特征上;当局部特征判断单元43a和整体特征判断单元43b都一致时,系统输出与照片匹配的人脸和ID识别结果。
[0020] 存储子系统5包括人脸模板训练库51和识别结果存储库52。人脸模板训练库51由局部特征判断单元43a和整体特征判断单元43b访问。识别结果存储库52由监控管理子系统6访问。 [0021]监控管理子系统6通过查询访问识别结果存储库52。 [0022] 本实用新型可以将现场拍摄的人脸转换成灰度图像,并进行归一化和光均衡处理;人脸检测使用RFID数据处理后的图像作为肤色检测,使用Adaboost算法剔除不必要的训练数据,并将重点放在重要的训练数据上;人脸验证使用基于二进制模式(LBP)的方法来提取人脸特征,然后使用基于特征的人脸(PCA)方法来实现人脸识别,最终达到二代身份证明自动人脸识别的效果RFID 照片和现场快照。 [0023] 在一个具体应用于考生身份识别的实施例中,整个系统包括三部分:摄像头、身份证和RFID阅读器。其中摄像头用于视频图像的采集,将视频流数据发送到数据处理计算机;身份证收录持有人姓名、照片等身份信息,身份证在RFID读写器的读取范围内。在内部,收录的数据被发送到 RFID 阅读器; RFID阅读器通过串口与计算机相连,当接收到RFID电子标签中存储的信息时,将信息传送给计算机。
[0024]输入数据分析子系统4是本实用新型的核心部分,涉及RFID识别卡中的信息处理、视频图像中正面位置的检测、人脸的提取特征,以及人脸验证以及各功能模块之间的同步互斥控制。 [0025] 存储子系统5包括人脸模块数据库、访问控制记录数据库和转发服务器。人脸模块数据库收录原创人脸图像和从原创图像训练中提取的人脸特征;门禁记录数据库智能识别系统在RFID卡中记录持卡人身份证、姓名、照片、刷卡时间、是否通过门禁系统等;转发服务器负责监控信息与手机之间的信息传递。负责将拍摄终端的图像数据转发到对应的手机终端。 [0026] 监控管理子系统6和存储子系统5通过数据库连接。系统支持的查询条件包括按时间查询、按ID查询、按记录内容查询。
声明1.一种自动识别照片和人脸识别系统,包括信息采集子系统和数据分析子系统,其特征在于信息采集子系统包括摄像装置、身份证件和读卡器;身份证与读卡器匹配,身份证内含RFID电子标签,用于存储身份证照片;分别输入摄像设备采集人脸信息数据和阅读器采集身份证照片分析子系统;数据分析子系统包括人脸验证模块,由依次连接的局部特征判断单元和整体特征判断单元组成。一个人脸识别单元,将人脸信息和身份证照片对局部特征进行比较;整体特征判断单元是根据特征人脸对采集的人脸信息和身份证照片信息人脸识别单元对整体特征进行比较的人。
2.如权利要求1所述的自动识别系统,其特征在于,所述识别卡为第二代中国身份证,所述读卡器为身份证读卡器。
3.如权利要求1所述的自动识别系统,其特征在于,所述身份证存储有两眼距离为15-25像素的证件照片。
4.如权利要求1所述的自动识别系统,其特征在于,所述数据分析子系统在人脸验证模块之前还包括人脸检测模块。
5.根据权利要求4所述的自动识别系统,其中人脸检测模块根据肤色检测确定人脸区域,并通过类Haar特征和Adaboost算法提取人脸特征点检测模块。
6.如权利要求5所述的自动识别系统,其特征在于,所述数据分析子系统还包括用于灰度图像转换、图像归一化和光均衡处理的图像处理模块。
7.根据权利要求1至6中任一项所述的自动识别系统,其特征在于,所述数据分析子系统设置在主机中,摄像设备连接到主机,阅读器连接到主机串口方式的计算机。
8.如权利要求1所述的自动识别系统,其特征在于,还包括存储子系统和监控管理子系统,所述存储子系统包括人脸模板训练库和识别结果存储库。人脸模板训练库由局部特征判断单元和整体特征判断单元访问,识别结果存储库由监控管理子系统访问。
9.如权利要求8所述的自动识别系统,其特征在于,所述监控管理子系统通过查询访问所述识别结果存储库。
10.根据权利要求1所述的自动识别系统,其中信息采集子系统用于从视频文件中获取采集人脸信息。
专利摘要本实用新型提供了一种身份证照片和人脸自动识别系统。系统包括信息采集子系统和数据分析子系统。数据分析子系统具有人脸验证模块。验证模块由依次连接的局部特征判断单元和整体特征判断单元组成。局部特征判断单元将采集的人脸信息与身份证照片进行局部特征对比,整体特征判断单元将采集的人脸信息与身份证照片信息进行整体特征对比。只有当局部特征判断单元和整体特征判断单元都认为人脸与照片匹配时,系统才最终得到人脸与身份证照片匹配的识别结果。本实用新型可有效防止借用或冒用他人证件的行为,免去工作人员反复目视核对证件持有人的麻烦,提高实名制工作效率。
文件编号 G06K7/00GK202815870SQ20122048809
出版日期2013年3月20日申请日期2012年9月20日优先权日期2012年4月28日
发明人程远、王浩、范辉、张勇申请人:王浩

