
网页新闻抓取
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-02 19:26
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:

我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:

具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:

首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code

使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(影响蜘蛛爬行并最终影响到页面收录结果主要有几个方面的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 20:17
影响蜘蛛抓取并最终影响页面收录结果的原因有多种。
1. 网站 更新
一般情况下,网站 更新很快,并且蜘蛛爬取 网站 的内容更快。如果网站的内容长时间没有更新,蜘蛛也会相应调整网站的爬取频率。更新频率对于新闻等至关重要。网站。因此,保持一定数量的每日更新对于吸引蜘蛛非常重要。
2. 网站内容质量
对于低质量的页面,搜索引擎总是在争吵,所以创造高质量的内容对于吸引蜘蛛非常关键。从这个角度来说,“内容取胜”是完全正确的。如果网页质量低,比如很多采集相同的内容,而页面的核心内容是空的,就不会受到蜘蛛的青睐。
3. 网站是否可以正常访问
网站能否正常访问是搜索引擎的连接度。连接需求网站不能频繁访问,或者访问速度极慢。从蜘蛛的角度来看,我希望提供给检索客户的网页都是可以正常访问的页面。对于响应速度慢或者经常崩溃的服务器,相关的网站肯定会有负面印象,严重的是逐渐减少爬取甚至剔除已经是收录的页面。
现实中,由于国内服务器服务成本相对较高,另外,基于监管要求,建立国内网站需要备案系统,需要经过网上上传备案信息的流程。一些中小型网站网站长期可能会在国外租用服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问国外服务器时,由于距离较远,访问速度慢或死机在所难免。从长远来看,网站 的 SEO 效果是一个约束。如果你想用心运行一个网站,你应该尝试使用国内的服务器服务。您可以选择一些服务更好、界面友好的服务器提供商。现在,
此外,搜索引擎会根据网站的综合表现对网站进行评分。这个评分不能完全等于权重,但是评分的高低会影响蜘蛛对网站策略的爬取。
在爬取频率方面,搜索引擎一般都会提供可以调整爬取频率设置的工具,SEO人员可以根据实际情况进行调整。对于大型网站,服务请求多,可以使用调整频率的工具来减轻网站的压力。
在实际的爬取过程中,如果出现不可访问的爬取异常,将会大大降低搜索引擎对网站的评分,从而影响爬取、索引、排序等一系列SEO效果。流量损失。
爬网异常的发生可能有多种原因,例如服务器不稳定、服务器不断过载或协议错误。因此,网站运维人员需要持续跟踪网站的运行情况,保证网站的稳定运行。在协议配置中,需要避免一些低级错误,例如 Robots Disallow 设置错误。有一次,公司经理咨询了SEO人员,问他们为什么委托外部开发人员做好网站后在搜索引擎中找不到。SEO人员直接在网址和地址栏输入他的网站Robots地址,发现禁止蜘蛛爬行(Disallow命令)!
关于无法访问网站还有其他可能,比如网络运营商异常,即蜘蛛无法通过电信或网通等服务商访问网站;DNS异常,即蜘蛛无法解析网站IP,地址可能有误,也可能被域名提供商屏蔽。在这种情况下,您需要联系域名提供商。网页也可能存在死链接,例如当前页面失效或出现错误,部分网页可能已经批量下线。在这种情况下,最好的方法是提交死链接描述;如果是 url 更改导致的旧链接 URL 无效,无法访问。最好设置一个 301 跳转,将旧 URL 和相关权重转移到新页面。当然,
对于已经捕获的数据,然后蜘蛛建立数据库。在这个链接中,搜索引擎会根据一些原则来判断链接的重要性。一般来说,判断的原则如下:内容是否为原创,如果是则加权;主要内容是否显着,即核心内容是否显着,如果是,则加权;内容是否丰富,如果内容非常丰富,则进行加权;用户体验是否好,比如页面更流畅,广告加载少等,如果是,会加权等等。
因此,我们在网站的日常操作中需要坚持以下原则。
(1)请勿抄袭。因为独特的内容是所有搜索引擎公司都喜欢的,所以互联网鼓励原创。很多互联网公司希望通过大量的采集@组织自己的网站>网页内容@>,从SEO的角度来看,其实是一种不受欢迎的行为。
(2)在网站的内容设计中,要坚持主题内容的突出,也就是让搜索引擎爬过来知道网页的内容是什么表达,而不是从一堆内容网站判断网站到底是做什么业务的。主题不突出,很多网站操作混乱的典型案例。例如,在一些小说网站中,一个800字的章节被分成8个,每页100字左右,剩下的页面收录各种广告和各种不相关的内容信息。还有网站,主要内容是一个frame框架或者AIAX框架,蜘蛛可以抓取的信息都是不相关的内容。
尤其是弹出大量低质量广告和有混淆页面主要内容的垃圾广告的页面。目前一些大型门户网站网站从收入来看,还是挂了很多广告。作为SEO人员,你需要考虑这个问题。
(4)维护网页内容的可访问性。有些网页承载了很多内容,但是以js、AJAX等方式呈现,搜索引擎无法识别,导致网页内容空洞、短小.网页的评分大大降低。
此外,在链接的重要性方面,有两个重要的判断原则:从目录层面来看,坚持浅层优先原则;从内链设计的角度,坚持热门页面优先的原则。
所谓浅优先,是指搜索引擎在处理新链接和判断链接重要性时,会优先考虑URL。更多页面,即来自 url 组织的更接近主页域名的页面。因此,SEO在优化重要页面时,一定要注意扁平化的原则,尽可能缩短URL的中间链接。
既然浅层优先,那么是否可以将所有页面平铺在网站根目录下,从而选择最佳的SEO效果?当然不是,首先,优先级是一个相对的概念,如果所有的内容都放在根目录下,那么赋予什么优先级都无所谓。重要内容和不重要内容之间没有区别。另外,从SEO的角度来看,URL也用于分析爬取后的网站的结构。通过URL的构成,可以大致判断内容的分组情况。SEO人员可以完成由关键词和内容组成的URL。关键词网页的组织。
目前在网站上的人气主要体现在以下几个指标上。
・网站上指向该页面的内部链接数。
・通过网站上的自然浏览行为到达页面的 PV。
・此页面的点击流失率。
所以,从SEO的角度来说,如果需要快速提升一个页面的搜索排名,可以在人气方面做一些工作,如下。
・多做从其他页面到页面的锚文本,尤其是高PR页面。
・给页面一个吸引人的标题,引导更多自然浏览的用户点击页面链接。
・提高页面内容质量,降低页面流量 查看全部
网页新闻抓取(影响蜘蛛爬行并最终影响到页面收录结果主要有几个方面的原因)
影响蜘蛛抓取并最终影响页面收录结果的原因有多种。

1. 网站 更新
一般情况下,网站 更新很快,并且蜘蛛爬取 网站 的内容更快。如果网站的内容长时间没有更新,蜘蛛也会相应调整网站的爬取频率。更新频率对于新闻等至关重要。网站。因此,保持一定数量的每日更新对于吸引蜘蛛非常重要。
2. 网站内容质量
对于低质量的页面,搜索引擎总是在争吵,所以创造高质量的内容对于吸引蜘蛛非常关键。从这个角度来说,“内容取胜”是完全正确的。如果网页质量低,比如很多采集相同的内容,而页面的核心内容是空的,就不会受到蜘蛛的青睐。
3. 网站是否可以正常访问
网站能否正常访问是搜索引擎的连接度。连接需求网站不能频繁访问,或者访问速度极慢。从蜘蛛的角度来看,我希望提供给检索客户的网页都是可以正常访问的页面。对于响应速度慢或者经常崩溃的服务器,相关的网站肯定会有负面印象,严重的是逐渐减少爬取甚至剔除已经是收录的页面。
现实中,由于国内服务器服务成本相对较高,另外,基于监管要求,建立国内网站需要备案系统,需要经过网上上传备案信息的流程。一些中小型网站网站长期可能会在国外租用服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问国外服务器时,由于距离较远,访问速度慢或死机在所难免。从长远来看,网站 的 SEO 效果是一个约束。如果你想用心运行一个网站,你应该尝试使用国内的服务器服务。您可以选择一些服务更好、界面友好的服务器提供商。现在,
此外,搜索引擎会根据网站的综合表现对网站进行评分。这个评分不能完全等于权重,但是评分的高低会影响蜘蛛对网站策略的爬取。
在爬取频率方面,搜索引擎一般都会提供可以调整爬取频率设置的工具,SEO人员可以根据实际情况进行调整。对于大型网站,服务请求多,可以使用调整频率的工具来减轻网站的压力。
在实际的爬取过程中,如果出现不可访问的爬取异常,将会大大降低搜索引擎对网站的评分,从而影响爬取、索引、排序等一系列SEO效果。流量损失。
爬网异常的发生可能有多种原因,例如服务器不稳定、服务器不断过载或协议错误。因此,网站运维人员需要持续跟踪网站的运行情况,保证网站的稳定运行。在协议配置中,需要避免一些低级错误,例如 Robots Disallow 设置错误。有一次,公司经理咨询了SEO人员,问他们为什么委托外部开发人员做好网站后在搜索引擎中找不到。SEO人员直接在网址和地址栏输入他的网站Robots地址,发现禁止蜘蛛爬行(Disallow命令)!
关于无法访问网站还有其他可能,比如网络运营商异常,即蜘蛛无法通过电信或网通等服务商访问网站;DNS异常,即蜘蛛无法解析网站IP,地址可能有误,也可能被域名提供商屏蔽。在这种情况下,您需要联系域名提供商。网页也可能存在死链接,例如当前页面失效或出现错误,部分网页可能已经批量下线。在这种情况下,最好的方法是提交死链接描述;如果是 url 更改导致的旧链接 URL 无效,无法访问。最好设置一个 301 跳转,将旧 URL 和相关权重转移到新页面。当然,
对于已经捕获的数据,然后蜘蛛建立数据库。在这个链接中,搜索引擎会根据一些原则来判断链接的重要性。一般来说,判断的原则如下:内容是否为原创,如果是则加权;主要内容是否显着,即核心内容是否显着,如果是,则加权;内容是否丰富,如果内容非常丰富,则进行加权;用户体验是否好,比如页面更流畅,广告加载少等,如果是,会加权等等。
因此,我们在网站的日常操作中需要坚持以下原则。
(1)请勿抄袭。因为独特的内容是所有搜索引擎公司都喜欢的,所以互联网鼓励原创。很多互联网公司希望通过大量的采集@组织自己的网站>网页内容@>,从SEO的角度来看,其实是一种不受欢迎的行为。
(2)在网站的内容设计中,要坚持主题内容的突出,也就是让搜索引擎爬过来知道网页的内容是什么表达,而不是从一堆内容网站判断网站到底是做什么业务的。主题不突出,很多网站操作混乱的典型案例。例如,在一些小说网站中,一个800字的章节被分成8个,每页100字左右,剩下的页面收录各种广告和各种不相关的内容信息。还有网站,主要内容是一个frame框架或者AIAX框架,蜘蛛可以抓取的信息都是不相关的内容。
尤其是弹出大量低质量广告和有混淆页面主要内容的垃圾广告的页面。目前一些大型门户网站网站从收入来看,还是挂了很多广告。作为SEO人员,你需要考虑这个问题。
(4)维护网页内容的可访问性。有些网页承载了很多内容,但是以js、AJAX等方式呈现,搜索引擎无法识别,导致网页内容空洞、短小.网页的评分大大降低。
此外,在链接的重要性方面,有两个重要的判断原则:从目录层面来看,坚持浅层优先原则;从内链设计的角度,坚持热门页面优先的原则。
所谓浅优先,是指搜索引擎在处理新链接和判断链接重要性时,会优先考虑URL。更多页面,即来自 url 组织的更接近主页域名的页面。因此,SEO在优化重要页面时,一定要注意扁平化的原则,尽可能缩短URL的中间链接。
既然浅层优先,那么是否可以将所有页面平铺在网站根目录下,从而选择最佳的SEO效果?当然不是,首先,优先级是一个相对的概念,如果所有的内容都放在根目录下,那么赋予什么优先级都无所谓。重要内容和不重要内容之间没有区别。另外,从SEO的角度来看,URL也用于分析爬取后的网站的结构。通过URL的构成,可以大致判断内容的分组情况。SEO人员可以完成由关键词和内容组成的URL。关键词网页的组织。
目前在网站上的人气主要体现在以下几个指标上。
・网站上指向该页面的内部链接数。
・通过网站上的自然浏览行为到达页面的 PV。
・此页面的点击流失率。
所以,从SEO的角度来说,如果需要快速提升一个页面的搜索排名,可以在人气方面做一些工作,如下。
・多做从其他页面到页面的锚文本,尤其是高PR页面。
・给页面一个吸引人的标题,引导更多自然浏览的用户点击页面链接。
・提高页面内容质量,降低页面流量
网页新闻抓取(学习机器学习算法,分为回归,分类,爬取一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-20 02:04
)
作者简历地址:
Python爬虫一步步爬取文章后台
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据做练习,所以想爬取国内各大网站的新闻,通过训练,然后对未来的News进行分类预测。在这样的背景下,我的爬虫之旅开始了。
网站分析
国内重大新闻汇总网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。. .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了urllib2和BeautifulSoup这两个包。以搜狐新闻为例,做了一个简单的爬取内容的爬虫,没有做任何优化等问题,所以会出现假死等情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
以上代码在运行过程中,会遇到一些问题,导致爬虫运行中断,运行缓慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后通过设置爬虫的代理解决IP问题。代码显示如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果找不到网页,则直接丢弃,因为丢弃少量网页不会影响以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
关于速度慢,爬取可以采用多进程的方式。解析完URL,就可以在Redis中使用有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。(尚未实现)
第 4 步:运行
昨晚试运行,爬取了搜狐新闻的部分网页,大概50*5*15=3750个网页,解析了2000多条新闻。当网速接近1Mbps时,我花了很多钱。1101s的时间约为18分钟。
查看全部
网页新闻抓取(学习机器学习算法,分为回归,分类,爬取一下
)
作者简历地址:
Python爬虫一步步爬取文章后台
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据做练习,所以想爬取国内各大网站的新闻,通过训练,然后对未来的News进行分类预测。在这样的背景下,我的爬虫之旅开始了。
网站分析
国内重大新闻汇总网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。. .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了urllib2和BeautifulSoup这两个包。以搜狐新闻为例,做了一个简单的爬取内容的爬虫,没有做任何优化等问题,所以会出现假死等情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
以上代码在运行过程中,会遇到一些问题,导致爬虫运行中断,运行缓慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后通过设置爬虫的代理解决IP问题。代码显示如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果找不到网页,则直接丢弃,因为丢弃少量网页不会影响以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
关于速度慢,爬取可以采用多进程的方式。解析完URL,就可以在Redis中使用有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。(尚未实现)
第 4 步:运行
昨晚试运行,爬取了搜狐新闻的部分网页,大概50*5*15=3750个网页,解析了2000多条新闻。当网速接近1Mbps时,我花了很多钱。1101s的时间约为18分钟。

网页新闻抓取( Python3实战入门数据库篇--把爬取到的数据存到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-18 11:26
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于抓到的html文档比较长,这里简单贴个帖子给大家看看。
..........后面省略一大堆
复制代码
这是Python3爬虫的简单介绍,是不是很简单,建议你敲几遍
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看我爬过哪些美图
爬到 24 个女孩的照片是如此容易。是不是很简单。
四、Python3爬取新闻网站新闻列表
这里有点复杂,所以我会向你解释。
分析上图中我们要抓取的信息然后放到div中的a标签和img标签中,那么我们思考的是如何获取这些信息
这里会用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到的,但是太乱了,还有很多我们不想要的东西。让我们通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里增加了异常处理,主要是因为有些新闻可能没有标题、网址或图片。如果不进行异常处理,可能会导致我们爬取的中断。
过滤的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,完整代码贴在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取到数据后,我们还需要将数据存入数据库。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以利用这些爬取的文章,给app提供一个新闻api接口。当然,这是后话了。学完Python数据库操作后,我会写一篇文章文章《Python3实战入门数据库篇---将爬取的数据保存到数据库》 查看全部
网页新闻抓取(
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于抓到的html文档比较长,这里简单贴个帖子给大家看看。
..........后面省略一大堆
复制代码
这是Python3爬虫的简单介绍,是不是很简单,建议你敲几遍
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看我爬过哪些美图
爬到 24 个女孩的照片是如此容易。是不是很简单。
四、Python3爬取新闻网站新闻列表
这里有点复杂,所以我会向你解释。
分析上图中我们要抓取的信息然后放到div中的a标签和img标签中,那么我们思考的是如何获取这些信息
这里会用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到的,但是太乱了,还有很多我们不想要的东西。让我们通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里增加了异常处理,主要是因为有些新闻可能没有标题、网址或图片。如果不进行异常处理,可能会导致我们爬取的中断。
过滤的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,完整代码贴在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取到数据后,我们还需要将数据存入数据库。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以利用这些爬取的文章,给app提供一个新闻api接口。当然,这是后话了。学完Python数据库操作后,我会写一篇文章文章《Python3实战入门数据库篇---将爬取的数据保存到数据库》
网页新闻抓取( 测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2022-02-18 11:10
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:一般新闻网页文本的在线提取
摄影:产品经理
毛脑花和广粉
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
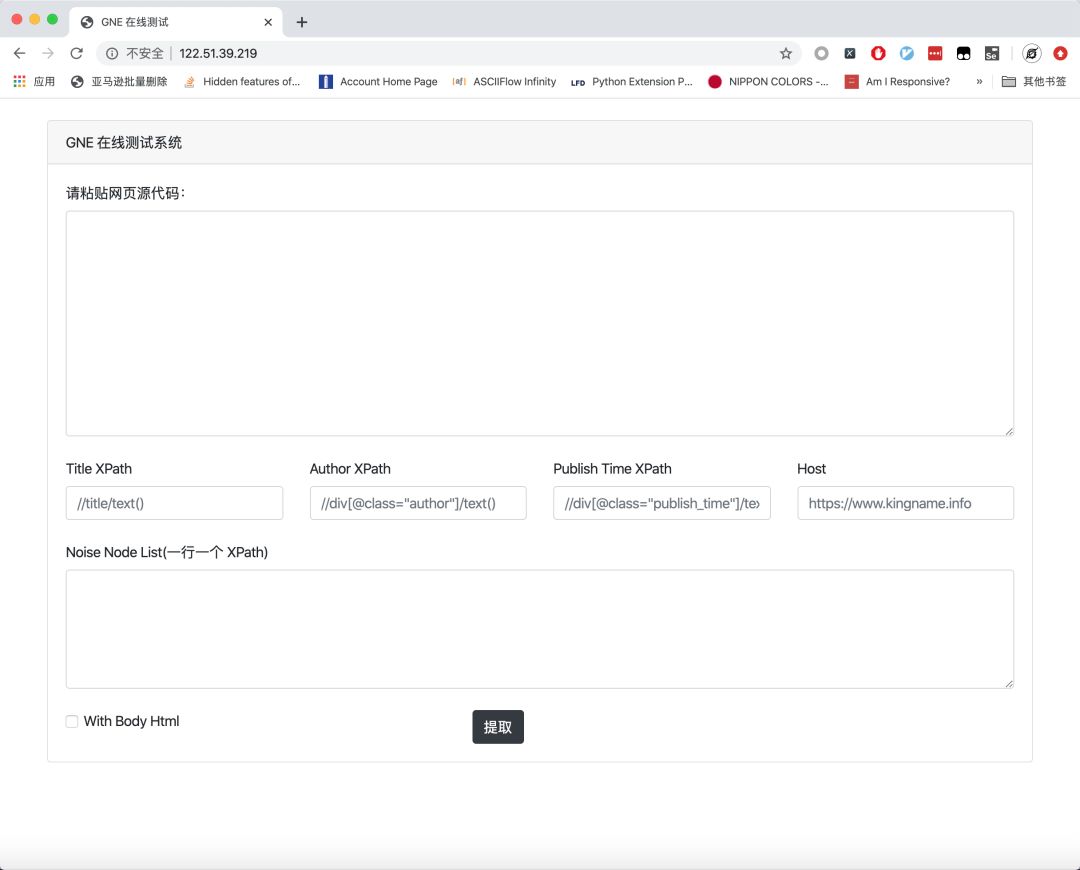
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
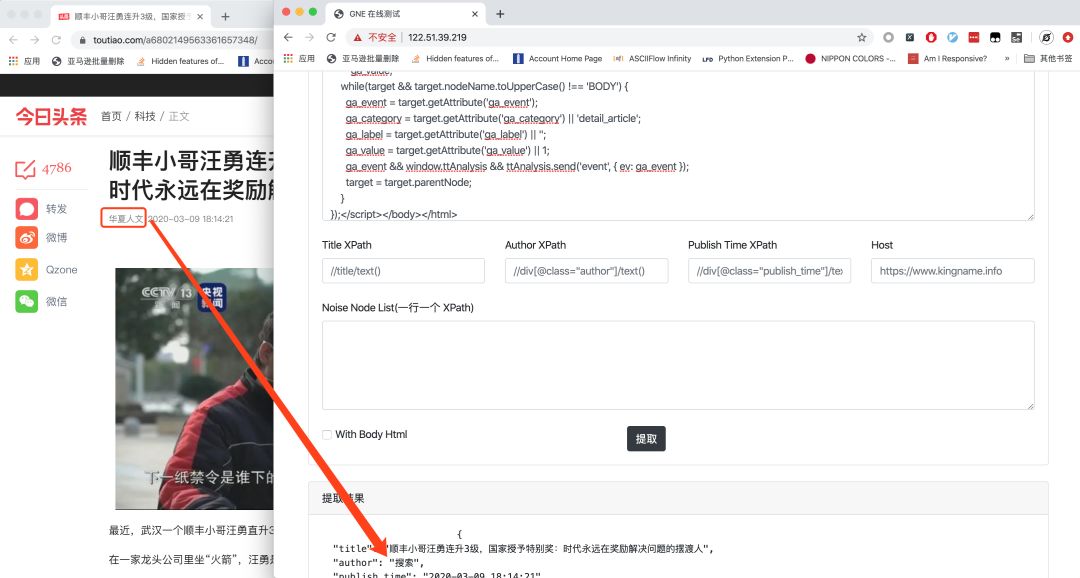
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
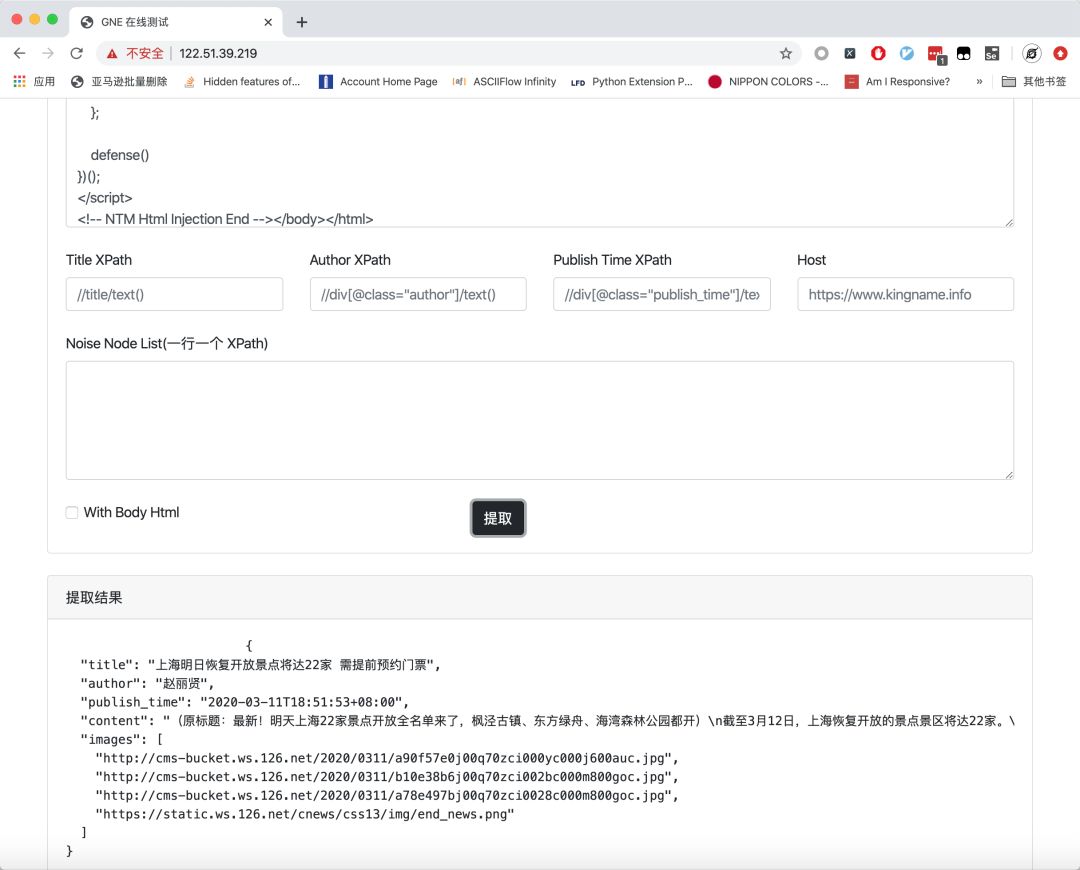
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考文献
[1]
GNE:
[2]
官方文档:
国王的名字
为产品经理省钱买房。 查看全部
网页新闻抓取(
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:一般新闻网页文本的在线提取

摄影:产品经理
毛脑花和广粉
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。

要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:

对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:

新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。

通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考文献
[1]
GNE:
[2]
官方文档:

国王的名字
为产品经理省钱买房。
网页新闻抓取(手机用户浏览桂林电子科技大学校园网新闻显示页面的多少?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-16 00:25
题目来源及背景:本题目来源于自选题目。软件可以抓取新闻网站的列表和内容,将列表和内容调整为适合手机屏幕浏览的界面风格,并显示在网页上;软件动态抓取桂林电子科技大学新闻网站信息内容,一旦布局成功,您可以在手机上轻松快速浏览桂林电子科技大学新闻,无需手机屏幕显示的效果还是难看的问题。技术创新与进步:基于普通电脑和win7操作系统,php环境,apache web服务器,开发一套技术成熟,适用范围及安全性:成熟;适用范围:适用于新闻网站自动抓取展示。安全:公平。应用及存在问题:一般。历年获奖:无。成就介绍:从新闻列表页面跳转具体新闻信息页面。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。具体新闻展示页面 该页面主要展示具体的新闻信息,从新闻列表页面跳转。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。 查看全部
网页新闻抓取(手机用户浏览桂林电子科技大学校园网新闻显示页面的多少?(图))
题目来源及背景:本题目来源于自选题目。软件可以抓取新闻网站的列表和内容,将列表和内容调整为适合手机屏幕浏览的界面风格,并显示在网页上;软件动态抓取桂林电子科技大学新闻网站信息内容,一旦布局成功,您可以在手机上轻松快速浏览桂林电子科技大学新闻,无需手机屏幕显示的效果还是难看的问题。技术创新与进步:基于普通电脑和win7操作系统,php环境,apache web服务器,开发一套技术成熟,适用范围及安全性:成熟;适用范围:适用于新闻网站自动抓取展示。安全:公平。应用及存在问题:一般。历年获奖:无。成就介绍:从新闻列表页面跳转具体新闻信息页面。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。具体新闻展示页面 该页面主要展示具体的新闻信息,从新闻列表页面跳转。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-08 10:18
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-08 08:08
)
为什么要提取文本
一般来说,舆情分析都会涉及到网页内容的提取。对于分析,有价值的信息是身体部分。大多数情况下,为了便于分析,需要将网页中与正文无关的部分去掉。可以说,文本提取的好坏直接影响分析结果的好坏。
对于具体的网站,我们可以分析其html结构,根据其结构获取body信息。看看下面的图片:
在body部分,不同的网站,body的位置不同,Html的结构也不同。对于爬虫来说,要爬取的页面是多种多样的,不可能对所有页面都写爬取。规则来提取文本内容,因此需要一个通用的算法来提取文本。
现有网页文本提取算法
前两种方法比较容易实现,主要是处理简单。之前实现过标签密度提取算法,但是实际中错误率还是挺高的;后两种方法在实现上稍微复杂一些。算法效率应该不会高很多。
我们需要的是一种简单且易于实现的算法,可以保证处理速度和良好的提取精度。因此,结合前两种算法,研究网页的html页面结构,有一个更好的处理思路,称为基于文本密度的文本提取算法。后来在网上找了一个类似的算法,发现也有类似的处理文本提取的处理方法,但还是有些不同。接下来给大家分享一下这个算法的一些处理思路。
网页分析
我随便从百度、搜狐、网易拿了一个新闻页面,拿来分析。
先看一个百度文章
任正非为什么要主动和我合影?
先请求这个页面,然后过滤到所有的html标签,只留下文本信息,我们可以看到body信息集中在以下几个位置:
使用Excel分析行数与每行字符的关系可以发现:
显然,文本内容集中在65-100行之间的位置,这个区间的字符数比较密集。
网易的另一篇文章文章
张小龙的神话破灭了,马化腾接手微信的时候到了。
或者先过滤html标签后看body部分:
另一个Excel分析结果:
文本部分集中在第 279-282 行之间。从图中可以看出,正是这些行具有特别高的文本密度。
搜狐新闻最后分析
李克强在天津考察考察期间的几个瞬间,
或者看一下标签后面的文字:
看一下Excel中的分析结果:
而搜狐的文章正文部分主要集中在200-255行之间。其余的文字都是杂乱无章的标签文字。
对不起,我漏掉了一个很重要的解释:为什么我们在分析的时候要过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关注的是body的内容。如果有这样的标签 style="color: #0000ff;">varchart =style="color: #0000ff;">newstyle="color: #000000;">来分析一下,可以想象会干扰到我们的文字分析,这就是为什么需要去掉html标签,只分析文本以减少干扰。
基于网页分析的文本提取算法
回顾上面的网页分析,如果按照文本密度提取文本,那么编写一个算法,可以从过滤html标签后的文本中找到文本的起止行号,以及文本之间的文本行号是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文字密度远高于非正文部分。根据这个特性,我们可以很容易地实现算法,即根据阈值(发音:yu)值来分析文本的位置。
那么需要解决一些问题:
阈值的确定可以通过统计分析得到一个较好的值。在实际处理过程中,我发现这个值是180比较合适,也就是在分析文本的时候,如果分析出来的文本超过180,那么就可以认为达到了body部分。
然后是如何分析的问题。这实际上是比较容易确定的。逐行分析的效果肯定不好。如果在逐行分析的过程中分析多行,效果会更好。也就是说,一次分析5行左右,把字符加起来,看看是否达到了设定的阈值。如果达到,则认为已进入文本部分。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
<p>int preTextLen = 0; // 记录上一次统计的字符数量(lines就是去除html标签后的文本,_limitCount是阈值,_depth是我们要分析的深度,sb用于记录正文)int startPos = -1; // 记录文章正文的起始位置for (int i = 0; i < lines.Length - _depth; i++){ int len = 0; for (int j = 0; j < _depth; j++) { len += lines[i + j].Length; } if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置 { if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置 { // 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部 int emptyCount = 0; for (int j = i - 1; j > 0; j--) { if (String.IsNullOrEmpty(lines[j])) { emptyCount++; } else { emptyCount = 0; } if (emptyCount == _headEmptyLines) { startPos = j + _headEmptyLines; break; } } // 如果没有定位到文章头,则以当前查找位置作为文章头 if (startPos == -1) { startPos = i; } // 填充发现的文章起始部分 for (int j = startPos; j 查看全部
网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏
)
为什么要提取文本
一般来说,舆情分析都会涉及到网页内容的提取。对于分析,有价值的信息是身体部分。大多数情况下,为了便于分析,需要将网页中与正文无关的部分去掉。可以说,文本提取的好坏直接影响分析结果的好坏。
对于具体的网站,我们可以分析其html结构,根据其结构获取body信息。看看下面的图片:
在body部分,不同的网站,body的位置不同,Html的结构也不同。对于爬虫来说,要爬取的页面是多种多样的,不可能对所有页面都写爬取。规则来提取文本内容,因此需要一个通用的算法来提取文本。
现有网页文本提取算法
前两种方法比较容易实现,主要是处理简单。之前实现过标签密度提取算法,但是实际中错误率还是挺高的;后两种方法在实现上稍微复杂一些。算法效率应该不会高很多。
我们需要的是一种简单且易于实现的算法,可以保证处理速度和良好的提取精度。因此,结合前两种算法,研究网页的html页面结构,有一个更好的处理思路,称为基于文本密度的文本提取算法。后来在网上找了一个类似的算法,发现也有类似的处理文本提取的处理方法,但还是有些不同。接下来给大家分享一下这个算法的一些处理思路。
网页分析
我随便从百度、搜狐、网易拿了一个新闻页面,拿来分析。
先看一个百度文章
任正非为什么要主动和我合影?
先请求这个页面,然后过滤到所有的html标签,只留下文本信息,我们可以看到body信息集中在以下几个位置:
使用Excel分析行数与每行字符的关系可以发现:
显然,文本内容集中在65-100行之间的位置,这个区间的字符数比较密集。
网易的另一篇文章文章
张小龙的神话破灭了,马化腾接手微信的时候到了。
或者先过滤html标签后看body部分:
另一个Excel分析结果:
文本部分集中在第 279-282 行之间。从图中可以看出,正是这些行具有特别高的文本密度。
搜狐新闻最后分析
李克强在天津考察考察期间的几个瞬间,
或者看一下标签后面的文字:
看一下Excel中的分析结果:
而搜狐的文章正文部分主要集中在200-255行之间。其余的文字都是杂乱无章的标签文字。
对不起,我漏掉了一个很重要的解释:为什么我们在分析的时候要过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关注的是body的内容。如果有这样的标签 style="color: #0000ff;">varchart =style="color: #0000ff;">newstyle="color: #000000;">来分析一下,可以想象会干扰到我们的文字分析,这就是为什么需要去掉html标签,只分析文本以减少干扰。
基于网页分析的文本提取算法
回顾上面的网页分析,如果按照文本密度提取文本,那么编写一个算法,可以从过滤html标签后的文本中找到文本的起止行号,以及文本之间的文本行号是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文字密度远高于非正文部分。根据这个特性,我们可以很容易地实现算法,即根据阈值(发音:yu)值来分析文本的位置。
那么需要解决一些问题:
阈值的确定可以通过统计分析得到一个较好的值。在实际处理过程中,我发现这个值是180比较合适,也就是在分析文本的时候,如果分析出来的文本超过180,那么就可以认为达到了body部分。
然后是如何分析的问题。这实际上是比较容易确定的。逐行分析的效果肯定不好。如果在逐行分析的过程中分析多行,效果会更好。也就是说,一次分析5行左右,把字符加起来,看看是否达到了设定的阈值。如果达到,则认为已进入文本部分。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
<p>int preTextLen = 0; // 记录上一次统计的字符数量(lines就是去除html标签后的文本,_limitCount是阈值,_depth是我们要分析的深度,sb用于记录正文)int startPos = -1; // 记录文章正文的起始位置for (int i = 0; i < lines.Length - _depth; i++){ int len = 0; for (int j = 0; j < _depth; j++) { len += lines[i + j].Length; } if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置 { if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置 { // 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部 int emptyCount = 0; for (int j = i - 1; j > 0; j--) { if (String.IsNullOrEmpty(lines[j])) { emptyCount++; } else { emptyCount = 0; } if (emptyCount == _headEmptyLines) { startPos = j + _headEmptyLines; break; } } // 如果没有定位到文章头,则以当前查找位置作为文章头 if (startPos == -1) { startPos = i; } // 填充发现的文章起始部分 for (int j = startPos; j
网页新闻抓取(测试GNE的原因和解决方法,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-06 21:11
Gne是如何提取新闻网页的,相信很多没有经验的人对此都束手无策。为此,本文总结了问题的原因和解决方法。通过这个文章希望你能解决这个问题。
GNE[1] 是我开源的新闻网站 的通用提取器。自发布以来,受到了很多学生的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
打开Gne Online的地址是:,打开后的页面如下图所示。
要测试 GNE 的功能,您只需将网页的源代码粘贴到顶部文本框中,然后单击提取按钮:
对于标题、作者、新闻发布时间可能发错的情况,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取新闻时犯了一个错误。这时候可以指定 XPath://div[@class="article-sub"]/span[1]/text() 来定向提取,如下图所示。
通过设置 Host 输入框,可以在网页正文中的图片为相对路径时拼写 URL。
通过勾选下方的With Body Html复选框,可以返回body所在区域的网页源代码。
看完以上内容,你是否掌握了Gne是如何提取新闻网页的呢?如果您想学习更多技能或想了解更多相关内容,请关注易宿云行业资讯频道,感谢您的阅读! 查看全部
网页新闻抓取(测试GNE的原因和解决方法,你get到了吗?)
Gne是如何提取新闻网页的,相信很多没有经验的人对此都束手无策。为此,本文总结了问题的原因和解决方法。通过这个文章希望你能解决这个问题。
GNE[1] 是我开源的新闻网站 的通用提取器。自发布以来,受到了很多学生的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
打开Gne Online的地址是:,打开后的页面如下图所示。
要测试 GNE 的功能,您只需将网页的源代码粘贴到顶部文本框中,然后单击提取按钮:
对于标题、作者、新闻发布时间可能发错的情况,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取新闻时犯了一个错误。这时候可以指定 XPath://div[@class="article-sub"]/span[1]/text() 来定向提取,如下图所示。
通过设置 Host 输入框,可以在网页正文中的图片为相对路径时拼写 URL。
通过勾选下方的With Body Html复选框,可以返回body所在区域的网页源代码。
看完以上内容,你是否掌握了Gne是如何提取新闻网页的呢?如果您想学习更多技能或想了解更多相关内容,请关注易宿云行业资讯频道,感谢您的阅读!
网页新闻抓取( 网站数据编写的应用框架-Scrapy )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 06:06
网站数据编写的应用框架-Scrapy
)
使用scrapy爬虫框架爬取伯乐在线的文章标题、标题url和发布时间
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可用于数据挖掘、信息处理或存储历史数据等一系列程序中。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于检索 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
图1
根据scrapy里面的调度,
第1步:创建一个项目scrapy startproject jobbole2,我使用的是虚拟环境,之前也下载过这个项目。输入命令后出现如下提示。
创建项目
第二步:创建成功后会自动给出下一步的提示命令,如下,根据提示输入cd jobbole2,然后输入命令scrapy genspider my_jobbole2,创建成功后进入我们的编译器,我用的是pycharm。
创建下一个文件
第三步:虚拟环境和pycharm配置好后,同步目录,下载刚刚创建的scrapy项目,进入my_jobbole2.py文件编写爬虫代码
Step 4:网页的解析步骤和爬虫的代码编写,这部分比较简单。只要熟悉request请求的网页的lxml解析步骤,这部分的代码就很容易理解了。先学爬虫基础,再学爬虫框架。这里就不赘述了,直接上代码吧(提醒一下scrapy和pyspider是不同的,方便调试,建议在scrapy shell中调试)。
Step 5:完成以上代码后,scrapy框架相信大家已经很熟悉了。看图1,了解一下这个框架的爬取思路。蟒蛇之禅,古朴典雅。了解每个文件的分工。这种想法还在继续。,你会接触到的队列,生产者-消费者模式,或者代理池之类的其实都认为py文件相互调用,每个文件负责一个。最后粘贴成功的代码。
查看全部
网页新闻抓取(
网站数据编写的应用框架-Scrapy
)
使用scrapy爬虫框架爬取伯乐在线的文章标题、标题url和发布时间
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可用于数据挖掘、信息处理或存储历史数据等一系列程序中。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于检索 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
图1
根据scrapy里面的调度,
第1步:创建一个项目scrapy startproject jobbole2,我使用的是虚拟环境,之前也下载过这个项目。输入命令后出现如下提示。
创建项目
第二步:创建成功后会自动给出下一步的提示命令,如下,根据提示输入cd jobbole2,然后输入命令scrapy genspider my_jobbole2,创建成功后进入我们的编译器,我用的是pycharm。
创建下一个文件
第三步:虚拟环境和pycharm配置好后,同步目录,下载刚刚创建的scrapy项目,进入my_jobbole2.py文件编写爬虫代码
Step 4:网页的解析步骤和爬虫的代码编写,这部分比较简单。只要熟悉request请求的网页的lxml解析步骤,这部分的代码就很容易理解了。先学爬虫基础,再学爬虫框架。这里就不赘述了,直接上代码吧(提醒一下scrapy和pyspider是不同的,方便调试,建议在scrapy shell中调试)。
Step 5:完成以上代码后,scrapy框架相信大家已经很熟悉了。看图1,了解一下这个框架的爬取思路。蟒蛇之禅,古朴典雅。了解每个文件的分工。这种想法还在继续。,你会接触到的队列,生产者-消费者模式,或者代理池之类的其实都认为py文件相互调用,每个文件负责一个。最后粘贴成功的代码。
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-01 18:00
从网页中准确提取新闻内容是新闻信息平台的基础。目前新闻信息平台的大部分内容来自于对其他新闻网站内容的爬取、排序和分类,因此如何准确地从网页中提取新闻非常重要。很重要~
方法一:《基于行块分布函数的通用网页文本提取》
它的思想是一个主题网页的详情页(我们这里是新闻)只有一个数据区,你只需要提取这个数据区;找到这个数据区的方法是将网页的内容分成块,一个块是指来自某个区域的数据。从行首到某行尾的区域,例如第n块由第n行、n+1行和n+2行组成,第n+1个块由第n+1行组成, n+2行和n+3行,然后提取每个块中的纯文本,文本中必须收录纯文本最多的块;如果找到了某个区块,就可以利用这部分内容来寻找文字边界,在文字中指出,主题网页的主体中存在大量纯文字,而其他部分则是相对较小。您可以从之前放置块的位置开始,来回走动。找到的纯文本数量直线下降的点是边界;从文本中提取边界信息。这种方法可以准确提取大部分新闻的正文,但正文末尾收录一些杂质信息。而且这种方法只能提取文本,很难提取出与文本相关的非常重要的信息,即标题、出处、时间、以及标题和文本之间的图片。
方法二:可读性算法
它的主要思想是通过给一个网页构建一个DOM树,对body节点的子树中的每个后代节点进行评分,得到评分满足要求的节点,这些节点收录了读者想要阅读的内容,并且然后把这些节点排列成一个网页返回。使用算法的Java实现来处理上面的例子新闻,结果和前面的方法差不多。但是,通过DOM树,可以通过另一种方式轻松获取新闻的时间和来源。新闻时间可以通过正则表达式匹配标题和正文之间的内容;可以通过标题和正文之间的内容上的“source”关键字找到来源,并将找到的来源存储起来,在没有“来源”的情况下使用来匹配来源 这部分内容的关键词;终于解决了问题。如果不能为任何一个新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但是它还有其他问题,比如在大多数情况下会丢失新闻标题之间的图片等信息。文字和文字,有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。
方法 3:RoadRunner 算法
该算法试图从同一个模板生成的一组网页中找到一个模板,然后使用该模板解析该模板生成的其他网页。(目前效果不好) 查看全部
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
从网页中准确提取新闻内容是新闻信息平台的基础。目前新闻信息平台的大部分内容来自于对其他新闻网站内容的爬取、排序和分类,因此如何准确地从网页中提取新闻非常重要。很重要~
方法一:《基于行块分布函数的通用网页文本提取》
它的思想是一个主题网页的详情页(我们这里是新闻)只有一个数据区,你只需要提取这个数据区;找到这个数据区的方法是将网页的内容分成块,一个块是指来自某个区域的数据。从行首到某行尾的区域,例如第n块由第n行、n+1行和n+2行组成,第n+1个块由第n+1行组成, n+2行和n+3行,然后提取每个块中的纯文本,文本中必须收录纯文本最多的块;如果找到了某个区块,就可以利用这部分内容来寻找文字边界,在文字中指出,主题网页的主体中存在大量纯文字,而其他部分则是相对较小。您可以从之前放置块的位置开始,来回走动。找到的纯文本数量直线下降的点是边界;从文本中提取边界信息。这种方法可以准确提取大部分新闻的正文,但正文末尾收录一些杂质信息。而且这种方法只能提取文本,很难提取出与文本相关的非常重要的信息,即标题、出处、时间、以及标题和文本之间的图片。
方法二:可读性算法
它的主要思想是通过给一个网页构建一个DOM树,对body节点的子树中的每个后代节点进行评分,得到评分满足要求的节点,这些节点收录了读者想要阅读的内容,并且然后把这些节点排列成一个网页返回。使用算法的Java实现来处理上面的例子新闻,结果和前面的方法差不多。但是,通过DOM树,可以通过另一种方式轻松获取新闻的时间和来源。新闻时间可以通过正则表达式匹配标题和正文之间的内容;可以通过标题和正文之间的内容上的“source”关键字找到来源,并将找到的来源存储起来,在没有“来源”的情况下使用来匹配来源 这部分内容的关键词;终于解决了问题。如果不能为任何一个新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但是它还有其他问题,比如在大多数情况下会丢失新闻标题之间的图片等信息。文字和文字,有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。
方法 3:RoadRunner 算法
该算法试图从同一个模板生成的一组网页中找到一个模板,然后使用该模板解析该模板生成的其他网页。(目前效果不好)
网页新闻抓取(Web上信息的重要表现形式(图)专利(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-01 17:18
专利名称:一种从新闻网页中提取文本信息的方法
技术领域:
:本发明属于网页信息分析与处理
技术领域:
,具体涉及一种新闻网页正文信息的提取方法。
背景技术:
: 互联网的飞速发展,使得互联网即Web上的信息量每天都以惊人的速度增长。许多公司经常需要各种信息,并且通常从互联网上大规模采集信息。每个企业都应该关注的问题。由于目前的信息处理技术针对的是纯文本格式的内容,而Web上的信息主要以静态Html的形式存在,如何将Web上Html形式的信息采集转换成有用价值 文本格式的信息便于后续信息处理,已成为亟待解决的技术问题。Web 上一种重要的信息形式是新闻。每天各大门户网站网站都会添加大量各种新闻。如何采集这些新闻信息成为Web信息采集问题的重要组成部分。通常,一个新闻网页,除了主要的新闻内容(通常称为网页正文)外,还收录大量与新闻内容无关的信息(如广告、网页导航信息、版权等)。信息等。为方便起见,以下将这些与新闻无关的信息统称为广告),如何从新闻网页中准确提取新闻,去除与新闻信息无关的广告等其他信息,尽量减少原版的失效网页修改引起的网页爬取方式。也是目前需要解决的技术问题。现在,网络上的新闻信息大部分来自于重要的门户网站,而这些网站的新闻页面往往是模板背景生成的,而且它们的风格和风格在一定时期内是一致的的时间。的。目前,Internet 上的大部分网页都是用 HTML 语言编写的。
Html语言提供的标签主要用于控制网页内容的显示格式,如<table>、<tr>、<td>、<th>用于绘制表格;<li>, <ol>, <ul> 用于表示一个列表。这些标签的使用没有规律,网页设计师可以随意设计。但不同种类的数据一般放在不同的显示单元中。经过对主要网站新闻页面的实际分析,结果表明,要提取的新闻页面中的大部分文本信息都存在于Html标签“<table>”和“<div>”中。传统的网页数据提取方法是通过包装器从网页中提取有趣的数据。包装器根据信息模式识别的知识,从固定的信息源中提取相关内容,并以固定的形式表达出来。早期,最简单的包装器是通过人工分析目标网页的结构特征提取信息,然后编写目标软件来实现的。这种方法需要大量的人工干预,成本高;后来,引入了一些模式识别。然而,到目前为止,获取包装器所需的信息模式识别知识仍然是一项耗时耗力的任务,需要很高的智能性。因此,目前网页数据抽取的研究热点之一就是探索简单的获取和构建一个wrapper。所需规则的有效方法。现在,
TSIMMIS 系统中的包装器需要手动编写数据提取规则。规则放置在特殊文件中,规则的形式为 [variables, source, pattern]。其中,variables保存提取结果,source保存输入,pattern保存source中数据的模式信息;variables 可以作为以下规则的来源,文件中的最后一条规则执行完后,最后的提取结果保存在 variables 中。这种方法需要人工编写规则,费时费力,容易出错,维护困难。XWRAP 系统中的包装器采用半自动的方式获取数据抽取规则。它提供了友好的人机交互界面。用户可以根据系统的指导完成数据抽取规则的编写。最后,系统为特定的数据源生成一个用java语言编写的包装器。在数据提取之前,XWRAP 系统会检查网页,纠正任何不符合规范的语法错误和标签,并将网页解析成树。上面介绍的几种包装器都是基于一定的固定网页架构,按照固定的规则或模式提取数据,具有比较大的局限性。由于网页结构的复杂性和不规则性,一旦网页被修改,网页结构发生变化,原来适用的包装器就不能再使用了。信息来源。如前所述,目前的网页数据抽取工具都需要针对特定的数据源编写相应的包装器或抽取规则。所以,如果信息来自多个信息源,则需要很多包装器,包装器的生成和维护就成为一项复杂的工作。对于互联网上存在的具有不同结构风格的新闻网页的文本信息提取任务,使用包装器的成本非常高。
发明内容针对现有技术中存在的缺陷,本发明的目的在于提供一种新闻网页正文信息的提取方法。就网页中的数据信息而言,可以实现对各种不同结构的模板生成的一系列新闻网页内容的自动提取,提高网页信息提取的效率和准确性。为了实现上述目的,本发明采用的技术方案是一种新闻网页文本信息的提取方法,包括以下步骤(1)对网页进行归一化预处理,使其满足Html语言标准,然后根据Html语言的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)将是模板生成的两个网页的Html树,来自同一个站点在时间上相邻的两个网页比较Html树的每一层数据,去掉table节点或div节点坐标相同,信息相同;(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;(4)中的数据Html树中的每个节点经过重组处理后,提取出需要的数据信息。进一步地,为了本发明有更好的效果,步骤(1)解析Html树中所有新闻网页的Html数据,以及要构造 Html 树,请使用以下方法 1) 初始化一个空数组T,用于保存Html树中的每个表结构;表结构用于表示表节点,形式为structTable{该表节点的坐标;此表节点中收录的信息;};上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2)
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。进一步地,为了使本发明有更好的效果,在步骤(2)中过滤数据,在删除不需要的数据信息时,采用如下方法将C和D设置为同一模板生成的两个释放时间相邻新闻网页,1)经过步骤(1),网页C的结构数组为T1;2)经过步骤(1),得到网页D的结构) 数组为 T2;3) 遍历 T1 中的每个表结构,并将 T1 中的每个结构设置为 S1,执行以下操作: a) 遍历 T2,在 T2 中找到与 S1 坐标值相同的结构, 设为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。进一步,为了使本发明有更好的效果,在步骤(3)中,对Html树中各层表节点中的数据进行细化识别,当标题信息和内容信息区分,下面的方法使用1)来标识表节点中的结构如果这个结构中有多个title元素,则取第一个作为这个结构的标题,如果没有title元素,表示该表结构的标题为空。另外,为了使本发明有更好的效果,
本发明的效果是利用本发明的方法,可以处理来自通过模板生成网页的新闻站点的信息采集的任务,以及目标新闻的文本内容。即使网页被修改,也可以快速自动提取网页。需要重写程序,大大减少了人工干预,从而大大提高了网页信息提取的效率和准确性。本发明之所以有上述效果,是因为本发明所描述的方法采用了一种新的Html树解析方法,能够高效、准确地获知Html中各个表节点的坐标以及所收录的信息。还可以快速解析新模板的树结构信息,再对比新模板生成的网页,依然能够准确提取新闻文本信息。图1是本发明的流程图;图2为本发明具体实施例中解析Html树的流程图。具体实施方式下面结合实施例和附图对本发明的方法作进一步的说明。以从新浪新闻体育频道截取的1000个按时间顺序排列的新闻网页中提取文本信息为例,如图1所示,一种从新闻网页中提取文本信息的方法包括以下步骤(1)@ >使用第三方网页净化工具(例如,可以使用 tidy 工具)对 1000 个网页进行规范化和预处理,使其符合 Html 语言标准,然后根据 Html 语言中的 <table> 和 <div> 标签解析所有页面。获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似.
以如下Html片段为例(如前所述,只标注了感兴趣的<table>节点,//为注释),明确本发明涉及的谓词<table> //第一个<table>节点开始Text1<table>//第二个<table>节点开始Text2<table>//第三个<table>节点开始Text3</table>//第三个<table>节点结束Text4</table>//第二个<table>节点结束<table>//第四个<table>节点开始Text4</table>//第四个<table>节点结束</table>//第一个<table>节点结束取中间的Html内容每个表的开始字符(由<table>标记)和结束字符(由</table>标记)作为一个表节点,那么从上面的代码片段可以看出,在每个表节点内 您还可以嵌套其他表节点,例如,第三个表节点嵌套在第二个表节点内。
如果一个表节点 A 嵌套在另一个表节点 B 中,则 A 称为 B 的子节点,B 称为 A 的父节点。位于表节点 A 的开始字符和结束字符之间的 Html 内容,以及不位于该节点的任何子节点的首尾字符之间的,称为A中收录的信息。一个表节点对应的向量称为该表节点在Html树中的坐标。在上面的Html片段中,第二个表节点收录的信息是Text2和Text4,第三个表节点收录的信息是Text3。用直观的形式表达Html树层次结构的嵌套信息,即用一个向量来表示关心的表节点在整个Html树中的位置。每个表节点对应一个向量 v=(n1, n2, n3, ..., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点。如果一个表节点对应的向量是(1, 2, 3),那么这个表节点就是Html树第一层第一个表节点的第二个子节点的第三个子节点。上面的Html片段第三和第四个表节点的坐标分别是(1, 1, 1)和(1, 2))。表节点用结构体的形式表示,形式如下 structTable{此表节点表节点的坐标;此表节点收录的信息;};将Html文档转换为各个表节点的结构体时,使用如下方法1)初始化一个空数组T保存每个表结构;2)初始化一个栈,让栈底到栈顶的元素分别标记为a,a[1],a[2],a[3],...,0=a=a[1]=a [2]=a[3]=...; 并设置堆栈元素指针 p 指向堆栈的顶部元素。
由于最初栈中没有元素,可以假设p指向一个虚元素a[-1];3) 扫描待处理的 Html 文档,如果遇到 <table> 标签,即遇到新的表节点时,将栈元素指针 p 上移一个空格,然后将值加 1堆栈元素指针 p 指向的元素。设栈元素指针p指向的栈元素为a[k],则表节点A的坐标为从栈底元素a到a[k]形成的序列,即向量(a, a[1], a[2], ..., a[k]),从中获得表节点A的坐标;4)@ >如果遇到了一个</table>节点,即当一个表节点结束时,将栈元素指针p下移一个空格,并且此时构造一个新的表结构,将当前表节点的坐标和其中收录的信息存储在这个表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。
将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,在T2中找到与S1坐标值相同的结构设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;经过步骤(2),不必要的广告信息有被删除了,但是还是需要使用未过滤的表结构来提炼和识别内容,识别标题信息和内容信息。通常新闻的标题一般以大粗体的形式出现。在Html中,
因此,可以采取以下具体步骤来实现对表结构内容的精细化识别。1)对于表节点中的结构,判断结构信息中是否有title元素;2)如果结构有多个title元素,则取第一个作为结构的title ,如果没有title元素,则该表结构的title为空。(4)处理后对Html树中各个节点中的数据进行重组,提取出需要的数据信息。步骤(1)经过步骤(2)@)得到的表结构数组T > 和经过step(3)的处理,已经识别出数组T中每个结构体的信息,接下来要做的就是将这些数组T中的每个表结构所收录的信息组合起来,可以使用以下方法1)初始化一个空字符串S;2)遍历表中的每个表结构结构数组T,并将各个表结构所收录的信息添加到S中;3)删除S中的Html标签,删除Html标签后的S1就是要提取的新闻网页的文本内容。实验结果表明,新闻网页抓取的准确率非常高。仍然可以达到98%以上的准确率,时间效率高。本发明描述的方法不限于具体实施例中描述的实施例,本领域技术人员可以根据本发明的技术方案获得其他实施例。,也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3)
v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 初始化一个栈,将栈底到栈顶的元素设置为a, a[1], a[2], a[3],...,和 0=a=a[1]=a[2]=a[3]=...; 并设置一个栈元素指针p,指向栈顶元素,由于栈最初没有元素,可以假设p指向一个虚元素a[-1];3)扫描要处理的Html文档,如果遇到<table>标签,则遇到一个新的table Node,将栈元素指针p上移一格,然后将指向的元素的值加1由栈元素指针p指向,并将栈元素指针p指向的栈元素设置为a[k],那么表节点 A 的坐标就是栈底元素 a 到 a[k] 形成的序列,即向量 (a, a[1], a[2], ... , a[k]),从中得到表节点A的坐标;4)如果遇到一个</table>节点,即当一个表节点结束时,栈元素指针p下移一个空格,此时就构造了一个新的表结构,坐标当前表节点的信息和信息存储在这个表结构中,然后把这个结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。3.如权利要求1、2所述的一种新闻网页文本信息提取方法,其特征在于,在步骤(2)中,对数据进行过滤,当不需要的数据信息删除,使用下面的方法假设C和D是同一模板生成的发布时间相邻的两个新闻网页,1)经过步骤(1),网页C的结构体数组为T1;@>经过步骤(1),网页D的结构数组为T2;3)遍历T1中的各个表结构,并将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,找到T2中与S1坐标值相同的结构,设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同,除了链接文本,如果相同则在T1 S1中删除,在T2中删除S2。4.一种如权利要求1、2所述的新闻网页文本信息提取方法,其特征在于,在步骤(3)中,Html树中各层表节点中的数据为提炼识别,并区分标题信息和内容信息,使用如下方法1)表节点中的结构,判断结构信息中是否有标题元素;2) 如果结构有多个标题元素,则将第一个作为该结构的标题。如果没有title元素,则表示此表结构的标题为空。
初始化一个空字符串 S;2) 遍历表结构数组T中的每个表结构,将每个表结构收录的信息添加到S中;3)删除S中的Html标记,删除Html标记后的S1为要提取的新闻网页的文本内容。全文摘要本发明涉及一种新闻文本信息的提取方法网页,属于网页信息的分析处理
技术领域:
. 在现有技术中,通常使用包装器来提取网页中感兴趣的数据,包装器根据一定的信息模式识别知识,按照固定的规则从特定信息源中提取相关内容,并以一种形式表达出来。具体形式。获取包装器所需的信息模式识别知识是一项耗时耗力的任务,对智能的要求很高。本发明的方法利用栈数据结构将网页数据的层次结构信息转化为向量表达式,构造并解析Html树,然后对Html树的每一层数据进行比较,进行数据过滤、细化和识别, 和数据重组以提取所需的数据信息。本发明方法适用于对固定站点模板生成的新闻网页中的新闻信息进行长期抓取,速度快、准确率高。文号G06F17/30GK1786965SQ20051013237 公布日期2006年6月14日申请日期2005年12月21日优先权日期2005年12月21日发明人舒文兵、吴玉倩、肖建国申请人:,,, 北京大学 查看全部
网页新闻抓取(Web上信息的重要表现形式(图)专利(组图))
专利名称:一种从新闻网页中提取文本信息的方法
技术领域:
:本发明属于网页信息分析与处理
技术领域:
,具体涉及一种新闻网页正文信息的提取方法。
背景技术:
: 互联网的飞速发展,使得互联网即Web上的信息量每天都以惊人的速度增长。许多公司经常需要各种信息,并且通常从互联网上大规模采集信息。每个企业都应该关注的问题。由于目前的信息处理技术针对的是纯文本格式的内容,而Web上的信息主要以静态Html的形式存在,如何将Web上Html形式的信息采集转换成有用价值 文本格式的信息便于后续信息处理,已成为亟待解决的技术问题。Web 上一种重要的信息形式是新闻。每天各大门户网站网站都会添加大量各种新闻。如何采集这些新闻信息成为Web信息采集问题的重要组成部分。通常,一个新闻网页,除了主要的新闻内容(通常称为网页正文)外,还收录大量与新闻内容无关的信息(如广告、网页导航信息、版权等)。信息等。为方便起见,以下将这些与新闻无关的信息统称为广告),如何从新闻网页中准确提取新闻,去除与新闻信息无关的广告等其他信息,尽量减少原版的失效网页修改引起的网页爬取方式。也是目前需要解决的技术问题。现在,网络上的新闻信息大部分来自于重要的门户网站,而这些网站的新闻页面往往是模板背景生成的,而且它们的风格和风格在一定时期内是一致的的时间。的。目前,Internet 上的大部分网页都是用 HTML 语言编写的。
Html语言提供的标签主要用于控制网页内容的显示格式,如<table>、<tr>、<td>、<th>用于绘制表格;<li>, <ol>, <ul> 用于表示一个列表。这些标签的使用没有规律,网页设计师可以随意设计。但不同种类的数据一般放在不同的显示单元中。经过对主要网站新闻页面的实际分析,结果表明,要提取的新闻页面中的大部分文本信息都存在于Html标签“<table>”和“<div>”中。传统的网页数据提取方法是通过包装器从网页中提取有趣的数据。包装器根据信息模式识别的知识,从固定的信息源中提取相关内容,并以固定的形式表达出来。早期,最简单的包装器是通过人工分析目标网页的结构特征提取信息,然后编写目标软件来实现的。这种方法需要大量的人工干预,成本高;后来,引入了一些模式识别。然而,到目前为止,获取包装器所需的信息模式识别知识仍然是一项耗时耗力的任务,需要很高的智能性。因此,目前网页数据抽取的研究热点之一就是探索简单的获取和构建一个wrapper。所需规则的有效方法。现在,
TSIMMIS 系统中的包装器需要手动编写数据提取规则。规则放置在特殊文件中,规则的形式为 [variables, source, pattern]。其中,variables保存提取结果,source保存输入,pattern保存source中数据的模式信息;variables 可以作为以下规则的来源,文件中的最后一条规则执行完后,最后的提取结果保存在 variables 中。这种方法需要人工编写规则,费时费力,容易出错,维护困难。XWRAP 系统中的包装器采用半自动的方式获取数据抽取规则。它提供了友好的人机交互界面。用户可以根据系统的指导完成数据抽取规则的编写。最后,系统为特定的数据源生成一个用java语言编写的包装器。在数据提取之前,XWRAP 系统会检查网页,纠正任何不符合规范的语法错误和标签,并将网页解析成树。上面介绍的几种包装器都是基于一定的固定网页架构,按照固定的规则或模式提取数据,具有比较大的局限性。由于网页结构的复杂性和不规则性,一旦网页被修改,网页结构发生变化,原来适用的包装器就不能再使用了。信息来源。如前所述,目前的网页数据抽取工具都需要针对特定的数据源编写相应的包装器或抽取规则。所以,如果信息来自多个信息源,则需要很多包装器,包装器的生成和维护就成为一项复杂的工作。对于互联网上存在的具有不同结构风格的新闻网页的文本信息提取任务,使用包装器的成本非常高。
发明内容针对现有技术中存在的缺陷,本发明的目的在于提供一种新闻网页正文信息的提取方法。就网页中的数据信息而言,可以实现对各种不同结构的模板生成的一系列新闻网页内容的自动提取,提高网页信息提取的效率和准确性。为了实现上述目的,本发明采用的技术方案是一种新闻网页文本信息的提取方法,包括以下步骤(1)对网页进行归一化预处理,使其满足Html语言标准,然后根据Html语言的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)将是模板生成的两个网页的Html树,来自同一个站点在时间上相邻的两个网页比较Html树的每一层数据,去掉table节点或div节点坐标相同,信息相同;(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;(4)中的数据Html树中的每个节点经过重组处理后,提取出需要的数据信息。进一步地,为了本发明有更好的效果,步骤(1)解析Html树中所有新闻网页的Html数据,以及要构造 Html 树,请使用以下方法 1) 初始化一个空数组T,用于保存Html树中的每个表结构;表结构用于表示表节点,形式为structTable{该表节点的坐标;此表节点中收录的信息;};上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2)
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。进一步地,为了使本发明有更好的效果,在步骤(2)中过滤数据,在删除不需要的数据信息时,采用如下方法将C和D设置为同一模板生成的两个释放时间相邻新闻网页,1)经过步骤(1),网页C的结构数组为T1;2)经过步骤(1),得到网页D的结构) 数组为 T2;3) 遍历 T1 中的每个表结构,并将 T1 中的每个结构设置为 S1,执行以下操作: a) 遍历 T2,在 T2 中找到与 S1 坐标值相同的结构, 设为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。进一步,为了使本发明有更好的效果,在步骤(3)中,对Html树中各层表节点中的数据进行细化识别,当标题信息和内容信息区分,下面的方法使用1)来标识表节点中的结构如果这个结构中有多个title元素,则取第一个作为这个结构的标题,如果没有title元素,表示该表结构的标题为空。另外,为了使本发明有更好的效果,
本发明的效果是利用本发明的方法,可以处理来自通过模板生成网页的新闻站点的信息采集的任务,以及目标新闻的文本内容。即使网页被修改,也可以快速自动提取网页。需要重写程序,大大减少了人工干预,从而大大提高了网页信息提取的效率和准确性。本发明之所以有上述效果,是因为本发明所描述的方法采用了一种新的Html树解析方法,能够高效、准确地获知Html中各个表节点的坐标以及所收录的信息。还可以快速解析新模板的树结构信息,再对比新模板生成的网页,依然能够准确提取新闻文本信息。图1是本发明的流程图;图2为本发明具体实施例中解析Html树的流程图。具体实施方式下面结合实施例和附图对本发明的方法作进一步的说明。以从新浪新闻体育频道截取的1000个按时间顺序排列的新闻网页中提取文本信息为例,如图1所示,一种从新闻网页中提取文本信息的方法包括以下步骤(1)@ >使用第三方网页净化工具(例如,可以使用 tidy 工具)对 1000 个网页进行规范化和预处理,使其符合 Html 语言标准,然后根据 Html 语言中的 <table> 和 <div> 标签解析所有页面。获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似.
以如下Html片段为例(如前所述,只标注了感兴趣的<table>节点,//为注释),明确本发明涉及的谓词<table> //第一个<table>节点开始Text1<table>//第二个<table>节点开始Text2<table>//第三个<table>节点开始Text3</table>//第三个<table>节点结束Text4</table>//第二个<table>节点结束<table>//第四个<table>节点开始Text4</table>//第四个<table>节点结束</table>//第一个<table>节点结束取中间的Html内容每个表的开始字符(由<table>标记)和结束字符(由</table>标记)作为一个表节点,那么从上面的代码片段可以看出,在每个表节点内 您还可以嵌套其他表节点,例如,第三个表节点嵌套在第二个表节点内。
如果一个表节点 A 嵌套在另一个表节点 B 中,则 A 称为 B 的子节点,B 称为 A 的父节点。位于表节点 A 的开始字符和结束字符之间的 Html 内容,以及不位于该节点的任何子节点的首尾字符之间的,称为A中收录的信息。一个表节点对应的向量称为该表节点在Html树中的坐标。在上面的Html片段中,第二个表节点收录的信息是Text2和Text4,第三个表节点收录的信息是Text3。用直观的形式表达Html树层次结构的嵌套信息,即用一个向量来表示关心的表节点在整个Html树中的位置。每个表节点对应一个向量 v=(n1, n2, n3, ..., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点。如果一个表节点对应的向量是(1, 2, 3),那么这个表节点就是Html树第一层第一个表节点的第二个子节点的第三个子节点。上面的Html片段第三和第四个表节点的坐标分别是(1, 1, 1)和(1, 2))。表节点用结构体的形式表示,形式如下 structTable{此表节点表节点的坐标;此表节点收录的信息;};将Html文档转换为各个表节点的结构体时,使用如下方法1)初始化一个空数组T保存每个表结构;2)初始化一个栈,让栈底到栈顶的元素分别标记为a,a[1],a[2],a[3],...,0=a=a[1]=a [2]=a[3]=...; 并设置堆栈元素指针 p 指向堆栈的顶部元素。
由于最初栈中没有元素,可以假设p指向一个虚元素a[-1];3) 扫描待处理的 Html 文档,如果遇到 <table> 标签,即遇到新的表节点时,将栈元素指针 p 上移一个空格,然后将值加 1堆栈元素指针 p 指向的元素。设栈元素指针p指向的栈元素为a[k],则表节点A的坐标为从栈底元素a到a[k]形成的序列,即向量(a, a[1], a[2], ..., a[k]),从中获得表节点A的坐标;4)@ >如果遇到了一个</table>节点,即当一个表节点结束时,将栈元素指针p下移一个空格,并且此时构造一个新的表结构,将当前表节点的坐标和其中收录的信息存储在这个表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。
将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,在T2中找到与S1坐标值相同的结构设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;经过步骤(2),不必要的广告信息有被删除了,但是还是需要使用未过滤的表结构来提炼和识别内容,识别标题信息和内容信息。通常新闻的标题一般以大粗体的形式出现。在Html中,
因此,可以采取以下具体步骤来实现对表结构内容的精细化识别。1)对于表节点中的结构,判断结构信息中是否有title元素;2)如果结构有多个title元素,则取第一个作为结构的title ,如果没有title元素,则该表结构的title为空。(4)处理后对Html树中各个节点中的数据进行重组,提取出需要的数据信息。步骤(1)经过步骤(2)@)得到的表结构数组T > 和经过step(3)的处理,已经识别出数组T中每个结构体的信息,接下来要做的就是将这些数组T中的每个表结构所收录的信息组合起来,可以使用以下方法1)初始化一个空字符串S;2)遍历表中的每个表结构结构数组T,并将各个表结构所收录的信息添加到S中;3)删除S中的Html标签,删除Html标签后的S1就是要提取的新闻网页的文本内容。实验结果表明,新闻网页抓取的准确率非常高。仍然可以达到98%以上的准确率,时间效率高。本发明描述的方法不限于具体实施例中描述的实施例,本领域技术人员可以根据本发明的技术方案获得其他实施例。,也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3)
v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 初始化一个栈,将栈底到栈顶的元素设置为a, a[1], a[2], a[3],...,和 0=a=a[1]=a[2]=a[3]=...; 并设置一个栈元素指针p,指向栈顶元素,由于栈最初没有元素,可以假设p指向一个虚元素a[-1];3)扫描要处理的Html文档,如果遇到<table>标签,则遇到一个新的table Node,将栈元素指针p上移一格,然后将指向的元素的值加1由栈元素指针p指向,并将栈元素指针p指向的栈元素设置为a[k],那么表节点 A 的坐标就是栈底元素 a 到 a[k] 形成的序列,即向量 (a, a[1], a[2], ... , a[k]),从中得到表节点A的坐标;4)如果遇到一个</table>节点,即当一个表节点结束时,栈元素指针p下移一个空格,此时就构造了一个新的表结构,坐标当前表节点的信息和信息存储在这个表结构中,然后把这个结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。3.如权利要求1、2所述的一种新闻网页文本信息提取方法,其特征在于,在步骤(2)中,对数据进行过滤,当不需要的数据信息删除,使用下面的方法假设C和D是同一模板生成的发布时间相邻的两个新闻网页,1)经过步骤(1),网页C的结构体数组为T1;@>经过步骤(1),网页D的结构数组为T2;3)遍历T1中的各个表结构,并将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,找到T2中与S1坐标值相同的结构,设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同,除了链接文本,如果相同则在T1 S1中删除,在T2中删除S2。4.一种如权利要求1、2所述的新闻网页文本信息提取方法,其特征在于,在步骤(3)中,Html树中各层表节点中的数据为提炼识别,并区分标题信息和内容信息,使用如下方法1)表节点中的结构,判断结构信息中是否有标题元素;2) 如果结构有多个标题元素,则将第一个作为该结构的标题。如果没有title元素,则表示此表结构的标题为空。
初始化一个空字符串 S;2) 遍历表结构数组T中的每个表结构,将每个表结构收录的信息添加到S中;3)删除S中的Html标记,删除Html标记后的S1为要提取的新闻网页的文本内容。全文摘要本发明涉及一种新闻文本信息的提取方法网页,属于网页信息的分析处理
技术领域:
. 在现有技术中,通常使用包装器来提取网页中感兴趣的数据,包装器根据一定的信息模式识别知识,按照固定的规则从特定信息源中提取相关内容,并以一种形式表达出来。具体形式。获取包装器所需的信息模式识别知识是一项耗时耗力的任务,对智能的要求很高。本发明的方法利用栈数据结构将网页数据的层次结构信息转化为向量表达式,构造并解析Html树,然后对Html树的每一层数据进行比较,进行数据过滤、细化和识别, 和数据重组以提取所需的数据信息。本发明方法适用于对固定站点模板生成的新闻网页中的新闻信息进行长期抓取,速度快、准确率高。文号G06F17/30GK1786965SQ20051013237 公布日期2006年6月14日申请日期2005年12月21日优先权日期2005年12月21日发明人舒文兵、吴玉倩、肖建国申请人:,,, 北京大学
网页新闻抓取(PDF文档拆分的方式,但让PDF问题迎刃而解。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-31 12:22
福昕高级 PDF 编辑器涵盖整个文档生命周期,集成了创建、编辑、注释、协作/共享、保护、页面管理、导出、扫描和光学字符识别 (OCR) 以及签署 PDF 文档和表单等基本功能。还有一些高级功能,例如高级编辑、发起共享审阅、高级加密、高压缩、PDF A/E/X 创建和添加贝茨编号。使用福昕高级 PDF 编辑器解决 PDF 问题。
在之前的操作分享中,我们介绍了拆分PDF文档的方式,但是文档拆分不同于页面提取~
文档拆分是将一个完整的PDF文档拆分为多个PDF文件;而页面提取是从完整的PDF文档中提取一些页面。
以电子书的相关操作为例:
当团队需要合作翻译电子书时,可以通过文档拆分将电子书按章节拆分成多个PDF文件;
当你在电子书中看到一段很精彩的片段,想分享给你的朋友时,更适合使用提取页面的功能~
适当使用提取页面的方法,不仅可以减轻文件存储的负担,还可以更快的找到想要的内容!接下来,我们来学习如何提取PDF文档的部分页面~
打开“提取”功能区,自定义页面范围
第一步是在Foxit PhantomPDF中打开需要提取页面的PDF文档,点击功能区中的“页面管理”选项卡,选择“提取”进入详细的页面提取操作。
在“提取页面”对话框中,您可以选择页码范围。您只需在“页面”功能框中填写您要提取的页面即可。连续页用“-”表示,分开的页用“,”表示。需要注意的是,这里要使用“,”号。哦英文的。(例如,如果要提取PDF文档的第1、4到9、12页,只需在方框中填写“1,4-9,12”即可。)
另外,在框内填写要提取的页面范围后,还可以在“提取”中选择提取上述范围的子集,如“范围内的所有页面”、“仅偶数页”或“仅奇数页”。(如果要提取PDF文档第1、4到9、12页的偶数页,则在“提取”选项中选择“仅偶数页”,然后最后生成的文档收录原创文档的第 4、6、8 和 12 页。)
如果不知道要选择哪些页面,可以勾选左下角的“显示预览”选项,在“提取页面”窗口中预览文件页面,方便查看。
福昕高级 PDF 编辑器下载链接: 查看全部
网页新闻抓取(PDF文档拆分的方式,但让PDF问题迎刃而解。)
福昕高级 PDF 编辑器涵盖整个文档生命周期,集成了创建、编辑、注释、协作/共享、保护、页面管理、导出、扫描和光学字符识别 (OCR) 以及签署 PDF 文档和表单等基本功能。还有一些高级功能,例如高级编辑、发起共享审阅、高级加密、高压缩、PDF A/E/X 创建和添加贝茨编号。使用福昕高级 PDF 编辑器解决 PDF 问题。
在之前的操作分享中,我们介绍了拆分PDF文档的方式,但是文档拆分不同于页面提取~
文档拆分是将一个完整的PDF文档拆分为多个PDF文件;而页面提取是从完整的PDF文档中提取一些页面。
以电子书的相关操作为例:
当团队需要合作翻译电子书时,可以通过文档拆分将电子书按章节拆分成多个PDF文件;
当你在电子书中看到一段很精彩的片段,想分享给你的朋友时,更适合使用提取页面的功能~
适当使用提取页面的方法,不仅可以减轻文件存储的负担,还可以更快的找到想要的内容!接下来,我们来学习如何提取PDF文档的部分页面~
打开“提取”功能区,自定义页面范围
第一步是在Foxit PhantomPDF中打开需要提取页面的PDF文档,点击功能区中的“页面管理”选项卡,选择“提取”进入详细的页面提取操作。

在“提取页面”对话框中,您可以选择页码范围。您只需在“页面”功能框中填写您要提取的页面即可。连续页用“-”表示,分开的页用“,”表示。需要注意的是,这里要使用“,”号。哦英文的。(例如,如果要提取PDF文档的第1、4到9、12页,只需在方框中填写“1,4-9,12”即可。)

另外,在框内填写要提取的页面范围后,还可以在“提取”中选择提取上述范围的子集,如“范围内的所有页面”、“仅偶数页”或“仅奇数页”。(如果要提取PDF文档第1、4到9、12页的偶数页,则在“提取”选项中选择“仅偶数页”,然后最后生成的文档收录原创文档的第 4、6、8 和 12 页。)
如果不知道要选择哪些页面,可以勾选左下角的“显示预览”选项,在“提取页面”窗口中预览文件页面,方便查看。

福昕高级 PDF 编辑器下载链接:
网页新闻抓取(文档介绍:UDC国孥研究生学位论文基于Web搜索和网页结构分析的IT相关主题新闻抓取研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-30 13:12
文件介绍:UDC研究生论文基于Web搜索和IT相关话题的网页结构分析 新闻抓取 研究 研究生姓名 赵玉勇 研究生姓名 丝谷玉 - 导师姓名 玉伟 数量 4.学位级驱虫剂申请数量 雅在驱魔。论文答辩日期截止到Q]Q同学!!并且学位授予日期直到Q!Q学生]]和中国海洋大学,U Y1927076 我在此为中国海洋大学教师讨论文学。?? 赵玉勇基于Web搜索和网页结构分析的IT相关课题论文研究。完成日期: 指导员签名: 辩护委员会成员签名:#肥西L基金会土!本人声明,本人提交的论文是在导师指导下获得的研究工作和研究成果。据我所知,除文中特别标注和感谢的地方外,论文中不收录他人已发表或撰写的研究成果,也不收录未获得的内容。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。
本人授权学校将学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩微打印或扫描等复印方式保存和编纂学位论文。(本授权书适用于解密后的机密论文) 论文作者签名:郑雨燕导师 胜'7飞!I!Iii=III:Si p年"月2]日II!ii=IIII:force/o年, 》27日~毕业后论文作者下落:工作单位:通讯地址:电话:邮编 l 基于网页搜索和网页结构分析的IT相关课题组。研究摘要新闻与人们日常工作和娱乐生活相关的高度相关的信息,对于有影响力的新闻事件,深度和跨度较大的专题新闻信息量更大,更有趣。突出“主题”和专题,着力“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在网上迅速传播。另一方面,互联网上信息的爆炸式增长 互联网的快速发展使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎已经将触角伸向了互联网上的信息。如何挖掘深入、全面的新闻信息,对许多新闻相关工作具有重要意义,
IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出行业角色模型(Trade.roleModel)。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,而提取的好坏直接决定了后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们在几种方案中选择使用原生程序来实现其搜索结果的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,
从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于人工提取互联网新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。关键词:话题新闻;搜索引擎:行业榜样;文本挖掘 k 查看全部
网页新闻抓取(文档介绍:UDC国孥研究生学位论文基于Web搜索和网页结构分析的IT相关主题新闻抓取研究)
文件介绍:UDC研究生论文基于Web搜索和IT相关话题的网页结构分析 新闻抓取 研究 研究生姓名 赵玉勇 研究生姓名 丝谷玉 - 导师姓名 玉伟 数量 4.学位级驱虫剂申请数量 雅在驱魔。论文答辩日期截止到Q]Q同学!!并且学位授予日期直到Q!Q学生]]和中国海洋大学,U Y1927076 我在此为中国海洋大学教师讨论文学。?? 赵玉勇基于Web搜索和网页结构分析的IT相关课题论文研究。完成日期: 指导员签名: 辩护委员会成员签名:#肥西L基金会土!本人声明,本人提交的论文是在导师指导下获得的研究工作和研究成果。据我所知,除文中特别标注和感谢的地方外,论文中不收录他人已发表或撰写的研究成果,也不收录未获得的内容。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。
本人授权学校将学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩微打印或扫描等复印方式保存和编纂学位论文。(本授权书适用于解密后的机密论文) 论文作者签名:郑雨燕导师 胜'7飞!I!Iii=III:Si p年"月2]日II!ii=IIII:force/o年, 》27日~毕业后论文作者下落:工作单位:通讯地址:电话:邮编 l 基于网页搜索和网页结构分析的IT相关课题组。研究摘要新闻与人们日常工作和娱乐生活相关的高度相关的信息,对于有影响力的新闻事件,深度和跨度较大的专题新闻信息量更大,更有趣。突出“主题”和专题,着力“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在网上迅速传播。另一方面,互联网上信息的爆炸式增长 互联网的快速发展使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎已经将触角伸向了互联网上的信息。如何挖掘深入、全面的新闻信息,对许多新闻相关工作具有重要意义,
IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出行业角色模型(Trade.roleModel)。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,而提取的好坏直接决定了后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们在几种方案中选择使用原生程序来实现其搜索结果的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,
从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于人工提取互联网新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。关键词:话题新闻;搜索引擎:行业榜样;文本挖掘 k
网页新闻抓取(Python爬虫系列(一)(1)_Python基础视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-26 12:21
阿里云>云栖社区>主题图>P>Python爬虫新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
Python爬取新闻网站相关博文看更多博文
[python爬虫] Selenium定向爬取虎扑篮球海量美图
作者:肖洛洛 4370 浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他会经常逛虎扑篮球、Wet等论坛。论坛里会有很多美图,包括NBA球队、CBA球星、花边新闻、漂亮球鞋等等,如果右键另存为一张,伤手。作为程序员还是写个程序来做吧!
阅读全文
Python爬虫系列(一)早学习爬虫的补充和总结
作者:山茶花开2838人查看评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda 2、IDE:Pycharm、Pydev 3、工具:Jupyter Notebook(安装Anaconda后会有)二、Python基础视频教程1、疯狂Python:
阅读全文
《精通Python网络爬虫:核心技术、框架和项目》——第2章网络爬虫技能概览2.1网络爬虫技能概览
作者:华章电脑1908 浏览评论:04年前
本章节选自华章出版社,作者魏伟所著《精通Python网络爬虫:核心技术、框架与项目》一书第2章第2.1节,更多章节可上云查看齐社区“华章电脑”公众号。第2章网络爬虫技能概述在上一章中,我们已经对网络爬虫有了初步的了解。
阅读全文
常用python爬虫框架整理
作者:优迪1689 浏览评论:03年前
Python中好用的爬虫框架一般比较小爬虫需求的价格。我通过直接使用请求库 + bs4 解决了它。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫教程9-100河北阳光政诉科
作者:Dream Eraser 1430 浏览评论:02年前
1.河北阳光管理投诉科-之前的文章文章都是关于图片爬虫的。今天写了一个留言板,爬出来找另一套数据分析案例教程。做好准备,作为一个河北人,遵守规章制度,抱怨什么是必备的技能,那么让我们看看我们河北人抱怨了什么?网站 今天要爬取的地址
阅读全文
采集CloudBlog网站 的 Python 爬虫 文章
作者:朱培1423 浏览评论:04年前
本文使用python爬虫获取网站中的文章,包括文章的标题、发表时间、作者、内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页所有的文章连接,存放在URL集合中,然后对这些采集的链接一一访问,再次解析
阅读全文
跟我一起开始python爬虫
作者:cxa1415 人浏览评论:02年前
前几天想写一个爬虫系列文章。我没有写它是因为我很忙(不是因为我懒惰)。趁着房间里的凉意和内心的宁静,总结一下我目前所遇到的事情。一些爬虫知识,本系列将从一个简单的爬虫开始,然后逐渐增加难度。同时,对反爬的方法进行总结,并用具体的例子来论证,不同的反爬现象和现实。
阅读全文
Python爬虫学习,记抓包获取js,从js函数取数据的过程
作者:云飞学习编程 1203人浏览评论:03年前
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里面,很有意思,分吧
阅读全文 查看全部
网页新闻抓取(Python爬虫系列(一)(1)_Python基础视频教程(组图))
阿里云>云栖社区>主题图>P>Python爬虫新闻网站

推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
Python爬取新闻网站相关博文看更多博文
[python爬虫] Selenium定向爬取虎扑篮球海量美图

作者:肖洛洛 4370 浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他会经常逛虎扑篮球、Wet等论坛。论坛里会有很多美图,包括NBA球队、CBA球星、花边新闻、漂亮球鞋等等,如果右键另存为一张,伤手。作为程序员还是写个程序来做吧!
阅读全文
Python爬虫系列(一)早学习爬虫的补充和总结


作者:山茶花开2838人查看评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda 2、IDE:Pycharm、Pydev 3、工具:Jupyter Notebook(安装Anaconda后会有)二、Python基础视频教程1、疯狂Python:
阅读全文
《精通Python网络爬虫:核心技术、框架和项目》——第2章网络爬虫技能概览2.1网络爬虫技能概览

作者:华章电脑1908 浏览评论:04年前
本章节选自华章出版社,作者魏伟所著《精通Python网络爬虫:核心技术、框架与项目》一书第2章第2.1节,更多章节可上云查看齐社区“华章电脑”公众号。第2章网络爬虫技能概述在上一章中,我们已经对网络爬虫有了初步的了解。
阅读全文
常用python爬虫框架整理

作者:优迪1689 浏览评论:03年前
Python中好用的爬虫框架一般比较小爬虫需求的价格。我通过直接使用请求库 + bs4 解决了它。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫教程9-100河北阳光政诉科

作者:Dream Eraser 1430 浏览评论:02年前
1.河北阳光管理投诉科-之前的文章文章都是关于图片爬虫的。今天写了一个留言板,爬出来找另一套数据分析案例教程。做好准备,作为一个河北人,遵守规章制度,抱怨什么是必备的技能,那么让我们看看我们河北人抱怨了什么?网站 今天要爬取的地址
阅读全文
采集CloudBlog网站 的 Python 爬虫 文章


作者:朱培1423 浏览评论:04年前
本文使用python爬虫获取网站中的文章,包括文章的标题、发表时间、作者、内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页所有的文章连接,存放在URL集合中,然后对这些采集的链接一一访问,再次解析
阅读全文
跟我一起开始python爬虫


作者:cxa1415 人浏览评论:02年前
前几天想写一个爬虫系列文章。我没有写它是因为我很忙(不是因为我懒惰)。趁着房间里的凉意和内心的宁静,总结一下我目前所遇到的事情。一些爬虫知识,本系列将从一个简单的爬虫开始,然后逐渐增加难度。同时,对反爬的方法进行总结,并用具体的例子来论证,不同的反爬现象和现实。
阅读全文
Python爬虫学习,记抓包获取js,从js函数取数据的过程

作者:云飞学习编程 1203人浏览评论:03年前
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里面,很有意思,分吧
阅读全文
网页新闻抓取( Python通用抽取器--GnePython环境了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-25 00:08
Python通用抽取器--GnePython环境了
)
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
查看全部
网页新闻抓取(
Python通用抽取器--GnePython环境了
)

GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。

要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:

对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:

新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。

通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。

网页新闻抓取(网页抓取和网络爬虫的优点太技术化了!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-25 00:07
所以你知道网络抓取和网络爬虫,你听说过一些令人信服的优点,但你有点担心缺点。我们认为我们可以帮助您了解利大于弊。
好吧,让我们从网络抓取的好处开始,我们保证它不会太技术化。
网页抓取的优点
速度
首先,使用网络抓取技术最好的一点是它提供的速度。每个了解网络抓取的人都将其与速度联系起来。当您使用网络抓取工具(程序、软件或技术)时,它们基本上结束了从 网站 手动采集数据的过程。网页抓取可以让你快速同时抓取多个网站,而无需查看和控制每个请求。您也可以只设置一次,它会在一小时或更短的时间内抓取整个 网站 - 这不是一项需要一个人一周才能完成的工作。这是创建网页抓取来解决的主要问题。
网络抓取速度快的另一个原因不仅在于它扫描网络并从中提取数据的速度有多快,而且还在于将网络抓取纳入您的日常生活的过程。开始使用网络爬虫相当容易,因为您不必担心构建、下载、集成或安装它们。因此,完成设置后,您就可以开始网页抓取了。现在想象一下,您可以在五分钟内从在线商店获取大约 1,000 种产品的信息并将其打包到一张简洁的 Excel 表格中,这是多么令人惊奇。
网络抓取提供了成功且动态的未来评估。由于数据抓取可以评估消费者的态度、需求和愿望,因此甚至可以进行广泛的预测分析。深入了解消费者的喜好是一件好事,它有助于企业有效地规划未来。
大规模数据提取
这很简单——人类 0,机器人 1——这并没有错。很难想象手动处理数据,因为它太多了。网络爬虫为您提供的数据远远多于您手动采集的数据。例如,如果您的挑战是每周检查竞争对手的产品和服务的价格,那可能会花费您很多时间。它也不会很有效,因为即使您拥有一支强大且积极进取的团队,您也无法保持这种状态。相反,您决定使用该系统并运行一个爬虫,该爬虫每小时以相对较低的成本采集您需要的所有数据并且永不疲倦。
以下是投资行业如何从网络抓取中受益。对冲基金偶尔会使用网络抓取技术来采集替代数据以避免失败。它有助于检测意外威胁以及潜在的投资机会。投资决策很复杂,因为它们通常需要一系列步骤,从开发假设文件到进行实验和研究,然后再做出明智的决定。历史数据研究是评估投资概念的最有效技术。它使您能够深入了解以前失败或成就的根本原因、可避免的错误以及潜在的未来投资回报。
网络抓取是提取历史数据的一种更有效的方法,然后可以将其输入机器学习数据库进行模型训练。因此,使用大数据的投资机构可以提高分析结果的准确性,做出更好的决策。
具有成本效益
关于网络抓取的最好的事情之一是它是一项以相当低的成本提供的复杂服务。时间就是金钱,随着网络的发展和加速,如果没有重复性任务的自动化,专业的数据提取项目将是不可能的。例如,您可以聘请临时人员来运行分析、检查网站、执行例行任务,但所有这些都可以通过简单的脚本实现自动化。
另一件事是,一旦提取数据的核心机制启动并运行,您就有机会爬取整个域,而不仅仅是一个或几个页面。网络抓取甚至可以使情绪分析成为一项更实惠的任务:众所周知,每天都有成千上万的消费者在在线评论中发布他们对产品和服务的体验网站。这些海量数据对公众开放,可能只是为了获取有关企业、竞争对手、可能的机会和趋势的信息而被抓取。
灵活性和系统化方法
这是唯一可以与抓取数据提供的速度竞争的优势,因为抓取工具本质上是不断变化的。因此,它们具有高度的可修改性、开放性并与其他脚本兼容。您可以在一个系统中设置抓取工具、重复数据删除参与者、监控参与者和应用程序集成。它将协同工作,不受任何限制、额外成本或任何新平台的实施。
性能可靠性和稳健性
网页抓取本身就是一个确保数据准确性的过程。这是如何运作的?嗯,单调和重复的任务往往会导致错误,因为它们对人类来说简直是无聊。如果您正在处理财务、定价、时间敏感数据或良好的旧销售 - 不准确和错误可能需要大量时间和资源来查找和修复,如果没有找到 - 从那时起问题就会滚雪球。这涉及任何类型的数据,因此不仅要能够采集数据,而且要以可读和干净的格式保存数据,这一点至关重要。在现代世界,这不是人类的任务,而是机器的任务。机器人只会犯人类预先写在代码中的错误。如果您的脚本正确,您可以在很大程度上消除人为错误的因素,并确保您采集的信息和数据每次都具有更好的质量。
网页抓取的缺点
网页抓取需要永久维护
要记住的另一件事是,在 SaaS 的世界中,服务只是旅程的开始。真正的交易是产品维护。我们提到维护的原因很简单:由于您的爬虫工作本质上与外部 网站 相关联,因此您无法控制该 网站 何时更改其 HTML 结构或内容。因此,开发人员必须对这些变化做出反应。
数据提取不等于数据分析
在处理数据提取和数据处理等复杂问题时,设定正确的期望非常重要。无论您使用多么好的网络爬虫,在大多数情况下它都无法为您完成数据分析工作。数据将以结构化格式到达,但是,需要处理更复杂的数据,以便它们可以在其他程序中使用。整个过程可能非常耗费资源和时间,如果您面临一个大数据分析项目,您应该做好准备。 查看全部
网页新闻抓取(网页抓取和网络爬虫的优点太技术化了!!)
所以你知道网络抓取和网络爬虫,你听说过一些令人信服的优点,但你有点担心缺点。我们认为我们可以帮助您了解利大于弊。

好吧,让我们从网络抓取的好处开始,我们保证它不会太技术化。
网页抓取的优点
速度
首先,使用网络抓取技术最好的一点是它提供的速度。每个了解网络抓取的人都将其与速度联系起来。当您使用网络抓取工具(程序、软件或技术)时,它们基本上结束了从 网站 手动采集数据的过程。网页抓取可以让你快速同时抓取多个网站,而无需查看和控制每个请求。您也可以只设置一次,它会在一小时或更短的时间内抓取整个 网站 - 这不是一项需要一个人一周才能完成的工作。这是创建网页抓取来解决的主要问题。
网络抓取速度快的另一个原因不仅在于它扫描网络并从中提取数据的速度有多快,而且还在于将网络抓取纳入您的日常生活的过程。开始使用网络爬虫相当容易,因为您不必担心构建、下载、集成或安装它们。因此,完成设置后,您就可以开始网页抓取了。现在想象一下,您可以在五分钟内从在线商店获取大约 1,000 种产品的信息并将其打包到一张简洁的 Excel 表格中,这是多么令人惊奇。
网络抓取提供了成功且动态的未来评估。由于数据抓取可以评估消费者的态度、需求和愿望,因此甚至可以进行广泛的预测分析。深入了解消费者的喜好是一件好事,它有助于企业有效地规划未来。
大规模数据提取
这很简单——人类 0,机器人 1——这并没有错。很难想象手动处理数据,因为它太多了。网络爬虫为您提供的数据远远多于您手动采集的数据。例如,如果您的挑战是每周检查竞争对手的产品和服务的价格,那可能会花费您很多时间。它也不会很有效,因为即使您拥有一支强大且积极进取的团队,您也无法保持这种状态。相反,您决定使用该系统并运行一个爬虫,该爬虫每小时以相对较低的成本采集您需要的所有数据并且永不疲倦。
以下是投资行业如何从网络抓取中受益。对冲基金偶尔会使用网络抓取技术来采集替代数据以避免失败。它有助于检测意外威胁以及潜在的投资机会。投资决策很复杂,因为它们通常需要一系列步骤,从开发假设文件到进行实验和研究,然后再做出明智的决定。历史数据研究是评估投资概念的最有效技术。它使您能够深入了解以前失败或成就的根本原因、可避免的错误以及潜在的未来投资回报。
网络抓取是提取历史数据的一种更有效的方法,然后可以将其输入机器学习数据库进行模型训练。因此,使用大数据的投资机构可以提高分析结果的准确性,做出更好的决策。
具有成本效益
关于网络抓取的最好的事情之一是它是一项以相当低的成本提供的复杂服务。时间就是金钱,随着网络的发展和加速,如果没有重复性任务的自动化,专业的数据提取项目将是不可能的。例如,您可以聘请临时人员来运行分析、检查网站、执行例行任务,但所有这些都可以通过简单的脚本实现自动化。
另一件事是,一旦提取数据的核心机制启动并运行,您就有机会爬取整个域,而不仅仅是一个或几个页面。网络抓取甚至可以使情绪分析成为一项更实惠的任务:众所周知,每天都有成千上万的消费者在在线评论中发布他们对产品和服务的体验网站。这些海量数据对公众开放,可能只是为了获取有关企业、竞争对手、可能的机会和趋势的信息而被抓取。
灵活性和系统化方法
这是唯一可以与抓取数据提供的速度竞争的优势,因为抓取工具本质上是不断变化的。因此,它们具有高度的可修改性、开放性并与其他脚本兼容。您可以在一个系统中设置抓取工具、重复数据删除参与者、监控参与者和应用程序集成。它将协同工作,不受任何限制、额外成本或任何新平台的实施。
性能可靠性和稳健性
网页抓取本身就是一个确保数据准确性的过程。这是如何运作的?嗯,单调和重复的任务往往会导致错误,因为它们对人类来说简直是无聊。如果您正在处理财务、定价、时间敏感数据或良好的旧销售 - 不准确和错误可能需要大量时间和资源来查找和修复,如果没有找到 - 从那时起问题就会滚雪球。这涉及任何类型的数据,因此不仅要能够采集数据,而且要以可读和干净的格式保存数据,这一点至关重要。在现代世界,这不是人类的任务,而是机器的任务。机器人只会犯人类预先写在代码中的错误。如果您的脚本正确,您可以在很大程度上消除人为错误的因素,并确保您采集的信息和数据每次都具有更好的质量。
网页抓取的缺点
网页抓取需要永久维护
要记住的另一件事是,在 SaaS 的世界中,服务只是旅程的开始。真正的交易是产品维护。我们提到维护的原因很简单:由于您的爬虫工作本质上与外部 网站 相关联,因此您无法控制该 网站 何时更改其 HTML 结构或内容。因此,开发人员必须对这些变化做出反应。
数据提取不等于数据分析
在处理数据提取和数据处理等复杂问题时,设定正确的期望非常重要。无论您使用多么好的网络爬虫,在大多数情况下它都无法为您完成数据分析工作。数据将以结构化格式到达,但是,需要处理更复杂的数据,以便它们可以在其他程序中使用。整个过程可能非常耗费资源和时间,如果您面临一个大数据分析项目,您应该做好准备。
网页新闻抓取(网页获取和解析速度和性能的应用场景详解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-23 17:21
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源码下载:网络爬虫(网络蜘蛛)网络爬虫示例源码 查看全部
网页新闻抓取(网页获取和解析速度和性能的应用场景详解!)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源码下载:网络爬虫(网络蜘蛛)网络爬虫示例源码
网页新闻抓取(如何深入全面的挖掘新闻信息,对于许多新闻相关工作意义重大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-21 16:11
【摘要】 新闻是与人们日常工作、娱乐和生活密切相关的信息。对于有影响力的新闻事件,具有更大深度和跨度的专题新闻信息量更大,更有趣。所谓话题新闻,是因为它的时效性。更多还原 突出新闻的“新”,突出“主题”和时间跨度大的话题,强调“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在互联网上迅速传播。另一方面,互联网上信息的爆炸式增长使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎 该引擎将触角伸入互联网信息的各个角落。如何深入、全面地挖掘新闻信息,对许多新闻相关工作具有重要意义。通过搜索引擎挖掘深入、全面的新闻信息是本文的重点,即通过进一步挖掘与某一主题相关的新闻内容,形成主题新闻。IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出贸易角色模型。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。
第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,提取的好坏直接决定后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们选择使用原生程序实现其搜索结果在几种方案中的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,通过行业角色模型进行文本挖掘,基于段落使用TRM模型进行评估,最后动态平衡每个段落的分数用于比较上述分数和新闻网页的特征,以提取相应的新闻文本内容。从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于在网上手动提取新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。 查看全部
网页新闻抓取(如何深入全面的挖掘新闻信息,对于许多新闻相关工作意义重大)
【摘要】 新闻是与人们日常工作、娱乐和生活密切相关的信息。对于有影响力的新闻事件,具有更大深度和跨度的专题新闻信息量更大,更有趣。所谓话题新闻,是因为它的时效性。更多还原 突出新闻的“新”,突出“主题”和时间跨度大的话题,强调“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在互联网上迅速传播。另一方面,互联网上信息的爆炸式增长使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎 该引擎将触角伸入互联网信息的各个角落。如何深入、全面地挖掘新闻信息,对许多新闻相关工作具有重要意义。通过搜索引擎挖掘深入、全面的新闻信息是本文的重点,即通过进一步挖掘与某一主题相关的新闻内容,形成主题新闻。IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出贸易角色模型。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。
第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,提取的好坏直接决定后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们选择使用原生程序实现其搜索结果在几种方案中的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,通过行业角色模型进行文本挖掘,基于段落使用TRM模型进行评估,最后动态平衡每个段落的分数用于比较上述分数和新闻网页的特征,以提取相应的新闻文本内容。从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于在网上手动提取新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。
网页新闻抓取(手机版简版网易新闻网址获取新闻链接列表列表的网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-01-20 22:10
网站分析
为了方便抓取,选择了简化版网易新闻网站的手机版。
在以下位置获取新闻链接列表
其中1-40代表当前列表中的页数,爬取列表时只需要修改页数即可。
爬取进程获取新闻链接地址
使用requests包读取新闻列表页面,然后使用正则表达式提取新闻页面链接,返回urls列表
def getList(url):
li = requests.get(url)
res = r'url":"http:.*?.html'
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
获取新闻内容
使用requests获取新闻页面的内容,然后使用BeautifulSoup包解析网页内容。
def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
移动短版新闻通常将一条新闻分成若干页来展示,这使得爬取内容非常麻烦。分析后发现在新闻链接地址后加_0可以显示所有新闻内容,所以先处理链接地址。然后使用requests获取网页,BeautifulSoup提取新闻的标题、时间、类别和内容。
保存结果
def saveAsTxt(news):
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
"\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
运行程序代码
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新闻标题
self.time = time #新闻时间
self.type = type #新闻类别
self.content = content #新闻内容
def getList(url): #获取新闻链接地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正则表达式获取链接地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #获取新闻内容
url = url[:-5]+"_0.html" #处理链接获取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #获取新闻内容,注意编码
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #保存新闻内容
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
# "\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/articl ... ot%3B %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "当前页解析出 %s 条" %len(urls)
j = 1
for url in urls:
print "正在读取第%s页第%s/%s条:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s条新闻,耗时%f s" %(sum,end - start)
结果
程序的运行时间主要与页面打开的速度有关。如果网络速度理想,程序运行速度相当快。
笔记
程序也是入门级爬虫,不涉及代理ip池和多线程效率问题。但是如果附加你需要这些后处理,比如
高效存储(数据库应该如何排列)
有效判断权重(这里指的是网页判断,我们不想爬抄抄袭的人民日报和大民报)
有效的信息提取(比如如何提取网页上的所有地址,“朝阳区奋进路中国路”),搜索引擎通常不需要存储所有信息,比如图片,我为什么要保存它们...
及时更新(预测此页面的更新频率)
可以想象,这里的每一点都可以被许多研究人员研究数十年。(知乎:谢克)
附录
请求文件 查看全部
网页新闻抓取(手机版简版网易新闻网址获取新闻链接列表列表的网址)
网站分析
为了方便抓取,选择了简化版网易新闻网站的手机版。
在以下位置获取新闻链接列表
其中1-40代表当前列表中的页数,爬取列表时只需要修改页数即可。
爬取进程获取新闻链接地址
使用requests包读取新闻列表页面,然后使用正则表达式提取新闻页面链接,返回urls列表
def getList(url):
li = requests.get(url)
res = r'url":"http:.*?.html'
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
获取新闻内容
使用requests获取新闻页面的内容,然后使用BeautifulSoup包解析网页内容。
def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
移动短版新闻通常将一条新闻分成若干页来展示,这使得爬取内容非常麻烦。分析后发现在新闻链接地址后加_0可以显示所有新闻内容,所以先处理链接地址。然后使用requests获取网页,BeautifulSoup提取新闻的标题、时间、类别和内容。
保存结果
def saveAsTxt(news):
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
"\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
运行程序代码
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新闻标题
self.time = time #新闻时间
self.type = type #新闻类别
self.content = content #新闻内容
def getList(url): #获取新闻链接地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正则表达式获取链接地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #获取新闻内容
url = url[:-5]+"_0.html" #处理链接获取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #获取新闻内容,注意编码
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #保存新闻内容
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
# "\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/articl ... ot%3B %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "当前页解析出 %s 条" %len(urls)
j = 1
for url in urls:
print "正在读取第%s页第%s/%s条:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s条新闻,耗时%f s" %(sum,end - start)
结果
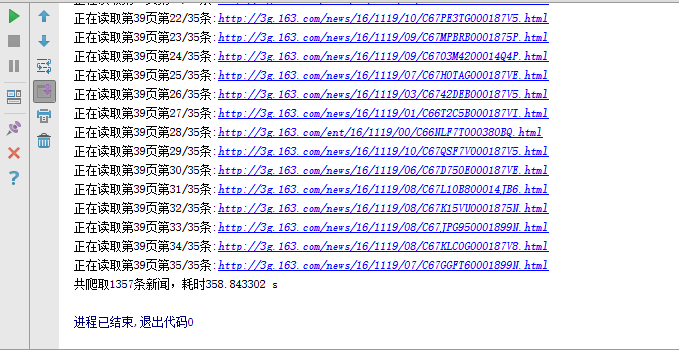
程序的运行时间主要与页面打开的速度有关。如果网络速度理想,程序运行速度相当快。
笔记
程序也是入门级爬虫,不涉及代理ip池和多线程效率问题。但是如果附加你需要这些后处理,比如
高效存储(数据库应该如何排列)
有效判断权重(这里指的是网页判断,我们不想爬抄抄袭的人民日报和大民报)
有效的信息提取(比如如何提取网页上的所有地址,“朝阳区奋进路中国路”),搜索引擎通常不需要存储所有信息,比如图片,我为什么要保存它们...
及时更新(预测此页面的更新频率)
可以想象,这里的每一点都可以被许多研究人员研究数十年。(知乎:谢克)
附录
请求文件
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-02 19:26
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(影响蜘蛛爬行并最终影响到页面收录结果主要有几个方面的原因)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-28 20:17
影响蜘蛛抓取并最终影响页面收录结果的原因有多种。
1. 网站 更新
一般情况下,网站 更新很快,并且蜘蛛爬取 网站 的内容更快。如果网站的内容长时间没有更新,蜘蛛也会相应调整网站的爬取频率。更新频率对于新闻等至关重要。网站。因此,保持一定数量的每日更新对于吸引蜘蛛非常重要。
2. 网站内容质量
对于低质量的页面,搜索引擎总是在争吵,所以创造高质量的内容对于吸引蜘蛛非常关键。从这个角度来说,“内容取胜”是完全正确的。如果网页质量低,比如很多采集相同的内容,而页面的核心内容是空的,就不会受到蜘蛛的青睐。
3. 网站是否可以正常访问
网站能否正常访问是搜索引擎的连接度。连接需求网站不能频繁访问,或者访问速度极慢。从蜘蛛的角度来看,我希望提供给检索客户的网页都是可以正常访问的页面。对于响应速度慢或者经常崩溃的服务器,相关的网站肯定会有负面印象,严重的是逐渐减少爬取甚至剔除已经是收录的页面。
现实中,由于国内服务器服务成本相对较高,另外,基于监管要求,建立国内网站需要备案系统,需要经过网上上传备案信息的流程。一些中小型网站网站长期可能会在国外租用服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问国外服务器时,由于距离较远,访问速度慢或死机在所难免。从长远来看,网站 的 SEO 效果是一个约束。如果你想用心运行一个网站,你应该尝试使用国内的服务器服务。您可以选择一些服务更好、界面友好的服务器提供商。现在,
此外,搜索引擎会根据网站的综合表现对网站进行评分。这个评分不能完全等于权重,但是评分的高低会影响蜘蛛对网站策略的爬取。
在爬取频率方面,搜索引擎一般都会提供可以调整爬取频率设置的工具,SEO人员可以根据实际情况进行调整。对于大型网站,服务请求多,可以使用调整频率的工具来减轻网站的压力。
在实际的爬取过程中,如果出现不可访问的爬取异常,将会大大降低搜索引擎对网站的评分,从而影响爬取、索引、排序等一系列SEO效果。流量损失。
爬网异常的发生可能有多种原因,例如服务器不稳定、服务器不断过载或协议错误。因此,网站运维人员需要持续跟踪网站的运行情况,保证网站的稳定运行。在协议配置中,需要避免一些低级错误,例如 Robots Disallow 设置错误。有一次,公司经理咨询了SEO人员,问他们为什么委托外部开发人员做好网站后在搜索引擎中找不到。SEO人员直接在网址和地址栏输入他的网站Robots地址,发现禁止蜘蛛爬行(Disallow命令)!
关于无法访问网站还有其他可能,比如网络运营商异常,即蜘蛛无法通过电信或网通等服务商访问网站;DNS异常,即蜘蛛无法解析网站IP,地址可能有误,也可能被域名提供商屏蔽。在这种情况下,您需要联系域名提供商。网页也可能存在死链接,例如当前页面失效或出现错误,部分网页可能已经批量下线。在这种情况下,最好的方法是提交死链接描述;如果是 url 更改导致的旧链接 URL 无效,无法访问。最好设置一个 301 跳转,将旧 URL 和相关权重转移到新页面。当然,
对于已经捕获的数据,然后蜘蛛建立数据库。在这个链接中,搜索引擎会根据一些原则来判断链接的重要性。一般来说,判断的原则如下:内容是否为原创,如果是则加权;主要内容是否显着,即核心内容是否显着,如果是,则加权;内容是否丰富,如果内容非常丰富,则进行加权;用户体验是否好,比如页面更流畅,广告加载少等,如果是,会加权等等。
因此,我们在网站的日常操作中需要坚持以下原则。
(1)请勿抄袭。因为独特的内容是所有搜索引擎公司都喜欢的,所以互联网鼓励原创。很多互联网公司希望通过大量的采集@组织自己的网站>网页内容@>,从SEO的角度来看,其实是一种不受欢迎的行为。
(2)在网站的内容设计中,要坚持主题内容的突出,也就是让搜索引擎爬过来知道网页的内容是什么表达,而不是从一堆内容网站判断网站到底是做什么业务的。主题不突出,很多网站操作混乱的典型案例。例如,在一些小说网站中,一个800字的章节被分成8个,每页100字左右,剩下的页面收录各种广告和各种不相关的内容信息。还有网站,主要内容是一个frame框架或者AIAX框架,蜘蛛可以抓取的信息都是不相关的内容。
尤其是弹出大量低质量广告和有混淆页面主要内容的垃圾广告的页面。目前一些大型门户网站网站从收入来看,还是挂了很多广告。作为SEO人员,你需要考虑这个问题。
(4)维护网页内容的可访问性。有些网页承载了很多内容,但是以js、AJAX等方式呈现,搜索引擎无法识别,导致网页内容空洞、短小.网页的评分大大降低。
此外,在链接的重要性方面,有两个重要的判断原则:从目录层面来看,坚持浅层优先原则;从内链设计的角度,坚持热门页面优先的原则。
所谓浅优先,是指搜索引擎在处理新链接和判断链接重要性时,会优先考虑URL。更多页面,即来自 url 组织的更接近主页域名的页面。因此,SEO在优化重要页面时,一定要注意扁平化的原则,尽可能缩短URL的中间链接。
既然浅层优先,那么是否可以将所有页面平铺在网站根目录下,从而选择最佳的SEO效果?当然不是,首先,优先级是一个相对的概念,如果所有的内容都放在根目录下,那么赋予什么优先级都无所谓。重要内容和不重要内容之间没有区别。另外,从SEO的角度来看,URL也用于分析爬取后的网站的结构。通过URL的构成,可以大致判断内容的分组情况。SEO人员可以完成由关键词和内容组成的URL。关键词网页的组织。
目前在网站上的人气主要体现在以下几个指标上。
・网站上指向该页面的内部链接数。
・通过网站上的自然浏览行为到达页面的 PV。
・此页面的点击流失率。
所以,从SEO的角度来说,如果需要快速提升一个页面的搜索排名,可以在人气方面做一些工作,如下。
・多做从其他页面到页面的锚文本,尤其是高PR页面。
・给页面一个吸引人的标题,引导更多自然浏览的用户点击页面链接。
・提高页面内容质量,降低页面流量 查看全部
网页新闻抓取(影响蜘蛛爬行并最终影响到页面收录结果主要有几个方面的原因)
影响蜘蛛抓取并最终影响页面收录结果的原因有多种。
1. 网站 更新
一般情况下,网站 更新很快,并且蜘蛛爬取 网站 的内容更快。如果网站的内容长时间没有更新,蜘蛛也会相应调整网站的爬取频率。更新频率对于新闻等至关重要。网站。因此,保持一定数量的每日更新对于吸引蜘蛛非常重要。
2. 网站内容质量
对于低质量的页面,搜索引擎总是在争吵,所以创造高质量的内容对于吸引蜘蛛非常关键。从这个角度来说,“内容取胜”是完全正确的。如果网页质量低,比如很多采集相同的内容,而页面的核心内容是空的,就不会受到蜘蛛的青睐。
3. 网站是否可以正常访问
网站能否正常访问是搜索引擎的连接度。连接需求网站不能频繁访问,或者访问速度极慢。从蜘蛛的角度来看,我希望提供给检索客户的网页都是可以正常访问的页面。对于响应速度慢或者经常崩溃的服务器,相关的网站肯定会有负面印象,严重的是逐渐减少爬取甚至剔除已经是收录的页面。
现实中,由于国内服务器服务成本相对较高,另外,基于监管要求,建立国内网站需要备案系统,需要经过网上上传备案信息的流程。一些中小型网站网站长期可能会在国外租用服务器服务,比如Godaddy(一家提供域名注册和互联网托管服务的美国公司)服务。但是,从中国访问国外服务器时,由于距离较远,访问速度慢或死机在所难免。从长远来看,网站 的 SEO 效果是一个约束。如果你想用心运行一个网站,你应该尝试使用国内的服务器服务。您可以选择一些服务更好、界面友好的服务器提供商。现在,
此外,搜索引擎会根据网站的综合表现对网站进行评分。这个评分不能完全等于权重,但是评分的高低会影响蜘蛛对网站策略的爬取。
在爬取频率方面,搜索引擎一般都会提供可以调整爬取频率设置的工具,SEO人员可以根据实际情况进行调整。对于大型网站,服务请求多,可以使用调整频率的工具来减轻网站的压力。
在实际的爬取过程中,如果出现不可访问的爬取异常,将会大大降低搜索引擎对网站的评分,从而影响爬取、索引、排序等一系列SEO效果。流量损失。
爬网异常的发生可能有多种原因,例如服务器不稳定、服务器不断过载或协议错误。因此,网站运维人员需要持续跟踪网站的运行情况,保证网站的稳定运行。在协议配置中,需要避免一些低级错误,例如 Robots Disallow 设置错误。有一次,公司经理咨询了SEO人员,问他们为什么委托外部开发人员做好网站后在搜索引擎中找不到。SEO人员直接在网址和地址栏输入他的网站Robots地址,发现禁止蜘蛛爬行(Disallow命令)!
关于无法访问网站还有其他可能,比如网络运营商异常,即蜘蛛无法通过电信或网通等服务商访问网站;DNS异常,即蜘蛛无法解析网站IP,地址可能有误,也可能被域名提供商屏蔽。在这种情况下,您需要联系域名提供商。网页也可能存在死链接,例如当前页面失效或出现错误,部分网页可能已经批量下线。在这种情况下,最好的方法是提交死链接描述;如果是 url 更改导致的旧链接 URL 无效,无法访问。最好设置一个 301 跳转,将旧 URL 和相关权重转移到新页面。当然,
对于已经捕获的数据,然后蜘蛛建立数据库。在这个链接中,搜索引擎会根据一些原则来判断链接的重要性。一般来说,判断的原则如下:内容是否为原创,如果是则加权;主要内容是否显着,即核心内容是否显着,如果是,则加权;内容是否丰富,如果内容非常丰富,则进行加权;用户体验是否好,比如页面更流畅,广告加载少等,如果是,会加权等等。
因此,我们在网站的日常操作中需要坚持以下原则。
(1)请勿抄袭。因为独特的内容是所有搜索引擎公司都喜欢的,所以互联网鼓励原创。很多互联网公司希望通过大量的采集@组织自己的网站>网页内容@>,从SEO的角度来看,其实是一种不受欢迎的行为。
(2)在网站的内容设计中,要坚持主题内容的突出,也就是让搜索引擎爬过来知道网页的内容是什么表达,而不是从一堆内容网站判断网站到底是做什么业务的。主题不突出,很多网站操作混乱的典型案例。例如,在一些小说网站中,一个800字的章节被分成8个,每页100字左右,剩下的页面收录各种广告和各种不相关的内容信息。还有网站,主要内容是一个frame框架或者AIAX框架,蜘蛛可以抓取的信息都是不相关的内容。
尤其是弹出大量低质量广告和有混淆页面主要内容的垃圾广告的页面。目前一些大型门户网站网站从收入来看,还是挂了很多广告。作为SEO人员,你需要考虑这个问题。
(4)维护网页内容的可访问性。有些网页承载了很多内容,但是以js、AJAX等方式呈现,搜索引擎无法识别,导致网页内容空洞、短小.网页的评分大大降低。
此外,在链接的重要性方面,有两个重要的判断原则:从目录层面来看,坚持浅层优先原则;从内链设计的角度,坚持热门页面优先的原则。
所谓浅优先,是指搜索引擎在处理新链接和判断链接重要性时,会优先考虑URL。更多页面,即来自 url 组织的更接近主页域名的页面。因此,SEO在优化重要页面时,一定要注意扁平化的原则,尽可能缩短URL的中间链接。
既然浅层优先,那么是否可以将所有页面平铺在网站根目录下,从而选择最佳的SEO效果?当然不是,首先,优先级是一个相对的概念,如果所有的内容都放在根目录下,那么赋予什么优先级都无所谓。重要内容和不重要内容之间没有区别。另外,从SEO的角度来看,URL也用于分析爬取后的网站的结构。通过URL的构成,可以大致判断内容的分组情况。SEO人员可以完成由关键词和内容组成的URL。关键词网页的组织。
目前在网站上的人气主要体现在以下几个指标上。
・网站上指向该页面的内部链接数。
・通过网站上的自然浏览行为到达页面的 PV。
・此页面的点击流失率。
所以,从SEO的角度来说,如果需要快速提升一个页面的搜索排名,可以在人气方面做一些工作,如下。
・多做从其他页面到页面的锚文本,尤其是高PR页面。
・给页面一个吸引人的标题,引导更多自然浏览的用户点击页面链接。
・提高页面内容质量,降低页面流量
网页新闻抓取(学习机器学习算法,分为回归,分类,爬取一下 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-20 02:04
)
作者简历地址:
Python爬虫一步步爬取文章后台
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据做练习,所以想爬取国内各大网站的新闻,通过训练,然后对未来的News进行分类预测。在这样的背景下,我的爬虫之旅开始了。
网站分析
国内重大新闻汇总网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。. .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了urllib2和BeautifulSoup这两个包。以搜狐新闻为例,做了一个简单的爬取内容的爬虫,没有做任何优化等问题,所以会出现假死等情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
以上代码在运行过程中,会遇到一些问题,导致爬虫运行中断,运行缓慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后通过设置爬虫的代理解决IP问题。代码显示如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果找不到网页,则直接丢弃,因为丢弃少量网页不会影响以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
关于速度慢,爬取可以采用多进程的方式。解析完URL,就可以在Redis中使用有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。(尚未实现)
第 4 步:运行
昨晚试运行,爬取了搜狐新闻的部分网页,大概50*5*15=3750个网页,解析了2000多条新闻。当网速接近1Mbps时,我花了很多钱。1101s的时间约为18分钟。
查看全部
网页新闻抓取(学习机器学习算法,分为回归,分类,爬取一下
)
作者简历地址:
Python爬虫一步步爬取文章后台
最近在学习机器学习算法,分为回归、分类、聚类等,学习过程中没有数据做练习,所以想爬取国内各大网站的新闻,通过训练,然后对未来的News进行分类预测。在这样的背景下,我的爬虫之旅开始了。
网站分析
国内重大新闻汇总网站(待续):
搜狐新闻:
时政:http://m.sohu.com/cr/32/%3Fpag ... v%3D2
社会:http://m.sohu.com/cr/53/%3Fpag ... v%3D2
天下:http://m.sohu.com/cr/57/%3F_sm ... v%3D2
总的网址:http://m.sohu.com/cr/4/?page=4 第一个4代表类别,第二个4代表页数
网易新闻
推荐:http://3g.163.com/touch/articl ... .html 主要修改20-20
新闻:http://3g.163.com/touch/articl ... .html
娱乐:http://3g.163.com/touch/articl ... .html
体育:http://3g.163.com/touch/articl ... .html
财经:http://3g.163.com/touch/articl ... .html
时尚:http://3g.163.com/touch/articl ... .html
军事:http://3g.163.com/touch/articl ... .html
手机:http://3g.163.com/touch/articl ... .html
科技:http://3g.163.com/touch/articl ... .html
游戏:http://3g.163.com/touch/articl ... .html
数码:http://3g.163.com/touch/articl ... .html
教育:http://3g.163.com/touch/articl ... .html
健康:http://3g.163.com/touch/articl ... .html
汽车:http://3g.163.com/touch/articl ... .html
家居:http://3g.163.com/touch/articl ... .html
房产:http://3g.163.com/touch/articl ... .html
旅游:http://3g.163.com/touch/articl ... .html
亲子:http://3g.163.com/touch/articl ... .html
待续。. .
爬取过程的第一步:简单爬取
在这个过程中,主要用到了urllib2和BeautifulSoup这两个包。以搜狐新闻为例,做了一个简单的爬取内容的爬虫,没有做任何优化等问题,所以会出现假死等情况。
# -*- coding:utf-8 -*-
'''
Created on 2016-3-15
@author: AndyCoder
'''
import urllib2
from bs4 import BeautifulSoup
import socket
import httplib
class Spider(object):
"""Spider"""
def __init__(self, url):
self.url = url
def getNextUrls(self):
urls = []
request = urllib2.Request(self.url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
soup = BeautifulSoup(html,'html.parser')
for link in soup.find_all('a'):
print("http://m.sohu.com" + link.get('href'))
if link.get('href')[0] == '/':
urls.append("http://m.sohu.com" + link.get('href'))
return urls
def getNews(url):
print url
xinwen = ''
request = urllib2.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
except urllib2.HTTPError, e:
print e.code
soup = BeautifulSoup(html,'html.parser')
for news in soup.select('p.para'):
xinwen += news.get_text().decode('utf-8')
return xinwen
class News(object):
"""
source:from where 从哪里爬取的网站
title:title of news 文章的标题
time:published time of news 文章发布时间
content:content of news 文章内容
type:type of news 文章类型
"""
def __init__(self, source, title, time, content, type):
self.source = source
self.title = title
self.time = time
self.content = content
self.type = type
file = open('C:/test.txt','a')
for i in range(38,50):
for j in range(1,5):
url = "http://m.sohu.com/cr/" + str(i) + "/?page=" + str(j)
print url
s = Spider(url)
for newsUrl in s.getNextUrls():
file.write(getNews(newsUrl))
file.write("\n")
print "---------------------------"
第 2 步:遇到的问题
以上代码在运行过程中,会遇到一些问题,导致爬虫运行中断,运行缓慢。这里有几个问题:
第 3 步:解决方案
代理服务器
可以从网上找一些代理服务器,然后通过设置爬虫的代理解决IP问题。代码显示如下:
def setProxy(pro):
proxy_support=urllib2.ProxyHandler({'https':pro})
opener=urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
关于状态问题,如果找不到网页,则直接丢弃,因为丢弃少量网页不会影响以后的工作。
def getHtml(url,pro):
urls = []
request = urllib2.Request(url)
setProxy(pro)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; \
WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36')
try:
html = urllib2.urlopen(request)
statusCod = html.getcode()
if statusCod != 200:
return urls
except socket.timeout, e:
pass
except urllib2.URLError,ee:
pass
except httplib.BadStatusLine:
pass
return html
关于速度慢,爬取可以采用多进程的方式。解析完URL,就可以在Redis中使用有序集作为队列,既解决了URL重复的问题,也解决了多进程的问题。(尚未实现)
第 4 步:运行
昨晚试运行,爬取了搜狐新闻的部分网页,大概50*5*15=3750个网页,解析了2000多条新闻。当网速接近1Mbps时,我花了很多钱。1101s的时间约为18分钟。
网页新闻抓取( Python3实战入门数据库篇--把爬取到的数据存到数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2022-02-18 11:26
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/")
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于抓到的html文档比较长,这里简单贴个帖子给大家看看。
..........后面省略一大堆
复制代码
这是Python3爬虫的简单介绍,是不是很简单,建议你敲几遍
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090")
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看我爬过哪些美图
爬到 24 个女孩的照片是如此容易。是不是很简单。
四、Python3爬取新闻网站新闻列表
这里有点复杂,所以我会向你解释。
分析上图中我们要抓取的信息然后放到div中的a标签和img标签中,那么我们思考的是如何获取这些信息
这里会用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到的,但是太乱了,还有很多我们不想要的东西。让我们通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里增加了异常处理,主要是因为有些新闻可能没有标题、网址或图片。如果不进行异常处理,可能会导致我们爬取的中断。
过滤的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,完整代码贴在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取到数据后,我们还需要将数据存入数据库。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以利用这些爬取的文章,给app提供一个新闻api接口。当然,这是后话了。学完Python数据库操作后,我会写一篇文章文章《Python3实战入门数据库篇---将爬取的数据保存到数据库》 查看全部
网页新闻抓取(
Python3实战入门数据库篇--把爬取到的数据存到数据库)
# 简单的网络爬虫
from urllib import request
import chardet
response = request.urlopen("http://www.jianshu.com/";)
html = response.read()
charset = chardet.detect(html)# {'language': '', 'encoding': 'utf-8', 'confidence': 0.99}
html = html.decode(str(charset["encoding"])) # 解码
print(html)
复制代码
由于抓到的html文档比较长,这里简单贴个帖子给大家看看。
..........后面省略一大堆
复制代码
这是Python3爬虫的简单介绍,是不是很简单,建议你敲几遍
三、Python3抓取网页中的图片并将图片保存到本地文件夹
目标
import re
import urllib.request
#爬取网页html
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
return html
html = getHtml("http://tieba.baidu.com/p/3205263090";)
html = html.decode('UTF-8')
#获取图片链接的方法
def getImg(html):
# 利用正则表达式匹配网页里的图片地址
reg = r'src="([.*\S]*\.jpg)" pic_ext="jpeg"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html)
return imglist
imgList=getImg(html)
imgCount=0
#for把获取到的图片都下载到本地pic文件夹里,保存之前先在本地建一个pic文件夹
for imgPath in imgList:
f=open("../pic/"+str(imgCount)+".jpg",'wb')
f.write((urllib.request.urlopen(imgPath)).read())
f.close()
imgCount+=1
print("全部抓取完成")
复制代码
迫不及待想看看我爬过哪些美图
爬到 24 个女孩的照片是如此容易。是不是很简单。
四、Python3爬取新闻网站新闻列表
这里有点复杂,所以我会向你解释。
分析上图中我们要抓取的信息然后放到div中的a标签和img标签中,那么我们思考的是如何获取这些信息
这里会用到我们导入的BeautifulSoup4库,关键代码在这里
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
复制代码
上面代码得到的allList就是我们要获取的新闻列表,如下
[
<a href=span class="hljs-string""/article/211390.html"/span target=span class="hljs-string""_blank"/span>

</a>
,
<a href=span class="hljs-string""/article/214982.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""TFBOYS成员各自飞,商业价值天花板已现?"/span>

</a>
,
<a href=span class="hljs-string""/article/213703.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""买手店江湖"/span>

</a>
,
<a href=span class="hljs-string""/article/214679.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""iPhone X正式告诉我们,手机和相机开始分道扬镳"/span>

</a>
,
<a href=span class="hljs-string""/article/214962.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""信用已被透支殆尽,乐视汽车或成贾跃亭弃子"/span>

</a>
,
<a href=span class="hljs-string""/article/214867.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""别小看“搞笑诺贝尔奖”,要向好奇心致敬"/span>

</a>
,
<a href=span class="hljs-string""/article/214954.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""10 年前改变世界的,可不止有 iPhone | 发车"/span>

</a>
,
<a href=span class="hljs-string""/article/214908.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""感谢微博替我做主"/span>

</a>
,
<a href=span class="hljs-string""/article/215001.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?"/span>

</a>
,
<a href=span class="hljs-string""/article/214969.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""中国音乐的“全面付费”时代即将到来?"/span>

</a>
,
<a href=span class="hljs-string""/article/214964.html"/span target=span class="hljs-string""_blank"/span title=span class="hljs-string""百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远"/span>

</a>
]
复制代码
这里的数据是抓到的,但是太乱了,还有很多我们不想要的东西。让我们通过遍历提取我们的有效信息
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
这里增加了异常处理,主要是因为有些新闻可能没有标题、网址或图片。如果不进行异常处理,可能会导致我们爬取的中断。
过滤的有效信息
标题 标题为空
url: https://www.huxiu.com/article/211390.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 TFBOYS成员各自飞,商业价值天花板已现?
url: https://www.huxiu.com/article/214982.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 买手店江湖
url: https://www.huxiu.com/article/213703.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 iPhone X正式告诉我们,手机和相机开始分道扬镳
url: https://www.huxiu.com/article/214679.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 信用已被透支殆尽,乐视汽车或成贾跃亭弃子
url: https://www.huxiu.com/article/214962.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 别小看“搞笑诺贝尔奖”,要向好奇心致敬
url: https://www.huxiu.com/article/214867.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 10 年前改变世界的,可不止有 iPhone | 发车
url: https://www.huxiu.com/article/214954.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 感谢微博替我做主
url: https://www.huxiu.com/article/214908.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 苹果确认取消打赏抽成,但还有多少内容让你觉得值得掏腰包?
url: https://www.huxiu.com/article/215001.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 中国音乐的“全面付费”时代即将到来?
url: https://www.huxiu.com/article/214969.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
标题 百丽退市启示录:“一代鞋王”如何与新生代消费者渐行渐远
url: https://www.huxiu.com/article/214964.html
图片地址: https://img.huxiucdn.com/artic ... /210/|imageMogr2/strip/interlace/1/quality/85/format/jpg
==============================================================================================
复制代码
这里我们抓取新闻网站新闻信息就大功告成了,完整代码贴在下面
from bs4 import BeautifulSoup
from urllib import request
import chardet
url = "https://www.huxiu.com"
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
html = html.decode(str(charset["encoding"])) # 设置抓取到的html的编码方式
# 使用剖析器为html.parser
soup = BeautifulSoup(html, 'html.parser')
# 获取到每一个class=hot-article-img的a节点
allList = soup.select('.hot-article-img')
#遍历列表,获取有效信息
for news in allList:
aaa = news.select('a')
# 只选择长度大于0的结果
if len(aaa) > 0:
# 文章链接
try:#如果抛出异常就代表为空
href = url + aaa[0]['href']
except Exception:
href=''
# 文章图片url
try:
imgUrl = aaa[0].select('img')[0]['src']
except Exception:
imgUrl=""
# 新闻标题
try:
title = aaa[0]['title']
except Exception:
title = "标题为空"
print("标题",title,"\nurl:",href,"\n图片地址:",imgUrl)
print("==============================================================================================")
复制代码
获取到数据后,我们还需要将数据存入数据库。只要存储在我们的数据库中,并且数据库中有数据,我们就可以做后续的数据分析处理,也可以利用这些爬取的文章,给app提供一个新闻api接口。当然,这是后话了。学完Python数据库操作后,我会写一篇文章文章《Python3实战入门数据库篇---将爬取的数据保存到数据库》
网页新闻抓取( 测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2022-02-18 11:10
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:一般新闻网页文本的在线提取
摄影:产品经理
毛脑花和广粉
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考文献
[1]
GNE:
[2]
官方文档:
国王的名字
为产品经理省钱买房。 查看全部
网页新闻抓取(
测试GNE的功能,你只需要在最上面的文本框中粘贴网页源代码)
Gne Online:一般新闻网页文本的在线提取
摄影:产品经理
毛脑花和广粉
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
参考文献
[1]
GNE:
[2]
官方文档:
国王的名字
为产品经理省钱买房。
网页新闻抓取(手机用户浏览桂林电子科技大学校园网新闻显示页面的多少?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-16 00:25
题目来源及背景:本题目来源于自选题目。软件可以抓取新闻网站的列表和内容,将列表和内容调整为适合手机屏幕浏览的界面风格,并显示在网页上;软件动态抓取桂林电子科技大学新闻网站信息内容,一旦布局成功,您可以在手机上轻松快速浏览桂林电子科技大学新闻,无需手机屏幕显示的效果还是难看的问题。技术创新与进步:基于普通电脑和win7操作系统,php环境,apache web服务器,开发一套技术成熟,适用范围及安全性:成熟;适用范围:适用于新闻网站自动抓取展示。安全:公平。应用及存在问题:一般。历年获奖:无。成就介绍:从新闻列表页面跳转具体新闻信息页面。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。具体新闻展示页面 该页面主要展示具体的新闻信息,从新闻列表页面跳转。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。 查看全部
网页新闻抓取(手机用户浏览桂林电子科技大学校园网新闻显示页面的多少?(图))
题目来源及背景:本题目来源于自选题目。软件可以抓取新闻网站的列表和内容,将列表和内容调整为适合手机屏幕浏览的界面风格,并显示在网页上;软件动态抓取桂林电子科技大学新闻网站信息内容,一旦布局成功,您可以在手机上轻松快速浏览桂林电子科技大学新闻,无需手机屏幕显示的效果还是难看的问题。技术创新与进步:基于普通电脑和win7操作系统,php环境,apache web服务器,开发一套技术成熟,适用范围及安全性:成熟;适用范围:适用于新闻网站自动抓取展示。安全:公平。应用及存在问题:一般。历年获奖:无。成就介绍:从新闻列表页面跳转具体新闻信息页面。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。具体新闻展示页面 该页面主要展示具体的新闻信息,从新闻列表页面跳转。此页面有四个部分。版块选择部分主要负责选择新闻的类别,根据选择的版块跳转到对应的列表页。新闻标题和发布时间负责突出新闻标题并以小字标记发布时间。文字内容根据手机屏幕大小自动调整一行文字的大小。图片部分的图片会根据手机屏幕的大小自动调整宽高。以上内容让手机用户在桂林电子科技大学校园网浏览新闻更加方便。
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-08 10:18
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/").get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i 查看全部
网页新闻抓取(关于Jsoup分析与思路虎扑NBA新闻网页的新闻列表)
前言:作为一个篮球迷,每天都要刷NBA新闻。用了这么多新闻应用后,我想知道我是否可以制作一个简单的新闻应用。于是我用Jsoup抓取了虎扑NBA新闻的数据,完成了一个简单的新闻APP。虽然没有什么技术含量,但还是把过程写下来,满足菜鸟的小成就感。
关于Jsoup分析及思路虎扑NBA新闻页面的新闻列表如图:
我们要做的就是获取图片中每条新闻的新闻标题、新闻摘要、新闻时间和来源、新闻链接地址,然后用实体类News封装以上四个数据,然后在列表视图。. 点击ListView的每个子项,用WebView显示子项显示的新闻的链接地址,大功告成。效果如图:
具体实施过程
1.在AndroidStudio新建项目JsoupTest,然后将Jsoup jar包【下载地址】复制到项目的libs中,然后右键Add As Library...
2.修改activity_main.xml的布局,简单的添加一个ListView,设置Listview每两个子项的间隔距离和颜色
3.创建一个实体类News来封装我们将从网页中获取的新闻的标题、摘要、时间和来源、链接地址四个数据。很简单,用四个变量来表示以上四个数据,并建立对应的构造方法和四个变量的get和set方法。
public class News {
private String newsTitle; //新闻标题
private String newsUrl; //新闻链接地址
private String desc; //新闻概要
private String newsTime; //新闻时间与来源
public News(String newsTitle, String newsUrl, String desc, String newsTime) {
this.newsTitle = newsTitle;
this.newsUrl = newsUrl;
this.desc = desc;
this.newsTime = newsTime;
}
public String getDesc() {
return desc;
}
public void setDesc(String desc) {
this.desc = desc;
}
public String getNewsTime() {
return newsTime;
}
public void setNewsTime(String newsTime) {
this.newsTime = newsTime;
}
public String getNewsTitle() {
return newsTitle;
}
public void setNewsTitle(String newsTitle) {
this.newsTitle = newsTitle;
}
public String getNewsUrl() {
return newsUrl;
}
public void setNewsUrl(String newsUrl) {
this.newsUrl = newsUrl;
}
}
4.最重要的一步:使用Jsoup获取虎扑NBA新闻网页的数据,封装到News实体类中。只是简要概述了如何实施
分析上图中两条新闻的源码,找到我们打算获取的新闻的标题、摘要、时间和来源、链接地址四个数据。我们可以发现,在每条新闻的[div][/div]标签下,都有两条数据,一条新闻的链接地址,一条新闻的标题。而我们要做的就是使用Jsoup来解析这两个数据:
首先用 Jsoup.connect("URL to grab data").get() 获取一个 Document 对象
Document doc = Jsoup.connect("https://voice.hupu.com/nba/";).get();
使用方法 doc.select("div.list-hd") 返回一个 Elements 对象,该对象封装了每个新闻 [div][/div] 标签的内容。数据格式为:[{news1},{news 2}, {news 3}, {news 4}...]
对于每个 Element 对象,使用 for 循环遍历 titleLinks:
使用e.select("a").text()获取[a][/a]之间的内容,即新闻标题;
使用e.select("a").attr("href") 获取每个标签中href的值,即新闻的链接地址
Elements titleLinks = doc.select("div.list-hd");
for(Element e:titleLinks){
String title = e.select("a").text();
String uri = e.select("a").attr("href");
}
其他两个数据:news profile 和 news time and source 同理,我们分析源码,解析news profile source code
使用以下代码获取新闻简介
Elements descLinks = doc.select("div.list-content");
for(Element e:titleLinks){
String desc = e.select("span").text();
}
- 新闻时间及来源源代码

用如下代码获得新闻时间与来源
```
Elements timeLinks = doc.select("div.otherInfo");
for(元素 e:timeLinks){
String time = e.select("span.other-left").select("a").text();
}
````
<p> private void getNews(){
new Thread(new Runnable() {
@Override
public void run() {
try{
//获取虎扑新闻20页的数据,网址格式为:https://voice.hupu.com/nba/第几页
for(int i = 1;i
网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-08 08:08
)
为什么要提取文本
一般来说,舆情分析都会涉及到网页内容的提取。对于分析,有价值的信息是身体部分。大多数情况下,为了便于分析,需要将网页中与正文无关的部分去掉。可以说,文本提取的好坏直接影响分析结果的好坏。
对于具体的网站,我们可以分析其html结构,根据其结构获取body信息。看看下面的图片:
在body部分,不同的网站,body的位置不同,Html的结构也不同。对于爬虫来说,要爬取的页面是多种多样的,不可能对所有页面都写爬取。规则来提取文本内容,因此需要一个通用的算法来提取文本。
现有网页文本提取算法
前两种方法比较容易实现,主要是处理简单。之前实现过标签密度提取算法,但是实际中错误率还是挺高的;后两种方法在实现上稍微复杂一些。算法效率应该不会高很多。
我们需要的是一种简单且易于实现的算法,可以保证处理速度和良好的提取精度。因此,结合前两种算法,研究网页的html页面结构,有一个更好的处理思路,称为基于文本密度的文本提取算法。后来在网上找了一个类似的算法,发现也有类似的处理文本提取的处理方法,但还是有些不同。接下来给大家分享一下这个算法的一些处理思路。
网页分析
我随便从百度、搜狐、网易拿了一个新闻页面,拿来分析。
先看一个百度文章
任正非为什么要主动和我合影?
先请求这个页面,然后过滤到所有的html标签,只留下文本信息,我们可以看到body信息集中在以下几个位置:
使用Excel分析行数与每行字符的关系可以发现:
显然,文本内容集中在65-100行之间的位置,这个区间的字符数比较密集。
网易的另一篇文章文章
张小龙的神话破灭了,马化腾接手微信的时候到了。
或者先过滤html标签后看body部分:
另一个Excel分析结果:
文本部分集中在第 279-282 行之间。从图中可以看出,正是这些行具有特别高的文本密度。
搜狐新闻最后分析
李克强在天津考察考察期间的几个瞬间,
或者看一下标签后面的文字:
看一下Excel中的分析结果:
而搜狐的文章正文部分主要集中在200-255行之间。其余的文字都是杂乱无章的标签文字。
对不起,我漏掉了一个很重要的解释:为什么我们在分析的时候要过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关注的是body的内容。如果有这样的标签 style="color: #0000ff;">varchart =style="color: #0000ff;">newstyle="color: #000000;">来分析一下,可以想象会干扰到我们的文字分析,这就是为什么需要去掉html标签,只分析文本以减少干扰。
基于网页分析的文本提取算法
回顾上面的网页分析,如果按照文本密度提取文本,那么编写一个算法,可以从过滤html标签后的文本中找到文本的起止行号,以及文本之间的文本行号是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文字密度远高于非正文部分。根据这个特性,我们可以很容易地实现算法,即根据阈值(发音:yu)值来分析文本的位置。
那么需要解决一些问题:
阈值的确定可以通过统计分析得到一个较好的值。在实际处理过程中,我发现这个值是180比较合适,也就是在分析文本的时候,如果分析出来的文本超过180,那么就可以认为达到了body部分。
然后是如何分析的问题。这实际上是比较容易确定的。逐行分析的效果肯定不好。如果在逐行分析的过程中分析多行,效果会更好。也就是说,一次分析5行左右,把字符加起来,看看是否达到了设定的阈值。如果达到,则认为已进入文本部分。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
<p>int preTextLen = 0; // 记录上一次统计的字符数量(lines就是去除html标签后的文本,_limitCount是阈值,_depth是我们要分析的深度,sb用于记录正文)int startPos = -1; // 记录文章正文的起始位置for (int i = 0; i < lines.Length - _depth; i++){ int len = 0; for (int j = 0; j < _depth; j++) { len += lines[i + j].Length; } if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置 { if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置 { // 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部 int emptyCount = 0; for (int j = i - 1; j > 0; j--) { if (String.IsNullOrEmpty(lines[j])) { emptyCount++; } else { emptyCount = 0; } if (emptyCount == _headEmptyLines) { startPos = j + _headEmptyLines; break; } } // 如果没有定位到文章头,则以当前查找位置作为文章头 if (startPos == -1) { startPos = i; } // 填充发现的文章起始部分 for (int j = startPos; j 查看全部
网页新闻抓取(为什么要做提取一般做舆情分析,正文提取的好坏
)
为什么要提取文本
一般来说,舆情分析都会涉及到网页内容的提取。对于分析,有价值的信息是身体部分。大多数情况下,为了便于分析,需要将网页中与正文无关的部分去掉。可以说,文本提取的好坏直接影响分析结果的好坏。
对于具体的网站,我们可以分析其html结构,根据其结构获取body信息。看看下面的图片:
在body部分,不同的网站,body的位置不同,Html的结构也不同。对于爬虫来说,要爬取的页面是多种多样的,不可能对所有页面都写爬取。规则来提取文本内容,因此需要一个通用的算法来提取文本。
现有网页文本提取算法
前两种方法比较容易实现,主要是处理简单。之前实现过标签密度提取算法,但是实际中错误率还是挺高的;后两种方法在实现上稍微复杂一些。算法效率应该不会高很多。
我们需要的是一种简单且易于实现的算法,可以保证处理速度和良好的提取精度。因此,结合前两种算法,研究网页的html页面结构,有一个更好的处理思路,称为基于文本密度的文本提取算法。后来在网上找了一个类似的算法,发现也有类似的处理文本提取的处理方法,但还是有些不同。接下来给大家分享一下这个算法的一些处理思路。
网页分析
我随便从百度、搜狐、网易拿了一个新闻页面,拿来分析。
先看一个百度文章
任正非为什么要主动和我合影?
先请求这个页面,然后过滤到所有的html标签,只留下文本信息,我们可以看到body信息集中在以下几个位置:
使用Excel分析行数与每行字符的关系可以发现:
显然,文本内容集中在65-100行之间的位置,这个区间的字符数比较密集。
网易的另一篇文章文章
张小龙的神话破灭了,马化腾接手微信的时候到了。
或者先过滤html标签后看body部分:
另一个Excel分析结果:
文本部分集中在第 279-282 行之间。从图中可以看出,正是这些行具有特别高的文本密度。
搜狐新闻最后分析
李克强在天津考察考察期间的几个瞬间,
或者看一下标签后面的文字:
看一下Excel中的分析结果:
而搜狐的文章正文部分主要集中在200-255行之间。其余的文字都是杂乱无章的标签文字。
对不起,我漏掉了一个很重要的解释:为什么我们在分析的时候要过滤掉html标签?过滤html标签的目的是为了减少干扰,因为我们关注的是body的内容。如果有这样的标签 style="color: #0000ff;">varchart =style="color: #0000ff;">newstyle="color: #000000;">来分析一下,可以想象会干扰到我们的文字分析,这就是为什么需要去掉html标签,只分析文本以减少干扰。
基于网页分析的文本提取算法
回顾上面的网页分析,如果按照文本密度提取文本,那么编写一个算法,可以从过滤html标签后的文本中找到文本的起止行号,以及文本之间的文本行号是网页的主体。
从以上三个网页的分析结果来看,它们都具有这样一个特点:正文部分的文字密度远高于非正文部分。根据这个特性,我们可以很容易地实现算法,即根据阈值(发音:yu)值来分析文本的位置。
那么需要解决一些问题:
阈值的确定可以通过统计分析得到一个较好的值。在实际处理过程中,我发现这个值是180比较合适,也就是在分析文本的时候,如果分析出来的文本超过180,那么就可以认为达到了body部分。
然后是如何分析的问题。这实际上是比较容易确定的。逐行分析的效果肯定不好。如果在逐行分析的过程中分析多行,效果会更好。也就是说,一次分析5行左右,把字符加起来,看看是否达到了设定的阈值。如果达到,则认为已进入文本部分。
嗯,主要的处理逻辑是这样的,怎么样,不复杂。
我还将发布实现的核心算法:
<p>int preTextLen = 0; // 记录上一次统计的字符数量(lines就是去除html标签后的文本,_limitCount是阈值,_depth是我们要分析的深度,sb用于记录正文)int startPos = -1; // 记录文章正文的起始位置for (int i = 0; i < lines.Length - _depth; i++){ int len = 0; for (int j = 0; j < _depth; j++) { len += lines[i + j].Length; } if (startPos == -1) // 还没有找到文章起始位置,需要判断起始位置 { if (preTextLen > _limitCount && len > 0) // 如果上次查找的文本数量超过了限定字数,且当前行数字符数不为0,则认为是开始位置 { // 查找文章起始位置, 如果向上查找,发现2行连续的空行则认为是头部 int emptyCount = 0; for (int j = i - 1; j > 0; j--) { if (String.IsNullOrEmpty(lines[j])) { emptyCount++; } else { emptyCount = 0; } if (emptyCount == _headEmptyLines) { startPos = j + _headEmptyLines; break; } } // 如果没有定位到文章头,则以当前查找位置作为文章头 if (startPos == -1) { startPos = i; } // 填充发现的文章起始部分 for (int j = startPos; j
网页新闻抓取(测试GNE的原因和解决方法,你get到了吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-06 21:11
Gne是如何提取新闻网页的,相信很多没有经验的人对此都束手无策。为此,本文总结了问题的原因和解决方法。通过这个文章希望你能解决这个问题。
GNE[1] 是我开源的新闻网站 的通用提取器。自发布以来,受到了很多学生的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
打开Gne Online的地址是:,打开后的页面如下图所示。
要测试 GNE 的功能,您只需将网页的源代码粘贴到顶部文本框中,然后单击提取按钮:
对于标题、作者、新闻发布时间可能发错的情况,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取新闻时犯了一个错误。这时候可以指定 XPath://div[@class="article-sub"]/span[1]/text() 来定向提取,如下图所示。
通过设置 Host 输入框,可以在网页正文中的图片为相对路径时拼写 URL。
通过勾选下方的With Body Html复选框,可以返回body所在区域的网页源代码。
看完以上内容,你是否掌握了Gne是如何提取新闻网页的呢?如果您想学习更多技能或想了解更多相关内容,请关注易宿云行业资讯频道,感谢您的阅读! 查看全部
网页新闻抓取(测试GNE的原因和解决方法,你get到了吗?)
Gne是如何提取新闻网页的,相信很多没有经验的人对此都束手无策。为此,本文总结了问题的原因和解决方法。通过这个文章希望你能解决这个问题。
GNE[1] 是我开源的新闻网站 的通用提取器。自发布以来,受到了很多学生的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
打开Gne Online的地址是:,打开后的页面如下图所示。
要测试 GNE 的功能,您只需将网页的源代码粘贴到顶部文本框中,然后单击提取按钮:
对于标题、作者、新闻发布时间可能发错的情况,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取新闻时犯了一个错误。这时候可以指定 XPath://div[@class="article-sub"]/span[1]/text() 来定向提取,如下图所示。
通过设置 Host 输入框,可以在网页正文中的图片为相对路径时拼写 URL。
通过勾选下方的With Body Html复选框,可以返回body所在区域的网页源代码。
看完以上内容,你是否掌握了Gne是如何提取新闻网页的呢?如果您想学习更多技能或想了解更多相关内容,请关注易宿云行业资讯频道,感谢您的阅读!
网页新闻抓取( 网站数据编写的应用框架-Scrapy )
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-02-02 06:06
网站数据编写的应用框架-Scrapy
)
使用scrapy爬虫框架爬取伯乐在线的文章标题、标题url和发布时间
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可用于数据挖掘、信息处理或存储历史数据等一系列程序中。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于检索 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
图1
根据scrapy里面的调度,
第1步:创建一个项目scrapy startproject jobbole2,我使用的是虚拟环境,之前也下载过这个项目。输入命令后出现如下提示。
创建项目
第二步:创建成功后会自动给出下一步的提示命令,如下,根据提示输入cd jobbole2,然后输入命令scrapy genspider my_jobbole2,创建成功后进入我们的编译器,我用的是pycharm。
创建下一个文件
第三步:虚拟环境和pycharm配置好后,同步目录,下载刚刚创建的scrapy项目,进入my_jobbole2.py文件编写爬虫代码
Step 4:网页的解析步骤和爬虫的代码编写,这部分比较简单。只要熟悉request请求的网页的lxml解析步骤,这部分的代码就很容易理解了。先学爬虫基础,再学爬虫框架。这里就不赘述了,直接上代码吧(提醒一下scrapy和pyspider是不同的,方便调试,建议在scrapy shell中调试)。
Step 5:完成以上代码后,scrapy框架相信大家已经很熟悉了。看图1,了解一下这个框架的爬取思路。蟒蛇之禅,古朴典雅。了解每个文件的分工。这种想法还在继续。,你会接触到的队列,生产者-消费者模式,或者代理池之类的其实都认为py文件相互调用,每个文件负责一个。最后粘贴成功的代码。
查看全部
网页新闻抓取(
网站数据编写的应用框架-Scrapy
)
使用scrapy爬虫框架爬取伯乐在线的文章标题、标题url和发布时间
Scrapy 是一个应用程序框架,用于抓取 网站 数据并提取结构化数据。它可用于数据挖掘、信息处理或存储历史数据等一系列程序中。它最初是为网页抓取(更准确地说,网页抓取)而设计的,但也可用于检索 API(例如 Amazon Associates Web 服务)或通用网络爬虫返回的数据。Scrapy 用途广泛,可用于数据挖掘、监控和自动化测试。Scrapy 使用 Twisted 异步网络库来处理网络通信。整体结构大致如下
图1
根据scrapy里面的调度,
第1步:创建一个项目scrapy startproject jobbole2,我使用的是虚拟环境,之前也下载过这个项目。输入命令后出现如下提示。
创建项目
第二步:创建成功后会自动给出下一步的提示命令,如下,根据提示输入cd jobbole2,然后输入命令scrapy genspider my_jobbole2,创建成功后进入我们的编译器,我用的是pycharm。
创建下一个文件
第三步:虚拟环境和pycharm配置好后,同步目录,下载刚刚创建的scrapy项目,进入my_jobbole2.py文件编写爬虫代码
Step 4:网页的解析步骤和爬虫的代码编写,这部分比较简单。只要熟悉request请求的网页的lxml解析步骤,这部分的代码就很容易理解了。先学爬虫基础,再学爬虫框架。这里就不赘述了,直接上代码吧(提醒一下scrapy和pyspider是不同的,方便调试,建议在scrapy shell中调试)。
Step 5:完成以上代码后,scrapy框架相信大家已经很熟悉了。看图1,了解一下这个框架的爬取思路。蟒蛇之禅,古朴典雅。了解每个文件的分工。这种想法还在继续。,你会接触到的队列,生产者-消费者模式,或者代理池之类的其实都认为py文件相互调用,每个文件负责一个。最后粘贴成功的代码。
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-01 18:00
从网页中准确提取新闻内容是新闻信息平台的基础。目前新闻信息平台的大部分内容来自于对其他新闻网站内容的爬取、排序和分类,因此如何准确地从网页中提取新闻非常重要。很重要~
方法一:《基于行块分布函数的通用网页文本提取》
它的思想是一个主题网页的详情页(我们这里是新闻)只有一个数据区,你只需要提取这个数据区;找到这个数据区的方法是将网页的内容分成块,一个块是指来自某个区域的数据。从行首到某行尾的区域,例如第n块由第n行、n+1行和n+2行组成,第n+1个块由第n+1行组成, n+2行和n+3行,然后提取每个块中的纯文本,文本中必须收录纯文本最多的块;如果找到了某个区块,就可以利用这部分内容来寻找文字边界,在文字中指出,主题网页的主体中存在大量纯文字,而其他部分则是相对较小。您可以从之前放置块的位置开始,来回走动。找到的纯文本数量直线下降的点是边界;从文本中提取边界信息。这种方法可以准确提取大部分新闻的正文,但正文末尾收录一些杂质信息。而且这种方法只能提取文本,很难提取出与文本相关的非常重要的信息,即标题、出处、时间、以及标题和文本之间的图片。
方法二:可读性算法
它的主要思想是通过给一个网页构建一个DOM树,对body节点的子树中的每个后代节点进行评分,得到评分满足要求的节点,这些节点收录了读者想要阅读的内容,并且然后把这些节点排列成一个网页返回。使用算法的Java实现来处理上面的例子新闻,结果和前面的方法差不多。但是,通过DOM树,可以通过另一种方式轻松获取新闻的时间和来源。新闻时间可以通过正则表达式匹配标题和正文之间的内容;可以通过标题和正文之间的内容上的“source”关键字找到来源,并将找到的来源存储起来,在没有“来源”的情况下使用来匹配来源 这部分内容的关键词;终于解决了问题。如果不能为任何一个新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但是它还有其他问题,比如在大多数情况下会丢失新闻标题之间的图片等信息。文字和文字,有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。
方法 3:RoadRunner 算法
该算法试图从同一个模板生成的一组网页中找到一个模板,然后使用该模板解析该模板生成的其他网页。(目前效果不好) 查看全部
网页新闻抓取(如何精确提取网页中的新闻内容是新闻资讯平台的基础)
从网页中准确提取新闻内容是新闻信息平台的基础。目前新闻信息平台的大部分内容来自于对其他新闻网站内容的爬取、排序和分类,因此如何准确地从网页中提取新闻非常重要。很重要~
方法一:《基于行块分布函数的通用网页文本提取》
它的思想是一个主题网页的详情页(我们这里是新闻)只有一个数据区,你只需要提取这个数据区;找到这个数据区的方法是将网页的内容分成块,一个块是指来自某个区域的数据。从行首到某行尾的区域,例如第n块由第n行、n+1行和n+2行组成,第n+1个块由第n+1行组成, n+2行和n+3行,然后提取每个块中的纯文本,文本中必须收录纯文本最多的块;如果找到了某个区块,就可以利用这部分内容来寻找文字边界,在文字中指出,主题网页的主体中存在大量纯文字,而其他部分则是相对较小。您可以从之前放置块的位置开始,来回走动。找到的纯文本数量直线下降的点是边界;从文本中提取边界信息。这种方法可以准确提取大部分新闻的正文,但正文末尾收录一些杂质信息。而且这种方法只能提取文本,很难提取出与文本相关的非常重要的信息,即标题、出处、时间、以及标题和文本之间的图片。
方法二:可读性算法
它的主要思想是通过给一个网页构建一个DOM树,对body节点的子树中的每个后代节点进行评分,得到评分满足要求的节点,这些节点收录了读者想要阅读的内容,并且然后把这些节点排列成一个网页返回。使用算法的Java实现来处理上面的例子新闻,结果和前面的方法差不多。但是,通过DOM树,可以通过另一种方式轻松获取新闻的时间和来源。新闻时间可以通过正则表达式匹配标题和正文之间的内容;可以通过标题和正文之间的内容上的“source”关键字找到来源,并将找到的来源存储起来,在没有“来源”的情况下使用来匹配来源 这部分内容的关键词;终于解决了问题。如果不能为任何一个新闻网页提取新闻的来源和时间,那么它已经可以满足准确提取新闻内容的要求,但是它还有其他问题,比如在大多数情况下会丢失新闻标题之间的图片等信息。文字和文字,有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。有时文字后面还会出现其他不必要的信息(二维码图片、版权信息等)。同样,核心问题是信息丢失。
方法 3:RoadRunner 算法
该算法试图从同一个模板生成的一组网页中找到一个模板,然后使用该模板解析该模板生成的其他网页。(目前效果不好)
网页新闻抓取(Web上信息的重要表现形式(图)专利(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-02-01 17:18
专利名称:一种从新闻网页中提取文本信息的方法
技术领域:
:本发明属于网页信息分析与处理
技术领域:
,具体涉及一种新闻网页正文信息的提取方法。
背景技术:
: 互联网的飞速发展,使得互联网即Web上的信息量每天都以惊人的速度增长。许多公司经常需要各种信息,并且通常从互联网上大规模采集信息。每个企业都应该关注的问题。由于目前的信息处理技术针对的是纯文本格式的内容,而Web上的信息主要以静态Html的形式存在,如何将Web上Html形式的信息采集转换成有用价值 文本格式的信息便于后续信息处理,已成为亟待解决的技术问题。Web 上一种重要的信息形式是新闻。每天各大门户网站网站都会添加大量各种新闻。如何采集这些新闻信息成为Web信息采集问题的重要组成部分。通常,一个新闻网页,除了主要的新闻内容(通常称为网页正文)外,还收录大量与新闻内容无关的信息(如广告、网页导航信息、版权等)。信息等。为方便起见,以下将这些与新闻无关的信息统称为广告),如何从新闻网页中准确提取新闻,去除与新闻信息无关的广告等其他信息,尽量减少原版的失效网页修改引起的网页爬取方式。也是目前需要解决的技术问题。现在,网络上的新闻信息大部分来自于重要的门户网站,而这些网站的新闻页面往往是模板背景生成的,而且它们的风格和风格在一定时期内是一致的的时间。的。目前,Internet 上的大部分网页都是用 HTML 语言编写的。
Html语言提供的标签主要用于控制网页内容的显示格式,如<table>、<tr>、<td>、<th>用于绘制表格;<li>, <ol>, <ul> 用于表示一个列表。这些标签的使用没有规律,网页设计师可以随意设计。但不同种类的数据一般放在不同的显示单元中。经过对主要网站新闻页面的实际分析,结果表明,要提取的新闻页面中的大部分文本信息都存在于Html标签“<table>”和“<div>”中。传统的网页数据提取方法是通过包装器从网页中提取有趣的数据。包装器根据信息模式识别的知识,从固定的信息源中提取相关内容,并以固定的形式表达出来。早期,最简单的包装器是通过人工分析目标网页的结构特征提取信息,然后编写目标软件来实现的。这种方法需要大量的人工干预,成本高;后来,引入了一些模式识别。然而,到目前为止,获取包装器所需的信息模式识别知识仍然是一项耗时耗力的任务,需要很高的智能性。因此,目前网页数据抽取的研究热点之一就是探索简单的获取和构建一个wrapper。所需规则的有效方法。现在,
TSIMMIS 系统中的包装器需要手动编写数据提取规则。规则放置在特殊文件中,规则的形式为 [variables, source, pattern]。其中,variables保存提取结果,source保存输入,pattern保存source中数据的模式信息;variables 可以作为以下规则的来源,文件中的最后一条规则执行完后,最后的提取结果保存在 variables 中。这种方法需要人工编写规则,费时费力,容易出错,维护困难。XWRAP 系统中的包装器采用半自动的方式获取数据抽取规则。它提供了友好的人机交互界面。用户可以根据系统的指导完成数据抽取规则的编写。最后,系统为特定的数据源生成一个用java语言编写的包装器。在数据提取之前,XWRAP 系统会检查网页,纠正任何不符合规范的语法错误和标签,并将网页解析成树。上面介绍的几种包装器都是基于一定的固定网页架构,按照固定的规则或模式提取数据,具有比较大的局限性。由于网页结构的复杂性和不规则性,一旦网页被修改,网页结构发生变化,原来适用的包装器就不能再使用了。信息来源。如前所述,目前的网页数据抽取工具都需要针对特定的数据源编写相应的包装器或抽取规则。所以,如果信息来自多个信息源,则需要很多包装器,包装器的生成和维护就成为一项复杂的工作。对于互联网上存在的具有不同结构风格的新闻网页的文本信息提取任务,使用包装器的成本非常高。
发明内容针对现有技术中存在的缺陷,本发明的目的在于提供一种新闻网页正文信息的提取方法。就网页中的数据信息而言,可以实现对各种不同结构的模板生成的一系列新闻网页内容的自动提取,提高网页信息提取的效率和准确性。为了实现上述目的,本发明采用的技术方案是一种新闻网页文本信息的提取方法,包括以下步骤(1)对网页进行归一化预处理,使其满足Html语言标准,然后根据Html语言的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)将是模板生成的两个网页的Html树,来自同一个站点在时间上相邻的两个网页比较Html树的每一层数据,去掉table节点或div节点坐标相同,信息相同;(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;(4)中的数据Html树中的每个节点经过重组处理后,提取出需要的数据信息。进一步地,为了本发明有更好的效果,步骤(1)解析Html树中所有新闻网页的Html数据,以及要构造 Html 树,请使用以下方法 1) 初始化一个空数组T,用于保存Html树中的每个表结构;表结构用于表示表节点,形式为structTable{该表节点的坐标;此表节点中收录的信息;};上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2)
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。进一步地,为了使本发明有更好的效果,在步骤(2)中过滤数据,在删除不需要的数据信息时,采用如下方法将C和D设置为同一模板生成的两个释放时间相邻新闻网页,1)经过步骤(1),网页C的结构数组为T1;2)经过步骤(1),得到网页D的结构) 数组为 T2;3) 遍历 T1 中的每个表结构,并将 T1 中的每个结构设置为 S1,执行以下操作: a) 遍历 T2,在 T2 中找到与 S1 坐标值相同的结构, 设为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。进一步,为了使本发明有更好的效果,在步骤(3)中,对Html树中各层表节点中的数据进行细化识别,当标题信息和内容信息区分,下面的方法使用1)来标识表节点中的结构如果这个结构中有多个title元素,则取第一个作为这个结构的标题,如果没有title元素,表示该表结构的标题为空。另外,为了使本发明有更好的效果,
本发明的效果是利用本发明的方法,可以处理来自通过模板生成网页的新闻站点的信息采集的任务,以及目标新闻的文本内容。即使网页被修改,也可以快速自动提取网页。需要重写程序,大大减少了人工干预,从而大大提高了网页信息提取的效率和准确性。本发明之所以有上述效果,是因为本发明所描述的方法采用了一种新的Html树解析方法,能够高效、准确地获知Html中各个表节点的坐标以及所收录的信息。还可以快速解析新模板的树结构信息,再对比新模板生成的网页,依然能够准确提取新闻文本信息。图1是本发明的流程图;图2为本发明具体实施例中解析Html树的流程图。具体实施方式下面结合实施例和附图对本发明的方法作进一步的说明。以从新浪新闻体育频道截取的1000个按时间顺序排列的新闻网页中提取文本信息为例,如图1所示,一种从新闻网页中提取文本信息的方法包括以下步骤(1)@ >使用第三方网页净化工具(例如,可以使用 tidy 工具)对 1000 个网页进行规范化和预处理,使其符合 Html 语言标准,然后根据 Html 语言中的 <table> 和 <div> 标签解析所有页面。获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似.
以如下Html片段为例(如前所述,只标注了感兴趣的<table>节点,//为注释),明确本发明涉及的谓词<table> //第一个<table>节点开始Text1<table>//第二个<table>节点开始Text2<table>//第三个<table>节点开始Text3</table>//第三个<table>节点结束Text4</table>//第二个<table>节点结束<table>//第四个<table>节点开始Text4</table>//第四个<table>节点结束</table>//第一个<table>节点结束取中间的Html内容每个表的开始字符(由<table>标记)和结束字符(由</table>标记)作为一个表节点,那么从上面的代码片段可以看出,在每个表节点内 您还可以嵌套其他表节点,例如,第三个表节点嵌套在第二个表节点内。
如果一个表节点 A 嵌套在另一个表节点 B 中,则 A 称为 B 的子节点,B 称为 A 的父节点。位于表节点 A 的开始字符和结束字符之间的 Html 内容,以及不位于该节点的任何子节点的首尾字符之间的,称为A中收录的信息。一个表节点对应的向量称为该表节点在Html树中的坐标。在上面的Html片段中,第二个表节点收录的信息是Text2和Text4,第三个表节点收录的信息是Text3。用直观的形式表达Html树层次结构的嵌套信息,即用一个向量来表示关心的表节点在整个Html树中的位置。每个表节点对应一个向量 v=(n1, n2, n3, ..., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点。如果一个表节点对应的向量是(1, 2, 3),那么这个表节点就是Html树第一层第一个表节点的第二个子节点的第三个子节点。上面的Html片段第三和第四个表节点的坐标分别是(1, 1, 1)和(1, 2))。表节点用结构体的形式表示,形式如下 structTable{此表节点表节点的坐标;此表节点收录的信息;};将Html文档转换为各个表节点的结构体时,使用如下方法1)初始化一个空数组T保存每个表结构;2)初始化一个栈,让栈底到栈顶的元素分别标记为a,a[1],a[2],a[3],...,0=a=a[1]=a [2]=a[3]=...; 并设置堆栈元素指针 p 指向堆栈的顶部元素。
由于最初栈中没有元素,可以假设p指向一个虚元素a[-1];3) 扫描待处理的 Html 文档,如果遇到 <table> 标签,即遇到新的表节点时,将栈元素指针 p 上移一个空格,然后将值加 1堆栈元素指针 p 指向的元素。设栈元素指针p指向的栈元素为a[k],则表节点A的坐标为从栈底元素a到a[k]形成的序列,即向量(a, a[1], a[2], ..., a[k]),从中获得表节点A的坐标;4)@ >如果遇到了一个</table>节点,即当一个表节点结束时,将栈元素指针p下移一个空格,并且此时构造一个新的表结构,将当前表节点的坐标和其中收录的信息存储在这个表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。
将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,在T2中找到与S1坐标值相同的结构设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;经过步骤(2),不必要的广告信息有被删除了,但是还是需要使用未过滤的表结构来提炼和识别内容,识别标题信息和内容信息。通常新闻的标题一般以大粗体的形式出现。在Html中,
因此,可以采取以下具体步骤来实现对表结构内容的精细化识别。1)对于表节点中的结构,判断结构信息中是否有title元素;2)如果结构有多个title元素,则取第一个作为结构的title ,如果没有title元素,则该表结构的title为空。(4)处理后对Html树中各个节点中的数据进行重组,提取出需要的数据信息。步骤(1)经过步骤(2)@)得到的表结构数组T > 和经过step(3)的处理,已经识别出数组T中每个结构体的信息,接下来要做的就是将这些数组T中的每个表结构所收录的信息组合起来,可以使用以下方法1)初始化一个空字符串S;2)遍历表中的每个表结构结构数组T,并将各个表结构所收录的信息添加到S中;3)删除S中的Html标签,删除Html标签后的S1就是要提取的新闻网页的文本内容。实验结果表明,新闻网页抓取的准确率非常高。仍然可以达到98%以上的准确率,时间效率高。本发明描述的方法不限于具体实施例中描述的实施例,本领域技术人员可以根据本发明的技术方案获得其他实施例。,也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3)
v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 初始化一个栈,将栈底到栈顶的元素设置为a, a[1], a[2], a[3],...,和 0=a=a[1]=a[2]=a[3]=...; 并设置一个栈元素指针p,指向栈顶元素,由于栈最初没有元素,可以假设p指向一个虚元素a[-1];3)扫描要处理的Html文档,如果遇到<table>标签,则遇到一个新的table Node,将栈元素指针p上移一格,然后将指向的元素的值加1由栈元素指针p指向,并将栈元素指针p指向的栈元素设置为a[k],那么表节点 A 的坐标就是栈底元素 a 到 a[k] 形成的序列,即向量 (a, a[1], a[2], ... , a[k]),从中得到表节点A的坐标;4)如果遇到一个</table>节点,即当一个表节点结束时,栈元素指针p下移一个空格,此时就构造了一个新的表结构,坐标当前表节点的信息和信息存储在这个表结构中,然后把这个结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。3.如权利要求1、2所述的一种新闻网页文本信息提取方法,其特征在于,在步骤(2)中,对数据进行过滤,当不需要的数据信息删除,使用下面的方法假设C和D是同一模板生成的发布时间相邻的两个新闻网页,1)经过步骤(1),网页C的结构体数组为T1;@>经过步骤(1),网页D的结构数组为T2;3)遍历T1中的各个表结构,并将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,找到T2中与S1坐标值相同的结构,设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同,除了链接文本,如果相同则在T1 S1中删除,在T2中删除S2。4.一种如权利要求1、2所述的新闻网页文本信息提取方法,其特征在于,在步骤(3)中,Html树中各层表节点中的数据为提炼识别,并区分标题信息和内容信息,使用如下方法1)表节点中的结构,判断结构信息中是否有标题元素;2) 如果结构有多个标题元素,则将第一个作为该结构的标题。如果没有title元素,则表示此表结构的标题为空。
初始化一个空字符串 S;2) 遍历表结构数组T中的每个表结构,将每个表结构收录的信息添加到S中;3)删除S中的Html标记,删除Html标记后的S1为要提取的新闻网页的文本内容。全文摘要本发明涉及一种新闻文本信息的提取方法网页,属于网页信息的分析处理
技术领域:
. 在现有技术中,通常使用包装器来提取网页中感兴趣的数据,包装器根据一定的信息模式识别知识,按照固定的规则从特定信息源中提取相关内容,并以一种形式表达出来。具体形式。获取包装器所需的信息模式识别知识是一项耗时耗力的任务,对智能的要求很高。本发明的方法利用栈数据结构将网页数据的层次结构信息转化为向量表达式,构造并解析Html树,然后对Html树的每一层数据进行比较,进行数据过滤、细化和识别, 和数据重组以提取所需的数据信息。本发明方法适用于对固定站点模板生成的新闻网页中的新闻信息进行长期抓取,速度快、准确率高。文号G06F17/30GK1786965SQ20051013237 公布日期2006年6月14日申请日期2005年12月21日优先权日期2005年12月21日发明人舒文兵、吴玉倩、肖建国申请人:,,, 北京大学 查看全部
网页新闻抓取(Web上信息的重要表现形式(图)专利(组图))
专利名称:一种从新闻网页中提取文本信息的方法
技术领域:
:本发明属于网页信息分析与处理
技术领域:
,具体涉及一种新闻网页正文信息的提取方法。
背景技术:
: 互联网的飞速发展,使得互联网即Web上的信息量每天都以惊人的速度增长。许多公司经常需要各种信息,并且通常从互联网上大规模采集信息。每个企业都应该关注的问题。由于目前的信息处理技术针对的是纯文本格式的内容,而Web上的信息主要以静态Html的形式存在,如何将Web上Html形式的信息采集转换成有用价值 文本格式的信息便于后续信息处理,已成为亟待解决的技术问题。Web 上一种重要的信息形式是新闻。每天各大门户网站网站都会添加大量各种新闻。如何采集这些新闻信息成为Web信息采集问题的重要组成部分。通常,一个新闻网页,除了主要的新闻内容(通常称为网页正文)外,还收录大量与新闻内容无关的信息(如广告、网页导航信息、版权等)。信息等。为方便起见,以下将这些与新闻无关的信息统称为广告),如何从新闻网页中准确提取新闻,去除与新闻信息无关的广告等其他信息,尽量减少原版的失效网页修改引起的网页爬取方式。也是目前需要解决的技术问题。现在,网络上的新闻信息大部分来自于重要的门户网站,而这些网站的新闻页面往往是模板背景生成的,而且它们的风格和风格在一定时期内是一致的的时间。的。目前,Internet 上的大部分网页都是用 HTML 语言编写的。
Html语言提供的标签主要用于控制网页内容的显示格式,如<table>、<tr>、<td>、<th>用于绘制表格;<li>, <ol>, <ul> 用于表示一个列表。这些标签的使用没有规律,网页设计师可以随意设计。但不同种类的数据一般放在不同的显示单元中。经过对主要网站新闻页面的实际分析,结果表明,要提取的新闻页面中的大部分文本信息都存在于Html标签“<table>”和“<div>”中。传统的网页数据提取方法是通过包装器从网页中提取有趣的数据。包装器根据信息模式识别的知识,从固定的信息源中提取相关内容,并以固定的形式表达出来。早期,最简单的包装器是通过人工分析目标网页的结构特征提取信息,然后编写目标软件来实现的。这种方法需要大量的人工干预,成本高;后来,引入了一些模式识别。然而,到目前为止,获取包装器所需的信息模式识别知识仍然是一项耗时耗力的任务,需要很高的智能性。因此,目前网页数据抽取的研究热点之一就是探索简单的获取和构建一个wrapper。所需规则的有效方法。现在,
TSIMMIS 系统中的包装器需要手动编写数据提取规则。规则放置在特殊文件中,规则的形式为 [variables, source, pattern]。其中,variables保存提取结果,source保存输入,pattern保存source中数据的模式信息;variables 可以作为以下规则的来源,文件中的最后一条规则执行完后,最后的提取结果保存在 variables 中。这种方法需要人工编写规则,费时费力,容易出错,维护困难。XWRAP 系统中的包装器采用半自动的方式获取数据抽取规则。它提供了友好的人机交互界面。用户可以根据系统的指导完成数据抽取规则的编写。最后,系统为特定的数据源生成一个用java语言编写的包装器。在数据提取之前,XWRAP 系统会检查网页,纠正任何不符合规范的语法错误和标签,并将网页解析成树。上面介绍的几种包装器都是基于一定的固定网页架构,按照固定的规则或模式提取数据,具有比较大的局限性。由于网页结构的复杂性和不规则性,一旦网页被修改,网页结构发生变化,原来适用的包装器就不能再使用了。信息来源。如前所述,目前的网页数据抽取工具都需要针对特定的数据源编写相应的包装器或抽取规则。所以,如果信息来自多个信息源,则需要很多包装器,包装器的生成和维护就成为一项复杂的工作。对于互联网上存在的具有不同结构风格的新闻网页的文本信息提取任务,使用包装器的成本非常高。
发明内容针对现有技术中存在的缺陷,本发明的目的在于提供一种新闻网页正文信息的提取方法。就网页中的数据信息而言,可以实现对各种不同结构的模板生成的一系列新闻网页内容的自动提取,提高网页信息提取的效率和准确性。为了实现上述目的,本发明采用的技术方案是一种新闻网页文本信息的提取方法,包括以下步骤(1)对网页进行归一化预处理,使其满足Html语言标准,然后根据Html语言的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)将是模板生成的两个网页的Html树,来自同一个站点在时间上相邻的两个网页比较Html树的每一层数据,去掉table节点或div节点坐标相同,信息相同;(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;(4)中的数据Html树中的每个节点经过重组处理后,提取出需要的数据信息。进一步地,为了本发明有更好的效果,步骤(1)解析Html树中所有新闻网页的Html数据,以及要构造 Html 树,请使用以下方法 1) 初始化一个空数组T,用于保存Html树中的每个表结构;表结构用于表示表节点,形式为structTable{该表节点的坐标;此表节点中收录的信息;};上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 上面表格节点的坐标,也就是表格节点在整个Html树中的位置,用一个向量来表示,即每个表格节点对应一个向量v=(n1, n2, n3, . .., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点;2)
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。进一步地,为了使本发明有更好的效果,在步骤(2)中过滤数据,在删除不需要的数据信息时,采用如下方法将C和D设置为同一模板生成的两个释放时间相邻新闻网页,1)经过步骤(1),网页C的结构数组为T1;2)经过步骤(1),得到网页D的结构) 数组为 T2;3) 遍历 T1 中的每个表结构,并将 T1 中的每个结构设置为 S1,执行以下操作: a) 遍历 T2,在 T2 中找到与 S1 坐标值相同的结构, 设为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。进一步,为了使本发明有更好的效果,在步骤(3)中,对Html树中各层表节点中的数据进行细化识别,当标题信息和内容信息区分,下面的方法使用1)来标识表节点中的结构如果这个结构中有多个title元素,则取第一个作为这个结构的标题,如果没有title元素,表示该表结构的标题为空。另外,为了使本发明有更好的效果,
本发明的效果是利用本发明的方法,可以处理来自通过模板生成网页的新闻站点的信息采集的任务,以及目标新闻的文本内容。即使网页被修改,也可以快速自动提取网页。需要重写程序,大大减少了人工干预,从而大大提高了网页信息提取的效率和准确性。本发明之所以有上述效果,是因为本发明所描述的方法采用了一种新的Html树解析方法,能够高效、准确地获知Html中各个表节点的坐标以及所收录的信息。还可以快速解析新模板的树结构信息,再对比新模板生成的网页,依然能够准确提取新闻文本信息。图1是本发明的流程图;图2为本发明具体实施例中解析Html树的流程图。具体实施方式下面结合实施例和附图对本发明的方法作进一步的说明。以从新浪新闻体育频道截取的1000个按时间顺序排列的新闻网页中提取文本信息为例,如图1所示,一种从新闻网页中提取文本信息的方法包括以下步骤(1)@ >使用第三方网页净化工具(例如,可以使用 tidy 工具)对 1000 个网页进行规范化和预处理,使其符合 Html 语言标准,然后根据 Html 语言中的 <table> 和 <div> 标签解析所有页面。获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似. 获取新闻网页的Html数据,得到Html树;解析所有新闻网页的Html数据,构建Html树时采用如下方法。因为在本发明中,Html标签<table>和<div>功能相同,所以本发明以<table>为例说明,<div>的情况与<table>完全相似.
以如下Html片段为例(如前所述,只标注了感兴趣的<table>节点,//为注释),明确本发明涉及的谓词<table> //第一个<table>节点开始Text1<table>//第二个<table>节点开始Text2<table>//第三个<table>节点开始Text3</table>//第三个<table>节点结束Text4</table>//第二个<table>节点结束<table>//第四个<table>节点开始Text4</table>//第四个<table>节点结束</table>//第一个<table>节点结束取中间的Html内容每个表的开始字符(由<table>标记)和结束字符(由</table>标记)作为一个表节点,那么从上面的代码片段可以看出,在每个表节点内 您还可以嵌套其他表节点,例如,第三个表节点嵌套在第二个表节点内。
如果一个表节点 A 嵌套在另一个表节点 B 中,则 A 称为 B 的子节点,B 称为 A 的父节点。位于表节点 A 的开始字符和结束字符之间的 Html 内容,以及不位于该节点的任何子节点的首尾字符之间的,称为A中收录的信息。一个表节点对应的向量称为该表节点在Html树中的坐标。在上面的Html片段中,第二个表节点收录的信息是Text2和Text4,第三个表节点收录的信息是Text3。用直观的形式表达Html树层次结构的嵌套信息,即用一个向量来表示关心的表节点在整个Html树中的位置。每个表节点对应一个向量 v=(n1, n2, n3, ..., nk),v的第i个分量ni的含义是Html树中第i层的第ni个节点。如果一个表节点对应的向量是(1, 2, 3),那么这个表节点就是Html树第一层第一个表节点的第二个子节点的第三个子节点。上面的Html片段第三和第四个表节点的坐标分别是(1, 1, 1)和(1, 2))。表节点用结构体的形式表示,形式如下 structTable{此表节点表节点的坐标;此表节点收录的信息;};将Html文档转换为各个表节点的结构体时,使用如下方法1)初始化一个空数组T保存每个表结构;2)初始化一个栈,让栈底到栈顶的元素分别标记为a,a[1],a[2],a[3],...,0=a=a[1]=a [2]=a[3]=...; 并设置堆栈元素指针 p 指向堆栈的顶部元素。
由于最初栈中没有元素,可以假设p指向一个虚元素a[-1];3) 扫描待处理的 Html 文档,如果遇到 <table> 标签,即遇到新的表节点时,将栈元素指针 p 上移一个空格,然后将值加 1堆栈元素指针 p 指向的元素。设栈元素指针p指向的栈元素为a[k],则表节点A的坐标为从栈底元素a到a[k]形成的序列,即向量(a, a[1], a[2], ..., a[k]),从中获得表节点A的坐标;4)@ >如果遇到了一个</table>节点,即当一个表节点结束时,将栈元素指针p下移一个空格,并且此时构造一个新的表结构,将当前表节点的坐标和其中收录的信息存储在这个表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。并将当前表节点的坐标和其中收录的信息存储在该表结构中,然后将该结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],则当前扫描的表节点的坐标为元素a到a[形成的序列k] 在栈底,即向量(a, a[1], a[2], ..., a[k])。将该字符添加到表节点收录的信息中的坐标为 (a, a[1], a[2], ..., a[k])。6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。
将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,在T2中找到与S1坐标值相同的结构设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同(链接文本除外),然后在T1中删除S1,在T2中删除S2。(3)细化Html树中各层表节点中数据的标识,区分标题信息和内容信息;经过步骤(2),不必要的广告信息有被删除了,但是还是需要使用未过滤的表结构来提炼和识别内容,识别标题信息和内容信息。通常新闻的标题一般以大粗体的形式出现。在Html中,
因此,可以采取以下具体步骤来实现对表结构内容的精细化识别。1)对于表节点中的结构,判断结构信息中是否有title元素;2)如果结构有多个title元素,则取第一个作为结构的title ,如果没有title元素,则该表结构的title为空。(4)处理后对Html树中各个节点中的数据进行重组,提取出需要的数据信息。步骤(1)经过步骤(2)@)得到的表结构数组T > 和经过step(3)的处理,已经识别出数组T中每个结构体的信息,接下来要做的就是将这些数组T中的每个表结构所收录的信息组合起来,可以使用以下方法1)初始化一个空字符串S;2)遍历表中的每个表结构结构数组T,并将各个表结构所收录的信息添加到S中;3)删除S中的Html标签,删除Html标签后的S1就是要提取的新闻网页的文本内容。实验结果表明,新闻网页抓取的准确率非常高。仍然可以达到98%以上的准确率,时间效率高。本发明描述的方法不限于具体实施例中描述的实施例,本领域技术人员可以根据本发明的技术方案获得其他实施例。,也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 也属于本发明的技术创新范围。声称1.是一种新闻网页文本信息提取方法,包括以下步骤(1)对网页进行规范化预处理,使其符合Html语言标准,然后根据<table>和<div > Html语言中的标签,解析所有新闻网页的Html数据得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3) 使其符合Html语言标准,然后根据Html语言中的<table>和<div>标签,解析所有新闻网页的Html数据,得到Html树;(2)比较同一模板生成的Html树的各级数据,使坐标相同,收录相同有效信息的table节点或div节点也被淘汰;(3)
v的第i个分量ni的含义是Html树中第i层的第ni个节点;2) 初始化一个栈,将栈底到栈顶的元素设置为a, a[1], a[2], a[3],...,和 0=a=a[1]=a[2]=a[3]=...; 并设置一个栈元素指针p,指向栈顶元素,由于栈最初没有元素,可以假设p指向一个虚元素a[-1];3)扫描要处理的Html文档,如果遇到<table>标签,则遇到一个新的table Node,将栈元素指针p上移一格,然后将指向的元素的值加1由栈元素指针p指向,并将栈元素指针p指向的栈元素设置为a[k],那么表节点 A 的坐标就是栈底元素 a 到 a[k] 形成的序列,即向量 (a, a[1], a[2], ... , a[k]),从中得到表节点A的坐标;4)如果遇到一个</table>节点,即当一个表节点结束时,栈元素指针p下移一个空格,此时就构造了一个新的表结构,坐标当前表节点的信息和信息存储在这个表结构中,然后把这个结构添加到数组T的末尾;5) 如果遇到其他字符,将栈元素指针p指向的栈元素设置为a[k],
6)如果没有扫描到Html文档的末尾,继续扫描,转到步骤3),否则结束,返回存储Html树级信息的数组T。3.如权利要求1、2所述的一种新闻网页文本信息提取方法,其特征在于,在步骤(2)中,对数据进行过滤,当不需要的数据信息删除,使用下面的方法假设C和D是同一模板生成的发布时间相邻的两个新闻网页,1)经过步骤(1),网页C的结构体数组为T1;@>经过步骤(1),网页D的结构数组为T2;3)遍历T1中的各个表结构,并将T1中的每个结构设置为S1,并进行如下操作 a) 遍历T2,找到T2中与S1坐标值相同的结构,设置为S2;b) 判断S1中收录的信息是否与S2中收录的信息相同,除了链接文本,如果相同则在T1 S1中删除,在T2中删除S2。4.一种如权利要求1、2所述的新闻网页文本信息提取方法,其特征在于,在步骤(3)中,Html树中各层表节点中的数据为提炼识别,并区分标题信息和内容信息,使用如下方法1)表节点中的结构,判断结构信息中是否有标题元素;2) 如果结构有多个标题元素,则将第一个作为该结构的标题。如果没有title元素,则表示此表结构的标题为空。
初始化一个空字符串 S;2) 遍历表结构数组T中的每个表结构,将每个表结构收录的信息添加到S中;3)删除S中的Html标记,删除Html标记后的S1为要提取的新闻网页的文本内容。全文摘要本发明涉及一种新闻文本信息的提取方法网页,属于网页信息的分析处理
技术领域:
. 在现有技术中,通常使用包装器来提取网页中感兴趣的数据,包装器根据一定的信息模式识别知识,按照固定的规则从特定信息源中提取相关内容,并以一种形式表达出来。具体形式。获取包装器所需的信息模式识别知识是一项耗时耗力的任务,对智能的要求很高。本发明的方法利用栈数据结构将网页数据的层次结构信息转化为向量表达式,构造并解析Html树,然后对Html树的每一层数据进行比较,进行数据过滤、细化和识别, 和数据重组以提取所需的数据信息。本发明方法适用于对固定站点模板生成的新闻网页中的新闻信息进行长期抓取,速度快、准确率高。文号G06F17/30GK1786965SQ20051013237 公布日期2006年6月14日申请日期2005年12月21日优先权日期2005年12月21日发明人舒文兵、吴玉倩、肖建国申请人:,,, 北京大学
网页新闻抓取(PDF文档拆分的方式,但让PDF问题迎刃而解。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-31 12:22
福昕高级 PDF 编辑器涵盖整个文档生命周期,集成了创建、编辑、注释、协作/共享、保护、页面管理、导出、扫描和光学字符识别 (OCR) 以及签署 PDF 文档和表单等基本功能。还有一些高级功能,例如高级编辑、发起共享审阅、高级加密、高压缩、PDF A/E/X 创建和添加贝茨编号。使用福昕高级 PDF 编辑器解决 PDF 问题。
在之前的操作分享中,我们介绍了拆分PDF文档的方式,但是文档拆分不同于页面提取~
文档拆分是将一个完整的PDF文档拆分为多个PDF文件;而页面提取是从完整的PDF文档中提取一些页面。
以电子书的相关操作为例:
当团队需要合作翻译电子书时,可以通过文档拆分将电子书按章节拆分成多个PDF文件;
当你在电子书中看到一段很精彩的片段,想分享给你的朋友时,更适合使用提取页面的功能~
适当使用提取页面的方法,不仅可以减轻文件存储的负担,还可以更快的找到想要的内容!接下来,我们来学习如何提取PDF文档的部分页面~
打开“提取”功能区,自定义页面范围
第一步是在Foxit PhantomPDF中打开需要提取页面的PDF文档,点击功能区中的“页面管理”选项卡,选择“提取”进入详细的页面提取操作。
在“提取页面”对话框中,您可以选择页码范围。您只需在“页面”功能框中填写您要提取的页面即可。连续页用“-”表示,分开的页用“,”表示。需要注意的是,这里要使用“,”号。哦英文的。(例如,如果要提取PDF文档的第1、4到9、12页,只需在方框中填写“1,4-9,12”即可。)
另外,在框内填写要提取的页面范围后,还可以在“提取”中选择提取上述范围的子集,如“范围内的所有页面”、“仅偶数页”或“仅奇数页”。(如果要提取PDF文档第1、4到9、12页的偶数页,则在“提取”选项中选择“仅偶数页”,然后最后生成的文档收录原创文档的第 4、6、8 和 12 页。)
如果不知道要选择哪些页面,可以勾选左下角的“显示预览”选项,在“提取页面”窗口中预览文件页面,方便查看。
福昕高级 PDF 编辑器下载链接: 查看全部
网页新闻抓取(PDF文档拆分的方式,但让PDF问题迎刃而解。)
福昕高级 PDF 编辑器涵盖整个文档生命周期,集成了创建、编辑、注释、协作/共享、保护、页面管理、导出、扫描和光学字符识别 (OCR) 以及签署 PDF 文档和表单等基本功能。还有一些高级功能,例如高级编辑、发起共享审阅、高级加密、高压缩、PDF A/E/X 创建和添加贝茨编号。使用福昕高级 PDF 编辑器解决 PDF 问题。
在之前的操作分享中,我们介绍了拆分PDF文档的方式,但是文档拆分不同于页面提取~
文档拆分是将一个完整的PDF文档拆分为多个PDF文件;而页面提取是从完整的PDF文档中提取一些页面。
以电子书的相关操作为例:
当团队需要合作翻译电子书时,可以通过文档拆分将电子书按章节拆分成多个PDF文件;
当你在电子书中看到一段很精彩的片段,想分享给你的朋友时,更适合使用提取页面的功能~
适当使用提取页面的方法,不仅可以减轻文件存储的负担,还可以更快的找到想要的内容!接下来,我们来学习如何提取PDF文档的部分页面~
打开“提取”功能区,自定义页面范围
第一步是在Foxit PhantomPDF中打开需要提取页面的PDF文档,点击功能区中的“页面管理”选项卡,选择“提取”进入详细的页面提取操作。
在“提取页面”对话框中,您可以选择页码范围。您只需在“页面”功能框中填写您要提取的页面即可。连续页用“-”表示,分开的页用“,”表示。需要注意的是,这里要使用“,”号。哦英文的。(例如,如果要提取PDF文档的第1、4到9、12页,只需在方框中填写“1,4-9,12”即可。)
另外,在框内填写要提取的页面范围后,还可以在“提取”中选择提取上述范围的子集,如“范围内的所有页面”、“仅偶数页”或“仅奇数页”。(如果要提取PDF文档第1、4到9、12页的偶数页,则在“提取”选项中选择“仅偶数页”,然后最后生成的文档收录原创文档的第 4、6、8 和 12 页。)
如果不知道要选择哪些页面,可以勾选左下角的“显示预览”选项,在“提取页面”窗口中预览文件页面,方便查看。
福昕高级 PDF 编辑器下载链接:
网页新闻抓取(文档介绍:UDC国孥研究生学位论文基于Web搜索和网页结构分析的IT相关主题新闻抓取研究)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-01-30 13:12
文件介绍:UDC研究生论文基于Web搜索和IT相关话题的网页结构分析 新闻抓取 研究 研究生姓名 赵玉勇 研究生姓名 丝谷玉 - 导师姓名 玉伟 数量 4.学位级驱虫剂申请数量 雅在驱魔。论文答辩日期截止到Q]Q同学!!并且学位授予日期直到Q!Q学生]]和中国海洋大学,U Y1927076 我在此为中国海洋大学教师讨论文学。?? 赵玉勇基于Web搜索和网页结构分析的IT相关课题论文研究。完成日期: 指导员签名: 辩护委员会成员签名:#肥西L基金会土!本人声明,本人提交的论文是在导师指导下获得的研究工作和研究成果。据我所知,除文中特别标注和感谢的地方外,论文中不收录他人已发表或撰写的研究成果,也不收录未获得的内容。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。
本人授权学校将学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩微打印或扫描等复印方式保存和编纂学位论文。(本授权书适用于解密后的机密论文) 论文作者签名:郑雨燕导师 胜'7飞!I!Iii=III:Si p年"月2]日II!ii=IIII:force/o年, 》27日~毕业后论文作者下落:工作单位:通讯地址:电话:邮编 l 基于网页搜索和网页结构分析的IT相关课题组。研究摘要新闻与人们日常工作和娱乐生活相关的高度相关的信息,对于有影响力的新闻事件,深度和跨度较大的专题新闻信息量更大,更有趣。突出“主题”和专题,着力“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在网上迅速传播。另一方面,互联网上信息的爆炸式增长 互联网的快速发展使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎已经将触角伸向了互联网上的信息。如何挖掘深入、全面的新闻信息,对许多新闻相关工作具有重要意义,
IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出行业角色模型(Trade.roleModel)。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,而提取的好坏直接决定了后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们在几种方案中选择使用原生程序来实现其搜索结果的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,
从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于人工提取互联网新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。关键词:话题新闻;搜索引擎:行业榜样;文本挖掘 k 查看全部
网页新闻抓取(文档介绍:UDC国孥研究生学位论文基于Web搜索和网页结构分析的IT相关主题新闻抓取研究)
文件介绍:UDC研究生论文基于Web搜索和IT相关话题的网页结构分析 新闻抓取 研究 研究生姓名 赵玉勇 研究生姓名 丝谷玉 - 导师姓名 玉伟 数量 4.学位级驱虫剂申请数量 雅在驱魔。论文答辩日期截止到Q]Q同学!!并且学位授予日期直到Q!Q学生]]和中国海洋大学,U Y1927076 我在此为中国海洋大学教师讨论文学。?? 赵玉勇基于Web搜索和网页结构分析的IT相关课题论文研究。完成日期: 指导员签名: 辩护委员会成员签名:#肥西L基金会土!本人声明,本人提交的论文是在导师指导下获得的研究工作和研究成果。据我所知,除文中特别标注和感谢的地方外,论文中不收录他人已发表或撰写的研究成果,也不收录未获得的内容。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。除文中特别标注和感谢的地方外,论文不收录他人已发表或撰写的研究成果,也不收录未获得的研究成果。明确:用于科威特 2 或其他教育机构的学位或证书的材料。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。与我一起工作的同志对这项研究的任何贡献都在论文中得到了明确的陈述和承认。论文作者署名:桂署名日期:刁日,当年7月7日及盘,允许论文查阅和借阅。
本人授权学校将学位论文的全部或部分内容编入相关数据库进行检索,并以影印、缩微打印或扫描等复印方式保存和编纂学位论文。(本授权书适用于解密后的机密论文) 论文作者签名:郑雨燕导师 胜'7飞!I!Iii=III:Si p年"月2]日II!ii=IIII:force/o年, 》27日~毕业后论文作者下落:工作单位:通讯地址:电话:邮编 l 基于网页搜索和网页结构分析的IT相关课题组。研究摘要新闻与人们日常工作和娱乐生活相关的高度相关的信息,对于有影响力的新闻事件,深度和跨度较大的专题新闻信息量更大,更有趣。突出“主题”和专题,着力“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在网上迅速传播。另一方面,互联网上信息的爆炸式增长 互联网的快速发展使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎已经将触角伸向了互联网上的信息。如何挖掘深入、全面的新闻信息,对许多新闻相关工作具有重要意义,
IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出行业角色模型(Trade.roleModel)。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,而提取的好坏直接决定了后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们在几种方案中选择使用原生程序来实现其搜索结果的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,
从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于人工提取互联网新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。关键词:话题新闻;搜索引擎:行业榜样;文本挖掘 k
网页新闻抓取(Python爬虫系列(一)(1)_Python基础视频教程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-26 12:21
阿里云>云栖社区>主题图>P>Python爬虫新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
Python爬取新闻网站相关博文看更多博文
[python爬虫] Selenium定向爬取虎扑篮球海量美图
作者:肖洛洛 4370 浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他会经常逛虎扑篮球、Wet等论坛。论坛里会有很多美图,包括NBA球队、CBA球星、花边新闻、漂亮球鞋等等,如果右键另存为一张,伤手。作为程序员还是写个程序来做吧!
阅读全文
Python爬虫系列(一)早学习爬虫的补充和总结
作者:山茶花开2838人查看评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda 2、IDE:Pycharm、Pydev 3、工具:Jupyter Notebook(安装Anaconda后会有)二、Python基础视频教程1、疯狂Python:
阅读全文
《精通Python网络爬虫:核心技术、框架和项目》——第2章网络爬虫技能概览2.1网络爬虫技能概览
作者:华章电脑1908 浏览评论:04年前
本章节选自华章出版社,作者魏伟所著《精通Python网络爬虫:核心技术、框架与项目》一书第2章第2.1节,更多章节可上云查看齐社区“华章电脑”公众号。第2章网络爬虫技能概述在上一章中,我们已经对网络爬虫有了初步的了解。
阅读全文
常用python爬虫框架整理
作者:优迪1689 浏览评论:03年前
Python中好用的爬虫框架一般比较小爬虫需求的价格。我通过直接使用请求库 + bs4 解决了它。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫教程9-100河北阳光政诉科
作者:Dream Eraser 1430 浏览评论:02年前
1.河北阳光管理投诉科-之前的文章文章都是关于图片爬虫的。今天写了一个留言板,爬出来找另一套数据分析案例教程。做好准备,作为一个河北人,遵守规章制度,抱怨什么是必备的技能,那么让我们看看我们河北人抱怨了什么?网站 今天要爬取的地址
阅读全文
采集CloudBlog网站 的 Python 爬虫 文章
作者:朱培1423 浏览评论:04年前
本文使用python爬虫获取网站中的文章,包括文章的标题、发表时间、作者、内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页所有的文章连接,存放在URL集合中,然后对这些采集的链接一一访问,再次解析
阅读全文
跟我一起开始python爬虫
作者:cxa1415 人浏览评论:02年前
前几天想写一个爬虫系列文章。我没有写它是因为我很忙(不是因为我懒惰)。趁着房间里的凉意和内心的宁静,总结一下我目前所遇到的事情。一些爬虫知识,本系列将从一个简单的爬虫开始,然后逐渐增加难度。同时,对反爬的方法进行总结,并用具体的例子来论证,不同的反爬现象和现实。
阅读全文
Python爬虫学习,记抓包获取js,从js函数取数据的过程
作者:云飞学习编程 1203人浏览评论:03年前
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里面,很有意思,分吧
阅读全文 查看全部
网页新闻抓取(Python爬虫系列(一)(1)_Python基础视频教程(组图))
阿里云>云栖社区>主题图>P>Python爬虫新闻网站
推荐活动:
更多优惠>
当前话题:python爬取新闻网站加入采集
相关话题:
Python爬取新闻网站相关博文看更多博文
[python爬虫] Selenium定向爬取虎扑篮球海量美图
作者:肖洛洛 4370 浏览评论:06年前
前言:作为一个从小就看篮球的球迷,他会经常逛虎扑篮球、Wet等论坛。论坛里会有很多美图,包括NBA球队、CBA球星、花边新闻、漂亮球鞋等等,如果右键另存为一张,伤手。作为程序员还是写个程序来做吧!
阅读全文
Python爬虫系列(一)早学习爬虫的补充和总结
作者:山茶花开2838人查看评论:04年前
一、环境搭建和工具准备1、为了节省时间和学习投入,建议直接安装集成环境Anaconda 2、IDE:Pycharm、Pydev 3、工具:Jupyter Notebook(安装Anaconda后会有)二、Python基础视频教程1、疯狂Python:
阅读全文
《精通Python网络爬虫:核心技术、框架和项目》——第2章网络爬虫技能概览2.1网络爬虫技能概览
作者:华章电脑1908 浏览评论:04年前
本章节选自华章出版社,作者魏伟所著《精通Python网络爬虫:核心技术、框架与项目》一书第2章第2.1节,更多章节可上云查看齐社区“华章电脑”公众号。第2章网络爬虫技能概述在上一章中,我们已经对网络爬虫有了初步的了解。
阅读全文
常用python爬虫框架整理
作者:优迪1689 浏览评论:03年前
Python中好用的爬虫框架一般比较小爬虫需求的价格。我通过直接使用请求库 + bs4 解决了它。如果比较麻烦,我会用selenium来解决js的异步加载问题。该框架用于比较大规模的需求,主要是为了便于管理和扩展。1.Scrapy Scrapy 是一个
阅读全文
Python爬虫教程9-100河北阳光政诉科
作者:Dream Eraser 1430 浏览评论:02年前
1.河北阳光管理投诉科-之前的文章文章都是关于图片爬虫的。今天写了一个留言板,爬出来找另一套数据分析案例教程。做好准备,作为一个河北人,遵守规章制度,抱怨什么是必备的技能,那么让我们看看我们河北人抱怨了什么?网站 今天要爬取的地址
阅读全文
采集CloudBlog网站 的 Python 爬虫 文章
作者:朱培1423 浏览评论:04年前
本文使用python爬虫获取网站中的文章,包括文章的标题、发表时间、作者、内容等基本信息,并将这些数据存入数据库,是一个非常完整的过程。获取首页所有的文章连接,存放在URL集合中,然后对这些采集的链接一一访问,再次解析
阅读全文
跟我一起开始python爬虫
作者:cxa1415 人浏览评论:02年前
前几天想写一个爬虫系列文章。我没有写它是因为我很忙(不是因为我懒惰)。趁着房间里的凉意和内心的宁静,总结一下我目前所遇到的事情。一些爬虫知识,本系列将从一个简单的爬虫开始,然后逐渐增加难度。同时,对反爬的方法进行总结,并用具体的例子来论证,不同的反爬现象和现实。
阅读全文
Python爬虫学习,记抓包获取js,从js函数取数据的过程
作者:云飞学习编程 1203人浏览评论:03年前
昨天,一个小伙伴来找我。新浪新闻的国内新闻页面,其他部分都是可以抓到的静态网页,但是左下角的最新新闻版块不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里面,很有意思,分吧
阅读全文
网页新闻抓取( Python通用抽取器--GnePython环境了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-25 00:08
Python通用抽取器--GnePython环境了
)
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
查看全部
网页新闻抓取(
Python通用抽取器--GnePython环境了
)
GNE[1]是我的开源新闻网站通用文本提取器,自发布以来受到了很多同学的好评。
长期以来,GNE 以 Python 包的形式存在。测试GNE的提取效果,需要先使用pip安装,然后编写代码使用。
为了降低测试GNE的成本,让更多的同学了解GNE,测试GNE,我开发了GNE的网页版——Gne Online。
Gne Online的打开地址是:,打开后的页面如下图所示。
要测试GNE的功能,只需将网页的源代码粘贴到顶部的文本框中,然后点击提取按钮:
对于标题、作者、新闻发布时间的情况,可能会发送不正确的提取,我们可以通过下面对应的Title XPath、Author、Publish Time XPath输入XPath定向提取。比如今日头条的文章:
新闻的作者在提取它时犯了一个错误。这时候可以指定XPath://div[@class="article-sub"]/span[1]/text()来定向提取,如下图所示。
通过设置Host输入框,可以在网页正文中的图片为相对路径时拼写URL。
勾选下方的With Body Html复选框,即可返回body所在区域的网页源代码。
更多GNE使用说明请参考官方文档[2]。
使用 Gne Online,您不再需要提前准备 Python 环境。
网页新闻抓取(网页抓取和网络爬虫的优点太技术化了!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-25 00:07
所以你知道网络抓取和网络爬虫,你听说过一些令人信服的优点,但你有点担心缺点。我们认为我们可以帮助您了解利大于弊。
好吧,让我们从网络抓取的好处开始,我们保证它不会太技术化。
网页抓取的优点
速度
首先,使用网络抓取技术最好的一点是它提供的速度。每个了解网络抓取的人都将其与速度联系起来。当您使用网络抓取工具(程序、软件或技术)时,它们基本上结束了从 网站 手动采集数据的过程。网页抓取可以让你快速同时抓取多个网站,而无需查看和控制每个请求。您也可以只设置一次,它会在一小时或更短的时间内抓取整个 网站 - 这不是一项需要一个人一周才能完成的工作。这是创建网页抓取来解决的主要问题。
网络抓取速度快的另一个原因不仅在于它扫描网络并从中提取数据的速度有多快,而且还在于将网络抓取纳入您的日常生活的过程。开始使用网络爬虫相当容易,因为您不必担心构建、下载、集成或安装它们。因此,完成设置后,您就可以开始网页抓取了。现在想象一下,您可以在五分钟内从在线商店获取大约 1,000 种产品的信息并将其打包到一张简洁的 Excel 表格中,这是多么令人惊奇。
网络抓取提供了成功且动态的未来评估。由于数据抓取可以评估消费者的态度、需求和愿望,因此甚至可以进行广泛的预测分析。深入了解消费者的喜好是一件好事,它有助于企业有效地规划未来。
大规模数据提取
这很简单——人类 0,机器人 1——这并没有错。很难想象手动处理数据,因为它太多了。网络爬虫为您提供的数据远远多于您手动采集的数据。例如,如果您的挑战是每周检查竞争对手的产品和服务的价格,那可能会花费您很多时间。它也不会很有效,因为即使您拥有一支强大且积极进取的团队,您也无法保持这种状态。相反,您决定使用该系统并运行一个爬虫,该爬虫每小时以相对较低的成本采集您需要的所有数据并且永不疲倦。
以下是投资行业如何从网络抓取中受益。对冲基金偶尔会使用网络抓取技术来采集替代数据以避免失败。它有助于检测意外威胁以及潜在的投资机会。投资决策很复杂,因为它们通常需要一系列步骤,从开发假设文件到进行实验和研究,然后再做出明智的决定。历史数据研究是评估投资概念的最有效技术。它使您能够深入了解以前失败或成就的根本原因、可避免的错误以及潜在的未来投资回报。
网络抓取是提取历史数据的一种更有效的方法,然后可以将其输入机器学习数据库进行模型训练。因此,使用大数据的投资机构可以提高分析结果的准确性,做出更好的决策。
具有成本效益
关于网络抓取的最好的事情之一是它是一项以相当低的成本提供的复杂服务。时间就是金钱,随着网络的发展和加速,如果没有重复性任务的自动化,专业的数据提取项目将是不可能的。例如,您可以聘请临时人员来运行分析、检查网站、执行例行任务,但所有这些都可以通过简单的脚本实现自动化。
另一件事是,一旦提取数据的核心机制启动并运行,您就有机会爬取整个域,而不仅仅是一个或几个页面。网络抓取甚至可以使情绪分析成为一项更实惠的任务:众所周知,每天都有成千上万的消费者在在线评论中发布他们对产品和服务的体验网站。这些海量数据对公众开放,可能只是为了获取有关企业、竞争对手、可能的机会和趋势的信息而被抓取。
灵活性和系统化方法
这是唯一可以与抓取数据提供的速度竞争的优势,因为抓取工具本质上是不断变化的。因此,它们具有高度的可修改性、开放性并与其他脚本兼容。您可以在一个系统中设置抓取工具、重复数据删除参与者、监控参与者和应用程序集成。它将协同工作,不受任何限制、额外成本或任何新平台的实施。
性能可靠性和稳健性
网页抓取本身就是一个确保数据准确性的过程。这是如何运作的?嗯,单调和重复的任务往往会导致错误,因为它们对人类来说简直是无聊。如果您正在处理财务、定价、时间敏感数据或良好的旧销售 - 不准确和错误可能需要大量时间和资源来查找和修复,如果没有找到 - 从那时起问题就会滚雪球。这涉及任何类型的数据,因此不仅要能够采集数据,而且要以可读和干净的格式保存数据,这一点至关重要。在现代世界,这不是人类的任务,而是机器的任务。机器人只会犯人类预先写在代码中的错误。如果您的脚本正确,您可以在很大程度上消除人为错误的因素,并确保您采集的信息和数据每次都具有更好的质量。
网页抓取的缺点
网页抓取需要永久维护
要记住的另一件事是,在 SaaS 的世界中,服务只是旅程的开始。真正的交易是产品维护。我们提到维护的原因很简单:由于您的爬虫工作本质上与外部 网站 相关联,因此您无法控制该 网站 何时更改其 HTML 结构或内容。因此,开发人员必须对这些变化做出反应。
数据提取不等于数据分析
在处理数据提取和数据处理等复杂问题时,设定正确的期望非常重要。无论您使用多么好的网络爬虫,在大多数情况下它都无法为您完成数据分析工作。数据将以结构化格式到达,但是,需要处理更复杂的数据,以便它们可以在其他程序中使用。整个过程可能非常耗费资源和时间,如果您面临一个大数据分析项目,您应该做好准备。 查看全部
网页新闻抓取(网页抓取和网络爬虫的优点太技术化了!!)
所以你知道网络抓取和网络爬虫,你听说过一些令人信服的优点,但你有点担心缺点。我们认为我们可以帮助您了解利大于弊。
好吧,让我们从网络抓取的好处开始,我们保证它不会太技术化。
网页抓取的优点
速度
首先,使用网络抓取技术最好的一点是它提供的速度。每个了解网络抓取的人都将其与速度联系起来。当您使用网络抓取工具(程序、软件或技术)时,它们基本上结束了从 网站 手动采集数据的过程。网页抓取可以让你快速同时抓取多个网站,而无需查看和控制每个请求。您也可以只设置一次,它会在一小时或更短的时间内抓取整个 网站 - 这不是一项需要一个人一周才能完成的工作。这是创建网页抓取来解决的主要问题。
网络抓取速度快的另一个原因不仅在于它扫描网络并从中提取数据的速度有多快,而且还在于将网络抓取纳入您的日常生活的过程。开始使用网络爬虫相当容易,因为您不必担心构建、下载、集成或安装它们。因此,完成设置后,您就可以开始网页抓取了。现在想象一下,您可以在五分钟内从在线商店获取大约 1,000 种产品的信息并将其打包到一张简洁的 Excel 表格中,这是多么令人惊奇。
网络抓取提供了成功且动态的未来评估。由于数据抓取可以评估消费者的态度、需求和愿望,因此甚至可以进行广泛的预测分析。深入了解消费者的喜好是一件好事,它有助于企业有效地规划未来。
大规模数据提取
这很简单——人类 0,机器人 1——这并没有错。很难想象手动处理数据,因为它太多了。网络爬虫为您提供的数据远远多于您手动采集的数据。例如,如果您的挑战是每周检查竞争对手的产品和服务的价格,那可能会花费您很多时间。它也不会很有效,因为即使您拥有一支强大且积极进取的团队,您也无法保持这种状态。相反,您决定使用该系统并运行一个爬虫,该爬虫每小时以相对较低的成本采集您需要的所有数据并且永不疲倦。
以下是投资行业如何从网络抓取中受益。对冲基金偶尔会使用网络抓取技术来采集替代数据以避免失败。它有助于检测意外威胁以及潜在的投资机会。投资决策很复杂,因为它们通常需要一系列步骤,从开发假设文件到进行实验和研究,然后再做出明智的决定。历史数据研究是评估投资概念的最有效技术。它使您能够深入了解以前失败或成就的根本原因、可避免的错误以及潜在的未来投资回报。
网络抓取是提取历史数据的一种更有效的方法,然后可以将其输入机器学习数据库进行模型训练。因此,使用大数据的投资机构可以提高分析结果的准确性,做出更好的决策。
具有成本效益
关于网络抓取的最好的事情之一是它是一项以相当低的成本提供的复杂服务。时间就是金钱,随着网络的发展和加速,如果没有重复性任务的自动化,专业的数据提取项目将是不可能的。例如,您可以聘请临时人员来运行分析、检查网站、执行例行任务,但所有这些都可以通过简单的脚本实现自动化。
另一件事是,一旦提取数据的核心机制启动并运行,您就有机会爬取整个域,而不仅仅是一个或几个页面。网络抓取甚至可以使情绪分析成为一项更实惠的任务:众所周知,每天都有成千上万的消费者在在线评论中发布他们对产品和服务的体验网站。这些海量数据对公众开放,可能只是为了获取有关企业、竞争对手、可能的机会和趋势的信息而被抓取。
灵活性和系统化方法
这是唯一可以与抓取数据提供的速度竞争的优势,因为抓取工具本质上是不断变化的。因此,它们具有高度的可修改性、开放性并与其他脚本兼容。您可以在一个系统中设置抓取工具、重复数据删除参与者、监控参与者和应用程序集成。它将协同工作,不受任何限制、额外成本或任何新平台的实施。
性能可靠性和稳健性
网页抓取本身就是一个确保数据准确性的过程。这是如何运作的?嗯,单调和重复的任务往往会导致错误,因为它们对人类来说简直是无聊。如果您正在处理财务、定价、时间敏感数据或良好的旧销售 - 不准确和错误可能需要大量时间和资源来查找和修复,如果没有找到 - 从那时起问题就会滚雪球。这涉及任何类型的数据,因此不仅要能够采集数据,而且要以可读和干净的格式保存数据,这一点至关重要。在现代世界,这不是人类的任务,而是机器的任务。机器人只会犯人类预先写在代码中的错误。如果您的脚本正确,您可以在很大程度上消除人为错误的因素,并确保您采集的信息和数据每次都具有更好的质量。
网页抓取的缺点
网页抓取需要永久维护
要记住的另一件事是,在 SaaS 的世界中,服务只是旅程的开始。真正的交易是产品维护。我们提到维护的原因很简单:由于您的爬虫工作本质上与外部 网站 相关联,因此您无法控制该 网站 何时更改其 HTML 结构或内容。因此,开发人员必须对这些变化做出反应。
数据提取不等于数据分析
在处理数据提取和数据处理等复杂问题时,设定正确的期望非常重要。无论您使用多么好的网络爬虫,在大多数情况下它都无法为您完成数据分析工作。数据将以结构化格式到达,但是,需要处理更复杂的数据,以便它们可以在其他程序中使用。整个过程可能非常耗费资源和时间,如果您面临一个大数据分析项目,您应该做好准备。
网页新闻抓取(网页获取和解析速度和性能的应用场景详解!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-23 17:21
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源码下载:网络爬虫(网络蜘蛛)网络爬虫示例源码 查看全部
网页新闻抓取(网页获取和解析速度和性能的应用场景详解!)
(4)支持代理
(5)支持自动cookie管理等。
Java爬虫开发是应用最广泛的网页获取技术。它具有一流的速度和性能。它在功能支持方面相对较低。不支持JS脚本执行、CSS解析、渲染等准浏览器功能。推荐用于快速访问网页。无需解析脚本和 CSS 的场景。
示例代码如下:
package cn.ysh.studio.crawler.httpclient;import org.apache.http.client.HttpClient;import org.apache.http.client.ResponseHandler;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.BasicResponseHandler;import org.apache.http.impl.client.DefaultHttpClient;/**
* 基于HtmlClient抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHttpClientTest{publicstaticvoid main(String[] args)throwsException{//目标页面String url ="http://www.yshjava.cn";//创建一个默认的HttpClientHttpClient httpclient =newDefaultHttpClient();try{//以get方式请求网页http://www.yshjava.cnHttpGet httpget =newHttpGet(url);//打印请求地址System.out.println("executing request "+ httpget.getURI());//创建响应处理器处理服务器响应内容ResponseHandlerresponseHandler=newBasicResponseHandler();//执行请求并获取结果String responseBody = httpclient.execute(httpget, responseHandler);System.out.println("----------------------------------------");System.out.println(responseBody);System.out.println("----------------------------------------");}finally{//关闭连接管理器
httpclient.getConnectionManager().shutdown();}}}
汤
jsoup 是一个 Java HTML 解析器,可以直接解析一个 URL 地址和 HTML 文本内容。它提供了一个非常省力的 API,用于通过 DOM、CSS 和类似 jQuery 的操作方法获取和操作数据。
网页获取解析速度快,推荐。
主要功能如下:
1. 从 URL、文件或字符串解析 HTML;
2. 使用 DOM 或 CSS 选择器来查找和检索数据;
3. 可以操作 HTML 元素、属性、文本;
示例代码如下:
package cn.ysh.studio.crawler.jsoup;import java.io.IOException;import org.jsoup.Jsoup;/**
* 基于Jsoup抓取网页内容
* @author www.yshjava.cn
*/publicclassJsoupTest{publicstaticvoid main(String[] args)throwsIOException{//目标页面String url ="http://www.yshjava.cn";//使用Jsoup连接目标页面,并执行请求,获取服务器响应内容String html =Jsoup.connect(url).execute().body();//打印页面内容System.out.println(html);}}
html单元
htmlunit 是一个开源的java页面分析工具。阅读完页面后,可以有效地使用htmlunit分析页面上的内容。该项目可以模拟浏览器的操作,称为java浏览器的开源实现。这个没有界面的浏览器运行速度非常快。使用 Rhinojs 引擎。模拟js运行。
网页获取和解析速度快,性能更好。推荐用于需要解析网页脚本的应用场景。
示例代码如下:
package cn.ysh.studio.crawler.htmlunit;import com.gargoylesoftware.htmlunit.BrowserVersion;import com.gargoylesoftware.htmlunit.Page;import com.gargoylesoftware.htmlunit.WebClient;/**
* 基于HtmlUnit抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlUnitSpider{publicstaticvoid main(String[] s)throwsException{//目标网页String url ="http://www.yshjava.cn";//模拟特定浏览器FIREFOX_3WebClient spider =newWebClient(BrowserVersion.FIREFOX_3);//获取目标网页Page page = spider.getPage(url);//打印网页内容System.out.println(page.getWebResponse().getContentAsString());//关闭所有窗口
spider.closeAllWindows();}}
瓦蒂
Watij(发音为 wattage)是一个用 Java 开发的 Web 应用程序测试工具。鉴于 Watij 的简单性和 Java 语言的强大功能,Watij 使您能够在真实浏览器中自动测试 Web 应用程序。因为调用本地浏览器,所以支持CSS渲染和JS执行。
网页访问速度一般,IE版本太低(6/7)可能会导致内存泄漏。
示例代码如下:
package cn.ysh.studio.crawler.ie;import watij.runtime.ie.IE;/**
* 基于Watij抓取网页内容,仅限Windows平台
*
* @author www.yshjava.cn
*/publicclassWatijTest{publicstaticvoid main(String[] s){//目标页面String url ="http://www.yshjava.cn";//实例化IE浏览器对象
IE ie =new IE();try{//启动浏览器
ie.start();//转到目标网页
ie.goTo(url);//等待网页加载就绪
ie.waitUntilReady();//打印页面内容System.out.println(ie.html());}catch(Exception e){
e.printStackTrace();}finally{try{//关闭IE浏览器
ie.close();}catch(Exception e){}}}}
硒
Selenium 也是一个用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。支持的浏览器包括 IE、Mozilla Firefox、Mozilla Suite 等。该工具的主要功能包括: 测试与浏览器的兼容性——测试您的应用程序是否在不同的浏览器和操作系统上运行良好。测试系统功能 - 创建回归测试以验证软件功能和用户需求。支持动作的自动记录和自动生成。Net、Java、Perl 和其他不同语言的测试脚本。Selenium 是 ThoughtWorks 专门为 Web 应用程序编写的验收测试工具。
网页抓取速度慢,对于爬虫来说不是一个好的选择。
示例代码如下:
package cn.ysh.studio.crawler.selenium;import org.openqa.selenium.htmlunit.HtmlUnitDriver;/**
* 基于HtmlDriver抓取网页内容
*
* @author www.yshjava.cn
*/publicclassHtmlDriverTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";HtmlUnitDriver driver =newHtmlUnitDriver();try{//禁用JS脚本功能
driver.setJavascriptEnabled(false);//打开目标网页
driver.get(url);//获取当前网页源码String html = driver.getPageSource();//打印网页源码System.out.println(html);}catch(Exception e){//打印堆栈信息
e.printStackTrace();}finally{try{//关闭并退出
driver.close();
driver.quit();}catch(Exception e){}}}}
网络规范
具有支持脚本执行和 CSS 呈现的界面的开源 Java 浏览器。平均速度。
示例代码如下:
package cn.ysh.studio.crawler.webspec;import org.watij.webspec.dsl.WebSpec;/**
* 基于WebSpec抓取网页内容
*
* @author www.yshjava.cn
*/publicclassWebspecTest{publicstaticvoid main(String[] s){//目标网页String url ="http://www.yshjava.cn";//实例化浏览器对象WebSpec spec =newWebSpec().mozilla();//隐藏浏览器窗体
spec.hide();//打开目标页面
spec.open(url);//打印网页源码System.out.println(spec.source());//关闭所有窗口
spec.closeAll();}}
源码下载:网络爬虫(网络蜘蛛)网络爬虫示例源码
网页新闻抓取(如何深入全面的挖掘新闻信息,对于许多新闻相关工作意义重大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-21 16:11
【摘要】 新闻是与人们日常工作、娱乐和生活密切相关的信息。对于有影响力的新闻事件,具有更大深度和跨度的专题新闻信息量更大,更有趣。所谓话题新闻,是因为它的时效性。更多还原 突出新闻的“新”,突出“主题”和时间跨度大的话题,强调“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在互联网上迅速传播。另一方面,互联网上信息的爆炸式增长使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎 该引擎将触角伸入互联网信息的各个角落。如何深入、全面地挖掘新闻信息,对许多新闻相关工作具有重要意义。通过搜索引擎挖掘深入、全面的新闻信息是本文的重点,即通过进一步挖掘与某一主题相关的新闻内容,形成主题新闻。IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出贸易角色模型。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。
第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,提取的好坏直接决定后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们选择使用原生程序实现其搜索结果在几种方案中的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,通过行业角色模型进行文本挖掘,基于段落使用TRM模型进行评估,最后动态平衡每个段落的分数用于比较上述分数和新闻网页的特征,以提取相应的新闻文本内容。从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于在网上手动提取新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。 查看全部
网页新闻抓取(如何深入全面的挖掘新闻信息,对于许多新闻相关工作意义重大)
【摘要】 新闻是与人们日常工作、娱乐和生活密切相关的信息。对于有影响力的新闻事件,具有更大深度和跨度的专题新闻信息量更大,更有趣。所谓话题新闻,是因为它的时效性。更多还原 突出新闻的“新”,突出“主题”和时间跨度大的话题,强调“深”。近年来,互联网已成为新闻信息发布的最佳平台和最大来源,各种新闻以各种形式在互联网上迅速传播。另一方面,互联网上信息的爆炸式增长使得人工获取越来越全面的新闻内容变得越来越困难。作为信息获取解决方案之一,搜索引擎技术取得了长足的进步。以谷歌为代表的搜索引擎 该引擎将触角伸入互联网信息的各个角落。如何深入、全面地挖掘新闻信息,对许多新闻相关工作具有重要意义。通过搜索引擎挖掘深入、全面的新闻信息是本文的重点,即通过进一步挖掘与某一主题相关的新闻内容,形成主题新闻。IT新闻抓取的过程本质上就是Web数据挖掘的过程。在挖掘过程中,首先对2009年的热点新闻样本进行分类分析。在对样本进行分类的基础上,找出每个样本的特征,提出贸易角色模型。该模型的提出是在与基于用户兴趣的搜索模型进行对比分析的基础上完成的,最后形成行业角色评分公式对样本进行评价。基于该模型,本文分两步实现主题新闻抓取。
第一步是转换关键词搜索并提取搜索引擎搜索结果URL。这一步是本文研究工作的基础,提取的好坏直接决定后续工作的成败。通过对Google在搜索引擎中的搜索特性的研究,我们选择使用原生程序实现其搜索结果在几种方案中的利用,通过基于行业角色的模型比较URL链接,并通过分数。通过过滤,这一步去除了大部分垃圾或无用的链接,保留与新闻主题相关的链接,并选择得分最高的链接供以后使用。第二步,提取URL对应的新闻文本。这一步是本文的最终研究成果。通过分析上一步搜索到的URL链接对应的页面,提取该页面对应的文本文件,通过行业角色模型进行文本挖掘,基于段落使用TRM模型进行评估,最后动态平衡每个段落的分数用于比较上述分数和新闻网页的特征,以提取相应的新闻文本内容。从新闻样本捕获的最终结果来看,平均准确率达到90.2%,平均召回率达到72.8%。最终捕获的新闻文本也形成了主题新闻的文本文本。由于在网上手动提取新闻需要大量人力,利用搜索引擎结果和节目提取相关新闻内容,将节省大量人力资源,使新闻事件快速、全面地呈现给网络受众。这也是本研究的价值所在。
网页新闻抓取(手机版简版网易新闻网址获取新闻链接列表列表的网址)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2022-01-20 22:10
网站分析
为了方便抓取,选择了简化版网易新闻网站的手机版。
在以下位置获取新闻链接列表
其中1-40代表当前列表中的页数,爬取列表时只需要修改页数即可。
爬取进程获取新闻链接地址
使用requests包读取新闻列表页面,然后使用正则表达式提取新闻页面链接,返回urls列表
def getList(url):
li = requests.get(url)
res = r'url":"http:.*?.html'
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
获取新闻内容
使用requests获取新闻页面的内容,然后使用BeautifulSoup包解析网页内容。
def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
移动短版新闻通常将一条新闻分成若干页来展示,这使得爬取内容非常麻烦。分析后发现在新闻链接地址后加_0可以显示所有新闻内容,所以先处理链接地址。然后使用requests获取网页,BeautifulSoup提取新闻的标题、时间、类别和内容。
保存结果
def saveAsTxt(news):
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
"\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
运行程序代码
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新闻标题
self.time = time #新闻时间
self.type = type #新闻类别
self.content = content #新闻内容
def getList(url): #获取新闻链接地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正则表达式获取链接地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #获取新闻内容
url = url[:-5]+"_0.html" #处理链接获取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #获取新闻内容,注意编码
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #保存新闻内容
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
# "\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/articl ... ot%3B %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "当前页解析出 %s 条" %len(urls)
j = 1
for url in urls:
print "正在读取第%s页第%s/%s条:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s条新闻,耗时%f s" %(sum,end - start)
结果
程序的运行时间主要与页面打开的速度有关。如果网络速度理想,程序运行速度相当快。
笔记
程序也是入门级爬虫,不涉及代理ip池和多线程效率问题。但是如果附加你需要这些后处理,比如
高效存储(数据库应该如何排列)
有效判断权重(这里指的是网页判断,我们不想爬抄抄袭的人民日报和大民报)
有效的信息提取(比如如何提取网页上的所有地址,“朝阳区奋进路中国路”),搜索引擎通常不需要存储所有信息,比如图片,我为什么要保存它们...
及时更新(预测此页面的更新频率)
可以想象,这里的每一点都可以被许多研究人员研究数十年。(知乎:谢克)
附录
请求文件 查看全部
网页新闻抓取(手机版简版网易新闻网址获取新闻链接列表列表的网址)
网站分析
为了方便抓取,选择了简化版网易新闻网站的手机版。
在以下位置获取新闻链接列表
其中1-40代表当前列表中的页数,爬取列表时只需要修改页数即可。
爬取进程获取新闻链接地址
使用requests包读取新闻列表页面,然后使用正则表达式提取新闻页面链接,返回urls列表
def getList(url):
li = requests.get(url)
res = r'url":"http:.*?.html'
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
获取新闻内容
使用requests获取新闻页面的内容,然后使用BeautifulSoup包解析网页内容。
def getNews(url):
url = url[:-5]+"_0.html"
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser")
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
移动短版新闻通常将一条新闻分成若干页来展示,这使得爬取内容非常麻烦。分析后发现在新闻链接地址后加_0可以显示所有新闻内容,所以先处理链接地址。然后使用requests获取网页,BeautifulSoup提取新闻的标题、时间、类别和内容。
保存结果
def saveAsTxt(news):
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
"\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
运行程序代码
# encoding: utf-8
import requests
import re
from bs4 import BeautifulSoup
import time
class News:
def __init__(self,title,time,type,content):
self.title = title #新闻标题
self.time = time #新闻时间
self.type = type #新闻类别
self.content = content #新闻内容
def getList(url): #获取新闻链接地址
li = requests.get(url)
res = r'url":"http:.*?.html' #正则表达式获取链接地址
urls = re.findall(res,li.text)
for i in range(len(urls)):
urls[i] = urls[i][6:]
return urls
def getNews(url): #获取新闻内容
url = url[:-5]+"_0.html" #处理链接获取全文
ss = requests.get(url)
soup = BeautifulSoup(ss.text,"html.parser") #获取新闻内容,注意编码
title = soup.title.string[:-6].encode('utf-8')
time = soup.find("div","about").contents[0][9:].encode('utf-8')
# type = soup.find("div","position lBlue").contents[3].string.encode('utf-8')
content = soup.find("div","content").get_text()[1:-1].encode('utf-8')
news = News(title,time,type,content)
return news
def saveAsTxt(news): #保存新闻内容
file = open('E:/news.txt','a')
file.write("标题:" + news.title +
"\t时间:" + news.time +
# "\t类型:"+ news.type +
"\t内容:"+ news.content +
"\"\n")
start = time.clock()
sum = 0
for i in range(1,40):
wangzhi = "http://3g.163.com/touch/articl ... ot%3B %i
urls = getList(wangzhi)
sum = sum + len(urls)
# print "当前页解析出 %s 条" %len(urls)
j = 1
for url in urls:
print "正在读取第%s页第%s/%s条:%s" %(i,j,len(urls),url.encode('utf-8'))
news = getNews(url)
saveAsTxt(news)
j = j + 1
end = time.clock()
print "共爬取%s条新闻,耗时%f s" %(sum,end - start)
结果
程序的运行时间主要与页面打开的速度有关。如果网络速度理想,程序运行速度相当快。
笔记
程序也是入门级爬虫,不涉及代理ip池和多线程效率问题。但是如果附加你需要这些后处理,比如
高效存储(数据库应该如何排列)
有效判断权重(这里指的是网页判断,我们不想爬抄抄袭的人民日报和大民报)
有效的信息提取(比如如何提取网页上的所有地址,“朝阳区奋进路中国路”),搜索引擎通常不需要存储所有信息,比如图片,我为什么要保存它们...
及时更新(预测此页面的更新频率)
可以想象,这里的每一点都可以被许多研究人员研究数十年。(知乎:谢克)
附录
请求文件

