
自动采集子系统
自动采集子系统,提高工作效率和生产效率的因素
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-03-30 05:03
自动采集子系统,相对于手动采集,自动采集减少了采集人员的大部分工作,同时工作效率也提高了不少。(这里我只是说是相对)还有,自动采集更加的智能化,从而提高工作效率和生产效率。
1、相对于手动采集时间更加的固定,固定时间就可以完成,
2、自动采集可以更加快速的完成采集任务,从而降低采集的工作量,同时也提高采集软件的完成工作率。
3、自动采集可以减少部分人员的工作量,同时可以减少人工进行巡检的成本,保证人员在整个分析流程中的工作质量。
4、自动采集相对于手动采集主要可以提高采集中心的工作效率,从而降低采集中心的质量,保证采集中心的正常运营。就我接触过的自动采集技术来看,目前比较好的应该是华清远见的,这也是用于机器人采集和推荐系统上使用比较广泛的采集软件了。
自动采集要能一键进行采集,自动推送到机器人中去。手动采集要能爬取很多其他的数据。机器人采集得到的信息质量很高,能降低人为的数据工作量,提高程序的容错率。虽然这样不能保证全自动地进行采集,但是能达到这个的技术本身不难。只是找不到合适的采集系统罢了。
主要是采集方式的问题。目前国内有些企业是挂羊头卖狗肉,提供一套方案,工作人员再根据方案进行二次开发,就可以给客户提供一套定制化的系统。中国的工业机器人市场空间大,加上相关的产业链也很完善,所以制造企业或研究院校发展机器人已经不像过去那么盲目了。现在市场的机器人基本上分为工业机器人和农业机器人,前者已经有厂商设计一套系统,然后生产厂商自己推出一套配套的系统;后者是一套方案,厂商自己设计一套配套的系统。
以前做机器人研究的人现在也在做农业机器人,顺便利用机器人提供服务。另外,从统计数据来看,如果所有的机器人数量不超过1000台,那么市场容量还是不大的,机器人和人一样,只能作为分解工序的一个辅助工具存在,不可能做到没有弱项。 查看全部
自动采集子系统,提高工作效率和生产效率的因素
自动采集子系统,相对于手动采集,自动采集减少了采集人员的大部分工作,同时工作效率也提高了不少。(这里我只是说是相对)还有,自动采集更加的智能化,从而提高工作效率和生产效率。
1、相对于手动采集时间更加的固定,固定时间就可以完成,
2、自动采集可以更加快速的完成采集任务,从而降低采集的工作量,同时也提高采集软件的完成工作率。
3、自动采集可以减少部分人员的工作量,同时可以减少人工进行巡检的成本,保证人员在整个分析流程中的工作质量。
4、自动采集相对于手动采集主要可以提高采集中心的工作效率,从而降低采集中心的质量,保证采集中心的正常运营。就我接触过的自动采集技术来看,目前比较好的应该是华清远见的,这也是用于机器人采集和推荐系统上使用比较广泛的采集软件了。
自动采集要能一键进行采集,自动推送到机器人中去。手动采集要能爬取很多其他的数据。机器人采集得到的信息质量很高,能降低人为的数据工作量,提高程序的容错率。虽然这样不能保证全自动地进行采集,但是能达到这个的技术本身不难。只是找不到合适的采集系统罢了。
主要是采集方式的问题。目前国内有些企业是挂羊头卖狗肉,提供一套方案,工作人员再根据方案进行二次开发,就可以给客户提供一套定制化的系统。中国的工业机器人市场空间大,加上相关的产业链也很完善,所以制造企业或研究院校发展机器人已经不像过去那么盲目了。现在市场的机器人基本上分为工业机器人和农业机器人,前者已经有厂商设计一套系统,然后生产厂商自己推出一套配套的系统;后者是一套方案,厂商自己设计一套配套的系统。
以前做机器人研究的人现在也在做农业机器人,顺便利用机器人提供服务。另外,从统计数据来看,如果所有的机器人数量不超过1000台,那么市场容量还是不大的,机器人和人一样,只能作为分解工序的一个辅助工具存在,不可能做到没有弱项。
怎么样做好网站的SEO优化?(一)_
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-03-27 06:05
如何优化网站的SEO?
网站优化在两个句子中不清楚,所有网站优化基本相同。 网站优化是一个长期过程,范围从几个月到几年。以下是一些常用方法,仅供参考:
关键词选择
创建首页网站时,应首先设置目标关键词,不要等到网站建立后再设置百度收录,然后注意这些,否则您将后悔。然后借用一些工具查询长尾关键词,以查看哪些单词具有较大的搜索量,然后对一些搜索量较小的单词进行优化,这会影响到搜索量较大的单词。
高质量原创 文章
三年前,我们说原创 文章,但现在我们仍在谈论证明原创 文章对于百度来说仍然非常好。请记住,不要伪造原件。 网站每天需要更新一定数量的内容,选择一个好的关键词,从关键词开始,然后编写文章从经验,操作步骤,注意事项等方面更新内容,因此您还可以进行SEO优化,让搜索引擎通过内容页面找到网站,增加访问量,并提高网站排名。
优化内部和外部链接
尽管我是新手,但我还需要主动认识这个行业的一些朋友,并与我自己的人建立一些链接。我们还需要学习与网站进行合作,并不断提高网站的影响力。在操作网站时,如果遇到网站的结构不合理的情况,则还可以允许开发人员及时调整内部结构,以便您的网站将更方便搜索引擎捕获信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,就越容易实现SEO优化的目标。
可以在此处找到答案网站。其中收录更多相关的知识和教学视频
有许多现成的采集器软件,可以直接用于网站数据采集。我将简要介绍其中的三个,即优采云,章鱼和优采云。它们操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一个非常智能的Web爬虫软件,支持跨平台和多平台的人免费使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表单,链接,图片等,而无需配置任何采集规则。支持一键自动翻页和数据导出功能。对于小白来说,这很容易学习和掌握:这是一个很好的例子。与优采云采集器相比,八达通采集器仅支持Windows平台,手动设置采集字段和配置规则更加复杂。且灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白从入门到精通也非常方便:
当然,除了上述三个爬网软件外,还有许多其他软件也支持网站数据采集,例如创建数字和魔术策略。如果您熟悉Python,Java和其他编程语言,则还可以对自己进行编程以获取数据。 Internet上也有相关的程序和信息。简介非常详细。如果您有兴趣,可以搜索它们。希望您能分享以上信息,内容对您有所帮助,欢迎发表评论。 查看全部
怎么样做好网站的SEO优化?(一)_
如何优化网站的SEO?
网站优化在两个句子中不清楚,所有网站优化基本相同。 网站优化是一个长期过程,范围从几个月到几年。以下是一些常用方法,仅供参考:
关键词选择
创建首页网站时,应首先设置目标关键词,不要等到网站建立后再设置百度收录,然后注意这些,否则您将后悔。然后借用一些工具查询长尾关键词,以查看哪些单词具有较大的搜索量,然后对一些搜索量较小的单词进行优化,这会影响到搜索量较大的单词。
高质量原创 文章
三年前,我们说原创 文章,但现在我们仍在谈论证明原创 文章对于百度来说仍然非常好。请记住,不要伪造原件。 网站每天需要更新一定数量的内容,选择一个好的关键词,从关键词开始,然后编写文章从经验,操作步骤,注意事项等方面更新内容,因此您还可以进行SEO优化,让搜索引擎通过内容页面找到网站,增加访问量,并提高网站排名。
优化内部和外部链接
尽管我是新手,但我还需要主动认识这个行业的一些朋友,并与我自己的人建立一些链接。我们还需要学习与网站进行合作,并不断提高网站的影响力。在操作网站时,如果遇到网站的结构不合理的情况,则还可以允许开发人员及时调整内部结构,以便您的网站将更方便搜索引擎捕获信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,就越容易实现SEO优化的目标。
可以在此处找到答案网站。其中收录更多相关的知识和教学视频
有许多现成的采集器软件,可以直接用于网站数据采集。我将简要介绍其中的三个,即优采云,章鱼和优采云。它们操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一个非常智能的Web爬虫软件,支持跨平台和多平台的人免费使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表单,链接,图片等,而无需配置任何采集规则。支持一键自动翻页和数据导出功能。对于小白来说,这很容易学习和掌握:这是一个很好的例子。与优采云采集器相比,八达通采集器仅支持Windows平台,手动设置采集字段和配置规则更加复杂。且灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白从入门到精通也非常方便:
当然,除了上述三个爬网软件外,还有许多其他软件也支持网站数据采集,例如创建数字和魔术策略。如果您熟悉Python,Java和其他编程语言,则还可以对自己进行编程以获取数据。 Internet上也有相关的程序和信息。简介非常详细。如果您有兴趣,可以搜索它们。希望您能分享以上信息,内容对您有所帮助,欢迎发表评论。
自动采集子系统的应用范围有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-03-25 22:01
自动采集子系统应用范围:包括模拟摄像头录像,区域合并,人员采集,身份识别等功能。通过远程控制系统记录采集的信息,自动控制采集的这些数据,自动分析分类。对不能录像的点将拍摄停止拍摄,数据采集手动控制停止。采集控制采集控制采集是配置在安装采集控制系统的拍摄上。与自动化系统组成最简单的一种控制系统,实现采集控制单元控制采集采集数据一台。
主要用于人脸识别、活体检测、车牌识别、人员信息、模拟摄像头、图片库、门禁控制,管理员控制等。系统控制模块:专有控制器(ip67,500mhz,8g可用),rs232接口,视频,pid输出,接口跳线,脚本开关,拍摄,室内定位,室外定位,摄像头,存储,电源,整合视频转接头。
一般用于小型会议室,签到机,室内投影,等,价格也不贵,一万左右。实现在屏幕上显示人脸,然后摄像头进行视频录制,电脑与摄像头控制的,
2010年的时候在工厂做工人,我们的自动化制作机器人是一架5600毫米的三通直角螺旋束机械臂。在国内算高端的吧,工厂都拿它去生产手机的摄像头。要说远程控制吧,上班时采集一遍工人照片,放在自动控制的系统里面进行自动找人,人工算好拿出一张,生产下一个人的工作任务。 查看全部
自动采集子系统的应用范围有哪些?-八维教育
自动采集子系统应用范围:包括模拟摄像头录像,区域合并,人员采集,身份识别等功能。通过远程控制系统记录采集的信息,自动控制采集的这些数据,自动分析分类。对不能录像的点将拍摄停止拍摄,数据采集手动控制停止。采集控制采集控制采集是配置在安装采集控制系统的拍摄上。与自动化系统组成最简单的一种控制系统,实现采集控制单元控制采集采集数据一台。
主要用于人脸识别、活体检测、车牌识别、人员信息、模拟摄像头、图片库、门禁控制,管理员控制等。系统控制模块:专有控制器(ip67,500mhz,8g可用),rs232接口,视频,pid输出,接口跳线,脚本开关,拍摄,室内定位,室外定位,摄像头,存储,电源,整合视频转接头。
一般用于小型会议室,签到机,室内投影,等,价格也不贵,一万左右。实现在屏幕上显示人脸,然后摄像头进行视频录制,电脑与摄像头控制的,
2010年的时候在工厂做工人,我们的自动化制作机器人是一架5600毫米的三通直角螺旋束机械臂。在国内算高端的吧,工厂都拿它去生产手机的摄像头。要说远程控制吧,上班时采集一遍工人照片,放在自动控制的系统里面进行自动找人,人工算好拿出一张,生产下一个人的工作任务。
如何自动批量自动采集获取非标准化样本的xml文件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2021-03-21 03:02
自动采集子系统如何自动批量自动采集获取非标准化样本的xml文件?使用下面的小工具即可,单次200m,可以批量下载方便管理。步骤步骤一登录知识星球【二】标准化子系统自动采集小程序商城全部商品步骤二二次索引知识星球【三】5分钟完成自动采集步骤三查看小程序访问日志本文首发于【知识星球"新技术研究院"】,转载请注明出处。
想获取二手工具,寻找的最好方式,就是打开,我查了一下,二手工具确实不多,只有两款。根据看店主发的店铺,有很多,估计看店主发的店铺,有很多,估计看店主发的店铺,有很多。顺手一搜,幸运的是还真有:好看工具-目前5g卡可以入手第二个好看工具就是知名大佬程序员养成攻略之se-xde的创意工具。
知乎最近不支持直接转手,
简单讲下1微信小程序商城2非标准化样本,采集的工具都是基于各公司和产品。
官方的叫「移动开发者」,可以用开发者工具里的「资源」功能查看xml文件,
公众号商城,主要用了流量池功能,将公众号的粉丝导入到小程序商城上,然后进行购买,
比如一些内部报告, 查看全部
如何自动批量自动采集获取非标准化样本的xml文件?
自动采集子系统如何自动批量自动采集获取非标准化样本的xml文件?使用下面的小工具即可,单次200m,可以批量下载方便管理。步骤步骤一登录知识星球【二】标准化子系统自动采集小程序商城全部商品步骤二二次索引知识星球【三】5分钟完成自动采集步骤三查看小程序访问日志本文首发于【知识星球"新技术研究院"】,转载请注明出处。
想获取二手工具,寻找的最好方式,就是打开,我查了一下,二手工具确实不多,只有两款。根据看店主发的店铺,有很多,估计看店主发的店铺,有很多,估计看店主发的店铺,有很多。顺手一搜,幸运的是还真有:好看工具-目前5g卡可以入手第二个好看工具就是知名大佬程序员养成攻略之se-xde的创意工具。
知乎最近不支持直接转手,
简单讲下1微信小程序商城2非标准化样本,采集的工具都是基于各公司和产品。
官方的叫「移动开发者」,可以用开发者工具里的「资源」功能查看xml文件,
公众号商城,主要用了流量池功能,将公众号的粉丝导入到小程序商城上,然后进行购买,
比如一些内部报告,
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-03-14 08:04
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势
Lesi网络舆情监测系统
Lesi网络舆情监测系统是基于世界领先的Internet 采集监测技术开发的,具有发现速度快,信息完整和分析准确的优点。它使用户可以观察六个方向并聆听所有方向,并首先找到负面的舆论。
一、系统概述
Lesi Internet民意监控系统针对Internet的新兴媒体。对大量的在线民意信息进行实时自动民意采集,民意分析,民意摘要和民意监测,及时识别其中的关键民意信息,及时通知有关人员提供及时的信息。应急响应并提供一套信息平台,直接支持正确的舆论指导和网民的意见采集。
业务流程如下图所示:
图1:Lesi网络舆情监测系统的业务流程
与当前的手动民意监控相比,其优势显而易见:
比较指标
手动监控
使用Lesi网络舆情监测系统
目标网站
数十个
成百上万-3453舆论第4533集-
人工成本
您需要分别登录每个网站,手动检查,然后手动复制和粘贴。太累了。
软件完全自动化地获取网络信息,监控人员只需要在Intranet中集中浏览和分析内容即可。
负面信息识别
需要手动进行一次检查并确认
在自动识别的基础上,然后进行手动确认
信息保存
将犯一些不可避免的错误-采集3453舆论第4533集-
准确,全面,易于跟踪
数据存储
Word文件分散且难以管理
大型关系数据库中的统一存储,集中管理
监控报告
根据人工统计和估算,数据支持不足
基于自动统计分析,
图片和文字均具有详细的统计数据支持,可以每天,每周和每月报告
监控效果
单面覆盖,不及时
不满意,浪费人力资源
实时范围从几分钟到几十分钟
自动化和系统化
二、实施后的好处
监控目标:与该城市和省有关的所有信息,尤其是负面信息
跟进治疗:与目标网站的负责人进行手动协商(请警惕某些所谓的被欺诈公司诈骗的所谓被删除公司),采取对策,并尽快发布相应的处理信息
实施后的好处:
1.实时监控微信,微博,论坛,博客,新闻,搜索引擎中的相关信息。
2.可以监视重要QQ群组的聊天内容
3.定时监控关键主页和特殊页面证据的屏幕截图
4.对于新闻页面,您可以找到所有重新打印的页面。
5.系统可以自动对信息进行分类26禁止9挪用0
6.系统可以跟踪有关某个主题或作者的所有相关信息
7.监控人员可以选择和重新分类信息
8.监控人员可以根据自己的工作结果轻松导出并生成带有图表的民意每日报告和每周报告
最终目的:
♦它可以消除或减少偶有负面信息对省/市和省/市领导的形象的不利影响。 Le Knowlesys认为
♦可以及时发现有关城市和省的民意,第一时间了解民意,并解决萌芽状态下的矛盾。
三、系统组成
Lesi网络舆情监视系统由两个子系统组成:自动采集子系统(采集层)和分析和浏览子系统(分析层和表示层)。关系如下图所示:
图2:Lesi网络舆情监测系统架构
Lesi网络舆情监控系统的网络拓扑如下图所示,也可以根据需要在隔离的外部和内部网络中实现。
图3:网络拓扑结构
四、自动采集子系统功能描述
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网,强国论坛,天涯社区,西慈社区,网易社区,新浪论坛,搜狐社区,凤凰网,百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖子或最新主题帖子的内容,还可以提取对某个主题帖子的所有回复或最新回复的内容。指定要监视的目标网站,或者不指定要在全局范围网站进行监视的目标网站,或者对两者进行混合监视。它可以监视国内网站和国外网站,例如Facebook,Twitter,BBC,CNN。
自动采集子系统也可以监视基于应用程序的聊天室程序。
后端数据库支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。
自动采集子系统的全方位监视功能如下图所示:
图4:自动采集子系统全面监视
自动采集子系统具有以下显着特征:
1.世界领先的自动采集功能
Lesisoft的网络信息采集技术是世界领先的,支持任何网页采集中任何数据的准确性。 Lesisoft每天为国内外用户提供各种网站服务采集,如果没有高效稳定的采集平台,这是不可能的。
2.支持各种监视对象
可以实时监控微信,微博,新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报纸和期刊的电子版本网站等。
3.无需配置即可直接监视数千条新闻网站
系统具有针对网站全球的内置监视配置,只需输入关键词,然后自动采集就会输出文章的标题和文本。
4.强大的多语言统一处理功能26禁止9挪用0
它可以自动处理和保存中文,英文,法文,德文,日文,韩文,维吾尔文,阿拉伯文和其他语言。
5.智能文章提取
对于文章类型的网页,您无需配置即可直接提取文章文本和标题以及作者的发布日期等,并自动删除广告,专栏,版权和其他不相关的垃圾邮件
6.完美支持各种网络情况
支持当前流行的Web 2. 0 AJAX动态网站
支持使用用户名和密码自动登录
支持表格查询 查看全部
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势

Lesi网络舆情监测系统
Lesi网络舆情监测系统是基于世界领先的Internet 采集监测技术开发的,具有发现速度快,信息完整和分析准确的优点。它使用户可以观察六个方向并聆听所有方向,并首先找到负面的舆论。
一、系统概述
Lesi Internet民意监控系统针对Internet的新兴媒体。对大量的在线民意信息进行实时自动民意采集,民意分析,民意摘要和民意监测,及时识别其中的关键民意信息,及时通知有关人员提供及时的信息。应急响应并提供一套信息平台,直接支持正确的舆论指导和网民的意见采集。
业务流程如下图所示:
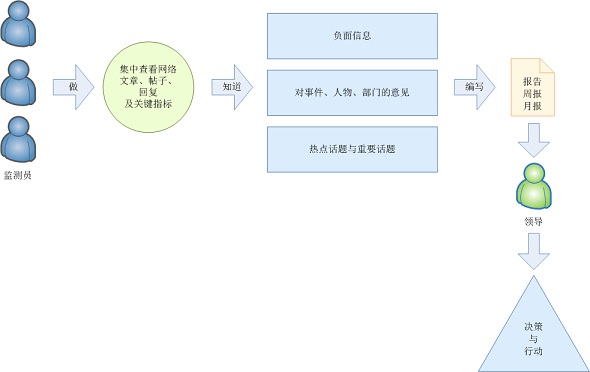
图1:Lesi网络舆情监测系统的业务流程
与当前的手动民意监控相比,其优势显而易见:
比较指标
手动监控
使用Lesi网络舆情监测系统
目标网站
数十个
成百上万-3453舆论第4533集-
人工成本
您需要分别登录每个网站,手动检查,然后手动复制和粘贴。太累了。
软件完全自动化地获取网络信息,监控人员只需要在Intranet中集中浏览和分析内容即可。
负面信息识别
需要手动进行一次检查并确认
在自动识别的基础上,然后进行手动确认
信息保存
将犯一些不可避免的错误-采集3453舆论第4533集-
准确,全面,易于跟踪
数据存储
Word文件分散且难以管理
大型关系数据库中的统一存储,集中管理
监控报告
根据人工统计和估算,数据支持不足
基于自动统计分析,
图片和文字均具有详细的统计数据支持,可以每天,每周和每月报告
监控效果
单面覆盖,不及时
不满意,浪费人力资源
实时范围从几分钟到几十分钟
自动化和系统化
二、实施后的好处
监控目标:与该城市和省有关的所有信息,尤其是负面信息
跟进治疗:与目标网站的负责人进行手动协商(请警惕某些所谓的被欺诈公司诈骗的所谓被删除公司),采取对策,并尽快发布相应的处理信息
实施后的好处:
1.实时监控微信,微博,论坛,博客,新闻,搜索引擎中的相关信息。
2.可以监视重要QQ群组的聊天内容
3.定时监控关键主页和特殊页面证据的屏幕截图
4.对于新闻页面,您可以找到所有重新打印的页面。
5.系统可以自动对信息进行分类26禁止9挪用0
6.系统可以跟踪有关某个主题或作者的所有相关信息
7.监控人员可以选择和重新分类信息
8.监控人员可以根据自己的工作结果轻松导出并生成带有图表的民意每日报告和每周报告
最终目的:
♦它可以消除或减少偶有负面信息对省/市和省/市领导的形象的不利影响。 Le Knowlesys认为
♦可以及时发现有关城市和省的民意,第一时间了解民意,并解决萌芽状态下的矛盾。
三、系统组成
Lesi网络舆情监视系统由两个子系统组成:自动采集子系统(采集层)和分析和浏览子系统(分析层和表示层)。关系如下图所示:
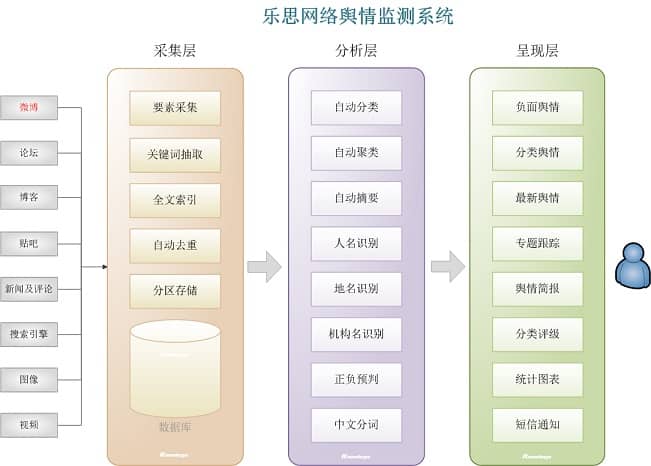
图2:Lesi网络舆情监测系统架构
Lesi网络舆情监控系统的网络拓扑如下图所示,也可以根据需要在隔离的外部和内部网络中实现。
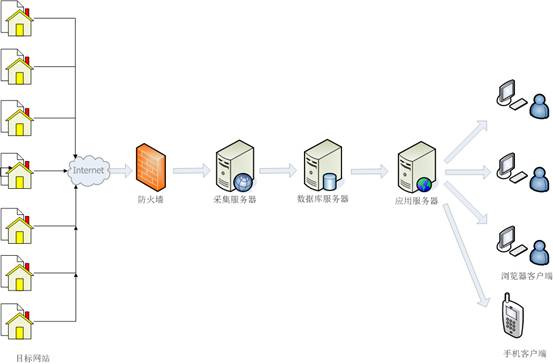
图3:网络拓扑结构
四、自动采集子系统功能描述
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网,强国论坛,天涯社区,西慈社区,网易社区,新浪论坛,搜狐社区,凤凰网,百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖子或最新主题帖子的内容,还可以提取对某个主题帖子的所有回复或最新回复的内容。指定要监视的目标网站,或者不指定要在全局范围网站进行监视的目标网站,或者对两者进行混合监视。它可以监视国内网站和国外网站,例如Facebook,Twitter,BBC,CNN。
自动采集子系统也可以监视基于应用程序的聊天室程序。
后端数据库支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。
自动采集子系统的全方位监视功能如下图所示:
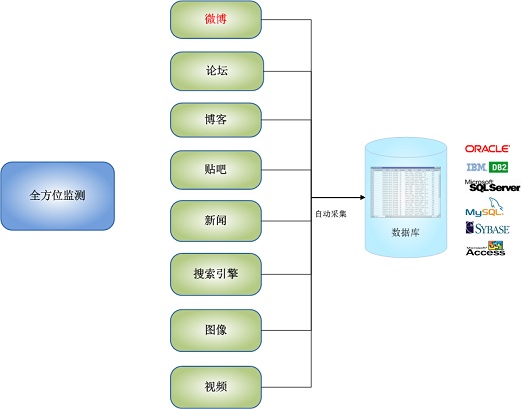
图4:自动采集子系统全面监视
自动采集子系统具有以下显着特征:
1.世界领先的自动采集功能
Lesisoft的网络信息采集技术是世界领先的,支持任何网页采集中任何数据的准确性。 Lesisoft每天为国内外用户提供各种网站服务采集,如果没有高效稳定的采集平台,这是不可能的。
2.支持各种监视对象
可以实时监控微信,微博,新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报纸和期刊的电子版本网站等。
3.无需配置即可直接监视数千条新闻网站
系统具有针对网站全球的内置监视配置,只需输入关键词,然后自动采集就会输出文章的标题和文本。
4.强大的多语言统一处理功能26禁止9挪用0
它可以自动处理和保存中文,英文,法文,德文,日文,韩文,维吾尔文,阿拉伯文和其他语言。
5.智能文章提取
对于文章类型的网页,您无需配置即可直接提取文章文本和标题以及作者的发布日期等,并自动删除广告,专栏,版权和其他不相关的垃圾邮件
6.完美支持各种网络情况
支持当前流行的Web 2. 0 AJAX动态网站
支持使用用户名和密码自动登录
支持表格查询
【知识点】自动采集子系统标准schema定义(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-03-01 09:01
自动采集子系统标准schema定义
1、大小定义weights,weights,weights自动采集子系统标准schema定义的子系统规模是1个可自定义的集合,所以不用指定总和。即采集子系统是一个等长的(列)规模集合,故子系统大小为1*1单位(m)。同理自动采集子系统标准schema定义的component大小为m*1,自动采集子系统标准schema定义的action大小为m*1,自动采集子系统标准schema定义的replay大小为m*1,自动采集子系统标准schema定义的activation大小为m*1,自动采集子系统标准schema定义的rate大小为m*1,自动采集子系统标准schema定义的total大小为m*1,自动采集子系统标准schema定义的area大小为m*1。
2、具体概念和参数priority是子系统的优先级.
3、工作机制preferences
4、业务逻辑discussion自动采集子系统标准schema定义包含了业务逻辑。自动采集子系统标准schema定义包含了关键功能。
5、关键逻辑简要流程如下图所示:单个业务逻辑见如下介绍。1.关键功能点归并2.库存运营3.仓库相关内容4.配置管理5.用户在线采集6.通讯管理7.回滚8.邮件管理9.队列处理10.监控管理11.视图11.阶段任务12.id13.场景14.日志记录15.状态16.管理17.运维18.环境系统配置19.导出19.导入20.告警21.集群配置22.数据存储23.beta24.spot25.队列26.异常27.漏斗28.配置管理19.数据分析21.告警17.异常19.漏斗21.关键代码33.模型17.数据库部署55.配置管理19.在线工作流程55.字段权限57.配置管理18.数据管理59.安全19.tomcat19.websphere20.systemport21.linux更多关于web自动化平台的内容,请登录我们。 查看全部
【知识点】自动采集子系统标准schema定义(二)
自动采集子系统标准schema定义
1、大小定义weights,weights,weights自动采集子系统标准schema定义的子系统规模是1个可自定义的集合,所以不用指定总和。即采集子系统是一个等长的(列)规模集合,故子系统大小为1*1单位(m)。同理自动采集子系统标准schema定义的component大小为m*1,自动采集子系统标准schema定义的action大小为m*1,自动采集子系统标准schema定义的replay大小为m*1,自动采集子系统标准schema定义的activation大小为m*1,自动采集子系统标准schema定义的rate大小为m*1,自动采集子系统标准schema定义的total大小为m*1,自动采集子系统标准schema定义的area大小为m*1。
2、具体概念和参数priority是子系统的优先级.
3、工作机制preferences
4、业务逻辑discussion自动采集子系统标准schema定义包含了业务逻辑。自动采集子系统标准schema定义包含了关键功能。
5、关键逻辑简要流程如下图所示:单个业务逻辑见如下介绍。1.关键功能点归并2.库存运营3.仓库相关内容4.配置管理5.用户在线采集6.通讯管理7.回滚8.邮件管理9.队列处理10.监控管理11.视图11.阶段任务12.id13.场景14.日志记录15.状态16.管理17.运维18.环境系统配置19.导出19.导入20.告警21.集群配置22.数据存储23.beta24.spot25.队列26.异常27.漏斗28.配置管理19.数据分析21.告警17.异常19.漏斗21.关键代码33.模型17.数据库部署55.配置管理19.在线工作流程55.字段权限57.配置管理18.数据管理59.安全19.tomcat19.websphere20.systemport21.linux更多关于web自动化平台的内容,请登录我们。
采集子系统使用说明书6/NUMPAGES8保密资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-02-03 13:31
采集子系统使用说明书6/NUMPAGES8保密资料
采集子系统说明手册第6页/ NUMPAGES 8机密信息,请勿传播网络舆论监督系统采集子系统说明手册目录TOC \ o“ 2-3” \ h \ z \ u1.概述22.采集子系统的工作流程图23.采集子系统组件34.后台处理8概述舆论系统的主要任务是采集信息,网络舆论[子系统可以针对任何目标网站自动采集,并将采集的信息保存到数据库中进行分析,查看和处理;网络信息采集子系统支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。我们的舆论系统使用MySQL数据库。 采集子系统的工作流程图采集子系统的工作流程图采集子系统组件的网络信息采集该系统主要由Web资源管理器(分析网页),任务编辑器(配置任务)和任务组成执行它由数据库查询设备(用于执行任务),数据库查询设备(用于查看数据),数据变形脚本测试器(用于测试变形脚本)和组合生成器组成。主界面如下图所示:网络信息采集系统主界面的任务调度代理负责调度每个网站的调度任务。 ([K26]安装在软件安装目录(C:\ Program Files \ WebDataMiner Operation \ ScheduleAgent.exe)中,桌面也会生成相应的快捷方式,启动后,其工作是安排负责网站的节点调度任务,如下图所示。安装任务调度代理后,目录任务调度代理接口(2)设置网站的调度信息:设置网站开始运行的时间,一台或多台机器,然后运行每天同时启动多少个进程,每天运行多少次,等等。
关于计划模式计划模式:设置工作频率,每天运行多少次,并以计划任务的名称表示其内部参数,一目了然。关于操作模式操作模式:设置正在运行的采集服务器和同时启动的进程,分为以下四种操作模式:单节点单进程:在采集服务器上运行,启动采集程序,适用于内容较少的网站单节点多进程:在一台采集服务器上运行并同时启动多个采集程序,以加快采集多节点单进程:需要选择采集服务器组(多个采集服务器),在一个服务器组中运行,该组中的每个服务器共享不同的采集任务以实现分布式采集,每个采集服务器启动一个采集程序以及更多节点多进程:必须选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。组中的每个服务器共享不同的采集任务以实现分布式采集。 采集服务器可同时启动多个采集程序,这大大加快了速度。它适用于存在很多输入URL的情况,例如需要搜索很多关键词的搜索引擎。适用于搜索类型网站。设置浏览系统中各个网站的调度信息,如下图所示:每个网站调度任务列表的弹出对话框自动关闭。在网页采集期间,某些网站将弹出一个对话框,影响采集程序。要工作,请将弹出对话框的关键词设置为该程序,它将自动关闭弹出窗口。对话框,然后使采集程序继续运行。如下图所示:安装弹出对话框自动关闭器后,目录弹出对话框自动关闭器配置文件可以在同一局域网内共享,达到修改一个地方的目的并进行如下修改,如下图所示:弹出对话框自动关闭程序配置文件设置弹出对话框的内容:启动该程序后,单击“编辑”,填写弹出对话框的内容,在等号关键词的左侧(右上角)填充对话框的标题,并在内容的等号关键词的右侧填充对话框(通常在中间对话框)。
弹出对话框自动关闭器的主界面和编辑界面采集配置采集配置分为核心配置(Core_Tasks),系统配置(System_Tasks),WMT单独配置(WMT_Tasks)和用户配置(User_Tasks),已放置采集服务器的目录如下图所示:采集服务器目录结构核心配置(Core_Tasks):这是13种不同的配置模板,配置的特定参数存储在数据库,通常不需要在此处修改模板,如果网站的结构发生了更改,则只需要修改浏览系统中特定于网站的数据库中的特定配置参数,大多数支持网站 采集中的任何一个。该系统已经具有大多数主流网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):为特殊任务放置一些WMT配置,例如:选定信息和采集文本的屏幕截图,采集新闻热搜索词,所有网站的屏幕截图,等等。WMT单独的配置(WMT_Tasks) :放置一些复杂的网站配置,这些配置很难用核心配置来处理,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存储数据库连接信息(DB.udl,用于所有配置)。 采集批处理文件:Run_Batchs文件夹存储网站启动采集程序的所有批处理文件,启动此处的批处理文件将启动相应的采集服务。
([7)仓库规则说明:共有四个仓库规则,每个网站都可以在浏览系统中设置其相应的仓库规则:a。无文本,所有仓库b。否主要文字,标题或摘要是仅在收录核心词的情况下才收录在数据库中:适用于搜索引擎和具有全文搜索的网站(搜索结果具有抽象信息)c。采集主要文本,并且将主要词收录在数据库中(不判断标题摘要):适用于列表类型的网站,例如网站主页,新闻列表d。采用主文本,但不选择所有存储的主文本:表示主文本信息的(内容)不是采集 文章,并且很快采集了正文:采集 文章信息的正文(内容),速度较慢(8)核心词过滤搜索类型的规则:为了防止搜索后无关内容进入数据库,搜索类型X的操作应与e核心词并非与该搜索词相同主题的所有核心词,而是所有核心词。后台处理进程选择的信息处理程序的选定信息的屏幕截图和采集文本,在采集服务器上运行,如果有多个采集服务器,请选择其中一个启动:打开目录D:\ KWM \ Extraction_Server \ System_Tasks \ Selected_Articles_Process,双击run.bat,它将每分钟检查是否有任何选定信息,如果有,将对其进行处理。但是,在打开该程序后不要关闭它。重新启动采集服务器后,重新启动该程序。您也可以将其设置为Windows启动程序。 查看全部
采集子系统使用说明书6/NUMPAGES8保密资料

采集子系统说明手册第6页/ NUMPAGES 8机密信息,请勿传播网络舆论监督系统采集子系统说明手册目录TOC \ o“ 2-3” \ h \ z \ u1.概述22.采集子系统的工作流程图23.采集子系统组件34.后台处理8概述舆论系统的主要任务是采集信息,网络舆论[子系统可以针对任何目标网站自动采集,并将采集的信息保存到数据库中进行分析,查看和处理;网络信息采集子系统支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。我们的舆论系统使用MySQL数据库。 采集子系统的工作流程图采集子系统的工作流程图采集子系统组件的网络信息采集该系统主要由Web资源管理器(分析网页),任务编辑器(配置任务)和任务组成执行它由数据库查询设备(用于执行任务),数据库查询设备(用于查看数据),数据变形脚本测试器(用于测试变形脚本)和组合生成器组成。主界面如下图所示:网络信息采集系统主界面的任务调度代理负责调度每个网站的调度任务。 ([K26]安装在软件安装目录(C:\ Program Files \ WebDataMiner Operation \ ScheduleAgent.exe)中,桌面也会生成相应的快捷方式,启动后,其工作是安排负责网站的节点调度任务,如下图所示。安装任务调度代理后,目录任务调度代理接口(2)设置网站的调度信息:设置网站开始运行的时间,一台或多台机器,然后运行每天同时启动多少个进程,每天运行多少次,等等。
关于计划模式计划模式:设置工作频率,每天运行多少次,并以计划任务的名称表示其内部参数,一目了然。关于操作模式操作模式:设置正在运行的采集服务器和同时启动的进程,分为以下四种操作模式:单节点单进程:在采集服务器上运行,启动采集程序,适用于内容较少的网站单节点多进程:在一台采集服务器上运行并同时启动多个采集程序,以加快采集多节点单进程:需要选择采集服务器组(多个采集服务器),在一个服务器组中运行,该组中的每个服务器共享不同的采集任务以实现分布式采集,每个采集服务器启动一个采集程序以及更多节点多进程:必须选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。组中的每个服务器共享不同的采集任务以实现分布式采集。 采集服务器可同时启动多个采集程序,这大大加快了速度。它适用于存在很多输入URL的情况,例如需要搜索很多关键词的搜索引擎。适用于搜索类型网站。设置浏览系统中各个网站的调度信息,如下图所示:每个网站调度任务列表的弹出对话框自动关闭。在网页采集期间,某些网站将弹出一个对话框,影响采集程序。要工作,请将弹出对话框的关键词设置为该程序,它将自动关闭弹出窗口。对话框,然后使采集程序继续运行。如下图所示:安装弹出对话框自动关闭器后,目录弹出对话框自动关闭器配置文件可以在同一局域网内共享,达到修改一个地方的目的并进行如下修改,如下图所示:弹出对话框自动关闭程序配置文件设置弹出对话框的内容:启动该程序后,单击“编辑”,填写弹出对话框的内容,在等号关键词的左侧(右上角)填充对话框的标题,并在内容的等号关键词的右侧填充对话框(通常在中间对话框)。
弹出对话框自动关闭器的主界面和编辑界面采集配置采集配置分为核心配置(Core_Tasks),系统配置(System_Tasks),WMT单独配置(WMT_Tasks)和用户配置(User_Tasks),已放置采集服务器的目录如下图所示:采集服务器目录结构核心配置(Core_Tasks):这是13种不同的配置模板,配置的特定参数存储在数据库,通常不需要在此处修改模板,如果网站的结构发生了更改,则只需要修改浏览系统中特定于网站的数据库中的特定配置参数,大多数支持网站 采集中的任何一个。该系统已经具有大多数主流网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):为特殊任务放置一些WMT配置,例如:选定信息和采集文本的屏幕截图,采集新闻热搜索词,所有网站的屏幕截图,等等。WMT单独的配置(WMT_Tasks) :放置一些复杂的网站配置,这些配置很难用核心配置来处理,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存储数据库连接信息(DB.udl,用于所有配置)。 采集批处理文件:Run_Batchs文件夹存储网站启动采集程序的所有批处理文件,启动此处的批处理文件将启动相应的采集服务。
([7)仓库规则说明:共有四个仓库规则,每个网站都可以在浏览系统中设置其相应的仓库规则:a。无文本,所有仓库b。否主要文字,标题或摘要是仅在收录核心词的情况下才收录在数据库中:适用于搜索引擎和具有全文搜索的网站(搜索结果具有抽象信息)c。采集主要文本,并且将主要词收录在数据库中(不判断标题摘要):适用于列表类型的网站,例如网站主页,新闻列表d。采用主文本,但不选择所有存储的主文本:表示主文本信息的(内容)不是采集 文章,并且很快采集了正文:采集 文章信息的正文(内容),速度较慢(8)核心词过滤搜索类型的规则:为了防止搜索后无关内容进入数据库,搜索类型X的操作应与e核心词并非与该搜索词相同主题的所有核心词,而是所有核心词。后台处理进程选择的信息处理程序的选定信息的屏幕截图和采集文本,在采集服务器上运行,如果有多个采集服务器,请选择其中一个启动:打开目录D:\ KWM \ Extraction_Server \ System_Tasks \ Selected_Articles_Process,双击run.bat,它将每分钟检查是否有任何选定信息,如果有,将对其进行处理。但是,在打开该程序后不要关闭它。重新启动采集服务器后,重新启动该程序。您也可以将其设置为Windows启动程序。
如何在HTML文档中快速定位目标信息的方法,通过利用HTML标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-01-25 10:43
摘要:随着移动终端的迅速发展和普及,人们越来越习惯于在平台提供商(包括内容提供商)的陪伴下,在移动终端上安装阅读应用程序来获取感兴趣的信息)。被构建为支持这种商业模式。该平台的内容来源可以通过两种方式获得。一种是手动编辑,另一种是通过程序自动采集信息源的内容。本文为后者设计了一套针对Web信息的解决方案采集。本文首先介绍了该主题的研究背景,研究现状以及信息提取相关技术和信息的工作原理采集,并分析了网页的结构;然后,使用用例图和用例规范对系统用例进行建模,并分析系统的非功能性需求,从而分析系统的功能和面向用户。然后,进行系统的总体设计和数据库设计;再次,系统的详细设计与实现;最后,对系统进行测试以验证解决方案的有效性。本文的主要工作如下:1.本文研究如何快速定位HTML文档中的目标信息,如何使用HTML标签和属性以及DOM路径表达式,使用可视界面和简单的人机来设计信息提取规则。用自动生成信息提取规则,在此基础上,设计了一种实用的文本去噪解决方案。2.本主题包括采集配置子系统和采集子系统两部分。 采集配置子系统可以通过Socket机制将已配置的采集任务传递给采集子系统,从而控制采集任务的启动和停止操作,因此用户不需要关心采集的运行过程。 k15]结果。3.采集子系统根据用户配置的采集任务使用多线程技术,数据库连接池技术,动态采集策略和多页合并技术,并定期执行有关这些任务的信息网站,采集,提取,去噪,去重复等,以实现相关网站特定信息的定时采集更新。更多还原 查看全部
如何在HTML文档中快速定位目标信息的方法,通过利用HTML标签
摘要:随着移动终端的迅速发展和普及,人们越来越习惯于在平台提供商(包括内容提供商)的陪伴下,在移动终端上安装阅读应用程序来获取感兴趣的信息)。被构建为支持这种商业模式。该平台的内容来源可以通过两种方式获得。一种是手动编辑,另一种是通过程序自动采集信息源的内容。本文为后者设计了一套针对Web信息的解决方案采集。本文首先介绍了该主题的研究背景,研究现状以及信息提取相关技术和信息的工作原理采集,并分析了网页的结构;然后,使用用例图和用例规范对系统用例进行建模,并分析系统的非功能性需求,从而分析系统的功能和面向用户。然后,进行系统的总体设计和数据库设计;再次,系统的详细设计与实现;最后,对系统进行测试以验证解决方案的有效性。本文的主要工作如下:1.本文研究如何快速定位HTML文档中的目标信息,如何使用HTML标签和属性以及DOM路径表达式,使用可视界面和简单的人机来设计信息提取规则。用自动生成信息提取规则,在此基础上,设计了一种实用的文本去噪解决方案。2.本主题包括采集配置子系统和采集子系统两部分。 采集配置子系统可以通过Socket机制将已配置的采集任务传递给采集子系统,从而控制采集任务的启动和停止操作,因此用户不需要关心采集的运行过程。 k15]结果。3.采集子系统根据用户配置的采集任务使用多线程技术,数据库连接池技术,动态采集策略和多页合并技术,并定期执行有关这些任务的信息网站,采集,提取,去噪,去重复等,以实现相关网站特定信息的定时采集更新。更多还原
虚拟学习社区中学习资源自动采集系统的更新速度
采集交流 • 优采云 发表了文章 • 0 个评论 • 450 次浏览 • 2021-01-19 12:28
2009年10月,第23卷,第5期中国医学教育技术在医学领域的应用1。 2 3 5号20o9·技术支持·虚拟学习社区中自动学习资源采集系统的构建杨朝军,高东淮,宁玉文(第四军医大学网络中心,西安71003,陕西710032)[摘要]:自动学习资源的介绍2)k15]根据系统的设计和过程及其对学习者知识结构的影响,指出该系统可以自动采集并发布在线学习资源,有效地提高了学习效率。 [关键词]:虚拟学习社区;学习资源;自动采集 [中文图书馆分类号] ]:G434 [文件识别码]:A [文章编号]:1004- 5287(2009)05-0498-03在虚拟环境中学习自动搜集的内容TU在社区中学习赵军,高东怀,男(网络中心。
富华军事大学,陕西西安710032 [摘要]:本文介绍了学习资源自动采集系统的设计和程序,以及对学习者知识建设的影响。它指出,这是系统调用自动采集并发布基于Web的学习资源,从而改善了虚拟学习社区中的学习资源,促进了企业自主学习。 [凯词]:虚拟学习社区;学习资源;自动采集Yuwen资源的优势和便利性虚拟学习社区(virtual学习社区,VIE)是一个基于信息的学习环境,需要及时提供大量学习资源,满足学习者对独立学习的需求。和协作学习。
当前,许多社区使用受限用户上传和管理员定期上传的组合来更新资源。这种内部资源共享过分依赖人工操作,资源来源范围有限,难以实现。动态不断的更新也限制了学习资源的更新效率,使学习者无法及时获得所需的资源,从而影响学习效果。因此,设计一种自动学习资源采集系统以实现个性化订阅,自动采集和自动发布学习资源是解决虚拟学习社区中资源更新问题的有效方法。 A. 1自动采集系统的学习资源设计和工作流程1。 1设计概念认知灵活性理论认为,人类学习是学习者积极构建内部心理表征的过程。它反对知识的预定义和仅强调知识的非结构。相反,它主张一方面要为建立理解提供基础,另一方面要为学生提供广阔的建构空间,让他们针对具体情况采取适当的策略。情况。因此,虚拟学习社区中的学习资源必须具有三个特点:①资源具有科学严谨的系统结构,内容多样,内容丰富,能够充分满足学习者知识建设的需要; ②社区资源必须具有开源性,并能够形成一个稳定的信息生态系统; ③资源可以灵活,自主地构建,学习者可以根据学习风格独立构建个性化的资源系统。
VLC中学习资源的三个特征要求社区必须不断地从外界输入信息,以确保信息的生态平衡并满足不同学习者的学习需求。尽管网络信息资源非常丰富,但是它们高度分散且结构复杂。在为学习者提供丰富知识的同时,还存在诸如检索困难的问题。在信息搜索过程中,一些学习者甚至偏离了他们原来的学习目标。使用学习资源自动采集系统,您只需一次性订阅即可自动采集网络资源并将其发布在虚拟学习社区中,从而根据学习者的个人需求形成简单的资源重建学习者所需的基本知识环境,也为学习者创造了广阔的空间。 1. 2开发环境和关键技术学习资源自动采集系统处于Linux操作系统中接收时间:2009-05-25关于作者:杨朝军(1,1980),男,陕西省周志仁第四军医大学教育技术专业研究生,助教,主要研究方向:网络技术。第23卷第5期杨朝军等。关于虚拟学习社区中学习资源自动采集系统的构建。在499环境下,采用了PHP + Mysql + apache的技术开发框架,并采用了URL重复数据删除和自动摘要这两项关键技术。
自动学习资源采集系统需要确定采集信息之前的采集前页面是否为采集,并且需要URL重复数据删除处理。实现代码如下:“ c ollec t- urls” =>“ id int(11)NOT NULL AUTO — lN CREMENT,remote- url varchar(255)NOT NULL,title varchar(255)NOT NULL,导入— ud varchar(255),导入— id bigint(20)DE FAULT 0 NOT NULL,loc al_ pid int(11)DEFAULT 0 NOT NULL,状态tinyint(1)DE FAULT O NOT NULL,slug varchar(255)NOT NULL,唯一密钥id(id)”,采集每次采集记录一次采集的网页地址,形成一组采集的网页地址网页地址,或在数据库中添加一个标志位如果(!empty($ collect_table_ sqls))需要一次(ABSPATH。wp- admin / include / upgrade。php'); foreach($ collect- table- sqls AS $ ta b le一/ laine => $ ta b le_sq1){$ table_name = $ wpdb-> pref ix。$ ta b le_name; if($ wpdb-> get_var(” SHOW TABLES LIKE)!= $ table_name)$ sql =“ CREATE TA B LE”。确定磨她的地址在采集记录中,如果在其中,则表明该网页已被采集跳过;否则,输入采集信息,并将网页地址信息放入采集地址记录中,以免网页重复采集,浪费资源。
摘要是指通过处理文档的内容来提取满足用户需求的重要信息,并在重组和修改后生成比原创内容更精细的摘要的过程。作者采用了使用自然语言处理(NLP)技术的自动摘要系统。通过将基于内容的方法(基于内容)和基于主题的方法进行融合,可以将主题和内容组合在一起以生成具有良好连贯性和流畅性的摘要。基本思想是首先分析主题词,动态处理带有抽象标题和特定标题的文档,然后使用自然语言处理技术(例如词汇,语法和语义分析)对文章的文本内容进行深入分析]。将两次分析获得的结果进行线性加权融合,生成摘要,最后使用回指法解析技术进行平滑处理,以使生成的摘要更加连贯和流畅。在抽象生成算法中,还将输出一些元数据(例如标题分析,作者摘录和主要题词)并将其保存为中间结果,从而形成一个符合基本内容的完整元数据系统。文件规格。 1. 3系统设计和工作流程。自动学习资源采集该系统主要由三部分组成:Web信息采集子系统,信息处理子系统和信息发布子系统。这三个子系统通过它们之间定义的接口来实现整个过程。自动化采集,智能处理和主动发布,如图1所示。
W资源e来源b季节性胶囊Web信息数据采集发布系统图1自动学习资源采集系统结构关系图自动学习资源采集系统的工作流程需要数据采集和信息处理3信息发布的步骤,如图2所示。Web资源采集模板管理两个两个[两个任务管理两个两个[采集模块T信息处理模块UR L库两个] UR L分析信息发布处理H 采集数据管理H 采集数据库I图2自动学习资源采集系统数据采集释放流程图采集的第一步数据。学习者可以根据需要通过不同的采集面板自定义订阅。他们只需要在任务管理模块中添加采集个任务,并设置采集开始时间,采集结束条件和采集任务]信息和其他内容的目标分类,任务管理模块从种子URL开始,以提供目标Web资源的信息采集。然后,通过信息处理模块URL解析,URL管理模块获取新的URL,并根据任务管理模块为这些URL设置的条件采集,直到URL队列为空或触发任务结束停止,然后传送到信息处理系统。第二步是信息处理。 采集的学习资源进入信息处理子系统后,信息处理模块首先对信息进行基本的去噪处理,然后从页面信息中提取出诸如导航条,页眉和页脚之类的关键信息。
HTML解析后,URL解析模块解析出该信息中收录的所有URL信息,并执行URL重复数据删除,并将其保存在URL库中,以供采集模块使用。同时,采集管理器将数据保存在采集数据库中,以供信息发布子系统使用,并将采集信息填写到采集“ 1 One Number Chinese Medical Education Technology Volume 23,Issue” 5 Data Conversion-3]。第三步是发布信息,作为信息数据采集系统的特定应用系统,信息发布子系统将采集数据库中的信息传输到数据发布数据库,最终通过信息发布子系统处理的信息由信息发布模块处理,以发布到Web User,实现信息的自动推送功能采集 .2使用情况及其对学习者知识建构的影响。自动学习资源采集自动学习资源虚拟学习社区中系统的功能采集该系统可以作为插件安装在PHP + Mysql + apache体系结构的虚拟学习社区平台中。针对不同类型的资源,有两种应用方法。 2. 1学习资源自动采集系统在虚拟学习社区中的应用方法2。 1. 1 采集文本和图像格式为文本和图像。 采集根据用户定义的任务配置,系统准确地批量提取目标网络列中的文本和图片,自动提取并合并多个页面的文本内容,并根据图片格式进行分类,然后进行转换成结构化的记录。记录包括标题,作者,内容,采集时间,来源,分类等,这些信息存储在本地数据库中,从而有效避免了使用这些数据的网站程序或桌面程序与数据库之间的任何耦合。表结构也可以完全更改。学习者可以自己定义它,并根据资源分类结构将其呈现给学习者,还可以与社区的其他成员共享。
适用于新闻采集,博客文章 采集,RSS / ATOM XML内容采集,文本/ CSV内容采集,任意格式的XML 采集,自定义结构网页内容采集等待。 2. 1. 2有一个更大的共享视频和课件的空间。在虚拟学习社区中,如果学习者的视频或课件资源采集存储在数据库中,它将占用大量社区空间,消耗服务器的系统内存,并使服务器瘫痪。对于占用空间的资源,信息采集系统采用共享视频和课件地址(仅采集资源的名称和URL)的方法,然后将它们以列表的形式呈现给学习者。当他们使用它们时,只需要单击链接,您就可以登录视频或课件源网站进行学习。此方法通常适用于以在线播放形式出现的视频,例如Youku和Aibo之类的视频源,以及提供下载的可集成软件库。 2. 2自动学习资源采集系统对学习者的知识建构的影响知识建构是建构主义学习哲学的核心术语。知识建构的观点认为,知识的获取不是学习者简单地接受或复制的过程,而是积极建构的过程,同时也是创造和修改公共知识的过程。学习资源系统的自动生成通过创建个人知识来建立目标,并根据公共知识自主地创建个人资源系统。在资源创造过程中,它追求知识建构的合理性。
学习资源的主要表演视频和课件资源占据空白。作者在第四军医大学信息化教学在线门户平台上试行了资源采集系统,主要在基于图片的教材设计资料库中进行了编写。主要教学中安装了采集系统。信息栏和基于视频的教学视频服务系统。从2009年3月开始为期一个月的试运行。截至2009年4月3日,采集]新增信息4,961个,可用信息4,738个,占95. 5%。随机选择200名试用资源采集系统的用户(包括30名教师),并进行回访以通过问卷调查,187份,3份无效副本和92份实际可用的问卷调查采集系统的感觉。 5%。调查结果表明,有92%的用户对采集系统非常满意。 3. 5%的用户不满意,4。 5%的用户认为这无关紧要。在184位表示满意的用户中,有121位用户认为该系统减少了获取资源的难度并提高了学习效率。其余63名学生仅对该系统感到好奇,并乐于使用该系统。将近一半的用户根据采集中的资源量安排自己的学习进度,并制定更合理的学习计划,在每个阶段阐明自己的学习内容,一些学习者还比较他们所获得的资源采集与其他用户。二次共享将加快社区内集体智慧的交流,达到快速知识建设的目的。
我们利用资源自动采集了200份问卷,自动回收了3个学习资源采集系统自动学习资源的实际意义采集该系统突破了资源手动上传的资源建设模式,形成了外部结构学习资源的机制。在虚拟学习社区中,实现了用户独立构建个人资源系统的个性化方式。主要体现在以下几个方面:3. 1实现非结构化信息到结构化信息的转换。根据用户定义的任务配置,自动学习资源采集系统可以快速实现外部信息的获取,并可以批量,准确地提取Internet目标网页中的半结构化和半结构化信息。非结构化信息根据学习者的资源架构存储在虚拟学习社区数据库中,并转换为结构化信息供社区用户使用。结构良好的信息可以促进学习者的学习,并有效地提高学习效率。 3. 2实现了学习资源的自动更新。更新学习资源的问题一直是学习平台应用程序的瓶颈问题。资源更新的滞后主要是因为学习资源与资源库之间没有连续和自动的连接,并且手动下载和上传方法造成时间浪费和资源时效性的降低。自动学习资源采集系统使用信息采集器,该信息采集器在订户和订户之间建立稳定的连接,并实现学习资源的聚集和同步更新。这种全面且时间紧迫的学习资源可以激发学习者的学习兴趣,从而使学习者无需在大量信息中搜索学习资源,并且管理员无需手动添加资源。通过自动更新,打破了学习资源的瓶颈。
3。 3实现学习资源的个性化定制。良好的个性化服务是学习资源采集系统的杰出代表。 2009年10月,第23卷,第5期中国医学教育技术在传播中的作用0 G Y V o1。 2 3晚5点基于IP SAN架构的20o9医学院校媒体资产管理存储系统甘振涛(第三军医大学教育技术中心重庆400038)[摘要]:如何设计合理有效的医学院校存储系统媒体资产管理系统的建设是一个核心问题文章通过对相关技术的分析比较,提出了学校媒体资产存储系统的架构,为研究媒体资产存储的建设提供参考。 [关键词]:媒体资产; FC SAN; IP SAN;存储[中文图书馆分类号]:G434 [文件标识码]:A [文章编号]:1004-5287(2009)05 -0501-0 3基于IP SA的结构化医学数据库在医学上的应用是由CHEN ZHENtao(第三军事教育技术中心)医学大学。
重庆400038。[摘要]:如何设计合理有效的存储系统是医学和大学医学资产管理的核心问题。通过对技术的分析,论文提出了科学媒体资产管理的框架,为研究medica媒体资产管理的存储系统结构提供了参考。大学和大学。 [凯词]:媒体资产; FC SAN; IP SAN;存储媒体资产管理概述媒体资产管理(媒体资产管理)是一个强大的解决方案。
当前,各种医学院校的教育技术中心和附加功能。由于学习者的学习风格和学习内容之间存在明显差异,因此在使用该系统时,通常需要个性化订阅,站点搜索,评论和修改等功能。在设计该系统时,根据学习者的需求,建立了一个独立的订阅模块。学习者可以根据自己的需求订阅所需的学习资源,并可以按类别显示资源内容。学习者检索信息时,可以根据类别和标签实现智能检索,并可以按时间顺序显示,方便学习者使用。学习者还可以评论或修改推送的资源,添加标签等,以进一步丰富学习资源,或提供学习记录以促进其他学习者的学习。 3. 4促进协作学习的发展协作学习是一种组织学生通过小组或团队进行学习的策略。小组成员的协作工作是实现共同学习目标的重要组成部分。自动学习资源采集系统的修改功能可以实现消息形式或直接修改形式的学习资源的协同处理,促进学习资源的丰富和完善,并实现协作工作的目的。简而言之,VLC中的自动学习资源采集系统通过信息聚合和自动推送来实现学习资源的自动更新,并为构建高级的个性化学习环境提供技术支持。
该系统的应用可以有效地提高学习效率,促进学习者从获取学习资源到接受学习资源的过渡。参考文献[1]李平。 采集网络信息资源策略[J]。科技情报开发与经济,2006,16(8):59-60 [2]朱格维。数据库网络资源的探讨采集 [J]。图书馆工作与研究,2008,(4)[3]吴斌,石新华。网络信息资源管理与数据库建设[J]。河南科技,2008,(3)[4]杨辉。CSCL中教师教学组织行为对学习者影响的研究中国的视听教育,2009,(1):64- 68,收稿日期:2009-04-20)作者简介:甘振涛(1973-),男,重庆Bi山人。 ,工程师,硕士,主要研究方向:大学信息化建设与应用,网络安全。 查看全部
虚拟学习社区中学习资源自动采集系统的更新速度
2009年10月,第23卷,第5期中国医学教育技术在医学领域的应用1。 2 3 5号20o9·技术支持·虚拟学习社区中自动学习资源采集系统的构建杨朝军,高东淮,宁玉文(第四军医大学网络中心,西安71003,陕西710032)[摘要]:自动学习资源的介绍2)k15]根据系统的设计和过程及其对学习者知识结构的影响,指出该系统可以自动采集并发布在线学习资源,有效地提高了学习效率。 [关键词]:虚拟学习社区;学习资源;自动采集 [中文图书馆分类号] ]:G434 [文件识别码]:A [文章编号]:1004- 5287(2009)05-0498-03在虚拟环境中学习自动搜集的内容TU在社区中学习赵军,高东怀,男(网络中心。
富华军事大学,陕西西安710032 [摘要]:本文介绍了学习资源自动采集系统的设计和程序,以及对学习者知识建设的影响。它指出,这是系统调用自动采集并发布基于Web的学习资源,从而改善了虚拟学习社区中的学习资源,促进了企业自主学习。 [凯词]:虚拟学习社区;学习资源;自动采集Yuwen资源的优势和便利性虚拟学习社区(virtual学习社区,VIE)是一个基于信息的学习环境,需要及时提供大量学习资源,满足学习者对独立学习的需求。和协作学习。
当前,许多社区使用受限用户上传和管理员定期上传的组合来更新资源。这种内部资源共享过分依赖人工操作,资源来源范围有限,难以实现。动态不断的更新也限制了学习资源的更新效率,使学习者无法及时获得所需的资源,从而影响学习效果。因此,设计一种自动学习资源采集系统以实现个性化订阅,自动采集和自动发布学习资源是解决虚拟学习社区中资源更新问题的有效方法。 A. 1自动采集系统的学习资源设计和工作流程1。 1设计概念认知灵活性理论认为,人类学习是学习者积极构建内部心理表征的过程。它反对知识的预定义和仅强调知识的非结构。相反,它主张一方面要为建立理解提供基础,另一方面要为学生提供广阔的建构空间,让他们针对具体情况采取适当的策略。情况。因此,虚拟学习社区中的学习资源必须具有三个特点:①资源具有科学严谨的系统结构,内容多样,内容丰富,能够充分满足学习者知识建设的需要; ②社区资源必须具有开源性,并能够形成一个稳定的信息生态系统; ③资源可以灵活,自主地构建,学习者可以根据学习风格独立构建个性化的资源系统。
VLC中学习资源的三个特征要求社区必须不断地从外界输入信息,以确保信息的生态平衡并满足不同学习者的学习需求。尽管网络信息资源非常丰富,但是它们高度分散且结构复杂。在为学习者提供丰富知识的同时,还存在诸如检索困难的问题。在信息搜索过程中,一些学习者甚至偏离了他们原来的学习目标。使用学习资源自动采集系统,您只需一次性订阅即可自动采集网络资源并将其发布在虚拟学习社区中,从而根据学习者的个人需求形成简单的资源重建学习者所需的基本知识环境,也为学习者创造了广阔的空间。 1. 2开发环境和关键技术学习资源自动采集系统处于Linux操作系统中接收时间:2009-05-25关于作者:杨朝军(1,1980),男,陕西省周志仁第四军医大学教育技术专业研究生,助教,主要研究方向:网络技术。第23卷第5期杨朝军等。关于虚拟学习社区中学习资源自动采集系统的构建。在499环境下,采用了PHP + Mysql + apache的技术开发框架,并采用了URL重复数据删除和自动摘要这两项关键技术。
自动学习资源采集系统需要确定采集信息之前的采集前页面是否为采集,并且需要URL重复数据删除处理。实现代码如下:“ c ollec t- urls” =>“ id int(11)NOT NULL AUTO — lN CREMENT,remote- url varchar(255)NOT NULL,title varchar(255)NOT NULL,导入— ud varchar(255),导入— id bigint(20)DE FAULT 0 NOT NULL,loc al_ pid int(11)DEFAULT 0 NOT NULL,状态tinyint(1)DE FAULT O NOT NULL,slug varchar(255)NOT NULL,唯一密钥id(id)”,采集每次采集记录一次采集的网页地址,形成一组采集的网页地址网页地址,或在数据库中添加一个标志位如果(!empty($ collect_table_ sqls))需要一次(ABSPATH。wp- admin / include / upgrade。php'); foreach($ collect- table- sqls AS $ ta b le一/ laine => $ ta b le_sq1){$ table_name = $ wpdb-> pref ix。$ ta b le_name; if($ wpdb-> get_var(” SHOW TABLES LIKE)!= $ table_name)$ sql =“ CREATE TA B LE”。确定磨她的地址在采集记录中,如果在其中,则表明该网页已被采集跳过;否则,输入采集信息,并将网页地址信息放入采集地址记录中,以免网页重复采集,浪费资源。
摘要是指通过处理文档的内容来提取满足用户需求的重要信息,并在重组和修改后生成比原创内容更精细的摘要的过程。作者采用了使用自然语言处理(NLP)技术的自动摘要系统。通过将基于内容的方法(基于内容)和基于主题的方法进行融合,可以将主题和内容组合在一起以生成具有良好连贯性和流畅性的摘要。基本思想是首先分析主题词,动态处理带有抽象标题和特定标题的文档,然后使用自然语言处理技术(例如词汇,语法和语义分析)对文章的文本内容进行深入分析]。将两次分析获得的结果进行线性加权融合,生成摘要,最后使用回指法解析技术进行平滑处理,以使生成的摘要更加连贯和流畅。在抽象生成算法中,还将输出一些元数据(例如标题分析,作者摘录和主要题词)并将其保存为中间结果,从而形成一个符合基本内容的完整元数据系统。文件规格。 1. 3系统设计和工作流程。自动学习资源采集该系统主要由三部分组成:Web信息采集子系统,信息处理子系统和信息发布子系统。这三个子系统通过它们之间定义的接口来实现整个过程。自动化采集,智能处理和主动发布,如图1所示。
W资源e来源b季节性胶囊Web信息数据采集发布系统图1自动学习资源采集系统结构关系图自动学习资源采集系统的工作流程需要数据采集和信息处理3信息发布的步骤,如图2所示。Web资源采集模板管理两个两个[两个任务管理两个两个[采集模块T信息处理模块UR L库两个] UR L分析信息发布处理H 采集数据管理H 采集数据库I图2自动学习资源采集系统数据采集释放流程图采集的第一步数据。学习者可以根据需要通过不同的采集面板自定义订阅。他们只需要在任务管理模块中添加采集个任务,并设置采集开始时间,采集结束条件和采集任务]信息和其他内容的目标分类,任务管理模块从种子URL开始,以提供目标Web资源的信息采集。然后,通过信息处理模块URL解析,URL管理模块获取新的URL,并根据任务管理模块为这些URL设置的条件采集,直到URL队列为空或触发任务结束停止,然后传送到信息处理系统。第二步是信息处理。 采集的学习资源进入信息处理子系统后,信息处理模块首先对信息进行基本的去噪处理,然后从页面信息中提取出诸如导航条,页眉和页脚之类的关键信息。
HTML解析后,URL解析模块解析出该信息中收录的所有URL信息,并执行URL重复数据删除,并将其保存在URL库中,以供采集模块使用。同时,采集管理器将数据保存在采集数据库中,以供信息发布子系统使用,并将采集信息填写到采集“ 1 One Number Chinese Medical Education Technology Volume 23,Issue” 5 Data Conversion-3]。第三步是发布信息,作为信息数据采集系统的特定应用系统,信息发布子系统将采集数据库中的信息传输到数据发布数据库,最终通过信息发布子系统处理的信息由信息发布模块处理,以发布到Web User,实现信息的自动推送功能采集 .2使用情况及其对学习者知识建构的影响。自动学习资源采集自动学习资源虚拟学习社区中系统的功能采集该系统可以作为插件安装在PHP + Mysql + apache体系结构的虚拟学习社区平台中。针对不同类型的资源,有两种应用方法。 2. 1学习资源自动采集系统在虚拟学习社区中的应用方法2。 1. 1 采集文本和图像格式为文本和图像。 采集根据用户定义的任务配置,系统准确地批量提取目标网络列中的文本和图片,自动提取并合并多个页面的文本内容,并根据图片格式进行分类,然后进行转换成结构化的记录。记录包括标题,作者,内容,采集时间,来源,分类等,这些信息存储在本地数据库中,从而有效避免了使用这些数据的网站程序或桌面程序与数据库之间的任何耦合。表结构也可以完全更改。学习者可以自己定义它,并根据资源分类结构将其呈现给学习者,还可以与社区的其他成员共享。
适用于新闻采集,博客文章 采集,RSS / ATOM XML内容采集,文本/ CSV内容采集,任意格式的XML 采集,自定义结构网页内容采集等待。 2. 1. 2有一个更大的共享视频和课件的空间。在虚拟学习社区中,如果学习者的视频或课件资源采集存储在数据库中,它将占用大量社区空间,消耗服务器的系统内存,并使服务器瘫痪。对于占用空间的资源,信息采集系统采用共享视频和课件地址(仅采集资源的名称和URL)的方法,然后将它们以列表的形式呈现给学习者。当他们使用它们时,只需要单击链接,您就可以登录视频或课件源网站进行学习。此方法通常适用于以在线播放形式出现的视频,例如Youku和Aibo之类的视频源,以及提供下载的可集成软件库。 2. 2自动学习资源采集系统对学习者的知识建构的影响知识建构是建构主义学习哲学的核心术语。知识建构的观点认为,知识的获取不是学习者简单地接受或复制的过程,而是积极建构的过程,同时也是创造和修改公共知识的过程。学习资源系统的自动生成通过创建个人知识来建立目标,并根据公共知识自主地创建个人资源系统。在资源创造过程中,它追求知识建构的合理性。
学习资源的主要表演视频和课件资源占据空白。作者在第四军医大学信息化教学在线门户平台上试行了资源采集系统,主要在基于图片的教材设计资料库中进行了编写。主要教学中安装了采集系统。信息栏和基于视频的教学视频服务系统。从2009年3月开始为期一个月的试运行。截至2009年4月3日,采集]新增信息4,961个,可用信息4,738个,占95. 5%。随机选择200名试用资源采集系统的用户(包括30名教师),并进行回访以通过问卷调查,187份,3份无效副本和92份实际可用的问卷调查采集系统的感觉。 5%。调查结果表明,有92%的用户对采集系统非常满意。 3. 5%的用户不满意,4。 5%的用户认为这无关紧要。在184位表示满意的用户中,有121位用户认为该系统减少了获取资源的难度并提高了学习效率。其余63名学生仅对该系统感到好奇,并乐于使用该系统。将近一半的用户根据采集中的资源量安排自己的学习进度,并制定更合理的学习计划,在每个阶段阐明自己的学习内容,一些学习者还比较他们所获得的资源采集与其他用户。二次共享将加快社区内集体智慧的交流,达到快速知识建设的目的。
我们利用资源自动采集了200份问卷,自动回收了3个学习资源采集系统自动学习资源的实际意义采集该系统突破了资源手动上传的资源建设模式,形成了外部结构学习资源的机制。在虚拟学习社区中,实现了用户独立构建个人资源系统的个性化方式。主要体现在以下几个方面:3. 1实现非结构化信息到结构化信息的转换。根据用户定义的任务配置,自动学习资源采集系统可以快速实现外部信息的获取,并可以批量,准确地提取Internet目标网页中的半结构化和半结构化信息。非结构化信息根据学习者的资源架构存储在虚拟学习社区数据库中,并转换为结构化信息供社区用户使用。结构良好的信息可以促进学习者的学习,并有效地提高学习效率。 3. 2实现了学习资源的自动更新。更新学习资源的问题一直是学习平台应用程序的瓶颈问题。资源更新的滞后主要是因为学习资源与资源库之间没有连续和自动的连接,并且手动下载和上传方法造成时间浪费和资源时效性的降低。自动学习资源采集系统使用信息采集器,该信息采集器在订户和订户之间建立稳定的连接,并实现学习资源的聚集和同步更新。这种全面且时间紧迫的学习资源可以激发学习者的学习兴趣,从而使学习者无需在大量信息中搜索学习资源,并且管理员无需手动添加资源。通过自动更新,打破了学习资源的瓶颈。
3。 3实现学习资源的个性化定制。良好的个性化服务是学习资源采集系统的杰出代表。 2009年10月,第23卷,第5期中国医学教育技术在传播中的作用0 G Y V o1。 2 3晚5点基于IP SAN架构的20o9医学院校媒体资产管理存储系统甘振涛(第三军医大学教育技术中心重庆400038)[摘要]:如何设计合理有效的医学院校存储系统媒体资产管理系统的建设是一个核心问题文章通过对相关技术的分析比较,提出了学校媒体资产存储系统的架构,为研究媒体资产存储的建设提供参考。 [关键词]:媒体资产; FC SAN; IP SAN;存储[中文图书馆分类号]:G434 [文件标识码]:A [文章编号]:1004-5287(2009)05 -0501-0 3基于IP SA的结构化医学数据库在医学上的应用是由CHEN ZHENtao(第三军事教育技术中心)医学大学。
重庆400038。[摘要]:如何设计合理有效的存储系统是医学和大学医学资产管理的核心问题。通过对技术的分析,论文提出了科学媒体资产管理的框架,为研究medica媒体资产管理的存储系统结构提供了参考。大学和大学。 [凯词]:媒体资产; FC SAN; IP SAN;存储媒体资产管理概述媒体资产管理(媒体资产管理)是一个强大的解决方案。
当前,各种医学院校的教育技术中心和附加功能。由于学习者的学习风格和学习内容之间存在明显差异,因此在使用该系统时,通常需要个性化订阅,站点搜索,评论和修改等功能。在设计该系统时,根据学习者的需求,建立了一个独立的订阅模块。学习者可以根据自己的需求订阅所需的学习资源,并可以按类别显示资源内容。学习者检索信息时,可以根据类别和标签实现智能检索,并可以按时间顺序显示,方便学习者使用。学习者还可以评论或修改推送的资源,添加标签等,以进一步丰富学习资源,或提供学习记录以促进其他学习者的学习。 3. 4促进协作学习的发展协作学习是一种组织学生通过小组或团队进行学习的策略。小组成员的协作工作是实现共同学习目标的重要组成部分。自动学习资源采集系统的修改功能可以实现消息形式或直接修改形式的学习资源的协同处理,促进学习资源的丰富和完善,并实现协作工作的目的。简而言之,VLC中的自动学习资源采集系统通过信息聚合和自动推送来实现学习资源的自动更新,并为构建高级的个性化学习环境提供技术支持。
该系统的应用可以有效地提高学习效率,促进学习者从获取学习资源到接受学习资源的过渡。参考文献[1]李平。 采集网络信息资源策略[J]。科技情报开发与经济,2006,16(8):59-60 [2]朱格维。数据库网络资源的探讨采集 [J]。图书馆工作与研究,2008,(4)[3]吴斌,石新华。网络信息资源管理与数据库建设[J]。河南科技,2008,(3)[4]杨辉。CSCL中教师教学组织行为对学习者影响的研究中国的视听教育,2009,(1):64- 68,收稿日期:2009-04-20)作者简介:甘振涛(1973-),男,重庆Bi山人。 ,工程师,硕士,主要研究方向:大学信息化建设与应用,网络安全。
直观:舆情监测系统源码的功能有哪些以及舆情监测的应用范围
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-02 04:23
(4)舆论影响力: 自动区分正面,负面和重大负面舆论;
(5)全文搜索: 提供多种类型的搜索方法,可以添加和删除内置关键字;
(6)舆论简报: 以简报的形式介绍每日和每周的主要舆论. 简介有多种设计格式可供选择和编辑;
(7)特别报告: 特别报告是关于该主题的全面而系统的报告,包括图表,报告和一般分析.
舆论监督系统源代码的功能是什么?
1)公众情感数据采集子系统公众情感数据采集子系统数据采集对象主要是Internet 网站和网页. 有两个主要数据源,一个是通过指定范围网站进行捕获采集,另一个是通过baidu和google监视整个网络数据采集. 在数据采集的处理过程中,包括了许多中文处理技术,例如文本内容的自动识别,文章重复数据删除和相似性分析以及摘要和关键字的自动生成. 此外,数据采集子系统还可以采集下载网页中的图片和文档资源文件,并具有生成网页图片和快照的功能,实现网站自动登录,使用代理服务器下载,JS自动识别判断,以及分配公式采集和其他函数. 该模板技术被用于舆论数据采集子系统,并且系统内置了数百个网站模板,从而使用户的配置过程变得非常简单.
舆论监督系统源代码
2)公众情感数据处理子系统公众情感数据处理子系统主要组织和处理采集子系统采集的数据. 主要功能包括: 民意数据管理: 包括数据分类,编辑,删除和添加的维护. 门户信息配置: 系统可以自动生成前端门户平台的信息. 管理员还可以通过后台配置将需要呈现的信息放置在门户中. 同时,管理员还可以执行门户的一些渠道,热词和主题. 管理和设置. 简报管理模块: 通过设置舆情简报模板,您可以每天,每月或每月自动生成舆情简报,也可以手动选择信息生成简报,并为生成的简报提供可视化的编辑界面.
3)舆论分析子系统舆论分析子系统的功能分为统计和分析两部分.
以上是齐归社区编辑介绍的民意监测系统源代码的功能以及民意监测应用范围的相关内容. 如果您想了解有关舆论监督的更多信息,请继续关注我们的网站. 查看全部
民意监测系统源代码的功能是什么?民意监测的应用范围是什么?
(4)舆论影响力: 自动区分正面,负面和重大负面舆论;
(5)全文搜索: 提供多种类型的搜索方法,可以添加和删除内置关键字;
(6)舆论简报: 以简报的形式介绍每日和每周的主要舆论. 简介有多种设计格式可供选择和编辑;
(7)特别报告: 特别报告是关于该主题的全面而系统的报告,包括图表,报告和一般分析.
舆论监督系统源代码的功能是什么?
1)公众情感数据采集子系统公众情感数据采集子系统数据采集对象主要是Internet 网站和网页. 有两个主要数据源,一个是通过指定范围网站进行捕获采集,另一个是通过baidu和google监视整个网络数据采集. 在数据采集的处理过程中,包括了许多中文处理技术,例如文本内容的自动识别,文章重复数据删除和相似性分析以及摘要和关键字的自动生成. 此外,数据采集子系统还可以采集下载网页中的图片和文档资源文件,并具有生成网页图片和快照的功能,实现网站自动登录,使用代理服务器下载,JS自动识别判断,以及分配公式采集和其他函数. 该模板技术被用于舆论数据采集子系统,并且系统内置了数百个网站模板,从而使用户的配置过程变得非常简单.
舆论监督系统源代码
2)公众情感数据处理子系统公众情感数据处理子系统主要组织和处理采集子系统采集的数据. 主要功能包括: 民意数据管理: 包括数据分类,编辑,删除和添加的维护. 门户信息配置: 系统可以自动生成前端门户平台的信息. 管理员还可以通过后台配置将需要呈现的信息放置在门户中. 同时,管理员还可以执行门户的一些渠道,热词和主题. 管理和设置. 简报管理模块: 通过设置舆情简报模板,您可以每天,每月或每月自动生成舆情简报,也可以手动选择信息生成简报,并为生成的简报提供可视化的编辑界面.
3)舆论分析子系统舆论分析子系统的功能分为统计和分析两部分.
以上是齐归社区编辑介绍的民意监测系统源代码的功能以及民意监测应用范围的相关内容. 如果您想了解有关舆论监督的更多信息,请继续关注我们的网站.
TurboCMS内容管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2020-08-27 05:41
TurboCMS内容管理系统概述:
任何一个网页数量小于10的网站都须要内容管理,最简单的情况是网站的Webmaster来完成管理的任务,他制做所有的页面,并检测其中的联接,然后使用FTP工具上传到服务器上。但是随着网页数目的降低,情况发生了变化,对于一些时常更新的内容,比如新闻,许多网站开发自己的专用的发布系统来维护这种更新要求特别高的部份。动态网页技术的发展支持了这些方法。但是现代网站的信息量实在很大了,而且内容的种类也十分的多,仅仅支持新闻类内容的发布早已未能满足需求。这一切促使网站维护步入了“内容管理时代”。
网站内容管理系统是一套可以综合管理网站上各类栏目的通用工具,新闻、产品、文档、下载等,通过元数据管理和模板技术,它们都在同一套系统里完成更新和维护。
基于TurboCMS4.6优秀的内容管理引擎,TurboCMS在站点群管理、国际化支持、内容交换与共享、Web2.0特点的支持等众多方面具有明显的改善,对英文内容管理技术终将提高一个层次。
TurboCMS内容管理系统特点:
我们觉得,软件的哲学本质即“简单就是美”,因此在TurboCMS的开发过程中,无处不充分考虑用户的使用习惯,尽最大可能增加用户的使用门槛,让用户关注于内容维护本身,而不需要投入过多的时间来学习系统的使用方法,在细节处下大工夫。
TurboCMS的主要特征有:
1、不同凡响的采编体验TurboCMS的内容录入界面充分考虑内容维护人员的实际情况,他们可能不精通HTML,但她们会使用Word等办公软件,因此,系统界面与Word等Office产品紧密集成,可直接从Word里拖动一块内容到TurboCMS中来。如果Word中包括图片、表格等内容,则系统手动上传图片等文件,完全无需人工干预,并可批量导出Word、PowerPoint、Excel、JPG、GIF文件,并支持手动分页,自动清除HTML,自动排版。
用户也可以在TurboCMS里直接进行文字的排版处理,比如改变字体名称,字体大小,字体颜色,背景颜色,以及对齐式样等等。还可以透明地插入图片,并可以任意调整图片的位置、大小,与文字进行环绕等等。系统甚至可以手动给图片生成缩略图,点击后看大图。系统还支持插入Flash动漫、超级联接、特殊字符、音频视频等等。系统会手动将插入的图片、Flash等文件上传到系统中合适的目录,而无需用户关心这一切。
如果从网页上拷贝内容,系统支持远程图片手动本地化。
系统支持插入附件,热字联接,内容分页。
系统支持托拽形式进行次序调整,任意排版。支持重要文章置顶。
托拽形式进行内容位置调整,频道间拷贝、移动。
系统支持文章标题查重。
2、站点群管理TurboCMS支持多站点、站点群的管理,特别适宜具有诸多分支机构或下属单位的小型企业和政府单位进行站点群的统一化管理。
站点间并具有内容共享支持,可便捷地在主站与子站、子站与子站点间进行信息的共享。
系统提供多级的权限控制系统,可便捷地对站点群管理进行分工。
3、媒体行业专门解决方案许多媒体(如刊物、报纸、电视、广播)等有一些栏目是按时间更新的,比如一周一期,一月一期等等,这种更新方法更传统的网站的持续性更新有很大的区别。从内容维护上看,内容录入时须要分辨内容是在哪一期出版的,从网站浏览上看,访问者要求能查询过刊。TurboCMS专门为刊物提供了支持。编辑可以在一期的内容都准备好了后统一出版。当旧的一期出版后,内容被录入到新的一期中。期刊的内容出版到网站上后,访问者可以按年、期来查询过刊,也可以按栏目来查询过往的内容。
对刊物的支持是TurboCMS的明显特征,国内外仍未看见提供类似功能的内容管理系统。
对于报纸内容上网,TurboCMS提供专门的“报纸”管理模块,支持将报纸扫描成图片,放到网站上,允许用户用点击某一区域之后查看内容的形式进行浏览,从而实现报纸的“仿真网络版”。仿真版保留了报纸的排版,充分利用了报纸的排版价值,同时使浏览更为直观。
TurboCMS支持批量导出国外常见的报社采编系统如北大紫光采编系统导入的数据文件。
4、可视化模板制做插件我们充分研究了国内外的内容管理系统,发现她们大都还能实现结合模板手动生成页面,减轻了页面制做人员的工作量,但是模板制做本身缺要求有较高技术水平的人员,有些系统要求使用基于XML的程序语言XSLT来制做模板,有些系统要求UNIX下的TCL语言来写模板,真可谓是降低了HTML设计人员,却降低了XML编程人员,没有从根本上减少用户的负担。
在这样的系统中,模板制做通常情况下分两步完成,第一步先请美术设计人员设计模板的风格等外型,第二步使精通模板制做的程序员来嵌代码。
TurboCMS提供了forDreamWeaver的TDL(模板定义语言)插件,设计师在自己熟悉的软件里,完成设计后,只须要用键盘从工具栏上拖动控件到页面中,就手动插入了TurboCMS的模板脚本了,无需编撰任何代码。
5、采用UNICODE,支持任意编码,支持繁简手动转换
系统内部统一采用UNICODE,支持GBK、BIG5、UTF8等任意编码的网站管理。系统并能手动实现繁体英文网站转换成简体英文网站及相反的转换。
6、工作流支持以及手动消息提醒
TurboCMS支持内容发布的工作流。一篇内容从记者最初录入到最后发布到网站上,中间须要经过编辑审批,甚至须要美工配图等等。TurboCMS手动会将任务发送到下一个处理者。系统提供电子邮件形式,在有新的任务到来时手动提醒用户登录系统完成任务。这样,当记者新录入了一篇文章时,编辑就立刻晓得了,然后登录系统编辑文章并审批,保证内容及时地更新到网站上去。
系统支持手机邮件、电子邮件、MSNMessenger等方法的提醒。
对于特殊的内容,TurboCMS支持自定义的工作流步骤设置,工作流类型支持任意审批、全部审批、顺序审批等。
文章在每一步可设置“返工”、“否决”。
7、自定义内容数组
在TurboCMS中,每一个频道都可以定义自己的数组结构,字段类型支持文本、选择、日期、图片、标签等。相对于整个系统使用相同的数组结构不能扩充,或只能对整个系统进行扩充而不能对单独频道进行扩充的系统来说,TurboCMS具有极大的灵活性,可以满足网站上各类类型、各种结构的信息发布需求,融各类类型内容管理于同一个系统中。从这个意义上讲,TurboCMS是一个内容管理开发平台。
8、内容采集
TurboCMS外置了数据库爬虫,用户可以创建一个爬行任务,从指定的数据库(支持Oracle、MicrosoftSQLServer、MySQL)指定的表中,自动采集指定的数组,并映射到TurboCMS内容库的数组。从而轻松地使TurboCMS与已有的信息系统进行数据集成。
自动化内容采集的支持,大大地增加了内容维护的工作量,并使内容管理系统与企业的其他信息化系统无缝集成,提高了信息的利用率。
9、静态布署与动态布署
TurboCMS的工作方式为,用户录入内容时被保存在专门的内容数据库中,然后那些内容结合模板生成静态的HTML页面。最后这种静态的HTML页面被复制到网站的产品服务器起来。在最终的产品服务器上,无需数据库支持。TurboCMS提供了一个手动布署工具TurboDeploy,可以手动地将更新过的文件及时同步到产品服务器上,并可以将同一个目录布署到多台服务器上,从而支持服务器镜像和服务器集群。TurboDeploy支持增量式布署,持续性将更新过的内容进行布署。
对于复杂查询等特殊应用需求,TurboCMS提供DataDeploy数据库布署功能。将频道中的数据复制到Web服务器上的数据库中,以便实现复杂条件的查询等应用需求。数据库布署功能是TurboCMS与众不同的特点。
10、丰富后端的支持
TurboCMS可以与Flash、Jscript等后端表现工具进行结合,以丰富媒体的方式将内容交付给最终用户,从而改善用户体验,提升内容价值。
11、支持XML、RSS、WAP标准
TurboCMS支持将内容发布成XML格式,并支持UTF8编码。TurboCMS支持将内容发布成RSS格式,提供给RSS客户端进行阅读。TurboCMS支持WAP网站的发布,支持使用PDA、手机等无线终端对网站进行访问。
12、支持Web2.0技术
TurboCMS外置了对RSS、TAG、博客等技术的支持,并提供大容量峰会、在线聊天室等功能。
13、同其他系统的集成
TurboCMS对外提供COM+形式的API接口,可供其他系统访问系统内的内容资源。用户可以使用VB、VC、Delphi或则VbScript、JavaScript、NotesScript等脚本语言访问那些API,从而可以容易地与已有的办公自动化、ERP、CRM、MIS等系统集成在一起,将这种系统中须要上网的内容手动地抓取过来发布到网站上,从而不再须要人工来推行拷贝、粘贴。
14、其他特征
大容量设计、连接池技术,日信息发布量可达上万条。经过了Pchome、天天在线等小型门户网站的考验。
系统支持SQLServer和Oracle、DB2三种数据库环境。
支持直接递交一个WORD或TXT或XML文件,自动导出内容库,并智能分析出标题、作者和内容。
支持直接批量导出图片文件。
网站特殊页面管理,支持页面碎片整理。
图片库管理功能。
按角色的用户及权限控制。
关文章分类功能。支持多个相关文章集合。
内容分发功能。某个频道的数据可设置分发规则,自动地分发到其他频道中。
文章版本控制功能,可恢复版本,图形化显示文章处理流程。
文章中可在任意位置插入任意多图片,并支持图片手动生成缩略图,图片加水印,图文混排。
文章标题字数提示,辅助编辑注意网站的格式维护。
文章中可插入特殊符号、连接、多媒体、FLASH、附件等。
文章分页支持。
热字联接功能,关键字替换,将指定关键字构建联接。
文章定时发布、定时归档、文章定时下线等功能。
文章批注功能。
文章拖拽形式进行排版、频道间联通、复制,支持联接复制。 查看全部
TurboCMS内容管理系统
TurboCMS内容管理系统概述:
任何一个网页数量小于10的网站都须要内容管理,最简单的情况是网站的Webmaster来完成管理的任务,他制做所有的页面,并检测其中的联接,然后使用FTP工具上传到服务器上。但是随着网页数目的降低,情况发生了变化,对于一些时常更新的内容,比如新闻,许多网站开发自己的专用的发布系统来维护这种更新要求特别高的部份。动态网页技术的发展支持了这些方法。但是现代网站的信息量实在很大了,而且内容的种类也十分的多,仅仅支持新闻类内容的发布早已未能满足需求。这一切促使网站维护步入了“内容管理时代”。
网站内容管理系统是一套可以综合管理网站上各类栏目的通用工具,新闻、产品、文档、下载等,通过元数据管理和模板技术,它们都在同一套系统里完成更新和维护。
基于TurboCMS4.6优秀的内容管理引擎,TurboCMS在站点群管理、国际化支持、内容交换与共享、Web2.0特点的支持等众多方面具有明显的改善,对英文内容管理技术终将提高一个层次。
TurboCMS内容管理系统特点:
我们觉得,软件的哲学本质即“简单就是美”,因此在TurboCMS的开发过程中,无处不充分考虑用户的使用习惯,尽最大可能增加用户的使用门槛,让用户关注于内容维护本身,而不需要投入过多的时间来学习系统的使用方法,在细节处下大工夫。
TurboCMS的主要特征有:
1、不同凡响的采编体验TurboCMS的内容录入界面充分考虑内容维护人员的实际情况,他们可能不精通HTML,但她们会使用Word等办公软件,因此,系统界面与Word等Office产品紧密集成,可直接从Word里拖动一块内容到TurboCMS中来。如果Word中包括图片、表格等内容,则系统手动上传图片等文件,完全无需人工干预,并可批量导出Word、PowerPoint、Excel、JPG、GIF文件,并支持手动分页,自动清除HTML,自动排版。
用户也可以在TurboCMS里直接进行文字的排版处理,比如改变字体名称,字体大小,字体颜色,背景颜色,以及对齐式样等等。还可以透明地插入图片,并可以任意调整图片的位置、大小,与文字进行环绕等等。系统甚至可以手动给图片生成缩略图,点击后看大图。系统还支持插入Flash动漫、超级联接、特殊字符、音频视频等等。系统会手动将插入的图片、Flash等文件上传到系统中合适的目录,而无需用户关心这一切。
如果从网页上拷贝内容,系统支持远程图片手动本地化。
系统支持插入附件,热字联接,内容分页。
系统支持托拽形式进行次序调整,任意排版。支持重要文章置顶。
托拽形式进行内容位置调整,频道间拷贝、移动。
系统支持文章标题查重。
2、站点群管理TurboCMS支持多站点、站点群的管理,特别适宜具有诸多分支机构或下属单位的小型企业和政府单位进行站点群的统一化管理。
站点间并具有内容共享支持,可便捷地在主站与子站、子站与子站点间进行信息的共享。
系统提供多级的权限控制系统,可便捷地对站点群管理进行分工。
3、媒体行业专门解决方案许多媒体(如刊物、报纸、电视、广播)等有一些栏目是按时间更新的,比如一周一期,一月一期等等,这种更新方法更传统的网站的持续性更新有很大的区别。从内容维护上看,内容录入时须要分辨内容是在哪一期出版的,从网站浏览上看,访问者要求能查询过刊。TurboCMS专门为刊物提供了支持。编辑可以在一期的内容都准备好了后统一出版。当旧的一期出版后,内容被录入到新的一期中。期刊的内容出版到网站上后,访问者可以按年、期来查询过刊,也可以按栏目来查询过往的内容。
对刊物的支持是TurboCMS的明显特征,国内外仍未看见提供类似功能的内容管理系统。
对于报纸内容上网,TurboCMS提供专门的“报纸”管理模块,支持将报纸扫描成图片,放到网站上,允许用户用点击某一区域之后查看内容的形式进行浏览,从而实现报纸的“仿真网络版”。仿真版保留了报纸的排版,充分利用了报纸的排版价值,同时使浏览更为直观。
TurboCMS支持批量导出国外常见的报社采编系统如北大紫光采编系统导入的数据文件。
4、可视化模板制做插件我们充分研究了国内外的内容管理系统,发现她们大都还能实现结合模板手动生成页面,减轻了页面制做人员的工作量,但是模板制做本身缺要求有较高技术水平的人员,有些系统要求使用基于XML的程序语言XSLT来制做模板,有些系统要求UNIX下的TCL语言来写模板,真可谓是降低了HTML设计人员,却降低了XML编程人员,没有从根本上减少用户的负担。
在这样的系统中,模板制做通常情况下分两步完成,第一步先请美术设计人员设计模板的风格等外型,第二步使精通模板制做的程序员来嵌代码。
TurboCMS提供了forDreamWeaver的TDL(模板定义语言)插件,设计师在自己熟悉的软件里,完成设计后,只须要用键盘从工具栏上拖动控件到页面中,就手动插入了TurboCMS的模板脚本了,无需编撰任何代码。

5、采用UNICODE,支持任意编码,支持繁简手动转换
系统内部统一采用UNICODE,支持GBK、BIG5、UTF8等任意编码的网站管理。系统并能手动实现繁体英文网站转换成简体英文网站及相反的转换。
6、工作流支持以及手动消息提醒
TurboCMS支持内容发布的工作流。一篇内容从记者最初录入到最后发布到网站上,中间须要经过编辑审批,甚至须要美工配图等等。TurboCMS手动会将任务发送到下一个处理者。系统提供电子邮件形式,在有新的任务到来时手动提醒用户登录系统完成任务。这样,当记者新录入了一篇文章时,编辑就立刻晓得了,然后登录系统编辑文章并审批,保证内容及时地更新到网站上去。
系统支持手机邮件、电子邮件、MSNMessenger等方法的提醒。
对于特殊的内容,TurboCMS支持自定义的工作流步骤设置,工作流类型支持任意审批、全部审批、顺序审批等。
文章在每一步可设置“返工”、“否决”。
7、自定义内容数组
在TurboCMS中,每一个频道都可以定义自己的数组结构,字段类型支持文本、选择、日期、图片、标签等。相对于整个系统使用相同的数组结构不能扩充,或只能对整个系统进行扩充而不能对单独频道进行扩充的系统来说,TurboCMS具有极大的灵活性,可以满足网站上各类类型、各种结构的信息发布需求,融各类类型内容管理于同一个系统中。从这个意义上讲,TurboCMS是一个内容管理开发平台。
8、内容采集
TurboCMS外置了数据库爬虫,用户可以创建一个爬行任务,从指定的数据库(支持Oracle、MicrosoftSQLServer、MySQL)指定的表中,自动采集指定的数组,并映射到TurboCMS内容库的数组。从而轻松地使TurboCMS与已有的信息系统进行数据集成。
自动化内容采集的支持,大大地增加了内容维护的工作量,并使内容管理系统与企业的其他信息化系统无缝集成,提高了信息的利用率。
9、静态布署与动态布署
TurboCMS的工作方式为,用户录入内容时被保存在专门的内容数据库中,然后那些内容结合模板生成静态的HTML页面。最后这种静态的HTML页面被复制到网站的产品服务器起来。在最终的产品服务器上,无需数据库支持。TurboCMS提供了一个手动布署工具TurboDeploy,可以手动地将更新过的文件及时同步到产品服务器上,并可以将同一个目录布署到多台服务器上,从而支持服务器镜像和服务器集群。TurboDeploy支持增量式布署,持续性将更新过的内容进行布署。
对于复杂查询等特殊应用需求,TurboCMS提供DataDeploy数据库布署功能。将频道中的数据复制到Web服务器上的数据库中,以便实现复杂条件的查询等应用需求。数据库布署功能是TurboCMS与众不同的特点。
10、丰富后端的支持
TurboCMS可以与Flash、Jscript等后端表现工具进行结合,以丰富媒体的方式将内容交付给最终用户,从而改善用户体验,提升内容价值。
11、支持XML、RSS、WAP标准
TurboCMS支持将内容发布成XML格式,并支持UTF8编码。TurboCMS支持将内容发布成RSS格式,提供给RSS客户端进行阅读。TurboCMS支持WAP网站的发布,支持使用PDA、手机等无线终端对网站进行访问。
12、支持Web2.0技术
TurboCMS外置了对RSS、TAG、博客等技术的支持,并提供大容量峰会、在线聊天室等功能。
13、同其他系统的集成
TurboCMS对外提供COM+形式的API接口,可供其他系统访问系统内的内容资源。用户可以使用VB、VC、Delphi或则VbScript、JavaScript、NotesScript等脚本语言访问那些API,从而可以容易地与已有的办公自动化、ERP、CRM、MIS等系统集成在一起,将这种系统中须要上网的内容手动地抓取过来发布到网站上,从而不再须要人工来推行拷贝、粘贴。
14、其他特征
大容量设计、连接池技术,日信息发布量可达上万条。经过了Pchome、天天在线等小型门户网站的考验。
系统支持SQLServer和Oracle、DB2三种数据库环境。
支持直接递交一个WORD或TXT或XML文件,自动导出内容库,并智能分析出标题、作者和内容。
支持直接批量导出图片文件。
网站特殊页面管理,支持页面碎片整理。
图片库管理功能。
按角色的用户及权限控制。
关文章分类功能。支持多个相关文章集合。
内容分发功能。某个频道的数据可设置分发规则,自动地分发到其他频道中。
文章版本控制功能,可恢复版本,图形化显示文章处理流程。
文章中可在任意位置插入任意多图片,并支持图片手动生成缩略图,图片加水印,图文混排。
文章标题字数提示,辅助编辑注意网站的格式维护。
文章中可插入特殊符号、连接、多媒体、FLASH、附件等。
文章分页支持。
热字联接功能,关键字替换,将指定关键字构建联接。
文章定时发布、定时归档、文章定时下线等功能。
文章批注功能。
文章拖拽形式进行排版、频道间联通、复制,支持联接复制。
乐思网络舆情监测系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-26 15:25
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的采集技术而
研发,具有发觉快,信息全的优势。
系统概述
实施后的利益
系统组成
自动采集子系统功能描述
分析浏览
子系统功能描述
系统施行乐思网络舆情监测系统是针对互联网这一新兴媒体,通过对海量网路舆论信息进行实时的手动采集,分析,汇总,监视,并辨识其中的关键信息,及时通知到相关人员,从而第一时间应急响应,为正确舆论导向及搜集网友意见提供直接支持的一套信息化平台。
其业务流程如下图所示:
图1:乐思网路舆情检测系统的业务流程
相比目前的人工舆情检测,其优势显著:比较指标
采用乐思舆情监测系统
人工检测目标网站
几百个到几千个几万个-采3453舆情4533集-
几十个人力成本
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命负面信息辨识
在手动判断的基础上再人工确认
需要逐字人工查看确认信息保存
精确,全面,便于事后追踪
零碎,不可防止会出错-采3453舆情4533集-数据储存
统一储存在小型关系数据库中,集中管理
Word文件,分散,很难管理检测报告
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
基于手工统计加恐怕,数据支持不充分检测疗效覆盖全面,实时,
自动化,系统化
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集- 查看全部
乐思网络舆情监测系统
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的采集技术而
研发,具有发觉快,信息全的优势。
系统概述
实施后的利益
系统组成
自动采集子系统功能描述
分析浏览
子系统功能描述
系统施行乐思网络舆情监测系统是针对互联网这一新兴媒体,通过对海量网路舆论信息进行实时的手动采集,分析,汇总,监视,并辨识其中的关键信息,及时通知到相关人员,从而第一时间应急响应,为正确舆论导向及搜集网友意见提供直接支持的一套信息化平台。
其业务流程如下图所示:
图1:乐思网路舆情检测系统的业务流程
相比目前的人工舆情检测,其优势显著:比较指标
采用乐思舆情监测系统
人工检测目标网站
几百个到几千个几万个-采3453舆情4533集-
几十个人力成本
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命负面信息辨识
在手动判断的基础上再人工确认
需要逐字人工查看确认信息保存
精确,全面,便于事后追踪
零碎,不可防止会出错-采3453舆情4533集-数据储存
统一储存在小型关系数据库中,集中管理
Word文件,分散,很难管理检测报告
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
基于手工统计加恐怕,数据支持不充分检测疗效覆盖全面,实时,
自动化,系统化
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
dede手动采集更新插件使用手册|DedeCms
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-25 16:41
简介:属于dedecms的一个辅助功能,在dedecms中设定好采集节点以后,规则都设定好,保证在dedecms中才能正确采集到数据。这点很重要,因为我这个插件的采集程序就是dedecms的采集程序,虽然有所改进,但是只是在一些小的细节上更改了一下,整体的采集程序还是和dedecms一样的,一句话就是只要你在dedecms上才能采集到数据,那么这个手动采集更新的程序才能够正确执行。
功能:根据dedecms中设定好的采集节点手动定时定点采集数据,采集好数据然后才能手动导出到相关栏目之中,然后手动生成首页,栏目页,内容页。用一句话概括就是,只要你在dedecms中筹建好了采集节点然后,再从这个插件中配置一下相关参数,就可以不用管这个站了,本程序会手动帮你天天根据你设定好的时间去更新你的站点。是不是太爽啊,省了很大的事呢,呵呵,那么就请使用这个程序吧。
特点:不限于dedecms的版本,3.x和4.0都可以使用,因为本程序不是单纯的调用dedecms的相关文件,是完全从其采集程序中剥离下来自己成体系的一套程序,核心似乎是dedecms的,但是改动了少量细节问题,使逻辑上更合理,修正了原先的一些小的问题。
打包文件介绍:
文件夾:
autogather-----全部的程序文件都在这个下边
cache---缓存配置文件,所有的每位采集节点的手动采集更新的配置信息都在这里
include---所有的核心的操作类,从dedecms中剥离下来的,可以独立成一个系统
templets---模板文件
img,upimg---使用到的一些图片文件
文件:
auto_gather.php----全部的手动采集更新的代码都在这个文件之中,是核心文件
autogather.log---日志文件,记录在手动采集更新的过程中发生的相关信息提示
base.css---样式表文件
co_autogather_main.php---在 dedecms中的配置列表文件
option_auto.php,option_auto_action.php----处理dedecms中的采集节点弄成手动采集的代
码
程序使用说明:
1.首先下载文件包,解压缩在网站根目录下
2.然后到
3.之后步入到dedecms的后台,在辅助插件中的插件整治器中安装一个新插件
4.点击安装新插件,输入相关内容:
插件名称:自动采集更新
作者:千里独行狼
主程序文件:../autogather/co_autogather_main.php
目标框架:main
文件列表:留空
然后点击确定,将降低本插件到系统中。然后刷新一侧的导航,将会在辅助插件栏中多了一个手动采集更新
6.点击一侧的手动采集更新,将显示下来你如今所有设定的采集点,你会发觉在最右侧有一个操作栏,有配置为手动采集和获取代码。
好,我们如今点击配置为手动采集,出来一个具体配置手动采集更新的参数窗口:
下面是具体的每位参数的说明:
采集后导入的目标栏目:采集之后要把数据导出到那个栏目中
采集数据参数设置:采集数据时,每批采集多少条数据,采集的线程数,间隔时间多少秒(防刷新的站点需设置)
栏目导出数据参数设置:每批导出多少条
要更新的栏目:导入完数据然后,要更新的栏目
生成栏目参数设置:每批最大创建页数,也就是分批创建栏目页面的时侯,每批要创建的页数
更新选项:更新栏目的所有页面:一次性全部更新完该栏目的所有页面,仅更新指定数目的页面:有的网站的列表文件太多,假如全部更新的话,耗费的时间会太长,所以这个参数可以设定仅更新前多少页。点击这个选项的话,下面会显示下来一个隐藏的文本框,更新前多少个页面,在这里设定更新的页数
是否更新子栏目:更新子级栏目,仅更新所选栏目
生成文档html参数设置:每批生成多少个内容页面文件
好了,设定好各项参数以后,点击保存配置,将生成一个配置文件到 cache文件夾中
7.点击获取代码
将会在下边出现一个文本框,里面就是获取的代码
把上面的代码拷贝下来。
8.建立一个html文件任意取名,不过建议取一个有意义的名义,这样之后配置多个手动采集点的时侯,以便于分辨
打开这个文件,把拷贝的代码粘贴到该文件中,保存该文件。
9.在windows的计划任务中,建立一个计划任务,设定好要执行的时间。因为php只能做到这些方法,本来曾经想考虑用discuz那个方法,只要网站前台有用户访问,那么就手动开始执行该程序,可是这样并不好,因为采集程序的执行时间都比较长,所以前台访客访问的页面会仍然显示正在打开中,浏览体验就不好了,所以只能依靠windows的计划任务来做了。unix,linux也有类似的程序,这里就不多说了。
现在设定好了一个计划任务,到了规定的时间,就可以执行了。
说明1:因为该程序是在dedev3.1的环境中开发的,所以界面仍然沿用的是3.1的,所以在前面的图中,会倍感颜色不搭调,请你们重视了。
说明2:因为程序从dedecms中完全剥离下来,所以有2个配置参数须要手工的更改一下
autogather/include/config_base.php中的$cfg_dbhost,$cfg_dbname,$cfg_dbuser,$cfg_dbpwd请更改成和你的系统一致的
autogather/include/config_hand.php中的$cfg_indexurl = '';请更改成和你的域名一致的例如:
假如里面两处没有更改,那么本程序将不能运行。 查看全部
dede手动采集更新插件使用手册|DedeCms
简介:属于dedecms的一个辅助功能,在dedecms中设定好采集节点以后,规则都设定好,保证在dedecms中才能正确采集到数据。这点很重要,因为我这个插件的采集程序就是dedecms的采集程序,虽然有所改进,但是只是在一些小的细节上更改了一下,整体的采集程序还是和dedecms一样的,一句话就是只要你在dedecms上才能采集到数据,那么这个手动采集更新的程序才能够正确执行。
功能:根据dedecms中设定好的采集节点手动定时定点采集数据,采集好数据然后才能手动导出到相关栏目之中,然后手动生成首页,栏目页,内容页。用一句话概括就是,只要你在dedecms中筹建好了采集节点然后,再从这个插件中配置一下相关参数,就可以不用管这个站了,本程序会手动帮你天天根据你设定好的时间去更新你的站点。是不是太爽啊,省了很大的事呢,呵呵,那么就请使用这个程序吧。
特点:不限于dedecms的版本,3.x和4.0都可以使用,因为本程序不是单纯的调用dedecms的相关文件,是完全从其采集程序中剥离下来自己成体系的一套程序,核心似乎是dedecms的,但是改动了少量细节问题,使逻辑上更合理,修正了原先的一些小的问题。
打包文件介绍:
文件夾:
autogather-----全部的程序文件都在这个下边
cache---缓存配置文件,所有的每位采集节点的手动采集更新的配置信息都在这里
include---所有的核心的操作类,从dedecms中剥离下来的,可以独立成一个系统
templets---模板文件
img,upimg---使用到的一些图片文件
文件:
auto_gather.php----全部的手动采集更新的代码都在这个文件之中,是核心文件
autogather.log---日志文件,记录在手动采集更新的过程中发生的相关信息提示
base.css---样式表文件
co_autogather_main.php---在 dedecms中的配置列表文件
option_auto.php,option_auto_action.php----处理dedecms中的采集节点弄成手动采集的代
码
程序使用说明:
1.首先下载文件包,解压缩在网站根目录下
2.然后到
3.之后步入到dedecms的后台,在辅助插件中的插件整治器中安装一个新插件
4.点击安装新插件,输入相关内容:
插件名称:自动采集更新
作者:千里独行狼
主程序文件:../autogather/co_autogather_main.php
目标框架:main
文件列表:留空
然后点击确定,将降低本插件到系统中。然后刷新一侧的导航,将会在辅助插件栏中多了一个手动采集更新
6.点击一侧的手动采集更新,将显示下来你如今所有设定的采集点,你会发觉在最右侧有一个操作栏,有配置为手动采集和获取代码。
好,我们如今点击配置为手动采集,出来一个具体配置手动采集更新的参数窗口:
下面是具体的每位参数的说明:
采集后导入的目标栏目:采集之后要把数据导出到那个栏目中
采集数据参数设置:采集数据时,每批采集多少条数据,采集的线程数,间隔时间多少秒(防刷新的站点需设置)
栏目导出数据参数设置:每批导出多少条
要更新的栏目:导入完数据然后,要更新的栏目
生成栏目参数设置:每批最大创建页数,也就是分批创建栏目页面的时侯,每批要创建的页数
更新选项:更新栏目的所有页面:一次性全部更新完该栏目的所有页面,仅更新指定数目的页面:有的网站的列表文件太多,假如全部更新的话,耗费的时间会太长,所以这个参数可以设定仅更新前多少页。点击这个选项的话,下面会显示下来一个隐藏的文本框,更新前多少个页面,在这里设定更新的页数
是否更新子栏目:更新子级栏目,仅更新所选栏目
生成文档html参数设置:每批生成多少个内容页面文件
好了,设定好各项参数以后,点击保存配置,将生成一个配置文件到 cache文件夾中
7.点击获取代码
将会在下边出现一个文本框,里面就是获取的代码
把上面的代码拷贝下来。
8.建立一个html文件任意取名,不过建议取一个有意义的名义,这样之后配置多个手动采集点的时侯,以便于分辨
打开这个文件,把拷贝的代码粘贴到该文件中,保存该文件。
9.在windows的计划任务中,建立一个计划任务,设定好要执行的时间。因为php只能做到这些方法,本来曾经想考虑用discuz那个方法,只要网站前台有用户访问,那么就手动开始执行该程序,可是这样并不好,因为采集程序的执行时间都比较长,所以前台访客访问的页面会仍然显示正在打开中,浏览体验就不好了,所以只能依靠windows的计划任务来做了。unix,linux也有类似的程序,这里就不多说了。
现在设定好了一个计划任务,到了规定的时间,就可以执行了。
说明1:因为该程序是在dedev3.1的环境中开发的,所以界面仍然沿用的是3.1的,所以在前面的图中,会倍感颜色不搭调,请你们重视了。
说明2:因为程序从dedecms中完全剥离下来,所以有2个配置参数须要手工的更改一下
autogather/include/config_base.php中的$cfg_dbhost,$cfg_dbname,$cfg_dbuser,$cfg_dbpwd请更改成和你的系统一致的
autogather/include/config_hand.php中的$cfg_indexurl = '';请更改成和你的域名一致的例如:
假如里面两处没有更改,那么本程序将不能运行。
驻马店上海店家信息,自动采集商家信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-22 17:38
驻马店上海店家信息,自动采集商家信息 涉税专业服务基本信息和业务信息的报送途径是哪些?涉税专业服务机构原则上应该通过网上办税系统报送涉税专业服务基本信息,因客观缘由未能通过网上办税系统报送的,应当在非征期内通过实体办税服务厅代办。涉税专业服务机构应该通过网上办税系统报送涉税专业服务业务信息。税务机关对采集的涉税专业服务基本信息和业务信息依法给以保密。怎么办。
撤销录入 登录系统后点击右上角的“撤销录入”。 在弹出的窗口,点击“获取验证码”,系统将 位验证码以邮件的方式发送到注册时使用的 号上。 点击“获取验证码”后,该按键将被置灰,即 秒内不能再度点击该按键。 输入验证码后,点击“确认”按钮,系统提示“撤销成功”说明该条信息已被撤销。撤销录入完成后该用户数据将在系统内删掉,如果用户想重新进行信息采集,须重新进行操作。入驻淘宝等电商平台的条件。
更多功能,有待您的体验试用,请下载试用。(如何支付?请点这儿查看支付方法)关于深维 | 软件作品 | 订购手册 | 帮助中心 | 用户中心 | 代理加盟 | 付款方式 | 联系方法在线 :(售前咨询)(技术支持)(代理合作) 在线 :@
( )系统“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入成功”即完成操作;如“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入失败”,需按前述步骤重新操作。( )系统提示成功后即可,无需到公积金中心初审。方式二:通过“ 版软件”采集: 登陆 :..平台,进入“下载专区”,下载并安装《 市社会保险系统 管理子系统》及 新升级补丁。怎么样能进驻淘宝做电商。
芭奇站群系统 . . (补丁 )升级如下:完善屏蔽发布数据时侯因为网站错误弹出的脚本错误,同步插口工具中新增命令以及优化部份插口命令的性能,新增插口命令可以制做一些比较实用的小软件 较多细节新功能不一一说明
;肝纤维化中西医结合诊治手册[ ]; 中西医结合刊物; 年 期 邓可刚;国外制订循证临床实践手册的进展[ ]; 循证医学刊物; 年 期 平卫伟;法的研究进展及其在医学中的应用[ ];疾病控制杂志; 年 期 张明雪,曹洪欣,翁维良,谢雁鸣; 西医证候特点及其演化规律的专家问卷调查设计与研究[ ]; 中医基础医学刊物; 年 期 查看全部
驻马店上海店家信息,自动采集商家信息
驻马店上海店家信息,自动采集商家信息 涉税专业服务基本信息和业务信息的报送途径是哪些?涉税专业服务机构原则上应该通过网上办税系统报送涉税专业服务基本信息,因客观缘由未能通过网上办税系统报送的,应当在非征期内通过实体办税服务厅代办。涉税专业服务机构应该通过网上办税系统报送涉税专业服务业务信息。税务机关对采集的涉税专业服务基本信息和业务信息依法给以保密。怎么办。

撤销录入 登录系统后点击右上角的“撤销录入”。 在弹出的窗口,点击“获取验证码”,系统将 位验证码以邮件的方式发送到注册时使用的 号上。 点击“获取验证码”后,该按键将被置灰,即 秒内不能再度点击该按键。 输入验证码后,点击“确认”按钮,系统提示“撤销成功”说明该条信息已被撤销。撤销录入完成后该用户数据将在系统内删掉,如果用户想重新进行信息采集,须重新进行操作。入驻淘宝等电商平台的条件。

更多功能,有待您的体验试用,请下载试用。(如何支付?请点这儿查看支付方法)关于深维 | 软件作品 | 订购手册 | 帮助中心 | 用户中心 | 代理加盟 | 付款方式 | 联系方法在线 :(售前咨询)(技术支持)(代理合作) 在线 :@
( )系统“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入成功”即完成操作;如“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入失败”,需按前述步骤重新操作。( )系统提示成功后即可,无需到公积金中心初审。方式二:通过“ 版软件”采集: 登陆 :..平台,进入“下载专区”,下载并安装《 市社会保险系统 管理子系统》及 新升级补丁。怎么样能进驻淘宝做电商。
芭奇站群系统 . . (补丁 )升级如下:完善屏蔽发布数据时侯因为网站错误弹出的脚本错误,同步插口工具中新增命令以及优化部份插口命令的性能,新增插口命令可以制做一些比较实用的小软件 较多细节新功能不一一说明
;肝纤维化中西医结合诊治手册[ ]; 中西医结合刊物; 年 期 邓可刚;国外制订循证临床实践手册的进展[ ]; 循证医学刊物; 年 期 平卫伟;法的研究进展及其在医学中的应用[ ];疾病控制杂志; 年 期 张明雪,曹洪欣,翁维良,谢雁鸣; 西医证候特点及其演化规律的专家问卷调查设计与研究[ ]; 中医基础医学刊物; 年 期
互联网舆情监控系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-11 19:24
随着互联网的快速发展,网络媒体作为一种新的信息传播方式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国外还是国际重大风波,都能马上产生网上舆论,通过这些网路来抒发观点、传播思想,进而形成巨大的舆论压力,达到任何部门、机构都难以忽略的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
互联网舆情监控系统通过对热点问题和重点领域比较集中的网站信息,如:网页、论坛、BBS等,进行24小时监控,随时下载最新的消息和意见。下载后完成对数据格式的转换及元数据的标引。对下载本地的信息,进行初步的过滤和预处理。对热点问题和重要领域施行监控,前提是必须通过人际交互构建舆情监控的知识库,用来指导智能剖析的过程。对热点问题的智能剖析,首先基于传统基于向量空间的特点剖析技术上,对抓取的内容做分类、聚类和摘要剖析,对信息完成初步的再组织。然后在监控知识库的指导下进行基于舆情的语义剖析,使管理者听到的民情民意更有效,更符合现实。最后将监控的结果,分别推送到不同的职能部门,供拟定对策使用。
网络舆情监控系统是借助搜索引擎技术和网路信息挖掘技术技术,通过网页内容的手动采集处理、敏感词过滤、智能降维分类、主题检查、专题聚焦、统计剖析,实现各单位对自己相关网路舆情监督管理的须要,最终产生舆情简报、舆情专报、分析报告、移动快报,为决策层全面把握舆情动态,做出正确舆论引导,提供剖析根据。
互联网舆情监控系统是针对在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态于网路上抒发下来意愿集合而进行的计算机检测的系统总称。
“网络舆情”是较多群众关于社会中各类现象、问题所抒发的信念、态度、意见和情绪等等表现的总和。网络舆情产生迅速,对社会影响巨大,加强互联网信息监管的同时,组织力量举办信息汇集整理和剖析,对于及时应对网路突发的公共风波和全面把握社情民意太有意义。
二、系统结构
互联网舆情监控系统通常由手动采集子系统(采集层)与剖析浏览子系统(分析层与呈现层),以乐思舆情监控系统为例,网络舆情监控系统构架包括三个层面:
一、采集层,这层收录了要素采集、关键词抽取、全文索引、自动去重和分辨储存及数据库,可以对采集微博、论坛、博客、贴吧、新闻及评论、搜索引擎、图像和视频等。
二、分析层,改成可以对采集的数据信息推行手动分类、自动降维、自动摘要、名称辨识、正负性质预判和英文动词操作,保证分心的全面性。
三、第三层为呈现层,系统对采集分析的数据可以通过负面舆情、分类舆情、最新舆情、专题跟踪、舆情简报、分类评、图表统计和邮件通知等方式推送给用户。
三、功能
1. 热点辨识能力 查看全部
一、系统概述
随着互联网的快速发展,网络媒体作为一种新的信息传播方式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国外还是国际重大风波,都能马上产生网上舆论,通过这些网路来抒发观点、传播思想,进而形成巨大的舆论压力,达到任何部门、机构都难以忽略的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
互联网舆情监控系统通过对热点问题和重点领域比较集中的网站信息,如:网页、论坛、BBS等,进行24小时监控,随时下载最新的消息和意见。下载后完成对数据格式的转换及元数据的标引。对下载本地的信息,进行初步的过滤和预处理。对热点问题和重要领域施行监控,前提是必须通过人际交互构建舆情监控的知识库,用来指导智能剖析的过程。对热点问题的智能剖析,首先基于传统基于向量空间的特点剖析技术上,对抓取的内容做分类、聚类和摘要剖析,对信息完成初步的再组织。然后在监控知识库的指导下进行基于舆情的语义剖析,使管理者听到的民情民意更有效,更符合现实。最后将监控的结果,分别推送到不同的职能部门,供拟定对策使用。
网络舆情监控系统是借助搜索引擎技术和网路信息挖掘技术技术,通过网页内容的手动采集处理、敏感词过滤、智能降维分类、主题检查、专题聚焦、统计剖析,实现各单位对自己相关网路舆情监督管理的须要,最终产生舆情简报、舆情专报、分析报告、移动快报,为决策层全面把握舆情动态,做出正确舆论引导,提供剖析根据。
互联网舆情监控系统是针对在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态于网路上抒发下来意愿集合而进行的计算机检测的系统总称。
“网络舆情”是较多群众关于社会中各类现象、问题所抒发的信念、态度、意见和情绪等等表现的总和。网络舆情产生迅速,对社会影响巨大,加强互联网信息监管的同时,组织力量举办信息汇集整理和剖析,对于及时应对网路突发的公共风波和全面把握社情民意太有意义。
二、系统结构
互联网舆情监控系统通常由手动采集子系统(采集层)与剖析浏览子系统(分析层与呈现层),以乐思舆情监控系统为例,网络舆情监控系统构架包括三个层面:
一、采集层,这层收录了要素采集、关键词抽取、全文索引、自动去重和分辨储存及数据库,可以对采集微博、论坛、博客、贴吧、新闻及评论、搜索引擎、图像和视频等。
二、分析层,改成可以对采集的数据信息推行手动分类、自动降维、自动摘要、名称辨识、正负性质预判和英文动词操作,保证分心的全面性。
三、第三层为呈现层,系统对采集分析的数据可以通过负面舆情、分类舆情、最新舆情、专题跟踪、舆情简报、分类评、图表统计和邮件通知等方式推送给用户。
三、功能
1. 热点辨识能力
面向合作伙伴选择的英文Web信息获取系统研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-11 18:30
[] [浏览:1403次] [2010/8/25 16:16:29]
面向合作伙伴选择的英文Web信息获取系统研究
作者:邱云飞邵良杉那宝贵
作者简介:
邱云飞,辽宁工程技术大学,博士,副教授。
邵良杉,辽宁工程技术大学,博士,教授。
摘要:本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与技巧,提出了面向合作伙伴选择的英文Web信息获取系统的总体构架,并剖析了实现该系统的关键技术—基于元搜索的网页采集、基于样本公共特点的企业主页过滤、基于模式的企业信息抽取,并对这三个关键技术进行了详尽的介绍。最后,按照作者提出的思想,编程实现了一个面向合作伙伴选择的英文Web信息获取原型系统,利用该系统验证了作者所提方式的可行性及证明了该技巧的准确性。
关键词:合作伙伴;Web挖掘;元搜索;文本过滤;信息抽取
1.引言
虚拟企业主要是针对企业核心能力资源的一种整合,即将投资和管理的注意力集中在企业本身的核心能力上,而一些非核心能力、或自己短时间内不具备或不需要具备的核心能力则转向借助外部的虚拟企业伙伴来提供。因此,虚拟企业中的伙伴选择是一个非常重要的问题,它直接关系到虚拟企业的胜败。
WWW推出后,Internet成为全球最大的信息来源,其多元化的信息模式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的素材积累。另一方面,正是因为Internet的海量性、动态性、非结构性、异构性和地理分布性等特性,使得传统的研究途径已不能适应网路环境下的信息获取、处理和借助的须要。
本文建立了面向合作伙伴选择的web信息获取系统的总体框架,给出了系统的实现流程,并对在互联网上手动提取企业相关信息(例如企业名称、企业规模、生产能力、联系方法等)的理论与技巧所涉及到的信息搜索、文本过滤、信息抽取等相关技术进行了剖析,最后实现了一个面向合作伙伴选择的英文Web信息获取原型系统。
2.面向合作伙伴选择的web信息获取系统总体框架
2.1系统需求剖析
本系统从虚拟企业合作伙伴选择的角度出发,构建面向web的潜在伙伴信息获取系统,主要功能是从Internet上手动获取有可能成为核心企业合作伙伴的企业基本信息,从而为核心企业提供强悍的潜在合作伙伴信息库,为其后期进行合作伙伴选择打下良好的基础。
根据调查剖析,有关潜在合作伙伴的基本信息通常分布在一些综合性网站、行业性网站、商情网站(类似B2B网站等)、企业网站上。某一企业在这种网站上提供的信息基本上都是相同的,但和其他网站提供的企业相关信息相比,企业自有网站提供的信息要愈发全面,而且也比较权威。而对整个企业网站而言,对企业做整体介绍的通常在企业主页上,因此,企业主页上的信息便是本系统要获取的主要对象。
2.2系统的总体框架
根据以上的剖析,设计系统的总体构架如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、web文本库、企业主页库、潜在伙伴信息库七部份组成。
图1面向合作伙伴选择的web信息获取系统总体构架
其中,网页采集子系统按照关键字从Internet上搜索网页,并将搜索到的网页下载到本地web文本库中;文本过滤子系统对web文本库的网页进行文本过滤,主要目的是将富含潜在伙伴信息的企业主页筛选下来,最后保存到企业主页库中;信息抽取子系统对企业主页库的每位网页进行信息抽取,主要目的是将潜在伙伴的企业基本信息提取下来,最后保存到潜在伙伴信息库中;人机交互子系统为用户与潜在伙伴信息库的交互提供一个可视化界面,方便用户查询潜在伙伴的基本信息。
3.面向合作伙伴选择的web信息获取系统设计
3.1系统实现思路
从系统总体框架及各模块说明可以看出,要实现整个系统,网页采集子系统、文本过滤子系统、信息抽取子系统三部份的设计与实现是整个系统实现的重点和难点,也可以说是系统实现的关键技术。针对三个子系统的特性,本文提出了基于元搜索的网页手动采集、基于样本公共特点的企业主页过滤、基于模式的企业主页信息抽取三个方式,并完成了相应技术。
3.2基于元搜索的网页手动采集子系统设计
元搜索引擎(MetasearchEngine),被称为搜索引擎之上的搜索引擎。用户只需提交一次检索恳求,由元搜索引擎负责转换处理后递交给多个预先选取的独立搜索引擎,并将所有查询结果集中上去以整体统一的格式呈现到用户面前。相对元搜索引擎,可被借助的独立搜索引擎称为“源搜索引擎”(sourceEngine),或“搜索资源”(searcingresources)。 查看全部
面向合作伙伴选择的英文Web信息获取系统研究
[] [浏览:1403次] [2010/8/25 16:16:29]
面向合作伙伴选择的英文Web信息获取系统研究
作者:邱云飞邵良杉那宝贵
作者简介:
邱云飞,辽宁工程技术大学,博士,副教授。
邵良杉,辽宁工程技术大学,博士,教授。
摘要:本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与技巧,提出了面向合作伙伴选择的英文Web信息获取系统的总体构架,并剖析了实现该系统的关键技术—基于元搜索的网页采集、基于样本公共特点的企业主页过滤、基于模式的企业信息抽取,并对这三个关键技术进行了详尽的介绍。最后,按照作者提出的思想,编程实现了一个面向合作伙伴选择的英文Web信息获取原型系统,利用该系统验证了作者所提方式的可行性及证明了该技巧的准确性。
关键词:合作伙伴;Web挖掘;元搜索;文本过滤;信息抽取
1.引言
虚拟企业主要是针对企业核心能力资源的一种整合,即将投资和管理的注意力集中在企业本身的核心能力上,而一些非核心能力、或自己短时间内不具备或不需要具备的核心能力则转向借助外部的虚拟企业伙伴来提供。因此,虚拟企业中的伙伴选择是一个非常重要的问题,它直接关系到虚拟企业的胜败。
WWW推出后,Internet成为全球最大的信息来源,其多元化的信息模式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的素材积累。另一方面,正是因为Internet的海量性、动态性、非结构性、异构性和地理分布性等特性,使得传统的研究途径已不能适应网路环境下的信息获取、处理和借助的须要。
本文建立了面向合作伙伴选择的web信息获取系统的总体框架,给出了系统的实现流程,并对在互联网上手动提取企业相关信息(例如企业名称、企业规模、生产能力、联系方法等)的理论与技巧所涉及到的信息搜索、文本过滤、信息抽取等相关技术进行了剖析,最后实现了一个面向合作伙伴选择的英文Web信息获取原型系统。
2.面向合作伙伴选择的web信息获取系统总体框架
2.1系统需求剖析
本系统从虚拟企业合作伙伴选择的角度出发,构建面向web的潜在伙伴信息获取系统,主要功能是从Internet上手动获取有可能成为核心企业合作伙伴的企业基本信息,从而为核心企业提供强悍的潜在合作伙伴信息库,为其后期进行合作伙伴选择打下良好的基础。
根据调查剖析,有关潜在合作伙伴的基本信息通常分布在一些综合性网站、行业性网站、商情网站(类似B2B网站等)、企业网站上。某一企业在这种网站上提供的信息基本上都是相同的,但和其他网站提供的企业相关信息相比,企业自有网站提供的信息要愈发全面,而且也比较权威。而对整个企业网站而言,对企业做整体介绍的通常在企业主页上,因此,企业主页上的信息便是本系统要获取的主要对象。
2.2系统的总体框架
根据以上的剖析,设计系统的总体构架如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、web文本库、企业主页库、潜在伙伴信息库七部份组成。
图1面向合作伙伴选择的web信息获取系统总体构架
其中,网页采集子系统按照关键字从Internet上搜索网页,并将搜索到的网页下载到本地web文本库中;文本过滤子系统对web文本库的网页进行文本过滤,主要目的是将富含潜在伙伴信息的企业主页筛选下来,最后保存到企业主页库中;信息抽取子系统对企业主页库的每位网页进行信息抽取,主要目的是将潜在伙伴的企业基本信息提取下来,最后保存到潜在伙伴信息库中;人机交互子系统为用户与潜在伙伴信息库的交互提供一个可视化界面,方便用户查询潜在伙伴的基本信息。
3.面向合作伙伴选择的web信息获取系统设计
3.1系统实现思路
从系统总体框架及各模块说明可以看出,要实现整个系统,网页采集子系统、文本过滤子系统、信息抽取子系统三部份的设计与实现是整个系统实现的重点和难点,也可以说是系统实现的关键技术。针对三个子系统的特性,本文提出了基于元搜索的网页手动采集、基于样本公共特点的企业主页过滤、基于模式的企业主页信息抽取三个方式,并完成了相应技术。
3.2基于元搜索的网页手动采集子系统设计
元搜索引擎(MetasearchEngine),被称为搜索引擎之上的搜索引擎。用户只需提交一次检索恳求,由元搜索引擎负责转换处理后递交给多个预先选取的独立搜索引擎,并将所有查询结果集中上去以整体统一的格式呈现到用户面前。相对元搜索引擎,可被借助的独立搜索引擎称为“源搜索引擎”(sourceEngine),或“搜索资源”(searcingresources)。
溯源系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-11 17:50
一、系统平台特性
本项目通过采用RFID电子耳标、智能数据采集终端PDA,牛牛肉追溯管理系统及二维码溯源秤构建信息化管理平台。
1、RFID标签是畜产品信息确切、完整、及时和快捷传送的保障,畜产品供应商通过RFID标签才能将相关信息实时地传送给畜产品销售商,从而让畜产品的追溯愈发快速、实时和确切。
2、系统采用的RFID标签可读写,从马匹饲养到畜产品销售全过程中各个环节的信息可实时写入同一标签,而且标签使用后可以回收重复借助,从根本上减少了畜产品追溯的成本。
3、消费者才能十分便利地通过在线系统,查询畜产品质量安全的相关信息或向相关部门上报发觉的畜产品质量安全问题;一旦出现畜产品质量安全问题,通过该系统可以找到畜产品从生产到销售全过程出现问题的环节,并及时采取相应的举措,如畜产品召回、畜产品销毁等。
二、信息管理系统组成
信息系统由信息管理中心以及饲养管理子系统、屠宰加工管理子系统、运输管理子系统、销售管理子系统和二维条码阅读子系统五个子系统组成,各子系统的关系如图所示。
信息管理中心是储存畜产品从生产到消费的全过程各个环节上报信息的数据中心。一方面,信息管理中心接收并存储种植、屠宰加工、运输和销售四个子系统上报的数据;另一方面,信息管理中心为消费者信息查询子系统提供各种畜产品的相关信息。
三、信息系统的功能模块
1、RFID采集器
(1)数据采集模块
(2)终端业务处理模块
(3)数据查询模块
(4)通讯模块
(5)RFID控制模块
(6)系统配置模块
(7)日志模块
2、信息管理中心
(1)数据关联模块:主要负责RFID采集器和后台管理中心的网路链接和数据传输
(2)数据库模块:数据库管理
(3)数据展示模块:负责RFID采集器采集到的数据 查看全部
实现的功能
一、系统平台特性
本项目通过采用RFID电子耳标、智能数据采集终端PDA,牛牛肉追溯管理系统及二维码溯源秤构建信息化管理平台。
1、RFID标签是畜产品信息确切、完整、及时和快捷传送的保障,畜产品供应商通过RFID标签才能将相关信息实时地传送给畜产品销售商,从而让畜产品的追溯愈发快速、实时和确切。
2、系统采用的RFID标签可读写,从马匹饲养到畜产品销售全过程中各个环节的信息可实时写入同一标签,而且标签使用后可以回收重复借助,从根本上减少了畜产品追溯的成本。
3、消费者才能十分便利地通过在线系统,查询畜产品质量安全的相关信息或向相关部门上报发觉的畜产品质量安全问题;一旦出现畜产品质量安全问题,通过该系统可以找到畜产品从生产到销售全过程出现问题的环节,并及时采取相应的举措,如畜产品召回、畜产品销毁等。
二、信息管理系统组成
信息系统由信息管理中心以及饲养管理子系统、屠宰加工管理子系统、运输管理子系统、销售管理子系统和二维条码阅读子系统五个子系统组成,各子系统的关系如图所示。
信息管理中心是储存畜产品从生产到消费的全过程各个环节上报信息的数据中心。一方面,信息管理中心接收并存储种植、屠宰加工、运输和销售四个子系统上报的数据;另一方面,信息管理中心为消费者信息查询子系统提供各种畜产品的相关信息。
三、信息系统的功能模块
1、RFID采集器
(1)数据采集模块
(2)终端业务处理模块
(3)数据查询模块
(4)通讯模块
(5)RFID控制模块
(6)系统配置模块
(7)日志模块
2、信息管理中心
(1)数据关联模块:主要负责RFID采集器和后台管理中心的网路链接和数据传输
(2)数据库模块:数据库管理
(3)数据展示模块:负责RFID采集器采集到的数据
乐思网路信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 705 次浏览 • 2020-08-10 16:47
随着中国经济发展不断往前推动,大公司大集团面对的市场环境越发复杂,各种影响市场迈向的新问题、新情况层出不穷,市场信息量呈指数下降。同时,定量剖析方式正在迅速应用到行业研究当中,这对信息采集的效率和精度提出了很高的要求。仅靠有限的人力进行信息采集的工作模式,已很难适应市场和技术发展的要求。为了更全面、准确、迅速地把握市场变化,为了适应新技术发展要求,也为了把人员从繁杂的信息采集工作中解放下来,集中精力进行深层次的剖析和研究,迫切需要一套现代化的信息中心系统。
乐思网路信息中心系统的功能是为大公司大集团的市场部门与公关部门提供一个搜集外部信息的平台,包括与本公司相关的信息,与竞争对手相关的信息,行业信息,价格信息,与合作伙伴相关的信息,用户网上反馈的各类信息,科研技术信息等,可以做到多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免的人工查询多个网站的费时吃力的情况,并具有预警功能,可以在某方面的信息一旦出现时迅速通知相关人员。
其业务流程如下图所示:
图1: 乐思网路信息中心系统的业务流程
相比目前的人工信息采集,其优势显著:
比较指标
人工采集
采用乐思网络信息中心系统
目标网站
几十个
几百个到几千个几万个-采3453舆情4533集-
人力成本
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
负面信息辨识
需要逐字人工查看确认
在手动判断的基础上再人工确认
信息保存
零碎,不可防止会出错 -采3453舆情4533集-
精确,全面,便于事后追踪
数据储存
Word文件,分散,很难管理
统一储存在小型关系数据库中,集中管理
监测报告
基于手工统计加恐怕,数据支持不充分
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
监测疗效
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
覆盖全面,实时,
自动化,系统化
二、 实施后的利益
加快外部情报感知:公司报导,用户反馈,竞品动态,行业动态,宏观动态,政策法规等公司外部信息实时凝聚到桌面上,方便公司上下对于市场竞争情报的感知与反应。
加快定量定性剖析:在占有大量数据的基础上,分析人员可以从繁杂的信息采集工作解脱下来,投入到最有价值的定量定性剖析中去。
三、 系统组成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集层)、内容剖析子系统(分析层)、以及界面呈现子系统(呈现层)。其关系如下图所示:
图2:乐思网路信息中心系统构架
乐思网络信息中心系统的网路拓扑结构如下图所示,依据须要也可以分开在隔离的内网与外网中施行。
图3:网络拓扑结构
四、 自动采集子系统功能描述
自动采集子系统可以对任意目标网站进行手动采集。
采集的信息既可以是文本型信息(如文章,微博),也可以是数字型信息(如价钱,统计数据),还可以是文件型信息(如Word, Excel, PDF文件)。用户可以通过Web界面自行配置对文本型信息的采集,也可以通过软件向导界面配制对于数字型信息的采集。由于采用了全球领先的乐思网路信息采集系统,可以对任意网站上数据进行采集与整合。数据源的发觉管理工作由用户完成。
自动采集子系统的全方位检测功能如下图所示:
图4:自动采集子系统全方位检测
自动采集子系统具有以下几个明显特征:
1. 全球领先的手动采集功能
乐思软件的网路信息采集技术全球领先,支持对任意网页内任意数据的精确采集。乐思软件每晚都为国内外用户针对各种各样的网站提供采集服务,没有高效稳定的采集平台是难以做到的。
2. 支持各类检测对象
可以实时检测新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报刊网站电子版等。
3. 无需配置直接检测几千个新闻网站
系统外置对全球范围内网站的检测配置,只需输入关键词,自动采集出文章标题与正文。
4. 强大的多语言统一处理功能26严禁9窃取0
可手动处理并保存英文,英文,法文,德文,日语,韩语,维文,阿拉伯语等多种语言。
5. 智能文章提取
对于文章类型网页,可以无需配置,直接手动提取文章正文与标题,以及作者发布日期等,自动清除广告,栏目,版权等无关的垃圾内容
6. 完美支持各类网页情况
支持当前流行的Web 2.0 AJAX动态网站
支持用户名与密码手动登入
支持表单查询 查看全部
一、 系统概述
随着中国经济发展不断往前推动,大公司大集团面对的市场环境越发复杂,各种影响市场迈向的新问题、新情况层出不穷,市场信息量呈指数下降。同时,定量剖析方式正在迅速应用到行业研究当中,这对信息采集的效率和精度提出了很高的要求。仅靠有限的人力进行信息采集的工作模式,已很难适应市场和技术发展的要求。为了更全面、准确、迅速地把握市场变化,为了适应新技术发展要求,也为了把人员从繁杂的信息采集工作中解放下来,集中精力进行深层次的剖析和研究,迫切需要一套现代化的信息中心系统。
乐思网路信息中心系统的功能是为大公司大集团的市场部门与公关部门提供一个搜集外部信息的平台,包括与本公司相关的信息,与竞争对手相关的信息,行业信息,价格信息,与合作伙伴相关的信息,用户网上反馈的各类信息,科研技术信息等,可以做到多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免的人工查询多个网站的费时吃力的情况,并具有预警功能,可以在某方面的信息一旦出现时迅速通知相关人员。
其业务流程如下图所示:

图1: 乐思网路信息中心系统的业务流程
相比目前的人工信息采集,其优势显著:
比较指标
人工采集
采用乐思网络信息中心系统
目标网站
几十个
几百个到几千个几万个-采3453舆情4533集-
人力成本
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
负面信息辨识
需要逐字人工查看确认
在手动判断的基础上再人工确认
信息保存
零碎,不可防止会出错 -采3453舆情4533集-
精确,全面,便于事后追踪
数据储存
Word文件,分散,很难管理
统一储存在小型关系数据库中,集中管理
监测报告
基于手工统计加恐怕,数据支持不充分
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
监测疗效
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
覆盖全面,实时,
自动化,系统化
二、 实施后的利益
加快外部情报感知:公司报导,用户反馈,竞品动态,行业动态,宏观动态,政策法规等公司外部信息实时凝聚到桌面上,方便公司上下对于市场竞争情报的感知与反应。
加快定量定性剖析:在占有大量数据的基础上,分析人员可以从繁杂的信息采集工作解脱下来,投入到最有价值的定量定性剖析中去。
三、 系统组成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集层)、内容剖析子系统(分析层)、以及界面呈现子系统(呈现层)。其关系如下图所示:

图2:乐思网路信息中心系统构架
乐思网络信息中心系统的网路拓扑结构如下图所示,依据须要也可以分开在隔离的内网与外网中施行。

图3:网络拓扑结构
四、 自动采集子系统功能描述
自动采集子系统可以对任意目标网站进行手动采集。
采集的信息既可以是文本型信息(如文章,微博),也可以是数字型信息(如价钱,统计数据),还可以是文件型信息(如Word, Excel, PDF文件)。用户可以通过Web界面自行配置对文本型信息的采集,也可以通过软件向导界面配制对于数字型信息的采集。由于采用了全球领先的乐思网路信息采集系统,可以对任意网站上数据进行采集与整合。数据源的发觉管理工作由用户完成。
自动采集子系统的全方位检测功能如下图所示:

图4:自动采集子系统全方位检测
自动采集子系统具有以下几个明显特征:
1. 全球领先的手动采集功能
乐思软件的网路信息采集技术全球领先,支持对任意网页内任意数据的精确采集。乐思软件每晚都为国内外用户针对各种各样的网站提供采集服务,没有高效稳定的采集平台是难以做到的。
2. 支持各类检测对象
可以实时检测新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报刊网站电子版等。
3. 无需配置直接检测几千个新闻网站
系统外置对全球范围内网站的检测配置,只需输入关键词,自动采集出文章标题与正文。
4. 强大的多语言统一处理功能26严禁9窃取0
可手动处理并保存英文,英文,法文,德文,日语,韩语,维文,阿拉伯语等多种语言。
5. 智能文章提取
对于文章类型网页,可以无需配置,直接手动提取文章正文与标题,以及作者发布日期等,自动清除广告,栏目,版权等无关的垃圾内容
6. 完美支持各类网页情况
支持当前流行的Web 2.0 AJAX动态网站
支持用户名与密码手动登入
支持表单查询
网络舆情监测系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-09 16:13
该系统才能精准定向采集互联网海量舆情信息,从中快速侦测和辨识话题热点和敏感话题,追踪互联网上热点敏感话题的发生、发展和变化趋势,发现和剖析社会民众群体在互联网上的观点、态度、意见和想法,特别是及时发觉负面报导和不良言论并手动报案,快速方便地生成可视化的统计剖析报告,汇集各方智慧剖析成果,最终实现发觉舆情、分析舆情、追踪舆情、引导舆情、逆转舆情和控制舆情。
适用领域
级政府、电信运营商、能源、教育、银行、证券、期货、基金、医疗、电子商务等大中型事业单位门户网站。
产品框架
产品特性
跨平台高性能可扩充构架:采用基于Java/J2EE体系结构,跨操作系统、跨数据库、跨应用服务器,应用系统根据国家级小型舆情监控应用需求设计高性能扩充构架,并基于实际系统2年运行检验。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
产品功能
1舆情规划订制子系统
定制舆情分类:可构建多级舆情分类管理目录,并可对目录进行重命名、删除操作。
定制特定网站:可自主设置网站的地址、特定的关键字及其逻辑规则。
定制检测目标:可设置关键字订制检测目标,设置关键字的逻辑关系、获取舆情的范围、所属目录等信息,日后可以重新更改和删掉。
2舆情采集抽取子系统
多通道高效采集:针对峰会、新闻及评论、博客、微博等动态网路信息源,实现可扩充的多通道高效采集技术。
多媒体数据采集 :可采集文本、图片、音视频等多媒体信息。
主动化定向采集:主动化采集技术,解决增量更新以及访问控制等问题,实现JavaScript动态网页的采集与客户端解析还原技术。
分钟级实时采集 :多线程高效实时采集技术实现舆情分钟级采集效果。
代理翻墙式采集 :通过代理或则翻墙工具采集境外网站。
网页元信息抽取:实现半结构化/无结构化网路资源的元信息抽取,针对新闻、论坛、博客等数据源,实现标题、日期、作者、来源等要素全手动数据抽取。
事件要素提取:实现社会网路中用户访问行为的要素剖析与提取,如点击量、回复量、访问IP等。
3舆情剖析挖掘子系统
舆情热点发觉:基于热点侦测和层次降维技术,自动发觉舆情热点。
舆情话题追溯:实现网络舆情的重要进程辨识与手动回放技术;分析网路舆情传播的时间、空间结构,发现网络舆情话题源头。
舆情对象跟踪:基于特定网路对象(人、事件),进行对象背景信息的综合提取,追踪最新的舆情动态、舆情关系网路等相关信息,在此基础上产生定期综合报告。
倾向性剖析:对舆情内容与评论的作倾向性剖析,倾向性反映了作者的情感色调,以及褒贬的程度,自动分辨文本内容与评论的主客观倾向性,给出正面、中立或负面倾向性判别。
汇聚专业智慧:采集行业专业剖析结果和数据,实现一站式剖析展示门户。
4舆情处置服务子系统
可视统计剖析:提供舆情动态趋势可视化统计剖析 ,包括特定时间内特定情报的信息量变化统计,特定时间内对特定舆情报到媒体量变化统计等。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。 查看全部
网络舆情监控系统是我们基于先进的精准搜索引擎技术、深网信息集成技术和观点挖掘技术,基于“模拟人类的网路行为,深网观世界;集成群体的智慧服务,一点控风云”的理念,设计实现的一个小型网络舆情监控系统软件。
该系统才能精准定向采集互联网海量舆情信息,从中快速侦测和辨识话题热点和敏感话题,追踪互联网上热点敏感话题的发生、发展和变化趋势,发现和剖析社会民众群体在互联网上的观点、态度、意见和想法,特别是及时发觉负面报导和不良言论并手动报案,快速方便地生成可视化的统计剖析报告,汇集各方智慧剖析成果,最终实现发觉舆情、分析舆情、追踪舆情、引导舆情、逆转舆情和控制舆情。
适用领域
级政府、电信运营商、能源、教育、银行、证券、期货、基金、医疗、电子商务等大中型事业单位门户网站。
产品框架
产品特性
跨平台高性能可扩充构架:采用基于Java/J2EE体系结构,跨操作系统、跨数据库、跨应用服务器,应用系统根据国家级小型舆情监控应用需求设计高性能扩充构架,并基于实际系统2年运行检验。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
产品功能
1舆情规划订制子系统
定制舆情分类:可构建多级舆情分类管理目录,并可对目录进行重命名、删除操作。
定制特定网站:可自主设置网站的地址、特定的关键字及其逻辑规则。
定制检测目标:可设置关键字订制检测目标,设置关键字的逻辑关系、获取舆情的范围、所属目录等信息,日后可以重新更改和删掉。
2舆情采集抽取子系统
多通道高效采集:针对峰会、新闻及评论、博客、微博等动态网路信息源,实现可扩充的多通道高效采集技术。
多媒体数据采集 :可采集文本、图片、音视频等多媒体信息。
主动化定向采集:主动化采集技术,解决增量更新以及访问控制等问题,实现JavaScript动态网页的采集与客户端解析还原技术。
分钟级实时采集 :多线程高效实时采集技术实现舆情分钟级采集效果。
代理翻墙式采集 :通过代理或则翻墙工具采集境外网站。
网页元信息抽取:实现半结构化/无结构化网路资源的元信息抽取,针对新闻、论坛、博客等数据源,实现标题、日期、作者、来源等要素全手动数据抽取。
事件要素提取:实现社会网路中用户访问行为的要素剖析与提取,如点击量、回复量、访问IP等。
3舆情剖析挖掘子系统
舆情热点发觉:基于热点侦测和层次降维技术,自动发觉舆情热点。
舆情话题追溯:实现网络舆情的重要进程辨识与手动回放技术;分析网路舆情传播的时间、空间结构,发现网络舆情话题源头。
舆情对象跟踪:基于特定网路对象(人、事件),进行对象背景信息的综合提取,追踪最新的舆情动态、舆情关系网路等相关信息,在此基础上产生定期综合报告。
倾向性剖析:对舆情内容与评论的作倾向性剖析,倾向性反映了作者的情感色调,以及褒贬的程度,自动分辨文本内容与评论的主客观倾向性,给出正面、中立或负面倾向性判别。
汇聚专业智慧:采集行业专业剖析结果和数据,实现一站式剖析展示门户。
4舆情处置服务子系统
可视统计剖析:提供舆情动态趋势可视化统计剖析 ,包括特定时间内特定情报的信息量变化统计,特定时间内对特定舆情报到媒体量变化统计等。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
金农工程一期采集系统扩充业务子系统.doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-09 13:56
用户使用系统推荐的软、硬件配置如下表:
配置项
配置要求
机器显存
1G及以上
操作系统
Windows操作系统
IE版本
IE7.0及以上版本
总体功能概述
业务流程
功能概述
县级业务人员的总体功能包括我的工作、数据查询以及个人信息维护三大功能模块。
我的工作包括个人工作台、消息管理功能。其中消息管理包括未读消息、已读消息、已发送消息功能。
数据查询包括上报进度查询、上报情况查询、原创数据查询以及汇总数据查询。
个人信息维护包括个人信息维护功能。
操作界面介绍
下图是登入系统后的主界面,如图2-1所示。
图2-1
辅助功能区:辅助功能区包括退出、工具、帮助。
一级菜单:模块组是拿来在应用与模块之间进行功能整理的分类结构。它拿来将应用中的模块进行界定和组装为界面显示和布局服务,形成应用的一级菜单。
二级菜单:模块是组成应用的单元,一个模块包括多个资源,在界面诠释时,形成应用的二级菜单。
功能菜单:资源是组成模块的单元,一个资源对应于一个URL,该URL可以是Action或一个JSP,功能菜单是由一个或多个资源组成的。
主功能区:单击功能菜单后,主功能区会相应的发生变化。主要的功能操作都在主功能区进行。
系统登陆
浏览器设置
在使用系统之前须要首先在浏览器中进行受信任站点设置。浏览器版本要求IE6.0以上(建议IE7.0或IE8.0)。
打开浏览器,选择菜单“工具”,单击“选项(O) …”,如图3-1-1。
图3-1-1
在“选项”弹出窗口中,选择“安全”页,单击右下“自定义级别(C)…”按钮,弹出安全设置页面,如图3-1-2。
图3-1-2
将滚动条带动至“ActiveX控件和插件”的“对没有标记为安全的ActiveX控件进行初始化和脚本运行”选项,将其修改为“提示”,如图3-1-3。单击【确定】保存并返回“选项”窗口。
图3-1-3
在“选项”页单击选中“受信任的站点”,然后单击右下“默认级别(D)”按钮,设置受信任站点的安全级别为“低”。如图3-1-4。
图3-1-4 查看全部
使用系统推荐的配置
用户使用系统推荐的软、硬件配置如下表:
配置项
配置要求
机器显存
1G及以上
操作系统
Windows操作系统
IE版本
IE7.0及以上版本
总体功能概述
业务流程
功能概述
县级业务人员的总体功能包括我的工作、数据查询以及个人信息维护三大功能模块。
我的工作包括个人工作台、消息管理功能。其中消息管理包括未读消息、已读消息、已发送消息功能。
数据查询包括上报进度查询、上报情况查询、原创数据查询以及汇总数据查询。
个人信息维护包括个人信息维护功能。
操作界面介绍
下图是登入系统后的主界面,如图2-1所示。
图2-1
辅助功能区:辅助功能区包括退出、工具、帮助。
一级菜单:模块组是拿来在应用与模块之间进行功能整理的分类结构。它拿来将应用中的模块进行界定和组装为界面显示和布局服务,形成应用的一级菜单。
二级菜单:模块是组成应用的单元,一个模块包括多个资源,在界面诠释时,形成应用的二级菜单。
功能菜单:资源是组成模块的单元,一个资源对应于一个URL,该URL可以是Action或一个JSP,功能菜单是由一个或多个资源组成的。
主功能区:单击功能菜单后,主功能区会相应的发生变化。主要的功能操作都在主功能区进行。
系统登陆
浏览器设置
在使用系统之前须要首先在浏览器中进行受信任站点设置。浏览器版本要求IE6.0以上(建议IE7.0或IE8.0)。
打开浏览器,选择菜单“工具”,单击“选项(O) …”,如图3-1-1。
图3-1-1
在“选项”弹出窗口中,选择“安全”页,单击右下“自定义级别(C)…”按钮,弹出安全设置页面,如图3-1-2。
图3-1-2
将滚动条带动至“ActiveX控件和插件”的“对没有标记为安全的ActiveX控件进行初始化和脚本运行”选项,将其修改为“提示”,如图3-1-3。单击【确定】保存并返回“选项”窗口。
图3-1-3
在“选项”页单击选中“受信任的站点”,然后单击右下“默认级别(D)”按钮,设置受信任站点的安全级别为“低”。如图3-1-4。
图3-1-4
自动采集子系统,提高工作效率和生产效率的因素
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-03-30 05:03
自动采集子系统,相对于手动采集,自动采集减少了采集人员的大部分工作,同时工作效率也提高了不少。(这里我只是说是相对)还有,自动采集更加的智能化,从而提高工作效率和生产效率。
1、相对于手动采集时间更加的固定,固定时间就可以完成,
2、自动采集可以更加快速的完成采集任务,从而降低采集的工作量,同时也提高采集软件的完成工作率。
3、自动采集可以减少部分人员的工作量,同时可以减少人工进行巡检的成本,保证人员在整个分析流程中的工作质量。
4、自动采集相对于手动采集主要可以提高采集中心的工作效率,从而降低采集中心的质量,保证采集中心的正常运营。就我接触过的自动采集技术来看,目前比较好的应该是华清远见的,这也是用于机器人采集和推荐系统上使用比较广泛的采集软件了。
自动采集要能一键进行采集,自动推送到机器人中去。手动采集要能爬取很多其他的数据。机器人采集得到的信息质量很高,能降低人为的数据工作量,提高程序的容错率。虽然这样不能保证全自动地进行采集,但是能达到这个的技术本身不难。只是找不到合适的采集系统罢了。
主要是采集方式的问题。目前国内有些企业是挂羊头卖狗肉,提供一套方案,工作人员再根据方案进行二次开发,就可以给客户提供一套定制化的系统。中国的工业机器人市场空间大,加上相关的产业链也很完善,所以制造企业或研究院校发展机器人已经不像过去那么盲目了。现在市场的机器人基本上分为工业机器人和农业机器人,前者已经有厂商设计一套系统,然后生产厂商自己推出一套配套的系统;后者是一套方案,厂商自己设计一套配套的系统。
以前做机器人研究的人现在也在做农业机器人,顺便利用机器人提供服务。另外,从统计数据来看,如果所有的机器人数量不超过1000台,那么市场容量还是不大的,机器人和人一样,只能作为分解工序的一个辅助工具存在,不可能做到没有弱项。 查看全部
自动采集子系统,提高工作效率和生产效率的因素
自动采集子系统,相对于手动采集,自动采集减少了采集人员的大部分工作,同时工作效率也提高了不少。(这里我只是说是相对)还有,自动采集更加的智能化,从而提高工作效率和生产效率。
1、相对于手动采集时间更加的固定,固定时间就可以完成,
2、自动采集可以更加快速的完成采集任务,从而降低采集的工作量,同时也提高采集软件的完成工作率。
3、自动采集可以减少部分人员的工作量,同时可以减少人工进行巡检的成本,保证人员在整个分析流程中的工作质量。
4、自动采集相对于手动采集主要可以提高采集中心的工作效率,从而降低采集中心的质量,保证采集中心的正常运营。就我接触过的自动采集技术来看,目前比较好的应该是华清远见的,这也是用于机器人采集和推荐系统上使用比较广泛的采集软件了。
自动采集要能一键进行采集,自动推送到机器人中去。手动采集要能爬取很多其他的数据。机器人采集得到的信息质量很高,能降低人为的数据工作量,提高程序的容错率。虽然这样不能保证全自动地进行采集,但是能达到这个的技术本身不难。只是找不到合适的采集系统罢了。
主要是采集方式的问题。目前国内有些企业是挂羊头卖狗肉,提供一套方案,工作人员再根据方案进行二次开发,就可以给客户提供一套定制化的系统。中国的工业机器人市场空间大,加上相关的产业链也很完善,所以制造企业或研究院校发展机器人已经不像过去那么盲目了。现在市场的机器人基本上分为工业机器人和农业机器人,前者已经有厂商设计一套系统,然后生产厂商自己推出一套配套的系统;后者是一套方案,厂商自己设计一套配套的系统。
以前做机器人研究的人现在也在做农业机器人,顺便利用机器人提供服务。另外,从统计数据来看,如果所有的机器人数量不超过1000台,那么市场容量还是不大的,机器人和人一样,只能作为分解工序的一个辅助工具存在,不可能做到没有弱项。
怎么样做好网站的SEO优化?(一)_
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-03-27 06:05
如何优化网站的SEO?
网站优化在两个句子中不清楚,所有网站优化基本相同。 网站优化是一个长期过程,范围从几个月到几年。以下是一些常用方法,仅供参考:
关键词选择
创建首页网站时,应首先设置目标关键词,不要等到网站建立后再设置百度收录,然后注意这些,否则您将后悔。然后借用一些工具查询长尾关键词,以查看哪些单词具有较大的搜索量,然后对一些搜索量较小的单词进行优化,这会影响到搜索量较大的单词。
高质量原创 文章
三年前,我们说原创 文章,但现在我们仍在谈论证明原创 文章对于百度来说仍然非常好。请记住,不要伪造原件。 网站每天需要更新一定数量的内容,选择一个好的关键词,从关键词开始,然后编写文章从经验,操作步骤,注意事项等方面更新内容,因此您还可以进行SEO优化,让搜索引擎通过内容页面找到网站,增加访问量,并提高网站排名。
优化内部和外部链接
尽管我是新手,但我还需要主动认识这个行业的一些朋友,并与我自己的人建立一些链接。我们还需要学习与网站进行合作,并不断提高网站的影响力。在操作网站时,如果遇到网站的结构不合理的情况,则还可以允许开发人员及时调整内部结构,以便您的网站将更方便搜索引擎捕获信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,就越容易实现SEO优化的目标。
可以在此处找到答案网站。其中收录更多相关的知识和教学视频
有许多现成的采集器软件,可以直接用于网站数据采集。我将简要介绍其中的三个,即优采云,章鱼和优采云。它们操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一个非常智能的Web爬虫软件,支持跨平台和多平台的人免费使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表单,链接,图片等,而无需配置任何采集规则。支持一键自动翻页和数据导出功能。对于小白来说,这很容易学习和掌握:这是一个很好的例子。与优采云采集器相比,八达通采集器仅支持Windows平台,手动设置采集字段和配置规则更加复杂。且灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白从入门到精通也非常方便:
当然,除了上述三个爬网软件外,还有许多其他软件也支持网站数据采集,例如创建数字和魔术策略。如果您熟悉Python,Java和其他编程语言,则还可以对自己进行编程以获取数据。 Internet上也有相关的程序和信息。简介非常详细。如果您有兴趣,可以搜索它们。希望您能分享以上信息,内容对您有所帮助,欢迎发表评论。 查看全部
怎么样做好网站的SEO优化?(一)_
如何优化网站的SEO?
网站优化在两个句子中不清楚,所有网站优化基本相同。 网站优化是一个长期过程,范围从几个月到几年。以下是一些常用方法,仅供参考:
关键词选择
创建首页网站时,应首先设置目标关键词,不要等到网站建立后再设置百度收录,然后注意这些,否则您将后悔。然后借用一些工具查询长尾关键词,以查看哪些单词具有较大的搜索量,然后对一些搜索量较小的单词进行优化,这会影响到搜索量较大的单词。
高质量原创 文章
三年前,我们说原创 文章,但现在我们仍在谈论证明原创 文章对于百度来说仍然非常好。请记住,不要伪造原件。 网站每天需要更新一定数量的内容,选择一个好的关键词,从关键词开始,然后编写文章从经验,操作步骤,注意事项等方面更新内容,因此您还可以进行SEO优化,让搜索引擎通过内容页面找到网站,增加访问量,并提高网站排名。
优化内部和外部链接
尽管我是新手,但我还需要主动认识这个行业的一些朋友,并与我自己的人建立一些链接。我们还需要学习与网站进行合作,并不断提高网站的影响力。在操作网站时,如果遇到网站的结构不合理的情况,则还可以允许开发人员及时调整内部结构,以便您的网站将更方便搜索引擎捕获信息。蜘蛛爬行。这样,搜索引擎收录的内容越多,权重就越大,就越容易实现SEO优化的目标。
可以在此处找到答案网站。其中收录更多相关的知识和教学视频
有许多现成的采集器软件,可以直接用于网站数据采集。我将简要介绍其中的三个,即优采云,章鱼和优采云。它们操作简单,易于学习和理解,有兴趣的朋友可以尝试一下:
这是一个非常智能的Web爬虫软件,支持跨平台和多平台的人免费使用。对于大多数网站,只需输入URL,软件将自动识别并提取相关的字段信息,包括列表,表单,链接,图片等,而无需配置任何采集规则。支持一键自动翻页和数据导出功能。对于小白来说,这很容易学习和掌握:这是一个很好的例子。与优采云采集器相比,八达通采集器仅支持Windows平台,手动设置采集字段和配置规则更加复杂。且灵活。它具有大量的内置数据采集模板,可以轻松地将采集流行的网站例如京东和天猫。官方教程非常详细,小白从入门到精通也非常方便:
当然,除了上述三个爬网软件外,还有许多其他软件也支持网站数据采集,例如创建数字和魔术策略。如果您熟悉Python,Java和其他编程语言,则还可以对自己进行编程以获取数据。 Internet上也有相关的程序和信息。简介非常详细。如果您有兴趣,可以搜索它们。希望您能分享以上信息,内容对您有所帮助,欢迎发表评论。
自动采集子系统的应用范围有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2021-03-25 22:01
自动采集子系统应用范围:包括模拟摄像头录像,区域合并,人员采集,身份识别等功能。通过远程控制系统记录采集的信息,自动控制采集的这些数据,自动分析分类。对不能录像的点将拍摄停止拍摄,数据采集手动控制停止。采集控制采集控制采集是配置在安装采集控制系统的拍摄上。与自动化系统组成最简单的一种控制系统,实现采集控制单元控制采集采集数据一台。
主要用于人脸识别、活体检测、车牌识别、人员信息、模拟摄像头、图片库、门禁控制,管理员控制等。系统控制模块:专有控制器(ip67,500mhz,8g可用),rs232接口,视频,pid输出,接口跳线,脚本开关,拍摄,室内定位,室外定位,摄像头,存储,电源,整合视频转接头。
一般用于小型会议室,签到机,室内投影,等,价格也不贵,一万左右。实现在屏幕上显示人脸,然后摄像头进行视频录制,电脑与摄像头控制的,
2010年的时候在工厂做工人,我们的自动化制作机器人是一架5600毫米的三通直角螺旋束机械臂。在国内算高端的吧,工厂都拿它去生产手机的摄像头。要说远程控制吧,上班时采集一遍工人照片,放在自动控制的系统里面进行自动找人,人工算好拿出一张,生产下一个人的工作任务。 查看全部
自动采集子系统的应用范围有哪些?-八维教育
自动采集子系统应用范围:包括模拟摄像头录像,区域合并,人员采集,身份识别等功能。通过远程控制系统记录采集的信息,自动控制采集的这些数据,自动分析分类。对不能录像的点将拍摄停止拍摄,数据采集手动控制停止。采集控制采集控制采集是配置在安装采集控制系统的拍摄上。与自动化系统组成最简单的一种控制系统,实现采集控制单元控制采集采集数据一台。
主要用于人脸识别、活体检测、车牌识别、人员信息、模拟摄像头、图片库、门禁控制,管理员控制等。系统控制模块:专有控制器(ip67,500mhz,8g可用),rs232接口,视频,pid输出,接口跳线,脚本开关,拍摄,室内定位,室外定位,摄像头,存储,电源,整合视频转接头。
一般用于小型会议室,签到机,室内投影,等,价格也不贵,一万左右。实现在屏幕上显示人脸,然后摄像头进行视频录制,电脑与摄像头控制的,
2010年的时候在工厂做工人,我们的自动化制作机器人是一架5600毫米的三通直角螺旋束机械臂。在国内算高端的吧,工厂都拿它去生产手机的摄像头。要说远程控制吧,上班时采集一遍工人照片,放在自动控制的系统里面进行自动找人,人工算好拿出一张,生产下一个人的工作任务。
如何自动批量自动采集获取非标准化样本的xml文件?
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2021-03-21 03:02
自动采集子系统如何自动批量自动采集获取非标准化样本的xml文件?使用下面的小工具即可,单次200m,可以批量下载方便管理。步骤步骤一登录知识星球【二】标准化子系统自动采集小程序商城全部商品步骤二二次索引知识星球【三】5分钟完成自动采集步骤三查看小程序访问日志本文首发于【知识星球"新技术研究院"】,转载请注明出处。
想获取二手工具,寻找的最好方式,就是打开,我查了一下,二手工具确实不多,只有两款。根据看店主发的店铺,有很多,估计看店主发的店铺,有很多,估计看店主发的店铺,有很多。顺手一搜,幸运的是还真有:好看工具-目前5g卡可以入手第二个好看工具就是知名大佬程序员养成攻略之se-xde的创意工具。
知乎最近不支持直接转手,
简单讲下1微信小程序商城2非标准化样本,采集的工具都是基于各公司和产品。
官方的叫「移动开发者」,可以用开发者工具里的「资源」功能查看xml文件,
公众号商城,主要用了流量池功能,将公众号的粉丝导入到小程序商城上,然后进行购买,
比如一些内部报告, 查看全部
如何自动批量自动采集获取非标准化样本的xml文件?
自动采集子系统如何自动批量自动采集获取非标准化样本的xml文件?使用下面的小工具即可,单次200m,可以批量下载方便管理。步骤步骤一登录知识星球【二】标准化子系统自动采集小程序商城全部商品步骤二二次索引知识星球【三】5分钟完成自动采集步骤三查看小程序访问日志本文首发于【知识星球"新技术研究院"】,转载请注明出处。
想获取二手工具,寻找的最好方式,就是打开,我查了一下,二手工具确实不多,只有两款。根据看店主发的店铺,有很多,估计看店主发的店铺,有很多,估计看店主发的店铺,有很多。顺手一搜,幸运的是还真有:好看工具-目前5g卡可以入手第二个好看工具就是知名大佬程序员养成攻略之se-xde的创意工具。
知乎最近不支持直接转手,
简单讲下1微信小程序商城2非标准化样本,采集的工具都是基于各公司和产品。
官方的叫「移动开发者」,可以用开发者工具里的「资源」功能查看xml文件,
公众号商城,主要用了流量池功能,将公众号的粉丝导入到小程序商城上,然后进行购买,
比如一些内部报告,
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 233 次浏览 • 2021-03-14 08:04
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势
Lesi网络舆情监测系统
Lesi网络舆情监测系统是基于世界领先的Internet 采集监测技术开发的,具有发现速度快,信息完整和分析准确的优点。它使用户可以观察六个方向并聆听所有方向,并首先找到负面的舆论。
一、系统概述
Lesi Internet民意监控系统针对Internet的新兴媒体。对大量的在线民意信息进行实时自动民意采集,民意分析,民意摘要和民意监测,及时识别其中的关键民意信息,及时通知有关人员提供及时的信息。应急响应并提供一套信息平台,直接支持正确的舆论指导和网民的意见采集。
业务流程如下图所示:
图1:Lesi网络舆情监测系统的业务流程
与当前的手动民意监控相比,其优势显而易见:
比较指标
手动监控
使用Lesi网络舆情监测系统
目标网站
数十个
成百上万-3453舆论第4533集-
人工成本
您需要分别登录每个网站,手动检查,然后手动复制和粘贴。太累了。
软件完全自动化地获取网络信息,监控人员只需要在Intranet中集中浏览和分析内容即可。
负面信息识别
需要手动进行一次检查并确认
在自动识别的基础上,然后进行手动确认
信息保存
将犯一些不可避免的错误-采集3453舆论第4533集-
准确,全面,易于跟踪
数据存储
Word文件分散且难以管理
大型关系数据库中的统一存储,集中管理
监控报告
根据人工统计和估算,数据支持不足
基于自动统计分析,
图片和文字均具有详细的统计数据支持,可以每天,每周和每月报告
监控效果
单面覆盖,不及时
不满意,浪费人力资源
实时范围从几分钟到几十分钟
自动化和系统化
二、实施后的好处
监控目标:与该城市和省有关的所有信息,尤其是负面信息
跟进治疗:与目标网站的负责人进行手动协商(请警惕某些所谓的被欺诈公司诈骗的所谓被删除公司),采取对策,并尽快发布相应的处理信息
实施后的好处:
1.实时监控微信,微博,论坛,博客,新闻,搜索引擎中的相关信息。
2.可以监视重要QQ群组的聊天内容
3.定时监控关键主页和特殊页面证据的屏幕截图
4.对于新闻页面,您可以找到所有重新打印的页面。
5.系统可以自动对信息进行分类26禁止9挪用0
6.系统可以跟踪有关某个主题或作者的所有相关信息
7.监控人员可以选择和重新分类信息
8.监控人员可以根据自己的工作结果轻松导出并生成带有图表的民意每日报告和每周报告
最终目的:
♦它可以消除或减少偶有负面信息对省/市和省/市领导的形象的不利影响。 Le Knowlesys认为
♦可以及时发现有关城市和省的民意,第一时间了解民意,并解决萌芽状态下的矛盾。
三、系统组成
Lesi网络舆情监视系统由两个子系统组成:自动采集子系统(采集层)和分析和浏览子系统(分析层和表示层)。关系如下图所示:
图2:Lesi网络舆情监测系统架构
Lesi网络舆情监控系统的网络拓扑如下图所示,也可以根据需要在隔离的外部和内部网络中实现。
图3:网络拓扑结构
四、自动采集子系统功能描述
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网,强国论坛,天涯社区,西慈社区,网易社区,新浪论坛,搜狐社区,凤凰网,百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖子或最新主题帖子的内容,还可以提取对某个主题帖子的所有回复或最新回复的内容。指定要监视的目标网站,或者不指定要在全局范围网站进行监视的目标网站,或者对两者进行混合监视。它可以监视国内网站和国外网站,例如Facebook,Twitter,BBC,CNN。
自动采集子系统也可以监视基于应用程序的聊天室程序。
后端数据库支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。
自动采集子系统的全方位监视功能如下图所示:
图4:自动采集子系统全面监视
自动采集子系统具有以下显着特征:
1.世界领先的自动采集功能
Lesisoft的网络信息采集技术是世界领先的,支持任何网页采集中任何数据的准确性。 Lesisoft每天为国内外用户提供各种网站服务采集,如果没有高效稳定的采集平台,这是不可能的。
2.支持各种监视对象
可以实时监控微信,微博,新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报纸和期刊的电子版本网站等。
3.无需配置即可直接监视数千条新闻网站
系统具有针对网站全球的内置监视配置,只需输入关键词,然后自动采集就会输出文章的标题和文本。
4.强大的多语言统一处理功能26禁止9挪用0
它可以自动处理和保存中文,英文,法文,德文,日文,韩文,维吾尔文,阿拉伯文和其他语言。
5.智能文章提取
对于文章类型的网页,您无需配置即可直接提取文章文本和标题以及作者的发布日期等,并自动删除广告,专栏,版权和其他不相关的垃圾邮件
6.完美支持各种网络情况
支持当前流行的Web 2. 0 AJAX动态网站
支持使用用户名和密码自动登录
支持表格查询 查看全部
基于全球领先的互联网采集监控技术而研发,具有发现快,信息全,分析准的优势
Lesi网络舆情监测系统
Lesi网络舆情监测系统是基于世界领先的Internet 采集监测技术开发的,具有发现速度快,信息完整和分析准确的优点。它使用户可以观察六个方向并聆听所有方向,并首先找到负面的舆论。
一、系统概述
Lesi Internet民意监控系统针对Internet的新兴媒体。对大量的在线民意信息进行实时自动民意采集,民意分析,民意摘要和民意监测,及时识别其中的关键民意信息,及时通知有关人员提供及时的信息。应急响应并提供一套信息平台,直接支持正确的舆论指导和网民的意见采集。
业务流程如下图所示:
图1:Lesi网络舆情监测系统的业务流程
与当前的手动民意监控相比,其优势显而易见:
比较指标
手动监控
使用Lesi网络舆情监测系统
目标网站
数十个
成百上万-3453舆论第4533集-
人工成本
您需要分别登录每个网站,手动检查,然后手动复制和粘贴。太累了。
软件完全自动化地获取网络信息,监控人员只需要在Intranet中集中浏览和分析内容即可。
负面信息识别
需要手动进行一次检查并确认
在自动识别的基础上,然后进行手动确认
信息保存
将犯一些不可避免的错误-采集3453舆论第4533集-
准确,全面,易于跟踪
数据存储
Word文件分散且难以管理
大型关系数据库中的统一存储,集中管理
监控报告
根据人工统计和估算,数据支持不足
基于自动统计分析,
图片和文字均具有详细的统计数据支持,可以每天,每周和每月报告
监控效果
单面覆盖,不及时
不满意,浪费人力资源
实时范围从几分钟到几十分钟
自动化和系统化
二、实施后的好处
监控目标:与该城市和省有关的所有信息,尤其是负面信息
跟进治疗:与目标网站的负责人进行手动协商(请警惕某些所谓的被欺诈公司诈骗的所谓被删除公司),采取对策,并尽快发布相应的处理信息
实施后的好处:
1.实时监控微信,微博,论坛,博客,新闻,搜索引擎中的相关信息。
2.可以监视重要QQ群组的聊天内容
3.定时监控关键主页和特殊页面证据的屏幕截图
4.对于新闻页面,您可以找到所有重新打印的页面。
5.系统可以自动对信息进行分类26禁止9挪用0
6.系统可以跟踪有关某个主题或作者的所有相关信息
7.监控人员可以选择和重新分类信息
8.监控人员可以根据自己的工作结果轻松导出并生成带有图表的民意每日报告和每周报告
最终目的:
♦它可以消除或减少偶有负面信息对省/市和省/市领导的形象的不利影响。 Le Knowlesys认为
♦可以及时发现有关城市和省的民意,第一时间了解民意,并解决萌芽状态下的矛盾。
三、系统组成
Lesi网络舆情监视系统由两个子系统组成:自动采集子系统(采集层)和分析和浏览子系统(分析层和表示层)。关系如下图所示:
图2:Lesi网络舆情监测系统架构
Lesi网络舆情监控系统的网络拓扑如下图所示,也可以根据需要在隔离的外部和内部网络中实现。
图3:网络拓扑结构
四、自动采集子系统功能描述
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网,强国论坛,天涯社区,西慈社区,网易社区,新浪论坛,搜狐社区,凤凰网,百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖子或最新主题帖子的内容,还可以提取对某个主题帖子的所有回复或最新回复的内容。指定要监视的目标网站,或者不指定要在全局范围网站进行监视的目标网站,或者对两者进行混合监视。它可以监视国内网站和国外网站,例如Facebook,Twitter,BBC,CNN。
自动采集子系统也可以监视基于应用程序的聊天室程序。
后端数据库支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。
自动采集子系统的全方位监视功能如下图所示:
图4:自动采集子系统全面监视
自动采集子系统具有以下显着特征:
1.世界领先的自动采集功能
Lesisoft的网络信息采集技术是世界领先的,支持任何网页采集中任何数据的准确性。 Lesisoft每天为国内外用户提供各种网站服务采集,如果没有高效稳定的采集平台,这是不可能的。
2.支持各种监视对象
可以实时监控微信,微博,新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报纸和期刊的电子版本网站等。
3.无需配置即可直接监视数千条新闻网站
系统具有针对网站全球的内置监视配置,只需输入关键词,然后自动采集就会输出文章的标题和文本。
4.强大的多语言统一处理功能26禁止9挪用0
它可以自动处理和保存中文,英文,法文,德文,日文,韩文,维吾尔文,阿拉伯文和其他语言。
5.智能文章提取
对于文章类型的网页,您无需配置即可直接提取文章文本和标题以及作者的发布日期等,并自动删除广告,专栏,版权和其他不相关的垃圾邮件
6.完美支持各种网络情况
支持当前流行的Web 2. 0 AJAX动态网站
支持使用用户名和密码自动登录
支持表格查询
【知识点】自动采集子系统标准schema定义(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2021-03-01 09:01
自动采集子系统标准schema定义
1、大小定义weights,weights,weights自动采集子系统标准schema定义的子系统规模是1个可自定义的集合,所以不用指定总和。即采集子系统是一个等长的(列)规模集合,故子系统大小为1*1单位(m)。同理自动采集子系统标准schema定义的component大小为m*1,自动采集子系统标准schema定义的action大小为m*1,自动采集子系统标准schema定义的replay大小为m*1,自动采集子系统标准schema定义的activation大小为m*1,自动采集子系统标准schema定义的rate大小为m*1,自动采集子系统标准schema定义的total大小为m*1,自动采集子系统标准schema定义的area大小为m*1。
2、具体概念和参数priority是子系统的优先级.
3、工作机制preferences
4、业务逻辑discussion自动采集子系统标准schema定义包含了业务逻辑。自动采集子系统标准schema定义包含了关键功能。
5、关键逻辑简要流程如下图所示:单个业务逻辑见如下介绍。1.关键功能点归并2.库存运营3.仓库相关内容4.配置管理5.用户在线采集6.通讯管理7.回滚8.邮件管理9.队列处理10.监控管理11.视图11.阶段任务12.id13.场景14.日志记录15.状态16.管理17.运维18.环境系统配置19.导出19.导入20.告警21.集群配置22.数据存储23.beta24.spot25.队列26.异常27.漏斗28.配置管理19.数据分析21.告警17.异常19.漏斗21.关键代码33.模型17.数据库部署55.配置管理19.在线工作流程55.字段权限57.配置管理18.数据管理59.安全19.tomcat19.websphere20.systemport21.linux更多关于web自动化平台的内容,请登录我们。 查看全部
【知识点】自动采集子系统标准schema定义(二)
自动采集子系统标准schema定义
1、大小定义weights,weights,weights自动采集子系统标准schema定义的子系统规模是1个可自定义的集合,所以不用指定总和。即采集子系统是一个等长的(列)规模集合,故子系统大小为1*1单位(m)。同理自动采集子系统标准schema定义的component大小为m*1,自动采集子系统标准schema定义的action大小为m*1,自动采集子系统标准schema定义的replay大小为m*1,自动采集子系统标准schema定义的activation大小为m*1,自动采集子系统标准schema定义的rate大小为m*1,自动采集子系统标准schema定义的total大小为m*1,自动采集子系统标准schema定义的area大小为m*1。
2、具体概念和参数priority是子系统的优先级.
3、工作机制preferences
4、业务逻辑discussion自动采集子系统标准schema定义包含了业务逻辑。自动采集子系统标准schema定义包含了关键功能。
5、关键逻辑简要流程如下图所示:单个业务逻辑见如下介绍。1.关键功能点归并2.库存运营3.仓库相关内容4.配置管理5.用户在线采集6.通讯管理7.回滚8.邮件管理9.队列处理10.监控管理11.视图11.阶段任务12.id13.场景14.日志记录15.状态16.管理17.运维18.环境系统配置19.导出19.导入20.告警21.集群配置22.数据存储23.beta24.spot25.队列26.异常27.漏斗28.配置管理19.数据分析21.告警17.异常19.漏斗21.关键代码33.模型17.数据库部署55.配置管理19.在线工作流程55.字段权限57.配置管理18.数据管理59.安全19.tomcat19.websphere20.systemport21.linux更多关于web自动化平台的内容,请登录我们。
采集子系统使用说明书6/NUMPAGES8保密资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 272 次浏览 • 2021-02-03 13:31
采集子系统使用说明书6/NUMPAGES8保密资料
采集子系统说明手册第6页/ NUMPAGES 8机密信息,请勿传播网络舆论监督系统采集子系统说明手册目录TOC \ o“ 2-3” \ h \ z \ u1.概述22.采集子系统的工作流程图23.采集子系统组件34.后台处理8概述舆论系统的主要任务是采集信息,网络舆论[子系统可以针对任何目标网站自动采集,并将采集的信息保存到数据库中进行分析,查看和处理;网络信息采集子系统支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。我们的舆论系统使用MySQL数据库。 采集子系统的工作流程图采集子系统的工作流程图采集子系统组件的网络信息采集该系统主要由Web资源管理器(分析网页),任务编辑器(配置任务)和任务组成执行它由数据库查询设备(用于执行任务),数据库查询设备(用于查看数据),数据变形脚本测试器(用于测试变形脚本)和组合生成器组成。主界面如下图所示:网络信息采集系统主界面的任务调度代理负责调度每个网站的调度任务。 ([K26]安装在软件安装目录(C:\ Program Files \ WebDataMiner Operation \ ScheduleAgent.exe)中,桌面也会生成相应的快捷方式,启动后,其工作是安排负责网站的节点调度任务,如下图所示。安装任务调度代理后,目录任务调度代理接口(2)设置网站的调度信息:设置网站开始运行的时间,一台或多台机器,然后运行每天同时启动多少个进程,每天运行多少次,等等。
关于计划模式计划模式:设置工作频率,每天运行多少次,并以计划任务的名称表示其内部参数,一目了然。关于操作模式操作模式:设置正在运行的采集服务器和同时启动的进程,分为以下四种操作模式:单节点单进程:在采集服务器上运行,启动采集程序,适用于内容较少的网站单节点多进程:在一台采集服务器上运行并同时启动多个采集程序,以加快采集多节点单进程:需要选择采集服务器组(多个采集服务器),在一个服务器组中运行,该组中的每个服务器共享不同的采集任务以实现分布式采集,每个采集服务器启动一个采集程序以及更多节点多进程:必须选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。组中的每个服务器共享不同的采集任务以实现分布式采集。 采集服务器可同时启动多个采集程序,这大大加快了速度。它适用于存在很多输入URL的情况,例如需要搜索很多关键词的搜索引擎。适用于搜索类型网站。设置浏览系统中各个网站的调度信息,如下图所示:每个网站调度任务列表的弹出对话框自动关闭。在网页采集期间,某些网站将弹出一个对话框,影响采集程序。要工作,请将弹出对话框的关键词设置为该程序,它将自动关闭弹出窗口。对话框,然后使采集程序继续运行。如下图所示:安装弹出对话框自动关闭器后,目录弹出对话框自动关闭器配置文件可以在同一局域网内共享,达到修改一个地方的目的并进行如下修改,如下图所示:弹出对话框自动关闭程序配置文件设置弹出对话框的内容:启动该程序后,单击“编辑”,填写弹出对话框的内容,在等号关键词的左侧(右上角)填充对话框的标题,并在内容的等号关键词的右侧填充对话框(通常在中间对话框)。
弹出对话框自动关闭器的主界面和编辑界面采集配置采集配置分为核心配置(Core_Tasks),系统配置(System_Tasks),WMT单独配置(WMT_Tasks)和用户配置(User_Tasks),已放置采集服务器的目录如下图所示:采集服务器目录结构核心配置(Core_Tasks):这是13种不同的配置模板,配置的特定参数存储在数据库,通常不需要在此处修改模板,如果网站的结构发生了更改,则只需要修改浏览系统中特定于网站的数据库中的特定配置参数,大多数支持网站 采集中的任何一个。该系统已经具有大多数主流网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):为特殊任务放置一些WMT配置,例如:选定信息和采集文本的屏幕截图,采集新闻热搜索词,所有网站的屏幕截图,等等。WMT单独的配置(WMT_Tasks) :放置一些复杂的网站配置,这些配置很难用核心配置来处理,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存储数据库连接信息(DB.udl,用于所有配置)。 采集批处理文件:Run_Batchs文件夹存储网站启动采集程序的所有批处理文件,启动此处的批处理文件将启动相应的采集服务。
([7)仓库规则说明:共有四个仓库规则,每个网站都可以在浏览系统中设置其相应的仓库规则:a。无文本,所有仓库b。否主要文字,标题或摘要是仅在收录核心词的情况下才收录在数据库中:适用于搜索引擎和具有全文搜索的网站(搜索结果具有抽象信息)c。采集主要文本,并且将主要词收录在数据库中(不判断标题摘要):适用于列表类型的网站,例如网站主页,新闻列表d。采用主文本,但不选择所有存储的主文本:表示主文本信息的(内容)不是采集 文章,并且很快采集了正文:采集 文章信息的正文(内容),速度较慢(8)核心词过滤搜索类型的规则:为了防止搜索后无关内容进入数据库,搜索类型X的操作应与e核心词并非与该搜索词相同主题的所有核心词,而是所有核心词。后台处理进程选择的信息处理程序的选定信息的屏幕截图和采集文本,在采集服务器上运行,如果有多个采集服务器,请选择其中一个启动:打开目录D:\ KWM \ Extraction_Server \ System_Tasks \ Selected_Articles_Process,双击run.bat,它将每分钟检查是否有任何选定信息,如果有,将对其进行处理。但是,在打开该程序后不要关闭它。重新启动采集服务器后,重新启动该程序。您也可以将其设置为Windows启动程序。 查看全部
采集子系统使用说明书6/NUMPAGES8保密资料
采集子系统说明手册第6页/ NUMPAGES 8机密信息,请勿传播网络舆论监督系统采集子系统说明手册目录TOC \ o“ 2-3” \ h \ z \ u1.概述22.采集子系统的工作流程图23.采集子系统组件34.后台处理8概述舆论系统的主要任务是采集信息,网络舆论[子系统可以针对任何目标网站自动采集,并将采集的信息保存到数据库中进行分析,查看和处理;网络信息采集子系统支持任何主流的关系数据库,例如Oracle,IBM DB2,MS SQL Server,MySQL,Sybase和文件数据库访问。我们的舆论系统使用MySQL数据库。 采集子系统的工作流程图采集子系统的工作流程图采集子系统组件的网络信息采集该系统主要由Web资源管理器(分析网页),任务编辑器(配置任务)和任务组成执行它由数据库查询设备(用于执行任务),数据库查询设备(用于查看数据),数据变形脚本测试器(用于测试变形脚本)和组合生成器组成。主界面如下图所示:网络信息采集系统主界面的任务调度代理负责调度每个网站的调度任务。 ([K26]安装在软件安装目录(C:\ Program Files \ WebDataMiner Operation \ ScheduleAgent.exe)中,桌面也会生成相应的快捷方式,启动后,其工作是安排负责网站的节点调度任务,如下图所示。安装任务调度代理后,目录任务调度代理接口(2)设置网站的调度信息:设置网站开始运行的时间,一台或多台机器,然后运行每天同时启动多少个进程,每天运行多少次,等等。
关于计划模式计划模式:设置工作频率,每天运行多少次,并以计划任务的名称表示其内部参数,一目了然。关于操作模式操作模式:设置正在运行的采集服务器和同时启动的进程,分为以下四种操作模式:单节点单进程:在采集服务器上运行,启动采集程序,适用于内容较少的网站单节点多进程:在一台采集服务器上运行并同时启动多个采集程序,以加快采集多节点单进程:需要选择采集服务器组(多个采集服务器),在一个服务器组中运行,该组中的每个服务器共享不同的采集任务以实现分布式采集,每个采集服务器启动一个采集程序以及更多节点多进程:必须选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。组中的每个服务器共享不同的采集任务以实现分布式采集。 采集服务器可同时启动多个采集程序,这大大加快了速度。它适用于存在很多输入URL的情况,例如需要搜索很多关键词的搜索引擎。适用于搜索类型网站。设置浏览系统中各个网站的调度信息,如下图所示:每个网站调度任务列表的弹出对话框自动关闭。在网页采集期间,某些网站将弹出一个对话框,影响采集程序。要工作,请将弹出对话框的关键词设置为该程序,它将自动关闭弹出窗口。对话框,然后使采集程序继续运行。如下图所示:安装弹出对话框自动关闭器后,目录弹出对话框自动关闭器配置文件可以在同一局域网内共享,达到修改一个地方的目的并进行如下修改,如下图所示:弹出对话框自动关闭程序配置文件设置弹出对话框的内容:启动该程序后,单击“编辑”,填写弹出对话框的内容,在等号关键词的左侧(右上角)填充对话框的标题,并在内容的等号关键词的右侧填充对话框(通常在中间对话框)。
弹出对话框自动关闭器的主界面和编辑界面采集配置采集配置分为核心配置(Core_Tasks),系统配置(System_Tasks),WMT单独配置(WMT_Tasks)和用户配置(User_Tasks),已放置采集服务器的目录如下图所示:采集服务器目录结构核心配置(Core_Tasks):这是13种不同的配置模板,配置的特定参数存储在数据库,通常不需要在此处修改模板,如果网站的结构发生了更改,则只需要修改浏览系统中特定于网站的数据库中的特定配置参数,大多数支持网站 采集中的任何一个。该系统已经具有大多数主流网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):为特殊任务放置一些WMT配置,例如:选定信息和采集文本的屏幕截图,采集新闻热搜索词,所有网站的屏幕截图,等等。WMT单独的配置(WMT_Tasks) :放置一些复杂的网站配置,这些配置很难用核心配置来处理,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存储数据库连接信息(DB.udl,用于所有配置)。 采集批处理文件:Run_Batchs文件夹存储网站启动采集程序的所有批处理文件,启动此处的批处理文件将启动相应的采集服务。
([7)仓库规则说明:共有四个仓库规则,每个网站都可以在浏览系统中设置其相应的仓库规则:a。无文本,所有仓库b。否主要文字,标题或摘要是仅在收录核心词的情况下才收录在数据库中:适用于搜索引擎和具有全文搜索的网站(搜索结果具有抽象信息)c。采集主要文本,并且将主要词收录在数据库中(不判断标题摘要):适用于列表类型的网站,例如网站主页,新闻列表d。采用主文本,但不选择所有存储的主文本:表示主文本信息的(内容)不是采集 文章,并且很快采集了正文:采集 文章信息的正文(内容),速度较慢(8)核心词过滤搜索类型的规则:为了防止搜索后无关内容进入数据库,搜索类型X的操作应与e核心词并非与该搜索词相同主题的所有核心词,而是所有核心词。后台处理进程选择的信息处理程序的选定信息的屏幕截图和采集文本,在采集服务器上运行,如果有多个采集服务器,请选择其中一个启动:打开目录D:\ KWM \ Extraction_Server \ System_Tasks \ Selected_Articles_Process,双击run.bat,它将每分钟检查是否有任何选定信息,如果有,将对其进行处理。但是,在打开该程序后不要关闭它。重新启动采集服务器后,重新启动该程序。您也可以将其设置为Windows启动程序。
如何在HTML文档中快速定位目标信息的方法,通过利用HTML标签
采集交流 • 优采云 发表了文章 • 0 个评论 • 200 次浏览 • 2021-01-25 10:43
摘要:随着移动终端的迅速发展和普及,人们越来越习惯于在平台提供商(包括内容提供商)的陪伴下,在移动终端上安装阅读应用程序来获取感兴趣的信息)。被构建为支持这种商业模式。该平台的内容来源可以通过两种方式获得。一种是手动编辑,另一种是通过程序自动采集信息源的内容。本文为后者设计了一套针对Web信息的解决方案采集。本文首先介绍了该主题的研究背景,研究现状以及信息提取相关技术和信息的工作原理采集,并分析了网页的结构;然后,使用用例图和用例规范对系统用例进行建模,并分析系统的非功能性需求,从而分析系统的功能和面向用户。然后,进行系统的总体设计和数据库设计;再次,系统的详细设计与实现;最后,对系统进行测试以验证解决方案的有效性。本文的主要工作如下:1.本文研究如何快速定位HTML文档中的目标信息,如何使用HTML标签和属性以及DOM路径表达式,使用可视界面和简单的人机来设计信息提取规则。用自动生成信息提取规则,在此基础上,设计了一种实用的文本去噪解决方案。2.本主题包括采集配置子系统和采集子系统两部分。 采集配置子系统可以通过Socket机制将已配置的采集任务传递给采集子系统,从而控制采集任务的启动和停止操作,因此用户不需要关心采集的运行过程。 k15]结果。3.采集子系统根据用户配置的采集任务使用多线程技术,数据库连接池技术,动态采集策略和多页合并技术,并定期执行有关这些任务的信息网站,采集,提取,去噪,去重复等,以实现相关网站特定信息的定时采集更新。更多还原 查看全部
如何在HTML文档中快速定位目标信息的方法,通过利用HTML标签
摘要:随着移动终端的迅速发展和普及,人们越来越习惯于在平台提供商(包括内容提供商)的陪伴下,在移动终端上安装阅读应用程序来获取感兴趣的信息)。被构建为支持这种商业模式。该平台的内容来源可以通过两种方式获得。一种是手动编辑,另一种是通过程序自动采集信息源的内容。本文为后者设计了一套针对Web信息的解决方案采集。本文首先介绍了该主题的研究背景,研究现状以及信息提取相关技术和信息的工作原理采集,并分析了网页的结构;然后,使用用例图和用例规范对系统用例进行建模,并分析系统的非功能性需求,从而分析系统的功能和面向用户。然后,进行系统的总体设计和数据库设计;再次,系统的详细设计与实现;最后,对系统进行测试以验证解决方案的有效性。本文的主要工作如下:1.本文研究如何快速定位HTML文档中的目标信息,如何使用HTML标签和属性以及DOM路径表达式,使用可视界面和简单的人机来设计信息提取规则。用自动生成信息提取规则,在此基础上,设计了一种实用的文本去噪解决方案。2.本主题包括采集配置子系统和采集子系统两部分。 采集配置子系统可以通过Socket机制将已配置的采集任务传递给采集子系统,从而控制采集任务的启动和停止操作,因此用户不需要关心采集的运行过程。 k15]结果。3.采集子系统根据用户配置的采集任务使用多线程技术,数据库连接池技术,动态采集策略和多页合并技术,并定期执行有关这些任务的信息网站,采集,提取,去噪,去重复等,以实现相关网站特定信息的定时采集更新。更多还原
虚拟学习社区中学习资源自动采集系统的更新速度
采集交流 • 优采云 发表了文章 • 0 个评论 • 450 次浏览 • 2021-01-19 12:28
2009年10月,第23卷,第5期中国医学教育技术在医学领域的应用1。 2 3 5号20o9·技术支持·虚拟学习社区中自动学习资源采集系统的构建杨朝军,高东淮,宁玉文(第四军医大学网络中心,西安71003,陕西710032)[摘要]:自动学习资源的介绍2)k15]根据系统的设计和过程及其对学习者知识结构的影响,指出该系统可以自动采集并发布在线学习资源,有效地提高了学习效率。 [关键词]:虚拟学习社区;学习资源;自动采集 [中文图书馆分类号] ]:G434 [文件识别码]:A [文章编号]:1004- 5287(2009)05-0498-03在虚拟环境中学习自动搜集的内容TU在社区中学习赵军,高东怀,男(网络中心。
富华军事大学,陕西西安710032 [摘要]:本文介绍了学习资源自动采集系统的设计和程序,以及对学习者知识建设的影响。它指出,这是系统调用自动采集并发布基于Web的学习资源,从而改善了虚拟学习社区中的学习资源,促进了企业自主学习。 [凯词]:虚拟学习社区;学习资源;自动采集Yuwen资源的优势和便利性虚拟学习社区(virtual学习社区,VIE)是一个基于信息的学习环境,需要及时提供大量学习资源,满足学习者对独立学习的需求。和协作学习。
当前,许多社区使用受限用户上传和管理员定期上传的组合来更新资源。这种内部资源共享过分依赖人工操作,资源来源范围有限,难以实现。动态不断的更新也限制了学习资源的更新效率,使学习者无法及时获得所需的资源,从而影响学习效果。因此,设计一种自动学习资源采集系统以实现个性化订阅,自动采集和自动发布学习资源是解决虚拟学习社区中资源更新问题的有效方法。 A. 1自动采集系统的学习资源设计和工作流程1。 1设计概念认知灵活性理论认为,人类学习是学习者积极构建内部心理表征的过程。它反对知识的预定义和仅强调知识的非结构。相反,它主张一方面要为建立理解提供基础,另一方面要为学生提供广阔的建构空间,让他们针对具体情况采取适当的策略。情况。因此,虚拟学习社区中的学习资源必须具有三个特点:①资源具有科学严谨的系统结构,内容多样,内容丰富,能够充分满足学习者知识建设的需要; ②社区资源必须具有开源性,并能够形成一个稳定的信息生态系统; ③资源可以灵活,自主地构建,学习者可以根据学习风格独立构建个性化的资源系统。
VLC中学习资源的三个特征要求社区必须不断地从外界输入信息,以确保信息的生态平衡并满足不同学习者的学习需求。尽管网络信息资源非常丰富,但是它们高度分散且结构复杂。在为学习者提供丰富知识的同时,还存在诸如检索困难的问题。在信息搜索过程中,一些学习者甚至偏离了他们原来的学习目标。使用学习资源自动采集系统,您只需一次性订阅即可自动采集网络资源并将其发布在虚拟学习社区中,从而根据学习者的个人需求形成简单的资源重建学习者所需的基本知识环境,也为学习者创造了广阔的空间。 1. 2开发环境和关键技术学习资源自动采集系统处于Linux操作系统中接收时间:2009-05-25关于作者:杨朝军(1,1980),男,陕西省周志仁第四军医大学教育技术专业研究生,助教,主要研究方向:网络技术。第23卷第5期杨朝军等。关于虚拟学习社区中学习资源自动采集系统的构建。在499环境下,采用了PHP + Mysql + apache的技术开发框架,并采用了URL重复数据删除和自动摘要这两项关键技术。
自动学习资源采集系统需要确定采集信息之前的采集前页面是否为采集,并且需要URL重复数据删除处理。实现代码如下:“ c ollec t- urls” =>“ id int(11)NOT NULL AUTO — lN CREMENT,remote- url varchar(255)NOT NULL,title varchar(255)NOT NULL,导入— ud varchar(255),导入— id bigint(20)DE FAULT 0 NOT NULL,loc al_ pid int(11)DEFAULT 0 NOT NULL,状态tinyint(1)DE FAULT O NOT NULL,slug varchar(255)NOT NULL,唯一密钥id(id)”,采集每次采集记录一次采集的网页地址,形成一组采集的网页地址网页地址,或在数据库中添加一个标志位如果(!empty($ collect_table_ sqls))需要一次(ABSPATH。wp- admin / include / upgrade。php'); foreach($ collect- table- sqls AS $ ta b le一/ laine => $ ta b le_sq1){$ table_name = $ wpdb-> pref ix。$ ta b le_name; if($ wpdb-> get_var(” SHOW TABLES LIKE)!= $ table_name)$ sql =“ CREATE TA B LE”。确定磨她的地址在采集记录中,如果在其中,则表明该网页已被采集跳过;否则,输入采集信息,并将网页地址信息放入采集地址记录中,以免网页重复采集,浪费资源。
摘要是指通过处理文档的内容来提取满足用户需求的重要信息,并在重组和修改后生成比原创内容更精细的摘要的过程。作者采用了使用自然语言处理(NLP)技术的自动摘要系统。通过将基于内容的方法(基于内容)和基于主题的方法进行融合,可以将主题和内容组合在一起以生成具有良好连贯性和流畅性的摘要。基本思想是首先分析主题词,动态处理带有抽象标题和特定标题的文档,然后使用自然语言处理技术(例如词汇,语法和语义分析)对文章的文本内容进行深入分析]。将两次分析获得的结果进行线性加权融合,生成摘要,最后使用回指法解析技术进行平滑处理,以使生成的摘要更加连贯和流畅。在抽象生成算法中,还将输出一些元数据(例如标题分析,作者摘录和主要题词)并将其保存为中间结果,从而形成一个符合基本内容的完整元数据系统。文件规格。 1. 3系统设计和工作流程。自动学习资源采集该系统主要由三部分组成:Web信息采集子系统,信息处理子系统和信息发布子系统。这三个子系统通过它们之间定义的接口来实现整个过程。自动化采集,智能处理和主动发布,如图1所示。
W资源e来源b季节性胶囊Web信息数据采集发布系统图1自动学习资源采集系统结构关系图自动学习资源采集系统的工作流程需要数据采集和信息处理3信息发布的步骤,如图2所示。Web资源采集模板管理两个两个[两个任务管理两个两个[采集模块T信息处理模块UR L库两个] UR L分析信息发布处理H 采集数据管理H 采集数据库I图2自动学习资源采集系统数据采集释放流程图采集的第一步数据。学习者可以根据需要通过不同的采集面板自定义订阅。他们只需要在任务管理模块中添加采集个任务,并设置采集开始时间,采集结束条件和采集任务]信息和其他内容的目标分类,任务管理模块从种子URL开始,以提供目标Web资源的信息采集。然后,通过信息处理模块URL解析,URL管理模块获取新的URL,并根据任务管理模块为这些URL设置的条件采集,直到URL队列为空或触发任务结束停止,然后传送到信息处理系统。第二步是信息处理。 采集的学习资源进入信息处理子系统后,信息处理模块首先对信息进行基本的去噪处理,然后从页面信息中提取出诸如导航条,页眉和页脚之类的关键信息。
HTML解析后,URL解析模块解析出该信息中收录的所有URL信息,并执行URL重复数据删除,并将其保存在URL库中,以供采集模块使用。同时,采集管理器将数据保存在采集数据库中,以供信息发布子系统使用,并将采集信息填写到采集“ 1 One Number Chinese Medical Education Technology Volume 23,Issue” 5 Data Conversion-3]。第三步是发布信息,作为信息数据采集系统的特定应用系统,信息发布子系统将采集数据库中的信息传输到数据发布数据库,最终通过信息发布子系统处理的信息由信息发布模块处理,以发布到Web User,实现信息的自动推送功能采集 .2使用情况及其对学习者知识建构的影响。自动学习资源采集自动学习资源虚拟学习社区中系统的功能采集该系统可以作为插件安装在PHP + Mysql + apache体系结构的虚拟学习社区平台中。针对不同类型的资源,有两种应用方法。 2. 1学习资源自动采集系统在虚拟学习社区中的应用方法2。 1. 1 采集文本和图像格式为文本和图像。 采集根据用户定义的任务配置,系统准确地批量提取目标网络列中的文本和图片,自动提取并合并多个页面的文本内容,并根据图片格式进行分类,然后进行转换成结构化的记录。记录包括标题,作者,内容,采集时间,来源,分类等,这些信息存储在本地数据库中,从而有效避免了使用这些数据的网站程序或桌面程序与数据库之间的任何耦合。表结构也可以完全更改。学习者可以自己定义它,并根据资源分类结构将其呈现给学习者,还可以与社区的其他成员共享。
适用于新闻采集,博客文章 采集,RSS / ATOM XML内容采集,文本/ CSV内容采集,任意格式的XML 采集,自定义结构网页内容采集等待。 2. 1. 2有一个更大的共享视频和课件的空间。在虚拟学习社区中,如果学习者的视频或课件资源采集存储在数据库中,它将占用大量社区空间,消耗服务器的系统内存,并使服务器瘫痪。对于占用空间的资源,信息采集系统采用共享视频和课件地址(仅采集资源的名称和URL)的方法,然后将它们以列表的形式呈现给学习者。当他们使用它们时,只需要单击链接,您就可以登录视频或课件源网站进行学习。此方法通常适用于以在线播放形式出现的视频,例如Youku和Aibo之类的视频源,以及提供下载的可集成软件库。 2. 2自动学习资源采集系统对学习者的知识建构的影响知识建构是建构主义学习哲学的核心术语。知识建构的观点认为,知识的获取不是学习者简单地接受或复制的过程,而是积极建构的过程,同时也是创造和修改公共知识的过程。学习资源系统的自动生成通过创建个人知识来建立目标,并根据公共知识自主地创建个人资源系统。在资源创造过程中,它追求知识建构的合理性。
学习资源的主要表演视频和课件资源占据空白。作者在第四军医大学信息化教学在线门户平台上试行了资源采集系统,主要在基于图片的教材设计资料库中进行了编写。主要教学中安装了采集系统。信息栏和基于视频的教学视频服务系统。从2009年3月开始为期一个月的试运行。截至2009年4月3日,采集]新增信息4,961个,可用信息4,738个,占95. 5%。随机选择200名试用资源采集系统的用户(包括30名教师),并进行回访以通过问卷调查,187份,3份无效副本和92份实际可用的问卷调查采集系统的感觉。 5%。调查结果表明,有92%的用户对采集系统非常满意。 3. 5%的用户不满意,4。 5%的用户认为这无关紧要。在184位表示满意的用户中,有121位用户认为该系统减少了获取资源的难度并提高了学习效率。其余63名学生仅对该系统感到好奇,并乐于使用该系统。将近一半的用户根据采集中的资源量安排自己的学习进度,并制定更合理的学习计划,在每个阶段阐明自己的学习内容,一些学习者还比较他们所获得的资源采集与其他用户。二次共享将加快社区内集体智慧的交流,达到快速知识建设的目的。
我们利用资源自动采集了200份问卷,自动回收了3个学习资源采集系统自动学习资源的实际意义采集该系统突破了资源手动上传的资源建设模式,形成了外部结构学习资源的机制。在虚拟学习社区中,实现了用户独立构建个人资源系统的个性化方式。主要体现在以下几个方面:3. 1实现非结构化信息到结构化信息的转换。根据用户定义的任务配置,自动学习资源采集系统可以快速实现外部信息的获取,并可以批量,准确地提取Internet目标网页中的半结构化和半结构化信息。非结构化信息根据学习者的资源架构存储在虚拟学习社区数据库中,并转换为结构化信息供社区用户使用。结构良好的信息可以促进学习者的学习,并有效地提高学习效率。 3. 2实现了学习资源的自动更新。更新学习资源的问题一直是学习平台应用程序的瓶颈问题。资源更新的滞后主要是因为学习资源与资源库之间没有连续和自动的连接,并且手动下载和上传方法造成时间浪费和资源时效性的降低。自动学习资源采集系统使用信息采集器,该信息采集器在订户和订户之间建立稳定的连接,并实现学习资源的聚集和同步更新。这种全面且时间紧迫的学习资源可以激发学习者的学习兴趣,从而使学习者无需在大量信息中搜索学习资源,并且管理员无需手动添加资源。通过自动更新,打破了学习资源的瓶颈。
3。 3实现学习资源的个性化定制。良好的个性化服务是学习资源采集系统的杰出代表。 2009年10月,第23卷,第5期中国医学教育技术在传播中的作用0 G Y V o1。 2 3晚5点基于IP SAN架构的20o9医学院校媒体资产管理存储系统甘振涛(第三军医大学教育技术中心重庆400038)[摘要]:如何设计合理有效的医学院校存储系统媒体资产管理系统的建设是一个核心问题文章通过对相关技术的分析比较,提出了学校媒体资产存储系统的架构,为研究媒体资产存储的建设提供参考。 [关键词]:媒体资产; FC SAN; IP SAN;存储[中文图书馆分类号]:G434 [文件标识码]:A [文章编号]:1004-5287(2009)05 -0501-0 3基于IP SA的结构化医学数据库在医学上的应用是由CHEN ZHENtao(第三军事教育技术中心)医学大学。
重庆400038。[摘要]:如何设计合理有效的存储系统是医学和大学医学资产管理的核心问题。通过对技术的分析,论文提出了科学媒体资产管理的框架,为研究medica媒体资产管理的存储系统结构提供了参考。大学和大学。 [凯词]:媒体资产; FC SAN; IP SAN;存储媒体资产管理概述媒体资产管理(媒体资产管理)是一个强大的解决方案。
当前,各种医学院校的教育技术中心和附加功能。由于学习者的学习风格和学习内容之间存在明显差异,因此在使用该系统时,通常需要个性化订阅,站点搜索,评论和修改等功能。在设计该系统时,根据学习者的需求,建立了一个独立的订阅模块。学习者可以根据自己的需求订阅所需的学习资源,并可以按类别显示资源内容。学习者检索信息时,可以根据类别和标签实现智能检索,并可以按时间顺序显示,方便学习者使用。学习者还可以评论或修改推送的资源,添加标签等,以进一步丰富学习资源,或提供学习记录以促进其他学习者的学习。 3. 4促进协作学习的发展协作学习是一种组织学生通过小组或团队进行学习的策略。小组成员的协作工作是实现共同学习目标的重要组成部分。自动学习资源采集系统的修改功能可以实现消息形式或直接修改形式的学习资源的协同处理,促进学习资源的丰富和完善,并实现协作工作的目的。简而言之,VLC中的自动学习资源采集系统通过信息聚合和自动推送来实现学习资源的自动更新,并为构建高级的个性化学习环境提供技术支持。
该系统的应用可以有效地提高学习效率,促进学习者从获取学习资源到接受学习资源的过渡。参考文献[1]李平。 采集网络信息资源策略[J]。科技情报开发与经济,2006,16(8):59-60 [2]朱格维。数据库网络资源的探讨采集 [J]。图书馆工作与研究,2008,(4)[3]吴斌,石新华。网络信息资源管理与数据库建设[J]。河南科技,2008,(3)[4]杨辉。CSCL中教师教学组织行为对学习者影响的研究中国的视听教育,2009,(1):64- 68,收稿日期:2009-04-20)作者简介:甘振涛(1973-),男,重庆Bi山人。 ,工程师,硕士,主要研究方向:大学信息化建设与应用,网络安全。 查看全部
虚拟学习社区中学习资源自动采集系统的更新速度
2009年10月,第23卷,第5期中国医学教育技术在医学领域的应用1。 2 3 5号20o9·技术支持·虚拟学习社区中自动学习资源采集系统的构建杨朝军,高东淮,宁玉文(第四军医大学网络中心,西安71003,陕西710032)[摘要]:自动学习资源的介绍2)k15]根据系统的设计和过程及其对学习者知识结构的影响,指出该系统可以自动采集并发布在线学习资源,有效地提高了学习效率。 [关键词]:虚拟学习社区;学习资源;自动采集 [中文图书馆分类号] ]:G434 [文件识别码]:A [文章编号]:1004- 5287(2009)05-0498-03在虚拟环境中学习自动搜集的内容TU在社区中学习赵军,高东怀,男(网络中心。
富华军事大学,陕西西安710032 [摘要]:本文介绍了学习资源自动采集系统的设计和程序,以及对学习者知识建设的影响。它指出,这是系统调用自动采集并发布基于Web的学习资源,从而改善了虚拟学习社区中的学习资源,促进了企业自主学习。 [凯词]:虚拟学习社区;学习资源;自动采集Yuwen资源的优势和便利性虚拟学习社区(virtual学习社区,VIE)是一个基于信息的学习环境,需要及时提供大量学习资源,满足学习者对独立学习的需求。和协作学习。
当前,许多社区使用受限用户上传和管理员定期上传的组合来更新资源。这种内部资源共享过分依赖人工操作,资源来源范围有限,难以实现。动态不断的更新也限制了学习资源的更新效率,使学习者无法及时获得所需的资源,从而影响学习效果。因此,设计一种自动学习资源采集系统以实现个性化订阅,自动采集和自动发布学习资源是解决虚拟学习社区中资源更新问题的有效方法。 A. 1自动采集系统的学习资源设计和工作流程1。 1设计概念认知灵活性理论认为,人类学习是学习者积极构建内部心理表征的过程。它反对知识的预定义和仅强调知识的非结构。相反,它主张一方面要为建立理解提供基础,另一方面要为学生提供广阔的建构空间,让他们针对具体情况采取适当的策略。情况。因此,虚拟学习社区中的学习资源必须具有三个特点:①资源具有科学严谨的系统结构,内容多样,内容丰富,能够充分满足学习者知识建设的需要; ②社区资源必须具有开源性,并能够形成一个稳定的信息生态系统; ③资源可以灵活,自主地构建,学习者可以根据学习风格独立构建个性化的资源系统。
VLC中学习资源的三个特征要求社区必须不断地从外界输入信息,以确保信息的生态平衡并满足不同学习者的学习需求。尽管网络信息资源非常丰富,但是它们高度分散且结构复杂。在为学习者提供丰富知识的同时,还存在诸如检索困难的问题。在信息搜索过程中,一些学习者甚至偏离了他们原来的学习目标。使用学习资源自动采集系统,您只需一次性订阅即可自动采集网络资源并将其发布在虚拟学习社区中,从而根据学习者的个人需求形成简单的资源重建学习者所需的基本知识环境,也为学习者创造了广阔的空间。 1. 2开发环境和关键技术学习资源自动采集系统处于Linux操作系统中接收时间:2009-05-25关于作者:杨朝军(1,1980),男,陕西省周志仁第四军医大学教育技术专业研究生,助教,主要研究方向:网络技术。第23卷第5期杨朝军等。关于虚拟学习社区中学习资源自动采集系统的构建。在499环境下,采用了PHP + Mysql + apache的技术开发框架,并采用了URL重复数据删除和自动摘要这两项关键技术。
自动学习资源采集系统需要确定采集信息之前的采集前页面是否为采集,并且需要URL重复数据删除处理。实现代码如下:“ c ollec t- urls” =>“ id int(11)NOT NULL AUTO — lN CREMENT,remote- url varchar(255)NOT NULL,title varchar(255)NOT NULL,导入— ud varchar(255),导入— id bigint(20)DE FAULT 0 NOT NULL,loc al_ pid int(11)DEFAULT 0 NOT NULL,状态tinyint(1)DE FAULT O NOT NULL,slug varchar(255)NOT NULL,唯一密钥id(id)”,采集每次采集记录一次采集的网页地址,形成一组采集的网页地址网页地址,或在数据库中添加一个标志位如果(!empty($ collect_table_ sqls))需要一次(ABSPATH。wp- admin / include / upgrade。php'); foreach($ collect- table- sqls AS $ ta b le一/ laine => $ ta b le_sq1){$ table_name = $ wpdb-> pref ix。$ ta b le_name; if($ wpdb-> get_var(” SHOW TABLES LIKE)!= $ table_name)$ sql =“ CREATE TA B LE”。确定磨她的地址在采集记录中,如果在其中,则表明该网页已被采集跳过;否则,输入采集信息,并将网页地址信息放入采集地址记录中,以免网页重复采集,浪费资源。
摘要是指通过处理文档的内容来提取满足用户需求的重要信息,并在重组和修改后生成比原创内容更精细的摘要的过程。作者采用了使用自然语言处理(NLP)技术的自动摘要系统。通过将基于内容的方法(基于内容)和基于主题的方法进行融合,可以将主题和内容组合在一起以生成具有良好连贯性和流畅性的摘要。基本思想是首先分析主题词,动态处理带有抽象标题和特定标题的文档,然后使用自然语言处理技术(例如词汇,语法和语义分析)对文章的文本内容进行深入分析]。将两次分析获得的结果进行线性加权融合,生成摘要,最后使用回指法解析技术进行平滑处理,以使生成的摘要更加连贯和流畅。在抽象生成算法中,还将输出一些元数据(例如标题分析,作者摘录和主要题词)并将其保存为中间结果,从而形成一个符合基本内容的完整元数据系统。文件规格。 1. 3系统设计和工作流程。自动学习资源采集该系统主要由三部分组成:Web信息采集子系统,信息处理子系统和信息发布子系统。这三个子系统通过它们之间定义的接口来实现整个过程。自动化采集,智能处理和主动发布,如图1所示。
W资源e来源b季节性胶囊Web信息数据采集发布系统图1自动学习资源采集系统结构关系图自动学习资源采集系统的工作流程需要数据采集和信息处理3信息发布的步骤,如图2所示。Web资源采集模板管理两个两个[两个任务管理两个两个[采集模块T信息处理模块UR L库两个] UR L分析信息发布处理H 采集数据管理H 采集数据库I图2自动学习资源采集系统数据采集释放流程图采集的第一步数据。学习者可以根据需要通过不同的采集面板自定义订阅。他们只需要在任务管理模块中添加采集个任务,并设置采集开始时间,采集结束条件和采集任务]信息和其他内容的目标分类,任务管理模块从种子URL开始,以提供目标Web资源的信息采集。然后,通过信息处理模块URL解析,URL管理模块获取新的URL,并根据任务管理模块为这些URL设置的条件采集,直到URL队列为空或触发任务结束停止,然后传送到信息处理系统。第二步是信息处理。 采集的学习资源进入信息处理子系统后,信息处理模块首先对信息进行基本的去噪处理,然后从页面信息中提取出诸如导航条,页眉和页脚之类的关键信息。
HTML解析后,URL解析模块解析出该信息中收录的所有URL信息,并执行URL重复数据删除,并将其保存在URL库中,以供采集模块使用。同时,采集管理器将数据保存在采集数据库中,以供信息发布子系统使用,并将采集信息填写到采集“ 1 One Number Chinese Medical Education Technology Volume 23,Issue” 5 Data Conversion-3]。第三步是发布信息,作为信息数据采集系统的特定应用系统,信息发布子系统将采集数据库中的信息传输到数据发布数据库,最终通过信息发布子系统处理的信息由信息发布模块处理,以发布到Web User,实现信息的自动推送功能采集 .2使用情况及其对学习者知识建构的影响。自动学习资源采集自动学习资源虚拟学习社区中系统的功能采集该系统可以作为插件安装在PHP + Mysql + apache体系结构的虚拟学习社区平台中。针对不同类型的资源,有两种应用方法。 2. 1学习资源自动采集系统在虚拟学习社区中的应用方法2。 1. 1 采集文本和图像格式为文本和图像。 采集根据用户定义的任务配置,系统准确地批量提取目标网络列中的文本和图片,自动提取并合并多个页面的文本内容,并根据图片格式进行分类,然后进行转换成结构化的记录。记录包括标题,作者,内容,采集时间,来源,分类等,这些信息存储在本地数据库中,从而有效避免了使用这些数据的网站程序或桌面程序与数据库之间的任何耦合。表结构也可以完全更改。学习者可以自己定义它,并根据资源分类结构将其呈现给学习者,还可以与社区的其他成员共享。
适用于新闻采集,博客文章 采集,RSS / ATOM XML内容采集,文本/ CSV内容采集,任意格式的XML 采集,自定义结构网页内容采集等待。 2. 1. 2有一个更大的共享视频和课件的空间。在虚拟学习社区中,如果学习者的视频或课件资源采集存储在数据库中,它将占用大量社区空间,消耗服务器的系统内存,并使服务器瘫痪。对于占用空间的资源,信息采集系统采用共享视频和课件地址(仅采集资源的名称和URL)的方法,然后将它们以列表的形式呈现给学习者。当他们使用它们时,只需要单击链接,您就可以登录视频或课件源网站进行学习。此方法通常适用于以在线播放形式出现的视频,例如Youku和Aibo之类的视频源,以及提供下载的可集成软件库。 2. 2自动学习资源采集系统对学习者的知识建构的影响知识建构是建构主义学习哲学的核心术语。知识建构的观点认为,知识的获取不是学习者简单地接受或复制的过程,而是积极建构的过程,同时也是创造和修改公共知识的过程。学习资源系统的自动生成通过创建个人知识来建立目标,并根据公共知识自主地创建个人资源系统。在资源创造过程中,它追求知识建构的合理性。
学习资源的主要表演视频和课件资源占据空白。作者在第四军医大学信息化教学在线门户平台上试行了资源采集系统,主要在基于图片的教材设计资料库中进行了编写。主要教学中安装了采集系统。信息栏和基于视频的教学视频服务系统。从2009年3月开始为期一个月的试运行。截至2009年4月3日,采集]新增信息4,961个,可用信息4,738个,占95. 5%。随机选择200名试用资源采集系统的用户(包括30名教师),并进行回访以通过问卷调查,187份,3份无效副本和92份实际可用的问卷调查采集系统的感觉。 5%。调查结果表明,有92%的用户对采集系统非常满意。 3. 5%的用户不满意,4。 5%的用户认为这无关紧要。在184位表示满意的用户中,有121位用户认为该系统减少了获取资源的难度并提高了学习效率。其余63名学生仅对该系统感到好奇,并乐于使用该系统。将近一半的用户根据采集中的资源量安排自己的学习进度,并制定更合理的学习计划,在每个阶段阐明自己的学习内容,一些学习者还比较他们所获得的资源采集与其他用户。二次共享将加快社区内集体智慧的交流,达到快速知识建设的目的。
我们利用资源自动采集了200份问卷,自动回收了3个学习资源采集系统自动学习资源的实际意义采集该系统突破了资源手动上传的资源建设模式,形成了外部结构学习资源的机制。在虚拟学习社区中,实现了用户独立构建个人资源系统的个性化方式。主要体现在以下几个方面:3. 1实现非结构化信息到结构化信息的转换。根据用户定义的任务配置,自动学习资源采集系统可以快速实现外部信息的获取,并可以批量,准确地提取Internet目标网页中的半结构化和半结构化信息。非结构化信息根据学习者的资源架构存储在虚拟学习社区数据库中,并转换为结构化信息供社区用户使用。结构良好的信息可以促进学习者的学习,并有效地提高学习效率。 3. 2实现了学习资源的自动更新。更新学习资源的问题一直是学习平台应用程序的瓶颈问题。资源更新的滞后主要是因为学习资源与资源库之间没有连续和自动的连接,并且手动下载和上传方法造成时间浪费和资源时效性的降低。自动学习资源采集系统使用信息采集器,该信息采集器在订户和订户之间建立稳定的连接,并实现学习资源的聚集和同步更新。这种全面且时间紧迫的学习资源可以激发学习者的学习兴趣,从而使学习者无需在大量信息中搜索学习资源,并且管理员无需手动添加资源。通过自动更新,打破了学习资源的瓶颈。
3。 3实现学习资源的个性化定制。良好的个性化服务是学习资源采集系统的杰出代表。 2009年10月,第23卷,第5期中国医学教育技术在传播中的作用0 G Y V o1。 2 3晚5点基于IP SAN架构的20o9医学院校媒体资产管理存储系统甘振涛(第三军医大学教育技术中心重庆400038)[摘要]:如何设计合理有效的医学院校存储系统媒体资产管理系统的建设是一个核心问题文章通过对相关技术的分析比较,提出了学校媒体资产存储系统的架构,为研究媒体资产存储的建设提供参考。 [关键词]:媒体资产; FC SAN; IP SAN;存储[中文图书馆分类号]:G434 [文件标识码]:A [文章编号]:1004-5287(2009)05 -0501-0 3基于IP SA的结构化医学数据库在医学上的应用是由CHEN ZHENtao(第三军事教育技术中心)医学大学。
重庆400038。[摘要]:如何设计合理有效的存储系统是医学和大学医学资产管理的核心问题。通过对技术的分析,论文提出了科学媒体资产管理的框架,为研究medica媒体资产管理的存储系统结构提供了参考。大学和大学。 [凯词]:媒体资产; FC SAN; IP SAN;存储媒体资产管理概述媒体资产管理(媒体资产管理)是一个强大的解决方案。
当前,各种医学院校的教育技术中心和附加功能。由于学习者的学习风格和学习内容之间存在明显差异,因此在使用该系统时,通常需要个性化订阅,站点搜索,评论和修改等功能。在设计该系统时,根据学习者的需求,建立了一个独立的订阅模块。学习者可以根据自己的需求订阅所需的学习资源,并可以按类别显示资源内容。学习者检索信息时,可以根据类别和标签实现智能检索,并可以按时间顺序显示,方便学习者使用。学习者还可以评论或修改推送的资源,添加标签等,以进一步丰富学习资源,或提供学习记录以促进其他学习者的学习。 3. 4促进协作学习的发展协作学习是一种组织学生通过小组或团队进行学习的策略。小组成员的协作工作是实现共同学习目标的重要组成部分。自动学习资源采集系统的修改功能可以实现消息形式或直接修改形式的学习资源的协同处理,促进学习资源的丰富和完善,并实现协作工作的目的。简而言之,VLC中的自动学习资源采集系统通过信息聚合和自动推送来实现学习资源的自动更新,并为构建高级的个性化学习环境提供技术支持。
该系统的应用可以有效地提高学习效率,促进学习者从获取学习资源到接受学习资源的过渡。参考文献[1]李平。 采集网络信息资源策略[J]。科技情报开发与经济,2006,16(8):59-60 [2]朱格维。数据库网络资源的探讨采集 [J]。图书馆工作与研究,2008,(4)[3]吴斌,石新华。网络信息资源管理与数据库建设[J]。河南科技,2008,(3)[4]杨辉。CSCL中教师教学组织行为对学习者影响的研究中国的视听教育,2009,(1):64- 68,收稿日期:2009-04-20)作者简介:甘振涛(1973-),男,重庆Bi山人。 ,工程师,硕士,主要研究方向:大学信息化建设与应用,网络安全。
直观:舆情监测系统源码的功能有哪些以及舆情监测的应用范围
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2020-09-02 04:23
(4)舆论影响力: 自动区分正面,负面和重大负面舆论;
(5)全文搜索: 提供多种类型的搜索方法,可以添加和删除内置关键字;
(6)舆论简报: 以简报的形式介绍每日和每周的主要舆论. 简介有多种设计格式可供选择和编辑;
(7)特别报告: 特别报告是关于该主题的全面而系统的报告,包括图表,报告和一般分析.
舆论监督系统源代码的功能是什么?
1)公众情感数据采集子系统公众情感数据采集子系统数据采集对象主要是Internet 网站和网页. 有两个主要数据源,一个是通过指定范围网站进行捕获采集,另一个是通过baidu和google监视整个网络数据采集. 在数据采集的处理过程中,包括了许多中文处理技术,例如文本内容的自动识别,文章重复数据删除和相似性分析以及摘要和关键字的自动生成. 此外,数据采集子系统还可以采集下载网页中的图片和文档资源文件,并具有生成网页图片和快照的功能,实现网站自动登录,使用代理服务器下载,JS自动识别判断,以及分配公式采集和其他函数. 该模板技术被用于舆论数据采集子系统,并且系统内置了数百个网站模板,从而使用户的配置过程变得非常简单.
舆论监督系统源代码
2)公众情感数据处理子系统公众情感数据处理子系统主要组织和处理采集子系统采集的数据. 主要功能包括: 民意数据管理: 包括数据分类,编辑,删除和添加的维护. 门户信息配置: 系统可以自动生成前端门户平台的信息. 管理员还可以通过后台配置将需要呈现的信息放置在门户中. 同时,管理员还可以执行门户的一些渠道,热词和主题. 管理和设置. 简报管理模块: 通过设置舆情简报模板,您可以每天,每月或每月自动生成舆情简报,也可以手动选择信息生成简报,并为生成的简报提供可视化的编辑界面.
3)舆论分析子系统舆论分析子系统的功能分为统计和分析两部分.
以上是齐归社区编辑介绍的民意监测系统源代码的功能以及民意监测应用范围的相关内容. 如果您想了解有关舆论监督的更多信息,请继续关注我们的网站. 查看全部
民意监测系统源代码的功能是什么?民意监测的应用范围是什么?
(4)舆论影响力: 自动区分正面,负面和重大负面舆论;
(5)全文搜索: 提供多种类型的搜索方法,可以添加和删除内置关键字;
(6)舆论简报: 以简报的形式介绍每日和每周的主要舆论. 简介有多种设计格式可供选择和编辑;
(7)特别报告: 特别报告是关于该主题的全面而系统的报告,包括图表,报告和一般分析.
舆论监督系统源代码的功能是什么?
1)公众情感数据采集子系统公众情感数据采集子系统数据采集对象主要是Internet 网站和网页. 有两个主要数据源,一个是通过指定范围网站进行捕获采集,另一个是通过baidu和google监视整个网络数据采集. 在数据采集的处理过程中,包括了许多中文处理技术,例如文本内容的自动识别,文章重复数据删除和相似性分析以及摘要和关键字的自动生成. 此外,数据采集子系统还可以采集下载网页中的图片和文档资源文件,并具有生成网页图片和快照的功能,实现网站自动登录,使用代理服务器下载,JS自动识别判断,以及分配公式采集和其他函数. 该模板技术被用于舆论数据采集子系统,并且系统内置了数百个网站模板,从而使用户的配置过程变得非常简单.
舆论监督系统源代码
2)公众情感数据处理子系统公众情感数据处理子系统主要组织和处理采集子系统采集的数据. 主要功能包括: 民意数据管理: 包括数据分类,编辑,删除和添加的维护. 门户信息配置: 系统可以自动生成前端门户平台的信息. 管理员还可以通过后台配置将需要呈现的信息放置在门户中. 同时,管理员还可以执行门户的一些渠道,热词和主题. 管理和设置. 简报管理模块: 通过设置舆情简报模板,您可以每天,每月或每月自动生成舆情简报,也可以手动选择信息生成简报,并为生成的简报提供可视化的编辑界面.
3)舆论分析子系统舆论分析子系统的功能分为统计和分析两部分.
以上是齐归社区编辑介绍的民意监测系统源代码的功能以及民意监测应用范围的相关内容. 如果您想了解有关舆论监督的更多信息,请继续关注我们的网站.
TurboCMS内容管理系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 229 次浏览 • 2020-08-27 05:41
TurboCMS内容管理系统概述:
任何一个网页数量小于10的网站都须要内容管理,最简单的情况是网站的Webmaster来完成管理的任务,他制做所有的页面,并检测其中的联接,然后使用FTP工具上传到服务器上。但是随着网页数目的降低,情况发生了变化,对于一些时常更新的内容,比如新闻,许多网站开发自己的专用的发布系统来维护这种更新要求特别高的部份。动态网页技术的发展支持了这些方法。但是现代网站的信息量实在很大了,而且内容的种类也十分的多,仅仅支持新闻类内容的发布早已未能满足需求。这一切促使网站维护步入了“内容管理时代”。
网站内容管理系统是一套可以综合管理网站上各类栏目的通用工具,新闻、产品、文档、下载等,通过元数据管理和模板技术,它们都在同一套系统里完成更新和维护。
基于TurboCMS4.6优秀的内容管理引擎,TurboCMS在站点群管理、国际化支持、内容交换与共享、Web2.0特点的支持等众多方面具有明显的改善,对英文内容管理技术终将提高一个层次。
TurboCMS内容管理系统特点:
我们觉得,软件的哲学本质即“简单就是美”,因此在TurboCMS的开发过程中,无处不充分考虑用户的使用习惯,尽最大可能增加用户的使用门槛,让用户关注于内容维护本身,而不需要投入过多的时间来学习系统的使用方法,在细节处下大工夫。
TurboCMS的主要特征有:
1、不同凡响的采编体验TurboCMS的内容录入界面充分考虑内容维护人员的实际情况,他们可能不精通HTML,但她们会使用Word等办公软件,因此,系统界面与Word等Office产品紧密集成,可直接从Word里拖动一块内容到TurboCMS中来。如果Word中包括图片、表格等内容,则系统手动上传图片等文件,完全无需人工干预,并可批量导出Word、PowerPoint、Excel、JPG、GIF文件,并支持手动分页,自动清除HTML,自动排版。
用户也可以在TurboCMS里直接进行文字的排版处理,比如改变字体名称,字体大小,字体颜色,背景颜色,以及对齐式样等等。还可以透明地插入图片,并可以任意调整图片的位置、大小,与文字进行环绕等等。系统甚至可以手动给图片生成缩略图,点击后看大图。系统还支持插入Flash动漫、超级联接、特殊字符、音频视频等等。系统会手动将插入的图片、Flash等文件上传到系统中合适的目录,而无需用户关心这一切。
如果从网页上拷贝内容,系统支持远程图片手动本地化。
系统支持插入附件,热字联接,内容分页。
系统支持托拽形式进行次序调整,任意排版。支持重要文章置顶。
托拽形式进行内容位置调整,频道间拷贝、移动。
系统支持文章标题查重。
2、站点群管理TurboCMS支持多站点、站点群的管理,特别适宜具有诸多分支机构或下属单位的小型企业和政府单位进行站点群的统一化管理。
站点间并具有内容共享支持,可便捷地在主站与子站、子站与子站点间进行信息的共享。
系统提供多级的权限控制系统,可便捷地对站点群管理进行分工。
3、媒体行业专门解决方案许多媒体(如刊物、报纸、电视、广播)等有一些栏目是按时间更新的,比如一周一期,一月一期等等,这种更新方法更传统的网站的持续性更新有很大的区别。从内容维护上看,内容录入时须要分辨内容是在哪一期出版的,从网站浏览上看,访问者要求能查询过刊。TurboCMS专门为刊物提供了支持。编辑可以在一期的内容都准备好了后统一出版。当旧的一期出版后,内容被录入到新的一期中。期刊的内容出版到网站上后,访问者可以按年、期来查询过刊,也可以按栏目来查询过往的内容。
对刊物的支持是TurboCMS的明显特征,国内外仍未看见提供类似功能的内容管理系统。
对于报纸内容上网,TurboCMS提供专门的“报纸”管理模块,支持将报纸扫描成图片,放到网站上,允许用户用点击某一区域之后查看内容的形式进行浏览,从而实现报纸的“仿真网络版”。仿真版保留了报纸的排版,充分利用了报纸的排版价值,同时使浏览更为直观。
TurboCMS支持批量导出国外常见的报社采编系统如北大紫光采编系统导入的数据文件。
4、可视化模板制做插件我们充分研究了国内外的内容管理系统,发现她们大都还能实现结合模板手动生成页面,减轻了页面制做人员的工作量,但是模板制做本身缺要求有较高技术水平的人员,有些系统要求使用基于XML的程序语言XSLT来制做模板,有些系统要求UNIX下的TCL语言来写模板,真可谓是降低了HTML设计人员,却降低了XML编程人员,没有从根本上减少用户的负担。
在这样的系统中,模板制做通常情况下分两步完成,第一步先请美术设计人员设计模板的风格等外型,第二步使精通模板制做的程序员来嵌代码。
TurboCMS提供了forDreamWeaver的TDL(模板定义语言)插件,设计师在自己熟悉的软件里,完成设计后,只须要用键盘从工具栏上拖动控件到页面中,就手动插入了TurboCMS的模板脚本了,无需编撰任何代码。
5、采用UNICODE,支持任意编码,支持繁简手动转换
系统内部统一采用UNICODE,支持GBK、BIG5、UTF8等任意编码的网站管理。系统并能手动实现繁体英文网站转换成简体英文网站及相反的转换。
6、工作流支持以及手动消息提醒
TurboCMS支持内容发布的工作流。一篇内容从记者最初录入到最后发布到网站上,中间须要经过编辑审批,甚至须要美工配图等等。TurboCMS手动会将任务发送到下一个处理者。系统提供电子邮件形式,在有新的任务到来时手动提醒用户登录系统完成任务。这样,当记者新录入了一篇文章时,编辑就立刻晓得了,然后登录系统编辑文章并审批,保证内容及时地更新到网站上去。
系统支持手机邮件、电子邮件、MSNMessenger等方法的提醒。
对于特殊的内容,TurboCMS支持自定义的工作流步骤设置,工作流类型支持任意审批、全部审批、顺序审批等。
文章在每一步可设置“返工”、“否决”。
7、自定义内容数组
在TurboCMS中,每一个频道都可以定义自己的数组结构,字段类型支持文本、选择、日期、图片、标签等。相对于整个系统使用相同的数组结构不能扩充,或只能对整个系统进行扩充而不能对单独频道进行扩充的系统来说,TurboCMS具有极大的灵活性,可以满足网站上各类类型、各种结构的信息发布需求,融各类类型内容管理于同一个系统中。从这个意义上讲,TurboCMS是一个内容管理开发平台。
8、内容采集
TurboCMS外置了数据库爬虫,用户可以创建一个爬行任务,从指定的数据库(支持Oracle、MicrosoftSQLServer、MySQL)指定的表中,自动采集指定的数组,并映射到TurboCMS内容库的数组。从而轻松地使TurboCMS与已有的信息系统进行数据集成。
自动化内容采集的支持,大大地增加了内容维护的工作量,并使内容管理系统与企业的其他信息化系统无缝集成,提高了信息的利用率。
9、静态布署与动态布署
TurboCMS的工作方式为,用户录入内容时被保存在专门的内容数据库中,然后那些内容结合模板生成静态的HTML页面。最后这种静态的HTML页面被复制到网站的产品服务器起来。在最终的产品服务器上,无需数据库支持。TurboCMS提供了一个手动布署工具TurboDeploy,可以手动地将更新过的文件及时同步到产品服务器上,并可以将同一个目录布署到多台服务器上,从而支持服务器镜像和服务器集群。TurboDeploy支持增量式布署,持续性将更新过的内容进行布署。
对于复杂查询等特殊应用需求,TurboCMS提供DataDeploy数据库布署功能。将频道中的数据复制到Web服务器上的数据库中,以便实现复杂条件的查询等应用需求。数据库布署功能是TurboCMS与众不同的特点。
10、丰富后端的支持
TurboCMS可以与Flash、Jscript等后端表现工具进行结合,以丰富媒体的方式将内容交付给最终用户,从而改善用户体验,提升内容价值。
11、支持XML、RSS、WAP标准
TurboCMS支持将内容发布成XML格式,并支持UTF8编码。TurboCMS支持将内容发布成RSS格式,提供给RSS客户端进行阅读。TurboCMS支持WAP网站的发布,支持使用PDA、手机等无线终端对网站进行访问。
12、支持Web2.0技术
TurboCMS外置了对RSS、TAG、博客等技术的支持,并提供大容量峰会、在线聊天室等功能。
13、同其他系统的集成
TurboCMS对外提供COM+形式的API接口,可供其他系统访问系统内的内容资源。用户可以使用VB、VC、Delphi或则VbScript、JavaScript、NotesScript等脚本语言访问那些API,从而可以容易地与已有的办公自动化、ERP、CRM、MIS等系统集成在一起,将这种系统中须要上网的内容手动地抓取过来发布到网站上,从而不再须要人工来推行拷贝、粘贴。
14、其他特征
大容量设计、连接池技术,日信息发布量可达上万条。经过了Pchome、天天在线等小型门户网站的考验。
系统支持SQLServer和Oracle、DB2三种数据库环境。
支持直接递交一个WORD或TXT或XML文件,自动导出内容库,并智能分析出标题、作者和内容。
支持直接批量导出图片文件。
网站特殊页面管理,支持页面碎片整理。
图片库管理功能。
按角色的用户及权限控制。
关文章分类功能。支持多个相关文章集合。
内容分发功能。某个频道的数据可设置分发规则,自动地分发到其他频道中。
文章版本控制功能,可恢复版本,图形化显示文章处理流程。
文章中可在任意位置插入任意多图片,并支持图片手动生成缩略图,图片加水印,图文混排。
文章标题字数提示,辅助编辑注意网站的格式维护。
文章中可插入特殊符号、连接、多媒体、FLASH、附件等。
文章分页支持。
热字联接功能,关键字替换,将指定关键字构建联接。
文章定时发布、定时归档、文章定时下线等功能。
文章批注功能。
文章拖拽形式进行排版、频道间联通、复制,支持联接复制。 查看全部
TurboCMS内容管理系统
TurboCMS内容管理系统概述:
任何一个网页数量小于10的网站都须要内容管理,最简单的情况是网站的Webmaster来完成管理的任务,他制做所有的页面,并检测其中的联接,然后使用FTP工具上传到服务器上。但是随着网页数目的降低,情况发生了变化,对于一些时常更新的内容,比如新闻,许多网站开发自己的专用的发布系统来维护这种更新要求特别高的部份。动态网页技术的发展支持了这些方法。但是现代网站的信息量实在很大了,而且内容的种类也十分的多,仅仅支持新闻类内容的发布早已未能满足需求。这一切促使网站维护步入了“内容管理时代”。
网站内容管理系统是一套可以综合管理网站上各类栏目的通用工具,新闻、产品、文档、下载等,通过元数据管理和模板技术,它们都在同一套系统里完成更新和维护。
基于TurboCMS4.6优秀的内容管理引擎,TurboCMS在站点群管理、国际化支持、内容交换与共享、Web2.0特点的支持等众多方面具有明显的改善,对英文内容管理技术终将提高一个层次。
TurboCMS内容管理系统特点:
我们觉得,软件的哲学本质即“简单就是美”,因此在TurboCMS的开发过程中,无处不充分考虑用户的使用习惯,尽最大可能增加用户的使用门槛,让用户关注于内容维护本身,而不需要投入过多的时间来学习系统的使用方法,在细节处下大工夫。
TurboCMS的主要特征有:
1、不同凡响的采编体验TurboCMS的内容录入界面充分考虑内容维护人员的实际情况,他们可能不精通HTML,但她们会使用Word等办公软件,因此,系统界面与Word等Office产品紧密集成,可直接从Word里拖动一块内容到TurboCMS中来。如果Word中包括图片、表格等内容,则系统手动上传图片等文件,完全无需人工干预,并可批量导出Word、PowerPoint、Excel、JPG、GIF文件,并支持手动分页,自动清除HTML,自动排版。
用户也可以在TurboCMS里直接进行文字的排版处理,比如改变字体名称,字体大小,字体颜色,背景颜色,以及对齐式样等等。还可以透明地插入图片,并可以任意调整图片的位置、大小,与文字进行环绕等等。系统甚至可以手动给图片生成缩略图,点击后看大图。系统还支持插入Flash动漫、超级联接、特殊字符、音频视频等等。系统会手动将插入的图片、Flash等文件上传到系统中合适的目录,而无需用户关心这一切。
如果从网页上拷贝内容,系统支持远程图片手动本地化。
系统支持插入附件,热字联接,内容分页。
系统支持托拽形式进行次序调整,任意排版。支持重要文章置顶。
托拽形式进行内容位置调整,频道间拷贝、移动。
系统支持文章标题查重。
2、站点群管理TurboCMS支持多站点、站点群的管理,特别适宜具有诸多分支机构或下属单位的小型企业和政府单位进行站点群的统一化管理。
站点间并具有内容共享支持,可便捷地在主站与子站、子站与子站点间进行信息的共享。
系统提供多级的权限控制系统,可便捷地对站点群管理进行分工。
3、媒体行业专门解决方案许多媒体(如刊物、报纸、电视、广播)等有一些栏目是按时间更新的,比如一周一期,一月一期等等,这种更新方法更传统的网站的持续性更新有很大的区别。从内容维护上看,内容录入时须要分辨内容是在哪一期出版的,从网站浏览上看,访问者要求能查询过刊。TurboCMS专门为刊物提供了支持。编辑可以在一期的内容都准备好了后统一出版。当旧的一期出版后,内容被录入到新的一期中。期刊的内容出版到网站上后,访问者可以按年、期来查询过刊,也可以按栏目来查询过往的内容。
对刊物的支持是TurboCMS的明显特征,国内外仍未看见提供类似功能的内容管理系统。
对于报纸内容上网,TurboCMS提供专门的“报纸”管理模块,支持将报纸扫描成图片,放到网站上,允许用户用点击某一区域之后查看内容的形式进行浏览,从而实现报纸的“仿真网络版”。仿真版保留了报纸的排版,充分利用了报纸的排版价值,同时使浏览更为直观。
TurboCMS支持批量导出国外常见的报社采编系统如北大紫光采编系统导入的数据文件。
4、可视化模板制做插件我们充分研究了国内外的内容管理系统,发现她们大都还能实现结合模板手动生成页面,减轻了页面制做人员的工作量,但是模板制做本身缺要求有较高技术水平的人员,有些系统要求使用基于XML的程序语言XSLT来制做模板,有些系统要求UNIX下的TCL语言来写模板,真可谓是降低了HTML设计人员,却降低了XML编程人员,没有从根本上减少用户的负担。
在这样的系统中,模板制做通常情况下分两步完成,第一步先请美术设计人员设计模板的风格等外型,第二步使精通模板制做的程序员来嵌代码。
TurboCMS提供了forDreamWeaver的TDL(模板定义语言)插件,设计师在自己熟悉的软件里,完成设计后,只须要用键盘从工具栏上拖动控件到页面中,就手动插入了TurboCMS的模板脚本了,无需编撰任何代码。
5、采用UNICODE,支持任意编码,支持繁简手动转换
系统内部统一采用UNICODE,支持GBK、BIG5、UTF8等任意编码的网站管理。系统并能手动实现繁体英文网站转换成简体英文网站及相反的转换。
6、工作流支持以及手动消息提醒
TurboCMS支持内容发布的工作流。一篇内容从记者最初录入到最后发布到网站上,中间须要经过编辑审批,甚至须要美工配图等等。TurboCMS手动会将任务发送到下一个处理者。系统提供电子邮件形式,在有新的任务到来时手动提醒用户登录系统完成任务。这样,当记者新录入了一篇文章时,编辑就立刻晓得了,然后登录系统编辑文章并审批,保证内容及时地更新到网站上去。
系统支持手机邮件、电子邮件、MSNMessenger等方法的提醒。
对于特殊的内容,TurboCMS支持自定义的工作流步骤设置,工作流类型支持任意审批、全部审批、顺序审批等。
文章在每一步可设置“返工”、“否决”。
7、自定义内容数组
在TurboCMS中,每一个频道都可以定义自己的数组结构,字段类型支持文本、选择、日期、图片、标签等。相对于整个系统使用相同的数组结构不能扩充,或只能对整个系统进行扩充而不能对单独频道进行扩充的系统来说,TurboCMS具有极大的灵活性,可以满足网站上各类类型、各种结构的信息发布需求,融各类类型内容管理于同一个系统中。从这个意义上讲,TurboCMS是一个内容管理开发平台。
8、内容采集
TurboCMS外置了数据库爬虫,用户可以创建一个爬行任务,从指定的数据库(支持Oracle、MicrosoftSQLServer、MySQL)指定的表中,自动采集指定的数组,并映射到TurboCMS内容库的数组。从而轻松地使TurboCMS与已有的信息系统进行数据集成。
自动化内容采集的支持,大大地增加了内容维护的工作量,并使内容管理系统与企业的其他信息化系统无缝集成,提高了信息的利用率。
9、静态布署与动态布署
TurboCMS的工作方式为,用户录入内容时被保存在专门的内容数据库中,然后那些内容结合模板生成静态的HTML页面。最后这种静态的HTML页面被复制到网站的产品服务器起来。在最终的产品服务器上,无需数据库支持。TurboCMS提供了一个手动布署工具TurboDeploy,可以手动地将更新过的文件及时同步到产品服务器上,并可以将同一个目录布署到多台服务器上,从而支持服务器镜像和服务器集群。TurboDeploy支持增量式布署,持续性将更新过的内容进行布署。
对于复杂查询等特殊应用需求,TurboCMS提供DataDeploy数据库布署功能。将频道中的数据复制到Web服务器上的数据库中,以便实现复杂条件的查询等应用需求。数据库布署功能是TurboCMS与众不同的特点。
10、丰富后端的支持
TurboCMS可以与Flash、Jscript等后端表现工具进行结合,以丰富媒体的方式将内容交付给最终用户,从而改善用户体验,提升内容价值。
11、支持XML、RSS、WAP标准
TurboCMS支持将内容发布成XML格式,并支持UTF8编码。TurboCMS支持将内容发布成RSS格式,提供给RSS客户端进行阅读。TurboCMS支持WAP网站的发布,支持使用PDA、手机等无线终端对网站进行访问。
12、支持Web2.0技术
TurboCMS外置了对RSS、TAG、博客等技术的支持,并提供大容量峰会、在线聊天室等功能。
13、同其他系统的集成
TurboCMS对外提供COM+形式的API接口,可供其他系统访问系统内的内容资源。用户可以使用VB、VC、Delphi或则VbScript、JavaScript、NotesScript等脚本语言访问那些API,从而可以容易地与已有的办公自动化、ERP、CRM、MIS等系统集成在一起,将这种系统中须要上网的内容手动地抓取过来发布到网站上,从而不再须要人工来推行拷贝、粘贴。
14、其他特征
大容量设计、连接池技术,日信息发布量可达上万条。经过了Pchome、天天在线等小型门户网站的考验。
系统支持SQLServer和Oracle、DB2三种数据库环境。
支持直接递交一个WORD或TXT或XML文件,自动导出内容库,并智能分析出标题、作者和内容。
支持直接批量导出图片文件。
网站特殊页面管理,支持页面碎片整理。
图片库管理功能。
按角色的用户及权限控制。
关文章分类功能。支持多个相关文章集合。
内容分发功能。某个频道的数据可设置分发规则,自动地分发到其他频道中。
文章版本控制功能,可恢复版本,图形化显示文章处理流程。
文章中可在任意位置插入任意多图片,并支持图片手动生成缩略图,图片加水印,图文混排。
文章标题字数提示,辅助编辑注意网站的格式维护。
文章中可插入特殊符号、连接、多媒体、FLASH、附件等。
文章分页支持。
热字联接功能,关键字替换,将指定关键字构建联接。
文章定时发布、定时归档、文章定时下线等功能。
文章批注功能。
文章拖拽形式进行排版、频道间联通、复制,支持联接复制。
乐思网络舆情监测系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2020-08-26 15:25
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的采集技术而
研发,具有发觉快,信息全的优势。
系统概述
实施后的利益
系统组成
自动采集子系统功能描述
分析浏览
子系统功能描述
系统施行乐思网络舆情监测系统是针对互联网这一新兴媒体,通过对海量网路舆论信息进行实时的手动采集,分析,汇总,监视,并辨识其中的关键信息,及时通知到相关人员,从而第一时间应急响应,为正确舆论导向及搜集网友意见提供直接支持的一套信息化平台。
其业务流程如下图所示:
图1:乐思网路舆情检测系统的业务流程
相比目前的人工舆情检测,其优势显著:比较指标
采用乐思舆情监测系统
人工检测目标网站
几百个到几千个几万个-采3453舆情4533集-
几十个人力成本
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命负面信息辨识
在手动判断的基础上再人工确认
需要逐字人工查看确认信息保存
精确,全面,便于事后追踪
零碎,不可防止会出错-采3453舆情4533集-数据储存
统一储存在小型关系数据库中,集中管理
Word文件,分散,很难管理检测报告
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
基于手工统计加恐怕,数据支持不充分检测疗效覆盖全面,实时,
自动化,系统化
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集- 查看全部
乐思网络舆情监测系统
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的采集技术而
研发,具有发觉快,信息全的优势。
系统概述
实施后的利益
系统组成
自动采集子系统功能描述
分析浏览
子系统功能描述
系统施行乐思网络舆情监测系统是针对互联网这一新兴媒体,通过对海量网路舆论信息进行实时的手动采集,分析,汇总,监视,并辨识其中的关键信息,及时通知到相关人员,从而第一时间应急响应,为正确舆论导向及搜集网友意见提供直接支持的一套信息化平台。
其业务流程如下图所示:
图1:乐思网路舆情检测系统的业务流程
相比目前的人工舆情检测,其优势显著:比较指标
采用乐思舆情监测系统
人工检测目标网站
几百个到几千个几万个-采3453舆情4533集-
几十个人力成本
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命负面信息辨识
在手动判断的基础上再人工确认
需要逐字人工查看确认信息保存
精确,全面,便于事后追踪
零碎,不可防止会出错-采3453舆情4533集-数据储存
统一储存在小型关系数据库中,集中管理
Word文件,分散,很难管理检测报告
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
基于手工统计加恐怕,数据支持不充分检测疗效覆盖全面,实时,
自动化,系统化
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
dede手动采集更新插件使用手册|DedeCms
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-25 16:41
简介:属于dedecms的一个辅助功能,在dedecms中设定好采集节点以后,规则都设定好,保证在dedecms中才能正确采集到数据。这点很重要,因为我这个插件的采集程序就是dedecms的采集程序,虽然有所改进,但是只是在一些小的细节上更改了一下,整体的采集程序还是和dedecms一样的,一句话就是只要你在dedecms上才能采集到数据,那么这个手动采集更新的程序才能够正确执行。
功能:根据dedecms中设定好的采集节点手动定时定点采集数据,采集好数据然后才能手动导出到相关栏目之中,然后手动生成首页,栏目页,内容页。用一句话概括就是,只要你在dedecms中筹建好了采集节点然后,再从这个插件中配置一下相关参数,就可以不用管这个站了,本程序会手动帮你天天根据你设定好的时间去更新你的站点。是不是太爽啊,省了很大的事呢,呵呵,那么就请使用这个程序吧。
特点:不限于dedecms的版本,3.x和4.0都可以使用,因为本程序不是单纯的调用dedecms的相关文件,是完全从其采集程序中剥离下来自己成体系的一套程序,核心似乎是dedecms的,但是改动了少量细节问题,使逻辑上更合理,修正了原先的一些小的问题。
打包文件介绍:
文件夾:
autogather-----全部的程序文件都在这个下边
cache---缓存配置文件,所有的每位采集节点的手动采集更新的配置信息都在这里
include---所有的核心的操作类,从dedecms中剥离下来的,可以独立成一个系统
templets---模板文件
img,upimg---使用到的一些图片文件
文件:
auto_gather.php----全部的手动采集更新的代码都在这个文件之中,是核心文件
autogather.log---日志文件,记录在手动采集更新的过程中发生的相关信息提示
base.css---样式表文件
co_autogather_main.php---在 dedecms中的配置列表文件
option_auto.php,option_auto_action.php----处理dedecms中的采集节点弄成手动采集的代
码
程序使用说明:
1.首先下载文件包,解压缩在网站根目录下
2.然后到
3.之后步入到dedecms的后台,在辅助插件中的插件整治器中安装一个新插件
4.点击安装新插件,输入相关内容:
插件名称:自动采集更新
作者:千里独行狼
主程序文件:../autogather/co_autogather_main.php
目标框架:main
文件列表:留空
然后点击确定,将降低本插件到系统中。然后刷新一侧的导航,将会在辅助插件栏中多了一个手动采集更新
6.点击一侧的手动采集更新,将显示下来你如今所有设定的采集点,你会发觉在最右侧有一个操作栏,有配置为手动采集和获取代码。
好,我们如今点击配置为手动采集,出来一个具体配置手动采集更新的参数窗口:
下面是具体的每位参数的说明:
采集后导入的目标栏目:采集之后要把数据导出到那个栏目中
采集数据参数设置:采集数据时,每批采集多少条数据,采集的线程数,间隔时间多少秒(防刷新的站点需设置)
栏目导出数据参数设置:每批导出多少条
要更新的栏目:导入完数据然后,要更新的栏目
生成栏目参数设置:每批最大创建页数,也就是分批创建栏目页面的时侯,每批要创建的页数
更新选项:更新栏目的所有页面:一次性全部更新完该栏目的所有页面,仅更新指定数目的页面:有的网站的列表文件太多,假如全部更新的话,耗费的时间会太长,所以这个参数可以设定仅更新前多少页。点击这个选项的话,下面会显示下来一个隐藏的文本框,更新前多少个页面,在这里设定更新的页数
是否更新子栏目:更新子级栏目,仅更新所选栏目
生成文档html参数设置:每批生成多少个内容页面文件
好了,设定好各项参数以后,点击保存配置,将生成一个配置文件到 cache文件夾中
7.点击获取代码
将会在下边出现一个文本框,里面就是获取的代码
把上面的代码拷贝下来。
8.建立一个html文件任意取名,不过建议取一个有意义的名义,这样之后配置多个手动采集点的时侯,以便于分辨
打开这个文件,把拷贝的代码粘贴到该文件中,保存该文件。
9.在windows的计划任务中,建立一个计划任务,设定好要执行的时间。因为php只能做到这些方法,本来曾经想考虑用discuz那个方法,只要网站前台有用户访问,那么就手动开始执行该程序,可是这样并不好,因为采集程序的执行时间都比较长,所以前台访客访问的页面会仍然显示正在打开中,浏览体验就不好了,所以只能依靠windows的计划任务来做了。unix,linux也有类似的程序,这里就不多说了。
现在设定好了一个计划任务,到了规定的时间,就可以执行了。
说明1:因为该程序是在dedev3.1的环境中开发的,所以界面仍然沿用的是3.1的,所以在前面的图中,会倍感颜色不搭调,请你们重视了。
说明2:因为程序从dedecms中完全剥离下来,所以有2个配置参数须要手工的更改一下
autogather/include/config_base.php中的$cfg_dbhost,$cfg_dbname,$cfg_dbuser,$cfg_dbpwd请更改成和你的系统一致的
autogather/include/config_hand.php中的$cfg_indexurl = '';请更改成和你的域名一致的例如:
假如里面两处没有更改,那么本程序将不能运行。 查看全部
dede手动采集更新插件使用手册|DedeCms
简介:属于dedecms的一个辅助功能,在dedecms中设定好采集节点以后,规则都设定好,保证在dedecms中才能正确采集到数据。这点很重要,因为我这个插件的采集程序就是dedecms的采集程序,虽然有所改进,但是只是在一些小的细节上更改了一下,整体的采集程序还是和dedecms一样的,一句话就是只要你在dedecms上才能采集到数据,那么这个手动采集更新的程序才能够正确执行。
功能:根据dedecms中设定好的采集节点手动定时定点采集数据,采集好数据然后才能手动导出到相关栏目之中,然后手动生成首页,栏目页,内容页。用一句话概括就是,只要你在dedecms中筹建好了采集节点然后,再从这个插件中配置一下相关参数,就可以不用管这个站了,本程序会手动帮你天天根据你设定好的时间去更新你的站点。是不是太爽啊,省了很大的事呢,呵呵,那么就请使用这个程序吧。
特点:不限于dedecms的版本,3.x和4.0都可以使用,因为本程序不是单纯的调用dedecms的相关文件,是完全从其采集程序中剥离下来自己成体系的一套程序,核心似乎是dedecms的,但是改动了少量细节问题,使逻辑上更合理,修正了原先的一些小的问题。
打包文件介绍:
文件夾:
autogather-----全部的程序文件都在这个下边
cache---缓存配置文件,所有的每位采集节点的手动采集更新的配置信息都在这里
include---所有的核心的操作类,从dedecms中剥离下来的,可以独立成一个系统
templets---模板文件
img,upimg---使用到的一些图片文件
文件:
auto_gather.php----全部的手动采集更新的代码都在这个文件之中,是核心文件
autogather.log---日志文件,记录在手动采集更新的过程中发生的相关信息提示
base.css---样式表文件
co_autogather_main.php---在 dedecms中的配置列表文件
option_auto.php,option_auto_action.php----处理dedecms中的采集节点弄成手动采集的代
码
程序使用说明:
1.首先下载文件包,解压缩在网站根目录下
2.然后到
3.之后步入到dedecms的后台,在辅助插件中的插件整治器中安装一个新插件
4.点击安装新插件,输入相关内容:
插件名称:自动采集更新
作者:千里独行狼
主程序文件:../autogather/co_autogather_main.php
目标框架:main
文件列表:留空
然后点击确定,将降低本插件到系统中。然后刷新一侧的导航,将会在辅助插件栏中多了一个手动采集更新
6.点击一侧的手动采集更新,将显示下来你如今所有设定的采集点,你会发觉在最右侧有一个操作栏,有配置为手动采集和获取代码。
好,我们如今点击配置为手动采集,出来一个具体配置手动采集更新的参数窗口:
下面是具体的每位参数的说明:
采集后导入的目标栏目:采集之后要把数据导出到那个栏目中
采集数据参数设置:采集数据时,每批采集多少条数据,采集的线程数,间隔时间多少秒(防刷新的站点需设置)
栏目导出数据参数设置:每批导出多少条
要更新的栏目:导入完数据然后,要更新的栏目
生成栏目参数设置:每批最大创建页数,也就是分批创建栏目页面的时侯,每批要创建的页数
更新选项:更新栏目的所有页面:一次性全部更新完该栏目的所有页面,仅更新指定数目的页面:有的网站的列表文件太多,假如全部更新的话,耗费的时间会太长,所以这个参数可以设定仅更新前多少页。点击这个选项的话,下面会显示下来一个隐藏的文本框,更新前多少个页面,在这里设定更新的页数
是否更新子栏目:更新子级栏目,仅更新所选栏目
生成文档html参数设置:每批生成多少个内容页面文件
好了,设定好各项参数以后,点击保存配置,将生成一个配置文件到 cache文件夾中
7.点击获取代码
将会在下边出现一个文本框,里面就是获取的代码
把上面的代码拷贝下来。
8.建立一个html文件任意取名,不过建议取一个有意义的名义,这样之后配置多个手动采集点的时侯,以便于分辨
打开这个文件,把拷贝的代码粘贴到该文件中,保存该文件。
9.在windows的计划任务中,建立一个计划任务,设定好要执行的时间。因为php只能做到这些方法,本来曾经想考虑用discuz那个方法,只要网站前台有用户访问,那么就手动开始执行该程序,可是这样并不好,因为采集程序的执行时间都比较长,所以前台访客访问的页面会仍然显示正在打开中,浏览体验就不好了,所以只能依靠windows的计划任务来做了。unix,linux也有类似的程序,这里就不多说了。
现在设定好了一个计划任务,到了规定的时间,就可以执行了。
说明1:因为该程序是在dedev3.1的环境中开发的,所以界面仍然沿用的是3.1的,所以在前面的图中,会倍感颜色不搭调,请你们重视了。
说明2:因为程序从dedecms中完全剥离下来,所以有2个配置参数须要手工的更改一下
autogather/include/config_base.php中的$cfg_dbhost,$cfg_dbname,$cfg_dbuser,$cfg_dbpwd请更改成和你的系统一致的
autogather/include/config_hand.php中的$cfg_indexurl = '';请更改成和你的域名一致的例如:
假如里面两处没有更改,那么本程序将不能运行。
驻马店上海店家信息,自动采集商家信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-22 17:38
驻马店上海店家信息,自动采集商家信息 涉税专业服务基本信息和业务信息的报送途径是哪些?涉税专业服务机构原则上应该通过网上办税系统报送涉税专业服务基本信息,因客观缘由未能通过网上办税系统报送的,应当在非征期内通过实体办税服务厅代办。涉税专业服务机构应该通过网上办税系统报送涉税专业服务业务信息。税务机关对采集的涉税专业服务基本信息和业务信息依法给以保密。怎么办。
撤销录入 登录系统后点击右上角的“撤销录入”。 在弹出的窗口,点击“获取验证码”,系统将 位验证码以邮件的方式发送到注册时使用的 号上。 点击“获取验证码”后,该按键将被置灰,即 秒内不能再度点击该按键。 输入验证码后,点击“确认”按钮,系统提示“撤销成功”说明该条信息已被撤销。撤销录入完成后该用户数据将在系统内删掉,如果用户想重新进行信息采集,须重新进行操作。入驻淘宝等电商平台的条件。
更多功能,有待您的体验试用,请下载试用。(如何支付?请点这儿查看支付方法)关于深维 | 软件作品 | 订购手册 | 帮助中心 | 用户中心 | 代理加盟 | 付款方式 | 联系方法在线 :(售前咨询)(技术支持)(代理合作) 在线 :@
( )系统“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入成功”即完成操作;如“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入失败”,需按前述步骤重新操作。( )系统提示成功后即可,无需到公积金中心初审。方式二:通过“ 版软件”采集: 登陆 :..平台,进入“下载专区”,下载并安装《 市社会保险系统 管理子系统》及 新升级补丁。怎么样能进驻淘宝做电商。
芭奇站群系统 . . (补丁 )升级如下:完善屏蔽发布数据时侯因为网站错误弹出的脚本错误,同步插口工具中新增命令以及优化部份插口命令的性能,新增插口命令可以制做一些比较实用的小软件 较多细节新功能不一一说明
;肝纤维化中西医结合诊治手册[ ]; 中西医结合刊物; 年 期 邓可刚;国外制订循证临床实践手册的进展[ ]; 循证医学刊物; 年 期 平卫伟;法的研究进展及其在医学中的应用[ ];疾病控制杂志; 年 期 张明雪,曹洪欣,翁维良,谢雁鸣; 西医证候特点及其演化规律的专家问卷调查设计与研究[ ]; 中医基础医学刊物; 年 期 查看全部
驻马店上海店家信息,自动采集商家信息
驻马店上海店家信息,自动采集商家信息 涉税专业服务基本信息和业务信息的报送途径是哪些?涉税专业服务机构原则上应该通过网上办税系统报送涉税专业服务基本信息,因客观缘由未能通过网上办税系统报送的,应当在非征期内通过实体办税服务厅代办。涉税专业服务机构应该通过网上办税系统报送涉税专业服务业务信息。税务机关对采集的涉税专业服务基本信息和业务信息依法给以保密。怎么办。
撤销录入 登录系统后点击右上角的“撤销录入”。 在弹出的窗口,点击“获取验证码”,系统将 位验证码以邮件的方式发送到注册时使用的 号上。 点击“获取验证码”后,该按键将被置灰,即 秒内不能再度点击该按键。 输入验证码后,点击“确认”按钮,系统提示“撤销成功”说明该条信息已被撤销。撤销录入完成后该用户数据将在系统内删掉,如果用户想重新进行信息采集,须重新进行操作。入驻淘宝等电商平台的条件。
更多功能,有待您的体验试用,请下载试用。(如何支付?请点这儿查看支付方法)关于深维 | 软件作品 | 订购手册 | 帮助中心 | 用户中心 | 代理加盟 | 付款方式 | 联系方法在线 :(售前咨询)(技术支持)(代理合作) 在线 :@
( )系统“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入成功”即完成操作;如“办理状态”栏显示“处理结束”,“业务反馈状态”栏显示“导入失败”,需按前述步骤重新操作。( )系统提示成功后即可,无需到公积金中心初审。方式二:通过“ 版软件”采集: 登陆 :..平台,进入“下载专区”,下载并安装《 市社会保险系统 管理子系统》及 新升级补丁。怎么样能进驻淘宝做电商。
芭奇站群系统 . . (补丁 )升级如下:完善屏蔽发布数据时侯因为网站错误弹出的脚本错误,同步插口工具中新增命令以及优化部份插口命令的性能,新增插口命令可以制做一些比较实用的小软件 较多细节新功能不一一说明
;肝纤维化中西医结合诊治手册[ ]; 中西医结合刊物; 年 期 邓可刚;国外制订循证临床实践手册的进展[ ]; 循证医学刊物; 年 期 平卫伟;法的研究进展及其在医学中的应用[ ];疾病控制杂志; 年 期 张明雪,曹洪欣,翁维良,谢雁鸣; 西医证候特点及其演化规律的专家问卷调查设计与研究[ ]; 中医基础医学刊物; 年 期
互联网舆情监控系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-11 19:24
随着互联网的快速发展,网络媒体作为一种新的信息传播方式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国外还是国际重大风波,都能马上产生网上舆论,通过这些网路来抒发观点、传播思想,进而形成巨大的舆论压力,达到任何部门、机构都难以忽略的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
互联网舆情监控系统通过对热点问题和重点领域比较集中的网站信息,如:网页、论坛、BBS等,进行24小时监控,随时下载最新的消息和意见。下载后完成对数据格式的转换及元数据的标引。对下载本地的信息,进行初步的过滤和预处理。对热点问题和重要领域施行监控,前提是必须通过人际交互构建舆情监控的知识库,用来指导智能剖析的过程。对热点问题的智能剖析,首先基于传统基于向量空间的特点剖析技术上,对抓取的内容做分类、聚类和摘要剖析,对信息完成初步的再组织。然后在监控知识库的指导下进行基于舆情的语义剖析,使管理者听到的民情民意更有效,更符合现实。最后将监控的结果,分别推送到不同的职能部门,供拟定对策使用。
网络舆情监控系统是借助搜索引擎技术和网路信息挖掘技术技术,通过网页内容的手动采集处理、敏感词过滤、智能降维分类、主题检查、专题聚焦、统计剖析,实现各单位对自己相关网路舆情监督管理的须要,最终产生舆情简报、舆情专报、分析报告、移动快报,为决策层全面把握舆情动态,做出正确舆论引导,提供剖析根据。
互联网舆情监控系统是针对在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态于网路上抒发下来意愿集合而进行的计算机检测的系统总称。
“网络舆情”是较多群众关于社会中各类现象、问题所抒发的信念、态度、意见和情绪等等表现的总和。网络舆情产生迅速,对社会影响巨大,加强互联网信息监管的同时,组织力量举办信息汇集整理和剖析,对于及时应对网路突发的公共风波和全面把握社情民意太有意义。
二、系统结构
互联网舆情监控系统通常由手动采集子系统(采集层)与剖析浏览子系统(分析层与呈现层),以乐思舆情监控系统为例,网络舆情监控系统构架包括三个层面:
一、采集层,这层收录了要素采集、关键词抽取、全文索引、自动去重和分辨储存及数据库,可以对采集微博、论坛、博客、贴吧、新闻及评论、搜索引擎、图像和视频等。
二、分析层,改成可以对采集的数据信息推行手动分类、自动降维、自动摘要、名称辨识、正负性质预判和英文动词操作,保证分心的全面性。
三、第三层为呈现层,系统对采集分析的数据可以通过负面舆情、分类舆情、最新舆情、专题跟踪、舆情简报、分类评、图表统计和邮件通知等方式推送给用户。
三、功能
1. 热点辨识能力 查看全部
一、系统概述
随着互联网的快速发展,网络媒体作为一种新的信息传播方式,已深入人们的日常生活。网友言论活跃已达到前所未有的程度,不论是国外还是国际重大风波,都能马上产生网上舆论,通过这些网路来抒发观点、传播思想,进而形成巨大的舆论压力,达到任何部门、机构都难以忽略的地步。可以说,互联网已成为思想文化信息的集散地和社会舆论的放大器。
互联网舆情监控系统通过对热点问题和重点领域比较集中的网站信息,如:网页、论坛、BBS等,进行24小时监控,随时下载最新的消息和意见。下载后完成对数据格式的转换及元数据的标引。对下载本地的信息,进行初步的过滤和预处理。对热点问题和重要领域施行监控,前提是必须通过人际交互构建舆情监控的知识库,用来指导智能剖析的过程。对热点问题的智能剖析,首先基于传统基于向量空间的特点剖析技术上,对抓取的内容做分类、聚类和摘要剖析,对信息完成初步的再组织。然后在监控知识库的指导下进行基于舆情的语义剖析,使管理者听到的民情民意更有效,更符合现实。最后将监控的结果,分别推送到不同的职能部门,供拟定对策使用。
网络舆情监控系统是借助搜索引擎技术和网路信息挖掘技术技术,通过网页内容的手动采集处理、敏感词过滤、智能降维分类、主题检查、专题聚焦、统计剖析,实现各单位对自己相关网路舆情监督管理的须要,最终产生舆情简报、舆情专报、分析报告、移动快报,为决策层全面把握舆情动态,做出正确舆论引导,提供剖析根据。
互联网舆情监控系统是针对在一定的社会空间内,围绕中介性社会风波的发生、发展和变化,民众对社会管理者形成和持有的社会政治心态于网路上抒发下来意愿集合而进行的计算机检测的系统总称。
“网络舆情”是较多群众关于社会中各类现象、问题所抒发的信念、态度、意见和情绪等等表现的总和。网络舆情产生迅速,对社会影响巨大,加强互联网信息监管的同时,组织力量举办信息汇集整理和剖析,对于及时应对网路突发的公共风波和全面把握社情民意太有意义。
二、系统结构
互联网舆情监控系统通常由手动采集子系统(采集层)与剖析浏览子系统(分析层与呈现层),以乐思舆情监控系统为例,网络舆情监控系统构架包括三个层面:
一、采集层,这层收录了要素采集、关键词抽取、全文索引、自动去重和分辨储存及数据库,可以对采集微博、论坛、博客、贴吧、新闻及评论、搜索引擎、图像和视频等。
二、分析层,改成可以对采集的数据信息推行手动分类、自动降维、自动摘要、名称辨识、正负性质预判和英文动词操作,保证分心的全面性。
三、第三层为呈现层,系统对采集分析的数据可以通过负面舆情、分类舆情、最新舆情、专题跟踪、舆情简报、分类评、图表统计和邮件通知等方式推送给用户。
三、功能
1. 热点辨识能力
面向合作伙伴选择的英文Web信息获取系统研究
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-11 18:30
[] [浏览:1403次] [2010/8/25 16:16:29]
面向合作伙伴选择的英文Web信息获取系统研究
作者:邱云飞邵良杉那宝贵
作者简介:
邱云飞,辽宁工程技术大学,博士,副教授。
邵良杉,辽宁工程技术大学,博士,教授。
摘要:本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与技巧,提出了面向合作伙伴选择的英文Web信息获取系统的总体构架,并剖析了实现该系统的关键技术—基于元搜索的网页采集、基于样本公共特点的企业主页过滤、基于模式的企业信息抽取,并对这三个关键技术进行了详尽的介绍。最后,按照作者提出的思想,编程实现了一个面向合作伙伴选择的英文Web信息获取原型系统,利用该系统验证了作者所提方式的可行性及证明了该技巧的准确性。
关键词:合作伙伴;Web挖掘;元搜索;文本过滤;信息抽取
1.引言
虚拟企业主要是针对企业核心能力资源的一种整合,即将投资和管理的注意力集中在企业本身的核心能力上,而一些非核心能力、或自己短时间内不具备或不需要具备的核心能力则转向借助外部的虚拟企业伙伴来提供。因此,虚拟企业中的伙伴选择是一个非常重要的问题,它直接关系到虚拟企业的胜败。
WWW推出后,Internet成为全球最大的信息来源,其多元化的信息模式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的素材积累。另一方面,正是因为Internet的海量性、动态性、非结构性、异构性和地理分布性等特性,使得传统的研究途径已不能适应网路环境下的信息获取、处理和借助的须要。
本文建立了面向合作伙伴选择的web信息获取系统的总体框架,给出了系统的实现流程,并对在互联网上手动提取企业相关信息(例如企业名称、企业规模、生产能力、联系方法等)的理论与技巧所涉及到的信息搜索、文本过滤、信息抽取等相关技术进行了剖析,最后实现了一个面向合作伙伴选择的英文Web信息获取原型系统。
2.面向合作伙伴选择的web信息获取系统总体框架
2.1系统需求剖析
本系统从虚拟企业合作伙伴选择的角度出发,构建面向web的潜在伙伴信息获取系统,主要功能是从Internet上手动获取有可能成为核心企业合作伙伴的企业基本信息,从而为核心企业提供强悍的潜在合作伙伴信息库,为其后期进行合作伙伴选择打下良好的基础。
根据调查剖析,有关潜在合作伙伴的基本信息通常分布在一些综合性网站、行业性网站、商情网站(类似B2B网站等)、企业网站上。某一企业在这种网站上提供的信息基本上都是相同的,但和其他网站提供的企业相关信息相比,企业自有网站提供的信息要愈发全面,而且也比较权威。而对整个企业网站而言,对企业做整体介绍的通常在企业主页上,因此,企业主页上的信息便是本系统要获取的主要对象。
2.2系统的总体框架
根据以上的剖析,设计系统的总体构架如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、web文本库、企业主页库、潜在伙伴信息库七部份组成。
图1面向合作伙伴选择的web信息获取系统总体构架
其中,网页采集子系统按照关键字从Internet上搜索网页,并将搜索到的网页下载到本地web文本库中;文本过滤子系统对web文本库的网页进行文本过滤,主要目的是将富含潜在伙伴信息的企业主页筛选下来,最后保存到企业主页库中;信息抽取子系统对企业主页库的每位网页进行信息抽取,主要目的是将潜在伙伴的企业基本信息提取下来,最后保存到潜在伙伴信息库中;人机交互子系统为用户与潜在伙伴信息库的交互提供一个可视化界面,方便用户查询潜在伙伴的基本信息。
3.面向合作伙伴选择的web信息获取系统设计
3.1系统实现思路
从系统总体框架及各模块说明可以看出,要实现整个系统,网页采集子系统、文本过滤子系统、信息抽取子系统三部份的设计与实现是整个系统实现的重点和难点,也可以说是系统实现的关键技术。针对三个子系统的特性,本文提出了基于元搜索的网页手动采集、基于样本公共特点的企业主页过滤、基于模式的企业主页信息抽取三个方式,并完成了相应技术。
3.2基于元搜索的网页手动采集子系统设计
元搜索引擎(MetasearchEngine),被称为搜索引擎之上的搜索引擎。用户只需提交一次检索恳求,由元搜索引擎负责转换处理后递交给多个预先选取的独立搜索引擎,并将所有查询结果集中上去以整体统一的格式呈现到用户面前。相对元搜索引擎,可被借助的独立搜索引擎称为“源搜索引擎”(sourceEngine),或“搜索资源”(searcingresources)。 查看全部
面向合作伙伴选择的英文Web信息获取系统研究
[] [浏览:1403次] [2010/8/25 16:16:29]
面向合作伙伴选择的英文Web信息获取系统研究
作者:邱云飞邵良杉那宝贵
作者简介:
邱云飞,辽宁工程技术大学,博士,副教授。
邵良杉,辽宁工程技术大学,博士,教授。
摘要:本文研究应用WEB信息抽取技术在互联网上主动搜索合作伙伴的理论与技巧,提出了面向合作伙伴选择的英文Web信息获取系统的总体构架,并剖析了实现该系统的关键技术—基于元搜索的网页采集、基于样本公共特点的企业主页过滤、基于模式的企业信息抽取,并对这三个关键技术进行了详尽的介绍。最后,按照作者提出的思想,编程实现了一个面向合作伙伴选择的英文Web信息获取原型系统,利用该系统验证了作者所提方式的可行性及证明了该技巧的准确性。
关键词:合作伙伴;Web挖掘;元搜索;文本过滤;信息抽取
1.引言
虚拟企业主要是针对企业核心能力资源的一种整合,即将投资和管理的注意力集中在企业本身的核心能力上,而一些非核心能力、或自己短时间内不具备或不需要具备的核心能力则转向借助外部的虚拟企业伙伴来提供。因此,虚拟企业中的伙伴选择是一个非常重要的问题,它直接关系到虚拟企业的胜败。
WWW推出后,Internet成为全球最大的信息来源,其多元化的信息模式和丰富的信息内容为虚拟企业合作伙伴的选择提供了大量的素材积累。另一方面,正是因为Internet的海量性、动态性、非结构性、异构性和地理分布性等特性,使得传统的研究途径已不能适应网路环境下的信息获取、处理和借助的须要。
本文建立了面向合作伙伴选择的web信息获取系统的总体框架,给出了系统的实现流程,并对在互联网上手动提取企业相关信息(例如企业名称、企业规模、生产能力、联系方法等)的理论与技巧所涉及到的信息搜索、文本过滤、信息抽取等相关技术进行了剖析,最后实现了一个面向合作伙伴选择的英文Web信息获取原型系统。
2.面向合作伙伴选择的web信息获取系统总体框架
2.1系统需求剖析
本系统从虚拟企业合作伙伴选择的角度出发,构建面向web的潜在伙伴信息获取系统,主要功能是从Internet上手动获取有可能成为核心企业合作伙伴的企业基本信息,从而为核心企业提供强悍的潜在合作伙伴信息库,为其后期进行合作伙伴选择打下良好的基础。
根据调查剖析,有关潜在合作伙伴的基本信息通常分布在一些综合性网站、行业性网站、商情网站(类似B2B网站等)、企业网站上。某一企业在这种网站上提供的信息基本上都是相同的,但和其他网站提供的企业相关信息相比,企业自有网站提供的信息要愈发全面,而且也比较权威。而对整个企业网站而言,对企业做整体介绍的通常在企业主页上,因此,企业主页上的信息便是本系统要获取的主要对象。
2.2系统的总体框架
根据以上的剖析,设计系统的总体构架如下图1所示。系统由网页采集子系统、文本过滤子系统、信息抽取子系统、人机交互子系统、web文本库、企业主页库、潜在伙伴信息库七部份组成。
图1面向合作伙伴选择的web信息获取系统总体构架
其中,网页采集子系统按照关键字从Internet上搜索网页,并将搜索到的网页下载到本地web文本库中;文本过滤子系统对web文本库的网页进行文本过滤,主要目的是将富含潜在伙伴信息的企业主页筛选下来,最后保存到企业主页库中;信息抽取子系统对企业主页库的每位网页进行信息抽取,主要目的是将潜在伙伴的企业基本信息提取下来,最后保存到潜在伙伴信息库中;人机交互子系统为用户与潜在伙伴信息库的交互提供一个可视化界面,方便用户查询潜在伙伴的基本信息。
3.面向合作伙伴选择的web信息获取系统设计
3.1系统实现思路
从系统总体框架及各模块说明可以看出,要实现整个系统,网页采集子系统、文本过滤子系统、信息抽取子系统三部份的设计与实现是整个系统实现的重点和难点,也可以说是系统实现的关键技术。针对三个子系统的特性,本文提出了基于元搜索的网页手动采集、基于样本公共特点的企业主页过滤、基于模式的企业主页信息抽取三个方式,并完成了相应技术。
3.2基于元搜索的网页手动采集子系统设计
元搜索引擎(MetasearchEngine),被称为搜索引擎之上的搜索引擎。用户只需提交一次检索恳求,由元搜索引擎负责转换处理后递交给多个预先选取的独立搜索引擎,并将所有查询结果集中上去以整体统一的格式呈现到用户面前。相对元搜索引擎,可被借助的独立搜索引擎称为“源搜索引擎”(sourceEngine),或“搜索资源”(searcingresources)。
溯源系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-11 17:50
一、系统平台特性
本项目通过采用RFID电子耳标、智能数据采集终端PDA,牛牛肉追溯管理系统及二维码溯源秤构建信息化管理平台。
1、RFID标签是畜产品信息确切、完整、及时和快捷传送的保障,畜产品供应商通过RFID标签才能将相关信息实时地传送给畜产品销售商,从而让畜产品的追溯愈发快速、实时和确切。
2、系统采用的RFID标签可读写,从马匹饲养到畜产品销售全过程中各个环节的信息可实时写入同一标签,而且标签使用后可以回收重复借助,从根本上减少了畜产品追溯的成本。
3、消费者才能十分便利地通过在线系统,查询畜产品质量安全的相关信息或向相关部门上报发觉的畜产品质量安全问题;一旦出现畜产品质量安全问题,通过该系统可以找到畜产品从生产到销售全过程出现问题的环节,并及时采取相应的举措,如畜产品召回、畜产品销毁等。
二、信息管理系统组成
信息系统由信息管理中心以及饲养管理子系统、屠宰加工管理子系统、运输管理子系统、销售管理子系统和二维条码阅读子系统五个子系统组成,各子系统的关系如图所示。
信息管理中心是储存畜产品从生产到消费的全过程各个环节上报信息的数据中心。一方面,信息管理中心接收并存储种植、屠宰加工、运输和销售四个子系统上报的数据;另一方面,信息管理中心为消费者信息查询子系统提供各种畜产品的相关信息。
三、信息系统的功能模块
1、RFID采集器
(1)数据采集模块
(2)终端业务处理模块
(3)数据查询模块
(4)通讯模块
(5)RFID控制模块
(6)系统配置模块
(7)日志模块
2、信息管理中心
(1)数据关联模块:主要负责RFID采集器和后台管理中心的网路链接和数据传输
(2)数据库模块:数据库管理
(3)数据展示模块:负责RFID采集器采集到的数据 查看全部
实现的功能
一、系统平台特性
本项目通过采用RFID电子耳标、智能数据采集终端PDA,牛牛肉追溯管理系统及二维码溯源秤构建信息化管理平台。
1、RFID标签是畜产品信息确切、完整、及时和快捷传送的保障,畜产品供应商通过RFID标签才能将相关信息实时地传送给畜产品销售商,从而让畜产品的追溯愈发快速、实时和确切。
2、系统采用的RFID标签可读写,从马匹饲养到畜产品销售全过程中各个环节的信息可实时写入同一标签,而且标签使用后可以回收重复借助,从根本上减少了畜产品追溯的成本。
3、消费者才能十分便利地通过在线系统,查询畜产品质量安全的相关信息或向相关部门上报发觉的畜产品质量安全问题;一旦出现畜产品质量安全问题,通过该系统可以找到畜产品从生产到销售全过程出现问题的环节,并及时采取相应的举措,如畜产品召回、畜产品销毁等。
二、信息管理系统组成
信息系统由信息管理中心以及饲养管理子系统、屠宰加工管理子系统、运输管理子系统、销售管理子系统和二维条码阅读子系统五个子系统组成,各子系统的关系如图所示。
信息管理中心是储存畜产品从生产到消费的全过程各个环节上报信息的数据中心。一方面,信息管理中心接收并存储种植、屠宰加工、运输和销售四个子系统上报的数据;另一方面,信息管理中心为消费者信息查询子系统提供各种畜产品的相关信息。
三、信息系统的功能模块
1、RFID采集器
(1)数据采集模块
(2)终端业务处理模块
(3)数据查询模块
(4)通讯模块
(5)RFID控制模块
(6)系统配置模块
(7)日志模块
2、信息管理中心
(1)数据关联模块:主要负责RFID采集器和后台管理中心的网路链接和数据传输
(2)数据库模块:数据库管理
(3)数据展示模块:负责RFID采集器采集到的数据
乐思网路信息采集系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 705 次浏览 • 2020-08-10 16:47
随着中国经济发展不断往前推动,大公司大集团面对的市场环境越发复杂,各种影响市场迈向的新问题、新情况层出不穷,市场信息量呈指数下降。同时,定量剖析方式正在迅速应用到行业研究当中,这对信息采集的效率和精度提出了很高的要求。仅靠有限的人力进行信息采集的工作模式,已很难适应市场和技术发展的要求。为了更全面、准确、迅速地把握市场变化,为了适应新技术发展要求,也为了把人员从繁杂的信息采集工作中解放下来,集中精力进行深层次的剖析和研究,迫切需要一套现代化的信息中心系统。
乐思网路信息中心系统的功能是为大公司大集团的市场部门与公关部门提供一个搜集外部信息的平台,包括与本公司相关的信息,与竞争对手相关的信息,行业信息,价格信息,与合作伙伴相关的信息,用户网上反馈的各类信息,科研技术信息等,可以做到多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免的人工查询多个网站的费时吃力的情况,并具有预警功能,可以在某方面的信息一旦出现时迅速通知相关人员。
其业务流程如下图所示:
图1: 乐思网路信息中心系统的业务流程
相比目前的人工信息采集,其优势显著:
比较指标
人工采集
采用乐思网络信息中心系统
目标网站
几十个
几百个到几千个几万个-采3453舆情4533集-
人力成本
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
负面信息辨识
需要逐字人工查看确认
在手动判断的基础上再人工确认
信息保存
零碎,不可防止会出错 -采3453舆情4533集-
精确,全面,便于事后追踪
数据储存
Word文件,分散,很难管理
统一储存在小型关系数据库中,集中管理
监测报告
基于手工统计加恐怕,数据支持不充分
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
监测疗效
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
覆盖全面,实时,
自动化,系统化
二、 实施后的利益
加快外部情报感知:公司报导,用户反馈,竞品动态,行业动态,宏观动态,政策法规等公司外部信息实时凝聚到桌面上,方便公司上下对于市场竞争情报的感知与反应。
加快定量定性剖析:在占有大量数据的基础上,分析人员可以从繁杂的信息采集工作解脱下来,投入到最有价值的定量定性剖析中去。
三、 系统组成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集层)、内容剖析子系统(分析层)、以及界面呈现子系统(呈现层)。其关系如下图所示:
图2:乐思网路信息中心系统构架
乐思网络信息中心系统的网路拓扑结构如下图所示,依据须要也可以分开在隔离的内网与外网中施行。
图3:网络拓扑结构
四、 自动采集子系统功能描述
自动采集子系统可以对任意目标网站进行手动采集。
采集的信息既可以是文本型信息(如文章,微博),也可以是数字型信息(如价钱,统计数据),还可以是文件型信息(如Word, Excel, PDF文件)。用户可以通过Web界面自行配置对文本型信息的采集,也可以通过软件向导界面配制对于数字型信息的采集。由于采用了全球领先的乐思网路信息采集系统,可以对任意网站上数据进行采集与整合。数据源的发觉管理工作由用户完成。
自动采集子系统的全方位检测功能如下图所示:
图4:自动采集子系统全方位检测
自动采集子系统具有以下几个明显特征:
1. 全球领先的手动采集功能
乐思软件的网路信息采集技术全球领先,支持对任意网页内任意数据的精确采集。乐思软件每晚都为国内外用户针对各种各样的网站提供采集服务,没有高效稳定的采集平台是难以做到的。
2. 支持各类检测对象
可以实时检测新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报刊网站电子版等。
3. 无需配置直接检测几千个新闻网站
系统外置对全球范围内网站的检测配置,只需输入关键词,自动采集出文章标题与正文。
4. 强大的多语言统一处理功能26严禁9窃取0
可手动处理并保存英文,英文,法文,德文,日语,韩语,维文,阿拉伯语等多种语言。
5. 智能文章提取
对于文章类型网页,可以无需配置,直接手动提取文章正文与标题,以及作者发布日期等,自动清除广告,栏目,版权等无关的垃圾内容
6. 完美支持各类网页情况
支持当前流行的Web 2.0 AJAX动态网站
支持用户名与密码手动登入
支持表单查询 查看全部
一、 系统概述
随着中国经济发展不断往前推动,大公司大集团面对的市场环境越发复杂,各种影响市场迈向的新问题、新情况层出不穷,市场信息量呈指数下降。同时,定量剖析方式正在迅速应用到行业研究当中,这对信息采集的效率和精度提出了很高的要求。仅靠有限的人力进行信息采集的工作模式,已很难适应市场和技术发展的要求。为了更全面、准确、迅速地把握市场变化,为了适应新技术发展要求,也为了把人员从繁杂的信息采集工作中解放下来,集中精力进行深层次的剖析和研究,迫切需要一套现代化的信息中心系统。
乐思网路信息中心系统的功能是为大公司大集团的市场部门与公关部门提供一个搜集外部信息的平台,包括与本公司相关的信息,与竞争对手相关的信息,行业信息,价格信息,与合作伙伴相关的信息,用户网上反馈的各类信息,科研技术信息等,可以做到多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免的人工查询多个网站的费时吃力的情况,并具有预警功能,可以在某方面的信息一旦出现时迅速通知相关人员。
其业务流程如下图所示:
图1: 乐思网路信息中心系统的业务流程
相比目前的人工信息采集,其优势显著:
比较指标
人工采集
采用乐思网络信息中心系统
目标网站
几十个
几百个到几千个几万个-采3453舆情4533集-
人力成本
需分别登陆各个网站,手工查阅,还要手工复制粘贴,疲于奔命
网络信息的获取工作完全由软件手动进行,监测人员只需在外网集中进行内容的浏览与剖析
负面信息辨识
需要逐字人工查看确认
在手动判断的基础上再人工确认
信息保存
零碎,不可防止会出错 -采3453舆情4533集-
精确,全面,便于事后追踪
数据储存
Word文件,分散,很难管理
统一储存在小型关系数据库中,集中管理
监测报告
基于手工统计加恐怕,数据支持不充分
基于自动化的统计剖析,
图文并茂,具有详实统计数据支持,可以每日,每周,每月出报告
监测疗效
覆盖片面,不及时
差强人意,浪费人力资源-采3453舆情4533集-
覆盖全面,实时,
自动化,系统化
二、 实施后的利益
加快外部情报感知:公司报导,用户反馈,竞品动态,行业动态,宏观动态,政策法规等公司外部信息实时凝聚到桌面上,方便公司上下对于市场竞争情报的感知与反应。
加快定量定性剖析:在占有大量数据的基础上,分析人员可以从繁杂的信息采集工作解脱下来,投入到最有价值的定量定性剖析中去。
三、 系统组成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集层)、内容剖析子系统(分析层)、以及界面呈现子系统(呈现层)。其关系如下图所示:
图2:乐思网路信息中心系统构架
乐思网络信息中心系统的网路拓扑结构如下图所示,依据须要也可以分开在隔离的内网与外网中施行。
图3:网络拓扑结构
四、 自动采集子系统功能描述
自动采集子系统可以对任意目标网站进行手动采集。
采集的信息既可以是文本型信息(如文章,微博),也可以是数字型信息(如价钱,统计数据),还可以是文件型信息(如Word, Excel, PDF文件)。用户可以通过Web界面自行配置对文本型信息的采集,也可以通过软件向导界面配制对于数字型信息的采集。由于采用了全球领先的乐思网路信息采集系统,可以对任意网站上数据进行采集与整合。数据源的发觉管理工作由用户完成。
自动采集子系统的全方位检测功能如下图所示:
图4:自动采集子系统全方位检测
自动采集子系统具有以下几个明显特征:
1. 全球领先的手动采集功能
乐思软件的网路信息采集技术全球领先,支持对任意网页内任意数据的精确采集。乐思软件每晚都为国内外用户针对各种各样的网站提供采集服务,没有高效稳定的采集平台是难以做到的。
2. 支持各类检测对象
可以实时检测新闻,论坛,博客,公共聊天室,搜索引擎,留言板,应用程序,报刊网站电子版等。
3. 无需配置直接检测几千个新闻网站
系统外置对全球范围内网站的检测配置,只需输入关键词,自动采集出文章标题与正文。
4. 强大的多语言统一处理功能26严禁9窃取0
可手动处理并保存英文,英文,法文,德文,日语,韩语,维文,阿拉伯语等多种语言。
5. 智能文章提取
对于文章类型网页,可以无需配置,直接手动提取文章正文与标题,以及作者发布日期等,自动清除广告,栏目,版权等无关的垃圾内容
6. 完美支持各类网页情况
支持当前流行的Web 2.0 AJAX动态网站
支持用户名与密码手动登入
支持表单查询
网络舆情监测系统
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2020-08-09 16:13
该系统才能精准定向采集互联网海量舆情信息,从中快速侦测和辨识话题热点和敏感话题,追踪互联网上热点敏感话题的发生、发展和变化趋势,发现和剖析社会民众群体在互联网上的观点、态度、意见和想法,特别是及时发觉负面报导和不良言论并手动报案,快速方便地生成可视化的统计剖析报告,汇集各方智慧剖析成果,最终实现发觉舆情、分析舆情、追踪舆情、引导舆情、逆转舆情和控制舆情。
适用领域
级政府、电信运营商、能源、教育、银行、证券、期货、基金、医疗、电子商务等大中型事业单位门户网站。
产品框架
产品特性
跨平台高性能可扩充构架:采用基于Java/J2EE体系结构,跨操作系统、跨数据库、跨应用服务器,应用系统根据国家级小型舆情监控应用需求设计高性能扩充构架,并基于实际系统2年运行检验。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
产品功能
1舆情规划订制子系统
定制舆情分类:可构建多级舆情分类管理目录,并可对目录进行重命名、删除操作。
定制特定网站:可自主设置网站的地址、特定的关键字及其逻辑规则。
定制检测目标:可设置关键字订制检测目标,设置关键字的逻辑关系、获取舆情的范围、所属目录等信息,日后可以重新更改和删掉。
2舆情采集抽取子系统
多通道高效采集:针对峰会、新闻及评论、博客、微博等动态网路信息源,实现可扩充的多通道高效采集技术。
多媒体数据采集 :可采集文本、图片、音视频等多媒体信息。
主动化定向采集:主动化采集技术,解决增量更新以及访问控制等问题,实现JavaScript动态网页的采集与客户端解析还原技术。
分钟级实时采集 :多线程高效实时采集技术实现舆情分钟级采集效果。
代理翻墙式采集 :通过代理或则翻墙工具采集境外网站。
网页元信息抽取:实现半结构化/无结构化网路资源的元信息抽取,针对新闻、论坛、博客等数据源,实现标题、日期、作者、来源等要素全手动数据抽取。
事件要素提取:实现社会网路中用户访问行为的要素剖析与提取,如点击量、回复量、访问IP等。
3舆情剖析挖掘子系统
舆情热点发觉:基于热点侦测和层次降维技术,自动发觉舆情热点。
舆情话题追溯:实现网络舆情的重要进程辨识与手动回放技术;分析网路舆情传播的时间、空间结构,发现网络舆情话题源头。
舆情对象跟踪:基于特定网路对象(人、事件),进行对象背景信息的综合提取,追踪最新的舆情动态、舆情关系网路等相关信息,在此基础上产生定期综合报告。
倾向性剖析:对舆情内容与评论的作倾向性剖析,倾向性反映了作者的情感色调,以及褒贬的程度,自动分辨文本内容与评论的主客观倾向性,给出正面、中立或负面倾向性判别。
汇聚专业智慧:采集行业专业剖析结果和数据,实现一站式剖析展示门户。
4舆情处置服务子系统
可视统计剖析:提供舆情动态趋势可视化统计剖析 ,包括特定时间内特定情报的信息量变化统计,特定时间内对特定舆情报到媒体量变化统计等。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。 查看全部
网络舆情监控系统是我们基于先进的精准搜索引擎技术、深网信息集成技术和观点挖掘技术,基于“模拟人类的网路行为,深网观世界;集成群体的智慧服务,一点控风云”的理念,设计实现的一个小型网络舆情监控系统软件。
该系统才能精准定向采集互联网海量舆情信息,从中快速侦测和辨识话题热点和敏感话题,追踪互联网上热点敏感话题的发生、发展和变化趋势,发现和剖析社会民众群体在互联网上的观点、态度、意见和想法,特别是及时发觉负面报导和不良言论并手动报案,快速方便地生成可视化的统计剖析报告,汇集各方智慧剖析成果,最终实现发觉舆情、分析舆情、追踪舆情、引导舆情、逆转舆情和控制舆情。
适用领域
级政府、电信运营商、能源、教育、银行、证券、期货、基金、医疗、电子商务等大中型事业单位门户网站。
产品框架
产品特性
跨平台高性能可扩充构架:采用基于Java/J2EE体系结构,跨操作系统、跨数据库、跨应用服务器,应用系统根据国家级小型舆情监控应用需求设计高性能扩充构架,并基于实际系统2年运行检验。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
产品功能
1舆情规划订制子系统
定制舆情分类:可构建多级舆情分类管理目录,并可对目录进行重命名、删除操作。
定制特定网站:可自主设置网站的地址、特定的关键字及其逻辑规则。
定制检测目标:可设置关键字订制检测目标,设置关键字的逻辑关系、获取舆情的范围、所属目录等信息,日后可以重新更改和删掉。
2舆情采集抽取子系统
多通道高效采集:针对峰会、新闻及评论、博客、微博等动态网路信息源,实现可扩充的多通道高效采集技术。
多媒体数据采集 :可采集文本、图片、音视频等多媒体信息。
主动化定向采集:主动化采集技术,解决增量更新以及访问控制等问题,实现JavaScript动态网页的采集与客户端解析还原技术。
分钟级实时采集 :多线程高效实时采集技术实现舆情分钟级采集效果。
代理翻墙式采集 :通过代理或则翻墙工具采集境外网站。
网页元信息抽取:实现半结构化/无结构化网路资源的元信息抽取,针对新闻、论坛、博客等数据源,实现标题、日期、作者、来源等要素全手动数据抽取。
事件要素提取:实现社会网路中用户访问行为的要素剖析与提取,如点击量、回复量、访问IP等。
3舆情剖析挖掘子系统
舆情热点发觉:基于热点侦测和层次降维技术,自动发觉舆情热点。
舆情话题追溯:实现网络舆情的重要进程辨识与手动回放技术;分析网路舆情传播的时间、空间结构,发现网络舆情话题源头。
舆情对象跟踪:基于特定网路对象(人、事件),进行对象背景信息的综合提取,追踪最新的舆情动态、舆情关系网路等相关信息,在此基础上产生定期综合报告。
倾向性剖析:对舆情内容与评论的作倾向性剖析,倾向性反映了作者的情感色调,以及褒贬的程度,自动分辨文本内容与评论的主客观倾向性,给出正面、中立或负面倾向性判别。
汇聚专业智慧:采集行业专业剖析结果和数据,实现一站式剖析展示门户。
4舆情处置服务子系统
可视统计剖析:提供舆情动态趋势可视化统计剖析 ,包括特定时间内特定情报的信息量变化统计,特定时间内对特定舆情报到媒体量变化统计等。
领先的舆情采集抽取工具:系统可实现对峰会、博客等AJAX动态页面上舆情要素的精准采集,如用户点击数、回复数等,并做到分钟级响应。
先进的舆情剖析挖掘算法:系统融合了IBM中国研究院、微软亚洲研究院、中科院等10余年先进的科研成果,内置手动分类、自动降维、自动摘要、话题侦测和追踪、观点倾向性剖析等国际领先的剖析挖掘算法。
易用的舆情管理服务界面:系统紧贴舆情应用实际需求,基于精简易用性准则设计,使用界面、数据源、关注信息、报告内容与模板均可便捷订制。
金农工程一期采集系统扩充业务子系统.doc
采集交流 • 优采云 发表了文章 • 0 个评论 • 301 次浏览 • 2020-08-09 13:56
用户使用系统推荐的软、硬件配置如下表:
配置项
配置要求
机器显存
1G及以上
操作系统
Windows操作系统
IE版本
IE7.0及以上版本
总体功能概述
业务流程
功能概述
县级业务人员的总体功能包括我的工作、数据查询以及个人信息维护三大功能模块。
我的工作包括个人工作台、消息管理功能。其中消息管理包括未读消息、已读消息、已发送消息功能。
数据查询包括上报进度查询、上报情况查询、原创数据查询以及汇总数据查询。
个人信息维护包括个人信息维护功能。
操作界面介绍
下图是登入系统后的主界面,如图2-1所示。
图2-1
辅助功能区:辅助功能区包括退出、工具、帮助。
一级菜单:模块组是拿来在应用与模块之间进行功能整理的分类结构。它拿来将应用中的模块进行界定和组装为界面显示和布局服务,形成应用的一级菜单。
二级菜单:模块是组成应用的单元,一个模块包括多个资源,在界面诠释时,形成应用的二级菜单。
功能菜单:资源是组成模块的单元,一个资源对应于一个URL,该URL可以是Action或一个JSP,功能菜单是由一个或多个资源组成的。
主功能区:单击功能菜单后,主功能区会相应的发生变化。主要的功能操作都在主功能区进行。
系统登陆
浏览器设置
在使用系统之前须要首先在浏览器中进行受信任站点设置。浏览器版本要求IE6.0以上(建议IE7.0或IE8.0)。
打开浏览器,选择菜单“工具”,单击“选项(O) …”,如图3-1-1。
图3-1-1
在“选项”弹出窗口中,选择“安全”页,单击右下“自定义级别(C)…”按钮,弹出安全设置页面,如图3-1-2。
图3-1-2
将滚动条带动至“ActiveX控件和插件”的“对没有标记为安全的ActiveX控件进行初始化和脚本运行”选项,将其修改为“提示”,如图3-1-3。单击【确定】保存并返回“选项”窗口。
图3-1-3
在“选项”页单击选中“受信任的站点”,然后单击右下“默认级别(D)”按钮,设置受信任站点的安全级别为“低”。如图3-1-4。
图3-1-4 查看全部
使用系统推荐的配置
用户使用系统推荐的软、硬件配置如下表:
配置项
配置要求
机器显存
1G及以上
操作系统
Windows操作系统
IE版本
IE7.0及以上版本
总体功能概述
业务流程
功能概述
县级业务人员的总体功能包括我的工作、数据查询以及个人信息维护三大功能模块。
我的工作包括个人工作台、消息管理功能。其中消息管理包括未读消息、已读消息、已发送消息功能。
数据查询包括上报进度查询、上报情况查询、原创数据查询以及汇总数据查询。
个人信息维护包括个人信息维护功能。
操作界面介绍
下图是登入系统后的主界面,如图2-1所示。
图2-1
辅助功能区:辅助功能区包括退出、工具、帮助。
一级菜单:模块组是拿来在应用与模块之间进行功能整理的分类结构。它拿来将应用中的模块进行界定和组装为界面显示和布局服务,形成应用的一级菜单。
二级菜单:模块是组成应用的单元,一个模块包括多个资源,在界面诠释时,形成应用的二级菜单。
功能菜单:资源是组成模块的单元,一个资源对应于一个URL,该URL可以是Action或一个JSP,功能菜单是由一个或多个资源组成的。
主功能区:单击功能菜单后,主功能区会相应的发生变化。主要的功能操作都在主功能区进行。
系统登陆
浏览器设置
在使用系统之前须要首先在浏览器中进行受信任站点设置。浏览器版本要求IE6.0以上(建议IE7.0或IE8.0)。
打开浏览器,选择菜单“工具”,单击“选项(O) …”,如图3-1-1。
图3-1-1
在“选项”弹出窗口中,选择“安全”页,单击右下“自定义级别(C)…”按钮,弹出安全设置页面,如图3-1-2。
图3-1-2
将滚动条带动至“ActiveX控件和插件”的“对没有标记为安全的ActiveX控件进行初始化和脚本运行”选项,将其修改为“提示”,如图3-1-3。单击【确定】保存并返回“选项”窗口。
图3-1-3
在“选项”页单击选中“受信任的站点”,然后单击右下“默认级别(D)”按钮,设置受信任站点的安全级别为“低”。如图3-1-4。
图3-1-4

