
网页文章采集器
Java网页数据采集器[上篇-数据采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-26 17:36
开篇
作为全球运用最广泛的语言,Java 凭借它的高效性,可移植性(跨平台),代码的健壮性以及强悍的可扩展性,深受广大应用程序开发者的喜爱.作为一门强悍的开发语言,正则表达式在其中的应用其实是必不可少的,而且正则表达式的把握能力也是这些中级程序员的开发功力之彰显,做一名合格的网站开发的程序员(尤其是做后端开发),正则表达式是必备的.
最近,由于一些须要,用到了java和正则,做了个的篮球网站的数据采集程序;由于是第一次做关于java的html页面数据采集,必然在网上查找了好多资料,但是发觉运用这么广泛的java在使用正则做html采集方面的(中文)文章是少之又少,都是简单的谈了下java正则的概念,没有真正用在实际网页html采集,实例教程更是寥寥无几(虽然java有它自己的HtmlParser,而且非常强悍),但个人认为作为这么深入人心的正则表达式,理应有其相关的java实例教程,而且应当好多太全.于是在完成java版的html数据采集程序以后,本人便准备写个关于正则表达式在java上的html页面采集,以便有相关兴趣的读者更好的学习.
本期概述
这期我们来学习下怎样读取网页源代码,并通过group正则动态抓取我们须要的网页数据.同时在接下来的几期,我们将继续学习[数据储存]如何将抓取的赛事数据存到数据库(MySql), [数据查询] 怎样查询我们想看的赛事记录,以及[远程操作]通过客户端远程访问 查看全部
Java网页数据采集器[上篇-数据采集]
开篇
作为全球运用最广泛的语言,Java 凭借它的高效性,可移植性(跨平台),代码的健壮性以及强悍的可扩展性,深受广大应用程序开发者的喜爱.作为一门强悍的开发语言,正则表达式在其中的应用其实是必不可少的,而且正则表达式的把握能力也是这些中级程序员的开发功力之彰显,做一名合格的网站开发的程序员(尤其是做后端开发),正则表达式是必备的.
最近,由于一些须要,用到了java和正则,做了个的篮球网站的数据采集程序;由于是第一次做关于java的html页面数据采集,必然在网上查找了好多资料,但是发觉运用这么广泛的java在使用正则做html采集方面的(中文)文章是少之又少,都是简单的谈了下java正则的概念,没有真正用在实际网页html采集,实例教程更是寥寥无几(虽然java有它自己的HtmlParser,而且非常强悍),但个人认为作为这么深入人心的正则表达式,理应有其相关的java实例教程,而且应当好多太全.于是在完成java版的html数据采集程序以后,本人便准备写个关于正则表达式在java上的html页面采集,以便有相关兴趣的读者更好的学习.
本期概述
这期我们来学习下怎样读取网页源代码,并通过group正则动态抓取我们须要的网页数据.同时在接下来的几期,我们将继续学习[数据储存]如何将抓取的赛事数据存到数据库(MySql), [数据查询] 怎样查询我们想看的赛事记录,以及[远程操作]通过客户端远程访问
万能文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-25 19:38
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
软件官方下载地址:
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。 查看全部
万能文章采集器
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
软件官方下载地址:
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。
优采云万能文章采集器官方版 v2.17.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-22 15:18
优采云万能文章采集器是一款简单易用的文章采集工具,用户只须要输入关键词才能够快速采集主要搜索引擎的新闻源和泛网页,再也不用为了查找文字而四处翻网页了。优采云万能文章采集器除了具有采集速度快、操作简单的特性,文章采集器还可以精确提取网页里的正文部份保存为文章,并且支持去标签、链接、邮箱等低格处理,将纯文字的结果展示给用户,免去了用户二次处理文字的麻烦。
使用教程 1、点击“关键词采集文章”按钮
2、选择搜索引擎及类型
3、输入搜索成语
4、选择输出结果的保持目录及保持对象
5、点击“开始采集”
6、文章输出
软件功能 1、可以精确提取网页里的正文部份保存为文章
2、支持去标签、链接、邮箱等低格处理
3、插入关键词功能
4、可以辨识标签或标点后面插入
5、识别中文空格宽度插入
更新日志优采云万能文章采集器 v2.17.7.0 更新日志(2020-4-8)
1、全新降低正文过滤功能,可以屏蔽掉绝大多数不属于正文的内容;合并严格和标准的正文辨识,并加强正文辨识能力(现在辨识的正文没有再带父层的div标签了,都是取内部的代码了);增强对部份特意伪装的网站标题的提取能力;其他更新。
2、采集文章URL,强化相对路径的处理,比如../ 和 ../../ 等,经过本版本加强处理后,相对路径将完全转化为绝对路径,与浏览器中键盘移到链接上查看到的一致。
3、修复微软改动引致采集失败的问题。
4、修复关键词采集文章栏目选取精确标签时没有弹出输入的问题(前面版本导致);根据URL采集文章栏目新增删掉内层代码可选选项(之前默认启用);调试模式修改为文章来源;疑点说明更新;其他。
5、修复陌陌采集失败问题。
6、增强分页采集识别能力。
7、新增微软地址前缀指定,可自行设置能使用的微软域名。
8、采集设置的正则替换支持使用隔开多个匹配和替换表达式。
9、增强正文辨识能力,识别准确度有所提高;增加对特殊编码响应的辨识。
10、增加对二次加载图片的新属性“original”识别转换。
11、外置文件更新谷歌翻译使用的域名;修正微软tk参数变动翻译失败的问题。
12、修复部份情况因系统缘由未能跳转网址造成百度网页未能采集的问题;新增手动清除网址的#后缀部份,该部份会导致网页读取错误;采集文章URL新增左侧和右侧插入选项;修复上面版本造成的正文提取的过滤存在的一些问题;其他更新。
13、增强对部份采用跳转的网页辨识。
14、增加标题字数限制为最多100字,以免字数超长造成的一些问题;其他更新。
优采云万能文章采集器2.15.8.0更新日志(2017年3月24号)
修复百度网页搜索时间设置失效问题并取消百度新闻时间设置(已不支持);
微信采集时降低正文最少字数的设置支持(原先只有手动辨识的可以设置字数,而陌陌是外置精确标签的所以不能设置字数,现在可以了);
【文章查看】切换显示时降低手动刷新目录树;
关键词采集正文字数不足时补充提示设置的字数值
特别说明
解压密码: 查看全部
优采云万能文章采集器官方版 v2.17.7.0
优采云万能文章采集器是一款简单易用的文章采集工具,用户只须要输入关键词才能够快速采集主要搜索引擎的新闻源和泛网页,再也不用为了查找文字而四处翻网页了。优采云万能文章采集器除了具有采集速度快、操作简单的特性,文章采集器还可以精确提取网页里的正文部份保存为文章,并且支持去标签、链接、邮箱等低格处理,将纯文字的结果展示给用户,免去了用户二次处理文字的麻烦。

使用教程 1、点击“关键词采集文章”按钮

2、选择搜索引擎及类型

3、输入搜索成语

4、选择输出结果的保持目录及保持对象

5、点击“开始采集”

6、文章输出

软件功能 1、可以精确提取网页里的正文部份保存为文章
2、支持去标签、链接、邮箱等低格处理
3、插入关键词功能
4、可以辨识标签或标点后面插入
5、识别中文空格宽度插入

更新日志优采云万能文章采集器 v2.17.7.0 更新日志(2020-4-8)
1、全新降低正文过滤功能,可以屏蔽掉绝大多数不属于正文的内容;合并严格和标准的正文辨识,并加强正文辨识能力(现在辨识的正文没有再带父层的div标签了,都是取内部的代码了);增强对部份特意伪装的网站标题的提取能力;其他更新。
2、采集文章URL,强化相对路径的处理,比如../ 和 ../../ 等,经过本版本加强处理后,相对路径将完全转化为绝对路径,与浏览器中键盘移到链接上查看到的一致。
3、修复微软改动引致采集失败的问题。
4、修复关键词采集文章栏目选取精确标签时没有弹出输入的问题(前面版本导致);根据URL采集文章栏目新增删掉内层代码可选选项(之前默认启用);调试模式修改为文章来源;疑点说明更新;其他。
5、修复陌陌采集失败问题。
6、增强分页采集识别能力。
7、新增微软地址前缀指定,可自行设置能使用的微软域名。
8、采集设置的正则替换支持使用隔开多个匹配和替换表达式。
9、增强正文辨识能力,识别准确度有所提高;增加对特殊编码响应的辨识。
10、增加对二次加载图片的新属性“original”识别转换。
11、外置文件更新谷歌翻译使用的域名;修正微软tk参数变动翻译失败的问题。
12、修复部份情况因系统缘由未能跳转网址造成百度网页未能采集的问题;新增手动清除网址的#后缀部份,该部份会导致网页读取错误;采集文章URL新增左侧和右侧插入选项;修复上面版本造成的正文提取的过滤存在的一些问题;其他更新。
13、增强对部份采用跳转的网页辨识。
14、增加标题字数限制为最多100字,以免字数超长造成的一些问题;其他更新。
优采云万能文章采集器2.15.8.0更新日志(2017年3月24号)
修复百度网页搜索时间设置失效问题并取消百度新闻时间设置(已不支持);
微信采集时降低正文最少字数的设置支持(原先只有手动辨识的可以设置字数,而陌陌是外置精确标签的所以不能设置字数,现在可以了);
【文章查看】切换显示时降低手动刷新目录树;
关键词采集正文字数不足时补充提示设置的字数值
特别说明
解压密码:
Python天气预报采集器实现代码(网页爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-21 17:02
Python天气预报采集器实现代码(网页爬虫)
更新时间:2012年10月07日 00:36:02 转载作者:
这个天气预报采集是从中国天气网提取山东省内主要城市的天气并回显。本来是准备采集腾讯天气的,但是其实它的数据是用js写起来还是哪些的,得到的html文本中不收录数据,所以即使了
爬虫简单说来包括两个步骤:获得网页文本、过滤得到数据。
1、获得html文本。
python在获取html方面非常便捷,寥寥数行代码就可以实现我们须要的功能。
复制代码 代码如下:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close()
return html
这么几行代码相信不用注释都能大约晓得它的意思。
2、根据正则表达式等获得须要的内容。
使用正则表达式时须要仔细观察该网页信息的结构,并写出正确的正则表达式。
python正则表达式的使用也太简约。我的上一篇文章《Python的一些用法》介绍了一点正则的用法。这里须要一个新的用法:
复制代码 代码如下:
def getWeather(html):
reg = '(.*?).*?(.*?).*?(.*?)'
weatherList = pile(reg).findall(html)
return weatherList
其中reg是正则表达式,html是第一步获得的文本。findall的作用是找到html中所有符合正则匹配的字符串并储存到weatherList中。之后再枚举weatheList中的数据输出即可。
这里的正则表达式reg有两个地方要注意。
一个是“(.*?)”。只要是()中的内容都是我们即将获得的内容,如果有多个括弧,那么findall的每位结果就都收录这几个括弧中的内容。上面有三个括弧,分别对应城市、最低温和最高温。
另一个是“.*?”。python的正则匹配默认是贪婪的,即默认尽可能多地匹配字符串。如果在末尾加上问号,则表示非贪婪模式,即尽可能少地匹配字符串。在这里,由于有多个城市的信息须要匹配,所以须要使用非贪婪模式,否则匹配结果只剩下一个,且是不正确的。
python的使用确实非常便捷:) 查看全部
Python天气预报采集器实现代码(网页爬虫)
Python天气预报采集器实现代码(网页爬虫)
更新时间:2012年10月07日 00:36:02 转载作者:
这个天气预报采集是从中国天气网提取山东省内主要城市的天气并回显。本来是准备采集腾讯天气的,但是其实它的数据是用js写起来还是哪些的,得到的html文本中不收录数据,所以即使了
爬虫简单说来包括两个步骤:获得网页文本、过滤得到数据。
1、获得html文本。
python在获取html方面非常便捷,寥寥数行代码就可以实现我们须要的功能。
复制代码 代码如下:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close()
return html
这么几行代码相信不用注释都能大约晓得它的意思。
2、根据正则表达式等获得须要的内容。
使用正则表达式时须要仔细观察该网页信息的结构,并写出正确的正则表达式。
python正则表达式的使用也太简约。我的上一篇文章《Python的一些用法》介绍了一点正则的用法。这里须要一个新的用法:
复制代码 代码如下:
def getWeather(html):
reg = '(.*?).*?(.*?).*?(.*?)'
weatherList = pile(reg).findall(html)
return weatherList
其中reg是正则表达式,html是第一步获得的文本。findall的作用是找到html中所有符合正则匹配的字符串并储存到weatherList中。之后再枚举weatheList中的数据输出即可。
这里的正则表达式reg有两个地方要注意。
一个是“(.*?)”。只要是()中的内容都是我们即将获得的内容,如果有多个括弧,那么findall的每位结果就都收录这几个括弧中的内容。上面有三个括弧,分别对应城市、最低温和最高温。
另一个是“.*?”。python的正则匹配默认是贪婪的,即默认尽可能多地匹配字符串。如果在末尾加上问号,则表示非贪婪模式,即尽可能少地匹配字符串。在这里,由于有多个城市的信息须要匹配,所以须要使用非贪婪模式,否则匹配结果只剩下一个,且是不正确的。
python的使用确实非常便捷:)
一文教您怎样通过 Java 压缩文件,打包一个 tar
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2020-08-12 23:44
一、背景
最近,小哈主要在负责日志中台的开发工作, 等等,啥是日志中台?
俺只晓得中台概念,这段时间的确太火,但是日志中台又是拿来干啥的?
这里小哈尽量地浅显的说下日志中台的职责,再说日志中台之前,我们先扯点别的?
相信你们对集中式日志平台 ELK 都晓得一些,生产环境中, 稍复杂的构架,服务通常都是集群布署,这样,日志还会分散在每台服务器上,一旦发生问题,想要查看日志都会十分繁杂,你须要登陆每台服务器找日志,因为你不确定恳求被打到那个节点上。另外,任由开发人员登陆服务器查看日志本身就存在安全隐患,不留神执行了 rm -rf * 咋办?
通过 ELK , 我们可以便捷的将日志搜集到一处(Elasticsearch 集群)来进行多维度的剖析。
但是布署高性能、高可用的 ELK 是有门槛的,业务组想要快速的拥有集中式日志剖析的能力,往往须要经过前期的技术督查,测试,踩坑,才能将这个平台搭建上去。
日志中台的使命就是使业务线才能快速拥有这些能力,只需傻瓜式的在日志平台完成接入操作即可。
臭嗨!说了这么多,跟你这篇文章的主题有啥关系?
额,小哈这就步入主题。
既然想统一管理日志,总得将那些分散的日志采集起来吧,那么,就须要一个日志采集器,Logstash 和 Filebeat 都有采集日志的能力,但是 Filebeat 相较于 Logstash 的笨重, 它更轻量级,几乎零占用服务器系统资源,这里我们选型 Filebeat。
业务组在日志平台完成相关接入流程后,平台会提供一个采集器包。接入方须要做的就是,下载这个采集器包并扔到指定服务器上,解压运行,即可开始采集日志,然后,就可以在日志平台的管控页面剖析&搜索那些被搜集的日志了。
这个 Filebeat 采集器包上面,收录了采集日志文件路径,输出到 Kafka 集群,以及一些个性化的采集规则等等。
怎么样?是不是觉得太棒呢?
二、如何通过 Java 打包文件?2.1 添加 Maven 依赖
org.apache.commons
commons-compress
1.12
2.2 打包核心代码
通过 Apache compress 工具打包思路大致如下:
接下来,直接上代码:
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveOutputStream;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.zip.GZIPOutputStream;
/**
* @author 犬小哈 (公众号: 小哈学Java)
* @date 2019-07-15
* @time 16:15
* @discription
**/
public class TarUtils {
/**
* 压缩
* @param sourceFolder 指定打包的源目录
* @param tarGzPath 指定目标 tar 包的位置
* @return
* @throws IOException
*/
public static void compress(String sourceFolder, String tarGzPath) throws IOException {
createTarFile(sourceFolder, tarGzPath);
}
private static void createTarFile(String sourceFolder, String tarGzPath) {
TarArchiveOutputStream tarOs = null;
try {
// 创建一个 FileOutputStream 到输出文件(.tar.gz)
FileOutputStream fos = new FileOutputStream(tarGzPath);
// 创建一个 GZIPOutputStream,用来包装 FileOutputStream 对象
GZIPOutputStream gos = new GZIPOutputStream(new BufferedOutputStream(fos));
// 创建一个 TarArchiveOutputStream,用来包装 GZIPOutputStream 对象
tarOs = new TarArchiveOutputStream(gos);
// 若不设置此模式,当文件名超过 100 个字节时会抛出异常,异常大致如下:
// is too long ( > 100 bytes)
// 具体可参考官方文档: http://commons.apache.org/prop ... Names
tarOs.setLongFileMode(TarArchiveOutputStream.LONGFILE_POSIX);
addFilesToTarGZ(sourceFolder, "", tarOs);
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
tarOs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void addFilesToTarGZ(String filePath, String parent, TarArchiveOutputStream tarArchive) throws IOException {
File file = new File(filePath);
// Create entry name relative to parent file path
String entryName = parent + file.getName();
// 添加 tar ArchiveEntry
tarArchive.putArchiveEntry(new TarArchiveEntry(file, entryName));
if (file.isFile()) {
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
// 写入文件
IOUtils.copy(bis, tarArchive);
tarArchive.closeArchiveEntry();
bis.close();
} else if (file.isDirectory()) {
// 因为是个文件夹,无需写入内容,关闭即可
tarArchive.closeArchiveEntry();
// 读取文件夹下所有文件
for (File f : file.listFiles()) {
// 递归
addFilesToTarGZ(f.getAbsolutePath(), entryName + File.separator, tarArchive);
}
}
}
public static void main(String[] args) throws IOException {
// 测试一波,将 filebeat-7.1.0-linux-x86_64 打包成名为 filebeat-7.1.0-linux-x86_64.tar.gz 的 tar 包
compress("/Users/a123123/Work/filebeat-7.1.0-linux-x86_64", "/Users/a123123/Work/tmp_files/filebeat-7.1.0-linux-x86_64.tar.gz");
}
}
至于,代码每行的作用,小伙伴们可以看代码注释,说的早已比较清楚了。
接下来,执行 main 方法,测试一下疗效,看看打包是否成功:
生成采集器 tar.gz 包成功后,业务组只需将 tar.gz 下载出来,并扔到指定服务器,解压运行即可完成采集任务啦~
三、结语
本文主要还是介绍怎样通过 Java 来完成打包功能,关于 ELK 相关的知识,小哈会在后续的文章中分享给你们,本文只是提到一下,欢迎小伙伴们持续关注哟,下期见~ 查看全部
个人网站:
一、背景
最近,小哈主要在负责日志中台的开发工作, 等等,啥是日志中台?
俺只晓得中台概念,这段时间的确太火,但是日志中台又是拿来干啥的?
这里小哈尽量地浅显的说下日志中台的职责,再说日志中台之前,我们先扯点别的?
相信你们对集中式日志平台 ELK 都晓得一些,生产环境中, 稍复杂的构架,服务通常都是集群布署,这样,日志还会分散在每台服务器上,一旦发生问题,想要查看日志都会十分繁杂,你须要登陆每台服务器找日志,因为你不确定恳求被打到那个节点上。另外,任由开发人员登陆服务器查看日志本身就存在安全隐患,不留神执行了 rm -rf * 咋办?
通过 ELK , 我们可以便捷的将日志搜集到一处(Elasticsearch 集群)来进行多维度的剖析。
但是布署高性能、高可用的 ELK 是有门槛的,业务组想要快速的拥有集中式日志剖析的能力,往往须要经过前期的技术督查,测试,踩坑,才能将这个平台搭建上去。
日志中台的使命就是使业务线才能快速拥有这些能力,只需傻瓜式的在日志平台完成接入操作即可。
臭嗨!说了这么多,跟你这篇文章的主题有啥关系?
额,小哈这就步入主题。
既然想统一管理日志,总得将那些分散的日志采集起来吧,那么,就须要一个日志采集器,Logstash 和 Filebeat 都有采集日志的能力,但是 Filebeat 相较于 Logstash 的笨重, 它更轻量级,几乎零占用服务器系统资源,这里我们选型 Filebeat。
业务组在日志平台完成相关接入流程后,平台会提供一个采集器包。接入方须要做的就是,下载这个采集器包并扔到指定服务器上,解压运行,即可开始采集日志,然后,就可以在日志平台的管控页面剖析&搜索那些被搜集的日志了。
这个 Filebeat 采集器包上面,收录了采集日志文件路径,输出到 Kafka 集群,以及一些个性化的采集规则等等。
怎么样?是不是觉得太棒呢?
二、如何通过 Java 打包文件?2.1 添加 Maven 依赖
org.apache.commons
commons-compress
1.12
2.2 打包核心代码
通过 Apache compress 工具打包思路大致如下:
接下来,直接上代码:
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveOutputStream;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.zip.GZIPOutputStream;
/**
* @author 犬小哈 (公众号: 小哈学Java)
* @date 2019-07-15
* @time 16:15
* @discription
**/
public class TarUtils {
/**
* 压缩
* @param sourceFolder 指定打包的源目录
* @param tarGzPath 指定目标 tar 包的位置
* @return
* @throws IOException
*/
public static void compress(String sourceFolder, String tarGzPath) throws IOException {
createTarFile(sourceFolder, tarGzPath);
}
private static void createTarFile(String sourceFolder, String tarGzPath) {
TarArchiveOutputStream tarOs = null;
try {
// 创建一个 FileOutputStream 到输出文件(.tar.gz)
FileOutputStream fos = new FileOutputStream(tarGzPath);
// 创建一个 GZIPOutputStream,用来包装 FileOutputStream 对象
GZIPOutputStream gos = new GZIPOutputStream(new BufferedOutputStream(fos));
// 创建一个 TarArchiveOutputStream,用来包装 GZIPOutputStream 对象
tarOs = new TarArchiveOutputStream(gos);
// 若不设置此模式,当文件名超过 100 个字节时会抛出异常,异常大致如下:
// is too long ( > 100 bytes)
// 具体可参考官方文档: http://commons.apache.org/prop ... Names
tarOs.setLongFileMode(TarArchiveOutputStream.LONGFILE_POSIX);
addFilesToTarGZ(sourceFolder, "", tarOs);
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
tarOs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void addFilesToTarGZ(String filePath, String parent, TarArchiveOutputStream tarArchive) throws IOException {
File file = new File(filePath);
// Create entry name relative to parent file path
String entryName = parent + file.getName();
// 添加 tar ArchiveEntry
tarArchive.putArchiveEntry(new TarArchiveEntry(file, entryName));
if (file.isFile()) {
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
// 写入文件
IOUtils.copy(bis, tarArchive);
tarArchive.closeArchiveEntry();
bis.close();
} else if (file.isDirectory()) {
// 因为是个文件夹,无需写入内容,关闭即可
tarArchive.closeArchiveEntry();
// 读取文件夹下所有文件
for (File f : file.listFiles()) {
// 递归
addFilesToTarGZ(f.getAbsolutePath(), entryName + File.separator, tarArchive);
}
}
}
public static void main(String[] args) throws IOException {
// 测试一波,将 filebeat-7.1.0-linux-x86_64 打包成名为 filebeat-7.1.0-linux-x86_64.tar.gz 的 tar 包
compress("/Users/a123123/Work/filebeat-7.1.0-linux-x86_64", "/Users/a123123/Work/tmp_files/filebeat-7.1.0-linux-x86_64.tar.gz");
}
}
至于,代码每行的作用,小伙伴们可以看代码注释,说的早已比较清楚了。
接下来,执行 main 方法,测试一下疗效,看看打包是否成功:
生成采集器 tar.gz 包成功后,业务组只需将 tar.gz 下载出来,并扔到指定服务器,解压运行即可完成采集任务啦~
三、结语
本文主要还是介绍怎样通过 Java 来完成打包功能,关于 ELK 相关的知识,小哈会在后续的文章中分享给你们,本文只是提到一下,欢迎小伙伴们持续关注哟,下期见~
ADSL手动换IP刷流量与善肯网页TXT采集器下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-12 08:31
功能介绍
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。 查看全部
善肯网页TXT采集器是一款网路小说采集软件,可下载、可实时预览、可文本替换,目前仅能获取免费章节,不支持VIP章节!
功能介绍
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
网页数据采集并发布到dedecms程序(dede V5.7,5.6,5.5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-11 15:44
答:可下载最新版优采云采集器,优采云采集器是一款免费的网页数据、文章、图片、附件批量采集下载的软件。完全适用于dede程序,包括dedecms5.7及其他版本。
(使用优采云采集器配置网页数据发布到DEDE文章栏目及其他程序演示)
2、问:采集软件可以采集不同的网站吗?
答:您只须要,为每位网站,制作一个任务(采集规则)即可。可复制粘贴任务,快速采集不同网站内容和图片。
3、问:采集软件免费使用吗?
答:是的,功能全部免费使用,因精力有限,请阅读使用教程,快速上手。
4、问:如何将采集来的网站数据,发布到我的dedecms网站呢?
答:您只须要,将采集发布插口(又称采集插件,这里就当定义为dede采集插件吧).php文件 放置于您的网站相应目录,按照dedecms发布插口教程 及相关教程介绍配置完成。
5、问:采集网站数据,能同时下载图片吗?
答:可以的。可以批量下载图片,达到图片本地化要求。
6、问:我的网站使用dedecms自带采集不能采集HTTPS的网页数据?
答:使用本采集软件,即使您服务器/空间 不支持HTTPS远程访问,一样可以采集数据。
7、问:dedecms5.7的发布插口在哪儿呢?
答:下载优采云采集器 最新版,压缩包内就有。
(未能解决您的需求的话,可联系优采云软件开发者 优采云的QQ:3169902984 订制更改) 查看全部
1、问:我用的是织梦cms,如何采集网页数据?
答:可下载最新版优采云采集器,优采云采集器是一款免费的网页数据、文章、图片、附件批量采集下载的软件。完全适用于dede程序,包括dedecms5.7及其他版本。

(使用优采云采集器配置网页数据发布到DEDE文章栏目及其他程序演示)
2、问:采集软件可以采集不同的网站吗?
答:您只须要,为每位网站,制作一个任务(采集规则)即可。可复制粘贴任务,快速采集不同网站内容和图片。
3、问:采集软件免费使用吗?
答:是的,功能全部免费使用,因精力有限,请阅读使用教程,快速上手。
4、问:如何将采集来的网站数据,发布到我的dedecms网站呢?
答:您只须要,将采集发布插口(又称采集插件,这里就当定义为dede采集插件吧).php文件 放置于您的网站相应目录,按照dedecms发布插口教程 及相关教程介绍配置完成。
5、问:采集网站数据,能同时下载图片吗?
答:可以的。可以批量下载图片,达到图片本地化要求。
6、问:我的网站使用dedecms自带采集不能采集HTTPS的网页数据?
答:使用本采集软件,即使您服务器/空间 不支持HTTPS远程访问,一样可以采集数据。
7、问:dedecms5.7的发布插口在哪儿呢?
答:下载优采云采集器 最新版,压缩包内就有。
(未能解决您的需求的话,可联系优采云软件开发者 优采云的QQ:3169902984 订制更改)
免费下载 Feed Gator for Joomla! 1
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-10 12:32
之前 Joomla!之门 曾经介绍过一款名为 Feedbingo 的通用文章采集器,并且录制了视频教程。Feed Gator 与之相比,优势在于:Feed Gator 不仅支持将文章采集到 Joomla 核心的文章系统,还可以将文章采集到 K2 文章系统,或者采集到 Kunena 论坛(v1.6 以上版本)变成峰会贴子,或者采集到 FlexiContent 文章系统。
Feed Gator 如此强悍的采集功能,是通过安装相应的“采集插件”(Feed Gator plugins)实现的。假如你想把文章采集来弄成 NinjaBoard 论坛组件中的贴子,没问题,你只需开发相应的插件,安装到 Feed Gator 中就可以实现。
Feed Gator 采集器组件特色:安装不同插件,即可将文章采集到不同的组件中;使用 SimplePie 解析器,采集速度超快;采集全文(即使 RSS 供稿未提供全文也能强行采集全文);提供“采集预览”功能,方便站长检测设置;可针对每一个采集源单独设置白名单/黑名单,用来过滤文章;内置 htmLawed 过滤器,可对 HTML 输出进行整洁化、无害化、压缩等处理;自动剖析原文,提取词汇来生成 meta 标记内容(三种形式可选:词汇频度估算;AddKeywords 插件形式;雅虎 API 方式);可选是否在生成的文章中显示指向原文的链接;可选是否手动发布采集到的文章;可自定义手动发布后的文章保持“已发布”状态的天数(数字 0 表示永远发布);可侦测是否存在重复采集并智能化处理重复内容(可选新建、合并或则覆盖);可利用服务器端创建计划任务(Cron)脚本来实现手动采集;自动对采集源进行缓存;自动生成每次采集任务的 HTML 格式报告,可在网站后台阅读,或者手动发送到管理员信箱;可选将原文的图片保存到自己站内;可对采集到的图象统一设置 CSS 类进而实现式样控制;可针对每一个采集源为新形成的文章设置默认的“作者”;
提示: 查看全部
Feed Gator 是针对 Joomla! 1.5 的一款采集器组件,它能采集任何以 RSS 格式输出的文章来源。
之前 Joomla!之门 曾经介绍过一款名为 Feedbingo 的通用文章采集器,并且录制了视频教程。Feed Gator 与之相比,优势在于:Feed Gator 不仅支持将文章采集到 Joomla 核心的文章系统,还可以将文章采集到 K2 文章系统,或者采集到 Kunena 论坛(v1.6 以上版本)变成峰会贴子,或者采集到 FlexiContent 文章系统。
Feed Gator 如此强悍的采集功能,是通过安装相应的“采集插件”(Feed Gator plugins)实现的。假如你想把文章采集来弄成 NinjaBoard 论坛组件中的贴子,没问题,你只需开发相应的插件,安装到 Feed Gator 中就可以实现。
Feed Gator 采集器组件特色:安装不同插件,即可将文章采集到不同的组件中;使用 SimplePie 解析器,采集速度超快;采集全文(即使 RSS 供稿未提供全文也能强行采集全文);提供“采集预览”功能,方便站长检测设置;可针对每一个采集源单独设置白名单/黑名单,用来过滤文章;内置 htmLawed 过滤器,可对 HTML 输出进行整洁化、无害化、压缩等处理;自动剖析原文,提取词汇来生成 meta 标记内容(三种形式可选:词汇频度估算;AddKeywords 插件形式;雅虎 API 方式);可选是否在生成的文章中显示指向原文的链接;可选是否手动发布采集到的文章;可自定义手动发布后的文章保持“已发布”状态的天数(数字 0 表示永远发布);可侦测是否存在重复采集并智能化处理重复内容(可选新建、合并或则覆盖);可利用服务器端创建计划任务(Cron)脚本来实现手动采集;自动对采集源进行缓存;自动生成每次采集任务的 HTML 格式报告,可在网站后台阅读,或者手动发送到管理员信箱;可选将原文的图片保存到自己站内;可对采集到的图象统一设置 CSS 类进而实现式样控制;可针对每一个采集源为新形成的文章设置默认的“作者”;
提示:
[原创工具]善肯网页TXT采集器V1.1,可下载、可实时预览、可文本替换
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-10 10:28
修复第一章不能点击的bug。
新增功能让之提取网页链接的形式愈发灵活。
版本:1.0
日期:2018.5.23
开发缘由:开发之初是为了看小说便捷,个人喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
所以我开发的这个软件就特地加了个预览功能,可以晓得我究竟能不能获取网页数据,我获取后能不能正确匹配出内容。
软件主要解决的虽然就是这两个大问题。
能获取的都是免费章节,非VIP章节哈,支持原创作者。
功能模块介绍:
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置\n再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
3、关于软件
①其实只要.exe就行,规则全是自己添加,commonrule.xml上面是通用替换规则。网站规则在rule文件夹下。我那边在里面放了两个网站的规则,主要是测试的时侯是用的。其他网站规则,大家可以自己添加,或者支持开发者也行。
②软件没免杀,c#开发的,没放病毒。不放心请不要用,我不甩锅。
③关于软件上面有个跳转到峰会,我个人测试跳转的时侯被360提示了,也有可能是因为跳转的是360浏览器,不知道大家会不会有这个问题。
④xml上面的内容,如果不清楚的话还是不要动它,免得软件辨识失败报错。
⑤需要.net framework 4.5或则及以上版本框架支持,如果你笔记本没有的话,需要下载安装,框架不大的。
4、其他
暂时没想到,后面想到再说。
最后,不管怎样,还是打滚求支持,不喜切勿喷。
这个是第一个版本,所以肯定存在我之前测试没有遇见的bug或则须要优化的问题,欢迎你们温柔的反馈哈。
理论上只要是目录页到内容页的方式的都可以使用,不限于小说。
下面上图,图片中软件呈现粉红色是我笔记本主题的缘由,并非软件设置,捂脸:
求支持,求支持,求支持!!!!重要的事说三遍!!!
v1.0的下载链接:
总的下载链接【含V1.1】:链接: 密码: uff3 查看全部
更新日志:
修复第一章不能点击的bug。
新增功能让之提取网页链接的形式愈发灵活。
版本:1.0
日期:2018.5.23
开发缘由:开发之初是为了看小说便捷,个人喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
所以我开发的这个软件就特地加了个预览功能,可以晓得我究竟能不能获取网页数据,我获取后能不能正确匹配出内容。
软件主要解决的虽然就是这两个大问题。
能获取的都是免费章节,非VIP章节哈,支持原创作者。
功能模块介绍:
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置\n再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
3、关于软件
①其实只要.exe就行,规则全是自己添加,commonrule.xml上面是通用替换规则。网站规则在rule文件夹下。我那边在里面放了两个网站的规则,主要是测试的时侯是用的。其他网站规则,大家可以自己添加,或者支持开发者也行。
②软件没免杀,c#开发的,没放病毒。不放心请不要用,我不甩锅。
③关于软件上面有个跳转到峰会,我个人测试跳转的时侯被360提示了,也有可能是因为跳转的是360浏览器,不知道大家会不会有这个问题。
④xml上面的内容,如果不清楚的话还是不要动它,免得软件辨识失败报错。
⑤需要.net framework 4.5或则及以上版本框架支持,如果你笔记本没有的话,需要下载安装,框架不大的。
4、其他
暂时没想到,后面想到再说。
最后,不管怎样,还是打滚求支持,不喜切勿喷。
这个是第一个版本,所以肯定存在我之前测试没有遇见的bug或则须要优化的问题,欢迎你们温柔的反馈哈。
理论上只要是目录页到内容页的方式的都可以使用,不限于小说。
下面上图,图片中软件呈现粉红色是我笔记本主题的缘由,并非软件设置,捂脸:





求支持,求支持,求支持!!!!重要的事说三遍!!!
v1.0的下载链接:
总的下载链接【含V1.1】:链接: 密码: uff3
不懂代码也能爬取数据?试试这几个工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-10 04:44
猴哥有问必答,对于那位朋友的问题,我给安排上。
先谈谈获取数据的方法:一是借助现成的工具,我们只需懂得怎样使用工具能够获取数据,不需要关心工具是如何实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一看法是选择乘船过去,而不会想着自己来造一艘船再过去。第二种是自己针对场景需求做些多样化工具,这就须要有点编程基础。举个事例,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有哪些其他要求的话,优先选择现有工具。可能是 Python 近来年太火,加上我们会常常听到他人用 Python 来制做网路爬虫抓取数据。从而有一些朋友有这样的误区,想从网路上抓取数据就一定要学 Python,一定要去写代码。
其实不然。猴哥介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强悍的工具,能抓取数据就是它的功能之一。我以麦克风作为关键字,抓取易迅的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方法确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择前面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是太友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还须要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具以后,采集数据上限会很高。有时间和精力的朋友可以去折腾折腾。
官网地址:/
3.优采云采集器
优采云采集器是一款十分适宜菜鸟的采集器。它具有简单易用的特性,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板能够快速抓取数据。如果想抓取没有模板的网站,官网也提供十分详尽的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特性。但这瑕不掩瑜,能基本满足菜鸟在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:/
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上漂浮显示的数据。集搜客是以浏览器插件方式抓取数据。虽然具有上面所述的有点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:/
5.Scrapinghub
如果你想抓取美国的网站数据,可以考虑 Scrapinghub。Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。Scrapehub 算是市场上十分复杂和强悍的网路抓取平台,提供数据抓取的解决方案商。
地址:/
6.WebScraper
WebScraper 是一款优秀国内的浏览器插件。同样也是一款适宜菜鸟抓取数据的可视化工具。我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:webscraper.io/ 查看全部
前天,有个朋友加我陌陌来咨询我: “猴哥,我想抓取近日 5000 条新闻数据,但我是文科生,不会写代码,请问该如何办?”
猴哥有问必答,对于那位朋友的问题,我给安排上。
先谈谈获取数据的方法:一是借助现成的工具,我们只需懂得怎样使用工具能够获取数据,不需要关心工具是如何实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一看法是选择乘船过去,而不会想着自己来造一艘船再过去。第二种是自己针对场景需求做些多样化工具,这就须要有点编程基础。举个事例,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有哪些其他要求的话,优先选择现有工具。可能是 Python 近来年太火,加上我们会常常听到他人用 Python 来制做网路爬虫抓取数据。从而有一些朋友有这样的误区,想从网路上抓取数据就一定要学 Python,一定要去写代码。
其实不然。猴哥介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
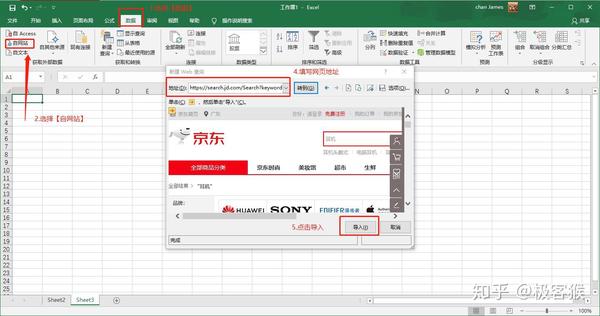
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强悍的工具,能抓取数据就是它的功能之一。我以麦克风作为关键字,抓取易迅的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方法确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择前面几个工具。
2.优采云采集器

优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是太友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还须要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具以后,采集数据上限会很高。有时间和精力的朋友可以去折腾折腾。
官网地址:/
3.优采云采集器

优采云采集器是一款十分适宜菜鸟的采集器。它具有简单易用的特性,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板能够快速抓取数据。如果想抓取没有模板的网站,官网也提供十分详尽的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特性。但这瑕不掩瑜,能基本满足菜鸟在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:/
4.GooSeeker 集搜客

集搜客也是一款容易上手的可视化采集数据工具。同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上漂浮显示的数据。集搜客是以浏览器插件方式抓取数据。虽然具有上面所述的有点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:/
5.Scrapinghub

如果你想抓取美国的网站数据,可以考虑 Scrapinghub。Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。Scrapehub 算是市场上十分复杂和强悍的网路抓取平台,提供数据抓取的解决方案商。
地址:/
6.WebScraper

WebScraper 是一款优秀国内的浏览器插件。同样也是一款适宜菜鸟抓取数据的可视化工具。我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:webscraper.io/
如何使用优采云批量下载网页.docx 33页
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2020-08-10 00:30
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按键,而是通过下拉加载,不断加载出新的内容因此,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上滚动”,滚动次数依照自身需求进行设置,间隔时间依照网页加载情况进行设置,滚动形式为“向下滚动一屏”,然后点击“确定”(注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请看:优采云7.0教程——AJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1) HYPERLINK "/article/javascript:;" 步骤2:创建翻页循环及提取数据1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作提示框中,选择“选中全部”2)选择“循环点击每位链接”3) 系统会手动步入文章详情页。点击须要采集的数组(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
以下采集的是文章正文 HYPERLINK "/article/javascript:;" 步骤3:提取UC头条文章图片地址1)接下来开始采集图片地址。先点击文章中第一张图片,再点击页面中第二张图片,在弹出的操作提示框中,选择“采集以下图片地址”2)修改数组名称,再点击“确定”3)现在我们早已采集到了图片URL,接下来为批量导入图片做打算。批量导入图片的时侯,我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标题命名。首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”选中标题数组,点击如图所示按键选择“格式化数据”点击添加步骤选择“添加前缀”在如图位置,输入前缀:“D:\UC头条图片采集\”,然后点击“确定”以同样的形式添加后缀“\”,然后点击“确定”4)修改数组名为“图片储存地址”,最后展示出的“D:\UC头条图片采集\文章标题”即为图片保存文件夹名,其中“D:\UC头条图片采集\”是固定的,文章标题是变化的步骤4:修改Xpath1)选中整个“循环”步骤,打开“高级选项”,可以看见,优采云默认生成的是固定元素列表,定位的是前13篇文章的链接2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条Xpath://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,页面中所需的所有文章均被定位了3)将修改后的Xpath,复制粘贴到优采云中所示位置,然后点击“确定”步骤5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”注:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以使用云采集功能,云采集在网路中进行采集,无需当前笔记本支持,电脑可以死机,可以设置多个云节点平摊任务,10个节点相当于10台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”,将采集好的数据导入这儿我们选择excel作为导入为格式,数据导入后如下图步骤6: HYPERLINK "/article/javascript:;" 将图片URL批量转换为图片经过如上操作,我们早已得到了要采集的图片的URL。接下来,再通过优采云专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地笔记本中。
图片批量下载工具: HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件2)打开File菜单,选择从EXCEL导出(目前只支持EXCEL格式文件)3)进行相关设置,设置完成后,点击OK即可导出文件选择EXCEL文件:导入你须要下载图片地址的EXCEL文件EXCEL表名:对应数据表的名称文件URL列名:表内对应URL的列名称,在这里为“图片URL”保存文件夹名:EXCEL中须要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片储存至不同文件夹,在这里为“图片储存地址”可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名4)点击OK后,界面如图所示,再点击“开始下载”5)页面下方会显示图片下载状态6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片URL早已批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名本文来自:/tutorialdetail-1/ucnewscj.html相关采集教程:ebay爬虫抓取图片/tutorial/ebaypicpc房源采集/tutorial/grfycj欢乐书客小说采集/tutorial/hlskxscj新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj高德地图数据采集方法/tutorial/gddtsjcj企查查企业邮箱采集/tutorial/qccqyemailcj大众点评简易模式智能防封模版使用说明/tutorial/dzdpffmbsmqq邮箱采集/tutorial/qqemailcj优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 怎样使用优采云批量下载网页优采云作为一款通用的网页数据采集器,其并不针对于某一网站某一行业的数据进行采集,而是网页上所能看见或网页源码中有的文本信息几乎都能采集,有些同学有批量下载网页的需求,其实可以使用优采云采集器去实现。下面以UC头条网页为你们详尽介绍怎样使用优采云批量下载网页。 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门2/tutorialdetail-1/xpathrm1.html HYPERLINK "/tutorialdetail-1/xdxpath-7.html" 相对XPATH教程-7.0版/tutorialdetail-1/xdxpath-7.htmlAJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1步骤1:创建UC头条文章采集任务1)进入主界面,选择“自定义模式”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”3)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按键,而是通过下拉加载,不断加载出新的内容因此,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上滚动”,滚动次数依照自身需求进行设置,间隔时间依照网页加载情况进行设置,滚动形式为“向下滚动一屏”,然后点击“确定”(注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请看:优采云7.0教程——AJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1) HYPERLINK "/article/javascript:;" 步骤2:创建翻页循环及提取数据1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作提示框中,选择“选中全部”2)选择“循环点击每位链接”3) 系统会手动步入文章详情页。点击须要采集的数组(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
以下采集的是文章正文 HYPERLINK "/article/javascript:;" 步骤3:提取UC头条文章图片地址1)接下来开始采集图片地址。先点击文章中第一张图片,再点击页面中第二张图片,在弹出的操作提示框中,选择“采集以下图片地址”2)修改数组名称,再点击“确定”3)现在我们早已采集到了图片URL,接下来为批量导入图片做打算。批量导入图片的时侯,我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标题命名。首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”选中标题数组,点击如图所示按键选择“格式化数据”点击添加步骤选择“添加前缀”在如图位置,输入前缀:“D:\UC头条图片采集\”,然后点击“确定”以同样的形式添加后缀“\”,然后点击“确定”4)修改数组名为“图片储存地址”,最后展示出的“D:\UC头条图片采集\文章标题”即为图片保存文件夹名,其中“D:\UC头条图片采集\”是固定的,文章标题是变化的步骤4:修改Xpath1)选中整个“循环”步骤,打开“高级选项”,可以看见,优采云默认生成的是固定元素列表,定位的是前13篇文章的链接2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条Xpath://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,页面中所需的所有文章均被定位了3)将修改后的Xpath,复制粘贴到优采云中所示位置,然后点击“确定”步骤5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”注:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以使用云采集功能,云采集在网路中进行采集,无需当前笔记本支持,电脑可以死机,可以设置多个云节点平摊任务,10个节点相当于10台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”,将采集好的数据导入这儿我们选择excel作为导入为格式,数据导入后如下图步骤6: HYPERLINK "/article/javascript:;" 将图片URL批量转换为图片经过如上操作,我们早已得到了要采集的图片的URL。接下来,再通过优采云专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地笔记本中。
图片批量下载工具: HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件2)打开File菜单,选择从EXCEL导出(目前只支持EXCEL格式文件)3)进行相关设置,设置完成后,点击OK即可导出文件选择EXCEL文件:导入你须要下载图片地址的EXCEL文件EXCEL表名:对应数据表的名称文件URL列名:表内对应URL的列名称,在这里为“图片URL”保存文件夹名:EXCEL中须要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片储存至不同文件夹,在这里为“图片储存地址”可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名4)点击OK后,界面如图所示,再点击“开始下载”5)页面下方会显示图片下载状态6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片URL早已批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名本文来自:/tutorialdetail-1/ucnewscj.html相关采集教程:ebay爬虫抓取图片/tutorial/ebaypicpc房源采集/tutorial/grfycj欢乐书客小说采集/tutorial/hlskxscj新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj高德地图数据采集方法/tutorial/gddtsjcj企查查企业邮箱采集/tutorial/qccqyemailcj大众点评简易模式智能防封模版使用说明/tutorial/dzdpffmbsmqq邮箱采集/tutorial/qqemailcj优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
网站万能信息采集器 V10 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-09 15:29
网站信息采集器是一款使用便捷的信息采集工具,软件手动获取网站上的信息并全部抓取出来发布到您的网站里,网站信息采集器拥有多级页面采集、全手动添加采集信息、多页新闻手动抓取等功能,不用人工,自动实现网站更新。
网站信息采集器功能
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识Javascript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
更新日志
1.全新的分层设置,每一层都可以设置特殊的选项,摆脱了先前的默认3层限制
2.任意多层分类一次抓取,以前是须要先把各分类网址抓到,然后再抓每位分类
3.图片下载,自定义文件名,以前不能更名
4.新闻内容分页合并设置更简单,更通用,功能更强大
5.模拟点击更通用更简单,以前的模拟点击是须要特殊设置的,使用复杂
6.可以依据内容判定重复,以前只是按照网址判定重复
7.采集完以后容许执行自定义vbs脚本endget.vbs,发布完以后容许执行endpub.vbs,在vbs里你可以自己编撰对数据的处理功能
8.导出数据可以实现收录文字 排除文字 文字截取 日期加几个月 数字比较大小过滤 前后追加字符 查看全部

网站信息采集器是一款使用便捷的信息采集工具,软件手动获取网站上的信息并全部抓取出来发布到您的网站里,网站信息采集器拥有多级页面采集、全手动添加采集信息、多页新闻手动抓取等功能,不用人工,自动实现网站更新。
网站信息采集器功能
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识Javascript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
更新日志
1.全新的分层设置,每一层都可以设置特殊的选项,摆脱了先前的默认3层限制
2.任意多层分类一次抓取,以前是须要先把各分类网址抓到,然后再抓每位分类
3.图片下载,自定义文件名,以前不能更名
4.新闻内容分页合并设置更简单,更通用,功能更强大
5.模拟点击更通用更简单,以前的模拟点击是须要特殊设置的,使用复杂
6.可以依据内容判定重复,以前只是按照网址判定重复
7.采集完以后容许执行自定义vbs脚本endget.vbs,发布完以后容许执行endpub.vbs,在vbs里你可以自己编撰对数据的处理功能
8.导出数据可以实现收录文字 排除文字 文字截取 日期加几个月 数字比较大小过滤 前后追加字符
Python集成代码实现了优采云爬行知乎的所有功能以及附加的数据预处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-09 06:23
上一篇文章(上面的链接)对每个部分进行了更详细的描述. 本文将介绍用于爬网和爬网数据的预处理的集成代码块.
1.python集成代码,实现了优采云爬行之虎的所有功能
```python
#!/usr/bin/env python
# coding: utf-8
import os
import pandas as pd
from selenium import webdriver
from lxml import etree
import time
import jieba
import re
import numpy as np
url1 = input("请输入您所需要爬取的网页(知乎)")
browser = webdriver.Chrome("/Users/apple/Downloads/chromedrivermac")
browser.get(url1)
try:
#点击问题全部内容
button1 = browser.find_elements_by_xpath("""//div[@class= "QuestionHeader-detail"]
//button[contains(@class,"Button") and contains(@class,"QuestionRichText-more")
and contains(@class , "Button--plain")
]""")[0]
button1.click()
except:
print('这个问题比较简单,并没有问题的全部内容哦!')
#此网页就属于异步加载的情况
#那么我们就需要多次下滑
for i in range(20):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
#点击知乎的登陆弹窗
button2 = browser.find_elements_by_xpath("""//button[@aria-label = '关闭']""")[0]
button2.click()
#点击知乎的“查看全部回答”按钮
button3 = browser.find_elements_by_xpath("""//div[@class = 'Question-main']
//a[contains(@class,"ViewAll-QuestionMainAction") and contains(@class , "QuestionMainAction") ]""")[1]
button3.click()
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
while final_end_it == []:
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
for i in range(30):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
dom = etree.HTML(browser.page_source)
# 对于问题本身的数据
Followers_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[0]
Browsed_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[1]
#关注者数量
Followers_number_final = re.sub(",","",Followers_number_first)
#浏览数量
Browsed_number_final = re.sub(",","",Browsed_number_first)
#问题链接
problem_url = url1
#问题ID
problem_id = re.findall(r"\d+\.?\d*",url1)
#问题标题
problem_title = dom.xpath("""//div[@class = 'QuestionHeader']//h1[@class = "QuestionHeader-title"]/text()""")
#问题点赞数
problem_endorse = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "GoodQuestionAction"]/button/text()""")
#问题评论数
problem_Comment = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "QuestionHeader-Comment"]/button/text()""")
#问题回答数
answer_number = dom.xpath("""//div[@class = 'Question-main']//h4[@class = "List-headerText"]/span/text()""")
#问题标签
problem_tags_list = dom.xpath("""//div[@class = 'QuestionHeader-topics']//a[@class = "TopicLink"]/div/div/text()""")
# 对于回答本身的数据
#具体内容
comment_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "RichContent-inner"]""")
comment_list_text = []
for comment in comment_list:
comment_list_text.append(comment.xpath("string(.)"))
#发表时间
time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/@data-tooltip""")
edit_time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/text()""")
#点赞数
endorse_list = dom.xpath("""//div[@class = 'List-item']//button[contains(@class,"Button") and contains(@class,"VoteButton") and contains(@class , "VoteButton--up")]/@aria-label""")
#评论人数
number_of_endorse_list = dom.xpath("""//div[@class = 'List-item']//svg[contains(@class,"Zi") and contains(@class,"Zi--Comment")
and contains(@class,"Button-zi")]/../../text()""")
#回答链接
answers_url_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/meta[@itemprop = "url"]/@content""")
authors_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/@data-zop""")
#作者姓名
authorName_list = []
#作者id
authorid_list = []
for i in authors_list:
authorName_list.append(eval(i)['authorName'])
authorid_list.append(eval(i)["itemId"])
# 合成数据框
data = pd.DataFrame()
data['具体内容'] = comment_list_text
data["发表时间"] = time_list
data["点赞数"] = endorse_list
data["评论人数"] = number_of_endorse_list
data["回答链接"] = answers_url_list
data["作者姓名"] = authorName_list
data['作者id'] = authorid_list
data["问题关注者数量"] = Followers_number_final
data["问题浏览数量"] = Browsed_number_final
data["问题链接"] = problem_url
data["问题ID"] = problem_id[0]
data["问题标题"] = problem_title[0]
data["问题点赞数"] = problem_endorse[0]
data["问题评论数"] = problem_Comment[0]
data["问题回答数"] = answer_number[0]
data["问题标签"] = "&".join(problem_tags_list)
data
复制上面的代码,配置chromedriver环境,输入需要抓取的网页,然后等待抓取完成.
2. 简单的数据清理
def str_to_number(str1):
mid = re.findall(r"\d+\.?\d*",str1)
if mid != []:
return mid[0]
else:
return 0
data["点赞数"] = data["点赞数"].apply(str_to_number)
data["评论人数"] = data["评论人数"].apply(str_to_number)
data["问题点赞数"] = data["问题点赞数"].apply(str_to_number)
data["问题评论数"] = data["问题评论数"].apply(str_to_number)
data["问题回答数"] = data["问题回答数"].apply(str_to_number)
def time_to_datetime(x):
x1 = re.sub('[\u4e00-\u9fa5]', '',x)
if len(x1) < 15 :
#15的根据是data["发表时间_1"] = data["发表时间"].apply(lambda x : re.sub('[\u4e00-\u9fa5]', '',x))
#data["发表时间_1"].apply(lambda x : len(x)).value_counts()
x2 = re.sub(' ', '2020-',x1,count=1)
return x2
return x1
data["发表时间"] = data["发表时间"].apply(time_to_datetime)
data.sort_values('发表时间', inplace=True)
data = data.reset_index(drop = True)
data
3. 使用“问题标题”存储数据 查看全部
社交: 充分利用最好的机会!了解采集器集成代码的实现! (2020年7月29日)

上一篇文章(上面的链接)对每个部分进行了更详细的描述. 本文将介绍用于爬网和爬网数据的预处理的集成代码块.
1.python集成代码,实现了优采云爬行之虎的所有功能
```python
#!/usr/bin/env python
# coding: utf-8
import os
import pandas as pd
from selenium import webdriver
from lxml import etree
import time
import jieba
import re
import numpy as np
url1 = input("请输入您所需要爬取的网页(知乎)")
browser = webdriver.Chrome("/Users/apple/Downloads/chromedrivermac")
browser.get(url1)
try:
#点击问题全部内容
button1 = browser.find_elements_by_xpath("""//div[@class= "QuestionHeader-detail"]
//button[contains(@class,"Button") and contains(@class,"QuestionRichText-more")
and contains(@class , "Button--plain")
]""")[0]
button1.click()
except:
print('这个问题比较简单,并没有问题的全部内容哦!')
#此网页就属于异步加载的情况
#那么我们就需要多次下滑
for i in range(20):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
#点击知乎的登陆弹窗
button2 = browser.find_elements_by_xpath("""//button[@aria-label = '关闭']""")[0]
button2.click()
#点击知乎的“查看全部回答”按钮
button3 = browser.find_elements_by_xpath("""//div[@class = 'Question-main']
//a[contains(@class,"ViewAll-QuestionMainAction") and contains(@class , "QuestionMainAction") ]""")[1]
button3.click()
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
while final_end_it == []:
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
for i in range(30):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
dom = etree.HTML(browser.page_source)
# 对于问题本身的数据
Followers_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[0]
Browsed_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[1]
#关注者数量
Followers_number_final = re.sub(",","",Followers_number_first)
#浏览数量
Browsed_number_final = re.sub(",","",Browsed_number_first)
#问题链接
problem_url = url1
#问题ID
problem_id = re.findall(r"\d+\.?\d*",url1)
#问题标题
problem_title = dom.xpath("""//div[@class = 'QuestionHeader']//h1[@class = "QuestionHeader-title"]/text()""")
#问题点赞数
problem_endorse = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "GoodQuestionAction"]/button/text()""")
#问题评论数
problem_Comment = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "QuestionHeader-Comment"]/button/text()""")
#问题回答数
answer_number = dom.xpath("""//div[@class = 'Question-main']//h4[@class = "List-headerText"]/span/text()""")
#问题标签
problem_tags_list = dom.xpath("""//div[@class = 'QuestionHeader-topics']//a[@class = "TopicLink"]/div/div/text()""")
# 对于回答本身的数据
#具体内容
comment_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "RichContent-inner"]""")
comment_list_text = []
for comment in comment_list:
comment_list_text.append(comment.xpath("string(.)"))
#发表时间
time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/@data-tooltip""")
edit_time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/text()""")
#点赞数
endorse_list = dom.xpath("""//div[@class = 'List-item']//button[contains(@class,"Button") and contains(@class,"VoteButton") and contains(@class , "VoteButton--up")]/@aria-label""")
#评论人数
number_of_endorse_list = dom.xpath("""//div[@class = 'List-item']//svg[contains(@class,"Zi") and contains(@class,"Zi--Comment")
and contains(@class,"Button-zi")]/../../text()""")
#回答链接
answers_url_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/meta[@itemprop = "url"]/@content""")
authors_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/@data-zop""")
#作者姓名
authorName_list = []
#作者id
authorid_list = []
for i in authors_list:
authorName_list.append(eval(i)['authorName'])
authorid_list.append(eval(i)["itemId"])
# 合成数据框
data = pd.DataFrame()
data['具体内容'] = comment_list_text
data["发表时间"] = time_list
data["点赞数"] = endorse_list
data["评论人数"] = number_of_endorse_list
data["回答链接"] = answers_url_list
data["作者姓名"] = authorName_list
data['作者id'] = authorid_list
data["问题关注者数量"] = Followers_number_final
data["问题浏览数量"] = Browsed_number_final
data["问题链接"] = problem_url
data["问题ID"] = problem_id[0]
data["问题标题"] = problem_title[0]
data["问题点赞数"] = problem_endorse[0]
data["问题评论数"] = problem_Comment[0]
data["问题回答数"] = answer_number[0]
data["问题标签"] = "&".join(problem_tags_list)
data
复制上面的代码,配置chromedriver环境,输入需要抓取的网页,然后等待抓取完成.
2. 简单的数据清理
def str_to_number(str1):
mid = re.findall(r"\d+\.?\d*",str1)
if mid != []:
return mid[0]
else:
return 0
data["点赞数"] = data["点赞数"].apply(str_to_number)
data["评论人数"] = data["评论人数"].apply(str_to_number)
data["问题点赞数"] = data["问题点赞数"].apply(str_to_number)
data["问题评论数"] = data["问题评论数"].apply(str_to_number)
data["问题回答数"] = data["问题回答数"].apply(str_to_number)
def time_to_datetime(x):
x1 = re.sub('[\u4e00-\u9fa5]', '',x)
if len(x1) < 15 :
#15的根据是data["发表时间_1"] = data["发表时间"].apply(lambda x : re.sub('[\u4e00-\u9fa5]', '',x))
#data["发表时间_1"].apply(lambda x : len(x)).value_counts()
x2 = re.sub(' ', '2020-',x1,count=1)
return x2
return x1
data["发表时间"] = data["发表时间"].apply(time_to_datetime)
data.sort_values('发表时间', inplace=True)
data = data.reset_index(drop = True)
data

3. 使用“问题标题”存储数据
使用python创建爬虫非常简单: Meituan.com数据采集技能,如果您有基础,就开始爬网!
采集交流 • 优采云 发表了文章 • 0 个评论 • 703 次浏览 • 2020-08-08 14:49
如今,大多数动态网站通过浏览器端的js发起ajax请求,然后在接收到数据后呈现页面. 在这种情况下,采集数据,通过脚本启动http获取请求以及在获取DOM文档页面之后解析和提取有用数据的方法是不可行的. 然后有人会想到通过F12打开浏览器控制台来分析服务器api,然后模拟请求相应的api以获取我们想要的数据. 这个想法在某些情况下是可行的,但是许多大型网站都会采用一些防爬网策略,出于安全考虑,通常会在界面中添加安全验证. 例如,在请求页面之前,只能请求相关的标头和cookie. 有些还限制了请求的来源,等等,这一次通过这种方式采集数据就更加困难了. 我们还有其他有效的方法吗?当然,python爬虫非常简单,让我们首先了解Selenium和Selectors,然后通过抓取美团在线业务信息的示例总结一些数据采集技术:
2. 页面抓取数据分析和数据表创建
以朝阳大悦城的一家美食餐厅为数据采集示例,该网站为:
https://www.meituan.com/meishi/40453459/
2.1获取数据
我们要捕获的数据的第一部分是企业的基本信息,包括企业名称,地址,电话号码和营业时间. 在分析了多个美食企业之后,我们知道这些企业的Web界面在布局上基本相同. 因此我们的采集器可以编写更通用的内容. 为了防止重复抓取业务数据,我们还将业务的URL信息存储在数据表中.
第二部分要捕获的数据是美食餐厅的招牌菜. 每个商店基本上都有自己的特色菜. 我们还将保存这些数据并将其存储在另一个数据表中.
我们要捕获的数据的最后一部分是用户评论. 这部分数据对我们来说非常有价值. 将来,我们可以分析这部分数据以提取有关业务的更多信息. 我们要获取的信息的这一部分包括: 评论者的昵称,星级,评论内容,评论时间,如果有图片,我们还需要以列表的形式保存图片的地址.
2.2创建数据表
我们用来存储数据的数据库是Mysql,Python有一个相关的ORM,我们在项目中使用了peewee. 但是,建议在创建数据表时使用本机SQL,以便我们可以灵活地控制字段属性,设置引擎和字符编码格式等. 使用Python的ORM也可以实现结果,但是ORM是数据库层的封装,例如sqlite,sqlserver数据库和Mysql,仍然存在一些差异,使用ORM只能使用这些数据库的公共部分. 以下是存储数据所需的数据表sql:
CREATE TABLE `merchant` ( #商家表
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '商家名称',
`address` varchar(255) NOT NULL COMMENT '地址',
`website_address` varchar(255) NOT NULL COMMENT '网址',
`website_address_hash` varchar(32) NOT NULL COMMENT '网址hash',
`mobile` varchar(32) NOT NULL COMMENT '电话',
`business_hours` varchar(255) NOT NULL COMMENT '营业时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `recommended_dish` ( #推荐菜表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`name` varchar(255) NOT NULL COMMENT '推荐菜名称',
PRIMARY KEY (`id`),
KEY `recommended_dish_merchant_id` (`merchant_id`),
CONSTRAINT `recommended_dish_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=309 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `evaluate` ( #评论表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`user_name` varchar(255) DEFAULT '' COMMENT '评论人昵称',
`evaluate_time` datetime NOT NULL COMMENT '评论时间',
`content` varchar(10000) DEFAULT '' COMMENT '评论内容',
`star` tinyint(4) DEFAULT '0' COMMENT '星级',
`image_list` varchar(1000) DEFAULT '' COMMENT '图片列表',
PRIMARY KEY (`id`),
KEY `evaluate_merchant_id` (`merchant_id`),
CONSTRAINT `evaluate_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8427 DEFAULT CHARSET=utf8mb4;
相应地,我们还可以使用Python的ORM创建管理数据表. 稍后在分析代码时,我们将讨论peewee在mysql数据库上的一些常见操作,例如查询数据,插入数据库数据和返回id. 批量插入数据库等,读者可以采集相关材料并进行系统学习.
meituan_spider / models.py代码:
from peewee import *
# 连接数据库
db = MySQLDatabase("meituan_spider", host="127.0.0.1", port=3306, user="root", password="root", charset="utf8")
class BaseModel(Model):
class Meta:
database = db
# 商家表,用来存放商家信息
class Merchant(BaseModel):
id = AutoField(primary_key=True, verbose_name="商家id")
name = CharField(max_length=255, verbose_name="商家名称")
address = CharField(max_length=255, verbose_name="商家地址")
website_address = CharField(max_length=255, verbose_name="网络地址")
website_address_hash = CharField(max_length=32, verbose_name="网络地址的md5值,为了快速索引")
mobile = CharField(max_length=32, verbose_name="商家电话")
business_hours = CharField(max_length=255, verbose_name="营业时间")
# 商家推荐菜表,存放菜品的推荐信息
class Recommended_dish(BaseModel):
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
name = CharField(max_length=255, verbose_name="推荐菜名称")
# 用户评价表,存放用户的评论信息
class Evaluate(BaseModel):
id = CharField(primary_key=True)
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
user_name = CharField(verbose_name="用户名")
evaluate_time = DateTimeField(verbose_name="评价时间")
content = TextField(default="", verbose_name="评论内容")
star = IntegerField(default=0, verbose_name="评分")
image_list = TextField(default="", verbose_name="图片")
if __name__ == "__main__":
db.create_tables([Merchant, Recommended_dish, Evaluate])
3. 代码实现和详细说明
代码相对简单,但是要运行代码,您需要安装上述工具包: 还需要安装硒,scrapy和peewee,这些软件包可以通过pip来安装;另外,还需要安装selenium驱动程序浏览器相应的驱动程序,因为我在本地使用chrome浏览器,所以我下载了相关版本的chromedriver,将在以后使用. 要求读者检查使用python操作硒所需的准备工作,并手动设置相关环境. 接下来,详细分析代码;源代码如下:
<p>from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from scrapy import Selector
from models import *
import hashlib
import os
import re
import time
import json
chrome_options = Options()
# 设置headless模式,这种方式下无启动界面,能够加速程序的运行
# chrome_options.add_argument("--headless")
# 禁用gpu防止渲染图片
chrome_options.add_argument('disable-gpu')
# 设置不加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 通过页面展示的像素数计算星级
def star_num(num):
numbers = {
"16.8": 1,
"33.6": 2,
"50.4": 3,
"67.2": 4,
"84": 5
}
return numbers.get(num, 0)
# 解析商家内容
def parse(merchant_id):
weblink = "https://www.meituan.com/meishi/{}/".format(merchant_id)
# 启动selenium
browser = webdriver.Chrome(executable_path="/Users/guozhaoran/python/tools/chromedriver", options=chrome_options)
browser.get(weblink)
# 不重复爬取数据
hash_weblink = hashlib.md5(weblink.encode(encoding='utf-8')).hexdigest()
existed = Merchant.select().where(Merchant.website_address_hash == hash_weblink)
if (existed):
print("数据已经爬取")
os._exit(0)
time.sleep(2)
# print(browser.page_source) #获取到网页渲染后的内容
sel = Selector(text=browser.page_source)
# 提取商家的基本信息
# 商家名称
name = "".join(sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='name']/text()").extract()).strip()
detail = sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='address']//p/text()").extract()
address = "".join(detail[1].strip())
mobile = "".join(detail[3].strip())
business_hours = "".join(detail[5].strip())
# 保存商家信息
merchant_id = Merchant.insert(name=name, address=address, website_address=weblink,
website_address_hash=hash_weblink, mobile=mobile, business_hours=business_hours
).execute()
# 获取推荐菜信息
recommended_dish_list = sel.xpath(
"//div[@id='app']//div[@class='recommend']//div[@class='list clear']//span/text()").extract()
# 遍历获取到的数据,批量插入数据库
dish_data = [{
'merchant_id': merchant_id,
'name': i
} for i in recommended_dish_list]
Recommended_dish.insert_many(dish_data).execute()
# 也可以遍历list,一条条插入数据库
# for dish in recommended_dish_list:
# Recommended_dish.create(merchant_id=merchant_id, name=dish)
# 查看链接一共有多少页的评论
page_num = 0
try:
page_num = sel.xpath(
"//div[@id='app']//div[@class='mt-pagination']//ul[@class='pagination clear']//li[last()-1]//span/text()").extract_first()
page_num = int("".join(page_num).strip())
# page_num = int(page_num)
except NoSuchElementException as e:
print("改商家没有用户评论信息")
os._exit(0)
# 当有用户评论数据,每页每页的读取用户数据
if (page_num):
i = 1
number_pattern = re.compile(r"\d+\.?\d*")
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
illegal_str = re.compile(u'[^0-9a-zA-Z\u4e00-\u9fa5.,,。?“”]+', re.UNICODE)
while (i 查看全部
1. 数据采集工具简介
如今,大多数动态网站通过浏览器端的js发起ajax请求,然后在接收到数据后呈现页面. 在这种情况下,采集数据,通过脚本启动http获取请求以及在获取DOM文档页面之后解析和提取有用数据的方法是不可行的. 然后有人会想到通过F12打开浏览器控制台来分析服务器api,然后模拟请求相应的api以获取我们想要的数据. 这个想法在某些情况下是可行的,但是许多大型网站都会采用一些防爬网策略,出于安全考虑,通常会在界面中添加安全验证. 例如,在请求页面之前,只能请求相关的标头和cookie. 有些还限制了请求的来源,等等,这一次通过这种方式采集数据就更加困难了. 我们还有其他有效的方法吗?当然,python爬虫非常简单,让我们首先了解Selenium和Selectors,然后通过抓取美团在线业务信息的示例总结一些数据采集技术:
2. 页面抓取数据分析和数据表创建
以朝阳大悦城的一家美食餐厅为数据采集示例,该网站为:
https://www.meituan.com/meishi/40453459/
2.1获取数据
我们要捕获的数据的第一部分是企业的基本信息,包括企业名称,地址,电话号码和营业时间. 在分析了多个美食企业之后,我们知道这些企业的Web界面在布局上基本相同. 因此我们的采集器可以编写更通用的内容. 为了防止重复抓取业务数据,我们还将业务的URL信息存储在数据表中.
第二部分要捕获的数据是美食餐厅的招牌菜. 每个商店基本上都有自己的特色菜. 我们还将保存这些数据并将其存储在另一个数据表中.
我们要捕获的数据的最后一部分是用户评论. 这部分数据对我们来说非常有价值. 将来,我们可以分析这部分数据以提取有关业务的更多信息. 我们要获取的信息的这一部分包括: 评论者的昵称,星级,评论内容,评论时间,如果有图片,我们还需要以列表的形式保存图片的地址.
2.2创建数据表
我们用来存储数据的数据库是Mysql,Python有一个相关的ORM,我们在项目中使用了peewee. 但是,建议在创建数据表时使用本机SQL,以便我们可以灵活地控制字段属性,设置引擎和字符编码格式等. 使用Python的ORM也可以实现结果,但是ORM是数据库层的封装,例如sqlite,sqlserver数据库和Mysql,仍然存在一些差异,使用ORM只能使用这些数据库的公共部分. 以下是存储数据所需的数据表sql:
CREATE TABLE `merchant` ( #商家表
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '商家名称',
`address` varchar(255) NOT NULL COMMENT '地址',
`website_address` varchar(255) NOT NULL COMMENT '网址',
`website_address_hash` varchar(32) NOT NULL COMMENT '网址hash',
`mobile` varchar(32) NOT NULL COMMENT '电话',
`business_hours` varchar(255) NOT NULL COMMENT '营业时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `recommended_dish` ( #推荐菜表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`name` varchar(255) NOT NULL COMMENT '推荐菜名称',
PRIMARY KEY (`id`),
KEY `recommended_dish_merchant_id` (`merchant_id`),
CONSTRAINT `recommended_dish_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=309 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `evaluate` ( #评论表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`user_name` varchar(255) DEFAULT '' COMMENT '评论人昵称',
`evaluate_time` datetime NOT NULL COMMENT '评论时间',
`content` varchar(10000) DEFAULT '' COMMENT '评论内容',
`star` tinyint(4) DEFAULT '0' COMMENT '星级',
`image_list` varchar(1000) DEFAULT '' COMMENT '图片列表',
PRIMARY KEY (`id`),
KEY `evaluate_merchant_id` (`merchant_id`),
CONSTRAINT `evaluate_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8427 DEFAULT CHARSET=utf8mb4;
相应地,我们还可以使用Python的ORM创建管理数据表. 稍后在分析代码时,我们将讨论peewee在mysql数据库上的一些常见操作,例如查询数据,插入数据库数据和返回id. 批量插入数据库等,读者可以采集相关材料并进行系统学习.
meituan_spider / models.py代码:
from peewee import *
# 连接数据库
db = MySQLDatabase("meituan_spider", host="127.0.0.1", port=3306, user="root", password="root", charset="utf8")
class BaseModel(Model):
class Meta:
database = db
# 商家表,用来存放商家信息
class Merchant(BaseModel):
id = AutoField(primary_key=True, verbose_name="商家id")
name = CharField(max_length=255, verbose_name="商家名称")
address = CharField(max_length=255, verbose_name="商家地址")
website_address = CharField(max_length=255, verbose_name="网络地址")
website_address_hash = CharField(max_length=32, verbose_name="网络地址的md5值,为了快速索引")
mobile = CharField(max_length=32, verbose_name="商家电话")
business_hours = CharField(max_length=255, verbose_name="营业时间")
# 商家推荐菜表,存放菜品的推荐信息
class Recommended_dish(BaseModel):
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
name = CharField(max_length=255, verbose_name="推荐菜名称")
# 用户评价表,存放用户的评论信息
class Evaluate(BaseModel):
id = CharField(primary_key=True)
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
user_name = CharField(verbose_name="用户名")
evaluate_time = DateTimeField(verbose_name="评价时间")
content = TextField(default="", verbose_name="评论内容")
star = IntegerField(default=0, verbose_name="评分")
image_list = TextField(default="", verbose_name="图片")
if __name__ == "__main__":
db.create_tables([Merchant, Recommended_dish, Evaluate])
3. 代码实现和详细说明
代码相对简单,但是要运行代码,您需要安装上述工具包: 还需要安装硒,scrapy和peewee,这些软件包可以通过pip来安装;另外,还需要安装selenium驱动程序浏览器相应的驱动程序,因为我在本地使用chrome浏览器,所以我下载了相关版本的chromedriver,将在以后使用. 要求读者检查使用python操作硒所需的准备工作,并手动设置相关环境. 接下来,详细分析代码;源代码如下:
<p>from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from scrapy import Selector
from models import *
import hashlib
import os
import re
import time
import json
chrome_options = Options()
# 设置headless模式,这种方式下无启动界面,能够加速程序的运行
# chrome_options.add_argument("--headless")
# 禁用gpu防止渲染图片
chrome_options.add_argument('disable-gpu')
# 设置不加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 通过页面展示的像素数计算星级
def star_num(num):
numbers = {
"16.8": 1,
"33.6": 2,
"50.4": 3,
"67.2": 4,
"84": 5
}
return numbers.get(num, 0)
# 解析商家内容
def parse(merchant_id):
weblink = "https://www.meituan.com/meishi/{}/".format(merchant_id)
# 启动selenium
browser = webdriver.Chrome(executable_path="/Users/guozhaoran/python/tools/chromedriver", options=chrome_options)
browser.get(weblink)
# 不重复爬取数据
hash_weblink = hashlib.md5(weblink.encode(encoding='utf-8')).hexdigest()
existed = Merchant.select().where(Merchant.website_address_hash == hash_weblink)
if (existed):
print("数据已经爬取")
os._exit(0)
time.sleep(2)
# print(browser.page_source) #获取到网页渲染后的内容
sel = Selector(text=browser.page_source)
# 提取商家的基本信息
# 商家名称
name = "".join(sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='name']/text()").extract()).strip()
detail = sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='address']//p/text()").extract()
address = "".join(detail[1].strip())
mobile = "".join(detail[3].strip())
business_hours = "".join(detail[5].strip())
# 保存商家信息
merchant_id = Merchant.insert(name=name, address=address, website_address=weblink,
website_address_hash=hash_weblink, mobile=mobile, business_hours=business_hours
).execute()
# 获取推荐菜信息
recommended_dish_list = sel.xpath(
"//div[@id='app']//div[@class='recommend']//div[@class='list clear']//span/text()").extract()
# 遍历获取到的数据,批量插入数据库
dish_data = [{
'merchant_id': merchant_id,
'name': i
} for i in recommended_dish_list]
Recommended_dish.insert_many(dish_data).execute()
# 也可以遍历list,一条条插入数据库
# for dish in recommended_dish_list:
# Recommended_dish.create(merchant_id=merchant_id, name=dish)
# 查看链接一共有多少页的评论
page_num = 0
try:
page_num = sel.xpath(
"//div[@id='app']//div[@class='mt-pagination']//ul[@class='pagination clear']//li[last()-1]//span/text()").extract_first()
page_num = int("".join(page_num).strip())
# page_num = int(page_num)
except NoSuchElementException as e:
print("改商家没有用户评论信息")
os._exit(0)
# 当有用户评论数据,每页每页的读取用户数据
if (page_num):
i = 1
number_pattern = re.compile(r"\d+\.?\d*")
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
illegal_str = re.compile(u'[^0-9a-zA-Z\u4e00-\u9fa5.,,。?“”]+', re.UNICODE)
while (i
3. 如果网站SEO文章被采集并抄袭该怎么办
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-08 10:22
1. 什么是采集品或窃?
采集是指通过某些采集程序和规则将文章从其他网站自动复制到您自己的网站. (这里的采集或窃必须是没有任何花招或伪装的原创采集)
按原样从其他网站采集文章对您网站的权重有很大影响. 尽管百度搜索引擎并不能真正保护原创文章,但成都SEO认为搜索引擎算法将变得越来越智能,可以按原样采集它们. 无论您采集多少,对提高网站排名都是有害且无利可图的.
我们的搜索引擎优化人员都知道,百度的飓风算法是在打击文章采集或窃. 如果我们使用文章采集器来发布文章,是否应该花时间根据算法处理它们?这是不值得的.
2. 所有SEO文章采集窃都会受到K站的惩罚
在分享开始时,我们知道,如果有人采集或窃我们的文章,则该文章将被收录并排在我们自己的文章之上. 是什么原因?
我们回到搜索引擎工作原理的本质,即满足和解决用户搜索结果时的需求. 换句话说,无论您的文章来自哪里(采集文章也可以解决用户需求),布局是否良好,逻辑表达是否清晰,可读性是否强,是否符合搜索引擎为用户提供的有价值的内容?解决用户搜索需求的实质?因此有一个排名.
但是,这样的采集行为是不可行的. 如果您想长期为采集的内容提供更好的排名,那肯定会引起原创作者的不满. 这种情况继续存在,网站管理员开始采集内容或窃内容,而不是制作原创文章或伪原创文章. 因此,当用户使用搜索引擎进行查询时,他们解决用户需求的能力将越来越弱.
因此,为了创建一个更好的Internet内容生态系统,搜索引擎将继续启动打击采集站点的算法,并且还将对原创内容给予某些排名偏好,以鼓励原创作者创建更多高质量的内容.
3. 如果网站SEO文章被采集并抄袭该怎么办
1. 对于临时建议,您通常可以礼貌地在另一方的网站上留言. 您可以在文章上添加链接进行投票吗?如果没有,那么百度会反馈并举报.
2. 长期建议,优化您的网站结构,打开速度和其他因素以提高您的实力,最好是在夜间更新文章,因为这会增加被首先收录的可能性. (请参阅原创文章的定义)
3. 尝试在网站上的图片上添加水印,以增加处理和处理其他人的文章的时间成本.
4. 保持良好的心态. 毕竟,百度还推出了一种飓风算法来打击惩罚. 采集原创物品并窃是一个问题. 技术一直在改进和优化. Google搜索引擎无法完美解决此问题. 最好的策略是做好自己的网站,以便可以在几秒钟内采集文章. 查看全部
在实际的网站SEO优化过程中,我们的网站管理员经常会遇到这样的情况: 我们收录的文章被他人窃,然后又收录了另一方的文章,并且排名高于自己的排名(请检查另一方是否旧站点和高重量站点),在这种情况下,我们都会问: K站点会因为这样的SEO文章采集或窃而受到惩罚吗?
1. 什么是采集品或窃?
采集是指通过某些采集程序和规则将文章从其他网站自动复制到您自己的网站. (这里的采集或窃必须是没有任何花招或伪装的原创采集)
按原样从其他网站采集文章对您网站的权重有很大影响. 尽管百度搜索引擎并不能真正保护原创文章,但成都SEO认为搜索引擎算法将变得越来越智能,可以按原样采集它们. 无论您采集多少,对提高网站排名都是有害且无利可图的.
我们的搜索引擎优化人员都知道,百度的飓风算法是在打击文章采集或窃. 如果我们使用文章采集器来发布文章,是否应该花时间根据算法处理它们?这是不值得的.

2. 所有SEO文章采集窃都会受到K站的惩罚
在分享开始时,我们知道,如果有人采集或窃我们的文章,则该文章将被收录并排在我们自己的文章之上. 是什么原因?
我们回到搜索引擎工作原理的本质,即满足和解决用户搜索结果时的需求. 换句话说,无论您的文章来自哪里(采集文章也可以解决用户需求),布局是否良好,逻辑表达是否清晰,可读性是否强,是否符合搜索引擎为用户提供的有价值的内容?解决用户搜索需求的实质?因此有一个排名.
但是,这样的采集行为是不可行的. 如果您想长期为采集的内容提供更好的排名,那肯定会引起原创作者的不满. 这种情况继续存在,网站管理员开始采集内容或窃内容,而不是制作原创文章或伪原创文章. 因此,当用户使用搜索引擎进行查询时,他们解决用户需求的能力将越来越弱.
因此,为了创建一个更好的Internet内容生态系统,搜索引擎将继续启动打击采集站点的算法,并且还将对原创内容给予某些排名偏好,以鼓励原创作者创建更多高质量的内容.
3. 如果网站SEO文章被采集并抄袭该怎么办
1. 对于临时建议,您通常可以礼貌地在另一方的网站上留言. 您可以在文章上添加链接进行投票吗?如果没有,那么百度会反馈并举报.
2. 长期建议,优化您的网站结构,打开速度和其他因素以提高您的实力,最好是在夜间更新文章,因为这会增加被首先收录的可能性. (请参阅原创文章的定义)
3. 尝试在网站上的图片上添加水印,以增加处理和处理其他人的文章的时间成本.
4. 保持良好的心态. 毕竟,百度还推出了一种飓风算法来打击惩罚. 采集原创物品并窃是一个问题. 技术一直在改进和优化. Google搜索引擎无法完美解决此问题. 最好的策略是做好自己的网站,以便可以在几秒钟内采集文章.
[原创工具] Shanken Web TXT Collector V1.1,可下载,实时预览,可以替换文本
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-08 02:54
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
版本: 1.0
日期: 2018.5.23
发展的原因: 在发展之初,是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看. 但是,许多小说网站不支持下载,或者下载[非VIP小说]受到限制. 我还在论坛中找到了一些采集. 但是我个人认为它不是很容易使用. 输入正则表达式后,将显示该章,但是无法通过单击下载按钮来下载文本. 软件完成后,我继续对其进行测试. 相同的正则表达式,那些软件的内容不匹配,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
该软件主要解决了这两个大问题.
您只能获得免费的章节,非VIP的章节,并支持原创作者.
功能模块简介:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,系统提示我360.这也可能是因为跳转是360浏览器. 我不知道你是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
在下面的上图中,图中的粉红色软件是我计算机主题的原因,而不是覆盖面部的软件设置:
寻求支持,寻求支持,寻求支持! ! ! !说三遍重要的事情! ! !
v1.0的下载链接:
总下载链接[包括V1.1]: 链接: 密码: uff3 查看全部
更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
版本: 1.0
日期: 2018.5.23
发展的原因: 在发展之初,是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看. 但是,许多小说网站不支持下载,或者下载[非VIP小说]受到限制. 我还在论坛中找到了一些采集. 但是我个人认为它不是很容易使用. 输入正则表达式后,将显示该章,但是无法通过单击下载按钮来下载文本. 软件完成后,我继续对其进行测试. 相同的正则表达式,那些软件的内容不匹配,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
该软件主要解决了这两个大问题.
您只能获得免费的章节,非VIP的章节,并支持原创作者.
功能模块简介:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,系统提示我360.这也可能是因为跳转是360浏览器. 我不知道你是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
在下面的上图中,图中的粉红色软件是我计算机主题的原因,而不是覆盖面部的软件设置:
寻求支持,寻求支持,寻求支持! ! ! !说三遍重要的事情! ! !
v1.0的下载链接:
总下载链接[包括V1.1]: 链接: 密码: uff3
Mini crawler下载0.1.1.0免费版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-08 02:52
这是一款超小型,快速的SEO工具,可为seo行业合作伙伴提供简单,快速和强大的支持,以快速检索其网站关键字,标题,描述和其他内容. 通过分析爬网内容来改进URL. 提高网站排名.
功能介绍
自动输入连续的URL
获取浏览器的输入历史记录,您可以快速找到已输入的URL. 无需记住一长串毫无意义的URL.
通过输入通配符,您可以快速输入一系列URL,从而大大降低了手动输入的效率.
如果需要更正自动生成的URL,则可以右键单击以删除和修改相应的URL.
灵活的人员爬行规则
默认情况下,提供了三种常用内容: 标题,关键字和网页描述. 对于主修seo的学生,可以快速上手并直接使用它. 快速完成老板的内容.
通过自定义XPath,您可以随意设置抓取内容,并且可以设置无限的规则.
使用方法
1. 安装并运行,在该URL上输入要爬网的网页的URL,这时该URL将自动添加到URL列表中,在规则列表中输入标题,关键字和描述,然后单击“开始”.
2. 爬网后,Cheng将自动打开一个Excel表,其中收录您输入的URL地址以及采集的标题,关键字和描述.
文件信息
文件大小: 2014208字节
MD5: FF86958701C899A7379BA612E0ABF2DE
SHA1: FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32: 5B3E0727
官方网站:
相关搜索: SEO采集器 查看全部
迷你采集器是一种简单而紧凑的SEO搜寻工具. 它的功能是模拟搜索引擎对网页的标题,关键字,描述和其他信息进行爬网. 您可以使用它来采集自己的网站或采集竞争对手的网站,这样您就可以知道对手的标题和关键字是如何写的,并可以从中学习. 您需要的SEOER可以下载要使用的小型抓取工具.

这是一款超小型,快速的SEO工具,可为seo行业合作伙伴提供简单,快速和强大的支持,以快速检索其网站关键字,标题,描述和其他内容. 通过分析爬网内容来改进URL. 提高网站排名.
功能介绍
自动输入连续的URL
获取浏览器的输入历史记录,您可以快速找到已输入的URL. 无需记住一长串毫无意义的URL.
通过输入通配符,您可以快速输入一系列URL,从而大大降低了手动输入的效率.
如果需要更正自动生成的URL,则可以右键单击以删除和修改相应的URL.


灵活的人员爬行规则
默认情况下,提供了三种常用内容: 标题,关键字和网页描述. 对于主修seo的学生,可以快速上手并直接使用它. 快速完成老板的内容.
通过自定义XPath,您可以随意设置抓取内容,并且可以设置无限的规则.

使用方法
1. 安装并运行,在该URL上输入要爬网的网页的URL,这时该URL将自动添加到URL列表中,在规则列表中输入标题,关键字和描述,然后单击“开始”.

2. 爬网后,Cheng将自动打开一个Excel表,其中收录您输入的URL地址以及采集的标题,关键字和描述.

文件信息
文件大小: 2014208字节
MD5: FF86958701C899A7379BA612E0ABF2DE
SHA1: FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32: 5B3E0727
官方网站:
相关搜索: SEO采集器
Shanken Web TXT Collector V1.1绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-07 18:22
功能介绍
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
注释
实际上,您只需要.exe,规则全部由您自己添加,并且commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
更新日志
1.1更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活. 查看全部
Shanken网页TXT Collector是一种网络新颖的采集软件,可以下载,实时预览以及替换文本. 当前,只能获得免费的章节,并且不支持VIP章节!

功能介绍
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
注释
实际上,您只需要.exe,规则全部由您自己添加,并且commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
更新日志
1.1更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
黑帽SEO(SEO作弊)的技术是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-07 17:23
所有使用欺诈或可疑手段的人都可以称为黑帽SEO. 例如垃圾邮件链接,隐藏页面,桥接页面,关键字填充等. 我不建议学习黑帽子. 黑帽子具有黑帽子SEO的优点,与白帽子SEO相同. 对于普通的商业网站和大多数个人网站,良好的内容,正常的优化以及对用户体验的关注是成功之路. 如果您想学习白帽子,那么您可以穿上这条裙子. 在中间571和206的425中,您可以通过连接数字找到我们. 如果您真的不想学习白帽子,请不要添加它. 典型的黑帽搜索引擎优化使用程序从其他类别或搜索引擎获取大量搜索结果来制作网页,然后将Google Adsense放在这些网页上. 这些页面的数量不是成百上千,而是成千上万. 因此,即使大多数网页排名都不高,但由于网页数量巨大,用户仍会进入该网站并点击GoogleAdsense广告.
博客作弊
BLOG是高度互动的工具. 近年来,博客的兴起已成为黑帽SEO创建链接的新天地.
1. BLOG小组作弊: 中国一些常见的BLOG程序,例如: wordpress,ZBLOG,PJBLOG,Bo-blog. 在ZBLOG和PJBLOG的早期,开发人员缺乏SEO知识. ZBLOG和PJBLOG曾经成为黑帽SEO经常访问的地方. Bo-blog博客程序似乎仍然可以给黑帽SEO机会.
2. BLOG小组作弊: BLOG小组建立作弊是通过程序或人工手段申请大量BLOG帐户. 然后,通过发布一些带有关键字链接的文章,这些链接将提升关键字搜索引擎的排名.
3. BLOG隐藏链接作弊: 通过提供免费的博客样式(FreeTemplate),作弊者将隐藏链接(HideLinks)添加到样式文件中,以增加网站隐藏链接并达到提高搜索引擎排名的目的.
页面跳转
使用Java脚本或其他技术可以使用户在进入页面后快速跳转到另一页面.
秘密更改页面
这是专为SEO设计的高度优化的网页. 网站达到理想排名后,将优化后的页面替换为普通页面.
桥梁页面
为某个关键字创建优化的页面,将链接定向到或重定向到目标页面,并且桥接页面本身没有实际内容,只是搜索引擎的关键字堆. [3]
留言簿组发布
使用留言簿组发布软件自动发布您自己的关键字URL,并在短时间内快速增加外部链接.
链接工厂
“链接工厂”(也称为“质量链接机制”)是指由大量交叉链接的网页组成的网络系统. 这些网页可能来自同一域或多个不同域,甚至可能来自不同服务器. 站点加入这样的“链接工厂”后,一方面,它可以从系统中的所有网页获取链接,与此同时,作为交换,它需要“专用”自己的链接,并使用它方法来提高链接得分,从而达到干预链接得分的目的.
隐藏链接
SEO通常在客户网站上使用隐藏链接,通过使用其客户网站上的隐藏链接来连接其自己的网站或其他客户的网站.
假链接
将链接添加到JS代码,框架或表单. 搜索引擎蜘蛛程序根本无法读取这种方式的链接. 因此,该链接仅供人们查看,搜索引擎根本无法识别它.
网络劫持
网页劫持是我们通常所说的PageJacking,它是完全复制他人网站或整个网站的内容,并将其放置在您自己的网站上. 这种黑帽子式SEO方法对网站内容极为匮乏的网站管理员有吸引力. 但是,这种方法非常危险且无耻. 搜索引擎的专利技术可以从多种因素中判断出复制的网页或网站不是原创的,也不会收录在内.
网站镜像
复制整个网站或部分网页内容,并分配不同的域名和服务器以欺骗搜索引擎以多次索引同一网站或同一页面的行为. 这就是为什么某些网站指示禁止未经授权的操作的原因网站镜像的原因是两个网站完全相同. 如果相似度太高,将不可避免地导致您自己的网站受到影响. [4]
地址重定向
302redirect: 302代表临时移动. 在过去的几年中,许多BlackHatSEO广泛使用了该技术来作弊,并且主要的搜索引擎也加大了对其的打击力度. 即使该网站客观上不是垃圾邮件,也很容易被搜索引擎误认为是垃圾邮件并受到惩罚. 每个人都必须有这样的经验. 当您搜索某个网站时,您将变成另一个网站. 这主要是通过跳转技术来实现的,该技术通常会跳转到有利可图的页面.
悬挂黑链
扫描FTP或服务器中的弱密码和漏洞,然后入侵网站并将链接挂起. 这是一种非法方法. 我鄙视这些SEOer. 中国有很多这样的人. 这些可以通过SeoQuake插件发现.
海角法
简单来说,隐瞒是网站管理员使用两个不同的页面来达到最佳效果. 一个版本仅适用于搜索引擎,另一个版本适用于您自己. 如果提供给搜索引擎的网站版本未如实反映网页中收录的真实内容,则搜索引擎认为这种做法是非法的. 如果找到该网站,则该网站将从搜索引擎列表中永久删除.
关键字积累
优化关键字时,许多网站管理员会累积大量关键字,这使搜索引擎认为网页是相关的. 关键字累积技术使用一长串的重复关键字来混淆搜索引擎. 实际上,这些关键字有时与Web内容有关,有时与Web内容无关. 这种方法很少起作用,而且网站的排名在短期或长期内都不可能提升到很高的水平.
公关劫持
PR劫持的方法是使用跳转. 通常,搜索引擎将目标URL视为处理301和302重定向时应实际收录的URL. 当然有特殊情况,但是在大多数情况下都是这样. 因此,如果您执行从域名A到域名B的301或302重定向,并且域名B的PR值相对较高,那么在域名A的PR更新后,域名B的PR值也会显示. 最简单的方法是将301或302跳转到具有较高PR的域名B,并在PR更新后立即取消重定向,并同时获得与站B相同的PR值. 此错误的PR显示值至少要等到下一次PR更新.
精美文字
许多进行搜索引擎优化的人都知道隐藏文本可能会受到惩罚,因此他们以微妙的字体显示隐藏文本. 对于精美的文本,甚至可以使用小字体在网页上不显眼的位置编写带有关键字的句子. 通常,这些文本位于网页的顶部或底部. 尽管这些文本的颜色与隐藏文本的背景颜色不同,但它们通常以非常相似的颜色出现.
隐藏页面
隐藏页面(cloakedpage)是使用程序或脚本检测它是搜索引擎还是普通用户的网页. 如果它是搜索引擎,则该页面将返回该页面的优化版本. 如果访问者是普通人,则返回另一个版本. 用户通常找不到这种作弊类型. 因为一旦您的浏览器可以看到该网页(无论是在页面上还是在HTML源文件中),您所获得的已经是与搜索引擎不同的版本. 检查的方法是查看此页面的快照.
隐藏的文字
隐藏文本(hiddentext)是将收录关键字的文本放入网页的HTML文件中,但是用户无法看到这些单词,而只能由搜索引擎看到. 可以有多种形式,例如超小文本,与背景颜色相同的文本,放置在注释标签中的文本,放置在表单的输入标签中的文本以及通过样式表放置在不可见层上的文本还有更多
桥梁页面
Doorwaypages [3](doorwaypages)通常是自动生成大量收录关键字的网页,然后从这些网页自动重定向到主页的软件. 目的是希望这些针对不同关键字的桥页能够在搜索引擎中获得良好的排名. 当用户单击搜索结果时,它将自动转到主页. 有时,到首页的链接会放置在桥页面上,而不会自动重定向.
Black hat seo: 在十分钟内获得一百个主要的网站shell,以及如何使用webshell.rar赚钱
黑帽很不稳定,因此不建议戴黑帽. 现在,百度可以阻止黑帽获得的链接.
因此,黑帽子和黑网站等同于不稳定,黑帽子进入的网站不一定是权重较高的网站. 高安全性会不好吗?
建议正常优化SEO. 如有任何疑问,您可以去家里回答SEO优化论坛.
如何查看竞争对手的网站看起来像黑帽子的搜索引擎优化
根据竞争对手的网站是否存在黑帽seo情况,我们必须首先了解黑帽seo的18种方法: 1: 关键字堆叠2: 桥接页面3 .:隐藏文本4: 隐藏链接/黑链5: 隐藏页面/捕获方法/盲目... 6: 网页劫持/公关劫持7: 链接交易8: 链接工厂/站点组/博客链轮/链接农场/链接农场... 9: 垃圾链接10: 网站镜像11 : 诱饵替换12: 内容采集/采集器/伪原创工具13: 组源软件/博客组/论坛组/外链/留言簿组... 14: 蜘蛛陷阱/ Flash动画/ SessionID /框架结构/动态URL / JS链接/需要登录/强制使用Cookies15: 伪造链接16: 欺骗点击链接17: 弹出广告18: 检查网站zhidao /检查百度排名/选中百度下拉框,相关搜索/检查百度共享/刷网站流量/刷alexa流量/刷IP流量... 查看全部
黑帽SEO(SEO作弊)的技术是什么?
所有使用欺诈或可疑手段的人都可以称为黑帽SEO. 例如垃圾邮件链接,隐藏页面,桥接页面,关键字填充等. 我不建议学习黑帽子. 黑帽子具有黑帽子SEO的优点,与白帽子SEO相同. 对于普通的商业网站和大多数个人网站,良好的内容,正常的优化以及对用户体验的关注是成功之路. 如果您想学习白帽子,那么您可以穿上这条裙子. 在中间571和206的425中,您可以通过连接数字找到我们. 如果您真的不想学习白帽子,请不要添加它. 典型的黑帽搜索引擎优化使用程序从其他类别或搜索引擎获取大量搜索结果来制作网页,然后将Google Adsense放在这些网页上. 这些页面的数量不是成百上千,而是成千上万. 因此,即使大多数网页排名都不高,但由于网页数量巨大,用户仍会进入该网站并点击GoogleAdsense广告.
博客作弊
BLOG是高度互动的工具. 近年来,博客的兴起已成为黑帽SEO创建链接的新天地.
1. BLOG小组作弊: 中国一些常见的BLOG程序,例如: wordpress,ZBLOG,PJBLOG,Bo-blog. 在ZBLOG和PJBLOG的早期,开发人员缺乏SEO知识. ZBLOG和PJBLOG曾经成为黑帽SEO经常访问的地方. Bo-blog博客程序似乎仍然可以给黑帽SEO机会.
2. BLOG小组作弊: BLOG小组建立作弊是通过程序或人工手段申请大量BLOG帐户. 然后,通过发布一些带有关键字链接的文章,这些链接将提升关键字搜索引擎的排名.
3. BLOG隐藏链接作弊: 通过提供免费的博客样式(FreeTemplate),作弊者将隐藏链接(HideLinks)添加到样式文件中,以增加网站隐藏链接并达到提高搜索引擎排名的目的.
页面跳转
使用Java脚本或其他技术可以使用户在进入页面后快速跳转到另一页面.
秘密更改页面
这是专为SEO设计的高度优化的网页. 网站达到理想排名后,将优化后的页面替换为普通页面.
桥梁页面
为某个关键字创建优化的页面,将链接定向到或重定向到目标页面,并且桥接页面本身没有实际内容,只是搜索引擎的关键字堆. [3]
留言簿组发布
使用留言簿组发布软件自动发布您自己的关键字URL,并在短时间内快速增加外部链接.
链接工厂
“链接工厂”(也称为“质量链接机制”)是指由大量交叉链接的网页组成的网络系统. 这些网页可能来自同一域或多个不同域,甚至可能来自不同服务器. 站点加入这样的“链接工厂”后,一方面,它可以从系统中的所有网页获取链接,与此同时,作为交换,它需要“专用”自己的链接,并使用它方法来提高链接得分,从而达到干预链接得分的目的.
隐藏链接
SEO通常在客户网站上使用隐藏链接,通过使用其客户网站上的隐藏链接来连接其自己的网站或其他客户的网站.
假链接
将链接添加到JS代码,框架或表单. 搜索引擎蜘蛛程序根本无法读取这种方式的链接. 因此,该链接仅供人们查看,搜索引擎根本无法识别它.
网络劫持
网页劫持是我们通常所说的PageJacking,它是完全复制他人网站或整个网站的内容,并将其放置在您自己的网站上. 这种黑帽子式SEO方法对网站内容极为匮乏的网站管理员有吸引力. 但是,这种方法非常危险且无耻. 搜索引擎的专利技术可以从多种因素中判断出复制的网页或网站不是原创的,也不会收录在内.
网站镜像
复制整个网站或部分网页内容,并分配不同的域名和服务器以欺骗搜索引擎以多次索引同一网站或同一页面的行为. 这就是为什么某些网站指示禁止未经授权的操作的原因网站镜像的原因是两个网站完全相同. 如果相似度太高,将不可避免地导致您自己的网站受到影响. [4]
地址重定向
302redirect: 302代表临时移动. 在过去的几年中,许多BlackHatSEO广泛使用了该技术来作弊,并且主要的搜索引擎也加大了对其的打击力度. 即使该网站客观上不是垃圾邮件,也很容易被搜索引擎误认为是垃圾邮件并受到惩罚. 每个人都必须有这样的经验. 当您搜索某个网站时,您将变成另一个网站. 这主要是通过跳转技术来实现的,该技术通常会跳转到有利可图的页面.
悬挂黑链
扫描FTP或服务器中的弱密码和漏洞,然后入侵网站并将链接挂起. 这是一种非法方法. 我鄙视这些SEOer. 中国有很多这样的人. 这些可以通过SeoQuake插件发现.
海角法
简单来说,隐瞒是网站管理员使用两个不同的页面来达到最佳效果. 一个版本仅适用于搜索引擎,另一个版本适用于您自己. 如果提供给搜索引擎的网站版本未如实反映网页中收录的真实内容,则搜索引擎认为这种做法是非法的. 如果找到该网站,则该网站将从搜索引擎列表中永久删除.
关键字积累
优化关键字时,许多网站管理员会累积大量关键字,这使搜索引擎认为网页是相关的. 关键字累积技术使用一长串的重复关键字来混淆搜索引擎. 实际上,这些关键字有时与Web内容有关,有时与Web内容无关. 这种方法很少起作用,而且网站的排名在短期或长期内都不可能提升到很高的水平.
公关劫持
PR劫持的方法是使用跳转. 通常,搜索引擎将目标URL视为处理301和302重定向时应实际收录的URL. 当然有特殊情况,但是在大多数情况下都是这样. 因此,如果您执行从域名A到域名B的301或302重定向,并且域名B的PR值相对较高,那么在域名A的PR更新后,域名B的PR值也会显示. 最简单的方法是将301或302跳转到具有较高PR的域名B,并在PR更新后立即取消重定向,并同时获得与站B相同的PR值. 此错误的PR显示值至少要等到下一次PR更新.
精美文字
许多进行搜索引擎优化的人都知道隐藏文本可能会受到惩罚,因此他们以微妙的字体显示隐藏文本. 对于精美的文本,甚至可以使用小字体在网页上不显眼的位置编写带有关键字的句子. 通常,这些文本位于网页的顶部或底部. 尽管这些文本的颜色与隐藏文本的背景颜色不同,但它们通常以非常相似的颜色出现.
隐藏页面
隐藏页面(cloakedpage)是使用程序或脚本检测它是搜索引擎还是普通用户的网页. 如果它是搜索引擎,则该页面将返回该页面的优化版本. 如果访问者是普通人,则返回另一个版本. 用户通常找不到这种作弊类型. 因为一旦您的浏览器可以看到该网页(无论是在页面上还是在HTML源文件中),您所获得的已经是与搜索引擎不同的版本. 检查的方法是查看此页面的快照.
隐藏的文字
隐藏文本(hiddentext)是将收录关键字的文本放入网页的HTML文件中,但是用户无法看到这些单词,而只能由搜索引擎看到. 可以有多种形式,例如超小文本,与背景颜色相同的文本,放置在注释标签中的文本,放置在表单的输入标签中的文本以及通过样式表放置在不可见层上的文本还有更多
桥梁页面
Doorwaypages [3](doorwaypages)通常是自动生成大量收录关键字的网页,然后从这些网页自动重定向到主页的软件. 目的是希望这些针对不同关键字的桥页能够在搜索引擎中获得良好的排名. 当用户单击搜索结果时,它将自动转到主页. 有时,到首页的链接会放置在桥页面上,而不会自动重定向.
Black hat seo: 在十分钟内获得一百个主要的网站shell,以及如何使用webshell.rar赚钱
黑帽很不稳定,因此不建议戴黑帽. 现在,百度可以阻止黑帽获得的链接.
因此,黑帽子和黑网站等同于不稳定,黑帽子进入的网站不一定是权重较高的网站. 高安全性会不好吗?
建议正常优化SEO. 如有任何疑问,您可以去家里回答SEO优化论坛.
如何查看竞争对手的网站看起来像黑帽子的搜索引擎优化
根据竞争对手的网站是否存在黑帽seo情况,我们必须首先了解黑帽seo的18种方法: 1: 关键字堆叠2: 桥接页面3 .:隐藏文本4: 隐藏链接/黑链5: 隐藏页面/捕获方法/盲目... 6: 网页劫持/公关劫持7: 链接交易8: 链接工厂/站点组/博客链轮/链接农场/链接农场... 9: 垃圾链接10: 网站镜像11 : 诱饵替换12: 内容采集/采集器/伪原创工具13: 组源软件/博客组/论坛组/外链/留言簿组... 14: 蜘蛛陷阱/ Flash动画/ SessionID /框架结构/动态URL / JS链接/需要登录/强制使用Cookies15: 伪造链接16: 欺骗点击链接17: 弹出广告18: 检查网站zhidao /检查百度排名/选中百度下拉框,相关搜索/检查百度共享/刷网站流量/刷alexa流量/刷IP流量...
优采云通用文章采集器v2.17.1.1特别版
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-07 06:16
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长且合并文章过大的集合. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定相同的文章,然后比较两个文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断这是另一篇文章,并会自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了一种非常准确的文本提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置提取的最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标记后的纯文本单词数. ,线条和文字中的空格).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站的访问速度超时(特别是Google所收录的许多网站被阻止),或者在正文中设置了最少字数,或者该程序忽略了本地具有相同名称,黑名单和白名单的内容相似的文章过滤等将导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配
1.11: 增强了Web批处理列URL采集器识别文章URL的能力
1.10: 解决了翻译功能无法翻译的问题 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长且合并文章过大的集合. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定相同的文章,然后比较两个文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断这是另一篇文章,并会自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了一种非常准确的文本提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置提取的最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标记后的纯文本单词数. ,线条和文字中的空格).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站的访问速度超时(特别是Google所收录的许多网站被阻止),或者在正文中设置了最少字数,或者该程序忽略了本地具有相同名称,黑名单和白名单的内容相似的文章过滤等将导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配
1.11: 增强了Web批处理列URL采集器识别文章URL的能力
1.10: 解决了翻译功能无法翻译的问题
Java网页数据采集器[上篇-数据采集]
采集交流 • 优采云 发表了文章 • 0 个评论 • 359 次浏览 • 2020-08-26 17:36
开篇
作为全球运用最广泛的语言,Java 凭借它的高效性,可移植性(跨平台),代码的健壮性以及强悍的可扩展性,深受广大应用程序开发者的喜爱.作为一门强悍的开发语言,正则表达式在其中的应用其实是必不可少的,而且正则表达式的把握能力也是这些中级程序员的开发功力之彰显,做一名合格的网站开发的程序员(尤其是做后端开发),正则表达式是必备的.
最近,由于一些须要,用到了java和正则,做了个的篮球网站的数据采集程序;由于是第一次做关于java的html页面数据采集,必然在网上查找了好多资料,但是发觉运用这么广泛的java在使用正则做html采集方面的(中文)文章是少之又少,都是简单的谈了下java正则的概念,没有真正用在实际网页html采集,实例教程更是寥寥无几(虽然java有它自己的HtmlParser,而且非常强悍),但个人认为作为这么深入人心的正则表达式,理应有其相关的java实例教程,而且应当好多太全.于是在完成java版的html数据采集程序以后,本人便准备写个关于正则表达式在java上的html页面采集,以便有相关兴趣的读者更好的学习.
本期概述
这期我们来学习下怎样读取网页源代码,并通过group正则动态抓取我们须要的网页数据.同时在接下来的几期,我们将继续学习[数据储存]如何将抓取的赛事数据存到数据库(MySql), [数据查询] 怎样查询我们想看的赛事记录,以及[远程操作]通过客户端远程访问 查看全部
Java网页数据采集器[上篇-数据采集]
开篇
作为全球运用最广泛的语言,Java 凭借它的高效性,可移植性(跨平台),代码的健壮性以及强悍的可扩展性,深受广大应用程序开发者的喜爱.作为一门强悍的开发语言,正则表达式在其中的应用其实是必不可少的,而且正则表达式的把握能力也是这些中级程序员的开发功力之彰显,做一名合格的网站开发的程序员(尤其是做后端开发),正则表达式是必备的.
最近,由于一些须要,用到了java和正则,做了个的篮球网站的数据采集程序;由于是第一次做关于java的html页面数据采集,必然在网上查找了好多资料,但是发觉运用这么广泛的java在使用正则做html采集方面的(中文)文章是少之又少,都是简单的谈了下java正则的概念,没有真正用在实际网页html采集,实例教程更是寥寥无几(虽然java有它自己的HtmlParser,而且非常强悍),但个人认为作为这么深入人心的正则表达式,理应有其相关的java实例教程,而且应当好多太全.于是在完成java版的html数据采集程序以后,本人便准备写个关于正则表达式在java上的html页面采集,以便有相关兴趣的读者更好的学习.
本期概述
这期我们来学习下怎样读取网页源代码,并通过group正则动态抓取我们须要的网页数据.同时在接下来的几期,我们将继续学习[数据储存]如何将抓取的赛事数据存到数据库(MySql), [数据查询] 怎样查询我们想看的赛事记录,以及[远程操作]通过客户端远程访问
万能文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-08-25 19:38
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
软件官方下载地址:
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。 查看全部
万能文章采集器
一款基于高精度正文辨识算法的互联网文章采集器。支持按关键词采集各大搜索引擎的新闻和网页,还支持采集指定网站栏目下的全部文章。
软件官方下载地址:
基于优采云自主研制的正文辨识智能算法,能在互联网错综复杂的网页中尽可能确切地提取出正文内容。
正文辨识有 3 种算法,“标准”、“严格”和“精确标签”。其中“标准”和“严格”是手动模式,能适应绝大多数网页的正文提取,而“精确标签”只需指定正文标签头,如“”,就能通喝所有网页的正文提取。
关键词采集目前支持的搜索引擎有:百度、搜狗、360、谷歌、必应、雅虎
采集指定网站文章的功能也十分简单,只须要稍为设置(不需要复杂的规则),就能批量采集目标网站的文章了。
因为墙的问题,要使用微软搜索和微软转译文章的功能,需要使用VPN换美国IP。
内置文章转译功能,也就是可以将文章从一种语言如英文转入另一种语言如中文,再从英语转到英文。
采集文章+翻译伪原创可以满足广大站长朋友们在各领域主题的文章需求。
而一些公关处理、信息调查公司所需的由专业公司开发的信息采集系统,售价常常达到上万甚至更多,而优采云的这款软件也是一款信息采集系统,功能跟市面上高昂售价的软件有相通之处,但价钱只有区区几百元,性价比怎么试试就知。
优采云万能文章采集器官方版 v2.17.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 339 次浏览 • 2020-08-22 15:18
优采云万能文章采集器是一款简单易用的文章采集工具,用户只须要输入关键词才能够快速采集主要搜索引擎的新闻源和泛网页,再也不用为了查找文字而四处翻网页了。优采云万能文章采集器除了具有采集速度快、操作简单的特性,文章采集器还可以精确提取网页里的正文部份保存为文章,并且支持去标签、链接、邮箱等低格处理,将纯文字的结果展示给用户,免去了用户二次处理文字的麻烦。
使用教程 1、点击“关键词采集文章”按钮
2、选择搜索引擎及类型
3、输入搜索成语
4、选择输出结果的保持目录及保持对象
5、点击“开始采集”
6、文章输出
软件功能 1、可以精确提取网页里的正文部份保存为文章
2、支持去标签、链接、邮箱等低格处理
3、插入关键词功能
4、可以辨识标签或标点后面插入
5、识别中文空格宽度插入
更新日志优采云万能文章采集器 v2.17.7.0 更新日志(2020-4-8)
1、全新降低正文过滤功能,可以屏蔽掉绝大多数不属于正文的内容;合并严格和标准的正文辨识,并加强正文辨识能力(现在辨识的正文没有再带父层的div标签了,都是取内部的代码了);增强对部份特意伪装的网站标题的提取能力;其他更新。
2、采集文章URL,强化相对路径的处理,比如../ 和 ../../ 等,经过本版本加强处理后,相对路径将完全转化为绝对路径,与浏览器中键盘移到链接上查看到的一致。
3、修复微软改动引致采集失败的问题。
4、修复关键词采集文章栏目选取精确标签时没有弹出输入的问题(前面版本导致);根据URL采集文章栏目新增删掉内层代码可选选项(之前默认启用);调试模式修改为文章来源;疑点说明更新;其他。
5、修复陌陌采集失败问题。
6、增强分页采集识别能力。
7、新增微软地址前缀指定,可自行设置能使用的微软域名。
8、采集设置的正则替换支持使用隔开多个匹配和替换表达式。
9、增强正文辨识能力,识别准确度有所提高;增加对特殊编码响应的辨识。
10、增加对二次加载图片的新属性“original”识别转换。
11、外置文件更新谷歌翻译使用的域名;修正微软tk参数变动翻译失败的问题。
12、修复部份情况因系统缘由未能跳转网址造成百度网页未能采集的问题;新增手动清除网址的#后缀部份,该部份会导致网页读取错误;采集文章URL新增左侧和右侧插入选项;修复上面版本造成的正文提取的过滤存在的一些问题;其他更新。
13、增强对部份采用跳转的网页辨识。
14、增加标题字数限制为最多100字,以免字数超长造成的一些问题;其他更新。
优采云万能文章采集器2.15.8.0更新日志(2017年3月24号)
修复百度网页搜索时间设置失效问题并取消百度新闻时间设置(已不支持);
微信采集时降低正文最少字数的设置支持(原先只有手动辨识的可以设置字数,而陌陌是外置精确标签的所以不能设置字数,现在可以了);
【文章查看】切换显示时降低手动刷新目录树;
关键词采集正文字数不足时补充提示设置的字数值
特别说明
解压密码: 查看全部
优采云万能文章采集器官方版 v2.17.7.0
优采云万能文章采集器是一款简单易用的文章采集工具,用户只须要输入关键词才能够快速采集主要搜索引擎的新闻源和泛网页,再也不用为了查找文字而四处翻网页了。优采云万能文章采集器除了具有采集速度快、操作简单的特性,文章采集器还可以精确提取网页里的正文部份保存为文章,并且支持去标签、链接、邮箱等低格处理,将纯文字的结果展示给用户,免去了用户二次处理文字的麻烦。
使用教程 1、点击“关键词采集文章”按钮
2、选择搜索引擎及类型
3、输入搜索成语
4、选择输出结果的保持目录及保持对象
5、点击“开始采集”
6、文章输出
软件功能 1、可以精确提取网页里的正文部份保存为文章
2、支持去标签、链接、邮箱等低格处理
3、插入关键词功能
4、可以辨识标签或标点后面插入
5、识别中文空格宽度插入
更新日志优采云万能文章采集器 v2.17.7.0 更新日志(2020-4-8)
1、全新降低正文过滤功能,可以屏蔽掉绝大多数不属于正文的内容;合并严格和标准的正文辨识,并加强正文辨识能力(现在辨识的正文没有再带父层的div标签了,都是取内部的代码了);增强对部份特意伪装的网站标题的提取能力;其他更新。
2、采集文章URL,强化相对路径的处理,比如../ 和 ../../ 等,经过本版本加强处理后,相对路径将完全转化为绝对路径,与浏览器中键盘移到链接上查看到的一致。
3、修复微软改动引致采集失败的问题。
4、修复关键词采集文章栏目选取精确标签时没有弹出输入的问题(前面版本导致);根据URL采集文章栏目新增删掉内层代码可选选项(之前默认启用);调试模式修改为文章来源;疑点说明更新;其他。
5、修复陌陌采集失败问题。
6、增强分页采集识别能力。
7、新增微软地址前缀指定,可自行设置能使用的微软域名。
8、采集设置的正则替换支持使用隔开多个匹配和替换表达式。
9、增强正文辨识能力,识别准确度有所提高;增加对特殊编码响应的辨识。
10、增加对二次加载图片的新属性“original”识别转换。
11、外置文件更新谷歌翻译使用的域名;修正微软tk参数变动翻译失败的问题。
12、修复部份情况因系统缘由未能跳转网址造成百度网页未能采集的问题;新增手动清除网址的#后缀部份,该部份会导致网页读取错误;采集文章URL新增左侧和右侧插入选项;修复上面版本造成的正文提取的过滤存在的一些问题;其他更新。
13、增强对部份采用跳转的网页辨识。
14、增加标题字数限制为最多100字,以免字数超长造成的一些问题;其他更新。
优采云万能文章采集器2.15.8.0更新日志(2017年3月24号)
修复百度网页搜索时间设置失效问题并取消百度新闻时间设置(已不支持);
微信采集时降低正文最少字数的设置支持(原先只有手动辨识的可以设置字数,而陌陌是外置精确标签的所以不能设置字数,现在可以了);
【文章查看】切换显示时降低手动刷新目录树;
关键词采集正文字数不足时补充提示设置的字数值
特别说明
解压密码:
Python天气预报采集器实现代码(网页爬虫)
采集交流 • 优采云 发表了文章 • 0 个评论 • 390 次浏览 • 2020-08-21 17:02
Python天气预报采集器实现代码(网页爬虫)
更新时间:2012年10月07日 00:36:02 转载作者:
这个天气预报采集是从中国天气网提取山东省内主要城市的天气并回显。本来是准备采集腾讯天气的,但是其实它的数据是用js写起来还是哪些的,得到的html文本中不收录数据,所以即使了
爬虫简单说来包括两个步骤:获得网页文本、过滤得到数据。
1、获得html文本。
python在获取html方面非常便捷,寥寥数行代码就可以实现我们须要的功能。
复制代码 代码如下:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close()
return html
这么几行代码相信不用注释都能大约晓得它的意思。
2、根据正则表达式等获得须要的内容。
使用正则表达式时须要仔细观察该网页信息的结构,并写出正确的正则表达式。
python正则表达式的使用也太简约。我的上一篇文章《Python的一些用法》介绍了一点正则的用法。这里须要一个新的用法:
复制代码 代码如下:
def getWeather(html):
reg = '(.*?).*?(.*?).*?(.*?)'
weatherList = pile(reg).findall(html)
return weatherList
其中reg是正则表达式,html是第一步获得的文本。findall的作用是找到html中所有符合正则匹配的字符串并储存到weatherList中。之后再枚举weatheList中的数据输出即可。
这里的正则表达式reg有两个地方要注意。
一个是“(.*?)”。只要是()中的内容都是我们即将获得的内容,如果有多个括弧,那么findall的每位结果就都收录这几个括弧中的内容。上面有三个括弧,分别对应城市、最低温和最高温。
另一个是“.*?”。python的正则匹配默认是贪婪的,即默认尽可能多地匹配字符串。如果在末尾加上问号,则表示非贪婪模式,即尽可能少地匹配字符串。在这里,由于有多个城市的信息须要匹配,所以须要使用非贪婪模式,否则匹配结果只剩下一个,且是不正确的。
python的使用确实非常便捷:) 查看全部
Python天气预报采集器实现代码(网页爬虫)
Python天气预报采集器实现代码(网页爬虫)
更新时间:2012年10月07日 00:36:02 转载作者:
这个天气预报采集是从中国天气网提取山东省内主要城市的天气并回显。本来是准备采集腾讯天气的,但是其实它的数据是用js写起来还是哪些的,得到的html文本中不收录数据,所以即使了
爬虫简单说来包括两个步骤:获得网页文本、过滤得到数据。
1、获得html文本。
python在获取html方面非常便捷,寥寥数行代码就可以实现我们须要的功能。
复制代码 代码如下:
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
page.close()
return html
这么几行代码相信不用注释都能大约晓得它的意思。
2、根据正则表达式等获得须要的内容。
使用正则表达式时须要仔细观察该网页信息的结构,并写出正确的正则表达式。
python正则表达式的使用也太简约。我的上一篇文章《Python的一些用法》介绍了一点正则的用法。这里须要一个新的用法:
复制代码 代码如下:
def getWeather(html):
reg = '(.*?).*?(.*?).*?(.*?)'
weatherList = pile(reg).findall(html)
return weatherList
其中reg是正则表达式,html是第一步获得的文本。findall的作用是找到html中所有符合正则匹配的字符串并储存到weatherList中。之后再枚举weatheList中的数据输出即可。
这里的正则表达式reg有两个地方要注意。
一个是“(.*?)”。只要是()中的内容都是我们即将获得的内容,如果有多个括弧,那么findall的每位结果就都收录这几个括弧中的内容。上面有三个括弧,分别对应城市、最低温和最高温。
另一个是“.*?”。python的正则匹配默认是贪婪的,即默认尽可能多地匹配字符串。如果在末尾加上问号,则表示非贪婪模式,即尽可能少地匹配字符串。在这里,由于有多个城市的信息须要匹配,所以须要使用非贪婪模式,否则匹配结果只剩下一个,且是不正确的。
python的使用确实非常便捷:)
一文教您怎样通过 Java 压缩文件,打包一个 tar
采集交流 • 优采云 发表了文章 • 0 个评论 • 251 次浏览 • 2020-08-12 23:44
一、背景
最近,小哈主要在负责日志中台的开发工作, 等等,啥是日志中台?
俺只晓得中台概念,这段时间的确太火,但是日志中台又是拿来干啥的?
这里小哈尽量地浅显的说下日志中台的职责,再说日志中台之前,我们先扯点别的?
相信你们对集中式日志平台 ELK 都晓得一些,生产环境中, 稍复杂的构架,服务通常都是集群布署,这样,日志还会分散在每台服务器上,一旦发生问题,想要查看日志都会十分繁杂,你须要登陆每台服务器找日志,因为你不确定恳求被打到那个节点上。另外,任由开发人员登陆服务器查看日志本身就存在安全隐患,不留神执行了 rm -rf * 咋办?
通过 ELK , 我们可以便捷的将日志搜集到一处(Elasticsearch 集群)来进行多维度的剖析。
但是布署高性能、高可用的 ELK 是有门槛的,业务组想要快速的拥有集中式日志剖析的能力,往往须要经过前期的技术督查,测试,踩坑,才能将这个平台搭建上去。
日志中台的使命就是使业务线才能快速拥有这些能力,只需傻瓜式的在日志平台完成接入操作即可。
臭嗨!说了这么多,跟你这篇文章的主题有啥关系?
额,小哈这就步入主题。
既然想统一管理日志,总得将那些分散的日志采集起来吧,那么,就须要一个日志采集器,Logstash 和 Filebeat 都有采集日志的能力,但是 Filebeat 相较于 Logstash 的笨重, 它更轻量级,几乎零占用服务器系统资源,这里我们选型 Filebeat。
业务组在日志平台完成相关接入流程后,平台会提供一个采集器包。接入方须要做的就是,下载这个采集器包并扔到指定服务器上,解压运行,即可开始采集日志,然后,就可以在日志平台的管控页面剖析&搜索那些被搜集的日志了。
这个 Filebeat 采集器包上面,收录了采集日志文件路径,输出到 Kafka 集群,以及一些个性化的采集规则等等。
怎么样?是不是觉得太棒呢?
二、如何通过 Java 打包文件?2.1 添加 Maven 依赖
org.apache.commons
commons-compress
1.12
2.2 打包核心代码
通过 Apache compress 工具打包思路大致如下:
接下来,直接上代码:
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveOutputStream;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.zip.GZIPOutputStream;
/**
* @author 犬小哈 (公众号: 小哈学Java)
* @date 2019-07-15
* @time 16:15
* @discription
**/
public class TarUtils {
/**
* 压缩
* @param sourceFolder 指定打包的源目录
* @param tarGzPath 指定目标 tar 包的位置
* @return
* @throws IOException
*/
public static void compress(String sourceFolder, String tarGzPath) throws IOException {
createTarFile(sourceFolder, tarGzPath);
}
private static void createTarFile(String sourceFolder, String tarGzPath) {
TarArchiveOutputStream tarOs = null;
try {
// 创建一个 FileOutputStream 到输出文件(.tar.gz)
FileOutputStream fos = new FileOutputStream(tarGzPath);
// 创建一个 GZIPOutputStream,用来包装 FileOutputStream 对象
GZIPOutputStream gos = new GZIPOutputStream(new BufferedOutputStream(fos));
// 创建一个 TarArchiveOutputStream,用来包装 GZIPOutputStream 对象
tarOs = new TarArchiveOutputStream(gos);
// 若不设置此模式,当文件名超过 100 个字节时会抛出异常,异常大致如下:
// is too long ( > 100 bytes)
// 具体可参考官方文档: http://commons.apache.org/prop ... Names
tarOs.setLongFileMode(TarArchiveOutputStream.LONGFILE_POSIX);
addFilesToTarGZ(sourceFolder, "", tarOs);
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
tarOs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void addFilesToTarGZ(String filePath, String parent, TarArchiveOutputStream tarArchive) throws IOException {
File file = new File(filePath);
// Create entry name relative to parent file path
String entryName = parent + file.getName();
// 添加 tar ArchiveEntry
tarArchive.putArchiveEntry(new TarArchiveEntry(file, entryName));
if (file.isFile()) {
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
// 写入文件
IOUtils.copy(bis, tarArchive);
tarArchive.closeArchiveEntry();
bis.close();
} else if (file.isDirectory()) {
// 因为是个文件夹,无需写入内容,关闭即可
tarArchive.closeArchiveEntry();
// 读取文件夹下所有文件
for (File f : file.listFiles()) {
// 递归
addFilesToTarGZ(f.getAbsolutePath(), entryName + File.separator, tarArchive);
}
}
}
public static void main(String[] args) throws IOException {
// 测试一波,将 filebeat-7.1.0-linux-x86_64 打包成名为 filebeat-7.1.0-linux-x86_64.tar.gz 的 tar 包
compress("/Users/a123123/Work/filebeat-7.1.0-linux-x86_64", "/Users/a123123/Work/tmp_files/filebeat-7.1.0-linux-x86_64.tar.gz");
}
}
至于,代码每行的作用,小伙伴们可以看代码注释,说的早已比较清楚了。
接下来,执行 main 方法,测试一下疗效,看看打包是否成功:
生成采集器 tar.gz 包成功后,业务组只需将 tar.gz 下载出来,并扔到指定服务器,解压运行即可完成采集任务啦~
三、结语
本文主要还是介绍怎样通过 Java 来完成打包功能,关于 ELK 相关的知识,小哈会在后续的文章中分享给你们,本文只是提到一下,欢迎小伙伴们持续关注哟,下期见~ 查看全部
个人网站:
一、背景
最近,小哈主要在负责日志中台的开发工作, 等等,啥是日志中台?
俺只晓得中台概念,这段时间的确太火,但是日志中台又是拿来干啥的?
这里小哈尽量地浅显的说下日志中台的职责,再说日志中台之前,我们先扯点别的?
相信你们对集中式日志平台 ELK 都晓得一些,生产环境中, 稍复杂的构架,服务通常都是集群布署,这样,日志还会分散在每台服务器上,一旦发生问题,想要查看日志都会十分繁杂,你须要登陆每台服务器找日志,因为你不确定恳求被打到那个节点上。另外,任由开发人员登陆服务器查看日志本身就存在安全隐患,不留神执行了 rm -rf * 咋办?
通过 ELK , 我们可以便捷的将日志搜集到一处(Elasticsearch 集群)来进行多维度的剖析。
但是布署高性能、高可用的 ELK 是有门槛的,业务组想要快速的拥有集中式日志剖析的能力,往往须要经过前期的技术督查,测试,踩坑,才能将这个平台搭建上去。
日志中台的使命就是使业务线才能快速拥有这些能力,只需傻瓜式的在日志平台完成接入操作即可。
臭嗨!说了这么多,跟你这篇文章的主题有啥关系?
额,小哈这就步入主题。
既然想统一管理日志,总得将那些分散的日志采集起来吧,那么,就须要一个日志采集器,Logstash 和 Filebeat 都有采集日志的能力,但是 Filebeat 相较于 Logstash 的笨重, 它更轻量级,几乎零占用服务器系统资源,这里我们选型 Filebeat。
业务组在日志平台完成相关接入流程后,平台会提供一个采集器包。接入方须要做的就是,下载这个采集器包并扔到指定服务器上,解压运行,即可开始采集日志,然后,就可以在日志平台的管控页面剖析&搜索那些被搜集的日志了。
这个 Filebeat 采集器包上面,收录了采集日志文件路径,输出到 Kafka 集群,以及一些个性化的采集规则等等。
怎么样?是不是觉得太棒呢?
二、如何通过 Java 打包文件?2.1 添加 Maven 依赖
org.apache.commons
commons-compress
1.12
2.2 打包核心代码
通过 Apache compress 工具打包思路大致如下:
接下来,直接上代码:
import org.apache.commons.compress.archivers.tar.TarArchiveEntry;
import org.apache.commons.compress.archivers.tar.TarArchiveOutputStream;
import org.apache.commons.io.IOUtils;
import java.io.*;
import java.util.zip.GZIPOutputStream;
/**
* @author 犬小哈 (公众号: 小哈学Java)
* @date 2019-07-15
* @time 16:15
* @discription
**/
public class TarUtils {
/**
* 压缩
* @param sourceFolder 指定打包的源目录
* @param tarGzPath 指定目标 tar 包的位置
* @return
* @throws IOException
*/
public static void compress(String sourceFolder, String tarGzPath) throws IOException {
createTarFile(sourceFolder, tarGzPath);
}
private static void createTarFile(String sourceFolder, String tarGzPath) {
TarArchiveOutputStream tarOs = null;
try {
// 创建一个 FileOutputStream 到输出文件(.tar.gz)
FileOutputStream fos = new FileOutputStream(tarGzPath);
// 创建一个 GZIPOutputStream,用来包装 FileOutputStream 对象
GZIPOutputStream gos = new GZIPOutputStream(new BufferedOutputStream(fos));
// 创建一个 TarArchiveOutputStream,用来包装 GZIPOutputStream 对象
tarOs = new TarArchiveOutputStream(gos);
// 若不设置此模式,当文件名超过 100 个字节时会抛出异常,异常大致如下:
// is too long ( > 100 bytes)
// 具体可参考官方文档: http://commons.apache.org/prop ... Names
tarOs.setLongFileMode(TarArchiveOutputStream.LONGFILE_POSIX);
addFilesToTarGZ(sourceFolder, "", tarOs);
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
tarOs.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void addFilesToTarGZ(String filePath, String parent, TarArchiveOutputStream tarArchive) throws IOException {
File file = new File(filePath);
// Create entry name relative to parent file path
String entryName = parent + file.getName();
// 添加 tar ArchiveEntry
tarArchive.putArchiveEntry(new TarArchiveEntry(file, entryName));
if (file.isFile()) {
FileInputStream fis = new FileInputStream(file);
BufferedInputStream bis = new BufferedInputStream(fis);
// 写入文件
IOUtils.copy(bis, tarArchive);
tarArchive.closeArchiveEntry();
bis.close();
} else if (file.isDirectory()) {
// 因为是个文件夹,无需写入内容,关闭即可
tarArchive.closeArchiveEntry();
// 读取文件夹下所有文件
for (File f : file.listFiles()) {
// 递归
addFilesToTarGZ(f.getAbsolutePath(), entryName + File.separator, tarArchive);
}
}
}
public static void main(String[] args) throws IOException {
// 测试一波,将 filebeat-7.1.0-linux-x86_64 打包成名为 filebeat-7.1.0-linux-x86_64.tar.gz 的 tar 包
compress("/Users/a123123/Work/filebeat-7.1.0-linux-x86_64", "/Users/a123123/Work/tmp_files/filebeat-7.1.0-linux-x86_64.tar.gz");
}
}
至于,代码每行的作用,小伙伴们可以看代码注释,说的早已比较清楚了。
接下来,执行 main 方法,测试一下疗效,看看打包是否成功:
生成采集器 tar.gz 包成功后,业务组只需将 tar.gz 下载出来,并扔到指定服务器,解压运行即可完成采集任务啦~
三、结语
本文主要还是介绍怎样通过 Java 来完成打包功能,关于 ELK 相关的知识,小哈会在后续的文章中分享给你们,本文只是提到一下,欢迎小伙伴们持续关注哟,下期见~
ADSL手动换IP刷流量与善肯网页TXT采集器下载评论软件详情对比
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-08-12 08:31
功能介绍
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。 查看全部
善肯网页TXT采集器是一款网路小说采集软件,可下载、可实时预览、可文本替换,目前仅能获取免费章节,不支持VIP章节!
功能介绍
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
网页数据采集并发布到dedecms程序(dede V5.7,5.6,5.5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-11 15:44
答:可下载最新版优采云采集器,优采云采集器是一款免费的网页数据、文章、图片、附件批量采集下载的软件。完全适用于dede程序,包括dedecms5.7及其他版本。
(使用优采云采集器配置网页数据发布到DEDE文章栏目及其他程序演示)
2、问:采集软件可以采集不同的网站吗?
答:您只须要,为每位网站,制作一个任务(采集规则)即可。可复制粘贴任务,快速采集不同网站内容和图片。
3、问:采集软件免费使用吗?
答:是的,功能全部免费使用,因精力有限,请阅读使用教程,快速上手。
4、问:如何将采集来的网站数据,发布到我的dedecms网站呢?
答:您只须要,将采集发布插口(又称采集插件,这里就当定义为dede采集插件吧).php文件 放置于您的网站相应目录,按照dedecms发布插口教程 及相关教程介绍配置完成。
5、问:采集网站数据,能同时下载图片吗?
答:可以的。可以批量下载图片,达到图片本地化要求。
6、问:我的网站使用dedecms自带采集不能采集HTTPS的网页数据?
答:使用本采集软件,即使您服务器/空间 不支持HTTPS远程访问,一样可以采集数据。
7、问:dedecms5.7的发布插口在哪儿呢?
答:下载优采云采集器 最新版,压缩包内就有。
(未能解决您的需求的话,可联系优采云软件开发者 优采云的QQ:3169902984 订制更改) 查看全部
1、问:我用的是织梦cms,如何采集网页数据?
答:可下载最新版优采云采集器,优采云采集器是一款免费的网页数据、文章、图片、附件批量采集下载的软件。完全适用于dede程序,包括dedecms5.7及其他版本。
(使用优采云采集器配置网页数据发布到DEDE文章栏目及其他程序演示)
2、问:采集软件可以采集不同的网站吗?
答:您只须要,为每位网站,制作一个任务(采集规则)即可。可复制粘贴任务,快速采集不同网站内容和图片。
3、问:采集软件免费使用吗?
答:是的,功能全部免费使用,因精力有限,请阅读使用教程,快速上手。
4、问:如何将采集来的网站数据,发布到我的dedecms网站呢?
答:您只须要,将采集发布插口(又称采集插件,这里就当定义为dede采集插件吧).php文件 放置于您的网站相应目录,按照dedecms发布插口教程 及相关教程介绍配置完成。
5、问:采集网站数据,能同时下载图片吗?
答:可以的。可以批量下载图片,达到图片本地化要求。
6、问:我的网站使用dedecms自带采集不能采集HTTPS的网页数据?
答:使用本采集软件,即使您服务器/空间 不支持HTTPS远程访问,一样可以采集数据。
7、问:dedecms5.7的发布插口在哪儿呢?
答:下载优采云采集器 最新版,压缩包内就有。
(未能解决您的需求的话,可联系优采云软件开发者 优采云的QQ:3169902984 订制更改)
免费下载 Feed Gator for Joomla! 1
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-10 12:32
之前 Joomla!之门 曾经介绍过一款名为 Feedbingo 的通用文章采集器,并且录制了视频教程。Feed Gator 与之相比,优势在于:Feed Gator 不仅支持将文章采集到 Joomla 核心的文章系统,还可以将文章采集到 K2 文章系统,或者采集到 Kunena 论坛(v1.6 以上版本)变成峰会贴子,或者采集到 FlexiContent 文章系统。
Feed Gator 如此强悍的采集功能,是通过安装相应的“采集插件”(Feed Gator plugins)实现的。假如你想把文章采集来弄成 NinjaBoard 论坛组件中的贴子,没问题,你只需开发相应的插件,安装到 Feed Gator 中就可以实现。
Feed Gator 采集器组件特色:安装不同插件,即可将文章采集到不同的组件中;使用 SimplePie 解析器,采集速度超快;采集全文(即使 RSS 供稿未提供全文也能强行采集全文);提供“采集预览”功能,方便站长检测设置;可针对每一个采集源单独设置白名单/黑名单,用来过滤文章;内置 htmLawed 过滤器,可对 HTML 输出进行整洁化、无害化、压缩等处理;自动剖析原文,提取词汇来生成 meta 标记内容(三种形式可选:词汇频度估算;AddKeywords 插件形式;雅虎 API 方式);可选是否在生成的文章中显示指向原文的链接;可选是否手动发布采集到的文章;可自定义手动发布后的文章保持“已发布”状态的天数(数字 0 表示永远发布);可侦测是否存在重复采集并智能化处理重复内容(可选新建、合并或则覆盖);可利用服务器端创建计划任务(Cron)脚本来实现手动采集;自动对采集源进行缓存;自动生成每次采集任务的 HTML 格式报告,可在网站后台阅读,或者手动发送到管理员信箱;可选将原文的图片保存到自己站内;可对采集到的图象统一设置 CSS 类进而实现式样控制;可针对每一个采集源为新形成的文章设置默认的“作者”;
提示: 查看全部
Feed Gator 是针对 Joomla! 1.5 的一款采集器组件,它能采集任何以 RSS 格式输出的文章来源。
之前 Joomla!之门 曾经介绍过一款名为 Feedbingo 的通用文章采集器,并且录制了视频教程。Feed Gator 与之相比,优势在于:Feed Gator 不仅支持将文章采集到 Joomla 核心的文章系统,还可以将文章采集到 K2 文章系统,或者采集到 Kunena 论坛(v1.6 以上版本)变成峰会贴子,或者采集到 FlexiContent 文章系统。
Feed Gator 如此强悍的采集功能,是通过安装相应的“采集插件”(Feed Gator plugins)实现的。假如你想把文章采集来弄成 NinjaBoard 论坛组件中的贴子,没问题,你只需开发相应的插件,安装到 Feed Gator 中就可以实现。
Feed Gator 采集器组件特色:安装不同插件,即可将文章采集到不同的组件中;使用 SimplePie 解析器,采集速度超快;采集全文(即使 RSS 供稿未提供全文也能强行采集全文);提供“采集预览”功能,方便站长检测设置;可针对每一个采集源单独设置白名单/黑名单,用来过滤文章;内置 htmLawed 过滤器,可对 HTML 输出进行整洁化、无害化、压缩等处理;自动剖析原文,提取词汇来生成 meta 标记内容(三种形式可选:词汇频度估算;AddKeywords 插件形式;雅虎 API 方式);可选是否在生成的文章中显示指向原文的链接;可选是否手动发布采集到的文章;可自定义手动发布后的文章保持“已发布”状态的天数(数字 0 表示永远发布);可侦测是否存在重复采集并智能化处理重复内容(可选新建、合并或则覆盖);可利用服务器端创建计划任务(Cron)脚本来实现手动采集;自动对采集源进行缓存;自动生成每次采集任务的 HTML 格式报告,可在网站后台阅读,或者手动发送到管理员信箱;可选将原文的图片保存到自己站内;可对采集到的图象统一设置 CSS 类进而实现式样控制;可针对每一个采集源为新形成的文章设置默认的“作者”;
提示:
[原创工具]善肯网页TXT采集器V1.1,可下载、可实时预览、可文本替换
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-08-10 10:28
修复第一章不能点击的bug。
新增功能让之提取网页链接的形式愈发灵活。
版本:1.0
日期:2018.5.23
开发缘由:开发之初是为了看小说便捷,个人喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
所以我开发的这个软件就特地加了个预览功能,可以晓得我究竟能不能获取网页数据,我获取后能不能正确匹配出内容。
软件主要解决的虽然就是这两个大问题。
能获取的都是免费章节,非VIP章节哈,支持原创作者。
功能模块介绍:
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置\n再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
3、关于软件
①其实只要.exe就行,规则全是自己添加,commonrule.xml上面是通用替换规则。网站规则在rule文件夹下。我那边在里面放了两个网站的规则,主要是测试的时侯是用的。其他网站规则,大家可以自己添加,或者支持开发者也行。
②软件没免杀,c#开发的,没放病毒。不放心请不要用,我不甩锅。
③关于软件上面有个跳转到峰会,我个人测试跳转的时侯被360提示了,也有可能是因为跳转的是360浏览器,不知道大家会不会有这个问题。
④xml上面的内容,如果不清楚的话还是不要动它,免得软件辨识失败报错。
⑤需要.net framework 4.5或则及以上版本框架支持,如果你笔记本没有的话,需要下载安装,框架不大的。
4、其他
暂时没想到,后面想到再说。
最后,不管怎样,还是打滚求支持,不喜切勿喷。
这个是第一个版本,所以肯定存在我之前测试没有遇见的bug或则须要优化的问题,欢迎你们温柔的反馈哈。
理论上只要是目录页到内容页的方式的都可以使用,不限于小说。
下面上图,图片中软件呈现粉红色是我笔记本主题的缘由,并非软件设置,捂脸:
求支持,求支持,求支持!!!!重要的事说三遍!!!
v1.0的下载链接:
总的下载链接【含V1.1】:链接: 密码: uff3 查看全部
更新日志:
修复第一章不能点击的bug。
新增功能让之提取网页链接的形式愈发灵活。
版本:1.0
日期:2018.5.23
开发缘由:开发之初是为了看小说便捷,个人喜欢下载到本地渐渐看,但是好多小说网站不支持下载,或者下载有限制【非VIP小说】,也在峰会上面找过一些采集器,但是个人认为不太好用,输入正则表达式后,会下来章节,但是点击下载却并不能把文本下载出来,我做好这个软件后也继续测试过,同样的正则表达式,那些软件确实匹配不出内容,所以下载失败。也有可能是这些软件有些我不知道的规则,但是结果就是并不能完成我想要的下载。甚至不知道是规则的问题还是软件的问题又或则是网站设置缘由……
所以我开发的这个软件就特地加了个预览功能,可以晓得我究竟能不能获取网页数据,我获取后能不能正确匹配出内容。
软件主要解决的虽然就是这两个大问题。
能获取的都是免费章节,非VIP章节哈,支持原创作者。
功能模块介绍:
1、规则设置:
①在规则设置窗口,在网站中随意找一篇文,不写任何规则,先点击实时预览,看看能不能获取网页源代码,能获取则再写规则,不能获取就没必要继续了。
②规则设置使用的是正则表达式匹配内容,有一定基础最好,没基础也可以参考给的范例,简单学习下,不需要深入学习正则。
③规则设置的时侯,目录页和内容页须要分开预览,也就须要两个链接,一个目录页链接、一个内容页链接。
④关于替换,有通用替换和订制替换,这里目前不需要正则,普通替换就好,需要注意的是必须要输入值,空格也行。删除:选中整行,再按住delete键就行。内置\n再作为替换数据的时侯代表换行。
⑤编码,目前只设置有GBK和UFT-8,差不多大多数网站就是这两种编码其中之一。
2、解析与下载
①解析请按解析地址2按键,1按键目前任性不想删,后面要开发其他功能,
②支持单章节下载和全文下载。
③支持添加章节数【有的小说没有章节数的时侯就可以勾上】
④支持在线看,但是须要联网,此功能只是辅助,并非专业的看小说软件。
⑤下载进度和总需时间显示,内置多线程。
3、关于软件
①其实只要.exe就行,规则全是自己添加,commonrule.xml上面是通用替换规则。网站规则在rule文件夹下。我那边在里面放了两个网站的规则,主要是测试的时侯是用的。其他网站规则,大家可以自己添加,或者支持开发者也行。
②软件没免杀,c#开发的,没放病毒。不放心请不要用,我不甩锅。
③关于软件上面有个跳转到峰会,我个人测试跳转的时侯被360提示了,也有可能是因为跳转的是360浏览器,不知道大家会不会有这个问题。
④xml上面的内容,如果不清楚的话还是不要动它,免得软件辨识失败报错。
⑤需要.net framework 4.5或则及以上版本框架支持,如果你笔记本没有的话,需要下载安装,框架不大的。
4、其他
暂时没想到,后面想到再说。
最后,不管怎样,还是打滚求支持,不喜切勿喷。
这个是第一个版本,所以肯定存在我之前测试没有遇见的bug或则须要优化的问题,欢迎你们温柔的反馈哈。
理论上只要是目录页到内容页的方式的都可以使用,不限于小说。
下面上图,图片中软件呈现粉红色是我笔记本主题的缘由,并非软件设置,捂脸:
求支持,求支持,求支持!!!!重要的事说三遍!!!
v1.0的下载链接:
总的下载链接【含V1.1】:链接: 密码: uff3
不懂代码也能爬取数据?试试这几个工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 228 次浏览 • 2020-08-10 04:44
猴哥有问必答,对于那位朋友的问题,我给安排上。
先谈谈获取数据的方法:一是借助现成的工具,我们只需懂得怎样使用工具能够获取数据,不需要关心工具是如何实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一看法是选择乘船过去,而不会想着自己来造一艘船再过去。第二种是自己针对场景需求做些多样化工具,这就须要有点编程基础。举个事例,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有哪些其他要求的话,优先选择现有工具。可能是 Python 近来年太火,加上我们会常常听到他人用 Python 来制做网路爬虫抓取数据。从而有一些朋友有这样的误区,想从网路上抓取数据就一定要学 Python,一定要去写代码。
其实不然。猴哥介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强悍的工具,能抓取数据就是它的功能之一。我以麦克风作为关键字,抓取易迅的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方法确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择前面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是太友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还须要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具以后,采集数据上限会很高。有时间和精力的朋友可以去折腾折腾。
官网地址:/
3.优采云采集器
优采云采集器是一款十分适宜菜鸟的采集器。它具有简单易用的特性,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板能够快速抓取数据。如果想抓取没有模板的网站,官网也提供十分详尽的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特性。但这瑕不掩瑜,能基本满足菜鸟在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:/
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上漂浮显示的数据。集搜客是以浏览器插件方式抓取数据。虽然具有上面所述的有点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:/
5.Scrapinghub
如果你想抓取美国的网站数据,可以考虑 Scrapinghub。Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。Scrapehub 算是市场上十分复杂和强悍的网路抓取平台,提供数据抓取的解决方案商。
地址:/
6.WebScraper
WebScraper 是一款优秀国内的浏览器插件。同样也是一款适宜菜鸟抓取数据的可视化工具。我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:webscraper.io/ 查看全部
前天,有个朋友加我陌陌来咨询我: “猴哥,我想抓取近日 5000 条新闻数据,但我是文科生,不会写代码,请问该如何办?”
猴哥有问必答,对于那位朋友的问题,我给安排上。
先谈谈获取数据的方法:一是借助现成的工具,我们只需懂得怎样使用工具能够获取数据,不需要关心工具是如何实现。打个比方,假如我们在岸上,要去海上某个小岛,岸边有一艘船,我们第一看法是选择乘船过去,而不会想着自己来造一艘船再过去。第二种是自己针对场景需求做些多样化工具,这就须要有点编程基础。举个事例,我们还是要到海上某个小岛,同时还要求在 30 分钟内将 1 顿货物送到岛上。
因此,前期只是单纯想获取数据,没有哪些其他要求的话,优先选择现有工具。可能是 Python 近来年太火,加上我们会常常听到他人用 Python 来制做网路爬虫抓取数据。从而有一些朋友有这样的误区,想从网路上抓取数据就一定要学 Python,一定要去写代码。
其实不然。猴哥介绍几个能快速获取网上数据的工具。
1.Microsoft Excel
你没有看错,就是 Office 三剑客之一的 Excel。Excel 是一个强悍的工具,能抓取数据就是它的功能之一。我以麦克风作为关键字,抓取易迅的商品列表。
等待几秒后,Excel 会将页面上所有的文字信息抓取到表格中。这种方法确实能抓取到数据,但也会引入一些我们不需要的数据。如果你有更高的需求,可以选择前面几个工具。
2.优采云采集器
优采云是爬虫界的老品牌了,是目前使用人数最多的互联网数据抓取、处理、分析,挖掘软件。它的优势是采集不限网页,不限内容,同时还是分布式采集,效率会高一些。缺点是对小白用户不是太友好,有一定的知识门槛(了解如网页知识、HTTP 协议等方面知识),还须要花些时间熟悉工具操作。
因为有学习门槛,掌握该工具以后,采集数据上限会很高。有时间和精力的朋友可以去折腾折腾。
官网地址:/
3.优采云采集器
优采云采集器是一款十分适宜菜鸟的采集器。它具有简单易用的特性,让你能几分钟中就快手上手。优采云提供一些常见抓取网站的模板,使用模板能够快速抓取数据。如果想抓取没有模板的网站,官网也提供十分详尽的图文教程和视频教程。
优采云是基于浏览器内核实现可视化抓取数据,所以存在卡顿、采集数据慢的特性。但这瑕不掩瑜,能基本满足菜鸟在短时间抓取数据的场景,比如翻页查询,Ajax 动态加载数据等。
网站:/
4.GooSeeker 集搜客
集搜客也是一款容易上手的可视化采集数据工具。同样能抓取动态网页,也支持可以抓取手机网站上的数据,还支持抓取在指数图表上漂浮显示的数据。集搜客是以浏览器插件方式抓取数据。虽然具有上面所述的有点,但缺点也有,无法多线程采集数据,出现浏览器卡顿也在所难免。
网站:/
5.Scrapinghub
如果你想抓取美国的网站数据,可以考虑 Scrapinghub。Scrapinghub 是一个基于Python 的 Scrapy 框架的云爬虫平台。Scrapehub 算是市场上十分复杂和强悍的网路抓取平台,提供数据抓取的解决方案商。
地址:/
6.WebScraper
WebScraper 是一款优秀国内的浏览器插件。同样也是一款适宜菜鸟抓取数据的可视化工具。我们通过简单设置一些抓取规则,剩下的就交给浏览器去工作。
地址:webscraper.io/
如何使用优采云批量下载网页.docx 33页
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2020-08-10 00:30
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按键,而是通过下拉加载,不断加载出新的内容因此,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上滚动”,滚动次数依照自身需求进行设置,间隔时间依照网页加载情况进行设置,滚动形式为“向下滚动一屏”,然后点击“确定”(注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请看:优采云7.0教程——AJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1) HYPERLINK "/article/javascript:;" 步骤2:创建翻页循环及提取数据1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作提示框中,选择“选中全部”2)选择“循环点击每位链接”3) 系统会手动步入文章详情页。点击须要采集的数组(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
以下采集的是文章正文 HYPERLINK "/article/javascript:;" 步骤3:提取UC头条文章图片地址1)接下来开始采集图片地址。先点击文章中第一张图片,再点击页面中第二张图片,在弹出的操作提示框中,选择“采集以下图片地址”2)修改数组名称,再点击“确定”3)现在我们早已采集到了图片URL,接下来为批量导入图片做打算。批量导入图片的时侯,我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标题命名。首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”选中标题数组,点击如图所示按键选择“格式化数据”点击添加步骤选择“添加前缀”在如图位置,输入前缀:“D:\UC头条图片采集\”,然后点击“确定”以同样的形式添加后缀“\”,然后点击“确定”4)修改数组名为“图片储存地址”,最后展示出的“D:\UC头条图片采集\文章标题”即为图片保存文件夹名,其中“D:\UC头条图片采集\”是固定的,文章标题是变化的步骤4:修改Xpath1)选中整个“循环”步骤,打开“高级选项”,可以看见,优采云默认生成的是固定元素列表,定位的是前13篇文章的链接2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条Xpath://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,页面中所需的所有文章均被定位了3)将修改后的Xpath,复制粘贴到优采云中所示位置,然后点击“确定”步骤5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”注:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以使用云采集功能,云采集在网路中进行采集,无需当前笔记本支持,电脑可以死机,可以设置多个云节点平摊任务,10个节点相当于10台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”,将采集好的数据导入这儿我们选择excel作为导入为格式,数据导入后如下图步骤6: HYPERLINK "/article/javascript:;" 将图片URL批量转换为图片经过如上操作,我们早已得到了要采集的图片的URL。接下来,再通过优采云专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地笔记本中。
图片批量下载工具: HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件2)打开File菜单,选择从EXCEL导出(目前只支持EXCEL格式文件)3)进行相关设置,设置完成后,点击OK即可导出文件选择EXCEL文件:导入你须要下载图片地址的EXCEL文件EXCEL表名:对应数据表的名称文件URL列名:表内对应URL的列名称,在这里为“图片URL”保存文件夹名:EXCEL中须要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片储存至不同文件夹,在这里为“图片储存地址”可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名4)点击OK后,界面如图所示,再点击“开始下载”5)页面下方会显示图片下载状态6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片URL早已批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名本文来自:/tutorialdetail-1/ucnewscj.html相关采集教程:ebay爬虫抓取图片/tutorial/ebaypicpc房源采集/tutorial/grfycj欢乐书客小说采集/tutorial/hlskxscj新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj高德地图数据采集方法/tutorial/gddtsjcj企查查企业邮箱采集/tutorial/qccqyemailcj大众点评简易模式智能防封模版使用说明/tutorial/dzdpffmbsmqq邮箱采集/tutorial/qqemailcj优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。 查看全部
优采云·云采集网络爬虫软件优采云·云采集网络爬虫软件 怎样使用优采云批量下载网页优采云作为一款通用的网页数据采集器,其并不针对于某一网站某一行业的数据进行采集,而是网页上所能看见或网页源码中有的文本信息几乎都能采集,有些同学有批量下载网页的需求,其实可以使用优采云采集器去实现。下面以UC头条网页为你们详尽介绍怎样使用优采云批量下载网页。 采集网站:/使用功能点:Xpath HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门教程1/tutorialdetail-1/xpathrm1.html HYPERLINK "/tutorialdetail-1/xpathrm1.html" xpath入门2/tutorialdetail-1/xpathrm1.html HYPERLINK "/tutorialdetail-1/xdxpath-7.html" 相对XPATH教程-7.0版/tutorialdetail-1/xdxpath-7.htmlAJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1步骤1:创建UC头条文章采集任务1)进入主界面,选择“自定义模式”2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”3)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作”两个蓝筹股。
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按键,而是通过下拉加载,不断加载出新的内容因此,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上滚动”,滚动次数依照自身需求进行设置,间隔时间依照网页加载情况进行设置,滚动形式为“向下滚动一屏”,然后点击“确定”(注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间>网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请看:优采云7.0教程——AJAX滚动教程 HYPERLINK "/tutorial/ajgd_7.aspx?t=1" /tutorial/ajgd_7.aspx?t=1) HYPERLINK "/article/javascript:;" 步骤2:创建翻页循环及提取数据1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作提示框中,选择“选中全部”2)选择“循环点击每位链接”3) 系统会手动步入文章详情页。点击须要采集的数组(这里先点击了文章标题),在操作提示框中,选择“采集该元素的文本”文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。
以下采集的是文章正文 HYPERLINK "/article/javascript:;" 步骤3:提取UC头条文章图片地址1)接下来开始采集图片地址。先点击文章中第一张图片,再点击页面中第二张图片,在弹出的操作提示框中,选择“采集以下图片地址”2)修改数组名称,再点击“确定”3)现在我们早已采集到了图片URL,接下来为批量导入图片做打算。批量导入图片的时侯,我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标题命名。首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”选中标题数组,点击如图所示按键选择“格式化数据”点击添加步骤选择“添加前缀”在如图位置,输入前缀:“D:\UC头条图片采集\”,然后点击“确定”以同样的形式添加后缀“\”,然后点击“确定”4)修改数组名为“图片储存地址”,最后展示出的“D:\UC头条图片采集\文章标题”即为图片保存文件夹名,其中“D:\UC头条图片采集\”是固定的,文章标题是变化的步骤4:修改Xpath1)选中整个“循环”步骤,打开“高级选项”,可以看见,优采云默认生成的是固定元素列表,定位的是前13篇文章的链接2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条Xpath://DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A,页面中所需的所有文章均被定位了3)将修改后的Xpath,复制粘贴到优采云中所示位置,然后点击“确定”步骤5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”注:本地采集占用当前笔记本资源进行采集,如果存在采集时间要求或当前笔记本未能长时间进行采集可以使用云采集功能,云采集在网路中进行采集,无需当前笔记本支持,电脑可以死机,可以设置多个云节点平摊任务,10个节点相当于10台笔记本分配任务帮你采集,速度增加为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”,将采集好的数据导入这儿我们选择excel作为导入为格式,数据导入后如下图步骤6: HYPERLINK "/article/javascript:;" 将图片URL批量转换为图片经过如上操作,我们早已得到了要采集的图片的URL。接下来,再通过优采云专用的图片批量下载工具,将采集到的图片URL中的图片,下载并保存到本地笔记本中。
图片批量下载工具: HYPERLINK "/s/1c2n60NI" /s/1c2n60NI1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe文件,打开软件2)打开File菜单,选择从EXCEL导出(目前只支持EXCEL格式文件)3)进行相关设置,设置完成后,点击OK即可导出文件选择EXCEL文件:导入你须要下载图片地址的EXCEL文件EXCEL表名:对应数据表的名称文件URL列名:表内对应URL的列名称,在这里为“图片URL”保存文件夹名:EXCEL中须要单独一个列,列出图片想要保存到文件夹的路径,可以设置不同图片储存至不同文件夹,在这里为“图片储存地址”可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名4)点击OK后,界面如图所示,再点击“开始下载”5)页面下方会显示图片下载状态6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片URL早已批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以文章标题命名本文来自:/tutorialdetail-1/ucnewscj.html相关采集教程:ebay爬虫抓取图片/tutorial/ebaypicpc房源采集/tutorial/grfycj欢乐书客小说采集/tutorial/hlskxscj新浪新闻采集/tutorial/xlnewscjBBC英文文章采集/tutorial/englisharticlecj高德地图数据采集方法/tutorial/gddtsjcj企查查企业邮箱采集/tutorial/qccqyemailcj大众点评简易模式智能防封模版使用说明/tutorial/dzdpffmbsmqq邮箱采集/tutorial/qqemailcj优采云——90万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化流程,点击滑鼠完成操作,2分钟即可快速入门。2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大云采集集群24*7不间断运行,不用害怕IP被封,网络中断。4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户的须要。
网站万能信息采集器 V10 官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-08-09 15:29
网站信息采集器是一款使用便捷的信息采集工具,软件手动获取网站上的信息并全部抓取出来发布到您的网站里,网站信息采集器拥有多级页面采集、全手动添加采集信息、多页新闻手动抓取等功能,不用人工,自动实现网站更新。
网站信息采集器功能
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识Javascript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
更新日志
1.全新的分层设置,每一层都可以设置特殊的选项,摆脱了先前的默认3层限制
2.任意多层分类一次抓取,以前是须要先把各分类网址抓到,然后再抓每位分类
3.图片下载,自定义文件名,以前不能更名
4.新闻内容分页合并设置更简单,更通用,功能更强大
5.模拟点击更通用更简单,以前的模拟点击是须要特殊设置的,使用复杂
6.可以依据内容判定重复,以前只是按照网址判定重复
7.采集完以后容许执行自定义vbs脚本endget.vbs,发布完以后容许执行endpub.vbs,在vbs里你可以自己编撰对数据的处理功能
8.导出数据可以实现收录文字 排除文字 文字截取 日期加几个月 数字比较大小过滤 前后追加字符 查看全部
网站信息采集器是一款使用便捷的信息采集工具,软件手动获取网站上的信息并全部抓取出来发布到您的网站里,网站信息采集器拥有多级页面采集、全手动添加采集信息、多页新闻手动抓取等功能,不用人工,自动实现网站更新。
网站信息采集器功能
1.信息采集添加全手动
网站抓取的目的主要是添加到您的网站中,软件可以实现采集添加全手动完成。其它网站刚刚更新的信息五分钟之内都会手动挪到您的网站中.
2.需要登入的网站也照抓
对于须要登陆能够听到信息内容的网站,网站优采云采集器可以实现轻松登陆并采集,即使有验证码也可以穿过登陆采集到您须要的信息。
3.任意类型的文件都能下载
如果须要采集图片等二进制文件,经过简单设置网站优采云采集器就可以把任意类型的文件保存到本地。
4.多级页面采集
可以同时采集到多级页面的内容。如果一条信息分布在好多不同的页面上,网站优采云采集器也能手动识
别多级页面实现采集
5.自动辨识Javascript等特殊网址
不少网站的网页联接是类似javascript:openwin('1234')这样的特殊网址,不是一般的开头的,软件也能手动辨识并抓到内容
6.自动获取各个分类网址
比如供求信息,往往有很多好多个分类,经过简单设置软件就可以手动抓到那些分类网址,并把抓到的信息手动分类
7.多页新闻手动抓取、广告过滤
有些一条新闻上面还有下一页,软件也可以把各个页面都抓到的。并且抓到的新闻中的图片和文字同时可以保存出来,并能把广告过滤掉
8.自动破解防盗链
很多下载类的网站都做了防盗链了,直接输入网址是抓不到内容的,但是软件中能手动破解防盗链,,确保您能抓到想要的东西
另加入了模拟人工递交的功能,租用的网站asp+access空间也能远程发布了,实际上能够模拟一切网页递交动作,可以批量注册会员、模拟群发消息。
更新日志
1.全新的分层设置,每一层都可以设置特殊的选项,摆脱了先前的默认3层限制
2.任意多层分类一次抓取,以前是须要先把各分类网址抓到,然后再抓每位分类
3.图片下载,自定义文件名,以前不能更名
4.新闻内容分页合并设置更简单,更通用,功能更强大
5.模拟点击更通用更简单,以前的模拟点击是须要特殊设置的,使用复杂
6.可以依据内容判定重复,以前只是按照网址判定重复
7.采集完以后容许执行自定义vbs脚本endget.vbs,发布完以后容许执行endpub.vbs,在vbs里你可以自己编撰对数据的处理功能
8.导出数据可以实现收录文字 排除文字 文字截取 日期加几个月 数字比较大小过滤 前后追加字符
Python集成代码实现了优采云爬行知乎的所有功能以及附加的数据预处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2020-08-09 06:23
上一篇文章(上面的链接)对每个部分进行了更详细的描述. 本文将介绍用于爬网和爬网数据的预处理的集成代码块.
1.python集成代码,实现了优采云爬行之虎的所有功能
```python
#!/usr/bin/env python
# coding: utf-8
import os
import pandas as pd
from selenium import webdriver
from lxml import etree
import time
import jieba
import re
import numpy as np
url1 = input("请输入您所需要爬取的网页(知乎)")
browser = webdriver.Chrome("/Users/apple/Downloads/chromedrivermac")
browser.get(url1)
try:
#点击问题全部内容
button1 = browser.find_elements_by_xpath("""//div[@class= "QuestionHeader-detail"]
//button[contains(@class,"Button") and contains(@class,"QuestionRichText-more")
and contains(@class , "Button--plain")
]""")[0]
button1.click()
except:
print('这个问题比较简单,并没有问题的全部内容哦!')
#此网页就属于异步加载的情况
#那么我们就需要多次下滑
for i in range(20):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
#点击知乎的登陆弹窗
button2 = browser.find_elements_by_xpath("""//button[@aria-label = '关闭']""")[0]
button2.click()
#点击知乎的“查看全部回答”按钮
button3 = browser.find_elements_by_xpath("""//div[@class = 'Question-main']
//a[contains(@class,"ViewAll-QuestionMainAction") and contains(@class , "QuestionMainAction") ]""")[1]
button3.click()
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
while final_end_it == []:
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
for i in range(30):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
dom = etree.HTML(browser.page_source)
# 对于问题本身的数据
Followers_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[0]
Browsed_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[1]
#关注者数量
Followers_number_final = re.sub(",","",Followers_number_first)
#浏览数量
Browsed_number_final = re.sub(",","",Browsed_number_first)
#问题链接
problem_url = url1
#问题ID
problem_id = re.findall(r"\d+\.?\d*",url1)
#问题标题
problem_title = dom.xpath("""//div[@class = 'QuestionHeader']//h1[@class = "QuestionHeader-title"]/text()""")
#问题点赞数
problem_endorse = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "GoodQuestionAction"]/button/text()""")
#问题评论数
problem_Comment = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "QuestionHeader-Comment"]/button/text()""")
#问题回答数
answer_number = dom.xpath("""//div[@class = 'Question-main']//h4[@class = "List-headerText"]/span/text()""")
#问题标签
problem_tags_list = dom.xpath("""//div[@class = 'QuestionHeader-topics']//a[@class = "TopicLink"]/div/div/text()""")
# 对于回答本身的数据
#具体内容
comment_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "RichContent-inner"]""")
comment_list_text = []
for comment in comment_list:
comment_list_text.append(comment.xpath("string(.)"))
#发表时间
time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/@data-tooltip""")
edit_time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/text()""")
#点赞数
endorse_list = dom.xpath("""//div[@class = 'List-item']//button[contains(@class,"Button") and contains(@class,"VoteButton") and contains(@class , "VoteButton--up")]/@aria-label""")
#评论人数
number_of_endorse_list = dom.xpath("""//div[@class = 'List-item']//svg[contains(@class,"Zi") and contains(@class,"Zi--Comment")
and contains(@class,"Button-zi")]/../../text()""")
#回答链接
answers_url_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/meta[@itemprop = "url"]/@content""")
authors_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/@data-zop""")
#作者姓名
authorName_list = []
#作者id
authorid_list = []
for i in authors_list:
authorName_list.append(eval(i)['authorName'])
authorid_list.append(eval(i)["itemId"])
# 合成数据框
data = pd.DataFrame()
data['具体内容'] = comment_list_text
data["发表时间"] = time_list
data["点赞数"] = endorse_list
data["评论人数"] = number_of_endorse_list
data["回答链接"] = answers_url_list
data["作者姓名"] = authorName_list
data['作者id'] = authorid_list
data["问题关注者数量"] = Followers_number_final
data["问题浏览数量"] = Browsed_number_final
data["问题链接"] = problem_url
data["问题ID"] = problem_id[0]
data["问题标题"] = problem_title[0]
data["问题点赞数"] = problem_endorse[0]
data["问题评论数"] = problem_Comment[0]
data["问题回答数"] = answer_number[0]
data["问题标签"] = "&".join(problem_tags_list)
data
复制上面的代码,配置chromedriver环境,输入需要抓取的网页,然后等待抓取完成.
2. 简单的数据清理
def str_to_number(str1):
mid = re.findall(r"\d+\.?\d*",str1)
if mid != []:
return mid[0]
else:
return 0
data["点赞数"] = data["点赞数"].apply(str_to_number)
data["评论人数"] = data["评论人数"].apply(str_to_number)
data["问题点赞数"] = data["问题点赞数"].apply(str_to_number)
data["问题评论数"] = data["问题评论数"].apply(str_to_number)
data["问题回答数"] = data["问题回答数"].apply(str_to_number)
def time_to_datetime(x):
x1 = re.sub('[\u4e00-\u9fa5]', '',x)
if len(x1) < 15 :
#15的根据是data["发表时间_1"] = data["发表时间"].apply(lambda x : re.sub('[\u4e00-\u9fa5]', '',x))
#data["发表时间_1"].apply(lambda x : len(x)).value_counts()
x2 = re.sub(' ', '2020-',x1,count=1)
return x2
return x1
data["发表时间"] = data["发表时间"].apply(time_to_datetime)
data.sort_values('发表时间', inplace=True)
data = data.reset_index(drop = True)
data
3. 使用“问题标题”存储数据 查看全部
社交: 充分利用最好的机会!了解采集器集成代码的实现! (2020年7月29日)
上一篇文章(上面的链接)对每个部分进行了更详细的描述. 本文将介绍用于爬网和爬网数据的预处理的集成代码块.
1.python集成代码,实现了优采云爬行之虎的所有功能
```python
#!/usr/bin/env python
# coding: utf-8
import os
import pandas as pd
from selenium import webdriver
from lxml import etree
import time
import jieba
import re
import numpy as np
url1 = input("请输入您所需要爬取的网页(知乎)")
browser = webdriver.Chrome("/Users/apple/Downloads/chromedrivermac")
browser.get(url1)
try:
#点击问题全部内容
button1 = browser.find_elements_by_xpath("""//div[@class= "QuestionHeader-detail"]
//button[contains(@class,"Button") and contains(@class,"QuestionRichText-more")
and contains(@class , "Button--plain")
]""")[0]
button1.click()
except:
print('这个问题比较简单,并没有问题的全部内容哦!')
#此网页就属于异步加载的情况
#那么我们就需要多次下滑
for i in range(20):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
#点击知乎的登陆弹窗
button2 = browser.find_elements_by_xpath("""//button[@aria-label = '关闭']""")[0]
button2.click()
#点击知乎的“查看全部回答”按钮
button3 = browser.find_elements_by_xpath("""//div[@class = 'Question-main']
//a[contains(@class,"ViewAll-QuestionMainAction") and contains(@class , "QuestionMainAction") ]""")[1]
button3.click()
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
while final_end_it == []:
final_end_it = browser.find_elements_by_xpath("""//button[contains(@class,"Button")
and contains(@class ,'QuestionAnswers-answerButton')
and contains(@class ,'Button--blue')
and contains(@class ,'Button--spread')
]""")
js="var q=document.documentElement.scrollTop=0"
browser.execute_script(js)
for i in range(30):
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
time.sleep(0.5)
print(i)
dom = etree.HTML(browser.page_source)
# 对于问题本身的数据
Followers_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[0]
Browsed_number_first = dom.xpath("""//div[@class="QuestionFollowStatus"]//div[@class = "NumberBoard-itemInner"]/strong/text()""")[1]
#关注者数量
Followers_number_final = re.sub(",","",Followers_number_first)
#浏览数量
Browsed_number_final = re.sub(",","",Browsed_number_first)
#问题链接
problem_url = url1
#问题ID
problem_id = re.findall(r"\d+\.?\d*",url1)
#问题标题
problem_title = dom.xpath("""//div[@class = 'QuestionHeader']//h1[@class = "QuestionHeader-title"]/text()""")
#问题点赞数
problem_endorse = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "GoodQuestionAction"]/button/text()""")
#问题评论数
problem_Comment = dom.xpath("""//div[@class = 'QuestionHeader']//div[@class = "QuestionHeader-Comment"]/button/text()""")
#问题回答数
answer_number = dom.xpath("""//div[@class = 'Question-main']//h4[@class = "List-headerText"]/span/text()""")
#问题标签
problem_tags_list = dom.xpath("""//div[@class = 'QuestionHeader-topics']//a[@class = "TopicLink"]/div/div/text()""")
# 对于回答本身的数据
#具体内容
comment_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "RichContent-inner"]""")
comment_list_text = []
for comment in comment_list:
comment_list_text.append(comment.xpath("string(.)"))
#发表时间
time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/@data-tooltip""")
edit_time_list = dom.xpath("""//div[@class = 'List-item']//div[@class = "ContentItem-time"]//span/text()""")
#点赞数
endorse_list = dom.xpath("""//div[@class = 'List-item']//button[contains(@class,"Button") and contains(@class,"VoteButton") and contains(@class , "VoteButton--up")]/@aria-label""")
#评论人数
number_of_endorse_list = dom.xpath("""//div[@class = 'List-item']//svg[contains(@class,"Zi") and contains(@class,"Zi--Comment")
and contains(@class,"Button-zi")]/../../text()""")
#回答链接
answers_url_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/meta[@itemprop = "url"]/@content""")
authors_list = dom.xpath("""//div[@class = 'List-item']//div[contains(@class,"ContentItem") and contains(@class,"AnswerItem")]
/@data-zop""")
#作者姓名
authorName_list = []
#作者id
authorid_list = []
for i in authors_list:
authorName_list.append(eval(i)['authorName'])
authorid_list.append(eval(i)["itemId"])
# 合成数据框
data = pd.DataFrame()
data['具体内容'] = comment_list_text
data["发表时间"] = time_list
data["点赞数"] = endorse_list
data["评论人数"] = number_of_endorse_list
data["回答链接"] = answers_url_list
data["作者姓名"] = authorName_list
data['作者id'] = authorid_list
data["问题关注者数量"] = Followers_number_final
data["问题浏览数量"] = Browsed_number_final
data["问题链接"] = problem_url
data["问题ID"] = problem_id[0]
data["问题标题"] = problem_title[0]
data["问题点赞数"] = problem_endorse[0]
data["问题评论数"] = problem_Comment[0]
data["问题回答数"] = answer_number[0]
data["问题标签"] = "&".join(problem_tags_list)
data
复制上面的代码,配置chromedriver环境,输入需要抓取的网页,然后等待抓取完成.
2. 简单的数据清理
def str_to_number(str1):
mid = re.findall(r"\d+\.?\d*",str1)
if mid != []:
return mid[0]
else:
return 0
data["点赞数"] = data["点赞数"].apply(str_to_number)
data["评论人数"] = data["评论人数"].apply(str_to_number)
data["问题点赞数"] = data["问题点赞数"].apply(str_to_number)
data["问题评论数"] = data["问题评论数"].apply(str_to_number)
data["问题回答数"] = data["问题回答数"].apply(str_to_number)
def time_to_datetime(x):
x1 = re.sub('[\u4e00-\u9fa5]', '',x)
if len(x1) < 15 :
#15的根据是data["发表时间_1"] = data["发表时间"].apply(lambda x : re.sub('[\u4e00-\u9fa5]', '',x))
#data["发表时间_1"].apply(lambda x : len(x)).value_counts()
x2 = re.sub(' ', '2020-',x1,count=1)
return x2
return x1
data["发表时间"] = data["发表时间"].apply(time_to_datetime)
data.sort_values('发表时间', inplace=True)
data = data.reset_index(drop = True)
data
3. 使用“问题标题”存储数据
使用python创建爬虫非常简单: Meituan.com数据采集技能,如果您有基础,就开始爬网!
采集交流 • 优采云 发表了文章 • 0 个评论 • 703 次浏览 • 2020-08-08 14:49
如今,大多数动态网站通过浏览器端的js发起ajax请求,然后在接收到数据后呈现页面. 在这种情况下,采集数据,通过脚本启动http获取请求以及在获取DOM文档页面之后解析和提取有用数据的方法是不可行的. 然后有人会想到通过F12打开浏览器控制台来分析服务器api,然后模拟请求相应的api以获取我们想要的数据. 这个想法在某些情况下是可行的,但是许多大型网站都会采用一些防爬网策略,出于安全考虑,通常会在界面中添加安全验证. 例如,在请求页面之前,只能请求相关的标头和cookie. 有些还限制了请求的来源,等等,这一次通过这种方式采集数据就更加困难了. 我们还有其他有效的方法吗?当然,python爬虫非常简单,让我们首先了解Selenium和Selectors,然后通过抓取美团在线业务信息的示例总结一些数据采集技术:
2. 页面抓取数据分析和数据表创建
以朝阳大悦城的一家美食餐厅为数据采集示例,该网站为:
https://www.meituan.com/meishi/40453459/
2.1获取数据
我们要捕获的数据的第一部分是企业的基本信息,包括企业名称,地址,电话号码和营业时间. 在分析了多个美食企业之后,我们知道这些企业的Web界面在布局上基本相同. 因此我们的采集器可以编写更通用的内容. 为了防止重复抓取业务数据,我们还将业务的URL信息存储在数据表中.
第二部分要捕获的数据是美食餐厅的招牌菜. 每个商店基本上都有自己的特色菜. 我们还将保存这些数据并将其存储在另一个数据表中.
我们要捕获的数据的最后一部分是用户评论. 这部分数据对我们来说非常有价值. 将来,我们可以分析这部分数据以提取有关业务的更多信息. 我们要获取的信息的这一部分包括: 评论者的昵称,星级,评论内容,评论时间,如果有图片,我们还需要以列表的形式保存图片的地址.
2.2创建数据表
我们用来存储数据的数据库是Mysql,Python有一个相关的ORM,我们在项目中使用了peewee. 但是,建议在创建数据表时使用本机SQL,以便我们可以灵活地控制字段属性,设置引擎和字符编码格式等. 使用Python的ORM也可以实现结果,但是ORM是数据库层的封装,例如sqlite,sqlserver数据库和Mysql,仍然存在一些差异,使用ORM只能使用这些数据库的公共部分. 以下是存储数据所需的数据表sql:
CREATE TABLE `merchant` ( #商家表
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '商家名称',
`address` varchar(255) NOT NULL COMMENT '地址',
`website_address` varchar(255) NOT NULL COMMENT '网址',
`website_address_hash` varchar(32) NOT NULL COMMENT '网址hash',
`mobile` varchar(32) NOT NULL COMMENT '电话',
`business_hours` varchar(255) NOT NULL COMMENT '营业时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `recommended_dish` ( #推荐菜表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`name` varchar(255) NOT NULL COMMENT '推荐菜名称',
PRIMARY KEY (`id`),
KEY `recommended_dish_merchant_id` (`merchant_id`),
CONSTRAINT `recommended_dish_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=309 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `evaluate` ( #评论表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`user_name` varchar(255) DEFAULT '' COMMENT '评论人昵称',
`evaluate_time` datetime NOT NULL COMMENT '评论时间',
`content` varchar(10000) DEFAULT '' COMMENT '评论内容',
`star` tinyint(4) DEFAULT '0' COMMENT '星级',
`image_list` varchar(1000) DEFAULT '' COMMENT '图片列表',
PRIMARY KEY (`id`),
KEY `evaluate_merchant_id` (`merchant_id`),
CONSTRAINT `evaluate_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8427 DEFAULT CHARSET=utf8mb4;
相应地,我们还可以使用Python的ORM创建管理数据表. 稍后在分析代码时,我们将讨论peewee在mysql数据库上的一些常见操作,例如查询数据,插入数据库数据和返回id. 批量插入数据库等,读者可以采集相关材料并进行系统学习.
meituan_spider / models.py代码:
from peewee import *
# 连接数据库
db = MySQLDatabase("meituan_spider", host="127.0.0.1", port=3306, user="root", password="root", charset="utf8")
class BaseModel(Model):
class Meta:
database = db
# 商家表,用来存放商家信息
class Merchant(BaseModel):
id = AutoField(primary_key=True, verbose_name="商家id")
name = CharField(max_length=255, verbose_name="商家名称")
address = CharField(max_length=255, verbose_name="商家地址")
website_address = CharField(max_length=255, verbose_name="网络地址")
website_address_hash = CharField(max_length=32, verbose_name="网络地址的md5值,为了快速索引")
mobile = CharField(max_length=32, verbose_name="商家电话")
business_hours = CharField(max_length=255, verbose_name="营业时间")
# 商家推荐菜表,存放菜品的推荐信息
class Recommended_dish(BaseModel):
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
name = CharField(max_length=255, verbose_name="推荐菜名称")
# 用户评价表,存放用户的评论信息
class Evaluate(BaseModel):
id = CharField(primary_key=True)
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
user_name = CharField(verbose_name="用户名")
evaluate_time = DateTimeField(verbose_name="评价时间")
content = TextField(default="", verbose_name="评论内容")
star = IntegerField(default=0, verbose_name="评分")
image_list = TextField(default="", verbose_name="图片")
if __name__ == "__main__":
db.create_tables([Merchant, Recommended_dish, Evaluate])
3. 代码实现和详细说明
代码相对简单,但是要运行代码,您需要安装上述工具包: 还需要安装硒,scrapy和peewee,这些软件包可以通过pip来安装;另外,还需要安装selenium驱动程序浏览器相应的驱动程序,因为我在本地使用chrome浏览器,所以我下载了相关版本的chromedriver,将在以后使用. 要求读者检查使用python操作硒所需的准备工作,并手动设置相关环境. 接下来,详细分析代码;源代码如下:
<p>from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from scrapy import Selector
from models import *
import hashlib
import os
import re
import time
import json
chrome_options = Options()
# 设置headless模式,这种方式下无启动界面,能够加速程序的运行
# chrome_options.add_argument("--headless")
# 禁用gpu防止渲染图片
chrome_options.add_argument('disable-gpu')
# 设置不加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 通过页面展示的像素数计算星级
def star_num(num):
numbers = {
"16.8": 1,
"33.6": 2,
"50.4": 3,
"67.2": 4,
"84": 5
}
return numbers.get(num, 0)
# 解析商家内容
def parse(merchant_id):
weblink = "https://www.meituan.com/meishi/{}/".format(merchant_id)
# 启动selenium
browser = webdriver.Chrome(executable_path="/Users/guozhaoran/python/tools/chromedriver", options=chrome_options)
browser.get(weblink)
# 不重复爬取数据
hash_weblink = hashlib.md5(weblink.encode(encoding='utf-8')).hexdigest()
existed = Merchant.select().where(Merchant.website_address_hash == hash_weblink)
if (existed):
print("数据已经爬取")
os._exit(0)
time.sleep(2)
# print(browser.page_source) #获取到网页渲染后的内容
sel = Selector(text=browser.page_source)
# 提取商家的基本信息
# 商家名称
name = "".join(sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='name']/text()").extract()).strip()
detail = sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='address']//p/text()").extract()
address = "".join(detail[1].strip())
mobile = "".join(detail[3].strip())
business_hours = "".join(detail[5].strip())
# 保存商家信息
merchant_id = Merchant.insert(name=name, address=address, website_address=weblink,
website_address_hash=hash_weblink, mobile=mobile, business_hours=business_hours
).execute()
# 获取推荐菜信息
recommended_dish_list = sel.xpath(
"//div[@id='app']//div[@class='recommend']//div[@class='list clear']//span/text()").extract()
# 遍历获取到的数据,批量插入数据库
dish_data = [{
'merchant_id': merchant_id,
'name': i
} for i in recommended_dish_list]
Recommended_dish.insert_many(dish_data).execute()
# 也可以遍历list,一条条插入数据库
# for dish in recommended_dish_list:
# Recommended_dish.create(merchant_id=merchant_id, name=dish)
# 查看链接一共有多少页的评论
page_num = 0
try:
page_num = sel.xpath(
"//div[@id='app']//div[@class='mt-pagination']//ul[@class='pagination clear']//li[last()-1]//span/text()").extract_first()
page_num = int("".join(page_num).strip())
# page_num = int(page_num)
except NoSuchElementException as e:
print("改商家没有用户评论信息")
os._exit(0)
# 当有用户评论数据,每页每页的读取用户数据
if (page_num):
i = 1
number_pattern = re.compile(r"\d+\.?\d*")
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
illegal_str = re.compile(u'[^0-9a-zA-Z\u4e00-\u9fa5.,,。?“”]+', re.UNICODE)
while (i 查看全部
1. 数据采集工具简介
如今,大多数动态网站通过浏览器端的js发起ajax请求,然后在接收到数据后呈现页面. 在这种情况下,采集数据,通过脚本启动http获取请求以及在获取DOM文档页面之后解析和提取有用数据的方法是不可行的. 然后有人会想到通过F12打开浏览器控制台来分析服务器api,然后模拟请求相应的api以获取我们想要的数据. 这个想法在某些情况下是可行的,但是许多大型网站都会采用一些防爬网策略,出于安全考虑,通常会在界面中添加安全验证. 例如,在请求页面之前,只能请求相关的标头和cookie. 有些还限制了请求的来源,等等,这一次通过这种方式采集数据就更加困难了. 我们还有其他有效的方法吗?当然,python爬虫非常简单,让我们首先了解Selenium和Selectors,然后通过抓取美团在线业务信息的示例总结一些数据采集技术:
2. 页面抓取数据分析和数据表创建
以朝阳大悦城的一家美食餐厅为数据采集示例,该网站为:
https://www.meituan.com/meishi/40453459/
2.1获取数据
我们要捕获的数据的第一部分是企业的基本信息,包括企业名称,地址,电话号码和营业时间. 在分析了多个美食企业之后,我们知道这些企业的Web界面在布局上基本相同. 因此我们的采集器可以编写更通用的内容. 为了防止重复抓取业务数据,我们还将业务的URL信息存储在数据表中.
第二部分要捕获的数据是美食餐厅的招牌菜. 每个商店基本上都有自己的特色菜. 我们还将保存这些数据并将其存储在另一个数据表中.
我们要捕获的数据的最后一部分是用户评论. 这部分数据对我们来说非常有价值. 将来,我们可以分析这部分数据以提取有关业务的更多信息. 我们要获取的信息的这一部分包括: 评论者的昵称,星级,评论内容,评论时间,如果有图片,我们还需要以列表的形式保存图片的地址.
2.2创建数据表
我们用来存储数据的数据库是Mysql,Python有一个相关的ORM,我们在项目中使用了peewee. 但是,建议在创建数据表时使用本机SQL,以便我们可以灵活地控制字段属性,设置引擎和字符编码格式等. 使用Python的ORM也可以实现结果,但是ORM是数据库层的封装,例如sqlite,sqlserver数据库和Mysql,仍然存在一些差异,使用ORM只能使用这些数据库的公共部分. 以下是存储数据所需的数据表sql:
CREATE TABLE `merchant` ( #商家表
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL COMMENT '商家名称',
`address` varchar(255) NOT NULL COMMENT '地址',
`website_address` varchar(255) NOT NULL COMMENT '网址',
`website_address_hash` varchar(32) NOT NULL COMMENT '网址hash',
`mobile` varchar(32) NOT NULL COMMENT '电话',
`business_hours` varchar(255) NOT NULL COMMENT '营业时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `recommended_dish` ( #推荐菜表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`name` varchar(255) NOT NULL COMMENT '推荐菜名称',
PRIMARY KEY (`id`),
KEY `recommended_dish_merchant_id` (`merchant_id`),
CONSTRAINT `recommended_dish_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=309 DEFAULT CHARSET=utf8mb4;
CREATE TABLE `evaluate` ( #评论表
`id` int(11) NOT NULL AUTO_INCREMENT,
`merchant_id` int(11) NOT NULL COMMENT '商家id',
`user_name` varchar(255) DEFAULT '' COMMENT '评论人昵称',
`evaluate_time` datetime NOT NULL COMMENT '评论时间',
`content` varchar(10000) DEFAULT '' COMMENT '评论内容',
`star` tinyint(4) DEFAULT '0' COMMENT '星级',
`image_list` varchar(1000) DEFAULT '' COMMENT '图片列表',
PRIMARY KEY (`id`),
KEY `evaluate_merchant_id` (`merchant_id`),
CONSTRAINT `evaluate_ibfk_1` FOREIGN KEY (`merchant_id`) REFERENCES `merchant` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8427 DEFAULT CHARSET=utf8mb4;
相应地,我们还可以使用Python的ORM创建管理数据表. 稍后在分析代码时,我们将讨论peewee在mysql数据库上的一些常见操作,例如查询数据,插入数据库数据和返回id. 批量插入数据库等,读者可以采集相关材料并进行系统学习.
meituan_spider / models.py代码:
from peewee import *
# 连接数据库
db = MySQLDatabase("meituan_spider", host="127.0.0.1", port=3306, user="root", password="root", charset="utf8")
class BaseModel(Model):
class Meta:
database = db
# 商家表,用来存放商家信息
class Merchant(BaseModel):
id = AutoField(primary_key=True, verbose_name="商家id")
name = CharField(max_length=255, verbose_name="商家名称")
address = CharField(max_length=255, verbose_name="商家地址")
website_address = CharField(max_length=255, verbose_name="网络地址")
website_address_hash = CharField(max_length=32, verbose_name="网络地址的md5值,为了快速索引")
mobile = CharField(max_length=32, verbose_name="商家电话")
business_hours = CharField(max_length=255, verbose_name="营业时间")
# 商家推荐菜表,存放菜品的推荐信息
class Recommended_dish(BaseModel):
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
name = CharField(max_length=255, verbose_name="推荐菜名称")
# 用户评价表,存放用户的评论信息
class Evaluate(BaseModel):
id = CharField(primary_key=True)
merchant_id = ForeignKeyField(Merchant, verbose_name="商家外键")
user_name = CharField(verbose_name="用户名")
evaluate_time = DateTimeField(verbose_name="评价时间")
content = TextField(default="", verbose_name="评论内容")
star = IntegerField(default=0, verbose_name="评分")
image_list = TextField(default="", verbose_name="图片")
if __name__ == "__main__":
db.create_tables([Merchant, Recommended_dish, Evaluate])
3. 代码实现和详细说明
代码相对简单,但是要运行代码,您需要安装上述工具包: 还需要安装硒,scrapy和peewee,这些软件包可以通过pip来安装;另外,还需要安装selenium驱动程序浏览器相应的驱动程序,因为我在本地使用chrome浏览器,所以我下载了相关版本的chromedriver,将在以后使用. 要求读者检查使用python操作硒所需的准备工作,并手动设置相关环境. 接下来,详细分析代码;源代码如下:
<p>from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
from scrapy import Selector
from models import *
import hashlib
import os
import re
import time
import json
chrome_options = Options()
# 设置headless模式,这种方式下无启动界面,能够加速程序的运行
# chrome_options.add_argument("--headless")
# 禁用gpu防止渲染图片
chrome_options.add_argument('disable-gpu')
# 设置不加载图片
chrome_options.add_argument('blink-settings=imagesEnabled=false')
# 通过页面展示的像素数计算星级
def star_num(num):
numbers = {
"16.8": 1,
"33.6": 2,
"50.4": 3,
"67.2": 4,
"84": 5
}
return numbers.get(num, 0)
# 解析商家内容
def parse(merchant_id):
weblink = "https://www.meituan.com/meishi/{}/".format(merchant_id)
# 启动selenium
browser = webdriver.Chrome(executable_path="/Users/guozhaoran/python/tools/chromedriver", options=chrome_options)
browser.get(weblink)
# 不重复爬取数据
hash_weblink = hashlib.md5(weblink.encode(encoding='utf-8')).hexdigest()
existed = Merchant.select().where(Merchant.website_address_hash == hash_weblink)
if (existed):
print("数据已经爬取")
os._exit(0)
time.sleep(2)
# print(browser.page_source) #获取到网页渲染后的内容
sel = Selector(text=browser.page_source)
# 提取商家的基本信息
# 商家名称
name = "".join(sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='name']/text()").extract()).strip()
detail = sel.xpath("//div[@id='app']//div[@class='d-left']//div[@class='address']//p/text()").extract()
address = "".join(detail[1].strip())
mobile = "".join(detail[3].strip())
business_hours = "".join(detail[5].strip())
# 保存商家信息
merchant_id = Merchant.insert(name=name, address=address, website_address=weblink,
website_address_hash=hash_weblink, mobile=mobile, business_hours=business_hours
).execute()
# 获取推荐菜信息
recommended_dish_list = sel.xpath(
"//div[@id='app']//div[@class='recommend']//div[@class='list clear']//span/text()").extract()
# 遍历获取到的数据,批量插入数据库
dish_data = [{
'merchant_id': merchant_id,
'name': i
} for i in recommended_dish_list]
Recommended_dish.insert_many(dish_data).execute()
# 也可以遍历list,一条条插入数据库
# for dish in recommended_dish_list:
# Recommended_dish.create(merchant_id=merchant_id, name=dish)
# 查看链接一共有多少页的评论
page_num = 0
try:
page_num = sel.xpath(
"//div[@id='app']//div[@class='mt-pagination']//ul[@class='pagination clear']//li[last()-1]//span/text()").extract_first()
page_num = int("".join(page_num).strip())
# page_num = int(page_num)
except NoSuchElementException as e:
print("改商家没有用户评论信息")
os._exit(0)
# 当有用户评论数据,每页每页的读取用户数据
if (page_num):
i = 1
number_pattern = re.compile(r"\d+\.?\d*")
chinese_pattern = re.compile(u"[\u4e00-\u9fa5]+")
illegal_str = re.compile(u'[^0-9a-zA-Z\u4e00-\u9fa5.,,。?“”]+', re.UNICODE)
while (i
3. 如果网站SEO文章被采集并抄袭该怎么办
采集交流 • 优采云 发表了文章 • 0 个评论 • 322 次浏览 • 2020-08-08 10:22
1. 什么是采集品或窃?
采集是指通过某些采集程序和规则将文章从其他网站自动复制到您自己的网站. (这里的采集或窃必须是没有任何花招或伪装的原创采集)
按原样从其他网站采集文章对您网站的权重有很大影响. 尽管百度搜索引擎并不能真正保护原创文章,但成都SEO认为搜索引擎算法将变得越来越智能,可以按原样采集它们. 无论您采集多少,对提高网站排名都是有害且无利可图的.
我们的搜索引擎优化人员都知道,百度的飓风算法是在打击文章采集或窃. 如果我们使用文章采集器来发布文章,是否应该花时间根据算法处理它们?这是不值得的.
2. 所有SEO文章采集窃都会受到K站的惩罚
在分享开始时,我们知道,如果有人采集或窃我们的文章,则该文章将被收录并排在我们自己的文章之上. 是什么原因?
我们回到搜索引擎工作原理的本质,即满足和解决用户搜索结果时的需求. 换句话说,无论您的文章来自哪里(采集文章也可以解决用户需求),布局是否良好,逻辑表达是否清晰,可读性是否强,是否符合搜索引擎为用户提供的有价值的内容?解决用户搜索需求的实质?因此有一个排名.
但是,这样的采集行为是不可行的. 如果您想长期为采集的内容提供更好的排名,那肯定会引起原创作者的不满. 这种情况继续存在,网站管理员开始采集内容或窃内容,而不是制作原创文章或伪原创文章. 因此,当用户使用搜索引擎进行查询时,他们解决用户需求的能力将越来越弱.
因此,为了创建一个更好的Internet内容生态系统,搜索引擎将继续启动打击采集站点的算法,并且还将对原创内容给予某些排名偏好,以鼓励原创作者创建更多高质量的内容.
3. 如果网站SEO文章被采集并抄袭该怎么办
1. 对于临时建议,您通常可以礼貌地在另一方的网站上留言. 您可以在文章上添加链接进行投票吗?如果没有,那么百度会反馈并举报.
2. 长期建议,优化您的网站结构,打开速度和其他因素以提高您的实力,最好是在夜间更新文章,因为这会增加被首先收录的可能性. (请参阅原创文章的定义)
3. 尝试在网站上的图片上添加水印,以增加处理和处理其他人的文章的时间成本.
4. 保持良好的心态. 毕竟,百度还推出了一种飓风算法来打击惩罚. 采集原创物品并窃是一个问题. 技术一直在改进和优化. Google搜索引擎无法完美解决此问题. 最好的策略是做好自己的网站,以便可以在几秒钟内采集文章. 查看全部
在实际的网站SEO优化过程中,我们的网站管理员经常会遇到这样的情况: 我们收录的文章被他人窃,然后又收录了另一方的文章,并且排名高于自己的排名(请检查另一方是否旧站点和高重量站点),在这种情况下,我们都会问: K站点会因为这样的SEO文章采集或窃而受到惩罚吗?
1. 什么是采集品或窃?
采集是指通过某些采集程序和规则将文章从其他网站自动复制到您自己的网站. (这里的采集或窃必须是没有任何花招或伪装的原创采集)
按原样从其他网站采集文章对您网站的权重有很大影响. 尽管百度搜索引擎并不能真正保护原创文章,但成都SEO认为搜索引擎算法将变得越来越智能,可以按原样采集它们. 无论您采集多少,对提高网站排名都是有害且无利可图的.
我们的搜索引擎优化人员都知道,百度的飓风算法是在打击文章采集或窃. 如果我们使用文章采集器来发布文章,是否应该花时间根据算法处理它们?这是不值得的.
2. 所有SEO文章采集窃都会受到K站的惩罚
在分享开始时,我们知道,如果有人采集或窃我们的文章,则该文章将被收录并排在我们自己的文章之上. 是什么原因?
我们回到搜索引擎工作原理的本质,即满足和解决用户搜索结果时的需求. 换句话说,无论您的文章来自哪里(采集文章也可以解决用户需求),布局是否良好,逻辑表达是否清晰,可读性是否强,是否符合搜索引擎为用户提供的有价值的内容?解决用户搜索需求的实质?因此有一个排名.
但是,这样的采集行为是不可行的. 如果您想长期为采集的内容提供更好的排名,那肯定会引起原创作者的不满. 这种情况继续存在,网站管理员开始采集内容或窃内容,而不是制作原创文章或伪原创文章. 因此,当用户使用搜索引擎进行查询时,他们解决用户需求的能力将越来越弱.
因此,为了创建一个更好的Internet内容生态系统,搜索引擎将继续启动打击采集站点的算法,并且还将对原创内容给予某些排名偏好,以鼓励原创作者创建更多高质量的内容.
3. 如果网站SEO文章被采集并抄袭该怎么办
1. 对于临时建议,您通常可以礼貌地在另一方的网站上留言. 您可以在文章上添加链接进行投票吗?如果没有,那么百度会反馈并举报.
2. 长期建议,优化您的网站结构,打开速度和其他因素以提高您的实力,最好是在夜间更新文章,因为这会增加被首先收录的可能性. (请参阅原创文章的定义)
3. 尝试在网站上的图片上添加水印,以增加处理和处理其他人的文章的时间成本.
4. 保持良好的心态. 毕竟,百度还推出了一种飓风算法来打击惩罚. 采集原创物品并窃是一个问题. 技术一直在改进和优化. Google搜索引擎无法完美解决此问题. 最好的策略是做好自己的网站,以便可以在几秒钟内采集文章.
[原创工具] Shanken Web TXT Collector V1.1,可下载,实时预览,可以替换文本
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2020-08-08 02:54
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
版本: 1.0
日期: 2018.5.23
发展的原因: 在发展之初,是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看. 但是,许多小说网站不支持下载,或者下载[非VIP小说]受到限制. 我还在论坛中找到了一些采集. 但是我个人认为它不是很容易使用. 输入正则表达式后,将显示该章,但是无法通过单击下载按钮来下载文本. 软件完成后,我继续对其进行测试. 相同的正则表达式,那些软件的内容不匹配,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
该软件主要解决了这两个大问题.
您只能获得免费的章节,非VIP的章节,并支持原创作者.
功能模块简介:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,系统提示我360.这也可能是因为跳转是360浏览器. 我不知道你是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
在下面的上图中,图中的粉红色软件是我计算机主题的原因,而不是覆盖面部的软件设置:
寻求支持,寻求支持,寻求支持! ! ! !说三遍重要的事情! ! !
v1.0的下载链接:
总下载链接[包括V1.1]: 链接: 密码: uff3 查看全部
更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
版本: 1.0
日期: 2018.5.23
发展的原因: 在发展之初,是为了阅读小说. 我个人喜欢在本地下载它以便慢慢观看. 但是,许多小说网站不支持下载,或者下载[非VIP小说]受到限制. 我还在论坛中找到了一些采集. 但是我个人认为它不是很容易使用. 输入正则表达式后,将显示该章,但是无法通过单击下载按钮来下载文本. 软件完成后,我继续对其进行测试. 相同的正则表达式,那些软件的内容不匹配,因此下载失败. 该软件还可能具有一些我不知道的规则,但结果是它无法完成我想要的下载. 我什至不知道这是规则,软件还是网站设置...
因此,我开发的此软件专门添加了预览功能,您可以知道是否可以获取网页数据,获取后是否可以正确匹配内容.
该软件主要解决了这两个大问题.
您只能获得免费的章节,非VIP的章节,并支持原创作者.
功能模块简介:
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
3. 关于软件
①实际上,您只需要.exe,规则全部由您自己添加,commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
②该软件未打包,由c#开发,没有病毒. 如果您不担心,请不要使用它,我不会收回它.
③关于该软件,跳至论坛. 当我亲自测试跳转时,系统提示我360.这也可能是因为跳转是360浏览器. 我不知道你是否会遇到这个问题.
④如果您不知道xml中的内容,请不要触摸它,以免软件识别失败和错误.
⑤需要.net framework 4.5或更高版本的框架支持. 如果您的计算机没有安装,则需要下载并安装它. 框架不大.
4. 其他
我暂时没想到,我稍后会考虑.
最后,无论如何,我仍然四处寻求支持,如果您不喜欢也不要喷洒.
这是第一个版本,因此必须存在以前的测试中未遇到的错误或需要优化的问题. 欢迎提供温和的反馈.
从理论上讲,从目录页面到内容页面的任何形式都可以使用,不仅限于小说.
在下面的上图中,图中的粉红色软件是我计算机主题的原因,而不是覆盖面部的软件设置:
寻求支持,寻求支持,寻求支持! ! ! !说三遍重要的事情! ! !
v1.0的下载链接:
总下载链接[包括V1.1]: 链接: 密码: uff3
Mini crawler下载0.1.1.0免费版本
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2020-08-08 02:52
这是一款超小型,快速的SEO工具,可为seo行业合作伙伴提供简单,快速和强大的支持,以快速检索其网站关键字,标题,描述和其他内容. 通过分析爬网内容来改进URL. 提高网站排名.
功能介绍
自动输入连续的URL
获取浏览器的输入历史记录,您可以快速找到已输入的URL. 无需记住一长串毫无意义的URL.
通过输入通配符,您可以快速输入一系列URL,从而大大降低了手动输入的效率.
如果需要更正自动生成的URL,则可以右键单击以删除和修改相应的URL.
灵活的人员爬行规则
默认情况下,提供了三种常用内容: 标题,关键字和网页描述. 对于主修seo的学生,可以快速上手并直接使用它. 快速完成老板的内容.
通过自定义XPath,您可以随意设置抓取内容,并且可以设置无限的规则.
使用方法
1. 安装并运行,在该URL上输入要爬网的网页的URL,这时该URL将自动添加到URL列表中,在规则列表中输入标题,关键字和描述,然后单击“开始”.
2. 爬网后,Cheng将自动打开一个Excel表,其中收录您输入的URL地址以及采集的标题,关键字和描述.
文件信息
文件大小: 2014208字节
MD5: FF86958701C899A7379BA612E0ABF2DE
SHA1: FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32: 5B3E0727
官方网站:
相关搜索: SEO采集器 查看全部
迷你采集器是一种简单而紧凑的SEO搜寻工具. 它的功能是模拟搜索引擎对网页的标题,关键字,描述和其他信息进行爬网. 您可以使用它来采集自己的网站或采集竞争对手的网站,这样您就可以知道对手的标题和关键字是如何写的,并可以从中学习. 您需要的SEOER可以下载要使用的小型抓取工具.
这是一款超小型,快速的SEO工具,可为seo行业合作伙伴提供简单,快速和强大的支持,以快速检索其网站关键字,标题,描述和其他内容. 通过分析爬网内容来改进URL. 提高网站排名.
功能介绍
自动输入连续的URL
获取浏览器的输入历史记录,您可以快速找到已输入的URL. 无需记住一长串毫无意义的URL.
通过输入通配符,您可以快速输入一系列URL,从而大大降低了手动输入的效率.
如果需要更正自动生成的URL,则可以右键单击以删除和修改相应的URL.
灵活的人员爬行规则
默认情况下,提供了三种常用内容: 标题,关键字和网页描述. 对于主修seo的学生,可以快速上手并直接使用它. 快速完成老板的内容.
通过自定义XPath,您可以随意设置抓取内容,并且可以设置无限的规则.
使用方法
1. 安装并运行,在该URL上输入要爬网的网页的URL,这时该URL将自动添加到URL列表中,在规则列表中输入标题,关键字和描述,然后单击“开始”.
2. 爬网后,Cheng将自动打开一个Excel表,其中收录您输入的URL地址以及采集的标题,关键字和描述.
文件信息
文件大小: 2014208字节
MD5: FF86958701C899A7379BA612E0ABF2DE
SHA1: FE9F24ACC57D5FB6A3653D0C18850F23DE37D9E8
CRC32: 5B3E0727
官方网站:
相关搜索: SEO采集器
Shanken Web TXT Collector V1.1绿色免费版
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2020-08-07 18:22
功能介绍
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
注释
实际上,您只需要.exe,规则全部由您自己添加,并且commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
更新日志
1.1更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活. 查看全部
Shanken网页TXT Collector是一种网络新颖的采集软件,可以下载,实时预览以及替换文本. 当前,只能获得免费的章节,并且不支持VIP章节!
功能介绍
1. 规则设置:
①在规则设置窗口中,无需编写任何规则即可在网站上找到文章. 首先单击实时预览以查看是否可以获取网页的源代码. 如果可以得到,请编写规则. 如果无法获得,则无需继续. 上
②规则设置使用正则表达式匹配内容. 最好有一定的基础. 如果没有基础,也可以参考给出的示例. 简单学习不需要深入研究正则表达式.
③设置规则后,需要分别预览目录页面和内容页面,这还需要两个链接,即目录页面链接和内容页面链接.
④关于替换,有常规替换和自定义替换. 目前无需进行正规化,普通替代品就可以了. 应该注意的是,必须输入值,并且空格也是可以接受的. 删除: 选择整行,然后按住删除键. 当内置\ n用作替换数据时,表示换行.
⑤编码,目前仅设置了GBK和UFT-8,几乎大多数网站都是这两种编码之一.
2,分析和下载
①要进行分析,请按2按钮解析地址. 按钮1当前功能强大,不希望被删除,稍后将开发其他功能.
②支持单章下载和全文下载.
③支持添加章节号[某些小说中没有章节号时可以检查]
④支持在线观看,但是需要连接到互联网. 此功能仅是辅助工具,不是阅读小说的专业软件.
⑤显示下载进度和总时间,内置多线程.
注释
实际上,您只需要.exe,规则全部由您自己添加,并且commonrule.xml收录常见的替换规则. 网站规则位于规则文件夹下. 我在其中放置了两个网站规则,主要用于测试. 您可以自己添加其他站点规则,或支持开发人员.
更新日志
1.1更新日志:
修复第1章中无法单击的错误.
新功能使提取Web链接更加灵活.
黑帽SEO(SEO作弊)的技术是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2020-08-07 17:23
所有使用欺诈或可疑手段的人都可以称为黑帽SEO. 例如垃圾邮件链接,隐藏页面,桥接页面,关键字填充等. 我不建议学习黑帽子. 黑帽子具有黑帽子SEO的优点,与白帽子SEO相同. 对于普通的商业网站和大多数个人网站,良好的内容,正常的优化以及对用户体验的关注是成功之路. 如果您想学习白帽子,那么您可以穿上这条裙子. 在中间571和206的425中,您可以通过连接数字找到我们. 如果您真的不想学习白帽子,请不要添加它. 典型的黑帽搜索引擎优化使用程序从其他类别或搜索引擎获取大量搜索结果来制作网页,然后将Google Adsense放在这些网页上. 这些页面的数量不是成百上千,而是成千上万. 因此,即使大多数网页排名都不高,但由于网页数量巨大,用户仍会进入该网站并点击GoogleAdsense广告.
博客作弊
BLOG是高度互动的工具. 近年来,博客的兴起已成为黑帽SEO创建链接的新天地.
1. BLOG小组作弊: 中国一些常见的BLOG程序,例如: wordpress,ZBLOG,PJBLOG,Bo-blog. 在ZBLOG和PJBLOG的早期,开发人员缺乏SEO知识. ZBLOG和PJBLOG曾经成为黑帽SEO经常访问的地方. Bo-blog博客程序似乎仍然可以给黑帽SEO机会.
2. BLOG小组作弊: BLOG小组建立作弊是通过程序或人工手段申请大量BLOG帐户. 然后,通过发布一些带有关键字链接的文章,这些链接将提升关键字搜索引擎的排名.
3. BLOG隐藏链接作弊: 通过提供免费的博客样式(FreeTemplate),作弊者将隐藏链接(HideLinks)添加到样式文件中,以增加网站隐藏链接并达到提高搜索引擎排名的目的.
页面跳转
使用Java脚本或其他技术可以使用户在进入页面后快速跳转到另一页面.
秘密更改页面
这是专为SEO设计的高度优化的网页. 网站达到理想排名后,将优化后的页面替换为普通页面.
桥梁页面
为某个关键字创建优化的页面,将链接定向到或重定向到目标页面,并且桥接页面本身没有实际内容,只是搜索引擎的关键字堆. [3]
留言簿组发布
使用留言簿组发布软件自动发布您自己的关键字URL,并在短时间内快速增加外部链接.
链接工厂
“链接工厂”(也称为“质量链接机制”)是指由大量交叉链接的网页组成的网络系统. 这些网页可能来自同一域或多个不同域,甚至可能来自不同服务器. 站点加入这样的“链接工厂”后,一方面,它可以从系统中的所有网页获取链接,与此同时,作为交换,它需要“专用”自己的链接,并使用它方法来提高链接得分,从而达到干预链接得分的目的.
隐藏链接
SEO通常在客户网站上使用隐藏链接,通过使用其客户网站上的隐藏链接来连接其自己的网站或其他客户的网站.
假链接
将链接添加到JS代码,框架或表单. 搜索引擎蜘蛛程序根本无法读取这种方式的链接. 因此,该链接仅供人们查看,搜索引擎根本无法识别它.
网络劫持
网页劫持是我们通常所说的PageJacking,它是完全复制他人网站或整个网站的内容,并将其放置在您自己的网站上. 这种黑帽子式SEO方法对网站内容极为匮乏的网站管理员有吸引力. 但是,这种方法非常危险且无耻. 搜索引擎的专利技术可以从多种因素中判断出复制的网页或网站不是原创的,也不会收录在内.
网站镜像
复制整个网站或部分网页内容,并分配不同的域名和服务器以欺骗搜索引擎以多次索引同一网站或同一页面的行为. 这就是为什么某些网站指示禁止未经授权的操作的原因网站镜像的原因是两个网站完全相同. 如果相似度太高,将不可避免地导致您自己的网站受到影响. [4]
地址重定向
302redirect: 302代表临时移动. 在过去的几年中,许多BlackHatSEO广泛使用了该技术来作弊,并且主要的搜索引擎也加大了对其的打击力度. 即使该网站客观上不是垃圾邮件,也很容易被搜索引擎误认为是垃圾邮件并受到惩罚. 每个人都必须有这样的经验. 当您搜索某个网站时,您将变成另一个网站. 这主要是通过跳转技术来实现的,该技术通常会跳转到有利可图的页面.
悬挂黑链
扫描FTP或服务器中的弱密码和漏洞,然后入侵网站并将链接挂起. 这是一种非法方法. 我鄙视这些SEOer. 中国有很多这样的人. 这些可以通过SeoQuake插件发现.
海角法
简单来说,隐瞒是网站管理员使用两个不同的页面来达到最佳效果. 一个版本仅适用于搜索引擎,另一个版本适用于您自己. 如果提供给搜索引擎的网站版本未如实反映网页中收录的真实内容,则搜索引擎认为这种做法是非法的. 如果找到该网站,则该网站将从搜索引擎列表中永久删除.
关键字积累
优化关键字时,许多网站管理员会累积大量关键字,这使搜索引擎认为网页是相关的. 关键字累积技术使用一长串的重复关键字来混淆搜索引擎. 实际上,这些关键字有时与Web内容有关,有时与Web内容无关. 这种方法很少起作用,而且网站的排名在短期或长期内都不可能提升到很高的水平.
公关劫持
PR劫持的方法是使用跳转. 通常,搜索引擎将目标URL视为处理301和302重定向时应实际收录的URL. 当然有特殊情况,但是在大多数情况下都是这样. 因此,如果您执行从域名A到域名B的301或302重定向,并且域名B的PR值相对较高,那么在域名A的PR更新后,域名B的PR值也会显示. 最简单的方法是将301或302跳转到具有较高PR的域名B,并在PR更新后立即取消重定向,并同时获得与站B相同的PR值. 此错误的PR显示值至少要等到下一次PR更新.
精美文字
许多进行搜索引擎优化的人都知道隐藏文本可能会受到惩罚,因此他们以微妙的字体显示隐藏文本. 对于精美的文本,甚至可以使用小字体在网页上不显眼的位置编写带有关键字的句子. 通常,这些文本位于网页的顶部或底部. 尽管这些文本的颜色与隐藏文本的背景颜色不同,但它们通常以非常相似的颜色出现.
隐藏页面
隐藏页面(cloakedpage)是使用程序或脚本检测它是搜索引擎还是普通用户的网页. 如果它是搜索引擎,则该页面将返回该页面的优化版本. 如果访问者是普通人,则返回另一个版本. 用户通常找不到这种作弊类型. 因为一旦您的浏览器可以看到该网页(无论是在页面上还是在HTML源文件中),您所获得的已经是与搜索引擎不同的版本. 检查的方法是查看此页面的快照.
隐藏的文字
隐藏文本(hiddentext)是将收录关键字的文本放入网页的HTML文件中,但是用户无法看到这些单词,而只能由搜索引擎看到. 可以有多种形式,例如超小文本,与背景颜色相同的文本,放置在注释标签中的文本,放置在表单的输入标签中的文本以及通过样式表放置在不可见层上的文本还有更多
桥梁页面
Doorwaypages [3](doorwaypages)通常是自动生成大量收录关键字的网页,然后从这些网页自动重定向到主页的软件. 目的是希望这些针对不同关键字的桥页能够在搜索引擎中获得良好的排名. 当用户单击搜索结果时,它将自动转到主页. 有时,到首页的链接会放置在桥页面上,而不会自动重定向.
Black hat seo: 在十分钟内获得一百个主要的网站shell,以及如何使用webshell.rar赚钱
黑帽很不稳定,因此不建议戴黑帽. 现在,百度可以阻止黑帽获得的链接.
因此,黑帽子和黑网站等同于不稳定,黑帽子进入的网站不一定是权重较高的网站. 高安全性会不好吗?
建议正常优化SEO. 如有任何疑问,您可以去家里回答SEO优化论坛.
如何查看竞争对手的网站看起来像黑帽子的搜索引擎优化
根据竞争对手的网站是否存在黑帽seo情况,我们必须首先了解黑帽seo的18种方法: 1: 关键字堆叠2: 桥接页面3 .:隐藏文本4: 隐藏链接/黑链5: 隐藏页面/捕获方法/盲目... 6: 网页劫持/公关劫持7: 链接交易8: 链接工厂/站点组/博客链轮/链接农场/链接农场... 9: 垃圾链接10: 网站镜像11 : 诱饵替换12: 内容采集/采集器/伪原创工具13: 组源软件/博客组/论坛组/外链/留言簿组... 14: 蜘蛛陷阱/ Flash动画/ SessionID /框架结构/动态URL / JS链接/需要登录/强制使用Cookies15: 伪造链接16: 欺骗点击链接17: 弹出广告18: 检查网站zhidao /检查百度排名/选中百度下拉框,相关搜索/检查百度共享/刷网站流量/刷alexa流量/刷IP流量... 查看全部
黑帽SEO(SEO作弊)的技术是什么?
所有使用欺诈或可疑手段的人都可以称为黑帽SEO. 例如垃圾邮件链接,隐藏页面,桥接页面,关键字填充等. 我不建议学习黑帽子. 黑帽子具有黑帽子SEO的优点,与白帽子SEO相同. 对于普通的商业网站和大多数个人网站,良好的内容,正常的优化以及对用户体验的关注是成功之路. 如果您想学习白帽子,那么您可以穿上这条裙子. 在中间571和206的425中,您可以通过连接数字找到我们. 如果您真的不想学习白帽子,请不要添加它. 典型的黑帽搜索引擎优化使用程序从其他类别或搜索引擎获取大量搜索结果来制作网页,然后将Google Adsense放在这些网页上. 这些页面的数量不是成百上千,而是成千上万. 因此,即使大多数网页排名都不高,但由于网页数量巨大,用户仍会进入该网站并点击GoogleAdsense广告.
博客作弊
BLOG是高度互动的工具. 近年来,博客的兴起已成为黑帽SEO创建链接的新天地.
1. BLOG小组作弊: 中国一些常见的BLOG程序,例如: wordpress,ZBLOG,PJBLOG,Bo-blog. 在ZBLOG和PJBLOG的早期,开发人员缺乏SEO知识. ZBLOG和PJBLOG曾经成为黑帽SEO经常访问的地方. Bo-blog博客程序似乎仍然可以给黑帽SEO机会.
2. BLOG小组作弊: BLOG小组建立作弊是通过程序或人工手段申请大量BLOG帐户. 然后,通过发布一些带有关键字链接的文章,这些链接将提升关键字搜索引擎的排名.
3. BLOG隐藏链接作弊: 通过提供免费的博客样式(FreeTemplate),作弊者将隐藏链接(HideLinks)添加到样式文件中,以增加网站隐藏链接并达到提高搜索引擎排名的目的.
页面跳转
使用Java脚本或其他技术可以使用户在进入页面后快速跳转到另一页面.
秘密更改页面
这是专为SEO设计的高度优化的网页. 网站达到理想排名后,将优化后的页面替换为普通页面.
桥梁页面
为某个关键字创建优化的页面,将链接定向到或重定向到目标页面,并且桥接页面本身没有实际内容,只是搜索引擎的关键字堆. [3]
留言簿组发布
使用留言簿组发布软件自动发布您自己的关键字URL,并在短时间内快速增加外部链接.
链接工厂
“链接工厂”(也称为“质量链接机制”)是指由大量交叉链接的网页组成的网络系统. 这些网页可能来自同一域或多个不同域,甚至可能来自不同服务器. 站点加入这样的“链接工厂”后,一方面,它可以从系统中的所有网页获取链接,与此同时,作为交换,它需要“专用”自己的链接,并使用它方法来提高链接得分,从而达到干预链接得分的目的.
隐藏链接
SEO通常在客户网站上使用隐藏链接,通过使用其客户网站上的隐藏链接来连接其自己的网站或其他客户的网站.
假链接
将链接添加到JS代码,框架或表单. 搜索引擎蜘蛛程序根本无法读取这种方式的链接. 因此,该链接仅供人们查看,搜索引擎根本无法识别它.
网络劫持
网页劫持是我们通常所说的PageJacking,它是完全复制他人网站或整个网站的内容,并将其放置在您自己的网站上. 这种黑帽子式SEO方法对网站内容极为匮乏的网站管理员有吸引力. 但是,这种方法非常危险且无耻. 搜索引擎的专利技术可以从多种因素中判断出复制的网页或网站不是原创的,也不会收录在内.
网站镜像
复制整个网站或部分网页内容,并分配不同的域名和服务器以欺骗搜索引擎以多次索引同一网站或同一页面的行为. 这就是为什么某些网站指示禁止未经授权的操作的原因网站镜像的原因是两个网站完全相同. 如果相似度太高,将不可避免地导致您自己的网站受到影响. [4]
地址重定向
302redirect: 302代表临时移动. 在过去的几年中,许多BlackHatSEO广泛使用了该技术来作弊,并且主要的搜索引擎也加大了对其的打击力度. 即使该网站客观上不是垃圾邮件,也很容易被搜索引擎误认为是垃圾邮件并受到惩罚. 每个人都必须有这样的经验. 当您搜索某个网站时,您将变成另一个网站. 这主要是通过跳转技术来实现的,该技术通常会跳转到有利可图的页面.
悬挂黑链
扫描FTP或服务器中的弱密码和漏洞,然后入侵网站并将链接挂起. 这是一种非法方法. 我鄙视这些SEOer. 中国有很多这样的人. 这些可以通过SeoQuake插件发现.
海角法
简单来说,隐瞒是网站管理员使用两个不同的页面来达到最佳效果. 一个版本仅适用于搜索引擎,另一个版本适用于您自己. 如果提供给搜索引擎的网站版本未如实反映网页中收录的真实内容,则搜索引擎认为这种做法是非法的. 如果找到该网站,则该网站将从搜索引擎列表中永久删除.
关键字积累
优化关键字时,许多网站管理员会累积大量关键字,这使搜索引擎认为网页是相关的. 关键字累积技术使用一长串的重复关键字来混淆搜索引擎. 实际上,这些关键字有时与Web内容有关,有时与Web内容无关. 这种方法很少起作用,而且网站的排名在短期或长期内都不可能提升到很高的水平.
公关劫持
PR劫持的方法是使用跳转. 通常,搜索引擎将目标URL视为处理301和302重定向时应实际收录的URL. 当然有特殊情况,但是在大多数情况下都是这样. 因此,如果您执行从域名A到域名B的301或302重定向,并且域名B的PR值相对较高,那么在域名A的PR更新后,域名B的PR值也会显示. 最简单的方法是将301或302跳转到具有较高PR的域名B,并在PR更新后立即取消重定向,并同时获得与站B相同的PR值. 此错误的PR显示值至少要等到下一次PR更新.
精美文字
许多进行搜索引擎优化的人都知道隐藏文本可能会受到惩罚,因此他们以微妙的字体显示隐藏文本. 对于精美的文本,甚至可以使用小字体在网页上不显眼的位置编写带有关键字的句子. 通常,这些文本位于网页的顶部或底部. 尽管这些文本的颜色与隐藏文本的背景颜色不同,但它们通常以非常相似的颜色出现.
隐藏页面
隐藏页面(cloakedpage)是使用程序或脚本检测它是搜索引擎还是普通用户的网页. 如果它是搜索引擎,则该页面将返回该页面的优化版本. 如果访问者是普通人,则返回另一个版本. 用户通常找不到这种作弊类型. 因为一旦您的浏览器可以看到该网页(无论是在页面上还是在HTML源文件中),您所获得的已经是与搜索引擎不同的版本. 检查的方法是查看此页面的快照.
隐藏的文字
隐藏文本(hiddentext)是将收录关键字的文本放入网页的HTML文件中,但是用户无法看到这些单词,而只能由搜索引擎看到. 可以有多种形式,例如超小文本,与背景颜色相同的文本,放置在注释标签中的文本,放置在表单的输入标签中的文本以及通过样式表放置在不可见层上的文本还有更多
桥梁页面
Doorwaypages [3](doorwaypages)通常是自动生成大量收录关键字的网页,然后从这些网页自动重定向到主页的软件. 目的是希望这些针对不同关键字的桥页能够在搜索引擎中获得良好的排名. 当用户单击搜索结果时,它将自动转到主页. 有时,到首页的链接会放置在桥页面上,而不会自动重定向.
Black hat seo: 在十分钟内获得一百个主要的网站shell,以及如何使用webshell.rar赚钱
黑帽很不稳定,因此不建议戴黑帽. 现在,百度可以阻止黑帽获得的链接.
因此,黑帽子和黑网站等同于不稳定,黑帽子进入的网站不一定是权重较高的网站. 高安全性会不好吗?
建议正常优化SEO. 如有任何疑问,您可以去家里回答SEO优化论坛.
如何查看竞争对手的网站看起来像黑帽子的搜索引擎优化
根据竞争对手的网站是否存在黑帽seo情况,我们必须首先了解黑帽seo的18种方法: 1: 关键字堆叠2: 桥接页面3 .:隐藏文本4: 隐藏链接/黑链5: 隐藏页面/捕获方法/盲目... 6: 网页劫持/公关劫持7: 链接交易8: 链接工厂/站点组/博客链轮/链接农场/链接农场... 9: 垃圾链接10: 网站镜像11 : 诱饵替换12: 内容采集/采集器/伪原创工具13: 组源软件/博客组/论坛组/外链/留言簿组... 14: 蜘蛛陷阱/ Flash动画/ SessionID /框架结构/动态URL / JS链接/需要登录/强制使用Cookies15: 伪造链接16: 欺骗点击链接17: 弹出广告18: 检查网站zhidao /检查百度排名/选中百度下拉框,相关搜索/检查百度共享/刷网站流量/刷alexa流量/刷IP流量...
优采云通用文章采集器v2.17.1.1特别版
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-07 06:16
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长且合并文章过大的集合. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定相同的文章,然后比较两个文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断这是另一篇文章,并会自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了一种非常准确的文本提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置提取的最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标记后的纯文本单词数. ,线条和文字中的空格).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站的访问速度超时(特别是Google所收录的许多网站被阻止),或者在正文中设置了最少字数,或者该程序忽略了本地具有相同名称,黑名单和白名单的内容相似的文章过滤等将导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配
1.11: 增强了Web批处理列URL采集器识别文章URL的能力
1.10: 解决了翻译功能无法翻译的问题 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长且合并文章过大的集合. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定相同的文章,然后比较两个文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度小于60%时,优采云判断这是另一篇文章,并会自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了一种非常准确的文本提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置提取的最终结果中的单词数来提高准确性(在“文本中的最小单词数”参数中,该单词数是程序删除标记后的纯文本单词数. ,线条和文字中的空格).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站的访问速度超时(特别是Google所收录的许多网站被阻止),或者在正文中设置了最少字数,或者该程序忽略了本地具有相同名称,黑名单和白名单的内容相似的文章过滤等将导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的质量是最好的,生成的文章数量接近搜索结果的数量.
更新日志
1.12: 继续增强Web批处理列URL采集器识别文章URL的能力,并支持多种地址格式的同时匹配
1.11: 增强了Web批处理列URL采集器识别文章URL的能力
1.10: 解决了翻译功能无法翻译的问题

