
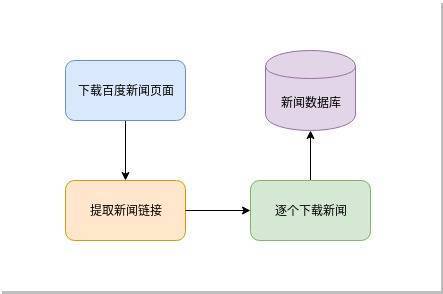
网页新闻抓取
利用机器学习通过网页预提取技术加快网站加载速度
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-07-02 03:50
发布人:Minko Gechev、David Zats、Na Li、Ping Yu、Anusha Ramesh 和 Sandeep Gupta
页面加载时间是网站用户体验最重要的决定因素之一。研究表明,更短的网页加载时间会直接增加网页浏览量、转化率,提升客户满意度。零售超市 Newegg 在应用网页预提取技术优化页面加载体验之后,网页转化率增加了 50%。
现在使用 TensorFlow 工具就能利用机器学习建立强大的解决方案,帮助网站缩短页面加载时间。在本篇文章中,我们将展示一种端到端的工作流,涉及从 Google Analytics 获取网站导航数据并加以利用,以及训练一种能预测用户下一步操作的自定义机器学习模型。您可以在 Angular 应用中利用这些预测,预提取候选页面,从而大幅改进网站的用户体验。在下图中通过并列对比的方式,将未优化的默认页面加载体验(左)与已应用基于机器学习的预测式、预提取技术,而大幅改进页面加载时间的情况(右)做了比较。这两个示例都是在模拟慢速 3G 网络上进行运行。
未优化页面和基于机器学习的页面在示例 Web 应用中的加载时间对比
该解决方案的简要示意图如下:
解决方案概览
我们利用 Google Cloud 服务(BigQuery 和 Dataflow)存储和预处理网站的 Google Analytics 数据,然后使用 TensorFlow Extended (TFX) 运行模型训练流水线来训练自定义模型,由此产生一个网站专属模型,再将其转换为可在网络上部署的 TensorFlow.js 格式。这个客户端模型将被加载到一个电子商店的示例 Angular Web 应用中,用来演示如何在 Web 应用中部署该模型。让我们来具体了解一下这些组件。
数据的准备与提取
Google Analytics 将每个页面访问存储为一个事件,并为事件提供诸如页面名称、访问时间和加载时间等关键切面。该数据包含了我们训练模型所需的一切内容。我们需要:
1. 将该数据转换为包含特征和标签的训练示例。
2. 确保该数据可被 TFX 用于训练。
为完成第一步,我们将利用现有支持,把 Google Analytics 数据导出到一个名为“BigQuery ”的大规模云数据仓库中。为了完成第二步操作,我们会创建一个 Apache Beam 流水线,它可以:
1. 从 BigQuery 读取数据
2. 排序和过滤会话中的事件
3. 检查每个会话、创建示例、将当前事件的属性作为示例的特征、将下一事件中的访问页面作为示例的标签
4. 将这些生成的示例存储到 Google Cloud Storage 中,以便 TFX 进行训练。
我们将在 Dataflow 中运行 Beam 流水线。
在以下表格中,每一行代表一个训练示例:
虽然本文中的训练示例只包含两个训练特征(cur_page 和 session_index),但我们可以方便地添加从 Google Analytics 获取更多特征来创建一个更丰富的数据集,并将其用于训练,从而创建更强大的模型。要想添加更多特征,可以扩展以下代码:
def ga_session_to_tensorflow_examples(session):<br /> examples = []<br /><br /> for i in range(len(session)-1):<br /> features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],<br /> ‘label’: [session[i+1][‘page’][‘pagePath’]],<br /> ‘session_index’: [i],<br /> # Add additional features here.<br /> …<br /> }<br /> examples.append(create_tensorflow_example(features))<br /> return examples
模型训练
TensorFlow Extended (TFX) 是一个端到端的生产级机器学习平台,可用于数据验证、规模化训练(使用加速器)、评估和验证已生成模型等过程。
若要在 TFX 中创建模型,必须提供预处理函数和运行函数。预处理函数定义了在数据传递至主模型之前应对该数据执行的操作。这些操作包括完整地传递数据,例如创建 vocab。运行函数定义了主模型及其接受训练的方式。
我们的示例演示了如何实现 preprocessing_fn 函数和 run_fn 函数以定义和训练用于预测下一页面的模型。TFX 示例流水线则演示了如何针对众多其他关键用例实现这些函数。
创建可在网络上部署的模型
完成自定义模型训练后,我们将在 Web 应用中部署该模型,这样在用户访问网站时,我们就可以利用它进行实时预测。要实现这一目的,可以使用 TensorFlow.js,它是 TensorFlow 的框架,用于直接在浏览器客户端运行机器学习模型。通过在浏览器客户端运行这段代码,可以减少与服务器端往返流量相关的延迟时间,降低服务器端费用,而且由于不必向服务器发送任何会话数据,也保护了用户的数据隐私。
TFX 运用模型重写库在训练好的 TensorFlow 模型和 TensorFlow.js 格式之间实现自动转换。作为这个库的一部分,我们已经实现了一个 TensorFlow.js 重写器。我们可以方便地在 run_fn 函数中调用该重写器来执行所需的转换。请参阅此示例了解更多详细信息。
Angular 应用
一旦准备好模型,我们就可以在 Angular 应用中使用它了。对于每次导航,我们会查询模型并预提取与未来可能被访问的页面相关的资源。
作为替代解决方案,也可以预提取与未来导航路径相关所有可能的资源,但这种做法需要更高的带宽消耗。利用机器学习,我们可以只预测下一步可能用到的页面,并减少假正例的数量。
根据应用的具体情况,可能需要预提取不同类型的资源,例如:JavaScript、图像或数据。在这个演示中,我们将预提取产品的图像。
这里面临的挑战在于:如何以一种高效的方式实现这一机制,同时又不影响应用加载时间或运行时性能。我们可以使用以下技术来降低性能倒退的风险:
能同时满足以上两个约束条件的网络平台 API 就是 Service Worker。Service Worker 是一个脱离网页、由浏览器在后台的新线程中运行的脚本。它允许您接入请求周期,并为您提供缓存控制。
当用户在应用中导航时,我们会向 Service Worker 发送消息,告知用户已经访问过哪些页面。根据导航历史记录,Service Worker 会对未来的导航进行预测,并预提取相关的产品资源。
让我们来看看各个运行部分的简要概览。
我们可以从 Angular 应用的主文件中加载 Service Worker:
// main.ts<br /><br />if ('serviceWorker' in navigator) {<br /> navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });<br />}
以上代码片段将下载 prefetch.worker.js 脚本并在后台运行该脚本。下一步,我们要将导航事件发送到 Service Worker:
// app.component.ts<br /><br />this.route.params.subscribe((routeParams) => {<br /> if (this._serviceWorker) {<br /> this._serviceWorker.postMessage({ page: routeParams.category });<br /> }<br />});
在以上代码片段中,需要注意网址参数的变更。在变更时,我们将页面类别发送到 Service Worker。
在 Service Worker 的实现过程中,我们需要处理来自主线程的消息,根据这些消息做出预测,然后预提取相关的信息。简要过程如以下代码所示:
// prefetch.worker.js<br /><br />addEventListener('message', ({ data }) => prefetch(data.page));<br /><br />const prefetch = async (path) => {<br /> const predictions = await predict(path);<br /> const cache = await caches.open(ImageCache);<br /><br /><br /> predictions.forEach(async ([probability, category]) => {<br /> const products = (await getProductList(category)).map(getUrl);<br /> [...new Set(products)].forEach(url => {<br /> const request = new Request(url, {<br /> mode: 'no-cors',<br /> });<br /> fetch(request).then(response => cache.put(request, response));<br /> });<br /> });<br />};
我们要在 Service Worker 中监听来自主线程的消息。接收到消息后,则触发逻辑响应,进行预测和预提取信息。
首先在预提取函数中预测:哪些是用户接下来可能会访问的页面。然后,对所有预测进行迭代并提取相应资源,用于提升后续导航的用户体验。
如果想了解详细信息,可以关注 TensorFlow.js 示例代码库中的示例应用。
亲自试一试
您可以查看模型训练代码示例,该示例展示了 TFX 流水线和 Apache Beam 流水线,前者用于训练页面预提取模型,后者用于将 Google Analytics(分析)数据转换为训练示例;还可以查看部署示例,了解如何在 Angular 示例应用中部署 TensorFlow.js 模型用于客户端预测。
致谢
该项目的成功离不开 Becky Chan、Deepak Aujla、Fei Dong 和 Jason Mayes 的巨大努力和有力支持,在此深表感谢。 查看全部
利用机器学习通过网页预提取技术加快网站加载速度
发布人:Minko Gechev、David Zats、Na Li、Ping Yu、Anusha Ramesh 和 Sandeep Gupta
页面加载时间是网站用户体验最重要的决定因素之一。研究表明,更短的网页加载时间会直接增加网页浏览量、转化率,提升客户满意度。零售超市 Newegg 在应用网页预提取技术优化页面加载体验之后,网页转化率增加了 50%。
现在使用 TensorFlow 工具就能利用机器学习建立强大的解决方案,帮助网站缩短页面加载时间。在本篇文章中,我们将展示一种端到端的工作流,涉及从 Google Analytics 获取网站导航数据并加以利用,以及训练一种能预测用户下一步操作的自定义机器学习模型。您可以在 Angular 应用中利用这些预测,预提取候选页面,从而大幅改进网站的用户体验。在下图中通过并列对比的方式,将未优化的默认页面加载体验(左)与已应用基于机器学习的预测式、预提取技术,而大幅改进页面加载时间的情况(右)做了比较。这两个示例都是在模拟慢速 3G 网络上进行运行。
未优化页面和基于机器学习的页面在示例 Web 应用中的加载时间对比
该解决方案的简要示意图如下:
解决方案概览
我们利用 Google Cloud 服务(BigQuery 和 Dataflow)存储和预处理网站的 Google Analytics 数据,然后使用 TensorFlow Extended (TFX) 运行模型训练流水线来训练自定义模型,由此产生一个网站专属模型,再将其转换为可在网络上部署的 TensorFlow.js 格式。这个客户端模型将被加载到一个电子商店的示例 Angular Web 应用中,用来演示如何在 Web 应用中部署该模型。让我们来具体了解一下这些组件。
数据的准备与提取
Google Analytics 将每个页面访问存储为一个事件,并为事件提供诸如页面名称、访问时间和加载时间等关键切面。该数据包含了我们训练模型所需的一切内容。我们需要:
1. 将该数据转换为包含特征和标签的训练示例。
2. 确保该数据可被 TFX 用于训练。
为完成第一步,我们将利用现有支持,把 Google Analytics 数据导出到一个名为“BigQuery ”的大规模云数据仓库中。为了完成第二步操作,我们会创建一个 Apache Beam 流水线,它可以:
1. 从 BigQuery 读取数据
2. 排序和过滤会话中的事件
3. 检查每个会话、创建示例、将当前事件的属性作为示例的特征、将下一事件中的访问页面作为示例的标签
4. 将这些生成的示例存储到 Google Cloud Storage 中,以便 TFX 进行训练。

我们将在 Dataflow 中运行 Beam 流水线。
在以下表格中,每一行代表一个训练示例:
虽然本文中的训练示例只包含两个训练特征(cur_page 和 session_index),但我们可以方便地添加从 Google Analytics 获取更多特征来创建一个更丰富的数据集,并将其用于训练,从而创建更强大的模型。要想添加更多特征,可以扩展以下代码:
def ga_session_to_tensorflow_examples(session):<br /> examples = []<br /><br /> for i in range(len(session)-1):<br /> features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],<br /> ‘label’: [session[i+1][‘page’][‘pagePath’]],<br /> ‘session_index’: [i],<br /> # Add additional features here.<br /> …<br /> }<br /> examples.append(create_tensorflow_example(features))<br /> return examples
模型训练
TensorFlow Extended (TFX) 是一个端到端的生产级机器学习平台,可用于数据验证、规模化训练(使用加速器)、评估和验证已生成模型等过程。
若要在 TFX 中创建模型,必须提供预处理函数和运行函数。预处理函数定义了在数据传递至主模型之前应对该数据执行的操作。这些操作包括完整地传递数据,例如创建 vocab。运行函数定义了主模型及其接受训练的方式。
我们的示例演示了如何实现 preprocessing_fn 函数和 run_fn 函数以定义和训练用于预测下一页面的模型。TFX 示例流水线则演示了如何针对众多其他关键用例实现这些函数。
创建可在网络上部署的模型
完成自定义模型训练后,我们将在 Web 应用中部署该模型,这样在用户访问网站时,我们就可以利用它进行实时预测。要实现这一目的,可以使用 TensorFlow.js,它是 TensorFlow 的框架,用于直接在浏览器客户端运行机器学习模型。通过在浏览器客户端运行这段代码,可以减少与服务器端往返流量相关的延迟时间,降低服务器端费用,而且由于不必向服务器发送任何会话数据,也保护了用户的数据隐私。
TFX 运用模型重写库在训练好的 TensorFlow 模型和 TensorFlow.js 格式之间实现自动转换。作为这个库的一部分,我们已经实现了一个 TensorFlow.js 重写器。我们可以方便地在 run_fn 函数中调用该重写器来执行所需的转换。请参阅此示例了解更多详细信息。
Angular 应用
一旦准备好模型,我们就可以在 Angular 应用中使用它了。对于每次导航,我们会查询模型并预提取与未来可能被访问的页面相关的资源。
作为替代解决方案,也可以预提取与未来导航路径相关所有可能的资源,但这种做法需要更高的带宽消耗。利用机器学习,我们可以只预测下一步可能用到的页面,并减少假正例的数量。
根据应用的具体情况,可能需要预提取不同类型的资源,例如:JavaScript、图像或数据。在这个演示中,我们将预提取产品的图像。
这里面临的挑战在于:如何以一种高效的方式实现这一机制,同时又不影响应用加载时间或运行时性能。我们可以使用以下技术来降低性能倒退的风险:

能同时满足以上两个约束条件的网络平台 API 就是 Service Worker。Service Worker 是一个脱离网页、由浏览器在后台的新线程中运行的脚本。它允许您接入请求周期,并为您提供缓存控制。
当用户在应用中导航时,我们会向 Service Worker 发送消息,告知用户已经访问过哪些页面。根据导航历史记录,Service Worker 会对未来的导航进行预测,并预提取相关的产品资源。
让我们来看看各个运行部分的简要概览。
我们可以从 Angular 应用的主文件中加载 Service Worker:
// main.ts<br /><br />if ('serviceWorker' in navigator) {<br /> navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });<br />}
以上代码片段将下载 prefetch.worker.js 脚本并在后台运行该脚本。下一步,我们要将导航事件发送到 Service Worker:
// app.component.ts<br /><br />this.route.params.subscribe((routeParams) => {<br /> if (this._serviceWorker) {<br /> this._serviceWorker.postMessage({ page: routeParams.category });<br /> }<br />});
在以上代码片段中,需要注意网址参数的变更。在变更时,我们将页面类别发送到 Service Worker。
在 Service Worker 的实现过程中,我们需要处理来自主线程的消息,根据这些消息做出预测,然后预提取相关的信息。简要过程如以下代码所示:
// prefetch.worker.js<br /><br />addEventListener('message', ({ data }) => prefetch(data.page));<br /><br />const prefetch = async (path) => {<br /> const predictions = await predict(path);<br /> const cache = await caches.open(ImageCache);<br /><br /><br /> predictions.forEach(async ([probability, category]) => {<br /> const products = (await getProductList(category)).map(getUrl);<br /> [...new Set(products)].forEach(url => {<br /> const request = new Request(url, {<br /> mode: 'no-cors',<br /> });<br /> fetch(request).then(response => cache.put(request, response));<br /> });<br /> });<br />};
我们要在 Service Worker 中监听来自主线程的消息。接收到消息后,则触发逻辑响应,进行预测和预提取信息。
首先在预提取函数中预测:哪些是用户接下来可能会访问的页面。然后,对所有预测进行迭代并提取相应资源,用于提升后续导航的用户体验。
如果想了解详细信息,可以关注 TensorFlow.js 示例代码库中的示例应用。
亲自试一试
您可以查看模型训练代码示例,该示例展示了 TFX 流水线和 Apache Beam 流水线,前者用于训练页面预提取模型,后者用于将 Google Analytics(分析)数据转换为训练示例;还可以查看部署示例,了解如何在 Angular 示例应用中部署 TensorFlow.js 模型用于客户端预测。
致谢
该项目的成功离不开 Becky Chan、Deepak Aujla、Fei Dong 和 Jason Mayes 的巨大努力和有力支持,在此深表感谢。
【资料】通过模式发现从半结构化网页中自动提取信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-06-17 13:12
【摘要】
毫无疑问,现在万维网是最丰富,最密集的信息源。然而,其结构使得难以系统地利用该信息。本文提出了一种用于快速生成信息提取器的模式发现方法,该方法可以从半结构化Web文档中提取结构化数据。包装感应的先前工作目的是从用户标记的训练示例中学习提取规则,但是,在某些实际应用中这可能会很昂贵。本文介绍了IEPAD(Information Extraction based on PAttern Discovery首字母缩写),该系统无需用户标记的示例即可从网页中发现提取模式。IEPAD应用了多种模式发现技术,包括PAT树,多个字符串对齐方式和模式匹配算法。由IEPAD生成的提取器可以在同一Web数据源中看不见的页面上进行概括。作者根据经验评估了IEPAD在从14个实际Web数据源进行的信息提取任务中的性能。实验结果表明,借助从单个页面中发现的提取规则,IEPAD可以实现96%的平均检索率。
信息提取的问题是将文档的内容转变为结构化的数据,从网页提取信息的问题是将信息提取应用于网页。信息提取产生的结果化数据可以用于后续处理,这对于文本挖掘的许多应用是至关重要的。因此,从网页提取信息是实现内容挖掘和许多其他网络智能应用的关键
上图包含了来自搜索引擎关于“基因组”的搜索结果,目标是将这个网页的内容提取成结构化的数据记录,如图中的方框所示。在这个例子中,这个网页有四条记录,每条记录包含三个数据属性:标题、内容和URL。然后,这些结构化的数据可以输入到其他应用中。
半结构化网页布局对于不同的网站来说是独一无二的,几乎没有一个通用的语法可以描述所有可能的布局格式,因此我们可以对所有的半结构化网页有一个提取器。因此,每种格式都可能需要一个特定的提取器,这使得手工编程提取器不切实际。
之前游戏快速生成提取器的方法,利用机器学习技术为每个网页数据源生成一个专门的提取器。但是提取器的生成需要人工标注/注释作为训练样本,并且对于每个新的网站,必须收集一组新的标注训练样本。
本文设计了一种模式发现算法,它可以应用于任何半结构化的网页,而无需训练实例。这个大大降低了提取器的构建成本。
【作者】
张家辉
台湾国立中央大学计算机科学与信息工程系
电话:+ 886-3-422-7151分机35302
传真:+ 886-3-422-2681
徐春南
中国科学院信息科学研究所
吕少成
中华电信实验室
原文PDF文档和翻译已上传知识星球 查看全部
【资料】通过模式发现从半结构化网页中自动提取信息
【摘要】
毫无疑问,现在万维网是最丰富,最密集的信息源。然而,其结构使得难以系统地利用该信息。本文提出了一种用于快速生成信息提取器的模式发现方法,该方法可以从半结构化Web文档中提取结构化数据。包装感应的先前工作目的是从用户标记的训练示例中学习提取规则,但是,在某些实际应用中这可能会很昂贵。本文介绍了IEPAD(Information Extraction based on PAttern Discovery首字母缩写),该系统无需用户标记的示例即可从网页中发现提取模式。IEPAD应用了多种模式发现技术,包括PAT树,多个字符串对齐方式和模式匹配算法。由IEPAD生成的提取器可以在同一Web数据源中看不见的页面上进行概括。作者根据经验评估了IEPAD在从14个实际Web数据源进行的信息提取任务中的性能。实验结果表明,借助从单个页面中发现的提取规则,IEPAD可以实现96%的平均检索率。
信息提取的问题是将文档的内容转变为结构化的数据,从网页提取信息的问题是将信息提取应用于网页。信息提取产生的结果化数据可以用于后续处理,这对于文本挖掘的许多应用是至关重要的。因此,从网页提取信息是实现内容挖掘和许多其他网络智能应用的关键
上图包含了来自搜索引擎关于“基因组”的搜索结果,目标是将这个网页的内容提取成结构化的数据记录,如图中的方框所示。在这个例子中,这个网页有四条记录,每条记录包含三个数据属性:标题、内容和URL。然后,这些结构化的数据可以输入到其他应用中。
半结构化网页布局对于不同的网站来说是独一无二的,几乎没有一个通用的语法可以描述所有可能的布局格式,因此我们可以对所有的半结构化网页有一个提取器。因此,每种格式都可能需要一个特定的提取器,这使得手工编程提取器不切实际。
之前游戏快速生成提取器的方法,利用机器学习技术为每个网页数据源生成一个专门的提取器。但是提取器的生成需要人工标注/注释作为训练样本,并且对于每个新的网站,必须收集一组新的标注训练样本。
本文设计了一种模式发现算法,它可以应用于任何半结构化的网页,而无需训练实例。这个大大降低了提取器的构建成本。
【作者】
张家辉
台湾国立中央大学计算机科学与信息工程系
电话:+ 886-3-422-7151分机35302
传真:+ 886-3-422-2681
徐春南
中国科学院信息科学研究所
吕少成
中华电信实验室
原文PDF文档和翻译已上传知识星球
新闻推荐实战(四):scrapy爬虫框架基础
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-29 21:10
本文属于新闻推荐实战-数据层-构建物料池之scrapy爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,希望读者可以快速掌握scrapy的基本使用方法,并能够举一反三。
Scrapy基础及新闻爬取实战python环境的安装
python 环境,使用miniconda搭建,安装miniconda的参考链接:。
在安装完miniconda之后,创建一个新闻推荐的虚拟环境,我这边将其命名为news_rec_py3,这个环境将会在整个新闻推荐项目中使用。
conda create -n news_rec_py3 python==3.8<br />
Scrapy的简介与安装
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,用于对网站内容进行爬取,并从其页面提取结构化数据。
Ubuntu下安装Scrapy,需要先安装依赖Linux依赖
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev<br />
在新闻推荐系统虚拟conda环境中安装scrapy
pip install scrapy<br />
scrapy项目结构
默认情况下,所有scrapy项目的项目结构都是相似的,在指定目录对应的命令行中输入如下命令,就会在当前目录创建一个scrapy项目
scrapy startproject myproject<br />
项目的目录结构如下:
myproject/<br /> scrapy.cfg<br /> <br /> myproject/ <br /> __init__.py<br /> items.py<br /> middlewares.py<br /> pipelines.py<br /> settings.py<br /> spiders/<br /> __init__.py<br />
spider
spider是定义一个特定站点(或一组站点)如何被抓取的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取项)。换言之,spider是为特定站点(或者在某些情况下,一组站点)定义爬行和解析页面的自定义行为的地方。
爬行器是自己定义的类,Scrapy使用它从一个网站(或一组网站)中抓取信息。它们必须继承 Spider 并定义要做出的初始请求,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
对于spider来说,抓取周期是这样的:
首先生成对第一个URL进行爬网的初始请求,然后指定一个回调函数,该函数使用从这些请求下载的响应进行调用。要执行的第一个请求是通过调用 start_requests() 方法,该方法(默认情况下)生成 Request 中指定的URL的 start_urls 以及 parse 方法作为请求的回调函数。在回调函数中,解析响应(网页)并返回 item objects , Request 对象,或这些对象的可迭代。这些请求还将包含一个回调(可能相同),然后由Scrapy下载,然后由指定的回调处理它们的响应。在回调函数中,解析页面内容,通常使用 选择器 (但您也可以使用beautifulsoup、lxml或任何您喜欢的机制)并使用解析的数据生成项。最后,从spider返回的项目通常被持久化到数据库(在某些 Item Pipeline )或者使用 Feed 导出 .
下面是官网给出的Demo:
import scrapy<br /><br />class QuotesSpider(scrapy.Spider):<br /> name = "quotes" # 表示一个spider 它在一个项目中必须是唯一的,即不能为不同的spider设置相同的名称。<br /> <br /> # 必须返回请求的可迭代(您可以返回请求列表或编写生成器函数),spider将从该请求开始爬行。后续请求将从这些初始请求中相继生成。<br /> def start_requests(self):<br /> urls = [<br /> 'http://quotes.toscrape.com/page/1/',<br /> 'http://quotes.toscrape.com/page/2/',<br /> ]<br /> for url in urls:<br /> yield scrapy.Request(url=url, callback=self.parse) # 注意,这里callback调用了下面定义的parse方法<br /> <br /> # 将被调用以处理为每个请求下载的响应的方法。Response参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。<br /> def parse(self, response):<br /> # 下面是直接从response中获取内容,为了更方便的爬取内容,后面会介绍使用selenium来模拟人用浏览器,并且使用对应的方法来提取我们想要爬取的内容<br /> page = response.url.split("/")[-2]<br /> filename = f'quotes-{page}.html'<br /> with open(filename, 'wb') as f:<br /> f.write(response.body)<br /> self.log(f'Saved file {filename}')<br />
Xpath
XPath 是一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历。在爬虫的时候使用xpath来选择我们想要爬取的内容是非常方便的,这里就提一下xpath中需要掌握的内容,参考资料中的内容更加的详细(建议花一个小时看看)。
要了解xpath, 需要先了解一下HTML(是用来描述网页的一种语言), 这个的细节就不详细展开
划重点:
**xpath路径表达式:**XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
了解如何使用xpath语法选取我们想要的内容,所以需要熟悉xpath的基本语法
scrapy爬取新闻内容实战
在介绍这个项目之前先说一下这个项目的基本逻辑。
环境准备:
首先Ubuntu系统里面需要安装好MongoDB数据库,这个可以参考开源项目MongoDB基础python环境中安装好了scrapy, pymongo包
项目逻辑:
每天定时从新浪新闻网站上爬取新闻数据存储到mongodb数据库中,并且需要监控每天爬取新闻的状态(比如某天爬取的数据特别少可能是哪里出了问题,需要进行排查)每天爬取新闻的时候只爬取当天日期的新闻,主要是为了防止相同的新闻重复爬取(当然这个也不能完全避免爬取重复的新闻,爬取新闻之后需要有一些单独的去重的逻辑)爬虫项目中实现三个核心文件,分别是sina.py(spider),items.py(抽取数据的规范化及字段的定义),pipelines.py(数据写入数据库)
因为新闻爬取项目和新闻推荐系统是放在一起的,为了方便提前学习,下面直接给出项目的目录结构以及重要文件中的代码实现,最终的项目将会和新闻推荐系统一起开源出来
创建一个scrapy项目:
scrapy startproject sinanews<br />
实现item.py逻辑
# Define here the models for your scraped items<br />#<br /># See documentation in:<br /># https://docs.scrapy.org/en/lat ... %3Bbr /><br />import scrapy<br />from scrapy import Item, Field<br /><br /># 定义新闻数据的字段<br />class SinanewsItem(scrapy.Item):<br /> """数据格式化,数据不同字段的定义<br /> """<br /> title = Field() # 新闻标题<br /> ctime = Field() # 新闻发布时间<br /> url = Field() # 新闻原始url<br /> raw_key_words = Field() # 新闻关键词(爬取的关键词)<br /> content = Field() # 新闻的具体内容<br /> cate = Field() # 新闻类别<br />
实现sina.py (spider)逻辑
这里需要注意的一点,这里在爬取新闻的时候选择的是一个比较简洁的展示网站进行爬取的,相比直接去最新的新浪新闻观光爬取新闻简单很多,简洁的网站大概的链接:#pageid=153&lid=2509&k=&num=50&page=1
# -*- coding: utf-8 -*-<br />import re<br />import json<br />import random<br />import scrapy<br />from scrapy import Request<br />from ..items import SinanewsItem<br />from datetime import datetime<br /><br /><br />class SinaSpider(scrapy.Spider):<br /> # spider的名字<br /> name = 'sina_spider'<br /><br /> def __init__(self, pages=None):<br /> super(SinaSpider).__init__()<br /><br /> self.total_pages = int(pages)<br /> # base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分<br /> self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'<br /> # lid和分类映射字典<br /> self.cate_dict = {<br /> "2510": "国内",<br /> "2511": "国际",<br /> "2669": "社会",<br /> "2512": "体育",<br /> "2513": "娱乐",<br /> "2514": "军事",<br /> "2515": "科技",<br /> "2516": "财经",<br /> "2517": "股市",<br /> "2518": "美股"<br /> }<br /><br /> def start_requests(self):<br /> """返回一个Request迭代器<br /> """<br /> # 遍历所有类型的论文<br /> for cate_id in self.cate_dict.keys():<br /> for page in range(1, self.total_pages + 1):<br /> lid = cate_id<br /> # 这里就是一个随机数,具体含义不是很清楚<br /> r = random.random()<br /> # cb_kwargs 是用来往解析函数parse中传递参数的<br /> yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})<br /> <br /> def parse(self, response, cate_id):<br /> """解析网页内容,并提取网页中需要的内容<br /> """<br /> json_result = json.loads(response.text) # 将请求回来的页面解析成json<br /> # 提取json中我们想要的字段<br /> # json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常<br /> data_list = json_result.get('result').get('data')<br /> for data in data_list:<br /> item = SinanewsItem()<br /><br /> item['cate'] = self.cate_dict[cate_id]<br /> item['title'] = data.get('title')<br /> item['url'] = data.get('url')<br /> item['raw_key_words'] = data.get('keywords')<br /><br /> # ctime = datetime.fromtimestamp(int(data.get('ctime')))<br /> # ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')<br /><br /> # 保留的是一个时间戳<br /> item['ctime'] = data.get('ctime')<br /><br /> # meta参数传入的是一个字典,在下一层可以将当前层的item进行复制<br /> yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})<br /> <br /> def parse_content(self, response):<br /> """解析文章内容<br /> """<br /> item = response.meta['item']<br /> content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())<br /> content = re.sub(r'\u3000', '', content)<br /> content = re.sub(r'[ \xa0?]+', ' ', content)<br /> content = re.sub(r'\s*\n\s*', '\n', content)<br /> content = re.sub(r'\s*(\s)', r'\1', content)<br /> content = ''.join([x.strip() for x in content])<br /> item['content'] = content<br /> yield item <br />
数据持久化实现,piplines.py
这里需要注意的就是实现SinanewsPipeline类的时候,里面很多方法都是固定的,不是随便写的,不同的方法又不同的功能,这个可以参考scrapy官方文档。 <p># Define your item pipelines here<br />#<br /># Don't forget to add your pipeline to the ITEM_PIPELINES setting<br /># See: https://docs.scrapy.org/en/lat ... %3Bbr /># useful for handling different item types with a single interface<br />import time<br />import datetime<br />import pymongo<br />from pymongo.errors import DuplicateKeyError<br />from sinanews.items import SinanewsItem<br />from itemadapter import ItemAdapter<br /><br /><br /># 新闻item持久化<br />class SinanewsPipeline:<br /> """数据持久化:将数据存放到mongodb中<br /> """<br /> def __init__(self, host, port, db_name, collection_name):<br /> self.host = host<br /> self.port = port<br /> self.db_name = db_name<br /> self.collection_name = collection_name<br /><br /> @classmethod <br /> def from_crawler(cls, crawler):<br /> """自带的方法,这个方法可以重新返回一个新的pipline对象,并且可以调用配置文件中的参数<br /> """<br /> return cls(<br /> host = crawler.settings.get("MONGO_HOST"),<br /> port = crawler.settings.get("MONGO_PORT"),<br /> db_name = crawler.settings.get("DB_NAME"),<br /> # mongodb中数据的集合按照日期存储<br /> collection_name = crawler.settings.get("COLLECTION_NAME") + \<br /> "_" + time.strftime("%Y%m%d", time.localtime())<br /> )<br /><br /> def open_spider(self, spider):<br /> """开始爬虫的操作,主要就是链接数据库及对应的集合<br /> """<br /> self.client = pymongo.MongoClient(self.host, self.port)<br /> self.db = self.client[self.db_name]<br /> self.collection = self.db[self.collection_name]<br /> <br /> def close_spider(self, spider):<br /> """关闭爬虫操作的时候,需要将数据库断开<br /> """<br /> self.client.close()<br /><br /> def process_item(self, item, spider):<br /> """处理每一条数据,注意这里需要将item返回<br /> 注意:判断新闻是否是今天的,每天只保存当天产出的新闻,这样可以增量的添加新的新闻数据源<br /> """<br /> if isinstance(item, SinanewsItem):<br /> try:<br /> # TODO 物料去重逻辑,根据title进行去重,先读取物料池中的所有物料的title然后进行去重<br /><br /> cur_time = int(item['ctime'])<br /> str_today = str(datetime.date.today())<br /> min_time = int(time.mktime(time.strptime(str_today + " 00:00:00", '%Y-%m-%d %H:%M:%S')))<br /> max_time = int(time.mktime(time.strptime(str_today + " 23:59:59", '%Y-%m-%d %H:%M:%S')))<br /> if cur_time > min_time and cur_time 查看全部
新闻推荐实战(四):scrapy爬虫框架基础
本文属于新闻推荐实战-数据层-构建物料池之scrapy爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,希望读者可以快速掌握scrapy的基本使用方法,并能够举一反三。
Scrapy基础及新闻爬取实战python环境的安装
python 环境,使用miniconda搭建,安装miniconda的参考链接:。
在安装完miniconda之后,创建一个新闻推荐的虚拟环境,我这边将其命名为news_rec_py3,这个环境将会在整个新闻推荐项目中使用。
conda create -n news_rec_py3 python==3.8<br />
Scrapy的简介与安装
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,用于对网站内容进行爬取,并从其页面提取结构化数据。
Ubuntu下安装Scrapy,需要先安装依赖Linux依赖
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev<br />
在新闻推荐系统虚拟conda环境中安装scrapy
pip install scrapy<br />
scrapy项目结构
默认情况下,所有scrapy项目的项目结构都是相似的,在指定目录对应的命令行中输入如下命令,就会在当前目录创建一个scrapy项目
scrapy startproject myproject<br />
项目的目录结构如下:
myproject/<br /> scrapy.cfg<br /> <br /> myproject/ <br /> __init__.py<br /> items.py<br /> middlewares.py<br /> pipelines.py<br /> settings.py<br /> spiders/<br /> __init__.py<br />
spider
spider是定义一个特定站点(或一组站点)如何被抓取的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取项)。换言之,spider是为特定站点(或者在某些情况下,一组站点)定义爬行和解析页面的自定义行为的地方。
爬行器是自己定义的类,Scrapy使用它从一个网站(或一组网站)中抓取信息。它们必须继承 Spider 并定义要做出的初始请求,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
对于spider来说,抓取周期是这样的:
首先生成对第一个URL进行爬网的初始请求,然后指定一个回调函数,该函数使用从这些请求下载的响应进行调用。要执行的第一个请求是通过调用 start_requests() 方法,该方法(默认情况下)生成 Request 中指定的URL的 start_urls 以及 parse 方法作为请求的回调函数。在回调函数中,解析响应(网页)并返回 item objects , Request 对象,或这些对象的可迭代。这些请求还将包含一个回调(可能相同),然后由Scrapy下载,然后由指定的回调处理它们的响应。在回调函数中,解析页面内容,通常使用 选择器 (但您也可以使用beautifulsoup、lxml或任何您喜欢的机制)并使用解析的数据生成项。最后,从spider返回的项目通常被持久化到数据库(在某些 Item Pipeline )或者使用 Feed 导出 .
下面是官网给出的Demo:
import scrapy<br /><br />class QuotesSpider(scrapy.Spider):<br /> name = "quotes" # 表示一个spider 它在一个项目中必须是唯一的,即不能为不同的spider设置相同的名称。<br /> <br /> # 必须返回请求的可迭代(您可以返回请求列表或编写生成器函数),spider将从该请求开始爬行。后续请求将从这些初始请求中相继生成。<br /> def start_requests(self):<br /> urls = [<br /> 'http://quotes.toscrape.com/page/1/',<br /> 'http://quotes.toscrape.com/page/2/',<br /> ]<br /> for url in urls:<br /> yield scrapy.Request(url=url, callback=self.parse) # 注意,这里callback调用了下面定义的parse方法<br /> <br /> # 将被调用以处理为每个请求下载的响应的方法。Response参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。<br /> def parse(self, response):<br /> # 下面是直接从response中获取内容,为了更方便的爬取内容,后面会介绍使用selenium来模拟人用浏览器,并且使用对应的方法来提取我们想要爬取的内容<br /> page = response.url.split("/")[-2]<br /> filename = f'quotes-{page}.html'<br /> with open(filename, 'wb') as f:<br /> f.write(response.body)<br /> self.log(f'Saved file {filename}')<br />
Xpath
XPath 是一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历。在爬虫的时候使用xpath来选择我们想要爬取的内容是非常方便的,这里就提一下xpath中需要掌握的内容,参考资料中的内容更加的详细(建议花一个小时看看)。
要了解xpath, 需要先了解一下HTML(是用来描述网页的一种语言), 这个的细节就不详细展开
划重点:
**xpath路径表达式:**XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
了解如何使用xpath语法选取我们想要的内容,所以需要熟悉xpath的基本语法
scrapy爬取新闻内容实战
在介绍这个项目之前先说一下这个项目的基本逻辑。
环境准备:
首先Ubuntu系统里面需要安装好MongoDB数据库,这个可以参考开源项目MongoDB基础python环境中安装好了scrapy, pymongo包
项目逻辑:
每天定时从新浪新闻网站上爬取新闻数据存储到mongodb数据库中,并且需要监控每天爬取新闻的状态(比如某天爬取的数据特别少可能是哪里出了问题,需要进行排查)每天爬取新闻的时候只爬取当天日期的新闻,主要是为了防止相同的新闻重复爬取(当然这个也不能完全避免爬取重复的新闻,爬取新闻之后需要有一些单独的去重的逻辑)爬虫项目中实现三个核心文件,分别是sina.py(spider),items.py(抽取数据的规范化及字段的定义),pipelines.py(数据写入数据库)
因为新闻爬取项目和新闻推荐系统是放在一起的,为了方便提前学习,下面直接给出项目的目录结构以及重要文件中的代码实现,最终的项目将会和新闻推荐系统一起开源出来
创建一个scrapy项目:
scrapy startproject sinanews<br />
实现item.py逻辑
# Define here the models for your scraped items<br />#<br /># See documentation in:<br /># https://docs.scrapy.org/en/lat ... %3Bbr /><br />import scrapy<br />from scrapy import Item, Field<br /><br /># 定义新闻数据的字段<br />class SinanewsItem(scrapy.Item):<br /> """数据格式化,数据不同字段的定义<br /> """<br /> title = Field() # 新闻标题<br /> ctime = Field() # 新闻发布时间<br /> url = Field() # 新闻原始url<br /> raw_key_words = Field() # 新闻关键词(爬取的关键词)<br /> content = Field() # 新闻的具体内容<br /> cate = Field() # 新闻类别<br />
实现sina.py (spider)逻辑
这里需要注意的一点,这里在爬取新闻的时候选择的是一个比较简洁的展示网站进行爬取的,相比直接去最新的新浪新闻观光爬取新闻简单很多,简洁的网站大概的链接:#pageid=153&lid=2509&k=&num=50&page=1
# -*- coding: utf-8 -*-<br />import re<br />import json<br />import random<br />import scrapy<br />from scrapy import Request<br />from ..items import SinanewsItem<br />from datetime import datetime<br /><br /><br />class SinaSpider(scrapy.Spider):<br /> # spider的名字<br /> name = 'sina_spider'<br /><br /> def __init__(self, pages=None):<br /> super(SinaSpider).__init__()<br /><br /> self.total_pages = int(pages)<br /> # base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分<br /> self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'<br /> # lid和分类映射字典<br /> self.cate_dict = {<br /> "2510": "国内",<br /> "2511": "国际",<br /> "2669": "社会",<br /> "2512": "体育",<br /> "2513": "娱乐",<br /> "2514": "军事",<br /> "2515": "科技",<br /> "2516": "财经",<br /> "2517": "股市",<br /> "2518": "美股"<br /> }<br /><br /> def start_requests(self):<br /> """返回一个Request迭代器<br /> """<br /> # 遍历所有类型的论文<br /> for cate_id in self.cate_dict.keys():<br /> for page in range(1, self.total_pages + 1):<br /> lid = cate_id<br /> # 这里就是一个随机数,具体含义不是很清楚<br /> r = random.random()<br /> # cb_kwargs 是用来往解析函数parse中传递参数的<br /> yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})<br /> <br /> def parse(self, response, cate_id):<br /> """解析网页内容,并提取网页中需要的内容<br /> """<br /> json_result = json.loads(response.text) # 将请求回来的页面解析成json<br /> # 提取json中我们想要的字段<br /> # json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常<br /> data_list = json_result.get('result').get('data')<br /> for data in data_list:<br /> item = SinanewsItem()<br /><br /> item['cate'] = self.cate_dict[cate_id]<br /> item['title'] = data.get('title')<br /> item['url'] = data.get('url')<br /> item['raw_key_words'] = data.get('keywords')<br /><br /> # ctime = datetime.fromtimestamp(int(data.get('ctime')))<br /> # ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')<br /><br /> # 保留的是一个时间戳<br /> item['ctime'] = data.get('ctime')<br /><br /> # meta参数传入的是一个字典,在下一层可以将当前层的item进行复制<br /> yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})<br /> <br /> def parse_content(self, response):<br /> """解析文章内容<br /> """<br /> item = response.meta['item']<br /> content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())<br /> content = re.sub(r'\u3000', '', content)<br /> content = re.sub(r'[ \xa0?]+', ' ', content)<br /> content = re.sub(r'\s*\n\s*', '\n', content)<br /> content = re.sub(r'\s*(\s)', r'\1', content)<br /> content = ''.join([x.strip() for x in content])<br /> item['content'] = content<br /> yield item <br />
数据持久化实现,piplines.py
这里需要注意的就是实现SinanewsPipeline类的时候,里面很多方法都是固定的,不是随便写的,不同的方法又不同的功能,这个可以参考scrapy官方文档。 <p># Define your item pipelines here<br />#<br /># Don't forget to add your pipeline to the ITEM_PIPELINES setting<br /># See: https://docs.scrapy.org/en/lat ... %3Bbr /># useful for handling different item types with a single interface<br />import time<br />import datetime<br />import pymongo<br />from pymongo.errors import DuplicateKeyError<br />from sinanews.items import SinanewsItem<br />from itemadapter import ItemAdapter<br /><br /><br /># 新闻item持久化<br />class SinanewsPipeline:<br /> """数据持久化:将数据存放到mongodb中<br /> """<br /> def __init__(self, host, port, db_name, collection_name):<br /> self.host = host<br /> self.port = port<br /> self.db_name = db_name<br /> self.collection_name = collection_name<br /><br /> @classmethod <br /> def from_crawler(cls, crawler):<br /> """自带的方法,这个方法可以重新返回一个新的pipline对象,并且可以调用配置文件中的参数<br /> """<br /> return cls(<br /> host = crawler.settings.get("MONGO_HOST"),<br /> port = crawler.settings.get("MONGO_PORT"),<br /> db_name = crawler.settings.get("DB_NAME"),<br /> # mongodb中数据的集合按照日期存储<br /> collection_name = crawler.settings.get("COLLECTION_NAME") + \<br /> "_" + time.strftime("%Y%m%d", time.localtime())<br /> )<br /><br /> def open_spider(self, spider):<br /> """开始爬虫的操作,主要就是链接数据库及对应的集合<br /> """<br /> self.client = pymongo.MongoClient(self.host, self.port)<br /> self.db = self.client[self.db_name]<br /> self.collection = self.db[self.collection_name]<br /> <br /> def close_spider(self, spider):<br /> """关闭爬虫操作的时候,需要将数据库断开<br /> """<br /> self.client.close()<br /><br /> def process_item(self, item, spider):<br /> """处理每一条数据,注意这里需要将item返回<br /> 注意:判断新闻是否是今天的,每天只保存当天产出的新闻,这样可以增量的添加新的新闻数据源<br /> """<br /> if isinstance(item, SinanewsItem):<br /> try:<br /> # TODO 物料去重逻辑,根据title进行去重,先读取物料池中的所有物料的title然后进行去重<br /><br /> cur_time = int(item['ctime'])<br /> str_today = str(datetime.date.today())<br /> min_time = int(time.mktime(time.strptime(str_today + " 00:00:00", '%Y-%m-%d %H:%M:%S')))<br /> max_time = int(time.mktime(time.strptime(str_today + " 23:59:59", '%Y-%m-%d %H:%M:%S')))<br /> if cur_time > min_time and cur_time
GneList 来了!抓取列表页-极-其-简-单!
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 05:35
摄影:产品经理
好戏开场
Gne[1]发布以后,大家自动化抓取新闻正文页的需求被解决了。但随之而来的,不断有同学希望能出一个抓取列表页的工具,于是,就有了今天的 GneList。
GneList 是什么
GneList是一个浏览器插件,专门用来生成列表页的 XPath。使用这个 XPath,你可以快速获取到列表页中的每一个条目。
GneList 怎么用?
GneList 的使用非常简单,几乎不需要说明。
打开带有列表的页面点击插件输入名字,点击开始抓取鼠标点击列表的前两项,GneList 会自动选中所有项点击提交按钮去数据库查看 XPath怎么安装 GneList?
GneList 由两个部分组成:插件端与后端。
插件端的下载地址:
后端的代码: ,并且后端依赖 MongoDB。
安装后端
首先确保你有一个可以连接的 MongoDB,我们假设它的 URI 是:mongodb://localhost。从 Github上面 clone 后端的代码:。
进入后端代码的根目录中的 config 文件夹中,你会发现一个local.yml文件。打开它,第一行填写 MongoDB 的 URI 地址,第二行是数据库名,第三行是集合名。插件生成的 XPath 会保存在这里供你的下游调用。
改好配置文件以后,回到后端的根目录,分别执行如下命令(你需要先安装 Pipenv):
pipenv install<br />pipenv shell<br />export local # 你自己创建的 yml文件的名字<br />uvicorn main:app --port 8800 --host 0.0.0.0 # 使用8800端口<br />
命令执行完成后,如果你使用浏览器访问:8800,应该会看到下图的内容,说明后端搭建成功。
安装插件
GneList 插件支持所有基于 Chromium 内核的浏览器,包括但不限于 Chrome/Chromium/Edge。
从上面的地址下载GneList.zip后,把它解压到任何一个文件夹中,如下图所示:
然后打开你的浏览器的插件管理页面,启动开发人员模式,例如下图是我在 Edge 中开启开发人员模式的方法。
然后点击右上角的加载解压缩的扩展,选中GneList文件夹。完成。
现在,刷新已有的列表页,或者重新开一个新的列表页,然后点击插件,试用一下吧。
管理配置页面
在插件上右键,选择扩展选项。Chrome 上面,名字可能是叫做选项或者英文Options。可以打开如下图所示的页面:
如果你没有启动后端,或者后端地址不是:8800(例如你把后端部署在服务器上,需要使用 IP 或者域名来访问,或者端口不是8800),那么这个页面应该如上图所示。
你可以把输入框中的地址改为后端地址/rule,例如:8888/rule。然后点击提交按钮。接下来刷新页面,你就可以看到如下图所示的内容:
这个页面显示了你已经添加的所有网站的XPath,你可以对他们进行修改或者删除。
Q&A
为什么插件生成的 XPath 这么奇怪?
因为这些 XPath 是从 CssSelector 转成的 XPath,我用了一个第三方的 JavaScript 包。那个包转出来的就是这么奇怪。但不影响它的功能。我后面会更换更好的包,让 XPath 变得更好看。
我的爬虫怎么使用这些 XPath?
还记得一开始配置的 MongoDB 吗?让你的爬虫去里面读取就可以了。
为什么我启动插件以后,点网页上面的元素第一次没有反应?
第一次点击的时候,如果发现没有生成红框框,就多点一下。看到红框框了再点第二个元素。
GneList 的原理是什么?
接下来的几篇文章,我会介绍 GneList 的原理。如果你等不及的话,也可以到 Github上查看源代码[2]。GneList 与 Gne 一样,他们是站在其他优秀开源项目的肩膀上做出来的,尤其是受到web-scraper-chrome-extension[3]的启发。因此,GneList也是完全开源的,允许非商业使用。
参考文献
[1]Gne:
[2]源代码:
[3]web-scraper-chrome-extension:
END
未闻 Code·知识星球开放啦!
一对一答疑爬虫相关问题
职业生涯咨询 查看全部
GneList 来了!抓取列表页-极-其-简-单!
摄影:产品经理
好戏开场
Gne[1]发布以后,大家自动化抓取新闻正文页的需求被解决了。但随之而来的,不断有同学希望能出一个抓取列表页的工具,于是,就有了今天的 GneList。
GneList 是什么
GneList是一个浏览器插件,专门用来生成列表页的 XPath。使用这个 XPath,你可以快速获取到列表页中的每一个条目。
GneList 怎么用?
GneList 的使用非常简单,几乎不需要说明。
打开带有列表的页面点击插件输入名字,点击开始抓取鼠标点击列表的前两项,GneList 会自动选中所有项点击提交按钮去数据库查看 XPath怎么安装 GneList?
GneList 由两个部分组成:插件端与后端。
插件端的下载地址:
后端的代码: ,并且后端依赖 MongoDB。
安装后端
首先确保你有一个可以连接的 MongoDB,我们假设它的 URI 是:mongodb://localhost。从 Github上面 clone 后端的代码:。
进入后端代码的根目录中的 config 文件夹中,你会发现一个local.yml文件。打开它,第一行填写 MongoDB 的 URI 地址,第二行是数据库名,第三行是集合名。插件生成的 XPath 会保存在这里供你的下游调用。
改好配置文件以后,回到后端的根目录,分别执行如下命令(你需要先安装 Pipenv):
pipenv install<br />pipenv shell<br />export local # 你自己创建的 yml文件的名字<br />uvicorn main:app --port 8800 --host 0.0.0.0 # 使用8800端口<br />
命令执行完成后,如果你使用浏览器访问:8800,应该会看到下图的内容,说明后端搭建成功。
安装插件
GneList 插件支持所有基于 Chromium 内核的浏览器,包括但不限于 Chrome/Chromium/Edge。
从上面的地址下载GneList.zip后,把它解压到任何一个文件夹中,如下图所示:
然后打开你的浏览器的插件管理页面,启动开发人员模式,例如下图是我在 Edge 中开启开发人员模式的方法。
然后点击右上角的加载解压缩的扩展,选中GneList文件夹。完成。
现在,刷新已有的列表页,或者重新开一个新的列表页,然后点击插件,试用一下吧。
管理配置页面
在插件上右键,选择扩展选项。Chrome 上面,名字可能是叫做选项或者英文Options。可以打开如下图所示的页面:
如果你没有启动后端,或者后端地址不是:8800(例如你把后端部署在服务器上,需要使用 IP 或者域名来访问,或者端口不是8800),那么这个页面应该如上图所示。
你可以把输入框中的地址改为后端地址/rule,例如:8888/rule。然后点击提交按钮。接下来刷新页面,你就可以看到如下图所示的内容:
这个页面显示了你已经添加的所有网站的XPath,你可以对他们进行修改或者删除。
Q&A
为什么插件生成的 XPath 这么奇怪?
因为这些 XPath 是从 CssSelector 转成的 XPath,我用了一个第三方的 JavaScript 包。那个包转出来的就是这么奇怪。但不影响它的功能。我后面会更换更好的包,让 XPath 变得更好看。
我的爬虫怎么使用这些 XPath?
还记得一开始配置的 MongoDB 吗?让你的爬虫去里面读取就可以了。
为什么我启动插件以后,点网页上面的元素第一次没有反应?
第一次点击的时候,如果发现没有生成红框框,就多点一下。看到红框框了再点第二个元素。
GneList 的原理是什么?
接下来的几篇文章,我会介绍 GneList 的原理。如果你等不及的话,也可以到 Github上查看源代码[2]。GneList 与 Gne 一样,他们是站在其他优秀开源项目的肩膀上做出来的,尤其是受到web-scraper-chrome-extension[3]的启发。因此,GneList也是完全开源的,允许非商业使用。
参考文献
[1]Gne:
[2]源代码:
[3]web-scraper-chrome-extension:
END
未闻 Code·知识星球开放啦!
一对一答疑爬虫相关问题
职业生涯咨询
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-18 07:10
等标注Html新闻网页,可实现新闻列表标题内容、链接地址、发布时间的精准抓取,对抓取结果进行分类,保存在本地txt。为实现上述目的,本发明采用如下技术方案:(1)创建存储对象:在本地服务器建立一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置Encoding格式,避免文档存储过程中出现乱码,实现文档的可写性;(2)解析对象:使用Jsoup解析器解析新闻列表页URL的Html,以及创建一个 Document 对象,获取解析后的文本 Content;进一步分析 Document 对象,提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。
以某企业<以@k17@的通知公告>为例,如图2所示,一种基于Jsoup的网页新闻列表抓取保存方法,包括以下步骤: 步骤1:创建空新闻。 txt文档本地或服务器上,用Java为txt文档构造一个FileWriter对象,并将其编码格式设置为“UTF-8”,避免乱码;第二步:输入通知公告的新闻列表页的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器的方法提取Document对象,返回Elements集合,或者使用getElementsByClass/Tag的方法提取指定的样式和标签内容,同样返回Elements对象es;选择方法是 Elementses=dom.select("table"); getElementsByClass/Tag 方法是指 Elementses=dom.getElementsByTag("table"); 第四步:定义几个字符串title、linkHref、datetime,获取Element对象中的title、链接地址和发布时间;Step 5:根据es tr, td 中是否有多个字符串来判断。
如果存在,使用for循环通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并传递StringlinkHref=es。 get(i).getElementsByTag("a").attr("abs:href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:如Step(4),如果没有的话,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=获取链接es.getElementsByTag("a").attr("href"); 第七步:将得到的title、linkHref、datetime按照一定的顺序和格式封装起来,封装的结果通过fwrite的方式不断写入txt .write(); 第八步:程序运行后,使用flush清除缓存并关闭文件,实现本页新闻列表的抓取和保存过程。当前页面 1 2 3 当前页面 1 1 2 3 查看全部
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
等标注Html新闻网页,可实现新闻列表标题内容、链接地址、发布时间的精准抓取,对抓取结果进行分类,保存在本地txt。为实现上述目的,本发明采用如下技术方案:(1)创建存储对象:在本地服务器建立一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置Encoding格式,避免文档存储过程中出现乱码,实现文档的可写性;(2)解析对象:使用Jsoup解析器解析新闻列表页URL的Html,以及创建一个 Document 对象,获取解析后的文本 Content;进一步分析 Document 对象,提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。
以某企业<以@k17@的通知公告>为例,如图2所示,一种基于Jsoup的网页新闻列表抓取保存方法,包括以下步骤: 步骤1:创建空新闻。 txt文档本地或服务器上,用Java为txt文档构造一个FileWriter对象,并将其编码格式设置为“UTF-8”,避免乱码;第二步:输入通知公告的新闻列表页的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器的方法提取Document对象,返回Elements集合,或者使用getElementsByClass/Tag的方法提取指定的样式和标签内容,同样返回Elements对象es;选择方法是 Elementses=dom.select("table"); getElementsByClass/Tag 方法是指 Elementses=dom.getElementsByTag("table"); 第四步:定义几个字符串title、linkHref、datetime,获取Element对象中的title、链接地址和发布时间;Step 5:根据es tr, td 中是否有多个字符串来判断。
如果存在,使用for循环通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并传递StringlinkHref=es。 get(i).getElementsByTag("a").attr("abs:href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:如Step(4),如果没有的话,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=获取链接es.getElementsByTag("a").attr("href"); 第七步:将得到的title、linkHref、datetime按照一定的顺序和格式封装起来,封装的结果通过fwrite的方式不断写入txt .write(); 第八步:程序运行后,使用flush清除缓存并关闭文件,实现本页新闻列表的抓取和保存过程。当前页面 1 2 3 当前页面 1 1 2 3
网页新闻抓取(前段时间爬过某家公司的信息怎么样?本地测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-18 05:21
因为前段时间爬过某家公司的资料,也因为有网友比较感兴趣,特写一封小信表示诚意:
npm i node-fetch
npm i cheerio
然后我们在根目录下创建一个文件 server.js:
const fetch = require('node-fetch')
const cheerio = require('cheerio')
const getPagesArray = (numberOfPosts) =>
Array(Math.ceil(numberOfPosts / 30)) //divides by 30 (posts per page)
.fill() //creates a new array
.map((_, index) => index + 1) //[1, 2, 3, 4,..] PagesArray
const getPageHTML = (pageNumber) =>
fetch(`https://news.ycombinator.com/news?p=${pageNumber}`)
.then(resp => resp.text()) //Promise
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => console.log(htmls.join(''))) //one JOINED html
}
getAllHTML(5) // get all HTML for 5 posts
代码写好后,我们可以在本地测试node server.js,会发现我们有五个html文件:
接下来我们需要做的是获取我们想要的有价值的数据,例如作者、时间、文章 连接等:
const getPosts = (html, posts) => {
let results = []
let $ = cheerio.load(html)
$('span.comhead').each(function() {
let a = $(this).prev()
let title = a.text()
let uri = a.attr('href')
let rank = a.parent().parent().text()
let subtext = a.parent().parent().next().children('.subtext').children()
let author = $(subtext).eq(1).text()
let points = $(subtext).eq(0).text()
let comments = $(subtext).eq(5).text()
let obj = {
title: title,
uri: uri,
author: author,
points: points,
comments: comments,
rank: parseInt(rank)
}
if (obj.rank 0) {
console.log(results)
return results
}
}
我们现在修改 getAllHTML 函数以调用 getPosts 方法:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => getPosts(htmls.join(''), numberOfPosts))
}
getAllHTML(5)
节点服务器,我们可以通过本地测试获取相关信息,但显然我们希望这是一个爬虫工具,而不是本地测试脚本。让我们开始包装这个脚本。
首先安装指挥官,npm i 指挥官。然后添加以下代码:
#!/usr/bin/env node
const program = require('commander')
program
.option('-p, --posts [value]', 'Number of posts', 30)
.action(args =>
getAllHTML(args.posts)
.then(html => getPosts(html, args.posts))
)
program.parse(process.argv)
修改getAllHTML:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => htmls.join(''))
}
本地测试请求数:node server -p 10
最后我们将命令行添加到工具中:
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"commander": "^2.18.0",
"node-fetch": "^2.2.0"
},
"bin": {
"hackernews": "./server.js"
}
}
通过npm publish上传并安装到本机后,我们可以直接在本地运行hackernew -p [number]。 查看全部
网页新闻抓取(前段时间爬过某家公司的信息怎么样?本地测试)
因为前段时间爬过某家公司的资料,也因为有网友比较感兴趣,特写一封小信表示诚意:
npm i node-fetch
npm i cheerio
然后我们在根目录下创建一个文件 server.js:
const fetch = require('node-fetch')
const cheerio = require('cheerio')
const getPagesArray = (numberOfPosts) =>
Array(Math.ceil(numberOfPosts / 30)) //divides by 30 (posts per page)
.fill() //creates a new array
.map((_, index) => index + 1) //[1, 2, 3, 4,..] PagesArray
const getPageHTML = (pageNumber) =>
fetch(`https://news.ycombinator.com/news?p=${pageNumber}`)
.then(resp => resp.text()) //Promise
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => console.log(htmls.join(''))) //one JOINED html
}
getAllHTML(5) // get all HTML for 5 posts
代码写好后,我们可以在本地测试node server.js,会发现我们有五个html文件:
接下来我们需要做的是获取我们想要的有价值的数据,例如作者、时间、文章 连接等:
const getPosts = (html, posts) => {
let results = []
let $ = cheerio.load(html)
$('span.comhead').each(function() {
let a = $(this).prev()
let title = a.text()
let uri = a.attr('href')
let rank = a.parent().parent().text()
let subtext = a.parent().parent().next().children('.subtext').children()
let author = $(subtext).eq(1).text()
let points = $(subtext).eq(0).text()
let comments = $(subtext).eq(5).text()
let obj = {
title: title,
uri: uri,
author: author,
points: points,
comments: comments,
rank: parseInt(rank)
}
if (obj.rank 0) {
console.log(results)
return results
}
}
我们现在修改 getAllHTML 函数以调用 getPosts 方法:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => getPosts(htmls.join(''), numberOfPosts))
}
getAllHTML(5)
节点服务器,我们可以通过本地测试获取相关信息,但显然我们希望这是一个爬虫工具,而不是本地测试脚本。让我们开始包装这个脚本。
首先安装指挥官,npm i 指挥官。然后添加以下代码:
#!/usr/bin/env node
const program = require('commander')
program
.option('-p, --posts [value]', 'Number of posts', 30)
.action(args =>
getAllHTML(args.posts)
.then(html => getPosts(html, args.posts))
)
program.parse(process.argv)
修改getAllHTML:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => htmls.join(''))
}
本地测试请求数:node server -p 10
最后我们将命令行添加到工具中:
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"commander": "^2.18.0",
"node-fetch": "^2.2.0"
},
"bin": {
"hackernews": "./server.js"
}
}
通过npm publish上传并安装到本机后,我们可以直接在本地运行hackernew -p [number]。
网页新闻抓取(如何通过Python爬虫按关键词抓取相关的新闻(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-17 18:00
)
输入 网站
现在各大网站的反爬机制可以说是疯了,比如大众点评的字符加密、微博的登录验证等等。相比之下,新闻网站的反爬机制@> 稍微弱一些。那么今天就以新浪新闻为例,分析一下如何通过Python爬虫按关键词抓取相关新闻。首先,如果你直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们必须从新浪首页搜索,这样就没有页数限制。
网页结构分析
<b>1span>b>2a>3a>4a>5a>6a>7a>8a>9a>10a>下一页a>div>
进入新浪网,进行关键词搜索后,发现无论怎么翻页,URL都不会改变,但页面内容却更新了。我的经验告诉我这是通过ajax完成的,所以我把新浪的页面代码拿下来看了看。看。显然,每次翻页都是通过点击a标签向一个地址发送请求,如果你把这个地址直接放到浏览器的地址栏,然后回车:
那么恭喜,收到错误,仔细查看html的onclick,发现调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它是在每次ajax请求之前构造的请求的url使用,使用get请求,返回数据格式为jsonp(跨域)。所以我们只需要模仿它的请求格式来获取数据。
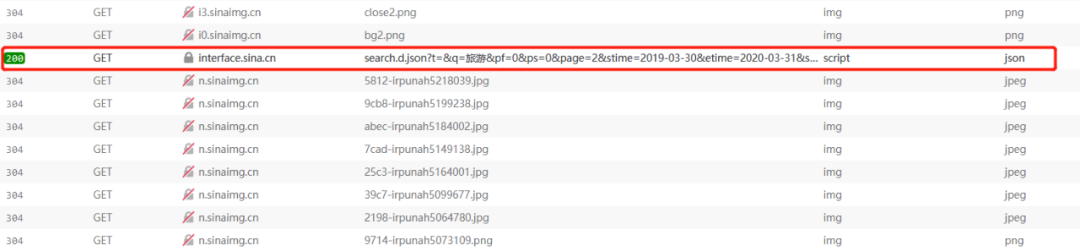
var loopnum = 0;function getNewsData(url){var oldurl = url;if(!key){<br /> $("#result").html("无搜索热词");return false;<br /> }if(!url){<br /> url = 'https://interface.sina.cn/home ... onent(key);<br /> }var stime = getStartDay();var etime = getEndDay();<br /> url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';<br /> $.ajax({type: 'GET',dataType: 'jsonp',cache : false,url:url,success: //回调函数太长了就不写了<br /> })
发送请求
import requests<br />headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",<br />}<br />params = {"t":"","q":"旅游","pf":"0","ps":"0","page":"1","stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br />}<br />response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br />print(response)
这次使用requests库,构造相同的url,发送请求。收到的结果是一个冷的 403Forbidden:
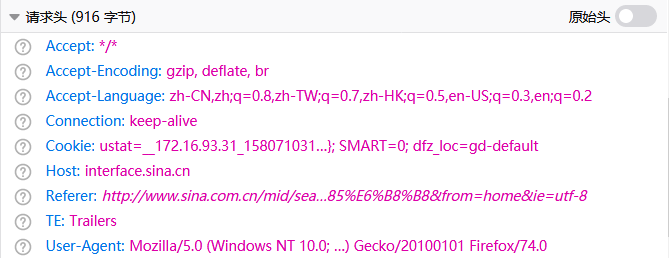
所以回到 网站 看看出了什么问题
从开发工具中找到返回的json文件,查看请求头,发现它的请求头有一个cookie,所以在构造头的时候,我们直接复制它的请求头即可。再次运行,response200!剩下的很简单,只需解析返回的数据,写入Excel即可。
完整代码
import requestsimport jsonimport xlwtdef getData(page, news):<br /> headers = {"Host": "interface.sina.cn","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0","Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Accept-Encoding": "gzip, deflate, br","Connection": "keep-alive","Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default","TE": "Trailers"<br /> }<br /> params = {"t":"","q":"旅游","pf":"0","ps":"0","page":page,"stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br /> }<br /> response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br /> dic = json.loads(response.text)<br /> news += dic["result"]["list"]return newsdef writeData(news):<br /> workbook = xlwt.Workbook(encoding = 'utf-8')<br /> worksheet = workbook.add_sheet('MySheet')<br /> worksheet.write(0, 0, "标题")<br /> worksheet.write(0, 1, "时间")<br /> worksheet.write(0, 2, "媒体")<br /> worksheet.write(0, 3, "网址")for i in range(len(news)):<br /> print(news[i])<br /> worksheet.write(i+1, 0, news[i]["origin_title"])<br /> worksheet.write(i+1, 1, news[i]["datetime"])<br /> worksheet.write(i+1, 2, news[i]["media"])<br /> worksheet.write(i+1, 3, news[i]["url"])<br /> workbook.save('data.xls')def main():<br /> news = []for i in range(1,501):<br /> news = getData(i, news)<br /> writeData(news)if __name__ == '__main__':<br /> main()
最后结果
查看全部
网页新闻抓取(如何通过Python爬虫按关键词抓取相关的新闻(图)
)
输入 网站
现在各大网站的反爬机制可以说是疯了,比如大众点评的字符加密、微博的登录验证等等。相比之下,新闻网站的反爬机制@> 稍微弱一些。那么今天就以新浪新闻为例,分析一下如何通过Python爬虫按关键词抓取相关新闻。首先,如果你直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们必须从新浪首页搜索,这样就没有页数限制。

网页结构分析
<b>1span>b>2a>3a>4a>5a>6a>7a>8a>9a>10a>下一页a>div>
进入新浪网,进行关键词搜索后,发现无论怎么翻页,URL都不会改变,但页面内容却更新了。我的经验告诉我这是通过ajax完成的,所以我把新浪的页面代码拿下来看了看。看。显然,每次翻页都是通过点击a标签向一个地址发送请求,如果你把这个地址直接放到浏览器的地址栏,然后回车:

那么恭喜,收到错误,仔细查看html的onclick,发现调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它是在每次ajax请求之前构造的请求的url使用,使用get请求,返回数据格式为jsonp(跨域)。所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;function getNewsData(url){var oldurl = url;if(!key){<br /> $("#result").html("无搜索热词");return false;<br /> }if(!url){<br /> url = 'https://interface.sina.cn/home ... onent(key);<br /> }var stime = getStartDay();var etime = getEndDay();<br /> url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';<br /> $.ajax({type: 'GET',dataType: 'jsonp',cache : false,url:url,success: //回调函数太长了就不写了<br /> })
发送请求
import requests<br />headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",<br />}<br />params = {"t":"","q":"旅游","pf":"0","ps":"0","page":"1","stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br />}<br />response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br />print(response)
这次使用requests库,构造相同的url,发送请求。收到的结果是一个冷的 403Forbidden:

所以回到 网站 看看出了什么问题
从开发工具中找到返回的json文件,查看请求头,发现它的请求头有一个cookie,所以在构造头的时候,我们直接复制它的请求头即可。再次运行,response200!剩下的很简单,只需解析返回的数据,写入Excel即可。

完整代码
import requestsimport jsonimport xlwtdef getData(page, news):<br /> headers = {"Host": "interface.sina.cn","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0","Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Accept-Encoding": "gzip, deflate, br","Connection": "keep-alive","Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default","TE": "Trailers"<br /> }<br /> params = {"t":"","q":"旅游","pf":"0","ps":"0","page":page,"stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br /> }<br /> response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br /> dic = json.loads(response.text)<br /> news += dic["result"]["list"]return newsdef writeData(news):<br /> workbook = xlwt.Workbook(encoding = 'utf-8')<br /> worksheet = workbook.add_sheet('MySheet')<br /> worksheet.write(0, 0, "标题")<br /> worksheet.write(0, 1, "时间")<br /> worksheet.write(0, 2, "媒体")<br /> worksheet.write(0, 3, "网址")for i in range(len(news)):<br /> print(news[i])<br /> worksheet.write(i+1, 0, news[i]["origin_title"])<br /> worksheet.write(i+1, 1, news[i]["datetime"])<br /> worksheet.write(i+1, 2, news[i]["media"])<br /> worksheet.write(i+1, 3, news[i]["url"])<br /> workbook.save('data.xls')def main():<br /> news = []for i in range(1,501):<br /> news = getData(i, news)<br /> writeData(news)if __name__ == '__main__':<br /> main()
最后结果

网页新闻抓取(《教你用Python进阶量化交易》专栏(二):扩展篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-17 17:41
欢迎大家订阅《用Python教你进阶量化交易》专栏!为了给大家提供一个更轻松的学习过程,笔者在栏目内容之外还陆续引入了一些笔记,以帮助同学们学习本栏目内容。目前上线的扩展链接如下:
为了把栏目中零散的知识点贯穿始终,笔者在栏末“自制量化交易工具”小节中分享了之前制作的量化交易小工具的简化版。希望大家可以通过调试代码掌握相关信息。知识。
目前已经移植到站外文章第九部分的Python3.7x版本。接下来我们会在这个版本的基础上逐步完善这个工具,让专栏的读者不仅可以通过小工具掌握专栏的相关知识点,还可以在自己的量化交易中使用工具股票。
量化交易策略的研究主要涵盖微观和宏观两个方面。微观方面更多是以市场价格、交易头寸等基本信息为研究对象。技术指标是通过算法计算出来的,然后根据技术指标的变化来构建。交易模型。宏观方面是开发基于更多市场信息的交易模型,如以CPI、PPI、货币发行等宏观经济指标为研究对象构建交易模型;或使用数据挖掘技术挖掘可能导致市场异常的新闻事件。波动性事件获得交易机会。
在这篇笔记中,我们先梳理一下可以获取股票信息的网站,然后介绍如何在我们的GUI工具上展示抓取到的股票信息。
证券从业人员网站包括上海证券交易所、深圳证券交易所、中国证监会、证券业协会;
行业资讯网站有慧聪、阿里、万德;
知名股票论坛:点金投资之家、分享世界、MACD股市、东方财富网股吧、和讯股吧、创世论坛。
接下来,我们使用爬虫来爬取东方财富网股票论坛的帖子内容。
当我们点击第2页和第3页时,我们检查URL是:,002372_2.html, ,002372_3.html,所以论坛URL的模式是,002372_%d.html中表单,规则比较简单,%d是论坛的页码,但是这个表单是评论时间排列的URL。如果按发帖时间排列,则为002372,f_%d.html。
读取网页内容的关键代码如下:
html_cont=request.urlopen(page_url).read()
需要注意的是,在Python2中有urllib、urllib2和urlparse,但是在Python3中,这些都集成到了urllib中。Python2中urllib和urllib2的内容集成到urllib.request模块中,urlparse集成到urllib.parse模块中。在Python3中,urllib还收录了response、error、robotparse等各种子模块。
获取到的HTML代码内容如下:
得到 HTML 代码后,开始解析 HTML 代码。该帖由两部分组成,一部分为《财经评论》或《东方财富网》发布的公告或官方消息,另一部分为散户发布的讨论帖,如下:
前一篇文章的URL是,cjpl,902659513.html,后一篇文章的URL是,002372,902629178.html,这两个URL都可以在HTML文件的内容中找到,如下所示:
因此,《财经评论》、《东方财富网》或散户发布的帖子的主要特点是/news。我们使用正则表达式进行删除和选择,实现代码如下,
模式 = pile('/news\S+html',re.S)
news_comment_urls = re.findall(pattern, html_cont.decode('utf-8')) # 非空白字符N次
"""
['/news,cjpl,902659513.html', '/news,cjpl,902684967.html',
'/news,cjpl,902602349.html', '/news,cjpl,902529812.html',
'/news,cjpl,857016161.html', '/news,002372,902629178.html',
'/news,002372,902557935.html', '/news,002372,902533930.html',
'/news,002372,902519348.html', '/news,002372,902468635.html',
'/news,002372,902466626.html', '/news,002372,902464127.html',
……
'/news,002372,901168702.html', '/news,002372,901153848.html']
"""
正则表达式的 \S+ 表示匹配多个非空白字符,然后使用 findall 函数查找所有匹配的字符串并以列表的形式返回。
然后使用 urljoin 方法拼接整个 url 来抓取单个帖子的标题内容。代码如下:
对于 news_comment_urls 中的 comment_url :
whole_url = parse.urljoin(page_url, comment_url)
post_urls.add(whole_url)
返回 post_urls
单个帖子的爬取内容包括帖子的发帖时间、作者和帖子标题三部分,如下:
我们可以通过正则表达式进行提取,其中在组合正则表达式时,需要考虑HTML代码中是否存在重复匹配的关键字。作者和帖子标题的常规代码如下。关键词mainbody和zwcontentmain在正文中只出现一次,匹配度高。
com_cont = 桩(r'
.*?zwconttbn.*?(.*?).*?.*?"zwconttbt">(.*?)
.*?social clearfix',re.DOTALL)
发布时间的正则代码如下,分两步逐步清晰提取时间。由于搜索是扫描字符串以找到RE匹配的位置,因此添加group()返回匹配的字符串。
pub_elems = re.search('
',html_cont2).group()
# 查看全部
网页新闻抓取(《教你用Python进阶量化交易》专栏(二):扩展篇)
欢迎大家订阅《用Python教你进阶量化交易》专栏!为了给大家提供一个更轻松的学习过程,笔者在栏目内容之外还陆续引入了一些笔记,以帮助同学们学习本栏目内容。目前上线的扩展链接如下:
为了把栏目中零散的知识点贯穿始终,笔者在栏末“自制量化交易工具”小节中分享了之前制作的量化交易小工具的简化版。希望大家可以通过调试代码掌握相关信息。知识。
目前已经移植到站外文章第九部分的Python3.7x版本。接下来我们会在这个版本的基础上逐步完善这个工具,让专栏的读者不仅可以通过小工具掌握专栏的相关知识点,还可以在自己的量化交易中使用工具股票。
量化交易策略的研究主要涵盖微观和宏观两个方面。微观方面更多是以市场价格、交易头寸等基本信息为研究对象。技术指标是通过算法计算出来的,然后根据技术指标的变化来构建。交易模型。宏观方面是开发基于更多市场信息的交易模型,如以CPI、PPI、货币发行等宏观经济指标为研究对象构建交易模型;或使用数据挖掘技术挖掘可能导致市场异常的新闻事件。波动性事件获得交易机会。
在这篇笔记中,我们先梳理一下可以获取股票信息的网站,然后介绍如何在我们的GUI工具上展示抓取到的股票信息。
证券从业人员网站包括上海证券交易所、深圳证券交易所、中国证监会、证券业协会;
行业资讯网站有慧聪、阿里、万德;
知名股票论坛:点金投资之家、分享世界、MACD股市、东方财富网股吧、和讯股吧、创世论坛。
接下来,我们使用爬虫来爬取东方财富网股票论坛的帖子内容。

当我们点击第2页和第3页时,我们检查URL是:,002372_2.html, ,002372_3.html,所以论坛URL的模式是,002372_%d.html中表单,规则比较简单,%d是论坛的页码,但是这个表单是评论时间排列的URL。如果按发帖时间排列,则为002372,f_%d.html。
读取网页内容的关键代码如下:
html_cont=request.urlopen(page_url).read()
需要注意的是,在Python2中有urllib、urllib2和urlparse,但是在Python3中,这些都集成到了urllib中。Python2中urllib和urllib2的内容集成到urllib.request模块中,urlparse集成到urllib.parse模块中。在Python3中,urllib还收录了response、error、robotparse等各种子模块。
获取到的HTML代码内容如下:
得到 HTML 代码后,开始解析 HTML 代码。该帖由两部分组成,一部分为《财经评论》或《东方财富网》发布的公告或官方消息,另一部分为散户发布的讨论帖,如下:
前一篇文章的URL是,cjpl,902659513.html,后一篇文章的URL是,002372,902629178.html,这两个URL都可以在HTML文件的内容中找到,如下所示:
因此,《财经评论》、《东方财富网》或散户发布的帖子的主要特点是/news。我们使用正则表达式进行删除和选择,实现代码如下,
模式 = pile('/news\S+html',re.S)
news_comment_urls = re.findall(pattern, html_cont.decode('utf-8')) # 非空白字符N次
"""
['/news,cjpl,902659513.html', '/news,cjpl,902684967.html',
'/news,cjpl,902602349.html', '/news,cjpl,902529812.html',
'/news,cjpl,857016161.html', '/news,002372,902629178.html',
'/news,002372,902557935.html', '/news,002372,902533930.html',
'/news,002372,902519348.html', '/news,002372,902468635.html',
'/news,002372,902466626.html', '/news,002372,902464127.html',
……
'/news,002372,901168702.html', '/news,002372,901153848.html']
"""
正则表达式的 \S+ 表示匹配多个非空白字符,然后使用 findall 函数查找所有匹配的字符串并以列表的形式返回。
然后使用 urljoin 方法拼接整个 url 来抓取单个帖子的标题内容。代码如下:
对于 news_comment_urls 中的 comment_url :
whole_url = parse.urljoin(page_url, comment_url)
post_urls.add(whole_url)
返回 post_urls
单个帖子的爬取内容包括帖子的发帖时间、作者和帖子标题三部分,如下:
我们可以通过正则表达式进行提取,其中在组合正则表达式时,需要考虑HTML代码中是否存在重复匹配的关键字。作者和帖子标题的常规代码如下。关键词mainbody和zwcontentmain在正文中只出现一次,匹配度高。
com_cont = 桩(r'
.*?zwconttbn.*?(.*?).*?.*?"zwconttbt">(.*?)
.*?social clearfix',re.DOTALL)
发布时间的正则代码如下,分两步逐步清晰提取时间。由于搜索是扫描字符串以找到RE匹配的位置,因此添加group()返回匹配的字符串。
pub_elems = re.search('
',html_cont2).group()
#
网页新闻抓取(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-15 21:31
本文属于入门级爬虫,老司机不用看。html
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。Python
首先我们打开163的网站,我们可以随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。面试
然后确认可以用F12打开谷歌浏览器的控制台后,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。json
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么很明显:api
*).js
上面的链接也是我们这次爬取要请求的地址。
接下来只需要用到python的两个库:browser
请求 json BeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
因为我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup 用于解析 HTML 文档,可以很方便的帮助我们获取指定 div 的内容。互联网
让我们开始编写我们的爬虫:app
第一步,导入以上三个包:异步
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:post
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到文档中文章源的位置是:一个id=“ne_article_source”的标签。
作者的立场是:class="ep-editor"的span标签。
主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要捕获的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为json字符串,"title": ['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现方式是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,感兴趣的可以关注下文章。 查看全部
网页新闻抓取(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机不用看。html
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。Python
首先我们打开163的网站,我们可以随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。面试
然后确认可以用F12打开谷歌浏览器的控制台后,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。json

可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么很明显:api
*).js
上面的链接也是我们这次爬取要请求的地址。
接下来只需要用到python的两个库:browser
请求 json BeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
因为我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup 用于解析 HTML 文档,可以很方便的帮助我们获取指定 div 的内容。互联网
让我们开始编写我们的爬虫:app
第一步,导入以上三个包:异步
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:post
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到文档中文章源的位置是:一个id=“ne_article_source”的标签。
作者的立场是:class="ep-editor"的span标签。
主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要捕获的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为json字符串,"title": ['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现方式是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,感兴趣的可以关注下文章。
网页新闻抓取( 就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-10 19:21
就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻头条及其原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
新闻爬虫简单流程图
按照这个简单的流程,我们先实现下面的简单代码:
#!/usr/bin/envpython3
#作者:veelion
进口商
进口时间
进口请求
进口提取物
defsave_to_db(url,html):
#将网页保存到数据库中,我们暂时替换为打印相关信息
print('%s:%s'%(url,len(html)))
defcrawl():
#1\.downloadbaidunews
hub_url='#39;
res=requests.get(hub_url)
html=res.text
#2\.extractnewslinks
##2.1extractalllinkswith'href'
链接=re.findall(r'href=[\'"]?(.*?)[\'"\s]',html)
print('findlinks:',len(链接))
新闻链接=[]
##2.2filter非新闻链接
链接链接:
ifnotlink.startswith('http'):
继续
tld=tldextract.extract(链接)
iftld.domain=='百度':
继续
news_links.append(链接)
print('findnewslinks:',len(news_links))
#3\.downloadnewsandsavetodatabase
forlinkinnews_links:
html=requests.get(link).text
save_to_db(链接,html)
print('工作完成!')
定义():
而1:
爬行()
time.sleep(300)
如果__name__=='__main__':
主要的()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 先用正则表达式提取a标签的href属性,即网页中的链接;然后找出新闻链接,方法是:假设非百度外链是新闻链接;
3. 将找到的所有新闻链接一一下载并保存到数据库中;暂时用打印相关信息代替保存到数据库的功能。
4. 每 300 秒重复步骤 1-3 以获取最新消息。
上面的代码可以工作,但是只能工作,而且槽数也不多。让我们在抱怨的同时一起改进这个爬虫。
1. 添加异常处理
在编写爬虫时,尤其是与网络请求相关的代码,
必须
有异常处理。目标服务器是否正常,当时网络连接是否畅通(超时)等都是爬虫无法控制的,所以处理网络请求时必须处理异常。网络请求最好设置一个超时时间,以免在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时的异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301,该URL永久转移到另一个URL,如果稍后请求,转移的URL将被请求
404,基本上这个网站已经过期了,以后不要再尝试了
500,服务器内部有错误,可能是暂时的,稍后再试
3. 管理 URL 的状态
记下这次失败的 URL,以便稍后重试。对于超时的URL,需要稍后再去抓取,所以需要记录所有URL的各种状态,包括:
下载成功
多次下载失败,无需重新下载
下载
下载失败,重试
增加了对网络请求的各种处理,使得爬虫更加健壮,不会随时异常退出,给后续的运维带来了很大的工作量。
下一节我们将结合代码一一讲述上述三个插槽的改进。有关更多详细信息,请收听下一个细分。
Python爬虫知识点
本节我们使用Python的几个模块,它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET、POST 触手可及:
进口请求
res=requests.get(url,timeout=5,headers=my_headers)
res2=requests.post(url,data=post_data,timeout=5,headers=my_headers)
get() 和 post() 函数有很多可选参数。以上用于设置超时和自定义标头。更多参数请参考requests文档。
无论是get()还是post(),requests都会返回一个Response对象,通过这个对象获取下载的内容:
res.content 为获取的二进制内容,类型为字节;
res.text 是二进制内容内容解码后的str内容;
它首先从响应标头中找到编码。如果没有找到,则通过chardet自动判断编码,赋值给res.encoding,最后将二进制内容解密为str类型。
经验谈:
res.text在判断中文编码时,有时会出现错误,或者通过cchardet(chardet用C语言实现)来获取更准确。在这里,我们举一个例子:
在[1]:导入请求
在[2]:r=requests.get('#39;)
在[3]:r.encoding
输出[3]:'ISO-8859-1'
在[4]:importchardet
在[5]:chardet.detect(r.content)
出[5]:{'置信度':0.99,'编码':'utf-8','语言':''}
以上是使用 ipython 交互解释器的演示(强烈推荐使用 ipython,比 Python 自带的解释器好很多)。打开的网址是山西日报数字新闻,网页源码手动编码为utf8,chardet获取的编码也是utf8。而requests本身判断的编码是ISO-8859-1,那么返回文本的中文文本也会出现乱码。
requests 的另一个有用特性是 Session,它部分类似于浏览器并保存 cookie。之后,需要登录并与cookies相关的爬虫可以使用它的session来实现它。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,推荐使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要
点安装 tldextract
安装。即Top Level Domain extract,即顶级域名提取。前面我们讲过URL的结构,叫做host,是注册域名的子域,com是顶级域名TLD。它的结果是这样的:
在[6]:importtlextract
在[7]:tldextract.extract('#39;)
Out[7]:ExtractResult(subdomain='news',domain='baidu',suffix='com')
返回结构由三部分组成:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。时间模块就是提供时间相关功能的模块。At the same time, there is another module, datetime, which is also time-related, and can be appropriately selected and used according to the situation.
记住这些模块,你将在未来的爬虫写作生涯中受益匪浅。 查看全部
网页新闻抓取(
就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻头条及其原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
新闻爬虫简单流程图
按照这个简单的流程,我们先实现下面的简单代码:
#!/usr/bin/envpython3
#作者:veelion
进口商
进口时间
进口请求
进口提取物
defsave_to_db(url,html):
#将网页保存到数据库中,我们暂时替换为打印相关信息
print('%s:%s'%(url,len(html)))
defcrawl():
#1\.downloadbaidunews
hub_url='#39;
res=requests.get(hub_url)
html=res.text
#2\.extractnewslinks
##2.1extractalllinkswith'href'
链接=re.findall(r'href=[\'"]?(.*?)[\'"\s]',html)
print('findlinks:',len(链接))
新闻链接=[]
##2.2filter非新闻链接
链接链接:
ifnotlink.startswith('http'):
继续
tld=tldextract.extract(链接)
iftld.domain=='百度':
继续
news_links.append(链接)
print('findnewslinks:',len(news_links))
#3\.downloadnewsandsavetodatabase
forlinkinnews_links:
html=requests.get(link).text
save_to_db(链接,html)
print('工作完成!')
定义():
而1:
爬行()
time.sleep(300)
如果__name__=='__main__':
主要的()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 先用正则表达式提取a标签的href属性,即网页中的链接;然后找出新闻链接,方法是:假设非百度外链是新闻链接;
3. 将找到的所有新闻链接一一下载并保存到数据库中;暂时用打印相关信息代替保存到数据库的功能。
4. 每 300 秒重复步骤 1-3 以获取最新消息。
上面的代码可以工作,但是只能工作,而且槽数也不多。让我们在抱怨的同时一起改进这个爬虫。
1. 添加异常处理
在编写爬虫时,尤其是与网络请求相关的代码,
必须
有异常处理。目标服务器是否正常,当时网络连接是否畅通(超时)等都是爬虫无法控制的,所以处理网络请求时必须处理异常。网络请求最好设置一个超时时间,以免在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时的异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301,该URL永久转移到另一个URL,如果稍后请求,转移的URL将被请求
404,基本上这个网站已经过期了,以后不要再尝试了
500,服务器内部有错误,可能是暂时的,稍后再试
3. 管理 URL 的状态
记下这次失败的 URL,以便稍后重试。对于超时的URL,需要稍后再去抓取,所以需要记录所有URL的各种状态,包括:
下载成功
多次下载失败,无需重新下载
下载
下载失败,重试
增加了对网络请求的各种处理,使得爬虫更加健壮,不会随时异常退出,给后续的运维带来了很大的工作量。
下一节我们将结合代码一一讲述上述三个插槽的改进。有关更多详细信息,请收听下一个细分。
Python爬虫知识点
本节我们使用Python的几个模块,它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET、POST 触手可及:
进口请求
res=requests.get(url,timeout=5,headers=my_headers)
res2=requests.post(url,data=post_data,timeout=5,headers=my_headers)
get() 和 post() 函数有很多可选参数。以上用于设置超时和自定义标头。更多参数请参考requests文档。
无论是get()还是post(),requests都会返回一个Response对象,通过这个对象获取下载的内容:
res.content 为获取的二进制内容,类型为字节;
res.text 是二进制内容内容解码后的str内容;
它首先从响应标头中找到编码。如果没有找到,则通过chardet自动判断编码,赋值给res.encoding,最后将二进制内容解密为str类型。
经验谈:
res.text在判断中文编码时,有时会出现错误,或者通过cchardet(chardet用C语言实现)来获取更准确。在这里,我们举一个例子:
在[1]:导入请求
在[2]:r=requests.get('#39;)
在[3]:r.encoding
输出[3]:'ISO-8859-1'
在[4]:importchardet
在[5]:chardet.detect(r.content)
出[5]:{'置信度':0.99,'编码':'utf-8','语言':''}
以上是使用 ipython 交互解释器的演示(强烈推荐使用 ipython,比 Python 自带的解释器好很多)。打开的网址是山西日报数字新闻,网页源码手动编码为utf8,chardet获取的编码也是utf8。而requests本身判断的编码是ISO-8859-1,那么返回文本的中文文本也会出现乱码。
requests 的另一个有用特性是 Session,它部分类似于浏览器并保存 cookie。之后,需要登录并与cookies相关的爬虫可以使用它的session来实现它。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,推荐使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要
点安装 tldextract
安装。即Top Level Domain extract,即顶级域名提取。前面我们讲过URL的结构,叫做host,是注册域名的子域,com是顶级域名TLD。它的结果是这样的:
在[6]:importtlextract
在[7]:tldextract.extract('#39;)
Out[7]:ExtractResult(subdomain='news',domain='baidu',suffix='com')
返回结构由三部分组成:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。时间模块就是提供时间相关功能的模块。At the same time, there is another module, datetime, which is also time-related, and can be appropriately selected and used according to the situation.
记住这些模块,你将在未来的爬虫写作生涯中受益匪浅。
网页新闻抓取(2019独角兽企业重金招聘Python工程师标准;gt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-10 19:16
2019独角兽企业招聘Python工程师标准>>>
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
前面说过,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个非常棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫操作全过程不需要人工干预,你有更多的时间喝茶聊天
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。 查看全部
网页新闻抓取(2019独角兽企业重金招聘Python工程师标准;gt)
2019独角兽企业招聘Python工程师标准>>>

写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:

从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
前面说过,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个非常棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫操作全过程不需要人工干预,你有更多的时间喝茶聊天
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。
网页新闻抓取(搜狗3.0发布的改进和提高的方面有哪些改进?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-08 23:20
A:用户可以直接体验的功能有:
a) 按时间排序功能:使用搜狗3.0时,用户可以按时间检索最新的搜索结果,信息更新更快。
b) 分类检索功能:用户在使用搜狗3.0进行搜索时,可以同时得到分类形式的搜索结果索引,可以更方便的在相关领域找到自己需要的信息。
c) 只在标题和文本中搜索的功能:搜狗3.0的搜索结果可以更准确地直接从相关网站内容的标题和文本中抓取数据,从而使搜索可以有效地判断结果的准确性,减少更多的错误,使搜索结果更加准确和客观。
技术改进和增强包括:
a) 更大的数据容量,支持百亿网页的爬取和检索:
b) 更新速度更快,每天更新5亿网页;
c) 相关性的提高(包括海量数据、搜索速度、自然语言理解)。
Q:除了网页搜索,搜狗3.0做了哪些改进?
A:音乐、图片、谈话、新闻都将升级到3.0。3.0的升级是搜狗的全面升级。
a) 音乐升级后,死链接率下降到2.%,而其他竞争对手在20-30%;
b) 图片升级后,数据量从1亿增加到5亿;
c) 新闻升级后,爬取优化,保证1分钟后能检索到最新新闻;
d) 升级后变为bbs+wiki(合编)模式。
Q:用户在使用搜狗3.0时,如何让用户知道自己使用的是新版搜索引擎?
A:搜狗3.0发布后,用户首次访问会有明显提示。此外,随着3.0的上线,高级搜索和搜索设置功能将同时上线。
Q:搜狗3.0明显提升了收录的信息量,但是对于普通用户来说,搜索结果的有效性比信息量更重要。搜狗在这方面有什么优势?
- 答:有大幅增加。具体表现如下:抓取次数从50亿增加到100亿,更新能力从每天几千万增加到每天几亿。
Q:搜狗3.0和百度等搜索引擎搜索同一个关键词有什么区别,用户可以直接体验到的明显区别是什么?
A:百度的结果相对比较草根,但是多词组合搜索效果弱于谷歌。谷歌的学术成绩比较高,雅虎的成绩比较官方。搜狗综合了几家公司的优势,找到了一家。平衡点可以让不同的用户更容易找到他们需要的结果。
Q:能否用一句话总结一下搜狗3.0在众多搜索引擎中的优势?
A:海量、及时、准确。
Q:对于我们的记者来说,经常使用新闻搜索功能。搜狗在这方面相对于竞争对手有哪些优势?
A:搜狗新闻首页依托搜狐门户矩阵的资源优势,真实反映了用户对搜狐热点新闻的关注度,是统计意义上的“最受用户欢迎”的热点新闻。搜狐内容频道的新闻已经覆盖了互联网上的大部分重大新闻。我们可以认为这个主页反映了整个互联网的新闻热点。这与其他竞争对手完全依靠机器进行判断而忽视网友反馈的方式不同。在搜索效果方面,搜狗新闻的抓取和更新能力更加强大。经测试,互联网热点新闻只需一分钟即可完成从抓取到页面分析到索引到上线的全过程。 查看全部
网页新闻抓取(搜狗3.0发布的改进和提高的方面有哪些改进?)
A:用户可以直接体验的功能有:
a) 按时间排序功能:使用搜狗3.0时,用户可以按时间检索最新的搜索结果,信息更新更快。
b) 分类检索功能:用户在使用搜狗3.0进行搜索时,可以同时得到分类形式的搜索结果索引,可以更方便的在相关领域找到自己需要的信息。
c) 只在标题和文本中搜索的功能:搜狗3.0的搜索结果可以更准确地直接从相关网站内容的标题和文本中抓取数据,从而使搜索可以有效地判断结果的准确性,减少更多的错误,使搜索结果更加准确和客观。
技术改进和增强包括:
a) 更大的数据容量,支持百亿网页的爬取和检索:
b) 更新速度更快,每天更新5亿网页;
c) 相关性的提高(包括海量数据、搜索速度、自然语言理解)。
Q:除了网页搜索,搜狗3.0做了哪些改进?
A:音乐、图片、谈话、新闻都将升级到3.0。3.0的升级是搜狗的全面升级。
a) 音乐升级后,死链接率下降到2.%,而其他竞争对手在20-30%;
b) 图片升级后,数据量从1亿增加到5亿;
c) 新闻升级后,爬取优化,保证1分钟后能检索到最新新闻;
d) 升级后变为bbs+wiki(合编)模式。
Q:用户在使用搜狗3.0时,如何让用户知道自己使用的是新版搜索引擎?
A:搜狗3.0发布后,用户首次访问会有明显提示。此外,随着3.0的上线,高级搜索和搜索设置功能将同时上线。
Q:搜狗3.0明显提升了收录的信息量,但是对于普通用户来说,搜索结果的有效性比信息量更重要。搜狗在这方面有什么优势?
- 答:有大幅增加。具体表现如下:抓取次数从50亿增加到100亿,更新能力从每天几千万增加到每天几亿。
Q:搜狗3.0和百度等搜索引擎搜索同一个关键词有什么区别,用户可以直接体验到的明显区别是什么?
A:百度的结果相对比较草根,但是多词组合搜索效果弱于谷歌。谷歌的学术成绩比较高,雅虎的成绩比较官方。搜狗综合了几家公司的优势,找到了一家。平衡点可以让不同的用户更容易找到他们需要的结果。
Q:能否用一句话总结一下搜狗3.0在众多搜索引擎中的优势?
A:海量、及时、准确。
Q:对于我们的记者来说,经常使用新闻搜索功能。搜狗在这方面相对于竞争对手有哪些优势?
A:搜狗新闻首页依托搜狐门户矩阵的资源优势,真实反映了用户对搜狐热点新闻的关注度,是统计意义上的“最受用户欢迎”的热点新闻。搜狐内容频道的新闻已经覆盖了互联网上的大部分重大新闻。我们可以认为这个主页反映了整个互联网的新闻热点。这与其他竞争对手完全依靠机器进行判断而忽视网友反馈的方式不同。在搜索效果方面,搜狗新闻的抓取和更新能力更加强大。经测试,互联网热点新闻只需一分钟即可完成从抓取到页面分析到索引到上线的全过程。
网页新闻抓取(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-03 15:13
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装aiomysql,进行数据库mysql操作更方便;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程 查看全部
网页新闻抓取(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。

让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。

1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装aiomysql,进行数据库mysql操作更方便;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程
网页新闻抓取(如何快速将不同新闻网站中的大量新闻文章导出到一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-04-03 11:25
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们对各个新闻平台特有的html结构有深入的了解。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何快速从不同的新闻网站s中抓取大量新闻文章到一个简单的python脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaperfrom newspaper import Article#将文章下载到内存的基础article = Article("url link to your article")article.download()article.parse()article.nlp()# 输出全文print(article.text)# 输出文本摘要# 因为newspaper3k内置了NLP工具,这一步行之有效print(article.summary)# 输出作者名字print(article.authors)# 输出关键字列表print(article.keywords)#收集文章中其他有用元数据的其他函数article.title # 给出标题article.publish_date #给出文章发表的日期article.top_image # 链接到文章的主要图像article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaperfrom newspaper import Articlefrom newspaper import Sourceimport pandas as pd# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False) #我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。# 全新运行,每次运行时都基本上执行此脚本final_df = pd.DataFrame()for each_article in gamespot.articles: each_article.download() each_article.parse() each_article.nlp() temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text', 'Summary', 'published_date', 'Source']) temp_df['Authors'] = each_article.authors temp_df['Title'] = each_article.title temp_df['Text'] = each_article.text temp_df['Summary'] = each_article.summary temp_df['published_date'] = each_article.publish_date temp_df['Source'] = each_article.source_url final_df = final_df.append(temp_df, ignore_index = True) #从这里可以将此Pandas数据框导出到csv文件final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~ 查看全部
网页新闻抓取(如何快速将不同新闻网站中的大量新闻文章导出到一个)
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。

我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们对各个新闻平台特有的html结构有深入的了解。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何快速从不同的新闻网站s中抓取大量新闻文章到一个简单的python脚本中。

如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaperfrom newspaper import Article#将文章下载到内存的基础article = Article("url link to your article")article.download()article.parse()article.nlp()# 输出全文print(article.text)# 输出文本摘要# 因为newspaper3k内置了NLP工具,这一步行之有效print(article.summary)# 输出作者名字print(article.authors)# 输出关键字列表print(article.keywords)#收集文章中其他有用元数据的其他函数article.title # 给出标题article.publish_date #给出文章发表的日期article.top_image # 链接到文章的主要图像article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaperfrom newspaper import Articlefrom newspaper import Sourceimport pandas as pd# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False) #我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。# 全新运行,每次运行时都基本上执行此脚本final_df = pd.DataFrame()for each_article in gamespot.articles: each_article.download() each_article.parse() each_article.nlp() temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text', 'Summary', 'published_date', 'Source']) temp_df['Authors'] = each_article.authors temp_df['Title'] = each_article.title temp_df['Text'] = each_article.text temp_df['Summary'] = each_article.summary temp_df['published_date'] = each_article.publish_date temp_df['Source'] = each_article.source_url final_df = final_df.append(temp_df, ignore_index = True) #从这里可以将此Pandas数据框导出到csv文件final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:

- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~
网页新闻抓取( 全球顶尖调查记者与调查报道专家分享网络报道用到技巧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-03 11:19
全球顶尖调查记者与调查报道专家分享网络报道用到技巧
)
今天,各种在线工具可以帮助记者更有效地制作有影响力的数据新闻。在上周刚刚结束的第二届亚洲深度报道大会上,世界顶级调查记者和调查报道专家分享了他们在工作中使用的工具和技术,从数据挖掘、数据清洗到可视化。以下由深度君为您整理。
电子表格
尽管市面上有很多优秀的数据处理工具,但 Excel 仍然被公认为最适合初学者的数据处理工具。Excel 软件中的电子表格可以有效地组织和分析数据。OpenNews 的 Sandhya Kambhampati 分享了她在使用 Excel 时的一些经验和见解,点击查看她的演示文稿,并开始您自己的数据探索之旅。(OpenNews 是由 Knight Foundation 和 Mozilla 支持的一个联合项目,旨在建立一个由开发人员、设计师和数据记者组成的社区,以帮助在开放的 Web 环境中推进新闻业。)
数据抓取
如果您在选择主题时,在网页上遇到大量非传播形式的数据信息,您应该怎么办?来自丹麦的记者 Nils Mulvad 表示,此时您需要 Import.io 工具来帮助您捕获数据。它可以节省您的时间并使您从重复性工作中解放出来。
数据清洗
有时您遇到的数据可能非常混乱,但不用担心,OpenRefine 可以有效地帮助您清理、结构化和改进数据集。更重要的是,它仍然是开源的。点击查看 Nils Mulvad 的演示,教你如何使用该工具。
数据库管理
你准备好处理大数据了吗?如何处理千兆字节、TB 级的数据集?如何进行更快更全面的数据分析?Vox 的开发人员 Kavya Sukumar 告诉您,这需要数据库管理技能。点击查看她分享的内容。
网络搜索
互联网上混杂的信息很多,我们现在需要更可靠的方法来检索和验证,以免被信息误导。路透社记者Irene Liu为大家分享了网络报道所需的信息验证工具和方法,包括反向图片搜索、地理位置验证、社交网络检测等。点击查看更多关于网络搜索的精彩内容。
地图
空间分析可以帮助记者发现隐藏在数据中的故事线索,而映射可以有效地呈现数据。纽约时报记者 Andy Lehren 经常使用 ESRI 开发的工具 ArcGIS 进行空间分析和制图。点击查看他在大会上的演讲,一步步教你绘制地图。
数据可视化
如果您想使用酷炫的设计图表来展示您的数据,但团队中没有工程师或设计师怎么办?编辑 Sanjit Oberai 整理了一份数据可视化工具列表,这些工具操作简单,效果出众。点击查看他的分享。
结尾。
查看全部
网页新闻抓取(
全球顶尖调查记者与调查报道专家分享网络报道用到技巧
)
今天,各种在线工具可以帮助记者更有效地制作有影响力的数据新闻。在上周刚刚结束的第二届亚洲深度报道大会上,世界顶级调查记者和调查报道专家分享了他们在工作中使用的工具和技术,从数据挖掘、数据清洗到可视化。以下由深度君为您整理。
电子表格
尽管市面上有很多优秀的数据处理工具,但 Excel 仍然被公认为最适合初学者的数据处理工具。Excel 软件中的电子表格可以有效地组织和分析数据。OpenNews 的 Sandhya Kambhampati 分享了她在使用 Excel 时的一些经验和见解,点击查看她的演示文稿,并开始您自己的数据探索之旅。(OpenNews 是由 Knight Foundation 和 Mozilla 支持的一个联合项目,旨在建立一个由开发人员、设计师和数据记者组成的社区,以帮助在开放的 Web 环境中推进新闻业。)
数据抓取
如果您在选择主题时,在网页上遇到大量非传播形式的数据信息,您应该怎么办?来自丹麦的记者 Nils Mulvad 表示,此时您需要 Import.io 工具来帮助您捕获数据。它可以节省您的时间并使您从重复性工作中解放出来。
数据清洗
有时您遇到的数据可能非常混乱,但不用担心,OpenRefine 可以有效地帮助您清理、结构化和改进数据集。更重要的是,它仍然是开源的。点击查看 Nils Mulvad 的演示,教你如何使用该工具。
数据库管理
你准备好处理大数据了吗?如何处理千兆字节、TB 级的数据集?如何进行更快更全面的数据分析?Vox 的开发人员 Kavya Sukumar 告诉您,这需要数据库管理技能。点击查看她分享的内容。
网络搜索
互联网上混杂的信息很多,我们现在需要更可靠的方法来检索和验证,以免被信息误导。路透社记者Irene Liu为大家分享了网络报道所需的信息验证工具和方法,包括反向图片搜索、地理位置验证、社交网络检测等。点击查看更多关于网络搜索的精彩内容。
地图
空间分析可以帮助记者发现隐藏在数据中的故事线索,而映射可以有效地呈现数据。纽约时报记者 Andy Lehren 经常使用 ESRI 开发的工具 ArcGIS 进行空间分析和制图。点击查看他在大会上的演讲,一步步教你绘制地图。
数据可视化
如果您想使用酷炫的设计图表来展示您的数据,但团队中没有工程师或设计师怎么办?编辑 Sanjit Oberai 整理了一份数据可视化工具列表,这些工具操作简单,效果出众。点击查看他的分享。
结尾。
网页新闻抓取(查看网页源码的时候(chrome浏览器)中的查看方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-01 07:22
)
标签,然后找到这个标签下的所有标签,然后再次找到该标签,然后找到所需的数据。
但是,当我们打开查看网页的源代码时(比如chrome浏览器,右键查看网页的源代码),发现源代码中并没有我们需要的数据,而是类似的东西到一个模板。数据通过后续的动态加载加载。
当我们使用爬虫进行爬取时,我们得到的是相同的源代码,但是我们当然无法获取数据。
Tips1:在分析网页时,可以先查看网页的源代码,看看里面有没有你需要的数据。如果有,可以继续分析。如果不是,则意味着数据是动态加载的,您需要改变主意。
1.2 如何获取数据
既然在网页源代码中找不到数据,那我们从哪里得到数据呢?
这涉及到一个叫“抓包”的词,听起来可能很深奥很难,但其实很简单。我们知道,必须通过发起网络请求来获取数据,即网页向服务器发送请求,然后服务器返回所需的数据。我们使用一些工具和方法将网页的请求发送到服务器以及浏览器返回的数据。截取分析,这个过程就是“抓包”。
可能大家还有点迷茫,下面我来详细演示一下。
打开开发者工具,切换到网络,然后刷新网页(这里可以捕获页面加载过程中对服务器的各种类型的请求)。
那么上图中红框圈出来的就是我们一一抓到的请求包,包括js脚本、css文件、图片等。在众多的“请求包”中我们要找到收录数据的包我们需要。
从上到下点击列表中的请求(可以在 Preview 中预览请求返回的数据),看看我们要查找的请求是哪个。
点击上图中箭头标记的请求后,预览中的内容就是布局导航栏中的内容(点击预览中的小箭头展开),我们就成功找到了正确的请求。
即抓包成功!
1.3 如何使用抓包?
我们抓到了收录数据的请求包,但是具体怎么使用呢?如何在爬虫程序中使用它来通过它来爬取数据?
仍然是那个请求,我们切换到 Headers 选项卡以查看有关此请求的一些基本信息。
主要关注几个部分Request URL(请求链接),Request Method(请求方法),Query String Parameters(请求参数),(当然是请求头中的那些东西,User-Agent,Cookie等,根据实际情况而定情况如何添加如何添加)。
我们的目的是通过python代码模拟浏览器发出这个请求,直接获取服务端返回的数据(返回的数据就是之前预览的那个)。
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
我们简单写几行代码来模拟这个过程(url是上图中Request URL的内容,requests.get()是因为Request Method是GET)。
运行结果如下,可以成功获取数据。
1.4 如何爬取其他日期的数据
运行上面的代码,我们可以得到截至2021年4月24日的新闻数据,那么如果我们要爬取其他日期的新闻数据呢?
这里我们观察请求的 url
有一段2021-04-24,我们猜测,这可能是用来控制获取数据的日期,改成其他日期如2021-04-20再试一次。
发现也可以成功。
这样我们就知道可以通过修改url中的日期字符串来抓取指定日期的数据了。
1.5 解析数据
这个请求返回的数据是一个json格式的字符串,我们需要使用json库来解析。
(可能有同学要问,怎么知道一串乱码是json格式的?总之看两个特征,一个是用大括号{}包裹的,另一个是key value的格式, 是 xxx : xxx 的形式,如果实在不知道怎么判断,直接去抓包部分看预览,如果有可以折叠和展开的小箭头,那就是json格式)
我们可以看到pages中有一个pages列表,每个page的articleList都有一个文章列表,里面收录了我们需要的page和文章列表信息。具体解析Python代码这里不做讨论,源码贴在文末。
1.6 如何攀登文章详情
首先点击文章的文本页面,和之前一样的分析方法。不难知道,文本的内容也是动态加载的,通过如下请求获取文本的数据。
让我们写一个简单的代码来验证
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
运行结果
通过分析这个请求的url可以知道,/2021-04-24是日期,/01是页码,/312840是文章的id。
至此,我们完成了网站的分析,讲解了如何判断网站的数据是动态加载还是静态加载,如果是动态加载,如何抓包,如何使用它在抓包等之后,并抓包到新闻页面列表、文章列表、文章请求正文内容的接口。如果上面的内容有什么我没有解释清楚,或者有什么我不太明白的地方,可以留言问我。
写下下面的代码就可以正式爬取了。
二、编码链接
以下为爬虫源码,供大家学习交流,请勿用于非法用途。
import requests
import bs4
import os
import datetime
import time
import json
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_jfrb(year, month, day, destdir):
'''
功能:网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
url = 'https://www.shobserver.com/sta ... 39%3B + year + '-' + month + '-' + day + '/navi.json'
html = fetchUrl(url)
jsonObj = json.loads(html)
for page in jsonObj["pages"]:
pageName = page["pname"]
pageNo = page["pnumber"]
print(pageNo, pageName)
for article in page["articleList"]:
title = article["title"]
subtitle = article["subtitle"]
pid = article["id"]
url = "https://www.shobserver.com/sta ... ot%3B + year + '-' + month + '-' + day + "/" + str(pageNo) + "/article/" + str(pid) + ".json"
print(pid, title, subtitle)
html = fetchUrl(url)
cont = json.loads(html)["article"]["content"]
bsobj = bs4.BeautifulSoup(cont, 'html.parser')
content = title + subtitle + bsobj.text
print(content)
path = destdir + '/' + year + month + day + '/' + str(pageNo) + " " + pageName + "/"
fileName = year + month + day + '-' + pageNo + '-' + str(pid) + "-" + title + '.txt'
saveFile(content, path, fileName)
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20210416 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_jfrb(year, month, day, 'Data')
print("爬取完成:" + year + month + day)
以上是爬取单日新闻文章的爬虫。如果想爬取一段时间内的新闻文章数据,可以参考《Python网络爬虫:爬取人民日报文章》中的代码修改。
三、运行效果
运行程序并输入20210424后,爬虫会自动爬取2021年4月24日的新闻数据,并保存在Data/20210424/目录下。
2021 年 12 月 15 日更新
为通过审核,部分涉及敏感内容的网站截图已被删除,仅保留部分解释爬虫技术所必需的截图,部分涉及网站的页面将被重新编码。我希望每个人都能理解。
如果在文章中有没有解释清楚,或者解释有问题的地方,请在评论区批评指正,或者扫描下方二维码,加我微信,大家可以学习和学习一起交流,一起进步。
查看全部
网页新闻抓取(查看网页源码的时候(chrome浏览器)中的查看方法
)
标签,然后找到这个标签下的所有标签,然后再次找到该标签,然后找到所需的数据。
但是,当我们打开查看网页的源代码时(比如chrome浏览器,右键查看网页的源代码),发现源代码中并没有我们需要的数据,而是类似的东西到一个模板。数据通过后续的动态加载加载。

当我们使用爬虫进行爬取时,我们得到的是相同的源代码,但是我们当然无法获取数据。
Tips1:在分析网页时,可以先查看网页的源代码,看看里面有没有你需要的数据。如果有,可以继续分析。如果不是,则意味着数据是动态加载的,您需要改变主意。
1.2 如何获取数据
既然在网页源代码中找不到数据,那我们从哪里得到数据呢?
这涉及到一个叫“抓包”的词,听起来可能很深奥很难,但其实很简单。我们知道,必须通过发起网络请求来获取数据,即网页向服务器发送请求,然后服务器返回所需的数据。我们使用一些工具和方法将网页的请求发送到服务器以及浏览器返回的数据。截取分析,这个过程就是“抓包”。
可能大家还有点迷茫,下面我来详细演示一下。
打开开发者工具,切换到网络,然后刷新网页(这里可以捕获页面加载过程中对服务器的各种类型的请求)。

那么上图中红框圈出来的就是我们一一抓到的请求包,包括js脚本、css文件、图片等。在众多的“请求包”中我们要找到收录数据的包我们需要。
从上到下点击列表中的请求(可以在 Preview 中预览请求返回的数据),看看我们要查找的请求是哪个。

点击上图中箭头标记的请求后,预览中的内容就是布局导航栏中的内容(点击预览中的小箭头展开),我们就成功找到了正确的请求。
即抓包成功!
1.3 如何使用抓包?
我们抓到了收录数据的请求包,但是具体怎么使用呢?如何在爬虫程序中使用它来通过它来爬取数据?
仍然是那个请求,我们切换到 Headers 选项卡以查看有关此请求的一些基本信息。

主要关注几个部分Request URL(请求链接),Request Method(请求方法),Query String Parameters(请求参数),(当然是请求头中的那些东西,User-Agent,Cookie等,根据实际情况而定情况如何添加如何添加)。
我们的目的是通过python代码模拟浏览器发出这个请求,直接获取服务端返回的数据(返回的数据就是之前预览的那个)。
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
我们简单写几行代码来模拟这个过程(url是上图中Request URL的内容,requests.get()是因为Request Method是GET)。
运行结果如下,可以成功获取数据。

1.4 如何爬取其他日期的数据
运行上面的代码,我们可以得到截至2021年4月24日的新闻数据,那么如果我们要爬取其他日期的新闻数据呢?
这里我们观察请求的 url
有一段2021-04-24,我们猜测,这可能是用来控制获取数据的日期,改成其他日期如2021-04-20再试一次。
发现也可以成功。
这样我们就知道可以通过修改url中的日期字符串来抓取指定日期的数据了。
1.5 解析数据
这个请求返回的数据是一个json格式的字符串,我们需要使用json库来解析。
(可能有同学要问,怎么知道一串乱码是json格式的?总之看两个特征,一个是用大括号{}包裹的,另一个是key value的格式, 是 xxx : xxx 的形式,如果实在不知道怎么判断,直接去抓包部分看预览,如果有可以折叠和展开的小箭头,那就是json格式)

我们可以看到pages中有一个pages列表,每个page的articleList都有一个文章列表,里面收录了我们需要的page和文章列表信息。具体解析Python代码这里不做讨论,源码贴在文末。
1.6 如何攀登文章详情
首先点击文章的文本页面,和之前一样的分析方法。不难知道,文本的内容也是动态加载的,通过如下请求获取文本的数据。

让我们写一个简单的代码来验证
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
运行结果

通过分析这个请求的url可以知道,/2021-04-24是日期,/01是页码,/312840是文章的id。
至此,我们完成了网站的分析,讲解了如何判断网站的数据是动态加载还是静态加载,如果是动态加载,如何抓包,如何使用它在抓包等之后,并抓包到新闻页面列表、文章列表、文章请求正文内容的接口。如果上面的内容有什么我没有解释清楚,或者有什么我不太明白的地方,可以留言问我。
写下下面的代码就可以正式爬取了。
二、编码链接
以下为爬虫源码,供大家学习交流,请勿用于非法用途。
import requests
import bs4
import os
import datetime
import time
import json
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_jfrb(year, month, day, destdir):
'''
功能:网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
url = 'https://www.shobserver.com/sta ... 39%3B + year + '-' + month + '-' + day + '/navi.json'
html = fetchUrl(url)
jsonObj = json.loads(html)
for page in jsonObj["pages"]:
pageName = page["pname"]
pageNo = page["pnumber"]
print(pageNo, pageName)
for article in page["articleList"]:
title = article["title"]
subtitle = article["subtitle"]
pid = article["id"]
url = "https://www.shobserver.com/sta ... ot%3B + year + '-' + month + '-' + day + "/" + str(pageNo) + "/article/" + str(pid) + ".json"
print(pid, title, subtitle)
html = fetchUrl(url)
cont = json.loads(html)["article"]["content"]
bsobj = bs4.BeautifulSoup(cont, 'html.parser')
content = title + subtitle + bsobj.text
print(content)
path = destdir + '/' + year + month + day + '/' + str(pageNo) + " " + pageName + "/"
fileName = year + month + day + '-' + pageNo + '-' + str(pid) + "-" + title + '.txt'
saveFile(content, path, fileName)
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20210416 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_jfrb(year, month, day, 'Data')
print("爬取完成:" + year + month + day)
以上是爬取单日新闻文章的爬虫。如果想爬取一段时间内的新闻文章数据,可以参考《Python网络爬虫:爬取人民日报文章》中的代码修改。
三、运行效果
运行程序并输入20210424后,爬虫会自动爬取2021年4月24日的新闻数据,并保存在Data/20210424/目录下。

2021 年 12 月 15 日更新
为通过审核,部分涉及敏感内容的网站截图已被删除,仅保留部分解释爬虫技术所必需的截图,部分涉及网站的页面将被重新编码。我希望每个人都能理解。
如果在文章中有没有解释清楚,或者解释有问题的地方,请在评论区批评指正,或者扫描下方二维码,加我微信,大家可以学习和学习一起交流,一起进步。

网页新闻抓取(Python学习资料获取指定页码内数据的方法及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-01 07:21
PS:如需Python学习资料,可点击下方链接自行获取
本文属于入门级爬虫,老司机不用看。
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先,我们打开163的网站,我们随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。
然后确认后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的连接也是我们这次爬取要请求的地址。
接下来只需要两个python库:
要求
json
美丽汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup用于解析html文档,可以很方便的帮我们获取到指定div的内容。
让我们开始编写我们的爬虫:
第一步,导入以上三个包:
importjsonimportrequestsfrom bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:
1 defget_page(page):2 url_temp = '{}.js'
3 return_list =[]4 for i inrange(page):5 url =url_temp.format(i)6 response =requests.get(url)7 if response.status_code != 200:8 继续
9 content = response.text #获取响应正文
10 _content = formatContent(content) #格式化json字符串
11 结果 =json.loads(_content)12 return_list.append(result)13 return return_list
这将得到每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到 文章 源在文档中的位置为:id = "ne_article_source" 的标签。作者的立场是:class="ep-editor"的span标签。主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
1 defget_content(url):2 源 = ''
3作者=''
4 身体 = ''
5 resp =requests.get(url)6 if resp.status_code == 200:7 body =resp.text8 bs4 =BeautifulSoup(body)9 source = bs4.find('a', id='ne_article_source' ).get_text()10 author = bs4.find('span', class_='ep-editor').get_text()11 body = bs4.find('div', class_=' post_text').get_text()12 返回源、作者、正文
到目前为止,我们一直在抓取的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为 json 字符串,“title”:['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO上,可以升级为异步IO,异步采集。 查看全部
网页新闻抓取(Python学习资料获取指定页码内数据的方法及方法)
PS:如需Python学习资料,可点击下方链接自行获取
本文属于入门级爬虫,老司机不用看。
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先,我们打开163的网站,我们随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。
然后确认后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的连接也是我们这次爬取要请求的地址。
接下来只需要两个python库:
要求
json
美丽汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup用于解析html文档,可以很方便的帮我们获取到指定div的内容。
让我们开始编写我们的爬虫:
第一步,导入以上三个包:
importjsonimportrequestsfrom bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:
1 defget_page(page):2 url_temp = '{}.js'
3 return_list =[]4 for i inrange(page):5 url =url_temp.format(i)6 response =requests.get(url)7 if response.status_code != 200:8 继续
9 content = response.text #获取响应正文
10 _content = formatContent(content) #格式化json字符串
11 结果 =json.loads(_content)12 return_list.append(result)13 return return_list
这将得到每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到 文章 源在文档中的位置为:id = "ne_article_source" 的标签。作者的立场是:class="ep-editor"的span标签。主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
1 defget_content(url):2 源 = ''
3作者=''
4 身体 = ''
5 resp =requests.get(url)6 if resp.status_code == 200:7 body =resp.text8 bs4 =BeautifulSoup(body)9 source = bs4.find('a', id='ne_article_source' ).get_text()10 author = bs4.find('span', class_='ep-editor').get_text()11 body = bs4.find('div', class_=' post_text').get_text()12 返回源、作者、正文
到目前为止,我们一直在抓取的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为 json 字符串,“title”:['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO上,可以升级为异步IO,异步采集。
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-31 15:20
搜索引擎收录爬虫、索引和算法,其中爬虫跟踪链接,由 网站 创建的链接,爬虫将 HTML 版本的页面保存在索引数据库中。每当爬虫绕过 网站 以查找新版本时,索引就会更新。
爬虫爬取的可追溯性,与爬取网站有关,网站可能会阻塞爬虫,有几种方法可以防止对网站的爬取。如果网站上的网页被屏蔽,会被爬虫拒绝,相应的页面也不会出现在搜索结果中。如果机器人文件阻塞了爬虫,在爬取网站之前,爬虫工具会查看网页的HTTP头,HTTP头中收录状态码,如果状态码显示网页不存在,它不会抓取网站,在关于HTTP headers的模块中,会告诉所有相关信息。如果特定页面上的元标记阻止搜索引擎将该页面编入索引,则该页面会被抓取但不会添加到索引中。
虽然可爬取只是一个技术基础,但所有类型的站长都会问的一个常见问题是如何更快地爬取网站,以及可以做些什么来提高爬取速度。抓到网站时,搜索引擎有两种可能,如果没有找到足够的网站链接,没关系,网站响应太慢,或者遇到错误太多。当没有足够的高质量入站链接时,内容不会很快被爬取,如果您希望爬虫进行更多的爬取,则需要进行一些链接构建。
网站为解决爬虫爬取响应慢的问题,如动态页面中大量JS代码,服务器不稳定,收录404页面,网站在生产过程中修改模板导致一些内容页面的文件夹如果没有删除,但是显示404的页面是连接的,先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好自动将代码推送到页面。如果要细化每个内容页面,会自动触发提交,从而提高爬虫的爬取频率。最后,核心是做高质量。对于外链,尽量在与自己的网站主题相关的网站上做外链,并保持一定的垂直度。目前很多网站都设置了外链的nofollow标签,选择在外链上发布。在论坛或者博客,或者推广软文的时候,首先检查外部链接的标签是否设置为nofollow,保证爬虫的链接可以引入。 查看全部
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
搜索引擎收录爬虫、索引和算法,其中爬虫跟踪链接,由 网站 创建的链接,爬虫将 HTML 版本的页面保存在索引数据库中。每当爬虫绕过 网站 以查找新版本时,索引就会更新。

爬虫爬取的可追溯性,与爬取网站有关,网站可能会阻塞爬虫,有几种方法可以防止对网站的爬取。如果网站上的网页被屏蔽,会被爬虫拒绝,相应的页面也不会出现在搜索结果中。如果机器人文件阻塞了爬虫,在爬取网站之前,爬虫工具会查看网页的HTTP头,HTTP头中收录状态码,如果状态码显示网页不存在,它不会抓取网站,在关于HTTP headers的模块中,会告诉所有相关信息。如果特定页面上的元标记阻止搜索引擎将该页面编入索引,则该页面会被抓取但不会添加到索引中。
虽然可爬取只是一个技术基础,但所有类型的站长都会问的一个常见问题是如何更快地爬取网站,以及可以做些什么来提高爬取速度。抓到网站时,搜索引擎有两种可能,如果没有找到足够的网站链接,没关系,网站响应太慢,或者遇到错误太多。当没有足够的高质量入站链接时,内容不会很快被爬取,如果您希望爬虫进行更多的爬取,则需要进行一些链接构建。
网站为解决爬虫爬取响应慢的问题,如动态页面中大量JS代码,服务器不稳定,收录404页面,网站在生产过程中修改模板导致一些内容页面的文件夹如果没有删除,但是显示404的页面是连接的,先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好自动将代码推送到页面。如果要细化每个内容页面,会自动触发提交,从而提高爬虫的爬取频率。最后,核心是做高质量。对于外链,尽量在与自己的网站主题相关的网站上做外链,并保持一定的垂直度。目前很多网站都设置了外链的nofollow标签,选择在外链上发布。在论坛或者博客,或者推广软文的时候,首先检查外部链接的标签是否设置为nofollow,保证爬虫的链接可以引入。
网页新闻抓取(一下百度抓取诊断失败,蜘蛛过不去才导致了这种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-29 19:17
最近有两个兄弟来找我,说网站搬家后,曲线暴跌,页面收录消失了。难道搬家对SEO有这么大的影响吗?
听到这里,基本可以断定,这位兄弟没有进行百度爬虫诊断!
还有兄弟反馈,说新成立的网站已经几天没有收录了,通过“公共消防系统”吸引了蜘蛛,没有蜘蛛通过经过。抱着试试看的心态,搜索了一下原因,原来是这种情况,是爬虫诊断失败,爬虫无法通过造成的。下面就来介绍一下百度爬虫诊断吧!
百度爬虫诊断的主要功能有哪些?对我来说,它其实是衡量你的网页是否能被百度抓取的一个标准。如果这里连爬都失败了,那么网页的100%不能是收录。
所以很多人在收录的第一步就犯了一个错误,连最基本的判断自己能不能被百度收录使用,就开始引蜘蛛投稿。
一般情况下,捕获是可以成功的。但也有爬取不成功的情况!失败的原因百度也有解释。
如果IP不正确(显示的IP和你解析的IP不对应),可以点击报错。如果还是不正确,点击几次,直到显示对应的IP。
如果是因为DNS错误,等1-2天再爬吧!如果 1-2 天后仍然无法正常工作,请更改 DNS。
爬取诊断是保证网站收录的前提,只有爬取成功才有机会成为收录。抓取诊断有两种应用场景:
1、新成立网站,加入百度站长工具平台,保证爬取诊断成功!
2、网站搬家换IP后,抢同诊断确保成功!
文章来源:公众号反冬黑帽SEO(ID:gh_c3dd79adc24e),原文链接: 查看全部
网页新闻抓取(一下百度抓取诊断失败,蜘蛛过不去才导致了这种情况)
最近有两个兄弟来找我,说网站搬家后,曲线暴跌,页面收录消失了。难道搬家对SEO有这么大的影响吗?
听到这里,基本可以断定,这位兄弟没有进行百度爬虫诊断!
还有兄弟反馈,说新成立的网站已经几天没有收录了,通过“公共消防系统”吸引了蜘蛛,没有蜘蛛通过经过。抱着试试看的心态,搜索了一下原因,原来是这种情况,是爬虫诊断失败,爬虫无法通过造成的。下面就来介绍一下百度爬虫诊断吧!

百度爬虫诊断的主要功能有哪些?对我来说,它其实是衡量你的网页是否能被百度抓取的一个标准。如果这里连爬都失败了,那么网页的100%不能是收录。
所以很多人在收录的第一步就犯了一个错误,连最基本的判断自己能不能被百度收录使用,就开始引蜘蛛投稿。
一般情况下,捕获是可以成功的。但也有爬取不成功的情况!失败的原因百度也有解释。

如果IP不正确(显示的IP和你解析的IP不对应),可以点击报错。如果还是不正确,点击几次,直到显示对应的IP。
如果是因为DNS错误,等1-2天再爬吧!如果 1-2 天后仍然无法正常工作,请更改 DNS。
爬取诊断是保证网站收录的前提,只有爬取成功才有机会成为收录。抓取诊断有两种应用场景:
1、新成立网站,加入百度站长工具平台,保证爬取诊断成功!
2、网站搬家换IP后,抢同诊断确保成功!
文章来源:公众号反冬黑帽SEO(ID:gh_c3dd79adc24e),原文链接:
网页新闻抓取(Python开发的一个快速、高层次框架会自动该类的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-29 19:13
记得十几年前还是高中生的时候,所谓的智能手机还没有普及。如果你想在学校阅读大量的电子书,你基本上依赖于具有阅读功能的 MP3 或 MP4。以及电子书的来源?在随时随地无法上网的情况下,有时我们靠的是一种傻瓜式方法:一页一页地粘贴复制一些小说网站的内容。而那些上百章的网络小说,靠这样的人工操作,确实很头疼。我多么希望我有一个工具可以为我自动化繁重的手工工作!!!
好了,言归正传,我最近一直在研究如何使用爬虫框架Scrapy。说一下想学Scrapy的初衷。
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy应用广泛,可用于数据挖掘、监控和自动化测试(百度百科上的介绍)。
经过几天的学习,初次使用Scrapy,首先需要了解的是以下几个概念:
所以,你需要做的就是编写上面提到的四个类,剩下的交给 Scrapy 框架。
你可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
在文件 spiderForShortPageMsg.py 中是我们要编写的 Spiders 子类。
例子:现在我想在网站中获取所有文章的标题和文章的地址。
第 1 步:编写一个继承自 Spiders 的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()来解析具体的html页面,找到我想要的数据,保存在数据类的一个Items中目的。
不要被这行代码吓倒:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的Selectors。这是用于定位您要查找的 html 标记的内容。有两种选择器,即XPath选择器和CSS选择器,这两种选择器都会用到。
这是我的 Item 数据类(即上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类 Item 执行的所有操作。
现在所需的数据已经在 Item 对象中。考虑到您的最终目的,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需几个简单的设置,就可以直接调用Django中的models类,从而省去复杂的数据库操作。不要太担心。谁用谁知道!! 查看全部
网页新闻抓取(Python开发的一个快速、高层次框架会自动该类的方法)
记得十几年前还是高中生的时候,所谓的智能手机还没有普及。如果你想在学校阅读大量的电子书,你基本上依赖于具有阅读功能的 MP3 或 MP4。以及电子书的来源?在随时随地无法上网的情况下,有时我们靠的是一种傻瓜式方法:一页一页地粘贴复制一些小说网站的内容。而那些上百章的网络小说,靠这样的人工操作,确实很头疼。我多么希望我有一个工具可以为我自动化繁重的手工工作!!!
好了,言归正传,我最近一直在研究如何使用爬虫框架Scrapy。说一下想学Scrapy的初衷。
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy应用广泛,可用于数据挖掘、监控和自动化测试(百度百科上的介绍)。
经过几天的学习,初次使用Scrapy,首先需要了解的是以下几个概念:
所以,你需要做的就是编写上面提到的四个类,剩下的交给 Scrapy 框架。
你可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
在文件 spiderForShortPageMsg.py 中是我们要编写的 Spiders 子类。
例子:现在我想在网站中获取所有文章的标题和文章的地址。
第 1 步:编写一个继承自 Spiders 的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()来解析具体的html页面,找到我想要的数据,保存在数据类的一个Items中目的。
不要被这行代码吓倒:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的Selectors。这是用于定位您要查找的 html 标记的内容。有两种选择器,即XPath选择器和CSS选择器,这两种选择器都会用到。
这是我的 Item 数据类(即上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类 Item 执行的所有操作。
现在所需的数据已经在 Item 对象中。考虑到您的最终目的,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需几个简单的设置,就可以直接调用Django中的models类,从而省去复杂的数据库操作。不要太担心。谁用谁知道!!
利用机器学习通过网页预提取技术加快网站加载速度
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-07-02 03:50
发布人:Minko Gechev、David Zats、Na Li、Ping Yu、Anusha Ramesh 和 Sandeep Gupta
页面加载时间是网站用户体验最重要的决定因素之一。研究表明,更短的网页加载时间会直接增加网页浏览量、转化率,提升客户满意度。零售超市 Newegg 在应用网页预提取技术优化页面加载体验之后,网页转化率增加了 50%。
现在使用 TensorFlow 工具就能利用机器学习建立强大的解决方案,帮助网站缩短页面加载时间。在本篇文章中,我们将展示一种端到端的工作流,涉及从 Google Analytics 获取网站导航数据并加以利用,以及训练一种能预测用户下一步操作的自定义机器学习模型。您可以在 Angular 应用中利用这些预测,预提取候选页面,从而大幅改进网站的用户体验。在下图中通过并列对比的方式,将未优化的默认页面加载体验(左)与已应用基于机器学习的预测式、预提取技术,而大幅改进页面加载时间的情况(右)做了比较。这两个示例都是在模拟慢速 3G 网络上进行运行。
未优化页面和基于机器学习的页面在示例 Web 应用中的加载时间对比
该解决方案的简要示意图如下:
解决方案概览
我们利用 Google Cloud 服务(BigQuery 和 Dataflow)存储和预处理网站的 Google Analytics 数据,然后使用 TensorFlow Extended (TFX) 运行模型训练流水线来训练自定义模型,由此产生一个网站专属模型,再将其转换为可在网络上部署的 TensorFlow.js 格式。这个客户端模型将被加载到一个电子商店的示例 Angular Web 应用中,用来演示如何在 Web 应用中部署该模型。让我们来具体了解一下这些组件。
数据的准备与提取
Google Analytics 将每个页面访问存储为一个事件,并为事件提供诸如页面名称、访问时间和加载时间等关键切面。该数据包含了我们训练模型所需的一切内容。我们需要:
1. 将该数据转换为包含特征和标签的训练示例。
2. 确保该数据可被 TFX 用于训练。
为完成第一步,我们将利用现有支持,把 Google Analytics 数据导出到一个名为“BigQuery ”的大规模云数据仓库中。为了完成第二步操作,我们会创建一个 Apache Beam 流水线,它可以:
1. 从 BigQuery 读取数据
2. 排序和过滤会话中的事件
3. 检查每个会话、创建示例、将当前事件的属性作为示例的特征、将下一事件中的访问页面作为示例的标签
4. 将这些生成的示例存储到 Google Cloud Storage 中,以便 TFX 进行训练。
我们将在 Dataflow 中运行 Beam 流水线。
在以下表格中,每一行代表一个训练示例:
虽然本文中的训练示例只包含两个训练特征(cur_page 和 session_index),但我们可以方便地添加从 Google Analytics 获取更多特征来创建一个更丰富的数据集,并将其用于训练,从而创建更强大的模型。要想添加更多特征,可以扩展以下代码:
def ga_session_to_tensorflow_examples(session):<br /> examples = []<br /><br /> for i in range(len(session)-1):<br /> features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],<br /> ‘label’: [session[i+1][‘page’][‘pagePath’]],<br /> ‘session_index’: [i],<br /> # Add additional features here.<br /> …<br /> }<br /> examples.append(create_tensorflow_example(features))<br /> return examples
模型训练
TensorFlow Extended (TFX) 是一个端到端的生产级机器学习平台,可用于数据验证、规模化训练(使用加速器)、评估和验证已生成模型等过程。
若要在 TFX 中创建模型,必须提供预处理函数和运行函数。预处理函数定义了在数据传递至主模型之前应对该数据执行的操作。这些操作包括完整地传递数据,例如创建 vocab。运行函数定义了主模型及其接受训练的方式。
我们的示例演示了如何实现 preprocessing_fn 函数和 run_fn 函数以定义和训练用于预测下一页面的模型。TFX 示例流水线则演示了如何针对众多其他关键用例实现这些函数。
创建可在网络上部署的模型
完成自定义模型训练后,我们将在 Web 应用中部署该模型,这样在用户访问网站时,我们就可以利用它进行实时预测。要实现这一目的,可以使用 TensorFlow.js,它是 TensorFlow 的框架,用于直接在浏览器客户端运行机器学习模型。通过在浏览器客户端运行这段代码,可以减少与服务器端往返流量相关的延迟时间,降低服务器端费用,而且由于不必向服务器发送任何会话数据,也保护了用户的数据隐私。
TFX 运用模型重写库在训练好的 TensorFlow 模型和 TensorFlow.js 格式之间实现自动转换。作为这个库的一部分,我们已经实现了一个 TensorFlow.js 重写器。我们可以方便地在 run_fn 函数中调用该重写器来执行所需的转换。请参阅此示例了解更多详细信息。
Angular 应用
一旦准备好模型,我们就可以在 Angular 应用中使用它了。对于每次导航,我们会查询模型并预提取与未来可能被访问的页面相关的资源。
作为替代解决方案,也可以预提取与未来导航路径相关所有可能的资源,但这种做法需要更高的带宽消耗。利用机器学习,我们可以只预测下一步可能用到的页面,并减少假正例的数量。
根据应用的具体情况,可能需要预提取不同类型的资源,例如:JavaScript、图像或数据。在这个演示中,我们将预提取产品的图像。
这里面临的挑战在于:如何以一种高效的方式实现这一机制,同时又不影响应用加载时间或运行时性能。我们可以使用以下技术来降低性能倒退的风险:
能同时满足以上两个约束条件的网络平台 API 就是 Service Worker。Service Worker 是一个脱离网页、由浏览器在后台的新线程中运行的脚本。它允许您接入请求周期,并为您提供缓存控制。
当用户在应用中导航时,我们会向 Service Worker 发送消息,告知用户已经访问过哪些页面。根据导航历史记录,Service Worker 会对未来的导航进行预测,并预提取相关的产品资源。
让我们来看看各个运行部分的简要概览。
我们可以从 Angular 应用的主文件中加载 Service Worker:
// main.ts<br /><br />if ('serviceWorker' in navigator) {<br /> navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });<br />}
以上代码片段将下载 prefetch.worker.js 脚本并在后台运行该脚本。下一步,我们要将导航事件发送到 Service Worker:
// app.component.ts<br /><br />this.route.params.subscribe((routeParams) => {<br /> if (this._serviceWorker) {<br /> this._serviceWorker.postMessage({ page: routeParams.category });<br /> }<br />});
在以上代码片段中,需要注意网址参数的变更。在变更时,我们将页面类别发送到 Service Worker。
在 Service Worker 的实现过程中,我们需要处理来自主线程的消息,根据这些消息做出预测,然后预提取相关的信息。简要过程如以下代码所示:
// prefetch.worker.js<br /><br />addEventListener('message', ({ data }) => prefetch(data.page));<br /><br />const prefetch = async (path) => {<br /> const predictions = await predict(path);<br /> const cache = await caches.open(ImageCache);<br /><br /><br /> predictions.forEach(async ([probability, category]) => {<br /> const products = (await getProductList(category)).map(getUrl);<br /> [...new Set(products)].forEach(url => {<br /> const request = new Request(url, {<br /> mode: 'no-cors',<br /> });<br /> fetch(request).then(response => cache.put(request, response));<br /> });<br /> });<br />};
我们要在 Service Worker 中监听来自主线程的消息。接收到消息后,则触发逻辑响应,进行预测和预提取信息。
首先在预提取函数中预测:哪些是用户接下来可能会访问的页面。然后,对所有预测进行迭代并提取相应资源,用于提升后续导航的用户体验。
如果想了解详细信息,可以关注 TensorFlow.js 示例代码库中的示例应用。
亲自试一试
您可以查看模型训练代码示例,该示例展示了 TFX 流水线和 Apache Beam 流水线,前者用于训练页面预提取模型,后者用于将 Google Analytics(分析)数据转换为训练示例;还可以查看部署示例,了解如何在 Angular 示例应用中部署 TensorFlow.js 模型用于客户端预测。
致谢
该项目的成功离不开 Becky Chan、Deepak Aujla、Fei Dong 和 Jason Mayes 的巨大努力和有力支持,在此深表感谢。 查看全部
利用机器学习通过网页预提取技术加快网站加载速度
发布人:Minko Gechev、David Zats、Na Li、Ping Yu、Anusha Ramesh 和 Sandeep Gupta
页面加载时间是网站用户体验最重要的决定因素之一。研究表明,更短的网页加载时间会直接增加网页浏览量、转化率,提升客户满意度。零售超市 Newegg 在应用网页预提取技术优化页面加载体验之后,网页转化率增加了 50%。
现在使用 TensorFlow 工具就能利用机器学习建立强大的解决方案,帮助网站缩短页面加载时间。在本篇文章中,我们将展示一种端到端的工作流,涉及从 Google Analytics 获取网站导航数据并加以利用,以及训练一种能预测用户下一步操作的自定义机器学习模型。您可以在 Angular 应用中利用这些预测,预提取候选页面,从而大幅改进网站的用户体验。在下图中通过并列对比的方式,将未优化的默认页面加载体验(左)与已应用基于机器学习的预测式、预提取技术,而大幅改进页面加载时间的情况(右)做了比较。这两个示例都是在模拟慢速 3G 网络上进行运行。
未优化页面和基于机器学习的页面在示例 Web 应用中的加载时间对比
该解决方案的简要示意图如下:
解决方案概览
我们利用 Google Cloud 服务(BigQuery 和 Dataflow)存储和预处理网站的 Google Analytics 数据,然后使用 TensorFlow Extended (TFX) 运行模型训练流水线来训练自定义模型,由此产生一个网站专属模型,再将其转换为可在网络上部署的 TensorFlow.js 格式。这个客户端模型将被加载到一个电子商店的示例 Angular Web 应用中,用来演示如何在 Web 应用中部署该模型。让我们来具体了解一下这些组件。
数据的准备与提取
Google Analytics 将每个页面访问存储为一个事件,并为事件提供诸如页面名称、访问时间和加载时间等关键切面。该数据包含了我们训练模型所需的一切内容。我们需要:
1. 将该数据转换为包含特征和标签的训练示例。
2. 确保该数据可被 TFX 用于训练。
为完成第一步,我们将利用现有支持,把 Google Analytics 数据导出到一个名为“BigQuery ”的大规模云数据仓库中。为了完成第二步操作,我们会创建一个 Apache Beam 流水线,它可以:
1. 从 BigQuery 读取数据
2. 排序和过滤会话中的事件
3. 检查每个会话、创建示例、将当前事件的属性作为示例的特征、将下一事件中的访问页面作为示例的标签
4. 将这些生成的示例存储到 Google Cloud Storage 中,以便 TFX 进行训练。
我们将在 Dataflow 中运行 Beam 流水线。
在以下表格中,每一行代表一个训练示例:
虽然本文中的训练示例只包含两个训练特征(cur_page 和 session_index),但我们可以方便地添加从 Google Analytics 获取更多特征来创建一个更丰富的数据集,并将其用于训练,从而创建更强大的模型。要想添加更多特征,可以扩展以下代码:
def ga_session_to_tensorflow_examples(session):<br /> examples = []<br /><br /> for i in range(len(session)-1):<br /> features = {‘cur_page’: [session[i][‘page’][‘pagePath’]],<br /> ‘label’: [session[i+1][‘page’][‘pagePath’]],<br /> ‘session_index’: [i],<br /> # Add additional features here.<br /> …<br /> }<br /> examples.append(create_tensorflow_example(features))<br /> return examples
模型训练
TensorFlow Extended (TFX) 是一个端到端的生产级机器学习平台,可用于数据验证、规模化训练(使用加速器)、评估和验证已生成模型等过程。
若要在 TFX 中创建模型,必须提供预处理函数和运行函数。预处理函数定义了在数据传递至主模型之前应对该数据执行的操作。这些操作包括完整地传递数据,例如创建 vocab。运行函数定义了主模型及其接受训练的方式。
我们的示例演示了如何实现 preprocessing_fn 函数和 run_fn 函数以定义和训练用于预测下一页面的模型。TFX 示例流水线则演示了如何针对众多其他关键用例实现这些函数。
创建可在网络上部署的模型
完成自定义模型训练后,我们将在 Web 应用中部署该模型,这样在用户访问网站时,我们就可以利用它进行实时预测。要实现这一目的,可以使用 TensorFlow.js,它是 TensorFlow 的框架,用于直接在浏览器客户端运行机器学习模型。通过在浏览器客户端运行这段代码,可以减少与服务器端往返流量相关的延迟时间,降低服务器端费用,而且由于不必向服务器发送任何会话数据,也保护了用户的数据隐私。
TFX 运用模型重写库在训练好的 TensorFlow 模型和 TensorFlow.js 格式之间实现自动转换。作为这个库的一部分,我们已经实现了一个 TensorFlow.js 重写器。我们可以方便地在 run_fn 函数中调用该重写器来执行所需的转换。请参阅此示例了解更多详细信息。
Angular 应用
一旦准备好模型,我们就可以在 Angular 应用中使用它了。对于每次导航,我们会查询模型并预提取与未来可能被访问的页面相关的资源。
作为替代解决方案,也可以预提取与未来导航路径相关所有可能的资源,但这种做法需要更高的带宽消耗。利用机器学习,我们可以只预测下一步可能用到的页面,并减少假正例的数量。
根据应用的具体情况,可能需要预提取不同类型的资源,例如:JavaScript、图像或数据。在这个演示中,我们将预提取产品的图像。
这里面临的挑战在于:如何以一种高效的方式实现这一机制,同时又不影响应用加载时间或运行时性能。我们可以使用以下技术来降低性能倒退的风险:
能同时满足以上两个约束条件的网络平台 API 就是 Service Worker。Service Worker 是一个脱离网页、由浏览器在后台的新线程中运行的脚本。它允许您接入请求周期,并为您提供缓存控制。
当用户在应用中导航时,我们会向 Service Worker 发送消息,告知用户已经访问过哪些页面。根据导航历史记录,Service Worker 会对未来的导航进行预测,并预提取相关的产品资源。
让我们来看看各个运行部分的简要概览。
我们可以从 Angular 应用的主文件中加载 Service Worker:
// main.ts<br /><br />if ('serviceWorker' in navigator) {<br /> navigator.serviceWorker.register('/prefetch.worker.js', { scope: '/' });<br />}
以上代码片段将下载 prefetch.worker.js 脚本并在后台运行该脚本。下一步,我们要将导航事件发送到 Service Worker:
// app.component.ts<br /><br />this.route.params.subscribe((routeParams) => {<br /> if (this._serviceWorker) {<br /> this._serviceWorker.postMessage({ page: routeParams.category });<br /> }<br />});
在以上代码片段中,需要注意网址参数的变更。在变更时,我们将页面类别发送到 Service Worker。
在 Service Worker 的实现过程中,我们需要处理来自主线程的消息,根据这些消息做出预测,然后预提取相关的信息。简要过程如以下代码所示:
// prefetch.worker.js<br /><br />addEventListener('message', ({ data }) => prefetch(data.page));<br /><br />const prefetch = async (path) => {<br /> const predictions = await predict(path);<br /> const cache = await caches.open(ImageCache);<br /><br /><br /> predictions.forEach(async ([probability, category]) => {<br /> const products = (await getProductList(category)).map(getUrl);<br /> [...new Set(products)].forEach(url => {<br /> const request = new Request(url, {<br /> mode: 'no-cors',<br /> });<br /> fetch(request).then(response => cache.put(request, response));<br /> });<br /> });<br />};
我们要在 Service Worker 中监听来自主线程的消息。接收到消息后,则触发逻辑响应,进行预测和预提取信息。
首先在预提取函数中预测:哪些是用户接下来可能会访问的页面。然后,对所有预测进行迭代并提取相应资源,用于提升后续导航的用户体验。
如果想了解详细信息,可以关注 TensorFlow.js 示例代码库中的示例应用。
亲自试一试
您可以查看模型训练代码示例,该示例展示了 TFX 流水线和 Apache Beam 流水线,前者用于训练页面预提取模型,后者用于将 Google Analytics(分析)数据转换为训练示例;还可以查看部署示例,了解如何在 Angular 示例应用中部署 TensorFlow.js 模型用于客户端预测。
致谢
该项目的成功离不开 Becky Chan、Deepak Aujla、Fei Dong 和 Jason Mayes 的巨大努力和有力支持,在此深表感谢。
【资料】通过模式发现从半结构化网页中自动提取信息
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-06-17 13:12
【摘要】
毫无疑问,现在万维网是最丰富,最密集的信息源。然而,其结构使得难以系统地利用该信息。本文提出了一种用于快速生成信息提取器的模式发现方法,该方法可以从半结构化Web文档中提取结构化数据。包装感应的先前工作目的是从用户标记的训练示例中学习提取规则,但是,在某些实际应用中这可能会很昂贵。本文介绍了IEPAD(Information Extraction based on PAttern Discovery首字母缩写),该系统无需用户标记的示例即可从网页中发现提取模式。IEPAD应用了多种模式发现技术,包括PAT树,多个字符串对齐方式和模式匹配算法。由IEPAD生成的提取器可以在同一Web数据源中看不见的页面上进行概括。作者根据经验评估了IEPAD在从14个实际Web数据源进行的信息提取任务中的性能。实验结果表明,借助从单个页面中发现的提取规则,IEPAD可以实现96%的平均检索率。
信息提取的问题是将文档的内容转变为结构化的数据,从网页提取信息的问题是将信息提取应用于网页。信息提取产生的结果化数据可以用于后续处理,这对于文本挖掘的许多应用是至关重要的。因此,从网页提取信息是实现内容挖掘和许多其他网络智能应用的关键
上图包含了来自搜索引擎关于“基因组”的搜索结果,目标是将这个网页的内容提取成结构化的数据记录,如图中的方框所示。在这个例子中,这个网页有四条记录,每条记录包含三个数据属性:标题、内容和URL。然后,这些结构化的数据可以输入到其他应用中。
半结构化网页布局对于不同的网站来说是独一无二的,几乎没有一个通用的语法可以描述所有可能的布局格式,因此我们可以对所有的半结构化网页有一个提取器。因此,每种格式都可能需要一个特定的提取器,这使得手工编程提取器不切实际。
之前游戏快速生成提取器的方法,利用机器学习技术为每个网页数据源生成一个专门的提取器。但是提取器的生成需要人工标注/注释作为训练样本,并且对于每个新的网站,必须收集一组新的标注训练样本。
本文设计了一种模式发现算法,它可以应用于任何半结构化的网页,而无需训练实例。这个大大降低了提取器的构建成本。
【作者】
张家辉
台湾国立中央大学计算机科学与信息工程系
电话:+ 886-3-422-7151分机35302
传真:+ 886-3-422-2681
徐春南
中国科学院信息科学研究所
吕少成
中华电信实验室
原文PDF文档和翻译已上传知识星球 查看全部
【资料】通过模式发现从半结构化网页中自动提取信息
【摘要】
毫无疑问,现在万维网是最丰富,最密集的信息源。然而,其结构使得难以系统地利用该信息。本文提出了一种用于快速生成信息提取器的模式发现方法,该方法可以从半结构化Web文档中提取结构化数据。包装感应的先前工作目的是从用户标记的训练示例中学习提取规则,但是,在某些实际应用中这可能会很昂贵。本文介绍了IEPAD(Information Extraction based on PAttern Discovery首字母缩写),该系统无需用户标记的示例即可从网页中发现提取模式。IEPAD应用了多种模式发现技术,包括PAT树,多个字符串对齐方式和模式匹配算法。由IEPAD生成的提取器可以在同一Web数据源中看不见的页面上进行概括。作者根据经验评估了IEPAD在从14个实际Web数据源进行的信息提取任务中的性能。实验结果表明,借助从单个页面中发现的提取规则,IEPAD可以实现96%的平均检索率。
信息提取的问题是将文档的内容转变为结构化的数据,从网页提取信息的问题是将信息提取应用于网页。信息提取产生的结果化数据可以用于后续处理,这对于文本挖掘的许多应用是至关重要的。因此,从网页提取信息是实现内容挖掘和许多其他网络智能应用的关键
上图包含了来自搜索引擎关于“基因组”的搜索结果,目标是将这个网页的内容提取成结构化的数据记录,如图中的方框所示。在这个例子中,这个网页有四条记录,每条记录包含三个数据属性:标题、内容和URL。然后,这些结构化的数据可以输入到其他应用中。
半结构化网页布局对于不同的网站来说是独一无二的,几乎没有一个通用的语法可以描述所有可能的布局格式,因此我们可以对所有的半结构化网页有一个提取器。因此,每种格式都可能需要一个特定的提取器,这使得手工编程提取器不切实际。
之前游戏快速生成提取器的方法,利用机器学习技术为每个网页数据源生成一个专门的提取器。但是提取器的生成需要人工标注/注释作为训练样本,并且对于每个新的网站,必须收集一组新的标注训练样本。
本文设计了一种模式发现算法,它可以应用于任何半结构化的网页,而无需训练实例。这个大大降低了提取器的构建成本。
【作者】
张家辉
台湾国立中央大学计算机科学与信息工程系
电话:+ 886-3-422-7151分机35302
传真:+ 886-3-422-2681
徐春南
中国科学院信息科学研究所
吕少成
中华电信实验室
原文PDF文档和翻译已上传知识星球
新闻推荐实战(四):scrapy爬虫框架基础
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-05-29 21:10
本文属于新闻推荐实战-数据层-构建物料池之scrapy爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,希望读者可以快速掌握scrapy的基本使用方法,并能够举一反三。
Scrapy基础及新闻爬取实战python环境的安装
python 环境,使用miniconda搭建,安装miniconda的参考链接:。
在安装完miniconda之后,创建一个新闻推荐的虚拟环境,我这边将其命名为news_rec_py3,这个环境将会在整个新闻推荐项目中使用。
conda create -n news_rec_py3 python==3.8<br />
Scrapy的简介与安装
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,用于对网站内容进行爬取,并从其页面提取结构化数据。
Ubuntu下安装Scrapy,需要先安装依赖Linux依赖
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev<br />
在新闻推荐系统虚拟conda环境中安装scrapy
pip install scrapy<br />
scrapy项目结构
默认情况下,所有scrapy项目的项目结构都是相似的,在指定目录对应的命令行中输入如下命令,就会在当前目录创建一个scrapy项目
scrapy startproject myproject<br />
项目的目录结构如下:
myproject/<br /> scrapy.cfg<br /> <br /> myproject/ <br /> __init__.py<br /> items.py<br /> middlewares.py<br /> pipelines.py<br /> settings.py<br /> spiders/<br /> __init__.py<br />
spider
spider是定义一个特定站点(或一组站点)如何被抓取的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取项)。换言之,spider是为特定站点(或者在某些情况下,一组站点)定义爬行和解析页面的自定义行为的地方。
爬行器是自己定义的类,Scrapy使用它从一个网站(或一组网站)中抓取信息。它们必须继承 Spider 并定义要做出的初始请求,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
对于spider来说,抓取周期是这样的:
首先生成对第一个URL进行爬网的初始请求,然后指定一个回调函数,该函数使用从这些请求下载的响应进行调用。要执行的第一个请求是通过调用 start_requests() 方法,该方法(默认情况下)生成 Request 中指定的URL的 start_urls 以及 parse 方法作为请求的回调函数。在回调函数中,解析响应(网页)并返回 item objects , Request 对象,或这些对象的可迭代。这些请求还将包含一个回调(可能相同),然后由Scrapy下载,然后由指定的回调处理它们的响应。在回调函数中,解析页面内容,通常使用 选择器 (但您也可以使用beautifulsoup、lxml或任何您喜欢的机制)并使用解析的数据生成项。最后,从spider返回的项目通常被持久化到数据库(在某些 Item Pipeline )或者使用 Feed 导出 .
下面是官网给出的Demo:
import scrapy<br /><br />class QuotesSpider(scrapy.Spider):<br /> name = "quotes" # 表示一个spider 它在一个项目中必须是唯一的,即不能为不同的spider设置相同的名称。<br /> <br /> # 必须返回请求的可迭代(您可以返回请求列表或编写生成器函数),spider将从该请求开始爬行。后续请求将从这些初始请求中相继生成。<br /> def start_requests(self):<br /> urls = [<br /> 'http://quotes.toscrape.com/page/1/',<br /> 'http://quotes.toscrape.com/page/2/',<br /> ]<br /> for url in urls:<br /> yield scrapy.Request(url=url, callback=self.parse) # 注意,这里callback调用了下面定义的parse方法<br /> <br /> # 将被调用以处理为每个请求下载的响应的方法。Response参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。<br /> def parse(self, response):<br /> # 下面是直接从response中获取内容,为了更方便的爬取内容,后面会介绍使用selenium来模拟人用浏览器,并且使用对应的方法来提取我们想要爬取的内容<br /> page = response.url.split("/")[-2]<br /> filename = f'quotes-{page}.html'<br /> with open(filename, 'wb') as f:<br /> f.write(response.body)<br /> self.log(f'Saved file {filename}')<br />
Xpath
XPath 是一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历。在爬虫的时候使用xpath来选择我们想要爬取的内容是非常方便的,这里就提一下xpath中需要掌握的内容,参考资料中的内容更加的详细(建议花一个小时看看)。
要了解xpath, 需要先了解一下HTML(是用来描述网页的一种语言), 这个的细节就不详细展开
划重点:
**xpath路径表达式:**XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
了解如何使用xpath语法选取我们想要的内容,所以需要熟悉xpath的基本语法
scrapy爬取新闻内容实战
在介绍这个项目之前先说一下这个项目的基本逻辑。
环境准备:
首先Ubuntu系统里面需要安装好MongoDB数据库,这个可以参考开源项目MongoDB基础python环境中安装好了scrapy, pymongo包
项目逻辑:
每天定时从新浪新闻网站上爬取新闻数据存储到mongodb数据库中,并且需要监控每天爬取新闻的状态(比如某天爬取的数据特别少可能是哪里出了问题,需要进行排查)每天爬取新闻的时候只爬取当天日期的新闻,主要是为了防止相同的新闻重复爬取(当然这个也不能完全避免爬取重复的新闻,爬取新闻之后需要有一些单独的去重的逻辑)爬虫项目中实现三个核心文件,分别是sina.py(spider),items.py(抽取数据的规范化及字段的定义),pipelines.py(数据写入数据库)
因为新闻爬取项目和新闻推荐系统是放在一起的,为了方便提前学习,下面直接给出项目的目录结构以及重要文件中的代码实现,最终的项目将会和新闻推荐系统一起开源出来
创建一个scrapy项目:
scrapy startproject sinanews<br />
实现item.py逻辑
# Define here the models for your scraped items<br />#<br /># See documentation in:<br /># https://docs.scrapy.org/en/lat ... %3Bbr /><br />import scrapy<br />from scrapy import Item, Field<br /><br /># 定义新闻数据的字段<br />class SinanewsItem(scrapy.Item):<br /> """数据格式化,数据不同字段的定义<br /> """<br /> title = Field() # 新闻标题<br /> ctime = Field() # 新闻发布时间<br /> url = Field() # 新闻原始url<br /> raw_key_words = Field() # 新闻关键词(爬取的关键词)<br /> content = Field() # 新闻的具体内容<br /> cate = Field() # 新闻类别<br />
实现sina.py (spider)逻辑
这里需要注意的一点,这里在爬取新闻的时候选择的是一个比较简洁的展示网站进行爬取的,相比直接去最新的新浪新闻观光爬取新闻简单很多,简洁的网站大概的链接:#pageid=153&lid=2509&k=&num=50&page=1
# -*- coding: utf-8 -*-<br />import re<br />import json<br />import random<br />import scrapy<br />from scrapy import Request<br />from ..items import SinanewsItem<br />from datetime import datetime<br /><br /><br />class SinaSpider(scrapy.Spider):<br /> # spider的名字<br /> name = 'sina_spider'<br /><br /> def __init__(self, pages=None):<br /> super(SinaSpider).__init__()<br /><br /> self.total_pages = int(pages)<br /> # base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分<br /> self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'<br /> # lid和分类映射字典<br /> self.cate_dict = {<br /> "2510": "国内",<br /> "2511": "国际",<br /> "2669": "社会",<br /> "2512": "体育",<br /> "2513": "娱乐",<br /> "2514": "军事",<br /> "2515": "科技",<br /> "2516": "财经",<br /> "2517": "股市",<br /> "2518": "美股"<br /> }<br /><br /> def start_requests(self):<br /> """返回一个Request迭代器<br /> """<br /> # 遍历所有类型的论文<br /> for cate_id in self.cate_dict.keys():<br /> for page in range(1, self.total_pages + 1):<br /> lid = cate_id<br /> # 这里就是一个随机数,具体含义不是很清楚<br /> r = random.random()<br /> # cb_kwargs 是用来往解析函数parse中传递参数的<br /> yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})<br /> <br /> def parse(self, response, cate_id):<br /> """解析网页内容,并提取网页中需要的内容<br /> """<br /> json_result = json.loads(response.text) # 将请求回来的页面解析成json<br /> # 提取json中我们想要的字段<br /> # json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常<br /> data_list = json_result.get('result').get('data')<br /> for data in data_list:<br /> item = SinanewsItem()<br /><br /> item['cate'] = self.cate_dict[cate_id]<br /> item['title'] = data.get('title')<br /> item['url'] = data.get('url')<br /> item['raw_key_words'] = data.get('keywords')<br /><br /> # ctime = datetime.fromtimestamp(int(data.get('ctime')))<br /> # ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')<br /><br /> # 保留的是一个时间戳<br /> item['ctime'] = data.get('ctime')<br /><br /> # meta参数传入的是一个字典,在下一层可以将当前层的item进行复制<br /> yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})<br /> <br /> def parse_content(self, response):<br /> """解析文章内容<br /> """<br /> item = response.meta['item']<br /> content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())<br /> content = re.sub(r'\u3000', '', content)<br /> content = re.sub(r'[ \xa0?]+', ' ', content)<br /> content = re.sub(r'\s*\n\s*', '\n', content)<br /> content = re.sub(r'\s*(\s)', r'\1', content)<br /> content = ''.join([x.strip() for x in content])<br /> item['content'] = content<br /> yield item <br />
数据持久化实现,piplines.py
这里需要注意的就是实现SinanewsPipeline类的时候,里面很多方法都是固定的,不是随便写的,不同的方法又不同的功能,这个可以参考scrapy官方文档。 <p># Define your item pipelines here<br />#<br /># Don't forget to add your pipeline to the ITEM_PIPELINES setting<br /># See: https://docs.scrapy.org/en/lat ... %3Bbr /># useful for handling different item types with a single interface<br />import time<br />import datetime<br />import pymongo<br />from pymongo.errors import DuplicateKeyError<br />from sinanews.items import SinanewsItem<br />from itemadapter import ItemAdapter<br /><br /><br /># 新闻item持久化<br />class SinanewsPipeline:<br /> """数据持久化:将数据存放到mongodb中<br /> """<br /> def __init__(self, host, port, db_name, collection_name):<br /> self.host = host<br /> self.port = port<br /> self.db_name = db_name<br /> self.collection_name = collection_name<br /><br /> @classmethod <br /> def from_crawler(cls, crawler):<br /> """自带的方法,这个方法可以重新返回一个新的pipline对象,并且可以调用配置文件中的参数<br /> """<br /> return cls(<br /> host = crawler.settings.get("MONGO_HOST"),<br /> port = crawler.settings.get("MONGO_PORT"),<br /> db_name = crawler.settings.get("DB_NAME"),<br /> # mongodb中数据的集合按照日期存储<br /> collection_name = crawler.settings.get("COLLECTION_NAME") + \<br /> "_" + time.strftime("%Y%m%d", time.localtime())<br /> )<br /><br /> def open_spider(self, spider):<br /> """开始爬虫的操作,主要就是链接数据库及对应的集合<br /> """<br /> self.client = pymongo.MongoClient(self.host, self.port)<br /> self.db = self.client[self.db_name]<br /> self.collection = self.db[self.collection_name]<br /> <br /> def close_spider(self, spider):<br /> """关闭爬虫操作的时候,需要将数据库断开<br /> """<br /> self.client.close()<br /><br /> def process_item(self, item, spider):<br /> """处理每一条数据,注意这里需要将item返回<br /> 注意:判断新闻是否是今天的,每天只保存当天产出的新闻,这样可以增量的添加新的新闻数据源<br /> """<br /> if isinstance(item, SinanewsItem):<br /> try:<br /> # TODO 物料去重逻辑,根据title进行去重,先读取物料池中的所有物料的title然后进行去重<br /><br /> cur_time = int(item['ctime'])<br /> str_today = str(datetime.date.today())<br /> min_time = int(time.mktime(time.strptime(str_today + " 00:00:00", '%Y-%m-%d %H:%M:%S')))<br /> max_time = int(time.mktime(time.strptime(str_today + " 23:59:59", '%Y-%m-%d %H:%M:%S')))<br /> if cur_time > min_time and cur_time 查看全部
新闻推荐实战(四):scrapy爬虫框架基础
本文属于新闻推荐实战-数据层-构建物料池之scrapy爬虫框架基础。对于开源的推荐系统来说数据的不断获取是非常重要的,scrapy是一个非常易用且强大的爬虫框架,有固定的文件结构、类和方法,在实际使用过程中我们只需要按照要求实现相应的类方法,就可以完成我们的爬虫任务。文中给出了新闻推荐系统中新闻爬取的实战代码,希望读者可以快速掌握scrapy的基本使用方法,并能够举一反三。
Scrapy基础及新闻爬取实战python环境的安装
python 环境,使用miniconda搭建,安装miniconda的参考链接:。
在安装完miniconda之后,创建一个新闻推荐的虚拟环境,我这边将其命名为news_rec_py3,这个环境将会在整个新闻推荐项目中使用。
conda create -n news_rec_py3 python==3.8<br />
Scrapy的简介与安装
Scrapy 是一种快速的高级 web crawling 和 web scraping 框架,用于对网站内容进行爬取,并从其页面提取结构化数据。
Ubuntu下安装Scrapy,需要先安装依赖Linux依赖
sudo apt-get install python3 python3-dev python3-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev<br />
在新闻推荐系统虚拟conda环境中安装scrapy
pip install scrapy<br />
scrapy项目结构
默认情况下,所有scrapy项目的项目结构都是相似的,在指定目录对应的命令行中输入如下命令,就会在当前目录创建一个scrapy项目
scrapy startproject myproject<br />
项目的目录结构如下:
myproject/<br /> scrapy.cfg<br /> <br /> myproject/ <br /> __init__.py<br /> items.py<br /> middlewares.py<br /> pipelines.py<br /> settings.py<br /> spiders/<br /> __init__.py<br />
spider
spider是定义一个特定站点(或一组站点)如何被抓取的类,包括如何执行抓取(即跟踪链接)以及如何从页面中提取结构化数据(即抓取项)。换言之,spider是为特定站点(或者在某些情况下,一组站点)定义爬行和解析页面的自定义行为的地方。
爬行器是自己定义的类,Scrapy使用它从一个网站(或一组网站)中抓取信息。它们必须继承 Spider 并定义要做出的初始请求,可选的是如何跟随页面中的链接,以及如何解析下载的页面内容以提取数据。
对于spider来说,抓取周期是这样的:
首先生成对第一个URL进行爬网的初始请求,然后指定一个回调函数,该函数使用从这些请求下载的响应进行调用。要执行的第一个请求是通过调用 start_requests() 方法,该方法(默认情况下)生成 Request 中指定的URL的 start_urls 以及 parse 方法作为请求的回调函数。在回调函数中,解析响应(网页)并返回 item objects , Request 对象,或这些对象的可迭代。这些请求还将包含一个回调(可能相同),然后由Scrapy下载,然后由指定的回调处理它们的响应。在回调函数中,解析页面内容,通常使用 选择器 (但您也可以使用beautifulsoup、lxml或任何您喜欢的机制)并使用解析的数据生成项。最后,从spider返回的项目通常被持久化到数据库(在某些 Item Pipeline )或者使用 Feed 导出 .
下面是官网给出的Demo:
import scrapy<br /><br />class QuotesSpider(scrapy.Spider):<br /> name = "quotes" # 表示一个spider 它在一个项目中必须是唯一的,即不能为不同的spider设置相同的名称。<br /> <br /> # 必须返回请求的可迭代(您可以返回请求列表或编写生成器函数),spider将从该请求开始爬行。后续请求将从这些初始请求中相继生成。<br /> def start_requests(self):<br /> urls = [<br /> 'http://quotes.toscrape.com/page/1/',<br /> 'http://quotes.toscrape.com/page/2/',<br /> ]<br /> for url in urls:<br /> yield scrapy.Request(url=url, callback=self.parse) # 注意,这里callback调用了下面定义的parse方法<br /> <br /> # 将被调用以处理为每个请求下载的响应的方法。Response参数是 TextResponse 它保存页面内容,并具有进一步有用的方法来处理它。<br /> def parse(self, response):<br /> # 下面是直接从response中获取内容,为了更方便的爬取内容,后面会介绍使用selenium来模拟人用浏览器,并且使用对应的方法来提取我们想要爬取的内容<br /> page = response.url.split("/")[-2]<br /> filename = f'quotes-{page}.html'<br /> with open(filename, 'wb') as f:<br /> f.write(response.body)<br /> self.log(f'Saved file {filename}')<br />
Xpath
XPath 是一门在 XML 文档中查找信息的语言,XPath 可用来在 XML 文档中对元素和属性进行遍历。在爬虫的时候使用xpath来选择我们想要爬取的内容是非常方便的,这里就提一下xpath中需要掌握的内容,参考资料中的内容更加的详细(建议花一个小时看看)。
要了解xpath, 需要先了解一下HTML(是用来描述网页的一种语言), 这个的细节就不详细展开
划重点:
**xpath路径表达式:**XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
了解如何使用xpath语法选取我们想要的内容,所以需要熟悉xpath的基本语法
scrapy爬取新闻内容实战
在介绍这个项目之前先说一下这个项目的基本逻辑。
环境准备:
首先Ubuntu系统里面需要安装好MongoDB数据库,这个可以参考开源项目MongoDB基础python环境中安装好了scrapy, pymongo包
项目逻辑:
每天定时从新浪新闻网站上爬取新闻数据存储到mongodb数据库中,并且需要监控每天爬取新闻的状态(比如某天爬取的数据特别少可能是哪里出了问题,需要进行排查)每天爬取新闻的时候只爬取当天日期的新闻,主要是为了防止相同的新闻重复爬取(当然这个也不能完全避免爬取重复的新闻,爬取新闻之后需要有一些单独的去重的逻辑)爬虫项目中实现三个核心文件,分别是sina.py(spider),items.py(抽取数据的规范化及字段的定义),pipelines.py(数据写入数据库)
因为新闻爬取项目和新闻推荐系统是放在一起的,为了方便提前学习,下面直接给出项目的目录结构以及重要文件中的代码实现,最终的项目将会和新闻推荐系统一起开源出来
创建一个scrapy项目:
scrapy startproject sinanews<br />
实现item.py逻辑
# Define here the models for your scraped items<br />#<br /># See documentation in:<br /># https://docs.scrapy.org/en/lat ... %3Bbr /><br />import scrapy<br />from scrapy import Item, Field<br /><br /># 定义新闻数据的字段<br />class SinanewsItem(scrapy.Item):<br /> """数据格式化,数据不同字段的定义<br /> """<br /> title = Field() # 新闻标题<br /> ctime = Field() # 新闻发布时间<br /> url = Field() # 新闻原始url<br /> raw_key_words = Field() # 新闻关键词(爬取的关键词)<br /> content = Field() # 新闻的具体内容<br /> cate = Field() # 新闻类别<br />
实现sina.py (spider)逻辑
这里需要注意的一点,这里在爬取新闻的时候选择的是一个比较简洁的展示网站进行爬取的,相比直接去最新的新浪新闻观光爬取新闻简单很多,简洁的网站大概的链接:#pageid=153&lid=2509&k=&num=50&page=1
# -*- coding: utf-8 -*-<br />import re<br />import json<br />import random<br />import scrapy<br />from scrapy import Request<br />from ..items import SinanewsItem<br />from datetime import datetime<br /><br /><br />class SinaSpider(scrapy.Spider):<br /> # spider的名字<br /> name = 'sina_spider'<br /><br /> def __init__(self, pages=None):<br /> super(SinaSpider).__init__()<br /><br /> self.total_pages = int(pages)<br /> # base_url 对应的是新浪新闻的简洁版页面,方便爬虫,并且不同类别的新闻也很好区分<br /> self.base_url = 'https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid={}&k=&num=50&page={}&r={}'<br /> # lid和分类映射字典<br /> self.cate_dict = {<br /> "2510": "国内",<br /> "2511": "国际",<br /> "2669": "社会",<br /> "2512": "体育",<br /> "2513": "娱乐",<br /> "2514": "军事",<br /> "2515": "科技",<br /> "2516": "财经",<br /> "2517": "股市",<br /> "2518": "美股"<br /> }<br /><br /> def start_requests(self):<br /> """返回一个Request迭代器<br /> """<br /> # 遍历所有类型的论文<br /> for cate_id in self.cate_dict.keys():<br /> for page in range(1, self.total_pages + 1):<br /> lid = cate_id<br /> # 这里就是一个随机数,具体含义不是很清楚<br /> r = random.random()<br /> # cb_kwargs 是用来往解析函数parse中传递参数的<br /> yield Request(self.base_url.format(lid, page, r), callback=self.parse, cb_kwargs={"cate_id": lid})<br /> <br /> def parse(self, response, cate_id):<br /> """解析网页内容,并提取网页中需要的内容<br /> """<br /> json_result = json.loads(response.text) # 将请求回来的页面解析成json<br /> # 提取json中我们想要的字段<br /> # json使用get方法比直接通过字典的形式获取数据更方便,因为不需要处理异常<br /> data_list = json_result.get('result').get('data')<br /> for data in data_list:<br /> item = SinanewsItem()<br /><br /> item['cate'] = self.cate_dict[cate_id]<br /> item['title'] = data.get('title')<br /> item['url'] = data.get('url')<br /> item['raw_key_words'] = data.get('keywords')<br /><br /> # ctime = datetime.fromtimestamp(int(data.get('ctime')))<br /> # ctime = datetime.strftime(ctime, '%Y-%m-%d %H:%M')<br /><br /> # 保留的是一个时间戳<br /> item['ctime'] = data.get('ctime')<br /><br /> # meta参数传入的是一个字典,在下一层可以将当前层的item进行复制<br /> yield Request(url=item['url'], callback=self.parse_content, meta={'item': item})<br /> <br /> def parse_content(self, response):<br /> """解析文章内容<br /> """<br /> item = response.meta['item']<br /> content = ''.join(response.xpath('//*[@id="artibody" or @id="article"]//p/text()').extract())<br /> content = re.sub(r'\u3000', '', content)<br /> content = re.sub(r'[ \xa0?]+', ' ', content)<br /> content = re.sub(r'\s*\n\s*', '\n', content)<br /> content = re.sub(r'\s*(\s)', r'\1', content)<br /> content = ''.join([x.strip() for x in content])<br /> item['content'] = content<br /> yield item <br />
数据持久化实现,piplines.py
这里需要注意的就是实现SinanewsPipeline类的时候,里面很多方法都是固定的,不是随便写的,不同的方法又不同的功能,这个可以参考scrapy官方文档。 <p># Define your item pipelines here<br />#<br /># Don't forget to add your pipeline to the ITEM_PIPELINES setting<br /># See: https://docs.scrapy.org/en/lat ... %3Bbr /># useful for handling different item types with a single interface<br />import time<br />import datetime<br />import pymongo<br />from pymongo.errors import DuplicateKeyError<br />from sinanews.items import SinanewsItem<br />from itemadapter import ItemAdapter<br /><br /><br /># 新闻item持久化<br />class SinanewsPipeline:<br /> """数据持久化:将数据存放到mongodb中<br /> """<br /> def __init__(self, host, port, db_name, collection_name):<br /> self.host = host<br /> self.port = port<br /> self.db_name = db_name<br /> self.collection_name = collection_name<br /><br /> @classmethod <br /> def from_crawler(cls, crawler):<br /> """自带的方法,这个方法可以重新返回一个新的pipline对象,并且可以调用配置文件中的参数<br /> """<br /> return cls(<br /> host = crawler.settings.get("MONGO_HOST"),<br /> port = crawler.settings.get("MONGO_PORT"),<br /> db_name = crawler.settings.get("DB_NAME"),<br /> # mongodb中数据的集合按照日期存储<br /> collection_name = crawler.settings.get("COLLECTION_NAME") + \<br /> "_" + time.strftime("%Y%m%d", time.localtime())<br /> )<br /><br /> def open_spider(self, spider):<br /> """开始爬虫的操作,主要就是链接数据库及对应的集合<br /> """<br /> self.client = pymongo.MongoClient(self.host, self.port)<br /> self.db = self.client[self.db_name]<br /> self.collection = self.db[self.collection_name]<br /> <br /> def close_spider(self, spider):<br /> """关闭爬虫操作的时候,需要将数据库断开<br /> """<br /> self.client.close()<br /><br /> def process_item(self, item, spider):<br /> """处理每一条数据,注意这里需要将item返回<br /> 注意:判断新闻是否是今天的,每天只保存当天产出的新闻,这样可以增量的添加新的新闻数据源<br /> """<br /> if isinstance(item, SinanewsItem):<br /> try:<br /> # TODO 物料去重逻辑,根据title进行去重,先读取物料池中的所有物料的title然后进行去重<br /><br /> cur_time = int(item['ctime'])<br /> str_today = str(datetime.date.today())<br /> min_time = int(time.mktime(time.strptime(str_today + " 00:00:00", '%Y-%m-%d %H:%M:%S')))<br /> max_time = int(time.mktime(time.strptime(str_today + " 23:59:59", '%Y-%m-%d %H:%M:%S')))<br /> if cur_time > min_time and cur_time
GneList 来了!抓取列表页-极-其-简-单!
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-05-13 05:35
摄影:产品经理
好戏开场
Gne[1]发布以后,大家自动化抓取新闻正文页的需求被解决了。但随之而来的,不断有同学希望能出一个抓取列表页的工具,于是,就有了今天的 GneList。
GneList 是什么
GneList是一个浏览器插件,专门用来生成列表页的 XPath。使用这个 XPath,你可以快速获取到列表页中的每一个条目。
GneList 怎么用?
GneList 的使用非常简单,几乎不需要说明。
打开带有列表的页面点击插件输入名字,点击开始抓取鼠标点击列表的前两项,GneList 会自动选中所有项点击提交按钮去数据库查看 XPath怎么安装 GneList?
GneList 由两个部分组成:插件端与后端。
插件端的下载地址:
后端的代码: ,并且后端依赖 MongoDB。
安装后端
首先确保你有一个可以连接的 MongoDB,我们假设它的 URI 是:mongodb://localhost。从 Github上面 clone 后端的代码:。
进入后端代码的根目录中的 config 文件夹中,你会发现一个local.yml文件。打开它,第一行填写 MongoDB 的 URI 地址,第二行是数据库名,第三行是集合名。插件生成的 XPath 会保存在这里供你的下游调用。
改好配置文件以后,回到后端的根目录,分别执行如下命令(你需要先安装 Pipenv):
pipenv install<br />pipenv shell<br />export local # 你自己创建的 yml文件的名字<br />uvicorn main:app --port 8800 --host 0.0.0.0 # 使用8800端口<br />
命令执行完成后,如果你使用浏览器访问:8800,应该会看到下图的内容,说明后端搭建成功。
安装插件
GneList 插件支持所有基于 Chromium 内核的浏览器,包括但不限于 Chrome/Chromium/Edge。
从上面的地址下载GneList.zip后,把它解压到任何一个文件夹中,如下图所示:
然后打开你的浏览器的插件管理页面,启动开发人员模式,例如下图是我在 Edge 中开启开发人员模式的方法。
然后点击右上角的加载解压缩的扩展,选中GneList文件夹。完成。
现在,刷新已有的列表页,或者重新开一个新的列表页,然后点击插件,试用一下吧。
管理配置页面
在插件上右键,选择扩展选项。Chrome 上面,名字可能是叫做选项或者英文Options。可以打开如下图所示的页面:
如果你没有启动后端,或者后端地址不是:8800(例如你把后端部署在服务器上,需要使用 IP 或者域名来访问,或者端口不是8800),那么这个页面应该如上图所示。
你可以把输入框中的地址改为后端地址/rule,例如:8888/rule。然后点击提交按钮。接下来刷新页面,你就可以看到如下图所示的内容:
这个页面显示了你已经添加的所有网站的XPath,你可以对他们进行修改或者删除。
Q&A
为什么插件生成的 XPath 这么奇怪?
因为这些 XPath 是从 CssSelector 转成的 XPath,我用了一个第三方的 JavaScript 包。那个包转出来的就是这么奇怪。但不影响它的功能。我后面会更换更好的包,让 XPath 变得更好看。
我的爬虫怎么使用这些 XPath?
还记得一开始配置的 MongoDB 吗?让你的爬虫去里面读取就可以了。
为什么我启动插件以后,点网页上面的元素第一次没有反应?
第一次点击的时候,如果发现没有生成红框框,就多点一下。看到红框框了再点第二个元素。
GneList 的原理是什么?
接下来的几篇文章,我会介绍 GneList 的原理。如果你等不及的话,也可以到 Github上查看源代码[2]。GneList 与 Gne 一样,他们是站在其他优秀开源项目的肩膀上做出来的,尤其是受到web-scraper-chrome-extension[3]的启发。因此,GneList也是完全开源的,允许非商业使用。
参考文献
[1]Gne:
[2]源代码:
[3]web-scraper-chrome-extension:
END
未闻 Code·知识星球开放啦!
一对一答疑爬虫相关问题
职业生涯咨询 查看全部
GneList 来了!抓取列表页-极-其-简-单!
摄影:产品经理
好戏开场
Gne[1]发布以后,大家自动化抓取新闻正文页的需求被解决了。但随之而来的,不断有同学希望能出一个抓取列表页的工具,于是,就有了今天的 GneList。
GneList 是什么
GneList是一个浏览器插件,专门用来生成列表页的 XPath。使用这个 XPath,你可以快速获取到列表页中的每一个条目。
GneList 怎么用?
GneList 的使用非常简单,几乎不需要说明。
打开带有列表的页面点击插件输入名字,点击开始抓取鼠标点击列表的前两项,GneList 会自动选中所有项点击提交按钮去数据库查看 XPath怎么安装 GneList?
GneList 由两个部分组成:插件端与后端。
插件端的下载地址:
后端的代码: ,并且后端依赖 MongoDB。
安装后端
首先确保你有一个可以连接的 MongoDB,我们假设它的 URI 是:mongodb://localhost。从 Github上面 clone 后端的代码:。
进入后端代码的根目录中的 config 文件夹中,你会发现一个local.yml文件。打开它,第一行填写 MongoDB 的 URI 地址,第二行是数据库名,第三行是集合名。插件生成的 XPath 会保存在这里供你的下游调用。
改好配置文件以后,回到后端的根目录,分别执行如下命令(你需要先安装 Pipenv):
pipenv install<br />pipenv shell<br />export local # 你自己创建的 yml文件的名字<br />uvicorn main:app --port 8800 --host 0.0.0.0 # 使用8800端口<br />
命令执行完成后,如果你使用浏览器访问:8800,应该会看到下图的内容,说明后端搭建成功。
安装插件
GneList 插件支持所有基于 Chromium 内核的浏览器,包括但不限于 Chrome/Chromium/Edge。
从上面的地址下载GneList.zip后,把它解压到任何一个文件夹中,如下图所示:
然后打开你的浏览器的插件管理页面,启动开发人员模式,例如下图是我在 Edge 中开启开发人员模式的方法。
然后点击右上角的加载解压缩的扩展,选中GneList文件夹。完成。
现在,刷新已有的列表页,或者重新开一个新的列表页,然后点击插件,试用一下吧。
管理配置页面
在插件上右键,选择扩展选项。Chrome 上面,名字可能是叫做选项或者英文Options。可以打开如下图所示的页面:
如果你没有启动后端,或者后端地址不是:8800(例如你把后端部署在服务器上,需要使用 IP 或者域名来访问,或者端口不是8800),那么这个页面应该如上图所示。
你可以把输入框中的地址改为后端地址/rule,例如:8888/rule。然后点击提交按钮。接下来刷新页面,你就可以看到如下图所示的内容:
这个页面显示了你已经添加的所有网站的XPath,你可以对他们进行修改或者删除。
Q&A
为什么插件生成的 XPath 这么奇怪?
因为这些 XPath 是从 CssSelector 转成的 XPath,我用了一个第三方的 JavaScript 包。那个包转出来的就是这么奇怪。但不影响它的功能。我后面会更换更好的包,让 XPath 变得更好看。
我的爬虫怎么使用这些 XPath?
还记得一开始配置的 MongoDB 吗?让你的爬虫去里面读取就可以了。
为什么我启动插件以后,点网页上面的元素第一次没有反应?
第一次点击的时候,如果发现没有生成红框框,就多点一下。看到红框框了再点第二个元素。
GneList 的原理是什么?
接下来的几篇文章,我会介绍 GneList 的原理。如果你等不及的话,也可以到 Github上查看源代码[2]。GneList 与 Gne 一样,他们是站在其他优秀开源项目的肩膀上做出来的,尤其是受到web-scraper-chrome-extension[3]的启发。因此,GneList也是完全开源的,允许非商业使用。
参考文献
[1]Gne:
[2]源代码:
[3]web-scraper-chrome-extension:
END
未闻 Code·知识星球开放啦!
一对一答疑爬虫相关问题
职业生涯咨询
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-04-18 07:10
等标注Html新闻网页,可实现新闻列表标题内容、链接地址、发布时间的精准抓取,对抓取结果进行分类,保存在本地txt。为实现上述目的,本发明采用如下技术方案:(1)创建存储对象:在本地服务器建立一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置Encoding格式,避免文档存储过程中出现乱码,实现文档的可写性;(2)解析对象:使用Jsoup解析器解析新闻列表页URL的Html,以及创建一个 Document 对象,获取解析后的文本 Content;进一步分析 Document 对象,提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。
以某企业<以@k17@的通知公告>为例,如图2所示,一种基于Jsoup的网页新闻列表抓取保存方法,包括以下步骤: 步骤1:创建空新闻。 txt文档本地或服务器上,用Java为txt文档构造一个FileWriter对象,并将其编码格式设置为“UTF-8”,避免乱码;第二步:输入通知公告的新闻列表页的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器的方法提取Document对象,返回Elements集合,或者使用getElementsByClass/Tag的方法提取指定的样式和标签内容,同样返回Elements对象es;选择方法是 Elementses=dom.select("table"); getElementsByClass/Tag 方法是指 Elementses=dom.getElementsByTag("table"); 第四步:定义几个字符串title、linkHref、datetime,获取Element对象中的title、链接地址和发布时间;Step 5:根据es tr, td 中是否有多个字符串来判断。
如果存在,使用for循环通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并传递StringlinkHref=es。 get(i).getElementsByTag("a").attr("abs:href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:如Step(4),如果没有的话,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=获取链接es.getElementsByTag("a").attr("href"); 第七步:将得到的title、linkHref、datetime按照一定的顺序和格式封装起来,封装的结果通过fwrite的方式不断写入txt .write(); 第八步:程序运行后,使用flush清除缓存并关闭文件,实现本页新闻列表的抓取和保存过程。当前页面 1 2 3 当前页面 1 1 2 3 查看全部
网页新闻抓取(Java程序中本发明文档构造一个FileWriter文件对象的说明图)
等标注Html新闻网页,可实现新闻列表标题内容、链接地址、发布时间的精准抓取,对抓取结果进行分类,保存在本地txt。为实现上述目的,本发明采用如下技术方案:(1)创建存储对象:在本地服务器建立一个txt空文档,在Java程序中为该txt文档构造一个FileWriter文件对象,并设置Encoding格式,避免文档存储过程中出现乱码,实现文档的可写性;(2)解析对象:使用Jsoup解析器解析新闻列表页URL的Html,以及创建一个 Document 对象,获取解析后的文本 Content;进一步分析 Document 对象,提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。提取目标内容:继续使用Elements对象的select方法或getElementsByClass/Tag方法,对对象中各个元素节点的数据进行细化识别,区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。区分标题内容、链接地址和发布时间;在Elements对象中定义几个字符串分别获取标题内容、链接地址和发布时间,实现新闻列表信息的提取。(4)使用流文件写入的方法,将标题内容、链接地址和发布时间按一定顺序保存到txt,并使用for循环导出所有列表信息,实现对整个新闻的A爬取列表页面。
以某企业<以@k17@的通知公告>为例,如图2所示,一种基于Jsoup的网页新闻列表抓取保存方法,包括以下步骤: 步骤1:创建空新闻。 txt文档本地或服务器上,用Java为txt文档构造一个FileWriter对象,并将其编码格式设置为“UTF-8”,避免乱码;第二步:输入通知公告的新闻列表页的url,使用Jsoup.connect("url")。get()方法解析页面的Html,得到一个Document对象dom,其中Documentdom=Jsoup.connect("url").get(); 第三步:使用select选择器的方法提取Document对象,返回Elements集合,或者使用getElementsByClass/Tag的方法提取指定的样式和标签内容,同样返回Elements对象es;选择方法是 Elementses=dom.select("table"); getElementsByClass/Tag 方法是指 Elementses=dom.getElementsByTag("table"); 第四步:定义几个字符串title、linkHref、datetime,获取Element对象中的title、链接地址和发布时间;Step 5:根据es tr, td 中是否有多个字符串来判断。
如果存在,使用for循环通过Stringtitle/datetime=es.get(i).select("td").get(j).text()获取标题内容或发布时间,并传递StringlinkHref=es。 get(i).getElementsByTag("a").attr("abs:href") 获取链接地址;其中i代表行数tr,j代表列数td;第六步:如Step(4),如果没有的话,直接根据Stringtitle/datetime=es.getElementsByTag("").text()获取标题或时间,通过StringlinkHref=获取链接es.getElementsByTag("a").attr("href"); 第七步:将得到的title、linkHref、datetime按照一定的顺序和格式封装起来,封装的结果通过fwrite的方式不断写入txt .write(); 第八步:程序运行后,使用flush清除缓存并关闭文件,实现本页新闻列表的抓取和保存过程。当前页面 1 2 3 当前页面 1 1 2 3
网页新闻抓取(前段时间爬过某家公司的信息怎么样?本地测试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-04-18 05:21
因为前段时间爬过某家公司的资料,也因为有网友比较感兴趣,特写一封小信表示诚意:
npm i node-fetch
npm i cheerio
然后我们在根目录下创建一个文件 server.js:
const fetch = require('node-fetch')
const cheerio = require('cheerio')
const getPagesArray = (numberOfPosts) =>
Array(Math.ceil(numberOfPosts / 30)) //divides by 30 (posts per page)
.fill() //creates a new array
.map((_, index) => index + 1) //[1, 2, 3, 4,..] PagesArray
const getPageHTML = (pageNumber) =>
fetch(`https://news.ycombinator.com/news?p=${pageNumber}`)
.then(resp => resp.text()) //Promise
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => console.log(htmls.join(''))) //one JOINED html
}
getAllHTML(5) // get all HTML for 5 posts
代码写好后,我们可以在本地测试node server.js,会发现我们有五个html文件:
接下来我们需要做的是获取我们想要的有价值的数据,例如作者、时间、文章 连接等:
const getPosts = (html, posts) => {
let results = []
let $ = cheerio.load(html)
$('span.comhead').each(function() {
let a = $(this).prev()
let title = a.text()
let uri = a.attr('href')
let rank = a.parent().parent().text()
let subtext = a.parent().parent().next().children('.subtext').children()
let author = $(subtext).eq(1).text()
let points = $(subtext).eq(0).text()
let comments = $(subtext).eq(5).text()
let obj = {
title: title,
uri: uri,
author: author,
points: points,
comments: comments,
rank: parseInt(rank)
}
if (obj.rank 0) {
console.log(results)
return results
}
}
我们现在修改 getAllHTML 函数以调用 getPosts 方法:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => getPosts(htmls.join(''), numberOfPosts))
}
getAllHTML(5)
节点服务器,我们可以通过本地测试获取相关信息,但显然我们希望这是一个爬虫工具,而不是本地测试脚本。让我们开始包装这个脚本。
首先安装指挥官,npm i 指挥官。然后添加以下代码:
#!/usr/bin/env node
const program = require('commander')
program
.option('-p, --posts [value]', 'Number of posts', 30)
.action(args =>
getAllHTML(args.posts)
.then(html => getPosts(html, args.posts))
)
program.parse(process.argv)
修改getAllHTML:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => htmls.join(''))
}
本地测试请求数:node server -p 10
最后我们将命令行添加到工具中:
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"commander": "^2.18.0",
"node-fetch": "^2.2.0"
},
"bin": {
"hackernews": "./server.js"
}
}
通过npm publish上传并安装到本机后,我们可以直接在本地运行hackernew -p [number]。 查看全部
网页新闻抓取(前段时间爬过某家公司的信息怎么样?本地测试)
因为前段时间爬过某家公司的资料,也因为有网友比较感兴趣,特写一封小信表示诚意:
npm i node-fetch
npm i cheerio
然后我们在根目录下创建一个文件 server.js:
const fetch = require('node-fetch')
const cheerio = require('cheerio')
const getPagesArray = (numberOfPosts) =>
Array(Math.ceil(numberOfPosts / 30)) //divides by 30 (posts per page)
.fill() //creates a new array
.map((_, index) => index + 1) //[1, 2, 3, 4,..] PagesArray
const getPageHTML = (pageNumber) =>
fetch(`https://news.ycombinator.com/news?p=${pageNumber}`)
.then(resp => resp.text()) //Promise
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => console.log(htmls.join(''))) //one JOINED html
}
getAllHTML(5) // get all HTML for 5 posts
代码写好后,我们可以在本地测试node server.js,会发现我们有五个html文件:
接下来我们需要做的是获取我们想要的有价值的数据,例如作者、时间、文章 连接等:
const getPosts = (html, posts) => {
let results = []
let $ = cheerio.load(html)
$('span.comhead').each(function() {
let a = $(this).prev()
let title = a.text()
let uri = a.attr('href')
let rank = a.parent().parent().text()
let subtext = a.parent().parent().next().children('.subtext').children()
let author = $(subtext).eq(1).text()
let points = $(subtext).eq(0).text()
let comments = $(subtext).eq(5).text()
let obj = {
title: title,
uri: uri,
author: author,
points: points,
comments: comments,
rank: parseInt(rank)
}
if (obj.rank 0) {
console.log(results)
return results
}
}
我们现在修改 getAllHTML 函数以调用 getPosts 方法:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => getPosts(htmls.join(''), numberOfPosts))
}
getAllHTML(5)
节点服务器,我们可以通过本地测试获取相关信息,但显然我们希望这是一个爬虫工具,而不是本地测试脚本。让我们开始包装这个脚本。
首先安装指挥官,npm i 指挥官。然后添加以下代码:
#!/usr/bin/env node
const program = require('commander')
program
.option('-p, --posts [value]', 'Number of posts', 30)
.action(args =>
getAllHTML(args.posts)
.then(html => getPosts(html, args.posts))
)
program.parse(process.argv)
修改getAllHTML:
const getAllHTML = async (numberOfPosts) => {
return Promise.all(getPagesArray(numberOfPosts).map(getPageHTML))
.then(htmls => htmls.join(''))
}
本地测试请求数:node server -p 10
最后我们将命令行添加到工具中:
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"commander": "^2.18.0",
"node-fetch": "^2.2.0"
},
"bin": {
"hackernews": "./server.js"
}
}
通过npm publish上传并安装到本机后,我们可以直接在本地运行hackernew -p [number]。
网页新闻抓取(如何通过Python爬虫按关键词抓取相关的新闻(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-17 18:00
)
输入 网站
现在各大网站的反爬机制可以说是疯了,比如大众点评的字符加密、微博的登录验证等等。相比之下,新闻网站的反爬机制@> 稍微弱一些。那么今天就以新浪新闻为例,分析一下如何通过Python爬虫按关键词抓取相关新闻。首先,如果你直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们必须从新浪首页搜索,这样就没有页数限制。
网页结构分析
<b>1span>b>2a>3a>4a>5a>6a>7a>8a>9a>10a>下一页a>div>
进入新浪网,进行关键词搜索后,发现无论怎么翻页,URL都不会改变,但页面内容却更新了。我的经验告诉我这是通过ajax完成的,所以我把新浪的页面代码拿下来看了看。看。显然,每次翻页都是通过点击a标签向一个地址发送请求,如果你把这个地址直接放到浏览器的地址栏,然后回车:
那么恭喜,收到错误,仔细查看html的onclick,发现调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它是在每次ajax请求之前构造的请求的url使用,使用get请求,返回数据格式为jsonp(跨域)。所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;function getNewsData(url){var oldurl = url;if(!key){<br /> $("#result").html("无搜索热词");return false;<br /> }if(!url){<br /> url = 'https://interface.sina.cn/home ... onent(key);<br /> }var stime = getStartDay();var etime = getEndDay();<br /> url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';<br /> $.ajax({type: 'GET',dataType: 'jsonp',cache : false,url:url,success: //回调函数太长了就不写了<br /> })
发送请求
import requests<br />headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",<br />}<br />params = {"t":"","q":"旅游","pf":"0","ps":"0","page":"1","stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br />}<br />response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br />print(response)
这次使用requests库,构造相同的url,发送请求。收到的结果是一个冷的 403Forbidden:
所以回到 网站 看看出了什么问题
从开发工具中找到返回的json文件,查看请求头,发现它的请求头有一个cookie,所以在构造头的时候,我们直接复制它的请求头即可。再次运行,response200!剩下的很简单,只需解析返回的数据,写入Excel即可。
完整代码
import requestsimport jsonimport xlwtdef getData(page, news):<br /> headers = {"Host": "interface.sina.cn","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0","Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Accept-Encoding": "gzip, deflate, br","Connection": "keep-alive","Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default","TE": "Trailers"<br /> }<br /> params = {"t":"","q":"旅游","pf":"0","ps":"0","page":page,"stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br /> }<br /> response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br /> dic = json.loads(response.text)<br /> news += dic["result"]["list"]return newsdef writeData(news):<br /> workbook = xlwt.Workbook(encoding = 'utf-8')<br /> worksheet = workbook.add_sheet('MySheet')<br /> worksheet.write(0, 0, "标题")<br /> worksheet.write(0, 1, "时间")<br /> worksheet.write(0, 2, "媒体")<br /> worksheet.write(0, 3, "网址")for i in range(len(news)):<br /> print(news[i])<br /> worksheet.write(i+1, 0, news[i]["origin_title"])<br /> worksheet.write(i+1, 1, news[i]["datetime"])<br /> worksheet.write(i+1, 2, news[i]["media"])<br /> worksheet.write(i+1, 3, news[i]["url"])<br /> workbook.save('data.xls')def main():<br /> news = []for i in range(1,501):<br /> news = getData(i, news)<br /> writeData(news)if __name__ == '__main__':<br /> main()
最后结果
查看全部
网页新闻抓取(如何通过Python爬虫按关键词抓取相关的新闻(图)
)
输入 网站
现在各大网站的反爬机制可以说是疯了,比如大众点评的字符加密、微博的登录验证等等。相比之下,新闻网站的反爬机制@> 稍微弱一些。那么今天就以新浪新闻为例,分析一下如何通过Python爬虫按关键词抓取相关新闻。首先,如果你直接从新闻中搜索,你会发现它的内容最多显示20页,所以我们必须从新浪首页搜索,这样就没有页数限制。
网页结构分析
<b>1span>b>2a>3a>4a>5a>6a>7a>8a>9a>10a>下一页a>div>
进入新浪网,进行关键词搜索后,发现无论怎么翻页,URL都不会改变,但页面内容却更新了。我的经验告诉我这是通过ajax完成的,所以我把新浪的页面代码拿下来看了看。看。显然,每次翻页都是通过点击a标签向一个地址发送请求,如果你把这个地址直接放到浏览器的地址栏,然后回车:
那么恭喜,收到错误,仔细查看html的onclick,发现调用了一个叫getNewsData的函数,于是在相关的js文件中查找这个函数,可以看到它是在每次ajax请求之前构造的请求的url使用,使用get请求,返回数据格式为jsonp(跨域)。所以我们只需要模仿它的请求格式来获取数据。
var loopnum = 0;function getNewsData(url){var oldurl = url;if(!key){<br /> $("#result").html("无搜索热词");return false;<br /> }if(!url){<br /> url = 'https://interface.sina.cn/home ... onent(key);<br /> }var stime = getStartDay();var etime = getEndDay();<br /> url +='&stime='+stime+'&etime='+etime+'&sort=rel&highlight=1&num=10&ie=utf-8'; //'&from=sina_index_hot_words&sort=time&highlight=1&num=10&ie=utf-8';<br /> $.ajax({type: 'GET',dataType: 'jsonp',cache : false,url:url,success: //回调函数太长了就不写了<br /> })
发送请求
import requests<br />headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0",<br />}<br />params = {"t":"","q":"旅游","pf":"0","ps":"0","page":"1","stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br />}<br />response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br />print(response)
这次使用requests库,构造相同的url,发送请求。收到的结果是一个冷的 403Forbidden:
所以回到 网站 看看出了什么问题
从开发工具中找到返回的json文件,查看请求头,发现它的请求头有一个cookie,所以在构造头的时候,我们直接复制它的请求头即可。再次运行,response200!剩下的很简单,只需解析返回的数据,写入Excel即可。
完整代码
import requestsimport jsonimport xlwtdef getData(page, news):<br /> headers = {"Host": "interface.sina.cn","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:74.0) Gecko/20100101 Firefox/74.0","Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2","Accept-Encoding": "gzip, deflate, br","Connection": "keep-alive","Referer": r"http://www.sina.com.cn/mid/sea ... ot%3B,"Cookie": "ustat=__172.16.93.31_1580710312_0.68442000; genTime=1580710312; vt=99; Apache=9855012519393.69.1585552043971; SINAGLOBAL=9855012519393.69.1585552043971; ULV=1585552043972:1:1:1:9855012519393.69.1585552043971:; historyRecord={'href':'https://news.sina.cn/','refer':'https://sina.cn/'}; SMART=0; dfz_loc=gd-default","TE": "Trailers"<br /> }<br /> params = {"t":"","q":"旅游","pf":"0","ps":"0","page":page,"stime":"2019-03-30","etime":"2020-03-31","sort":"rel","highlight":"1","num":"10","ie":"utf-8"<br /> }<br /> response = requests.get("https://interface.sina.cn/home ... ot%3B, params=params, headers=headers)<br /> dic = json.loads(response.text)<br /> news += dic["result"]["list"]return newsdef writeData(news):<br /> workbook = xlwt.Workbook(encoding = 'utf-8')<br /> worksheet = workbook.add_sheet('MySheet')<br /> worksheet.write(0, 0, "标题")<br /> worksheet.write(0, 1, "时间")<br /> worksheet.write(0, 2, "媒体")<br /> worksheet.write(0, 3, "网址")for i in range(len(news)):<br /> print(news[i])<br /> worksheet.write(i+1, 0, news[i]["origin_title"])<br /> worksheet.write(i+1, 1, news[i]["datetime"])<br /> worksheet.write(i+1, 2, news[i]["media"])<br /> worksheet.write(i+1, 3, news[i]["url"])<br /> workbook.save('data.xls')def main():<br /> news = []for i in range(1,501):<br /> news = getData(i, news)<br /> writeData(news)if __name__ == '__main__':<br /> main()
最后结果
网页新闻抓取(《教你用Python进阶量化交易》专栏(二):扩展篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-17 17:41
欢迎大家订阅《用Python教你进阶量化交易》专栏!为了给大家提供一个更轻松的学习过程,笔者在栏目内容之外还陆续引入了一些笔记,以帮助同学们学习本栏目内容。目前上线的扩展链接如下:
为了把栏目中零散的知识点贯穿始终,笔者在栏末“自制量化交易工具”小节中分享了之前制作的量化交易小工具的简化版。希望大家可以通过调试代码掌握相关信息。知识。
目前已经移植到站外文章第九部分的Python3.7x版本。接下来我们会在这个版本的基础上逐步完善这个工具,让专栏的读者不仅可以通过小工具掌握专栏的相关知识点,还可以在自己的量化交易中使用工具股票。
量化交易策略的研究主要涵盖微观和宏观两个方面。微观方面更多是以市场价格、交易头寸等基本信息为研究对象。技术指标是通过算法计算出来的,然后根据技术指标的变化来构建。交易模型。宏观方面是开发基于更多市场信息的交易模型,如以CPI、PPI、货币发行等宏观经济指标为研究对象构建交易模型;或使用数据挖掘技术挖掘可能导致市场异常的新闻事件。波动性事件获得交易机会。
在这篇笔记中,我们先梳理一下可以获取股票信息的网站,然后介绍如何在我们的GUI工具上展示抓取到的股票信息。
证券从业人员网站包括上海证券交易所、深圳证券交易所、中国证监会、证券业协会;
行业资讯网站有慧聪、阿里、万德;
知名股票论坛:点金投资之家、分享世界、MACD股市、东方财富网股吧、和讯股吧、创世论坛。
接下来,我们使用爬虫来爬取东方财富网股票论坛的帖子内容。
当我们点击第2页和第3页时,我们检查URL是:,002372_2.html, ,002372_3.html,所以论坛URL的模式是,002372_%d.html中表单,规则比较简单,%d是论坛的页码,但是这个表单是评论时间排列的URL。如果按发帖时间排列,则为002372,f_%d.html。
读取网页内容的关键代码如下:
html_cont=request.urlopen(page_url).read()
需要注意的是,在Python2中有urllib、urllib2和urlparse,但是在Python3中,这些都集成到了urllib中。Python2中urllib和urllib2的内容集成到urllib.request模块中,urlparse集成到urllib.parse模块中。在Python3中,urllib还收录了response、error、robotparse等各种子模块。
获取到的HTML代码内容如下:
得到 HTML 代码后,开始解析 HTML 代码。该帖由两部分组成,一部分为《财经评论》或《东方财富网》发布的公告或官方消息,另一部分为散户发布的讨论帖,如下:
前一篇文章的URL是,cjpl,902659513.html,后一篇文章的URL是,002372,902629178.html,这两个URL都可以在HTML文件的内容中找到,如下所示:
因此,《财经评论》、《东方财富网》或散户发布的帖子的主要特点是/news。我们使用正则表达式进行删除和选择,实现代码如下,
模式 = pile('/news\S+html',re.S)
news_comment_urls = re.findall(pattern, html_cont.decode('utf-8')) # 非空白字符N次
"""
['/news,cjpl,902659513.html', '/news,cjpl,902684967.html',
'/news,cjpl,902602349.html', '/news,cjpl,902529812.html',
'/news,cjpl,857016161.html', '/news,002372,902629178.html',
'/news,002372,902557935.html', '/news,002372,902533930.html',
'/news,002372,902519348.html', '/news,002372,902468635.html',
'/news,002372,902466626.html', '/news,002372,902464127.html',
……
'/news,002372,901168702.html', '/news,002372,901153848.html']
"""
正则表达式的 \S+ 表示匹配多个非空白字符,然后使用 findall 函数查找所有匹配的字符串并以列表的形式返回。
然后使用 urljoin 方法拼接整个 url 来抓取单个帖子的标题内容。代码如下:
对于 news_comment_urls 中的 comment_url :
whole_url = parse.urljoin(page_url, comment_url)
post_urls.add(whole_url)
返回 post_urls
单个帖子的爬取内容包括帖子的发帖时间、作者和帖子标题三部分,如下:
我们可以通过正则表达式进行提取,其中在组合正则表达式时,需要考虑HTML代码中是否存在重复匹配的关键字。作者和帖子标题的常规代码如下。关键词mainbody和zwcontentmain在正文中只出现一次,匹配度高。
com_cont = 桩(r'
.*?zwconttbn.*?(.*?).*?.*?"zwconttbt">(.*?)
.*?social clearfix',re.DOTALL)
发布时间的正则代码如下,分两步逐步清晰提取时间。由于搜索是扫描字符串以找到RE匹配的位置,因此添加group()返回匹配的字符串。
pub_elems = re.search('
',html_cont2).group()
# 查看全部
网页新闻抓取(《教你用Python进阶量化交易》专栏(二):扩展篇)
欢迎大家订阅《用Python教你进阶量化交易》专栏!为了给大家提供一个更轻松的学习过程,笔者在栏目内容之外还陆续引入了一些笔记,以帮助同学们学习本栏目内容。目前上线的扩展链接如下:
为了把栏目中零散的知识点贯穿始终,笔者在栏末“自制量化交易工具”小节中分享了之前制作的量化交易小工具的简化版。希望大家可以通过调试代码掌握相关信息。知识。
目前已经移植到站外文章第九部分的Python3.7x版本。接下来我们会在这个版本的基础上逐步完善这个工具,让专栏的读者不仅可以通过小工具掌握专栏的相关知识点,还可以在自己的量化交易中使用工具股票。
量化交易策略的研究主要涵盖微观和宏观两个方面。微观方面更多是以市场价格、交易头寸等基本信息为研究对象。技术指标是通过算法计算出来的,然后根据技术指标的变化来构建。交易模型。宏观方面是开发基于更多市场信息的交易模型,如以CPI、PPI、货币发行等宏观经济指标为研究对象构建交易模型;或使用数据挖掘技术挖掘可能导致市场异常的新闻事件。波动性事件获得交易机会。
在这篇笔记中,我们先梳理一下可以获取股票信息的网站,然后介绍如何在我们的GUI工具上展示抓取到的股票信息。
证券从业人员网站包括上海证券交易所、深圳证券交易所、中国证监会、证券业协会;
行业资讯网站有慧聪、阿里、万德;
知名股票论坛:点金投资之家、分享世界、MACD股市、东方财富网股吧、和讯股吧、创世论坛。
接下来,我们使用爬虫来爬取东方财富网股票论坛的帖子内容。
当我们点击第2页和第3页时,我们检查URL是:,002372_2.html, ,002372_3.html,所以论坛URL的模式是,002372_%d.html中表单,规则比较简单,%d是论坛的页码,但是这个表单是评论时间排列的URL。如果按发帖时间排列,则为002372,f_%d.html。
读取网页内容的关键代码如下:
html_cont=request.urlopen(page_url).read()
需要注意的是,在Python2中有urllib、urllib2和urlparse,但是在Python3中,这些都集成到了urllib中。Python2中urllib和urllib2的内容集成到urllib.request模块中,urlparse集成到urllib.parse模块中。在Python3中,urllib还收录了response、error、robotparse等各种子模块。
获取到的HTML代码内容如下:
得到 HTML 代码后,开始解析 HTML 代码。该帖由两部分组成,一部分为《财经评论》或《东方财富网》发布的公告或官方消息,另一部分为散户发布的讨论帖,如下:
前一篇文章的URL是,cjpl,902659513.html,后一篇文章的URL是,002372,902629178.html,这两个URL都可以在HTML文件的内容中找到,如下所示:
因此,《财经评论》、《东方财富网》或散户发布的帖子的主要特点是/news。我们使用正则表达式进行删除和选择,实现代码如下,
模式 = pile('/news\S+html',re.S)
news_comment_urls = re.findall(pattern, html_cont.decode('utf-8')) # 非空白字符N次
"""
['/news,cjpl,902659513.html', '/news,cjpl,902684967.html',
'/news,cjpl,902602349.html', '/news,cjpl,902529812.html',
'/news,cjpl,857016161.html', '/news,002372,902629178.html',
'/news,002372,902557935.html', '/news,002372,902533930.html',
'/news,002372,902519348.html', '/news,002372,902468635.html',
'/news,002372,902466626.html', '/news,002372,902464127.html',
……
'/news,002372,901168702.html', '/news,002372,901153848.html']
"""
正则表达式的 \S+ 表示匹配多个非空白字符,然后使用 findall 函数查找所有匹配的字符串并以列表的形式返回。
然后使用 urljoin 方法拼接整个 url 来抓取单个帖子的标题内容。代码如下:
对于 news_comment_urls 中的 comment_url :
whole_url = parse.urljoin(page_url, comment_url)
post_urls.add(whole_url)
返回 post_urls
单个帖子的爬取内容包括帖子的发帖时间、作者和帖子标题三部分,如下:
我们可以通过正则表达式进行提取,其中在组合正则表达式时,需要考虑HTML代码中是否存在重复匹配的关键字。作者和帖子标题的常规代码如下。关键词mainbody和zwcontentmain在正文中只出现一次,匹配度高。
com_cont = 桩(r'
.*?zwconttbn.*?(.*?).*?.*?"zwconttbt">(.*?)
.*?social clearfix',re.DOTALL)
发布时间的正则代码如下,分两步逐步清晰提取时间。由于搜索是扫描字符串以找到RE匹配的位置,因此添加group()返回匹配的字符串。
pub_elems = re.search('
',html_cont2).group()
#
网页新闻抓取(此文属于入门级级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-04-15 21:31
本文属于入门级爬虫,老司机不用看。html
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。Python
首先我们打开163的网站,我们可以随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。面试
然后确认可以用F12打开谷歌浏览器的控制台后,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。json
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么很明显:api
*).js
上面的链接也是我们这次爬取要请求的地址。
接下来只需要用到python的两个库:browser
请求 json BeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
因为我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup 用于解析 HTML 文档,可以很方便的帮助我们获取指定 div 的内容。互联网
让我们开始编写我们的爬虫:app
第一步,导入以上三个包:异步
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:post
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到文档中文章源的位置是:一个id=“ne_article_source”的标签。
作者的立场是:class="ep-editor"的span标签。
主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要捕获的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为json字符串,"title": ['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现方式是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,感兴趣的可以关注下文章。 查看全部
网页新闻抓取(此文属于入门级级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机不用看。html
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。Python
首先我们打开163的网站,我们可以随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。面试
然后确认可以用F12打开谷歌浏览器的控制台后,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。json
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么很明显:api
*).js
上面的链接也是我们这次爬取要请求的地址。
接下来只需要用到python的两个库:browser
请求 json BeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
因为我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup 用于解析 HTML 文档,可以很方便的帮助我们获取指定 div 的内容。互联网
让我们开始编写我们的爬虫:app
第一步,导入以上三个包:异步
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:post
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到文档中文章源的位置是:一个id=“ne_article_source”的标签。
作者的立场是:class="ep-editor"的span标签。
主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要捕获的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为json字符串,"title": ['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现方式是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,感兴趣的可以关注下文章。
网页新闻抓取( 就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-04-10 19:21
就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻头条及其原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
新闻爬虫简单流程图
按照这个简单的流程,我们先实现下面的简单代码:
#!/usr/bin/envpython3
#作者:veelion
进口商
进口时间
进口请求
进口提取物
defsave_to_db(url,html):
#将网页保存到数据库中,我们暂时替换为打印相关信息
print('%s:%s'%(url,len(html)))
defcrawl():
#1\.downloadbaidunews
hub_url='#39;
res=requests.get(hub_url)
html=res.text
#2\.extractnewslinks
##2.1extractalllinkswith'href'
链接=re.findall(r'href=[\'"]?(.*?)[\'"\s]',html)
print('findlinks:',len(链接))
新闻链接=[]
##2.2filter非新闻链接
链接链接:
ifnotlink.startswith('http'):
继续
tld=tldextract.extract(链接)
iftld.domain=='百度':
继续
news_links.append(链接)
print('findnewslinks:',len(news_links))
#3\.downloadnewsandsavetodatabase
forlinkinnews_links:
html=requests.get(link).text
save_to_db(链接,html)
print('工作完成!')
定义():
而1:
爬行()
time.sleep(300)
如果__name__=='__main__':
主要的()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 先用正则表达式提取a标签的href属性,即网页中的链接;然后找出新闻链接,方法是:假设非百度外链是新闻链接;
3. 将找到的所有新闻链接一一下载并保存到数据库中;暂时用打印相关信息代替保存到数据库的功能。
4. 每 300 秒重复步骤 1-3 以获取最新消息。
上面的代码可以工作,但是只能工作,而且槽数也不多。让我们在抱怨的同时一起改进这个爬虫。
1. 添加异常处理
在编写爬虫时,尤其是与网络请求相关的代码,
必须
有异常处理。目标服务器是否正常,当时网络连接是否畅通(超时)等都是爬虫无法控制的,所以处理网络请求时必须处理异常。网络请求最好设置一个超时时间,以免在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时的异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301,该URL永久转移到另一个URL,如果稍后请求,转移的URL将被请求
404,基本上这个网站已经过期了,以后不要再尝试了
500,服务器内部有错误,可能是暂时的,稍后再试
3. 管理 URL 的状态
记下这次失败的 URL,以便稍后重试。对于超时的URL,需要稍后再去抓取,所以需要记录所有URL的各种状态,包括:
下载成功
多次下载失败,无需重新下载
下载
下载失败,重试
增加了对网络请求的各种处理,使得爬虫更加健壮,不会随时异常退出,给后续的运维带来了很大的工作量。
下一节我们将结合代码一一讲述上述三个插槽的改进。有关更多详细信息,请收听下一个细分。
Python爬虫知识点
本节我们使用Python的几个模块,它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET、POST 触手可及:
进口请求
res=requests.get(url,timeout=5,headers=my_headers)
res2=requests.post(url,data=post_data,timeout=5,headers=my_headers)
get() 和 post() 函数有很多可选参数。以上用于设置超时和自定义标头。更多参数请参考requests文档。
无论是get()还是post(),requests都会返回一个Response对象,通过这个对象获取下载的内容:
res.content 为获取的二进制内容,类型为字节;
res.text 是二进制内容内容解码后的str内容;
它首先从响应标头中找到编码。如果没有找到,则通过chardet自动判断编码,赋值给res.encoding,最后将二进制内容解密为str类型。
经验谈:
res.text在判断中文编码时,有时会出现错误,或者通过cchardet(chardet用C语言实现)来获取更准确。在这里,我们举一个例子:
在[1]:导入请求
在[2]:r=requests.get('#39;)
在[3]:r.encoding
输出[3]:'ISO-8859-1'
在[4]:importchardet
在[5]:chardet.detect(r.content)
出[5]:{'置信度':0.99,'编码':'utf-8','语言':''}
以上是使用 ipython 交互解释器的演示(强烈推荐使用 ipython,比 Python 自带的解释器好很多)。打开的网址是山西日报数字新闻,网页源码手动编码为utf8,chardet获取的编码也是utf8。而requests本身判断的编码是ISO-8859-1,那么返回文本的中文文本也会出现乱码。
requests 的另一个有用特性是 Session,它部分类似于浏览器并保存 cookie。之后,需要登录并与cookies相关的爬虫可以使用它的session来实现它。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,推荐使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要
点安装 tldextract
安装。即Top Level Domain extract,即顶级域名提取。前面我们讲过URL的结构,叫做host,是注册域名的子域,com是顶级域名TLD。它的结果是这样的:
在[6]:importtlextract
在[7]:tldextract.extract('#39;)
Out[7]:ExtractResult(subdomain='news',domain='baidu',suffix='com')
返回结构由三部分组成:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。时间模块就是提供时间相关功能的模块。At the same time, there is another module, datetime, which is also time-related, and can be appropriately selected and used according to the situation.
记住这些模块,你将在未来的爬虫写作生涯中受益匪浅。 查看全部
网页新闻抓取(
就是一个新闻聚合网页下载流程:新闻爬虫简单流程图)
我们可以看到这是一个新闻聚合页面,里面列出了很多新闻头条及其原创链接。如图所示:
我们的目标是从这里提取这些新闻的链接并下载它们。过程比较简单:
新闻爬虫简单流程图
按照这个简单的流程,我们先实现下面的简单代码:
#!/usr/bin/envpython3
#作者:veelion
进口商
进口时间
进口请求
进口提取物
defsave_to_db(url,html):
#将网页保存到数据库中,我们暂时替换为打印相关信息
print('%s:%s'%(url,len(html)))
defcrawl():
#1\.downloadbaidunews
hub_url='#39;
res=requests.get(hub_url)
html=res.text
#2\.extractnewslinks
##2.1extractalllinkswith'href'
链接=re.findall(r'href=[\'"]?(.*?)[\'"\s]',html)
print('findlinks:',len(链接))
新闻链接=[]
##2.2filter非新闻链接
链接链接:
ifnotlink.startswith('http'):
继续
tld=tldextract.extract(链接)
iftld.domain=='百度':
继续
news_links.append(链接)
print('findnewslinks:',len(news_links))
#3\.downloadnewsandsavetodatabase
forlinkinnews_links:
html=requests.get(link).text
save_to_db(链接,html)
print('工作完成!')
定义():
而1:
爬行()
time.sleep(300)
如果__name__=='__main__':
主要的()
简单解释一下上面的代码:
1. 使用请求下载百度新闻首页;
2. 先用正则表达式提取a标签的href属性,即网页中的链接;然后找出新闻链接,方法是:假设非百度外链是新闻链接;
3. 将找到的所有新闻链接一一下载并保存到数据库中;暂时用打印相关信息代替保存到数据库的功能。
4. 每 300 秒重复步骤 1-3 以获取最新消息。
上面的代码可以工作,但是只能工作,而且槽数也不多。让我们在抱怨的同时一起改进这个爬虫。
1. 添加异常处理
在编写爬虫时,尤其是与网络请求相关的代码,
必须
有异常处理。目标服务器是否正常,当时网络连接是否畅通(超时)等都是爬虫无法控制的,所以处理网络请求时必须处理异常。网络请求最好设置一个超时时间,以免在某个请求上花费太多时间。超时导致的识别可能是服务器无法响应,也可能是暂时的网络问题。因此,对于超时的异常,我们需要过一段时间再试一次。
2. 处理服务器返回的状态,如404、500等。
服务器返回的状态非常重要,它决定了我们的爬虫接下来应该做什么。需要处理的常见状态有:
301,该URL永久转移到另一个URL,如果稍后请求,转移的URL将被请求
404,基本上这个网站已经过期了,以后不要再尝试了
500,服务器内部有错误,可能是暂时的,稍后再试
3. 管理 URL 的状态
记下这次失败的 URL,以便稍后重试。对于超时的URL,需要稍后再去抓取,所以需要记录所有URL的各种状态,包括:
下载成功
多次下载失败,无需重新下载
下载
下载失败,重试
增加了对网络请求的各种处理,使得爬虫更加健壮,不会随时异常退出,给后续的运维带来了很大的工作量。
下一节我们将结合代码一一讲述上述三个插槽的改进。有关更多详细信息,请收听下一个细分。
Python爬虫知识点
本节我们使用Python的几个模块,它们在爬虫中的作用如下:
1. 请求模块
它用于发出 http 网络请求和下载 URL 内容。与 Python 自带的 urllib.request 相比,requests 更容易使用。GET、POST 触手可及:
进口请求
res=requests.get(url,timeout=5,headers=my_headers)
res2=requests.post(url,data=post_data,timeout=5,headers=my_headers)
get() 和 post() 函数有很多可选参数。以上用于设置超时和自定义标头。更多参数请参考requests文档。
无论是get()还是post(),requests都会返回一个Response对象,通过这个对象获取下载的内容:
res.content 为获取的二进制内容,类型为字节;
res.text 是二进制内容内容解码后的str内容;
它首先从响应标头中找到编码。如果没有找到,则通过chardet自动判断编码,赋值给res.encoding,最后将二进制内容解密为str类型。
经验谈:
res.text在判断中文编码时,有时会出现错误,或者通过cchardet(chardet用C语言实现)来获取更准确。在这里,我们举一个例子:
在[1]:导入请求
在[2]:r=requests.get('#39;)
在[3]:r.encoding
输出[3]:'ISO-8859-1'
在[4]:importchardet
在[5]:chardet.detect(r.content)
出[5]:{'置信度':0.99,'编码':'utf-8','语言':''}
以上是使用 ipython 交互解释器的演示(强烈推荐使用 ipython,比 Python 自带的解释器好很多)。打开的网址是山西日报数字新闻,网页源码手动编码为utf8,chardet获取的编码也是utf8。而requests本身判断的编码是ISO-8859-1,那么返回文本的中文文本也会出现乱码。
requests 的另一个有用特性是 Session,它部分类似于浏览器并保存 cookie。之后,需要登录并与cookies相关的爬虫可以使用它的session来实现它。
2. 重新模块
正则表达式主要用于提取html中的相关内容,例如本例中的链接提取。对于更复杂的 html 内容提取,推荐使用 lxml。
3. tldextract 模块
这是一个第三方模块,需要
点安装 tldextract
安装。即Top Level Domain extract,即顶级域名提取。前面我们讲过URL的结构,叫做host,是注册域名的子域,com是顶级域名TLD。它的结果是这样的:
在[6]:importtlextract
在[7]:tldextract.extract('#39;)
Out[7]:ExtractResult(subdomain='news',domain='baidu',suffix='com')
返回结构由三部分组成:子域、域、后缀
4. 时间模块
时间是我们在程序中经常用到的一个概念,比如在循环中暂停一段时间,获取当前时间戳等。时间模块就是提供时间相关功能的模块。At the same time, there is another module, datetime, which is also time-related, and can be appropriately selected and used according to the situation.
记住这些模块,你将在未来的爬虫写作生涯中受益匪浅。
网页新闻抓取(2019独角兽企业重金招聘Python工程师标准;gt)
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-04-10 19:16
2019独角兽企业招聘Python工程师标准>>>
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
前面说过,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个非常棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫操作全过程不需要人工干预,你有更多的时间喝茶聊天
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。 查看全部
网页新闻抓取(2019独角兽企业重金招聘Python工程师标准;gt)
2019独角兽企业招聘Python工程师标准>>>
写爬虫是一项考验综合实力的工作。有时,您可以轻松获取所需的数据;有时候,你努力了,却一无所获。
很多Python爬虫入门教程都是用一行代码把你骗进“海盗船”,等你上了贼船才发现水这么深~比如爬一个网页就可以了一个非常简单的代码行:
r = requests.get('http://news.baidu.com')
很简单,但它的作用只是爬取一个网页,而一个有用的爬虫远不止是爬取一个网页。
一个有用的爬虫,只用两个词衡量:
但是要实现这两个字,还需要下一番功夫。自己努力是一方面,但同样很重要的一点是你想要达到的网站的目标是它给你带来了多少问题。综合来看,写爬虫有多难。
网络爬虫难点一:只爬 HTML 页面但可扩展
这里我们以新闻爬虫为例。大家都用过百度的新闻搜索,我就用它的爬虫说说实现的难点。
新闻网站基本不设防,新闻内容全部在网页的html代码中,抓取整个网页基本上就是一行。听起来很简单,但对于一个搜索引擎级别的爬虫来说,就不是那么简单了,要及时爬取上万条新闻网站的新闻也不是一件容易的事。
我们先来看一下新闻爬虫的简单流程图:
从一些种子页开始,种子页往往是一些新闻网站的首页,爬虫抓取该页面,从中提取出网站的URL,放入URL池中进行爬取。这从几页开始,然后继续扩展到其他页面。爬虫爬取的网页越来越多,提取的新网址也会成倍增加。
如何在最短的时间内抓取更多的网址?
这是难点之一,不是目的URL带来的,而是对我们自身意愿的考验:
如何及时掌握最新消息?
这是效率之外的另一个难点。如何保证时效?上千条新闻网站时刻都在发布最新消息。爬虫如何在织网抓取“旧”新闻的同时兼顾“新”新闻的获取?
如何存储大量捕获的新闻?
爬虫的抓取会翻出几年前和几十年前的每一个新闻页面网站,从而获取大量需要存储的页面。就是存储的难点。
如何清理提取的网页内容?
快速准确地从新闻网页的html中提取想要的信息数据,如标题、发布时间、正文内容等,给内容提取带来困难。
网络爬虫难点二:需要登录才能抓取想要的数据
人们很贪婪,想要无穷无尽的数据,但是很多数据并不容易提供给你。有一大类数据,只有账号登录才能看到。也就是说,爬虫在请求的时候必须登录才能抓取数据。
如何获取登录状态?
前面说过,http协议的性质决定了登录状态是一些cookies,所以如何获取登录状态是一个非常棘手的问题。有的网站登录过程很简单,将账号和密码发送到服务器,服务器验证后返回cookies表示登录。这样的网站,更容易实现自动登录,爬虫操作全过程不需要人工干预,你有更多的时间喝茶聊天
如何处理验证码?
不过,既然网站们已经让你登录了,他们不会那么轻易放过你的。他们要做的就是让小猿们放弃,那就是上传验证码!没错,就是变态的验证码!!作为一个见多识广的老猿猴,到现在还是经常认不出验证码,觉得很丢脸。
据说有人雇了一群阿姨手动识别验证码;有人利用图像处理技术,特别是热门的深度学习和人工智能技术,自动识别验证码。
那么,在编写爬虫时遇到验证码该怎么办呢?
网络爬虫难点三:ajax异步加载甚至JavaScript解密
前两个难点是基于我们对数据加载过程的研究,然后我们可以用Python代码复现并爬取。
在第三个难点上,研究数据加载过程可能很痛苦,几乎崩溃。异步加载过程和服务器来回多次,最终数据只能通过JavaScript解密才能看到,是压垮爬虫的最后一根稻草。
网页新闻抓取(搜狗3.0发布的改进和提高的方面有哪些改进?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-08 23:20
A:用户可以直接体验的功能有:
a) 按时间排序功能:使用搜狗3.0时,用户可以按时间检索最新的搜索结果,信息更新更快。
b) 分类检索功能:用户在使用搜狗3.0进行搜索时,可以同时得到分类形式的搜索结果索引,可以更方便的在相关领域找到自己需要的信息。
c) 只在标题和文本中搜索的功能:搜狗3.0的搜索结果可以更准确地直接从相关网站内容的标题和文本中抓取数据,从而使搜索可以有效地判断结果的准确性,减少更多的错误,使搜索结果更加准确和客观。
技术改进和增强包括:
a) 更大的数据容量,支持百亿网页的爬取和检索:
b) 更新速度更快,每天更新5亿网页;
c) 相关性的提高(包括海量数据、搜索速度、自然语言理解)。
Q:除了网页搜索,搜狗3.0做了哪些改进?
A:音乐、图片、谈话、新闻都将升级到3.0。3.0的升级是搜狗的全面升级。
a) 音乐升级后,死链接率下降到2.%,而其他竞争对手在20-30%;
b) 图片升级后,数据量从1亿增加到5亿;
c) 新闻升级后,爬取优化,保证1分钟后能检索到最新新闻;
d) 升级后变为bbs+wiki(合编)模式。
Q:用户在使用搜狗3.0时,如何让用户知道自己使用的是新版搜索引擎?
A:搜狗3.0发布后,用户首次访问会有明显提示。此外,随着3.0的上线,高级搜索和搜索设置功能将同时上线。
Q:搜狗3.0明显提升了收录的信息量,但是对于普通用户来说,搜索结果的有效性比信息量更重要。搜狗在这方面有什么优势?
- 答:有大幅增加。具体表现如下:抓取次数从50亿增加到100亿,更新能力从每天几千万增加到每天几亿。
Q:搜狗3.0和百度等搜索引擎搜索同一个关键词有什么区别,用户可以直接体验到的明显区别是什么?
A:百度的结果相对比较草根,但是多词组合搜索效果弱于谷歌。谷歌的学术成绩比较高,雅虎的成绩比较官方。搜狗综合了几家公司的优势,找到了一家。平衡点可以让不同的用户更容易找到他们需要的结果。
Q:能否用一句话总结一下搜狗3.0在众多搜索引擎中的优势?
A:海量、及时、准确。
Q:对于我们的记者来说,经常使用新闻搜索功能。搜狗在这方面相对于竞争对手有哪些优势?
A:搜狗新闻首页依托搜狐门户矩阵的资源优势,真实反映了用户对搜狐热点新闻的关注度,是统计意义上的“最受用户欢迎”的热点新闻。搜狐内容频道的新闻已经覆盖了互联网上的大部分重大新闻。我们可以认为这个主页反映了整个互联网的新闻热点。这与其他竞争对手完全依靠机器进行判断而忽视网友反馈的方式不同。在搜索效果方面,搜狗新闻的抓取和更新能力更加强大。经测试,互联网热点新闻只需一分钟即可完成从抓取到页面分析到索引到上线的全过程。 查看全部
网页新闻抓取(搜狗3.0发布的改进和提高的方面有哪些改进?)
A:用户可以直接体验的功能有:
a) 按时间排序功能:使用搜狗3.0时,用户可以按时间检索最新的搜索结果,信息更新更快。
b) 分类检索功能:用户在使用搜狗3.0进行搜索时,可以同时得到分类形式的搜索结果索引,可以更方便的在相关领域找到自己需要的信息。
c) 只在标题和文本中搜索的功能:搜狗3.0的搜索结果可以更准确地直接从相关网站内容的标题和文本中抓取数据,从而使搜索可以有效地判断结果的准确性,减少更多的错误,使搜索结果更加准确和客观。
技术改进和增强包括:
a) 更大的数据容量,支持百亿网页的爬取和检索:
b) 更新速度更快,每天更新5亿网页;
c) 相关性的提高(包括海量数据、搜索速度、自然语言理解)。
Q:除了网页搜索,搜狗3.0做了哪些改进?
A:音乐、图片、谈话、新闻都将升级到3.0。3.0的升级是搜狗的全面升级。
a) 音乐升级后,死链接率下降到2.%,而其他竞争对手在20-30%;
b) 图片升级后,数据量从1亿增加到5亿;
c) 新闻升级后,爬取优化,保证1分钟后能检索到最新新闻;
d) 升级后变为bbs+wiki(合编)模式。
Q:用户在使用搜狗3.0时,如何让用户知道自己使用的是新版搜索引擎?
A:搜狗3.0发布后,用户首次访问会有明显提示。此外,随着3.0的上线,高级搜索和搜索设置功能将同时上线。
Q:搜狗3.0明显提升了收录的信息量,但是对于普通用户来说,搜索结果的有效性比信息量更重要。搜狗在这方面有什么优势?
- 答:有大幅增加。具体表现如下:抓取次数从50亿增加到100亿,更新能力从每天几千万增加到每天几亿。
Q:搜狗3.0和百度等搜索引擎搜索同一个关键词有什么区别,用户可以直接体验到的明显区别是什么?
A:百度的结果相对比较草根,但是多词组合搜索效果弱于谷歌。谷歌的学术成绩比较高,雅虎的成绩比较官方。搜狗综合了几家公司的优势,找到了一家。平衡点可以让不同的用户更容易找到他们需要的结果。
Q:能否用一句话总结一下搜狗3.0在众多搜索引擎中的优势?
A:海量、及时、准确。
Q:对于我们的记者来说,经常使用新闻搜索功能。搜狗在这方面相对于竞争对手有哪些优势?
A:搜狗新闻首页依托搜狐门户矩阵的资源优势,真实反映了用户对搜狐热点新闻的关注度,是统计意义上的“最受用户欢迎”的热点新闻。搜狐内容频道的新闻已经覆盖了互联网上的大部分重大新闻。我们可以认为这个主页反映了整个互联网的新闻热点。这与其他竞争对手完全依靠机器进行判断而忽视网友反馈的方式不同。在搜索效果方面,搜狗新闻的抓取和更新能力更加强大。经测试,互联网热点新闻只需一分钟即可完成从抓取到页面分析到索引到上线的全过程。
网页新闻抓取(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-04-03 15:13
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装aiomysql,进行数据库mysql操作更方便;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程 查看全部
网页新闻抓取(新闻网站多如牛毛,我们该如何去爬呢?从哪里开爬呢?)
越来越多的人使用python编写爬虫,这也说明用python编写爬虫比其他语言更方便。很多新闻网站没有反爬策略,所以抓取新闻网站的数据比较方便。然而,消息网站铺天盖地,我们怎么爬呢?从哪里开始攀登?是我们需要考虑的第一个问题。
你需要的是异步IO来实现一个高效的爬虫。
让我们看看 Python3 的基于 asyncio 的新闻爬虫,以及我们如何高效地实现它。
从 Python3.5 开始,增加了一个新的语法,async 和 await 这两个关键字,asyncio 也成为了标准库,这对我们编写异步 IO 的程序来说是一个很好的补充,让我们轻松实现一个用于有针对性的新闻抓取的异步爬虫。
1. 异步爬虫依赖的模块
asyncio:一个标准的异步模块,实现了python的异步机制;uvloop:C语言开发的异步循环模块,大大提高了异步机制的效率;aiohttp:用于下载网页的异步http请求模块;urllib.parse:解析url 网站的模块;logging:记录爬虫日志;leveldb:谷歌的Key-Value数据库,记录url的状态;farmhash:对url进行hash计算,作为url的唯一标识;sanicdb:封装aiomysql,进行数据库mysql操作更方便;2.异步爬虫实现流程2.1 消息源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以需要管理一个定向源列表,里面记录了很多我们要抓取的新闻网站的URL , 这些url指向的网页称为hub网页,它们具有以下特点:
Hub 网页是爬取的起点,爬虫从中提取新闻页面的链接,然后进行爬取。Hub URL可以存储在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表来更新目标爬取任务。这需要爬虫中的循环来定期读取中心 URL。
2.2 网址池
异步爬虫的所有过程都不是一个循环就能完成的,它是由多个循环(至少两个循环)交互完成的。它们之间的桥梁是“URL 池”(用 asyncio.Queue 实现)。
这个URL池就是我们比较熟悉的“生产者-消费者”模型。
一方面,hub URL会间隔进入URL池,爬虫从网页中提取的新闻链接也进入URL池,也就是产生URL的过程;
另一方面,爬虫需要从URL池中取出URL进行下载,这个过程就是消费过程;
两个进程相互配合,不断有url进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存中心 URL 和下载的网页;后者用于存储所有url的状态(是否抓取成功)。
很多从网页中提取出来的链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前要进行检查,leveldb可以快速查看它们的状态。
3. 异步爬虫实现细节
前面爬虫过程中提到了两个循环:
周期 1:定期更新 hub网站 列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环 2:用于抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if span > 3:
rate = counter / span
print('\tloop_crawl2() rate:%s, counter: %s, workers: %s' % (round(rate, 2), counter, self._workers))
last_rating_time = time.time()
counter = 0
if self._workers > self.workers_max:
print('====== got workers_max, sleep 3 sec to next worker =====')
await asyncio.sleep(3)
4. 异步要点:
阅读 asyncio 的文档,了解它的运行过程。以下是您在使用它时注意到的一些事项。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
文章首发于我的技术博客猿人学习Python基础教程
网页新闻抓取(如何快速将不同新闻网站中的大量新闻文章导出到一个)
网站优化 • 优采云 发表了文章 • 0 个评论 • 425 次浏览 • 2022-04-03 11:25
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们对各个新闻平台特有的html结构有深入的了解。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何快速从不同的新闻网站s中抓取大量新闻文章到一个简单的python脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaperfrom newspaper import Article#将文章下载到内存的基础article = Article("url link to your article")article.download()article.parse()article.nlp()# 输出全文print(article.text)# 输出文本摘要# 因为newspaper3k内置了NLP工具,这一步行之有效print(article.summary)# 输出作者名字print(article.authors)# 输出关键字列表print(article.keywords)#收集文章中其他有用元数据的其他函数article.title # 给出标题article.publish_date #给出文章发表的日期article.top_image # 链接到文章的主要图像article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaperfrom newspaper import Articlefrom newspaper import Sourceimport pandas as pd# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False) #我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。# 全新运行,每次运行时都基本上执行此脚本final_df = pd.DataFrame()for each_article in gamespot.articles: each_article.download() each_article.parse() each_article.nlp() temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text', 'Summary', 'published_date', 'Source']) temp_df['Authors'] = each_article.authors temp_df['Title'] = each_article.title temp_df['Text'] = each_article.text temp_df['Summary'] = each_article.summary temp_df['published_date'] = each_article.publish_date temp_df['Source'] = each_article.source_url final_df = final_df.append(temp_df, ignore_index = True) #从这里可以将此Pandas数据框导出到csv文件final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~ 查看全部
网页新闻抓取(如何快速将不同新闻网站中的大量新闻文章导出到一个)
前几天,公司给我安排了一个新项目,让我在网上抓取新闻文章。为了用最简单快捷的方式完成这个任务,特意做了一些准备。
我们都知道有一些Python插件可以帮助我们完成爬虫的工作,其中一个叫做BeautifulSoup。这是一个非常有用的插件,但是这个插件需要我们对各个新闻平台特有的html结构有深入的了解。像我这种懒惰的人绝对不会这样做。每个 网站 都需要了解框架,这是浪费时间。
通过大量搜索,我找到了一个简单的解决我的问题的方法,Newspaper3k!
在本教程中,我将向您展示如何快速从不同的新闻网站s中抓取大量新闻文章到一个简单的python脚本中。
如何使用 Newspaper3k 抓取新闻?
首先,我们需要将python插件安装到开发环境中。
提示:我们最好再创建一个虚拟 python 环境。
$ pip install newspaper3k
1、基础知识
import newspaperfrom newspaper import Article#将文章下载到内存的基础article = Article("url link to your article")article.download()article.parse()article.nlp()# 输出全文print(article.text)# 输出文本摘要# 因为newspaper3k内置了NLP工具,这一步行之有效print(article.summary)# 输出作者名字print(article.authors)# 输出关键字列表print(article.keywords)#收集文章中其他有用元数据的其他函数article.title # 给出标题article.publish_date #给出文章发表的日期article.top_image # 链接到文章的主要图像article.images # 提供一组图像链接
2、进阶:一条新闻下载多篇文章网站文章
当我正在抓取一堆新闻文章 时,我想从新闻网站上抓取多个 文章 并将所有内容放在 pandas 数据框中,这样我就可以将这些数据导出到 .csv 文件中,这很容易与这个插件有关。
import newspaperfrom newspaper import Articlefrom newspaper import Sourceimport pandas as pd# 假设我们要从Gamespot(该网站讨论视频游戏)下载文章gamespot = newspaper.build("https://www.gamespot.com//news/", memoize_articles = False) #我将memoize_articles设置为False,因为我不希望它缓存文章并将其保存到内存中,然后再运行。# 全新运行,每次运行时都基本上执行此脚本final_df = pd.DataFrame()for each_article in gamespot.articles: each_article.download() each_article.parse() each_article.nlp() temp_df = pd.DataFrame(columns = ['Title', 'Authors', 'Text', 'Summary', 'published_date', 'Source']) temp_df['Authors'] = each_article.authors temp_df['Title'] = each_article.title temp_df['Text'] = each_article.text temp_df['Summary'] = each_article.summary temp_df['published_date'] = each_article.publish_date temp_df['Source'] = each_article.source_url final_df = final_df.append(temp_df, ignore_index = True) #从这里可以将此Pandas数据框导出到csv文件final_df.to_csv('my_scraped_articles.csv')
得到它!很容易爬到很多文章。
使用上面的代码,你可以实现一个for循环来循环遍历大量的报纸资源。创建一个可以导出和使用的海量最终数据框。
3、多线程网络爬取
我上面提出的解决方案对某些人来说可能有点慢,因为它会一一下载 文章。如果您有许多新闻来源,则可能需要一段时间才能浏览。还有一种方法可以加快这个过程:就是借助多线程技术,我们可以做快速爬取。
Python多线程技术解决方案:
注意:在下面的代码中,我实现了每个源的下载限制。运行此脚本时可能需要将其删除。实施此限制是为了允许用户在运行代码时对其进行测试。
我喜欢边做边学,我建议任何看到这个文章的人都可以使用上面的代码,自己动手。从这里,您现在可以使用 Newspaper3k 来抓取网络 文章。
防范措施:
- 结尾 -
希望以上内容对大家有所帮助,喜欢本文的同学记得转发+采集哦~
网页新闻抓取( 全球顶尖调查记者与调查报道专家分享网络报道用到技巧 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-04-03 11:19
全球顶尖调查记者与调查报道专家分享网络报道用到技巧
)
今天,各种在线工具可以帮助记者更有效地制作有影响力的数据新闻。在上周刚刚结束的第二届亚洲深度报道大会上,世界顶级调查记者和调查报道专家分享了他们在工作中使用的工具和技术,从数据挖掘、数据清洗到可视化。以下由深度君为您整理。
电子表格
尽管市面上有很多优秀的数据处理工具,但 Excel 仍然被公认为最适合初学者的数据处理工具。Excel 软件中的电子表格可以有效地组织和分析数据。OpenNews 的 Sandhya Kambhampati 分享了她在使用 Excel 时的一些经验和见解,点击查看她的演示文稿,并开始您自己的数据探索之旅。(OpenNews 是由 Knight Foundation 和 Mozilla 支持的一个联合项目,旨在建立一个由开发人员、设计师和数据记者组成的社区,以帮助在开放的 Web 环境中推进新闻业。)
数据抓取
如果您在选择主题时,在网页上遇到大量非传播形式的数据信息,您应该怎么办?来自丹麦的记者 Nils Mulvad 表示,此时您需要 Import.io 工具来帮助您捕获数据。它可以节省您的时间并使您从重复性工作中解放出来。
数据清洗
有时您遇到的数据可能非常混乱,但不用担心,OpenRefine 可以有效地帮助您清理、结构化和改进数据集。更重要的是,它仍然是开源的。点击查看 Nils Mulvad 的演示,教你如何使用该工具。
数据库管理
你准备好处理大数据了吗?如何处理千兆字节、TB 级的数据集?如何进行更快更全面的数据分析?Vox 的开发人员 Kavya Sukumar 告诉您,这需要数据库管理技能。点击查看她分享的内容。
网络搜索
互联网上混杂的信息很多,我们现在需要更可靠的方法来检索和验证,以免被信息误导。路透社记者Irene Liu为大家分享了网络报道所需的信息验证工具和方法,包括反向图片搜索、地理位置验证、社交网络检测等。点击查看更多关于网络搜索的精彩内容。
地图
空间分析可以帮助记者发现隐藏在数据中的故事线索,而映射可以有效地呈现数据。纽约时报记者 Andy Lehren 经常使用 ESRI 开发的工具 ArcGIS 进行空间分析和制图。点击查看他在大会上的演讲,一步步教你绘制地图。
数据可视化
如果您想使用酷炫的设计图表来展示您的数据,但团队中没有工程师或设计师怎么办?编辑 Sanjit Oberai 整理了一份数据可视化工具列表,这些工具操作简单,效果出众。点击查看他的分享。
结尾。
查看全部
网页新闻抓取(
全球顶尖调查记者与调查报道专家分享网络报道用到技巧
)
今天,各种在线工具可以帮助记者更有效地制作有影响力的数据新闻。在上周刚刚结束的第二届亚洲深度报道大会上,世界顶级调查记者和调查报道专家分享了他们在工作中使用的工具和技术,从数据挖掘、数据清洗到可视化。以下由深度君为您整理。
电子表格
尽管市面上有很多优秀的数据处理工具,但 Excel 仍然被公认为最适合初学者的数据处理工具。Excel 软件中的电子表格可以有效地组织和分析数据。OpenNews 的 Sandhya Kambhampati 分享了她在使用 Excel 时的一些经验和见解,点击查看她的演示文稿,并开始您自己的数据探索之旅。(OpenNews 是由 Knight Foundation 和 Mozilla 支持的一个联合项目,旨在建立一个由开发人员、设计师和数据记者组成的社区,以帮助在开放的 Web 环境中推进新闻业。)
数据抓取
如果您在选择主题时,在网页上遇到大量非传播形式的数据信息,您应该怎么办?来自丹麦的记者 Nils Mulvad 表示,此时您需要 Import.io 工具来帮助您捕获数据。它可以节省您的时间并使您从重复性工作中解放出来。
数据清洗
有时您遇到的数据可能非常混乱,但不用担心,OpenRefine 可以有效地帮助您清理、结构化和改进数据集。更重要的是,它仍然是开源的。点击查看 Nils Mulvad 的演示,教你如何使用该工具。
数据库管理
你准备好处理大数据了吗?如何处理千兆字节、TB 级的数据集?如何进行更快更全面的数据分析?Vox 的开发人员 Kavya Sukumar 告诉您,这需要数据库管理技能。点击查看她分享的内容。
网络搜索
互联网上混杂的信息很多,我们现在需要更可靠的方法来检索和验证,以免被信息误导。路透社记者Irene Liu为大家分享了网络报道所需的信息验证工具和方法,包括反向图片搜索、地理位置验证、社交网络检测等。点击查看更多关于网络搜索的精彩内容。
地图
空间分析可以帮助记者发现隐藏在数据中的故事线索,而映射可以有效地呈现数据。纽约时报记者 Andy Lehren 经常使用 ESRI 开发的工具 ArcGIS 进行空间分析和制图。点击查看他在大会上的演讲,一步步教你绘制地图。
数据可视化
如果您想使用酷炫的设计图表来展示您的数据,但团队中没有工程师或设计师怎么办?编辑 Sanjit Oberai 整理了一份数据可视化工具列表,这些工具操作简单,效果出众。点击查看他的分享。
结尾。
网页新闻抓取(查看网页源码的时候(chrome浏览器)中的查看方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-04-01 07:22
)
标签,然后找到这个标签下的所有标签,然后再次找到该标签,然后找到所需的数据。
但是,当我们打开查看网页的源代码时(比如chrome浏览器,右键查看网页的源代码),发现源代码中并没有我们需要的数据,而是类似的东西到一个模板。数据通过后续的动态加载加载。
当我们使用爬虫进行爬取时,我们得到的是相同的源代码,但是我们当然无法获取数据。
Tips1:在分析网页时,可以先查看网页的源代码,看看里面有没有你需要的数据。如果有,可以继续分析。如果不是,则意味着数据是动态加载的,您需要改变主意。
1.2 如何获取数据
既然在网页源代码中找不到数据,那我们从哪里得到数据呢?
这涉及到一个叫“抓包”的词,听起来可能很深奥很难,但其实很简单。我们知道,必须通过发起网络请求来获取数据,即网页向服务器发送请求,然后服务器返回所需的数据。我们使用一些工具和方法将网页的请求发送到服务器以及浏览器返回的数据。截取分析,这个过程就是“抓包”。
可能大家还有点迷茫,下面我来详细演示一下。
打开开发者工具,切换到网络,然后刷新网页(这里可以捕获页面加载过程中对服务器的各种类型的请求)。
那么上图中红框圈出来的就是我们一一抓到的请求包,包括js脚本、css文件、图片等。在众多的“请求包”中我们要找到收录数据的包我们需要。
从上到下点击列表中的请求(可以在 Preview 中预览请求返回的数据),看看我们要查找的请求是哪个。
点击上图中箭头标记的请求后,预览中的内容就是布局导航栏中的内容(点击预览中的小箭头展开),我们就成功找到了正确的请求。
即抓包成功!
1.3 如何使用抓包?
我们抓到了收录数据的请求包,但是具体怎么使用呢?如何在爬虫程序中使用它来通过它来爬取数据?
仍然是那个请求,我们切换到 Headers 选项卡以查看有关此请求的一些基本信息。
主要关注几个部分Request URL(请求链接),Request Method(请求方法),Query String Parameters(请求参数),(当然是请求头中的那些东西,User-Agent,Cookie等,根据实际情况而定情况如何添加如何添加)。
我们的目的是通过python代码模拟浏览器发出这个请求,直接获取服务端返回的数据(返回的数据就是之前预览的那个)。
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
我们简单写几行代码来模拟这个过程(url是上图中Request URL的内容,requests.get()是因为Request Method是GET)。
运行结果如下,可以成功获取数据。
1.4 如何爬取其他日期的数据
运行上面的代码,我们可以得到截至2021年4月24日的新闻数据,那么如果我们要爬取其他日期的新闻数据呢?
这里我们观察请求的 url
有一段2021-04-24,我们猜测,这可能是用来控制获取数据的日期,改成其他日期如2021-04-20再试一次。
发现也可以成功。
这样我们就知道可以通过修改url中的日期字符串来抓取指定日期的数据了。
1.5 解析数据
这个请求返回的数据是一个json格式的字符串,我们需要使用json库来解析。
(可能有同学要问,怎么知道一串乱码是json格式的?总之看两个特征,一个是用大括号{}包裹的,另一个是key value的格式, 是 xxx : xxx 的形式,如果实在不知道怎么判断,直接去抓包部分看预览,如果有可以折叠和展开的小箭头,那就是json格式)
我们可以看到pages中有一个pages列表,每个page的articleList都有一个文章列表,里面收录了我们需要的page和文章列表信息。具体解析Python代码这里不做讨论,源码贴在文末。
1.6 如何攀登文章详情
首先点击文章的文本页面,和之前一样的分析方法。不难知道,文本的内容也是动态加载的,通过如下请求获取文本的数据。
让我们写一个简单的代码来验证
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
运行结果
通过分析这个请求的url可以知道,/2021-04-24是日期,/01是页码,/312840是文章的id。
至此,我们完成了网站的分析,讲解了如何判断网站的数据是动态加载还是静态加载,如果是动态加载,如何抓包,如何使用它在抓包等之后,并抓包到新闻页面列表、文章列表、文章请求正文内容的接口。如果上面的内容有什么我没有解释清楚,或者有什么我不太明白的地方,可以留言问我。
写下下面的代码就可以正式爬取了。
二、编码链接
以下为爬虫源码,供大家学习交流,请勿用于非法用途。
import requests
import bs4
import os
import datetime
import time
import json
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_jfrb(year, month, day, destdir):
'''
功能:网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
url = 'https://www.shobserver.com/sta ... 39%3B + year + '-' + month + '-' + day + '/navi.json'
html = fetchUrl(url)
jsonObj = json.loads(html)
for page in jsonObj["pages"]:
pageName = page["pname"]
pageNo = page["pnumber"]
print(pageNo, pageName)
for article in page["articleList"]:
title = article["title"]
subtitle = article["subtitle"]
pid = article["id"]
url = "https://www.shobserver.com/sta ... ot%3B + year + '-' + month + '-' + day + "/" + str(pageNo) + "/article/" + str(pid) + ".json"
print(pid, title, subtitle)
html = fetchUrl(url)
cont = json.loads(html)["article"]["content"]
bsobj = bs4.BeautifulSoup(cont, 'html.parser')
content = title + subtitle + bsobj.text
print(content)
path = destdir + '/' + year + month + day + '/' + str(pageNo) + " " + pageName + "/"
fileName = year + month + day + '-' + pageNo + '-' + str(pid) + "-" + title + '.txt'
saveFile(content, path, fileName)
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20210416 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_jfrb(year, month, day, 'Data')
print("爬取完成:" + year + month + day)
以上是爬取单日新闻文章的爬虫。如果想爬取一段时间内的新闻文章数据,可以参考《Python网络爬虫:爬取人民日报文章》中的代码修改。
三、运行效果
运行程序并输入20210424后,爬虫会自动爬取2021年4月24日的新闻数据,并保存在Data/20210424/目录下。
2021 年 12 月 15 日更新
为通过审核,部分涉及敏感内容的网站截图已被删除,仅保留部分解释爬虫技术所必需的截图,部分涉及网站的页面将被重新编码。我希望每个人都能理解。
如果在文章中有没有解释清楚,或者解释有问题的地方,请在评论区批评指正,或者扫描下方二维码,加我微信,大家可以学习和学习一起交流,一起进步。
查看全部
网页新闻抓取(查看网页源码的时候(chrome浏览器)中的查看方法
)
标签,然后找到这个标签下的所有标签,然后再次找到该标签,然后找到所需的数据。
但是,当我们打开查看网页的源代码时(比如chrome浏览器,右键查看网页的源代码),发现源代码中并没有我们需要的数据,而是类似的东西到一个模板。数据通过后续的动态加载加载。
当我们使用爬虫进行爬取时,我们得到的是相同的源代码,但是我们当然无法获取数据。
Tips1:在分析网页时,可以先查看网页的源代码,看看里面有没有你需要的数据。如果有,可以继续分析。如果不是,则意味着数据是动态加载的,您需要改变主意。
1.2 如何获取数据
既然在网页源代码中找不到数据,那我们从哪里得到数据呢?
这涉及到一个叫“抓包”的词,听起来可能很深奥很难,但其实很简单。我们知道,必须通过发起网络请求来获取数据,即网页向服务器发送请求,然后服务器返回所需的数据。我们使用一些工具和方法将网页的请求发送到服务器以及浏览器返回的数据。截取分析,这个过程就是“抓包”。
可能大家还有点迷茫,下面我来详细演示一下。
打开开发者工具,切换到网络,然后刷新网页(这里可以捕获页面加载过程中对服务器的各种类型的请求)。
那么上图中红框圈出来的就是我们一一抓到的请求包,包括js脚本、css文件、图片等。在众多的“请求包”中我们要找到收录数据的包我们需要。
从上到下点击列表中的请求(可以在 Preview 中预览请求返回的数据),看看我们要查找的请求是哪个。
点击上图中箭头标记的请求后,预览中的内容就是布局导航栏中的内容(点击预览中的小箭头展开),我们就成功找到了正确的请求。
即抓包成功!
1.3 如何使用抓包?
我们抓到了收录数据的请求包,但是具体怎么使用呢?如何在爬虫程序中使用它来通过它来爬取数据?
仍然是那个请求,我们切换到 Headers 选项卡以查看有关此请求的一些基本信息。
主要关注几个部分Request URL(请求链接),Request Method(请求方法),Query String Parameters(请求参数),(当然是请求头中的那些东西,User-Agent,Cookie等,根据实际情况而定情况如何添加如何添加)。
我们的目的是通过python代码模拟浏览器发出这个请求,直接获取服务端返回的数据(返回的数据就是之前预览的那个)。
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
我们简单写几行代码来模拟这个过程(url是上图中Request URL的内容,requests.get()是因为Request Method是GET)。
运行结果如下,可以成功获取数据。
1.4 如何爬取其他日期的数据
运行上面的代码,我们可以得到截至2021年4月24日的新闻数据,那么如果我们要爬取其他日期的新闻数据呢?
这里我们观察请求的 url
有一段2021-04-24,我们猜测,这可能是用来控制获取数据的日期,改成其他日期如2021-04-20再试一次。
发现也可以成功。
这样我们就知道可以通过修改url中的日期字符串来抓取指定日期的数据了。
1.5 解析数据
这个请求返回的数据是一个json格式的字符串,我们需要使用json库来解析。
(可能有同学要问,怎么知道一串乱码是json格式的?总之看两个特征,一个是用大括号{}包裹的,另一个是key value的格式, 是 xxx : xxx 的形式,如果实在不知道怎么判断,直接去抓包部分看预览,如果有可以折叠和展开的小箭头,那就是json格式)
我们可以看到pages中有一个pages列表,每个page的articleList都有一个文章列表,里面收录了我们需要的page和文章列表信息。具体解析Python代码这里不做讨论,源码贴在文末。
1.6 如何攀登文章详情
首先点击文章的文本页面,和之前一样的分析方法。不难知道,文本的内容也是动态加载的,通过如下请求获取文本的数据。
让我们写一个简单的代码来验证
import requests
url = "https://www.shobserver.com/sta ... ot%3B
r = requests.get(url)
print(r.text)
运行结果
通过分析这个请求的url可以知道,/2021-04-24是日期,/01是页码,/312840是文章的id。
至此,我们完成了网站的分析,讲解了如何判断网站的数据是动态加载还是静态加载,如果是动态加载,如何抓包,如何使用它在抓包等之后,并抓包到新闻页面列表、文章列表、文章请求正文内容的接口。如果上面的内容有什么我没有解释清楚,或者有什么我不太明白的地方,可以留言问我。
写下下面的代码就可以正式爬取了。
二、编码链接
以下为爬虫源码,供大家学习交流,请勿用于非法用途。
import requests
import bs4
import os
import datetime
import time
import json
def fetchUrl(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def saveFile(content, path, filename):
'''
功能:将文章内容 content 保存到本地文件中
参数:要保存的内容,路径,文件名
'''
# 如果没有该文件夹,则自动生成
if not os.path.exists(path):
os.makedirs(path)
# 保存文件
with open(path + filename, 'w', encoding='utf-8') as f:
f.write(content)
def download_jfrb(year, month, day, destdir):
'''
功能:网站 某年 某月 某日 的新闻内容,并保存在 指定目录下
参数:年,月,日,文件保存的根目录
'''
url = 'https://www.shobserver.com/sta ... 39%3B + year + '-' + month + '-' + day + '/navi.json'
html = fetchUrl(url)
jsonObj = json.loads(html)
for page in jsonObj["pages"]:
pageName = page["pname"]
pageNo = page["pnumber"]
print(pageNo, pageName)
for article in page["articleList"]:
title = article["title"]
subtitle = article["subtitle"]
pid = article["id"]
url = "https://www.shobserver.com/sta ... ot%3B + year + '-' + month + '-' + day + "/" + str(pageNo) + "/article/" + str(pid) + ".json"
print(pid, title, subtitle)
html = fetchUrl(url)
cont = json.loads(html)["article"]["content"]
bsobj = bs4.BeautifulSoup(cont, 'html.parser')
content = title + subtitle + bsobj.text
print(content)
path = destdir + '/' + year + month + day + '/' + str(pageNo) + " " + pageName + "/"
fileName = year + month + day + '-' + pageNo + '-' + str(pid) + "-" + title + '.txt'
saveFile(content, path, fileName)
if __name__ == '__main__':
'''
主函数:程序入口
'''
# 爬取指定日期的新闻
newsDate = input('请输入要爬取的日期(格式如 20210416 ):')
year = newsDate[0:4]
month = newsDate[4:6]
day = newsDate[6:8]
download_jfrb(year, month, day, 'Data')
print("爬取完成:" + year + month + day)
以上是爬取单日新闻文章的爬虫。如果想爬取一段时间内的新闻文章数据,可以参考《Python网络爬虫:爬取人民日报文章》中的代码修改。
三、运行效果
运行程序并输入20210424后,爬虫会自动爬取2021年4月24日的新闻数据,并保存在Data/20210424/目录下。
2021 年 12 月 15 日更新
为通过审核,部分涉及敏感内容的网站截图已被删除,仅保留部分解释爬虫技术所必需的截图,部分涉及网站的页面将被重新编码。我希望每个人都能理解。
如果在文章中有没有解释清楚,或者解释有问题的地方,请在评论区批评指正,或者扫描下方二维码,加我微信,大家可以学习和学习一起交流,一起进步。
网页新闻抓取(Python学习资料获取指定页码内数据的方法及方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-04-01 07:21
PS:如需Python学习资料,可点击下方链接自行获取
本文属于入门级爬虫,老司机不用看。
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先,我们打开163的网站,我们随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。
然后确认后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的连接也是我们这次爬取要请求的地址。
接下来只需要两个python库:
要求
json
美丽汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup用于解析html文档,可以很方便的帮我们获取到指定div的内容。
让我们开始编写我们的爬虫:
第一步,导入以上三个包:
importjsonimportrequestsfrom bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:
1 defget_page(page):2 url_temp = '{}.js'
3 return_list =[]4 for i inrange(page):5 url =url_temp.format(i)6 response =requests.get(url)7 if response.status_code != 200:8 继续
9 content = response.text #获取响应正文
10 _content = formatContent(content) #格式化json字符串
11 结果 =json.loads(_content)12 return_list.append(result)13 return return_list
这将得到每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到 文章 源在文档中的位置为:id = "ne_article_source" 的标签。作者的立场是:class="ep-editor"的span标签。主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
1 defget_content(url):2 源 = ''
3作者=''
4 身体 = ''
5 resp =requests.get(url)6 if resp.status_code == 200:7 body =resp.text8 bs4 =BeautifulSoup(body)9 source = bs4.find('a', id='ne_article_source' ).get_text()10 author = bs4.find('span', class_='ep-editor').get_text()11 body = bs4.find('div', class_=' post_text').get_text()12 返回源、作者、正文
到目前为止,我们一直在抓取的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为 json 字符串,“title”:['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO上,可以升级为异步IO,异步采集。 查看全部
网页新闻抓取(Python学习资料获取指定页码内数据的方法及方法)
PS:如需Python学习资料,可点击下方链接自行获取
本文属于入门级爬虫,老司机不用看。
这次我们主要抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先,我们打开163的网站,我们随意选择一个类别。我这里选择的类别是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这意味着该页面是异步的。即通过api接口获取的数据。
然后确认后就可以用F12打开谷歌浏览器的控制台,点击网络,我们一直往下拉,在右侧发现:“... special/00804KVA/cm_guonei_03.js?.. ..” 这样的地址,点击Response,发现就是我们要找的api接口。
可以看出这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的连接也是我们这次爬取要请求的地址。
接下来只需要两个python库:
要求
json
美丽汤
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析它。BeautifulSoup用于解析html文档,可以很方便的帮我们获取到指定div的内容。
让我们开始编写我们的爬虫:
第一步,导入以上三个包:
importjsonimportrequestsfrom bs4 import BeautifulSoup
然后我们定义一个获取指定页码数据的方法:
1 defget_page(page):2 url_temp = '{}.js'
3 return_list =[]4 for i inrange(page):5 url =url_temp.format(i)6 response =requests.get(url)7 if response.status_code != 200:8 继续
9 content = response.text #获取响应正文
10 _content = formatContent(content) #格式化json字符串
11 结果 =json.loads(_content)12 return_list.append(result)13 return return_list
这将得到每个页码对应的内容列表:
分析数据后,我们可以看到下图中圈出了需要抓取的标题、发布时间、新闻内容页面。
既然已经获取到了内容页的url,接下来就是爬取新闻正文了。
在抓取文本之前,首先要分析文本的html页面,找到文本、作者、出处在html文档中的位置。
我们看到 文章 源在文档中的位置为:id = "ne_article_source" 的标签。作者的立场是:class="ep-editor"的span标签。主体位置是:带有 class = "post_text" 的 div 标签。
我们试试采集这三个内容的代码:
1 defget_content(url):2 源 = ''
3作者=''
4 身体 = ''
5 resp =requests.get(url)6 if resp.status_code == 200:7 body =resp.text8 bs4 =BeautifulSoup(body)9 source = bs4.find('a', id='ne_article_source' ).get_text()10 author = bs4.find('span', class_='ep-editor').get_text()11 body = bs4.find('div', class_=' post_text').get_text()12 返回源、作者、正文
到目前为止,我们一直在抓取的所有数据都是 采集。
然后,当然,下一步是保存它们。为了方便,我直接以文本的形式保存。这是最终结果:
格式为 json 字符串,“title”:['date', 'url', 'source', 'author', 'body']。
需要注意的是,目前的实现是完全同步和线性的,问题是采集会很慢。主要延迟在网络IO上,可以升级为异步IO,异步采集。
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-31 15:20
搜索引擎收录爬虫、索引和算法,其中爬虫跟踪链接,由 网站 创建的链接,爬虫将 HTML 版本的页面保存在索引数据库中。每当爬虫绕过 网站 以查找新版本时,索引就会更新。
爬虫爬取的可追溯性,与爬取网站有关,网站可能会阻塞爬虫,有几种方法可以防止对网站的爬取。如果网站上的网页被屏蔽,会被爬虫拒绝,相应的页面也不会出现在搜索结果中。如果机器人文件阻塞了爬虫,在爬取网站之前,爬虫工具会查看网页的HTTP头,HTTP头中收录状态码,如果状态码显示网页不存在,它不会抓取网站,在关于HTTP headers的模块中,会告诉所有相关信息。如果特定页面上的元标记阻止搜索引擎将该页面编入索引,则该页面会被抓取但不会添加到索引中。
虽然可爬取只是一个技术基础,但所有类型的站长都会问的一个常见问题是如何更快地爬取网站,以及可以做些什么来提高爬取速度。抓到网站时,搜索引擎有两种可能,如果没有找到足够的网站链接,没关系,网站响应太慢,或者遇到错误太多。当没有足够的高质量入站链接时,内容不会很快被爬取,如果您希望爬虫进行更多的爬取,则需要进行一些链接构建。
网站为解决爬虫爬取响应慢的问题,如动态页面中大量JS代码,服务器不稳定,收录404页面,网站在生产过程中修改模板导致一些内容页面的文件夹如果没有删除,但是显示404的页面是连接的,先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好自动将代码推送到页面。如果要细化每个内容页面,会自动触发提交,从而提高爬虫的爬取频率。最后,核心是做高质量。对于外链,尽量在与自己的网站主题相关的网站上做外链,并保持一定的垂直度。目前很多网站都设置了外链的nofollow标签,选择在外链上发布。在论坛或者博客,或者推广软文的时候,首先检查外部链接的标签是否设置为nofollow,保证爬虫的链接可以引入。 查看全部
网页新闻抓取(搜索引擎问题是如何更快地网站网站,可采取哪些措施来提高速度)
搜索引擎收录爬虫、索引和算法,其中爬虫跟踪链接,由 网站 创建的链接,爬虫将 HTML 版本的页面保存在索引数据库中。每当爬虫绕过 网站 以查找新版本时,索引就会更新。
爬虫爬取的可追溯性,与爬取网站有关,网站可能会阻塞爬虫,有几种方法可以防止对网站的爬取。如果网站上的网页被屏蔽,会被爬虫拒绝,相应的页面也不会出现在搜索结果中。如果机器人文件阻塞了爬虫,在爬取网站之前,爬虫工具会查看网页的HTTP头,HTTP头中收录状态码,如果状态码显示网页不存在,它不会抓取网站,在关于HTTP headers的模块中,会告诉所有相关信息。如果特定页面上的元标记阻止搜索引擎将该页面编入索引,则该页面会被抓取但不会添加到索引中。
虽然可爬取只是一个技术基础,但所有类型的站长都会问的一个常见问题是如何更快地爬取网站,以及可以做些什么来提高爬取速度。抓到网站时,搜索引擎有两种可能,如果没有找到足够的网站链接,没关系,网站响应太慢,或者遇到错误太多。当没有足够的高质量入站链接时,内容不会很快被爬取,如果您希望爬虫进行更多的爬取,则需要进行一些链接构建。
网站为解决爬虫爬取响应慢的问题,如动态页面中大量JS代码,服务器不稳定,收录404页面,网站在生产过程中修改模板导致一些内容页面的文件夹如果没有删除,但是显示404的页面是连接的,先解决自己网站的所有问题。
那么最重要的就是提交给爬虫了。最好自动将代码推送到页面。如果要细化每个内容页面,会自动触发提交,从而提高爬虫的爬取频率。最后,核心是做高质量。对于外链,尽量在与自己的网站主题相关的网站上做外链,并保持一定的垂直度。目前很多网站都设置了外链的nofollow标签,选择在外链上发布。在论坛或者博客,或者推广软文的时候,首先检查外部链接的标签是否设置为nofollow,保证爬虫的链接可以引入。
网页新闻抓取(一下百度抓取诊断失败,蜘蛛过不去才导致了这种情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-29 19:17
最近有两个兄弟来找我,说网站搬家后,曲线暴跌,页面收录消失了。难道搬家对SEO有这么大的影响吗?
听到这里,基本可以断定,这位兄弟没有进行百度爬虫诊断!
还有兄弟反馈,说新成立的网站已经几天没有收录了,通过“公共消防系统”吸引了蜘蛛,没有蜘蛛通过经过。抱着试试看的心态,搜索了一下原因,原来是这种情况,是爬虫诊断失败,爬虫无法通过造成的。下面就来介绍一下百度爬虫诊断吧!
百度爬虫诊断的主要功能有哪些?对我来说,它其实是衡量你的网页是否能被百度抓取的一个标准。如果这里连爬都失败了,那么网页的100%不能是收录。
所以很多人在收录的第一步就犯了一个错误,连最基本的判断自己能不能被百度收录使用,就开始引蜘蛛投稿。
一般情况下,捕获是可以成功的。但也有爬取不成功的情况!失败的原因百度也有解释。
如果IP不正确(显示的IP和你解析的IP不对应),可以点击报错。如果还是不正确,点击几次,直到显示对应的IP。
如果是因为DNS错误,等1-2天再爬吧!如果 1-2 天后仍然无法正常工作,请更改 DNS。
爬取诊断是保证网站收录的前提,只有爬取成功才有机会成为收录。抓取诊断有两种应用场景:
1、新成立网站,加入百度站长工具平台,保证爬取诊断成功!
2、网站搬家换IP后,抢同诊断确保成功!
文章来源:公众号反冬黑帽SEO(ID:gh_c3dd79adc24e),原文链接: 查看全部
网页新闻抓取(一下百度抓取诊断失败,蜘蛛过不去才导致了这种情况)
最近有两个兄弟来找我,说网站搬家后,曲线暴跌,页面收录消失了。难道搬家对SEO有这么大的影响吗?
听到这里,基本可以断定,这位兄弟没有进行百度爬虫诊断!
还有兄弟反馈,说新成立的网站已经几天没有收录了,通过“公共消防系统”吸引了蜘蛛,没有蜘蛛通过经过。抱着试试看的心态,搜索了一下原因,原来是这种情况,是爬虫诊断失败,爬虫无法通过造成的。下面就来介绍一下百度爬虫诊断吧!
百度爬虫诊断的主要功能有哪些?对我来说,它其实是衡量你的网页是否能被百度抓取的一个标准。如果这里连爬都失败了,那么网页的100%不能是收录。
所以很多人在收录的第一步就犯了一个错误,连最基本的判断自己能不能被百度收录使用,就开始引蜘蛛投稿。
一般情况下,捕获是可以成功的。但也有爬取不成功的情况!失败的原因百度也有解释。
如果IP不正确(显示的IP和你解析的IP不对应),可以点击报错。如果还是不正确,点击几次,直到显示对应的IP。
如果是因为DNS错误,等1-2天再爬吧!如果 1-2 天后仍然无法正常工作,请更改 DNS。
爬取诊断是保证网站收录的前提,只有爬取成功才有机会成为收录。抓取诊断有两种应用场景:
1、新成立网站,加入百度站长工具平台,保证爬取诊断成功!
2、网站搬家换IP后,抢同诊断确保成功!
文章来源:公众号反冬黑帽SEO(ID:gh_c3dd79adc24e),原文链接:
网页新闻抓取(Python开发的一个快速、高层次框架会自动该类的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-03-29 19:13
记得十几年前还是高中生的时候,所谓的智能手机还没有普及。如果你想在学校阅读大量的电子书,你基本上依赖于具有阅读功能的 MP3 或 MP4。以及电子书的来源?在随时随地无法上网的情况下,有时我们靠的是一种傻瓜式方法:一页一页地粘贴复制一些小说网站的内容。而那些上百章的网络小说,靠这样的人工操作,确实很头疼。我多么希望我有一个工具可以为我自动化繁重的手工工作!!!
好了,言归正传,我最近一直在研究如何使用爬虫框架Scrapy。说一下想学Scrapy的初衷。
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy应用广泛,可用于数据挖掘、监控和自动化测试(百度百科上的介绍)。
经过几天的学习,初次使用Scrapy,首先需要了解的是以下几个概念:
所以,你需要做的就是编写上面提到的四个类,剩下的交给 Scrapy 框架。
你可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
在文件 spiderForShortPageMsg.py 中是我们要编写的 Spiders 子类。
例子:现在我想在网站中获取所有文章的标题和文章的地址。
第 1 步:编写一个继承自 Spiders 的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()来解析具体的html页面,找到我想要的数据,保存在数据类的一个Items中目的。
不要被这行代码吓倒:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的Selectors。这是用于定位您要查找的 html 标记的内容。有两种选择器,即XPath选择器和CSS选择器,这两种选择器都会用到。
这是我的 Item 数据类(即上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类 Item 执行的所有操作。
现在所需的数据已经在 Item 对象中。考虑到您的最终目的,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需几个简单的设置,就可以直接调用Django中的models类,从而省去复杂的数据库操作。不要太担心。谁用谁知道!! 查看全部
网页新闻抓取(Python开发的一个快速、高层次框架会自动该类的方法)
记得十几年前还是高中生的时候,所谓的智能手机还没有普及。如果你想在学校阅读大量的电子书,你基本上依赖于具有阅读功能的 MP3 或 MP4。以及电子书的来源?在随时随地无法上网的情况下,有时我们靠的是一种傻瓜式方法:一页一页地粘贴复制一些小说网站的内容。而那些上百章的网络小说,靠这样的人工操作,确实很头疼。我多么希望我有一个工具可以为我自动化繁重的手工工作!!!
好了,言归正传,我最近一直在研究如何使用爬虫框架Scrapy。说一下想学Scrapy的初衷。
Scrapy 是一个用 Python 开发的快速、高级的屏幕抓取和网页抓取框架,用于抓取网站并从页面中提取结构化数据。Scrapy应用广泛,可用于数据挖掘、监控和自动化测试(百度百科上的介绍)。
经过几天的学习,初次使用Scrapy,首先需要了解的是以下几个概念:
所以,你需要做的就是编写上面提到的四个类,剩下的交给 Scrapy 框架。
你可以先创建一个scrapy项目:
scrapy startproject getMyFavoritePages
在文件 spiderForShortPageMsg.py 中是我们要编写的 Spiders 子类。
例子:现在我想在网站中获取所有文章的标题和文章的地址。
第 1 步:编写一个继承自 Spiders 的类
Scrapy框架会自动调用这个类的方法parse(),其中parse()最后调用自定义方法parse_lobste_com()来解析具体的html页面,找到我想要的数据,保存在数据类的一个Items中目的。
不要被这行代码吓倒:
response.xpath("//div/div[2]/span[1]/a[@class='u-url']"
就是前面提到的Selectors。这是用于定位您要查找的 html 标记的内容。有两种选择器,即XPath选择器和CSS选择器,这两种选择器都会用到。
这是我的 Item 数据类(即上面的 pageItem)。
第 2 步:在 Item Pipeline 中定义要对数据类 Item 执行的所有操作。
现在所需的数据已经在 Item 对象中。考虑到您的最终目的,最好的选择当然是将所有数据保存在数据库中。
说到数据库操作,不得不提Django中的models类。只需几个简单的设置,就可以直接调用Django中的models类,从而省去复杂的数据库操作。不要太担心。谁用谁知道!!

