
网页新闻抓取
网页新闻抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-11-01 20:09
媒体的现状,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题本来需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。另一个例子是我们的金融市场,它也可以更新并自动组织成一个动态的媒体专栏。
对于某些方面的关注程度,还可以根据网络爬虫抓取的阅读量或数据量进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
但是,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑具有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容 特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页新闻抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
媒体的现状,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题本来需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。

网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。另一个例子是我们的金融市场,它也可以更新并自动组织成一个动态的媒体专栏。
对于某些方面的关注程度,还可以根据网络爬虫抓取的阅读量或数据量进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
但是,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑具有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容 特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页新闻抓取(如何抓取网易新闻的网站数据(涉及Ajax技术)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-01 09:01
如何抓取网易新闻的网站数据(涉及Ajax技术) 互联网数据爆炸式增长,有效获取和分析这些数据并使其产生价值是我们的工作。那么,首先要思考的问题是:如何抓取网站数据?今天分享的是一个完整的使用web数据采集器-优采云、采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站栏目后,下拉页面,会发现页面有新数据加载。分析表明,这个网站涉及Ajax技术,需要在优采云中设置一些高级选项。这一点需要特别注意。具体可以到优采云官网查看 学习 AJAX 滚动教程。采集网站:/world/示例规则下载:/1875781361/FhuTqwUjk?from=page_81361_profile&wvr=6&mod=weibotime&type=comment#_rnd79 第一步:创建采集任务1)选择主界面,选择自定义模式。如何抓取网易新闻的网站数据 图12) 将上述网址的网址复制粘贴到网站的输入框中,点击“保存网址”。抓取网易新闻的网站数据 图23) 保存URL后,页面会在优采云采集器中打开,红框中的信息是关键这个演示。如何抓取@采集网易新闻网站数据的内容 图3 第二步:
右击,需要采集的内容会变成绿色。如何抓取网易新闻的网站数据 图6 注:点击右上角“处理”按钮,显示可视化流程图。2) 系统会识别新闻信息框中的子元素。在操作提示框中,选择“选中的子元素”。找出页面上的其他相似元素,在操作提示框中选择“全选”创建列表循环。字段上会出现删除标记,点击删除该字段。如何抓取网易新闻的网站数据 图94) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”如何抓取网易新闻的< 并且可以设置多个云节点来共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集
<p>2)采集 完成后会弹出提示选择如何导出数据抓取网易新闻的网站数据图133)选择合适的导出方式并设置 查看全部
网页新闻抓取(如何抓取网易新闻的网站数据(涉及Ajax技术)(组图))
如何抓取网易新闻的网站数据(涉及Ajax技术) 互联网数据爆炸式增长,有效获取和分析这些数据并使其产生价值是我们的工作。那么,首先要思考的问题是:如何抓取网站数据?今天分享的是一个完整的使用web数据采集器-优采云、采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站栏目后,下拉页面,会发现页面有新数据加载。分析表明,这个网站涉及Ajax技术,需要在优采云中设置一些高级选项。这一点需要特别注意。具体可以到优采云官网查看 学习 AJAX 滚动教程。采集网站:/world/示例规则下载:/1875781361/FhuTqwUjk?from=page_81361_profile&wvr=6&mod=weibotime&type=comment#_rnd79 第一步:创建采集任务1)选择主界面,选择自定义模式。如何抓取网易新闻的网站数据 图12) 将上述网址的网址复制粘贴到网站的输入框中,点击“保存网址”。抓取网易新闻的网站数据 图23) 保存URL后,页面会在优采云采集器中打开,红框中的信息是关键这个演示。如何抓取@采集网易新闻网站数据的内容 图3 第二步:
右击,需要采集的内容会变成绿色。如何抓取网易新闻的网站数据 图6 注:点击右上角“处理”按钮,显示可视化流程图。2) 系统会识别新闻信息框中的子元素。在操作提示框中,选择“选中的子元素”。找出页面上的其他相似元素,在操作提示框中选择“全选”创建列表循环。字段上会出现删除标记,点击删除该字段。如何抓取网易新闻的网站数据 图94) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”如何抓取网易新闻的< 并且可以设置多个云节点来共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集
<p>2)采集 完成后会弹出提示选择如何导出数据抓取网易新闻的网站数据图133)选择合适的导出方式并设置
网页新闻抓取(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-29 21:14
一个完整的网络爬虫的基本框架如下图所示:
整个架构有以下几个流程:
1) 需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级建立待爬取的URL队列(先到先得);
2) 根据要爬取的URL队列的顺序进行网页爬取;
3) 将获取到的网页内容和信息下载到本地网页库,建立爬取的网址列表(用于去除重复和确定爬取过程);
4)将抓取到的网页放入待抓取的URL队列,进行循环抓取操作;
2. 网络爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个非常重要的问题,因为这涉及到先爬取哪个页面,后爬哪个页面的问题。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很容易理解,这和我们有向图中的深度优先遍历是一样的,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始页开始爬取,然后根据链接一个一个爬取,直到不能再爬取,返回上一页继续跟踪链接。
有向图中深度优先搜索的示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式是完全相对的。思路是将新下载的网页中找到的链接直接插入到要爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
上图是上例的有向图的广度优先搜索流程图,遍历的结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树结构的角度来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4)大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个爬取的URL),OPIC搜索策略(也是一种重要性)。最后需要指出的是,我们可以根据自己的需要设置网页的爬取间隔,这样可以保证我们的一些基本的主要站点或者活跃站点的内容不会被遗漏。
3. 网络爬虫更新策略
互联网是实时变化的,是高度动态的。网页更新策略主要是决定什么时候更新之前下载过的页面。常见的更新策略有以下三种:
1)历史参考攻略
顾名思义,就是根据页面之前的历史更新数据,预测页面未来什么时候会发生变化。一般来说,预测是通过泊松过程建模进行的。
2)用户体验策略
尽管搜索引擎可以针对某个查询条件返回大量结果,但用户往往只关注结果的前几页。因此,爬虫系统可以先更新那些实际在查询结果前几页的网页,然后再更新后面的那些网页。此更新策略还需要历史信息。用户体验策略保留网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,并以此值作为决定何时重新抓取的依据。
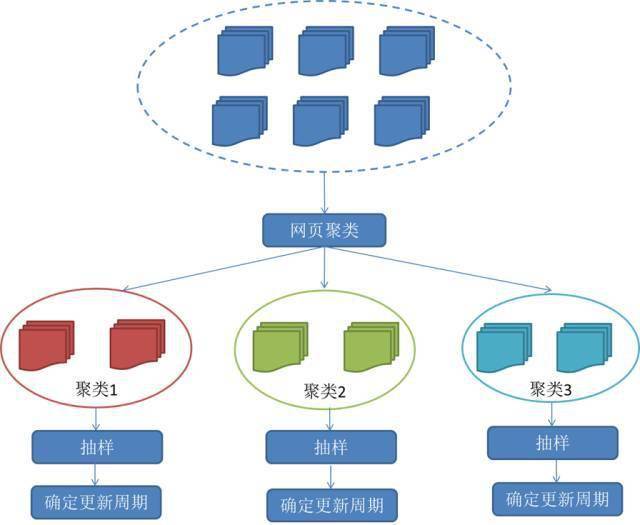
3)集群采样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加系统的负担;第二,如果新网页根本没有历史信息,就无法确定更新策略。
该策略认为网页有很多属性,属性相似的网页可以认为更新频率相似。计算某一类网页的更新频率,只需对该类网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如图:
4. 分布式爬取系统结构
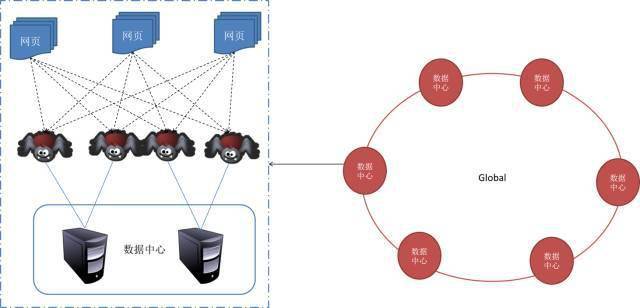
一般来说,爬虫系统需要面对整个互联网上亿万个网页。单个爬虫不可能完成这样的任务。通常需要多个抓取程序来一起处理。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
底层是分布在不同地理位置的数据中心。在每个数据中心,有多个爬虫服务器,每个爬虫服务器可能部署了多套爬虫程序。这就构成了一个基本的分布式爬虫系统。
对于数据中心内的不同抓取服务器,有多种方式可以协同工作:
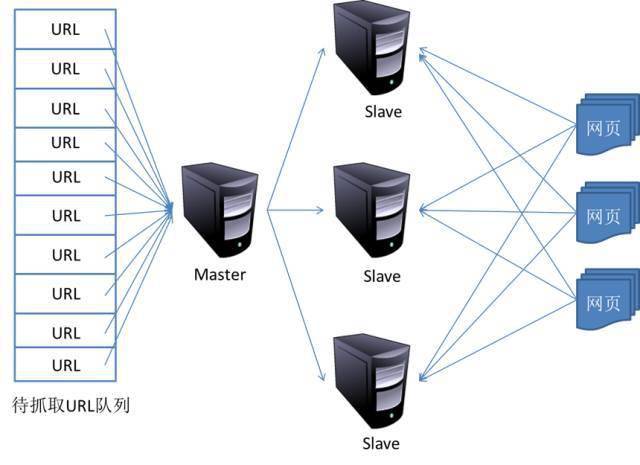
1)主从
主从式的基本结构如图:
对于主从模式,有一个专门的Master服务器维护一个待抓取的URL队列,负责每次将URL分发到不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL之外,还负责调解各个Slave服务器的负载。为了避免一些Slave服务器太闲或者太累。
在这种模式下,Master往往容易成为系统瓶颈。
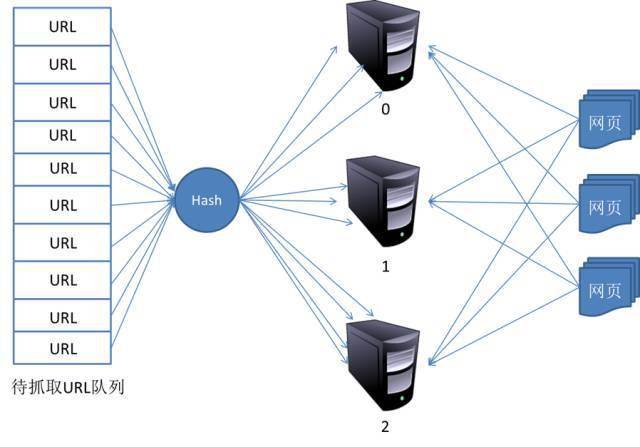
2)点对点
点对点方程的基本结构如图所示:
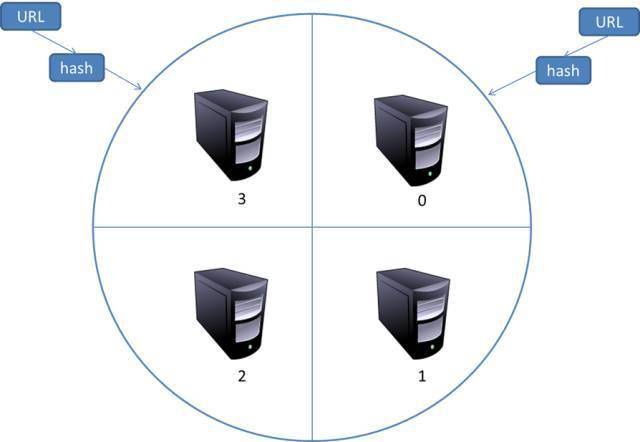
在这种模式下,所有爬取服务器之间的分工没有区别。每个爬虫服务器都可以从要爬取的URL队列中获取URL,然后得到该URL主域名的hash值H,然后计算H mod m(其中m为服务器数量,上图为例如,m为3),计算出的数字就是处理该URL的主机数。
示例:假设对于URL,计算器哈希值H=8,m=3,那么H mod m=2,那么编号为2的服务器就会抓取链接。假设此时服务器0获取到了URL,它会将URL转发给服务器2,服务器2就会抓取它。
这个模型有问题。当服务器崩溃或添加新服务器时,所有 URL 的散列剩余部分的结果将更改。换句话说,这种方法的可扩展性不好。针对这种情况,又提出了另一个改进方案。这种改进的方案是通过一致性哈希来确定服务器上的分工。其基本结构如图:
一致性哈希对URL的主域名进行哈希,映射到0到232之间的一个数字,这个范围平均分配给m台服务器,判断URL主域名哈希运算的取值范围是哪个服务器用于抓取。
如果某个服务器出现问题,那么应该负责该服务器的网页会顺时针推迟,下一个服务器会被爬取。在这种情况下,如果一个服务器及时出现问题,不会影响其他任务。
5. 参考内容
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎-网络爬虫;
[3] 《这就是搜索引擎:核心技术详解》。 查看全部
网页新闻抓取(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫的基本框架如下图所示:
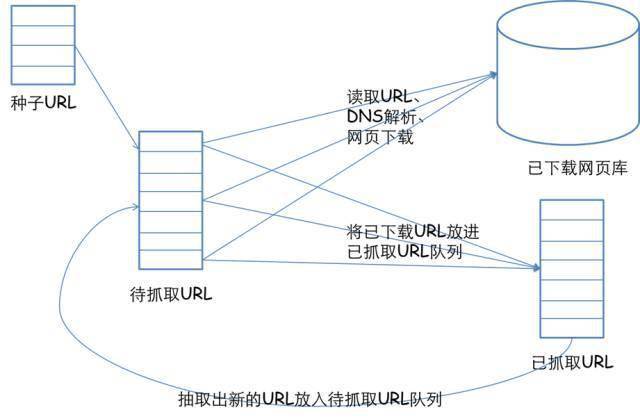
整个架构有以下几个流程:
1) 需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级建立待爬取的URL队列(先到先得);
2) 根据要爬取的URL队列的顺序进行网页爬取;
3) 将获取到的网页内容和信息下载到本地网页库,建立爬取的网址列表(用于去除重复和确定爬取过程);
4)将抓取到的网页放入待抓取的URL队列,进行循环抓取操作;
2. 网络爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个非常重要的问题,因为这涉及到先爬取哪个页面,后爬哪个页面的问题。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很容易理解,这和我们有向图中的深度优先遍历是一样的,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始页开始爬取,然后根据链接一个一个爬取,直到不能再爬取,返回上一页继续跟踪链接。
有向图中深度优先搜索的示例如下所示:
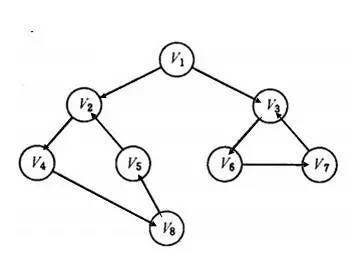
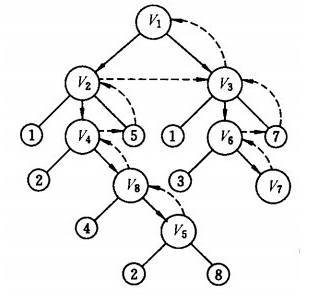
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式是完全相对的。思路是将新下载的网页中找到的链接直接插入到要爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
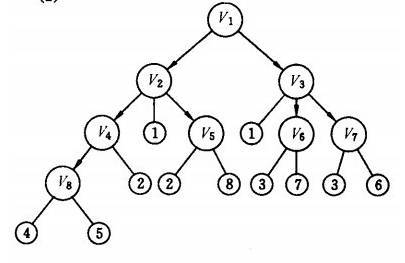
上图是上例的有向图的广度优先搜索流程图,遍历的结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树结构的角度来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4)大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个爬取的URL),OPIC搜索策略(也是一种重要性)。最后需要指出的是,我们可以根据自己的需要设置网页的爬取间隔,这样可以保证我们的一些基本的主要站点或者活跃站点的内容不会被遗漏。
3. 网络爬虫更新策略
互联网是实时变化的,是高度动态的。网页更新策略主要是决定什么时候更新之前下载过的页面。常见的更新策略有以下三种:
1)历史参考攻略
顾名思义,就是根据页面之前的历史更新数据,预测页面未来什么时候会发生变化。一般来说,预测是通过泊松过程建模进行的。
2)用户体验策略
尽管搜索引擎可以针对某个查询条件返回大量结果,但用户往往只关注结果的前几页。因此,爬虫系统可以先更新那些实际在查询结果前几页的网页,然后再更新后面的那些网页。此更新策略还需要历史信息。用户体验策略保留网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,并以此值作为决定何时重新抓取的依据。
3)集群采样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加系统的负担;第二,如果新网页根本没有历史信息,就无法确定更新策略。
该策略认为网页有很多属性,属性相似的网页可以认为更新频率相似。计算某一类网页的更新频率,只需对该类网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如图:
4. 分布式爬取系统结构
一般来说,爬虫系统需要面对整个互联网上亿万个网页。单个爬虫不可能完成这样的任务。通常需要多个抓取程序来一起处理。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
底层是分布在不同地理位置的数据中心。在每个数据中心,有多个爬虫服务器,每个爬虫服务器可能部署了多套爬虫程序。这就构成了一个基本的分布式爬虫系统。
对于数据中心内的不同抓取服务器,有多种方式可以协同工作:
1)主从
主从式的基本结构如图:
对于主从模式,有一个专门的Master服务器维护一个待抓取的URL队列,负责每次将URL分发到不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL之外,还负责调解各个Slave服务器的负载。为了避免一些Slave服务器太闲或者太累。
在这种模式下,Master往往容易成为系统瓶颈。
2)点对点
点对点方程的基本结构如图所示:
在这种模式下,所有爬取服务器之间的分工没有区别。每个爬虫服务器都可以从要爬取的URL队列中获取URL,然后得到该URL主域名的hash值H,然后计算H mod m(其中m为服务器数量,上图为例如,m为3),计算出的数字就是处理该URL的主机数。
示例:假设对于URL,计算器哈希值H=8,m=3,那么H mod m=2,那么编号为2的服务器就会抓取链接。假设此时服务器0获取到了URL,它会将URL转发给服务器2,服务器2就会抓取它。
这个模型有问题。当服务器崩溃或添加新服务器时,所有 URL 的散列剩余部分的结果将更改。换句话说,这种方法的可扩展性不好。针对这种情况,又提出了另一个改进方案。这种改进的方案是通过一致性哈希来确定服务器上的分工。其基本结构如图:
一致性哈希对URL的主域名进行哈希,映射到0到232之间的一个数字,这个范围平均分配给m台服务器,判断URL主域名哈希运算的取值范围是哪个服务器用于抓取。
如果某个服务器出现问题,那么应该负责该服务器的网页会顺时针推迟,下一个服务器会被爬取。在这种情况下,如果一个服务器及时出现问题,不会影响其他任务。
5. 参考内容
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎-网络爬虫;
[3] 《这就是搜索引擎:核心技术详解》。
网页新闻抓取( 2017年04月21日Python正则抓取网易新闻的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-29 21:13
2017年04月21日Python正则抓取网易新闻的方法
)
抓取网易新闻的方法的python正则示例
更新时间:2017年4月21日14:37:22 作者:shine
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考到以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
网页新闻抓取(
2017年04月21日Python正则抓取网易新闻的方法
)
抓取网易新闻的方法的python正则示例
更新时间:2017年4月21日14:37:22 作者:shine
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考到以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的

然后打开链接,找到相关的评论内容。(下图为第一页内容)

接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
网页新闻抓取(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-10-27 19:05
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终的结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等。
因此,爬虫不仅要做下载的工作,还要做数据清洗和提取的工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们抓取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取。但是,我们的爬虫抓取了数百个 网站 网页。将正则表达式写到这么多不同格式的网页上会很累,而且一旦对网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不通,还得探索一个好的算法来实现。
1. 标题提取
基本上,标题会出现在html标签中,但会附加频道名称、网站名称等信息;
标题也会出现在网页的“标题区”中。
那么这两个地方哪里比较容易提取title呢?
网页的“标题区”没有明显的标记,不同网站的“标题区”的html代码部分差别很大。所以这个区域不容易提取。
然后只剩下标签。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名称、网站名称等信息如何去除,并不容易。
我们先来看看,标签中的附加信息是:
观察这些标题,不难发现新闻标题、频道名称、网站名称之间有一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猴子们作为思考练习自己去实现。
2. 发布时间提取
发布时间是指这个网页在这个网站上上线的时间,一般出现在文本标题下——元数据区。从html代码来看,这块区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子前面,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
就像标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些具有不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配和提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3. 文本提取
正文(包括新闻图片)是新闻网页的主体部分,视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的html代码是由不同标签(tags)的树状结构树组成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
像新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在标签的class和id中的关键词。这些词表明标签可能是身体,也可能不是。我们用这些词来计算标签节点的权重,这是calc_node_weight()方法的函数。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,忽略它们即可。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取label的内容,然后尝试从中找到title,然后尝试从中找到id和class收录title的节点,最后比较可能是不同地方获取的title的文本,并最终获得标题。比较的原则是:
要从标签中获取标题,就需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成树状,从body节点开始遍历每个节点,查看直接收录的文本长度(不带子节点),找到最长的节点的文本。这个过程在方法中实现:get_main_block()。其中一些细节可以被小猿体验。
细节之一是 clean_node() 函数。get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去除,就会给相关新闻的新闻内容(标题、概览等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用text_content(),而是做一些格式化处理,比如在一些标签后添加换行符以匹配\n,以及在表格的单元格之间添加空格。经过这样的处理,得到的文本格式更加符合原网页的效果。
爬虫知识点
1. cchardet 模块
快速判断文本编码的模块
2. lxml.html 模块
结构化html代码模块,通过xpath解析网页的工具,高效易用,是家庭爬虫必备模块。
3. 内容提取的复杂性
这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
然而,世界上没有千篇一律的网页,也没有一劳永逸的提取算法。在大规模使用本文算法的过程中,你会遇到奇怪的网页。这时候就必须针对这些网页来完善这个算法类。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
网页新闻抓取(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终的结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等。

因此,爬虫不仅要做下载的工作,还要做数据清洗和提取的工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:

新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们抓取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取。但是,我们的爬虫抓取了数百个 网站 网页。将正则表达式写到这么多不同格式的网页上会很累,而且一旦对网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不通,还得探索一个好的算法来实现。
1. 标题提取
基本上,标题会出现在html标签中,但会附加频道名称、网站名称等信息;
标题也会出现在网页的“标题区”中。
那么这两个地方哪里比较容易提取title呢?
网页的“标题区”没有明显的标记,不同网站的“标题区”的html代码部分差别很大。所以这个区域不容易提取。
然后只剩下标签。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名称、网站名称等信息如何去除,并不容易。
我们先来看看,标签中的附加信息是:
观察这些标题,不难发现新闻标题、频道名称、网站名称之间有一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猴子们作为思考练习自己去实现。
2. 发布时间提取
发布时间是指这个网页在这个网站上上线的时间,一般出现在文本标题下——元数据区。从html代码来看,这块区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子前面,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
就像标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些具有不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配和提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3. 文本提取
正文(包括新闻图片)是新闻网页的主体部分,视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的html代码是由不同标签(tags)的树状结构树组成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
像新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在标签的class和id中的关键词。这些词表明标签可能是身体,也可能不是。我们用这些词来计算标签节点的权重,这是calc_node_weight()方法的函数。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,忽略它们即可。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取label的内容,然后尝试从中找到title,然后尝试从中找到id和class收录title的节点,最后比较可能是不同地方获取的title的文本,并最终获得标题。比较的原则是:
要从标签中获取标题,就需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成树状,从body节点开始遍历每个节点,查看直接收录的文本长度(不带子节点),找到最长的节点的文本。这个过程在方法中实现:get_main_block()。其中一些细节可以被小猿体验。
细节之一是 clean_node() 函数。get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去除,就会给相关新闻的新闻内容(标题、概览等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用text_content(),而是做一些格式化处理,比如在一些标签后添加换行符以匹配\n,以及在表格的单元格之间添加空格。经过这样的处理,得到的文本格式更加符合原网页的效果。
爬虫知识点
1. cchardet 模块
快速判断文本编码的模块
2. lxml.html 模块
结构化html代码模块,通过xpath解析网页的工具,高效易用,是家庭爬虫必备模块。
3. 内容提取的复杂性
这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
然而,世界上没有千篇一律的网页,也没有一劳永逸的提取算法。在大规模使用本文算法的过程中,你会遇到奇怪的网页。这时候就必须针对这些网页来完善这个算法类。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
网页新闻抓取(基于互联网的人物实体关系提取研究的主要素材——,本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-25 17:00
[摘要] 互联网经过多年的快速发展,积累了大量的信息资源。其中收录的人物之间的关系是一种重要的信息,用于情报分析、网络舆情监测、社交网络分析等领域。有非常重要的应用。研究人员已经意识到这一点,并展开了相关研究。新闻网页因其术语规范、报道及时、信息可信度高而受到研究人员的青睐。新闻网页已成为基于互联网的人与实体关系提取研究的主要材料。基于以上认识,本文结合新闻网页中实体关系抽取主体的实际需求,进行了多项研究。这些研究包括: 1、 在分析一般网页采集器的特点和不足的基础上,结合具体的应用背景和实际需求,为了准确、高效地下载新闻网页,本文根据新闻网页网址的特点构造新闻网页网址模式,设计并实现了新闻主题网页采集器,很好的完成了网页采集的任务。2、 仔细分析了当前网页过滤算法效率低下的原因。在总结新闻网页特点的基础上,提出了一种基于文本块字符数的新闻网页过滤算法,并通过实验验证了该算法的有效性。性别。3、 针对支持向量机(SVM)在多类划分中的不足,引入kNN算法来消除拒绝向量。由于kNN算法的时空开销较大,当向量数量较多时,其分类性能很差,会严重影响最终的字符关系提取。因此本文提出了一种改进的kNN算法,大大提高了其性能。4、 最后,本文设计并实现了新闻网页中人物关系抽取的原型系统。该系统集成了主题网页采集、中文分词、词性标注、字符信息提取、关系提取、关系存储等功能。它是新闻网页中字符关系抽取的整体实现,也是测试本文所研究方法的最佳方式。道路。 查看全部
网页新闻抓取(基于互联网的人物实体关系提取研究的主要素材——,本文)
[摘要] 互联网经过多年的快速发展,积累了大量的信息资源。其中收录的人物之间的关系是一种重要的信息,用于情报分析、网络舆情监测、社交网络分析等领域。有非常重要的应用。研究人员已经意识到这一点,并展开了相关研究。新闻网页因其术语规范、报道及时、信息可信度高而受到研究人员的青睐。新闻网页已成为基于互联网的人与实体关系提取研究的主要材料。基于以上认识,本文结合新闻网页中实体关系抽取主体的实际需求,进行了多项研究。这些研究包括: 1、 在分析一般网页采集器的特点和不足的基础上,结合具体的应用背景和实际需求,为了准确、高效地下载新闻网页,本文根据新闻网页网址的特点构造新闻网页网址模式,设计并实现了新闻主题网页采集器,很好的完成了网页采集的任务。2、 仔细分析了当前网页过滤算法效率低下的原因。在总结新闻网页特点的基础上,提出了一种基于文本块字符数的新闻网页过滤算法,并通过实验验证了该算法的有效性。性别。3、 针对支持向量机(SVM)在多类划分中的不足,引入kNN算法来消除拒绝向量。由于kNN算法的时空开销较大,当向量数量较多时,其分类性能很差,会严重影响最终的字符关系提取。因此本文提出了一种改进的kNN算法,大大提高了其性能。4、 最后,本文设计并实现了新闻网页中人物关系抽取的原型系统。该系统集成了主题网页采集、中文分词、词性标注、字符信息提取、关系提取、关系存储等功能。它是新闻网页中字符关系抽取的整体实现,也是测试本文所研究方法的最佳方式。道路。
网页新闻抓取(百度爬虫工作原理抓取系统的核心问题及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-24 21:16
1、百度爬虫的工作原理
爬虫系统是站长服务器和百度搜索之间的桥梁。我们通常称爬行系统为爬行环。
示例:以首页为例,“爬虫”与“网站服务器”交互抓取首页,了解页面,包括类型和值的计算,提取页面上的所有超链接。提取的链接称为“反向链接”,是下一轮捕获的链接的集合。下一轮爬取会从上一轮的后链中选择需要爬取的数据进行爬取,继续与网站交互获取页面提取链接,逐层重复循环形成一个爬行循环。
2、 抓取友好优化
网址规范
url 不应该尽可能复杂。新网站刚开始爬,蜘蛛不知道网址的内容是什么,网址的长度是多少?它是标准的吗?是否被选中(指抓取)非常关键。URL核心有两点:主流和简单。不要使用中文/中文编码。虽然百度可以识别,但蜘蛛支持256个字符。建议小于
参数有问题,参数无效?
不要使用无效参数“?” 并且尽可能多地为 URL 使用“&”,以允许资源抓取多个相同的内容而不会被蜘蛛抓取。不同的网址导致重复抓取,浪费网站的权限。希望站长尽量不要应用参数,或者简化参数,只保留必要的参数,不要使用-#等连接符
合理的链接发现
蜘蛛想要尽可能抓取完整的网站资源,需要首页和各个资源(页面)之间有良好的超链接关系,这样蜘蛛也会省力。从首页到内容的路径是从首页到栏目再到内容的循环往复。我称这种链接关系为发现链接。
例如:仅搜索主页的提要流和页面。对于此类网站,建议添加索引页,让蜘蛛找到更有价值的内容。索引页应按时间和历史顺序排列,新资源应实时发布在索引页上。就是尽量暴露给蜘蛛,不要做大量的泛洪索引页。后链的URL应该直接暴露在页面源码中,不应该引入动作触发器。最好使用百度资源平台的资源提交工具。
Q:提交更多资源更好吗?
A:收录 效果的核心永远是内容质量。如果提交大量低质量、泛滥的资源,会被算法识别为低质量,带来惩罚性压制。
Q:为什么我提交了普通的收录却没有被抓到?
A:资源提交只能加速资源发现,不能保证短期捕获;同时,该技术极大地不断优化筛选算法,以便更快地捕获优质资源。普通收录和sitemap的作用不是提交后立即抓取。什么时候去抢,要看对策略的计算和选择。
注:这么多新站点/低质量站点刚刚提交,看不到蜘蛛爬行。
访问友好性
爬虫和网站必须交互,服务器必须稳定。
访问速度优化
两个建议,第一点加载时间,建议控制在两秒内加载,会有一定的优惠。第二点是避免不必要的跳转,多级跳转也会影响加载速度。
服务器负载稳定:
尤其是短时间内提交了大量优质资源后,要注意服务器的稳定性,对于真正优质、海量的内容,蜘蛛爬行的频率会非常高。
爬取频率和网站收录有关系吗?
爬取频率其实和网站收录的效果没有必然关系。
爬取的目的主要分为两种:第一种是爬取网站上没有被爬取过的页面。第二种爬虫已经爬过了,看看这个页面有没有更新。
注意:第二个爬取目的被很多站长忽略了。对于收录已经爬取过的页面,一次爬取,应该不是为了发现新页面(猜测),而是看页面是否“更新”了。.
提问时间
新站会不会有固定的爬行次数?
任何网站 都没有特定的固定爬行次数。我自己建了一个新网站。事实上,百度采用抓取问题由来已久。基于这个问题,我们也做了一些相应的优化。对于我们能识别的新站点,对比一下已经抓到的站点,我会做一些对应流量的斜率的支持。先给你一些流量,让站长在百度的系统中转入,然后根据你的价值判断,给你流量高低,以及是否需要继续改进。
注:本公开课时间为 5 月 21 日。今年确实有很多新网站已经备案。在线爬取的频率很高,大概会有1-2个月的支持。很多人利用百度的支持期疯狂填充低质量的内容。这是一个错误的操作。
如何让百度知道你是新网站? 查看全部
网页新闻抓取(百度爬虫工作原理抓取系统的核心问题及解决办法!)
1、百度爬虫的工作原理
爬虫系统是站长服务器和百度搜索之间的桥梁。我们通常称爬行系统为爬行环。
示例:以首页为例,“爬虫”与“网站服务器”交互抓取首页,了解页面,包括类型和值的计算,提取页面上的所有超链接。提取的链接称为“反向链接”,是下一轮捕获的链接的集合。下一轮爬取会从上一轮的后链中选择需要爬取的数据进行爬取,继续与网站交互获取页面提取链接,逐层重复循环形成一个爬行循环。
2、 抓取友好优化
网址规范
url 不应该尽可能复杂。新网站刚开始爬,蜘蛛不知道网址的内容是什么,网址的长度是多少?它是标准的吗?是否被选中(指抓取)非常关键。URL核心有两点:主流和简单。不要使用中文/中文编码。虽然百度可以识别,但蜘蛛支持256个字符。建议小于
参数有问题,参数无效?
不要使用无效参数“?” 并且尽可能多地为 URL 使用“&”,以允许资源抓取多个相同的内容而不会被蜘蛛抓取。不同的网址导致重复抓取,浪费网站的权限。希望站长尽量不要应用参数,或者简化参数,只保留必要的参数,不要使用-#等连接符
合理的链接发现
蜘蛛想要尽可能抓取完整的网站资源,需要首页和各个资源(页面)之间有良好的超链接关系,这样蜘蛛也会省力。从首页到内容的路径是从首页到栏目再到内容的循环往复。我称这种链接关系为发现链接。
例如:仅搜索主页的提要流和页面。对于此类网站,建议添加索引页,让蜘蛛找到更有价值的内容。索引页应按时间和历史顺序排列,新资源应实时发布在索引页上。就是尽量暴露给蜘蛛,不要做大量的泛洪索引页。后链的URL应该直接暴露在页面源码中,不应该引入动作触发器。最好使用百度资源平台的资源提交工具。
Q:提交更多资源更好吗?
A:收录 效果的核心永远是内容质量。如果提交大量低质量、泛滥的资源,会被算法识别为低质量,带来惩罚性压制。
Q:为什么我提交了普通的收录却没有被抓到?
A:资源提交只能加速资源发现,不能保证短期捕获;同时,该技术极大地不断优化筛选算法,以便更快地捕获优质资源。普通收录和sitemap的作用不是提交后立即抓取。什么时候去抢,要看对策略的计算和选择。
注:这么多新站点/低质量站点刚刚提交,看不到蜘蛛爬行。
访问友好性
爬虫和网站必须交互,服务器必须稳定。
访问速度优化
两个建议,第一点加载时间,建议控制在两秒内加载,会有一定的优惠。第二点是避免不必要的跳转,多级跳转也会影响加载速度。
服务器负载稳定:
尤其是短时间内提交了大量优质资源后,要注意服务器的稳定性,对于真正优质、海量的内容,蜘蛛爬行的频率会非常高。
爬取频率和网站收录有关系吗?
爬取频率其实和网站收录的效果没有必然关系。
爬取的目的主要分为两种:第一种是爬取网站上没有被爬取过的页面。第二种爬虫已经爬过了,看看这个页面有没有更新。
注意:第二个爬取目的被很多站长忽略了。对于收录已经爬取过的页面,一次爬取,应该不是为了发现新页面(猜测),而是看页面是否“更新”了。.
提问时间
新站会不会有固定的爬行次数?
任何网站 都没有特定的固定爬行次数。我自己建了一个新网站。事实上,百度采用抓取问题由来已久。基于这个问题,我们也做了一些相应的优化。对于我们能识别的新站点,对比一下已经抓到的站点,我会做一些对应流量的斜率的支持。先给你一些流量,让站长在百度的系统中转入,然后根据你的价值判断,给你流量高低,以及是否需要继续改进。
注:本公开课时间为 5 月 21 日。今年确实有很多新网站已经备案。在线爬取的频率很高,大概会有1-2个月的支持。很多人利用百度的支持期疯狂填充低质量的内容。这是一个错误的操作。
如何让百度知道你是新网站?
网页新闻抓取(接到公共管理学院官网()所有的新闻咨询.实验流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-24 21:15
)
接到以上任务安排后,我需要使用scrapy抓取学院的新闻报道。所以,新官三火了,刚学会爬数据就迫不及待上手了。
任务
从四川大学公共管理学院官网获取所有新闻查询()。
实验过程
1.确定爬取目标。
2.制定爬取规则。
3.'Write/Debug' 爬取规则。
4.获取爬取数据
1.确定爬取目标
这次我们要捕捉的目标是四川大学公共管理学院的所有新闻和信息。所以我们需要了解一下公共管理学院官网的布局。
微信截图_245.png
在这里我们发现,如果要抓取所有的新闻信息,不能在官网首页直接抓取,需要点击“更多”进入新闻主栏目。
Paste_Image.png
我们看到了具体的新闻栏目,但这显然不能满足我们的抓取需求:目前的新闻动态网页只能抓取新闻的时间、标题和网址,不能抓取新闻的内容。所以我们要进入到新闻详情页面来抓取新闻的具体内容。2. 制定爬取规则
通过第一部分的分析,我们会认为,如果要抓取一条新闻的具体信息,需要点击新闻动态页面,进入新闻详情页,才能抓取该新闻的具体内容。让我们点击一个新闻来试试看
Paste_Image.png
我们发现可以直接在新闻详情页抓取我们需要的数据:title、time、content.URL。
好了,现在我们对抓取一条新闻有了一个清晰的想法。但是如何抓取所有的新闻内容呢?
这对我们来说显然不难。
我们可以在新闻版块底部看到页面跳转按钮。然后我们可以使用“下一页”按钮来抓取所有新闻。
于是整理了一下思路,我们可以想到一个明显的爬取规则:
抓取'新闻栏目'下的所有新闻链接,进入新闻详情链接抓取所有新闻内容。
3.'编写/调试'爬取规则
为了让调试爬虫的粒度尽可能小,我将编写和调试模块结合起来。
在爬虫中,我会实现以下功能点:
1. 抓取页面新闻部分下的所有新闻链接
2. 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
3. 通过循环抓取所有新闻。
对应的知识点是:
1. 抓取一个页面下的基本数据。
2. 对爬取的数据执行第二次爬取。
3.通过循环抓取网页的所有数据。
话不多说,现在就去做吧。
3.1 抓取页面新闻部分下的所有新闻链接
Paste_Image.png
通过对新闻版块源码的分析,我们发现抓取到的数据结构为
Paste_Image.png
那么我们只需要将爬虫的selector定位到(li:newsinfo_box_cf),然后进行for循环捕获即可。
写代码
import scrapy
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
测试,通过!
Paste_Image.png
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要输入网址,在原代码抓取网址时抓取即可。只需获取相应的数据。所以,我只需要再写一个爬取方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
Paste_Image.png
这时候我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM 查看全部
网页新闻抓取(接到公共管理学院官网()所有的新闻咨询.实验流程
)
接到以上任务安排后,我需要使用scrapy抓取学院的新闻报道。所以,新官三火了,刚学会爬数据就迫不及待上手了。
任务
从四川大学公共管理学院官网获取所有新闻查询()。
实验过程
1.确定爬取目标。
2.制定爬取规则。
3.'Write/Debug' 爬取规则。
4.获取爬取数据
1.确定爬取目标
这次我们要捕捉的目标是四川大学公共管理学院的所有新闻和信息。所以我们需要了解一下公共管理学院官网的布局。

微信截图_245.png
在这里我们发现,如果要抓取所有的新闻信息,不能在官网首页直接抓取,需要点击“更多”进入新闻主栏目。
Paste_Image.png
我们看到了具体的新闻栏目,但这显然不能满足我们的抓取需求:目前的新闻动态网页只能抓取新闻的时间、标题和网址,不能抓取新闻的内容。所以我们要进入到新闻详情页面来抓取新闻的具体内容。2. 制定爬取规则
通过第一部分的分析,我们会认为,如果要抓取一条新闻的具体信息,需要点击新闻动态页面,进入新闻详情页,才能抓取该新闻的具体内容。让我们点击一个新闻来试试看
Paste_Image.png
我们发现可以直接在新闻详情页抓取我们需要的数据:title、time、content.URL。
好了,现在我们对抓取一条新闻有了一个清晰的想法。但是如何抓取所有的新闻内容呢?
这对我们来说显然不难。
我们可以在新闻版块底部看到页面跳转按钮。然后我们可以使用“下一页”按钮来抓取所有新闻。
于是整理了一下思路,我们可以想到一个明显的爬取规则:
抓取'新闻栏目'下的所有新闻链接,进入新闻详情链接抓取所有新闻内容。
3.'编写/调试'爬取规则
为了让调试爬虫的粒度尽可能小,我将编写和调试模块结合起来。
在爬虫中,我会实现以下功能点:
1. 抓取页面新闻部分下的所有新闻链接
2. 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
3. 通过循环抓取所有新闻。
对应的知识点是:
1. 抓取一个页面下的基本数据。
2. 对爬取的数据执行第二次爬取。
3.通过循环抓取网页的所有数据。
话不多说,现在就去做吧。
3.1 抓取页面新闻部分下的所有新闻链接
Paste_Image.png
通过对新闻版块源码的分析,我们发现抓取到的数据结构为
Paste_Image.png
那么我们只需要将爬虫的selector定位到(li:newsinfo_box_cf),然后进行for循环捕获即可。
写代码
import scrapy
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
测试,通过!
Paste_Image.png
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要输入网址,在原代码抓取网址时抓取即可。只需获取相应的数据。所以,我只需要再写一个爬取方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
Paste_Image.png
这时候我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM
网页新闻抓取( 一下搜索引擎收录新闻源的四个要点要点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-24 06:22
一下搜索引擎收录新闻源的四个要点要点)
在日常生活中,大多数用户都可以在搜索引擎上搜索和查看一些较新的实时关键点和时事通讯。一般来说,百度收录是大型门户网站网站的新闻来源,或者是百度自己的产品,比如百家号。但也有一些公司网站也想优化自己公司的新闻来源网站,以吸引更多的用户,从而获得更多的流量。同时,网站要想获得更好的排名也需要更好地针对新闻源进行优化,以推动新闻源获得收录。接下来带大家了解一下搜索引擎收录新闻源的四大要点。
一、内容质量要求
新闻源的内容质量无疑将成为搜索引擎判断收录的关键。新闻源的内容更真实有价值,原创的信息将更有利于搜索引擎蜘蛛的抓取和抓取。爬取和提升用户体验会给网站带来更多的流量和利润转化,促进网页收录。
二、新闻属性
审稿人每天都会收到大量的加入申请,很多内容在质量上都是非常优质的,但就是满足不了新闻来源对新闻属性的要求。这也是不可能的。
三、网站类型
众所周知,百度新闻源迅速收录网站在频道和目录层面。但是,每种类型的网站都有优先的 收录 频道或目录,并且视情况而定,没有 收录 或 收录 频道或目录。所以优化器一定要做好网站的某个目录或频道的新闻源更新,为网站的收录量而努力。
综上所述,以下是网站新闻来源收录为大家总结的一些搜索引擎关心的关键点。通过以上内容,相信大家也会对此有更多的了解,希望以上内容能给大家带来更多的帮助。 查看全部
网页新闻抓取(
一下搜索引擎收录新闻源的四个要点要点)

在日常生活中,大多数用户都可以在搜索引擎上搜索和查看一些较新的实时关键点和时事通讯。一般来说,百度收录是大型门户网站网站的新闻来源,或者是百度自己的产品,比如百家号。但也有一些公司网站也想优化自己公司的新闻来源网站,以吸引更多的用户,从而获得更多的流量。同时,网站要想获得更好的排名也需要更好地针对新闻源进行优化,以推动新闻源获得收录。接下来带大家了解一下搜索引擎收录新闻源的四大要点。
一、内容质量要求
新闻源的内容质量无疑将成为搜索引擎判断收录的关键。新闻源的内容更真实有价值,原创的信息将更有利于搜索引擎蜘蛛的抓取和抓取。爬取和提升用户体验会给网站带来更多的流量和利润转化,促进网页收录。
二、新闻属性
审稿人每天都会收到大量的加入申请,很多内容在质量上都是非常优质的,但就是满足不了新闻来源对新闻属性的要求。这也是不可能的。
三、网站类型
众所周知,百度新闻源迅速收录网站在频道和目录层面。但是,每种类型的网站都有优先的 收录 频道或目录,并且视情况而定,没有 收录 或 收录 频道或目录。所以优化器一定要做好网站的某个目录或频道的新闻源更新,为网站的收录量而努力。
综上所述,以下是网站新闻来源收录为大家总结的一些搜索引擎关心的关键点。通过以上内容,相信大家也会对此有更多的了解,希望以上内容能给大家带来更多的帮助。
网页新闻抓取(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-24 06:19
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站的类型很多,传输规律也不同。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这些问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,您可以使用蚂蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需行业信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
查看全部
网页新闻抓取(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站的类型很多,传输规律也不同。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统

接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这些问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。

如何监控行业网站信息信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,您可以使用蚂蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需行业信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
网页新闻抓取( URL,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-24 01:12
URL,)
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要在原代码抓取网址时输入网址即可。 URL并抓取相应的数据。所以,我只需要另外写一个grab方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
此时,我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM 查看全部
网页新闻抓取(
URL,)

3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要在原代码抓取网址时输入网址即可。 URL并抓取相应的数据。所以,我只需要另外写一个grab方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!

此时,我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM
网页新闻抓取(我用python及其网址的一个简单爬虫及其)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-24 01:11
最近也学习了一些爬虫的知识。以我个人的理解,当我们使用浏览器查看网页时,通常是通过浏览器向服务器发送请求,服务器响应并返回一些代码数据,然后由浏览器解析并呈现。爬虫通过程序向服务器发送请求,对服务器返回的信息进行一些处理后,就可以得到我们想要的数据。
下面是我前段时间用python写的一个简单的爬虫爬取TX新闻头条和网址:
首先需要使用python(一个方便全面的http请求库)和BeautifulSoup(html解析库)中的requests。
通过pip安装这两个库,命令为:pip install requests和pip install bs4(如下图)
先放完整代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
先介绍一下上面两个库
import requests
from bs4 import BeautifulSoup
然后获取请求腾讯新闻的网址。返回的字符串本质上就是我们手动打开这个网站然后查看网页源码的html代码。
wbdata = requests.get(url).text
我们只需要某些标签的内容:
可以看出,每个新闻链接和标题都在
在标签的标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候就需要用到BeautifulSoap库了。
soup = BeautifulSoup(wbdata,'lxml')
这行的意思是解析得到的信息,也可以用html.parser库替换lxml库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚解析出来的soup对象来选择我们需要的标签,返回值是一个列表。我们需要的所有标签内容都存储在列表中。您还可以使用 BeautifulSoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存入数据字典
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
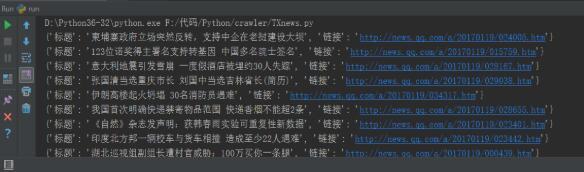
数据存储所有新闻标题和链接,下图为部分结果
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,还有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说爬虫是个深坑。
python中爬虫可以通过各种库或者框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫相关库。例如,PHP 可以使用 curl 库。爬虫的原理是一样的,只是不同语言、不同库实现的方法不同。
以上通过请求实现腾讯新闻爬虫的Python方法就是我和大家分享的全部内容。希望能给大家一个参考,也希望大家支持Scripthome。 查看全部
网页新闻抓取(我用python及其网址的一个简单爬虫及其)
最近也学习了一些爬虫的知识。以我个人的理解,当我们使用浏览器查看网页时,通常是通过浏览器向服务器发送请求,服务器响应并返回一些代码数据,然后由浏览器解析并呈现。爬虫通过程序向服务器发送请求,对服务器返回的信息进行一些处理后,就可以得到我们想要的数据。
下面是我前段时间用python写的一个简单的爬虫爬取TX新闻头条和网址:
首先需要使用python(一个方便全面的http请求库)和BeautifulSoup(html解析库)中的requests。
通过pip安装这两个库,命令为:pip install requests和pip install bs4(如下图)

先放完整代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
先介绍一下上面两个库
import requests
from bs4 import BeautifulSoup
然后获取请求腾讯新闻的网址。返回的字符串本质上就是我们手动打开这个网站然后查看网页源码的html代码。
wbdata = requests.get(url).text
我们只需要某些标签的内容:
可以看出,每个新闻链接和标题都在
在标签的标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候就需要用到BeautifulSoap库了。
soup = BeautifulSoup(wbdata,'lxml')
这行的意思是解析得到的信息,也可以用html.parser库替换lxml库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚解析出来的soup对象来选择我们需要的标签,返回值是一个列表。我们需要的所有标签内容都存储在列表中。您还可以使用 BeautifulSoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存入数据字典
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
数据存储所有新闻标题和链接,下图为部分结果
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,还有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说爬虫是个深坑。
python中爬虫可以通过各种库或者框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫相关库。例如,PHP 可以使用 curl 库。爬虫的原理是一样的,只是不同语言、不同库实现的方法不同。
以上通过请求实现腾讯新闻爬虫的Python方法就是我和大家分享的全部内容。希望能给大家一个参考,也希望大家支持Scripthome。
网页新闻抓取(网页抓取功能的各个功能介绍及注意事项介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-23 06:20
网页抓取功能主要包括索引量、Robots、链接提交、死链接提交、抓取频率、抓取诊断、抓取异常等,通过索引量可以看到一定时期内被索引站点的数量和变化趋势时间,可以及时掌握网站的实际情况,可以指定规则来检测某个频道或话题是否为收录和Index情况。下面介绍网络爬虫的功能:
网页抓取-链接提交
链接提交包括四种提交方式:主动推送、自动推送、站点地图、手动提交。其中,主动推送是保证当天新链接收录到来的最快方式。自动推送是最方便的方式。JS代码部署到每个页面,页面浏览时自动推送到百度。一般与主动推送结合使用。站点地图提交比主动推送慢,需要定期更新。手动提交比较机械,但是可以一次性提交链接到百度。
网页抓取死链接提交
死链提交主要是处理网站上已经存在的死链。当网站死链数据积累过多并显示在搜索结果页面时,对网站本身的访问体验和用户转化都产生了负面影响。此外,百度对死链接的检查过程也会给网站带来额外的负担,影响网站其他正常页面的抓取和索引。死链接提交方式包括文档提交和规则提交。文件提交是将创建的死链接文件上传到网站的根目录,然后提交死链接文件地址。规则提交是指将相同链接前缀下的死链接写成链接规则,所有匹配的链接都是死链接,然后提交这个死链接规则。目前支持两种类型的死链接规则:目录规则、以“/”结尾的前缀;CGI 规则,前缀以“?”结尾。
网络爬虫-机器人
Robots函数用于检测和更新网站的robots.txt文件。如果网站长时间没有被搜索引擎抓取,可能是robots.txt文件有问题,需要检测更新。需要注意的是robots.txt文件不超过48k,目录不超过250个字符。
网页抓取-抓取频率
爬取频率功能可以监控蜘蛛爬取网站的频率以及每次爬取所花费的时间。
网络爬行-爬行诊断
爬行诊断功能可以监控蜘蛛爬行网站是否正常,是否可以正常爬取网站的内容。每个站点每周最多可以抓取整个段落 200 次。通过抓取整个段落,可以监控网站的内容是否符合预期,是否被黑链,文字是否隐藏,连接是否正常等。
网页抓取-抓取异常
爬行异常监控既可以监控网站异常,也可以监控链接异常。网站异常会导致DNS异常、连接爬取超时、链接错误;链接异常会导致访问被拒绝(40 3), page not found (404), server error (SXX), other errors (4XX))。
网络爬虫功能的分析和介绍到此结束。以上仅为鼎轩科技的评论,仅供参考。 查看全部
网页新闻抓取(网页抓取功能的各个功能介绍及注意事项介绍-乐题库)
网页抓取功能主要包括索引量、Robots、链接提交、死链接提交、抓取频率、抓取诊断、抓取异常等,通过索引量可以看到一定时期内被索引站点的数量和变化趋势时间,可以及时掌握网站的实际情况,可以指定规则来检测某个频道或话题是否为收录和Index情况。下面介绍网络爬虫的功能:

网页抓取-链接提交
链接提交包括四种提交方式:主动推送、自动推送、站点地图、手动提交。其中,主动推送是保证当天新链接收录到来的最快方式。自动推送是最方便的方式。JS代码部署到每个页面,页面浏览时自动推送到百度。一般与主动推送结合使用。站点地图提交比主动推送慢,需要定期更新。手动提交比较机械,但是可以一次性提交链接到百度。
网页抓取死链接提交
死链提交主要是处理网站上已经存在的死链。当网站死链数据积累过多并显示在搜索结果页面时,对网站本身的访问体验和用户转化都产生了负面影响。此外,百度对死链接的检查过程也会给网站带来额外的负担,影响网站其他正常页面的抓取和索引。死链接提交方式包括文档提交和规则提交。文件提交是将创建的死链接文件上传到网站的根目录,然后提交死链接文件地址。规则提交是指将相同链接前缀下的死链接写成链接规则,所有匹配的链接都是死链接,然后提交这个死链接规则。目前支持两种类型的死链接规则:目录规则、以“/”结尾的前缀;CGI 规则,前缀以“?”结尾。
网络爬虫-机器人
Robots函数用于检测和更新网站的robots.txt文件。如果网站长时间没有被搜索引擎抓取,可能是robots.txt文件有问题,需要检测更新。需要注意的是robots.txt文件不超过48k,目录不超过250个字符。
网页抓取-抓取频率
爬取频率功能可以监控蜘蛛爬取网站的频率以及每次爬取所花费的时间。
网络爬行-爬行诊断
爬行诊断功能可以监控蜘蛛爬行网站是否正常,是否可以正常爬取网站的内容。每个站点每周最多可以抓取整个段落 200 次。通过抓取整个段落,可以监控网站的内容是否符合预期,是否被黑链,文字是否隐藏,连接是否正常等。
网页抓取-抓取异常
爬行异常监控既可以监控网站异常,也可以监控链接异常。网站异常会导致DNS异常、连接爬取超时、链接错误;链接异常会导致访问被拒绝(40 3), page not found (404), server error (SXX), other errors (4XX))。
网络爬虫功能的分析和介绍到此结束。以上仅为鼎轩科技的评论,仅供参考。
网页新闻抓取( 公众号的第一篇文章,就先来介绍介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-22 23:01
公众号的第一篇文章,就先来介绍介绍(组图))
为公众号文章的第一篇文章介绍我做过的最简单的新闻爬虫,最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载,今天用python实现。这个爬虫我在双星的舞台上,在新生的导航课上(两次),在课堂上都跟别人说过很多次了。其实现在回过头来看这个爬虫真的是低级简单,不过好歹也是学了很久,今天就用python来系统的实现一下。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官方网站。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
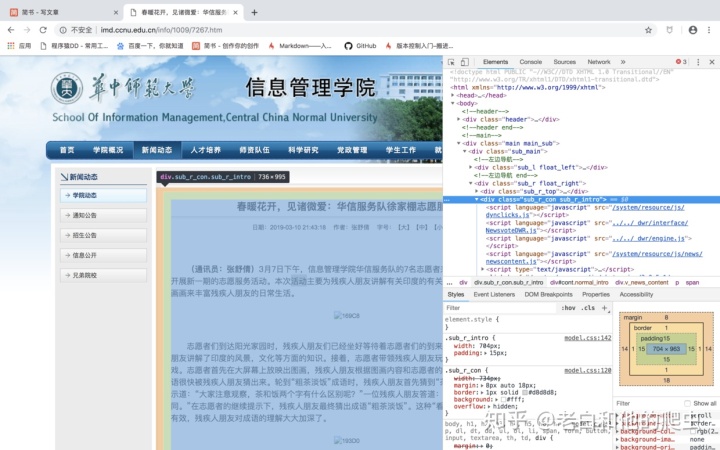
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要什么信息(其实这一步必须在你写爬虫之前就确定了)。这里需要的是新闻标题、日期、作者和正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,将解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面专门学习BeautifulSoup的部分会学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签并赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再多一句,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
我相信,如果你之前已经做到了一切,那么你会非常熟练地完成这一步。首先找到文本所在的div为category class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。当我们浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码发现翻页标签链接收录xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你之前能做到这一步,你就已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再梳理一遍这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获得网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们必须设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护计算机。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。这个文章一开始我就说我觉得这个爬虫很low很简单,但是在实际操作中我还是发现我花了两天时间,当然不是全部两天。我在实习期间编写了该程序。似乎一切都不容易。让我们一步一步来。 查看全部
网页新闻抓取(
公众号的第一篇文章,就先来介绍介绍(组图))

为公众号文章的第一篇文章介绍我做过的最简单的新闻爬虫,最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载,今天用python实现。这个爬虫我在双星的舞台上,在新生的导航课上(两次),在课堂上都跟别人说过很多次了。其实现在回过头来看这个爬虫真的是低级简单,不过好歹也是学了很久,今天就用python来系统的实现一下。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官方网站。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要什么信息(其实这一步必须在你写爬虫之前就确定了)。这里需要的是新闻标题、日期、作者和正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里

标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,将解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面专门学习BeautifulSoup的部分会学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签并赋值给title
但是当我们输出这段代码时,问题就来了

结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再多一句,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
我相信,如果你之前已经做到了一切,那么你会非常熟练地完成这一步。首先找到文本所在的div为category class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。当我们浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码发现翻页标签链接收录xydt/

网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你之前能做到这一步,你就已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再梳理一遍这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获得网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们必须设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护计算机。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。这个文章一开始我就说我觉得这个爬虫很low很简单,但是在实际操作中我还是发现我花了两天时间,当然不是全部两天。我在实习期间编写了该程序。似乎一切都不容易。让我们一步一步来。
网页新闻抓取(各个_encoding(_status)O_O完整代码分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-22 11:08
)
我有点白。我只是简单地记录了学校的作业项目。代码很简单,主要是对各个库的理解。希望对其他初学者有所启发。O(∩_∩)O
Python定期抓取网络新闻并存入数据库并发送邮件
一、项目需求
1、该程序可以抓取北京工业大学主页的新闻内容:
2、程序可以将爬取到的数据写入本地MySQL数据库。
3、程序可以将抓取到的数据发送到邮箱。
4、程序可以定时执行。
二、项目分析
1、 爬虫部分使用requests库抓取html文本,然后使用bs4中的BeaultifulSoup库解析html文本,提取需要的内容。
2、使用pymysql库连接MySQL数据库,实现建表和内容插入操作。
3、使用smtplib库建立邮箱连接,然后使用email库将文本信息处理成邮件发送。
4、使用调度库定时执行程序。
三、代码分析1、导入需要的库:
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
2、获取html文件:
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
必须添加请求头,否则在发出get请求时会返回错误页面。raise_for_status() 可以根据状态码判断连接对象的状态,如果成功则继续执行,如果连接失败则抛出异常,所以使用try-except捕捉。apparent_encoding() 方法可以分析判断可能的编码方式。
3、分析html提取数据:
首先观察网页源代码,确定news标签的位置:
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
4、保存到数据库
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
5、发送邮件
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
6、主要功能
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
toMysql(news)
print(news)
sendMail(news)
main() #测试需要,之后会删除
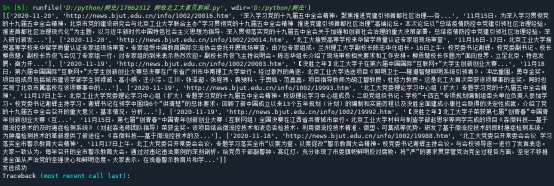
结果如下:
可以看出程序运行正常。7、定时执行
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
使用无限循环来确保计划始终运行。设置为每周一早上8:00执行程序。
为了方便查看效果,先将运行时间改为每5s运行一次:
schedule.every(5).seconds.do(main)
您可以每 5 秒收到一封电子邮件,表明满足了时间要求。至此,程序结束。
四、完整代码
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
print(news)
sendMail(news)
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1) 查看全部
网页新闻抓取(各个_encoding(_status)O_O完整代码分析
)
我有点白。我只是简单地记录了学校的作业项目。代码很简单,主要是对各个库的理解。希望对其他初学者有所启发。O(∩_∩)O
Python定期抓取网络新闻并存入数据库并发送邮件
一、项目需求
1、该程序可以抓取北京工业大学主页的新闻内容:

2、程序可以将爬取到的数据写入本地MySQL数据库。
3、程序可以将抓取到的数据发送到邮箱。
4、程序可以定时执行。
二、项目分析
1、 爬虫部分使用requests库抓取html文本,然后使用bs4中的BeaultifulSoup库解析html文本,提取需要的内容。
2、使用pymysql库连接MySQL数据库,实现建表和内容插入操作。
3、使用smtplib库建立邮箱连接,然后使用email库将文本信息处理成邮件发送。
4、使用调度库定时执行程序。
三、代码分析1、导入需要的库:
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
2、获取html文件:
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
必须添加请求头,否则在发出get请求时会返回错误页面。raise_for_status() 可以根据状态码判断连接对象的状态,如果成功则继续执行,如果连接失败则抛出异常,所以使用try-except捕捉。apparent_encoding() 方法可以分析判断可能的编码方式。
3、分析html提取数据:
首先观察网页源代码,确定news标签的位置:

# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
4、保存到数据库
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
5、发送邮件
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()

6、主要功能
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
toMysql(news)
print(news)
sendMail(news)
main() #测试需要,之后会删除
结果如下:

可以看出程序运行正常。7、定时执行
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
使用无限循环来确保计划始终运行。设置为每周一早上8:00执行程序。
为了方便查看效果,先将运行时间改为每5s运行一次:
schedule.every(5).seconds.do(main)

您可以每 5 秒收到一封电子邮件,表明满足了时间要求。至此,程序结束。
四、完整代码
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
print(news)
sendMail(news)
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
网页新闻抓取(谷歌浏览器级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-22 05:13
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下滚动,发现右侧:“... special/00804KVA/cm_guonei_03.js? . ……》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
requestsjsonBeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。 查看全部
网页新闻抓取(谷歌浏览器级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下滚动,发现右侧:“... special/00804KVA/cm_guonei_03.js? . ……》这样的地址,点击Response,发现就是我们要找的api接口。

可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
requestsjsonBeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:

对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。

既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:

格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
网页新闻抓取(2..parse异步爬虫实现的流程(2.1新闻源列表))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-21 15:14
urllib.parse:解析url网站的模块;
logging:记录爬虫日志;
leveldb:谷歌的Key-Value数据库,用于记录URL的状态;
farmhash:对url进行hash计算,作为url的唯一标识;
sanicdb:封装aiomysql,使数据库mysql操作更方便;
2.异步爬虫实现过程2.1新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些 URL 指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if self._workers > self.workers_max:
print('got workers_max, sleep 3 sec to next worker')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。 查看全部
网页新闻抓取(2..parse异步爬虫实现的流程(2.1新闻源列表))
urllib.parse:解析url网站的模块;
logging:记录爬虫日志;
leveldb:谷歌的Key-Value数据库,用于记录URL的状态;
farmhash:对url进行hash计算,作为url的唯一标识;
sanicdb:封装aiomysql,使数据库mysql操作更方便;
2.异步爬虫实现过程2.1新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些 URL 指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if self._workers > self.workers_max:
print('got workers_max, sleep 3 sec to next worker')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-10-21 15:12
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网上获取新闻(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转换为视图视图,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的一个WEB应用程序中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户interface),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前的适配器来显示新闻。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml");// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
XML资源文件转换为视图的三种方式,底层实现是一样的,这里是如下方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView时,可以通过重用convertView来减少视图的创建次数,此外还可以通过定义一个类来将视图中的控件声明为成员,例如上面的ViewHolder类。
最后是最后的渲染:
查看全部
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3.
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网上获取新闻(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转换为视图视图,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的一个WEB应用程序中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:

)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户interface),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前的适配器来显示新闻。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml";);// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
XML资源文件转换为视图的三种方式,底层实现是一样的,这里是如下方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView时,可以通过重用convertView来减少视图的创建次数,此外还可以通过定义一个类来将视图中的控件声明为成员,例如上面的ViewHolder类。
最后是最后的渲染:

网页新闻抓取( 我们想要的图片信息利用正则表达式取到链接进一步抓取到图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-21 00:02
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来我们就要开始抓图了,打开图集的详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20 查看全部
网页新闻抓取(
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)

并且数据收录了我们需要的信息

接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来我们就要开始抓图了,打开图集的详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息

使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,

和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的

完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20
网页新闻抓取(网站排名好不好怎样优化才容易被蜘蛛抓取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-20 06:17
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录,虽然收录不能直接决定网站的排名,但网站的基础是内容。没有内容更难排名。好的内容可以被用户和搜索引擎所满足。可以给网站加分,从而提升排名,扩大网站曝光页面。而如果你想让你的网站页面更多的成为收录,你必须先让网页被百度蜘蛛抓取,那么如何优化网站容易被蜘蛛抓取?小编将为您详细介绍。
1、 不使用Flash结构
因为搜索引擎蜘蛛抓取这样的页面并不容易,在这种情况下,你的网站首页会给搜索引擎蜘蛛留下非常不好的印象。
2、扁平网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
3、URL 动态参数
在网站中,尽可能少的URL动态页面。该页面的结算难度远高于静态页面。静态页面更容易被搜索引擎和用户的记忆抓取。
4、网站更新频率
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬取,不仅让你的更新文章被更快的捕获,而且不会导致蜘蛛频繁运行徒然。
5、网站页面跳转
现在网站的页面跳转一般是:301/302这样的跳转会引起很多蜘蛛的反感。也不利于搜索引擎蜘蛛的抓取。建议您尽量不要使用。
6、文章原创 性别
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的宠儿,自然会对你的网站产生好感,频频过来爬取。
7、建筑网站地图
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接 网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难捕捉到。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
8、检查robots文件
很多网站有意无意屏蔽了百度或网站直接在robots文件中的部分页面,却是在找蜘蛛不爬我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么来的?所以需要不时检查网站robots文件是否正常。
对于网站如何优化,让蜘蛛更容易爬行,我在这里和大家分享一下。网站要获得更多收录,需要做好搜索引擎蜘蛛的爬取优化工作,只有提高网站的整体爬取率,才能相应的收录提升@>率,让网站的内容得到更多展示和推荐,提升网站的排名。 查看全部
网页新闻抓取(网站排名好不好怎样优化才容易被蜘蛛抓取呢?(图))
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录,虽然收录不能直接决定网站的排名,但网站的基础是内容。没有内容更难排名。好的内容可以被用户和搜索引擎所满足。可以给网站加分,从而提升排名,扩大网站曝光页面。而如果你想让你的网站页面更多的成为收录,你必须先让网页被百度蜘蛛抓取,那么如何优化网站容易被蜘蛛抓取?小编将为您详细介绍。
1、 不使用Flash结构
因为搜索引擎蜘蛛抓取这样的页面并不容易,在这种情况下,你的网站首页会给搜索引擎蜘蛛留下非常不好的印象。
2、扁平网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
3、URL 动态参数
在网站中,尽可能少的URL动态页面。该页面的结算难度远高于静态页面。静态页面更容易被搜索引擎和用户的记忆抓取。
4、网站更新频率
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬取,不仅让你的更新文章被更快的捕获,而且不会导致蜘蛛频繁运行徒然。
5、网站页面跳转
现在网站的页面跳转一般是:301/302这样的跳转会引起很多蜘蛛的反感。也不利于搜索引擎蜘蛛的抓取。建议您尽量不要使用。
6、文章原创 性别
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的宠儿,自然会对你的网站产生好感,频频过来爬取。
7、建筑网站地图
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接 网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难捕捉到。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
8、检查robots文件
很多网站有意无意屏蔽了百度或网站直接在robots文件中的部分页面,却是在找蜘蛛不爬我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么来的?所以需要不时检查网站robots文件是否正常。
对于网站如何优化,让蜘蛛更容易爬行,我在这里和大家分享一下。网站要获得更多收录,需要做好搜索引擎蜘蛛的爬取优化工作,只有提高网站的整体爬取率,才能相应的收录提升@>率,让网站的内容得到更多展示和推荐,提升网站的排名。
网页新闻抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-11-01 20:09
媒体的现状,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题本来需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。另一个例子是我们的金融市场,它也可以更新并自动组织成一个动态的媒体专栏。
对于某些方面的关注程度,还可以根据网络爬虫抓取的阅读量或数据量进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
但是,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑具有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容 特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。 查看全部
网页新闻抓取(网页抓取工具优采云采集器中给出信息输出页后的应用)
媒体的现状,在一个焦点事件发生后或者在一个连续的话题中,形成一个媒体话题本来需要大量的人工操作,比如信息的采集和整理,及时更新等,但是高效的网络爬虫工具会为我们打造大数据智能媒体。
网络爬虫工具优采云采集器可以自动采集互联网焦点事件对应的舆情。例如,对于连续发生多天的事件,数据必须在每个重要节点的时间进行捕获和更新,那么您只需在优采云采集器中设置更新时间和频率。另一个例子是我们的金融市场,它也可以更新并自动组织成一个动态的媒体专栏。
对于某些方面的关注程度,还可以根据网络爬虫抓取的阅读量或数据量进行排名推荐和智能评分。我们甚至可以使用网络爬虫工具来维护智能媒体站。用户要做的就是锁定几个或多个信息输出页面,并在网络爬虫工具中给出信息优采云采集器 输出页面后,配置URL爬取和内容爬取的详细规则。获取到需要的数据后,可以对数据进行一系列的重新加权、过滤、清洗等处理,最后可以选择自动定时处理内容的精华发布到网站@指定栏目>.
未来的智能媒体必然是以大数据为引擎的媒体。核心要素是数据规模。我们要学会有效地使用数据,发挥数据的价值。国内已经有基于媒体稿件大数据的高科技媒体产品,让人们更快更准确地了解信息,帮助人们更好地发现信息的价值和本质。
有专家指出,如果没有大数据的支持,其实很多新闻是无法启动的。传统媒体很难进行智能分析、预警或决策。因此,大数据智能化是必然趋势。
但是,目前由网络大数据创造的智能媒体还不能完全取代人脑的工作,因为人脑具有自我理解知识或事件的倾向,人工智能还需要继续探索语言和文本分析,以及大量枯燥的内容 特定信息的整合和提取有朝一日可能会取代人脑来实现更复杂的原创。届时,智能媒体将更加个性化、定制化、高效化。
网页新闻抓取(如何抓取网易新闻的网站数据(涉及Ajax技术)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-01 09:01
如何抓取网易新闻的网站数据(涉及Ajax技术) 互联网数据爆炸式增长,有效获取和分析这些数据并使其产生价值是我们的工作。那么,首先要思考的问题是:如何抓取网站数据?今天分享的是一个完整的使用web数据采集器-优采云、采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站栏目后,下拉页面,会发现页面有新数据加载。分析表明,这个网站涉及Ajax技术,需要在优采云中设置一些高级选项。这一点需要特别注意。具体可以到优采云官网查看 学习 AJAX 滚动教程。采集网站:/world/示例规则下载:/1875781361/FhuTqwUjk?from=page_81361_profile&wvr=6&mod=weibotime&type=comment#_rnd79 第一步:创建采集任务1)选择主界面,选择自定义模式。如何抓取网易新闻的网站数据 图12) 将上述网址的网址复制粘贴到网站的输入框中,点击“保存网址”。抓取网易新闻的网站数据 图23) 保存URL后,页面会在优采云采集器中打开,红框中的信息是关键这个演示。如何抓取@采集网易新闻网站数据的内容 图3 第二步:
右击,需要采集的内容会变成绿色。如何抓取网易新闻的网站数据 图6 注:点击右上角“处理”按钮,显示可视化流程图。2) 系统会识别新闻信息框中的子元素。在操作提示框中,选择“选中的子元素”。找出页面上的其他相似元素,在操作提示框中选择“全选”创建列表循环。字段上会出现删除标记,点击删除该字段。如何抓取网易新闻的网站数据 图94) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”如何抓取网易新闻的< 并且可以设置多个云节点来共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集
<p>2)采集 完成后会弹出提示选择如何导出数据抓取网易新闻的网站数据图133)选择合适的导出方式并设置 查看全部
网页新闻抓取(如何抓取网易新闻的网站数据(涉及Ajax技术)(组图))
如何抓取网易新闻的网站数据(涉及Ajax技术) 互联网数据爆炸式增长,有效获取和分析这些数据并使其产生价值是我们的工作。那么,首先要思考的问题是:如何抓取网站数据?今天分享的是一个完整的使用web数据采集器-优采云、采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站栏目后,下拉页面,会发现页面有新数据加载。分析表明,这个网站涉及Ajax技术,需要在优采云中设置一些高级选项。这一点需要特别注意。具体可以到优采云官网查看 学习 AJAX 滚动教程。采集网站:/world/示例规则下载:/1875781361/FhuTqwUjk?from=page_81361_profile&wvr=6&mod=weibotime&type=comment#_rnd79 第一步:创建采集任务1)选择主界面,选择自定义模式。如何抓取网易新闻的网站数据 图12) 将上述网址的网址复制粘贴到网站的输入框中,点击“保存网址”。抓取网易新闻的网站数据 图23) 保存URL后,页面会在优采云采集器中打开,红框中的信息是关键这个演示。如何抓取@采集网易新闻网站数据的内容 图3 第二步:
右击,需要采集的内容会变成绿色。如何抓取网易新闻的网站数据 图6 注:点击右上角“处理”按钮,显示可视化流程图。2) 系统会识别新闻信息框中的子元素。在操作提示框中,选择“选中的子元素”。找出页面上的其他相似元素,在操作提示框中选择“全选”创建列表循环。字段上会出现删除标记,点击删除该字段。如何抓取网易新闻的网站数据 图94) 我们可以看到页面第一个电影评论块中的所有元素都被选中并变成了绿色。选择“采集以下数据”如何抓取网易新闻的< 并且可以设置多个云节点来共享任务。10个节点相当于10台电脑分配任务帮你采集,速度降低到原来的十分之一;采集
<p>2)采集 完成后会弹出提示选择如何导出数据抓取网易新闻的网站数据图133)选择合适的导出方式并设置
网页新闻抓取(一个完整的网络爬虫基础框架如下图所示:整个架构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-10-29 21:14
一个完整的网络爬虫的基本框架如下图所示:
整个架构有以下几个流程:
1) 需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级建立待爬取的URL队列(先到先得);
2) 根据要爬取的URL队列的顺序进行网页爬取;
3) 将获取到的网页内容和信息下载到本地网页库,建立爬取的网址列表(用于去除重复和确定爬取过程);
4)将抓取到的网页放入待抓取的URL队列,进行循环抓取操作;
2. 网络爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个非常重要的问题,因为这涉及到先爬取哪个页面,后爬哪个页面的问题。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很容易理解,这和我们有向图中的深度优先遍历是一样的,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始页开始爬取,然后根据链接一个一个爬取,直到不能再爬取,返回上一页继续跟踪链接。
有向图中深度优先搜索的示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式是完全相对的。思路是将新下载的网页中找到的链接直接插入到要爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
上图是上例的有向图的广度优先搜索流程图,遍历的结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树结构的角度来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4)大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个爬取的URL),OPIC搜索策略(也是一种重要性)。最后需要指出的是,我们可以根据自己的需要设置网页的爬取间隔,这样可以保证我们的一些基本的主要站点或者活跃站点的内容不会被遗漏。
3. 网络爬虫更新策略
互联网是实时变化的,是高度动态的。网页更新策略主要是决定什么时候更新之前下载过的页面。常见的更新策略有以下三种:
1)历史参考攻略
顾名思义,就是根据页面之前的历史更新数据,预测页面未来什么时候会发生变化。一般来说,预测是通过泊松过程建模进行的。
2)用户体验策略
尽管搜索引擎可以针对某个查询条件返回大量结果,但用户往往只关注结果的前几页。因此,爬虫系统可以先更新那些实际在查询结果前几页的网页,然后再更新后面的那些网页。此更新策略还需要历史信息。用户体验策略保留网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,并以此值作为决定何时重新抓取的依据。
3)集群采样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加系统的负担;第二,如果新网页根本没有历史信息,就无法确定更新策略。
该策略认为网页有很多属性,属性相似的网页可以认为更新频率相似。计算某一类网页的更新频率,只需对该类网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如图:
4. 分布式爬取系统结构
一般来说,爬虫系统需要面对整个互联网上亿万个网页。单个爬虫不可能完成这样的任务。通常需要多个抓取程序来一起处理。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
底层是分布在不同地理位置的数据中心。在每个数据中心,有多个爬虫服务器,每个爬虫服务器可能部署了多套爬虫程序。这就构成了一个基本的分布式爬虫系统。
对于数据中心内的不同抓取服务器,有多种方式可以协同工作:
1)主从
主从式的基本结构如图:
对于主从模式,有一个专门的Master服务器维护一个待抓取的URL队列,负责每次将URL分发到不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL之外,还负责调解各个Slave服务器的负载。为了避免一些Slave服务器太闲或者太累。
在这种模式下,Master往往容易成为系统瓶颈。
2)点对点
点对点方程的基本结构如图所示:
在这种模式下,所有爬取服务器之间的分工没有区别。每个爬虫服务器都可以从要爬取的URL队列中获取URL,然后得到该URL主域名的hash值H,然后计算H mod m(其中m为服务器数量,上图为例如,m为3),计算出的数字就是处理该URL的主机数。
示例:假设对于URL,计算器哈希值H=8,m=3,那么H mod m=2,那么编号为2的服务器就会抓取链接。假设此时服务器0获取到了URL,它会将URL转发给服务器2,服务器2就会抓取它。
这个模型有问题。当服务器崩溃或添加新服务器时,所有 URL 的散列剩余部分的结果将更改。换句话说,这种方法的可扩展性不好。针对这种情况,又提出了另一个改进方案。这种改进的方案是通过一致性哈希来确定服务器上的分工。其基本结构如图:
一致性哈希对URL的主域名进行哈希,映射到0到232之间的一个数字,这个范围平均分配给m台服务器,判断URL主域名哈希运算的取值范围是哪个服务器用于抓取。
如果某个服务器出现问题,那么应该负责该服务器的网页会顺时针推迟,下一个服务器会被爬取。在这种情况下,如果一个服务器及时出现问题,不会影响其他任务。
5. 参考内容
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎-网络爬虫;
[3] 《这就是搜索引擎:核心技术详解》。 查看全部
网页新闻抓取(一个完整的网络爬虫基础框架如下图所示:整个架构)
一个完整的网络爬虫的基本框架如下图所示:
整个架构有以下几个流程:
1) 需求方提供需要爬取的种子URL列表,根据提供的URL列表和对应的优先级建立待爬取的URL队列(先到先得);
2) 根据要爬取的URL队列的顺序进行网页爬取;
3) 将获取到的网页内容和信息下载到本地网页库,建立爬取的网址列表(用于去除重复和确定爬取过程);
4)将抓取到的网页放入待抓取的URL队列,进行循环抓取操作;
2. 网络爬虫的爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL按什么顺序排列也是一个非常重要的问题,因为这涉及到先爬取哪个页面,后爬哪个页面的问题。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1)深度优先遍历策略
深度优先遍历策略很容易理解,这和我们有向图中的深度优先遍历是一样的,因为网络本身就是一个图模型。深度优先遍历的思路是从一个起始页开始爬取,然后根据链接一个一个爬取,直到不能再爬取,返回上一页继续跟踪链接。
有向图中深度优先搜索的示例如下所示:
上图左图是有向图的示意图,右图是深度优先遍历的搜索过程示意图。深度优先遍历的结果是:
2)广度优先搜索策略
广度优先搜索和深度优先搜索的工作方式是完全相对的。思路是将新下载的网页中找到的链接直接插入到要爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。
上图是上例的有向图的广度优先搜索流程图,遍历的结果为:
v1→v2→v3→v4→v5→v6→v7→v8
从树结构的角度来看,图的广度优先遍历就是树的层次遍历。
3)反向链接搜索策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4)大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
5)其他搜索策略
一些比较常用的爬虫搜索率还包括Partial PageRank搜索策略(根据PageRank分数确定下一个爬取的URL),OPIC搜索策略(也是一种重要性)。最后需要指出的是,我们可以根据自己的需要设置网页的爬取间隔,这样可以保证我们的一些基本的主要站点或者活跃站点的内容不会被遗漏。
3. 网络爬虫更新策略
互联网是实时变化的,是高度动态的。网页更新策略主要是决定什么时候更新之前下载过的页面。常见的更新策略有以下三种:
1)历史参考攻略
顾名思义,就是根据页面之前的历史更新数据,预测页面未来什么时候会发生变化。一般来说,预测是通过泊松过程建模进行的。
2)用户体验策略
尽管搜索引擎可以针对某个查询条件返回大量结果,但用户往往只关注结果的前几页。因此,爬虫系统可以先更新那些实际在查询结果前几页的网页,然后再更新后面的那些网页。此更新策略还需要历史信息。用户体验策略保留网页的多个历史版本,并根据过去每次内容变化对搜索质量的影响取平均值,并以此值作为决定何时重新抓取的依据。
3)集群采样策略
上面提到的两种更新策略都有一个前提:需要网页的历史信息。这种方式存在两个问题:第一,如果系统为每个系统保存多个版本的历史信息,无疑会增加系统的负担;第二,如果新网页根本没有历史信息,就无法确定更新策略。
该策略认为网页有很多属性,属性相似的网页可以认为更新频率相似。计算某一类网页的更新频率,只需对该类网页进行采样,并将其更新周期作为整个类别的更新周期。基本思路如图:
4. 分布式爬取系统结构
一般来说,爬虫系统需要面对整个互联网上亿万个网页。单个爬虫不可能完成这样的任务。通常需要多个抓取程序来一起处理。一般来说,爬虫系统往往是分布式的三层结构。如图所示:
底层是分布在不同地理位置的数据中心。在每个数据中心,有多个爬虫服务器,每个爬虫服务器可能部署了多套爬虫程序。这就构成了一个基本的分布式爬虫系统。
对于数据中心内的不同抓取服务器,有多种方式可以协同工作:
1)主从
主从式的基本结构如图:
对于主从模式,有一个专门的Master服务器维护一个待抓取的URL队列,负责每次将URL分发到不同的从服务器,从服务器负责实际的网页下载工作。Master服务器除了维护要爬取的URL队列和分发URL之外,还负责调解各个Slave服务器的负载。为了避免一些Slave服务器太闲或者太累。
在这种模式下,Master往往容易成为系统瓶颈。
2)点对点
点对点方程的基本结构如图所示:
在这种模式下,所有爬取服务器之间的分工没有区别。每个爬虫服务器都可以从要爬取的URL队列中获取URL,然后得到该URL主域名的hash值H,然后计算H mod m(其中m为服务器数量,上图为例如,m为3),计算出的数字就是处理该URL的主机数。
示例:假设对于URL,计算器哈希值H=8,m=3,那么H mod m=2,那么编号为2的服务器就会抓取链接。假设此时服务器0获取到了URL,它会将URL转发给服务器2,服务器2就会抓取它。
这个模型有问题。当服务器崩溃或添加新服务器时,所有 URL 的散列剩余部分的结果将更改。换句话说,这种方法的可扩展性不好。针对这种情况,又提出了另一个改进方案。这种改进的方案是通过一致性哈希来确定服务器上的分工。其基本结构如图:
一致性哈希对URL的主域名进行哈希,映射到0到232之间的一个数字,这个范围平均分配给m台服务器,判断URL主域名哈希运算的取值范围是哪个服务器用于抓取。
如果某个服务器出现问题,那么应该负责该服务器的网页会顺时针推迟,下一个服务器会被爬取。在这种情况下,如果一个服务器及时出现问题,不会影响其他任务。
5. 参考内容
[1] wawlian:网络爬虫基本原理(一)(二);
[2] guisu:搜索引擎-网络爬虫;
[3] 《这就是搜索引擎:核心技术详解》。
网页新闻抓取( 2017年04月21日Python正则抓取网易新闻的方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-10-29 21:13
2017年04月21日Python正则抓取网易新闻的方法
)
抓取网易新闻的方法的python正则示例
更新时间:2017年4月21日14:37:22 作者:shine
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考到以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON() 查看全部
网页新闻抓取(
2017年04月21日Python正则抓取网易新闻的方法
)
抓取网易新闻的方法的python正则示例
更新时间:2017年4月21日14:37:22 作者:shine
本文文章主要介绍Python定时抓取网易新闻的方法,结合实例形式,更详细的分析了使用Python进行网易新闻抓取操作的相关实现技巧和注意事项,有需要的朋友可以参考到以下
本文介绍Python定时抓取网易新闻的方法。分享给大家,供大家参考,如下:
写了一些爬取网易新闻的爬虫,发现它的网页源代码和网页上的评论根本不正确,于是我用抓包工具获取了它的评论隐藏地址(每个浏览器都有自己的)自己的抓包工具可以用来分析网站)
如果你仔细观察,你会发现有一个特别的,那么这个就是你想要的
然后打开链接,找到相关的评论内容。(下图为第一页内容)
接下来是代码(也是按照大神重写的)。
#coding=utf-8
import urllib2
import re
import json
import time
class WY():
def __init__(self):
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/534.24 (KHTML, like '}
self.url='http://comment.news.163.com/data/news3_bbs/df/B9IBDHEH000146BE_1.html'
def getpage(self,page):
full_url='http://comment.news.163.com/cache/newlist/news3_bbs/B9IBDHEH000146BE_'+str(page)+'.html'
return full_url
def gethtml(self,page):
try:
req=urllib2.Request(page,None,self.headers)
response = urllib2.urlopen(req)
html = response.read()
return html
except urllib2.URLError,e:
if hasattr(e,'reason'):
print u"连接失败",e.reason
return None
#处理字符串
def Process(self,data,page):
if page == 1:
data=data.replace('var replyData=','')
else:
data=data.replace('var newPostList=','')
reg1=re.compile(" \[<a href=''>")
data=reg1.sub(' ',data)
reg2=re.compile('\]')
data=reg2.sub('',data)
reg3=re.compile('
')
data=reg3.sub('',data)
return data
#解析json
def dealJSON(self):
with open("WY.txt","a") as file:
file.write('ID'+'|'+'评论'+'|'+'踩'+'|'+'顶'+'\n')
for i in range(1,12):
if i == 1:
data=self.gethtml(self.url)
data=self.Process(data,i)[:-1]
value=json.loads(data)
file=open('WY.txt','a')
for item in value['hotPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
else:
page=self.getpage(i)
data = self.gethtml(page)
data = self.Process(data,i)[:-2]
# print data
value=json.loads(data)
# print value
file=open('WY.txt','a')
for item in value['newPosts']:
try:
file.write(item['1']['f'].encode('utf-8')+'|')
file.write(item['1']['b'].encode('utf-8')+'|')
file.write(item['1']['a'].encode('utf-8')+'|')
file.write(item['1']['v'].encode('utf-8')+'\n')
except:
continue
file.close()
print '--正在采集%d/12--'%i
time.sleep(5)
if __name__ == '__main__':
WY().dealJSON()
网页新闻抓取(一个典型的新闻网页包括几个不同区域:如何写爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2021-10-27 19:05
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终的结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等。
因此,爬虫不仅要做下载的工作,还要做数据清洗和提取的工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们抓取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取。但是,我们的爬虫抓取了数百个 网站 网页。将正则表达式写到这么多不同格式的网页上会很累,而且一旦对网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不通,还得探索一个好的算法来实现。
1. 标题提取
基本上,标题会出现在html标签中,但会附加频道名称、网站名称等信息;
标题也会出现在网页的“标题区”中。
那么这两个地方哪里比较容易提取title呢?
网页的“标题区”没有明显的标记,不同网站的“标题区”的html代码部分差别很大。所以这个区域不容易提取。
然后只剩下标签。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名称、网站名称等信息如何去除,并不容易。
我们先来看看,标签中的附加信息是:
观察这些标题,不难发现新闻标题、频道名称、网站名称之间有一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猴子们作为思考练习自己去实现。
2. 发布时间提取
发布时间是指这个网页在这个网站上上线的时间,一般出现在文本标题下——元数据区。从html代码来看,这块区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子前面,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
就像标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些具有不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配和提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3. 文本提取
正文(包括新闻图片)是新闻网页的主体部分,视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的html代码是由不同标签(tags)的树状结构树组成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
像新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在标签的class和id中的关键词。这些词表明标签可能是身体,也可能不是。我们用这些词来计算标签节点的权重,这是calc_node_weight()方法的函数。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,忽略它们即可。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取label的内容,然后尝试从中找到title,然后尝试从中找到id和class收录title的节点,最后比较可能是不同地方获取的title的文本,并最终获得标题。比较的原则是:
要从标签中获取标题,就需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成树状,从body节点开始遍历每个节点,查看直接收录的文本长度(不带子节点),找到最长的节点的文本。这个过程在方法中实现:get_main_block()。其中一些细节可以被小猿体验。
细节之一是 clean_node() 函数。get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去除,就会给相关新闻的新闻内容(标题、概览等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用text_content(),而是做一些格式化处理,比如在一些标签后添加换行符以匹配\n,以及在表格的单元格之间添加空格。经过这样的处理,得到的文本格式更加符合原网页的效果。
爬虫知识点
1. cchardet 模块
快速判断文本编码的模块
2. lxml.html 模块
结构化html代码模块,通过xpath解析网页的工具,高效易用,是家庭爬虫必备模块。
3. 内容提取的复杂性
这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
然而,世界上没有千篇一律的网页,也没有一劳永逸的提取算法。在大规模使用本文算法的过程中,你会遇到奇怪的网页。这时候就必须针对这些网页来完善这个算法类。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
网页新闻抓取(一个典型的新闻网页包括几个不同区域:如何写爬虫)
我们之前实现的新闻爬虫运行后很快就可以爬取大量的新闻网页。数据库中存储的网页的html代码并不是我们想要的最终结果。最终的结果应该是结构化数据,至少包括url、标题、发布时间、正文内容、来源网站等。
因此,爬虫不仅要做下载的工作,还要做数据清洗和提取的工作。所以,写爬虫是综合能力的体现。
一个典型的新闻页面包括几个不同的区域:
新闻页面区
我们要提取的新闻元素收录在:
导航栏区域和相关链接区域的文字不属于新闻元素。
新闻的标题、发布时间、正文内容一般都是从我们抓取的html中提取出来的。如果只是网站的一个新闻页面,提取这三个内容很简单,写三个正则表达式就可以完美提取。但是,我们的爬虫抓取了数百个 网站 网页。将正则表达式写到这么多不同格式的网页上会很累,而且一旦对网页稍作修改,表达式可能会失效,维护这组表达式也很累。
当然,穷尽的方法我们想不通,还得探索一个好的算法来实现。
1. 标题提取
基本上,标题会出现在html标签中,但会附加频道名称、网站名称等信息;
标题也会出现在网页的“标题区”中。
那么这两个地方哪里比较容易提取title呢?
网页的“标题区”没有明显的标记,不同网站的“标题区”的html代码部分差别很大。所以这个区域不容易提取。
然后只剩下标签。这个标签很容易提取,无论是正则表达式还是lxml解析。频道名称、网站名称等信息如何去除,并不容易。
我们先来看看,标签中的附加信息是:
观察这些标题,不难发现新闻标题、频道名称、网站名称之间有一些连接符号。然后我可以通过这些连接器拆分标题,并找出最长的部分是新闻标题。
这个想法也很容易实现。这里就不写代码了,留给小猴子们作为思考练习自己去实现。
2. 发布时间提取
发布时间是指这个网页在这个网站上上线的时间,一般出现在文本标题下——元数据区。从html代码来看,这块区域并没有什么特别的地方可供我们定位,尤其是在很多网站板子前面,几乎不可能定位到这个区域。这就需要我们另辟蹊径。
就像标题一样,我们来看看一些网站的发布时间是怎么写的:
这些写在网页上的发布时间都有一个共同的特点,就是一个代表时间、年、月、日、时、分、秒的字符串,无非就是这些元素。通过正则表达式,我们列出一些具有不同时间表达式的正则表达式(也就是几个),然后我们就可以从网页文本中匹配和提取发布时间。
这也是一个很容易实现的想法,但是细节比较多,应该尽量覆盖表达。写一个这样的函数来提取发布时间并不是那么容易的。小猴子们充分发挥自己的动手能力,看看能写出什么样的函数实现。这也是小猿的一种练习。
3. 文本提取
正文(包括新闻图片)是新闻网页的主体部分,视觉上占据中间位置,是新闻内容的主要文本区域。提取文本的方法有很多,实现起来复杂而简单。本文介绍的方法是基于老猿多年实践经验和思考的一种简单快捷的方法。我们称之为“节点文本密度方法”。
我们知道,一个网页的html代码是由不同标签(tags)的树状结构树组成的,每个标签都是树的一个节点。通过遍历这个树结构的每个节点,找到文本最多的节点,就是文本所在的节点。按照这个思路,我们来实现代码。
3.1 实现源码
#!/usr/bin/env python3
#File: maincontent.py
#Author: veelion
import re
import time
import traceback
import cchardet
import lxml
import lxml.html
from lxml.html import HtmlComment
REGEXES = {
'okMaybeItsACandidateRe': re.compile(
'and|article|artical|body|column|main|shadow', re.I),
'positiveRe': re.compile(
('article|arti|body|content|entry|hentry|main|page|'
'artical|zoom|arti|context|message|editor|'
'pagination|post|txt|text|blog|story'), re.I),
'negativeRe': re.compile(
('copyright|combx|comment||contact|foot|footer|footnote|decl|copy|'
'notice|'
'masthead|media|meta|outbrain|promo|related|scroll|link|pagebottom|bottom|'
'other|shoutbox|sidebar|sponsor|shopping|tags|tool|widget'), re.I),
}
class MainContent:
def __init__(self,):
self.non_content_tag = set([
'head',
'meta',
'script',
'style',
'object', 'embed',
'iframe',
'marquee',
'select',
])
self.title = ''
self.p_space = re.compile(r'\s')
self.p_html = re.compile(r' len(title) or len(ti) > 7:
title = ti
return title
def shorten_title(self, title):
spliters = [' - ', '–', '—', '-', '|', '::']
for s in spliters:
if s not in title:
continue
tts = title.split(s)
if len(tts) text_node * 0.4:
to_drop.append(node)
for node in to_drop:
try:
node.drop_tree()
except:
pass
return tree
def get_text(self, doc):
lxml.etree.strip_elements(doc, 'script')
lxml.etree.strip_elements(doc, 'style')
for ch in doc.iterdescendants():
if not isinstance(ch.tag, str):
continue
if ch.tag in ['div', 'h1', 'h2', 'h3', 'p', 'br', 'table', 'tr', 'dl']:
if not ch.tail:
ch.tail = '\n'
else:
ch.tail = '\n' + ch.tail.strip() + '\n'
if ch.tag in ['th', 'td']:
if not ch.text:
ch.text = ' '
else:
ch.text += ' '
# if ch.tail:
# ch.tail = ch.tail.strip()
lines = doc.text_content().split('\n')
content = []
for l in lines:
l = l.strip()
if not l:
continue
content.append(l)
return '\n'.join(content)
def extract(self, url, html):
'''return (title, content)
'''
title, node = self.get_main_block(url, html)
if node is None:
print('\tno main block got !!!!!', url)
return title, '', ''
content = self.get_text(node)
return title, content
3.2 代码分析
像新闻爬虫一样,我们将整个算法实现为一个类:MainContent。
首先,定义一个全局变量:REGEXES。它采集了一些经常出现在标签的class和id中的关键词。这些词表明标签可能是身体,也可能不是。我们用这些词来计算标签节点的权重,这是calc_node_weight()方法的函数。
MainContent 类的初始化首先定义了一些不收录文本的标签 self.non_content_tag。当遇到这些标签节点时,忽略它们即可。
提取标题的算法在函数 get_title() 中实现。首先,它首先获取label的内容,然后尝试从中找到title,然后尝试从中找到id和class收录title的节点,最后比较可能是不同地方获取的title的文本,并最终获得标题。比较的原则是:
要从标签中获取标题,就需要解决标题清洗的问题。这里实现了一个简单的方法:clean_title()。
在这个实现中,我们使用lxml.html将网页的html转换成树状,从body节点开始遍历每个节点,查看直接收录的文本长度(不带子节点),找到最长的节点的文本。这个过程在方法中实现:get_main_block()。其中一些细节可以被小猿体验。
细节之一是 clean_node() 函数。get_main_block() 获得的节点可能收录相关新闻的链接。这些链接收录大量新闻标题。如果不去除,就会给相关新闻的新闻内容(标题、概览等)带来杂质。
还有一个细节,get_text() 函数。我们从主块中提取文本内容,而不是直接使用text_content(),而是做一些格式化处理,比如在一些标签后添加换行符以匹配\n,以及在表格的单元格之间添加空格。经过这样的处理,得到的文本格式更加符合原网页的效果。
爬虫知识点
1. cchardet 模块
快速判断文本编码的模块
2. lxml.html 模块
结构化html代码模块,通过xpath解析网页的工具,高效易用,是家庭爬虫必备模块。
3. 内容提取的复杂性
这里实现的文本提取算法基本可以正确处理90%以上的新闻网页。
然而,世界上没有千篇一律的网页,也没有一劳永逸的提取算法。在大规模使用本文算法的过程中,你会遇到奇怪的网页。这时候就必须针对这些网页来完善这个算法类。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
网页新闻抓取(基于互联网的人物实体关系提取研究的主要素材——,本文)
网站优化 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-10-25 17:00
[摘要] 互联网经过多年的快速发展,积累了大量的信息资源。其中收录的人物之间的关系是一种重要的信息,用于情报分析、网络舆情监测、社交网络分析等领域。有非常重要的应用。研究人员已经意识到这一点,并展开了相关研究。新闻网页因其术语规范、报道及时、信息可信度高而受到研究人员的青睐。新闻网页已成为基于互联网的人与实体关系提取研究的主要材料。基于以上认识,本文结合新闻网页中实体关系抽取主体的实际需求,进行了多项研究。这些研究包括: 1、 在分析一般网页采集器的特点和不足的基础上,结合具体的应用背景和实际需求,为了准确、高效地下载新闻网页,本文根据新闻网页网址的特点构造新闻网页网址模式,设计并实现了新闻主题网页采集器,很好的完成了网页采集的任务。2、 仔细分析了当前网页过滤算法效率低下的原因。在总结新闻网页特点的基础上,提出了一种基于文本块字符数的新闻网页过滤算法,并通过实验验证了该算法的有效性。性别。3、 针对支持向量机(SVM)在多类划分中的不足,引入kNN算法来消除拒绝向量。由于kNN算法的时空开销较大,当向量数量较多时,其分类性能很差,会严重影响最终的字符关系提取。因此本文提出了一种改进的kNN算法,大大提高了其性能。4、 最后,本文设计并实现了新闻网页中人物关系抽取的原型系统。该系统集成了主题网页采集、中文分词、词性标注、字符信息提取、关系提取、关系存储等功能。它是新闻网页中字符关系抽取的整体实现,也是测试本文所研究方法的最佳方式。道路。 查看全部
网页新闻抓取(基于互联网的人物实体关系提取研究的主要素材——,本文)
[摘要] 互联网经过多年的快速发展,积累了大量的信息资源。其中收录的人物之间的关系是一种重要的信息,用于情报分析、网络舆情监测、社交网络分析等领域。有非常重要的应用。研究人员已经意识到这一点,并展开了相关研究。新闻网页因其术语规范、报道及时、信息可信度高而受到研究人员的青睐。新闻网页已成为基于互联网的人与实体关系提取研究的主要材料。基于以上认识,本文结合新闻网页中实体关系抽取主体的实际需求,进行了多项研究。这些研究包括: 1、 在分析一般网页采集器的特点和不足的基础上,结合具体的应用背景和实际需求,为了准确、高效地下载新闻网页,本文根据新闻网页网址的特点构造新闻网页网址模式,设计并实现了新闻主题网页采集器,很好的完成了网页采集的任务。2、 仔细分析了当前网页过滤算法效率低下的原因。在总结新闻网页特点的基础上,提出了一种基于文本块字符数的新闻网页过滤算法,并通过实验验证了该算法的有效性。性别。3、 针对支持向量机(SVM)在多类划分中的不足,引入kNN算法来消除拒绝向量。由于kNN算法的时空开销较大,当向量数量较多时,其分类性能很差,会严重影响最终的字符关系提取。因此本文提出了一种改进的kNN算法,大大提高了其性能。4、 最后,本文设计并实现了新闻网页中人物关系抽取的原型系统。该系统集成了主题网页采集、中文分词、词性标注、字符信息提取、关系提取、关系存储等功能。它是新闻网页中字符关系抽取的整体实现,也是测试本文所研究方法的最佳方式。道路。
网页新闻抓取(百度爬虫工作原理抓取系统的核心问题及解决办法!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-24 21:16
1、百度爬虫的工作原理
爬虫系统是站长服务器和百度搜索之间的桥梁。我们通常称爬行系统为爬行环。
示例:以首页为例,“爬虫”与“网站服务器”交互抓取首页,了解页面,包括类型和值的计算,提取页面上的所有超链接。提取的链接称为“反向链接”,是下一轮捕获的链接的集合。下一轮爬取会从上一轮的后链中选择需要爬取的数据进行爬取,继续与网站交互获取页面提取链接,逐层重复循环形成一个爬行循环。
2、 抓取友好优化
网址规范
url 不应该尽可能复杂。新网站刚开始爬,蜘蛛不知道网址的内容是什么,网址的长度是多少?它是标准的吗?是否被选中(指抓取)非常关键。URL核心有两点:主流和简单。不要使用中文/中文编码。虽然百度可以识别,但蜘蛛支持256个字符。建议小于
参数有问题,参数无效?
不要使用无效参数“?” 并且尽可能多地为 URL 使用“&”,以允许资源抓取多个相同的内容而不会被蜘蛛抓取。不同的网址导致重复抓取,浪费网站的权限。希望站长尽量不要应用参数,或者简化参数,只保留必要的参数,不要使用-#等连接符
合理的链接发现
蜘蛛想要尽可能抓取完整的网站资源,需要首页和各个资源(页面)之间有良好的超链接关系,这样蜘蛛也会省力。从首页到内容的路径是从首页到栏目再到内容的循环往复。我称这种链接关系为发现链接。
例如:仅搜索主页的提要流和页面。对于此类网站,建议添加索引页,让蜘蛛找到更有价值的内容。索引页应按时间和历史顺序排列,新资源应实时发布在索引页上。就是尽量暴露给蜘蛛,不要做大量的泛洪索引页。后链的URL应该直接暴露在页面源码中,不应该引入动作触发器。最好使用百度资源平台的资源提交工具。
Q:提交更多资源更好吗?
A:收录 效果的核心永远是内容质量。如果提交大量低质量、泛滥的资源,会被算法识别为低质量,带来惩罚性压制。
Q:为什么我提交了普通的收录却没有被抓到?
A:资源提交只能加速资源发现,不能保证短期捕获;同时,该技术极大地不断优化筛选算法,以便更快地捕获优质资源。普通收录和sitemap的作用不是提交后立即抓取。什么时候去抢,要看对策略的计算和选择。
注:这么多新站点/低质量站点刚刚提交,看不到蜘蛛爬行。
访问友好性
爬虫和网站必须交互,服务器必须稳定。
访问速度优化
两个建议,第一点加载时间,建议控制在两秒内加载,会有一定的优惠。第二点是避免不必要的跳转,多级跳转也会影响加载速度。
服务器负载稳定:
尤其是短时间内提交了大量优质资源后,要注意服务器的稳定性,对于真正优质、海量的内容,蜘蛛爬行的频率会非常高。
爬取频率和网站收录有关系吗?
爬取频率其实和网站收录的效果没有必然关系。
爬取的目的主要分为两种:第一种是爬取网站上没有被爬取过的页面。第二种爬虫已经爬过了,看看这个页面有没有更新。
注意:第二个爬取目的被很多站长忽略了。对于收录已经爬取过的页面,一次爬取,应该不是为了发现新页面(猜测),而是看页面是否“更新”了。.
提问时间
新站会不会有固定的爬行次数?
任何网站 都没有特定的固定爬行次数。我自己建了一个新网站。事实上,百度采用抓取问题由来已久。基于这个问题,我们也做了一些相应的优化。对于我们能识别的新站点,对比一下已经抓到的站点,我会做一些对应流量的斜率的支持。先给你一些流量,让站长在百度的系统中转入,然后根据你的价值判断,给你流量高低,以及是否需要继续改进。
注:本公开课时间为 5 月 21 日。今年确实有很多新网站已经备案。在线爬取的频率很高,大概会有1-2个月的支持。很多人利用百度的支持期疯狂填充低质量的内容。这是一个错误的操作。
如何让百度知道你是新网站? 查看全部
网页新闻抓取(百度爬虫工作原理抓取系统的核心问题及解决办法!)
1、百度爬虫的工作原理
爬虫系统是站长服务器和百度搜索之间的桥梁。我们通常称爬行系统为爬行环。
示例:以首页为例,“爬虫”与“网站服务器”交互抓取首页,了解页面,包括类型和值的计算,提取页面上的所有超链接。提取的链接称为“反向链接”,是下一轮捕获的链接的集合。下一轮爬取会从上一轮的后链中选择需要爬取的数据进行爬取,继续与网站交互获取页面提取链接,逐层重复循环形成一个爬行循环。
2、 抓取友好优化
网址规范
url 不应该尽可能复杂。新网站刚开始爬,蜘蛛不知道网址的内容是什么,网址的长度是多少?它是标准的吗?是否被选中(指抓取)非常关键。URL核心有两点:主流和简单。不要使用中文/中文编码。虽然百度可以识别,但蜘蛛支持256个字符。建议小于
参数有问题,参数无效?
不要使用无效参数“?” 并且尽可能多地为 URL 使用“&”,以允许资源抓取多个相同的内容而不会被蜘蛛抓取。不同的网址导致重复抓取,浪费网站的权限。希望站长尽量不要应用参数,或者简化参数,只保留必要的参数,不要使用-#等连接符
合理的链接发现
蜘蛛想要尽可能抓取完整的网站资源,需要首页和各个资源(页面)之间有良好的超链接关系,这样蜘蛛也会省力。从首页到内容的路径是从首页到栏目再到内容的循环往复。我称这种链接关系为发现链接。
例如:仅搜索主页的提要流和页面。对于此类网站,建议添加索引页,让蜘蛛找到更有价值的内容。索引页应按时间和历史顺序排列,新资源应实时发布在索引页上。就是尽量暴露给蜘蛛,不要做大量的泛洪索引页。后链的URL应该直接暴露在页面源码中,不应该引入动作触发器。最好使用百度资源平台的资源提交工具。
Q:提交更多资源更好吗?
A:收录 效果的核心永远是内容质量。如果提交大量低质量、泛滥的资源,会被算法识别为低质量,带来惩罚性压制。
Q:为什么我提交了普通的收录却没有被抓到?
A:资源提交只能加速资源发现,不能保证短期捕获;同时,该技术极大地不断优化筛选算法,以便更快地捕获优质资源。普通收录和sitemap的作用不是提交后立即抓取。什么时候去抢,要看对策略的计算和选择。
注:这么多新站点/低质量站点刚刚提交,看不到蜘蛛爬行。
访问友好性
爬虫和网站必须交互,服务器必须稳定。
访问速度优化
两个建议,第一点加载时间,建议控制在两秒内加载,会有一定的优惠。第二点是避免不必要的跳转,多级跳转也会影响加载速度。
服务器负载稳定:
尤其是短时间内提交了大量优质资源后,要注意服务器的稳定性,对于真正优质、海量的内容,蜘蛛爬行的频率会非常高。
爬取频率和网站收录有关系吗?
爬取频率其实和网站收录的效果没有必然关系。
爬取的目的主要分为两种:第一种是爬取网站上没有被爬取过的页面。第二种爬虫已经爬过了,看看这个页面有没有更新。
注意:第二个爬取目的被很多站长忽略了。对于收录已经爬取过的页面,一次爬取,应该不是为了发现新页面(猜测),而是看页面是否“更新”了。.
提问时间
新站会不会有固定的爬行次数?
任何网站 都没有特定的固定爬行次数。我自己建了一个新网站。事实上,百度采用抓取问题由来已久。基于这个问题,我们也做了一些相应的优化。对于我们能识别的新站点,对比一下已经抓到的站点,我会做一些对应流量的斜率的支持。先给你一些流量,让站长在百度的系统中转入,然后根据你的价值判断,给你流量高低,以及是否需要继续改进。
注:本公开课时间为 5 月 21 日。今年确实有很多新网站已经备案。在线爬取的频率很高,大概会有1-2个月的支持。很多人利用百度的支持期疯狂填充低质量的内容。这是一个错误的操作。
如何让百度知道你是新网站?
网页新闻抓取(接到公共管理学院官网()所有的新闻咨询.实验流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-10-24 21:15
)
接到以上任务安排后,我需要使用scrapy抓取学院的新闻报道。所以,新官三火了,刚学会爬数据就迫不及待上手了。
任务
从四川大学公共管理学院官网获取所有新闻查询()。
实验过程
1.确定爬取目标。
2.制定爬取规则。
3.'Write/Debug' 爬取规则。
4.获取爬取数据
1.确定爬取目标
这次我们要捕捉的目标是四川大学公共管理学院的所有新闻和信息。所以我们需要了解一下公共管理学院官网的布局。
微信截图_245.png
在这里我们发现,如果要抓取所有的新闻信息,不能在官网首页直接抓取,需要点击“更多”进入新闻主栏目。
Paste_Image.png
我们看到了具体的新闻栏目,但这显然不能满足我们的抓取需求:目前的新闻动态网页只能抓取新闻的时间、标题和网址,不能抓取新闻的内容。所以我们要进入到新闻详情页面来抓取新闻的具体内容。2. 制定爬取规则
通过第一部分的分析,我们会认为,如果要抓取一条新闻的具体信息,需要点击新闻动态页面,进入新闻详情页,才能抓取该新闻的具体内容。让我们点击一个新闻来试试看
Paste_Image.png
我们发现可以直接在新闻详情页抓取我们需要的数据:title、time、content.URL。
好了,现在我们对抓取一条新闻有了一个清晰的想法。但是如何抓取所有的新闻内容呢?
这对我们来说显然不难。
我们可以在新闻版块底部看到页面跳转按钮。然后我们可以使用“下一页”按钮来抓取所有新闻。
于是整理了一下思路,我们可以想到一个明显的爬取规则:
抓取'新闻栏目'下的所有新闻链接,进入新闻详情链接抓取所有新闻内容。
3.'编写/调试'爬取规则
为了让调试爬虫的粒度尽可能小,我将编写和调试模块结合起来。
在爬虫中,我会实现以下功能点:
1. 抓取页面新闻部分下的所有新闻链接
2. 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
3. 通过循环抓取所有新闻。
对应的知识点是:
1. 抓取一个页面下的基本数据。
2. 对爬取的数据执行第二次爬取。
3.通过循环抓取网页的所有数据。
话不多说,现在就去做吧。
3.1 抓取页面新闻部分下的所有新闻链接
Paste_Image.png
通过对新闻版块源码的分析,我们发现抓取到的数据结构为
Paste_Image.png
那么我们只需要将爬虫的selector定位到(li:newsinfo_box_cf),然后进行for循环捕获即可。
写代码
import scrapy
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
测试,通过!
Paste_Image.png
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要输入网址,在原代码抓取网址时抓取即可。只需获取相应的数据。所以,我只需要再写一个爬取方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
Paste_Image.png
这时候我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM 查看全部
网页新闻抓取(接到公共管理学院官网()所有的新闻咨询.实验流程
)
接到以上任务安排后,我需要使用scrapy抓取学院的新闻报道。所以,新官三火了,刚学会爬数据就迫不及待上手了。
任务
从四川大学公共管理学院官网获取所有新闻查询()。
实验过程
1.确定爬取目标。
2.制定爬取规则。
3.'Write/Debug' 爬取规则。
4.获取爬取数据
1.确定爬取目标
这次我们要捕捉的目标是四川大学公共管理学院的所有新闻和信息。所以我们需要了解一下公共管理学院官网的布局。
微信截图_245.png
在这里我们发现,如果要抓取所有的新闻信息,不能在官网首页直接抓取,需要点击“更多”进入新闻主栏目。
Paste_Image.png
我们看到了具体的新闻栏目,但这显然不能满足我们的抓取需求:目前的新闻动态网页只能抓取新闻的时间、标题和网址,不能抓取新闻的内容。所以我们要进入到新闻详情页面来抓取新闻的具体内容。2. 制定爬取规则
通过第一部分的分析,我们会认为,如果要抓取一条新闻的具体信息,需要点击新闻动态页面,进入新闻详情页,才能抓取该新闻的具体内容。让我们点击一个新闻来试试看
Paste_Image.png
我们发现可以直接在新闻详情页抓取我们需要的数据:title、time、content.URL。
好了,现在我们对抓取一条新闻有了一个清晰的想法。但是如何抓取所有的新闻内容呢?
这对我们来说显然不难。
我们可以在新闻版块底部看到页面跳转按钮。然后我们可以使用“下一页”按钮来抓取所有新闻。
于是整理了一下思路,我们可以想到一个明显的爬取规则:
抓取'新闻栏目'下的所有新闻链接,进入新闻详情链接抓取所有新闻内容。
3.'编写/调试'爬取规则
为了让调试爬虫的粒度尽可能小,我将编写和调试模块结合起来。
在爬虫中,我会实现以下功能点:
1. 抓取页面新闻部分下的所有新闻链接
2. 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
3. 通过循环抓取所有新闻。
对应的知识点是:
1. 抓取一个页面下的基本数据。
2. 对爬取的数据执行第二次爬取。
3.通过循环抓取网页的所有数据。
话不多说,现在就去做吧。
3.1 抓取页面新闻部分下的所有新闻链接
Paste_Image.png
通过对新闻版块源码的分析,我们发现抓取到的数据结构为
Paste_Image.png
那么我们只需要将爬虫的selector定位到(li:newsinfo_box_cf),然后进行for循环捕获即可。
写代码
import scrapy
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
测试,通过!
Paste_Image.png
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要输入网址,在原代码抓取网址时抓取即可。只需获取相应的数据。所以,我只需要再写一个爬取方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
Paste_Image.png
这时候我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM
网页新闻抓取( 一下搜索引擎收录新闻源的四个要点要点)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-24 06:22
一下搜索引擎收录新闻源的四个要点要点)
在日常生活中,大多数用户都可以在搜索引擎上搜索和查看一些较新的实时关键点和时事通讯。一般来说,百度收录是大型门户网站网站的新闻来源,或者是百度自己的产品,比如百家号。但也有一些公司网站也想优化自己公司的新闻来源网站,以吸引更多的用户,从而获得更多的流量。同时,网站要想获得更好的排名也需要更好地针对新闻源进行优化,以推动新闻源获得收录。接下来带大家了解一下搜索引擎收录新闻源的四大要点。
一、内容质量要求
新闻源的内容质量无疑将成为搜索引擎判断收录的关键。新闻源的内容更真实有价值,原创的信息将更有利于搜索引擎蜘蛛的抓取和抓取。爬取和提升用户体验会给网站带来更多的流量和利润转化,促进网页收录。
二、新闻属性
审稿人每天都会收到大量的加入申请,很多内容在质量上都是非常优质的,但就是满足不了新闻来源对新闻属性的要求。这也是不可能的。
三、网站类型
众所周知,百度新闻源迅速收录网站在频道和目录层面。但是,每种类型的网站都有优先的 收录 频道或目录,并且视情况而定,没有 收录 或 收录 频道或目录。所以优化器一定要做好网站的某个目录或频道的新闻源更新,为网站的收录量而努力。
综上所述,以下是网站新闻来源收录为大家总结的一些搜索引擎关心的关键点。通过以上内容,相信大家也会对此有更多的了解,希望以上内容能给大家带来更多的帮助。 查看全部
网页新闻抓取(
一下搜索引擎收录新闻源的四个要点要点)
在日常生活中,大多数用户都可以在搜索引擎上搜索和查看一些较新的实时关键点和时事通讯。一般来说,百度收录是大型门户网站网站的新闻来源,或者是百度自己的产品,比如百家号。但也有一些公司网站也想优化自己公司的新闻来源网站,以吸引更多的用户,从而获得更多的流量。同时,网站要想获得更好的排名也需要更好地针对新闻源进行优化,以推动新闻源获得收录。接下来带大家了解一下搜索引擎收录新闻源的四大要点。
一、内容质量要求
新闻源的内容质量无疑将成为搜索引擎判断收录的关键。新闻源的内容更真实有价值,原创的信息将更有利于搜索引擎蜘蛛的抓取和抓取。爬取和提升用户体验会给网站带来更多的流量和利润转化,促进网页收录。
二、新闻属性
审稿人每天都会收到大量的加入申请,很多内容在质量上都是非常优质的,但就是满足不了新闻来源对新闻属性的要求。这也是不可能的。
三、网站类型
众所周知,百度新闻源迅速收录网站在频道和目录层面。但是,每种类型的网站都有优先的 收录 频道或目录,并且视情况而定,没有 收录 或 收录 频道或目录。所以优化器一定要做好网站的某个目录或频道的新闻源更新,为网站的收录量而努力。
综上所述,以下是网站新闻来源收录为大家总结的一些搜索引擎关心的关键点。通过以上内容,相信大家也会对此有更多的了解,希望以上内容能给大家带来更多的帮助。
网页新闻抓取(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-24 06:19
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站的类型很多,传输规律也不同。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这些问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,您可以使用蚂蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需行业信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
查看全部
网页新闻抓取(如何获取最新的行业资讯、收集到新闻及如何监测行业网站资讯信息
)
目前,行业信息和行业信息的传播来源广泛。各个行业网站可能都有自己需要查找的行业信息信息。所以从搜索的角度来看,网站的类型很多,传输规律也不同。仅靠人力来完成这项工作,既费时又费力。那么,如何获取最新的行业信息,采集最新的行业新闻,以及如何监控行业网站信息信息?
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
接下来,专注于大数据监测、挖掘和分析服务的蚁方软件将回答这些问题,并整合相应的行业信息获取渠道和舆情监测软件,供大家参考。
如何监控行业网站信息信息?
方法一:新闻源监控采集
可以列出的所有新闻来源都是大规模的网站,数据和信息有一定的参考价值。因此,您可以使用百度和360的新闻源搜索功能来检索所需的信息。另外,你可以关注一些新闻来源网站。
方法二:使用信息监控软件进行监控
例如,您可以使用蚂蚁方软件等为政企用户提供大数据监控的系统软件,也可以使用RSS等聚合新闻订阅工具。
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
行业网站及信息获取渠道
频道一:行业网站
比如关注一些与行业相关的网站,采集它的行业信息栏目,查看栏目是否有行业网站信息信息等等。
渠道 2:搜索引擎
您可以使用不同的搜索引擎同时搜索相同的关键词信息,过滤所需信息,获取行业信息。
通道三:免费网络信息监控系统采集
例如,您可以使用蚁方软件等支持免费试用的在线舆情监测系统,自定义目标,自行监测所需行业信息。
行业舆情监测软件推荐
推荐1:微企业舆情监测平台
功能说明:这是一个适合企业用户监测网络舆情、舆情、正反面、口碑、行业政策、竞品等相关信息的专业平台。支持全网信息24小时监控,对需要关注的关键信息自动跟踪分析其动态变化。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
推荐二:蚁方软件大数据舆情监测系统
功能描述:这是一款适用于政企用户的数据舆情监测系统。本系统的主要功能是对新闻媒体、行业资讯、社交媒体、社区等全网信息进行7*24持续监控,公众号、短视频等微信平台信息监控可以智能识别负面新闻。及时预警,自动跟踪分析相关信息的发展脉络,生成舆情分析简报。
免费试用入口>>>>
点击下方小卡片填写表格,即可免费领取舆情报告,免费试用舆情系统
网页新闻抓取( URL,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-24 01:12
URL,)
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要在原代码抓取网址时输入网址即可。 URL并抓取相应的数据。所以,我只需要另外写一个grab方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
此时,我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM 查看全部
网页新闻抓取(
URL,)
3.2 通过抓取的一页新闻链接输入新闻详情,抓取所需数据(主要是新闻内容)
现在我已经获得了一组网址,现在我需要输入每个网址来抓取我需要的标题、时间和内容。代码实现也很简单。我只需要在原代码抓取网址时输入网址即可。 URL并抓取相应的数据。所以,我只需要另外写一个grab方法进入新闻详情页,使用scapy.request调用即可。
写代码
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
集成到原代码后,有:
import scrapy
from ggglxy.items import GgglxyItem
class News2Spider(scrapy.Spider):
name = "news_info_2"
start_urls = [
"http://ggglxy.scu.edu.cn/index ... ot%3B,
]
def parse(self, response):
for href in response.xpath("//div[@class='newsinfo_box cf']"):
url = response.urljoin(href.xpath("div[@class='news_c fr']/h3/a/@href").extract_first())
#调用新闻抓取方法
yield scrapy.Request(url, callback=self.parse_dir_contents)
#进入新闻详情页的抓取方法
def parse_dir_contents(self, response):
item = GgglxyItem()
item['date'] = response.xpath("//div[@class='detail_zy_title']/p/text()").extract_first()
item['href'] = response
item['title'] = response.xpath("//div[@class='detail_zy_title']/h1/text()").extract_first()
data = response.xpath("//div[@class='detail_zy_c pb30 mb30']")
item['content'] = data[0].xpath('string(.)').extract()[0]
yield item
测试,通过!
此时,我们添加一个循环:
<p>NEXT_PAGE_NUM = 1
NEXT_PAGE_NUM = NEXT_PAGE_NUM + 1
if NEXT_PAGE_NUM
网页新闻抓取(我用python及其网址的一个简单爬虫及其)
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-24 01:11
最近也学习了一些爬虫的知识。以我个人的理解,当我们使用浏览器查看网页时,通常是通过浏览器向服务器发送请求,服务器响应并返回一些代码数据,然后由浏览器解析并呈现。爬虫通过程序向服务器发送请求,对服务器返回的信息进行一些处理后,就可以得到我们想要的数据。
下面是我前段时间用python写的一个简单的爬虫爬取TX新闻头条和网址:
首先需要使用python(一个方便全面的http请求库)和BeautifulSoup(html解析库)中的requests。
通过pip安装这两个库,命令为:pip install requests和pip install bs4(如下图)
先放完整代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
先介绍一下上面两个库
import requests
from bs4 import BeautifulSoup
然后获取请求腾讯新闻的网址。返回的字符串本质上就是我们手动打开这个网站然后查看网页源码的html代码。
wbdata = requests.get(url).text
我们只需要某些标签的内容:
可以看出,每个新闻链接和标题都在
在标签的标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候就需要用到BeautifulSoap库了。
soup = BeautifulSoup(wbdata,'lxml')
这行的意思是解析得到的信息,也可以用html.parser库替换lxml库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚解析出来的soup对象来选择我们需要的标签,返回值是一个列表。我们需要的所有标签内容都存储在列表中。您还可以使用 BeautifulSoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存入数据字典
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
数据存储所有新闻标题和链接,下图为部分结果
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,还有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说爬虫是个深坑。
python中爬虫可以通过各种库或者框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫相关库。例如,PHP 可以使用 curl 库。爬虫的原理是一样的,只是不同语言、不同库实现的方法不同。
以上通过请求实现腾讯新闻爬虫的Python方法就是我和大家分享的全部内容。希望能给大家一个参考,也希望大家支持Scripthome。 查看全部
网页新闻抓取(我用python及其网址的一个简单爬虫及其)
最近也学习了一些爬虫的知识。以我个人的理解,当我们使用浏览器查看网页时,通常是通过浏览器向服务器发送请求,服务器响应并返回一些代码数据,然后由浏览器解析并呈现。爬虫通过程序向服务器发送请求,对服务器返回的信息进行一些处理后,就可以得到我们想要的数据。
下面是我前段时间用python写的一个简单的爬虫爬取TX新闻头条和网址:
首先需要使用python(一个方便全面的http请求库)和BeautifulSoup(html解析库)中的requests。
通过pip安装这两个库,命令为:pip install requests和pip install bs4(如下图)
先放完整代码
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = "http://news.qq.com/"
# 请求腾讯新闻的URL,获取其text文本
wbdata = requests.get(url).text
# 对获取到的文本进行解析
soup = BeautifulSoup(wbdata,'lxml')
# 从解析文件中通过select选择器定位指定的元素,返回一个列表
news_titles = soup.select("div.text > em.f14 > a.linkto")
# 对返回的列表进行遍历
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
print(data)
先介绍一下上面两个库
import requests
from bs4 import BeautifulSoup
然后获取请求腾讯新闻的网址。返回的字符串本质上就是我们手动打开这个网站然后查看网页源码的html代码。
wbdata = requests.get(url).text
我们只需要某些标签的内容:
可以看出,每个新闻链接和标题都在
在标签的标签下
之后,我们将处理我们刚刚请求的 html 代码。这时候就需要用到BeautifulSoap库了。
soup = BeautifulSoup(wbdata,'lxml')
这行的意思是解析得到的信息,也可以用html.parser库替换lxml库,效果是一样的
news_titles = soup.select("div.text > em.f14 > a.linkto")
这一行是利用刚刚解析出来的soup对象来选择我们需要的标签,返回值是一个列表。我们需要的所有标签内容都存储在列表中。您还可以使用 BeautifulSoup 中的 find() 方法或 findall() 方法来选择标签。
最后使用for in遍历列表,取出标签中的内容(新闻标题)和标签中href的值(新闻网址),存入数据字典
for n in news_titles:
title = n.get_text()
link = n.get("href")
data = {
'标题':title,
'链接':link
}
数据存储所有新闻标题和链接,下图为部分结果
这样一个爬虫就完成了,当然这只是最简单的爬虫。如果深入爬虫,还有很多模拟浏览器行为、安全问题、效率优化、多线程等需要考虑。不得不说爬虫是个深坑。
python中爬虫可以通过各种库或者框架来完成,请求只是比较常用的一种。还有很多其他语言的爬虫相关库。例如,PHP 可以使用 curl 库。爬虫的原理是一样的,只是不同语言、不同库实现的方法不同。
以上通过请求实现腾讯新闻爬虫的Python方法就是我和大家分享的全部内容。希望能给大家一个参考,也希望大家支持Scripthome。
网页新闻抓取(网页抓取功能的各个功能介绍及注意事项介绍-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-23 06:20
网页抓取功能主要包括索引量、Robots、链接提交、死链接提交、抓取频率、抓取诊断、抓取异常等,通过索引量可以看到一定时期内被索引站点的数量和变化趋势时间,可以及时掌握网站的实际情况,可以指定规则来检测某个频道或话题是否为收录和Index情况。下面介绍网络爬虫的功能:
网页抓取-链接提交
链接提交包括四种提交方式:主动推送、自动推送、站点地图、手动提交。其中,主动推送是保证当天新链接收录到来的最快方式。自动推送是最方便的方式。JS代码部署到每个页面,页面浏览时自动推送到百度。一般与主动推送结合使用。站点地图提交比主动推送慢,需要定期更新。手动提交比较机械,但是可以一次性提交链接到百度。
网页抓取死链接提交
死链提交主要是处理网站上已经存在的死链。当网站死链数据积累过多并显示在搜索结果页面时,对网站本身的访问体验和用户转化都产生了负面影响。此外,百度对死链接的检查过程也会给网站带来额外的负担,影响网站其他正常页面的抓取和索引。死链接提交方式包括文档提交和规则提交。文件提交是将创建的死链接文件上传到网站的根目录,然后提交死链接文件地址。规则提交是指将相同链接前缀下的死链接写成链接规则,所有匹配的链接都是死链接,然后提交这个死链接规则。目前支持两种类型的死链接规则:目录规则、以“/”结尾的前缀;CGI 规则,前缀以“?”结尾。
网络爬虫-机器人
Robots函数用于检测和更新网站的robots.txt文件。如果网站长时间没有被搜索引擎抓取,可能是robots.txt文件有问题,需要检测更新。需要注意的是robots.txt文件不超过48k,目录不超过250个字符。
网页抓取-抓取频率
爬取频率功能可以监控蜘蛛爬取网站的频率以及每次爬取所花费的时间。
网络爬行-爬行诊断
爬行诊断功能可以监控蜘蛛爬行网站是否正常,是否可以正常爬取网站的内容。每个站点每周最多可以抓取整个段落 200 次。通过抓取整个段落,可以监控网站的内容是否符合预期,是否被黑链,文字是否隐藏,连接是否正常等。
网页抓取-抓取异常
爬行异常监控既可以监控网站异常,也可以监控链接异常。网站异常会导致DNS异常、连接爬取超时、链接错误;链接异常会导致访问被拒绝(40 3), page not found (404), server error (SXX), other errors (4XX))。
网络爬虫功能的分析和介绍到此结束。以上仅为鼎轩科技的评论,仅供参考。 查看全部
网页新闻抓取(网页抓取功能的各个功能介绍及注意事项介绍-乐题库)
网页抓取功能主要包括索引量、Robots、链接提交、死链接提交、抓取频率、抓取诊断、抓取异常等,通过索引量可以看到一定时期内被索引站点的数量和变化趋势时间,可以及时掌握网站的实际情况,可以指定规则来检测某个频道或话题是否为收录和Index情况。下面介绍网络爬虫的功能:
网页抓取-链接提交
链接提交包括四种提交方式:主动推送、自动推送、站点地图、手动提交。其中,主动推送是保证当天新链接收录到来的最快方式。自动推送是最方便的方式。JS代码部署到每个页面,页面浏览时自动推送到百度。一般与主动推送结合使用。站点地图提交比主动推送慢,需要定期更新。手动提交比较机械,但是可以一次性提交链接到百度。
网页抓取死链接提交
死链提交主要是处理网站上已经存在的死链。当网站死链数据积累过多并显示在搜索结果页面时,对网站本身的访问体验和用户转化都产生了负面影响。此外,百度对死链接的检查过程也会给网站带来额外的负担,影响网站其他正常页面的抓取和索引。死链接提交方式包括文档提交和规则提交。文件提交是将创建的死链接文件上传到网站的根目录,然后提交死链接文件地址。规则提交是指将相同链接前缀下的死链接写成链接规则,所有匹配的链接都是死链接,然后提交这个死链接规则。目前支持两种类型的死链接规则:目录规则、以“/”结尾的前缀;CGI 规则,前缀以“?”结尾。
网络爬虫-机器人
Robots函数用于检测和更新网站的robots.txt文件。如果网站长时间没有被搜索引擎抓取,可能是robots.txt文件有问题,需要检测更新。需要注意的是robots.txt文件不超过48k,目录不超过250个字符。
网页抓取-抓取频率
爬取频率功能可以监控蜘蛛爬取网站的频率以及每次爬取所花费的时间。
网络爬行-爬行诊断
爬行诊断功能可以监控蜘蛛爬行网站是否正常,是否可以正常爬取网站的内容。每个站点每周最多可以抓取整个段落 200 次。通过抓取整个段落,可以监控网站的内容是否符合预期,是否被黑链,文字是否隐藏,连接是否正常等。
网页抓取-抓取异常
爬行异常监控既可以监控网站异常,也可以监控链接异常。网站异常会导致DNS异常、连接爬取超时、链接错误;链接异常会导致访问被拒绝(40 3), page not found (404), server error (SXX), other errors (4XX))。
网络爬虫功能的分析和介绍到此结束。以上仅为鼎轩科技的评论,仅供参考。
网页新闻抓取( 公众号的第一篇文章,就先来介绍介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-10-22 23:01
公众号的第一篇文章,就先来介绍介绍(组图))
为公众号文章的第一篇文章介绍我做过的最简单的新闻爬虫,最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载,今天用python实现。这个爬虫我在双星的舞台上,在新生的导航课上(两次),在课堂上都跟别人说过很多次了。其实现在回过头来看这个爬虫真的是低级简单,不过好歹也是学了很久,今天就用python来系统的实现一下。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官方网站。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要什么信息(其实这一步必须在你写爬虫之前就确定了)。这里需要的是新闻标题、日期、作者和正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,将解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面专门学习BeautifulSoup的部分会学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签并赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再多一句,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
我相信,如果你之前已经做到了一切,那么你会非常熟练地完成这一步。首先找到文本所在的div为category class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。当我们浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码发现翻页标签链接收录xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你之前能做到这一步,你就已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再梳理一遍这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获得网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们必须设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护计算机。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。这个文章一开始我就说我觉得这个爬虫很low很简单,但是在实际操作中我还是发现我花了两天时间,当然不是全部两天。我在实习期间编写了该程序。似乎一切都不容易。让我们一步一步来。 查看全部
网页新闻抓取(
公众号的第一篇文章,就先来介绍介绍(组图))
为公众号文章的第一篇文章介绍我做过的最简单的新闻爬虫,最简单的新闻爬虫。这个爬虫本身是java写的,在我之前项目的服务器上搭载,今天用python实现。这个爬虫我在双星的舞台上,在新生的导航课上(两次),在课堂上都跟别人说过很多次了。其实现在回过头来看这个爬虫真的是低级简单,不过好歹也是学了很久,今天就用python来系统的实现一下。
欢迎关注公众号:老白和他的爬虫
新闻爬虫1.单个网页信息爬取1.1获取目标网址信息
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
print(req.text)
我选择的网站是华世征信官方网站。在这段代码中,我们通过 requests.get() 获取目标对象。这一步可以理解为用浏览器打开一个网页。记得通过req.encoding统一编码格式,避免乱码。最后一行是输出这个网页的源代码
1.2. 提取目标 URL 信息
我们使用浏览器打开特定的网页来查看我们需要的信息
谷歌浏览器可以直接查看我们需要的信息在哪里
网址
可以看到我们需要的文本信息在class="sub_r_con sub_r_intro"的div中。到这里,我们就得搞清楚我们需要什么信息(其实这一步必须在你写爬虫之前就确定了)。这里需要的是新闻标题、日期、作者和正文,下面我们一一分解
1.2.1获取称号
同样,我们检查标题在哪里
标题
我们发现这个标题在中间,下面通过代码获取
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
title = bf.find_all('h1') #获取页面所有的h1标签
print(title)
逐行阅读代码其实很容易理解。之前我们拿到了网页的源代码。通过bf = BeautifulSoup(html,'lxml')对网页进行解析,将解析出的网页结构赋予bf
. 这里要说明一下,lxml是一个参数,后面专门学习BeautifulSoup的部分会学习。
我们将所有模块分配给标题。这一步是通过 bf.find_all() 实现的。这也很好理解。解析出来的网页子模块赋值给bf,我们通过操作bf.find_all()找到它的标签并赋值给title
但是当我们输出这段代码时,问题就来了
结果
这是因为整个页面有多个标签,只有第三个标签符合我们的要求。您只需要修改代码即可达到最终想要的效果。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print(title)
1.2.2获取日期和作者
同样,我们找到日期和作者所在的div标签,发现它的类别是class_="cz",提取出来。
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
author_date = bf.find_all('div',class_="cz") #获取页面的作者和日期
print(author_date[0].text)
这里再多一句,即使模块中只有一个标签,元素也必须以列表的形式表示,就像这里的author_date一样,否则会报错
1.2.3获取文本
我相信,如果你之前已经做到了一切,那么你会非常熟练地完成这一步。首先找到文本所在的div为category class="normal_intro",修改之前的代码
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/info/1009/7267.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
article = bf.find_all('div',class_="normal_intro") #获取页面正文
print(article[0].text)
2.多网页链接抓取
以上只是针对某个新闻页面的信息抓取,我们需要做的是,给定华世征信网站,可以自动抓取上述所有网址
2.1获取翻页链接
首先,我们有一个问题。当我们浏览新闻网站时,需要翻页,我们的爬虫也需要获取目标网页的翻页地址。
翻页
这里需要两个步骤:
查看源码发现翻页标签链接收录xydt/
网页网址
这个很简单,我们可以通过下面的代码得到翻页的链接
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fan_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('xydt/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
fan_linklist.append(link) #存入列表
print(fan_linklist)
2.2获取新闻链接地址
通过上面的代码,你只需要找到新闻链接标签的特征,修改代码即可。仔细检查可以发现所有新闻链接都收录info/
from bs4 import BeautifulSoup
import re
import requests
if __name__ == "__main__":
target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
xinwen_linklist.append(link) #存入列表
print(xinwen_linklist)
3.集成代码
好的,如果你之前能做到这一步,你就已经明白原理了,嗯……你没听错,但是你明白原理。编写程序最麻烦的部分是调试和修改,所以后面的工作你会做。金额可能是您面前金额的数倍
我们再梳理一遍这个爬虫的逻辑
获取当前地址的翻页地址,即下一页地址。重复此步骤,直到获得网站的所有翻页地址。获取每个地址中的新闻链接。新闻信息被提取。
还有一点需要注意的是,在第一步和第二步中,我们必须设置一个重复数据删除程序,即去除重复爬取的地址,这样才能保证效率,保护计算机。这对你有好处。
让我们现在就开始做吧!
另外,我需要说明一下,上面的代码片段侧重于原理。最终的爬虫代码可能与上面的代码略有不同,但实际上,它们始终是密不可分的。
from bs4 import BeautifulSoup
import re
import requests
class downloader(object):
def __init__(self):
self.target = 'http://imd.ccnu.edu.cn/xwdt/xydt.htm' #目标网址
"""
函数说明:获取翻页地址
Parameters:
xiayiye - 下一页地址(string)
Returns:
fanye - 当前页面的翻页地址(list)
"""
def get_fanye_url(self,target):
req = requests.get(target) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
fanye = []
for x in bf.find_all('a',class_="Next"): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = link.replace('xydt/','')
link = "http://imd.ccnu.edu.cn/xwdt/xydt/" + link #将提取出来的链接补充完整
fanye.append(link) #存入列表
return fanye
"""
函数说明:获取新闻地址
Parameters:
fanye - 翻页地址(string)
Returns:
xinwen_linklist - 新闻链接(list)
"""
def get_xinwen_url(self, fanye):
req = requests.get(fanye) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
xinwen_linklist = [] #存入翻页地址
for x in bf.find_all('a',href = re.compile('info/')): #找到目标a标签
link = x.get('href') #提取链接
if link:
link = "http://imd.ccnu.edu.cn" + link.replace('../..','') #将提取出来的链接补充完整
xinwen_linklist.append(link) #存入列表
return xinwen_linklist
"""
函数说明:获取新闻信息
Parameters:
xinwen_url - 新闻链接(string)
Returns:
xinwen - 新闻信息(list)
"""
def get_xinwen(self, xinwen_url):
req = requests.get(xinwen_url) #获取对象
req.encoding = "utf-8" #设置编码格式
html = req.text #获得网页源代码
bf = BeautifulSoup(html,'lxml') #利用BeautifulSoup进行解析
titles = bf.find_all('h1') #获取页面所有的h1标签
title = titles[2].text#提取最后一个节点转换为文本
print("标题:"+title)
author_date = bf.find_all('div',class_="cz")[0].text #获取页面的作者和日期
print("作者和日期:"+author_date)
article = bf.find_all('div',class_="normal_intro")[0].text #获取页面正文
print("正文:"+article)
xinwen = ["标题:"+title,"作者和日期:"+author_date,"正文:"+article]
return xinwen
if __name__ == "__main__":
dl = downloader()
fanye = dl.get_fanye_url(dl.target)
'''
获取全部的翻页链接
'''
for x in fanye:
b = dl.get_fanye_url(x)
for w in b: #这一个循环的目的是获取翻页链接的同时去重
if w not in fanye:
fanye.append(w)
print("翻页链接"+w)
'''
获取每一个翻页链接里的新闻链接
'''
xinwen_url = []
for x in fanye:
a = dl.get_xinwen_url(x)
for w in a: #这一个循环的目的是获取新闻链接的同时去重
if w not in xinwen_url:
xinwen_url.append(w)
print("新闻地址"+w)
'''
获取每一个新闻链接的新闻信息
'''
xinwen = []
for x in xinwen_url:
xinwen.append(dl.get_xinwen(x))
好了,爬虫就写到这里了,复制我的代码在编辑器中运行,就可以爬取华世征信官网的所有新闻,复制这段代码可能只需要几秒钟,但是如果你能看懂每一步的逻辑,相信你能很快学会一个简单的爬虫。(运行时间约20分钟,数据量1200)
另外,我还想投诉。这个文章一开始我就说我觉得这个爬虫很low很简单,但是在实际操作中我还是发现我花了两天时间,当然不是全部两天。我在实习期间编写了该程序。似乎一切都不容易。让我们一步一步来。
网页新闻抓取(各个_encoding(_status)O_O完整代码分析 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-10-22 11:08
)
我有点白。我只是简单地记录了学校的作业项目。代码很简单,主要是对各个库的理解。希望对其他初学者有所启发。O(∩_∩)O
Python定期抓取网络新闻并存入数据库并发送邮件
一、项目需求
1、该程序可以抓取北京工业大学主页的新闻内容:
2、程序可以将爬取到的数据写入本地MySQL数据库。
3、程序可以将抓取到的数据发送到邮箱。
4、程序可以定时执行。
二、项目分析
1、 爬虫部分使用requests库抓取html文本,然后使用bs4中的BeaultifulSoup库解析html文本,提取需要的内容。
2、使用pymysql库连接MySQL数据库,实现建表和内容插入操作。
3、使用smtplib库建立邮箱连接,然后使用email库将文本信息处理成邮件发送。
4、使用调度库定时执行程序。
三、代码分析1、导入需要的库:
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
2、获取html文件:
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
必须添加请求头,否则在发出get请求时会返回错误页面。raise_for_status() 可以根据状态码判断连接对象的状态,如果成功则继续执行,如果连接失败则抛出异常,所以使用try-except捕捉。apparent_encoding() 方法可以分析判断可能的编码方式。
3、分析html提取数据:
首先观察网页源代码,确定news标签的位置:
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
4、保存到数据库
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
5、发送邮件
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
6、主要功能
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
toMysql(news)
print(news)
sendMail(news)
main() #测试需要,之后会删除
结果如下:
可以看出程序运行正常。7、定时执行
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
使用无限循环来确保计划始终运行。设置为每周一早上8:00执行程序。
为了方便查看效果,先将运行时间改为每5s运行一次:
schedule.every(5).seconds.do(main)
您可以每 5 秒收到一封电子邮件,表明满足了时间要求。至此,程序结束。
四、完整代码
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
print(news)
sendMail(news)
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1) 查看全部
网页新闻抓取(各个_encoding(_status)O_O完整代码分析
)
我有点白。我只是简单地记录了学校的作业项目。代码很简单,主要是对各个库的理解。希望对其他初学者有所启发。O(∩_∩)O
Python定期抓取网络新闻并存入数据库并发送邮件
一、项目需求
1、该程序可以抓取北京工业大学主页的新闻内容:
2、程序可以将爬取到的数据写入本地MySQL数据库。
3、程序可以将抓取到的数据发送到邮箱。
4、程序可以定时执行。
二、项目分析
1、 爬虫部分使用requests库抓取html文本,然后使用bs4中的BeaultifulSoup库解析html文本,提取需要的内容。
2、使用pymysql库连接MySQL数据库,实现建表和内容插入操作。
3、使用smtplib库建立邮箱连接,然后使用email库将文本信息处理成邮件发送。
4、使用调度库定时执行程序。
三、代码分析1、导入需要的库:
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
2、获取html文件:
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
必须添加请求头,否则在发出get请求时会返回错误页面。raise_for_status() 可以根据状态码判断连接对象的状态,如果成功则继续执行,如果连接失败则抛出异常,所以使用try-except捕捉。apparent_encoding() 方法可以分析判断可能的编码方式。
3、分析html提取数据:
首先观察网页源代码,确定news标签的位置:
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
4、保存到数据库
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
5、发送邮件
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
6、主要功能
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
toMysql(news)
print(news)
sendMail(news)
main() #测试需要,之后会删除
结果如下:
可以看出程序运行正常。7、定时执行
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
使用无限循环来确保计划始终运行。设置为每周一早上8:00执行程序。
为了方便查看效果,先将运行时间改为每5s运行一次:
schedule.every(5).seconds.do(main)
您可以每 5 秒收到一封电子邮件,表明满足了时间要求。至此,程序结束。
四、完整代码
# 爬虫相关模块
import requests
from bs4 import BeautifulSoup
import pymysql
# 发邮件相关模块
import smtplib
from email.mime.text import MIMEText
from email.header import Header
import time
# 定时模块
import schedule
# 连接获取html文本
def getHTMLtext(url):
try:
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36",
} # 浏览器请求头
r = requests.get(url, headers = headers, timeout = 30) # 获取连接
r.raise_for_status() # 测试连接是否成功,若失败则报异常
r.encoding = r.apparent_encoding # 解析编码
return r.text
except:
return ""
# 解析html提取数据
def parseHTML(news, html):
soup = BeautifulSoup(html, "html.parser") # 获取soup
for i in soup.find(attrs = {'class' : 'list'}).find_all('li'): # 存放新闻的li标签
date = i.p.string + '-' + i.h2.string # 日期
href = i.a['href'] # 链接
title = i.find('h1').string # 标题
content = i.find_all('p')[1].string # 梗概
news.append([date, href, title, content]) # 添加到列表中
# 存入数据库
def toMysql(news):
conn = pymysql.connect(host = 'localhost', port = 3306, user = 'root', passwd = '数据库密码', db = '数据库名称',charset = 'gbk', connect_timeout = 1000)
cursor = conn.cursor()
sql = '''
create table if not exists tb_news(
日期 date,
链接 varchar(400),
标题 varchar(400),
梗概 varchar(400))
'''
cursor.execute(sql) # 建表
for new in news: # 循环存入数据
sql = 'insert into tb_news(日期, 链接, 标题, 梗概) values(%s, %s, %s, %s)'
date = new[0]
href = new[1]
title = new[2]
content = new[3]
cursor.execute(sql, (date, href, title, content))
conn.commit()
conn.close()
# 发送邮件
def sendMail(news):
from_addr = '发送邮箱' # 发送邮箱
password = '16位授权码' # 邮箱授权码
to_addr = '接收邮箱' # 接收邮箱
mailhost = 'smtp.qq.com' # qq邮箱的smtp地址
qqmail = smtplib.SMTP() # 建立SMTP对象
qqmail.connect(mailhost, 25) # 25为SMTP常用端口
qqmail.login(from_addr, password) # 登录邮箱
content = ''
for new in news: # 拼接邮件内容字符串
content += '新闻时间:' + new[0] + '\n' + '新闻链接:' + new[1] + '\n' + '新闻标题:' + new[2] + '\n' + '新闻梗概:' + new[3] + '\n'
content += '======================================================================\n'
# 拼接题目字符串
subject = time.strftime('%Y-%m-%d %X', time.localtime(time.time())) + '时爬取的北工大首页主要新闻\n'
# 加工邮件message格式
msg = MIMEText(content, 'plain', 'utf-8')
msg['subject'] = Header(subject, 'utf-8')
try:
qqmail.sendmail(from_addr, to_addr, msg.as_string())
print('发送成功')
except:
print('发送失败')
qqmail.quit()
# 主函数
def main():
news = []
url = "http://www.bjut.edu.cn/"
html = getHTMLtext(url)
parseHTML(news, html)
print(news)
sendMail(news)
# 定时执行整个任务
schedule.every().monday.at("08:00").do(main) # 每周一早上八点执行main函数
while True:
schedule.run_pending()
time.sleep(1)
网页新闻抓取(谷歌浏览器级别的爬虫,老司机们就不用看了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-10-22 05:13
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下滚动,发现右侧:“... special/00804KVA/cm_guonei_03.js? . ……》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
requestsjsonBeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。 查看全部
网页新闻抓取(谷歌浏览器级别的爬虫,老司机们就不用看了)
本文属于入门级爬虫,老司机无需阅读。
这次主要是抓取网易新闻,包括新闻标题、作者、来源、发布时间、新闻正文。
首先我们打开163的网站,我们随意选择一个分类,这里我选择的分类是国内新闻。然后右键查看源码,发现源码中页面中间没有新闻列表。这说明这个页面是异步的。即通过api接口获取的数据。
然后确定后就可以用F12打开谷歌浏览器的控制台,点击Network,我们一直往下滚动,发现右侧:“... special/00804KVA/cm_guonei_03.js? . ……》这样的地址,点击Response,发现就是我们要找的api接口。
可以看到这些接口的地址有一定的规律:“cm_guonei_03.js”、“cm_guonei_04.js”,那么就很明显了:
*).js
上面的链接就是我们这次爬取要请求的地址。
接下来只需要两个python库:
requestsjsonBeautifulSoup
requests 库用于发出网络请求。说白了就是模拟浏览器获取资源。
由于我们的采集是一个api接口,它的格式是json,所以我们需要使用json库来解析。BeautifulSoup用于解析html文档,可以方便的帮助我们获取指定div的内容。
让我们开始编写我们的爬虫:
第一步是导入以上三个包:
import json
import requests
from bs4 import BeautifulSoup
然后我们定义一个方法来获取指定页码中的数据:
def get_page(page):
url_temp = 'http://temp.163.com/special/00804KVA/cm_guonei_0{}.js'
return_list = []
for i in range(page):
url = url_temp.format(i)
response = requests.get(url)
if response.status_code != 200:
continue
content = response.text # 获取响应正文
_content = formatContent(content) # 格式化json字符串
result = json.loads(_content)
return_list.append(result)
return return_list
这样就得到了每个页码对应的内容列表:
对数据进行分析后,我们可以看到下图圈出了需要爬取的标题、发布时间、新闻内容页面。
既然已经获取到内容页面的url,那么就开始爬取新闻正文。
在抓取文本之前,分析文本的html页面,找到文本、作者、来源在html文档中的位置。
我们看到文章的source在文档中的位置是:id = "ne_article_source"的标签。
作者的立场是:span标签,class="ep-editor"。
正文位置是:带有 class = "post_text" 的 div 标签。
我们来试试采集这三个内容的代码:
def get_content(url):
source = ''
author = ''
body = ''
resp = requests.get(url)
if resp.status_code == 200:
body = resp.text
bs4 = BeautifulSoup(body)
source = bs4.find('a', id='ne_article_source').get_text()
author = bs4.find('span', class_='ep-editor').get_text()
body = bs4.find('div', class_='post_text').get_text()
return source, author, body
到目前为止,我们要抓取的数据都是采集。
然后,当然,保存它们。为了方便起见,我直接以文本的形式保存它们。这是最终结果:
格式为json字符串,"title": ['date','url','source','author','body']。
需要说明的是,目前的实现方式是完全同步和线性的。问题是 采集 会很慢。主要延迟在网络IO,下次可以升级为异步IO,异步采集,有兴趣可以关注下文章。
网页新闻抓取(2..parse异步爬虫实现的流程(2.1新闻源列表))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-10-21 15:14
urllib.parse:解析url网站的模块;
logging:记录爬虫日志;
leveldb:谷歌的Key-Value数据库,用于记录URL的状态;
farmhash:对url进行hash计算,作为url的唯一标识;
sanicdb:封装aiomysql,使数据库mysql操作更方便;
2.异步爬虫实现过程2.1新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些 URL 指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if self._workers > self.workers_max:
print('got workers_max, sleep 3 sec to next worker')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。 查看全部
网页新闻抓取(2..parse异步爬虫实现的流程(2.1新闻源列表))
urllib.parse:解析url网站的模块;
logging:记录爬虫日志;
leveldb:谷歌的Key-Value数据库,用于记录URL的状态;
farmhash:对url进行hash计算,作为url的唯一标识;
sanicdb:封装aiomysql,使数据库mysql操作更方便;
2.异步爬虫实现过程2.1新闻来源列表
本文要实现的异步爬虫是一个定向抓取新闻网站的爬虫,所以我们需要管理一个定向源列表,里面记录了很多我们想要的新闻网站的url抓住。这些 URL 指向的网页称为枢纽网页,它们具有以下特点:
Hub网页是爬虫的起点,爬虫从中提取指向新闻页面的链接,然后对其进行爬取。Hub URL可以保存在MySQL数据库中,运维可以随时添加或删除这个列表;爬虫会定期读取这个列表,更新有针对性的爬虫任务。这需要爬虫中有一个循环来定期读取集线器 URL。
2.2 网址池
异步爬虫的所有进程都不是一个循环就能完成的,它是通过多个循环(至少两个)的交互来完成的。它们交互的桥梁是“URL 池”(使用 asyncio.Queue 实现)。
这个 URL 池是熟悉的“生产者-消费者”模型。
一方面,hub URL每隔一段时间就会进入URL池,爬虫从网页中提取的新闻链接也会进入URL池。这是生成 URL 的过程;
另一方面,爬虫需要从URL池中取出URL进行下载。这个过程是一个消费过程;
两个进程相互配合,URL不断进出URL池。
2.3 数据库
这里使用了两个数据库:MySQL 和 Leveldb。前者用于保存集线器 URL 和下载的网页;后者用于存储所有网址的状态(是否抓取成功)。
从网页中提取出来的很多链接可能已经被爬取过,不需要再次爬取,所以在进入URL池之前必须进行检查,通过leveldb可以快速查看其状态。
3. 异步爬虫的实现细节
前面爬虫过程中提到了两个循环:
周期一:定期更新hub网站列表
async def loop_get_urls(self,):
print('loop_get_urls() start')
while 1:
await self.get_urls() # 从MySQL读取hub列表并将hub url放入queue
await asyncio.sleep(50)
循环二:抓取网页的循环
async def loop_crawl(self,):
print('loop_crawl() start')
last_rating_time = time.time()
asyncio.ensure_future(self.loop_get_urls())
counter = 0
while 1:
item = await self.queue.get()
url, ishub = item
self._workers += 1
counter += 1
asyncio.ensure_future(self.process(url, ishub))
span = time.time() - last_rating_time
if self._workers > self.workers_max:
print('got workers_max, sleep 3 sec to next worker')
await asyncio.sleep(3)
4. asyncio 关键点:
阅读 asyncio 的文档以了解其运行过程。以下是您在使用时注意到的一些要点。
(1)使用loop.run_until_complete(self.loop_crawl())启动整个程序的主循环;
(2)使用asyncio.ensure_future()异步调用一个函数,相当于gevent的多进程fork和spawn(),具体可以参考上面的代码。
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 36 次浏览 • 2021-10-21 15:12
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网上获取新闻(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转换为视图视图,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的一个WEB应用程序中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户interface),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前的适配器来显示新闻。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml");// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
XML资源文件转换为视图的三种方式,底层实现是一样的,这里是如下方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView时,可以通过重用convertView来减少视图的创建次数,此外还可以通过定义一个类来将视图中的控件声明为成员,例如上面的ViewHolder类。
最后是最后的渲染:
查看全部
网页新闻抓取(new.xml通过HttpClient抓取网页新闻的demolist3.
)
一、概览
这是一个通过HttpClient抓取网页新闻的demo。涉及知识点:通过HttpClient从网上获取新闻(整理成XML格式),拉取解析XML,Android下ListView的使用和优化,将XML资源文件转换为视图视图,Android下的简单布局,Android消息处理机制。这里使用的网页消息是在tomcat下的一个WEB应用程序中用new.xml模拟的。虚拟机可以通过以下链接访问本机:8080/应用程序名称/new.xml。
二、步骤
说说思路:将新闻内容封装在JavaBean中(新闻内容包括图片、标题、详细信息、发帖数)。创建Activity时,启动子线程访问网络资源(因为Android4.0之后不支持主线程访问网络资源,会抛出异常:
)。解析得到的XML文件,遍历节点获取新闻信息并封装成bean加入集合中,将该集合通过Message发送给主线程的Handler对象进行处理(只有主线程可以修改用户interface),然后自定义一个适配器,将新闻bean的内容添加到指定控件中,并为ListView指定当前的适配器来显示新闻。
主要代码分为以下几部分:
1.从网络获取XML文件的输入流
/**
* 从网络上获取新闻输入流
* @return 新闻bean组成的list集合
*/
protected List getNewsFromIntenet() {
HttpClient client = null;
try {
// 定义一个客户端
client = new DefaultHttpClient();
HttpGet get = new HttpGet("http://10.0.2.2:8080/Example/new.xml";);// 访问网络资源
HttpResponse response = client.execute(get);// 执行get请求得到响应
int code = response.getStatusLine().getStatusCode();// 获得状态码
if(code == 200){// 请求成功,得到数据并返回
InputStream in = response.getEntity().getContent();// 获得内容输入流
newsList = getNewsListFromInputStream(in);// 根据流解析指定XML
return newsList;// 返回新闻bean组成的list集合
}else{
// 请求失败,打印日志
Log.i(TAG, "请求失败,请检查代码" + code);
}
} catch (Exception e) {
e.printStackTrace();
}finally{
if(client != null){
client.getConnectionManager().shutdown();// 关闭客户端资源
}
}
return null;
}
2.解析XML文件获取新闻bean列表
/**
* 从XML中解析newsList
* @return News组成的集合
* @throws Exception
*/
private List getNewsListFromInputStream(InputStream in) throws Exception {
XmlPullParser parser = Xml.newPullParser();// 创建一个解析XML的pull解析器
parser.setInput(in, "utf-8");
int eventType = parser.getEventType();// 获取事件类型
List list = null;
NewsInfo newsInfo = null;
while(eventType != XmlPullParser.END_DOCUMENT){
String tagName = parser.getName();// 获取标签名
switch(eventType){
case XmlPullParser.START_TAG:// 设置指定的内容
if("news".equals(tagName)){
list = new ArrayList();
}else if("new".equals(tagName)){
newsInfo = new NewsInfo();
}else if("title".equals(tagName)){
newsInfo.setTitle(parser.nextText());
}else if("detail".equals(tagName)){
newsInfo.setDetail(parser.nextText());
}else if("comment".equals(tagName)){
newsInfo.setComment(Integer.valueOf(parser.nextText()));
}else if("image".equals(tagName)){
newsInfo.setImage(parser.nextText());
}
break;
case XmlPullParser.END_TAG:
if("new".equals(tagName)){// 一个new结束,将封装好的新闻bean添加到集合中
list.add(newsInfo);
}
break;
default:
break;
}
eventType = parser.next();// 取下一个事件类型
}
return list;
}
3.将获取到的信息通过Message发送给Handler
/**
* 初始化操作,开启新的线程去网络获取资源
*/
public void init() {
lvNews = (ListView) findViewById(R.id.lv_news);// 找到用来显示新闻的ListView
new Thread(new Runnable(){// 开启一个线程去访问网络资源
@Override
public void run() {
List newsList = getNewsFromIntenet();
Message msg = new Message();
if(newsList != null){
msg.what = SUCCESS;// 指定消息类型
msg.obj = newsList;
}else{
msg.what = FAILED;
}
handler.sendMessage(msg);// 发送消息
}
}).start();// 开启线程
}
4.Handler根据Message类型进行相应处理:列表为空时提示错误,非空时通过adapter将信息显示在ListView上
适配器核心代码:
public View getView(int position, View convertView, ViewGroup parent) {
View view = null;
ViewHolder holder = null;
if(convertView == null){
holder = new ViewHolder();
view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
holder.sivIcon = (SmartImageView) view.findViewById(R.id.image);
holder.tv_title = (TextView) view.findViewById(R.id.tv_title);
holder.tv_comment = (TextView) view.findViewById(R.id.tv_comment);
holder.tv_detail = (TextView) view.findViewById(R.id.tv_detail);
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
view.setTag(holder);// 将holder对象中的成员变量添加到view中
}else{
System.out.println("复用以前的view,位置:"+position);
view = convertView;
holder = (ViewHolder) view.getTag();
holder.sivIcon.setImageUrl(newsList.get(position).getImage()); // 设置图片
holder.tv_title.setText(newsList.get(position).getTitle());
holder.tv_comment.setText(newsList.get(position).getComment() + "跟帖");
holder.tv_detail.setText(newsList.get(position).getDetail());
}
return view;
}
注意:
XML资源文件转换为视图的三种方式,底层实现是一样的,这里是如下方式: view = View.inflate(MainActivity.this, R.layout.layout_news_list, null);
在优化ListView时,可以通过重用convertView来减少视图的创建次数,此外还可以通过定义一个类来将视图中的控件声明为成员,例如上面的ViewHolder类。
最后是最后的渲染:
网页新闻抓取( 我们想要的图片信息利用正则表达式取到链接进一步抓取到图片 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2021-10-21 00:02
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来我们就要开始抓图了,打开图集的详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20 查看全部
网页新闻抓取(
我们想要的图片信息利用正则表达式取到链接进一步抓取到图片
)
并且数据收录了我们需要的信息
接下来我们需要获取这个详细页面的url:
def parse_page_index(html):
try:
data = json.loads(html) //json无法直接读取所以将json转换成dict
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
现在我们可以开始抓取图片了
抓一张图
接下来我们就要开始抓图了,打开图集的详情页,查看元素,我们点击Doc,下图中的下划线就是我们想要的图片信息
使用正则表达式获取链接
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
进一步抓取sub_images中的url,这个url就是我们需要的图片
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
顺便说一下,我们使用 BeautifulSoup 的 CSS 选择器来输出图集的标题
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
这样我们就成功抓取图片了,下一步就是下载图片了
下载并保存
我们使用抓图的URL存储在本地数据库中,这里我使用的是MonGoDB
首先我们创建数据库,
和链接
然后我们开始下载图片并以'jpg'格式保存到本地
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
为了加快速度,我们可以引入Pool来使用多线程下载
from multiprocessing import Pool
pool = Pool()
pool.map(main,groups)
最后我们可以看到效果是这样的
完整的代码附在下面:
#coding:utf-8
import os
from hashlib import md5
import pymongo
import re
from urllib.parse import urlencode
from bs4 import BeautifulSoup
from requests.exceptions import RequestException
import requests
import json
from config import *
from multiprocessing import Pool
from json.decoder import JSONDecodeError
client = pymongo.MongoClient(MONGO_URL,connect=False)
db = client[MONGO_DB]
def get_page_index(offset,keyword):
data={
'offset': offset ,
'format': 'json',
'keyword': keyword,
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from':'search_tab'
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(data)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求检索页出错',url)
return None
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
yield item.get('article_url')
except JSONDecodeError:
pass
def get_page_detail(url):
try:
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求详情页出错',url)
return None
def parse_page_detail(html,url):
soup = BeautifulSoup(html,'lxml')
title = soup.select('title')[0].get_text()
print(title)
images_pattern = re.compile('gallery: JSON.parse\((.*?)\),',re.S)
result = re.search(images_pattern,html)
if result:
data = json.loads(result.group(1))
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]
for image in images :
download_image(image)
return {
'title':title ,
'url':url ,
'images':images ,
}
def save_to_mongo(result):
if db[MONGO_TABLE].insert(result):
print('存储到MongoDB成功',result)
return True
return False
def download_image(url):
print('正在下载图片',url)
try:
response = requests.get(url)
if response.status_code == 200:
save_images(response.content)
return None
except RequestException:
print('请求图片失败',url)
return None
def save_images(content):
file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg')
if not os.path.exists(file_path):
with open(file_path,'wb') as f:
f.write(content)
f.close()
def main(offset):
html = get_page_index(offset,'世界杯美女')
for url in parse_page_index(html):
html = get_page_detail(url)
if html:
result = parse_page_detail(html,url)
if result:
save_to_mongo(result)
if __name__ == '__main__' :
groups = [ x * 20 for x in range(group_strat,group_end + 1 )]
pool = Pool()
pool.map(main,groups)
MONGO_URL = 'localhost'
MONGO_DB = 'toutiao'
MONGO_TABLE = 'toutiao'
group_strat = 1
group_end = 20
网页新闻抓取(网站排名好不好怎样优化才容易被蜘蛛抓取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-20 06:17
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录,虽然收录不能直接决定网站的排名,但网站的基础是内容。没有内容更难排名。好的内容可以被用户和搜索引擎所满足。可以给网站加分,从而提升排名,扩大网站曝光页面。而如果你想让你的网站页面更多的成为收录,你必须先让网页被百度蜘蛛抓取,那么如何优化网站容易被蜘蛛抓取?小编将为您详细介绍。
1、 不使用Flash结构
因为搜索引擎蜘蛛抓取这样的页面并不容易,在这种情况下,你的网站首页会给搜索引擎蜘蛛留下非常不好的印象。
2、扁平网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
3、URL 动态参数
在网站中,尽可能少的URL动态页面。该页面的结算难度远高于静态页面。静态页面更容易被搜索引擎和用户的记忆抓取。
4、网站更新频率
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬取,不仅让你的更新文章被更快的捕获,而且不会导致蜘蛛频繁运行徒然。
5、网站页面跳转
现在网站的页面跳转一般是:301/302这样的跳转会引起很多蜘蛛的反感。也不利于搜索引擎蜘蛛的抓取。建议您尽量不要使用。
6、文章原创 性别
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的宠儿,自然会对你的网站产生好感,频频过来爬取。
7、建筑网站地图
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接 网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难捕捉到。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
8、检查robots文件
很多网站有意无意屏蔽了百度或网站直接在robots文件中的部分页面,却是在找蜘蛛不爬我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么来的?所以需要不时检查网站robots文件是否正常。
对于网站如何优化,让蜘蛛更容易爬行,我在这里和大家分享一下。网站要获得更多收录,需要做好搜索引擎蜘蛛的爬取优化工作,只有提高网站的整体爬取率,才能相应的收录提升@>率,让网站的内容得到更多展示和推荐,提升网站的排名。 查看全部
网页新闻抓取(网站排名好不好怎样优化才容易被蜘蛛抓取呢?(图))
网站 排名好吗?没有太多的交通。其中一个关键因素是网站收录,虽然收录不能直接决定网站的排名,但网站的基础是内容。没有内容更难排名。好的内容可以被用户和搜索引擎所满足。可以给网站加分,从而提升排名,扩大网站曝光页面。而如果你想让你的网站页面更多的成为收录,你必须先让网页被百度蜘蛛抓取,那么如何优化网站容易被蜘蛛抓取?小编将为您详细介绍。
1、 不使用Flash结构
因为搜索引擎蜘蛛抓取这样的页面并不容易,在这种情况下,你的网站首页会给搜索引擎蜘蛛留下非常不好的印象。
2、扁平网站结构
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
3、URL 动态参数
在网站中,尽可能少的URL动态页面。该页面的结算难度远高于静态页面。静态页面更容易被搜索引擎和用户的记忆抓取。
4、网站更新频率
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛不是你一个人的,不可能蹲在这里等你更新,所以一定要主动展示给蜘蛛文章更新,让蜘蛛按照你的规则有效爬取,不仅让你的更新文章被更快的捕获,而且不会导致蜘蛛频繁运行徒然。
5、网站页面跳转
现在网站的页面跳转一般是:301/302这样的跳转会引起很多蜘蛛的反感。也不利于搜索引擎蜘蛛的抓取。建议您尽量不要使用。
6、文章原创 性别
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要为蜘蛛提供真正有价值的 原创 内容。蜘蛛如果能得到自己的宠儿,自然会对你的网站产生好感,频频过来爬取。
7、建筑网站地图
搜索引擎蜘蛛非常喜欢网站 地图。网站 地图是所有链接 网站 的容器。很多网站 链接都有很深的层次,蜘蛛很难捕捉到。网站地图可以方便搜索引擎蜘蛛抓取网站页面。通过爬取网站页面,很清楚的了解了网站的结构,所以构建一张网站地图不仅可以提高爬取率,还可以得到蜘蛛的青睐。
8、检查robots文件
很多网站有意无意屏蔽了百度或网站直接在robots文件中的部分页面,却是在找蜘蛛不爬我的页面的原因。你能怪百度吗?让别人进来,百度收录你的网页是怎么来的?所以需要不时检查网站robots文件是否正常。
对于网站如何优化,让蜘蛛更容易爬行,我在这里和大家分享一下。网站要获得更多收录,需要做好搜索引擎蜘蛛的爬取优化工作,只有提高网站的整体爬取率,才能相应的收录提升@>率,让网站的内容得到更多展示和推荐,提升网站的排名。

