
网页采集器的自动识别算法
浅识网页正文提取算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-25 20:39
这种算法须要对网站HTML构建DOM树,然后对之进行遍历递归,去除相应的噪声信息然后再从剩余的节点中进行选择。由于要构建DOM树,算法的时间/空间复杂度均较高。
基于标签的算法都潜在默认了这样的一个信息:即网站的网页生成,制作都遵守了一定的标签使用规范。不过现今的互联网网页五花八门,很难都按常理出牌,所以这在一定程度上减少了算法的准确性和通用性。
2.基于内容
网页根据内容方式分类大约分为:主题型,图片型和目录型。
对于主体型的网页,例如新闻类,博客类等,主要特征是文字内容比较多。基于这一点,另外一种正文提取思路是基于正文本身的特性。在一定程度上,正文的文字数目要比其他部份多。这在一定程度上有助于产生了区域的区分度。文字数目的飙升和飙升在一定程度上可以作为正文开始和介绍的判读点。
这类算法在本质上没有多大的差别,只是选择测度文字密度的方法不同而已。有的是基于块,有的是基于行,有的是基于转化函数。算法都很容易理解,也相对比较容易实现。下面的几篇文章就是基于网页内容的算法。
《基于行块分布函数的通用网页正文抽取》陈鑫
《基于网页分块的正文信息提取方式》黄玲,陈龙
博文《我为开源作贡献,网页正文提取--HtmlArticle2》
3. 基于视觉
想对于上面两种思路,这类算法的思路有一种"高大上"的觉得。这里不得不提及这类算法的基础:VIPS(Vision-based Page Segementation)算法。
VIPS算法:利用背景颜色,字体颜色和大小,边框,逻辑块和逻辑块之间的宽度等视觉特点,制定相应的规则把页面分割成各个视觉块!(视觉疗效真的是千变万化,如何制订规则集仍然是个复杂的问题)
VIPS算法充分利用了Web页面的布局特点。它首先从DOM 树中提取出所有合适的页面块,然后按照这种页面块测量出它们之间所有的分割条,包括水平和垂直方向;最后基于这种分割条.重新建立Web页面的语义结构。对于每一个语义块又可以使用VIPS算法继续分割为更小的语义块。该算法分为页面块提取、分隔条提取和语义块构建3部分,并且是递归调用的过程,直到条件不满足为止.
相关文献:
《基于视觉特点的网页正文提取方式研究》安增文,徐杰锋
《A vision—based page segmentation algorithm》
4. 基于数据挖掘/机器学习
看到好多作者对这一思路的普遍评价是"杀鸡焉用牛刀"。
基本思路是使用一定数目的网页作为训练集,通过训练得到网页正文的一些特征,然后将这种特点作为网页片断是否符合网页正文的判定根据。对于数据挖掘/机器学习算法来讲,训练样本的采集很重要,然而现实是互联网中网页方式千变万化,不太可能取太多数目作为训练样本。这样这些算法的准确性和通用性就遭到了阻碍,同时这类算法前期工作也比较复杂。 查看全部
浅识网页正文提取算法

这种算法须要对网站HTML构建DOM树,然后对之进行遍历递归,去除相应的噪声信息然后再从剩余的节点中进行选择。由于要构建DOM树,算法的时间/空间复杂度均较高。
基于标签的算法都潜在默认了这样的一个信息:即网站的网页生成,制作都遵守了一定的标签使用规范。不过现今的互联网网页五花八门,很难都按常理出牌,所以这在一定程度上减少了算法的准确性和通用性。
2.基于内容
网页根据内容方式分类大约分为:主题型,图片型和目录型。
对于主体型的网页,例如新闻类,博客类等,主要特征是文字内容比较多。基于这一点,另外一种正文提取思路是基于正文本身的特性。在一定程度上,正文的文字数目要比其他部份多。这在一定程度上有助于产生了区域的区分度。文字数目的飙升和飙升在一定程度上可以作为正文开始和介绍的判读点。
这类算法在本质上没有多大的差别,只是选择测度文字密度的方法不同而已。有的是基于块,有的是基于行,有的是基于转化函数。算法都很容易理解,也相对比较容易实现。下面的几篇文章就是基于网页内容的算法。
《基于行块分布函数的通用网页正文抽取》陈鑫
《基于网页分块的正文信息提取方式》黄玲,陈龙
博文《我为开源作贡献,网页正文提取--HtmlArticle2》
3. 基于视觉
想对于上面两种思路,这类算法的思路有一种"高大上"的觉得。这里不得不提及这类算法的基础:VIPS(Vision-based Page Segementation)算法。
VIPS算法:利用背景颜色,字体颜色和大小,边框,逻辑块和逻辑块之间的宽度等视觉特点,制定相应的规则把页面分割成各个视觉块!(视觉疗效真的是千变万化,如何制订规则集仍然是个复杂的问题)
VIPS算法充分利用了Web页面的布局特点。它首先从DOM 树中提取出所有合适的页面块,然后按照这种页面块测量出它们之间所有的分割条,包括水平和垂直方向;最后基于这种分割条.重新建立Web页面的语义结构。对于每一个语义块又可以使用VIPS算法继续分割为更小的语义块。该算法分为页面块提取、分隔条提取和语义块构建3部分,并且是递归调用的过程,直到条件不满足为止.
相关文献:
《基于视觉特点的网页正文提取方式研究》安增文,徐杰锋
《A vision—based page segmentation algorithm》
4. 基于数据挖掘/机器学习
看到好多作者对这一思路的普遍评价是"杀鸡焉用牛刀"。
基本思路是使用一定数目的网页作为训练集,通过训练得到网页正文的一些特征,然后将这种特点作为网页片断是否符合网页正文的判定根据。对于数据挖掘/机器学习算法来讲,训练样本的采集很重要,然而现实是互联网中网页方式千变万化,不太可能取太多数目作为训练样本。这样这些算法的准确性和通用性就遭到了阻碍,同时这类算法前期工作也比较复杂。
如何使用爬虫工具采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-25 20:36
(图2)
图2是java程序使用webmagic框架开发的爬虫程序,这段代码就是抓取对应的标签,和图1是相对应的,运行后得到结果如下:
当然,以上是专业程序员干的事情,但是有助于我们理解爬虫工具工作的原理。非专业人员可以通过爬虫工具来自己爬取数据。
1.首先输入你要爬取的网站的网址,点击“开始采集”。
2.工具手动辨识到当前页面是多页数据,会默认翻页采集,我们只要点击“生成采集设置”即可。
3.点击要采集的详尽链接,这里我们要采集这个网站上所有的化工产品的信息,所以点击英文名称这一列某个链接,再点击一侧“点击该链接”,如右图
4.爬虫工具步入到详尽链接的页面,这个页面的数据也就是我们要爬取的,点击“生成采集设置”,会生成爬虫工具最后的爬取流程,如下图所示,爬虫工具都会根据这个流程给我们采集数据,直到数据采集完成。
5.点击“采集”按钮,爬虫工具即将开始运行,爬虫工具工作时如下:
列表的那些数据都是爬虫采集到的,我们还可以对那些采集的数据做处理,可以选择导成Excel文档,或者直接导出数据库,这些是后续剖析数据,对数据做进一步处理的必要条件。有了这种基础数据,可以对数据做剖析,得出一些商业根据,可以作为商业决策时的支撑。比如曾经家乐福就通过她们的大数据,发现买尿布的奶爸喜欢一起买饮料,于是就把尿布和饮料摆在一起,啤酒的销量大增,这个就是大数据的价值。
这次讲的爬虫工具使用,只是比较基础的应用,希望对你们有帮助。科技惠威带你徜徉科技,后续会不断更新相关知识,欢迎关注。 查看全部
如何使用爬虫工具采集数据
(图2)
图2是java程序使用webmagic框架开发的爬虫程序,这段代码就是抓取对应的标签,和图1是相对应的,运行后得到结果如下:
当然,以上是专业程序员干的事情,但是有助于我们理解爬虫工具工作的原理。非专业人员可以通过爬虫工具来自己爬取数据。
1.首先输入你要爬取的网站的网址,点击“开始采集”。
2.工具手动辨识到当前页面是多页数据,会默认翻页采集,我们只要点击“生成采集设置”即可。
3.点击要采集的详尽链接,这里我们要采集这个网站上所有的化工产品的信息,所以点击英文名称这一列某个链接,再点击一侧“点击该链接”,如右图
4.爬虫工具步入到详尽链接的页面,这个页面的数据也就是我们要爬取的,点击“生成采集设置”,会生成爬虫工具最后的爬取流程,如下图所示,爬虫工具都会根据这个流程给我们采集数据,直到数据采集完成。
5.点击“采集”按钮,爬虫工具即将开始运行,爬虫工具工作时如下:
列表的那些数据都是爬虫采集到的,我们还可以对那些采集的数据做处理,可以选择导成Excel文档,或者直接导出数据库,这些是后续剖析数据,对数据做进一步处理的必要条件。有了这种基础数据,可以对数据做剖析,得出一些商业根据,可以作为商业决策时的支撑。比如曾经家乐福就通过她们的大数据,发现买尿布的奶爸喜欢一起买饮料,于是就把尿布和饮料摆在一起,啤酒的销量大增,这个就是大数据的价值。
这次讲的爬虫工具使用,只是比较基础的应用,希望对你们有帮助。科技惠威带你徜徉科技,后续会不断更新相关知识,欢迎关注。
一种高效地生成网页信息抽取规则的方式及系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-25 17:54
本发明专利技术公开了一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;该高效地生成网页信息抽取规则的方式及系统,可以克服纯人工配置抽取规则的低效问题,避免纯自动化抽取的精准度增长的问题,满足了企业级系统应用对精度及工作效率的要求,在不影响抽取精度的前提下,又增强了自动化程度,大大提升了网页信息抽取工作的效率以及实用性。
An efficient method and system for generating web information extraction rules
全部详尽技术资料下载
【技术实现步骤摘要】
一种高效地生成网页信息抽取规则的方式及系统
本专利技术涉及计算机网页采集
,具体为一种高效地生成网页信息抽取规则的方式及系统。
技术介绍
网页是构成网站的基本元素,是承载各类网站应用的平台,通俗地说,网站就是由网页组成的,如果只有域名和虚拟主机而没有制做任何网页的话,使用者将难以访问网站,也难以通过人机会话来实现其使用意图。网页是一个收录HTML标签的纯文本文件,它可以储存在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式,网页一般用图象档来提供图画,文字与图片是构成一个网页的两个最基本的元素,可以简单地理解为:文字就是网页的内容,图片就是网页的美观,除此之外,网页的元素还包括动漫、音乐、程序等,网页须要通过网页浏览器来完成人与计算机的信息交互。传统的生成网页信息抽取规则的技术方案主要有两种:第一种方案是由技术人员通过对网页结构的观察,使用专用的计算机语言或软件工具,自行编撰、生成抽取规则。比较常见的专用计算机语言有:正则表达式,比较常见的软件工具有:xpath和css选择器。采用这些技术方案所才能达到的疗效,很大程度上依赖于编撰规则的技术人员的专业水平,即:对网页结构的理解程度以及对正则表达式、xpath和css选择器等技术的把握程度。不同网站的网页结构不同,不同技术人员的专业度也不相同,导致该技术方案受主观诱因影响成份较多,工作效率和质量误差较大,不能有效地产生技术成果;第二种方案是技术人员通过软件工具,将网页具象成文档结构树(DOM-Tree)的方式,结合概率统计学知识,计算文档结构树(DOM-Tree)中所有节点的相像机率,得到符合文本密度特点的文档结构树(DOM-Tree)节点,采用这些基于机率模型生成网页信息抽取规则的方案,所形成的技术成果不能否满足抽取精度的要求。在企业级的系统应用中,以单“日”为级别的网页采集数量一般为在万、十万以上。上述两种技术方案在企业级的系统应用中均存在致命缺陷,第一种方案的效率与质量无法保证,第二种方案的精度无法保证。在此技术背景下,急需专利技术一种高效地生成网页信息抽取规则的方式及系统,来同时满足效率与精度的要求,本专利技术应运而生。
技术实现思路
(一)解决的技术问题针对现有技术的不足,本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统,解决了纯人工生成网页信息抽取规则的低效以及纯自动化生成网页信息抽取规则的精度无法保证的问题。(二)技术方案为实现以上目的,本专利技术通过以下技术方案给以实现:一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。
优选的,所述S4中的Jsoup抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对列表类型网页的抽取规则生成而设计。优选的,所述S3中的Json抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对Json类型网页的抽取规则生成而设计。优选的,所述S5中的正文手动抽取方案是一种基于对文本密度进行机率统计的抽取规则生成方案,专门针对正文类型网页而设计。优选的,所述S5中的文本密度是一种表示正文节点的特点,其算法为Dom节点中纯文本字符串宽度或该节点的字符串宽度。优选的,所述S6中的正则表达式抽取方案是为了提升抽取精度,进行人工纠错,并当S3、S4和S5这三种抽取方案均未能满足精度要求而设计。(三)有益疗效本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统。具备以下有益疗效:该高效地生成网页信息抽取规则的方式及系统,通过S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和
【技术保护点】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:/nS1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。/n
【技术特点摘要】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:
S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;
S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;
S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正...
【专利技术属性】
技术研制人员:黄国舜,吴蓟晔,
申请(专利权)人:上海嘉道信息技术有限公司,
类型:发明
国别省市:上海;31
全部详尽技术资料下载 我是这个专利的主人 查看全部
一种高效地生成网页信息抽取规则的方式及系统技术方案
本发明专利技术公开了一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;该高效地生成网页信息抽取规则的方式及系统,可以克服纯人工配置抽取规则的低效问题,避免纯自动化抽取的精准度增长的问题,满足了企业级系统应用对精度及工作效率的要求,在不影响抽取精度的前提下,又增强了自动化程度,大大提升了网页信息抽取工作的效率以及实用性。
An efficient method and system for generating web information extraction rules
全部详尽技术资料下载
【技术实现步骤摘要】
一种高效地生成网页信息抽取规则的方式及系统
本专利技术涉及计算机网页采集
,具体为一种高效地生成网页信息抽取规则的方式及系统。
技术介绍
网页是构成网站的基本元素,是承载各类网站应用的平台,通俗地说,网站就是由网页组成的,如果只有域名和虚拟主机而没有制做任何网页的话,使用者将难以访问网站,也难以通过人机会话来实现其使用意图。网页是一个收录HTML标签的纯文本文件,它可以储存在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式,网页一般用图象档来提供图画,文字与图片是构成一个网页的两个最基本的元素,可以简单地理解为:文字就是网页的内容,图片就是网页的美观,除此之外,网页的元素还包括动漫、音乐、程序等,网页须要通过网页浏览器来完成人与计算机的信息交互。传统的生成网页信息抽取规则的技术方案主要有两种:第一种方案是由技术人员通过对网页结构的观察,使用专用的计算机语言或软件工具,自行编撰、生成抽取规则。比较常见的专用计算机语言有:正则表达式,比较常见的软件工具有:xpath和css选择器。采用这些技术方案所才能达到的疗效,很大程度上依赖于编撰规则的技术人员的专业水平,即:对网页结构的理解程度以及对正则表达式、xpath和css选择器等技术的把握程度。不同网站的网页结构不同,不同技术人员的专业度也不相同,导致该技术方案受主观诱因影响成份较多,工作效率和质量误差较大,不能有效地产生技术成果;第二种方案是技术人员通过软件工具,将网页具象成文档结构树(DOM-Tree)的方式,结合概率统计学知识,计算文档结构树(DOM-Tree)中所有节点的相像机率,得到符合文本密度特点的文档结构树(DOM-Tree)节点,采用这些基于机率模型生成网页信息抽取规则的方案,所形成的技术成果不能否满足抽取精度的要求。在企业级的系统应用中,以单“日”为级别的网页采集数量一般为在万、十万以上。上述两种技术方案在企业级的系统应用中均存在致命缺陷,第一种方案的效率与质量无法保证,第二种方案的精度无法保证。在此技术背景下,急需专利技术一种高效地生成网页信息抽取规则的方式及系统,来同时满足效率与精度的要求,本专利技术应运而生。
技术实现思路
(一)解决的技术问题针对现有技术的不足,本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统,解决了纯人工生成网页信息抽取规则的低效以及纯自动化生成网页信息抽取规则的精度无法保证的问题。(二)技术方案为实现以上目的,本专利技术通过以下技术方案给以实现:一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。
优选的,所述S4中的Jsoup抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对列表类型网页的抽取规则生成而设计。优选的,所述S3中的Json抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对Json类型网页的抽取规则生成而设计。优选的,所述S5中的正文手动抽取方案是一种基于对文本密度进行机率统计的抽取规则生成方案,专门针对正文类型网页而设计。优选的,所述S5中的文本密度是一种表示正文节点的特点,其算法为Dom节点中纯文本字符串宽度或该节点的字符串宽度。优选的,所述S6中的正则表达式抽取方案是为了提升抽取精度,进行人工纠错,并当S3、S4和S5这三种抽取方案均未能满足精度要求而设计。(三)有益疗效本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统。具备以下有益疗效:该高效地生成网页信息抽取规则的方式及系统,通过S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和
【技术保护点】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:/nS1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。/n
【技术特点摘要】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:
S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;
S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;
S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正...
【专利技术属性】
技术研制人员:黄国舜,吴蓟晔,
申请(专利权)人:上海嘉道信息技术有限公司,
类型:发明
国别省市:上海;31
全部详尽技术资料下载 我是这个专利的主人
利用专业数据采集工具获取网路数据的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2020-08-25 15:42
杨健
随着联通互联网的日渐普及和广泛应用,网络上的资讯成为人们获取信息的重要来源。人们一般依据需求使用百度等搜索引擎,输入关键字,检索所需的网页内容。在浏览网路资讯信息的同时,人们还希望还能将这种信息保存出来,选择适当的方式进行数据剖析,得出有效推论,为日后相关决策提供可靠根据。
那么怎么保存网页上的信息呢?通常情况下,大家会选中网页上须要的信息,然后通过“复制”和“粘贴”操作,保存在笔记本的本地文件中。这种方式其实简单直观,但是操作繁复,不适宜大批量数据信息的采集。为了确切方便地获取网路中的海量数据,人们设计开发了多种用于采集数据信息的专业工具,借助专业工具中网路爬虫的强悍功能,能够愈发确切、方便、快速地获取网页信息。这样的专业数据采集工具有很多种,本文以“优采云”数据采集工具为例,介绍专业数据采集工具的功能、原理及使用方式。
“优采云”数据采集工具的功能
“优采云”数据采集工具是一款通用的数据采集器,能够采集98%的网页上的文本信息。它可依照不同网站提供多种网页采集策略,也可以自定义配置,以本地采集或云采集的形式对选中网站中的单个网页或多个网页的内容信息进行手动提取,并将获取结果保存在Excel、CSV、HTML、数据库格式文件中,以便捷后续的数据处理与剖析。
“优采云”数据采集工具的原理
一般情况下,人们浏览网页时,首先要输入网站的网址;然后通过键盘单击网页上的按键或热点等操作,找到所要获取的相关信息;最后选中这种信息,提取下来,保存到特定格式的文件中。“优采云”数据采集工具的核心原理是通过外置Firefox内核浏览器,模拟上述人为浏览网页的行为,对网页的信息进行全手动提取。这些功能由“优采云”采集器的三个程序完成:负责任务配置及管理的主程序;任务的云采集控制和云集成数据的管理程序;数据导入程序。
“优采云”数据采集工具的操作
使用“优采云”采集器之前,我们要步入其官方网站https:///,下载并安装“优采云”采集器客户端(本文以“优采云”8.0版软件为例)。打开客户端软件,注册登入后即可使用。
1.使用模板采集数据
“优采云”客户端中外置了好多网站的采集模板,我们可以依据需求使用这种模板,如图1所示,按照提示步骤简单快捷地全手动获取网站信息。操作过程分三步:第一,选择目标网站的模板;第二,配置数据采集参数(采集的关键字、采集的页数等),选择采集模式(本地采集或云采集)自动提取数据;第三,选择输出的文件格式,导出数据。
图1 客户端中外置的网站采集模板
上述操作完成后,“优采云”客户端会将整个操作过程及提取的数据以任务的方式进行保存。通过客户端“我的任务”项,可以随时查看已提取的数据,也可以重复执行或更改当前任务。
2.自定义采集数据
当我们希望根据自己的要求获取网页上的个性化数据时,就须要使用自定义数据采集模式。首先要确定目标网站和采集需求;然后打开网页,配置采集选项,提取数据;最后导入数据到指定格式的文件中。
不管使用“优采云”客户端的哪种模式采集网页数据信息,整个流程都可统一为配置任务、采集数据和导入数据三个步骤。其中,配置采集选项参数是确切获取网页数据的关键。
“优采云”数据采集工具的应用案例
“优采云”数据采集工具才能采集大多数网站上的网页信息,而非只针对某类专业网站数据进行采集。下面以获取豆瓣影片Top 250(https:///top 250)网页数据为例,介绍“优采云”数据采集工具的具体使用技巧。
豆瓣网站是按照每部电影看过的人数以及该电影所得的评价等综合数据,通过算法剖析形成豆瓣影片Top 250榜单。豆瓣影片前250名的数据信息分10个连续网页显示,每个网页呈现25部连续剧,每部影片都包括影片排行、电影海报、电影中英文名称、电影编剧及执导、参评人数、豆瓣得分等相关信息。我们可以按照实际需求,使用“优采云”数据采集工具获取豆瓣影片Top 250的详尽数据,具体方式如下。
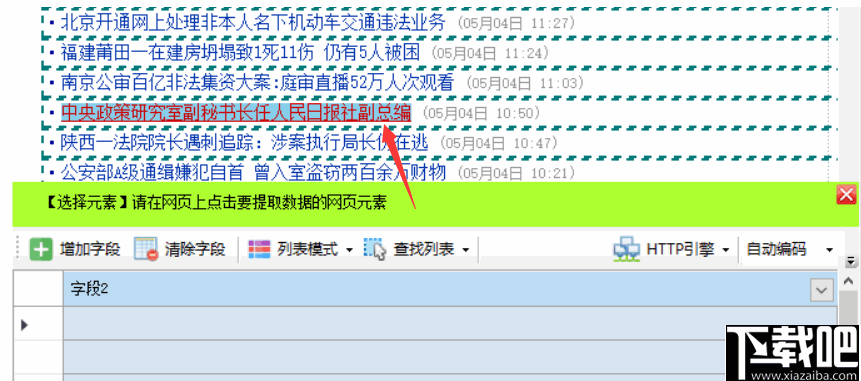
1.获取榜单中某一部影片的信息
首先,查看豆瓣影片网页中关于某部影片的信息,如《霸王别姬》,确定要获取的信息内容:电影排行、电影名、导演、主要艺人和剧情简介五项。其次,在“优采云”客户端的首页中,输入该部影片网页的网址,鼠标单击“开始采集”按钮,打开该网页;在显示网页的窗口中,鼠标单击“NO2 豆瓣影片Top 250”标签;在弹出的“操作提示”窗口中选择“采集该元素文本”,在“配置采集字段”窗口中显示出“ NO2 豆瓣影片Top 250 ”选项。重复上述操作,分别选中网页中“霸王别姬(1993)”“导演:陈凯歌”等其他标签完成采集字段的配置,并更改数组名称。再次,在“操作提示”窗口中执行“保存并开始采集”命令,在“运行任务”窗口中启动“本地采集”选项搜集数据信息。最后,将采集到的数据保存到特定格式的文件中。
数据信息采集完毕后,除了通过打开数据文件查看采集的信息外,还可以从“优采云”客户端首页的“我的任务”项中查看采集好的数据。
2.获取某个网页的全部影片信息
豆瓣影片榜单中每页就会显示25部影片的相关信息,每部影片展示了相同的信息项,如影片排行、海报、电影英文名称、导演及出演等。那么,“优采云”客户端提取每部影片数据的操作都是相同的。因此,我们只需完成一部影片的数据采集配置,其余影片使用循环重复操作即可。
首先要确定需求,在“优采云”客户端的首页输入要获取信息的网址并打开网页。其次,单击键盘选中一部影片相关数据区域。在弹出的“操作提示”窗口中选择“选中子元素”选项,选中该影片的影片排行、海报、电影英文名称、导演及出演等数组;然后再单击键盘选择“选中全部”,建立循环列表,选中该网页中25部影片的相关数据项;再单击“采集数据”选项,在预览窗口中,查看更改要采集的数据数组名。最后启动“本地采集”,获取数据信息,生成数据文件。
3.获取榜单中全部影片信息
除了上述自动选择数据采集字段外,由于豆瓣影片Top 250榜单中每部影片显示的信息都是相同的,在获取全部250部電影数据时,我们可以通过“操作提示”窗口中的提示信息,自动配置要提取的数据项,来完成影片信息的获取。
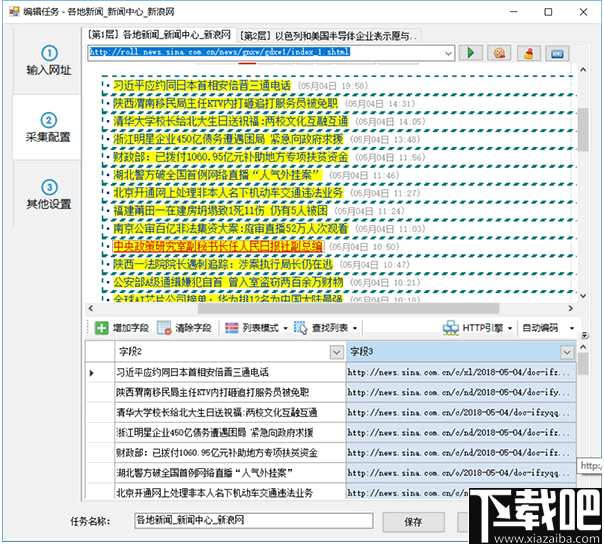
首先明晰获取信息需求,确定网址https://movie.douban. com/top 250,在“优采云”客户端打开网页;在“操作提示”窗口中选择“自动辨识网页”。经过“优采云”算法的辨识,自动完成采集字段配置,如图2所示。在“数据预览”窗口中,可以看见正式采集的数组及数据,通过“修改”和“删除”操作可以调整数组相关信息。然后选择“生成采集设置”,保存并开始采集数据。数据提取完成后,保存到特定格式的文件中。
图2 自动完成采集字段配置
除了以上这种应用之外,“优采云”数据采集工具还可以针对好多采集需求和不同结构的网页进行数据采集,如获取特定网页数量的数据、使用云采集等。这些都是你们可以进一步学习研究的内容。
专业数据采集工具及网路爬虫技术日渐成为获取网路信息的重要手段,但是在现实社会中,并不是所有数据都可以任意提取和使用。在数据采集时,我们要遵循有关的法律法规,负责任地、合理地使用网路技术和网路信息。
基金项目:北京市教育科学“十三五”规划2018年度通常课题“高中信息技术教学中估算思维培养的教学案例研究”,立项编号:CDDB18183。作者系北京教育学院“北京市中小学人工智能教学实践研究”特级班主任工作室成员
参考文献
[1]祝智庭,樊磊. 普通中学教科书·信息技术选修 [M]. 北京:人民教育出版社、中国地图出版社,2019. 查看全部
利用专业数据采集工具获取网路数据的方式
杨健


随着联通互联网的日渐普及和广泛应用,网络上的资讯成为人们获取信息的重要来源。人们一般依据需求使用百度等搜索引擎,输入关键字,检索所需的网页内容。在浏览网路资讯信息的同时,人们还希望还能将这种信息保存出来,选择适当的方式进行数据剖析,得出有效推论,为日后相关决策提供可靠根据。
那么怎么保存网页上的信息呢?通常情况下,大家会选中网页上须要的信息,然后通过“复制”和“粘贴”操作,保存在笔记本的本地文件中。这种方式其实简单直观,但是操作繁复,不适宜大批量数据信息的采集。为了确切方便地获取网路中的海量数据,人们设计开发了多种用于采集数据信息的专业工具,借助专业工具中网路爬虫的强悍功能,能够愈发确切、方便、快速地获取网页信息。这样的专业数据采集工具有很多种,本文以“优采云”数据采集工具为例,介绍专业数据采集工具的功能、原理及使用方式。
“优采云”数据采集工具的功能
“优采云”数据采集工具是一款通用的数据采集器,能够采集98%的网页上的文本信息。它可依照不同网站提供多种网页采集策略,也可以自定义配置,以本地采集或云采集的形式对选中网站中的单个网页或多个网页的内容信息进行手动提取,并将获取结果保存在Excel、CSV、HTML、数据库格式文件中,以便捷后续的数据处理与剖析。
“优采云”数据采集工具的原理
一般情况下,人们浏览网页时,首先要输入网站的网址;然后通过键盘单击网页上的按键或热点等操作,找到所要获取的相关信息;最后选中这种信息,提取下来,保存到特定格式的文件中。“优采云”数据采集工具的核心原理是通过外置Firefox内核浏览器,模拟上述人为浏览网页的行为,对网页的信息进行全手动提取。这些功能由“优采云”采集器的三个程序完成:负责任务配置及管理的主程序;任务的云采集控制和云集成数据的管理程序;数据导入程序。
“优采云”数据采集工具的操作
使用“优采云”采集器之前,我们要步入其官方网站https:///,下载并安装“优采云”采集器客户端(本文以“优采云”8.0版软件为例)。打开客户端软件,注册登入后即可使用。
1.使用模板采集数据
“优采云”客户端中外置了好多网站的采集模板,我们可以依据需求使用这种模板,如图1所示,按照提示步骤简单快捷地全手动获取网站信息。操作过程分三步:第一,选择目标网站的模板;第二,配置数据采集参数(采集的关键字、采集的页数等),选择采集模式(本地采集或云采集)自动提取数据;第三,选择输出的文件格式,导出数据。
图1 客户端中外置的网站采集模板
上述操作完成后,“优采云”客户端会将整个操作过程及提取的数据以任务的方式进行保存。通过客户端“我的任务”项,可以随时查看已提取的数据,也可以重复执行或更改当前任务。
2.自定义采集数据
当我们希望根据自己的要求获取网页上的个性化数据时,就须要使用自定义数据采集模式。首先要确定目标网站和采集需求;然后打开网页,配置采集选项,提取数据;最后导入数据到指定格式的文件中。
不管使用“优采云”客户端的哪种模式采集网页数据信息,整个流程都可统一为配置任务、采集数据和导入数据三个步骤。其中,配置采集选项参数是确切获取网页数据的关键。
“优采云”数据采集工具的应用案例
“优采云”数据采集工具才能采集大多数网站上的网页信息,而非只针对某类专业网站数据进行采集。下面以获取豆瓣影片Top 250(https:///top 250)网页数据为例,介绍“优采云”数据采集工具的具体使用技巧。
豆瓣网站是按照每部电影看过的人数以及该电影所得的评价等综合数据,通过算法剖析形成豆瓣影片Top 250榜单。豆瓣影片前250名的数据信息分10个连续网页显示,每个网页呈现25部连续剧,每部影片都包括影片排行、电影海报、电影中英文名称、电影编剧及执导、参评人数、豆瓣得分等相关信息。我们可以按照实际需求,使用“优采云”数据采集工具获取豆瓣影片Top 250的详尽数据,具体方式如下。
1.获取榜单中某一部影片的信息
首先,查看豆瓣影片网页中关于某部影片的信息,如《霸王别姬》,确定要获取的信息内容:电影排行、电影名、导演、主要艺人和剧情简介五项。其次,在“优采云”客户端的首页中,输入该部影片网页的网址,鼠标单击“开始采集”按钮,打开该网页;在显示网页的窗口中,鼠标单击“NO2 豆瓣影片Top 250”标签;在弹出的“操作提示”窗口中选择“采集该元素文本”,在“配置采集字段”窗口中显示出“ NO2 豆瓣影片Top 250 ”选项。重复上述操作,分别选中网页中“霸王别姬(1993)”“导演:陈凯歌”等其他标签完成采集字段的配置,并更改数组名称。再次,在“操作提示”窗口中执行“保存并开始采集”命令,在“运行任务”窗口中启动“本地采集”选项搜集数据信息。最后,将采集到的数据保存到特定格式的文件中。
数据信息采集完毕后,除了通过打开数据文件查看采集的信息外,还可以从“优采云”客户端首页的“我的任务”项中查看采集好的数据。
2.获取某个网页的全部影片信息
豆瓣影片榜单中每页就会显示25部影片的相关信息,每部影片展示了相同的信息项,如影片排行、海报、电影英文名称、导演及出演等。那么,“优采云”客户端提取每部影片数据的操作都是相同的。因此,我们只需完成一部影片的数据采集配置,其余影片使用循环重复操作即可。
首先要确定需求,在“优采云”客户端的首页输入要获取信息的网址并打开网页。其次,单击键盘选中一部影片相关数据区域。在弹出的“操作提示”窗口中选择“选中子元素”选项,选中该影片的影片排行、海报、电影英文名称、导演及出演等数组;然后再单击键盘选择“选中全部”,建立循环列表,选中该网页中25部影片的相关数据项;再单击“采集数据”选项,在预览窗口中,查看更改要采集的数据数组名。最后启动“本地采集”,获取数据信息,生成数据文件。
3.获取榜单中全部影片信息
除了上述自动选择数据采集字段外,由于豆瓣影片Top 250榜单中每部影片显示的信息都是相同的,在获取全部250部電影数据时,我们可以通过“操作提示”窗口中的提示信息,自动配置要提取的数据项,来完成影片信息的获取。
首先明晰获取信息需求,确定网址https://movie.douban. com/top 250,在“优采云”客户端打开网页;在“操作提示”窗口中选择“自动辨识网页”。经过“优采云”算法的辨识,自动完成采集字段配置,如图2所示。在“数据预览”窗口中,可以看见正式采集的数组及数据,通过“修改”和“删除”操作可以调整数组相关信息。然后选择“生成采集设置”,保存并开始采集数据。数据提取完成后,保存到特定格式的文件中。
图2 自动完成采集字段配置
除了以上这种应用之外,“优采云”数据采集工具还可以针对好多采集需求和不同结构的网页进行数据采集,如获取特定网页数量的数据、使用云采集等。这些都是你们可以进一步学习研究的内容。
专业数据采集工具及网路爬虫技术日渐成为获取网路信息的重要手段,但是在现实社会中,并不是所有数据都可以任意提取和使用。在数据采集时,我们要遵循有关的法律法规,负责任地、合理地使用网路技术和网路信息。
基金项目:北京市教育科学“十三五”规划2018年度通常课题“高中信息技术教学中估算思维培养的教学案例研究”,立项编号:CDDB18183。作者系北京教育学院“北京市中小学人工智能教学实践研究”特级班主任工作室成员
参考文献
[1]祝智庭,樊磊. 普通中学教科书·信息技术选修 [M]. 北京:人民教育出版社、中国地图出版社,2019.
搜索引擎
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-08-25 10:22
5)正向索引
6)倒排索引
7)链接关系估算
8)特殊文件处理
当用户在搜索框进行搜索时,搜索引擎并没有在网路上实时的搜索用户的恳求,而是在检索索引数据库,搜索引擎定期更新其索引库。
首先搜索引擎查看搜索索引中的每一个搜索关键词,可以得到收录那些关键词的所有网页列表,这会得到特别庞大的数据。
每一种搜索引擎都有自己的算法,基于它对用户需求的猜想来排序网页。搜索引擎的排序算法可能会检测,是否你的搜索词收录在页面的标题中,它可能会用同义词匹配与你的搜索关键词语义相仿的查询结果。生成初步的查询结果,对查询结果集按权威性和PageRank进行排序,重复的查询结果被剔除。
对查询结果进行过滤处理。最终返回给浏览器端的用户一个人性化的、布局良好的、查询结果和广告泾渭分明的有机查询结果页面。
使用机器学习更好的理解成语,它使算法不仅仅是搜索页面上的单个字母或词组,而是理解成语的潜在意义。
如果能晓得用户查找的关键词(query(查询)切词后)都出现在什么页面中,那么用户检索的处理过程即可以想像为收录了query(查询)中切词后不同部份的页面集合求交的过程,而检索即弄成了页面名称之间的比较、求交。这样,在微秒内以亿为单位的检索成为了可能。这就是一般所说的倒排索引及求交检索的过程。
页面剖析的过程实际上是将原创页面的不同部份进行辨识并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等,分词的过程实际上包括了切词动词同义词转换同义词替换等等,以对某页面title动词为例,得到的将是这样的数据:term文本、termid(标识)、词类、词性等等,之前的打算工作完成后,接下来即是构建倒排索引,形成{termàdoc}(文档集合),
索引系统在构建倒排索引的最后还须要有一个入库写库的过程,而为了提升效率这个过程还须要将全部term以及偏移量保存在文件背部,并且对数据进行压缩.
(1) Query串切词动词正式用户的查询词进行动词,对以后的查询做打算,以“10号线轻轨故障”为例,可能的动词如下:
10 0x123abc
号 0x13445d
线 0x234d
地铁 0x145cf
故障 0x354df
(2)查出含每位term的文档集合,即找出待选集合,如下:
10 1 2 3 4 7 9……
号 2 5 8 9 10 11……
(3)求交,上述求交,文档2和文档9可能是我们须要找的,整个求交过程实际上关系着整个系统的性能,这上面收录了使用缓存等等手段进行性能优化;
(4)各种过滤,举例可能收录过滤掉死链、重复数据、色情、垃圾结果;
(5)最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等。用户在搜索框输入关键词后,排名程序调用索引库数据,计算排行显示给用户,排名过程与用户直接互动的
倒排索引通常表示为一个关键词,然后是它的频率(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签通常。
图片搜索:
1.缩小规格。将图片缩小到8x8的规格,总共64个象素。这一步的作用是清除图片的细节,只保留结构、明暗等基本信息,摒弃不同规格、比例带来的图片差别。
2.简化色调。将缩小后的图片,转为64级灰度。也就是说,所有象素点总共只有64种颜色。
3.计算平均值。计算所有64个象素的灰度平均值。
4.比较象素的灰度。将每位象素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
5.计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的顺序并不重要,只要保证所有图片都采用同样顺序就行了。 查看全部
搜索引擎
5)正向索引
6)倒排索引
7)链接关系估算
8)特殊文件处理
当用户在搜索框进行搜索时,搜索引擎并没有在网路上实时的搜索用户的恳求,而是在检索索引数据库,搜索引擎定期更新其索引库。
首先搜索引擎查看搜索索引中的每一个搜索关键词,可以得到收录那些关键词的所有网页列表,这会得到特别庞大的数据。
每一种搜索引擎都有自己的算法,基于它对用户需求的猜想来排序网页。搜索引擎的排序算法可能会检测,是否你的搜索词收录在页面的标题中,它可能会用同义词匹配与你的搜索关键词语义相仿的查询结果。生成初步的查询结果,对查询结果集按权威性和PageRank进行排序,重复的查询结果被剔除。
对查询结果进行过滤处理。最终返回给浏览器端的用户一个人性化的、布局良好的、查询结果和广告泾渭分明的有机查询结果页面。
使用机器学习更好的理解成语,它使算法不仅仅是搜索页面上的单个字母或词组,而是理解成语的潜在意义。
如果能晓得用户查找的关键词(query(查询)切词后)都出现在什么页面中,那么用户检索的处理过程即可以想像为收录了query(查询)中切词后不同部份的页面集合求交的过程,而检索即弄成了页面名称之间的比较、求交。这样,在微秒内以亿为单位的检索成为了可能。这就是一般所说的倒排索引及求交检索的过程。
页面剖析的过程实际上是将原创页面的不同部份进行辨识并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等,分词的过程实际上包括了切词动词同义词转换同义词替换等等,以对某页面title动词为例,得到的将是这样的数据:term文本、termid(标识)、词类、词性等等,之前的打算工作完成后,接下来即是构建倒排索引,形成{termàdoc}(文档集合),
索引系统在构建倒排索引的最后还须要有一个入库写库的过程,而为了提升效率这个过程还须要将全部term以及偏移量保存在文件背部,并且对数据进行压缩.
(1) Query串切词动词正式用户的查询词进行动词,对以后的查询做打算,以“10号线轻轨故障”为例,可能的动词如下:
10 0x123abc
号 0x13445d
线 0x234d
地铁 0x145cf
故障 0x354df
(2)查出含每位term的文档集合,即找出待选集合,如下:
10 1 2 3 4 7 9……
号 2 5 8 9 10 11……
(3)求交,上述求交,文档2和文档9可能是我们须要找的,整个求交过程实际上关系着整个系统的性能,这上面收录了使用缓存等等手段进行性能优化;
(4)各种过滤,举例可能收录过滤掉死链、重复数据、色情、垃圾结果;
(5)最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等。用户在搜索框输入关键词后,排名程序调用索引库数据,计算排行显示给用户,排名过程与用户直接互动的
倒排索引通常表示为一个关键词,然后是它的频率(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签通常。
图片搜索:
1.缩小规格。将图片缩小到8x8的规格,总共64个象素。这一步的作用是清除图片的细节,只保留结构、明暗等基本信息,摒弃不同规格、比例带来的图片差别。
2.简化色调。将缩小后的图片,转为64级灰度。也就是说,所有象素点总共只有64种颜色。
3.计算平均值。计算所有64个象素的灰度平均值。
4.比较象素的灰度。将每位象素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
5.计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的顺序并不重要,只要保证所有图片都采用同样顺序就行了。
网站万能信息采集器终极版与心宽网页采集系统下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-25 04:29
5年来不断的建立改进缔造了史无前例的强悍采集软件--网站万能信息采集器。
网站优采云采集器:能看到的信息都能抓到.
八大特色功能:
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识JavaScript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。 查看全部
网站万能信息采集器终极版与心宽网页采集系统下载评论软件详情对比
5年来不断的建立改进缔造了史无前例的强悍采集软件--网站万能信息采集器。
网站优采云采集器:能看到的信息都能抓到.
八大特色功能:
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识JavaScript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
如何抓取网页实时数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-25 03:49
excel确实可以抓取网页数据,但是功能有限,如果网页比较复杂,就要花上好多时间设置,另外对于防采集比较严重的网站,基本上就没办法了。
所以假如要采集网页数据,还是得用专业的采集工具,比如优采云采集器。下面就从上手难度方面给你们介绍介绍。
上手难度
优采云内置两种采集模式
1、模板采集(0基础,简单三步获取数据,纯键盘和输入文字操作,小白友好)
打开运行在PC端的优采云客户端,直接搜索网站,看看有没有收录您想要采集的目标网站。万一收录,只须要动动键盘输入文字,采就完事了。
目标采集模板数也是特别多的,基本上主流网站都有收录,看看下边的图片就晓得了。
图片仅展示部份外置的数据源
以易迅商品采集给你们详尽演示采集过程:
简单3步,日采集海量数据
具体详尽使用教程:使用模板采集数据
2、自定义采集模式(内置智能模式,自动辨识网页内容数据,自由度高,轻松采数据)
如果【模板采集】里没有想要采集的网站,那就自己来,优采云内置智能模式,可以手动辨识网页内容进行采集。
以优采云教程列表页采集给你们演示操作流程:
只需输入网址,一键智能辨识采集数据
具体详尽使用教程:自定义配置采集数据(含智能辨识)
如果您对用优采云采集网页数据有兴趣,可以用笔记本下载客户端试试。
下载地址:
免费下载 - 优采云采集器 查看全部
如何抓取网页实时数据?
excel确实可以抓取网页数据,但是功能有限,如果网页比较复杂,就要花上好多时间设置,另外对于防采集比较严重的网站,基本上就没办法了。
所以假如要采集网页数据,还是得用专业的采集工具,比如优采云采集器。下面就从上手难度方面给你们介绍介绍。
上手难度
优采云内置两种采集模式
1、模板采集(0基础,简单三步获取数据,纯键盘和输入文字操作,小白友好)
打开运行在PC端的优采云客户端,直接搜索网站,看看有没有收录您想要采集的目标网站。万一收录,只须要动动键盘输入文字,采就完事了。
目标采集模板数也是特别多的,基本上主流网站都有收录,看看下边的图片就晓得了。

图片仅展示部份外置的数据源
以易迅商品采集给你们详尽演示采集过程:

简单3步,日采集海量数据
具体详尽使用教程:使用模板采集数据
2、自定义采集模式(内置智能模式,自动辨识网页内容数据,自由度高,轻松采数据)
如果【模板采集】里没有想要采集的网站,那就自己来,优采云内置智能模式,可以手动辨识网页内容进行采集。
以优采云教程列表页采集给你们演示操作流程:

只需输入网址,一键智能辨识采集数据
具体详尽使用教程:自定义配置采集数据(含智能辨识)
如果您对用优采云采集网页数据有兴趣,可以用笔记本下载客户端试试。
下载地址:
免费下载 - 优采云采集器
优采云采集器最新版(网页数据采集工具) v2.1.8.0 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-23 15:55
非常关注某几个网站,可以用优采云采集器最新版来实时的关注哦,一键简单提取数据、快速高效、适用于大部分的网站,同时优采云采集器最新版海域简单易用的向导模式、独创的高速内核、脚本定时运行,优采云采集器最新版能智能的辨识网页中的列表表单,这款专业的网页数据采集工具是你日常好帮手!
优采云采集器最新版软件特色
独创高速内核
自研的浏览器内核,速度飞快,远超对手
智能辨识
对于网页中的列表、表单结构(多选框下拉列表等)能够智能辨识
广告屏蔽
定制的广告屏蔽模块,兼容AdblockPlus句型,可添加自定义规则
多种数据导入
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用各类网站
能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
功能介绍
向导模式
简单易用,轻松通过滑鼠点击手动生成
脚本定时运行
可依照计划定时运行,无需人工
优采云采集器最新版使用方式
第一步:输入采集网址
打开软件,新建任务,输入须要采集的网站地址。
第二步:智能剖析,全程自动化提取数据
进入到第二步后,优采云采集器全手动智能剖析网页,并且从中提取出列表数据。
第三步:导出数据到表格、数据库、网站等
运行任务,将采集到的数据导入为Csv、Excel以及各类数据库,支持api导入。 查看全部
优采云采集器最新版(网页数据采集工具) v2.1.8.0 最新版
非常关注某几个网站,可以用优采云采集器最新版来实时的关注哦,一键简单提取数据、快速高效、适用于大部分的网站,同时优采云采集器最新版海域简单易用的向导模式、独创的高速内核、脚本定时运行,优采云采集器最新版能智能的辨识网页中的列表表单,这款专业的网页数据采集工具是你日常好帮手!
优采云采集器最新版软件特色
独创高速内核
自研的浏览器内核,速度飞快,远超对手
智能辨识
对于网页中的列表、表单结构(多选框下拉列表等)能够智能辨识
广告屏蔽
定制的广告屏蔽模块,兼容AdblockPlus句型,可添加自定义规则
多种数据导入
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用各类网站
能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
功能介绍
向导模式
简单易用,轻松通过滑鼠点击手动生成
脚本定时运行
可依照计划定时运行,无需人工
优采云采集器最新版使用方式
第一步:输入采集网址
打开软件,新建任务,输入须要采集的网站地址。
第二步:智能剖析,全程自动化提取数据
进入到第二步后,优采云采集器全手动智能剖析网页,并且从中提取出列表数据。
第三步:导出数据到表格、数据库、网站等
运行任务,将采集到的数据导入为Csv、Excel以及各类数据库,支持api导入。
善肯网页TXT采集器1.0 绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-23 15:46
喜欢看小说的用户好多的都是须要把小说下载到自己的手机里面,但是好多的网站不支持一键下载,可以使用善肯网页TXT采集器,自动采集以及下载!
善肯网页TXT采集器介绍
喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
善肯网页TXT采集器使用教程
关于规则设置
1、输入网址后,可以实时预览(不论有有没规则,有规则就是匹配规则后的内容,没有就是源代码,目前测试,并非所有网页都能获取其内容,具体你们可以自己去实验,能获取源代码的就是可以匹配出内容的)
2、目录页和内容页分别匹配不同的规则:
目录页:
文本名称规则
作者名称规则
章节规则(此处需有两个()一处匹配章节路径,一个匹配章节名称)
内容页:
内容规则
3、关于替换:
通用替换(非正则):所有规则就会手动加上通用替换(有共性的替换规则)
定制替换(非正则):单个网站的特有替换规则
正则替换:暂未开发,请求打赏支持开发~~。
想换行可用内容与\n进行替换,\n是替换数据不是原数据。
可以依照自己的需求增删,。(原数据和替换数据必填,一个空格都行,否则会抛异常)
删除:选中一行,按DELETE键删掉
4、关于规则保存:
保存都是以文件名来的,不同的名称则为不同的规则,最终保存为xml方式。
5、关于地址解析
解析地址1:测试未删,以后会加功能,暂留着
解析地址2:推荐使用
6、理论上,只要是目录页指向内容页的方式都可以抓取【能获取源代码的情况下】。具体请你们自己去实验。
关于文件
1、commonrule.xml 文件储存的是通用替换规则,
2、rule文件夹下储存的是以网站为单位的规则。
如果须要直接拷贝单条规则放在rule文件夹下就可以使用规则了,前提是xml文件格式是对的,
3、其他
暂时还没想到大家可能就会出现哪些问题。如果碰到问题欢迎反馈。
最后附上常用匹配全部内容的表达式:
(.*?) ([\w\W]*?) ([\s\S]*?)
PC官方版
安卓官方手机版
IOS官方手机版 查看全部
善肯网页TXT采集器1.0 绿色免费版
喜欢看小说的用户好多的都是须要把小说下载到自己的手机里面,但是好多的网站不支持一键下载,可以使用善肯网页TXT采集器,自动采集以及下载!
善肯网页TXT采集器介绍
喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
善肯网页TXT采集器使用教程
关于规则设置
1、输入网址后,可以实时预览(不论有有没规则,有规则就是匹配规则后的内容,没有就是源代码,目前测试,并非所有网页都能获取其内容,具体你们可以自己去实验,能获取源代码的就是可以匹配出内容的)
2、目录页和内容页分别匹配不同的规则:
目录页:
文本名称规则
作者名称规则
章节规则(此处需有两个()一处匹配章节路径,一个匹配章节名称)
内容页:
内容规则
3、关于替换:
通用替换(非正则):所有规则就会手动加上通用替换(有共性的替换规则)
定制替换(非正则):单个网站的特有替换规则
正则替换:暂未开发,请求打赏支持开发~~。
想换行可用内容与\n进行替换,\n是替换数据不是原数据。
可以依照自己的需求增删,。(原数据和替换数据必填,一个空格都行,否则会抛异常)
删除:选中一行,按DELETE键删掉
4、关于规则保存:
保存都是以文件名来的,不同的名称则为不同的规则,最终保存为xml方式。
5、关于地址解析
解析地址1:测试未删,以后会加功能,暂留着
解析地址2:推荐使用
6、理论上,只要是目录页指向内容页的方式都可以抓取【能获取源代码的情况下】。具体请你们自己去实验。
关于文件
1、commonrule.xml 文件储存的是通用替换规则,
2、rule文件夹下储存的是以网站为单位的规则。
如果须要直接拷贝单条规则放在rule文件夹下就可以使用规则了,前提是xml文件格式是对的,
3、其他
暂时还没想到大家可能就会出现哪些问题。如果碰到问题欢迎反馈。
最后附上常用匹配全部内容的表达式:
(.*?) ([\w\W]*?) ([\s\S]*?)
PC官方版
安卓官方手机版
IOS官方手机版
Java+opencv+mysql实现人脸辨识源码(人脸采集入库+人脸辨识相似度
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-22 23:27
Java+opencv实现人脸辨识
写这篇博客,是因为曾经常常使用python+opencv实现人脸处理,后来发觉java也可以实现,于是便学习了下,以下将代码和实现过程贴出。
目录1、环境打算
使用到的技术:java+opencv+mysql
我这儿用的是opencv4.1,这里可以自行下载(其实只须要一个opencv的dll文件置于java安装目录的bin下边既可)
2、代码实现
核心opencv人脸识别类(识别算法):
package com.dialect.utils;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.objdetect.CascadeClassifier;
import java.util.Arrays;
/**
* 1. 灰度化(减小图片大小)
* 2. 人脸识别
* 3. 人脸切割
* 4. 规一化(人脸直方图)
* 5. 直方图相似度匹配
*
*
* @Description: 比较两张图片人脸的匹配度
* @date 2019/2/1813:47
*/
public class FaceCompare {
// 初始化人脸探测器
static CascadeClassifier faceDetector;
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
faceDetector = new CascadeClassifier("E:\\eclipseworkspace\\FaceDectcoSys\\src\\haarcascade_frontalface_default.xml");
}
// 灰度化人脸
public static Mat conv_Mat(String img) {
Mat image0 = Imgcodecs.imread(img);
Mat image1 = new Mat();
// 灰度化
Imgproc.cvtColor(image0, image1, Imgproc.COLOR_BGR2GRAY);
// 探测人脸
MatOfRect faceDetections = new MatOfRect();
faceDetector.detectMultiScale(image1, faceDetections);
// rect中人脸图片的范围
for (Rect rect : faceDetections.toArray()) {
Mat face = new Mat(image1, rect);
return face;
}
return null;
}
public static double compare_image(String img_1, String img_2) {
Mat mat_1 = conv_Mat(img_1);
Mat mat_2 = conv_Mat(img_2);
Mat hist_1 = new Mat();
Mat hist_2 = new Mat();
//颜色范围
MatOfFloat ranges = new MatOfFloat(0f, 256f);
//直方图大小, 越大匹配越精确 (越慢)
MatOfInt histSize = new MatOfInt(1000);
Imgproc.calcHist(Arrays.asList(mat_1), new MatOfInt(0), new Mat(), hist_1, histSize, ranges);
Imgproc.calcHist(Arrays.asList(mat_2), new MatOfInt(0), new Mat(), hist_2, histSize, ranges);
// CORREL 相关系数
double res = Imgproc.compareHist(hist_1, hist_2, Imgproc.CV_COMP_CORREL);
return res;
}
public static void main(String[] args) {
String basePicPath = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\";
double compareHist = compare_image(basePicPath + "fbb1.jpg", basePicPath + "fbb2.jpg");
System.out.println(compareHist);
if (compareHist > 0.72) {
System.out.println("人脸匹配");
} else {
System.out.println("人脸不匹配");
}
}
}
测试两张图片相似度(美女相片自己网上找):
测试结果:相似度0.82左右,还好了
接着实现网页
数据库dao:
package com.dialect.info.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import com.dialect.info.bean.Dect;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectDao {
/**
* 添加
* @param con
* @param Dialect
* @return
* @throws Exception
*/
public int add(Connection con,Dect dect)throws Exception{
dect.setId(UUID.randomUUID().toString().replace("-", ""));
String sql="insert into dect values(?,?)";
PreparedStatement pstmt=con.prepareStatement(sql);
pstmt.setString(1,dect.getId());
pstmt.setString(2,dect.getBase64());
return pstmt.executeUpdate();
}
/**
* 查询所有
* @param con
* @param dialect
* @return
* @throws Exception
*/
public List list(Connection con)throws Exception{
List list = new ArrayList();
Dect entity=null;
String sql = "select a.* from dect a";
PreparedStatement pstmt=con.prepareStatement(sql);
ResultSet rs=pstmt.executeQuery();
while(rs.next()){
entity = new Dect();
entity.setId(rs.getString("id"));
entity.setBase64(rs.getString("base64"));
list.add(entity);
}
return list;
}
}
service层:
package com.dialect.info.service.impl;
import java.sql.Connection;
import java.util.List;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.utils.DbUtil;
import com.dialect.utils.Page;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectServiceImpl implements DectService {
DectDao dectDao = new DectDao();
@Override
public int add(Dect dect) {
try {
Connection con = DbUtil.getCon();
Integer result =dectDao.add(con, dect);
DbUtil.closeCon(con);
return result;
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
@Override
public List select() {
try {
Connection con = DbUtil.getCon();
List list = dectDao.list(con);
DbUtil.closeCon(con);
return list;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
control控制层:
package com.dialect.info.controller;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.info.service.impl.DectServiceImpl;
import com.dialect.utils.Page;
import com.dialect.utils.picToBase64;
import com.dialect.utils.FaceCompare;
@WebServlet("/dect")
public class DectController extends HttpServlet {
private static final long serialVersionUID = 1L;
DectDao dectDao=new DectDao();
DectService dectService = new DectServiceImpl();
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String method = request.getParameter("method");
if ("upload".equals(method)) {
upload(request,response);
}else if ("select".equals(method)) {
select(request, response);
}else if ("list".equals(method)) {
list(request, response);
}else if ("form".equals(method)) {
form(request, response);
}
}
//添加
private void upload(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---开始上传---");
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
Dect dect = new Dect();
dect.setBase64(s);
int res = dectService.add(dect);
// System.err.println(res);
// String res = "1";
// String res2 = "3";
// 解决json中文乱码
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
// String str ="{\"success\":"+res+",\"age\":"+res2 +"}";
String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
}
//添加
private void select(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---进来了select方法---");
FaceCompare faceCompare = new FaceCompare();
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
picToBase64 pic = new picToBase64();
String imgPath1 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img1.jpg";
String imgPath2 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img2.jpg";
// String imgPath1 = "E:\\img1.jpg";
// String imgPath2 = "E:\\img2.jpg";
//String imgPath2 = "E:\\eclipseworkspace\\FaceDectcogSys\\WebContent\\static\\images\\img2";
pic.Base64ToImage(s, imgPath1);
List list = dectService.select();
int shibie_flag = 0;
double res = 0;
System.err.println(list.size());
if (list.size()>0){
for(Dect dect:list){
System.err.println(dect.getBase64());
String s1 = dect.getBase64().replace("data:image/jpeg;base64,","");
System.err.println("s1:"+s1);
picToBase64 pic2 = new picToBase64();
pic2.Base64ToImage(s1, imgPath2);
res = faceCompare.compare_image(imgPath1, imgPath2);
if (res > 0.72){
System.out.println("人脸匹配");
shibie_flag = 1;
break;
}
}
}
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
String str ="{\"success\":"+shibie_flag+",\"res\":"+res +"}";
// String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
// response.sendRedirect(contextPath+"/dialect?method=list");
}
//列表查询
private void list(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList2.jsp").forward(request, response);
}
//form跳转页面
private void form(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList3.jsp").forward(request, response);
}
}
3、运行疗效
网站操作流程如下:
第一步:人脸采集(支持上传图片预览)
入库成功:
开始人脸辨识(人脸匹配成功):
写在最后:因篇幅有限,不能讲所有代码贴出,如果须要可以加我:3459067873 查看全部
Java+opencv+mysql实现人脸辨识源码(人脸采集入库+人脸辨识相似度
Java+opencv实现人脸辨识
写这篇博客,是因为曾经常常使用python+opencv实现人脸处理,后来发觉java也可以实现,于是便学习了下,以下将代码和实现过程贴出。
目录1、环境打算
使用到的技术:java+opencv+mysql
我这儿用的是opencv4.1,这里可以自行下载(其实只须要一个opencv的dll文件置于java安装目录的bin下边既可)
2、代码实现
核心opencv人脸识别类(识别算法):
package com.dialect.utils;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.objdetect.CascadeClassifier;
import java.util.Arrays;
/**
* 1. 灰度化(减小图片大小)
* 2. 人脸识别
* 3. 人脸切割
* 4. 规一化(人脸直方图)
* 5. 直方图相似度匹配
*
*
* @Description: 比较两张图片人脸的匹配度
* @date 2019/2/1813:47
*/
public class FaceCompare {
// 初始化人脸探测器
static CascadeClassifier faceDetector;
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
faceDetector = new CascadeClassifier("E:\\eclipseworkspace\\FaceDectcoSys\\src\\haarcascade_frontalface_default.xml");
}
// 灰度化人脸
public static Mat conv_Mat(String img) {
Mat image0 = Imgcodecs.imread(img);
Mat image1 = new Mat();
// 灰度化
Imgproc.cvtColor(image0, image1, Imgproc.COLOR_BGR2GRAY);
// 探测人脸
MatOfRect faceDetections = new MatOfRect();
faceDetector.detectMultiScale(image1, faceDetections);
// rect中人脸图片的范围
for (Rect rect : faceDetections.toArray()) {
Mat face = new Mat(image1, rect);
return face;
}
return null;
}
public static double compare_image(String img_1, String img_2) {
Mat mat_1 = conv_Mat(img_1);
Mat mat_2 = conv_Mat(img_2);
Mat hist_1 = new Mat();
Mat hist_2 = new Mat();
//颜色范围
MatOfFloat ranges = new MatOfFloat(0f, 256f);
//直方图大小, 越大匹配越精确 (越慢)
MatOfInt histSize = new MatOfInt(1000);
Imgproc.calcHist(Arrays.asList(mat_1), new MatOfInt(0), new Mat(), hist_1, histSize, ranges);
Imgproc.calcHist(Arrays.asList(mat_2), new MatOfInt(0), new Mat(), hist_2, histSize, ranges);
// CORREL 相关系数
double res = Imgproc.compareHist(hist_1, hist_2, Imgproc.CV_COMP_CORREL);
return res;
}
public static void main(String[] args) {
String basePicPath = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\";
double compareHist = compare_image(basePicPath + "fbb1.jpg", basePicPath + "fbb2.jpg");
System.out.println(compareHist);
if (compareHist > 0.72) {
System.out.println("人脸匹配");
} else {
System.out.println("人脸不匹配");
}
}
}
测试两张图片相似度(美女相片自己网上找):


测试结果:相似度0.82左右,还好了

接着实现网页
数据库dao:
package com.dialect.info.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import com.dialect.info.bean.Dect;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectDao {
/**
* 添加
* @param con
* @param Dialect
* @return
* @throws Exception
*/
public int add(Connection con,Dect dect)throws Exception{
dect.setId(UUID.randomUUID().toString().replace("-", ""));
String sql="insert into dect values(?,?)";
PreparedStatement pstmt=con.prepareStatement(sql);
pstmt.setString(1,dect.getId());
pstmt.setString(2,dect.getBase64());
return pstmt.executeUpdate();
}
/**
* 查询所有
* @param con
* @param dialect
* @return
* @throws Exception
*/
public List list(Connection con)throws Exception{
List list = new ArrayList();
Dect entity=null;
String sql = "select a.* from dect a";
PreparedStatement pstmt=con.prepareStatement(sql);
ResultSet rs=pstmt.executeQuery();
while(rs.next()){
entity = new Dect();
entity.setId(rs.getString("id"));
entity.setBase64(rs.getString("base64"));
list.add(entity);
}
return list;
}
}
service层:
package com.dialect.info.service.impl;
import java.sql.Connection;
import java.util.List;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.utils.DbUtil;
import com.dialect.utils.Page;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectServiceImpl implements DectService {
DectDao dectDao = new DectDao();
@Override
public int add(Dect dect) {
try {
Connection con = DbUtil.getCon();
Integer result =dectDao.add(con, dect);
DbUtil.closeCon(con);
return result;
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
@Override
public List select() {
try {
Connection con = DbUtil.getCon();
List list = dectDao.list(con);
DbUtil.closeCon(con);
return list;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
control控制层:
package com.dialect.info.controller;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.info.service.impl.DectServiceImpl;
import com.dialect.utils.Page;
import com.dialect.utils.picToBase64;
import com.dialect.utils.FaceCompare;
@WebServlet("/dect")
public class DectController extends HttpServlet {
private static final long serialVersionUID = 1L;
DectDao dectDao=new DectDao();
DectService dectService = new DectServiceImpl();
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String method = request.getParameter("method");
if ("upload".equals(method)) {
upload(request,response);
}else if ("select".equals(method)) {
select(request, response);
}else if ("list".equals(method)) {
list(request, response);
}else if ("form".equals(method)) {
form(request, response);
}
}
//添加
private void upload(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---开始上传---");
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
Dect dect = new Dect();
dect.setBase64(s);
int res = dectService.add(dect);
// System.err.println(res);
// String res = "1";
// String res2 = "3";
// 解决json中文乱码
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
// String str ="{\"success\":"+res+",\"age\":"+res2 +"}";
String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
}
//添加
private void select(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---进来了select方法---");
FaceCompare faceCompare = new FaceCompare();
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
picToBase64 pic = new picToBase64();
String imgPath1 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img1.jpg";
String imgPath2 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img2.jpg";
// String imgPath1 = "E:\\img1.jpg";
// String imgPath2 = "E:\\img2.jpg";
//String imgPath2 = "E:\\eclipseworkspace\\FaceDectcogSys\\WebContent\\static\\images\\img2";
pic.Base64ToImage(s, imgPath1);
List list = dectService.select();
int shibie_flag = 0;
double res = 0;
System.err.println(list.size());
if (list.size()>0){
for(Dect dect:list){
System.err.println(dect.getBase64());
String s1 = dect.getBase64().replace("data:image/jpeg;base64,","");
System.err.println("s1:"+s1);
picToBase64 pic2 = new picToBase64();
pic2.Base64ToImage(s1, imgPath2);
res = faceCompare.compare_image(imgPath1, imgPath2);
if (res > 0.72){
System.out.println("人脸匹配");
shibie_flag = 1;
break;
}
}
}
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
String str ="{\"success\":"+shibie_flag+",\"res\":"+res +"}";
// String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
// response.sendRedirect(contextPath+"/dialect?method=list");
}
//列表查询
private void list(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList2.jsp").forward(request, response);
}
//form跳转页面
private void form(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList3.jsp").forward(request, response);
}
}
3、运行疗效
网站操作流程如下:
第一步:人脸采集(支持上传图片预览)
入库成功:
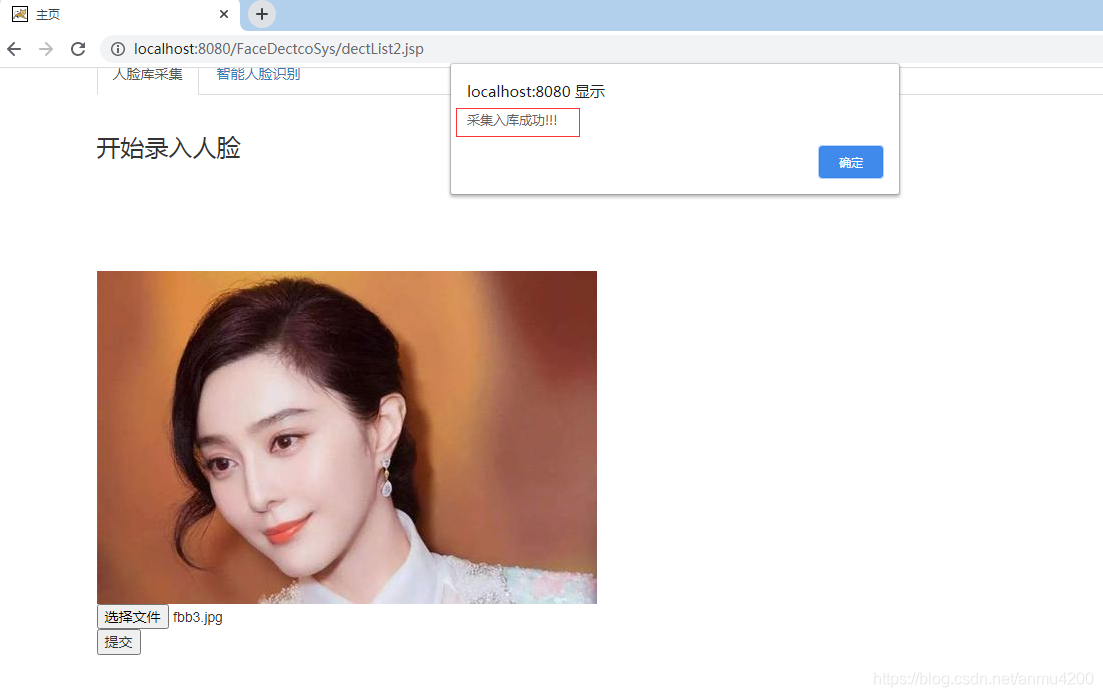
开始人脸辨识(人脸匹配成功):
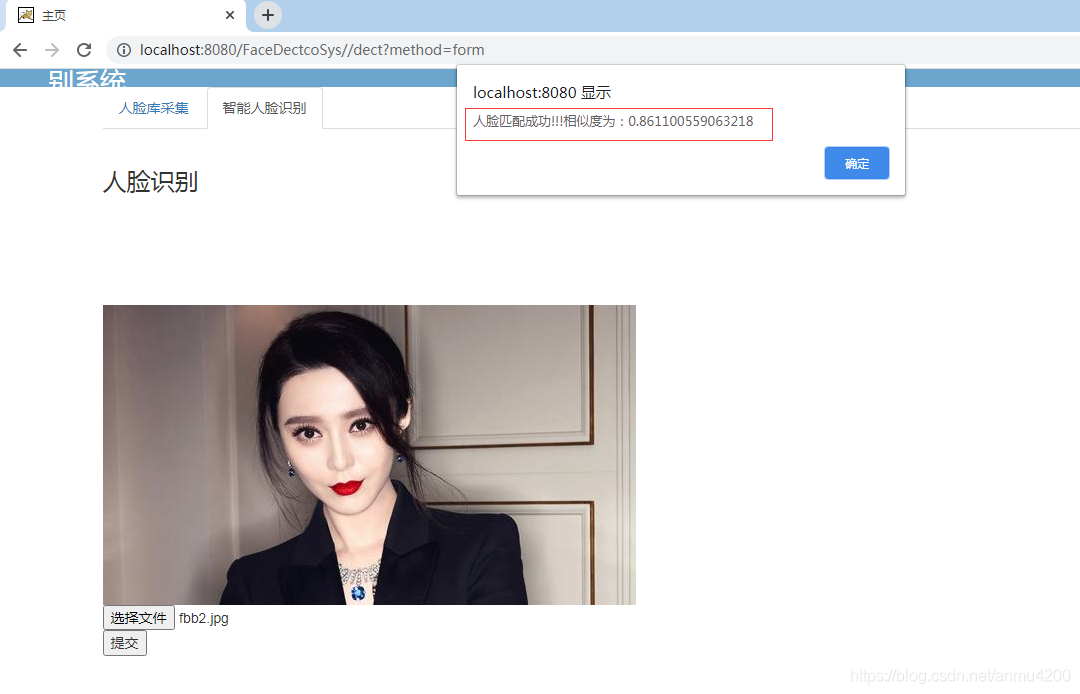
写在最后:因篇幅有限,不能讲所有代码贴出,如果须要可以加我:3459067873
优采云采集器官方版下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-22 18:11
优采云采集器是一款十分强悍又实用的网页抓取采集工具,让我们可以将采集到的内容进行独立保存,让您在浏览完网站的时侯可以将他人的内容复制到自己的素材文件夹上,而且还支持多种抓取方法,可以实现单个网页抓取,也可以选择多个HTML页面抓取,还可以自动选择数组,有须要的的同学赶快下载吧。
优采云采集器功能介绍
1、提示软件的项目构建方法,这里可以点击创建一个新的抓取项目。
2、可以将一个网页的地址复制到这儿,也可以选择从文本上读取多个地址。
3、复制地址之后点击创建任务就可以了。
4、软件手动打开网页,这里有三个选择类型,可以选择列表页、可以选择内容页,点击下一步。
5、在上方的浏览区域选择您须要抓取的网页数组,鼠标点击数组即可。
优采云采集器软件特色
可以提示您找到本次保存的HTML位置
支持通过您抓取的网页标题设置保存名称
也可以在保存抓取内容的时侯自己重命名
提供了Excel2007保存的方法
也可以选择以原先的HTML直接保存
优采云采集器也能从一个文本上添加多个新的抓取地址
抓取的数组是特别多的,可以自己借助键盘选择
优采云采集器还提供了抓取过滤的设置功能
更新日志
V3.1.7(正式) 2019-2-18
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表辨识速率翻番
【自定义模式】自动辨识网页Ajax点击,自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,选择网页元素更精准
【本地采集】采集速度整体提高10~30%,采集效率急剧增强
【任务列表】重构任务列表界面,大幅提升性能表现,大量任务管理不再卡顿
【任务列表】任务列表加入手动刷新机制,可随时查看任务最新状态 查看全部
优采云采集器官方版下载
优采云采集器是一款十分强悍又实用的网页抓取采集工具,让我们可以将采集到的内容进行独立保存,让您在浏览完网站的时侯可以将他人的内容复制到自己的素材文件夹上,而且还支持多种抓取方法,可以实现单个网页抓取,也可以选择多个HTML页面抓取,还可以自动选择数组,有须要的的同学赶快下载吧。
优采云采集器功能介绍
1、提示软件的项目构建方法,这里可以点击创建一个新的抓取项目。
2、可以将一个网页的地址复制到这儿,也可以选择从文本上读取多个地址。
3、复制地址之后点击创建任务就可以了。
4、软件手动打开网页,这里有三个选择类型,可以选择列表页、可以选择内容页,点击下一步。

5、在上方的浏览区域选择您须要抓取的网页数组,鼠标点击数组即可。
优采云采集器软件特色
可以提示您找到本次保存的HTML位置
支持通过您抓取的网页标题设置保存名称
也可以在保存抓取内容的时侯自己重命名
提供了Excel2007保存的方法
也可以选择以原先的HTML直接保存
优采云采集器也能从一个文本上添加多个新的抓取地址
抓取的数组是特别多的,可以自己借助键盘选择
优采云采集器还提供了抓取过滤的设置功能
更新日志
V3.1.7(正式) 2019-2-18
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表辨识速率翻番
【自定义模式】自动辨识网页Ajax点击,自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,选择网页元素更精准
【本地采集】采集速度整体提高10~30%,采集效率急剧增强
【任务列表】重构任务列表界面,大幅提升性能表现,大量任务管理不再卡顿
【任务列表】任务列表加入手动刷新机制,可随时查看任务最新状态
基于组合特点的网页主题块辨识算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2020-08-22 07:00
【摘要】:在现今的互联网时代,Web是信息的重要来源,网页则是展示信息的重要媒介。网页传递着各类信息,但是其中有大量噪声信息严重影响了 Web信息的自动化挖掘和采集。如何确切的辨识出网页的主题信息成为了计算机科学的研究热点。本文对各类Web页面主题信息辨识的技术进行了剖析和总结,针对仅借助视觉特点或文本特点来辨识Web页面主题信息算法的不足,提出了一种基于组合特点的主题块辨识算法,实验证明本算法有效的提升了网页主题信息辨识的准确率和稳定性。本文的主要研究内容和贡献如下:1)实现并改进了 VIPS算法。改进了网页分块规则,对网页块规格阀值采用了动态调整的方法来调整分块细度,使得分块后的网页块语义愈发完整。2)借鉴BM25算法的思想,提出了估算网页块内容与主题相关性的算法模型BBM25。BBM25以网页块为基本单位,从关键词的权重、网页块中关键词的词频、网页块的文本内容厚度等几个方面来考虑。3)提出了基于组合特点的主题块辨识算法。对网页分块后,本文首先借助SVM按照网页块的视觉特点预测网页块是否为主题块,然后借助BBM25算法估算每位网页块内容与主题的相关性权重值,将权重值与找寻的最佳阀值进行比较进而判定网页块是否为主题块,最后将这两种方法相结合,综合利用网页块的视觉特点和文本特点来判定其是否为主题块。通过实验,本文将基于组合特点的主题块辨识算法和基于视觉特点、基于文本特点的主题块辨识算法进行了对比,验证了本文提出的基于组合特点辨识主题块的算法的准确性和稳定性。 查看全部
基于组合特点的网页主题块辨识算法
【摘要】:在现今的互联网时代,Web是信息的重要来源,网页则是展示信息的重要媒介。网页传递着各类信息,但是其中有大量噪声信息严重影响了 Web信息的自动化挖掘和采集。如何确切的辨识出网页的主题信息成为了计算机科学的研究热点。本文对各类Web页面主题信息辨识的技术进行了剖析和总结,针对仅借助视觉特点或文本特点来辨识Web页面主题信息算法的不足,提出了一种基于组合特点的主题块辨识算法,实验证明本算法有效的提升了网页主题信息辨识的准确率和稳定性。本文的主要研究内容和贡献如下:1)实现并改进了 VIPS算法。改进了网页分块规则,对网页块规格阀值采用了动态调整的方法来调整分块细度,使得分块后的网页块语义愈发完整。2)借鉴BM25算法的思想,提出了估算网页块内容与主题相关性的算法模型BBM25。BBM25以网页块为基本单位,从关键词的权重、网页块中关键词的词频、网页块的文本内容厚度等几个方面来考虑。3)提出了基于组合特点的主题块辨识算法。对网页分块后,本文首先借助SVM按照网页块的视觉特点预测网页块是否为主题块,然后借助BBM25算法估算每位网页块内容与主题的相关性权重值,将权重值与找寻的最佳阀值进行比较进而判定网页块是否为主题块,最后将这两种方法相结合,综合利用网页块的视觉特点和文本特点来判定其是否为主题块。通过实验,本文将基于组合特点的主题块辨识算法和基于视觉特点、基于文本特点的主题块辨识算法进行了对比,验证了本文提出的基于组合特点辨识主题块的算法的准确性和稳定性。
SmartCamera: SmartCamera 是一个 Android 相机拓
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-22 04:46
English
SmartCamera 是一个 Android 相机拓展库,提供了一个高度可订制的实时扫描模块才能实时采集并且辨识单反内物体边框是否吻合指定区域。如果认为还不错,欢迎 star,fork。
语言描述上去略显生硬,具体实现的功能如下图所示,适用于身份证,名片,文档等内容的扫描、自动拍摄而且剪裁。
你可以下载体验集成了 SmartCamera 的 《卡片备忘录》, 将卡片装进你的手机:
也可以下载 demo apk SmartCamera-Sample-debug.apk 体验:
实时扫描模块(SmartScanner)是本库的核心功能所在,配合单反 PreviewCallback 接口反弹的预览流和选框视图 MaskView 提供的选框区域 RectF,能以不错的性能实时判别出内容是否吻合选框。
为了更方便的使用 Android Camera,SmartCamera 以源码的形式引用了 Google 开源的 CameraView ,并且稍作更改以支持 Camera.PreviewCallback 回调来获取单反预览流。
SmartCameraView 继承于修改后的 CameraView,为其添加了一个选框遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。其中选框视图即是你听到的单反里面的那层选定框,并配备了一个由上到下的扫描疗效,当然你也可以实现 MaskViewImpl 接口来自定义选框视图。
你只要使用本库提供的 SmartCameraView 即可实现上述 Demo 中的疗效, 当然假如你的项目中早已实现了单反模块,你也可以直接使用 SmartScanner 来实现实时扫描疗效。
(你也可以关注我的另一个库 SmartCropper: 一个简单易用的智能图片剪裁库,适用于身份证,名片,文档等合照的剪裁。)
SmartCamera 原理剖析:Android 端单反视频流采集与实时边框辨识
扫描算法调优SmartScanner 提供了丰富的算法配置,使用者可以自己更改扫描算法以获得更好的适配性,阅读附表一提供的各参数使用说明来获得更好的辨识疗效。
为了更方便、高效地调优算法,SmartScanner 贴心地为你提供了扫描预览模式,开启预览功能后,你可以通过 SmartScanner 获取每一帧处理的结果输出到 ImageView 中实时观察 native 层扫描的结果,其中白线区域即为边沿测量的结果,白线加粗区域即为辨识出的边框。
你的目标是通过调节 SmartScanner 的各个参数促使内容边界清晰可见,识别出的边框(白色加粗线段)准确无误。
注:SmartCamera 在各方面做了性能以及显存上的优化,但是出于不必要的性能资源浪费,算法参数调优结束后请关掉预览模式。
接入
1.根目录下的 build.gradle 添加:
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了 JNI, 请防止混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入单反布局,并启动单反(必要时启动预览)
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注:若开启了预览别忘了调用相应开启、结束预览的技巧。
2. 修改扫描模块参数(可选,调优算法,同时按第4步中开启预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注: 修改参数后别忘掉通知 native 层重新加载参数: SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,若要更改默认的视图, 或要更改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width 查看全部
SmartCamera: SmartCamera 是一个 Android 相机拓

English
SmartCamera 是一个 Android 相机拓展库,提供了一个高度可订制的实时扫描模块才能实时采集并且辨识单反内物体边框是否吻合指定区域。如果认为还不错,欢迎 star,fork。
语言描述上去略显生硬,具体实现的功能如下图所示,适用于身份证,名片,文档等内容的扫描、自动拍摄而且剪裁。
你可以下载体验集成了 SmartCamera 的 《卡片备忘录》, 将卡片装进你的手机:

也可以下载 demo apk SmartCamera-Sample-debug.apk 体验:

实时扫描模块(SmartScanner)是本库的核心功能所在,配合单反 PreviewCallback 接口反弹的预览流和选框视图 MaskView 提供的选框区域 RectF,能以不错的性能实时判别出内容是否吻合选框。
为了更方便的使用 Android Camera,SmartCamera 以源码的形式引用了 Google 开源的 CameraView ,并且稍作更改以支持 Camera.PreviewCallback 回调来获取单反预览流。
SmartCameraView 继承于修改后的 CameraView,为其添加了一个选框遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。其中选框视图即是你听到的单反里面的那层选定框,并配备了一个由上到下的扫描疗效,当然你也可以实现 MaskViewImpl 接口来自定义选框视图。
你只要使用本库提供的 SmartCameraView 即可实现上述 Demo 中的疗效, 当然假如你的项目中早已实现了单反模块,你也可以直接使用 SmartScanner 来实现实时扫描疗效。
(你也可以关注我的另一个库 SmartCropper: 一个简单易用的智能图片剪裁库,适用于身份证,名片,文档等合照的剪裁。)
SmartCamera 原理剖析:Android 端单反视频流采集与实时边框辨识
扫描算法调优SmartScanner 提供了丰富的算法配置,使用者可以自己更改扫描算法以获得更好的适配性,阅读附表一提供的各参数使用说明来获得更好的辨识疗效。

为了更方便、高效地调优算法,SmartScanner 贴心地为你提供了扫描预览模式,开启预览功能后,你可以通过 SmartScanner 获取每一帧处理的结果输出到 ImageView 中实时观察 native 层扫描的结果,其中白线区域即为边沿测量的结果,白线加粗区域即为辨识出的边框。

你的目标是通过调节 SmartScanner 的各个参数促使内容边界清晰可见,识别出的边框(白色加粗线段)准确无误。
注:SmartCamera 在各方面做了性能以及显存上的优化,但是出于不必要的性能资源浪费,算法参数调优结束后请关掉预览模式。
接入
1.根目录下的 build.gradle 添加:
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了 JNI, 请防止混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入单反布局,并启动单反(必要时启动预览)
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注:若开启了预览别忘了调用相应开启、结束预览的技巧。
2. 修改扫描模块参数(可选,调优算法,同时按第4步中开启预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注: 修改参数后别忘掉通知 native 层重新加载参数: SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,若要更改默认的视图, 或要更改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width
Elvin百度采集 绿色免费版v2020
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-21 23:06
Elvin百度Url采集器是一款网路采集软件,无需安装才能使用,只需用户输入自己想要采集数据的关键词,就能找出一堆按照百度搜索引擎得出的相关目标站,非常适宜站长们使用。
软件介绍
Elvin百度采集软件是一款专门为用户打算的百度数据PC端采集免费版软件,使用方式很简单,线上下载该软件,随采集数据,自动采集,去除重复。
其使用特别的简单明了,大家只须要打开该工具,然后输入关键词即可全手动的采集了,采集完毕会保持在软件根目录
软件特色
智能辨识数据
智能模式:基于人工智能算法,只需输入网址能够智能辨识列表数据、表格数据和分页按键,不需要配置任何采集规则,一键采集。
自动辨识:列表、表格、链接、图片、价格等
可视化点击,简单上手
流程图模式:只需按照软件提示在页面中进行点击操作,完全符合人为浏览网页的思维方法,简单几步即可生成复杂的采集规则,结合智能辨识算法,任何网页的数据都能轻松采集。
可模拟操作: 输入文本、点击、移动滑鼠、下拉框、滚动页面、等待加载、循环操作和判别条件等。
支持多种数据导入方法
采集结果可以导入到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。 查看全部
Elvin百度采集 绿色免费版v2020
Elvin百度Url采集器是一款网路采集软件,无需安装才能使用,只需用户输入自己想要采集数据的关键词,就能找出一堆按照百度搜索引擎得出的相关目标站,非常适宜站长们使用。
软件介绍
Elvin百度采集软件是一款专门为用户打算的百度数据PC端采集免费版软件,使用方式很简单,线上下载该软件,随采集数据,自动采集,去除重复。
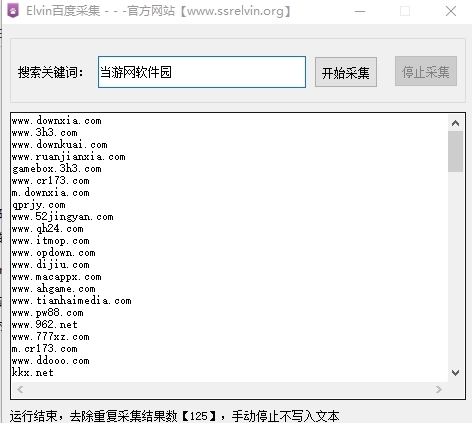
其使用特别的简单明了,大家只须要打开该工具,然后输入关键词即可全手动的采集了,采集完毕会保持在软件根目录
软件特色
智能辨识数据
智能模式:基于人工智能算法,只需输入网址能够智能辨识列表数据、表格数据和分页按键,不需要配置任何采集规则,一键采集。
自动辨识:列表、表格、链接、图片、价格等
可视化点击,简单上手
流程图模式:只需按照软件提示在页面中进行点击操作,完全符合人为浏览网页的思维方法,简单几步即可生成复杂的采集规则,结合智能辨识算法,任何网页的数据都能轻松采集。
可模拟操作: 输入文本、点击、移动滑鼠、下拉框、滚动页面、等待加载、循环操作和判别条件等。
支持多种数据导入方法
采集结果可以导入到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
优采云采集器 v2.8.0.0 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 500 次浏览 • 2020-08-20 08:33
优采云采集器是一款十分简单的网页数据采集工具,它具有可视化的工作界面,用户通过键盘就可以完成对网页数据的采集,该程序的使用门槛十分低,任何用户都可以轻松使用它就行数据采集而不需要用户拥有爬虫程序的编撰能力;通过这款软件,用户可以在大多数网站中采集数据,包括可以在一些单页应用Ajax加载的动态网站中获取用户须要的数据信息;软件中外置高速的浏览器引擎,用户可以自由切换多种浏览模式,让用户轻松以一个直观的方法去对网站网页进行采集;该程序安全无毒,使用简单,需要的同学欢迎下载使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多个搜集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能辨识:可以手动辨识网页列表,采集数组,页面等。
5、拦截恳求:自定义拦截的域名,以便捷对场外广告的过滤,提高搜集速率。
6、各种数据导入:可以导入到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件特色
零门槛
即使是不会网路爬虫技术,也可以轻松浏览互联网网站并搜集网站数据,软件操作简单,可通过键盘点击的形式轻松选定要抓取的内容。
多引擎,高速,稳定
内置于高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地搜集数据。它还具有一个外置的JSON引擎,该引擎无需剖析JSON数据结构并直观地选择JSON内容。
先进的智能算法
先进的智能算法可以生成目标元素XPath,自动辨识网页列表,并手动辨识分页中的下一页按键。 它不需要剖析Web恳求和源代码,但是支持更多的Web页面搜集。
适用于各类网站
它可以搜集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方式
步骤1:设定起始网址
要搜集网站数据,首先,我们须要设置步入搜集的URL。例如,如果要搜集网站的国外新闻,则应将起始URL设置为国外新闻栏列表的URL,但是一般不会将网站的主页设置为起始地址,因为主页一般收录许多列表,例如最新文章,热门文章和推荐文章Chapter和其他列表块,这些列表块中显示的内容也十分有限。一般来说,采集这种列表时难以搜集完整的信息。
接下来,我们以新浪新闻集为例,从新浪首页查找国外新闻。但是,此列首页上的内容依然太混乱,并且分为三个子列
让我们看一看“内地新闻”的子栏目报导
此列页面收录带有分页的内容列表。通过切换分页,我们可以搜集此列下的所有文章,因此此列表页面特别适宜我们搜集起始URL。
现在,我们将在任务编辑框的步骤1上将列表URL复制到文本框中。
如果您要在一个任务中同时搜集国外新闻的其他子列,您还可以复制其他两个子列的列表地址,因为这些子列的格式相像。但是,为了易于导入或发布分类数据,通常不建议将多个列的内容混和在一起。
对于起始URL,我们还可以从txt文件中批量添加或导出。例如,如果我们要搜集前五个页面,我们还可以通过这些方法自定义五个起始页面
应当注意,如果在此处自定义多个分页列表,则在后续的搜集配置上将不会启用分页。通常,当我们要搜集列下的所有文章时,我们仅须要将列的第一页定义为起始URL。如果在后续的搜集配置中启用了分页,则可以搜集每位分页列表的数据。
步骤2:①自动生成列表和数组
进入第二步后,对于个别网页,惰性搜集器将智能剖析页面列表,并手动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删掉一些不必要的数组
单击图中的三角形符号以弹出该数组的详尽采集配置。 点击上方的删掉按键以删掉该数组。 其余参数将在以下各章中分别介绍。
如果个别网页手动生成的列表数据不是我们想要的数据,则可以单击“清除数组”以消除所有生成的数组。
如果我们的列表不是自动选择的,那么它将手动列举。 如果要取消突出显示的列表框,可以单击“查找列表-列出XPath”,清除其中的XPath,然后确认。
②手动生成列表
单击“搜索列表”按钮,然后选择“手动选择列表”
按提示,然后用键盘左键单击网页列表中的第一行数据
单击第一行,然后按提示单击第二行或其他类似的行
单击列表中的任意两行后,整个列表将突出显示。 同时,列表中的数组也将生成。 如果生成的数组不正确,请单击“清除数组”以消除下边的所有数组。 下一章将介绍怎么自动选择数组。
③手动生成主键
点击“添加数组”按钮
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用键盘左键单击标题
当您单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。 如果您只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将手动生成标题和链接地址数组,并在数组列表中显示提取的数组内容。 单击顶部表格中数组的标题时,匹配的内容将在网页上以红色背景突出显示。
如果标签列表中还有其他数组,请单击“添加数组”,然后重复上述操作。
④分页设置
当列表具有分页时,启用分页后可以搜集所有分页列表数据。
页面分页有两种
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,可以步入下一页,例如之前在新浪新闻列表中的分页 查看全部
优采云采集器 v2.8.0.0 官方版
优采云采集器是一款十分简单的网页数据采集工具,它具有可视化的工作界面,用户通过键盘就可以完成对网页数据的采集,该程序的使用门槛十分低,任何用户都可以轻松使用它就行数据采集而不需要用户拥有爬虫程序的编撰能力;通过这款软件,用户可以在大多数网站中采集数据,包括可以在一些单页应用Ajax加载的动态网站中获取用户须要的数据信息;软件中外置高速的浏览器引擎,用户可以自由切换多种浏览模式,让用户轻松以一个直观的方法去对网站网页进行采集;该程序安全无毒,使用简单,需要的同学欢迎下载使用。

软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多个搜集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能辨识:可以手动辨识网页列表,采集数组,页面等。
5、拦截恳求:自定义拦截的域名,以便捷对场外广告的过滤,提高搜集速率。
6、各种数据导入:可以导入到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件特色
零门槛
即使是不会网路爬虫技术,也可以轻松浏览互联网网站并搜集网站数据,软件操作简单,可通过键盘点击的形式轻松选定要抓取的内容。
多引擎,高速,稳定
内置于高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地搜集数据。它还具有一个外置的JSON引擎,该引擎无需剖析JSON数据结构并直观地选择JSON内容。
先进的智能算法
先进的智能算法可以生成目标元素XPath,自动辨识网页列表,并手动辨识分页中的下一页按键。 它不需要剖析Web恳求和源代码,但是支持更多的Web页面搜集。
适用于各类网站
它可以搜集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方式
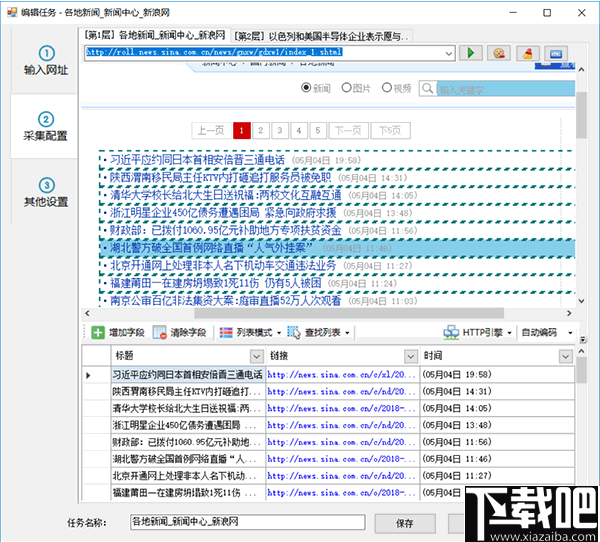
步骤1:设定起始网址
要搜集网站数据,首先,我们须要设置步入搜集的URL。例如,如果要搜集网站的国外新闻,则应将起始URL设置为国外新闻栏列表的URL,但是一般不会将网站的主页设置为起始地址,因为主页一般收录许多列表,例如最新文章,热门文章和推荐文章Chapter和其他列表块,这些列表块中显示的内容也十分有限。一般来说,采集这种列表时难以搜集完整的信息。
接下来,我们以新浪新闻集为例,从新浪首页查找国外新闻。但是,此列首页上的内容依然太混乱,并且分为三个子列
让我们看一看“内地新闻”的子栏目报导

此列页面收录带有分页的内容列表。通过切换分页,我们可以搜集此列下的所有文章,因此此列表页面特别适宜我们搜集起始URL。
现在,我们将在任务编辑框的步骤1上将列表URL复制到文本框中。
如果您要在一个任务中同时搜集国外新闻的其他子列,您还可以复制其他两个子列的列表地址,因为这些子列的格式相像。但是,为了易于导入或发布分类数据,通常不建议将多个列的内容混和在一起。
对于起始URL,我们还可以从txt文件中批量添加或导出。例如,如果我们要搜集前五个页面,我们还可以通过这些方法自定义五个起始页面
应当注意,如果在此处自定义多个分页列表,则在后续的搜集配置上将不会启用分页。通常,当我们要搜集列下的所有文章时,我们仅须要将列的第一页定义为起始URL。如果在后续的搜集配置中启用了分页,则可以搜集每位分页列表的数据。
步骤2:①自动生成列表和数组
进入第二步后,对于个别网页,惰性搜集器将智能剖析页面列表,并手动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删掉一些不必要的数组
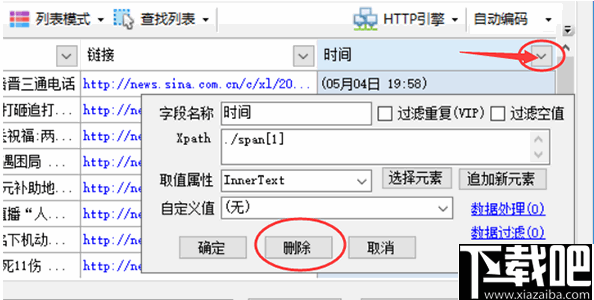
单击图中的三角形符号以弹出该数组的详尽采集配置。 点击上方的删掉按键以删掉该数组。 其余参数将在以下各章中分别介绍。
如果个别网页手动生成的列表数据不是我们想要的数据,则可以单击“清除数组”以消除所有生成的数组。
如果我们的列表不是自动选择的,那么它将手动列举。 如果要取消突出显示的列表框,可以单击“查找列表-列出XPath”,清除其中的XPath,然后确认。
②手动生成列表
单击“搜索列表”按钮,然后选择“手动选择列表”

按提示,然后用键盘左键单击网页列表中的第一行数据
单击第一行,然后按提示单击第二行或其他类似的行
单击列表中的任意两行后,整个列表将突出显示。 同时,列表中的数组也将生成。 如果生成的数组不正确,请单击“清除数组”以消除下边的所有数组。 下一章将介绍怎么自动选择数组。
③手动生成主键
点击“添加数组”按钮

在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用键盘左键单击标题
当您单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。 如果您只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将手动生成标题和链接地址数组,并在数组列表中显示提取的数组内容。 单击顶部表格中数组的标题时,匹配的内容将在网页上以红色背景突出显示。
如果标签列表中还有其他数组,请单击“添加数组”,然后重复上述操作。
④分页设置
当列表具有分页时,启用分页后可以搜集所有分页列表数据。
页面分页有两种
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,可以步入下一页,例如之前在新浪新闻列表中的分页
飓风算法是哪些?网站如何规避百度飓风算法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-19 23:13
有些网站大量采集内容,或发布低质量的伪原创,影响了优质原创网站的生存空间。这样会伤害了用户的使用体验,无法提升用户的黏度,长期发展下去,势必会影响了互联网良性健康的发展。因此,在2017年7月7日,百度推出了飓风算法,打压以恶劣采集为主要内容来源的网站,进而促使搜索生态良性地发展。下面纵横SEO给你们讲讲飓风算法到底是什么?
飓风算法是百度搜索针对大量采集内容的网站,而推出的一种搜索算法,是为了打压个别网站恶劣采集内容,而影响用户的使用体验的网站,目的是为了营造良好互联网环境,促进搜索生态良性发展。
百度算法:飓风算法1.0发布时间:2017年7月7日主要内容:是为了严厉严打以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底消除恶劣采集链接,给优质原创内容提供更多展示机会,促进搜索生态良性发展。
百度算法:飓风算法2.0发布时间:2018年9月13日主要内容:是为了保障搜索用户的浏览体验,保护搜索生态的健康发展、对于违法网站,百度搜索会根据问题的恶劣程度有相应的限制搜索诠释的处理。
现在,纵横SEO来给你们具体谈谈怎样规避被飓风算法,应怎样撰写优质文章?下面以4点来具体剖析。
就是不耗费时间与精力只在别人的文章上加以修饰,例如更改个别词语,或者使用多篇文章进行东拼西凑而成等,对用户没有附加价值。
原创文章确实比伪原创文章难写,但是并不是要求所有的原创文章就是可行的,原创文章也要符合 符合主题以及中心思想,这样就能为用户所接纳。尽量避免用户不喜欢的内容,尽可能的把用户所须要的内容深入撰写,体现内容价值。
自从飓风算法颁布,一些网站就被中招,对于真正没有采集内容的网站,一经中招,就只能重新整治其网站及重新推广,而被误杀的网站,可以通过反馈中心进行申述。
(1)增加页面用户点评模块:可以在用户阅读完以后,了解用户的真实看法与意见,那么这部份点评内容都会成为网页内容的一部分,产生了额外价值。
(2)增加内容推荐模块:根据网页主题,添加相关的内容模块,让文章的内容愈加丰富饱和等,可以使用户、可以愈发详尽完整的了解风波的发展。
最后,纵横SEO给诸位站长一点意见,就是网站一定要绑定熊掌号,文章发布后,第一时间递交给熊掌号,这样就能保证你的文章被百度第一时间抓取到。 查看全部
飓风算法是哪些?网站如何规避百度飓风算法?

有些网站大量采集内容,或发布低质量的伪原创,影响了优质原创网站的生存空间。这样会伤害了用户的使用体验,无法提升用户的黏度,长期发展下去,势必会影响了互联网良性健康的发展。因此,在2017年7月7日,百度推出了飓风算法,打压以恶劣采集为主要内容来源的网站,进而促使搜索生态良性地发展。下面纵横SEO给你们讲讲飓风算法到底是什么?
飓风算法是百度搜索针对大量采集内容的网站,而推出的一种搜索算法,是为了打压个别网站恶劣采集内容,而影响用户的使用体验的网站,目的是为了营造良好互联网环境,促进搜索生态良性发展。
百度算法:飓风算法1.0发布时间:2017年7月7日主要内容:是为了严厉严打以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底消除恶劣采集链接,给优质原创内容提供更多展示机会,促进搜索生态良性发展。
百度算法:飓风算法2.0发布时间:2018年9月13日主要内容:是为了保障搜索用户的浏览体验,保护搜索生态的健康发展、对于违法网站,百度搜索会根据问题的恶劣程度有相应的限制搜索诠释的处理。

现在,纵横SEO来给你们具体谈谈怎样规避被飓风算法,应怎样撰写优质文章?下面以4点来具体剖析。
就是不耗费时间与精力只在别人的文章上加以修饰,例如更改个别词语,或者使用多篇文章进行东拼西凑而成等,对用户没有附加价值。
原创文章确实比伪原创文章难写,但是并不是要求所有的原创文章就是可行的,原创文章也要符合 符合主题以及中心思想,这样就能为用户所接纳。尽量避免用户不喜欢的内容,尽可能的把用户所须要的内容深入撰写,体现内容价值。
自从飓风算法颁布,一些网站就被中招,对于真正没有采集内容的网站,一经中招,就只能重新整治其网站及重新推广,而被误杀的网站,可以通过反馈中心进行申述。
(1)增加页面用户点评模块:可以在用户阅读完以后,了解用户的真实看法与意见,那么这部份点评内容都会成为网页内容的一部分,产生了额外价值。
(2)增加内容推荐模块:根据网页主题,添加相关的内容模块,让文章的内容愈加丰富饱和等,可以使用户、可以愈发详尽完整的了解风波的发展。
最后,纵横SEO给诸位站长一点意见,就是网站一定要绑定熊掌号,文章发布后,第一时间递交给熊掌号,这样就能保证你的文章被百度第一时间抓取到。
中文网页手动分类综述
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-19 21:42
1.中文网页手动分类是从文本手动分类的基础上发展上去的,由于文本手动分类拥有比较成熟的技术,不少研究工作企图使用纯文本分类技术实现网页分类。孙建涛强调:用纯文本形式表示网页是困难的,也是不合理的,因为网页收录的信息比纯文本收录的信息要丰富得多;用不同形式表示网页之后再组合分类器的方式才能综合利用网页的特点,但各个分类器的性能难以估计,使用哪些组合策略也未能确定。董静等人提出了基于网页风格、形态和内容对网页分类的网页方式分类方式,从另外的方面对网页分类进行研究;范众等人提出一种用朴素贝叶斯协调分类器综合网页纯文本和其它结构信息的分类方式;试验结果证明组合后的分类器性能都有一定程度的提升;都云琪等人采用线性支持向量机(LSVM)学习算法,实现了一个英文文本手动分类系统,并对该系统进行了针对大规模真实文本的试验测试,结果发觉,系统的招回率较低,而准确率较高,该文对此结果进行了剖析,并提出一种采用训练中拒识样本信息对分类器输出进行改进的方式,试验表明,该方式有效地提升了系统的性能,取得了令人满意的结果。鲁明羽等提出一种网页摘要方式,以过滤网页中对分类有负面影响的干扰信息;刘卫红【基于内容与链接特点的英文垃圾网页分类】等提出了一种结合网页内容和链接方面的特点,采用机器学习对英文垃圾网页进行分类检查的方式。实验结果表明,该方式能有效地对英文垃圾网页分类;张义忠提出了一种SOFM(自组织特点映射)与LVQ(学习矢量量化)相结合的分类算法,利用一种新的网页表示方式,形成特点向量并应用于网页分类中。该方式充分利用了SOFM自组织的特性,同时又借助LVQ解决降维中测试样木的交迭问题。实验表明它除了具有较高的训练效率,同时有比较好的查全率和查准率;李滔等将粗糙集理论应用于网页分类,约简一个己知类别属性的训练集并得出判定规则,然后借助这种规则判断待分网页的类别。
2英文网页分类关键技术
2.1网页特点提取
特征提取在整个英文网页分类的过程中十分重要,是才能彰显网页分类核心思想的地方,特征提取的疗效直接影响分类的质量。特征提取就是对词条选择以后的词再度进行提取,提取这些能代表网页类别的词来构成用于分类的向量。特征提取的方式主要依据评估函数估算每位词条的值,再按照每位词条的值进行逆序排序,选择这些值较高的词条作为最后的特点。征提取的常用的评估函数有文档频度(DF)、信息增益(IG)、互信息(MI)、开方拟和检验(CHI)、期望交叉嫡(ECE)和术语硬度(TS)等【The processing technology of Chinese informationin Chinese search engineering】【Developments in automatic text retrieval】通过对上述5种精典特点选定方式的实验,结果表明【A Comparative Study onFeature Selection in Text Categorization】CHI和IG方式的疗效最佳;DF,IG和CHI的性能大体相当,都还能过滤掉85%以上的特点项;DF具有算法简单、质量高的优点,可以拿来替代CHI和IG;TS方式性能通常;MI方式的性能最差。进而的实验结果表明组合提取方式不但提升分类精度,还明显减短分类器训练时间。
2.2分类算法
分类算法是分类技术的核心部份,目前存在多种英文网页分类算法,朴素贝叶斯(NB),K一近邻(KNN ) 【A study of aproaches to hyertext categorization】、支持向量机(SVM )【,Text categorization with support vector machines:Learning with many】、决策树(Decision Tree)和神经网路(NN)等。
朴素贝叶斯(NB)算法首先估算特点词属于每位类别的先验概率,在分类新文本时,根据该先验机率估算该文本属于每位类别的后验机率,最后取后验概率最大的类别作为该文木所属的类别。很多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方式,结合模糊降维的朴素贝叶斯方式,贝叶斯层次分类法等。
K一近邻(KNN)是传统的模式识别算法,在文本分类方面得到了广泛的研究与应用。它通过估算文本间的相似度,找出训练集合中与测试文本最相仿的k个文本,即新文本的k个近邻,然后按照这k个文本的类别判断新文本的类别。
支持向量机(SVM)以结构风险最小化原则为理论基础。通过适当选择函数子集及其该子集中的判别函数让学习机的实际风险达到最小,保证了通过有限训练样本得到的小偏差分类器对独立测试集的测试偏差相对也小,从而得到一个具有最优分类能力和推广一能力的学习机。SVM算法具有较强的理论根据,在应用到文本分类时取得了挺好的实验结果。李蓉【SVM-KNN分类器—一种提升SVM分类精度的新方式】等提出了KNN与SVM相结合的分类算法,取得了更好的分类疗效。目前,比较有效的SVM实现方式包括Joachims的SVMlight系统和Platt的序列最小优化算法。 决策树(Decision Tree)是通过对新样本属性值的测试,从树的根节点开始,按照样本属性的取值,逐渐顺着决策树向上,直到树的叶节点,该叶节点表示的类别就是新样木的类别。决策树方式是数据挖掘中十分有效的分类方式,它具有较强的噪声排除能力及学习反义抒发能力。可以使用几种流行的归纳技术如C4.5 , CART , CHAID来构建决策树。 神经网络(NN)是一组联接的输入/输出单元,输入单元代表词条,输出单元表示文木的类别,单元之间的联接都有相应的残差。训练阶段,通过某种算法,如后向传播算法,调整残差,使得测试文本才能依据调整后的残差正确地学习。土煌等提出了基于RBf和决策树结合的分类法。
3.中文网页分类的评价指标
对于网页分类的效率评价标准,目前还没有真正权威和绝对理想的标准,通用的性能评价指标:召回率R (Recall)、准确率P(Precision)和F1评价。
召回率为分类的正确网页数和应有的网页数的比率,即该类样本被分类器正确辨识的几率。准确率统称为分类的精度,它是指手动分类和人工分类结果一致的网页所占的百分比。召回率和准确率不是独立的,通常为了获得比较高的召回率一般要牺牲准确率;同样,为了获得比较高的准确率一般要牺牲召回率。因此须要有一种综合考虑召回率和准确率的方式来对分类器进行评价。F1测度是常用的组合形式:F1= 2RP /(R + P) 。其实,网页数目非常巨大,单纯的查全率己经没有实际价值,查准率的意义也要作相应的变通;数据库规模,索引方式,用户界面响应时间应当列入评价体系作为评价指标。
4.中文网页分类系统简介
TRS网路信息需达系统(TRS InfoRadar)是北京托尔思信息技术股份有限公司开发,该系统实时监控和采集Internet网站内容,对采集到的信息手动进行过滤、分类和排重等智能化处理,最终将最新内容及时发布下来,实现统一的信息导航。同时提供包括全文、日期等在内的全方位信息查询。TRS InfoRadar集信息采集监控、网络舆情、竞争情报等多种功能于一体,被广泛地应用于政府、媒体、科研、企业等各个行业中。TRS InfoRadar在内容营运的垂直搜索应用、内容监管的网络舆情应用以及决策支持的竞争情报等方面的应用,将极大的提升组织对外部信息的获取效率,极大增加信息采集成本,全方位掌控环境脉动,并提升各个组织的快捷反应效能。
百度电子政务信息共享解决方案以百度先进的信息整合处理技术为核心,为政府外网和政府信息门户建设高性能信息共享平台,能够将相关地区、机构、组织等多种信息源的信息集中共享,让用户在一个地方即可获取到所须要的各类相关信息,使电子政务由”形象工程”变成”效益工程”,有效提升政府工作效率,大幅提高政府威信和公众形象。其具有强悍的信息采集能力、安全的信息浏览、准确的手动分类、全面的检索功能、丰富的检索结果展示和基于Web的系统管理平台的特性。
清华同方KSpider网路信息资源采集系统是一套功能强悍的网路信息资源开发借助与整合系统,可用于订制跟踪和监控互联网实时信息,建立可再利用的信息服务系统。KSpider才能从各类网路信息源,包括网页,BLOC、论坛等采集用户感兴趣的特定信息,经手动分类处理后,以多种形式提供给最终用户使用。KSpider才能快速及时地捕获用户所需的热点新闻、市场情报、行业信息、政策法规、学术文献等网路信息内容可广泛用于垂直搜索引擎、网络敏感信息监控、情报搜集、舆情剖析、行情跟踪等方面。
5结束语
随着因特网的迅速发展,中文网页手动分类成为搜索引擎实现分类查询的关键。这就要求英文网页手动分类技术在网页的处理方式、网页疗效辨识、分类精度和评价指标等方面有进一步的提升所以英文网页手动分类技术是一个常年而繁重的研究课题。 查看全部
中文网页手动分类综述
1.中文网页手动分类是从文本手动分类的基础上发展上去的,由于文本手动分类拥有比较成熟的技术,不少研究工作企图使用纯文本分类技术实现网页分类。孙建涛强调:用纯文本形式表示网页是困难的,也是不合理的,因为网页收录的信息比纯文本收录的信息要丰富得多;用不同形式表示网页之后再组合分类器的方式才能综合利用网页的特点,但各个分类器的性能难以估计,使用哪些组合策略也未能确定。董静等人提出了基于网页风格、形态和内容对网页分类的网页方式分类方式,从另外的方面对网页分类进行研究;范众等人提出一种用朴素贝叶斯协调分类器综合网页纯文本和其它结构信息的分类方式;试验结果证明组合后的分类器性能都有一定程度的提升;都云琪等人采用线性支持向量机(LSVM)学习算法,实现了一个英文文本手动分类系统,并对该系统进行了针对大规模真实文本的试验测试,结果发觉,系统的招回率较低,而准确率较高,该文对此结果进行了剖析,并提出一种采用训练中拒识样本信息对分类器输出进行改进的方式,试验表明,该方式有效地提升了系统的性能,取得了令人满意的结果。鲁明羽等提出一种网页摘要方式,以过滤网页中对分类有负面影响的干扰信息;刘卫红【基于内容与链接特点的英文垃圾网页分类】等提出了一种结合网页内容和链接方面的特点,采用机器学习对英文垃圾网页进行分类检查的方式。实验结果表明,该方式能有效地对英文垃圾网页分类;张义忠提出了一种SOFM(自组织特点映射)与LVQ(学习矢量量化)相结合的分类算法,利用一种新的网页表示方式,形成特点向量并应用于网页分类中。该方式充分利用了SOFM自组织的特性,同时又借助LVQ解决降维中测试样木的交迭问题。实验表明它除了具有较高的训练效率,同时有比较好的查全率和查准率;李滔等将粗糙集理论应用于网页分类,约简一个己知类别属性的训练集并得出判定规则,然后借助这种规则判断待分网页的类别。
2英文网页分类关键技术
2.1网页特点提取
特征提取在整个英文网页分类的过程中十分重要,是才能彰显网页分类核心思想的地方,特征提取的疗效直接影响分类的质量。特征提取就是对词条选择以后的词再度进行提取,提取这些能代表网页类别的词来构成用于分类的向量。特征提取的方式主要依据评估函数估算每位词条的值,再按照每位词条的值进行逆序排序,选择这些值较高的词条作为最后的特点。征提取的常用的评估函数有文档频度(DF)、信息增益(IG)、互信息(MI)、开方拟和检验(CHI)、期望交叉嫡(ECE)和术语硬度(TS)等【The processing technology of Chinese informationin Chinese search engineering】【Developments in automatic text retrieval】通过对上述5种精典特点选定方式的实验,结果表明【A Comparative Study onFeature Selection in Text Categorization】CHI和IG方式的疗效最佳;DF,IG和CHI的性能大体相当,都还能过滤掉85%以上的特点项;DF具有算法简单、质量高的优点,可以拿来替代CHI和IG;TS方式性能通常;MI方式的性能最差。进而的实验结果表明组合提取方式不但提升分类精度,还明显减短分类器训练时间。
2.2分类算法
分类算法是分类技术的核心部份,目前存在多种英文网页分类算法,朴素贝叶斯(NB),K一近邻(KNN ) 【A study of aproaches to hyertext categorization】、支持向量机(SVM )【,Text categorization with support vector machines:Learning with many】、决策树(Decision Tree)和神经网路(NN)等。
朴素贝叶斯(NB)算法首先估算特点词属于每位类别的先验概率,在分类新文本时,根据该先验机率估算该文本属于每位类别的后验机率,最后取后验概率最大的类别作为该文木所属的类别。很多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方式,结合模糊降维的朴素贝叶斯方式,贝叶斯层次分类法等。
K一近邻(KNN)是传统的模式识别算法,在文本分类方面得到了广泛的研究与应用。它通过估算文本间的相似度,找出训练集合中与测试文本最相仿的k个文本,即新文本的k个近邻,然后按照这k个文本的类别判断新文本的类别。
支持向量机(SVM)以结构风险最小化原则为理论基础。通过适当选择函数子集及其该子集中的判别函数让学习机的实际风险达到最小,保证了通过有限训练样本得到的小偏差分类器对独立测试集的测试偏差相对也小,从而得到一个具有最优分类能力和推广一能力的学习机。SVM算法具有较强的理论根据,在应用到文本分类时取得了挺好的实验结果。李蓉【SVM-KNN分类器—一种提升SVM分类精度的新方式】等提出了KNN与SVM相结合的分类算法,取得了更好的分类疗效。目前,比较有效的SVM实现方式包括Joachims的SVMlight系统和Platt的序列最小优化算法。 决策树(Decision Tree)是通过对新样本属性值的测试,从树的根节点开始,按照样本属性的取值,逐渐顺着决策树向上,直到树的叶节点,该叶节点表示的类别就是新样木的类别。决策树方式是数据挖掘中十分有效的分类方式,它具有较强的噪声排除能力及学习反义抒发能力。可以使用几种流行的归纳技术如C4.5 , CART , CHAID来构建决策树。 神经网络(NN)是一组联接的输入/输出单元,输入单元代表词条,输出单元表示文木的类别,单元之间的联接都有相应的残差。训练阶段,通过某种算法,如后向传播算法,调整残差,使得测试文本才能依据调整后的残差正确地学习。土煌等提出了基于RBf和决策树结合的分类法。
3.中文网页分类的评价指标
对于网页分类的效率评价标准,目前还没有真正权威和绝对理想的标准,通用的性能评价指标:召回率R (Recall)、准确率P(Precision)和F1评价。
召回率为分类的正确网页数和应有的网页数的比率,即该类样本被分类器正确辨识的几率。准确率统称为分类的精度,它是指手动分类和人工分类结果一致的网页所占的百分比。召回率和准确率不是独立的,通常为了获得比较高的召回率一般要牺牲准确率;同样,为了获得比较高的准确率一般要牺牲召回率。因此须要有一种综合考虑召回率和准确率的方式来对分类器进行评价。F1测度是常用的组合形式:F1= 2RP /(R + P) 。其实,网页数目非常巨大,单纯的查全率己经没有实际价值,查准率的意义也要作相应的变通;数据库规模,索引方式,用户界面响应时间应当列入评价体系作为评价指标。
4.中文网页分类系统简介
TRS网路信息需达系统(TRS InfoRadar)是北京托尔思信息技术股份有限公司开发,该系统实时监控和采集Internet网站内容,对采集到的信息手动进行过滤、分类和排重等智能化处理,最终将最新内容及时发布下来,实现统一的信息导航。同时提供包括全文、日期等在内的全方位信息查询。TRS InfoRadar集信息采集监控、网络舆情、竞争情报等多种功能于一体,被广泛地应用于政府、媒体、科研、企业等各个行业中。TRS InfoRadar在内容营运的垂直搜索应用、内容监管的网络舆情应用以及决策支持的竞争情报等方面的应用,将极大的提升组织对外部信息的获取效率,极大增加信息采集成本,全方位掌控环境脉动,并提升各个组织的快捷反应效能。
百度电子政务信息共享解决方案以百度先进的信息整合处理技术为核心,为政府外网和政府信息门户建设高性能信息共享平台,能够将相关地区、机构、组织等多种信息源的信息集中共享,让用户在一个地方即可获取到所须要的各类相关信息,使电子政务由”形象工程”变成”效益工程”,有效提升政府工作效率,大幅提高政府威信和公众形象。其具有强悍的信息采集能力、安全的信息浏览、准确的手动分类、全面的检索功能、丰富的检索结果展示和基于Web的系统管理平台的特性。
清华同方KSpider网路信息资源采集系统是一套功能强悍的网路信息资源开发借助与整合系统,可用于订制跟踪和监控互联网实时信息,建立可再利用的信息服务系统。KSpider才能从各类网路信息源,包括网页,BLOC、论坛等采集用户感兴趣的特定信息,经手动分类处理后,以多种形式提供给最终用户使用。KSpider才能快速及时地捕获用户所需的热点新闻、市场情报、行业信息、政策法规、学术文献等网路信息内容可广泛用于垂直搜索引擎、网络敏感信息监控、情报搜集、舆情剖析、行情跟踪等方面。
5结束语
随着因特网的迅速发展,中文网页手动分类成为搜索引擎实现分类查询的关键。这就要求英文网页手动分类技术在网页的处理方式、网页疗效辨识、分类精度和评价指标等方面有进一步的提升所以英文网页手动分类技术是一个常年而繁重的研究课题。
数据采集器 - 互联网数据挖掘指引工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-08-17 14:08
今天,互联网已然成为我们生活/工作必需品的重中之重,每个人每晚都在和互联网打交道,都离不开互联网,现在都不敢想像我们的生活或工作离开了互联网是怎么样的一个场景,不过一定是一夜回到了原创社会,文化倒退五百年。
互联网涉及到每行每业,从政府部门到娱乐休闲再到衣食住行日常生活网购,都是围绕互联网在转,世界权威机构强调,目前的互联网数据已然达到几百兆兆,而且每晚都在成倍增长,这么庞大的数据就像宇宙中的小星星,里面隐藏了世界上百分之九十以上的信息资料,说是一个知识的宝库一点也不过份,但是这个宝库实在很大了,没有经过专业的数据搜集、过滤、处理、分析以及统计,你只能看见冰山一角,永远没法窥探概貌,只能眼睁睁的看着如此丰富的资源而无能为力,不能为你所用。
所以随着互联网的崛起,诞生了数据挖掘这个行业,并且也发布了许多与之相关的技术和研究成果。互联网数据挖掘和分类对于有用信息汇总、网络计费、流量工程、知识学习、网络安全等领域具有广泛应用价值。网民对这个行业寄寓厚望,希望通过数据挖掘剖析技术,轻易获得可用的网路资源。
但是真正要实现互联网数据的挖掘,看上去似乎很简单,其实困难重重。
1.上面也有说过,互联网的数据达到几百兆兆,把如此庞大的数据全部搜集并储存上去,如同挖一个水塘把大海的水都保存在水塘内,目前的技术和硬件都还没达到这个水平。
2.互联网的内容就像海浪一样,一直在波动,你很难从海浪中看见自己的倒影,也就是说你很难从互联网的动态资料中轻易抓到您要的全部资料。
3.互联网的数据结果复杂,很难捉住规律。这些数据可以是一个HTML网页,或者是一张图片、一份flash文件、也可以是一段声音、一段视频、甚至是一个压缩文件等等。
4.互联网的那么多海量信息,您须要的却可能只有一点点,还吞没在互联网这个知识的海洋深处,杂乱无章,无规律可循。就像大海的虾那么多,但您只须要捕获大黄鱼,可是这大黄鱼都藏在大海深处,还被各式各样的虾包围干扰,所以要把大海里的大黄鱼都过滤并抓出来,是个世界困局。
5.互联网的WEB页面数目很大,而且分布广泛,质量参差不齐,内容多元化,也给数据挖掘带来了重重困难。
说了这么多有没有吓住您,您是不是已然绝望了?没有关系,人民的智慧是无穷无尽的,而且这么多的知识海洋,我们也用不完,世界上99%的需求,都是只要搬开互联网知识海洋一角就已受用不尽。这就促使数据挖掘在技术层面上不需要很复杂就可以满足99%的需求,剩下的1%,就抛给科学家们去难受吧。
互联网数据,占很大比列都是以文字和图片的方式抒发的,而这种数据的表现形式,基本都是通过万维网的HTML的形式抒发,所以通常只要充分利用这几部份数据,就可以满足很大的数据挖掘需求,实际上那些早已提供了足够丰富的数据来源。
一般的应用,因为需求的明确性,数据挖掘目标都是十分清晰,只是人工搜集成本很高,耗时很长,所以要利用相关的软件支持。目前市面上数据挖掘软件形形色色,各有各的优势,根据需求不同,可以选购到最合适的工具,比如微搜微点采集器。
有些互联网数据挖掘工具功能太强悍,但须要繁杂的策略配置才可以满足需求用途,有些采集器外置了采集策略,但支持的范围有限,只局限于一些网站数据的抓取,数据抓取格式也比较固定,微搜微点采集器集成了几乎所有采集器的优势,这是一款由国外院校的计算机系著名院士的指导和经验丰富的资深软件研究人员合作开发的。
微搜微点采集器的优势在于数据采集的灵活性和操作上的简便性,并集成了多个采集引擎,可以快速搜索互联网页并过滤出符合条件的内容或图片,然后把内容或图片采集下来储存到本地c盘。
首先为何说灵活性是个优势呢,因为这款采集器可以兼容各类HTML环境,互联网上99.9%的网页资料都能采集,可以支持手动翻页、过滤干扰信息、跨网页采集、精准定位(这点很重要,有些采集器就由于适应不了特殊的HTML标签,导致定位错误,采集到的数据不准)、可以模拟点击按键、模拟输入操作、识别同一个网站的不同的HTML框架、并能找出之后过滤出目标URL以及目录URL,进行深度采集。
其次为何说是简便性呢,用户不需要接触到采集策略,采集策略都是由官方维护,用户只要使用就行,就算对计算机一窍不通,只要会上网才能使用。 查看全部
数据采集器 - 互联网数据挖掘指引工具
今天,互联网已然成为我们生活/工作必需品的重中之重,每个人每晚都在和互联网打交道,都离不开互联网,现在都不敢想像我们的生活或工作离开了互联网是怎么样的一个场景,不过一定是一夜回到了原创社会,文化倒退五百年。
互联网涉及到每行每业,从政府部门到娱乐休闲再到衣食住行日常生活网购,都是围绕互联网在转,世界权威机构强调,目前的互联网数据已然达到几百兆兆,而且每晚都在成倍增长,这么庞大的数据就像宇宙中的小星星,里面隐藏了世界上百分之九十以上的信息资料,说是一个知识的宝库一点也不过份,但是这个宝库实在很大了,没有经过专业的数据搜集、过滤、处理、分析以及统计,你只能看见冰山一角,永远没法窥探概貌,只能眼睁睁的看着如此丰富的资源而无能为力,不能为你所用。
所以随着互联网的崛起,诞生了数据挖掘这个行业,并且也发布了许多与之相关的技术和研究成果。互联网数据挖掘和分类对于有用信息汇总、网络计费、流量工程、知识学习、网络安全等领域具有广泛应用价值。网民对这个行业寄寓厚望,希望通过数据挖掘剖析技术,轻易获得可用的网路资源。
但是真正要实现互联网数据的挖掘,看上去似乎很简单,其实困难重重。
1.上面也有说过,互联网的数据达到几百兆兆,把如此庞大的数据全部搜集并储存上去,如同挖一个水塘把大海的水都保存在水塘内,目前的技术和硬件都还没达到这个水平。
2.互联网的内容就像海浪一样,一直在波动,你很难从海浪中看见自己的倒影,也就是说你很难从互联网的动态资料中轻易抓到您要的全部资料。
3.互联网的数据结果复杂,很难捉住规律。这些数据可以是一个HTML网页,或者是一张图片、一份flash文件、也可以是一段声音、一段视频、甚至是一个压缩文件等等。
4.互联网的那么多海量信息,您须要的却可能只有一点点,还吞没在互联网这个知识的海洋深处,杂乱无章,无规律可循。就像大海的虾那么多,但您只须要捕获大黄鱼,可是这大黄鱼都藏在大海深处,还被各式各样的虾包围干扰,所以要把大海里的大黄鱼都过滤并抓出来,是个世界困局。
5.互联网的WEB页面数目很大,而且分布广泛,质量参差不齐,内容多元化,也给数据挖掘带来了重重困难。
说了这么多有没有吓住您,您是不是已然绝望了?没有关系,人民的智慧是无穷无尽的,而且这么多的知识海洋,我们也用不完,世界上99%的需求,都是只要搬开互联网知识海洋一角就已受用不尽。这就促使数据挖掘在技术层面上不需要很复杂就可以满足99%的需求,剩下的1%,就抛给科学家们去难受吧。
互联网数据,占很大比列都是以文字和图片的方式抒发的,而这种数据的表现形式,基本都是通过万维网的HTML的形式抒发,所以通常只要充分利用这几部份数据,就可以满足很大的数据挖掘需求,实际上那些早已提供了足够丰富的数据来源。
一般的应用,因为需求的明确性,数据挖掘目标都是十分清晰,只是人工搜集成本很高,耗时很长,所以要利用相关的软件支持。目前市面上数据挖掘软件形形色色,各有各的优势,根据需求不同,可以选购到最合适的工具,比如微搜微点采集器。
有些互联网数据挖掘工具功能太强悍,但须要繁杂的策略配置才可以满足需求用途,有些采集器外置了采集策略,但支持的范围有限,只局限于一些网站数据的抓取,数据抓取格式也比较固定,微搜微点采集器集成了几乎所有采集器的优势,这是一款由国外院校的计算机系著名院士的指导和经验丰富的资深软件研究人员合作开发的。
微搜微点采集器的优势在于数据采集的灵活性和操作上的简便性,并集成了多个采集引擎,可以快速搜索互联网页并过滤出符合条件的内容或图片,然后把内容或图片采集下来储存到本地c盘。
首先为何说灵活性是个优势呢,因为这款采集器可以兼容各类HTML环境,互联网上99.9%的网页资料都能采集,可以支持手动翻页、过滤干扰信息、跨网页采集、精准定位(这点很重要,有些采集器就由于适应不了特殊的HTML标签,导致定位错误,采集到的数据不准)、可以模拟点击按键、模拟输入操作、识别同一个网站的不同的HTML框架、并能找出之后过滤出目标URL以及目录URL,进行深度采集。
其次为何说是简便性呢,用户不需要接触到采集策略,采集策略都是由官方维护,用户只要使用就行,就算对计算机一窍不通,只要会上网才能使用。
圣者网页电邮采集器V2.3.1官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-08-17 12:32
圣者网页电邮采集器是一款支持搜索邮箱地址并手动采集邮件的专业工具,它可以快速采集目标网站上所有页面的所有电邮地址,速度极快,推荐有须要的用户下载。
圣者网页电邮采集器基本简介
什么是网页邮件采集器?它是一个支持短信地址采集、邮箱地址搜索并保存到文件的工具,你只须要输入一个网站的其中一个网页地址(URL),它能够搜索这个网站的所有页面,然后搜集那些页面上出现的所有电邮地址并保存到指定文件。
圣者网页电邮采集器可以采集目标网站上所有页面及联接站的所有电邮地址,而这种电邮地址必须是不登录网站即可见到的,采集迅速高效,使用便捷快捷。圣者网页电邮地址采集器可以只导入须要的后缀邮箱,比如只导入QQ或则163邮箱,支持自定义,并且有替换功能,比如将#替换为@,欢迎专业级人士测试!
圣者网页电邮采集器功能介绍
1、只要填写一个网站里的其中一个页面的地址URL,它即可爬行这个网站的所有页面,并把这种页面所出现的电邮地址记录出来。
2、新增页面过滤(排它)功能,即:采集指定页面或不采集指定页面。
3、采集进度和结果缓存功能,在采集过程中,软件手动保存当前采集进度和采集结果,预防软件意外退出而导致数据遗失。
4、多线程爬行,用户可以按照具体情况定义多少线程去爬行一个网站。
5、界面简约友好,操作简单,免安装无插件红色软件。
6、实时保存采集结果,可以挂机无人值守地采集,一晚睡醒就可以采集成千上万电邮地址。
圣者网页电邮采集器使用方式
1、新建采集项目,
2、选择采集项目,
3、点击【开始采集】按钮,
4、采集完毕,导出数据。 查看全部
圣者网页电邮采集器V2.3.1官方版

圣者网页电邮采集器是一款支持搜索邮箱地址并手动采集邮件的专业工具,它可以快速采集目标网站上所有页面的所有电邮地址,速度极快,推荐有须要的用户下载。
圣者网页电邮采集器基本简介
什么是网页邮件采集器?它是一个支持短信地址采集、邮箱地址搜索并保存到文件的工具,你只须要输入一个网站的其中一个网页地址(URL),它能够搜索这个网站的所有页面,然后搜集那些页面上出现的所有电邮地址并保存到指定文件。
圣者网页电邮采集器可以采集目标网站上所有页面及联接站的所有电邮地址,而这种电邮地址必须是不登录网站即可见到的,采集迅速高效,使用便捷快捷。圣者网页电邮地址采集器可以只导入须要的后缀邮箱,比如只导入QQ或则163邮箱,支持自定义,并且有替换功能,比如将#替换为@,欢迎专业级人士测试!
圣者网页电邮采集器功能介绍
1、只要填写一个网站里的其中一个页面的地址URL,它即可爬行这个网站的所有页面,并把这种页面所出现的电邮地址记录出来。
2、新增页面过滤(排它)功能,即:采集指定页面或不采集指定页面。
3、采集进度和结果缓存功能,在采集过程中,软件手动保存当前采集进度和采集结果,预防软件意外退出而导致数据遗失。
4、多线程爬行,用户可以按照具体情况定义多少线程去爬行一个网站。
5、界面简约友好,操作简单,免安装无插件红色软件。
6、实时保存采集结果,可以挂机无人值守地采集,一晚睡醒就可以采集成千上万电邮地址。
圣者网页电邮采集器使用方式
1、新建采集项目,
2、选择采集项目,
3、点击【开始采集】按钮,
4、采集完毕,导出数据。
熊猫网页信息采集器 2.6 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-17 11:33
熊猫网页信息采集器是一款专业的网页信息采集工具。需要一个信息采集器,那就下载熊猫网页信息采集器使用吧,利用精准搜索引擎的解析内核,对网页内容的仿浏览器解析,对网页框架内容和核心内容分离和抽取,对相像的页面进行有效对比,熊猫网页信息采集器使用上去便捷简单,如果你也须要那就来jz5u下载使用吧,别错过了哦!
熊猫网页信息采集器功能介绍
1、采集速度快
优采云采集器的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方外置浏览器访问的技术。使用自己研制的解析引擎
2、全方位的采集功能
浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容。支持图文混排对象的同时采集
3、面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的兄妹表结构。
4、结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以手动纠正模板和目标页面的不一致。
5、JS解析的手动判定辨识
现在好多网页都采用了ajax网页内容动态生成技术。此时仅仅借助网页源码,并不能获取须要的有效内容。此时就须要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对须要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速率效率太低,因此熊猫外置了智能判定功能,自动检测是否须要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
6、多模板手动适应能力
很多网站的内容页面会存在多个不同种类的模板,因此优采云采集器软件容许每位采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会手动匹配找寻最合适的参考模板拿来剖析内容页面。
7、实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用菜鸟提供实时帮助。因此优采云采集器软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触优采云采集器软件,也可以较轻松实现采集项目的配置工作。
8、分页内容的轻松合并
支持各类类型的分页模式,用户只须要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将须要分页合并的数组项勾选上分页合并项即可。如果页面内具有重复子项存在,则能手动在分页中找寻该重复子项,隐含手动进行分页内容合并。
熊猫网页信息采集器用途介绍
1、舆情监测
借助全部英文搜素引擎,轻松实现全网舆情信息的检测,信息覆盖面广。对于须要重点检测的网站,只须要录入网址即可实现检测。PC端独立运行,普通的联通PC即可胜任舆情检测工作。同时熊猫智能采集监测引擎,也是第三方舆情系统外置爬虫的首选。
2、大数据采集
熊猫拥有极高的采集速度和效率,是大数据采集场合的最优选择。同时熊猫独有的海量数据处理能力,可以应付大数据采集的须要。是大数据采集场合的首选
3、招标信息检测
利用熊猫智能采集监测引擎,可以轻松实现对招标信息发布网站的最新招标信息进行检测。优采云采集器,是招标信息检测软件的最优选择:操作容易、维护简单、结果直观便捷
4、客户资料搜集
利用熊猫可以轻松从网路中批量获取须要的顾客信息,利用熊猫的各种绕过防采集机制(,如熊猫独有的云采集功能),可以轻松绕过被采集网站的防采集机制。如58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站内容手动填充
熊猫是操作最简单的采集器,是诸多网站站长的首先。同时熊猫也是功能复杂的采集器,可以应用几乎所有的复杂网站的采集、搬家操作。 查看全部
熊猫网页信息采集器 2.6 免费版

熊猫网页信息采集器是一款专业的网页信息采集工具。需要一个信息采集器,那就下载熊猫网页信息采集器使用吧,利用精准搜索引擎的解析内核,对网页内容的仿浏览器解析,对网页框架内容和核心内容分离和抽取,对相像的页面进行有效对比,熊猫网页信息采集器使用上去便捷简单,如果你也须要那就来jz5u下载使用吧,别错过了哦!
熊猫网页信息采集器功能介绍
1、采集速度快
优采云采集器的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方外置浏览器访问的技术。使用自己研制的解析引擎
2、全方位的采集功能
浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容。支持图文混排对象的同时采集
3、面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的兄妹表结构。
4、结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以手动纠正模板和目标页面的不一致。
5、JS解析的手动判定辨识
现在好多网页都采用了ajax网页内容动态生成技术。此时仅仅借助网页源码,并不能获取须要的有效内容。此时就须要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对须要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速率效率太低,因此熊猫外置了智能判定功能,自动检测是否须要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
6、多模板手动适应能力
很多网站的内容页面会存在多个不同种类的模板,因此优采云采集器软件容许每位采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会手动匹配找寻最合适的参考模板拿来剖析内容页面。
7、实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用菜鸟提供实时帮助。因此优采云采集器软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触优采云采集器软件,也可以较轻松实现采集项目的配置工作。
8、分页内容的轻松合并
支持各类类型的分页模式,用户只须要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将须要分页合并的数组项勾选上分页合并项即可。如果页面内具有重复子项存在,则能手动在分页中找寻该重复子项,隐含手动进行分页内容合并。

熊猫网页信息采集器用途介绍
1、舆情监测
借助全部英文搜素引擎,轻松实现全网舆情信息的检测,信息覆盖面广。对于须要重点检测的网站,只须要录入网址即可实现检测。PC端独立运行,普通的联通PC即可胜任舆情检测工作。同时熊猫智能采集监测引擎,也是第三方舆情系统外置爬虫的首选。
2、大数据采集
熊猫拥有极高的采集速度和效率,是大数据采集场合的最优选择。同时熊猫独有的海量数据处理能力,可以应付大数据采集的须要。是大数据采集场合的首选
3、招标信息检测
利用熊猫智能采集监测引擎,可以轻松实现对招标信息发布网站的最新招标信息进行检测。优采云采集器,是招标信息检测软件的最优选择:操作容易、维护简单、结果直观便捷
4、客户资料搜集
利用熊猫可以轻松从网路中批量获取须要的顾客信息,利用熊猫的各种绕过防采集机制(,如熊猫独有的云采集功能),可以轻松绕过被采集网站的防采集机制。如58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站内容手动填充
熊猫是操作最简单的采集器,是诸多网站站长的首先。同时熊猫也是功能复杂的采集器,可以应用几乎所有的复杂网站的采集、搬家操作。
浅识网页正文提取算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-25 20:39
这种算法须要对网站HTML构建DOM树,然后对之进行遍历递归,去除相应的噪声信息然后再从剩余的节点中进行选择。由于要构建DOM树,算法的时间/空间复杂度均较高。
基于标签的算法都潜在默认了这样的一个信息:即网站的网页生成,制作都遵守了一定的标签使用规范。不过现今的互联网网页五花八门,很难都按常理出牌,所以这在一定程度上减少了算法的准确性和通用性。
2.基于内容
网页根据内容方式分类大约分为:主题型,图片型和目录型。
对于主体型的网页,例如新闻类,博客类等,主要特征是文字内容比较多。基于这一点,另外一种正文提取思路是基于正文本身的特性。在一定程度上,正文的文字数目要比其他部份多。这在一定程度上有助于产生了区域的区分度。文字数目的飙升和飙升在一定程度上可以作为正文开始和介绍的判读点。
这类算法在本质上没有多大的差别,只是选择测度文字密度的方法不同而已。有的是基于块,有的是基于行,有的是基于转化函数。算法都很容易理解,也相对比较容易实现。下面的几篇文章就是基于网页内容的算法。
《基于行块分布函数的通用网页正文抽取》陈鑫
《基于网页分块的正文信息提取方式》黄玲,陈龙
博文《我为开源作贡献,网页正文提取--HtmlArticle2》
3. 基于视觉
想对于上面两种思路,这类算法的思路有一种"高大上"的觉得。这里不得不提及这类算法的基础:VIPS(Vision-based Page Segementation)算法。
VIPS算法:利用背景颜色,字体颜色和大小,边框,逻辑块和逻辑块之间的宽度等视觉特点,制定相应的规则把页面分割成各个视觉块!(视觉疗效真的是千变万化,如何制订规则集仍然是个复杂的问题)
VIPS算法充分利用了Web页面的布局特点。它首先从DOM 树中提取出所有合适的页面块,然后按照这种页面块测量出它们之间所有的分割条,包括水平和垂直方向;最后基于这种分割条.重新建立Web页面的语义结构。对于每一个语义块又可以使用VIPS算法继续分割为更小的语义块。该算法分为页面块提取、分隔条提取和语义块构建3部分,并且是递归调用的过程,直到条件不满足为止.
相关文献:
《基于视觉特点的网页正文提取方式研究》安增文,徐杰锋
《A vision—based page segmentation algorithm》
4. 基于数据挖掘/机器学习
看到好多作者对这一思路的普遍评价是"杀鸡焉用牛刀"。
基本思路是使用一定数目的网页作为训练集,通过训练得到网页正文的一些特征,然后将这种特点作为网页片断是否符合网页正文的判定根据。对于数据挖掘/机器学习算法来讲,训练样本的采集很重要,然而现实是互联网中网页方式千变万化,不太可能取太多数目作为训练样本。这样这些算法的准确性和通用性就遭到了阻碍,同时这类算法前期工作也比较复杂。 查看全部
浅识网页正文提取算法
这种算法须要对网站HTML构建DOM树,然后对之进行遍历递归,去除相应的噪声信息然后再从剩余的节点中进行选择。由于要构建DOM树,算法的时间/空间复杂度均较高。
基于标签的算法都潜在默认了这样的一个信息:即网站的网页生成,制作都遵守了一定的标签使用规范。不过现今的互联网网页五花八门,很难都按常理出牌,所以这在一定程度上减少了算法的准确性和通用性。
2.基于内容
网页根据内容方式分类大约分为:主题型,图片型和目录型。
对于主体型的网页,例如新闻类,博客类等,主要特征是文字内容比较多。基于这一点,另外一种正文提取思路是基于正文本身的特性。在一定程度上,正文的文字数目要比其他部份多。这在一定程度上有助于产生了区域的区分度。文字数目的飙升和飙升在一定程度上可以作为正文开始和介绍的判读点。
这类算法在本质上没有多大的差别,只是选择测度文字密度的方法不同而已。有的是基于块,有的是基于行,有的是基于转化函数。算法都很容易理解,也相对比较容易实现。下面的几篇文章就是基于网页内容的算法。
《基于行块分布函数的通用网页正文抽取》陈鑫
《基于网页分块的正文信息提取方式》黄玲,陈龙
博文《我为开源作贡献,网页正文提取--HtmlArticle2》
3. 基于视觉
想对于上面两种思路,这类算法的思路有一种"高大上"的觉得。这里不得不提及这类算法的基础:VIPS(Vision-based Page Segementation)算法。
VIPS算法:利用背景颜色,字体颜色和大小,边框,逻辑块和逻辑块之间的宽度等视觉特点,制定相应的规则把页面分割成各个视觉块!(视觉疗效真的是千变万化,如何制订规则集仍然是个复杂的问题)
VIPS算法充分利用了Web页面的布局特点。它首先从DOM 树中提取出所有合适的页面块,然后按照这种页面块测量出它们之间所有的分割条,包括水平和垂直方向;最后基于这种分割条.重新建立Web页面的语义结构。对于每一个语义块又可以使用VIPS算法继续分割为更小的语义块。该算法分为页面块提取、分隔条提取和语义块构建3部分,并且是递归调用的过程,直到条件不满足为止.
相关文献:
《基于视觉特点的网页正文提取方式研究》安增文,徐杰锋
《A vision—based page segmentation algorithm》
4. 基于数据挖掘/机器学习
看到好多作者对这一思路的普遍评价是"杀鸡焉用牛刀"。
基本思路是使用一定数目的网页作为训练集,通过训练得到网页正文的一些特征,然后将这种特点作为网页片断是否符合网页正文的判定根据。对于数据挖掘/机器学习算法来讲,训练样本的采集很重要,然而现实是互联网中网页方式千变万化,不太可能取太多数目作为训练样本。这样这些算法的准确性和通用性就遭到了阻碍,同时这类算法前期工作也比较复杂。
如何使用爬虫工具采集数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-25 20:36
(图2)
图2是java程序使用webmagic框架开发的爬虫程序,这段代码就是抓取对应的标签,和图1是相对应的,运行后得到结果如下:
当然,以上是专业程序员干的事情,但是有助于我们理解爬虫工具工作的原理。非专业人员可以通过爬虫工具来自己爬取数据。
1.首先输入你要爬取的网站的网址,点击“开始采集”。
2.工具手动辨识到当前页面是多页数据,会默认翻页采集,我们只要点击“生成采集设置”即可。
3.点击要采集的详尽链接,这里我们要采集这个网站上所有的化工产品的信息,所以点击英文名称这一列某个链接,再点击一侧“点击该链接”,如右图
4.爬虫工具步入到详尽链接的页面,这个页面的数据也就是我们要爬取的,点击“生成采集设置”,会生成爬虫工具最后的爬取流程,如下图所示,爬虫工具都会根据这个流程给我们采集数据,直到数据采集完成。
5.点击“采集”按钮,爬虫工具即将开始运行,爬虫工具工作时如下:
列表的那些数据都是爬虫采集到的,我们还可以对那些采集的数据做处理,可以选择导成Excel文档,或者直接导出数据库,这些是后续剖析数据,对数据做进一步处理的必要条件。有了这种基础数据,可以对数据做剖析,得出一些商业根据,可以作为商业决策时的支撑。比如曾经家乐福就通过她们的大数据,发现买尿布的奶爸喜欢一起买饮料,于是就把尿布和饮料摆在一起,啤酒的销量大增,这个就是大数据的价值。
这次讲的爬虫工具使用,只是比较基础的应用,希望对你们有帮助。科技惠威带你徜徉科技,后续会不断更新相关知识,欢迎关注。 查看全部
如何使用爬虫工具采集数据
(图2)
图2是java程序使用webmagic框架开发的爬虫程序,这段代码就是抓取对应的标签,和图1是相对应的,运行后得到结果如下:
当然,以上是专业程序员干的事情,但是有助于我们理解爬虫工具工作的原理。非专业人员可以通过爬虫工具来自己爬取数据。
1.首先输入你要爬取的网站的网址,点击“开始采集”。
2.工具手动辨识到当前页面是多页数据,会默认翻页采集,我们只要点击“生成采集设置”即可。
3.点击要采集的详尽链接,这里我们要采集这个网站上所有的化工产品的信息,所以点击英文名称这一列某个链接,再点击一侧“点击该链接”,如右图
4.爬虫工具步入到详尽链接的页面,这个页面的数据也就是我们要爬取的,点击“生成采集设置”,会生成爬虫工具最后的爬取流程,如下图所示,爬虫工具都会根据这个流程给我们采集数据,直到数据采集完成。
5.点击“采集”按钮,爬虫工具即将开始运行,爬虫工具工作时如下:
列表的那些数据都是爬虫采集到的,我们还可以对那些采集的数据做处理,可以选择导成Excel文档,或者直接导出数据库,这些是后续剖析数据,对数据做进一步处理的必要条件。有了这种基础数据,可以对数据做剖析,得出一些商业根据,可以作为商业决策时的支撑。比如曾经家乐福就通过她们的大数据,发现买尿布的奶爸喜欢一起买饮料,于是就把尿布和饮料摆在一起,啤酒的销量大增,这个就是大数据的价值。
这次讲的爬虫工具使用,只是比较基础的应用,希望对你们有帮助。科技惠威带你徜徉科技,后续会不断更新相关知识,欢迎关注。
一种高效地生成网页信息抽取规则的方式及系统技术方案
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2020-08-25 17:54
本发明专利技术公开了一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;该高效地生成网页信息抽取规则的方式及系统,可以克服纯人工配置抽取规则的低效问题,避免纯自动化抽取的精准度增长的问题,满足了企业级系统应用对精度及工作效率的要求,在不影响抽取精度的前提下,又增强了自动化程度,大大提升了网页信息抽取工作的效率以及实用性。
An efficient method and system for generating web information extraction rules
全部详尽技术资料下载
【技术实现步骤摘要】
一种高效地生成网页信息抽取规则的方式及系统
本专利技术涉及计算机网页采集
,具体为一种高效地生成网页信息抽取规则的方式及系统。
技术介绍
网页是构成网站的基本元素,是承载各类网站应用的平台,通俗地说,网站就是由网页组成的,如果只有域名和虚拟主机而没有制做任何网页的话,使用者将难以访问网站,也难以通过人机会话来实现其使用意图。网页是一个收录HTML标签的纯文本文件,它可以储存在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式,网页一般用图象档来提供图画,文字与图片是构成一个网页的两个最基本的元素,可以简单地理解为:文字就是网页的内容,图片就是网页的美观,除此之外,网页的元素还包括动漫、音乐、程序等,网页须要通过网页浏览器来完成人与计算机的信息交互。传统的生成网页信息抽取规则的技术方案主要有两种:第一种方案是由技术人员通过对网页结构的观察,使用专用的计算机语言或软件工具,自行编撰、生成抽取规则。比较常见的专用计算机语言有:正则表达式,比较常见的软件工具有:xpath和css选择器。采用这些技术方案所才能达到的疗效,很大程度上依赖于编撰规则的技术人员的专业水平,即:对网页结构的理解程度以及对正则表达式、xpath和css选择器等技术的把握程度。不同网站的网页结构不同,不同技术人员的专业度也不相同,导致该技术方案受主观诱因影响成份较多,工作效率和质量误差较大,不能有效地产生技术成果;第二种方案是技术人员通过软件工具,将网页具象成文档结构树(DOM-Tree)的方式,结合概率统计学知识,计算文档结构树(DOM-Tree)中所有节点的相像机率,得到符合文本密度特点的文档结构树(DOM-Tree)节点,采用这些基于机率模型生成网页信息抽取规则的方案,所形成的技术成果不能否满足抽取精度的要求。在企业级的系统应用中,以单“日”为级别的网页采集数量一般为在万、十万以上。上述两种技术方案在企业级的系统应用中均存在致命缺陷,第一种方案的效率与质量无法保证,第二种方案的精度无法保证。在此技术背景下,急需专利技术一种高效地生成网页信息抽取规则的方式及系统,来同时满足效率与精度的要求,本专利技术应运而生。
技术实现思路
(一)解决的技术问题针对现有技术的不足,本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统,解决了纯人工生成网页信息抽取规则的低效以及纯自动化生成网页信息抽取规则的精度无法保证的问题。(二)技术方案为实现以上目的,本专利技术通过以下技术方案给以实现:一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。
优选的,所述S4中的Jsoup抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对列表类型网页的抽取规则生成而设计。优选的,所述S3中的Json抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对Json类型网页的抽取规则生成而设计。优选的,所述S5中的正文手动抽取方案是一种基于对文本密度进行机率统计的抽取规则生成方案,专门针对正文类型网页而设计。优选的,所述S5中的文本密度是一种表示正文节点的特点,其算法为Dom节点中纯文本字符串宽度或该节点的字符串宽度。优选的,所述S6中的正则表达式抽取方案是为了提升抽取精度,进行人工纠错,并当S3、S4和S5这三种抽取方案均未能满足精度要求而设计。(三)有益疗效本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统。具备以下有益疗效:该高效地生成网页信息抽取规则的方式及系统,通过S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和
【技术保护点】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:/nS1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。/n
【技术特点摘要】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:
S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;
S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;
S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正...
【专利技术属性】
技术研制人员:黄国舜,吴蓟晔,
申请(专利权)人:上海嘉道信息技术有限公司,
类型:发明
国别省市:上海;31
全部详尽技术资料下载 我是这个专利的主人 查看全部
一种高效地生成网页信息抽取规则的方式及系统技术方案
本发明专利技术公开了一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;该高效地生成网页信息抽取规则的方式及系统,可以克服纯人工配置抽取规则的低效问题,避免纯自动化抽取的精准度增长的问题,满足了企业级系统应用对精度及工作效率的要求,在不影响抽取精度的前提下,又增强了自动化程度,大大提升了网页信息抽取工作的效率以及实用性。
An efficient method and system for generating web information extraction rules
全部详尽技术资料下载
【技术实现步骤摘要】
一种高效地生成网页信息抽取规则的方式及系统
本专利技术涉及计算机网页采集
,具体为一种高效地生成网页信息抽取规则的方式及系统。
技术介绍
网页是构成网站的基本元素,是承载各类网站应用的平台,通俗地说,网站就是由网页组成的,如果只有域名和虚拟主机而没有制做任何网页的话,使用者将难以访问网站,也难以通过人机会话来实现其使用意图。网页是一个收录HTML标签的纯文本文件,它可以储存在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式,网页一般用图象档来提供图画,文字与图片是构成一个网页的两个最基本的元素,可以简单地理解为:文字就是网页的内容,图片就是网页的美观,除此之外,网页的元素还包括动漫、音乐、程序等,网页须要通过网页浏览器来完成人与计算机的信息交互。传统的生成网页信息抽取规则的技术方案主要有两种:第一种方案是由技术人员通过对网页结构的观察,使用专用的计算机语言或软件工具,自行编撰、生成抽取规则。比较常见的专用计算机语言有:正则表达式,比较常见的软件工具有:xpath和css选择器。采用这些技术方案所才能达到的疗效,很大程度上依赖于编撰规则的技术人员的专业水平,即:对网页结构的理解程度以及对正则表达式、xpath和css选择器等技术的把握程度。不同网站的网页结构不同,不同技术人员的专业度也不相同,导致该技术方案受主观诱因影响成份较多,工作效率和质量误差较大,不能有效地产生技术成果;第二种方案是技术人员通过软件工具,将网页具象成文档结构树(DOM-Tree)的方式,结合概率统计学知识,计算文档结构树(DOM-Tree)中所有节点的相像机率,得到符合文本密度特点的文档结构树(DOM-Tree)节点,采用这些基于机率模型生成网页信息抽取规则的方案,所形成的技术成果不能否满足抽取精度的要求。在企业级的系统应用中,以单“日”为级别的网页采集数量一般为在万、十万以上。上述两种技术方案在企业级的系统应用中均存在致命缺陷,第一种方案的效率与质量无法保证,第二种方案的精度无法保证。在此技术背景下,急需专利技术一种高效地生成网页信息抽取规则的方式及系统,来同时满足效率与精度的要求,本专利技术应运而生。
技术实现思路
(一)解决的技术问题针对现有技术的不足,本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统,解决了纯人工生成网页信息抽取规则的低效以及纯自动化生成网页信息抽取规则的精度无法保证的问题。(二)技术方案为实现以上目的,本专利技术通过以下技术方案给以实现:一种高效地生成网页信息抽取规则的方式及系统,具体包括以下步骤:S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。
优选的,所述S4中的Jsoup抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对列表类型网页的抽取规则生成而设计。优选的,所述S3中的Json抽取方案是一种半自动化地、可视化地抽取规则生成方案,专门针对Json类型网页的抽取规则生成而设计。优选的,所述S5中的正文手动抽取方案是一种基于对文本密度进行机率统计的抽取规则生成方案,专门针对正文类型网页而设计。优选的,所述S5中的文本密度是一种表示正文节点的特点,其算法为Dom节点中纯文本字符串宽度或该节点的字符串宽度。优选的,所述S6中的正则表达式抽取方案是为了提升抽取精度,进行人工纠错,并当S3、S4和S5这三种抽取方案均未能满足精度要求而设计。(三)有益疗效本专利技术提供了一种高效地生成网页信息抽取规则的方式及系统。具备以下有益疗效:该高效地生成网页信息抽取规则的方式及系统,通过S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;S6、正则表达式抽取方案:是S3、S4和
【技术保护点】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:/nS1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;/nS3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正文类型网页结构,将其解析成Dom树结构,并以文本密度最大的节点作为正文,考虑到本方案可能存在错判,该步骤支持人工纠错;/nS6、正则表达式抽取方案:是S3、S4和S5的人工纠错方式之一,当S3、S4和S5这三种抽取方案均未能满足抽取精度的要求时,可以使用本方案。/n
【技术特点摘要】
1.一种高效地生成网页信息抽取规则的方式及系统,其特点在于:具体包括以下步骤:
S1、页面结构手动辨识以及Html结构与Json结构的判断:首先通过网页信息采集技术获取该网页的源码,分析其结构是通用的Html结构还是Json结构,Html结构与Json结构的判断是通过Html标签来判定Html结构,通过开源Json解析器解析Json结构,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S2、列表类型页面与正文类型页面的判断:由S1中得出该页面结构若是Html结构,还需判断该页面是列表类型页面或正文类型页面,将Html结构网页转化成Dom树结构,自动解析Dom树中的叶子节点,若存在标签,则觉得该网页为列表类型页面,否则该页面为正文类型页面,考虑到手动解析可能存在错判,该步骤支持人工纠错;
S3、Json抽取方案:由S1中得出该页面结构若是Json结构,系统将手动解析Json网页结构,并可视化呈现在页面中,用户只需点击页面中的数组信息,系统即可按照用户的点击生成相应的抽取规则,考虑到本方案可能存在错判,该步骤支持人工纠错;
S4、Jsoup抽取方案:由S2中得出该页面结构若是列表类型页面,系统将手动解析列表类型网页结构,将其解析成Dom树结构,并可视化呈现在页面中,用户只需点击页面中任意数组信息,系统即可按照用户的点击生成相应的抽取规则,并高亮该数组与其相关数组,考虑到本方案可能存在错判,该步骤支持人工纠错;
S5、正文手动抽取方案:由S2中得出该页面结构若是正文类型页面,系统将手动解析正...
【专利技术属性】
技术研制人员:黄国舜,吴蓟晔,
申请(专利权)人:上海嘉道信息技术有限公司,
类型:发明
国别省市:上海;31
全部详尽技术资料下载 我是这个专利的主人
利用专业数据采集工具获取网路数据的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 422 次浏览 • 2020-08-25 15:42
杨健
随着联通互联网的日渐普及和广泛应用,网络上的资讯成为人们获取信息的重要来源。人们一般依据需求使用百度等搜索引擎,输入关键字,检索所需的网页内容。在浏览网路资讯信息的同时,人们还希望还能将这种信息保存出来,选择适当的方式进行数据剖析,得出有效推论,为日后相关决策提供可靠根据。
那么怎么保存网页上的信息呢?通常情况下,大家会选中网页上须要的信息,然后通过“复制”和“粘贴”操作,保存在笔记本的本地文件中。这种方式其实简单直观,但是操作繁复,不适宜大批量数据信息的采集。为了确切方便地获取网路中的海量数据,人们设计开发了多种用于采集数据信息的专业工具,借助专业工具中网路爬虫的强悍功能,能够愈发确切、方便、快速地获取网页信息。这样的专业数据采集工具有很多种,本文以“优采云”数据采集工具为例,介绍专业数据采集工具的功能、原理及使用方式。
“优采云”数据采集工具的功能
“优采云”数据采集工具是一款通用的数据采集器,能够采集98%的网页上的文本信息。它可依照不同网站提供多种网页采集策略,也可以自定义配置,以本地采集或云采集的形式对选中网站中的单个网页或多个网页的内容信息进行手动提取,并将获取结果保存在Excel、CSV、HTML、数据库格式文件中,以便捷后续的数据处理与剖析。
“优采云”数据采集工具的原理
一般情况下,人们浏览网页时,首先要输入网站的网址;然后通过键盘单击网页上的按键或热点等操作,找到所要获取的相关信息;最后选中这种信息,提取下来,保存到特定格式的文件中。“优采云”数据采集工具的核心原理是通过外置Firefox内核浏览器,模拟上述人为浏览网页的行为,对网页的信息进行全手动提取。这些功能由“优采云”采集器的三个程序完成:负责任务配置及管理的主程序;任务的云采集控制和云集成数据的管理程序;数据导入程序。
“优采云”数据采集工具的操作
使用“优采云”采集器之前,我们要步入其官方网站https:///,下载并安装“优采云”采集器客户端(本文以“优采云”8.0版软件为例)。打开客户端软件,注册登入后即可使用。
1.使用模板采集数据
“优采云”客户端中外置了好多网站的采集模板,我们可以依据需求使用这种模板,如图1所示,按照提示步骤简单快捷地全手动获取网站信息。操作过程分三步:第一,选择目标网站的模板;第二,配置数据采集参数(采集的关键字、采集的页数等),选择采集模式(本地采集或云采集)自动提取数据;第三,选择输出的文件格式,导出数据。
图1 客户端中外置的网站采集模板
上述操作完成后,“优采云”客户端会将整个操作过程及提取的数据以任务的方式进行保存。通过客户端“我的任务”项,可以随时查看已提取的数据,也可以重复执行或更改当前任务。
2.自定义采集数据
当我们希望根据自己的要求获取网页上的个性化数据时,就须要使用自定义数据采集模式。首先要确定目标网站和采集需求;然后打开网页,配置采集选项,提取数据;最后导入数据到指定格式的文件中。
不管使用“优采云”客户端的哪种模式采集网页数据信息,整个流程都可统一为配置任务、采集数据和导入数据三个步骤。其中,配置采集选项参数是确切获取网页数据的关键。
“优采云”数据采集工具的应用案例
“优采云”数据采集工具才能采集大多数网站上的网页信息,而非只针对某类专业网站数据进行采集。下面以获取豆瓣影片Top 250(https:///top 250)网页数据为例,介绍“优采云”数据采集工具的具体使用技巧。
豆瓣网站是按照每部电影看过的人数以及该电影所得的评价等综合数据,通过算法剖析形成豆瓣影片Top 250榜单。豆瓣影片前250名的数据信息分10个连续网页显示,每个网页呈现25部连续剧,每部影片都包括影片排行、电影海报、电影中英文名称、电影编剧及执导、参评人数、豆瓣得分等相关信息。我们可以按照实际需求,使用“优采云”数据采集工具获取豆瓣影片Top 250的详尽数据,具体方式如下。
1.获取榜单中某一部影片的信息
首先,查看豆瓣影片网页中关于某部影片的信息,如《霸王别姬》,确定要获取的信息内容:电影排行、电影名、导演、主要艺人和剧情简介五项。其次,在“优采云”客户端的首页中,输入该部影片网页的网址,鼠标单击“开始采集”按钮,打开该网页;在显示网页的窗口中,鼠标单击“NO2 豆瓣影片Top 250”标签;在弹出的“操作提示”窗口中选择“采集该元素文本”,在“配置采集字段”窗口中显示出“ NO2 豆瓣影片Top 250 ”选项。重复上述操作,分别选中网页中“霸王别姬(1993)”“导演:陈凯歌”等其他标签完成采集字段的配置,并更改数组名称。再次,在“操作提示”窗口中执行“保存并开始采集”命令,在“运行任务”窗口中启动“本地采集”选项搜集数据信息。最后,将采集到的数据保存到特定格式的文件中。
数据信息采集完毕后,除了通过打开数据文件查看采集的信息外,还可以从“优采云”客户端首页的“我的任务”项中查看采集好的数据。
2.获取某个网页的全部影片信息
豆瓣影片榜单中每页就会显示25部影片的相关信息,每部影片展示了相同的信息项,如影片排行、海报、电影英文名称、导演及出演等。那么,“优采云”客户端提取每部影片数据的操作都是相同的。因此,我们只需完成一部影片的数据采集配置,其余影片使用循环重复操作即可。
首先要确定需求,在“优采云”客户端的首页输入要获取信息的网址并打开网页。其次,单击键盘选中一部影片相关数据区域。在弹出的“操作提示”窗口中选择“选中子元素”选项,选中该影片的影片排行、海报、电影英文名称、导演及出演等数组;然后再单击键盘选择“选中全部”,建立循环列表,选中该网页中25部影片的相关数据项;再单击“采集数据”选项,在预览窗口中,查看更改要采集的数据数组名。最后启动“本地采集”,获取数据信息,生成数据文件。
3.获取榜单中全部影片信息
除了上述自动选择数据采集字段外,由于豆瓣影片Top 250榜单中每部影片显示的信息都是相同的,在获取全部250部電影数据时,我们可以通过“操作提示”窗口中的提示信息,自动配置要提取的数据项,来完成影片信息的获取。
首先明晰获取信息需求,确定网址https://movie.douban. com/top 250,在“优采云”客户端打开网页;在“操作提示”窗口中选择“自动辨识网页”。经过“优采云”算法的辨识,自动完成采集字段配置,如图2所示。在“数据预览”窗口中,可以看见正式采集的数组及数据,通过“修改”和“删除”操作可以调整数组相关信息。然后选择“生成采集设置”,保存并开始采集数据。数据提取完成后,保存到特定格式的文件中。
图2 自动完成采集字段配置
除了以上这种应用之外,“优采云”数据采集工具还可以针对好多采集需求和不同结构的网页进行数据采集,如获取特定网页数量的数据、使用云采集等。这些都是你们可以进一步学习研究的内容。
专业数据采集工具及网路爬虫技术日渐成为获取网路信息的重要手段,但是在现实社会中,并不是所有数据都可以任意提取和使用。在数据采集时,我们要遵循有关的法律法规,负责任地、合理地使用网路技术和网路信息。
基金项目:北京市教育科学“十三五”规划2018年度通常课题“高中信息技术教学中估算思维培养的教学案例研究”,立项编号:CDDB18183。作者系北京教育学院“北京市中小学人工智能教学实践研究”特级班主任工作室成员
参考文献
[1]祝智庭,樊磊. 普通中学教科书·信息技术选修 [M]. 北京:人民教育出版社、中国地图出版社,2019. 查看全部
利用专业数据采集工具获取网路数据的方式
杨健
随着联通互联网的日渐普及和广泛应用,网络上的资讯成为人们获取信息的重要来源。人们一般依据需求使用百度等搜索引擎,输入关键字,检索所需的网页内容。在浏览网路资讯信息的同时,人们还希望还能将这种信息保存出来,选择适当的方式进行数据剖析,得出有效推论,为日后相关决策提供可靠根据。
那么怎么保存网页上的信息呢?通常情况下,大家会选中网页上须要的信息,然后通过“复制”和“粘贴”操作,保存在笔记本的本地文件中。这种方式其实简单直观,但是操作繁复,不适宜大批量数据信息的采集。为了确切方便地获取网路中的海量数据,人们设计开发了多种用于采集数据信息的专业工具,借助专业工具中网路爬虫的强悍功能,能够愈发确切、方便、快速地获取网页信息。这样的专业数据采集工具有很多种,本文以“优采云”数据采集工具为例,介绍专业数据采集工具的功能、原理及使用方式。
“优采云”数据采集工具的功能
“优采云”数据采集工具是一款通用的数据采集器,能够采集98%的网页上的文本信息。它可依照不同网站提供多种网页采集策略,也可以自定义配置,以本地采集或云采集的形式对选中网站中的单个网页或多个网页的内容信息进行手动提取,并将获取结果保存在Excel、CSV、HTML、数据库格式文件中,以便捷后续的数据处理与剖析。
“优采云”数据采集工具的原理
一般情况下,人们浏览网页时,首先要输入网站的网址;然后通过键盘单击网页上的按键或热点等操作,找到所要获取的相关信息;最后选中这种信息,提取下来,保存到特定格式的文件中。“优采云”数据采集工具的核心原理是通过外置Firefox内核浏览器,模拟上述人为浏览网页的行为,对网页的信息进行全手动提取。这些功能由“优采云”采集器的三个程序完成:负责任务配置及管理的主程序;任务的云采集控制和云集成数据的管理程序;数据导入程序。
“优采云”数据采集工具的操作
使用“优采云”采集器之前,我们要步入其官方网站https:///,下载并安装“优采云”采集器客户端(本文以“优采云”8.0版软件为例)。打开客户端软件,注册登入后即可使用。
1.使用模板采集数据
“优采云”客户端中外置了好多网站的采集模板,我们可以依据需求使用这种模板,如图1所示,按照提示步骤简单快捷地全手动获取网站信息。操作过程分三步:第一,选择目标网站的模板;第二,配置数据采集参数(采集的关键字、采集的页数等),选择采集模式(本地采集或云采集)自动提取数据;第三,选择输出的文件格式,导出数据。
图1 客户端中外置的网站采集模板
上述操作完成后,“优采云”客户端会将整个操作过程及提取的数据以任务的方式进行保存。通过客户端“我的任务”项,可以随时查看已提取的数据,也可以重复执行或更改当前任务。
2.自定义采集数据
当我们希望根据自己的要求获取网页上的个性化数据时,就须要使用自定义数据采集模式。首先要确定目标网站和采集需求;然后打开网页,配置采集选项,提取数据;最后导入数据到指定格式的文件中。
不管使用“优采云”客户端的哪种模式采集网页数据信息,整个流程都可统一为配置任务、采集数据和导入数据三个步骤。其中,配置采集选项参数是确切获取网页数据的关键。
“优采云”数据采集工具的应用案例
“优采云”数据采集工具才能采集大多数网站上的网页信息,而非只针对某类专业网站数据进行采集。下面以获取豆瓣影片Top 250(https:///top 250)网页数据为例,介绍“优采云”数据采集工具的具体使用技巧。
豆瓣网站是按照每部电影看过的人数以及该电影所得的评价等综合数据,通过算法剖析形成豆瓣影片Top 250榜单。豆瓣影片前250名的数据信息分10个连续网页显示,每个网页呈现25部连续剧,每部影片都包括影片排行、电影海报、电影中英文名称、电影编剧及执导、参评人数、豆瓣得分等相关信息。我们可以按照实际需求,使用“优采云”数据采集工具获取豆瓣影片Top 250的详尽数据,具体方式如下。
1.获取榜单中某一部影片的信息
首先,查看豆瓣影片网页中关于某部影片的信息,如《霸王别姬》,确定要获取的信息内容:电影排行、电影名、导演、主要艺人和剧情简介五项。其次,在“优采云”客户端的首页中,输入该部影片网页的网址,鼠标单击“开始采集”按钮,打开该网页;在显示网页的窗口中,鼠标单击“NO2 豆瓣影片Top 250”标签;在弹出的“操作提示”窗口中选择“采集该元素文本”,在“配置采集字段”窗口中显示出“ NO2 豆瓣影片Top 250 ”选项。重复上述操作,分别选中网页中“霸王别姬(1993)”“导演:陈凯歌”等其他标签完成采集字段的配置,并更改数组名称。再次,在“操作提示”窗口中执行“保存并开始采集”命令,在“运行任务”窗口中启动“本地采集”选项搜集数据信息。最后,将采集到的数据保存到特定格式的文件中。
数据信息采集完毕后,除了通过打开数据文件查看采集的信息外,还可以从“优采云”客户端首页的“我的任务”项中查看采集好的数据。
2.获取某个网页的全部影片信息
豆瓣影片榜单中每页就会显示25部影片的相关信息,每部影片展示了相同的信息项,如影片排行、海报、电影英文名称、导演及出演等。那么,“优采云”客户端提取每部影片数据的操作都是相同的。因此,我们只需完成一部影片的数据采集配置,其余影片使用循环重复操作即可。
首先要确定需求,在“优采云”客户端的首页输入要获取信息的网址并打开网页。其次,单击键盘选中一部影片相关数据区域。在弹出的“操作提示”窗口中选择“选中子元素”选项,选中该影片的影片排行、海报、电影英文名称、导演及出演等数组;然后再单击键盘选择“选中全部”,建立循环列表,选中该网页中25部影片的相关数据项;再单击“采集数据”选项,在预览窗口中,查看更改要采集的数据数组名。最后启动“本地采集”,获取数据信息,生成数据文件。
3.获取榜单中全部影片信息
除了上述自动选择数据采集字段外,由于豆瓣影片Top 250榜单中每部影片显示的信息都是相同的,在获取全部250部電影数据时,我们可以通过“操作提示”窗口中的提示信息,自动配置要提取的数据项,来完成影片信息的获取。
首先明晰获取信息需求,确定网址https://movie.douban. com/top 250,在“优采云”客户端打开网页;在“操作提示”窗口中选择“自动辨识网页”。经过“优采云”算法的辨识,自动完成采集字段配置,如图2所示。在“数据预览”窗口中,可以看见正式采集的数组及数据,通过“修改”和“删除”操作可以调整数组相关信息。然后选择“生成采集设置”,保存并开始采集数据。数据提取完成后,保存到特定格式的文件中。
图2 自动完成采集字段配置
除了以上这种应用之外,“优采云”数据采集工具还可以针对好多采集需求和不同结构的网页进行数据采集,如获取特定网页数量的数据、使用云采集等。这些都是你们可以进一步学习研究的内容。
专业数据采集工具及网路爬虫技术日渐成为获取网路信息的重要手段,但是在现实社会中,并不是所有数据都可以任意提取和使用。在数据采集时,我们要遵循有关的法律法规,负责任地、合理地使用网路技术和网路信息。
基金项目:北京市教育科学“十三五”规划2018年度通常课题“高中信息技术教学中估算思维培养的教学案例研究”,立项编号:CDDB18183。作者系北京教育学院“北京市中小学人工智能教学实践研究”特级班主任工作室成员
参考文献
[1]祝智庭,樊磊. 普通中学教科书·信息技术选修 [M]. 北京:人民教育出版社、中国地图出版社,2019.
搜索引擎
采集交流 • 优采云 发表了文章 • 0 个评论 • 230 次浏览 • 2020-08-25 10:22
5)正向索引
6)倒排索引
7)链接关系估算
8)特殊文件处理
当用户在搜索框进行搜索时,搜索引擎并没有在网路上实时的搜索用户的恳求,而是在检索索引数据库,搜索引擎定期更新其索引库。
首先搜索引擎查看搜索索引中的每一个搜索关键词,可以得到收录那些关键词的所有网页列表,这会得到特别庞大的数据。
每一种搜索引擎都有自己的算法,基于它对用户需求的猜想来排序网页。搜索引擎的排序算法可能会检测,是否你的搜索词收录在页面的标题中,它可能会用同义词匹配与你的搜索关键词语义相仿的查询结果。生成初步的查询结果,对查询结果集按权威性和PageRank进行排序,重复的查询结果被剔除。
对查询结果进行过滤处理。最终返回给浏览器端的用户一个人性化的、布局良好的、查询结果和广告泾渭分明的有机查询结果页面。
使用机器学习更好的理解成语,它使算法不仅仅是搜索页面上的单个字母或词组,而是理解成语的潜在意义。
如果能晓得用户查找的关键词(query(查询)切词后)都出现在什么页面中,那么用户检索的处理过程即可以想像为收录了query(查询)中切词后不同部份的页面集合求交的过程,而检索即弄成了页面名称之间的比较、求交。这样,在微秒内以亿为单位的检索成为了可能。这就是一般所说的倒排索引及求交检索的过程。
页面剖析的过程实际上是将原创页面的不同部份进行辨识并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等,分词的过程实际上包括了切词动词同义词转换同义词替换等等,以对某页面title动词为例,得到的将是这样的数据:term文本、termid(标识)、词类、词性等等,之前的打算工作完成后,接下来即是构建倒排索引,形成{termàdoc}(文档集合),
索引系统在构建倒排索引的最后还须要有一个入库写库的过程,而为了提升效率这个过程还须要将全部term以及偏移量保存在文件背部,并且对数据进行压缩.
(1) Query串切词动词正式用户的查询词进行动词,对以后的查询做打算,以“10号线轻轨故障”为例,可能的动词如下:
10 0x123abc
号 0x13445d
线 0x234d
地铁 0x145cf
故障 0x354df
(2)查出含每位term的文档集合,即找出待选集合,如下:
10 1 2 3 4 7 9……
号 2 5 8 9 10 11……
(3)求交,上述求交,文档2和文档9可能是我们须要找的,整个求交过程实际上关系着整个系统的性能,这上面收录了使用缓存等等手段进行性能优化;
(4)各种过滤,举例可能收录过滤掉死链、重复数据、色情、垃圾结果;
(5)最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等。用户在搜索框输入关键词后,排名程序调用索引库数据,计算排行显示给用户,排名过程与用户直接互动的
倒排索引通常表示为一个关键词,然后是它的频率(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签通常。
图片搜索:
1.缩小规格。将图片缩小到8x8的规格,总共64个象素。这一步的作用是清除图片的细节,只保留结构、明暗等基本信息,摒弃不同规格、比例带来的图片差别。
2.简化色调。将缩小后的图片,转为64级灰度。也就是说,所有象素点总共只有64种颜色。
3.计算平均值。计算所有64个象素的灰度平均值。
4.比较象素的灰度。将每位象素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
5.计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的顺序并不重要,只要保证所有图片都采用同样顺序就行了。 查看全部
搜索引擎
5)正向索引
6)倒排索引
7)链接关系估算
8)特殊文件处理
当用户在搜索框进行搜索时,搜索引擎并没有在网路上实时的搜索用户的恳求,而是在检索索引数据库,搜索引擎定期更新其索引库。
首先搜索引擎查看搜索索引中的每一个搜索关键词,可以得到收录那些关键词的所有网页列表,这会得到特别庞大的数据。
每一种搜索引擎都有自己的算法,基于它对用户需求的猜想来排序网页。搜索引擎的排序算法可能会检测,是否你的搜索词收录在页面的标题中,它可能会用同义词匹配与你的搜索关键词语义相仿的查询结果。生成初步的查询结果,对查询结果集按权威性和PageRank进行排序,重复的查询结果被剔除。
对查询结果进行过滤处理。最终返回给浏览器端的用户一个人性化的、布局良好的、查询结果和广告泾渭分明的有机查询结果页面。
使用机器学习更好的理解成语,它使算法不仅仅是搜索页面上的单个字母或词组,而是理解成语的潜在意义。
如果能晓得用户查找的关键词(query(查询)切词后)都出现在什么页面中,那么用户检索的处理过程即可以想像为收录了query(查询)中切词后不同部份的页面集合求交的过程,而检索即弄成了页面名称之间的比较、求交。这样,在微秒内以亿为单位的检索成为了可能。这就是一般所说的倒排索引及求交检索的过程。
页面剖析的过程实际上是将原创页面的不同部份进行辨识并标记,例如:title、keywords、content、link、anchor、评论、其他非重要区域等等,分词的过程实际上包括了切词动词同义词转换同义词替换等等,以对某页面title动词为例,得到的将是这样的数据:term文本、termid(标识)、词类、词性等等,之前的打算工作完成后,接下来即是构建倒排索引,形成{termàdoc}(文档集合),
索引系统在构建倒排索引的最后还须要有一个入库写库的过程,而为了提升效率这个过程还须要将全部term以及偏移量保存在文件背部,并且对数据进行压缩.
(1) Query串切词动词正式用户的查询词进行动词,对以后的查询做打算,以“10号线轻轨故障”为例,可能的动词如下:
10 0x123abc
号 0x13445d
线 0x234d
地铁 0x145cf
故障 0x354df
(2)查出含每位term的文档集合,即找出待选集合,如下:
10 1 2 3 4 7 9……
号 2 5 8 9 10 11……
(3)求交,上述求交,文档2和文档9可能是我们须要找的,整个求交过程实际上关系着整个系统的性能,这上面收录了使用缓存等等手段进行性能优化;
(4)各种过滤,举例可能收录过滤掉死链、重复数据、色情、垃圾结果;
(5)最终排序,将最能满足用户需求的结果排序在最前,可能包括的有用信息如:网站的整体评价、网页质量、内容质量、资源质量、匹配程度、分散度、时效性等等。用户在搜索框输入关键词后,排名程序调用索引库数据,计算排行显示给用户,排名过程与用户直接互动的
倒排索引通常表示为一个关键词,然后是它的频率(出现的次数),位置(出现在哪一篇文章或网页中,及有关的日期,作者等信息),它相当于为互联网上几千亿页网页做了一个索引,好比一本书的目录、标签通常。
图片搜索:
1.缩小规格。将图片缩小到8x8的规格,总共64个象素。这一步的作用是清除图片的细节,只保留结构、明暗等基本信息,摒弃不同规格、比例带来的图片差别。
2.简化色调。将缩小后的图片,转为64级灰度。也就是说,所有象素点总共只有64种颜色。
3.计算平均值。计算所有64个象素的灰度平均值。
4.比较象素的灰度。将每位象素的灰度,与平均值进行比较。大于或等于平均值,记为1;小于平均值,记为0。
5.计算哈希值。将上一步的比较结果,组合在一起,就构成了一个64位的整数,这就是这张图片的指纹。组合的顺序并不重要,只要保证所有图片都采用同样顺序就行了。
网站万能信息采集器终极版与心宽网页采集系统下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 285 次浏览 • 2020-08-25 04:29
5年来不断的建立改进缔造了史无前例的强悍采集软件--网站万能信息采集器。
网站优采云采集器:能看到的信息都能抓到.
八大特色功能:
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识JavaScript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。 查看全部
网站万能信息采集器终极版与心宽网页采集系统下载评论软件详情对比
5年来不断的建立改进缔造了史无前例的强悍采集软件--网站万能信息采集器。
网站优采云采集器:能看到的信息都能抓到.
八大特色功能:
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识JavaScript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
如何抓取网页实时数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2020-08-25 03:49
excel确实可以抓取网页数据,但是功能有限,如果网页比较复杂,就要花上好多时间设置,另外对于防采集比较严重的网站,基本上就没办法了。
所以假如要采集网页数据,还是得用专业的采集工具,比如优采云采集器。下面就从上手难度方面给你们介绍介绍。
上手难度
优采云内置两种采集模式
1、模板采集(0基础,简单三步获取数据,纯键盘和输入文字操作,小白友好)
打开运行在PC端的优采云客户端,直接搜索网站,看看有没有收录您想要采集的目标网站。万一收录,只须要动动键盘输入文字,采就完事了。
目标采集模板数也是特别多的,基本上主流网站都有收录,看看下边的图片就晓得了。
图片仅展示部份外置的数据源
以易迅商品采集给你们详尽演示采集过程:
简单3步,日采集海量数据
具体详尽使用教程:使用模板采集数据
2、自定义采集模式(内置智能模式,自动辨识网页内容数据,自由度高,轻松采数据)
如果【模板采集】里没有想要采集的网站,那就自己来,优采云内置智能模式,可以手动辨识网页内容进行采集。
以优采云教程列表页采集给你们演示操作流程:
只需输入网址,一键智能辨识采集数据
具体详尽使用教程:自定义配置采集数据(含智能辨识)
如果您对用优采云采集网页数据有兴趣,可以用笔记本下载客户端试试。
下载地址:
免费下载 - 优采云采集器 查看全部
如何抓取网页实时数据?
excel确实可以抓取网页数据,但是功能有限,如果网页比较复杂,就要花上好多时间设置,另外对于防采集比较严重的网站,基本上就没办法了。
所以假如要采集网页数据,还是得用专业的采集工具,比如优采云采集器。下面就从上手难度方面给你们介绍介绍。
上手难度
优采云内置两种采集模式
1、模板采集(0基础,简单三步获取数据,纯键盘和输入文字操作,小白友好)
打开运行在PC端的优采云客户端,直接搜索网站,看看有没有收录您想要采集的目标网站。万一收录,只须要动动键盘输入文字,采就完事了。
目标采集模板数也是特别多的,基本上主流网站都有收录,看看下边的图片就晓得了。
图片仅展示部份外置的数据源
以易迅商品采集给你们详尽演示采集过程:
简单3步,日采集海量数据
具体详尽使用教程:使用模板采集数据
2、自定义采集模式(内置智能模式,自动辨识网页内容数据,自由度高,轻松采数据)
如果【模板采集】里没有想要采集的网站,那就自己来,优采云内置智能模式,可以手动辨识网页内容进行采集。
以优采云教程列表页采集给你们演示操作流程:
只需输入网址,一键智能辨识采集数据
具体详尽使用教程:自定义配置采集数据(含智能辨识)
如果您对用优采云采集网页数据有兴趣,可以用笔记本下载客户端试试。
下载地址:
免费下载 - 优采云采集器
优采云采集器最新版(网页数据采集工具) v2.1.8.0 最新版
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-23 15:55
非常关注某几个网站,可以用优采云采集器最新版来实时的关注哦,一键简单提取数据、快速高效、适用于大部分的网站,同时优采云采集器最新版海域简单易用的向导模式、独创的高速内核、脚本定时运行,优采云采集器最新版能智能的辨识网页中的列表表单,这款专业的网页数据采集工具是你日常好帮手!
优采云采集器最新版软件特色
独创高速内核
自研的浏览器内核,速度飞快,远超对手
智能辨识
对于网页中的列表、表单结构(多选框下拉列表等)能够智能辨识
广告屏蔽
定制的广告屏蔽模块,兼容AdblockPlus句型,可添加自定义规则
多种数据导入
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用各类网站
能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
功能介绍
向导模式
简单易用,轻松通过滑鼠点击手动生成
脚本定时运行
可依照计划定时运行,无需人工
优采云采集器最新版使用方式
第一步:输入采集网址
打开软件,新建任务,输入须要采集的网站地址。
第二步:智能剖析,全程自动化提取数据
进入到第二步后,优采云采集器全手动智能剖析网页,并且从中提取出列表数据。
第三步:导出数据到表格、数据库、网站等
运行任务,将采集到的数据导入为Csv、Excel以及各类数据库,支持api导入。 查看全部
优采云采集器最新版(网页数据采集工具) v2.1.8.0 最新版
非常关注某几个网站,可以用优采云采集器最新版来实时的关注哦,一键简单提取数据、快速高效、适用于大部分的网站,同时优采云采集器最新版海域简单易用的向导模式、独创的高速内核、脚本定时运行,优采云采集器最新版能智能的辨识网页中的列表表单,这款专业的网页数据采集工具是你日常好帮手!
优采云采集器最新版软件特色
独创高速内核
自研的浏览器内核,速度飞快,远超对手
智能辨识
对于网页中的列表、表单结构(多选框下拉列表等)能够智能辨识
广告屏蔽
定制的广告屏蔽模块,兼容AdblockPlus句型,可添加自定义规则
多种数据导入
支持Txt 、Excel、MySQL、SQLServer、SQlite、Access、网站等
一键提取数据
简单易学,通过可视化界面,鼠标点击即可抓取数据
快速高效
内置一套高速浏览器内核,加上HTTP引擎模式,实现快速采集数据
适用各类网站
能够采集互联网99%的网站,包括单页应用Ajax加载等等动态类型网站
功能介绍
向导模式
简单易用,轻松通过滑鼠点击手动生成
脚本定时运行
可依照计划定时运行,无需人工
优采云采集器最新版使用方式
第一步:输入采集网址
打开软件,新建任务,输入须要采集的网站地址。
第二步:智能剖析,全程自动化提取数据
进入到第二步后,优采云采集器全手动智能剖析网页,并且从中提取出列表数据。
第三步:导出数据到表格、数据库、网站等
运行任务,将采集到的数据导入为Csv、Excel以及各类数据库,支持api导入。
善肯网页TXT采集器1.0 绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 418 次浏览 • 2020-08-23 15:46
喜欢看小说的用户好多的都是须要把小说下载到自己的手机里面,但是好多的网站不支持一键下载,可以使用善肯网页TXT采集器,自动采集以及下载!
善肯网页TXT采集器介绍
喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
善肯网页TXT采集器使用教程
关于规则设置
1、输入网址后,可以实时预览(不论有有没规则,有规则就是匹配规则后的内容,没有就是源代码,目前测试,并非所有网页都能获取其内容,具体你们可以自己去实验,能获取源代码的就是可以匹配出内容的)
2、目录页和内容页分别匹配不同的规则:
目录页:
文本名称规则
作者名称规则
章节规则(此处需有两个()一处匹配章节路径,一个匹配章节名称)
内容页:
内容规则
3、关于替换:
通用替换(非正则):所有规则就会手动加上通用替换(有共性的替换规则)
定制替换(非正则):单个网站的特有替换规则
正则替换:暂未开发,请求打赏支持开发~~。
想换行可用内容与\n进行替换,\n是替换数据不是原数据。
可以依照自己的需求增删,。(原数据和替换数据必填,一个空格都行,否则会抛异常)
删除:选中一行,按DELETE键删掉
4、关于规则保存:
保存都是以文件名来的,不同的名称则为不同的规则,最终保存为xml方式。
5、关于地址解析
解析地址1:测试未删,以后会加功能,暂留着
解析地址2:推荐使用
6、理论上,只要是目录页指向内容页的方式都可以抓取【能获取源代码的情况下】。具体请你们自己去实验。
关于文件
1、commonrule.xml 文件储存的是通用替换规则,
2、rule文件夹下储存的是以网站为单位的规则。
如果须要直接拷贝单条规则放在rule文件夹下就可以使用规则了,前提是xml文件格式是对的,
3、其他
暂时还没想到大家可能就会出现哪些问题。如果碰到问题欢迎反馈。
最后附上常用匹配全部内容的表达式:
(.*?) ([\w\W]*?) ([\s\S]*?)
PC官方版
安卓官方手机版
IOS官方手机版 查看全部
善肯网页TXT采集器1.0 绿色免费版
喜欢看小说的用户好多的都是须要把小说下载到自己的手机里面,但是好多的网站不支持一键下载,可以使用善肯网页TXT采集器,自动采集以及下载!
善肯网页TXT采集器介绍
喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
善肯网页TXT采集器使用教程
关于规则设置
1、输入网址后,可以实时预览(不论有有没规则,有规则就是匹配规则后的内容,没有就是源代码,目前测试,并非所有网页都能获取其内容,具体你们可以自己去实验,能获取源代码的就是可以匹配出内容的)
2、目录页和内容页分别匹配不同的规则:
目录页:
文本名称规则
作者名称规则
章节规则(此处需有两个()一处匹配章节路径,一个匹配章节名称)
内容页:
内容规则
3、关于替换:
通用替换(非正则):所有规则就会手动加上通用替换(有共性的替换规则)
定制替换(非正则):单个网站的特有替换规则
正则替换:暂未开发,请求打赏支持开发~~。
想换行可用内容与\n进行替换,\n是替换数据不是原数据。
可以依照自己的需求增删,。(原数据和替换数据必填,一个空格都行,否则会抛异常)
删除:选中一行,按DELETE键删掉
4、关于规则保存:
保存都是以文件名来的,不同的名称则为不同的规则,最终保存为xml方式。
5、关于地址解析
解析地址1:测试未删,以后会加功能,暂留着
解析地址2:推荐使用
6、理论上,只要是目录页指向内容页的方式都可以抓取【能获取源代码的情况下】。具体请你们自己去实验。
关于文件
1、commonrule.xml 文件储存的是通用替换规则,
2、rule文件夹下储存的是以网站为单位的规则。
如果须要直接拷贝单条规则放在rule文件夹下就可以使用规则了,前提是xml文件格式是对的,
3、其他
暂时还没想到大家可能就会出现哪些问题。如果碰到问题欢迎反馈。
最后附上常用匹配全部内容的表达式:
(.*?) ([\w\W]*?) ([\s\S]*?)
PC官方版
安卓官方手机版
IOS官方手机版
Java+opencv+mysql实现人脸辨识源码(人脸采集入库+人脸辨识相似度
采集交流 • 优采云 发表了文章 • 0 个评论 • 395 次浏览 • 2020-08-22 23:27
Java+opencv实现人脸辨识
写这篇博客,是因为曾经常常使用python+opencv实现人脸处理,后来发觉java也可以实现,于是便学习了下,以下将代码和实现过程贴出。
目录1、环境打算
使用到的技术:java+opencv+mysql
我这儿用的是opencv4.1,这里可以自行下载(其实只须要一个opencv的dll文件置于java安装目录的bin下边既可)
2、代码实现
核心opencv人脸识别类(识别算法):
package com.dialect.utils;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.objdetect.CascadeClassifier;
import java.util.Arrays;
/**
* 1. 灰度化(减小图片大小)
* 2. 人脸识别
* 3. 人脸切割
* 4. 规一化(人脸直方图)
* 5. 直方图相似度匹配
*
*
* @Description: 比较两张图片人脸的匹配度
* @date 2019/2/1813:47
*/
public class FaceCompare {
// 初始化人脸探测器
static CascadeClassifier faceDetector;
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
faceDetector = new CascadeClassifier("E:\\eclipseworkspace\\FaceDectcoSys\\src\\haarcascade_frontalface_default.xml");
}
// 灰度化人脸
public static Mat conv_Mat(String img) {
Mat image0 = Imgcodecs.imread(img);
Mat image1 = new Mat();
// 灰度化
Imgproc.cvtColor(image0, image1, Imgproc.COLOR_BGR2GRAY);
// 探测人脸
MatOfRect faceDetections = new MatOfRect();
faceDetector.detectMultiScale(image1, faceDetections);
// rect中人脸图片的范围
for (Rect rect : faceDetections.toArray()) {
Mat face = new Mat(image1, rect);
return face;
}
return null;
}
public static double compare_image(String img_1, String img_2) {
Mat mat_1 = conv_Mat(img_1);
Mat mat_2 = conv_Mat(img_2);
Mat hist_1 = new Mat();
Mat hist_2 = new Mat();
//颜色范围
MatOfFloat ranges = new MatOfFloat(0f, 256f);
//直方图大小, 越大匹配越精确 (越慢)
MatOfInt histSize = new MatOfInt(1000);
Imgproc.calcHist(Arrays.asList(mat_1), new MatOfInt(0), new Mat(), hist_1, histSize, ranges);
Imgproc.calcHist(Arrays.asList(mat_2), new MatOfInt(0), new Mat(), hist_2, histSize, ranges);
// CORREL 相关系数
double res = Imgproc.compareHist(hist_1, hist_2, Imgproc.CV_COMP_CORREL);
return res;
}
public static void main(String[] args) {
String basePicPath = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\";
double compareHist = compare_image(basePicPath + "fbb1.jpg", basePicPath + "fbb2.jpg");
System.out.println(compareHist);
if (compareHist > 0.72) {
System.out.println("人脸匹配");
} else {
System.out.println("人脸不匹配");
}
}
}
测试两张图片相似度(美女相片自己网上找):
测试结果:相似度0.82左右,还好了
接着实现网页
数据库dao:
package com.dialect.info.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import com.dialect.info.bean.Dect;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectDao {
/**
* 添加
* @param con
* @param Dialect
* @return
* @throws Exception
*/
public int add(Connection con,Dect dect)throws Exception{
dect.setId(UUID.randomUUID().toString().replace("-", ""));
String sql="insert into dect values(?,?)";
PreparedStatement pstmt=con.prepareStatement(sql);
pstmt.setString(1,dect.getId());
pstmt.setString(2,dect.getBase64());
return pstmt.executeUpdate();
}
/**
* 查询所有
* @param con
* @param dialect
* @return
* @throws Exception
*/
public List list(Connection con)throws Exception{
List list = new ArrayList();
Dect entity=null;
String sql = "select a.* from dect a";
PreparedStatement pstmt=con.prepareStatement(sql);
ResultSet rs=pstmt.executeQuery();
while(rs.next()){
entity = new Dect();
entity.setId(rs.getString("id"));
entity.setBase64(rs.getString("base64"));
list.add(entity);
}
return list;
}
}
service层:
package com.dialect.info.service.impl;
import java.sql.Connection;
import java.util.List;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.utils.DbUtil;
import com.dialect.utils.Page;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectServiceImpl implements DectService {
DectDao dectDao = new DectDao();
@Override
public int add(Dect dect) {
try {
Connection con = DbUtil.getCon();
Integer result =dectDao.add(con, dect);
DbUtil.closeCon(con);
return result;
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
@Override
public List select() {
try {
Connection con = DbUtil.getCon();
List list = dectDao.list(con);
DbUtil.closeCon(con);
return list;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
control控制层:
package com.dialect.info.controller;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.info.service.impl.DectServiceImpl;
import com.dialect.utils.Page;
import com.dialect.utils.picToBase64;
import com.dialect.utils.FaceCompare;
@WebServlet("/dect")
public class DectController extends HttpServlet {
private static final long serialVersionUID = 1L;
DectDao dectDao=new DectDao();
DectService dectService = new DectServiceImpl();
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String method = request.getParameter("method");
if ("upload".equals(method)) {
upload(request,response);
}else if ("select".equals(method)) {
select(request, response);
}else if ("list".equals(method)) {
list(request, response);
}else if ("form".equals(method)) {
form(request, response);
}
}
//添加
private void upload(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---开始上传---");
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
Dect dect = new Dect();
dect.setBase64(s);
int res = dectService.add(dect);
// System.err.println(res);
// String res = "1";
// String res2 = "3";
// 解决json中文乱码
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
// String str ="{\"success\":"+res+",\"age\":"+res2 +"}";
String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
}
//添加
private void select(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---进来了select方法---");
FaceCompare faceCompare = new FaceCompare();
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
picToBase64 pic = new picToBase64();
String imgPath1 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img1.jpg";
String imgPath2 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img2.jpg";
// String imgPath1 = "E:\\img1.jpg";
// String imgPath2 = "E:\\img2.jpg";
//String imgPath2 = "E:\\eclipseworkspace\\FaceDectcogSys\\WebContent\\static\\images\\img2";
pic.Base64ToImage(s, imgPath1);
List list = dectService.select();
int shibie_flag = 0;
double res = 0;
System.err.println(list.size());
if (list.size()>0){
for(Dect dect:list){
System.err.println(dect.getBase64());
String s1 = dect.getBase64().replace("data:image/jpeg;base64,","");
System.err.println("s1:"+s1);
picToBase64 pic2 = new picToBase64();
pic2.Base64ToImage(s1, imgPath2);
res = faceCompare.compare_image(imgPath1, imgPath2);
if (res > 0.72){
System.out.println("人脸匹配");
shibie_flag = 1;
break;
}
}
}
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
String str ="{\"success\":"+shibie_flag+",\"res\":"+res +"}";
// String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
// response.sendRedirect(contextPath+"/dialect?method=list");
}
//列表查询
private void list(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList2.jsp").forward(request, response);
}
//form跳转页面
private void form(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList3.jsp").forward(request, response);
}
}
3、运行疗效
网站操作流程如下:
第一步:人脸采集(支持上传图片预览)
入库成功:
开始人脸辨识(人脸匹配成功):
写在最后:因篇幅有限,不能讲所有代码贴出,如果须要可以加我:3459067873 查看全部
Java+opencv+mysql实现人脸辨识源码(人脸采集入库+人脸辨识相似度
Java+opencv实现人脸辨识
写这篇博客,是因为曾经常常使用python+opencv实现人脸处理,后来发觉java也可以实现,于是便学习了下,以下将代码和实现过程贴出。
目录1、环境打算
使用到的技术:java+opencv+mysql
我这儿用的是opencv4.1,这里可以自行下载(其实只须要一个opencv的dll文件置于java安装目录的bin下边既可)
2、代码实现
核心opencv人脸识别类(识别算法):
package com.dialect.utils;
import org.opencv.core.*;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.imgproc.Imgproc;
import org.opencv.objdetect.CascadeClassifier;
import java.util.Arrays;
/**
* 1. 灰度化(减小图片大小)
* 2. 人脸识别
* 3. 人脸切割
* 4. 规一化(人脸直方图)
* 5. 直方图相似度匹配
*
*
* @Description: 比较两张图片人脸的匹配度
* @date 2019/2/1813:47
*/
public class FaceCompare {
// 初始化人脸探测器
static CascadeClassifier faceDetector;
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
faceDetector = new CascadeClassifier("E:\\eclipseworkspace\\FaceDectcoSys\\src\\haarcascade_frontalface_default.xml");
}
// 灰度化人脸
public static Mat conv_Mat(String img) {
Mat image0 = Imgcodecs.imread(img);
Mat image1 = new Mat();
// 灰度化
Imgproc.cvtColor(image0, image1, Imgproc.COLOR_BGR2GRAY);
// 探测人脸
MatOfRect faceDetections = new MatOfRect();
faceDetector.detectMultiScale(image1, faceDetections);
// rect中人脸图片的范围
for (Rect rect : faceDetections.toArray()) {
Mat face = new Mat(image1, rect);
return face;
}
return null;
}
public static double compare_image(String img_1, String img_2) {
Mat mat_1 = conv_Mat(img_1);
Mat mat_2 = conv_Mat(img_2);
Mat hist_1 = new Mat();
Mat hist_2 = new Mat();
//颜色范围
MatOfFloat ranges = new MatOfFloat(0f, 256f);
//直方图大小, 越大匹配越精确 (越慢)
MatOfInt histSize = new MatOfInt(1000);
Imgproc.calcHist(Arrays.asList(mat_1), new MatOfInt(0), new Mat(), hist_1, histSize, ranges);
Imgproc.calcHist(Arrays.asList(mat_2), new MatOfInt(0), new Mat(), hist_2, histSize, ranges);
// CORREL 相关系数
double res = Imgproc.compareHist(hist_1, hist_2, Imgproc.CV_COMP_CORREL);
return res;
}
public static void main(String[] args) {
String basePicPath = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\";
double compareHist = compare_image(basePicPath + "fbb1.jpg", basePicPath + "fbb2.jpg");
System.out.println(compareHist);
if (compareHist > 0.72) {
System.out.println("人脸匹配");
} else {
System.out.println("人脸不匹配");
}
}
}
测试两张图片相似度(美女相片自己网上找):
测试结果:相似度0.82左右,还好了
接着实现网页
数据库dao:
package com.dialect.info.dao;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import com.dialect.info.bean.Dect;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectDao {
/**
* 添加
* @param con
* @param Dialect
* @return
* @throws Exception
*/
public int add(Connection con,Dect dect)throws Exception{
dect.setId(UUID.randomUUID().toString().replace("-", ""));
String sql="insert into dect values(?,?)";
PreparedStatement pstmt=con.prepareStatement(sql);
pstmt.setString(1,dect.getId());
pstmt.setString(2,dect.getBase64());
return pstmt.executeUpdate();
}
/**
* 查询所有
* @param con
* @param dialect
* @return
* @throws Exception
*/
public List list(Connection con)throws Exception{
List list = new ArrayList();
Dect entity=null;
String sql = "select a.* from dect a";
PreparedStatement pstmt=con.prepareStatement(sql);
ResultSet rs=pstmt.executeQuery();
while(rs.next()){
entity = new Dect();
entity.setId(rs.getString("id"));
entity.setBase64(rs.getString("base64"));
list.add(entity);
}
return list;
}
}
service层:
package com.dialect.info.service.impl;
import java.sql.Connection;
import java.util.List;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.utils.DbUtil;
import com.dialect.utils.Page;
/**
* 人脸信息DAO接口
* @author admin
* @version 2020-05-10
*/
public class DectServiceImpl implements DectService {
DectDao dectDao = new DectDao();
@Override
public int add(Dect dect) {
try {
Connection con = DbUtil.getCon();
Integer result =dectDao.add(con, dect);
DbUtil.closeCon(con);
return result;
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
@Override
public List select() {
try {
Connection con = DbUtil.getCon();
List list = dectDao.list(con);
DbUtil.closeCon(con);
return list;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
control控制层:
package com.dialect.info.controller;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.PrintWriter;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.annotation.WebServlet;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import com.dialect.info.bean.Dect;
import com.dialect.info.dao.DectDao;
import com.dialect.info.service.DectService;
import com.dialect.info.service.impl.DectServiceImpl;
import com.dialect.utils.Page;
import com.dialect.utils.picToBase64;
import com.dialect.utils.FaceCompare;
@WebServlet("/dect")
public class DectController extends HttpServlet {
private static final long serialVersionUID = 1L;
DectDao dectDao=new DectDao();
DectService dectService = new DectServiceImpl();
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
doPost(request, response);
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String method = request.getParameter("method");
if ("upload".equals(method)) {
upload(request,response);
}else if ("select".equals(method)) {
select(request, response);
}else if ("list".equals(method)) {
list(request, response);
}else if ("form".equals(method)) {
form(request, response);
}
}
//添加
private void upload(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---开始上传---");
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
Dect dect = new Dect();
dect.setBase64(s);
int res = dectService.add(dect);
// System.err.println(res);
// String res = "1";
// String res2 = "3";
// 解决json中文乱码
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
// String str ="{\"success\":"+res+",\"age\":"+res2 +"}";
String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
}
//添加
private void select(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.err.println("---进来了select方法---");
FaceCompare faceCompare = new FaceCompare();
String para = request.getParameter("base64");
String s = para.replace("data:image/jpeg;base64,","");
System.err.println(para);
System.err.println(s);
picToBase64 pic = new picToBase64();
String imgPath1 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img1.jpg";
String imgPath2 = "E:\\eclipseworkspace\\FaceDectcoSys\\WebContent\\static\\images\\img2.jpg";
// String imgPath1 = "E:\\img1.jpg";
// String imgPath2 = "E:\\img2.jpg";
//String imgPath2 = "E:\\eclipseworkspace\\FaceDectcogSys\\WebContent\\static\\images\\img2";
pic.Base64ToImage(s, imgPath1);
List list = dectService.select();
int shibie_flag = 0;
double res = 0;
System.err.println(list.size());
if (list.size()>0){
for(Dect dect:list){
System.err.println(dect.getBase64());
String s1 = dect.getBase64().replace("data:image/jpeg;base64,","");
System.err.println("s1:"+s1);
picToBase64 pic2 = new picToBase64();
pic2.Base64ToImage(s1, imgPath2);
res = faceCompare.compare_image(imgPath1, imgPath2);
if (res > 0.72){
System.out.println("人脸匹配");
shibie_flag = 1;
break;
}
}
}
response.setContentType("text/json;charset=UTF-8");
response.setCharacterEncoding("UTF-8");
PrintWriter out = response.getWriter();
String str ="{\"success\":"+shibie_flag+",\"res\":"+res +"}";
// String str ="{\"success\":"+res+"}";
out.println(str);
out.flush();
out.close();
// response.sendRedirect(contextPath+"/dialect?method=list");
}
//列表查询
private void list(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList2.jsp").forward(request, response);
}
//form跳转页面
private void form(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
request.getRequestDispatcher("/dectList3.jsp").forward(request, response);
}
}
3、运行疗效
网站操作流程如下:
第一步:人脸采集(支持上传图片预览)
入库成功:
开始人脸辨识(人脸匹配成功):
写在最后:因篇幅有限,不能讲所有代码贴出,如果须要可以加我:3459067873
优采云采集器官方版下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 379 次浏览 • 2020-08-22 18:11
优采云采集器是一款十分强悍又实用的网页抓取采集工具,让我们可以将采集到的内容进行独立保存,让您在浏览完网站的时侯可以将他人的内容复制到自己的素材文件夹上,而且还支持多种抓取方法,可以实现单个网页抓取,也可以选择多个HTML页面抓取,还可以自动选择数组,有须要的的同学赶快下载吧。
优采云采集器功能介绍
1、提示软件的项目构建方法,这里可以点击创建一个新的抓取项目。
2、可以将一个网页的地址复制到这儿,也可以选择从文本上读取多个地址。
3、复制地址之后点击创建任务就可以了。
4、软件手动打开网页,这里有三个选择类型,可以选择列表页、可以选择内容页,点击下一步。
5、在上方的浏览区域选择您须要抓取的网页数组,鼠标点击数组即可。
优采云采集器软件特色
可以提示您找到本次保存的HTML位置
支持通过您抓取的网页标题设置保存名称
也可以在保存抓取内容的时侯自己重命名
提供了Excel2007保存的方法
也可以选择以原先的HTML直接保存
优采云采集器也能从一个文本上添加多个新的抓取地址
抓取的数组是特别多的,可以自己借助键盘选择
优采云采集器还提供了抓取过滤的设置功能
更新日志
V3.1.7(正式) 2019-2-18
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表辨识速率翻番
【自定义模式】自动辨识网页Ajax点击,自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,选择网页元素更精准
【本地采集】采集速度整体提高10~30%,采集效率急剧增强
【任务列表】重构任务列表界面,大幅提升性能表现,大量任务管理不再卡顿
【任务列表】任务列表加入手动刷新机制,可随时查看任务最新状态 查看全部
优采云采集器官方版下载
优采云采集器是一款十分强悍又实用的网页抓取采集工具,让我们可以将采集到的内容进行独立保存,让您在浏览完网站的时侯可以将他人的内容复制到自己的素材文件夹上,而且还支持多种抓取方法,可以实现单个网页抓取,也可以选择多个HTML页面抓取,还可以自动选择数组,有须要的的同学赶快下载吧。
优采云采集器功能介绍
1、提示软件的项目构建方法,这里可以点击创建一个新的抓取项目。
2、可以将一个网页的地址复制到这儿,也可以选择从文本上读取多个地址。
3、复制地址之后点击创建任务就可以了。
4、软件手动打开网页,这里有三个选择类型,可以选择列表页、可以选择内容页,点击下一步。
5、在上方的浏览区域选择您须要抓取的网页数组,鼠标点击数组即可。
优采云采集器软件特色
可以提示您找到本次保存的HTML位置
支持通过您抓取的网页标题设置保存名称
也可以在保存抓取内容的时侯自己重命名
提供了Excel2007保存的方法
也可以选择以原先的HTML直接保存
优采云采集器也能从一个文本上添加多个新的抓取地址
抓取的数组是特别多的,可以自己借助键盘选择
优采云采集器还提供了抓取过滤的设置功能
更新日志
V3.1.7(正式) 2019-2-18
主要体验改进
【自定义模式】新增JSON采集功能
【自定义模式】新增滑动验证码识别
【自定义模式】优化效率,列表辨识速率翻番
【自定义模式】自动辨识网页Ajax点击,自动配置Ajax超时时间,配置任务更方便
【自定义模式】改进算法,选择网页元素更精准
【本地采集】采集速度整体提高10~30%,采集效率急剧增强
【任务列表】重构任务列表界面,大幅提升性能表现,大量任务管理不再卡顿
【任务列表】任务列表加入手动刷新机制,可随时查看任务最新状态
基于组合特点的网页主题块辨识算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 241 次浏览 • 2020-08-22 07:00
【摘要】:在现今的互联网时代,Web是信息的重要来源,网页则是展示信息的重要媒介。网页传递着各类信息,但是其中有大量噪声信息严重影响了 Web信息的自动化挖掘和采集。如何确切的辨识出网页的主题信息成为了计算机科学的研究热点。本文对各类Web页面主题信息辨识的技术进行了剖析和总结,针对仅借助视觉特点或文本特点来辨识Web页面主题信息算法的不足,提出了一种基于组合特点的主题块辨识算法,实验证明本算法有效的提升了网页主题信息辨识的准确率和稳定性。本文的主要研究内容和贡献如下:1)实现并改进了 VIPS算法。改进了网页分块规则,对网页块规格阀值采用了动态调整的方法来调整分块细度,使得分块后的网页块语义愈发完整。2)借鉴BM25算法的思想,提出了估算网页块内容与主题相关性的算法模型BBM25。BBM25以网页块为基本单位,从关键词的权重、网页块中关键词的词频、网页块的文本内容厚度等几个方面来考虑。3)提出了基于组合特点的主题块辨识算法。对网页分块后,本文首先借助SVM按照网页块的视觉特点预测网页块是否为主题块,然后借助BBM25算法估算每位网页块内容与主题的相关性权重值,将权重值与找寻的最佳阀值进行比较进而判定网页块是否为主题块,最后将这两种方法相结合,综合利用网页块的视觉特点和文本特点来判定其是否为主题块。通过实验,本文将基于组合特点的主题块辨识算法和基于视觉特点、基于文本特点的主题块辨识算法进行了对比,验证了本文提出的基于组合特点辨识主题块的算法的准确性和稳定性。 查看全部
基于组合特点的网页主题块辨识算法
【摘要】:在现今的互联网时代,Web是信息的重要来源,网页则是展示信息的重要媒介。网页传递着各类信息,但是其中有大量噪声信息严重影响了 Web信息的自动化挖掘和采集。如何确切的辨识出网页的主题信息成为了计算机科学的研究热点。本文对各类Web页面主题信息辨识的技术进行了剖析和总结,针对仅借助视觉特点或文本特点来辨识Web页面主题信息算法的不足,提出了一种基于组合特点的主题块辨识算法,实验证明本算法有效的提升了网页主题信息辨识的准确率和稳定性。本文的主要研究内容和贡献如下:1)实现并改进了 VIPS算法。改进了网页分块规则,对网页块规格阀值采用了动态调整的方法来调整分块细度,使得分块后的网页块语义愈发完整。2)借鉴BM25算法的思想,提出了估算网页块内容与主题相关性的算法模型BBM25。BBM25以网页块为基本单位,从关键词的权重、网页块中关键词的词频、网页块的文本内容厚度等几个方面来考虑。3)提出了基于组合特点的主题块辨识算法。对网页分块后,本文首先借助SVM按照网页块的视觉特点预测网页块是否为主题块,然后借助BBM25算法估算每位网页块内容与主题的相关性权重值,将权重值与找寻的最佳阀值进行比较进而判定网页块是否为主题块,最后将这两种方法相结合,综合利用网页块的视觉特点和文本特点来判定其是否为主题块。通过实验,本文将基于组合特点的主题块辨识算法和基于视觉特点、基于文本特点的主题块辨识算法进行了对比,验证了本文提出的基于组合特点辨识主题块的算法的准确性和稳定性。
SmartCamera: SmartCamera 是一个 Android 相机拓
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-22 04:46
English
SmartCamera 是一个 Android 相机拓展库,提供了一个高度可订制的实时扫描模块才能实时采集并且辨识单反内物体边框是否吻合指定区域。如果认为还不错,欢迎 star,fork。
语言描述上去略显生硬,具体实现的功能如下图所示,适用于身份证,名片,文档等内容的扫描、自动拍摄而且剪裁。
你可以下载体验集成了 SmartCamera 的 《卡片备忘录》, 将卡片装进你的手机:
也可以下载 demo apk SmartCamera-Sample-debug.apk 体验:
实时扫描模块(SmartScanner)是本库的核心功能所在,配合单反 PreviewCallback 接口反弹的预览流和选框视图 MaskView 提供的选框区域 RectF,能以不错的性能实时判别出内容是否吻合选框。
为了更方便的使用 Android Camera,SmartCamera 以源码的形式引用了 Google 开源的 CameraView ,并且稍作更改以支持 Camera.PreviewCallback 回调来获取单反预览流。
SmartCameraView 继承于修改后的 CameraView,为其添加了一个选框遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。其中选框视图即是你听到的单反里面的那层选定框,并配备了一个由上到下的扫描疗效,当然你也可以实现 MaskViewImpl 接口来自定义选框视图。
你只要使用本库提供的 SmartCameraView 即可实现上述 Demo 中的疗效, 当然假如你的项目中早已实现了单反模块,你也可以直接使用 SmartScanner 来实现实时扫描疗效。
(你也可以关注我的另一个库 SmartCropper: 一个简单易用的智能图片剪裁库,适用于身份证,名片,文档等合照的剪裁。)
SmartCamera 原理剖析:Android 端单反视频流采集与实时边框辨识
扫描算法调优SmartScanner 提供了丰富的算法配置,使用者可以自己更改扫描算法以获得更好的适配性,阅读附表一提供的各参数使用说明来获得更好的辨识疗效。
为了更方便、高效地调优算法,SmartScanner 贴心地为你提供了扫描预览模式,开启预览功能后,你可以通过 SmartScanner 获取每一帧处理的结果输出到 ImageView 中实时观察 native 层扫描的结果,其中白线区域即为边沿测量的结果,白线加粗区域即为辨识出的边框。
你的目标是通过调节 SmartScanner 的各个参数促使内容边界清晰可见,识别出的边框(白色加粗线段)准确无误。
注:SmartCamera 在各方面做了性能以及显存上的优化,但是出于不必要的性能资源浪费,算法参数调优结束后请关掉预览模式。
接入
1.根目录下的 build.gradle 添加:
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了 JNI, 请防止混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入单反布局,并启动单反(必要时启动预览)
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注:若开启了预览别忘了调用相应开启、结束预览的技巧。
2. 修改扫描模块参数(可选,调优算法,同时按第4步中开启预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注: 修改参数后别忘掉通知 native 层重新加载参数: SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,若要更改默认的视图, 或要更改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width 查看全部
SmartCamera: SmartCamera 是一个 Android 相机拓
English
SmartCamera 是一个 Android 相机拓展库,提供了一个高度可订制的实时扫描模块才能实时采集并且辨识单反内物体边框是否吻合指定区域。如果认为还不错,欢迎 star,fork。
语言描述上去略显生硬,具体实现的功能如下图所示,适用于身份证,名片,文档等内容的扫描、自动拍摄而且剪裁。
你可以下载体验集成了 SmartCamera 的 《卡片备忘录》, 将卡片装进你的手机:
也可以下载 demo apk SmartCamera-Sample-debug.apk 体验:
实时扫描模块(SmartScanner)是本库的核心功能所在,配合单反 PreviewCallback 接口反弹的预览流和选框视图 MaskView 提供的选框区域 RectF,能以不错的性能实时判别出内容是否吻合选框。
为了更方便的使用 Android Camera,SmartCamera 以源码的形式引用了 Google 开源的 CameraView ,并且稍作更改以支持 Camera.PreviewCallback 回调来获取单反预览流。
SmartCameraView 继承于修改后的 CameraView,为其添加了一个选框遮罩视图(MaskView)和一个实时扫描模块(SmartScanner)。其中选框视图即是你听到的单反里面的那层选定框,并配备了一个由上到下的扫描疗效,当然你也可以实现 MaskViewImpl 接口来自定义选框视图。
你只要使用本库提供的 SmartCameraView 即可实现上述 Demo 中的疗效, 当然假如你的项目中早已实现了单反模块,你也可以直接使用 SmartScanner 来实现实时扫描疗效。
(你也可以关注我的另一个库 SmartCropper: 一个简单易用的智能图片剪裁库,适用于身份证,名片,文档等合照的剪裁。)
SmartCamera 原理剖析:Android 端单反视频流采集与实时边框辨识
扫描算法调优SmartScanner 提供了丰富的算法配置,使用者可以自己更改扫描算法以获得更好的适配性,阅读附表一提供的各参数使用说明来获得更好的辨识疗效。
为了更方便、高效地调优算法,SmartScanner 贴心地为你提供了扫描预览模式,开启预览功能后,你可以通过 SmartScanner 获取每一帧处理的结果输出到 ImageView 中实时观察 native 层扫描的结果,其中白线区域即为边沿测量的结果,白线加粗区域即为辨识出的边框。
你的目标是通过调节 SmartScanner 的各个参数促使内容边界清晰可见,识别出的边框(白色加粗线段)准确无误。
注:SmartCamera 在各方面做了性能以及显存上的优化,但是出于不必要的性能资源浪费,算法参数调优结束后请关掉预览模式。
接入
1.根目录下的 build.gradle 添加:
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
2.添加依赖
dependencies {
implementation 'com.github.pqpo:SmartCamera:v2.0.0'
}
注意:由于使用了 JNI, 请防止混淆
-keep class me.pqpo.smartcameralib.**{*;}
使用1. 引入单反布局,并启动单反(必要时启动预览)
@Override
protected void onResume() {
super.onResume();
mCameraView.start();
mCameraView.startScan();
}
@Override
protected void onPause() {
mCameraView.stop();
super.onPause();
if (alertDialog != null) {
alertDialog.dismiss();
}
mCameraView.stopScan();
}
注:若开启了预览别忘了调用相应开启、结束预览的技巧。
2. 修改扫描模块参数(可选,调优算法,同时按第4步中开启预览模式)
扫描模块各个参数含义详见附录一
private void initScannerParams() {
SmartScanner.DEBUG = true;
SmartScanner.detectionRatio = 0.1f;
SmartScanner.checkMinLengthRatio = 0.8f;
SmartScanner.cannyThreshold1 = 20;
SmartScanner.cannyThreshold2 = 50;
SmartScanner.houghLinesThreshold = 130;
SmartScanner.houghLinesMinLineLength = 80;
SmartScanner.houghLinesMaxLineGap = 10;
SmartScanner.firstGaussianBlurRadius = 3;
SmartScanner.secondGaussianBlurRadius = 3;
SmartScanner.maxSize = 300;
SmartScanner.angleThreshold = 5;
// don't forget reload params
SmartScanner.reloadParams();
}
注: 修改参数后别忘掉通知 native 层重新加载参数: SmartScanner.reloadParams();
3. 配置遮罩选框视图(可选,若要更改默认的视图, 或要更改选框区域)
配置 MaskView 各个方法的含义详见附录二
<p>final MaskView maskView = (MaskView) mCameraView.getMaskView();;
maskView.setMaskLineColor(0xff00adb5);
maskView.setShowScanLine(true);
maskView.setScanLineGradient(0xff00adb5, 0x0000adb5);
maskView.setMaskLineWidth(2);
maskView.setMaskRadius(5);
maskView.setScanSpeed(6);
maskView.setScanGradientSpread(80);
mCameraView.post(new Runnable() {
@Override
public void run() {
int width = mCameraView.getWidth();
int height = mCameraView.getHeight();
if (width
Elvin百度采集 绿色免费版v2020
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-21 23:06
Elvin百度Url采集器是一款网路采集软件,无需安装才能使用,只需用户输入自己想要采集数据的关键词,就能找出一堆按照百度搜索引擎得出的相关目标站,非常适宜站长们使用。
软件介绍
Elvin百度采集软件是一款专门为用户打算的百度数据PC端采集免费版软件,使用方式很简单,线上下载该软件,随采集数据,自动采集,去除重复。
其使用特别的简单明了,大家只须要打开该工具,然后输入关键词即可全手动的采集了,采集完毕会保持在软件根目录
软件特色
智能辨识数据
智能模式:基于人工智能算法,只需输入网址能够智能辨识列表数据、表格数据和分页按键,不需要配置任何采集规则,一键采集。
自动辨识:列表、表格、链接、图片、价格等
可视化点击,简单上手
流程图模式:只需按照软件提示在页面中进行点击操作,完全符合人为浏览网页的思维方法,简单几步即可生成复杂的采集规则,结合智能辨识算法,任何网页的数据都能轻松采集。
可模拟操作: 输入文本、点击、移动滑鼠、下拉框、滚动页面、等待加载、循环操作和判别条件等。
支持多种数据导入方法
采集结果可以导入到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。 查看全部
Elvin百度采集 绿色免费版v2020
Elvin百度Url采集器是一款网路采集软件,无需安装才能使用,只需用户输入自己想要采集数据的关键词,就能找出一堆按照百度搜索引擎得出的相关目标站,非常适宜站长们使用。
软件介绍
Elvin百度采集软件是一款专门为用户打算的百度数据PC端采集免费版软件,使用方式很简单,线上下载该软件,随采集数据,自动采集,去除重复。
其使用特别的简单明了,大家只须要打开该工具,然后输入关键词即可全手动的采集了,采集完毕会保持在软件根目录
软件特色
智能辨识数据
智能模式:基于人工智能算法,只需输入网址能够智能辨识列表数据、表格数据和分页按键,不需要配置任何采集规则,一键采集。
自动辨识:列表、表格、链接、图片、价格等
可视化点击,简单上手
流程图模式:只需按照软件提示在页面中进行点击操作,完全符合人为浏览网页的思维方法,简单几步即可生成复杂的采集规则,结合智能辨识算法,任何网页的数据都能轻松采集。
可模拟操作: 输入文本、点击、移动滑鼠、下拉框、滚动页面、等待加载、循环操作和判别条件等。
支持多种数据导入方法
采集结果可以导入到本地,支持TXT、EXCEL、CSV和HTML文件格式,也可以直接发布到数据库(MySQL、MongoDB、SQL Server、PostgreSQL)供您使用。
优采云采集器 v2.8.0.0 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 500 次浏览 • 2020-08-20 08:33
优采云采集器是一款十分简单的网页数据采集工具,它具有可视化的工作界面,用户通过键盘就可以完成对网页数据的采集,该程序的使用门槛十分低,任何用户都可以轻松使用它就行数据采集而不需要用户拥有爬虫程序的编撰能力;通过这款软件,用户可以在大多数网站中采集数据,包括可以在一些单页应用Ajax加载的动态网站中获取用户须要的数据信息;软件中外置高速的浏览器引擎,用户可以自由切换多种浏览模式,让用户轻松以一个直观的方法去对网站网页进行采集;该程序安全无毒,使用简单,需要的同学欢迎下载使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多个搜集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能辨识:可以手动辨识网页列表,采集数组,页面等。
5、拦截恳求:自定义拦截的域名,以便捷对场外广告的过滤,提高搜集速率。
6、各种数据导入:可以导入到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件特色
零门槛
即使是不会网路爬虫技术,也可以轻松浏览互联网网站并搜集网站数据,软件操作简单,可通过键盘点击的形式轻松选定要抓取的内容。
多引擎,高速,稳定
内置于高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地搜集数据。它还具有一个外置的JSON引擎,该引擎无需剖析JSON数据结构并直观地选择JSON内容。
先进的智能算法
先进的智能算法可以生成目标元素XPath,自动辨识网页列表,并手动辨识分页中的下一页按键。 它不需要剖析Web恳求和源代码,但是支持更多的Web页面搜集。
适用于各类网站
它可以搜集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方式
步骤1:设定起始网址
要搜集网站数据,首先,我们须要设置步入搜集的URL。例如,如果要搜集网站的国外新闻,则应将起始URL设置为国外新闻栏列表的URL,但是一般不会将网站的主页设置为起始地址,因为主页一般收录许多列表,例如最新文章,热门文章和推荐文章Chapter和其他列表块,这些列表块中显示的内容也十分有限。一般来说,采集这种列表时难以搜集完整的信息。
接下来,我们以新浪新闻集为例,从新浪首页查找国外新闻。但是,此列首页上的内容依然太混乱,并且分为三个子列
让我们看一看“内地新闻”的子栏目报导
此列页面收录带有分页的内容列表。通过切换分页,我们可以搜集此列下的所有文章,因此此列表页面特别适宜我们搜集起始URL。
现在,我们将在任务编辑框的步骤1上将列表URL复制到文本框中。
如果您要在一个任务中同时搜集国外新闻的其他子列,您还可以复制其他两个子列的列表地址,因为这些子列的格式相像。但是,为了易于导入或发布分类数据,通常不建议将多个列的内容混和在一起。
对于起始URL,我们还可以从txt文件中批量添加或导出。例如,如果我们要搜集前五个页面,我们还可以通过这些方法自定义五个起始页面
应当注意,如果在此处自定义多个分页列表,则在后续的搜集配置上将不会启用分页。通常,当我们要搜集列下的所有文章时,我们仅须要将列的第一页定义为起始URL。如果在后续的搜集配置中启用了分页,则可以搜集每位分页列表的数据。
步骤2:①自动生成列表和数组
进入第二步后,对于个别网页,惰性搜集器将智能剖析页面列表,并手动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删掉一些不必要的数组
单击图中的三角形符号以弹出该数组的详尽采集配置。 点击上方的删掉按键以删掉该数组。 其余参数将在以下各章中分别介绍。
如果个别网页手动生成的列表数据不是我们想要的数据,则可以单击“清除数组”以消除所有生成的数组。
如果我们的列表不是自动选择的,那么它将手动列举。 如果要取消突出显示的列表框,可以单击“查找列表-列出XPath”,清除其中的XPath,然后确认。
②手动生成列表
单击“搜索列表”按钮,然后选择“手动选择列表”
按提示,然后用键盘左键单击网页列表中的第一行数据
单击第一行,然后按提示单击第二行或其他类似的行
单击列表中的任意两行后,整个列表将突出显示。 同时,列表中的数组也将生成。 如果生成的数组不正确,请单击“清除数组”以消除下边的所有数组。 下一章将介绍怎么自动选择数组。
③手动生成主键
点击“添加数组”按钮
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用键盘左键单击标题
当您单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。 如果您只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将手动生成标题和链接地址数组,并在数组列表中显示提取的数组内容。 单击顶部表格中数组的标题时,匹配的内容将在网页上以红色背景突出显示。
如果标签列表中还有其他数组,请单击“添加数组”,然后重复上述操作。
④分页设置
当列表具有分页时,启用分页后可以搜集所有分页列表数据。
页面分页有两种
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,可以步入下一页,例如之前在新浪新闻列表中的分页 查看全部
优采云采集器 v2.8.0.0 官方版
优采云采集器是一款十分简单的网页数据采集工具,它具有可视化的工作界面,用户通过键盘就可以完成对网页数据的采集,该程序的使用门槛十分低,任何用户都可以轻松使用它就行数据采集而不需要用户拥有爬虫程序的编撰能力;通过这款软件,用户可以在大多数网站中采集数据,包括可以在一些单页应用Ajax加载的动态网站中获取用户须要的数据信息;软件中外置高速的浏览器引擎,用户可以自由切换多种浏览模式,让用户轻松以一个直观的方法去对网站网页进行采集;该程序安全无毒,使用简单,需要的同学欢迎下载使用。
软件功能
1、可视化向导:自动为所有集合元素生成集合数据。
2、计划任务:灵活定义运行时间,自动运行。
3、多引擎支持:支持多个搜集引擎,内置的高速浏览器内核,HTTP引擎,JSON引擎。
4、智能辨识:可以手动辨识网页列表,采集数组,页面等。
5、拦截恳求:自定义拦截的域名,以便捷对场外广告的过滤,提高搜集速率。
6、各种数据导入:可以导入到TXT,Excel,mysql,SQL Server,SQLite,access,网站等。
软件特色
零门槛
即使是不会网路爬虫技术,也可以轻松浏览互联网网站并搜集网站数据,软件操作简单,可通过键盘点击的形式轻松选定要抓取的内容。
多引擎,高速,稳定
内置于高速浏览器引擎中,您也可以切换到HTTP引擎模式以更有效地搜集数据。它还具有一个外置的JSON引擎,该引擎无需剖析JSON数据结构并直观地选择JSON内容。
先进的智能算法
先进的智能算法可以生成目标元素XPath,自动辨识网页列表,并手动辨识分页中的下一页按键。 它不需要剖析Web恳求和源代码,但是支持更多的Web页面搜集。
适用于各类网站
它可以搜集99%的Internet站点,包括动态类型,例如单页应用程序Ajax加载。
使用方式
步骤1:设定起始网址
要搜集网站数据,首先,我们须要设置步入搜集的URL。例如,如果要搜集网站的国外新闻,则应将起始URL设置为国外新闻栏列表的URL,但是一般不会将网站的主页设置为起始地址,因为主页一般收录许多列表,例如最新文章,热门文章和推荐文章Chapter和其他列表块,这些列表块中显示的内容也十分有限。一般来说,采集这种列表时难以搜集完整的信息。
接下来,我们以新浪新闻集为例,从新浪首页查找国外新闻。但是,此列首页上的内容依然太混乱,并且分为三个子列
让我们看一看“内地新闻”的子栏目报导
此列页面收录带有分页的内容列表。通过切换分页,我们可以搜集此列下的所有文章,因此此列表页面特别适宜我们搜集起始URL。
现在,我们将在任务编辑框的步骤1上将列表URL复制到文本框中。
如果您要在一个任务中同时搜集国外新闻的其他子列,您还可以复制其他两个子列的列表地址,因为这些子列的格式相像。但是,为了易于导入或发布分类数据,通常不建议将多个列的内容混和在一起。
对于起始URL,我们还可以从txt文件中批量添加或导出。例如,如果我们要搜集前五个页面,我们还可以通过这些方法自定义五个起始页面
应当注意,如果在此处自定义多个分页列表,则在后续的搜集配置上将不会启用分页。通常,当我们要搜集列下的所有文章时,我们仅须要将列的第一页定义为起始URL。如果在后续的搜集配置中启用了分页,则可以搜集每位分页列表的数据。
步骤2:①自动生成列表和数组
进入第二步后,对于个别网页,惰性搜集器将智能剖析页面列表,并手动突出显示页面列表并生成列表数据,例如
然后我们可以修剪数据,例如删掉一些不必要的数组
单击图中的三角形符号以弹出该数组的详尽采集配置。 点击上方的删掉按键以删掉该数组。 其余参数将在以下各章中分别介绍。
如果个别网页手动生成的列表数据不是我们想要的数据,则可以单击“清除数组”以消除所有生成的数组。
如果我们的列表不是自动选择的,那么它将手动列举。 如果要取消突出显示的列表框,可以单击“查找列表-列出XPath”,清除其中的XPath,然后确认。
②手动生成列表
单击“搜索列表”按钮,然后选择“手动选择列表”
按提示,然后用键盘左键单击网页列表中的第一行数据
单击第一行,然后按提示单击第二行或其他类似的行
单击列表中的任意两行后,整个列表将突出显示。 同时,列表中的数组也将生成。 如果生成的数组不正确,请单击“清除数组”以消除下边的所有数组。 下一章将介绍怎么自动选择数组。
③手动生成主键
点击“添加数组”按钮
在列表的任何行中单击要提取的元素,例如标题和链接地址,然后用键盘左键单击标题
当您单击Web链接时,系统将提示您是否获取链接地址
如果要提取链接的标题和地址,请单击“是”。 如果您只想提取标题文本,请单击“否”。在这里,我们单击“是”。
系统将手动生成标题和链接地址数组,并在数组列表中显示提取的数组内容。 单击顶部表格中数组的标题时,匹配的内容将在网页上以红色背景突出显示。
如果标签列表中还有其他数组,请单击“添加数组”,然后重复上述操作。
④分页设置
当列表具有分页时,启用分页后可以搜集所有分页列表数据。
页面分页有两种
常规分页:有一个分页栏,并显示“下一页”按钮。单击后,可以步入下一页,例如之前在新浪新闻列表中的分页
飓风算法是哪些?网站如何规避百度飓风算法?
采集交流 • 优采云 发表了文章 • 0 个评论 • 188 次浏览 • 2020-08-19 23:13
有些网站大量采集内容,或发布低质量的伪原创,影响了优质原创网站的生存空间。这样会伤害了用户的使用体验,无法提升用户的黏度,长期发展下去,势必会影响了互联网良性健康的发展。因此,在2017年7月7日,百度推出了飓风算法,打压以恶劣采集为主要内容来源的网站,进而促使搜索生态良性地发展。下面纵横SEO给你们讲讲飓风算法到底是什么?
飓风算法是百度搜索针对大量采集内容的网站,而推出的一种搜索算法,是为了打压个别网站恶劣采集内容,而影响用户的使用体验的网站,目的是为了营造良好互联网环境,促进搜索生态良性发展。
百度算法:飓风算法1.0发布时间:2017年7月7日主要内容:是为了严厉严打以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底消除恶劣采集链接,给优质原创内容提供更多展示机会,促进搜索生态良性发展。
百度算法:飓风算法2.0发布时间:2018年9月13日主要内容:是为了保障搜索用户的浏览体验,保护搜索生态的健康发展、对于违法网站,百度搜索会根据问题的恶劣程度有相应的限制搜索诠释的处理。
现在,纵横SEO来给你们具体谈谈怎样规避被飓风算法,应怎样撰写优质文章?下面以4点来具体剖析。
就是不耗费时间与精力只在别人的文章上加以修饰,例如更改个别词语,或者使用多篇文章进行东拼西凑而成等,对用户没有附加价值。
原创文章确实比伪原创文章难写,但是并不是要求所有的原创文章就是可行的,原创文章也要符合 符合主题以及中心思想,这样就能为用户所接纳。尽量避免用户不喜欢的内容,尽可能的把用户所须要的内容深入撰写,体现内容价值。
自从飓风算法颁布,一些网站就被中招,对于真正没有采集内容的网站,一经中招,就只能重新整治其网站及重新推广,而被误杀的网站,可以通过反馈中心进行申述。
(1)增加页面用户点评模块:可以在用户阅读完以后,了解用户的真实看法与意见,那么这部份点评内容都会成为网页内容的一部分,产生了额外价值。
(2)增加内容推荐模块:根据网页主题,添加相关的内容模块,让文章的内容愈加丰富饱和等,可以使用户、可以愈发详尽完整的了解风波的发展。
最后,纵横SEO给诸位站长一点意见,就是网站一定要绑定熊掌号,文章发布后,第一时间递交给熊掌号,这样就能保证你的文章被百度第一时间抓取到。 查看全部
飓风算法是哪些?网站如何规避百度飓风算法?
有些网站大量采集内容,或发布低质量的伪原创,影响了优质原创网站的生存空间。这样会伤害了用户的使用体验,无法提升用户的黏度,长期发展下去,势必会影响了互联网良性健康的发展。因此,在2017年7月7日,百度推出了飓风算法,打压以恶劣采集为主要内容来源的网站,进而促使搜索生态良性地发展。下面纵横SEO给你们讲讲飓风算法到底是什么?
飓风算法是百度搜索针对大量采集内容的网站,而推出的一种搜索算法,是为了打压个别网站恶劣采集内容,而影响用户的使用体验的网站,目的是为了营造良好互联网环境,促进搜索生态良性发展。
百度算法:飓风算法1.0发布时间:2017年7月7日主要内容:是为了严厉严打以恶劣采集为内容主要来源的网站,同时百度搜索将从索引库中彻底消除恶劣采集链接,给优质原创内容提供更多展示机会,促进搜索生态良性发展。
百度算法:飓风算法2.0发布时间:2018年9月13日主要内容:是为了保障搜索用户的浏览体验,保护搜索生态的健康发展、对于违法网站,百度搜索会根据问题的恶劣程度有相应的限制搜索诠释的处理。
现在,纵横SEO来给你们具体谈谈怎样规避被飓风算法,应怎样撰写优质文章?下面以4点来具体剖析。
就是不耗费时间与精力只在别人的文章上加以修饰,例如更改个别词语,或者使用多篇文章进行东拼西凑而成等,对用户没有附加价值。
原创文章确实比伪原创文章难写,但是并不是要求所有的原创文章就是可行的,原创文章也要符合 符合主题以及中心思想,这样就能为用户所接纳。尽量避免用户不喜欢的内容,尽可能的把用户所须要的内容深入撰写,体现内容价值。
自从飓风算法颁布,一些网站就被中招,对于真正没有采集内容的网站,一经中招,就只能重新整治其网站及重新推广,而被误杀的网站,可以通过反馈中心进行申述。
(1)增加页面用户点评模块:可以在用户阅读完以后,了解用户的真实看法与意见,那么这部份点评内容都会成为网页内容的一部分,产生了额外价值。
(2)增加内容推荐模块:根据网页主题,添加相关的内容模块,让文章的内容愈加丰富饱和等,可以使用户、可以愈发详尽完整的了解风波的发展。
最后,纵横SEO给诸位站长一点意见,就是网站一定要绑定熊掌号,文章发布后,第一时间递交给熊掌号,这样就能保证你的文章被百度第一时间抓取到。
中文网页手动分类综述
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-19 21:42
1.中文网页手动分类是从文本手动分类的基础上发展上去的,由于文本手动分类拥有比较成熟的技术,不少研究工作企图使用纯文本分类技术实现网页分类。孙建涛强调:用纯文本形式表示网页是困难的,也是不合理的,因为网页收录的信息比纯文本收录的信息要丰富得多;用不同形式表示网页之后再组合分类器的方式才能综合利用网页的特点,但各个分类器的性能难以估计,使用哪些组合策略也未能确定。董静等人提出了基于网页风格、形态和内容对网页分类的网页方式分类方式,从另外的方面对网页分类进行研究;范众等人提出一种用朴素贝叶斯协调分类器综合网页纯文本和其它结构信息的分类方式;试验结果证明组合后的分类器性能都有一定程度的提升;都云琪等人采用线性支持向量机(LSVM)学习算法,实现了一个英文文本手动分类系统,并对该系统进行了针对大规模真实文本的试验测试,结果发觉,系统的招回率较低,而准确率较高,该文对此结果进行了剖析,并提出一种采用训练中拒识样本信息对分类器输出进行改进的方式,试验表明,该方式有效地提升了系统的性能,取得了令人满意的结果。鲁明羽等提出一种网页摘要方式,以过滤网页中对分类有负面影响的干扰信息;刘卫红【基于内容与链接特点的英文垃圾网页分类】等提出了一种结合网页内容和链接方面的特点,采用机器学习对英文垃圾网页进行分类检查的方式。实验结果表明,该方式能有效地对英文垃圾网页分类;张义忠提出了一种SOFM(自组织特点映射)与LVQ(学习矢量量化)相结合的分类算法,利用一种新的网页表示方式,形成特点向量并应用于网页分类中。该方式充分利用了SOFM自组织的特性,同时又借助LVQ解决降维中测试样木的交迭问题。实验表明它除了具有较高的训练效率,同时有比较好的查全率和查准率;李滔等将粗糙集理论应用于网页分类,约简一个己知类别属性的训练集并得出判定规则,然后借助这种规则判断待分网页的类别。
2英文网页分类关键技术
2.1网页特点提取
特征提取在整个英文网页分类的过程中十分重要,是才能彰显网页分类核心思想的地方,特征提取的疗效直接影响分类的质量。特征提取就是对词条选择以后的词再度进行提取,提取这些能代表网页类别的词来构成用于分类的向量。特征提取的方式主要依据评估函数估算每位词条的值,再按照每位词条的值进行逆序排序,选择这些值较高的词条作为最后的特点。征提取的常用的评估函数有文档频度(DF)、信息增益(IG)、互信息(MI)、开方拟和检验(CHI)、期望交叉嫡(ECE)和术语硬度(TS)等【The processing technology of Chinese informationin Chinese search engineering】【Developments in automatic text retrieval】通过对上述5种精典特点选定方式的实验,结果表明【A Comparative Study onFeature Selection in Text Categorization】CHI和IG方式的疗效最佳;DF,IG和CHI的性能大体相当,都还能过滤掉85%以上的特点项;DF具有算法简单、质量高的优点,可以拿来替代CHI和IG;TS方式性能通常;MI方式的性能最差。进而的实验结果表明组合提取方式不但提升分类精度,还明显减短分类器训练时间。
2.2分类算法
分类算法是分类技术的核心部份,目前存在多种英文网页分类算法,朴素贝叶斯(NB),K一近邻(KNN ) 【A study of aproaches to hyertext categorization】、支持向量机(SVM )【,Text categorization with support vector machines:Learning with many】、决策树(Decision Tree)和神经网路(NN)等。
朴素贝叶斯(NB)算法首先估算特点词属于每位类别的先验概率,在分类新文本时,根据该先验机率估算该文本属于每位类别的后验机率,最后取后验概率最大的类别作为该文木所属的类别。很多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方式,结合模糊降维的朴素贝叶斯方式,贝叶斯层次分类法等。
K一近邻(KNN)是传统的模式识别算法,在文本分类方面得到了广泛的研究与应用。它通过估算文本间的相似度,找出训练集合中与测试文本最相仿的k个文本,即新文本的k个近邻,然后按照这k个文本的类别判断新文本的类别。
支持向量机(SVM)以结构风险最小化原则为理论基础。通过适当选择函数子集及其该子集中的判别函数让学习机的实际风险达到最小,保证了通过有限训练样本得到的小偏差分类器对独立测试集的测试偏差相对也小,从而得到一个具有最优分类能力和推广一能力的学习机。SVM算法具有较强的理论根据,在应用到文本分类时取得了挺好的实验结果。李蓉【SVM-KNN分类器—一种提升SVM分类精度的新方式】等提出了KNN与SVM相结合的分类算法,取得了更好的分类疗效。目前,比较有效的SVM实现方式包括Joachims的SVMlight系统和Platt的序列最小优化算法。 决策树(Decision Tree)是通过对新样本属性值的测试,从树的根节点开始,按照样本属性的取值,逐渐顺着决策树向上,直到树的叶节点,该叶节点表示的类别就是新样木的类别。决策树方式是数据挖掘中十分有效的分类方式,它具有较强的噪声排除能力及学习反义抒发能力。可以使用几种流行的归纳技术如C4.5 , CART , CHAID来构建决策树。 神经网络(NN)是一组联接的输入/输出单元,输入单元代表词条,输出单元表示文木的类别,单元之间的联接都有相应的残差。训练阶段,通过某种算法,如后向传播算法,调整残差,使得测试文本才能依据调整后的残差正确地学习。土煌等提出了基于RBf和决策树结合的分类法。
3.中文网页分类的评价指标
对于网页分类的效率评价标准,目前还没有真正权威和绝对理想的标准,通用的性能评价指标:召回率R (Recall)、准确率P(Precision)和F1评价。
召回率为分类的正确网页数和应有的网页数的比率,即该类样本被分类器正确辨识的几率。准确率统称为分类的精度,它是指手动分类和人工分类结果一致的网页所占的百分比。召回率和准确率不是独立的,通常为了获得比较高的召回率一般要牺牲准确率;同样,为了获得比较高的准确率一般要牺牲召回率。因此须要有一种综合考虑召回率和准确率的方式来对分类器进行评价。F1测度是常用的组合形式:F1= 2RP /(R + P) 。其实,网页数目非常巨大,单纯的查全率己经没有实际价值,查准率的意义也要作相应的变通;数据库规模,索引方式,用户界面响应时间应当列入评价体系作为评价指标。
4.中文网页分类系统简介
TRS网路信息需达系统(TRS InfoRadar)是北京托尔思信息技术股份有限公司开发,该系统实时监控和采集Internet网站内容,对采集到的信息手动进行过滤、分类和排重等智能化处理,最终将最新内容及时发布下来,实现统一的信息导航。同时提供包括全文、日期等在内的全方位信息查询。TRS InfoRadar集信息采集监控、网络舆情、竞争情报等多种功能于一体,被广泛地应用于政府、媒体、科研、企业等各个行业中。TRS InfoRadar在内容营运的垂直搜索应用、内容监管的网络舆情应用以及决策支持的竞争情报等方面的应用,将极大的提升组织对外部信息的获取效率,极大增加信息采集成本,全方位掌控环境脉动,并提升各个组织的快捷反应效能。
百度电子政务信息共享解决方案以百度先进的信息整合处理技术为核心,为政府外网和政府信息门户建设高性能信息共享平台,能够将相关地区、机构、组织等多种信息源的信息集中共享,让用户在一个地方即可获取到所须要的各类相关信息,使电子政务由”形象工程”变成”效益工程”,有效提升政府工作效率,大幅提高政府威信和公众形象。其具有强悍的信息采集能力、安全的信息浏览、准确的手动分类、全面的检索功能、丰富的检索结果展示和基于Web的系统管理平台的特性。
清华同方KSpider网路信息资源采集系统是一套功能强悍的网路信息资源开发借助与整合系统,可用于订制跟踪和监控互联网实时信息,建立可再利用的信息服务系统。KSpider才能从各类网路信息源,包括网页,BLOC、论坛等采集用户感兴趣的特定信息,经手动分类处理后,以多种形式提供给最终用户使用。KSpider才能快速及时地捕获用户所需的热点新闻、市场情报、行业信息、政策法规、学术文献等网路信息内容可广泛用于垂直搜索引擎、网络敏感信息监控、情报搜集、舆情剖析、行情跟踪等方面。
5结束语
随着因特网的迅速发展,中文网页手动分类成为搜索引擎实现分类查询的关键。这就要求英文网页手动分类技术在网页的处理方式、网页疗效辨识、分类精度和评价指标等方面有进一步的提升所以英文网页手动分类技术是一个常年而繁重的研究课题。 查看全部
中文网页手动分类综述
1.中文网页手动分类是从文本手动分类的基础上发展上去的,由于文本手动分类拥有比较成熟的技术,不少研究工作企图使用纯文本分类技术实现网页分类。孙建涛强调:用纯文本形式表示网页是困难的,也是不合理的,因为网页收录的信息比纯文本收录的信息要丰富得多;用不同形式表示网页之后再组合分类器的方式才能综合利用网页的特点,但各个分类器的性能难以估计,使用哪些组合策略也未能确定。董静等人提出了基于网页风格、形态和内容对网页分类的网页方式分类方式,从另外的方面对网页分类进行研究;范众等人提出一种用朴素贝叶斯协调分类器综合网页纯文本和其它结构信息的分类方式;试验结果证明组合后的分类器性能都有一定程度的提升;都云琪等人采用线性支持向量机(LSVM)学习算法,实现了一个英文文本手动分类系统,并对该系统进行了针对大规模真实文本的试验测试,结果发觉,系统的招回率较低,而准确率较高,该文对此结果进行了剖析,并提出一种采用训练中拒识样本信息对分类器输出进行改进的方式,试验表明,该方式有效地提升了系统的性能,取得了令人满意的结果。鲁明羽等提出一种网页摘要方式,以过滤网页中对分类有负面影响的干扰信息;刘卫红【基于内容与链接特点的英文垃圾网页分类】等提出了一种结合网页内容和链接方面的特点,采用机器学习对英文垃圾网页进行分类检查的方式。实验结果表明,该方式能有效地对英文垃圾网页分类;张义忠提出了一种SOFM(自组织特点映射)与LVQ(学习矢量量化)相结合的分类算法,利用一种新的网页表示方式,形成特点向量并应用于网页分类中。该方式充分利用了SOFM自组织的特性,同时又借助LVQ解决降维中测试样木的交迭问题。实验表明它除了具有较高的训练效率,同时有比较好的查全率和查准率;李滔等将粗糙集理论应用于网页分类,约简一个己知类别属性的训练集并得出判定规则,然后借助这种规则判断待分网页的类别。
2英文网页分类关键技术
2.1网页特点提取
特征提取在整个英文网页分类的过程中十分重要,是才能彰显网页分类核心思想的地方,特征提取的疗效直接影响分类的质量。特征提取就是对词条选择以后的词再度进行提取,提取这些能代表网页类别的词来构成用于分类的向量。特征提取的方式主要依据评估函数估算每位词条的值,再按照每位词条的值进行逆序排序,选择这些值较高的词条作为最后的特点。征提取的常用的评估函数有文档频度(DF)、信息增益(IG)、互信息(MI)、开方拟和检验(CHI)、期望交叉嫡(ECE)和术语硬度(TS)等【The processing technology of Chinese informationin Chinese search engineering】【Developments in automatic text retrieval】通过对上述5种精典特点选定方式的实验,结果表明【A Comparative Study onFeature Selection in Text Categorization】CHI和IG方式的疗效最佳;DF,IG和CHI的性能大体相当,都还能过滤掉85%以上的特点项;DF具有算法简单、质量高的优点,可以拿来替代CHI和IG;TS方式性能通常;MI方式的性能最差。进而的实验结果表明组合提取方式不但提升分类精度,还明显减短分类器训练时间。
2.2分类算法
分类算法是分类技术的核心部份,目前存在多种英文网页分类算法,朴素贝叶斯(NB),K一近邻(KNN ) 【A study of aproaches to hyertext categorization】、支持向量机(SVM )【,Text categorization with support vector machines:Learning with many】、决策树(Decision Tree)和神经网路(NN)等。
朴素贝叶斯(NB)算法首先估算特点词属于每位类别的先验概率,在分类新文本时,根据该先验机率估算该文本属于每位类别的后验机率,最后取后验概率最大的类别作为该文木所属的类别。很多学者对贝叶斯分类算法进行了改进,如结合潜在语义索引的贝叶斯方式,结合模糊降维的朴素贝叶斯方式,贝叶斯层次分类法等。
K一近邻(KNN)是传统的模式识别算法,在文本分类方面得到了广泛的研究与应用。它通过估算文本间的相似度,找出训练集合中与测试文本最相仿的k个文本,即新文本的k个近邻,然后按照这k个文本的类别判断新文本的类别。
支持向量机(SVM)以结构风险最小化原则为理论基础。通过适当选择函数子集及其该子集中的判别函数让学习机的实际风险达到最小,保证了通过有限训练样本得到的小偏差分类器对独立测试集的测试偏差相对也小,从而得到一个具有最优分类能力和推广一能力的学习机。SVM算法具有较强的理论根据,在应用到文本分类时取得了挺好的实验结果。李蓉【SVM-KNN分类器—一种提升SVM分类精度的新方式】等提出了KNN与SVM相结合的分类算法,取得了更好的分类疗效。目前,比较有效的SVM实现方式包括Joachims的SVMlight系统和Platt的序列最小优化算法。 决策树(Decision Tree)是通过对新样本属性值的测试,从树的根节点开始,按照样本属性的取值,逐渐顺着决策树向上,直到树的叶节点,该叶节点表示的类别就是新样木的类别。决策树方式是数据挖掘中十分有效的分类方式,它具有较强的噪声排除能力及学习反义抒发能力。可以使用几种流行的归纳技术如C4.5 , CART , CHAID来构建决策树。 神经网络(NN)是一组联接的输入/输出单元,输入单元代表词条,输出单元表示文木的类别,单元之间的联接都有相应的残差。训练阶段,通过某种算法,如后向传播算法,调整残差,使得测试文本才能依据调整后的残差正确地学习。土煌等提出了基于RBf和决策树结合的分类法。
3.中文网页分类的评价指标
对于网页分类的效率评价标准,目前还没有真正权威和绝对理想的标准,通用的性能评价指标:召回率R (Recall)、准确率P(Precision)和F1评价。
召回率为分类的正确网页数和应有的网页数的比率,即该类样本被分类器正确辨识的几率。准确率统称为分类的精度,它是指手动分类和人工分类结果一致的网页所占的百分比。召回率和准确率不是独立的,通常为了获得比较高的召回率一般要牺牲准确率;同样,为了获得比较高的准确率一般要牺牲召回率。因此须要有一种综合考虑召回率和准确率的方式来对分类器进行评价。F1测度是常用的组合形式:F1= 2RP /(R + P) 。其实,网页数目非常巨大,单纯的查全率己经没有实际价值,查准率的意义也要作相应的变通;数据库规模,索引方式,用户界面响应时间应当列入评价体系作为评价指标。
4.中文网页分类系统简介
TRS网路信息需达系统(TRS InfoRadar)是北京托尔思信息技术股份有限公司开发,该系统实时监控和采集Internet网站内容,对采集到的信息手动进行过滤、分类和排重等智能化处理,最终将最新内容及时发布下来,实现统一的信息导航。同时提供包括全文、日期等在内的全方位信息查询。TRS InfoRadar集信息采集监控、网络舆情、竞争情报等多种功能于一体,被广泛地应用于政府、媒体、科研、企业等各个行业中。TRS InfoRadar在内容营运的垂直搜索应用、内容监管的网络舆情应用以及决策支持的竞争情报等方面的应用,将极大的提升组织对外部信息的获取效率,极大增加信息采集成本,全方位掌控环境脉动,并提升各个组织的快捷反应效能。
百度电子政务信息共享解决方案以百度先进的信息整合处理技术为核心,为政府外网和政府信息门户建设高性能信息共享平台,能够将相关地区、机构、组织等多种信息源的信息集中共享,让用户在一个地方即可获取到所须要的各类相关信息,使电子政务由”形象工程”变成”效益工程”,有效提升政府工作效率,大幅提高政府威信和公众形象。其具有强悍的信息采集能力、安全的信息浏览、准确的手动分类、全面的检索功能、丰富的检索结果展示和基于Web的系统管理平台的特性。
清华同方KSpider网路信息资源采集系统是一套功能强悍的网路信息资源开发借助与整合系统,可用于订制跟踪和监控互联网实时信息,建立可再利用的信息服务系统。KSpider才能从各类网路信息源,包括网页,BLOC、论坛等采集用户感兴趣的特定信息,经手动分类处理后,以多种形式提供给最终用户使用。KSpider才能快速及时地捕获用户所需的热点新闻、市场情报、行业信息、政策法规、学术文献等网路信息内容可广泛用于垂直搜索引擎、网络敏感信息监控、情报搜集、舆情剖析、行情跟踪等方面。
5结束语
随着因特网的迅速发展,中文网页手动分类成为搜索引擎实现分类查询的关键。这就要求英文网页手动分类技术在网页的处理方式、网页疗效辨识、分类精度和评价指标等方面有进一步的提升所以英文网页手动分类技术是一个常年而繁重的研究课题。
数据采集器 - 互联网数据挖掘指引工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-08-17 14:08
今天,互联网已然成为我们生活/工作必需品的重中之重,每个人每晚都在和互联网打交道,都离不开互联网,现在都不敢想像我们的生活或工作离开了互联网是怎么样的一个场景,不过一定是一夜回到了原创社会,文化倒退五百年。
互联网涉及到每行每业,从政府部门到娱乐休闲再到衣食住行日常生活网购,都是围绕互联网在转,世界权威机构强调,目前的互联网数据已然达到几百兆兆,而且每晚都在成倍增长,这么庞大的数据就像宇宙中的小星星,里面隐藏了世界上百分之九十以上的信息资料,说是一个知识的宝库一点也不过份,但是这个宝库实在很大了,没有经过专业的数据搜集、过滤、处理、分析以及统计,你只能看见冰山一角,永远没法窥探概貌,只能眼睁睁的看着如此丰富的资源而无能为力,不能为你所用。
所以随着互联网的崛起,诞生了数据挖掘这个行业,并且也发布了许多与之相关的技术和研究成果。互联网数据挖掘和分类对于有用信息汇总、网络计费、流量工程、知识学习、网络安全等领域具有广泛应用价值。网民对这个行业寄寓厚望,希望通过数据挖掘剖析技术,轻易获得可用的网路资源。
但是真正要实现互联网数据的挖掘,看上去似乎很简单,其实困难重重。
1.上面也有说过,互联网的数据达到几百兆兆,把如此庞大的数据全部搜集并储存上去,如同挖一个水塘把大海的水都保存在水塘内,目前的技术和硬件都还没达到这个水平。
2.互联网的内容就像海浪一样,一直在波动,你很难从海浪中看见自己的倒影,也就是说你很难从互联网的动态资料中轻易抓到您要的全部资料。
3.互联网的数据结果复杂,很难捉住规律。这些数据可以是一个HTML网页,或者是一张图片、一份flash文件、也可以是一段声音、一段视频、甚至是一个压缩文件等等。
4.互联网的那么多海量信息,您须要的却可能只有一点点,还吞没在互联网这个知识的海洋深处,杂乱无章,无规律可循。就像大海的虾那么多,但您只须要捕获大黄鱼,可是这大黄鱼都藏在大海深处,还被各式各样的虾包围干扰,所以要把大海里的大黄鱼都过滤并抓出来,是个世界困局。
5.互联网的WEB页面数目很大,而且分布广泛,质量参差不齐,内容多元化,也给数据挖掘带来了重重困难。
说了这么多有没有吓住您,您是不是已然绝望了?没有关系,人民的智慧是无穷无尽的,而且这么多的知识海洋,我们也用不完,世界上99%的需求,都是只要搬开互联网知识海洋一角就已受用不尽。这就促使数据挖掘在技术层面上不需要很复杂就可以满足99%的需求,剩下的1%,就抛给科学家们去难受吧。
互联网数据,占很大比列都是以文字和图片的方式抒发的,而这种数据的表现形式,基本都是通过万维网的HTML的形式抒发,所以通常只要充分利用这几部份数据,就可以满足很大的数据挖掘需求,实际上那些早已提供了足够丰富的数据来源。
一般的应用,因为需求的明确性,数据挖掘目标都是十分清晰,只是人工搜集成本很高,耗时很长,所以要利用相关的软件支持。目前市面上数据挖掘软件形形色色,各有各的优势,根据需求不同,可以选购到最合适的工具,比如微搜微点采集器。
有些互联网数据挖掘工具功能太强悍,但须要繁杂的策略配置才可以满足需求用途,有些采集器外置了采集策略,但支持的范围有限,只局限于一些网站数据的抓取,数据抓取格式也比较固定,微搜微点采集器集成了几乎所有采集器的优势,这是一款由国外院校的计算机系著名院士的指导和经验丰富的资深软件研究人员合作开发的。
微搜微点采集器的优势在于数据采集的灵活性和操作上的简便性,并集成了多个采集引擎,可以快速搜索互联网页并过滤出符合条件的内容或图片,然后把内容或图片采集下来储存到本地c盘。
首先为何说灵活性是个优势呢,因为这款采集器可以兼容各类HTML环境,互联网上99.9%的网页资料都能采集,可以支持手动翻页、过滤干扰信息、跨网页采集、精准定位(这点很重要,有些采集器就由于适应不了特殊的HTML标签,导致定位错误,采集到的数据不准)、可以模拟点击按键、模拟输入操作、识别同一个网站的不同的HTML框架、并能找出之后过滤出目标URL以及目录URL,进行深度采集。
其次为何说是简便性呢,用户不需要接触到采集策略,采集策略都是由官方维护,用户只要使用就行,就算对计算机一窍不通,只要会上网才能使用。 查看全部
数据采集器 - 互联网数据挖掘指引工具
今天,互联网已然成为我们生活/工作必需品的重中之重,每个人每晚都在和互联网打交道,都离不开互联网,现在都不敢想像我们的生活或工作离开了互联网是怎么样的一个场景,不过一定是一夜回到了原创社会,文化倒退五百年。
互联网涉及到每行每业,从政府部门到娱乐休闲再到衣食住行日常生活网购,都是围绕互联网在转,世界权威机构强调,目前的互联网数据已然达到几百兆兆,而且每晚都在成倍增长,这么庞大的数据就像宇宙中的小星星,里面隐藏了世界上百分之九十以上的信息资料,说是一个知识的宝库一点也不过份,但是这个宝库实在很大了,没有经过专业的数据搜集、过滤、处理、分析以及统计,你只能看见冰山一角,永远没法窥探概貌,只能眼睁睁的看着如此丰富的资源而无能为力,不能为你所用。
所以随着互联网的崛起,诞生了数据挖掘这个行业,并且也发布了许多与之相关的技术和研究成果。互联网数据挖掘和分类对于有用信息汇总、网络计费、流量工程、知识学习、网络安全等领域具有广泛应用价值。网民对这个行业寄寓厚望,希望通过数据挖掘剖析技术,轻易获得可用的网路资源。
但是真正要实现互联网数据的挖掘,看上去似乎很简单,其实困难重重。
1.上面也有说过,互联网的数据达到几百兆兆,把如此庞大的数据全部搜集并储存上去,如同挖一个水塘把大海的水都保存在水塘内,目前的技术和硬件都还没达到这个水平。
2.互联网的内容就像海浪一样,一直在波动,你很难从海浪中看见自己的倒影,也就是说你很难从互联网的动态资料中轻易抓到您要的全部资料。
3.互联网的数据结果复杂,很难捉住规律。这些数据可以是一个HTML网页,或者是一张图片、一份flash文件、也可以是一段声音、一段视频、甚至是一个压缩文件等等。
4.互联网的那么多海量信息,您须要的却可能只有一点点,还吞没在互联网这个知识的海洋深处,杂乱无章,无规律可循。就像大海的虾那么多,但您只须要捕获大黄鱼,可是这大黄鱼都藏在大海深处,还被各式各样的虾包围干扰,所以要把大海里的大黄鱼都过滤并抓出来,是个世界困局。
5.互联网的WEB页面数目很大,而且分布广泛,质量参差不齐,内容多元化,也给数据挖掘带来了重重困难。
说了这么多有没有吓住您,您是不是已然绝望了?没有关系,人民的智慧是无穷无尽的,而且这么多的知识海洋,我们也用不完,世界上99%的需求,都是只要搬开互联网知识海洋一角就已受用不尽。这就促使数据挖掘在技术层面上不需要很复杂就可以满足99%的需求,剩下的1%,就抛给科学家们去难受吧。
互联网数据,占很大比列都是以文字和图片的方式抒发的,而这种数据的表现形式,基本都是通过万维网的HTML的形式抒发,所以通常只要充分利用这几部份数据,就可以满足很大的数据挖掘需求,实际上那些早已提供了足够丰富的数据来源。
一般的应用,因为需求的明确性,数据挖掘目标都是十分清晰,只是人工搜集成本很高,耗时很长,所以要利用相关的软件支持。目前市面上数据挖掘软件形形色色,各有各的优势,根据需求不同,可以选购到最合适的工具,比如微搜微点采集器。
有些互联网数据挖掘工具功能太强悍,但须要繁杂的策略配置才可以满足需求用途,有些采集器外置了采集策略,但支持的范围有限,只局限于一些网站数据的抓取,数据抓取格式也比较固定,微搜微点采集器集成了几乎所有采集器的优势,这是一款由国外院校的计算机系著名院士的指导和经验丰富的资深软件研究人员合作开发的。
微搜微点采集器的优势在于数据采集的灵活性和操作上的简便性,并集成了多个采集引擎,可以快速搜索互联网页并过滤出符合条件的内容或图片,然后把内容或图片采集下来储存到本地c盘。
首先为何说灵活性是个优势呢,因为这款采集器可以兼容各类HTML环境,互联网上99.9%的网页资料都能采集,可以支持手动翻页、过滤干扰信息、跨网页采集、精准定位(这点很重要,有些采集器就由于适应不了特殊的HTML标签,导致定位错误,采集到的数据不准)、可以模拟点击按键、模拟输入操作、识别同一个网站的不同的HTML框架、并能找出之后过滤出目标URL以及目录URL,进行深度采集。
其次为何说是简便性呢,用户不需要接触到采集策略,采集策略都是由官方维护,用户只要使用就行,就算对计算机一窍不通,只要会上网才能使用。
圣者网页电邮采集器V2.3.1官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-08-17 12:32
圣者网页电邮采集器是一款支持搜索邮箱地址并手动采集邮件的专业工具,它可以快速采集目标网站上所有页面的所有电邮地址,速度极快,推荐有须要的用户下载。
圣者网页电邮采集器基本简介
什么是网页邮件采集器?它是一个支持短信地址采集、邮箱地址搜索并保存到文件的工具,你只须要输入一个网站的其中一个网页地址(URL),它能够搜索这个网站的所有页面,然后搜集那些页面上出现的所有电邮地址并保存到指定文件。
圣者网页电邮采集器可以采集目标网站上所有页面及联接站的所有电邮地址,而这种电邮地址必须是不登录网站即可见到的,采集迅速高效,使用便捷快捷。圣者网页电邮地址采集器可以只导入须要的后缀邮箱,比如只导入QQ或则163邮箱,支持自定义,并且有替换功能,比如将#替换为@,欢迎专业级人士测试!
圣者网页电邮采集器功能介绍
1、只要填写一个网站里的其中一个页面的地址URL,它即可爬行这个网站的所有页面,并把这种页面所出现的电邮地址记录出来。
2、新增页面过滤(排它)功能,即:采集指定页面或不采集指定页面。
3、采集进度和结果缓存功能,在采集过程中,软件手动保存当前采集进度和采集结果,预防软件意外退出而导致数据遗失。
4、多线程爬行,用户可以按照具体情况定义多少线程去爬行一个网站。
5、界面简约友好,操作简单,免安装无插件红色软件。
6、实时保存采集结果,可以挂机无人值守地采集,一晚睡醒就可以采集成千上万电邮地址。
圣者网页电邮采集器使用方式
1、新建采集项目,
2、选择采集项目,
3、点击【开始采集】按钮,
4、采集完毕,导出数据。 查看全部
圣者网页电邮采集器V2.3.1官方版
圣者网页电邮采集器是一款支持搜索邮箱地址并手动采集邮件的专业工具,它可以快速采集目标网站上所有页面的所有电邮地址,速度极快,推荐有须要的用户下载。
圣者网页电邮采集器基本简介
什么是网页邮件采集器?它是一个支持短信地址采集、邮箱地址搜索并保存到文件的工具,你只须要输入一个网站的其中一个网页地址(URL),它能够搜索这个网站的所有页面,然后搜集那些页面上出现的所有电邮地址并保存到指定文件。
圣者网页电邮采集器可以采集目标网站上所有页面及联接站的所有电邮地址,而这种电邮地址必须是不登录网站即可见到的,采集迅速高效,使用便捷快捷。圣者网页电邮地址采集器可以只导入须要的后缀邮箱,比如只导入QQ或则163邮箱,支持自定义,并且有替换功能,比如将#替换为@,欢迎专业级人士测试!
圣者网页电邮采集器功能介绍
1、只要填写一个网站里的其中一个页面的地址URL,它即可爬行这个网站的所有页面,并把这种页面所出现的电邮地址记录出来。
2、新增页面过滤(排它)功能,即:采集指定页面或不采集指定页面。
3、采集进度和结果缓存功能,在采集过程中,软件手动保存当前采集进度和采集结果,预防软件意外退出而导致数据遗失。
4、多线程爬行,用户可以按照具体情况定义多少线程去爬行一个网站。
5、界面简约友好,操作简单,免安装无插件红色软件。
6、实时保存采集结果,可以挂机无人值守地采集,一晚睡醒就可以采集成千上万电邮地址。
圣者网页电邮采集器使用方式
1、新建采集项目,
2、选择采集项目,
3、点击【开始采集】按钮,
4、采集完毕,导出数据。
熊猫网页信息采集器 2.6 免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2020-08-17 11:33
熊猫网页信息采集器是一款专业的网页信息采集工具。需要一个信息采集器,那就下载熊猫网页信息采集器使用吧,利用精准搜索引擎的解析内核,对网页内容的仿浏览器解析,对网页框架内容和核心内容分离和抽取,对相像的页面进行有效对比,熊猫网页信息采集器使用上去便捷简单,如果你也须要那就来jz5u下载使用吧,别错过了哦!
熊猫网页信息采集器功能介绍
1、采集速度快
优采云采集器的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方外置浏览器访问的技术。使用自己研制的解析引擎
2、全方位的采集功能
浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容。支持图文混排对象的同时采集
3、面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的兄妹表结构。
4、结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以手动纠正模板和目标页面的不一致。
5、JS解析的手动判定辨识
现在好多网页都采用了ajax网页内容动态生成技术。此时仅仅借助网页源码,并不能获取须要的有效内容。此时就须要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对须要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速率效率太低,因此熊猫外置了智能判定功能,自动检测是否须要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
6、多模板手动适应能力
很多网站的内容页面会存在多个不同种类的模板,因此优采云采集器软件容许每位采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会手动匹配找寻最合适的参考模板拿来剖析内容页面。
7、实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用菜鸟提供实时帮助。因此优采云采集器软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触优采云采集器软件,也可以较轻松实现采集项目的配置工作。
8、分页内容的轻松合并
支持各类类型的分页模式,用户只须要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将须要分页合并的数组项勾选上分页合并项即可。如果页面内具有重复子项存在,则能手动在分页中找寻该重复子项,隐含手动进行分页内容合并。
熊猫网页信息采集器用途介绍
1、舆情监测
借助全部英文搜素引擎,轻松实现全网舆情信息的检测,信息覆盖面广。对于须要重点检测的网站,只须要录入网址即可实现检测。PC端独立运行,普通的联通PC即可胜任舆情检测工作。同时熊猫智能采集监测引擎,也是第三方舆情系统外置爬虫的首选。
2、大数据采集
熊猫拥有极高的采集速度和效率,是大数据采集场合的最优选择。同时熊猫独有的海量数据处理能力,可以应付大数据采集的须要。是大数据采集场合的首选
3、招标信息检测
利用熊猫智能采集监测引擎,可以轻松实现对招标信息发布网站的最新招标信息进行检测。优采云采集器,是招标信息检测软件的最优选择:操作容易、维护简单、结果直观便捷
4、客户资料搜集
利用熊猫可以轻松从网路中批量获取须要的顾客信息,利用熊猫的各种绕过防采集机制(,如熊猫独有的云采集功能),可以轻松绕过被采集网站的防采集机制。如58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站内容手动填充
熊猫是操作最简单的采集器,是诸多网站站长的首先。同时熊猫也是功能复杂的采集器,可以应用几乎所有的复杂网站的采集、搬家操作。 查看全部
熊猫网页信息采集器 2.6 免费版
熊猫网页信息采集器是一款专业的网页信息采集工具。需要一个信息采集器,那就下载熊猫网页信息采集器使用吧,利用精准搜索引擎的解析内核,对网页内容的仿浏览器解析,对网页框架内容和核心内容分离和抽取,对相像的页面进行有效对比,熊猫网页信息采集器使用上去便捷简单,如果你也须要那就来jz5u下载使用吧,别错过了哦!
熊猫网页信息采集器功能介绍
1、采集速度快
优采云采集器的采集速度是采集软件中最快的(之一)。不使用落后低效的正则匹配技术。也不使用第三方外置浏览器访问的技术。使用自己研制的解析引擎
2、全方位的采集功能
浏览器可见的内容都可以采集。采集的对象包括文字内容,图片,flash动漫视频等等各种网路内容。支持图文混排对象的同时采集
3、面向对象的采集方式
面向对象的采集方式。正文和回复内容同时采集的能力,分页的内容可轻松合并,采集内容可以是分散在多个页面内。结果可以是复杂的兄妹表结构。
4、结果数据完整度高
熊猫独有的多模板功能,确保结果数据完整不遗漏。独有的智能纠错模式,可以手动纠正模板和目标页面的不一致。
5、JS解析的手动判定辨识
现在好多网页都采用了ajax网页内容动态生成技术。此时仅仅借助网页源码,并不能获取须要的有效内容。此时就须要对被采集的页面执行JavaScript(JS)解析,获取JS执行后的结果代码。
熊猫支持对须要JS解析的页面,执行JS解析,获取JS解析后的实际内容。鉴于执行JS解析的速率效率太低,因此熊猫外置了智能判定功能,自动检测是否须要对被采集的页面执行JS解析,如果不需要的,尽量不使用低效的JS解析模式。
6、多模板手动适应能力
很多网站的内容页面会存在多个不同种类的模板,因此优采云采集器软件容许每位采集项目可以同时设置多个内容页面参考模板,在采集运行时,系统会手动匹配找寻最合适的参考模板拿来剖析内容页面。
7、实时帮助窗口
在采集项目设置环节,系统会在窗口右上显示与当前配置相关的实时帮助内容,为使用菜鸟提供实时帮助。因此优采云采集器软件的使用可以轻松上手。配合全程智能化辅助能力,即便是第一次接触优采云采集器软件,也可以较轻松实现采集项目的配置工作。
8、分页内容的轻松合并
支持各类类型的分页模式,用户只须要做两步就可以实现分页内容的合并:鼠标点选确认分页链接所在,将须要分页合并的数组项勾选上分页合并项即可。如果页面内具有重复子项存在,则能手动在分页中找寻该重复子项,隐含手动进行分页内容合并。
熊猫网页信息采集器用途介绍
1、舆情监测
借助全部英文搜素引擎,轻松实现全网舆情信息的检测,信息覆盖面广。对于须要重点检测的网站,只须要录入网址即可实现检测。PC端独立运行,普通的联通PC即可胜任舆情检测工作。同时熊猫智能采集监测引擎,也是第三方舆情系统外置爬虫的首选。
2、大数据采集
熊猫拥有极高的采集速度和效率,是大数据采集场合的最优选择。同时熊猫独有的海量数据处理能力,可以应付大数据采集的须要。是大数据采集场合的首选
3、招标信息检测
利用熊猫智能采集监测引擎,可以轻松实现对招标信息发布网站的最新招标信息进行检测。优采云采集器,是招标信息检测软件的最优选择:操作容易、维护简单、结果直观便捷
4、客户资料搜集
利用熊猫可以轻松从网路中批量获取须要的顾客信息,利用熊猫的各种绕过防采集机制(,如熊猫独有的云采集功能),可以轻松绕过被采集网站的防采集机制。如58、赶集、百姓网、阿里巴巴、慧聪等等。
5、众多站长:网站搬家、网站内容手动填充
熊猫是操作最简单的采集器,是诸多网站站长的首先。同时熊猫也是功能复杂的采集器,可以应用几乎所有的复杂网站的采集、搬家操作。

