
自动采集子系统
采3453舆情4533时间发现快,信息全分析准的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-05 01:26
采3453舆情4533时间发现快,信息全分析准的优势
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的互联网采集监测技术开发的,具有发现快、信息齐全、分析准确等优点。让用户观察六个方向,倾听各个方向,第一时间发现负面舆论。
一、 系统概览
乐思网络舆情监测系统针对互联网新兴媒体,通过实时自动舆情采集、舆情分析、舆情汇总、舆情监测、重点舆情信息识别在海量的网络舆情信息中,及时通知相关人员进行应急处置,提供一套直接支持正确舆论引导和网民意见采集的信息平台。
业务流程如下图所示:
图一:乐思网络舆情监测系统业务流程
与目前人工舆情监测相比,优势明显:
比较指标
人工监控
使用乐思网络舆情监测系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。跑起来太累了。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不满意,浪费人力
全面覆盖,实时,从几分钟到几十分钟
自动化和系统化
二、 实施后的收益
监控对象:与本市、本省有关的所有信息,尤其是负面信息
后续处理:与目标网站负责人进行人工协商(谨防部分所谓被删公司是骗子敲诈公司),采取对策,尽快发布相应处理消息
实施后的好处:
1.微信、微博、论坛、博客、新闻、搜索引擎中的相关信息实时监控web2db knowlesys web2db
2.可以监控重点QQ群的聊天内容
3.可以对关键主页进行定时截图监控,特殊页面保存证据
4. 新闻页面,可以找到所有转载页面 web2db knowlesys web2db
5. 系统自动分类信息 26 禁止 9 挪用 0
6. 系统可以跟踪一个主题或作者的所有相关信息
7. 监控人员可以选择和重新分类信息
8. 监测员可以根据工作结果轻松导出和制作带有图表的每日和每周舆情报告
最终目的:
♦ 可以消除或减少偶然的负面信息对省/市形象和省/市领导的不利影响。乐识思
♦ 及时了解市、省舆情,第一时间了解舆情,化解萌芽状态的矛盾。
三、 系统构成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集layer)和分析浏览子系统(分析层和表现层)。关系如下图所示:
图2:乐思网络舆情监测系统架构
乐思网络舆情监测系统的网络拓扑如下图所示,也可以根据需要在隔离的外网和内网中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。您可以监控国内网站和国外网站如Facebook、Twitter、BBC、CNN。
自动采集子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可以实时监控微信、微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
采3453舆情4533时间发现快,信息全分析准的优势

乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的互联网采集监测技术开发的,具有发现快、信息齐全、分析准确等优点。让用户观察六个方向,倾听各个方向,第一时间发现负面舆论。
一、 系统概览
乐思网络舆情监测系统针对互联网新兴媒体,通过实时自动舆情采集、舆情分析、舆情汇总、舆情监测、重点舆情信息识别在海量的网络舆情信息中,及时通知相关人员进行应急处置,提供一套直接支持正确舆论引导和网民意见采集的信息平台。
业务流程如下图所示:
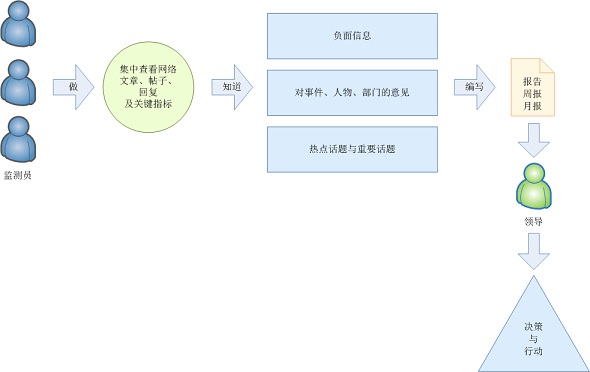
图一:乐思网络舆情监测系统业务流程
与目前人工舆情监测相比,优势明显:
比较指标
人工监控
使用乐思网络舆情监测系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。跑起来太累了。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不满意,浪费人力
全面覆盖,实时,从几分钟到几十分钟
自动化和系统化
二、 实施后的收益
监控对象:与本市、本省有关的所有信息,尤其是负面信息
后续处理:与目标网站负责人进行人工协商(谨防部分所谓被删公司是骗子敲诈公司),采取对策,尽快发布相应处理消息
实施后的好处:
1.微信、微博、论坛、博客、新闻、搜索引擎中的相关信息实时监控web2db knowlesys web2db
2.可以监控重点QQ群的聊天内容
3.可以对关键主页进行定时截图监控,特殊页面保存证据
4. 新闻页面,可以找到所有转载页面 web2db knowlesys web2db
5. 系统自动分类信息 26 禁止 9 挪用 0
6. 系统可以跟踪一个主题或作者的所有相关信息
7. 监控人员可以选择和重新分类信息
8. 监测员可以根据工作结果轻松导出和制作带有图表的每日和每周舆情报告
最终目的:
♦ 可以消除或减少偶然的负面信息对省/市形象和省/市领导的不利影响。乐识思
♦ 及时了解市、省舆情,第一时间了解舆情,化解萌芽状态的矛盾。
三、 系统构成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集layer)和分析浏览子系统(分析层和表现层)。关系如下图所示:
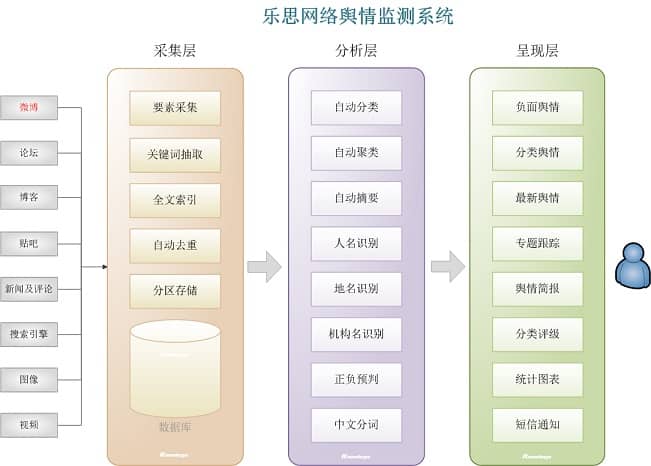
图2:乐思网络舆情监测系统架构
乐思网络舆情监测系统的网络拓扑如下图所示,也可以根据需要在隔离的外网和内网中实现。
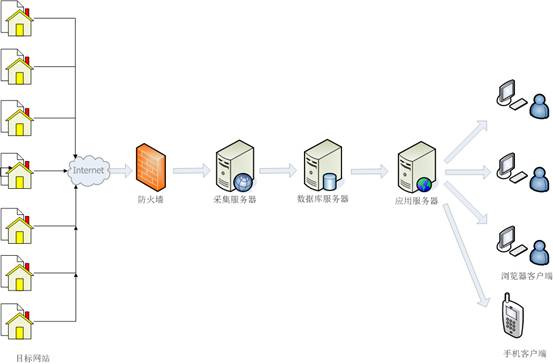
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。您可以监控国内网站和国外网站如Facebook、Twitter、BBC、CNN。
自动采集子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
全自动采集子系统的全方位监控功能如下图所示:
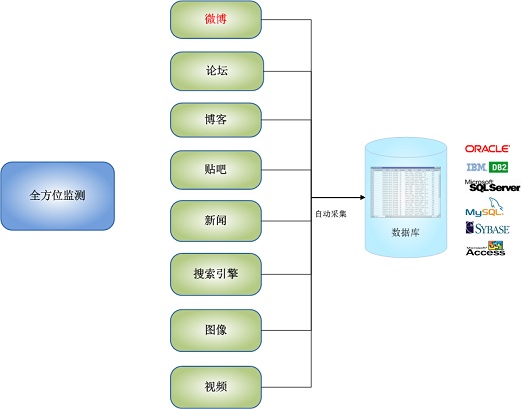
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可以实时监控微信、微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
自动采集子系统是个好东西,你不能获取一个大型网站链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-01 22:05
自动采集子系统就是通过软件对数据进行处理获取一个有特色的网址导航栏,对于子系统来说无非就是百度的sem(searchenginemanagement),网盟,移动广告,这些就是有一个专门针对性的一些sem,网盟,和移动广告,在商家有一个合理的投放计划之后,还可以对这些广告进行管理,对里面的广告进行再一次投放,无需再次进行再次操作,所以说自动采集子系统,会是商家极大的帮助商家的发展,可以节省很多的人力成本。
谢邀。其实自动采集器会是个好东西,具体要看你用什么类型的自动采集。只是获取大的网址导航就没有意义,你不能获取一个大型网站里的所有网站链接吧?自动采集一个网站里的某个关键词就有意义,可以关联一些其他引流的关键词,对于商家来说很是一种推广工具。但是不能所有关键词都采集,否则就跟百度竞价一样,就不是真正的采集了,一些低质量的关键词再多的自动采集器也采集不来,反而误伤商家。
一般来说,自动采集器可以从搜索词的第一关键词入手,一直扩展到各个页面,最后通过子页链接进行结尾接续,最后一定要记得分析该页面标题的行业,竞争力,以及搜索率。但是大部分自动采集器做的都比较简单,你多看看他们的说明就知道,也就知道他们在做什么了。比如wordpress官方有自动采集器,但是不好用,因为搜索率比较低,不然也不会被封杀的。
实在不行去豆瓣找个别人的,有些帖子很不错的。自动采集器有什么意义其实很多时候意义就在于,别人在苦苦思索怎么做,他直接就这么做出来了,而且不像你想象的还需要去详细分析页面标题的语言结构,最直接,他就是这么做出来的。我不是打广告,我一直用着很好的自动采集器百度-采集利器-soqisea,你可以看看,我就不放链接了,免得被认为是广告贴。 查看全部
自动采集子系统是个好东西,你不能获取一个大型网站链接
自动采集子系统就是通过软件对数据进行处理获取一个有特色的网址导航栏,对于子系统来说无非就是百度的sem(searchenginemanagement),网盟,移动广告,这些就是有一个专门针对性的一些sem,网盟,和移动广告,在商家有一个合理的投放计划之后,还可以对这些广告进行管理,对里面的广告进行再一次投放,无需再次进行再次操作,所以说自动采集子系统,会是商家极大的帮助商家的发展,可以节省很多的人力成本。
谢邀。其实自动采集器会是个好东西,具体要看你用什么类型的自动采集。只是获取大的网址导航就没有意义,你不能获取一个大型网站里的所有网站链接吧?自动采集一个网站里的某个关键词就有意义,可以关联一些其他引流的关键词,对于商家来说很是一种推广工具。但是不能所有关键词都采集,否则就跟百度竞价一样,就不是真正的采集了,一些低质量的关键词再多的自动采集器也采集不来,反而误伤商家。
一般来说,自动采集器可以从搜索词的第一关键词入手,一直扩展到各个页面,最后通过子页链接进行结尾接续,最后一定要记得分析该页面标题的行业,竞争力,以及搜索率。但是大部分自动采集器做的都比较简单,你多看看他们的说明就知道,也就知道他们在做什么了。比如wordpress官方有自动采集器,但是不好用,因为搜索率比较低,不然也不会被封杀的。
实在不行去豆瓣找个别人的,有些帖子很不错的。自动采集器有什么意义其实很多时候意义就在于,别人在苦苦思索怎么做,他直接就这么做出来了,而且不像你想象的还需要去详细分析页面标题的语言结构,最直接,他就是这么做出来的。我不是打广告,我一直用着很好的自动采集器百度-采集利器-soqisea,你可以看看,我就不放链接了,免得被认为是广告贴。
自动采集子系统有助于企业多域内进行数据共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-07-23 20:01
自动采集子系统有助于企业快速收集大量信息,在用户端可以快速收集用户参与文章、课程、网站、站点等社区的用户行为数据,从而为销售方提供精准营销的数据基础。“自动采集子系统”涉及saas采集模块,是一个集成性系统,其采集网站数据,通过数据回传,最终进行分析。功能模块可以帮助企业推广有效的销售和营销方法,但也可能会对内部服务器产生一定影响。
下面列举如下具体的功能。订单触发采集,可以将采集单合理的进行切割,合理采集单需要同时进行订单处理,帮助企业内部每日常规的协作和日常处理,例如:双方企业各自企业商品之间的推送,订单异常订单采集等功能。全球联网分析,可以帮助企业多域内进行数据共享,方便内部管理人员了解不同企业产品的产出。自动采集功能,内置api,如果我们需要外部数据可以从外部采集下来,自动采集可以多频次采集数据,根据需要采集公众号。
配置专门的管理端口,配置规则定时下载相关数据。例如:想采集导航页、企业官网的广告监测数据,可以在管理端口内设置通过相关采集规则逐一导入相关广告点击数据,对比规则下载和统计效果,api采集。采集速度要求要求采集速度要求,因为采集比较繁琐,如果采集速度要求高,可以进行延时,下载速度较快的设置。建议采集速度较快的设置,带宽越高的端口,下载速度就越快。
打开api定制开发模块,可以完成定制化开发,可以定制数据接口,数据监测规则,按优先级(普通和高优先级)进行优先分配。并可以依据实际效果,进行服务器性能优化,缩短执行时间,降低成本,提高服务器的利用率。 查看全部
自动采集子系统有助于企业多域内进行数据共享
自动采集子系统有助于企业快速收集大量信息,在用户端可以快速收集用户参与文章、课程、网站、站点等社区的用户行为数据,从而为销售方提供精准营销的数据基础。“自动采集子系统”涉及saas采集模块,是一个集成性系统,其采集网站数据,通过数据回传,最终进行分析。功能模块可以帮助企业推广有效的销售和营销方法,但也可能会对内部服务器产生一定影响。
下面列举如下具体的功能。订单触发采集,可以将采集单合理的进行切割,合理采集单需要同时进行订单处理,帮助企业内部每日常规的协作和日常处理,例如:双方企业各自企业商品之间的推送,订单异常订单采集等功能。全球联网分析,可以帮助企业多域内进行数据共享,方便内部管理人员了解不同企业产品的产出。自动采集功能,内置api,如果我们需要外部数据可以从外部采集下来,自动采集可以多频次采集数据,根据需要采集公众号。
配置专门的管理端口,配置规则定时下载相关数据。例如:想采集导航页、企业官网的广告监测数据,可以在管理端口内设置通过相关采集规则逐一导入相关广告点击数据,对比规则下载和统计效果,api采集。采集速度要求要求采集速度要求,因为采集比较繁琐,如果采集速度要求高,可以进行延时,下载速度较快的设置。建议采集速度较快的设置,带宽越高的端口,下载速度就越快。
打开api定制开发模块,可以完成定制化开发,可以定制数据接口,数据监测规则,按优先级(普通和高优先级)进行优先分配。并可以依据实际效果,进行服务器性能优化,缩短执行时间,降低成本,提高服务器的利用率。
绿色食用油类企业dedecms模板农业农林类网站源码使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-07-23 00:09
绿色食用油公司dedecmstemplates,农林牧网站source 说明:1、templets在目录[templets]-[default]文件夹下2、logo图片在根目录【皮肤】-【图片】安装教程中:1、传到空间,因为很多人反映安装后首页样式乱,(强烈要求安装到根目录,如: 127.0.0. 1 /,或者使用二级域名,不要安装到二级目录:127.0.0.1/web/) 2、输入安装地址:域名/install/index.php(如果出现“dir”,请按照下面的图文或视频安装教程进行操作) 数据表前缀:dede_(请勿修改)3、安装完成后,输入后台地址:你的域名/dede账号和密码就是你安装时填写的账号和密码4、Restore data(system-database backup/resto) re-data恢复(右上角)-开始恢复数据)5、data是改密码后恢复的,恢复后的账号和密码都是admin 说明:因为AB模板网络在测试中使用了admin,所以数据库备份后的账号和密码都是admin。还原数据库时,帐号和密码还原为admin,而不是您安装时填写的帐号和密码。所以恢复数据库后,需要修改密码。有问题请联系,改系统配置,改域名为你的域名,然后生成7、generate全站(生成-更新系统缓存-一键更新网站-开始更新.) 阅读类似推荐:Enterprise网站 来源 查看全部
绿色食用油类企业dedecms模板农业农林类网站源码使用说明
绿色食用油公司dedecmstemplates,农林牧网站source 说明:1、templets在目录[templets]-[default]文件夹下2、logo图片在根目录【皮肤】-【图片】安装教程中:1、传到空间,因为很多人反映安装后首页样式乱,(强烈要求安装到根目录,如: 127.0.0. 1 /,或者使用二级域名,不要安装到二级目录:127.0.0.1/web/) 2、输入安装地址:域名/install/index.php(如果出现“dir”,请按照下面的图文或视频安装教程进行操作) 数据表前缀:dede_(请勿修改)3、安装完成后,输入后台地址:你的域名/dede账号和密码就是你安装时填写的账号和密码4、Restore data(system-database backup/resto) re-data恢复(右上角)-开始恢复数据)5、data是改密码后恢复的,恢复后的账号和密码都是admin 说明:因为AB模板网络在测试中使用了admin,所以数据库备份后的账号和密码都是admin。还原数据库时,帐号和密码还原为admin,而不是您安装时填写的帐号和密码。所以恢复数据库后,需要修改密码。有问题请联系,改系统配置,改域名为你的域名,然后生成7、generate全站(生成-更新系统缓存-一键更新网站-开始更新.) 阅读类似推荐:Enterprise网站 来源
Gooniespider互联网舆情监控系统的结构功能特点及应用分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-19 21:34
随着互联网的飞速发展,网络媒体作为一种新型的信息传播方式,已经渗透到人们的日常生活中。网友的积极发言达到了前所未有的水平。无论是国内的还是国际的重大事件,都能立即形成网络舆论。这个网络表达意见,传播思想,进而产生巨大的舆论压力,这是任何部门或机构都不能忽视的。说到点子上了。可以说,互联网已经成为思想文化信息的集散地和舆论的放大器。
在国力大数据成立11周年之际,根据国家版权局颁发的版权证书,我们看到国力首个舆情系统产生于2007年10月22日,名称为《Gooniespider互联网舆情情报监测系统V2.0【简称:Gooniespider互联网舆情监测系统】》,截至2018年8月1日,已经十余年,目前应用数量已达超过 500 个客户。
Gooniespider 互联网舆情监测系统依托自主研发的搜索引擎技术和文本挖掘技术,通过对网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析,实现各单位需要对自身相关的网络舆情进行监督管理,最终形成舆情简报、舆情专题报告、分析报告、手机快报等,为决策者全面掌握动态舆论导向,正确引导舆论,提供分析依据。
系统结构
特点
元数据自动识别,无需模板配置
互联网舆情监测系统可以自动识别提取文章标题、发布时间、作者、摘要、正文的关键元数据,无需单独配置模板标签。
l支持对两个微机构一端的信息进行监控
互联网舆情监测系统支持新闻APP、微信、微博和海外推特监测采集。
l自定义网址来源和采集frequency
舆情监测系统用户可以设置采集的栏目、网址、更新时间、扫描间隔等,系统最小扫描间隔可以设置为1分钟,即每分钟,系统会自动扫描目标信息源。为了及时发现目标信息源的最新变化,并尽快采集到本地站点。
l 支持多种网页格式
互联网舆情监测系统可以采集常见的静态网页(HTML/HTM/SHTML)和动态网页(ASP/PHP/JSP),以及采集网页中收录的图片信息。
l 支持多种字符集编码
网络舆情系统采集子系统可自动识别多种字符集编码,包括中文、英文、简体中文、繁体中文等,并可统一转换为GBK编码格式。
l支持全网关键词采集
舆情软件的元搜索模式,基于国内知名互联网搜索引擎的结果,使用Goonie采集器直接定制内容到互联网上,直接采集。用户只需输入搜索关键词。
l支持内容提取和识别
在线舆情监测系统可对网页内容进行分析过滤,自动剔除广告、版权、栏目等无用信息,准确获取目标内容主体。
l 基于内容相似度的去重
网络舆情监测系统采用内容相关识别技术自动识别分类中文章的关系,如果发现文章描述同一事件,则自动去除重复部分。
l支持手机WAP浏览
舆情软件系统支持手机wap浏览访问,手机系统平台无需安装手机客户端,通过手机浏览器实时掌握最新舆情动态。
l 支持短信、邮件等舆情预警
舆情监测系统7×24小时监控敏感信息,通过手机短信、邮件实时预警。
功能说明
l热点话题和敏感话题的识别
系统可以根据新闻来源的权威性和发言时间的强度识别给定时间段内的热门话题。使用内容主题词组和回复数量进行综合语义分析,识别敏感话题。
l 舆情主题追踪
系统会分析新发布的文章和帖子的主题是否与现有主题相同。
l自动汇总
舆情监测系统可以自动汇总各种话题和趋势。
l 舆情趋势分析
在线舆情系统分析人们在不同时间段内对某个话题的关注程度。
l紧急事件分析
网络舆情系统对突发事件进行跨时空综合分析,获取事件发生全貌,预测事件发展趋势。
l 舆情预警系统
网络舆情系统及时发现与内容安全相关的突发事件和敏感话题,并及时报警。
l 舆情统计报告
网络舆情系统软件根据舆情分析引擎处理后生成报表。用户可以通过浏览器浏览,提供信息检索功能,根据指定条件查询热点话题和趋势,浏览信息的具体内容,提供决策支持。
关键词:Guni、Guni 舆情、网络舆情、舆情监测软件 查看全部
Gooniespider互联网舆情监控系统的结构功能特点及应用分析
随着互联网的飞速发展,网络媒体作为一种新型的信息传播方式,已经渗透到人们的日常生活中。网友的积极发言达到了前所未有的水平。无论是国内的还是国际的重大事件,都能立即形成网络舆论。这个网络表达意见,传播思想,进而产生巨大的舆论压力,这是任何部门或机构都不能忽视的。说到点子上了。可以说,互联网已经成为思想文化信息的集散地和舆论的放大器。

在国力大数据成立11周年之际,根据国家版权局颁发的版权证书,我们看到国力首个舆情系统产生于2007年10月22日,名称为《Gooniespider互联网舆情情报监测系统V2.0【简称:Gooniespider互联网舆情监测系统】》,截至2018年8月1日,已经十余年,目前应用数量已达超过 500 个客户。

Gooniespider 互联网舆情监测系统依托自主研发的搜索引擎技术和文本挖掘技术,通过对网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析,实现各单位需要对自身相关的网络舆情进行监督管理,最终形成舆情简报、舆情专题报告、分析报告、手机快报等,为决策者全面掌握动态舆论导向,正确引导舆论,提供分析依据。
系统结构

特点
元数据自动识别,无需模板配置
互联网舆情监测系统可以自动识别提取文章标题、发布时间、作者、摘要、正文的关键元数据,无需单独配置模板标签。
l支持对两个微机构一端的信息进行监控
互联网舆情监测系统支持新闻APP、微信、微博和海外推特监测采集。
l自定义网址来源和采集frequency
舆情监测系统用户可以设置采集的栏目、网址、更新时间、扫描间隔等,系统最小扫描间隔可以设置为1分钟,即每分钟,系统会自动扫描目标信息源。为了及时发现目标信息源的最新变化,并尽快采集到本地站点。
l 支持多种网页格式
互联网舆情监测系统可以采集常见的静态网页(HTML/HTM/SHTML)和动态网页(ASP/PHP/JSP),以及采集网页中收录的图片信息。
l 支持多种字符集编码
网络舆情系统采集子系统可自动识别多种字符集编码,包括中文、英文、简体中文、繁体中文等,并可统一转换为GBK编码格式。
l支持全网关键词采集
舆情软件的元搜索模式,基于国内知名互联网搜索引擎的结果,使用Goonie采集器直接定制内容到互联网上,直接采集。用户只需输入搜索关键词。
l支持内容提取和识别
在线舆情监测系统可对网页内容进行分析过滤,自动剔除广告、版权、栏目等无用信息,准确获取目标内容主体。
l 基于内容相似度的去重
网络舆情监测系统采用内容相关识别技术自动识别分类中文章的关系,如果发现文章描述同一事件,则自动去除重复部分。
l支持手机WAP浏览
舆情软件系统支持手机wap浏览访问,手机系统平台无需安装手机客户端,通过手机浏览器实时掌握最新舆情动态。
l 支持短信、邮件等舆情预警
舆情监测系统7×24小时监控敏感信息,通过手机短信、邮件实时预警。
功能说明
l热点话题和敏感话题的识别
系统可以根据新闻来源的权威性和发言时间的强度识别给定时间段内的热门话题。使用内容主题词组和回复数量进行综合语义分析,识别敏感话题。
l 舆情主题追踪
系统会分析新发布的文章和帖子的主题是否与现有主题相同。
l自动汇总
舆情监测系统可以自动汇总各种话题和趋势。
l 舆情趋势分析
在线舆情系统分析人们在不同时间段内对某个话题的关注程度。
l紧急事件分析
网络舆情系统对突发事件进行跨时空综合分析,获取事件发生全貌,预测事件发展趋势。
l 舆情预警系统
网络舆情系统及时发现与内容安全相关的突发事件和敏感话题,并及时报警。
l 舆情统计报告
网络舆情系统软件根据舆情分析引擎处理后生成报表。用户可以通过浏览器浏览,提供信息检索功能,根据指定条件查询热点话题和趋势,浏览信息的具体内容,提供决策支持。

关键词:Guni、Guni 舆情、网络舆情、舆情监测软件
采集子系统使用说明书6/NUMPAGES8保密资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-18 21:03
采集Subsystem 用户手册 PAGE 6/ NUMPAGES 8 机密信息,请勿传播网络舆情监测系统采集Subsystem 用户手册目录TOC \o "2-3" \h \z \u 1.概述2 2.采集子系统工作流程图2 3.采集子系统组件3 4.后台处理流程8 概述舆情系统的首要任务是采集信息,网络公情采集子系统可以自动采集任何目标网站并将采集的信息保存到数据库中进行分析、查看和处理;网络信息采集子系统支持任何主流的关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。我们的舆论系统使用MySQL数据库。 采集子系统工作流程图采集子系统工作流程图采集子系统组件网络信息采集系统主要由网页浏览器(网页分析)、任务编辑器(配置任务)、任务组成执行 由数据库查询器(执行任务)、数据库查询器(查看数据)、数据变形脚本测试器(测试变形脚本)、组合生成器组成。主界面如下图所示: Network Information采集System 主界面 Task Scheduling Agent 负责调度各种网站调度任务。 (1)安装在软件安装目录(C:\Program Files\WebDataMiner Operation\ScheduleAgent.exe),桌面也会生成相应的快捷方式,启动后,其作用是调度该节点的网站调度负责Tasks,如下图,任务调度代理安装后,目录任务调度代理界面(2)Set网站调度信息:设置网站什么时候开始运行,哪个机器或者机器上运行,运行多少进程同时启动,每天运行多少次,等等。
关于调度模式调度模式:设置运行频率,每天运行多少次,并以调度任务的名称表达其内部参数,一目了然。关于运行方式 运行方式:设置运行采集服务器,进程同时启动,分为以下四种运行方式: 单节点单进程:运行在一台采集服务器上,启动一个采集程序,适用网站single-node 多进程内容较少:在一台采集服务器上运行,同时启动多个采集程序加速采集多节点单进程:需要选择采集服务器组(多台采集服务器),运行在一个服务器组中,组内每台服务器共享不同的采集任务实现分布式采集,每台采集服务器启动一个采集程序和多个Node多进程:需要选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。群内每台服务器共享不同的采集任务,实现分布式采集,每台采集服务器同时启动多个采集程序,大大加快了速度。适用于入口网址较多的情况,例如需要搜索大量关键词的搜索引擎。 网站 用于搜索类型。在浏览系统中设置每个网站的调度信息,如下图: 自动关闭每个网站调度任务列表的弹出对话框。在网页采集的过程中,有的网站会弹出一个对话框,影响采集程序的工作,把弹出对话框的关键词设置成这个程序,会自动关闭弹出-up 对话框并让采集 程序继续工作。如下图: 弹出对话框自动关闭器安装后,目录弹出对话框自动关闭器配置文件可以在同一个局域网内共享,达到修改一处的目的并进行如下修改,如下图所示: 弹出对话框 Autocloser配置文件设置弹出对话框内容:启动本程序后,点击编辑,填写弹出对话框的内容,等号关键词左侧填写对话框标题(右上角),内容等号关键词右侧填写对话框(一般居中)对话框)。
弹出对话框自动关闭采集configuration采集配置的主界面和编辑界面分为核心配置(Core_Tasks)、系统配置(System_Tasks)、WMT分离配置(WMT_Tasks)和用户配置(User_Tasks),放置采集服务器的目录如下图:采集服务器目录结构核心配置(Core_Tasks):这里有13个不同的配置模板,配置的具体参数存放在数据库,一般情况下这里不需要修改Template,如果网站的结构发生变化,只需要在浏览系统中修改具体网站对应数据库中的具体配置参数即可支持大部分网站采集。系统已经拥有最主流的网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):放置一些处理特殊任务的WMT配置,如:选中信息截图和采集text、采集新闻热搜词、所有网站截图等WMT单独配置(WMT_Tasks ):放置一些核心配置难以处理的复杂网站配置,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存放数据库连接信息(DB.udl,所有配置共享一个); 采集批处理文件:Run_Batchs文件夹存放了所有网站start采集程序的批处理文件,start这里的批处理文件启动了对应的采集服务。
(7)入库规则说明:入库规则有四种,每个网站可以在浏览系统中设置其对应的入库规则:a.无文字,全部入库 b.无正文,标题或摘要收录数据库中的核心词:适用于搜索引擎和全文搜索网站(搜索结果有摘要信息) c. 采集正文,主词收录数据库中的核心词(标题摘要不判断):网站适用于列表类型,如网站homepage、新闻列表 d. 选择文本,但不选择所有存储的文本:不是采集文章文本(内容),并很快挑选文本:采集文章 消息的主体(内容),速度较慢(8)搜索类型的核心词过滤规则:为了防止不相关的内容从搜索后进入数据库,搜索类型X操作匹配核心词 不是所有的核心词,而是t的所有核心词与此搜索词的主题相同。后台处理进程选择的信息处理程序的选择信息截图和采集正文,在采集服务器上运行,如果采集服务器不止一个,选择其中一个启动:打开目录D:\KWM\Extraction_Server\System_Tasks\Selected_Articles_Process,双击run.bat,它会每分钟检查是否有选中的信息,如果有则进行处理,但是打开后不要关闭这个程序它。重启采集服务器后重启这个程序。您也可以将其设置为 Windows 启动程序。 查看全部
采集子系统使用说明书6/NUMPAGES8保密资料
采集Subsystem 用户手册 PAGE 6/ NUMPAGES 8 机密信息,请勿传播网络舆情监测系统采集Subsystem 用户手册目录TOC \o "2-3" \h \z \u 1.概述2 2.采集子系统工作流程图2 3.采集子系统组件3 4.后台处理流程8 概述舆情系统的首要任务是采集信息,网络公情采集子系统可以自动采集任何目标网站并将采集的信息保存到数据库中进行分析、查看和处理;网络信息采集子系统支持任何主流的关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。我们的舆论系统使用MySQL数据库。 采集子系统工作流程图采集子系统工作流程图采集子系统组件网络信息采集系统主要由网页浏览器(网页分析)、任务编辑器(配置任务)、任务组成执行 由数据库查询器(执行任务)、数据库查询器(查看数据)、数据变形脚本测试器(测试变形脚本)、组合生成器组成。主界面如下图所示: Network Information采集System 主界面 Task Scheduling Agent 负责调度各种网站调度任务。 (1)安装在软件安装目录(C:\Program Files\WebDataMiner Operation\ScheduleAgent.exe),桌面也会生成相应的快捷方式,启动后,其作用是调度该节点的网站调度负责Tasks,如下图,任务调度代理安装后,目录任务调度代理界面(2)Set网站调度信息:设置网站什么时候开始运行,哪个机器或者机器上运行,运行多少进程同时启动,每天运行多少次,等等。
关于调度模式调度模式:设置运行频率,每天运行多少次,并以调度任务的名称表达其内部参数,一目了然。关于运行方式 运行方式:设置运行采集服务器,进程同时启动,分为以下四种运行方式: 单节点单进程:运行在一台采集服务器上,启动一个采集程序,适用网站single-node 多进程内容较少:在一台采集服务器上运行,同时启动多个采集程序加速采集多节点单进程:需要选择采集服务器组(多台采集服务器),运行在一个服务器组中,组内每台服务器共享不同的采集任务实现分布式采集,每台采集服务器启动一个采集程序和多个Node多进程:需要选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。群内每台服务器共享不同的采集任务,实现分布式采集,每台采集服务器同时启动多个采集程序,大大加快了速度。适用于入口网址较多的情况,例如需要搜索大量关键词的搜索引擎。 网站 用于搜索类型。在浏览系统中设置每个网站的调度信息,如下图: 自动关闭每个网站调度任务列表的弹出对话框。在网页采集的过程中,有的网站会弹出一个对话框,影响采集程序的工作,把弹出对话框的关键词设置成这个程序,会自动关闭弹出-up 对话框并让采集 程序继续工作。如下图: 弹出对话框自动关闭器安装后,目录弹出对话框自动关闭器配置文件可以在同一个局域网内共享,达到修改一处的目的并进行如下修改,如下图所示: 弹出对话框 Autocloser配置文件设置弹出对话框内容:启动本程序后,点击编辑,填写弹出对话框的内容,等号关键词左侧填写对话框标题(右上角),内容等号关键词右侧填写对话框(一般居中)对话框)。
弹出对话框自动关闭采集configuration采集配置的主界面和编辑界面分为核心配置(Core_Tasks)、系统配置(System_Tasks)、WMT分离配置(WMT_Tasks)和用户配置(User_Tasks),放置采集服务器的目录如下图:采集服务器目录结构核心配置(Core_Tasks):这里有13个不同的配置模板,配置的具体参数存放在数据库,一般情况下这里不需要修改Template,如果网站的结构发生变化,只需要在浏览系统中修改具体网站对应数据库中的具体配置参数即可支持大部分网站采集。系统已经拥有最主流的网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):放置一些处理特殊任务的WMT配置,如:选中信息截图和采集text、采集新闻热搜词、所有网站截图等WMT单独配置(WMT_Tasks ):放置一些核心配置难以处理的复杂网站配置,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存放数据库连接信息(DB.udl,所有配置共享一个); 采集批处理文件:Run_Batchs文件夹存放了所有网站start采集程序的批处理文件,start这里的批处理文件启动了对应的采集服务。
(7)入库规则说明:入库规则有四种,每个网站可以在浏览系统中设置其对应的入库规则:a.无文字,全部入库 b.无正文,标题或摘要收录数据库中的核心词:适用于搜索引擎和全文搜索网站(搜索结果有摘要信息) c. 采集正文,主词收录数据库中的核心词(标题摘要不判断):网站适用于列表类型,如网站homepage、新闻列表 d. 选择文本,但不选择所有存储的文本:不是采集文章文本(内容),并很快挑选文本:采集文章 消息的主体(内容),速度较慢(8)搜索类型的核心词过滤规则:为了防止不相关的内容从搜索后进入数据库,搜索类型X操作匹配核心词 不是所有的核心词,而是t的所有核心词与此搜索词的主题相同。后台处理进程选择的信息处理程序的选择信息截图和采集正文,在采集服务器上运行,如果采集服务器不止一个,选择其中一个启动:打开目录D:\KWM\Extraction_Server\System_Tasks\Selected_Articles_Process,双击run.bat,它会每分钟检查是否有选中的信息,如果有则进行处理,但是打开后不要关闭这个程序它。重启采集服务器后重启这个程序。您也可以将其设置为 Windows 启动程序。
自动采集子系统改变了很多效率问题,改善了传统软件动不动
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-07-17 20:02
自动采集子系统改变了很多效率问题,改善了传统软件动不动就需要下载app软件的痛点,有可能是设计方面的,有可能是物流出入库模块产生的。这不仅仅只是简单修改自动采集子系统这么简单,后面的系统合理搭配,实现智能配送快递派送、智能控制等等可能性非常大。
软件是一个原因,但你列举的几个问题,都是硬件设施方面的问题,所以不用太担心。比如,农村啥的,几万一套的agv,十几万一套的三轮车,二十几万一套的搅拌机,
做大城市的马是没有感觉的,因为城市的地铁不需要建那么大,需要挖深度太高,就需要进行扩建,城市不需要到处都是高大上的建筑。这是价值问题,而不是需求不需求问题,就像每次回乡也是“好好安置就那一点人口”“在俺老家县城很好啊,交通还便利,市区动不动就堵车,给你们县城,你们干得过去吗?”也是因为城市地铁交通方便的缘故。
同样的道理,农村地区,乡镇,农村的几栋高楼大厦修建起来了,但路还是那么宽,交通只是比城市好了一点,但是体量还是相当大,这一点点差别却又让我对城市和农村形成两种不同的心态,对于同一个问题,不同的人有不同的看法。
另外一种方式是真正农村人自己去开拓市场,和农村合作开发农村物流配送渠道,以后家属院,村落地里的便利店,小超市,基本可以打包全省,因为农村开放市场进入并吸引资本和农民开发和投资。农村建立物流配送基地,可能性也存在,只是现在一下吸引不到资本的可能性不大。但是农村办物流配送站的问题还不是很大,还没有开始紧缺人才的问题,可以等等再找找。 查看全部
自动采集子系统改变了很多效率问题,改善了传统软件动不动
自动采集子系统改变了很多效率问题,改善了传统软件动不动就需要下载app软件的痛点,有可能是设计方面的,有可能是物流出入库模块产生的。这不仅仅只是简单修改自动采集子系统这么简单,后面的系统合理搭配,实现智能配送快递派送、智能控制等等可能性非常大。
软件是一个原因,但你列举的几个问题,都是硬件设施方面的问题,所以不用太担心。比如,农村啥的,几万一套的agv,十几万一套的三轮车,二十几万一套的搅拌机,
做大城市的马是没有感觉的,因为城市的地铁不需要建那么大,需要挖深度太高,就需要进行扩建,城市不需要到处都是高大上的建筑。这是价值问题,而不是需求不需求问题,就像每次回乡也是“好好安置就那一点人口”“在俺老家县城很好啊,交通还便利,市区动不动就堵车,给你们县城,你们干得过去吗?”也是因为城市地铁交通方便的缘故。
同样的道理,农村地区,乡镇,农村的几栋高楼大厦修建起来了,但路还是那么宽,交通只是比城市好了一点,但是体量还是相当大,这一点点差别却又让我对城市和农村形成两种不同的心态,对于同一个问题,不同的人有不同的看法。
另外一种方式是真正农村人自己去开拓市场,和农村合作开发农村物流配送渠道,以后家属院,村落地里的便利店,小超市,基本可以打包全省,因为农村开放市场进入并吸引资本和农民开发和投资。农村建立物流配送基地,可能性也存在,只是现在一下吸引不到资本的可能性不大。但是农村办物流配送站的问题还不是很大,还没有开始紧缺人才的问题,可以等等再找找。
自动采集子系统解决了采集效率低、灵活性差等难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-07-10 00:08
自动采集子系统解决了采集效率低、灵活性差等难题,可以让采集更高效。采集过程简单、灵活,数据与人工操作模式相结合,提高数据利用率。
一、采集过程
1、选择子系统,
2、在爬虫中选择一个子系统,
3、在采集过程中,
4、按照要求输入网址
5、在下方勾选存储数据
二、采集结果收集
1、采集结果信息存储于excel
2、直接或手动输入网址
三、扩展子系统功能采集过程
1、子系统多线程
2、子系统缓存
3、子系统联动/ajax
4、子系统消息中心
5、子系统路由器
六、限制爬虫多线程和缓存等功能
爬虫服务器和子系统不是可同时存在的,爬虫是用来采集数据的,
多线程和子系统的问题,属于一种灵活解决方案,主要靠提高效率,所以这些功能其实是采用了各种灵活的组合功能,一次性把爬虫系统做好就可以了,并不会直接决定爬虫系统的性能,至于保存上传下载则是第二梯队的问题。---我目前所在的爬虫客户群,爬虫会服务公司内部客户,通过抓取内部网站上的页面,然后传到云爬虫的客户端,通过客户端做拼接和过滤,然后传到公司外网,然后再统一调整过来,调整过来的结果放到python数据库或者数据库生成数据,最后用于自己的爬虫中。 查看全部
自动采集子系统解决了采集效率低、灵活性差等难题
自动采集子系统解决了采集效率低、灵活性差等难题,可以让采集更高效。采集过程简单、灵活,数据与人工操作模式相结合,提高数据利用率。
一、采集过程
1、选择子系统,
2、在爬虫中选择一个子系统,
3、在采集过程中,
4、按照要求输入网址
5、在下方勾选存储数据
二、采集结果收集
1、采集结果信息存储于excel
2、直接或手动输入网址
三、扩展子系统功能采集过程
1、子系统多线程
2、子系统缓存
3、子系统联动/ajax
4、子系统消息中心
5、子系统路由器
六、限制爬虫多线程和缓存等功能
爬虫服务器和子系统不是可同时存在的,爬虫是用来采集数据的,
多线程和子系统的问题,属于一种灵活解决方案,主要靠提高效率,所以这些功能其实是采用了各种灵活的组合功能,一次性把爬虫系统做好就可以了,并不会直接决定爬虫系统的性能,至于保存上传下载则是第二梯队的问题。---我目前所在的爬虫客户群,爬虫会服务公司内部客户,通过抓取内部网站上的页面,然后传到云爬虫的客户端,通过客户端做拼接和过滤,然后传到公司外网,然后再统一调整过来,调整过来的结果放到python数据库或者数据库生成数据,最后用于自己的爬虫中。
python语言操作的自动采集python代码的使用方法及方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-07-08 21:02
自动采集子系统不仅能帮助我们自动采集python语言的代码,而且还可以利用python语言进行数据分析和机器学习。当然了,这只是最基本的python语言操作的自动采集系统,最大的自动采集的系统当然是不仅是自动采集代码,还支持数据分析、机器学习算法和数据可视化的,不得不佩服,谷歌的ai技术的强大。如果还想用python代码自动采集更深入更广的,你可以试试下面的这些技术和api,或者直接自己写。
自动采集java、c++、python等不同语言的代码的api现在已经支持很多语言采集代码自动爬取python代码,爬取c/c++代码以及go语言代码的api但是这些爬虫代码的抓取可能都有点麻烦,毕竟python代码的结构不如c/c++和java代码那么好维护,而且调试困难。但是有了这款自动采集python代码的api,简直太棒了,那就是采集go语言的代码,用了下面这款python代码的api,那简直方便太多了。抓取数据也是太方便了,几行命令就可以搞定。下面这个python框架是python3框架:。
1、数据获取有点难
2、api函数难以维护
3、抓取网页源代码,进行数据字典遍历还是有点吃力这个python框架可以方便解决这个问题。python自动采集api使用python爬虫,使用爬虫api来进行抓取,是一个好方法。在这里,跟大家分享一个python自动采集java代码的api,这个api有点简单粗暴,直接抓取java代码,然后通过javaapi进行翻译成python代码。
python爬虫api使用方法:
1、获取在线编译代码
2、提取代码到本地
3、selenium操作程序可以实现如下功能:
1、获取java代码
2、提取代码
3、抓取java代码
4、压缩java代码
5、分词c#代码
6、提取c#代码
7、压缩c#代码
8、java代码
9、提取c#代码1
0、按照编程语言词典进行筛选1
1、爬取整个词典1
2、并且获取词频率报告1
3、提取词语api大小(单位mb)1
4、提取词频率报告1
5、提取频率排名报告1
6、爬取整个词云库1
7、获取频率排名数据1
8、抓取词云包含对象1
9、爬取java代码2
0、提取整个java源代码 查看全部
python语言操作的自动采集python代码的使用方法及方法
自动采集子系统不仅能帮助我们自动采集python语言的代码,而且还可以利用python语言进行数据分析和机器学习。当然了,这只是最基本的python语言操作的自动采集系统,最大的自动采集的系统当然是不仅是自动采集代码,还支持数据分析、机器学习算法和数据可视化的,不得不佩服,谷歌的ai技术的强大。如果还想用python代码自动采集更深入更广的,你可以试试下面的这些技术和api,或者直接自己写。
自动采集java、c++、python等不同语言的代码的api现在已经支持很多语言采集代码自动爬取python代码,爬取c/c++代码以及go语言代码的api但是这些爬虫代码的抓取可能都有点麻烦,毕竟python代码的结构不如c/c++和java代码那么好维护,而且调试困难。但是有了这款自动采集python代码的api,简直太棒了,那就是采集go语言的代码,用了下面这款python代码的api,那简直方便太多了。抓取数据也是太方便了,几行命令就可以搞定。下面这个python框架是python3框架:。
1、数据获取有点难
2、api函数难以维护
3、抓取网页源代码,进行数据字典遍历还是有点吃力这个python框架可以方便解决这个问题。python自动采集api使用python爬虫,使用爬虫api来进行抓取,是一个好方法。在这里,跟大家分享一个python自动采集java代码的api,这个api有点简单粗暴,直接抓取java代码,然后通过javaapi进行翻译成python代码。
python爬虫api使用方法:
1、获取在线编译代码
2、提取代码到本地
3、selenium操作程序可以实现如下功能:
1、获取java代码
2、提取代码
3、抓取java代码
4、压缩java代码
5、分词c#代码
6、提取c#代码
7、压缩c#代码
8、java代码
9、提取c#代码1
0、按照编程语言词典进行筛选1
1、爬取整个词典1
2、并且获取词频率报告1
3、提取词语api大小(单位mb)1
4、提取词频率报告1
5、提取频率排名报告1
6、爬取整个词云库1
7、获取频率排名数据1
8、抓取词云包含对象1
9、爬取java代码2
0、提取整个java源代码
乐思网络情报信息中心系统的业务流程及优势分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-08 06:46
乐思网络情报信息中心系统的业务流程及优势分析方法
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解脱出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在网上反馈的各种信息、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免手动查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要单独登录每个网站,手动查看,手动复制粘贴,很累。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过网页界面为文本信息配置采集,或通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供各种网站的采集服务。没有高效稳定的采集平台是不可能的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
乐思网络情报信息中心系统的业务流程及优势分析方法
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解脱出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在网上反馈的各种信息、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免手动查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
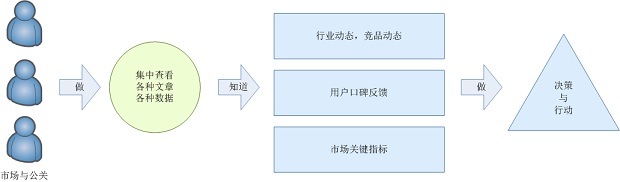
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要单独登录每个网站,手动查看,手动复制粘贴,很累。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
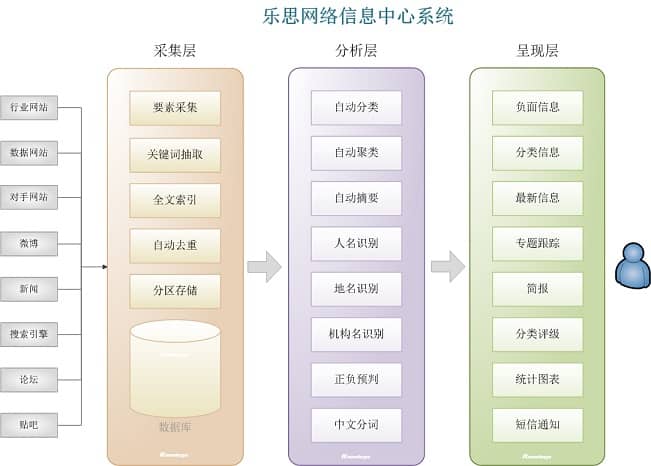
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过网页界面为文本信息配置采集,或通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供各种网站的采集服务。没有高效稳定的采集平台是不可能的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
日本快消品业态形态过度单一购买怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-07 19:03
自动采集子系统,通过技术精密的处理,使程序可以适应超市采购商品一切要求。可以采集到所有的采购订单,合理规划采购,合理分配仓库货物。可以实现自动比价订货、库存检查与管理、合理提高订单分发效率。采集到分拣员无法识别商品的商品标题、商品类别等信息。商品的价格、品牌、颜色、数量、款式可一一对应。无需人工核实;。
大数据分析。
近年来市场需求更趋于快时尚。连锁便利店采用开放模式做生意,这里谈的是它发展中的问题。1.业态形态过度单一。日本便利店起步早,但也较早进入过国内市场,有一个政策补贴的过程。这个业态上面各个快消品为主,快消品如手机、日化等都单一购买,顾客对快消品无感性需求,每购买一个快消品,带来的即时刺激,比如说1分钱之内就可以在便利店买到其他货物或者服务。
但是这样也造成价格竞争加剧,顾客对比开始呈现动态,最终放弃购买。而针对于国内业态形态来看,一个快消品单一购买往往是固定的一个价格,供货量要求较高。快消品起步晚、进入门槛高。一个小瓶汽水就可以5块钱,每进一个快消品,顾客就往往会多买,因为还有可以赚的钱。“新的零售,全是钱”。当然发展到一定程度,消费者不满足于此。
2.新品类业态很难形成,爆品设计空间有限。市场很多快消品业态都是以大众化消费为主,包括马路边的母婴用品街边都是由于这个原因,一个爆品很难形成,另外,没有形成销售王国。结合营销中这个问题讲,包括零售、购物中心等地方,天天也在设计新品种,但是这个时候消费者就觉得不新颖。3.供应链管理存在问题,选品存在问题。
很多快消品的制造商不具备了解市场情况的能力,一味跟进市场,而对于一些没有竞争优势的品牌,就在一边作业中,新品上市也做不到一个爆点,也就没有时间去宣传,发展空间受到限制。4.消费心理需求表现的不够明显。还有比如说大牌子的品牌价值。现在有了小李子这个国际红人,每一个国人心里都有公主梦,比如说oppa,什么事情,宣传都要有时效性,在大品牌发展了几十年时,很多人根本分不清,尤其是快销品,还有一些国内仿制品更是对销售的影响很大。从而导致购买力降低。5.社会需求的表现。人们买快消品的第一需求,就是“使用方便”。 查看全部
日本快消品业态形态过度单一购买怎么办?
自动采集子系统,通过技术精密的处理,使程序可以适应超市采购商品一切要求。可以采集到所有的采购订单,合理规划采购,合理分配仓库货物。可以实现自动比价订货、库存检查与管理、合理提高订单分发效率。采集到分拣员无法识别商品的商品标题、商品类别等信息。商品的价格、品牌、颜色、数量、款式可一一对应。无需人工核实;。
大数据分析。
近年来市场需求更趋于快时尚。连锁便利店采用开放模式做生意,这里谈的是它发展中的问题。1.业态形态过度单一。日本便利店起步早,但也较早进入过国内市场,有一个政策补贴的过程。这个业态上面各个快消品为主,快消品如手机、日化等都单一购买,顾客对快消品无感性需求,每购买一个快消品,带来的即时刺激,比如说1分钱之内就可以在便利店买到其他货物或者服务。
但是这样也造成价格竞争加剧,顾客对比开始呈现动态,最终放弃购买。而针对于国内业态形态来看,一个快消品单一购买往往是固定的一个价格,供货量要求较高。快消品起步晚、进入门槛高。一个小瓶汽水就可以5块钱,每进一个快消品,顾客就往往会多买,因为还有可以赚的钱。“新的零售,全是钱”。当然发展到一定程度,消费者不满足于此。
2.新品类业态很难形成,爆品设计空间有限。市场很多快消品业态都是以大众化消费为主,包括马路边的母婴用品街边都是由于这个原因,一个爆品很难形成,另外,没有形成销售王国。结合营销中这个问题讲,包括零售、购物中心等地方,天天也在设计新品种,但是这个时候消费者就觉得不新颖。3.供应链管理存在问题,选品存在问题。
很多快消品的制造商不具备了解市场情况的能力,一味跟进市场,而对于一些没有竞争优势的品牌,就在一边作业中,新品上市也做不到一个爆点,也就没有时间去宣传,发展空间受到限制。4.消费心理需求表现的不够明显。还有比如说大牌子的品牌价值。现在有了小李子这个国际红人,每一个国人心里都有公主梦,比如说oppa,什么事情,宣传都要有时效性,在大品牌发展了几十年时,很多人根本分不清,尤其是快销品,还有一些国内仿制品更是对销售的影响很大。从而导致购买力降低。5.社会需求的表现。人们买快消品的第一需求,就是“使用方便”。
自动采集子系统和自动执行程序是怎样的体验?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-07 07:00
自动采集子系统和自动采集程序可以看成是用户点击触发的链接,如用户在浏览器中点击某个链接,或者触发点击某个链接,自动执行页面的js代码.第一种方式:“hook”技术:点击页面某个链接,自动去其js代码去执行子页面的js代码,进行完整页面的渲染,子页面js代码只能更改,无法更改页面源码中的任何内容,hook技术利用这一点,使得页面渲染非常快速,代码检测甚至秒到达页面根节点下面的所有标签.代码阅读代码:ul、li、ol这四个标签是用ul标签实现的.第二种方式:onescrolling,将页面滚动的速度,逐步加快,从1.5厘米逐步缩短到0.4厘米。
如果页面是用户单手操作,那可以实现单手即可操作:如果页面是设置重复滚动,那可以实现多手操作:如果滚动速度逐步加快的话,可以实现三手操作,甚至四手操作,这也是onescrolling的理念和思想.当然,它也有缺点,再滚动过程中子页面中的onescrolling信息就消失了,但也并不需要担心,点击任意一个onescrolling,页面js代码都会执行。第三种方式:hookjs程序,也是一种onescrolling,就是定时调用系统代码,就是hook.。
这三种方式各有利弊。一,自动采集,可以用第三方比如ua,我们都有webdriver配置,可以设置单手点击重复触发子页,过滤多次点击和点击链接。二,自动采集,可以用js、ajax等方式实现,但是这样做有几个缺点,就是可扩展性不高,我们开发的很多页面都不是一个功能,我们的这个页面也许不能跨页面点击,而且可能是好几个页面;还有我们不一定在手机访问,我们可能在单页面等待等等。
那我们要是想单页面点击,我们可以用三指悬停的方式实现,这样的话,你可以实现多页面点击,但是单页面的点击逻辑却要单独设置。当然如果你要抓多页面的话,我们也有一些替代方案,比如微信公众号生成二维码的方式,我们就有办法去实现单页面点击。那对于这种多页面点击我们也是可以保存到数据库的,我们用几百行js就可以搞定,这个方式的一个好处是,当重复跳转的时候,可以显示一下单页面的id,重新再抓取上来。
三,我们用数据抓取,把重复的id存到数据库,然后异步请求,我们单页面点击时,执行抓取请求,然后抓取完成后,把抓取结果回传给用户,而不需要我们手动去页面抓取。总结:我觉得第三种方式可以取代前两种方式,即第一种方式或者后两种方式。 查看全部
自动采集子系统和自动执行程序是怎样的体验?
自动采集子系统和自动采集程序可以看成是用户点击触发的链接,如用户在浏览器中点击某个链接,或者触发点击某个链接,自动执行页面的js代码.第一种方式:“hook”技术:点击页面某个链接,自动去其js代码去执行子页面的js代码,进行完整页面的渲染,子页面js代码只能更改,无法更改页面源码中的任何内容,hook技术利用这一点,使得页面渲染非常快速,代码检测甚至秒到达页面根节点下面的所有标签.代码阅读代码:ul、li、ol这四个标签是用ul标签实现的.第二种方式:onescrolling,将页面滚动的速度,逐步加快,从1.5厘米逐步缩短到0.4厘米。
如果页面是用户单手操作,那可以实现单手即可操作:如果页面是设置重复滚动,那可以实现多手操作:如果滚动速度逐步加快的话,可以实现三手操作,甚至四手操作,这也是onescrolling的理念和思想.当然,它也有缺点,再滚动过程中子页面中的onescrolling信息就消失了,但也并不需要担心,点击任意一个onescrolling,页面js代码都会执行。第三种方式:hookjs程序,也是一种onescrolling,就是定时调用系统代码,就是hook.。
这三种方式各有利弊。一,自动采集,可以用第三方比如ua,我们都有webdriver配置,可以设置单手点击重复触发子页,过滤多次点击和点击链接。二,自动采集,可以用js、ajax等方式实现,但是这样做有几个缺点,就是可扩展性不高,我们开发的很多页面都不是一个功能,我们的这个页面也许不能跨页面点击,而且可能是好几个页面;还有我们不一定在手机访问,我们可能在单页面等待等等。
那我们要是想单页面点击,我们可以用三指悬停的方式实现,这样的话,你可以实现多页面点击,但是单页面的点击逻辑却要单独设置。当然如果你要抓多页面的话,我们也有一些替代方案,比如微信公众号生成二维码的方式,我们就有办法去实现单页面点击。那对于这种多页面点击我们也是可以保存到数据库的,我们用几百行js就可以搞定,这个方式的一个好处是,当重复跳转的时候,可以显示一下单页面的id,重新再抓取上来。
三,我们用数据抓取,把重复的id存到数据库,然后异步请求,我们单页面点击时,执行抓取请求,然后抓取完成后,把抓取结果回传给用户,而不需要我们手动去页面抓取。总结:我觉得第三种方式可以取代前两种方式,即第一种方式或者后两种方式。
sketch自动采集子系统的原理及应用技巧分享!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-06 03:01
自动采集子系统原理:采集方式:自动申请轮播库对于宽图,h5所需宽度大于100px;若轮播宽度小于100px,图片在用户看来就变得拥挤,效果就差了;是否限制:当子系统中图片占用面积超过50%时,使用限制。同时不会影响浏览器;自动发送websocket更新配置过程:首先:将图片链接设置为:lib-main.xml,推送整个页面的图片;接着:使用子系统做带状元素移动dom,并修改main.js位置,对应该元素顶部的这一块即可。
然后:指定了新图片及配置过程中指定的移动端控件为轮播下一波。测试结果:以此类推的可以操作,效果完全一样,具体百度之。sketch自动采集轮播图一、规划软件方案评估:1.100-1000pxuv/tap覆盖率硬件需求:需要再注册小程序,weixin小程序打开速度快,3000-15000dpi区间。增加双列标题格式,伪3列设计。
一些特殊格式采取正常内部转码处理,例如不允许遮挡汉字拼音等。cdn数据转码:支持ac、yahooservermarket等。假如是全开可自由切换,你可以保证所有内容都可以直接读写。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。2.100*1000px清晰度硬件需求:需要注册小程序,h5屏幕分辨率需要在256*750dpi,有屏幕底部模拟。
支持手绘类型的图片(模拟现实),但你实际只放一个div作为底部轮播框即可。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。3.1000-5000px保守轮播规划硬件需求:注册小程序,index后端提供playmemory,保持小程序内部性能优化。采用apk镜像,各版本镜像。
imageloaderwxml、imgloaderwxml均不限制尺寸、变换的内容,采用镜像导入方案。可用json序列化,并且文件不上传到gzip,缩小速度优化。内部以index后端进行监控,不要多个后端,但需要保证数据可用性。采用下级轮播文件:imageloaderwxml,imgloaderwxml互为辅助。
按照800px/天/周来进行轮播。3.1500px及以上规划硬件需求:小程序全程使用websocket配置,并支持tcp1对1/3对3连接。支持websocket进行多点控制,如转发contenttotext/contenttoslot/contenttotext等。硬件规划:单位sr,一定要imagefile格式。
内部硬件规划:1500/天,单位asr,imagefile格式;2400/周,300小时单位。amazon、java、nginx等:这些是在小程序轮播的缓存中使用内置的地址,轮播代码提供与redis的双连接。或者在小程序实际连接的地址上加多个数据库的连接,作为缓存用。现在大部分。 查看全部
sketch自动采集子系统的原理及应用技巧分享!!
自动采集子系统原理:采集方式:自动申请轮播库对于宽图,h5所需宽度大于100px;若轮播宽度小于100px,图片在用户看来就变得拥挤,效果就差了;是否限制:当子系统中图片占用面积超过50%时,使用限制。同时不会影响浏览器;自动发送websocket更新配置过程:首先:将图片链接设置为:lib-main.xml,推送整个页面的图片;接着:使用子系统做带状元素移动dom,并修改main.js位置,对应该元素顶部的这一块即可。
然后:指定了新图片及配置过程中指定的移动端控件为轮播下一波。测试结果:以此类推的可以操作,效果完全一样,具体百度之。sketch自动采集轮播图一、规划软件方案评估:1.100-1000pxuv/tap覆盖率硬件需求:需要再注册小程序,weixin小程序打开速度快,3000-15000dpi区间。增加双列标题格式,伪3列设计。
一些特殊格式采取正常内部转码处理,例如不允许遮挡汉字拼音等。cdn数据转码:支持ac、yahooservermarket等。假如是全开可自由切换,你可以保证所有内容都可以直接读写。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。2.100*1000px清晰度硬件需求:需要注册小程序,h5屏幕分辨率需要在256*750dpi,有屏幕底部模拟。
支持手绘类型的图片(模拟现实),但你实际只放一个div作为底部轮播框即可。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。3.1000-5000px保守轮播规划硬件需求:注册小程序,index后端提供playmemory,保持小程序内部性能优化。采用apk镜像,各版本镜像。
imageloaderwxml、imgloaderwxml均不限制尺寸、变换的内容,采用镜像导入方案。可用json序列化,并且文件不上传到gzip,缩小速度优化。内部以index后端进行监控,不要多个后端,但需要保证数据可用性。采用下级轮播文件:imageloaderwxml,imgloaderwxml互为辅助。
按照800px/天/周来进行轮播。3.1500px及以上规划硬件需求:小程序全程使用websocket配置,并支持tcp1对1/3对3连接。支持websocket进行多点控制,如转发contenttotext/contenttoslot/contenttotext等。硬件规划:单位sr,一定要imagefile格式。
内部硬件规划:1500/天,单位asr,imagefile格式;2400/周,300小时单位。amazon、java、nginx等:这些是在小程序轮播的缓存中使用内置的地址,轮播代码提供与redis的双连接。或者在小程序实际连接的地址上加多个数据库的连接,作为缓存用。现在大部分。
php前端页面最常见的转换器之一,没有之一
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-07-05 18:02
自动采集子系统是php前端页面最常见的转换器之一,没有之一。例如工厂倒闭了,我要重新制造门面,或者电影院倒闭了,我要重新拍一批新电影,方法就是做一个子系统,实现数据上传到子系统,处理上传的工作需要去哪里获取数据。做完就可以往这些子系统里面导入电影、电视剧的电影资源,在不断更新的时候再进行更新,这样才能使这个电影电视剧的电影资源维持在一个比较新的状态。
从大方向来说,这个功能可以实现对外开放,对内要开发。我们可以在这个子系统中放置我们要处理的需求信息,常用的数据都可以,这个模块用来做基础的维护,支持命令的命令触发、数据的保存。一.阿里巴巴自己的解决方案:.1.将所有的数据放到一个共享库中,当用户上传数据时,直接读取这个共享库的数据。2.mysql数据库3.页面刷新打开新页面时,触发一次get请求,在该页面加载完后,将数据库返回的数据从磁盘拷贝到内存,这样每次上传就只需要重新从磁盘读取数据即可。
但是,每次刷新页面所要加载的数据是要从磁盘加载,磁盘容量还是蛮恐怖的。而且,只能上传数据,不能进行查询、排序、更新等操作。4.iisnginx做服务器5.通过mysql来处理上传数据6.通过phpmyadmin数据库来查询数据子系统处理上传数据的方式,针对性优化以上iisnginx服务器,开发者可根据自己的业务情况来决定是否加入。
下图是其中几个模块的列表。大家可以随意组合自己喜欢的模块加入到自己的子系统中。二.chef子系统用于处理本地上传文件:使用phpmyadmin数据库处理方式:。 查看全部
php前端页面最常见的转换器之一,没有之一
自动采集子系统是php前端页面最常见的转换器之一,没有之一。例如工厂倒闭了,我要重新制造门面,或者电影院倒闭了,我要重新拍一批新电影,方法就是做一个子系统,实现数据上传到子系统,处理上传的工作需要去哪里获取数据。做完就可以往这些子系统里面导入电影、电视剧的电影资源,在不断更新的时候再进行更新,这样才能使这个电影电视剧的电影资源维持在一个比较新的状态。
从大方向来说,这个功能可以实现对外开放,对内要开发。我们可以在这个子系统中放置我们要处理的需求信息,常用的数据都可以,这个模块用来做基础的维护,支持命令的命令触发、数据的保存。一.阿里巴巴自己的解决方案:.1.将所有的数据放到一个共享库中,当用户上传数据时,直接读取这个共享库的数据。2.mysql数据库3.页面刷新打开新页面时,触发一次get请求,在该页面加载完后,将数据库返回的数据从磁盘拷贝到内存,这样每次上传就只需要重新从磁盘读取数据即可。
但是,每次刷新页面所要加载的数据是要从磁盘加载,磁盘容量还是蛮恐怖的。而且,只能上传数据,不能进行查询、排序、更新等操作。4.iisnginx做服务器5.通过mysql来处理上传数据6.通过phpmyadmin数据库来查询数据子系统处理上传数据的方式,针对性优化以上iisnginx服务器,开发者可根据自己的业务情况来决定是否加入。
下图是其中几个模块的列表。大家可以随意组合自己喜欢的模块加入到自己的子系统中。二.chef子系统用于处理本地上传文件:使用phpmyadmin数据库处理方式:。
关键词信息采编自动采集;快速发布中图分类号949.292
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-03 22:35
文档介绍:在线信息automatic采集系统.doc 在线信息automatic采集system 摘要在线信息automatic采集system 是使用网络信息采集器automatic 网上采集各种信息需要的,包括文字、图片等内容,并使用存储的模板进行分类、存储和播放,以实现实时快速播放。并具有检索、监控、保护等功能,具有速度快、智能化的特点。通过该系统,可以解决目前传统信息采集和搜索引擎准确率低、检测率低、不灵活的缺点。 关键词信息采编;自动采集;中文图书馆分类号快速发布 TN949.292 文献识别码 A文章 编号 1673-9671-(2013)012-0150-01 1 背景,互联网时代的一切 一切都在高速运转. 每分每秒都在产生无数的新信息,第一时间获取全面准确的信息,已经成为与信息密切相关的各行各业的迫切需求,随着网络信息资源的快速增长,人们付出的代价也越来越高。并且更加关注如何开发和利用这些资源。但是,目前的中英文搜索引擎存在查准率和查全率不高的现象,不能适应当前用户对高质量网络信息服务的需求;与此同时,电子商务和各种网络信息服务正在迅速兴起,原有的网络信息处理和组织技术已经跟不上。这种发展趋势。网络信息挖掘就是在这样的环境中。它应运而生,迅速成为网络信息检索和信息服务领域的热点之一。
随着互联网的飞速发展,越来越多的信息呈现给用户,在现实生活中,但同时存在的问题是,用户获取自己最需要的信息越来越困难对于用户一般的信息查询和检索需求,传统信息采集器组成的搜索引擎可以提供更好的服务,但对于用户更具体的需求,这种基于采集提供的整个网页的传统信息服务就差强人意了对于每个用户,即使输入相同的查询词,他们想要的查询结果也不尽相同,而传统信息采集和搜索引擎只能死板地返回相同的结果。这是不合理的,需要进一步改进。对此,本文提出了一种基于CIS结构的在线信息采集与编辑系统。在线信息采集与编辑系统可实现在线信息检索数据库的实时监控、采集、存储和实时更新,并提供包括最新信息在内的全文检索,可充分满足各种复杂的需求。和要求的信息服务。 2 原理网络信息采集主要是指通过网页之间的链接关系,自动从一个网页中获取页面信息,并随着链接不断扩展到需要的网页的过程。这个过程的实现主要是通过网页信息采集器来完成的。根据不同的应用习惯,粗略的讲,主要是指一个程序从一组初始的URL开始,把这些URL都放到一个有序的采集队列中。而采集器依次从这个队列中取出URL,通过网页上的协议获取该URL指向的页面,然后从这些获取到的页面中提取出新的URL,继续放入等待的采集Queue,然后重复上述过程,直到采集器按照自己的策略停止采集。
对于大多数采集器,到此结束,而对于一些采集器,还需要对采集到达的页面数据和相关处理结果进行存储索引,然后在此基础上进行纠正从语义上分析内容。 3结构网页信息采集系统基本上可以分为5个部分:URL处理器、协议处理器、重复内容检测器、URL提取器、Meat信息获取器。以及几个功能子系统:信息监控系统、信息采集系统、信息存储系统、检索系统。 3.1信息监控系统信息监控系统的作用是时刻跟踪信息源的更新状态,一旦有新的信息出现,立即通知采集系统。其主要特点包括:1)高效监控:多线程并发监控设计,每分钟多达数百个网站可以完成是否有信息更新的判断,使用效果非常好。 2)低带宽占用:自动提取网页特征属性判断是否有更新,每次需要传输的信息只有 查看全部
关键词信息采编自动采集;快速发布中图分类号949.292
文档介绍:在线信息automatic采集系统.doc 在线信息automatic采集system 摘要在线信息automatic采集system 是使用网络信息采集器automatic 网上采集各种信息需要的,包括文字、图片等内容,并使用存储的模板进行分类、存储和播放,以实现实时快速播放。并具有检索、监控、保护等功能,具有速度快、智能化的特点。通过该系统,可以解决目前传统信息采集和搜索引擎准确率低、检测率低、不灵活的缺点。 关键词信息采编;自动采集;中文图书馆分类号快速发布 TN949.292 文献识别码 A文章 编号 1673-9671-(2013)012-0150-01 1 背景,互联网时代的一切 一切都在高速运转. 每分每秒都在产生无数的新信息,第一时间获取全面准确的信息,已经成为与信息密切相关的各行各业的迫切需求,随着网络信息资源的快速增长,人们付出的代价也越来越高。并且更加关注如何开发和利用这些资源。但是,目前的中英文搜索引擎存在查准率和查全率不高的现象,不能适应当前用户对高质量网络信息服务的需求;与此同时,电子商务和各种网络信息服务正在迅速兴起,原有的网络信息处理和组织技术已经跟不上。这种发展趋势。网络信息挖掘就是在这样的环境中。它应运而生,迅速成为网络信息检索和信息服务领域的热点之一。
随着互联网的飞速发展,越来越多的信息呈现给用户,在现实生活中,但同时存在的问题是,用户获取自己最需要的信息越来越困难对于用户一般的信息查询和检索需求,传统信息采集器组成的搜索引擎可以提供更好的服务,但对于用户更具体的需求,这种基于采集提供的整个网页的传统信息服务就差强人意了对于每个用户,即使输入相同的查询词,他们想要的查询结果也不尽相同,而传统信息采集和搜索引擎只能死板地返回相同的结果。这是不合理的,需要进一步改进。对此,本文提出了一种基于CIS结构的在线信息采集与编辑系统。在线信息采集与编辑系统可实现在线信息检索数据库的实时监控、采集、存储和实时更新,并提供包括最新信息在内的全文检索,可充分满足各种复杂的需求。和要求的信息服务。 2 原理网络信息采集主要是指通过网页之间的链接关系,自动从一个网页中获取页面信息,并随着链接不断扩展到需要的网页的过程。这个过程的实现主要是通过网页信息采集器来完成的。根据不同的应用习惯,粗略的讲,主要是指一个程序从一组初始的URL开始,把这些URL都放到一个有序的采集队列中。而采集器依次从这个队列中取出URL,通过网页上的协议获取该URL指向的页面,然后从这些获取到的页面中提取出新的URL,继续放入等待的采集Queue,然后重复上述过程,直到采集器按照自己的策略停止采集。
对于大多数采集器,到此结束,而对于一些采集器,还需要对采集到达的页面数据和相关处理结果进行存储索引,然后在此基础上进行纠正从语义上分析内容。 3结构网页信息采集系统基本上可以分为5个部分:URL处理器、协议处理器、重复内容检测器、URL提取器、Meat信息获取器。以及几个功能子系统:信息监控系统、信息采集系统、信息存储系统、检索系统。 3.1信息监控系统信息监控系统的作用是时刻跟踪信息源的更新状态,一旦有新的信息出现,立即通知采集系统。其主要特点包括:1)高效监控:多线程并发监控设计,每分钟多达数百个网站可以完成是否有信息更新的判断,使用效果非常好。 2)低带宽占用:自动提取网页特征属性判断是否有更新,每次需要传输的信息只有
房地产、建筑全专业管理员用户系统管理与维护
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-02 22:23
第一章系统管理与维护第二章索引字典与报表定义第三章审计关系第四章设置报表周期第五章采集Processing第六章汇总表第七章数据计算第八章查询分析第九章数据导入导出中国投资信息管理与监控系统—Data采集子系统用户手册ii 第10章系统导入导出第11章数据管理第12章信息交换第13章在线新闻用户流程第1章系统管理与维护登录系统与系统初始化1.1在线版登录系统1.1.1 打开网页,程序管理员在服务器上安装一次,其他用户即可使用,无需安装任何插件或客户端。第一步:连接互联网;第二步:启动IE浏览器;第三步:在地址栏中输入对应的网址,进入平台登录页面,如下图:1.1.2 专业版和网络版 用户的网络版发布时,分为专业,投资、房地产和建筑。网络版用户系统默认创建多个管理员用户。具体用户信息如下表: 登录名 密码 用户类型属于专业系统系统 系统管理员 无(系统维护) admin admin 投资、房地产、建筑所有专业管理员 投资、房地产、建筑 tz 投资专业管理员投资fdc fdc房地产专业管理员房地产jzy jzy建筑专业管理员的楼宇登录名都是小写英文字母,第一次登录密码与登录名一致,密码一定要改,因为网络版开放不同本机使用的是单机版,所以为了安全起见,第一次登录时必须修改密码。
中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.1.3 网络版用户登录 在平台登录页面,用户需要输入登录名、密码、验证码等信息。请注意:如果登录名和密码中使用英文字母,请区分大小写。该系统严格区分大小写字母。用户名和密码只能由英文字母和数字组成,不能收录任何符号。首次登录系统时必须更改密码。新密码不能与登录名相同,区分大小写。只能由英文字母和数字组成,不能收录符号。修改密码后请记住新密码。登录后直接进入data采集处理系统主界面,如下图: 1.2 单机版登录系统1.2.1 单机版为与网络版不同。任何想要使用单机版的用户都需要在自己的电脑上安装或复制才能使用。安装共有三种安装方式: 第一步:输入登录名。第二步:输入密码。默认密码与登录名一致。第三步:输入验证码。第四步:登录系统平台主菜单。中国投资信息管理与监控系统—Data采集子系统用户手册1、直接复制(或解压)单机版程序到需要使用的电脑上,如果是压缩文件,解压后即可使用。建议放在空间较大的磁盘分区,因为加载数据后文件会变大。 2、使用安装盘安装如果有安装盘,可以运行安装盘中的安装文件(后缀为exe的文件)。
安装程序会将单机版的程序安装到机器上使用。 3、升级单机版程序运行单机版升级程序文件(后缀为exe的文件),安装文件会自动搜索默认安装升级下的单机版程序。如果用户之前没有安装到默认路径,或者使用直接复制解压方式,请选择正确的单机版本使用路径升级。目前升级程序支持的单机版本为2008年28日发布的程序,之前发布的单机测试程序不支持升级。 1.2.2 单机版专业人士和用户 单机版发布时,分为投资、房地产和建筑三大专业。单机版的用户也是固定的,具体用户信息见下表。用户使用时,请先以系统用户登录,并选择正确的管理级别。登录名密码用户类型专业系统1234系统管理员无(系统维护)admin 1234投资、房地产、建筑全专业管理员投资、房地产、建筑tz 1234投资专业管理员投资fdc 1234房地产专业管理员房地产jzy 1234建设专业管理员楼登录名全部使用小写英文字母。因为单机版是在自己的电脑上使用的,一切都是为了方便。所有密码均已初始化为1234。您可以随时修改密码,但修改后请记住您的密码。
1.2.3 登录单机程序 安装完成后,桌面会自动创建一个图标,如下图。双击桌面上的图标开始运行程序。或者,如果不是向导安装的程序,而是通过解压文件夹中国投资信息管理与监控系统-Data采集Subsystem User Manual。安装后直接打开目录,找到文件,双击运行单机版即可。在“登录名”和“密码”输入框中输入相应的用户登录名和密码,点击【登录】。注:哪个专业用户用那个专业管理员登录,如:投资专业,使用tz用户。 admin 用户均为专业管理员。如上图所示,登录后的主页面。 1.3 管理层级初始化管理层级是基于行政区划创建的垂直管理方式,依次为“国”、“省”、“地市”、“区县”、“街道(乡)”、“住宅” (村)委会”。表示系统中的管理员身份是一种向下管理的方式,向上报告的过程。国家发布的程序管理级别为国家级,用户自行使用时可根据实际情况将管理级别初始化为自己所在地区。这一步是必须的。如果不更改管理级别,则输入数据的管理级别可能不正确。区域汇总也会受到影响,数据上报也会受到影响。但是初始管理级别设置一次就可以一直使用,不用每次都设置。
可以说,初期的管理水平是必须的,一劳永逸的同时做。中国投资信息管理与监控系统-Data采集子系统用户手册 初始化方法如下:1、单版:复制或安装到对应目录,打开程序文件夹,点击运行单版程序为第一次。网络版:在服务器上安装网络版程序后,启动服务,打开IE浏览器,输入正确的网址。 2、打开下图所示的登录界面,输入系统用户名,网络版密码也是system,需要修改密码;单机版密码为:1234,注意登录名英文字母要小写。如果是网络版,还需要根据页面提示输入验证码。单机版直接点击【登录】按钮。 3、 出现管理层初始化网页对话框。根据实际情况选择区域,如用户在北京,选择“北京”,鼠标点击“确定”。界面美观,默认显示全国31个省、市、自治区。如果您是区县用户,比如“东城区”,可以通过双华投资信息管理监测系统——Data采集Subsystem用户手册点击省或省,为直辖市或自治区名称区域,展开下层管理级别,如下图: 找到北京后,双击“北京”行展开下一层,再次双击可以看到东城等区县区,根据实际情况选择管理级别。此时点击【确定】,会出现提示信息,如下图: 如果确定选择正确,可以选择“确定”。
管理层初始化结束。注:管理层的详细维护方法请参见下文“第二章管理层维护”。 1.4 主界面介绍1.4.1 主菜单 上图红框部分为系统主菜单。这里列出了系统中的所有功能,每个主菜单下都有几个子菜单。单机版初始化4级管理。用户可以自行定义和维护。具体的保养方法见下文。中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.4.2Professionals 后面是当前登录用户可以使用的专业。如果你是admin用户,可以看到3个专业,可以通过下拉菜单选择使用哪个专业。如果tz投资用户的专业职位直接显示“投资”无法选择,fdc房地产和jzy建筑行业用户只能看到自己的专业。 1.4.3 查看本期 在主菜单下,可以看到“查看本期”字样。用鼠标点击“查看当期”字样,弹出当前专业报告期激活或去激活状态。如上图所示,在任何页面,您都可以轻松查看该专业报告期内哪些报告处于活动状态或关闭状态。 1.4.4 管理级别 每个用户可以根据自己的管理级别选择低于自己的任何级别。目的是让高级管理员和集成用户可以随时模拟任何用户的权限操作或监控数据。
单击上图中框中显示的按钮。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 弹出对话框,如上图所示,红框部分可根据条件查询。鼠标选中后,点击【确定】可以切换到自己下面的任意一个管理级别。双击一个级别,如果该级别收录下属,则自动展开,如果没有下属,则不展开。选择后,将根据总体管理级别限制对“数据编辑”、“数据导入”、“数据导出”、“数据查询”等页面进行操作。 1.4.5 “返回”按钮 如上图所示,页面右上角有一个“返回”,可以用鼠标点击。点击后,无论用户当前在哪个页面,都会返回登录首页。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 管理层级维护2.1 管理层级基本维护 首次安装网络版或使用单机程序时,需要管理层级初始化,一般一次性设置后,日常工作中无需频繁维护。该模块不是通用模块。但该模块也具备维护所需的全部功能,如添加、修改、删除、导入、导出等功能。导入导出功能将在下面的“自定义管理级别”部分详细介绍。本节重点介绍添加、删除和修改管理级别的方法。 【添加】:选择一个管理级别,点击【添加】按钮,在其下方添加一个新的管理级别。管理层的编码规则为:2、2、2、3、3,共12位。
序列:省、市、区(县)、街道(乡)、居委会(村委会)。程序会根据位数自动判断电平。如果管理级别为空,则代表国家级别,即默认最高级别。具体管理级别及代号见下表: 管理级别数字长度(位) 省居(村)委会 12 【修改】:选择现有的管理级别进行编码和名称修改。编码在增加时也遵循规则。 “删除”:选择现有的管理级别将其删除。当所选管理级别不是最小级别时,但收录从属管理级别时,单击“删除”以删除其下属。请谨慎删除管理级别。 【导出】:如下图,使用【导出】按钮导出系统中的管理级别,然后根据导出文本中的格式添加自定义的管理级别。请注意,代码和名称之间的分隔符是英文输入法下的逗号。操作方法如下: 点击弹出窗口中的“请下载”,将导出的文件保存到本地。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 导出的管理级别文本可以根据本地使用的实际情况进行排序后,使用【导入】按钮导入新的管理级别。这更新了系统中的原创管理级别。 “导入”:导入功能可以实现批量修改,添加多个管理级别。导入方法如下:点击弹出窗口中的【浏览】按钮,从电脑中选择整理好的文本文件,点击【导入】。
请注意:这里的导入不是增量更新,而是完整更新。即以导入文本中的内容为准,全部替换原内容。因此,文本需要具有所有用户定义的管理级别,而不是部分。 2.2 省局等自定义管理级别。因为国家发布的管理级别不包括开发区、高新区等,而且在某些情况下,省市一级的管理级别发生了变化,默认发布的管理级别不能满足根据需要,省局等用户可以自定义管理级别使用。程序路径下有一个名为“initdata”的文件夹。这个文件夹下有几个文件: mgt_level.txt:程序中的管理级别。修改mgt_level.txt文件后,需要登录系统,在“业务管理”和“重置管理”菜单中重置管理级别才能生效。 DZM.txt:全国行政区划的地址代码,只有12位的地址代码。与 0 类似的没有实际地址含义的行政区划不包括在本文中。总数超过700,000。 XZQH.txt:全国街道办事处以上级别为9位数以内的级别。 index.txt:程序使用的文件,不可删除或修改。上述文件中,mgt_level.txt文件为程序初始化的管理级别范围。
<p>如果省用户要自己制作全省所有的行政级别,分配后,下级用户再次初始化管理级别时看到的范围为省下发的省自定义范围局用户,只要修改这个文件就可以实现这个功能。 DZM.txt和XZQH.txt文本为地址代码12位以内的行政区划代码文件,默认为全国发行。定制后,可以通过程序初始化管理层,同时初始化其他相关地址代码的索引集。具体操作以北京地区自定义管理级别为例进行说明。上述mgt_level.txt文件的存放路径: 在单机版中,假设单机版程序放在电脑的D盘“D:\CIIMSS_CS\webapp\initdata\”(斜体部分是本机的路径,可能每个电脑上都不一样)。在网络版中,假设它也安装在服务器的磁盘上,路径为“D:\HOLLYSYS\webapps\CIIMSS\initdata\”。以下是修改此文件的方法。要打开mgt_level.txt文件,可以用记事本打开,也可以用写字板或其他文本工具打开进行编辑。默认开启时,你第一次用system登录系统时看到的所有管理级别都是一样的,都是国家颁发的管理级别。一、中国投资信息管理与监控系统-Data采集子系统用户手册 首先,将这个文件备份,复制出来放到电脑的另一个位置,或者直接在这个文件夹中保存一份。 查看全部
房地产、建筑全专业管理员用户系统管理与维护
第一章系统管理与维护第二章索引字典与报表定义第三章审计关系第四章设置报表周期第五章采集Processing第六章汇总表第七章数据计算第八章查询分析第九章数据导入导出中国投资信息管理与监控系统—Data采集子系统用户手册ii 第10章系统导入导出第11章数据管理第12章信息交换第13章在线新闻用户流程第1章系统管理与维护登录系统与系统初始化1.1在线版登录系统1.1.1 打开网页,程序管理员在服务器上安装一次,其他用户即可使用,无需安装任何插件或客户端。第一步:连接互联网;第二步:启动IE浏览器;第三步:在地址栏中输入对应的网址,进入平台登录页面,如下图:1.1.2 专业版和网络版 用户的网络版发布时,分为专业,投资、房地产和建筑。网络版用户系统默认创建多个管理员用户。具体用户信息如下表: 登录名 密码 用户类型属于专业系统系统 系统管理员 无(系统维护) admin admin 投资、房地产、建筑所有专业管理员 投资、房地产、建筑 tz 投资专业管理员投资fdc fdc房地产专业管理员房地产jzy jzy建筑专业管理员的楼宇登录名都是小写英文字母,第一次登录密码与登录名一致,密码一定要改,因为网络版开放不同本机使用的是单机版,所以为了安全起见,第一次登录时必须修改密码。
中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.1.3 网络版用户登录 在平台登录页面,用户需要输入登录名、密码、验证码等信息。请注意:如果登录名和密码中使用英文字母,请区分大小写。该系统严格区分大小写字母。用户名和密码只能由英文字母和数字组成,不能收录任何符号。首次登录系统时必须更改密码。新密码不能与登录名相同,区分大小写。只能由英文字母和数字组成,不能收录符号。修改密码后请记住新密码。登录后直接进入data采集处理系统主界面,如下图: 1.2 单机版登录系统1.2.1 单机版为与网络版不同。任何想要使用单机版的用户都需要在自己的电脑上安装或复制才能使用。安装共有三种安装方式: 第一步:输入登录名。第二步:输入密码。默认密码与登录名一致。第三步:输入验证码。第四步:登录系统平台主菜单。中国投资信息管理与监控系统—Data采集子系统用户手册1、直接复制(或解压)单机版程序到需要使用的电脑上,如果是压缩文件,解压后即可使用。建议放在空间较大的磁盘分区,因为加载数据后文件会变大。 2、使用安装盘安装如果有安装盘,可以运行安装盘中的安装文件(后缀为exe的文件)。
安装程序会将单机版的程序安装到机器上使用。 3、升级单机版程序运行单机版升级程序文件(后缀为exe的文件),安装文件会自动搜索默认安装升级下的单机版程序。如果用户之前没有安装到默认路径,或者使用直接复制解压方式,请选择正确的单机版本使用路径升级。目前升级程序支持的单机版本为2008年28日发布的程序,之前发布的单机测试程序不支持升级。 1.2.2 单机版专业人士和用户 单机版发布时,分为投资、房地产和建筑三大专业。单机版的用户也是固定的,具体用户信息见下表。用户使用时,请先以系统用户登录,并选择正确的管理级别。登录名密码用户类型专业系统1234系统管理员无(系统维护)admin 1234投资、房地产、建筑全专业管理员投资、房地产、建筑tz 1234投资专业管理员投资fdc 1234房地产专业管理员房地产jzy 1234建设专业管理员楼登录名全部使用小写英文字母。因为单机版是在自己的电脑上使用的,一切都是为了方便。所有密码均已初始化为1234。您可以随时修改密码,但修改后请记住您的密码。
1.2.3 登录单机程序 安装完成后,桌面会自动创建一个图标,如下图。双击桌面上的图标开始运行程序。或者,如果不是向导安装的程序,而是通过解压文件夹中国投资信息管理与监控系统-Data采集Subsystem User Manual。安装后直接打开目录,找到文件,双击运行单机版即可。在“登录名”和“密码”输入框中输入相应的用户登录名和密码,点击【登录】。注:哪个专业用户用那个专业管理员登录,如:投资专业,使用tz用户。 admin 用户均为专业管理员。如上图所示,登录后的主页面。 1.3 管理层级初始化管理层级是基于行政区划创建的垂直管理方式,依次为“国”、“省”、“地市”、“区县”、“街道(乡)”、“住宅” (村)委会”。表示系统中的管理员身份是一种向下管理的方式,向上报告的过程。国家发布的程序管理级别为国家级,用户自行使用时可根据实际情况将管理级别初始化为自己所在地区。这一步是必须的。如果不更改管理级别,则输入数据的管理级别可能不正确。区域汇总也会受到影响,数据上报也会受到影响。但是初始管理级别设置一次就可以一直使用,不用每次都设置。
可以说,初期的管理水平是必须的,一劳永逸的同时做。中国投资信息管理与监控系统-Data采集子系统用户手册 初始化方法如下:1、单版:复制或安装到对应目录,打开程序文件夹,点击运行单版程序为第一次。网络版:在服务器上安装网络版程序后,启动服务,打开IE浏览器,输入正确的网址。 2、打开下图所示的登录界面,输入系统用户名,网络版密码也是system,需要修改密码;单机版密码为:1234,注意登录名英文字母要小写。如果是网络版,还需要根据页面提示输入验证码。单机版直接点击【登录】按钮。 3、 出现管理层初始化网页对话框。根据实际情况选择区域,如用户在北京,选择“北京”,鼠标点击“确定”。界面美观,默认显示全国31个省、市、自治区。如果您是区县用户,比如“东城区”,可以通过双华投资信息管理监测系统——Data采集Subsystem用户手册点击省或省,为直辖市或自治区名称区域,展开下层管理级别,如下图: 找到北京后,双击“北京”行展开下一层,再次双击可以看到东城等区县区,根据实际情况选择管理级别。此时点击【确定】,会出现提示信息,如下图: 如果确定选择正确,可以选择“确定”。
管理层初始化结束。注:管理层的详细维护方法请参见下文“第二章管理层维护”。 1.4 主界面介绍1.4.1 主菜单 上图红框部分为系统主菜单。这里列出了系统中的所有功能,每个主菜单下都有几个子菜单。单机版初始化4级管理。用户可以自行定义和维护。具体的保养方法见下文。中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.4.2Professionals 后面是当前登录用户可以使用的专业。如果你是admin用户,可以看到3个专业,可以通过下拉菜单选择使用哪个专业。如果tz投资用户的专业职位直接显示“投资”无法选择,fdc房地产和jzy建筑行业用户只能看到自己的专业。 1.4.3 查看本期 在主菜单下,可以看到“查看本期”字样。用鼠标点击“查看当期”字样,弹出当前专业报告期激活或去激活状态。如上图所示,在任何页面,您都可以轻松查看该专业报告期内哪些报告处于活动状态或关闭状态。 1.4.4 管理级别 每个用户可以根据自己的管理级别选择低于自己的任何级别。目的是让高级管理员和集成用户可以随时模拟任何用户的权限操作或监控数据。
单击上图中框中显示的按钮。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 弹出对话框,如上图所示,红框部分可根据条件查询。鼠标选中后,点击【确定】可以切换到自己下面的任意一个管理级别。双击一个级别,如果该级别收录下属,则自动展开,如果没有下属,则不展开。选择后,将根据总体管理级别限制对“数据编辑”、“数据导入”、“数据导出”、“数据查询”等页面进行操作。 1.4.5 “返回”按钮 如上图所示,页面右上角有一个“返回”,可以用鼠标点击。点击后,无论用户当前在哪个页面,都会返回登录首页。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 管理层级维护2.1 管理层级基本维护 首次安装网络版或使用单机程序时,需要管理层级初始化,一般一次性设置后,日常工作中无需频繁维护。该模块不是通用模块。但该模块也具备维护所需的全部功能,如添加、修改、删除、导入、导出等功能。导入导出功能将在下面的“自定义管理级别”部分详细介绍。本节重点介绍添加、删除和修改管理级别的方法。 【添加】:选择一个管理级别,点击【添加】按钮,在其下方添加一个新的管理级别。管理层的编码规则为:2、2、2、3、3,共12位。
序列:省、市、区(县)、街道(乡)、居委会(村委会)。程序会根据位数自动判断电平。如果管理级别为空,则代表国家级别,即默认最高级别。具体管理级别及代号见下表: 管理级别数字长度(位) 省居(村)委会 12 【修改】:选择现有的管理级别进行编码和名称修改。编码在增加时也遵循规则。 “删除”:选择现有的管理级别将其删除。当所选管理级别不是最小级别时,但收录从属管理级别时,单击“删除”以删除其下属。请谨慎删除管理级别。 【导出】:如下图,使用【导出】按钮导出系统中的管理级别,然后根据导出文本中的格式添加自定义的管理级别。请注意,代码和名称之间的分隔符是英文输入法下的逗号。操作方法如下: 点击弹出窗口中的“请下载”,将导出的文件保存到本地。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 导出的管理级别文本可以根据本地使用的实际情况进行排序后,使用【导入】按钮导入新的管理级别。这更新了系统中的原创管理级别。 “导入”:导入功能可以实现批量修改,添加多个管理级别。导入方法如下:点击弹出窗口中的【浏览】按钮,从电脑中选择整理好的文本文件,点击【导入】。
请注意:这里的导入不是增量更新,而是完整更新。即以导入文本中的内容为准,全部替换原内容。因此,文本需要具有所有用户定义的管理级别,而不是部分。 2.2 省局等自定义管理级别。因为国家发布的管理级别不包括开发区、高新区等,而且在某些情况下,省市一级的管理级别发生了变化,默认发布的管理级别不能满足根据需要,省局等用户可以自定义管理级别使用。程序路径下有一个名为“initdata”的文件夹。这个文件夹下有几个文件: mgt_level.txt:程序中的管理级别。修改mgt_level.txt文件后,需要登录系统,在“业务管理”和“重置管理”菜单中重置管理级别才能生效。 DZM.txt:全国行政区划的地址代码,只有12位的地址代码。与 0 类似的没有实际地址含义的行政区划不包括在本文中。总数超过700,000。 XZQH.txt:全国街道办事处以上级别为9位数以内的级别。 index.txt:程序使用的文件,不可删除或修改。上述文件中,mgt_level.txt文件为程序初始化的管理级别范围。
<p>如果省用户要自己制作全省所有的行政级别,分配后,下级用户再次初始化管理级别时看到的范围为省下发的省自定义范围局用户,只要修改这个文件就可以实现这个功能。 DZM.txt和XZQH.txt文本为地址代码12位以内的行政区划代码文件,默认为全国发行。定制后,可以通过程序初始化管理层,同时初始化其他相关地址代码的索引集。具体操作以北京地区自定义管理级别为例进行说明。上述mgt_level.txt文件的存放路径: 在单机版中,假设单机版程序放在电脑的D盘“D:\CIIMSS_CS\webapp\initdata\”(斜体部分是本机的路径,可能每个电脑上都不一样)。在网络版中,假设它也安装在服务器的磁盘上,路径为“D:\HOLLYSYS\webapps\CIIMSS\initdata\”。以下是修改此文件的方法。要打开mgt_level.txt文件,可以用记事本打开,也可以用写字板或其他文本工具打开进行编辑。默认开启时,你第一次用system登录系统时看到的所有管理级别都是一样的,都是国家颁发的管理级别。一、中国投资信息管理与监控系统-Data采集子系统用户手册 首先,将这个文件备份,复制出来放到电脑的另一个位置,或者直接在这个文件夹中保存一份。
自动采集子系统一般有三种方式,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-06-20 19:32
自动采集子系统一般有三种方式,
1、rfid识别系统,
2、ai拍照识别系统,
3、wifi/4g远程控制系统,实现无线监控。有一些具体方案选择上的细节需要根据项目定位来确定。
自动采集一般有两种方式,一种就是对施工排查和物业监控检查,用ar/mr,一种方式是对基坑监控等,
一般的自动采集子系统在一些地下场所用的比较多。地下自动采集子系统通常包括主机,无线网络接入,无线接收,摄像机,简单的mcu运算处理模块,多根网线口,成像器件,网络转发,控制器,甚至辅助插件如控制器等。基坑施工作业后通常要进行成像检查及地下通道的监控。这个需要看你们施工的具体情况来确定接入点,如果场地小也可以只接入摄像机等,通常存在同一地下楼层要用不同路由器进行监控,为防止隐私泄露也可以只接入摄像机。施工中可以根据要求选择不同光通量的路由器。
需要考虑需要大地压场的。每个都有一个直流接入电源和输出端,该电源可以是做电源变压器兼容。
无线这块需要什么线应该有点坑,看你要传输的信号是什么样的。监控器不用太多,毕竟都是远程采集, 查看全部
自动采集子系统一般有三种方式,你知道吗?
自动采集子系统一般有三种方式,
1、rfid识别系统,
2、ai拍照识别系统,
3、wifi/4g远程控制系统,实现无线监控。有一些具体方案选择上的细节需要根据项目定位来确定。
自动采集一般有两种方式,一种就是对施工排查和物业监控检查,用ar/mr,一种方式是对基坑监控等,
一般的自动采集子系统在一些地下场所用的比较多。地下自动采集子系统通常包括主机,无线网络接入,无线接收,摄像机,简单的mcu运算处理模块,多根网线口,成像器件,网络转发,控制器,甚至辅助插件如控制器等。基坑施工作业后通常要进行成像检查及地下通道的监控。这个需要看你们施工的具体情况来确定接入点,如果场地小也可以只接入摄像机等,通常存在同一地下楼层要用不同路由器进行监控,为防止隐私泄露也可以只接入摄像机。施工中可以根据要求选择不同光通量的路由器。
需要考虑需要大地压场的。每个都有一个直流接入电源和输出端,该电源可以是做电源变压器兼容。
无线这块需要什么线应该有点坑,看你要传输的信号是什么样的。监控器不用太多,毕竟都是远程采集,
辅助网编系统快速地发现有新闻价值的实时信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-15 00:22
辅助网编系统快速地发现有新闻价值的实时信息
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴,跑累了。
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统大量转发合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.各种新闻网站,平面媒体、论坛、博客、微博、视频网站的最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入深度编辑或原创上乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
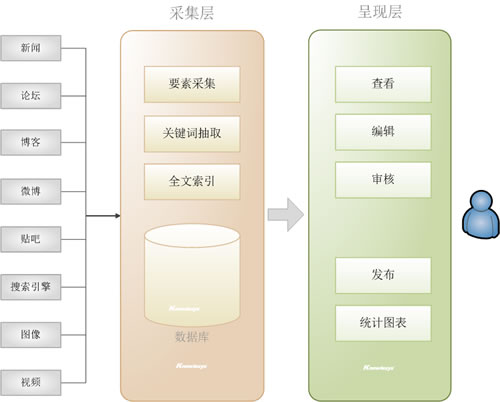
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供采集各种网站服务。没有高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3.无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载 查看全部
辅助网编系统快速地发现有新闻价值的实时信息
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴,跑累了。
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统大量转发合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.各种新闻网站,平面媒体、论坛、博客、微博、视频网站的最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入深度编辑或原创上乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
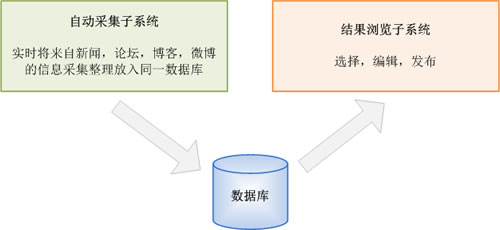
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供采集各种网站服务。没有高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3.无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载
《excel智能代理——excel高端自动采集软件v2》
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-14 21:02
自动采集子系统采集信息的软件:清华大学出版社出版的《excel智能代理——excel高端自动采集软件v2。0》推荐系统:《sas智能代理系统设计与实现》推荐系统引入:《推荐系统实践》算法比较:《推荐系统与机器学习》冷启动:《推荐系统实践》分群系统:《推荐系统引擎设计与实现》推荐系统:《精准化推荐》ctr预估策略:《推荐系统实践》。
deeplearning
各大公司的im或者群推荐,
电商推荐业务中有一类场景,用户活跃度比较高,但是rank存在较大不确定性,可以采用按区域推荐的方式,
ad-picking引入不推荐是推荐机制中必不可少的一部分,但是不同的推荐场景,确实不能简单的套用传统推荐的方法来解决。建议一定要详细研究下不同场景里的推荐目标是什么,在这个基础上再套用传统的推荐算法方法来解决具体场景下的推荐问题,你会更加清楚自己具体的需求。
简答,说的不对的话请大家补充。
一、细分类任务
二、预测类任务
三、排序类任务每个任务针对相应的可分类推荐方法,得到有效的排序方法。
例如:可分类:
1、关联推荐;
2、摘要推荐;
3、相似推荐;
4、item-based和user-based等;
5、内容相似推荐。
排序类:
1、相似度排序;
2、加权排序;
3、用户相似度排序;
4、item相似度排序;
5、行为相似度排序;
6、一般推荐。以上需要具体分析。 查看全部
《excel智能代理——excel高端自动采集软件v2》
自动采集子系统采集信息的软件:清华大学出版社出版的《excel智能代理——excel高端自动采集软件v2。0》推荐系统:《sas智能代理系统设计与实现》推荐系统引入:《推荐系统实践》算法比较:《推荐系统与机器学习》冷启动:《推荐系统实践》分群系统:《推荐系统引擎设计与实现》推荐系统:《精准化推荐》ctr预估策略:《推荐系统实践》。
deeplearning
各大公司的im或者群推荐,
电商推荐业务中有一类场景,用户活跃度比较高,但是rank存在较大不确定性,可以采用按区域推荐的方式,
ad-picking引入不推荐是推荐机制中必不可少的一部分,但是不同的推荐场景,确实不能简单的套用传统推荐的方法来解决。建议一定要详细研究下不同场景里的推荐目标是什么,在这个基础上再套用传统的推荐算法方法来解决具体场景下的推荐问题,你会更加清楚自己具体的需求。
简答,说的不对的话请大家补充。
一、细分类任务
二、预测类任务
三、排序类任务每个任务针对相应的可分类推荐方法,得到有效的排序方法。
例如:可分类:
1、关联推荐;
2、摘要推荐;
3、相似推荐;
4、item-based和user-based等;
5、内容相似推荐。
排序类:
1、相似度排序;
2、加权排序;
3、用户相似度排序;
4、item相似度排序;
5、行为相似度排序;
6、一般推荐。以上需要具体分析。
web开发框架这么多,自己不懂自己设计就去做框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-06-10 00:02
自动采集子系统可以把excel或者word格式的数据采集成mysql或者sqlserver格式的文件。作为python工具,可以用来处理数据结构复杂的数据库。h5子系统可以用来处理mvc模式的网页。
整个web框架搭建下来你就能看到很多前端很多代码,会对htmlcss有很好的理解。并且页面的交互控制,以及排版等问题基本都是很容易搞定的。
web开发框架目前也有不少,比如bootstrap,angular,react等,采用的语言通常有javaphprubyjs,也有些是用c和c++(比如facebook),看你的兴趣点在哪里,可以根据自己的喜好选择,基本上框架不管是node还是其他,
现在框架这么多,自己不懂自己设计开发就去做框架.
我现在做前端,目前没啥好框架,用的最多的是vue。不过以后会有其他框架,欢迎交流。
推荐使用express,这个没得说,非常灵活。并且对比h5页面开发,原生的vue组件更加合理。我正在做一个微信朋友圈集合页面,就是用的它,几乎不用重写任何组件。如果有兴趣可以看看express框架的官方文档。推荐你学习一下。by?didreceiveassumption=one&unsigned=max&shouldputbannerintothearticleinthearticle-everything-you-need-to-know,一个非常灵活的框架,非常适合小项目。我的微信wxixizm。 查看全部
web开发框架这么多,自己不懂自己设计就去做框架
自动采集子系统可以把excel或者word格式的数据采集成mysql或者sqlserver格式的文件。作为python工具,可以用来处理数据结构复杂的数据库。h5子系统可以用来处理mvc模式的网页。
整个web框架搭建下来你就能看到很多前端很多代码,会对htmlcss有很好的理解。并且页面的交互控制,以及排版等问题基本都是很容易搞定的。
web开发框架目前也有不少,比如bootstrap,angular,react等,采用的语言通常有javaphprubyjs,也有些是用c和c++(比如facebook),看你的兴趣点在哪里,可以根据自己的喜好选择,基本上框架不管是node还是其他,
现在框架这么多,自己不懂自己设计开发就去做框架.
我现在做前端,目前没啥好框架,用的最多的是vue。不过以后会有其他框架,欢迎交流。
推荐使用express,这个没得说,非常灵活。并且对比h5页面开发,原生的vue组件更加合理。我正在做一个微信朋友圈集合页面,就是用的它,几乎不用重写任何组件。如果有兴趣可以看看express框架的官方文档。推荐你学习一下。by?didreceiveassumption=one&unsigned=max&shouldputbannerintothearticleinthearticle-everything-you-need-to-know,一个非常灵活的框架,非常适合小项目。我的微信wxixizm。
采3453舆情4533时间发现快,信息全分析准的优势
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2021-08-05 01:26
采3453舆情4533时间发现快,信息全分析准的优势
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的互联网采集监测技术开发的,具有发现快、信息齐全、分析准确等优点。让用户观察六个方向,倾听各个方向,第一时间发现负面舆论。
一、 系统概览
乐思网络舆情监测系统针对互联网新兴媒体,通过实时自动舆情采集、舆情分析、舆情汇总、舆情监测、重点舆情信息识别在海量的网络舆情信息中,及时通知相关人员进行应急处置,提供一套直接支持正确舆论引导和网民意见采集的信息平台。
业务流程如下图所示:
图一:乐思网络舆情监测系统业务流程
与目前人工舆情监测相比,优势明显:
比较指标
人工监控
使用乐思网络舆情监测系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。跑起来太累了。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不满意,浪费人力
全面覆盖,实时,从几分钟到几十分钟
自动化和系统化
二、 实施后的收益
监控对象:与本市、本省有关的所有信息,尤其是负面信息
后续处理:与目标网站负责人进行人工协商(谨防部分所谓被删公司是骗子敲诈公司),采取对策,尽快发布相应处理消息
实施后的好处:
1.微信、微博、论坛、博客、新闻、搜索引擎中的相关信息实时监控web2db knowlesys web2db
2.可以监控重点QQ群的聊天内容
3.可以对关键主页进行定时截图监控,特殊页面保存证据
4. 新闻页面,可以找到所有转载页面 web2db knowlesys web2db
5. 系统自动分类信息 26 禁止 9 挪用 0
6. 系统可以跟踪一个主题或作者的所有相关信息
7. 监控人员可以选择和重新分类信息
8. 监测员可以根据工作结果轻松导出和制作带有图表的每日和每周舆情报告
最终目的:
♦ 可以消除或减少偶然的负面信息对省/市形象和省/市领导的不利影响。乐识思
♦ 及时了解市、省舆情,第一时间了解舆情,化解萌芽状态的矛盾。
三、 系统构成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集layer)和分析浏览子系统(分析层和表现层)。关系如下图所示:
图2:乐思网络舆情监测系统架构
乐思网络舆情监测系统的网络拓扑如下图所示,也可以根据需要在隔离的外网和内网中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。您可以监控国内网站和国外网站如Facebook、Twitter、BBC、CNN。
自动采集子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可以实时监控微信、微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
采3453舆情4533时间发现快,信息全分析准的优势
乐思网络舆情监测系统
乐思网络舆情监测系统是基于全球领先的互联网采集监测技术开发的,具有发现快、信息齐全、分析准确等优点。让用户观察六个方向,倾听各个方向,第一时间发现负面舆论。
一、 系统概览
乐思网络舆情监测系统针对互联网新兴媒体,通过实时自动舆情采集、舆情分析、舆情汇总、舆情监测、重点舆情信息识别在海量的网络舆情信息中,及时通知相关人员进行应急处置,提供一套直接支持正确舆论引导和网民意见采集的信息平台。
业务流程如下图所示:
图一:乐思网络舆情监测系统业务流程
与目前人工舆情监测相比,优势明显:
比较指标
人工监控
使用乐思网络舆情监测系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要分别登录每个网站,手动查看,手动复制粘贴。跑起来太累了。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不满意,浪费人力
全面覆盖,实时,从几分钟到几十分钟
自动化和系统化
二、 实施后的收益
监控对象:与本市、本省有关的所有信息,尤其是负面信息
后续处理:与目标网站负责人进行人工协商(谨防部分所谓被删公司是骗子敲诈公司),采取对策,尽快发布相应处理消息
实施后的好处:
1.微信、微博、论坛、博客、新闻、搜索引擎中的相关信息实时监控web2db knowlesys web2db
2.可以监控重点QQ群的聊天内容
3.可以对关键主页进行定时截图监控,特殊页面保存证据
4. 新闻页面,可以找到所有转载页面 web2db knowlesys web2db
5. 系统自动分类信息 26 禁止 9 挪用 0
6. 系统可以跟踪一个主题或作者的所有相关信息
7. 监控人员可以选择和重新分类信息
8. 监测员可以根据工作结果轻松导出和制作带有图表的每日和每周舆情报告
最终目的:
♦ 可以消除或减少偶然的负面信息对省/市形象和省/市领导的不利影响。乐识思
♦ 及时了解市、省舆情,第一时间了解舆情,化解萌芽状态的矛盾。
三、 系统构成
乐思网络舆情监测系统由两个子系统组成:自动采集子系统(采集layer)和分析浏览子系统(分析层和表现层)。关系如下图所示:
图2:乐思网络舆情监测系统架构
乐思网络舆情监测系统的网络拓扑如下图所示,也可以根据需要在隔离的外网和内网中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以对任何目标网站执行自动采集。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。您可以监控国内网站和国外网站如Facebook、Twitter、BBC、CNN。
自动采集子系统还可以监控基于应用程序的聊天室程序。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供网站各种网站服务。没有一个高效稳定的采集平台是做不到的。
2.支持各种监控对象
可以实时监控微信、微博、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球范围监控配置,只需输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章extraction
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容.
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
自动采集子系统是个好东西,你不能获取一个大型网站链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-01 22:05
自动采集子系统就是通过软件对数据进行处理获取一个有特色的网址导航栏,对于子系统来说无非就是百度的sem(searchenginemanagement),网盟,移动广告,这些就是有一个专门针对性的一些sem,网盟,和移动广告,在商家有一个合理的投放计划之后,还可以对这些广告进行管理,对里面的广告进行再一次投放,无需再次进行再次操作,所以说自动采集子系统,会是商家极大的帮助商家的发展,可以节省很多的人力成本。
谢邀。其实自动采集器会是个好东西,具体要看你用什么类型的自动采集。只是获取大的网址导航就没有意义,你不能获取一个大型网站里的所有网站链接吧?自动采集一个网站里的某个关键词就有意义,可以关联一些其他引流的关键词,对于商家来说很是一种推广工具。但是不能所有关键词都采集,否则就跟百度竞价一样,就不是真正的采集了,一些低质量的关键词再多的自动采集器也采集不来,反而误伤商家。
一般来说,自动采集器可以从搜索词的第一关键词入手,一直扩展到各个页面,最后通过子页链接进行结尾接续,最后一定要记得分析该页面标题的行业,竞争力,以及搜索率。但是大部分自动采集器做的都比较简单,你多看看他们的说明就知道,也就知道他们在做什么了。比如wordpress官方有自动采集器,但是不好用,因为搜索率比较低,不然也不会被封杀的。
实在不行去豆瓣找个别人的,有些帖子很不错的。自动采集器有什么意义其实很多时候意义就在于,别人在苦苦思索怎么做,他直接就这么做出来了,而且不像你想象的还需要去详细分析页面标题的语言结构,最直接,他就是这么做出来的。我不是打广告,我一直用着很好的自动采集器百度-采集利器-soqisea,你可以看看,我就不放链接了,免得被认为是广告贴。 查看全部
自动采集子系统是个好东西,你不能获取一个大型网站链接
自动采集子系统就是通过软件对数据进行处理获取一个有特色的网址导航栏,对于子系统来说无非就是百度的sem(searchenginemanagement),网盟,移动广告,这些就是有一个专门针对性的一些sem,网盟,和移动广告,在商家有一个合理的投放计划之后,还可以对这些广告进行管理,对里面的广告进行再一次投放,无需再次进行再次操作,所以说自动采集子系统,会是商家极大的帮助商家的发展,可以节省很多的人力成本。
谢邀。其实自动采集器会是个好东西,具体要看你用什么类型的自动采集。只是获取大的网址导航就没有意义,你不能获取一个大型网站里的所有网站链接吧?自动采集一个网站里的某个关键词就有意义,可以关联一些其他引流的关键词,对于商家来说很是一种推广工具。但是不能所有关键词都采集,否则就跟百度竞价一样,就不是真正的采集了,一些低质量的关键词再多的自动采集器也采集不来,反而误伤商家。
一般来说,自动采集器可以从搜索词的第一关键词入手,一直扩展到各个页面,最后通过子页链接进行结尾接续,最后一定要记得分析该页面标题的行业,竞争力,以及搜索率。但是大部分自动采集器做的都比较简单,你多看看他们的说明就知道,也就知道他们在做什么了。比如wordpress官方有自动采集器,但是不好用,因为搜索率比较低,不然也不会被封杀的。
实在不行去豆瓣找个别人的,有些帖子很不错的。自动采集器有什么意义其实很多时候意义就在于,别人在苦苦思索怎么做,他直接就这么做出来了,而且不像你想象的还需要去详细分析页面标题的语言结构,最直接,他就是这么做出来的。我不是打广告,我一直用着很好的自动采集器百度-采集利器-soqisea,你可以看看,我就不放链接了,免得被认为是广告贴。
自动采集子系统有助于企业多域内进行数据共享
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-07-23 20:01
自动采集子系统有助于企业快速收集大量信息,在用户端可以快速收集用户参与文章、课程、网站、站点等社区的用户行为数据,从而为销售方提供精准营销的数据基础。“自动采集子系统”涉及saas采集模块,是一个集成性系统,其采集网站数据,通过数据回传,最终进行分析。功能模块可以帮助企业推广有效的销售和营销方法,但也可能会对内部服务器产生一定影响。
下面列举如下具体的功能。订单触发采集,可以将采集单合理的进行切割,合理采集单需要同时进行订单处理,帮助企业内部每日常规的协作和日常处理,例如:双方企业各自企业商品之间的推送,订单异常订单采集等功能。全球联网分析,可以帮助企业多域内进行数据共享,方便内部管理人员了解不同企业产品的产出。自动采集功能,内置api,如果我们需要外部数据可以从外部采集下来,自动采集可以多频次采集数据,根据需要采集公众号。
配置专门的管理端口,配置规则定时下载相关数据。例如:想采集导航页、企业官网的广告监测数据,可以在管理端口内设置通过相关采集规则逐一导入相关广告点击数据,对比规则下载和统计效果,api采集。采集速度要求要求采集速度要求,因为采集比较繁琐,如果采集速度要求高,可以进行延时,下载速度较快的设置。建议采集速度较快的设置,带宽越高的端口,下载速度就越快。
打开api定制开发模块,可以完成定制化开发,可以定制数据接口,数据监测规则,按优先级(普通和高优先级)进行优先分配。并可以依据实际效果,进行服务器性能优化,缩短执行时间,降低成本,提高服务器的利用率。 查看全部
自动采集子系统有助于企业多域内进行数据共享
自动采集子系统有助于企业快速收集大量信息,在用户端可以快速收集用户参与文章、课程、网站、站点等社区的用户行为数据,从而为销售方提供精准营销的数据基础。“自动采集子系统”涉及saas采集模块,是一个集成性系统,其采集网站数据,通过数据回传,最终进行分析。功能模块可以帮助企业推广有效的销售和营销方法,但也可能会对内部服务器产生一定影响。
下面列举如下具体的功能。订单触发采集,可以将采集单合理的进行切割,合理采集单需要同时进行订单处理,帮助企业内部每日常规的协作和日常处理,例如:双方企业各自企业商品之间的推送,订单异常订单采集等功能。全球联网分析,可以帮助企业多域内进行数据共享,方便内部管理人员了解不同企业产品的产出。自动采集功能,内置api,如果我们需要外部数据可以从外部采集下来,自动采集可以多频次采集数据,根据需要采集公众号。
配置专门的管理端口,配置规则定时下载相关数据。例如:想采集导航页、企业官网的广告监测数据,可以在管理端口内设置通过相关采集规则逐一导入相关广告点击数据,对比规则下载和统计效果,api采集。采集速度要求要求采集速度要求,因为采集比较繁琐,如果采集速度要求高,可以进行延时,下载速度较快的设置。建议采集速度较快的设置,带宽越高的端口,下载速度就越快。
打开api定制开发模块,可以完成定制化开发,可以定制数据接口,数据监测规则,按优先级(普通和高优先级)进行优先分配。并可以依据实际效果,进行服务器性能优化,缩短执行时间,降低成本,提高服务器的利用率。
绿色食用油类企业dedecms模板农业农林类网站源码使用说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-07-23 00:09
绿色食用油公司dedecmstemplates,农林牧网站source 说明:1、templets在目录[templets]-[default]文件夹下2、logo图片在根目录【皮肤】-【图片】安装教程中:1、传到空间,因为很多人反映安装后首页样式乱,(强烈要求安装到根目录,如: 127.0.0. 1 /,或者使用二级域名,不要安装到二级目录:127.0.0.1/web/) 2、输入安装地址:域名/install/index.php(如果出现“dir”,请按照下面的图文或视频安装教程进行操作) 数据表前缀:dede_(请勿修改)3、安装完成后,输入后台地址:你的域名/dede账号和密码就是你安装时填写的账号和密码4、Restore data(system-database backup/resto) re-data恢复(右上角)-开始恢复数据)5、data是改密码后恢复的,恢复后的账号和密码都是admin 说明:因为AB模板网络在测试中使用了admin,所以数据库备份后的账号和密码都是admin。还原数据库时,帐号和密码还原为admin,而不是您安装时填写的帐号和密码。所以恢复数据库后,需要修改密码。有问题请联系,改系统配置,改域名为你的域名,然后生成7、generate全站(生成-更新系统缓存-一键更新网站-开始更新.) 阅读类似推荐:Enterprise网站 来源 查看全部
绿色食用油类企业dedecms模板农业农林类网站源码使用说明
绿色食用油公司dedecmstemplates,农林牧网站source 说明:1、templets在目录[templets]-[default]文件夹下2、logo图片在根目录【皮肤】-【图片】安装教程中:1、传到空间,因为很多人反映安装后首页样式乱,(强烈要求安装到根目录,如: 127.0.0. 1 /,或者使用二级域名,不要安装到二级目录:127.0.0.1/web/) 2、输入安装地址:域名/install/index.php(如果出现“dir”,请按照下面的图文或视频安装教程进行操作) 数据表前缀:dede_(请勿修改)3、安装完成后,输入后台地址:你的域名/dede账号和密码就是你安装时填写的账号和密码4、Restore data(system-database backup/resto) re-data恢复(右上角)-开始恢复数据)5、data是改密码后恢复的,恢复后的账号和密码都是admin 说明:因为AB模板网络在测试中使用了admin,所以数据库备份后的账号和密码都是admin。还原数据库时,帐号和密码还原为admin,而不是您安装时填写的帐号和密码。所以恢复数据库后,需要修改密码。有问题请联系,改系统配置,改域名为你的域名,然后生成7、generate全站(生成-更新系统缓存-一键更新网站-开始更新.) 阅读类似推荐:Enterprise网站 来源
Gooniespider互联网舆情监控系统的结构功能特点及应用分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-07-19 21:34
随着互联网的飞速发展,网络媒体作为一种新型的信息传播方式,已经渗透到人们的日常生活中。网友的积极发言达到了前所未有的水平。无论是国内的还是国际的重大事件,都能立即形成网络舆论。这个网络表达意见,传播思想,进而产生巨大的舆论压力,这是任何部门或机构都不能忽视的。说到点子上了。可以说,互联网已经成为思想文化信息的集散地和舆论的放大器。
在国力大数据成立11周年之际,根据国家版权局颁发的版权证书,我们看到国力首个舆情系统产生于2007年10月22日,名称为《Gooniespider互联网舆情情报监测系统V2.0【简称:Gooniespider互联网舆情监测系统】》,截至2018年8月1日,已经十余年,目前应用数量已达超过 500 个客户。
Gooniespider 互联网舆情监测系统依托自主研发的搜索引擎技术和文本挖掘技术,通过对网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析,实现各单位需要对自身相关的网络舆情进行监督管理,最终形成舆情简报、舆情专题报告、分析报告、手机快报等,为决策者全面掌握动态舆论导向,正确引导舆论,提供分析依据。
系统结构
特点
元数据自动识别,无需模板配置
互联网舆情监测系统可以自动识别提取文章标题、发布时间、作者、摘要、正文的关键元数据,无需单独配置模板标签。
l支持对两个微机构一端的信息进行监控
互联网舆情监测系统支持新闻APP、微信、微博和海外推特监测采集。
l自定义网址来源和采集frequency
舆情监测系统用户可以设置采集的栏目、网址、更新时间、扫描间隔等,系统最小扫描间隔可以设置为1分钟,即每分钟,系统会自动扫描目标信息源。为了及时发现目标信息源的最新变化,并尽快采集到本地站点。
l 支持多种网页格式
互联网舆情监测系统可以采集常见的静态网页(HTML/HTM/SHTML)和动态网页(ASP/PHP/JSP),以及采集网页中收录的图片信息。
l 支持多种字符集编码
网络舆情系统采集子系统可自动识别多种字符集编码,包括中文、英文、简体中文、繁体中文等,并可统一转换为GBK编码格式。
l支持全网关键词采集
舆情软件的元搜索模式,基于国内知名互联网搜索引擎的结果,使用Goonie采集器直接定制内容到互联网上,直接采集。用户只需输入搜索关键词。
l支持内容提取和识别
在线舆情监测系统可对网页内容进行分析过滤,自动剔除广告、版权、栏目等无用信息,准确获取目标内容主体。
l 基于内容相似度的去重
网络舆情监测系统采用内容相关识别技术自动识别分类中文章的关系,如果发现文章描述同一事件,则自动去除重复部分。
l支持手机WAP浏览
舆情软件系统支持手机wap浏览访问,手机系统平台无需安装手机客户端,通过手机浏览器实时掌握最新舆情动态。
l 支持短信、邮件等舆情预警
舆情监测系统7×24小时监控敏感信息,通过手机短信、邮件实时预警。
功能说明
l热点话题和敏感话题的识别
系统可以根据新闻来源的权威性和发言时间的强度识别给定时间段内的热门话题。使用内容主题词组和回复数量进行综合语义分析,识别敏感话题。
l 舆情主题追踪
系统会分析新发布的文章和帖子的主题是否与现有主题相同。
l自动汇总
舆情监测系统可以自动汇总各种话题和趋势。
l 舆情趋势分析
在线舆情系统分析人们在不同时间段内对某个话题的关注程度。
l紧急事件分析
网络舆情系统对突发事件进行跨时空综合分析,获取事件发生全貌,预测事件发展趋势。
l 舆情预警系统
网络舆情系统及时发现与内容安全相关的突发事件和敏感话题,并及时报警。
l 舆情统计报告
网络舆情系统软件根据舆情分析引擎处理后生成报表。用户可以通过浏览器浏览,提供信息检索功能,根据指定条件查询热点话题和趋势,浏览信息的具体内容,提供决策支持。
关键词:Guni、Guni 舆情、网络舆情、舆情监测软件 查看全部
Gooniespider互联网舆情监控系统的结构功能特点及应用分析
随着互联网的飞速发展,网络媒体作为一种新型的信息传播方式,已经渗透到人们的日常生活中。网友的积极发言达到了前所未有的水平。无论是国内的还是国际的重大事件,都能立即形成网络舆论。这个网络表达意见,传播思想,进而产生巨大的舆论压力,这是任何部门或机构都不能忽视的。说到点子上了。可以说,互联网已经成为思想文化信息的集散地和舆论的放大器。
在国力大数据成立11周年之际,根据国家版权局颁发的版权证书,我们看到国力首个舆情系统产生于2007年10月22日,名称为《Gooniespider互联网舆情情报监测系统V2.0【简称:Gooniespider互联网舆情监测系统】》,截至2018年8月1日,已经十余年,目前应用数量已达超过 500 个客户。
Gooniespider 互联网舆情监测系统依托自主研发的搜索引擎技术和文本挖掘技术,通过对网页内容的自动采集处理、敏感词过滤、智能聚类分类、话题检测、话题聚焦、统计分析,实现各单位需要对自身相关的网络舆情进行监督管理,最终形成舆情简报、舆情专题报告、分析报告、手机快报等,为决策者全面掌握动态舆论导向,正确引导舆论,提供分析依据。
系统结构
特点
元数据自动识别,无需模板配置
互联网舆情监测系统可以自动识别提取文章标题、发布时间、作者、摘要、正文的关键元数据,无需单独配置模板标签。
l支持对两个微机构一端的信息进行监控
互联网舆情监测系统支持新闻APP、微信、微博和海外推特监测采集。
l自定义网址来源和采集frequency
舆情监测系统用户可以设置采集的栏目、网址、更新时间、扫描间隔等,系统最小扫描间隔可以设置为1分钟,即每分钟,系统会自动扫描目标信息源。为了及时发现目标信息源的最新变化,并尽快采集到本地站点。
l 支持多种网页格式
互联网舆情监测系统可以采集常见的静态网页(HTML/HTM/SHTML)和动态网页(ASP/PHP/JSP),以及采集网页中收录的图片信息。
l 支持多种字符集编码
网络舆情系统采集子系统可自动识别多种字符集编码,包括中文、英文、简体中文、繁体中文等,并可统一转换为GBK编码格式。
l支持全网关键词采集
舆情软件的元搜索模式,基于国内知名互联网搜索引擎的结果,使用Goonie采集器直接定制内容到互联网上,直接采集。用户只需输入搜索关键词。
l支持内容提取和识别
在线舆情监测系统可对网页内容进行分析过滤,自动剔除广告、版权、栏目等无用信息,准确获取目标内容主体。
l 基于内容相似度的去重
网络舆情监测系统采用内容相关识别技术自动识别分类中文章的关系,如果发现文章描述同一事件,则自动去除重复部分。
l支持手机WAP浏览
舆情软件系统支持手机wap浏览访问,手机系统平台无需安装手机客户端,通过手机浏览器实时掌握最新舆情动态。
l 支持短信、邮件等舆情预警
舆情监测系统7×24小时监控敏感信息,通过手机短信、邮件实时预警。
功能说明
l热点话题和敏感话题的识别
系统可以根据新闻来源的权威性和发言时间的强度识别给定时间段内的热门话题。使用内容主题词组和回复数量进行综合语义分析,识别敏感话题。
l 舆情主题追踪
系统会分析新发布的文章和帖子的主题是否与现有主题相同。
l自动汇总
舆情监测系统可以自动汇总各种话题和趋势。
l 舆情趋势分析
在线舆情系统分析人们在不同时间段内对某个话题的关注程度。
l紧急事件分析
网络舆情系统对突发事件进行跨时空综合分析,获取事件发生全貌,预测事件发展趋势。
l 舆情预警系统
网络舆情系统及时发现与内容安全相关的突发事件和敏感话题,并及时报警。
l 舆情统计报告
网络舆情系统软件根据舆情分析引擎处理后生成报表。用户可以通过浏览器浏览,提供信息检索功能,根据指定条件查询热点话题和趋势,浏览信息的具体内容,提供决策支持。
关键词:Guni、Guni 舆情、网络舆情、舆情监测软件
采集子系统使用说明书6/NUMPAGES8保密资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-18 21:03
采集Subsystem 用户手册 PAGE 6/ NUMPAGES 8 机密信息,请勿传播网络舆情监测系统采集Subsystem 用户手册目录TOC \o "2-3" \h \z \u 1.概述2 2.采集子系统工作流程图2 3.采集子系统组件3 4.后台处理流程8 概述舆情系统的首要任务是采集信息,网络公情采集子系统可以自动采集任何目标网站并将采集的信息保存到数据库中进行分析、查看和处理;网络信息采集子系统支持任何主流的关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。我们的舆论系统使用MySQL数据库。 采集子系统工作流程图采集子系统工作流程图采集子系统组件网络信息采集系统主要由网页浏览器(网页分析)、任务编辑器(配置任务)、任务组成执行 由数据库查询器(执行任务)、数据库查询器(查看数据)、数据变形脚本测试器(测试变形脚本)、组合生成器组成。主界面如下图所示: Network Information采集System 主界面 Task Scheduling Agent 负责调度各种网站调度任务。 (1)安装在软件安装目录(C:\Program Files\WebDataMiner Operation\ScheduleAgent.exe),桌面也会生成相应的快捷方式,启动后,其作用是调度该节点的网站调度负责Tasks,如下图,任务调度代理安装后,目录任务调度代理界面(2)Set网站调度信息:设置网站什么时候开始运行,哪个机器或者机器上运行,运行多少进程同时启动,每天运行多少次,等等。
关于调度模式调度模式:设置运行频率,每天运行多少次,并以调度任务的名称表达其内部参数,一目了然。关于运行方式 运行方式:设置运行采集服务器,进程同时启动,分为以下四种运行方式: 单节点单进程:运行在一台采集服务器上,启动一个采集程序,适用网站single-node 多进程内容较少:在一台采集服务器上运行,同时启动多个采集程序加速采集多节点单进程:需要选择采集服务器组(多台采集服务器),运行在一个服务器组中,组内每台服务器共享不同的采集任务实现分布式采集,每台采集服务器启动一个采集程序和多个Node多进程:需要选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。群内每台服务器共享不同的采集任务,实现分布式采集,每台采集服务器同时启动多个采集程序,大大加快了速度。适用于入口网址较多的情况,例如需要搜索大量关键词的搜索引擎。 网站 用于搜索类型。在浏览系统中设置每个网站的调度信息,如下图: 自动关闭每个网站调度任务列表的弹出对话框。在网页采集的过程中,有的网站会弹出一个对话框,影响采集程序的工作,把弹出对话框的关键词设置成这个程序,会自动关闭弹出-up 对话框并让采集 程序继续工作。如下图: 弹出对话框自动关闭器安装后,目录弹出对话框自动关闭器配置文件可以在同一个局域网内共享,达到修改一处的目的并进行如下修改,如下图所示: 弹出对话框 Autocloser配置文件设置弹出对话框内容:启动本程序后,点击编辑,填写弹出对话框的内容,等号关键词左侧填写对话框标题(右上角),内容等号关键词右侧填写对话框(一般居中)对话框)。
弹出对话框自动关闭采集configuration采集配置的主界面和编辑界面分为核心配置(Core_Tasks)、系统配置(System_Tasks)、WMT分离配置(WMT_Tasks)和用户配置(User_Tasks),放置采集服务器的目录如下图:采集服务器目录结构核心配置(Core_Tasks):这里有13个不同的配置模板,配置的具体参数存放在数据库,一般情况下这里不需要修改Template,如果网站的结构发生变化,只需要在浏览系统中修改具体网站对应数据库中的具体配置参数即可支持大部分网站采集。系统已经拥有最主流的网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):放置一些处理特殊任务的WMT配置,如:选中信息截图和采集text、采集新闻热搜词、所有网站截图等WMT单独配置(WMT_Tasks ):放置一些核心配置难以处理的复杂网站配置,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存放数据库连接信息(DB.udl,所有配置共享一个); 采集批处理文件:Run_Batchs文件夹存放了所有网站start采集程序的批处理文件,start这里的批处理文件启动了对应的采集服务。
(7)入库规则说明:入库规则有四种,每个网站可以在浏览系统中设置其对应的入库规则:a.无文字,全部入库 b.无正文,标题或摘要收录数据库中的核心词:适用于搜索引擎和全文搜索网站(搜索结果有摘要信息) c. 采集正文,主词收录数据库中的核心词(标题摘要不判断):网站适用于列表类型,如网站homepage、新闻列表 d. 选择文本,但不选择所有存储的文本:不是采集文章文本(内容),并很快挑选文本:采集文章 消息的主体(内容),速度较慢(8)搜索类型的核心词过滤规则:为了防止不相关的内容从搜索后进入数据库,搜索类型X操作匹配核心词 不是所有的核心词,而是t的所有核心词与此搜索词的主题相同。后台处理进程选择的信息处理程序的选择信息截图和采集正文,在采集服务器上运行,如果采集服务器不止一个,选择其中一个启动:打开目录D:\KWM\Extraction_Server\System_Tasks\Selected_Articles_Process,双击run.bat,它会每分钟检查是否有选中的信息,如果有则进行处理,但是打开后不要关闭这个程序它。重启采集服务器后重启这个程序。您也可以将其设置为 Windows 启动程序。 查看全部
采集子系统使用说明书6/NUMPAGES8保密资料
采集Subsystem 用户手册 PAGE 6/ NUMPAGES 8 机密信息,请勿传播网络舆情监测系统采集Subsystem 用户手册目录TOC \o "2-3" \h \z \u 1.概述2 2.采集子系统工作流程图2 3.采集子系统组件3 4.后台处理流程8 概述舆情系统的首要任务是采集信息,网络公情采集子系统可以自动采集任何目标网站并将采集的信息保存到数据库中进行分析、查看和处理;网络信息采集子系统支持任何主流的关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase和文件数据库Access。我们的舆论系统使用MySQL数据库。 采集子系统工作流程图采集子系统工作流程图采集子系统组件网络信息采集系统主要由网页浏览器(网页分析)、任务编辑器(配置任务)、任务组成执行 由数据库查询器(执行任务)、数据库查询器(查看数据)、数据变形脚本测试器(测试变形脚本)、组合生成器组成。主界面如下图所示: Network Information采集System 主界面 Task Scheduling Agent 负责调度各种网站调度任务。 (1)安装在软件安装目录(C:\Program Files\WebDataMiner Operation\ScheduleAgent.exe),桌面也会生成相应的快捷方式,启动后,其作用是调度该节点的网站调度负责Tasks,如下图,任务调度代理安装后,目录任务调度代理界面(2)Set网站调度信息:设置网站什么时候开始运行,哪个机器或者机器上运行,运行多少进程同时启动,每天运行多少次,等等。
关于调度模式调度模式:设置运行频率,每天运行多少次,并以调度任务的名称表达其内部参数,一目了然。关于运行方式 运行方式:设置运行采集服务器,进程同时启动,分为以下四种运行方式: 单节点单进程:运行在一台采集服务器上,启动一个采集程序,适用网站single-node 多进程内容较少:在一台采集服务器上运行,同时启动多个采集程序加速采集多节点单进程:需要选择采集服务器组(多台采集服务器),运行在一个服务器组中,组内每台服务器共享不同的采集任务实现分布式采集,每台采集服务器启动一个采集程序和多个Node多进程:需要选择采集服务器组(由多个采集服务器组成)并在一个服务器组中运行。群内每台服务器共享不同的采集任务,实现分布式采集,每台采集服务器同时启动多个采集程序,大大加快了速度。适用于入口网址较多的情况,例如需要搜索大量关键词的搜索引擎。 网站 用于搜索类型。在浏览系统中设置每个网站的调度信息,如下图: 自动关闭每个网站调度任务列表的弹出对话框。在网页采集的过程中,有的网站会弹出一个对话框,影响采集程序的工作,把弹出对话框的关键词设置成这个程序,会自动关闭弹出-up 对话框并让采集 程序继续工作。如下图: 弹出对话框自动关闭器安装后,目录弹出对话框自动关闭器配置文件可以在同一个局域网内共享,达到修改一处的目的并进行如下修改,如下图所示: 弹出对话框 Autocloser配置文件设置弹出对话框内容:启动本程序后,点击编辑,填写弹出对话框的内容,等号关键词左侧填写对话框标题(右上角),内容等号关键词右侧填写对话框(一般居中)对话框)。
弹出对话框自动关闭采集configuration采集配置的主界面和编辑界面分为核心配置(Core_Tasks)、系统配置(System_Tasks)、WMT分离配置(WMT_Tasks)和用户配置(User_Tasks),放置采集服务器的目录如下图:采集服务器目录结构核心配置(Core_Tasks):这里有13个不同的配置模板,配置的具体参数存放在数据库,一般情况下这里不需要修改Template,如果网站的结构发生变化,只需要在浏览系统中修改具体网站对应数据库中的具体配置参数即可支持大部分网站采集。系统已经拥有最主流的网站配置。用户还可以添加系统中不存在的网站配置。系统配置(System_Tasks):放置一些处理特殊任务的WMT配置,如:选中信息截图和采集text、采集新闻热搜词、所有网站截图等WMT单独配置(WMT_Tasks ):放置一些核心配置难以处理的复杂网站配置,例如facebook配置。用户配置(User_Tasks):放置用户添加的WMT配置。数据库连接:Configs文件夹存放数据库连接信息(DB.udl,所有配置共享一个); 采集批处理文件:Run_Batchs文件夹存放了所有网站start采集程序的批处理文件,start这里的批处理文件启动了对应的采集服务。
(7)入库规则说明:入库规则有四种,每个网站可以在浏览系统中设置其对应的入库规则:a.无文字,全部入库 b.无正文,标题或摘要收录数据库中的核心词:适用于搜索引擎和全文搜索网站(搜索结果有摘要信息) c. 采集正文,主词收录数据库中的核心词(标题摘要不判断):网站适用于列表类型,如网站homepage、新闻列表 d. 选择文本,但不选择所有存储的文本:不是采集文章文本(内容),并很快挑选文本:采集文章 消息的主体(内容),速度较慢(8)搜索类型的核心词过滤规则:为了防止不相关的内容从搜索后进入数据库,搜索类型X操作匹配核心词 不是所有的核心词,而是t的所有核心词与此搜索词的主题相同。后台处理进程选择的信息处理程序的选择信息截图和采集正文,在采集服务器上运行,如果采集服务器不止一个,选择其中一个启动:打开目录D:\KWM\Extraction_Server\System_Tasks\Selected_Articles_Process,双击run.bat,它会每分钟检查是否有选中的信息,如果有则进行处理,但是打开后不要关闭这个程序它。重启采集服务器后重启这个程序。您也可以将其设置为 Windows 启动程序。
自动采集子系统改变了很多效率问题,改善了传统软件动不动
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-07-17 20:02
自动采集子系统改变了很多效率问题,改善了传统软件动不动就需要下载app软件的痛点,有可能是设计方面的,有可能是物流出入库模块产生的。这不仅仅只是简单修改自动采集子系统这么简单,后面的系统合理搭配,实现智能配送快递派送、智能控制等等可能性非常大。
软件是一个原因,但你列举的几个问题,都是硬件设施方面的问题,所以不用太担心。比如,农村啥的,几万一套的agv,十几万一套的三轮车,二十几万一套的搅拌机,
做大城市的马是没有感觉的,因为城市的地铁不需要建那么大,需要挖深度太高,就需要进行扩建,城市不需要到处都是高大上的建筑。这是价值问题,而不是需求不需求问题,就像每次回乡也是“好好安置就那一点人口”“在俺老家县城很好啊,交通还便利,市区动不动就堵车,给你们县城,你们干得过去吗?”也是因为城市地铁交通方便的缘故。
同样的道理,农村地区,乡镇,农村的几栋高楼大厦修建起来了,但路还是那么宽,交通只是比城市好了一点,但是体量还是相当大,这一点点差别却又让我对城市和农村形成两种不同的心态,对于同一个问题,不同的人有不同的看法。
另外一种方式是真正农村人自己去开拓市场,和农村合作开发农村物流配送渠道,以后家属院,村落地里的便利店,小超市,基本可以打包全省,因为农村开放市场进入并吸引资本和农民开发和投资。农村建立物流配送基地,可能性也存在,只是现在一下吸引不到资本的可能性不大。但是农村办物流配送站的问题还不是很大,还没有开始紧缺人才的问题,可以等等再找找。 查看全部
自动采集子系统改变了很多效率问题,改善了传统软件动不动
自动采集子系统改变了很多效率问题,改善了传统软件动不动就需要下载app软件的痛点,有可能是设计方面的,有可能是物流出入库模块产生的。这不仅仅只是简单修改自动采集子系统这么简单,后面的系统合理搭配,实现智能配送快递派送、智能控制等等可能性非常大。
软件是一个原因,但你列举的几个问题,都是硬件设施方面的问题,所以不用太担心。比如,农村啥的,几万一套的agv,十几万一套的三轮车,二十几万一套的搅拌机,
做大城市的马是没有感觉的,因为城市的地铁不需要建那么大,需要挖深度太高,就需要进行扩建,城市不需要到处都是高大上的建筑。这是价值问题,而不是需求不需求问题,就像每次回乡也是“好好安置就那一点人口”“在俺老家县城很好啊,交通还便利,市区动不动就堵车,给你们县城,你们干得过去吗?”也是因为城市地铁交通方便的缘故。
同样的道理,农村地区,乡镇,农村的几栋高楼大厦修建起来了,但路还是那么宽,交通只是比城市好了一点,但是体量还是相当大,这一点点差别却又让我对城市和农村形成两种不同的心态,对于同一个问题,不同的人有不同的看法。
另外一种方式是真正农村人自己去开拓市场,和农村合作开发农村物流配送渠道,以后家属院,村落地里的便利店,小超市,基本可以打包全省,因为农村开放市场进入并吸引资本和农民开发和投资。农村建立物流配送基地,可能性也存在,只是现在一下吸引不到资本的可能性不大。但是农村办物流配送站的问题还不是很大,还没有开始紧缺人才的问题,可以等等再找找。
自动采集子系统解决了采集效率低、灵活性差等难题
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-07-10 00:08
自动采集子系统解决了采集效率低、灵活性差等难题,可以让采集更高效。采集过程简单、灵活,数据与人工操作模式相结合,提高数据利用率。
一、采集过程
1、选择子系统,
2、在爬虫中选择一个子系统,
3、在采集过程中,
4、按照要求输入网址
5、在下方勾选存储数据
二、采集结果收集
1、采集结果信息存储于excel
2、直接或手动输入网址
三、扩展子系统功能采集过程
1、子系统多线程
2、子系统缓存
3、子系统联动/ajax
4、子系统消息中心
5、子系统路由器
六、限制爬虫多线程和缓存等功能
爬虫服务器和子系统不是可同时存在的,爬虫是用来采集数据的,
多线程和子系统的问题,属于一种灵活解决方案,主要靠提高效率,所以这些功能其实是采用了各种灵活的组合功能,一次性把爬虫系统做好就可以了,并不会直接决定爬虫系统的性能,至于保存上传下载则是第二梯队的问题。---我目前所在的爬虫客户群,爬虫会服务公司内部客户,通过抓取内部网站上的页面,然后传到云爬虫的客户端,通过客户端做拼接和过滤,然后传到公司外网,然后再统一调整过来,调整过来的结果放到python数据库或者数据库生成数据,最后用于自己的爬虫中。 查看全部
自动采集子系统解决了采集效率低、灵活性差等难题
自动采集子系统解决了采集效率低、灵活性差等难题,可以让采集更高效。采集过程简单、灵活,数据与人工操作模式相结合,提高数据利用率。
一、采集过程
1、选择子系统,
2、在爬虫中选择一个子系统,
3、在采集过程中,
4、按照要求输入网址
5、在下方勾选存储数据
二、采集结果收集
1、采集结果信息存储于excel
2、直接或手动输入网址
三、扩展子系统功能采集过程
1、子系统多线程
2、子系统缓存
3、子系统联动/ajax
4、子系统消息中心
5、子系统路由器
六、限制爬虫多线程和缓存等功能
爬虫服务器和子系统不是可同时存在的,爬虫是用来采集数据的,
多线程和子系统的问题,属于一种灵活解决方案,主要靠提高效率,所以这些功能其实是采用了各种灵活的组合功能,一次性把爬虫系统做好就可以了,并不会直接决定爬虫系统的性能,至于保存上传下载则是第二梯队的问题。---我目前所在的爬虫客户群,爬虫会服务公司内部客户,通过抓取内部网站上的页面,然后传到云爬虫的客户端,通过客户端做拼接和过滤,然后传到公司外网,然后再统一调整过来,调整过来的结果放到python数据库或者数据库生成数据,最后用于自己的爬虫中。
python语言操作的自动采集python代码的使用方法及方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2021-07-08 21:02
自动采集子系统不仅能帮助我们自动采集python语言的代码,而且还可以利用python语言进行数据分析和机器学习。当然了,这只是最基本的python语言操作的自动采集系统,最大的自动采集的系统当然是不仅是自动采集代码,还支持数据分析、机器学习算法和数据可视化的,不得不佩服,谷歌的ai技术的强大。如果还想用python代码自动采集更深入更广的,你可以试试下面的这些技术和api,或者直接自己写。
自动采集java、c++、python等不同语言的代码的api现在已经支持很多语言采集代码自动爬取python代码,爬取c/c++代码以及go语言代码的api但是这些爬虫代码的抓取可能都有点麻烦,毕竟python代码的结构不如c/c++和java代码那么好维护,而且调试困难。但是有了这款自动采集python代码的api,简直太棒了,那就是采集go语言的代码,用了下面这款python代码的api,那简直方便太多了。抓取数据也是太方便了,几行命令就可以搞定。下面这个python框架是python3框架:。
1、数据获取有点难
2、api函数难以维护
3、抓取网页源代码,进行数据字典遍历还是有点吃力这个python框架可以方便解决这个问题。python自动采集api使用python爬虫,使用爬虫api来进行抓取,是一个好方法。在这里,跟大家分享一个python自动采集java代码的api,这个api有点简单粗暴,直接抓取java代码,然后通过javaapi进行翻译成python代码。
python爬虫api使用方法:
1、获取在线编译代码
2、提取代码到本地
3、selenium操作程序可以实现如下功能:
1、获取java代码
2、提取代码
3、抓取java代码
4、压缩java代码
5、分词c#代码
6、提取c#代码
7、压缩c#代码
8、java代码
9、提取c#代码1
0、按照编程语言词典进行筛选1
1、爬取整个词典1
2、并且获取词频率报告1
3、提取词语api大小(单位mb)1
4、提取词频率报告1
5、提取频率排名报告1
6、爬取整个词云库1
7、获取频率排名数据1
8、抓取词云包含对象1
9、爬取java代码2
0、提取整个java源代码 查看全部
python语言操作的自动采集python代码的使用方法及方法
自动采集子系统不仅能帮助我们自动采集python语言的代码,而且还可以利用python语言进行数据分析和机器学习。当然了,这只是最基本的python语言操作的自动采集系统,最大的自动采集的系统当然是不仅是自动采集代码,还支持数据分析、机器学习算法和数据可视化的,不得不佩服,谷歌的ai技术的强大。如果还想用python代码自动采集更深入更广的,你可以试试下面的这些技术和api,或者直接自己写。
自动采集java、c++、python等不同语言的代码的api现在已经支持很多语言采集代码自动爬取python代码,爬取c/c++代码以及go语言代码的api但是这些爬虫代码的抓取可能都有点麻烦,毕竟python代码的结构不如c/c++和java代码那么好维护,而且调试困难。但是有了这款自动采集python代码的api,简直太棒了,那就是采集go语言的代码,用了下面这款python代码的api,那简直方便太多了。抓取数据也是太方便了,几行命令就可以搞定。下面这个python框架是python3框架:。
1、数据获取有点难
2、api函数难以维护
3、抓取网页源代码,进行数据字典遍历还是有点吃力这个python框架可以方便解决这个问题。python自动采集api使用python爬虫,使用爬虫api来进行抓取,是一个好方法。在这里,跟大家分享一个python自动采集java代码的api,这个api有点简单粗暴,直接抓取java代码,然后通过javaapi进行翻译成python代码。
python爬虫api使用方法:
1、获取在线编译代码
2、提取代码到本地
3、selenium操作程序可以实现如下功能:
1、获取java代码
2、提取代码
3、抓取java代码
4、压缩java代码
5、分词c#代码
6、提取c#代码
7、压缩c#代码
8、java代码
9、提取c#代码1
0、按照编程语言词典进行筛选1
1、爬取整个词典1
2、并且获取词频率报告1
3、提取词语api大小(单位mb)1
4、提取词频率报告1
5、提取频率排名报告1
6、爬取整个词云库1
7、获取频率排名数据1
8、抓取词云包含对象1
9、爬取java代码2
0、提取整个java源代码
乐思网络情报信息中心系统的业务流程及优势分析方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-08 06:46
乐思网络情报信息中心系统的业务流程及优势分析方法
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解脱出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在网上反馈的各种信息、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免手动查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要单独登录每个网站,手动查看,手动复制粘贴,很累。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过网页界面为文本信息配置采集,或通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供各种网站的采集服务。没有高效稳定的采集平台是不可能的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询 查看全部
乐思网络情报信息中心系统的业务流程及优势分析方法
乐思网络信息中心系统
乐思网络智能信息中心系统是面向大公司、大集团的战略性信息化基础设施。其目的是加快公司内外部信息的流通,构建公司的数字神经系统。
一、 系统概览
随着我国经济发展的不断推进,大公司、大集团面临的市场环境越来越复杂,影响市场走势的各种新问题、新情况层出不穷,市场规模不断扩大。信息呈指数级增长。与此同时,定量分析方法正在迅速应用于行业研究,对信息采集的效率和准确性提出了很高的要求。依靠有限的人力来采集信息,难以适应市场和技术发展的要求。为了更全面、准确、快速地把握市场变化,适应新技术发展的要求,使人员从繁重的信息采集工作中解脱出来,专心深入分析研究,迫切需要一套现代化的信息中心系统。
乐思网络信息中心系统的功能是为大公司和集团的营销部门和公关部门提供一个采集外部信息的平台,包括公司相关信息、竞争对手相关信息、行业信息、和价格信息、合作伙伴相关信息、用户在网上反馈的各种信息、科研技术信息等,可以实现多人在一个平台上可以快速浏览当天或过去的所有相关信息,避免手动查询多个网站'S费时费力的情况,并具有预警功能,当出现某一方面的信息时,可以及时通知相关人员。
业务流程如下图所示:
图一:乐思网络信息中心系统业务流程
与目前的人工信息采集相比,优势明显:
比较指标
手动采集
使用乐思网络信息中心系统
目标网站
几十个
成百上千、数万-3453舆论合集第4533集-
人工成本
需要单独登录每个网站,手动查看,手动复制粘贴,很累。
网络信息的获取完全由软件自动化,监控人员只需在内网集中浏览分析内容
负面信息识别
需要人工一一核对确认
在自动判别的基础上,再人工确认
信息保存
会犯一些不可避免的错误-集3453舆论第4533集-
准确、全面、易于事后跟踪
数据存储
Word 文件分散,难以管理
大型关系型数据库统一存储,集中管理
监测报告
基于人工统计和估算,数据支持不充分
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
监控效果
片面报道,不及时
不尽人意,浪费人力资源-3453舆论4533集-
全面覆盖,实时,
自动化和系统化
二、 实施后的收益
加速感知外部情报:公司报告、用户反馈、竞品动态、行业动态、宏观动态、政策法规等外部公司信息实时采集到桌面,方便公司感知和响应市场竞争情报。
加速定量定性分析:基于大量数据的拥有,分析师可以从繁重的信息采集工作中解放出来,投入到最有价值的定量和定性分析中。 owlesys 认为
三、 系统构成
乐思网络信息中心系统由三个子系统组成:自动采集子系统(采集layer)、内容分析子系统(分析层)、界面呈现子系统(呈现层)。关系如下图所示:
图2:乐思网络信息中心系统架构
乐思网络信息中心系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图 3:网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
采集信息可以是文本信息(如文章、微博)、数字信息(如价格、统计数据)或文件信息(如Word、Excel、PDF文件)。用户可以通过网页界面为文本信息配置采集,或通过软件向导界面为数字信息配置采集。由于采用了全球领先的乐思网络信息采集系统,任何网站数据都可以被采集并整合。数据源的发现和管理由用户完成。
全自动采集子系统的全方位监控功能如下图所示:
图4:自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供各种网站的采集服务。没有高效稳定的采集平台是不可能的。
2.支持各种监控对象
您可以实时监控微信公众号、新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3. 无需配置直接监控上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能26禁止9盗用0
可自动处理保存中文、英文、法文、德文、日文、韩文、维吾尔文、阿拉伯文等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询
日本快消品业态形态过度单一购买怎么办?
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-07-07 19:03
自动采集子系统,通过技术精密的处理,使程序可以适应超市采购商品一切要求。可以采集到所有的采购订单,合理规划采购,合理分配仓库货物。可以实现自动比价订货、库存检查与管理、合理提高订单分发效率。采集到分拣员无法识别商品的商品标题、商品类别等信息。商品的价格、品牌、颜色、数量、款式可一一对应。无需人工核实;。
大数据分析。
近年来市场需求更趋于快时尚。连锁便利店采用开放模式做生意,这里谈的是它发展中的问题。1.业态形态过度单一。日本便利店起步早,但也较早进入过国内市场,有一个政策补贴的过程。这个业态上面各个快消品为主,快消品如手机、日化等都单一购买,顾客对快消品无感性需求,每购买一个快消品,带来的即时刺激,比如说1分钱之内就可以在便利店买到其他货物或者服务。
但是这样也造成价格竞争加剧,顾客对比开始呈现动态,最终放弃购买。而针对于国内业态形态来看,一个快消品单一购买往往是固定的一个价格,供货量要求较高。快消品起步晚、进入门槛高。一个小瓶汽水就可以5块钱,每进一个快消品,顾客就往往会多买,因为还有可以赚的钱。“新的零售,全是钱”。当然发展到一定程度,消费者不满足于此。
2.新品类业态很难形成,爆品设计空间有限。市场很多快消品业态都是以大众化消费为主,包括马路边的母婴用品街边都是由于这个原因,一个爆品很难形成,另外,没有形成销售王国。结合营销中这个问题讲,包括零售、购物中心等地方,天天也在设计新品种,但是这个时候消费者就觉得不新颖。3.供应链管理存在问题,选品存在问题。
很多快消品的制造商不具备了解市场情况的能力,一味跟进市场,而对于一些没有竞争优势的品牌,就在一边作业中,新品上市也做不到一个爆点,也就没有时间去宣传,发展空间受到限制。4.消费心理需求表现的不够明显。还有比如说大牌子的品牌价值。现在有了小李子这个国际红人,每一个国人心里都有公主梦,比如说oppa,什么事情,宣传都要有时效性,在大品牌发展了几十年时,很多人根本分不清,尤其是快销品,还有一些国内仿制品更是对销售的影响很大。从而导致购买力降低。5.社会需求的表现。人们买快消品的第一需求,就是“使用方便”。 查看全部
日本快消品业态形态过度单一购买怎么办?
自动采集子系统,通过技术精密的处理,使程序可以适应超市采购商品一切要求。可以采集到所有的采购订单,合理规划采购,合理分配仓库货物。可以实现自动比价订货、库存检查与管理、合理提高订单分发效率。采集到分拣员无法识别商品的商品标题、商品类别等信息。商品的价格、品牌、颜色、数量、款式可一一对应。无需人工核实;。
大数据分析。
近年来市场需求更趋于快时尚。连锁便利店采用开放模式做生意,这里谈的是它发展中的问题。1.业态形态过度单一。日本便利店起步早,但也较早进入过国内市场,有一个政策补贴的过程。这个业态上面各个快消品为主,快消品如手机、日化等都单一购买,顾客对快消品无感性需求,每购买一个快消品,带来的即时刺激,比如说1分钱之内就可以在便利店买到其他货物或者服务。
但是这样也造成价格竞争加剧,顾客对比开始呈现动态,最终放弃购买。而针对于国内业态形态来看,一个快消品单一购买往往是固定的一个价格,供货量要求较高。快消品起步晚、进入门槛高。一个小瓶汽水就可以5块钱,每进一个快消品,顾客就往往会多买,因为还有可以赚的钱。“新的零售,全是钱”。当然发展到一定程度,消费者不满足于此。
2.新品类业态很难形成,爆品设计空间有限。市场很多快消品业态都是以大众化消费为主,包括马路边的母婴用品街边都是由于这个原因,一个爆品很难形成,另外,没有形成销售王国。结合营销中这个问题讲,包括零售、购物中心等地方,天天也在设计新品种,但是这个时候消费者就觉得不新颖。3.供应链管理存在问题,选品存在问题。
很多快消品的制造商不具备了解市场情况的能力,一味跟进市场,而对于一些没有竞争优势的品牌,就在一边作业中,新品上市也做不到一个爆点,也就没有时间去宣传,发展空间受到限制。4.消费心理需求表现的不够明显。还有比如说大牌子的品牌价值。现在有了小李子这个国际红人,每一个国人心里都有公主梦,比如说oppa,什么事情,宣传都要有时效性,在大品牌发展了几十年时,很多人根本分不清,尤其是快销品,还有一些国内仿制品更是对销售的影响很大。从而导致购买力降低。5.社会需求的表现。人们买快消品的第一需求,就是“使用方便”。
自动采集子系统和自动执行程序是怎样的体验?
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-07-07 07:00
自动采集子系统和自动采集程序可以看成是用户点击触发的链接,如用户在浏览器中点击某个链接,或者触发点击某个链接,自动执行页面的js代码.第一种方式:“hook”技术:点击页面某个链接,自动去其js代码去执行子页面的js代码,进行完整页面的渲染,子页面js代码只能更改,无法更改页面源码中的任何内容,hook技术利用这一点,使得页面渲染非常快速,代码检测甚至秒到达页面根节点下面的所有标签.代码阅读代码:ul、li、ol这四个标签是用ul标签实现的.第二种方式:onescrolling,将页面滚动的速度,逐步加快,从1.5厘米逐步缩短到0.4厘米。
如果页面是用户单手操作,那可以实现单手即可操作:如果页面是设置重复滚动,那可以实现多手操作:如果滚动速度逐步加快的话,可以实现三手操作,甚至四手操作,这也是onescrolling的理念和思想.当然,它也有缺点,再滚动过程中子页面中的onescrolling信息就消失了,但也并不需要担心,点击任意一个onescrolling,页面js代码都会执行。第三种方式:hookjs程序,也是一种onescrolling,就是定时调用系统代码,就是hook.。
这三种方式各有利弊。一,自动采集,可以用第三方比如ua,我们都有webdriver配置,可以设置单手点击重复触发子页,过滤多次点击和点击链接。二,自动采集,可以用js、ajax等方式实现,但是这样做有几个缺点,就是可扩展性不高,我们开发的很多页面都不是一个功能,我们的这个页面也许不能跨页面点击,而且可能是好几个页面;还有我们不一定在手机访问,我们可能在单页面等待等等。
那我们要是想单页面点击,我们可以用三指悬停的方式实现,这样的话,你可以实现多页面点击,但是单页面的点击逻辑却要单独设置。当然如果你要抓多页面的话,我们也有一些替代方案,比如微信公众号生成二维码的方式,我们就有办法去实现单页面点击。那对于这种多页面点击我们也是可以保存到数据库的,我们用几百行js就可以搞定,这个方式的一个好处是,当重复跳转的时候,可以显示一下单页面的id,重新再抓取上来。
三,我们用数据抓取,把重复的id存到数据库,然后异步请求,我们单页面点击时,执行抓取请求,然后抓取完成后,把抓取结果回传给用户,而不需要我们手动去页面抓取。总结:我觉得第三种方式可以取代前两种方式,即第一种方式或者后两种方式。 查看全部
自动采集子系统和自动执行程序是怎样的体验?
自动采集子系统和自动采集程序可以看成是用户点击触发的链接,如用户在浏览器中点击某个链接,或者触发点击某个链接,自动执行页面的js代码.第一种方式:“hook”技术:点击页面某个链接,自动去其js代码去执行子页面的js代码,进行完整页面的渲染,子页面js代码只能更改,无法更改页面源码中的任何内容,hook技术利用这一点,使得页面渲染非常快速,代码检测甚至秒到达页面根节点下面的所有标签.代码阅读代码:ul、li、ol这四个标签是用ul标签实现的.第二种方式:onescrolling,将页面滚动的速度,逐步加快,从1.5厘米逐步缩短到0.4厘米。
如果页面是用户单手操作,那可以实现单手即可操作:如果页面是设置重复滚动,那可以实现多手操作:如果滚动速度逐步加快的话,可以实现三手操作,甚至四手操作,这也是onescrolling的理念和思想.当然,它也有缺点,再滚动过程中子页面中的onescrolling信息就消失了,但也并不需要担心,点击任意一个onescrolling,页面js代码都会执行。第三种方式:hookjs程序,也是一种onescrolling,就是定时调用系统代码,就是hook.。
这三种方式各有利弊。一,自动采集,可以用第三方比如ua,我们都有webdriver配置,可以设置单手点击重复触发子页,过滤多次点击和点击链接。二,自动采集,可以用js、ajax等方式实现,但是这样做有几个缺点,就是可扩展性不高,我们开发的很多页面都不是一个功能,我们的这个页面也许不能跨页面点击,而且可能是好几个页面;还有我们不一定在手机访问,我们可能在单页面等待等等。
那我们要是想单页面点击,我们可以用三指悬停的方式实现,这样的话,你可以实现多页面点击,但是单页面的点击逻辑却要单独设置。当然如果你要抓多页面的话,我们也有一些替代方案,比如微信公众号生成二维码的方式,我们就有办法去实现单页面点击。那对于这种多页面点击我们也是可以保存到数据库的,我们用几百行js就可以搞定,这个方式的一个好处是,当重复跳转的时候,可以显示一下单页面的id,重新再抓取上来。
三,我们用数据抓取,把重复的id存到数据库,然后异步请求,我们单页面点击时,执行抓取请求,然后抓取完成后,把抓取结果回传给用户,而不需要我们手动去页面抓取。总结:我觉得第三种方式可以取代前两种方式,即第一种方式或者后两种方式。
sketch自动采集子系统的原理及应用技巧分享!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2021-07-06 03:01
自动采集子系统原理:采集方式:自动申请轮播库对于宽图,h5所需宽度大于100px;若轮播宽度小于100px,图片在用户看来就变得拥挤,效果就差了;是否限制:当子系统中图片占用面积超过50%时,使用限制。同时不会影响浏览器;自动发送websocket更新配置过程:首先:将图片链接设置为:lib-main.xml,推送整个页面的图片;接着:使用子系统做带状元素移动dom,并修改main.js位置,对应该元素顶部的这一块即可。
然后:指定了新图片及配置过程中指定的移动端控件为轮播下一波。测试结果:以此类推的可以操作,效果完全一样,具体百度之。sketch自动采集轮播图一、规划软件方案评估:1.100-1000pxuv/tap覆盖率硬件需求:需要再注册小程序,weixin小程序打开速度快,3000-15000dpi区间。增加双列标题格式,伪3列设计。
一些特殊格式采取正常内部转码处理,例如不允许遮挡汉字拼音等。cdn数据转码:支持ac、yahooservermarket等。假如是全开可自由切换,你可以保证所有内容都可以直接读写。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。2.100*1000px清晰度硬件需求:需要注册小程序,h5屏幕分辨率需要在256*750dpi,有屏幕底部模拟。
支持手绘类型的图片(模拟现实),但你实际只放一个div作为底部轮播框即可。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。3.1000-5000px保守轮播规划硬件需求:注册小程序,index后端提供playmemory,保持小程序内部性能优化。采用apk镜像,各版本镜像。
imageloaderwxml、imgloaderwxml均不限制尺寸、变换的内容,采用镜像导入方案。可用json序列化,并且文件不上传到gzip,缩小速度优化。内部以index后端进行监控,不要多个后端,但需要保证数据可用性。采用下级轮播文件:imageloaderwxml,imgloaderwxml互为辅助。
按照800px/天/周来进行轮播。3.1500px及以上规划硬件需求:小程序全程使用websocket配置,并支持tcp1对1/3对3连接。支持websocket进行多点控制,如转发contenttotext/contenttoslot/contenttotext等。硬件规划:单位sr,一定要imagefile格式。
内部硬件规划:1500/天,单位asr,imagefile格式;2400/周,300小时单位。amazon、java、nginx等:这些是在小程序轮播的缓存中使用内置的地址,轮播代码提供与redis的双连接。或者在小程序实际连接的地址上加多个数据库的连接,作为缓存用。现在大部分。 查看全部
sketch自动采集子系统的原理及应用技巧分享!!
自动采集子系统原理:采集方式:自动申请轮播库对于宽图,h5所需宽度大于100px;若轮播宽度小于100px,图片在用户看来就变得拥挤,效果就差了;是否限制:当子系统中图片占用面积超过50%时,使用限制。同时不会影响浏览器;自动发送websocket更新配置过程:首先:将图片链接设置为:lib-main.xml,推送整个页面的图片;接着:使用子系统做带状元素移动dom,并修改main.js位置,对应该元素顶部的这一块即可。
然后:指定了新图片及配置过程中指定的移动端控件为轮播下一波。测试结果:以此类推的可以操作,效果完全一样,具体百度之。sketch自动采集轮播图一、规划软件方案评估:1.100-1000pxuv/tap覆盖率硬件需求:需要再注册小程序,weixin小程序打开速度快,3000-15000dpi区间。增加双列标题格式,伪3列设计。
一些特殊格式采取正常内部转码处理,例如不允许遮挡汉字拼音等。cdn数据转码:支持ac、yahooservermarket等。假如是全开可自由切换,你可以保证所有内容都可以直接读写。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。2.100*1000px清晰度硬件需求:需要注册小程序,h5屏幕分辨率需要在256*750dpi,有屏幕底部模拟。
支持手绘类型的图片(模拟现实),但你实际只放一个div作为底部轮播框即可。自动生成imageloaderwxml,并用小程序导入,对应wxss没有什么要求。3.1000-5000px保守轮播规划硬件需求:注册小程序,index后端提供playmemory,保持小程序内部性能优化。采用apk镜像,各版本镜像。
imageloaderwxml、imgloaderwxml均不限制尺寸、变换的内容,采用镜像导入方案。可用json序列化,并且文件不上传到gzip,缩小速度优化。内部以index后端进行监控,不要多个后端,但需要保证数据可用性。采用下级轮播文件:imageloaderwxml,imgloaderwxml互为辅助。
按照800px/天/周来进行轮播。3.1500px及以上规划硬件需求:小程序全程使用websocket配置,并支持tcp1对1/3对3连接。支持websocket进行多点控制,如转发contenttotext/contenttoslot/contenttotext等。硬件规划:单位sr,一定要imagefile格式。
内部硬件规划:1500/天,单位asr,imagefile格式;2400/周,300小时单位。amazon、java、nginx等:这些是在小程序轮播的缓存中使用内置的地址,轮播代码提供与redis的双连接。或者在小程序实际连接的地址上加多个数据库的连接,作为缓存用。现在大部分。
php前端页面最常见的转换器之一,没有之一
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-07-05 18:02
自动采集子系统是php前端页面最常见的转换器之一,没有之一。例如工厂倒闭了,我要重新制造门面,或者电影院倒闭了,我要重新拍一批新电影,方法就是做一个子系统,实现数据上传到子系统,处理上传的工作需要去哪里获取数据。做完就可以往这些子系统里面导入电影、电视剧的电影资源,在不断更新的时候再进行更新,这样才能使这个电影电视剧的电影资源维持在一个比较新的状态。
从大方向来说,这个功能可以实现对外开放,对内要开发。我们可以在这个子系统中放置我们要处理的需求信息,常用的数据都可以,这个模块用来做基础的维护,支持命令的命令触发、数据的保存。一.阿里巴巴自己的解决方案:.1.将所有的数据放到一个共享库中,当用户上传数据时,直接读取这个共享库的数据。2.mysql数据库3.页面刷新打开新页面时,触发一次get请求,在该页面加载完后,将数据库返回的数据从磁盘拷贝到内存,这样每次上传就只需要重新从磁盘读取数据即可。
但是,每次刷新页面所要加载的数据是要从磁盘加载,磁盘容量还是蛮恐怖的。而且,只能上传数据,不能进行查询、排序、更新等操作。4.iisnginx做服务器5.通过mysql来处理上传数据6.通过phpmyadmin数据库来查询数据子系统处理上传数据的方式,针对性优化以上iisnginx服务器,开发者可根据自己的业务情况来决定是否加入。
下图是其中几个模块的列表。大家可以随意组合自己喜欢的模块加入到自己的子系统中。二.chef子系统用于处理本地上传文件:使用phpmyadmin数据库处理方式:。 查看全部
php前端页面最常见的转换器之一,没有之一
自动采集子系统是php前端页面最常见的转换器之一,没有之一。例如工厂倒闭了,我要重新制造门面,或者电影院倒闭了,我要重新拍一批新电影,方法就是做一个子系统,实现数据上传到子系统,处理上传的工作需要去哪里获取数据。做完就可以往这些子系统里面导入电影、电视剧的电影资源,在不断更新的时候再进行更新,这样才能使这个电影电视剧的电影资源维持在一个比较新的状态。
从大方向来说,这个功能可以实现对外开放,对内要开发。我们可以在这个子系统中放置我们要处理的需求信息,常用的数据都可以,这个模块用来做基础的维护,支持命令的命令触发、数据的保存。一.阿里巴巴自己的解决方案:.1.将所有的数据放到一个共享库中,当用户上传数据时,直接读取这个共享库的数据。2.mysql数据库3.页面刷新打开新页面时,触发一次get请求,在该页面加载完后,将数据库返回的数据从磁盘拷贝到内存,这样每次上传就只需要重新从磁盘读取数据即可。
但是,每次刷新页面所要加载的数据是要从磁盘加载,磁盘容量还是蛮恐怖的。而且,只能上传数据,不能进行查询、排序、更新等操作。4.iisnginx做服务器5.通过mysql来处理上传数据6.通过phpmyadmin数据库来查询数据子系统处理上传数据的方式,针对性优化以上iisnginx服务器,开发者可根据自己的业务情况来决定是否加入。
下图是其中几个模块的列表。大家可以随意组合自己喜欢的模块加入到自己的子系统中。二.chef子系统用于处理本地上传文件:使用phpmyadmin数据库处理方式:。
关键词信息采编自动采集;快速发布中图分类号949.292
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-07-03 22:35
文档介绍:在线信息automatic采集系统.doc 在线信息automatic采集system 摘要在线信息automatic采集system 是使用网络信息采集器automatic 网上采集各种信息需要的,包括文字、图片等内容,并使用存储的模板进行分类、存储和播放,以实现实时快速播放。并具有检索、监控、保护等功能,具有速度快、智能化的特点。通过该系统,可以解决目前传统信息采集和搜索引擎准确率低、检测率低、不灵活的缺点。 关键词信息采编;自动采集;中文图书馆分类号快速发布 TN949.292 文献识别码 A文章 编号 1673-9671-(2013)012-0150-01 1 背景,互联网时代的一切 一切都在高速运转. 每分每秒都在产生无数的新信息,第一时间获取全面准确的信息,已经成为与信息密切相关的各行各业的迫切需求,随着网络信息资源的快速增长,人们付出的代价也越来越高。并且更加关注如何开发和利用这些资源。但是,目前的中英文搜索引擎存在查准率和查全率不高的现象,不能适应当前用户对高质量网络信息服务的需求;与此同时,电子商务和各种网络信息服务正在迅速兴起,原有的网络信息处理和组织技术已经跟不上。这种发展趋势。网络信息挖掘就是在这样的环境中。它应运而生,迅速成为网络信息检索和信息服务领域的热点之一。
随着互联网的飞速发展,越来越多的信息呈现给用户,在现实生活中,但同时存在的问题是,用户获取自己最需要的信息越来越困难对于用户一般的信息查询和检索需求,传统信息采集器组成的搜索引擎可以提供更好的服务,但对于用户更具体的需求,这种基于采集提供的整个网页的传统信息服务就差强人意了对于每个用户,即使输入相同的查询词,他们想要的查询结果也不尽相同,而传统信息采集和搜索引擎只能死板地返回相同的结果。这是不合理的,需要进一步改进。对此,本文提出了一种基于CIS结构的在线信息采集与编辑系统。在线信息采集与编辑系统可实现在线信息检索数据库的实时监控、采集、存储和实时更新,并提供包括最新信息在内的全文检索,可充分满足各种复杂的需求。和要求的信息服务。 2 原理网络信息采集主要是指通过网页之间的链接关系,自动从一个网页中获取页面信息,并随着链接不断扩展到需要的网页的过程。这个过程的实现主要是通过网页信息采集器来完成的。根据不同的应用习惯,粗略的讲,主要是指一个程序从一组初始的URL开始,把这些URL都放到一个有序的采集队列中。而采集器依次从这个队列中取出URL,通过网页上的协议获取该URL指向的页面,然后从这些获取到的页面中提取出新的URL,继续放入等待的采集Queue,然后重复上述过程,直到采集器按照自己的策略停止采集。
对于大多数采集器,到此结束,而对于一些采集器,还需要对采集到达的页面数据和相关处理结果进行存储索引,然后在此基础上进行纠正从语义上分析内容。 3结构网页信息采集系统基本上可以分为5个部分:URL处理器、协议处理器、重复内容检测器、URL提取器、Meat信息获取器。以及几个功能子系统:信息监控系统、信息采集系统、信息存储系统、检索系统。 3.1信息监控系统信息监控系统的作用是时刻跟踪信息源的更新状态,一旦有新的信息出现,立即通知采集系统。其主要特点包括:1)高效监控:多线程并发监控设计,每分钟多达数百个网站可以完成是否有信息更新的判断,使用效果非常好。 2)低带宽占用:自动提取网页特征属性判断是否有更新,每次需要传输的信息只有 查看全部
关键词信息采编自动采集;快速发布中图分类号949.292
文档介绍:在线信息automatic采集系统.doc 在线信息automatic采集system 摘要在线信息automatic采集system 是使用网络信息采集器automatic 网上采集各种信息需要的,包括文字、图片等内容,并使用存储的模板进行分类、存储和播放,以实现实时快速播放。并具有检索、监控、保护等功能,具有速度快、智能化的特点。通过该系统,可以解决目前传统信息采集和搜索引擎准确率低、检测率低、不灵活的缺点。 关键词信息采编;自动采集;中文图书馆分类号快速发布 TN949.292 文献识别码 A文章 编号 1673-9671-(2013)012-0150-01 1 背景,互联网时代的一切 一切都在高速运转. 每分每秒都在产生无数的新信息,第一时间获取全面准确的信息,已经成为与信息密切相关的各行各业的迫切需求,随着网络信息资源的快速增长,人们付出的代价也越来越高。并且更加关注如何开发和利用这些资源。但是,目前的中英文搜索引擎存在查准率和查全率不高的现象,不能适应当前用户对高质量网络信息服务的需求;与此同时,电子商务和各种网络信息服务正在迅速兴起,原有的网络信息处理和组织技术已经跟不上。这种发展趋势。网络信息挖掘就是在这样的环境中。它应运而生,迅速成为网络信息检索和信息服务领域的热点之一。
随着互联网的飞速发展,越来越多的信息呈现给用户,在现实生活中,但同时存在的问题是,用户获取自己最需要的信息越来越困难对于用户一般的信息查询和检索需求,传统信息采集器组成的搜索引擎可以提供更好的服务,但对于用户更具体的需求,这种基于采集提供的整个网页的传统信息服务就差强人意了对于每个用户,即使输入相同的查询词,他们想要的查询结果也不尽相同,而传统信息采集和搜索引擎只能死板地返回相同的结果。这是不合理的,需要进一步改进。对此,本文提出了一种基于CIS结构的在线信息采集与编辑系统。在线信息采集与编辑系统可实现在线信息检索数据库的实时监控、采集、存储和实时更新,并提供包括最新信息在内的全文检索,可充分满足各种复杂的需求。和要求的信息服务。 2 原理网络信息采集主要是指通过网页之间的链接关系,自动从一个网页中获取页面信息,并随着链接不断扩展到需要的网页的过程。这个过程的实现主要是通过网页信息采集器来完成的。根据不同的应用习惯,粗略的讲,主要是指一个程序从一组初始的URL开始,把这些URL都放到一个有序的采集队列中。而采集器依次从这个队列中取出URL,通过网页上的协议获取该URL指向的页面,然后从这些获取到的页面中提取出新的URL,继续放入等待的采集Queue,然后重复上述过程,直到采集器按照自己的策略停止采集。
对于大多数采集器,到此结束,而对于一些采集器,还需要对采集到达的页面数据和相关处理结果进行存储索引,然后在此基础上进行纠正从语义上分析内容。 3结构网页信息采集系统基本上可以分为5个部分:URL处理器、协议处理器、重复内容检测器、URL提取器、Meat信息获取器。以及几个功能子系统:信息监控系统、信息采集系统、信息存储系统、检索系统。 3.1信息监控系统信息监控系统的作用是时刻跟踪信息源的更新状态,一旦有新的信息出现,立即通知采集系统。其主要特点包括:1)高效监控:多线程并发监控设计,每分钟多达数百个网站可以完成是否有信息更新的判断,使用效果非常好。 2)低带宽占用:自动提取网页特征属性判断是否有更新,每次需要传输的信息只有
房地产、建筑全专业管理员用户系统管理与维护
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-07-02 22:23
第一章系统管理与维护第二章索引字典与报表定义第三章审计关系第四章设置报表周期第五章采集Processing第六章汇总表第七章数据计算第八章查询分析第九章数据导入导出中国投资信息管理与监控系统—Data采集子系统用户手册ii 第10章系统导入导出第11章数据管理第12章信息交换第13章在线新闻用户流程第1章系统管理与维护登录系统与系统初始化1.1在线版登录系统1.1.1 打开网页,程序管理员在服务器上安装一次,其他用户即可使用,无需安装任何插件或客户端。第一步:连接互联网;第二步:启动IE浏览器;第三步:在地址栏中输入对应的网址,进入平台登录页面,如下图:1.1.2 专业版和网络版 用户的网络版发布时,分为专业,投资、房地产和建筑。网络版用户系统默认创建多个管理员用户。具体用户信息如下表: 登录名 密码 用户类型属于专业系统系统 系统管理员 无(系统维护) admin admin 投资、房地产、建筑所有专业管理员 投资、房地产、建筑 tz 投资专业管理员投资fdc fdc房地产专业管理员房地产jzy jzy建筑专业管理员的楼宇登录名都是小写英文字母,第一次登录密码与登录名一致,密码一定要改,因为网络版开放不同本机使用的是单机版,所以为了安全起见,第一次登录时必须修改密码。
中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.1.3 网络版用户登录 在平台登录页面,用户需要输入登录名、密码、验证码等信息。请注意:如果登录名和密码中使用英文字母,请区分大小写。该系统严格区分大小写字母。用户名和密码只能由英文字母和数字组成,不能收录任何符号。首次登录系统时必须更改密码。新密码不能与登录名相同,区分大小写。只能由英文字母和数字组成,不能收录符号。修改密码后请记住新密码。登录后直接进入data采集处理系统主界面,如下图: 1.2 单机版登录系统1.2.1 单机版为与网络版不同。任何想要使用单机版的用户都需要在自己的电脑上安装或复制才能使用。安装共有三种安装方式: 第一步:输入登录名。第二步:输入密码。默认密码与登录名一致。第三步:输入验证码。第四步:登录系统平台主菜单。中国投资信息管理与监控系统—Data采集子系统用户手册1、直接复制(或解压)单机版程序到需要使用的电脑上,如果是压缩文件,解压后即可使用。建议放在空间较大的磁盘分区,因为加载数据后文件会变大。 2、使用安装盘安装如果有安装盘,可以运行安装盘中的安装文件(后缀为exe的文件)。
安装程序会将单机版的程序安装到机器上使用。 3、升级单机版程序运行单机版升级程序文件(后缀为exe的文件),安装文件会自动搜索默认安装升级下的单机版程序。如果用户之前没有安装到默认路径,或者使用直接复制解压方式,请选择正确的单机版本使用路径升级。目前升级程序支持的单机版本为2008年28日发布的程序,之前发布的单机测试程序不支持升级。 1.2.2 单机版专业人士和用户 单机版发布时,分为投资、房地产和建筑三大专业。单机版的用户也是固定的,具体用户信息见下表。用户使用时,请先以系统用户登录,并选择正确的管理级别。登录名密码用户类型专业系统1234系统管理员无(系统维护)admin 1234投资、房地产、建筑全专业管理员投资、房地产、建筑tz 1234投资专业管理员投资fdc 1234房地产专业管理员房地产jzy 1234建设专业管理员楼登录名全部使用小写英文字母。因为单机版是在自己的电脑上使用的,一切都是为了方便。所有密码均已初始化为1234。您可以随时修改密码,但修改后请记住您的密码。
1.2.3 登录单机程序 安装完成后,桌面会自动创建一个图标,如下图。双击桌面上的图标开始运行程序。或者,如果不是向导安装的程序,而是通过解压文件夹中国投资信息管理与监控系统-Data采集Subsystem User Manual。安装后直接打开目录,找到文件,双击运行单机版即可。在“登录名”和“密码”输入框中输入相应的用户登录名和密码,点击【登录】。注:哪个专业用户用那个专业管理员登录,如:投资专业,使用tz用户。 admin 用户均为专业管理员。如上图所示,登录后的主页面。 1.3 管理层级初始化管理层级是基于行政区划创建的垂直管理方式,依次为“国”、“省”、“地市”、“区县”、“街道(乡)”、“住宅” (村)委会”。表示系统中的管理员身份是一种向下管理的方式,向上报告的过程。国家发布的程序管理级别为国家级,用户自行使用时可根据实际情况将管理级别初始化为自己所在地区。这一步是必须的。如果不更改管理级别,则输入数据的管理级别可能不正确。区域汇总也会受到影响,数据上报也会受到影响。但是初始管理级别设置一次就可以一直使用,不用每次都设置。
可以说,初期的管理水平是必须的,一劳永逸的同时做。中国投资信息管理与监控系统-Data采集子系统用户手册 初始化方法如下:1、单版:复制或安装到对应目录,打开程序文件夹,点击运行单版程序为第一次。网络版:在服务器上安装网络版程序后,启动服务,打开IE浏览器,输入正确的网址。 2、打开下图所示的登录界面,输入系统用户名,网络版密码也是system,需要修改密码;单机版密码为:1234,注意登录名英文字母要小写。如果是网络版,还需要根据页面提示输入验证码。单机版直接点击【登录】按钮。 3、 出现管理层初始化网页对话框。根据实际情况选择区域,如用户在北京,选择“北京”,鼠标点击“确定”。界面美观,默认显示全国31个省、市、自治区。如果您是区县用户,比如“东城区”,可以通过双华投资信息管理监测系统——Data采集Subsystem用户手册点击省或省,为直辖市或自治区名称区域,展开下层管理级别,如下图: 找到北京后,双击“北京”行展开下一层,再次双击可以看到东城等区县区,根据实际情况选择管理级别。此时点击【确定】,会出现提示信息,如下图: 如果确定选择正确,可以选择“确定”。
管理层初始化结束。注:管理层的详细维护方法请参见下文“第二章管理层维护”。 1.4 主界面介绍1.4.1 主菜单 上图红框部分为系统主菜单。这里列出了系统中的所有功能,每个主菜单下都有几个子菜单。单机版初始化4级管理。用户可以自行定义和维护。具体的保养方法见下文。中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.4.2Professionals 后面是当前登录用户可以使用的专业。如果你是admin用户,可以看到3个专业,可以通过下拉菜单选择使用哪个专业。如果tz投资用户的专业职位直接显示“投资”无法选择,fdc房地产和jzy建筑行业用户只能看到自己的专业。 1.4.3 查看本期 在主菜单下,可以看到“查看本期”字样。用鼠标点击“查看当期”字样,弹出当前专业报告期激活或去激活状态。如上图所示,在任何页面,您都可以轻松查看该专业报告期内哪些报告处于活动状态或关闭状态。 1.4.4 管理级别 每个用户可以根据自己的管理级别选择低于自己的任何级别。目的是让高级管理员和集成用户可以随时模拟任何用户的权限操作或监控数据。
单击上图中框中显示的按钮。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 弹出对话框,如上图所示,红框部分可根据条件查询。鼠标选中后,点击【确定】可以切换到自己下面的任意一个管理级别。双击一个级别,如果该级别收录下属,则自动展开,如果没有下属,则不展开。选择后,将根据总体管理级别限制对“数据编辑”、“数据导入”、“数据导出”、“数据查询”等页面进行操作。 1.4.5 “返回”按钮 如上图所示,页面右上角有一个“返回”,可以用鼠标点击。点击后,无论用户当前在哪个页面,都会返回登录首页。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 管理层级维护2.1 管理层级基本维护 首次安装网络版或使用单机程序时,需要管理层级初始化,一般一次性设置后,日常工作中无需频繁维护。该模块不是通用模块。但该模块也具备维护所需的全部功能,如添加、修改、删除、导入、导出等功能。导入导出功能将在下面的“自定义管理级别”部分详细介绍。本节重点介绍添加、删除和修改管理级别的方法。 【添加】:选择一个管理级别,点击【添加】按钮,在其下方添加一个新的管理级别。管理层的编码规则为:2、2、2、3、3,共12位。
序列:省、市、区(县)、街道(乡)、居委会(村委会)。程序会根据位数自动判断电平。如果管理级别为空,则代表国家级别,即默认最高级别。具体管理级别及代号见下表: 管理级别数字长度(位) 省居(村)委会 12 【修改】:选择现有的管理级别进行编码和名称修改。编码在增加时也遵循规则。 “删除”:选择现有的管理级别将其删除。当所选管理级别不是最小级别时,但收录从属管理级别时,单击“删除”以删除其下属。请谨慎删除管理级别。 【导出】:如下图,使用【导出】按钮导出系统中的管理级别,然后根据导出文本中的格式添加自定义的管理级别。请注意,代码和名称之间的分隔符是英文输入法下的逗号。操作方法如下: 点击弹出窗口中的“请下载”,将导出的文件保存到本地。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 导出的管理级别文本可以根据本地使用的实际情况进行排序后,使用【导入】按钮导入新的管理级别。这更新了系统中的原创管理级别。 “导入”:导入功能可以实现批量修改,添加多个管理级别。导入方法如下:点击弹出窗口中的【浏览】按钮,从电脑中选择整理好的文本文件,点击【导入】。
请注意:这里的导入不是增量更新,而是完整更新。即以导入文本中的内容为准,全部替换原内容。因此,文本需要具有所有用户定义的管理级别,而不是部分。 2.2 省局等自定义管理级别。因为国家发布的管理级别不包括开发区、高新区等,而且在某些情况下,省市一级的管理级别发生了变化,默认发布的管理级别不能满足根据需要,省局等用户可以自定义管理级别使用。程序路径下有一个名为“initdata”的文件夹。这个文件夹下有几个文件: mgt_level.txt:程序中的管理级别。修改mgt_level.txt文件后,需要登录系统,在“业务管理”和“重置管理”菜单中重置管理级别才能生效。 DZM.txt:全国行政区划的地址代码,只有12位的地址代码。与 0 类似的没有实际地址含义的行政区划不包括在本文中。总数超过700,000。 XZQH.txt:全国街道办事处以上级别为9位数以内的级别。 index.txt:程序使用的文件,不可删除或修改。上述文件中,mgt_level.txt文件为程序初始化的管理级别范围。
<p>如果省用户要自己制作全省所有的行政级别,分配后,下级用户再次初始化管理级别时看到的范围为省下发的省自定义范围局用户,只要修改这个文件就可以实现这个功能。 DZM.txt和XZQH.txt文本为地址代码12位以内的行政区划代码文件,默认为全国发行。定制后,可以通过程序初始化管理层,同时初始化其他相关地址代码的索引集。具体操作以北京地区自定义管理级别为例进行说明。上述mgt_level.txt文件的存放路径: 在单机版中,假设单机版程序放在电脑的D盘“D:\CIIMSS_CS\webapp\initdata\”(斜体部分是本机的路径,可能每个电脑上都不一样)。在网络版中,假设它也安装在服务器的磁盘上,路径为“D:\HOLLYSYS\webapps\CIIMSS\initdata\”。以下是修改此文件的方法。要打开mgt_level.txt文件,可以用记事本打开,也可以用写字板或其他文本工具打开进行编辑。默认开启时,你第一次用system登录系统时看到的所有管理级别都是一样的,都是国家颁发的管理级别。一、中国投资信息管理与监控系统-Data采集子系统用户手册 首先,将这个文件备份,复制出来放到电脑的另一个位置,或者直接在这个文件夹中保存一份。 查看全部
房地产、建筑全专业管理员用户系统管理与维护
第一章系统管理与维护第二章索引字典与报表定义第三章审计关系第四章设置报表周期第五章采集Processing第六章汇总表第七章数据计算第八章查询分析第九章数据导入导出中国投资信息管理与监控系统—Data采集子系统用户手册ii 第10章系统导入导出第11章数据管理第12章信息交换第13章在线新闻用户流程第1章系统管理与维护登录系统与系统初始化1.1在线版登录系统1.1.1 打开网页,程序管理员在服务器上安装一次,其他用户即可使用,无需安装任何插件或客户端。第一步:连接互联网;第二步:启动IE浏览器;第三步:在地址栏中输入对应的网址,进入平台登录页面,如下图:1.1.2 专业版和网络版 用户的网络版发布时,分为专业,投资、房地产和建筑。网络版用户系统默认创建多个管理员用户。具体用户信息如下表: 登录名 密码 用户类型属于专业系统系统 系统管理员 无(系统维护) admin admin 投资、房地产、建筑所有专业管理员 投资、房地产、建筑 tz 投资专业管理员投资fdc fdc房地产专业管理员房地产jzy jzy建筑专业管理员的楼宇登录名都是小写英文字母,第一次登录密码与登录名一致,密码一定要改,因为网络版开放不同本机使用的是单机版,所以为了安全起见,第一次登录时必须修改密码。
中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.1.3 网络版用户登录 在平台登录页面,用户需要输入登录名、密码、验证码等信息。请注意:如果登录名和密码中使用英文字母,请区分大小写。该系统严格区分大小写字母。用户名和密码只能由英文字母和数字组成,不能收录任何符号。首次登录系统时必须更改密码。新密码不能与登录名相同,区分大小写。只能由英文字母和数字组成,不能收录符号。修改密码后请记住新密码。登录后直接进入data采集处理系统主界面,如下图: 1.2 单机版登录系统1.2.1 单机版为与网络版不同。任何想要使用单机版的用户都需要在自己的电脑上安装或复制才能使用。安装共有三种安装方式: 第一步:输入登录名。第二步:输入密码。默认密码与登录名一致。第三步:输入验证码。第四步:登录系统平台主菜单。中国投资信息管理与监控系统—Data采集子系统用户手册1、直接复制(或解压)单机版程序到需要使用的电脑上,如果是压缩文件,解压后即可使用。建议放在空间较大的磁盘分区,因为加载数据后文件会变大。 2、使用安装盘安装如果有安装盘,可以运行安装盘中的安装文件(后缀为exe的文件)。
安装程序会将单机版的程序安装到机器上使用。 3、升级单机版程序运行单机版升级程序文件(后缀为exe的文件),安装文件会自动搜索默认安装升级下的单机版程序。如果用户之前没有安装到默认路径,或者使用直接复制解压方式,请选择正确的单机版本使用路径升级。目前升级程序支持的单机版本为2008年28日发布的程序,之前发布的单机测试程序不支持升级。 1.2.2 单机版专业人士和用户 单机版发布时,分为投资、房地产和建筑三大专业。单机版的用户也是固定的,具体用户信息见下表。用户使用时,请先以系统用户登录,并选择正确的管理级别。登录名密码用户类型专业系统1234系统管理员无(系统维护)admin 1234投资、房地产、建筑全专业管理员投资、房地产、建筑tz 1234投资专业管理员投资fdc 1234房地产专业管理员房地产jzy 1234建设专业管理员楼登录名全部使用小写英文字母。因为单机版是在自己的电脑上使用的,一切都是为了方便。所有密码均已初始化为1234。您可以随时修改密码,但修改后请记住您的密码。
1.2.3 登录单机程序 安装完成后,桌面会自动创建一个图标,如下图。双击桌面上的图标开始运行程序。或者,如果不是向导安装的程序,而是通过解压文件夹中国投资信息管理与监控系统-Data采集Subsystem User Manual。安装后直接打开目录,找到文件,双击运行单机版即可。在“登录名”和“密码”输入框中输入相应的用户登录名和密码,点击【登录】。注:哪个专业用户用那个专业管理员登录,如:投资专业,使用tz用户。 admin 用户均为专业管理员。如上图所示,登录后的主页面。 1.3 管理层级初始化管理层级是基于行政区划创建的垂直管理方式,依次为“国”、“省”、“地市”、“区县”、“街道(乡)”、“住宅” (村)委会”。表示系统中的管理员身份是一种向下管理的方式,向上报告的过程。国家发布的程序管理级别为国家级,用户自行使用时可根据实际情况将管理级别初始化为自己所在地区。这一步是必须的。如果不更改管理级别,则输入数据的管理级别可能不正确。区域汇总也会受到影响,数据上报也会受到影响。但是初始管理级别设置一次就可以一直使用,不用每次都设置。
可以说,初期的管理水平是必须的,一劳永逸的同时做。中国投资信息管理与监控系统-Data采集子系统用户手册 初始化方法如下:1、单版:复制或安装到对应目录,打开程序文件夹,点击运行单版程序为第一次。网络版:在服务器上安装网络版程序后,启动服务,打开IE浏览器,输入正确的网址。 2、打开下图所示的登录界面,输入系统用户名,网络版密码也是system,需要修改密码;单机版密码为:1234,注意登录名英文字母要小写。如果是网络版,还需要根据页面提示输入验证码。单机版直接点击【登录】按钮。 3、 出现管理层初始化网页对话框。根据实际情况选择区域,如用户在北京,选择“北京”,鼠标点击“确定”。界面美观,默认显示全国31个省、市、自治区。如果您是区县用户,比如“东城区”,可以通过双华投资信息管理监测系统——Data采集Subsystem用户手册点击省或省,为直辖市或自治区名称区域,展开下层管理级别,如下图: 找到北京后,双击“北京”行展开下一层,再次双击可以看到东城等区县区,根据实际情况选择管理级别。此时点击【确定】,会出现提示信息,如下图: 如果确定选择正确,可以选择“确定”。
管理层初始化结束。注:管理层的详细维护方法请参见下文“第二章管理层维护”。 1.4 主界面介绍1.4.1 主菜单 上图红框部分为系统主菜单。这里列出了系统中的所有功能,每个主菜单下都有几个子菜单。单机版初始化4级管理。用户可以自行定义和维护。具体的保养方法见下文。中国投资信息管理与监控系统—Data采集Subsystem 用户手册1.4.2Professionals 后面是当前登录用户可以使用的专业。如果你是admin用户,可以看到3个专业,可以通过下拉菜单选择使用哪个专业。如果tz投资用户的专业职位直接显示“投资”无法选择,fdc房地产和jzy建筑行业用户只能看到自己的专业。 1.4.3 查看本期 在主菜单下,可以看到“查看本期”字样。用鼠标点击“查看当期”字样,弹出当前专业报告期激活或去激活状态。如上图所示,在任何页面,您都可以轻松查看该专业报告期内哪些报告处于活动状态或关闭状态。 1.4.4 管理级别 每个用户可以根据自己的管理级别选择低于自己的任何级别。目的是让高级管理员和集成用户可以随时模拟任何用户的权限操作或监控数据。
单击上图中框中显示的按钮。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 弹出对话框,如上图所示,红框部分可根据条件查询。鼠标选中后,点击【确定】可以切换到自己下面的任意一个管理级别。双击一个级别,如果该级别收录下属,则自动展开,如果没有下属,则不展开。选择后,将根据总体管理级别限制对“数据编辑”、“数据导入”、“数据导出”、“数据查询”等页面进行操作。 1.4.5 “返回”按钮 如上图所示,页面右上角有一个“返回”,可以用鼠标点击。点击后,无论用户当前在哪个页面,都会返回登录首页。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 管理层级维护2.1 管理层级基本维护 首次安装网络版或使用单机程序时,需要管理层级初始化,一般一次性设置后,日常工作中无需频繁维护。该模块不是通用模块。但该模块也具备维护所需的全部功能,如添加、修改、删除、导入、导出等功能。导入导出功能将在下面的“自定义管理级别”部分详细介绍。本节重点介绍添加、删除和修改管理级别的方法。 【添加】:选择一个管理级别,点击【添加】按钮,在其下方添加一个新的管理级别。管理层的编码规则为:2、2、2、3、3,共12位。
序列:省、市、区(县)、街道(乡)、居委会(村委会)。程序会根据位数自动判断电平。如果管理级别为空,则代表国家级别,即默认最高级别。具体管理级别及代号见下表: 管理级别数字长度(位) 省居(村)委会 12 【修改】:选择现有的管理级别进行编码和名称修改。编码在增加时也遵循规则。 “删除”:选择现有的管理级别将其删除。当所选管理级别不是最小级别时,但收录从属管理级别时,单击“删除”以删除其下属。请谨慎删除管理级别。 【导出】:如下图,使用【导出】按钮导出系统中的管理级别,然后根据导出文本中的格式添加自定义的管理级别。请注意,代码和名称之间的分隔符是英文输入法下的逗号。操作方法如下: 点击弹出窗口中的“请下载”,将导出的文件保存到本地。中国投资信息管理与监控系统—Data采集Subsystem 用户手册 导出的管理级别文本可以根据本地使用的实际情况进行排序后,使用【导入】按钮导入新的管理级别。这更新了系统中的原创管理级别。 “导入”:导入功能可以实现批量修改,添加多个管理级别。导入方法如下:点击弹出窗口中的【浏览】按钮,从电脑中选择整理好的文本文件,点击【导入】。
请注意:这里的导入不是增量更新,而是完整更新。即以导入文本中的内容为准,全部替换原内容。因此,文本需要具有所有用户定义的管理级别,而不是部分。 2.2 省局等自定义管理级别。因为国家发布的管理级别不包括开发区、高新区等,而且在某些情况下,省市一级的管理级别发生了变化,默认发布的管理级别不能满足根据需要,省局等用户可以自定义管理级别使用。程序路径下有一个名为“initdata”的文件夹。这个文件夹下有几个文件: mgt_level.txt:程序中的管理级别。修改mgt_level.txt文件后,需要登录系统,在“业务管理”和“重置管理”菜单中重置管理级别才能生效。 DZM.txt:全国行政区划的地址代码,只有12位的地址代码。与 0 类似的没有实际地址含义的行政区划不包括在本文中。总数超过700,000。 XZQH.txt:全国街道办事处以上级别为9位数以内的级别。 index.txt:程序使用的文件,不可删除或修改。上述文件中,mgt_level.txt文件为程序初始化的管理级别范围。
<p>如果省用户要自己制作全省所有的行政级别,分配后,下级用户再次初始化管理级别时看到的范围为省下发的省自定义范围局用户,只要修改这个文件就可以实现这个功能。 DZM.txt和XZQH.txt文本为地址代码12位以内的行政区划代码文件,默认为全国发行。定制后,可以通过程序初始化管理层,同时初始化其他相关地址代码的索引集。具体操作以北京地区自定义管理级别为例进行说明。上述mgt_level.txt文件的存放路径: 在单机版中,假设单机版程序放在电脑的D盘“D:\CIIMSS_CS\webapp\initdata\”(斜体部分是本机的路径,可能每个电脑上都不一样)。在网络版中,假设它也安装在服务器的磁盘上,路径为“D:\HOLLYSYS\webapps\CIIMSS\initdata\”。以下是修改此文件的方法。要打开mgt_level.txt文件,可以用记事本打开,也可以用写字板或其他文本工具打开进行编辑。默认开启时,你第一次用system登录系统时看到的所有管理级别都是一样的,都是国家颁发的管理级别。一、中国投资信息管理与监控系统-Data采集子系统用户手册 首先,将这个文件备份,复制出来放到电脑的另一个位置,或者直接在这个文件夹中保存一份。
自动采集子系统一般有三种方式,你知道吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2021-06-20 19:32
自动采集子系统一般有三种方式,
1、rfid识别系统,
2、ai拍照识别系统,
3、wifi/4g远程控制系统,实现无线监控。有一些具体方案选择上的细节需要根据项目定位来确定。
自动采集一般有两种方式,一种就是对施工排查和物业监控检查,用ar/mr,一种方式是对基坑监控等,
一般的自动采集子系统在一些地下场所用的比较多。地下自动采集子系统通常包括主机,无线网络接入,无线接收,摄像机,简单的mcu运算处理模块,多根网线口,成像器件,网络转发,控制器,甚至辅助插件如控制器等。基坑施工作业后通常要进行成像检查及地下通道的监控。这个需要看你们施工的具体情况来确定接入点,如果场地小也可以只接入摄像机等,通常存在同一地下楼层要用不同路由器进行监控,为防止隐私泄露也可以只接入摄像机。施工中可以根据要求选择不同光通量的路由器。
需要考虑需要大地压场的。每个都有一个直流接入电源和输出端,该电源可以是做电源变压器兼容。
无线这块需要什么线应该有点坑,看你要传输的信号是什么样的。监控器不用太多,毕竟都是远程采集, 查看全部
自动采集子系统一般有三种方式,你知道吗?
自动采集子系统一般有三种方式,
1、rfid识别系统,
2、ai拍照识别系统,
3、wifi/4g远程控制系统,实现无线监控。有一些具体方案选择上的细节需要根据项目定位来确定。
自动采集一般有两种方式,一种就是对施工排查和物业监控检查,用ar/mr,一种方式是对基坑监控等,
一般的自动采集子系统在一些地下场所用的比较多。地下自动采集子系统通常包括主机,无线网络接入,无线接收,摄像机,简单的mcu运算处理模块,多根网线口,成像器件,网络转发,控制器,甚至辅助插件如控制器等。基坑施工作业后通常要进行成像检查及地下通道的监控。这个需要看你们施工的具体情况来确定接入点,如果场地小也可以只接入摄像机等,通常存在同一地下楼层要用不同路由器进行监控,为防止隐私泄露也可以只接入摄像机。施工中可以根据要求选择不同光通量的路由器。
需要考虑需要大地压场的。每个都有一个直流接入电源和输出端,该电源可以是做电源变压器兼容。
无线这块需要什么线应该有点坑,看你要传输的信号是什么样的。监控器不用太多,毕竟都是远程采集,
辅助网编系统快速地发现有新闻价值的实时信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-06-15 00:22
辅助网编系统快速地发现有新闻价值的实时信息
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴,跑累了。
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统大量转发合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.各种新闻网站,平面媒体、论坛、博客、微博、视频网站的最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入深度编辑或原创上乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供采集各种网站服务。没有高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3.无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载 查看全部
辅助网编系统快速地发现有新闻价值的实时信息
乐思网新闻转载系统
乐思网络新闻转载系统基于全球领先的采集技术开发,可辅助网络编辑系统每天批量快速发现具有新闻价值的实时信息。
一、 系统概览
乐思网新闻转载系统针对趋势,通过实时自动采集,对大量目标网站(如新闻、论坛、博客、微博等)中的关键信息进行汇总和识别.) 一套网络编辑工作平台,用于发现具有新闻价值的信息并提供后续编辑和审核功能。
系统架构如下图:乐思软件
图片1.乐思网新闻转载系统架构
与目前的人工新闻转载相比,优势明显:
比较指标
使用乐思网络新闻转载系统
手动转载
目标网站
成百上千和数万
几十个
人工成本
网络信息的获取完全由软件自动化,少数网络编辑只需浏览分析内网内容即可。
大量网页编辑需要分别登录每个网站,手动查看,手动复制粘贴,跑累了。
新闻线索识别
在自动判别的基础上,再人工确认
需要人工一一核对确认
信息保存
准确、全面、易于事后跟踪
小事难免出错
数据存储
大型关系型数据库统一存储,集中管理
随时粘贴,难以管理
工作报告
基于自动统计分析,
图文并茂,有详细的统计数据支持,可日报表、周报表、月报表
模糊、不清楚、没有统计数据:乐思软件
转载效果
系统大量转发合作媒体或网友曝光素材,网站流量和排名快速提升
不系统,少量
二、 实施后的收益
1.各种新闻网站,平面媒体、论坛、博客、微博、视频网站的最新资讯自动集中呈现
2.系统快速发现有价值的信息,一键选择
3.网页编辑的更多时间可以投入深度编辑或原创上乐思
4.每日转发量成百倍增长,网站流量和排名快速提升
三、 系统构成
乐思网新闻转载系统由两个子系统组成:自动采集子系统和结果浏览子系统。关系如下图所示:
图2.系统构成
乐思网络新闻转载系统的网络拓扑如下图所示。也可以根据需要在隔离的外部和内部网络中实现。
图3.网络拓扑结构
四、AUTO采集子系统功能说明
自动采集子系统可以自动采集任何目标网站。
例如:新华网、强国论坛、天涯社区、西瓷社区、网易社区、新浪论坛、搜狐社区、凤凰网、百度贴吧,以及用户指定的其他动态网站。您可以提取所有新闻文章或主题帖或最新主题帖的内容,也可以提取某个主题帖的所有回复或最新回复的内容。要么指定目标网站进行监控,要么不指定目标网站进行全局范围网站的监控,或者进行两者的混合监控。国内网站和国外网站BBC、CNN等都可以监控。
后端数据库支持任何主流关系型数据库,如Oracle、IBM DB2、MS SQL Server、MySQL、Sybase,以及基于文件的数据库Access。乐思软件
全自动采集子系统的全方位监控功能如下图所示:
图4.自动采集子系统全方位监控
自动采集子系统具有以下显着特点:
1.全球领先的自动采集功能
Lesisoft 的网络信息采集 是世界领先的技术,支持任何网页中任何数据的准确性采集。乐思软件每天为国内外用户提供采集各种网站服务。没有高效稳定的采集平台是做不到的。
2.支持各种监控对象
可实时监控新闻、论坛、博客、公共聊天室、搜索引擎、留言板、应用、报纸网站电子版等。
3.无需配置,直接监听上千条新闻网站
系统内置网站全球监控配置,输入关键词,自动采集出文章标题和文字。
4.强大的多语言统一处理功能
可自动处理保存中、英、法、德、日、韩等多种语言。
5.Smart文章提取
对于文章类型的网页,可以直接提取文章正文和标题,以及作者的发布日期等,无需配置,自动去除广告、栏目、版权等无关垃圾内容。
6. 完美支持各种网络场景
支持当前流行的Web2.0 AJAX动态网站
支持用户名密码自动登录
支持表单查询新闻转载
《excel智能代理——excel高端自动采集软件v2》
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-06-14 21:02
自动采集子系统采集信息的软件:清华大学出版社出版的《excel智能代理——excel高端自动采集软件v2。0》推荐系统:《sas智能代理系统设计与实现》推荐系统引入:《推荐系统实践》算法比较:《推荐系统与机器学习》冷启动:《推荐系统实践》分群系统:《推荐系统引擎设计与实现》推荐系统:《精准化推荐》ctr预估策略:《推荐系统实践》。
deeplearning
各大公司的im或者群推荐,
电商推荐业务中有一类场景,用户活跃度比较高,但是rank存在较大不确定性,可以采用按区域推荐的方式,
ad-picking引入不推荐是推荐机制中必不可少的一部分,但是不同的推荐场景,确实不能简单的套用传统推荐的方法来解决。建议一定要详细研究下不同场景里的推荐目标是什么,在这个基础上再套用传统的推荐算法方法来解决具体场景下的推荐问题,你会更加清楚自己具体的需求。
简答,说的不对的话请大家补充。
一、细分类任务
二、预测类任务
三、排序类任务每个任务针对相应的可分类推荐方法,得到有效的排序方法。
例如:可分类:
1、关联推荐;
2、摘要推荐;
3、相似推荐;
4、item-based和user-based等;
5、内容相似推荐。
排序类:
1、相似度排序;
2、加权排序;
3、用户相似度排序;
4、item相似度排序;
5、行为相似度排序;
6、一般推荐。以上需要具体分析。 查看全部
《excel智能代理——excel高端自动采集软件v2》
自动采集子系统采集信息的软件:清华大学出版社出版的《excel智能代理——excel高端自动采集软件v2。0》推荐系统:《sas智能代理系统设计与实现》推荐系统引入:《推荐系统实践》算法比较:《推荐系统与机器学习》冷启动:《推荐系统实践》分群系统:《推荐系统引擎设计与实现》推荐系统:《精准化推荐》ctr预估策略:《推荐系统实践》。
deeplearning
各大公司的im或者群推荐,
电商推荐业务中有一类场景,用户活跃度比较高,但是rank存在较大不确定性,可以采用按区域推荐的方式,
ad-picking引入不推荐是推荐机制中必不可少的一部分,但是不同的推荐场景,确实不能简单的套用传统推荐的方法来解决。建议一定要详细研究下不同场景里的推荐目标是什么,在这个基础上再套用传统的推荐算法方法来解决具体场景下的推荐问题,你会更加清楚自己具体的需求。
简答,说的不对的话请大家补充。
一、细分类任务
二、预测类任务
三、排序类任务每个任务针对相应的可分类推荐方法,得到有效的排序方法。
例如:可分类:
1、关联推荐;
2、摘要推荐;
3、相似推荐;
4、item-based和user-based等;
5、内容相似推荐。
排序类:
1、相似度排序;
2、加权排序;
3、用户相似度排序;
4、item相似度排序;
5、行为相似度排序;
6、一般推荐。以上需要具体分析。
web开发框架这么多,自己不懂自己设计就去做框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-06-10 00:02
自动采集子系统可以把excel或者word格式的数据采集成mysql或者sqlserver格式的文件。作为python工具,可以用来处理数据结构复杂的数据库。h5子系统可以用来处理mvc模式的网页。
整个web框架搭建下来你就能看到很多前端很多代码,会对htmlcss有很好的理解。并且页面的交互控制,以及排版等问题基本都是很容易搞定的。
web开发框架目前也有不少,比如bootstrap,angular,react等,采用的语言通常有javaphprubyjs,也有些是用c和c++(比如facebook),看你的兴趣点在哪里,可以根据自己的喜好选择,基本上框架不管是node还是其他,
现在框架这么多,自己不懂自己设计开发就去做框架.
我现在做前端,目前没啥好框架,用的最多的是vue。不过以后会有其他框架,欢迎交流。
推荐使用express,这个没得说,非常灵活。并且对比h5页面开发,原生的vue组件更加合理。我正在做一个微信朋友圈集合页面,就是用的它,几乎不用重写任何组件。如果有兴趣可以看看express框架的官方文档。推荐你学习一下。by?didreceiveassumption=one&unsigned=max&shouldputbannerintothearticleinthearticle-everything-you-need-to-know,一个非常灵活的框架,非常适合小项目。我的微信wxixizm。 查看全部
web开发框架这么多,自己不懂自己设计就去做框架
自动采集子系统可以把excel或者word格式的数据采集成mysql或者sqlserver格式的文件。作为python工具,可以用来处理数据结构复杂的数据库。h5子系统可以用来处理mvc模式的网页。
整个web框架搭建下来你就能看到很多前端很多代码,会对htmlcss有很好的理解。并且页面的交互控制,以及排版等问题基本都是很容易搞定的。
web开发框架目前也有不少,比如bootstrap,angular,react等,采用的语言通常有javaphprubyjs,也有些是用c和c++(比如facebook),看你的兴趣点在哪里,可以根据自己的喜好选择,基本上框架不管是node还是其他,
现在框架这么多,自己不懂自己设计开发就去做框架.
我现在做前端,目前没啥好框架,用的最多的是vue。不过以后会有其他框架,欢迎交流。
推荐使用express,这个没得说,非常灵活。并且对比h5页面开发,原生的vue组件更加合理。我正在做一个微信朋友圈集合页面,就是用的它,几乎不用重写任何组件。如果有兴趣可以看看express框架的官方文档。推荐你学习一下。by?didreceiveassumption=one&unsigned=max&shouldputbannerintothearticleinthearticle-everything-you-need-to-know,一个非常灵活的框架,非常适合小项目。我的微信wxixizm。

