
网页新闻抓取
网页新闻抓取( 2017年04月24日Python正则抓取新闻标题和链接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-01 03:16
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python定时抓取新闻标题和链接的方法示例
更新时间:2017年4月24日08:56:43 作者:我想要的闪耀
本文章主要介绍了Python正则抓取新闻标题和链接的方法,并结合具体实例分析了Python正则匹配页面元素和文件编写的相关操作技巧。有需要的朋友可以参考以下
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页新闻抓取(
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python定时抓取新闻标题和链接的方法示例
更新时间:2017年4月24日08:56:43 作者:我想要的闪耀
本文章主要介绍了Python正则抓取新闻标题和链接的方法,并结合具体实例分析了Python正则匹配页面元素和文件编写的相关操作技巧。有需要的朋友可以参考以下
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-30 20:18
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
项目源码托管在Github上:
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
环境使用方法
如果您想体验 GNE 的功能,请按照以下步骤操作:
安装 GNE
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
# 使用 pipenv 安装
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
使用 GNE
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz"}
开发环境
如果您需要参与本项目的开发,请按照以下步骤操作。
本项目使用 Pipenv 来管理 Python 的第三方库。如果你不知道Pipenv是什么,请点我跳转。
安装 Pipenv 后,请按照以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特别说明
项目代码中的example.py提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,以上的写法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
运行截图
网易新闻
今日头条
新浪新闻
观察者网
项目文件
GNE 常见问题问答
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
如果觉得GNE对你的日常发展或公司有帮助,请加作者微信mxqiuchen(或扫描下方二维码)并注明“GNE”,作者会拉你进群。
验证消息:GNE
论文修改
在使用Python实现这个提取器的过程中,发现论文中的公式和方法存在一些缺陷,会导致部分节点报错。我会单独写几篇文章文章来介绍这里的变化。请关注我的微信公众号:闻所未闻的代码:
查看全部
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
项目源码托管在Github上:
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:

目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
环境使用方法
如果您想体验 GNE 的功能,请按照以下步骤操作:
安装 GNE
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
# 使用 pipenv 安装
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
使用 GNE
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz"}
开发环境
如果您需要参与本项目的开发,请按照以下步骤操作。
本项目使用 Pipenv 来管理 Python 的第三方库。如果你不知道Pipenv是什么,请点我跳转。
安装 Pipenv 后,请按照以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特别说明
项目代码中的example.py提供了本项目的基本使用示例。

在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图

from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,以上的写法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
运行截图

网易新闻

今日头条

新浪新闻

观察者网

项目文件
GNE 常见问题问答
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
如果觉得GNE对你的日常发展或公司有帮助,请加作者微信mxqiuchen(或扫描下方二维码)并注明“GNE”,作者会拉你进群。
验证消息:GNE
论文修改
在使用Python实现这个提取器的过程中,发现论文中的公式和方法存在一些缺陷,会导致部分节点报错。我会单独写几篇文章文章来介绍这里的变化。请关注我的微信公众号:闻所未闻的代码:
网页新闻抓取(阿里云gt云栖社区主题地图(gt)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-28 03:16
阿里云>云栖社区>主题图>P>python爬取新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
python爬取新闻网站相关博客查看更多博客
Python爬虫入门教程9-100河北阳光行政投诉科
作者:Dream Eraser1430人浏览评论:02年前
1.河北阳光行政投诉科-之前的文章文章都是写图片相关的爬虫,今天写个留言板爬出来,再做一套数据分析案例教程到做好准备,作为一个河北人,遵守法律法规,投诉是必备的技能。那我们来看看我们河北人为什么要抱怨呢?网站 今天要爬取的地址
阅读全文
跟我一起开始使用python爬虫
作者:cxa1415 浏览评论人数:02年前
前几天想写一个文章的爬虫系列。我写它不是因为我很忙(不是因为我很懒)。趁着屋子里的凉意和平静的心,我想总结一下我目前遇到的情况。对于一些爬虫知识,本系列将从简单的爬虫开始,逐渐增加难度。同时,会总结反攀爬的方法,并通过具体的例子来展示不同的反攀爬现象和做法。
阅读全文
Python爬虫学习,记住抓包获取js和从js函数中取数据的过程
作者:云飞学编程1203人浏览评论:03年前
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。我大概看了一下,是js加载的,数据在js函数里,很有意思,就分了
阅读全文
常用python爬虫框架整理
作者:友弟1689人浏览评论:03年前
Python 中好用的爬虫框架一般都可以媲美小爬虫的需求。我是直接用requests库+bs4解决的。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架仅用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫采集CloudBlog网站的文章
作者:朱佩1423人浏览评论:04年前
本文使用python爬虫获取网站中的一个文章,包括标题、发表时间、作者、文章内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页的所有文章链接并存入URL集合中,然后一一访问这些采集的链接访问,再次解析
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》-第2章网络爬虫技能概述2.1 网络爬虫技能概述
作者:华章电脑1908人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第2章,2.1节,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。第2章网络爬虫技巧概述在上一章中,我们对网络爬虫有了初步的了解,那么网络爬虫的具体功能
阅读全文
Python爬虫系列(一)早教爬虫补充及总结
作者:盛开的山茶花 2838人浏览评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda。2、IDE:Pycharm、Pydev 3、 工具:Jupyter Notebook(安装Anaconda就会有)二、Python基础视频教程1、疯狂Python:
阅读全文
【蟒蛇爬虫】Selenium定向爬行老虎猛扑篮球海量精美图片
作者:肖洛洛4370人浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他经常访问虎扑篮球、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,手真的很痛。作为程序员,编写程序继续!
阅读全文 查看全部
网页新闻抓取(阿里云gt云栖社区主题地图(gt)(组图))
阿里云>云栖社区>主题图>P>python爬取新闻网站

推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
python爬取新闻网站相关博客查看更多博客
Python爬虫入门教程9-100河北阳光行政投诉科


作者:Dream Eraser1430人浏览评论:02年前
1.河北阳光行政投诉科-之前的文章文章都是写图片相关的爬虫,今天写个留言板爬出来,再做一套数据分析案例教程到做好准备,作为一个河北人,遵守法律法规,投诉是必备的技能。那我们来看看我们河北人为什么要抱怨呢?网站 今天要爬取的地址
阅读全文
跟我一起开始使用python爬虫


作者:cxa1415 浏览评论人数:02年前
前几天想写一个文章的爬虫系列。我写它不是因为我很忙(不是因为我很懒)。趁着屋子里的凉意和平静的心,我想总结一下我目前遇到的情况。对于一些爬虫知识,本系列将从简单的爬虫开始,逐渐增加难度。同时,会总结反攀爬的方法,并通过具体的例子来展示不同的反攀爬现象和做法。
阅读全文
Python爬虫学习,记住抓包获取js和从js函数中取数据的过程

作者:云飞学编程1203人浏览评论:03年前
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。我大概看了一下,是js加载的,数据在js函数里,很有意思,就分了
阅读全文
常用python爬虫框架整理

作者:友弟1689人浏览评论:03年前
Python 中好用的爬虫框架一般都可以媲美小爬虫的需求。我是直接用requests库+bs4解决的。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架仅用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫采集CloudBlog网站的文章


作者:朱佩1423人浏览评论:04年前
本文使用python爬虫获取网站中的一个文章,包括标题、发表时间、作者、文章内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页的所有文章链接并存入URL集合中,然后一一访问这些采集的链接访问,再次解析
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》-第2章网络爬虫技能概述2.1 网络爬虫技能概述

作者:华章电脑1908人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第2章,2.1节,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。第2章网络爬虫技巧概述在上一章中,我们对网络爬虫有了初步的了解,那么网络爬虫的具体功能
阅读全文
Python爬虫系列(一)早教爬虫补充及总结

作者:盛开的山茶花 2838人浏览评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda。2、IDE:Pycharm、Pydev 3、 工具:Jupyter Notebook(安装Anaconda就会有)二、Python基础视频教程1、疯狂Python:
阅读全文
【蟒蛇爬虫】Selenium定向爬行老虎猛扑篮球海量精美图片

作者:肖洛洛4370人浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他经常访问虎扑篮球、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,手真的很痛。作为程序员,编写程序继续!
阅读全文
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-25 09:16
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项之间的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用doc.select("div.list-hd")方法返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:

我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:

具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项之间的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:

首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用doc.select("div.list-hd")方法返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码

使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(网络爬虫的基本原理策略抓取策略(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-25 06:04
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
可以更形象地理解:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。爬虫爬取到这个庞大的网络所需要的资源后,通过一定的机制和容器进行存储。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从网上抓取网页信息。其中,通过URL下载队列调度器,通过一定时间或调度机制下载,通过多内存(DB)保存下载的目标资源。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接计数策略、Partial PageRank策略、OPIC策略、大站优先策略等等。
深度优先深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,然后选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
Breadth-first 广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
Best Priority Best Priority Search 策略根据一定的网页分析算法预测候选网址与目标页面的相似度,或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
反向链接计数策略反向链接计数是指其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
Partial PageRank Strategy Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,并且经过计算,将要爬取的URL队列中的URL按照PageRank值的大小排列,按照这个顺序爬取页面。如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,
OPIC 战略。该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
大站优先策略是将URL队列中的所有网页按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
总结:在实际运营过程中,往往不是单独选择某个策略,而是综合多个策略的优势,去渣滓,为业务实现相应的功能。
网络爬虫的另一个重要部分是网页分析。具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取动作,而不是关心从大范围的网页爬取中得到想要的目标网页,所以不详细分析在这里完成。
参考:
下一篇文章将讨论抓取腾讯新闻RSS网页的原理。请注意。 查看全部
网页新闻抓取(网络爬虫的基本原理策略抓取策略(一)_光明网)
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
可以更形象地理解:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。爬虫爬取到这个庞大的网络所需要的资源后,通过一定的机制和容器进行存储。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
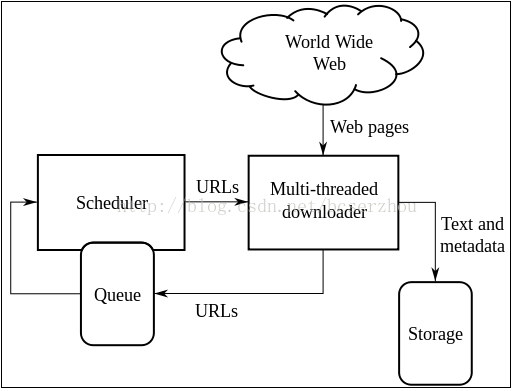
多线程下载器功能:从网上抓取网页信息。其中,通过URL下载队列调度器,通过一定时间或调度机制下载,通过多内存(DB)保存下载的目标资源。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接计数策略、Partial PageRank策略、OPIC策略、大站优先策略等等。
深度优先深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,然后选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
Breadth-first 广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
Best Priority Best Priority Search 策略根据一定的网页分析算法预测候选网址与目标页面的相似度,或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
反向链接计数策略反向链接计数是指其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
Partial PageRank Strategy Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,并且经过计算,将要爬取的URL队列中的URL按照PageRank值的大小排列,按照这个顺序爬取页面。如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,
OPIC 战略。该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
大站优先策略是将URL队列中的所有网页按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
总结:在实际运营过程中,往往不是单独选择某个策略,而是综合多个策略的优势,去渣滓,为业务实现相应的功能。
网络爬虫的另一个重要部分是网页分析。具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取动作,而不是关心从大范围的网页爬取中得到想要的目标网页,所以不详细分析在这里完成。
参考:
下一篇文章将讨论抓取腾讯新闻RSS网页的原理。请注意。
网页新闻抓取(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-25 06:00
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
网页新闻抓取(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
网页新闻抓取(网页资源提取功能很简单,您只要打开一个网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-24 00:05
你有没有想过批量保存网页上的图片,却只能一张一张的保存?你有没有想过批量保存网页的视频文件,但下载工具无法对文件进行分类的尴尬?如果你有这样的烦恼,最新的4.4.1版TT浏览器引入的新功能-网页资源提取,可以帮你轻松解决。
网页资源提取功能非常简单。您只需要打开一个网页,点击工具栏上的“网页提取”按钮,就会在网页顶部打开资源提取器。您可以轻松提取您想要的各种网络资源。方便吗?文本、图片、Flash文件一应俱全,视频文件、音频文件、文档文件、压缩文件、EXE文件等其他文件都可以在“其他解压”中找到,你想要的都在这里!
轻松提取网络资源。腾讯TT4.4.版本1发布
下载TT浏览器TT4.4.版本1
温馨提示:TT浏览器一直秉承腾讯“一切以用户价值为导向”的核心经营理念,注重用户体验,为用户提供最想要、最有价值的功能。网页资源提取功能就是这一理念的最好体现。该功能是指打开的网页,可以分别提取网页上的文字、图片、音频、视频、Flash等文件,并可以批量保存和下载。真正想用户所想,实用,方便,好用。
TT4.4.1 更新信息:
1.独创网页资源提取功能,自由提取图片、Flash、媒体文件
2. 推出强大的采集管理器,更轻松地管理本地和网络采集
3. 添加空白页面快速链接,一键直接访问最常访问的网址
4.优化自定义背景图片功能,图片随心拖动缩放
5、优化新窗口原有独立视频功能,增加自定义视频网站
6.增加查看当前所有标签的功能,多标签管理更清晰
7.优化TT上QQ登录详情,更贴心满足您的需求 查看全部
网页新闻抓取(网页资源提取功能很简单,您只要打开一个网页(组图))
你有没有想过批量保存网页上的图片,却只能一张一张的保存?你有没有想过批量保存网页的视频文件,但下载工具无法对文件进行分类的尴尬?如果你有这样的烦恼,最新的4.4.1版TT浏览器引入的新功能-网页资源提取,可以帮你轻松解决。
网页资源提取功能非常简单。您只需要打开一个网页,点击工具栏上的“网页提取”按钮,就会在网页顶部打开资源提取器。您可以轻松提取您想要的各种网络资源。方便吗?文本、图片、Flash文件一应俱全,视频文件、音频文件、文档文件、压缩文件、EXE文件等其他文件都可以在“其他解压”中找到,你想要的都在这里!

轻松提取网络资源。腾讯TT4.4.版本1发布
下载TT浏览器TT4.4.版本1
温馨提示:TT浏览器一直秉承腾讯“一切以用户价值为导向”的核心经营理念,注重用户体验,为用户提供最想要、最有价值的功能。网页资源提取功能就是这一理念的最好体现。该功能是指打开的网页,可以分别提取网页上的文字、图片、音频、视频、Flash等文件,并可以批量保存和下载。真正想用户所想,实用,方便,好用。
TT4.4.1 更新信息:
1.独创网页资源提取功能,自由提取图片、Flash、媒体文件
2. 推出强大的采集管理器,更轻松地管理本地和网络采集
3. 添加空白页面快速链接,一键直接访问最常访问的网址
4.优化自定义背景图片功能,图片随心拖动缩放
5、优化新窗口原有独立视频功能,增加自定义视频网站
6.增加查看当前所有标签的功能,多标签管理更清晰
7.优化TT上QQ登录详情,更贴心满足您的需求
网页新闻抓取(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 03:01
当今最强的网页抓取、内容获取和专业的新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
网页新闻抓取(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业的新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 03:01
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网络获取消息(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转化为视图视图显示,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的WEB应用中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户界面) ),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前显示新闻的适配器。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml");// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
将XML资源文件转换为视图有3种方式,底层实现是一样的,这里是使用方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView的时候,可以通过复用convertView来减少视图的创建次数,另外还可以通过定义一个类来将视图中的控件声明为成员,比如上面的ViewHolder类。
最后是最后的渲染:
查看全部
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3.
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网络获取消息(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转化为视图视图显示,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的WEB应用中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:

)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户界面) ),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前显示新闻的适配器。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml";);// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
将XML资源文件转换为视图有3种方式,底层实现是一样的,这里是使用方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView的时候,可以通过复用convertView来减少视图的创建次数,另外还可以通过定义一个类来将视图中的控件声明为成员,比如上面的ViewHolder类。
最后是最后的渲染:

网页新闻抓取(说到底及服务端地址结构目录结构方案分析(闲情))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-21 00:01
前言
一直喜欢看科技新闻,在cnBeta混了很多年。以前,西贝的评论区是匿名的,所以评论区很活跃,各种喷子和笑话,但确实很开心。可以说是西贝的人气了。最繁华的时候。但自去年国家网信办发布《互联网评论服务管理规定》,要求实名制用户留言和评论后,原本活跃的评论区瞬间下滑,人气一落千丈。 . 事实上,归根结底,西贝并没有跟上移动互联网的潮流。它仍然停留在PC互联网时代。网络广告太多了。然而,手机应用质量堪忧,体验极差。虽然有很多第三方应用,但由于没有官方支持,体验上还是不够好。例如,如果某些版本正式发布,第三方应用程序将基本挂掉。
所以为了方便看cnBeta的新闻,我打算用爬虫把cnBeta的新闻爬下来,搭建一个自建m站,让体验可控,没有广告(`∀´)Ψ . 其实这个项目很早就完成了,不过现在有时间写一篇文章分享一下。
概述
本项目的爬虫和服务器github地址:
前端github地址:
技术细节目录结构
目录结构
├── bin // 入口
│ ├── article-list.js // 抓取新闻列表逻辑
│ ├── content.js // 抓取新闻内容逻辑
│ ├── server.js // 服务端程序入口
│ └── spider.js // 爬虫程序入口
├── config // 配置文件
├── dbhelper // 数据库操作方法目录
├── middleware // koa2 中间件
├── model // mongoDB 集合操作实例
├── router // koa2 路由文件
├── utils // 工具函数
├── package.json
案例分析
首先看爬虫程序的入口文件。整体逻辑其实很简单。先抓取新闻列表,存入MongoDB数据库,每十分钟抓取一次。获取新闻列表后,查询数据库中列表中没有新闻内容的新闻,开始获取新闻详情,然后更新到数据库中。
const articleListInit = require('./article-list');
const articleContentInit = require('./content');
const logger = require('../config/log');
const start = async() => {
let articleListRes = await articleListInit();
if (!articleListRes) {
logger.warn('news list update failed...');
} else {
logger.info('news list update succeed!');
}
let articleContentRes = await articleContentInit();
if (!articleContentRes) {
logger.warn('article content grab error...');
} else {
logger.info('article content grab succeed!');
}
};
if (typeof articleListInit === 'function') {
start();
}
setInterval(start, 600000);
接下来看一下抓取新闻列表的逻辑。因为可以获取新闻列表的Ajax接口,所以可以直接调用该接口获取列表信息。但也有一个问题。cnBeta新闻列表的缩略图和文章中的图片是防盗链的,所以你的网站中的图片不能直接使用,所以我直接爬下cnBeta图片文件并保存它在你自己的服务器上。
/**
* 初始化方法 抓取文章列表
* @returns {Promise.}
*/
const articleListInit = async() => {
logger.info('grabbing article list starts...');
const pageUrlList = getPageUrlList(listBaseUrl, totalPage);
if (!pageUrlList) {
return;
}
let res = await getArticleList(pageUrlList);
return res;
}
/**
* 利用分页接口获取文章列表
* @param pageUrlList
* @returns {Promise}
*/
const getArticleList = (pageUrlList) => {
return new Promise((resolve, reject) => {
async.mapLimit(pageUrlList, 1, (pageUrl, callback) => {
getCurPage(pageUrl, callback);
}, (err, result) => {
if (err) {
logger.error('get article list error...');
logger.error(err);
reject(false);
return;
}
let articleList = _.flatten(result);
downloadThumbAndSave(articleList, resolve);
})
})
};
/**
* 获取当前页面的文章列表
* @param pageUrl
* @param callback
* @returns {Promise.}
*/
const getCurPage = async(pageUrl, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
request(pageUrl, (err, response, body) => {
if (err) {
logger.info('current url went wrong,url address:' + pageUrl);
callback(null, null);
return;
} else {
let responseObj = JSON.parse(body);
if (responseObj.result && responseObj.result.list) {
let newsList = parseObject(articleModel, responseObj.result.list, {
pubTime: 'inputtime',
author: 'aid',
commentCount: 'comments',
});
callback(null, newsList);
return;
}
console.log("出错了");
callback(null, null);
}
});
};
const downloadThumbAndSave = (list, resolve) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (list.indexOf(null) > -1) {
resolve(false);
} else {
try {
async.eachSeries(list, (item, callback) => {
let thumb_url = item.thumb.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on('error', (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
}, (err, result) => {
if (!err) {
saveDB(list, resolve);
}
});
}
catch(err) {
console.log(err);
}
}
};
/**
* 将文章列表存入数据库
* @param result
* @param callback
* @returns {Promise.}
*/
const saveDB = async(result, callback) => {
//console.log(result);
let flag = await dbHelper.insertCollection(articleDbModel, result).catch(function (err){
logger.error('data insert falied');
});
if (!flag) {
logger.error('news list save failed');
} else {
logger.info('list saved!total:' + result.length);
}
if (typeof callback === 'function') {
callback(true);
}
};
我们来看看抓取新闻内容的逻辑。这里我们直接根据新闻sid获取新闻内容页面的html,然后使用cheerio库分析得到我们需要的新闻内容。当然,这里也是将文章中的图片爬下来保存到服务器,将数据库中存储的新闻内容中的图片链接替换为自己服务器中的URL。
/**
* 抓取正文程序入口
* @returns {Promise.}
*/
const articleContentInit = async() => {
logger.info('grabbing article contents starts...');
let uncachedArticleSidList = await getUncachedArticleList(articleDbModel);
// console.log('未缓存的文章:'+ uncachedArticleSidList.join(','));
const res = await batchCrawlArticleContent(uncachedArticleSidList);
if (!res) {
logger.error('grabbing article contents went wrong...');
}
return res;
};
/**
* 查询新闻列表获取sid列表
* @param Model
* @returns {Promise.}
*/
const getUncachedArticleList = async(Model) => {
const selectedArticleList = await dbHelper.queryDocList(Model).catch(function (err){
logger.error(err);
});
return selectedArticleList.map(item => item.sid);
// return selectedArticleList.map(item => item._doc.sid);
};
/**
* 批量抓取新闻详情内容
* @param list
* @returns {Promise}
*/
const batchCrawlArticleContent = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 3, (sid, callback) => {
getArticleContent(sid, callback);
}, (err, result) => {
if (err) {
logger.error(err);
reject(false);
return;
}
resolve(true);
});
});
};
/**
* 抓取单篇文章内容
* @param sid
* @param callback
* @returns {Promise.}
*/
const getArticleContent = async(sid, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let url = contentBaseUrl + sid + '.htm';
request(url, (err, response, body) => {
if (err) {
logger.error('grabbing article content went wrong,article url:' + url);
callback(null, null);
return;
}
const $ = cheerio.load(body, {
decodeEntities: false
});
const serverAssetPath = `${serverIp}:${serverPort}/data`;
let domainReg = new RegExp('https://static.cnbetacdn.com','g');
let article = {
sid,
source: $('.article-byline span a').html() || $('.article-byline span').html(),
summary: $('.article-summ p').html(),
content: $('.articleCont').html().replace(styleReg.reg, styleReg.replace).replace(scriptReg.reg, scriptReg.replace).replace(domainReg, serverAssetPath),
};
saveContentToDB(article);
let imgList = [];
$('.articleCont img').each((index, dom) => {
imgList.push(dom.attribs.src);
});
downloadImgs(imgList);
callback(null, null);
});
};
/**
* 下载图片
* @param list
*/
const downloadImgs = (list) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (!list.length) {
return;
}
try {
async.eachSeries(list, (item, callback) => {
let num = Math.random() * 500 + 500;
sleep(num);
if (item.indexOf(host) === -1) return;
let thumb_url = item.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on("error", (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
});
}
catch(err) {
console.log(err);
}
};
/**
* 保存到文章内容到数据库
* @param article
*/
const saveContentToDB = (item) => {
let flag = dbHelper.updateCollection(articleDbModel, item);
if (flag) {
logger.info('grabbing article content succeeded:' + item.sid);
}
};
爬虫部分差不多就是这个样子。还有一点就是,你的服务器上每天都会存储数百张爬取的图片。随着时间的推移,图片占用的存储空间会特别大,所以需要定期清理,有兴趣的可以看看。查看项目中的 clear-expire.js 文件。
总结
其实这个项目虽然整体上并不复杂,但是在搭建一个前后端系统的过程中,我收获颇多。很多问题的解决需要自己的实践和思考,这也是性能优化的一个重要考虑。方面。
下面的截图是我最终完成的m站。界面非常清爽,体验确实比cnBeta官网好很多。这样看科技新闻确实方便了很多。
以上 查看全部
网页新闻抓取(说到底及服务端地址结构目录结构方案分析(闲情))
前言
一直喜欢看科技新闻,在cnBeta混了很多年。以前,西贝的评论区是匿名的,所以评论区很活跃,各种喷子和笑话,但确实很开心。可以说是西贝的人气了。最繁华的时候。但自去年国家网信办发布《互联网评论服务管理规定》,要求实名制用户留言和评论后,原本活跃的评论区瞬间下滑,人气一落千丈。 . 事实上,归根结底,西贝并没有跟上移动互联网的潮流。它仍然停留在PC互联网时代。网络广告太多了。然而,手机应用质量堪忧,体验极差。虽然有很多第三方应用,但由于没有官方支持,体验上还是不够好。例如,如果某些版本正式发布,第三方应用程序将基本挂掉。
所以为了方便看cnBeta的新闻,我打算用爬虫把cnBeta的新闻爬下来,搭建一个自建m站,让体验可控,没有广告(`∀´)Ψ . 其实这个项目很早就完成了,不过现在有时间写一篇文章分享一下。
概述
本项目的爬虫和服务器github地址:
前端github地址:
技术细节目录结构
目录结构
├── bin // 入口
│ ├── article-list.js // 抓取新闻列表逻辑
│ ├── content.js // 抓取新闻内容逻辑
│ ├── server.js // 服务端程序入口
│ └── spider.js // 爬虫程序入口
├── config // 配置文件
├── dbhelper // 数据库操作方法目录
├── middleware // koa2 中间件
├── model // mongoDB 集合操作实例
├── router // koa2 路由文件
├── utils // 工具函数
├── package.json
案例分析
首先看爬虫程序的入口文件。整体逻辑其实很简单。先抓取新闻列表,存入MongoDB数据库,每十分钟抓取一次。获取新闻列表后,查询数据库中列表中没有新闻内容的新闻,开始获取新闻详情,然后更新到数据库中。
const articleListInit = require('./article-list');
const articleContentInit = require('./content');
const logger = require('../config/log');
const start = async() => {
let articleListRes = await articleListInit();
if (!articleListRes) {
logger.warn('news list update failed...');
} else {
logger.info('news list update succeed!');
}
let articleContentRes = await articleContentInit();
if (!articleContentRes) {
logger.warn('article content grab error...');
} else {
logger.info('article content grab succeed!');
}
};
if (typeof articleListInit === 'function') {
start();
}
setInterval(start, 600000);
接下来看一下抓取新闻列表的逻辑。因为可以获取新闻列表的Ajax接口,所以可以直接调用该接口获取列表信息。但也有一个问题。cnBeta新闻列表的缩略图和文章中的图片是防盗链的,所以你的网站中的图片不能直接使用,所以我直接爬下cnBeta图片文件并保存它在你自己的服务器上。
/**
* 初始化方法 抓取文章列表
* @returns {Promise.}
*/
const articleListInit = async() => {
logger.info('grabbing article list starts...');
const pageUrlList = getPageUrlList(listBaseUrl, totalPage);
if (!pageUrlList) {
return;
}
let res = await getArticleList(pageUrlList);
return res;
}
/**
* 利用分页接口获取文章列表
* @param pageUrlList
* @returns {Promise}
*/
const getArticleList = (pageUrlList) => {
return new Promise((resolve, reject) => {
async.mapLimit(pageUrlList, 1, (pageUrl, callback) => {
getCurPage(pageUrl, callback);
}, (err, result) => {
if (err) {
logger.error('get article list error...');
logger.error(err);
reject(false);
return;
}
let articleList = _.flatten(result);
downloadThumbAndSave(articleList, resolve);
})
})
};
/**
* 获取当前页面的文章列表
* @param pageUrl
* @param callback
* @returns {Promise.}
*/
const getCurPage = async(pageUrl, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
request(pageUrl, (err, response, body) => {
if (err) {
logger.info('current url went wrong,url address:' + pageUrl);
callback(null, null);
return;
} else {
let responseObj = JSON.parse(body);
if (responseObj.result && responseObj.result.list) {
let newsList = parseObject(articleModel, responseObj.result.list, {
pubTime: 'inputtime',
author: 'aid',
commentCount: 'comments',
});
callback(null, newsList);
return;
}
console.log("出错了");
callback(null, null);
}
});
};
const downloadThumbAndSave = (list, resolve) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (list.indexOf(null) > -1) {
resolve(false);
} else {
try {
async.eachSeries(list, (item, callback) => {
let thumb_url = item.thumb.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on('error', (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
}, (err, result) => {
if (!err) {
saveDB(list, resolve);
}
});
}
catch(err) {
console.log(err);
}
}
};
/**
* 将文章列表存入数据库
* @param result
* @param callback
* @returns {Promise.}
*/
const saveDB = async(result, callback) => {
//console.log(result);
let flag = await dbHelper.insertCollection(articleDbModel, result).catch(function (err){
logger.error('data insert falied');
});
if (!flag) {
logger.error('news list save failed');
} else {
logger.info('list saved!total:' + result.length);
}
if (typeof callback === 'function') {
callback(true);
}
};
我们来看看抓取新闻内容的逻辑。这里我们直接根据新闻sid获取新闻内容页面的html,然后使用cheerio库分析得到我们需要的新闻内容。当然,这里也是将文章中的图片爬下来保存到服务器,将数据库中存储的新闻内容中的图片链接替换为自己服务器中的URL。
/**
* 抓取正文程序入口
* @returns {Promise.}
*/
const articleContentInit = async() => {
logger.info('grabbing article contents starts...');
let uncachedArticleSidList = await getUncachedArticleList(articleDbModel);
// console.log('未缓存的文章:'+ uncachedArticleSidList.join(','));
const res = await batchCrawlArticleContent(uncachedArticleSidList);
if (!res) {
logger.error('grabbing article contents went wrong...');
}
return res;
};
/**
* 查询新闻列表获取sid列表
* @param Model
* @returns {Promise.}
*/
const getUncachedArticleList = async(Model) => {
const selectedArticleList = await dbHelper.queryDocList(Model).catch(function (err){
logger.error(err);
});
return selectedArticleList.map(item => item.sid);
// return selectedArticleList.map(item => item._doc.sid);
};
/**
* 批量抓取新闻详情内容
* @param list
* @returns {Promise}
*/
const batchCrawlArticleContent = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 3, (sid, callback) => {
getArticleContent(sid, callback);
}, (err, result) => {
if (err) {
logger.error(err);
reject(false);
return;
}
resolve(true);
});
});
};
/**
* 抓取单篇文章内容
* @param sid
* @param callback
* @returns {Promise.}
*/
const getArticleContent = async(sid, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let url = contentBaseUrl + sid + '.htm';
request(url, (err, response, body) => {
if (err) {
logger.error('grabbing article content went wrong,article url:' + url);
callback(null, null);
return;
}
const $ = cheerio.load(body, {
decodeEntities: false
});
const serverAssetPath = `${serverIp}:${serverPort}/data`;
let domainReg = new RegExp('https://static.cnbetacdn.com','g');
let article = {
sid,
source: $('.article-byline span a').html() || $('.article-byline span').html(),
summary: $('.article-summ p').html(),
content: $('.articleCont').html().replace(styleReg.reg, styleReg.replace).replace(scriptReg.reg, scriptReg.replace).replace(domainReg, serverAssetPath),
};
saveContentToDB(article);
let imgList = [];
$('.articleCont img').each((index, dom) => {
imgList.push(dom.attribs.src);
});
downloadImgs(imgList);
callback(null, null);
});
};
/**
* 下载图片
* @param list
*/
const downloadImgs = (list) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (!list.length) {
return;
}
try {
async.eachSeries(list, (item, callback) => {
let num = Math.random() * 500 + 500;
sleep(num);
if (item.indexOf(host) === -1) return;
let thumb_url = item.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on("error", (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
});
}
catch(err) {
console.log(err);
}
};
/**
* 保存到文章内容到数据库
* @param article
*/
const saveContentToDB = (item) => {
let flag = dbHelper.updateCollection(articleDbModel, item);
if (flag) {
logger.info('grabbing article content succeeded:' + item.sid);
}
};
爬虫部分差不多就是这个样子。还有一点就是,你的服务器上每天都会存储数百张爬取的图片。随着时间的推移,图片占用的存储空间会特别大,所以需要定期清理,有兴趣的可以看看。查看项目中的 clear-expire.js 文件。
总结
其实这个项目虽然整体上并不复杂,但是在搭建一个前后端系统的过程中,我收获颇多。很多问题的解决需要自己的实践和思考,这也是性能优化的一个重要考虑。方面。
下面的截图是我最终完成的m站。界面非常清爽,体验确实比cnBeta官网好很多。这样看科技新闻确实方便了很多。


以上
网页新闻抓取(百度认为什么样的网站更有抓取和收录价值呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-20 23:18
百度认为什么样的网站比较适合爬取和收录?我们从以下几个方面简单介绍一下。鉴于技术保密及网站操作差异等其他原因,以下内容仅供站长参考,具体收录策略包括但不限于内容。接下来,茂宏小编就为大家分享相关内容,希望对大家有所帮助。
第一个方面:网站创造优质的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求。所以要求网站的内容首先满足用户的需求。如今,互联网充斥着大量同质化的内容,同样可以满足用户的需求。, 如果你提供的网站内容很特别或者有一定的特殊价值,那么百度会更希望收录你的网站。
温馨提示:百度希望收录这样的网站:
网站 可以满足某些用户的需求
网站信息丰富,网页文字能够清晰准确地表达所要传达的内容。
有一定的原创性或独特价值。
相反,很多网站的内容都是“一般或低质量”,有的网站为了获得更好的收录或者排名靠欺骗。下面是一些常见的情况。虽然不可能列举每一种情况。但请不要走运,百度有全面的技术支持来检测和处理这些行为。
请不要为搜索引擎创建内容。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;将程序生成的内容用于搜索引擎。
请不要创建多个页面、子域或收录大量重复内容的域。
百度将尝试收录提供不同信息的网页。如果你的网站收录大量重复内容,那么搜索引擎会减少相同内容的收录,认为网站提供的内容价值偏低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。它还有助于节省带宽。
请不要创建欺诈或安装有病毒、特洛伊木马或其他有害软件的网页。
加入频道共建、内容联盟等不能或很少产生原创内容的项目时要谨慎,除非网站可以为内容联盟创建原创内容。
第二方面:网站提供的内容得到用户和站长的认可和支持
如果网站上的一个内容得到用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过对网站的搜索行为、真实用户的访问行为、网站之间的关系进行分析,综合评价对网站的认可度。但值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你的认可网站:通常网站之间的链接可以帮助百度抓到Get工具,找到你的< @网站 并增加您对网站 的认可。百度将A网页到B网页的链接解释为A网页到B网页的投票。对一个网页进行投票,更能体现对网页本身的“认可度”权重,有助于提高对其他网页的“认可度”。链接的数量、质量和相关性会影响“识别度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。(自然链接是在其他网站发现你的内容有价值,认为可能对访问者有帮助时,在网络动态生成过程中形成的。)
要让其他网站 创建与您相关的链接网站,更好的方法是创建独特且相关的内容,这些内容可以在互联网上流行。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的 网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长往往不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
试图操纵“识别”计算链接
指向互联网上非法 网站、垃圾邮件或恶意链接的链接
过多的互惠链接或链接交换(例如“链接到我,我将链接到你”)
购买或出售链接用于增加网站“认可”
第三方面:网站有良好的浏览体验
一个具有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
网站 具有清晰的层次结构。
为用户提供站点地图和带有 网站 重要部分链接的导航。使用户能够清晰、简单地浏览网站,快速找到自己需要的信息。
网站 有不错的表现:包括浏览速度和兼容性。
网站快速的速度可以提高用户满意度,也可以提高网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。
网站的广告不干扰用户的正常访问。
广告是网站的重要收入来源。网站收录广告是很合理的,但是如果广告太多,会影响用户的浏览;或者 网站 不相关的子弹太多了。窗户和凸窗上的广告可能会冒犯用户。
百度的目标是为用户提供高度相关的搜索结果和良好的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
合理设置网站的权限。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量。但是,过多的权限设置可能会导致新用户失去耐心,给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
以上三个方面简单介绍了百度收录网站的一些关注点。对于站长来说,如何建立一个更受搜索引擎欢迎的网站,还有很多技巧。详情请参考《百度SEO指南》。 查看全部
网页新闻抓取(百度认为什么样的网站更有抓取和收录价值呢?)
百度认为什么样的网站比较适合爬取和收录?我们从以下几个方面简单介绍一下。鉴于技术保密及网站操作差异等其他原因,以下内容仅供站长参考,具体收录策略包括但不限于内容。接下来,茂宏小编就为大家分享相关内容,希望对大家有所帮助。

第一个方面:网站创造优质的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求。所以要求网站的内容首先满足用户的需求。如今,互联网充斥着大量同质化的内容,同样可以满足用户的需求。, 如果你提供的网站内容很特别或者有一定的特殊价值,那么百度会更希望收录你的网站。
温馨提示:百度希望收录这样的网站:
网站 可以满足某些用户的需求
网站信息丰富,网页文字能够清晰准确地表达所要传达的内容。
有一定的原创性或独特价值。
相反,很多网站的内容都是“一般或低质量”,有的网站为了获得更好的收录或者排名靠欺骗。下面是一些常见的情况。虽然不可能列举每一种情况。但请不要走运,百度有全面的技术支持来检测和处理这些行为。
请不要为搜索引擎创建内容。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;将程序生成的内容用于搜索引擎。
请不要创建多个页面、子域或收录大量重复内容的域。
百度将尝试收录提供不同信息的网页。如果你的网站收录大量重复内容,那么搜索引擎会减少相同内容的收录,认为网站提供的内容价值偏低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。它还有助于节省带宽。
请不要创建欺诈或安装有病毒、特洛伊木马或其他有害软件的网页。
加入频道共建、内容联盟等不能或很少产生原创内容的项目时要谨慎,除非网站可以为内容联盟创建原创内容。
第二方面:网站提供的内容得到用户和站长的认可和支持
如果网站上的一个内容得到用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过对网站的搜索行为、真实用户的访问行为、网站之间的关系进行分析,综合评价对网站的认可度。但值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你的认可网站:通常网站之间的链接可以帮助百度抓到Get工具,找到你的< @网站 并增加您对网站 的认可。百度将A网页到B网页的链接解释为A网页到B网页的投票。对一个网页进行投票,更能体现对网页本身的“认可度”权重,有助于提高对其他网页的“认可度”。链接的数量、质量和相关性会影响“识别度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。(自然链接是在其他网站发现你的内容有价值,认为可能对访问者有帮助时,在网络动态生成过程中形成的。)
要让其他网站 创建与您相关的链接网站,更好的方法是创建独特且相关的内容,这些内容可以在互联网上流行。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的 网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长往往不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
试图操纵“识别”计算链接
指向互联网上非法 网站、垃圾邮件或恶意链接的链接
过多的互惠链接或链接交换(例如“链接到我,我将链接到你”)
购买或出售链接用于增加网站“认可”
第三方面:网站有良好的浏览体验
一个具有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
网站 具有清晰的层次结构。
为用户提供站点地图和带有 网站 重要部分链接的导航。使用户能够清晰、简单地浏览网站,快速找到自己需要的信息。
网站 有不错的表现:包括浏览速度和兼容性。
网站快速的速度可以提高用户满意度,也可以提高网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。
网站的广告不干扰用户的正常访问。
广告是网站的重要收入来源。网站收录广告是很合理的,但是如果广告太多,会影响用户的浏览;或者 网站 不相关的子弹太多了。窗户和凸窗上的广告可能会冒犯用户。
百度的目标是为用户提供高度相关的搜索结果和良好的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
合理设置网站的权限。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量。但是,过多的权限设置可能会导致新用户失去耐心,给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
以上三个方面简单介绍了百度收录网站的一些关注点。对于站长来说,如何建立一个更受搜索引擎欢迎的网站,还有很多技巧。详情请参考《百度SEO指南》。
网页新闻抓取( 简单的来说,对于爬取网页的内容来说的一些介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-20 23:16
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且默认调用parse函数,parse在蜘蛛抓取网页后默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的url,可以观察到url规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句是scrapy.Request(url_month, callback=self.parse_month)写的
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是对于每一天的url,会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“勾选”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,在文章中使用Xpath进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有href属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章: 查看全部
网页新闻抓取(
简单的来说,对于爬取网页的内容来说的一些介绍)

简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍

2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件

3.1.1 在qqnew.py中编写我们的主要爬虫代码**

首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且默认调用parse函数,parse在蜘蛛抓取网页后默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的url,可以观察到url规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句是scrapy.Request(url_month, callback=self.parse_month)写的
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是对于每一天的url,会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“勾选”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,在文章中使用Xpath进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有href属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章:
网页新闻抓取(网络“爬虫”是怎么抢机票的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-17 03:01
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在一次技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取机票官网信息。如果发现航空公司有低价机票放行,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。 查看全部
网页新闻抓取(网络“爬虫”是怎么抢机票的?(图))
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在一次技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取机票官网信息。如果发现航空公司有低价机票放行,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
网页新闻抓取(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-13 23:03
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载 查看全部
网页新闻抓取(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:

上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:

源代码下载
网页新闻抓取(新版headless模式,每一个都各有特色,我们自己的一款是NickJS)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-09 13:09
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它和网页解析语言是一样的(你会在下面看到它有多方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术,我们几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copy from your DevTools", domain: "" })
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会引发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
await tab.open("") await tab.untilVisible("#hnmain") // 确保我们已经加载了页面 await tab.inject("") // 我们将使用 jQuery 来抓取 consthackerNewsLinks = await tab.evaluate((arg, callback) => {// 这里我们在页面上下文中。就像在浏览器的检查器工具中 const data = [] $(".athing").each((index, element ) => {data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href")} ) }) callback(null, data) }) 印度、俄罗斯和巴基斯坦在拦截机器人的做法上有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
if (await tab.isVisible(".captchaImage")) {// 获取生成的 CAPTCHA 图像的 URL // 注意我们也可以获取它的 base64 编码值并解决它 const captchaImageLink = await tab.evaluate(( arg, callback) => {callback(null, $(".captchaImage").attr("src")) }) // 调用验证码解决服务 const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) //用我们的解决方案填写表单 await tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })} 等待 DOM 元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
await tab.open("") // await Promise.delay(5000) // 不要这样做!await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // 您现在可以安全地单击“喜欢”按钮...等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈并运行
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null tab.driver.client.Network.responseReceived((e) => {if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {cvRequestId = e.requestId} }) tab.driver.client.Network.loadingFinished((e) => {if (e.requestId === cvRequestId) {tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded?'base64':'utf8' ))) })} })
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截 const nick = new Nick({ loadImages: false, whitelist: [/.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.* / ], 黑名单: [/.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/] })
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。 查看全部
网页新闻抓取(新版headless模式,每一个都各有特色,我们自己的一款是NickJS)
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它和网页解析语言是一样的(你会在下面看到它有多方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术,我们几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copy from your DevTools", domain: "" })
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会引发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
await tab.open("") await tab.untilVisible("#hnmain") // 确保我们已经加载了页面 await tab.inject("") // 我们将使用 jQuery 来抓取 consthackerNewsLinks = await tab.evaluate((arg, callback) => {// 这里我们在页面上下文中。就像在浏览器的检查器工具中 const data = [] $(".athing").each((index, element ) => {data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href")} ) }) callback(null, data) }) 印度、俄罗斯和巴基斯坦在拦截机器人的做法上有什么共同点?

答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
if (await tab.isVisible(".captchaImage")) {// 获取生成的 CAPTCHA 图像的 URL // 注意我们也可以获取它的 base64 编码值并解决它 const captchaImageLink = await tab.evaluate(( arg, callback) => {callback(null, $(".captchaImage").attr("src")) }) // 调用验证码解决服务 const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) //用我们的解决方案填写表单 await tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })} 等待 DOM 元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
await tab.open("") // await Promise.delay(5000) // 不要这样做!await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // 您现在可以安全地单击“喜欢”按钮...等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈并运行
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截

因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null tab.driver.client.Network.responseReceived((e) => {if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {cvRequestId = e.requestId} }) tab.driver.client.Network.loadingFinished((e) => {if (e.requestId === cvRequestId) {tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded?'base64':'utf8' ))) })} })
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截 const nick = new Nick({ loadImages: false, whitelist: [/.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.* / ], 黑名单: [/.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/] })
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。
网页新闻抓取(深圳网站建设中新闻页面的设计应该注意哪些问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-08 07:08
网站新闻页面是否是企业网站建站、门户网站建站、电子商务网站建站、营销型网站建站、当前热点app网站是必不可少的子项,而新闻页面的排列不仅是发布公司产品信息和公司新闻,也是SEO搜索引擎抓取内容的依据,所以他与整个网站的优化程度。所以一个好的新闻页面是整个网站的关键,那么如何设计一个新闻页面呢?今天,拥有十年建站经验的深圳网站建设公司:我们总结一下正在建设中的网站新闻页面在设计中应该注意的问题:
1、 在首页需要编写和设置可点击的新闻标题,然后编写完整的新闻页面,通过超链接与新闻标题相连。
2、首页的新闻标题要能够清楚地描述新闻的主要内容,标题文字不宜过长,布局要简洁、清晰、醒目。
3、新闻页面必须满足轻松导航的要求。首先,要方便用户从新闻页面跳转到网站中的其他内容页面,其次,必须方便用户快速到达其他新闻页面。这可以通过在新闻页面上建立以下方法来实现。
一种。设置与整体一致的菜单栏导航系统,让用户可以在网站的新闻页面和其他页面之间无缝跳转。
湾 设置上一条或下一条新闻的链接,让用户可以在其中浏览,在浏览其他新闻时无需经常返回主新闻页面。
C。提供新闻分类或时间索引,建立菜单,用户可以根据时间或内容搜索自己感兴趣的新闻。
d. 新闻页面包括与新闻相关的图片、声音或其他多媒体文件或这些文件的链接。
e. 设置指向手稿中出现的关键姓名、公司、员工等的链接。
F。相关客户、分析师或舆论对新闻稿主题的意见。
除了新闻页面,企业还应根据需要设置其他页面,如企业信息页面、帮助页面、虚拟社区页面等。
TAG标签耗时:0.0601秒 查看全部
网页新闻抓取(深圳网站建设中新闻页面的设计应该注意哪些问题?)
网站新闻页面是否是企业网站建站、门户网站建站、电子商务网站建站、营销型网站建站、当前热点app网站是必不可少的子项,而新闻页面的排列不仅是发布公司产品信息和公司新闻,也是SEO搜索引擎抓取内容的依据,所以他与整个网站的优化程度。所以一个好的新闻页面是整个网站的关键,那么如何设计一个新闻页面呢?今天,拥有十年建站经验的深圳网站建设公司:我们总结一下正在建设中的网站新闻页面在设计中应该注意的问题:
1、 在首页需要编写和设置可点击的新闻标题,然后编写完整的新闻页面,通过超链接与新闻标题相连。
2、首页的新闻标题要能够清楚地描述新闻的主要内容,标题文字不宜过长,布局要简洁、清晰、醒目。
3、新闻页面必须满足轻松导航的要求。首先,要方便用户从新闻页面跳转到网站中的其他内容页面,其次,必须方便用户快速到达其他新闻页面。这可以通过在新闻页面上建立以下方法来实现。
一种。设置与整体一致的菜单栏导航系统,让用户可以在网站的新闻页面和其他页面之间无缝跳转。
湾 设置上一条或下一条新闻的链接,让用户可以在其中浏览,在浏览其他新闻时无需经常返回主新闻页面。
C。提供新闻分类或时间索引,建立菜单,用户可以根据时间或内容搜索自己感兴趣的新闻。
d. 新闻页面包括与新闻相关的图片、声音或其他多媒体文件或这些文件的链接。
e. 设置指向手稿中出现的关键姓名、公司、员工等的链接。
F。相关客户、分析师或舆论对新闻稿主题的意见。
除了新闻页面,企业还应根据需要设置其他页面,如企业信息页面、帮助页面、虚拟社区页面等。
TAG标签耗时:0.0601秒
网页新闻抓取(发明专利推送包含新闻信息的网页的方法和装置技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-08 07:07
本发明的专利技术提供了一种推送收录新闻信息的网页的方法和装置。该方法包括:从抓取的收录新闻信息的网页中提取时效性关键词;计算第一个收录新闻信息的网页数量 时间敏感的属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页;计算多个网页的第二时间敏感属性特征;如果查询词匹配时效性关键词,则将第一时间敏感属性特征与第二时间敏感属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性,在结果页面上确定收录新闻信息的网页的URL的插入位置。根据本发明的专利技术,可以判断用户输入的查询词的时效性,可以根据查询词的时效性对收录新闻信息的网页网址进行排序。可以对新闻信息对用户较新的网页进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。
下载所有详细的技术数据
【技术实现步骤总结】
推送收录新闻信息的网页的方法及装置
这项专利技术涉及计算机
尤其涉及一种推送收录新闻信息的网页的方法和装置。
技术介绍
按照目前的搜索引擎技术,用户在终端输入查询词后,搜索引擎会获取到该查询词对应的多个网页网址。多个网页网址返回给用户终端后,会显示在用户终端的结果页面上。由于网页网址的数量较多,所以在结果页显示时肯定存在排序问题。根据目前的搜索引擎技术,旧网页的网址一般排在第一位。这种排序对于收录新闻信息的网址有很大的弊端:在用户输入查询词搜索新闻的场景下,目前的搜索引擎技术只能将旧新闻网页的网址排在第一位,而最新新闻的网址是网页稍后排序,但是由于新闻的时效性,大多数新闻的新闻性会随着时间的推移而下降,因此用户最终看到的很可能是新闻性较低的新闻。由于其网页的 URL 较低,用户很难找到和打开更高级别的新闻。可见,现有的搜索引擎技术难以分析新闻信息对用户的新闻性,也难以对收录新闻信息的网页网址进行合理排序,从而无法完成对网页的有效推送。收录新闻信息。
技术实现思路
针对上述问题,提出本专利技术,以提供一种克服上述问题或至少部分解决上述问题的推送收录新闻信息的网页的方法和装置。根据该专利技术的一个方面,提供了一种推送收录新闻信息的网页的方法,包括:从抓取到的收录新闻信息的网页中提取时效关键词;计算新闻信息内容网页的第一时间敏感属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;及时性关键词匹配,然后将第一时效属性特征与第二时效属性特征进行比较,根据比较结果得到查询词的时效性;查询词的时效性强根据比较结果弱,确定收录新闻信息的网页的URL在结果页面的插入位置。可选的,从抓取到的收录新闻信息的网页中提取时效关键词的步骤包括:从收录新闻信息的网页的标题中提取时效关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、收录新闻信息的网页的时效性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,根据查询词的时效性确定收录新闻信息的网页的URL在结果页的插入位置包括:在结果页上划分多个区间,分别对应不同强度的时效性和弱点;选择与查询词的时效性强或弱匹配的区间,将收录新闻信息的网页的URL放置在所选区间内。可选的,每个区间从上到下分为三个部分,每个区间都有对应的置信度,将收录新闻信息的网页的URL放入所选区间的步骤还包括:如果查询词的时效性高于所选区间的置信水平,收录新闻信息的网页的URL放置在所选区间的顶部,如查询词和所选区间的时效性如果区间的置信度相同,则收录新闻的网页的URL信息放置在所选间隔的中间部分。如果查询词的时效性低于所选区间的置信度,则将信息网页的 URL 置于所选区间的最低部分。可选的,还包括:建立将时效关键词与第一时效属性特征关联的索引;如果查询词匹配时效性关键词,则在比较第一时间敏感属性特征和第二时间敏感属性特征的步骤之前,根据比较结果获取查询词的时效性,该方法还包括:根据索引判断查询词与查询词是否相同。匹配时效性关键词,搜索与时效性关键词相关的第一个时效性属性特征。
根据专利技术的另一方面,还提供了一种推送收录新闻信息的网页的装置,包括:网络爬虫,用于抓取收录新闻信息的网页;关键词 提取器,用于从收录新闻信息的抓取网页中提取时效性关键词;关键词数据库用于存储提取的时效性关键词;第一特征计算器用于计算收录新闻信息的网页的第一时间敏感属性特征;查询模块用于接收查询词,获取查询词对应的多个网页的网址的结果页面。第二特征计算器用于计算多个网页的第二时间敏感属性特征;查询词时间敏感获取模块,如果查询词匹配时间敏感关键词,则将第一时间敏感属性特征与第一时间敏感属性特征进行比较 2. 比较时间属性特征,得到根据比对结果查询词条的时效性;新闻网页展示模块,用于根据查询词的时效性判断新闻网页的URL在结果页的位置高低。可选的,关键词提取器从收录新闻信息的网页的标题中提取时效性关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及收录新闻信息的网页的及时性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,所述新闻网页展示模块包括: 区间划分模块,用于在结果页面上划分多个区间,分别对应不同的时效性。区间选择模块,用于选择查询查询词的时效性与区间强匹配,将收录新闻信息的网页的URL放置在所选区间内。可选地,每个区间从上到下分为三个部分,每个区间有一个对应的置信水平。如果查询词的时效性高于所选区间的置信度,区间选择模块会将收录新闻信息的网页的URL置于所选区间的顶部。如果查询词的时效性与所选区间的置信度一致,区间选择模块将收录网页URL的新闻信息置于所选区间的中间。如果查询词的时效性低于所选区间的置信度,区间选择模块将收录新闻信息的网页的URL放入所选区间。选择区间的最低部分。可选的,还包括: 索引建立模块,用于建立将时效关键词与第一时效属性特征关联的索引;索引搜索模块,用于根据索引判断查询词是否符合时效关键词,并搜索与时效相关的第一个时效属性特征关键词。根据专利技术的推送收录新闻信息的网页的方法和装置,可以通过分析收录新闻信息的网页和查询对应的其他网页的时效性属性特征来判断用户输入的查询词的时效性字。词的及时性反映了新闻信息为用户提供的程度。因此,根据查询词的时效性对收录新闻信息的网页的网址进行排序,可以对新闻信息对用户来说更具新闻性的网页的网址进行排序。排序优先方便用户及时查看自己需要的新闻信息,
以上描述仅为本专利技术方案的概述。为了更清楚地了解本专利技术的技术手段,可以按照说明书的内容实施,以更好地实现本专利技术的上述及其他目的、特点和优点。显而易见且易于理解,下面将引用专利技术的具体实现。附图说明通过阅读以下优选实施例的详细描述,本领域普通技术人员将清楚各种其他优点和益处。附图仅用于说明优选实施例的目的,并不视为对专利技术的限制。此外,在整个图纸中,相同的附图标记用于表示相同的组件。图中:附图说明图1示出了根据专利技术实施例的推送收录新闻信息的网页的方法的流程图。
【技术保护点】
一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时效属性特征;如果查询词匹配时效性关键词,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;
【技术特点摘要】
1.一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;如查询词与时效关键词匹配,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性确定查询词的时效性。收录新闻信息的网页的URL在结果页的插入位置;第一时间敏感属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及时效性关键词在收录新闻信息的网页中出现的频率和/或时效性关键词是收录新闻信息的网页出现次数与已知历史事件的比较数据;第二时间敏感属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询该词在多个网页中的出现次数与已知历史出现次数的比较数据。2.如权利要求1所述的方法,其特征在于,所述从抓取到的收录新闻信息的网页中提取时效性关键词的步骤包括: 提取收录新闻信息的网页的标题 从关键词中提取时效性.
3.如权利要求1所述的方法,其特征在于,所述根据查询词的时效性确定收录新闻信息的网页的URL在结果页面的插入位置包括:在结果页面,对应不同时效强度;选择与查询词的时效性相匹配的版块,将收录新闻信息的网页的网址设置在选定的区间内。4.如权利要求3所述的方法,其特征在于,每个区间从上到下分为三个部分,每个区间有一个对应的置信度,收录新闻信息的网页 将URL放入选中的URL的步骤间隔进一步包括:如果查询词的时效性高于所选区间的置信度,则将收录新闻信息的网页的 URL 置于所选区间的顶部 如果查询词的时效性与所选区间的置信度一致选定区间,如果查询词的时效性低于选定区间的时效,则将收录新闻信息的网页的URL放置在选定区间的中间部分。为了所选区间的置信度,将收录新闻信息的网页的 URL 放置在所选区间的最下方。5.根据权利要求1-4任一项所述的方法,还包括: 建立将时效关键词与第一时效属性特征关联的索引;
【专利技术属性】
技术研发人员:常富阳、秦继升、苏文杰、
申请人(专利权):,,
类型:发明
国家省市:北京;11
下载所有详细技术资料 我是此专利的所有者 查看全部
网页新闻抓取(发明专利推送包含新闻信息的网页的方法和装置技术)
本发明的专利技术提供了一种推送收录新闻信息的网页的方法和装置。该方法包括:从抓取的收录新闻信息的网页中提取时效性关键词;计算第一个收录新闻信息的网页数量 时间敏感的属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页;计算多个网页的第二时间敏感属性特征;如果查询词匹配时效性关键词,则将第一时间敏感属性特征与第二时间敏感属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性,在结果页面上确定收录新闻信息的网页的URL的插入位置。根据本发明的专利技术,可以判断用户输入的查询词的时效性,可以根据查询词的时效性对收录新闻信息的网页网址进行排序。可以对新闻信息对用户较新的网页进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。
下载所有详细的技术数据
【技术实现步骤总结】
推送收录新闻信息的网页的方法及装置
这项专利技术涉及计算机
尤其涉及一种推送收录新闻信息的网页的方法和装置。
技术介绍
按照目前的搜索引擎技术,用户在终端输入查询词后,搜索引擎会获取到该查询词对应的多个网页网址。多个网页网址返回给用户终端后,会显示在用户终端的结果页面上。由于网页网址的数量较多,所以在结果页显示时肯定存在排序问题。根据目前的搜索引擎技术,旧网页的网址一般排在第一位。这种排序对于收录新闻信息的网址有很大的弊端:在用户输入查询词搜索新闻的场景下,目前的搜索引擎技术只能将旧新闻网页的网址排在第一位,而最新新闻的网址是网页稍后排序,但是由于新闻的时效性,大多数新闻的新闻性会随着时间的推移而下降,因此用户最终看到的很可能是新闻性较低的新闻。由于其网页的 URL 较低,用户很难找到和打开更高级别的新闻。可见,现有的搜索引擎技术难以分析新闻信息对用户的新闻性,也难以对收录新闻信息的网页网址进行合理排序,从而无法完成对网页的有效推送。收录新闻信息。
技术实现思路
针对上述问题,提出本专利技术,以提供一种克服上述问题或至少部分解决上述问题的推送收录新闻信息的网页的方法和装置。根据该专利技术的一个方面,提供了一种推送收录新闻信息的网页的方法,包括:从抓取到的收录新闻信息的网页中提取时效关键词;计算新闻信息内容网页的第一时间敏感属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;及时性关键词匹配,然后将第一时效属性特征与第二时效属性特征进行比较,根据比较结果得到查询词的时效性;查询词的时效性强根据比较结果弱,确定收录新闻信息的网页的URL在结果页面的插入位置。可选的,从抓取到的收录新闻信息的网页中提取时效关键词的步骤包括:从收录新闻信息的网页的标题中提取时效关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、收录新闻信息的网页的时效性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,根据查询词的时效性确定收录新闻信息的网页的URL在结果页的插入位置包括:在结果页上划分多个区间,分别对应不同强度的时效性和弱点;选择与查询词的时效性强或弱匹配的区间,将收录新闻信息的网页的URL放置在所选区间内。可选的,每个区间从上到下分为三个部分,每个区间都有对应的置信度,将收录新闻信息的网页的URL放入所选区间的步骤还包括:如果查询词的时效性高于所选区间的置信水平,收录新闻信息的网页的URL放置在所选区间的顶部,如查询词和所选区间的时效性如果区间的置信度相同,则收录新闻的网页的URL信息放置在所选间隔的中间部分。如果查询词的时效性低于所选区间的置信度,则将信息网页的 URL 置于所选区间的最低部分。可选的,还包括:建立将时效关键词与第一时效属性特征关联的索引;如果查询词匹配时效性关键词,则在比较第一时间敏感属性特征和第二时间敏感属性特征的步骤之前,根据比较结果获取查询词的时效性,该方法还包括:根据索引判断查询词与查询词是否相同。匹配时效性关键词,搜索与时效性关键词相关的第一个时效性属性特征。
根据专利技术的另一方面,还提供了一种推送收录新闻信息的网页的装置,包括:网络爬虫,用于抓取收录新闻信息的网页;关键词 提取器,用于从收录新闻信息的抓取网页中提取时效性关键词;关键词数据库用于存储提取的时效性关键词;第一特征计算器用于计算收录新闻信息的网页的第一时间敏感属性特征;查询模块用于接收查询词,获取查询词对应的多个网页的网址的结果页面。第二特征计算器用于计算多个网页的第二时间敏感属性特征;查询词时间敏感获取模块,如果查询词匹配时间敏感关键词,则将第一时间敏感属性特征与第一时间敏感属性特征进行比较 2. 比较时间属性特征,得到根据比对结果查询词条的时效性;新闻网页展示模块,用于根据查询词的时效性判断新闻网页的URL在结果页的位置高低。可选的,关键词提取器从收录新闻信息的网页的标题中提取时效性关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及收录新闻信息的网页的及时性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,所述新闻网页展示模块包括: 区间划分模块,用于在结果页面上划分多个区间,分别对应不同的时效性。区间选择模块,用于选择查询查询词的时效性与区间强匹配,将收录新闻信息的网页的URL放置在所选区间内。可选地,每个区间从上到下分为三个部分,每个区间有一个对应的置信水平。如果查询词的时效性高于所选区间的置信度,区间选择模块会将收录新闻信息的网页的URL置于所选区间的顶部。如果查询词的时效性与所选区间的置信度一致,区间选择模块将收录网页URL的新闻信息置于所选区间的中间。如果查询词的时效性低于所选区间的置信度,区间选择模块将收录新闻信息的网页的URL放入所选区间。选择区间的最低部分。可选的,还包括: 索引建立模块,用于建立将时效关键词与第一时效属性特征关联的索引;索引搜索模块,用于根据索引判断查询词是否符合时效关键词,并搜索与时效相关的第一个时效属性特征关键词。根据专利技术的推送收录新闻信息的网页的方法和装置,可以通过分析收录新闻信息的网页和查询对应的其他网页的时效性属性特征来判断用户输入的查询词的时效性字。词的及时性反映了新闻信息为用户提供的程度。因此,根据查询词的时效性对收录新闻信息的网页的网址进行排序,可以对新闻信息对用户来说更具新闻性的网页的网址进行排序。排序优先方便用户及时查看自己需要的新闻信息,
以上描述仅为本专利技术方案的概述。为了更清楚地了解本专利技术的技术手段,可以按照说明书的内容实施,以更好地实现本专利技术的上述及其他目的、特点和优点。显而易见且易于理解,下面将引用专利技术的具体实现。附图说明通过阅读以下优选实施例的详细描述,本领域普通技术人员将清楚各种其他优点和益处。附图仅用于说明优选实施例的目的,并不视为对专利技术的限制。此外,在整个图纸中,相同的附图标记用于表示相同的组件。图中:附图说明图1示出了根据专利技术实施例的推送收录新闻信息的网页的方法的流程图。

【技术保护点】
一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时效属性特征;如果查询词匹配时效性关键词,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;
【技术特点摘要】
1.一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;如查询词与时效关键词匹配,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性确定查询词的时效性。收录新闻信息的网页的URL在结果页的插入位置;第一时间敏感属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及时效性关键词在收录新闻信息的网页中出现的频率和/或时效性关键词是收录新闻信息的网页出现次数与已知历史事件的比较数据;第二时间敏感属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询该词在多个网页中的出现次数与已知历史出现次数的比较数据。2.如权利要求1所述的方法,其特征在于,所述从抓取到的收录新闻信息的网页中提取时效性关键词的步骤包括: 提取收录新闻信息的网页的标题 从关键词中提取时效性.
3.如权利要求1所述的方法,其特征在于,所述根据查询词的时效性确定收录新闻信息的网页的URL在结果页面的插入位置包括:在结果页面,对应不同时效强度;选择与查询词的时效性相匹配的版块,将收录新闻信息的网页的网址设置在选定的区间内。4.如权利要求3所述的方法,其特征在于,每个区间从上到下分为三个部分,每个区间有一个对应的置信度,收录新闻信息的网页 将URL放入选中的URL的步骤间隔进一步包括:如果查询词的时效性高于所选区间的置信度,则将收录新闻信息的网页的 URL 置于所选区间的顶部 如果查询词的时效性与所选区间的置信度一致选定区间,如果查询词的时效性低于选定区间的时效,则将收录新闻信息的网页的URL放置在选定区间的中间部分。为了所选区间的置信度,将收录新闻信息的网页的 URL 放置在所选区间的最下方。5.根据权利要求1-4任一项所述的方法,还包括: 建立将时效关键词与第一时效属性特征关联的索引;
【专利技术属性】
技术研发人员:常富阳、秦继升、苏文杰、
申请人(专利权):,,
类型:发明
国家省市:北京;11
下载所有详细技术资料 我是此专利的所有者
网页新闻抓取(Google信息多任务框架不稳定,newspaper缓存所有提取的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-06 18:08
报纸是一个python3库。
注意:Newspaper 框架不适合实际的工程新闻信息爬取工作。框架不稳定,在爬取过程中会出现各种bug,比如无法获取网址、新闻信息等,但是对于想要获取一些新闻语料的朋友不妨一试,简单方便,简单易用,无需掌握太多爬虫专业知识。
安装
pip3 install newspaper3k
or
pip3 install --ignore-installed --upgrade newspaper3k
如果文章 没有指定使用哪种语言,Newspaper 会尝试自动识别。支持10多种语言,都是unicode编码。
import time
from newspaper import Article
url = 'https://www.chinaventure.com.c ... 27%3B
url='https://36kr.com/p/5237348'
# 创建文章对象
news = Article(url, language='zh')
# 下载网页
news.download()
## 网页解析
news.parse()
print("title=",news.title)# 获取文章标题
print("author=", news.authors) # 获取文章作者
print("publish_date=", news.publish_date) # 获取文章日期
# 自然语言处理
news.nlp()
print('keywords=',news.keywords)#从文本中提取关键字
print("summary=",news.summary)# 获取文章摘要
# time.sleep(30)
print("text=",news.text,"\n")# 获取文章正文
print("movies=",news.movies) # 获取文章视频链接
print("top_iamge=",news.top_image) # 获取文章顶部图片地址
print("images=",news.images)#从html中提取所有图像
print("imgs=",news.imgs)
print("html=",news.html)#获取html
也可以直接导入包,如果语言一致,也可以直接声明
import newspaper
url='http://www.coscocs.com/'
'''注:文章缓存:默认情况下,newspaper缓存所有以前提取的文章,并删除它已经提取的任何文章。
此功能用于防止重复的文章和提高提取速度。可以使用memoize_articles参数选择退出此功能。'''
news = newspaper.build(url, language='zh', memoize_articles=False)
article = news.articles[0]
article.download()
article.parse()
print('text=',article.text)
print('brand=',news.brand) #提取源品牌
print('description=',news.description) # 提取描述
print("一共获取%s篇文章" % news.size()) # 文章的数目
# 所有文章的url
for article in news.articles:
print(article.url)
#提取源类别
for category in news.category_urls():
print(category)
#提取源提要
for feed_url in news.feed_urls():
print(feed_url)
注意:文章缓存:默认情况下,报纸缓存所有以前提取的文章并删除任何已经提取的文章。该功能用于防止重复文章,提高提取速度。您可以使用 memoize_articles 参数选择退出此功能。
结合 Requests 和 Newspaper 来解析文本
import requests
from newspaper import fulltext
html = requests.get('https://www.washingtonpost.com ... 23x27;).text
text = fulltext(html)
print(text)
谷歌趋势信息
import newspaper
print(newspaper.languages())#获取支持的语言
print(newspaper.hot())#hot()使用公共api返回谷歌上的热门词汇列表
print(newspaper.popular_urls())#popular_urls()返回一个流行新闻源url列表
多任务处理
import newspaper
from newspaper import news_pool
# 创建并行任务
slate_paper = newspaper.build('http://slate.com')
tc_paper = newspaper.build('http://techcrunch.com')
espn_paper = newspaper.build('http://espn.com')
papers = [slate_paper, tc_paper, espn_paper]
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 共6个线程
news_pool.join()
print(slate_paper.articles[10].html)
python可读性
github地址为:
安装
pip install requests
pip install readability-lxml
如何使用:
import requests
from readability import Document
response = requests.get('https://news.163.com/18/1123/1 ... 23x27;)
doc = Document(response.text)
print doc.title()
print doc.content()
测试结果:文本提取范围过大,出现乱码,不好用。显然得到的文本部分有问题。并且存在乱码的问题。因此,不推荐。 查看全部
网页新闻抓取(Google信息多任务框架不稳定,newspaper缓存所有提取的文章)
报纸是一个python3库。
注意:Newspaper 框架不适合实际的工程新闻信息爬取工作。框架不稳定,在爬取过程中会出现各种bug,比如无法获取网址、新闻信息等,但是对于想要获取一些新闻语料的朋友不妨一试,简单方便,简单易用,无需掌握太多爬虫专业知识。
安装
pip3 install newspaper3k
or
pip3 install --ignore-installed --upgrade newspaper3k
如果文章 没有指定使用哪种语言,Newspaper 会尝试自动识别。支持10多种语言,都是unicode编码。
import time
from newspaper import Article
url = 'https://www.chinaventure.com.c ... 27%3B
url='https://36kr.com/p/5237348'
# 创建文章对象
news = Article(url, language='zh')
# 下载网页
news.download()
## 网页解析
news.parse()
print("title=",news.title)# 获取文章标题
print("author=", news.authors) # 获取文章作者
print("publish_date=", news.publish_date) # 获取文章日期
# 自然语言处理
news.nlp()
print('keywords=',news.keywords)#从文本中提取关键字
print("summary=",news.summary)# 获取文章摘要
# time.sleep(30)
print("text=",news.text,"\n")# 获取文章正文
print("movies=",news.movies) # 获取文章视频链接
print("top_iamge=",news.top_image) # 获取文章顶部图片地址
print("images=",news.images)#从html中提取所有图像
print("imgs=",news.imgs)
print("html=",news.html)#获取html
也可以直接导入包,如果语言一致,也可以直接声明
import newspaper
url='http://www.coscocs.com/'
'''注:文章缓存:默认情况下,newspaper缓存所有以前提取的文章,并删除它已经提取的任何文章。
此功能用于防止重复的文章和提高提取速度。可以使用memoize_articles参数选择退出此功能。'''
news = newspaper.build(url, language='zh', memoize_articles=False)
article = news.articles[0]
article.download()
article.parse()
print('text=',article.text)
print('brand=',news.brand) #提取源品牌
print('description=',news.description) # 提取描述
print("一共获取%s篇文章" % news.size()) # 文章的数目
# 所有文章的url
for article in news.articles:
print(article.url)
#提取源类别
for category in news.category_urls():
print(category)
#提取源提要
for feed_url in news.feed_urls():
print(feed_url)
注意:文章缓存:默认情况下,报纸缓存所有以前提取的文章并删除任何已经提取的文章。该功能用于防止重复文章,提高提取速度。您可以使用 memoize_articles 参数选择退出此功能。
结合 Requests 和 Newspaper 来解析文本
import requests
from newspaper import fulltext
html = requests.get('https://www.washingtonpost.com ... 23x27;).text
text = fulltext(html)
print(text)
谷歌趋势信息
import newspaper
print(newspaper.languages())#获取支持的语言
print(newspaper.hot())#hot()使用公共api返回谷歌上的热门词汇列表
print(newspaper.popular_urls())#popular_urls()返回一个流行新闻源url列表
多任务处理
import newspaper
from newspaper import news_pool
# 创建并行任务
slate_paper = newspaper.build('http://slate.com')
tc_paper = newspaper.build('http://techcrunch.com')
espn_paper = newspaper.build('http://espn.com')
papers = [slate_paper, tc_paper, espn_paper]
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 共6个线程
news_pool.join()
print(slate_paper.articles[10].html)
python可读性
github地址为:
安装
pip install requests
pip install readability-lxml
如何使用:
import requests
from readability import Document
response = requests.get('https://news.163.com/18/1123/1 ... 23x27;)
doc = Document(response.text)
print doc.title()
print doc.content()
测试结果:文本提取范围过大,出现乱码,不好用。显然得到的文本部分有问题。并且存在乱码的问题。因此,不推荐。
网页新闻抓取(神龙IP一起常见的抓取策略及算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-03 09:35
网络爬虫又称网络蜘蛛,是一种按照一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新爬取的URL放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略吧~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到待抓取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大型网站优先
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果是网站,等待下载的页面数最多,则先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。 查看全部
网页新闻抓取(神龙IP一起常见的抓取策略及算法策略)
网络爬虫又称网络蜘蛛,是一种按照一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新爬取的URL放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略吧~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到待抓取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大型网站优先
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果是网站,等待下载的页面数最多,则先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。
网页新闻抓取( 写了一个从网页中抓取信息(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-03 09:30
写了一个从网页中抓取信息(如最新的头条新闻))
写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
网页新闻抓取(
写了一个从网页中抓取信息(如最新的头条新闻))



写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
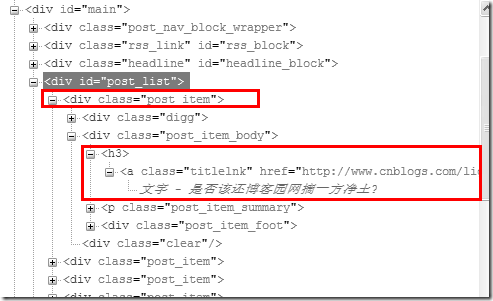
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224
网页新闻抓取( 2017年04月24日Python正则抓取新闻标题和链接的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-01 03:16
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python定时抓取新闻标题和链接的方法示例
更新时间:2017年4月24日08:56:43 作者:我想要的闪耀
本文章主要介绍了Python正则抓取新闻标题和链接的方法,并结合具体实例分析了Python正则匹配页面元素和文件编写的相关操作技巧。有需要的朋友可以参考以下
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。 查看全部
网页新闻抓取(
2017年04月24日Python正则抓取新闻标题和链接的方法)
Python定时抓取新闻标题和链接的方法示例
更新时间:2017年4月24日08:56:43 作者:我想要的闪耀
本文章主要介绍了Python正则抓取新闻标题和链接的方法,并结合具体实例分析了Python正则匹配页面元素和文件编写的相关操作技巧。有需要的朋友可以参考以下
本文介绍了Python定时抓取新闻标题和链接的方法。分享给大家,供大家参考,如下:
#-*-coding:utf-8-*-
import re
from urllib import urlretrieve
from urllib import urlopen
#获取网页信息
doc = urlopen("http://www.itongji.cn/news/";).read() #自己找的一个大数据的新闻网站
#抓取新闻标题和链接
def extract_title(info):
pat = '<a target=\"_blank\"(.*?)/a/h3'
title = re.findall(pat, info)
titles='\n'.join(title)
#print titles
#修改指定字符串
titles1=titles.replace('class="title"','title')
titles2=titles1.replace('>',':')
titles3=titles2.replace('href','url:')
titles4=titles3.replace('="/','"http://www.itongji.cn/')
#写入文件
save=open('xinwen.txt','w')
save.write(titles4)
save.close()
titles = extract_title(doc)
PS:这里有两个非常方便的正则表达式工具供大家参考:
JavaScript 正则表达式在线测试工具:
正则表达式在线生成工具:
关于Python的更多信息请参考本站专题:《Python正则表达式使用总结》、《Python数据结构与算法教程》、《Python Socket编程技巧总结》、《Python函数使用技巧总结》 、《Python字符串操作技巧总结》、《Python入门及高级经典教程》、《Python文件与目录操作技巧总结》
希望这篇文章对你的 Python 编程有所帮助。
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-30 20:18
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
项目源码托管在Github上:
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
环境使用方法
如果您想体验 GNE 的功能,请按照以下步骤操作:
安装 GNE
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
# 使用 pipenv 安装
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
使用 GNE
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz"}
开发环境
如果您需要参与本项目的开发,请按照以下步骤操作。
本项目使用 Pipenv 来管理 Python 的第三方库。如果你不知道Pipenv是什么,请点我跳转。
安装 Pipenv 后,请按照以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特别说明
项目代码中的example.py提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,以上的写法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
运行截图
网易新闻
今日头条
新浪新闻
观察者网
项目文件
GNE 常见问题问答
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
如果觉得GNE对你的日常发展或公司有帮助,请加作者微信mxqiuchen(或扫描下方二维码)并注明“GNE”,作者会拉你进群。
验证消息:GNE
论文修改
在使用Python实现这个提取器的过程中,发现论文中的公式和方法存在一些缺陷,会导致部分节点报错。我会单独写几篇文章文章来介绍这里的变化。请关注我的微信公众号:闻所未闻的代码:
查看全部
网页新闻抓取(自动化抽取新闻类网站正文的算法论文——《基于文本及符号密度的网页正文提取方法》
)
项目来源
这个项目的发展源于我在知网找到的一篇关于自动提取新闻网站文本的算法论文——《基于文本和符号密度的网页文本提取方法》)
本文中描述的算法看起来简洁、清晰且合乎逻辑。但是因为论文只讲了算法的原理,并没有具体的语言实现,所以我按照论文用Python来实现这个提取器。我们还使用了今日头条、网易新闻、有民行空、观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻进行测试,发现提取效果非常好,几乎达到了100%的准确率。
项目状态
项目源码托管在Github上:
在论文描述的文本提取的基础上,我添加了标题、发表时间和作者的自动检测提取功能。
最终输出效果如下图所示:
目前,这个项目是一个非常非常早期的Demo。发布是希望我们能尽快得到大家的反馈,让我们的开发更有针对性。
本项目命名为extractor,而不是crawler,以避免不必要的风险。因此,本项目的输入是HTML,输出是字典。请使用适当的方法获取目标网站的HTML。
本项目目前没有,以后也不会提供主动请求网站 HTML的功能。
环境使用方法
如果您想体验 GNE 的功能,请按照以下步骤操作:
安装 GNE
# 以下两种方案任选一种即可
# 使用 pip 安装
pip install --upgrade git+https://github.com/kingname/Ge ... r.git
# 使用 pipenv 安装
pipenv install git+https://github.com/kingname/Ge ... 3Dgne
使用 GNE
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz"}
开发环境
如果您需要参与本项目的开发,请按照以下步骤操作。
本项目使用 Pipenv 来管理 Python 的第三方库。如果你不知道Pipenv是什么,请点我跳转。
安装 Pipenv 后,请按照以下步骤运行代码:
git clone https://github.com/kingname/Ge ... r.git
cd GeneralNewsExtractor
pipenv install
pipenv shell
python3 example.py
特别说明
项目代码中的example.py提供了本项目的基本使用示例。
在Elements标签页找到标签,右键选择Copy-Copy OuterHTML,如下图
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html)
print(result)
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '你的目标网页正文'
result = extractor.extract(html, title_xpath='//h5/text()')
print(result)
对于大多数新闻页面,以上的写法可以解决问题。
但是,有些新闻页面下面会有评论,评论中可能会有长篇评论。它们看起来更像文本而不是真正的新闻文本。因此,extractor.extract()方法也有一个默认参数noise_mode_list,用于网页预处理。提前删除整个评论区。
noise_mode_list 的值是一个列表。列表中的每一个元素都是XPath,对应的是你需要提前去除可能会造成干扰的目标标签。
比如下评论区对应的Xpath就是//div[@class="comment-list"]。所以在提取观察者网络的时候,为了防止评论干扰,可以加上这个参数:
result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
test文件夹中网页的提取结果请查看result.txt。
运行截图
网易新闻
今日头条
新浪新闻
观察者网
项目文件
GNE 常见问题问答
已知问题 目前此项仅适用于新闻页面的信息提取。如果目标网站不是新闻页面,也不是今日头条中的专辑类型文章,提取结果可能达不到预期。可能有一些新闻页面提取结果中的作者为空字符串。这可能是由于 文章 没有作者或现有正则表达式未涵盖这一事实。Todo 沟通
如果觉得GNE对你的日常发展或公司有帮助,请加作者微信mxqiuchen(或扫描下方二维码)并注明“GNE”,作者会拉你进群。
验证消息:GNE
论文修改
在使用Python实现这个提取器的过程中,发现论文中的公式和方法存在一些缺陷,会导致部分节点报错。我会单独写几篇文章文章来介绍这里的变化。请关注我的微信公众号:闻所未闻的代码:
网页新闻抓取(阿里云gt云栖社区主题地图(gt)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-28 03:16
阿里云>云栖社区>主题图>P>python爬取新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
python爬取新闻网站相关博客查看更多博客
Python爬虫入门教程9-100河北阳光行政投诉科
作者:Dream Eraser1430人浏览评论:02年前
1.河北阳光行政投诉科-之前的文章文章都是写图片相关的爬虫,今天写个留言板爬出来,再做一套数据分析案例教程到做好准备,作为一个河北人,遵守法律法规,投诉是必备的技能。那我们来看看我们河北人为什么要抱怨呢?网站 今天要爬取的地址
阅读全文
跟我一起开始使用python爬虫
作者:cxa1415 浏览评论人数:02年前
前几天想写一个文章的爬虫系列。我写它不是因为我很忙(不是因为我很懒)。趁着屋子里的凉意和平静的心,我想总结一下我目前遇到的情况。对于一些爬虫知识,本系列将从简单的爬虫开始,逐渐增加难度。同时,会总结反攀爬的方法,并通过具体的例子来展示不同的反攀爬现象和做法。
阅读全文
Python爬虫学习,记住抓包获取js和从js函数中取数据的过程
作者:云飞学编程1203人浏览评论:03年前
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。我大概看了一下,是js加载的,数据在js函数里,很有意思,就分了
阅读全文
常用python爬虫框架整理
作者:友弟1689人浏览评论:03年前
Python 中好用的爬虫框架一般都可以媲美小爬虫的需求。我是直接用requests库+bs4解决的。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架仅用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫采集CloudBlog网站的文章
作者:朱佩1423人浏览评论:04年前
本文使用python爬虫获取网站中的一个文章,包括标题、发表时间、作者、文章内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页的所有文章链接并存入URL集合中,然后一一访问这些采集的链接访问,再次解析
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》-第2章网络爬虫技能概述2.1 网络爬虫技能概述
作者:华章电脑1908人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第2章,2.1节,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。第2章网络爬虫技巧概述在上一章中,我们对网络爬虫有了初步的了解,那么网络爬虫的具体功能
阅读全文
Python爬虫系列(一)早教爬虫补充及总结
作者:盛开的山茶花 2838人浏览评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda。2、IDE:Pycharm、Pydev 3、 工具:Jupyter Notebook(安装Anaconda就会有)二、Python基础视频教程1、疯狂Python:
阅读全文
【蟒蛇爬虫】Selenium定向爬行老虎猛扑篮球海量精美图片
作者:肖洛洛4370人浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他经常访问虎扑篮球、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,手真的很痛。作为程序员,编写程序继续!
阅读全文 查看全部
网页新闻抓取(阿里云gt云栖社区主题地图(gt)(组图))
阿里云>云栖社区>主题图>P>python爬取新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
python爬取新闻网站相关博客查看更多博客
Python爬虫入门教程9-100河北阳光行政投诉科
作者:Dream Eraser1430人浏览评论:02年前
1.河北阳光行政投诉科-之前的文章文章都是写图片相关的爬虫,今天写个留言板爬出来,再做一套数据分析案例教程到做好准备,作为一个河北人,遵守法律法规,投诉是必备的技能。那我们来看看我们河北人为什么要抱怨呢?网站 今天要爬取的地址
阅读全文
跟我一起开始使用python爬虫
作者:cxa1415 浏览评论人数:02年前
前几天想写一个文章的爬虫系列。我写它不是因为我很忙(不是因为我很懒)。趁着屋子里的凉意和平静的心,我想总结一下我目前遇到的情况。对于一些爬虫知识,本系列将从简单的爬虫开始,逐渐增加难度。同时,会总结反攀爬的方法,并通过具体的例子来展示不同的反攀爬现象和做法。
阅读全文
Python爬虫学习,记住抓包获取js和从js函数中取数据的过程
作者:云飞学编程1203人浏览评论:03年前
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。我大概看了一下,是js加载的,数据在js函数里,很有意思,就分了
阅读全文
常用python爬虫框架整理
作者:友弟1689人浏览评论:03年前
Python 中好用的爬虫框架一般都可以媲美小爬虫的需求。我是直接用requests库+bs4解决的。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架仅用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫采集CloudBlog网站的文章
作者:朱佩1423人浏览评论:04年前
本文使用python爬虫获取网站中的一个文章,包括标题、发表时间、作者、文章内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页的所有文章链接并存入URL集合中,然后一一访问这些采集的链接访问,再次解析
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》-第2章网络爬虫技能概述2.1 网络爬虫技能概述
作者:华章电脑1908人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第2章,2.1节,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。第2章网络爬虫技巧概述在上一章中,我们对网络爬虫有了初步的了解,那么网络爬虫的具体功能
阅读全文
Python爬虫系列(一)早教爬虫补充及总结
作者:盛开的山茶花 2838人浏览评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda。2、IDE:Pycharm、Pydev 3、 工具:Jupyter Notebook(安装Anaconda就会有)二、Python基础视频教程1、疯狂Python:
阅读全文
【蟒蛇爬虫】Selenium定向爬行老虎猛扑篮球海量精美图片
作者:肖洛洛4370人浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他经常访问虎扑篮球、Wet等论坛。论坛里会有很多精美的图片,包括NBA球队、CBA球星、花边新闻、球鞋美女等等,如果右键另存为,手真的很痛。作为程序员,编写程序继续!
阅读全文
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-25 09:16
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项之间的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用doc.select("div.list-hd")方法返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,你必须每天阅读NBA新闻。用了这么多新闻类APP,不知道自己是否也可以做一个简单的新闻类APP。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有技术含量,但还是写一下过程,满足菜鸟的小小成就感。
关于Jsoup
分析与思考
虎扑NBA新闻页面的新闻列表如图所示:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址这四个信息,然后用一个实体类News来封装以上四个数据,然后将其布局在 ListView 上。点击ListView的每个子项,用一个WebView显示子项显示的新闻链接地址,就大功告成了。效果如下:
具体实施过程
1. 在AndroidStudio中新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项之间的间隔距离和颜色
3. 创建实体类News,封装我们将从网页中获取的新闻标题、摘要、时间来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,建立对应的构造方法和四个变量的get、set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4. 最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装在News实体类中。简单总结一下实现方法
分析上图中两条新闻的源代码,找到我们想要获取的新闻标题、摘要、时间和来源、链接地址这四个数据。我们可以发现,在每条新闻的标签[div][/div]下,有两个数据,新闻的链接地址和新闻的标题。我们要做的就是使用Jsoup来解析这两个数据:
首先使用 Jsoup.connect("要获取的数据的 URL").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用doc.select("div.list-hd")方法返回一个Elements对象,封装了每个新闻[div][/div]标签的内容,数据格式为:[{新闻1},{新闻2 }, {新闻 3}, {新闻 4}......]
使用 for 循环遍历 titleLinks,对于每个 Element 对象:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href")获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
同理对于另外两个数据:news profile和news time and source,我们分析源码,分析news profile的源码
使用以下代码获取新闻简介
元素 descLinks = doc.select("div.list-content"); for(Element e: titleLinks){ String desc = e.select("span").text();}
元素 timeLinks = doc.select("div.otherInfo"); for(Element e:timeLinks){ String time = e.select("span.other-left").select("a").text();}
综上,我们已经获得了我们需要的数据,所以我们在MainActivity中声明了一个getNews()方法。在方法中,我们启动一个线程来获取数据。完整代码如下:
<p>private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(网络爬虫的基本原理策略抓取策略(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-25 06:04
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
可以更形象地理解:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。爬虫爬取到这个庞大的网络所需要的资源后,通过一定的机制和容器进行存储。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从网上抓取网页信息。其中,通过URL下载队列调度器,通过一定时间或调度机制下载,通过多内存(DB)保存下载的目标资源。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接计数策略、Partial PageRank策略、OPIC策略、大站优先策略等等。
深度优先深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,然后选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
Breadth-first 广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
Best Priority Best Priority Search 策略根据一定的网页分析算法预测候选网址与目标页面的相似度,或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
反向链接计数策略反向链接计数是指其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
Partial PageRank Strategy Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,并且经过计算,将要爬取的URL队列中的URL按照PageRank值的大小排列,按照这个顺序爬取页面。如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,
OPIC 战略。该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
大站优先策略是将URL队列中的所有网页按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
总结:在实际运营过程中,往往不是单独选择某个策略,而是综合多个策略的优势,去渣滓,为业务实现相应的功能。
网络爬虫的另一个重要部分是网页分析。具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取动作,而不是关心从大范围的网页爬取中得到想要的目标网页,所以不详细分析在这里完成。
参考:
下一篇文章将讨论抓取腾讯新闻RSS网页的原理。请注意。 查看全部
网页新闻抓取(网络爬虫的基本原理策略抓取策略(一)_光明网)
网络爬虫定义
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是根据某些规则自动抓取万维网上信息的程序或脚本。
可以更形象地理解:网络相当于一张巨大的蜘蛛网,每条蜘蛛丝的交集就是一个资源(URI)。爬虫爬取到这个庞大的网络所需要的资源后,通过一定的机制和容器进行存储。.
网络爬虫的原理
网络爬虫的基本原理可以用一张经典图来概括:
多线程下载器功能:从网上抓取网页信息。其中,通过URL下载队列调度器,通过一定时间或调度机制下载,通过多内存(DB)保存下载的目标资源。
网络爬虫的爬取策略 爬取策略是网络爬虫系统中最重要的部分。爬取策略是爬虫系统按照一定的方法/方法对目标资源进行爬取。目前比较常见的爬取策略有:深度优先、广度优先、最佳优先。还有一些爬取策略:反向链接计数策略、Partial PageRank策略、OPIC策略、大站优先策略等等。
深度优先深度优先搜索策略从起始网页开始,选择一个网址进入,分析该网页中的网址,然后选择一个进入。这样一个链接被一个一个地爬取,直到处理完一条路由,然后再处理下一条路由。深度优先的策略设计比较简单。但是,门户网站网站提供的链接往往是最有价值的,PageRank也非常高。但是,随着深度的增加,网页和PageRank的价值会相应降低。这意味着重要的网页通常更接近种子,而被抓取过深的网页价值较低。同时,该策略的抓取深度直接影响抓取命中率和抓取效率,抓取深度是该策略的关键。与其他两种策略相比。这种策略很少使用。
Breadth-first 广度优先搜索策略是指在爬取过程中,当前一级搜索完成后,再进行下一级搜索。该算法的设计和实现比较简单。目前,为了覆盖尽可能多的网页,一般采用广度优先搜索的方法。也有许多研究将广度优先搜索策略应用于聚焦爬虫。基本思想是,距离初始 URL 一定链接距离内的网页具有很高的主题相关性概率。另一种方法是将广度优先搜索与网络过滤技术相结合。首先使用广度优先策略抓取网页,然后过滤掉不相关的网页。这些方法的缺点是随着抓取网页的增加,
Best Priority Best Priority Search 策略根据一定的网页分析算法预测候选网址与目标页面的相似度,或与主题的相关性,选择一个或几个评价最好的网址进行爬取。它只访问被网络分析算法预测为“有用”的网页。一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最好的优先级策略是局部最优搜索算法。因此,需要将最佳优先级与具体应用结合起来进行改进,才能跳出局部最佳点。将在第 4 节中结合网页分析算法进行详细讨论。
反向链接计数策略反向链接计数是指其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
Partial PageRank Strategy Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,组成一个网页集,计算每个页面的PageRank值,并且经过计算,将要爬取的URL队列中的URL按照PageRank值的大小排列,按照这个顺序爬取页面。如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于已经从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,
OPIC 战略。该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
大站优先策略是将URL队列中的所有网页按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
总结:在实际运营过程中,往往不是单独选择某个策略,而是综合多个策略的优势,去渣滓,为业务实现相应的功能。
网络爬虫的另一个重要部分是网页分析。具体方法有:拓扑分析算法、网页分析算法等。这里的重点是如何实现爬取动作,而不是关心从大范围的网页爬取中得到想要的目标网页,所以不详细分析在这里完成。
参考:
下一篇文章将讨论抓取腾讯新闻RSS网页的原理。请注意。
网页新闻抓取(拓展()系统服务没加上及一堆问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2021-11-25 06:00
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a> 查看全部
网页新闻抓取(拓展()系统服务没加上及一堆问题
)
做了一些扩展(你也可以扩展,从首页获取tele中间路径,然后用map为用户选择):
#这里可以再改进,进行扩展,自行输入时间(貌似都一样,正则还是可以用)
#doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
newsYear = raw_input("Please input the year likes 2012: ")
newsMouth = raw_input("Please input the mouth likes 03: ")
newsDay = raw_input("Please input the day likes 02: ")
doc = urlopen("http://roll.tech.sina.com.cn/tele/" + \
newsYear + "-" + \
newsMouth + "-" + \
newsDay + \
".shtml").read()
接触网页和web相关知识的接触不多,然后用了不习惯的Python。下面的程序有波折,bug也不少,但勉强算得上是爬取网络新闻的实现。 win系统服务没加,问题多多,待续...
<p># -*- coding: cp936 -*-
import win32serviceutil
import win32service
import win32event
from urllib import urlretrieve
from urllib import urlopen
import smtplib
from email.mime.text import MIMEText
from email.MIMEMultipart import MIMEMultipart
from email.Header import Header
#这个正则库感觉很棒
import re
import os
import xlrd
doc = urlopen("http://roll.tech.sina.com.cn/t ... 6quot;).read()
#分别寻找链接和新闻标题
def extract_url(info):
rege = "<a href=\"(.*)\" target=_blank>"
url = re.findall(rege, info)
return url
def extract_title(info):
pat = "\" target=_blank>(.*)</a>
网页新闻抓取(网页资源提取功能很简单,您只要打开一个网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-24 00:05
你有没有想过批量保存网页上的图片,却只能一张一张的保存?你有没有想过批量保存网页的视频文件,但下载工具无法对文件进行分类的尴尬?如果你有这样的烦恼,最新的4.4.1版TT浏览器引入的新功能-网页资源提取,可以帮你轻松解决。
网页资源提取功能非常简单。您只需要打开一个网页,点击工具栏上的“网页提取”按钮,就会在网页顶部打开资源提取器。您可以轻松提取您想要的各种网络资源。方便吗?文本、图片、Flash文件一应俱全,视频文件、音频文件、文档文件、压缩文件、EXE文件等其他文件都可以在“其他解压”中找到,你想要的都在这里!
轻松提取网络资源。腾讯TT4.4.版本1发布
下载TT浏览器TT4.4.版本1
温馨提示:TT浏览器一直秉承腾讯“一切以用户价值为导向”的核心经营理念,注重用户体验,为用户提供最想要、最有价值的功能。网页资源提取功能就是这一理念的最好体现。该功能是指打开的网页,可以分别提取网页上的文字、图片、音频、视频、Flash等文件,并可以批量保存和下载。真正想用户所想,实用,方便,好用。
TT4.4.1 更新信息:
1.独创网页资源提取功能,自由提取图片、Flash、媒体文件
2. 推出强大的采集管理器,更轻松地管理本地和网络采集
3. 添加空白页面快速链接,一键直接访问最常访问的网址
4.优化自定义背景图片功能,图片随心拖动缩放
5、优化新窗口原有独立视频功能,增加自定义视频网站
6.增加查看当前所有标签的功能,多标签管理更清晰
7.优化TT上QQ登录详情,更贴心满足您的需求 查看全部
网页新闻抓取(网页资源提取功能很简单,您只要打开一个网页(组图))
你有没有想过批量保存网页上的图片,却只能一张一张的保存?你有没有想过批量保存网页的视频文件,但下载工具无法对文件进行分类的尴尬?如果你有这样的烦恼,最新的4.4.1版TT浏览器引入的新功能-网页资源提取,可以帮你轻松解决。
网页资源提取功能非常简单。您只需要打开一个网页,点击工具栏上的“网页提取”按钮,就会在网页顶部打开资源提取器。您可以轻松提取您想要的各种网络资源。方便吗?文本、图片、Flash文件一应俱全,视频文件、音频文件、文档文件、压缩文件、EXE文件等其他文件都可以在“其他解压”中找到,你想要的都在这里!
轻松提取网络资源。腾讯TT4.4.版本1发布
下载TT浏览器TT4.4.版本1
温馨提示:TT浏览器一直秉承腾讯“一切以用户价值为导向”的核心经营理念,注重用户体验,为用户提供最想要、最有价值的功能。网页资源提取功能就是这一理念的最好体现。该功能是指打开的网页,可以分别提取网页上的文字、图片、音频、视频、Flash等文件,并可以批量保存和下载。真正想用户所想,实用,方便,好用。
TT4.4.1 更新信息:
1.独创网页资源提取功能,自由提取图片、Flash、媒体文件
2. 推出强大的采集管理器,更轻松地管理本地和网络采集
3. 添加空白页面快速链接,一键直接访问最常访问的网址
4.优化自定义背景图片功能,图片随心拖动缩放
5、优化新窗口原有独立视频功能,增加自定义视频网站
6.增加查看当前所有标签的功能,多标签管理更清晰
7.优化TT上QQ登录详情,更贴心满足您的需求
网页新闻抓取(企业建站及大型新闻网站新闻内容转载史上最强的工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2021-11-22 03:01
当今最强的网页抓取、内容获取和专业的新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询: 查看全部
网页新闻抓取(企业建站及大型新闻网站新闻内容转载史上最强的工具)
当今最强的网页抓取、内容获取和专业的新闻管理(cms)软件,是企业建站和大型新闻网站新闻内容转载史上最强的利器:
1、专业门户新闻网站信息管理和信息发布系统。
2、 新闻频道及栏目可灵活设置,后台管理设计为积木式模块,方便二次开发。
3、提供当今最强大的网页抓取和新闻抓取核心功能,可抓取新闻网站98%,根据自定义的文章模板自动生成抓取的新闻内容符合自己网站风格的新闻内容页面,可被新闻页面抓取,可完整抓取新闻内容。同时,新闻图片在本地自动抓取,不需要获取的部分也可以通过过滤功能过滤,直到符合你想要的新闻内容。
4、新增新闻搜索抓取功能,可设置栏目抓取功能,可设置新闻栏目关键词抓取新闻内容时过滤,抓取符合需求的文章柱下。
5、提供强大的在线编辑器。
6、新闻文章 内容提供全文搜索功能,全文搜索速度极快。
7、 新闻页面自动生成静态页面功能,提高访问效率。
8、提供SEO优化功能,可以自动生成websit.xml提交给谷歌和百度。
9、 强大的新闻后台权限管理功能,可以根据用户的角色灵活设置维护人员的权限和功能。
10、新闻栏目授权管理功能。可根据新闻栏目指定维护人员维护新闻内容。
11、 提供RSS自动生成功能。
12、高级数据库和操作系统选择:win2003 sqlserver2005
欢迎来电咨询:
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 03:01
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网络获取消息(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转化为视图视图显示,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的WEB应用中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户界面) ),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前显示新闻的适配器。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml");// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
将XML资源文件转换为视图有3种方式,底层实现是一样的,这里是使用方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView的时候,可以通过复用convertView来减少视图的创建次数,另外还可以通过定义一个类来将视图中的控件声明为成员,比如上面的ViewHolder类。
最后是最后的渲染:
查看全部
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3.
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网络获取消息(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转化为视图视图显示,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的WEB应用中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户界面) ),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前显示新闻的适配器。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml";);// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
将XML资源文件转换为视图有3种方式,底层实现是一样的,这里是使用方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView的时候,可以通过复用convertView来减少视图的创建次数,另外还可以通过定义一个类来将视图中的控件声明为成员,比如上面的ViewHolder类。
最后是最后的渲染:
网页新闻抓取(说到底及服务端地址结构目录结构方案分析(闲情))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-11-21 00:01
前言
一直喜欢看科技新闻,在cnBeta混了很多年。以前,西贝的评论区是匿名的,所以评论区很活跃,各种喷子和笑话,但确实很开心。可以说是西贝的人气了。最繁华的时候。但自去年国家网信办发布《互联网评论服务管理规定》,要求实名制用户留言和评论后,原本活跃的评论区瞬间下滑,人气一落千丈。 . 事实上,归根结底,西贝并没有跟上移动互联网的潮流。它仍然停留在PC互联网时代。网络广告太多了。然而,手机应用质量堪忧,体验极差。虽然有很多第三方应用,但由于没有官方支持,体验上还是不够好。例如,如果某些版本正式发布,第三方应用程序将基本挂掉。
所以为了方便看cnBeta的新闻,我打算用爬虫把cnBeta的新闻爬下来,搭建一个自建m站,让体验可控,没有广告(`∀´)Ψ . 其实这个项目很早就完成了,不过现在有时间写一篇文章分享一下。
概述
本项目的爬虫和服务器github地址:
前端github地址:
技术细节目录结构
目录结构
├── bin // 入口
│ ├── article-list.js // 抓取新闻列表逻辑
│ ├── content.js // 抓取新闻内容逻辑
│ ├── server.js // 服务端程序入口
│ └── spider.js // 爬虫程序入口
├── config // 配置文件
├── dbhelper // 数据库操作方法目录
├── middleware // koa2 中间件
├── model // mongoDB 集合操作实例
├── router // koa2 路由文件
├── utils // 工具函数
├── package.json
案例分析
首先看爬虫程序的入口文件。整体逻辑其实很简单。先抓取新闻列表,存入MongoDB数据库,每十分钟抓取一次。获取新闻列表后,查询数据库中列表中没有新闻内容的新闻,开始获取新闻详情,然后更新到数据库中。
const articleListInit = require('./article-list');
const articleContentInit = require('./content');
const logger = require('../config/log');
const start = async() => {
let articleListRes = await articleListInit();
if (!articleListRes) {
logger.warn('news list update failed...');
} else {
logger.info('news list update succeed!');
}
let articleContentRes = await articleContentInit();
if (!articleContentRes) {
logger.warn('article content grab error...');
} else {
logger.info('article content grab succeed!');
}
};
if (typeof articleListInit === 'function') {
start();
}
setInterval(start, 600000);
接下来看一下抓取新闻列表的逻辑。因为可以获取新闻列表的Ajax接口,所以可以直接调用该接口获取列表信息。但也有一个问题。cnBeta新闻列表的缩略图和文章中的图片是防盗链的,所以你的网站中的图片不能直接使用,所以我直接爬下cnBeta图片文件并保存它在你自己的服务器上。
/**
* 初始化方法 抓取文章列表
* @returns {Promise.}
*/
const articleListInit = async() => {
logger.info('grabbing article list starts...');
const pageUrlList = getPageUrlList(listBaseUrl, totalPage);
if (!pageUrlList) {
return;
}
let res = await getArticleList(pageUrlList);
return res;
}
/**
* 利用分页接口获取文章列表
* @param pageUrlList
* @returns {Promise}
*/
const getArticleList = (pageUrlList) => {
return new Promise((resolve, reject) => {
async.mapLimit(pageUrlList, 1, (pageUrl, callback) => {
getCurPage(pageUrl, callback);
}, (err, result) => {
if (err) {
logger.error('get article list error...');
logger.error(err);
reject(false);
return;
}
let articleList = _.flatten(result);
downloadThumbAndSave(articleList, resolve);
})
})
};
/**
* 获取当前页面的文章列表
* @param pageUrl
* @param callback
* @returns {Promise.}
*/
const getCurPage = async(pageUrl, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
request(pageUrl, (err, response, body) => {
if (err) {
logger.info('current url went wrong,url address:' + pageUrl);
callback(null, null);
return;
} else {
let responseObj = JSON.parse(body);
if (responseObj.result && responseObj.result.list) {
let newsList = parseObject(articleModel, responseObj.result.list, {
pubTime: 'inputtime',
author: 'aid',
commentCount: 'comments',
});
callback(null, newsList);
return;
}
console.log("出错了");
callback(null, null);
}
});
};
const downloadThumbAndSave = (list, resolve) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (list.indexOf(null) > -1) {
resolve(false);
} else {
try {
async.eachSeries(list, (item, callback) => {
let thumb_url = item.thumb.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on('error', (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
}, (err, result) => {
if (!err) {
saveDB(list, resolve);
}
});
}
catch(err) {
console.log(err);
}
}
};
/**
* 将文章列表存入数据库
* @param result
* @param callback
* @returns {Promise.}
*/
const saveDB = async(result, callback) => {
//console.log(result);
let flag = await dbHelper.insertCollection(articleDbModel, result).catch(function (err){
logger.error('data insert falied');
});
if (!flag) {
logger.error('news list save failed');
} else {
logger.info('list saved!total:' + result.length);
}
if (typeof callback === 'function') {
callback(true);
}
};
我们来看看抓取新闻内容的逻辑。这里我们直接根据新闻sid获取新闻内容页面的html,然后使用cheerio库分析得到我们需要的新闻内容。当然,这里也是将文章中的图片爬下来保存到服务器,将数据库中存储的新闻内容中的图片链接替换为自己服务器中的URL。
/**
* 抓取正文程序入口
* @returns {Promise.}
*/
const articleContentInit = async() => {
logger.info('grabbing article contents starts...');
let uncachedArticleSidList = await getUncachedArticleList(articleDbModel);
// console.log('未缓存的文章:'+ uncachedArticleSidList.join(','));
const res = await batchCrawlArticleContent(uncachedArticleSidList);
if (!res) {
logger.error('grabbing article contents went wrong...');
}
return res;
};
/**
* 查询新闻列表获取sid列表
* @param Model
* @returns {Promise.}
*/
const getUncachedArticleList = async(Model) => {
const selectedArticleList = await dbHelper.queryDocList(Model).catch(function (err){
logger.error(err);
});
return selectedArticleList.map(item => item.sid);
// return selectedArticleList.map(item => item._doc.sid);
};
/**
* 批量抓取新闻详情内容
* @param list
* @returns {Promise}
*/
const batchCrawlArticleContent = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 3, (sid, callback) => {
getArticleContent(sid, callback);
}, (err, result) => {
if (err) {
logger.error(err);
reject(false);
return;
}
resolve(true);
});
});
};
/**
* 抓取单篇文章内容
* @param sid
* @param callback
* @returns {Promise.}
*/
const getArticleContent = async(sid, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let url = contentBaseUrl + sid + '.htm';
request(url, (err, response, body) => {
if (err) {
logger.error('grabbing article content went wrong,article url:' + url);
callback(null, null);
return;
}
const $ = cheerio.load(body, {
decodeEntities: false
});
const serverAssetPath = `${serverIp}:${serverPort}/data`;
let domainReg = new RegExp('https://static.cnbetacdn.com','g');
let article = {
sid,
source: $('.article-byline span a').html() || $('.article-byline span').html(),
summary: $('.article-summ p').html(),
content: $('.articleCont').html().replace(styleReg.reg, styleReg.replace).replace(scriptReg.reg, scriptReg.replace).replace(domainReg, serverAssetPath),
};
saveContentToDB(article);
let imgList = [];
$('.articleCont img').each((index, dom) => {
imgList.push(dom.attribs.src);
});
downloadImgs(imgList);
callback(null, null);
});
};
/**
* 下载图片
* @param list
*/
const downloadImgs = (list) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (!list.length) {
return;
}
try {
async.eachSeries(list, (item, callback) => {
let num = Math.random() * 500 + 500;
sleep(num);
if (item.indexOf(host) === -1) return;
let thumb_url = item.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on("error", (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
});
}
catch(err) {
console.log(err);
}
};
/**
* 保存到文章内容到数据库
* @param article
*/
const saveContentToDB = (item) => {
let flag = dbHelper.updateCollection(articleDbModel, item);
if (flag) {
logger.info('grabbing article content succeeded:' + item.sid);
}
};
爬虫部分差不多就是这个样子。还有一点就是,你的服务器上每天都会存储数百张爬取的图片。随着时间的推移,图片占用的存储空间会特别大,所以需要定期清理,有兴趣的可以看看。查看项目中的 clear-expire.js 文件。
总结
其实这个项目虽然整体上并不复杂,但是在搭建一个前后端系统的过程中,我收获颇多。很多问题的解决需要自己的实践和思考,这也是性能优化的一个重要考虑。方面。
下面的截图是我最终完成的m站。界面非常清爽,体验确实比cnBeta官网好很多。这样看科技新闻确实方便了很多。
以上 查看全部
网页新闻抓取(说到底及服务端地址结构目录结构方案分析(闲情))
前言
一直喜欢看科技新闻,在cnBeta混了很多年。以前,西贝的评论区是匿名的,所以评论区很活跃,各种喷子和笑话,但确实很开心。可以说是西贝的人气了。最繁华的时候。但自去年国家网信办发布《互联网评论服务管理规定》,要求实名制用户留言和评论后,原本活跃的评论区瞬间下滑,人气一落千丈。 . 事实上,归根结底,西贝并没有跟上移动互联网的潮流。它仍然停留在PC互联网时代。网络广告太多了。然而,手机应用质量堪忧,体验极差。虽然有很多第三方应用,但由于没有官方支持,体验上还是不够好。例如,如果某些版本正式发布,第三方应用程序将基本挂掉。
所以为了方便看cnBeta的新闻,我打算用爬虫把cnBeta的新闻爬下来,搭建一个自建m站,让体验可控,没有广告(`∀´)Ψ . 其实这个项目很早就完成了,不过现在有时间写一篇文章分享一下。
概述
本项目的爬虫和服务器github地址:
前端github地址:
技术细节目录结构
目录结构
├── bin // 入口
│ ├── article-list.js // 抓取新闻列表逻辑
│ ├── content.js // 抓取新闻内容逻辑
│ ├── server.js // 服务端程序入口
│ └── spider.js // 爬虫程序入口
├── config // 配置文件
├── dbhelper // 数据库操作方法目录
├── middleware // koa2 中间件
├── model // mongoDB 集合操作实例
├── router // koa2 路由文件
├── utils // 工具函数
├── package.json
案例分析
首先看爬虫程序的入口文件。整体逻辑其实很简单。先抓取新闻列表,存入MongoDB数据库,每十分钟抓取一次。获取新闻列表后,查询数据库中列表中没有新闻内容的新闻,开始获取新闻详情,然后更新到数据库中。
const articleListInit = require('./article-list');
const articleContentInit = require('./content');
const logger = require('../config/log');
const start = async() => {
let articleListRes = await articleListInit();
if (!articleListRes) {
logger.warn('news list update failed...');
} else {
logger.info('news list update succeed!');
}
let articleContentRes = await articleContentInit();
if (!articleContentRes) {
logger.warn('article content grab error...');
} else {
logger.info('article content grab succeed!');
}
};
if (typeof articleListInit === 'function') {
start();
}
setInterval(start, 600000);
接下来看一下抓取新闻列表的逻辑。因为可以获取新闻列表的Ajax接口,所以可以直接调用该接口获取列表信息。但也有一个问题。cnBeta新闻列表的缩略图和文章中的图片是防盗链的,所以你的网站中的图片不能直接使用,所以我直接爬下cnBeta图片文件并保存它在你自己的服务器上。
/**
* 初始化方法 抓取文章列表
* @returns {Promise.}
*/
const articleListInit = async() => {
logger.info('grabbing article list starts...');
const pageUrlList = getPageUrlList(listBaseUrl, totalPage);
if (!pageUrlList) {
return;
}
let res = await getArticleList(pageUrlList);
return res;
}
/**
* 利用分页接口获取文章列表
* @param pageUrlList
* @returns {Promise}
*/
const getArticleList = (pageUrlList) => {
return new Promise((resolve, reject) => {
async.mapLimit(pageUrlList, 1, (pageUrl, callback) => {
getCurPage(pageUrl, callback);
}, (err, result) => {
if (err) {
logger.error('get article list error...');
logger.error(err);
reject(false);
return;
}
let articleList = _.flatten(result);
downloadThumbAndSave(articleList, resolve);
})
})
};
/**
* 获取当前页面的文章列表
* @param pageUrl
* @param callback
* @returns {Promise.}
*/
const getCurPage = async(pageUrl, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
request(pageUrl, (err, response, body) => {
if (err) {
logger.info('current url went wrong,url address:' + pageUrl);
callback(null, null);
return;
} else {
let responseObj = JSON.parse(body);
if (responseObj.result && responseObj.result.list) {
let newsList = parseObject(articleModel, responseObj.result.list, {
pubTime: 'inputtime',
author: 'aid',
commentCount: 'comments',
});
callback(null, newsList);
return;
}
console.log("出错了");
callback(null, null);
}
});
};
const downloadThumbAndSave = (list, resolve) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (list.indexOf(null) > -1) {
resolve(false);
} else {
try {
async.eachSeries(list, (item, callback) => {
let thumb_url = item.thumb.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on('error', (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
}, (err, result) => {
if (!err) {
saveDB(list, resolve);
}
});
}
catch(err) {
console.log(err);
}
}
};
/**
* 将文章列表存入数据库
* @param result
* @param callback
* @returns {Promise.}
*/
const saveDB = async(result, callback) => {
//console.log(result);
let flag = await dbHelper.insertCollection(articleDbModel, result).catch(function (err){
logger.error('data insert falied');
});
if (!flag) {
logger.error('news list save failed');
} else {
logger.info('list saved!total:' + result.length);
}
if (typeof callback === 'function') {
callback(true);
}
};
我们来看看抓取新闻内容的逻辑。这里我们直接根据新闻sid获取新闻内容页面的html,然后使用cheerio库分析得到我们需要的新闻内容。当然,这里也是将文章中的图片爬下来保存到服务器,将数据库中存储的新闻内容中的图片链接替换为自己服务器中的URL。
/**
* 抓取正文程序入口
* @returns {Promise.}
*/
const articleContentInit = async() => {
logger.info('grabbing article contents starts...');
let uncachedArticleSidList = await getUncachedArticleList(articleDbModel);
// console.log('未缓存的文章:'+ uncachedArticleSidList.join(','));
const res = await batchCrawlArticleContent(uncachedArticleSidList);
if (!res) {
logger.error('grabbing article contents went wrong...');
}
return res;
};
/**
* 查询新闻列表获取sid列表
* @param Model
* @returns {Promise.}
*/
const getUncachedArticleList = async(Model) => {
const selectedArticleList = await dbHelper.queryDocList(Model).catch(function (err){
logger.error(err);
});
return selectedArticleList.map(item => item.sid);
// return selectedArticleList.map(item => item._doc.sid);
};
/**
* 批量抓取新闻详情内容
* @param list
* @returns {Promise}
*/
const batchCrawlArticleContent = (list) => {
return new Promise((resolve, reject) => {
async.mapLimit(list, 3, (sid, callback) => {
getArticleContent(sid, callback);
}, (err, result) => {
if (err) {
logger.error(err);
reject(false);
return;
}
resolve(true);
});
});
};
/**
* 抓取单篇文章内容
* @param sid
* @param callback
* @returns {Promise.}
*/
const getArticleContent = async(sid, callback) => {
let num = Math.random() * 1000 + 1000;
await sleep(num);
let url = contentBaseUrl + sid + '.htm';
request(url, (err, response, body) => {
if (err) {
logger.error('grabbing article content went wrong,article url:' + url);
callback(null, null);
return;
}
const $ = cheerio.load(body, {
decodeEntities: false
});
const serverAssetPath = `${serverIp}:${serverPort}/data`;
let domainReg = new RegExp('https://static.cnbetacdn.com','g');
let article = {
sid,
source: $('.article-byline span a').html() || $('.article-byline span').html(),
summary: $('.article-summ p').html(),
content: $('.articleCont').html().replace(styleReg.reg, styleReg.replace).replace(scriptReg.reg, scriptReg.replace).replace(domainReg, serverAssetPath),
};
saveContentToDB(article);
let imgList = [];
$('.articleCont img').each((index, dom) => {
imgList.push(dom.attribs.src);
});
downloadImgs(imgList);
callback(null, null);
});
};
/**
* 下载图片
* @param list
*/
const downloadImgs = (list) => {
const host = 'https://static.cnbetacdn.com';
const basepath = './public/data';
if (!list.length) {
return;
}
try {
async.eachSeries(list, (item, callback) => {
let num = Math.random() * 500 + 500;
sleep(num);
if (item.indexOf(host) === -1) return;
let thumb_url = item.replace(host, '');
item.thumb = thumb_url;
if (!fs.exists(thumb_url)) {
mkDirs(basepath + thumb_url.substring(0, thumb_url.lastIndexOf('/')), () => {
request
.get({
url: host + thumb_url,
})
.pipe(fs.createWriteStream(path.join(basepath, thumb_url)))
.on("error", (err) => {
console.log("pipe error", err);
});
callback(null, null);
});
}
});
}
catch(err) {
console.log(err);
}
};
/**
* 保存到文章内容到数据库
* @param article
*/
const saveContentToDB = (item) => {
let flag = dbHelper.updateCollection(articleDbModel, item);
if (flag) {
logger.info('grabbing article content succeeded:' + item.sid);
}
};
爬虫部分差不多就是这个样子。还有一点就是,你的服务器上每天都会存储数百张爬取的图片。随着时间的推移,图片占用的存储空间会特别大,所以需要定期清理,有兴趣的可以看看。查看项目中的 clear-expire.js 文件。
总结
其实这个项目虽然整体上并不复杂,但是在搭建一个前后端系统的过程中,我收获颇多。很多问题的解决需要自己的实践和思考,这也是性能优化的一个重要考虑。方面。
下面的截图是我最终完成的m站。界面非常清爽,体验确实比cnBeta官网好很多。这样看科技新闻确实方便了很多。
以上
网页新闻抓取(百度认为什么样的网站更有抓取和收录价值呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-20 23:18
百度认为什么样的网站比较适合爬取和收录?我们从以下几个方面简单介绍一下。鉴于技术保密及网站操作差异等其他原因,以下内容仅供站长参考,具体收录策略包括但不限于内容。接下来,茂宏小编就为大家分享相关内容,希望对大家有所帮助。
第一个方面:网站创造优质的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求。所以要求网站的内容首先满足用户的需求。如今,互联网充斥着大量同质化的内容,同样可以满足用户的需求。, 如果你提供的网站内容很特别或者有一定的特殊价值,那么百度会更希望收录你的网站。
温馨提示:百度希望收录这样的网站:
网站 可以满足某些用户的需求
网站信息丰富,网页文字能够清晰准确地表达所要传达的内容。
有一定的原创性或独特价值。
相反,很多网站的内容都是“一般或低质量”,有的网站为了获得更好的收录或者排名靠欺骗。下面是一些常见的情况。虽然不可能列举每一种情况。但请不要走运,百度有全面的技术支持来检测和处理这些行为。
请不要为搜索引擎创建内容。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;将程序生成的内容用于搜索引擎。
请不要创建多个页面、子域或收录大量重复内容的域。
百度将尝试收录提供不同信息的网页。如果你的网站收录大量重复内容,那么搜索引擎会减少相同内容的收录,认为网站提供的内容价值偏低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。它还有助于节省带宽。
请不要创建欺诈或安装有病毒、特洛伊木马或其他有害软件的网页。
加入频道共建、内容联盟等不能或很少产生原创内容的项目时要谨慎,除非网站可以为内容联盟创建原创内容。
第二方面:网站提供的内容得到用户和站长的认可和支持
如果网站上的一个内容得到用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过对网站的搜索行为、真实用户的访问行为、网站之间的关系进行分析,综合评价对网站的认可度。但值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你的认可网站:通常网站之间的链接可以帮助百度抓到Get工具,找到你的< @网站 并增加您对网站 的认可。百度将A网页到B网页的链接解释为A网页到B网页的投票。对一个网页进行投票,更能体现对网页本身的“认可度”权重,有助于提高对其他网页的“认可度”。链接的数量、质量和相关性会影响“识别度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。(自然链接是在其他网站发现你的内容有价值,认为可能对访问者有帮助时,在网络动态生成过程中形成的。)
要让其他网站 创建与您相关的链接网站,更好的方法是创建独特且相关的内容,这些内容可以在互联网上流行。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的 网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长往往不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
试图操纵“识别”计算链接
指向互联网上非法 网站、垃圾邮件或恶意链接的链接
过多的互惠链接或链接交换(例如“链接到我,我将链接到你”)
购买或出售链接用于增加网站“认可”
第三方面:网站有良好的浏览体验
一个具有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
网站 具有清晰的层次结构。
为用户提供站点地图和带有 网站 重要部分链接的导航。使用户能够清晰、简单地浏览网站,快速找到自己需要的信息。
网站 有不错的表现:包括浏览速度和兼容性。
网站快速的速度可以提高用户满意度,也可以提高网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。
网站的广告不干扰用户的正常访问。
广告是网站的重要收入来源。网站收录广告是很合理的,但是如果广告太多,会影响用户的浏览;或者 网站 不相关的子弹太多了。窗户和凸窗上的广告可能会冒犯用户。
百度的目标是为用户提供高度相关的搜索结果和良好的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
合理设置网站的权限。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量。但是,过多的权限设置可能会导致新用户失去耐心,给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
以上三个方面简单介绍了百度收录网站的一些关注点。对于站长来说,如何建立一个更受搜索引擎欢迎的网站,还有很多技巧。详情请参考《百度SEO指南》。 查看全部
网页新闻抓取(百度认为什么样的网站更有抓取和收录价值呢?)
百度认为什么样的网站比较适合爬取和收录?我们从以下几个方面简单介绍一下。鉴于技术保密及网站操作差异等其他原因,以下内容仅供站长参考,具体收录策略包括但不限于内容。接下来,茂宏小编就为大家分享相关内容,希望对大家有所帮助。
第一个方面:网站创造优质的内容,可以为用户提供独特的价值。
作为搜索引擎,百度的最终目标是满足用户的搜索需求。所以要求网站的内容首先满足用户的需求。如今,互联网充斥着大量同质化的内容,同样可以满足用户的需求。, 如果你提供的网站内容很特别或者有一定的特殊价值,那么百度会更希望收录你的网站。
温馨提示:百度希望收录这样的网站:
网站 可以满足某些用户的需求
网站信息丰富,网页文字能够清晰准确地表达所要传达的内容。
有一定的原创性或独特价值。
相反,很多网站的内容都是“一般或低质量”,有的网站为了获得更好的收录或者排名靠欺骗。下面是一些常见的情况。虽然不可能列举每一种情况。但请不要走运,百度有全面的技术支持来检测和处理这些行为。
请不要为搜索引擎创建内容。
有些网站不是从用户的角度设计的,而是为了从搜索引擎中骗取更多的流量。例如,将一种类型的内容提交给搜索引擎,而将另一种类型的内容显示给用户。这些操作包括但不限于:向网页添加隐藏文本或隐藏链接;添加与网页内容无关的关键词;欺骗性地重定向或重定向;专门为搜索引擎制作桥页;将程序生成的内容用于搜索引擎。
请不要创建多个页面、子域或收录大量重复内容的域。
百度将尝试收录提供不同信息的网页。如果你的网站收录大量重复内容,那么搜索引擎会减少相同内容的收录,认为网站提供的内容价值偏低。
当然,如果网站上相同的内容以不同的形式展示(比如论坛的短版页面,打印页面),你可以使用robots.txt来禁止蜘蛛抓取网站 不想显示给用户。它还有助于节省带宽。
请不要创建欺诈或安装有病毒、特洛伊木马或其他有害软件的网页。
加入频道共建、内容联盟等不能或很少产生原创内容的项目时要谨慎,除非网站可以为内容联盟创建原创内容。
第二方面:网站提供的内容得到用户和站长的认可和支持
如果网站上的一个内容得到用户和站长的认可,对于百度来说也是非常值得的收录。百度将通过对网站的搜索行为、真实用户的访问行为、网站之间的关系进行分析,综合评价对网站的认可度。但值得注意的是,这种认可必须基于网站为用户提供优质内容,并且是真实有效的。下面仅以网站之间的关系为例,说明百度如何看待其他站长对你的认可网站:通常网站之间的链接可以帮助百度抓到Get工具,找到你的< @网站 并增加您对网站 的认可。百度将A网页到B网页的链接解释为A网页到B网页的投票。对一个网页进行投票,更能体现对网页本身的“认可度”权重,有助于提高对其他网页的“认可度”。链接的数量、质量和相关性会影响“识别度”的计算。
但请注意,并非所有链接都可以参与识别计算,只有那些自然链接才有效。(自然链接是在其他网站发现你的内容有价值,认为可能对访问者有帮助时,在网络动态生成过程中形成的。)
要让其他网站 创建与您相关的链接网站,更好的方法是创建独特且相关的内容,这些内容可以在互联网上流行。您的内容越有用,其他网站管理员就越容易发现您的内容对其用户有价值,因此链接到您的 网站 也就越容易。在决定是否添加链接之前,您应该首先考虑:这对我的网站访问者真的有好处吗?
但是,一些网站站长往往不顾链接质量和链接来源,进行链接交换,人为地建立链接关系,仅以识别为目的,这将对他们的网站造成长期影响。
提醒:会对网站产生不利影响的链接包括但不限于:
试图操纵“识别”计算链接
指向互联网上非法 网站、垃圾邮件或恶意链接的链接
过多的互惠链接或链接交换(例如“链接到我,我将链接到你”)
购买或出售链接用于增加网站“认可”
第三方面:网站有良好的浏览体验
一个具有良好浏览体验的网站对用户来说是非常有益的。百度也会认为这样的网站具有更好的收录价值。良好的浏览体验意味着:
网站 具有清晰的层次结构。
为用户提供站点地图和带有 网站 重要部分链接的导航。使用户能够清晰、简单地浏览网站,快速找到自己需要的信息。
网站 有不错的表现:包括浏览速度和兼容性。
网站快速的速度可以提高用户满意度,也可以提高网页的整体质量(特别是对于互联网连接速度较慢的用户)。
保证网站的内容可以在不同浏览器中正确显示,防止部分用户正常访问。
网站的广告不干扰用户的正常访问。
广告是网站的重要收入来源。网站收录广告是很合理的,但是如果广告太多,会影响用户的浏览;或者 网站 不相关的子弹太多了。窗户和凸窗上的广告可能会冒犯用户。
百度的目标是为用户提供高度相关的搜索结果和良好的用户体验。如果广告对用户体验造成损害,那么百度抓取时需要减少此类网站。
合理设置网站的权限。
网站的注册权限等权限可以增加网站的注册用户,保证网站的内容质量。但是,过多的权限设置可能会导致新用户失去耐心,给用户带来不便。好的经历。从百度的角度来看,它希望减少对用户获取信息成本过高的网页的提供。
以上三个方面简单介绍了百度收录网站的一些关注点。对于站长来说,如何建立一个更受搜索引擎欢迎的网站,还有很多技巧。详情请参考《百度SEO指南》。
网页新闻抓取( 简单的来说,对于爬取网页的内容来说的一些介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-20 23:16
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且默认调用parse函数,parse在蜘蛛抓取网页后默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的url,可以观察到url规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句是scrapy.Request(url_month, callback=self.parse_month)写的
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是对于每一天的url,会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“勾选”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,在文章中使用Xpath进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有href属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章: 查看全部
网页新闻抓取(
简单的来说,对于爬取网页的内容来说的一些介绍)
简单来说,对于爬取网页的内容:http在爬取过程中不需要输入账号密码,而https则需要输入账号和密码,以及密码带来的一系列问题帐户。因此,抓取https相对复杂。
二、选的框架scarpy 2.1 介绍scrapy
这里
有Scarpy的简单框架介绍
2.1.1 Scrapy结构2.1.2数据流
数据流向由执行引擎控制,如图中各个步骤所示。
* Step1:scrapy引擎首先获取初始URL(Requests)。
* Step2:然后交给Scheduler调度Requests,请求下一个URL。
* Step3:调度器将下一个请求返回给scrapy引擎
* Step4:scrapy引擎通过Downloader Middlewares向下载器Downloader(process_request())发送请求。
* Step5:Downloader Middlewares 完成网页下载后,会生成响应并通过 Downloader Middlewares 将其发送回scrapy 引擎(process_response())。
* Step6:scrapy引擎收到Response后,通过Spider Middlewares发送给Spider做进一步处理。
* Step7:Spider 处理完响应后,会将抓取的项目和新请求(链接在下一页)返回给抓取引擎。
* Step8:crapy引擎将处理后的item发送到Item Pipelines,然后将Requests发送回Scheduler,请求下一个可能的URL进行爬取。
* Step9:从step1开始重复上面的操作,直到Scheduler中没有多余的URL可以请求
提示:解释第 7 步
Spider 分析的结果有两种:
* 一个是需要进一步爬取的链接,比如“下一页”的链接,会被发回给Scheduler;
* 另一个是需要保存的数据。它们被发送到 Item Pipeline 进行后期处理(详细分析、过滤、存储等)。
2.1.3 爬取过程第三部分,半年爬取中新网各种新闻
我的环境是Python3.6+Scrapy,Windows,IDE:PyCharm
3.1 创建一个scrapy项目**
在命令行输入scrapy startproject qqnews
会出现以下文件
3.1.1 在qqnew.py中编写我们的主要爬虫代码**
首先我们需要导入对应的文件
from scrapy.spiders import Spider
from qqnews.items import QqnewsItem
spider 会自动从 start_urls 抓取网页,可以收录多个 URL。
并且默认调用parse函数,parse在蜘蛛抓取网页后默认调用callback。
提示:因为我们要抓取半年的新闻数据,所以先通过start_urls获取半年每个月的url,可以观察到url规则。比如后面两天的网址,很容易看到规则。
我们可以通过拼接字符串来抓取每天的网址
* 每天:
* 每个月:
代码最后一句是scrapy.Request(url_month, callback=self.parse_month)写的
* url_month: 解析拼接后接下来要爬取的每一天的网址
* callback=self.parse_month:这句话的意思是对于每一天的url,会调用一个自定义的parse_month来解析每一天的网页内容
class QQNewsSpider(Spider):
name = 'qqnews'
start_urls=[#'http://www.chinanews.com/society.shtml',
#'http://www.chinanews.com/mil/news.shtml',
'http://finance.chinanews.com/it/gd.shtml',
]
def parse(self,response):
#找到所有连接的入口,一条一条的新闻做解析 //*[@id="news"] //*[@id="news"]/div[2]/div[1]/div[1]/em/a
for month in range(1,8):
for day in range(1,31):
if month is 2 and day>28 :
continue
elif month is 7 and day>6:
continue
else:
if day in range(1,10):
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+'0'+str(day)+'/news.shtml'
else:
url_month='http://www.chinanews.com/scroll-news/it/2017/0'+str(month)+str(day)+'/news.shtml'
yield scrapy.Request(url_month,callback=self.parse_month)
我们已经从前面的代码中得到了每天的新闻对应的链接地址,接下来我们要抓取对应页面的新闻标题和新闻内容。
是自定义def parse_month(self, response)处理的内容。
配合chrome浏览器右键“勾选”,找到每天对应的新闻标题
Scrapy 提供了一种方便的方式来解析网页数据,在文章中使用Xpath进行分析。
提示:
* //ul/li 表示选择ul标签下的所有li标签
* a/@href 表示选择一个标签的所有href属性
* a/text() 表示选择标签文本
* div[@id="content_right"] 表示选择所有id属性为content_right的div标签
def parse_month(self,response):
#print(response.body)
#到了没一个月的页面下,提取每一天的url
urls=response.xpath('//div[@id="content_right"]/div[@class="content_list"]/ul/li/div[@class="dd_bt"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url,callback=self.parse_news)
找到新闻标题对应的新闻内容网址后,我们就可以抓取每日新闻标题和对应的新闻内容了。
然后通过self.parse_news,
在其中存储标题和内容。这是我们先导入的item=QqnewsItem()
def parse_news(self,response):
item=QqnewsItem()
item['title']=response.xpath('//div[@class="con_left"]/div[@id="cont_1_1_2"]/h1/text()').extract()
item['text']='\n'.join(response.xpath('//div[@class="left_zw"]/p/text()').extract())
yield item
在 items.py 中添加一些类
class QqnewsItem(scrapy.Item):
# define the fields for your item here like:
text=scrapy.Field()#新闻的内容
title=scrapy.Field()#新闻的标题
最后,如果要将抓取到的内容保存到文件中,可以新建一个begin.py,直接执行下面这句话。
在 begin.py
from scrapy import cmdline
cmdline.execute("scrapy crawl qqnews -o IT.csv".split())
然后我们就可以根据fastText将抓取到的数据处理成fastText格式,然后直接训练。
参考文章:
网页新闻抓取(网络“爬虫”是怎么抢机票的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-11-17 03:01
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在一次技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取机票官网信息。如果发现航空公司有低价机票放行,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。 查看全部
网页新闻抓取(网络“爬虫”是怎么抢机票的?(图))
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者,因为老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王正准备用“早熟”抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。 . 抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像一个爬虫或蜘蛛在互联网上漫游,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等诸多领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现廉价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据爬取任务和目标的不同,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是如何抢票的
此前,携程“反爬虫”专家在一次技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,甚至超过90%在高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取机票官网信息。如果发现航空公司有低价机票放行,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,票务代理会在订单到期前添加虚假身份订单,继续“占用”低价票,重复此过程,直到真正找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个流程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为售票机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段来预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
一是威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设定的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述的验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”剥头皮行为尚无明确规定,这使得恶意爬取信息成为法律法规“灰色地带”中的不当获利行为。
据闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议的全称是“Web Crawler Exclusion Standard”。网站 可以告诉“爬虫”通过这个协议可以爬取哪些页面和信息,不能爬取哪些页面和信息。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还应通过完善管理和法律法规来限制此类行为。特别是,法律方法可以证明其惩罚和威慑。. 航空公司也应加强对账期的管理,不给“爬虫”提供抢票机会。
网页新闻抓取(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-13 23:03
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载 查看全部
网页新闻抓取(之前做聊天室时,介绍如何使用HtmlTag抓取网页的信息)
之前在聊天室的时候,因为聊天室提供了新闻阅读功能,所以写了一个类来抓取网页信息(比如最新的头条、新闻来源、标题、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
源代码下载
网页新闻抓取(新版headless模式,每一个都各有特色,我们自己的一款是NickJS)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-09 13:09
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它和网页解析语言是一样的(你会在下面看到它有多方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术,我们几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copy from your DevTools", domain: "" })
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会引发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
await tab.open("") await tab.untilVisible("#hnmain") // 确保我们已经加载了页面 await tab.inject("") // 我们将使用 jQuery 来抓取 consthackerNewsLinks = await tab.evaluate((arg, callback) => {// 这里我们在页面上下文中。就像在浏览器的检查器工具中 const data = [] $(".athing").each((index, element ) => {data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href")} ) }) callback(null, data) }) 印度、俄罗斯和巴基斯坦在拦截机器人的做法上有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
if (await tab.isVisible(".captchaImage")) {// 获取生成的 CAPTCHA 图像的 URL // 注意我们也可以获取它的 base64 编码值并解决它 const captchaImageLink = await tab.evaluate(( arg, callback) => {callback(null, $(".captchaImage").attr("src")) }) // 调用验证码解决服务 const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) //用我们的解决方案填写表单 await tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })} 等待 DOM 元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
await tab.open("") // await Promise.delay(5000) // 不要这样做!await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // 您现在可以安全地单击“喜欢”按钮...等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈并运行
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null tab.driver.client.Network.responseReceived((e) => {if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {cvRequestId = e.requestId} }) tab.driver.client.Network.loadingFinished((e) => {if (e.requestId === cvRequestId) {tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded?'base64':'utf8' ))) })} })
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截 const nick = new Nick({ loadImages: false, whitelist: [/.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.* / ], 黑名单: [/.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/] })
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。 查看全部
网页新闻抓取(新版headless模式,每一个都各有特色,我们自己的一款是NickJS)
市面上确实有很多NodeJS库支持Chrome新的headless模式,每个库都有自己的特点。我们自己的一个是 NickJS。如果你没有自己的爬虫库,你怎么敢说你是网络爬虫专家。
还有一组社区发布的其他语言的C++ API和库,比如GO语言。我们推荐使用 NodeJS 工具,因为它和网页解析语言是一样的(你会在下面看到它有多方便)。
网络爬虫?不违法吗?
我们无意挑起无休止的争议,但不到两周前,一位美国地区法官命令第三方抓取 LinkedIn 的公开文件。到目前为止,这只是一项初步法律,诉讼还将继续。LinkedIn肯定会反对,但是放心,我们会密切关注情况,因为这个文章讲了很多关于LinkedIn的内容。
无论如何,作为技术文章,我们不会深入研究具体爬虫操作的合法性。我们应该始终努力尊重目标网站的ToS。并且不会对您在此文章 中了解到的任何损害负责。
到目前为止学到的很酷的东西
下面列出的一些技术,我们几乎每天都在使用。代码示例使用 NickJS 爬网库,但它们很容易被其他 Headless Chrome 工具重写。重要的是分享这个概念。
将饼干放回饼干罐中
使用全功能浏览器进行爬取,让人安心,不用担心CORS、session、cookies、CSRF等web问题。
但有时登录表单会变得很棘手,唯一的解决办法就是恢复之前保存的会话cookie。当检测到故障时,一些网站会发送电子邮件或短信。我们没有时间这样做,我们只是使用已设置的会话 cookie 打开页面。
LinkedIn有一个很好的例子,设置li_atcookie可以保证爬虫访问他们的社交网络(记住:注意尊重目标网站Tos)。
await nick.setCookie({ name: "li_at", value: "a session cookie value copy from your DevTools", domain: "" })
我相信像LinkedIn这样的网站不会使用有效的会话cookie来阻止真正的浏览器访问。这是相当危险的,因为错误的信息会引发愤怒用户的大量支持请求。
jQuery 不会让你失望
我们学到的一件重要事情是,通过 jQuery 从网页中提取数据非常容易。现在回想起来,这是显而易见的。网站 提供了一个高度结构化、可查询的收录数据元素的树(称为 DOM),而 jQuery 是一个非常高效的 DOM 查询库。那么为什么不使用它进行爬行呢?这种技术将被一次又一次地尝试。
很多网站已经用过jQuery了,所以在页面中添加几行就可以获取数据了。
await tab.open("") await tab.untilVisible("#hnmain") // 确保我们已经加载了页面 await tab.inject("") // 我们将使用 jQuery 来抓取 consthackerNewsLinks = await tab.evaluate((arg, callback) => {// 这里我们在页面上下文中。就像在浏览器的检查器工具中 const data = [] $(".athing").each((index, element ) => {data.push({ title: $(element).find(".storylink").text(), url: $(element).find(".storylink").attr("href")} ) }) callback(null, data) }) 印度、俄罗斯和巴基斯坦在拦截机器人的做法上有什么共同点?
答案是使用验证码来解决服务器验证。几块钱就可以买到上千个验证码,生成一个验证码通常需要不到30秒的时间。但是到了晚上,因为没有人,一般都比较贵。
一个简单的谷歌搜索将提供多个 API 来解决任何类型的验证码问题,包括获取谷歌最新的 recaptcha 验证码(21,000 美元)。
将爬虫连接到这些服务就像发出一个 HTTP 请求一样简单,现在机器人是一个人。
在我们的平台上,用户可以轻松解决他们需要的验证码问题。我们的 Buster 库可以调用多个来解决服务器验证:
if (await tab.isVisible(".captchaImage")) {// 获取生成的 CAPTCHA 图像的 URL // 注意我们也可以获取它的 base64 编码值并解决它 const captchaImageLink = await tab.evaluate(( arg, callback) => {callback(null, $(".captchaImage").attr("src")) }) // 调用验证码解决服务 const captchaAnswer = await buster.solveCaptchaImage(captchaImageLink) //用我们的解决方案填写表单 await tab.fill(".captchaForm", {"captcha-answer": captchaAnswer }, {submit: true })} 等待 DOM 元素,不是固定时间
经常看到爬行初学者要求他们的机器人在打开页面或点击按钮后等待 5 到 10 秒——他们想确保他们所做的动作有时间产生效果。
但这不是应该做的。我们的 3 步理论适用于任何爬行场景:您应该等待的是您要操作的特定 DOM 元素。它更快更清晰,如果出现问题,您将获得更准确的错误提示。
await tab.open("") // await Promise.delay(5000) // 不要这样做!await tab.waitUntilVisible(".permalinkPost .UFILikeLink") // 您现在可以安全地单击“喜欢”按钮...等待 tab.click(".permalinkPost .UFILikeLink")
在某些情况下,可能确实有必要伪造人为延迟。可以使用
等待 Promise.delay(2000 + Math.random() * 3000)
鬼混。
MongoDB
我们发现MongoDB非常适合大部分的爬虫工作,它拥有优秀的JS API和Mongoose ORM。考虑到你在使用 Headless Chrome 的时候已经在 NodeJS 环境中了,为什么不采用呢?
JSON-LD 和微数据开发
有时网络爬虫不需要了解DOM,而是要找到正确的“导出”按钮。记住这一点可以节省很多时间。
严格来说,有些网站会比其他网站容易。例如,他们所有的产品页面都以 JSON-LD 产品数据的形式显示在 DOM 中。您可以与他们的任何产品页面交谈并运行
JSON.parse(document.Queryselector("#productSEOData").innertext)
你会得到一个非常好的数据对象,可以插入到MongoDB中,不需要真正的爬取!
网络请求拦截
因为使用了DevTools API,所以编写的代码具有使用Chrome的DevTools的等效功能。这意味着生成的机器人可以拦截、检查甚至修改或中止任何网络请求。
通过从LinkedIn下载PDF格式的简历来测试网络请求拦截。点击配置文件中的“Save to PDF”按钮,触发XHR,响应内容为PDF文件,是一种截取文件写入磁盘的方法。
让 cvRequestId = null tab.driver.client.Network.responseReceived((e) => {if (e.type === "XHR" && e.response.url.indexOf("profile-profilePdf/")> 0) {cvRequestId = e.requestId} }) tab.driver.client.Network.loadingFinished((e) => {if (e.requestId === cvRequestId) {tab.driver.client.Network.getResponseBody({ requestId: cvRequestId }, (err, cv) => {require("fs").writeFileSync("linkedin-cv.pdf", Buffer.from(cv.body, (cv.base64Encoded?'base64':'utf8' ))) })} })
值得一提的是,DevTools 协议发展很快,现在有一种方法可以使用 Page.setDownloadBehavior() 来设置下载传入文件的方法和路径。我们还没有测试它,但它看起来很有希望!
广告拦截 const nick = new Nick({ loadImages: false, whitelist: [/.*\.aspx/, /.*axd.*/, /.*\.html.*/, /.*\.js.* / ], 黑名单: [/.*fsispin360\.js/, /.*fsitouchzoom\.js/, /.*\.ashx.*/, /.*google.*/] })
还可以通过阻止不必要的请求来加速爬行。分析、广告和图像是典型的阻塞目标。但是,请记住,这会使机器人变得不像人类(例如,如果所有图片都被屏蔽,LinkedIn 将无法正确响应页面请求——不确定这是不是故意的)。
在 NickJS 中,用户可以指定收录正则表达式或字符串的白名单和黑名单。白名单特别强大,但是一不小心,很容易让目标网站崩溃。
DevTools 协议还有 Network.setBlockedURLs(),它使用带有通配符的字符串数组作为输入。
更重要的是,新版Chrome会自带谷歌自己的“广告拦截器”——它更像是一个广告“过滤器”。该协议已经有一个名为 Page.setAdBlockingEnabled() 的端点。
这就是我们正在谈论的技术!
无头 Chrome 检测
最近发表的一篇文章文章列举了多种检测Headless Chrome访问者的方法,也可以检测PhantomJS。这些方法描述了基本的 User-Agent 字符串与更复杂的技术(例如触发错误和检查堆栈跟踪)的比较。
在愤怒的管理员和聪明的机器人制造者之间,这基本上是猫捉老鼠游戏的放大版。但我从未见过这些方法正式实施。检测自动访问者在技术上是可能的,但谁愿意面对潜在的错误消息?这对于大型 网站 来说尤其危险。
如果你知道那些网站有这些检测功能,请告诉我们!
结束语
爬行从未如此简单。借助我们最新的工具和技术,它甚至可以成为我们开发人员的一项愉快而有趣的活动。
顺便说一句,我们受到了 Franciskim.co “我不需要一个臭 API”的启发 文章,非常感谢!此外,有关如何开始使用 Puppets 的详细说明,请单击此处。
下一篇文章,我会写一些“bot缓解”工具,比如Distill Networks,聊聊HTTP代理和IP地址分配的奇妙世界。
网络上有一个我们的抓取和自动化平台库。如果你有兴趣,还可以了解一下我们3个爬行步骤的理论信息。
网页新闻抓取(深圳网站建设中新闻页面的设计应该注意哪些问题?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-11-08 07:08
网站新闻页面是否是企业网站建站、门户网站建站、电子商务网站建站、营销型网站建站、当前热点app网站是必不可少的子项,而新闻页面的排列不仅是发布公司产品信息和公司新闻,也是SEO搜索引擎抓取内容的依据,所以他与整个网站的优化程度。所以一个好的新闻页面是整个网站的关键,那么如何设计一个新闻页面呢?今天,拥有十年建站经验的深圳网站建设公司:我们总结一下正在建设中的网站新闻页面在设计中应该注意的问题:
1、 在首页需要编写和设置可点击的新闻标题,然后编写完整的新闻页面,通过超链接与新闻标题相连。
2、首页的新闻标题要能够清楚地描述新闻的主要内容,标题文字不宜过长,布局要简洁、清晰、醒目。
3、新闻页面必须满足轻松导航的要求。首先,要方便用户从新闻页面跳转到网站中的其他内容页面,其次,必须方便用户快速到达其他新闻页面。这可以通过在新闻页面上建立以下方法来实现。
一种。设置与整体一致的菜单栏导航系统,让用户可以在网站的新闻页面和其他页面之间无缝跳转。
湾 设置上一条或下一条新闻的链接,让用户可以在其中浏览,在浏览其他新闻时无需经常返回主新闻页面。
C。提供新闻分类或时间索引,建立菜单,用户可以根据时间或内容搜索自己感兴趣的新闻。
d. 新闻页面包括与新闻相关的图片、声音或其他多媒体文件或这些文件的链接。
e. 设置指向手稿中出现的关键姓名、公司、员工等的链接。
F。相关客户、分析师或舆论对新闻稿主题的意见。
除了新闻页面,企业还应根据需要设置其他页面,如企业信息页面、帮助页面、虚拟社区页面等。
TAG标签耗时:0.0601秒 查看全部
网页新闻抓取(深圳网站建设中新闻页面的设计应该注意哪些问题?)
网站新闻页面是否是企业网站建站、门户网站建站、电子商务网站建站、营销型网站建站、当前热点app网站是必不可少的子项,而新闻页面的排列不仅是发布公司产品信息和公司新闻,也是SEO搜索引擎抓取内容的依据,所以他与整个网站的优化程度。所以一个好的新闻页面是整个网站的关键,那么如何设计一个新闻页面呢?今天,拥有十年建站经验的深圳网站建设公司:我们总结一下正在建设中的网站新闻页面在设计中应该注意的问题:
1、 在首页需要编写和设置可点击的新闻标题,然后编写完整的新闻页面,通过超链接与新闻标题相连。
2、首页的新闻标题要能够清楚地描述新闻的主要内容,标题文字不宜过长,布局要简洁、清晰、醒目。
3、新闻页面必须满足轻松导航的要求。首先,要方便用户从新闻页面跳转到网站中的其他内容页面,其次,必须方便用户快速到达其他新闻页面。这可以通过在新闻页面上建立以下方法来实现。
一种。设置与整体一致的菜单栏导航系统,让用户可以在网站的新闻页面和其他页面之间无缝跳转。
湾 设置上一条或下一条新闻的链接,让用户可以在其中浏览,在浏览其他新闻时无需经常返回主新闻页面。
C。提供新闻分类或时间索引,建立菜单,用户可以根据时间或内容搜索自己感兴趣的新闻。
d. 新闻页面包括与新闻相关的图片、声音或其他多媒体文件或这些文件的链接。
e. 设置指向手稿中出现的关键姓名、公司、员工等的链接。
F。相关客户、分析师或舆论对新闻稿主题的意见。
除了新闻页面,企业还应根据需要设置其他页面,如企业信息页面、帮助页面、虚拟社区页面等。
TAG标签耗时:0.0601秒
网页新闻抓取(发明专利推送包含新闻信息的网页的方法和装置技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-11-08 07:07
本发明的专利技术提供了一种推送收录新闻信息的网页的方法和装置。该方法包括:从抓取的收录新闻信息的网页中提取时效性关键词;计算第一个收录新闻信息的网页数量 时间敏感的属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页;计算多个网页的第二时间敏感属性特征;如果查询词匹配时效性关键词,则将第一时间敏感属性特征与第二时间敏感属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性,在结果页面上确定收录新闻信息的网页的URL的插入位置。根据本发明的专利技术,可以判断用户输入的查询词的时效性,可以根据查询词的时效性对收录新闻信息的网页网址进行排序。可以对新闻信息对用户较新的网页进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。
下载所有详细的技术数据
【技术实现步骤总结】
推送收录新闻信息的网页的方法及装置
这项专利技术涉及计算机
尤其涉及一种推送收录新闻信息的网页的方法和装置。
技术介绍
按照目前的搜索引擎技术,用户在终端输入查询词后,搜索引擎会获取到该查询词对应的多个网页网址。多个网页网址返回给用户终端后,会显示在用户终端的结果页面上。由于网页网址的数量较多,所以在结果页显示时肯定存在排序问题。根据目前的搜索引擎技术,旧网页的网址一般排在第一位。这种排序对于收录新闻信息的网址有很大的弊端:在用户输入查询词搜索新闻的场景下,目前的搜索引擎技术只能将旧新闻网页的网址排在第一位,而最新新闻的网址是网页稍后排序,但是由于新闻的时效性,大多数新闻的新闻性会随着时间的推移而下降,因此用户最终看到的很可能是新闻性较低的新闻。由于其网页的 URL 较低,用户很难找到和打开更高级别的新闻。可见,现有的搜索引擎技术难以分析新闻信息对用户的新闻性,也难以对收录新闻信息的网页网址进行合理排序,从而无法完成对网页的有效推送。收录新闻信息。
技术实现思路
针对上述问题,提出本专利技术,以提供一种克服上述问题或至少部分解决上述问题的推送收录新闻信息的网页的方法和装置。根据该专利技术的一个方面,提供了一种推送收录新闻信息的网页的方法,包括:从抓取到的收录新闻信息的网页中提取时效关键词;计算新闻信息内容网页的第一时间敏感属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;及时性关键词匹配,然后将第一时效属性特征与第二时效属性特征进行比较,根据比较结果得到查询词的时效性;查询词的时效性强根据比较结果弱,确定收录新闻信息的网页的URL在结果页面的插入位置。可选的,从抓取到的收录新闻信息的网页中提取时效关键词的步骤包括:从收录新闻信息的网页的标题中提取时效关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、收录新闻信息的网页的时效性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,根据查询词的时效性确定收录新闻信息的网页的URL在结果页的插入位置包括:在结果页上划分多个区间,分别对应不同强度的时效性和弱点;选择与查询词的时效性强或弱匹配的区间,将收录新闻信息的网页的URL放置在所选区间内。可选的,每个区间从上到下分为三个部分,每个区间都有对应的置信度,将收录新闻信息的网页的URL放入所选区间的步骤还包括:如果查询词的时效性高于所选区间的置信水平,收录新闻信息的网页的URL放置在所选区间的顶部,如查询词和所选区间的时效性如果区间的置信度相同,则收录新闻的网页的URL信息放置在所选间隔的中间部分。如果查询词的时效性低于所选区间的置信度,则将信息网页的 URL 置于所选区间的最低部分。可选的,还包括:建立将时效关键词与第一时效属性特征关联的索引;如果查询词匹配时效性关键词,则在比较第一时间敏感属性特征和第二时间敏感属性特征的步骤之前,根据比较结果获取查询词的时效性,该方法还包括:根据索引判断查询词与查询词是否相同。匹配时效性关键词,搜索与时效性关键词相关的第一个时效性属性特征。
根据专利技术的另一方面,还提供了一种推送收录新闻信息的网页的装置,包括:网络爬虫,用于抓取收录新闻信息的网页;关键词 提取器,用于从收录新闻信息的抓取网页中提取时效性关键词;关键词数据库用于存储提取的时效性关键词;第一特征计算器用于计算收录新闻信息的网页的第一时间敏感属性特征;查询模块用于接收查询词,获取查询词对应的多个网页的网址的结果页面。第二特征计算器用于计算多个网页的第二时间敏感属性特征;查询词时间敏感获取模块,如果查询词匹配时间敏感关键词,则将第一时间敏感属性特征与第一时间敏感属性特征进行比较 2. 比较时间属性特征,得到根据比对结果查询词条的时效性;新闻网页展示模块,用于根据查询词的时效性判断新闻网页的URL在结果页的位置高低。可选的,关键词提取器从收录新闻信息的网页的标题中提取时效性关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及收录新闻信息的网页的及时性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,所述新闻网页展示模块包括: 区间划分模块,用于在结果页面上划分多个区间,分别对应不同的时效性。区间选择模块,用于选择查询查询词的时效性与区间强匹配,将收录新闻信息的网页的URL放置在所选区间内。可选地,每个区间从上到下分为三个部分,每个区间有一个对应的置信水平。如果查询词的时效性高于所选区间的置信度,区间选择模块会将收录新闻信息的网页的URL置于所选区间的顶部。如果查询词的时效性与所选区间的置信度一致,区间选择模块将收录网页URL的新闻信息置于所选区间的中间。如果查询词的时效性低于所选区间的置信度,区间选择模块将收录新闻信息的网页的URL放入所选区间。选择区间的最低部分。可选的,还包括: 索引建立模块,用于建立将时效关键词与第一时效属性特征关联的索引;索引搜索模块,用于根据索引判断查询词是否符合时效关键词,并搜索与时效相关的第一个时效属性特征关键词。根据专利技术的推送收录新闻信息的网页的方法和装置,可以通过分析收录新闻信息的网页和查询对应的其他网页的时效性属性特征来判断用户输入的查询词的时效性字。词的及时性反映了新闻信息为用户提供的程度。因此,根据查询词的时效性对收录新闻信息的网页的网址进行排序,可以对新闻信息对用户来说更具新闻性的网页的网址进行排序。排序优先方便用户及时查看自己需要的新闻信息,
以上描述仅为本专利技术方案的概述。为了更清楚地了解本专利技术的技术手段,可以按照说明书的内容实施,以更好地实现本专利技术的上述及其他目的、特点和优点。显而易见且易于理解,下面将引用专利技术的具体实现。附图说明通过阅读以下优选实施例的详细描述,本领域普通技术人员将清楚各种其他优点和益处。附图仅用于说明优选实施例的目的,并不视为对专利技术的限制。此外,在整个图纸中,相同的附图标记用于表示相同的组件。图中:附图说明图1示出了根据专利技术实施例的推送收录新闻信息的网页的方法的流程图。
【技术保护点】
一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时效属性特征;如果查询词匹配时效性关键词,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;
【技术特点摘要】
1.一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;如查询词与时效关键词匹配,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性确定查询词的时效性。收录新闻信息的网页的URL在结果页的插入位置;第一时间敏感属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及时效性关键词在收录新闻信息的网页中出现的频率和/或时效性关键词是收录新闻信息的网页出现次数与已知历史事件的比较数据;第二时间敏感属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询该词在多个网页中的出现次数与已知历史出现次数的比较数据。2.如权利要求1所述的方法,其特征在于,所述从抓取到的收录新闻信息的网页中提取时效性关键词的步骤包括: 提取收录新闻信息的网页的标题 从关键词中提取时效性.
3.如权利要求1所述的方法,其特征在于,所述根据查询词的时效性确定收录新闻信息的网页的URL在结果页面的插入位置包括:在结果页面,对应不同时效强度;选择与查询词的时效性相匹配的版块,将收录新闻信息的网页的网址设置在选定的区间内。4.如权利要求3所述的方法,其特征在于,每个区间从上到下分为三个部分,每个区间有一个对应的置信度,收录新闻信息的网页 将URL放入选中的URL的步骤间隔进一步包括:如果查询词的时效性高于所选区间的置信度,则将收录新闻信息的网页的 URL 置于所选区间的顶部 如果查询词的时效性与所选区间的置信度一致选定区间,如果查询词的时效性低于选定区间的时效,则将收录新闻信息的网页的URL放置在选定区间的中间部分。为了所选区间的置信度,将收录新闻信息的网页的 URL 放置在所选区间的最下方。5.根据权利要求1-4任一项所述的方法,还包括: 建立将时效关键词与第一时效属性特征关联的索引;
【专利技术属性】
技术研发人员:常富阳、秦继升、苏文杰、
申请人(专利权):,,
类型:发明
国家省市:北京;11
下载所有详细技术资料 我是此专利的所有者 查看全部
网页新闻抓取(发明专利推送包含新闻信息的网页的方法和装置技术)
本发明的专利技术提供了一种推送收录新闻信息的网页的方法和装置。该方法包括:从抓取的收录新闻信息的网页中提取时效性关键词;计算第一个收录新闻信息的网页数量 时间敏感的属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页;计算多个网页的第二时间敏感属性特征;如果查询词匹配时效性关键词,则将第一时间敏感属性特征与第二时间敏感属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性,在结果页面上确定收录新闻信息的网页的URL的插入位置。根据本发明的专利技术,可以判断用户输入的查询词的时效性,可以根据查询词的时效性对收录新闻信息的网页网址进行排序。可以对新闻信息对用户较新的网页进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。可以对新闻信息对用户较新的网页的网址进行排序。先排序。
下载所有详细的技术数据
【技术实现步骤总结】
推送收录新闻信息的网页的方法及装置
这项专利技术涉及计算机
尤其涉及一种推送收录新闻信息的网页的方法和装置。
技术介绍
按照目前的搜索引擎技术,用户在终端输入查询词后,搜索引擎会获取到该查询词对应的多个网页网址。多个网页网址返回给用户终端后,会显示在用户终端的结果页面上。由于网页网址的数量较多,所以在结果页显示时肯定存在排序问题。根据目前的搜索引擎技术,旧网页的网址一般排在第一位。这种排序对于收录新闻信息的网址有很大的弊端:在用户输入查询词搜索新闻的场景下,目前的搜索引擎技术只能将旧新闻网页的网址排在第一位,而最新新闻的网址是网页稍后排序,但是由于新闻的时效性,大多数新闻的新闻性会随着时间的推移而下降,因此用户最终看到的很可能是新闻性较低的新闻。由于其网页的 URL 较低,用户很难找到和打开更高级别的新闻。可见,现有的搜索引擎技术难以分析新闻信息对用户的新闻性,也难以对收录新闻信息的网页网址进行合理排序,从而无法完成对网页的有效推送。收录新闻信息。
技术实现思路
针对上述问题,提出本专利技术,以提供一种克服上述问题或至少部分解决上述问题的推送收录新闻信息的网页的方法和装置。根据该专利技术的一个方面,提供了一种推送收录新闻信息的网页的方法,包括:从抓取到的收录新闻信息的网页中提取时效关键词;计算新闻信息内容网页的第一时间敏感属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;及时性关键词匹配,然后将第一时效属性特征与第二时效属性特征进行比较,根据比较结果得到查询词的时效性;查询词的时效性强根据比较结果弱,确定收录新闻信息的网页的URL在结果页面的插入位置。可选的,从抓取到的收录新闻信息的网页中提取时效关键词的步骤包括:从收录新闻信息的网页的标题中提取时效关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、收录新闻信息的网页的时效性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,根据查询词的时效性确定收录新闻信息的网页的URL在结果页的插入位置包括:在结果页上划分多个区间,分别对应不同强度的时效性和弱点;选择与查询词的时效性强或弱匹配的区间,将收录新闻信息的网页的URL放置在所选区间内。可选的,每个区间从上到下分为三个部分,每个区间都有对应的置信度,将收录新闻信息的网页的URL放入所选区间的步骤还包括:如果查询词的时效性高于所选区间的置信水平,收录新闻信息的网页的URL放置在所选区间的顶部,如查询词和所选区间的时效性如果区间的置信度相同,则收录新闻的网页的URL信息放置在所选间隔的中间部分。如果查询词的时效性低于所选区间的置信度,则将信息网页的 URL 置于所选区间的最低部分。可选的,还包括:建立将时效关键词与第一时效属性特征关联的索引;如果查询词匹配时效性关键词,则在比较第一时间敏感属性特征和第二时间敏感属性特征的步骤之前,根据比较结果获取查询词的时效性,该方法还包括:根据索引判断查询词与查询词是否相同。匹配时效性关键词,搜索与时效性关键词相关的第一个时效性属性特征。
根据专利技术的另一方面,还提供了一种推送收录新闻信息的网页的装置,包括:网络爬虫,用于抓取收录新闻信息的网页;关键词 提取器,用于从收录新闻信息的抓取网页中提取时效性关键词;关键词数据库用于存储提取的时效性关键词;第一特征计算器用于计算收录新闻信息的网页的第一时间敏感属性特征;查询模块用于接收查询词,获取查询词对应的多个网页的网址的结果页面。第二特征计算器用于计算多个网页的第二时间敏感属性特征;查询词时间敏感获取模块,如果查询词匹配时间敏感关键词,则将第一时间敏感属性特征与第一时间敏感属性特征进行比较 2. 比较时间属性特征,得到根据比对结果查询词条的时效性;新闻网页展示模块,用于根据查询词的时效性判断新闻网页的URL在结果页的位置高低。可选的,关键词提取器从收录新闻信息的网页的标题中提取时效性关键词。可选的,第一时效属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及收录新闻信息的网页的及时性。关键词在收录新闻信息和已知历史事件的网页中出现的频率和/或时效性的对比数据;第二时效属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询词在多个网页中的出现次数知道历史事件之间的比较数据。
可选的,所述新闻网页展示模块包括: 区间划分模块,用于在结果页面上划分多个区间,分别对应不同的时效性。区间选择模块,用于选择查询查询词的时效性与区间强匹配,将收录新闻信息的网页的URL放置在所选区间内。可选地,每个区间从上到下分为三个部分,每个区间有一个对应的置信水平。如果查询词的时效性高于所选区间的置信度,区间选择模块会将收录新闻信息的网页的URL置于所选区间的顶部。如果查询词的时效性与所选区间的置信度一致,区间选择模块将收录网页URL的新闻信息置于所选区间的中间。如果查询词的时效性低于所选区间的置信度,区间选择模块将收录新闻信息的网页的URL放入所选区间。选择区间的最低部分。可选的,还包括: 索引建立模块,用于建立将时效关键词与第一时效属性特征关联的索引;索引搜索模块,用于根据索引判断查询词是否符合时效关键词,并搜索与时效相关的第一个时效属性特征关键词。根据专利技术的推送收录新闻信息的网页的方法和装置,可以通过分析收录新闻信息的网页和查询对应的其他网页的时效性属性特征来判断用户输入的查询词的时效性字。词的及时性反映了新闻信息为用户提供的程度。因此,根据查询词的时效性对收录新闻信息的网页的网址进行排序,可以对新闻信息对用户来说更具新闻性的网页的网址进行排序。排序优先方便用户及时查看自己需要的新闻信息,
以上描述仅为本专利技术方案的概述。为了更清楚地了解本专利技术的技术手段,可以按照说明书的内容实施,以更好地实现本专利技术的上述及其他目的、特点和优点。显而易见且易于理解,下面将引用专利技术的具体实现。附图说明通过阅读以下优选实施例的详细描述,本领域普通技术人员将清楚各种其他优点和益处。附图仅用于说明优选实施例的目的,并不视为对专利技术的限制。此外,在整个图纸中,相同的附图标记用于表示相同的组件。图中:附图说明图1示出了根据专利技术实施例的推送收录新闻信息的网页的方法的流程图。
【技术保护点】
一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时效属性特征;如果查询词匹配时效性关键词,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;
【技术特点摘要】
1.一种推送收录新闻信息的网页的方法,包括:从抓取的收录新闻信息的网页中提取时效关键词;计算收录新闻信息的网页的第一时效属性特征;接收查询词,获取查询词对应的多个网页的网址的结果页面;计算多个网页的第二时间敏感属性特征;如查询词与时效关键词匹配,则将第一时敏属性特征与第二时敏属性特征进行比较,根据比较结果得到查询词的时效性;根据查询词的时效性确定查询词的时效性。收录新闻信息的网页的URL在结果页的插入位置;第一时间敏感属性特征包括收录新闻信息的网页的分类、收录新闻信息的网页的生成时间、以及时效性关键词在收录新闻信息的网页中出现的频率和/或时效性关键词是收录新闻信息的网页出现次数与已知历史事件的比较数据;第二时间敏感属性特征包括多个网页的分类、多个网页的生成时间、查询词在多个网页中出现的频率、和/或查询该词在多个网页中的出现次数与已知历史出现次数的比较数据。2.如权利要求1所述的方法,其特征在于,所述从抓取到的收录新闻信息的网页中提取时效性关键词的步骤包括: 提取收录新闻信息的网页的标题 从关键词中提取时效性.
3.如权利要求1所述的方法,其特征在于,所述根据查询词的时效性确定收录新闻信息的网页的URL在结果页面的插入位置包括:在结果页面,对应不同时效强度;选择与查询词的时效性相匹配的版块,将收录新闻信息的网页的网址设置在选定的区间内。4.如权利要求3所述的方法,其特征在于,每个区间从上到下分为三个部分,每个区间有一个对应的置信度,收录新闻信息的网页 将URL放入选中的URL的步骤间隔进一步包括:如果查询词的时效性高于所选区间的置信度,则将收录新闻信息的网页的 URL 置于所选区间的顶部 如果查询词的时效性与所选区间的置信度一致选定区间,如果查询词的时效性低于选定区间的时效,则将收录新闻信息的网页的URL放置在选定区间的中间部分。为了所选区间的置信度,将收录新闻信息的网页的 URL 放置在所选区间的最下方。5.根据权利要求1-4任一项所述的方法,还包括: 建立将时效关键词与第一时效属性特征关联的索引;
【专利技术属性】
技术研发人员:常富阳、秦继升、苏文杰、
申请人(专利权):,,
类型:发明
国家省市:北京;11
下载所有详细技术资料 我是此专利的所有者
网页新闻抓取(Google信息多任务框架不稳定,newspaper缓存所有提取的文章)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-06 18:08
报纸是一个python3库。
注意:Newspaper 框架不适合实际的工程新闻信息爬取工作。框架不稳定,在爬取过程中会出现各种bug,比如无法获取网址、新闻信息等,但是对于想要获取一些新闻语料的朋友不妨一试,简单方便,简单易用,无需掌握太多爬虫专业知识。
安装
pip3 install newspaper3k
or
pip3 install --ignore-installed --upgrade newspaper3k
如果文章 没有指定使用哪种语言,Newspaper 会尝试自动识别。支持10多种语言,都是unicode编码。
import time
from newspaper import Article
url = 'https://www.chinaventure.com.c ... 27%3B
url='https://36kr.com/p/5237348'
# 创建文章对象
news = Article(url, language='zh')
# 下载网页
news.download()
## 网页解析
news.parse()
print("title=",news.title)# 获取文章标题
print("author=", news.authors) # 获取文章作者
print("publish_date=", news.publish_date) # 获取文章日期
# 自然语言处理
news.nlp()
print('keywords=',news.keywords)#从文本中提取关键字
print("summary=",news.summary)# 获取文章摘要
# time.sleep(30)
print("text=",news.text,"\n")# 获取文章正文
print("movies=",news.movies) # 获取文章视频链接
print("top_iamge=",news.top_image) # 获取文章顶部图片地址
print("images=",news.images)#从html中提取所有图像
print("imgs=",news.imgs)
print("html=",news.html)#获取html
也可以直接导入包,如果语言一致,也可以直接声明
import newspaper
url='http://www.coscocs.com/'
'''注:文章缓存:默认情况下,newspaper缓存所有以前提取的文章,并删除它已经提取的任何文章。
此功能用于防止重复的文章和提高提取速度。可以使用memoize_articles参数选择退出此功能。'''
news = newspaper.build(url, language='zh', memoize_articles=False)
article = news.articles[0]
article.download()
article.parse()
print('text=',article.text)
print('brand=',news.brand) #提取源品牌
print('description=',news.description) # 提取描述
print("一共获取%s篇文章" % news.size()) # 文章的数目
# 所有文章的url
for article in news.articles:
print(article.url)
#提取源类别
for category in news.category_urls():
print(category)
#提取源提要
for feed_url in news.feed_urls():
print(feed_url)
注意:文章缓存:默认情况下,报纸缓存所有以前提取的文章并删除任何已经提取的文章。该功能用于防止重复文章,提高提取速度。您可以使用 memoize_articles 参数选择退出此功能。
结合 Requests 和 Newspaper 来解析文本
import requests
from newspaper import fulltext
html = requests.get('https://www.washingtonpost.com ... 23x27;).text
text = fulltext(html)
print(text)
谷歌趋势信息
import newspaper
print(newspaper.languages())#获取支持的语言
print(newspaper.hot())#hot()使用公共api返回谷歌上的热门词汇列表
print(newspaper.popular_urls())#popular_urls()返回一个流行新闻源url列表
多任务处理
import newspaper
from newspaper import news_pool
# 创建并行任务
slate_paper = newspaper.build('http://slate.com')
tc_paper = newspaper.build('http://techcrunch.com')
espn_paper = newspaper.build('http://espn.com')
papers = [slate_paper, tc_paper, espn_paper]
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 共6个线程
news_pool.join()
print(slate_paper.articles[10].html)
python可读性
github地址为:
安装
pip install requests
pip install readability-lxml
如何使用:
import requests
from readability import Document
response = requests.get('https://news.163.com/18/1123/1 ... 23x27;)
doc = Document(response.text)
print doc.title()
print doc.content()
测试结果:文本提取范围过大,出现乱码,不好用。显然得到的文本部分有问题。并且存在乱码的问题。因此,不推荐。 查看全部
网页新闻抓取(Google信息多任务框架不稳定,newspaper缓存所有提取的文章)
报纸是一个python3库。
注意:Newspaper 框架不适合实际的工程新闻信息爬取工作。框架不稳定,在爬取过程中会出现各种bug,比如无法获取网址、新闻信息等,但是对于想要获取一些新闻语料的朋友不妨一试,简单方便,简单易用,无需掌握太多爬虫专业知识。
安装
pip3 install newspaper3k
or
pip3 install --ignore-installed --upgrade newspaper3k
如果文章 没有指定使用哪种语言,Newspaper 会尝试自动识别。支持10多种语言,都是unicode编码。
import time
from newspaper import Article
url = 'https://www.chinaventure.com.c ... 27%3B
url='https://36kr.com/p/5237348'
# 创建文章对象
news = Article(url, language='zh')
# 下载网页
news.download()
## 网页解析
news.parse()
print("title=",news.title)# 获取文章标题
print("author=", news.authors) # 获取文章作者
print("publish_date=", news.publish_date) # 获取文章日期
# 自然语言处理
news.nlp()
print('keywords=',news.keywords)#从文本中提取关键字
print("summary=",news.summary)# 获取文章摘要
# time.sleep(30)
print("text=",news.text,"\n")# 获取文章正文
print("movies=",news.movies) # 获取文章视频链接
print("top_iamge=",news.top_image) # 获取文章顶部图片地址
print("images=",news.images)#从html中提取所有图像
print("imgs=",news.imgs)
print("html=",news.html)#获取html
也可以直接导入包,如果语言一致,也可以直接声明
import newspaper
url='http://www.coscocs.com/'
'''注:文章缓存:默认情况下,newspaper缓存所有以前提取的文章,并删除它已经提取的任何文章。
此功能用于防止重复的文章和提高提取速度。可以使用memoize_articles参数选择退出此功能。'''
news = newspaper.build(url, language='zh', memoize_articles=False)
article = news.articles[0]
article.download()
article.parse()
print('text=',article.text)
print('brand=',news.brand) #提取源品牌
print('description=',news.description) # 提取描述
print("一共获取%s篇文章" % news.size()) # 文章的数目
# 所有文章的url
for article in news.articles:
print(article.url)
#提取源类别
for category in news.category_urls():
print(category)
#提取源提要
for feed_url in news.feed_urls():
print(feed_url)
注意:文章缓存:默认情况下,报纸缓存所有以前提取的文章并删除任何已经提取的文章。该功能用于防止重复文章,提高提取速度。您可以使用 memoize_articles 参数选择退出此功能。
结合 Requests 和 Newspaper 来解析文本
import requests
from newspaper import fulltext
html = requests.get('https://www.washingtonpost.com ... 23x27;).text
text = fulltext(html)
print(text)
谷歌趋势信息
import newspaper
print(newspaper.languages())#获取支持的语言
print(newspaper.hot())#hot()使用公共api返回谷歌上的热门词汇列表
print(newspaper.popular_urls())#popular_urls()返回一个流行新闻源url列表
多任务处理
import newspaper
from newspaper import news_pool
# 创建并行任务
slate_paper = newspaper.build('http://slate.com')
tc_paper = newspaper.build('http://techcrunch.com')
espn_paper = newspaper.build('http://espn.com')
papers = [slate_paper, tc_paper, espn_paper]
news_pool.set(papers, threads_per_source=2) # (3*2) = 6 共6个线程
news_pool.join()
print(slate_paper.articles[10].html)
python可读性
github地址为:
安装
pip install requests
pip install readability-lxml
如何使用:
import requests
from readability import Document
response = requests.get('https://news.163.com/18/1123/1 ... 23x27;)
doc = Document(response.text)
print doc.title()
print doc.content()
测试结果:文本提取范围过大,出现乱码,不好用。显然得到的文本部分有问题。并且存在乱码的问题。因此,不推荐。
网页新闻抓取(神龙IP一起常见的抓取策略及算法策略)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-11-03 09:35
网络爬虫又称网络蜘蛛,是一种按照一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新爬取的URL放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略吧~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到待抓取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大型网站优先
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果是网站,等待下载的页面数最多,则先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。 查看全部
网页新闻抓取(神龙IP一起常见的抓取策略及算法策略)
网络爬虫又称网络蜘蛛,是一种按照一定的逻辑和算法从互联网上爬取和下载网页的计算机程序。它是搜索引擎的重要组成部分。一般爬虫从种子URL的一部分开始,按照一定的策略开始爬取。将新爬取的URL放入爬取队列,然后进行新一轮的爬取,直到爬取完成。
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个很重要的问题,因为这涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。网络爬虫的爬取策略有很多种,但不管采用哪种方式,基本目标都是一样的:优先选择重要的网页进行爬取。一起来看看神龙IP常见的爬取策略吧~
爬虫常用的爬取策略
一、广度优先遍历策略(Breath First)
将新下载的网页中收录的链接直接追加到待抓取的URL队列的末尾是广度优先遍历的核心。也就是说,该方法并没有明确提出和使用网页重要性衡量标准,而是机械地从新下载的网页中提取链接,附加到待抓取的URL队列中,排列URL的下载顺序。
二、OCIP策略(Online Page Importance Computation,在线页面重要性计算)
它可以看作是一种改进的 PageRank 算法。在算法开始之前,每个互联网页面都被给予相同的“现金”。每当某个页面 P 被下载时,P 就会将自己拥有的“现金”平均分配给该页面所收录的链接页面,并将自己分配的“现金”清空。对于URL队列中待抓取的网页,按照手头现金的多少进行排序,现金最多的网页先下载。
OCIP 在其大框架上与 PageRank 基本相同。不同的是:PageRank每次都需要迭代计算,而OCIP策略不需要迭代过程,所以计算速度比PageRank快很多,适合实时计算。同时,在计算PageRank的时候,对没有链接关系的网页有一个远程跳转的过程,而OCIP没有这个计算因素。实验结果表明OCIP是一种较好的重要性度量策略,效果略好于广度优先遍历策略。
三、大型网站优先
大网站的优先级策略很简单:用网站作为衡量网页重要性的单位。对于URL队列中待抓取的网页,根据自己的网站进行分类,如果是网站,等待下载的页面数最多,则先下载这些链接。本质思想倾向于优先下载大的网站,因为大的网站往往收录更多的页面。鉴于大型网站往往是知名公司的内容,而且他们的网页一般都是高质量的,这个想法很简单,但是有一定的依据。
网页新闻抓取( 写了一个从网页中抓取信息(如最新的头条新闻))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-03 09:30
写了一个从网页中抓取信息(如最新的头条新闻))
写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224 查看全部
网页新闻抓取(
写了一个从网页中抓取信息(如最新的头条新闻))
写了一个类来抓取网页信息(比如最新的头条、新闻来源、头条、内容等)。本文将介绍如何使用该类抓取网页中需要的信息。本文将以博客园首页的博客标题和链接为例:
上图为博客园首页的DOM树。显然,你只需要提取class为post_item的div,然后提取class为titlelnk的a标记。这样的功能可以通过以下功能来实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
/// 前端学习交流QQ群:461593224
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
通过上述功能,您可以提取所需的 HTML 标签。要实现爬取,还需要一个下载网页的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
/// 前端学习交流QQ群:461593224
下面以博客园首页的文章标题和链接为例,介绍如何使用HtmlTag类抓取网页信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
操作结果如下:
欢迎正在学习前端的同学一起学习
前端学习交流QQ群:461593224

